
diff options
| author | 2018-02-20 13:33:42 -0800 | |
|---|---|---|
| committer | 2018-02-20 13:33:42 -0800 | |
| commit | f0a965f268c0527704469d9c9a68acb9a1647afa (patch) | |
| tree | c6285712bf6718bfc1ec7f4d866f5fd6cab354f5 | |
| parent | 8624880b1efec0d12b559e42c107d43a176255db (diff) | |
| parent | 1adc14b317b7578cc7c220b05447795edd8474df (diff) | |
Merge pull request #17141 from drpngx/branch_186214551
Branch 186214551
140 files changed, 3303 insertions, 725 deletions
diff --git a/configure.py b/configure.py index 3aa1a3e956..2f268ee9d8 100644 --- a/configure.py +++ b/configure.py @@ -916,7 +916,7 @@ def set_tf_cudnn_version(environ_cp): tf_cudnn_version = get_from_env_or_user_or_default( environ_cp, 'TF_CUDNN_VERSION', ask_cudnn_version, _DEFAULT_CUDNN_VERSION) - tf_cudnn_version = reformat_version_sequence(str(tf_cudnn_version) ,1) + tf_cudnn_version = reformat_version_sequence(str(tf_cudnn_version), 1) default_cudnn_path = environ_cp.get('CUDA_TOOLKIT_PATH') ask_cudnn_path = (r'Please specify the location where cuDNN %s library is ' @@ -1433,8 +1433,10 @@ def main(): if is_linux(): set_tf_tensorrt_install_path(environ_cp) set_tf_cuda_compute_capabilities(environ_cp) - if 'LD_LIBRARY_PATH' in environ_cp and environ_cp.get('LD_LIBRARY_PATH') != '1': - write_action_env_to_bazelrc('LD_LIBRARY_PATH', environ_cp.get('LD_LIBRARY_PATH')) + if 'LD_LIBRARY_PATH' in environ_cp and environ_cp.get( + 'LD_LIBRARY_PATH') != '1': + write_action_env_to_bazelrc('LD_LIBRARY_PATH', + environ_cp.get('LD_LIBRARY_PATH')) set_tf_cuda_clang(environ_cp) if environ_cp.get('TF_CUDA_CLANG') == '1': diff --git a/tensorflow/c/BUILD b/tensorflow/c/BUILD index 9060c58c13..5dfb743681 100644 --- a/tensorflow/c/BUILD +++ b/tensorflow/c/BUILD @@ -12,12 +12,6 @@ load( "tf_custom_op_library", ) -# For platform specific build config -load( - "//tensorflow/core:platform/default/build_config.bzl", - "tf_kernel_tests_linkstatic", -) - # ----------------------------------------------------------------------------- # Public targets @@ -34,7 +28,11 @@ filegroup( "*.cc", "*.h", ], - exclude = ["*test*"], + exclude = [ + "c_api_experimental.cc", + "c_api_experimental.h", + "*test*", + ], ), visibility = ["//visibility:public"], ) @@ -101,6 +99,24 @@ tf_cuda_library( }), ) +tf_cuda_library( + name = "c_api_experimental", + srcs = [ + "c_api_experimental.cc", + ], + hdrs = [ + "c_api_experimental.h", + ], + copts = tf_copts(), + visibility = ["//visibility:public"], + deps = [ + ":c_api", + ":c_api_internal", + "//tensorflow/compiler/jit/legacy_flags:mark_for_compilation_pass_flags", + "//tensorflow/core:protos_all_cc", + ], +) + exports_files( [ "version_script.lds", @@ -148,7 +164,7 @@ tf_cuda_library( ], deps = [ ":c_api", - "//tensorflow/compiler/jit/legacy_flags:mark_for_compilation_pass_flags", + ":c_api_experimental", "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", "//tensorflow/core:session_options", diff --git a/tensorflow/c/c_api_experimental.cc b/tensorflow/c/c_api_experimental.cc new file mode 100644 index 0000000000..be7f85a5bb --- /dev/null +++ b/tensorflow/c/c_api_experimental.cc @@ -0,0 +1,39 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/c/c_api_experimental.h" + +#include "tensorflow/c/c_api_internal.h" +#include "tensorflow/compiler/jit/legacy_flags/mark_for_compilation_pass_flags.h" +#include "tensorflow/core/protobuf/config.pb.h" + +void TF_EnableXLACompilation(TF_SessionOptions* options, unsigned char enable) { + tensorflow::ConfigProto& config = options->options.config; + auto* optimizer_options = + config.mutable_graph_options()->mutable_optimizer_options(); + if (enable) { + optimizer_options->set_global_jit_level(tensorflow::OptimizerOptions::ON_1); + + // These XLA flags are needed to trigger XLA properly from C (more generally + // non-Python) clients. If this API is called again with `enable` set to + // false, it is safe to keep these flag values as is. + tensorflow::legacy_flags::MarkForCompilationPassFlags* flags = + tensorflow::legacy_flags::GetMarkForCompilationPassFlags(); + flags->tf_xla_cpu_global_jit = true; + flags->tf_xla_min_cluster_size = 1; + } else { + optimizer_options->set_global_jit_level(tensorflow::OptimizerOptions::OFF); + } +} diff --git a/tensorflow/c/c_api_experimental.h b/tensorflow/c/c_api_experimental.h new file mode 100644 index 0000000000..5a7b007e40 --- /dev/null +++ b/tensorflow/c/c_api_experimental.h @@ -0,0 +1,66 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_C_C_API_EXPERIMENTAL_H_ +#define TENSORFLOW_C_C_API_EXPERIMENTAL_H_ + +#include <stddef.h> +#include <stdint.h> + +#include "tensorflow/c/c_api.h" + +// -------------------------------------------------------------------------- +// Experimental C API for TensorFlow. +// +// The API here is subject to changes in the future. + +// Macro to control visibility of exported symbols in the shared library (.so, +// .dylib, .dll). +// This duplicates the TF_EXPORT macro definition in +// tensorflow/core/platform/macros.h in order to keep this .h file independent +// of any other includes.$a +#ifdef SWIG +#define TF_CAPI_EXPORT +#else +#if defined(COMPILER_MSVC) +#ifdef TF_COMPILE_LIBRARY +#define TF_CAPI_EXPORT __declspec(dllexport) +#else +#define TF_CAPI_EXPORT __declspec(dllimport) +#endif // TF_COMPILE_LIBRARY +#else +#define TF_CAPI_EXPORT __attribute__((visibility("default"))) +#endif // COMPILER_MSVC +#endif // SWIG + +#ifdef __cplusplus +extern "C" { +#endif + +// When `enable` is true, set +// tensorflow.ConfigProto.OptimizerOptions.global_jit_level to ON_1, and also +// set XLA flag values to prepare for XLA compilation. Otherwise set +// global_jit_level to OFF. +// +// This API is syntax sugar over TF_SetConfig(), and is used by clients that +// cannot read/write the tensorflow.ConfigProto proto. +TF_CAPI_EXPORT extern void TF_EnableXLACompilation(TF_SessionOptions* options, + unsigned char enable); + +#ifdef __cplusplus +} /* end extern "C" */ +#endif + +#endif // TENSORFLOW_C_C_API_EXPERIMENTAL_H_ diff --git a/tensorflow/c/c_test_util.cc b/tensorflow/c/c_test_util.cc index a55af46ae2..3db2852ce6 100644 --- a/tensorflow/c/c_test_util.cc +++ b/tensorflow/c/c_test_util.cc @@ -15,7 +15,7 @@ limitations under the License. #include "tensorflow/c/c_test_util.h" -#include "tensorflow/compiler/jit/legacy_flags/mark_for_compilation_pass_flags.h" +#include "tensorflow/c/c_api_experimental.h" #include "tensorflow/core/framework/function.pb.h" #include "tensorflow/core/framework/op_def.pb.h" #include "tensorflow/core/framework/tensor.pb.h" @@ -404,19 +404,7 @@ std::vector<string> GetFuncNames(const tensorflow::GraphDef& graph_def) { CSession::CSession(TF_Graph* graph, TF_Status* s, bool use_XLA) { TF_SessionOptions* opts = TF_NewSessionOptions(); - tensorflow::legacy_flags::MarkForCompilationPassFlags* flags = - tensorflow::legacy_flags::GetMarkForCompilationPassFlags(); - flags->tf_xla_cpu_global_jit = use_XLA; - if (use_XLA) { - tensorflow::ConfigProto config; - config.mutable_graph_options() - ->mutable_optimizer_options() - ->set_global_jit_level(tensorflow::OptimizerOptions::ON_1); - std::string contents; - contents.resize(config.ByteSizeLong()); - config.SerializeToArray(&contents[0], contents.size()); - TF_SetConfig(opts, contents.data(), contents.size(), s); - } + TF_EnableXLACompilation(opts, use_XLA); session_ = TF_NewSession(graph, opts, s); TF_DeleteSessionOptions(opts); } diff --git a/tensorflow/c/eager/c_api.cc b/tensorflow/c/eager/c_api.cc index 8e834eb99c..98ef6f0d0a 100644 --- a/tensorflow/c/eager/c_api.cc +++ b/tensorflow/c/eager/c_api.cc @@ -161,10 +161,11 @@ int64_t TFE_TensorHandleDim(TFE_TensorHandle* h, int dim_index) { } const char* TFE_TensorHandleDeviceName(TFE_TensorHandle* h) { - // This might be a bit confusing as a tensor on CPU can sometimes return - // "CPU:0" and sometimes "/job:localhost/replica:0/task:0/cpu:0". - // TODO(ashankar): Figure out which one would be nicer. - return (h->d == nullptr) ? "CPU:0" : h->d->name().c_str(); + // TODO(apassos) this will be potentially incorrect in the distributed case as + // our local device will have a name which depends on the ClusterSpec and + // hence will require the context to resolve. + return (h->d == nullptr) ? "/job:localhost/replica:0/task:0/device:CPU:0" + : h->d->name().c_str(); } TF_Tensor* TFE_TensorHandleResolve(TFE_TensorHandle* h, TF_Status* status) { diff --git a/tensorflow/compiler/tests/segment_reduction_ops_test.py b/tensorflow/compiler/tests/segment_reduction_ops_test.py index 23bc39cf3f..4a9c0e7471 100644 --- a/tensorflow/compiler/tests/segment_reduction_ops_test.py +++ b/tensorflow/compiler/tests/segment_reduction_ops_test.py @@ -63,10 +63,10 @@ class SegmentReductionOpsTest(XLATestCase): def testUnsortedSegmentSum1DIndices1DDataNegativeIndices(self): for dtype in self.numeric_types: self.assertAllClose( - np.array([0, 3, 2, 5], dtype=dtype), + np.array([6, 3, 0, 6], dtype=dtype), self.UnsortedSegmentSum( - np.array([0, 1, 2, 3, 4, 5], dtype=dtype), - np.array([3, -1, 2, 1, -1, 3], dtype=np.int32), 4)) + np.array([0, 1, 2, 3, 4, 5, 6], dtype=dtype), + np.array([3, -1, 0, 1, 0, -1, 3], dtype=np.int32), 4)) def testUnsortedSegmentSum1DIndices2DDataDisjoint(self): for dtype in self.numeric_types: diff --git a/tensorflow/compiler/tf2xla/lib/scatter.cc b/tensorflow/compiler/tf2xla/lib/scatter.cc index 6009243f97..45699233ea 100644 --- a/tensorflow/compiler/tf2xla/lib/scatter.cc +++ b/tensorflow/compiler/tf2xla/lib/scatter.cc @@ -141,6 +141,8 @@ xla::StatusOr<xla::ComputationDataHandle> XlaScatter( body_builder->ConstantR0<bool>(true), xla::CreateScalarAndComputation(body_builder)); + // Make the index in bounds to prevent implementation defined behavior. + index = body_builder->Max(index, zero_index); index = body_builder->Pad( index, zero_index, xla::MakeEdgePaddingConfig({{0, buffer_shape_post_axes.size()}})); @@ -157,8 +159,8 @@ xla::StatusOr<xla::ComputationDataHandle> XlaScatter( auto update = body_builder->DynamicSlice(updates, updates_offset, flat_updates_slice_shape); - // Unflatten the major (iteration) dimensions of the slice to their original - // shape. + // Unflatten the major (iteration) dimensions of the slice to their + // original shape. std::vector<int64> updates_slice_shape(num_index_dims, 1); updates_slice_shape.insert(updates_slice_shape.end(), buffer_shape_post_axes.begin(), @@ -167,15 +169,16 @@ xla::StatusOr<xla::ComputationDataHandle> XlaScatter( // Apply the update to the buffer. If there is a combiner, use it to merge // the current values with the update. + auto current_value = + body_builder->DynamicSlice(buffer, index, updates_slice_shape); if (combiner) { - auto current_value = - body_builder->DynamicSlice(buffer, index, updates_slice_shape); update = combiner(current_value, update, body_builder); } - // Apply the update if it is in range. - buffer = body_builder->Select( - index_in_range, body_builder->DynamicUpdateSlice(buffer, update, index), - buffer); + // Use the current value instead of the update if the index is out of + // bounds. + update = body_builder->Select(index_in_range, update, current_value); + // Apply the update. + buffer = body_builder->DynamicUpdateSlice(buffer, update, index); return std::vector<xla::ComputationDataHandle>{indices, updates, buffer}; }; diff --git a/tensorflow/compiler/xla/client/computation_builder.cc b/tensorflow/compiler/xla/client/computation_builder.cc index b1dcad6a49..2a6e02649d 100644 --- a/tensorflow/compiler/xla/client/computation_builder.cc +++ b/tensorflow/compiler/xla/client/computation_builder.cc @@ -789,6 +789,20 @@ ComputationDataHandle ComputationBuilder::CustomCall( return RunOpAndParseResponse(&op_request); } +ComputationDataHandle ComputationBuilder::HostCompute( + tensorflow::gtl::ArraySlice<ComputationDataHandle> operands, + const string& channel_name, int64 cost_estimate_ns, const Shape& shape) { + OpRequest op_request; + HostComputeRequest* request = op_request.mutable_host_compute_request(); + for (const ComputationDataHandle& operand : operands) { + *request->add_operands() = operand; + } + *request->mutable_shape() = shape; + request->set_channel_name(channel_name); + request->set_cost_estimate_ns(cost_estimate_ns); + return RunOpAndParseResponse(&op_request); +} + ComputationDataHandle ComputationBuilder::Complex( const ComputationDataHandle& real, const ComputationDataHandle& imag, tensorflow::gtl::ArraySlice<int64> broadcast_dimensions) { @@ -1220,6 +1234,22 @@ ComputationDataHandle ComputationBuilder::While( return RunOpAndParseResponse(&op_request); } +ComputationDataHandle ComputationBuilder::Gather( + const ComputationDataHandle& input, + const ComputationDataHandle& gather_indices, + const GatherDimensionNumbers& dimension_numbers, + tensorflow::gtl::ArraySlice<int64> window_bounds) { + OpRequest op_request; + GatherRequest* gather_request = op_request.mutable_gather_request(); + *gather_request->mutable_input() = input; + *gather_request->mutable_gather_indices() = gather_indices; + *gather_request->mutable_dimension_numbers() = dimension_numbers; + for (int64 window_bound : window_bounds) { + gather_request->add_window_bounds(window_bound); + } + return RunOpAndParseResponse(&op_request); +} + ComputationDataHandle ComputationBuilder::Conditional( const ComputationDataHandle& predicate, const ComputationDataHandle& true_operand, diff --git a/tensorflow/compiler/xla/client/computation_builder.h b/tensorflow/compiler/xla/client/computation_builder.h index 7cae91e9e0..e3facb3f25 100644 --- a/tensorflow/compiler/xla/client/computation_builder.h +++ b/tensorflow/compiler/xla/client/computation_builder.h @@ -446,6 +446,16 @@ class ComputationBuilder { tensorflow::gtl::ArraySlice<ComputationDataHandle> operands, const Shape& shape); + // Enqueues a pseudo-op to represent host-side computation data-dependencies. + // During code generation, host send and receive operations will be generated + // to transfer |operands| to the host and a single result of |shape| back to + // the device. Host send/recv operations are emitted using |channel_name|. + // Dataflow dependencies and the |cost_estimate_ns| field may be used in HLO + // instruction scheduling. + ComputationDataHandle HostCompute( + tensorflow::gtl::ArraySlice<ComputationDataHandle> operands, + const string& channel_name, int64 cost_estimate_ns, const Shape& shape); + // The following methods enqueue element-wise binary arithmetic operations // onto the computation. The shapes of the operands have to match unless one // of the operands is a scalar, or an explicit broadcast dimension is given @@ -708,6 +718,13 @@ class ComputationBuilder { const int exponent_bits, const int mantissa_bits); + // Enqueues a Gather node onto the computation. + ComputationDataHandle Gather( + const ComputationDataHandle& input, + const ComputationDataHandle& gather_indices, + const GatherDimensionNumbers& dimension_numbers, + tensorflow::gtl::ArraySlice<int64> window_bounds); + // Enqueues a Send node onto the computation, to send the given operand to // a Recv instruction that shares the same channel handle. void Send(const ComputationDataHandle& operand, const ChannelHandle& handle); diff --git a/tensorflow/compiler/xla/service/BUILD b/tensorflow/compiler/xla/service/BUILD index 83c67ed936..4a076ac090 100644 --- a/tensorflow/compiler/xla/service/BUILD +++ b/tensorflow/compiler/xla/service/BUILD @@ -145,7 +145,8 @@ tf_cc_test( "//tensorflow/compiler/xla:test_helpers", "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:xla_data_proto", - "//tensorflow/compiler/xla/tests:xla_internal_test_main", + "//tensorflow/compiler/xla/tests:xla_internal_test_main", # fixdeps: keep + "//tensorflow/core:lib", ], ) @@ -718,6 +719,7 @@ cc_library( hdrs = ["llvm_compiler.h"], deps = [ ":compiler", + "//tensorflow/core:lib_internal", "@llvm//:core", ], ) diff --git a/tensorflow/compiler/xla/service/copy_insertion.cc b/tensorflow/compiler/xla/service/copy_insertion.cc index cd983bc03e..cc195879a6 100644 --- a/tensorflow/compiler/xla/service/copy_insertion.cc +++ b/tensorflow/compiler/xla/service/copy_insertion.cc @@ -729,7 +729,8 @@ class CopyRemover { // has a different operand (the operand of the elided copy). for (const HloUse* copy_use : copy_value_node->uses) { operand_node->uses.push_back(copy_use); - if (copy_use->instruction->opcode() == HloOpcode::kCopy) { + if (copy_use->instruction->opcode() == HloOpcode::kCopy && + ContainsKey(copy_map_, copy_use->instruction)) { copy_map_.at(copy_use->instruction).src = operand_node; } } @@ -1155,7 +1156,7 @@ bool IsWhileBody(const HloComputation* computation, HloModule* module) { std::unique_ptr<CallGraph> call_graph = CallGraph::Build(module); TF_ASSIGN_OR_RETURN(std::unique_ptr<HloDataflowAnalysis> dataflow, - HloDataflowAnalysis::Run(module)); + HloDataflowAnalysis::Run(*module)); bool changed = false; diff --git a/tensorflow/compiler/xla/service/cpu/cpu_executable.cc b/tensorflow/compiler/xla/service/cpu/cpu_executable.cc index 802d0a6fb4..c053703c35 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_executable.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_executable.cc @@ -63,7 +63,7 @@ CpuExecutable::CpuExecutable( assignment_(std::move(assignment)) { // Resolve symbols in the constructor rather than at execution time to avoid // races because FindSymbol is not thread safe. - llvm::JITSymbol sym = jit_->FindSymbol(entry_function_name); + llvm::JITSymbol sym = jit_->FindCompiledSymbol(entry_function_name); // We expect to find the symbol provided with entry_function_name; otherwise // this is an internal error. CHECK(sym) << "Symbol " << entry_function_name << " not found."; diff --git a/tensorflow/compiler/xla/service/cpu/parallel_cpu_executable.cc b/tensorflow/compiler/xla/service/cpu/parallel_cpu_executable.cc index cd997f0789..07a9f0efcb 100644 --- a/tensorflow/compiler/xla/service/cpu/parallel_cpu_executable.cc +++ b/tensorflow/compiler/xla/service/cpu/parallel_cpu_executable.cc @@ -394,7 +394,7 @@ Status ParallelCpuExecutable::ExecuteComputeFunctions( for (auto& entry : *function_names_) { tensorflow::mutex_lock lock(jit_mutex_); HloInstruction* instruction = entry.first; - llvm::JITSymbol sym = jit_->FindSymbol(entry.second); + llvm::JITSymbol sym = jit_->FindCompiledSymbol(entry.second); TF_RET_CHECK(sym); InsertOrDie( &functions, instruction, diff --git a/tensorflow/compiler/xla/service/cpu/simple_orc_jit.cc b/tensorflow/compiler/xla/service/cpu/simple_orc_jit.cc index cfed551eed..aa8d4ad9dc 100644 --- a/tensorflow/compiler/xla/service/cpu/simple_orc_jit.cc +++ b/tensorflow/compiler/xla/service/cpu/simple_orc_jit.cc @@ -44,36 +44,6 @@ namespace xla { namespace cpu { namespace { -// A simple SymbolResolver that delegates to the host dynamic linker. -class SimpleResolver : public llvm::LegacyJITSymbolResolver { - public: - explicit SimpleResolver(ExternalConstantPool* external_constant_pool) - : external_constant_pool_(external_constant_pool) {} - - llvm::JITSymbol findSymbol(const std::string& name) override { - if (const uint8* from_constant_pool = - external_constant_pool_->Find(string(name))) { - return llvm::JITEvaluatedSymbol( - reinterpret_cast<uint64_t>(from_constant_pool), - llvm::JITSymbolFlags::None); - } - - void* func_addr = CustomCallTargetRegistry::Global()->Lookup(name); - if (func_addr == nullptr) { - return nullptr; - } - llvm::JITEvaluatedSymbol symbol_info(reinterpret_cast<uint64_t>(func_addr), - llvm::JITSymbolFlags::None); - return symbol_info; - } - llvm::JITSymbol findSymbolInLogicalDylib(const std::string& name) override { - return nullptr; - } - - private: - ExternalConstantPool* external_constant_pool_; -}; - llvm::SmallVector<std::string, 0> DetectMachineAttributes() { llvm::SmallVector<std::string, 0> result; llvm::StringMap<bool> host_features; @@ -119,21 +89,7 @@ SimpleOrcJIT::SimpleOrcJIT(const llvm::TargetOptions& target_options, execution_session_(string_pool_), symbol_resolver_(llvm::orc::createLegacyLookupResolver( [this](const std::string& name) -> llvm::JITSymbol { - if (const uint8* from_constant_pool = - external_constant_pool_.Find(string(name))) { - return llvm::JITEvaluatedSymbol( - reinterpret_cast<uint64_t>(from_constant_pool), - llvm::JITSymbolFlags::None); - } - - void* func_addr = CustomCallTargetRegistry::Global()->Lookup(name); - if (func_addr == nullptr) { - return nullptr; - } - llvm::JITEvaluatedSymbol symbol_info( - reinterpret_cast<uint64_t>(func_addr), - llvm::JITSymbolFlags::None); - return symbol_info; + return this->ResolveRuntimeSymbol(name); }, [](llvm::Error Err) { cantFail(std::move(Err), "lookupFlags failed"); @@ -157,6 +113,23 @@ SimpleOrcJIT::SimpleOrcJIT(const llvm::TargetOptions& target_options, << " features: " << target_machine_->getTargetFeatureString().str(); } +llvm::JITSymbol SimpleOrcJIT::ResolveRuntimeSymbol(const std::string& name) { + if (const uint8* from_constant_pool = + external_constant_pool_.Find(string(name))) { + return llvm::JITEvaluatedSymbol( + reinterpret_cast<uint64_t>(from_constant_pool), + llvm::JITSymbolFlags::None); + } + + void* func_addr = CustomCallTargetRegistry::Global()->Lookup(name); + if (func_addr == nullptr) { + return nullptr; + } + llvm::JITEvaluatedSymbol symbol_info(reinterpret_cast<uint64_t>(func_addr), + llvm::JITSymbolFlags::None); + return symbol_info; +} + SimpleOrcJIT::VModuleKeyT SimpleOrcJIT::AddModule( std::unique_ptr<llvm::Module> module) { auto key = execution_session_.allocateVModule(); @@ -171,19 +144,13 @@ void SimpleOrcJIT::RemoveModule(SimpleOrcJIT::VModuleKeyT key) { cantFail(compile_layer_.removeModule(key)); } -llvm::JITSymbol SimpleOrcJIT::FindSymbol(const std::string& name) { - std::string mangled_name; - { - llvm::raw_string_ostream mangled_name_stream(mangled_name); - llvm::Mangler::getNameWithPrefix(mangled_name_stream, name, data_layout_); - } - +llvm::JITSymbol SimpleOrcJIT::FindCompiledSymbol(const std::string& name) { // Resolve symbol from last module to first, allowing later redefinitions of // symbols shadow earlier ones. for (auto& key : llvm::make_range(module_keys_.rbegin(), module_keys_.rend())) { if (auto symbol = - compile_layer_.findSymbolIn(key, mangled_name, + compile_layer_.findSymbolIn(key, name, /*ExportedSymbolsOnly=*/true)) { return symbol; } diff --git a/tensorflow/compiler/xla/service/cpu/simple_orc_jit.h b/tensorflow/compiler/xla/service/cpu/simple_orc_jit.h index 50993afc8f..d0011e0a18 100644 --- a/tensorflow/compiler/xla/service/cpu/simple_orc_jit.h +++ b/tensorflow/compiler/xla/service/cpu/simple_orc_jit.h @@ -89,7 +89,7 @@ class SimpleOrcJIT { // Get the runtime address of the compiled symbol whose name is given. Returns // nullptr if the symbol cannot be found. - llvm::JITSymbol FindSymbol(const std::string& name); + llvm::JITSymbol FindCompiledSymbol(const std::string& name); llvm::TargetMachine* target_machine() const { return target_machine_.get(); } @@ -98,6 +98,8 @@ class SimpleOrcJIT { } private: + llvm::JITSymbol ResolveRuntimeSymbol(const std::string& name); + std::vector<VModuleKeyT> module_keys_; std::unique_ptr<llvm::TargetMachine> target_machine_; const Disassembler disassembler_; diff --git a/tensorflow/compiler/xla/service/dfs_hlo_visitor.h b/tensorflow/compiler/xla/service/dfs_hlo_visitor.h index a803b3171f..56723e7650 100644 --- a/tensorflow/compiler/xla/service/dfs_hlo_visitor.h +++ b/tensorflow/compiler/xla/service/dfs_hlo_visitor.h @@ -190,6 +190,7 @@ class DfsHloVisitorBase { virtual Status HandleInfeed(HloInstructionPtr hlo) = 0; virtual Status HandleOutfeed(HloInstructionPtr hlo) = 0; + virtual Status HandleHostCompute(HloInstructionPtr hlo) = 0; virtual Status HandleRng(HloInstructionPtr hlo) = 0; virtual Status HandleReverse(HloInstructionPtr hlo) = 0; virtual Status HandleSort(HloInstructionPtr hlo) = 0; @@ -213,6 +214,7 @@ class DfsHloVisitorBase { virtual Status HandleSelectAndScatter(HloInstructionPtr hlo) = 0; virtual Status HandleWhile(HloInstructionPtr hlo) = 0; virtual Status HandleConditional(HloInstructionPtr hlo) = 0; + virtual Status HandleGather(HloInstructionPtr hlo) = 0; virtual Status HandlePad(HloInstructionPtr hlo) = 0; diff --git a/tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h b/tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h index 170adb3d24..ecda5288ee 100644 --- a/tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h +++ b/tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h @@ -103,6 +103,9 @@ class DfsHloVisitorWithDefaultBase Status HandleOutfeed(HloInstructionPtr outfeed) override { return DefaultAction(outfeed); } + Status HandleHostCompute(HloInstructionPtr host_compute) override { + return DefaultAction(host_compute); + } Status HandleReverse(HloInstructionPtr reverse) override { return DefaultAction(reverse); } @@ -185,6 +188,9 @@ class DfsHloVisitorWithDefaultBase Status HandleSendDone(HloInstructionPtr send_done) override { return DefaultAction(send_done); } + Status HandleGather(HloInstructionPtr gather) override { + return DefaultAction(gather); + } // Invoked to inform the visitor that the traversal has completed, and that // the root was "root". diff --git a/tensorflow/compiler/xla/service/gpu/gemm_thunk.cc b/tensorflow/compiler/xla/service/gpu/gemm_thunk.cc index 8e3aebbc12..ba482793e7 100644 --- a/tensorflow/compiler/xla/service/gpu/gemm_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/gemm_thunk.cc @@ -137,9 +137,9 @@ StatusOr<se::blas::AlgorithmType> DoGemmAutotune( // for all algorithms if we're targeting < sm_50. But because we pass a // non-null ProfileResult, DoGemmWithAlgorithm should always return true, // and the actual success-ness is returned in ProfileResult::is_valid. - DCHECK(DoGemmWithAlgorithm<Element>(lhs_matrix, rhs_matrix, output_matrix, - computation_type, algorithm, stream, - &profile_result)); + CHECK(DoGemmWithAlgorithm<Element>(lhs_matrix, rhs_matrix, output_matrix, + computation_type, algorithm, stream, + &profile_result)); if (profile_result.is_valid() && profile_result.elapsed_time_in_ms() < best_result.elapsed_time_in_ms()) { diff --git a/tensorflow/compiler/xla/service/gpu/gpu_copy_insertion.cc b/tensorflow/compiler/xla/service/gpu/gpu_copy_insertion.cc index 916b556fd4..9db85bc788 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_copy_insertion.cc +++ b/tensorflow/compiler/xla/service/gpu/gpu_copy_insertion.cc @@ -49,7 +49,7 @@ StatusOr<bool> GpuCopyInsertion::Run(HloModule* module) { TF_ASSIGN_OR_RETURN(bool changed, generic_copy_insertion.Run(module)); TF_ASSIGN_OR_RETURN(std::unique_ptr<HloDataflowAnalysis> dataflow, - HloDataflowAnalysis::Run(module)); + HloDataflowAnalysis::Run(*module)); // Make sure all operands of a library call are in memory instead of constants // in IR. diff --git a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc index aa2a0a9800..30c88c0a5d 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc +++ b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc @@ -2064,6 +2064,11 @@ GetHloBufferSlices(const HloInstruction* hlo, return slices; } +Status IrEmitterUnnested::HandleGather(HloInstruction* gather) { + // TODO(b/72710576): Gather is not implemented on GPUs + return Unimplemented("Gather is not implemented on GPUs."); +} + std::unique_ptr<Thunk> IrEmitterUnnested::BuildKernelThunk( const HloInstruction* inst) { const BufferAssignment& buffer_assn = diff --git a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.h b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.h index 688760efbd..b83a2337e2 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.h +++ b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.h @@ -67,6 +67,7 @@ class IrEmitterUnnested : public IrEmitter { Status HandleDot(HloInstruction* dot) override; Status HandleFft(HloInstruction* fft) override; Status HandleFusion(HloInstruction* fusion) override; + Status HandleGather(HloInstruction* gather) override; Status HandleGetTupleElement(HloInstruction* get_tuple_element) override; Status HandleReduce(HloInstruction* reduce) override; Status HandleSelectAndScatter(HloInstruction* instruction) override; diff --git a/tensorflow/compiler/xla/service/heap_simulator.cc b/tensorflow/compiler/xla/service/heap_simulator.cc index cde5877e29..a2d13c013c 100644 --- a/tensorflow/compiler/xla/service/heap_simulator.cc +++ b/tensorflow/compiler/xla/service/heap_simulator.cc @@ -225,6 +225,7 @@ Status HeapSimulator::RunComputation( // sub-computations will never be run concurrently. if (module_sequence_ != nullptr) { if (instruction->opcode() == HloOpcode::kCall || + instruction->opcode() == HloOpcode::kConditional || instruction->opcode() == HloOpcode::kWhile) { for (const HloComputation* called_computation : instruction->called_computations()) { diff --git a/tensorflow/compiler/xla/service/hlo.proto b/tensorflow/compiler/xla/service/hlo.proto index 36db711c6c..a43785b4a9 100644 --- a/tensorflow/compiler/xla/service/hlo.proto +++ b/tensorflow/compiler/xla/service/hlo.proto @@ -129,6 +129,10 @@ message HloInstructionProto { // FFT length. repeated int64 fft_length = 32; + + // Gather dimension numbers. + xla.GatherDimensionNumbers gather_dimension_numbers = 33; + repeated int64 gather_window_bounds = 34; } // Serialization of HloComputation. diff --git a/tensorflow/compiler/xla/service/hlo_alias_analysis.cc b/tensorflow/compiler/xla/service/hlo_alias_analysis.cc index 6d2a3aa5b5..30e32a46d7 100644 --- a/tensorflow/compiler/xla/service/hlo_alias_analysis.cc +++ b/tensorflow/compiler/xla/service/hlo_alias_analysis.cc @@ -419,7 +419,7 @@ StatusOr<std::unique_ptr<HloAliasAnalysis>> HloAliasAnalysis::Run( auto alias_analysis = WrapUnique(new HloAliasAnalysis(module)); TF_ASSIGN_OR_RETURN( alias_analysis->dataflow_analysis_, - HloDataflowAnalysis::Run(module, /*ssa_form=*/true, + HloDataflowAnalysis::Run(*module, /*ssa_form=*/true, /*bitcast_defines_value=*/false)); BufferValueMap buffer_map(alias_analysis->dataflow_analysis()); diff --git a/tensorflow/compiler/xla/service/hlo_computation.cc b/tensorflow/compiler/xla/service/hlo_computation.cc index 5432419e4a..21e6b2ca73 100644 --- a/tensorflow/compiler/xla/service/hlo_computation.cc +++ b/tensorflow/compiler/xla/service/hlo_computation.cc @@ -509,13 +509,14 @@ StatusOr<HloInstruction*> HloComputation::DeepCopyInstruction( "Can't deep copy instruction %s: instruction is not in computation %s", instruction->name().c_str(), name().c_str()); } - if (indices_to_copy != nullptr && !ShapeUtil::Compatible(instruction->shape(), indices_to_copy->shape())) { return FailedPrecondition( "Can't deep copy instruction %s: given shape tree of indices to copy " - "has incompatible shape", - instruction->name().c_str()); + "has incompatible shapes: %s vs. %s", + instruction->name().c_str(), + ShapeUtil::HumanString(instruction->shape()).c_str(), + ShapeUtil::HumanString(indices_to_copy->shape()).c_str()); } ShapeIndex index; diff --git a/tensorflow/compiler/xla/service/hlo_computation.h b/tensorflow/compiler/xla/service/hlo_computation.h index 061c59abe5..39d864efcb 100644 --- a/tensorflow/compiler/xla/service/hlo_computation.h +++ b/tensorflow/compiler/xla/service/hlo_computation.h @@ -77,6 +77,14 @@ class HloComputation { return last_added_instruction_; } + Status ForEachInstruction( + const std::function<Status(const HloInstruction*)>& func) const { + for (const auto& instruction : instructions_) { + TF_RETURN_IF_ERROR(func(instruction.get())); + } + return Status::OK(); + } + private: const string name_; HloInstruction* last_added_instruction_; diff --git a/tensorflow/compiler/xla/service/hlo_cost_analysis.cc b/tensorflow/compiler/xla/service/hlo_cost_analysis.cc index 9cd5a1e2b7..4ec2ef27bf 100644 --- a/tensorflow/compiler/xla/service/hlo_cost_analysis.cc +++ b/tensorflow/compiler/xla/service/hlo_cost_analysis.cc @@ -229,6 +229,10 @@ Status HloCostAnalysis::HandleOutfeed(const HloInstruction*) { return Status::OK(); } +Status HloCostAnalysis::HandleHostCompute(const HloInstruction*) { + return Status::OK(); +} + Status HloCostAnalysis::HandleMap(const HloInstruction* map) { // Compute properties of the mapped function. TF_ASSIGN_OR_RETURN(const Properties sub_properties, @@ -529,6 +533,11 @@ Status HloCostAnalysis::HandleConditional(const HloInstruction* conditional) { return Status::OK(); } +Status HloCostAnalysis::HandleGather(const HloInstruction* gather) { + // Gather does not issue any flops. + return Status::OK(); +} + Status HloCostAnalysis::FinishVisit(const HloInstruction*) { return Status::OK(); } diff --git a/tensorflow/compiler/xla/service/hlo_cost_analysis.h b/tensorflow/compiler/xla/service/hlo_cost_analysis.h index e5783539e5..d17678d20f 100644 --- a/tensorflow/compiler/xla/service/hlo_cost_analysis.h +++ b/tensorflow/compiler/xla/service/hlo_cost_analysis.h @@ -71,6 +71,7 @@ class HloCostAnalysis : public ConstDfsHloVisitor { Status HandleCrossReplicaSum(const HloInstruction* crs) override; Status HandleInfeed(const HloInstruction* infeed) override; Status HandleOutfeed(const HloInstruction* outfeed) override; + Status HandleHostCompute(const HloInstruction* host_compute) override; Status HandleRng(const HloInstruction* random) override; Status HandleReverse(const HloInstruction* reverse) override; Status HandleSort(const HloInstruction* sort) override; @@ -99,6 +100,7 @@ class HloCostAnalysis : public ConstDfsHloVisitor { Status HandleTranspose(const HloInstruction* transpose) override; Status HandleWhile(const HloInstruction* xla_while) override; Status HandleConditional(const HloInstruction* conditional) override; + Status HandleGather(const HloInstruction* gather) override; Status FinishVisit(const HloInstruction* root) override; Status Preprocess(const HloInstruction* hlo) override; diff --git a/tensorflow/compiler/xla/service/hlo_dataflow_analysis.cc b/tensorflow/compiler/xla/service/hlo_dataflow_analysis.cc index ccbbe8f196..934e43ba48 100644 --- a/tensorflow/compiler/xla/service/hlo_dataflow_analysis.cc +++ b/tensorflow/compiler/xla/service/hlo_dataflow_analysis.cc @@ -38,12 +38,12 @@ namespace xla { using ::tensorflow::strings::StrAppend; using ::tensorflow::strings::StrCat; -HloDataflowAnalysis::HloDataflowAnalysis(HloModule* module, bool ssa_form, +HloDataflowAnalysis::HloDataflowAnalysis(const HloModule& module, bool ssa_form, bool bitcast_defines_value) : module_(module), ssa_form_(ssa_form), bitcast_defines_value_(bitcast_defines_value), - call_graph_(CallGraph::Build(module)) {} + call_graph_(CallGraph::Build(&module)) {} bool HloDataflowAnalysis::ValueIsDefinedAt(const HloInstruction* instruction, const ShapeIndex& index) const { @@ -115,9 +115,9 @@ void HloDataflowAnalysis::DeleteMarkedValues() { } string HloDataflowAnalysis::ToString() const { - string out = StrCat("HloDataflowAnalysis, module ", module_->name(), "\n"); + string out = StrCat("HloDataflowAnalysis, module ", module_.name(), "\n"); StrAppend(&out, " Instruction value sets:\n"); - for (const HloComputation* computation : module_->computations()) { + for (const HloComputation* computation : module_.computations()) { for (const HloInstruction* instruction : computation->instructions()) { StrAppend(&out, " ", instruction->name(), ":\n"); if (ShapeUtil::IsTuple(instruction->shape())) { @@ -592,7 +592,7 @@ void HloDataflowAnalysis::Propagate() { } }; - for (HloComputation* computation : module_->computations()) { + for (HloComputation* computation : module_.computations()) { for (HloInstruction* instruction : computation->instructions()) { add_to_worklist(instruction); } @@ -686,7 +686,7 @@ InstructionValueSet& HloDataflowAnalysis::GetInstructionValueSet( } Status HloDataflowAnalysis::InitializeInstructionValueSets() { - for (const HloComputation* computation : module_->computations()) { + for (const HloComputation* computation : module_.computations()) { const CallGraphNode& call_graph_node = call_graph_->GetNode(computation); for (HloInstruction* instruction : computation->instructions()) { // Create an empty shape tree. @@ -787,9 +787,9 @@ Status HloDataflowAnalysis::InitializeInstructionValueSets() { /* static */ StatusOr<std::unique_ptr<HloDataflowAnalysis>> HloDataflowAnalysis::Run( - HloModule* module, bool