1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
|
# Input Pipeline Performance Guide
GPUs and TPUs can radically reduce the time required to execute a single
training step. Achieving peak performance requires an efficient input pipeline
that delivers data for the next step before the current step has finished. The
`tf.data` API helps to build flexible and efficient input pipelines. This
document explains the `tf.data` API's features and best practices for building
high performance TensorFlow input pipelines across a variety of models and
accelerators.
This guide does the following:
* Illustrates that TensorFlow input pipelines are essentially an
[ETL](https://en.wikipedia.org/wiki/Extract,_transform,_load) process.
* Describes common performance optimizations in the context of the `tf.data`
API.
* Discusses the performance implications of the order in which you apply
transformations.
* Summarizes the best practices for designing performant TensorFlow input
pipelines.
## Input Pipeline Structure
A typical TensorFlow training input pipeline can be framed as an ETL process:
1. **Extract**: Read data from persistent storage -- either local (e.g. HDD or
SSD) or remote (e.g. [GCS](https://cloud.google.com/storage/) or
[HDFS](https://en.wikipedia.org/wiki/Apache_Hadoop#Hadoop_distributed_file_system)).
2. **Transform**: Use CPU cores to parse and perform preprocessing operations
on the data such as image decompression, data augmentation transformations
(such as random crop, flips, and color distortions), shuffling, and batching.
3. **Load**: Load the transformed data onto the accelerator device(s) (for
example, GPU(s) or TPU(s)) that execute the machine learning model.
This pattern effectively utilizes the CPU, while reserving the accelerator for
the heavy lifting of training your model. In addition, viewing input pipelines
as an ETL process provides structure that facilitates the application of
performance optimizations.
When using the @{tf.estimator.Estimator} API, the first two phases (Extract and
Transform) are captured in the `input_fn` passed to
@{tf.estimator.Estimator.train}. In code, this might look like the following
(naive, sequential) implementation:
```
def parse_fn(example):
"Parse TFExample records and perform simple data augmentation."
example_fmt = {
"image": tf.FixedLengthFeature((), tf.string, ""),
"label": tf.FixedLengthFeature((), tf.int64, -1)
}
parsed = tf.parse_single_example(example, example_fmt)
image = tf.image.decode_image(parsed["image"])
image = _augment_helper(image) # augments image using slice, reshape, resize_bilinear
return image, parsed["label"]
def input_fn():
files = tf.data.Dataset.list_files("/path/to/dataset/train-*.tfrecord")
dataset = files.interleave(tf.data.TFRecordDataset)
dataset = dataset.shuffle(buffer_size=FLAGS.shuffle_buffer_size)
dataset = dataset.map(map_func=parse_fn)
dataset = dataset.batch(batch_size=FLAGS.batch_size)
return dataset
```
The next section builds on this input pipeline, adding performance
optimizations.
## Optimizing Performance
As new computing devices (such as GPUs and TPUs) make it possible to train
neural networks at an increasingly fast rate, the CPU processing is prone to
becoming the bottleneck. The `tf.data` API provides users with building blocks
to design input pipelines that effectively utilize the CPU, optimizing each step
of the ETL process.
### Pipelining
To perform a training step, you must first extract and transform the training
data and then feed it to a model running on an accelerator. However, in a naive
synchronous implementation, while the CPU is preparing the data, the accelerator
is sitting idle. Conversely, while the accelerator is training the model, the
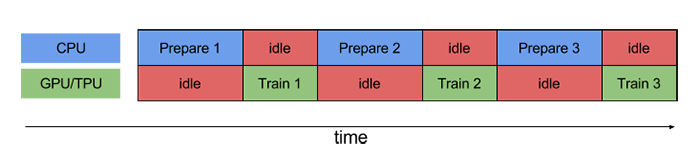
CPU is sitting idle. The training step time is thus the sum of both CPU
pre-processing time and the accelerator training time.
**Pipelining** overlaps the preprocessing and model execution of a training
step. While the accelerator is performing training step `N`, the CPU is
preparing the data for step `N+1`. Doing so reduces the step time to the maximum
(as opposed to the sum) of the training and the time it takes to extract and
transform the data.
Without pipelining, the CPU and the GPU/TPU sit idle much of the time:
With pipelining, idle time diminishes significantly:
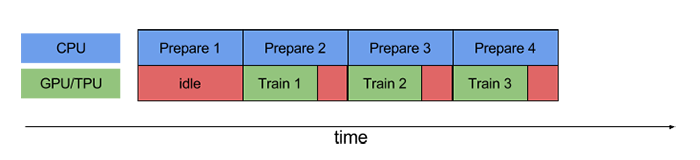
The `tf.data` API provides a software pipelining mechanism through the
@{tf.data.Dataset.prefetch} transformation, which can be used to decouple the
time data is produced from the time it is consumed. In particular, the
transformation uses a background thread and an internal buffer to prefetch
elements from the input dataset ahead of the time they are requested. Thus, to
achieve the pipelining effect illustrated above, you can add `prefetch(1)` as
the final transformation to your dataset pipeline (or `prefetch(n)` if a single
training step consumes n elements).
