
diff options
Diffstat (limited to 'tensorflow/docs_src/extend/architecture.md')
| -rw-r--r-- | tensorflow/docs_src/extend/architecture.md | 217 |
1 files changed, 0 insertions, 217 deletions
diff --git a/tensorflow/docs_src/extend/architecture.md b/tensorflow/docs_src/extend/architecture.md deleted file mode 100644 index eb33336bee..0000000000 --- a/tensorflow/docs_src/extend/architecture.md +++ /dev/null @@ -1,217 +0,0 @@ -# TensorFlow Architecture - -We designed TensorFlow for large-scale distributed training and inference, but -it is also flexible enough to support experimentation with new machine -learning models and system-level optimizations. - -This document describes the system architecture that makes this -combination of scale and flexibility possible. It assumes that you have basic familiarity -with TensorFlow programming concepts such as the computation graph, operations, -and sessions. See [this document](../guide/low_level_intro.md) for an introduction to -these topics. Some familiarity with [distributed TensorFlow](../deploy/distributed.md) -will also be helpful. - -This document is for developers who want to extend TensorFlow in some way not -supported by current APIs, hardware engineers who want to optimize for -TensorFlow, implementers of machine learning systems working on scaling and -distribution, or anyone who wants to look under Tensorflow's hood. By the end of this document -you should understand the TensorFlow architecture well enough to read -and modify the core TensorFlow code. - -## Overview - -The TensorFlow runtime is a cross-platform library. Figure 1 illustrates its -general architecture. A C API separates user level code in different languages -from the core runtime. - -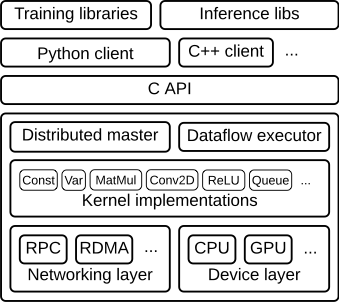{: width="300"} - -**Figure 1** - - -This document focuses on the following layers: - -* **Client**: - * Defines the computation as a dataflow graph. - * Initiates graph execution using a [**session**]( - https://www.tensorflow.org/code/tensorflow/python/client/session.py). -* **Distributed Master** - * Prunes a specific subgraph from the graph, as defined by the arguments - to Session.run(). - * Partitions the subgraph into multiple pieces that run in different - processes and devices. - * Distributes the graph pieces to worker services. - * Initiates graph piece execution by worker services. -* **Worker Services** (one for each task) - * Schedule the execution of graph operations using kernel implementations - appropriate to the available hardware (CPUs, GPUs, etc). - * Send and receive operation results to and from other worker services. -* **Kernel Implementations** - * Perform the computation for individual graph operations. - -Figure 2 illustrates the interaction of these components. "/job:worker/task:0" and -"/job:ps/task:0" are both tasks with worker services. "PS" stands for "parameter -server": a task responsible for storing and updating the model's parameters. -Other tasks send updates to these parameters as they work on optimizing the -parameters. This particular division of labor between tasks is not required, but - is common for distributed training. - -{: width="500"} - -**Figure 2** - -Note that the Distributed Master and Worker Service only exist in -distributed TensorFlow. The single-process version of TensorFlow includes a -special Session implementation that does everything the distributed master does -but only communicates with devices in the local process. - -The following sections describe the core TensorFlow layers in greater detail and -step through the processing of an example graph. - -## Client - -Users write the client TensorFlow program that builds the computation graph. -This program can either directly compose individual operations or use a -convenience library like the Estimators API to compose neural network layers and -other higher-level abstractions. TensorFlow supports multiple client -languages, and we have prioritized Python and C++, because our internal users -are most familiar with these languages. As features become more established, -we typically port them to C++, so that users can access an optimized -implementation from all client languages. Most of the training libraries are -still Python-only, but C++ does have support for efficient inference. - -The client creates a session, which sends the graph definition to the -distributed master as a `tf.GraphDef` -protocol buffer. When the client evaluates a node or nodes in the -graph, the evaluation triggers a call to the distributed master to initiate -computation. - -In Figure 3, the client has