ssa_form, bool bitcast_defines_value) { - VLOG(1) << "HloDataflowAnalysis::Run on module " << module->name(); - XLA_VLOG_LINES(2, module->ToString()); + const HloModule& module, bool ssa_form, bool bitcast_defines_value) { + VLOG(1) << "HloDataflowAnalysis::Run on module " << module.name(); + XLA_VLOG_LINES(2, module.ToString()); auto dataflow_analysis = WrapUnique( new HloDataflowAnalysis(module, ssa_form, bitcast_defines_value)); @@ -806,7 +806,7 @@ StatusOr<std::unique_ptr<HloDataflowAnalysis>> HloDataflowAnalysis::Run( // lookup is faster. std::vector<std::vector<HloPosition>> value_positions( dataflow_analysis->next_value_id_); - for (const HloComputation* computation : module->computations()) { + for (const HloComputation* computation : module.computations()) { for (HloInstruction* instruction : computation->instructions()) { for (const auto& pair : dataflow_analysis->GetInstructionValueSet(instruction)) { @@ -858,7 +858,7 @@ Status HloDataflowAnalysis::Verify() const { // For each value in each value set, verify that the value set's position // appears in the value's positions(). - for (const auto& computation : module_->computations()) { + for (const auto& computation : module_.computations()) { for (const auto& instruction : computation->instructions()) { for (const auto& pair : GetInstructionValueSet(instruction)) { const ShapeIndex& index = pair.first; diff --git a/tensorflow/compiler/xla/service/hlo_dataflow_analysis.h b/tensorflow/compiler/xla/service/hlo_dataflow_analysis.h index 89d318188f..7b8a74b096 100644 --- a/tensorflow/compiler/xla/service/hlo_dataflow_analysis.h +++ b/tensorflow/compiler/xla/service/hlo_dataflow_analysis.h @@ -60,7 +60,7 @@ class HloDataflowAnalysis { // a new HLO value in the analysis. If false then Bitcast forwards the // value of its operand. static StatusOr<std::unique_ptr<HloDataflowAnalysis>> Run( - HloModule* module, bool ssa_form = false, + const HloModule& module, bool ssa_form = false, bool bitcast_defines_value = false); // Returns true if 'instruction' defines an HLO value at the given shape index @@ -119,7 +119,7 @@ class HloDataflowAnalysis { string ToString() const; protected: - HloDataflowAnalysis(HloModule* module, bool ssa_form, + HloDataflowAnalysis(const HloModule& module, bool ssa_form, bool bitcast_defines_value = false); // Returns a new HloValue defined at the given instruction and shape index. @@ -180,7 +180,7 @@ class HloDataflowAnalysis { // Verify various invariants of the dataflow analysis. Status Verify() const; - HloModule* const module_; + const HloModule& module_; const bool ssa_form_; const bool bitcast_defines_value_; diff --git a/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc b/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc index e714b2567f..7bf3a1a060 100644 --- a/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc +++ b/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc @@ -50,7 +50,7 @@ class HloDataflowAnalysisTest : public HloTestBase, bool bitcast_defines_value = false) { hlo_graph_dumper::MaybeDumpHloModule(*module_, "Before dataflow analysis"); analysis_ = - HloDataflowAnalysis::Run(module_.get(), ssa_form, bitcast_defines_value) + HloDataflowAnalysis::Run(*module_, ssa_form, bitcast_defines_value) .ConsumeValueOrDie(); return *analysis_; } diff --git a/tensorflow/compiler/xla/service/hlo_evaluator.cc b/tensorflow/compiler/xla/service/hlo_evaluator.cc index 8016b38d15..296f010a92 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator.cc +++ b/tensorflow/compiler/xla/service/hlo_evaluator.cc @@ -34,8 +34,6 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_query.h" #include "tensorflow/compiler/xla/service/shape_inference.h" #include "tensorflow/compiler/xla/shape_util.h" -#include "tensorflow/compiler/xla/status.h" -#include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/window_util.h" diff --git a/tensorflow/compiler/xla/service/hlo_graph_dumper.cc b/tensorflow/compiler/xla/service/hlo_graph_dumper.cc index 44fcd36370..2861fec39e 100644 --- a/tensorflow/compiler/xla/service/hlo_graph_dumper.cc +++ b/tensorflow/compiler/xla/service/hlo_graph_dumper.cc @@ -940,6 +940,7 @@ ColorScheme HloDotDumper::GetInstructionColor(const HloInstruction* instr) { case HloOpcode::kConcatenate: case HloOpcode::kCopy: case HloOpcode::kDynamicSlice: + case HloOpcode::kGather: case HloOpcode::kPad: case HloOpcode::kReshape: case HloOpcode::kReverse: @@ -988,6 +989,7 @@ ColorScheme HloDotDumper::GetInstructionColor(const HloInstruction* instr) { case HloOpcode::kCall: case HloOpcode::kConditional: case HloOpcode::kCustomCall: + case HloOpcode::kHostCompute: case HloOpcode::kWhile: return kDarkGreen; case HloOpcode::kConstant: diff --git a/tensorflow/compiler/xla/service/hlo_instruction.cc b/tensorflow/compiler/xla/service/hlo_instruction.cc index 0981f1f4fe..b7dd055d7c 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.cc +++ b/tensorflow/compiler/xla/service/hlo_instruction.cc @@ -801,6 +801,22 @@ static string FusionNodeName(HloInstruction::FusionKind fusion_kind) { return instruction; } +HloInstruction* HloInstruction::AddFusionOperand(HloInstruction* new_operand) { + CHECK_EQ(opcode(), HloOpcode::kFusion); + CHECK_EQ(operand_count(), + fused_instructions_computation()->parameter_instructions().size()); + const int64 param_no = operand_count(); + // Name the parameter after the instruction it represents in the outer + // (non-fusion) computation. + string param_name = StrCat(new_operand->name(), ".param_", param_no); + HloInstruction* fused_parameter = + fused_instructions_computation()->AddParameter( + HloInstruction::CreateParameter(param_no, new_operand->shape(), + param_name)); + AppendOperand(new_operand); + return fused_parameter; +} + void HloInstruction::MergeFusionInstruction( HloInstruction* instruction_to_merge) { CHECK_EQ(opcode_, HloOpcode::kFusion); @@ -993,13 +1009,7 @@ HloInstruction* HloInstruction::CloneAndFuseInternal( // Clone's operand was not already an operand of the fusion // instruction. Add it as an operand and add a corresponding fused // parameter instruction. - int64 param_no = fused_parameters.size(); - // Name the parameter after the instruction it represents in the outer - // (non-fusion) computation. - string param_name = StrCat(operand->name(), ".param_", param_no); - fused_param = fused_instructions_computation()->AddParameter( - CreateParameter(param_no, operand->shape(), param_name)); - AppendOperand(operand); + fused_param = AddFusionOperand(operand); } TF_CHECK_OK(clone->ReplaceOperandWith(operand_num, fused_param)); } @@ -1084,6 +1094,7 @@ bool HloInstruction::HasSideEffect() const { case HloOpcode::kInfeed: case HloOpcode::kOutfeed: case HloOpcode::kTrace: + case HloOpcode::kHostCompute: return true; default: { // Check if any of the called computations has a side effect. @@ -1121,6 +1132,19 @@ bool HloInstruction::HasSideEffect() const { return instruction; } +/* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateHostCompute( + const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, + tensorflow::StringPiece channel_name, const int64 cost_estimate_ns) { + std::unique_ptr<HloInstruction> instruction = + WrapUnique(new HloInstruction(HloOpcode::kHostCompute, shape)); + for (auto operand : operands) { + instruction->AppendOperand(operand); + } + instruction->channel_name_ = channel_name.ToString(); + instruction->cost_estimate_ns_ = cost_estimate_ns; + return instruction; +} + /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateTuple( tensorflow::gtl::ArraySlice<HloInstruction*> elements) { std::vector<Shape> element_shapes; @@ -1131,6 +1155,38 @@ bool HloInstruction::HasSideEffect() const { return CreateVariadic(tuple_shape, HloOpcode::kTuple, elements); } +/* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateGather( + const Shape& shape, HloInstruction* operand, HloInstruction* gather_indices, + const GatherDimensionNumbers& gather_dim_numbers, + tensorflow::gtl::ArraySlice<int64> window_bounds) { + std::unique_ptr<HloInstruction> instruction = + WrapUnique(new HloInstruction(HloOpcode::kGather, shape)); + instruction->AppendOperand(operand); + instruction->AppendOperand(gather_indices); + instruction->gather_dimension_numbers_ = + MakeUnique<GatherDimensionNumbers>(gather_dim_numbers); + c_copy(window_bounds, std::back_inserter(instruction->gather_window_bounds_)); + return instruction; +} + +/* static */ GatherDimensionNumbers HloInstruction::MakeGatherDimNumbers( + tensorflow::gtl::ArraySlice<int64> output_window_dims, + tensorflow::gtl::ArraySlice<int64> elided_window_dims, + tensorflow::gtl::ArraySlice<int64> gather_dims_to_operand_dims) { + GatherDimensionNumbers gather_dim_numbers; + for (int64 output_window_dim : output_window_dims) { + gather_dim_numbers.add_output_window_dims(output_window_dim); + } + for (int64 elided_window_dim : elided_window_dims) { + gather_dim_numbers.add_elided_window_dims(elided_window_dim); + } + for (int64 gather_dim_to_input_dim : gather_dims_to_operand_dims) { + gather_dim_numbers.add_gather_dims_to_operand_dims(gather_dim_to_input_dim); + } + + return gather_dim_numbers; +} + std::unique_ptr<HloInstruction> HloInstruction::CloneWithNewOperands( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, @@ -1212,6 +1268,10 @@ std::unique_ptr<HloInstruction> HloInstruction::CloneWithNewOperands( case HloOpcode::kCustomCall: clone = CreateCustomCall(shape, new_operands, custom_call_target_); break; + case HloOpcode::kHostCompute: + clone = CreateHostCompute(shape, new_operands, channel_name_, + cost_estimate_ns_); + break; case HloOpcode::kConcatenate: clone = CreateConcatenate(shape, new_operands, dimensions(0)); break; @@ -1361,12 +1421,19 @@ std::unique_ptr<HloInstruction> HloInstruction::CloneWithNewOperands( break; case HloOpcode::kRecv: CHECK_EQ(new_operands.size(), 0); - clone = CreateRecv(shape, channel_id()); + // The shape is a tuple, but CreateRecv() wants the raw data shape. + clone = + CreateRecv(ShapeUtil::GetTupleElementShape(shape, 0), channel_id()); break; case HloOpcode::kRecvDone: CHECK_EQ(new_operands.size(), 1); clone = CreateRecvDone(new_operands[0]); break; + case HloOpcode::kGather: + CHECK_EQ(new_operands.size(), 2); + clone = CreateGather(shape, new_operands[0], new_operands[1], + *gather_dimension_numbers_, gather_window_bounds_); + break; case HloOpcode::kTrace: LOG(FATAL) << "Not yet implemented, clone: " << HloOpcodeString(opcode_); } @@ -1710,6 +1777,11 @@ bool HloInstruction::IdenticalSlowPath( return protobuf_util::ProtobufEquals(dot_dimension_numbers(), other.dot_dimension_numbers()); + case HloOpcode::kGather: + return protobuf_util::ProtobufEquals(gather_dimension_numbers(), + other.gather_dimension_numbers()) && + gather_window_bounds() == other.gather_window_bounds(); + // FFT has various types & lengths. case HloOpcode::kFft: return fft_type() == other.fft_type() && @@ -1780,6 +1852,7 @@ bool HloInstruction::IdenticalSlowPath( case HloOpcode::kRecvDone: case HloOpcode::kSend: case HloOpcode::kSendDone: + case HloOpcode::kHostCompute: return false; } } @@ -2140,6 +2213,11 @@ std::vector<string> HloInstruction::ExtraAttributesToString( if (dot_dimension_numbers_ != nullptr) { extra.push_back(DotDimensionNumbersToString()); } + if (gather_dimension_numbers_ != nullptr) { + extra.push_back(GatherDimensionNumbersToString()); + extra.push_back( + StrCat("window_bounds={", Join(gather_window_bounds(), ","), "}")); + } if (opcode() == HloOpcode::kFft) { extra.push_back(StrCat("fft_type=", FftType_Name(fft_type()))); extra.push_back(StrCat("fft_length={", Join(fft_length(), ","), "}")); @@ -2271,6 +2349,14 @@ HloInstructionProto HloInstruction::ToProto() const { if (dot_dimension_numbers_ != nullptr) { *proto.mutable_dot_dimension_numbers() = *dot_dimension_numbers_; } + if (gather_dimension_numbers_ != nullptr) { + *proto.mutable_gather_dimension_numbers() = *gather_dimension_numbers_; + } + if (opcode() == HloOpcode::kGather) { + for (int64 bound : gather_window_bounds()) { + proto.add_gather_window_bounds(bound); + } + } for (int i = 0; i < slice_starts_.size(); ++i) { auto* slice_dimension = proto.add_slice_dimensions(); slice_dimension->set_start(slice_starts_[i]); @@ -2565,6 +2651,8 @@ Status HloInstruction::Visit(DfsHloVisitorBase<HloInstructionPtr>* visitor) { return visitor->HandleInfeed(this); case HloOpcode::kOutfeed: return visitor->HandleOutfeed(this); + case HloOpcode::kHostCompute: + return visitor->HandleHostCompute(this); case HloOpcode::kRng: return visitor->HandleRng(this); case HloOpcode::kWhile: @@ -2585,6 +2673,8 @@ Status HloInstruction::Visit(DfsHloVisitorBase<HloInstructionPtr>* visitor) { return visitor->HandleSend(this); case HloOpcode::kSendDone: return visitor->HandleSendDone(this); + case HloOpcode::kGather: + return visitor->HandleGather(this); // These opcodes are not handled here. case HloOpcode::kTrace: @@ -3268,6 +3358,23 @@ string HloInstruction::DotDimensionNumbersToString() const { return Join(result, ", "); } +string HloInstruction::GatherDimensionNumbersToString() const { + CHECK_NE(gather_dimension_numbers_.get(), nullptr); + string output_window_dims = + StrCat("output_window_dims={", + Join(gather_dimension_numbers_->output_window_dims(), ","), "}"); + string elided_window_dims = + StrCat("elided_window_dims={", + Join(gather_dimension_numbers_->elided_window_dims(), ","), "}"); + string gather_dims_to_operand_dims = StrCat( + "gather_dims_to_operand_dims={", + Join(gather_dimension_numbers_->gather_dims_to_operand_dims(), ","), "}"); + + return Join<std::initializer_list<string>>( + {output_window_dims, elided_window_dims, gather_dims_to_operand_dims}, + ", "); +} + bool HloInstruction::CouldBeBitcast() const { switch (opcode_) { case HloOpcode::kTranspose: diff --git a/tensorflow/compiler/xla/service/hlo_instruction.h b/tensorflow/compiler/xla/service/hlo_instruction.h index 3170746157..c4fe132d1d 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.h +++ b/tensorflow/compiler/xla/service/hlo_instruction.h @@ -451,6 +451,12 @@ class HloInstruction { HloInstruction* true_computation_arg, HloComputation* true_computation, HloInstruction* false_computation_arg, HloComputation* false_computation); + static std::unique_ptr<HloInstruction> CreateGather( + const Shape& shape, HloInstruction* operand, + HloInstruction* gather_indices, + const GatherDimensionNumbers& gather_dim_numbers, + tensorflow::gtl::ArraySlice<int64> window_bounds); + // Creates a fusion instruction. A fusion instruction contains one or more // fused instructions forming an expression with a single root // "fused_root". Additional instructions can be added to the fusion @@ -475,6 +481,12 @@ class HloInstruction { const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, tensorflow::StringPiece custom_call_target); + // Creates a HostCompute instruction, which records host-side control and + // data dependencies for use in instruction scheduling. + static std::unique_ptr<HloInstruction> CreateHostCompute( + const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, + tensorflow::StringPiece channel_name, const int64 cost_estimate_ns); + // Creates a tuple instruction with the given elements. This is a convenience // wrapper around CreateVariadic. static std::unique_ptr<HloInstruction> CreateTuple( @@ -486,6 +498,12 @@ class HloInstruction { const Shape& shape, HloInstruction* operand, tensorflow::gtl::ArraySlice<int64> dimensions); + // Creates an instance of GatherDimensionNumbers. + static GatherDimensionNumbers MakeGatherDimNumbers( + tensorflow::gtl::ArraySlice<int64> output_window_dims, + tensorflow::gtl::ArraySlice<int64> elided_window_dims, + tensorflow::gtl::ArraySlice<int64> gather_dims_to_operand_dims); + // Returns the opcode for this instruction. HloOpcode opcode() const { return opcode_; } @@ -767,6 +785,10 @@ class HloInstruction { // // (We express the default options using an overload rather than a default // param because gdb ignores default params, but does resolve overloads.) + // + // TODO(b/73348663): Make ToString() adaptive to the size of the string by + // default, backing off on providing full information for very large strings, + // or provide a different name for a ToString-like function that does that. string ToString() const { return ToString(HloPrintOptions()); } string ToString(const HloPrintOptions& options) const; @@ -914,6 +936,9 @@ class HloInstruction { // Return true if this operator has a sharding assigned. bool has_sharding() const { return sharding_ != nullptr; } + // Adds a new operand the fusion instruction. + HloInstruction* AddFusionOperand(HloInstruction* new_operand); + // Merges the fused instructions from 'instruction_to_merge' into the // fused instruction set of 'this', updating operands as necessary. // @@ -1086,6 +1111,19 @@ class HloInstruction { // Returns the dump string of the dot dimension numbers. string DotDimensionNumbersToString() const; + const GatherDimensionNumbers& gather_dimension_numbers() const { + CHECK(gather_dimension_numbers_ != nullptr); + return *gather_dimension_numbers_; + } + + tensorflow::gtl::ArraySlice<int64> gather_window_bounds() const { + CHECK_EQ(opcode(), HloOpcode::kGather); + return gather_window_bounds_; + } + + // Returns the dump string of the gather dimension numbers. + string GatherDimensionNumbersToString() const; + // Returns the random distribution for this rng node. // // Precondition: opcode() == HloOpcode::kRng @@ -1350,6 +1388,9 @@ class HloInstruction { // Describes the dimension numbers used for a dot. std::unique_ptr<DotDimensionNumbers> dot_dimension_numbers_; + std::unique_ptr<GatherDimensionNumbers> gather_dimension_numbers_; + std::vector<int64> gather_window_bounds_; + // Describes FFT type for an FFT instruction. FftType fft_type_ = FftType::FFT; @@ -1388,6 +1429,12 @@ class HloInstruction { // Name of a global symbol to call, only present for kCustomCall. string custom_call_target_; + // Name to use for host send/recv channels, only present for kHostCompute. + string channel_name_; + + // Estimate of the duration of a host computation in nanoseconds. + int64 cost_estimate_ns_; + // Computations called by this instruction. std::vector<HloComputation*> called_computations_; diff --git a/tensorflow/compiler/xla/service/hlo_instruction_test.cc b/tensorflow/compiler/xla/service/hlo_instruction_test.cc index 94e9bfe56e..32d3ed272b 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction_test.cc +++ b/tensorflow/compiler/xla/service/hlo_instruction_test.cc @@ -1271,5 +1271,40 @@ TEST_F(HloInstructionTest, Stringification) { "true_computation=%TransposeDot, false_computation=%TransposeDot"); } +TEST_F(HloInstructionTest, StringifyGather) { + Shape input_tensor_shape = ShapeUtil::MakeShape(F32, {50, 49, 48, 47, 46}); + Shape gather_indices_tensor_shape = + ShapeUtil::MakeShape(S64, {10, 9, 8, 7, 5}); + Shape gather_result_shape = + ShapeUtil::MakeShape(F32, {10, 9, 8, 7, 30, 29, 28, 27, 26}); + + HloComputation::Builder builder("Gather"); + HloInstruction* input = builder.AddInstruction( + HloInstruction::CreateParameter(0, input_tensor_shape, "input_tensor")); + HloInstruction* gather_indices = + builder.AddInstruction(HloInstruction::CreateParameter( + 1, gather_indices_tensor_shape, "gather_indices")); + + HloInstruction* gather_instruction = + builder.AddInstruction(HloInstruction::CreateGather( + gather_result_shape, input, gather_indices, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 27, 26})); + + HloModule module(TestName()); + module.AddEntryComputation(builder.Build()); + + EXPECT_EQ(gather_instruction->ToString(), + "%gather = f32[10,9,8,7,30,29,28,27,26]{8,7,6,5,4,3,2,1,0} " + "gather(f32[50,49,48,47,46]{4,3,2,1,0} %input_tensor, " + "s64[10,9,8,7,5]{4,3,2,1,0} %gather_indices), " + "output_window_dims={4,5,6,7,8}, elided_window_dims={}, " + "gather_dims_to_operand_dims={0,1,2,3,4}, " + "window_bounds={30,29,28,27,26}"); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_module.cc b/tensorflow/compiler/xla/service/hlo_module.cc index 60270b0595..cb2fe9f874 100644 --- a/tensorflow/compiler/xla/service/hlo_module.cc +++ b/tensorflow/compiler/xla/service/hlo_module.cc @@ -145,6 +145,21 @@ void HloModule::ReplaceComputations( } break; } + case HloOpcode::kConditional: { + HloComputation* new_true_computation = + tensorflow::gtl::FindWithDefault( + replacements, instruction->true_computation(), nullptr); + if (new_true_computation != nullptr) { + instruction->set_true_computation(new_true_computation); + } + HloComputation* new_false_computation = + tensorflow::gtl::FindWithDefault( + replacements, instruction->false_computation(), nullptr); + if (new_false_computation != nullptr) { + instruction->set_false_computation(new_false_computation); + } + break; + } case HloOpcode::kSelectAndScatter: { HloComputation* new_select = tensorflow::gtl::FindWithDefault( replacements, instruction->select(), nullptr); @@ -563,6 +578,18 @@ std::unique_ptr<HloModule> HloModule::Clone(const string& suffix) const { return module; } +HloComputation* HloModule::DeepCloneComputation(HloComputation* computation) { + HloComputation* clone = AddEmbeddedComputation(computation->Clone("", this)); + TF_CHECK_OK( + clone->root_instruction()->Accept([this](HloInstruction* instruction) { + instruction->ReplaceCalledComputations([this](HloComputation* callee) { + return DeepCloneComputation(callee); + }); + return Status::OK(); + })); + return clone; +} + uint64 HloModule::RandomNew64() const { tensorflow::mutex_lock l(rng_mutex_); return rng_(); diff --git a/tensorflow/compiler/xla/service/hlo_module.h b/tensorflow/compiler/xla/service/hlo_module.h index 4bfe8d89ce..06d92f94fd 100644 --- a/tensorflow/compiler/xla/service/hlo_module.h +++ b/tensorflow/compiler/xla/service/hlo_module.h @@ -85,6 +85,10 @@ class HloModule { // Returns a deep copy of this module including all computations. std::unique_ptr<HloModule> Clone(const string& suffix = "clone") const; + // Performs a deep clone of the computation, by recursively cloning all + // the called computations as well. + HloComputation* DeepCloneComputation(HloComputation* computation); + // Return a pointer to the entry computation of the module.. const HloComputation* entry_computation() const { CHECK_NE(nullptr, entry_computation_); diff --git a/tensorflow/compiler/xla/service/hlo_opcode.h b/tensorflow/compiler/xla/service/hlo_opcode.h index 3d64523a79..af24604c39 100644 --- a/tensorflow/compiler/xla/service/hlo_opcode.h +++ b/tensorflow/compiler/xla/service/hlo_opcode.h @@ -76,9 +76,11 @@ namespace xla { V(kFft, "fft") \ V(kFloor, "floor") \ V(kFusion, "fusion", kHloOpcodeIsVariadic) \ + V(kGather, "gather") \ V(kGe, "greater-than-or-equal-to", kHloOpcodeIsComparison) \ V(kGetTupleElement, "get-tuple-element") \ V(kGt, "greater-than", kHloOpcodeIsComparison) \ + V(kHostCompute, "host-compute") \ V(kImag, "imag") \ V(kInfeed, "infeed") \ V(kIsFinite, "is-finite") \ diff --git a/tensorflow/compiler/xla/service/hlo_ordering.cc b/tensorflow/compiler/xla/service/hlo_ordering.cc index 68e3c9618c..1b24d8da9e 100644 --- a/tensorflow/compiler/xla/service/hlo_ordering.cc +++ b/tensorflow/compiler/xla/service/hlo_ordering.cc @@ -186,6 +186,22 @@ bool HloOrdering::UseIsBeforeValueDefinition( } } + if (use.instruction->opcode() == HloOpcode::kConditional) { + const HloInstruction* conditional = use.instruction; + if (call_graph_->InstructionIsNestedIn(value.defining_instruction(), + conditional->true_computation())) { + VLOG(4) << " use is conditional " << use.instruction->name() + << " and def is in TRUE computation"; + return true; + } + if (call_graph_->InstructionIsNestedIn(value.defining_instruction(), + conditional->false_computation())) { + VLOG(4) << " use is conditional " << use.instruction->name() + << " and def is in FALSE computation"; + return true; + } + } + VLOG(4) << " use is not before value"; return false; } diff --git a/tensorflow/compiler/xla/service/hlo_ordering_test.cc b/tensorflow/compiler/xla/service/hlo_ordering_test.cc index aba66114de..a989fce632 100644 --- a/tensorflow/compiler/xla/service/hlo_ordering_test.cc +++ b/tensorflow/compiler/xla/service/hlo_ordering_test.cc @@ -262,8 +262,8 @@ TEST_F(HloOrderingTest, ValuesInWhileComputations) { scalar_shape, HloOpcode::kAdd, constant, xla_while)); module->AddEntryComputation(builder.Build()); - TF_ASSERT_OK_AND_ASSIGN( - auto dataflow, HloDataflowAnalysis::Run(module.get(), /*ssa_form=*/true)); + TF_ASSERT_OK_AND_ASSIGN(auto dataflow, + HloDataflowAnalysis::Run(*module, /*ssa_form=*/true)); DependencyHloOrdering ordering(module.get()); // Init value is defined before the while, but live range is not before the diff --git a/tensorflow/compiler/xla/service/hlo_rematerialization.cc b/tensorflow/compiler/xla/service/hlo_rematerialization.cc index c6b4dc0368..98b8d34be1 100644 --- a/tensorflow/compiler/xla/service/hlo_rematerialization.cc +++ b/tensorflow/compiler/xla/service/hlo_rematerialization.cc @@ -60,6 +60,7 @@ bool IsRematerializable(const HloInstruction* instruction) { switch (instruction->opcode()) { case HloOpcode::kCall: case HloOpcode::kConstant: + case HloOpcode::kConditional: case HloOpcode::kCrossReplicaSum: case HloOpcode::kCustomCall: case HloOpcode::kParameter: diff --git a/tensorflow/compiler/xla/service/hlo_scheduling.cc b/tensorflow/compiler/xla/service/hlo_scheduling.cc index 8dc4d4f7ba..f6e33403f5 100644 --- a/tensorflow/compiler/xla/service/hlo_scheduling.cc +++ b/tensorflow/compiler/xla/service/hlo_scheduling.cc @@ -15,7 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_scheduling.h" -#include <queue> +#include <map> #include <utility> #include <vector> @@ -151,8 +151,10 @@ class ListScheduler { int64 bytes_defined; // For each buffer B used by this instruction, we keep a pair (B, U), where - // U is the number of uses of B that have not yet been scheduled. - std::vector<std::pair<const LogicalBuffer* const, int64>> + // U is the number of uses of B that have not yet been scheduled. This pair + // is a pointer into the unscheduled_use_count_ map, so it gets updated for + // free when we update counts in the map. + std::vector<const std::pair<const LogicalBuffer* const, int64>*> used_buffer_unscheduled_use_counts; }; @@ -175,8 +177,8 @@ class ListScheduler { } auto unscheduled_use_count_it = unscheduled_use_count_.find(buffer); CHECK(unscheduled_use_count_it != unscheduled_use_count_.end()); - entry.used_buffer_unscheduled_use_counts.emplace_back( - unscheduled_use_count_it->first, unscheduled_use_count_it->second); + entry.used_buffer_unscheduled_use_counts.push_back( + &*unscheduled_use_count_it); } return entry; } @@ -185,8 +187,8 @@ class ListScheduler { int64 BytesFreedIfScheduled(const ReadyListEntry& entry) { int64 freed_bytes = 0; for (const auto& kv : entry.used_buffer_unscheduled_use_counts) { - auto buffer = kv.first; - auto use_count = kv.second; + auto buffer = kv->first; + auto use_count = kv->second; if (use_count == 1) { freed_bytes += size_function_(*buffer); } @@ -217,23 +219,18 @@ class ListScheduler { } } - auto priority_comparator = - [this](const std::pair<Priority, ReadyListEntry>& lhs, - const std::pair<Priority, ReadyListEntry>& rhs) { - return lhs.first < rhs.first; - }; - std::priority_queue<std::pair<Priority, ReadyListEntry>, - std::vector<std::pair<Priority, ReadyListEntry>>, - decltype(priority_comparator)> - ready_queue(priority_comparator); + // Use a multimap to sort ReadyListEntry according to their priority. + std::multimap<Priority, ReadyListEntry> ready_queue; - // Set of instructions in the ready list. - tensorflow::gtl::FlatSet<const HloInstruction*> ready_instructions; + // Map of ready instructions to their iterators in ready_queue. + tensorflow::gtl::FlatMap<const HloInstruction*, + std::multimap<Priority, ReadyListEntry>::iterator> + ready_instructions; auto add_to_ready_queue = [&](HloInstruction* inst) { auto entry = MakeReadyListEntry(inst); - ready_queue.emplace(GetPriority(entry), std::move(entry)); - ready_instructions.insert(inst); + auto it = ready_queue.emplace(GetPriority(entry), std::move(entry)); + ready_instructions[inst] = it; }; for (auto* instruction : computation_.instructions()) { @@ -247,14 +244,10 @@ class ListScheduler { while (!ready_queue.empty()) { // Remove the selected instruction from the ready list and add it to the // schedule. - const HloInstruction* best = ready_queue.top().second.instruction; - ready_queue.pop(); - // We may have duplicates in the priority queue, because when a ready - // instruction's priority goes up, we reinsert it to the priority queue. - // Skip the duplicate. - if (scheduled_instructions_.find(best) != scheduled_instructions_.end()) { - continue; - } + auto best_it = ready_queue.end(); + --best_it; + const HloInstruction* best = best_it->second.instruction; + ready_queue.erase(best_it); ready_instructions.erase(best); schedule.push_back(best); scheduled_instructions_.insert(best); @@ -287,16 +280,27 @@ class ListScheduler { update_pred_count(succ); } // The unscheduled use count for a buffer has changed to 1, so the - // priorities of some ready instructions may go up. We reinsert them to - // the priority queue, so that they can appear earlier. The old entries - // will become duplicates and will be skipped. + // priorities of some ready instructions may go up. We update them in the + // ready queue, so that they can appear earlier. if (adjust_ready_queue) { for (HloInstruction* operand : best->operands()) { for (HloInstruction* operand_user : operand->users()) { - if (ready_instructions.find(operand_user) != - ready_instructions.end()) { - add_to_ready_queue(operand_user); + auto ready_instructions_it = ready_instructions.find(operand_user); + if (ready_instructions_it == ready_instructions.end()) { + continue; + } + auto ready_queue_it = ready_instructions_it->second; + auto& entry = ready_queue_it->second; + Priority new_priority = GetPriority(entry); + if (new_priority == ready_queue_it->first) { + continue; } + // Create a new entry in ready_queue, then update + // ready_instructions[operand_user] to refer to the new entry. + ready_instructions_it->second = + ready_queue.emplace(new_priority, std::move(entry)); + // Remove the old entry in ready_queue. + ready_queue.erase(ready_queue_it); } } } @@ -317,8 +321,9 @@ class ListScheduler { buffer_uses_; // A map containing the count of unscheduled HLOs which using a particular - // LogicalBuffer. We rely on iterator stability in this map. - tensorflow::gtl::FlatMap<const LogicalBuffer*, int64> unscheduled_use_count_; + // LogicalBuffer. We rely on iterator stability in this map, and that the map + // entries are std::pair's. + std::unordered_map<const LogicalBuffer*, int64> unscheduled_use_count_; // Set of instructions which have been scheduled. tensorflow::gtl::FlatSet<const HloInstruction*> scheduled_instructions_; diff --git a/tensorflow/compiler/xla/service/hlo_verifier.cc b/tensorflow/compiler/xla/service/hlo_verifier.cc index e2b3bb9d71..b1fd068115 100644 --- a/tensorflow/compiler/xla/service/hlo_verifier.cc +++ b/tensorflow/compiler/xla/service/hlo_verifier.cc @@ -125,6 +125,10 @@ Status ShapeVerifier::HandleOutfeed(HloInstruction* outfeed) { return CheckShape(outfeed, ShapeUtil::MakeNil()); } +Status ShapeVerifier::HandleHostCompute(HloInstruction*) { + return tensorflow::Status::OK(); +} + Status ShapeVerifier::HandleRng(HloInstruction*) { return tensorflow::Status::OK(); } @@ -420,6 +424,14 @@ Status CheckMixedPrecisionOperands(const HloInstruction* instruction) { } // namespace +Status ShapeVerifier::HandleGather(HloInstruction* gather) { + return CheckShape( + gather, + ShapeInference::InferGatherShape( + gather->operand(0)->shape(), gather->operand(1)->shape(), + gather->gather_dimension_numbers(), gather->gather_window_bounds())); +} + Status ShapeVerifier::CheckShape(const HloInstruction* instruction, const Shape& inferred_shape) { // If allow_mixed_precision_ is false, check if there are operands with diff --git a/tensorflow/compiler/xla/service/hlo_verifier.h b/tensorflow/compiler/xla/service/hlo_verifier.h index 7eccf834bb..1dd7ec3c51 100644 --- a/tensorflow/compiler/xla/service/hlo_verifier.h +++ b/tensorflow/compiler/xla/service/hlo_verifier.h @@ -60,6 +60,7 @@ class ShapeVerifier : public DfsHloVisitor { Status HandleFusion(HloInstruction*) override; Status HandleCall(HloInstruction* call) override; Status HandleCustomCall(HloInstruction*) override; + Status HandleHostCompute(HloInstruction*) override; Status HandleSlice(HloInstruction* slice) override; Status HandleDynamicSlice(HloInstruction* dynamic_slice) override; Status HandleDynamicUpdateSlice( @@ -79,6 +80,7 @@ class ShapeVerifier : public DfsHloVisitor { Status HandleBatchNormInference( HloInstruction* batch_norm_inference) override; Status HandleBatchNormGrad(HloInstruction* batch_norm_grad) override; + Status HandleGather(HloInstruction* gather) override; Status FinishVisit(HloInstruction*) override { return tensorflow::Status::OK(); diff --git a/tensorflow/compiler/xla/service/instruction_fusion.cc b/tensorflow/compiler/xla/service/instruction_fusion.cc index 90e1f0acdc..f494748e17 100644 --- a/tensorflow/compiler/xla/service/instruction_fusion.cc +++ b/tensorflow/compiler/xla/service/instruction_fusion.cc @@ -102,6 +102,8 @@ namespace xla { case HloOpcode::kExp: case HloOpcode::kFft: case HloOpcode::kFusion: + case HloOpcode::kGather: + case HloOpcode::kHostCompute: case HloOpcode::kLog: case HloOpcode::kMap: case HloOpcode::kParameter: diff --git a/tensorflow/compiler/xla/service/layout_assignment.cc b/tensorflow/compiler/xla/service/layout_assignment.cc index fce135ef61..0668f66051 100644 --- a/tensorflow/compiler/xla/service/layout_assignment.cc +++ b/tensorflow/compiler/xla/service/layout_assignment.cc @@ -53,6 +53,83 @@ limitations under the License. namespace xla { +// For now moving only one API here, but we should have a single top level +// anonymous namespace, instead of three or four spread all over this file. +namespace { + +// Creates and returns a copy of the given instruction with a different +// layout. Tuple-shaped instructions will be deep-copied, and the last Tuple +// instruction producing the copy is returned. +StatusOr<HloInstruction*> CreateCopyWithNewLayout( + const Shape& shape_with_layout, HloInstruction* instruction) { + TF_RET_CHECK(LayoutUtil::HasLayout(shape_with_layout)); + DCHECK(ShapeUtil::Compatible(shape_with_layout, instruction->shape())) + << ShapeUtil::HumanString(shape_with_layout) << " " + << ShapeUtil::HumanString(instruction->shape()) + << " instruction: " << instruction->ToString(); + + if (ShapeUtil::IsTuple(instruction->shape())) { + // Deep-copy tuples. + std::vector<HloInstruction*> element_copies; + for (int64 i = 0; i < ShapeUtil::TupleElementCount(instruction->shape()); + ++i) { + HloInstruction* gte = instruction->parent()->AddInstruction( + HloInstruction::CreateGetTupleElement( + ShapeUtil::GetSubshape(instruction->shape(), {i}), instruction, + i)); + + // Recurse to copy each elements. + TF_ASSIGN_OR_RETURN( + HloInstruction * element_copy, + CreateCopyWithNewLayout( + ShapeUtil::GetSubshape(shape_with_layout, {i}), gte)); + element_copies.push_back(element_copy); + } + // Gather element copies into a tuple with a new Tuple instruction. + HloInstruction* tuple_copy = instruction->parent()->AddInstruction( + HloInstruction::CreateTuple(element_copies)); + LayoutUtil::ClearLayout(tuple_copy->mutable_shape()); + TF_RETURN_IF_ERROR(LayoutUtil::CopyLayoutBetweenShapes( + shape_with_layout, tuple_copy->mutable_shape())); + return tuple_copy; + } else if (ShapeUtil::IsArray(instruction->shape())) { + HloInstruction* copy = + instruction->parent()->AddInstruction(HloInstruction::CreateUnary( + instruction->shape(), HloOpcode::kCopy, instruction)); + LayoutUtil::ClearLayout(copy->mutable_shape()); + TF_RETURN_IF_ERROR(LayoutUtil::CopyLayoutBetweenShapes( + shape_with_layout, copy->mutable_shape())); + + return copy; + } else { + return FailedPrecondition( + "Can only copy array and tuple shaped instructions"); + } +} + +// Creates