
diff options
| author | 2018-08-28 22:25:04 -0700 | |
|---|---|---|
| committer | 2018-08-28 22:25:04 -0700 | |
| commit | a41a2d06823079165f09860cb8e28df7854389d0 (patch) | |
| tree | 6e12ec04aec52ddcf58ebe3652b4538e01347c2f | |
| parent | f5ef2477b6337fd30cf3c1348d35e8296c349b30 (diff) | |
| parent | c010fec6abbe2039febe285ea35de52923eb6d75 (diff) | |
Merge branch 'master' into relu3D
{kind=link}
{kind=link}
2746 files changed, 70798 insertions, 75324 deletions
diff --git a/.gitignore b/.gitignore index 5afe375f46..1ef4c297ee 100644 --- a/.gitignore +++ b/.gitignore @@ -14,6 +14,7 @@ __pycache__ *.swp .vscode/ cmake_build/ +tensorflow/contrib/cmake/_build/ .idea/** /build/ [Bb]uild/ @@ -30,6 +31,7 @@ Podfile.lock xcuserdata/** /api_init_files_list.txt /estimator_api_init_files_list.txt +*.whl # Android .gradle diff --git a/CODEOWNERS b/CODEOWNERS index b9f0313cc6..113eaf798f 100644 --- a/CODEOWNERS +++ b/CODEOWNERS @@ -1,53 +1,62 @@ -# NOTE: Disabled temporarily because it's too noisy on pushes. # Where component owners are known, add them here. -# /tensorflow/core/platform/windows/ @mrry -# /tensorflow/java/ @asimshankar -# /tensorflow/tensorboard/ @jart @dandelionmane -# /tensorflow/tools/docs/ @markdaoust +/tenosrflow/core/debug @caisq +/tensorflow/core/platform/windows/ @mrry +/tensorflow/go @asimshankar +/tensorflow/java/ @asimshankar +/tensorflow/python/debug @caisq +/tensorflow/python/tools/api/generator/ @annarev +/tensorflow/tensorboard/ @jart +/tensorflow/tools/docs/ @markdaoust # contrib -# NEED OWNER: /tensorflow/contrib/avro/ -# /tensorflow/contrib/batching/ @alextp @chrisolston -# /tensorflow/contrib/bayesflow/ @ebrevdo @rsepassi @jvdillon -# /tensorflow/contrib/boosted_trees/ @sshrdp @yk5 @nataliaponomareva -# /tensorflow/contrib/cmake/ @mrry @benoitsteiner -# /tensorflow/contrib/copy_graph/ @tucker @poxvoculi -# /tensorflow/contrib/crf/ @kentonl -# /tensorflow/contrib/data/ @mrry -# /tensorflow/contrib/distributions/ @jvdillon @langmore @rsepassi -# /tensorflow/contrib/factorization/ @agarwal-ashish @xavigonzalvo -# /tensorflow/contrib/ffmpeg/ @fredbertsch -# NEED OWNER: /tensorflow/contrib/framework/ -# /tensorflow/contrib/graph_editor/ @purpledog +# NEED OWNER: /tensorflow/contrib/all_reduce +/tensorflow/contrib/batching/ @alextp @chrisolston +/tensorflow/contrib/bayesflow/ @ebrevdo @rsepassi @jvdillon +/tensorflow/contrib/boosted_trees/ @sshrdp @yk5 @nataliaponomareva +/tensorflow/contrib/checkpoint/ @allenlavoie +/tensorflow/contrib/contrib/cluster_resolver/ @frankchn +/tensorflow/contrib/cmake/ @mrry +/tensorflow/contrib/copy_graph/ @tucker @poxvoculi +/tensorflow/contrib/crf/ @kentonl +/tensorflow/contrib/data/ @mrry +/tensorflow/tensorflow/contrib/distribute @joshl @priyag @sourabhbajaj @frankchn +/tensorflow/contrib/distributions/ @jvdillon @langmore @rsepassi +/tensorflow/contrib/eager @alextp @asimshankar +/tensorflow/contrib/factorization/ @agarwal-ashish @xavigonzalvo +/tensorflow/contrib/ffmpeg/ @fredbertsch +/tensorflow/contrib/framework/ @ebrevdo +/tensorflow/contrib/gan/ @joel-shor +/tensorflow/contrib/graph_editor/ @purpledog # NEED OWNER: /tensorflow/contrib/grid_rnn/ -# /tensorflow/contrib/hvx/ @satok16 -# /tensorflow/contrib/integrate/ @shoyer -# /tensorflow/contrib/kernel_methods/ @petrosmol -# /tensorflow/contrib/ios_examples/ @petewarden -# /tensorflow/contrib/labeled_tensor/ @shoyer -# /tensorflow/contrib/layers/ @fchollet @martinwicke -# /tensorflow/contrib/learn/ @martinwicke @ispirmustafa @alextp -# /tensorflow/contrib/linalg/ @langmore -# /tensorflow/contrib/linear_optimizer/ @petrosmol @andreasst @katsiapis -# /tensorflow/contrib/lookup/ @ysuematsu @andreasst -# /tensorflow/contrib/losses/ @alextp @ispirmustafa -# /tensorflow/contrib/makefile/ @petewarden @satok16 @wolffg -# /tensorflow/contrib/metrics/ @alextp @honkentuber @ispirmustafa -# /tensorflow/contrib/nccl/ @cwhipkey @zheng-xq -# /tensorflow/contrib/opt/ @strategist333 -# /tensorflow/contrib/pi_examples/ @maciekcc -# /tensorflow/contrib/quantization/ @petewarden @cwhipkey @keveman -# /tensorflow/contrib/rnn/ @ebrevdo -# /tensorflow/contrib/saved_model/ @nfiedel @sukritiramesh -# /tensorflow/contrib/seq2seq/ @lukaszkaiser -# /tensorflow/contrib/session_bundle/ @nfiedel @sukritiramesh -# /tensorflow/contrib/slim/ @sguada @thenbasilmanran -# /tensorflow/contrib/stateless/ @girving -# /tensorflow/contrib/tensor_forest/ @gilberthendry @thomascolthurst @yupbank -# /tensorflow/contrib/testing/ @dandelionmane -# /tensorflow/contrib/timeseries/ @allenlavoie -# /tensorflow/contrib/tpu/ @frankchn @saeta @jhseu -# /tensorflow/contrib/training/ @joel-shor @ebrevdo -# /tensorflow/contrib/util/ @sherrym +/tensorflow/contrib/hvx/ @satok16 +/tensorflow/contrib/integrate/ @shoyer +/tensorflow/contrib/kernel_methods/ @petrosmol +/tensorflow/contrib/ios_examples/ @petewarden +/tensorflow/contrib/labeled_tensor/ @shoyer +/tensorflow/contrib/layers/ @fchollet @martinwicke +/tensorflow/contrib/learn/ @martinwicke @ispirmustafa @alextp +/tensorflow/contrib/linalg/ @langmore +/tensorflow/contrib/linear_optimizer/ @petrosmol @andreasst @katsiapis +/tensorflow/contrib/lookup/ @ysuematsu @andreasst +/tensorflow/contrib/losses/ @alextp @ispirmustafa +/tensorflow/contrib/makefile/ @petewarden @satok16 @wolffg +/tensorflow/contrib/metrics/ @alextp @honkentuber @ispirmustafa +/tensorflow/contrib/nccl/ @cwhipkey @zheng-xq +/tensorflow/contrib/opt/ @strategist333 @alextp +/tensorflow/contrib/pi_examples/ @maciekcc +/tensorflow/contrib/quantization/ @petewarden +/tensorflow/contrib/rnn/ @ebrevdo @scottzhu +/tensorflow/contrib/saved_model/ @nfiedel @sukritiramesh @allenl +/tensorflow/contrib/seq2seq/ @ebrevdo @lmthang +/tensorflow/contrib/session_bundle/ @nfiedel @sukritiramesh +/tensorflow/contrib/slim/ @sguada @thenbasilmanran +/tensorflow/contrib/stateless/ @girving @alextp +/tensorflow/contrib/tensor_forest/ @gilberthendry @thomascolthurst @yupbank +/tensorflow/contrib/tensorrt/ @laigd +# NEED OWNER: /tensorflow/contrib/testing/ +/tensorflow/contrib/timeseries/ @allenlavoie +/tensorflow/contrib/tpu/ @frankchn @saeta @jhseu @sourabhbajaj +/tensorflow/contrib/training/ @joel-shor @ebrevdo +/tensorflow/contrib/util/ @sherrym
\ No newline at end of file @@ -100,16 +100,16 @@ The TensorFlow project strives to abide by generally accepted best practices in | **IBM ppc64le CPU** | [](http://powerci.osuosl.org/job/TensorFlow_Ubuntu_16.04_CPU/) | TBA | | **IBM ppc64le GPU** | [](http://powerci.osuosl.org/job/TensorFlow_Ubuntu_16.04_PPC64LE_GPU/) | TBA | | **Linux CPU with Intel® MKL-DNN** Nightly | [](https://tensorflow-ci.intel.com/job/tensorflow-mkl-linux-cpu/) | [Nightly](https://tensorflow-ci.intel.com/job/tensorflow-mkl-build-whl-nightly/) | -| **Linux CPU with Intel® MKL-DNN** Python 2.7<br> **Linux CPU with Intel® MKL-DNN** Python 3.5<br> **Linux CPU with Intel® MKL-DNN** Python 3.6| |[1.9.0 py2.7](https://storage.googleapis.com/intel-optimized-tensorflow/tensorflow-1.9.0-cp27-cp27mu-linux_x86_64.whl)<br>[1.9.0 py3.5](https://storage.googleapis.com/intel-optimized-tensorflow/tensorflow-1.9.0-cp35-cp35m-linux_x86_64.whl)<br>[1.9.0 py3.6](https://storage.cloud.google.com/intel-optimized-tensorflow/tensorflow-1.9.0-cp36-cp36m-linux_x86_64.whl) | +| **Linux CPU with Intel® MKL-DNN** Python 2.7<br> **Linux CPU with Intel® MKL-DNN** Python 3.5<br> **Linux CPU with Intel® MKL-DNN** Python 3.6 | [](https://tensorflow-ci.intel.com/job/tensorflow-mkl-build-release-whl/lastStableBuild)|[1.10.0 py2.7](https://storage.googleapis.com/intel-optimized-tensorflow/tensorflow-1.10.0-cp27-cp27mu-linux_x86_64.whl)<br>[1.10.0 py3.5](https://storage.googleapis.com/intel-optimized-tensorflow/tensorflow-1.10.0-cp35-cp35m-linux_x86_64.whl)<br>[1.10.0 py3.6](https://storage.googleapis.com/intel-optimized-tensorflow/tensorflow-1.10.0-cp36-cp36m-linux_x86_64.whl) | ## For more information -* [Tensorflow Blog](https://medium.com/tensorflow) +* [TensorFlow Blog](https://medium.com/tensorflow) * [TensorFlow Course at Stanford](https://web.stanford.edu/class/cs20si) * [TensorFlow Model Zoo](https://github.com/tensorflow/models) * [TensorFlow MOOC on Udacity](https://www.udacity.com/course/deep-learning--ud730) * [TensorFlow Roadmap](https://www.tensorflow.org/community/roadmap) -* [Tensorflow Twitter](https://twitter.com/tensorflow) +* [TensorFlow Twitter](https://twitter.com/tensorflow) * [TensorFlow Website](https://www.tensorflow.org) * [TensorFlow White Papers](https://www.tensorflow.org/about/bib) * [TensorFlow YouTube Channel](https://www.youtube.com/channel/UC0rqucBdTuFTjJiefW5t-IQ) diff --git a/configure.py b/configure.py index 79293d18e6..10fee6993e 100644 --- a/configure.py +++ b/configure.py @@ -848,7 +848,7 @@ def set_tf_cuda_version(environ_cp): cuda_toolkit_paths_full = [os.path.join(cuda_toolkit_path, x) for x in cuda_rt_lib_paths] if any([os.path.exists(x) for x in cuda_toolkit_paths_full]): - break + break # Reset and retry print('Invalid path to CUDA %s toolkit. %s cannot be found' % @@ -1399,6 +1399,13 @@ def set_grpc_build_flags(): write_to_bazelrc('build --define grpc_no_ares=true') +def set_system_libs_flag(environ_cp): + syslibs = environ_cp.get('TF_SYSTEM_LIBS', '') + syslibs = ','.join(sorted(syslibs.split(','))) + if syslibs and syslibs != '': + write_action_env_to_bazelrc('TF_SYSTEM_LIBS', syslibs) + + def set_windows_build_flags(environ_cp): """Set Windows specific build options.""" # The non-monolithic build is not supported yet @@ -1501,6 +1508,8 @@ def main(): False, 'gdr') set_build_var(environ_cp, 'TF_NEED_VERBS', 'VERBS', 'with_verbs_support', False, 'verbs') + set_build_var(environ_cp, 'TF_NEED_NGRAPH', 'nGraph', + 'with_ngraph_support', False, 'ngraph') set_action_env_var(environ_cp, 'TF_NEED_OPENCL_SYCL', 'OpenCL SYCL', False) if environ_cp.get('TF_NEED_OPENCL_SYCL') == '1': @@ -1555,6 +1564,7 @@ def main(): set_grpc_build_flags() set_cc_opt_flags(environ_cp) + set_system_libs_flag(environ_cp) if is_windows(): set_windows_build_flags(environ_cp) diff --git a/tensorflow/BUILD b/tensorflow/BUILD index 94e059b914..9cc4c4567b 100644 --- a/tensorflow/BUILD +++ b/tensorflow/BUILD @@ -23,6 +23,10 @@ load( "//tensorflow/python/tools/api/generator:api_gen.bzl", "gen_api_init_files", # @unused ) +load( + "//third_party/ngraph:build_defs.bzl", + "if_ngraph", +) # Config setting used when building for products # which requires restricted licenses to be avoided. @@ -411,6 +415,14 @@ config_setting( visibility = ["//visibility:public"], ) +# This flag is set from the configure step when the user selects with nGraph option. +# By default it should be false +config_setting( + name = "with_ngraph_support", + values = {"define": "with_ngraph_support=true"}, + visibility = ["//visibility:public"], +) + package_group( name = "internal", packages = [ @@ -563,7 +575,7 @@ tf_cc_shared_object( "//tensorflow/cc:scope", "//tensorflow/cc/profiler", "//tensorflow/core:tensorflow", - ], + ] + if_ngraph(["@ngraph_tf//:ngraph_tf"]), ) exports_files( diff --git a/tensorflow/__init__.py b/tensorflow/__init__.py index 440e9f8dbd..21677512b6 100644 --- a/tensorflow/__init__.py +++ b/tensorflow/__init__.py @@ -28,7 +28,8 @@ contrib = LazyLoader('contrib', globals(), 'tensorflow.contrib') del LazyLoader from tensorflow.python.platform import flags # pylint: disable=g-import-not-at-top -app.flags = flags # pylint: disable=undefined-variable +from tensorflow.python.platform import app # pylint: disable=g-import-not-at-top +app.flags = flags del absolute_import del division diff --git a/tensorflow/c/c_api.cc b/tensorflow/c/c_api.cc index 19ccb6e71d..173bbea596 100644 --- a/tensorflow/c/c_api.cc +++ b/tensorflow/c/c_api.cc @@ -202,7 +202,8 @@ TF_Tensor* TF_NewTensor(TF_DataType dtype, const int64_t* dims, int num_dims, buf->len_ = len; if (dtype != TF_STRING && dtype != TF_RESOURCE && tensorflow::DataTypeCanUseMemcpy(static_cast<DataType>(dtype)) && - reinterpret_cast<intptr_t>(data) % EIGEN_MAX_ALIGN_BYTES != 0) { + reinterpret_cast<intptr_t>(data) % std::max(1, EIGEN_MAX_ALIGN_BYTES) != + 0) { // TF_STRING and TF_RESOURCE tensors have a different representation in // TF_Tensor than they do in tensorflow::Tensor. So a copy here is a waste // (any alignment requirements will be taken care of by TF_TensorToTensor @@ -1239,7 +1240,7 @@ void TF_SetAttrTypeList(TF_OperationDescription* desc, const char* attr_name, void TF_SetAttrFuncName(TF_OperationDescription* desc, const char* attr_name, const char* value, size_t length) { tensorflow::NameAttrList func_name; - func_name.set_name(std::string(value, value + length)); + func_name.set_name(string(value, value + length)); desc->node_builder.Attr(attr_name, func_name); } @@ -2064,7 +2065,7 @@ static void GraphImportGraphDefLocked(TF_Graph* graph, const GraphDef& def, for (int i = 0; i < size; ++i) { TensorId id = results.missing_unused_input_map_keys[i]; - tf_results->missing_unused_key_names_data.push_back(std::string(id.first)); + tf_results->missing_unused_key_names_data.emplace_back(id.first); tf_results->missing_unused_key_names[i] = tf_results->missing_unused_key_names_data.back().c_str(); tf_results->missing_unused_key_indexes[i] = id.second; diff --git a/tensorflow/c/c_api_test.cc b/tensorflow/c/c_api_test.cc index aa2a537f03..03516c39dc 100644 --- a/tensorflow/c/c_api_test.cc +++ b/tensorflow/c/c_api_test.cc @@ -259,8 +259,8 @@ TEST(CAPI, DeprecatedSession) { TF_Run(session, run_options, nullptr, nullptr, 0, nullptr, nullptr, 0, nullptr, 0, run_metadata, s); EXPECT_EQ(TF_INVALID_ARGUMENT, TF_GetCode(s)) << TF_Message(s); - EXPECT_EQ(std::string("Session was not created with a graph before Run()!"), - std::string(TF_Message(s))); + EXPECT_EQ("Session was not created with a graph before Run()!", + string(TF_Message(s))); TF_DeleteBuffer(run_metadata); TF_DeleteBuffer(run_options); @@ -1224,8 +1224,8 @@ class CApiColocationTest : public ::testing::Test { TF_OperationGetAttrMetadata(op, tensorflow::kColocationAttrName, s_); if (expected.empty()) { ASSERT_EQ(TF_INVALID_ARGUMENT, TF_GetCode(s_)) << TF_Message(s_); - EXPECT_EQ(std::string("Operation 'add' has no attr named '_class'."), - std::string(TF_Message(s_))); + EXPECT_EQ("Operation 'add' has no attr named '_class'.", + string(TF_Message(s_))); return; } EXPECT_EQ(TF_OK, TF_GetCode(s_)) << TF_Message(s_); @@ -1369,16 +1369,16 @@ TEST(CAPI, SavedModel) { input.flat<string>()(i) = example.SerializeAsString(); } - const tensorflow::string input_op_name = - std::string(tensorflow::ParseTensorName(input_name).first); + const tensorflow::string input_op_name( + tensorflow::ParseTensorName(input_name).first); TF_Operation* input_op = TF_GraphOperationByName(graph, input_op_name.c_str()); ASSERT_TRUE(input_op != nullptr); csession.SetInputs({{input_op, TF_TensorFromTensor(input, s)}}); ASSERT_EQ(TF_OK, TF_GetCode(s)) << TF_Message(s); - const tensorflow::string output_op_name = - std::string(tensorflow::ParseTensorName(output_name).first); + const tensorflow::string output_op_name( + tensorflow::ParseTensorName(output_name).first); TF_Operation* output_op = TF_GraphOperationByName(graph, output_op_name.c_str()); ASSERT_TRUE(output_op != nullptr); diff --git a/tensorflow/c/checkpoint_reader.cc b/tensorflow/c/checkpoint_reader.cc index 74bc25a491..d3311f0cd0 100644 --- a/tensorflow/c/checkpoint_reader.cc +++ b/tensorflow/c/checkpoint_reader.cc @@ -125,7 +125,7 @@ CheckpointReader::BuildV2VarMaps() { const auto& slice_proto = entry.slices(i); CHECK(filtered_keys .insert(EncodeTensorNameSlice( - std::string(v2_reader_->key()) /* full var's name */, + string(v2_reader_->key()) /* full var's name */, TensorSlice(slice_proto))) .second); } @@ -138,11 +138,11 @@ CheckpointReader::BuildV2VarMaps() { new TensorSliceReader::VarToDataTypeMap); v2_reader_->Seek(kHeaderEntryKey); for (v2_reader_->Next(); v2_reader_->Valid(); v2_reader_->Next()) { - if (filtered_keys.count(std::string(v2_reader_->key())) > 0) continue; + if (filtered_keys.count(string(v2_reader_->key())) > 0) continue; CHECK(entry.ParseFromArray(v2_reader_->value().data(), v2_reader_->value().size())) << entry.InitializationErrorString(); - string key = std::string(v2_reader_->key()); + string key(v2_reader_->key()); (*var_to_shape_map)[key] = TensorShape(entry.shape()); (*var_to_data_type_map)[key] = DataType(entry.dtype()); } diff --git a/tensorflow/c/checkpoint_reader.h b/tensorflow/c/checkpoint_reader.h index 4de1300a7f..91654c8d4f 100644 --- a/tensorflow/c/checkpoint_reader.h +++ b/tensorflow/c/checkpoint_reader.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_C_CHECKPOINT_READER_H -#define TENSORFLOW_C_CHECKPOINT_READER_H +#ifndef TENSORFLOW_C_CHECKPOINT_READER_H_ +#define TENSORFLOW_C_CHECKPOINT_READER_H_ #include <memory> #include <string> @@ -79,4 +79,4 @@ class CheckpointReader { } // namespace checkpoint } // namespace tensorflow -#endif // TENSORFLOW_C_CHECKPOINT_READER_H +#endif // TENSORFLOW_C_CHECKPOINT_READER_H_ diff --git a/tensorflow/c/eager/c_api.cc b/tensorflow/c/eager/c_api.cc index dfb1c9a376..1ccae3f138 100644..100755 --- a/tensorflow/c/eager/c_api.cc +++ b/tensorflow/c/eager/c_api.cc @@ -244,8 +244,8 @@ void TFE_ContextOptionsSetConfig(TFE_ContextOptions* options, const void* proto, } void TFE_ContextOptionsSetAsync(TFE_ContextOptions* options, - unsigned char async) { - options->async = async; + unsigned char enable) { + options->async = enable; } void TFE_ContextOptionsSetDevicePlacementPolicy( TFE_ContextOptions* options, TFE_ContextDevicePlacementPolicy policy) { @@ -253,9 +253,9 @@ void TFE_ContextOptionsSetDevicePlacementPolicy( } TF_CAPI_EXPORT extern void TFE_ContextSetAsyncForThread(TFE_Context* ctx, - unsigned char async, + unsigned char enable, TF_Status* status) { - status->status = ctx->context.SetAsyncForThread(async); + status->status = ctx->context.SetAsyncForThread(enable); } void TFE_DeleteContextOptions(TFE_ContextOptions* options) { delete options; } diff --git a/tensorflow/c/eager/c_api.h b/tensorflow/c/eager/c_api.h index a0ebc6fa0a..eec2750d6e 100644..100755 --- a/tensorflow/c/eager/c_api.h +++ b/tensorflow/c/eager/c_api.h @@ -76,7 +76,7 @@ typedef enum TFE_ContextDevicePlacementPolicy { // Sets the default execution mode (sync/async). Note that this can be // overridden per thread using TFE_ContextSetAsyncForThread. TF_CAPI_EXPORT extern void TFE_ContextOptionsSetAsync(TFE_ContextOptions*, - unsigned char async); + unsigned char enable); TF_CAPI_EXPORT extern void TFE_ContextOptionsSetDevicePlacementPolicy( TFE_ContextOptions*, TFE_ContextDevicePlacementPolicy); @@ -114,7 +114,7 @@ TFE_ContextGetDevicePlacementPolicy(TFE_Context*); // Overrides the execution mode (sync/async) for the current thread. TF_CAPI_EXPORT extern void TFE_ContextSetAsyncForThread(TFE_Context*, - unsigned char async, + unsigned char enable, TF_Status* status); // A tensorflow.ServerDef specifies remote workers (in addition to the current diff --git a/tensorflow/c/tf_status_helper.h b/tensorflow/c/tf_status_helper.h index 86e687df20..7661a01de4 100644 --- a/tensorflow/c/tf_status_helper.h +++ b/tensorflow/c/tf_status_helper.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_C_TF_STATUS_HELPER_H -#define TENSORFLOW_C_TF_STATUS_HELPER_H +#ifndef TENSORFLOW_C_TF_STATUS_HELPER_H_ +#define TENSORFLOW_C_TF_STATUS_HELPER_H_ #include "tensorflow/c/c_api.h" #include "tensorflow/core/lib/core/status.h" @@ -29,4 +29,4 @@ Status StatusFromTF_Status(const TF_Status* tf_status); } // namespace tensorflow -#endif // TENSORFLOW_C_TF_STATUS_HELPER_H +#endif // TENSORFLOW_C_TF_STATUS_HELPER_H_ diff --git a/tensorflow/cc/framework/cc_op_gen.cc b/tensorflow/cc/framework/cc_op_gen.cc index dfdef88945..a32d1b1eb5 100644 --- a/tensorflow/cc/framework/cc_op_gen.cc +++ b/tensorflow/cc/framework/cc_op_gen.cc @@ -466,7 +466,7 @@ string AvoidCPPKeywords(StringPiece name) { if (IsCPPKeyword(name)) { return strings::StrCat(name, "_"); } - return std::string(name); + return string(name); } void InferArgAttributes(const OpDef::ArgDef& arg, @@ -508,15 +508,6 @@ bool HasOptionalAttrs( return false; } -const ApiDef::Arg* FindInputArg(StringPiece name, const ApiDef& api_def) { - for (int i = 0; i < api_def.in_arg_size(); ++i) { - if (api_def.in_arg(i).name() == name) { - return &api_def.in_arg(i); - } - } - return nullptr; -} - struct OpInfo { // graph_op_def: The OpDef used by the runtime, has the names that // must be used when calling NodeBuilder. diff --git a/tensorflow/cc/framework/scope.cc b/tensorflow/cc/framework/scope.cc index 8c886f3171..7f6ac4cae7 100644 --- a/tensorflow/cc/framework/scope.cc +++ b/tensorflow/cc/framework/scope.cc @@ -225,7 +225,7 @@ std::unordered_set<string> Scope::Impl::GetColocationConstraints( for (const string& entry : node_constraints) { StringPiece s(entry); if (str_util::ConsumePrefix(&s, kColocationGroupPrefix)) { - current_constraints.insert(std::string(s)); + current_constraints.emplace(s); } } } else { diff --git a/tensorflow/cc/gradients/math_grad.cc b/tensorflow/cc/gradients/math_grad.cc index 5dcf00857d..1329b568ab 100644 --- a/tensorflow/cc/gradients/math_grad.cc +++ b/tensorflow/cc/gradients/math_grad.cc @@ -441,21 +441,20 @@ Status RealDivGrad(const Scope& scope, const Operation& op, } REGISTER_GRADIENT_OP("RealDiv", RealDivGrad); -Status UnsafeDivGrad(const Scope& scope, const Operation& op, - const std::vector<Output>& grad_inputs, - std::vector<Output>* grad_outputs) { +Status DivNoNanGrad(const Scope& scope, const Operation& op, + const std::vector<Output>& grad_inputs, + std::vector<Output>* grad_outputs) { auto x_1 = ConjugateHelper(scope, op.input(0)); auto x_2 = ConjugateHelper(scope, op.input(1)); // y = x_1 / x_2 // dy/dx_1 = 1/x_2 // dy/dx_2 = -x_1/x_2^2 - auto gx_1 = UnsafeDiv(scope, grad_inputs[0], x_2); - auto gx_2 = - Mul(scope, grad_inputs[0], - UnsafeDiv(scope, UnsafeDiv(scope, Neg(scope, x_1), x_2), x_2)); + auto gx_1 = DivNoNan(scope, grad_inputs[0], x_2); + auto gx_2 = Mul(scope, grad_inputs[0], + DivNoNan(scope, DivNoNan(scope, Neg(scope, x_1), x_2), x_2)); return BinaryGradCommon(scope, op, grad_outputs, gx_1, gx_2); } -REGISTER_GRADIENT_OP("UnsafeDiv", UnsafeDivGrad); +REGISTER_GRADIENT_OP("DivNoNan", DivNoNanGrad); Status SquaredDifferenceGrad(const Scope& scope, const Operation& op, const std::vector<Output>& grad_inputs, diff --git a/tensorflow/cc/gradients/math_grad_test.cc b/tensorflow/cc/gradients/math_grad_test.cc index 88aef1fab4..c16938322c 100644 --- a/tensorflow/cc/gradients/math_grad_test.cc +++ b/tensorflow/cc/gradients/math_grad_test.cc @@ -33,6 +33,7 @@ using ops::AddN; using ops::BatchMatMul; using ops::Const; using ops::Div; +using ops::DivNoNan; using ops::MatMul; using ops::Max; using ops::Maximum; @@ -48,7 +49,6 @@ using ops::SegmentSum; using ops::SquaredDifference; using ops::Sub; using ops::Sum; -using ops::UnsafeDiv; // TODO(andydavis) Test gradient function against numeric gradients output. // TODO(andydavis) As more gradients are added move common test functions @@ -854,13 +854,13 @@ TEST_F(NaryGradTest, RealDiv) { RunTest({x}, {x_shape}, {y}, {x_shape}); } -TEST_F(NaryGradTest, UnsafeDiv) { +TEST_F(NaryGradTest, DivNoNan) { { TensorShape x_shape({3, 2, 5}); const auto x = Placeholder(scope_, DT_FLOAT, Placeholder::Shape(x_shape)); // Test x / (1 + |x|) rather than x_1 / x_2 to avoid triggering large // division errors in the numeric estimator used by the gradient checker. - const auto y = UnsafeDiv( + const auto y = DivNoNan( scope_, x, Add(scope_, Const<float>(scope_, 1), Abs(scope_, x))); RunTest({x}, {x_shape}, {y}, {x_shape}); } @@ -868,7 +868,7 @@ TEST_F(NaryGradTest, UnsafeDiv) { // Return 0 gradient (rather than NaN) for division by zero. const auto x = Placeholder(scope_, DT_FLOAT); const auto zero = Const<float>(scope_, 0.0); - const auto y = UnsafeDiv(scope_, x, zero); + const auto y = DivNoNan(scope_, x, zero); std::vector<Output> grad_outputs; TF_EXPECT_OK(AddSymbolicGradients(scope_, {y}, {x}, &grad_outputs)); diff --git a/tensorflow/cc/saved_model/loader.cc b/tensorflow/cc/saved_model/loader.cc index 3830416159..c6abe2f41b 100644 --- a/tensorflow/cc/saved_model/loader.cc +++ b/tensorflow/cc/saved_model/loader.cc @@ -148,7 +148,7 @@ Status RunMainOp(const RunOptions& run_options, const string& export_dir, AddAssetsTensorsToInputs(export_dir, asset_file_defs, &inputs); RunMetadata run_metadata; const StringPiece main_op_name = main_op_it->second.node_list().value(0); - return RunOnce(run_options, inputs, {}, {main_op_name.ToString()}, + return RunOnce(run_options, inputs, {}, {string(main_op_name)}, nullptr /* outputs */, &run_metadata, session); } return Status::OK(); @@ -182,12 +182,12 @@ Status RunRestore(const RunOptions& run_options, const string& export_dir, variables_path_tensor.scalar<string>()() = variables_path; std::vector<std::pair<string, Tensor>> inputs = { - {variable_filename_const_op_name.ToString(), variables_path_tensor}}; + {string(variable_filename_const_op_name), variables_path_tensor}}; AddAssetsTensorsToInputs(export_dir, asset_file_defs, &inputs); RunMetadata run_metadata; - return RunOnce(run_options, inputs, {}, {restore_op_name.ToString()}, + return RunOnce(run_options, inputs, {}, {string(restore_op_name)}, nullptr /* outputs */, &run_metadata, session); } diff --git a/tensorflow/compiler/aot/BUILD b/tensorflow/compiler/aot/BUILD index 1899a32e4d..59b961cdd9 100644 --- a/tensorflow/compiler/aot/BUILD +++ b/tensorflow/compiler/aot/BUILD @@ -32,7 +32,6 @@ cc_library( deps = [ ":embedded_protocol_buffers", "//tensorflow/compiler/tf2xla", - "//tensorflow/compiler/tf2xla:common", "//tensorflow/compiler/tf2xla:cpu_function_runtime", "//tensorflow/compiler/tf2xla:tf2xla_proto", "//tensorflow/compiler/tf2xla:tf2xla_util", @@ -55,6 +54,8 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:lib_internal", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -71,6 +72,7 @@ tf_cc_test( "//tensorflow/core:lib", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/strings", "@llvm//:support", # fixdeps: keep "@llvm//:x86_code_gen", # fixdeps: keep ], @@ -99,6 +101,7 @@ cc_library( "//tensorflow/core:graph", "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/strings", ], ) @@ -193,6 +196,8 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", "@llvm//:core", "@llvm//:support", "@llvm//:target", diff --git a/tensorflow/compiler/aot/codegen.cc b/tensorflow/compiler/aot/codegen.cc index 89fefdad54..e77a8fecf0 100644 --- a/tensorflow/compiler/aot/codegen.cc +++ b/tensorflow/compiler/aot/codegen.cc @@ -19,9 +19,11 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/str_join.h" +#include "absl/strings/str_replace.h" #include "tensorflow/compiler/aot/embedded_protocol_buffers.h" #include "tensorflow/compiler/tf2xla/cpu_function_runtime.h" -#include "tensorflow/compiler/tf2xla/str_util.h" #include "tensorflow/compiler/tf2xla/tf2xla_util.h" #include "tensorflow/compiler/xla/service/compiler.h" #include "tensorflow/compiler/xla/service/cpu/buffer_info_util.h" @@ -29,7 +31,6 @@ limitations under the License. #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/lib/strings/strcat.h" namespace tensorflow { @@ -141,7 +142,7 @@ Status AddRewritesForShape(int i, const xla::Shape& shape, } rewrites->push_back({"{{I}}", strings::StrCat(i)}); rewrites->push_back({"{{TYPE}}", type}); - rewrites->push_back({"{{DIM_VARS}}", str_util::Join(dim_vars, ", ")}); + rewrites->push_back({"{{DIM_VARS}}", absl::StrJoin(dim_vars, ", ")}); rewrites->push_back({"{{DIM_SIZES}}", dim_sizes}); rewrites->push_back({"{{INDICES}}", indices}); return Status::OK(); @@ -157,8 +158,9 @@ Status AddRewritesForShape(int i, const xla::Shape& shape, // text-templating mechanism. string RewriteWithName(const string& name, string code, const std::vector<std::pair<string, string>>& rewrites) { - str_util::ReplaceAllPairs(&code, rewrites); - return str_util::StringReplace(code, "{{NAME}}", name, /*replace_all=*/true); + absl::StrReplaceAll(rewrites, &code); + absl::StrReplaceAll({{"{{NAME}}", name}}, &code); + return code; } // Generate methods for args (inputs). @@ -570,11 +572,11 @@ class {{CLASS}} : public tensorflow::XlaCompiledCpuFunction { {"{{ARG_BYTES_TOTAL}}", strings::StrCat(arg_bytes_total)}, {"{{ARG_NAMES_CODE}}", arg_names_code}, {"{{ARG_NUM}}", strings::StrCat(arg_index_table.size())}, - {"{{ARG_INDEX_TABLE}}", str_util::Join(arg_index_table, ", ")}, + {"{{ARG_INDEX_TABLE}}", absl::StrJoin(arg_index_table, ", ")}, {"{{ASSIGN_PROFILE_COUNTERS_SIZE}}", assign_profile_counters_size}, {"{{CLASS}}", opts.class_name}, {"{{DECLS_FROM_OBJ_FILE}}", - str_util::Join(metadata_result.header_variable_decls, "\n")}, + absl::StrJoin(metadata_result.header_variable_decls, "\n")}, {"{{ENTRY}}", compile_result.entry_point}, {"{{HLO_PROFILE_PRINTER_DATA_SHIM_EXPRESSION}}", metadata_result.hlo_profile_printer_data_access_shim}, @@ -594,8 +596,8 @@ class {{CLASS}} : public tensorflow::XlaCompiledCpuFunction { {"{{TEMP_BYTES_TOTAL}}", strings::StrCat(temp_bytes_total)}, {"{{NUM_BUFFERS}}", strings::StrCat(buffer_infos.size())}, {"{{BUFFER_INFOS_AS_STRING}}", - str_util::Join(buffer_infos_as_strings, ",\n")}}; - str_util::ReplaceAllPairs(header, rewrites); + absl::StrJoin(buffer_infos_as_strings, ",\n")}}; + absl::StrReplaceAll(rewrites, header); return Status::OK(); } @@ -617,7 +619,8 @@ Status GenerateMetadata(const CodegenOpts& opts, if (opts.gen_program_shape) { program_shape = - tensorflow::MakeUnique<xla::ProgramShape>(compile_result.program_shape); + absl::make_unique<xla::ProgramShape>(compile_result.program_shape); + // The parameter names are currently meaningless, and redundant with the // rest of our metadata, so clear them out to avoid confusion and save // space. diff --git a/tensorflow/compiler/aot/codegen_test.cc b/tensorflow/compiler/aot/codegen_test.cc index 60d59ae996..e3a53edb73 100644 --- a/tensorflow/compiler/aot/codegen_test.cc +++ b/tensorflow/compiler/aot/codegen_test.cc @@ -18,13 +18,13 @@ limitations under the License. #include <string> #include <vector> +#include "absl/strings/match.h" #include "llvm/Support/TargetSelect.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/core/status_test_util.h" #include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/io/path.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/test.h" @@ -34,9 +34,9 @@ namespace { using ::tensorflow::cpu_function_runtime::BufferInfo; -void ExpectErrorContains(const Status& status, StringPiece str) { +void ExpectErrorContains(const Status& status, absl::string_view str) { EXPECT_NE(Status::OK(), status); - EXPECT_TRUE(str_util::StrContains(status.error_message(), str)) + EXPECT_TRUE(absl::StrContains(status.error_message(), str)) << "expected error: " << status.error_message() << " to contain: " << str; } diff --git a/tensorflow/compiler/aot/embedded_protocol_buffers.cc b/tensorflow/compiler/aot/embedded_protocol_buffers.cc index 4e27aafec7..1401aae758 100644 --- a/tensorflow/compiler/aot/embedded_protocol_buffers.cc +++ b/tensorflow/compiler/aot/embedded_protocol_buffers.cc @@ -18,6 +18,8 @@ limitations under the License. #include <memory> #include <string> +#include "absl/memory/memory.h" +#include "absl/strings/str_replace.h" #include "llvm/ADT/Triple.h" #include "llvm/IR/GlobalVariable.h" #include "llvm/IR/LLVMContext.h" @@ -26,8 +28,6 @@ limitations under the License. #include "llvm/Support/TargetRegistry.h" #include "llvm/Target/TargetMachine.h" #include "llvm/Target/TargetOptions.h" -#include "tensorflow/compiler/tf2xla/str_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_util.h" #include "tensorflow/compiler/xla/util.h" @@ -65,14 +65,13 @@ static string CreateCPPShimExpression(StringPiece qualified_cpp_protobuf_name, " return proto;\n" " }()"; - str_util::ReplaceAllPairs( - &code, + return absl::StrReplaceAll( + code, { {"{{ARRAY_SYMBOL}}", strings::StrCat(protobuf_array_symbol_name)}, {"{{ARRAY_SIZE}}", strings::StrCat(protobuf_array_size)}, {"{{PROTOBUF_NAME}}", strings::StrCat(qualified_cpp_protobuf_name)}, }); - return code; } static StatusOr<string> CodegenModule(llvm::TargetMachine* target_machine, @@ -97,7 +96,7 @@ static StatusOr<std::unique_ptr<llvm::TargetMachine>> GetTargetMachineFromTriple(StringPiece target_triple) { std::string error; std::string normalized_triple = - llvm::Triple::normalize(AsStringRef(target_triple)); + llvm::Triple::normalize(AsStringRef(absl::string_view(target_triple))); const llvm::Target* target = llvm::TargetRegistry::lookupTarget(normalized_triple, error); if (target == nullptr) { @@ -105,7 +104,7 @@ GetTargetMachineFromTriple(StringPiece target_triple) { error.c_str()); } - return WrapUnique(target->createTargetMachine( + return absl::WrapUnique(target->createTargetMachine( normalized_triple, /*CPU=*/"", /*Features=*/"", llvm::TargetOptions(), llvm::None)); } @@ -118,7 +117,7 @@ StatusOr<EmbeddedProtocolBuffers> CreateEmbeddedProtocolBuffers( llvm::LLVMContext llvm_context; std::unique_ptr<llvm::Module> module_with_serialized_proto = - MakeUnique<llvm::Module>("embedded_data_module", llvm_context); + absl::make_unique<llvm::Module>("embedded_data_module", llvm_context); EmbeddedProtocolBuffers result; diff --git a/tensorflow/compiler/aot/tests/BUILD b/tensorflow/compiler/aot/tests/BUILD index 0ecc3feeb6..723e9bec8a 100644 --- a/tensorflow/compiler/aot/tests/BUILD +++ b/tensorflow/compiler/aot/tests/BUILD @@ -187,6 +187,9 @@ tf_library( cpp_class = "MatMulAndAddCompWithProfiling", enable_xla_hlo_profiling = True, graph = "test_graph_tfmatmulandadd.pb", + tags = [ + "manual", + ], ) tf_library( @@ -226,5 +229,6 @@ tf_cc_test( "//tensorflow/core:test", "//tensorflow/core:test_main", "//third_party/eigen3", + "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/aot/tests/tfcompile_test.cc b/tensorflow/compiler/aot/tests/tfcompile_test.cc index 0c0c676ece..dd2b151098 100644 --- a/tensorflow/compiler/aot/tests/tfcompile_test.cc +++ b/tensorflow/compiler/aot/tests/tfcompile_test.cc @@ -16,6 +16,7 @@ limitations under the License. #define EIGEN_USE_THREADS #define EIGEN_USE_CUSTOM_THREAD_POOL +#include "absl/strings/str_split.h" #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/compiler/aot/tests/test_graph_tfadd.h" #include "tensorflow/compiler/aot/tests/test_graph_tfadd_with_ckpt.h" @@ -32,7 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/test.h" namespace tensorflow { @@ -546,7 +546,7 @@ TEST(TFCompileTest, HloProfiling) { VLOG(1) << "HLO profile string:\n" << hlo_profile_as_string; std::vector<string> hlo_profile_lines = - tensorflow::str_util::Split(hlo_profile_as_string, '\n'); + absl::StrSplit(hlo_profile_as_string, '\n'); auto header = HasSubstr("Execution profile for"); auto total_cycles_profile_line = HasSubstr("[total]"); diff --git a/tensorflow/compiler/aot/tfcompile_main.cc b/tensorflow/compiler/aot/tfcompile_main.cc index 839e1588b7..f3c44e9dda 100644 --- a/tensorflow/compiler/aot/tfcompile_main.cc +++ b/tensorflow/compiler/aot/tfcompile_main.cc @@ -18,6 +18,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/match.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/aot/codegen.h" #include "tensorflow/compiler/aot/compile.h" #include "tensorflow/compiler/aot/flags.h" @@ -34,7 +36,6 @@ limitations under the License. #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/init_main.h" #include "tensorflow/core/platform/logging.h" @@ -55,7 +56,7 @@ const char kUsageHeader[] = "\n"; Status ReadProtoFile(const string& fname, protobuf::Message* proto) { - if (str_util::EndsWith(fname, ".pbtxt")) { + if (absl::EndsWith(fname, ".pbtxt")) { return ReadTextProto(Env::Default(), fname, proto); } else { return ReadBinaryProto(Env::Default(), fname, proto); @@ -75,7 +76,7 @@ Status Main(const MainFlags& flags) { for (const tf2xla::Fetch& fetch : config.fetch()) { nodes.insert(fetch.id().node_name()); } - std::cout << str_util::Join(nodes, ","); + std::cout << absl::StrJoin(nodes, ","); return Status::OK(); } diff --git a/tensorflow/compiler/jit/BUILD b/tensorflow/compiler/jit/BUILD index e059f77563..df81f3c23e 100644 --- a/tensorflow/compiler/jit/BUILD +++ b/tensorflow/compiler/jit/BUILD @@ -128,11 +128,11 @@ cc_library( "//tensorflow/compiler/tf2xla:common", "//tensorflow/compiler/xla/client:local_client", "//tensorflow/compiler/xla/service:shaped_buffer", - "//tensorflow/core:core_cpu", "//tensorflow/core:core_cpu_internal", "//tensorflow/core:framework", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/memory", ], ) @@ -191,6 +191,7 @@ cc_library( "//tensorflow/core/kernels/data:generator_dataset_op", "//tensorflow/core/kernels/data:iterator_ops", "//tensorflow/core/kernels/data:prefetch_dataset_op", + "@com_google_absl//absl/memory", ], ) @@ -235,6 +236,7 @@ cc_library( "//tensorflow/core:lib_internal", "//tensorflow/core:protos_all_cc", "//tensorflow/core/kernels:variable_ops", + "@com_google_absl//absl/memory", ], ) @@ -283,6 +285,7 @@ cc_library( "//tensorflow/core:framework", "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/memory", ], alwayslink = 1, ) @@ -303,6 +306,52 @@ tf_cc_test( "//tensorflow/core:test", "//tensorflow/core:test_main", "//tensorflow/core:testlib", + "@com_google_absl//absl/memory", + ], +) + +cc_library( + name = "resource_operation_safety_analysis", + srcs = ["resource_operation_safety_analysis.cc"], + hdrs = ["resource_operation_safety_analysis.h"], + deps = [ + "//tensorflow/compiler/jit/graphcycles", + "//tensorflow/compiler/tf2xla:resource_operation_table", + "//tensorflow/core:framework", + "//tensorflow/core:graph", + "//tensorflow/core:lib", + "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", + ], +) + +tf_cc_test( + name = "resource_operation_safety_analysis_test", + srcs = ["resource_operation_safety_analysis_test.cc"], + deps = [ + ":common", + ":resource_operation_safety_analysis", + "//tensorflow/cc:cc_ops", + "//tensorflow/cc:cc_ops_internal", + "//tensorflow/cc:function_ops", + "//tensorflow/cc:functional_ops", + "//tensorflow/cc:ops", + "//tensorflow/cc:resource_variable_ops", + "//tensorflow/cc:sendrecv_ops", + "//tensorflow/compiler/jit/kernels:xla_launch_op", + "//tensorflow/compiler/tf2xla:xla_compiler", + "//tensorflow/compiler/tf2xla/kernels:xla_ops", + "//tensorflow/core:core_cpu", + "//tensorflow/core:framework", + "//tensorflow/core:framework_internal", + "//tensorflow/core:graph", + "//tensorflow/core:lib", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + "//tensorflow/core:testlib", + "@com_google_absl//absl/strings", ], ) @@ -331,11 +380,10 @@ cc_library( ":union_find", ":xla_cluster_util", "//tensorflow/compiler/jit/graphcycles", - "//tensorflow/compiler/jit/kernels:parallel_check_op", "//tensorflow/compiler/jit/legacy_flags:mark_for_compilation_pass_flags", - "//tensorflow/compiler/jit/ops:parallel_check_op", "//tensorflow/compiler/jit/ops:xla_ops", "//tensorflow/compiler/tf2xla:dump_graph", + "//tensorflow/compiler/tf2xla:resource_operation_table", "//tensorflow/compiler/tf2xla:xla_compiler", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:util", @@ -347,6 +395,7 @@ cc_library( "//tensorflow/core:lib_internal", "//tensorflow/core:protos_all_cc", "//tensorflow/core/kernels:bounds_check", + "@com_google_absl//absl/strings", ], ) @@ -355,12 +404,13 @@ cc_library( srcs = ["xla_cluster_util.cc"], hdrs = ["xla_cluster_util.h"], deps = [ + ":resource_operation_safety_analysis", "//tensorflow/compiler/jit/graphcycles", "//tensorflow/core:framework", "//tensorflow/core:graph", - "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", "//tensorflow/core/kernels:bounds_check", + "@com_google_absl//absl/types:optional", ], ) @@ -433,6 +483,7 @@ tf_cc_test( "//tensorflow/cc:cc_ops_internal", "//tensorflow/cc:function_ops", "//tensorflow/cc:ops", + "//tensorflow/cc:resource_variable_ops", "//tensorflow/cc:sendrecv_ops", "//tensorflow/compiler/jit/kernels:xla_launch_op", "//tensorflow/compiler/tf2xla:xla_compiler", @@ -444,6 +495,7 @@ tf_cc_test( "//tensorflow/core:test", "//tensorflow/core:test_main", "//tensorflow/core:testlib", + "@com_google_absl//absl/strings", ], ) @@ -524,6 +576,9 @@ tf_cuda_cc_test( ":common", ":xla_cluster_util", ":xla_fusion_optimizer", + "//tensorflow/cc:cc_ops", + "//tensorflow/cc:ops", + "//tensorflow/cc:resource_variable_ops", "//tensorflow/core:graph", "//tensorflow/core:test", "//tensorflow/core:test_main", diff --git a/tensorflow/compiler/jit/create_xla_launch_op.cc b/tensorflow/compiler/jit/create_xla_launch_op.cc index a2e6285339..56b034a30b 100644 --- a/tensorflow/compiler/jit/create_xla_launch_op.cc +++ b/tensorflow/compiler/jit/create_xla_launch_op.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/jit/create_xla_launch_op.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/jit/defs.h" #include "tensorflow/compiler/jit/kernels/xla_launch_op.h" #include "tensorflow/compiler/jit/mark_for_compilation_pass.h" @@ -125,7 +126,8 @@ Status GetBodyAndConstantsAndResources(FunctionLibraryRuntime* flr, const DataTypeVector& arg_types = (*fbody)->arg_types; std::vector<bool> const_args(arg_types.size()); // If we can't analyze the const args. Bail out. - TF_RETURN_IF_ERROR(BackwardsConstAnalysis(*((*fbody)->graph), &const_args)); + TF_RETURN_IF_ERROR(BackwardsConstAnalysis( + *((*fbody)->graph), &const_args, /*compile_time_const_nodes=*/nullptr)); for (int i = 0; i < const_args.size(); ++i) { if (const_args[i]) { @@ -207,8 +209,13 @@ Status CreateXlaLaunchOp(FunctionLibraryRuntime* flr, const NodeDef& node_def, // device memory. // XlaLaunch kernel keeps all outputs (including constants, which it copies), - // in device memory + // in device memory except for resources. MemoryTypeVector output_memory_types(fbody->ret_types.size(), DEVICE_MEMORY); + for (int i = 0; i < fbody->ret_types.size(); ++i) { + if (fbody->ret_types[i] == DT_RESOURCE) { + output_memory_types[i] = HOST_MEMORY; + } + } // Create the kernel. NameAttrList function; @@ -223,8 +230,8 @@ Status CreateXlaLaunchOp(FunctionLibraryRuntime* flr, const NodeDef& node_def, &fbody->fdef.signature(), flr, fbody->arg_types, input_memory_types, fbody->ret_types, output_memory_types, flr->graph_def_version(), &s); - *kernel = MakeUnique<XlaLocalLaunchBase>(&construction, constant_arg_indices, - resource_arg_indices, function); + *kernel = absl::make_unique<XlaLocalLaunchBase>( + &construction, constant_arg_indices, resource_arg_indices, function); return s; } diff --git a/tensorflow/compiler/jit/create_xla_launch_op_test.cc b/tensorflow/compiler/jit/create_xla_launch_op_test.cc index b75ab486b8..7386660762 100644 --- a/tensorflow/compiler/jit/create_xla_launch_op_test.cc +++ b/tensorflow/compiler/jit/create_xla_launch_op_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/jit/create_xla_launch_op.h" +#include "absl/memory/memory.h" #include "tensorflow/core/common_runtime/device_factory.h" #include "tensorflow/core/common_runtime/function.h" #include "tensorflow/core/framework/function_testlib.h" @@ -65,11 +66,11 @@ class CreateXlaLaunchOpTest : public ::testing::Test { for (const auto& fdef : flib) { *(proto.add_function()) = fdef; } - lib_def_ = - MakeUnique<FunctionLibraryDefinition>(OpRegistry::Global(), proto); + lib_def_ = absl::make_unique<FunctionLibraryDefinition>( + OpRegistry::Global(), proto); OptimizerOptions opts; - device_mgr_ = MakeUnique<DeviceMgr>(devices_); - pflr_ = MakeUnique<ProcessFunctionLibraryRuntime>( + device_mgr_ = absl::make_unique<DeviceMgr>(devices_); + pflr_ = absl::make_unique<ProcessFunctionLibraryRuntime>( device_mgr_.get(), Env::Default(), TF_GRAPH_DEF_VERSION, lib_def_.get(), opts, /*default_thread_pool=*/nullptr, /*cluster_flr=*/nullptr); flr_ = pflr_->GetFLR("/job:localhost/replica:0/task:0/cpu:0"); diff --git a/tensorflow/compiler/jit/deadness_analysis.cc b/tensorflow/compiler/jit/deadness_analysis.cc index 309aeffc18..fe28502f69 100644 --- a/tensorflow/compiler/jit/deadness_analysis.cc +++ b/tensorflow/compiler/jit/deadness_analysis.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/jit/deadness_analysis.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/jit/deadness_analysis_internal.h" #include "tensorflow/core/graph/algorithm.h" #include "tensorflow/core/graph/tensor_id.h" @@ -153,7 +154,7 @@ class AndPredicate : public Predicate { std::back_inserter(operands_str), [](Predicate* pred) { return pred->ToString(); }); - return strings::StrCat("(", str_util::Join(operands_str, " & "), ")"); + return strings::StrCat("(", absl::StrJoin(operands_str, " & "), ")"); } Kind kind() const override { return Kind::kAnd; } @@ -182,7 +183,7 @@ class OrPredicate : public Predicate { std::back_inserter(operands_str), [](Predicate* pred) { return pred->ToString(); }); - return strings::StrCat("(", str_util::Join(operands_str, " | "), ")"); + return strings::StrCat("(", absl::StrJoin(operands_str, " | "), ")"); } Kind kind() const override { return Kind::kOr; } @@ -508,8 +509,8 @@ class DeadnessAnalysisImpl : public DeadnessAnalysis { // Sets the predicate for output `output_idx` of `n` to `pred`. Sets the i'th // bit of `should_revisit` if `pred` is different from the current predicate // for the `output_idx` output of `n`. - void SetPred(Node* n, int output_idx, Predicate* pred, - std::vector<bool>* should_revisit) { + void SetPredicate(Node* n, int output_idx, Predicate* pred, + std::vector<bool>* should_revisit) { auto insert_result = predicate_map_.insert({TensorId(n->name(), output_idx), pred}); if (!insert_result.second && insert_result.first->second != pred) { @@ -526,10 +527,10 @@ class DeadnessAnalysisImpl : public DeadnessAnalysis { } } - void SetPred(Node* n, gtl::ArraySlice<int> output_idxs, Predicate* pred, - std::vector<bool>* should_revisit) { + void SetPredicate(Node* n, gtl::ArraySlice<int> output_idxs, Predicate* pred, + std::vector<bool>* should_revisit) { for (int output_idx : output_idxs) { - SetPred(n, output_idx, pred, should_revisit); + SetPredicate(n, output_idx, pred, should_revisit); } } @@ -580,19 +581,20 @@ Status DeadnessAnalysisImpl::HandleSwitch(Node* n, // Output 0 is alive iff all inputs are alive and the condition is false. input_preds.push_back(false_switch); - SetPred(n, 0, predicate_factory_.MakeAndPredicate(input_preds), - should_revisit); + SetPredicate(n, 0, predicate_factory_.MakeAndPredicate(input_preds), + should_revisit); input_preds.pop_back(); // Output 1 is alive iff all inputs are alive and the condition is true. input_preds.push_back(true_switch); - SetPred(n, 1, predicate_factory_.MakeAndPredicate(input_preds), - should_revisit); + SetPredicate(n, 1, predicate_factory_.MakeAndPredicate(input_preds), + should_revisit); input_preds.pop_back(); // Control is alive iff all inputs are alive. - SetPred(n, Graph::kControlSlot, - predicate_factory_.MakeAndPredicate(input_preds), should_revisit); + SetPredicate(n, Graph::kControlSlot, + predicate_factory_.MakeAndPredicate(input_preds), + should_revisit); return Status::OK(); } @@ -682,14 +684,16 @@ Status DeadnessAnalysisImpl::HandleMerge(Node* n, // backedge. Predicate* input_data_pred = predicate_factory_.MakeSymbolPredicate( TensorId(n->name(), 0), /*must_be_true=*/false); - SetPred(n, {0, 1, Graph::kControlSlot}, input_data_pred, should_revisit); + SetPredicate(n, {0, 1, Graph::kControlSlot}, input_data_pred, + should_revisit); return Status::OK(); } // We're visiting this merge for the first time and it is a acyclic merge. Predicate* input_data_pred = predicate_factory_.MakeOrPredicate( GetIncomingPreds(n, EdgeKind::kDataOnly)); - SetPred(n, {0, 1, Graph::kControlSlot}, input_data_pred, should_revisit); + SetPredicate(n, {0, 1, Graph::kControlSlot}, input_data_pred, + should_revisit); return Status::OK(); } @@ -717,7 +721,7 @@ Status DeadnessAnalysisImpl::HandleMerge(Node* n, predicate_factory_.MakeOrPredicate(non_recurrent_inputs); Predicate* and_rec = predicate_factory_.MakeAndRecurrencePredicate(start, step); - SetPred(n, {0, 1, Graph::kControlSlot}, and_rec, should_revisit); + SetPredicate(n, {0, 1, Graph::kControlSlot}, and_rec, should_revisit); return Status::OK(); } } @@ -733,8 +737,9 @@ Status DeadnessAnalysisImpl::HandleRecv(Node* n, GetIncomingPreds(n, EdgeKind::kDataAndControl); input_preds.push_back(predicate_factory_.MakeSymbolPredicate( TensorId(n->name(), 0), /*must_be_true=*/false)); - SetPred(n, {0, Graph::kControlSlot}, - predicate_factory_.MakeAndPredicate(input_preds), should_revisit); + SetPredicate(n, {0, Graph::kControlSlot}, + predicate_factory_.MakeAndPredicate(input_preds), + should_revisit); return Status::OK(); } @@ -744,9 +749,9 @@ Status DeadnessAnalysisImpl::HandleGeneric(Node* n, Predicate* pred = predicate_factory_.MakeAndPredicate( GetIncomingPreds(n, EdgeKind::kDataAndControl)); for (int output_idx = 0; output_idx < n->num_outputs(); output_idx++) { - SetPred(n, output_idx, pred, should_revisit); + SetPredicate(n, output_idx, pred, should_revisit); } - SetPred(n, Graph::kControlSlot, pred, should_revisit); + SetPredicate(n, Graph::kControlSlot, pred, should_revisit); return Status::OK(); } @@ -757,7 +762,8 @@ Status DeadnessAnalysisImpl::HandleNode(Node* n, } else if (n->IsMerge()) { TF_RETURN_IF_ERROR(HandleMerge(n, should_revisit)); } else if (n->IsControlTrigger()) { - SetPred(n, Graph::kControlSlot, predicate_factory_.MakeTrue(), nullptr); + SetPredicate(n, Graph::kControlSlot, predicate_factory_.MakeTrue(), + nullptr); } else if (n->IsRecv() || n->IsHostRecv()) { TF_RETURN_IF_ERROR(HandleRecv(n, should_revisit)); } else if (n->IsNextIteration()) { @@ -770,7 +776,7 @@ Status DeadnessAnalysisImpl::HandleNode(Node* n, Status DeadnessAnalysisImpl::Populate() { std::vector<Node*> rpo; - GetReversePostOrder(graph_, &rpo, /*stable_comparator=*/{}, + GetReversePostOrder(graph_, &rpo, /*stable_comparator=*/NodeComparatorName(), /*edge_filter=*/[](const Edge& edge) { return !edge.src()->IsNextIteration(); }); diff --git a/tensorflow/compiler/jit/deadness_analysis_test.cc b/tensorflow/compiler/jit/deadness_analysis_test.cc index cc9f102398..28a56044d5 100644 --- a/tensorflow/compiler/jit/deadness_analysis_test.cc +++ b/tensorflow/compiler/jit/deadness_analysis_test.cc @@ -32,7 +32,6 @@ limitations under the License. #include "tensorflow/core/graph/graph_def_builder.h" #include "tensorflow/core/graph/graph_def_builder_util.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/test.h" namespace tensorflow { diff --git a/tensorflow/compiler/jit/encapsulate_subgraphs_pass.cc b/tensorflow/compiler/jit/encapsulate_subgraphs_pass.cc index f150bf1819..2788102620 100644 --- a/tensorflow/compiler/jit/encapsulate_subgraphs_pass.cc +++ b/tensorflow/compiler/jit/encapsulate_subgraphs_pass.cc @@ -36,6 +36,7 @@ limitations under the License. #include "tensorflow/core/framework/graph_to_functiondef.h" #include "tensorflow/core/framework/node_def_builder.h" #include "tensorflow/core/framework/node_def_util.h" +#include "tensorflow/core/framework/tensor.pb.h" #include "tensorflow/core/graph/algorithm.h" #include "tensorflow/core/graph/control_flow.h" #include "tensorflow/core/graph/graph.h" @@ -44,7 +45,6 @@ limitations under the License. #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/lib/gtl/map_util.h" #include "tensorflow/core/lib/hash/hash.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/public/session_options.h" #include "tensorflow/core/public/version.h" @@ -2504,7 +2504,8 @@ Status EncapsulateSubgraphsPass::Run( const int num_args = input_permutation->size(); std::vector<bool> const_args(num_args); - TF_RETURN_IF_ERROR(BackwardsConstAnalysis(**subgraph, &const_args)); + TF_RETURN_IF_ERROR(BackwardsConstAnalysis( + **subgraph, &const_args, /*compile_time_const_nodes=*/nullptr)); DataTypeVector arg_types(num_args); TF_RETURN_IF_ERROR(GetArgTypes(**subgraph, &arg_types)); diff --git a/tensorflow/compiler/jit/encapsulate_subgraphs_pass_test.cc b/tensorflow/compiler/jit/encapsulate_subgraphs_pass_test.cc index c0543a0079..b3600fc48b 100644 --- a/tensorflow/compiler/jit/encapsulate_subgraphs_pass_test.cc +++ b/tensorflow/compiler/jit/encapsulate_subgraphs_pass_test.cc @@ -18,6 +18,7 @@ limitations under the License. #include "tensorflow/compiler/jit/encapsulate_subgraphs_pass.h" +#include "absl/strings/match.h" #include "tensorflow/cc/framework/ops.h" #include "tensorflow/cc/ops/standard_ops.h" #include "tensorflow/core/framework/function_testlib.h" @@ -25,7 +26,6 @@ limitations under the License. #include "tensorflow/core/graph/graph_constructor.h" #include "tensorflow/core/graph/graph_def_builder.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/util/equal_graph_def.h" @@ -124,8 +124,8 @@ bool EqualFunctionNodeDef(const NodeDef& a, const NodeDef& b, std::unordered_set<string> control_input_a; std::unordered_set<string> control_input_b; for (int i = 0; i < a.input_size(); ++i) { - if (str_util::StartsWith(a.input(i), "^")) { - if (!str_util::StartsWith(b.input(i), "^")) { + if (absl::StartsWith(a.input(i), "^")) { + if (!absl::StartsWith(b.input(i), "^")) { if (diff) { *diff = strings::StrCat( diff_preamble, " mismatch for node ", a.name(), " input ", i, @@ -768,7 +768,7 @@ TEST(EncapsulateSubgraphsWithGuaranteeConstOpTest, Simple) { Graph* graph = graph_ptr->get(); for (const Node* n : graph->nodes()) { if (n->type_string() == "_Arg" && - str_util::StartsWith(n->name(), "const")) { + absl::StartsWith(n->name(), "const")) { ++guaranteed_consts; EXPECT_TRUE(HasGuaranteeConstAttr(*n)); } else { @@ -813,7 +813,7 @@ TEST(EncapsulateSubgraphsWithGuaranteeConstOpTest, Add) { Graph* graph = graph_ptr->get(); for (const Node* n : graph->nodes()) { if (n->type_string() == "_Arg" && - str_util::StartsWith(n->name(), "const")) { + absl::StartsWith(n->name(), "const")) { ++guaranteed_consts; EXPECT_TRUE(HasGuaranteeConstAttr(*n)); } else { diff --git a/tensorflow/compiler/jit/kernels/BUILD b/tensorflow/compiler/jit/kernels/BUILD index 8f78c110cb..253a5d2547 100644 --- a/tensorflow/compiler/jit/kernels/BUILD +++ b/tensorflow/compiler/jit/kernels/BUILD @@ -29,16 +29,3 @@ cc_library( ], alwayslink = 1, ) - -cc_library( - name = "parallel_check_op", - srcs = ["parallel_check_op.cc"], - visibility = ["//tensorflow/compiler/jit:friends"], - deps = [ - "//tensorflow/compiler/jit/legacy_flags:parallel_check_op_flags", - "//tensorflow/core:core_cpu", - "//tensorflow/core:framework", - "//tensorflow/core:lib", - ], - alwayslink = 1, -) diff --git a/tensorflow/compiler/jit/kernels/parallel_check_op.cc b/tensorflow/compiler/jit/kernels/parallel_check_op.cc deleted file mode 100644 index bd4eefbc0b..0000000000 --- a/tensorflow/compiler/jit/kernels/parallel_check_op.cc +++ /dev/null @@ -1,144 +0,0 @@ -/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/compiler/jit/legacy_flags/parallel_check_op_flags.h" -#include "tensorflow/core/common_runtime/device.h" -#include "tensorflow/core/framework/op.h" -#include "tensorflow/core/framework/op_kernel.h" -#include "tensorflow/core/framework/types.h" -#include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/platform/logging.h" -#include "tensorflow/core/platform/macros.h" - -namespace tensorflow { -namespace { - -// Inputs 2*N tensors, outputs the first N inputs. -// Logs errors if input tensor i and i + N are not (near) identical -// in any position. -class ParallelCheckOp : public OpKernel { - public: - explicit ParallelCheckOp(OpKernelConstruction* ctx) : OpKernel(ctx) {} - - template <typename T> - int CompareTensors(DataType dtype, const char* v0, const char* v1, - int64 num_elts, int input_idx) { - int failed = 0; - const T* p0 = reinterpret_cast<const T*>(v0); - const T* p1 = reinterpret_cast<const T*>(v1); - double rtol; - legacy_flags::ParallelCheckOpFlags* flags = - legacy_flags::GetParallelCheckOpFlags(); - if (!tensorflow::strings::safe_strtod(flags->parallel_check_rtol.c_str(), - &rtol)) { - LOG(ERROR) << "can't convert parallel_check_rtol " - << flags->parallel_check_rtol << " to double"; - } - double atol; - if (!tensorflow::strings::safe_strtod(flags->parallel_check_atol.c_str(), - &atol)) { - LOG(ERROR) << "can't convert parallel_check_atol " - << flags->parallel_check_atol << " to double"; - } - for (int i = 0; i < num_elts; ++i) { - bool ok = (p0[i] == p1[i]); - VLOG(2) << "output " << input_idx << " element " << i << ": " << p0[i]; - if (!ok) { - if (std::is_same<T, float>::value || std::is_same<T, double>::value) { - float tolerance = - std::max(atol, std::max(fabs(rtol * p0[i]), fabs(rtol * p1[i]))); - T diff = p0[i] - p1[i]; - if (diff < 0) diff = 0 - diff; - ok = (diff <= tolerance); - } - if (ok) continue; - LOG(ERROR) << "Op " << name() << " fails equality at output " - << input_idx << " type " << DataTypeString(dtype) - << " element " << i << ": std_val=" << p0[i] - << " test_val=" << p1[i] << " diff=" << (p0[i] - p1[i]); - if (++failed > 10) break; - } - } - return failed; - } - - void Compute(OpKernelContext* ctx) override { - VLOG(1) << "Compute " << name(); - const int num_pairs = ctx->num_inputs() / 2; - for (int i = 0; i < num_pairs; ++i) { - CHECK_EQ(ctx->input_dtype(i), ctx->input_dtype(i + num_pairs)); - Tensor t0 = ctx->input(i); - Tensor t1 = ctx->input(i + num_pairs); - int64 num_elts = t0.NumElements(); - CHECK_EQ(num_elts, t1.NumElements()); - - // Compare inputs elementwise for near-exact equality. - const char* v0 = t0.tensor_data().data(); - const char* v1 = t1.tensor_data().data(); - int failed = 0; - switch (ctx->input_dtype(i)) { - case DT_INT32: - failed = - CompareTensors<int32>(ctx->input_dtype(i), v0, v1, num_elts, i); - break; - case DT_INT64: - failed = - CompareTensors<int64>(ctx->input_dtype(i), v0, v1, num_elts, i); - break; - case DT_FLOAT: - failed = - CompareTensors<float>(ctx->input_dtype(i), v0, v1, num_elts, i); - break; - case DT_DOUBLE: - failed = - CompareTensors<double>(ctx->input_dtype(i), v0, v1, num_elts, i); - break; - case DT_BOOL: - failed = - CompareTensors<bool>(ctx->input_dtype(i), v0, v1, num_elts, i); - break; - default: - LOG(FATAL) << "unimpl: " << ctx->input_dtype(i); - } - if (failed > 0) { - LOG(ERROR) << "check failed for " << name() << " output " << i - << " num_elts: " << num_elts; - legacy_flags::ParallelCheckOpFlags* flags = - legacy_flags::GetParallelCheckOpFlags(); - if (flags->parallel_check_failfast) { - LOG(QFATAL) << "failfast on first parallel-check failure"; - } - } else { - VLOG(1) << "check passed for " << name() << " output " << i - << " num_elts: " << num_elts; - } - - // Propagate the std value. - if (IsRefType(ctx->input_dtype(i))) { - ctx->forward_ref_input_to_ref_output(i, i); - } else { - ctx->set_output(i, ctx->input(i)); - } - } - } - - TF_DISALLOW_COPY_AND_ASSIGN(ParallelCheckOp); -}; - -REGISTER_KERNEL_BUILDER(Name("ParallelCheck").Device(DEVICE_CPU), - ParallelCheckOp); - -} // namespace -} // namespace tensorflow diff --git a/tensorflow/compiler/jit/kernels/xla_launch_op.cc b/tensorflow/compiler/jit/kernels/xla_launch_op.cc index 7f4370b5b0..fde4135bf7 100644 --- a/tensorflow/compiler/jit/kernels/xla_launch_op.cc +++ b/tensorflow/compiler/jit/kernels/xla_launch_op.cc @@ -176,17 +176,18 @@ void XlaLocalLaunchBase::Compute(OpKernelContext* ctx) { } XlaCompiler::CompileOptions compile_options; compile_options.is_entry_computation = true; - // Optimization: don't resolve constants. If we resolve constants we never - // emit them on the device, meaning that if they are needed by a following - // computation the host has to transfer them. - compile_options.resolve_compile_time_constants = false; + // If we resolve constants we never emit them on the device, meaning that if + // they are needed by a following computation the host has to transfer + // them. Not resolving constants is expected to be faster than resolving + // constants. + compile_options.resolve_compile_time_constants = true; // Optimization: where possible, have the computation return a naked array // rather than a one-element tuple. compile_options.always_return_tuple = false; OP_REQUIRES_OK( ctx, cache->Compile(options, function_, constant_args, variables, ctx, - &kernel, &executable, &compile_options)); + &kernel, &executable, compile_options)); VLOG(1) << "Executing XLA Computation..."; diff --git a/tensorflow/compiler/jit/kernels/xla_launch_op.h b/tensorflow/compiler/jit/kernels/xla_launch_op.h index 8dfc4b382d..bf1e990668 100644 --- a/tensorflow/compiler/jit/kernels/xla_launch_op.h +++ b/tensorflow/compiler/jit/kernels/xla_launch_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_JIT_KERNELS_XLA_LOCAL_LAUNCH_OP_H_ -#define TENSORFLOW_COMPILER_JIT_KERNELS_XLA_LOCAL_LAUNCH_OP_H_ +#ifndef TENSORFLOW_COMPILER_JIT_KERNELS_XLA_LAUNCH_OP_H_ +#define TENSORFLOW_COMPILER_JIT_KERNELS_XLA_LAUNCH_OP_H_ #include "tensorflow/compiler/jit/xla_compilation_cache.h" #include "tensorflow/core/framework/allocator.h" @@ -81,4 +81,4 @@ class XlaLocalLaunchOp : public XlaLocalLaunchBase { } // namespace tensorflow -#endif // TENSORFLOW_COMPILER_JIT_KERNELS_XLA_LOCAL_LAUNCH_OP_H_ +#endif // TENSORFLOW_COMPILER_JIT_KERNELS_XLA_LAUNCH_OP_H_ diff --git a/tensorflow/compiler/jit/mark_for_compilation_pass.cc b/tensorflow/compiler/jit/mark_for_compilation_pass.cc index 6415c05acb..4e4abade32 100644 --- a/tensorflow/compiler/jit/mark_for_compilation_pass.cc +++ b/tensorflow/compiler/jit/mark_for_compilation_pass.cc @@ -27,7 +27,9 @@ limitations under the License. #include "tensorflow/compiler/jit/legacy_flags/mark_for_compilation_pass_flags.h" #include "tensorflow/compiler/jit/union_find.h" #include "tensorflow/compiler/jit/xla_cluster_util.h" +#include "tensorflow/compiler/tf2xla/const_analysis.h" #include "tensorflow/compiler/tf2xla/dump_graph.h" +#include "tensorflow/compiler/tf2xla/resource_operation_table.h" #include "tensorflow/compiler/tf2xla/xla_op_registry.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/common_runtime/function.h" @@ -39,6 +41,8 @@ limitations under the License. #include "tensorflow/core/graph/algorithm.h" #include "tensorflow/core/graph/control_flow.h" #include "tensorflow/core/kernels/bounds_check.h" +#include "tensorflow/core/lib/gtl/cleanup.h" +#include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/public/version.h" @@ -73,18 +77,40 @@ bool HasXLAKernel(const Node& node, const DeviceType& jit_device_type) { return FindKernelDef(jit_device_type, node.def(), nullptr, nullptr).ok(); } +bool HasResourceOutput(const Node& node) { + return std::find(node.output_types().begin(), node.output_types().end(), + DT_RESOURCE) != node.output_types().end(); +} + +bool HasResourceInput(const Node& node) { + return std::find(node.input_types().begin(), node.input_types().end(), + DT_RESOURCE) != node.input_types().end(); +} + +// Returns true if `node` is a resource operation recognized by tf2xla that +// operates on something other than resource variables. +bool IsNonResourceVarResourceOp(const Node& node) { + // TODO(b/112837194): We can't cluster these because we only support + // snapshotting resource variables (and we can't e.g. snapshot stacks). This + // limitation may be fixable with some work. + const XlaResourceOpInfo* op_info = GetResourceOpInfoForOp(node.type_string()); + return op_info && op_info->resource_kind() != XlaResourceKind::kVariable; +} + // Make sure we don't recurse infinitely on recursive functions. const int kMaxRecursionDepth = 10; bool IsCompilableCall(const NodeDef& call_def, - const DeviceType& jit_device_type, int depth, + const DeviceType& jit_device_type, + bool allow_resource_ops, int depth, FunctionLibraryRuntime* lib_runtime); // Tests whether 'while_node' is a completely compilable loop. // Every operator in the condition and body functions must be compilable for a // while loop to be compilable. bool IsCompilableWhile(const Node& while_node, - const DeviceType& jit_device_type, int depth, + const DeviceType& jit_device_type, + bool allow_resource_ops, int depth, FunctionLibraryRuntime* lib_runtime) { const NameAttrList* name_attr; NodeDef call; @@ -99,7 +125,8 @@ bool IsCompilableWhile(const Node& while_node, call.set_name("while_cond"); call.set_op(cond_func); *call.mutable_attr() = name_attr->attr(); - if (!IsCompilableCall(call, jit_device_type, depth + 1, lib_runtime)) { + if (!IsCompilableCall(call, jit_device_type, allow_resource_ops, depth + 1, + lib_runtime)) { VLOG(2) << "Rejecting While " << while_node.name() << ": can't compile loop condition: " << cond_func; return false; @@ -114,7 +141,8 @@ bool IsCompilableWhile(const Node& while_node, call.set_name("while_body"); call.set_op(body_func); *call.mutable_attr() = name_attr->attr(); - if (!IsCompilableCall(call, jit_device_type, depth + 1, lib_runtime)) { + if (!IsCompilableCall(call, jit_device_type, allow_resource_ops, depth + 1, + lib_runtime)) { VLOG(2) << "Rejecting While " << while_node.name() << ": can't compile loop body: " << body_func; return false; @@ -126,7 +154,8 @@ bool IsCompilableWhile(const Node& while_node, // Every operator in the function must be compilable for a function to be // compilable. bool IsCompilableCall(const NodeDef& call_def, - const DeviceType& jit_device_type, int depth, + const DeviceType& jit_device_type, + bool allow_resource_ops, int depth, FunctionLibraryRuntime* lib_runtime) { if (depth > kMaxRecursionDepth) { VLOG(2) << "Rejecting " << call_def.op() @@ -142,6 +171,10 @@ bool IsCompilableCall(const NodeDef& call_def, << ": could not instantiate: " << status; return false; } + + auto release_handle_on_return = gtl::MakeCleanup( + [&] { TF_CHECK_OK(lib_runtime->ReleaseHandle(handle)); }); + const FunctionBody* fbody = lib_runtime->GetFunctionBody(handle); CHECK(fbody); const FunctionDef& fdef = fbody->fdef; @@ -162,12 +195,17 @@ bool IsCompilableCall(const NodeDef& call_def, if (node->type_string() == "_Arg" || node->type_string() == "_Retval") continue; if (node->type_string() == "While") { - // Handle functional While loop (not in open source build). - return IsCompilableWhile(*node, jit_device_type, depth + 1, lib_runtime); + // Handle functional While loop. + return IsCompilableWhile(*node, jit_device_type, allow_resource_ops, + depth + 1, lib_runtime); + } + if (!allow_resource_ops && + (HasResourceInput(*node) || HasResourceOutput(*node))) { + return false; } if (!HasXLAKernel(*node, jit_device_type) && - !IsCompilableCall(node->def(), jit_device_type, depth + 1, - lib_runtime)) { + !IsCompilableCall(node->def(), jit_device_type, allow_resource_ops, + depth + 1, lib_runtime)) { VLOG(2) << "Rejecting " << call_def.op() << ": unsupported op " << node->name() << ": " << node->def().ShortDebugString(); return false; @@ -338,6 +376,10 @@ Status FindCompilationCandidates( flib_def, opts)); FunctionLibraryRuntime* lib_runtime = pflr->GetFLR(ProcessFunctionLibraryRuntime::kDefaultFLRDevice); + std::vector<bool> compile_time_const_nodes(graph.num_node_ids(), false); + TF_RETURN_IF_ERROR( + BackwardsConstAnalysis(graph, /*compile_time_const_arg_indices=*/nullptr, + &compile_time_const_nodes)); int64& fuel = legacy_flags::GetMarkForCompilationPassFlags()->tf_xla_clustering_fuel; @@ -381,19 +423,46 @@ Status FindCompilationCandidates( XlaOpRegistry::GetCompilationDevice(device_type.type(), ®istration)); DeviceType jit_device_type(registration->compilation_device_name); if (!HasXLAKernel(*node, jit_device_type) && - !IsCompilableCall(node->def(), jit_device_type, 0, lib_runtime)) { + !IsCompilableCall(node->def(), jit_device_type, + registration->compile_resource_ops, 0, lib_runtime)) { VLOG(2) << "Rejecting " << node->name() << ": unsupported op " << node->type_string(); continue; } if (!registration->compile_resource_ops && - HasResourceInputOrOutput(*node)) { - VLOG(2) << "Rejecting: " << node->name() << ": resource input/output " + (HasResourceOutput(*node) || IsNonResourceVarResourceOp(*node))) { + // We don't have a way of returning values of type DT_RESOURCE from XLA + // computations so we avoid auto-clustering nodes producing DT_RESOURCE. + // XlaLaunchOp also cannot snapshot resources that are not resource + // variables so we avoid clustering resource operations that operate on + // non-resource variables. + VLOG(2) << "Rejecting: " << node->name() << ": resource output " << node->type_string(); continue; } + if (compile_time_const_nodes[node->id()] && + !registration->requires_compilation) { + const OpDef* op_def; + TF_RETURN_IF_ERROR( + OpRegistry::Global()->LookUpOpDef(node->type_string(), &op_def)); + if (op_def->is_stateful()) { + // We need to be able to constant fold the nodes in + // compile_time_const_nodes given constant inputs (required by XLA) and + // therefore can't auto-cluster stateful ops since these can never be + // constant folded. + VLOG(2) << "Rejecting " << node->name() + << ": must-be-constant stateful op"; + continue; + } + } + // We don't auto-cluster functional control flow nodes containing resource + // operations because safety checks are trickier in this case. + // registration->compile_resource_ops is true for XLA_CPU/XLA_GPU but not + // for CPU/GPU. if (node->type_string() == "While" && - !IsCompilableWhile(*node, jit_device_type, 0, lib_runtime)) { + !IsCompilableWhile(*node, jit_device_type, + registration->compile_resource_ops, 0, + lib_runtime)) { continue; } // _Arg nodes in a top-level function represent feeds. @@ -413,6 +482,31 @@ Status FindCompilationCandidates( return Status::OK(); } +// Determine the global jit level which is ON if either the +// GraphOptimizationPassOptions has the jit ON, or if the --tf_xla_auto_jit flag +// is true. +OptimizerOptions::GlobalJitLevel GetGlobalJitLevel( + const GraphOptimizationPassOptions& options) { + OptimizerOptions::GlobalJitLevel global_jit_level = + options.session_options->config.graph_options() + .optimizer_options() + .global_jit_level(); + if (global_jit_level == OptimizerOptions::DEFAULT) { + // To set compilation to be on by default, change the following line. + global_jit_level = OptimizerOptions::OFF; + } + legacy_flags::MarkForCompilationPassFlags* flags = + legacy_flags::GetMarkForCompilationPassFlags(); + if (flags->tf_xla_auto_jit == -1 || + (1 <= flags->tf_xla_auto_jit && flags->tf_xla_auto_jit <= 2)) { + // If the flag tf_xla_auto_jit is a valid, non-zero setting, it overrides + // the setting in ConfigProto. + global_jit_level = + static_cast<OptimizerOptions::GlobalJitLevel>(flags->tf_xla_auto_jit); + } + return global_jit_level; +} + struct Cluster { // Identifies the node that represents this cluster in the cycle detection // graph. @@ -427,7 +521,11 @@ bool IsCompilable(FunctionLibraryRuntime* flr, const NodeDef& ndef) { CHECK(XlaOpRegistry::GetCompilationDevice(device->device_type(), ®istration)); DeviceType jit_device_type(registration->compilation_device_name); - return IsCompilableCall(ndef, jit_device_type, 0, flr); + + // We can always *compile* resource operations, even if we are sometimes + // unable to auto-cluster them. + const bool compile_resource_ops = true; + return IsCompilableCall(ndef, jit_device_type, compile_resource_ops, 0, flr); } Status MarkForCompilationPass::Run( @@ -435,22 +533,9 @@ Status MarkForCompilationPass::Run( // TODO(phawkins): precompute the "GetCompilationDevice" properties of each // device ahead of time. OptimizerOptions::GlobalJitLevel global_jit_level = - options.session_options->config.graph_options() - .optimizer_options() - .global_jit_level(); - if (global_jit_level == OptimizerOptions::DEFAULT) { - // To set compilation to be on by default, change the following line. - global_jit_level = OptimizerOptions::OFF; - } + GetGlobalJitLevel(options); legacy_flags::MarkForCompilationPassFlags* flags = legacy_flags::GetMarkForCompilationPassFlags(); - if (flags->tf_xla_auto_jit == -1 || - (1 <= flags->tf_xla_auto_jit && flags->tf_xla_auto_jit <= 2)) { - // If the flag tf_xla_auto_jit is a valid, non-zero setting, it overrides - // the setting in ConfigProto. - global_jit_level = - static_cast<OptimizerOptions::GlobalJitLevel>(flags->tf_xla_auto_jit); - } bool cpu_global_jit = flags->tf_xla_cpu_global_jit; bool fusion_only = flags->tf_xla_fusion_only; @@ -518,9 +603,9 @@ Status MarkForCompilationPass::Run( bool ignore_registration = cpu_global_jit && device_type == DEVICE_CPU; bool should_compile = (ignore_registration || registration->enable_jit_by_default) && - global_jit_level > 0; + global_jit_level != OptimizerOptions::OFF; if (!should_compile) { - if (global_jit_level <= 0) { + if (global_jit_level == OptimizerOptions::OFF) { VLOG(2) << "Rejecting " << node->name() << ": global jit disabled."; } else { VLOG(2) << "Rejecting " << node->name() << ": JIT for device disabled."; @@ -548,7 +633,7 @@ static void VLogClusteringSummary(const Graph& g) { int clustered_node_count = 0; for (Node* n : g.nodes()) { - gtl::optional<StringPiece> cluster_name = GetXlaClusterForNode(*n); + absl::optional<StringPiece> cluster_name = GetXlaClusterForNode(*n); if (cluster_name) { clustered_node_count++; cluster_name_to_size[*cluster_name]++; @@ -583,6 +668,82 @@ static void VLogClusteringSummary(const Graph& g) { VLOG(3) << " " << pair.first << ": " << pair.second << " instances"; } } + + struct EdgeInfo { + StringPiece node_name; + absl::optional<StringPiece> cluster_name; + + StringPiece GetClusterName() const { + return cluster_name ? *cluster_name : "[none]"; + } + + std::pair<StringPiece, absl::optional<StringPiece>> AsPair() const { + return {node_name, cluster_name}; + } + + bool operator<(const EdgeInfo& other) const { + return AsPair() < other.AsPair(); + } + }; + + using EdgeInfoMap = std::map<StringPiece, std::map<EdgeInfo, int64>>; + + EdgeInfoMap incoming_edge_infos; + EdgeInfoMap outgoing_edge_infos; + + std::set<StringPiece> cluster_names_to_print; + + for (const Edge* e : g.edges()) { + const Node* from = e->src(); + absl::optional<StringPiece> from_cluster_name = GetXlaClusterForNode(*from); + + const Node* to = e->dst(); + absl::optional<StringPiece> to_cluster_name = GetXlaClusterForNode(*to); + + if (to_cluster_name == from_cluster_name) { + continue; + } + + if (to_cluster_name) { + incoming_edge_infos[*to_cluster_name] + [EdgeInfo{from->name(), from_cluster_name}]++; + cluster_names_to_print.insert(*to_cluster_name); + } + + if (from_cluster_name) { + outgoing_edge_infos[*from_cluster_name][{to->name(), to_cluster_name}]++; + cluster_names_to_print.insert(*from_cluster_name); + } + } + + VLOG(2) << "*** Inter-Cluster edges:"; + if (cluster_names_to_print.empty()) { + VLOG(2) << " [none]"; + } + + auto print_edge_info_set_for_cluster = [&](StringPiece cluster_name, + const EdgeInfoMap& edge_info_map, + StringPiece desc) { + auto it = edge_info_map.find(cluster_name); + if (it != edge_info_map.end()) { + VLOG(2) << " " << it->second.size() << " " << desc << " edges"; + for (const auto& edge_info_count_pair : it->second) { + VLOG(2) << " " << edge_info_count_pair.first.GetClusterName() << " " + << edge_info_count_pair.first.node_name << " # " + << edge_info_count_pair.second; + } + } else { + VLOG(2) << " No " << desc << " edges."; + } + }; + + for (StringPiece cluster_name : cluster_names_to_print) { + VLOG(2) << " ** Cluster " << cluster_name; + print_edge_info_set_for_cluster(cluster_name, incoming_edge_infos, + "incoming"); + print_edge_info_set_for_cluster(cluster_name, outgoing_edge_infos, + "outgoing"); + } } // Is 'node' an operator that consumes only the shape of its input, not the @@ -592,6 +753,43 @@ static bool IsShapeConsumerOp(const Node& node) { node.type_string() == "Size"; } +static Status IgnoreResourceOpForSafetyAnalysis(const Node& n, bool* ignore) { + // If a resource operation is assigned to XLA_CPU or XLA_GPU explicitly then + // ignore it during resource operation safety analysis. We need this hack + // because of two reasons: + // + // 1. Operations assigned to XLA_CPU and XLA_GPU have to always be compiled. + // 2. We don't support live-out values of type DT_RESOURCE and live-in values + // of type DT_RESOURCE that are not resource variables. + // + // Together these imply we cannot let resource variable safety analysis + // constrain e.g. a TensorArrayV3->TensorArrayAssignV3 edge to be in different + // clusters: both of them will have to be clustered because of (1) and we + // won't be able to keep the edge between the two as neither the input to the + // second XLA cluster nor the output from the first XLA cluster are supported + // because of (2). + // + // TODO(b/113100872): This can be fixed if the TensorFlow representation for + // TensorArray and Stack on the XLA_{C|G}PU devices were the same in XLA; then + // (2) would no longer hold. + + if (n.assigned_device_name().empty()) { + *ignore = false; + return Status::OK(); + } + DeviceType device_type(""); + TF_RETURN_IF_ERROR( + DeviceToDeviceType(n.assigned_device_name(), &device_type)); + + const XlaOpRegistry::DeviceRegistration* registration; + if (!XlaOpRegistry::GetCompilationDevice(device_type.type(), ®istration)) { + *ignore = true; + } else { + *ignore = registration->compile_resource_ops; + } + return Status::OK(); +} + // Sequence number generator to ensure clusters have unique names. static std::atomic<int64> cluster_sequence_num; @@ -620,6 +818,8 @@ Status MarkForCompilationPass::RunImpl( GraphCycles cycles; TF_RETURN_IF_ERROR(CreateCycleDetectionGraph(graph, &cycles)); + TF_RETURN_IF_ERROR(AdjustCycleDetectionGraphForResourceOps( + graph, options.flib_def, IgnoreResourceOpForSafetyAnalysis, &cycles)); // Each compilation candidate belongs to a cluster. The cluster's // representative @@ -632,6 +832,8 @@ Status MarkForCompilationPass::RunImpl( worklist.push_back(&clusters[node->id()]); } + OptimizerOptions::GlobalJitLevel global_jit_level = + GetGlobalJitLevel(options); legacy_flags::MarkForCompilationPassFlags* flags = legacy_flags::GetMarkForCompilationPassFlags(); @@ -656,7 +858,7 @@ Status MarkForCompilationPass::RunImpl( string to_scope; for (int to : cycles.Successors(from)) { if (to >= graph->num_node_ids()) { - // Node is a "frame" node that is present only in the cycle detection + // Node is a fictitious node that is present only in the cycle detection // graph. No clustering is possible. continue; } @@ -671,13 +873,15 @@ Status MarkForCompilationPass::RunImpl( } // Look for an _XlaScope on both nodes. If both nodes have a // scope and the scopes do not match, do not cluster along this - // edge. If even one of the nodes lacks an _XlaScope attribute, + // edge. This restriction is overridden if the global_jit_level is ON. If + // even one of the nodes lacks an _XlaScope attribute, // then it is treated as a "bridge" and a cluster may be created // along it. We may want to restrict this behavior to require // all nodes marked with _XlaCompile=true to also have a // _XlaScope property set (and raise an error otherwise); but // for now we don't do this. - if (GetNodeAttr(node_from->attrs(), kXlaScopeAttr, &from_scope).ok() && + if (global_jit_level == OptimizerOptions::OFF && + GetNodeAttr(node_from->attrs(), kXlaScopeAttr, &from_scope).ok() && GetNodeAttr(node_to->attrs(), kXlaScopeAttr, &to_scope).ok() && from_scope != to_scope) { continue; diff --git a/tensorflow/compiler/jit/mark_for_compilation_pass_test.cc b/tensorflow/compiler/jit/mark_for_compilation_pass_test.cc index a780d4a936..807ab51fd3 100644 --- a/tensorflow/compiler/jit/mark_for_compilation_pass_test.cc +++ b/tensorflow/compiler/jit/mark_for_compilation_pass_test.cc @@ -15,10 +15,12 @@ limitations under the License. #include "tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.h" +#include "absl/strings/match.h" #include "tensorflow/cc/framework/ops.h" #include "tensorflow/cc/ops/array_ops.h" #include "tensorflow/cc/ops/control_flow_ops_internal.h" #include "tensorflow/cc/ops/function_ops.h" +#include "tensorflow/cc/ops/resource_variable_ops.h" #include "tensorflow/cc/ops/sendrecv_ops.h" #include "tensorflow/cc/ops/standard_ops.h" #include "tensorflow/compiler/jit/defs.h" @@ -26,11 +28,11 @@ limitations under the License. #include "tensorflow/compiler/tf2xla/xla_op_registry.h" #include "tensorflow/core/framework/node_def_util.h" #include "tensorflow/core/framework/op.h" +#include "tensorflow/core/graph/algorithm.h" #include "tensorflow/core/graph/graph_constructor.h" #include "tensorflow/core/graph/graph_def_builder.h" #include "tensorflow/core/graph/graph_def_builder_util.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/test.h" namespace tensorflow { @@ -48,9 +50,35 @@ std::unordered_map<string, string> GetClusters(const Graph& graph) { ids[node->name()] = cluster; } } + + if (VLOG_IS_ON(2)) { + VLOG(2) << "Clusters:"; + for (const auto& p : ids) { + VLOG(2) << " " << p.first << " -> " << p.second; + } + } return ids; } +gtl::FlatMap<string, std::vector<string>> GetClusterSets( + const Graph& g, std::vector<string>* cluster_names = nullptr) { + CHECK(cluster_names == nullptr || cluster_names->empty()); + gtl::FlatMap<string, std::vector<string>> cluster_sets; + for (const auto& p : GetClusters(g)) { + cluster_sets[p.second].push_back(p.first); + } + for (auto& p : cluster_sets) { + if (cluster_names != nullptr) { + cluster_names->push_back(p.first); + } + std::sort(p.second.begin(), p.second.end()); + } + if (cluster_names != nullptr) { + std::sort(cluster_names->begin(), cluster_names->end()); + } + return cluster_sets; +} + TEST(XlaCompilationTest, Chains) { std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); GraphDef graphdef; @@ -199,7 +227,7 @@ TEST(XlaCompilationTest, FunctionCalls) { {}, {{{"n_c"}, "UncompilableUnary", {"n_a"}}}); FunctionDef noinline = compilable; noinline.mutable_signature()->set_name("NoInlineFn"); - AddAttr("_noinline", bool(true), noinline.mutable_attr()); + AddAttr("_noinline", static_cast<bool>(true), noinline.mutable_attr()); FunctionDefLibrary flib; *flib.add_function() = compilable; @@ -372,6 +400,44 @@ TEST(XlaCompilationTest, Loops) { EXPECT_EQ(0, clusters.size()); } +TEST(XlaCompilationTest, CyclesWithAllDifferentScopesGlobalJitOverridden) { + std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); + GraphDef graphdef; + { + GraphDefBuilder builder(GraphDefBuilder::kFailImmediately); + Node* a = ops::SourceOp("Const", builder.opts() + .WithName("A") + .WithAttr("dtype", DT_FLOAT) + .WithAttr("value", Tensor()) + .WithAttr(kXlaScopeAttr, "ScopeA")); + Node* b = ops::UnaryOp( + "Relu", a, + builder.opts().WithName("B").WithAttr(kXlaScopeAttr, "ScopeB")); + ops::BinaryOp( + "MatMul", a, b, + builder.opts().WithName("C").WithAttr(kXlaScopeAttr, "ScopeC")); + TF_CHECK_OK(GraphDefBuilderToGraph(builder, graph.get())); + } + + FunctionDefLibrary flib; + FunctionLibraryDefinition flib_def(graph->op_registry(), flib); + SessionOptions session_options; + session_options.config.mutable_graph_options() + ->mutable_optimizer_options() + ->set_global_jit_level(OptimizerOptions::ON_2); + TF_ASSERT_OK(MarkForCompilationPassTestHelper::MarkForCompilation( + &graph, &flib_def, &session_options)); + auto clusters = GetClusters(*graph); + + // The computation is: C = A + relu(A) + // where A sits in ScopeA, relu(A) sits in ScopeB, and C sits in ScopeC. + // In this case, the GlobalJitLevel overrides the scopes to cluster while + // ignoring scopes. + EXPECT_EQ(3, clusters.size()); + EXPECT_EQ(clusters["A"], clusters["B"]); + EXPECT_EQ(clusters["A"], clusters["C"]); +} + TEST(XlaCompilationTest, CyclesWithAllDifferentScopes) { std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); GraphDef graphdef; @@ -463,38 +529,104 @@ TEST(XlaCompilationTest, CyclesWithDifferentScopesAndBridge) { EXPECT_EQ(clusters["B"], clusters["C"]); } -REGISTER_OP("ResourceInput").Input("a: resource").Output("o: float"); -REGISTER_OP("ResourceOutput").Input("a: float").Output("o: resource"); - namespace { +Node* MakeRead(const Scope& scope, const string& id) { + Output var_handle = + ops::VarHandleOp(scope.WithOpName("Var" + id), DT_FLOAT, TensorShape({})); + Output read = + ops::ReadVariableOp(scope.WithOpName("Read" + id), var_handle, DT_FLOAT); + return read.node(); +} -class DummyOp : public XlaOpKernel { - using XlaOpKernel::XlaOpKernel; - void Compile(XlaOpKernelContext* ctx) override {} -}; - -REGISTER_XLA_OP(Name("ResourceInput"), DummyOp); -REGISTER_XLA_OP(Name("ResourceOutput"), DummyOp); +Node* MakeWrite(const Scope& scope, const string& id) { + Output var_handle = + ops::VarHandleOp(scope.WithOpName("Var" + id), DT_FLOAT, TensorShape({})); + Output value_to_write = + ops::Const(scope.WithOpName("ValueToAssign" + id), 1.0f); + ops::AssignVariableOp assign_op(scope.WithOpName("Assignment" + id), + var_handle, value_to_write); + return assign_op.operation.node(); +} +Node* MakeNeutral(const Scope& scope, const string& id) { + return ops::Const(scope.WithOpName("Const" + id), 42.0f).node(); +} } // namespace -TEST(XlaCompilationTest, Resources) { +TEST(XlaCompilationTest, ResourcesClusteringAllowed) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* read = MakeRead(root, "R"); + Node* write = MakeWrite(root, "W"); + + root.graph()->AddControlEdge(read, write); + + FixupSourceAndSinkEdges(root.graph()); std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); - GraphDef graphdef; - { - GraphDefBuilder builder(GraphDefBuilder::kFailImmediately); - Node* a = - ops::SourceOp("UncompilableNullary", builder.opts().WithName("A")); - Node* b = ops::UnaryOp("Relu", a, builder.opts().WithName("B")); - // We should not form clusters with resource ops by default. - Node* c = ops::UnaryOp("ResourceOutput", b, builder.opts().WithName("C")); - Node* d = ops::UnaryOp("ResourceInput", c, builder.opts().WithName("D")); - ops::UnaryOp("Relu", d, builder.opts().WithName("E")); - TF_EXPECT_OK(GraphDefBuilderToGraph(builder, graph.get())); - } + TF_EXPECT_OK(root.ToGraph(graph.get())); TF_ASSERT_OK(MarkForCompilationPassTestHelper::MarkForCompilation(&graph)); - auto clusters = GetClusters(*graph); - EXPECT_EQ(0, clusters.size()); // Nothing should be compiled. + gtl::FlatMap<string, std::vector<string>> cluster_sets = + GetClusterSets(*graph); + ASSERT_EQ(cluster_sets.size(), 1); + std::vector<string> expected_clustered_nodes = {"AssignmentW", "ReadR", + "ValueToAssignW"}; + ASSERT_EQ(cluster_sets.begin()->second, expected_clustered_nodes); +} + +TEST(XlaCompilationTest, ResourcesClusteringDisallowed) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* read = MakeRead(root, "R"); + Node* write = MakeWrite(root, "W"); + + root.graph()->AddControlEdge(write, read); + + FixupSourceAndSinkEdges(root.graph()); + std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); + TF_EXPECT_OK(root.ToGraph(graph.get())); + TF_ASSERT_OK(MarkForCompilationPassTestHelper::MarkForCompilation(&graph)); + gtl::FlatMap<string, std::vector<string>> cluster_sets = + GetClusterSets(*graph); + ASSERT_EQ(cluster_sets.size(), 1); + std::vector<string> expected_clustered_nodes = {"AssignmentW", + "ValueToAssignW"}; + ASSERT_EQ(cluster_sets.begin()->second, expected_clustered_nodes); +} + +TEST(XlaCompilationTest, ChainOfOps) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* write_0 = MakeWrite(root, "W0"); + Node* neutral_0 = MakeNeutral(root, "N0"); + Node* read_0 = MakeRead(root, "R0"); + Node* write_1 = MakeWrite(root, "W1"); + Node* neutral_1 = MakeNeutral(root, "N1"); + Node* read_1 = MakeRead(root, "R1"); + + root.graph()->AddControlEdge(write_0, neutral_0); + root.graph()->AddControlEdge(neutral_0, read_0); + root.graph()->AddControlEdge(read_0, write_1); + root.graph()->AddControlEdge(write_1, neutral_1); + root.graph()->AddControlEdge(neutral_1, read_1); + + FixupSourceAndSinkEdges(root.graph()); + std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); + TF_EXPECT_OK(root.ToGraph(graph.get())); + TF_ASSERT_OK(MarkForCompilationPassTestHelper::MarkForCompilation(&graph)); + + std::vector<string> cluster_names; + gtl::FlatMap<string, std::vector<string>> cluster_sets = + GetClusterSets(*graph, &cluster_names); + + ASSERT_EQ(cluster_sets.size(), 2); + + std::vector<string> expected_clustered_nodes_a = {"AssignmentW0", "ConstN0", + "ValueToAssignW0"}; + ASSERT_EQ(cluster_sets[cluster_names[0]], expected_clustered_nodes_a); + + std::vector<string> expected_clustered_nodes_b = { + "AssignmentW1", "ConstN1", "ReadR0", "ValueToAssignW1"}; + ASSERT_EQ(cluster_sets[cluster_names[1]], expected_clustered_nodes_b); } TEST(XlaCompilationTest, IllegalCycle_UsefulErrorMessage) { @@ -524,11 +656,11 @@ TEST(XlaCompilationTest, IllegalCycle_UsefulErrorMessage) { Status status = MarkForCompilationPassTestHelper::MarkForCompilation(&graph); EXPECT_FALSE(status.ok()); - EXPECT_TRUE(str_util::StrContains(status.ToString(), - "Edge from c to a would create a cycle.\n" - "+-> a\n" - "| b\n" - "+-- c\n")); + EXPECT_TRUE(absl::StrContains(status.ToString(), + "Edge from c to a would create a cycle.\n" + "+-> a\n" + "| b\n" + "+-- c\n")); } TEST(XlaCompilationTest, Retval) { @@ -693,5 +825,27 @@ TEST(XlaCompilationTest, ClusterControlTrigger) { EXPECT_EQ(clusters, expected_clusters); } +TEST(XlaCompilationTest, RandomShape) { + Scope root = Scope::NewRootScope().ExitOnError(); + Output shape_shape = ops::Const(root.WithOpName("shape_shape"), {2}, {1}); + Output shape = + ops::RandomUniformInt(root.WithOpName("shape"), shape_shape, + ops::Const(root.WithOpName("minval"), 1), + ops::Const(root.WithOpName("maxval"), 20)); + Output reshape_input = + ops::Placeholder(root.WithOpName("reshape_input"), DT_FLOAT, + ops::Placeholder::Shape(TensorShape({500, 500}))); + Output reshape = + ops::Reshape(root.WithOpName("reshape"), reshape_input, shape); + + std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); + + TF_ASSERT_OK(root.ToGraph(graph.get())); + TF_ASSERT_OK(MarkForCompilationPassTestHelper::MarkForCompilation(&graph)); + + std::unordered_map<string, string> clusters = GetClusters(*graph); + EXPECT_EQ(clusters["shape"], ""); +} + } // namespace } // namespace tensorflow diff --git a/tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.cc b/tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.cc index a84b82e479..65669877f7 100644 --- a/tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.cc +++ b/tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.cc @@ -14,10 +14,12 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.h" +#include "tensorflow/core/public/session_options.h" namespace tensorflow { /*static*/ Status MarkForCompilationPassTestHelper::MarkForCompilation( - std::unique_ptr<Graph>* graph, FunctionLibraryDefinition* flib_def) { + std::unique_ptr<Graph>* graph, FunctionLibraryDefinition* flib_def, + SessionOptions* session_options) { // Assign all nodes to the CPU device. static const char* kCpuDevice = "/job:localhost/replica:0/task:0/cpu:0"; for (Node* n : (*graph)->nodes()) { @@ -26,12 +28,19 @@ namespace tensorflow { GraphOptimizationPassOptions opt_options; opt_options.graph = graph; + opt_options.session_options = session_options; opt_options.flib_def = flib_def; MarkForCompilationPass pass; return pass.RunImpl(opt_options); } /*static*/ Status MarkForCompilationPassTestHelper::MarkForCompilation( + std::unique_ptr<Graph>* graph, FunctionLibraryDefinition* flib_def) { + SessionOptions session_options; + return MarkForCompilation(graph, flib_def, &session_options); +} + +/*static*/ Status MarkForCompilationPassTestHelper::MarkForCompilation( std::unique_ptr<Graph>* graph) { FunctionDefLibrary flib; FunctionLibraryDefinition flib_def((*graph)->op_registry(), flib); diff --git a/tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.h b/tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.h index b9a0531cb0..216baaf933 100644 --- a/tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.h +++ b/tensorflow/compiler/jit/mark_for_compilation_pass_test_helper.h @@ -25,6 +25,11 @@ class MarkForCompilationPassTestHelper { // `graph` to the CPU device. To make testing easier, ignores device // registration, _XlaCompile attributes, input deadness and global jit level. static Status MarkForCompilation(std::unique_ptr<Graph>* graph, + FunctionLibraryDefinition* flib_def, + SessionOptions* session_options); + + // Like `MarkForCompilation` but creates a default SessionOptions. + static Status MarkForCompilation(std::unique_ptr<Graph>* graph, FunctionLibraryDefinition* flib_def); // Like `MarkForCompilation` but creates `flib_def` from the op registry. diff --git a/tensorflow/compiler/jit/ops/BUILD b/tensorflow/compiler/jit/ops/BUILD index c9e46bc147..13804c6a05 100644 --- a/tensorflow/compiler/jit/ops/BUILD +++ b/tensorflow/compiler/jit/ops/BUILD @@ -10,10 +10,3 @@ cc_library( deps = ["//tensorflow/core:framework"], alwayslink = 1, ) - -cc_library( - name = "parallel_check_op", - srcs = ["parallel_check_op.cc"], - deps = ["//tensorflow/core:framework"], - alwayslink = 1, -) diff --git a/tensorflow/compiler/jit/partially_decluster_pass.cc b/tensorflow/compiler/jit/partially_decluster_pass.cc index 68ead39424..3a9a8c4988 100644 --- a/tensorflow/compiler/jit/partially_decluster_pass.cc +++ b/tensorflow/compiler/jit/partially_decluster_pass.cc @@ -30,7 +30,7 @@ Status FindNodesToDecluster(const Graph& graph, gtl::FlatSet<Node*>* result, MemoryTypeVector input_mtypes, output_mtypes; for (Node* n : post_order) { - gtl::optional<StringPiece> from_cluster = GetXlaClusterForNode(*n); + absl::optional<StringPiece> from_cluster = GetXlaClusterForNode(*n); if (!from_cluster) { continue; } @@ -79,8 +79,8 @@ Status FindNodesToDecluster(const Graph& graph, gtl::FlatSet<Node*>* result, // Check if `dst` is in a different cluster, unclustered, or about to be // partially declustered (here we rely on the post-order traversal order). // If yes, decluster `n` to avoid the device-to-host memcpy. - gtl::optional<StringPiece> dst_cluster = - result->count(dst) ? gtl::nullopt : GetXlaClusterForNode(*dst); + absl::optional<StringPiece> dst_cluster = + result->count(dst) ? absl::nullopt : GetXlaClusterForNode(*dst); if (from_cluster != dst_cluster) { CHECK(result->insert(n).second); break; @@ -99,7 +99,7 @@ Status PartiallyDeclusterNode(Graph* graph, Node* n) { } Node* dst = out_edge->dst(); - gtl::optional<StringPiece> dst_cluster_name = GetXlaClusterForNode(*dst); + absl::optional<StringPiece> dst_cluster_name = GetXlaClusterForNode(*dst); if (dst_cluster_name != cluster_name) { out_edges_to_clone.push_back(out_edge); } diff --git a/tensorflow/compiler/jit/partially_decluster_pass_test.cc b/tensorflow/compiler/jit/partially_decluster_pass_test.cc index 08a956e4c6..f61a955c22 100644 --- a/tensorflow/compiler/jit/partially_decluster_pass_test.cc +++ b/tensorflow/compiler/jit/partially_decluster_pass_test.cc @@ -32,7 +32,6 @@ limitations under the License. #include "tensorflow/core/graph/graph_def_builder.h" #include "tensorflow/core/graph/graph_def_builder_util.