To apply this change to our running example, change:
```
dataset = dataset.batch(batch_size=FLAGS.batch_size)
return dataset
```
to:
```
dataset = dataset.batch(batch_size=FLAGS.batch_size)
dataset = dataset.prefetch(buffer_size=FLAGS.prefetch_buffer_size)
return dataset
```
Note that the prefetch transformation will yield benefits any time there is an
opportunity to overlap the work of a "producer" with the work of a "consumer."
The preceding recommendation is simply the most common application.
### Parallelize Data Transformation
When preparing a batch, input elements may need to be pre-processed. To this
end, the `tf.data` API offers the @{tf.data.Dataset.map} transformation, which
applies a user-defined function (for example, `parse_fn` from the running
example) to each element of the input dataset. Because input elements are
independent of one another, the pre-processing can be parallelized across
multiple CPU cores. To make this possible, the `map` transformation provides the
`num_parallel_calls` argument to specify the level of parallelism. For example,
the following diagram illustrates the effect of setting `num_parallel_calls=2`
to the `map` transformation:
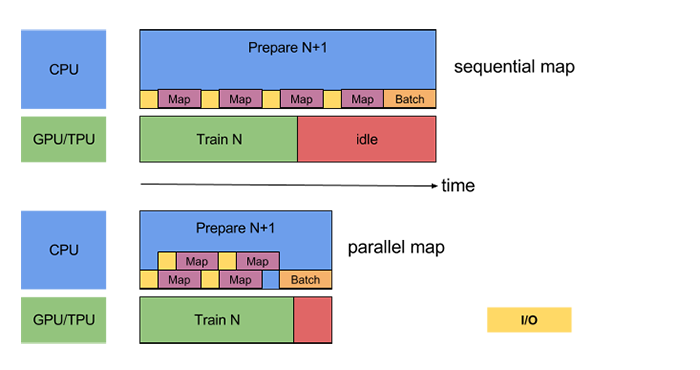
Choosing the best value for the `num_parallel_calls` argument depends on your
hardware, characteristics of your training data (such as its size and shape),
the cost of your map function, and what other processing is happening on the
CPU at the same time; a simple heuristic is to use the number of available CPU
cores. For instance, if the machine executing the example above had 4 cores, it
would have been more efficient to set `num_parallel_calls=4`. On the other hand,
setting `num_parallel_calls` to a value much greater than the number of
available CPUs can lead to inefficient scheduling, resulting in a slowdown.
To apply this change to our running example, change:
```
dataset = dataset.map(map_func=parse_fn)
```
to:
```
dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls)
```
Furthermore, if your batch size is in the hundreds or thousands, your pipeline
will likely additionally benefit from parallelizing the batch creation. To this
end, the `tf.data` API provides the @{tf.contrib.data.map_and_batch}
transformation, which effectively "fuses" the map and batch transformations.
To apply this change to our running example, change:
```
dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls)
dataset = dataset.batch(batch_size=FLAGS.batch_size)
```
to:
```
dataset = dataset.apply(tf.data.contrib.map_and_batch(
map_func=parse_fn, batch_size=FLAGS.batch_size))
```
### Parallelize Data Extraction
In a real-world setting, the input data may be stored remotely (for example,
GCS or HDFS), either because the input data would not fit locally or because the
training is distributed and it would not make sense to replicate the input data
on every machine. A dataset pipeline that works well when reading data locally
might become bottlenecked on I/O when reading data remotely because of the
following differences between local and remote storage:
* **Time-to-first-byte:** Reading the first byte of a file from remote storage
can take orders of magnitude longer than from local storage.
* **Read throughput:** While remote storage typically offers large aggregate
bandwidth, reading a single file might only be able to utilize a small
fraction of this bandwidth.
In addition, once the raw bytes are read into memory, it may also be necessary
to deserialize or decrypt the data
(e.g. [protobuf](https://developers.google.com/protocol-buffers/)), which adds
additional overhead. This overhead is present irrespective of whether the data
is stored locally or remotely, but can be worse in the remote case if data is
not prefetched effectively.
To mitigate the impact of the various data extraction overheads, the `tf.data`
API offers the @{tf.contrib.data.parallel_interleave} transformation. Use this
transformation to parallelize the execution of and interleave the contents of
other datasets (such as data file readers). The
number of datasets to overlap can be specified by the `cycle_length` argument.