a copy of the given operand if the operand's layout does not match +// the given layout. This copy replaces the use in the given instruction. Tuple +// operands will be deep-copied. +Status CopyOperandIfLayoutsDiffer(const ShapeLayout& operand_layout, + HloInstruction* instruction, + int64 operand_no) { + HloInstruction* operand = instruction->mutable_operand(operand_no); + TF_RET_CHECK(operand_layout.LayoutIsSet()); + TF_RET_CHECK(LayoutUtil::HasLayout(operand->shape())); + + if (ShapeUtil::Equal(operand_layout.shape(), operand->shape())) { + // Operand layout already matches our constraint. Nothing to do. + return Status::OK(); + } + + TF_ASSIGN_OR_RETURN(HloInstruction * operand_copy, + CreateCopyWithNewLayout(operand_layout.shape(), operand)); + + return instruction->ReplaceOperandWith(operand_no, operand_copy); +} + +} // namespace + std::ostream& operator<<(std::ostream& out, const LayoutConstraint& constraint) { out << constraint.ToString(); @@ -512,6 +589,36 @@ Status LayoutAssignment::AddMandatoryConstraints( body_layout.result_shape(), instruction)); TF_RETURN_IF_ERROR(constraints->SetOperandLayout( body_layout.result_shape(), instruction, 0)); + } else if (instruction->opcode() == HloOpcode::kConditional) { + // The layout of the true and false computations must match, and must + // be the layout of the kConditional instruction. + TF_RET_CHECK(instruction->operand_count() == 3); + + HloComputation* true_computation = instruction->true_computation(); + HloComputation* false_computation = instruction->false_computation(); + const HloInstruction* true_operand = instruction->operand(1); + const HloInstruction* false_operand = instruction->operand(2); + + TF_RET_CHECK(true_computation->num_parameters() == 1); + TF_RET_CHECK(false_computation->num_parameters() == 1); + ComputationLayout& true_computation_layout = + FindOrDie(computation_layouts_, true_computation); + ComputationLayout& false_computation_layout = + FindOrDie(computation_layouts_, false_computation); + + DCHECK(ShapeUtil::Compatible(true_operand->shape(), + true_computation_layout.parameter_shape(0))); + DCHECK(ShapeUtil::Compatible( + false_operand->shape(), false_computation_layout.parameter_shape(0))); + + TF_RETURN_IF_ERROR(constraints->SetInstructionLayout( + true_computation_layout.result_shape(), instruction)); + TF_RETURN_IF_ERROR(constraints->SetOperandLayout( + true_computation_layout.parameter_shape(0), instruction, 1, + /*mandatory=*/true)); + TF_RETURN_IF_ERROR(constraints->SetOperandLayout( + false_computation_layout.parameter_shape(0), instruction, 2, + /*mandatory=*/true)); } else if (instruction->opcode() == HloOpcode::kCustomCall) { if (!CustomCallRequiresMajorFirstLayout(instruction)) { continue; @@ -598,6 +705,33 @@ Status CheckWhileLayout(HloInstruction* while_inst, return Status::OK(); } +Status CheckConditionalLayout( + HloInstruction* instruction, + const ComputationLayout& true_computation_layout, + const ComputationLayout& false_computation_layout) { + HloComputation* true_computation = instruction->true_computation(); + HloComputation* false_computation = instruction->false_computation(); + const HloInstruction* true_operand = instruction->operand(1); + const HloInstruction* false_operand = instruction->operand(2); + + TF_RET_CHECK(true_computation_layout.result_layout() == + false_computation_layout.result_layout()); + TF_RET_CHECK(true_computation_layout.result_layout().MatchesLayoutInShape( + instruction->shape())); + TF_RET_CHECK(true_computation_layout.result_layout().MatchesLayoutInShape( + true_computation->root_instruction()->shape())); + TF_RET_CHECK(false_computation_layout.result_layout().MatchesLayoutInShape( + instruction->shape())); + TF_RET_CHECK(false_computation_layout.result_layout().MatchesLayoutInShape( + false_computation->root_instruction()->shape())); + TF_RET_CHECK(true_computation_layout.parameter_layout(0).MatchesLayoutInShape( + true_operand->shape())); + TF_RET_CHECK( + false_computation_layout.parameter_layout(0).MatchesLayoutInShape( + false_operand->shape())); + return Status::OK(); +} + // Fusion parameters must match the layout of the fusion instructions operands, // and the root of the fusion expression must match the layout of the fusion // instruction. @@ -710,6 +844,13 @@ Status LayoutAssignment::CheckLayouts(HloModule* module) { FindOrDie(computation_layouts_, instruction->while_condition()), FindOrDie(computation_layouts_, instruction->while_body()))); break; + case HloOpcode::kConditional: + TF_RETURN_IF_ERROR(CheckConditionalLayout( + instruction, + FindOrDie(computation_layouts_, instruction->true_computation()), + FindOrDie(computation_layouts_, + instruction->false_computation()))); + break; default: break; } @@ -1165,77 +1306,6 @@ StatusOr<Layout> InferArrayLayout( return *first_buffer_layout; } -// Creates and returns a copy of the given instruction with a different -// layout. Tuple-shaped instructions will be deep-copied, and the last Tuple -// instruction producing the copy is returned. -StatusOr<HloInstruction*> CreateCopyWithNewLayout( - const Shape& shape_with_layout, HloInstruction* instruction) { - TF_RET_CHECK(LayoutUtil::HasLayout(shape_with_layout)); - DCHECK(ShapeUtil::Compatible(shape_with_layout, instruction->shape())) - << ShapeUtil::HumanString(shape_with_layout) << " " - << ShapeUtil::HumanString(instruction->shape()) - << " instruction: " << instruction->ToString(); - - if (ShapeUtil::IsTuple(instruction->shape())) { - // Deep-copy tuples. - std::vector<HloInstruction*> element_copies; - for (int64 i = 0; i < ShapeUtil::TupleElementCount(instruction->shape()); - ++i) { - HloInstruction* gte = instruction->parent()->AddInstruction( - HloInstruction::CreateGetTupleElement( - ShapeUtil::GetSubshape(instruction->shape(), {i}), instruction, - i)); - - // Recurse to copy each elements. - TF_ASSIGN_OR_RETURN( - HloInstruction * element_copy, - CreateCopyWithNewLayout( - ShapeUtil::GetSubshape(shape_with_layout, {i}), gte)); - element_copies.push_back(element_copy); - } - // Gather element copies into a tuple with a new Tuple instruction. - HloInstruction* tuple_copy = instruction->parent()->AddInstruction( - HloInstruction::CreateTuple(element_copies)); - LayoutUtil::ClearLayout(tuple_copy->mutable_shape()); - TF_RETURN_IF_ERROR(LayoutUtil::CopyLayoutBetweenShapes( - shape_with_layout, tuple_copy->mutable_shape())); - return tuple_copy; - } else if (ShapeUtil::IsArray(instruction->shape())) { - HloInstruction* copy = - instruction->parent()->AddInstruction(HloInstruction::CreateUnary( - instruction->shape(), HloOpcode::kCopy, instruction)); - LayoutUtil::ClearLayout(copy->mutable_shape()); - TF_RETURN_IF_ERROR(LayoutUtil::CopyLayoutBetweenShapes( - shape_with_layout, copy->mutable_shape())); - - return copy; - } else { - return FailedPrecondition( - "Can only copy array and tuple shaped instructions"); - } -} - -// Creates a copy of the given operand if the operand's layout does not match -// the given layout. This copy replaces the use in the given instruction. Tuple -// operands will be deep-copied. -Status CopyOperandIfLayoutsDiffer(const ShapeLayout& operand_layout, - HloInstruction* instruction, - int64 operand_no) { - HloInstruction* operand = instruction->mutable_operand(operand_no); - TF_RET_CHECK(operand_layout.LayoutIsSet()); - TF_RET_CHECK(LayoutUtil::HasLayout(operand->shape())); - - if (ShapeUtil::Equal(operand_layout.shape(), operand->shape())) { - // Operand layout already matches our constraint. Nothing to do. - return Status::OK(); - } - - TF_ASSIGN_OR_RETURN(HloInstruction * operand_copy, - CreateCopyWithNewLayout(operand_layout.shape(), operand)); - - return instruction->ReplaceOperandWith(operand_no, operand_copy); -} - // For fusion instructions, set the layout of each fused parameter instruction // to match the layout of its corresponding fusion instruction operand. Also, // set the layout of the fused root to match the layout of the fusion diff --git a/tensorflow/compiler/xla/service/layout_assignment_test.cc b/tensorflow/compiler/xla/service/layout_assignment_test.cc index e269a13459..dd0fba2758 100644 --- a/tensorflow/compiler/xla/service/layout_assignment_test.cc +++ b/tensorflow/compiler/xla/service/layout_assignment_test.cc @@ -658,5 +658,68 @@ TEST_F(LayoutAssignmentTest, GTEInheritsLayoutFromOperand) { ElementsAre(2, 1, 0)); } +TEST_F(LayoutAssignmentTest, ConditionalAsymmetricLayout) { + auto builder = HloComputation::Builder(TestName()); + auto module = CreateNewModule(); + Shape shape = ShapeUtil::MakeShape(F32, {128, 8}); + Shape tshape = ShapeUtil::MakeTupleShape({shape, shape}); + Shape result_tshape = ShapeUtil::MakeTupleShape({shape}); + + auto param0 = builder.AddInstruction( + HloInstruction::CreateParameter(0, shape, "param0")); + auto param1 = builder.AddInstruction( + HloInstruction::CreateParameter(1, shape, "param1")); + auto pred = builder.AddInstruction(HloInstruction::CreateParameter( + 2, ShapeUtil::MakeShape(PRED, {}), "param2")); + auto tuple = + builder.AddInstruction(HloInstruction::CreateTuple({param0, param1})); + + auto true_builder = HloComputation::Builder(TestName() + "_TrueBranch"); + { + auto param = true_builder.AddInstruction( + HloInstruction::CreateParameter(0, tshape, "param")); + auto gte0 = true_builder.AddInstruction( + HloInstruction::CreateGetTupleElement(shape, param, 0)); + auto gte1 = true_builder.AddInstruction( + HloInstruction::CreateGetTupleElement(shape, param, 1)); + auto add = true_builder.AddInstruction( + HloInstruction::CreateBinary(shape, HloOpcode::kAdd, gte0, gte1)); + true_builder.AddInstruction(HloInstruction::CreateTuple({add})); + } + HloComputation* true_computation = + module->AddEmbeddedComputation(true_builder.Build()); + + auto false_builder = HloComputation::Builder(TestName() + "_FalseBranch"); + { + Shape xshape = ShapeUtil::MakeShapeWithLayout(F32, {128, 8}, {0, 1}); + false_builder.AddInstruction( + HloInstruction::CreateParameter(0, tshape, "param")); + // Using infeed as layout assignment does not mess up with it. + auto infeed = + false_builder.AddInstruction(HloInstruction::CreateInfeed(xshape, "")); + false_builder.AddInstruction(HloInstruction::CreateTuple({infeed})); + } + HloComputation* false_computation = + module->AddEmbeddedComputation(false_builder.Build()); + builder.AddInstruction(HloInstruction::CreateConditional( + result_tshape, pred, tuple, true_computation, tuple, false_computation)); + + HloComputation* computation = module->AddEntryComputation(builder.Build()); + ComputationLayout computation_layout(computation->ComputeProgramShape()); + + AssignLayouts(module.get(), &computation_layout); + + const HloInstruction* true_root = true_computation->root_instruction(); + const HloInstruction* false_root = false_computation->root_instruction(); + EXPECT_THAT(true_root->opcode(), HloOpcode::kTuple); + EXPECT_THAT(false_root->opcode(), HloOpcode::kTuple); + + const HloInstruction* true_result = true_root->operand(0); + const HloInstruction* false_result = false_root->operand(0); + EXPECT_TRUE(LayoutUtil::Equal(true_result->shape().layout(), + false_result->shape().layout())); + EXPECT_THAT(false_result->opcode(), HloOpcode::kCopy); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/liveness_util_test.cc b/tensorflow/compiler/xla/service/liveness_util_test.cc index 2c2a02f637..f8b309488e 100644 --- a/tensorflow/compiler/xla/service/liveness_util_test.cc +++ b/tensorflow/compiler/xla/service/liveness_util_test.cc @@ -35,8 +35,7 @@ class PointsToAnalysisTestBase : public HloTestBase { CHECK_NOTNULL(module_.get()); points_to_analysis_ = TuplePointsToAnalysis::Run(module_.get()).ConsumeValueOrDie(); - dataflow_analysis_ = - HloDataflowAnalysis::Run(module_.get()).ConsumeValueOrDie(); + dataflow_analysis_ = HloDataflowAnalysis::Run(*module_).ConsumeValueOrDie(); } void BuildModuleAndRunAnalysis(std::unique_ptr<HloComputation> computation) { diff --git a/tensorflow/compiler/xla/service/llvm_compiler.cc b/tensorflow/compiler/xla/service/llvm_compiler.cc index 68c35c0c1f..911b243fe2 100644 --- a/tensorflow/compiler/xla/service/llvm_compiler.cc +++ b/tensorflow/compiler/xla/service/llvm_compiler.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/llvm_compiler.h" +#include "tensorflow/core/platform/denormal.h" #ifdef __FAST_MATH__ #error "Don't build XLA with -ffast-math" @@ -24,6 +25,18 @@ StatusOr<std::vector<std::unique_ptr<Executable>>> LLVMCompiler::Compile( std::vector<std::unique_ptr<HloModule>> modules, std::vector<std::vector<perftools::gputools::StreamExecutor*>> stream_execs, DeviceMemoryAllocator* device_allocator) { + // Tensorflow tries to enable the following behaviors in all its threads: + // + // - Denormals are zero (DAZ): roughly, operations treat denormal floats as + // zero. + // - Flush denormals to zero (FTZ): roughly, operations produce zero instead + // of denormal floats. + // + // In theory enabling these shouldn't matter since the compiler should ideally + // not leak its environment into generated code, but we turn off DAZ and FTZ + // to get some defense-in-depth. + tensorflow::port::ScopedDontFlushDenormal dont_flush_denormals; + std::vector<std::unique_ptr<Executable>> result; for (size_t i = 0; i < modules.size(); i++) { if (stream_execs[i].size() != 1) { diff --git a/tensorflow/compiler/xla/service/service.cc b/tensorflow/compiler/xla/service/service.cc index 98dfc89867..e278eab690 100644 --- a/tensorflow/compiler/xla/service/service.cc +++ b/tensorflow/compiler/xla/service/service.cc @@ -44,6 +44,7 @@ limitations under the License. #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" +#include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/gtl/cleanup.h" #include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/lib/strings/stringprintf.h" @@ -1445,6 +1446,9 @@ tensorflow::Status Service::Op(const OpRequest* arg, OpResponse* result) { case OpRequest::kFftRequest: handle_status = computation->AddFftInstruction(arg->fft_request()); break; + case OpRequest::kGatherRequest: + handle_status = computation->AddGatherInstruction(arg->gather_request()); + break; case OpRequest::kGetTupleElementRequest: handle_status = computation->AddGetTupleElementInstruction( arg->get_tuple_element_request()); @@ -1456,6 +1460,10 @@ tensorflow::Status Service::Op(const OpRequest* arg, OpResponse* result) { handle_status = computation->AddOutfeedInstruction(arg->outfeed_request()); break; + case OpRequest::kHostComputeRequest: + handle_status = + computation->AddHostComputeInstruction(arg->host_compute_request()); + break; case OpRequest::kMapRequest: { TF_ASSIGN_OR_RETURN( UserComputation * to_apply, diff --git a/tensorflow/compiler/xla/service/shape_inference.cc b/tensorflow/compiler/xla/service/shape_inference.cc index 004889b5f2..c9692757b2 100644 --- a/tensorflow/compiler/xla/service/shape_inference.cc +++ b/tensorflow/compiler/xla/service/shape_inference.cc @@ -2448,4 +2448,197 @@ ShapeInference::InferDegenerateDimensionBroadcastShape( return to_apply.result(); } +static Status ValidateGatherDimensionNumbers( + const Shape& input_shape, + tensorflow::gtl::ArraySlice<int64> gather_indices_shape, + const GatherDimensionNumbers& dim_numbers) { + if (!c_is_sorted(dim_numbers.output_window_dims())) { + return InvalidArgument( + "Output window dimensions in gather op must be ascending; got: %s", + Join(dim_numbers.output_window_dims(), ", ").c_str()); + } + + if (c_adjacent_find(dim_numbers.output_window_dims()) != + dim_numbers.output_window_dims().end()) { + return InvalidArgument( + "Output window dimensions in gather op must not repeat; got: %s", + Join(dim_numbers.output_window_dims(), ", ").c_str()); + } + + const int64 output_window_dim_count = dim_numbers.output_window_dims_size(); + const int64 output_shape_rank = + output_window_dim_count + gather_indices_shape.size(); + + for (int i = 0; i < dim_numbers.output_window_dims_size(); ++i) { + int64 window_index = dim_numbers.output_window_dims(i); + if (window_index < 0 || window_index >= output_shape_rank) { + return InvalidArgument( + "Window index %d in gather op is out of bounds; got %lld, but should " + "have been in" + "[0,%lld)", + i, window_index, output_shape_rank); + } + } + + if (dim_numbers.gather_dims_to_operand_dims_size() != + gather_indices_shape.back()) { + return InvalidArgument( + "There must be exactly as many elements in gather_dims_to_operand_dims " + "as there are elements in the last dimension of %%gather_indices; got: " + "%d, expected %lld", + dim_numbers.gather_dims_to_operand_dims_size(), + gather_indices_shape.back()); + } + + for (int i = 0; i < dim_numbers.gather_dims_to_operand_dims_size(); i++) { + int64 gather_dim_to_input_dim = dim_numbers.gather_dims_to_operand_dims(i); + if (gather_dim_to_input_dim < 0 || + gather_dim_to_input_dim >= input_shape.dimensions_size()) { + return InvalidArgument( + "Invalid gather_dims_to_operand_dims mapping; domain is [0, %d), " + "got: %d->%lld", + input_shape.dimensions_size(), i, gather_dim_to_input_dim); + } + } + + std::vector<int64> sorted_gather_dims_to_operand_dims( + dim_numbers.gather_dims_to_operand_dims().begin(), + dim_numbers.gather_dims_to_operand_dims().end()); + + c_sort(sorted_gather_dims_to_operand_dims); + + if (c_adjacent_find(sorted_gather_dims_to_operand_dims) != + sorted_gather_dims_to_operand_dims.end()) { + return InvalidArgument( + "Repeated dimensions are not allowed in gather_dims_to_operand_dims; " + "got: %s", + Join(dim_numbers.gather_dims_to_operand_dims(), ", ").c_str()); + } + + for (int64 elided_dim : dim_numbers.elided_window_dims()) { + if (elided_dim < 0 || elided_dim >= input_shape.dimensions_size()) { + return InvalidArgument( + "Invalid elided_window_dims set in gather op; valid range is [0, " + "%d), got: %lld", + input_shape.dimensions_size(), elided_dim); + } + } + + if (!c_is_sorted(dim_numbers.elided_window_dims())) { + return InvalidArgument( + "elided_window_dims in gather op must be sorted; got: %s", + Join(dim_numbers.elided_window_dims(), ", ").c_str()); + } + + if (c_adjacent_find(dim_numbers.elided_window_dims()) != + dim_numbers.elided_window_dims().end()) { + return InvalidArgument( + "Repeated dimensions not allowed in elided_window_dims in gather op; " + "got: %s", + Join(dim_numbers.elided_window_dims(), ", ").c_str()); + } + + return Status::OK(); +} + +/*static*/ StatusOr<Shape> ShapeInference::InferGatherShape( + const Shape& input_shape, const Shape& gather_indices_shape, + const GatherDimensionNumbers& gather_dim_numbers, + tensorflow::gtl::ArraySlice<int64> window_bounds) { + TF_RETURN_IF_ERROR( + ExpectNotTupleOrOpaque(input_shape, "input tensor operand gather op")); + TF_RETURN_IF_ERROR(ExpectNotTupleOrOpaque( + gather_indices_shape, "gather indices operand of gather op")); + + if (gather_indices_shape.dimensions_size() < 1) { + return InvalidArgument( + "Gather indices parameter must at least of rank 1; got %s", + ShapeUtil::HumanString(gather_indices_shape).c_str()); + } + + if (!ShapeUtil::ElementIsIntegral(gather_indices_shape)) { + return InvalidArgument( + "Gather indices parameter must be an integral tensor; got %s", + ShapeUtil::HumanString(gather_indices_shape).c_str()); + } + + std::vector<int64> expanded_gather_indices_shape; + // We implicitly reshape gather indices of shape P[N] to P[N,1]. + expanded_gather_indices_shape.reserve(gather_indices_shape.dimensions_size()); + c_copy(gather_indices_shape.dimensions(), + std::back_inserter(expanded_gather_indices_shape)); + if (expanded_gather_indices_shape.size() == 1) { + expanded_gather_indices_shape.push_back(1); + } + + TF_RETURN_IF_ERROR(ValidateGatherDimensionNumbers( + input_shape, expanded_gather_indices_shape, gather_dim_numbers)); + + if (window_bounds.size() != input_shape.dimensions_size()) { + return InvalidArgument( + "Gather op must have one window bound for every input dimension; got: " + "len(window_bounds)=%lu, input_shape.rank=%d", + window_bounds.size(), input_shape.dimensions_size()); + } + + if (window_bounds.size() != + gather_dim_numbers.output_window_dims_size() + + gather_dim_numbers.elided_window_dims_size()) { + return InvalidArgument( + "All components of the window index in a gather op must either be a " + "output window index or explicitly elided; got len(window_bounds)=%lu, " + "output_window_bounds=%s, elided_window_bounds=%s", + window_bounds.size(), + Join(gather_dim_numbers.output_window_dims(), ",").c_str(), + Join(gather_dim_numbers.elided_window_dims(), ",").c_str()); + } + + for (int i = 0; i < window_bounds.size(); i++) { + int64 window_bound = window_bounds[i]; + int64 corresponding_input_bound = input_shape.dimensions(i); + if (window_bound < 0 || window_bound > corresponding_input_bound) { + return InvalidArgument( + "Window bound at index %d in gather op is out of range, must be " + "within " + "[0, %lld), got %lld", + i, corresponding_input_bound + 1, window_bound); + } + } + + for (int i = 0; i < gather_dim_numbers.elided_window_dims_size(); i++) { + if (window_bounds[gather_dim_numbers.elided_window_dims(i)] != 1) { + return InvalidArgument( + "Gather op can only elide window indices with bound 1, but bound is " + "%lld for index %lld at position %d", + window_bounds[gather_dim_numbers.elided_window_dims(i)], + gather_dim_numbers.elided_window_dims(i), i); + } + } + + int64 result_rank = gather_dim_numbers.output_window_dims_size() + + (expanded_gather_indices_shape.size() - 1); + int64 window_dims_seen = 0; + int64 gather_dims_seen = 0; + std::vector<int64> output_dim_bounds; + output_dim_bounds.reserve(result_rank); + for (int64 i = 0; i < result_rank; i++) { + int64 current_bound; + bool is_window_index = + c_binary_search(gather_dim_numbers.output_window_dims(), i); + if (is_window_index) { + while (c_binary_search(gather_dim_numbers.elided_window_dims(), + window_dims_seen)) { + window_dims_seen++; + } + current_bound = window_bounds[window_dims_seen++]; + } else { + current_bound = expanded_gather_indices_shape[gather_dims_seen++]; + } + + output_dim_bounds.push_back(current_bound); + } + + return ShapeUtil::MakeShape(input_shape.element_type(), output_dim_bounds); +} + } // namespace xla diff --git a/tensorflow/compiler/xla/service/shape_inference.h b/tensorflow/compiler/xla/service/shape_inference.h index b39151ebbc..0d3045213d 100644 --- a/tensorflow/compiler/xla/service/shape_inference.h +++ b/tensorflow/compiler/xla/service/shape_inference.h @@ -37,6 +37,11 @@ namespace xla { // the expected result type for computations that are built up via the API -- // the shape that results from an operation is inferred. Some methods have // overloads for inferring shape at the HLO level. +// +// TODO(b/73352135): Shape inference does not issue very good error messages, in +// part because HloInstruction::ToString() is not available since shape +// inference runs before the HloInstruction object is created. We need a +// solution for this. class ShapeInference { public: // Infers the shape produced by applying the given unary operation to the @@ -248,6 +253,14 @@ class ShapeInference { const Shape& lhs, const Shape& rhs, const DotDimensionNumbers& dimension_numbers); + // Helper that infers the shape of the tensor produced by a gather operation + // with the given input shape, gather indices shape and gather dimension + // numbers. + static StatusOr<Shape> InferGatherShape( + const Shape& input_shape, const Shape& gather_indices_shape, + const GatherDimensionNumbers& gather_dim_numbers, + tensorflow::gtl::ArraySlice<int64> window_bounds); + private: // Helper that infers the shape produced by performing an element-wise binary // operation with the given LHS and RHS shapes. diff --git a/tensorflow/compiler/xla/service/shape_inference_test.cc b/tensorflow/compiler/xla/service/shape_inference_test.cc index 026c021165..7eb120843f 100644 --- a/tensorflow/compiler/xla/service/shape_inference_test.cc +++ b/tensorflow/compiler/xla/service/shape_inference_test.cc @@ -18,15 +18,16 @@ limitations under the License. #include <string> #include "tensorflow/compiler/xla/shape_util.h" -#include "tensorflow/compiler/xla/xla_data.pb.h" - #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/test_helpers.h" #include "tensorflow/compiler/xla/types.h" +#include "tensorflow/compiler/xla/xla_data.pb.h" +#include "tensorflow/core/lib/gtl/array_slice.h" namespace xla { namespace { +using ::tensorflow::gtl::ArraySlice; using ::testing::ContainsRegex; using ::testing::HasSubstr; @@ -1527,5 +1528,341 @@ TEST_F(ShapeInferenceTest, BadSlice) { << statusor.status(); } +class GatherShapeInferenceTest : public ShapeInferenceTest { + protected: + const Shape s64_vector_32_ = ShapeUtil::MakeShape(S64, {32}); + const Shape s64_4d_tensor_10_9_8_7_1_ = + ShapeUtil::MakeShape(S64, {10, 9, 8, 7, 1}); + const Shape s64_4d_tensor_10_9_8_7_5_ = + ShapeUtil::MakeShape(S64, {10, 9, 8, 7, 5}); + const Shape f32_5d_tensor_50_49_48_47_46_ = + ShapeUtil::MakeShape(F32, {50, 49, 48, 47, 46}); + const Shape tuple_shape_ = ShapeUtil::MakeTupleShape( + {s64_4d_tensor_10_9_8_7_1_, s64_4d_tensor_10_9_8_7_1_}); +}; + +TEST_F(GatherShapeInferenceTest, TensorFlowGather) { + TF_ASSERT_OK_AND_ASSIGN( + Shape gather_shape, + ShapeInference::InferGatherShape(matrix_64_48_, s64_vector_32_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{0}, + /*elided_window_dims=*/{1}, + /*gather_dims_to_operand_dims=*/{1}), + /*window_bounds=*/{64, 1})); + EXPECT_TRUE( + ShapeUtil::Equal(gather_shape, ShapeUtil::MakeShape(F32, {64, 32}))) + << ShapeUtil::HumanString(gather_shape); +} + +TEST_F(GatherShapeInferenceTest, TensorFlowGatherV2) { + TF_ASSERT_OK_AND_ASSIGN( + Shape gather_shape, + ShapeInference::InferGatherShape(matrix_64_48_, s64_vector_32_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{1}, + /*elided_window_dims=*/{0}, + /*gather_dims_to_operand_dims=*/{0}), + /*window_bounds=*/{1, 48})); + EXPECT_TRUE( + ShapeUtil::Equal(gather_shape, ShapeUtil::MakeShape(F32, {32, 48}))) + << ShapeUtil::HumanString(gather_shape); +} + +TEST_F(GatherShapeInferenceTest, TensorFlowGatherNd) { + TF_ASSERT_OK_AND_ASSIGN( + Shape gather_shape, + ShapeInference::InferGatherShape(matrix_64_48_, s64_4d_tensor_10_9_8_7_1_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4}, + /*elided_window_dims=*/{0}, + /*gather_dims_to_operand_dims=*/{0}), + /*window_bounds=*/{1, 48})); + EXPECT_TRUE(ShapeUtil::Equal(gather_shape, + ShapeUtil::MakeShape(F32, {10, 9, 8, 7, 48}))) + << ShapeUtil::HumanString(gather_shape); +} + +TEST_F(GatherShapeInferenceTest, TensorFlowBatchDynamicSlice) { + TF_ASSERT_OK_AND_ASSIGN( + Shape gather_shape, + ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 27, 26})); + EXPECT_TRUE(ShapeUtil::Equal( + gather_shape, + ShapeUtil::MakeShape(F32, {10, 9, 8, 7, 30, 29, 28, 27, 26}))) + << ShapeUtil::HumanString(gather_shape); +} + +TEST_F(GatherShapeInferenceTest, TupleShapedTensorInput) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + tuple_shape_, s64_vector_32_, + HloInstruction::MakeGatherDimNumbers(/*output_window_dims=*/{0}, + /*elided_window_dims=*/{1}, + /*gather_dims_to_operand_dims=*/{1}), + /*window_bounds=*/{64, 1}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT(statusor.status().error_message(), + HasSubstr("Expected non-tuple argument for input")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, TupleShapedGatherIndicesInput) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + s64_vector_32_, tuple_shape_, + HloInstruction::MakeGatherDimNumbers(/*output_window_dims=*/{0}, + /*elided_window_dims=*/{1}, + /*gather_dims_to_operand_dims=*/{1}), + /*window_bounds=*/{64, 1}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT(statusor.status().error_message(), + HasSubstr("Expected non-tuple argument for gather indices")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, ScalarGatherIndicesInput) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + s64_vector_32_, s32_, + HloInstruction::MakeGatherDimNumbers(/*output_window_dims=*/{0}, + /*elided_window_dims=*/{1}, + /*gather_dims_to_operand_dims=*/{1}), + /*window_bounds=*/{64, 1}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT(statusor.status().error_message(), + HasSubstr("Gather indices parameter must at least of rank 1")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, FloatingPointGatherIndicesInput) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + s64_vector_32_, vector_32_, + HloInstruction::MakeGatherDimNumbers(/*output_window_dims=*/{0}, + /*elided_window_dims=*/{1}, + /*gather_dims_to_operand_dims=*/{1}), + /*window_bounds=*/{64, 1}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT(statusor.status().error_message(), + HasSubstr("Gather indices parameter must be an integral tensor")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_NonAscendingWindowIndices) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 8, 7}, + /*elided_window_dims=*/{}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT( + statusor.status().error_message(), + HasSubstr("Output window dimensions in gather op must be ascending")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_RepeatedWindowIndices) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 7}, + /*elided_window_dims=*/{}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT( + statusor.status().error_message(), + HasSubstr("Output window dimensions in gather op must not repeat")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_WindowIndexOutOfBounds) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 99, 100, 101}, + /*elided_window_dims=*/{}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT(statusor.status().error_message(), + HasSubstr("Window index 2 in gather op is out of bounds")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_MismatchingElidedWindowDims) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{4}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT( + statusor.status().error_message(), + HasSubstr("All components of the window index in a gather op must either " + "be a output window index or explicitly elided")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_OutOfBoundsWindowToInputMapping) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{0, 1, 2, 3, 19}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT(statusor.status().error_message(), + HasSubstr("Invalid elided_window_dims set in gather op; valid " + "range is [0, 5), got: 19")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_RepeatedWindowToInputMapping) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{0, 1, 2, 3, 3}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT( + statusor.status().error_message(), + HasSubstr( + "Repeated dimensions not allowed in elided_window_dims in gather op")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_MismatchingGatherToInputMapping) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3}), + /*window_bounds=*/{30, 29, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT( + statusor.status().error_message(), + HasSubstr( + "There must be exactly as many elements in " + "gather_dims_to_operand_dims " + "as there are elements in the last dimension of %gather_indices")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_OutOfBoundsGatherToInputMapping) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 7}), + /*window_bounds=*/{30, 29, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT( + statusor.status().error_message(), + HasSubstr("Invalid gather_dims_to_operand_dims mapping; domain is " + "[0, 5), got: 4->7")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_RepeatedGatherToInputMapping) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 3}), + /*window_bounds=*/{30, 29, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT( + statusor.status().error_message(), + HasSubstr( + "Repeated dimensions are not allowed in gather_dims_to_operand_dims")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_NonAscendingElidedWindowDims) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{2, 1}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{1, 1, 28, 27, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT(statusor.status().error_message(), + HasSubstr("elided_window_dims in gather op must be sorted")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, InvalidGatherDimNumbers_WindowBoundsTooLarge) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7}, + /*elided_window_dims=*/{2}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 1, 300, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT(statusor.status().error_message(), + HasSubstr("Window bound at index 3 in gather op is out of range, " + "must be within [0, 48), got 300")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_MismatchingNumberOfWindowBounds) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7, 8}, + /*elided_window_dims=*/{}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 26}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT( + statusor.status().error_message(), + HasSubstr( + "Gather op must have one window bound for every input dimension")) + << statusor.status(); +} + +TEST_F(GatherShapeInferenceTest, + InvalidGatherDimNumbers_WindowBoundsNot1ForElidedDim) { + StatusOr<Shape> statusor = ShapeInference::InferGatherShape( + f32_5d_tensor_50_49_48_47_46_, s64_4d_tensor_10_9_8_7_5_, + HloInstruction::MakeGatherDimNumbers( + /*output_window_dims=*/{4, 5, 6, 7}, + /*elided_window_dims=*/{1}, + /*gather_dims_to_operand_dims=*/{0, 1, 2, 3, 4}), + /*window_bounds=*/{30, 29, 28, 26, 20}); + ASSERT_FALSE(statusor.ok()); + EXPECT_THAT(statusor.status().error_message(), + HasSubstr("Gather op can only elide window indices with bound 1, " + "but bound is 29 for index 1 at position 0")) + << statusor.status(); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/user_computation.cc b/tensorflow/compiler/xla/service/user_computation.cc index fead9b9236..4a55e4095a 100644 --- a/tensorflow/compiler/xla/service/user_computation.cc +++ b/tensorflow/compiler/xla/service/user_computation.cc @@ -315,6 +315,36 @@ StatusOr<ComputationDataHandle> UserComputation::AddConstantInstruction( return handle; } +StatusOr<ComputationDataHandle> UserComputation::AddGatherInstruction( + const GatherRequest& gather_request) { + tensorflow::mutex_lock lock(mutex_); + + TF_ASSIGN_OR_RETURN(const OperationRequest* input_request, + LookUpRequest(gather_request.input())); + TF_ASSIGN_OR_RETURN(const OperationRequest* gather_indices_request, + LookUpRequest(gather_request.gather_indices())); + + TF_ASSIGN_OR_RETURN( + Shape shape, + ShapeInference::InferGatherShape( + input_request->output_shape(), gather_indices_request->output_shape(), + gather_request.dimension_numbers(), + AsInt64Slice(gather_request.window_bounds()))); + + const ComputationDataHandle handle = CreateComputationDataHandle(); + + OperationRequest& request = + (*session_computation_.mutable_requests())[handle.handle()]; + *request.mutable_output_handle() = handle; + *request.mutable_output_shape() = shape; + *request.mutable_request()->mutable_gather_request() = gather_request; + + VLOG(1) << "AddGatherInstruction (" << GetVersionedHandleInternal() + << "), data handle " << handle.handle() << ": " + << gather_request.ShortDebugString(); + return handle; +} + StatusOr<ComputationDataHandle> UserComputation::AddGetTupleElementInstruction( const GetTupleElementRequest& get_tuple_element_request) { tensorflow::mutex_lock lock(mutex_); @@ -1276,6 +1306,28 @@ StatusOr<ComputationDataHandle> UserComputation::AddCustomCallInstruction( return handle; } +StatusOr<ComputationDataHandle> UserComputation::AddHostComputeInstruction( + const HostComputeRequest& host_compute_request) { + tensorflow::mutex_lock lock(mutex_); + + for (const ComputationDataHandle& handle : host_compute_request.operands()) { + TF_RETURN_IF_ERROR(LookUpRequest(handle).status()); + } + + ComputationDataHandle handle = CreateComputationDataHandle(); + OperationRequest& request = + (*session_computation_.mutable_requests())[handle.handle()]; + *request.mutable_output_handle() = handle; + *request.mutable_output_shape() = host_compute_request.shape(); + *request.mutable_request()->mutable_host_compute_request() = + host_compute_request; + + VLOG(1) << "AddHostComputeInstruction (" << GetVersionedHandleInternal() + << "), data handle " << handle.handle() << ": " + << host_compute_request.ShortDebugString(); + return handle; +} + StatusOr<ComputationDataHandle> UserComputation::AddDotInstruction( const DotRequest& dot_request) { tensorflow::mutex_lock lock(mutex_); @@ -1713,6 +1765,11 @@ void PureFunctionalVisitor(const SessionComputation& session_computation, break; } + case OpRequest::kHostComputeRequest: { + *is_functional = false; + break; + } + case OpRequest::kCallRequest: { const CallRequest& call_request = request.request().call_request(); for (const ComputationDataHandle& handle : call_request.operands()) { @@ -1991,6 +2048,16 @@ void PureFunctionalVisitor(const SessionComputation& session_computation, break; } + case OpRequest::kGatherRequest: { + PureFunctionalVisitor(session_computation, + request.request().gather_request().input(), + num_parameters, visited, is_functional); + PureFunctionalVisitor(session_computation, + request.request().gather_request().gather_indices(), + num_parameters, visited, is_functional); + break; + } + case OpRequest::OP_NOT_SET: LOG(FATAL) << "OperationRequest doesn't contain a request"; @@ -2643,6 +2710,15 @@ static void ForEachOperand( break; } + case OpRequest::kHostComputeRequest: { + const HostComputeRequest& hc_request = + request.request().host_compute_request(); + for (const ComputationDataHandle& operand : hc_request.operands()) { + apply(operand); + } + break; + } + case OpRequest::kDotRequest: { const DotRequest& dot_request = request.request().dot_request(); apply(dot_request.rhs()); @@ -2684,6 +2760,13 @@ static void ForEachOperand( break; } + case OpRequest::kGatherRequest: { + const GatherRequest& gather_request = request.request().gather_request(); + apply(gather_request.input()); + apply(gather_request.gather_indices()); + break; + } + case OpRequest::OP_NOT_SET: LOG(FATAL) << "OperationRequest doesn't contain a request"; @@ -3299,6 +3382,22 @@ void ComputationLowerer::Visit( break; } + case OpRequest::kHostComputeRequest: { + const HostComputeRequest& host_compute_request = + request.request().host_compute_request(); + std::vector<HloInstruction*> operands; + for (const ComputationDataHandle& operand : + host_compute_request.operands()) { + operands.push_back(lookup_instruction(operand)); + } + auto output_shape = host_compute_request.shape(); + auto channel_name = host_compute_request.channel_name(); + auto cost_estimate_ns = host_compute_request.cost_estimate_ns(); + hlo_instruction = add_instruction(HloInstruction::CreateHostCompute( + output_shape, operands, channel_name, cost_estimate_ns)); + break; + } + case OpRequest::kUnaryOpRequest: { const UnaryOpRequest& unary_op_request = request.request().unary_op_request(); @@ -3401,6 +3500,20 @@ void ComputationLowerer::Visit( break; } + case OpRequest::kGatherRequest: { + const GatherRequest& gather_request = request.request().gather_request(); + HloInstruction* input_operand = + lookup_instruction(gather_request.input()); + HloInstruction* gather_indices_operand = + lookup_instruction(gather_request.gather_indices()); + std::vector<int64> window_bounds; + c_copy(gather_request.window_bounds(), std::back_inserter(window_bounds)); + hlo_instruction = add_instruction(HloInstruction::CreateGather( + request.output_shape(), input_operand, gather_indices_operand, + gather_request.dimension_numbers(), window_bounds)); + break; + } + case OpRequest::OP_NOT_SET: LOG(FATAL) << "OperationRequest doesn't contain a request"; diff --git a/tensorflow/compiler/xla/service/user_computation.h b/tensorflow/compiler/xla/service/user_computation.h index 54bb24d6d7..fd5a2ace9b 100644 --- a/tensorflow/compiler/xla/service/user_computation.h +++ b/tensorflow/compiler/xla/service/user_computation.h @@ -149,6 +149,10 @@ class UserComputation { StatusOr<ComputationDataHandle> AddOutfeedInstruction( const OutfeedRequest& outfeed_request); + // Enqueues a host compute instruction onto this user computation. + StatusOr<ComputationDataHandle> AddHostComputeInstruction( + const HostComputeRequest& host_compute_request); + // Enqueues a call instruction onto this user computation. StatusOr<ComputationDataHandle> AddCallInstruction( const CallRequest& call_request, @@ -238,6 +242,10 @@ class UserComputation { StatusOr<ComputationDataHandle> AddRecvInstruction( const RecvRequest& recv_request); + // Enqueues a Gather instruction onto this user computation. + StatusOr<ComputationDataHandle> AddGatherInstruction( + const GatherRequest& gather_request); + // Returns the user-provided name of this user computation, which is provided // via the XLA computation-building API. const string& name() const { return name_; } diff --git a/tensorflow/compiler/xla/tests/test_utils.cc b/tensorflow/compiler/xla/tests/test_utils.cc index b060fb13b1..0bc7df2a65 100644 --- a/tensorflow/compiler/xla/tests/test_utils.cc +++ b/tensorflow/compiler/xla/tests/test_utils.cc @@ -287,7 +287,7 @@ StatusOr<std::unique_ptr<Literal>> MakeFakeLiteral(const Shape& shape) { StatusOr<std::vector<std::unique_ptr<Literal>>> MakeFakeArguments( HloModule* const module) { - TF_ASSIGN_OR_RETURN(auto dataflow, HloDataflowAnalysis::Run(module)); + TF_ASSIGN_OR_RETURN(auto dataflow, HloDataflowAnalysis::Run(*module)); const auto params = module->entry_computation()->parameter_instructions(); std::minstd_rand0 engine; std::vector<std::unique_ptr<Literal>> arguments(params.size()); diff --git a/tensorflow/compiler/xla/tools/parser/hlo_parser.cc b/tensorflow/compiler/xla/tools/parser/hlo_parser.cc index 89def5d561..cd2b843ad3 100644 --- a/tensorflow/compiler/xla/tools/parser/hlo_parser.cc +++ b/tensorflow/compiler/xla/tools/parser/hlo_parser.cc @@ -994,6 +994,20 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, shape, operands, *custom_call_target)); break; } + case HloOpcode::kHostCompute: { + optional<string> channel_name; + optional<int64> cost_estimate_ns; + attrs["channel_name"] = {/*required=*/true, AttrTy::kString, + &channel_name}; + attrs["cost_estimate_ns"] = {/*required=*/true, AttrTy::kInt64, + &cost_estimate_ns}; + if (!ParseOperands(&operands) || !ParseAttributes(attrs)) { + return false; + } + instruction = builder->AddInstruction(HloInstruction::CreateHostCompute( + shape, operands, *channel_name, *cost_estimate_ns)); + break; + } case HloOpcode::kDot: { optional<std::vector<int64>> lhs_contracting_dims; attrs["lhs_contracting_dims"] = { @@ -1035,6 +1049,9 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, HloInstruction::CreateDot(shape, operands[0], operands[1], dnum)); break; } + case HloOpcode::kGather: + // TODO(b/72710576): HLO parsing is not implemented for Gather. + return TokenError("HLO parsing is not implemented for Gather"); case HloOpcode::kTrace: return TokenError(StrCat("parsing not yet implemented for op: ", HloOpcodeString(opcode))); diff --git a/tensorflow/compiler/xla/util.h b/tensorflow/compiler/xla/util.h index 08df5b12b3..46ec7af542 100644 --- a/tensorflow/compiler/xla/util.h +++ b/tensorflow/compiler/xla/util.h @@ -448,11 +448,38 @@ OutputIterator c_copy_if(InputContainer input_container, output_iterator, predicate); } +template <class InputContainer, class OutputIterator> +OutputIterator c_copy(InputContainer input_container, + OutputIterator output_iterator) { + return std::copy(std::begin(input_container), std::end(input_container), + output_iterator); +} + +template <class InputContainer> +void c_sort(InputContainer& input_container) { + std::sort(std::begin(input_container), std::end(input_container)); +} + template <class InputContainer, class Comparator> void c_sort(InputContainer& input_container, Comparator comparator) { - std::sort(input_container.begin(), input_container.end(), comparator); + std::sort(std::begin(input_container), std::end(input_container), comparator); } +template <typename Sequence, typename T> +bool c_binary_search(Sequence& sequence, T&& value) { + return std::binary_search(std::begin(sequence), std::end(sequence), + std::forward<T>(value)); +} + +template <typename C> +bool c_is_sorted(const C& c) { + return std::is_sorted(std::begin(c), std::end(c)); +} + +template <typename C> +auto c_adjacent_find(const C& c) -> decltype(std::begin(c)) { + return std::adjacent_find(std::begin(c), std::end(c)); +} } // namespace xla #define XLA_LOG_LINES(SEV, STRING) \ diff --git a/tensorflow/compiler/xla/xla_data.proto b/tensorflow/compiler/xla/xla_data.proto index 3aea021753..28620c3b86 100644 --- a/tensorflow/compiler/xla/xla_data.proto +++ b/tensorflow/compiler/xla/xla_data.proto @@ -393,6 +393,33 @@ message Window { repeated WindowDimension dimensions = 1; } +// Describes the dimension numbers for a gather operation. +// +// See https://www.tensorflow.org/performance/xla/operation_semantics#gather for +// more details. +message GatherDimensionNumbers { + // "Window indices" is a term for a set of indices that index into the + // interior of a dynamic-slice from the input tensor, the starting indices for + // which were computed from output_gather_dims (see the operation semantic for + // how this is defined) and the gather_indices tensor. + // + // The window indices for a specific output index Out is computed as: + // + // i = 0 + // for (k : [0, input_tensor_shape.rank)) + // window_indices[k] = + // if k in elided_window_dims + // then 0 + // else Out[output_window_dims[i++]] + repeated int64 output_window_dims = 1; + repeated int64 elided_window_dims = 2; + + // This is interpreted as a map from i to gather_dims_to_operand_dims[i]. It + // transforms the gather index looked up from the gather_indices tensor into + // the starting index in the input space. + repeated int64 gather_dims_to_operand_dims = 3; +} + // Operation requests that are all collected as a tagged union with a oneof // field in OpRequest. @@ -519,6 +546,20 @@ message CustomCallRequest { Shape shape = 4; } +message HostComputeRequest { + // Operand to the HostCompute. Supports tuple. + repeated ComputationDataHandle operands = 1; + + // Name used to identify HostSend/Recv channels. + string channel_name = 2; + + // Cost estimate in nanoseconds. + int64 cost_estimate_ns = 3; + + // The shape of any data returned by host. + Shape shape = 4; +} + message DotDimensionNumbers { // The dimension numbers that represent the 'lhs' contracting dimensions. repeated int64 lhs_contracting_dimensions = 1; @@ -880,6 +921,13 @@ message RecvRequest { ChannelHandle channel_handle = 2; } +message GatherRequest { + ComputationDataHandle input = 1; + ComputationDataHandle gather_indices = 2; + GatherDimensionNumbers dimension_numbers = 3; + repeated int64 window_bounds = 4; +} + message OpSharding { enum Type { // This sharding is replicated across all devices (implies maximal, @@ -957,7 +1005,9 @@ message OpRequest { FftRequest fft_request = 41; ConvertRequest bitcast_convert_request = 42; ConditionalRequest conditional_request = 44; - // Next: 45 + HostComputeRequest host_compute_request = 45; + GatherRequest gather_request = 46; + // Next: 47 } } diff --git a/tensorflow/contrib/cmake/tests/cuda/compatibility_test.c b/tensorflow/contrib/cmake/tests/cuda/compatibility_test.c index 968ab13a0c..9e355da33a 100644 --- a/tensorflow/contrib/cmake/tests/cuda/compatibility_test.c +++ b/tensorflow/contrib/cmake/tests/cuda/compatibility_test.c @@ -1,3 +1,18 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + // This is a program to test if compiler is compatible with CUDA. #define __CUDACC__ #include "crt/host_config.h" diff --git a/tensorflow/contrib/cmake/tests/cuda/compatibility_test.cc b/tensorflow/contrib/cmake/tests/cuda/compatibility_test.cc index 968ab13a0c..beb574061b 100644 --- a/tensorflow/contrib/cmake/tests/cuda/compatibility_test.cc +++ b/tensorflow/contrib/cmake/tests/cuda/compatibility_test.cc @@ -1,3 +1,18 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +============================================================================*/ + // This is a program to test if compiler is compatible with CUDA. #define __CUDACC__ #include "crt/host_config.h" diff --git a/tensorflow/contrib/data/python/ops/dataset_ops.py b/tensorflow/contrib/data/python/ops/dataset_ops.py index ff15c4451a..214641bb9a 100644 --- a/tensorflow/contrib/data/python/ops/dataset_ops.py +++ b/tensorflow/contrib/data/python/ops/dataset_ops.py @@ -475,7 +475,6 @@ class Dataset(dataset_ops.Dataset): @deprecation.deprecated_args( None, - "Replace `num_threads=T` with `num_parallel_calls=T`. Replace " "`output_buffer_size=N` with `ds.prefetch(N)` on the returned dataset.", "num_threads", "output_buffer_size") def map(self, diff --git a/tensorflow/contrib/eager/python/checkpointable_utils.py b/tensorflow/contrib/eager/python/checkpointable_utils.py index d3c57bc606..0506af391c 100644 --- a/tensorflow/contrib/eager/python/checkpointable_utils.py +++ b/tensorflow/contrib/eager/python/checkpointable_utils.py @@ -329,6 +329,7 @@ def save(file_prefix, root_checkpointable, checkpoint_number=None, class CheckpointLoadStatus(object): + """Checks the status of checkpoint loading.""" def __init__(self, checkpoint): self._checkpoint = checkpoint @@ -338,12 +339,22 @@ class CheckpointLoadStatus(object): for node_id, node in enumerate(self._checkpoint.object_graph_proto.nodes): checkpointable = self._checkpoint.object_by_proto_id.get(node_id, None) if checkpointable is None: - raise AssertionError("Unresolved object in checkpoint: %s" % (node)) + raise AssertionError("Unresolved object in checkpoint: %s" % (node,)) if checkpointable._update_uid < self._checkpoint.restore_uid: # pylint: disable=protected-access raise AssertionError( - "Object not assigned a value from checkpoint: %s" % (node)) + "Object not assigned a value from checkpoint: %s" % (node,)) + if self._checkpoint.slot_restorations: + # Sanity check; this collection should be clear if everything has been + # restored. + raise AssertionError("Unresolved slot restorations: %s" % ( + self._checkpoint.slot_restorations,)) return self + @property + def restore_ops(self): + """Operations to restore objects in the dependency graph.""" + return self._checkpoint.restore_ops + def restore(save_path, root_checkpointable, session=None): """Restore a training checkpoint. @@ -355,8 +366,8 @@ def restore(save_path, root_checkpointable, session=None): `root_checkpointable` after this call will be matched if they have a corresponding object in the checkpoint. - When building a graph, restorations are executed in the default session if - `session` is `None`. Variable initializers read checkpointed values. + When building a graph, restorations are added to the graph but not run. A + session is required to retrieve checkpoint metadata. To disallow deferred loading, assert immediately that all checkpointed variables have been matched to variable objects: @@ -368,21 +379,32 @@ def restore(save_path, root_checkpointable, session=None): An exception will be raised unless every object was matched and its variables already exist. + When graph building, `assert_consumed()` indicates that all of the restore ops + which will be created for this checkpoint have been created. They are + available in the `restore_ops` property of the status object: + + ```python + session.run(restore(path, root).assert_consumed().restore_ops) + ``` + + If the checkpoint has not been consumed completely, then the list of + `restore_ops` will grow as more objects are added to the dependency graph. + Args: save_path: The path to the checkpoint, as returned by `save` or `tf.train.latest_checkpoint`. If None (as when there is no latest checkpoint for `tf.train.latest_checkpoint` to return), does nothing. root_checkpointable: The root of the object graph to restore. Variables to restore need not have been created yet, but all dependencies on other - Checkpointable objects should already be declared. Objects in the + `Checkpointable` objects should already be declared. Objects in the dependency graph are matched to objects in the checkpointed graph, and matching objects have their variables restored (or the checkpointed values saved for eventual restoration when the variable is created). - session: The session to evaluate assignment ops in. Ignored when executing + session: The session to retrieve metadata with. Ignored when executing eagerly. If not provided when graph building, the default session is used. Returns: - A CheckpointLoadStatus object, which can be used to make assertions about - the status of checkpoint restoration. + A `CheckpointLoadStatus` object, which can be used to make assertions about + the status of checkpoint restoration and fetch restore ops. """ if save_path is None: return @@ -406,8 +428,8 @@ def restore(save_path, root_checkpointable, session=None): object_graph_proto.ParseFromString(object_graph_string) checkpoint = core_checkpointable._Checkpoint( # pylint: disable=protected-access object_graph_proto=object_graph_proto, - save_path=save_path, - session=session) + save_path=save_path) core_checkpointable._CheckpointPosition( # pylint: disable=protected-access checkpoint=checkpoint, proto_id=0).restore(root_checkpointable) - return CheckpointLoadStatus(checkpoint) + load_status = CheckpointLoadStatus(checkpoint) + return load_status diff --git a/tensorflow/contrib/eager/python/checkpointable_utils_test.py b/tensorflow/contrib/eager/python/checkpointable_utils_test.py index 1394f0cf0f..21ba6adc6a 100644 --- a/tensorflow/contrib/eager/python/checkpointable_utils_test.py +++ b/tensorflow/contrib/eager/python/checkpointable_utils_test.py @@ -398,36 +398,37 @@ class CheckpointingTests(test.TestCase): optimizer_variables = self.evaluate(optimizer.variables()) self.evaluate(state_ops.assign(m_bias_slot, [-2.])) # Immediate restoration - root_checkpointable.restore(save_path=save_path).assert_consumed() + status = root_checkpointable.restore(save_path=save_path).assert_consumed() + self.evaluate(status.restore_ops) self.assertAllEqual([42.], self.evaluate(network._named_dense.variables[1])) self.assertAllEqual(1, self.evaluate(root_checkpointable.save_counter)) self.assertAllEqual([1.5], self.evaluate(m_bias_slot)) - with ops.Graph().as_default(): - on_create_network = MyNetwork() - on_create_optimizer = CheckpointableAdam(0.001) - on_create_root = Checkpoint( - optimizer=on_create_optimizer, network=on_create_network) - with self.test_session(graph=ops.get_default_graph()): - # Deferred restoration - status = on_create_root.restore(save_path=save_path) - on_create_network(constant_op.constant([[3.]])) # create variables - self.assertAllEqual(1, self.evaluate(on_create_root.save_counter)) - self.assertAllEqual([42.], - self.evaluate( - on_create_network._named_dense.variables[1])) - on_create_m_bias_slot = on_create_optimizer.get_slot( - on_create_network._named_dense.variables[1], "m") - # Optimizer slot variables are created when the original variable is - # restored. - self.assertAllEqual([1.5], self.evaluate(on_create_m_bias_slot)) - self.assertAllEqual(optimizer_variables[2:], - self.evaluate(on_create_optimizer.variables())) - on_create_optimizer._create_slots( - [resource_variable_ops.ResourceVariable([1.])]) - status.assert_consumed() - beta1_power, beta2_power = on_create_optimizer._get_beta_accumulators() - self.assertAllEqual(optimizer_variables[0], self.evaluate(beta1_power)) - self.assertAllEqual(optimizer_variables[1], self.evaluate(beta2_power)) + if context.in_graph_mode(): + return # Restore-on-create is only supported when executing eagerly + on_create_network = MyNetwork() + on_create_optimizer = CheckpointableAdam(0.001) + on_create_root = Checkpoint( + optimizer=on_create_optimizer, network=on_create_network) + # Deferred restoration + status = on_create_root.restore(save_path=save_path) + on_create_network(constant_op.constant([[3.]])) # create variables + self.assertAllEqual(1, self.evaluate(on_create_root.save_counter)) + self.assertAllEqual([42.], + self.evaluate( + on_create_network._named_dense.variables[1])) + on_create_m_bias_slot = on_create_optimizer.get_slot( + on_create_network._named_dense.variables[1], "m") + # Optimizer slot variables are created when the original variable is + # restored. + self.assertAllEqual([1.5], self.evaluate(on_create_m_bias_slot)) + self.assertAllEqual(optimizer_variables[2:], + self.evaluate(on_create_optimizer.variables())) + on_create_optimizer._create_slots( + [resource_variable_ops.ResourceVariable([1.])]) + status.assert_consumed() + beta1_power, beta2_power = on_create_optimizer._get_beta_accumulators() + self.assertAllEqual(optimizer_variables[0], self.evaluate(beta1_power)) + self.assertAllEqual(optimizer_variables[1], self.evaluate(beta2_power)) def testDeferredRestorationUsageEager(self): """An idiomatic eager execution example.""" @@ -479,10 +480,11 @@ class CheckpointingTests(test.TestCase): # if no checkpoint is being loaded. This would make deferred # loading a bit more useful with graph execution. else: - checkpointable_utils.restore( + status = checkpointable_utils.restore( save_path=checkpoint_path, root_checkpointable=root, - session=session) + session=session).assert_consumed() + session.run(status.restore_ops) for _ in range(num_training_steps): session.run(train_op) root.save(file_prefix=checkpoint_prefix, @@ -560,6 +562,7 @@ class CheckpointingTests(test.TestCase): status.assert_consumed() load_into.add_dep() status.assert_consumed() + self.evaluate(status.restore_ops) self.assertEqual(123., self.evaluate(load_into.dep.var)) @test_util.run_in_graph_and_eager_modes() @@ -591,6 +594,7 @@ class CheckpointingTests(test.TestCase): save_path, loaded_dep_after_var) loaded_dep_after_var.add_dep() status.assert_consumed() + self.evaluate(status.restore_ops) self.assertEqual(-14., self.evaluate(loaded_dep_after_var.dep.var)) @test_util.run_in_graph_and_eager_modes(assert_no_eager_garbage=True) @@ -627,16 +631,28 @@ class CheckpointingTests(test.TestCase): no_slot_status.assert_consumed() new_root.var = checkpointable_utils.add_variable( new_root, name="var", shape=[]) - self.assertEqual(12., self.evaluate(new_root.var)) no_slot_status.assert_consumed() + self.evaluate(no_slot_status.restore_ops) + self.assertEqual(12., self.evaluate(new_root.var)) new_root.optimizer = CheckpointableAdam(0.1) with self.assertRaisesRegexp(AssertionError, "beta1_power"): slot_status.assert_consumed() self.assertEqual(12., self.evaluate(new_root.var)) - self.assertEqual(14., self.evaluate( - new_root.optimizer.get_slot(name="m", var=new_root.var))) + if context.in_eager_mode(): + # Slot variables are only created with restoring initializers when + # executing eagerly. + self.assertEqual(14., self.evaluate( + new_root.optimizer.get_slot(name="m", var=new_root.var))) + else: + self.assertIs(new_root.optimizer.get_slot(name="m", var=new_root.var), + None) if context.in_graph_mode(): train_op = new_root.optimizer.minimize(new_root.var) + # The slot variable now exists; restore() didn't create it, but we should + # now have a restore op for it. + self.evaluate(slot_status.restore_ops) + self.assertEqual(14., self.evaluate( + new_root.optimizer.get_slot(name="m", var=new_root.var))) self.evaluate(train_op) else: new_root.optimizer.minimize(new_root.var.read_value) @@ -667,9 +683,12 @@ class CheckpointingTests(test.TestCase): load_dep, name="var", shape=[]) first_root.dep = load_dep first_status.assert_consumed() + self.evaluate(first_status.restore_ops) + self.assertEqual([], second_status.restore_ops) self.assertEqual(12., self.evaluate(load_dep.var)) second_root.dep = load_dep second_status.assert_consumed() + self.evaluate(second_status.restore_ops) self.assertEqual(13., self.evaluate(load_dep.var)) # Try again with the order of the restore() reversed. The last restore @@ -685,9 +704,12 @@ class CheckpointingTests(test.TestCase): load_dep, name="var", shape=[]) first_root.dep = load_dep first_status.assert_consumed() + self.assertEqual([], second_status.restore_ops) + self.evaluate(first_status.restore_ops) self.assertEqual(12., self.evaluate(load_dep.var)) second_root.dep = load_dep second_status.assert_consumed() + self.evaluate(second_status.restore_ops) self.assertEqual(12., self.evaluate(load_dep.var)) @test_util.run_in_graph_and_eager_modes(assert_no_eager_garbage=True) @@ -734,7 +756,9 @@ class CheckpointingTests(test.TestCase): load_root.dep_one, name="var1", shape=[], dtype=dtypes.float64) v2 = checkpointable_utils.add_variable( load_root.dep_one, name="var2", shape=[], dtype=dtypes.float64) - checkpointable_utils.restore(save_path, load_root).assert_consumed() + status = checkpointable_utils.restore( + save_path, load_root).assert_consumed() + self.evaluate(status.restore_ops) self.assertEqual(32., self.evaluate(v1)) self.assertEqual(64., self.evaluate(v2)) @@ -768,6 +792,7 @@ class CheckpointingTests(test.TestCase): second_load.v = checkpointable_utils.add_variable( second_load, "v2", shape=[4]) status.assert_consumed() + self.evaluate(status.restore_ops) self.assertAllEqual([3., 1., 4.], self.evaluate(first_load.v)) self.assertAllEqual([1., 1., 2., 3.], self.evaluate(second_load.v)) @@ -776,8 +801,9 @@ class CheckpointingTests(test.TestCase): self.assertAllEqual([2., 7., 1.], self.evaluate(first_load.v)) self.evaluate(second_load.v.assign([2., 7., 1., 8.])) self.assertAllEqual([2., 7., 1., 8.], self.evaluate(second_load.v)) - checkpointable_utils.restore( + status = checkpointable_utils.restore( save_path, first_load).assert_consumed() + self.evaluate(status.restore_ops) self.assertAllEqual([3., 1., 4.], self.evaluate(first_load.v)) self.assertAllEqual([1., 1., 2., 3.], self.evaluate(second_load.v)) @@ -801,13 +827,16 @@ class CheckpointingTests(test.TestCase): second = checkpointable.Checkpointable() second.var2 = variable_scope.get_variable( name="blah", initializer=0.) - checkpointable_utils.restore(save_path, root_checkpointable=second) + status = checkpointable_utils.restore( + save_path, root_checkpointable=second) recreated_var1 = variable_scope.get_variable( name="outside_var", initializer=0.) + self.evaluate(status.restore_ops) self.assertEqual(8., self.evaluate(second.var2)) self.evaluate(recreated_var1.assign(-2.)) self.assertEqual(-2., self.evaluate(recreated_var1)) second.var1 = recreated_var1 + self.evaluate(status.restore_ops) self.assertEqual(4., self.evaluate(recreated_var1)) # TODO(allenl): Saver class that doesn't pollute the graph with constants. diff --git a/tensorflow/contrib/estimator/python/estimator/replicate_model_fn.py b/tensorflow/contrib/estimator/python/estimator/replicate_model_fn.py index 7134cd3f5a..e0fae2c992 100644 --- a/tensorflow/contrib/estimator/python/estimator/replicate_model_fn.py +++ b/tensorflow/contrib/estimator/python/estimator/replicate_model_fn.py @@ -110,7 +110,8 @@ def replicate_model_fn(model_fn, Certain algorithms were chosen for aggregating results of computations on multiple towers: - Losses from all towers are reduced according to `loss_reduction`. - - Gradients are reduced using sum for each trainable variable. + - Gradients from all towers are reduced according to `loss_reduction` + for each trainable variable. - `eval_metrics_ops` are reduced per metric using `reduce_mean`. - `EstimatorSpec.predictions` and `EstimatorSpec.export_outputs` are reduced using concatenation. diff --git a/tensorflow/contrib/gan/python/eval/python/summaries_test.py b/tensorflow/contrib/gan/python/eval/python/summaries_test.py index 7956db4334..45eb108586 100644 --- a/tensorflow/contrib/gan/python/eval/python/summaries_test.py +++ b/tensorflow/contrib/gan/python/eval/python/summaries_test.py @@ -90,8 +90,7 @@ class SummariesTest(test.TestCase): self._test_add_gan_model_image_summaries_impl(get_gan_model, 2, False) def test_add_gan_model_image_summaries_for_cyclegan(self): - self._test_add_gan_model_image_summaries_impl(get_cyclegan_model, 10, - True) + self._test_add_gan_model_image_summaries_impl(get_cyclegan_model, 10, True) def _test_add_gan_model_summaries_impl(self, get_model_fn, expected_num_summary_ops): diff --git a/tensorflow/contrib/labeled_tensor/python/ops/core.py b/tensorflow/contrib/labeled_tensor/python/ops/core.py index abc18aa123..0c6bba758b 100644 --- a/tensorflow/contrib/labeled_tensor/python/ops/core.py +++ b/tensorflow/contrib/labeled_tensor/python/ops/core.py @@ -362,6 +362,10 @@ class LabeledTensor(object): return self._tensor.dtype @property + def shape(self): + return self._tensor.shape + + @property def name(self): return self._tensor.name diff --git a/tensorflow/contrib/labeled_tensor/python/ops/core_test.py b/tensorflow/contrib/labeled_tensor/python/ops/core_test.py index e70b492374..e378db56af 100644 --- a/tensorflow/contrib/labeled_tensor/python/ops/core_test.py +++ b/tensorflow/contrib/labeled_tensor/python/ops/core_test.py @@ -244,6 +244,9 @@ class LabeledTensorTest(test_util.Base): def test_dtype(self): self.assertEqual(self.lt.dtype, self.lt.tensor.dtype) + def test_shape(self): + self.assertEqual(self.lt.shape, self.lt.tensor.shape) + def test_get_shape(self): self.assertEqual(self.lt.get_shape(), self.lt.tensor.get_shape()) diff --git a/tensorflow/contrib/labeled_tensor/python/ops/ops.py b/tensorflow/contrib/labeled_tensor/python/ops/ops.py index c957b41a49..3ba1026383 100644 --- a/tensorflow/contrib/labeled_tensor/python/ops/ops.py +++ b/tensorflow/contrib/labeled_tensor/python/ops/ops.py @@ -951,7 +951,7 @@ def define_reduce_op(op_name, reduce_fn): intermediate_axes.append(axis) reduce_op = reduce_fn( - labeled_tensor.tensor, reduction_dimensions, keep_dims=True) + labeled_tensor.tensor, reduction_dimensions, keepdims=True) reduce_lt = core.LabeledTensor(reduce_op, intermediate_axes) return squeeze(reduce_lt, axes_to_squeeze, name=scope) diff --git a/tensorflow/contrib/layers/python/layers/feature_column.py b/tensorflow/contrib/layers/python/layers/feature_column.py index b7d34d6435..9ccb589d69 100644 --- a/tensorflow/contrib/layers/python/layers/feature_column.py +++ b/tensorflow/contrib/layers/python/layers/feature_column.py @@ -154,6 +154,7 @@ from tensorflow.python.ops import string_ops from tensorflow.python.ops import variables from tensorflow.python.platform import tf_logging as logging from tensorflow.python.util import deprecation +from tensorflow.python.util import nest # Imports the core `InputLayer` symbol in contrib during development. @@ -554,28 +555,70 @@ def sparse_column_with_integerized_feature(column_name, class _SparseColumnHashed(_SparseColumn): """See `sparse_column_with_hash_bucket`.""" + def __new__(cls, + column_name, + is_integerized=False, + bucket_size=None, + lookup_config=None, + combiner="sum", + dtype=dtypes.string, + hash_keys=None): + if hash_keys is not None: + if not isinstance(hash_keys, list) or not hash_keys: + raise ValueError("hash_keys must be a non-empty list.") + if (any([not isinstance(key_pair, list) for key_pair in hash_keys]) or + any([len(key_pair) != 2 for key_pair in hash_keys]) or + any([not isinstance(key, int) for key in nest.flatten(hash_keys)])): + raise ValueError( + "Each element of hash_keys must be a pair of integers.") + obj = super(_SparseColumnHashed, cls).__new__( + cls, + column_name, + is_integerized=is_integerized, + bucket_size=bucket_size, + lookup_config=lookup_config, + combiner=combiner, + dtype=dtype) + obj.hash_keys = hash_keys + return obj + def _do_transform(self, input_tensor): if self.dtype.is_integer: sparse_values = string_ops.as_string(input_tensor.values) else: sparse_values = input_tensor.values - sparse_id_values = string_ops.string_to_hash_bucket_fast( - sparse_values, self.bucket_size, name="lookup") - return sparse_tensor_py.SparseTensor(input_tensor.indices, sparse_id_values, - input_tensor.dense_shape) + if self.hash_keys: + result = [] + for key in self.hash_keys: + sparse_id_values = string_ops.string_to_hash_bucket_strong( + sparse_values, self.bucket_size, key) + result.append( + sparse_tensor_py.SparseTensor(input_tensor.indices, + sparse_id_values, + input_tensor.dense_shape)) + return sparse_ops.sparse_concat(axis=1, sp_inputs=result, name="lookup") + else: + sparse_id_values = string_ops.string_to_hash_bucket_fast( + sparse_values, self.bucket_size, name="lookup") + return sparse_tensor_py.SparseTensor( + input_tensor.indices, sparse_id_values, input_tensor.dense_shape) def sparse_column_with_hash_bucket(column_name, hash_bucket_size, combiner="sum", - dtype=dtypes.string): + dtype=dtypes.string, + hash_keys=None): """Creates a _SparseColumn with hashed bucket configuration. Use this when your sparse features are in string or integer format, but you don't have a vocab file that maps each value to an integer ID. output_id = Hash(input_feature_string) % bucket_size + When hash_keys is set, multiple integer IDs would be created with each key + pair in the `hash_keys`. This is useful to reduce the collision of hashed ids. + Args: column_name: A string defining sparse column name. hash_bucket_size: An int that is > 1. The number of buckets. @@ -588,6 +631,9 @@ def sparse_column_with_hash_bucket(column_name, * "sqrtn": do l2 normalization on features in the column For more information: `tf.embedding_lookup_sparse`. dtype: The type of features. Only string and integer types are supported. + hash_keys: The hash keys to use. It is a list of lists of two uint64s. If + None, simple and fast hashing algorithm is used. Otherwise, multiple + strong hash ids would be produced with each two unit64s in this argument. Returns: A _SparseColumn with hashed bucket configuration @@ -600,7 +646,8 @@ def sparse_column_with_hash_bucket(column_name, column_name, bucket_size=hash_bucket_size, combiner=combiner, - dtype=dtype) + dtype=dtype, + hash_keys=hash_keys) class _SparseColumnKeys(_SparseColumn): diff --git a/tensorflow/contrib/layers/python/layers/feature_column_test.py b/tensorflow/contrib/layers/python/layers/feature_column_test.py index fc8f153fe3..1de9ab7056 100644 --- a/tensorflow/contrib/layers/python/layers/feature_column_test.py +++ b/tensorflow/contrib/layers/python/layers/feature_column_test.py @@ -329,6 +329,55 @@ class FeatureColumnTest(test.TestCase): self.assertEqual(one_hot.sparse_id_column.name, "ids_weighted_by_weights") self.assertEqual(one_hot.length, 3) + def testOneHotColumnWithSparseColumnWithHashKeys(self): + input_values = ["marlo", "unknown", "omar"] + inputs = constant_op.constant(input_values) + hash_keys = [[10, 20], [20, 30]] + hash_column = fc.sparse_column_with_hash_bucket( + column_name="ids", hash_bucket_size=10, hash_keys=hash_keys) + columns_to_tensors = {} + columns_to_tensors["ids"] = inputs + hash_column.insert_transformed_feature(columns_to_tensors) + self.assertEqual(len(columns_to_tensors), 2) + self.assertTrue(hash_column in columns_to_tensors) + + one_hot_column = fc.one_hot_column(hash_column) + one_hot_output = one_hot_column._to_dnn_input_layer( + columns_to_tensors[hash_column]) + + expected = np.array([[0., 1., 0., 0., 0., 0., 0., 1., 0., + 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 1.], + [1., 0., 0., 0., 0., 0., 0., 0., 0., 1.]]) + with self.test_session() as sess: + one_hot_value = sess.run(one_hot_output) + self.assertTrue(np.array_equal(one_hot_value, expected)) + + def testSparseColumnWithHashKeysWithUnexpectedHashKeys(self): + with self.assertRaisesRegexp(ValueError, + "hash_keys must be a non-empty list."): + fc.sparse_column_with_hash_bucket( + column_name="ids", hash_bucket_size=100, hash_keys=[]) + + with self.assertRaisesRegexp(ValueError, + "hash_keys must be a non-empty list."): + fc.sparse_column_with_hash_bucket( + column_name="ids", hash_bucket_size=100, hash_keys=1) + + with self.assertRaisesRegexp( + ValueError, "Each element of hash_keys must be a pair of integers."): + fc.sparse_column_with_hash_bucket( + column_name="ids", hash_bucket_size=100, hash_keys=[1, 2]) + + with self.assertRaisesRegexp( + ValueError, "Each element of hash_keys must be a pair of integers."): + fc.sparse_column_with_hash_bucket( + column_name="ids", hash_bucket_size=100, hash_keys=["key"]) + + with self.assertRaisesRegexp( + ValueError, "Each element of hash_keys must be a pair of integers."): + fc.sparse_column_with_hash_bucket( + column_name="ids", hash_bucket_size=100, hash_keys=[[1, 2.0]]) + def testMissingValueInOneHotColumnForWeightedSparseColumn(self): # Github issue 12583 ids = fc.sparse_column_with_keys("ids", ["marlo", "omar", "stringer"]) diff --git a/tensorflow/contrib/layers/python/layers/layers.py b/tensorflow/contrib/layers/python/layers/layers.py index 5c1ff9ec26..e27b36908e 100644 --- a/tensorflow/contrib/layers/python/layers/layers.py +++ b/tensorflow/contrib/layers/python/layers/layers.py @@ -2187,8 +2187,10 @@ def layer_norm(inputs, @add_arg_scope -def images_to_sequence(inputs, data_format=DATA_FORMAT_NHWC, - outputs_collections=None, scope=None): +def images_to_sequence(inputs, + data_format=DATA_FORMAT_NHWC, + outputs_collections=None, + scope=None): """Convert a batch of images into a batch of sequences. Args: inputs: a (num_images, height, width, depth) tensor @@ -2694,8 +2696,11 @@ def separable_convolution2d( @add_arg_scope -def sequence_to_images(inputs, height, output_data_format='channels_last', - outputs_collections=None, scope=None): +def sequence_to_images(inputs, + height, + output_data_format='channels_last', + outputs_collections=None, + scope=None): """Convert a batch of sequences into a batch of images. Args: inputs: (num_steps, num_batches, depth) sequence tensor diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h b/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h index dec58fea4f..7e8db95760 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h @@ -2081,6 +2081,198 @@ inline void LstmCell(const float* input_data, const Dims<4>& input_dims, output_state_map.tanh(); } +#ifdef GEMMLOWP_NEON +// In the common case of batch size 1, a fully-connected node degenerates +// to a matrix*vector product. LSTM cells contain a fully-connected node; +// when quantized, this becomes a special type of GEMV operation where +// the output is 16bit-quantized, thus needs its own special path. +inline void GEMVForLstmCell(const uint8* input_data, const Dims<4>& input_dims, + const uint8* weights_data, + const Dims<4>& weights_dims, + uint8 weights_zero_point, const int32* bias_data, + const Dims<4>& bias_dims, int32 accum_multiplier, + int accum_shift, int16* output_data, + const Dims<4>& output_dims) { + gemmlowp::ScopedProfilingLabel label("GEMVForLstmCell"); + TFLITE_DCHECK(IsPackedWithoutStrides(input_dims)); + TFLITE_DCHECK(IsPackedWithoutStrides(weights_dims)); + TFLITE_DCHECK(IsPackedWithoutStrides(bias_dims)); + TFLITE_DCHECK(IsPackedWithoutStrides(output_dims)); + TFLITE_DCHECK_EQ(ArraySize(output_dims, 1) * ArraySize(output_dims, 2) * + ArraySize(output_dims, 3), + 1); + const int input_size = input_dims.strides[3]; + const int output_size = MatchingArraySize(weights_dims, 1, output_dims, 0); + // This special fast path for quantized LSTM cells does not try to support + // odd sizes that we haven't encountered in any LSTM cell, that would + // require special code (that would go untested until any LSTM cell + // exercises it). We just guard our assumptions about size evenness with + // the following assertions. + TFLITE_DCHECK(!