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/test.h" namespace tensorflow { diff --git a/tensorflow/compiler/jit/resource_operation_safety_analysis.cc b/tensorflow/compiler/jit/resource_operation_safety_analysis.cc new file mode 100644 index 0000000000..1ba4a5ef73 --- /dev/null +++ b/tensorflow/compiler/jit/resource_operation_safety_analysis.cc @@ -0,0 +1,336 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +// ALGORITHM OVERVIEW +// ================== +// +// An XLA cluster hoists all resource reads to be beginning of the cluster +// execution and all the resource writes to the end. This means it cannot +// enforce arbitrary ordering dependencies (via control or data edges) between +// resource operations. Since all resource reads happen before all resource +// writes, edges constraining resource reads to happen before resource writes +// are fine, but all other kinds of edges are problematic. This analysis +// computes the set of pairs of resource operations that cannot be put in the +// same cluster because XLA cannot respect the dependencies between them in the +// TensorFlow program. +// +// TODO(b/112856632): We can, in theory, support Read->Read and Write->Write +// dependencies. +// +// Specifically the result computed by this analysis contains the edge {W, R} +// iff all of these hold true: +// +// - In the graph (g - {edges from NextIteration to Merge}) there is a path +// from W to R. +// - IsEdgeSafe(W, R) == False [defined below] +// - W != R (note: some resource operations both read from and write to +// resource variables). +// +// The result is incorrect around loops because we ignore edges from +// NextIteration to Merge, but that should be fine because we don't cluster +// these edges. For instance, in: +// +// Init -----> Merge <-------+ +// | | +// v | +// Read | +// | | +// v | +// Write | +// | | +// v | +// NextIteration --+ +// +// we won't put (Read, Write) in the returned set. This is fine if +// auto-clustering can only cluster the Read->Write edge, but it is a problem if +// it clusters the Write->NextIteration->Merge->Read edges instead. The same +// problem is present for the functional version of the loop above. We rely on +// auto-clustering to not cluster control flow edges like NextIteration->Merge. +// This is enough to avoid the explicit-control-flow problem shown above. One +// way to think about this is that we only care about cases where two nodes, A +// and B, would normally have been put in the same cluster but cannot legally be +// in the same cluster because of resourcevar-dependencies. If A and B would +// normally have been put in the same cluster then all paths between A and B +// would have to be clusterable (otherwise we'd have introduced a cycle). Ergo +// there could not have been a NextIteration->Merge edge between A and B since +// we don't cluster these edges. +// +// We also rely on auto-clustering to not cluster functional control flow nodes +// that contain resource operations. +// +// IMPLEMENTATION +// -------------- +// +// We traverse the graph minus backedges in reverse post order, mapping each +// node to the set of resource operation reaching that node. Since we visit +// producers before consumers, we can construct the set of reaching operations +// by taking the union of the operations reaching the input nodes. These +// "reaching resource operations" can then be used to create the pairs of +// incompatible nodes using `IsEdgeSafe`. + +#include "tensorflow/compiler/jit/resource_operation_safety_analysis.h" + +#include "absl/memory/memory.h" +#include "absl/strings/str_join.h" +#include "absl/types/optional.h" +#include "tensorflow/compiler/tf2xla/resource_operation_table.h" +#include "tensorflow/core/framework/node_def.pb.h" +#include "tensorflow/core/graph/algorithm.h" +#include "tensorflow/core/graph/tensor_id.h" +#include "tensorflow/core/lib/gtl/flatmap.h" +#include "tensorflow/core/lib/gtl/flatset.h" +#include "tensorflow/core/lib/hash/hash.h" +#include "tensorflow/core/util/ptr_util.h" + +namespace tensorflow { +namespace { +// Returns true if `n` may call a function. +Status MayCallFunction(const Node& n, const FunctionLibraryDefinition* flib_def, + bool* out_result) { + if (flib_def->Contains(n.type_string())) { + *out_result = true; + } else { + *out_result = + std::any_of(n.def().attr().begin(), n.def().attr().end(), + [](const std::pair<string, AttrValue>& name_attr_pair) { + return name_attr_pair.second.has_func(); + }); + } + + return Status::OK(); +} + +// Maps `n` to the XlaResourceOpKind corresponding to its operation. If `n` is +// not a resource operation recognized by XLA then sets `out_resource_op_kind` +// to nullopt. +Status XlaResourceOpKindForNode( + const Node& n, const FunctionLibraryDefinition* flib_def, + const std::function<Status(const Node&, bool*)>& resource_ops_to_ignore, + absl::optional<XlaResourceOpKind>* out_resource_op_kind) { + bool should_ignore = false; + if (resource_ops_to_ignore) { + TF_RETURN_IF_ERROR(resource_ops_to_ignore(n, &should_ignore)); + } + if (should_ignore) { + *out_resource_op_kind = absl::nullopt; + return Status::OK(); + } + + const XlaResourceOpInfo* op_info = GetResourceOpInfoForOp(n.type_string()); + if (op_info) { + *out_resource_op_kind = op_info->kind(); + return Status::OK(); + } + + // We conservatively assume that functions will both read and write resource + // variables. In the future we may consider doing some form of + // inter-procedural analysis. + bool may_call_function; + TF_RETURN_IF_ERROR(MayCallFunction(n, flib_def, &may_call_function)); + if (may_call_function) { + *out_resource_op_kind = XlaResourceOpKind::kReadWrite; + } else { + *out_resource_op_kind = absl::nullopt; + } + + return Status::OK(); +} + +// Returns true if a control or data dependence from a TensorFlow operation of +// resource op kind `from` to a TensorFlow operation of resource op kind `to` +// can be represented by an XLA cluster and needs no special handling around +// auto-jit. +bool IsEdgeSafe(XlaResourceOpKind from, XlaResourceOpKind to) { + // XLA clusters forces all reads to happen before all writes, which means the + // kinds of edges it can faithfully represent are: Read->Write, Read->Modify, + // Modify->Write, Read->Read, Write->Write. + // + // TODO(b/112856632): We can, in theory, support Read->Read and Write->Write + // dependencies. + return from == XlaResourceOpKind::kRead && to == XlaResourceOpKind::kWrite; +} + +using ResourceOp = std::pair<int, XlaResourceOpKind>; + +string ResourceOpToString(const ResourceOp& resource_op) { + return strings::StrCat( + resource_op.first, ": ", + XlaResourceOpInfo::XlaResourceOpKindToString(resource_op.second)); +} + +// A copy-on-write set used to store the set of ResourceOps reaching a node in a +// TensorFlow graph. +// +// TODO(sanjoy): It may be useful to pull this out into its own header at some +// point. +class ResourceOpSet { + private: + using Impl = gtl::FlatSet<ResourceOp>; + + public: + ResourceOpSet() = default; + + // Adds all ResourceOp s in `other` to this set. + void Add(const ResourceOpSet& other) { + CHECK(!frozen_); + if (other.impl_ == impl_) { + other.frozen_ = true; + return; + } + + if (!impl_) { + other.frozen_ = true; + impl_ = other.impl_; + return; + } + + for (ResourceOp resource_op : other) { + Add(resource_op); + } + } + + void Add(const ResourceOp& resource_op) { + CHECK(!frozen_); + if (!IsCopy() && Contains(resource_op)) { + // We can avoid the copy if the item we want to insert already exists. + return; + } + + EnsureIsCopied(); + impl_->insert(resource_op); + } + + Impl::const_iterator begin() const { + return impl_ ? impl_->begin() : GetEmptyImpl()->begin(); + } + + Impl::const_iterator end() const { + return impl_ ? impl_->end() : GetEmptyImpl()->end(); + } + + bool Contains(const ResourceOp& resource_op) const { + return impl_ != nullptr && impl_->count(resource_op); + } + + private: + bool IsCopy() const { return storage_ != nullptr; } + + void EnsureIsCopied() { + if (storage_ == nullptr) { + storage_ = absl::make_unique<Impl>(); + for (ResourceOp op : *this) { + storage_->insert(op); + } + impl_ = storage_.get(); + } + } + + static Impl* GetEmptyImpl() { + static Impl* empty_impl = new Impl; + return empty_impl; + } + + Impl* impl_ = nullptr; + std::unique_ptr<Impl> storage_; + + // frozen_ is true if there is another set pointing to this set's impl_. We + // can no longer add elements to this set in that case since the sets pointing + // to this set expect the contents of this set to be stable. + mutable bool frozen_ = false; + + TF_DISALLOW_COPY_AND_ASSIGN(ResourceOpSet); +}; + +string ResourceOpSetToString(const ResourceOpSet& resource_op_set) { + std::vector<string> elements_debug_string; + std::transform(resource_op_set.begin(), resource_op_set.end(), + std::back_inserter(elements_debug_string), ResourceOpToString); + return strings::StrCat("{", absl::StrJoin(elements_debug_string, ","), "}"); +} + +string NodeToString(const Node& n, XlaResourceOpKind resource_op_kind) { + return strings::StrCat( + "[", n.name(), ": ", n.type_string(), "(", + XlaResourceOpInfo::XlaResourceOpKindToString(resource_op_kind), ")", "]"); +} +} // namespace + +Status ComputeIncompatibleResourceOperationPairs( + const Graph& g, const FunctionLibraryDefinition* flib_def, + const std::function<Status(const Node&, bool*)>& resource_ops_to_ignore, + std::vector<std::pair<int, int>>* result) { + CHECK(result->empty()); + + std::vector<Node*> rpo; + GetReversePostOrder(g, &rpo, /*stable_comparator=*/NodeComparatorName(), + /*edge_filter=*/[](const Edge& edge) { + return !edge.src()->IsNextIteration(); + }); + + auto resource_op_set_for_node = + absl::make_unique<ResourceOpSet[]>(g.num_node_ids()); + + const bool vlog = VLOG_IS_ON(2); + + for (Node* n : rpo) { + absl::optional<XlaResourceOpKind> op_kind; + TF_RETURN_IF_ERROR(XlaResourceOpKindForNode( + *n, flib_def, resource_ops_to_ignore, &op_kind)); + + ResourceOpSet* resource_op_set = &resource_op_set_for_node[n->id()]; + + // Merge the reaching resource operations for all the incoming edges to + // create the set of all possible resource ops reaching `n`. + for (const Edge* e : n->in_edges()) { + if (n->IsMerge() && e->src()->IsNextIteration()) { + // Ignore back-edges (see file comment). + continue; + } + + const ResourceOpSet& incoming_op_set = + resource_op_set_for_node[e->src()->id()]; + resource_op_set->Add(incoming_op_set); + } + + // Add to the "incompatible resource ops" set if necessary. + if (op_kind) { + for (ResourceOp incoming_op : *resource_op_set) { + if (IsEdgeSafe(incoming_op.second, *op_kind)) { + continue; + } + + if (vlog) { + VLOG(2) << "Unsafe edge: " + << NodeToString(*g.FindNodeId(incoming_op.first), + incoming_op.second) + << " -> " << NodeToString(*n, *op_kind); + } + result->push_back({incoming_op.first, n->id()}); + } + + resource_op_set->Add({n->id(), *op_kind}); + } + + if (vlog) { + VLOG(3) << n->name() << " -> " << ResourceOpSetToString(*resource_op_set); + } + } + + std::sort(result->begin(), result->end()); + CHECK(std::unique(result->begin(), result->end()) == result->end()); + + return Status::OK(); +} +} // namespace tensorflow diff --git a/tensorflow/compiler/jit/resource_operation_safety_analysis.h b/tensorflow/compiler/jit/resource_operation_safety_analysis.h new file mode 100644 index 0000000000..ae8cfeecad --- /dev/null +++ b/tensorflow/compiler/jit/resource_operation_safety_analysis.h @@ -0,0 +1,73 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_JIT_RESOURCE_OPERATION_SAFETY_ANALYSIS_H_ +#define TENSORFLOW_COMPILER_JIT_RESOURCE_OPERATION_SAFETY_ANALYSIS_H_ + +#include "tensorflow/compiler/jit/graphcycles/graphcycles.h" +#include "tensorflow/core/framework/function.h" +#include "tensorflow/core/graph/graph.h" + +namespace tensorflow { +// An XLA cluster hoists all resource reads to be beginning of the cluster +// execution and all the resource writes to the end. This means it cannot +// enforce arbitrary ordering dependencies (via control or data edges) between +// resource operations. Since all resource reads happen before all resource +// writes, edges constraining resource reads to happen before resource writes +// are fine, but all other kinds of edges are problematic. This analysis +// returns the set of pairs of resource operations that cannot be put in the +// same cluster because XLA cannot respect the dependencies between them in the +// TensorFlow program. +// +// The restrictions are not transitive: it is fine to put A and C in the same +// cluster even if the returned set contains (A,B) and (B,C). +// +// In other words, if these pairs are seen as edges in an undirected graph of +// the nodes in `g` then auto-clustering is at least as constrained as the graph +// coloring problem on this graph. +// +// +// For instance if we auto-cluster all operations in this TensorFlow graph: +// +// ReadVariablepOp0 -> ReadVariableOp1 +// | +// v +// AssignVariableOp0 -> AssignVariableOp1 +// +// we will lose the ReadVariablepOp0 -> ReadVariableOp1 and the +// AssignVariableOp0 -> AssignVariableOp1 dependencies. I.e. it is possible for +// XlaLaunchOp to issue ReadVariableOp1 before ReadVariablepOp0 since it reads +// all the resource variables when the cluster starts executing without any +// particular ordering between them; same holds for the AssignVariableOp0 -> +// AssignVariableOp1 edge. The ReadVariableOp1 -> AssignVariableOp0 edge will +// be respected by XlaLaunchOp though because all reads happen before all +// writes. +// +// +// NB! The result computed by this analysis assumes that we don't auto-cluster +// back-edges (i.e. the edges from NextIteration to Merge). +// +// NB! The result computed by this analysis assumes that we don't auto-cluster +// functional control flow nodes containing resource operations. +// +// If `resource_ops_to_ignore` is set then nodes for which it returns true are +// ignored (we pretend these nodes are not resource operations). +Status ComputeIncompatibleResourceOperationPairs( + const Graph& g, const FunctionLibraryDefinition* flib_def, + const std::function<Status(const Node&, bool*)>& resource_ops_to_ignore, + std::vector<std::pair<int, int>>* result); +} // namespace tensorflow + +#endif // TENSORFLOW_COMPILER_JIT_RESOURCE_OPERATION_SAFETY_ANALYSIS_H_ diff --git a/tensorflow/compiler/jit/resource_operation_safety_analysis_test.cc b/tensorflow/compiler/jit/resource_operation_safety_analysis_test.cc new file mode 100644 index 0000000000..e54b547abc --- /dev/null +++ b/tensorflow/compiler/jit/resource_operation_safety_analysis_test.cc @@ -0,0 +1,540 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/jit/resource_operation_safety_analysis.h" + +#include "tensorflow/cc/framework/ops.h" +#include "tensorflow/cc/ops/array_ops.h" +#include "tensorflow/cc/ops/control_flow_ops_internal.h" +#include "tensorflow/cc/ops/function_ops.h" +#include "tensorflow/cc/ops/functional_ops.h" +#include "tensorflow/cc/ops/resource_variable_ops.h" +#include "tensorflow/cc/ops/sendrecv_ops.h" +#include "tensorflow/cc/ops/standard_ops.h" +#include "tensorflow/compiler/jit/defs.h" +#include "tensorflow/compiler/tf2xla/xla_op_kernel.h" +#include "tensorflow/compiler/tf2xla/xla_op_registry.h" +#include "tensorflow/core/framework/node_def_util.h" +#include "tensorflow/core/framework/op.h" +#include "tensorflow/core/graph/algorithm.h" +#include "tensorflow/core/graph/graph_constructor.h" +#include "tensorflow/core/graph/graph_def_builder.h" +#include "tensorflow/core/graph/graph_def_builder_util.h" +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/lib/strings/str_util.h" +#include "tensorflow/core/platform/test.h" + +namespace tensorflow { +namespace { + +Node* MakeRead(const Scope& scope, const string& id) { + Output var_handle = + ops::VarHandleOp(scope.WithOpName("Var" + id), DT_FLOAT, TensorShape({})); + Output read = + ops::ReadVariableOp(scope.WithOpName("Read" + id), var_handle, DT_FLOAT); + return read.node(); +} + +Node* MakeWrite(const Scope& scope, const string& id) { + Output var_handle = + ops::VarHandleOp(scope.WithOpName("Var" + id), DT_FLOAT, TensorShape({})); + Output value_to_write = + ops::Const(scope.WithOpName("ValueToAssign" + id), 1.0f); + ops::AssignVariableOp assign_op(scope.WithOpName("Assignee" + id), var_handle, + value_to_write); + return assign_op.operation.node(); +} + +Node* MakeModify(const Scope& scope, const string& id) { + Output var_handle = + ops::VarHandleOp(scope.WithOpName("Var" + id), DT_FLOAT, TensorShape({})); + Output value_to_write = ops::Const(scope.WithOpName("Increment" + id), 1.0f); + ops::AssignAddVariableOp assign_add_op(scope.WithOpName("Increment" + id), + var_handle, value_to_write); + return assign_add_op.operation.node(); +} + +Node* MakeNeutral(const Scope& scope, const string& id) { + return ops::Const(scope.WithOpName("Const" + id), 42.0f).node(); +} + +Status ComputeIncompatiblePairs(Graph* g, + std::vector<std::pair<int, int>>* result) { + FixupSourceAndSinkEdges(g); + return ComputeIncompatibleResourceOperationPairs(*g, &g->flib_def(), {}, + result); +} + +TEST(ResourceOperationSafetyAnalysisTest, WriteRead) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* read = MakeRead(root, "R"); + Node* write = MakeWrite(root, "W"); + + root.graph()->AddControlEdge(write, read); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> write_read_pair = {write->id(), read->id()}; + EXPECT_EQ(incompatible_pairs[0], write_read_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, ReadWrite) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* read = MakeRead(root, "R"); + Node* write = MakeWrite(root, "W"); + + root.graph()->AddControlEdge(read, write); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + EXPECT_EQ(incompatible_pairs.size(), 0); +} + +TEST(ResourceOperationSafetyAnalysisTest, ReadWriteNoEdges) { + Scope root = Scope::NewRootScope().ExitOnError(); + + MakeRead(root, "R"); + MakeWrite(root, "W"); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + EXPECT_EQ(incompatible_pairs.size(), 0); +} + +TEST(ResourceOperationSafetyAnalysisTest, ReadModify) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* read = MakeRead(root, "R"); + Node* modify = MakeModify(root, "M"); + + root.graph()->AddControlEdge(read, modify); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + EXPECT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> read_modify_pair = {read->id(), modify->id()}; + EXPECT_EQ(incompatible_pairs[0], read_modify_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, ModifyRead) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* read = MakeRead(root, "R"); + Node* modify = MakeModify(root, "M"); + + root.graph()->AddControlEdge(modify, read); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> modify_read_pair = {modify->id(), read->id()}; + EXPECT_EQ(incompatible_pairs[0], modify_read_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, ModifyWrite) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* modify = MakeModify(root, "M"); + Node* write = MakeWrite(root, "W"); + + root.graph()->AddControlEdge(modify, write); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + EXPECT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> modify_write_pair = {modify->id(), write->id()}; + EXPECT_EQ(incompatible_pairs[0], modify_write_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, WriteModify) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* modify = MakeModify(root, "M"); + Node* write = MakeWrite(root, "W"); + + root.graph()->AddControlEdge(write, modify); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> write_modify_pair = {write->id(), modify->id()}; + EXPECT_EQ(incompatible_pairs[0], write_modify_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, ReadModifyWrite) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* read = MakeRead(root, "R"); + Node* modify = MakeModify(root, "M"); + Node* write = MakeWrite(root, "W"); + + root.graph()->AddControlEdge(read, modify); + root.graph()->AddControlEdge(modify, write); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + EXPECT_EQ(incompatible_pairs.size(), 2); + std::pair<int, int> modify_write_pair = {modify->id(), write->id()}; + std::pair<int, int> read_modify_pair = {read->id(), modify->id()}; + EXPECT_EQ(incompatible_pairs[0], read_modify_pair); + EXPECT_EQ(incompatible_pairs[1], modify_write_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, WriteModifyRead) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* read = MakeRead(root, "R"); + Node* modify = MakeModify(root, "M"); + Node* write = MakeWrite(root, "W"); + + root.graph()->AddControlEdge(write, modify); + root.graph()->AddControlEdge(modify, read); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 3); + + std::pair<int, int> write_modify_pair = {write->id(), modify->id()}; + std::pair<int, int> modify_read_pair = {modify->id(), read->id()}; + std::pair<int, int> write_read_pair = {write->id(), read->id()}; + EXPECT_EQ(incompatible_pairs[0], modify_read_pair); + EXPECT_EQ(incompatible_pairs[1], write_read_pair); + EXPECT_EQ(incompatible_pairs[2], write_modify_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, WriteReadModify) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* read = MakeRead(root, "R"); + Node* modify = MakeModify(root, "M"); + Node* write = MakeWrite(root, "W"); + + root.graph()->AddControlEdge(write, read); + root.graph()->AddControlEdge(read, modify); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 3); + + std::pair<int, int> write_modify_pair = {write->id(), modify->id()}; + std::pair<int, int> write_read_pair = {write->id(), read->id()}; + std::pair<int, int> read_modify_pair = {read->id(), modify->id()}; + EXPECT_EQ(incompatible_pairs[0], read_modify_pair); + EXPECT_EQ(incompatible_pairs[1], write_read_pair); + EXPECT_EQ(incompatible_pairs[2], write_modify_pair); +} + +FunctionDefLibrary CreateFunctionDefLibWithConstFunction(const string& name) { + FunctionDefLibrary flib_def; + FunctionDef func = FunctionDefHelper::Create( + /*function_name=*/name, /*in_def=*/{}, /*out_def=*/{"out: float"}, + /*attr_def*/ + {}, /*node_def=*/{FunctionDefHelper::Const("one", 1.0f)}, + /*ret_def=*/{{"out", "out:output:0"}}); + *flib_def.add_function() = std::move(func); + return flib_def; +} + +Node* MakeCall(Graph* graph, const string& callee_name, const string& node_name, + Status* status) { + NodeDef call_node; + call_node.set_name(node_name); + call_node.set_op(callee_name); + return graph->AddNode(call_node, status); +} + +TEST(ResourceOperationSafetyAnalysisTest, CallRead) { + Scope root = Scope::NewRootScope().ExitOnError(); + + FunctionDefLibrary flib_def = + CreateFunctionDefLibWithConstFunction("Const_func"); + TF_ASSERT_OK(root.graph()->AddFunctionLibrary(flib_def)); + + Node* read = MakeRead(root, "R"); + Status status; + Node* call = MakeCall(root.graph(), "Const_func", "C", &status); + TF_ASSERT_OK(status); + + root.graph()->AddControlEdge(call, read); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> call_read_edge = {call->id(), read->id()}; + EXPECT_EQ(incompatible_pairs[0], call_read_edge); +} + +TEST(ResourceOperationSafetyAnalysisTest, ReadCall) { + Scope root = Scope::NewRootScope().ExitOnError(); + + FunctionDefLibrary flib_def = + CreateFunctionDefLibWithConstFunction("Const_func"); + TF_ASSERT_OK(root.graph()->AddFunctionLibrary(flib_def)); + + Node* read = MakeRead(root, "R"); + Status status; + Node* call = MakeCall(root.graph(), "Const_func", "C", &status); + TF_ASSERT_OK(status); + + root.graph()->AddControlEdge(read, call); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> read_call_edge = {read->id(), call->id()}; + EXPECT_EQ(incompatible_pairs[0], read_call_edge); +} + +TEST(ResourceOperationSafetyAnalysisTest, CallWrite) { + Scope root = Scope::NewRootScope().ExitOnError(); + + FunctionDefLibrary flib_def = + CreateFunctionDefLibWithConstFunction("Const_func"); + TF_ASSERT_OK(root.graph()->AddFunctionLibrary(flib_def)); + + Node* write = MakeWrite(root, "W"); + Status status; + Node* call = MakeCall(root.graph(), "Const_func", "C", &status); + TF_ASSERT_OK(status); + + root.graph()->AddControlEdge(call, write); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> call_write_edge = {call->id(), write->id()}; + EXPECT_EQ(incompatible_pairs[0], call_write_edge); +} + +TEST(ResourceOperationSafetyAnalysisTest, WriteCall) { + Scope root = Scope::NewRootScope().ExitOnError(); + + FunctionDefLibrary flib_def = + CreateFunctionDefLibWithConstFunction("Const_func"); + TF_ASSERT_OK(root.graph()->AddFunctionLibrary(flib_def)); + + Node* write = MakeWrite(root, "W"); + Status status; + Node* call = MakeCall(root.graph(), "Const_func", "C", &status); + TF_ASSERT_OK(status); + + root.graph()->AddControlEdge(write, call); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> write_call_edge = {write->id(), call->id()}; + EXPECT_EQ(incompatible_pairs[0], write_call_edge); +} + +TEST(ResourceOperationSafetyAnalysisTest, SymbolicGradientRead) { + Scope root = Scope::NewRootScope().ExitOnError(); + + FunctionDefLibrary flib_def = + CreateFunctionDefLibWithConstFunction("Const_func"); + TF_ASSERT_OK(root.graph()->AddFunctionLibrary(flib_def)); + + Node* read = MakeRead(root, "R"); + NameAttrList fn; + fn.set_name("Const_func"); + Node* symbolic_gradient = + ops::SymbolicGradient(root, /*input=*/{ops::Const(root, 1.0f)}, + /*Tout=*/{DT_FLOAT}, fn) + .output[0] + .node(); + + root.graph()->AddControlEdge(symbolic_gradient, read); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> symbolic_gradient_read_edge = {symbolic_gradient->id(), + read->id()}; + EXPECT_EQ(incompatible_pairs[0], symbolic_gradient_read_edge); +} + +TEST(ResourceOperationSafetyAnalysisTest, WriteSymbolicGradient) { + Scope root = Scope::NewRootScope().ExitOnError(); + + FunctionDefLibrary flib_def = + CreateFunctionDefLibWithConstFunction("Const_func"); + TF_ASSERT_OK(root.graph()->AddFunctionLibrary(flib_def)); + + Node* write = MakeWrite(root, "W"); + NameAttrList fn; + fn.set_name("Const_func"); + Node* symbolic_gradient = + ops::SymbolicGradient(root, /*input=*/{ops::Const(root, 1.0f)}, + /*Tout=*/{DT_FLOAT}, fn) + .output[0] + .node(); + + root.graph()->AddControlEdge(write, symbolic_gradient); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + std::pair<int, int> write_symbolic_gradient_edge = {write->id(), + symbolic_gradient->id()}; + EXPECT_EQ(incompatible_pairs[0], write_symbolic_gradient_edge); +} + +TEST(ResourceOperationSafetyAnalysisTest, ChainOfOps) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* write_0 = MakeWrite(root, "W0"); + Node* neutral_0 = MakeNeutral(root, "N0"); + Node* read_0 = MakeRead(root, "R0"); + Node* write_1 = MakeWrite(root, "W1"); + Node* neutral_1 = MakeNeutral(root, "N1"); + Node* read_1 = MakeRead(root, "R1"); + + root.graph()->AddControlEdge(write_0, neutral_0); + root.graph()->AddControlEdge(neutral_0, read_0); + root.graph()->AddControlEdge(read_0, write_1); + root.graph()->AddControlEdge(write_1, neutral_1); + root.graph()->AddControlEdge(neutral_1, read_1); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 5); + std::pair<int, int> write_0_read_0_pair = {write_0->id(), read_0->id()}; + std::pair<int, int> write_0_read_1_pair = {write_0->id(), read_1->id()}; + std::pair<int, int> write_1_read_1_pair = {write_1->id(), read_1->id()}; + std::pair<int, int> write_0_write_1_pair = {write_0->id(), write_1->id()}; + std::pair<int, int> read_0_read_1_pair = {read_0->id(), read_1->id()}; + + EXPECT_EQ(incompatible_pairs[0], write_0_read_0_pair); + EXPECT_EQ(incompatible_pairs[1], write_0_write_1_pair); + EXPECT_EQ(incompatible_pairs[2], write_0_read_1_pair); + EXPECT_EQ(incompatible_pairs[3], read_0_read_1_pair); + EXPECT_EQ(incompatible_pairs[4], write_1_read_1_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, DagOfOps) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* write_0 = MakeWrite(root, "W0"); + Node* write_1 = MakeWrite(root, "W1"); + Node* neutral = MakeNeutral(root, "N"); + Node* read_0 = MakeRead(root, "R0"); + Node* read_1 = MakeRead(root, "R1"); + + root.graph()->AddControlEdge(write_0, neutral); + root.graph()->AddControlEdge(write_1, neutral); + root.graph()->AddControlEdge(neutral, read_0); + root.graph()->AddControlEdge(neutral, read_1); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 4); + std::pair<int, int> write_0_read_0_pair = {write_0->id(), read_0->id()}; + std::pair<int, int> write_0_read_1_pair = {write_0->id(), read_1->id()}; + std::pair<int, int> write_1_read_0_pair = {write_1->id(), read_0->id()}; + std::pair<int, int> write_1_read_1_pair = {write_1->id(), read_1->id()}; + + EXPECT_EQ(incompatible_pairs[0], write_0_read_0_pair); + EXPECT_EQ(incompatible_pairs[1], write_0_read_1_pair); + EXPECT_EQ(incompatible_pairs[2], write_1_read_0_pair); + EXPECT_EQ(incompatible_pairs[3], write_1_read_1_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, DagOfOpsWithRepeatedPaths) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Node* write_0 = MakeWrite(root, "W0"); + Node* write_1 = MakeWrite(root, "W1"); + Node* neutral = MakeNeutral(root, "N"); + Node* read_0 = MakeRead(root, "R0"); + Node* read_1 = MakeRead(root, "R1"); + + root.graph()->AddControlEdge(write_0, neutral); + root.graph()->AddControlEdge(write_1, neutral); + root.graph()->AddControlEdge(neutral, read_0); + root.graph()->AddControlEdge(neutral, read_1); + root.graph()->AddControlEdge(write_1, read_1); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 4); + std::pair<int, int> write_0_read_0_pair = {write_0->id(), read_0->id()}; + std::pair<int, int> write_0_read_1_pair = {write_0->id(), read_1->id()}; + std::pair<int, int> write_1_read_0_pair = {write_1->id(), read_0->id()}; + std::pair<int, int> write_1_read_1_pair = {write_1->id(), read_1->id()}; + + EXPECT_EQ(incompatible_pairs[0], write_0_read_0_pair); + EXPECT_EQ(incompatible_pairs[1], write_0_read_1_pair); + EXPECT_EQ(incompatible_pairs[2], write_1_read_0_pair); + EXPECT_EQ(incompatible_pairs[3], write_1_read_1_pair); +} + +TEST(ResourceOperationSafetyAnalysisTest, Loop) { + Scope root = Scope::NewRootScope().ExitOnError(); + + Output init_value = ops::Placeholder(root.WithOpName("init"), DT_FLOAT); + Output loop_cond = ops::Placeholder(root.WithOpName("init"), DT_BOOL); + Output enter_value = + ops::internal::Enter(root.WithOpName("enter"), init_value, "fr"); + ops::Merge iv(root.WithOpName("iv"), {enter_value, enter_value}); + ops::Switch latch(root.WithOpName("latch"), iv.output, loop_cond); + ops::internal::Exit exit(root.WithOpName("exit"), iv.output); + Output next_iteration = + ops::NextIteration(root.WithOpName("next_iteration"), latch.output_true); + TF_ASSERT_OK( + root.graph()->UpdateEdge(next_iteration.node(), 0, iv.output.node(), 1)); + + Node* write = MakeWrite(root, "W"); + Node* read = MakeRead(root, "R"); + + root.graph()->AddControlEdge(iv.output.node(), write); + root.graph()->AddControlEdge(write, read); + root.graph()->AddControlEdge(read, next_iteration.node()); + + std::vector<std::pair<int, int>> incompatible_pairs; + TF_ASSERT_OK(ComputeIncompatiblePairs(root.graph(), &incompatible_pairs)); + + ASSERT_EQ(incompatible_pairs.size(), 1); + + std::pair<int, int> write_read_pair = {write->id(), read->id()}; + EXPECT_EQ(incompatible_pairs[0], write_read_pair); +} + +bool IsResourceArgDef(const OpDef::ArgDef& arg_def) { + return arg_def.type() == DT_RESOURCE; +} +} // namespace +} // namespace tensorflow diff --git a/tensorflow/compiler/jit/xla_cluster_util.cc b/tensorflow/compiler/jit/xla_cluster_util.cc index 0a025a1fc0..4f2fabd658 100644 --- a/tensorflow/compiler/jit/xla_cluster_util.cc +++ b/tensorflow/compiler/jit/xla_cluster_util.cc @@ -17,6 +17,7 @@ limitations under the License. #include <unordered_map> +#include "tensorflow/compiler/jit/resource_operation_safety_analysis.h" #include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/graph/control_flow.h" #include "tensorflow/core/kernels/bounds_check.h" @@ -185,14 +186,14 @@ Status CreateCycleDetectionGraph(const Graph* graph, GraphCycles* cycles) { return Status::OK(); } -gtl::optional<StringPiece> GetXlaClusterForNode(const Node& node) { +absl::optional<StringPiece> GetXlaClusterForNode(const Node& node) { const AttrValue* attr_value = node.attrs().Find(kXlaClusterAttr); if (attr_value == nullptr) { - return gtl::nullopt; + return absl::nullopt; } Status s = AttrValueHasType(*attr_value, "string"); if (!s.ok()) { - return gtl::nullopt; + return absl::nullopt; } return attr_value->s(); } @@ -207,4 +208,27 @@ bool HasResourceInputOrOutput(const Node& node) { void RemoveFromXlaCluster(NodeDef* node_def) { node_def->mutable_attr()->erase(kXlaClusterAttr); } + +Status AdjustCycleDetectionGraphForResourceOps( + const Graph* graph, const FunctionLibraryDefinition* flib_def, + const std::function<Status(const Node&, bool*)>& resource_ops_to_ignore, + GraphCycles* cycles) { + std::vector<std::pair<int, int>> unsafe_deps; + TF_RETURN_IF_ERROR(ComputeIncompatibleResourceOperationPairs( + *graph, flib_def, resource_ops_to_ignore, &unsafe_deps)); + + // An edge {P,Q} in `unsafe_deps` denotes that P and Q, both of which are + // operations that interact with resource variables, must not be put in the + // same cluster. We enforce this constraint by creating a phantom node, X, + // and adding edges P->X and X->Q. MarkForCompilation then cannot cluster P + // and Q together since that would create a cycle with X. + + for (std::pair<int, int> unsafe_dep : unsafe_deps) { + int phantom_node_id = cycles->NewNode(); + CHECK(cycles->InsertEdge(unsafe_dep.first, phantom_node_id)); + CHECK(cycles->InsertEdge(phantom_node_id, unsafe_dep.second)); + } + return Status::OK(); +} + } // namespace tensorflow diff --git a/tensorflow/compiler/jit/xla_cluster_util.h b/tensorflow/compiler/jit/xla_cluster_util.h index bff76da6f9..b0439a63ca 100644 --- a/tensorflow/compiler/jit/xla_cluster_util.h +++ b/tensorflow/compiler/jit/xla_cluster_util.h @@ -18,9 +18,9 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_JIT_XLA_CLUSTER_UTIL_H_ #define TENSORFLOW_COMPILER_JIT_XLA_CLUSTER_UTIL_H_ +#include "absl/types/optional.h" #include "tensorflow/compiler/jit/graphcycles/graphcycles.h" #include "tensorflow/core/graph/algorithm.h" -#include "tensorflow/core/lib/gtl/optional.h" namespace tensorflow { @@ -47,7 +47,7 @@ Status CreateCycleDetectionGraph(const Graph* graph, GraphCycles* cycles); // Returns the XLA cluster in which `node` is placed if it is in an XLA cluster, // otherwise returns nullopt. -gtl::optional<StringPiece> GetXlaClusterForNode(const Node& node); +absl::optional<StringPiece> GetXlaClusterForNode(const Node& node); // Removes `node_def` its XLA cluster (by clearing its _XlaCluster attribute). void RemoveFromXlaCluster(NodeDef* node_def); @@ -55,6 +55,13 @@ void RemoveFromXlaCluster(NodeDef* node_def); // Returns true if `node` has a DT_RESOURCE typed input or output. bool HasResourceInputOrOutput(const Node& node); +// Adds edges to `cycles` to prevent clustering resource operations that cannot +// be legally clustered. +Status AdjustCycleDetectionGraphForResourceOps( + const Graph* graph, const FunctionLibraryDefinition* flib_def, + const std::function<Status(const Node&, bool*)>& resource_ops_to_ignore, + GraphCycles* cycles); + } // namespace tensorflow #endif // TENSORFLOW_COMPILER_JIT_XLA_CLUSTER_UTIL_H_ diff --git a/tensorflow/compiler/jit/xla_cluster_util_test.cc b/tensorflow/compiler/jit/xla_cluster_util_test.cc index 2cb351e1ec..65bbf3efe8 100644 --- a/tensorflow/compiler/jit/xla_cluster_util_test.cc +++ b/tensorflow/compiler/jit/xla_cluster_util_test.cc @@ -25,7 +25,6 @@ limitations under the License. #include "tensorflow/core/graph/graph_def_builder.h" #include "tensorflow/core/graph/testlib.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/test.h" namespace tensorflow { diff --git a/tensorflow/compiler/jit/xla_compilation_cache.cc b/tensorflow/compiler/jit/xla_compilation_cache.cc index 7140d47a94..ef6b0e67d3 100644 --- a/tensorflow/compiler/jit/xla_compilation_cache.cc +++ b/tensorflow/compiler/jit/xla_compilation_cache.cc @@ -230,7 +230,7 @@ Status XlaCompilationCache::Compile( const std::map<int, OptionalTensor>& variable_args, OpKernelContext* ctx, const XlaCompiler::CompilationResult** compilation_result, xla::LocalExecutable** executable, - const XlaCompiler::CompileOptions* compile_options) { + const XlaCompiler::CompileOptions& compile_options) { return CompileImpl(options, function, constant_args, variable_args, ctx, compilation_result, executable, compile_options, false); } @@ -241,7 +241,7 @@ Status XlaCompilationCache::CompileSingleOp( const std::map<int, OptionalTensor>& variable_args, OpKernelContext* ctx, const XlaCompiler::CompilationResult** compilation_result, xla::LocalExecutable** executable, - const XlaCompiler::CompileOptions* compile_options) { + const XlaCompiler::CompileOptions& compile_options) { const NodeDef& def = ctx->op_kernel().def(); NameAttrList name; name.set_name(def.op()); @@ -256,7 +256,7 @@ Status XlaCompilationCache::CompileImpl( const std::map<int, OptionalTensor>& variable_args, OpKernelContext* ctx, const XlaCompiler::CompilationResult** compilation_result, xla::LocalExecutable** executable, - const XlaCompiler::CompileOptions* compile_options, + const XlaCompiler::CompileOptions& compile_options, bool compile_single_op) { CHECK_NE(executable, nullptr); VLOG(1) << "XlaCompilationCache::Compile " << DebugString(); @@ -324,13 +324,12 @@ Status XlaCompilationCache::CompileImpl( entry->compiled = true; if (compile_single_op) { - entry->compilation_status = compiler.CompileSingleOp( - compile_options ? *compile_options : XlaCompiler::CompileOptions(), - signature.name, ctx, args, &entry->compilation_result); + entry->compilation_status = + compiler.CompileSingleOp(compile_options, signature.name, ctx, args, + &entry->compilation_result); } else { entry->compilation_status = compiler.CompileFunction( - compile_options ? *compile_options : XlaCompiler::CompileOptions(), - function, args, &entry->compilation_result); + compile_options, function, args, &entry->compilation_result); } TF_RETURN_IF_ERROR(entry->compilation_status); CHECK_EQ(entry->executable.get(), nullptr); diff --git a/tensorflow/compiler/jit/xla_compilation_cache.h b/tensorflow/compiler/jit/xla_compilation_cache.h index fc5f008f4f..10ad87e38c 100644 --- a/tensorflow/compiler/jit/xla_compilation_cache.h +++ b/tensorflow/compiler/jit/xla_compilation_cache.h @@ -70,7 +70,7 @@ class XlaCompilationCache : public ResourceBase { OpKernelContext* ctx, const XlaCompiler::CompilationResult** compilation_result, xla::LocalExecutable** executable, - const XlaCompiler::CompileOptions* compile_options); + const XlaCompiler::CompileOptions& compile_options); // As above, but calls XlaCompiler::CompileSingleOp instead of // XlaCompiler::CompileFunction. @@ -80,7 +80,7 @@ class XlaCompilationCache : public ResourceBase { const std::map<int, OptionalTensor>& variable_args, OpKernelContext* ctx, const XlaCompiler::CompilationResult** compilation_result, xla::LocalExecutable** executable, - const XlaCompiler::CompileOptions* compile_options); + const XlaCompiler::CompileOptions& compile_options); xla::LocalClient* client() const { return client_; } const DeviceType& device_type() const { return device_type_; } @@ -96,7 +96,7 @@ class XlaCompilationCache : public ResourceBase { OpKernelContext* ctx, const XlaCompiler::CompilationResult** compilation_result, xla::LocalExecutable** executable, - const XlaCompiler::CompileOptions* compile_options, + const XlaCompiler::CompileOptions& compile_options, bool compile_single_op); // Takes `result` which has been compiled from a Tensorflow subgraph to a diff --git a/tensorflow/compiler/jit/xla_compile_on_demand_op.cc b/tensorflow/compiler/jit/xla_compile_on_demand_op.cc index dd84fb34c1..3ba48e8c31 100644 --- a/tensorflow/compiler/jit/xla_compile_on_demand_op.cc +++ b/tensorflow/compiler/jit/xla_compile_on_demand_op.cc @@ -177,7 +177,7 @@ Status XlaCompileOnDemandOp::Compile( std::map<int, OptionalTensor> variable_args = GetVariables(ctx); return cache->CompileSingleOp(options, constant_arguments, variable_args, ctx, - result, executable, &compile_options); + result, executable, compile_options); } void XlaCompileOnDemandOp::Compute(OpKernelContext* ctx) { diff --git a/tensorflow/compiler/jit/xla_device.cc b/tensorflow/compiler/jit/xla_device.cc index 2a2691a6a4..50c902fdfc 100644 --- a/tensorflow/compiler/jit/xla_device.cc +++ b/tensorflow/compiler/jit/xla_device.cc @@ -18,6 +18,7 @@ limitations under the License. #include <stdlib.h> #include <unordered_set> +#include "absl/memory/memory.h" #include "tensorflow/compiler/jit/defs.h" #include "tensorflow/compiler/jit/xla_compile_on_demand_op.h" #include "tensorflow/compiler/jit/xla_device_context.h" @@ -101,7 +102,7 @@ XlaDeviceAllocator* XlaDeviceAllocatorState::GetOrCreateXlaDeviceAllocator( } std::unique_ptr<XlaDeviceAllocator> alloc = - xla::MakeUnique<XlaDeviceAllocator>(); + absl::make_unique<XlaDeviceAllocator>(); XlaDeviceAllocator* alloc_ptr = alloc.get(); state.allocators_[{backend, device_ordinal}] = std::move(alloc); return alloc_ptr; @@ -327,7 +328,7 @@ xla::StatusOr<XlaDeviceContext*> XlaDevice::GetDeviceContextLocked() { // to those methods; see the bug for details. Our only saving grace at the // moment is that this race doesn't seem to occur in practice. if (use_gpu_device_info_) { - auto gpu_device_info = MakeUnique<GpuDeviceInfo>(); + auto gpu_device_info = absl::make_unique<GpuDeviceInfo>(); gpu_device_info->stream = stream_.get(); gpu_device_info->default_context = device_context_; set_tensorflow_gpu_device_info(gpu_device_info.get()); @@ -364,11 +365,7 @@ Status XlaDevice::FillContextMap(const Graph* graph, void XlaDevice::Compute(OpKernel* op_kernel, OpKernelContext* context) { VLOG(2) << "XlaDevice::Compute " << op_kernel->name() << ":" << op_kernel->type_string(); - // When Xprof profiling is off (which is the default), constructing the - // activity is simple enough that its overhead is negligible. - tracing::ScopedActivity activity(op_kernel->name(), op_kernel->type_string(), - op_kernel->IsExpensive()); - op_kernel->Compute(context); + TracingDevice::Compute(op_kernel, context); } void XlaDevice::ComputeAsync(AsyncOpKernel* op_kernel, OpKernelContext* context, diff --git a/tensorflow/compiler/jit/xla_device_context.cc b/tensorflow/compiler/jit/xla_device_context.cc index 0a0c089241..ee07c5c964 100644 --- a/tensorflow/compiler/jit/xla_device_context.cc +++ b/tensorflow/compiler/jit/xla_device_context.cc @@ -91,7 +91,8 @@ Status XlaTransferManager::TransferLiteralToDevice( const xla::ShapedBuffer& shaped_buffer = xla_tensor->shaped_buffer(); VLOG(1) << "Transfer to device as literal: " << literal->ToString() << " " << shaped_buffer.ToString(); - if (UseMultipleStreams()) { + if (UseMultipleStreams() && !transfer_manager_->CanShapedBufferBeAccessedNow( + stream_->parent(), shaped_buffer)) { // Initially wait for the compute stream so that memory allocations are // synchronized. host_to_device_stream_->ThenWaitFor(stream_.get()); @@ -123,11 +124,11 @@ void XlaTransferManager::TransferLiteralFromDevice( TensorReference ref(device_tensor); transfer_manager_->TransferLiteralFromDevice( device_to_host_stream_.get(), shaped_buffer, literal, - [=, &shaped_buffer, &literal](xla::Status status) { + [=, &shaped_buffer](xla::Status status) { ref.Unref(); done([&]() -> Status { - VLOG(1) << "Transfer from device as literal: " << literal.ToString() - << " " << shaped_buffer.ToString(); + VLOG(1) << "Transfer from device as literal: " + << shaped_buffer.ToString(); return status; }()); }); @@ -183,18 +184,6 @@ void XlaTransferManager::CopyCPUTensorToDevice(const Tensor* cpu_tensor, return; } status = TransferLiteralToDevice(reshaped_cpu_tensor, device_tensor); - if (status.ok()) { - xla_tensor->set_host_tensor(*cpu_tensor); - host_to_device_stream_->ThenDoHostCallback([this, done]() { - // We must not call the done closure directly from DoHostCallback - // to avoid a deadlock. If done() is the callback that ends an - // Executor's run, the Executor may call XlaDevice::Sync() inside the - // callback. This deadlocks, because XlaDevice::Sync() waits for all - // stream activity to complete. - thread_pool_->Schedule([done]() { done(Status::OK()); }); - }); - return; - } } else { se::DeviceMemoryBase dev_dst_ptr = XlaTensor::DeviceMemoryFromTensor(*device_tensor); @@ -207,8 +196,9 @@ void XlaTransferManager::CopyCPUTensorToDevice(const Tensor* cpu_tensor, host_to_device_stream_.get(), block_status.error_message().c_str()); } } - xla_tensor->set_host_tensor(*cpu_tensor); - + if (status.ok()) { + xla_tensor->set_host_tensor(*cpu_tensor); + } done(status); } diff --git a/tensorflow/compiler/jit/xla_device_ops.h b/tensorflow/compiler/jit/xla_device_ops.h index da3e329247..13da5d2f94 100644 --- a/tensorflow/compiler/jit/xla_device_ops.h +++ b/tensorflow/compiler/jit/xla_device_ops.h @@ -215,6 +215,8 @@ class XlaAssignVariableOp : public AsyncOpKernel { AnonymousIteratorHandleOp); \ REGISTER_KERNEL_BUILDER(Name("IteratorGetNext").Device(DEVICE), \ IteratorGetNextOp); \ + REGISTER_KERNEL_BUILDER(Name("IteratorGetNextSync").Device(DEVICE), \ + IteratorGetNextSyncOp); \ REGISTER_KERNEL_BUILDER(Name("IteratorToStringHandle") \ .Device(DEVICE) \ .HostMemory("string_handle"), \ diff --git a/tensorflow/compiler/jit/xla_fusion_optimizer.cc b/tensorflow/compiler/jit/xla_fusion_optimizer.cc index 4b499b1613..07cfab6151 100644 --- a/tensorflow/compiler/jit/xla_fusion_optimizer.cc +++ b/tensorflow/compiler/jit/xla_fusion_optimizer.cc @@ -41,8 +41,8 @@ static bool IsShapeConsumerOp(const Node& node) { } // Returns true if the op can be decomposed into XLA ops for which -// there are fusable elemental implementations. -bool IsXlaFusable(const NodeDef& node) { +// there are fusible elemental implementations. +static bool IsXlaFusible(const NodeDef& node) { static const std::unordered_set<std::string>* elementwise_ops = new std::unordered_set<std::string>( {// tf2xla/kernels/aggregate_ops.cc @@ -176,9 +176,9 @@ Status XlaFusionOptimizer::Optimize(grappler::Cluster* cluster, TF_RETURN_IF_ERROR(DeviceToDeviceType(node->def().device(), &device_type)); if (device_type.type_string().find("XLA") != string::npos) continue; - // Assume all fusable ops are registered. + // Assume all fusible ops are registered. // TODO(hpucha): Check for registration if possible. - if (!IsXlaFusable(node->def())) { + if (!IsXlaFusible(node->def())) { continue; } @@ -208,6 +208,8 @@ Status XlaFusionOptimizer::Optimize(grappler::Cluster* cluster, GraphCycles cycles; TF_RETURN_IF_ERROR(CreateCycleDetectionGraph(&graph, &cycles)); + TF_RETURN_IF_ERROR(AdjustCycleDetectionGraphForResourceOps( + &graph, &graph.flib_def(), /*resource_ops_to_ignore=*/{}, &cycles)); // TODO(hpucha): Make clustering more robust. There are two known issues that // we need to mitigate: (a) Non-resource variables can cause deadlocks diff --git a/tensorflow/compiler/jit/xla_fusion_optimizer_test.cc b/tensorflow/compiler/jit/xla_fusion_optimizer_test.cc index 5736760a87..68e19c8a13 100644 --- a/tensorflow/compiler/jit/xla_fusion_optimizer_test.cc +++ b/tensorflow/compiler/jit/xla_fusion_optimizer_test.cc @@ -14,6 +14,8 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/jit/xla_fusion_optimizer.h" +#include "tensorflow/cc/ops/resource_variable_ops.h" +#include "tensorflow/cc/ops/standard_ops.h" #include "tensorflow/compiler/jit/defs.h" #include "tensorflow/compiler/jit/xla_cluster_util.h" #include "tensorflow/core/graph/graph_def_builder.h" @@ -71,7 +73,7 @@ TEST_F(XlaFusionOptimizerTest, Chains) { EXPECT_TRUE(clusters.find("D") == clusters.cend()); } -TEST_F(XlaFusionOptimizerTest, FusableOps) { +TEST_F(XlaFusionOptimizerTest, FusibleOps) { GraphDef graph; { GraphDefBuilder builder(GraphDefBuilder::kFailImmediately); @@ -179,5 +181,28 @@ TEST_F(XlaFusionOptimizerTest, CompilableCycles) { EXPECT_EQ(clusters["A"], clusters["C"]); } +TEST_F(XlaFusionOptimizerTest, ResourcesClusteringDisallowed) { + Scope root = Scope::NewRootScope().ExitOnError(); + Output var_handle = + ops::VarHandleOp(root.WithOpName("Var"), DT_FLOAT, TensorShape({})); + Output to_assign = ops::Const(root.WithOpName("Const"), 10.0f); + Output begin = ops::Const(root.WithOpName("begin"), 0); + Output end = ops::Const(root.WithOpName("end"), 1); + Output strides = ops::Const(root.WithOpName("strides"), 1); + ops::ResourceStridedSliceAssign assign_1( + root.WithOpName("assign_1"), var_handle, begin, end, strides, to_assign); + ops::ResourceStridedSliceAssign assign_2( + root.WithOpName("assign_2"), var_handle, begin, end, strides, to_assign); + root.graph()->AddControlEdge(assign_1.operation.node(), + assign_2.operation.node()); + grappler::GrapplerItem item; + root.graph()->ToGraphDef(&item.graph); + + XlaFusionOptimizer optimizer; + GraphDef output; + TF_ASSERT_OK(optimizer.Optimize(nullptr, item, &output)); + auto clusters = GetClusters(output); + EXPECT_NE(clusters["assign_1"], clusters["assign_2"]); +} } // namespace } // namespace tensorflow diff --git a/tensorflow/compiler/jit/xla_launch_util.cc b/tensorflow/compiler/jit/xla_launch_util.cc index 4efbb2d5d7..affeab4a8c 100644 --- a/tensorflow/compiler/jit/xla_launch_util.cc +++ b/tensorflow/compiler/jit/xla_launch_util.cc @@ -17,6 +17,7 @@ limitations under the License. #include <memory> +#include "absl/memory/memory.h" #include "tensorflow/compiler/jit/defs.h" #include "tensorflow/compiler/tf2xla/shape_util.h" #include "tensorflow/compiler/tf2xla/xla_compiler.h" @@ -175,7 +176,7 @@ void XlaComputationLaunchContext::PopulateInputs( << " not the same as on-host shape " << xla::ShapeUtil::HumanStringWithLayout(shape); se::DeviceMemoryBase dmem = XlaTensor::DeviceMemoryFromTensor(*t); - arg_buffers_[i] = xla::MakeUnique<ShapedBuffer>( + arg_buffers_[i] = absl::make_unique<ShapedBuffer>( /*on_host_shape=*/shape, /*on_device_shape=*/shape, client_->platform(), client_->default_device_ordinal()); arg_buffers_[i]->set_buffer(dmem, /*index=*/{}); @@ -270,31 +271,36 @@ Status XlaComputationLaunchContext::PopulateOutputs( } } else { const TensorShape& shape = kernel->outputs[i].shape; - VLOG(2) << "Retval " << i << " shape " << shape.DebugString(); - - se::DeviceMemoryBase buffer = output.buffer({output_num}); - if (allocate_xla_tensors_) { - Tensor* output_tensor; - TF_RETURN_IF_ERROR(ctx->allocate_output(i, shape, &output_tensor)); - XlaTensor* xla_tensor = XlaTensor::FromTensor(output_tensor); - if (xla_tensor) { - xla_tensor->set_shaped_buffer(ScopedShapedBuffer( - ExtractSubShapedBuffer(&output, output_num, xla_allocator_))); - if (use_multiple_streams_) { - xla_tensor->SetDefinedOn(stream, definition_event); + const DataType& type = kernel->outputs[i].type; + VLOG(2) << "Retval " << i << " shape " << shape.DebugString() << " type " + << DataTypeString(type); + if (type == DT_RESOURCE) { + ctx->set_output(i, ctx->input(kernel->outputs[i].input_index)); + } else { + se::DeviceMemoryBase buffer = output.buffer({output_num}); + if (allocate_xla_tensors_) { + Tensor* output_tensor; + TF_RETURN_IF_ERROR(ctx->allocate_output(i, shape, &output_tensor)); + XlaTensor* xla_tensor = XlaTensor::FromTensor(output_tensor); + if (xla_tensor) { + xla_tensor->set_shaped_buffer(ScopedShapedBuffer( + ExtractSubShapedBuffer(&output, output_num, xla_allocator_))); + if (use_multiple_streams_) { + xla_tensor->SetDefinedOn(stream, definition_event); + } + } else { + // xla_tensor wasn't valid, which must mean this is a zero-element + // tensor. + CHECK_EQ(output_tensor->TotalBytes(), 0); } } else { - // xla_tensor wasn't valid, which must mean this is a zero-element - // tensor. - CHECK_EQ(output_tensor->TotalBytes(), 0); + Tensor output_tensor = XlaTensorBuffer::MakeTensor( + ctx->expected_output_dtype(i), shape, buffer, allocator); + output.set_buffer(xla::OwningDeviceMemory(), {output_num}); + ctx->set_output(i, output_tensor); } - } else { - Tensor output_tensor = XlaTensorBuffer::MakeTensor( - ctx->expected_output_dtype(i), shape, buffer, allocator); - output.set_buffer(xla::OwningDeviceMemory(), {output_num}); - ctx->set_output(i, output_tensor); + ++output_num; } - ++output_num; } if (VLOG_IS_ON(3)) { diff --git a/tensorflow/compiler/jit/xla_launch_util.h b/tensorflow/compiler/jit/xla_launch_util.h index 4232f514b3..7ac275fab8 100644 --- a/tensorflow/compiler/jit/xla_launch_util.h +++ b/tensorflow/compiler/jit/xla_launch_util.h @@ -167,4 +167,4 @@ xla::ScopedShapedBuffer ExtractSubShapedBuffer( } // namespace tensorflow -#endif +#endif // TENSORFLOW_COMPILER_JIT_XLA_LAUNCH_UTIL_H_ diff --git a/tensorflow/compiler/jit/xla_tensor.h b/tensorflow/compiler/jit/xla_tensor.h index 8d36d0fa0a..4c9bb2e27b 100644 --- a/tensorflow/compiler/jit/xla_tensor.h +++ b/tensorflow/compiler/jit/xla_tensor.h @@ -18,6 +18,7 @@ limitations under the License. #include <memory> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/service/shaped_buffer.h" #include "tensorflow/core/framework/allocator.h" @@ -70,7 +71,7 @@ class XlaTensor { // Mutates the XlaTensor to set the ShapedBuffer. void set_shaped_buffer(xla::ScopedShapedBuffer shaped_buffer) { shaped_buffer_ = - xla::MakeUnique<xla::ScopedShapedBuffer>(std::move(shaped_buffer)); + absl::make_unique<xla::ScopedShapedBuffer>(std::move(shaped_buffer)); } // Some tensors on the device may have known values on the host. We use these @@ -127,4 +128,4 @@ class XlaTensor { } // namespace tensorflow -#endif +#endif // TENSORFLOW_COMPILER_JIT_XLA_TENSOR_H_ diff --git a/tensorflow/compiler/tests/BUILD b/tensorflow/compiler/tests/BUILD index ae98b3f0f9..cf02926e06 100644 --- a/tensorflow/compiler/tests/BUILD +++ b/tensorflow/compiler/tests/BUILD @@ -72,7 +72,7 @@ py_test( tf_xla_py_test( name = "adadelta_test", - size = "medium", + size = "large", srcs = ["adadelta_test.py"], deps = [ ":xla_test", @@ -388,6 +388,19 @@ tf_xla_py_test( ) tf_xla_py_test( + name = "reshape_op_test", + size = "small", + srcs = ["reshape_op_test.py"], + deps = [ + "//tensorflow/compiler/tests:xla_test", + "//tensorflow/compiler/tf2xla/python:xla", + "//tensorflow/python:array_ops", + "//tensorflow/python:dtypes", + "@absl_py//absl/testing:parameterized", + ], +) + +tf_xla_py_test( name = "dynamic_stitch_test", size = "small", srcs = ["dynamic_stitch_test.py"], @@ -715,6 +728,7 @@ tf_xla_py_test( "//tensorflow/python:framework", "//tensorflow/python:math_ops", "//tensorflow/python:platform_test", + "@absl_py//absl/testing:parameterized", ], ) @@ -1177,3 +1191,19 @@ tf_xla_py_test( "//tensorflow/python:platform_test", ], ) + +tf_xla_py_test( + name = "xla_ops_test", + size = "small", + srcs = ["xla_ops_test.py"], + disabled_backends = ["cpu_ondemand"], + deps = [ + ":xla_test", + "//tensorflow/compiler/tf2xla/python:xla", + "//tensorflow/python:array_ops", + "//tensorflow/python:errors", + "//tensorflow/python:framework", + "//tensorflow/python:platform_test", + "@absl_py//absl/testing:parameterized", + ], +) diff --git a/tensorflow/compiler/tests/adadelta_test.py b/tensorflow/compiler/tests/adadelta_test.py index 3e3c09c66e..b7b7fda293 100644 --- a/tensorflow/compiler/tests/adadelta_test.py +++ b/tensorflow/compiler/tests/adadelta_test.py @@ -33,7 +33,7 @@ class AdadeltaOptimizerTest(xla_test.XLATestCase): def testBasic(self): num_updates = 4 # number of ADADELTA steps to perform for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): for grad in [0.2, 0.1, 0.01]: for lr in [1.0, 0.5, 0.1]: var0_init = [1.0, 2.0] diff --git a/tensorflow/compiler/tests/adagrad_da_test.py b/tensorflow/compiler/tests/adagrad_da_test.py index dc1625793a..69fb3ec296 100644 --- a/tensorflow/compiler/tests/adagrad_da_test.py +++ b/tensorflow/compiler/tests/adagrad_da_test.py @@ -33,7 +33,7 @@ class AdagradDAOptimizerTest(xla_test.XLATestCase): def testAdagradDAWithoutRegularizationBasic1(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): global_step = resource_variable_ops.ResourceVariable( 0, dtype=dtypes.int64) var0 = resource_variable_ops.ResourceVariable([0.0, 0.0], dtype=dtype) @@ -69,7 +69,7 @@ class AdagradDAOptimizerTest(xla_test.XLATestCase): def testAdagradDAwithoutRegularizationBasic2(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): global_step = resource_variable_ops.ResourceVariable( 0, dtype=dtypes.int64) var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) @@ -100,7 +100,7 @@ class AdagradDAOptimizerTest(xla_test.XLATestCase): def testAdagradDAWithL1(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): global_step = resource_variable_ops.ResourceVariable( 0, dtype=dtypes.int64) var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) @@ -131,7 +131,7 @@ class AdagradDAOptimizerTest(xla_test.XLATestCase): def testAdagradDAWithL1_L2(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): global_step = resource_variable_ops.ResourceVariable( 0, dtype=dtypes.int64) var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) diff --git a/tensorflow/compiler/tests/adagrad_test.py b/tensorflow/compiler/tests/adagrad_test.py index d775850a80..ab69319c59 100644 --- a/tensorflow/compiler/tests/adagrad_test.py +++ b/tensorflow/compiler/tests/adagrad_test.py @@ -32,7 +32,7 @@ class AdagradOptimizerTest(xla_test.XLATestCase): def testBasic(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -57,7 +57,7 @@ class AdagradOptimizerTest(xla_test.XLATestCase): def testTensorLearningRate(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -83,7 +83,7 @@ class AdagradOptimizerTest(xla_test.XLATestCase): def testSharing(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) diff --git a/tensorflow/compiler/tests/adamax_test.py b/tensorflow/compiler/tests/adamax_test.py index c4fdbc5974..3ed1d41b71 100644 --- a/tensorflow/compiler/tests/adamax_test.py +++ b/tensorflow/compiler/tests/adamax_test.py @@ -49,7 +49,7 @@ class AdaMaxOptimizerTest(xla_test.XLATestCase): def testBasic(self): for i, dtype in enumerate(self.float_types): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): variable_scope.get_variable_scope().set_use_resource(True) # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 @@ -100,7 +100,7 @@ class AdaMaxOptimizerTest(xla_test.XLATestCase): def testTensorLearningRate(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): variable_scope.get_variable_scope().set_use_resource(True) # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 diff --git a/tensorflow/compiler/tests/addsign_test.py b/tensorflow/compiler/tests/addsign_test.py index 9ec5a964cb..1bc07ace23 100644 --- a/tensorflow/compiler/tests/addsign_test.py +++ b/tensorflow/compiler/tests/addsign_test.py @@ -63,7 +63,7 @@ class AddSignTest(xla_test.XLATestCase): alpha=1.0, beta=0.9): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): # Initialize variables for numpy implementation. m0, m1 = 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype) diff --git a/tensorflow/compiler/tests/argminmax_test.py b/tensorflow/compiler/tests/argminmax_test.py index 9d3a889b1f..4155342787 100644 --- a/tensorflow/compiler/tests/argminmax_test.py +++ b/tensorflow/compiler/tests/argminmax_test.py @@ -40,7 +40,7 @@ class ArgMinMaxTest(xla_test.XLATestCase): op_input: numpy input array to use as input to 'op'. expected: numpy array representing the expected output of 'op'. """ - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): pinp = array_ops.placeholder( dtypes.as_dtype(op_input.dtype), op_input.shape, name="a") diff --git a/tensorflow/compiler/tests/binary_ops_test.py b/tensorflow/compiler/tests/binary_ops_test.py index 0aafda7fb4..17280e445b 100644 --- a/tensorflow/compiler/tests/binary_ops_test.py +++ b/tensorflow/compiler/tests/binary_ops_test.py @@ -36,7 +36,7 @@ class BinaryOpsTest(xla_test.XLATestCase): """Test cases for binary operators.""" def _testBinary(self, op, a, b, expected, equality_test=None): - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): pa = array_ops.placeholder(dtypes.as_dtype(a.dtype), a.shape, name="a") pb = array_ops.placeholder(dtypes.as_dtype(b.dtype), b.shape, name="b") @@ -1010,7 +1010,38 @@ class BinaryOpsTest(xla_test.XLATestCase): [7, 7, 7, 7, 7, 7]], dtype=dtype)) - def testMirrorPad(self): + def testSymmetricMirrorPad(self): + mirror_pad = lambda t, paddings: array_ops.pad(t, paddings, "SYMMETRIC") + for dtype in self.numeric_types: + self._testBinary( + mirror_pad, + np.array( + [ + [1, 2, 3], # + [4, 5, 6], # + ], + dtype=dtype), + np.array([[ + 2, + 2, + ], [3, 3]], dtype=np.int32), + expected=np.array( + [ + [6, 5, 4, 4, 5, 6, 6, 5, 4], # + [3, 2, 1, 1, 2, 3, 3, 2, 1], # + [3, 2, 1, 1, 2, 3, 3, 2, 1], # + [6, 5, 4, 4, 5, 6, 6, 5, 4], # + [6, 5, 4, 4, 5, 6, 6, 5, 4], # + [3, 2, 1, 1, 2, 3, 3, 2, 1], # + ], + dtype=dtype)) + self._testBinary( + mirror_pad, + np.array([[1, 2, 3], [4, 5, 6]], dtype=dtype), + np.array([[0, 0], [0, 0]], dtype=np.int32), + expected=np.array([[1, 2, 3], [4, 5, 6]], dtype=dtype)) + + def testReflectMirrorPad(self): mirror_pad = lambda t, paddings: array_ops.pad(t, paddings, "REFLECT") for dtype in self.numeric_types: self._testBinary( @@ -1167,6 +1198,16 @@ class BinaryOpsTest(xla_test.XLATestCase): for dtype in self.numeric_types: self._testBinary( array_ops.tile, + np.array([[6], [3], [4]], dtype=dtype), + np.array([2, 0], dtype=np.int32), + expected=np.empty([6, 0], dtype=dtype)) + self._testBinary( + array_ops.tile, + np.array([[6, 3, 4]], dtype=dtype), + np.array([2, 0], dtype=np.int32), + expected=np.empty([2, 0], dtype=dtype)) + self._testBinary( + array_ops.tile, np.array([[6]], dtype=dtype), np.array([1, 2], dtype=np.int32), expected=np.array([[6, 6]], dtype=dtype)) @@ -1362,5 +1403,40 @@ class BinaryOpsTest(xla_test.XLATestCase): [[-4.0, 0.0, 4.0], [0.0, -5.0, 0.0]]], dtype=dtype)) + def testBroadcastTo(self): + for dtype in self.all_types: + x = np.random.randint(0, high=100, size=[2, 3]) + self._testBinary( + array_ops.broadcast_to, + x, + np.array([2, 3], dtype=np.int32), + expected=x) + self._testBinary( + array_ops.broadcast_to, + x, + np.array([6, 6], dtype=np.int32), + expected=np.tile(x, [3, 2])) + self._testBinary( + array_ops.broadcast_to, + x, + np.array([7, 4, 3], dtype=np.int32), + expected=np.tile(x, [7, 2, 1])) + self._testBinary( + array_ops.broadcast_to, + x, + np.array([7, 0, 3], dtype=np.int32), + expected=np.zeros([7, 0, 3], dtype=dtype)) + self._testBinary( + array_ops.broadcast_to, + x, + np.array([7, 1, 2, 9], dtype=np.int32), + expected=np.tile(x, [7, 1, 1, 3])) + self._testBinary( + array_ops.broadcast_to, + np.zeros([2, 0], dtype=dtype), + np.array([4, 0], dtype=np.int32), + expected=np.zeros([4, 0], dtype=dtype)) + + if __name__ == "__main__": googletest.main() diff --git a/tensorflow/compiler/tests/bucketize_op_test.py b/tensorflow/compiler/tests/bucketize_op_test.py index ef4d5f6322..5c24db539b 100644 --- a/tensorflow/compiler/tests/bucketize_op_test.py +++ b/tensorflow/compiler/tests/bucketize_op_test.py @@ -29,7 +29,7 @@ from tensorflow.python.platform import test class BucketizationOpTest(xla_test.XLATestCase): def testInt(self): - with self.test_session() as sess: + with self.cached_session() as sess: p = array_ops.placeholder(dtypes.int32) with self.test_scope(): op = math_ops._bucketize(p, boundaries=[0, 3, 8, 11]) @@ -38,7 +38,7 @@ class BucketizationOpTest(xla_test.XLATestCase): sess.run(op, {p: [-5, 0, 2, 3, 5, 8, 10, 11, 12]})) def testFloat(self): - with self.test_session() as sess: + with self.cached_session() as sess: p = array_ops.placeholder(dtypes.float32) with self.test_scope(): op = math_ops._bucketize(p, boundaries=[0., 3., 8., 11.]) @@ -48,7 +48,7 @@ class BucketizationOpTest(xla_test.XLATestCase): sess.run(op, {p: [-5., 0., 2., 3., 5., 8., 10., 11., 12.]})) def test2DInput(self): - with self.test_session() as sess: + with self.cached_session() as sess: p = array_ops.placeholder(dtypes.float32) with self.test_scope(): op = math_ops._bucketize(p, boundaries=[0, 3, 8, 11]) @@ -58,7 +58,7 @@ class BucketizationOpTest(xla_test.XLATestCase): {p: [[-5, 0, 2, 3, 5], [8, 10, 11, 12, 0]]})) def testInvalidBoundariesOrder(self): - with self.test_session() as sess: + with self.cached_session() as sess: p = array_ops.placeholder(dtypes.int32) with self.test_scope(): op = math_ops._bucketize(p, boundaries=[0, 8, 3, 11]) @@ -67,7 +67,7 @@ class BucketizationOpTest(xla_test.XLATestCase): sess.run(op, {p: [-5, 0]}) def testBoundariesNotList(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesRegexp(TypeError, "Expected list.*"): p = array_ops.placeholder(dtypes.int32) with self.test_scope(): diff --git a/tensorflow/compiler/tests/categorical_op_test.py b/tensorflow/compiler/tests/categorical_op_test.py index a4e7f75081..a57d1dc81e 100644 --- a/tensorflow/compiler/tests/categorical_op_test.py +++ b/tensorflow/compiler/tests/categorical_op_test.py @@ -56,7 +56,7 @@ class CategoricalTest(xla_test.XLATestCase): Returns: Frequencies from sampled classes; shape [batch_size, num_classes]. """ - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): random_seed.set_random_seed(1618) op = random_ops.multinomial(logits, num_samples, output_dtype=dtypes.int32) @@ -79,7 +79,7 @@ class CategoricalTest(xla_test.XLATestCase): def _testRngIsNotConstant(self, rng, dtype, output_dtype): # Tests that 'rng' does not always return the same value. - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): x = rng(dtype, output_dtype) @@ -107,7 +107,7 @@ class CategoricalTest(xla_test.XLATestCase): def testCategoricalIsInRange(self): for dtype in self.float_types: for output_dtype in self.output_dtypes(): - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): x = random_ops.multinomial( array_ops.ones(shape=[1, 20], dtype=dtype), 1000, diff --git a/tensorflow/compiler/tests/cholesky_op_test.py b/tensorflow/compiler/tests/cholesky_op_test.py index ed532db0ee..d1896a50f7 100644 --- a/tensorflow/compiler/tests/cholesky_op_test.py +++ b/tensorflow/compiler/tests/cholesky_op_test.py @@ -54,7 +54,7 @@ class CholeskyOpTest(xla_test.XLATestCase): def _verifyCholesky(self, x, atol=1e-6): # Verify that LL^T == x. - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder( dtypes.as_dtype(x.dtype), shape=x.shape) with self.test_scope(): diff --git a/tensorflow/compiler/tests/clustering_test.py b/tensorflow/compiler/tests/clustering_test.py index e42ebf8f9e..88bd58b2da 100644 --- a/tensorflow/compiler/tests/clustering_test.py +++ b/tensorflow/compiler/tests/clustering_test.py @@ -38,7 +38,7 @@ class ClusteringTest(xla_test.XLATestCase): val1 = np.array([4, 3, 2, 1], dtype=np.float32) val2 = np.array([5, 6, 7, 8], dtype=np.float32) expected = val1 + val2 - with self.test_session(): + with self.cached_session(): with self.test_scope(): input1 = constant_op.constant(val1, name="const1") input2 = constant_op.constant(val2, name="const2") @@ -50,7 +50,7 @@ class ClusteringTest(xla_test.XLATestCase): val1 = np.array([4, 3, 2, 1]).astype(np.float32) val2 = np.array([5, 6, 7, 8]).astype(np.float32) expected = val1 + val2 - with self.test_session(): + with self.cached_session(): with ops.device(CPU_DEVICE): input1 = constant_op.constant(val1, name="const1") input2 = constant_op.constant(val2, name="const2") @@ -68,7 +68,7 @@ class ClusteringTest(xla_test.XLATestCase): # where x and z are placed on the CPU and y and w are placed on the XLA # device. If y and w are clustered for compilation, then the graph will # deadlock since the clustered graph will contain a self-loop. - with self.test_session() as sess: + with self.cached_session() as sess: with ops.device(CPU_DEVICE): x = array_ops.placeholder(dtypes.float32, [2]) with self.test_scope(): @@ -81,7 +81,7 @@ class ClusteringTest(xla_test.XLATestCase): self.assertAllClose(result, [12., 2.], rtol=1e-3) def testHostMemory(self): - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(dtypes.int32) with self.test_scope(): y = x + 1 diff --git a/tensorflow/compiler/tests/concat_ops_test.py b/tensorflow/compiler/tests/concat_ops_test.py index d9ad428147..37e5318bb5 100644 --- a/tensorflow/compiler/tests/concat_ops_test.py +++ b/tensorflow/compiler/tests/concat_ops_test.py @@ -33,7 +33,7 @@ from tensorflow.python.platform import googletest class ConcatTest(xla_test.XLATestCase): def testHStack(self): - with self.test_session(): + with self.cached_session(): p1 = array_ops.placeholder(dtypes.float32, shape=[4, 4]) p2 = array_ops.placeholder(dtypes.float32, shape=[4, 4]) with self.test_scope(): @@ -49,7 +49,7 @@ class ConcatTest(xla_test.XLATestCase): self.assertAllEqual(result[4:, :], params[p2]) def testVStack(self): - with self.test_session(): + with self.cached_session(): p1 = array_ops.placeholder(dtypes.float32, shape=[4, 4]) p2 = array_ops.placeholder(dtypes.float32, shape=[4, 4]) with self.test_scope(): @@ -65,7 +65,7 @@ class ConcatTest(xla_test.XLATestCase): self.assertAllEqual(result[:, 4:], params[p2]) def testInt32(self): - with self.test_session(): + with self.cached_session(): p1 = np.random.rand(2, 3).astype("i") p2 = np.random.rand(2, 3).astype("i") x1 = constant_op.constant(p1) @@ -88,7 +88,7 @@ class ConcatTest(xla_test.XLATestCase): dtype_feed = dtypes.float32 else: dtype_feed = dtype - with self.test_session(): + with self.cached_session(): p = [] for i in np.arange(num_tensors): input_shape = shape @@ -130,7 +130,7 @@ class ConcatTest(xla_test.XLATestCase): self._testRandom(dtypes.int32) def _testGradientsSimple(self): - with self.test_session(): + with self.cached_session(): inp = [] inp_tensors = [] with self.test_scope(): @@ -157,7 +157,7 @@ class ConcatTest(xla_test.XLATestCase): self._testGradientsSimple() def _testGradientsFirstDim(self): - with self.test_session(): + with self.cached_session(): inp = [] inp_tensors = [] with self.test_scope(): @@ -185,7 +185,7 @@ class ConcatTest(xla_test.XLATestCase): self._testGradientsFirstDim() def _testGradientsLastDim(self): - with self.test_session(): + with self.cached_session(): inp = [] inp_tensors = [] with self.test_scope(): @@ -220,7 +220,7 @@ class ConcatTest(xla_test.XLATestCase): # Random dim to concat on concat_dim = np.random.randint(5) concat_dim_sizes = np.random.randint(1, 5, size=num_tensors) - with self.test_session(): + with self.cached_session(): inp = [] inp_tensors = [] with self.test_scope(): @@ -254,7 +254,7 @@ class ConcatTest(xla_test.XLATestCase): def DISABLED_testZeroSize(self): # Verify that concat doesn't crash and burn for zero size inputs np.random.seed(7) - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): for shape0 in (), (2,): axis = len(shape0) @@ -276,14 +276,14 @@ class ConcatTest(xla_test.XLATestCase): def testConcatTuple(self): c1 = np.random.rand(4, 4).astype(np.float32) c2 = np.random.rand(4, 4).astype(np.float32) - with self.test_session(): + with self.cached_session(): with self.test_scope(): concat_list_t = array_ops.concat([c1, c2], 0) concat_tuple_t = array_ops.concat((c1, c2), 0) self.assertAllEqual(concat_list_t.eval(), concat_tuple_t.eval()) def testConcatNoScalars(self): - with self.test_session(): + with self.cached_session(): with self.test_scope(): scalar = constant_op.constant(7) dim = array_ops.placeholder(dtypes.int32) @@ -295,7 +295,7 @@ class ConcatTest(xla_test.XLATestCase): class ConcatOffsetTest(xla_test.XLATestCase): def testBasic(self): - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): cdim = constant_op.constant(1, dtypes.int32) s0 = constant_op.constant([2, 3, 5], dtypes.int32) @@ -309,7 +309,7 @@ class ConcatOffsetTest(xla_test.XLATestCase): class PackTest(xla_test.XLATestCase): def testBasic(self): - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): s0 = constant_op.constant([2, 3, 5], dtypes.int32) s1 = constant_op.constant([2, 7, 5], dtypes.int32) @@ -319,7 +319,7 @@ class PackTest(xla_test.XLATestCase): self.assertAllEqual(ans, [[2, 3, 5], [2, 7, 5], [2, 20, 5]]) def testScalars(self): - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): s0 = constant_op.constant(2, dtypes.int32) s1 = constant_op.constant(3, dtypes.int32) @@ -329,7 +329,7 @@ class PackTest(xla_test.XLATestCase): self.assertAllEqual(ans, [2, 3, 5]) def testEmpty(self): - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): s0 = constant_op.constant([[]], dtypes.int32) s1 = constant_op.constant([[]], dtypes.int32) diff --git a/tensorflow/compiler/tests/conv2d_test.py b/tensorflow/compiler/tests/conv2d_test.py index f9db103f6d..af00ff287d 100644 --- a/tensorflow/compiler/tests/conv2d_test.py +++ b/tensorflow/compiler/tests/conv2d_test.py @@ -87,7 +87,7 @@ class Conv2DTest(xla_test.XLATestCase, parameterized.TestCase): dilations = test_utils.PermuteDimsBetweenDataFormats( dilations, data_format_src, data_format_dst) - with self.test_session() as sess: + with self.cached_session() as sess: t1 = array_ops.placeholder(dtypes.float32, shape=input_sizes) t2 = array_ops.placeholder(dtypes.float32, shape=filter_sizes) with self.test_scope(): @@ -288,7 +288,7 @@ class Conv2DBackpropInputTest(xla_test.XLATestCase, parameterized.TestCase): dilations = test_utils.PermuteDimsBetweenDataFormats( dilations, data_format_src, data_format_dst) - with self.test_session() as sess: + with self.cached_session() as sess: t1 = array_ops.placeholder(dtypes.float32, shape=filter_sizes) t2 = array_ops.placeholder(dtypes.float32, shape=out_backprop_sizes) with self.test_scope(): @@ -586,7 +586,7 @@ class Conv2DBackpropFilterTest(xla_test.XLATestCase, parameterized.TestCase): dilations = test_utils.PermuteDimsBetweenDataFormats( dilations, data_format_src, data_format_dst) - with self.test_session() as sess: + with self.cached_session() as sess: t1 = array_ops.placeholder(dtypes.float32, shape=input_sizes) t2 = array_ops.placeholder(dtypes.float32, shape=out_backprop_sizes) with self.test_scope(): diff --git a/tensorflow/compiler/tests/conv3d_test.py b/tensorflow/compiler/tests/conv3d_test.py index 31ee41f04f..33fd983b54 100644 --- a/tensorflow/compiler/tests/conv3d_test.py +++ b/tensorflow/compiler/tests/conv3d_test.py @@ -36,7 +36,7 @@ from tensorflow.python.platform import googletest class Conv3DBackpropFilterV2GradTest(xla_test.XLATestCase): def testGradient(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): for padding in ["SAME", "VALID"]: for stride in [1, 2]: np.random.seed(1) @@ -69,7 +69,7 @@ class Conv3DBackpropFilterV2GradTest(xla_test.XLATestCase): class Conv3DTransposeTest(xla_test.XLATestCase): def testConv3DTransposeSingleStride(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): strides = [1, 1, 1, 1, 1] # Input, output: [batch, depth, height, width, channel] @@ -119,7 +119,7 @@ class Conv3DTransposeTest(xla_test.XLATestCase): self.assertAllClose(target, value[n, d, h, w, k]) def testConv3DTransposeSame(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): strides = [1, 2, 2, 2, 1] # Input, output: [batch, depth, height, width, depth] @@ -157,7 +157,7 @@ class Conv3DTransposeTest(xla_test.XLATestCase): self.assertAllClose(target, value[n, d, h, w, k]) def testConv3DTransposeValid(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): strides = [1, 2, 2, 2, 1] # Input, output: [batch, depth, height, width, depth] @@ -217,7 +217,7 @@ class Conv3DTransposeTest(xla_test.XLATestCase): np.random.seed(1) # Make it reproducible. x_val = np.random.random_sample(x_shape).astype(np.float64) f_val = np.random.random_sample(f_shape).astype(np.float64) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): x = constant_op.constant(x_val, name="x", dtype=dtypes.float32) f = constant_op.constant(f_val, name="f", dtype=dtypes.float32) output = nn_ops.conv3d_transpose( diff --git a/tensorflow/compiler/tests/dense_layer_test.py b/tensorflow/compiler/tests/dense_layer_test.py index 865f60ccab..04f3b3ef49 100644 --- a/tensorflow/compiler/tests/dense_layer_test.py +++ b/tensorflow/compiler/tests/dense_layer_test.py @@ -86,7 +86,7 @@ class DenseLayerTest(test.TestCase): XlaLaunch op by XLA. """ - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(shape=[2, 2, 3], dtype=np.float32) with jit_scope(): y = layers.dense(x, 3) @@ -113,7 +113,7 @@ class DenseLayerTest(test.TestCase): cluster, causing dense layer to be split into TWO XlaLaunch ops. """ - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(shape=[None, None, 3], dtype=np.float32) with jit_scope(): y = layers.dense(x, 3) diff --git a/tensorflow/compiler/tests/depthwise_conv_op_test.py b/tensorflow/compiler/tests/depthwise_conv_op_test.py index 98dc73e189..6ef8a68ca5 100644 --- a/tensorflow/compiler/tests/depthwise_conv_op_test.py +++ b/tensorflow/compiler/tests/depthwise_conv_op_test.py @@ -151,7 +151,7 @@ class DepthwiseConv2DTest(xla_test.XLATestCase): dtype=data_type).reshape(tensor_in_sizes) x2 = np.array([f * 1.0 for f in range(1, total_size_2 + 1)], dtype=data_type).reshape(filter_in_sizes) - with self.test_session() as sess: + with self.cached_session() as sess: if data_type == np.float32: tolerance = 1e-4 else: @@ -247,7 +247,7 @@ class DepthwiseConv2DTest(xla_test.XLATestCase): dtype=np.float32).reshape(tensor_in_sizes) x2 = np.array([f * 1.0 for f in range(1, total_size_2 + 1)], dtype=np.float32).reshape(filter_in_sizes) - with self.test_session() as sess: + with self.cached_session() as sess: t1 = array_ops.placeholder(shape=tensor_in_sizes, dtype=np.float32) t2 = array_ops.placeholder(shape=filter_in_sizes, dtype=np.float32) with self.test_scope(): @@ -321,7 +321,7 @@ class DepthwiseConv2DTest(xla_test.XLATestCase): x2 = np.random.rand(*output_sizes).astype(np.float32) def _GetVal(use_xla): - with self.test_session(): + with self.cached_session(): t0 = constant_op.constant(input_sizes, shape=[len(input_sizes)]) t1 = array_ops.placeholder(np.float32, shape=filter_sizes) t2 = array_ops.placeholder(np.float32, shape=output_sizes) @@ -356,7 +356,7 @@ class DepthwiseConv2DTest(xla_test.XLATestCase): x2 = np.random.rand(*output_sizes).astype(np.float32) def _GetVal(use_xla): - with self.test_session(): + with self.cached_session(): t0 = array_ops.placeholder(np.float32, shape=input_sizes) t1 = constant_op.constant(filter_sizes, shape=[len(filter_sizes)]) t2 = array_ops.placeholder(np.float32, shape=output_sizes) diff --git a/tensorflow/compiler/tests/dynamic_slice_ops_test.py b/tensorflow/compiler/tests/dynamic_slice_ops_test.py index 154e36b10e..5f01e128f0 100644 --- a/tensorflow/compiler/tests/dynamic_slice_ops_test.py +++ b/tensorflow/compiler/tests/dynamic_slice_ops_test.py @@ -30,7 +30,7 @@ from tensorflow.python.platform import test class DynamicUpdateSliceOpsTest(xla_test.XLATestCase): def _assertOpOutputMatchesExpected(self, op, args, expected): - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): placeholders = [ array_ops.placeholder(dtypes.as_dtype(arg.dtype), arg.shape) diff --git a/tensorflow/compiler/tests/dynamic_stitch_test.py b/tensorflow/compiler/tests/dynamic_stitch_test.py index edd78153b5..50b04daa6b 100644 --- a/tensorflow/compiler/tests/dynamic_stitch_test.py +++ b/tensorflow/compiler/tests/dynamic_stitch_test.py @@ -30,7 +30,7 @@ from tensorflow.python.platform import googletest class DynamicStitchTest(xla_test.XLATestCase): def _AssertDynamicStitchResultIs(self, indices, data, expected): - with self.test_session() as session: + with self.cached_session() as session: index_placeholders = [ array_ops.placeholder(dtypes.as_dtype(arg.dtype)) for arg in indices ] diff --git a/tensorflow/compiler/tests/eager_test.py b/tensorflow/compiler/tests/eager_test.py index ff097f80f1..63cee550fd 100644 --- a/tensorflow/compiler/tests/eager_test.py +++ b/tensorflow/compiler/tests/eager_test.py @@ -101,7 +101,7 @@ class EagerTest(xla_test.XLATestCase): self.assertAllEqual(15, product) # Run some ops graphly - with context.graph_mode(), self.test_session() as sess: + with context.graph_mode(), self.cached_session() as sess: with self.test_scope(): three = constant_op.constant(3) five = constant_op.constant(5) @@ -351,6 +351,38 @@ class EagerFunctionTest(xla_test.XLATestCase): var = f(v) self.assertEqual(2.0, var.numpy()) + def testReturnResourceHandle(self): + with self.test_scope(): + v = resource_variable_ops.ResourceVariable([[1.0, 2.0], [3.0, 4.0]]) + + def f(v): + return v.handle + + f = function.defun(f) + handle = f(v) + self.assertAllEqual(v.numpy(), + resource_variable_ops.read_variable_op( + handle, dtypes.float32).numpy()) + + def testReturnMultipleResourceHandles(self): + with self.test_scope(): + v1 = resource_variable_ops.ResourceVariable(1.25) + v2 = resource_variable_ops.ResourceVariable(2.0) + + def f(v): + return v.handle, 3.0 * v, v2.handle, v + v2 + + f = function.defun(f) + v1_handle, v1_times_3, v2_handle, variable_sum = f(v1) + self.assertAllEqual(v1.numpy(), + resource_variable_ops.read_variable_op( + v1_handle, dtypes.float32).numpy()) + self.assertEqual(3.75, v1_times_3.numpy()) + self.assertAllEqual(v2.numpy(), + resource_variable_ops.read_variable_op( + v2_handle, dtypes.float32).numpy()) + self.assertEqual(3.25, variable_sum.numpy()) + def testAllArgumentKinds(self): """Test a complex function that takes different argument kinds. @@ -443,7 +475,6 @@ class EagerFunctionTest(xla_test.XLATestCase): self.assertAllEqual((2, 3, 4), dz.shape.as_list()) def testNestedDefun(self): - self.skipTest('Nested defuns do not work on TPU at the moment') with self.test_scope(): @function.defun @@ -458,6 +489,72 @@ class EagerFunctionTest(xla_test.XLATestCase): y = two_x_plus_1(x) self.assertAllEqual([5, 7, 9], y.numpy()) + def testNestedDefunWithVariable(self): + with self.test_scope(): + v0 = resource_variable_ops.ResourceVariable(5.0) + + @function.defun + def g(x): + x = v0 * x + return x + + @function.defun + def f(x): + x = g(v0 * x) + return x + + x = constant_op.constant(3.0) + y = f(x) + + self.assertEqual(75, y.numpy()) + + def testNestedDefunInGradientTape(self): + with self.test_scope(): + v0 = resource_variable_ops.ResourceVariable(5.0) + + @function.defun + def g(x): + x = v0 * x + return x + + @function.defun + def f(x): + x = g(v0 * x) + return x + + x = constant_op.constant(3.0) + with backprop.GradientTape() as tape: + y = f(x) + dy = tape.gradient(y, v0) + + self.assertEqual(75, y.numpy()) + self.assertEqual(30, dy.numpy()) + + def testNestedDefunInGradientTapeDifferentVars(self): + with self.test_scope(): + v0 = resource_variable_ops.ResourceVariable(5.0) + v1 = resource_variable_ops.ResourceVariable(3.0) + + @function.defun + def g(x): + x = v1 * x + return x + + @function.defun + def f(x): + x = g(v0 * x) + return x + + x = constant_op.constant(3.0) + with backprop.GradientTape(persistent=True) as tape: + y = f(x) + dy_v0 = tape.gradient(y, v0) + dy_v1 = tape.gradient(y, v1) + + self.assertEqual(45, y.numpy()) + self.assertEqual(9, dy_v0.numpy()) + self.assertEqual(15, dy_v1.numpy()) + class ExcessivePaddingTest(xla_test.XLATestCase): """Test that eager execution works with TPU flattened tensors. diff --git a/tensorflow/compiler/tests/extract_image_patches_op_test.py b/tensorflow/compiler/tests/extract_image_patches_op_test.py index 5529fdbb09..37061e91d1 100644 --- a/tensorflow/compiler/tests/extract_image_patches_op_test.py +++ b/tensorflow/compiler/tests/extract_image_patches_op_test.py @@ -44,7 +44,7 @@ class ExtractImagePatches(xla_test.XLATestCase): strides = [1] + strides + [1] rates = [1] + rates + [1] - with self.test_session(): + with self.cached_session(): image_placeholder = array_ops.placeholder(dtypes.float32) with self.test_scope(): out_tensor = array_ops.extract_image_patches( diff --git a/tensorflow/compiler/tests/fake_quant_ops_test.py b/tensorflow/compiler/tests/fake_quant_ops_test.py index c48ab178bf..2178c44556 100644 --- a/tensorflow/compiler/tests/fake_quant_ops_test.py +++ b/tensorflow/compiler/tests/fake_quant_ops_test.py @@ -107,7 +107,7 @@ class FakeQuantWithMinMaxArgsTest(xla_test.XLATestCase): ], dtype=np.float32) - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): input_placeholder = array_ops.placeholder( dtypes.float32, inputs.shape, name="inputs") @@ -198,7 +198,7 @@ class FakeQuantWithMinMaxArgsGradientTest(xla_test.XLATestCase): [0.0, 0.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 0.0, 0.0], dtype=np.float32) - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): gradient_placeholder = array_ops.placeholder( dtypes.float32, gradients.shape, name="gradients") @@ -306,7 +306,7 @@ class FakeQuantWithMinMaxVarsTest(xla_test.XLATestCase): ], dtype=np.float32) - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): input_placeholder = array_ops.placeholder( dtypes.float32, inputs.shape, name="inputs") @@ -406,7 +406,7 @@ class FakeQuantWithMinMaxVarsGradientTest(xla_test.XLATestCase): expected_backprops_wrt_min = 1.0 + 2.0 expected_backprops_wrt_max = 10.0 + 11.0 - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): gradient_placeholder = array_ops.placeholder( dtypes.float32, gradients.shape, name="gradients") diff --git a/tensorflow/compiler/tests/fft_test.py b/tensorflow/compiler/tests/fft_test.py index c64ea249ec..b3e13fbaa6 100644 --- a/tensorflow/compiler/tests/fft_test.py +++ b/tensorflow/compiler/tests/fft_test.py @@ -71,7 +71,7 @@ class FFTTest(xla_test.XLATestCase): data = np.reshape(data.astype(np.float32).view(np.complex64), shape) data = to_32bit(complex_to_input(data)) expected = to_32bit(input_to_expected(data)) - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): ph = array_ops.placeholder( dtypes.as_dtype(data.dtype), shape=data.shape) @@ -93,7 +93,7 @@ class FFTTest(xla_test.XLATestCase): data, nperseg=ws, noverlap=ws - hs, boundary=None, window=window)[2] expected = np.swapaxes(expected, -1, -2) expected *= window.sum() # scipy divides by window sum - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): ph = array_ops.placeholder( dtypes.as_dtype(data.dtype), shape=data.shape) diff --git a/tensorflow/compiler/tests/fifo_queue_test.py b/tensorflow/compiler/tests/fifo_queue_test.py index 0f64cc87cd..8c7edfd277 100644 --- a/tensorflow/compiler/tests/fifo_queue_test.py +++ b/tensorflow/compiler/tests/fifo_queue_test.py @@ -31,13 +31,13 @@ from tensorflow.python.platform import test class FIFOQueueTest(xla_test.XLATestCase): def testEnqueue(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): q = data_flow_ops.FIFOQueue(10, dtypes_lib.float32) enqueue_op = q.enqueue((10.0,)) enqueue_op.run() def testEnqueueWithShape(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): q = data_flow_ops.FIFOQueue(10, dtypes_lib.float32, shapes=(3, 2)) enqueue_correct_op = q.enqueue(([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]],)) enqueue_correct_op.run() @@ -46,7 +46,7 @@ class FIFOQueueTest(xla_test.XLATestCase): self.assertEqual(1, q.size().eval()) def testMultipleDequeues(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): q = data_flow_ops.FIFOQueue(10, [dtypes_lib.int32], shapes=[()]) self.evaluate(q.enqueue([1])) self.evaluate(q.enqueue([2])) @@ -55,7 +55,7 @@ class FIFOQueueTest(xla_test.XLATestCase): self.assertAllEqual(set([1, 2, 3]), set([a, b, c])) def testQueuesDontShare(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): q = data_flow_ops.FIFOQueue(10, [dtypes_lib.int32], shapes=[()]) self.evaluate(q.enqueue(1)) q2 = data_flow_ops.FIFOQueue(10, [dtypes_lib.int32], shapes=[()]) @@ -64,13 +64,13 @@ class FIFOQueueTest(xla_test.XLATestCase): self.assertAllEqual(self.evaluate(q.dequeue()), 1) def testEnqueueDictWithoutNames(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): q = data_flow_ops.FIFOQueue(10, dtypes_lib.float32) with self.assertRaisesRegexp(ValueError, "must have names"): q.enqueue({"a": 12.0}) def testParallelEnqueue(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): q = data_flow_ops.FIFOQueue(10, dtypes_lib.float32) elems = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] enqueue_ops = [q.enqueue((x,)) for x in elems] @@ -95,7 +95,7 @@ class FIFOQueueTest(xla_test.XLATestCase): self.assertItemsEqual(elems, results) def testParallelDequeue(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): q = data_flow_ops.FIFOQueue(10, dtypes_lib.float32) elems = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] enqueue_ops = [q.enqueue((x,)) for x in elems] @@ -119,7 +119,7 @@ class FIFOQueueTest(xla_test.XLATestCase): self.assertItemsEqual(elems, results) def testDequeue(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): q = data_flow_ops.FIFOQueue(10, dtypes_lib.float32) elems = [10.0, 20.0, 30.0] enqueue_ops = [q.enqueue((x,)) for x in elems] @@ -133,7 +133,7 @@ class FIFOQueueTest(xla_test.XLATestCase): self.assertEqual([elems[i]], vals) def testEnqueueAndBlockingDequeue(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): q = data_flow_ops.FIFOQueue(3, dtypes_lib.float32) elems = [10.0, 20.0, 30.0] enqueue_ops = [q.enqueue((x,)) for x in elems] @@ -163,7 +163,7 @@ class FIFOQueueTest(xla_test.XLATestCase): self.assertEqual([elem], result) def testMultiEnqueueAndDequeue(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): q = data_flow_ops.FIFOQueue(10, (dtypes_lib.int32, dtypes_lib.float32)) elems = [(5, 10.0), (10, 20.0), (15, 30.0)] enqueue_ops = [q.enqueue((x, y)) for x, y in elems] @@ -179,12 +179,12 @@ class FIFOQueueTest(xla_test.XLATestCase): self.assertEqual([y], y_val) def testQueueSizeEmpty(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): q = data_flow_ops.FIFOQueue(10, dtypes_lib.float32) self.assertEqual([0], q.size().eval()) def testQueueSizeAfterEnqueueAndDequeue(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): q = data_flow_ops.FIFOQueue(10, dtypes_lib.float32) enqueue_op = q.enqueue((10.0,)) dequeued_t = q.dequeue() diff --git a/tensorflow/compiler/tests/ftrl_test.py b/tensorflow/compiler/tests/ftrl_test.py index 1da97fd512..b1deb7f6a7 100644 --- a/tensorflow/compiler/tests/ftrl_test.py +++ b/tensorflow/compiler/tests/ftrl_test.py @@ -112,7 +112,7 @@ class FtrlOptimizerTest(xla_test.XLATestCase): def testFtrlwithoutRegularization(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([0.0, 0.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([0.0, 0.