built a graph that applies weights (w) to a -feature vector (x), adds a bias term (b) and saves the result in a variable -(s). - -{: width="700"} - -**Figure 3** - -### Code - -* `tf.Session` - -## Distributed master - -The distributed master: - -* prunes the graph to obtain the subgraph required to evaluate the nodes - requested by the client, -* partitions the graph to obtain graph pieces for - each participating device, and -* caches these pieces so that they may be re-used in subsequent steps. - -Since the master sees the overall computation for -a step, it applies standard optimizations such as common subexpression -elimination and constant folding. It then coordinates execution of the -optimized subgraphs across a set of tasks. - -{: width="700"} - -**Figure 4** - - -Figure 5 shows a possible partition of our example graph. The distributed -master has grouped the model parameters in order to place them together on the -parameter server. - -{: width="700"} - -**Figure 5** - - -Where graph edges are cut by the partition, the distributed master inserts -send and receive nodes to pass information between the distributed tasks -(Figure 6). - -{: width="700"} - -**Figure 6** - - -The distributed master then ships the graph pieces to the distributed tasks. - -{: width="700"} - -**Figure 7** - -### Code - -* [MasterService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/master_service.proto) -* [Master interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/master_interface.h) - -## Worker Service - -The worker service in each task: - -* handles requests from the master, -* schedules the execution of the kernels for the operations that comprise a - local subgraph, and -* mediates direct communication between tasks. - -We optimize the worker service for running large graphs with low overhead. Our -current implementation can execute tens of thousands of subgraphs per second, -which enables a large number of replicas to make rapid, fine-grained training -steps. The worker service dispatches kernels to local devices and runs kernels -in parallel when possible, for example by using multiple CPU cores or GPU -streams. - -We specialize Send and Recv operations for each pair of source and destination -device types: - -* Transfers between local CPU and GPU devices use the - `cudaMemcpyAsync()` API to overlap computation and data transfer. -* Transfers between two local GPUs use peer-to-peer DMA, to avoid an expensive - copy via the host CPU. - -For transfers between tasks, TensorFlow uses multiple protocols, including: - -* gRPC over TCP. -* RDMA over Converged Ethernet. - -We also have preliminary support for NVIDIA's NCCL library for multi-GPU -communication (see [`tf.contrib.nccl`]( -https://www.tensorflow.org/code/tensorflow/contrib/nccl/python/ops/nccl_ops.py)). - -{: width="700"} - -**Figure 8** - -### Code - -* [WorkerService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/worker_service.proto) -* [Worker interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/worker_interface.h) -* [Remote rendezvous (for Send and Recv implementations)](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h) - -## Kernel Implementations - -The runtime contains over 200 standard operations including mathematical, array -manipulation, control flow, and state management operations. Each of these -operations can have kernel implementations optimized for a variety of devices. -Many of the operation kernels are implemented using Eigen::Tensor, which uses -C++ templates to generate efficient parallel code for multicore CPUs and GPUs; -however, we liberally use libraries like cuDNN where a more efficient kernel -implementation is possible. We have also implemented -[quantization](../performance/quantization.md), which enables -faster inference in environments such as mobile devices and high-throughput -datacenter applications, and use the -[gemmlowp](https://github.com/google/gemmlowp) low-precision matrix library to -accelerate quantized computation. - -If it is difficult or inefficient to represent a subcomputation as a composition -of operations, users can register additional kernels that provide an efficient -implementation written in C++. For example, we recommend registering your own -fused kernels for some performance critical operations, such as the ReLU and -Sigmoid activation functions and their corresponding gradients. The [XLA Compiler](../performance/xla/index.md) has an -experimental implementation of automatic kernel fusion. - -### Code - -* [`OpKernel` interface](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h) |