(output_size % 4)); + TFLITE_DCHECK(!(input_size % 8)); + const int32* bias_ptr = bias_data; + int16* output_ptr = output_data; + for (int out = 0; out < output_size; out += 4) { + int32x4_t acc_0 = vdupq_n_s32(0); + int32x4_t acc_1 = vdupq_n_s32(0); + int32x4_t acc_2 = vdupq_n_s32(0); + int32x4_t acc_3 = vdupq_n_s32(0); + const int16x8_t input_offset_vec = vdupq_n_s16(-128); + const int16x8_t weights_offset_vec = vdupq_n_s16(-weights_zero_point); + int in = 0; + // Handle 16 levels of depth at a time. + for (; in <= input_size - 16; in += 16) { + const uint8x16_t input_val_u8 = vld1q_u8(input_data + in); + const uint8* weights_ptr = weights_data + in + out * input_size; + uint8x16_t weights_val_u8_0 = vld1q_u8(weights_ptr + 0 * input_size); + uint8x16_t weights_val_u8_1 = vld1q_u8(weights_ptr + 1 * input_size); + uint8x16_t weights_val_u8_2 = vld1q_u8(weights_ptr + 2 * input_size); + uint8x16_t weights_val_u8_3 = vld1q_u8(weights_ptr + 3 * input_size); + int16x8_t input_val_0, input_val_1; + const uint8x8_t low = vget_low_u8(input_val_u8); + const uint8x8_t high = vget_high_u8(input_val_u8); + input_val_0 = vreinterpretq_s16_u16(vmovl_u8(low)); + input_val_1 = vreinterpretq_s16_u16(vmovl_u8(high)); + input_val_0 = vaddq_s16(input_val_0, input_offset_vec); + input_val_1 = vaddq_s16(input_val_1, input_offset_vec); + int16x8_t weights_val_0_0, weights_val_1_0, weights_val_2_0, + weights_val_3_0; + int16x8_t weights_val_0_1, weights_val_1_1, weights_val_2_1, + weights_val_3_1; + weights_val_0_0 = vaddq_s16( + vreinterpretq_s16_u16(vmovl_u8(vget_low_u8(weights_val_u8_0))), + weights_offset_vec); + weights_val_0_1 = vaddq_s16( + vreinterpretq_s16_u16(vmovl_u8(vget_high_u8(weights_val_u8_0))), + weights_offset_vec); + weights_val_1_0 = vaddq_s16( + vreinterpretq_s16_u16(vmovl_u8(vget_low_u8(weights_val_u8_1))), + weights_offset_vec); + weights_val_1_1 = vaddq_s16( + vreinterpretq_s16_u16(vmovl_u8(vget_high_u8(weights_val_u8_1))), + weights_offset_vec); + weights_val_2_0 = vaddq_s16( + vreinterpretq_s16_u16(vmovl_u8(vget_low_u8(weights_val_u8_2))), + weights_offset_vec); + weights_val_2_1 = vaddq_s16( + vreinterpretq_s16_u16(vmovl_u8(vget_high_u8(weights_val_u8_2))), + weights_offset_vec); + weights_val_3_0 = vaddq_s16( + vreinterpretq_s16_u16(vmovl_u8(vget_low_u8(weights_val_u8_3))), + weights_offset_vec); + weights_val_3_1 = vaddq_s16( + vreinterpretq_s16_u16(vmovl_u8(vget_high_u8(weights_val_u8_3))), + weights_offset_vec); + acc_0 = vmlal_s16(acc_0, vget_low_s16(weights_val_0_0), + vget_low_s16(input_val_0)); + acc_1 = vmlal_s16(acc_1, vget_low_s16(weights_val_1_0), + vget_low_s16(input_val_0)); + acc_2 = vmlal_s16(acc_2, vget_low_s16(weights_val_2_0), + vget_low_s16(input_val_0)); + acc_3 = vmlal_s16(acc_3, vget_low_s16(weights_val_3_0), + vget_low_s16(input_val_0)); + acc_0 = vmlal_s16(acc_0, vget_high_s16(weights_val_0_0), + vget_high_s16(input_val_0)); + acc_1 = vmlal_s16(acc_1, vget_high_s16(weights_val_1_0), + vget_high_s16(input_val_0)); + acc_2 = vmlal_s16(acc_2, vget_high_s16(weights_val_2_0), + vget_high_s16(input_val_0)); + acc_3 = vmlal_s16(acc_3, vget_high_s16(weights_val_3_0), + vget_high_s16(input_val_0)); + acc_0 = vmlal_s16(acc_0, vget_low_s16(weights_val_0_1), + vget_low_s16(input_val_1)); + acc_1 = vmlal_s16(acc_1, vget_low_s16(weights_val_1_1), + vget_low_s16(input_val_1)); + acc_2 = vmlal_s16(acc_2, vget_low_s16(weights_val_2_1), + vget_low_s16(input_val_1)); + acc_3 = vmlal_s16(acc_3, vget_low_s16(weights_val_3_1), + vget_low_s16(input_val_1)); + acc_0 = vmlal_s16(acc_0, vget_high_s16(weights_val_0_1), + vget_high_s16(input_val_1)); + acc_1 = vmlal_s16(acc_1, vget_high_s16(weights_val_1_1), + vget_high_s16(input_val_1)); + acc_2 = vmlal_s16(acc_2, vget_high_s16(weights_val_2_1), + vget_high_s16(input_val_1)); + acc_3 = vmlal_s16(acc_3, vget_high_s16(weights_val_3_1), + vget_high_s16(input_val_1)); + } + // Handle 8 levels of depth at a time. + for (; in < input_size; in += 8) { + const uint8x8_t input_val_u8 = vld1_u8(input_data + in); + const uint8* weights_ptr = weights_data + in + out * input_size; + uint8x8_t weights_val_u8_0 = vld1_u8(weights_ptr + 0 * input_size); + uint8x8_t weights_val_u8_1 = vld1_u8(weights_ptr + 1 * input_size); + uint8x8_t weights_val_u8_2 = vld1_u8(weights_ptr + 2 * input_size); + uint8x8_t weights_val_u8_3 = vld1_u8(weights_ptr + 3 * input_size); + int16x8_t input_val; + input_val = vreinterpretq_s16_u16(vmovl_u8(input_val_u8)); + input_val = vaddq_s16(input_val, input_offset_vec); + int16x8_t weights_val_0, weights_val_1, weights_val_2, weights_val_3; + weights_val_0 = + vaddq_s16(vreinterpretq_s16_u16(vmovl_u8(weights_val_u8_0)), + weights_offset_vec); + weights_val_1 = + vaddq_s16(vreinterpretq_s16_u16(vmovl_u8(weights_val_u8_1)), + weights_offset_vec); + weights_val_2 = + vaddq_s16(vreinterpretq_s16_u16(vmovl_u8(weights_val_u8_2)), + weights_offset_vec); + weights_val_3 = + vaddq_s16(vreinterpretq_s16_u16(vmovl_u8(weights_val_u8_3)), + weights_offset_vec); + acc_0 = vmlal_s16(acc_0, vget_low_s16(weights_val_0), + vget_low_s16(input_val)); + acc_1 = vmlal_s16(acc_1, vget_low_s16(weights_val_1), + vget_low_s16(input_val)); + acc_2 = vmlal_s16(acc_2, vget_low_s16(weights_val_2), + vget_low_s16(input_val)); + acc_3 = vmlal_s16(acc_3, vget_low_s16(weights_val_3), + vget_low_s16(input_val)); + acc_0 = vmlal_s16(acc_0, vget_high_s16(weights_val_0), + vget_high_s16(input_val)); + acc_1 = vmlal_s16(acc_1, vget_high_s16(weights_val_1), + vget_high_s16(input_val)); + acc_2 = vmlal_s16(acc_2, vget_high_s16(weights_val_2), + vget_high_s16(input_val)); + acc_3 = vmlal_s16(acc_3, vget_high_s16(weights_val_3), + vget_high_s16(input_val)); + } + // Horizontally reduce accumulators + int32x2_t pairwise_reduced_acc_0, pairwise_reduced_acc_1, + pairwise_reduced_acc_2, pairwise_reduced_acc_3; + pairwise_reduced_acc_0 = + vpadd_s32(vget_low_s32(acc_0), vget_high_s32(acc_0)); + pairwise_reduced_acc_1 = + vpadd_s32(vget_low_s32(acc_1), vget_high_s32(acc_1)); + pairwise_reduced_acc_2 = + vpadd_s32(vget_low_s32(acc_2), vget_high_s32(acc_2)); + pairwise_reduced_acc_3 = + vpadd_s32(vget_low_s32(acc_3), vget_high_s32(acc_3)); + const int32x2_t reduced_lo = + vpadd_s32(pairwise_reduced_acc_0, pairwise_reduced_acc_1); + const int32x2_t reduced_hi = + vpadd_s32(pairwise_reduced_acc_2, pairwise_reduced_acc_3); + int32x4_t reduced = vcombine_s32(reduced_lo, reduced_hi); + // Add bias values. + int32x4_t bias_vec = vld1q_s32(bias_ptr); + bias_ptr += 4; + reduced = vaddq_s32(reduced, bias_vec); + int left_shift = accum_shift > 0 ? accum_shift : 0; + int right_shift = accum_shift > 0 ? 0 : -accum_shift; + reduced = vshlq_s32(reduced, vdupq_n_s32(left_shift)); + // Multiply by the fixed-point multiplier. + reduced = vqrdmulhq_n_s32(reduced, accum_multiplier); + // Rounding-shift-right. + using gemmlowp::RoundingDivideByPOT; + reduced = RoundingDivideByPOT(reduced, right_shift); + // Narrow values down to 16 bit signed. + const int16x4_t res16 = vqmovn_s32(reduced); + vst1_s16(output_ptr, res16); + output_ptr += 4; + } +} +#endif + // Quantized LSTM cell. Currently just a copy of the reference impl in // reference_ops.h. See the big function comment there, not replicating it // here. @@ -2095,7 +2287,8 @@ void LstmCell(const uint8* input_data_uint8, const Dims<4>& input_dims, const Dims<4>& output_activ_dims, uint8* concat_temp_data_uint8, const Dims<4>& concat_temp_dims, int16* activ_temp_data_int16, const Dims<4>& activ_temp_dims, int32 weights_zero_point, - int32 accum_multiplier, int accum_shift) { + int32 accum_multiplier, int accum_shift, + gemmlowp::GemmContext* gemm_context) { gemmlowp::ScopedProfilingLabel label( "LstmCell/quantized (8bit external, 16bit internal)"); // Gather dimensions information, and perform consistency checks. @@ -2144,42 +2337,121 @@ void LstmCell(const uint8* input_data_uint8, const Dims<4>& input_dims, // integers, and the output is 16-bit fixed-point with 3 integer bits so // the output range is [-2^3, 2^3] == [-8, 8]. The rationale for that // is explained in the function comment above. - for (int b = 0; b < fc_batches; ++b) { - for (int out_c = 0; out_c < fc_output_depth; ++out_c) { - // Internal accumulation. - // Initialize accumulator with the bias-value. - int32 accum = bias_data_int32[out_c]; - // Accumulation loop. - for (int d = 0; d < fc_accum_depth; ++d) { - int16 input_val = concat_temp_data_uint8[b * fc_accum_depth + d] - 128; - int16 weights_val = - weights_data_uint8[out_c * fc_accum_depth + d] - weights_zero_point; - accum += input_val * weights_val; - } - // Down-scale the final int32 accumulator to the scale used by our - // (16-bit, using 3 integer bits) fixed-point format. The quantized - // multiplier and shift here have been pre-computed offline - // (e.g. by toco). - // Note that the implicit assumption here, that this multiplier is smaller - // than one, is equivalent to the assumption that the fully-connected - // weights min-max is enclosed within [-4, 4] (it may be narrower). - // If that eventually fails, offline tools (e.g. toco) will fail early - // and that will be easy to support as needed. For now, assuming that - // this multiplier is less than one allows us to use a simpler, more - // accurate implementation. - accum = - MultiplyByQuantizedMultiplier(accum, accum_multiplier, accum_shift); - // Saturate, cast to int16, and store to the temporary activations array. - accum = std::max(-32768, std::min(32767, accum)); - activ_temp_data_int16[out_c + fc_output_depth * b] = accum; - } + bool gemm_already_performed = false; +#ifdef GEMMLOWP_NEON + if (fc_batches == 1 && !(fc_output_depth % 4) && !(fc_accum_depth % 8)) { + GEMVForLstmCell(concat_temp_data_uint8, concat_temp_dims, + weights_data_uint8, weights_dims, weights_zero_point, + bias_data_int32, bias_dims, accum_multiplier, accum_shift, + activ_temp_data_int16, activ_temp_dims); + gemm_already_performed = true; + } +#endif + if (!gemm_already_performed) { + gemmlowp::MatrixMap<const uint8, gemmlowp::MapOrder::RowMajor> + weights_matrix(weights_data_uint8, fc_output_depth, fc_accum_depth); + gemmlowp::MatrixMap<const uint8, gemmlowp::MapOrder::ColMajor> input_matrix( + concat_temp_data_uint8, fc_accum_depth, fc_batches); + gemmlowp::MatrixMap<int16, gemmlowp::MapOrder::ColMajor> output_matrix( + activ_temp_data_int16, fc_output_depth, fc_batches); + typedef gemmlowp::VectorMap<const int32, gemmlowp::VectorShape::Col> + ColVectorMap; + ColVectorMap bias_vector(bias_data_int32, fc_output_depth); + gemmlowp::OutputStageBiasAddition<ColVectorMap> bias_addition_stage; + bias_addition_stage.bias_vector = bias_vector; + gemmlowp::OutputStageScaleInt32ByFixedPointAndExponent scale_stage; + scale_stage.result_offset_after_shift = 0; + scale_stage.result_fixedpoint_multiplier = accum_multiplier; + scale_stage.result_exponent = accum_shift; + gemmlowp::OutputStageSaturatingCastToInt16 saturating_cast_int16_stage; + auto output_pipeline = std::make_tuple(bias_addition_stage, scale_stage, + saturating_cast_int16_stage); + gemmlowp::GemmWithOutputPipeline< + uint8, int16, gemmlowp::L8R8WithLhsNonzeroBitDepthParams>( + gemm_context, weights_matrix, input_matrix, &output_matrix, + -weights_zero_point, -128, output_pipeline); } // Rest of the LSTM cell: tanh and logistic math functions, and some adds // and muls, all done in 16-bit fixed-point. const int outer_size = batches * width * height; + const int16* input_gate_input_ptr = activ_temp_data_int16; + const int16* input_modulation_gate_input_ptr = + activ_temp_data_int16 + output_depth; + const int16* forget_gate_input_ptr = activ_temp_data_int16 + 2 * output_depth; + const int16* output_gate_input_ptr = activ_temp_data_int16 + 3 * output_depth; + const int16* prev_state_ptr = prev_state_data_int16; + int16* output_state_data_ptr = output_state_data_int16; + uint8* output_activ_data_ptr = output_activ_data_uint8; + for (int b = 0; b < outer_size; ++b) { - for (int c = 0; c < output_depth; ++c) { + int c = 0; +#ifdef GEMMLOWP_NEON + for (; c <= output_depth - 8; c += 8) { + // Define the fixed-point data types that we will use here. All use + // int16 as the underlying integer type i.e. all are 16-bit fixed-point. + // They only differ by the number of integral vs. fractional bits, + // determining the range of values that they can represent. + // + // F0 uses 0 integer bits, range [-1, 1]. + // This is the return type of math functions such as tanh, logistic, + // whose range is in [-1, 1]. + using F0 = gemmlowp::FixedPoint<int16x8_t, 0>; + // F3 uses 3 integer bits, range [-8, 8]. + // This is the range of the previous fully-connected node's output, + // which is our input here. + using F3 = gemmlowp::FixedPoint<int16x8_t, 3>; + // FS uses StateIntegerBits integer bits, range [-2^StateIntegerBits, + // 2^StateIntegerBits]. It's used to represent the internal state, whose + // number of integer bits is currently dictated by the model. See comment + // on the StateIntegerBits template parameter above. + using FS = gemmlowp::FixedPoint<int16x8_t, StateIntegerBits>; + // Implementation of input gate, using fixed-point logistic function. + F3 input_gate_input = F3::FromRaw(vld1q_s16(input_gate_input_ptr)); + input_gate_input_ptr += 8; + F0 input_gate_output = gemmlowp::logistic(input_gate_input); + // Implementation of input modulation gate, using fixed-point tanh + // function. + F3 input_modulation_gate_input = + F3::FromRaw(vld1q_s16(input_modulation_gate_input_ptr)); + input_modulation_gate_input_ptr += 8; + F0 input_modulation_gate_output = + gemmlowp::tanh(input_modulation_gate_input); + // Implementation of forget gate, using fixed-point logistic function. + F3 forget_gate_input = F3::FromRaw(vld1q_s16(forget_gate_input_ptr)); + forget_gate_input_ptr += 8; + F0 forget_gate_output = gemmlowp::logistic(forget_gate_input); + // Implementation of output gate, using fixed-point logistic function. + F3 output_gate_input = F3::FromRaw(vld1q_s16(output_gate_input_ptr)); + output_gate_input_ptr += 8; + F0 output_gate_output = gemmlowp::logistic(output_gate_input); + // Implementation of internal multiplication nodes, still in fixed-point. + F0 input_times_input_modulation = + input_gate_output * input_modulation_gate_output; + FS prev_state = FS::FromRaw(vld1q_s16(prev_state_ptr)); + prev_state_ptr += 8; + FS prev_state_times_forget_state = forget_gate_output * prev_state; + // Implementation of internal addition node, saturating. + FS new_state = gemmlowp::SaturatingAdd( + gemmlowp::Rescale<StateIntegerBits>(input_times_input_modulation), + prev_state_times_forget_state); + // Implementation of last internal tanh node, still in fixed-point. + F0 output_activ_int16 = output_gate_output * gemmlowp::tanh(new_state); + // Store the new internal state back to memory, as 16-bit integers. + vst1q_s16(output_state_data_ptr, new_state.raw()); + output_state_data_ptr += 8; + // Down-scale the output activations to 8-bit integers, saturating, + // and store back to memory. + int16x8_t rescaled_output_activ = + gemmlowp::RoundingDivideByPOT(output_activ_int16.raw(), 8); + int8x8_t int8_output_activ = vqmovn_s16(rescaled_output_activ); + uint8x8_t uint8_output_activ = + vadd_u8(vdup_n_u8(128), vreinterpret_u8_s8(int8_output_activ)); + vst1_u8(output_activ_data_ptr, uint8_output_activ); + output_activ_data_ptr += 8; + } +#endif + for (; c < output_depth; ++c) { // Define the fixed-point data types that we will use here. All use // int16 as the underlying integer type i.e. all are 16-bit fixed-point. // They only differ by the number of integral vs. fractional bits, @@ -2199,27 +2471,24 @@ void LstmCell(const uint8* input_data_uint8, const Dims<4>& input_dims, // on the StateIntegerBits template parameter above. using FS = gemmlowp::FixedPoint<std::int16_t, StateIntegerBits>; // Implementation of input gate, using fixed-point logistic function. - F3 input_gate_input = F3::FromRaw( - activ_temp_data_int16[b * fc_output_depth + 0 * output_depth + c]); + F3 input_gate_input = F3::FromRaw(*input_gate_input_ptr++); F0 input_gate_output = gemmlowp::logistic(input_gate_input); // Implementation of input modulation gate, using fixed-point tanh // function. - F3 input_modulation_gate_input = F3::FromRaw( - activ_temp_data_int16[b * fc_output_depth + 1 * output_depth + c]); + F3 input_modulation_gate_input = + F3::FromRaw(*input_modulation_gate_input_ptr++); F0 input_modulation_gate_output = gemmlowp::tanh(input_modulation_gate_input); // Implementation of forget gate, using fixed-point logistic function. - F3 forget_gate_input = F3::FromRaw( - activ_temp_data_int16[b * fc_output_depth + 2 * output_depth + c]); + F3 forget_gate_input = F3::FromRaw(*forget_gate_input_ptr++); F0 forget_gate_output = gemmlowp::logistic(forget_gate_input); // Implementation of output gate, using fixed-point logistic function. - F3 output_gate_input = F3::FromRaw( - activ_temp_data_int16[b * fc_output_depth + 3 * output_depth + c]); + F3 output_gate_input = F3::FromRaw(*output_gate_input_ptr++); F0 output_gate_output = gemmlowp::logistic(output_gate_input); // Implementation of internal multiplication nodes, still in fixed-point. F0 input_times_input_modulation = input_gate_output * input_modulation_gate_output; - FS prev_state = FS::FromRaw(prev_state_data_int16[b * output_depth + c]); + FS prev_state = FS::FromRaw(*prev_state_ptr++); FS prev_state_times_forget_state = forget_gate_output * prev_state; // Implementation of internal addition node, saturating. FS new_state = gemmlowp::SaturatingAdd( @@ -2228,16 +2497,19 @@ void LstmCell(const uint8* input_data_uint8, const Dims<4>& input_dims, // Implementation of last internal tanh node, still in fixed-point. F0 output_activ_int16 = output_gate_output * gemmlowp::tanh(new_state); // Store the new internal state back to memory, as 16-bit integers. - output_state_data_int16[b * output_depth + c] = new_state.raw(); + *output_state_data_ptr++ = new_state.raw(); // Down-scale the output activations to 8-bit integers, saturating, // and store back to memory. int16 rescaled_output_activ = gemmlowp::RoundingDivideByPOT(output_activ_int16.raw(), 8); int16 clamped_output_activ = std::max<int16>(-128, std::min<int16>(127, rescaled_output_activ)); - output_activ_data_uint8[b * output_depth + c] = - 128 + clamped_output_activ; + *output_activ_data_ptr++ = 128 + clamped_output_activ; } + input_gate_input_ptr += 3 * output_depth; + input_modulation_gate_input_ptr += 3 * output_depth; + forget_gate_input_ptr += 3 * output_depth; + output_gate_input_ptr += 3 * output_depth; } } diff --git a/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h b/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h index 5f4d5be323..d8907d5d48 100644 --- a/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h @@ -1453,7 +1453,10 @@ void LstmCell(const uint8* input_data_uint8, const Dims<4>& input_dims, const Dims<4>& output_activ_dims, uint8* concat_temp_data_uint8, const Dims<4>& concat_temp_dims, int16* activ_temp_data_int16, const Dims<4>& activ_temp_dims, int32 weights_zero_point, - int32 accum_multiplier, int accum_shift) { + int32 accum_multiplier, int accum_shift, + gemmlowp::GemmContext* gemm_context) { + (void)gemm_context; // only used in optimized code. + // Gather dimensions information, and perform consistency checks. const int batches = MatchingArraySize(input_dims, 3, prev_activ_dims, 3, prev_state_dims, 3, @@ -1574,9 +1577,19 @@ void LstmCell(const uint8* input_data_uint8, const Dims<4>& input_dims, FS new_state = gemmlowp::SaturatingAdd( gemmlowp::Rescale<StateIntegerBits>(input_times_input_modulation), prev_state_times_forget_state); - // Implementation of last internal tanh node, still in fixed-point. - F0 output_activ_int16 = output_gate_output * gemmlowp::tanh(new_state); + // Implementation of last internal Tanh node, still in fixed-point. + // Since a Tanh fixed-point implementation is specialized for a given + // number or integer bits, and each specialization can have a substantial + // code size, and we already used above a Tanh on an input with 3 integer + // bits, and per the table in the above function comment there is no + // significant accuracy to be lost by clamping to [-8, +8] for a + // 3-integer-bits representation, let us just do that. This helps people + // porting this to targets where code footprint must be minimized. + F3 new_state_f3 = gemmlowp::Rescale<3>(new_state); + F0 output_activ_int16 = output_gate_output * gemmlowp::tanh(new_state_f3); // Store the new internal state back to memory, as 16-bit integers. + // Note: here we store the original value with StateIntegerBits, not + // the rescaled 3-integer-bits value fed to tanh. output_state_data_int16[b * output_depth + c] = new_state.raw(); // Down-scale the output activations to 8-bit integers, saturating, // and store back to memory. diff --git a/tensorflow/contrib/opt/BUILD b/tensorflow/contrib/opt/BUILD index 827279bd47..86ceda71b7 100644 --- a/tensorflow/contrib/opt/BUILD +++ b/tensorflow/contrib/opt/BUILD @@ -70,6 +70,7 @@ py_test( srcs = ["python/training/moving_average_optimizer_test.py"], srcs_version = "PY2AND3", tags = [ + "no_oss", # b/73507407 "notsan", # b/31055119 ], deps = [ diff --git a/tensorflow/contrib/py2tf/converters/BUILD b/tensorflow/contrib/py2tf/converters/BUILD index 93c751b28d..e9a96ec8d1 100644 --- a/tensorflow/contrib/py2tf/converters/BUILD +++ b/tensorflow/contrib/py2tf/converters/BUILD @@ -132,6 +132,7 @@ py_test( py_test( name = "for_loops_test", srcs = ["for_loops_test.py"], + srcs_version = "PY2AND3", deps = [ ":test_lib", "//tensorflow/contrib/py2tf/pyct", diff --git a/tensorflow/contrib/py2tf/impl/api.py b/tensorflow/contrib/py2tf/impl/api.py index 8ae1c70169..29d2e038a7 100644 --- a/tensorflow/contrib/py2tf/impl/api.py +++ b/tensorflow/contrib/py2tf/impl/api.py @@ -175,7 +175,8 @@ def to_graph(e, conversion_map = conversion.ConversionMap( recursive=recursive, nocompile_decorators=(convert, graph_ready, convert_inline), - partial_types=partial_types) + partial_types=partial_types, + api_module=tf_inspect.getmodule(to_graph)) _, name = conversion.entity_to_graph(e, conversion_map, arg_values, arg_types) module = gast.Module([]) @@ -221,7 +222,8 @@ def to_code(e, conversion_map = conversion.ConversionMap( recursive=recursive, nocompile_decorators=(convert, graph_ready, convert_inline), - partial_types=partial_types) + partial_types=partial_types, + api_module=tf_inspect.getmodule(to_graph)) conversion.entity_to_graph(e, conversion_map, arg_values, arg_types) imports = '\n'.join(config.COMPILED_IMPORT_STATEMENTS) diff --git a/tensorflow/contrib/py2tf/impl/config.py b/tensorflow/contrib/py2tf/impl/config.py index 7c3ecefff0..c90e85c96b 100644 --- a/tensorflow/contrib/py2tf/impl/config.py +++ b/tensorflow/contrib/py2tf/impl/config.py @@ -36,10 +36,11 @@ DEFAULT_UNCOMPILED_MODULES = set(( NO_SIDE_EFFECT_CONSTRUCTORS = set(('tensorflow',)) # TODO(mdan): Also allow controlling the generated names (for testability). -# TODO(mdan): Verify that these names are not hidden by generated code. # TODO(mdan): Make sure copybara renames the reference below. COMPILED_IMPORT_STATEMENTS = ( 'from __future__ import print_function', 'import tensorflow as tf', + 'from tensorflow.contrib.py2tf.impl import api as ' + 'py2tf_api', 'from tensorflow.contrib.py2tf import utils as ' 'py2tf_utils') diff --git a/tensorflow/contrib/py2tf/impl/conversion.py b/tensorflow/contrib/py2tf/impl/conversion.py index 3d5624b187..7610f0427b 100644 --- a/tensorflow/contrib/py2tf/impl/conversion.py +++ b/tensorflow/contrib/py2tf/impl/conversion.py @@ -58,16 +58,20 @@ class ConversionMap(object): converted AST name_map: dict[string]: string; maps original entities to the name of their converted counterparts + api_module: A reference to the api module. The reference needs to be passed + to avoid circular dependencies. """ # TODO(mdan): Rename to ConversionContext, and pull in additional flags. - def __init__(self, recursive, nocompile_decorators, partial_types): + def __init__(self, recursive, nocompile_decorators, partial_types, + api_module): self.recursive = recursive self.nocompile_decorators = nocompile_decorators self.partial_types = partial_types if partial_types else () self.dependency_cache = {} self.name_map = {} + self.api_module = api_module def new_namer(self, namespace): return naming.Namer(namespace, self.recursive, self.name_map, @@ -170,6 +174,24 @@ def class_to_graph(c, conversion_map): return node, class_name +def _add_self_references(namespace, api_module): + """Self refs are only required for analysis and are not used directly.""" + # Manually add the utils namespace which may be used from generated code. + if 'py2tf_util' not in namespace: + namespace['py2tf_utils'] = utils + elif namespace['py2tf_utils'] != utils: + raise ValueError( + 'The module name "py2tf_utils" is reserved and may not be used.') + + # We also make reference to the api module for dynamic conversion, but + # to avoid circular references we don't import it here. + if 'py2tf_api' not in namespace: + namespace['py2tf_api'] = api_module + elif namespace['py2tf_api'] != api_module: + raise ValueError( + 'The module name "py2tf_api" is reserved and may not be used.') + + def function_to_graph(f, conversion_map, arg_values, arg_types, owner_type=None): """Specialization of `entity_to_graph` for callable functions.""" @@ -185,12 +207,7 @@ def function_to_graph(f, conversion_map, arg_values, arg_types, fn = e.cell_contents namespace[fn.__name__] = fn - # Manually add the utils namespace which may be used from generated code. - if 'py2tf_util' not in namespace: - namespace['py2tf_utils'] = utils - elif namespace['py2tf_utils'] != utils: - raise ValueError( - 'The module name py2tf_utils is reserved and may not be used.') + _add_self_references(namespace, conversion_map.api_module) namer = conversion_map.new_namer(namespace) ctx = context.EntityContext( diff --git a/tensorflow/contrib/py2tf/impl/conversion_test.py b/tensorflow/contrib/py2tf/impl/conversion_test.py index 3888958f19..75e95ed888 100644 --- a/tensorflow/contrib/py2tf/impl/conversion_test.py +++ b/tensorflow/contrib/py2tf/impl/conversion_test.py @@ -28,7 +28,7 @@ class ConversionTest(test.TestCase): def test_entity_to_graph_unsupported_types(self): with self.assertRaises(ValueError): - conversion_map = conversion.ConversionMap(True, (), ()) + conversion_map = conversion.ConversionMap(True, (), (), None) conversion.entity_to_graph('dummy', conversion_map, None, None) def test_entity_to_graph_callable(self): @@ -36,7 +36,7 @@ class ConversionTest(test.TestCase): def f(a): return a - conversion_map = conversion.ConversionMap(True, (), ()) + conversion_map = conversion.ConversionMap(True, (), (), None) ast, new_name = conversion.entity_to_graph(f, conversion_map, None, None) self.assertTrue(isinstance(ast, gast.FunctionDef), ast) self.assertEqual('tf__f', new_name) @@ -49,7 +49,7 @@ class ConversionTest(test.TestCase): def f(a): return g(a) - conversion_map = conversion.ConversionMap(True, (), ()) + conversion_map = conversion.ConversionMap(True, (), (), None) conversion.entity_to_graph(f, conversion_map, None, None) self.assertTrue(f in conversion_map.dependency_cache) diff --git a/tensorflow/contrib/timeseries/python/timeseries/input_pipeline.py b/tensorflow/contrib/timeseries/python/timeseries/input_pipeline.py index d4ee590366..04225333b9 100644 --- a/tensorflow/contrib/timeseries/python/timeseries/input_pipeline.py +++ b/tensorflow/contrib/timeseries/python/timeseries/input_pipeline.py @@ -500,6 +500,41 @@ class CSVReader(ReaderBaseTimeSeriesParser): return features +class TFExampleReader(ReaderBaseTimeSeriesParser): + """Reads and parses `tf.Example`s from a TFRecords file.""" + + def __init__(self, + filenames, + features): + """Configure `tf.Example` parsing. + + Args: + filenames: A filename or list of filenames to read the time series + from. Each line must have columns corresponding to `column_names`. + features: A dictionary mapping from feature keys to `tf.FixedLenFeature` + objects. Must include `TrainEvalFeatures.TIMES` (scalar integer) and + `TrainEvalFeatures.VALUES` (floating point vector) features. + Raises: + ValueError: If required times/values features are not present. + """ + if feature_keys.TrainEvalFeatures.TIMES not in features: + raise ValueError("'{}' is a required column.".format( + feature_keys.TrainEvalFeatures.TIMES)) + if feature_keys.TrainEvalFeatures.VALUES not in features: + raise ValueError("'{}' is a required column.".format( + feature_keys.TrainEvalFeatures.VALUES)) + self._features = features + super(TFExampleReader, self).