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) @@ -146,7 +146,7 @@ class FtrlOptimizerTest(xla_test.XLATestCase): def testFtrlwithoutRegularization2(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) @@ -174,7 +174,7 @@ class FtrlOptimizerTest(xla_test.XLATestCase): def testFtrlWithL1(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) @@ -202,7 +202,7 @@ class FtrlOptimizerTest(xla_test.XLATestCase): def testFtrlWithL1_L2(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) @@ -236,7 +236,7 @@ class FtrlOptimizerTest(xla_test.XLATestCase): weights will tend to have smaller magnitudes with this parameter set. """ for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) @@ -259,9 +259,49 @@ class FtrlOptimizerTest(xla_test.XLATestCase): # Validate updated params self.assertAllCloseAccordingToType( - np.array([-0.21931979, -0.40642974]), var0.eval(), rtol=1e-4) + np.array([-0.22578996, -0.44345799]), var0.eval(), rtol=1e-4) self.assertAllCloseAccordingToType( - np.array([-0.0282721, -0.07188385]), var1.eval(), rtol=1e-4) + np.array([-0.14378493, -0.13229476]), var1.eval(), rtol=1e-4) + + def testFtrlWithL2ShrinkageDoesNotChangeLrSchedule(self): + """Verifies that l2 shrinkage in FTRL does not change lr schedule.""" + for dtype in self.float_types: + with self.test_session(), self.test_scope(): + var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) + var1 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) + grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) + grads1 = constant_op.constant([0.1, 0.2], dtype=dtype) + + opt0 = ftrl.FtrlOptimizer( + 3.0, + initial_accumulator_value=0.1, + l1_regularization_strength=0.001, + l2_regularization_strength=2.0, + l2_shrinkage_regularization_strength=0.1) + opt1 = ftrl.FtrlOptimizer( + 3.0, + initial_accumulator_value=0.1, + l1_regularization_strength=0.001, + l2_regularization_strength=2.0) + update0 = opt0.apply_gradients([(grads0, var0)]) + update1 = opt1.apply_gradients([(grads1, var1)]) + variables.global_variables_initializer().run() + + self.assertAllCloseAccordingToType([1.0, 2.0], var0.eval()) + self.assertAllCloseAccordingToType([1.0, 2.0], var1.eval()) + + # Run 10 steps FTRL + for _ in range(10): + update0.run() + update1.run() + + # var0 is experiencing L2 shrinkage so it should be smaller than var1 + # in magnitude. + self.assertTrue((var0.eval()**2 < var1.eval()**2).all()) + accum0 = list(opt0._slots["accum"].values())[0].eval() + accum1 = list(opt1._slots["accum"].values())[0].eval() + # L2 shrinkage should not change how we update grad accumulator. + self.assertAllCloseAccordingToType(accum0, accum1) # When variables are initialized with Zero, FTRL-Proximal has two properties: # 1. Without L1&L2 but with fixed learning rate, FTRL-Proximal is identical @@ -273,9 +313,9 @@ class FtrlOptimizerTest(xla_test.XLATestCase): def testEquivAdagradwithoutRegularization(self): steps = 5 for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): val0, val1 = self.equivAdagradTest_FtrlPart(steps, dtype) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): val2, val3 = self.equivAdagradTest_AdagradPart(steps, dtype) self.assertAllCloseAccordingToType(val0, val2, rtol=1e-4, half_rtol=1e-2) @@ -284,9 +324,9 @@ class FtrlOptimizerTest(xla_test.XLATestCase): def testEquivGradientDescentwithoutRegularization(self): steps = 5 for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): val0, val1 = self.equivGradientDescentTest_FtrlPart(steps, dtype) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): val2, val3 = self.equivGradientDescentTest_GradientDescentPart( steps, dtype) diff --git a/tensorflow/compiler/tests/function_test.py b/tensorflow/compiler/tests/function_test.py index 04fba44446..b1891b918c 100644 --- a/tensorflow/compiler/tests/function_test.py +++ b/tensorflow/compiler/tests/function_test.py @@ -40,7 +40,7 @@ class FunctionTest(xla_test.XLATestCase): bval = np.array([5, 6, 7, 8]).reshape([2, 2]).astype(np.float32) expected = APlus2B(aval, bval) - with self.test_session() as sess: + with self.cached_session() as sess: @function.Defun(dtypes.float32, dtypes.float32) def Foo(a, b): @@ -66,7 +66,7 @@ class FunctionTest(xla_test.XLATestCase): bval = np.array([4, 3, 2, 1]).reshape([2, 2]).astype(np.float32) expected = APlus2B(aval, bval) - with self.test_session() as sess: + with self.cached_session() as sess: @function.Defun(dtypes.float32, dtypes.float32) def Foo(a, b): @@ -90,7 +90,7 @@ class FunctionTest(xla_test.XLATestCase): bval = np.array([5, 6, 7, 8]).reshape([2, 2]).astype(np.float32) expected = Func(aval, bval) - with self.test_session() as sess: + with self.cached_session() as sess: @function.Defun(dtypes.float32, dtypes.float32) def Foo(a, b): @@ -105,7 +105,7 @@ class FunctionTest(xla_test.XLATestCase): def testCompileTimeConstantsInDefun(self): """Tests that XLA handles compile-time constants in defuns.""" - with self.test_session() as sess: + with self.cached_session() as sess: @function.Defun(dtypes.float32, dtypes.int32, dtypes.int32) def Foo(a, c, d): @@ -140,7 +140,7 @@ class FunctionTest(xla_test.XLATestCase): bval = np.array([4, 3, 2, 1]).reshape([2, 2]).astype(np.float32) expected = aval + bval * 2 - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): a = array_ops.placeholder(dtypes.float32, name="a") b = array_ops.placeholder(dtypes.float32, name="b") diff --git a/tensorflow/compiler/tests/fused_batchnorm_test.py b/tensorflow/compiler/tests/fused_batchnorm_test.py index 132e42ac7a..8c018cccb8 100644 --- a/tensorflow/compiler/tests/fused_batchnorm_test.py +++ b/tensorflow/compiler/tests/fused_batchnorm_test.py @@ -83,7 +83,7 @@ class FusedBatchNormTest(xla_test.XLATestCase, parameterized.TestCase): y_ref, mean_ref, var_ref = self._reference_training( x_val, scale_val, offset_val, epsilon, data_format_src) - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): # To avoid constant folding x_val_converted = test_utils.ConvertBetweenDataFormats( x_val, data_format_src, data_format) @@ -126,7 +126,7 @@ class FusedBatchNormTest(xla_test.XLATestCase, parameterized.TestCase): y_ref, mean_ref, var_ref = self._reference_training( x_val, scale_val, offset_val, epsilon, data_format_src) - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): # To avoid constant folding x_val_converted = test_utils.ConvertBetweenDataFormats( x_val, data_format_src, data_format) @@ -210,7 +210,7 @@ class FusedBatchNormTest(xla_test.XLATestCase, parameterized.TestCase): grad_x_ref, grad_scale_ref, grad_offset_ref = self._reference_grad( x_val, grad_val, scale_val, mean_val, var_val, epsilon, data_format_src) - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): grad_val_converted = test_utils.ConvertBetweenDataFormats( grad_val, data_format_src, data_format) x_val_converted = test_utils.ConvertBetweenDataFormats( @@ -260,7 +260,7 @@ class FusedBatchNormTest(xla_test.XLATestCase, parameterized.TestCase): var_val = np.random.random_sample(scale_shape).astype(np.float32) data_format_src = "NHWC" - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): grad_val_converted = test_utils.ConvertBetweenDataFormats( grad_val, data_format_src, data_format) x_val_converted = test_utils.ConvertBetweenDataFormats( diff --git a/tensorflow/compiler/tests/gather_nd_op_test.py b/tensorflow/compiler/tests/gather_nd_op_test.py index 23b0aed34f..7161f4ab33 100644 --- a/tensorflow/compiler/tests/gather_nd_op_test.py +++ b/tensorflow/compiler/tests/gather_nd_op_test.py @@ -29,7 +29,7 @@ from tensorflow.python.platform import test class GatherNdTest(xla_test.XLATestCase): def _runGather(self, params, indices): - with self.test_session(): + with self.cached_session(): paramsp = array_ops.placeholder(params.dtype) indicesp = array_ops.placeholder(indices.dtype) with self.test_scope(): @@ -46,7 +46,7 @@ class GatherNdTest(xla_test.XLATestCase): np.array([[4], [4], [0]], np.int32))) def testEmptyIndicesAndParamsOKButJustEmptyParamsFails(self): - with self.test_session(): + with self.cached_session(): params = np.ones((3, 3), dtype=np.float32) indices_empty = np.empty((0, 2), dtype=np.int32) diff --git a/tensorflow/compiler/tests/gather_test.py b/tensorflow/compiler/tests/gather_test.py index e9c8ef7c91..089d95daab 100644 --- a/tensorflow/compiler/tests/gather_test.py +++ b/tensorflow/compiler/tests/gather_test.py @@ -42,7 +42,7 @@ class GatherTest(xla_test.XLATestCase): return data def testScalar1D(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): data = np.array([0, 1, 2, 3, 7, 5]) for dtype in self.all_tf_types: for indices in 4, [4], [1, 2, 2, 4, 5]: @@ -55,7 +55,7 @@ class GatherTest(xla_test.XLATestCase): self.assertAllEqual(np_val, gather_val) def testScalar2D(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): data = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13, 14]]) for dtype in self.all_tf_types: @@ -69,7 +69,7 @@ class GatherTest(xla_test.XLATestCase): self.assertAllEqual(expected, gather_val) def testSimpleTwoD32(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): data = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13, 14]]) for dtype in self.all_tf_types: @@ -87,7 +87,7 @@ class GatherTest(xla_test.XLATestCase): if np.int64 not in self.int_types: return - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): data = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13, 14]]) # The indices must be in bounds for any axis. @@ -114,7 +114,7 @@ class GatherTest(xla_test.XLATestCase): for axis in 0, 1, 2, 3, -1, -2: params = self._buildParams(np.random.randn(*shape), dtype) indices = np.random.randint(shape[axis], size=indices_shape) - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): tf_params = array_ops.placeholder(dtype=dtype) tf_indices = constant_op.constant(indices, dtype=dtypes.int32) gather = array_ops.gather(tf_params, tf_indices, axis=axis) @@ -123,7 +123,7 @@ class GatherTest(xla_test.XLATestCase): self.assertAllEqual(gather_np, gather_value) def testIndicesWithDifferentDimensions(self): - with self.test_session(): + with self.cached_session(): for dtype in self.numeric_tf_types: params = array_ops.placeholder(dtype=dtype) indices = array_ops.placeholder(dtype=np.int32) @@ -137,7 +137,7 @@ class GatherTest(xla_test.XLATestCase): [[7]], gather.eval(feed_dict={params: [4, 7, 2], indices: [[1]]})) def testGatherPrecision(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): data = np.array([[0, 0, 0, 0], [0, 2 * (1 + np.exp2(-8)), 0, 0], [0, 0, 0, 0], [0.015789, 0.0985, 0.55789, 0.3842]]) indices = np.array([1, 2, 3, 1]) diff --git a/tensorflow/compiler/tests/image_ops_test.py b/tensorflow/compiler/tests/image_ops_test.py index bf986ade06..6fe5a66e0e 100644 --- a/tensorflow/compiler/tests/image_ops_test.py +++ b/tensorflow/compiler/tests/image_ops_test.py @@ -54,7 +54,7 @@ class RGBToHSVTest(xla_test.XLATestCase): inp = GenerateNumpyRandomRGB(shape).astype(nptype) # Convert to HSV and back, as a batch and individually - with self.test_session() as sess: + with self.cached_session() as sess: batch0 = array_ops.placeholder(nptype, shape=shape) with self.test_scope(): batch1 = image_ops.rgb_to_hsv(batch0) @@ -78,7 +78,7 @@ class RGBToHSVTest(xla_test.XLATestCase): data = [0, 5, 13, 54, 135, 226, 37, 8, 234, 90, 255, 1] for nptype in self.float_types: rgb_np = np.array(data, dtype=nptype).reshape([2, 2, 3]) / 255. - with self.test_session(): + with self.cached_session(): placeholder = array_ops.placeholder(nptype) with self.test_scope(): hsv = image_ops.rgb_to_hsv(placeholder) @@ -97,7 +97,7 @@ class RGBToHSVTest(xla_test.XLATestCase): for r, g, b in rgb_flat ]) hsv_np = hsv_np.reshape(4, 4, 4, 3) - with self.test_session(): + with self.cached_session(): placeholder = array_ops.placeholder(nptype) with self.test_scope(): hsv_op = image_ops.rgb_to_hsv(placeholder) @@ -108,7 +108,7 @@ class RGBToHSVTest(xla_test.XLATestCase): class AdjustContrastTest(xla_test.XLATestCase): def _testContrast(self, x_np, y_np, contrast_factor): - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(x_np.dtype, shape=x_np.shape) flt_x = image_ops.convert_image_dtype(x, dtypes.float32) with self.test_scope(): @@ -146,7 +146,7 @@ class AdjustContrastTest(xla_test.XLATestCase): return y_np def _adjustContrastTf(self, x_np, contrast_factor): - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(np.float32) with self.test_scope(): y = image_ops.adjust_contrast(x, contrast_factor) @@ -180,7 +180,7 @@ class AdjustHueTest(xla_test.XLATestCase): y_data = [0, 13, 1, 54, 226, 59, 8, 234, 150, 255, 39, 1] y_np = np.array(y_data, dtype=np.uint8).reshape(x_shape) - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(x_np.dtype, shape=x_shape) flt_x = image_ops.convert_image_dtype(x, dtypes.float32) with self.test_scope(): @@ -198,7 +198,7 @@ class AdjustHueTest(xla_test.XLATestCase): y_data = [13, 0, 11, 226, 54, 221, 234, 8, 92, 1, 217, 255] y_np = np.array(y_data, dtype=np.uint8).reshape(x_shape) - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(x_np.dtype, shape=x_shape) flt_x = image_ops.convert_image_dtype(x, dtypes.float32) with self.test_scope(): @@ -216,7 +216,7 @@ class AdjustHueTest(xla_test.XLATestCase): y_data = [13, 0, 11, 226, 54, 221, 234, 8, 92, 1, 217, 255] y_np = np.array(y_data, dtype=np.uint8).reshape(x_shape) - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(x_np.dtype, shape=x_shape) flt_x = image_ops.convert_image_dtype(x, dtypes.float32) with self.test_scope(): @@ -244,7 +244,7 @@ class AdjustHueTest(xla_test.XLATestCase): return y_v.reshape(x_np.shape) def _adjustHueTf(self, x_np, delta_h): - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(dtypes.float32) with self.test_scope(): y = gen_image_ops.adjust_hue(x, delta_h) @@ -324,7 +324,7 @@ class AdjustSaturationTest(xla_test.XLATestCase): y_rgb_data = [6, 9, 13, 140, 180, 226, 135, 121, 234, 172, 255, 128] y_np = np.array(y_rgb_data, dtype=np.uint8).reshape(x_shape) - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(x_np.dtype, shape=x_shape) y = self._adjust_saturation(x, saturation_factor) y_tf = y.eval({x: x_np}) @@ -339,7 +339,7 @@ class AdjustSaturationTest(xla_test.XLATestCase): y_data = [0, 5, 13, 0, 106, 226, 30, 0, 234, 89, 255, 0] y_np = np.array(y_data, dtype=np.uint8).reshape(x_shape) - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(x_np.dtype, shape=x_shape) y = self._adjust_saturation(x, saturation_factor) y_tf = y.eval({x: x_np}) @@ -378,7 +378,7 @@ class AdjustSaturationTest(xla_test.XLATestCase): "gb_same", "rgb_same", ] - with self.test_session(): + with self.cached_session(): for x_shape in x_shapes: for test_style in test_styles: x_np = np.random.rand(*x_shape) * 255. @@ -410,13 +410,14 @@ class ResizeBilinearTest(xla_test.XLATestCase): image_np, target_shape, expected=None, - large_tolerance=False): + large_tolerance=False, + align_corners=True): if expected is None: self.fail("expected must be specified") - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): image = array_ops.placeholder(image_np.dtype) resized = gen_image_ops.resize_bilinear( - image, target_shape, align_corners=True) + image, target_shape, align_corners=align_corners) out = sess.run(resized, {image: image_np[np.newaxis, :, :, np.newaxis]}) if large_tolerance: self.assertAllClose( @@ -433,7 +434,7 @@ class ResizeBilinearTest(xla_test.XLATestCase): self.fail("input_shape must be specified") if expected is None: self.fail("expected must be specified") - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): dtype = dtype or np.float32 grads = array_ops.placeholder(np.float32) resized = gen_image_ops.resize_bilinear_grad( @@ -579,6 +580,27 @@ class ResizeBilinearTest(xla_test.XLATestCase): dtype=np.float32)), large_tolerance=True) + def testNonAlignCorners3x2To6x4(self): + input_data = [[64, 32], [32, 64], [50, 100]] + expected_data = [[64.0, 48.0, 32.0, 32.0], [48.0, 48.0, 48.0, 48.0], + [32.0, 48.0, 64.0, 64.0], [41.0, 61.5, 82.0, 82.0], + [50.0, 75.0, 100.0, 100.0], [50.0, 75.0, 100.0, 100.0]] + for dtype in self.float_types: + self._assertForwardOpMatchesExpected( + np.array(input_data, dtype=dtype), [6, 4], + expected=np.array(expected_data, dtype=np.float32), + align_corners=False) + + def testNonAlignCorners6x4To3x2(self): + input_data = [[127, 127, 64, 64], [127, 127, 64, 64], [64, 64, 127, 127], + [64, 64, 127, 127], [50, 50, 100, 100], [50, 50, 100, 100]] + expected_data = [[127, 64], [64, 127], [50, 100]] + for dtype in self.float_types: + self._assertForwardOpMatchesExpected( + np.array(input_data, dtype=dtype), [3, 2], + expected=np.array(expected_data, dtype=dtype), + align_corners=False) + class NonMaxSuppressionTest(xla_test.XLATestCase): @@ -596,7 +618,7 @@ class NonMaxSuppressionTest(xla_test.XLATestCase): iou_threshold_np = np.array(0.5, dtype=np.float32) score_threshold_np = np.array(0.0, dtype=np.float32) - with self.test_session() as sess: + with self.cached_session() as sess: boxes = array_ops.placeholder(boxes_np.dtype, shape=boxes_np.shape) scores = array_ops.placeholder(scores_np.dtype, shape=scores_np.shape) iou_threshold = array_ops.placeholder(iou_threshold_np.dtype, @@ -639,7 +661,7 @@ class NonMaxSuppressionTest(xla_test.XLATestCase): iou_threshold_np = np.array(0.5, dtype=np.float32) score_threshold_np = np.array(0.0, dtype=np.float32) - with self.test_session() as sess: + with self.cached_session() as sess: boxes = array_ops.placeholder(boxes_np.dtype, shape=boxes_np.shape) scores = array_ops.placeholder(scores_np.dtype, shape=scores_np.shape) iou_threshold = array_ops.placeholder(iou_threshold_np.dtype, @@ -686,7 +708,7 @@ class NonMaxSuppressionTest(xla_test.XLATestCase): iou_threshold_np = np.array(0.5, dtype=np.float32) score_threshold_np = np.array(0.4, dtype=np.float32) - with self.test_session() as sess: + with self.cached_session() as sess: boxes = array_ops.placeholder(boxes_np.dtype, shape=boxes_np.shape) scores = array_ops.placeholder(scores_np.dtype, shape=scores_np.shape) iou_threshold = array_ops.placeholder(iou_threshold_np.dtype, diff --git a/tensorflow/compiler/tests/listdiff_op_test.py b/tensorflow/compiler/tests/listdiff_op_test.py index 45a04f0cf5..58622114e4 100644 --- a/tensorflow/compiler/tests/listdiff_op_test.py +++ b/tensorflow/compiler/tests/listdiff_op_test.py @@ -33,7 +33,7 @@ class ListDiffTest(xla_test.XLATestCase): def _testListDiff(self, x, y, out, idx): for dtype in [dtypes.int32, dtypes.int64]: for index_dtype in [dtypes.int32, dtypes.int64]: - with self.test_session() as sess: + with self.cached_session() as sess: x_tensor = ops.convert_to_tensor(x, dtype=dtype) y_tensor = ops.convert_to_tensor(y, dtype=dtype) with self.test_scope(): diff --git a/tensorflow/compiler/tests/lrn_ops_test.py b/tensorflow/compiler/tests/lrn_ops_test.py index 253b45902f..c6ad67993e 100644 --- a/tensorflow/compiler/tests/lrn_ops_test.py +++ b/tensorflow/compiler/tests/lrn_ops_test.py @@ -58,7 +58,7 @@ class LRNTest(xla_test.XLATestCase): return output def _RunAndVerify(self, dtype): - with self.test_session(): + with self.cached_session(): # random shape shape = np.random.randint(1, 16, size=4) # Make depth at least 2 to make it meaningful @@ -110,7 +110,7 @@ class LRNTest(xla_test.XLATestCase): alpha = 1.0 * np.random.rand() beta = 1.0 * np.random.rand() - with self.test_session(): + with self.cached_session(): in_image = constant_op.constant(in_image_vals, shape=shape) out_image = constant_op.constant(out_image_vals, shape=shape) out_grads = constant_op.constant(out_grads_vals, shape=shape) diff --git a/tensorflow/compiler/tests/lstm_test.py b/tensorflow/compiler/tests/lstm_test.py index 31093c6571..265c0b6d14 100644 --- a/tensorflow/compiler/tests/lstm_test.py +++ b/tensorflow/compiler/tests/lstm_test.py @@ -73,7 +73,7 @@ class LSTMTest(test.TestCase): def _RunLSTMCell(self, basename, init_weights, m_prev_scalar, c_prev_scalar, pad_scalar): - with self.test_session() as sess: + with self.cached_session() as sess: num_inputs = 1 num_nodes = 1 @@ -156,7 +156,7 @@ class LSTMTest(test.TestCase): def _RunLSTMLayer(self, basename, init_weights, m_init_scalar, c_init_scalar, pad_scalar): - with self.test_session() as sess: + with self.cached_session() as sess: num_inputs = 1 num_nodes = 1 seq_length = 3 diff --git a/tensorflow/compiler/tests/matrix_band_part_test.py b/tensorflow/compiler/tests/matrix_band_part_test.py index 0d9f99f8a6..9222db4b7e 100644 --- a/tensorflow/compiler/tests/matrix_band_part_test.py +++ b/tensorflow/compiler/tests/matrix_band_part_test.py @@ -29,7 +29,7 @@ from tensorflow.python.platform import test class MatrixBandPartTest(xla_test.XLATestCase): def _testMatrixBandPart(self, dtype, shape): - with self.test_session(): + with self.cached_session(): batch_shape = shape[:-2] mat = np.ones(shape).astype(dtype) batch_mat = np.tile(mat, batch_shape + [1, 1]) diff --git a/tensorflow/compiler/tests/matrix_triangular_solve_op_test.py b/tensorflow/compiler/tests/matrix_triangular_solve_op_test.py index 2bb8a97bda..94cd3eeb31 100644 --- a/tensorflow/compiler/tests/matrix_triangular_solve_op_test.py +++ b/tensorflow/compiler/tests/matrix_triangular_solve_op_test.py @@ -54,7 +54,7 @@ class MatrixTriangularSolveOpTest(xla_test.XLATestCase): def _VerifyTriangularSolve(self, a, b, lower, adjoint, atol): clean_a = np.tril(a) if lower else np.triu(a) - with self.test_session() as sess: + with self.cached_session() as sess: placeholder_a = MakePlaceholder(a) placeholder_ca = MakePlaceholder(clean_a) placeholder_b = MakePlaceholder(b) diff --git a/tensorflow/compiler/tests/momentum_test.py b/tensorflow/compiler/tests/momentum_test.py index c2592c54cf..f77521a7c4 100644 --- a/tensorflow/compiler/tests/momentum_test.py +++ b/tensorflow/compiler/tests/momentum_test.py @@ -41,7 +41,7 @@ class MomentumOptimizerTest(xla_test.XLATestCase): def testBasic(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -95,7 +95,7 @@ class MomentumOptimizerTest(xla_test.XLATestCase): def testNesterovMomentum(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([0.1, 0.2], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([0.3, 0.4], dtype=dtype) var0_np = np.array([0.1, 0.2], dtype=dtype) @@ -120,7 +120,7 @@ class MomentumOptimizerTest(xla_test.XLATestCase): def testTensorLearningRateAndMomentum(self): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) diff --git a/tensorflow/compiler/tests/nary_ops_test.py b/tensorflow/compiler/tests/nary_ops_test.py index da08225e9f..a1c07fce73 100644 --- a/tensorflow/compiler/tests/nary_ops_test.py +++ b/tensorflow/compiler/tests/nary_ops_test.py @@ -32,7 +32,7 @@ from tensorflow.python.platform import googletest class NAryOpsTest(xla_test.XLATestCase): def _testNAry(self, op, args, expected, equality_fn=None): - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): placeholders = [ array_ops.placeholder(dtypes.as_dtype(arg.dtype), arg.shape) @@ -126,7 +126,7 @@ class NAryOpsTest(xla_test.XLATestCase): [[1, 2, 3, 7, 8, 9], [4, 5, 6, 10, 11, 12]], dtype=np.float32)) def testOneHot(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): indices = array_ops.constant(np.array([[2, 3], [0, 1]], dtype=np.int32)) op = array_ops.one_hot(indices, np.int32(4), @@ -148,7 +148,7 @@ class NAryOpsTest(xla_test.XLATestCase): self.assertAllEqual(output, expected) def testSplitV(self): - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): output = session.run( array_ops.split(np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 0, 1, 2]], diff --git a/tensorflow/compiler/tests/nullary_ops_test.py b/tensorflow/compiler/tests/nullary_ops_test.py index 2f9122645d..f985c5d2d9 100644 --- a/tensorflow/compiler/tests/nullary_ops_test.py +++ b/tensorflow/compiler/tests/nullary_ops_test.py @@ -29,14 +29,14 @@ from tensorflow.python.platform import googletest class NullaryOpsTest(xla_test.XLATestCase): def _testNullary(self, op, expected): - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): output = op() result = session.run(output) self.assertAllClose(result, expected, rtol=1e-3) def testNoOp(self): - with self.test_session(): + with self.cached_session(): with self.test_scope(): output = control_flow_ops.no_op() # This should not crash. diff --git a/tensorflow/compiler/tests/oom_test.py b/tensorflow/compiler/tests/oom_test.py index d68d32057a..7635f89249 100644 --- a/tensorflow/compiler/tests/oom_test.py +++ b/tensorflow/compiler/tests/oom_test.py @@ -46,7 +46,7 @@ class OutOfMemoryTest(xla_test.XLATestCase): def test_loop(): size = int(2e8) while True: - with self.test_session(): + with self.cached_session(): # Force the compiled code to not be constant by feeding in a # parameter. p = array_ops.placeholder(dtypes.float32, shape=[2, 1, 1]) diff --git a/tensorflow/compiler/tests/placeholder_test.py b/tensorflow/compiler/tests/placeholder_test.py index a75d99189b..77bb839409 100644 --- a/tensorflow/compiler/tests/placeholder_test.py +++ b/tensorflow/compiler/tests/placeholder_test.py @@ -28,7 +28,7 @@ from tensorflow.python.platform import googletest class PlaceholderTest(xla_test.XLATestCase): def test_placeholder_with_default_default(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): v = resource_variable_ops.ResourceVariable(4.0) ph = array_ops.placeholder_with_default(v, shape=[]) out = ph * 2 @@ -36,7 +36,7 @@ class PlaceholderTest(xla_test.XLATestCase): self.assertEqual(8.0, sess.run(out)) def test_placeholder_with_default_fed(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): v = resource_variable_ops.ResourceVariable(4.0) ph = array_ops.placeholder_with_default(v, shape=[]) out = ph * 2 diff --git a/tensorflow/compiler/tests/pooling_ops_3d_test.py b/tensorflow/compiler/tests/pooling_ops_3d_test.py index 17f860db61..b6cdd38345 100644 --- a/tensorflow/compiler/tests/pooling_ops_3d_test.py +++ b/tensorflow/compiler/tests/pooling_ops_3d_test.py @@ -62,7 +62,7 @@ class Pooling3DTest(xla_test.XLATestCase): # numbers from 1. x = np.arange(1.0, total_size + 1, dtype=np.float32) x = x.reshape(input_sizes) - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): inputs = array_ops.placeholder(dtypes.float32) t = pool_func( inputs, @@ -210,7 +210,7 @@ class Pooling3DTest(xla_test.XLATestCase): strides = [1] + strides + [1] total_size = np.prod(input_sizes) x = np.arange(1, total_size + 1, dtype=np.float32).reshape(input_sizes) - with self.test_session() as sess: + with self.cached_session() as sess: # Use the forward pool function to compute some corresponding outputs # (needed for the CPU device, and we need the shape in both cases). with ops.device("CPU"): diff --git a/tensorflow/compiler/tests/pooling_ops_test.py b/tensorflow/compiler/tests/pooling_ops_test.py index 9fc94752ea..d03bd4fdbb 100644 --- a/tensorflow/compiler/tests/pooling_ops_test.py +++ b/tensorflow/compiler/tests/pooling_ops_test.py @@ -89,7 +89,7 @@ class PoolingTest(xla_test.XLATestCase): # numbers from 1. x = np.array([f * 1.0 for f in range(1, total_size + 1)], dtype=np.float32) x = x.reshape(input_sizes) - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): inputs = array_ops.placeholder(dtypes.float32) t = inputs @@ -324,7 +324,7 @@ class PoolGradTest(xla_test.XLATestCase): # TODO(b/74222344): Fix nan handling for max pool grad. # x[np.random.choice(total_size)] = np.nan x = x.reshape(input_sizes) - with self.test_session() as sess: + with self.cached_session() as sess: # Use the forward pool function to compute some corresponding outputs # (needed for the CPU device, and we need the shape in both cases). with ops.device(self.CPU_DEVICE): diff --git a/tensorflow/compiler/tests/powersign_test.py b/tensorflow/compiler/tests/powersign_test.py index 5fa7706d72..86536da7fe 100644 --- a/tensorflow/compiler/tests/powersign_test.py +++ b/tensorflow/compiler/tests/powersign_test.py @@ -64,7 +64,7 @@ class PowerSignTest(xla_test.XLATestCase): base=math.e, beta=0.9): for dtype in self.float_types: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): # Initialize variables for numpy implementation. m0, m1 = 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype) diff --git a/tensorflow/compiler/tests/proximal_adagrad_test.py b/tensorflow/compiler/tests/proximal_adagrad_test.py index cde87db63d..c41b4171e2 100644 --- a/tensorflow/compiler/tests/proximal_adagrad_test.py +++ b/tensorflow/compiler/tests/proximal_adagrad_test.py @@ -32,7 +32,7 @@ from tensorflow.python.training import proximal_adagrad class ProximalAdagradOptimizerTest(xla_test.XLATestCase): def testResourceProximalAdagradwithoutRegularization(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([0.0, 0.0]) var1 = resource_variable_ops.ResourceVariable([0.0, 0.0]) grads0 = constant_op.constant([0.1, 0.2]) @@ -60,7 +60,7 @@ class ProximalAdagradOptimizerTest(xla_test.XLATestCase): self.assertEqual(2, len(opt_vars)) def testProximalAdagradwithoutRegularization2(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0]) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0]) grads0 = constant_op.constant([0.1, 0.2]) @@ -84,7 +84,7 @@ class ProximalAdagradOptimizerTest(xla_test.XLATestCase): self.assertAllClose(np.array([3.715679, 2.433051]), var1.eval()) def testProximalAdagradWithL1(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0]) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0]) grads0 = constant_op.constant([0.1, 0.2]) @@ -108,7 +108,7 @@ class ProximalAdagradOptimizerTest(xla_test.XLATestCase): self.assertAllClose(np.array([2.959304, 1.029232]), var1.eval()) def testProximalAdagradWithL1_L2(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0]) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0]) grads0 = constant_op.constant([0.1, 0.2]) @@ -151,7 +151,7 @@ class ProximalAdagradOptimizerTest(xla_test.XLATestCase): return var0.eval(), var1.eval() def testEquivAdagradwithoutRegularization(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): val0, val1 = self.applyOptimizer( proximal_adagrad.ProximalAdagradOptimizer( 3.0, @@ -159,7 +159,7 @@ class ProximalAdagradOptimizerTest(xla_test.XLATestCase): l1_regularization_strength=0.0, l2_regularization_strength=0.0)) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): val2, val3 = self.applyOptimizer( adagrad.AdagradOptimizer( 3.0, initial_accumulator_value=0.1)) diff --git a/tensorflow/compiler/tests/proximal_gradient_descent_test.py b/tensorflow/compiler/tests/proximal_gradient_descent_test.py index 11eb768711..3d808e6b8a 100644 --- a/tensorflow/compiler/tests/proximal_gradient_descent_test.py +++ b/tensorflow/compiler/tests/proximal_gradient_descent_test.py @@ -32,7 +32,7 @@ from tensorflow.python.training import proximal_gradient_descent class ProximalGradientDescentOptimizerTest(xla_test.XLATestCase): def testResourceProximalGradientDescentwithoutRegularization(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([0.0, 0.0]) var1 = resource_variable_ops.ResourceVariable([0.0, 0.0]) grads0 = constant_op.constant([0.1, 0.2]) @@ -53,7 +53,7 @@ class ProximalGradientDescentOptimizerTest(xla_test.XLATestCase): self.assertAllClose(np.array([-0.09, -0.18]), var1.eval()) def testProximalGradientDescentwithoutRegularization2(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0]) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0]) grads0 = constant_op.constant([0.1, 0.2]) @@ -75,7 +75,7 @@ class ProximalGradientDescentOptimizerTest(xla_test.XLATestCase): self.assertAllClose(np.array([3.91, 2.82]), var1.eval()) def testProximalGradientDescentWithL1(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0]) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0]) grads0 = constant_op.constant([0.1, 0.2]) @@ -97,7 +97,7 @@ class ProximalGradientDescentOptimizerTest(xla_test.XLATestCase): self.assertAllClose(np.array([3.67, 2.37]), var1.eval()) def testProximalGradientDescentWithL1_L2(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0]) var1 = resource_variable_ops.ResourceVariable([4.0, 3.0]) grads0 = constant_op.constant([0.1, 0.2]) @@ -137,14 +137,14 @@ class ProximalGradientDescentOptimizerTest(xla_test.XLATestCase): return var0.eval(), var1.eval() def testEquivGradientDescentwithoutRegularization(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): val0, val1 = self.applyOptimizer( proximal_gradient_descent.ProximalGradientDescentOptimizer( 3.0, l1_regularization_strength=0.0, l2_regularization_strength=0.0)) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): val2, val3 = self.applyOptimizer( gradient_descent.GradientDescentOptimizer(3.0)) diff --git a/tensorflow/compiler/tests/qr_op_test.py b/tensorflow/compiler/tests/qr_op_test.py index 1b969ee2b3..3a268978bf 100644 --- a/tensorflow/compiler/tests/qr_op_test.py +++ b/tensorflow/compiler/tests/qr_op_test.py @@ -71,7 +71,7 @@ class QrOpTest(xla_test.XLATestCase, parameterized.TestCase): x_np = np.random.uniform( low=-1.0, high=1.0, size=np.prod(shape)).reshape(shape).astype(dtype) - with self.test_session() as sess: + with self.cached_session() as sess: x_tf = array_ops.placeholder(dtype) with self.test_scope(): q_tf, r_tf = linalg_ops.qr(x_tf, full_matrices=full_matrices) diff --git a/tensorflow/compiler/tests/random_ops_test.py b/tensorflow/compiler/tests/random_ops_test.py index 8c4e16e4e0..6e18344117 100644 --- a/tensorflow/compiler/tests/random_ops_test.py +++ b/tensorflow/compiler/tests/random_ops_test.py @@ -39,7 +39,7 @@ class RandomOpsTest(xla_test.XLATestCase): def _testRngIsNotConstant(self, rng, dtype): # Tests that 'rng' does not always return the same value. - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): x = rng(dtype) @@ -79,7 +79,7 @@ class RandomOpsTest(xla_test.XLATestCase): if (self.device in ["XLA_GPU", "XLA_CPU" ]) and (dtype in [dtypes.bfloat16, dtypes.half]): continue - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): x = random_ops.random_uniform( shape=[1000], dtype=dtype, minval=-2, maxval=33) @@ -99,7 +99,7 @@ class RandomOpsTest(xla_test.XLATestCase): count = 10000000 # TODO(b/34339814): implement inverse erf support for non-F32 types. for dtype in [dtypes.float32]: - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): x = random_ops.truncated_normal(shape=[count], dtype=dtype) y = sess.run(x) @@ -147,7 +147,7 @@ class RandomOpsTest(xla_test.XLATestCase): # TODO(b/26783907): this test requires the CPU backend to implement sort. if self.device in ["XLA_CPU"]: return - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): x = math_ops.range(1 << 16) shuffle = random_ops.random_shuffle(x) @@ -158,7 +158,7 @@ class RandomOpsTest(xla_test.XLATestCase): self.assertAllEqual(set(result), set(expected)) def testShuffle2d(self): - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): x = array_ops.diag(math_ops.range(20)) shuffle = random_ops.random_shuffle(x) diff --git a/tensorflow/compiler/tests/reduce_ops_test.py b/tensorflow/compiler/tests/reduce_ops_test.py index cea2ec816f..5ae5b1bc1d 100644 --- a/tensorflow/compiler/tests/reduce_ops_test.py +++ b/tensorflow/compiler/tests/reduce_ops_test.py @@ -20,6 +20,7 @@ from __future__ import print_function import functools import itertools +from absl.testing import parameterized import numpy as np from tensorflow.compiler.tests import xla_test @@ -30,22 +31,24 @@ from tensorflow.python.ops import math_ops from tensorflow.python.platform import googletest -class ReduceOpsTest(xla_test.XLATestCase): - +@parameterized.named_parameters(('32_bit_index', dtypes.int32), + ('64_bit_index', dtypes.int64)) +class ReduceOpsTest(xla_test.XLATestCase, parameterized.TestCase): def _testReduction(self, tf_reduce_fn, np_reduce_fn, dtype, test_inputs, + index_dtype, rtol=1e-4, atol=1e-4): """Tests that the output of 'tf_reduce_fn' matches numpy's output.""" for test_input in test_inputs: - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): a = array_ops.placeholder(dtype) - index = array_ops.placeholder(dtypes.int32) + index = array_ops.placeholder(index_dtype) out = tf_reduce_fn(a, index) result = sess.run(out, {a: test_input, index: [0]}) self.assertAllClose( @@ -89,22 +92,23 @@ class ReduceOpsTest(xla_test.XLATestCase): np.array([[False, True, False], [True, True, False]]), ] - def testReduceSumF32(self): - self._testReduction(math_ops.reduce_sum, np.sum, np.float32, self.REAL_DATA) + def testReduceSumF32(self, index_dtype): + self._testReduction(math_ops.reduce_sum, np.sum, np.float32, self.REAL_DATA, + index_dtype) - def testReduceSumC64(self): + def testReduceSumC64(self, index_dtype): self._testReduction(math_ops.reduce_sum, np.sum, np.complex64, - self.COMPLEX_DATA) + self.COMPLEX_DATA, index_dtype) - def testReduceProdF32(self): + def testReduceProdF32(self, index_dtype): self._testReduction(math_ops.reduce_prod, np.prod, np.float32, - self.REAL_DATA) + self.REAL_DATA, index_dtype) - def testReduceProdC64(self): + def testReduceProdC64(self, index_dtype): self._testReduction(math_ops.reduce_prod, np.prod, np.complex64, - self.COMPLEX_DATA) + self.COMPLEX_DATA, index_dtype) - def testReduceMin(self): + def testReduceMin(self, index_dtype): def reference_min(dtype, inp, axis): """Wrapper around np.amin that returns +infinity for an empty input.""" @@ -119,9 +123,9 @@ class ReduceOpsTest(xla_test.XLATestCase): [np.float32, np.int32, np.int64]): self._testReduction(math_ops.reduce_min, functools.partial(reference_min, dtype), dtype, - self.REAL_DATA) + self.REAL_DATA, index_dtype) - def testReduceMax(self): + def testReduceMax(self, index_dtype): def reference_max(dtype, inp, axis): """Wrapper around np.amax that returns -infinity for an empty input.""" @@ -137,23 +141,25 @@ class ReduceOpsTest(xla_test.XLATestCase): [np.float32, np.int32, np.int64]): self._testReduction(math_ops.reduce_max, functools.partial(reference_max, dtype), dtype, - self.REAL_DATA) + self.REAL_DATA, index_dtype) - def testReduceMeanF32(self): + def testReduceMeanF32(self, index_dtype): # TODO(phawkins): mean on XLA currently returns 0 instead of NaN when # reducing across zero inputs. self._testReduction(math_ops.reduce_mean, np.mean, np.float32, - self.NONEMPTY_REAL_DATA) + self.NONEMPTY_REAL_DATA, index_dtype) - def testReduceMeanC64(self): + def testReduceMeanC64(self, index_dtype): self._testReduction(math_ops.reduce_mean, np.mean, np.complex64, - self.NONEMPTY_COMPLEX_DATA) + self.NONEMPTY_COMPLEX_DATA, index_dtype) - def testReduceAll(self): - self._testReduction(math_ops.reduce_all, np.all, np.bool, self.BOOL_DATA) + def testReduceAll(self, index_dtype): + self._testReduction(math_ops.reduce_all, np.all, np.bool, self.BOOL_DATA, + index_dtype) - def testReduceAny(self): - self._testReduction(math_ops.reduce_any, np.any, np.bool, self.BOOL_DATA) + def testReduceAny(self, index_dtype): + self._testReduction(math_ops.reduce_any, np.any, np.bool, self.BOOL_DATA, + index_dtype) class ReduceOpPrecisionTest(xla_test.XLATestCase): @@ -178,7 +184,7 @@ class ReduceOpPrecisionTest(xla_test.XLATestCase): """ for test_input in test_inputs: - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): a = array_ops.placeholder(dtype) index = array_ops.placeholder(dtypes.int32) diff --git a/tensorflow/compiler/tests/reduce_window_test.py b/tensorflow/compiler/tests/reduce_window_test.py index c69b6837b0..ff20ea3f42 100644 --- a/tensorflow/compiler/tests/reduce_window_test.py +++ b/tensorflow/compiler/tests/reduce_window_test.py @@ -32,7 +32,7 @@ class ReduceWindowTest(xla_test.XLATestCase): """Test cases for xla.reduce_window.""" def _reduce_window(self, operand, init, reducer, **kwargs): - with self.test_session(): + with self.cached_session(): placeholder = array_ops.placeholder(operand.dtype) with self.test_scope(): output = xla.reduce_window(placeholder, init, reducer, **kwargs) diff --git a/tensorflow/compiler/tests/reshape_op_test.py b/tensorflow/compiler/tests/reshape_op_test.py new file mode 100644 index 0000000000..84c6777940 --- /dev/null +++ b/tensorflow/compiler/tests/reshape_op_test.py @@ -0,0 +1,50 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for slicing.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from absl.testing import parameterized + +from tensorflow.compiler.tests import xla_test +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.ops import array_ops +from tensorflow.python.platform import googletest + + +class ReshapeTest(xla_test.XLATestCase, parameterized.TestCase): + + @parameterized.named_parameters(('32_bit_index', dtypes.int32), + ('64_bit_index', dtypes.int64)) + def testBasic(self, index_dtype): + for dtype in self.numeric_types: + with self.test_session(): + i = array_ops.placeholder(dtype, shape=[2, 3]) + with self.test_scope(): + shape = constant_op.constant([3, 2], dtype=index_dtype) + o = array_ops.reshape(i, shape) + params = { + i: [[1, 2, 3], [4, 5, 6]], + } + result = o.eval(feed_dict=params) + + self.assertAllEqual([[1, 2], [3, 4], [5, 6]], result) + + +if __name__ == '__main__': + googletest.main() diff --git a/tensorflow/compiler/tests/reverse_ops_test.py b/tensorflow/compiler/tests/reverse_ops_test.py index d01c676e7c..392290fd92 100644 --- a/tensorflow/compiler/tests/reverse_ops_test.py +++ b/tensorflow/compiler/tests/reverse_ops_test.py @@ -32,33 +32,40 @@ class ReverseOpsTest(xla_test.XLATestCase): def testReverseOneDim(self): shape = (7, 5, 9, 11) - for revdim in range(len(shape)): + for revdim in range(-len(shape), len(shape)): self._AssertReverseEqual([revdim], shape) def testReverseMoreThanOneDim(self): shape = (7, 5, 9, 11) + # The offset is used to test various (but not all) combinations of negative + # and positive axis indices that are guaranteed to not collide at the same + # index. for revdims in itertools.chain.from_iterable( - itertools.combinations(range(len(shape)), k) - for k in range(2, len(shape)+1)): + itertools.combinations(range(-offset, + len(shape) - offset), k) + for k in range(2, + len(shape) + 1) + for offset in range(0, len(shape))): self._AssertReverseEqual(revdims, shape) def _AssertReverseEqual(self, revdims, shape): np.random.seed(120) pval = np.random.randint(0, 100, size=shape).astype(float) - with self.test_session(): + with self.cached_session(): with self.test_scope(): p = array_ops.placeholder(dtypes.int32, shape=shape) axis = constant_op.constant( np.array(revdims, dtype=np.int32), - shape=(len(revdims),), dtype=dtypes.int32) + shape=(len(revdims),), + dtype=dtypes.int32) rval = array_ops.reverse(p, axis).eval({p: pval}) slices = [ - slice(-1, None, -1) if d in revdims else slice(None) - for d in range(len(shape))] - self.assertEqual( - pval[slices].flatten().tolist(), - rval.flatten().tolist()) + slice(-1, None, -1) + if d in revdims or d - len(shape) in revdims else slice(None) + for d in range(len(shape)) + ] + self.assertEqual(pval[slices].flatten().tolist(), rval.flatten().tolist()) if __name__ == '__main__': diff --git a/tensorflow/compiler/tests/reverse_sequence_op_test.py b/tensorflow/compiler/tests/reverse_sequence_op_test.py index ccfa630016..60c2337743 100644 --- a/tensorflow/compiler/tests/reverse_sequence_op_test.py +++ b/tensorflow/compiler/tests/reverse_sequence_op_test.py @@ -35,7 +35,7 @@ class ReverseSequenceTest(xla_test.XLATestCase): seq_lengths, truth, expected_err_re=None): - with self.test_session(): + with self.cached_session(): p = array_ops.placeholder(dtypes.as_dtype(x.dtype)) lengths = array_ops.placeholder(dtypes.as_dtype(seq_lengths.dtype)) with self.test_scope(): diff --git a/tensorflow/compiler/tests/rmsprop_test.py b/tensorflow/compiler/tests/rmsprop_test.py index ff8bbac911..8840a1329a 100644 --- a/tensorflow/compiler/tests/rmsprop_test.py +++ b/tensorflow/compiler/tests/rmsprop_test.py @@ -55,7 +55,7 @@ class RmspropTest(xla_test.XLATestCase): def testBasic(self): for dtype in self.float_types: for centered in [False, True]: - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): # Initialize variables for numpy implementation. var0_np = np.array([1.0, 2.0], dtype=dtype) grads0_np = np.array([0.1, 0.1], dtype=dtype) diff --git a/tensorflow/compiler/tests/scan_ops_test.py b/tensorflow/compiler/tests/scan_ops_test.py index 4292352e76..897db384b7 100644 --- a/tensorflow/compiler/tests/scan_ops_test.py +++ b/tensorflow/compiler/tests/scan_ops_test.py @@ -78,7 +78,7 @@ class CumsumTest(xla_test.XLATestCase): def _compare(self, x, axis, exclusive, reverse): np_out = handle_options(np.cumsum, x, axis, exclusive, reverse) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): p = array_ops.placeholder(x.dtype) tf_out = math_ops.cumsum(p, axis, exclusive, reverse).eval( feed_dict={p: x}) @@ -100,7 +100,7 @@ class CumsumTest(xla_test.XLATestCase): for dtype in self.valid_dtypes: x = np.arange(1, 6).reshape([5]).astype(dtype) for axis_dtype in self.axis_dtypes(): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): p = array_ops.placeholder(x.dtype) axis = constant_op.constant(0, axis_dtype) math_ops.cumsum(p, axis).eval(feed_dict={p: x}) @@ -131,7 +131,7 @@ class CumsumTest(xla_test.XLATestCase): def testInvalidAxis(self): x = np.arange(0, 10).reshape([2, 5]).astype(np.float32) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): input_tensor = ops.convert_to_tensor(x) with self.assertRaisesWithPredicateMatch( errors_impl.InvalidArgumentError, @@ -156,7 +156,7 @@ class CumprodTest(xla_test.XLATestCase): def _compare(self, x, axis, exclusive, reverse): np_out = handle_options(np.cumprod, x, axis, exclusive, reverse) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): p = array_ops.placeholder(x.dtype) prod = math_ops.cumprod(p, axis, exclusive, reverse) tf_out = prod.eval(feed_dict={p: x}) @@ -178,7 +178,7 @@ class CumprodTest(xla_test.XLATestCase): for dtype in self.valid_dtypes: x = np.arange(1, 6).reshape([5]).astype(dtype) for axis_dtype in self.axis_dtypes(): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): p = array_ops.placeholder(x.dtype) axis = constant_op.constant(0, axis_dtype) math_ops.cumprod(x, axis).eval(feed_dict={p: x}) @@ -209,7 +209,7 @@ class CumprodTest(xla_test.XLATestCase): def testInvalidAxis(self): x = np.arange(0, 10).reshape([2, 5]).astype(np.float32) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): input_tensor = ops.convert_to_tensor(x) with self.assertRaisesWithPredicateMatch( errors_impl.InvalidArgumentError, diff --git a/tensorflow/compiler/tests/scatter_nd_op_test.py b/tensorflow/compiler/tests/scatter_nd_op_test.py index f606f88545..693f8513bc 100644 --- a/tensorflow/compiler/tests/scatter_nd_op_test.py +++ b/tensorflow/compiler/tests/scatter_nd_op_test.py @@ -119,7 +119,7 @@ class ScatterNdTest(xla_test.XLATestCase): self._VariableRankTest(np_scatter, tf_scatter, vtype, itype) def _runScatterNd(self, indices, updates, shape): - with self.test_session(): + with self.cached_session(): updates_placeholder = array_ops.placeholder(updates.dtype) indices_placeholder = array_ops.placeholder(indices.dtype) with self.test_scope(): diff --git a/tensorflow/compiler/tests/segment_reduction_ops_test.py b/tensorflow/compiler/tests/segment_reduction_ops_test.py index 772c20fd42..287bb0d84e 100644 --- a/tensorflow/compiler/tests/segment_reduction_ops_test.py +++ b/tensorflow/compiler/tests/segment_reduction_ops_test.py @@ -32,7 +32,7 @@ class SegmentReductionOpsTest(xla_test.XLATestCase): """Test cases for segment reduction ops.""" def _segmentReduction(self, op, data, indices, num_segments): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): d = array_ops.placeholder(data.dtype, shape=data.shape) if isinstance(indices, int): i = array_ops.placeholder(np.int32, shape=[]) diff --git a/tensorflow/compiler/tests/slice_ops_test.py b/tensorflow/compiler/tests/slice_ops_test.py index 6c4890565d..2c611a959e 100644 --- a/tensorflow/compiler/tests/slice_ops_test.py +++ b/tensorflow/compiler/tests/slice_ops_test.py @@ -29,7 +29,7 @@ class SliceTest(xla_test.XLATestCase): def test1D(self): for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[10]) with self.test_scope(): o = array_ops.slice(i, [2], [4]) @@ -40,9 +40,22 @@ class SliceTest(xla_test.XLATestCase): self.assertAllEqual([2, 3, 4, 5], result) + def testZeroSlice(self): + for dtype in self.numeric_types: + with self.cached_session(): + i = array_ops.placeholder(dtype, shape=[2]) + with self.test_scope(): + o = array_ops.slice(i, [0], [0]) + params = { + i: [0, 1], + } + result = o.eval(feed_dict=params) + + self.assertAllEqual([], result) + def test3D(self): for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[3, 3, 10]) with self.test_scope(): o = array_ops.slice(i, [1, 2, 2], [1, 1, 4]) @@ -64,7 +77,7 @@ class SliceTest(xla_test.XLATestCase): def test3DWithDynamicBegin(self): """Tests a slice where the start offset is not known at compile time.""" for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[3, 3, 10]) begin = array_ops.placeholder(dtypes.int32, shape=[3]) with self.test_scope(): @@ -88,7 +101,7 @@ class SliceTest(xla_test.XLATestCase): def test3DWithDynamicBeginAndNegativeSize(self): """Tests a slice where `begin` is fed dynamically and `size` contains -1.""" for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[3, 3, 10]) begin = array_ops.placeholder(dtypes.int32, shape=[3]) with self.test_scope(): @@ -114,7 +127,7 @@ class StridedSliceTest(xla_test.XLATestCase): def test1D(self): for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[10]) with self.test_scope(): o = array_ops.strided_slice(i, [2], [6], [2]) @@ -127,7 +140,7 @@ class StridedSliceTest(xla_test.XLATestCase): def test1DNegativeStride(self): for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[10]) with self.test_scope(): o = array_ops.strided_slice(i, [6], [2], [-2]) @@ -140,7 +153,7 @@ class StridedSliceTest(xla_test.XLATestCase): def test2DDegenerate(self): for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[2, 3]) with self.test_scope(): o = array_ops.strided_slice(i, [-1, 0], [0, 3]) @@ -154,7 +167,7 @@ class StridedSliceTest(xla_test.XLATestCase): def test2DDegenerateNegativeStride(self): for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[2, 3]) with self.test_scope(): o = array_ops.strided_slice(i, [0, 0], [-1, 3], [-1, 1]) @@ -168,7 +181,7 @@ class StridedSliceTest(xla_test.XLATestCase): def test3D(self): for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[3, 3, 10]) with self.test_scope(): o = array_ops.strided_slice(i, [0, 2, 2], [2, 3, 6], [1, 1, 2]) @@ -189,7 +202,7 @@ class StridedSliceTest(xla_test.XLATestCase): def test3DNegativeStride(self): for dtype in self.numeric_types: - with self.test_session(): + with self.cached_session(): i = array_ops.placeholder(dtype, shape=[3, 4, 10]) with self.test_scope(): o = array_ops.strided_slice(i, [2, 2, 6], [0, 0, 2], [-1, -1, -2]) diff --git a/tensorflow/compiler/tests/sort_ops_test.py b/tensorflow/compiler/tests/sort_ops_test.py index 7ff01be3cb..51c04b5c47 100644 --- a/tensorflow/compiler/tests/sort_ops_test.py +++ b/tensorflow/compiler/tests/sort_ops_test.py @@ -32,7 +32,7 @@ from tensorflow.python.platform import test class XlaSortOpTest(xla_test.XLATestCase): def _assertOpOutputMatchesExpected(self, op, args, expected): - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): placeholders = [ array_ops.placeholder(dtypes.as_dtype(arg.dtype), arg.shape) @@ -131,7 +131,7 @@ class XlaSortOpTest(xla_test.XLATestCase): if bfloat16 not in self.numeric_types: return - with self.test_session() as sess: + with self.cached_session() as sess: p = array_ops.placeholder(dtypes.bfloat16) with self.test_scope(): topk = nn_ops.top_k(p, k=4) @@ -153,7 +153,7 @@ class XlaSortOpTest(xla_test.XLATestCase): if bfloat16 not in self.numeric_types: return - with self.test_session() as sess: + with self.cached_session() as sess: p = array_ops.placeholder(dtypes.bfloat16) with self.test_scope(): topk = nn_ops.top_k(p, k=6) diff --git a/tensorflow/compiler/tests/spacetobatch_op_test.py b/tensorflow/compiler/tests/spacetobatch_op_test.py index c685bc548f..33b84cec71 100644 --- a/tensorflow/compiler/tests/spacetobatch_op_test.py +++ b/tensorflow/compiler/tests/spacetobatch_op_test.py @@ -72,7 +72,7 @@ class SpaceToBatchTest(xla_test.XLATestCase): """Tests input-output pairs for the SpaceToBatch and BatchToSpace ops.""" def _testPad(self, inputs, paddings, block_size, outputs): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): for dtype in self.float_types: # outputs = space_to_batch(inputs) placeholder = array_ops.placeholder(dtype) @@ -155,7 +155,7 @@ class SpaceToBatchNDTest(xla_test.XLATestCase): def _testPad(self, inputs, block_shape, paddings, outputs): block_shape = np.array(block_shape) paddings = np.array(paddings).reshape((len(block_shape), 2)) - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): for dtype in self.float_types: # TODO(b/68813416): Skip bfloat16's as the input type for direct is # float32 and results in a mismatch, while making testDirect provide the diff --git a/tensorflow/compiler/tests/sparse_to_dense_op_test.py b/tensorflow/compiler/tests/sparse_to_dense_op_test.py index 3db8101c4b..07afd1ab3f 100644 --- a/tensorflow/compiler/tests/sparse_to_dense_op_test.py +++ b/tensorflow/compiler/tests/sparse_to_dense_op_test.py @@ -45,32 +45,32 @@ def _SparseToDense(sparse_indices, class SparseToDenseTest(xla_test.XLATestCase): def testInt(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): tf_ans = _SparseToDense([1, 3], [5], 1, 0) np_ans = np.array([0, 1, 0, 1, 0]).astype(np.int32) self.assertAllClose(np_ans, tf_ans) def testFloat(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): tf_ans = _SparseToDense([1, 3], [5], 1.0, 0.0) np_ans = np.array([0, 1, 0, 1, 0]).astype(np.float32) self.assertAllClose(np_ans, tf_ans) def testSetValue(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): tf_ans = _SparseToDense([1, 3], [5], [1, 2], -1) np_ans = np.array([-1, 1, -1, 2, -1]).astype(np.int32) self.assertAllClose(np_ans, tf_ans) def testSetSingleValue(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): tf_ans = _SparseToDense([1, 3], [5], 1, -1) np_ans = np.array([-1, 1, -1, 1, -1]).astype(np.int32) self.assertAllClose(np_ans, tf_ans) def test2d(self): # pylint: disable=bad-whitespace - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): tf_ans = _SparseToDense([[1, 3], [2, 0]], [3, 4], 1, -1) np_ans = np.array([[-1, -1, -1, -1], [-1, -1, -1, 1], @@ -78,12 +78,12 @@ class SparseToDenseTest(xla_test.XLATestCase): self.assertAllClose(np_ans, tf_ans) def testZeroDefault(self): - with self.test_session(): + with self.cached_session(): x = sparse_ops.sparse_to_dense(2, [4], 7).eval() self.assertAllEqual(x, [0, 0, 7, 0]) def test3d(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): tf_ans = _SparseToDense([[1, 3, 0], [2, 0, 1]], [3, 4, 2], 1, -1) np_ans = np.ones((3, 4, 2), dtype=np.int32) * -1 np_ans[1, 3, 0] = 1 @@ -91,25 +91,25 @@ class SparseToDenseTest(xla_test.XLATestCase): self.assertAllClose(np_ans, tf_ans) def testBadShape(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): with self.assertRaisesWithPredicateMatch(ValueError, "must be rank 1"): _SparseToDense([1, 3], [[5], [3]], 1, -1) def testBadValue(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): with self.assertRaisesOpError( r"sparse_values has incorrect shape \[2,1\], " r"should be \[\] or \[2\]"): _SparseToDense([1, 3], [5], [[5], [3]], -1) def testBadNumValues(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): with self.assertRaisesOpError( r"sparse_values has incorrect shape \[3\], should be \[\] or \[2\]"): _SparseToDense([1, 3], [5], [1, 2, 3], -1) def testBadDefault(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): with self.assertRaisesOpError("default_value should be a scalar"): _SparseToDense([1, 3], [5], [1, 2], [0]) diff --git a/tensorflow/compiler/tests/stack_ops_test.py b/tensorflow/compiler/tests/stack_ops_test.py index b7dd787fef..720595a159 100644 --- a/tensorflow/compiler/tests/stack_ops_test.py +++ b/tensorflow/compiler/tests/stack_ops_test.py @@ -31,7 +31,7 @@ from tensorflow.python.platform import test class StackOpTest(xla_test.XLATestCase): def testStackPushPop(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): size = array_ops.placeholder(dtypes.int32) v = array_ops.placeholder(dtypes.float32) h = gen_data_flow_ops.stack_v2(size, dtypes.float32, stack_name="foo") @@ -41,7 +41,7 @@ class StackOpTest(xla_test.XLATestCase): self.assertAllClose([[4.0, 5.0]], c1.eval({size: 5, v: [[4.0, 5.0]]})) def testStackPushPopSwap(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): a = np.arange(2000) x = array_ops.placeholder(dtypes.float32) h = gen_data_flow_ops.stack_v2(5, dtypes.float32, stack_name="foo") @@ -51,7 +51,7 @@ class StackOpTest(xla_test.XLATestCase): self.assertAllClose(a, c1.eval({x: a})) def testMultiStack(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): v = array_ops.placeholder(dtypes.float32) h1 = gen_data_flow_ops.stack_v2(5, dtypes.float32, stack_name="foo") c1 = gen_data_flow_ops.stack_push_v2(h1, v) @@ -66,7 +66,7 @@ class StackOpTest(xla_test.XLATestCase): def testSameNameStacks(self): """Different stacks with the same name do not interfere.""" - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): v1 = array_ops.placeholder(dtypes.float32) v2 = array_ops.placeholder(dtypes.float32) h1 = gen_data_flow_ops.stack_v2(5, dtypes.float32, stack_name="foo") @@ -84,14 +84,14 @@ class StackOpTest(xla_test.XLATestCase): self.assertAllClose(out2, 5.0) def testCloseStack(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): size = array_ops.placeholder(dtypes.int32) h = gen_data_flow_ops.stack_v2(size, dtypes.float32, stack_name="foo") c1 = gen_data_flow_ops.stack_close_v2(h) sess.run(c1, {size: 5}) def testPushCloseStack(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): v = array_ops.placeholder(dtypes.float32) h = gen_data_flow_ops.stack_v2(5, dtypes.float32, stack_name="foo") c = gen_data_flow_ops.stack_push_v2(h, v) diff --git a/tensorflow/compiler/tests/stateless_random_ops_test.py b/tensorflow/compiler/tests/stateless_random_ops_test.py index d162675ef8..1bea7d9355 100644 --- a/tensorflow/compiler/tests/stateless_random_ops_test.py +++ b/tensorflow/compiler/tests/stateless_random_ops_test.py @@ -38,7 +38,7 @@ class StatelessRandomOpsTest(xla_test.XLATestCase): def testDeterminism(self): # Stateless values should be equal iff the seeds are equal (roughly) - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): seed_t = array_ops.placeholder(dtypes.int32, shape=[2]) seeds = [(x, y) for x in range(5) for y in range(5)] * 3 for stateless_op in [ @@ -55,7 +55,7 @@ class StatelessRandomOpsTest(xla_test.XLATestCase): self.assertEqual(s0 == s1, np.all(v0 == v1)) def testRandomUniformIsInRange(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): for dtype in self._random_types(): seed_t = array_ops.placeholder(dtypes.int32, shape=[2]) x = stateless.stateless_random_uniform( @@ -74,7 +74,7 @@ class StatelessRandomOpsTest(xla_test.XLATestCase): def testDistributionOfStatelessRandomUniform(self): """Use Pearson's Chi-squared test to test for uniformity.""" - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): for dtype in self._random_types(): seed_t = array_ops.placeholder(dtypes.int32, shape=[2]) n = 1000 @@ -88,7 +88,7 @@ class StatelessRandomOpsTest(xla_test.XLATestCase): self.assertTrue(self._chi_squared(y, 10) < 16.92) def testRandomNormalIsFinite(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): for dtype in self._random_types(): seed_t = array_ops.placeholder(dtypes.int32, shape=[2]) x = stateless.stateless_random_uniform( @@ -111,7 +111,7 @@ class StatelessRandomOpsTest(xla_test.XLATestCase): def testDistributionOfStatelessRandomNormal(self): """Use Anderson-Darling test to test distribution appears normal.""" - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): for dtype in self._random_types(): seed_t = array_ops.placeholder(dtypes.int32, shape=[2]) n = 1000 @@ -126,7 +126,7 @@ class StatelessRandomOpsTest(xla_test.XLATestCase): def testTruncatedNormalIsInRange(self): # TODO(b/34339814): implement inverse erf support for non-F32 types. for dtype in [dtypes.float32]: - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): seed_t = array_ops.placeholder(dtypes.int32, shape=[2]) n = 10000000 x = stateless.stateless_truncated_normal( diff --git a/tensorflow/compiler/tests/tensor_array_ops_test.py b/tensorflow/compiler/tests/tensor_array_ops_test.py index f332aa2e9b..78244d0b36 100644 --- a/tensorflow/compiler/tests/tensor_array_ops_test.py +++ b/tensorflow/compiler/tests/tensor_array_ops_test.py @@ -44,7 +44,7 @@ def _make_converter(dtype): class TensorArrayTest(xla_test.XLATestCase): def testTensorArrayWriteRead(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -66,7 +66,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual([], flow_val.shape) def _testTensorArrayWritePack(self, tf_dtype): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=tf_dtype, tensor_array_name="foo", size=3) @@ -86,7 +86,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArrayWritePack(dtype) def testEmptyTensorArrayPack(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", size=3) @@ -100,7 +100,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual([3, 0, 1], c0.eval().shape) def _testTensorArrayWriteConcat(self, tf_dtype): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=tf_dtype, tensor_array_name="foo", size=3) @@ -121,7 +121,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArrayWriteConcat(dtype) def _testTensorArrayUnpackRead(self, tf_dtype): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=tf_dtype, tensor_array_name="foo", size=3) @@ -176,7 +176,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArrayUnpackReadMaybeLegacy() def _testTensorArraySplitRead(self, tf_dtype): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=tf_dtype, tensor_array_name="foo", size=3) @@ -228,7 +228,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArraySplitRead(dtype) def testTensorGradArrayWriteRead(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -261,7 +261,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual([[-2.0]], g_d2) def testTensorGradArrayDynamicWriteRead(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -300,7 +300,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual(3, g_vs) def testTensorGradAccessTwiceReceiveSameObject(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", size=3, element_shape=[1, 2]) @@ -317,7 +317,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual([[4.0, 5.0]], d_r1_0) def testTensorArrayWriteWrongIndexOrDataTypeFails(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", size=3) @@ -331,7 +331,7 @@ class TensorArrayTest(xla_test.XLATestCase): # the first type, but try to read the other type. if len(self.float_types) > 1: dtype1, dtype2 = list(self.float_types)[:2] - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtype1, tensor_array_name="foo", size=3) @@ -347,7 +347,7 @@ class TensorArrayTest(xla_test.XLATestCase): w0.read(1) def testTensorArraySplitIncompatibleShapesFails(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -379,7 +379,7 @@ class TensorArrayTest(xla_test.XLATestCase): ta.split([1.0], [1]).flow.eval() def _testTensorArrayWriteGradientAddMultipleAdds(self, dtype): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtype, tensor_array_name="foo", size=3, infer_shape=False) @@ -410,7 +410,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArrayWriteGradientAddMultipleAdds(dtype) def testMultiTensorArray(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): h1 = tensor_array_ops.TensorArray( size=1, dtype=dtypes.float32, tensor_array_name="foo") w1 = h1.write(0, 4.0) @@ -425,7 +425,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllClose(9.0, r.eval()) def _testTensorArrayGradientWriteReadType(self, dtype): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.as_dtype(dtype), tensor_array_name="foo", @@ -478,7 +478,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArrayGradientWriteReadType(dtype) def _testTensorArrayGradientWritePackConcatAndRead(self): - with self.test_session() as sess, self.test_scope(): + with self.cached_session() as sess, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -513,7 +513,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArrayGradientWritePackConcatAndRead() def testTensorArrayReadTwice(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): value = constant_op.constant([[1.0, -1.0], [10.0, -10.0]]) ta_readtwice = tensor_array_ops.TensorArray( @@ -529,7 +529,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual([1.0, -1.0], r1_readtwice.eval()) def _testTensorArrayGradientUnpackRead(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -557,7 +557,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArrayGradientUnpackRead() def testTensorArrayGradientSplitConcat(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", size=2) @@ -581,21 +581,21 @@ class TensorArrayTest(xla_test.XLATestCase): grad_vals[0]) def testCloseTensorArray(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", size=3) c1 = ta.close() session.run(c1) def testSizeTensorArray(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", size=3) s = ta.size() self.assertAllEqual(3, s.eval()) def testWriteCloseTensorArray(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -608,7 +608,7 @@ class TensorArrayTest(xla_test.XLATestCase): # TODO(phawkins): implement while loops. # def _testWhileLoopWritePackGradients(self, dynamic_size, dtype): # np_dtype = dtype.as_numpy_dtype - # with self.test_session() as session, self.test_scope(): + # with self.cached_session() as session, self.test_scope(): # v0 = array_ops.identity(np.arange(3 * 5, dtype=np_dtype).reshape(3, 5)) # var = variables.Variable(np.arange(100, 105, dtype=np_dtype)) # state0 = array_ops.identity(np.array([1] * 5, dtype=np_dtype)) @@ -692,7 +692,7 @@ class TensorArrayTest(xla_test.XLATestCase): # dynamic_size=True, dtype=dtypes.float32) # def testGradSerialTwoLoops(self): - # with self.test_session(), self.test_scope(): + # with self.cached_session(), self.test_scope(): # num_steps = 100 # acc = tensor_array_ops.TensorArray( # dtype=dtypes.float32, @@ -725,7 +725,7 @@ class TensorArrayTest(xla_test.XLATestCase): # self.assertAllClose(31.0, grad.eval()) def testSumOfTwoReadVariablesWithoutRepeatGrad(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): a = array_ops.identity( np.arange( 3 * 5, dtype=np.float32).reshape(3, 5) + 1) @@ -757,7 +757,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual(joint_grad_b_t, g0) def testWriteShape(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", size=3) c0 = constant_op.constant([4.0, 5.0]) @@ -781,7 +781,7 @@ class TensorArrayTest(xla_test.XLATestCase): w0.write(0, c2) def testPartlyUnknownShape(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", size=6) @@ -821,7 +821,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual([5, 4, 2, 3], r5.get_shape().as_list()) def _testUnpackShape(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -846,7 +846,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testUnpackShape() def testSplitShape(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -867,7 +867,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual(r0.get_shape(), tensor_shape.unknown_shape()) def testWriteUnknownShape(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -879,7 +879,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual(r0.get_shape(), tensor_shape.unknown_shape()) def _testGradientWhenNotAllComponentsRead(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray(dtype=dtypes.float32, size=2) x = constant_op.constant([2.0, 3.0]) w = ta.unstack(x) @@ -893,7 +893,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testGradientWhenNotAllComponentsRead() def _testTensorArrayEvalEmpty(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, size=0, infer_shape=False) with self.assertRaisesOpError( @@ -906,7 +906,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArrayEvalEmpty() def _testTensorArrayEvalEmptyWithDefault(self): - with self.test_session(), self.test_scope(): + with self.cached_session(), self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, size=0, infer_shape=True) self.assertEqual(0, ta.size().eval()) @@ -921,7 +921,7 @@ class TensorArrayTest(xla_test.XLATestCase): self._testTensorArrayEvalEmptyWithDefault() def testTensorArrayScatterReadAndGradients(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -946,7 +946,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual([[2.0, 3.0], [4.0, 5.0]], grad_vals[0]) def testTensorArrayWriteGatherAndGradients(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta = tensor_array_ops.TensorArray( dtype=dtypes.float32, tensor_array_name="foo", @@ -974,7 +974,7 @@ class TensorArrayTest(xla_test.XLATestCase): self.assertAllEqual(expected_grad, grad_vals[0]) def testTensorArrayIdentity(self): - with self.test_session() as session, self.test_scope(): + with self.cached_session() as session, self.test_scope(): ta0 = tensor_array_ops.TensorArray(dtype=dtypes.float32, size=2, infer_shape=False) ta1 = tensor_array_ops.TensorArray(dtype=dtypes.int32, size=4, diff --git a/tensorflow/compiler/tests/ternary_ops_test.py b/tensorflow/compiler/tests/ternary_ops_test.py index effa5a59fe..55a992195f 100644 --- a/tensorflow/compiler/tests/ternary_ops_test.py +++ b/tensorflow/compiler/tests/ternary_ops_test.py @@ -31,7 +31,7 @@ from tensorflow.python.platform import googletest class TernaryOpsTest(xla_test.XLATestCase): def _testTernary(self, op, a, b, c, expected): - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): pa = array_ops.placeholder(dtypes.as_dtype(a.dtype), a.shape, name="a") pb = array_ops.placeholder(dtypes.as_dtype(b.dtype), b.shape, name="b") diff --git a/tensorflow/compiler/tests/unary_ops_test.py b/tensorflow/compiler/tests/unary_ops_test.py index 73adb0d243..5b0e57f83f 100644 --- a/tensorflow/compiler/tests/unary_ops_test.py +++ b/tensorflow/compiler/tests/unary_ops_test.py @@ -65,7 +65,7 @@ class UnaryOpsTest(xla_test.XLATestCase): rtol: relative tolerance for equality test. atol: absolute tolerance for equality test. """ - with self.test_session() as session: + with self.cached_session() as session: with self.test_scope(): pinp = array_ops.placeholder( dtypes.as_dtype(inp.dtype), inp.shape, name="a") @@ -202,7 +202,7 @@ class UnaryOpsTest(xla_test.XLATestCase): # Disable float16 testing for now if dtype != np.float16: x = np.arange(-10, 10, 1).astype(dtype) - with self.test_session() as session: + with self.cached_session() as session: erf_x = session.run(math_ops.erf(x)) erfc_x = session.run(math_ops.erfc(x)) @@ -398,6 +398,11 @@ class UnaryOpsTest(xla_test.XLATestCase): self._assertOpOutputMatchesExpected( math_ops.lgamma, + np.array(0.5, dtype=dtype), + expected=np.array(np.log(np.pi) / 2, dtype=dtype)) + + self._assertOpOutputMatchesExpected( + math_ops.lgamma, np.array( [[1, 2, 3], [4, 5, 6], [1 / 2, 3 / 2, 5 / 2], [-3 / 2, -7 / 2, -11 / 2]], @@ -420,6 +425,19 @@ class UnaryOpsTest(xla_test.XLATestCase): ], dtype=dtype)) + # The actual result is complex. Take the real part. + self._assertOpOutputMatchesExpected( + math_ops.lgamma, + np.array([-1 / 2, -5 / 2, -9 / 2], dtype=dtype), + expected=np.array( + [ + np.log(np.pi) / 2 + np.log(2), + np.log(np.pi) / 2 - np.log(15) + np.log(8), + np.log(np.pi) / 2 - np.log(945) + np.log(32), + ], + dtype=dtype), + atol=1e-4) + self._assertOpOutputMatchesExpected( math_ops.digamma, np.array( diff --git a/tensorflow/compiler/tests/while_test.py b/tensorflow/compiler/tests/while_test.py index b637cf31cf..4ee144beb7 100644 --- a/tensorflow/compiler/tests/while_test.py +++ b/tensorflow/compiler/tests/while_test.py @@ -43,7 +43,7 @@ class WhileTest(xla_test.XLATestCase): def loop_cond(step): return step < 10 - with self.test_session() as sess: + with self.cached_session() as sess: init_index = array_ops.placeholder(dtypes.int32, []) with self.test_scope(): loop_outputs = xla.while_loop([init_index], loop_cond, loop_body) @@ -65,7 +65,7 @@ class WhileTest(xla_test.XLATestCase): del rsum return step < 10 - with self.test_session() as sess: + with self.cached_session() as sess: init_index = array_ops.placeholder(dtypes.int32, []) init_sum = array_ops.placeholder(dtypes.float32, []) with self.test_scope(): @@ -91,7 +91,7 @@ class WhileTest(xla_test.XLATestCase): del rsum return step < 10 - with self.test_session() as sess: + with self.cached_session() as sess: init_index = array_ops.placeholder(dtypes.int32, []) init_sum = array_ops.placeholder(dtypes.complex64, []) with self.test_scope(): @@ -117,7 +117,7 @@ class WhileTest(xla_test.XLATestCase): del x return step < 10 - with self.test_session() as sess: + with self.cached_session() as sess: init_index = array_ops.placeholder(dtypes.int32, []) with self.test_scope(): loop_outputs = xla.while_loop([init_index, 42], loop_cond, loop_body) diff --git a/tensorflow/compiler/tests/xla_device_test.py b/tensorflow/compiler/tests/xla_device_test.py index 85084bb124..28d61fb07d 100644 --- a/tensorflow/compiler/tests/xla_device_test.py +++ b/tensorflow/compiler/tests/xla_device_test.py @@ -37,7 +37,7 @@ class XlaDeviceTest(xla_test.XLATestCase): [16384, 1], [1, 16384], [1, 20000, 1, 1]] for dtype in self.numeric_types: for shape in shapes: - with self.test_session() as sess: + with self.cached_session() as sess: with ops.device("CPU"): x = array_ops.placeholder(dtype, shape) with self.test_scope(): @@ -58,7 +58,7 @@ class XlaDeviceTest(xla_test.XLATestCase): ]) shape = (10, 10) for unsupported_dtype in test_types - self.all_types: - with self.test_session() as sess: + with self.cached_session() as sess: with ops.device("CPU"): x = array_ops.placeholder(unsupported_dtype, shape) with self.test_scope(): @@ -78,7 +78,7 @@ class XlaDeviceTest(xla_test.XLATestCase): pass def testControlTrigger(self): - with self.test_session() as sess: + with self.cached_session() as sess: with self.test_scope(): x = gen_control_flow_ops.control_trigger() sess.run(x) diff --git a/tensorflow/compiler/tests/xla_ops_test.py b/tensorflow/compiler/tests/xla_ops_test.py new file mode 100644 index 0000000000..b2f026df6c --- /dev/null +++ b/tensorflow/compiler/tests/xla_ops_test.py @@ -0,0 +1,301 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for XLA op wrappers.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from absl.testing import parameterized +import numpy as np + +from tensorflow.compiler.tests import xla_test +from tensorflow.compiler.tf2xla.python import xla +from tensorflow.compiler.xla import xla_data_pb2 +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import function +from tensorflow.python.ops import array_ops +from tensorflow.python.platform import googletest + + +class XlaOpsTest(xla_test.XLATestCase, parameterized.TestCase): + + def _assertOpOutputMatchesExpected(self, op, args, expected, + equality_fn=None): + with self.test_session() as session: + with self.test_scope(): + placeholders = [ + array_ops.placeholder(dtypes.as_dtype(arg.dtype), arg.shape) + for arg in args + ] + feeds = {placeholders[i]: args[i] for i in range(0, len(args))} + output = op(*placeholders) + result = session.run(output, feeds) + if not equality_fn: + equality_fn = self.assertAllClose + equality_fn(result, expected, rtol=1e-3) + + def testAdd(self): + for dtype in self.numeric_types: + self._assertOpOutputMatchesExpected( + xla.add, + args=(np.array([1, 2, 3], dtype=dtype), + np.array([4, 5, 6], dtype=dtype)), + expected=np.array([5, 7, 9], dtype=dtype)) + + self._assertOpOutputMatchesExpected( + lambda x, y: xla.add(x, y, broadcast_dims=(0,)), + args=(np.array([[1, 2], [3, 4]], dtype=dtype), + np.array([7, 11], dtype=dtype)), + expected=np.array([[8, 9], [14, 15]], dtype=dtype)) + + self._assertOpOutputMatchesExpected( + lambda x, y: xla.add(x, y, broadcast_dims=(1,)), + args=(np.array([[1, 2], [3, 4]], dtype=dtype), + np.array([7, 11], dtype=dtype)), + expected=np.array([[8, 13], [10, 15]], dtype=dtype)) + + def testBroadcast(self): + for dtype in self.numeric_types: + v = np.arange(4, dtype=np.int32).astype(dtype).reshape([2, 2]) + self._assertOpOutputMatchesExpected( + lambda x: xla.broadcast(x, (7, 42)), + args=(v,), + expected=np.tile(v, (7, 42, 1, 1))) + + def testShiftRightLogical(self): + self._assertOpOutputMatchesExpected( + xla.shift_right_logical, + args=(np.array([-1, 16], dtype=np.int32), np.int32(4)), + expected=np.array([0x0FFFFFFF, 1], dtype=np.int32)) + + self._assertOpOutputMatchesExpected( + xla.shift_right_logical, + args=(np.array([0xFFFFFFFF, 16], dtype=np.uint32), np.uint32(4)), + expected=np.array([0x0FFFFFFF, 1], dtype=np.uint32)) + + def testShiftRightArithmetic(self): + self._assertOpOutputMatchesExpected( + xla.shift_right_arithmetic, + args=(np.array([-1, 16], dtype=np.int32), np.int32(4)), + expected=np.array([-1, 1], dtype=np.int32)) + + self._assertOpOutputMatchesExpected( + xla.shift_right_arithmetic, + args=(np.array([0xFFFFFFFF, 16], dtype=np.uint32), np.uint32(4)), + expected=np.array([0xFFFFFFFF, 1], dtype=np.uint32)) + + PRECISION_VALUES = (None, xla_data_pb2.PrecisionConfigProto.DEFAULT, + xla_data_pb2.PrecisionConfigProto.HIGH, + xla_data_pb2.PrecisionConfigProto.HIGHEST) + + @parameterized.parameters(*PRECISION_VALUES) + def testConv(self, precision): + for dtype in set(self.float_types).intersection( + set([dtypes.bfloat16.as_numpy_dtype, np.float32])): + + def conv_1d_fn(lhs, rhs): + dnums = xla_data_pb2.ConvolutionDimensionNumbers() + num_spatial_dims = 1 + dnums.input_batch_dimension = 0 + dnums.input_feature_dimension = 1 + dnums.output_batch_dimension = 0 + dnums.output_feature_dimension = 1 + dnums.kernel_output_feature_dimension = 0 + dnums.kernel_input_feature_dimension = 1 + dnums.input_spatial_dimensions.extend(range(2, 2 + num_spatial_dims)) + dnums.kernel_spatial_dimensions.extend(range(2, 2 + num_spatial_dims)) + dnums.output_spatial_dimensions.extend(range(2, 2 + num_spatial_dims)) + precision_config = None + if precision: + precision_config = xla_data_pb2.PrecisionConfigProto() + precision_config.operand_precision.extend([precision, precision]) + return xla.conv( + lhs, + rhs, + window_strides=(1,), + padding=((2, 1),), + lhs_dilation=(1,), + rhs_dilation=(2,), + dimension_numbers=dnums) + + self._assertOpOutputMatchesExpected( + conv_1d_fn, + args=( + np.array([[[3, 4, 5, 6]]], dtype=dtype), + np.array([[[-2, -3]]], dtype=dtype), + ), + expected=np.array([[[-9, -12, -21, -26, -10]]], dtype=dtype)) + + @parameterized.parameters(*PRECISION_VALUES) + def testDotGeneral(self, precision): + for dtype in self.float_types: + + def dot_fn(lhs, rhs): + dnums = xla_data_pb2.DotDimensionNumbers() + dnums.lhs_contracting_dimensions.append(2) + dnums.rhs_contracting_dimensions.append(1) + dnums.lhs_batch_dimensions.append(0) + dnums.rhs_batch_dimensions.append(0) + precision_config = None + if precision: + precision_config = xla_data_pb2.PrecisionConfigProto() + precision_config.operand_precision.extend([precision, precision]) + return xla.dot_general( + lhs, + rhs, + dimension_numbers=dnums, + precision_config=precision_config) + + lhs = np.array( + [ + [[1, 2], [3, 4]], + [[5, 6], [7, 8]], + ], dtype=dtype) + rhs = np.array( + [ + [[1, 2, 3], [4, 5, 6]], + [[7, 8, 9], [10, 11, 12]], + ], dtype=dtype) + self._assertOpOutputMatchesExpected( + dot_fn, + args=(lhs, rhs), + expected=np.array( + [ + [[9, 12, 15], [19, 26, 33]], + [[95, 106, 117], [129, 144, 159]], + ], + dtype=dtype)) + + def testNeg(self): + for dtype in self.numeric_types: + self._assertOpOutputMatchesExpected( + xla.neg, + args=(np.array([1, 2, 3], dtype=dtype),), + expected=np.array([-1, -2, -3], dtype=dtype)) + + def testPad(self): + for dtype in self.numeric_types: + + def pad_fn(x): + return xla.pad( + x, + padding_value=7, + padding_low=[2, 1], + padding_high=[1, 2], + padding_interior=[1, 0]) + + self._assertOpOutputMatchesExpected( + pad_fn, + args=(np.arange(4, dtype=np.int32).astype(dtype).reshape([2, 2]),), + expected=np.array( + [[7, 7, 7, 7, 7], [7, 7, 7, 7, 7], [7, 0, 1, 7, 7], + [7, 7, 7, 7, 7], [7, 2, 3, 7, 7], [7, 7, 7, 7, 7]], + dtype=dtype)) + + def testReduce(self): + for dtype in set(self.numeric_types).intersection( + set([dtypes.bfloat16.as_numpy_dtype, np.float32])): + + @function.Defun(dtype, dtype) + def sum_reducer(x, y): + return x + y + + def sum_reduction(dims): + + def fn(x): + return xla.reduce( + x, init_value=0, dimensions_to_reduce=dims, reducer=sum_reducer) + + return fn + + self._assertOpOutputMatchesExpected( + sum_reduction(dims=[]), + args=(np.arange(12, dtype=np.int32).astype(dtype).reshape([3, 4]),), + expected=np.arange(12, dtype=np.int32).astype(dtype).reshape([3, 4])) + self._assertOpOutputMatchesExpected( + sum_reduction(dims=[0]), + args=(np.arange(12, dtype=np.int32).astype(dtype).reshape([3, 4]),), + expected=np.array([12, 15, 18, 21], dtype=dtype)) + self._assertOpOutputMatchesExpected( + sum_reduction(dims=[1]), + args=(np.arange(12, dtype=np.int32).astype(dtype).reshape([3, 4]),), + expected=np.array([6, 22, 38], dtype=dtype)) + self._assertOpOutputMatchesExpected( + sum_reduction(dims=[0, 1]), + args=(np.arange(12, dtype=np.int32).astype(dtype).reshape([3, 4]),), + expected=dtype(66)) + + @function.Defun(dtype, dtype) + def mul_reducer(x, y): + return x * y + + def mul_reduction(dims): + + def fn(x): + return xla.reduce( + x, init_value=1, dimensions_to_reduce=dims, reducer=mul_reducer) + + return fn + + self._assertOpOutputMatchesExpected( + mul_reduction(dims=[0]), + args=(np.arange(12, dtype=np.int32).astype(dtype).reshape([3, 4]),), + expected=np.array([0, 45, 120, 231], dtype=dtype)) + + def testSelectAndScatter(self): + for dtype in set(self.numeric_types).intersection( + set([dtypes.bfloat16.as_numpy_dtype, np.float32])): + + @function.Defun(dtype, dtype) + def add_scatter(x, y): + return x + y + + @function.Defun(dtype, dtype) + def ge_select(x, y): + return x >= y + + def test_fn(operand, source): + return xla.select_and_scatter( + operand, + window_dimensions=[2, 3, 1, 1], + window_strides=[2, 2, 1, 1], + padding=[[0, 0]] * 4, + source=source, + init_value=0, + select=ge_select, + scatter=add_scatter) + + self._assertOpOutputMatchesExpected( + test_fn, + args=(np.array( + [[7, 2, 5, 3, 8], [3, 8, 9, 3, 4], [1, 5, 7, 5, 6], + [0, 6, 2, 10, 2]], + dtype=dtype).reshape((4, 5, 1, 1)), + np.array([[2, 6], [3, 1]], dtype=dtype).reshape((2, 2, 1, 1))), + expected=np.array( + [[0, 0, 0, 0, 0], [0, 0, 8, 0, 0], [0, 0, 3, 0, 0], + [0, 0, 0, 1, 0]], + dtype=dtype).reshape((4, 5, 1, 1))) + + def testTranspose(self): + for dtype in self.numeric_types: + v = np.arange(4, dtype=np.int32).astype(dtype).reshape([2, 2]) + self._assertOpOutputMatchesExpected( + lambda x: xla.transpose(x, [1, 0]), args=(v,), expected=v.T) + + +if __name__ == '__main__': + googletest.main() diff --git a/tensorflow/compiler/tf2xla/BUILD b/tensorflow/compiler/tf2xla/BUILD index fda32c8a1c..92e577bb7b 100644 --- a/tensorflow/compiler/tf2xla/BUILD +++ b/tensorflow/compiler/tf2xla/BUILD @@ -39,6 +39,7 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:ops", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/strings", ], ) @@ -88,6 +89,7 @@ cc_library( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/strings", ], ) @@ -211,6 +213,7 @@ cc_library( "//tensorflow/core:lib_internal", "//tensorflow/core:protos_all_cc", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", ], alwayslink = 1, ) @@ -220,13 +223,11 @@ cc_library( srcs = [ "literal_util.cc", "shape_util.cc", - "str_util.cc", "type_util.cc", ], hdrs = [ "literal_util.h", "shape_util.h", - "str_util.h", "type_util.h", ], visibility = [":friends"], @@ -255,6 +256,7 @@ cc_library( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/strings", ], ) @@ -287,6 +289,7 @@ cc_library( "//tensorflow/core:graph", "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/types:optional", ], ) @@ -305,6 +308,7 @@ tf_cc_test( "//tensorflow/core:protos_all_cc", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/strings", ], ) @@ -372,19 +376,7 @@ tf_cc_test( "//tensorflow/core:test", "//tensorflow/core:test_main", "//tensorflow/core:testlib", - ], -) - -tf_cc_test( - name = "str_util_test", - srcs = [ - "str_util_test.cc", - ], - deps = [ - ":common", - "//tensorflow/core:lib", - "//tensorflow/core:test", - "//tensorflow/core:test_main", + "@com_google_absl//absl/strings", ], ) @@ -443,21 +435,96 @@ cc_library( ) cc_library( + name = "functionalize_control_flow_util", + srcs = [ + "functionalize_control_flow_util.cc", + ], + hdrs = [ + "functionalize_control_flow_util.h", + ], + deps = [ + "//tensorflow/compiler/tf2xla/ops:xla_ops", + "//tensorflow/compiler/xla:status_macros", + "//tensorflow/core:core_cpu", + "//tensorflow/core:core_cpu_internal", + "//tensorflow/core:graph", + "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/strings", + ], +) + +cc_library( + name = "functionalize_cond", + srcs = [ + "functionalize_cond.cc", + ], + hdrs = [ + "functionalize_cond.h", + ], + deps = [ + ":functionalize_control_flow_util", + ":tf2xla_util", + "//tensorflow/compiler/jit:union_find", + "//tensorflow/compiler/tf2xla:dump_graph", + "//tensorflow/compiler/tf2xla/ops:xla_ops", + "//tensorflow/compiler/xla:status_macros", + "//tensorflow/core:core_cpu", + "//tensorflow/core:core_cpu_internal", + "//tensorflow/core:framework", + "//tensorflow/core:graph", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", + ], +) + +cc_library( name = "functionalize_control_flow", - srcs = ["functionalize_control_flow.cc"], - hdrs = ["functionalize_control_flow.h"], + srcs = [ + "functionalize_control_flow.cc", + ], + hdrs = [ + "functionalize_control_flow.h", + ], deps = [ + ":functionalize_cond", + ":functionalize_control_flow_util", + ":functionalize_while", ":tf2xla_util", "//tensorflow/compiler/jit:union_find", "//tensorflow/compiler/tf2xla:dump_graph", "//tensorflow/compiler/tf2xla/ops:xla_ops", "//tensorflow/compiler/xla:status_macros", - "//tensorflow/compiler/xla:util", "//tensorflow/core:core_cpu", "//tensorflow/core:core_cpu_internal", "//tensorflow/core:framework", "//tensorflow/core:graph", - "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/types:optional", + ], +) + +cc_library( + name = "functionalize_while", + srcs = [ + "functionalize_while.cc", + ], + hdrs = [ + "functionalize_while.h", + ], + deps = [ + ":functionalize_control_flow_util", + ":tf2xla_util", + "//tensorflow/compiler/jit:union_find", + "//tensorflow/compiler/tf2xla:dump_graph", + "//tensorflow/compiler/tf2xla/ops:xla_ops", + "//tensorflow/compiler/xla:status_macros", + "//tensorflow/core:core_cpu", + "//tensorflow/core:core_cpu_internal", + "//tensorflow/core:framework", + "//tensorflow/core:graph", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/types:optional", ], ) @@ -485,6 +552,32 @@ tf_cc_test( ], ) +tf_cc_test( + name = "functionalize_cond_test", + srcs = ["functionalize_cond_test.cc"], + deps = [ + ":functionalize_cond", + ":functionalize_control_flow", + ":test_util", + "//tensorflow/cc:cc_ops", + "//tensorflow/cc:cc_ops_internal", + "//tensorflow/cc:function_ops", + "//tensorflow/cc:ops", + "//tensorflow/cc:resource_variable_ops", + "//tensorflow/compiler/tf2xla/cc:xla_ops", + "//tensorflow/compiler/xla:status_macros", + "//tensorflow/core:core_cpu", + "//tensorflow/core:core_cpu_internal", + "//tensorflow/core:framework", + "//tensorflow/core:framework_internal", + "//tensorflow/core:ops", + "//tensorflow/core:resource_variable_ops_op_lib", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + "//tensorflow/core:testlib", + ], +) + cc_library( name = "test_util", testonly = 1, @@ -508,3 +601,30 @@ tf_cc_test( "//tensorflow/core:test_main", ], ) + +cc_library( + name = "resource_operation_table", + srcs = ["resource_operation_table.cc"], + hdrs = ["resource_operation_table.h"], + deps = [ + "//tensorflow/core:framework", + "//tensorflow/core:lib", + "//tensorflow/core:ops", + "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/algorithm:container", + ], +) + +tf_cc_test( + name = "resource_operation_table_test", + srcs = ["resource_operation_table_test.cc"], + deps = [ + ":resource_operation_table", + ":xla_compiler", + "//tensorflow/compiler/tf2xla/kernels:xla_ops", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/strings", + ], +) diff --git a/tensorflow/compiler/tf2xla/const_analysis.cc b/tensorflow/compiler/tf2xla/const_analysis.cc index de1008803d..e8673d7790 100644 --- a/tensorflow/compiler/tf2xla/const_analysis.cc +++ b/tensorflow/compiler/tf2xla/const_analysis.cc @@ -23,11 +23,11 @@ limitations under the License. #include "tensorflow/core/graph/algorithm.h" namespace tensorflow { - // Backwards dataflow analysis that finds arguments to a graph that must be // compile-time constants. Status BackwardsConstAnalysis(const Graph& g, - std::vector<bool>* compile_time_const_args) { + std::vector<bool>* compile_time_const_args, + std::vector<bool>* compile_time_const_nodes) { // Operators that don't look at the data of their inputs, just the shapes. const std::unordered_set<string> metadata_ops = { "Rank", @@ -36,9 +36,16 @@ Status BackwardsConstAnalysis(const Graph& g, "Size", }; + std::vector<bool> compile_time_const_nodes_impl; + if (compile_time_const_nodes) { + CHECK_EQ(compile_time_const_nodes->size(), g.num_node_ids()); + } else { + compile_time_const_nodes_impl.resize(g.num_node_ids()); + compile_time_const_nodes = &compile_time_const_nodes_impl; + } + Status status; - std::unordered_set<const Node*> must_be_const; - auto visit = [&status, &metadata_ops, &must_be_const, + auto visit = [&status, &metadata_ops, compile_time_const_nodes, compile_time_const_args](Node* node) { if (!status.ok()) return; @@ -47,17 +54,19 @@ Status BackwardsConstAnalysis(const Graph& g, // If this node must be const, and it isn't a metadata op, then all of its // parents must be const. - if (must_be_const.find(node) != must_be_const.end()) { + if ((*compile_time_const_nodes)[node->id()]) { if (node->type_string() == "_Arg") { int index; status = GetNodeAttr(node->attrs(), "index", &index); if (!status.ok()) return; - compile_time_const_args->at(index) = true; + if (compile_time_const_args) { + (*compile_time_const_args)[index] = true; + } return; } for (const Edge* pred : node->in_edges()) { if (!pred->IsControlEdge()) { - must_be_const.insert(pred->src()); + (*compile_time_const_nodes)[pred->src()->id()] = true; } } return; @@ -80,7 +89,7 @@ Status BackwardsConstAnalysis(const Graph& g, for (Edge const* edge : node->in_edges()) { if (edge->dst_input() >= name_range->second.first && edge->dst_input() < name_range->second.second) { - must_be_const.insert(edge->src()); + (*compile_time_const_nodes)[edge->src()->id()] = true; } } } diff --git a/tensorflow/compiler/tf2xla/const_analysis.h b/tensorflow/compiler/tf2xla/const_analysis.h index 634b97d7e3..af57e5a403 100644 --- a/tensorflow/compiler/tf2xla/const_analysis.h +++ b/tensorflow/compiler/tf2xla/const_analysis.h @@ -23,10 +23,18 @@ limitations under the License. namespace tensorflow { -// Backwards dataflow analysis that finds arguments (_Arg nodes) to a graph that -// must be compile-time constants. +// Backwards dataflow analysis that finds nodes in a graph that must be +// compile-time constants for us to be able to lower the graph to XLA. +// +// The indices of the arguments to `graph` that must be constant are returned in +// `compile_time_const_arg_indices`, if `compile_time_const_arg_indices` is not +// null. +// +// The ids of the nodes in `graph` that must be constant are returned in +// `compile_time_const_nodes`, if `compile_time_const_nodes` is not null. Status BackwardsConstAnalysis(const Graph& graph, - std::vector<bool>* compile_time_const_args); + std::vector<bool>* compile_time_const_arg_indices, + std::vector<bool>* compile_time_const_nodes); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/const_analysis_test.cc b/tensorflow/compiler/tf2xla/const_analysis_test.cc index 992b12c06d..56065be894 100644 --- a/tensorflow/compiler/tf2xla/const_analysis_test.cc +++ b/tensorflow/compiler/tf2xla/const_analysis_test.cc @@ -20,6 +20,7 @@ limitations under the License. #include "tensorflow/cc/framework/ops.h" #include "tensorflow/cc/ops/function_ops.h" #include "tensorflow/cc/ops/standard_ops.h" +#include "tensorflow/core/graph/algorithm.h" #include "tensorflow/core/lib/core/status_test_util.h" #include "tensorflow/core/platform/test.h" @@ -38,17 +39,23 @@ TEST(ConstAnalysisTest, Basics) { auto c = ops::Reshape(root, arg2, b); auto d = ops::Mul(root, c, ops::Sum(root, arg3, arg3)); - Graph graph(OpRegistry::Global()); - TF_ASSERT_OK(root.ToGraph(&graph)); + FixupSourceAndSinkEdges(root.graph()); std::vector<bool> const_args(4, false); - TF_ASSERT_OK(BackwardsConstAnalysis(graph, &const_args)); + std::vector<bool> const_nodes(root.graph()->num_node_ids(), false); + TF_ASSERT_OK( + BackwardsConstAnalysis(*root.graph(), &const_args, &const_nodes)); // Arg 0 doesn't need to be constant since the graph only uses its shape. // Arg 1 must be constant because it flows to the shape argument of a Reshape. // Arg 2 is used only as the value input to a Reshape and need not be const. // Arg 3 is used as the reduction-indices argument to Sum and must be const. EXPECT_EQ(const_args, std::vector<bool>({false, true, false, true})); + + EXPECT_FALSE(const_nodes[arg0.node()->id()]); + EXPECT_TRUE(const_nodes[arg1.node()->id()]); + EXPECT_FALSE(const_nodes[arg2.node()->id()]); + EXPECT_TRUE(const_nodes[arg3.node()->id()]); } // Regression test for a case where the backward const analysis did @@ -73,7 +80,8 @@ TEST(ConstAnalysisTest, TopologicalOrder) { TF_ASSERT_OK(root.ToGraph(&graph)); std::vector<bool> const_args(3, false); - TF_ASSERT_OK(BackwardsConstAnalysis(graph, &const_args)); + TF_ASSERT_OK(BackwardsConstAnalysis(graph, &const_args, + /*compile_time_const_nodes=*/nullptr)); EXPECT_EQ(const_args, std::vector<bool>({true, true, false})); } @@ -93,7 +101,8 @@ TEST(ConstAnalysisTest, DontFollowControlDependencies) { TF_ASSERT_OK(root.ToGraph(&graph)); std::vector<bool> const_args(2, false); - TF_ASSERT_OK(BackwardsConstAnalysis(graph, &const_args)); + TF_ASSERT_OK(BackwardsConstAnalysis(graph, &const_args, + /*compile_time_const_nodes=*/nullptr)); EXPECT_EQ(const_args, std::vector<bool>({false, true})); } diff --git a/tensorflow/compiler/tf2xla/functionalize_cond.cc b/tensorflow/compiler/tf2xla/functionalize_cond.cc new file mode 100644 index 0000000000..b5667ca0d3 --- /dev/null +++ b/tensorflow/compiler/tf2xla/functionalize_cond.cc @@ -0,0 +1,1385 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/tf2xla/functionalize_cond.h" + +#include <algorithm> +#include <deque> +#include <stack> +#include <unordered_set> +#include <vector> + +#include "absl/memory/memory.h" +#include "absl/strings/str_join.h" +#include "absl/types/optional.h" +#include "tensorflow/compiler/jit/union_find.h" +#include "tensorflow/compiler/tf2xla/dump_graph.h" +#include "tensorflow/compiler/tf2xla/functionalize_control_flow_util.h" +#include "tensorflow/compiler/tf2xla/tf2xla_util.h" +#include "tensorflow/core/common_runtime/function.h" +#include "tensorflow/core/framework/graph_to_functiondef.h" +#include "tensorflow/core/framework/node_def_builder.h" +#include "tensorflow/core/graph/algorithm.h" +#include "tensorflow/core/graph/control_flow.h" +#include "tensorflow/core/graph/node_builder.h" + +using xla::StatusOr; + +namespace tensorflow { +namespace functionalize_cond { + +string DebugString(const CondStateMap::CondNode& node) { + return node.ToString(); +} + +// TODO(jpienaar): Move to OutputTensor. +string DebugString(const OutputTensor& tensor) { + return strings::StrCat(tensor.node->name(), ":", tensor.index); +} + +string DebugString(CondStateMap::CondId cond_state) { + if (cond_state == nullptr || cond_state->empty()) return "[]"; + return strings::StrCat( + "[", + absl::StrJoin(*cond_state, ", ", + [](string* output, const CondStateMap::CondNode& node) { + strings::StrAppend(output, node.ToString()); + }), + "]"); +} + +string Branch_Name(BranchType b) { + switch (b) { + case BranchType::kElseBranch: + return "else"; + case BranchType::kThenBranch: + return "then"; + case BranchType::kBoth: + return "both"; + case BranchType::kNeither: + return "neither"; + } +} + +// Returns the predicate of a switch. +Status GetSwitchPredicate(const Node& switch_node, OutputTensor* pred) { + const Edge* pred_edge; + TF_RETURN_IF_ERROR(switch_node.input_edge(1, &pred_edge)); + // The predicate can be preceded by a identity node. Look through + // identity nodes to predicate. + while (pred_edge->src()->IsIdentity()) { + TF_RETURN_IF_ERROR(pred_edge->src()->input_edge(0, &pred_edge)); + } + *pred = OutputTensor(pred_edge->src(), pred_edge->src_output()); + return Status::OK(); +} + +CondStateMap::CondNode::CondNode(Type type, Node* switch_node, + BranchType branch) + : type(type), branch(branch) { + if (type == Type::kSwitch) { + TF_CHECK_OK(GetSwitchPredicate(*switch_node, &predicate)); + } +} + +string CondStateMap::CondNode::ToString() const { + switch (type) { + case Type::kSwitch: + return strings::StrCat("s(", DebugString(predicate), ",", + Branch_Name(branch), ")"); + case Type::kMerge: + return "m"; + case Type::kDead: + return "d"; + } +} + +bool CondStateMap::CondNode::operator==(const CondNode& other) const { + if (type != Type::kSwitch) return type == other.type; + return type == other.type && predicate == other.predicate && + branch == other.branch; +} + +bool CondStateMap::CondNode::operator!