The following diagram illustrates the effect of supplying `cycle_length=2` to
the `parallel_interleave` transformation:
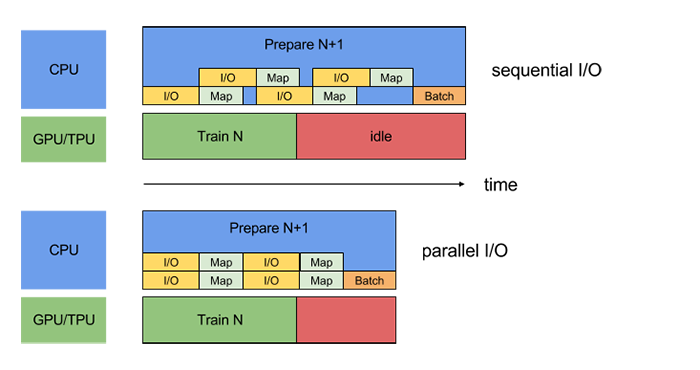
To apply this change to our running example, change:
```
dataset = files.interleave(tf.data.TFRecordDataset)
```
to:
```
dataset = files.apply(tf.data.contrib.parallel_interleave(
tf.data.TFRecordDataset, cycle_length=FLAGS.num_parallel_readers))
```
The throughput of remote storage systems can vary over time due to load or
network events. To account for this variance, the `parallel_interleave`
transformation can optionally use prefetching. (See
@{tf.contrib.data.parallel_interleave} for details).
By default, the `parallel_interleave` transformation provides a deterministic
ordering of elements to aid reproducibility. As an alternative to prefetching
(which may be ineffective in some cases), the `parallel_interleave`
transformation also provides an option that can boost performance at the expense
of ordering guarantees. In particular, if the `sloppy` argument is set to true,
the transformation may depart from its otherwise deterministic ordering, by
temporarily skipping over files whose elements are not available when the next
element is requested.
## Performance Considerations
The `tf.data` API is designed around composable transformations to provide its
users with flexibility. Although many of these transformations are commutative,
the ordering of certain transformations has performance implications.
### Map and Batch
Invoking the user-defined function passed into the `map` transformation has
overhead related to scheduling and executing the user-defined function.
Normally, this overhead is small compared to the amount of computation performed
by the function. However, if `map` does little work, this overhead can dominate
the total cost. In such cases, we recommend vectorizing the user-defined
function (that is, have it operate over a batch of inputs at once) and apply the
`batch` transformation _before_ the `map` transformation.
### Map and Cache
The @{tf.data.Dataset.cache} transformation can cache a dataset, either in
memory or on local storage. If the user-defined function passed into the `map`
transformation is expensive, apply the cache transformation after the map
transformation as long as the resulting dataset can still fit into memory or
local storage. If the user-defined function increases the space required to
store the dataset beyond the cache capacity, consider pre-processing your data
before your training job to reduce resource usage.
### Map and Interleave / Prefetch / Shuffle
A number of transformations, including `interleave`, `prefetch`, and `shuffle`,
maintain an internal buffer of elements. If the user-defined function passed
into the `map` transformation changes the size of the elements, then the
ordering of the map transformation and the transformations that buffer elements
affects the memory usage. In general, we recommend choosing the order that
results in lower memory footprint, unless different ordering is desirable for
performance (for example, to enable fusing of the map and batch transformations).
### Repeat and Shuffle
The @{tf.data.Dataset.repeat} transformation repeats the input data a finite (or
infinite) number of times; each repetition of the data is typically referred to
as an _epoch_. The @{tf.data.Dataset.shuffle} transformation randomizes the
order of the dataset's examples.
If the `repeat` transformation is applied before the `shuffle` transformation,
then the epoch boundaries are blurred. That is, certain elements can be repeated
before other elements appear even once. On the other hand, if the `shuffle`
transformation is applied before the repeat transformation, then performance
might slow down at the beginning of each epoch related to initialization of the
internal state of the `shuffle` transformation. In other words, the former
(`repeat` before `shuffle`) provides better performance, while the latter
(`shuffle` before `repeat`) provides stronger ordering guarantees.
When possible, we recommend using the fused
@{tf.contrib.data.shuffle_and_repeat} transformation, which combines the best of
both worlds (good performance and strong ordering guarantees). Otherwise, we
recommend shuffling before repeating.
## Summary of Best Practices
Here is a summary of the best practices for designing input pipelines:
* Use the `prefetch` transformation to overlap the work of a producer and
consumer. In particular, we recommend adding prefetch(n) (where n is the
number of elements / batches consumed by a training step) to the end of your
input pipeline to overlap the transformations performed on the CPU with the
training done on the accelerator.
* Parallelize the `map` transformation by setting the `num_parallel_calls`
argument. We recommend using the number of available CPU cores for its value.
* If you are combining pre-processed elements into a batch using the `batch`
transformation, we recommend using the fused `map_and_batch` transformation;
especially if you are using large batch sizes.
* If you are working with data stored remotely and / or requiring
deserialization, we recommend using the `parallel_interleave`
transformation to overlap the reading (and deserialization) of data from
different files.
* Vectorize cheap user-defined functions passed in to the `map` transformation
to amortize the overhead associated with scheduling and executing the
function.
* If your data can fit into memory, use the `cache` transformation to cache it
in memory during the first epoch, so that subsequent epochs can avoid the
overhead associated with reading, parsing, and transforming it.
* If your pre-processing increases the size of your data, we recommend
applying the `interleave`, `prefetch`, and `shuffle` first (if possible) to
reduce memory usage.
* We recommend applying the `shuffle` transformation _before_ the `repeat`
transformation, ideally using the fused `shuffle_and_repeat` transformation.
|