__init__(filenames=filenames) + + def _get_reader(self): + return io_ops.TFRecordReader() + + def _process_records(self, examples): + """Parse `tf.Example`s into `Tensors`.""" + return parsing_ops.parse_example( + serialized=examples, features=self._features) + + class TimeSeriesInputFn(object): """Base for classes which create batches of windows from a time series.""" diff --git a/tensorflow/contrib/timeseries/python/timeseries/input_pipeline_test.py b/tensorflow/contrib/timeseries/python/timeseries/input_pipeline_test.py index ed78a835a4..703537abf0 100644 --- a/tensorflow/contrib/timeseries/python/timeseries/input_pipeline_test.py +++ b/tensorflow/contrib/timeseries/python/timeseries/input_pipeline_test.py @@ -27,7 +27,11 @@ from tensorflow.contrib.timeseries.python.timeseries import input_pipeline from tensorflow.contrib.timeseries.python.timeseries import test_utils from tensorflow.contrib.timeseries.python.timeseries.feature_keys import TrainEvalFeatures +from tensorflow.core.example import example_pb2 +from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors +from tensorflow.python.lib.io import tf_record +from tensorflow.python.ops import parsing_ops from tensorflow.python.ops import variables from tensorflow.python.platform import test from tensorflow.python.training import coordinator as coordinator_lib @@ -52,6 +56,21 @@ def _make_csv_time_series(num_features, num_samples, test_tmpdir): return filename +def _make_tfexample_series(num_features, num_samples, test_tmpdir): + _, data_file = tempfile.mkstemp(dir=test_tmpdir) + with tf_record.TFRecordWriter(data_file) as writer: + for i in range(num_samples): + example = example_pb2.Example() + times = example.features.feature[TrainEvalFeatures.TIMES] + times.int64_list.value.append(i) + values = example.features.feature[TrainEvalFeatures.VALUES] + values.float_list.value.extend( + [float(i) * 2. + feature_number + for feature_number in range(num_features)]) + writer.write(example.SerializeToString()) + return data_file + + def _make_numpy_time_series(num_features, num_samples): times = numpy.arange(num_samples) values = times[:, None] * 2. + numpy.arange(num_features)[None, :] @@ -107,6 +126,19 @@ class RandomWindowInputFnTests(test.TestCase): time_series_reader = input_pipeline.CSVReader([filename]) self._test_out_of_order(time_series_reader, discard_out_of_order=False) + def test_tfexample_sort_out_of_order(self): + filename = _make_tfexample_series( + num_features=1, num_samples=50, + test_tmpdir=self.get_temp_dir()) + time_series_reader = input_pipeline.TFExampleReader( + [filename], + features={ + TrainEvalFeatures.TIMES: parsing_ops.FixedLenFeature( + shape=[], dtype=dtypes.int64), + TrainEvalFeatures.VALUES: parsing_ops.FixedLenFeature( + shape=[1], dtype=dtypes.float32)}) + self._test_out_of_order(time_series_reader, discard_out_of_order=False) + def test_numpy_sort_out_of_order(self): data = _make_numpy_time_series(num_features=1, num_samples=50) time_series_reader = input_pipeline.NumpyReader(data) @@ -183,6 +215,20 @@ class RandomWindowInputFnTests(test.TestCase): self._test_multivariate(time_series_reader=time_series_reader, num_features=2) + def test_tfexample_multivariate(self): + filename = _make_tfexample_series( + num_features=2, num_samples=50, + test_tmpdir=self.get_temp_dir()) + time_series_reader = input_pipeline.TFExampleReader( + [filename], + features={ + TrainEvalFeatures.TIMES: parsing_ops.FixedLenFeature( + shape=[], dtype=dtypes.int64), + TrainEvalFeatures.VALUES: parsing_ops.FixedLenFeature( + shape=[2], dtype=dtypes.float32)}) + self._test_multivariate(time_series_reader=time_series_reader, + num_features=2) + def test_numpy_multivariate(self): data = _make_numpy_time_series(num_features=3, num_samples=50) time_series_reader = input_pipeline.NumpyReader(data) @@ -248,6 +294,20 @@ class WholeDatasetInputFnTests(test.TestCase): self._whole_dataset_input_fn_test_template( time_series_reader=time_series_reader, num_features=1, num_samples=50) + def test_tfexample(self): + filename = _make_tfexample_series( + num_features=4, num_samples=100, + test_tmpdir=self.get_temp_dir()) + time_series_reader = input_pipeline.TFExampleReader( + [filename], + features={ + TrainEvalFeatures.TIMES: parsing_ops.FixedLenFeature( + shape=[], dtype=dtypes.int64), + TrainEvalFeatures.VALUES: parsing_ops.FixedLenFeature( + shape=[4], dtype=dtypes.float32)}) + self._whole_dataset_input_fn_test_template( + time_series_reader=time_series_reader, num_features=4, num_samples=100) + def test_numpy(self): data = _make_numpy_time_series(num_features=4, num_samples=100) time_series_reader = input_pipeline.NumpyReader(data) diff --git a/tensorflow/core/kernels/constant_op.cc b/tensorflow/core/kernels/constant_op.cc index 4ab6fdbca1..fdb03a5aae 100644 --- a/tensorflow/core/kernels/constant_op.cc +++ b/tensorflow/core/kernels/constant_op.cc @@ -102,6 +102,7 @@ REGISTER_KERNEL(GPU, float); REGISTER_KERNEL(GPU, double); REGISTER_KERNEL(GPU, uint8); REGISTER_KERNEL(GPU, int8); +REGISTER_KERNEL(GPU, qint8); REGISTER_KERNEL(GPU, uint16); REGISTER_KERNEL(GPU, int16); REGISTER_KERNEL(GPU, int64); diff --git a/tensorflow/core/kernels/conv_2d.h b/tensorflow/core/kernels/conv_2d.h index 2142207b0d..6949e5b5fd 100644 --- a/tensorflow/core/kernels/conv_2d.h +++ b/tensorflow/core/kernels/conv_2d.h @@ -54,10 +54,12 @@ struct InflatePadAndShuffle { template <typename Device, typename Input, typename Filter, typename Output> void SpatialConvolutionFunc(const Device& d, Output output, Input input, Filter filter, int row_stride, int col_stride, + int row_dilation, int col_dilation, const Eigen::PaddingType& padding) { // Need to swap row/col when calling Eigen. output.device(d) = - Eigen::SpatialConvolution(input, filter, col_stride, row_stride, padding); + Eigen::SpatialConvolution(input, filter, col_stride, row_stride, padding, + col_dilation, row_dilation); } template <typename Device, typename T> @@ -65,9 +67,10 @@ struct SpatialConvolution { void operator()(const Device& d, typename TTypes<T, 4>::Tensor output, typename TTypes<T, 4>::ConstTensor input, typename TTypes<T, 4>::ConstTensor filter, int row_stride, - int col_stride, const Eigen::PaddingType& padding) { + int col_stride, int row_dilation, int col_dilation, + const Eigen::PaddingType& padding) { SpatialConvolutionFunc(d, output, input, filter, row_stride, col_stride, - padding); + row_dilation, col_dilation, padding); } }; @@ -77,11 +80,12 @@ struct SpatialConvolution<Device, Eigen::half> { typename TTypes<Eigen::half, 4>::Tensor output, typename TTypes<Eigen::half, 4>::ConstTensor input, typename TTypes<Eigen::half, 4>::ConstTensor filter, - int row_stride, int col_stride, - const Eigen::PaddingType& padding) { + int row_stride, int col_stride, int row_dilation, + int col_dilation, const Eigen::PaddingType& padding) { output.device(d) = Eigen::SpatialConvolution(input.cast<float>(), filter.cast<float>(), - col_stride, row_stride, padding) + col_stride, row_stride, padding, col_dilation, + row_dilation) .cast<Eigen::half>(); } }; @@ -91,11 +95,13 @@ struct SpatialConvolutionBackwardInput { void operator()(const Device& d, typename TTypes<T, 4>::Tensor input_backward, typename TTypes<T, 4>::ConstTensor kernel, typename TTypes<T, 4>::ConstTensor output_backward, - int row_stride, int col_stride) { + int row_stride, int col_stride, int row_dilation, + int col_dilation) { // Need to swap row/col when calling Eigen. input_backward.device(d) = Eigen::SpatialConvolutionBackwardInput( kernel, output_backward, input_backward.dimension(2), - input_backward.dimension(1), col_stride, row_stride); + input_backward.dimension(1), col_stride, row_stride, col_dilation, + row_dilation); } }; @@ -105,11 +111,13 @@ struct SpatialConvolutionBackwardFilter { typename TTypes<T, 4>::Tensor kernel_backward, typename TTypes<T, 4>::ConstTensor input, typename TTypes<T, 4>::ConstTensor output_backward, - int row_stride, int col_stride) { + int row_stride, int col_stride, int row_dilation, + int col_dilation) { // Need to swap row/col when calling Eigen. kernel_backward.device(d) = Eigen::SpatialConvolutionBackwardKernel( input, output_backward, kernel_backward.dimension(1), - kernel_backward.dimension(0), col_stride, row_stride); + kernel_backward.dimension(0), col_stride, row_stride, col_dilation, + row_dilation); } }; diff --git a/tensorflow/core/kernels/conv_grad_filter_ops.cc b/tensorflow/core/kernels/conv_grad_filter_ops.cc index 512bcc6c01..b8a5ae6a08 100644 --- a/tensorflow/core/kernels/conv_grad_filter_ops.cc +++ b/tensorflow/core/kernels/conv_grad_filter_ops.cc @@ -101,7 +101,8 @@ struct LaunchConv2DBackpropFilterOp<CPUDevice, T> { const CPUDevice& d = ctx->eigen_device<CPUDevice>(); functor::SpatialConvolutionBackwardFilter<CPUDevice, T>()( d, filter_backprop->tensor<T, 4>(), input.tensor<T, 4>(), - out_backprop.tensor<T, 4>(), row_stride, col_stride); + out_backprop.tensor<T, 4>(), row_stride, col_stride, + /*row_dilation=*/1, /*col_dilation=*/1); } }; diff --git a/tensorflow/core/kernels/conv_grad_input_ops.cc b/tensorflow/core/kernels/conv_grad_input_ops.cc index 0356ff4c0f..b87c7899c0 100644 --- a/tensorflow/core/kernels/conv_grad_input_ops.cc +++ b/tensorflow/core/kernels/conv_grad_input_ops.cc @@ -106,7 +106,8 @@ struct LaunchConv2DBackpropInputOp<CPUDevice, T> { const CPUDevice& d = ctx->eigen_device<CPUDevice>(); functor::SpatialConvolutionBackwardInput<CPUDevice, T>()( d, in_backprop->tensor<T, 4>(), filter.tensor<T, 4>(), - out_backprop.tensor<T, 4>(), row_stride, col_stride); + out_backprop.tensor<T, 4>(), row_stride, col_stride, + /*row_dilation=*/1, /*col_dilation=*/1); } }; diff --git a/tensorflow/core/kernels/conv_ops.cc b/tensorflow/core/kernels/conv_ops.cc index dbddaf3dc6..2b81e14f95 100644 --- a/tensorflow/core/kernels/conv_ops.cc +++ b/tensorflow/core/kernels/conv_ops.cc @@ -60,8 +60,8 @@ template <typename Device, typename T> struct LaunchGeneric { void operator()(OpKernelContext* ctx, const Tensor& input, const Tensor& filter, int row_stride, int col_stride, - const Padding& padding, Tensor* output, - TensorFormat data_format) { + int row_dilation, int col_dilation, const Padding& padding, + Tensor* output, TensorFormat data_format) { CHECK(data_format == FORMAT_NHWC) << "Generic conv implementation only " "supports NHWC tensor format for now."; if (filter.dim_size(0) == 1 && filter.dim_size(1) == 1 && row_stride == 1 && @@ -86,7 +86,8 @@ struct LaunchGeneric { filter.shaped<T, 2>({filter.dim_size(2), filter.dim_size(3)}), dim_pair); } else if (filter.dim_size(0) == input.dim_size(1) && - filter.dim_size(1) == input.dim_size(2) && padding == VALID) { + filter.dim_size(1) == input.dim_size(2) && row_dilation == 1 && + col_dilation == 1 && padding == VALID) { // If the input data and filter have the same height/width, // the 2D convolution is reduced to matrix multiplication. const int k = // Length of reduction dimension. @@ -103,7 +104,7 @@ struct LaunchGeneric { functor::SpatialConvolution<Device, T>()( ctx->eigen_device<Device>(), output->tensor<T, 4>(), input.tensor<T, 4>(), filter.tensor<T, 4>(), row_stride, col_stride, - BrainPadding2EigenPadding(padding)); + row_dilation, col_dilation, BrainPadding2EigenPadding(padding)); } } }; @@ -122,15 +123,9 @@ struct LaunchConv2DOp<CPUDevice, T> { "NHWC tensor format for now.")); return; } - // TODO(yangzihao): Add the CPU implementation of dilated conv 2D. - if (row_dilation > 1 || col_dilation > 1) { - ctx->SetStatus( - errors::Unimplemented("Generic conv implementation only supports " - "dilated rate of 1 for now.")); - return; - } LaunchGeneric<CPUDevice, T>()(ctx, input, filter, row_stride, col_stride, - padding, output, data_format); + row_dilation, col_dilation, padding, output, + data_format); } }; @@ -792,7 +787,8 @@ namespace functor { const GPUDevice& d, typename TTypes<T, 4>::Tensor output, \ typename TTypes<T, 4>::ConstTensor input, \ typename TTypes<T, 4>::ConstTensor filter, int row_stride, \ - int col_stride, const Eigen::PaddingType& padding); \ + int col_stride, int row_dilation, int col_dilation, \ + const Eigen::PaddingType& padding); \ extern template struct SpatialConvolution<GPUDevice, T>; \ template <> \ void MatMulConvFunctor<GPUDevice, T>::operator()( \ diff --git a/tensorflow/core/kernels/depthwise_conv_op_gpu.cu.cc b/tensorflow/core/kernels/depthwise_conv_op_gpu.cu.cc index 505d33046e..94989089ec 100644 --- a/tensorflow/core/kernels/depthwise_conv_op_gpu.cu.cc +++ b/tensorflow/core/kernels/depthwise_conv_op_gpu.cu.cc @@ -186,6 +186,8 @@ __global__ __launch_bounds__(1024, 2) void DepthwiseConv2dGPUKernelNHWCSmall( const int pad_height = args.pad_rows; const int pad_width = args.pad_cols; + assert(blockDim.x == kBlockDepth); + assert(blockDim.y == args.in_cols); const int block_height = blockDim.z; // These values are the same for all threads and could @@ -465,6 +467,8 @@ __global__ __launch_bounds__(1024, 2) void DepthwiseConv2dGPUKernelNCHWSmall( const int pad_width = args.pad_cols; // Fixed blockDim.z, tailored for maximum grid size for images of size 16x16. + assert(blockDim.x == args.in_cols); + assert(blockDim.z == kBlockDepth); const int block_height = blockDim.y; // These values are the same for all threads and could @@ -588,20 +592,30 @@ void LaunchDepthwiseConv2dGPUSmall(const GpuDevice& device, TensorFormat data_format) { const int block_height = (args.in_rows + 1) / 2; dim3 block_dim; + int block_count; void (*kernel)(const DepthwiseArgs, const T*, const T*, T*); - if (data_format == FORMAT_NHWC) { - block_dim = dim3(kBlockDepth, args.in_cols, block_height); - kernel = DepthwiseConv2dGPUKernelNHWCSmall<T, kDirection, kKnownFilterWidth, - kKnownFilterHeight, kBlockDepth, - kKnownEvenHeight>; - } else if (data_format == FORMAT_NCHW) { - block_dim = dim3(args.in_cols, block_height, kBlockDepth); - kernel = DepthwiseConv2dGPUKernelNCHWSmall<T, kDirection, kKnownFilterWidth, - kKnownFilterHeight, kBlockDepth, - kKnownEvenHeight>; - } else { - assert(false && "Incorrect data format"); - return; + switch (data_format) { + case FORMAT_NHWC: + block_dim = dim3(kBlockDepth, args.in_cols, block_height); + block_count = + args.batch * DivUp(args.out_depth, kBlockDepth) * kBlockDepth; + kernel = + DepthwiseConv2dGPUKernelNHWCSmall<T, kDirection, kKnownFilterWidth, + kKnownFilterHeight, kBlockDepth, + kKnownEvenHeight>; + break; + case FORMAT_NCHW: + block_dim = dim3(args.in_cols, block_height, kBlockDepth); + block_count = + DivUp(args.batch * args.out_depth, kBlockDepth) * kBlockDepth; + kernel = + DepthwiseConv2dGPUKernelNCHWSmall<T, kDirection, kKnownFilterWidth, + kKnownFilterHeight, kBlockDepth, + kKnownEvenHeight>; + break; + case FORMAT_NCHW_VECT_C: + LOG(ERROR) << "FORMAT_NCHW_VECT_C is not supported"; + return; } const int tile_width = args.in_cols + args.filter_cols - 1; const int tile_height = block_height * 2 + args.filter_rows - 1; @@ -609,11 +623,10 @@ void LaunchDepthwiseConv2dGPUSmall(const GpuDevice& device, const int filter_pixels = args.filter_rows * args.filter_cols; const int shared_memory_size = kBlockDepth * (tile_pixels + filter_pixels) * sizeof(T); - const int num_outputs = - args.batch * args.out_rows * args.out_cols * args.out_depth; - CudaLaunchConfig config = - GetCudaLaunchConfig(num_outputs, device, kernel, shared_memory_size, - block_dim.x * block_dim.y * block_dim.z); + const int num_outputs = args.out_rows * args.out_cols * block_count; + CudaLaunchConfig config = GetCudaLaunchConfigFixedBlockSize( + num_outputs, device, kernel, shared_memory_size, + block_dim.x * block_dim.y * block_dim.z); kernel<<<config.block_count, block_dim, shared_memory_size, device.stream()>>>(args, input, filter, output); } @@ -666,17 +679,20 @@ void LaunchDepthwiseConv2dGPU(const GpuDevice& device, const T* filter, T* output, TensorFormat data_format) { void (*kernel)(const DepthwiseArgs, const T*, const T*, T*, int); - if (data_format == FORMAT_NHWC) { - kernel = - DepthwiseConv2dGPUKernelNHWC<T, kKnownFilterWidth, kKnownFilterHeight, - kKnownDepthMultiplier>; - } else if (data_format == FORMAT_NCHW) { - kernel = - DepthwiseConv2dGPUKernelNCHW<T, kKnownFilterWidth, kKnownFilterHeight, - kKnownDepthMultiplier>; - } else { - assert(false && "Incorrect data format"); - return; + switch (data_format) { + case FORMAT_NHWC: + kernel = + DepthwiseConv2dGPUKernelNHWC<T, kKnownFilterWidth, kKnownFilterHeight, + kKnownDepthMultiplier>; + break; + case FORMAT_NCHW: + kernel = + DepthwiseConv2dGPUKernelNCHW<T, kKnownFilterWidth, kKnownFilterHeight, + kKnownDepthMultiplier>; + break; + case FORMAT_NCHW_VECT_C: + LOG(ERROR) << "FORMAT_NCHW_VECT_C is not supported"; + return; } const int num_outputs = args.batch * args.out_rows * args.out_cols * args.out_depth; @@ -894,15 +910,18 @@ void LaunchDepthwiseConv2dBackpropInputGPU(const GpuDevice& device, const T* filter, T* in_backprop, TensorFormat data_format) { void (*kernel)(const DepthwiseArgs, const T*, const T*, T*, int); - if (data_format == FORMAT_NHWC) { - kernel = DepthwiseConv2dBackpropInputGPUKernelNHWC< - T, kKnownFilterWidth, kKnownFilterHeight, kKnownDepthMultiplier>; - } else if (data_format == FORMAT_NCHW) { - kernel = DepthwiseConv2dBackpropInputGPUKernelNCHW< - T, kKnownFilterWidth, kKnownFilterHeight, kKnownDepthMultiplier>; - } else { - assert(false && "Incorrect data format"); - return; + switch (data_format) { + case FORMAT_NHWC: + kernel = DepthwiseConv2dBackpropInputGPUKernelNHWC< + T, kKnownFilterWidth, kKnownFilterHeight, kKnownDepthMultiplier>; + break; + case FORMAT_NCHW: + kernel = DepthwiseConv2dBackpropInputGPUKernelNCHW< + T, kKnownFilterWidth, kKnownFilterHeight, kKnownDepthMultiplier>; + break; + case FORMAT_NCHW_VECT_C: + LOG(ERROR) << "FORMAT_NCHW_VECT_C is not supported"; + return; } const int num_in_backprop = args.batch * args.in_rows * args.in_cols * args.in_depth; @@ -1113,6 +1132,8 @@ __launch_bounds__(1024, 2) void DepthwiseConv2dBackpropFilterGPUKernelNHWCSmall( const int pad_height = args.pad_rows; const int pad_width = args.pad_cols; + assert(blockDim.x == kBlockDepth); + assert(blockDim.y == args.in_cols); const int block_height = blockDim.z; // These values are the same for all threads and could @@ -1381,6 +1402,8 @@ __launch_bounds__(1024, 2) void DepthwiseConv2dBackpropFilterGPUKernelNCHWSmall( const int pad_height = args.pad_rows; const int pad_width = args.pad_cols; + assert(blockDim.x == args.in_cols); + assert(blockDim.z == kBlockDepth); const int block_height = blockDim.y; // These values are the same for all threads and could @@ -1519,24 +1542,31 @@ bool TryLaunchDepthwiseConv2dBackpropFilterGPUSmall( } dim3 block_dim; + int block_count; void (*kernel)(const DepthwiseArgs, const T*, const T*, T*); - if (data_format == FORMAT_NHWC) { - block_dim = dim3(kBlockDepth, args.in_cols, block_height); - kernel = DepthwiseConv2dBackpropFilterGPUKernelNHWCSmall< - T, kKnownFilterWidth, kKnownFilterHeight, kBlockDepth, kAccumPixels>; - } else if (data_format == FORMAT_NCHW) { - block_dim = dim3(args.in_cols, block_height, kBlockDepth); - kernel = DepthwiseConv2dBackpropFilterGPUKernelNCHWSmall< - T, kKnownFilterWidth, kKnownFilterHeight, kBlockDepth, kAccumPixels>; - } else { - assert(false && "Incorrect data format"); - return false; + switch (data_format) { + case FORMAT_NHWC: + block_dim = dim3(kBlockDepth, args.in_cols, block_height); + block_count = + args.batch * DivUp(args.out_depth, kBlockDepth) * kBlockDepth; + kernel = DepthwiseConv2dBackpropFilterGPUKernelNHWCSmall< + T, kKnownFilterWidth, kKnownFilterHeight, kBlockDepth, kAccumPixels>; + break; + case FORMAT_NCHW: + block_dim = dim3(args.in_cols, block_height, kBlockDepth); + block_count = + DivUp(args.batch * args.out_depth, kBlockDepth) * kBlockDepth; + kernel = DepthwiseConv2dBackpropFilterGPUKernelNCHWSmall< + T, kKnownFilterWidth, kKnownFilterHeight, kBlockDepth, kAccumPixels>; + break; + case FORMAT_NCHW_VECT_C: + LOG(ERROR) << "FORMAT_NCHW_VECT_C is not supported"; + return false; } - const int num_out_backprop = - args.batch * args.out_rows * args.out_cols * args.out_depth; - CudaLaunchConfig config = - GetCudaLaunchConfig(num_out_backprop, device, kernel, shared_memory_size, - block_dim.x * block_dim.y * block_dim.z); + const int num_out_backprop = args.out_rows * args.out_cols * block_count; + CudaLaunchConfig config = GetCudaLaunchConfigFixedBlockSize( + num_out_backprop, device, kernel, shared_memory_size, + block_dim.x * block_dim.y * block_dim.z); kernel<<<config.block_count, block_dim, shared_memory_size, device.stream()>>>(args, out_backprop, input, filter_backprop); return true; @@ -1623,15 +1653,18 @@ void LaunchDepthwiseConv2dBackpropFilterGPU(const GpuDevice& device, const T* input, T* filter_backprop, TensorFormat data_format) { void (*kernel)(const DepthwiseArgs, const T*, const T*, T*, int); - if (data_format == FORMAT_NHWC) { - kernel = DepthwiseConv2dBackpropFilterGPUKernelNHWC< - T, kKnownFilterWidth, kKnownFilterHeight, kKnownDepthMultiplier>; - } else if (data_format == FORMAT_NCHW) { - kernel = DepthwiseConv2dBackpropFilterGPUKernelNCHW< - T, kKnownFilterWidth, kKnownFilterHeight, kKnownDepthMultiplier>; - } else { - assert(false && "Incorrect data format"); - return; + switch (data_format) { + case FORMAT_NHWC: + kernel = DepthwiseConv2dBackpropFilterGPUKernelNHWC< + T, kKnownFilterWidth, kKnownFilterHeight, kKnownDepthMultiplier>; + break; + case FORMAT_NCHW: + kernel = DepthwiseConv2dBackpropFilterGPUKernelNCHW< + T, kKnownFilterWidth, kKnownFilterHeight, kKnownDepthMultiplier>; + break; + case FORMAT_NCHW_VECT_C: + LOG(ERROR) << "FORMAT_NCHW_VECT_C is not supported"; + return; } const int num_out_backprop = args.batch * args.out_rows * args.out_cols * args.out_depth; diff --git a/tensorflow/core/kernels/training_ops.cc b/tensorflow/core/kernels/training_ops.cc index 07befa27bc..233aa03c32 100644 --- a/tensorflow/core/kernels/training_ops.cc +++ b/tensorflow/core/kernels/training_ops.cc @@ -1228,11 +1228,8 @@ inline T FtrlCompute(const T& accum, const T& linear, const T& lr, const T& l1, quadratic = Eigen::numext::pow(accum, -lr_power) / lr + static_cast<T>(2) * l2; } - if (Eigen::numext::abs(linear) > l1) { - return (l1 * sgn(linear) - linear) / quadratic; - } else { - return static_cast<T>(0.0); - } + auto l1_reg_adjust = std::max(std::min(linear, l1), -l1); + return (l1_reg_adjust - linear) / quadratic; } } // namespace diff --git a/tensorflow/core/platform/denormal.cc b/tensorflow/core/platform/denormal.cc index e00dbdb4ae..3631d9ddf9 100644 --- a/tensorflow/core/platform/denormal.cc +++ b/tensorflow/core/platform/denormal.cc @@ -40,36 +40,51 @@ limitations under the License. namespace tensorflow { namespace port { -ScopedFlushDenormal::ScopedFlushDenormal() { +static void SetDenormalState(bool flush_zero_mode, bool denormals_zero_mode) { // For now, we flush denormals only on SSE 3. Other architectures such as ARM // can be added as needed. #ifdef DENORM_USE_INTRINSICS if (TestCPUFeature(SSE3)) { - // Save existing flags - flush_zero_mode_ = _MM_GET_FLUSH_ZERO_MODE() == _MM_FLUSH_ZERO_ON; - denormals_zero_mode_ = - _MM_GET_DENORMALS_ZERO_MODE() == _MM_DENORMALS_ZERO_ON; - - // Flush denormals to zero (the FTZ flag). - _MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON); - - // Interpret denormal inputs as zero (the DAZ flag). - _MM_SET_DENORMALS_ZERO_MODE(_MM_DENORMALS_ZERO_ON); + // Restore flags + _MM_SET_FLUSH_ZERO_MODE(flush_zero_mode ? _MM_FLUSH_ZERO_ON + : _MM_FLUSH_ZERO_OFF); + _MM_SET_DENORMALS_ZERO_MODE(denormals_zero_mode ? _MM_DENORMALS_ZERO_ON + : _MM_DENORMALS_ZERO_OFF); } #endif } -ScopedFlushDenormal::~ScopedFlushDenormal() { +static std::pair<bool, bool> GetDernormalState() { + // For now, we flush denormals only on SSE 3. Other architectures such as ARM + // can be added as needed. + #ifdef DENORM_USE_INTRINSICS if (TestCPUFeature(SSE3)) { - // Restore flags - _MM_SET_FLUSH_ZERO_MODE(flush_zero_mode_ ? _MM_FLUSH_ZERO_ON - : _MM_FLUSH_ZERO_OFF); - _MM_SET_DENORMALS_ZERO_MODE(denormals_zero_mode_ ? _MM_DENORMALS_ZERO_ON - : _MM_DENORMALS_ZERO_OFF); + // Save existing flags + bool flush_zero_mode = _MM_GET_FLUSH_ZERO_MODE() == _MM_FLUSH_ZERO_ON; + bool denormals_zero_mode = + _MM_GET_DENORMALS_ZERO_MODE() == _MM_DENORMALS_ZERO_ON; + return {flush_zero_mode, denormals_zero_mode}; } #endif + return {false, false}; +} + +ScopedRestoreFlushDenormalState::ScopedRestoreFlushDenormalState() { + std::tie(flush_zero_mode_, denormals_zero_mode_) = GetDernormalState(); +} + +ScopedRestoreFlushDenormalState::~ScopedRestoreFlushDenormalState() { + SetDenormalState(flush_zero_mode_, denormals_zero_mode_); +} + +ScopedFlushDenormal::ScopedFlushDenormal() { + SetDenormalState(/*flush_zero_mode=*/true, /*denormals_zero_mode=*/true); +} + +ScopedDontFlushDenormal::ScopedDontFlushDenormal() { + SetDenormalState(/*flush_zero_mode=*/false, /*denormals_zero_mode=*/false); } } // namespace port diff --git a/tensorflow/core/platform/denormal.h b/tensorflow/core/platform/denormal.h index 5e34131a3b..09bb0352a2 100644 --- a/tensorflow/core/platform/denormal.h +++ b/tensorflow/core/platform/denormal.h @@ -21,19 +21,41 @@ limitations under the License. namespace tensorflow { namespace port { +// Remembers the flush denormal state on construction and restores that same +// state on destruction. +class ScopedRestoreFlushDenormalState { + public: + ScopedRestoreFlushDenormalState(); + ~ScopedRestoreFlushDenormalState(); + + private: + bool flush_zero_mode_; + bool denormals_zero_mode_; + TF_DISALLOW_COPY_AND_ASSIGN(ScopedRestoreFlushDenormalState); +}; + // While this class is active, denormal floating point numbers are flushed // to zero. The destructor restores the original flags. class ScopedFlushDenormal { public: ScopedFlushDenormal(); - ~ScopedFlushDenormal(); private: - bool flush_zero_mode_; - bool denormals_zero_mode_; + ScopedRestoreFlushDenormalState restore_; TF_DISALLOW_COPY_AND_ASSIGN(ScopedFlushDenormal); }; +// While this class is active, denormal floating point numbers are not flushed +// to zero. The destructor restores the original flags. +class ScopedDontFlushDenormal { + public: + ScopedDontFlushDenormal(); + + private: + ScopedRestoreFlushDenormalState restore_; + TF_DISALLOW_COPY_AND_ASSIGN(ScopedDontFlushDenormal); +}; + } // namespace port } // namespace tensorflow diff --git a/tensorflow/core/util/cuda_launch_config.h b/tensorflow/core/util/cuda_launch_config.h index 3ea33ee6cf..81df7a51d7 100644 --- a/tensorflow/core/util/cuda_launch_config.h +++ b/tensorflow/core/util/cuda_launch_config.h @@ -169,6 +169,30 @@ inline CudaLaunchConfig GetCudaLaunchConfig(int work_element_count, return config; } +// Calculate the Cuda launch config we should use for a kernel launch. This +// variant takes the resource limits of func into account to maximize occupancy. +// The returned launch config has thread_per_block set to fixed_block_size. +// REQUIRES: work_element_count > 0. +template <typename DeviceFunc> +inline CudaLaunchConfig GetCudaLaunchConfigFixedBlockSize( + int work_element_count, const Eigen::GpuDevice& d, DeviceFunc func, + size_t dynamic_shared_memory_size, int fixed_block_size) { + CHECK_GT(work_element_count, 0); + CudaLaunchConfig config; + int block_count = 0; + + cudaError_t err = cudaOccupancyMaxActiveBlocksPerMultiprocessor( + &block_count, func, fixed_block_size, dynamic_shared_memory_size); + CHECK_EQ(err, cudaSuccess); + block_count = std::min(block_count * d.getNumCudaMultiProcessors(), + DivUp(work_element_count, fixed_block_size)); + + config.virtual_thread_count = work_element_count; + config.thread_per_block = fixed_block_size; + config.block_count = block_count; + return config; +} + struct Cuda2DLaunchConfig { dim3 virtual_thread_count = dim3(0, 0, 0); dim3 thread_per_block = dim3(0, 0, 0); @@ -236,20 +260,18 @@ inline Cuda3DLaunchConfig GetCuda3DLaunchConfig( block_size_limit); CHECK_EQ(err, cudaSuccess); - auto min3 = [](int a, int b, int c) { return std::min(a, std::min(b, c)); }; - - int threadsx = min3(xdim, thread_per_block, xthreadlimit); + int threadsx = std::min({xdim, thread_per_block, xthreadlimit}); int threadsy = - min3(ydim, std::max(thread_per_block / threadsx, 1), ythreadlimit); + std::min({ydim, std::max(thread_per_block / threadsx, 1), ythreadlimit}); int threadsz = - min3(zdim, std::max(thread_per_block / (threadsx * threadsy), 1), - zthreadlimit); - - int blocksx = min3(block_count, DivUp(xdim, threadsx), xgridlimit); - int blocksy = - min3(DivUp(block_count, blocksx), DivUp(ydim, threadsy), ygridlimit); - int blocksz = min3(DivUp(block_count, (blocksx * blocksy)), - DivUp(zdim, threadsz), zgridlimit); + std::min({zdim, std::max(thread_per_block / (threadsx * threadsy), 1), + zthreadlimit}); + + int blocksx = std::min({block_count, DivUp(xdim, threadsx), xgridlimit}); + int blocksy = std::min( + {DivUp(block_count, blocksx), DivUp(ydim, threadsy), ygridlimit}); + int blocksz = std::min({DivUp(block_count, (blocksx * blocksy)), + DivUp(zdim, threadsz), zgridlimit}); config.virtual_thread_count = dim3(xdim, ydim, zdim); config.thread_per_block = dim3(threadsx, threadsy, threadsz); diff --git a/tensorflow/docs_src/get_started/get_started_for_beginners.md b/tensorflow/docs_src/get_started/get_started_for_beginners.md index 367c187e35..b88483be69 100644 --- a/tensorflow/docs_src/get_started/get_started_for_beginners.md +++ b/tensorflow/docs_src/get_started/get_started_for_beginners.md @@ -91,11 +91,10 @@ a number. Here's the representation scheme: A **model** is the relationship between features and the label. For the Iris problem, the model defines the relationship -between the sepal and petal measurements and the Iris species. -Some simple models can be described with a few lines of algebra; -more complex machine learning models -contain such a large number of interlacing mathematical functions and -parameters that they become hard to summarize mathematically. +between the sepal and petal measurements and the predicted Iris species. Some +simple models can be described with a few lines of algebra, but complex machine +learning models have a large number of parameters that are difficult to +summarize. Could you determine the relationship between the four features and the Iris species *without* using machine learning? That is, could you use diff --git a/tensorflow/docs_src/install/install_java.md b/tensorflow/docs_src/install/install_java.md index 1905f9729e..a63a6c7ebe 100644 --- a/tensorflow/docs_src/install/install_java.md +++ b/tensorflow/docs_src/install/install_java.md @@ -65,7 +65,11 @@ As an example, these steps will create a Maven project that uses TensorFlow: <dependency> <groupId>org.tensorflow</groupId> <artifactId>tensorflow</artifactId> +<<<<<<< HEAD <version>1.6.0-rc1</version> +======= + <version>1.6.0-rc0</version> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </dependency> </dependencies> </project> @@ -123,12 +127,20 @@ instead: <dependency> <groupId>org.tensorflow</groupId> <artifactId>libtensorflow</artifactId> +<<<<<<< HEAD <version>1.6.0-rc1</version> +======= + <version>1.6.0-rc0</version> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </dependency> <dependency> <groupId>org.tensorflow</groupId> <artifactId>libtensorflow_jni_gpu</artifactId> +<<<<<<< HEAD <version>1.6.0-rc1</version> +======= + <version>1.6.0-rc0</version> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </dependency> ``` @@ -147,7 +159,11 @@ refer to the simpler instructions above instead. Take the following steps to install TensorFlow for Java on Linux or macOS: 1. Download +<<<<<<< HEAD [libtensorflow.jar](https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-1.6.0-rc1.jar), +======= + [libtensorflow.jar](https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-1.6.0-rc0.jar), +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d which is the TensorFlow Java Archive (JAR). 2. Decide whether you will run TensorFlow for Java on CPU(s) only or with @@ -166,7 +182,11 @@ Take the following steps to install TensorFlow for Java on Linux or macOS: OS=$(uname -s | tr '[:upper:]' '[:lower:]') mkdir -p ./jni curl -L \ +<<<<<<< HEAD "https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow_jni-${TF_TYPE}-${OS}-x86_64-1.6.0-rc1.tar.gz" | +======= + "https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow_jni-${TF_TYPE}-${OS}-x86_64-1.6.0-rc0.tar.gz" | +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d tar -xz -C ./jni ### Install on Windows @@ -174,10 +194,17 @@ Take the following steps to install TensorFlow for Java on Linux or macOS: Take the following steps to install TensorFlow for Java on Windows: 1. Download +<<<<<<< HEAD [libtensorflow.jar](https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-1.6.0-rc1.jar), which is the TensorFlow Java Archive (JAR). 2. Download the following Java Native Interface (JNI) file appropriate for [TensorFlow for Java on Windows](https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow_jni-cpu-windows-x86_64-1.6.0-rc1.zip). +======= + [libtensorflow.jar](https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-1.6.0-rc0.jar), + which is the TensorFlow Java Archive (JAR). + 2. Download the following Java Native Interface (JNI) file appropriate for + [TensorFlow for Java on Windows](https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow_jni-cpu-windows-x86_64-1.6.0-rc0.zip). +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d 3. Extract this .zip file. @@ -225,7 +252,11 @@ must be part of your `classpath`. For example, you can include the downloaded `.jar` in your `classpath` by using the `-cp` compilation flag as follows: +<<<<<<< HEAD <pre><b>javac -cp libtensorflow-1.6.0-rc1.jar HelloTF.java</b></pre> +======= +<pre><b>javac -cp libtensorflow-1.6.0-rc0.jar HelloTF.java</b></pre> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d ### Running @@ -239,11 +270,19 @@ two files are available to the JVM: For example, the following command line executes the `HelloTF` program on Linux and macOS X: +<<<<<<< HEAD <pre><b>java -cp libtensorflow-1.6.0-rc1.jar:. -Djava.library.path=./jni HelloTF</b></pre> And the following command line executes the `HelloTF` program on Windows: <pre><b>java -cp libtensorflow-1.6.0-rc1.jar;. -Djava.library.path=jni HelloTF</b></pre> +======= +<pre><b>java -cp libtensorflow-1.6.0-rc0.jar:. -Djava.library.path=./jni HelloTF</b></pre> + +And the following command line executes the `HelloTF` program on Windows: + +<pre><b>java -cp libtensorflow-1.6.0-rc0.jar;. -Djava.library.path=jni HelloTF</b></pre> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d If the program prints <tt>Hello from <i>version</i></tt>, you've successfully installed TensorFlow for Java and are ready to use the API. If the program diff --git a/tensorflow/docs_src/install/install_linux.md b/tensorflow/docs_src/install/install_linux.md index 62bd45650a..681b45423f 100644 --- a/tensorflow/docs_src/install/install_linux.md +++ b/tensorflow/docs_src/install/install_linux.md @@ -293,7 +293,11 @@ take the following steps: <pre> $ <b>sudo pip3 install --upgrade \ +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc1-cp34-cp34m-linux_x86_64.whl</b> +======= + https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc0-cp34-cp34m-linux_x86_64.whl</b> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> If this step fails, see @@ -480,7 +484,11 @@ Take the following steps to install TensorFlow in an Anaconda environment: <pre> (tensorflow)$ <b>pip install --ignore-installed --upgrade \ +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc1-cp34-cp34m-linux_x86_64.whl</b></pre> +======= + https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc0-cp34-cp34m-linux_x86_64.whl</b></pre> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d <a name="ValidateYourInstallation"></a> @@ -648,14 +656,22 @@ This section documents the relevant values for Linux installations. CPU only: <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc1-cp27-none-linux_x86_64.whl +======= +https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc0-cp27-none-linux_x86_64.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> GPU support: <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0rc1-cp27-none-linux_x86_64.whl +======= +https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0rc0-cp27-none-linux_x86_64.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> Note that GPU support requires the NVIDIA hardware and software described in @@ -667,14 +683,22 @@ Note that GPU support requires the NVIDIA hardware and software described in CPU only: <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc1-cp34-cp34m-linux_x86_64.whl +======= +https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc0-cp34-cp34m-linux_x86_64.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> GPU support: <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0rc1-cp34-cp34m-linux_x86_64.whl +======= +https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0rc0-cp34-cp34m-linux_x86_64.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> Note that GPU support requires the NVIDIA hardware and software described in @@ -686,14 +710,22 @@ Note that GPU support requires the NVIDIA hardware and software described in CPU only: <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc1-cp35-cp35m-linux_x86_64.whl +======= +https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc0-cp35-cp35m-linux_x86_64.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> GPU support: <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0rc1-cp35-cp35m-linux_x86_64.whl +======= +https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0rc0-cp35-cp35m-linux_x86_64.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> @@ -705,14 +737,22 @@ Note that GPU support requires the NVIDIA hardware and software described in CPU only: <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc1-cp36-cp36m-linux_x86_64.whl +======= +https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.6.0rc0-cp36-cp36m-linux_x86_64.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> GPU support: <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0rc1-cp36-cp36m-linux_x86_64.whl +======= +https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0rc0-cp36-cp36m-linux_x86_64.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> diff --git a/tensorflow/docs_src/install/install_mac.md b/tensorflow/docs_src/install/install_mac.md index e3832a7a2a..a2f484ebf8 100644 --- a/tensorflow/docs_src/install/install_mac.md +++ b/tensorflow/docs_src/install/install_mac.md @@ -238,7 +238,11 @@ take the following steps: issue the following command: <pre> $ <b>sudo pip3 install --upgrade \ +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.6.0rc1-py3-none-any.whl</b> </pre> +======= + https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.6.0rc0-py3-none-any.whl</b> </pre> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d If the preceding command fails, see [installation problems](#common-installation-problems). @@ -347,7 +351,11 @@ Take the following steps to install TensorFlow in an Anaconda environment: TensorFlow for Python 2.7: <pre> (<i>targetDirectory</i>)$ <b>pip install --ignore-installed --upgrade \ +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.6.0rc1-py2-none-any.whl</b></pre> +======= + https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.6.0rc0-py2-none-any.whl</b></pre> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d <a name="ValidateYourInstallation"></a> @@ -520,7 +528,11 @@ This section documents the relevant values for Mac OS installations. <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.6.0rc1-py2-none-any.whl +======= +https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.6.0rc0-py2-none-any.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> @@ -528,5 +540,9 @@ https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.6.0rc1-py2-none-a <pre> +<<<<<<< HEAD https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.6.0rc1-py3-none-any.whl +======= +https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.6.0rc0-py3-none-any.whl +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d </pre> diff --git a/tensorflow/docs_src/install/install_sources.md b/tensorflow/docs_src/install/install_sources.md index 8d83e9f119..d01be21260 100644 --- a/tensorflow/docs_src/install/install_sources.md +++ b/tensorflow/docs_src/install/install_sources.md @@ -460,8 +460,13 @@ Stack Overflow and specify the `tensorflow` tag. **Linux** <table> <tr><th>Version:</th><th>CPU/GPU:</th><th>Python Version:</th><th>Compiler:</th><th>Build Tools:</th><th>cuDNN:</th><th>CUDA:</th></tr> +<<<<<<< HEAD <tr><td>tensorflow-1.6.