=(const CondNode& other) const { + return !(*this == other); +} + +CondStateMap::CondStateMap(Graph* graph) { + node_to_condid_map_.resize(graph->num_node_ids()); + // Initialize the dead state (empty state is designated with a nullptr). + dead_id_ = GetUniqueId({CondNode(CondStateMap::CondNode::Type::kDead)}); +} + +bool CondStateMap::IsDead(CondStateMap::CondId id) const { + return id == dead_id_; +} + +bool CondStateMap::IsEmpty(CondStateMap::CondId id) const { + return id == nullptr; +} + +size_t CondStateMap::CondHash::operator()( + const CondStateMap::CondNode& item) const { + return Hash64Combine(Hash64Combine(OutputTensor::Hash()(item.predicate), + hash<BranchType>()(item.branch)), + hash<CondStateMap::CondNode::Type>()(item.type)); +} + +size_t CondStateMap::CondHash::operator()( + const CondStateMap::CondState& vec) const { + if (vec.empty()) return 0; + size_t h = (*this)(vec.front()); + auto it = vec.begin(); + for (++it; it != vec.end(); ++it) { + h = Hash64Combine(h, (*this)(*it)); + } + return h; +} + +// CondArgNode represents a input to the conditional and its corresponding +// switch nodes. +struct CondArgNode { + explicit CondArgNode(Node* src, int src_output) + : src(src), src_output(src_output) {} + + string ToString() const { + return strings::StrCat("src=", src->name(), ":", src_output, + " switches=", NodesToString(switches)); + } + + Node* src; + int src_output; + std::array<Node*, 2> branch_copy; + std::vector<Node*> switches; +}; +using CondArgNodes = std::vector<CondArgNode>; + +string DebugString(const CondArgNodes& nodes) { + return strings::StrCat( + "[", + absl::StrJoin(nodes, ", ", + [](string* output, const CondArgNode& node) { + strings::StrAppend(output, node.ToString()); + }), + "]"); +} + +CondStateMap::CondId CondStateMap::LookupId(const Node* node) const { + if (node->id() < node_to_condid_map_.size()) + return node_to_condid_map_[node->id()]; + return added_node_mapping_.at(node->id()); +} + +CondStateMap::CondId CondStateMap::GetUniqueId( + const CondStateMap::CondState& state) { + if (state.empty()) return nullptr; + return &*condstate_set_.insert(state).first; +} + +const CondStateMap::CondState& CondStateMap::LookupState( + const Node* node) const { + return *LookupId(node); +} + +void CondStateMap::ResetId(const Node* node, CondStateMap::CondId id) { + if (node->id() < node_to_condid_map_.size()) + node_to_condid_map_[node->id()] = id; + else + added_node_mapping_[node->id()] = id; +} + +void CondStateMap::MarkDead(const Node* node) { ResetId(node, dead_id_); } + +string CondStateMap::CondStateToString(const Node* node) const { + return CondStateToString(LookupId(node)); +} + +string CondStateMap::CondStateToString(CondStateMap::CondId id) const { + return DebugString(id); +} + +FunctionalizeCond::FunctionalizeCond(Graph* graph, + FunctionLibraryDefinition* library) + : cond_state_map_(graph), library_(library), graph_(graph) {} + +// Class representing the merge/switch nodes that will become a conditional. +class Conditional { + public: + Conditional(OutputTensor predicate, FunctionalizeCond* parent, + CondStateMap* cond_state_map); + + // Adds merge node that is part of this conditional. + Status AddMerge(Node* m); + + // Constructs an If node from the merge nodes. + Status BuildAndReplace(Graph* graph, FunctionLibraryDefinition* library); + + private: + // Extracts the then/else bodies: creates new graphs with the nodes + // corresponding to the nodes in the then/else branches as of this conditional + // as function bodies. + Status ExtractBodies(Graph* graph); + + // Builds the arguments that are the input to the If. + Status BuildArgumentNodes(); + + // Builds the If node for the extracted bodies with the given predicate. + Status BuildIfNode(Graph* graph, FunctionLibraryDefinition* library); + + // Adds input edges to If node. + Status AddInputEdges(Graph* graph); + + // Adds output edges from If node. + Status AddOutputEdges(Graph* graph); + + // Adds switch node that is part of this conditional. + Status AddSwitch(Node* s); + + // Internal name of conditional. The name is based on the first merge node + // added. + string name() const; + + // The FunctionalizeCond instance that created this. + FunctionalizeCond* parent_; + + // Mapping between nodes and their cond state. + CondStateMap* cond_state_map_; + + // The predicate of the conditional. + OutputTensor predicate_; + + // The predicate of the switches of the conditional. This may be different + // than predicate (which is initialized from the original graph) as the + // predicate could be the output of a newly created If node. + OutputTensor switch_predicate_; + + // Switch nodes in graph that are part of this conditional. + std::set<Node*, NodeCmpByNameResourcesLast> switches_; + + // Merge nodes in graph that are part of this conditional. + std::set<Node*, NodeCmpByNameResourcesLast> merges_; + + // Vector of control inputs from outside the conditional to a node inside. + std::vector<Node*> external_control_inputs_; + std::vector<Node*> external_control_outputs_; + + // Graphs corresponding to the then and else branch. + std::array<std::unique_ptr<Graph>, 2> bodies_; + + // Maps from graph_ to the branch body's graph. + std::array<std::vector<Node*>, 2> node_maps_; + + // The argument nodes created for the switches. + CondArgNodes cond_arg_nodes_; + + // The constructed If node. + Node* if_node_ = nullptr; + + // Whether the merge nodes of this conditional have been replaced. + bool replaced_ = false; +}; + +Conditional::Conditional(OutputTensor predicate, FunctionalizeCond* parent, + CondStateMap* cond_state_map) + : parent_(parent), cond_state_map_(cond_state_map), predicate_(predicate) {} + +Status Conditional::AddMerge(Node* m) { + merges_.insert(m); + return Status::OK(); +} + +Status Conditional::AddSwitch(Node* s) { + VLOG(5) << "Adding switch " << s->DebugString(); + OutputTensor predicate; + TF_RETURN_IF_ERROR(GetSwitchPredicate(*s, &predicate)); + if (switch_predicate_.node == nullptr) switch_predicate_ = predicate; + if (!(switch_predicate_ == predicate)) { + return errors::InvalidArgument( + "Merge nodes ", NodesToString(merges_), + " directly dominated by switch nodes with different predicates (", + DebugString(switch_predicate_), " vs ", DebugString(predicate), ")."); + } + switches_.insert(s); + return Status::OK(); +} + +Status Conditional::BuildArgumentNodes() { + VLOG(1) << "Build function arguments"; + struct Hash { + size_t operator()(const std::pair<Node*, int>& item) const { + return Hash64Combine(hash<Node*>()(item.first), + std::hash<int>()(item.second)); + } + }; + + std::unordered_map<std::pair<Node*, int>, int, Hash> input_index; + for (Node* switch_node : switches_) { + const Edge* e; + TF_RETURN_IF_ERROR(switch_node->input_edge(0, &e)); + std::pair<Node*, int> key = std::make_pair(e->src(), e->src_output()); + if (input_index.find(key) == input_index.end()) { + input_index[key] = cond_arg_nodes_.size(); + cond_arg_nodes_.emplace_back(key.first, key.second); + } + cond_arg_nodes_.at(input_index.at(key)).switches.push_back(switch_node); + } + VLOG(5) << "CondArg nodes created: " << DebugString(cond_arg_nodes_); + + int arg_count = 0; + for (CondArgNode& cond_arg_node : cond_arg_nodes_) { + DataType dtype = cond_arg_node.src->output_type(cond_arg_node.src_output); + for (auto branch : {BranchType::kElseBranch, BranchType::kThenBranch}) { + int branch_index = static_cast<int>(branch); + TF_RETURN_IF_ERROR( + NodeBuilder(strings::StrCat("_Arg", arg_count), + FunctionLibraryDefinition::kArgOp) + .Attr("T", dtype) + .Attr("index", arg_count) + .Finalize(bodies_[branch_index].get(), + &cond_arg_node.branch_copy[branch_index])); + } + for (Node* node : cond_arg_node.switches) { + for (const Edge* e : node->out_edges()) { + if (e->IsControlEdge()) continue; + int branch_index = e->src_output(); + Node* src_copy = cond_arg_node.branch_copy[branch_index]; + Node* dst_copy = node_maps_[branch_index][e->dst()->id()]; + + // The graph may contain dead switch nodes, + if (dst_copy == nullptr) continue; + + TF_RET_CHECK(dst_copy != nullptr) + << "Unable to find copied node for " << e->dst()->DebugString() + << " on branch " << Branch_Name(BranchType(branch_index)); + // If the input goes directly to a merge then the merge has + // been replaced by a retval so the dst input is 0 instead of + // dst_input. + int dst_input = IsMerge(e->dst()) ? 0 : e->dst_input(); + bodies_[branch_index]->AddEdge(src_copy, 0, dst_copy, dst_input); + } + } + ++arg_count; + } + + // Verify that all retvals have an input. + // TODO(jpienaar): One could add a ZerosLike in the branch that doesn't have + // input. + for (Node* m : merges_) { + for (auto branch : {BranchType::kElseBranch, BranchType::kThenBranch}) { + bool has_input = false; + for (auto e : node_maps_[static_cast<int>(branch)][m->id()]->in_edges()) { + if (!e->IsControlEdge()) { + has_input = true; + break; + } + } + if (!has_input) { + return errors::Internal( + "Failed to functionalize control flow with merge ", + FormatNodeForError(*m), " that doesn't have input on ", + Branch_Name(branch), " branch."); + } + } + } + + return Status::OK(); +} + +Status Conditional::ExtractBodies(Graph* graph) { + VLOG(2) << "Extracting bodies for " << name(); + for (auto b : {BranchType::kElseBranch, BranchType::kThenBranch}) { + bodies_[static_cast<int>(b)] = + absl::make_unique<Graph>(graph->op_registry()); + } + + auto find_branch = [&](const Edge* e) { + const auto& id = cond_state_map_->LookupId(e->src()); + return IsSwitch(e->src()) ? BranchType(e->src_output()) + : cond_state_map_->FindBranchOf(id, predicate_); + }; + + std::array<std::vector<Node*>, 2> stacks; + VLOG(5) << "Merges: " << NodesToString(merges_); + for (Node* m : merges_) { + VLOG(5) << "For merge: " << m->DebugString() << " " + << cond_state_map_->CondStateToString(m); + for (auto e : m->in_edges()) { + if (e->IsControlEdge()) continue; + BranchType branch = find_branch(e); + TF_RET_CHECK(branch == BranchType::kThenBranch || + branch == BranchType::kElseBranch) + << "Error: " << e->src()->name() + << " is not on either then or else branch (" << Branch_Name(branch) + << ")."; + Node* src = e->src(); + if (IsSwitch(src)) { + // Switch node outputs and dependencies are handled separately. + TF_RETURN_IF_ERROR(AddSwitch(src)); + } else { + stacks[static_cast<int>(branch)].push_back(src); + } + } + } + + for (auto branch : {BranchType::kElseBranch, BranchType::kThenBranch}) { + int branch_index = static_cast<int>(branch); + auto output = bodies_[branch_index].get(); + auto& stack = stacks[branch_index]; + VLOG(5) << "In branch: " << Branch_Name(branch) << " " + << NodesToString(stack); + std::vector<bool> visited(graph->num_node_ids(), false); + node_maps_[branch_index].resize(graph->num_node_ids(), nullptr); + auto& node_map = node_maps_[branch_index]; + + while (!stack.empty()) { + Node* n = stack.back(); + stack.pop_back(); + + if (visited.at(n->id())) continue; + visited[n->id()] = true; + + // Verify output edges and record control edges exitting scope. + for (const Edge* e : n->out_edges()) { + Node* dst = e->dst(); + if (IsMerge(dst)) continue; + Node* src = e->src(); + + auto dst_id = cond_state_map_->LookupId(dst); + auto src_id = cond_state_map_->LookupId(src); + if (dst_id != src_id) { + if (e->IsControlEdge()) { + external_control_outputs_.push_back(e->src()); + } else { + // Constants are treated specially to workaround the case of + // non-dominated constant nodes. + if (!IsConstant(src)) { + // TODO(b/78882471): A node that feeds into two different + // CondState is not necessarily an error so log a warning for now + // but revisit to improve the testing to enable making this an + // error. + LOG(WARNING) << errors::InvalidArgument( + "Graph contains node ", FormatNodeForError(*src), + " that feeds into node ", FormatNodeForError(*dst), + " but these nodes are in different control contexts (", + DebugString(src_id), " vs ", DebugString(dst_id), + " (detected during out edge testing)"); + } + } + } + } + + // Copying incomming edges to dst node. + for (const Edge* e : n->in_edges()) { + Node* src = e->src(); + // Skip src/dst node. + if (!src->IsOp()) continue; + + Node* dst = e->dst(); + if (IsSwitch(src)) { + // Switch node outputs and dependencies are handled separately. + TF_RETURN_IF_ERROR(AddSwitch(src)); + continue; + } + + // Verify input is from the same context. + auto src_id = cond_state_map_->LookupId(src); + auto dst_id = cond_state_map_->LookupId(dst); + if (IsMerge(dst) || src_id == dst_id) { + // TODO(jpienaar): The merge case can be more strict. + if (node_map.at(src->id()) == nullptr) { + node_map.at(src->id()) = output->CopyNode(src); + stack.push_back(src); + } + } else if (e->IsControlEdge()) { + external_control_inputs_.push_back(src); + } else { + // This shouldn't happen, this means we have an external data input + // not entering via a switch node. Work around this for constant + // nodes as some constant nodes are inserted without the required + // control context dominance. + if (IsConstant(src)) { + node_map.at(src->id()) = output->CopyNode(src); + } else { + return errors::InvalidArgument( + "Graph contains node ", FormatNodeForError(*src), + " that feeds into node ", FormatNodeForError(*dst), + " but these nodes are in different control contexts (", + DebugString(src_id), " vs ", DebugString(dst_id), + " (detected during in edge testing)"); + } + } + + Node* src_copy = node_map.at(e->src()->id()); + int src_output = e->src_output(); + if (node_map.at(dst->id()) == nullptr) { + node_map.at(dst->id()) = output->CopyNode(dst); + } + Node* dst_copy = node_map.at(e->dst()->id()); + if (e->IsControlEdge()) { + // Skip control inputs from external context. + if (src_copy != nullptr) output->AddControlEdge(src_copy, dst_copy); + } else { + output->AddEdge(src_copy, src_output, dst_copy, e->dst_input()); + } + } + } + } + + // Build return values from the merge nodes. + int index = 0; + for (Node* m : merges_) { + for (auto branch : {BranchType::kElseBranch, BranchType::kThenBranch}) { + int branch_index = static_cast<int>(branch); + auto& node_map = node_maps_[branch_index]; + auto output = bodies_[branch_index].get(); + TF_ASSIGN_OR_RETURN(node_map[m->id()], + BuildRetvalNode(output, m->output_type(0), index)); + } + ++index; + + // Connect the input to the merge_ with the retval, except if it is a + // Swich node, which is handled separately. + for (auto e : m->in_edges()) { + if (e->IsControlEdge()) continue; + int branch_index = static_cast<int>(find_branch(e)); + auto& node_map = node_maps_[branch_index]; + auto output = bodies_[branch_index].get(); + Node* in = e->src(); + if (!IsSwitch(in)) { + if (node_map.at(in->id()) == nullptr) { + node_map[in->id()] = output->CopyNode(in); + } + output->AddEdge(node_map[in->id()], e->src_output(), + node_map.at(m->id()), 0); + } + } + } + return Status::OK(); +} + +Status Conditional::BuildIfNode(Graph* graph, + FunctionLibraryDefinition* library) { + VLOG(2) << "Build cond function for " << name(); + NodeDefBuilder builder(name(), "If"); + const string branch_name[] = {"else_branch", "then_branch"}; + for (auto branch : {BranchType::kElseBranch, BranchType::kThenBranch}) { + int branch_index = static_cast<int>(branch); + static std::atomic<int64> sequence_num(0LL); + int64 id = ++sequence_num; + + NameAttrList body_name; + body_name.set_name(strings::StrCat("_functionalize_if_", + branch_name[branch_index], "_", id)); + + VLOG(3) << "FunctionalizeControlFlow (" << branch_name[branch_index] + << "): " + << dump_graph::DumpGraphToFile( + "functionalize_cond_body_" + branch_name[branch_index], + *bodies_[branch_index], nullptr); + + FunctionDef body_fdef; + TF_RETURN_IF_ERROR(GraphToFunctionDef(*bodies_[branch_index], + body_name.name(), &body_fdef)); + TF_RETURN_IF_ERROR(library->AddFunctionDef(body_fdef)); + builder.Attr(branch_name[branch_index], body_name); + } + + VLOG(3) << "Build input type"; + std::vector<NodeDefBuilder::NodeOut> inputs; + DataTypeVector in_arg_types; + for (auto& kv : cond_arg_nodes_) { + bool inserted = false; + for (const Node* arg : kv.switches) { + const Edge* in_edge; + TF_RETURN_IF_ERROR(arg->input_edge(0, &in_edge)); + if (in_edge->IsControlEdge()) { + builder.ControlInput(in_edge->src()->name()); + } else { + if (!inserted) { + DataType dtype = arg->input_type(0); + inputs.emplace_back(NodeDefBuilder::NodeOut( + in_edge->src()->name(), in_edge->src_output(), dtype)); + in_arg_types.push_back(dtype); + inserted = true; + } + } + } + } + builder.Attr("Tin", in_arg_types); + + DataTypeVector out_type; + for (const Node* merge : merges_) { + DataType dtype = merge->output_type(0); + out_type.push_back(dtype); + } + builder.Attr("Tout", out_type); + VLOG(3) << "Build output type: " << DataTypeVectorString(out_type); + + builder.Attr("Tcond", DT_BOOL); + builder.Device(predicate_.node->assigned_device_name()); + // Conditional should be the first input ... + builder.Input(NodeDefBuilder::NodeOut(predicate_.node->name(), + predicate_.index, + predicate_.node->output_type(0))); + // ... followed by the other inputs. + builder.Input(inputs); + + VLOG(3) << "Build If node"; + NodeDef if_def; + TF_RETURN_IF_ERROR(builder.Finalize(&if_def)); + TF_ASSIGN_OR_RETURN(if_node_, parent_->AddIfNode(if_def, *merges_.begin())); + + return Status::OK(); +} + +Status Conditional::AddInputEdges(Graph* graph) { + VLOG(2) << "AddInputEdges for " << if_node_->name(); + int index = 0; + // Add predicate input. + graph->AddEdge(const_cast<Node*>(predicate_.node), predicate_.index, if_node_, + index++); + // Add function body inputs. + for (auto& arg : cond_arg_nodes_) { + if (arg.src_output == Graph::kControlSlot) { + graph->AddControlEdge(arg.src, if_node_); + } else { + graph->AddEdge(arg.src, arg.src_output, if_node_, index++); + } + } + for (Node* n : external_control_inputs_) { + graph->AddControlEdge(n, if_node_); + } + return Status::OK(); +} + +Status Conditional::AddOutputEdges(Graph* graph) { + VLOG(2) << "AddOutputEdges for " << if_node_->name(); + int i = 0; + for (Node* node : merges_) { + TF_RETURN_IF_ERROR(parent_->AddIdentityNode(node, if_node_, i)); + std::vector<const Edge*> edges(node->out_edges().begin(), + node->out_edges().end()); + for (const Edge* edge : edges) { + Node* dst = edge->dst(); + int dst_input = edge->dst_input(); + if (edge->src_output() > 0) { + return errors::Unimplemented("Output of index (", edge->src_output(), + ") of merge node ", + FormatNodeForError(*node)); + } + + bool control_edge = edge->IsControlEdge(); + graph->RemoveEdge(edge); + if (control_edge) { + graph->AddControlEdge(if_node_, dst); + } else { + graph->AddEdge(if_node_, i, dst, dst_input); + } + } + ++i; + } + for (Node* n : external_control_outputs_) { + graph->AddControlEdge(if_node_, n); + } + + return Status::OK(); +} + +Status Conditional::BuildAndReplace(Graph* graph, + FunctionLibraryDefinition* library) { + VLOG(1) << "Build If and replace merge nodes " << name(); + if (replaced_) return Status::OK(); + + TF_RETURN_IF_ERROR(ExtractBodies(graph)); + TF_RETURN_IF_ERROR(BuildArgumentNodes()); + + if (VLOG_IS_ON(3)) { + LOG(INFO) << "Extracted bodies:"; + for (auto branch : {BranchType::kElseBranch, BranchType::kThenBranch}) { + int branch_index = static_cast<int>(branch); + auto output = bodies_[branch_index].get(); + LOG(INFO) << Branch_Name(branch) << ": " + << DebugString(output->ToGraphDefDebug()); + } + } + + TF_RETURN_IF_ERROR(BuildIfNode(graph, library)); + TF_RETURN_IF_ERROR(AddInputEdges(graph)); + TF_RETURN_IF_ERROR(AddOutputEdges(graph)); + TF_RETURN_IF_ERROR(parent_->PropagateUpdatedState(if_node_)); + for (Node* m : merges_) cond_state_map_->MarkDead(m); + + // Check that the if_node doesn't feed into itself. + TF_RETURN_WITH_CONTEXT_IF_ERROR( + CheckNodeNotInCycle(if_node_, graph->num_node_ids()), + "Converting to If failed."); + + replaced_ = true; + return Status::OK(); +} + +string Conditional::name() const { + CHECK(!merges_.empty()); + return strings::StrCat((*merges_.begin())->name(), "_if"); +} + +bool CondStateMap::ScopeIn(CondStateMap::CondId id, + CondStateMap::CondId* scope) { + if (id == nullptr) { + *scope = nullptr; + return true; + } + CondState state; + for (const CondNode& node : *id) { + if (node.type == CondNode::Type::kSwitch) { + state.push_back(node); + } + if (node.type == CondNode::Type::kMerge) { + if (state.empty()) { + return false; + } + DCHECK(state.back().type == CondNode::Type::kSwitch && + state.back().branch == BranchType::kBoth); + state.pop_back(); + } + } + *scope = GetUniqueId(state); + return true; +} + +Status FunctionalizeCond::AddIdentityNode(const Node* replacee, Node* if_node, + int port) { + Node* id; + TF_RETURN_IF_ERROR(NodeBuilder(replacee->name(), "Identity") + .Input(if_node, port) + .Finalize(graph_, &id)); + cond_state_map_.ResetId(id, cond_state_map_.LookupId(if_node)); + return Status::OK(); +} + +StatusOr<Node*> FunctionalizeCond::AddIfNode(const NodeDef& def, + const Node* replacee) { + Status status; + Node* ret = graph_->AddNode(def, &status); + TF_RETURN_IF_ERROR(status); + CondStateMap::CondState state = cond_state_map_.LookupState(replacee); + state.pop_back(); + VLOG(1) << "Adding If for " << replacee->name(); + cond_state_map_.ResetId(ret, cond_state_map_.GetUniqueId(state)); + return ret; +} + +Status FunctionalizeCond::PropagateUpdatedState(const Node* replacee) { + VLOG(2) << "Propagating update state for " << replacee->name() << " " + << cond_state_map_.CondStateToString(replacee); + // Redo topological sort as the order could have changed. + // TODO(jpienaar): The original topological order could also be updated + // dynamically if needed. + std::vector<Node*> rev_topo_order; + GetPostOrder(*graph_, &rev_topo_order); + + // All the outputs of the new node could potentially be updated. + std::unordered_set<Node*> changed; + for (auto n : replacee->out_nodes()) + if (n->IsOp()) changed.insert(n); + + // Iterate through the changed/possible changed nodes in topological order. + for (auto it = rev_topo_order.rbegin(); + it != rev_topo_order.rend() && !changed.empty(); ++it) { + if (changed.find(*it) != changed.end()) { + // Update the node state. + Node* n = *it; + CondStateMap::CondId old_state = cond_state_map_.LookupId(n); + cond_state_map_.ResetId(n, nullptr); + TF_RETURN_IF_ERROR(DetermineCondState(n)); + if (cond_state_map_.LookupId(n) != old_state) { + for (auto out : n->out_nodes()) + if (out->IsOp()) changed.insert(out); + } + changed.erase(n); + } + } + return Status::OK(); +} + +// Returns the most restrictive branch of two branches or neither. This is the +// meet operator of the BranchType lattice. +BranchType MeetBranch(const BranchType& lhs, const BranchType& rhs) { + if (lhs == rhs) return lhs; + if (lhs == BranchType::kNeither) return rhs; + if (rhs == BranchType::kNeither) return lhs; + if (lhs == BranchType::kBoth) return rhs; + if (rhs == BranchType::kBoth) return lhs; + return BranchType::kNeither; +} + +CondStateMap::ContainsResult CondStateMap::LhsHoldsWhereverRhsHolds( + CondStateMap::CondId lhs, CondStateMap::CondId rhs) { + CondId lhs_scope; + CondId rhs_scope; + bool could_determine_scope = ScopeIn(lhs, &lhs_scope); + could_determine_scope = could_determine_scope && ScopeIn(rhs, &rhs_scope); + if (!could_determine_scope) return kIncomparable; + + // Returns whether a contains b. + auto contains = [&](CondId a, CondId b) { + // Handle empty states. + if (a == nullptr && b != nullptr) return true; + if (a == nullptr && b == nullptr) return true; + if (a != nullptr && b == nullptr) return false; + + if (a->size() > b->size()) return false; + auto a_it = a->begin(); + auto b_it = b->begin(); + while (a_it != a->end()) { + if (*a_it != *b_it) { + if (!(a_it->predicate == b_it->predicate)) return false; + BranchType mb = MeetBranch(a_it->branch, b_it->branch); + if (mb != b_it->branch) return false; + } + ++a_it; + ++b_it; + } + return true; + }; + + bool lhs_contains_rhs = contains(lhs_scope, rhs_scope); + bool rhs_contains_lhs = contains(rhs_scope, lhs_scope); + if (lhs_contains_rhs && rhs_contains_lhs) return kEqual; + if (lhs_contains_rhs) return kLhsContainsRhs; + if (rhs_contains_lhs) return kRhsContainsLhs; + return kIncomparable; +} + +BranchType CondStateMap::FindBranchOf(CondId id, OutputTensor predicate) const { + if (IsEmpty(id)) return BranchType::kNeither; + absl::optional<BranchType> b; + const CondState& nodes = *id; + for (auto it = nodes.rbegin(); it != nodes.rend(); ++it) { + if (it->type == CondStateMap::CondNode::Type::kSwitch && + it->predicate == predicate) { + if (b.has_value()) { + b = MeetBranch(*b, it->branch); + } else { + b = it->branch; + } + if (*b == BranchType::kNeither) { + LOG(FATAL) << "Inconsistent state for node: " << DebugString(id); + } + } + } + return b.has_value() ? *b : BranchType::kNeither; +} + +StatusOr<CondStateMap::CondId> FunctionalizeCond::JoinCondStatesNonMerge( + CondStateMap::CondId src, CondStateMap::CondId dst) { + VLOG(4) << "Joining src=" << DebugString(src) << " [" << src + << "] and dst=" << DebugString(dst) << " [" << dst << "]"; + + if (cond_state_map_.IsEmpty(dst) || cond_state_map_.IsDead(src)) return src; + if (cond_state_map_.IsDead(dst)) return dst; + + // Nothing to do if the CondState is the same. + if (src == dst) return src; + + CondStateMap::CondId src_scope; + CondStateMap::CondId dst_scope; + if (!cond_state_map_.ScopeIn(src, &src_scope)) + return errors::Unimplemented( + "Predicates that must hold for node to execute are invalid! ", + DebugString(src)); + if (!cond_state_map_.ScopeIn(dst, &dst_scope)) + return errors::Unimplemented( + "Predicates that must hold for node to execute are invalid! ", + DebugString(dst)); + + auto result = cond_state_map_.LhsHoldsWhereverRhsHolds(src_scope, dst_scope); + switch (result) { + case CondStateMap::kIncomparable: + return errors::InvalidArgument( + "Graph contains node with inputs predicated on incompatible " + "predicates: ", + DebugString(src), " and ", DebugString(dst)); + case CondStateMap::kEqual: + // If both respect the same predicates, propagate the longer constraint. + if ((src != nullptr && dst == nullptr) || + (src != nullptr && dst != nullptr && src->size() > dst->size())) + return src; + else + return dst; + case CondStateMap::kLhsContainsRhs: + // src contains dst, so dst is already more restrictive. + return dst; + case CondStateMap::kRhsContainsLhs: + // dst contains src, so src is more restrictive. + return src; + } +} + +StatusOr<CondStateMap::CondState::const_iterator> +FindThenElseSwitchForPredicate(const OutputTensor& pred, + CondStateMap::CondId id) { + for (auto it = id->begin(); it != id->end(); ++it) { + // Along every path one there can be only one instance of a then or else + // switch for a given predicate, so return once found. + if (it->type == CondStateMap::CondNode::Type::kSwitch && + it->predicate == pred && + (it->branch == BranchType::kThenBranch || + it->branch == BranchType::kElseBranch)) + return it; + } + return errors::Internal("Unable to find then/else branch with predicate ", + DebugString(pred), " for ", DebugString(id)); +} + +StatusOr<CondStateMap::CondId> FunctionalizeCond::JoinCondStatesMerge( + CondStateMap::CondId src, CondStateMap::CondId dst) { + // Determine the flow state when joining two states for a merge + // node. Combining the two states for a merge node is effectively performing a + // disjunction of the states along the different input edges. For a merge that + // can be transformed into a If the two inputs paths have to have a predicate + // on which they differ (e.g., along one edge predicate `p` has to hold while + // on another it should not). This function first determines this predicate + // and then the resultant state is the common path between the two inputs + // followed by s(p, both). + VLOG(4) << "Joining (for merge) " << DebugString(src) << " and " + << DebugString(dst); + if (cond_state_map_.IsEmpty(dst)) return src; + + if (cond_state_map_.IsDead(src)) return src; + if (cond_state_map_.IsDead(dst)) return dst; + + CondStateMap::CondId src_scope; + CondStateMap::CondId dst_scope; + if (!cond_state_map_.ScopeIn(src, &src_scope)) + return errors::Unimplemented( + "Predicates that must hold for node to execute are invalid! ", + DebugString(src)); + if (!cond_state_map_.ScopeIn(dst, &dst_scope)) + return errors::Unimplemented( + "Predicates that must hold for node to execute are invalid! ", + DebugString(dst)); + + TF_RET_CHECK(src_scope != nullptr && dst_scope != nullptr) + << "Illegal merge inputs from outer scope: src=" << DebugString(src) + << " dst=" << DebugString(dst); + auto src_it = src_scope->begin(); + auto dst_it = dst_scope->begin(); + + // Find branch divergent condition. + OutputTensor pred; + while (src_it != src_scope->end() && dst_it != dst_scope->end()) { + if (*src_it != *dst_it) { + VLOG(5) << "Diverges with: " << DebugString(*src_it) << " and " + << DebugString(*dst_it); + if (!(src_it->predicate == dst_it->predicate)) { + return errors::InvalidArgument( + "Unable to find common predicate which holds for one input " + "but not the other of the merge node."); + } + pred = src_it->predicate; + break; + } + ++src_it; + ++dst_it; + } + + if (pred.node == nullptr) + return errors::InvalidArgument("Unable to determine predicate for merge."); + + TF_ASSIGN_OR_RETURN(auto div_src_it, + FindThenElseSwitchForPredicate(pred, src)); + TF_ASSIGN_OR_RETURN(auto div_dst_it, + FindThenElseSwitchForPredicate(pred, dst)); + TF_RET_CHECK(*div_src_it != *div_dst_it); + + CondStateMap::CondState result; + // Populate result with the longest/most restrictive path up to the divergent + // node. For example, if the one input is `[switch(pred:0, then)]` and the + // other is `[switch(pred:0, both), merge, switch(pred:0, else)]` (as created + // in gradient of cond test), then the resultant state here should be + // `[switch(pred:0, both), merge, switch(pred:0, both)]`. + if (std::distance(src->begin(), div_src_it) > + std::distance(dst->begin(), div_dst_it)) { + result.assign(src->begin(), std::next(div_src_it)); + } else { + result.assign(dst->begin(), std::next(div_dst_it)); + } + result.back().branch = BranchType::kBoth; + return cond_state_map_.GetUniqueId(result); +} + +CondStateMap::CondId FunctionalizeCond::StateAlongEdge(const Edge* e) { + Node* src = e->src(); + CondStateMap::CondId id = cond_state_map_.LookupId(e->src()); + if (IsMerge(src)) { + CondStateMap::CondState state; + if (id != nullptr) state = *id; + state.emplace_back(CondStateMap::CondNode::Type::kMerge); + return cond_state_map_.GetUniqueId(state); + } + if (IsSwitch(src)) { + CondStateMap::CondState state; + if (id != nullptr) state = *id; + if (e->IsControlEdge()) { + state.emplace_back(CondStateMap::CondNode::Type::kSwitch, src, + BranchType::kBoth); + } else { + state.emplace_back(CondStateMap::CondNode::Type::kSwitch, src, + BranchType(e->src_output())); + } + return cond_state_map_.GetUniqueId(state); + } + return id; +} + +Status FunctionalizeCond::DetermineCondStateMerge(Node* dst) { + // Only Merge nodes with two inputs are supported, but if this is a redundant + // merge, then the dead edge may already have been removed (if due to a + // switch) and so the input count would be incorrect. + if (cond_state_map_.IsDead(cond_state_map_.LookupId(dst))) + return Status::OK(); + + int data_inputs = 0; + for (auto e : dst->in_edges()) { + Node* src = e->src(); + VLOG(5) << "Processing forward flow for merge: " << e->DebugString() << " " + << cond_state_map_.CondStateToString(src); + if (!src->IsOp()) continue; + if (!e->IsControlEdge()) ++data_inputs; + + CondStateMap::CondId prop = StateAlongEdge(e); + auto id_or = JoinCondStatesMerge(prop, cond_state_map_.LookupId(dst)); + TF_RETURN_WITH_CONTEXT_IF_ERROR(id_or.status(), "for node ", + FormatNodeForError(*dst)); + cond_state_map_.ResetId(dst, id_or.ValueOrDie()); + } + + // Incomplete Merge nodes are not supported. + if (data_inputs != 2) { + return errors::Unimplemented( + dst->name(), " only has ", data_inputs, + " inputs, while only merge nodes with two inputs supported."); + } + return Status::OK(); +} + +Status FunctionalizeCond::DetermineCondState(Node* dst) { + // The logic for the merge and non-merge case differ: for non-merge it is + // the most restrictive CondState, while for merge nodes the + // resultant state is less restrictive than either. + if (IsMerge(dst)) { + TF_RETURN_IF_ERROR(DetermineCondStateMerge(dst)); + } else { + // Handle non-merge join. + for (auto e : dst->in_edges()) { + VLOG(5) << "Processing forward flow for: " << e->DebugString() << " " + << cond_state_map_.CondStateToString(dst); + Node* src = e->src(); + if (!src->IsOp()) continue; + + // Joining the state between the current and propagated state. + CondStateMap::CondId prop = StateAlongEdge(e); + auto id_or = JoinCondStatesNonMerge(prop, cond_state_map_.LookupId(dst)); + TF_RETURN_WITH_CONTEXT_IF_ERROR(id_or.status(), "for node ", + FormatNodeForError(*dst)); + cond_state_map_.ResetId(dst, id_or.ValueOrDie()); + } + } + return Status::OK(); +} + +Status FunctionalizeCond::RemoveRedundantMerge(Node* node) { + // Handle redundant merge nodes. A merge node is considered redundant if + // one input edge is dead while the other has a value. + if (!cond_state_map_.IsDead(cond_state_map_.LookupId(node))) + return Status::OK(); + + const Edge* non_dead_edge = nullptr; + for (auto e : node->in_edges()) { + if (e->IsControlEdge()) continue; + Node* src = e->src(); + + // Handle merge with dead state. + const auto& src_id = cond_state_map_.LookupId(src); + if (!cond_state_map_.IsDead(src_id)) { + non_dead_edge = e; + break; + } + } + + if (non_dead_edge == nullptr) { + return errors::InvalidArgument("Merge node ", FormatNodeForError(*node), + " has no non-dead inputs."); + } + cond_state_map_.MarkDead(node); + delete_nodes_.push_back(node->id()); + VLOG(5) << "removing redundant merge: " << node->name(); + while (!node->out_edges().empty()) { + const Edge* oe = *node->out_edges().begin(); + Node* dst_node = oe->dst(); + int dst_port = oe->dst_input(); + graph_->RemoveEdge(oe); + graph_->AddEdge(non_dead_edge->src(), + dst_port == Graph::kControlSlot + ? Graph::kControlSlot + : non_dead_edge->src_output(), + dst_node, dst_port); + } + return Status::OK(); +} + +Status FunctionalizeCond::RemoveRedundantSwitch(Node* node) { + // Handle redundant switch nodes. A switch node is considered redundant if + // the predicate of the switch already holds on the current branch. E.g., if + // p is the predicate of the switch but p is already known to hold on this + // branch, then the switch can be removed and the dead state propagated + // along one. The checking of predicate is based on the exact predicate + // (rather than boolean equivalence) and aimed at redundant switches as + // currently generated by gradient code. + OutputTensor pred; + TF_RETURN_IF_ERROR(GetSwitchPredicate(*node, &pred)); + auto dst_id = cond_state_map_.LookupId(node); + BranchType b = cond_state_map_.FindBranchOf(dst_id, pred); + // Determine if we are already on a branch where the switch predicate is + // true/false. + if (b != BranchType::kThenBranch && b != BranchType::kElseBranch) + return Status::OK(); + + VLOG(5) << "Redundant switch " << node->name(); + const Edge* value_edge; + TF_RETURN_IF_ERROR(node->input_edge(0, &value_edge)); + Node* val_node = value_edge->src(); + int val_port = value_edge->src_output(); + while (!node->out_edges().empty()) { + auto e = *node->out_edges().begin(); + Node* dst_node = e->dst(); + int dst_input = e->dst_input(); + int switch_branch = e->src_output(); + graph_->RemoveEdge(e); + if (switch_branch == Graph::kControlSlot) { + if (IsMerge(dst_node)) { + auto id_or = + JoinCondStatesMerge(dst_id, cond_state_map_.LookupId(dst_node)); + TF_RETURN_WITH_CONTEXT_IF_ERROR(id_or.status(), "for node ", + FormatNodeForError(*dst_node)); + cond_state_map_.ResetId(dst_node, id_or.ValueOrDie()); + } else { + auto id_or = + JoinCondStatesNonMerge(dst_id, cond_state_map_.LookupId(dst_node)); + TF_RETURN_IF_ERROR(id_or.status()); + cond_state_map_.ResetId(dst_node, id_or.ValueOrDie()); + } + } else if (BranchType(switch_branch) != b) { + cond_state_map_.MarkDead(dst_node); + delete_nodes_.push_back(dst_node->id()); + continue; + } + graph_->AddEdge( + val_node, + switch_branch == Graph::kControlSlot ? Graph::kControlSlot : val_port, + dst_node, dst_input); + } + return Status::OK(); +} + +Status FunctionalizeCond::DetermineCondStates( + std::vector<Node*> rev_topo_order) { + // The state that is propagated along the given edge. + for (auto it = rev_topo_order.rbegin(); it != rev_topo_order.rend(); ++it) { + Node* dst = *it; + TF_RETURN_IF_ERROR(DetermineCondState(dst)); + if (IsSwitch(dst)) TF_RETURN_IF_ERROR(RemoveRedundantSwitch(dst)); + if (IsMerge(dst)) TF_RETURN_IF_ERROR(RemoveRedundantMerge(dst)); + + VLOG(5) << dst->name() << " :: " << cond_state_map_.CondStateToString(dst); + } + return Status::OK(); +} + +void FunctionalizeCond::DeleteReachableNodes() { + // Delete all nodes that have been extracted or are reachable from + // deleted/dead nodes. The input and outgoing edges should have already been + // removed. + std::vector<bool> deleted(graph_->num_node_ids(), false); + // Don't try to delete source or sink nodes. + deleted[graph_->kSourceId] = true; + deleted[graph_->kSinkId] = true; + while (!delete_nodes_.empty()) { + int d_id = delete_nodes_.front(); + delete_nodes_.pop_front(); + if (deleted[d_id]) continue; + Node* d = graph_->FindNodeId(d_id); + // Switch and Merge nodes could have been deleted already. + if (d == nullptr) continue; + for (const Edge* e : d->out_edges()) { + delete_nodes_.push_back(e->dst()->id()); + } + deleted[d_id] = true; + graph_->RemoveNode(d); + } +} + +void FunctionalizeCond::SortMergeNodes(std::vector<Node*>* merge_order) { + // Sort merge nodes by nesting depth. + using sort_pair = std::pair<int, Node*>; + std::vector<sort_pair> inner_to_outer_merge_order; + inner_to_outer_merge_order.reserve(merge_order->size()); + for (auto it = merge_order->rbegin(); it != merge_order->rend(); ++it) { + Node* merge = *it; + CondStateMap::CondId id = cond_state_map_.LookupId(merge); + int depth = 0; + for (auto cond_node_it = id->begin(); cond_node_it != id->end(); + ++cond_node_it) { + if (cond_node_it->type == CondStateMap::CondNode::Type::kSwitch && + (cond_node_it->branch == BranchType::kThenBranch || + cond_node_it->branch == BranchType::kElseBranch)) { + ++depth; + } + } + inner_to_outer_merge_order.emplace_back(depth, merge); + } + std::stable_sort( + inner_to_outer_merge_order.begin(), inner_to_outer_merge_order.end(), + [](sort_pair lhs, sort_pair rhs) { return lhs.first > rhs.first; }); + merge_order->clear(); + for (sort_pair t : inner_to_outer_merge_order) { + merge_order->push_back(t.second); + } +} + +Status FunctionalizeCond::FunctionalizeInternal() { + // The general approach for converting a tf.cond (as lowered via switch/merge + // nodes) to a functional if is as follows: + // 1. Determine the topological order and collect all the switch and merge + // nodes in the graph; + // 2. Compute the predicates and dominance structure for all the nodes in the + // graph - this includes which predicate must be true for a op to execute + // (predicate values are considered directly rather than attempting to + // determine deeper equivalence). We shall refer to this structure as the + // CondState; + // 3. Sort the merge nodes by nesting depth; + // 4. Extract merge nodes together that have the same CondState and whose + // input nodes have the same state from the innermost to the outermost into + // IfOps; Note: In the above only nodes paths that converge to a merge node + // will be considered for removal. + + // Perform a DFS over the graph and + // * Determine the reverse topological order of the nodes (there should be no + // cycles at this point so the post-order numbering corresponds to the + // reverse topological sorting); + // * Record reverse topological for merge and switch nodes; + std::vector<Node*> rev_topo_order; + std::vector<int> switch_ids; + std::vector<Node*> merge_order; + DFS(*graph_, nullptr, [&](Node* n) { + if (IsSwitch(n)) { + switch_ids.push_back(n->id()); + } + if (IsMerge(n)) { + merge_order.push_back(n); + } + if (n->IsOp()) { + rev_topo_order.push_back(n); + } + }); + + // No merges to functionalize. + if (merge_order.empty()) { + // No merges mean no switch values consumed (as only considering values + // fetchable as output of merge); + for (auto it = switch_ids.begin(); it != switch_ids.end(); ++it) { + graph_->RemoveNode(graph_->FindNodeId(*it)); + } + return Status::OK(); + } + + TF_RETURN_IF_ERROR(DetermineCondStates(std::move(rev_topo_order))); + + if (VLOG_IS_ON(4)) DumpGraphWithCondState("cond_id"); + + // Sort the merge nodes from innermost outwards. + SortMergeNodes(&merge_order); + + // Extract from innermost out. + for (auto it = merge_order.begin(); it != merge_order.end(); ++it) { + Node* merge = *it; + auto id = cond_state_map_.LookupId(merge); + if (cond_state_map_.IsDead(id)) continue; + + // Construct a Conditional with the predicate of the merge (which is the + // last entry of the CondState for the merge) and this as parent. + DCHECK(id->back().predicate.node != nullptr); + Conditional cond(id->back().predicate, this, &cond_state_map_); + TF_RETURN_IF_ERROR(cond.AddMerge(merge)); + + // Find all merge nodes with the same CondId. This is done repeatedly as + // the CondId can change due replaced conditionals. E.g., the one branch + // could previously have had a conditional nested in it, and so would have + // had CondState with sub-state [switch(p,b),m] (where p is some predicate), + // post removing the nested conditional that sub-state would no longer be + // path of the propagated state along that path. + auto end = merge_order.end(); + for (auto merge_candidate_it = std::next(it); merge_candidate_it != end; + ++merge_candidate_it) { + auto merge_candidate_it_id = + cond_state_map_.LookupId(*merge_candidate_it); + if (merge_candidate_it_id != id) continue; + TF_RETURN_IF_ERROR(cond.AddMerge(*merge_candidate_it)); + } + + TF_RETURN_IF_ERROR(cond.BuildAndReplace(graph_, library_)); + + if (VLOG_IS_ON(4)) DumpGraphWithCondState("after_extract"); + } + + // All remaining Switch nodes are not reachable from a Merge node and + // removed. This is to account for dead Switch nodes. + for (int s_id : switch_ids) delete_nodes_.push_back(s_id); + for (Node* m : merge_order) delete_nodes_.push_back(m->id()); + DeleteReachableNodes(); + + return Status::OK(); +} + +void FunctionalizeCond::DumpGraphWithCondState(const string& name) { + const char* const kCondGroupDebugAttr = "_XlaFunctionalizeCondGroup"; + + for (Node* n : graph_->nodes()) { + n->ClearAttr(kCondGroupDebugAttr); + n->AddAttr(kCondGroupDebugAttr, cond_state_map_.CondStateToString(n)); + } + LOG(INFO) << "FunctionalizeControlFlow (" << name << "): " + << dump_graph::DumpGraphToFile( + strings::StrCat("functionalize_", name), *graph_, library_); +} + +Status FunctionalizeCond::Functionalize(Graph* graph, + FunctionLibraryDefinition* library) { + VLOG(1) << "FunctionalizeCond::Functionalize"; + FunctionalizeCond fc(graph, library); + return fc.FunctionalizeInternal(); +} + +} // namespace functionalize_cond + +Status FunctionalizeCond(Graph* graph, FunctionLibraryDefinition* library) { + // FunctionalizeControlFlow is invoked for every function, so the loops's + // bodies and conditionals that were extracted into functions will be handled + // in successive invocations. + return functionalize_cond::FunctionalizeCond::Functionalize(graph, library); +} + +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/functionalize_cond.h b/tensorflow/compiler/tf2xla/functionalize_cond.h new file mode 100644 index 0000000000..86436011c6 --- /dev/null +++ b/tensorflow/compiler/tf2xla/functionalize_cond.h @@ -0,0 +1,248 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_COND_H_ +#define TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_COND_H_ + +#include <deque> +#include "tensorflow/compiler/xla/status_macros.h" +#include "tensorflow/core/framework/function.h" +#include "tensorflow/core/graph/graph.h" + +namespace tensorflow { + +// Functionalize all the switch-merge nodes of a loop-free graph into If +// nodes. That is, attempt to transform every remaining switch and merge nodes +// in the graph into If nodes. +// Precondition: All while loops have been removed from graph. +Status FunctionalizeCond(Graph* graph, FunctionLibraryDefinition* library); + +// Internal functions/classes exposed for testing purposes. +namespace functionalize_cond { + +// All nodes are assumed to be either in no branch, then branch, else branch, +// or both branches (such as merge nodes). +// The code below relies on Else and Then being 0 and 1 (corresponding to the +// switch outputs). Both and Neither are arbitrary. +enum class BranchType { + kElseBranch = 0, + kThenBranch = 1, + kBoth = 2, + kNeither = 3, +}; + +// CondStateMap is responsible for mapping from each graph Node to a CondState, +// where each CondState is the array of CondNodes (corresponding to switch, +// merge or dead states) as described below. For efficiency, this class interns +// the CondState, so that CondState equality comparisons are simply pointer +// comparisons. +class CondStateMap { + public: + explicit CondStateMap(Graph* graph); + + // Represents an entry in the CondState. An entry can either be the + // switch (along with predicate), merge, or dead: + // * switch node indicates a node that is executed along a branch with the + // given predicate - a branch can be then, else or both; + // * merge node indicates that the node is executed as output of a merge; + // * dead indicates that this node can never be executed; + struct CondNode { + enum class Type { kSwitch = 1, kMerge = 2, kDead = 3 }; + + CondNode(Type type, Node* switch_node = nullptr, + BranchType branch = BranchType::kNeither); + + string ToString() const; + bool operator==(const CondNode& other) const; + bool operator!=(const CondNode& other) const; + + // Type of node. + Type type; + + // Predicate and branch, only used when type is kSwitch. + OutputTensor predicate; + BranchType branch; + }; + + // A node in the graph is executed when multiple conditions hold. The order + // represents the nesting of the predicates that hold and is used when + // extracting the nested conditionals. + using CondState = std::vector<CondNode>; + + // Every unique ID is mapped to a CondState. + using CondId = const CondState*; + + // Returns the CondId for a given node. + CondId LookupId(const Node* node) const; + + // Returns the unique CondId for CondState. + CondId GetUniqueId(const CondState& state); + + // Returns the CondState for a Node. + // REQUIRES: node has a non-empty CondState. + const CondState& LookupState(const Node* node) const; + + // Resets the CondId for a given node. + void ResetId(const Node* node, CondId id); + + // Marks `node` as dead. + void MarkDead(const Node* node); + + // Determine branch execution of CondState. + BranchType FindBranchOf(CondId id, OutputTensor predicate) const; + + // Enum to represent whether one cond flow state contains another. + enum ContainsResult { + kIncomparable, + kEqual, + kLhsContainsRhs, + kRhsContainsLhs + }; + + // Returns whether the lhs CondState holds wherever rhs CondState hols. I.e., + // [(p,t)] contains [(p,t), (r,t)]. + ContainsResult LhsHoldsWhereverRhsHolds(CondId lhs, CondId rhs); + + // Returns textual representation of node's CondState. + string CondStateToString(const Node* node) const; + string CondStateToString(CondId id) const; + + // Returns whether the cond state is the dead state. + bool IsDead(CondId id) const; + + // Returns whether the cond state is the empty state. + bool IsEmpty(CondId id) const; + + // Computes the predicates that have to hold for a node to execute and returns + // whether it was possible to determine the predicates that must hold. `scope` + // is populated with these predicates. Scope differs from state in that it + // does not include merge and both nodes. + bool ScopeIn(CondId id, CondId* scope); + + private: + // Hash for CondNode and CondState. + struct CondHash { + size_t operator()(const CondNode& item) const; + size_t operator()(const CondState& vec) const; + }; + + // Set to keep track of unique CondStates. + // Pointers to the entries in the unordered set are used as identifiers: + // unordered_set guarantees that the pointers remain the same. + std::unordered_set<CondState, CondHash> condstate_set_; + + // Mapping from Node id to CondId. + std::vector<CondId> node_to_condid_map_; + + // Track the CondId for newly inserted nodes. We use a vector to quickly map + // from Node id in the original graph to the CondId, but there will be nodes + // added to the original graph (such as If nodes) whose CondState needs to be + // tracked too. + std::unordered_map<int, CondId> added_node_mapping_; + + // Identifier of the dead flow state. The empty flow state is represented with + // a nullptr. + CondId dead_id_; +}; + +// FunctionalizeCond groups all the state used by functionalizing conditionals +// of the given graph together. +class FunctionalizeCond { + public: + // Functionalize all the switch-merge nodes of a loop-free graph into If + // nodes. That is, attempt to transform every remaining switch and merge nodes + // in the graph into If nodes. + // Precondition: All while loops have been removed from graph. + static Status Functionalize(Graph* graph, FunctionLibraryDefinition* library); + + // Build identity node with the same name as the merge that will be replaced + // in case the output is fetched/colocated. + Status AddIdentityNode(const Node* replacee, Node* if_node, int port); + + // Add a If node to the graph defined by def that will, amongst other, replace + // replacee in the graph. + xla::StatusOr<Node*> AddIfNode(const NodeDef& def, const Node* replacee); + + // Propagates the state of a newly inserted node. + Status PropagateUpdatedState(const Node* replacee); + + // Dump graph with the CondState annotated. + void DumpGraphWithCondState(const string& name); + + private: + FunctionalizeCond(Graph* graph, FunctionLibraryDefinition* library); + + // Performs the actual cond functionalization. Iterate over groups of merge + // nodes (linked by common predicate & CondIds of the incomming edges), + // from innermost to outermost, and extract into If nodes. + Status FunctionalizeInternal(); + + // Returns the forward flow state propagated along edge `e`. + // This may modify cond_state_map_. + CondStateMap::CondId StateAlongEdge(const Edge* e); + + // Determines the CondState of all the nodes in the given vector where + // the input is expected in reverse topological order. + // This populates the cond_state_map_. + Status DetermineCondStates(std::vector<Node*> rev_topo_order); + + // Determine the CondState for a given node using the incomming edges + // to the node. Note: it is expected that this node's CondState is only + // determined once its input's CondState is. + Status DetermineCondState(Node* dst); + + // Helper functions for DetermineCondState. + Status DetermineCondStateMerge(Node* dst); + + // Helper functions for DetermineCondStates. Determines the dst node's + // CondState by joining the src and dst's CondState where either + // the dst node is a merge or not. + // These may modify cond_state_map_. + xla::StatusOr<CondStateMap::CondId> JoinCondStatesMerge( + CondStateMap::CondId src, CondStateMap::CondId dst); + xla::StatusOr<CondStateMap::CondId> JoinCondStatesNonMerge( + CondStateMap::CondId src, CondStateMap::CondId dst); + + // Checks if a merge node is redundant and if so removes it from the graph. + Status RemoveRedundantMerge(Node* node); + + // Checks if a switch node is redundant and if so removes it from the graph. + Status RemoveRedundantSwitch(Node* node); + + // Sorts merge nodes (in reverse topological order) in order of increasing + // nesting depth. + void SortMergeNodes(std::vector<Node*>* merge_order); + + // Deletes all nodes in/consumers of `delete_nodes_`. + void DeleteReachableNodes(); + + // Member used to unique the CondState to a unique CondId and keep track of + // CondState/CondId per Node. + CondStateMap cond_state_map_; + + // Nodes to be deleted. + std::deque<int> delete_nodes_; + + FunctionLibraryDefinition* library_; + Graph* graph_; + + friend class FunctionalizeCondTest; +}; + +} // namespace functionalize_cond + +} // namespace tensorflow + +#endif // TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_COND_H_ diff --git a/tensorflow/compiler/tf2xla/functionalize_cond_test.cc b/tensorflow/compiler/tf2xla/functionalize_cond_test.cc new file mode 100644 index 0000000000..a27f889392 --- /dev/null +++ b/tensorflow/compiler/tf2xla/functionalize_cond_test.cc @@ -0,0 +1,184 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +// Tests for the backward const analysis. + +#include "tensorflow/compiler/tf2xla/functionalize_cond.h" + +#include "tensorflow/cc/framework/ops.h" +#include "tensorflow/cc/ops/function_ops.h" +#include "tensorflow/cc/ops/standard_ops.h" +#include "tensorflow/core/graph/testlib.h" +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/platform/test.h" + +namespace tensorflow { +namespace functionalize_cond { + +class FunctionalizeCondTest : public ::testing::Test { + protected: + FunctionalizeCondTest() { + graph_.reset(new Graph(OpRegistry::Global())); + flib_def_.reset( + new FunctionLibraryDefinition(OpRegistry::Global(), fdef_lib_)); + fc_.reset(new functionalize_cond::FunctionalizeCond(graph_.get(), + flib_def_.get())); + } + + CondStateMap::CondId GetUniqueId( + const CondStateMap::CondStateMap::CondState& state) { + return fc_->cond_state_map_.GetUniqueId(state); + } + + xla::StatusOr<CondStateMap::CondId> JoinCondStatesNonMerge( + CondStateMap::CondId src, CondStateMap::CondId dst) { + return fc_->JoinCondStatesNonMerge(src, dst); + } + + xla::StatusOr<CondStateMap::CondId> JoinCondStatesMerge( + CondStateMap::CondId src, CondStateMap::CondId dst) { + return fc_->JoinCondStatesMerge(src, dst); + } + + bool ScopeIn(CondStateMap::CondId ff, CondStateMap::CondId* scope) { + return fc_->cond_state_map_.ScopeIn(ff, scope); + } + + CondStateMap::ContainsResult LhsHoldsWhereverRhsHolds( + CondStateMap::CondId lhs, CondStateMap::CondId rhs) { + return fc_->cond_state_map_.LhsHoldsWhereverRhsHolds(lhs, rhs); + } + + FunctionDefLibrary fdef_lib_; + std::unique_ptr<functionalize_cond::FunctionalizeCond> fc_; + std::unique_ptr<FunctionLibraryDefinition> flib_def_; + std::unique_ptr<Graph> graph_; +}; + +namespace { + +TEST_F(FunctionalizeCondTest, ScopeIn) { + Tensor pred_tensor(DT_BOOL, TensorShape()); + pred_tensor.flat<bool>().setZero(); + Node* pred = test::graph::Constant(graph_.get(), pred_tensor, "pred"); + Tensor val_tensor(DT_INT32, TensorShape()); + val_tensor.flat<int>().setZero(); + Node* val = test::graph::Constant(graph_.get(), val_tensor, "val"); + Node* s = test::graph::Switch(graph_.get(), val, pred); + + { + CondStateMap::CondStateMap::CondState ss; + ss.emplace_back(CondStateMap::CondNode( + CondStateMap::CondNode::Type::kSwitch, s, BranchType::kThenBranch)); + CondStateMap::CondId id = GetUniqueId(ss); + CondStateMap::CondId scope; + ASSERT_TRUE(ScopeIn(id, &scope)); + ASSERT_TRUE(id == scope); + } + + CondStateMap::CondState empty; + { + CondStateMap::CondState ss; + ss.emplace_back(CondStateMap::CondNode( + CondStateMap::CondNode::Type::kSwitch, s, BranchType::kBoth)); + ss.emplace_back( + CondStateMap::CondNode(CondStateMap::CondNode::Type::kMerge)); + CondStateMap::CondId id = GetUniqueId(ss); + CondStateMap::CondId scope_1; + ASSERT_TRUE(ScopeIn(id, &scope_1)); + ASSERT_TRUE(scope_1 == GetUniqueId(empty)); + ASSERT_TRUE(id != scope_1); + + ss.clear(); + ss.emplace_back(CondStateMap::CondNode( + CondStateMap::CondNode::Type::kSwitch, s, BranchType::kBoth)); + id = GetUniqueId(ss); + CondStateMap::CondId scope_2; + ASSERT_TRUE(ScopeIn(id, &scope_2)); + + ASSERT_TRUE(LhsHoldsWhereverRhsHolds(scope_1, scope_2) == + CondStateMap::ContainsResult::kLhsContainsRhs); + } +} + +TEST_F(FunctionalizeCondTest, JoinCondStates) { + Tensor pred_tensor(DT_BOOL, TensorShape()); + pred_tensor.flat<bool>().setZero(); + Node* pred = test::graph::Constant(graph_.get(), pred_tensor, "pred"); + Tensor val_tensor(DT_INT32, TensorShape()); + val_tensor.flat<int>().setZero(); + Node* val = test::graph::Constant(graph_.get(), val_tensor, "val"); + Node* s = test::graph::Switch(graph_.get(), val, pred); + + CondStateMap::CondId empty = GetUniqueId({}); + + CondStateMap::CondId then_branch; + { + CondStateMap::CondState ss; + ss.emplace_back(CondStateMap::CondNode( + CondStateMap::CondNode::Type::kSwitch, s, BranchType::kThenBranch)); + then_branch = GetUniqueId(ss); + } + CondStateMap::CondId else_branch; + { + CondStateMap::CondState ss; + ss.emplace_back(CondStateMap::CondNode( + CondStateMap::CondNode::Type::kSwitch, s, BranchType::kElseBranch)); + else_branch = GetUniqueId(ss); + } + + // An non-merge op with inputs from then and else branch. + Status status = JoinCondStatesNonMerge(then_branch, else_branch).status(); + EXPECT_TRUE(errors::IsInvalidArgument(status)); + + // Merge between then and else branch. + auto joined_or = JoinCondStatesMerge(then_branch, else_branch); + TF_EXPECT_OK(joined_or.status()); + CondStateMap::CondId joined = joined_or.ValueOrDie(); + + // Merge between then branch and both branch. + auto t = JoinCondStatesNonMerge(then_branch, joined); + // Note: this is OK in terms of constraint predication, but + TF_EXPECT_OK(t.status()); + + // Post merge the propagated forward flow state has an additional merge. + CondStateMap::CondId post_merge; + { + CondStateMap::CondState ss; + ss = *joined; + ss.emplace_back( + CondStateMap::CondNode(CondStateMap::CondNode::Type::kMerge)); + post_merge = GetUniqueId(ss); + } + + t = JoinCondStatesNonMerge(post_merge, joined); + TF_EXPECT_OK(t.status()); + EXPECT_TRUE(joined == t.ValueOrDie()); + + // No predicate that results in two paths predicated on different conditions + // merge. + t = JoinCondStatesMerge(post_merge, joined); + EXPECT_FALSE(t.ok()); + + // Post the merge we are effectively in the root scope and merging should + // result in the more restrictive post merge state. + t = JoinCondStatesNonMerge(post_merge, empty); + TF_EXPECT_OK(t.status()); + EXPECT_TRUE(post_merge == t.ValueOrDie()); +} + +} // namespace +} // namespace functionalize_cond +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/functionalize_control_flow.cc b/tensorflow/compiler/tf2xla/functionalize_control_flow.cc index 0904778f97..5932be4e52 100644 --- a/tensorflow/compiler/tf2xla/functionalize_control_flow.cc +++ b/tensorflow/compiler/tf2xla/functionalize_control_flow.cc @@ -21,1440 +21,24 @@ limitations under the License. #include <unordered_set> #include <vector> +#include "absl/memory/memory.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/jit/union_find.h" #include "tensorflow/compiler/tf2xla/dump_graph.h" +#include "tensorflow/compiler/tf2xla/functionalize_cond.h" +#include "tensorflow/compiler/tf2xla/functionalize_control_flow_util.h" +#include "tensorflow/compiler/tf2xla/functionalize_while.h" #include "tensorflow/compiler/tf2xla/tf2xla_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/core/common_runtime/function.h" #include "tensorflow/core/framework/graph_to_functiondef.h" #include "tensorflow/core/framework/node_def_builder.h" #include "tensorflow/core/graph/algorithm.h" #include "tensorflow/core/graph/control_flow.h" -#include "tensorflow/core/lib/gtl/optional.h" +#include "tensorflow/core/graph/node_builder.h" namespace tensorflow { -namespace { - -using xla::StatusOr; - -const char* const kArgOp = "_Arg"; -const char* const kRetValOp = "_Retval"; - -// Information about a loop argument. -struct Arg { - // Every loop argument has an Enter node. - Node* enter; - - // Is the loop argument a loop-invariant value? Taken from the `is_constant` - // attribute on the Enter node. - bool is_loop_invariant; - - // If 'is_loop_invariant' is true, the following are all nullptr. Non-constant - // arguments must have all of the following nodes: - Node* merge = nullptr; - Node* switch_node = nullptr; - Node* next_iteration = nullptr; - Node* exit = nullptr; -}; - -// Information about a loop frame. -struct Frame { - string name; - - // Pointer to the parent frame. The root frame has a pointer to itself. - Frame* parent = nullptr; - int num_children = 0; - - // Arguments to this loop. - std::vector<Arg> args; - - // The loop condition of the loop. There should be exactly one loop condition - // in every loop. - Node* loop_cond = nullptr; - - // Set of nodes that belong to the loop frame. - std::unordered_set<Node*> nodes; -}; - -// Comparison function used for sorting nodes consistently. -// a) resource variables are last, and -// b) sort lexicographically by name (for deterministic output). -struct NodeCmp { - bool operator()(const Node* lhs, const Node* rhs) const { - bool lhs_is_resource = - lhs->num_inputs() > 0 ? (lhs->input_type(0) == DT_RESOURCE) : false; - bool rhs_is_resource = - rhs->num_inputs() > 0 ? (rhs->input_type(0) == DT_RESOURCE) : false; - return std::tie(lhs_is_resource, lhs->name()) < - std::tie(rhs_is_resource, rhs->name()); - } -}; - -// Returns a textual representation of the names of the nodes in the input. -template <typename T> -string NodesToString(const T& nodes) { - return strings::StrCat("{", - str_util::Join(nodes, ",", - [](string* output, const Node* node) { - strings::StrAppend(output, - node->name()); - }), - "}"); -} - -// Copies a subgraph from `graph` to `output` by performing a reverse DFS -// starting at nodes in vector `stack`. -// `node_map` is a vector indexed by source node ID to dest nodes. -// Does not traverse into nodes in `node_map`, so by adding nodes to `node_map` -// before the traversal clients can cut the graph. If a frame is provided (frame -// != nullptr), then this functions will return an error if the -// traversal leaves 'frame'; the client must add enough nodes to `node_map` to -// cut the graph and prevent the traversal from escaping. -// -// `squash_src_outputs` contains a bool for each source node ID. If true, then -// the source output on that node will be replaced by zero when copied. This is -// used when replacing a Switch node with an _Arg node. The output we are -// taking from the Switch node was not necessarily the first output, but _Arg -// nodes only have one output. By adding the Switch node to `squash_src_outputs` -// we rewrite the src_output of the corresponding edge to be 0. -Status CopySubgraph(const Graph& graph, const Frame* frame, - std::vector<Node*> stack, - const std::vector<bool>& squash_src_outputs, - std::vector<Node*>* node_map, Graph* output) { - VLOG(3) << "Stack: " << NodesToString(stack); - std::vector<bool> visited(graph.num_node_ids(), false); - while (!stack.empty()) { - Node* n = stack.back(); - stack.pop_back(); - - VLOG(5) << "Copying node " << n->name(); - - if (visited[n->id()]) continue; - visited[n->id()] = true; - - for (const Edge* e : n->in_edges()) { - Node* src = e->src(); - if (frame != nullptr && frame->nodes.find(src) == frame->nodes.end()) { - // We traversed out of the loop frame, without encountering a cut node. - return errors::Internal("Graph traversal of loop frame ", frame->name, - " escaped frame at ", src->name(), - " without encountering an argument node."); - } - if ((*node_map)[src->id()] == nullptr) { - (*node_map)[src->id()] = output->CopyNode(src); - stack.push_back(src); - } - Node* src_copy = (*node_map)[e->src()->id()]; - int src_output = squash_src_outputs[e->src()->id()] && !e->IsControlEdge() - ? 0 - : e->src_output(); - Node* dst_copy = (*node_map)[e->dst()->id()]; - output->AddEdge(src_copy, src_output, dst_copy, e->dst_input()); - } - } - return Status::OK(); -} - -StatusOr<Node*> AddNode(const NodeDef& node_def, Graph* graph) { - Status status; - Node* inserted_node = graph->AddNode(node_def, &status); - if (!status.ok()) { - return status; - } - return inserted_node; -} - -// Check that the graph has no cycle containing the given node. -Status CheckNoCycleContains(const Node* node, const int num_nodes) { - std::vector<const Node*> ready; - ready.push_back(node); - std::vector<bool> visited(num_nodes); - while (!ready.empty()) { - const Node* current_node = ready.back(); - ready.pop_back(); - visited[current_node->id()] = true; - for (const Edge* out : current_node->out_edges()) { - if (out->dst() == node) { - return errors::Internal("Detected a cycle: ", FormatNodeForError(*node), - "(", node->def().op(), ") feeds into itself."); - } else if (!visited[out->dst()->id()]) { - ready.push_back(out->dst()); - } - } - } - return Status::OK(); -} - -StatusOr<Node*> BuildArgNode(Graph* graph, DataType type, int index) { - NodeDef arg_def; - NodeDefBuilder builder(strings::StrCat(kArgOp, index), kArgOp); - builder.Attr("T", type); - builder.Attr("index", index); - TF_RETURN_IF_ERROR(builder.Finalize(&arg_def)); - return AddNode(arg_def, graph); -} - -StatusOr<Node*> BuildRetvalNode(Graph* graph, DataType type, int index) { - NodeDef ret_def; - ret_def.set_op(kRetValOp); - ret_def.set_name(strings::StrCat(kRetValOp, index)); - AddNodeAttr("T", type, &ret_def); - AddNodeAttr("index", index, &ret_def); - return AddNode(ret_def, graph); -} - -// Builds a graph for the loop condition. -Status BuildLoopCondition(const Graph& graph, Frame* frame, - std::unique_ptr<Graph>* cond_output) { - VLOG(2) << "Building loop condition for " << frame->name; - *cond_output = xla::MakeUnique<Graph>(graph.op_registry()); - Graph* output = cond_output->get(); - - // Map from nodes in the original graph to the condition graph. - std::vector<Node*> node_map(graph.num_node_ids(), nullptr); - std::vector<bool> squash_src_outputs(graph.num_node_ids(), false); - - // Build one _Arg node for each Enter node. - for (int i = 0; i < frame->args.size(); ++i) { - const Arg& arg = frame->args[i]; - - TF_ASSIGN_OR_RETURN(Node * arg_node, - BuildArgNode(output, arg.enter->input_type(0), i)); - if (arg.is_loop_invariant) { - node_map[arg.enter->id()] = arg_node; - } else { - node_map[arg.merge->id()] = arg_node; - } - } - - // Build a Retval node for the loop condition. The LoopCond nodes are always - // boolean because of the type constraints on the LoopCond op. - TF_ASSIGN_OR_RETURN(node_map[frame->loop_cond->id()], - BuildRetvalNode(output, DT_BOOL, 0)); - - // Performs a reverse DFS, copying nodes and edges to the output graph. - // The _Arg and _Retval nodes were added unconditionally above, so we are - // guaranteed to get the correct function signature. - return CopySubgraph(graph, frame, {frame->loop_cond}, squash_src_outputs, - &node_map, output); -} - -// Builds a graph for the loop body. -Status BuildLoopBody(const Graph& graph, Frame* frame, - DataTypeVector* arg_types, - std::unique_ptr<Graph>* body_output) { - VLOG(2) << "Building loop body for " << frame->name; - *body_output = xla::MakeUnique<Graph>(graph.op_registry()); - Graph* output = body_output->get(); - - // Map from nodes in the original graph to the condition graph. - std::vector<Node*> node_map(graph.num_node_ids(), nullptr); - std::vector<bool> squash_src_outputs(graph.num_node_ids(), false); - - // Build one _Arg node for each Enter node. - std::vector<Node*> next_iterations; - next_iterations.reserve(frame->args.size()); - arg_types->reserve(frame->args.size()); - for (int i = 0; i < frame->args.size(); ++i) { - const Arg& arg = frame->args[i]; - - DataType dtype = arg.enter->input_type(0); - arg_types->push_back(dtype); - - TF_ASSIGN_OR_RETURN(Node * arg_node, BuildArgNode(output, dtype, i)); - - if (dtype == DT_RESOURCE) { - // The convention of the XLA bridge is that resource variable arguments - // are only inputs to the loop body and have no corresponding output. - // TODO(b/37741920): change the convention so that DT_RESOURCE variables - // are both inputs and outputs, and then remove this case. - TF_RET_CHECK(arg.is_loop_invariant); - node_map[arg.enter->id()] = arg_node; - } else { - TF_ASSIGN_OR_RETURN(Node * retval_node, - BuildRetvalNode(output, dtype, i)); - - if (arg.is_loop_invariant) { - // Argument is loop-invariant. Forward it from the Arg to the Retval. - node_map[arg.enter->id()] = arg_node; - output->AddEdge(arg_node, 0, retval_node, 0); - } else { - // Argument is loop-varying. - node_map[arg.switch_node->id()] = arg_node; - // The Switch node has two outputs, but _Arg only has one. This tells - // the CopySubgraph function to rewrite the output number of edges from - // the _Arg node to be 0 rather than copying the output number from the - // Switch node. - squash_src_outputs[arg.switch_node->id()] = true; - node_map[arg.next_iteration->id()] = retval_node; - next_iterations.push_back(arg.next_iteration); - } - } - } - - // Performs a reverse DFS, copying nodes and edges to the output graph. - // The _Arg and _Retval nodes were added unconditionally above, so we are - // guaranteed to get the correct function signature. - TF_RETURN_IF_ERROR(CopySubgraph(graph, frame, std::move(next_iterations), - squash_src_outputs, &node_map, output)); - - return Status::OK(); -} - -// Copy the FunctionDef of given function from lookup_library to library, if -// it can be found in lookup_library but is missing from library. -Status AddMissingFunctionByName(const string& function_name, - const FunctionLibraryDefinition* lookup_library, - FunctionLibraryDefinition* library) { - if (!library->Find(function_name) && lookup_library->Find(function_name)) { - return library->AddFunctionDef(*lookup_library->Find(function_name)); - } - return Status::OK(); -} - -// Iterate over all functions that the given fdef refers to. Copy the missing -// FunctionDefs from lookup_library to library. -Status AddMissingFunctionDef(const FunctionDef& fdef, - const FunctionLibraryDefinition* lookup_library, - FunctionLibraryDefinition* library) { - TF_RET_CHECK(lookup_library); - for (const NodeDef& node : fdef.node_def()) { - if (library->Find(node.op())) { - continue; - } - // The function referred by 'SymbolicGradient' node is specified in its - // attribute 'f'. - if (node.op() == FunctionLibraryDefinition::kGradientOp) { - const AttrValue* attr = - AttrSlice(&node.attr()).Find(FunctionLibraryDefinition::kFuncAttr); - if (!attr) { - return errors::InvalidArgument("SymbolicGradient is missing attr: f"); - } - const string& func_name = attr->func().name(); - TF_RETURN_IF_ERROR( - AddMissingFunctionByName(func_name, lookup_library, library)); - // Copy the user-defined gradient function if it exists. - const string grad_name = lookup_library->FindGradient(func_name); - if (!grad_name.empty() && library->FindGradient(func_name).empty()) { - TF_RETURN_IF_ERROR( - AddMissingFunctionByName(grad_name, lookup_library, library)); - GradientDef grad_def; - grad_def.set_function_name(func_name); - grad_def.set_gradient_func(grad_name); - TF_RETURN_IF_ERROR(library->AddGradientDef(grad_def)); - } - } else if (lookup_library->Find(node.op())) { - TF_RETURN_IF_ERROR( - library->AddFunctionDef(*lookup_library->Find(node.op()))); - } - } - return Status::OK(); -} - -Status FunctionalizeLoop(const FunctionLibraryDefinition* lookup_library, - Graph* graph, Frame* frame, - FunctionLibraryDefinition* library) { - VLOG(2) << "Frame " << frame->name << " before: " - << dump_graph::DumpGraphToFile("functionalize_before", *graph, - library); - - // Split loop-varying Enter nodes with multiple successors. If the same - // Tensor is fed as input to multiple loop arguments, we may end up with a - // shared Enter node. We clone Enter nodes with multiple successors to - // maintain the invariant of a unique Enter node per argument of the final - // loop. - std::vector<Arg> args; - for (const Arg& arg : frame->args) { - if (arg.is_loop_invariant) { - args.push_back(arg); - } else { - std::vector<const Edge*> edges(arg.enter->out_edges().begin(), - arg.enter->out_edges().end()); - for (int i = 0; i < edges.size(); ++i) { - if (edges[i]->IsControlEdge() && edges[i]->dst()->IsSink()) { - continue; - } - TF_RET_CHECK(!edges[i]->IsControlEdge()) << edges[i]->src()->name(); - Arg new_arg; - new_arg.is_loop_invariant = false; - if (i == 0) { - new_arg.enter = arg.enter; - } else { - new_arg.enter = graph->CopyNode(arg.enter); - frame->nodes.insert(new_arg.enter); - for (Edge const* e : arg.enter->in_edges()) { - graph->AddEdge(e->src(), e->src_output(), new_arg.enter, - e->IsControlEdge() ? Graph::kControlSlot : 0); - } - Node* dst = edges[i]->dst(); - int dst_input = edges[i]->dst_input(); - graph->RemoveEdge(edges[i]); - graph->AddEdge(new_arg.enter, 0, dst, dst_input); - } - args.push_back(new_arg); - } - } - } - frame->args = std::move(args); - - std::sort( - frame->args.begin(), frame->args.end(), - [](const Arg& a, const Arg& b) { return NodeCmp()(a.enter, b.enter); }); - - if (frame->loop_cond == nullptr) { - return errors::InvalidArgument("Loop ", frame->name, - " has no LoopCond node"); - } - - // Find the set of Switch nodes that are successors of the LoopCond. - std::unordered_set<Node*> switches; - for (const Edge* edge : frame->loop_cond->out_edges()) { - if (!edge->IsControlEdge() && IsSwitch(edge->dst()) && - edge->dst_input() == 1) { - switches.insert(edge->dst()); - } - } - - // For each non-constant argument, looks for the following pattern of nodes: - // Enter ----> Merge --------> Switch --> Exit - // ^ ^ - // | | - // NextIteration LoopCond - // ^ ^ - // | | - // ... ... - for (Arg& arg : frame->args) { - if (!arg.is_loop_invariant) { - // Follow the edge from the Enter to Merge. - const Edge* enter_merge = nullptr; - for (const Edge* e : arg.enter->out_edges()) { - // Ignore control-edges to the sink node. These are allowed by the - // graph invariants, although probably they should have been stripped - // off earlier. - if (e->IsControlEdge() && e->dst()->IsSink()) { - continue; - } - if (enter_merge != nullptr) { - return errors::Internal("Enter node for loop-varying argument ", - FormatNodeForError(*arg.enter), - " has multiple successors: ", - FormatNodeForError(*enter_merge->dst()), - " and ", FormatNodeForError(*e->dst())); - } - enter_merge = e; - } - if (enter_merge == nullptr) { - return errors::Internal("Enter node for loop-varying argument ", - FormatNodeForError(*arg.enter), - " has zero successors"); - } - arg.merge = enter_merge->dst(); - if (!IsMerge(arg.merge)) { - return errors::InvalidArgument( - "Successor of Enter node for loop-varying argument ", - FormatNodeForError(*arg.merge), - " is not a Merge node; got: ", arg.merge->type_string()); - } - - // Find the NextIteration from the merge. There should be two inputs to - // the Merge and the NextIteration should be the other input. - if (arg.merge->input_types().size() != 2) { - return errors::InvalidArgument( - "Unexpected number of inputs to Merge node for loop-varying " - "argument ", - FormatNodeForError(*arg.merge), "; expected 2, got ", - arg.merge->input_types().size()); - } - TF_RETURN_IF_ERROR(arg.merge->input_node(1 - enter_merge->dst_input(), - &arg.next_iteration)); - if (!IsNextIteration(arg.next_iteration)) { - return errors::InvalidArgument( - "Expected NextIteration node as input to Merge node; got node ", - FormatNodeForError(*arg.next_iteration), " with kind ", - arg.next_iteration->type_string()); - } - - // Find the Switch successor of the Merge. There should be exactly one - // Switch node that is a successor of both the Merge and the LoopCond. - for (const Edge* edge : arg.merge->out_edges()) { - if (edge->dst_input() == 0 && IsSwitch(edge->dst()) && - switches.find(edge->dst()) != switches.end()) { - if (arg.switch_node != nullptr) { - return errors::InvalidArgument("Duplicate Switch successors to ", - FormatNodeForError(*arg.merge)); - } - arg.switch_node = edge->dst(); - } - } - if (arg.switch_node == nullptr) { - return errors::InvalidArgument("Missing Switch successor to ", - FormatNodeForError(*arg.merge)); - } - - // Update the device on the Identity outputs of the switch to match their - // target. These Identity outputs do not - - // Loop over the switch node's output to: - // - Find the Exit successor. - // - Set the sharding on all Identity outputs of the switch. These - // identity nodes are values used by the loop body or condition. - // The Identity node may have the wrong device so copy the device from - // one of its outputs instead. - std::deque<const Edge*> possible_exit; - for (const Edge* edge : arg.switch_node->out_edges()) { - if (edge->src_output() == 0) { - possible_exit.push_back(edge); - } - if (IsIdentity(edge->dst())) { - TF_RETURN_IF_ERROR( - SetNodeShardingFromNeighbors(edge->dst(), /*out_edges=*/true)); - } - } - // TODO(b/67425339): Allow general graph between switch and exit. - while (!possible_exit.empty()) { - const Edge* edge = possible_exit.front(); - possible_exit.pop_front(); - if (IsExit(edge->dst())) { - if (arg.exit != nullptr) { - return errors::InvalidArgument( - "Duplicate Exit successors to ", - FormatNodeForError(*arg.switch_node)); - } - arg.exit = edge->dst(); - } else { - if (!IsIdentity(edge->dst())) { - return errors::Unimplemented("General graph between switch (", - FormatNodeForError(*arg.switch_node), - ") and exit node of frame ", - frame->name, " not supported yet."); - } - for (const Edge* out : edge->dst()->out_edges()) { - possible_exit.push_back(out); - } - } - } - } - } - - // Builds the condition and body functions. - std::unique_ptr<Graph> cond_graph; - TF_RETURN_IF_ERROR(BuildLoopCondition(*graph, frame, &cond_graph)); - DataTypeVector arg_types; - std::unique_ptr<Graph> body_graph; - TF_RETURN_IF_ERROR(BuildLoopBody(*graph, frame, &arg_types, &body_graph)); - - VLOG(2) << "Frame " << frame->name << " condition: " - << dump_graph::DumpGraphToFile("loop_condition", *cond_graph, library) - << " body: " << dump_graph::DumpGraphToFile("loop_body", *body_graph); - - static std::atomic<int64> sequence_num(0LL); - int64 id = ++sequence_num; - NameAttrList cond_name; - cond_name.set_name(strings::StrCat("_functionalize_cond_", id)); - NameAttrList body_name; - body_name.set_name(strings::StrCat("_functionalize_body_", id)); - FunctionDef cond_fdef; - TF_RETURN_IF_ERROR( - GraphToFunctionDef(*cond_graph, cond_name.name(), &cond_fdef)); - FunctionDef body_fdef; - TF_RETURN_IF_ERROR( - GraphToFunctionDef(*body_graph, body_name.name(), &body_fdef)); - - TF_RETURN_IF_ERROR(library->AddFunctionDef(cond_fdef)); - TF_RETURN_IF_ERROR(library->AddFunctionDef(body_fdef)); - if (lookup_library) { - // Copy missing FunctionDefs from lookup_library to library to make library - // self-contained. - TF_RETURN_IF_ERROR( - AddMissingFunctionDef(cond_fdef, lookup_library, library)); - TF_RETURN_IF_ERROR( - AddMissingFunctionDef(body_fdef, lookup_library, library)); - } - - // Builds a While operator. - NodeDef while_def; - NodeDefBuilder builder(frame->loop_cond->name(), "XlaWhile"); - builder.Attr("T", arg_types); - builder.Attr("cond", cond_name); - builder.Attr("body", body_name); - std::vector<NodeDefBuilder::NodeOut> inputs; - for (int i = 0; i < frame->args.size(); ++i) { - const Arg& arg = frame->args[i]; - const Edge* in_edge; - TF_RETURN_IF_ERROR(arg.enter->input_edge(0, &in_edge)); - if (in_edge->IsControlEdge()) { - builder.ControlInput(in_edge->src()->name()); - } else { - inputs.push_back(NodeDefBuilder::NodeOut( - in_edge->src()->name(), in_edge->src_output(), arg_types[i])); - } - } - builder.Input(inputs); - TF_RETURN_IF_ERROR(builder.Finalize(&while_def)); - TF_ASSIGN_OR_RETURN(Node * while_node, AddNode(while_def, graph)); - - // Copies edges to the Enter nodes and from the Exit nodes onto the While. - for (int i = 0; i < frame->args.size(); ++i) { - const Arg& arg = frame->args[i]; - const Edge* in_edge; - TF_RETURN_IF_ERROR(arg.enter->input_edge(0, &in_edge)); - if (in_edge->IsControlEdge()) { - graph->AddControlEdge(in_edge->src(), while_node); - } else { - graph->AddEdge(in_edge->src(), in_edge->src_output(), while_node, i); - } - - if (!arg.is_loop_invariant) { - // Add output edges if the output of the loop is consumed. - if (arg.exit != nullptr) { - std::vector<const Edge*> edges(arg.exit->out_edges().begin(), - arg.exit->out_edges().end()); - for (const Edge* edge : edges) { - Node* dst = edge->dst(); - int dst_input = edge->dst_input(); - graph->RemoveEdge(edge); - - if (dst_input == Graph::kControlSlot) { - graph->AddControlEdge(while_node, dst); - } else { - graph->AddEdge(while_node, i, dst, dst_input); - } - } - } - } - } - - // Remove the old nodes from the graph, and add the while node to the parent - // frame. - for (Node* node : frame->nodes) { - graph->RemoveNode(node); - } - frame->nodes.clear(); - frame->parent->nodes.insert(while_node); - - VLOG(2) << "Frame " << frame->name << " after: " - << dump_graph::DumpGraphToFile("functionalize_after", *graph, - library); - - return Status::OK(); -} - -class FunctionalizeCond { - public: - // All nodes are assumed to be either in no branch, then branch, else branch, - // or both branches (such as merge nodes). - enum Branch { - kElseBranch = 0, - kThenBranch = 1, - kBoth = 2, - kNeither = 3, - kNumBranchTypes = 4 - }; - - // Returns a textual representation of the Branch b. - static string Branch_Name(FunctionalizeCond::Branch b); - - // Functionalize all the switch-merge nodes of a loop-free graph into XlaIf - // nodes. That is, attempt to transform every remaining switch and merge nodes - // in the graph into XlaIf nodes. - // Precondition: All while loops have been removed from graph. - static Status Functionalize(Graph* graph, FunctionLibraryDefinition* library); - - private: - // CondArgNode represents a input to the conditional and its corresponding - // switch nodes. - struct CondArgNode { - explicit CondArgNode(Node* src, int src_output) - : src(src), src_output(src_output) {} - string ToString() const { - return strings::StrCat("src=", src->name(), ":", src_output, - " switches=", NodesToString(switches)); - } - - Node* src; - int src_output; - std::vector<Node*> switches; - }; - using CondArgNodes = std::vector<CondArgNode>; - - struct ForwardFlowNode { - explicit ForwardFlowNode(Branch branch = Branch::kNeither) - : branch(branch), count(0) {} - string ToString() const { - return strings::StrCat("branch=", Branch_Name(branch), " count=", count); - } - Branch branch; - int count; - }; - - // Group of switch nodes that will be part of the same XlaIf. - struct SwitchCluster { - explicit SwitchCluster(const Edge* predicate_edge) - : predicate_edge(predicate_edge) {} - string ToString() const { - return strings::StrCat(name, " predicate=", predicate_edge->src()->name(), - " switches=", NodesToString(switches)); - } - - string name; - const Edge* predicate_edge; - std::vector<Node*> switches; - }; - - FunctionalizeCond(Graph* graph, FunctionLibraryDefinition* library, - bool dump_graphs) - : library_(library), graph_(graph), dump_graphs_(dump_graphs) {} - - // Perform the actual cond functionalization. Iterate over groups of switch - // nodes (linked by common predicate), from innermost to outermost, and - // extract into XlaIf nodes. - Status FunctionalizeInternal(); - - // Determines the branch_map (mapping from node to branch of cond) and - // frontier (the nodes where the cond ends). - StatusOr<std::pair<std::unordered_map<Node*, ForwardFlowNode>, - std::unordered_set<Node*>>> - DetermineBranchMapAndFrontier(const SwitchCluster& switch_cluster); - - // Returns XlaIf node created from subgraph of merge and switch nodes. This - // encapsulates the process of extracting the bodies needed for the then and - // else branch, creates a XlaIf node, removing the nodes of the branches from - // the graph and replacing the merge node with a XlaIf. - StatusOr<Node*> ConvertToXlaIf(const CondArgNodes& cond_arg_nodes, - const SwitchCluster& switch_cluster, - const std::vector<Node*>& switches); - - // Builds a XlaIfOp to replace the Switch-Graph-Merge cluster with. - StatusOr<Node*> BuildAndAddXlaIfOp(const CondArgNodes& cond_arg_nodes, - const SwitchCluster& switch_cluster, - const std::vector<Node*>& merge_nodes); - - // Extracts a function body corresponding to the given input edge of the merge - // node. - Status ExtractBody(const CondArgNodes& cond_arg_nodes, - const std::vector<Node*>& switches, - const std::vector<Node*>& merge_nodes, int input_edge, - Graph* body); - - // Adds all the input edges to `if_node` corresponding to the arguments. - Status AddInputEdges(const CondArgNodes& cond_arg_nodes, - const Edge* predicate_edge, Node* if_node); - - // Adds all output edges from the `if_node`. - Status AddOutputEdges(const std::vector<Node*>& outputs, Node* if_node); - - // Returns the switch clusters of graph_ in postorder. Dead switch nodes are - // skipped and removed from the graph. - StatusOr<std::vector<SwitchCluster>> DeterminePredicateSwitchOrder(); - - // Update the state for destination based on the state of source and the node - // being updated. - Status Join(const ForwardFlowNode& src_state, const Node* dst, - ForwardFlowNode* dst_state); - - // Ensure that all nodes in the branch_map are dominated by the switch - // nodes. Returns nodes that are not dominated by the switches but are a - // control dependency of a node in the cond, and remove such control - // dependencies. - StatusOr<std::vector<Node*>> EnsureDominanceAndReturnNonDominatedControlNodes( - const std::unordered_map<Node*, ForwardFlowNode>& branch_map, - const std::vector<Node*>& switches); - - // Validates that the frontier of nodes for the conditional - // section are as expected. - Status ValidateFrontier( - const std::unordered_map<Node*, ForwardFlowNode>& branch_map, - const std::unordered_set<Node*>& frontier); - - FunctionLibraryDefinition* library_; - Graph* graph_; - bool dump_graphs_; -}; - -bool IsDeadSwitch(const Node* node) { - for (const Edge* e : node->out_edges()) { - const Node* dst = e->dst(); - if (!dst->IsIdentity()) { - return false; - } - for (const Edge* ee : dst->out_edges()) { - if (!ee->IsControlEdge() || !ee->dst()->IsSink()) { - return false; - } - } - } - return true; -} - -string FunctionalizeCond::Branch_Name(FunctionalizeCond::Branch b) { - const string branch_name[FunctionalizeCond::kNumBranchTypes + 1] = { - "else", "then", "both", "neither", "count"}; - return branch_name[b]; -} - -Status FunctionalizeCond::ValidateFrontier( - const std::unordered_map<Node*, FunctionalizeCond::ForwardFlowNode>& - branch_map, - const std::unordered_set<Node*>& frontier) { - std::unordered_set<const Node*> pending[kNumBranchTypes]; - for (Node* n : frontier) { - pending[branch_map.at(n).branch].insert(n); - } - TF_RET_CHECK(pending[kNeither].empty()) << NodesToString(pending[kNeither]); - for (const Node* n : pending[kBoth]) { - TF_RET_CHECK(IsMerge(n)) << n->DebugString(); - // Merge nodes may be in then or else branch too - } - int index = (pending[kThenBranch].size() <= pending[kElseBranch].size()) - ? kThenBranch - : kElseBranch; - int other = 1 - index; - for (const Node* n : pending[index]) { - if (pending[other].find(n) != pending[other].end()) { - return errors::Internal( - "Node (", n->DebugString().c_str(), - ") in both Else and Then branch should be in Both."); - } - } - // An empty frontier indicates a dead switch. Above we attempt to remove dead - // switch nodes, but not all are removed so don't treat it as an error yet. - // TODO(jpienaar): Find out why dead switch nodes remain. - // if (pending[kBoth].empty() && pending[kThenBranch].empty() && - // pending[kElseBranch].empty()) { - // return errors::Internal("Unexpected empty frontier for switch nodes"); - // } - return Status::OK(); -} - -Status FunctionalizeCond::Join(const ForwardFlowNode& src_state, - const Node* dst, ForwardFlowNode* dst_state) { - TF_RET_CHECK(dst_state->branch != Branch::kBoth && - dst_state->branch != Branch::kNumBranchTypes) - << "Unexpected/Invalid branch type: Merging " - << Branch_Name(src_state.branch) << " with " - << Branch_Name(dst_state->branch); - if (dst_state->branch == Branch::kNeither) { - dst_state->branch = src_state.branch; - } else if (src_state.branch != dst_state->branch && - src_state.branch != Branch::kNeither) { - if (IsMerge(dst)) { - dst_state->branch = Branch::kBoth; - } else { - return errors::Internal("Illegal merge:\n", src_state.ToString(), - " with ", dst_state->ToString(), " for\n", - dst->DebugString()); - } - } - ++dst_state->count; - return Status::OK(); -} - -StatusOr<std::vector<FunctionalizeCond::SwitchCluster>> -FunctionalizeCond::DeterminePredicateSwitchOrder() { - struct Cluster { - bool operator==(const Cluster& other) const { - return representative == other.representative; - } - int representative = -1; - }; - - // Perform a DFS over the graph and - // * Determine the reverse topological order of the nodes (there should be no - // cycles at this point so the post-order numbering corresponds to the - // reverse topological sorting); - // * Identify dead switches; - // * Initialize the cluster's representative; - std::vector<UnionFind<Cluster>> clusters(graph_->num_node_ids()); - std::vector<Node*> dead_switches; - std::vector<Node*> switch_order; - std::vector<Node*> rev_topo_sorted_nodes; - DFS(*graph_, nullptr, [&](Node* n) { - clusters[n->id()].Get().representative = n->id(); - if (IsSwitch(n)) { - if (IsDeadSwitch(n)) { - dead_switches.push_back(n); - } else { - rev_topo_sorted_nodes.push_back(n); - switch_order.push_back(n); - } - } else if (n->IsOp()) { - // Exclude src and sink nodes from further consideration. - rev_topo_sorted_nodes.push_back(n); - } - }); - - std::vector<SwitchCluster> switch_clusters; - // Return early if there are no switches in the graph. - if (switch_order.empty()) { - return switch_clusters; - } - - // Remove all dead switch nodes. - for (Node* n : dead_switches) { - VLOG(2) << "Removing dead switch: " << n->DebugString(); - graph_->RemoveNode(n); - } - - // Identify switch nodes that are part of the same control flow context by - // considering the operands of operations: an operation is part of the same - // control context as its operands unless the operation is a switch. Control - // dependencies are considered part of the same control flow context if the - // switch depth is the same (see comment below). - - // entry_cluster records the input cluster to a switch node. This is used when - // merging with a merge node where the dst's cluster is merged with the entry - // cluster of the merge node's cluster (which corresponds to a switch cluster - // and so has an entry cluster). - std::unordered_map<int, UnionFind<Cluster>*> entry_cluster; - - // Returns the output cluster of a node. Where the output cluster is cluster - // where the output of the node is used. For non-merge nodes this is simply - // the cluster they are part of, while for merge nodes it is the entry cluster - // of the cluster they are part of (this will correspond to the entry node of - // a switch node that dominates the merge). - auto find_output_cluster = [&](Node* n) { - UnionFind<Cluster>* cluster = &clusters[n->id()]; - if (!IsMerge(n)) return cluster; - auto it = entry_cluster.find(clusters[n->id()].Get().representative); - // If the cluster is not found in the entry_cluster map then an - // instruction not dominated by a switch node has been merged into the - // cluster of the merge. This indicates a failure of the clustering. - CHECK(it != entry_cluster.end()) - << "Unable to find entry for n=" << n->id() << " (" - << cluster->Get().representative << ")"; - return it->second; - }; - - // TODO(jpienaar): This could be combined with DetermineBranchMapAndFrontier. - std::vector<int> switch_depth(graph_->num_node_ids()); - for (auto it = rev_topo_sorted_nodes.rbegin(); - it != rev_topo_sorted_nodes.rend(); ++it) { - Node* n = *it; - - // Compute switch depth. - int new_switch_depth = 0; - for (const Edge* e : n->in_edges()) { - Node* src = e->src(); - new_switch_depth = std::max( - new_switch_depth, switch_depth[src->id()] - (IsMerge(src) ? 1 : 0)); - } - switch_depth[n->id()] = new_switch_depth + (IsSwitch(n) ? 1 : 0); - - // Only merge the input operands of a switch. The switch's clustering itself - // is determined by the interaction of the switch's outputs. - if (IsSwitch(n)) { - Node* input; - TF_CHECK_OK(n->input_node(0, &input)); - entry_cluster[n->id()] = find_output_cluster(input); - UnionFind<Cluster>* cluster = entry_cluster[n->id()]; - int cluster_depth = switch_depth[cluster->Get().representative]; - // Merge the inputs of the switch node with one another. This results in - // predicates and control input residing in the same cluster. - for (const Edge* e : n->in_edges()) { - // Only consider the data inputs to the Switch node. - if (e->IsControlEdge()) continue; - - Node* src = e->src(); - UnionFind<Cluster>* src_cluster = find_output_cluster(src); - int src_cluster_depth = switch_depth[src_cluster->Get().representative]; - if (cluster_depth != src_cluster_depth) { - return errors::InvalidArgument( - "Unable to functionalize control flow in graph: Switch ('", - n->name(), "') has operands ('", input->name(), "' and '", - src->name(), "') that have different switch depths (", - cluster_depth, " != ", src_cluster_depth, ")"); - } - cluster->Merge(src_cluster); - } - continue; - } - - for (const Edge* e : n->in_edges()) { - Node* src = e->src(); - if (!src->IsOp()) continue; - UnionFind<Cluster>* cluster = find_output_cluster(src); - // Merge a node with its data operands and with its control operands if - // the src and dst are in the same ControlContext. The ControlContext is - // not explicitly available here, and instead the switch depth is used as - // a proxy here. Due to the invariant that control edges can only be from - // a containing scope to an inner scope or from the inner scope to its - // containing scope (for exit nodes), the switch depth will only match if - // the src and dst are in the same ControlContext. Control edges between - // ControlContexts are handled during the extraction. - int src_id = cluster->Get().representative; - int src_depth = switch_depth[src_id]; - if (!e->IsControlEdge() || new_switch_depth == src_depth) { - if (src_depth != new_switch_depth) { - // TODO(b/77601805) remove this when outside_compilation supports - // control flow. - if (str_util::StrContains(src->name(), "outside_compilation") || - str_util::StrContains(n->name(), "outside_compilation")) { - return errors::InvalidArgument( - "outside_compilation is not yet supported within TensorFlow " - "control flow constructs b/77601805"); - } - return errors::InvalidArgument( - "Unable to functionalize control flow in graph: Operand ('", - src->name(), "') and operator ('", n->name(), - "') have different switch depths (", src_depth, - " != ", new_switch_depth, ")"); - } - cluster->Merge(&clusters[n->id()]); - } - } - } - - if (dump_graphs_) { - // Mark the switch cluster each node is part of. - for (Node* n : graph_->nodes()) { - n->ClearAttr("_XlaFunctionalizeSwitchGroup"); - n->AddAttr("_XlaFunctionalizeSwitchGroup", - clusters[n->id()].Get().representative); - } - LOG(INFO) << "FunctionalizeControlFlow (with_clusters): " - << dump_graph::DumpGraphToFile("functionalize_clustered", *graph_, - library_); - } - - // Verify all the nodes of a cluster are at the same depth. - std::unordered_map<int, std::pair<int, Node*>> cluster_to_depth_node; - for (Node* n : graph_->nodes()) { - int depth = switch_depth[n->id()]; - int cluster_rep = clusters[n->id()].Get().representative; - auto it = cluster_to_depth_node.find(cluster_rep); - if (it == cluster_to_depth_node.end()) { - cluster_to_depth_node[cluster_rep] = std::make_pair(depth, n); - } else { - if (it->second.first != depth) { - return errors::Internal( - "Illegal clustering created, mismatch in depths:", "\n\t", - n->DebugString(), "(", clusters[n->id()].Get().representative, - ") at depth=", depth, " vs\n\t", it->second.second->DebugString(), - "(", clusters[n->id()].Get().representative, ") at depth ", - it->second.first); - } - } - } - - struct Hash { - size_t operator()(const std::pair<Node*, Cluster>& item) const { - return Hash64Combine(hash<Node*>()(item.first), - std::hash<int>()(item.second.representative)); - } - }; - - // Merge Switch nodes with common predicate. - std::unordered_map<std::pair<Node*, Cluster>, int, Hash> predicate_index; - // The nodes in switch_order are in reverse topological order, but the - // clustered switches need not be (i.e., when considered as a cluster one - // element of a cluster may be later in the topological order than another - // node whose cluster is later in the topological order of clustered - // switches). - for (auto it = switch_order.rbegin(); it != switch_order.rend(); ++it) { - const Edge* pred_edge; - TF_CHECK_OK((*it)->input_edge(1, &pred_edge)); - // The predicate can be preceded by a identity node. Look through identity - // nodes to predicate. - while (pred_edge->src()->IsIdentity()) { - TF_CHECK_OK(pred_edge->src()->input_edge(0, &pred_edge)); - } - auto repr = std::make_pair(pred_edge->src(), clusters[(*it)->id()].Get()); - if (predicate_index.find(repr) == predicate_index.end()) { - predicate_index[repr] = switch_clusters.size(); - switch_clusters.emplace_back(pred_edge); - // Generate a name by concatenating with the cluster representative as - // there could be multiple switch clusters with the same predicate. - switch_clusters[predicate_index[repr]].name = strings::StrCat( - pred_edge->src()->name(), "_", repr.second.representative, "_If"); - } - switch_clusters[predicate_index[repr]].switches.push_back(*it); - } - - return switch_clusters; -} - -StatusOr<std::vector<Node*>> -FunctionalizeCond::EnsureDominanceAndReturnNonDominatedControlNodes( - const std::unordered_map<Node*, ForwardFlowNode>& branch_map, - const std::vector<Node*>& switches) { - std::vector<Node*> old_control_nodes; - for (const auto& kv : branch_map) { - if (kv.second.count != kv.first->in_edges().size()) { - std::vector<const Edge*> delete_edges; - for (const Edge* in : kv.first->in_edges()) { - auto it = branch_map.find(in->src()); - if (it == branch_map.end()) { - if (in->IsControlEdge()) { - old_control_nodes.push_back(in->src()); - delete_edges.push_back(in); - } else { - if (IsSwitch(in->src())) { - if (std::find(switches.begin(), switches.end(), in->src()) == - switches.end()) { - return errors::Internal( - "Unexpected switch node found during flow forward: ", - in->src()->DebugString()); - } - continue; - } - return errors::InvalidArgument( - "Value ", kv.first->name(), "'s input, ", in->src()->name(), - ", is not dominated by switch nodes ", NodesToString(switches)); - } - } - } - // Remove control edges from nodes that are not dominated by the switch - // nodes. New control dependencies will be added between these nodes and - // the XlaIf node inserted. - for (const Edge* e : delete_edges) { - graph_->RemoveEdge(e); - } - } - } - return old_control_nodes; -} - -StatusOr< - std::pair<std::unordered_map<Node*, FunctionalizeCond::ForwardFlowNode>, - std::unordered_set<Node*>>> -FunctionalizeCond::DetermineBranchMapAndFrontier( - const SwitchCluster& switch_cluster) { - std::unordered_map<Node*, ForwardFlowNode> branch_map; - std::unordered_set<Node*> frontier; - std::vector<Node*> stack = switch_cluster.switches; - std::vector<bool> visited(graph_->num_node_ids(), false); - while (!stack.empty()) { - Node* n = stack.back(); - stack.pop_back(); - - if (visited[n->id()]) { - continue; - } - visited[n->id()] = true; - - // Propagate branch state along each edge of a switch node. - bool sink_only = true; - for (const Edge* e : n->out_edges()) { - Node* out = e->dst(); - if (!out->IsOp()) { - continue; - } - sink_only = false; - // Propagate branch information. - ForwardFlowNode& ffn = branch_map[out]; - if (IsSwitch(n)) { - int index = e->IsControlEdge() ? Branch::kNeither : e->src_output(); - TF_RETURN_WITH_CONTEXT_IF_ERROR( - Join(ForwardFlowNode(Branch(index)), out, &ffn), " when joining ", - e->DebugString()); - } else { - TF_RETURN_WITH_CONTEXT_IF_ERROR(Join(branch_map[n], out, &ffn), - " when joining ", e->DebugString()); - } - if (IsMerge(out)) { - if (out->in_edges().size() == ffn.count) { - frontier.insert(out); - } - } else if (!visited[out->id()]) { - stack.push_back(out); - } - } - if (sink_only) { - if (!IsIdentity(n)) { - VLOG(1) << "Feeding into sink: " << n->DebugString(); - } - } - } - - if (dump_graphs_) { - for (const auto& kv : branch_map) { - // Append attribute to the graph if running with logging to make the - // changes clearer in the visualization. - kv.first->AddAttr("_XlaFunctionalizeBranch", - Branch_Name(kv.second.branch)); - } - } - return std::make_pair(std::move(branch_map), std::move(frontier)); -} - -Status FunctionalizeCond::FunctionalizeInternal() { - TF_ASSIGN_OR_RETURN(std::vector<SwitchCluster> predicate_switch_order, - DeterminePredicateSwitchOrder()); - - // Iterate from innermost set of clustered switches to outermost, replacing - // matching switch->merge subgraphs with single XlaIf nodes. - for (auto it = predicate_switch_order.rbegin(); - it != predicate_switch_order.rend(); ++it) { - auto& ps = *it; - VLOG(3) << "Flow down from: " << ps.ToString(); - - std::unordered_map<Node*, ForwardFlowNode> branch_map; - std::unordered_set<Node*> frontier; - TF_ASSIGN_OR_RETURN(std::tie(branch_map, frontier), - DetermineBranchMapAndFrontier(ps)); - - if (dump_graphs_) - LOG(INFO) << "FunctionalizeControlFlow (before XlaIf conversion): " - << dump_graph::DumpGraphToFile("functionalize_bc", *graph_, - library_); - TF_RETURN_IF_ERROR(ValidateFrontier(branch_map, frontier)); - - struct Hash { - size_t operator()(const std::pair<Node*, int>& item) const { - return Hash64Combine(hash<Node*>()(item.first), - std::hash<int>()(item.second)); - } - }; - - // Sort the merge and switch nodes using NodeCmp. The switch-nodes are - // further grouped (post sorting) by input to the switch node as in the - // functionalized form each input will be passed in only once. This grouping - // should retain the sorted order. - CondArgNodes cond_arg_nodes; - std::sort(ps.switches.begin(), ps.switches.end(), NodeCmp()); - std::unordered_map<std::pair<Node*, int>, int, Hash> input_index; - for (Node* switch_node : ps.switches) { - const Edge* e; - TF_RETURN_IF_ERROR(switch_node->input_edge(0, &e)); - std::pair<Node*, int> key = std::make_pair(e->src(), e->src_output()); - if (input_index.find(key) == input_index.end()) { - input_index[key] = cond_arg_nodes.size(); - cond_arg_nodes.emplace_back(key.first, key.second); - } - cond_arg_nodes.at(input_index.at(key)).switches.push_back(switch_node); - } - std::vector<Node*> merge_nodes(frontier.begin(), frontier.end()); - std::sort(merge_nodes.begin(), merge_nodes.end(), NodeCmp()); - - TF_ASSIGN_OR_RETURN(std::vector<Node*> old_control_nodes, - EnsureDominanceAndReturnNonDominatedControlNodes( - branch_map, ps.switches)); - - TF_ASSIGN_OR_RETURN(Node * if_node, - ConvertToXlaIf(cond_arg_nodes, ps, merge_nodes)); - for (Node* old : old_control_nodes) { - graph_->AddControlEdge(old, if_node); - } - - for (auto& del_kv : branch_map) { - graph_->RemoveNode(del_kv.first); - } - for (auto& kv : cond_arg_nodes) { - for (Node* node : kv.switches) { - graph_->RemoveNode(node); - } - } - if (dump_graphs_) - LOG(INFO) << "FunctionalizeControlFlow (after XlaIf conversion): " - << dump_graph::DumpGraphToFile("functionalize_ac", *graph_, - library_); - } - return Status::OK(); -} - -StatusOr<Node*> FunctionalizeCond::BuildAndAddXlaIfOp( - const CondArgNodes& cond_arg_nodes, const SwitchCluster& switch_cluster, - const std::vector<Node*>& merge_nodes) { - VLOG(2) << "Build if op for " << switch_cluster.name; - - NodeDef if_def; - // Create a new If node using the name of the merge node. - NodeDefBuilder builder(switch_cluster.name, "XlaIf"); - string branch[] = {"else_branch", "then_branch"}; - for (int i = 0; i < 2; ++i) { - static std::atomic<int64> sequence_num(0LL); - int64 id = ++sequence_num; - - NameAttrList body_name; - body_name.set_name( - strings::StrCat("_functionalize_if_", branch[i], "_", id)); - auto body = xla::MakeUnique<Graph>(graph_->op_registry()); - TF_RETURN_IF_ERROR(ExtractBody(cond_arg_nodes, switch_cluster.switches, - merge_nodes, i, body.get())); - VLOG(3) << "Body " << branch[i] << ": " << DebugString(body.get()); - FunctionDef body_fdef; - TF_RETURN_IF_ERROR(GraphToFunctionDef(*body, body_name.name(), &body_fdef)); - TF_RETURN_IF_ERROR(library_->AddFunctionDef(body_fdef)); - builder.Attr(branch[i], body_name); - } - - // Build input type. - std::vector<NodeDefBuilder::NodeOut> inputs; - DataTypeVector in_arg_types; - for (auto& kv : cond_arg_nodes) { - bool inserted = false; - for (const Node* arg : kv.switches) { - const Edge* in_edge; - TF_RETURN_IF_ERROR(arg->input_edge(0, &in_edge)); - if (in_edge->IsControlEdge()) { - builder.ControlInput(in_edge->src()->name()); - } else { - if (!inserted) { - DataType dtype = arg->input_type(0); - inputs.emplace_back(NodeDefBuilder::NodeOut( - in_edge->src()->name(), in_edge->src_output(), dtype)); - in_arg_types.push_back(dtype); - inserted = true; - } - } - } - } - builder.Attr("Tin", in_arg_types); - - // Build output type. - DataTypeVector out_type; - for (const Node* merge : merge_nodes) { - DataType dtype = merge->output_type(0); - out_type.push_back(dtype); - } - builder.Attr("Tout", out_type); - - builder.Attr("Tcond", DT_BOOL); - builder.Device(switch_cluster.predicate_edge->src()->assigned_device_name()); - // Conditional should be the first input ... - builder.Input(NodeDefBuilder::NodeOut( - switch_cluster.predicate_edge->src()->name(), - switch_cluster.predicate_edge->src_output(), - switch_cluster.predicate_edge->src()->output_type(0))); - // ... followed by the other inputs. - builder.Input(inputs); - - TF_RETURN_IF_ERROR(builder.Finalize(&if_def)); - TF_ASSIGN_OR_RETURN(Node * if_node, AddNode(if_def, graph_)); - return if_node; -} - -Status FunctionalizeCond::ExtractBody(const CondArgNodes& cond_arg_nodes, - const std::vector<Node*>& switches, - const std::vector<Node*>& merge_nodes, - int input_edge, Graph* body) { - VLOG(2) << "ExtractBody for " << NodesToString(merge_nodes) << " along edge " - << input_edge; - std::vector<bool> squash_src_outputs(graph_->num_node_ids(), false); - std::vector<Node*> node_map(graph_->num_node_ids(), nullptr); - int arg_count = 0; - for (auto& kv : cond_arg_nodes) { - Node* arg_node = nullptr; - for (const auto* arg : kv.switches) { - DataType dtype = arg->input_type(0); - if (arg_node == nullptr) { - TF_ASSIGN_OR_RETURN(arg_node, BuildArgNode(body, dtype, arg_count++)); - } - node_map.at(arg->id()) = arg_node; - squash_src_outputs.at(arg->id()) = true; - } - } - - std::vector<Node*> stack; - stack.reserve(merge_nodes.size()); - for (int j = 0; j < merge_nodes.size(); ++j) { - Node* node = merge_nodes[j]; - TF_ASSIGN_OR_RETURN(node_map.at(node->id()), - BuildRetvalNode(body, node->output_type(0), - /*index=*/j)); - const Edge* in_edge; - TF_RETURN_IF_ERROR(node->input_edge(input_edge, &in_edge)); - Node* in = in_edge->src(); - if (node_map.at(in->id()) == nullptr) { - node_map.at(in->id()) = body->CopyNode(in); - } - - if (std::find(switches.begin(), switches.end(), in) == switches.end()) { - body->AddEdge(node_map.at(in->id()), in_edge->src_output(), - node_map.at(node->id()), 0); - } else { - body->AddEdge(node_map.at(in->id()), 0, node_map.at(node->id()), 0); - // Don't include input nodes that are already just returned in stack. - continue; - } - stack.push_back(in); - } - - return CopySubgraph(*graph_, nullptr, stack, squash_src_outputs, &node_map, - body); -} - -Status FunctionalizeCond::AddInputEdges(const CondArgNodes& cond_arg_nodes, - const Edge* predicate_edge, - Node* if_node) { - VLOG(3) << "AddInputEdges for " << if_node->name(); - int index = 0; - graph_->AddEdge(predicate_edge->src(), predicate_edge->src_output(), if_node, - index++); - for (auto& arg : cond_arg_nodes) { - if (arg.src_output == Graph::kControlSlot) { - graph_->AddControlEdge(arg.src, if_node); - } else { - graph_->AddEdge(arg.src, arg.src_output, if_node, index++); - } - } - return Status::OK(); -} - -Status FunctionalizeCond::AddOutputEdges(const std::vector<Node*>& outputs, - Node* if_node) { - VLOG(3) << "AddOutputEdges for " << if_node->name(); - for (int i = 0; i < outputs.size(); ++i) { - Node* node = outputs[i]; - std::vector<const Edge*> edges(node->out_edges().begin(), - node->out_edges().end()); - for (const Edge* edge : edges) { - Node* dst = edge->dst(); - int dst_input = edge->dst_input(); - - if (edge->src_output() > 0) { - return errors::Unimplemented("Output of index (", edge->src_output(), - ") of merge node ", node->name()); - } - - int src_output = - dst_input == Graph::kControlSlot ? Graph::kControlSlot : i; - graph_->RemoveEdge(edge); - graph_->AddEdge(if_node, src_output, dst, dst_input); - } - } - return Status::OK(); -} - -StatusOr<Node*> FunctionalizeCond::ConvertToXlaIf( - const CondArgNodes& cond_arg_nodes, const SwitchCluster& switch_cluster, - const std::vector<Node*>& merge_nodes) { - VLOG(1) << "ConvertToXlaIf for " << switch_cluster.ToString() << " -> " - << NodesToString(merge_nodes); - - // Extract bodies and builds a If operator. - TF_ASSIGN_OR_RETURN( - Node * if_node, - BuildAndAddXlaIfOp(cond_arg_nodes, switch_cluster, merge_nodes)); - TF_RETURN_IF_ERROR( - AddInputEdges(cond_arg_nodes, switch_cluster.predicate_edge, if_node)); - TF_RETURN_IF_ERROR(AddOutputEdges(merge_nodes, if_node)); - // Check that the if_node doesn't feed into itself. - TF_RETURN_WITH_CONTEXT_IF_ERROR( - CheckNoCycleContains(if_node, graph_->num_node_ids()), - "ConvertToXlaIf failed."); - - return if_node; -} - -Status FunctionalizeCond::Functionalize(Graph* graph, - FunctionLibraryDefinition* library) { - VLOG(1) << "FunctionalizeCond::Functionalize"; - FunctionalizeCond fc(graph, library, /*dump_graphs=*/VLOG_IS_ON(2)); - return fc.FunctionalizeInternal(); -} - -} // namespace - -// Transformation that converts TensorFlow's graph control flow constructs into -// functional equivalents. -Status FunctionalizeControlFlow(Graph* graph, - FunctionLibraryDefinition* library) { - return FunctionalizeControlFlow(/*lookup_library=*/nullptr, graph, library); -} - Status FunctionalizeControlFlow(const FunctionLibraryDefinition* lookup_library, Graph* graph, FunctionLibraryDefinition* library) { @@ -1462,98 +46,26 @@ Status FunctionalizeControlFlow(const FunctionLibraryDefinition* lookup_library, << dump_graph::DumpGraphToFile("functionalize_initial", *graph, library); - // Note: BuildControlFlowInfo() requires that the graph's source node is - // connected to all source nodes in the graph. Many graphs violate this - // invariant. - std::vector<ControlFlowInfo> cf_info; - std::vector<string> unreachable_nodes; - TF_RETURN_WITH_CONTEXT_IF_ERROR( - BuildControlFlowInfo(graph, &cf_info, &unreachable_nodes), - "FunctionalizeControlFlow failed"); - if (!unreachable_nodes.empty()) { - return errors::InvalidArgument( - "The following nodes are unreachable from the source in the graph: ", - errors::FormatNodeNamesForError(unreachable_nodes)); - } - - // Builds Frames, indexed by name. - std::unordered_map<string, Frame> frames; - for (Node* node : graph->op_nodes()) { - const ControlFlowInfo& cf = cf_info[node->id()]; - - VLOG(2) << "node: " << node->name() << " (" << node->id() - << ") frame_name: " << cf.frame_name - << " frame: " << (cf.frame ? cf.frame->name() : "---") - << " parent_frame: " - << (cf.parent_frame ? cf.parent_frame->name() : "---"); - TF_RET_CHECK(cf.frame != nullptr && cf.parent_frame != nullptr); - - Frame& frame = frames[cf.frame_name]; - Frame* parent = &frames[cf_info[cf.parent_frame->id()].frame_name]; - if (frame.parent == nullptr) { - frame.parent = parent; - frame.name = cf.frame_name; - ++parent->num_children; - } - - if (IsEnter(node)) { - Arg arg; - arg.enter = node; - TF_RETURN_IF_ERROR(GetNodeAttr(arg.enter->attrs(), "is_constant", - &arg.is_loop_invariant)); - frame.args.push_back(arg); - } else if (IsLoopCond(node)) { - frame.loop_cond = node; - } - frame.nodes.insert(node); - } - - // Adds frames with no children (i.e., the innermost frames) to a worklist. - std::deque<Frame*> worklist; - for (auto& frame : frames) { - if (frame.second.num_children == 0) { - worklist.push_back(&frame.second); - } - } - - // Eliminate loops from innermost to outermost. - while (!worklist.empty()) { - Frame* frame = worklist.front(); - worklist.pop_front(); - if (frame->parent == frame) { - // Skip the root frame. - continue; - } - - TF_RETURN_IF_ERROR( - FunctionalizeLoop(lookup_library, graph, frame, library)); - - // If the parent has no remaining children, add it to the worklist. - --frame->parent->num_children; - if (frame->parent->num_children == 0) { - worklist.push_back(frame->parent); - } - } - // There should be no cycle at this point, since while loops have been removed - // from graph. - // Check that the newly added XlaWhile nodes don't feed into themselves. - for (const Node* node : graph->op_nodes()) { - if (node->def().op() == "XlaWhile") { - TF_RETURN_WITH_CONTEXT_IF_ERROR( - CheckNoCycleContains(node, graph->num_node_ids()), - "FunctionalizeLoop failed."); - } - } + // Functionalize and remove while loops from graph. + TF_RETURN_IF_ERROR(FunctionalizeWhileLoop(lookup_library, graph, library)); // FunctionalizeControlFlow is invoked for every function, so the loops's // bodies and conditionals that were extracted into functions will be handled // in successive invocations. - TF_RETURN_IF_ERROR(FunctionalizeCond::Functionalize(graph, library)); + TF_RETURN_IF_ERROR(FunctionalizeCond(graph, library)); VLOG(2) << "FunctionalizeControlFlow (final): " << dump_graph::DumpGraphToFile("functionalize_final", *graph, library); + return Status::OK(); } +// Transformation that converts TensorFlow's graph control flow constructs into +// functional equivalents. +Status FunctionalizeControlFlow(Graph* graph, + FunctionLibraryDefinition* library) { + return FunctionalizeControlFlow(/*lookup_library=*/nullptr, graph, library); +} + } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/functionalize_control_flow.h b/tensorflow/compiler/tf2xla/functionalize_control_flow.h index d941041d15..55600f2a8b 100644 --- a/tensorflow/compiler/tf2xla/functionalize_control_flow.h +++ b/tensorflow/compiler/tf2xla/functionalize_control_flow.h @@ -16,14 +16,16 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_CONTROL_FLOW_H_ #define TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_CONTROL_FLOW_H_ +#include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/core/framework/function.h" #include "tensorflow/core/graph/graph.h" namespace tensorflow { // Transformation that converts tf.while_loop() loops into functional While -// operators, suitable for XLA compilation. If lookup_library is provided, use -// it to make the library for control flow self-contained. +// operators and tf.cond() conditionals into function If operators, suitable for +// XLA compilation. If lookup_library is provided, use it to make the library +// for control flow self-contained. Status FunctionalizeControlFlow(Graph* graph, FunctionLibraryDefinition* library); Status FunctionalizeControlFlow(const FunctionLibraryDefinition* lookup_library, diff --git a/tensorflow/compiler/tf2xla/functionalize_control_flow_test.cc b/tensorflow/compiler/tf2xla/functionalize_control_flow_test.cc index ccf249b35d..cc52057f21 100644 --- a/tensorflow/compiler/tf2xla/functionalize_control_flow_test.cc +++ b/tensorflow/compiler/tf2xla/functionalize_control_flow_test.cc @@ -37,12 +37,12 @@ limitations under the License. namespace tensorflow { namespace { -// Returns the names of the "then" and "else" functions for the XlaIf node in a +// Returns the names of the "then" and "else" functions for the If node in a // graph. Status FindIfThenAndElse(const GraphDef& graph, string* op_name, NameAttrList* then_fn, NameAttrList* else_fn) { for (const NodeDef& node : graph.node()) { - if (node.op() == "XlaIf") { + if (node.op() == "If") { *op_name = node.name(); const NameAttrList* result; TF_RETURN_IF_ERROR(GetNodeAttr(node, "then_branch", &result)); @@ -52,7 +52,7 @@ Status FindIfThenAndElse(const GraphDef& graph, string* op_name, return Status::OK(); } } - return errors::NotFound("No XlaIf node found in graph"); + return errors::NotFound("No If node found in graph"); } // Graph: @@ -115,8 +115,13 @@ TEST(FunctionalizeControlFlow, Conditional) { auto if_op = ops::XlaIf(scope.WithOpName(op_name), less, std::initializer_list<Input>{less, y, x}, then_fn, else_fn, {DT_INT32}); + auto id = ops::Identity(scope.WithOpName("cond/Merge"), if_op.output[0]); GraphDef expected; TF_EXPECT_OK(scope.ToGraphDef(&expected)); + // TODO(jpienaar): Create wrapper for IfOp. + for (NodeDef& n : *expected.mutable_node()) { + if (n.op() == "XlaIf") n.set_op("If"); + } TF_EXPECT_GRAPH_EQ(expected, graph_def); } @@ -1013,63 +1018,5 @@ TEST(FunctionalizeControlFlow, Complex) { } } -TEST(FunctionalizeControlFlow, Cycle) { - std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); - // ----------------------------------------------------- - // | | - // | v - // less -> switch_1 --> add -> merge_1 -> identity -> switch_2 - // | ^ | - // | | v - // --------> one -------------------------> add_2 ---> merge_2 - { - Scope scope = Scope::NewRootScope().ExitOnError(); - - auto x = ops::Placeholder(scope.WithOpName("x"), DT_INT32); - auto y = ops::Placeholder(scope.WithOpName("y"), DT_INT32); - auto less = ops::Less(scope.WithOpName("cond/Less"), y, x); - auto switch_1 = ops::Switch(scope.WithOpName("cond/Switch"), x, less); - auto two = - ops::Const<int32>(scope.WithOpName("cond/two") - .WithControlDependencies(switch_1.output_true), - 2); - auto mul = ops::Multiply(scope.WithOpName("cond/true/mul"), - switch_1.output_true, two); - auto one = - ops::Const<int32>(scope.WithOpName("cond/one") - .WithControlDependencies(switch_1.output_false), - 1); - auto add = ops::Add(scope.WithOpName("cond/false/add"), - switch_1.output_false, one); - - auto merge_1 = ops::Merge(scope.WithOpName("cond/Merge"), - std::initializer_list<Input>{add, mul}); - auto identity = - ops::Identity(scope.WithOpName("cond/Merge/identity"), merge_1.output); - auto switch_2 = - ops::Switch(scope.WithOpName("grad/cond/Switch"), identity, less); - auto add_2 = ops::Add(scope.WithOpName("cond_2/false/add"), - switch_2.output_false, one); - auto mul_2 = ops::Multiply(scope.WithOpName("cond_2/true/mul"), - switch_2.output_true, two); - auto merge_2 = ops::Merge(scope.WithOpName("cond_2/Merge"), - std::initializer_list<Input>{add_2, mul_2}); - TF_ASSERT_OK(scope.ToGraph(graph.get())); - } - // No cycle before functionalize control flow. - TF_EXPECT_OK(graph::ValidateGraphHasNoCycle(*graph)); - FunctionLibraryDefinition library(OpRegistry::Global(), {}); - // switch_1 and switch_2 have the same switch depth. They are replaced by a - // single XlaIf node during FunctionalizeControlFlow, resulting in a cycle: - // less -> XlaIf <--> identity. - Status status = FunctionalizeControlFlow(graph.get(), &library); - EXPECT_FALSE(status.ok()); - EXPECT_TRUE(str_util::StrContains(status.error_message(), "Detected a cycle")) - << status.error_message(); - EXPECT_TRUE( - str_util::StrContains(status.error_message(), "{{node cond/Less_5_If}}")) - << status.error_message(); -} - } // namespace } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/functionalize_control_flow_util.cc b/tensorflow/compiler/tf2xla/functionalize_control_flow_util.cc new file mode 100644 index 0000000000..924fcdd9cd --- /dev/null +++ b/tensorflow/compiler/tf2xla/functionalize_control_flow_util.cc @@ -0,0 +1,72 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/tf2xla/functionalize_control_flow_util.h" + +#include "tensorflow/core/framework/node_def.pb.h" + +namespace tensorflow { + +bool NodeCmpByNameResourcesLast::operator()(const Node* lhs, + const Node* rhs) const { + bool lhs_is_resource = + lhs->num_inputs() > 0 ? (lhs->input_type(0) == DT_RESOURCE) : false; + bool rhs_is_resource = + rhs->num_inputs() > 0 ? (rhs->input_type(0) == DT_RESOURCE) : false; + return std::tie(lhs_is_resource, lhs->name()) < + std::tie(rhs_is_resource, rhs->name()); +} + +xla::StatusOr<Node*> AddNodeDefToGraph(const NodeDef& node_def, Graph* graph) { + Status status; + Node* inserted_node = graph->AddNode(node_def, &status); + if (!status.ok()) { + return status; + } + return inserted_node; +} + +xla::StatusOr<Node*> BuildRetvalNode(Graph* graph, DataType type, int index) { + const char* const kRetValOp = "_Retval"; + NodeDef ret_def; + ret_def.set_op(kRetValOp); + ret_def.set_name(strings::StrCat(kRetValOp, index)); + AddNodeAttr("T", type, &ret_def); + AddNodeAttr("index", index, &ret_def); + return AddNodeDefToGraph(ret_def, graph); +} + +// Check that the graph has no cycle containing the given node. +Status CheckNodeNotInCycle(const Node* node, const int num_nodes) { + std::vector<const Node*> ready; + ready.push_back(node); + std::vector<bool> visited(num_nodes); + while (!ready.empty()) { + const Node* current_node = ready.back(); + ready.pop_back(); + visited[current_node->id()] = true; + for (const Edge* out : current_node->out_edges()) { + if (out->dst() == node) { + return errors::Internal("Detected a cycle: ", FormatNodeForError(*node), + " (", node->def().op(), ") feeds into itself."); + } else if (!visited[out->dst()->id()]) { + ready.push_back(out->dst()); + } + } + } + return Status::OK(); +} + +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/functionalize_control_flow_util.h b/tensorflow/compiler/tf2xla/functionalize_control_flow_util.h new file mode 100644 index 0000000000..61940e3586 --- /dev/null +++ b/tensorflow/compiler/tf2xla/functionalize_control_flow_util.h @@ -0,0 +1,57 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_CONTROL_FLOW_UTIL_H_ +#define TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_CONTROL_FLOW_UTIL_H_ + +#include "absl/strings/str_join.h" +#include "tensorflow/compiler/xla/status_macros.h" +#include "tensorflow/core/graph/graph.h" + +// Utility functions shared between functionalize cond and while. + +namespace tensorflow { + +// Check that the graph has no cycle containing the given node. +Status CheckNodeNotInCycle(const Node* node, const int num_nodes); + +// Comparison function used for sorting nodes consistently. +// a) resource variables are last, and +// b) sort lexicographically by name (for deterministic output). +struct NodeCmpByNameResourcesLast { + bool operator()(const Node* lhs, const Node* rhs) const; +}; + +// Returns the Node* created from the NodeDef in the Graph. +xla::StatusOr<Node*> AddNodeDefToGraph(const NodeDef& node_def, Graph* graph); + +// Build a retval node of given type and index. +xla::StatusOr<Node*> BuildRetvalNode(Graph* graph, DataType type, int index); + +// Returns a textual representation of the names of the nodes in the input. +template <typename T> +string NodesToString(const T& nodes) { + return strings::StrCat("{", + absl::StrJoin(nodes, ",", + [](string* output, const Node* node) { + strings::StrAppend(output, + node->name()); + }), + "}"); +} + +} // namespace tensorflow + +#endif // TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_CONTROL_FLOW_UTIL_H_ diff --git a/tensorflow/compiler/tf2xla/functionalize_while.cc b/tensorflow/compiler/tf2xla/functionalize_while.cc new file mode 100644 index 0000000000..6e3c4b0e0f --- /dev/null +++ b/tensorflow/compiler/tf2xla/functionalize_while.cc @@ -0,0 +1,668 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/tf2xla/functionalize_while.h" + +#include <algorithm> +#include <deque> +#include <stack> +#include <unordered_set> +#include <vector> + +#include "absl/memory/memory.h" +#include "absl/types/optional.h" +#include "tensorflow/compiler/jit/union_find.h" +#include "tensorflow/compiler/tf2xla/dump_graph.h" +#include "tensorflow/compiler/tf2xla/functionalize_control_flow_util.h" +#include "tensorflow/compiler/tf2xla/tf2xla_util.h" +#include "tensorflow/compiler/xla/status_macros.h" +#include "tensorflow/core/common_runtime/function.h" +#include "tensorflow/core/framework/graph_to_functiondef.h" +#include "tensorflow/core/framework/node_def_builder.h" +#include "tensorflow/core/graph/algorithm.h" +#include "tensorflow/core/graph/control_flow.h" +#include "tensorflow/core/graph/node_builder.h" + +namespace tensorflow { +namespace { + +using xla::StatusOr; + +// Information about a loop argument. +struct Arg { + // Every loop argument has an Enter node. + Node* enter; + + // Is the loop argument a loop-invariant value? Taken from the `is_constant` + // attribute on the Enter node. + bool is_loop_invariant; + + // If 'is_loop_invariant' is true, the following are all nullptr. Non-constant + // arguments must have all of the following nodes: + Node* merge = nullptr; + Node* switch_node = nullptr; + Node* next_iteration = nullptr; + Node* exit = nullptr; +}; + +// Information about a loop frame. +struct Frame { + string name; + + // Pointer to the parent frame. The root frame has a pointer to itself. + Frame* parent = nullptr; + int num_children = 0; + + // Arguments to this loop. + std::vector<Arg> args; + + // The loop condition of the loop. There should be exactly one loop condition + // in every loop. + Node* loop_cond = nullptr; + + // Set of nodes that belong to the loop frame. + std::unordered_set<Node*> nodes; +}; + +// Copies a subgraph from `graph` to `output` by performing a reverse DFS +// starting at nodes in vector `stack`. +// `node_map` is a vector indexed by source node ID to dest nodes. +// Does not traverse into nodes in `node_map`, so by adding nodes to `node_map` +// before the traversal clients can cut the graph. If a frame is provided (frame +// != nullptr), then this functions will return an error if the +// traversal leaves 'frame'; the client must add enough nodes to `node_map` to +// cut the graph and prevent the traversal from escaping. +// +// `squash_src_outputs` contains a bool for each source node ID. If true, then +// the source output on that node will be replaced by zero when copied. This is +// used when replacing a Switch node with an _Arg node. The output we are +// taking from the Switch node was not necessarily the first output, but _Arg +// nodes only have one output. By adding the Switch node to `squash_src_outputs` +// we rewrite the src_output of the corresponding edge to be 0. +Status CopySubgraph(const Graph& graph, const Frame* frame, + std::vector<Node*> stack, + const std::vector<bool>& squash_src_outputs, + std::vector<Node*>* node_map, Graph* output) { + VLOG(3) << "Stack: " << NodesToString(stack); + std::vector<bool> visited(graph.num_node_ids(), false); + while (!stack.empty()) { + Node* n = stack.back(); + stack.pop_back(); + + VLOG(5) << "Copying node " << n->name(); + + if (visited[n->id()]) continue; + visited[n->id()] = true; + + for (const Edge* e : n->in_edges()) { + Node* src = e->src(); + if (frame != nullptr && frame->nodes.find(src) == frame->nodes.end()) { + // We traversed out of the loop frame, without encountering a cut node. + return errors::Internal("Graph traversal of loop frame ", frame->name, + " escaped frame at ", src->name(), + " without encountering an argument node."); + } + if ((*node_map)[src->id()] == nullptr) { + (*node_map)[src->id()] = output->CopyNode(src); + stack.push_back(src); + } + Node* src_copy = (*node_map)[e->src()->id()]; + int src_output = squash_src_outputs[e->src()->id()] && !e->IsControlEdge() + ? 0 + : e->src_output(); + Node* dst_copy = (*node_map)[e->dst()->id()]; + output->AddEdge(src_copy, src_output, dst_copy, e->dst_input()); + } + } + return Status::OK(); +} + +StatusOr<Node*> BuildArgNode(Graph* graph, DataType type, int index) { + const char* const kArgOp = "_Arg"; + NodeDef arg_def; + NodeDefBuilder builder(strings::StrCat(kArgOp, index), kArgOp); + builder.Attr("T", type); + builder.Attr("index", index); + TF_RETURN_IF_ERROR(builder.Finalize(&arg_def)); + return AddNodeDefToGraph(arg_def, graph); +} + +// Builds a graph for the loop condition. +Status BuildLoopCondition(const Graph& graph, Frame* frame, + std::unique_ptr<Graph>* cond_output) { + VLOG(2) << "Building loop condition for " << frame->name; + *cond_output = absl::make_unique<Graph>(graph.op_registry()); + Graph* output = cond_output->get(); + + // Map from nodes in the original graph to the condition graph. + std::vector<Node*> node_map(graph.num_node_ids(), nullptr); + std::vector<bool> squash_src_outputs(graph.num_node_ids(), false); + + // Build one _Arg node for each Enter node. + for (int i = 0; i < frame->args.size(); ++i) { + const Arg& arg = frame->args[i]; + + TF_ASSIGN_OR_RETURN(Node * arg_node, + BuildArgNode(output, arg.enter->input_type(0), i)); + if (arg.is_loop_invariant) { + node_map[arg.enter->id()] = arg_node; + } else { + node_map[arg.merge->id()] = arg_node; + } + } + + // Build a Retval node for the loop condition. The LoopCond nodes are always + // boolean because of the type constraints on the LoopCond op. + TF_ASSIGN_OR_RETURN(node_map[frame->loop_cond->id()], + BuildRetvalNode(output, DT_BOOL, 0)); + + // Performs a reverse DFS, copying nodes and edges to the output graph. + // The _Arg and _Retval nodes were added unconditionally above, so we are + // guaranteed to get the correct function signature. + return CopySubgraph(graph, frame, {frame->loop_cond}, squash_src_outputs, + &node_map, output); +} + +// Builds a graph for the loop body. +Status BuildLoopBody(const Graph& graph, Frame* frame, + DataTypeVector* arg_types, + std::unique_ptr<Graph>* body_output) { + VLOG(2) << "Building loop body for " << frame->name; + *body_output = absl::make_unique<Graph>(graph.op_registry()); + Graph* output = body_output->get(); + + // Map from nodes in the original graph to the condition graph. + std::vector<Node*> node_map(graph.num_node_ids(), nullptr); + std::vector<bool> squash_src_outputs(graph.num_node_ids(), false); + + // Build one _Arg node for each Enter node. + std::vector<Node*> next_iterations; + next_iterations.reserve(frame->args.size()); + arg_types->reserve(frame->args.size()); + for (int i = 0; i < frame->args.size(); ++i) { + const Arg& arg = frame->args[i]; + + DataType dtype = arg.enter->input_type(0); + arg_types->push_back(dtype); + + TF_ASSIGN_OR_RETURN(Node * arg_node, BuildArgNode(output, dtype, i)); + + if (dtype == DT_RESOURCE) { + // The convention of the XLA bridge is that resource variable arguments + // are only inputs to the loop body and have no corresponding output. + // TODO(b/37741920): change the convention so that DT_RESOURCE variables + // are both inputs and outputs, and then remove this case. + TF_RET_CHECK(arg.is_loop_invariant); + node_map[arg.enter->id()] = arg_node; + } else { + TF_ASSIGN_OR_RETURN(Node * retval_node, + BuildRetvalNode(output, dtype, i)); + + if (arg.is_loop_invariant) { + // Argument is loop-invariant. Forward it from the Arg to the Retval. + node_map[arg.enter->id()] = arg_node; + output->AddEdge(arg_node, 0, retval_node, 0); + } else { + // Argument is loop-varying. + node_map[arg.switch_node->id()] = arg_node; + // The Switch node has two outputs, but _Arg only has one. This tells + // the CopySubgraph function to rewrite the output number of edges from + // the _Arg node to be 0 rather than copying the output number from the + // Switch node. + squash_src_outputs[arg.switch_node->id()] = true; + node_map[arg.next_iteration->id()] = retval_node; + next_iterations.push_back(arg.next_iteration); + } + } + } + + // Performs a reverse DFS, copying nodes and edges to the output graph. + // The _Arg and _Retval nodes were added unconditionally above, so we are + // guaranteed to get the correct function signature. + TF_RETURN_IF_ERROR(CopySubgraph(graph, frame, std::move(next_iterations), + squash_src_outputs, &node_map, output)); + + return Status::OK(); +} + +// Copy the FunctionDef of given function from lookup_library to library, if +// it can be found in lookup_library but is missing from library. +Status AddMissingFunctionByName(const string& function_name, + const FunctionLibraryDefinition* lookup_library, + FunctionLibraryDefinition* library) { + if (!library->Find(function_name) && lookup_library->Find(function_name)) { + return library->AddFunctionDef(*lookup_library->Find(function_name)); + } + return Status::OK(); +} + +// Iterate over all functions that the given fdef refers to. Copy the missing +// FunctionDefs from lookup_library to library. +Status AddMissingFunctionDef(const FunctionDef& fdef, + const FunctionLibraryDefinition* lookup_library, + FunctionLibraryDefinition* library) { + TF_RET_CHECK(lookup_library); + for (const NodeDef& node : fdef.node_def()) { + if (library->Find(node.op())) { + continue; + } + // The function referred by 'SymbolicGradient' node is specified in its + // attribute 'f'. + if (node.op() == FunctionLibraryDefinition::kGradientOp) { + const AttrValue* attr = + AttrSlice(&node.attr()).Find(FunctionLibraryDefinition::kFuncAttr); + if (!attr) { + return errors::InvalidArgument("SymbolicGradient is missing attr: f"); + } + const string& func_name = attr->func().name(); + TF_RETURN_IF_ERROR( + AddMissingFunctionByName(func_name, lookup_library, library)); + // Copy the user-defined gradient function if it exists. + const string grad_name = lookup_library->FindGradient(func_name); + if (!grad_name.empty() && library->FindGradient(func_name).empty()) { + TF_RETURN_IF_ERROR( + AddMissingFunctionByName(grad_name, lookup_library, library)); + GradientDef grad_def; + grad_def.set_function_name(func_name); + grad_def.set_gradient_func(grad_name); + TF_RETURN_IF_ERROR(library->AddGradientDef(grad_def)); + } + } else if (lookup_library->Find(node.op())) { + TF_RETURN_IF_ERROR( + library->AddFunctionDef(*lookup_library->Find(node.op()))); + } + } + return Status::OK(); +} + +Status FunctionalizeLoop(const FunctionLibraryDefinition* lookup_library, + Graph* graph, Frame* frame, + FunctionLibraryDefinition* library) { + VLOG(2) << "Frame " << frame->name << " before: " + << dump_graph::DumpGraphToFile("functionalize_before", *graph, + library); + + // Split loop-varying Enter nodes with multiple successors. If the same + // Tensor is fed as input to multiple loop arguments, we may end up with a + // shared Enter node. We clone Enter nodes with multiple successors to + // maintain the invariant of a unique Enter node per argument of the final + // loop. + std::vector<Arg> args; + for (const Arg& arg : frame->args) { + if (arg.is_loop_invariant) { + args.push_back(arg); + } else { + std::vector<const Edge*> edges(arg.enter->out_edges().begin(), + arg.enter->out_edges().end()); + for (int i = 0; i < edges.size(); ++i) { + if (edges[i]->IsControlEdge() && edges[i]->dst()->IsSink()) { + continue; + } + TF_RET_CHECK(!edges[i]->IsControlEdge()) << edges[i]->src()->name(); + Arg new_arg; + new_arg.is_loop_invariant = false; + if (i == 0) { + new_arg.enter = arg.enter; + } else { + new_arg.enter = graph->CopyNode(arg.enter); + frame->nodes.insert(new_arg.enter); + for (Edge const* e : arg.enter->in_edges()) { + graph->AddEdge(e->src(), e->src_output(), new_arg.enter, + e->IsControlEdge() ? Graph::kControlSlot : 0); + } + Node* dst = edges[i]->dst(); + int dst_input = edges[i]->dst_input(); + graph->RemoveEdge(edges[i]); + graph->AddEdge(new_arg.enter, 0, dst, dst_input); + } + args.push_back(new_arg); + } + } + } + frame->args = std::move(args); + + std::sort(frame->args.begin(), frame->args.end(), + [](const Arg& a, const Arg& b) { + return NodeCmpByNameResourcesLast()(a.enter, b.enter); + }); + + if (frame->loop_cond == nullptr) { + return errors::InvalidArgument("Loop ", frame->name, + " has no LoopCond node"); + } + + // Find the set of Switch nodes that are successors of the LoopCond. + std::unordered_set<Node*> switches; + for (const Edge* edge : frame->loop_cond->out_edges()) { + if (!edge->IsControlEdge() && IsSwitch(edge->dst()) && + edge->dst_input() == 1) { + switches.insert(edge->dst()); + } + } + + // For each non-constant argument, looks for the following pattern of nodes: + // Enter ----> Merge --------> Switch --> Exit + // ^ ^ + // | | + // NextIteration LoopCond + // ^ ^ + // | | + // ... ... + for (Arg& arg : frame->args) { + if (!arg.is_loop_invariant) { + // Follow the edge from the Enter to Merge. + const Edge* enter_merge = nullptr; + for (const Edge* e : arg.enter->out_edges()) { + // Ignore control-edges to the sink node. These are allowed by the + // graph invariants, although probably they should have been stripped + // off earlier. + if (e->IsControlEdge() && e->dst()->IsSink()) { + continue; + } + if (enter_merge != nullptr) { + return errors::Internal("Enter node for loop-varying argument ", + FormatNodeForError(*arg.enter), + " has multiple successors: ", + FormatNodeForError(*enter_merge->dst()), + " and ", FormatNodeForError(*e->dst())); + } + enter_merge = e; + } + if (enter_merge == nullptr) { + return errors::Internal("Enter node for loop-varying argument ", + FormatNodeForError(*arg.enter), + " has zero successors"); + } + arg.merge = enter_merge->dst(); + if (!IsMerge(arg.merge)) { + return errors::InvalidArgument( + "Successor of Enter node for loop-varying argument ", + FormatNodeForError(*arg.merge), + " is not a Merge node; got: ", arg.merge->type_string()); + } + + // Find the NextIteration from the merge. There should be two inputs to + // the Merge and the NextIteration should be the other input. + if (arg.merge->input_types().size() != 2) { + return errors::InvalidArgument( + "Unexpected number of inputs to Merge node for loop-varying " + "argument ", + FormatNodeForError(*arg.merge), "; expected 2, got ", + arg.merge->input_types().size()); + } + TF_RETURN_IF_ERROR(arg.merge->input_node(1 - enter_merge->dst_input(), + &arg.next_iteration)); + if (!IsNextIteration(arg.next_iteration)) { + return errors::InvalidArgument( + "Expected NextIteration node as input to Merge node; got node ", + FormatNodeForError(*arg.next_iteration), " with kind ", + arg.next_iteration->type_string()); + } + + // Find the Switch successor of the Merge. There should be exactly one + // Switch node that is a successor of both the Merge and the LoopCond. + for (const Edge* edge : arg.merge->out_edges()) { + if (edge->dst_input() == 0 && IsSwitch(edge->dst()) && + switches.find(edge->dst()) != switches.end()) { + if (arg.switch_node != nullptr) { + return errors::InvalidArgument("Duplicate Switch successors to ", + FormatNodeForError(*arg.merge)); + } + arg.switch_node = edge->dst(); + } + } + if (arg.switch_node == nullptr) { + return errors::InvalidArgument("Missing Switch successor to ", + FormatNodeForError(*arg.merge)); + } + + // Update the device on the Identity outputs of the switch to match their + // target. These Identity outputs do not + + // Loop over the switch node's output to: + // - Find the Exit successor. + // - Set the sharding on all Identity outputs of the switch. These + // identity nodes are values used by the loop body or condition. + // The Identity node may have the wrong device so copy the device from + // one of its outputs instead. + std::deque<const Edge*> possible_exit; + for (const Edge* edge : arg.switch_node->out_edges()) { + if (edge->src_output() == 0) { + possible_exit.push_back(edge); + } + if (IsIdentity(edge->dst())) { + TF_RETURN_IF_ERROR( + SetNodeShardingFromNeighbors(edge->dst(), /*out_edges=*/true)); + } + } + // TODO(b/67425339): Allow general graph between switch and exit. + while (!possible_exit.empty()) { + const Edge* edge = possible_exit.front(); + possible_exit.pop_front(); + if (IsExit(edge->dst())) { + if (arg.exit != nullptr) { + return errors::InvalidArgument( + "Duplicate Exit successors to ", + FormatNodeForError(*arg.switch_node)); + } + arg.exit = edge->dst(); + } else { + if (!IsIdentity(edge->dst())) { + return errors::Unimplemented("General graph between switch (", + FormatNodeForError(*arg.switch_node), + ") and exit node of frame ", + frame->name, " not supported yet."); + } + for (const Edge* out : edge->dst()->out_edges()) { + possible_exit.push_back(out); + } + } + } + } + } + + // Builds the condition and body functions. + std::unique_ptr<Graph> cond_graph; + TF_RETURN_IF_ERROR(BuildLoopCondition(*graph, frame, &cond_graph)); + DataTypeVector arg_types; + std::unique_ptr<Graph> body_graph; + TF_RETURN_IF_ERROR(BuildLoopBody(*graph, frame, &arg_types, &body_graph)); + + VLOG(2) << "Frame " << frame->name << " condition: " + << dump_graph::DumpGraphToFile("loop_condition", *cond_graph, library) + << " body: " << dump_graph::DumpGraphToFile("loop_body", *body_graph); + + static std::atomic<int64> sequence_num(0LL); + int64 id = ++sequence_num; + NameAttrList cond_name; + cond_name.set_name(strings::StrCat("_functionalize_cond_", id)); + NameAttrList body_name; + body_name.set_name(strings::StrCat("_functionalize_body_", id)); + FunctionDef cond_fdef; + TF_RETURN_IF_ERROR( + GraphToFunctionDef(*cond_graph, cond_name.name(), &cond_fdef)); + FunctionDef body_fdef; + TF_RETURN_IF_ERROR( + GraphToFunctionDef(*body_graph, body_name.name(), &body_fdef)); + + TF_RETURN_IF_ERROR(library->AddFunctionDef(cond_fdef)); + TF_RETURN_IF_ERROR(library->AddFunctionDef(body_fdef)); + if (lookup_library) { + // Copy missing FunctionDefs from lookup_library to library to make library + // self-contained. + TF_RETURN_IF_ERROR( + AddMissingFunctionDef(cond_fdef, lookup_library, library)); + TF_RETURN_IF_ERROR( + AddMissingFunctionDef(body_fdef, lookup_library, library)); + } + + // Builds a While operator. + NodeDef while_def; + NodeDefBuilder builder(frame->loop_cond->name(), "XlaWhile"); + builder.Attr("T", arg_types); + builder.Attr("cond", cond_name); + builder.Attr("body", body_name); + std::vector<NodeDefBuilder::NodeOut> inputs; + for (int i = 0; i < frame->args.size(); ++i) { + const Arg& arg = frame->args[i]; + const Edge* in_edge; + TF_RETURN_IF_ERROR(arg.enter->input_edge(0, &in_edge)); + if (in_edge->IsControlEdge()) { + builder.ControlInput(in_edge->src()->name()); + } else { + inputs.push_back(NodeDefBuilder::NodeOut( + in_edge->src()->name(), in_edge->src_output(), arg_types[i])); + } + } + builder.Input(inputs); + TF_RETURN_IF_ERROR(builder.Finalize(&while_def)); + TF_ASSIGN_OR_RETURN(Node * while_node, AddNodeDefToGraph(while_def, graph)); + + // Copies edges to the Enter nodes and from the Exit nodes onto the While. + for (int i = 0; i < frame->args.size(); ++i) { + const Arg& arg = frame->args[i]; + const Edge* in_edge; + TF_RETURN_IF_ERROR(arg.enter->input_edge(0, &in_edge)); + if (in_edge->IsControlEdge()) { + graph->AddControlEdge(in_edge->src(), while_node); + } else { + graph->AddEdge(in_edge->src(), in_edge->src_output(), while_node, i); + } + + if (!arg.is_loop_invariant) { + // Add output edges if the output of the loop is consumed. + if (arg.exit != nullptr) { + std::vector<const Edge*> edges(arg.exit->out_edges().begin(), + arg.exit->out_edges().end()); + for (const Edge* edge : edges) { + Node* dst = edge->dst(); + int dst_input = edge->dst_input(); + graph->RemoveEdge(edge); + + if (dst_input == Graph::kControlSlot) { + graph->AddControlEdge(while_node, dst); + } else { + graph->AddEdge(while_node, i, dst, dst_input); + } + } + } + } + } + + // Remove the old nodes from the graph, and add the while node to the parent + // frame. + for (Node* node : frame->nodes) { + graph->RemoveNode(node); + } + frame->nodes.clear(); + frame->parent->nodes.insert(while_node); + + VLOG(2) << "Frame " << frame->name << " after: " + << dump_graph::DumpGraphToFile("functionalize_after", *graph, + library); + + return Status::OK(); +} +} // namespace + +Status FunctionalizeWhileLoop(const FunctionLibraryDefinition* lookup_library, + Graph* graph, + FunctionLibraryDefinition* library) { + // Note: BuildControlFlowInfo() requires that the graph's source node is + // connected to all source nodes in the graph. Many graphs violate this + // invariant. + std::vector<ControlFlowInfo> cf_info; + std::vector<string> unreachable_nodes; + TF_RETURN_IF_ERROR(BuildControlFlowInfo(graph, &cf_info, &unreachable_nodes)); + if (!unreachable_nodes.empty()) { + return errors::InvalidArgument( + "The following nodes are unreachable from the source in the graph: ", + errors::FormatNodeNamesForError(unreachable_nodes)); + } + + // Builds Frames, indexed by name. + std::unordered_map<string, Frame> frames; + for (Node* node : graph->op_nodes()) { + const ControlFlowInfo& cf = cf_info[node->id()]; + + VLOG(2) << "node: " << node->name() << " (" << node->id() + << ") frame_name: " << cf.frame_name + << " frame: " << (cf.frame ? cf.frame->name() : "---") + << " parent_frame: " + << (cf.parent_frame ? cf.parent_frame->name() : "---"); + TF_RET_CHECK(cf.frame != nullptr && cf.parent_frame != nullptr); + + Frame& frame = frames[cf.frame_name]; + Frame* parent = &frames[cf_info[cf.parent_frame->id()].frame_name]; + if (frame.parent == nullptr) { + frame.parent = parent; + frame.name = cf.frame_name; + ++parent->num_children; + } + + if (IsEnter(node)) { + Arg arg; + arg.enter = node; + TF_RETURN_IF_ERROR(GetNodeAttr(arg.enter->attrs(), "is_constant", + &arg.is_loop_invariant)); + frame.args.push_back(arg); + } else if (IsLoopCond(node)) { + frame.loop_cond = node; + } + frame.nodes.insert(node); + } + + // Adds frames with no children (i.e., the innermost frames) to a worklist. + std::deque<Frame*> worklist; + for (auto& frame : frames) { + if (frame.second.num_children == 0) { + worklist.push_back(&frame.second); + } + } + + // Eliminate loops from innermost to outermost. + while (!worklist.empty()) { + Frame* frame = worklist.front(); + worklist.pop_front(); + if (frame->parent == frame) { + // Skip the root frame. + continue; + } + + TF_RETURN_IF_ERROR( + FunctionalizeLoop(lookup_library, graph, frame, library)); + + // If the parent has no remaining children, add it to the worklist. + --frame->parent->num_children; + if (frame->parent->num_children == 0) { + worklist.push_back(frame->parent); + } + } + + // There should be no cycle at this point, since while loops have been removed + // from graph. + // Check that the newly added XlaWhile nodes don't feed into themselves. + for (const Node* node : graph->op_nodes()) { + if (node->def().op() == "XlaWhile") { + TF_RETURN_WITH_CONTEXT_IF_ERROR( + CheckNodeNotInCycle(node, graph->num_node_ids()), + "Functionalizing loop failed."); + } + } + + return Status::OK(); +} + +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/functionalize_while.h b/tensorflow/compiler/tf2xla/functionalize_while.h new file mode 100644 index 0000000000..a708c6e4ec --- /dev/null +++ b/tensorflow/compiler/tf2xla/functionalize_while.h @@ -0,0 +1,32 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_WHILE_H_ +#define TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_WHILE_H_ + +#include "tensorflow/core/framework/function.h" +#include "tensorflow/core/graph/graph.h" + +namespace tensorflow { + +// Transformation that converts tf.while_loop() loops into functional While +// operators, suitable for XLA compilation. If lookup_library is provided, use +// it to make the library for control flow self-contained. +Status FunctionalizeWhileLoop(const FunctionLibraryDefinition* lookup_library, + Graph* graph, FunctionLibraryDefinition* library); + +} // namespace tensorflow + +#endif // TENSORFLOW_COMPILER_TF2XLA_FUNCTIONALIZE_WHILE_H_ diff --git a/tensorflow/compiler/tf2xla/graph_compiler.cc b/tensorflow/compiler/tf2xla/graph_compiler.cc index e4fdf0a618..1ed1fb3b02 100644 --- a/tensorflow/compiler/tf2xla/graph_compiler.cc +++ b/tensorflow/compiler/tf2xla/graph_compiler.cc @@ -57,7 +57,8 @@ Status PrepareArguments(XlaOpKernelContext* ctx, Graph* graph, std::vector<bool> compile_time_constant_flags(expressions.size()); TF_RETURN_IF_ERROR( - BackwardsConstAnalysis(*graph, &compile_time_constant_flags)); + BackwardsConstAnalysis(*graph, &compile_time_constant_flags, + /*compile_time_const_nodes=*/nullptr)); args->resize(expressions.size()); for (int i = 0; i < args->size(); ++i) { @@ -145,6 +146,7 @@ Status GraphCompiler::Compile() { } OpKernelContext op_context(¶ms, n->num_outputs()); + VLOG(3) << "Translating " << params.op_kernel->name(); if (IsFunctional(n)) { TF_RETURN_IF_ERROR(CompileFunctionalNode(n, &op_context)); } else { diff --git a/tensorflow/compiler/tf2xla/kernels/BUILD b/tensorflow/compiler/tf2xla/kernels/BUILD index b1366e9e31..c1438f893f 100644 --- a/tensorflow/compiler/tf2xla/kernels/BUILD +++ b/tensorflow/compiler/tf2xla/kernels/BUILD @@ -22,6 +22,7 @@ tf_kernel_library( "bcast_ops.cc", "bias_ops.cc", "binary_ops.cc", + "broadcast_to_op.cc", "bucketize_op.cc", "cast_op.cc", "categorical_op.cc", @@ -100,6 +101,12 @@ tf_kernel_library( "unary_ops.cc", "unpack_op.cc", "variable_ops.cc", + "xla_broadcast_helper_op.cc", + "xla_conv_op.cc", + "xla_dot_op.cc", + "xla_pad_op.cc", + "xla_reduce_op.cc", + "xla_select_and_scatter_op.cc", ], hdrs = [ "index_ops.h", @@ -108,6 +115,8 @@ tf_kernel_library( deps = [ ":if_op", ":while_op", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/strings", "//tensorflow/compiler/tf2xla:common", "//tensorflow/compiler/tf2xla:xla_compiler", "//tensorflow/compiler/tf2xla/lib:batch_dot", diff --git a/tensorflow/compiler/tf2xla/kernels/bcast_ops.cc b/tensorflow/compiler/tf2xla/kernels/bcast_ops.cc index ba3b1c9dab..2e383b1473 100644 --- a/tensorflow/compiler/tf2xla/kernels/bcast_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/bcast_ops.cc @@ -16,6 +16,7 @@ limitations under the License. // XLA-specific Ops for broadcasting used in gradient // code. +#include "absl/strings/str_join.h" #include "tensorflow/compiler/tf2xla/xla_helpers.h" #include "tensorflow/compiler/tf2xla/xla_op_kernel.h" #include "tensorflow/compiler/tf2xla/xla_op_registry.h" @@ -51,8 +52,8 @@ class BCastArgsOp : public XlaOpKernel { BCast bcast(shapes[0], shapes[1]); OP_REQUIRES(ctx, bcast.IsValid(), errors::InvalidArgument( - "Incompatible shapes: [", str_util::Join(shapes[0], ","), - "] vs. [", str_util::Join(shapes[1], ","), "]")); + "Incompatible shapes: [", absl::StrJoin(shapes[0], ","), + "] vs. [", absl::StrJoin(shapes[1], ","), "]")); const int64 len = bcast.output_shape().size(); Tensor output(DT_INT32, TensorShape({len})); @@ -105,8 +106,8 @@ class BCastGradArgsOp : public XlaOpKernel { BCast bcast(shapes[0], shapes[1]); OP_REQUIRES(ctx, bcast.IsValid(), errors::InvalidArgument( - "Incompatible shapes: [", str_util::Join(shapes[0], ","), - "] vs. [", str_util::Join(shapes[1], ","), "]")); + "Incompatible shapes: [", absl::StrJoin(shapes[0], ","), + "] vs. [", absl::StrJoin(shapes[1], ","), "]")); Output(ctx, 0, bcast.grad_x_reduce_idx()); Output(ctx, 1, bcast.grad_y_reduce_idx()); } diff --git a/tensorflow/compiler/tf2xla/kernels/broadcast_to_op.cc b/tensorflow/compiler/tf2xla/kernels/broadcast_to_op.cc new file mode 100644 index 0000000000..4bd7c74dca --- /dev/null +++ b/tensorflow/compiler/tf2xla/kernels/broadcast_to_op.cc @@ -0,0 +1,101 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "absl/algorithm/container.h" +#include "tensorflow/compiler/tf2xla/shape_util.h" +#include "tensorflow/compiler/tf2xla/xla_helpers.h" +#include "tensorflow/compiler/tf2xla/xla_op_kernel.h" +#include "tensorflow/compiler/tf2xla/xla_op_registry.h" +#include "tensorflow/compiler/xla/client/lib/constants.h" +#include "tensorflow/compiler/xla/literal.h" +#include "tensorflow/core/platform/macros.h" +#include "tensorflow/core/platform/types.h" +#include "tensorflow/core/util/bcast.h" + +namespace tensorflow { +namespace { + +class BroadcastToOp : public XlaOpKernel { + public: + explicit BroadcastToOp(OpKernelConstruction* context) + : XlaOpKernel(context) {} + + void Compile(XlaOpKernelContext* context) override { + const TensorShape input_shape = context->InputShape(0); + TensorShape output_shape; + OP_REQUIRES_OK(context, context->ConstantInputAsShape(1, &output_shape)); + + OP_REQUIRES(context, input_shape.dims() <= output_shape.dims(), + errors::InvalidArgument( + "Input rank (", input_shape.dims(), + ") must be less than or equal to the output rank (", + output_shape.dims(), ")")); + + auto input_dims = input_shape.dim_sizes(); + auto output_dims = output_shape.dim_sizes(); + + // Broadcasting is done right-to-left on right-aligned dimensions; reverse + // the two vectors so elements to be broadcast are aligned. + absl::c_reverse(input_dims); + absl::c_reverse(output_dims); + + std::vector<int64> broadcast_dims; + std::vector<int64> broadcast_shape; + for (int i = 0; i < output_shape.dims(); ++i) { + if (i < input_shape.dims()) { + OP_REQUIRES( + context, + (output_dims[i] == 0 && input_dims[i] == 0) || + (input_dims[i] != 0 && output_dims[i] % input_dims[i] == 0), + errors::InvalidArgument("invalid shape to broadcast from ", + input_shape.DebugString(), " to ", + output_shape.DebugString())); + + broadcast_dims.push_back(broadcast_shape.size()); + if (output_dims[i] == input_dims[i] || input_dims[i] == 1) { + broadcast_shape.push_back(output_dims[i]); + } + if (output_dims[i] != input_dims[i]) { + // Add dimensions [I, O/I], which we will later flatten to just + // [O]. We must do this in two phases since XLA broadcasting does not + // support tiling. + broadcast_shape.push_back(input_dims[i]); + broadcast_shape.push_back(output_dims[i] / input_dims[i]); + } + } else { + broadcast_shape.push_back(output_dims[i]); + } + } + absl::c_reverse(broadcast_dims); + int broadcast_shape_size = broadcast_shape.size(); + for (int64& broadcast_dim : broadcast_dims) { + broadcast_dim = broadcast_shape_size - broadcast_dim - 1; + } + absl::c_reverse(broadcast_shape); + xla::XlaOp output = xla::Reshape( + xla::BroadcastInDim(context->Input(0), + xla::ShapeUtil::MakeShape( + context->input_xla_type(0), broadcast_shape), + broadcast_dims), + output_shape.dim_sizes()); + context->SetOutput(0, output); + } +}; + +REGISTER_XLA_OP(Name("BroadcastTo").CompileTimeConstInput("shape"), + BroadcastToOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/kernels/conv_ops.cc b/tensorflow/compiler/tf2xla/kernels/conv_ops.cc index 5da7972397..674720e22f 100644 --- a/tensorflow/compiler/tf2xla/kernels/conv_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/conv_ops.cc @@ -120,45 +120,30 @@ xla::XlaOp CreateExpandedFilterMask(const TensorShape& filter_shape, {expanded_filter_shape.dims() - 2}); } -// Expands a filter of shape [H, W, ..., M, N] to [H, W, ..., M, M*N] by adding -// zeros for the cross-depth filters. Used to build a depthwise convolution. -xla::XlaOp ExpandFilterForDepthwiseConvolution(const TensorShape& filter_shape, - DataType dtype, - const xla::XlaOp& filter, - xla::XlaBuilder* builder) { - int64 depthwise_multiplier = filter_shape.dim_size(filter_shape.dims() - 1); - int64 input_feature = filter_shape.dim_size(filter_shape.dims() - 2); - TensorShape expanded_filter_shape = - ExpandedFilterShapeForDepthwiseConvolution(filter_shape); +// Reshapes a filter of shape [H, W, ..., M, N] to [H, W, ..., 1, M*N]. Used to +// build a depthwise convolution. +xla::XlaOp ReshapeFilterForDepthwiseConvolution(const TensorShape& filter_shape, + const xla::XlaOp& filter) { + int64 input_feature_dim = filter_shape.dims() - 2; + int64 output_feature_dim = filter_shape.dims() - 1; + int64 depthwise_multiplier = filter_shape.dim_size(output_feature_dim); + int64 input_feature = filter_shape.dim_size(input_feature_dim); // Create a [H, W, ..., 1, N*M] reshape of the filter. - TensorShape implicit_broadcast_filter_shape = expanded_filter_shape; - implicit_broadcast_filter_shape.set_dim( - implicit_broadcast_filter_shape.dims() - 2, 1); - implicit_broadcast_filter_shape.set_dim( - implicit_broadcast_filter_shape.dims() - 1, - depthwise_multiplier * input_feature); - auto implicit_broadcast_filter = - xla::Reshape(filter, implicit_broadcast_filter_shape.dim_sizes()); - - // Broadcast the filter to [H, W, ..., M, M*N]. - auto expanded_zero = CreateExpandedZero(filter_shape, dtype, builder); - auto expanded_filter = xla::Add(implicit_broadcast_filter, expanded_zero); - - // If the filter mask is set, choose the broadcasted filter, othwerwise, - // choose zero. - return xla::Select(CreateExpandedFilterMask(filter_shape, builder), - expanded_filter, expanded_zero); + TensorShape implicit_broadcast_filter_shape = filter_shape; + implicit_broadcast_filter_shape.set_dim(input_feature_dim, 1); + implicit_broadcast_filter_shape.set_dim(output_feature_dim, + depthwise_multiplier * input_feature); + return xla::Reshape(filter, implicit_broadcast_filter_shape.dim_sizes()); } -// Inverse of ExpandFilterForDepthwiseConvolution. +// Reduces the results of the convolution with an expanded filter to the +// non-expanded filter. xla::XlaOp ContractFilterForDepthwiseBackprop(XlaOpKernelContext* ctx, const TensorShape& filter_shape, DataType dtype, const xla::XlaOp& filter_backprop, xla::XlaBuilder* builder) { - TensorShape expanded_filter_shape = - ExpandedFilterShapeForDepthwiseConvolution(filter_shape); auto masked_expanded_filter = xla::Select( CreateExpandedFilterMask(filter_shape, builder), filter_backprop, CreateExpandedZero(filter_shape, dtype, builder)); @@ -168,8 +153,7 @@ xla::XlaOp ContractFilterForDepthwiseBackprop(XlaOpKernelContext* ctx, // ExpandedZero guarantees that only one element is non zero, so there // cannot be accumulated precision error. xla::Reduce(masked_expanded_filter, XlaHelpers::Zero(builder, dtype), - *ctx->GetOrCreateAdd(dtype), - {expanded_filter_shape.dims() - 2}), + *ctx->GetOrCreateAdd(dtype), {filter_shape.dims() - 2}), filter_shape.dim_sizes()); } @@ -245,15 +229,9 @@ class ConvOp : public XlaOpKernel { "input and filter must have the same depth: ", in_depth, " vs ", input_shape.dim_size(feature_dim))); - xla::XlaBuilder* b = ctx->builder(); - xla::XlaOp filter = ctx->Input(1); - TensorShape expanded_filter_shape = filter_shape; if (depthwise_) { - filter = ExpandFilterForDepthwiseConvolution( - filter_shape, ctx->input_type(0), filter, b); - expanded_filter_shape = - ExpandedFilterShapeForDepthwiseConvolution(filter_shape); + filter = ReshapeFilterForDepthwiseConvolution(filter_shape, filter); } xla::ConvolutionDimensionNumbers dims; @@ -280,14 +258,15 @@ class ConvOp : public XlaOpKernel { int64 unused_output_size; OP_REQUIRES_OK( ctx, GetWindowedOutputSizeVerboseV2( - input_shape.dim_size(dim), expanded_filter_shape.dim_size(i), + input_shape.dim_size(dim), filter_shape.dim_size(i), rhs_dilation[i], window_strides[i], padding_, &unused_output_size, &padding[i].first, &padding[i].second)); } - xla::XlaOp conv = - xla::ConvGeneralDilated(ctx->Input(0), filter, window_strides, padding, - lhs_dilation, rhs_dilation, dims); + xla::XlaOp conv = xla::ConvGeneralDilated( + ctx->Input(0), filter, window_strides, padding, lhs_dilation, + rhs_dilation, dims, + /*feature_group_count=*/depthwise_ ? in_depth : 1); ctx->SetOutput(0, conv); } @@ -388,7 +367,6 @@ class ConvBackpropInputOp : public XlaOpKernel { expanded_filter_shape, out_backprop_shape, dilations_, strides_, padding_, data_format_, &dims)); - xla::XlaBuilder* b = ctx->builder(); auto filter = ctx->Input(1); auto out_backprop = ctx->Input(2); @@ -425,12 +403,6 @@ class ConvBackpropInputOp : public XlaOpKernel { rhs_dilation[i] = dilations_[dim]; } - // If this is a depthwise convolution, expand the filter. - if (depthwise_) { - filter = ExpandFilterForDepthwiseConvolution( - filter_shape, ctx->input_type(1), filter, b); - } - // Mirror the filter in the spatial dimensions. xla::XlaOp mirrored_weights = xla::Rev(filter, kernel_spatial_dims); @@ -438,7 +410,11 @@ class ConvBackpropInputOp : public XlaOpKernel { // = gradients (with padding and dilation) <conv> mirrored_weights xla::XlaOp in_backprop = xla::ConvGeneralDilated( out_backprop, mirrored_weights, /*window_strides=*/ones, padding, - lhs_dilation, rhs_dilation, dnums); + lhs_dilation, rhs_dilation, dnums, + /*feature_group_count=*/ + depthwise_ ? out_backprop_shape.dim_size(feature_dim) / + filter_shape.dim_size(num_spatial_dims_ + 1) + : 1); ctx->SetOutput(0, in_backprop); } diff --git a/tensorflow/compiler/tf2xla/kernels/diag_op.cc b/tensorflow/compiler/tf2xla/kernels/diag_op.cc index ed44ad218b..70c3eaf66b 100644 --- a/tensorflow/compiler/tf2xla/kernels/diag_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/diag_op.cc @@ -178,7 +178,7 @@ class MatrixDiagOp : public XlaOpKernel { int last_dim = dims.size() - 1; int64 last_dim_size = input_shape.dim_size(last_dim); tensorflow::gtl::ArraySlice<int64> other_dims(dims); - other_dims.pop_back(); + other_dims.remove_suffix(1); xla::XlaOp input = ctx->Input(0); xla::XlaOp diag = CreateDiagonal(input, last_dim_size, other_dims, diff --git a/tensorflow/compiler/tf2xla/kernels/identity_op.cc b/tensorflow/compiler/tf2xla/kernels/identity_op.cc index e72200bfbc..19dd38c46e 100644 --- a/tensorflow/compiler/tf2xla/kernels/identity_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/identity_op.cc @@ -25,7 +25,10 @@ class IdentityOp : public XlaOpKernel { void Compile(XlaOpKernelContext* ctx) override { for (int i = 0; i < ctx->num_inputs(); ++i) { - ctx->SetOutput(i, ctx->Input(i)); + // Forwards using the underlying op_kernel_context so both tensor and + // resource values are forwarded correctly. + ctx->op_kernel_context()->set_output(i, + ctx->op_kernel_context()->input(i)); } } @@ -35,9 +38,10 @@ class IdentityOp : public XlaOpKernel { // XLA_* devices also register a "real" Identity operator so we suppress the // dummy operator using CompilationOnly(). -REGISTER_XLA_OP(Name("Identity").CompilationOnly(), IdentityOp); - -REGISTER_XLA_OP(Name("IdentityN").CompilationOnly(), IdentityOp); +REGISTER_XLA_OP(Name("Identity").AllowResourceTypes().CompilationOnly(), + IdentityOp); +REGISTER_XLA_OP(Name("IdentityN").AllowResourceTypes().CompilationOnly(), + IdentityOp); REGISTER_XLA_OP(Name("PlaceholderWithDefault"), IdentityOp); REGISTER_XLA_OP(Name("PreventGradient"), IdentityOp); REGISTER_XLA_OP(Name("StopGradient"), IdentityOp); diff --git a/tensorflow/compiler/tf2xla/kernels/if_op.cc b/tensorflow/compiler/tf2xla/kernels/if_op.cc index 6a7eb8d90c..6e1dbf5472 100644 --- a/tensorflow/compiler/tf2xla/kernels/if_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/if_op.cc @@ -200,21 +200,10 @@ void XlaIfOp::Compile(XlaOpKernelContext* ctx) { } } - bool resource_variable_seen = false; - for (int i = 0; i < ctx->num_inputs(); ++i) { - if (ctx->input_type(i) == DT_RESOURCE) { - resource_variable_seen = true; - } else { - OP_REQUIRES( - ctx, !resource_variable_seen, - errors::FailedPrecondition( - "Resource variables and regular inputs cannot be interleaved.")); - } - } - - xla::XlaOp outputs = xla::Conditional( - ctx->Input(0), xla::Tuple(b, inputs), *then_result.computation, - xla::Tuple(b, inputs), *else_result.computation); + auto input_tuple = xla::Tuple(b, inputs); + xla::XlaOp outputs = + xla::Conditional(ctx->Input(0), input_tuple, *then_result.computation, + input_tuple, *else_result.computation); // Sets non-variable outputs. for (int i = 0; i < output_types_.size(); ++i) { xla::XlaOp output_handle = xla::GetTupleElement(outputs, i); diff --git a/tensorflow/compiler/tf2xla/kernels/image_resize_ops.cc b/tensorflow/compiler/tf2xla/kernels/image_resize_ops.cc index 8d75624e74..8e071bf0b7 100644 --- a/tensorflow/compiler/tf2xla/kernels/image_resize_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/image_resize_ops.cc @@ -32,13 +32,13 @@ namespace { // // 1. S := (N - 1) / gcd(N-1, R-1) // 2. k := (R - 1) / gcd(N-1, R-1) -// 3. Convolution(kxk, stride=S, lhs_dilation=k, padding=k-1) +// 3. Convolution((2k-1)x(2k-1), stride=S, lhs_dilation=k, padding=k-1) // // For example, to Scale from 7x7 -> 15x15: // // 1. S := (7-1) / gcd(7-1, 15-1) = 6 / gcd(6, 14) = 6 / 2 = 3 // 2. k := (15 - 1) / gcd(7-1, 15-1) = 14 / gcd(6, 14) = 14 / 2 = 7 -// 3. Convolution(7x7, stride=3, lhs_dilation=3, padding=2) +// 3. Convolution(15x15, stride=3, lhs_dilation=7, padding=2) // // // The 7x7 -> 15x15 case is much too large to write out in full as an @@ -65,6 +65,8 @@ namespace { // 1/9 * 3 6 9 6 3 // 2 4 6 4 2 // 1 2 3 2 1 +// Note that the convolution kernel matrix is separable and thus we can instead +// use 2 consecutive 1D kernel of the dimension 2k-1, along each axis. // Computes the size of the convolutional kernel and stride to use when resizing // from in_size to out_size. @@ -76,7 +78,8 @@ struct ResizeConvolutionDims { std::vector<int64> stride; }; ResizeConvolutionDims ComputeResizeConvolutionParameters( - gtl::ArraySlice<int64> in_size, gtl::ArraySlice<int64> out_size) { + gtl::ArraySlice<int64> in_size, gtl::ArraySlice<int64> out_size, + bool align_corners) { CHECK_EQ(in_size.size(), out_size.size()); int num_spatial_dims = in_size.size(); ResizeConvolutionDims dims; @@ -92,15 +95,32 @@ ResizeConvolutionDims ComputeResizeConvolutionParameters( // entry before resizing. dims.stride[i] = dims.kernel_size[i] = 1; } else { - int64 gcd = MathUtil::GCD(static_cast<uint64>(in_size[i] - 1), - static_cast<uint64>(out_size[i] - 1)); - dims.stride[i] = (in_size[i] - 1) / gcd; - dims.kernel_size[i] = (out_size[i] - 1) / gcd; + // The scaling factor changes depending on the alignment of corners. + const int64 in_size_factor = align_corners ? in_size[i] - 1 : in_size[i]; + const int64 out_size_factor = + align_corners ? out_size[i] - 1 : out_size[i]; + + int64 gcd = MathUtil::GCD(static_cast<uint64>(in_size_factor), + static_cast<uint64>(out_size_factor)); + dims.stride[i] = in_size_factor / gcd; + dims.kernel_size[i] = out_size_factor / gcd; } } return dims; } +// The upper padding of the input needed by ConvGeneralDilated calls is +// determined by solving two related relationships (assuming rhs_dilation == 0): +// 1. dilated_input_dim = lower_padding + upper_padding +// + lhs_dilation * (in_size - 1) + 1 +// 2. dilated_input_dim = (2 * dims.kernel-size - 1) +// + dims.stride * (out_size - 1) +int64 CalculateUpperPadding(int64 in_size, int64 out_size, int64 kernel_size, + int64 stride) { + return (2 * kernel_size - 1) + (out_size - 1) * stride - (kernel_size - 1) - + 1 - (kernel_size * (in_size - 1)); +} + // Form a 2D convolution kernel like: // 1 2 3 2 1 // 2 4 6 4 2 @@ -171,7 +191,8 @@ xla::XlaOp ResizeUsingDilationAndConvolution(xla::XlaBuilder* builder, const int num_spatial_dims, std::vector<int64> in_size, std::vector<int64> out_size, - const int64 channels) { + const int64 channels, + const bool align_corners) { // Picture for a 1x3 to 1x4 resize: // stride = 2, kernel size = 3 // Input: @@ -196,27 +217,82 @@ xla::XlaOp ResizeUsingDilationAndConvolution(xla::XlaBuilder* builder, dimension_numbers.set_kernel_output_feature_dimension(num_spatial_dims); ResizeConvolutionDims dims = - ComputeResizeConvolutionParameters(in_size, out_size); + ComputeResizeConvolutionParameters(in_size, out_size, align_corners); xla::XlaOp output; - // Split convolutions into independent dimensions if they wmuld be a very + + // Concatenation and padding below currently assumes num_spatial_dims is 2 to + // prevent needless code complexity. + CHECK_EQ(num_spatial_dims, 2) + << "ResizeUsingDilationAndConvolution pads only 2 dimensions currently."; + std::vector<int64> upper_padding(num_spatial_dims); + for (int i = 0; i < num_spatial_dims; ++i) { + upper_padding[i] = dims.kernel_size[i] - 1; + } + xla::XlaOp input_data = input; + + if (!align_corners) { + // When Tensorflow does not align_corners, the resize indexing can access + // beyond the upper bound and is instead clamped to prevent out of bounds + // reads. This is conceptually the same as extending the edges of the input. + // We emulate this by copying the last row/column of the input. + // Calculate what padding would be needed then determine how far to extend + // the border before lhs dilation. + std::vector<int64> num_extended(num_spatial_dims); + upper_padding[0] = CalculateUpperPadding( + in_size[0], out_size[0], dims.kernel_size[0], dims.stride[0]); + upper_padding[1] = CalculateUpperPadding( + in_size[1], out_size[1], dims.kernel_size[1], dims.stride[1]); + num_extended[0] = upper_padding[0] / (dims.kernel_size[0]); + num_extended[1] = upper_padding[1] / (dims.kernel_size[1]); + + if (num_extended[0] > 0) { + auto slice = + xla::Slice(input_data, {0, in_size[0] - 1, 0, 0}, + {1, in_size[0], in_size[1], channels}, {1, 1, 1, 1}); + for (int i = 0; i < num_extended[0]; i++) { + input_data = xla::ConcatInDim(builder, {input_data, slice}, 1); + } + } + + if (num_extended[1] > 0) { + auto slice = + xla::Slice(input_data, {0, 0, in_size[1] - 1, 0}, + {1, in_size[0] + num_extended[0], in_size[1], channels}, + {1, 1, 1, 1}); + for (int i = 0; i < num_extended[1]; i++) { + input_data = xla::ConcatInDim(builder, {input_data, slice}, 2); + } + } + + // Setting in_size to (in_size + num_extended) due to the above Slice and + // ConcatInDim. Recalculate needed padding after the above Slice/Concat. + upper_padding[0] = + CalculateUpperPadding(in_size[0] + num_extended[0], out_size[0], + dims.kernel_size[0], dims.stride[0]); + upper_padding[1] = + CalculateUpperPadding(in_size[1] + num_extended[1], out_size[1], + dims.kernel_size[1], dims.stride[1]); + } + + // Split convolutions into independent dimensions if they would be a very // large kernel. if (dims.kernel_size[0] * dims.kernel_size[1] < kMax2DKernelSize) { xla::XlaOp kernel = MakeBilinearResizeKernel(builder, dims.kernel_size, channels); - output = xla::ConvGeneralDilated( - input, kernel, dims.stride, - /*padding=*/ - {{dims.kernel_size[0] - 1, dims.kernel_size[0] - 1}, - {dims.kernel_size[1] - 1, dims.kernel_size[1] - 1}}, - /*lhs_dilation=*/dims.kernel_size, - /*rhs_dilation=*/{1, 1}, dimension_numbers); + output = + xla::ConvGeneralDilated(input_data, kernel, dims.stride, + /*padding=*/ + {{dims.kernel_size[0] - 1, upper_padding[0]}, + {dims.kernel_size[1] - 1, upper_padding[1]}}, + /*lhs_dilation=*/dims.kernel_size, + /*rhs_dilation=*/{1, 1}, dimension_numbers); } else { xla::XlaOp kernel0 = MakeBilinearResizeKernelInDim(builder, dims.kernel_size, channels, 0); output = xla::ConvGeneralDilated( - input, kernel0, {dims.stride[0], 1}, + input_data, kernel0, {dims.stride[0], 1}, /*padding=*/ - {{dims.kernel_size[0] - 1, dims.kernel_size[0] - 1}, {0, 0}}, + {{dims.kernel_size[0] - 1, upper_padding[0]}, {0, 0}}, /*lhs_dilation=*/{dims.kernel_size[0], 1}, /*rhs_dilation=*/{1, 1}, dimension_numbers); xla::XlaOp kernel1 = @@ -224,7 +300,7 @@ xla::XlaOp ResizeUsingDilationAndConvolution(xla::XlaBuilder* builder, output = xla::ConvGeneralDilated( output, kernel1, {1, dims.stride[1]}, /*padding=*/ - {{0, 0}, {dims.kernel_size[1] - 1, dims.kernel_size[1] - 1}}, + {{0, 0}, {dims.kernel_size[1] - 1, upper_padding[1]}}, /*lhs_dilation=*/{1, dims.kernel_size[1]}, /*rhs_dilation=*/{1, 1}, dimension_numbers); } @@ -245,9 +321,10 @@ xla::XlaOp ResizeUsingDilationAndConvolutionGradOp(xla::XlaBuilder* builder, const int num_spatial_dims, std::vector<int64> in_size, std::vector<int64> grad_size, - const int64 channels) { + const int64 channels, + const bool align_corners) { ResizeConvolutionDims dims = - ComputeResizeConvolutionParameters(in_size, grad_size); + ComputeResizeConvolutionParameters(in_size, grad_size, align_corners); // To form the backward convolution, we keep the kernel unchanged (it is // already symmetric) and swap the roles of strides and LHS dilation. @@ -341,10 +418,6 @@ class ResizeBilinearOp : public XlaOpKernel { public: explicit ResizeBilinearOp(OpKernelConstruction* ctx) : XlaOpKernel(ctx) { OP_REQUIRES_OK(ctx, ctx->GetAttr("align_corners", &align_corners_)); - OP_REQUIRES( - ctx, align_corners_ == true, - errors::Unimplemented( - "ResizeBilinear with align_corners=False is not yet implemented")); } void Compile(XlaOpKernelContext* ctx) override { @@ -377,20 +450,19 @@ class ResizeBilinearOp : public XlaOpKernel { // If in_size[i] > 1 and out_size[i] == 1, slice out the first input in // dimension i. - std::vector<int64> slice_size = in_size; bool slice_input = false; for (int i = 0; i < num_spatial_dims; ++i) { if (in_size[i] > 1 && out_size[i] == 1) { // If in_size[i] > 1 but out_size[i] == 1, then we slice out the first // entry before resizing. slice_input = true; - slice_size[i] = 1; + in_size[i] = 1; } } if (slice_input) { - input = xla::Slice(input, {0, 0, 0, 0}, - {batch, slice_size[0], slice_size[1], channels}, - {1, 1, 1, 1}); + input = + xla::Slice(input, {0, 0, 0, 0}, + {batch, in_size[0], in_size[1], channels}, {1, 1, 1, 1}); } // Output is always type float. @@ -406,6 +478,9 @@ class ResizeBilinearOp : public XlaOpKernel { // operations along different dimensions. // Given sufficient numerical stability and a<e<c and b<f<d, bilinear resize // from image of size axb -> cxd is same as resizing axb -> exf -> cxd. + // This does not work in the case of align_corners_=false because of special + // padding requirements that cause multiple resizes to be very different + // from a single resize. // // This makes the convolutions kernels smaller and the operation faster. xla::XlaOp output = input; @@ -415,21 +490,24 @@ class ResizeBilinearOp : public XlaOpKernel { (static_cast<float>(out_size[0]) - 1) / ((in_size[0] - 1) * 2), (static_cast<float>(out_size[1]) - 1) / ((in_size[1] - 1) * 2)}; if ((k[0] == std::floor(k[0])) && (k[1] == std::floor(k[1])) && - k[0] > 1 && k[1] > 1) { + k[0] > 1 && k[1] > 1 && align_corners_) { std::vector<int64> next_out_size = {(in_size[0] - 1) * 2 + 1, (in_size[1] - 1) * 2 + 1}; - output = ResizeUsingDilationAndConvolution( - b, input, num_spatial_dims, in_size, next_out_size, channels); + output = ResizeUsingDilationAndConvolution(b, input, num_spatial_dims, + in_size, next_out_size, + channels, align_corners_); input = output; in_size = next_out_size; } else { - output = ResizeUsingDilationAndConvolution( - b, input, num_spatial_dims, in_size, out_size, channels); + output = ResizeUsingDilationAndConvolution(b, input, num_spatial_dims, + in_size, out_size, + channels, align_corners_); in_size = out_size; } } else { output = ResizeUsingDilationAndConvolution(b, input, num_spatial_dims, - in_size, out_size, channels); + in_size, out_size, channels, + align_corners_); in_size = out_size; } } @@ -509,17 +587,20 @@ class ResizeBilinearGradOp : public XlaOpKernel { std::vector<int64> next_grad_size = {(in_size[0] - 1) * 2 + 1, (in_size[1] - 1) * 2 + 1}; output = ResizeUsingDilationAndConvolutionGradOp( - b, grad, num_spatial_dims, in_size, next_grad_size, channels); + b, grad, num_spatial_dims, in_size, next_grad_size, channels, + align_corners_); grad = output; in_size = next_grad_size; } else { output = ResizeUsingDilationAndConvolutionGradOp( - b, grad, num_spatial_dims, in_size, grad_size, channels); + b, grad, num_spatial_dims, in_size, grad_size, channels, + align_corners_); in_size = grad_size; } } else { output = ResizeUsingDilationAndConvolutionGradOp( - b, grad, num_spatial_dims, in_size, grad_size, channels); + b, grad, num_spatial_dims, in_size, grad_size, channels, + align_corners_); in_size = grad_size; } } diff --git a/tensorflow/compiler/tf2xla/kernels/mirror_pad_op.cc b/tensorflow/compiler/tf2xla/kernels/mirror_pad_op.cc index eedfc3c914..2a42eeaf76 100644 --- a/tensorflow/compiler/tf2xla/kernels/mirror_pad_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/mirror_pad_op.cc @@ -29,7 +29,14 @@ class MirrorPadOp : public XlaOpKernel { xla::StatusOr<xla::XlaOp> DoMirrorPad(const xla::XlaOp& t, const xla::Shape& original_shape, const xla::LiteralSlice& pad_literal, + const MirrorPadMode mode, xla::XlaBuilder* b) { + // The difference in the semantics of REFLECT and SYMMETRIC is that REFLECT + // will not mirror the border values while symmetric does. + // e.g. input is [1, 2, 3] and paddings is [0, 2], then the output is: + // - [1, 2, 3, 2, 1] in reflect mode + // - [1, 2, 3, 3, 2] in symmetric mode. + int64 excluded_edges = mode == MirrorPadMode::REFLECT ? 1 : 0; xla::XlaOp accum = t; for (int64 dimno = xla::ShapeUtil::Rank(original_shape) - 1; dimno >= 0; --dimno) { @@ -39,9 +46,19 @@ class MirrorPadOp : public XlaOpKernel { TF_ASSIGN_OR_RETURN(int64 rhs_padding, pad_literal.GetIntegralAsS64({dimno, 1})); int64 dim_size = original_shape.dimensions(dimno); - auto lhs_pad = xla::SliceInDim(t_rev, dim_size - 1 - lhs_padding, - dim_size - 1, 1, dimno); - auto rhs_pad = xla::SliceInDim(t_rev, 1, 1 + rhs_padding, 1, dimno); + + // Padding amounts on each side must be no more than the size of the + // original shape. + TF_RET_CHECK(lhs_padding >= 0 && + lhs_padding <= dim_size - excluded_edges); + TF_RET_CHECK(rhs_padding >= 0 && + rhs_padding <= dim_size - excluded_edges); + + auto lhs_pad = + xla::SliceInDim(t_rev, dim_size - excluded_edges - lhs_padding, + dim_size - excluded_edges, 1, dimno); + auto rhs_pad = xla::SliceInDim(t_rev, excluded_edges, + excluded_edges + rhs_padding, 1, dimno); accum = xla::ConcatInDim(b, {lhs_pad, accum, rhs_pad}, dimno); } return accum; @@ -53,9 +70,10 @@ class MirrorPadOp : public XlaOpKernel { MirrorPadMode mode; OP_REQUIRES_OK(ctx, GetNodeAttr(def(), "mode", &mode)); - OP_REQUIRES(ctx, mode == MirrorPadMode::REFLECT, - xla::Unimplemented( - "Only REFLECT MirrorPad mode is currently supported")); + OP_REQUIRES( + ctx, mode == MirrorPadMode::REFLECT || mode == MirrorPadMode::SYMMETRIC, + xla::Unimplemented("Unsupported MirrorPad mode. Only SYMMETRIC and " + "REFLECT modes are currently supported")); const int dims = input_shape.dims(); OP_REQUIRES( @@ -83,7 +101,7 @@ class MirrorPadOp : public XlaOpKernel { xla::StatusOr<xla::Shape> in0_shape = b->GetShape(in0); OP_REQUIRES(ctx, in0_shape.ok(), in0_shape.status()); xla::StatusOr<xla::XlaOp> accum_status = - DoMirrorPad(in0, in0_shape.ValueOrDie(), pad_literal, b); + DoMirrorPad(in0, in0_shape.ValueOrDie(), pad_literal, mode, b); OP_REQUIRES_OK(ctx, accum_status.status()); diff --git a/tensorflow/compiler/tf2xla/kernels/pooling_ops.cc b/tensorflow/compiler/tf2xla/kernels/pooling_ops.cc index d4d180aff8..f6f158a73b 100644 --- a/tensorflow/compiler/tf2xla/kernels/pooling_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/pooling_ops.cc @@ -199,59 +199,6 @@ class MaxPool3DOp : public MaxPoolOp { }; REGISTER_XLA_OP(Name("MaxPool3D"), MaxPool3DOp); -// Divide each element of an image by the count of elements that contributed to -// that element during pooling. -static xla::XlaOp AvgPoolDivideByCount( - XlaOpKernelContext* ctx, const xla::XlaOp& output, DataType dtype, - const TensorShape& input_shape, xla::Padding padding, - const std::vector<int64>& ksize, const std::vector<int64>& stride, - int num_spatial_dims, TensorFormat data_format) { - if (padding == xla::Padding::kValid) { - // In VALID padding, all windows have the same number of elements - // contributing to each average. Divide by the window size everywhere to - // get the average. - int64 window_size = std::accumulate(ksize.begin(), ksize.end(), 1, - [](int64 a, int64 b) { return a * b; }); - - auto divisor = - XlaHelpers::IntegerLiteral(ctx->builder(), dtype, window_size); - return xla::Div(output, divisor); - } else { - // For SAME padding, the padding shouldn't be included in the - // counts. We use another ReduceWindow to find the right counts. - - // TODO(phawkins): use a less brute-force way to compute this. Only - // the boundary regions will have interesting values here. - - std::vector<int64> input_dim_sizes(num_spatial_dims); - std::vector<int64> window_dims(num_spatial_dims); - std::vector<int64> window_ksize(num_spatial_dims); - std::vector<int64> window_stride(num_spatial_dims); - for (int i = 0; i < num_spatial_dims; ++i) { - int dim = GetTensorSpatialDimIndex(num_spatial_dims + 2, data_format, i); - input_dim_sizes[i] = input_shape.dim_size(dim); - window_dims[i] = dim; - window_ksize[i] = ksize[dim]; - window_stride[i] = stride[dim]; - } - - // Build a matrix of all 1s, with the same width/height as the input. - const DataType accumulation_type = XlaHelpers::SumAccumulationType(dtype); - auto ones = xla::Broadcast( - XlaHelpers::One(ctx->builder(), accumulation_type), input_dim_sizes); - - // Perform a ReduceWindow with the same window size, strides, and padding - // to count the number of contributions to each result element. - auto reduce = xla::ReduceWindow( - ones, XlaHelpers::Zero(ctx->builder(), accumulation_type), - *ctx->GetOrCreateAdd(accumulation_type), window_ksize, window_stride, - xla::Padding::kSame); - auto counts = XlaHelpers::ConvertElementType(ctx->builder(), reduce, dtype); - - return xla::Div(output, counts, window_dims); - } -} - class AvgPoolOp : public PoolingOp { public: AvgPoolOp(OpKernelConstruction* ctx, int num_spatial_dims) @@ -463,78 +410,31 @@ class AvgPoolGradOp : public XlaOpKernel { errors::InvalidArgument("out_backprop must be ", num_dims(), "-dimensional")); - int depth_dim = GetTensorFeatureDimIndex(num_dims(), data_format_); - int64 depth = out_backprop_shape.dim_size(depth_dim); - - // We can think of average-pooling as: - // * a convolution with a kernel consisting entirely of 1s, where the - // input feature and output feature are equal, and 0s everywhere else. - // * followed by dividing by the counts. - // - // This then gives us an algorithm to build the gradient: - // * divide out_backprop by the counts, followed by - // * Conv2DBackpropInput specialized for that kernel, which simplifies to - // a Pad and a ReduceWindow. - // - // For an explanation of backpropagation for convolution, see the comments - // in third_party/tensorflow/core/kernels/conv_grad_ops.h - - // TF filter shape is [ H, W, ..., inC, outC ] - std::vector<int64> filter_dims(num_dims()); - for (int i = 0; i < num_spatial_dims_; ++i) { - int dim = GetTensorSpatialDimIndex(num_dims(), data_format_, i); - filter_dims[i] = ksize_[dim]; - } - filter_dims[num_dims() - 2] = depth; - filter_dims[num_dims() - 1] = depth; - TensorShape filter_shape(filter_dims); - - // Reuse the logic from Conv2DBackpropInput to compute padding. - ConvBackpropDimensions dims; - OP_REQUIRES_OK( - ctx, ConvBackpropComputeDimensions( - type_string(), /*num_spatial_dims=*/num_spatial_dims_, - gradients_shape, filter_shape, out_backprop_shape, stride_, - padding_, data_format_, &dims)); - - // The input gradients are computed by a convolution of the output gradients - // and the filter, with some appropriate padding. See the comment at the top - // of conv_grad_ops.h for details. - xla::XlaBuilder* const b = ctx->builder(); auto out_backprop = ctx->Input(1); - auto dtype = input_type(1); + std::vector<int64> stride_int64s(stride_.begin(), stride_.end()); xla::Padding xla_padding = (padding_ == VALID) ? xla::Padding::kValid : xla::Padding::kSame; - - // Divide the out_backprop values by the counts for each spatial position. - std::vector<int64> stride_int64s(stride_.begin(), stride_.end()); - auto out_backprop_div = AvgPoolDivideByCount( - ctx, out_backprop, dtype, gradients_shape, xla_padding, ksize_, - stride_int64s, num_spatial_dims_, data_format_); - - // Pad the gradients in the spatial dimensions. We use the same padding - // as Conv2DBackpropInput. - xla::PaddingConfig padding_config = xla::MakeNoPaddingConfig(num_dims()); - for (int i = 0; i < num_spatial_dims_; ++i) { - int dim = GetTensorSpatialDimIndex(num_dims(), data_format_, i); - auto* padding = padding_config.mutable_dimensions(dim); - padding->set_edge_padding_low(dims.spatial_dims[i].pad_before); - padding->set_edge_padding_high(dims.spatial_dims[i].pad_after); - padding->set_interior_padding(dims.spatial_dims[i].stride - 1); - } - - auto zero = XlaHelpers::Zero(b, dtype); - auto padded_gradients = xla::Pad(out_backprop_div, zero, padding_config); - - // in_backprop = padded_gradients <conv> ones - std::vector<int64> ones(num_dims(), 1LL); - auto accumulation_type = XlaHelpers::SumAccumulationType(dtype); - auto in_backprop = xla::ReduceWindow( - XlaHelpers::ConvertElementType(b, padded_gradients, accumulation_type), - XlaHelpers::Zero(b, accumulation_type), - *ctx->GetOrCreateAdd(accumulation_type), ksize_, - /* window_strides=*/ones, xla::Padding::kValid); - ctx->SetOutput(0, XlaHelpers::ConvertElementType(b, in_backprop, dtype)); + xla::PrimitiveType xla_reduction_type; + auto reduction_type = XlaHelpers::SumAccumulationType(ctx->input_type(1)); + OP_REQUIRES_OK( + ctx, DataTypeToPrimitiveType(reduction_type, &xla_reduction_type)); + auto converted_out_backprop = + xla::ConvertElementType(out_backprop, xla_reduction_type); + auto xla_data_format = + XlaTensorFormat(data_format_, gradients_shape.dims() - 2); + auto padding_values = + MakeSpatialPadding(gradients_shape.dim_sizes(), ksize_, stride_int64s, + xla_padding, xla_data_format); + auto in_backprop = + xla::AvgPoolGrad(converted_out_backprop, gradients_shape.dim_sizes(), + ksize_, stride_int64s, padding_values, xla_data_format, + /*counts_include_padding=*/padding_ == VALID); + // Convert the pooling result back to the input type before returning it. + xla::PrimitiveType xla_out_backprop_type; + OP_REQUIRES_OK(ctx, DataTypeToPrimitiveType(ctx->input_type(1), + &xla_out_backprop_type)); + ctx->SetOutput(0, + xla::ConvertElementType(in_backprop, xla_out_backprop_type)); } protected: diff --git a/tensorflow/compiler/tf2xla/kernels/reduce_window_op.cc b/tensorflow/compiler/tf2xla/kernels/reduce_window_op.cc index b11a4ce36d..8102faad28 100644 --- a/tensorflow/compiler/tf2xla/kernels/reduce_window_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/reduce_window_op.cc @@ -32,41 +32,30 @@ class ReduceWindowOp : public XlaOpKernel { explicit ReduceWindowOp(OpKernelConstruction* context) : XlaOpKernel(context) { OP_REQUIRES_OK(context, context->GetAttr("computation", &computation_)); - OP_REQUIRES_OK(context, - context->GetAttr("window_dimensions", &window_dimensions_)); - OP_REQUIRES_OK(context, - context->GetAttr("window_strides", &window_strides_)); - OP_REQUIRES_OK(context, context->GetAttr("padding_low", &padding_low_)); - OP_REQUIRES_OK(context, context->GetAttr("padding_high", &padding_high_)); } void Compile(XlaOpKernelContext* context) override { const TensorShape input_shape = context->InputShape(0); const DataType dtype = context->input_type(0); + std::vector<int64> window_dimensions; + std::vector<int64> window_strides; + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector( + "window_dimensions", &window_dimensions)); + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector("window_strides", + &window_strides)); + const int rank = input_shape.dims(); - OP_REQUIRES(context, rank == window_dimensions_.size(), + OP_REQUIRES(context, rank == window_dimensions.size(), errors::InvalidArgument( "The size of window_dimensions must be equal to the input " "rank (", - window_dimensions_.size(), " vs. ", rank, ")")); - OP_REQUIRES(context, rank == window_strides_.size(), + window_dimensions.size(), " vs. ", rank, ")")); + OP_REQUIRES(context, rank == window_strides.size(), errors::InvalidArgument( "The size of window_strides must be equal to the input " "rank (", - window_strides_.size(), " vs. ", rank, ")")); - OP_REQUIRES(context, rank == padding_low_.size(), - errors::InvalidArgument( - "The size of padding_low must be equal to the input " - "rank (", - padding_low_.size(), " vs. ", rank, ")")); - OP_REQUIRES(context, rank == padding_high_.size(), - errors::InvalidArgument( - "The size of padding_high must be equal to the input " - "rank (", - padding_high_.size(), " vs. ", rank, ")")); - - xla::XlaBuilder* builder = context->builder(); + window_strides.size(), " vs. ", rank, ")")); // Build the reducer function. XlaCompiler::Argument reducer_arg; @@ -78,6 +67,7 @@ class ReduceWindowOp : public XlaOpKernel { compile_options.use_tuple_arg = false; compile_options.resolve_compile_time_constants = false; compile_options.is_entry_computation = false; + compile_options.always_return_tuple = false; XlaCompiler::CompilationResult reducer; OP_REQUIRES_OK(context, context->compiler()->CompileFunction( compile_options, *computation_, @@ -86,51 +76,47 @@ class ReduceWindowOp : public XlaOpKernel { xla::Shape scalar_shape; OP_REQUIRES_OK(context, TensorShapeToXLAShape(dtype, TensorShape(), &scalar_shape)); + OP_REQUIRES( + context, + xla::ShapeUtil::Compatible(reducer.xla_output_shape, scalar_shape), + errors::InvalidArgument( + "Invalid output shape of ReduceWindow reducer. Expected ", + xla::ShapeUtil::HumanString(scalar_shape), " got ", + xla::ShapeUtil::HumanString(reducer.xla_output_shape))); + + const TensorShape padding_shape = context->InputShape("padding"); OP_REQUIRES(context, - xla::ShapeUtil::Compatible( - reducer.xla_output_shape, - xla::ShapeUtil::MakeTupleShape({scalar_shape})), + TensorShapeUtils::IsMatrix(padding_shape) && + padding_shape.dim_size(1) == 2, errors::InvalidArgument( - "Invalid output shape of ReduceWindow reducer. Expected ", - xla::ShapeUtil::HumanString(scalar_shape), " got ", - xla::ShapeUtil::HumanString(reducer.xla_output_shape))); - - // Wraps the reducer in a computation that unpacks the output tuple. - xla::XlaComputation wrapper; - { - std::unique_ptr<xla::XlaBuilder> cb = - builder->CreateSubBuilder("wrapper"); - auto x = xla::Parameter(cb.get(), 0, scalar_shape, "x"); - auto y = xla::Parameter(cb.get(), 1, scalar_shape, "y"); - auto outputs = xla::Call(cb.get(), *reducer.computation, {x, y}); - xla::GetTupleElement(outputs, 0); - xla::StatusOr<xla::XlaComputation> result = cb->Build(); - OP_REQUIRES_OK(context, result.status()); - wrapper = std::move(result.ValueOrDie()); - } - - std::vector<std::pair<int64, int64>> padding(rank); - for (int i = 0; i < rank; ++i) { - padding[i] = {padding_low_[i], padding_high_[i]}; + "padding must be a matrix with minor dimension 2, got ", + padding_shape.DebugString())); + xla::Literal padding_literal; + OP_REQUIRES_OK(context, context->ConstantInputAsInt64Literal( + "padding", &padding_literal)); + std::vector<std::pair<int64, int64>> padding(padding_shape.dim_size(0)); + for (int i = 0; i < padding.size(); ++i) { + padding[i] = {padding_literal.Get<int64>({i, 0}), + padding_literal.Get<int64>({i, 1})}; } xla::XlaOp output = xla::ReduceWindowWithGeneralPadding( - context->Input(0), context->Input(1), wrapper, window_dimensions_, - window_strides_, padding); + context->Input(0), context->Input(1), *reducer.computation, + window_dimensions, window_strides, padding); context->SetOutput(0, output); } private: const NameAttrList* computation_; - std::vector<int64> window_dimensions_; - std::vector<int64> window_strides_; - std::vector<int64> padding_low_; - std::vector<int64> padding_high_; TF_DISALLOW_COPY_AND_ASSIGN(ReduceWindowOp); }; -REGISTER_XLA_OP(Name("XlaReduceWindow"), ReduceWindowOp); +REGISTER_XLA_OP(Name("XlaReduceWindow") + .CompileTimeConstInput("window_dimensions") + .CompileTimeConstInput("window_strides") + .CompileTimeConstInput("padding"), + ReduceWindowOp); } // namespace } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/kernels/reduction_ops_common.cc b/tensorflow/compiler/tf2xla/kernels/reduction_ops_common.cc index b52f0a0ab6..598248563b 100644 --- a/tensorflow/compiler/tf2xla/kernels/reduction_ops_common.cc +++ b/tensorflow/compiler/tf2xla/kernels/reduction_ops_common.cc @@ -15,6 +15,7 @@ limitations under the License. // XLA-specific reduction Ops. +#include "absl/strings/str_join.h" #include "tensorflow/compiler/tf2xla/kernels/reduction_ops.h" #include "tensorflow/compiler/tf2xla/type_util.h" #include "tensorflow/compiler/tf2xla/xla_helpers.h" @@ -29,9 +30,6 @@ namespace tensorflow { XlaReductionOp::XlaReductionOp(OpKernelConstruction* ctx, DataType reduction_type) : XlaOpKernel(ctx), reduction_type_(reduction_type) { - const DataType dt = BaseType(input_type(0)); - OP_REQUIRES_OK(ctx, ctx->MatchSignature({dt, DT_INT32}, {dt})); - OP_REQUIRES_OK(ctx, ctx->GetAttr("keep_dims", &keep_dims_)); OP_REQUIRES_OK( ctx, DataTypeToPrimitiveType(reduction_type_, &xla_reduction_type_)); @@ -58,20 +56,24 @@ void XlaReductionOp::Compile(XlaOpKernelContext* ctx) { return; } + OP_REQUIRES(ctx, axes_tensor_shape.dims() <= 1, + errors::InvalidArgument( + "Expected scalar or vector as index argument, got ", + axes_tensor_shape.DebugString())); + // Evaluate the constant, reshaping to a 1-vector if it is a scalar. + std::vector<int64> axes; xla::Literal axes_literal; - OP_REQUIRES_OK( - ctx, ctx->ConstantInputReshaped(1, {axes_tensor_shape.num_elements()}, - &axes_literal)); + OP_REQUIRES_OK(ctx, ctx->ConstantInputReshapedToIntVector(1, &axes)); VLOG(1) << "data shape: " << data_shape.DebugString(); - VLOG(1) << "axes : " << axes_literal.ToString(); + VLOG(1) << "axes : " << absl::StrJoin(axes, ","); gtl::InlinedVector<bool, 4> bitmap(data_shape.dims(), false); std::vector<int64> xla_axes; int64 num_elements_reduced = 1LL; for (int64 i = 0; i < axes_tensor_shape.num_elements(); ++i) { - int32 index = axes_literal.Get<int>({i}); + int64 index = axes[i]; OP_REQUIRES(ctx, !