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.9.0</td><td>N/A</td><td>N/A</td></tr> <tr><td>tensorflow_gpu-1.6.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.9.0</td><td>7</td><td>9</td></tr> +======= +<tr><td>tensorflow-1.6.0rc0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.9.0</td><td>N/A</td><td>N/A</td></tr> +<tr><td>tensorflow_gpu-1.6.0rc0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.9.0</td><td>7</td><td>9</td></tr> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d <tr><td>tensorflow-1.5.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.8.0</td><td>N/A</td><td>N/A</td></tr> <tr><td>tensorflow_gpu-1.5.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.8.0</td><td>7</td><td>9</td></tr> <tr><td>tensorflow-1.4.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.5.4</td><td>N/A</td><td>N/A</td></tr> @@ -479,7 +484,11 @@ Stack Overflow and specify the `tensorflow` tag. **Mac** <table> <tr><th>Version:</th><th>CPU/GPU:</th><th>Python Version:</th><th>Compiler:</th><th>Build Tools:</th><th>cuDNN:</th><th>CUDA:</th></tr> +<<<<<<< HEAD <tr><td>tensorflow-1.6.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.8.1</td><td>N/A</td><td>N/A</td></tr> +======= +<tr><td>tensorflow-1.6.0rc0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.8.1</td><td>N/A</td><td>N/A</td></tr> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d <tr><td>tensorflow-1.5.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.8.1</td><td>N/A</td><td>N/A</td></tr> <tr><td>tensorflow-1.4.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.5.4</td><td>N/A</td><td>N/A</td></tr> <tr><td>tensorflow-1.3.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.4.5</td><td>N/A</td><td>N/A</td></tr> @@ -493,8 +502,13 @@ Stack Overflow and specify the `tensorflow` tag. **Windows** <table> <tr><th>Version:</th><th>CPU/GPU:</th><th>Python Version:</th><th>Compiler:</th><th>Build Tools:</th><th>cuDNN:</th><th>CUDA:</th></tr> +<<<<<<< HEAD <tr><td>tensorflow-1.6.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> <tr><td>tensorflow_gpu-1.6.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>7</td><td>9</td></tr> +======= +<tr><td>tensorflow-1.6.0rc0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> +<tr><td>tensorflow_gpu-1.6.0rc0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>7</td><td>9</td></tr> +>>>>>>> 943a21fcdc1c48c8e95d872911ad52b13f0c037d <tr><td>tensorflow-1.5.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> <tr><td>tensorflow_gpu-1.5.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>7</td><td>9</td></tr> <tr><td>tensorflow-1.4.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> diff --git a/tensorflow/docs_src/performance/datasets_performance.md b/tensorflow/docs_src/performance/datasets_performance.md index 4f95e17c35..46b43b7673 100644 --- a/tensorflow/docs_src/performance/datasets_performance.md +++ b/tensorflow/docs_src/performance/datasets_performance.md @@ -92,11 +92,11 @@ transform the data. Without pipelining, the CPU and the GPU/TPU sit idle much of the time: -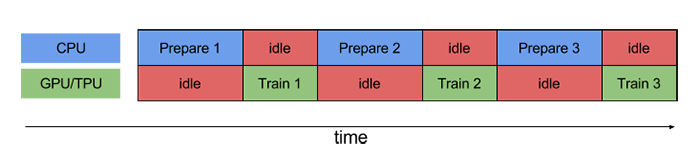 + With pipelining, idle time diminishes significantly: -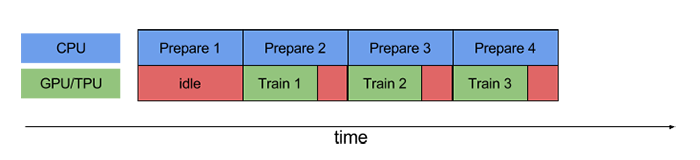 + The `tf.data` API provides a software pipelining mechanism through the @{tf.data.Dataset.prefetch} transformation, which can be used to decouple the @@ -139,7 +139,7 @@ multiple CPU cores. To make this possible, the `map` transformation provides the the following diagram illustrates the effect of setting `num_parallel_calls=2` to the `map` transformation: -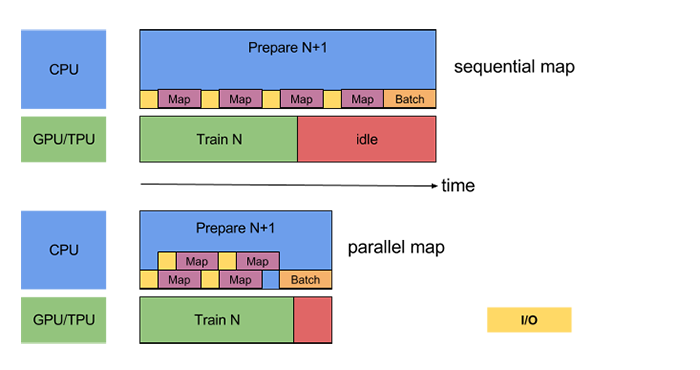 + Choosing the best value for the `num_parallel_calls` argument depends on your hardware, characteristics of your training data (such as its size and shape), @@ -213,7 +213,7 @@ number of datasets to overlap can be specified by the `cycle_length` argument. The following diagram illustrates the effect of supplying `cycle_length=2` to the `parallel_interleave` transformation: -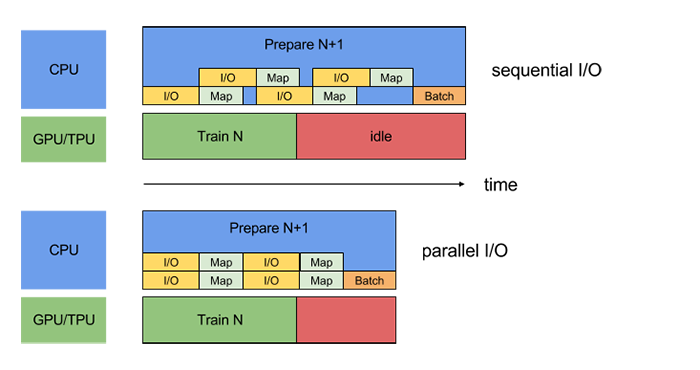 + To apply this change to our running example, change: diff --git a/tensorflow/docs_src/performance/xla/operation_semantics.md b/tensorflow/docs_src/performance/xla/operation_semantics.md index 5431572db8..daa2d4767c 100644 --- a/tensorflow/docs_src/performance/xla/operation_semantics.md +++ b/tensorflow/docs_src/performance/xla/operation_semantics.md @@ -1027,6 +1027,194 @@ Arguments | Type | Semantics The function is applied to each element in the `operand` array, resulting in an array with the same shape. It is allowed for `operand` to be a scalar (rank 0). +## Gather + +The XLA gather operation stitches together several slices (each slice at a +potentially different runtime offset) of an input tensor into an output tensor. + +### General Semantics + +See also +[`ComputationBuilder::Gather`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/computation_builder.h). +For a more intuitive description, see the "Informal Description" section below. + +<b> `gather(operand, gather_indices, output_window_dims, elided_window_dims, window_bounds, gather_dims_to_operand_dims)` </b> + +|Arguments | Type | Semantics | +|----------------- | ----------------------- | --------------------------------| +|`operand` | `ComputationDataHandle` | The tensor we’re gathering | +: : : from. : +|`gather_indices` | `ComputationDataHandle` | Tensor containing the starting | +: : : indices of the slices we're : +: : : we're stitching together into : +: : : the output tensor. : +|`output_window_dims` | `ArraySlice<int64>` | The set of dimensions in the | +: : : output shape that are _window : +: : : dimensions_ (defined below). : +: : : Not all window dimensions may : +: : : be present in the output shape. : +|`elided_window_dims` | `ArraySlice<int64>` | The set of _window dimensions_ | +: : : that are not present in the output shape. : +: : : `window_bounds[i]` must be `1` for all `i` : +: : : in `elided_window_dims`. : +|`window_bounds` | `ArraySlice<int64>` | `window_bounds[i]` is the bounds | +: : : for window dimension `i`. This includes : +: : : both the window dimensions that are : +: : : explicitly part of the output shape (via : +: : : `output_window_dims`) and the window : +: : : dimensions that are elided (via : +: : : `elided_window_dims`). : +|`gather_dims_to_operand_dims` | `ArraySlice<int64>` | A dimension map (the | +: : : array is interpreted as mapping `i` to : +: : : `gather_dims_to_operand_dims[i]`) from : +: : : the gather indices in `gather_indices` to : +: : : the operand index space. It has to be : +: : : one-to-one and total. : + +If `gather_indices` is a vector with `N` elements then we implicitly reshape it +to a tensor of shape `[N,1]` before proceeding. + +For every index `Out` in the output tensor, we compute two things (more +precisely described later): + + - An index into the first `gather_indices.rank` - `1` dimensions of + `gather_indices`, which gives us a starting index of a slice, _operand + slice_, in the operand tensor. + + - A _window index_ that has the same rank as the operand. This index is + composed of the values in `Out` at dimensions `output_window_dims`, embedded + with zeroes according to `elided_window_dims`. + +The _window index_ is the relative index of the element in _operand slice_ that +should be present in the output at index `Out`. + +The output is a tensor of rank `output_window_dims.size` + `gather_indices.rank` +- `1`. Additionally, as a shorthand, we define `output_gather_dims` of type +`ArraySlice<int64>` as the set of dimensions in the output shape but not in +`output_window_dims`, in ascending order. E.g. if the output tensor has rank 5, +`output_window_dims` is {`2`, `4`} then `output_gather_dims` is {`0`, `1`, `3`} + +The bounds for the output tensor along dimension `i` is computed as follows: + + 1. If `i` is present in `output_gather_dims` (i.e. is equal to + `output_gather_dims[k]` for some `k`) then we pick the corresponding + dimension bounds out of `gather_indices.shape` (i.e. pick + `gather_indices.shape.dims[k]`). + 2. If `i` is present in `output_window_dims` (i.e. equal to + `output_window_dims[k]` for some `k`) then we pick the corresponding bound + out of `window_bounds` after accounting for `elided_window_dims` (i.e. we + pick `adjusted_window_bounds[k]` where `adjusted_window_bounds` is + `window_bounds` with the bounds at indices `elided_window_dims` removed). + +The operand index `In` corresponding to an output index `Out` is computed as +follows: + + 1. Let `G` = { `Out`[`k`] for `k` in `output_gather_dims` }. Use `G` to slice + out vector `S` such that `S`[`i`] = `gather_indices`[`G`, `i`]. + 2. Create an index, `S`<sub>`in`</sub>, into `operand` using `S` by scattering + `S` using the `gather_dims_to_operand_dims` map (`S`<sub>`in`</sub> is the + starting indices for _operand slice_ mentioned above.). More precisely: + 1. `S`<sub>`in`</sub>[`gather_dims_to_operand_dims`[`k`]] = `S`[`k`] if `k` < + `gather_dims_to_operand_dims.size`. + 2. `S`<sub>`in`</sub>[`_`] = `0` otherwise. + 3. Create an index `W`<sub>`in`</sub> into `operand` by scattering the indices + at the output window dimensions in `Out` according to + the `elided_window_dims` set (`W`<sub>`in`</sub> is the _window index_ + mentioned above). More precisely: + 1. `W`<sub>`in`</sub>[`window_dims_to_operand_dims`(`k`)] = `Out`[`k`] if + `k` < `output_window_dims.size` (`window_dims_to_operand_dims` is + defined below). + 2. `W`<sub>`in`</sub>[`_`] = `0` otherwise. + 4. `In` is `W`<sub>`in`</sub> + `S`<sub>`in`</sub> where + is element-wise + addition. + +`window_dims_to_operand_dims` is the monotonic function with domain [`0`, +`output_window_dims.size`) and range [`0`, `operand.rank`) \ +`elided_window_dims`. So if, e.g., `output_window_dims.size` is `4`, +`operand.rank` is `6` and `elided_window_dims` is {`0`, `2`} then +`window_dims_to_operand_dims` is {`0`→`1`, `1`→`3`, `2`→`4`, `3`→`5`}. + +### Informal Description + +To get an intuition on how all of the above fits together, let's look at an +example that gathers 5 slices of shape `[8,6]` from a `[16,11]` tensor. The +position of a slice into the `[16,11]` tensor can be represented as an index +vector of shape `S64[2]`, so the set of 5 positions can be represented as a +`S64[5,2]` tensor. + +The behavior of the gather operation can then be depicted as an index +transformation that takes [`G`,`W`<sub>`0`</sub>,`W`<sub>`1`</sub>], an index in +the output shape, and maps it to an element in the input tensor in the following +way: + +<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> + <img style="width:100%" src="../../images/ops_xla_gather_0.svg"> +</div> + +We first select an (`X`,`Y`) vector from the gather indices tensor using `G`. +The element in the output tensor at index +[`G`,`W`<sub>`0`</sub>,`W`<sub>`1`</sub>] is then the element in the input +tensor at index [`X`+`W`<sub>`0`</sub>,`Y`+`W`<sub>`1`</sub>]. + +`window_bounds` is `[8,6]`, which decides the range of W<sub>`0`</sub> and +W<sub>`1`</sub>, and this in turn decides the bounds of the slice. + +This gather operation acts as a batch dynamic slice with `G` as the batch +dimension. + +The gather indices may be multidimensional. For instance, a more general +version of the example above using a "gather indices" tensor of shape `[4,5,2]` +would translate indices like this: + +<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> + <img style="width:100%" src="../../images/ops_xla_gather_1.svg"> +</div> + +Again, this acts as a batch dynamic slice `G`<sub>`0`</sub> and +`G`<sub>`1`</sub> as the batch dimensions. The window bounds are still `[8,6]`. + +The gather operation in XLA generalizes the informal semantics outlined above in +the following ways: + + 1. We can configure which dimensions in the output shape are the window + dimensions (dimensions containing `W`<sub>`0`</sub>, `W`<sub>`1`</sub> in + the last example). The output gather dimensions (dimensions containing + `G`<sub>`0`</sub>, `G`<sub>`1`</sub> in the last example) are defined to be + the output dimensions that are not window dimensions. + + 2. The number of output window dimensions explicitly present in the output + shape may be smaller than the input rank. These "missing" dimensions, which + are listed explicitly as `elided_window_dims`, must have a window bound of + `1`. Since they have a window bound of `1` the only valid index for them is + `0` and eliding them does not introduce ambiguity. + + 3. The slice extracted from the "Gather Indices" tensor ((`X`, `Y`) in the last + example) may have fewer elements than the input tensor rank, and an explicit + mapping dictates how the index should be expanded to have the same rank as + the input. + +As a final example, we use (2) and (3) to implement `tf.gather_nd`: + +<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> + <img style="width:100%" src="../../images/ops_xla_gather_2.svg"> +</div> + +`G`<sub>`0`</sub> and `G`<sub>`1`</sub> are used to slice out a starting index +from the gather indices tensor as usual, except the starting index has only one +element, `X`. Similarly, there is only one output window index with the value +`W`<sub>`0`</sub>. However, before being used as indices into the input tensor, +these are expanded in accordance to "Gather Index Mapping" +(`gather_dims_to_operand_dims` in the formal description) and "Window Mapping" +(`window_dims_to_operand_dims` in the formal description) into +[`0`,`W`<sub>`0`</sub>] and [`X`,`0`] respectively, adding up to +[`X`,`W`<sub>`0`</sub>]. In other words, the output index +[`G`<sub>`0`</sub>,`G`<sub>`1`</sub>,`W`<sub>`0`</sub>] maps to the input index +[`GatherIndices`[`G`<sub>`0`</sub>,`G`<sub>`1`</sub>,`0`],`X`] which gives us +the semantics for `tf.gather_nd`. + +`window_bounds` for this case is `[1,11]`. Intuitively this means that every +index `X` in the gather indices tensor picks an entire row and the result is the +concatenation of all these rows. ## GetTupleElement diff --git a/tensorflow/python/eager/context.py b/tensorflow/python/eager/context.py index 0e9c21b221..07652d3e02 100644 --- a/tensorflow/python/eager/context.py +++ b/tensorflow/python/eager/context.py @@ -60,7 +60,8 @@ class _EagerContext(threading.local): def __init__(self): super(_EagerContext, self).__init__() - self.device_spec = pydev.DeviceSpec.from_string("") + self.device_spec = pydev.DeviceSpec.from_string( + "/job:localhost/replica:0/task:0/device:CPU:0") self.device_name = self.device_spec.to_string() self.mode = _default_mode self.scope_name = "" diff --git a/tensorflow/python/eager/core_test.py b/tensorflow/python/eager/core_test.py index ee3c10633e..c68e2f422e 100644 --- a/tensorflow/python/eager/core_test.py +++ b/tensorflow/python/eager/core_test.py @@ -65,7 +65,8 @@ class TFETest(test_util.TensorFlowTestCase): ctx.summary_writer_resource = 'mock' self.assertEqual('mock', ctx.summary_writer_resource) - self.assertEqual('', ctx.device_name) + self.assertEqual('/job:localhost/replica:0/task:0/device:CPU:0', + ctx.device_name) self.assertEqual(ctx.device_name, ctx.device_spec.to_string()) with ctx.device('GPU:0'): self.assertEqual('/job:localhost/replica:0/task:0/device:GPU:0', diff --git a/tensorflow/python/framework/meta_graph.py b/tensorflow/python/framework/meta_graph.py index 8c03a5f19d..4c1bd736d7 100644 --- a/tensorflow/python/framework/meta_graph.py +++ b/tensorflow/python/framework/meta_graph.py @@ -741,6 +741,7 @@ def import_scoped_meta_graph(meta_graph_or_file, producer_op_list=producer_op_list) # Restores all the other collections. + variable_objects = {} for key, col_def in sorted(meta_graph_def.collection_def.items()): # Don't add unbound_inputs to the new graph. if key == unbound_inputs_col_name: @@ -756,11 +757,23 @@ def import_scoped_meta_graph(meta_graph_or_file, from_proto = ops.get_from_proto_function(key) if from_proto and kind == "bytes_list": proto_type = ops.get_collection_proto_type(key) - for value in col_def.bytes_list.value: - proto = proto_type() - proto.ParseFromString(value) - graph.add_to_collection( - key, from_proto(proto, import_scope=scope_to_prepend_to_names)) + if key in ops.GraphKeys._VARIABLE_COLLECTIONS: # pylint: disable=protected-access + for value in col_def.bytes_list.value: + variable = variable_objects.get(value, None) + if variable is None: + proto = proto_type() + proto.ParseFromString(value) + variable = from_proto( + proto, import_scope=scope_to_prepend_to_names) + variable_objects[value] = variable + graph.add_to_collection(key, variable) + else: + for value in col_def.bytes_list.value: + proto = proto_type() + proto.ParseFromString(value) + graph.add_to_collection( + key, from_proto( + proto, import_scope=scope_to_prepend_to_names)) else: field = getattr(col_def, kind) if key in _COMPAT_COLLECTION_LIST: diff --git a/tensorflow/python/framework/meta_graph_test.py b/tensorflow/python/framework/meta_graph_test.py index f2f1e83da1..19dcd6a1b3 100644 --- a/tensorflow/python/framework/meta_graph_test.py +++ b/tensorflow/python/framework/meta_graph_test.py @@ -261,6 +261,29 @@ class SimpleMetaGraphTest(test.TestCase): self.assertEqual(node_def.attr["attr_1"].i, 1) self.assertTrue(meta_graph_def.meta_info_def.stripped_default_attrs) + def testVariableObjectsAreSharedAmongCollections(self): + with ops.Graph().as_default() as graph1: + v = variables.Variable(3.0) + # A single instance of Variable is shared among the collections: + global_vars = graph1.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) + trainable_vars = graph1.get_collection(ops.GraphKeys.TRAINABLE_VARIABLES) + self.assertEqual(len(global_vars), 1) + self.assertEqual(len(trainable_vars), 1) + self.assertIs(global_vars[0], trainable_vars[0]) + self.assertIs(v, global_vars[0]) + + orig_meta_graph, _ = meta_graph.export_scoped_meta_graph(graph=graph1) + del graph1 # To avoid accidental references in code involving graph2. + + with ops.Graph().as_default() as graph2: + meta_graph.import_scoped_meta_graph(orig_meta_graph) + global_vars = graph2.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) + trainable_vars = graph2.get_collection(ops.GraphKeys.TRAINABLE_VARIABLES) + self.assertEqual(len(global_vars), 1) + self.assertEqual(len(trainable_vars), 1) + # A single instance of Variable is shared among the collections: + self.assertIs(global_vars[0], trainable_vars[0]) + @test_util.with_c_api class ScopedMetaGraphTest(test.TestCase): @@ -883,21 +906,25 @@ class ExportImportAcrossScopesTest(test.TestCase): graph_fn(use_resource=use_resource) if use_resource: - # Bringing in a collection that contains ResourceVariables adds ops - # to the graph, so mimic the same behavior. + # Bringing in collections that contain ResourceVariables will adds ops + # to the graph the first time a variable is encountered, so mimic the + # same behavior. + seen_variables = set() for collection_key in sorted([ ops.GraphKeys.GLOBAL_VARIABLES, ops.GraphKeys.TRAINABLE_VARIABLES, ]): for var in expected_graph.get_collection(collection_key): - var._read_variable_op() + if var not in seen_variables: + var._read_variable_op() + seen_variables.add(var) result = meta_graph.export_scoped_meta_graph(graph=imported_graph)[0] expected = meta_graph.export_scoped_meta_graph(graph=expected_graph)[0] if use_resource: # Clear all shared_name attributes before comparing, since they are - # supposed to be orthogonal to scopes. + # orthogonal to scopes and are not updated on export/import. for meta_graph_def in [result, expected]: for node in meta_graph_def.graph_def.node: shared_name_attr = "shared_name" diff --git a/tensorflow/python/framework/tensor_util.py b/tensorflow/python/framework/tensor_util.py index cbba112841..27afaa074a 100644 --- a/tensorflow/python/framework/tensor_util.py +++ b/tensorflow/python/framework/tensor_util.py @@ -557,7 +557,8 @@ def MakeNdarray(tensor): dtype = tensor_dtype.as_numpy_dtype if tensor.tensor_content: - return np.frombuffer(tensor.tensor_content, dtype=dtype).reshape(shape) + return (np.frombuffer(tensor.tensor_content, dtype=dtype).copy() + .reshape(shape)) elif tensor_dtype == dtypes.float16: # the half_val field of the TensorProto stores the binary representation # of the fp16: we need to reinterpret this as a proper float16 diff --git a/tensorflow/python/framework/tensor_util_test.py b/tensorflow/python/framework/tensor_util_test.py index f2de69e159..bea0ee34fd 100644 --- a/tensorflow/python/framework/tensor_util_test.py +++ b/tensorflow/python/framework/tensor_util_test.py @@ -199,6 +199,25 @@ class TensorUtilTest(test.TestCase): dtype=nptype), a) + def testFloatMutateArray(self): + t = tensor_util.make_tensor_proto([10.0, 20.0, 30.0], dtype=dtypes.float32) + a = tensor_util.MakeNdarray(t) + a[0] = 5.0 + self.assertEquals(np.float32, a.dtype) + self.assertAllClose(np.array([5.0, 20.0, 30.0], dtype=np.float32), a) + if sys.byteorder == "big": + self.assertProtoEquals(""" + dtype: DT_FLOAT + tensor_shape { dim { size: 3 } } + tensor_content: "A \000\000A\240\000\000A\360\000\000" + """, t) + else: + self.assertProtoEquals(""" + dtype: DT_FLOAT + tensor_shape { dim { size: 3 } } + tensor_content: "\000\000 A\000\000\240A\000\000\360A" + """, t) + def testHalf(self): t = tensor_util.make_tensor_proto(np.array([10.0, 20.0], dtype=np.float16)) self.assertProtoEquals(""" diff --git a/tensorflow/python/framework/test_util.py b/tensorflow/python/framework/test_util.py index 310bd75d4e..682b2b3667 100644 --- a/tensorflow/python/framework/test_util.py +++ b/tensorflow/python/framework/test_util.py @@ -1101,7 +1101,12 @@ class TensorFlowTestCase(googletest.TestCase): np.testing.assert_allclose( a, b, rtol=rtol, atol=atol, err_msg=msg, equal_nan=True) - def _assertAllCloseRecursive(self, a, b, rtol=1e-6, atol=1e-6, path=None, + def _assertAllCloseRecursive(self, + a, + b, + rtol=1e-6, + atol=1e-6, + path=None, msg=None): path = path or [] path_str = (("[" + "][".join([str(p) for p in path]) + "]") if path else "") @@ -1248,7 +1253,7 @@ class TensorFlowTestCase(googletest.TestCase): a = self._GetNdArray(a) b = self._GetNdArray(b) self.assertEqual(a.shape, b.shape, "Shape mismatch: expected %s, got %s." - " %s" % (a.shape, b.shape, msg)) + " %s" % (a.shape, b.shape, msg)) same = (a == b) if a.dtype == np.float32 or a.dtype == np.float64: @@ -1330,8 +1335,8 @@ class TensorFlowTestCase(googletest.TestCase): raise TypeError("np_array must be a Numpy ndarray or Numpy scalar") if not isinstance(tf_tensor, ops.Tensor): raise TypeError("tf_tensor must be a Tensor") - self.assertAllEqual(np_array.shape, tf_tensor.get_shape().as_list(), - msg=msg) + self.assertAllEqual( + np_array.shape, tf_tensor.get_shape().as_list(), msg=msg) def assertDeviceEqual(self, device1, device2, msg=None): """Asserts that the two given devices are the same. diff --git a/tensorflow/python/keras/_impl/keras/engine/topology.py b/tensorflow/python/keras/_impl/keras/engine/topology.py index dd7436e3d0..7de5af41c5 100644 --- a/tensorflow/python/keras/_impl/keras/engine/topology.py +++ b/tensorflow/python/keras/_impl/keras/engine/topology.py @@ -39,6 +39,7 @@ from tensorflow.python.layers import base as tf_base_layers from tensorflow.python.layers import network as tf_network from tensorflow.python.layers import utils as tf_layers_util from tensorflow.python.platform import tf_logging as logging +from tensorflow.python.util import tf_inspect from tensorflow.python.util.tf_export import tf_export @@ -263,7 +264,7 @@ class Layer(tf_base_layers.Layer): # Un-built subclassed network: build it if isinstance(self, Network) and not self.inputs: - self._set_inputs(inputs) + self._set_inputs(inputs, training=kwargs.get('training')) # Update learning phase info. output_tensors = _to_list(output) @@ -702,6 +703,8 @@ class Network(tf_network.GraphNetwork, Layer): super(Network, self).__init__(inputs, outputs, name=name) self._is_compiled = False + self._expects_training_arg = False + self.supports_masking = False self.optimizer = None @@ -744,6 +747,11 @@ class Network(tf_network.GraphNetwork, Layer): self._layers = [] self._is_graph_network = False self._is_compiled = False + if 'training' in tf_inspect.getargspec(self.call).args: + self._expects_training_arg = True + else: + self._expects_training_arg = False + self.outputs = None self.inputs = None self.trainable = True diff --git a/tensorflow/python/keras/_impl/keras/engine/training.py b/tensorflow/python/keras/_impl/keras/engine/training.py index fd14bf3d05..d8ea2fe3db 100644 --- a/tensorflow/python/keras/_impl/keras/engine/training.py +++ b/tensorflow/python/keras/_impl/keras/engine/training.py @@ -515,7 +515,65 @@ def _standardize_weights(y, @tf_export('keras.models.Model', 'keras.Model') class Model(Network): - """The `Model` class adds training & evaluation routines to a `Network`. + """`Model` groups layers into an object with training and inference features. + + There are two ways to instantiate a `Model`: + + 1 - With the "functional API", where you start from `Input`, + you chain layer calls to specify the model's forward pass, + and finally you create your model from inputs and outputs: + + ```python + import tensorflow as tf + + inputs = tf.keras.Input(shape=(3,)) + x = tf.keras.layers.Dense(4, activation=tf.nn.relu)(inputs) + outputs = tf.keras.layers.Dense(5, activation=tf.nn.softmax)(x) + model = tf.keras.Model(inputs=inputs, outputs=outputs) + ``` + + 2 - By subclassing the `Model` class: in that case, you should define your + layers in `__init__` and you should implement the model's forward pass + in `call`. + + ```python + import tensorflow as tf + + class MyModel(tf.keras.Model): + + def __init__(self): + self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu) + self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax) + + def call(self, inputs): + x = self.dense1(inputs) + return self.dense2(x) + + model = MyModel() + ``` + + If you subclass `Model`, you can optionally have + a `training` argument (boolean) in `call`, which you can use to specify + a different behavior in training and inference: + + ```python + import tensorflow as tf + + class MyModel(tf.keras.Model): + + def __init__(self): + self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu) + self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax) + self.dropout = tf.keras.layers.Dropout(0.5) + + def call(self, inputs, training=False): + x = self.dense1(inputs) + if training: + x = self.dropout(x, training=training) + return self.dense2(x) + + model = MyModel() + ``` """ def compile(self, @@ -1709,7 +1767,7 @@ class Model(Network): str(x[0].shape[0]) + ' samples') return x, y, sample_weights - def _set_inputs(self, inputs): + def _set_inputs(self, inputs, training=None): """Set model's input and output specs based on the input data received. This is to be used for Model subclasses, which do not know at instantiation @@ -1725,11 +1783,14 @@ class Model(Network): when calling `fit`/etc. - if data tensors: the model is built on top of these tensors. We do not expect any Numpy data to be provided when calling `fit`/etc. + training: Boolean or None. Only relevant in symbolic mode. Specifies + whether to build the model's graph in inference mode (False), training + mode (True), or using the Keras learning phase (None). """ if context.in_eager_mode(): self._eager_set_inputs(inputs) else: - self._symbolic_set_inputs(inputs) + self._symbolic_set_inputs(inputs, training=training) def _eager_set_inputs(self, inputs): """Set model's input and output specs based on the input data received. @@ -1775,7 +1836,7 @@ class Model(Network): 'output_%d' % (i + 1) for i in range(len(dummy_output_values))] self.built = True - def _symbolic_set_inputs(self, inputs): + def _symbolic_set_inputs(self, inputs, training=None): """Set model's inputs based on the input data received from the user. This is to be used for Model subclasses, which do not know at instantiation @@ -1783,6 +1844,9 @@ class Model(Network): Args: inputs: Argument `x` (input data) passed by the user upon first model use. + training: Boolean or None. Only relevant in symbolic mode. Specifies + whether to build the model's graph in inference mode (False), training + mode (True), or using the Keras learning phase (None). Raises: ValueError: If the model's inputs are already set. @@ -1831,9 +1895,15 @@ class Model(Network): # Obtain symbolic outputs by calling the model. if len(self.inputs) == 1: - outputs = self.call(self.inputs[0]) + if self._expects_training_arg: + outputs = self.call(self.inputs[0], training=training) + else: + outputs = self.call(self.inputs[0]) else: - outputs = self.call(self.inputs) + if self._expects_training_arg: + outputs = self.call(self.inputs, training=training) + else: + outputs = self.call(self.inputs) if isinstance(outputs, (list, tuple)): outputs = list(outputs) else: diff --git a/tensorflow/python/keras/_impl/keras/engine/training_eager.py b/tensorflow/python/keras/_impl/keras/engine/training_eager.py index 477bb2fe7a..3507f36e14 100644 --- a/tensorflow/python/keras/_impl/keras/engine/training_eager.py +++ b/tensorflow/python/keras/_impl/keras/engine/training_eager.py @@ -98,7 +98,7 @@ def _eager_metrics_fn(model, outputs, targets): return metric_names, metric_results -def _model_loss(model, inputs, targets): +def _model_loss(model, inputs, targets, training=False): """Calculates the loss for a given model. Arguments: @@ -106,6 +106,7 @@ def _model_loss(model, inputs, targets): inputs: The inputs of the given model. This is typically the mini batch of data that is fed to the model. targets: The predictions or targets of the given model. + training: Whether the model should be run in inference or training mode. Returns: Returns the model output, total loss and loss value calculated using the @@ -114,9 +115,15 @@ def _model_loss(model, inputs, targets): """ total_loss = 0 if len(inputs) == 1: - outs = model.call(inputs[0]) + if model._expects_training_arg: + outs = model.call(inputs[0], training=training) + else: + outs = model.call(inputs[0]) else: - outs = model.call(inputs) + if model._expects_training_arg: + outs = model.call(inputs, training=training) + else: + outs = model.call(inputs) if not isinstance(outs, list): outs = [outs] @@ -172,7 +179,7 @@ def _model_loss(model, inputs, targets): def _process_single_batch(eager_model_inputs, eager_model_outputs, model, - training=True): + training=False): """Calculate the loss and gradient for one input batch. The model weights are updated if training is set to True. @@ -195,7 +202,8 @@ def _process_single_batch(eager_model_inputs, eager_model_outputs, model, K.set_learning_phase(training) with GradientTape() as tape: outs, loss, loss_metrics = _model_loss(model, eager_model_inputs, - eager_model_outputs) + eager_model_outputs, + training=training) if loss is None: raise ValueError('The model cannot be run ' 'because it has no loss to optimize.') @@ -230,7 +238,7 @@ def train_on_batch(model, ins): for i in range(len(model.inputs), len(ins_batch_converted)): eager_model_outputs.append(ins_batch_converted[i]) outs, loss, _ = _process_single_batch( - eager_model_inputs, eager_model_outputs, model) + eager_model_inputs, eager_model_outputs, model, training=True) if not isinstance(outs, list): outs = [outs] _, metrics_results = _eager_metrics_fn( @@ -415,7 +423,8 @@ def fit_loop( outs, loss, loss_metrics = _process_single_batch(eager_model_inputs, eager_model_outputs, - model) + model, + training=True) if not isinstance(outs, list): outs = [outs] @@ -517,7 +526,8 @@ def test_loop(model, ins, batch_size=None, verbose=0, steps=None): eager_model_outputs.append(ins_batch_converted[i]) loss_outs, loss, loss_metrics = _model_loss(model, eager_model_inputs, - eager_model_outputs) + eager_model_outputs, + training=False) _, metrics_results = _eager_metrics_fn(model, loss_outs, eager_model_outputs) batch_outs = [] @@ -590,9 +600,15 @@ def predict_loop(model, ins, batch_size=32, verbose=0, steps=None): eager_model_inputs.append(ins_batch_converted[i]) if len(eager_model_inputs) == 1: - batch_outs = model.call(eager_model_inputs[0]) + if model._expects_training_arg: + batch_outs = model.call(eager_model_inputs[0], training=False) + else: + batch_outs = model.call(eager_model_inputs[0]) else: - batch_outs = model.call(eager_model_inputs) + if model._expects_training_arg: + batch_outs = model.call(eager_model_inputs, training=False) + else: + batch_outs = model.call(eager_model_inputs) if not isinstance(batch_outs, list): batch_outs = [batch_outs] diff --git a/tensorflow/python/keras/_impl/keras/layers/lstm_test.py b/tensorflow/python/keras/_impl/keras/layers/lstm_test.py index deb1d7c0c6..b7af1e8cf0 100644 --- a/tensorflow/python/keras/_impl/keras/layers/lstm_test.py +++ b/tensorflow/python/keras/_impl/keras/layers/lstm_test.py @@ -53,8 +53,7 @@ class LSTMLayerTest(test.TestCase): layer = keras.layers.LSTM(units, return_sequences=True) model.add(layer) outputs = model.layers[-1].output - self.assertEquals(outputs.get_shape().as_list(), - [None, timesteps, units]) + self.assertEquals(outputs.get_shape().as_list(), [None, timesteps, units]) def test_dynamic_behavior_LSTM(self): num_samples = 2 diff --git a/tensorflow/python/keras/_impl/keras/model_subclassing_test.py b/tensorflow/python/keras/_impl/keras/model_subclassing_test.py index 275985aa36..3d71a620fc 100644 --- a/tensorflow/python/keras/_impl/keras/model_subclassing_test.py +++ b/tensorflow/python/keras/_impl/keras/model_subclassing_test.py @@ -376,11 +376,11 @@ class ModelSubclassingTest(test.TestCase): with self.test_session(): model = MultiIOTestModel(num_classes=num_classes, use_bn=True) model.compile(loss='mse', optimizer=RMSPropOptimizer(learning_rate=0.001)) - model.fit([x1, x2], [y1, y2], epochs=2, batch_size=32) + model.fit([x1, x2], [y1, y2], epochs=2, batch_size=32, verbose=0) model.fit({'input_1': x1, 'input_2': x2}, {'output_1': y1, 'output_2': y2}, epochs=2, batch_size=32) - model.fit([x1, x2], [y1, y2], epochs=2, batch_size=32, + model.fit([x1, x2], [y1, y2], epochs=2, batch_size=32, verbose=0, validation_data=([x1, x2], [y1, y2])) model = MultiIOTestModel(num_classes=num_classes, use_bn=True) @@ -438,7 +438,7 @@ class ModelSubclassingTest(test.TestCase): with self.test_session(): model = MultiIOTestModel(num_classes=num_classes, use_bn=True) model.compile(loss='mse', optimizer=RMSPropOptimizer(learning_rate=0.001)) - model.fit([x1, x2], [y1, y2], epochs=2, batch_size=32) + model.fit([x1, x2], [y1, y2], epochs=2, batch_size=32, verbose=0) y_ref_1, y_ref_2 = model.predict([x1, x2]) fd, fname = tempfile.mkstemp('.h5') @@ -553,6 +553,37 @@ class ModelSubclassingTest(test.TestCase): len(model.non_trainable_weights), 4) self.assertEqual(len(model.trainable_weights), 12) + @test_util.run_in_graph_and_eager_modes() + def test_support_for_manual_training_arg(self): + # In most cases, the `training` argument is left unspecified, in which + # case it defaults to value corresponding to the Model method being used + # (fit -> True, predict -> False, etc). + # If the user writes their model `call` method to take + # an explicit `training` argument, we must check that the correct value + # is being passed to the model for each method call. + + class DPNet(keras.Model): + + def __init__(self): + super(DPNet, self).