(index < -data_shape.dims() || index >= data_shape.dims()), errors::InvalidArgument("Invalid reduction dimension (", index, diff --git a/tensorflow/compiler/tf2xla/kernels/reshape_op.cc b/tensorflow/compiler/tf2xla/kernels/reshape_op.cc index 121750a82a..366ce42866 100644 --- a/tensorflow/compiler/tf2xla/kernels/reshape_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/reshape_op.cc @@ -41,8 +41,8 @@ class ReshapeOp : public XlaOpKernel { sizes_shape.DebugString())); const int64 num_dims = sizes_shape.num_elements(); - xla::Literal literal; - OP_REQUIRES_OK(ctx, ctx->ConstantInput(1, &literal)); + std::vector<int64> shape_input; + OP_REQUIRES_OK(ctx, ctx->ConstantInputAsIntVector(1, &shape_input)); // Compute the output shape. Determine product of specified // dimensions, and find the index of the unspecified one if there @@ -51,7 +51,7 @@ class ReshapeOp : public XlaOpKernel { int64 product = 1; int unknown_index = -1; for (int d = 0; d < num_dims; ++d) { - const int32 size = literal.Get<int>({d}); + const int32 size = shape_input[d]; if (size == -1) { OP_REQUIRES( ctx, unknown_index == -1, diff --git a/tensorflow/compiler/tf2xla/kernels/retval_op.cc b/tensorflow/compiler/tf2xla/kernels/retval_op.cc index 64900e4709..e172c64932 100644 --- a/tensorflow/compiler/tf2xla/kernels/retval_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/retval_op.cc @@ -48,6 +48,15 @@ class RetvalOp : public XlaOpKernel { } else { xla::XlaOp input = ctx->Input(0); const TensorShape input_shape = ctx->InputShape(0); + DataType input_type = ctx->input_type(0); + XlaContext& tc = XlaContext::Get(ctx); + + if (input_type == DT_RESOURCE) { + XlaResource* resource; + OP_REQUIRES_OK(ctx, ctx->GetResourceInput(0, &resource)); + ctx->SetStatus(tc.AddResourceRetval(index_, resource)); + return; + } auto is_constant = ctx->builder()->IsConstant(input); if (!is_constant.ok()) { @@ -55,7 +64,6 @@ class RetvalOp : public XlaOpKernel { return; } - XlaContext& tc = XlaContext::Get(ctx); if (tc.resolve_compile_time_constants() && (input_shape.num_elements() == 0 || is_constant.ValueOrDie())) { xla::Literal literal; @@ -104,7 +112,8 @@ class RetvalOp : public XlaOpKernel { TF_DISALLOW_COPY_AND_ASSIGN(RetvalOp); }; -REGISTER_XLA_OP(Name("_Retval").CompilationOnly(), RetvalOp); +REGISTER_XLA_OP(Name("_Retval").AllowResourceTypes().CompilationOnly(), + RetvalOp); } // anonymous namespace } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/kernels/reverse_op.cc b/tensorflow/compiler/tf2xla/kernels/reverse_op.cc index d962ef4a5f..c0afccaa5b 100644 --- a/tensorflow/compiler/tf2xla/kernels/reverse_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/reverse_op.cc @@ -95,10 +95,24 @@ class ReverseV2Op : public XlaOpKernel { std::vector<int64> axes; OP_REQUIRES_OK(ctx, ctx->ConstantInputAsIntVector(1, &axes)); + // witnessed_axes is used to ensure that the same axis is not marked to be + // reversed multiple times. + gtl::InlinedVector<bool, 8> witnessed_axes(x_shape.dims(), false); + for (int d = 0; d < axes.size(); ++d) { - OP_REQUIRES(ctx, (0 <= axes[d]) && (axes[d] < x_shape.dims()), - errors::InvalidArgument(axes[d], " is out of range [0, ", - x_shape.dims(), ").")); + OP_REQUIRES( + ctx, (-x_shape.dims() <= axes[d]) && (axes[d] < x_shape.dims()), + errors::InvalidArgument(axes[d], " is out of range [-", + x_shape.dims(), ", ", x_shape.dims(), ").")); + // Axes can be negative and are shifted to the canonical index before + // being lowered to HLO. + if (axes[d] < 0) { + axes[d] += x_shape.dims(); + } + OP_REQUIRES(ctx, !witnessed_axes[axes[d]], + errors::InvalidArgument("canonicalized axis ", axes[d], + " was repeated.")); + witnessed_axes[axes[d]] = true; } ctx->SetOutput(0, xla::Rev(ctx->Input(0), axes)); diff --git a/tensorflow/compiler/tf2xla/kernels/select_op.cc b/tensorflow/compiler/tf2xla/kernels/select_op.cc index 6ce50efb4a..d9578eca5b 100644 --- a/tensorflow/compiler/tf2xla/kernels/select_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/select_op.cc @@ -67,7 +67,7 @@ class SelectOp : public XlaOpKernel { // to get the dimensions in the right order. const auto dim_sizes = then_shape.dim_sizes(); gtl::ArraySlice<int64> bdims = dim_sizes; - bdims.pop_front(); + bdims.remove_prefix(1); cond_handle = xla::Broadcast(cond_handle, bdims); std::vector<int64> dim_order(then_shape.dims()); diff --git a/tensorflow/compiler/tf2xla/kernels/softmax_op.cc b/tensorflow/compiler/tf2xla/kernels/softmax_op.cc index 025ba82741..d6bd927135 100644 --- a/tensorflow/compiler/tf2xla/kernels/softmax_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/softmax_op.cc @@ -15,6 +15,7 @@ limitations under the License. // XLA-specific Ops for softmax. +#include "absl/strings/match.h" #include "tensorflow/compiler/tf2xla/type_util.h" #include "tensorflow/compiler/tf2xla/xla_helpers.h" #include "tensorflow/compiler/tf2xla/xla_op_kernel.h" @@ -25,7 +26,6 @@ limitations under the License. #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/tensor.h" #include "tensorflow/core/framework/tensor_shape.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace tensorflow { namespace { @@ -33,7 +33,7 @@ namespace { class SoftmaxOp : public XlaOpKernel { public: explicit SoftmaxOp(OpKernelConstruction* ctx) : XlaOpKernel(ctx) { - log_ = str_util::StartsWith(type_string(), "Log"); + log_ = absl::StartsWith(type_string(), "Log"); } void Compile(XlaOpKernelContext* ctx) override { diff --git a/tensorflow/compiler/tf2xla/kernels/tile_ops.cc b/tensorflow/compiler/tf2xla/kernels/tile_ops.cc index 1233a37565..2c7213f322 100644 --- a/tensorflow/compiler/tf2xla/kernels/tile_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/tile_ops.cc @@ -70,7 +70,7 @@ class TileOp : public XlaOpKernel { bool one_dimension_is_broadcasted_without_multiple = true; for (int i = 0; i < input_dims; ++i) { int multiple = literal.Get<int>({i}); - OP_REQUIRES(ctx, multiple, + OP_REQUIRES(ctx, multiple >= 0, errors::InvalidArgument("Expected multiples[", i, "] >= 0, but got ", multiple)); int64 new_dim = input_shape.dim_size(i) * multiple; diff --git a/tensorflow/compiler/tf2xla/kernels/training_ops.cc b/tensorflow/compiler/tf2xla/kernels/training_ops.cc index be5e911386..7077c2e3a5 100644 --- a/tensorflow/compiler/tf2xla/kernels/training_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/training_ops.cc @@ -688,7 +688,7 @@ void CompileFtrl(XlaOpKernelContext* ctx, DataType dtype, } // grad_to_use = grad + 2 * l2_shrinkage * var - // new_accum = accum + grad_to_use * grad_to_use + // new_accum = accum + grad * grad // linear += grad_to_use - // (new_accum^(-lr_power) - accum^(-lr_power)) / lr * var // quadratic = (new_accum^(-lr_power) / lr) + 2 * l2 @@ -704,7 +704,7 @@ void CompileFtrl(XlaOpKernelContext* ctx, DataType dtype, grad_to_use = grad; } - xla::XlaOp new_accum = accum + xla::Square(grad_to_use); + xla::XlaOp new_accum = accum + xla::Square(grad); xla::XlaOp new_accum_lr_pow = xla::Pow(new_accum, -lr_power); xla::XlaOp accum_lr_pow = xla::Pow(accum, -lr_power); linear = linear + grad_to_use - (new_accum_lr_pow - accum_lr_pow) / lr * var; diff --git a/tensorflow/compiler/tf2xla/kernels/xla_broadcast_helper_op.cc b/tensorflow/compiler/tf2xla/kernels/xla_broadcast_helper_op.cc new file mode 100644 index 0000000000..412afeaaad --- /dev/null +++ b/tensorflow/compiler/tf2xla/kernels/xla_broadcast_helper_op.cc @@ -0,0 +1,115 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "absl/algorithm/container.h" +#include "absl/strings/str_join.h" +#include "tensorflow/compiler/tf2xla/shape_util.h" +#include "tensorflow/compiler/tf2xla/xla_compiler.h" +#include "tensorflow/compiler/tf2xla/xla_op_kernel.h" +#include "tensorflow/compiler/tf2xla/xla_op_registry.h" +#include "tensorflow/compiler/xla/client/xla_builder.h" +#include "tensorflow/compiler/xla/xla_data.pb.h" +#include "tensorflow/core/framework/op_kernel.h" +#include "tensorflow/core/lib/core/errors.h" + +namespace tensorflow { +namespace { + +class XlaBroadcastHelperOp : public XlaOpKernel { + public: + explicit XlaBroadcastHelperOp(OpKernelConstruction* context) + : XlaOpKernel(context) {} + + void Compile(XlaOpKernelContext* context) override { + xla::XlaOp lhs = context->Input(0); + xla::XlaOp rhs = context->Input(1); + const TensorShape lhs_shape = context->InputShape(0); + const TensorShape rhs_shape = context->InputShape(1); + + const bool broadcast_lhs = lhs_shape.dims() < rhs_shape.dims(); + const TensorShape* min_rank_shape = broadcast_lhs ? &lhs_shape : &rhs_shape; + const TensorShape* max_rank_shape = broadcast_lhs ? &rhs_shape : &lhs_shape; + + std::vector<int64> broadcast_dims; + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector("broadcast_dims", + &broadcast_dims)); + if (broadcast_dims.empty()) { + OP_REQUIRES( + context, + lhs_shape.dims() == rhs_shape.dims() || lhs_shape.dims() == 0 || + rhs_shape.dims() == 0, + errors::InvalidArgument( + "If broadcast_dims is empty, both " + "arguments must have equal rank; " + "argument shapes, or at least one argument must be a scalar: ", + lhs_shape.DebugString(), " and ", rhs_shape.DebugString())); + context->SetOutput(0, lhs); + context->SetOutput(1, rhs); + return; + } + + OP_REQUIRES( + context, broadcast_dims.size() == min_rank_shape->dims(), + errors::InvalidArgument( + "broadcast_dims must have size equal to the smaller argument rank; " + "broadcast_dims: [", + absl::StrJoin(broadcast_dims, ","), "]; argument shapes: ", + lhs_shape.DebugString(), " and ", rhs_shape.DebugString())); + std::vector<int64> sorted_broadcast_dims = broadcast_dims; + absl::c_sort(sorted_broadcast_dims); + std::set<int64> dims_set(broadcast_dims.begin(), broadcast_dims.end()); + OP_REQUIRES(context, + dims_set.size() == broadcast_dims.size() && + broadcast_dims == sorted_broadcast_dims, + errors::InvalidArgument( + "Duplicate or nonmonotonic dimension in broadcast_dims; " + "broadcast_dims: [", + absl::StrJoin(broadcast_dims, ","), "]")); + + std::vector<int64> broadcast_shape(max_rank_shape->dims(), 1LL); + for (int i = 0; i < broadcast_dims.size(); ++i) { + const int dim = broadcast_dims[i]; + OP_REQUIRES( + context, dim >= 0 && dim < broadcast_shape.size(), + errors::InvalidArgument( + "Invalid broadcast dimension (", dim, "); broadcast_dims: [", + absl::StrJoin(broadcast_dims, ","), "]; argument shapes: ", + lhs_shape.DebugString(), " and ", rhs_shape.DebugString())); + broadcast_shape[dim] = min_rank_shape->dim_size(i); + } + xla::PrimitiveType type = context->input_xla_type(0); + xla::Shape broadcast_xla_shape = + xla::ShapeUtil::MakeShape(type, broadcast_shape); + if (broadcast_lhs) { + lhs = xla::BroadcastInDim(lhs, broadcast_xla_shape, broadcast_dims); + } else { + rhs = xla::BroadcastInDim(rhs, broadcast_xla_shape, broadcast_dims); + } + context->SetOutput(0, lhs); + context->SetOutput(1, rhs); + } + + private: + xla::DotDimensionNumbers dnums_; + + TF_DISALLOW_COPY_AND_ASSIGN(XlaBroadcastHelperOp); +}; + +REGISTER_XLA_OP( + Name("XlaBroadcastHelper").CompileTimeConstInput("broadcast_dims"), + XlaBroadcastHelperOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/kernels/xla_conv_op.cc b/tensorflow/compiler/tf2xla/kernels/xla_conv_op.cc new file mode 100644 index 0000000000..8848623868 --- /dev/null +++ b/tensorflow/compiler/tf2xla/kernels/xla_conv_op.cc @@ -0,0 +1,101 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/tf2xla/shape_util.h" +#include "tensorflow/compiler/tf2xla/xla_compiler.h" +#include "tensorflow/compiler/tf2xla/xla_op_kernel.h" +#include "tensorflow/compiler/tf2xla/xla_op_registry.h" +#include "tensorflow/compiler/xla/client/xla_builder.h" +#include "tensorflow/compiler/xla/xla_data.pb.h" +#include "tensorflow/core/framework/op_kernel.h" + +namespace tensorflow { +namespace { + +class XlaConvOp : public XlaOpKernel { + public: + explicit XlaConvOp(OpKernelConstruction* context) : XlaOpKernel(context) { + string dnums_attr; + OP_REQUIRES_OK(context, context->GetAttr("dimension_numbers", &dnums_attr)); + OP_REQUIRES( + context, dnums_.ParsePartialFromString(dnums_attr), + errors::InvalidArgument("Error parsing convolution dimension numbers")); + string precision_config_attr; + OP_REQUIRES_OK( + context, context->GetAttr("precision_config", &precision_config_attr)); + OP_REQUIRES( + context, + precision_config_.ParsePartialFromString(precision_config_attr), + errors::InvalidArgument("Error parsing convolution dimension numbers")); + } + + void Compile(XlaOpKernelContext* context) override { + const TensorShape lhs_shape = context->InputShape(0); + const TensorShape rhs_shape = context->InputShape(1); + const TensorShape padding_shape = context->InputShape("padding"); + std::vector<int64> window_strides; + std::vector<int64> lhs_dilation; + std::vector<int64> rhs_dilation; + int64 feature_group_count; + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector("window_strides", + &window_strides)); + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector("lhs_dilation", + &lhs_dilation)); + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector("rhs_dilation", + &rhs_dilation)); + OP_REQUIRES_OK(context, context->ConstantInputAsIntScalar( + "feature_group_count", &feature_group_count)); + + OP_REQUIRES(context, + TensorShapeUtils::IsMatrix(padding_shape) && + padding_shape.dim_size(1) == 2, + errors::InvalidArgument( + "padding must be a matrix with minor dimension 2, got ", + padding_shape.DebugString())); + xla::Literal padding_literal; + OP_REQUIRES_OK(context, context->ConstantInputAsInt64Literal( + "padding", &padding_literal)); + std::vector<std::pair<int64, int64>> padding(padding_shape.dim_size(0)); + for (int i = 0; i < padding.size(); ++i) { + padding[i] = {padding_literal.Get<int64>({i, 0}), + padding_literal.Get<int64>({i, 1})}; + } + + // We do only minimal checking, relying on XLA to check the shape + // invariants. + xla::XlaOp output = xla::ConvGeneralDilated( + context->Input(0), context->Input(1), window_strides, padding, + lhs_dilation, rhs_dilation, dnums_, feature_group_count, + &precision_config_); + context->SetOutput(0, output); + } + + private: + xla::ConvolutionDimensionNumbers dnums_; + xla::PrecisionConfigProto precision_config_; + + TF_DISALLOW_COPY_AND_ASSIGN(XlaConvOp); +}; + +REGISTER_XLA_OP(Name("XlaConv") + .CompileTimeConstInput("window_strides") + .CompileTimeConstInput("lhs_dilation") + .CompileTimeConstInput("rhs_dilation") + .CompileTimeConstInput("feature_group_count") + .CompileTimeConstInput("padding"), + XlaConvOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/kernels/xla_dot_op.cc b/tensorflow/compiler/tf2xla/kernels/xla_dot_op.cc new file mode 100644 index 0000000000..2fed53e5c0 --- /dev/null +++ b/tensorflow/compiler/tf2xla/kernels/xla_dot_op.cc @@ -0,0 +1,65 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/tf2xla/shape_util.h" +#include "tensorflow/compiler/tf2xla/xla_compiler.h" +#include "tensorflow/compiler/tf2xla/xla_op_kernel.h" +#include "tensorflow/compiler/tf2xla/xla_op_registry.h" +#include "tensorflow/compiler/xla/client/xla_builder.h" +#include "tensorflow/compiler/xla/xla_data.pb.h" +#include "tensorflow/core/framework/op_kernel.h" + +namespace tensorflow { +namespace { + +class XlaDotOp : public XlaOpKernel { + public: + explicit XlaDotOp(OpKernelConstruction* context) : XlaOpKernel(context) { + string dnums_attr; + OP_REQUIRES_OK(context, context->GetAttr("dimension_numbers", &dnums_attr)); + OP_REQUIRES( + context, dnums_.ParsePartialFromString(dnums_attr), + errors::InvalidArgument("Error parsing convolution dimension numbers")); + string precision_config_attr; + OP_REQUIRES_OK( + context, context->GetAttr("precision_config", &precision_config_attr)); + OP_REQUIRES( + context, + precision_config_.ParsePartialFromString(precision_config_attr), + errors::InvalidArgument("Error parsing convolution dimension numbers")); + } + + void Compile(XlaOpKernelContext* context) override { + const TensorShape lhs_shape = context->InputShape(0); + const TensorShape rhs_shape = context->InputShape(1); + + // We do only minimal checking, relying on XLA to check the shape + // invariants. + xla::XlaOp output = xla::DotGeneral(context->Input(0), context->Input(1), + dnums_, &precision_config_); + context->SetOutput(0, output); + } + + private: + xla::DotDimensionNumbers dnums_; + xla::PrecisionConfigProto precision_config_; + + TF_DISALLOW_COPY_AND_ASSIGN(XlaDotOp); +}; + +REGISTER_XLA_OP(Name("XlaDot"), XlaDotOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/kernels/xla_pad_op.cc b/tensorflow/compiler/tf2xla/kernels/xla_pad_op.cc new file mode 100644 index 0000000000..59502d83c7 --- /dev/null +++ b/tensorflow/compiler/tf2xla/kernels/xla_pad_op.cc @@ -0,0 +1,105 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "absl/algorithm/container.h" +#include "absl/strings/str_join.h" +#include "tensorflow/compiler/tf2xla/shape_util.h" +#include "tensorflow/compiler/tf2xla/xla_compiler.h" +#include "tensorflow/compiler/tf2xla/xla_op_kernel.h" +#include "tensorflow/compiler/tf2xla/xla_op_registry.h" +#include "tensorflow/compiler/xla/client/xla_builder.h" +#include "tensorflow/core/framework/op_kernel.h" + +namespace tensorflow { +namespace { + +class XlaPadOp : public XlaOpKernel { + public: + explicit XlaPadOp(OpKernelConstruction* context) : XlaOpKernel(context) {} + + void Compile(XlaOpKernelContext* context) override { + const TensorShape input_shape = context->InputShape("input"); + const TensorShape padding_value_shape = + context->InputShape("padding_value"); + + std::vector<int64> padding_low; + std::vector<int64> padding_high; + std::vector<int64> padding_interior; + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector("padding_low", + &padding_low)); + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector("padding_high", + &padding_high)); + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector( + "padding_interior", &padding_interior)); + + OP_REQUIRES(context, TensorShapeUtils::IsScalar(padding_value_shape), + errors::InvalidArgument("padding_value must be a scalar")); + const int rank = input_shape.dims(); + OP_REQUIRES(context, rank == padding_low.size(), + errors::InvalidArgument( + "The size of padding_low must be equal to the input " + "rank (", + padding_low.size(), " vs. ", rank, ")")); + OP_REQUIRES(context, rank == padding_high.size(), + errors::InvalidArgument( + "The size of padding_high must be equal to the input " + "rank (", + padding_high.size(), " vs. ", rank, ")")); + OP_REQUIRES(context, rank == padding_interior.size(), + errors::InvalidArgument( + "The size of padding_interior must be equal to the input " + "rank (", + padding_interior.size(), " vs. ", rank, ")")); + + auto non_negative = [](int64 x) { return x >= 0; }; + OP_REQUIRES( + context, absl::c_all_of(padding_low, non_negative), + errors::InvalidArgument("padding_low must be non-negative, got [", + absl::StrJoin(padding_low, ","), "]")); + OP_REQUIRES( + context, absl::c_all_of(padding_high, non_negative), + errors::InvalidArgument("padding_high must be non-negative, got [", + absl::StrJoin(padding_high, ","), "]")); + OP_REQUIRES( + context, absl::c_all_of(padding_interior, non_negative), + errors::InvalidArgument("padding_interior must be non-negative, got [", + absl::StrJoin(padding_interior, ","), "]")); + + xla::PaddingConfig padding_config; + for (int i = 0; i < rank; ++i) { + auto* dim = padding_config.add_dimensions(); + dim->set_edge_padding_low(padding_low[i]); + dim->set_edge_padding_high(padding_high[i]); + dim->set_interior_padding(padding_interior[i]); + } + + xla::XlaOp output = + xla::Pad(context->Input("input"), context->Input("padding_value"), + padding_config); + context->SetOutput(0, output); + } + + private: + TF_DISALLOW_COPY_AND_ASSIGN(XlaPadOp); +}; + +REGISTER_XLA_OP(Name("XlaPad") + .CompileTimeConstInput("padding_low") + .CompileTimeConstInput("padding_high") + .CompileTimeConstInput("padding_interior"), + XlaPadOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/kernels/xla_reduce_op.cc b/tensorflow/compiler/tf2xla/kernels/xla_reduce_op.cc new file mode 100644 index 0000000000..fc2425f37b --- /dev/null +++ b/tensorflow/compiler/tf2xla/kernels/xla_reduce_op.cc @@ -0,0 +1,102 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "absl/algorithm/container.h" +#include "tensorflow/compiler/tf2xla/shape_util.h" +#include "tensorflow/compiler/tf2xla/xla_compiler.h" +#include "tensorflow/compiler/tf2xla/xla_op_kernel.h" +#include "tensorflow/compiler/tf2xla/xla_op_registry.h" +#include "tensorflow/compiler/xla/client/xla_builder.h" +#include "tensorflow/compiler/xla/client/xla_computation.h" +#include "tensorflow/core/framework/function.h" +#include "tensorflow/core/framework/op_kernel.h" + +namespace tensorflow { +namespace { + +class XlaReduceOp : public XlaOpKernel { + public: + explicit XlaReduceOp(OpKernelConstruction* context) : XlaOpKernel(context) { + OP_REQUIRES_OK(context, context->GetAttr("reducer", &reducer_)); + OP_REQUIRES_OK(context, context->GetAttr("dimensions_to_reduce", + &dimensions_to_reduce_)); + std::set<int64> dims_set(dimensions_to_reduce_.begin(), + dimensions_to_reduce_.end()); + OP_REQUIRES( + context, dims_set.size() == dimensions_to_reduce_.size(), + errors::InvalidArgument("Duplicate dimension in dimensions_to_reduce " + "argument to XlaReduce")); + } + + void Compile(XlaOpKernelContext* context) override { + const TensorShape input_shape = context->InputShape("input"); + const TensorShape init_value_shape = context->InputShape("init_value"); + const DataType dtype = context->input_type(0); + + const int rank = input_shape.dims(); + OP_REQUIRES(context, TensorShapeUtils::IsScalar(init_value_shape), + errors::InvalidArgument("init_value must be a scalar")); + + auto dim_in_range = [rank](int64 dim) { return dim >= 0 && dim < rank; }; + OP_REQUIRES(context, + rank >= dimensions_to_reduce_.size() && + absl::c_all_of(dimensions_to_reduce_, dim_in_range), + errors::InvalidArgument( + "Invalid dimensions_to_reduce argument to XlaReduce")); + + // Build the reducer function. + XlaCompiler::Argument reducer_arg; + reducer_arg.kind = XlaCompiler::Argument::kParameter; + reducer_arg.type = dtype; + reducer_arg.shape = TensorShape(); + + XlaCompiler::CompileOptions compile_options; + compile_options.use_tuple_arg = false; + compile_options.always_return_tuple = false; + compile_options.resolve_compile_time_constants = false; + compile_options.is_entry_computation = false; + XlaCompiler::CompilationResult reducer; + OP_REQUIRES_OK(context, context->compiler()->CompileFunction( + compile_options, *reducer_, + {reducer_arg, reducer_arg}, &reducer)); + + xla::Shape scalar_shape; + OP_REQUIRES_OK(context, + TensorShapeToXLAShape(dtype, TensorShape(), &scalar_shape)); + OP_REQUIRES( + context, + xla::ShapeUtil::Compatible(reducer.xla_output_shape, scalar_shape), + errors::InvalidArgument( + "Invalid output shape of XlaReduce reducer. Expected ", + xla::ShapeUtil::HumanString(scalar_shape), " got ", + xla::ShapeUtil::HumanString(reducer.xla_output_shape))); + + xla::XlaOp output = + xla::Reduce(context->Input("input"), context->Input("init_value"), + *reducer.computation, dimensions_to_reduce_); + context->SetOutput(0, output); + } + + private: + const NameAttrList* reducer_; + std::vector<int64> dimensions_to_reduce_; + + TF_DISALLOW_COPY_AND_ASSIGN(XlaReduceOp); +}; + +REGISTER_XLA_OP(Name("XlaReduce"), XlaReduceOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/kernels/xla_select_and_scatter_op.cc b/tensorflow/compiler/tf2xla/kernels/xla_select_and_scatter_op.cc new file mode 100644 index 0000000000..089776fcf7 --- /dev/null +++ b/tensorflow/compiler/tf2xla/kernels/xla_select_and_scatter_op.cc @@ -0,0 +1,147 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/tf2xla/kernels/while_op.h" + +#include "tensorflow/compiler/tf2xla/shape_util.h" +#include "tensorflow/compiler/tf2xla/xla_compiler.h" +#include "tensorflow/compiler/tf2xla/xla_op_kernel.h" +#include "tensorflow/compiler/tf2xla/xla_op_registry.h" +#include "tensorflow/compiler/xla/client/xla_builder.h" +#include "tensorflow/compiler/xla/client/xla_computation.h" +#include "tensorflow/core/framework/function.h" +#include "tensorflow/core/framework/op_kernel.h" + +namespace tensorflow { +namespace { + +class XlaSelectAndScatterOp : public XlaOpKernel { + public: + explicit XlaSelectAndScatterOp(OpKernelConstruction* context) + : XlaOpKernel(context) { + OP_REQUIRES_OK(context, context->GetAttr("select", &select_computation_)); + OP_REQUIRES_OK(context, context->GetAttr("scatter", &scatter_computation_)); + } + + void Compile(XlaOpKernelContext* context) override { + const TensorShape input_shape = context->InputShape(0); + const DataType dtype = context->input_type(0); + + std::vector<int64> window_dimensions; + std::vector<int64> window_strides; + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector( + "window_dimensions", &window_dimensions)); + OP_REQUIRES_OK(context, context->ConstantInputAsIntVector("window_strides", + &window_strides)); + + const int rank = input_shape.dims(); + OP_REQUIRES(context, rank == window_dimensions.size(), + errors::InvalidArgument( + "The size of window_dimensions must be equal to the input " + "rank (", + window_dimensions.size(), " vs. ", rank, ")")); + OP_REQUIRES(context, rank == window_strides.size(), + errors::InvalidArgument( + "The size of window_strides must be equal to the input " + "rank (", + window_strides.size(), " vs. ", rank, ")")); + + XlaCompiler::CompileOptions compile_options; + compile_options.use_tuple_arg = false; + compile_options.resolve_compile_time_constants = false; + compile_options.is_entry_computation = false; + compile_options.always_return_tuple = false; + + // Build the select function. + XlaCompiler::Argument select_arg; + select_arg.kind = XlaCompiler::Argument::kParameter; + select_arg.type = dtype; + select_arg.shape = TensorShape(); + + XlaCompiler::CompilationResult select; + OP_REQUIRES_OK(context, context->compiler()->CompileFunction( + compile_options, *select_computation_, + {select_arg, select_arg}, &select)); + + xla::Shape select_output_shape = xla::ShapeUtil::MakeShape(xla::PRED, {}); + OP_REQUIRES( + context, + xla::ShapeUtil::Compatible(select.xla_output_shape, + select_output_shape), + errors::InvalidArgument( + "Invalid output shape of XlaSelectAndScatter select. Expected ", + xla::ShapeUtil::HumanString(select_output_shape), " got ", + xla::ShapeUtil::HumanString(select.xla_output_shape))); + + // Build the scatter function. + XlaCompiler::Argument scatter_arg; + scatter_arg.kind = XlaCompiler::Argument::kParameter; + scatter_arg.type = dtype; + scatter_arg.shape = TensorShape(); + + XlaCompiler::CompilationResult scatter; + OP_REQUIRES_OK(context, context->compiler()->CompileFunction( + compile_options, *scatter_computation_, + {scatter_arg, scatter_arg}, &scatter)); + + xla::Shape scalar_shape; + OP_REQUIRES_OK(context, + TensorShapeToXLAShape(dtype, TensorShape(), &scalar_shape)); + OP_REQUIRES( + context, + xla::ShapeUtil::Compatible(scatter.xla_output_shape, scalar_shape), + errors::InvalidArgument( + "Invalid output shape of scatter. Expected ", + xla::ShapeUtil::HumanString(scalar_shape), " got ", + xla::ShapeUtil::HumanString(scatter.xla_output_shape))); + + const TensorShape padding_shape = context->InputShape("padding"); + OP_REQUIRES(context, + TensorShapeUtils::IsMatrix(padding_shape) && + padding_shape.dim_size(1) == 2, + errors::InvalidArgument( + "padding must be a matrix with minor dimension 2, got ", + padding_shape.DebugString())); + xla::Literal padding_literal; + OP_REQUIRES_OK(context, context->ConstantInputAsInt64Literal( + "padding", &padding_literal)); + std::vector<std::pair<int64, int64>> padding(padding_shape.dim_size(0)); + for (int i = 0; i < padding.size(); ++i) { + padding[i] = {padding_literal.Get<int64>({i, 0}), + padding_literal.Get<int64>({i, 1})}; + } + + xla::XlaOp output = xla::SelectAndScatterWithGeneralPadding( + context->Input("operand"), *select.computation, window_dimensions, + window_strides, padding, context->Input("source"), + context->Input("init_value"), *scatter.computation); + context->SetOutput(0, output); + } + + private: + const NameAttrList* select_computation_; + const NameAttrList* scatter_computation_; + + TF_DISALLOW_COPY_AND_ASSIGN(XlaSelectAndScatterOp); +}; + +REGISTER_XLA_OP(Name("XlaSelectAndScatter") + .CompileTimeConstInput("window_dimensions") + .CompileTimeConstInput("window_strides") + .CompileTimeConstInput("padding"), + XlaSelectAndScatterOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/lib/BUILD b/tensorflow/compiler/tf2xla/lib/BUILD index cb7a40e23d..99511e9914 100644 --- a/tensorflow/compiler/tf2xla/lib/BUILD +++ b/tensorflow/compiler/tf2xla/lib/BUILD @@ -25,8 +25,8 @@ cc_library( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", + "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:xla_builder", - "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/core:lib", ], ) @@ -44,8 +44,8 @@ cc_library( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", + "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:xla_builder", - "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/compiler/xla/client/lib:constants", "//tensorflow/core:lib", ], @@ -78,8 +78,8 @@ cc_library( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", + "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:xla_builder", - "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/compiler/xla/client/lib:arithmetic", "//tensorflow/compiler/xla/client/lib:constants", "//tensorflow/compiler/xla/client/lib:math", @@ -119,6 +119,7 @@ cc_library( "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:util", + "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:xla_builder", "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/compiler/xla/client/lib:constants", diff --git a/tensorflow/compiler/tf2xla/lib/batch_dot.cc b/tensorflow/compiler/tf2xla/lib/batch_dot.cc index f666d22ea4..d8c050d09e 100644 --- a/tensorflow/compiler/tf2xla/lib/batch_dot.cc +++ b/tensorflow/compiler/tf2xla/lib/batch_dot.cc @@ -27,7 +27,8 @@ limitations under the License. namespace tensorflow { xla::XlaOp BatchDot(xla::XlaOp x, xla::XlaOp y, bool transpose_x, - bool transpose_y, bool conjugate_x, bool conjugate_y) { + bool transpose_y, bool conjugate_x, bool conjugate_y, + xla::PrecisionConfigProto::Precision precision) { xla::XlaBuilder* builder = x.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape x_shape, builder->GetShape(x)); @@ -95,6 +96,10 @@ xla::XlaOp BatchDot(xla::XlaOp x, xla::XlaOp y, bool transpose_x, y = xla::Conj(y); } + xla::PrecisionConfigProto precision_proto; + precision_proto.add_operand_precision(precision); + precision_proto.add_operand_precision(precision); + // If there are no batch dimensions, use a regular Dot. // TODO(b/69062148) Remove this code when Dot emitters can be passed // dimensions to transpose directly (i.e. without requiring a Transpose @@ -102,7 +107,7 @@ xla::XlaOp BatchDot(xla::XlaOp x, xla::XlaOp y, bool transpose_x, if (batch_dimension_numbers.empty()) { auto lhs = transpose_x ? xla::Transpose(x, {1, 0}) : x; auto rhs = transpose_y ? xla::Transpose(y, {1, 0}) : y; - return xla::Dot(lhs, rhs); + return xla::Dot(lhs, rhs, &precision_proto); } xla::DotDimensionNumbers dot_dnums; @@ -112,7 +117,8 @@ xla::XlaOp BatchDot(xla::XlaOp x, xla::XlaOp y, bool transpose_x, dot_dnums.add_lhs_batch_dimensions(batch_dimension_number); dot_dnums.add_rhs_batch_dimensions(batch_dimension_number); } - return xla::DotGeneral(x, y, dot_dnums); + + return xla::DotGeneral(x, y, dot_dnums, &precision_proto); }); } diff --git a/tensorflow/compiler/tf2xla/lib/batch_dot.h b/tensorflow/compiler/tf2xla/lib/batch_dot.h index 8757b16a1c..6cfccd5553 100644 --- a/tensorflow/compiler/tf2xla/lib/batch_dot.h +++ b/tensorflow/compiler/tf2xla/lib/batch_dot.h @@ -17,7 +17,7 @@ limitations under the License. #define TENSORFLOW_COMPILER_TF2XLA_LIB_BATCH_DOT_H_ #include "tensorflow/compiler/xla/client/xla_builder.h" -#include "tensorflow/compiler/xla/client/xla_computation.h" +#include "tensorflow/compiler/xla/xla_data.pb.h" namespace tensorflow { @@ -45,7 +45,9 @@ namespace tensorflow { // output[..., :, :] = matrix(x[..., :, :]) * matrix(y[..., :, :]) xla::XlaOp BatchDot(xla::XlaOp x, xla::XlaOp y, bool transpose_x = false, bool transpose_y = false, bool conjugate_x = false, - bool conjugate_y = false); + bool conjugate_y = false, + xla::PrecisionConfigProto::Precision precision = + xla::PrecisionConfigProto::DEFAULT); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/lib/cholesky.cc b/tensorflow/compiler/tf2xla/lib/cholesky.cc index 87d73eb3f0..67fb56510c 100644 --- a/tensorflow/compiler/tf2xla/lib/cholesky.cc +++ b/tensorflow/compiler/tf2xla/lib/cholesky.cc @@ -49,7 +49,8 @@ namespace { // l[..., j+1:, j] = (a[..., j+1:, j] - np.dot(l[..., j+1:, :j], row_t)) / // l[..., j, j] // return l -xla::XlaOp CholeskyUnblocked(xla::XlaOp a) { +xla::XlaOp CholeskyUnblocked(xla::XlaOp a, + xla::PrecisionConfigProto::Precision precision) { xla::XlaBuilder* builder = a.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); @@ -101,7 +102,8 @@ xla::XlaOp CholeskyUnblocked(xla::XlaOp a) { // np.dot(row, np.swapaxes(row, -1, -2)) auto diag_dot = BatchDot(row, row, /*transpose_x=*/false, - /*transpose_y=*/true); + /*transpose_y=*/true, /*conjugate_x=*/false, + /*conjugate_y=*/false, precision); // l[..., i, i] = np.sqrt(a[..., i, i] - np.dot(row, // np.swapaxes(row, -1, -2))) auto l_ii = @@ -121,7 +123,8 @@ xla::XlaOp CholeskyUnblocked(xla::XlaOp a) { // r.T) auto dot = BatchDot(body_l, row, /*transpose_x=*/false, - /*transpose_y=*/true); + /*transpose_y=*/true, /*conjugate_x=*/false, + /*conjugate_y=*/false, precision); // np.dot(l[..., i+1:, :i], r.T) auto dot_ip1 = xla::Select(xla::Le(mask_range_col, i), mask_zeros_col, dot); @@ -145,7 +148,8 @@ xla::XlaOp CholeskyUnblocked(xla::XlaOp a) { } // namespace -xla::XlaOp Cholesky(xla::XlaOp a, int64 block_size) { +xla::XlaOp Cholesky(xla::XlaOp a, int64 block_size, + xla::PrecisionConfigProto::Precision precision) { xla::XlaBuilder* builder = a.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); @@ -181,14 +185,15 @@ xla::XlaOp Cholesky(xla::XlaOp a, int64 block_size) { auto lhs = SliceInMinorDims(l, {i, 0}, {n, i}); auto rhs = SliceInMinorDims(l, {i, 0}, {i + k, i}); auto delta = BatchDot(lhs, rhs, /*transpose_x=*/false, - /*transpose_y=*/true); + /*transpose_y=*/true, /*conjugate_x=*/false, + /*conjugate_y=*/false, precision); auto before = SliceInMinorDims(a, {i, i}, {n, i + k}); a = UpdateSliceInMinorDims(a, before - delta, {i, i}); } // l[i:i+k, i:i+k] = cholesky_unblocked(a[i:i+k, i:i+k]) auto x = SliceInMinorDims(a, {i, i}, {i + k, i + k}); - auto factorized = CholeskyUnblocked(x); + auto factorized = CholeskyUnblocked(x, precision); l = UpdateSliceInMinorDims(l, factorized, {i, i}); if (i + k < n) { diff --git a/tensorflow/compiler/tf2xla/lib/cholesky.h b/tensorflow/compiler/tf2xla/lib/cholesky.h index 1bef9bb166..60cd7ded53 100644 --- a/tensorflow/compiler/tf2xla/lib/cholesky.h +++ b/tensorflow/compiler/tf2xla/lib/cholesky.h @@ -17,7 +17,7 @@ limitations under the License. #define TENSORFLOW_COMPILER_TF2XLA_LIB_CHOLESKY_H_ #include "tensorflow/compiler/xla/client/xla_builder.h" -#include "tensorflow/compiler/xla/client/xla_computation.h" +#include "tensorflow/compiler/xla/xla_data.pb.h" namespace tensorflow { @@ -30,7 +30,9 @@ namespace tensorflow { // TODO(phawkins): check for negative values on the diagonal and return an // error, instead of silently yielding NaNs. // TODO(znado): handle the complex Hermitian case -xla::XlaOp Cholesky(xla::XlaOp a, int64 block_size = 256); +xla::XlaOp Cholesky(xla::XlaOp a, int64 block_size = 256, + xla::PrecisionConfigProto::Precision precision = + xla::PrecisionConfigProto::HIGHEST); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/lib/qr.cc b/tensorflow/compiler/tf2xla/lib/qr.cc index fc0c1ee838..b6f30d8d49 100644 --- a/tensorflow/compiler/tf2xla/lib/qr.cc +++ b/tensorflow/compiler/tf2xla/lib/qr.cc @@ -149,7 +149,8 @@ struct QRBlockResult { xla::XlaOp taus; // Shape: [..., n] xla::XlaOp vs; // Shape: [..., m, n] }; -xla::StatusOr<QRBlockResult> QRBlock(xla::XlaOp a) { +xla::StatusOr<QRBlockResult> QRBlock( + xla::XlaOp a, xla::PrecisionConfigProto::Precision precision) { xla::XlaBuilder* builder = a.builder(); TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); const int num_dims = xla::ShapeUtil::Rank(a_shape); @@ -190,8 +191,12 @@ xla::StatusOr<QRBlockResult> QRBlock(xla::XlaOp a) { auto v_broadcast = xla::Reshape(v, shape); // a[:, :] -= tau * np.dot(v[:, np.newaxis], // np.dot(v[np.newaxis, :], a[:, :])) - auto vva = BatchDot(v_broadcast, a); - vva = BatchDot(v_broadcast, vva, /*transpose_x=*/true); + auto vva = + BatchDot(v_broadcast, a, /*transpose_x=*/false, /*transpose_y=*/false, + /*conjugate_x=*/false, /*conjugate_y=*/false, precision); + vva = + BatchDot(v_broadcast, vva, /*transpose_x=*/true, /*transpose_y=*/false, + /*conjugate_x=*/false, /*conjugate_y=*/false, precision); a = a - xla::Mul(tau, vva, /*broadcast_dimensions=*/batch_dim_indices); @@ -251,7 +256,8 @@ xla::StatusOr<QRBlockResult> QRBlock(xla::XlaOp a) { // vs. xla::StatusOr<xla::XlaOp> ComputeWYRepresentation( xla::PrimitiveType type, gtl::ArraySlice<int64> batch_dims, xla::XlaOp vs, - xla::XlaOp taus, int64 m, int64 n) { + xla::XlaOp taus, int64 m, int64 n, + xla::PrecisionConfigProto::Precision precision) { std::vector<int64> batch_dim_indices(batch_dims.size()); std::iota(batch_dim_indices.begin(), batch_dim_indices.end(), 0); int64 n_index = batch_dims.size() + 1; @@ -272,9 +278,12 @@ xla::StatusOr<xla::XlaOp> ComputeWYRepresentation( auto beta = DynamicSliceInMinorDims(taus, {j}, {1}); // yv has shape [..., n, 1] - auto yv = BatchDot(y, v, /*transpose_x=*/true); + auto yv = BatchDot(y, v, /*transpose_x=*/true, /*transpose_y=*/false, + /*conjugate_x=*/false, /*conjugate_y=*/false, precision); // wyv has shape [..., m, 1] - auto wyv = BatchDot(w, yv); + auto wyv = + BatchDot(w, yv, /*transpose_x=*/false, /*transpose_y=*/false, + /*conjugate_x=*/false, /*conjugate_y=*/false, precision); auto z = xla::Mul( -beta, v + wyv, @@ -321,8 +330,9 @@ xla::StatusOr<xla::XlaOp> ComputeWYRepresentation( // return (q, a) // TODO(phawkins): consider using UT transformations (in the form I - V U V') // rather than WY transformations. -xla::StatusOr<QRDecompositionResult> QRDecomposition(xla::XlaOp a, - int64 block_size) { +xla::StatusOr<QRDecompositionResult> QRDecomposition( + xla::XlaOp a, int64 block_size, + xla::PrecisionConfigProto::Precision precision) { xla::XlaBuilder* builder = a.builder(); TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); const int num_dims = xla::ShapeUtil::Rank(a_shape); @@ -352,29 +362,36 @@ xla::StatusOr<QRDecompositionResult> QRDecomposition(xla::XlaOp a, int64 k = std::min(block_size, p - i); auto a_block = SliceInMinorDims(a, {i, i}, {m, i + k}); - TF_ASSIGN_OR_RETURN(auto qr_block, QRBlock(a_block)); + TF_ASSIGN_OR_RETURN(auto qr_block, QRBlock(a_block, precision)); a = UpdateSliceInMinorDims(a, qr_block.r, {i, i}); // Compute the I-WY block representation of a product of Householder // matrices. - TF_ASSIGN_OR_RETURN(auto w, - ComputeWYRepresentation(type, batch_dims, qr_block.vs, - qr_block.taus, m - i, k)); + TF_ASSIGN_OR_RETURN( + auto w, ComputeWYRepresentation(type, batch_dims, qr_block.vs, + qr_block.taus, m - i, k, precision)); auto y = qr_block.vs; // a[i:, i+k:] += np.dot(Y, np.dot(W.T, a[i:, i+k:])) auto a_panel = SliceInMinorDims(a, {i, i + k}, {m, n}); - auto a_update = BatchDot(w, a_panel, /*transpose_x=*/true); - a_update = BatchDot(y, a_update); + auto a_update = + BatchDot(w, a_panel, /*transpose_x=*/true, /*transpose_y=*/false, + /*conjugate_x=*/false, /*conjugate_y=*/false, precision); + a_update = + BatchDot(y, a_update, /*transpose_x=*/false, /*transpose_y=*/false, + /*conjugate_x=*/false, /*conjugate_y=*/false, precision); a_panel = a_panel + a_update; a = UpdateSliceInMinorDims(a, a_panel, {i, i + k}); // q[:, i:] += np.dot(np.dot(q[:, i:], W), Y.T)) auto q_panel = SliceInMinorDims(q, {0, i}, {m, m}); - auto q_update = BatchDot(q_panel, w); - q_update = - BatchDot(q_update, y, /*transpose_x=*/false, /*transpose_y=*/true); + auto q_update = + BatchDot(q_panel, w, /*transpose_x=*/false, /*transpose_y=*/false, + /*conjugate_x=*/false, /*conjugate_y=*/false, precision); + q_update = BatchDot(q_update, y, /*transpose_x=*/false, + /*transpose_y=*/true, /*conjugate_x=*/false, + /*conjugate_y=*/false, precision); q_panel = q_panel + q_update; q = UpdateSliceInMinorDims(q, q_panel, {0, i}); } diff --git a/tensorflow/compiler/tf2xla/lib/qr.h b/tensorflow/compiler/tf2xla/lib/qr.h index abd2316ac9..05565477b6 100644 --- a/tensorflow/compiler/tf2xla/lib/qr.h +++ b/tensorflow/compiler/tf2xla/lib/qr.h @@ -17,6 +17,7 @@ limitations under the License. #define TENSORFLOW_COMPILER_TF2XLA_LIB_QR_H_ #include "tensorflow/compiler/xla/client/xla_builder.h" +#include "tensorflow/compiler/xla/xla_data.pb.h" namespace tensorflow { @@ -32,8 +33,10 @@ struct QRDecompositionResult { xla::XlaOp r; }; -xla::StatusOr<QRDecompositionResult> QRDecomposition(xla::XlaOp a, - int64 block_size = 128); +xla::StatusOr<QRDecompositionResult> QRDecomposition( + xla::XlaOp a, int64 block_size = 128, + xla::PrecisionConfigProto::Precision precision = + xla::PrecisionConfigProto::HIGHEST); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/lib/scatter.cc b/tensorflow/compiler/tf2xla/lib/scatter.cc index ba22eff73a..bafe5099f2 100644 --- a/tensorflow/compiler/tf2xla/lib/scatter.cc +++ b/tensorflow/compiler/tf2xla/lib/scatter.cc @@ -58,7 +58,7 @@ xla::StatusOr<xla::XlaOp> XlaScatter( ") must be <= the rank of the buffer (shape: ", xla::ShapeUtil::HumanString(buffer_shape), ")"); } - indices_dims.pop_back(); + indices_dims.remove_suffix(1); } int64 num_indices = 1; diff --git a/tensorflow/compiler/tf2xla/lib/triangular_solve.cc b/tensorflow/compiler/tf2xla/lib/triangular_solve.cc index febb638e5e..37b2240b45 100644 --- a/tensorflow/compiler/tf2xla/lib/triangular_solve.cc +++ b/tensorflow/compiler/tf2xla/lib/triangular_solve.cc @@ -110,8 +110,9 @@ xla::XlaOp DiagonalBlocks(xla::XlaOp a, int64 block_size) { }); } -xla::XlaOp InvertDiagonalBlocks(xla::XlaOp diag_blocks, bool lower, - bool transpose_a, bool conjugate_a) { +xla::XlaOp InvertDiagonalBlocks( + xla::XlaOp diag_blocks, bool lower, bool transpose_a, bool conjugate_a, + xla::PrecisionConfigProto::Precision precision) { xla::XlaBuilder* builder = diag_blocks.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { // Input is a batch of square lower triangular square matrices. Its shape is @@ -215,7 +216,10 @@ xla::XlaOp InvertDiagonalBlocks(xla::XlaOp diag_blocks, bool lower, dnums.add_rhs_batch_dimensions(0); dnums.add_lhs_contracting_dimensions(2); dnums.add_rhs_contracting_dimensions(1); - auto update = -DotGeneral(input_row, body_out, dnums); + xla::PrecisionConfigProto precision_proto; + precision_proto.add_operand_precision(precision); + precision_proto.add_operand_precision(precision); + auto update = -DotGeneral(input_row, body_out, dnums, &precision_proto); body_out = DynamicUpdateSlice(body_out, update, start_indices); @@ -238,10 +242,10 @@ xla::XlaOp InvertDiagonalBlocks(xla::XlaOp diag_blocks, bool lower, }); } -xla::XlaOp SolveWithInvertedDiagonalBlocks(xla::XlaOp a, xla::XlaOp b, - xla::XlaOp inv_diag_blocks, - bool left_side, bool lower, - bool transpose_a, bool conjugate_a) { +xla::XlaOp SolveWithInvertedDiagonalBlocks( + xla::XlaOp a, xla::XlaOp b, xla::XlaOp inv_diag_blocks, bool left_side, + bool lower, bool transpose_a, bool conjugate_a, + xla::PrecisionConfigProto::Precision precision) { xla::XlaBuilder* builder = a.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape blocks_shape, @@ -307,9 +311,13 @@ xla::XlaOp SolveWithInvertedDiagonalBlocks(xla::XlaOp a, xla::XlaOp b, auto a_row = MaybeConjugate(SliceInMinorDims(a, start, end), conjugate_a); if (left_side) { - remainder = b_row - BatchDot(a_row, x, transpose_a, false); + remainder = b_row - BatchDot(a_row, x, transpose_a, false, + /*conjugate_x=*/false, + /*conjugate_y=*/false, precision); } else { - remainder = b_row - BatchDot(x, a_row, false, transpose_a); + remainder = b_row - BatchDot(x, a_row, false, transpose_a, + /*conjugate_x=*/false, + /*conjugate_y=*/false, precision); } } @@ -319,9 +327,13 @@ xla::XlaOp SolveWithInvertedDiagonalBlocks(xla::XlaOp a, xla::XlaOp b, xla::ConstantR0WithType(builder, xla::S32, j * block_size); std::vector<xla::XlaOp> update_starts = {start_index, zero}; if (left_side) { - x_update = BatchDot(inv_block, remainder, transpose_a, false); + x_update = + BatchDot(inv_block, remainder, transpose_a, false, + /*conjugate_x=*/false, /*conjugate_y=*/false, precision); } else { - x_update = BatchDot(remainder, inv_block, false, transpose_a); + x_update = + BatchDot(remainder, inv_block, false, transpose_a, + /*conjugate_x=*/false, /*conjugate_y=*/false, precision); std::swap(update_starts[0], update_starts[1]); } x = DynamicUpdateSliceInMinorDims(x, x_update, /*starts=*/update_starts); @@ -333,7 +345,8 @@ xla::XlaOp SolveWithInvertedDiagonalBlocks(xla::XlaOp a, xla::XlaOp b, xla::XlaOp TriangularSolve(xla::XlaOp a, xla::XlaOp b, bool left_side, bool lower, bool transpose_a, bool conjugate_a, - int64 block_size) { + int64 block_size, + xla::PrecisionConfigProto::Precision precision) { xla::XlaBuilder* builder = a.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); @@ -388,12 +401,13 @@ xla::XlaOp TriangularSolve(xla::XlaOp a, xla::XlaOp b, bool left_side, auto diag_blocks = DiagonalBlocks(a, block_size); // We invert these blocks in parallel using batched matrix-vector products - auto inv_diag_blocks = - InvertDiagonalBlocks(diag_blocks, lower, transpose_a, conjugate_a); + auto inv_diag_blocks = InvertDiagonalBlocks(diag_blocks, lower, transpose_a, + conjugate_a, precision); // We now find the solution using GEMMs - auto x = SolveWithInvertedDiagonalBlocks(a, b, inv_diag_blocks, left_side, - lower, transpose_a, conjugate_a); + auto x = + SolveWithInvertedDiagonalBlocks(a, b, inv_diag_blocks, left_side, lower, + transpose_a, conjugate_a, precision); return x; }); diff --git a/tensorflow/compiler/tf2xla/lib/triangular_solve.h b/tensorflow/compiler/tf2xla/lib/triangular_solve.h index 555760b7ef..ac42a48352 100644 --- a/tensorflow/compiler/tf2xla/lib/triangular_solve.h +++ b/tensorflow/compiler/tf2xla/lib/triangular_solve.h @@ -17,7 +17,7 @@ limitations under the License. #define TENSORFLOW_COMPILER_TF2XLA_LIB_TRIANGULAR_SOLVE_H_ #include "tensorflow/compiler/xla/client/xla_builder.h" -#include "tensorflow/compiler/xla/client/xla_computation.h" +#include "tensorflow/compiler/xla/xla_data.pb.h" namespace tensorflow { @@ -59,7 +59,9 @@ namespace tensorflow { // blocking is used. xla::XlaOp TriangularSolve(xla::XlaOp a, xla::XlaOp b, bool left_side, bool lower, bool transpose_a, bool conjugate_a, - int64 block_size = 128); + int64 block_size = 128, + xla::PrecisionConfigProto::Precision precision = + xla::PrecisionConfigProto::HIGHEST); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/ops/BUILD b/tensorflow/compiler/tf2xla/ops/BUILD index ace6fd1d8e..4dce0a2102 100644 --- a/tensorflow/compiler/tf2xla/ops/BUILD +++ b/tensorflow/compiler/tf2xla/ops/BUILD @@ -11,6 +11,8 @@ cc_library( srcs = ["xla_ops.cc"], deps = [ "//tensorflow/core:framework", + "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", ], alwayslink = 1, ) diff --git a/tensorflow/compiler/tf2xla/ops/xla_ops.cc b/tensorflow/compiler/tf2xla/ops/xla_ops.cc index a59c77f5c3..2cd9ae799f 100644 --- a/tensorflow/compiler/tf2xla/ops/xla_ops.cc +++ b/tensorflow/compiler/tf2xla/ops/xla_ops.cc @@ -13,11 +13,97 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#include "absl/algorithm/container.h" #include "tensorflow/core/framework/common_shape_fns.h" #include "tensorflow/core/framework/op.h" #include "tensorflow/core/framework/shape_inference.h" +#include "tensorflow/core/lib/core/errors.h" namespace tensorflow { +namespace { + +// Helper shape function for operators that return an output with the same rank +// as their first input. +Status UnchangedRank(shape_inference::InferenceContext* c) { + if (c->RankKnown(c->input(0))) { + c->set_output(0, c->UnknownShapeOfRank(c->Rank(c->input(0)))); + } else { + c->set_output(0, c->input(0)); + } + return Status::OK(); +} + +REGISTER_OP("XlaBroadcastHelper") + .Input("lhs: T") + .Input("rhs: T") + .Input("broadcast_dims: Tindices") + .Attr("T: numbertype") + .Attr("Tindices: {int32, int64}") + .Output("lhs_output: T") + .Output("rhs_output: T") + .SetShapeFn(shape_inference::UnknownShape) + .Doc(R"doc( +Helper operator for performing XLA-style broadcasts + +Broadcasts `lhs` and `rhs` to the same rank, by adding size 1 dimensions to +whichever of `lhs` and `rhs` has the lower rank, using XLA's broadcasting rules +for binary operators. + +lhs: the LHS input tensor +rhs: the RHS input tensor +broadcast_dims: an XLA-style broadcast dimension specification +lhs_output: the broadcasted LHS tensor +rhs_output: the broadcasted RHS tensor +)doc"); + +REGISTER_OP("XlaConv") + .Input("lhs: T") + .Input("rhs: T") + .Input("window_strides: Tindices") + .Input("padding: Tindices") + .Input("lhs_dilation: Tindices") + .Input("rhs_dilation: Tindices") + .Input("feature_group_count: Tindices") + .Attr("T: numbertype") + .Attr("Tindices: {int32, int64}") + .Attr("dimension_numbers: string") + .Attr("precision_config: string") + .Output("output: T") + .SetShapeFn(UnchangedRank) + .Doc(R"doc( +Wraps the XLA ConvGeneralDilated operator, documented at + https://www.tensorflow.org/performance/xla/operation_semantics#conv_convolution +. + +lhs: the input tensor +rhs: the kernel tensor +window_strides: the inter-window strides +padding: the padding to apply at the start and end of each input dimensions +lhs_dilation: dilation to apply between input elements +rhs_dilation: dilation to apply between kernel elements +feature_group_count: number of feature groups for grouped convolution. +dimension_numbers: a serialized xla::ConvolutionDimensionNumbers proto. +precision_config: a serialized xla::PrecisionConfigProto proto. +)doc"); + +REGISTER_OP("XlaDot") + .Input("lhs: T") + .Input("rhs: T") + .Attr("T: numbertype") + .Attr("dimension_numbers: string") + .Attr("precision_config: string") + .Output("output: T") + .SetShapeFn(shape_inference::UnknownShape) + .Doc(R"doc( +Wraps the XLA ConvGeneralDilated operator, documented at + https://www.tensorflow.org/performance/xla/operation_semantics#dotgeneral +. + +lhs: the LHS tensor +rhs: the RHS tensor +dimension_numbers: a serialized xla::DotDimensionNumbers proto. +precision_config: a serialized xla::PrecisionConfigProto proto. +)doc"); REGISTER_OP("XlaDynamicUpdateSlice") .Input("input: T") @@ -73,6 +159,29 @@ else_branch: A function takes 'inputs' and returns a list of tensors. whose types are the same as what then_branch returns. )doc"); +REGISTER_OP("XlaPad") + .Input("input: T") + .Input("padding_value: T") + .Input("padding_low: Tindices") + .Input("padding_high: Tindices") + .Input("padding_interior: Tindices") + .Output("output: T") + .Attr("T: type") + .Attr("Tindices: {int32, int64}") + .SetShapeFn(UnchangedRank) + .Doc(R"doc( +Wraps the XLA Pad operator, documented at + https://www.tensorflow.org/performance/xla/operation_semantics#pad +. + +input: A `Tensor` of type T. +padding_value: A scalar `Tensor` of type T. +padding_low: the padding to apply at the start of each input dimensions +padding_high: the padding to apply at the end of each input dimension. +padding_interior: the padding to apply between each input element. +output: A `Tensor` of type T. +)doc"); + REGISTER_OP("XlaRecv") .Output("tensor: dtype") .Attr("dtype: type") @@ -98,17 +207,58 @@ tensor_name: A string key that identifies the channel. shape: The shape of the tensor. )doc"); +REGISTER_OP("XlaReduce") + .Input("input: T") + .Input("init_value: T") + .Attr("T: numbertype") + .Attr("dimensions_to_reduce: list(int)") + .Attr("reducer: func") + .Output("output: T") + .SetShapeFn([](shape_inference::InferenceContext* c) { + if (c->RankKnown(c->input(0))) { + int rank = c->Rank(c->input(0)); + std::vector<int64> dimensions_to_reduce; + TF_RETURN_IF_ERROR( + c->GetAttr("dimensions_to_reduce", &dimensions_to_reduce)); + std::set<int64> dims_set(dimensions_to_reduce.begin(), + dimensions_to_reduce.end()); + auto dim_in_range = [rank](int64 dim) { + return dim >= 0 && dim < rank; + }; + if (rank < dimensions_to_reduce.size() || + dims_set.size() != dimensions_to_reduce.size() || + !absl::c_all_of(dimensions_to_reduce, dim_in_range)) { + return errors::InvalidArgument( + "Invalid dimensions_to_reduce argument to XlaReduce"); + } + c->set_output( + 0, c->UnknownShapeOfRank(rank - dimensions_to_reduce.size())); + } else { + c->set_output(0, c->input(0)); + } + return Status::OK(); + }) + .Doc(R"doc( +Wraps the XLA Reduce operator, documented at + https://www.tensorflow.org/performance/xla/operation_semantics#reduce . + +input: the input tensor +init_value: a scalar representing the initial value for the reduction +reducer: a reducer function to apply +dimensions_to_reduce: dimension numbers over which to reduce +)doc"); + REGISTER_OP("XlaReduceWindow") .Input("input: T") .Input("init_value: T") + .Input("window_dimensions: Tindices") + .Input("window_strides: Tindices") + .Input("padding: Tindices") .Attr("T: numbertype") + .Attr("Tindices: {int32, int64}") .Attr("computation: func") - .Attr("window_dimensions: list(int)") - .Attr("window_strides: list(int)") - .Attr("padding_low: list(int)") - .Attr("padding_high: list(int)") .Output("output: T") - .SetShapeFn(shape_inference::UnknownShape) + .SetShapeFn(UnchangedRank) .Doc(R"doc( Wraps the XLA ReduceWindow operator, documented at https://www.tensorflow.org/performance/xla/operation_semantics#reducewindow . @@ -118,8 +268,35 @@ init_value: a scalar representing the initial value for the reduction computation: a reducer function to apply window_dimensions: the shape of the window window_strides: the inter-window strides -padding_low: the padding to apply at the start of each input dimensions -padding_high: the padding to apply at the end of each input dimension. +padding: the padding to apply at the start and end of each input dimensions +)doc"); + +REGISTER_OP("XlaSelectAndScatter") + .Input("operand: T") + .Input("window_dimensions: Tindices") + .Input("window_strides: Tindices") + .Input("padding: Tindices") + .Input("source: T") + .Input("init_value: T") + .Attr("T: numbertype") + .Attr("Tindices: {int32, int64}") + .Attr("select: func") + .Attr("scatter: func") + .Output("output: T") + .SetShapeFn(UnchangedRank) + .Doc(R"doc( +Wraps the XLA SelectAndScatter operator, documented at + https://www.tensorflow.org/performance/xla/operation_semantics#selectandscatter +. + +operand: the input tensor +window_dimensions: the shape of the window +window_strides: the inter-window strides +padding: the padding to apply at the start and end of each input dimensions +source: a tensor of values to scatter +init_value: a scalar representing the initial value for the output tensor +select: a selection function to apply +scatter: a scatter function to apply )doc"); REGISTER_OP("XlaSend") @@ -179,4 +356,5 @@ body: A function that takes a list of tensors and returns another list of tensors. Both lists have the same types as specified by T. )doc"); +} // namespace } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/python/BUILD b/tensorflow/compiler/tf2xla/python/BUILD index 42b6292f79..69ca394360 100644 --- a/tensorflow/compiler/tf2xla/python/BUILD +++ b/tensorflow/compiler/tf2xla/python/BUILD @@ -28,5 +28,6 @@ py_library( srcs = ["xla.py"], deps = [ "//tensorflow/compiler/tf2xla/ops:gen_xla_ops", + "//tensorflow/compiler/xla:xla_data_proto_py", ], ) diff --git a/tensorflow/compiler/tf2xla/python/xla.py b/tensorflow/compiler/tf2xla/python/xla.py index 2fc47dffb8..3626de375e 100644 --- a/tensorflow/compiler/tf2xla/python/xla.py +++ b/tensorflow/compiler/tf2xla/python/xla.py @@ -15,11 +15,12 @@ """Experimental library that exposes XLA operations directly in TensorFlow. It is sometimes useful to be able to build HLO programs directly from -TensorFlow. This file provides Tensorflow operators that map as closely as -possible to HLO operators. +TensorFlow. This file provides Tensorflow operators that mirror the semantics of +HLO operators as closely as possible. -There is no promise of backward or forward compatibility for operators defined -in this module. +Note: There is no promise of backward or forward compatibility for operators +defined in this module. This is primarily because the underlying HLO operators +do not promise backward or forward compatibility. """ from __future__ import absolute_import @@ -27,11 +28,298 @@ from __future__ import division from __future__ import print_function from tensorflow.compiler.tf2xla.ops import gen_xla_ops +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import bitwise_ops +from tensorflow.python.ops import gen_math_ops +from tensorflow.python.ops import math_ops +from tensorflow.python.ops import random_ops + +# TODO(phawkins): provide wrappers for all XLA operators. Currently the missing +# ops include: +# infeed/outfeed (available via tf.contrib.tpu) +# collectives, e.g., cross-replica-sum (available via tf.contrib.tpu) +# conditional +# gather/scatter +# collapse + +# This file reuses builtin names (following XLA's names, so we can call things +# like xla.max), so we capture the builtin versions here. +# pylint: disable=redefined-builtin +_max = max +_min = min +_slice = slice # pylint: disable=invalid-name + +constant = constant_op.constant + +# Unary operators. + +# For most arithmetic operators there is a TensorFlow operator +# that exactly corresponds to each XLA operator. Rather than defining +# XLA-specific variants, we reuse the corresponding TensorFlow operator. +# TODO(phawkins): It would be even better to have TensorFlow operators that 1:1 +# wrap every HLO operator, because that would allow us to be confident that the +# semantics match. + + +def _unary_op(fn): + """Wrapper that restricts `fn` to have the correct signature.""" + + def unary_op_wrapper(x, name=None): + return fn(x, name=name) + + return unary_op_wrapper + + +abs = _unary_op(math_ops.abs) +# TODO(phawkins): implement clz. +conj = _unary_op(math_ops.conj) +cos = _unary_op(math_ops.cos) +ceil = _unary_op(math_ops.ceil) +digamma = _unary_op(math_ops.digamma) +erf = _unary_op(math_ops.erf) +erfc = _unary_op(math_ops.erfc) +# TODO(phawkins): implement erfinv +exp = _unary_op(math_ops.exp) +expm1 = _unary_op(math_ops.expm1) +floor = _unary_op(math_ops.floor) +imag = _unary_op(math_ops.imag) +is_finite = _unary_op(math_ops.is_finite) +lgamma = _unary_op(math_ops.lgamma) +log = _unary_op(math_ops.log) +log1p = _unary_op(math_ops.log1p) +logical_not = _unary_op(math_ops.logical_not) +neg = _unary_op(math_ops.neg) +real = _unary_op(math_ops.real) +# TODO(phawkins): unlike xla::Round, this rounds to even instead of zero for +# numbers halfway between two integers. +round = _unary_op(math_ops.round) +sin = _unary_op(math_ops.sin) +sign = _unary_op(math_ops.sign) +tanh = _unary_op(math_ops.tanh) + +# Binary operators + +# The main difference between TensorFlow and XLA binary ops is the broadcasting +# semantics. TensorFlow uses Numpy-style broadcasting semantics, whereas XLA +# requires an explicit specification of which dimensions to broadcast if the +# arguments have different ranks. + + +def _broadcasting_binary_op(fn): + """Wraps a binary Tensorflow operator and performs XLA-style broadcasting.""" + + def broadcasting_binary_op_wrapper(x, y, broadcast_dims=None, name=None): + """Inner wrapper function.""" + broadcast_dims = broadcast_dims or [] + broadcast_dims = ops.convert_to_tensor(broadcast_dims, dtypes.int64) + # Rather than relying on having static shape information in the TensorFlow + # graph, we use an XlaBroadcastHelper op that can compute the correct shapes + # at JIT compilation time. + x, y = gen_xla_ops.xla_broadcast_helper(x, y, broadcast_dims) + return fn(x, y, name=name) + + return broadcasting_binary_op_wrapper + + +# Map from TF signed types to TF unsigned types. +_SIGNED_TO_UNSIGNED_TABLE = { + dtypes.int8: dtypes.uint8, + dtypes.int16: dtypes.uint16, + dtypes.int32: dtypes.uint32, + dtypes.int64: dtypes.uint64, +} + +# Map from TF unsigned types to TF signed types. +_UNSIGNED_TO_SIGNED_TABLE = { + dtypes.uint8: dtypes.int8, + dtypes.uint16: dtypes.int16, + dtypes.uint32: dtypes.int32, + dtypes.uint64: dtypes.int64, +} + + +def _shift_right_logical_helper(x, y, name=None): + """Performs an integer right logical shift irrespective of input type.""" + assert y.dtype == x.dtype + dtype = x.dtype + signed = dtype in _SIGNED_TO_UNSIGNED_TABLE + if signed: + unsigned_dtype = _SIGNED_TO_UNSIGNED_TABLE[dtype] + x = math_ops.cast(x, unsigned_dtype) + y = math_ops.cast(y, unsigned_dtype) + output = bitwise_ops.right_shift(x, y, name=name) + if signed: + output = math_ops.cast(output, dtype) + return output + + +def _shift_right_arithmetic_helper(x, y, name=None): + """Performs an integer right arithmetic shift irrespective of input type.""" + assert y.dtype == x.dtype + dtype = x.dtype + unsigned = dtype in _UNSIGNED_TO_SIGNED_TABLE + if unsigned: + signed_dtype = _UNSIGNED_TO_SIGNED_TABLE[dtype] + x = math_ops.cast(x, signed_dtype) + y = math_ops.cast(y, signed_dtype) + output = bitwise_ops.right_shift(x, y, name=name) + if unsigned: + output = math_ops.cast(output, dtype) + return output + + +add = _broadcasting_binary_op(math_ops.add) +sub = _broadcasting_binary_op(math_ops.sub) +mul = _broadcasting_binary_op(math_ops.mul) +div = _broadcasting_binary_op(math_ops.div) +rem = _broadcasting_binary_op(gen_math_ops.mod) +max = _broadcasting_binary_op(math_ops.maximum) +min = _broadcasting_binary_op(math_ops.minimum) +atan2 = _broadcasting_binary_op(math_ops.atan2) +complex = _broadcasting_binary_op(math_ops.complex) +logical_and = _broadcasting_binary_op(math_ops.logical_and) +logical_or = _broadcasting_binary_op(math_ops.logical_or) +logical_xor = _broadcasting_binary_op(math_ops.logical_xor) +eq = _broadcasting_binary_op(math_ops.equal) +ne = _broadcasting_binary_op(math_ops.not_equal) +ge = _broadcasting_binary_op(math_ops.greater_equal) +gt = _broadcasting_binary_op(math_ops.greater) +le = _broadcasting_binary_op(math_ops.less_equal) +lt = _broadcasting_binary_op(math_ops.less) +pow = _broadcasting_binary_op(math_ops.pow) +shift_left = _broadcasting_binary_op(bitwise_ops.left_shift) +shift_right_logical = _broadcasting_binary_op(_shift_right_logical_helper) +shift_right_arithmetic = _broadcasting_binary_op(_shift_right_arithmetic_helper) + + +def _binary_op(fn): + """Wrapper that restricts `fn` to have the correct signature.""" + + def binary_op_wrapper(x, y, name=None): + return fn(x, y, name=name) + + return binary_op_wrapper + + +transpose = _binary_op(array_ops.transpose) +rev = _binary_op(array_ops.reverse) + +bitcast_convert_type = array_ops.bitcast + + +def broadcast(x, dims, name=None): + x = ops.convert_to_tensor(x) + shape = array_ops.concat( + [constant_op.constant(dims), + array_ops.shape(x)], axis=0) + return array_ops.broadcast_to(x, shape, name=name) + + +def clamp(a, x, b, name=None): + return min(max(a, x, name=name), b, name=name) + + +concatenate = array_ops.concat + + +def conv(lhs, + rhs, + window_strides, + padding, + lhs_dilation, + rhs_dilation, + dimension_numbers, + feature_group_count=1, + precision_config=None, + name=None): + """Wraps the XLA ConvGeneralDilated operator. + + ConvGeneralDilated is the most general form of XLA convolution and is + documented at + https://www.tensorflow.org/performance/xla/operation_semantics#conv_convolution + + Args: + lhs: the input tensor + rhs: the kernel tensor + window_strides: the inter-window strides + padding: the padding to apply at the start and end of each input dimensions + lhs_dilation: dilation to apply between input elements + rhs_dilation: dilation to apply between kernel elements + dimension_numbers: a `ConvolutionDimensionNumbers` proto. + feature_group_count: number of feature groups for grouped convolution. + precision_config: a `PrecisionConfigProto` proto. + name: an optional name for the operator + + Returns: + A tensor representing the output of the convolution. + """ + precision_config_proto = "" + if precision_config: + precision_config_proto = precision_config.SerializeToString() + return gen_xla_ops.xla_conv( + lhs, + rhs, + window_strides=window_strides, + padding=padding, + lhs_dilation=lhs_dilation, + rhs_dilation=rhs_dilation, + feature_group_count=feature_group_count, + dimension_numbers=dimension_numbers.SerializeToString(), + precision_config=precision_config_proto, + name=name) + + +convert_element_type = math_ops.cast + + +def dot(lhs, rhs, name=None): + return math_ops.tensordot(lhs, rhs, axes=1, name=name) + + +def dot_general(lhs, rhs, dimension_numbers, precision_config=None, name=None): + precision_config_proto = "" + if precision_config: + precision_config_proto = precision_config.SerializeToString() + return gen_xla_ops.xla_dot( + lhs, + rhs, + dimension_numbers=dimension_numbers.SerializeToString(), + precision_config=precision_config_proto, + name=name) + + +def dynamic_slice(x, starts, sizes, name=None): + # TODO(phawkins): the Slice operator lowers to DynamicSlice if `starts` is not + # a compile-time constant. This doesn't exactly mimic the semantics of dynamic + # slice if the slice is out of bounds. + return array_ops.slice(x, starts, sizes, name=name) -# TODO(phawkins): provide wrappers for all XLA operators. dynamic_update_slice = gen_xla_ops.xla_dynamic_update_slice +# TODO(phawkins): generalize tf.pad to support interior padding, and then remove +# the XLA-specific pad operator. +pad = gen_xla_ops.xla_pad + + +def random_normal(mu, sigma, dims, name=None): + mu = ops.convert_to_tensor(mu) + return random_ops.random_normal( + dims, mean=mu, stddev=sigma, dtype=mu.dtype, name=name) + + +def random_uniform(minval, maxval, dims, name=None): + minval = ops.convert_to_tensor(minval) + return random_ops.random_uniform( + dims, minval, maxval, dtype=minval.dtype, name=name) + + +recv = gen_xla_ops.xla_recv +reduce = gen_xla_ops.xla_reduce + def reduce_window(operand, init, @@ -61,22 +349,38 @@ def reduce_window(operand, """ window_strides = window_strides or [1] * len(window_dimensions) padding = padding or [(0, 0)] * len(window_dimensions) - padding_low = [x for (x, _) in padding] - padding_high = [y for (_, y) in padding] return gen_xla_ops.xla_reduce_window( - operand, - init, - reducer, - window_dimensions, - window_strides, - padding_low, - padding_high, + input=operand, + init_value=init, + window_dimensions=window_dimensions, + window_strides=window_strides, + padding=padding, + computation=reducer, name=name) -recv = gen_xla_ops.xla_recv +def reshape(x, new_sizes, dimensions=None, name=None): + if dimensions is not None: + x = array_ops.transpose(x, dimensions) + x = array_ops.reshape(x, new_sizes, name=name) + return x + + +def select(condition, x, y, name=None): + return array_ops.where(condition, x, y, name) + + +select_and_scatter = gen_xla_ops.xla_select_and_scatter send = gen_xla_ops.xla_send -sort = gen_xla_ops.xla_sort +def slice(x, start_dims, limit_dims, strides): + spec = [ + _slice(start, limit, stride) + for (start, limit, stride) in zip(start_dims, limit_dims, strides) + ] + return x[tuple(spec)] + + +sort = gen_xla_ops.xla_sort while_loop = gen_xla_ops.xla_while diff --git a/tensorflow/compiler/tf2xla/resource_operation_table.cc b/tensorflow/compiler/tf2xla/resource_operation_table.cc new file mode 100644 index 0000000000..32ba6df2e6 --- /dev/null +++ b/tensorflow/compiler/tf2xla/resource_operation_table.cc @@ -0,0 +1,130 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/tf2xla/resource_operation_table.h" +#include "absl/algorithm/container.h" +#include "tensorflow/core/lib/gtl/flatmap.h" + +namespace tensorflow { +/*static*/ StringPiece XlaResourceOpInfo::XlaResourceOpKindToString( + XlaResourceOpKind op_kind) { + switch (op_kind) { + case XlaResourceOpKind::kRead: + return "Read"; + case XlaResourceOpKind::kWrite: + return "Write"; + case XlaResourceOpKind::kReadWrite: + return "Modify"; + } +} + +static gtl::FlatMap<StringPiece, XlaResourceOpInfo>* CreateResourceOpInfoMap() { + gtl::FlatMap<StringPiece, XlaResourceOpInfo>* result = + new gtl::FlatMap<StringPiece, XlaResourceOpInfo>; + + auto add = [&](StringPiece op, XlaResourceOpKind op_kind, + XlaResourceKind resource_kind) { + auto insert_result = + result->insert({op, XlaResourceOpInfo(op_kind, resource_kind)}); + CHECK(insert_result.second); + }; + + auto kRead = XlaResourceOpKind::kRead; + auto kWrite = XlaResourceOpKind::kWrite; + auto kReadWrite = XlaResourceOpKind::kReadWrite; + + auto kVariable = XlaResourceKind::kVariable; + auto kStack = XlaResourceKind::kStack; + auto kTensorArray = XlaResourceKind::kTensorArray; + + // clang-format off + add("AssignAddVariableOp" , kReadWrite, kVariable); + add("AssignSubVariableOp" , kReadWrite, kVariable); + add("AssignVariableOp" , kWrite, kVariable); + add("ReadVariableOp" , kRead, kVariable); + add("ResourceApplyAdaMax" , kReadWrite, kVariable); + add("ResourceApplyAdadelta" , kReadWrite, kVariable); + add("ResourceApplyAdagrad" , kReadWrite, kVariable); + add("ResourceApplyAdagradDA" , kReadWrite, kVariable); + add("ResourceApplyAdam" , kReadWrite, kVariable); + add("ResourceApplyAddSign" , kReadWrite, kVariable); + add("ResourceApplyCenteredRMSProp" , kReadWrite, kVariable); + add("ResourceApplyFtrl" , kReadWrite, kVariable); + add("ResourceApplyFtrlV2" , kReadWrite, kVariable); + add("ResourceApplyGradientDescent" , kReadWrite, kVariable); + add("ResourceApplyMomentum" , kReadWrite, kVariable); + add("ResourceApplyPowerSign" , kReadWrite, kVariable); + add("ResourceApplyProximalAdagrad" , kReadWrite, kVariable); + add("ResourceApplyProximalGradientDescent" , kReadWrite, kVariable); + add("ResourceApplyRMSProp" , kReadWrite, kVariable); + add("ResourceGather" , kRead, kVariable); + add("ResourceScatterAdd" , kReadWrite, kVariable); + add("ResourceScatterDiv" , kReadWrite, kVariable); + add("ResourceScatterMax" , kReadWrite, kVariable); + add("ResourceScatterMin" , kReadWrite, kVariable); + add("ResourceScatterMul" , kReadWrite, kVariable); + add("ResourceScatterNdAdd" , kReadWrite, kVariable); + add("ResourceScatterNdUpdate" , kReadWrite, kVariable); + add("ResourceScatterSub" , kReadWrite, kVariable); + add("ResourceScatterUpdate" , kReadWrite, kVariable); + add("ResourceStridedSliceAssign" , kReadWrite, kVariable); + add("VarIsInitializedOp" , kRead, kVariable); + add("VariableShape" , kRead, kVariable); + + add("StackV2" , kWrite, kStack); + add("StackCloseV2" , kRead, kStack); + add("StackPopV2" , kReadWrite, kStack); + add("StackPushV2" , kReadWrite, kStack); + + add("TensorArrayV3" , kWrite, kTensorArray); + add("TensorArrayConcatV3" , kRead, kTensorArray); + add("TensorArrayGatherV3" , kRead, kTensorArray); + add("TensorArrayScatterV3" , kWrite, kTensorArray); + add("TensorArrayGradV3" , kRead, kTensorArray); + add("TensorArrayCloseV3" , kRead, kTensorArray); + add("TensorArrayReadV3" , kRead, kTensorArray); + add("TensorArraySizeV3" , kRead, kTensorArray); + add("TensorArraySplitV3" , kWrite, kTensorArray); + add("TensorArrayWriteV3" , kWrite, kTensorArray); + // clang-format on + + return result; +} + +static const gtl::FlatMap<StringPiece, XlaResourceOpInfo>& +GetStaticResourceOpInfoMap() { + static gtl::FlatMap<StringPiece, XlaResourceOpInfo>* op_info_map = + CreateResourceOpInfoMap(); + return *op_info_map; +} + +const XlaResourceOpInfo* GetResourceOpInfoForOp(StringPiece op) { + const gtl::FlatMap<StringPiece, XlaResourceOpInfo>& op_infos = + GetStaticResourceOpInfoMap(); + auto it = op_infos.find(op); + return it == op_infos.end() ? nullptr : &it->second; +} + +namespace resource_op_table_internal { +std::vector<StringPiece> GetKnownResourceOps() { + std::vector<StringPiece> result; + for (const auto& p : GetStaticResourceOpInfoMap()) { + result.push_back(p.first); + } + absl::c_sort(result); + return result; +} +} // namespace resource_op_table_internal +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/resource_operation_table.h b/tensorflow/compiler/tf2xla/resource_operation_table.h new file mode 100644 index 0000000000..7f627a64c6 --- /dev/null +++ b/tensorflow/compiler/tf2xla/resource_operation_table.h @@ -0,0 +1,71 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_TF2XLA_RESOURCE_OPERATION_TABLE_H_ +#define TENSORFLOW_COMPILER_TF2XLA_RESOURCE_OPERATION_TABLE_H_ + +#include <string> +#include <vector> + +#include "tensorflow/core/lib/core/stringpiece.h" +#include "tensorflow/core/platform/logging.h" + +// Exposes information about the resource operations supported by tf2xla in a +// structured form. + +namespace tensorflow { +enum class XlaResourceOpKind { + kRead, // Only reads from resources. + kWrite, // Only writes to resources. + kReadWrite // Reads from and writes to resources. +}; + +enum class XlaResourceKind { + kVariable, // Operates on resource variables. + kStack, // Operates on stacks. + kTensorArray // Operates on tensor arrays. +}; + +class XlaResourceOpInfo { + public: + explicit XlaResourceOpInfo(XlaResourceOpKind op_kind, + XlaResourceKind resource_kind) + : op_kind_(op_kind), resource_kind_(resource_kind) {} + + XlaResourceOpKind kind() const { return op_kind_; } + XlaResourceKind resource_kind() const { return resource_kind_; } + + static StringPiece XlaResourceOpKindToString(XlaResourceOpKind op_kind); + + private: + XlaResourceOpKind op_kind_; + XlaResourceKind resource_kind_; +}; + +// Returns a XlaResourceOpInfo describing `op` if it is a resource operation +// supported by tf2xla, otherwise returns null (i.e. if this returns null then +// `op` is either not a resource operation or is unsupported by XLA). +const XlaResourceOpInfo* GetResourceOpInfoForOp(StringPiece op); + +namespace resource_op_table_internal { +// NB! Implementation detail exposed for unit testing, do not use. +// +// Returns the set of resource operations known by this module. +std::vector<StringPiece> GetKnownResourceOps(); +} // namespace resource_op_table_internal + +} // namespace tensorflow + +#endif // TENSORFLOW_COMPILER_TF2XLA_RESOURCE_OPERATION_TABLE_H_ diff --git a/tensorflow/compiler/tf2xla/resource_operation_table_test.cc b/tensorflow/compiler/tf2xla/resource_operation_table_test.cc new file mode 100644 index 0000000000..0343f80de9 --- /dev/null +++ b/tensorflow/compiler/tf2xla/resource_operation_table_test.cc @@ -0,0 +1,66 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/tf2xla/resource_operation_table.h" + +#include "absl/algorithm/container.h" +#include "absl/strings/str_join.h" +#include "tensorflow/compiler/tf2xla/xla_op_registry.h" +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/platform/test.h" + +namespace tensorflow { +namespace { +bool IsResourceArgDef(const OpDef::ArgDef& arg_def) { + return arg_def.type() == DT_RESOURCE; +} + +bool HasResourceInputOrOutput(const OpDef& op_def) { + return absl::c_any_of(op_def.input_arg(), IsResourceArgDef) || + absl::c_any_of(op_def.output_arg(), IsResourceArgDef); +} + +TEST(ResourceOperationTableTest, HaveAllResourceOps) { + gtl::FlatMap<string, bool> known_resource_ops; + for (StringPiece known_resource_op : + resource_op_table_internal::GetKnownResourceOps()) { + ASSERT_TRUE( + known_resource_ops.insert({string(known_resource_op), false}).second); + } + + std::vector<string> xla_op_names = XlaOpRegistry::GetAllRegisteredOps(); + for (const string& xla_op_name : xla_op_names) { + const OpDef* op_def; + TF_ASSERT_OK(OpRegistry::Global()->LookUpOpDef(xla_op_name, &op_def)); + if (HasResourceInputOrOutput(*op_def)) { + EXPECT_EQ(known_resource_ops.count(xla_op_name), 1) + << "Unknown resource op " << xla_op_name; + known_resource_ops[xla_op_name] = true; + } + } + + std::vector<string> unnecessary_resource_ops; + for (const auto& pair : known_resource_ops) { + if (!pair.second) { + unnecessary_resource_ops.push_back(pair.first); + } + } + + EXPECT_TRUE(unnecessary_resource_ops.empty()) + << "Stale resource ops:\n" + << absl::StrJoin(unnecessary_resource_ops, "\n"); +} +} // namespace +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/sharding_util.cc b/tensorflow/compiler/tf2xla/sharding_util.cc index 5759c72af3..2d7eb8b915 100644 --- a/tensorflow/compiler/tf2xla/sharding_util.cc +++ b/tensorflow/compiler/tf2xla/sharding_util.cc @@ -14,9 +14,9 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/tf2xla/sharding_util.h" +#include "absl/strings/match.h" #include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/util/device_name_utils.h" @@ -27,10 +27,10 @@ const char kShardingAttribute[] = "_XlaSharding"; } // namespace namespace { -xla::StatusOr<tensorflow::gtl::optional<xla::OpSharding>> -GetShardingFromNodeDef(const NodeDef& node_def) { +xla::StatusOr<absl::optional<xla::OpSharding>> GetShardingFromNodeDef( + const NodeDef& node_def) { if (!HasNodeAttr(node_def, kShardingAttribute)) { - return tensorflow::gtl::optional<xla::OpSharding>(); + return absl::optional<xla::OpSharding>(); } string value; xla::OpSharding sharding; @@ -40,7 +40,7 @@ GetShardingFromNodeDef(const NodeDef& node_def) { "Experimental _XlaSharding attribute was not a valid encoded " "xla::OpSharding proto."); } - return tensorflow::gtl::optional<xla::OpSharding>(sharding); + return absl::optional<xla::OpSharding>(sharding); } Status CoreOutOfRangeError(int core, int num_cores_per_replica) { @@ -50,12 +50,11 @@ Status CoreOutOfRangeError(int core, int num_cores_per_replica) { } } // namespace -xla::StatusOr<tensorflow::gtl::optional<xla::OpSharding>> -ParseShardingFromDevice( +xla::StatusOr<absl::optional<xla::OpSharding>> ParseShardingFromDevice( const string& device_name, int num_cores_per_replica, - tensorflow::gtl::optional<xla::OpSharding> explicit_sharding) { + absl::optional<xla::OpSharding> explicit_sharding) { if (device_name.empty()) { - return tensorflow::gtl::optional<xla::OpSharding>(); + return absl::optional<xla::OpSharding>(); } DeviceNameUtils::ParsedName parsed_device; if (!DeviceNameUtils::ParseFullName(device_name, &parsed_device)) { @@ -66,34 +65,34 @@ ParseShardingFromDevice( if (explicit_sharding.has_value()) { return explicit_sharding; } else if (!parsed_device.has_type || !parsed_device.has_id || - !str_util::StrContains(parsed_device.type, - kDeviceSuffixReplicatedCore)) { - return tensorflow::gtl::optional<xla::OpSharding>(); + !absl::StrContains(parsed_device.type, + kDeviceSuffixReplicatedCore)) { + return absl::optional<xla::OpSharding>(); } else { const int core = parsed_device.id; if (core < 0 || core >= num_cores_per_replica) { return CoreOutOfRangeError(core, num_cores_per_replica); } - return tensorflow::gtl::optional<xla::OpSharding>( + return absl::optional<xla::OpSharding>( xla::sharding_builder::AssignDevice(core)); } } -xla::StatusOr<tensorflow::gtl::optional<xla::OpSharding>> -ParseShardingFromDevice(const NodeDef& node_def, int num_cores_per_replica) { +xla::StatusOr<absl::optional<xla::OpSharding>> ParseShardingFromDevice( + const NodeDef& node_def, int num_cores_per_replica) { const string& device_name = node_def.device(); - TF_ASSIGN_OR_RETURN(tensorflow::gtl::optional<xla::OpSharding> sharding, + TF_ASSIGN_OR_RETURN(absl::optional<xla::OpSharding> sharding, GetShardingFromNodeDef(node_def)); return ParseShardingFromDevice(device_name, num_cores_per_replica, sharding); } -xla::StatusOr<tensorflow::gtl::optional<xla::OpSharding>> -ParseShardingFromDevice(const Node& node, int num_cores_per_replica) { +xla::StatusOr<absl::optional<xla::OpSharding>> ParseShardingFromDevice( + const Node& node, int num_cores_per_replica) { string device_name = node.assigned_device_name(); if (device_name.empty()) { device_name = node.requested_device(); } - TF_ASSIGN_OR_RETURN(tensorflow::gtl::optional<xla::OpSharding> sharding, + TF_ASSIGN_OR_RETURN(absl::optional<xla::OpSharding> sharding, GetShardingFromNodeDef(node.def())); return ParseShardingFromDevice(device_name, num_cores_per_replica, sharding); } diff --git a/tensorflow/compiler/tf2xla/sharding_util.h b/tensorflow/compiler/tf2xla/sharding_util.h index b1c817bdcc..ab67d4f154 100644 --- a/tensorflow/compiler/tf2xla/sharding_util.h +++ b/tensorflow/compiler/tf2xla/sharding_util.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_TF2XLA_TPU_UTIL_H_ -#define TENSORFLOW_COMPILER_TF2XLA_TPU_UTIL_H_ +#ifndef TENSORFLOW_COMPILER_TF2XLA_SHARDING_UTIL_H_ +#define TENSORFLOW_COMPILER_TF2XLA_SHARDING_UTIL_H_ #include <string> @@ -33,19 +33,18 @@ namespace tensorflow { // - explicit_sharding if explicit_sharding.has_value() // - a non-value if there is no assigned core or // - a sharding set as per xla::sharding_builder::AssignDevice. -xla::StatusOr<tensorflow::gtl::optional<xla::OpSharding>> -ParseShardingFromDevice(const string& device_name, int num_cores_per_replica, - tensorflow::gtl::optional<xla::OpSharding> - explicit_sharding = tensorflow::gtl::nullopt); +xla::StatusOr<absl::optional<xla::OpSharding>> ParseShardingFromDevice( + const string& device_name, int num_cores_per_replica, + absl::optional<xla::OpSharding> explicit_sharding = absl::nullopt); -xla::StatusOr<tensorflow::gtl::optional<xla::OpSharding>> -ParseShardingFromDevice(const Node& node, int num_cores_per_replica); +xla::StatusOr<absl::optional<xla::OpSharding>> ParseShardingFromDevice( + const Node& node, int num_cores_per_replica); -xla::StatusOr<tensorflow::gtl::optional<xla::OpSharding>> -ParseShardingFromDevice(const NodeDef& node_def, int num_cores_per_replica); +xla::StatusOr<absl::optional<xla::OpSharding>> ParseShardingFromDevice( + const NodeDef& node_def, int num_cores_per_replica); void SetShardingDeviceAssignmentFromNode(const Node& src, Node* dst); } // namespace tensorflow -#endif // TENSORFLOW_COMPILER_TF2XLA_TPU_UTIL_H_ +#endif // TENSORFLOW_COMPILER_TF2XLA_SHARDING_UTIL_H_ diff --git a/tensorflow/compiler/tf2xla/sharding_util_test.cc b/tensorflow/compiler/tf2xla/sharding_util_test.cc index bff5978237..dcb7e212b7 100644 --- a/tensorflow/compiler/tf2xla/sharding_util_test.cc +++ b/tensorflow/compiler/tf2xla/sharding_util_test.cc @@ -23,7 +23,7 @@ TEST(CoreUtilTest, ParseShardingFromDevice) { Graph graph(OpRegistry::Global()); auto core_from_sharding = - [](tensorflow::gtl::optional<xla::OpSharding> sharding) -> int64 { + [](absl::optional<xla::OpSharding> sharding) -> int64 { if (sharding.has_value() && sharding.value().type() == xla::OpSharding::Type::OpSharding_Type_MAXIMAL) { diff --git a/tensorflow/compiler/tf2xla/str_util.cc b/tensorflow/compiler/tf2xla/str_util.cc deleted file mode 100644 index 2b0834fe7b..0000000000 --- a/tensorflow/compiler/tf2xla/str_util.cc +++ /dev/null @@ -1,44 +0,0 @@ -/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/compiler/tf2xla/str_util.h" - -#include <string> -#include <utility> -#include <vector> - -namespace tensorflow { -namespace str_util { - -static void ReplaceAll(string* text, StringPiece from, StringPiece to) { - size_t pos = 0; - while ((pos = text->find(from.data(), pos, from.size())) != string::npos) { - text->replace(pos, from.size(), to.data(), to.size()); - pos += to.size(); - if (from.empty()) { - pos++; // Match at the beginning of the text and after every byte - } - } -} - -void ReplaceAllPairs(string* text, - const std::vector<std::pair<string, string>>& replace) { - for (const std::pair<string, string>& from_to : replace) { - ReplaceAll(text, from_to.first, from_to.second); - } -} - -} // namespace str_util -} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/str_util.h b/tensorflow/compiler/tf2xla/str_util.h deleted file mode 100644 index 51f25009d7..0000000000 --- a/tensorflow/compiler/tf2xla/str_util.h +++ /dev/null @@ -1,42 +0,0 @@ -/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -// String utilities that are esoteric enough that they don't belong in -// third_party/tensorflow/core/lib/strings/str_util.h, but are still generally -// useful under xla. - -#ifndef TENSORFLOW_COMPILER_TF2XLA_STR_UTIL_H_ -#define TENSORFLOW_COMPILER_TF2XLA_STR_UTIL_H_ - -#include <string> -#include <utility> -#include <vector> - -#include "tensorflow/core/lib/core/stringpiece.h" - -namespace tensorflow { -namespace str_util { - -// Replace all non-overlapping occurrences of the given (from,to) pairs in-place -// in text. If from is empty, it matches at the beginning of the text and after -// every byte. Each (from,to) replacement pair is processed in the order it is -// given. -void ReplaceAllPairs(string* text, - const std::vector<std::pair<string, string>>& replace); - -} // namespace str_util -} // namespace tensorflow - -#endif // TENSORFLOW_COMPILER_TF2XLA_STR_UTIL_H_ diff --git a/tensorflow/compiler/tf2xla/str_util_test.cc b/tensorflow/compiler/tf2xla/str_util_test.cc deleted file mode 100644 index 8817f6902a..0000000000 --- a/tensorflow/compiler/tf2xla/str_util_test.cc +++ /dev/null @@ -1,60 +0,0 @@ -/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/compiler/tf2xla/str_util.h" - -#include <string> -#include <utility> -#include <vector> - -#include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/platform/test.h" - -namespace tensorflow { -namespace str_util { - -class ReplaceAllPairsTest : public ::testing::Test { - protected: - void ExpectReplaceAllPairs( - string text, const std::vector<std::pair<string, string>>& replace, - StringPiece want) { - ReplaceAllPairs(&text, replace); - EXPECT_EQ(text, want); - } -}; - -TEST_F(ReplaceAllPairsTest, Simple) { - ExpectReplaceAllPairs("", {}, ""); - ExpectReplaceAllPairs("", {{"", ""}}, ""); - ExpectReplaceAllPairs("", {{"", "X"}}, "X"); - ExpectReplaceAllPairs("", {{"", "XYZ"}}, "XYZ"); - ExpectReplaceAllPairs("", {{"", "XYZ"}, {"", "_"}}, "_X_Y_Z_"); - ExpectReplaceAllPairs("", {{"", "XYZ"}, {"", "_"}, {"_Y_", "a"}}, "_XaZ_"); - ExpectReplaceAllPairs("banana", {}, "banana"); - ExpectReplaceAllPairs("banana", {{"", ""}}, "banana"); - ExpectReplaceAllPairs("banana", {{"", "_"}}, "_b_a_n_a_n_a_"); - ExpectReplaceAllPairs("banana", {{"", "__"}}, "__b__a__n__a__n__a__"); - ExpectReplaceAllPairs("banana", {{"a", "a"}}, "banana"); - ExpectReplaceAllPairs("banana", {{"a", ""}}, "bnn"); - ExpectReplaceAllPairs("banana", {{"a", "X"}}, "bXnXnX"); - ExpectReplaceAllPairs("banana", {{"a", "XX"}}, "bXXnXXnXX"); - ExpectReplaceAllPairs("banana", {{"a", "XX"}, {"XnX", "z"}}, "bXzzX"); - ExpectReplaceAllPairs("a{{foo}}b{{bar}}c{{foo}}", - {{"{{foo}}", "0"}, {"{{bar}}", "123456789"}}, - "a0b123456789c0"); -} - -} // namespace str_util -} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/tf2xla.cc b/tensorflow/compiler/tf2xla/tf2xla.cc index 48568c825b..f34af2d67d 100644 --- a/tensorflow/compiler/tf2xla/tf2xla.cc +++ b/tensorflow/compiler/tf2xla/tf2xla.cc @@ -22,6 +22,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_join.h" #include "tensorflow/compiler/tf2xla/dump_graph.h" #include "tensorflow/compiler/tf2xla/shape_util.h" #include "tensorflow/compiler/tf2xla/tf2xla_util.h" @@ -40,7 +41,6 @@ limitations under the License. #include "tensorflow/core/graph/graph_constructor.h" #include "tensorflow/core/graph/node_builder.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -197,8 +197,8 @@ Status RewriteAndPruneGraph( if (!missing_feeds.empty() || !missing_fetches.empty()) { return errors::Aborted( "Post graph-pruning", - ", missing feeds: ", str_util::Join(missing_feeds, ", "), - ", missing fetches: ", str_util::Join(missing_fetches, ", ")); + ", missing feeds: ", absl::StrJoin(missing_feeds, ", "), + ", missing fetches: ", absl::StrJoin(missing_fetches, ", ")); } return Status::OK(); } diff --git a/tensorflow/compiler/tf2xla/tf2xla_supported_ops.cc b/tensorflow/compiler/tf2xla/tf2xla_supported_ops.cc index 7aca889a26..567d212b5e 100644 --- a/tensorflow/compiler/tf2xla/tf2xla_supported_ops.cc +++ b/tensorflow/compiler/tf2xla/tf2xla_supported_ops.cc @@ -20,11 +20,11 @@ limitations under the License. #include <string> #include <vector> +#include "absl/strings/str_join.h" #include "tensorflow/compiler/tf2xla/xla_op_registry.h" #include "tensorflow/core/framework/kernel_def.pb.h" #include "tensorflow/core/framework/types.h" #include "tensorflow/core/framework/types.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/init_main.h" #include "tensorflow/core/util/command_line_flags.h" @@ -54,10 +54,10 @@ void PrintSupportedOps(const string& device, const string& regen_run) { } std::sort(types.begin(), types.end()); constraints.push_back("`" + constraint.name() + "={" + - str_util::Join(types, ",") + "}`"); + absl::StrJoin(types, ",") + "}`"); } std::cout << "`" << kdef->op() << "` | " - << str_util::Join(constraints, "<br>") << std::endl; + << absl::StrJoin(constraints, "<br>") << std::endl; } std::cout << "\nTo regenerate this table, run:\n\n```shell\n" @@ -76,7 +76,7 @@ void SupportedOpsMain(int argc, char** argv, const char* regen_run) { {"device", &device, "Name of the compilation device for which to print supported ops, " "one of: " + - str_util::Join(device_names, ",")}, + absl::StrJoin(device_names, ",")}, }; string usage = Flags::Usage(argv[0], flag_list); bool parsed_flags_ok = Flags::Parse(&argc, argv, flag_list); diff --git a/tensorflow/compiler/tf2xla/tf2xla_util.cc b/tensorflow/compiler/tf2xla/tf2xla_util.cc index 0e07485d18..e284e0b191 100644 --- a/tensorflow/compiler/tf2xla/tf2xla_util.cc +++ b/tensorflow/compiler/tf2xla/tf2xla_util.cc @@ -20,6 +20,7 @@ limitations under the License. #include <set> #include <unordered_map> +#include "absl/types/optional.h" #include "tensorflow/compiler/tf2xla/sharding_util.h" #include "tensorflow/compiler/tf2xla/tf2xla.pb.h" #include "tensorflow/compiler/xla/xla_data.pb.h" @@ -32,7 +33,6 @@ limitations under the License. #include "tensorflow/core/graph/tensor_id.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/lib/strings/strcat.h" namespace tensorflow { @@ -233,7 +233,7 @@ Status PruneGraphDefInto(const tf2xla::Config& config, const GraphDef& in, // Push input nodes of the currently visited node to name_queue. for (const string& in_edge : map_entry.second->input()) { auto id = ParseTensorName(in_edge); - const string node_name = std::string(id.first); + const string node_name = string(id.first); if (feed_tensors.find(std::make_pair(node_name, id.second)) == feed_tensors.end()) { name_queue.push(node_name); @@ -268,7 +268,7 @@ Status SetNodeShardingFromNeighbors(Node* n, bool out_edges) { if (edge->IsControlEdge()) continue; const Node* possible_match = out_edges ? edge->dst() : edge->src(); TF_ASSIGN_OR_RETURN( - tensorflow::gtl::optional<xla::OpSharding> sharding, + absl::optional<xla::OpSharding> sharding, ParseShardingFromDevice( *possible_match, /*num_cores_per_replica=*/std::numeric_limits<int32>::max())); diff --git a/tensorflow/compiler/tf2xla/tf2xla_util_test.cc b/tensorflow/compiler/tf2xla/tf2xla_util_test.cc index ae51446204..2b1f724dc7 100644 --- a/tensorflow/compiler/tf2xla/tf2xla_util_test.cc +++ b/tensorflow/compiler/tf2xla/tf2xla_util_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/tf2xla/tf2xla_util.h" +#include "absl/strings/match.h" #include "tensorflow/cc/framework/ops.h" #include "tensorflow/cc/ops/data_flow_ops.h" #include "tensorflow/cc/ops/function_ops.h" @@ -25,16 +26,15 @@ limitations under the License. #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/core/status_test_util.h" #include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/test.h" namespace tensorflow { namespace { -void ExpectErrorContains(const Status& status, StringPiece str) { +void ExpectErrorContains(const Status& status, absl::string_view str) { EXPECT_NE(Status::OK(), status); - EXPECT_TRUE(str_util::StrContains(status.error_message(), str)) + EXPECT_TRUE(absl::StrContains(status.error_message(), str)) << "expected error: " << status.error_message() << " to contain: " << str; } diff --git a/tensorflow/compiler/tf2xla/xla_compilation_device.cc b/tensorflow/compiler/tf2xla/xla_compilation_device.cc index e89f473328..d98237bd5c 100644 --- a/tensorflow/compiler/tf2xla/xla_compilation_device.cc +++ b/tensorflow/compiler/tf2xla/xla_compilation_device.cc @@ -103,7 +103,7 @@ void XlaCompilationDevice::Compute(OpKernel* op_kernel, auto sharding_parse_result = ParseShardingFromDevice( op_kernel->def(), std::numeric_limits<int>::max()); OP_REQUIRES_OK(context, sharding_parse_result.status()); - tensorflow::gtl::optional<xla::OpSharding> op_sharding = + absl::optional<xla::OpSharding> op_sharding = sharding_parse_result.ValueOrDie(); // If no sharding metadata is found, XLA is free to use whatever device it diff --git a/tensorflow/compiler/tf2xla/xla_compiler.cc b/tensorflow/compiler/tf2xla/xla_compiler.cc index 226c89bcf1..aa2a521d98 100644 --- a/tensorflow/compiler/tf2xla/xla_compiler.cc +++ b/tensorflow/compiler/tf2xla/xla_compiler.cc @@ -18,6 +18,7 @@ limitations under the License. #include <numeric> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/tf2xla/dump_graph.h" #include "tensorflow/compiler/tf2xla/functionalize_control_flow.h" #include "tensorflow/compiler/tf2xla/graph_compiler.h" @@ -310,7 +311,7 @@ Status ExecuteGraph(XlaContext* xla_context, std::unique_ptr<Graph> graph, // unique_ptr so we can capture the cleanup status in the end. xla_context->Ref(); Status status; - auto step_container = xla::MakeUnique<ScopedStepContainer>( + auto step_container = absl::make_unique<ScopedStepContainer>( step_id, [&status, device](const string& name) { status = device->resource_manager()->Cleanup(name); }); @@ -360,6 +361,9 @@ Status BuildComputation( if (retval.has_constant_value()) { output.is_constant = true; output.constant_value = retval.constant_value(); + } else if (retval.resource() != nullptr) { + output.is_constant = false; + output.input_index = retval.resource()->arg_num(); } else { output.is_constant = false; elems.push_back(retval.handle()); @@ -413,7 +417,7 @@ Status BuildComputation( // Request that the value be returned on a specific core. xla::XlaScopedShardingAssignment assign_sharding( - builder, core == -1 ? tensorflow::gtl::optional<xla::OpSharding>() + builder, core == -1 ? absl::optional<xla::OpSharding>() : xla::sharding_builder::AssignDevice(core)); xla::XlaOp handle; @@ -464,8 +468,6 @@ Status XlaCompiler::BuildArguments( // XLA computation as runtime parameters. input_mapping->clear(); input_mapping->reserve(args.size()); - std::vector<int> resources; - resources.reserve(args.size()); // Fills in constant arguments, and computes non-constant argument order. for (std::vector<XlaCompiler::Argument>::size_type i = 0; i < args.size(); @@ -484,8 +486,9 @@ Status XlaCompiler::BuildArguments( /*tensor_array_gradients=*/arg.tensor_array_gradients, &resource)); arg_expression.set_resource(resource); if (arg.initialized) { - resources.push_back(i); + input_mapping->push_back(i); } + break; case XlaCompiler::Argument::kParameter: { input_mapping->push_back(i); @@ -495,14 +498,11 @@ Status XlaCompiler::BuildArguments( arg_expression.set_constant_value(arg.constant_value); break; case XlaCompiler::Argument::kInvalid: - return errors::Internal("Unreachable case in BuildArguments()"); + return errors::Internal( + "Unreachable case in BuildArguments() while filling constant args"); } } - // Append parameters containing variable values after the other runtime - // parameters. - input_mapping->insert(input_mapping->end(), resources.begin(), - resources.end()); if (input_mapping->empty()) { return Status::OK(); } @@ -570,7 +570,7 @@ Status XlaCompiler::BuildArguments( for (std::vector<int>::size_type i = 0; i < input_mapping->size(); ++i) { const int core = (*arg_cores)[input_mapping->at(i)]; xla::XlaScopedShardingAssignment assign_sharding( - builder, core == -1 ? tensorflow::gtl::optional<xla::OpSharding>() + builder, core == -1 ? absl::optional<xla::OpSharding>() : xla::sharding_builder::AssignDevice(core)); arg_handles[i] = xla::GetTupleElement(tuple, i); } @@ -578,7 +578,7 @@ Status XlaCompiler::BuildArguments( for (std::vector<int>::size_type i = 0; i < input_mapping->size(); ++i) { const int core = (*arg_cores)[input_mapping->at(i)]; xla::XlaScopedShardingAssignment assign_sharding( - builder, core == -1 ? tensorflow::gtl::optional<xla::OpSharding>() + builder, core == -1 ? absl::optional<xla::OpSharding>() : xla::sharding_builder::AssignDevice(core)); arg_handles[i] = xla::Parameter(builder, i, (*input_shapes)[i], strings::StrCat("arg", i)); @@ -619,7 +619,8 @@ Status XlaCompiler::BuildArguments( break; case XlaCompiler::Argument::kConstant: case XlaCompiler::Argument::kInvalid: - return errors::Internal("Unreachable case in BuildArguments()"); + return errors::Internal( + "Unreachable case in BuildArguments() while filling handles"); } } @@ -791,14 +792,6 @@ Status XlaCompiler::CompileGraph(const XlaCompiler::CompileOptions& options, VLOG(2) << "XLA output shape: " << xla::ShapeUtil::HumanString(result->xla_output_shape); - // Copy the host transfer metadata to the result. - for (const auto& send : host_compute_sends_) { - *result->host_compute_metadata.add_device_to_host() = send.second; - } - for (const auto& recv : host_compute_recvs_) { - *result->host_compute_metadata.add_host_to_device() = recv.second; - } - // Tensorflow expects a major-to-minor order of results. xla::LayoutUtil::SetToDefaultLayout(&result->xla_output_shape); @@ -816,6 +809,30 @@ Status XlaCompiler::GetChannelHandle(const string& key, return Status::OK(); } +Status XlaCompiler::GetHostToDeviceChannelHandle(const string& key, + xla::ChannelHandle* channel) { + auto result = channels_.emplace(key, xla::ChannelHandle()); + if (result.second) { + TF_ASSIGN_OR_RETURN(result.first->second, + client()->CreateHostToDeviceChannelHandle()); + } + *channel = result.first->second; + VLOG(1) << "Host to device channel: " << key << " " << channel->DebugString(); + return Status::OK(); +} + +Status XlaCompiler::GetDeviceToHostChannelHandle(const string& key, + xla::ChannelHandle* channel) { + auto result = channels_.emplace(key, xla::ChannelHandle()); + if (result.second) { + TF_ASSIGN_OR_RETURN(result.first->second, + client()->CreateDeviceToHostChannelHandle()); + } + *channel = result.first->second; + VLOG(1) << "Device to host channel: " << key << " " << channel->DebugString(); + return Status::OK(); +} + namespace { void SetTransfer(const string& key, gtl::ArraySlice<DataType> types, diff --git a/tensorflow/compiler/tf2xla/xla_compiler.h b/tensorflow/compiler/tf2xla/xla_compiler.h index 25332c8d8e..9e2c64fd42 100644 --- a/tensorflow/compiler/tf2xla/xla_compiler.h +++ b/tensorflow/compiler/tf2xla/xla_compiler.h @@ -183,6 +183,8 @@ class XlaCompiler { struct OutputDescription { // Type and shape of the output. The shape is the unflattened shape. + // When `type` is DT_RESOURCE, `shape` is the shape of the resource + // variable's value. DataType type; TensorShape shape; @@ -190,6 +192,10 @@ class XlaCompiler { // 'Tensor' is in host memory. bool is_constant = false; Tensor constant_value; + + // When this output is a resource, i.e. `type == DT_RESOURCE`, this is + // the index of the input that contains the resource. + int input_index; }; // Describes a variable write side effect of the computation. @@ -212,9 +218,9 @@ class XlaCompiler { struct CompilationResult { // Vector that maps from the parameters of the XLA computation to their - // original argument positions. To handle compile-time constant inputs and - // resources, the parameters to the XLA computation may be a subset of the - // original arguments, and are not necessarily in the same order.) + // original argument positions. To handle compile-time constant inputs, the + // parameters to the XLA computation may be a subset of the original + // arguments. The relative ordering of parameters are maintained. std::vector<int> input_mapping; // Input shapes of the computation. If we are flattening inputs, these are @@ -332,6 +338,16 @@ class XlaCompiler { // same XlaCompiler. Status GetChannelHandle(const string& key, xla::ChannelHandle* channel); + // Retrieves the host-to-device channel handle associated with `key`. + // Allocates a new channel handle if none exists. + Status GetHostToDeviceChannelHandle(const string& key, + xla::ChannelHandle* channel); + + // Retrieves the device-to-host channel handle associated with `key`. + // Allocates a new channel handle if none exists. + Status GetDeviceToHostChannelHandle(const string& key, + xla::ChannelHandle* channel); + // Sets the shapes and types for the device to host transfer associated with // 'key'. Status SetDeviceToHostMetadata(const string& key, diff --git a/tensorflow/compiler/tf2xla/xla_compiler_test.cc b/tensorflow/compiler/tf2xla/xla_compiler_test.cc index be00ed8813..be3c93ae47 100644 --- a/tensorflow/compiler/tf2xla/xla_compiler_test.cc +++ b/tensorflow/compiler/tf2xla/xla_compiler_test.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/tf2xla/xla_compiler.h" +#include "absl/strings/match.h" #include "tensorflow/cc/framework/ops.h" #include "tensorflow/cc/ops/data_flow_ops.h" #include "tensorflow/cc/ops/function_ops.h" @@ -38,7 +39,6 @@ limitations under the License. #include "tensorflow/core/graph/graph.h" #include "tensorflow/core/graph/graph_constructor.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/public/version.h" @@ -280,6 +280,54 @@ TEST_F(XlaCompilerTest, OutOfOrderGraph) { EXPECT_TRUE(xla::LiteralTestUtil::Equal(*param0_literal, *actual_literal)); } +// Tests that the compiler doesn't reorder the parameters. +TEST_F(XlaCompilerTest, MixedOrderArguments) { + for (bool swap_order : {false, true}) { + Scope scope = Scope::NewRootScope().ExitOnError(); + auto var = + ops::_Arg(scope.WithOpName("V"), DT_RESOURCE, swap_order ? 0 : 1); + auto a = ops::_Arg(scope.WithOpName("A"), DT_INT32, swap_order ? 1 : 0); + // Adds an identity op around the resource to make sure identity ops + // propagate resources correctly. + auto identity = ops::Identity(scope.WithOpName("VIdentity"), var); + auto write = ops::AssignAddVariableOp(scope, identity, a); + auto read = ops::ReadVariableOp( + scope.WithControlDependencies(std::vector<Operation>{write}), var, + DT_INT32); + auto read_plus_one = ops::Add(scope, read, ops::Const<int32>(scope, 1)); + auto d = ops::_Retval(scope.WithOpName("D"), read_plus_one, 0); + std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); + TF_ASSERT_OK(scope.ToGraph(graph.get())); + + // Builds a description of the arguments. + std::vector<XlaCompiler::Argument> args(2); + args[0].kind = XlaCompiler::Argument::kParameter; + args[0].type = DT_INT32; + args[0].shape = TensorShape({2}); + args[1].kind = XlaCompiler::Argument::kResource; + args[1].resource_kind = XlaResource::kVariable; + args[1].initialized = true; + args[1].type = DT_INT32; + args[1].shape = TensorShape({2}); + + if (swap_order) { + // Even after swapping arguments, the compiler should maintain the new + // ordering of parameters. + std::swap(args[0], args[1]); + } + // Compiles the graph. + XlaCompiler compiler(DefaultOptions()); + + XlaCompiler::CompileOptions compile_options; + compile_options.always_return_tuple = false; + XlaCompiler::CompilationResult result; + TF_ASSERT_OK(compiler.CompileGraph(compile_options, "add", std::move(graph), + args, &result)); + + EXPECT_THAT(result.input_mapping, ::testing::ElementsAre(0, 1)); + } +} + TEST_F(XlaCompilerTest, HasSaneErrorOnNonCompileTimeConstantInputToReshape) { // Builds a graph that adds reshapes a tensor, but with the shape not // statically known. @@ -309,10 +357,10 @@ TEST_F(XlaCompilerTest, HasSaneErrorOnNonCompileTimeConstantInputToReshape) { std::move(graph), args, &result); EXPECT_FALSE(status.ok()); EXPECT_TRUE( - str_util::StrContains(status.error_message(), "depends on a parameter")) + absl::StrContains(status.error_message(), "depends on a parameter")) << status.error_message(); EXPECT_TRUE( - str_util::StrContains(status.error_message(), "[[{{node C}} = Reshape")) + absl::StrContains(status.error_message(), "[[{{node C}} = Reshape")) << status.error_message(); } @@ -727,8 +775,7 @@ TEST_F(XlaCompilerTest, UndefinedFunctionFails) { compiler.CompileFunction(XlaCompiler::CompileOptions(), name_attr, /*args=*/{}, &result); EXPECT_FALSE(status.ok()); - EXPECT_TRUE(str_util::StrContains(StringPiece(status.error_message()), - "is not defined.")) + EXPECT_TRUE(absl::StrContains(status.error_message(), "is not defined.")) << status.error_message(); } @@ -807,21 +854,49 @@ TEST_F(XlaCompilerTest, LocalFunctionWithWrongArgumentsFail) { ASSERT_FALSE(status.ok()); // Flib lookup failure. - EXPECT_TRUE(str_util::StrContains(StringPiece(status.error_message()), - "is not defined.")) + EXPECT_TRUE(absl::StrContains(status.error_message(), "is not defined.")) << status.error_message(); // Local flib lookup failure. - EXPECT_TRUE(str_util::StrContains(StringPiece(status.error_message()), - "Attr T is not found")) + EXPECT_TRUE(absl::StrContains(status.error_message(), "Attr T is not found")) << status.error_message(); } +void RunAndCheckVariablesComputation( + xla::Client* client, const XlaCompiler::CompilationResult& result) { + std::unique_ptr<xla::Literal> param0_literal = + xla::LiteralUtil::CreateR1<int32>({7, 42}); + std::unique_ptr<xla::Literal> param1_literal = + xla::LiteralUtil::CreateR1<int32>({-3, 101}); + std::unique_ptr<xla::GlobalData> param0_data = + client->TransferToServer(*param0_literal).ConsumeValueOrDie(); + std::unique_ptr<xla::GlobalData> param1_data = + client->TransferToServer(*param1_literal).ConsumeValueOrDie(); + + std::unique_ptr<xla::GlobalData> actual = + client + ->Execute(*result.computation, {param0_data.get(), param1_data.get()}) + .ConsumeValueOrDie(); + std::unique_ptr<xla::Literal> actual_literal = + client->Transfer(*actual).ConsumeValueOrDie(); + + std::unique_ptr<xla::Literal> expected0 = + xla::LiteralUtil::CreateR1<int32>({5, 144}); + std::unique_ptr<xla::Literal> expected1 = + xla::LiteralUtil::CreateR1<int32>({4, 143}); + std::unique_ptr<xla::Literal> expected_literal = + xla::LiteralUtil::MakeTuple({expected0.get(), expected1.get()}); + EXPECT_TRUE(xla::LiteralTestUtil::Equal(*expected_literal, *actual_literal)); +} + // Tests a simple graph that reads and writes a variable. TEST_F(XlaCompilerTest, Variables) { Scope scope = Scope::NewRootScope().ExitOnError(); auto a = ops::_Arg(scope.WithOpName("A"), DT_INT32, 0); auto var = ops::_Arg(scope.WithOpName("V"), DT_RESOURCE, 1); - auto write = ops::AssignAddVariableOp(scope, var, a); + // Adds an identity op around the resource to make sure identity ops propagate + // resources correctly. + auto identity = ops::Identity(scope.WithOpName("VIdentity"), var); + auto write = ops::AssignAddVariableOp(scope, identity, a); auto read = ops::ReadVariableOp( scope.WithControlDependencies(std::vector<Operation>{write}), var, DT_INT32); @@ -847,33 +922,87 @@ TEST_F(XlaCompilerTest, Variables) { XlaCompiler::CompilationResult result; TF_ASSERT_OK(compiler.CompileGraph(XlaCompiler::CompileOptions(), "add", std::move(graph), args, &result)); + RunAndCheckVariablesComputation(client_, result); +} + +// Tests a simple graph that reads and writes a variable. +TEST_F(XlaCompilerTest, ReturnResourceHandleOnly) { + Scope scope = Scope::NewRootScope().ExitOnError(); + auto var = ops::_Arg(scope.WithOpName("V"), DT_RESOURCE, 0); + auto d = ops::_Retval(scope.WithOpName("D"), var, 0); + std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); + TF_ASSERT_OK(scope.ToGraph(graph.get())); + + // Builds a description of the arguments. + std::vector<XlaCompiler::Argument> args(1); + args[0].kind = XlaCompiler::Argument::kResource; + args[0].resource_kind = XlaResource::kVariable; + args[0].initialized = true; + args[0].type = DT_INT32; + args[0].shape = TensorShape({2}); + + // Compiles the graph. + XlaCompiler compiler(DefaultOptions()); + + XlaCompiler::CompilationResult result; + TF_ASSERT_OK(compiler.CompileGraph(XlaCompiler::CompileOptions(), "add", + std::move(graph), args, &result)); // Tests that the generated computation works. - std::unique_ptr<xla::Literal> param0_literal = - xla::LiteralUtil::CreateR1<int32>({7, 42}); std::unique_ptr<xla::Literal> param1_literal = xla::LiteralUtil::CreateR1<int32>({-3, 101}); - std::unique_ptr<xla::GlobalData> param0_data = - client_->TransferToServer(*param0_literal).ConsumeValueOrDie(); std::unique_ptr<xla::GlobalData> param1_data = client_->TransferToServer(*param1_literal).ConsumeValueOrDie(); std::unique_ptr<xla::GlobalData> actual = - client_ - ->Execute(*result.computation, {param0_data.get(), param1_data.get()}) + client_->Execute(*result.computation, {param1_data.get()}) .ConsumeValueOrDie(); std::unique_ptr<xla::Literal> actual_literal = client_->Transfer(*actual).ConsumeValueOrDie(); - std::unique_ptr<xla::Literal> expected0 = - xla::LiteralUtil::CreateR1<int32>({5, 144}); - std::unique_ptr<xla::Literal> expected1 = - xla::LiteralUtil::CreateR1<int32>({4, 143}); std::unique_ptr<xla::Literal> expected_literal = - xla::LiteralUtil::MakeTuple({expected0.get(), expected1.get()}); + xla::LiteralUtil::MakeTuple({}); EXPECT_TRUE(xla::LiteralTestUtil::Equal(*expected_literal, *actual_literal)); } +TEST_F(XlaCompilerTest, ReturnResourceHandle) { + Scope scope = Scope::NewRootScope().ExitOnError(); + auto a = ops::_Arg(scope.WithOpName("A"), DT_INT32, 0); + auto var = ops::_Arg(scope.WithOpName("V"), DT_RESOURCE, 1); + // Adds an identity op around the resource to make sure identity ops propagate + // resources correctly. + auto identity = ops::Identity(scope.WithOpName("VIdentity"), var); + auto write = ops::AssignAddVariableOp(scope, identity, a); + auto read = ops::ReadVariableOp( + scope.WithControlDependencies(std::vector<Operation>{write}), var, + DT_INT32); + auto read_plus_one = ops::Add(scope, read, ops::Const<int32>(scope, 1)); + auto r = ops::_Retval(scope.WithOpName("R"), var, 0); + auto d = ops::_Retval(scope.WithOpName("D"), read_plus_one, 1); + + std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); + TF_ASSERT_OK(scope.ToGraph(graph.get())); + + // Builds a description of the arguments. + std::vector<XlaCompiler::Argument> args(2); + args[0].kind = XlaCompiler::Argument::kParameter; + args[0].type = DT_INT32; + args[0].shape = TensorShape({2}); + args[1].kind = XlaCompiler::Argument::kResource; + args[1].resource_kind = XlaResource::kVariable; + args[1].initialized = true; + args[1].type = DT_INT32; + args[1].shape = TensorShape({2}); + + // Compiles the graph. + XlaCompiler compiler(DefaultOptions()); + + XlaCompiler::CompilationResult result; + TF_ASSERT_OK(compiler.CompileGraph(XlaCompiler::CompileOptions(), "add", + std::move(graph), args, &result)); + RunAndCheckVariablesComputation(client_, result); +} + xla::StatusOr<std::unique_ptr<Graph>> BuildTestGraph() { Scope scope = Scope::NewRootScope().ExitOnError(); auto a = ops::_Arg(scope.WithOpName("A"), DT_INT32, 0); @@ -1075,9 +1204,9 @@ TEST_F(XlaCompilerTest, FunctionWithInvalidOp) { status = compiler.CompileGraph(XlaCompiler::CompileOptions(), "fill", std::move(graph), args, &result); ASSERT_FALSE(status.ok()); - EXPECT_TRUE(str_util::StrContains(status.error_message(), "InvalidOp")) + EXPECT_TRUE(absl::StrContains(status.error_message(), "InvalidOp")) << status.error_message(); - EXPECT_TRUE(str_util::StrContains(status.error_message(), "{{node fill_fn}}")) + EXPECT_TRUE(absl::StrContains(status.error_message(), "{{node fill_fn}}")) << status.error_message(); } @@ -1100,10 +1229,10 @@ TEST_F(XlaCompilerTest, NodeWithInvalidDataType) { status = compiler.CompileGraph(XlaCompiler::CompileOptions(), "invalid_type", std::move(graph), args, &result); ASSERT_FALSE(status.ok()); - EXPECT_TRUE(str_util::StrContains(status.error_message(), - "is not in the list of allowed values")) + EXPECT_TRUE(absl::StrContains(status.error_message(), + "is not in the list of allowed values")) << status.error_message(); - EXPECT_TRUE(str_util::StrContains(status.error_message(), "{{node Shape}}")) + EXPECT_TRUE(absl::StrContains(status.error_message(), "{{node Shape}}")) << status.error_message(); } @@ -1127,9 +1256,9 @@ TEST_F(XlaCompilerTest, SingleOpWithoutInputs) { std::move(graph_copy), args, &result); ASSERT_FALSE(status.ok()); EXPECT_TRUE( - str_util::StrContains(status.error_message(), - "The following nodes are unreachable " - "from the source in the graph: {{node NoOp}}")) + absl::StrContains(status.error_message(), + "The following nodes are unreachable " + "from the source in the graph: {{node NoOp}}")) << status.error_message(); } diff --git a/tensorflow/compiler/tf2xla/xla_context.cc b/tensorflow/compiler/tf2xla/xla_context.cc index b24e3aabbe..e36039ada5 100644 --- a/tensorflow/compiler/tf2xla/xla_context.cc +++ b/tensorflow/compiler/tf2xla/xla_context.cc @@ -107,6 +107,19 @@ Status XlaContext::AddConstRetval(int retval_index, DataType dtype, return Status::OK(); } +Status XlaContext::AddResourceRetval(int retval_index, XlaResource* resource) { + VLOG(1) << "Adding retval index " << retval_index << " with resource " + << resource->name() << ":" << resource->shape().DebugString() + << " to XLA computation"; + if (retvals_.size() <= retval_index) { + retvals_.resize(retval_index + 1); + } + XlaExpression e; + e.set_resource(resource); + retvals_[retval_index] = Retval{DT_RESOURCE, resource->shape(), e}; + return Status::OK(); +} + xla::XlaBuilder* XlaContext::builder() { return builder_; } Status XlaContext::CreateResource( diff --git a/tensorflow/compiler/tf2xla/xla_context.h b/tensorflow/compiler/tf2xla/xla_context.h index 3db37afdba..4da891634e 100644 --- a/tensorflow/compiler/tf2xla/xla_context.h +++ b/tensorflow/compiler/tf2xla/xla_context.h @@ -86,6 +86,9 @@ class XlaContext : public ResourceBase { Status AddConstRetval(int retval_index, DataType dtype, const xla::LiteralSlice& literal); + // As for Retval, but for return values that are resource handles. + Status AddResourceRetval(int retval_index, XlaResource* resource); + // Creates a resource with resource `kind` and initial value `handle`. `name` // is a descriptive name for use in error messages. See the `XlaResource` // constructor for a description of the remaining arguments. diff --git a/tensorflow/compiler/tf2xla/xla_op_kernel.cc b/tensorflow/compiler/tf2xla/xla_op_kernel.cc index 82028c8b9c..9e8f5f2a1a 100644 --- a/tensorflow/compiler/tf2xla/xla_op_kernel.cc +++ b/tensorflow/compiler/tf2xla/xla_op_kernel.cc @@ -99,6 +99,25 @@ Status XlaOpKernelContext::ConstantInput(int index, index, context_->input(index).shape().dim_sizes(), constant_literal); } +static xla::StatusOr<int> InputIndex(XlaOpKernelContext* context, + StringPiece name) { + int start, stop; + TF_RETURN_IF_ERROR(context->op_kernel().InputRange(name, &start, &stop)); + if (stop != start + 1) { + return errors::InvalidArgument("OpKernel used list-valued input name '", + name, + "' when single-valued input was " + "expected"); + } + return start; +} + +Status XlaOpKernelContext::ConstantInput(StringPiece name, + xla::Literal* constant_literal) { + TF_ASSIGN_OR_RETURN(int index, InputIndex(this, name)); + return ConstantInput(index, constant_literal); +} + Status XlaOpKernelContext::ConstantInputReshaped( int index, gtl::ArraySlice<int64> new_dims, xla::Literal* constant_literal) { @@ -246,6 +265,12 @@ Status XlaOpKernelContext::ConstantInputAsIntScalar(int index, int64* out) { return LiteralToInt64Scalar(literal, out); } +Status XlaOpKernelContext::ConstantInputAsIntScalar(StringPiece name, + int64* out) { + TF_ASSIGN_OR_RETURN(int index, InputIndex(this, name)); + return ConstantInputAsIntScalar(index, out); +} + Status XlaOpKernelContext::ConstantInputAsFloatScalar(int index, double* out) { xla::Literal literal; TF_RETURN_IF_ERROR(ConstantInput(index, &literal)); @@ -280,6 +305,20 @@ Status XlaOpKernelContext::ConstantInputAsIntVector(int index, return LiteralToInt64Vector(literal, out); } +Status XlaOpKernelContext::ConstantInputAsIntVector(StringPiece name, + std::vector<int64>* out) { + TF_ASSIGN_OR_RETURN(int index, InputIndex(this, name)); + return ConstantInputAsIntVector(index, out); +} + +Status XlaOpKernelContext::ConstantInputReshapedToIntVector( + int index, std::vector<int64>* out) { + xla::Literal literal; + TF_RETURN_IF_ERROR(ConstantInputReshaped( + index, {InputShape(index).num_elements()}, &literal)); + return LiteralToInt64Vector(literal, out); +} + Status XlaOpKernelContext::ConstantInputAsInt64Literal(int index, xla::Literal* out) { xla::Literal literal; @@ -305,6 +344,12 @@ Status XlaOpKernelContext::ConstantInputAsInt64Literal(int index, } } +Status XlaOpKernelContext::ConstantInputAsInt64Literal(StringPiece name, + xla::Literal* out) { + TF_ASSIGN_OR_RETURN(int index, InputIndex(this, name)); + return ConstantInputAsInt64Literal(index, out); +} + // TODO(phawkins): validate that the dimensions form a valid shape, fail // gracefully if they do not. Status XlaOpKernelContext::ConstantInputAsShape(int index, TensorShape* shape) { diff --git a/tensorflow/compiler/tf2xla/xla_op_kernel.h b/tensorflow/compiler/tf2xla/xla_op_kernel.h index ac9dfe3369..3e26ba4f01 100644 --- a/tensorflow/compiler/tf2xla/xla_op_kernel.h +++ b/tensorflow/compiler/tf2xla/xla_op_kernel.h @@ -106,6 +106,7 @@ class XlaOpKernelContext { // expression cannot be evaluated, e.g., because it depends on unbound // parameters, returns a non-OK status. Status ConstantInput(int index, xla::Literal* constant_literal); + Status ConstantInput(StringPiece name, xla::Literal* constant_literal); // Evaluates input `index`, reshapes it to `new_shape` if new_shape != // InputShape(index), and stores it in `*constant_literal`. If the input @@ -117,15 +118,22 @@ class XlaOpKernelContext { // Converts a constant scalar int32 or int64 tensor into an int64. Status ConstantInputAsIntScalar(int index, int64* out); + Status ConstantInputAsIntScalar(StringPiece name, int64* out); // Converts a constant scalar float32 or float64 tensor into a float64. Status ConstantInputAsFloatScalar(int index, double* out); // Converts a constant 1D int32 or int64 tensor into a vector of int64s. Status ConstantInputAsIntVector(int index, std::vector<int64>* out); + Status ConstantInputAsIntVector(StringPiece name, std::vector<int64>* out); + + // Reshapes and converts a constant int32 or int64 tensor into a vector of + // int64s. + Status ConstantInputReshapedToIntVector(int index, std::vector<int64>* out); // Converts a constant int32 or int64 Tensor into an xla int64 Literal. Status ConstantInputAsInt64Literal(int index, xla::Literal* out); + Status ConstantInputAsInt64Literal(StringPiece name, xla::Literal* out); // Converts a constant 1D int32 or int64 tensor into a TensorShape. Status ConstantInputAsShape(int index, TensorShape* shape); diff --git a/tensorflow/compiler/tf2xla/xla_op_registry.cc b/tensorflow/compiler/tf2xla/xla_op_registry.cc index 46785bc1f0..2f3a4cd3b5 100644 --- a/tensorflow/compiler/tf2xla/xla_op_registry.cc +++ b/tensorflow/compiler/tf2xla/xla_op_registry.cc @@ -325,6 +325,17 @@ std::vector<const KernelDef*> XlaOpRegistry::DeviceKernels( return kernels; } +/*static*/ std::vector<string> XlaOpRegistry::GetAllRegisteredOps() { + std::vector<string> ops; + XlaOpRegistry& registry = Instance(); + mutex_lock lock(registry.mutex_); + for (const auto& pair : registry.ops_) { + ops.push_back(pair.first); + } + std::sort(ops.begin(), ops.end()); + return ops; +} + /* static */ const std::unordered_set<string>* XlaOpRegistry::CompileTimeConstantInputs(const string& op) { XlaOpRegistry& registry = Instance(); @@ -362,7 +373,7 @@ XlaOpRegistry& XlaOpRegistry::Instance() { XlaOpRegistrationBuilder::XlaOpRegistrationBuilder(StringPiece name) { registration_.reset(new XlaOpRegistry::OpRegistration); - registration_->name = std::string(name); + registration_->name = string(name); } XlaOpRegistrationBuilder XlaOpRegistrationBuilder::Name(StringPiece name) { @@ -374,14 +385,14 @@ XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::Device( gtl::ArraySlice<StringPiece> devices) { registration_->has_device_whitelist = true; for (StringPiece device : devices) { - registration_->device_whitelist.insert(std::string(device)); + registration_->device_whitelist.emplace(device); } return *this; } XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::Device(StringPiece device) { registration_->has_device_whitelist = true; - registration_->device_whitelist.insert(std::string(device)); + registration_->device_whitelist.emplace(device); return *this; } @@ -398,7 +409,7 @@ XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::AllowResourceTypes() { XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::TypeConstraint( StringPiece attr_name, DataType allowed) { std::set<DataType>& types = - registration_->type_constraints[std::string(attr_name)]; + registration_->type_constraints[string(attr_name)]; types.insert(allowed); return *this; } @@ -406,7 +417,7 @@ XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::TypeConstraint( XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::TypeConstraint( StringPiece attr_name, gtl::ArraySlice<DataType> allowed) { std::set<DataType>& types = - registration_->type_constraints[std::string(attr_name)]; + registration_->type_constraints[string(attr_name)]; for (DataType t : allowed) { types.insert(t); } @@ -415,7 +426,7 @@ XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::TypeConstraint( XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::CompileTimeConstInput( StringPiece input_name) { - registration_->compile_time_constant_inputs.insert(std::string(input_name)); + registration_->compile_time_constant_inputs.emplace(input_name); return *this; } @@ -444,7 +455,7 @@ XlaBackendRegistrar::XlaBackendRegistrar( StringPiece name, gtl::ArraySlice<DataType> types, XlaOpRegistry::BackendOpFilter op_filter) { XlaOpRegistry& registry = XlaOpRegistry::Instance(); - registry.RegisterBackend(std::string(name), types, op_filter); + registry.RegisterBackend(string(name), types, op_filter); } } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/xla_op_registry.h b/tensorflow/compiler/tf2xla/xla_op_registry.h index fc14834ca6..6ce0e2580b 100644 --- a/tensorflow/compiler/tf2xla/xla_op_registry.h +++ b/tensorflow/compiler/tf2xla/xla_op_registry.h @@ -128,6 +128,9 @@ class XlaOpRegistry { const string& compilation_device_name, bool include_compilation_only_kernels); + // Returns all operations for which there are XLA kernels on any device. + static std::vector<string> GetAllRegisteredOps(); + // Returns the set of compile-time constant inputs to 'op'. Returns nullptr // if the op is not registered. static const std::unordered_set<string>* CompileTimeConstantInputs( diff --git a/tensorflow/compiler/xla/BUILD b/tensorflow/compiler/xla/BUILD index fdf13bb18c..ddeba1d91d 100644 --- a/tensorflow/compiler/xla/BUILD +++ b/tensorflow/compiler/xla/BUILD @@ -113,6 +113,7 @@ cc_library( ":statusor", ":types", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -161,7 +162,6 @@ cc_library( "iterator_util.h", "map_util.h", "overflow_util.h", - "ptr_util.h", "util.h", ], visibility = ["//visibility:public"], @@ -172,7 +172,10 @@ cc_library( ":types", ":xla_data_proto", "//tensorflow/core:lib", - "//tensorflow/core:ptr_util", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -210,6 +213,7 @@ tf_cc_test( ":test", ":util", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", ], ) @@ -236,10 +240,12 @@ cc_library( ":types", ":util", ":xla_data_proto", - "//tensorflow/core:framework", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", "//tensorflow/core:regexp_internal", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", ], ) @@ -256,6 +262,7 @@ tf_cc_test( ":xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:test_main", + "@com_google_absl//absl/strings", ], ) @@ -297,6 +304,9 @@ cc_library( ":util", ":xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -315,6 +325,8 @@ tf_cc_test( "//tensorflow/core:lib", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -335,6 +347,8 @@ cc_library( ":util", ":xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -353,6 +367,8 @@ cc_library( ":literal_util", ":util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -364,6 +380,8 @@ cc_library( deps = [ ":util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -373,8 +391,8 @@ cc_library( visibility = ["//visibility:public"], deps = [ ":types", - "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/strings", ], ) @@ -385,6 +403,7 @@ cc_library( ":status", ":types", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -405,8 +424,9 @@ cc_library( deps = [ ":array", ":types", - ":util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -451,6 +471,7 @@ cc_library( ":array2d", ":types", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -489,6 +510,7 @@ cc_library( ":util", ":xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -503,6 +525,7 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:regexp_internal", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -521,6 +544,8 @@ cc_library( ":xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -551,6 +576,7 @@ cc_library( ":types", ":xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -576,10 +602,11 @@ cc_library( deps = [ ":shape_util", ":status_macros", - ":util", ":xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/types:optional", ], ) @@ -593,6 +620,7 @@ tf_cc_test( ":xla_data_proto", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", ], ) @@ -619,6 +647,7 @@ cc_library( ":types", ":xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -642,6 +671,7 @@ cc_library( "//tensorflow/compiler/xla/service:shape_inference", "//tensorflow/compiler/xla/service/cpu:runtime_single_threaded_matmul", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -660,6 +690,7 @@ tf_cc_test( "//tensorflow/compiler/xla/client:padding", "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", ], ) @@ -672,6 +703,7 @@ cc_library( ":shape_util", ":xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/container:inlined_vector", ], ) diff --git a/tensorflow/compiler/xla/array.h b/tensorflow/compiler/xla/array.h index 2d5d078aa7..c8e483712e 100644 --- a/tensorflow/compiler/xla/array.h +++ b/tensorflow/compiler/xla/array.h @@ -27,12 +27,12 @@ limitations under the License. #include <type_traits> #include <vector> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/status.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/core/bits.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/types.h" @@ -507,9 +507,7 @@ class Array { } } - pieces.push_back( - tensorflow::strings::AlphaNum(values_[calculate_index(index)]) - .data()); + pieces.push_back(absl::StrCat(values_[calculate_index(index)])); // Emit comma if it isn't the last element if (index.back() != sizes_.back() - 1) { @@ -527,7 +525,7 @@ class Array { } } } while (next_index(&index)); - return tensorflow::str_util::Join(pieces, ""); + return absl::StrJoin(pieces, ""); } private: diff --git a/tensorflow/compiler/xla/array2d.h b/tensorflow/compiler/xla/array2d.h index a17e81f448..782c966b4c 100644 --- a/tensorflow/compiler/xla/array2d.h +++ b/tensorflow/compiler/xla/array2d.h @@ -24,12 +24,11 @@ limitations under the License. #include <random> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/array.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/core/bits.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/types.h" @@ -101,7 +100,7 @@ class Array2D : public Array<T> { template <typename NativeT = float> std::unique_ptr<Array2D<NativeT>> MakeLinspaceArray2D(double from, double to, int64 n1, int64 n2) { - auto array = MakeUnique<Array2D<NativeT>>(n1, n2); + auto array = absl::make_unique<Array2D<NativeT>>(n1, n2); int64 count = n1 * n2; NativeT step = static_cast<NativeT>((count > 1) ? (to - from) / (count - 1) : 0); diff --git a/tensorflow/compiler/xla/array4d.h b/tensorflow/compiler/xla/array4d.h index a75fffc605..8557bb8fe4 100644 --- a/tensorflow/compiler/xla/array4d.h +++ b/tensorflow/compiler/xla/array4d.h @@ -26,13 +26,11 @@ limitations under the License. #include <string> #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/array.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/types.h" diff --git a/tensorflow/compiler/xla/client/BUILD b/tensorflow/compiler/xla/client/BUILD index ad3fcee05b..2638dea1bd 100644 --- a/tensorflow/compiler/xla/client/BUILD +++ b/tensorflow/compiler/xla/client/BUILD @@ -71,12 +71,13 @@ cc_library( "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:types", - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla:xla_proto", "//tensorflow/compiler/xla/legacy_flags:debug_options_flags", "//tensorflow/compiler/xla/service:hlo_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -90,6 +91,9 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service:device_memory_allocator", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", + "@com_google_absl//absl/types:optional", ], ) @@ -104,7 +108,6 @@ cc_library( "//tensorflow/compiler/xla:executable_run_options", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service:backend", "//tensorflow/compiler/xla/service:compiler", @@ -117,6 +120,7 @@ cc_library( "//tensorflow/compiler/xla/service:stream_pool", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", "@llvm//:support", ], ) @@ -130,11 +134,11 @@ cc_library( ":xla_computation", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service:compile_only_service", "//tensorflow/compiler/xla/service:compiler", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", "@llvm//:support", ], ) @@ -159,6 +163,7 @@ cc_library( "//tensorflow/compiler/xla/service:platform_util", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", ], ) @@ -186,6 +191,7 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service:hlo_proto", + "@com_google_absl//absl/memory", ], ) @@ -211,6 +217,9 @@ cc_library( "//tensorflow/compiler/xla/service:hlo_proto", "//tensorflow/compiler/xla/service:shape_inference", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/xla/client/client.cc b/tensorflow/compiler/xla/client/client.cc index d0ce5e8a6a..1fdf8f6260 100644 --- a/tensorflow/compiler/xla/client/client.cc +++ b/tensorflow/compiler/xla/client/client.cc @@ -18,15 +18,15 @@ limitations under the License. #include <string> #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/client/xla_computation.h" #include "tensorflow/compiler/xla/execution_options_util.h" #include "tensorflow/compiler/xla/legacy_flags/debug_options_flags.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/types.h" @@ -89,7 +89,7 @@ StatusOr<std::unique_ptr<GlobalData>> Client::TransferToServer( "TransferToServer request"); } - return MakeUnique<GlobalData>(stub_, response.data()); + return absl::make_unique<GlobalData>(stub_, response.data()); } Status Client::TransferToInfeed(const LiteralSlice& literal, int64 replica_id, @@ -248,7 +248,7 @@ StatusOr<std::unique_ptr<GlobalData>> Client::Execute( } } - return MakeUnique<GlobalData>(stub_, response.output()); + return absl::make_unique<GlobalData>(stub_, response.output()); } StatusOr<std::vector<std::unique_ptr<GlobalData>>> Client::ExecuteParallel( @@ -278,7 +278,7 @@ StatusOr<std::vector<std::unique_ptr<GlobalData>>> Client::ExecuteParallel( std::vector<std::unique_ptr<GlobalData>> outputs; for (size_t i = 0; i < computations.size(); ++i) { outputs.push_back( - MakeUnique<GlobalData>(stub_, response.responses(i).output())); + absl::make_unique<GlobalData>(stub_, response.responses(i).output())); if (computations[i].execution_profile != nullptr) { *computations[i].execution_profile = response.responses(i).profile(); } @@ -340,7 +340,7 @@ StatusOr<std::vector<std::unique_ptr<GlobalData>>> Client::DeconstructTuple( std::vector<std::unique_ptr<GlobalData>> handles; for (auto& handle : response.element_handles()) { - handles.push_back(MakeUnique<GlobalData>(stub_, handle)); + handles.push_back(absl::make_unique<GlobalData>(stub_, handle)); } return std::move(handles); } @@ -369,7 +369,7 @@ StatusOr<ComputationStats> Client::GetComputationStats( StatusOr<std::unique_ptr<ProgramShape>> Client::GetComputationShape( const XlaComputation& computation) { TF_ASSIGN_OR_RETURN(const auto& result, computation.GetProgramShape()); - return MakeUnique<ProgramShape>(result); + return absl::make_unique<ProgramShape>(result); } StatusOr<Shape> Client::GetShape(const GlobalData& data) { @@ -400,7 +400,7 @@ StatusOr<string> Client::ExecutionStatsAsString( int64 nanoseconds = profile.compute_time_ns(); int64 cycle_count = profile.compute_cycle_count(); double gflops = total_flops / nanoseconds; - return tensorflow::strings::StrCat( + return absl::StrCat( "[Execution Statistics] flop count: ", computation_stats.flop_count(), ", transcendental count: ", computation_stats.transcendental_count(), ", compute execution time: ", nanoseconds, " nsec", diff --git a/tensorflow/compiler/xla/client/client_library.cc b/tensorflow/compiler/xla/client/client_library.cc index 803a9e4009..27b7fa7b29 100644 --- a/tensorflow/compiler/xla/client/client_library.cc +++ b/tensorflow/compiler/xla/client/client_library.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/client/client_library.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/backend.h" #include "tensorflow/compiler/xla/service/platform_util.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -94,10 +95,10 @@ ClientLibrary::~ClientLibrary() = default; service_options.set_intra_op_parallelism_threads( options.intra_op_parallelism_threads()); - auto instance = MakeUnique<LocalInstance>(); + auto instance = absl::make_unique<LocalInstance>(); TF_ASSIGN_OR_RETURN(instance->service, LocalService::NewService(service_options)); - instance->client = MakeUnique<LocalClient>(instance->service.get()); + instance->client = absl::make_unique<LocalClient>(instance->service.get()); LocalClient* cl = instance->client.get(); client_library.local_instances_.insert( @@ -134,10 +135,11 @@ ClientLibrary::GetOrCreateCompileOnlyClient(se::Platform* platform) { return it->second->client.get(); } - auto instance = MakeUnique<CompileOnlyInstance>(); + auto instance = absl::make_unique<CompileOnlyInstance>(); TF_ASSIGN_OR_RETURN(instance->service, CompileOnlyService::NewService(platform)); - instance->client = MakeUnique<CompileOnlyClient>(instance->service.get()); + instance->client = + absl::make_unique<CompileOnlyClient>(instance->service.get()); CompileOnlyClient* cl = instance->client.get(); client_library.compile_only_instances_.insert( diff --git a/tensorflow/compiler/xla/client/compile_only_client.cc b/tensorflow/compiler/xla/client/compile_only_client.cc index 5c9abad4c3..040344c9a6 100644 --- a/tensorflow/compiler/xla/client/compile_only_client.cc +++ b/tensorflow/compiler/xla/client/compile_only_client.cc @@ -15,8 +15,8 @@ limitations under the License. #include "tensorflow/compiler/xla/client/compile_only_client.h" +#include "absl/memory/memory.h" #include "llvm/ADT/Triple.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/status_macros.h" namespace xla { @@ -41,7 +41,7 @@ CompileOnlyClient::CompileAheadOfTime( metadata); } -int64 CompileOnlyClient::PointerSizeForTriple(tensorflow::StringPiece triple) { +int64 CompileOnlyClient::PointerSizeForTriple(absl::string_view triple) { llvm::Triple llvm_triple( llvm::Triple::normalize(llvm::StringRef(triple.data(), triple.size()))); if (llvm_triple.isArch64Bit()) { diff --git a/tensorflow/compiler/xla/client/compile_only_client.h b/tensorflow/compiler/xla/client/compile_only_client.h index a551edeab0..d0c83cbfcc 100644 --- a/tensorflow/compiler/xla/client/compile_only_client.h +++ b/tensorflow/compiler/xla/client/compile_only_client.h @@ -57,7 +57,7 @@ class CompileOnlyClient : public Client { std::unique_ptr<AotCompilationMetadata>* metadata = nullptr); // Returns the size of a pointer in bytes for a given triple. - static int64 PointerSizeForTriple(tensorflow::StringPiece triple); + static int64 PointerSizeForTriple(absl::string_view triple); private: CompileOnlyService* compiler_service_; diff --git a/tensorflow/compiler/xla/client/executable_build_options.cc b/tensorflow/compiler/xla/client/executable_build_options.cc index 7dee41f6a0..0f1745366b 100644 --- a/tensorflow/compiler/xla/client/executable_build_options.cc +++ b/tensorflow/compiler/xla/client/executable_build_options.cc @@ -15,8 +15,8 @@ limitations under the License. #include "tensorflow/compiler/xla/client/executable_build_options.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/shape_util.h" -#include "tensorflow/core/lib/strings/stringprintf.h" namespace xla { @@ -59,10 +59,10 @@ string ExecutableBuildOptions::ToString() const { if (generate_hlo_graph_.has_value()) { generate_hlo_graph = generate_hlo_graph_.value(); } - return tensorflow::strings::Printf( + return absl::StrFormat( "ExecutableBuildOptions{device_ordinal=%d, result_layout=%s, " "generate_hlo_graph=%s}", - device_ordinal_, result_layout.c_str(), generate_hlo_graph.c_str()); + device_ordinal_, result_layout, generate_hlo_graph); } ExecutableBuildOptions& ExecutableBuildOptions::set_generate_hlo_graph( @@ -71,41 +71,41 @@ ExecutableBuildOptions& ExecutableBuildOptions::set_generate_hlo_graph( return *this; } -const tensorflow::gtl::optional<string>& -ExecutableBuildOptions::generate_hlo_graph() const { +const absl::optional<string>& ExecutableBuildOptions::generate_hlo_graph() + const { return generate_hlo_graph_; } ExecutableBuildOptions& ExecutableBuildOptions::set_dump_optimized_hlo_proto_to( - tensorflow::StringPiece dirpath) { - dump_optimized_hlo_proto_to_ = dirpath.ToString(); + absl::string_view dirpath) { + dump_optimized_hlo_proto_to_ = string(dirpath); return *this; } -const tensorflow::gtl::optional<string>& +const absl::optional<string>& ExecutableBuildOptions::dump_optimized_hlo_proto_to() const { return dump_optimized_hlo_proto_to_; } ExecutableBuildOptions& ExecutableBuildOptions::set_dump_unoptimized_hlo_proto_to( - tensorflow::StringPiece dirpath) { - dump_unoptimized_hlo_proto_to_ = dirpath.ToString(); + absl::string_view dirpath) { + dump_unoptimized_hlo_proto_to_ = string(dirpath); return *this; } -const tensorflow::gtl::optional<string>& +const absl::optional<string>& ExecutableBuildOptions::dump_unoptimized_hlo_proto_to() const { return dump_unoptimized_hlo_proto_to_; } ExecutableBuildOptions& ExecutableBuildOptions::set_dump_per_pass_hlo_proto_to( - tensorflow::StringPiece dirpath) { - dump_per_pass_hlo_proto_to_ = dirpath.ToString(); + absl::string_view dirpath) { + dump_per_pass_hlo_proto_to_ = string(dirpath); return *this; } -const tensorflow::gtl::optional<string>& +const absl::optional<string>& ExecutableBuildOptions::dump_per_pass_hlo_proto_to() const { return dump_per_pass_hlo_proto_to_; } @@ -115,7 +115,7 @@ ExecutableBuildOptions& ExecutableBuildOptions::set_hlo_profile(bool enabled) { return *this; } -tensorflow::gtl::optional<bool> ExecutableBuildOptions::hlo_profile() const { +absl::optional<bool> ExecutableBuildOptions::hlo_profile() const { return hlo_profile_; } diff --git a/tensorflow/compiler/xla/client/executable_build_options.h b/tensorflow/compiler/xla/client/executable_build_options.h index 9dc9be4423..888d2f28eb 100644 --- a/tensorflow/compiler/xla/client/executable_build_options.h +++ b/tensorflow/compiler/xla/client/executable_build_options.h @@ -16,11 +16,11 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_CLIENT_EXECUTABLE_BUILD_OPTIONS_H_ #define TENSORFLOW_COMPILER_XLA_CLIENT_EXECUTABLE_BUILD_OPTIONS_H_ +#include "absl/strings/string_view.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/device_memory_allocator.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/lib/gtl/optional.h" namespace xla { @@ -57,34 +57,33 @@ class ExecutableBuildOptions { // If set, specifies a regexp of HLO graphs to dump (as in DebugOptions). ExecutableBuildOptions& set_generate_hlo_graph(string regex); - const tensorflow::gtl::optional<string>& generate_hlo_graph() const; + const absl::optional<string>& generate_hlo_graph() const; // If set, specifies a dirpath to dump the end-of-optimization-pipeline HLO // protobuf to (as in DebugOptions). ExecutableBuildOptions& set_dump_optimized_hlo_proto_to( - tensorflow::StringPiece dirpath); - const tensorflow::gtl::optional<string>& dump_optimized_hlo_proto_to() const; + absl::string_view dirpath); + const absl::optional<string>& dump_optimized_hlo_proto_to() const; // If set, specifies a dirpath to dump the start-of-optimization-pipeline HLO // protobuf to (as in DebugOptions). ExecutableBuildOptions& set_dump_unoptimized_hlo_proto_to( - tensorflow::StringPiece dirpath); - const tensorflow::gtl::optional<string>& dump_unoptimized_hlo_proto_to() - const; + absl::string_view dirpath); + const absl::optional<string>& dump_unoptimized_hlo_proto_to() const; // If set, specifies a dirpath to dump the per-pass-in-pipeline HLO protobufs // to (as in DebugOptions). ExecutableBuildOptions& set_dump_per_pass_hlo_proto_to( - tensorflow::StringPiece dirpath); - const tensorflow::gtl::optional<string>& dump_per_pass_hlo_proto_to() const; + absl::string_view dirpath); + const absl::optional<string>& dump_per_pass_hlo_proto_to() const; // If true, specifies that we should record an HLO profile during execution // and log it after execution (as in DebugOptions). If nullopt the default is // used. ExecutableBuildOptions& set_hlo_profile(bool enabled); - tensorflow::gtl::optional<bool> hlo_profile() const; + absl::optional<bool> hlo_profile() const; - void add_disabled_hlo_pass(tensorflow::StringPiece pass_name) { + void add_disabled_hlo_pass(absl::string_view pass_name) { disabled_hlo_passes_.push_back(std::string(pass_name)); } const tensorflow::gtl::ArraySlice<std::string> disabled_hlo_passes() const { @@ -96,14 +95,14 @@ class ExecutableBuildOptions { string ToString() const; private: - tensorflow::gtl::optional<bool> hlo_profile_; + absl::optional<bool> hlo_profile_; int device_ordinal_ = -1; Shape result_layout_; bool result_layout_set_ = false; - tensorflow::gtl::optional<string> generate_hlo_graph_; - tensorflow::gtl::optional<string> dump_optimized_hlo_proto_to_; - tensorflow::gtl::optional<string> dump_unoptimized_hlo_proto_to_; - tensorflow::gtl::optional<string> dump_per_pass_hlo_proto_to_; + absl::optional<string> generate_hlo_graph_; + absl::optional<string> dump_optimized_hlo_proto_to_; + absl::optional<string> dump_unoptimized_hlo_proto_to_; + absl::optional<string> dump_per_pass_hlo_proto_to_; DeviceMemoryAllocator* device_allocator_ = nullptr; std::vector<std::string> disabled_hlo_passes_; }; diff --git a/tensorflow/compiler/xla/client/lib/BUILD b/tensorflow/compiler/xla/client/lib/BUILD index a2f32ab97e..8736f18dcf 100644 --- a/tensorflow/compiler/xla/client/lib/BUILD +++ b/tensorflow/compiler/xla/client/lib/BUILD @@ -31,7 +31,7 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:xla_builder", "//tensorflow/compiler/xla/client:xla_computation", - "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -65,6 +65,17 @@ xla_test( ) cc_library( + name = "conv_grad_size_util", + srcs = ["conv_grad_size_util.cc"], + hdrs = ["conv_grad_size_util.h"], + deps = [ + "//tensorflow/compiler/xla:status_macros", + "//tensorflow/compiler/xla/client:padding", + "//tensorflow/core:lib", + ], +) + +cc_library( name = "math", srcs = ["math.cc"], hdrs = ["math.h"], @@ -128,9 +139,9 @@ cc_library( deps = [ ":arithmetic", ":constants", - "//tensorflow/compiler/tf2xla/lib:util", + ":conv_grad_size_util", "//tensorflow/compiler/xla/client:xla_builder", - "//tensorflow/core:lib", + "@com_google_absl//absl/container:inlined_vector", ], ) @@ -142,6 +153,7 @@ xla_test( "//tensorflow/compiler/xla:test", "//tensorflow/compiler/xla/tests:client_library_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", + "@com_google_absl//absl/container:inlined_vector", ], ) @@ -209,5 +221,6 @@ cc_library( "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/compiler/xla/tests:test_utils", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/xla/client/lib/arithmetic.cc b/tensorflow/compiler/xla/client/lib/arithmetic.cc index 9225b1acd6..e86c10f030 100644 --- a/tensorflow/compiler/xla/client/lib/arithmetic.cc +++ b/tensorflow/compiler/xla/client/lib/arithmetic.cc @@ -17,6 +17,7 @@ limitations under the License. #include <string> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/client/lib/constants.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/client/xla_computation.h" @@ -24,7 +25,6 @@ limitations under the License. #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { namespace { @@ -39,7 +39,7 @@ XlaComputation CreateScalarComputation(const string& name, PrimitiveType type, b = builder->CreateSubBuilder(name); } else { b = builder->CreateSubBuilder( - tensorflow::strings::StrCat(name, "_", PrimitiveType_Name(type))); + absl::StrCat(name, "_", PrimitiveType_Name(type))); } const Shape scalar = ShapeUtil::MakeShape(type, {}); diff --git a/tensorflow/compiler/xla/client/lib/constants.cc b/tensorflow/compiler/xla/client/lib/constants.cc index 031d62e4ff..1ada7b4a96 100644 --- a/tensorflow/compiler/xla/client/lib/constants.cc +++ b/tensorflow/compiler/xla/client/lib/constants.cc @@ -56,7 +56,7 @@ XlaOp Epsilon(XlaBuilder* builder, PrimitiveType type) { std::numeric_limits<double>::epsilon()); default: return builder->ReportError(InvalidArgument( - "Invalid type for Epsilon (%s).", PrimitiveType_Name(type).c_str())); + "Invalid type for Epsilon (%s).", PrimitiveType_Name(type))); } } diff --git a/tensorflow/compiler/xla/client/lib/constants.h b/tensorflow/compiler/xla/client/lib/constants.h index 0c8a9b8cc0..81624614c1 100644 --- a/tensorflow/compiler/xla/client/lib/constants.h +++ b/tensorflow/compiler/xla/client/lib/constants.h @@ -37,13 +37,13 @@ XlaOp ConstantR0WithType(XlaBuilder* builder, PrimitiveType type, T value) { primitive_util::IsComplexType(type))) { return builder->ReportError(InvalidArgument( "Invalid cast from floating point type to %s in ConstantR0WithType.", - PrimitiveType_Name(type).c_str())); + PrimitiveType_Name(type))); } if (std::is_same<T, complex64>::value && !primitive_util::IsComplexType(type)) { return builder->ReportError(InvalidArgument( "Invalid cast from complex type to %s in ConstantR0WithType.", - PrimitiveType_Name(type).c_str())); + PrimitiveType_Name(type))); } switch (type) { case F16: @@ -71,7 +71,7 @@ XlaOp ConstantR0WithType(XlaBuilder* builder, PrimitiveType type, T value) { default: return builder->ReportError( InvalidArgument("Invalid type for ConstantR0WithType (%s).", - PrimitiveType_Name(type).c_str())); + PrimitiveType_Name(type))); } } diff --git a/tensorflow/compiler/xla/client/lib/conv_grad_size_util.cc b/tensorflow/compiler/xla/client/lib/conv_grad_size_util.cc new file mode 100644 index 0000000000..a4c50a5491 --- /dev/null +++ b/tensorflow/compiler/xla/client/lib/conv_grad_size_util.cc @@ -0,0 +1,96 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/xla/client/lib/conv_grad_size_util.h" +#include "tensorflow/compiler/xla/status_macros.h" +#include "tensorflow/core/lib/core/errors.h" + +namespace xla { + +namespace { + +StatusOr<SpatialDimensionOutputSizeAndPadding> GetWindowedOutputSize( + int64 input_size, int64 filter_size, int64 dilation_rate, int64 stride, + Padding padding_type) { + if (stride <= 0) { + return tensorflow::errors::InvalidArgument("Stride must be > 0, but got ", + stride); + } + if (dilation_rate < 1) { + return tensorflow::errors::InvalidArgument( + "Dilation rate must be >= 1, but got ", dilation_rate); + } + + int64 effective_filter_size = (filter_size - 1) * dilation_rate + 1; + SpatialDimensionOutputSizeAndPadding dim; + switch (padding_type) { + case Padding::kValid: + dim.output_size = (input_size - effective_filter_size + stride) / stride; + dim.pad_before = dim.pad_after = 0; + break; + case Padding::kSame: + dim.output_size = (input_size + stride - 1) / stride; + const int64 padding_needed = + std::max(int64{0}, (dim.output_size - 1) * stride + + effective_filter_size - input_size); + // For odd values of total padding, add more padding on the "after" side + // of the given dimension. + dim.pad_before = padding_needed / 2; + dim.pad_after = padding_needed - dim.pad_before; + break; + } + if (dim.output_size < 0) { + return tensorflow::errors::InvalidArgument( + "Computed output size would be negative: ", dim.output_size, + " [input_size: ", input_size, + ", effective_filter_size: ", effective_filter_size, + ", stride: ", stride, "]"); + } + return dim; +} + +} // namespace + +StatusOr<SpatialDimensionOutputSizeAndPadding> +ConvGradExtractAndVerifyDimension(int64 input_size, int64 filter_size, + int64 output_size, int64 dilation, + int64 stride, Padding padding) { + TF_ASSIGN_OR_RETURN(SpatialDimensionOutputSizeAndPadding output_dim, + GetWindowedOutputSize(input_size, filter_size, dilation, + stride, padding)); + if (output_size != output_dim.output_size) { + return tensorflow::errors::InvalidArgument( + "Size of out_backprop doesn't match computed: ", "actual = ", + output_size, ", computed = ", output_dim.output_size, + " input: ", input_size, " filter: ", filter_size, + " output: ", output_size, " stride: ", stride, " dilation: ", dilation); + } + + SpatialDimensionOutputSizeAndPadding dim; + int64 effective_filter_size = (filter_size - 1) * dilation + 1; + dim.output_size = (output_dim.output_size - 1) * stride + 1; + const auto padded_out_size = input_size + effective_filter_size - 1; + dim.pad_before = effective_filter_size - 1 - output_dim.pad_before; + dim.pad_after = padded_out_size - dim.output_size - dim.pad_before; + VLOG(2) << "expanded_out = " << dim.output_size + << ", effective_filter_size = " << effective_filter_size + << ", padded_out = " << padded_out_size + << ", pad_before = " << dim.pad_before + << ", pad_after = " << dim.pad_after << ", dilation = " << dilation + << ", strides = " << stride; + return dim; +} + +} // namespace xla diff --git a/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h b/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h new file mode 100644 index 0000000000..c18087ce6b --- /dev/null +++ b/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h @@ -0,0 +1,45 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_XLA_CLIENT_LIB_CONV_GRAD_SIZE_UTIL_H_ +#define TENSORFLOW_COMPILER_XLA_CLIENT_LIB_CONV_GRAD_SIZE_UTIL_H_ + +#include "tensorflow/compiler/xla/client/padding.h" +#include "tensorflow/core/lib/core/stringpiece.h" +#include "tensorflow/core/platform/types.h" + +namespace xla { + +// Information about a single spatial dimension for a convolution gradients and +// windowed operations. +struct SpatialDimensionOutputSizeAndPadding { + // Effective size of the operation output (potentially expanded). + int64 output_size; + // Number of padding elements to be added before/after this dimension of + // the input when computing the input gradient. + int64 pad_before; + int64 pad_after; +}; + +// Verifies that the dimensions all match, and computes the size and padding of +// a spatial dimension for convolution gradient operations. +StatusOr<SpatialDimensionOutputSizeAndPadding> +ConvGradExtractAndVerifyDimension(int64 input_size, int64 filter_size, + int64 output_size, int64 dilation, + int64 stride, Padding padding); + +} // namespace xla + +#endif // TENSORFLOW_COMPILER_XLA_CLIENT_LIB_CONV_GRAD_SIZE_UTIL_H_ diff --git a/tensorflow/compiler/xla/client/lib/math.cc b/tensorflow/compiler/xla/client/lib/math.cc index 0221de7672..e569610b85 100644 --- a/tensorflow/compiler/xla/client/lib/math.cc +++ b/tensorflow/compiler/xla/client/lib/math.cc @@ -207,7 +207,11 @@ XlaOp Lgamma(XlaOp input) { XlaOp log_y = log_sqrt_two_pi + (z + one_half) * log_t - t + Log(x); - XlaOp reflection = log_pi - Log(Sin(pi * input)) - log_y; + // If z = a + 0j, the analytic continuation of log reduces to taking the + // absolute value of the real part. + // Re(log(z)) = Re(log|z| + arg(z)j) + // = log|a| + XlaOp reflection = log_pi - Log(Abs(Sin(pi * input))) - log_y; XlaOp result = Select(need_to_reflect, reflection, log_y); return result; } diff --git a/tensorflow/compiler/xla/client/lib/numeric.cc b/tensorflow/compiler/xla/client/lib/numeric.cc index 1c91237ae1..02bed80162 100644 --- a/tensorflow/compiler/xla/client/lib/numeric.cc +++ b/tensorflow/compiler/xla/client/lib/numeric.cc @@ -65,9 +65,8 @@ XlaOp Iota(XlaBuilder* builder, PrimitiveType type, int64 size) { case C64: return MakeIota<complex64>(builder, size); default: - return builder->ReportError( - InvalidArgument("Unimplemented type for Iota: %s.", - PrimitiveType_Name(type).c_str())); + return builder->ReportError(InvalidArgument( + "Unimplemented type for Iota: %s.", PrimitiveType_Name(type))); } } diff --git a/tensorflow/compiler/xla/client/lib/pooling.cc b/tensorflow/compiler/xla/client/lib/pooling.cc index 7199269a6c..3ae9ae36f6 100644 --- a/tensorflow/compiler/xla/client/lib/pooling.cc +++ b/tensorflow/compiler/xla/client/lib/pooling.cc @@ -14,9 +14,9 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/client/lib/pooling.h" -#include "tensorflow/compiler/tf2xla/lib/util.h" #include "tensorflow/compiler/xla/client/lib/arithmetic.h" #include "tensorflow/compiler/xla/client/lib/constants.h" +#include "tensorflow/compiler/xla/client/lib/conv_grad_size_util.h" namespace xla { @@ -90,10 +90,8 @@ XlaOp ComputeSums(XlaOp operand, XlaOp init_value, // Creates a padding configuration out of spatial padding values. PaddingConfig MakeSpatialPaddingConfig( tensorflow::gtl::ArraySlice<std::pair<int64, int64>> spatial_padding, - tensorflow::gtl::ArraySlice<int64> kernel_size, - tensorflow::gtl::ArraySlice<int64> stride, + int num_spatial_dims, tensorflow::gtl::ArraySlice<int64> stride, const TensorFormat& data_format) { - const int num_spatial_dims = kernel_size.size() - 2; PaddingConfig padding_config; for (int i = 0; i < 2 + num_spatial_dims; ++i) { padding_config.add_dimensions(); @@ -109,6 +107,30 @@ PaddingConfig MakeSpatialPaddingConfig( return padding_config; } +XlaOp AvgPoolDivideByCount( + XlaOp pooled, tensorflow::gtl::ArraySlice<int64> input_size, + tensorflow::gtl::ArraySlice<int64> window_dimensions, + tensorflow::gtl::ArraySlice<int64> window_strides, + tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, + PrimitiveType dtype, const TensorFormat& data_format, + bool counts_include_padding) { + if (counts_include_padding) { + // If counts include padding, all windows have the same number of elements + // contributing to each average. Divide by the window size everywhere to get + // the average. + int64 window_size = + std::accumulate(window_dimensions.begin(), window_dimensions.end(), 1, + [](int64 a, int64 b) { return a * b; }); + auto divisor = ConstantR0WithType(pooled.builder(), dtype, window_size); + + return pooled / divisor; + } else { + return AvgPoolDivideByCountWithGeneralPadding(pooled, dtype, input_size, + padding, window_dimensions, + window_strides, data_format); + } +} + } // namespace XlaOp MaxPool(XlaOp operand, tensorflow::gtl::ArraySlice<int64> kernel_size, @@ -137,25 +159,16 @@ XlaOp AvgPool(XlaOp operand, tensorflow::gtl::ArraySlice<int64> kernel_size, auto init_value = Zero(b, dtype); std::vector<int64> input_size(operand_shape.dimensions().begin(), operand_shape.dimensions().end()); - auto padding_config = - MakeSpatialPaddingConfig(padding, kernel_size, stride, data_format); + const int num_dims = kernel_size.size(); + const int num_spatial_dims = num_dims - 2; + auto padding_config = MakeSpatialPaddingConfig(padding, num_spatial_dims, + stride, data_format); auto padded_operand = Pad(operand, Zero(b, dtype), padding_config); auto pooled = ComputeSums(padded_operand, init_value, kernel_size, stride, data_format); - if (counts_include_padding) { - // If counts include padding, all windows have the same number of elements - // contributing to each average. Divide by the window size everywhere to - // get the average. - int64 window_size = - std::accumulate(kernel_size.begin(), kernel_size.end(), 1, - [](int64 x, int64 y) { return x * y; }); - - auto divisor = ConstantR0WithType(b, dtype, window_size); - return pooled / divisor; - } else { - return AvgPoolDivideByCountWithGeneralPadding( - pooled, dtype, input_size, padding, kernel_size, stride, data_format); - } + return AvgPoolDivideByCount(pooled, input_size, kernel_size, stride, + padding, dtype, data_format, + counts_include_padding); }); } @@ -180,4 +193,101 @@ std::vector<std::pair<int64, int64>> MakeSpatialPadding( stride_spatial_dimensions, padding); } +XlaOp AvgPoolGrad( + XlaOp out_backprop, tensorflow::gtl::ArraySlice<int64> gradients_size, + tensorflow::gtl::ArraySlice<int64> kernel_size, + tensorflow::gtl::ArraySlice<int64> stride, + tensorflow::gtl::ArraySlice<std::pair<int64, int64>> spatial_padding, + const TensorFormat& data_format, const bool counts_include_padding) { + XlaBuilder* b = out_backprop.builder(); + return b->ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { + const int num_dims = kernel_size.size(); + + if (gradients_size.size() != num_dims) { + return tensorflow::errors::InvalidArgument("gradients must be ", num_dims, + "-dimensional"); + } + + TF_ASSIGN_OR_RETURN(Shape out_backprop_xla_shape, + b->GetShape(out_backprop)); + if (out_backprop_xla_shape.dimensions().size() != num_dims) { + return tensorflow::errors::InvalidArgument("out_backprop must be ", + num_dims, "-dimensional"); + } + + // We can think of average-pooling as: + // * a convolution with a kernel consisting entirely of 1s, where the + // input feature and output feature are equal, and 0s everywhere else. + // * followed by dividing by the counts. + // + // This then gives us an algorithm to build the gradient: + // * divide out_backprop by the counts, followed by + // * Conv2DBackpropInput specialized for that kernel, which simplifies to + // a Pad and a ReduceWindow. + // + // For an explanation of backpropagation for convolution, see the comments + // in third_party/tensorflow/core/kernels/conv_grad_ops.h + + // TF filter shape is [ H, W, ..., inC, outC ] + + // The input gradients are computed by a convolution of the output gradients + // and the filter, with some appropriate padding. See the comment at the top + // of conv_grad_ops.h for details. + PrimitiveType dtype = out_backprop_xla_shape.element_type(); + auto out_backprop_div = AvgPoolDivideByCount( + out_backprop, gradients_size, kernel_size, stride, spatial_padding, + dtype, data_format, counts_include_padding); + + // Pad the gradients in the spatial dimensions. We use the same padding + // as Conv2DBackpropInput. + PaddingConfig padding_config = MakeNoPaddingConfig(num_dims); + std::vector<int64> padded_gradients_size(gradients_size.begin(), + gradients_size.end()); + // First, pad the output gradients the same way as the input. The additional + // padding will be removed as a last step before returning the input + // gradients. + const int num_spatial_dims = num_dims - 2; + for (int i = 0; i < num_spatial_dims; ++i) { + int dim = data_format.spatial_dimension(i); + padded_gradients_size[dim] += + (spatial_padding[i].first + spatial_padding[i].second); + } + for (int i = 0; i < num_spatial_dims; ++i) { + int dim = data_format.spatial_dimension(i); + TF_ASSIGN_OR_RETURN( + SpatialDimensionOutputSizeAndPadding conv_backprop_spatial_dim, + ConvGradExtractAndVerifyDimension( + /*input_size=*/padded_gradients_size[dim], + /*filter_size=*/kernel_size[dim], + /*output_size=*/out_backprop_xla_shape.dimensions(dim), + /*dilation=*/1, + /*stride=*/stride[dim], /*padding=*/Padding::kValid)); + auto* padding = padding_config.mutable_dimensions(dim); + padding->set_edge_padding_low(conv_backprop_spatial_dim.pad_before); + padding->set_edge_padding_high(conv_backprop_spatial_dim.pad_after); + padding->set_interior_padding(stride[dim] - 1); + } + + auto zero = Zero(b, dtype); + auto padded_gradients = Pad(out_backprop_div, zero, padding_config); + + // in_backprop = padded_gradients <conv> ones + std::vector<int64> ones(num_dims, 1LL); + auto in_backprop = + ReduceWindow(padded_gradients, Zero(b, dtype), + CreateScalarAddComputation(dtype, b), kernel_size, + /*window_strides=*/ones, Padding::kValid); + // The input padding doesn't contribute to the gradient, remove it. + std::vector<std::pair<int64, int64>> neg_spatial_padding; + neg_spatial_padding.reserve(spatial_padding.size()); + for (const std::pair<int64, int64>& spatial_padding_dim : spatial_padding) { + neg_spatial_padding.emplace_back(-spatial_padding_dim.first, + -spatial_padding_dim.second); + } + auto remove_padding_config = MakeSpatialPaddingConfig( + neg_spatial_padding, num_spatial_dims, stride, data_format); + return Pad(in_backprop, zero, remove_padding_config); + }); +} + } // namespace xla diff --git a/tensorflow/compiler/xla/client/lib/pooling.h b/tensorflow/compiler/xla/client/lib/pooling.h index 1699c585d3..291c711a00 100644 --- a/tensorflow/compiler/xla/client/lib/pooling.h +++ b/tensorflow/compiler/xla/client/lib/pooling.h @@ -16,8 +16,8 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_CLIENT_LIB_POOLING_H_ #define TENSORFLOW_COMPILER_XLA_CLIENT_LIB_POOLING_H_ +#include "absl/container/inlined_vector.h" #include "tensorflow/compiler/xla/client/xla_builder.h" -#include "tensorflow/core/lib/gtl/inlined_vector.h" namespace xla { @@ -45,7 +45,7 @@ class TensorFormat { // The number of the dimension that represents the features. int feature_dimension_; // The dimension numbers for the spatial dimensions. - tensorflow::gtl::InlinedVector<int, 4> spatial_dimensions_; + absl::InlinedVector<int, 4> spatial_dimensions_; }; // Computes the max pool of 'operand'. @@ -68,6 +68,14 @@ std::vector<std::pair<int64, int64>> MakeSpatialPadding( tensorflow::gtl::ArraySlice<int64> stride, Padding padding, const TensorFormat& data_format); +// Computes the average pool gradient. +XlaOp AvgPoolGrad( + XlaOp out_backprop, tensorflow::gtl::ArraySlice<int64> gradients_size, + tensorflow::gtl::ArraySlice<int64> kernel_size, + tensorflow::gtl::ArraySlice<int64> stride, + tensorflow::gtl::ArraySlice<std::pair<int64, int64>> spatial_padding, + const TensorFormat& data_format, const bool counts_include_padding); + } // namespace xla #endif // TENSORFLOW_COMPILER_XLA_CLIENT_LIB_POOLING_H_ diff --git a/tensorflow/compiler/xla/client/lib/pooling_test.cc b/tensorflow/compiler/xla/client/lib/pooling_test.cc index 4b4553b60d..1890047918 100644 --- a/tensorflow/compiler/xla/client/lib/pooling_test.cc +++ b/tensorflow/compiler/xla/client/lib/pooling_test.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/client/lib/pooling.h" +#include "absl/container/inlined_vector.h" #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/tests/client_library_test_base.h" #include "tensorflow/compiler/xla/tests/test_macros.h" @@ -22,7 +23,7 @@ namespace xla { namespace { TensorFormat MakeNCHWFormat(int num_spatial_dims) { - tensorflow::gtl::InlinedVector<int64, 4> spatial_dimensions; + absl::InlinedVector<int64, 4> spatial_dimensions; for (int i = 0; i < num_spatial_dims; ++i) { spatial_dimensions.push_back(i + 2); } @@ -181,5 +182,109 @@ XLA_TEST_F(PoolingTest, error_spec_); } +XLA_TEST_F(PoolingTest, AvgPool2DGradNoPadding) { + XlaBuilder builder(TestName()); + for (bool counts_include_padding : {false, true}) { + XlaOp out_backprop = ConstantR4FromArray4D<float>(&builder, {{{{1.}}}}); + auto data_format = MakeNCHWFormat(2); + auto kernel_size = ExpandWithBatchAndFeatureDimensions({2, 2}, data_format); + auto stride = ExpandWithBatchAndFeatureDimensions({2, 2}, data_format); + AvgPoolGrad(out_backprop, {1, 1, 3, 3}, kernel_size, stride, + {{0, 0}, {0, 0}}, MakeNCHWFormat(2), + /*counts_include_padding=*/counts_include_padding); + // Without padding, counts_include_padding makes no difference. + ComputeAndCompareR4<float>( + &builder, {{{{0.25, 0.25, 0.}, {0.25, 0.25, 0.}, {0., 0., 0.}}}}, {}, + error_spec_); + } +} + +XLA_TEST_F(PoolingTest, AvgPool2DGradNoPaddingWithStride) { + XlaBuilder builder(TestName()); + for (bool counts_include_padding : {false, true}) { + XlaOp out_backprop = + ConstantR4FromArray4D<float>(&builder, {{{{1., 1.}, {1., 1.}}}}); + auto data_format = MakeNCHWFormat(2); + auto kernel_size = ExpandWithBatchAndFeatureDimensions({2, 2}, data_format); + auto stride = ExpandWithBatchAndFeatureDimensions({1, 1}, data_format); + AvgPoolGrad(out_backprop, {1, 1, 3, 3}, kernel_size, stride, + {{0, 0}, {0, 0}}, MakeNCHWFormat(2), + /*counts_include_padding=*/counts_include_padding); + // Without padding, counts_include_padding makes no difference. + ComputeAndCompareR4<float>( + &builder, {{{{0.25, 0.5, 0.25}, {0.5, 1., 0.5}, {0.25, 0.5, 0.25}}}}, + {}, error_spec_); + } +} + +XLA_TEST_F(PoolingTest, AvgPool2DGradWithPadding) { + XlaBuilder builder(TestName()); + + XlaOp out_backprop = + ConstantR4FromArray4D<float>(&builder, {{{{1., 1.}, {1., 1.}}}}); + auto data_format = MakeNCHWFormat(2); + auto kernel_size = ExpandWithBatchAndFeatureDimensions({2, 2}, data_format); + auto stride = ExpandWithBatchAndFeatureDimensions({2, 2}, data_format); + AvgPoolGrad(out_backprop, {1, 1, 3, 3}, kernel_size, stride, {{1, 1}, {1, 1}}, + MakeNCHWFormat(2), + /*counts_include_padding=*/true); + ComputeAndCompareR4<float>( + &builder, + {{{{0.25, 0.25, 0.25}, {0.25, 0.25, 0.25}, {0.25, 0.25, 0.25}}}}, {}, + error_spec_); +} + +XLA_TEST_F(PoolingTest, AvgPool2DGradWithPaddingCountNotIncludePadding) { + XlaBuilder builder(TestName()); + + XlaOp out_backprop = + ConstantR4FromArray4D<float>(&builder, {{{{1., 1.}, {1., 1.}}}}); + auto data_format = MakeNCHWFormat(2); + auto kernel_size = ExpandWithBatchAndFeatureDimensions({2, 2}, data_format); + auto stride = ExpandWithBatchAndFeatureDimensions({2, 2}, data_format); + AvgPoolGrad(out_backprop, {1, 1, 3, 3}, kernel_size, stride, {{1, 1}, {1, 1}}, + MakeNCHWFormat(2), false); + ComputeAndCompareR4<float>( + &builder, {{{{1., 0.5, 0.5}, {0.5, 0.25, 0.25}, {0.5, 0.25, 0.25}}}}, {}, + error_spec_); +} + +XLA_TEST_F(PoolingTest, AvgPool2DGradWithPaddingCountWithStride) { + XlaBuilder builder(TestName()); + + XlaOp out_backprop = + ConstantR4FromArray4D<float>(&builder, {{{{1., 1., 1., 1.}, + {1., 1., 1., 1.}, + {1., 1., 1., 1.}, + {1., 1., 1., 1.}}}}); + auto data_format = MakeNCHWFormat(2); + auto kernel_size = ExpandWithBatchAndFeatureDimensions({2, 2}, data_format); + auto stride = ExpandWithBatchAndFeatureDimensions({1, 1}, data_format); + AvgPoolGrad(out_backprop, {1, 1, 3, 3}, kernel_size, stride, {{1, 1}, {1, 1}}, + MakeNCHWFormat(2), true); + ComputeAndCompareR4<float>(&builder, + {{{{1., 1., 1.}, {1., 1., 1.}, {1., 1., 1.}}}}, {}, + error_spec_); +} + +XLA_TEST_F(PoolingTest, + AvgPool2DGradWithPaddingCountWithStrideNotIncludePadding) { + XlaBuilder builder(TestName()); + + XlaOp out_backprop = + ConstantR4FromArray4D<float>(&builder, {{{{1., 1., 1., 1.}, + {1., 1., 1., 1.}, + {1., 1., 1., 1.}, + {1., 1., 1., 1.}}}}); + auto data_format = MakeNCHWFormat(2); + auto kernel_size = ExpandWithBatchAndFeatureDimensions({2, 2}, data_format); + auto stride = ExpandWithBatchAndFeatureDimensions({1, 1}, data_format); + AvgPoolGrad(out_backprop, {1, 1, 3, 3}, kernel_size, stride, {{1, 1}, {1, 1}}, + MakeNCHWFormat(2), false); + ComputeAndCompareR4<float>( + &builder, {{{{2.25, 1.5, 2.25}, {1.5, 1., 1.5}, {2.25, 1.5, 2.25}}}}, {}, + error_spec_); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/client/lib/testing.cc b/tensorflow/compiler/xla/client/lib/testing.cc index 081fec7ad9..6861521acc 100644 --- a/tensorflow/compiler/xla/client/lib/testing.cc +++ b/tensorflow/compiler/xla/client/lib/testing.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/client/lib/testing.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/execution_options_util.h" #include "tensorflow/compiler/xla/literal.h" @@ -23,7 +24,6 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/test_utils.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/types.h" @@ -61,8 +61,7 @@ XlaOp BuildFakeDataOpOnDevice(const Shape& shape, XlaBuilder* builder) { std::unique_ptr<GlobalData> MakeFakeDataViaDeviceOrDie(const Shape& shape, Client* client) { - XlaBuilder b( - tensorflow::strings::StrCat("make_fake_", ShapeUtil::HumanString(shape))); + XlaBuilder b(absl::StrCat("make_fake_", ShapeUtil::HumanString(shape))); BuildFakeDataOpOnDevice(shape, &b); XlaComputation computation = b.Build().ConsumeValueOrDie(); diff --git a/tensorflow/compiler/xla/client/local_client.cc b/tensorflow/compiler/xla/client/local_client.cc index cffb24e29b..db7a8fc047 100644 --- a/tensorflow/compiler/xla/client/local_client.cc +++ b/tensorflow/compiler/xla/client/local_client.cc @@ -17,9 +17,9 @@ limitations under the License. #include <utility> +#include "absl/memory/memory.h" #include "llvm/ADT/Triple.h" #include "tensorflow/compiler/xla/client/xla_computation.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/backend.h" #include "tensorflow/compiler/xla/service/service_executable_run_options.h" #include "tensorflow/compiler/xla/service/source_map_util.h" @@ -59,7 +59,7 @@ Status LocalExecutable::ValidateExecutionOptions( // Check argument number, shapes, and layouts. if (arguments.size() != computation_layout.parameter_count()) { return InvalidArgument( - "invalid number of arguments for computation: expected %d, got %zu", + "invalid number of arguments for computation: expected %d, got %u", computation_layout.parameter_count(), arguments.size()); } for (int i = 0; i < arguments.size(); ++i) { @@ -71,9 +71,9 @@ Status LocalExecutable::ValidateExecutionOptions( "parameter " "%d: want %s, got %s", i, - ShapeUtil::HumanString(computation_layout.parameter_layout(i).shape()) - .c_str(), - ShapeUtil::HumanString(arguments[i]->on_host_shape()).c_str()); + ShapeUtil::HumanString( + computation_layout.parameter_layout(i).shape()), + ShapeUtil::HumanString(arguments[i]->on_host_shape())); } } @@ -88,8 +88,7 @@ Status LocalExecutable::ValidateExecutionOptions( if (stream_platform != backend_->platform()) { return InvalidArgument( "stream is for platform %s, but service targets platform %s", - stream_platform->Name().c_str(), - backend_->platform()->Name().c_str()); + stream_platform->Name(), backend_->platform()->Name()); } // Cannot specify device_ordinal with a stream. The stream determines these @@ -120,10 +119,10 @@ Status LocalExecutable::ValidateExecutionOptions( return InvalidArgument( "executable is built for device %s of type \"%s\"; cannot run it on " "device %s of type \"%s\"", - backend_->device_name(build_device_ordinal()).c_str(), - build_executor->GetDeviceDescription().name().c_str(), - backend_->device_name(run_device_ordinal).c_str(), - run_executor->GetDeviceDescription().name().c_str()); + backend_->device_name(build_device_ordinal()), + build_executor->GetDeviceDescription().name(), + backend_->device_name(run_device_ordinal), + run_executor->GetDeviceDescription().name()); } if (!run_options.allocator()) { @@ -133,8 +132,8 @@ Status LocalExecutable::ValidateExecutionOptions( if (run_options.allocator()->platform() != backend.platform()) { return InvalidArgument( "allocator platform (%s) does not match service platform (%s)", - run_options.allocator()->platform()->Name().c_str(), - backend.platform()->Name().c_str()); + run_options.allocator()->platform()->Name(), + backend.platform()->Name()); } return Status::OK(); @@ -257,9 +256,9 @@ StatusOr<std::unique_ptr<LocalExecutable>> LocalClient::Compile( TF_ASSIGN_OR_RETURN(std::unique_ptr<Executable> executable, local_service_->CompileExecutable( computation, argument_layouts, updated_options)); - return WrapUnique(new LocalExecutable(std::move(executable), - local_service_->mutable_backend(), - updated_options)); + return absl::WrapUnique(new LocalExecutable(std::move(executable), + local_service_->mutable_backend(), + updated_options)); } StatusOr<ScopedShapedBuffer> LocalClient::LiteralToShapedBuffer( diff --git a/tensorflow/compiler/xla/client/padding.cc b/tensorflow/compiler/xla/client/padding.cc index 6a9cf466ac..ed4dc8e9f6 100644 --- a/tensorflow/compiler/xla/client/padding.cc +++ b/tensorflow/compiler/xla/client/padding.cc @@ -31,8 +31,8 @@ Status ValidatePaddingValues( input_dimensions.size() == window_strides.size(); if (!ok) { return InvalidArgument( - "Want input dimensions size %zu = window dimensions size %zu = window " - "strides size %zu", + "Want input dimensions size %u = window dimensions size %u = window " + "strides size %u", input_dimensions.size(), window_dimensions.size(), window_strides.size()); } diff --git a/tensorflow/compiler/xla/client/sharding_builder.h b/tensorflow/compiler/xla/client/sharding_builder.h index 34763e54d9..59df3a8762 100644 --- a/tensorflow/compiler/xla/client/sharding_builder.h +++ b/tensorflow/compiler/xla/client/sharding_builder.h @@ -56,4 +56,4 @@ OpSharding Tuple(const ShapeTree<OpSharding>& shardings); } // namespace sharding_builder } // namespace xla -#endif +#endif // TENSORFLOW_COMPILER_XLA_CLIENT_SHARDING_BUILDER_H_ diff --git a/tensorflow/compiler/xla/client/xla_builder.cc b/tensorflow/compiler/xla/client/xla_builder.cc index 4dffab3c2c..819d324927 100644 --- a/tensorflow/compiler/xla/client/xla_builder.cc +++ b/tensorflow/compiler/xla/client/xla_builder.cc @@ -21,19 +21,24 @@ limitations under the License. #include <string> #include <utility> +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/client/sharding_builder.h" #include "tensorflow/compiler/xla/client/xla_computation.h" #include "tensorflow/compiler/xla/execution_options_util.h" +#include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/service/shape_inference.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/mutex.h" namespace xla { -using tensorflow::strings::StrCat; +using absl::StrCat; namespace { @@ -67,7 +72,7 @@ XlaOp operator>>(const XlaOp& x, const XlaOp& y) { if (!ShapeUtil::ElementIsIntegral(shape)) { return InvalidArgument( "Argument to >> operator does not have an integral type (%s).", - ShapeUtil::HumanString(shape).c_str()); + ShapeUtil::HumanString(shape)); } if (ShapeUtil::ElementIsSigned(shape)) { return ShiftRightArithmetic(x, y); @@ -194,7 +199,6 @@ void XlaBuilder::IsConstantVisitor(const int64 op_handle, // TODO(b/33009255): Implmement constant folding for cross replica sum. case HloOpcode::kInfeed: case HloOpcode::kOutfeed: - case HloOpcode::kHostCompute: case HloOpcode::kCall: // TODO(b/32495713): We aren't checking the to_apply computation itself, // so we conservatively say that computations containing the Call op @@ -221,8 +225,7 @@ XlaComputation XlaBuilder::BuildAndNoteError() { auto build_status = Build(); if (!build_status.ok()) { parent_builder_->ReportError( - AddStatus(build_status.status(), - tensorflow::strings::StrCat("error from: ", name_))); + AddStatus(build_status.status(), absl::StrCat("error from: ", name_))); return {}; } return build_status.ConsumeValueOrDie(); @@ -463,14 +466,27 @@ XlaOp XlaBuilder::ConstantLiteral(const LiteralSlice& literal) { }); } +XlaOp XlaBuilder::IotaGen(const Shape& shape, int64 iota_dimension) { + return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { + HloInstructionProto instr; + *instr.mutable_shape() = shape; + instr.add_dimensions(iota_dimension); + return AddInstruction(std::move(instr), HloOpcode::kIota); + }); +} + +XlaOp XlaBuilder::IotaGen(PrimitiveType type, int64 size) { + return IotaGen(ShapeUtil::MakeShape(type, {size}), /*iota_dimension=*/0); +} + XlaOp XlaBuilder::Call(const XlaComputation& computation, tensorflow::gtl::ArraySlice<XlaOp> operands) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; std::vector<const Shape*> operand_shape_ptrs; TF_ASSIGN_OR_RETURN(const auto& operand_shapes, GetOperandShapes(operands)); - c_transform(operand_shapes, std::back_inserter(operand_shape_ptrs), - [](const Shape& shape) { return &shape; }); + absl::c_transform(operand_shapes, std::back_inserter(operand_shape_ptrs), + [](const Shape& shape) { return &shape; }); TF_ASSIGN_OR_RETURN(const ProgramShape& called_program_shape, computation.GetProgramShape()); TF_ASSIGN_OR_RETURN( @@ -489,7 +505,7 @@ XlaOp XlaBuilder::Parameter(int64 parameter_number, const Shape& shape, return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; if (!parameter_numbers_.insert(parameter_number).second) { - return InvalidArgument("parameter %lld already registered", + return InvalidArgument("parameter %d already registered", parameter_number); } instr.set_parameter_number(parameter_number); @@ -622,8 +638,8 @@ XlaOp XlaBuilder::ConcatInDim(tensorflow::gtl::ArraySlice<XlaOp> operands, std::vector<const Shape*> operand_shape_ptrs; TF_ASSIGN_OR_RETURN(const auto& operand_shapes, GetOperandShapes(operands)); - c_transform(operand_shapes, std::back_inserter(operand_shape_ptrs), - [](const Shape& shape) { return &shape; }); + absl::c_transform(operand_shapes, std::back_inserter(operand_shape_ptrs), + [](const Shape& shape) { return &shape; }); TF_ASSIGN_OR_RETURN( *instr.mutable_shape(), ShapeInference::InferConcatOpShape(operand_shape_ptrs, dimension)); @@ -703,8 +719,7 @@ XlaOp XlaBuilder::Collapse(const XlaOp& operand, TF_ASSIGN_OR_RETURN(const Shape& original_shape, GetShape(operand)); VLOG(3) << "original shape: " << ShapeUtil::HumanString(original_shape); - VLOG(3) << "dims to collapse: " - << tensorflow::str_util::Join(dimensions, ","); + VLOG(3) << "dims to collapse: " << absl::StrJoin(dimensions, ","); std::vector<int64> new_sizes; for (int i = 0; i < ShapeUtil::Rank(original_shape); ++i) { @@ -715,8 +730,7 @@ XlaOp XlaBuilder::Collapse(const XlaOp& operand, } } - VLOG(3) << "new sizes: [" << tensorflow::str_util::Join(new_sizes, ",") - << "]"; + VLOG(3) << "new sizes: [" << absl::StrJoin(new_sizes, ",") << "]"; return Reshape(operand, new_sizes); }); @@ -749,8 +763,8 @@ XlaOp XlaBuilder::Tuple(tensorflow::gtl::ArraySlice<XlaOp> elements) { HloInstructionProto instr; std::vector<const Shape*> operand_shape_ptrs; TF_ASSIGN_OR_RETURN(const auto& operand_shapes, GetOperandShapes(elements)); - c_transform(operand_shapes, std::back_inserter(operand_shape_ptrs), - [](const Shape& shape) { return &shape; }); + absl::c_transform(operand_shapes, std::back_inserter(operand_shape_ptrs), + [](const Shape& shape) { return &shape; }); TF_ASSIGN_OR_RETURN(*instr.mutable_shape(), ShapeInference::InferVariadicOpShape( HloOpcode::kTuple, operand_shape_ptrs)); @@ -765,7 +779,7 @@ XlaOp XlaBuilder::GetTupleElement(const XlaOp& tuple_data, int64 index) { if (!ShapeUtil::IsTuple(tuple_shape)) { return InvalidArgument( "Operand to GetTupleElement() is not a tuple; got %s", - ShapeUtil::HumanString(tuple_shape).c_str()); + ShapeUtil::HumanString(tuple_shape)); } *instr.mutable_shape() = ShapeUtil::GetTupleElementShape(tuple_shape, index); @@ -807,7 +821,8 @@ XlaOp XlaBuilder::Lt(const XlaOp& lhs, const XlaOp& rhs, return BinaryOp(HloOpcode::kLt, lhs, rhs, broadcast_dimensions); } -XlaOp XlaBuilder::Dot(const XlaOp& lhs, const XlaOp& rhs) { +XlaOp XlaBuilder::Dot(const XlaOp& lhs, const XlaOp& rhs, + const PrecisionConfigProto* precision_config_proto) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { TF_ASSIGN_OR_RETURN(const Shape& lhs_shape, GetShape(lhs)); @@ -815,12 +830,14 @@ XlaOp XlaBuilder::Dot(const XlaOp& lhs, const XlaOp& rhs) { dimension_numbers.add_lhs_contracting_dimensions( lhs_shape.dimensions_size() == 1 ? 