__init__() + self.dp = keras.layers.Dropout(0.5) + self.dense = keras.layers.Dense(1, + use_bias=False, + kernel_initializer='ones') + + def call(self, inputs, training=False): + x = self.dp(inputs, training=training) + return self.dense(x) + + with self.test_session(): + model = DPNet() + x = np.ones((10, 10)) + y = model.predict(x) + self.assertEqual(np.sum(y), np.sum(x)) + model.compile(loss='mse', optimizer=RMSPropOptimizer(learning_rate=0.001)) + loss = model.train_on_batch(x, y) + self.assertGreater(loss, 0.1) + if __name__ == '__main__': test.main() diff --git a/tensorflow/python/kernel_tests/conv_ops_test.py b/tensorflow/python/kernel_tests/conv_ops_test.py index edfb20d6a2..2785798916 100644 --- a/tensorflow/python/kernel_tests/conv_ops_test.py +++ b/tensorflow/python/kernel_tests/conv_ops_test.py @@ -302,25 +302,20 @@ class Conv2DTest(test.TestCase): padding, dilations): expected_results = [] computed_results = [] - default_dilations = (dilations[0] == 1 and dilations[1] == 1) for data_format, use_gpu in GetTestConfigs(): - # If any dilation rate is larger than 1, only do test on the GPU - # because we currently do not have a CPU implementation for arbitrary - # dilation rates. - if default_dilations or use_gpu: - expected, computed = self._ComputeReferenceDilatedConv( - tensor_in_sizes, filter_in_sizes, strides, dilations, padding, - data_format, use_gpu) - expected_results.append(expected) - computed_results.append(computed) - tolerance = 1e-2 if use_gpu else 1e-5 - expected_values = self.evaluate(expected_results) - computed_values = self.evaluate(computed_results) - for e_value, c_value in zip(expected_values, computed_values): - print("expected = ", e_value) - print("actual = ", c_value) - self.assertAllClose( - e_value.flatten(), c_value.flatten(), atol=tolerance, rtol=1e-4) + expected, computed = self._ComputeReferenceDilatedConv( + tensor_in_sizes, filter_in_sizes, strides, dilations, padding, + data_format, use_gpu) + expected_results.append(expected) + computed_results.append(computed) + tolerance = 1e-2 if use_gpu else 1e-5 + expected_values = self.evaluate(expected_results) + computed_values = self.evaluate(computed_results) + for e_value, c_value in zip(expected_values, computed_values): + print("expected = ", e_value) + print("actual = ", c_value) + self.assertAllClose( + e_value.flatten(), c_value.flatten(), atol=tolerance, rtol=1e-4) def _VerifyValues(self, tensor_in_sizes, filter_in_sizes, strides, padding, expected): @@ -365,13 +360,12 @@ class Conv2DTest(test.TestCase): @test_util.run_in_graph_and_eager_modes() def testConv2D2x2Filter2x1Dilation(self): - if test.is_gpu_available(cuda_only=True): - self._VerifyDilatedConvValues( - tensor_in_sizes=[1, 4, 4, 1], - filter_in_sizes=[2, 2, 1, 1], - strides=[1, 1], - dilations=[2, 1], - padding="VALID") + self._VerifyDilatedConvValues( + tensor_in_sizes=[1, 4, 4, 1], + filter_in_sizes=[2, 2, 1, 1], + strides=[1, 1], + dilations=[2, 1], + padding="VALID") @test_util.run_in_graph_and_eager_modes() def testConv2DEmpty(self): @@ -385,13 +379,12 @@ class Conv2DTest(test.TestCase): @test_util.run_in_graph_and_eager_modes() def testConv2DEmptyDilation(self): - if test.is_gpu_available(cuda_only=True): - self._VerifyDilatedConvValues( - tensor_in_sizes=[0, 2, 3, 3], - filter_in_sizes=[1, 1, 3, 3], - strides=[1, 1], - dilations=[2, 1], - padding="VALID") + self._VerifyDilatedConvValues( + tensor_in_sizes=[0, 2, 3, 3], + filter_in_sizes=[1, 1, 3, 3], + strides=[1, 1], + dilations=[2, 1], + padding="VALID") @test_util.run_in_graph_and_eager_modes() def testConv2D2x2Filter(self): @@ -406,13 +399,12 @@ class Conv2DTest(test.TestCase): @test_util.run_in_graph_and_eager_modes() def testConv2D2x2FilterDilation(self): - if test.is_gpu_available(cuda_only=True): - self._VerifyDilatedConvValues( - tensor_in_sizes=[1, 2, 3, 3], - filter_in_sizes=[2, 2, 3, 3], - strides=[1, 1], - dilations=[1, 2], - padding="VALID") + self._VerifyDilatedConvValues( + tensor_in_sizes=[1, 2, 3, 3], + filter_in_sizes=[2, 2, 3, 3], + strides=[1, 1], + dilations=[1, 2], + padding="VALID") @test_util.run_in_graph_and_eager_modes() def testConv2D1x2Filter(self): @@ -430,13 +422,12 @@ class Conv2DTest(test.TestCase): @test_util.run_in_graph_and_eager_modes() def testConv2D1x2FilterDilation(self): - if test.is_gpu_available(cuda_only=True): - self._VerifyDilatedConvValues( - tensor_in_sizes=[1, 2, 3, 3], - filter_in_sizes=[1, 2, 3, 3], - strides=[1, 1], - dilations=[2, 1], - padding="VALID") + self._VerifyDilatedConvValues( + tensor_in_sizes=[1, 2, 3, 3], + filter_in_sizes=[1, 2, 3, 3], + strides=[1, 1], + dilations=[2, 1], + padding="VALID") @test_util.run_in_graph_and_eager_modes() def testConv2D2x2FilterStride2(self): @@ -512,13 +503,12 @@ class Conv2DTest(test.TestCase): @test_util.run_in_graph_and_eager_modes() def testConv2DKernelSizeMatchesInputSizeDilation(self): - if test.is_gpu_available(cuda_only=True): - self._VerifyDilatedConvValues( - tensor_in_sizes=[1, 3, 3, 1], - filter_in_sizes=[2, 2, 1, 2], - strides=[1, 1], - dilations=[2, 2], - padding="VALID") + self._VerifyDilatedConvValues( + tensor_in_sizes=[1, 3, 3, 1], + filter_in_sizes=[2, 2, 1, 2], + strides=[1, 1], + dilations=[2, 2], + padding="VALID") # TODO(yzhwang): this currently fails. # self._VerifyValues(tensor_in_sizes=[1, 8, 8, 1], @@ -1538,21 +1528,6 @@ class Conv2DTest(test.TestCase): use_gpu=False) self.evaluate(conv) - def testCPUConv2DDilatedUnimplemented(self): - with self.test_session(use_gpu=False): - with self.assertRaisesRegexp(errors_impl.UnimplementedError, - "dilated rate of 1 for now"): - conv = self._SetupValuesForDevice( - tensor_in_sizes=[1, 4, 4, 1], - filter_in_sizes=[2, 2, 1, 1], - dilations=[2, 1], - strides=[1, 1], - padding="VALID", - data_format="NHWC", - dtype=dtypes.float32, - use_gpu=False) - self.evaluate(conv) - class DepthwiseConv2DTest(test.TestCase): @@ -1887,7 +1862,7 @@ def GetInceptionFwdTest(input_size, filter_size, stride, padding, def GetInceptionFwdDilatedConvTest(input_size, filter_size, stride, padding): def Test(self): - if test.is_gpu_available(cuda_only=True) and stride == 1: + if stride == 1: tf_logging.info("Testing InceptionFwd with dilations %s", (input_size, filter_size, stride, padding)) self._VerifyDilatedConvValues( diff --git a/tensorflow/python/layers/utils.py b/tensorflow/python/layers/utils.py index 1a0f211cf3..79529e86c3 100644 --- a/tensorflow/python/layers/utils.py +++ b/tensorflow/python/layers/utils.py @@ -20,6 +20,7 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from tensorflow.python.eager import context from tensorflow.python.ops import variables from tensorflow.python.ops import control_flow_ops from tensorflow.python.framework import ops diff --git a/tensorflow/python/ops/array_ops.py b/tensorflow/python/ops/array_ops.py index ad409ad7e5..d63a9ea0dd 100644 --- a/tensorflow/python/ops/array_ops.py +++ b/tensorflow/python/ops/array_ops.py @@ -605,7 +605,7 @@ def slice(input_, begin, size, name=None): Note that @{tf.Tensor.__getitem__} is typically a more pythonic way to perform slices, as it allows you to write `foo[3:7, :-2]` instead of - `tf.slice([3, 0], [4, foo.get_shape()[1]-2])`. + `tf.slice(foo, [3, 0], [4, foo.get_shape()[1]-2])`. `begin` is zero-based; `size` is one-based. If `size[i]` is -1, all remaining elements in dimension i are included in the diff --git a/tensorflow/python/ops/distributions/beta.py b/tensorflow/python/ops/distributions/beta.py index be4ef550dd..469bcadb8e 100644 --- a/tensorflow/python/ops/distributions/beta.py +++ b/tensorflow/python/ops/distributions/beta.py @@ -304,11 +304,10 @@ class Beta(distribution.Distribution): if not self.validate_args: return x return control_flow_ops.with_dependencies([ - check_ops.assert_positive( - x, - message="sample must be positive"), + check_ops.assert_positive(x, message="sample must be positive"), check_ops.assert_less( - x, array_ops.ones([], self.dtype), + x, + array_ops.ones([], self.dtype), message="sample must be less than `1`."), ], x) diff --git a/tensorflow/python/ops/image_ops_test.py b/tensorflow/python/ops/image_ops_test.py index d944b803f2..dc3b581b22 100644 --- a/tensorflow/python/ops/image_ops_test.py +++ b/tensorflow/python/ops/image_ops_test.py @@ -2025,7 +2025,8 @@ class SelectDistortedCropBoxTest(test_util.TensorFlowTestCase): bounding_box = constant_op.constant( [[[0.0, 0.0, 1.0, 1.0]]], shape=[1, 1, 4], - dtype=dtypes.float32,) + dtype=dtypes.float32, + ) begin, end, bbox_for_drawing = image_ops.sample_distorted_bounding_box( image_size=image_size, bounding_boxes=bounding_box, @@ -2040,6 +2041,7 @@ class SelectDistortedCropBoxTest(test_util.TensorFlowTestCase): end = end.eval() bbox_for_drawing = bbox_for_drawing.eval() + class ResizeImagesTest(test_util.TensorFlowTestCase): OPTIONS = [ diff --git a/tensorflow/python/ops/losses/losses_impl.py b/tensorflow/python/ops/losses/losses_impl.py index 8e003fb7ac..aa74e11764 100644 --- a/tensorflow/python/ops/losses/losses_impl.py +++ b/tensorflow/python/ops/losses/losses_impl.py @@ -731,7 +731,6 @@ def softmax_cross_entropy( losses = nn.softmax_cross_entropy_with_logits_v2( labels=onehot_labels, logits=logits, name="xentropy") - return compute_weighted_loss( losses, weights, scope, loss_collection, reduction=reduction) diff --git a/tensorflow/python/ops/script_ops.py b/tensorflow/python/ops/script_ops.py index dcf1bffaf2..6fe2f61016 100644 --- a/tensorflow/python/ops/script_ops.py +++ b/tensorflow/python/ops/script_ops.py @@ -33,6 +33,7 @@ from tensorflow.python.eager import context from tensorflow.python.framework import function from tensorflow.python.framework import ops from tensorflow.python.ops import gen_script_ops +from tensorflow.python.util import nest from tensorflow.python.util.tf_export import tf_export @@ -318,6 +319,12 @@ def py_func(func, inp, Tout, stateful=True, name=None): Returns: A list of `Tensor` or a single `Tensor` which `func` computes. """ + if context.in_eager_mode(): + result = func(*[x.numpy() for x in inp]) + result = nest.flatten(result) + + return [x if x is None else ops.convert_to_tensor(x) for x in result] + return _internal_py_func( func=func, inp=inp, Tout=Tout, stateful=stateful, eager=False, name=name) diff --git a/tensorflow/python/ops/template.py b/tensorflow/python/ops/template.py index 806fdd3da7..424582b348 100644 --- a/tensorflow/python/ops/template.py +++ b/tensorflow/python/ops/template.py @@ -557,6 +557,7 @@ class EagerTemplate(Template): # is created in __call__. variable_scope_name = None self._template_store = _EagerTemplateVariableStore(variable_scope_name) + self._variable_scope_context_manager = None def _call_func(self, args, kwargs): try: @@ -611,8 +612,12 @@ class EagerTemplate(Template): # the variable scope is opened in order to ensure that templates nested at # the same level correctly uniquify lower variable scope names. if self._variable_scope: - with variable_scope.variable_scope( - self._variable_scope, reuse=variable_scope.AUTO_REUSE): + # Create a cache for the variable scope context manager the first time + # around so that we don't have to keep recreating it. + if not self._variable_scope_context_manager: + self._variable_scope_context_manager = variable_scope.variable_scope( + self._variable_scope, reuse=variable_scope.AUTO_REUSE) + with self._variable_scope_context_manager: with self._template_store.as_default(): result = self._call_func(args, kwargs) return result diff --git a/tensorflow/python/ops/variables.py b/tensorflow/python/ops/variables.py index 125922e296..b785d0ede7 100644 --- a/tensorflow/python/ops/variables.py +++ b/tensorflow/python/ops/variables.py @@ -37,7 +37,7 @@ from tensorflow.python.util.tf_export import tf_export @tf_export("Variable") -class Variable(checkpointable.Checkpointable): +class Variable(checkpointable.CheckpointableBase): """See the @{$variables$Variables How To} for a high level overview. A variable maintains state in the graph across calls to `run()`. You add a diff --git a/tensorflow/python/training/checkpointable.py b/tensorflow/python/training/checkpointable.py index c2fea0f40d..9d62c5ff91 100644 --- a/tensorflow/python/training/checkpointable.py +++ b/tensorflow/python/training/checkpointable.py @@ -99,9 +99,8 @@ class _CheckpointPosition(object): # This object's correspondence with a checkpointed object is new, so # process deferred restorations for it and its dependencies. restore_ops = checkpointable._restore_from_checkpoint_position(self) # pylint: disable=protected-access - session = self._checkpoint.session - if session: - session.run(restore_ops) + if restore_ops: + self._checkpoint.restore_ops.extend(restore_ops) def bind_object(self, checkpointable): """Set a checkpoint<->object correspondence and process slot variables. @@ -120,13 +119,13 @@ class _CheckpointPosition(object): checkpoint.object_by_proto_id[self._proto_id] = checkpointable for deferred_slot_restoration in ( checkpoint.deferred_slot_restorations.pop(self._proto_id, ())): - checkpointable._process_slot_restoration( # pylint: disable=protected-access + checkpointable._create_or_restore_slot_variable( # pylint: disable=protected-access slot_variable_position=_CheckpointPosition( checkpoint=checkpoint, proto_id=deferred_slot_restoration.slot_variable_id), variable=deferred_slot_restoration.original_variable, slot_name=deferred_slot_restoration.slot_name) - for slot_restoration in checkpoint.slot_restorations.get( + for slot_restoration in checkpoint.slot_restorations.pop( self._proto_id, ()): optimizer_object = checkpoint.object_by_proto_id.get( slot_restoration.optimizer_id, None) @@ -140,7 +139,7 @@ class _CheckpointPosition(object): slot_variable_id=slot_restoration.slot_variable_id, slot_name=slot_restoration.slot_name)) else: - optimizer_object._process_slot_restoration( # pylint: disable=protected-access + optimizer_object._create_or_restore_slot_variable( # pylint: disable=protected-access slot_variable_position=_CheckpointPosition( checkpoint=checkpoint, proto_id=slot_restoration.slot_variable_id), @@ -229,7 +228,7 @@ _SlotVariableRestoration = collections.namedtuple( class _Checkpoint(object): """Holds the status of an object-based checkpoint load.""" - def __init__(self, object_graph_proto, save_path, session): + def __init__(self, object_graph_proto, save_path): """Specify the checkpoint being loaded. Args: @@ -237,11 +236,6 @@ class _Checkpoint(object): associated with this checkpoint. save_path: The path to the checkpoint, as returned by `tf.train.latest_checkpoint`. - session: The session to evaluate assignment ops in. Should be None if - executing eagerly. - - Raises: - ValueError: If `session` is not None and eager execution is enabled. """ self.object_graph_proto = object_graph_proto self.restore_uid = ops.uid() @@ -255,6 +249,9 @@ class _Checkpoint(object): self.save_path = save_path reader = pywrap_tensorflow.NewCheckpointReader(save_path) self.dtype_map = reader.get_variable_to_dtype_map() + # When graph building, contains a list of ops to run to restore objects from + # this checkpoint. + self.restore_ops = [] # A mapping from optimizer proto ids to lists of slot variables to be # restored when the optimizer is tracked. Only includes slot variables whose # regular variables have already been created, and only for optimizer @@ -274,39 +271,15 @@ class _Checkpoint(object): optimizer_id=node_index, slot_variable_id=slot_reference.slot_variable_node_id, slot_name=slot_reference.slot_name)) - if session is not None and context.in_eager_mode(): - raise ValueError( - "Passed a session %s when executing eagerly." % (session,)) - self.session = session - - -class Checkpointable(object): - """Manages dependencies on other objects. - - `Checkpointable` objects may have dependencies: other `Checkpointable` objects - which should be saved if the object declaring the dependency is saved. A - correctly saveable program has a dependency graph such that if changing a - global variable affects an object (e.g. changes the behavior of any of its - methods) then there is a chain of dependencies from the influenced object to - the variable. - Dependency edges have names, and are created implicitly when a - `Checkpointable` object is assigned to an attribute of another - `Checkpointable` object. For example: - ``` - obj = Checkpointable() - obj.v = ResourceVariable(0.) - ``` - - The `Checkpointable` object `obj` now has a dependency named "v" on a - variable. +class CheckpointableBase(object): + """Base class for `Checkpointable` objects without automatic dependencies. - `Checkpointable` objects may specify `Tensor`s to be saved and restored - directly (e.g. a `Variable` indicating how to save itself) rather than through - dependencies on other objects. See - `Checkpointable._scatter_tensors_from_checkpoint` and - `Checkpointable._gather_tensors_for_checkpoint` for details. + This class has no __setattr__ override for performance reasons. Dependencies + must be added explicitly. Unless attribute assignment is performance-critical, + use `Checkpointable` instead. Use `CheckpointableBase` for `isinstance` + checks. """ def _maybe_initialize_checkpointable(self): @@ -333,21 +306,6 @@ class Checkpointable(object): "initialization code was run.") self._update_uid = -1 - def __setattr__(self, name, value): - """Support self.foo = checkpointable syntax.""" - # Perform the attribute assignment, and potentially call other __setattr__ - # overrides such as that for tf.keras.Model. - super(Checkpointable, self).__setattr__(name, value) - if isinstance(value, Checkpointable): - self._track_checkpointable( - value, name=name, - # Allow the user to switch the Checkpointable which is tracked by this - # name, since assigning a new variable to an attribute has - # historically been fine (e.g. Adam did this). - # TODO(allenl): Should this be a warning once Checkpointable save/load - # is usable? - overwrite=True) - def _add_variable_with_custom_getter( self, name, shape=None, dtype=dtypes.float32, initializer=None, getter=None, **kwargs_for_getter): @@ -383,11 +341,15 @@ class Checkpointable(object): "Checkpointable._add_variable called to create another with " "that name. Variable names must be unique within a Checkpointable " "object.") % (name,)) - # If this is a variable with a single Tensor stored in the checkpoint, we - # can set that value as an initializer rather than initializing and then - # assigning (when executing eagerly). - checkpoint_initializer = self._preload_simple_restoration( - name=name, shape=shape) + if context.in_eager_mode(): + # If this is a variable with a single Tensor stored in the checkpoint, we + # can set that value as an initializer rather than initializing and then + # assigning (when executing eagerly). This call returns None if there is + # nothing to restore. + checkpoint_initializer = self._preload_simple_restoration( + name=name, shape=shape) + else: + checkpoint_initializer = None if (checkpoint_initializer is not None and not ( isinstance(initializer, CheckpointInitialValue) @@ -400,20 +362,11 @@ class Checkpointable(object): # effort" to set the initializer with the highest restore UID. initializer = checkpoint_initializer shape = None - checkpoint_position = checkpoint_initializer.checkpoint_position - else: - checkpoint_position = None new_variable = getter( name=name, shape=shape, dtype=dtype, initializer=initializer, **kwargs_for_getter) - if (checkpoint_position is not None - and hasattr(new_variable, "_update_uid") - and new_variable._update_uid == checkpoint_position.restore_uid): # pylint: disable=protected-access - session = checkpoint_position.checkpoint.session - if session: - session.run(new_variable.initializer) # If we set an initializer and the variable processed it, tracking will not # assign again. It will add this variable to our dependencies, and if there # is a non-trivial restoration queued, it will handle that. This also @@ -487,7 +440,7 @@ class Checkpointable(object): ValueError: If another object is already tracked by this name. """ self._maybe_initialize_checkpointable() - if not isinstance(checkpointable, Checkpointable): + if not isinstance(checkpointable, CheckpointableBase): raise TypeError( ("Checkpointable._track_checkpointable() passed type %s, not a " "Checkpointable.") % (type(checkpointable),)) @@ -582,3 +535,48 @@ class Checkpointable(object): def _gather_tensors_for_checkpoint(self): """Returns a dictionary of Tensors to save with this object.""" return {} + + +class Checkpointable(CheckpointableBase): + """Manages dependencies on other objects. + + `Checkpointable` objects may have dependencies: other `Checkpointable` objects + which should be saved if the object declaring the dependency is saved. A + correctly saveable program has a dependency graph such that if changing a + global variable affects an object (e.g. changes the behavior of any of its + methods) then there is a chain of dependencies from the influenced object to + the variable. + + Dependency edges have names, and are created implicitly when a + `Checkpointable` object is assigned to an attribute of another + `Checkpointable` object. For example: + + ``` + obj = Checkpointable() + obj.v = ResourceVariable(0.) + ``` + + The `Checkpointable` object `obj` now has a dependency named "v" on a + variable. + + `Checkpointable` objects may specify `Tensor`s to be saved and restored + directly (e.g. a `Variable` indicating how to save itself) rather than through + dependencies on other objects. See + `Checkpointable._scatter_tensors_from_checkpoint` and + `Checkpointable._gather_tensors_for_checkpoint` for details. + """ + + def __setattr__(self, name, value): + """Support self.foo = checkpointable syntax.""" + # Perform the attribute assignment, and potentially call other __setattr__ + # overrides such as that for tf.keras.Model. + super(Checkpointable, self).__setattr__(name, value) + if isinstance(value, CheckpointableBase): + self._track_checkpointable( + value, name=name, + # Allow the user to switch the Checkpointable which is tracked by this + # name, since assigning a new variable to an attribute has + # historically been fine (e.g. Adam did this). + # TODO(allenl): Should this be a warning once Checkpointable save/load + # is usable? + overwrite=True) diff --git a/tensorflow/python/training/optimizer.py b/tensorflow/python/training/optimizer.py index 762658175a..678d6322aa 100644 --- a/tensorflow/python/training/optimizer.py +++ b/tensorflow/python/training/optimizer.py @@ -324,9 +324,18 @@ class Optimizer(checkpointable.Checkpointable): self._use_locking = use_locking self._name = name # Dictionary of slots. - # {slot_name : { variable_to_train: slot_for_the_variable, ...}, ... } + # {slot_name : + # {_var_key(variable_to_train): slot_for_the_variable, ... }, + # ... } self._slots = {} self._non_slot_dict = {} + # For implementing Checkpointable. Stores information about how to restore + # slot variables which have not yet been created + # (checkpointable._CheckpointPosition objects). + # {slot_name : + # {_var_key(variable_to_train): [checkpoint_position, ... ], ... }, + # ... } + self._deferred_slot_restorations = {} def get_name(self): return self._name @@ -884,7 +893,11 @@ class Optimizer(checkpointable.Checkpointable): """ named_slots = self._slot_dict(slot_name) if _var_key(var) not in named_slots: - named_slots[_var_key(var)] = slot_creator.create_slot(var, val, op_name) + new_slot_variable = slot_creator.create_slot(var, val, op_name) + self._restore_slot_variable( + slot_name=slot_name, variable=var, + slot_variable=new_slot_variable) + named_slots[_var_key(var)] = new_slot_variable return named_slots[_var_key(var)] def _get_or_make_slot_with_initializer(self, var, initializer, shape, dtype, @@ -905,8 +918,12 @@ class Optimizer(checkpointable.Checkpointable): """ named_slots = self._slot_dict(slot_name) if _var_key(var) not in named_slots: - named_slots[_var_key(var)] = slot_creator.create_slot_with_initializer( + new_slot_variable = slot_creator.create_slot_with_initializer( var, initializer, shape, dtype, op_name) + self._restore_slot_variable( + slot_name=slot_name, variable=var, + slot_variable=new_slot_variable) + named_slots[_var_key(var)] = new_slot_variable return named_slots[_var_key(var)] def _zeros_slot(self, var, slot_name, op_name): @@ -923,12 +940,43 @@ class Optimizer(checkpointable.Checkpointable): """ named_slots = self._slot_dict(slot_name) if _var_key(var) not in named_slots: - named_slots[_var_key(var)] = slot_creator.create_zeros_slot(var, op_name) + new_slot_variable = slot_creator.create_zeros_slot(var, op_name) + self._restore_slot_variable( + slot_name=slot_name, variable=var, + slot_variable=new_slot_variable) + named_slots[_var_key(var)] = new_slot_variable return named_slots[_var_key(var)] - def _process_slot_restoration( + # -------------- + # For implementing the Checkpointable interface. + # -------------- + + def _restore_slot_variable(self, slot_name, variable, slot_variable): + """Restore a newly created slot variable's value.""" + variable_key = _var_key(variable) + deferred_restorations = self._deferred_slot_restorations.get( + slot_name, {}).pop(variable_key, []) + # Iterate over restores, highest restore UID first to minimize the number + # of assignments. + deferred_restorations.sort(key=lambda position: position.restore_uid, + reverse=True) + for checkpoint_position in deferred_restorations: + checkpoint_position.restore(slot_variable) + + def _create_or_restore_slot_variable( self, slot_variable_position, slot_name, variable): - """Restore a slot variable's value (creating it if necessary). + """Restore a slot variable's value, possibly creating it. + + Called when a variable which has an associated slot variable is created or + restored. When executing eagerly, we create the slot variable with a + restoring initializer. + + No new variables are created when graph building. Instead, + _restore_slot_variable catches these after normal creation and adds restore + ops to the graph. This method is nonetheless important when graph building + for the case when a slot variable has already been created but `variable` + has just been added to a dependency graph (causing us to realize that the + slot variable needs to be restored). Args: slot_variable_position: A `checkpointable._CheckpointPosition` object @@ -939,28 +987,16 @@ class Optimizer(checkpointable.Checkpointable): named_slots = self._slot_dict(slot_name) variable_key = _var_key(variable) slot_variable = named_slots.get(variable_key, None) - if slot_variable is None: - if slot_variable_position.is_simple_variable(): - initializer = checkpointable.CheckpointInitialValue( - checkpoint_position=slot_variable_position) - slot_variable = self._get_or_make_slot( - var=variable, - val=initializer, - slot_name=slot_name, - op_name=self._name) - if slot_variable._update_uid == slot_variable_position.restore_uid: # pylint: disable=protected-access - # If our restoration was set (not given with custom getters), run - # it. Otherwise wait for the restore() call below to restore if - # necessary. - session = slot_variable_position.checkpoint.session - if session: - session.run(slot_variable.initializer) - - else: - raise NotImplementedError( - "Currently only variables with no dependencies can be loaded as " - "slot variables. File a feature request if this limitation bothers " - "you. (Got %s)" % (slot_variable_position,)) + if (slot_variable is None + and context.in_eager_mode() + and slot_variable_position.is_simple_variable()): + initializer = checkpointable.CheckpointInitialValue( + checkpoint_position=slot_variable_position) + slot_variable = self._get_or_make_slot( + var=variable, + val=initializer, + slot_name=slot_name, + op_name=self._name) # Slot variables are not owned by any one object (because we don't want to # save the slot variable if the optimizer is saved without the non-slot # variable, or if the non-slot variable is saved without the optimizer; @@ -968,4 +1004,15 @@ class Optimizer(checkpointable.Checkpointable): # variable, variable)). So we don't _track_ slot variables anywhere, and # instead special-case this dependency and otherwise pretend it's a normal # graph. - slot_variable_position.restore(slot_variable) + if slot_variable is not None: + # If we've either made this slot variable, or if we've pulled out an + # existing slot variable, we should restore it. + slot_variable_position.restore(slot_variable) + else: + # We didn't make the slot variable. Defer restoring until it gets created + # normally. We keep a list rather than the one with the highest restore + # UID in case slot variables have their own dependencies, in which case + # those could differ between restores. + self._deferred_slot_restorations.setdefault( + slot_name, {}).setdefault(variable_key, []).append( + slot_variable_position) diff --git a/tensorflow/python/util/tf_inspect.py b/tensorflow/python/util/tf_inspect.py index c4168f7b1a..c2fe6fc449 100644 --- a/tensorflow/python/util/tf_inspect.py +++ b/tensorflow/python/util/tf_inspect.py @@ -134,6 +134,11 @@ def getmembers(object, predicate=None): # pylint: disable=redefined-builtin return _inspect.getmembers(object, predicate) +def getmodule(object): # pylint: disable=redefined-builtin + """TFDecorator-aware replacement for inspect.getmodule.""" + return _inspect.getmodule(object) + + def getmro(cls): """TFDecorator-aware replacement for inspect.getmro.""" return _inspect.getmro(cls) diff --git a/tensorflow/python/util/tf_inspect_test.py b/tensorflow/python/util/tf_inspect_test.py index a9e8ffb30c..8903e1156b 100644 --- a/tensorflow/python/util/tf_inspect_test.py +++ b/tensorflow/python/util/tf_inspect_test.py @@ -124,6 +124,17 @@ class TfInspectTest(test.TestCase): inspect.getmembers(TestDecoratedClass), tf_inspect.getmembers(TestDecoratedClass)) + def testGetModule(self): + self.assertEqual( + inspect.getmodule(TestDecoratedClass), + tf_inspect.getmodule(TestDecoratedClass)) + self.assertEqual( + inspect.getmodule(test_decorated_function), + tf_inspect.getmodule(test_decorated_function)) + self.assertEqual( + inspect.getmodule(test_undecorated_function), + tf_inspect.getmodule(test_undecorated_function)) + def testGetSource(self): expected = '''@test_decorator('decorator') def test_decorated_function_with_defaults(a, b=2, c='Hello'): diff --git a/tensorflow/tools/api/golden/tensorflow.-variable.pbtxt b/tensorflow/tools/api/golden/tensorflow.-variable.pbtxt index 069200065a..5a02bb2175 100644 --- a/tensorflow/tools/api/golden/tensorflow.-variable.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.-variable.pbtxt @@ -1,7 +1,7 @@ path: "tensorflow.Variable" tf_class { is_instance: "<class \'tensorflow.python.ops.variables.Variable\'>" - is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "SaveSliceInfo" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-adadelta-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-adadelta-optimizer.pbtxt index 4eea52596a..c02e54adfb 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-adadelta-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-adadelta-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.adadelta.AdadeltaOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-adagrad-d-a-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-adagrad-d-a-optimizer.pbtxt index 5aaaf0e20b..2b619908fc 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-adagrad-d-a-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-adagrad-d-a-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.adagrad_da.AdagradDAOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-adagrad-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-adagrad-optimizer.pbtxt index 7f1201879c..2005cf4677 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-adagrad-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-adagrad-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.adagrad.AdagradOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-adam-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-adam-optimizer.pbtxt index 503c439d83..0a2bae1d90 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-adam-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-adam-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.adam.AdamOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-ftrl-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-ftrl-optimizer.pbtxt index 39c071748c..847f9ad759 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-ftrl-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-ftrl-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.ftrl.FtrlOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-gradient-descent-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-gradient-descent-optimizer.pbtxt index 6b441786ca..13a58e0608 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-gradient-descent-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-gradient-descent-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.gradient_descent.GradientDescentOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-momentum-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-momentum-optimizer.pbtxt index 80f3963bac..bfbc2357a3 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-momentum-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-momentum-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.momentum.MomentumOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-optimizer.pbtxt index c880ba328a..437efa0a2b 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-optimizer.pbtxt @@ -2,6 +2,7 @@ path: "tensorflow.train.Optimizer" tf_class { is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-proximal-adagrad-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-proximal-adagrad-optimizer.pbtxt index 6acdf35f78..72f224605f 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-proximal-adagrad-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-proximal-adagrad-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.proximal_adagrad.ProximalAdagradOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-proximal-gradient-descent-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-proximal-gradient-descent-optimizer.pbtxt index 00b1e309e3..316275b1fb 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-proximal-gradient-descent-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-proximal-gradient-descent-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.proximal_gradient_descent.ProximalGradientDescentOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-r-m-s-prop-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-r-m-s-prop-optimizer.pbtxt index 05dc391cab..af50a19861 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-r-m-s-prop-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-r-m-s-prop-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.rmsprop.RMSPropOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/tools/api/golden/tensorflow.train.-sync-replicas-optimizer.pbtxt b/tensorflow/tools/api/golden/tensorflow.train.-sync-replicas-optimizer.pbtxt index 4be2819261..6edc516c93 100644 --- a/tensorflow/tools/api/golden/tensorflow.train.-sync-replicas-optimizer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.train.-sync-replicas-optimizer.pbtxt @@ -3,6 +3,7 @@ tf_class { is_instance: "<class \'tensorflow.python.training.sync_replicas_optimizer.SyncReplicasOptimizer\'>" is_instance: "<class \'tensorflow.python.training.optimizer.Optimizer\'>" is_instance: "<class \'tensorflow.python.training.checkpointable.Checkpointable\'>" + is_instance: "<class \'tensorflow.python.training.checkpointable.CheckpointableBase\'>" is_instance: "<type \'object\'>" member { name: "GATE_GRAPH" diff --git a/tensorflow/workspace.bzl b/tensorflow/workspace.bzl index 96bd2d5326..2e84d83fe4 100644 --- a/tensorflow/workspace.bzl +++ b/tensorflow/workspace.bzl @@ -179,11 +179,11 @@ def tf_workspace(path_prefix="", tf_repo_name=""): tf_http_archive( name = "gemmlowp", urls = [ - "https://mirror.bazel.build/github.com/google/gemmlowp/archive/d4d1e29a62192d8defdc057b913ef36ca582ac98.zip", - "https://github.com/google/gemmlowp/archive/d4d1e29a62192d8defdc057b913ef36ca582ac98.zip", + "https://mirror.bazel.build/github.com/google/gemmlowp/archive/7c7c744640ddc3d0af18fb245b4d23228813a71b.zip", + "https://github.com/google/gemmlowp/archive/7c7c744640ddc3d0af18fb245b4d23228813a71b.zip", ], - sha256 = "e2bee7afd3c43028f23dd0d7f85ddd8b21aaf79c572b658e56164ef502b2b9c7", - strip_prefix = "gemmlowp-d4d1e29a62192d8defdc057b913ef36ca582ac98", + sha256 = "b852cc90259a7357c8a323f108f2cec6e85979fc3b18b5590b99e0130044b2cf", + strip_prefix = "gemmlowp-7c7c744640ddc3d0af18fb245b4d23228813a71b", ) tf_http_archive( |