0 : 1); dimension_numbers.add_rhs_contracting_dimensions(0); - return DotGeneral(lhs, rhs, dimension_numbers); + return DotGeneral(lhs, rhs, dimension_numbers, precision_config_proto); }); } -XlaOp XlaBuilder::DotGeneral(const XlaOp& lhs, const XlaOp& rhs, - const DotDimensionNumbers& dimension_numbers) { +XlaOp XlaBuilder::DotGeneral( + const XlaOp& lhs, const XlaOp& rhs, + const DotDimensionNumbers& dimension_numbers, + const PrecisionConfigProto* precision_config_proto) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; TF_ASSIGN_OR_RETURN(const Shape& lhs_shape, GetShape(lhs)); @@ -829,6 +846,9 @@ XlaOp XlaBuilder::DotGeneral(const XlaOp& lhs, const XlaOp& rhs, ShapeInference::InferDotOpShape(lhs_shape, rhs_shape, dimension_numbers)); *instr.mutable_dot_dimension_numbers() = dimension_numbers; + if (precision_config_proto != nullptr) { + *instr.mutable_precision_config() = *precision_config_proto; + } return AddInstruction(std::move(instr), HloOpcode::kDot, {lhs, rhs}); }); } @@ -840,16 +860,14 @@ Status XlaBuilder::VerifyConvolution( return InvalidArgument( "Convolution arguments must have same number of " "dimensions. Got: %s and %s", - ShapeUtil::HumanString(lhs_shape).c_str(), - ShapeUtil::HumanString(rhs_shape).c_str()); + ShapeUtil::HumanString(lhs_shape), ShapeUtil::HumanString(rhs_shape)); } int num_dims = ShapeUtil::Rank(lhs_shape); if (num_dims < 2) { return InvalidArgument( "Convolution expects argument arrays with >= 3 dimensions. " "Got: %s and %s", - ShapeUtil::HumanString(lhs_shape).c_str(), - ShapeUtil::HumanString(rhs_shape).c_str()); + ShapeUtil::HumanString(lhs_shape), ShapeUtil::HumanString(rhs_shape)); } int num_spatial_dims = num_dims - 2; @@ -863,7 +881,7 @@ Status XlaBuilder::VerifyConvolution( } for (int i = 0; i < numbers.size(); ++i) { if (numbers.Get(i) < 0 || numbers.Get(i) >= num_dims) { - return InvalidArgument("Convolution %s[%d] is out of bounds: %lld", + return InvalidArgument("Convolution %s[%d] is out of bounds: %d", field_name, i, numbers.Get(i)); } } @@ -882,28 +900,31 @@ Status XlaBuilder::VerifyConvolution( XlaOp XlaBuilder::Conv(const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, - Padding padding, int64 feature_group_count) { + Padding padding, int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { return ConvWithGeneralDimensions( lhs, rhs, window_strides, padding, CreateDefaultConvDimensionNumbers(window_strides.size()), - feature_group_count); + feature_group_count, precision_config_proto); } XlaOp XlaBuilder::ConvWithGeneralPadding( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, - int64 feature_group_count) { + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { return ConvGeneral(lhs, rhs, window_strides, padding, CreateDefaultConvDimensionNumbers(window_strides.size()), - feature_group_count); + feature_group_count, precision_config_proto); } XlaOp XlaBuilder::ConvWithGeneralDimensions( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count) { + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { TF_ASSIGN_OR_RETURN(const Shape& lhs_shape, GetShape(lhs)); TF_ASSIGN_OR_RETURN(const Shape& rhs_shape, GetShape(rhs)); @@ -930,7 +951,8 @@ XlaOp XlaBuilder::ConvWithGeneralDimensions( return ConvGeneral(lhs, rhs, window_strides, MakePadding(base_area_dimensions, window_dimensions, window_strides, padding), - dimension_numbers, feature_group_count); + dimension_numbers, feature_group_count, + precision_config_proto); }); } @@ -939,9 +961,11 @@ XlaOp XlaBuilder::ConvGeneral( tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count) { + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { return ConvGeneralDilated(lhs, rhs, window_strides, padding, {}, {}, - dimension_numbers, feature_group_count); + dimension_numbers, feature_group_count, + precision_config_proto); } XlaOp XlaBuilder::ConvGeneralDilated( @@ -951,7 +975,8 @@ XlaOp XlaBuilder::ConvGeneralDilated( tensorflow::gtl::ArraySlice<int64> lhs_dilation, tensorflow::gtl::ArraySlice<int64> rhs_dilation, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count) { + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; TF_ASSIGN_OR_RETURN(const Shape& lhs_shape, GetShape(lhs)); @@ -978,6 +1003,10 @@ XlaOp XlaBuilder::ConvGeneralDilated( *instr.mutable_convolution_dimension_numbers() = dimension_numbers; instr.set_feature_group_count(feature_group_count); + if (precision_config_proto != nullptr) { + *instr.mutable_precision_config() = *precision_config_proto; + } + return AddInstruction(std::move(instr), HloOpcode::kConvolution, {lhs, rhs}); }); @@ -994,12 +1023,11 @@ StatusOr<Window> XlaBuilder::MakeWindow( return Status::OK(); } else { return InvalidArgument( - "%s", tensorflow::strings::StrCat( + "%s", absl::StrCat( "Window has different number of window dimensions than of ", x_name, "\nNumber of window dimensions: ", window_dimensions.size(), - "\nNumber of ", x_name, ": ", x, "\n") - .c_str()); + "\nNumber of ", x_name, ": ", x, "\n")); } }; TF_RETURN_IF_ERROR(verify_size(window_strides.size(), "window strides")); @@ -1175,8 +1203,8 @@ void XlaBuilder::Outfeed(const XlaOp& operand, const Shape& shape_with_layout, if (!ShapeUtil::Compatible(operand_shape, shape_with_layout)) { return InvalidArgument( "Outfeed shape %s must be compatible with operand shape %s", - ShapeUtil::HumanStringWithLayout(shape_with_layout).c_str(), - ShapeUtil::HumanStringWithLayout(operand_shape).c_str()); + ShapeUtil::HumanStringWithLayout(shape_with_layout), + ShapeUtil::HumanStringWithLayout(operand_shape)); } *instr.mutable_outfeed_shape() = shape_with_layout; @@ -1228,8 +1256,8 @@ XlaOp XlaBuilder::OutfeedWithToken(const XlaOp& operand, const XlaOp& token, if (!ShapeUtil::Compatible(operand_shape, shape_with_layout)) { return InvalidArgument( "Outfeed shape %s must be compatible with operand shape %s", - ShapeUtil::HumanStringWithLayout(shape_with_layout).c_str(), - ShapeUtil::HumanStringWithLayout(operand_shape).c_str()); + ShapeUtil::HumanStringWithLayout(shape_with_layout), + ShapeUtil::HumanStringWithLayout(operand_shape)); } *instr.mutable_outfeed_shape() = shape_with_layout; @@ -1264,11 +1292,11 @@ XlaOp XlaBuilder::CustomCall(const string& call_target_name, const Shape& shape) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; - if (tensorflow::str_util::StartsWith(call_target_name, "$")) { + if (absl::StartsWith(call_target_name, "$")) { return InvalidArgument( "Invalid custom_call_target \"%s\": Call targets that start with '$' " "are reserved for internal use.", - call_target_name.c_str()); + call_target_name); } *instr.mutable_shape() = shape; instr.set_custom_call_target(call_target_name); @@ -1276,18 +1304,6 @@ XlaOp XlaBuilder::CustomCall(const string& call_target_name, }); } -XlaOp XlaBuilder::HostCompute(tensorflow::gtl::ArraySlice<XlaOp> operands, - const string& channel_name, - int64 cost_estimate_ns, const Shape& shape) { - return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { - HloInstructionProto instr; - *instr.mutable_shape() = shape; - instr.set_channel_name(channel_name); - instr.set_cost_estimate_ns(cost_estimate_ns); - return AddInstruction(std::move(instr), HloOpcode::kHostCompute, operands); - }); -} - XlaOp XlaBuilder::Complex( const XlaOp& real, const XlaOp& imag, tensorflow::gtl::ArraySlice<int64> broadcast_dimensions) { @@ -1462,7 +1478,7 @@ XlaOp XlaBuilder::Rev(const XlaOp& operand, }); } -XlaOp XlaBuilder::Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values, +XlaOp XlaBuilder::Sort(XlaOp keys, absl::optional<XlaOp> values, int64 dimension) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; @@ -1540,8 +1556,8 @@ XlaOp XlaBuilder::Map(tensorflow::gtl::ArraySlice<XlaOp> operands, HloInstructionProto instr; std::vector<const Shape*> operand_shape_ptrs; TF_ASSIGN_OR_RETURN(const auto& operand_shapes, GetOperandShapes(operands)); - c_transform(operand_shapes, std::back_inserter(operand_shape_ptrs), - [](const Shape& shape) { return &shape; }); + absl::c_transform(operand_shapes, std::back_inserter(operand_shape_ptrs), + [](const Shape& shape) { return &shape; }); TF_ASSIGN_OR_RETURN(const ProgramShape& called_program_shape, computation.GetProgramShape()); TF_ASSIGN_OR_RETURN( @@ -1584,7 +1600,7 @@ XlaOp XlaBuilder::RngOp(RandomDistribution distribution, if (parameters.size() != 2) { return InvalidArgument( "RNG distribution (%s) expects 2 parameters, but got %ld", - RandomDistribution_Name(distribution).c_str(), parameters.size()); + RandomDistribution_Name(distribution), parameters.size()); } break; default: @@ -1874,7 +1890,7 @@ XlaOp XlaBuilder::BatchNormGrad(const XlaOp& operand, const XlaOp& scale, XlaOp XlaBuilder::CrossReplicaSum( const XlaOp& operand, - tensorflow::gtl::ArraySlice<int64> replica_group_ids) { + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { TF_ASSIGN_OR_RETURN(const Shape& shape, GetShape(operand)); const Shape& scalar_shape = ShapeUtil::MakeShape(shape.element_type(), {}); @@ -1882,23 +1898,24 @@ XlaOp XlaBuilder::CrossReplicaSum( b->Add(b->Parameter(/*parameter_number=*/0, scalar_shape, "x"), b->Parameter(/*parameter_number=*/1, scalar_shape, "y")); TF_ASSIGN_OR_RETURN(auto computation, b->Build()); - return CrossReplicaSum(operand, computation, replica_group_ids, - /*channel_id=*/tensorflow::gtl::nullopt); + return CrossReplicaSum(operand, computation, replica_groups, + /*channel_id=*/absl::nullopt); }); } XlaOp XlaBuilder::CrossReplicaSum( const XlaOp& operand, const XlaComputation& computation, - tensorflow::gtl::ArraySlice<int64> replica_group_ids, - const tensorflow::gtl::optional<ChannelHandle>& channel_id) { + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups, + const absl::optional<ChannelHandle>& channel_id) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; TF_ASSIGN_OR_RETURN(const Shape& operand_shape, GetShape(operand)); TF_ASSIGN_OR_RETURN( *instr.mutable_shape(), ShapeInference::InferCrossReplicaSumShape({&operand_shape})); - for (int64 replica_group_id : replica_group_ids) { - instr.add_replica_group_ids(replica_group_id); + + for (const ReplicaGroup& group : replica_groups) { + *instr.add_replica_groups() = group; } if (channel_id.has_value()) { @@ -1945,8 +1962,8 @@ XlaOp XlaBuilder::AllToAll(const XlaOp& operand, int64 split_dimension, HloInstructionProto instr; TF_ASSIGN_OR_RETURN(auto slice_shapes, this->GetOperandShapes(slices)); std::vector<const Shape*> slice_shape_ptrs; - c_transform(slice_shapes, std::back_inserter(slice_shape_ptrs), - [](const Shape& shape) { return &shape; }); + absl::c_transform(slice_shapes, std::back_inserter(slice_shape_ptrs), + [](const Shape& shape) { return &shape; }); TF_ASSIGN_OR_RETURN( *instr.mutable_shape(), ShapeInference::InferAllToAllTupleShape(slice_shape_ptrs)); @@ -1967,6 +1984,27 @@ XlaOp XlaBuilder::AllToAll(const XlaOp& operand, int64 split_dimension, }); } +XlaOp XlaBuilder::CollectivePermute( + const XlaOp& operand, + const std::vector<std::pair<int64, int64>>& source_target_pairs) { + return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { + TF_ASSIGN_OR_RETURN(const Shape& operand_shape, GetShape(operand)); + HloInstructionProto instr; + TF_ASSIGN_OR_RETURN( + *instr.mutable_shape(), + ShapeInference::InferCollectivePermuteShape(operand_shape)); + + for (const auto& pair : source_target_pairs) { + auto* proto_pair = instr.add_source_target_pairs(); + proto_pair->set_source(pair.first); + proto_pair->set_target(pair.second); + } + + return AddInstruction(std::move(instr), HloOpcode::kCollectivePermute, + {operand}); + }); +} + XlaOp XlaBuilder::SelectAndScatter( const XlaOp& operand, const XlaComputation& select, tensorflow::gtl::ArraySlice<int64> window_dimensions, @@ -2133,13 +2171,13 @@ XlaOp XlaBuilder::SendToHost(const XlaOp& operand, const XlaOp& token, if (!ShapeUtil::Compatible(operand_shape, shape_with_layout)) { return InvalidArgument( "SendToHost shape %s must be compatible with operand shape %s", - ShapeUtil::HumanStringWithLayout(shape_with_layout).c_str(), - ShapeUtil::HumanStringWithLayout(operand_shape).c_str()); + ShapeUtil::HumanStringWithLayout(shape_with_layout), + ShapeUtil::HumanStringWithLayout(operand_shape)); } // TODO(b/111544877): Support tuple shapes. if (!ShapeUtil::IsArray(operand_shape)) { return InvalidArgument("SendToHost only supports array shapes, shape: %s", - ShapeUtil::HumanString(operand_shape).c_str()); + ShapeUtil::HumanString(operand_shape)); } if (handle.type() != ChannelHandle::DEVICE_TO_HOST) { @@ -2178,7 +2216,7 @@ XlaOp XlaBuilder::RecvFromHost(const XlaOp& token, const Shape& shape, if (!ShapeUtil::IsArray(shape)) { return InvalidArgument( "RecvFromHost only supports array shapes, shape: %s", - ShapeUtil::HumanString(shape).c_str()); + ShapeUtil::HumanString(shape)); } if (handle.type() != ChannelHandle::HOST_TO_DEVICE) { @@ -2233,7 +2271,7 @@ StatusOr<XlaComputation> XlaBuilder::BuildConstantSubGraph( "of being evaluated at XLA compile time.\n\n" "Please file a usability bug with the framework being used (e.g. " "TensorFlow).", - op_string.c_str()); + op_string); } TF_ASSIGN_OR_RETURN(const HloInstructionProto* root, @@ -2296,7 +2334,7 @@ StatusOr<XlaComputation> XlaBuilder::BuildConstantSubGraph( std::unique_ptr<XlaBuilder> XlaBuilder::CreateSubBuilder( const string& computation_name) { - auto sub_builder = MakeUnique<XlaBuilder>(computation_name); + auto sub_builder = absl::make_unique<XlaBuilder>(computation_name); sub_builder->parent_builder_ = this; sub_builder->die_immediately_on_error_ = this->die_immediately_on_error_; return sub_builder; @@ -2341,8 +2379,8 @@ XlaBuilder::CreateDefaultConvDimensionNumbers(int num_spatial_dims) { dnum.input_spatial_dimensions(0), dnum.input_spatial_dimensions(1)}) .size() != 4) { return FailedPrecondition( - "dimension numbers for the input are not unique: (%lld, %lld, %lld, " - "%lld)", + "dimension numbers for the input are not unique: (%d, %d, %d, " + "%d)", dnum.input_batch_dimension(), dnum.input_feature_dimension(), dnum.input_spatial_dimensions(0), dnum.input_spatial_dimensions(1)); } @@ -2352,8 +2390,8 @@ XlaBuilder::CreateDefaultConvDimensionNumbers(int num_spatial_dims) { dnum.kernel_spatial_dimensions(1)}) .size() != 4) { return FailedPrecondition( - "dimension numbers for the weight are not unique: (%lld, %lld, %lld, " - "%lld)", + "dimension numbers for the weight are not unique: (%d, %d, %d, " + "%d)", dnum.kernel_output_feature_dimension(), dnum.kernel_input_feature_dimension(), dnum.kernel_spatial_dimensions(0), dnum.kernel_spatial_dimensions(1)); @@ -2364,8 +2402,8 @@ XlaBuilder::CreateDefaultConvDimensionNumbers(int num_spatial_dims) { dnum.output_spatial_dimensions(1)}) .size() != 4) { return FailedPrecondition( - "dimension numbers for the output are not unique: (%lld, %lld, %lld, " - "%lld)", + "dimension numbers for the output are not unique: (%d, %d, %d, " + "%d)", dnum.output_batch_dimension(), dnum.output_feature_dimension(), dnum.output_spatial_dimensions(0), dnum.output_spatial_dimensions(1)); } @@ -2385,13 +2423,11 @@ StatusOr<XlaOp> XlaBuilder::AddInstruction( } for (const auto& operand : operands) { if (operand.builder_ == nullptr) { - return InvalidArgument("invalid XlaOp with handle %lld", - operand.handle()); + return InvalidArgument("invalid XlaOp with handle %d", operand.handle()); } if (operand.builder_ != this) { return InvalidArgument("Do not add XlaOp from builder %s to builder %s", - operand.builder_->name().c_str(), - this->name().c_str()); + operand.builder_->name(), this->name()); } instr.add_operand_ids(operand.handle()); } @@ -2421,18 +2457,18 @@ StatusOr<const HloInstructionProto*> XlaBuilder::LookUpInstruction( if (op.builder_ == nullptr) { return InvalidArgument( - "invalid XlaOp with handle %lld; the builder of this op is freed", + "invalid XlaOp with handle %d; the builder of this op is freed", op.handle()); } if (op.builder_ != this) { return InvalidArgument( - "XlaOp with handle %lld is built by builder '%s', but is trying to use " + "XlaOp with handle %d is built by builder '%s', but is trying to use " "it in builder '%s'", - op.handle(), op.builder_->name().c_str(), this->name().c_str()); + op.handle(), op.builder_->name(), this->name()); } if (op.handle() >= instructions_.size() || op.handle() < 0) { - return InvalidArgument("no XlaOp value %lld", op.handle()); + return InvalidArgument("no XlaOp value %d", op.handle()); } return &instructions_[op.handle()]; } @@ -2559,48 +2595,57 @@ XlaOp Le(const XlaOp& lhs, const XlaOp& rhs, return lhs.builder()->Le(lhs, rhs, broadcast_dimensions); } -XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs) { - return lhs.builder()->Dot(lhs, rhs); +XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs, + const PrecisionConfigProto* precision_config_proto) { + return lhs.builder()->Dot(lhs, rhs, precision_config_proto); } XlaOp DotGeneral(const XlaOp& lhs, const XlaOp& rhs, - const DotDimensionNumbers& dimension_numbers) { - return lhs.builder()->DotGeneral(lhs, rhs, dimension_numbers); + const DotDimensionNumbers& dimension_numbers, + const PrecisionConfigProto* precision_config_proto) { + return lhs.builder()->DotGeneral(lhs, rhs, dimension_numbers, + precision_config_proto); } XlaOp Conv(const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, Padding padding, - int64 feature_group_count) { + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { return lhs.builder()->Conv(lhs, rhs, window_strides, padding, - feature_group_count); + feature_group_count, precision_config_proto); } XlaOp ConvWithGeneralPadding( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, - int64 feature_group_count) { + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { return lhs.builder()->ConvWithGeneralPadding(lhs, rhs, window_strides, - padding, feature_group_count); + padding, feature_group_count, + precision_config_proto); } XlaOp ConvWithGeneralDimensions( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count) { - return lhs.builder()->ConvWithGeneralDimensions(lhs, rhs, window_strides, - padding, dimension_numbers, - feature_group_count); + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { + return lhs.builder()->ConvWithGeneralDimensions( + lhs, rhs, window_strides, padding, dimension_numbers, feature_group_count, + precision_config_proto); } XlaOp ConvGeneral(const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count) { + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { return lhs.builder()->ConvGeneral(lhs, rhs, window_strides, padding, - dimension_numbers, feature_group_count); + dimension_numbers, feature_group_count, + precision_config_proto); } XlaOp ConvGeneralDilated( @@ -2610,10 +2655,11 @@ XlaOp ConvGeneralDilated( tensorflow::gtl::ArraySlice<int64> lhs_dilation, tensorflow::gtl::ArraySlice<int64> rhs_dilation, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count) { + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto) { return lhs.builder()->ConvGeneralDilated( lhs, rhs, window_strides, padding, lhs_dilation, rhs_dilation, - dimension_numbers, feature_group_count); + dimension_numbers, feature_group_count, precision_config_proto); } XlaOp Fft(const XlaOp& operand, FftType fft_type, @@ -2641,13 +2687,6 @@ XlaOp CustomCall(XlaBuilder* builder, const string& call_target_name, return builder->CustomCall(call_target_name, operands, shape); } -XlaOp HostCompute(XlaBuilder* builder, - tensorflow::gtl::ArraySlice<XlaOp> operands, - const string& channel_name, int64 cost_estimate_ns, - const Shape& shape) { - return builder->HostCompute(operands, channel_name, cost_estimate_ns, shape); -} - XlaOp Complex(const XlaOp& real, const XlaOp& imag, tensorflow::gtl::ArraySlice<int64> broadcast_dimensions) { return real.builder()->Complex(real, imag, broadcast_dimensions); @@ -2757,17 +2796,17 @@ XlaOp ReduceWindowWithGeneralPadding( padding); } -XlaOp CrossReplicaSum(const XlaOp& operand, - tensorflow::gtl::ArraySlice<int64> replica_group_ids) { - return operand.builder()->CrossReplicaSum(operand, replica_group_ids); +XlaOp CrossReplicaSum( + const XlaOp& operand, + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups) { + return operand.builder()->CrossReplicaSum(operand, replica_groups); } -XlaOp CrossReplicaSum( - const XlaOp& operand, const XlaComputation& computation, - tensorflow::gtl::ArraySlice<int64> replica_group_ids, - const tensorflow::gtl::optional<ChannelHandle>& channel_id) { +XlaOp CrossReplicaSum(const XlaOp& operand, const XlaComputation& computation, + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups, + const absl::optional<ChannelHandle>& channel_id) { return operand.builder()->CrossReplicaSum(operand, computation, - replica_group_ids, channel_id); + replica_groups, channel_id); } XlaOp AllToAll(const XlaOp& operand, int64 split_dimension, @@ -2777,6 +2816,12 @@ XlaOp AllToAll(const XlaOp& operand, int64 split_dimension, split_count, replica_groups); } +XlaOp CollectivePermute( + const XlaOp& operand, + const std::vector<std::pair<int64, int64>>& source_target_pairs) { + return operand.builder()->CollectivePermute(operand, source_target_pairs); +} + XlaOp SelectAndScatter(const XlaOp& operand, const XlaComputation& select, tensorflow::gtl::ArraySlice<int64> window_dimensions, tensorflow::gtl::ArraySlice<int64> window_strides, @@ -2862,8 +2907,7 @@ XlaOp Rev(const XlaOp& operand, tensorflow::gtl::ArraySlice<int64> dimensions) { return operand.builder()->Rev(operand, dimensions); } -XlaOp Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values, - int64 dimension) { +XlaOp Sort(XlaOp keys, absl::optional<XlaOp> values, int64 dimension) { return keys.builder()->Sort(keys, std::move(values), dimension); } @@ -2992,10 +3036,11 @@ XlaOp BatchNormGrad(const XlaOp& operand, const XlaOp& scale, } XlaOp IotaGen(XlaBuilder* builder, PrimitiveType type, int64 size) { - HloInstructionProto instr; - *instr.mutable_shape() = ShapeUtil::MakeShape(type, {size}); - return builder->ReportErrorOrReturn( - builder->AddInstruction(std::move(instr), HloOpcode::kIota)); + return builder->IotaGen(type, size); +} + +XlaOp IotaGen(XlaBuilder* builder, const Shape& shape, int64 iota_dimension) { + return builder->IotaGen(shape, iota_dimension); } } // namespace xla diff --git a/tensorflow/compiler/xla/client/xla_builder.h b/tensorflow/compiler/xla/client/xla_builder.h index 469d5048b2..193d8ed071 100644 --- a/tensorflow/compiler/xla/client/xla_builder.h +++ b/tensorflow/compiler/xla/client/xla_builder.h @@ -21,6 +21,7 @@ limitations under the License. #include <type_traits> #include <utility> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/client/padding.h" #include "tensorflow/compiler/xla/client/xla_computation.h" #include "tensorflow/compiler/xla/literal.h" @@ -32,7 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/platform/macros.h" @@ -154,12 +154,10 @@ class XlaBuilder { // Clears the sharding. Ops will be sharded according to the default placement // policy. - void ClearSharding() { sharding_ = tensorflow::gtl::nullopt; } + void ClearSharding() { sharding_ = absl::nullopt; } // Returns the OpSharding that will be attached to all instructions. - const tensorflow::gtl::optional<OpSharding>& sharding() const { - return sharding_; - } + const absl::optional<OpSharding>& sharding() const { return sharding_; } // Sets the builder to a mode where it will die immediately when an error is // encountered, rather than producing it in a deferred fashion when Build() is @@ -503,17 +501,21 @@ class XlaBuilder { tensorflow::gtl::ArraySlice<int64> broadcast_dimensions = {}); // Enqueues a dot instruction onto the computation. - XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs); + XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a general dot instruction onto the computation. - XlaOp DotGeneral(const XlaOp& lhs, const XlaOp& rhs, - const DotDimensionNumbers& dimension_numbers); + XlaOp DotGeneral( + const XlaOp& lhs, const XlaOp& rhs, + const DotDimensionNumbers& dimension_numbers, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, which uses the // default convolution dimension numbers. XlaOp Conv(const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, Padding padding, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration in the format returned by MakePadding(). @@ -521,7 +523,8 @@ class XlaBuilder { const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided dimension numbers configuration. @@ -529,7 +532,8 @@ class XlaBuilder { const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration as well as the dimension numbers. @@ -538,7 +542,8 @@ class XlaBuilder { tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration, dilation factors and dimension numbers. @@ -549,7 +554,8 @@ class XlaBuilder { tensorflow::gtl::ArraySlice<int64> lhs_dilation, tensorflow::gtl::ArraySlice<int64> rhs_dilation, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues an FFT instruction onto the computation, of the given type and // with the given FFT length. @@ -586,16 +592,6 @@ class XlaBuilder { tensorflow::gtl::ArraySlice<XlaOp> operands, const Shape& shape); - // Enqueues a pseudo-op to represent host-side computation data-dependencies. - // During code generation, host send and receive operations will be generated - // to transfer |operands| to the host and a single result of |shape| back to - // the device. Host send/recv operations are emitted using |channel_name|. - // Dataflow dependencies and the |cost_estimate_ns| field may be used in HLO - // instruction scheduling. - XlaOp HostCompute(tensorflow::gtl::ArraySlice<XlaOp> operands, - const string& channel_name, int64 cost_estimate_ns, - const Shape& shape); - // The following methods enqueue element-wise binary arithmetic operations // onto the computation. The shapes of the operands have to match unless one // of the operands is a scalar, or an explicit broadcast dimension is given @@ -689,7 +685,7 @@ class XlaBuilder { // sum for each subgroup. XlaOp CrossReplicaSum( const XlaOp& operand, - tensorflow::gtl::ArraySlice<int64> replica_group_ids = {}); + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups = {}); // Enqueues an operation that do an AllReduce of the operand cross cores. Here // AllReduce means doing a reduction on the input operand cross cores and then @@ -698,10 +694,11 @@ class XlaBuilder { // scalars, e.g., add, min, or max. The way that AllReduce is applied is // configured by: // - // - `replica_group_ids`: maps replica ids to subgroup ids. If empty, all - // replicas belong to one group. Allreduce will be applied within subgroups. - // For example, we have 4 replicas, then replica_group_ids={0,1,0,1} means, - // replica 0 and 2 are in subgroup 0, replica 1 and 3 are in subgroup 1. + // - `replica_groups`: each ReplicaGroup contains a list of replica id. If + // empty, all replicas belong to one group. Allreduce will be applied within + // subgroups. For example, we have 4 replicas, then + // replica_groups={{0,2},{1,3}} means, replica 0 and 2 are in subgroup 0, + // replica 1 and 3 are in subgroup 1. // // - `channel_id`: for Allreduce nodes from different modules, if they have // the same channel_id, they will be 'Allreduce'd. If empty, Allreduce will @@ -710,17 +707,20 @@ class XlaBuilder { // TODO(b/79737069): Rename this to AllReduce when it's ready to use. XlaOp CrossReplicaSum( const XlaOp& operand, const XlaComputation& computation, - tensorflow::gtl::ArraySlice<int64> replica_group_ids = {}, - const tensorflow::gtl::optional<ChannelHandle>& channel_id = - tensorflow::gtl::nullopt); + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups = {}, + const absl::optional<ChannelHandle>& channel_id = absl::nullopt); // Enqueues an operation that do an Alltoall of the operand cross cores. - // - // TODO(b/110096724): This is NOT YET ready to use. XlaOp AllToAll(const XlaOp& operand, int64 split_dimension, int64 concat_dimension, int64 split_count, const std::vector<ReplicaGroup>& replica_groups); + // Enqueues an operation that do an CollectivePermute of the operand cross + // cores. + XlaOp CollectivePermute( + const XlaOp& operand, + const std::vector<std::pair<int64, int64>>& source_target_pairs); + // Enqueues an operation that scatters the `source` array to the selected // indices of each window. XlaOp SelectAndScatter(const XlaOp& operand, const XlaComputation& select, @@ -800,6 +800,12 @@ class XlaBuilder { // entry was NaN. XlaOp IsFinite(const XlaOp& operand); + // Enqueues an iota operation onto the computation. + XlaOp IotaGen(const Shape& shape, int64 iota_dimension); + + // Enqueues a rank-1 iota operation onto the computation. + XlaOp IotaGen(PrimitiveType type, int64 size); + // Enqueues a convert instruction onto the computation that changes the // element type of the operand array to primitive_type. XlaOp ConvertElementType(const XlaOp& operand, @@ -841,8 +847,7 @@ class XlaBuilder { // * The result is a tuple that consists of a sorted tensor of keys (along the // provided dimension, as above) as the first element, and a tensor with their // corresponding values as the second element. - XlaOp Sort(XlaOp keys, - tensorflow::gtl::optional<XlaOp> values = tensorflow::gtl::nullopt, + XlaOp Sort(XlaOp keys, absl::optional<XlaOp> values = absl::nullopt, int64 dimension = -1); // Enqueues a clamp instruction onto the computation. @@ -1049,7 +1054,7 @@ class XlaBuilder { // Sharding for this operator. This is structured as a "model"-like operation, // in order to simplify client code, similar to metadata_. - tensorflow::gtl::optional<OpSharding> sharding_; + absl::optional<OpSharding> sharding_; // Mode bit that indicates whether to die when a first error is encountered. bool die_immediately_on_error_ = false; @@ -1160,28 +1165,34 @@ class XlaBuilder { tensorflow::gtl::ArraySlice<int64> broadcast_dimensions); friend XlaOp Le(const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> broadcast_dimensions); - friend XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs); + friend XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs, + const PrecisionConfigProto* precision_config_proto); friend XlaOp DotGeneral(const XlaOp& lhs, const XlaOp& rhs, - const DotDimensionNumbers& dimension_numbers); + const DotDimensionNumbers& dimension_number, + const PrecisionConfigProto* precision_config_proto); friend XlaOp Conv(const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, - Padding padding, int64 feature_group_count); + Padding padding, int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto); friend XlaOp ConvWithGeneralPadding( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, - int64 feature_group_count); + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto); friend XlaOp ConvWithGeneralDimensions( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count); + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto); friend XlaOp ConvGeneral( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count); + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto); friend XlaOp ConvGeneralDilated( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, @@ -1189,7 +1200,8 @@ class XlaBuilder { tensorflow::gtl::ArraySlice<int64> lhs_dilation, tensorflow::gtl::ArraySlice<int64> rhs_dilation, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count); + int64 feature_group_count, + const PrecisionConfigProto* precision_config_proto); friend XlaOp Fft(const XlaOp& operand, FftType fft_type, tensorflow::gtl::ArraySlice<int64> fft_length); friend XlaOp Infeed(XlaBuilder* builder, const Shape& shape, @@ -1201,10 +1213,6 @@ class XlaBuilder { friend XlaOp CustomCall(XlaBuilder* builder, const string& call_target_name, tensorflow::gtl::ArraySlice<XlaOp> operands, const Shape& shape); - friend XlaOp HostCompute(XlaBuilder* builder, - tensorflow::gtl::ArraySlice<XlaOp> operands, - const string& channel_name, int64 cost_estimate_ns, - const Shape& shape); friend XlaOp Complex(const XlaOp& real, const XlaOp& imag, tensorflow::gtl::ArraySlice<int64> broadcast_dimensions); friend XlaOp Conj(const XlaOp& operand); @@ -1256,14 +1264,17 @@ class XlaBuilder { tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding); friend XlaOp CrossReplicaSum( const XlaOp& operand, - tensorflow::gtl::ArraySlice<int64> replica_group_ids); + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups); friend XlaOp CrossReplicaSum( const XlaOp& operand, const XlaComputation& computation, - tensorflow::gtl::ArraySlice<int64> replica_group_ids, - const tensorflow::gtl::optional<ChannelHandle>& channel_id); + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups, + const absl::optional<ChannelHandle>& channel_id); friend XlaOp AllToAll(const XlaOp& operand, int64 split_dimension, int64 concat_dimension, int64 split_count, const std::vector<ReplicaGroup>& replica_groups); + friend XlaOp CollectivePermute( + const XlaOp& operand, + const std::vector<std::pair<int64, int64>>& source_target_pairs); friend XlaOp SelectAndScatter( const XlaOp& operand, const XlaComputation& select, tensorflow::gtl::ArraySlice<int64> window_dimensions, @@ -1299,6 +1310,8 @@ class XlaBuilder { friend XlaOp IsFinite(const XlaOp& operand); // TODO(b/64798317): Finish CPU & GPU implementation, then replace xla::Iota // in xla/client/lib/numeric.h with this (renamed to xla::Iota). + friend XlaOp IotaGen(XlaBuilder* builder, const Shape& shape, + int64 iota_dimension); friend XlaOp IotaGen(XlaBuilder* builder, PrimitiveType type, int64 size); friend XlaOp ConvertElementType(const XlaOp& operand, PrimitiveType new_element_type); @@ -1309,8 +1322,7 @@ class XlaBuilder { tensorflow::gtl::ArraySlice<int64> permutation); friend XlaOp Rev(const XlaOp& operand, tensorflow::gtl::ArraySlice<int64> dimensions); - friend XlaOp Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values, - int64 dimension); + friend XlaOp Sort(XlaOp keys, absl::optional<XlaOp> values, int64 dimension); friend XlaOp Clamp(const XlaOp& min, const XlaOp& operand, const XlaOp& max); friend XlaOp Map(XlaBuilder* builder, tensorflow::gtl::ArraySlice<XlaOp> operands, @@ -1373,7 +1385,7 @@ class XlaBuilder { class XlaScopedShardingAssignment { public: XlaScopedShardingAssignment(xla::XlaBuilder* builder, - tensorflow::gtl::optional<OpSharding> sharding) + absl::optional<OpSharding> sharding) : builder_(builder), prev_sharding_(builder->sharding()) { SetSharding(sharding); } @@ -1385,7 +1397,7 @@ class XlaScopedShardingAssignment { ~XlaScopedShardingAssignment() { SetSharding(prev_sharding_); } private: - void SetSharding(const tensorflow::gtl::optional<OpSharding>& sharding) { + void SetSharding(const absl::optional<OpSharding>& sharding) { if (sharding.has_value()) { builder_->SetSharding(sharding.value()); } else { @@ -1394,7 +1406,7 @@ class XlaScopedShardingAssignment { } xla::XlaBuilder* const builder_; - tensorflow::gtl::optional<OpSharding> prev_sharding_; + absl::optional<OpSharding> prev_sharding_; }; // Free functions for building XlaOps. The intention is that these will @@ -1645,17 +1657,20 @@ XlaOp Le(const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> broadcast_dimensions = {}); // Enqueues a dot instruction onto the computation. -XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs); +XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a general dot instruction onto the computation. XlaOp DotGeneral(const XlaOp& lhs, const XlaOp& rhs, - const DotDimensionNumbers& dimension_numbers); + const DotDimensionNumbers& dimension_numbers, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, which uses the // default convolution dimension numbers. XlaOp Conv(const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, Padding padding, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration in the format returned by MakePadding(). @@ -1663,7 +1678,8 @@ XlaOp ConvWithGeneralPadding( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided dimension numbers configuration. @@ -1671,7 +1687,8 @@ XlaOp ConvWithGeneralDimensions( const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration as well as the dimension numbers. @@ -1679,7 +1696,8 @@ XlaOp ConvGeneral(const XlaOp& lhs, const XlaOp& rhs, tensorflow::gtl::ArraySlice<int64> window_strides, tensorflow::gtl::ArraySlice<std::pair<int64, int64>> padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration, dilation factors and dimension numbers. @@ -1690,7 +1708,8 @@ XlaOp ConvGeneralDilated( tensorflow::gtl::ArraySlice<int64> lhs_dilation, tensorflow::gtl::ArraySlice<int64> rhs_dilation, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1); + int64 feature_group_count = 1, + const PrecisionConfigProto* precision_config_proto = nullptr); // Enqueues an FFT instruction onto the computation, of the given type and // with the given FFT length. @@ -1737,17 +1756,6 @@ XlaOp CustomCall(XlaBuilder* builder, const string& call_target_name, tensorflow::gtl::ArraySlice<XlaOp> operands, const Shape& shape); -// Enqueues a pseudo-op to represent host-side computation data-dependencies. -// During code generation, host send and receive operations will be generated -// to transfer |operands| to the host and a single result of |shape| back to -// the device. Host send/recv operations are emitted using |channel_name|. -// Dataflow dependencies and the |cost_estimate_ns| field may be used in HLO -// instruction scheduling. -XlaOp HostCompute(XlaBuilder* builder, - tensorflow::gtl::ArraySlice<XlaOp> operands, - const string& channel_name, int64 cost_estimate_ns, - const Shape& shape); - // The following methods enqueue element-wise binary arithmetic operations // onto the computation. The shapes of the operands have to match unless one // of the operands is a scalar, or an explicit broadcast dimension is given @@ -1841,7 +1849,7 @@ XlaOp ReduceWindowWithGeneralPadding( // sum for each subgroup. XlaOp CrossReplicaSum( const XlaOp& operand, - tensorflow::gtl::ArraySlice<int64> replica_group_ids = {}); + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups = {}); // Enqueues an operation that do an AllReduce of the operand cross cores. Here // AllReduce means doing a reduction on the input operand cross cores and then @@ -1850,28 +1858,38 @@ XlaOp CrossReplicaSum( // scalars, e.g., add, min, or max. The way that AllReduce is applied is // configured by: // -// - `replica_group_ids`: maps replica ids to subgroup ids. If empty, all -// replicas belong to one group. Allreduce will be applied within subgroups. -// For example, we have 4 replicas, then replica_group_ids={0,1,0,1} means, -// replica 0 and 2 are in subgroup 0, replica 1 and 3 are in subgroup 1. +// - `replica_groups`: each ReplicaGroup contains a list of replica id. If +// empty, all replicas belong to one group. Allreduce will be applied within +// subgroups. For example, we have 4 replicas, then replica_groups={{0,2},{1,3}} +// means, replica 0 and 2 are in subgroup 0, replica 1 and 3 are in subgroup 1. // // - `channel_id`: for Allreduce nodes from different modules, if they have the // same channel_id, they will be 'Allreduce'd. If empty, Allreduce will not be // applied cross modules. // // TODO(b/79737069): Rename this to AllReduce when it's ready to use. -XlaOp CrossReplicaSum(const XlaOp& operand, const XlaComputation& computation, - tensorflow::gtl::ArraySlice<int64> replica_group_ids = {}, - const tensorflow::gtl::optional<ChannelHandle>& - channel_id = tensorflow::gtl::nullopt); +XlaOp CrossReplicaSum( + const XlaOp& operand, const XlaComputation& computation, + tensorflow::gtl::ArraySlice<ReplicaGroup> replica_groups = {}, + const absl::optional<ChannelHandle>& channel_id = absl::nullopt); // Enqueues an operation that do an Alltoall of the operand cross cores. -// -// TODO(b/110096724): This is NOT YET ready to use. XlaOp AllToAll(const XlaOp& operand, int64 split_dimension, int64 concat_dimension, int64 split_count, const std::vector<ReplicaGroup>& replica_groups = {}); +// Enqueues an collective operation that sends and receives data cross replicas. +// +// - `source_target_pair`: a list of (source_replica_id, target_replica_id) +// pairs. For each pair, the operand is sent from source replica to target +// replica. Note that, 1) any two pairs should not have the same target replica +// id, and they should not have the same source replica id; 2) if a replica id +// is not a target in any pair, then the output on that replica is a tensor +// consists of 0(s) with the same shape as the input. +XlaOp CollectivePermute( + const XlaOp& operand, + const std::vector<std::pair<int64, int64>>& source_target_pairs); + // Enqueues an operation that scatters the `source` array to the selected // indices of each window. XlaOp SelectAndScatter(const XlaOp& operand, const XlaComputation& select, @@ -1950,6 +1968,12 @@ XlaOp Pow(const XlaOp& lhs, const XlaOp& rhs, // entry was NaN. XlaOp IsFinite(const XlaOp& operand); +// Enqueues an iota operation onto the computation. +XlaOp IotaGen(XlaBuilder* builder, const Shape& shape, int64 iota_dimension); + +// Enqueues a rank-1 iota operation onto the computation. +XlaOp IotaGen(XlaBuilder* builder, PrimitiveType type, int64 size); + // Enqueues a convert instruction onto the computation that changes the // element type of the operand array to primitive_type. XlaOp ConvertElementType(const XlaOp& operand, PrimitiveType new_element_type); @@ -1988,8 +2012,7 @@ XlaOp Rev(const XlaOp& operand, tensorflow::gtl::ArraySlice<int64> dimensions); // * The result is a tuple that consists of a sorted tensor of keys (along the // provided dimension, as above) as the first element, and a tensor with their // corresponding values as the second element. -XlaOp Sort(XlaOp keys, - tensorflow::gtl::optional<XlaOp> values = tensorflow::gtl::nullopt, +XlaOp Sort(XlaOp keys, absl::optional<XlaOp> values = absl::nullopt, int64 dimension = -1); // Enqueues a clamp instruction onto the computation. diff --git a/tensorflow/compiler/xla/client/xla_builder_test.cc b/tensorflow/compiler/xla/client/xla_builder_test.cc index 49a15ec3b4..7c37ed00cd 100644 --- a/tensorflow/compiler/xla/client/xla_builder_test.cc +++ b/tensorflow/compiler/xla/client/xla_builder_test.cc @@ -320,6 +320,15 @@ TEST_F(XlaBuilderTest, AllToAll) { ShapeUtil::Equal(root->shape(), ShapeUtil::MakeShape(F32, {8, 8}))); } +TEST_F(XlaBuilderTest, CollectivePermute) { + XlaBuilder b(TestName()); + auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {5, 7}), "x"); + CollectivePermute(x, {{0, 1}, {1, 2}, {2, 3}}); + TF_ASSERT_OK_AND_ASSIGN(auto module, BuildHloModule(&b)); + auto root = module->entry_computation()->root_instruction(); + EXPECT_EQ(root->opcode(), HloOpcode::kCollectivePermute); +} + TEST_F(XlaBuilderTest, ReportError) { XlaBuilder b(TestName()); auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {5, 7}), "x"); diff --git a/tensorflow/compiler/xla/client/xla_computation.cc b/tensorflow/compiler/xla/client/xla_computation.cc index 3543d41fc2..22c9e83bb2 100644 --- a/tensorflow/compiler/xla/client/xla_computation.cc +++ b/tensorflow/compiler/xla/client/xla_computation.cc @@ -17,7 +17,7 @@ limitations under the License. #include <utility> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/util.h" @@ -32,7 +32,7 @@ StatusOr<std::unique_ptr<HloSnapshot>> XlaComputation::Snapshot() const { if (IsNull()) { return InvalidArgument("Computation is invalid."); } - auto session = MakeUnique<HloSnapshot>(); + auto session = absl::make_unique<HloSnapshot>(); *session->mutable_hlo()->mutable_hlo_module() = proto_; return std::move(session); } diff --git a/tensorflow/compiler/xla/device_util.h b/tensorflow/compiler/xla/device_util.h index 1a51fdee68..6d51126d88 100644 --- a/tensorflow/compiler/xla/device_util.h +++ b/tensorflow/compiler/xla/device_util.h @@ -21,8 +21,8 @@ limitations under the License. #include <string> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" namespace xla { @@ -30,8 +30,8 @@ namespace xla { // Returns a string that represents the device in terms of platform and ordinal; // e.g. the first CUDA device will be "cuda:0" string DeviceIdentifier(se::StreamExecutor* stream_exec) { - return tensorflow::strings::StrCat(stream_exec->platform()->Name(), ":", - stream_exec->device_ordinal()); + return absl::StrCat(stream_exec->platform()->Name(), ":", + stream_exec->device_ordinal()); } } // namespace xla diff --git a/tensorflow/compiler/xla/index_util.cc b/tensorflow/compiler/xla/index_util.cc index ffd1fb79e9..693dcb3a3e 100644 --- a/tensorflow/compiler/xla/index_util.cc +++ b/tensorflow/compiler/xla/index_util.cc @@ -18,10 +18,10 @@ limitations under the License. #include <algorithm> #include <string> +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/logging.h" namespace xla { @@ -36,7 +36,7 @@ namespace xla { DCHECK_GE(multi_index[i], 0); DCHECK_LT(multi_index[i], shape.dimensions(i)) << "indexing beyond extent in dimension " << i << ":" - << "\n\tindex: " << tensorflow::str_util::Join(multi_index, ",") + << "\n\tindex: " << absl::StrJoin(multi_index, ",") << "\n\tshape: " << ShapeUtil::HumanString(shape); } diff --git a/tensorflow/compiler/xla/iterator_util.h b/tensorflow/compiler/xla/iterator_util.h index a8bb8c7a7e..3a3ee21e76 100644 --- a/tensorflow/compiler/xla/iterator_util.h +++ b/tensorflow/compiler/xla/iterator_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_ITERATOR_UTIL_H_ -#define TENSORFLOW_COMPILER_XLA_SERVICE_ITERATOR_UTIL_H_ +#ifndef TENSORFLOW_COMPILER_XLA_ITERATOR_UTIL_H_ +#define TENSORFLOW_COMPILER_XLA_ITERATOR_UTIL_H_ #include <iterator> #include <utility> @@ -95,4 +95,4 @@ UnwrappingIterator<NestedIter> MakeUnwrappingIterator(NestedIter iter) { } // namespace xla -#endif // TENSORFLOW_COMPILER_XLA_SERVICE_ITERATOR_UTIL_H_ +#endif // TENSORFLOW_COMPILER_XLA_ITERATOR_UTIL_H_ diff --git a/tensorflow/compiler/xla/iterator_util_test.cc b/tensorflow/compiler/xla/iterator_util_test.cc index 7bc3189507..ec8b66df2d 100644 --- a/tensorflow/compiler/xla/iterator_util_test.cc +++ b/tensorflow/compiler/xla/iterator_util_test.cc @@ -18,7 +18,7 @@ limitations under the License. #include <algorithm> #include <list> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/test.h" namespace xla { @@ -27,7 +27,7 @@ namespace { TEST(UnwrappingIteratorTest, Simple) { std::vector<std::unique_ptr<int>> v; for (int i = 0; i < 3; ++i) { - v.push_back(MakeUnique<int>(i)); + v.push_back(absl::make_unique<int>(i)); } int i = 0; for (auto iter = MakeUnwrappingIterator(v.begin()); @@ -51,7 +51,7 @@ TEST(UnwrappingIteratorTest, PostincrementOperator) { TEST(UnwrappingIteratorTest, StdFind) { std::list<std::unique_ptr<int>> l; for (int i = 0; i < 3; ++i) { - l.push_back(MakeUnique<int>(i)); + l.push_back(absl::make_unique<int>(i)); } EXPECT_EQ(l.begin()->get(), *std::find(MakeUnwrappingIterator(l.begin()), diff --git a/tensorflow/compiler/xla/layout_util.cc b/tensorflow/compiler/xla/layout_util.cc index b72d190d54..cce1838ef3 100644 --- a/tensorflow/compiler/xla/layout_util.cc +++ b/tensorflow/compiler/xla/layout_util.cc @@ -23,6 +23,8 @@ limitations under the License. #include <unordered_map> #include <vector> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/protobuf_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -31,8 +33,6 @@ limitations under the License. #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/hash/hash.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" @@ -169,7 +169,7 @@ Layout CreateDefaultLayoutForRank(int64 rank) { } else if (ShapeUtil::IsArray(shape)) { if (!shape.has_layout()) { return InvalidArgument("shape %s does not have a layout", - ShapeUtil::HumanString(shape).c_str()); + ShapeUtil::HumanString(shape)); } return ValidateLayoutForShape(shape.layout(), shape); } else { @@ -177,7 +177,7 @@ Layout CreateDefaultLayoutForRank(int64 rank) { if (shape.has_layout()) { return InvalidArgument( "shape of primitive type %s should not have a layout", - PrimitiveType_Name(shape.element_type()).c_str()); + PrimitiveType_Name(shape.element_type())); } return Status::OK(); } @@ -194,7 +194,7 @@ Layout CreateDefaultLayoutForRank(int64 rank) { layout.padded_dimensions_size() != 0) { return InvalidArgument( "shape of primitive type %s should not have a non-trivial layout", - PrimitiveType_Name(shape.element_type()).c_str()); + PrimitiveType_Name(shape.element_type())); } return Status::OK(); } @@ -202,17 +202,17 @@ Layout CreateDefaultLayoutForRank(int64 rank) { if (layout.format() == INVALID_FORMAT) { return InvalidArgument( "Layout does not have a valid format: layout {%s}, shape {%s}", - layout.ShortDebugString().c_str(), shape.ShortDebugString().c_str()); + layout.ShortDebugString(), shape.ShortDebugString()); } if (layout.format() == DENSE) { if (layout.minor_to_major_size() != ShapeUtil::Rank(shape)) { return InvalidArgument( "layout minor_to_major field contains %d elements, " - "but shape is rank %lld: {%s}; shape: %s", + "but shape is rank %d: {%s}; shape: %s", layout.minor_to_major_size(), ShapeUtil::Rank(shape), - tensorflow::str_util::Join(layout.minor_to_major(), ", ").c_str(), - shape.ShortDebugString().c_str()); + absl::StrJoin(layout.minor_to_major(), ", "), + shape.ShortDebugString()); } std::vector<bool> dimensions_in_layout(ShapeUtil::Rank(shape), false); @@ -221,12 +221,12 @@ Layout CreateDefaultLayoutForRank(int64 rank) { if (dim < 0 || dim >= ShapeUtil::Rank(shape)) { return InvalidArgument( "layout minor_to_major field has out-of-bounds value: %s", - HumanString(layout).c_str()); + HumanString(layout)); } if (dimensions_in_layout[dim]) { return InvalidArgument( "layout minor_to_major field has duplicate values: {%s}", - HumanString(layout).c_str()); + HumanString(layout)); } dimensions_in_layout[dim] = true; } @@ -234,14 +234,14 @@ Layout CreateDefaultLayoutForRank(int64 rank) { if (layout.padded_dimensions_size() > 0) { if (layout.padded_dimensions_size() != ShapeUtil::Rank(shape)) { return InvalidArgument( - "layout has %d padded dimensions, but shape is rank %lld", + "layout has %d padded dimensions, but shape is rank %d", layout.padded_dimensions_size(), ShapeUtil::Rank(shape)); } for (int i = 0; i < layout.padded_dimensions_size(); ++i) { if (layout.padded_dimensions(i) < shape.dimensions(i)) { return InvalidArgument( - "for dimension %d, dimension padding (%lld) is smaller than " - "the dimension size (%lld) of the shape", + "for dimension %d, dimension padding (%d) is smaller than " + "the dimension size (%d) of the shape", i, layout.padded_dimensions(i), shape.dimensions(i)); } } @@ -403,12 +403,10 @@ Layout CreateDefaultLayoutForRank(int64 rank) { /* static */ string LayoutUtil::HumanString(const Layout& layout) { if (IsSparse(layout)) { - return tensorflow::strings::StrCat("sparse{", layout.max_sparse_elements(), - "}"); + return absl::StrCat("sparse{", layout.max_sparse_elements(), "}"); } CHECK(IsDense(layout)); - return tensorflow::strings::StrCat( - "{", tensorflow::str_util::Join(layout.minor_to_major(), ","), "}"); + return absl::StrCat("{", absl::StrJoin(layout.minor_to_major(), ","), "}"); } namespace { diff --git a/tensorflow/compiler/xla/legacy_flags/BUILD b/tensorflow/compiler/xla/legacy_flags/BUILD index 89353448e2..3e79129aaf 100644 --- a/tensorflow/compiler/xla/legacy_flags/BUILD +++ b/tensorflow/compiler/xla/legacy_flags/BUILD @@ -26,6 +26,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/core:framework_internal", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -39,6 +40,7 @@ tf_cc_test( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings:str_format", ], ) @@ -56,6 +58,7 @@ cc_library( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/core:framework_internal", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -73,5 +76,7 @@ tf_cc_test( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) diff --git a/tensorflow/compiler/xla/legacy_flags/debug_options_flags.cc b/tensorflow/compiler/xla/legacy_flags/debug_options_flags.cc index 5d27e4a46b..0d3136b0cc 100644 --- a/tensorflow/compiler/xla/legacy_flags/debug_options_flags.cc +++ b/tensorflow/compiler/xla/legacy_flags/debug_options_flags.cc @@ -17,9 +17,9 @@ limitations under the License. #include <mutex> // NOLINT(build/c++11): only using std::call_once, not mutex. #include <vector> +#include "absl/strings/str_split.h" #include "tensorflow/compiler/xla/legacy_flags/debug_options_parsers.h" #include "tensorflow/compiler/xla/legacy_flags/parse_flags_from_env.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace xla { namespace legacy_flags { @@ -87,7 +87,7 @@ void AllocateFlags() { // Custom "sub-parser" lambda for xla_disable_hlo_passes. auto setter_for_xla_disable_hlo_passes = [](string comma_separated_values) { std::vector<string> disabled_passes = - tensorflow::str_util::Split(comma_separated_values, ','); + absl::StrSplit(comma_separated_values, ','); for (const auto& passname : disabled_passes) { flag_values->add_xla_disable_hlo_passes(passname); } diff --git a/tensorflow/compiler/xla/legacy_flags/debug_options_parsers.h b/tensorflow/compiler/xla/legacy_flags/debug_options_parsers.h index e9cf435d83..ee7eb019c0 100644 --- a/tensorflow/compiler/xla/legacy_flags/debug_options_parsers.h +++ b/tensorflow/compiler/xla/legacy_flags/debug_options_parsers.h @@ -17,10 +17,10 @@ limitations under the License. #define TENSORFLOW_COMPILER_XLA_LEGACY_FLAGS_DEBUG_OPTIONS_PARSERS_H_ #include <vector> +#include "absl/strings/numbers.h" +#include "absl/strings/str_split.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/xla.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/stringprintf.h" namespace xla { namespace legacy_flags { @@ -30,7 +30,7 @@ template <typename T> void parse_xla_backend_extra_options(T* extra_options_map, string comma_separated_values) { std::vector<string> extra_options_parts = - tensorflow::str_util::Split(comma_separated_values, ','); + absl::StrSplit(comma_separated_values, ','); // The flag contains a comma-separated list of options; some options // have arguments following "=", some don't. @@ -59,8 +59,7 @@ void parse_xla_backend_extra_options(T* extra_options_map, inline bool parse_xla_reduce_precision_option( HloReducePrecisionOptions* options, string option_string) { // Split off "LOCATION" from remainder of string. - std::vector<string> eq_split = - tensorflow::str_util::Split(option_string, '='); + std::vector<string> eq_split = absl::StrSplit(option_string, '='); if (eq_split.size() != 2) { return false; } @@ -80,26 +79,25 @@ inline bool parse_xla_reduce_precision_option( } // Split off "E,M" from remainder of string. - std::vector<string> colon_split = - tensorflow::str_util::Split(eq_split[1], ':'); + std::vector<string> colon_split = absl::StrSplit(eq_split[1], ':'); if (colon_split.size() != 2) { return false; } // Split E and M, and parse. std::vector<int32> bitsizes; - if (!tensorflow::str_util::SplitAndParseAsInts(colon_split[0], ',', - &bitsizes) || - bitsizes.size() != 2) { - return false; + for (const auto& s : absl::StrSplit(colon_split[0], ',')) { + bitsizes.emplace_back(); + if (!absl::SimpleAtoi(s, &bitsizes.back())) { + return false; + } } options->set_exponent_bits(bitsizes[0]); options->set_mantissa_bits(bitsizes[1]); // Split off OPS comma-separated list from remainder of string, if the // remainder exists. - std::vector<string> semicolon_split = - tensorflow::str_util::Split(colon_split[1], ';'); + std::vector<string> semicolon_split = absl::StrSplit(colon_split[1], ';'); if (semicolon_split.size() > 2) { return false; } @@ -113,8 +111,7 @@ inline bool parse_xla_reduce_precision_option( options->add_opcodes_to_suffix(i); } } else { - std::vector<string> opcodes = - tensorflow::str_util::Split(opcode_string, ','); + std::vector<string> opcodes = absl::StrSplit(opcode_string, ','); for (const string& opcode : opcodes) { bool found = false; for (int i = 0; i < HloOpcodeCount(); i++) { @@ -132,8 +129,7 @@ inline bool parse_xla_reduce_precision_option( // Process the NAMES string, if it exists. if (semicolon_split.size() == 2) { - std::vector<string> opnames = - tensorflow::str_util::Split(semicolon_split[1], ','); + std::vector<string> opnames = absl::StrSplit(semicolon_split[1], ','); for (const string& opname : opnames) { if (opname.length() > 0) { options->add_opname_substrings_to_suffix(opname); diff --git a/tensorflow/compiler/xla/legacy_flags/debug_options_parsers_test.cc b/tensorflow/compiler/xla/legacy_flags/debug_options_parsers_test.cc index 0ed788a967..6f197aec53 100644 --- a/tensorflow/compiler/xla/legacy_flags/debug_options_parsers_test.cc +++ b/tensorflow/compiler/xla/legacy_flags/debug_options_parsers_test.cc @@ -20,7 +20,6 @@ limitations under the License. #include <unordered_map> #include <vector> -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/test.h" namespace xla { diff --git a/tensorflow/compiler/xla/legacy_flags/parse_flags_from_env_test.cc b/tensorflow/compiler/xla/legacy_flags/parse_flags_from_env_test.cc index 7b6ae311c1..138c0c852e 100644 --- a/tensorflow/compiler/xla/legacy_flags/parse_flags_from_env_test.cc +++ b/tensorflow/compiler/xla/legacy_flags/parse_flags_from_env_test.cc @@ -21,8 +21,8 @@ limitations under the License. #include <stdlib.h> #include <vector> +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/subprocess.h" #include "tensorflow/core/platform/test.h" @@ -106,8 +106,8 @@ TEST(ParseFlagsFromEnv, File) { if (tmp_dir == nullptr) { tmp_dir = kTempDir; } - string tmp_file = tensorflow::strings::Printf("%s/parse_flags_from_env.%d", - tmp_dir, getpid()); + string tmp_file = + absl::StrFormat("%s/parse_flags_from_env.%d", tmp_dir, getpid()); FILE* fp = fopen(tmp_file.c_str(), "w"); CHECK_NE(fp, nullptr) << "can't write to " << tmp_file; for (int i = 0; kTestFlagString[i] != '\0'; i++) { diff --git a/tensorflow/compiler/xla/literal.cc b/tensorflow/compiler/xla/literal.cc index 36e472568e..93e808469a 100644 --- a/tensorflow/compiler/xla/literal.cc +++ b/tensorflow/compiler/xla/literal.cc @@ -22,6 +22,10 @@ limitations under the License. #include <numeric> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/index_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -30,19 +34,15 @@ limitations under the License. #include "tensorflow/core/lib/core/casts.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/hash/hash.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" -using tensorflow::strings::Printf; -using tensorflow::strings::StrCat; - namespace xla { - namespace { +using absl::StrCat; +using absl::StrFormat; + constexpr bool kLittleEndian = __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__; // Converts between little and big endian. @@ -134,7 +134,7 @@ void Literal::SetPiece(const Shape& shape, Piece* piece, bool allocate_arrays) { Literal::Literal(const Shape& shape, bool allocate_arrays) : MutableLiteralBase() { - shape_ = MakeUnique<Shape>(shape); + shape_ = absl::make_unique<Shape>(shape); CHECK(LayoutUtil::HasLayout(*shape_)); root_piece_ = new Piece(); root_piece_->set_subshape(shape_.get()); @@ -175,7 +175,7 @@ Literal& Literal::operator=(Literal&& other) { } std::unique_ptr<Literal> LiteralBase::CreateFromShape(const Shape& shape) { - auto literal = MakeUnique<Literal>(shape); + auto literal = absl::make_unique<Literal>(shape); literal->root_piece_->ForEachMutableSubpiece( [&](const ShapeIndex& index, Piece* piece) { if (ShapeUtil::IsArray(piece->subshape())) { @@ -289,7 +289,7 @@ MutableLiteralBase::CreateFromProto(const LiteralProto& proto) { return InvalidArgument("LiteralProto has no layout"); } - auto literal = MakeUnique<Literal>(proto.shape()); + auto literal = absl::make_unique<Literal>(proto.shape()); TF_RETURN_IF_ERROR(literal->root_piece_->ForEachMutableSubpieceWithStatus( [&](const ShapeIndex& index, Piece* piece) { @@ -303,7 +303,7 @@ MutableLiteralBase::CreateFromProto(const LiteralProto& proto) { if (proto_element->tuple_literals_size() != ShapeUtil::TupleElementCount(piece->subshape())) { return InvalidArgument( - "Expected %lld tuple elements in LiteralProto, has %d", + "Expected %d tuple elements in LiteralProto, has %d", ShapeUtil::TupleElementCount(piece->subshape()), proto_element->tuple_literals_size()); } @@ -404,7 +404,7 @@ Status LiteralBase::Piece::CopyFrom(const LiteralBase::Piece& src) { default: return Unimplemented( "Copying a Literal object with element type %s is not implemented.", - PrimitiveType_Name(subshape().element_type()).c_str()); + PrimitiveType_Name(subshape().element_type())); } } return Status::OK(); @@ -420,8 +420,8 @@ Status MutableLiteralBase::CopyFrom(const LiteralSlice& src_literal, if (!ShapeUtil::Compatible(dest_subshape, src_subshape)) { return InvalidArgument( "Destination subshape incompatible with source subshape: %s vs %s", - ShapeUtil::HumanString(dest_subshape).c_str(), - ShapeUtil::HumanString(src_subshape).c_str()); + ShapeUtil::HumanString(dest_subshape), + ShapeUtil::HumanString(src_subshape)); } return root_piece_->ForEachMutableSubpieceWithStatus( [&](const ShapeIndex& index, Piece* piece) { @@ -458,8 +458,8 @@ Status Literal::MoveFrom(Literal&& src_literal, if (!ShapeUtil::Equal(dest_subshape, src_literal.shape())) { return InvalidArgument( "Destination subshape not equal to source shape: %s vs %s", - ShapeUtil::HumanString(dest_subshape).c_str(), - ShapeUtil::HumanString(src_literal.shape()).c_str()); + ShapeUtil::HumanString(dest_subshape), + ShapeUtil::HumanString(src_literal.shape())); } src_literal.root_piece_->ForEachSubpiece( @@ -479,7 +479,7 @@ Status Literal::MoveFrom(Literal&& src_literal, dest_piece.set_sparse_indices(src_piece.sparse_indices()); }); - src_literal.shape_ = MakeUnique<Shape>(ShapeUtil::MakeNil()); + src_literal.shape_ = absl::make_unique<Shape>(ShapeUtil::MakeNil()); delete src_literal.root_piece_; src_literal.root_piece_ = new LiteralBase::Piece(); src_literal.root_piece_->set_subshape(src_literal.shape_.get()); @@ -566,7 +566,7 @@ std::unique_ptr<Literal> LiteralBase::Relayout( Shape* subshape = ShapeUtil::GetMutableSubshape(&new_shape, shape_index); TF_CHECK_OK(LayoutUtil::ValidateLayoutForShape(new_layout, *subshape)); *subshape->mutable_layout() = new_layout; - auto result = MakeUnique<Literal>(new_shape); + auto result = absl::make_unique<Literal>(new_shape); TF_CHECK_OK(result->CopyFrom(*this)); return result; } @@ -602,7 +602,7 @@ StatusOr<std::unique_ptr<Literal>> LiteralBase::Broadcast( result_shape.dimensions(dimensions[i])); } - std::unique_ptr<Literal> result = MakeUnique<Literal>(result_shape); + std::unique_ptr<Literal> result = absl::make_unique<Literal>(result_shape); // scratch_source_index is temporary storage space for the computed index into // the input literal. We put it here to avoid allocating an std::vector in @@ -654,8 +654,8 @@ StatusOr<std::unique_ptr<Literal>> LiteralBase::Reshape( return InvalidArgument( "Shapes before and after Literal::Reshape have different numbers " "of elements: %s vs %s.", - ShapeUtil::HumanString(shape()).c_str(), - ShapeUtil::HumanString(output->shape()).c_str()); + ShapeUtil::HumanString(shape()), + ShapeUtil::HumanString(output->shape())); } return std::move(output); } @@ -691,7 +691,7 @@ std::unique_ptr<Literal> LiteralBase::Transpose( for (auto index : LayoutUtil::MinorToMajor(shape())) { layout->add_minor_to_major(inverse_permutation[index]); } - auto new_literal = MakeUnique<Literal>(permuted_shape); + auto new_literal = absl::make_unique<Literal>(permuted_shape); DCHECK_EQ(ShapeUtil::ByteSizeOf(new_literal->shape()), ShapeUtil::ByteSizeOf(shape())); std::memcpy(new_literal->untyped_data(), untyped_data(), size_bytes()); @@ -702,7 +702,7 @@ template <typename NativeT> std::unique_ptr<Literal> LiteralBase::SliceInternal( const Shape& result_shape, tensorflow::gtl::ArraySlice<int64> start_indices) const { - auto result_literal = MakeUnique<Literal>(result_shape); + auto result_literal = absl::make_unique<Literal>(result_shape); DimensionVector new_indices(ShapeUtil::Rank(result_shape)); result_literal->EachCell<NativeT>( [&](tensorflow::gtl::ArraySlice<int64> indices, NativeT /*value*/) { @@ -756,7 +756,7 @@ Literal LiteralBase::Clone() const { } std::unique_ptr<Literal> LiteralBase::CloneToUnique() const { - auto result = MakeUnique<Literal>(shape()); + auto result = absl::make_unique<Literal>(shape()); TF_CHECK_OK(result->CopyFrom(*this)); return result; } @@ -874,9 +874,8 @@ StatusOr<int64> LiteralBase::GetIntegralAsS64( case U64: return Get<uint64>(multi_index); default: - return FailedPrecondition( - "Array element type is not integral: %s", - PrimitiveType_Name(shape().element_type()).c_str()); + return FailedPrecondition("Array element type is not integral: %s", + PrimitiveType_Name(shape().element_type())); } } @@ -924,9 +923,8 @@ Status MutableLiteralBase::SetIntegralAsS64( Set<uint64>(multi_index, value); break; default: - return FailedPrecondition( - "Array element type is not integral: %s", - PrimitiveType_Name(shape().element_type()).c_str()); + return FailedPrecondition("Array element type is not integral: %s", + PrimitiveType_Name(shape().element_type())); } return Status::OK(); } @@ -1029,9 +1027,9 @@ void ToStringHelper(const LiteralBase& literal, const ShapeIndex& shape_index, element_index.push_back(i); std::vector<string> element_pieces; ToStringHelper(literal, element_index, print_layout, &element_pieces); - tuple_pieces.push_back(tensorflow::str_util::Join(element_pieces, "")); + tuple_pieces.push_back(absl::StrJoin(element_pieces, "")); } - pieces->push_back(tensorflow::str_util::Join(tuple_pieces, ",\n")); + pieces->push_back(absl::StrJoin(tuple_pieces, ",\n")); pieces->push_back("\n)"); return; } @@ -1055,8 +1053,7 @@ void ToStringHelper(const LiteralBase& literal, const ShapeIndex& shape_index, pieces->push_back(": "); } else { pieces->push_back("["); - pieces->push_back( - tensorflow::str_util::Join(literal.GetSparseIndex(i), ", ")); + pieces->push_back(absl::StrJoin(literal.GetSparseIndex(i), ", ")); pieces->push_back("]: "); } pieces->push_back(literal.GetSparseElementAsString(i)); @@ -1117,9 +1114,9 @@ void ToStringHelper(const LiteralBase& literal, const ShapeIndex& shape_index, pieces->push_back(shape_to_string(subshape)); pieces->push_back(" {\n"); for (int64 i0 = 0; i0 < subshape.dimensions(0); ++i0) { - pieces->push_back(Printf(" { /*i0=%lld*/\n", i0)); + pieces->push_back(StrFormat(" { /*i0=%d*/\n", i0)); for (int64 i1 = 0; i1 < subshape.dimensions(1); ++i1) { - pieces->push_back(Printf(" { /*i1=%lld*/\n", i1)); + pieces->push_back(StrFormat(" { /*i1=%d*/\n", i1)); for (int64 i2 = 0; i2 < subshape.dimensions(2); ++i2) { pieces->push_back(" {"); for (int64 i3 = 0; i3 < subshape.dimensions(3); ++i3) { @@ -1137,11 +1134,11 @@ void ToStringHelper(const LiteralBase& literal, const ShapeIndex& shape_index, pieces->push_back(shape_to_string(subshape)); pieces->push_back(" {\n"); for (int64 i0 = 0; i0 < subshape.dimensions(0); ++i0) { - pieces->push_back(Printf(" { /*i0=%lld*/\n", i0)); + pieces->push_back(StrFormat(" { /*i0=%d*/\n", i0)); for (int64 i1 = 0; i1 < subshape.dimensions(1); ++i1) { - pieces->push_back(Printf(" { /*i1=%lld*/\n", i1)); + pieces->push_back(StrFormat(" { /*i1=%d*/\n", i1)); for (int64 i2 = 0; i2 < subshape.dimensions(2); ++i2) { - pieces->push_back(Printf(" { /*i2=%lld*/\n", i2)); + pieces->push_back(StrFormat(" { /*i2=%d*/\n", i2)); for (int64 i3 = 0; i3 < subshape.dimensions(3); ++i3) { pieces->push_back(" {"); for (int64 i4 = 0; i4 < subshape.dimensions(4); ++i4) { @@ -1182,7 +1179,7 @@ string LiteralBase::ToString(bool print_layout) const { std::vector<string> pieces; CHECK(LayoutUtil::HasLayout(this->shape())); ToStringHelper(*this, {}, print_layout, &pieces); - return tensorflow::str_util::Join(pieces, ""); + return absl::StrJoin(pieces, ""); } void LiteralBase::EachCellAsString( @@ -1203,7 +1200,7 @@ template <typename NativeSrcT, typename NativeDestT, typename ConverterType> std::unique_ptr<Literal> ConvertBetweenNativeTypesWithConverter( const LiteralBase& src_literal, const ConverterType& converter) { CHECK(ShapeUtil::IsArray(src_literal.shape())); - auto result_literal = MakeUnique<Literal>(ShapeUtil::ChangeElementType( + auto result_literal = absl::make_unique<Literal>(ShapeUtil::ChangeElementType( src_literal.shape(), primitive_util::NativeToPrimitiveType<NativeDestT>())); auto src_data = src_literal.data<NativeSrcT>(); @@ -1249,7 +1246,7 @@ BitcastBetweenNativeTypes(const LiteralBase& src_literal) { template <PrimitiveType primitive_src_type> std::unique_ptr<Literal> ConvertToC64(const LiteralBase& src_literal) { CHECK(ShapeUtil::IsArray(src_literal.shape())); - auto result_literal = MakeUnique<Literal>( + auto result_literal = absl::make_unique<Literal>( ShapeUtil::ChangeElementType(src_literal.shape(), C64)); using NativeSrcT = typename primitive_util::PrimitiveTypeToNative<primitive_src_type>::type; @@ -1313,10 +1310,9 @@ StatusOr<std::unique_ptr<Literal>> ConvertIfDestTypeMatches( default: break; } - return Unimplemented( - "Converting from type %s to type %s is not implemented.", - PrimitiveType_Name(src_literal.shape().element_type()).c_str(), - PrimitiveType_Name(primitive_dest_type).c_str()); + return Unimplemented("Converting from type %s to type %s is not implemented.", + PrimitiveType_Name(src_literal.shape().element_type()), + PrimitiveType_Name(primitive_dest_type)); } StatusOr<std::unique_ptr<Literal>> ConvertSwitch( @@ -1345,11 +1341,10 @@ StatusOr<std::unique_ptr<Literal>> ConvertSwitch( #undef CONVERT_IF_DEST_TYPE_MATCHES // Other types are not yet supported. default: - return Unimplemented( - "%s from type %s to type %s is not implemented.", - (bitcast ? "Bitcast converting" : "Converting"), - PrimitiveType_Name(literal.shape().element_type()).c_str(), - PrimitiveType_Name(primitive_dest_type).c_str()); + return Unimplemented("%s from type %s to type %s is not implemented.", + (bitcast ? "Bitcast converting" : "Converting"), + PrimitiveType_Name(literal.shape().element_type()), + PrimitiveType_Name(primitive_dest_type)); } } @@ -1367,8 +1362,8 @@ StatusOr<std::unique_ptr<Literal>> LiteralBase::BitcastConvert( return InvalidArgument( "Cannot bitcast convert from %s to %s, bit widths are different: %d != " "%d", - PrimitiveType_Name(shape().element_type()).c_str(), - PrimitiveType_Name(primitive_dest_type).c_str(), + PrimitiveType_Name(shape().element_type()), + PrimitiveType_Name(primitive_dest_type), primitive_util::BitWidth(shape().element_type()), primitive_util::BitWidth(primitive_dest_type)); } @@ -1396,7 +1391,7 @@ StatusOr<std::unique_ptr<Literal>> LiteralBase::ConvertToShape( element.ConvertToShape(ShapeUtil::GetSubshape(dest_shape, {i}))); elements.push_back(std::move(*new_element)); } - auto converted = MakeUnique<Literal>(); + auto converted = absl::make_unique<Literal>(); *converted = MutableLiteralBase::MoveIntoTuple(&elements); return std::move(converted); } @@ -1435,6 +1430,12 @@ bool LiteralBase::Piece::EqualElementsInternal( bool LiteralBase::Piece::EqualElements(const LiteralBase::Piece& other) const { DCHECK(ShapeUtil::Compatible(subshape(), other.subshape())); + if (ShapeUtil::Equal(subshape(), other.subshape()) && + LayoutUtil::IsDenseArray(subshape())) { + CHECK_EQ(size_bytes(), other.size_bytes()); + return memcmp(buffer(), other.buffer(), size_bytes()) == 0; + } + std::vector<int64> multi_index; switch (subshape().element_type()) { case PRED: @@ -1956,7 +1957,7 @@ MutableLiteralBase::~MutableLiteralBase() {} MutableBorrowingLiteral::MutableBorrowingLiteral( const MutableBorrowingLiteral& literal) : MutableLiteralBase() { - shape_ = MakeUnique<Shape>(literal.shape()); + shape_ = absl::make_unique<Shape>(literal.shape()); CHECK(LayoutUtil::HasLayout(*shape_)); root_piece_ = new Piece(); @@ -1967,7 +1968,7 @@ MutableBorrowingLiteral::MutableBorrowingLiteral( MutableBorrowingLiteral& MutableBorrowingLiteral::operator=( const MutableBorrowingLiteral& literal) { - shape_ = MakeUnique<Shape>(literal.shape()); + shape_ = absl::make_unique<Shape>(literal.shape()); CHECK(LayoutUtil::HasLayout(*shape_)); root_piece_ = new Piece(); @@ -1981,7 +1982,7 @@ MutableBorrowingLiteral& MutableBorrowingLiteral::operator=( MutableBorrowingLiteral::MutableBorrowingLiteral( const MutableLiteralBase& literal) : MutableLiteralBase() { - shape_ = MakeUnique<Shape>(literal.shape()); + shape_ = absl::make_unique<Shape>(literal.shape()); CHECK(LayoutUtil::HasLayout(*shape_)); root_piece_ = new Piece(); @@ -1992,7 +1993,7 @@ MutableBorrowingLiteral::MutableBorrowingLiteral( MutableBorrowingLiteral::MutableBorrowingLiteral(MutableLiteralBase* literal) : MutableLiteralBase() { - shape_ = MakeUnique<Shape>(literal->shape()); + shape_ = absl::make_unique<Shape>(literal->shape()); CHECK(LayoutUtil::HasLayout(*shape_)); root_piece_ = new Piece(); @@ -2004,7 +2005,7 @@ MutableBorrowingLiteral::MutableBorrowingLiteral(MutableLiteralBase* literal) MutableBorrowingLiteral::MutableBorrowingLiteral( MutableBorrowingLiteral literal, const ShapeIndex& view_root) : MutableLiteralBase() { - shape_ = MakeUnique<Shape>(literal.piece(view_root).subshape()); + shape_ = absl::make_unique<Shape>(literal.piece(view_root).subshape()); CHECK(LayoutUtil::HasLayout(*shape_)); root_piece_ = new Piece(); @@ -2016,7 +2017,7 @@ MutableBorrowingLiteral::MutableBorrowingLiteral( MutableBorrowingLiteral::MutableBorrowingLiteral(const char* src_buf_ptr, const Shape& shape) : MutableLiteralBase() { - shape_ = MakeUnique<Shape>(shape); + shape_ = absl::make_unique<Shape>(shape); CHECK(LayoutUtil::HasLayout(*shape_)); CHECK(!ShapeUtil::IsTuple(*shape_)); @@ -2061,7 +2062,7 @@ void BorrowingLiteral::BuildPieceSubtree(const Shape& shape, Piece* piece) { } BorrowingLiteral::BorrowingLiteral(const char* src_buf_ptr, const Shape& shape) - : LiteralBase(), shape_(MakeUnique<Shape>(shape)) { + : LiteralBase(), shape_(absl::make_unique<Shape>(shape)) { CHECK(ShapeUtil::IsArray(*shape_)); CHECK(LayoutUtil::HasLayout(*shape_)); @@ -2072,7 +2073,7 @@ BorrowingLiteral::BorrowingLiteral(const char* src_buf_ptr, const Shape& shape) BorrowingLiteral::BorrowingLiteral( tensorflow::gtl::ArraySlice<const char*> src_buf_ptrs, const Shape& shape) - : LiteralBase(), shape_(MakeUnique<Shape>(shape)) { + : LiteralBase(), shape_(absl::make_unique<Shape>(shape)) { CHECK(ShapeUtil::IsTuple(*shape_)); CHECK(!ShapeUtil::IsNestedTuple(*shape_)); CHECK_EQ(src_buf_ptrs.size(), ShapeUtil::TupleElementCount(*shape_)); diff --git a/tensorflow/compiler/xla/literal.h b/tensorflow/compiler/xla/literal.h index 92c0f903cb..aad435ed5b 100644 --- a/tensorflow/compiler/xla/literal.h +++ b/tensorflow/compiler/xla/literal.h @@ -25,13 +25,14 @@ limitations under the License. #include <type_traits> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array3d.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/index_util.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/primitive_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/sparse_index_array.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -40,7 +41,6 @@ limitations under the License. #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/bitmap.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/macros.h" @@ -312,7 +312,7 @@ class LiteralBase { // Note: It's an antipattern to use this method then immediately call // MutableLiteralBase::Populate on the result (since that results in zero // initialization, then reinitialization. Conside if a call to - // MakeUnique<Literal>(shape), followed by the call to + // absl::make_unique<Literal>(shape), followed by the call to // MutableLiteralBase::Populate can be used instead. static std::unique_ptr<Literal> CreateFromShape(const Shape& shape); @@ -1154,8 +1154,8 @@ std::unique_ptr<Literal> LiteralBase::Replicate(int64 times) const { for (int64 bound : shape().dimensions()) { bounds.push_back(bound); } - auto literal = - MakeUnique<Literal>(ShapeUtil::MakeShape(shape().element_type(), bounds)); + auto literal = absl::make_unique<Literal>( + ShapeUtil::MakeShape(shape().element_type(), bounds)); int64 elements = ShapeUtil::ElementsIn(literal->shape()); if (elements == 0) { return literal; diff --git a/tensorflow/compiler/xla/literal_comparison.cc b/tensorflow/compiler/xla/literal_comparison.cc index 94993cc874..14ad08a681 100644 --- a/tensorflow/compiler/xla/literal_comparison.cc +++ b/tensorflow/compiler/xla/literal_comparison.cc @@ -19,16 +19,16 @@ limitations under the License. #include <cmath> #include <vector> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/casts.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/env.h" -using tensorflow::strings::Appendf; -using tensorflow::strings::Printf; -using tensorflow::strings::StrAppend; -using tensorflow::strings::StrCat; +using absl::StrAppend; +using absl::StrAppendFormat; +using absl::StrCat; namespace xla { namespace literal_comparison { @@ -38,7 +38,8 @@ namespace { // between the left-hand-side and right-hand-side, by bit-casting to UnsignedT // -- on miscompare, a nice error message is given in the AssertionFailure. template <typename FloatT, typename UnsignedT> -Status CompareFloatsBitwiseEqual(FloatT lhs, FloatT rhs) { +Status CompareFloatsBitwiseEqual( + FloatT lhs, FloatT rhs, tensorflow::gtl::ArraySlice<int64> multi_index) { auto ulhs = tensorflow::bit_cast<UnsignedT>(lhs); auto urhs = tensorflow::bit_cast<UnsignedT>(rhs); auto lhs_double = static_cast<double>(lhs); @@ -46,9 +47,10 @@ Status CompareFloatsBitwiseEqual(FloatT lhs, FloatT rhs) { if (ulhs != urhs) { return InvalidArgument( "floating values are not bitwise-equal; and equality testing " - "was requested: %s=%g=%a vs %s=%g=%a", - StrCat(tensorflow::strings::Hex(ulhs)).c_str(), lhs_double, lhs_double, - StrCat(tensorflow::strings::Hex(urhs)).c_str(), rhs_double, rhs_double); + "was requested: %s=%g=%a vs %s=%g=%a at array index %s", + StrCat(absl::Hex(ulhs)), lhs_double, lhs_double, + StrCat(absl::Hex(urhs)), rhs_double, rhs_double, + LiteralUtil::MultiIndexAsString(multi_index)); } return Status::OK(); } @@ -57,39 +59,48 @@ Status CompareFloatsBitwiseEqual(FloatT lhs, FloatT rhs) { // bitwise helper above (this is the un-specialized fallback, to just use the // default gunit implementation). template <typename NativeT> -Status CompareEqual(NativeT lhs, NativeT rhs) { +Status CompareEqual(NativeT lhs, NativeT rhs, + tensorflow::gtl::ArraySlice<int64> multi_index) { if (lhs == rhs) { return Status::OK(); } - return InvalidArgument("Expected equality of these values:\n %s\n %s", - StrCat(lhs).c_str(), StrCat(rhs).c_str()); + return InvalidArgument( + "first mismatch at array index %s:\n expected value: %s\n actual " + "value: %s", + LiteralUtil::MultiIndexAsString(multi_index), StrCat(lhs), StrCat(rhs)); } // Specializations for floating types that do bitwise comparisons when equality // comparison is requested. template <> -Status CompareEqual<bfloat16>(bfloat16 lhs, bfloat16 rhs) { - return CompareFloatsBitwiseEqual<bfloat16, uint16>(lhs, rhs); +Status CompareEqual<bfloat16>(bfloat16 lhs, bfloat16 rhs, + tensorflow::gtl::ArraySlice<int64> multi_index) { + return CompareFloatsBitwiseEqual<bfloat16, uint16>(lhs, rhs, multi_index); } template <> -Status CompareEqual<Eigen::half>(Eigen::half lhs, Eigen::half rhs) { - return CompareFloatsBitwiseEqual<Eigen::half, uint16>(lhs, rhs); +Status CompareEqual<Eigen::half>( + Eigen::half lhs, Eigen::half rhs, + tensorflow::gtl::ArraySlice<int64> multi_index) { + return CompareFloatsBitwiseEqual<Eigen::half, uint16>(lhs, rhs, multi_index); } template <> -Status CompareEqual<float>(float lhs, float rhs) { - return CompareFloatsBitwiseEqual<float, uint32>(lhs, rhs); +Status CompareEqual<float>(float lhs, float rhs, + tensorflow::gtl::ArraySlice<int64> multi_index) { + return CompareFloatsBitwiseEqual<float, uint32>(lhs, rhs, multi_index); } template <> -Status CompareEqual<double>(double lhs, double rhs) { - return CompareFloatsBitwiseEqual<double, uint64>(lhs, rhs); +Status CompareEqual<double>(double lhs, double rhs, + tensorflow::gtl::ArraySlice<int64> multi_index) { + return CompareFloatsBitwiseEqual<double, uint64>(lhs, rhs, multi_index); } template <> -Status CompareEqual<complex64>(complex64 lhs, complex64 rhs) { - auto res = CompareEqual<float>(lhs.real(), rhs.real()); +Status CompareEqual<complex64>(complex64 lhs, complex64 rhs, + tensorflow::gtl::ArraySlice<int64> multi_index) { + auto res = CompareEqual<float>(lhs.real(), rhs.real(), multi_index); if (!res.ok()) { return res; } - return CompareEqual<float>(lhs.imag(), rhs.imag()); + return CompareEqual<float>(lhs.imag(), rhs.imag(), multi_index); } // A recursive function which iterates through every index of expected and @@ -102,13 +113,14 @@ Status Equal(LiteralSlice expected, LiteralSlice actual, if (dimension == expected.shape().dimensions_size()) { NativeT expected_value = expected.Get<NativeT>(multi_index); NativeT actual_value = actual.Get<NativeT>(multi_index); - return CompareEqual<NativeT>(expected_value, actual_value); + return CompareEqual<NativeT>(expected_value, actual_value, multi_index); } Status result; for (int64 i = 0; i < expected.shape().dimensions(dimension); ++i) { multi_index[dimension] = i; - result.Update(Equal<NativeT>(expected, actual, multi_index, dimension + 1)); + TF_RETURN_IF_ERROR( + Equal<NativeT>(expected, actual, multi_index, dimension + 1)); } return result; } @@ -152,15 +164,26 @@ bool NanMismatch<half>(half expected, half actual, bool relaxed_nans) { static_cast<float>(actual), relaxed_nans); } +// Returns whether the given value is infinity. +template <typename NativeT> +bool IsInf(NativeT val) { + return std::isinf(val); +} + +template <> +bool IsInf<half>(half val) { + return std::isinf(static_cast<float>(val)); +} + // Converts the given floating-point value to a string. template <typename NativeT> string FpValueToString(NativeT value) { - return Printf("%8.4g", static_cast<double>(value)); + return absl::StrFormat("%8.4g", static_cast<double>(value)); } template <> string FpValueToString<complex64>(complex64 value) { - return Printf("%8.4g + %8.4fi", value.real(), value.imag()); + return absl::StrFormat("%8.4g + %8.4fi", value.real(), value.imag()); } // Returns the absolute value of the given floating point value. This function @@ -215,13 +238,12 @@ class NearComparator { } string ToString(const Shape& shape) const { - return Printf( + return absl::StrFormat( "actual %s, expected %s, index %s, rel error %8.3g, abs error %8.3g", - FpValueToString(actual).c_str(), FpValueToString(expected).c_str(), + FpValueToString(actual), FpValueToString(expected), LiteralUtil::MultiIndexAsString( IndexUtil::LinearIndexToMultidimensionalIndex(shape, - linear_index)) - .c_str(), + linear_index)), rel_error, abs_error); } }; @@ -240,17 +262,12 @@ class NearComparator { // Runs the comparison between expected and actual literals. Status Run() { - VLOG(1) << "expected:"; - XLA_VLOG_LINES(1, ToStringTruncated(expected_)); - VLOG(1) << "actual:"; - XLA_VLOG_LINES(1, ToStringTruncated(actual_)); - // If the shapes mismatch, we simply fail the expectation instead of // printing out data, as it's a type error rather than a value error. TF_RETURN_IF_ERROR(EqualShapes(expected_.shape(), actual_.shape())); if (!ShapeUtil::IsArray(expected_.shape())) { return InvalidArgument("Expected array shape; got %s.", - ShapeUtil::HumanString(expected_.shape()).c_str()); + ShapeUtil::HumanString(expected_.shape())); } mismatches_ = Literal(ShapeUtil::ChangeElementType(actual_.shape(), PRED)); @@ -263,7 +280,7 @@ class NearComparator { } else if (!VLOG_IS_ON(1) && miscompare_callback_ != nullptr) { miscompare_callback_(expected_, actual_, mismatches_); } - return InvalidArgument("%s", ErrorMessage().c_str()); + return InvalidArgument("%s", ErrorMessage()); } // Insert the given absolute value into the absolute value bucket vector. The @@ -300,12 +317,13 @@ class NearComparator { // Compares the two given elements from the expected and actual literals at // the given literal_index and keeps track of various mismatch statistics. - void CompareValues(NativeT expected, NativeT actual, int64 linear_index) { + template <typename T> + void CompareValues(T expected, T actual, int64 linear_index) { const bool is_nan_mismatch = NanMismatch(expected, actual, error_.relaxed_nans); float abs_error; float rel_error; - if (actual == expected) { + if (CompareEqual<T>(expected, actual, {linear_index}).ok()) { abs_error = 0; rel_error = 0; } else if (is_nan_mismatch) { @@ -316,6 +334,12 @@ class NearComparator { // weak ordering requirement of std containers. abs_error = std::numeric_limits<float>::infinity(); rel_error = std::numeric_limits<float>::infinity(); + } else if (IsInf(expected) || IsInf(actual)) { + // If either the expected or actual value is infinity but not both, + // then both absolute and relative error are regarded as inifity. + CHECK(!CompareEqual(expected, actual, {linear_index}).ok()); + abs_error = std::numeric_limits<float>::infinity(); + rel_error = std::numeric_limits<float>::infinity(); } else { abs_error = FpAbsoluteValue(actual - expected); rel_error = abs_error / FpAbsoluteValue(expected); @@ -358,6 +382,29 @@ class NearComparator { mismatches_.data<bool>()[linear_index] = true; } + // For complex64 types, we compare real and imaginary parts individually. + void CompareValues(complex64 expected, complex64 actual, int64 linear_index) { + bool mismatch = false; + CompareValues<float>(expected.real(), actual.real(), linear_index); + if (mismatches_.data<bool>()[linear_index] == true) { + mismatch = true; + // Delay the mismatch count increase for real part, instead increase + // mismatch by 1 for the entire complex number. + num_mismatches_--; + } + CompareValues<float>(expected.imag(), actual.imag(), linear_index); + if (mismatches_.data<bool>()[linear_index] == true) { + mismatch = true; + // Delay the mismatch count increase for imag part, instead increase + // mismatch by 1 for the entire complex number. + num_mismatches_--; + } + if (mismatch == true) { + num_mismatches_++; + } + mismatches_.data<bool>()[linear_index] = mismatch; + } + // Compares the two literals elementwise. void CompareLiterals() { // Fast path optimization for the case were layouts match. @@ -402,23 +449,23 @@ class NearComparator { auto percent_string = [](float a, float b) { float pct = b == 0.0 ? 0.0 : 100.0 * a / b; - return Printf("%0.4f%%", pct); + return absl::StrFormat("%0.4f%%", pct); }; - Appendf(&out, - "\nMismatch count %lld (%s) in shape %s (%lld elements), abs bound " - "%g, rel bound %g\n", - num_mismatches_, - percent_string(num_mismatches_, element_count).c_str(), - ShapeUtil::HumanString(actual_.shape()).c_str(), - ShapeUtil::ElementsIn(actual_.shape()), error_.abs, error_.rel); + StrAppendFormat( + &out, + "\nMismatch count %d (%s) in shape %s (%d elements), abs bound " + "%g, rel bound %g\n", + num_mismatches_, percent_string(num_mismatches_, element_count), + ShapeUtil::HumanString(actual_.shape()), + ShapeUtil::ElementsIn(actual_.shape()), error_.abs, error_.rel); if (num_nan_mismatches_ > 0) { StrAppend(&out, "nan mismatches ", num_nan_mismatches_, "\n"); } - Appendf(&out, "Top relative error mismatches:\n"); + StrAppendFormat(&out, "Top relative error mismatches:\n"); for (auto it = top_rel_mismatches_.rbegin(); it != top_rel_mismatches_.rend(); ++it) { - StrAppend(&out, " ", it->ToString(actual_.shape()).c_str(), "\n"); + StrAppend(&out, " ", it->ToString(actual_.shape()), "\n"); } if (!detailed_message_) { @@ -430,36 +477,37 @@ class NearComparator { for (int i = 0; i < abs_value_buckets_.size(); ++i) { const int64 bucket_size = abs_value_buckets_[i].first; const int64 bucket_mismatches = abs_value_buckets_[i].second; - string mismatch_str = bucket_mismatches > 0 - ? Printf(", mismatches %lld", bucket_mismatches) - : ""; - Appendf(&out, " %-6g <= x < %-6g : %7lld (%9s)%s\n", - kAbsValueBucketBounds[i], kAbsValueBucketBounds[i + 1], - bucket_size, percent_string(bucket_size, element_count).c_str(), - mismatch_str.c_str()); + string mismatch_str = + bucket_mismatches > 0 + ? absl::StrFormat(", mismatches %d", bucket_mismatches) + : ""; + StrAppendFormat(&out, " %-6g <= x < %-6g : %7d (%9s)%s\n", + kAbsValueBucketBounds[i], kAbsValueBucketBounds[i + 1], + bucket_size, percent_string(bucket_size, element_count), + mismatch_str); } auto print_accum_buckets = [&](const string& header, int64 total, tensorflow::gtl::ArraySlice<int64> buckets) { StrAppend(&out, header, ":\n"); - Appendf(&out, " < %-6g : %7lld (%s)\n", kErrorBucketBounds[0], - total - buckets[0], - percent_string(total - buckets[0], total).c_str()); + StrAppendFormat(&out, " < %-6g : %7d (%s)\n", kErrorBucketBounds[0], + total - buckets[0], + percent_string(total - buckets[0], total)); CHECK_EQ(buckets.size(), kErrorBucketBounds.size()); for (int i = 0; i < kErrorBucketBounds.size(); ++i) { - Appendf(&out, " >= %-6g : %7lld (%s)\n", kErrorBucketBounds[i], - buckets[i], percent_string(buckets[i], total).c_str()); + StrAppendFormat(&out, " >= %-6g : %7d (%s)\n", kErrorBucketBounds[i], + buckets[i], percent_string(buckets[i], total)); } }; - Appendf(&out, "Elements exceeding abs error bound %g: %lld (%s)\n", - error_.abs, num_abs_mismatches_, - percent_string(num_abs_mismatches_, element_count).c_str()); + StrAppendFormat(&out, "Elements exceeding abs error bound %g: %d (%s)\n", + error_.abs, num_abs_mismatches_, + percent_string(num_abs_mismatches_, element_count)); print_accum_buckets( "Relative error breakdown of elements exceeding abs error bound", num_abs_mismatches_, rel_error_buckets_); - Appendf(&out, "Elements exceeding rel error bound %g: %lld (%s)\n", - error_.rel, num_rel_mismatches_, - percent_string(num_rel_mismatches_, element_count).c_str()); + StrAppendFormat(&out, "Elements exceeding rel error bound %g: %d (%s)\n", + error_.rel, num_rel_mismatches_, + percent_string(num_rel_mismatches_, element_count)); print_accum_buckets( "Absolute error breakdown of elements exceeding rel error bound", num_rel_mismatches_, abs_error_buckets_); @@ -528,6 +576,62 @@ constexpr std::array<float, 7> NearComparator<NativeT>::kAbsValueBucketBounds; template <typename NativeT> constexpr std::array<float, 5> NearComparator<NativeT>::kErrorBucketBounds; +Status EqualHelper(const LiteralSlice& expected, const LiteralSlice& actual) { + TF_RETURN_IF_ERROR(EqualShapes(expected.shape(), actual.shape())); + std::vector<int64> multi_index(expected.shape().dimensions_size(), 0); + Status result; + switch (expected.shape().element_type()) { + case PRED: + result = Equal<bool>(expected, actual, &multi_index, 0); + break; + case U8: + result = Equal<uint8>(expected, actual, &multi_index, 0); + break; + case S32: + result = Equal<int32>(expected, actual, &multi_index, 0); + break; + case S64: + result = Equal<int64>(expected, actual, &multi_index, 0); + break; + case U32: + result = Equal<uint32>(expected, actual, &multi_index, 0); + break; + case U64: + result = Equal<uint64>(expected, actual, &multi_index, 0); + break; + case BF16: + result = Equal<bfloat16>(expected, actual, &multi_index, 0); + break; + case F16: + result = Equal<half>(expected, actual, &multi_index, 0); + break; + case F32: + result = Equal<float>(expected, actual, &multi_index, 0); + break; + case F64: + result = Equal<double>(expected, actual, &multi_index, 0); + break; + case C64: + result = Equal<complex64>(expected, actual, &multi_index, 0); + break; + case TUPLE: { + for (int i = 0; i < ShapeUtil::TupleElementCount(expected.shape()); ++i) { + result.Update(EqualHelper(LiteralSlice(expected, {i}), + LiteralSlice(actual, {i}))); + } + break; + } + case TOKEN: + // Tokens have no on-device representation and are trivially equal. + return Status::OK(); + default: + LOG(FATAL) << "Unsupported primitive type: " + << PrimitiveType_Name(expected.shape().element_type()); + } + + return result; +} + // Helper function for comparing two literals for nearness. Handles tuple-shapes // via recursion. shape_index is the ShapeIndex of expected (or actual) // currently being compared. @@ -544,17 +648,18 @@ Status NearHelper(const LiteralSlice& expected, const LiteralSlice& actual, const auto actual_element = LiteralSlice(actual, {i}); ShapeIndex element_index = shape_index; element_index.push_back(i); - Status res = + Status element_result = NearHelper(expected_element, actual_element, error, detailed_message, miscompare_callback, element_index); - if (!res.ok()) { - string err_message = Printf("\nArray at shape index %s%s", - element_index.ToString().c_str(), - res.error_message().c_str()); + if (!element_result.ok()) { + element_result = InvalidArgument("Array at shape index %s, %s", + element_index.ToString(), + element_result.error_message()); if (return_status.ok()) { - return_status = res; + return_status = element_result; } else { - return_status = AppendStatus(return_status, res.error_message()); + return_status = + AppendStatus(return_status, element_result.error_message()); } } } @@ -562,10 +667,10 @@ Status NearHelper(const LiteralSlice& expected, const LiteralSlice& actual, // Emit a top-level error message containing the top-level shape in case // of mismatch. int64 total_elements = RecursiveElementCount(actual.shape()); - return_status = InvalidArgument( - "\nMismatches in shape %s (%lld elements):\n%s", - ShapeUtil::HumanString(actual.shape()).c_str(), total_elements, - return_status.error_message().c_str()); + return_status = + InvalidArgument("\nMismatches in shape %s (%d elements):\n%s", + ShapeUtil::HumanString(actual.shape()), + total_elements, return_status.error_message()); } return return_status; } @@ -600,8 +705,8 @@ Status NearHelper(const LiteralSlice& expected, const LiteralSlice& actual, } } - // Non-floating point literal. - return literal_comparison::Equal(expected, actual); + // Non-floating point, non-tuple literal. + return EqualHelper(expected, actual); } } // namespace @@ -609,14 +714,14 @@ Status NearHelper(const LiteralSlice& expected, const LiteralSlice& actual, Status EqualShapes(const Shape& expected, const Shape& actual) { if (expected.element_type() != actual.element_type()) { return InvalidArgument("element type mismatch, want: %s got %s", - ShapeUtil::HumanString(expected).c_str(), - ShapeUtil::HumanString(actual).c_str()); + ShapeUtil::HumanString(expected), + ShapeUtil::HumanString(actual)); } if (ShapeUtil::IsTuple(expected)) { if (ShapeUtil::TupleElementCount(expected) != ShapeUtil::TupleElementCount(actual)) { return InvalidArgument( - "want tuple element count: %lld got tuple element count: %lld", + "want tuple element count: %d got tuple element count: %d", ShapeUtil::TupleElementCount(expected), ShapeUtil::TupleElementCount(actual)); } @@ -630,14 +735,13 @@ Status EqualShapes(const Shape& expected, const Shape& actual) { } else if (ShapeUtil::IsArray(expected)) { if (ShapeUtil::Rank(expected) != ShapeUtil::Rank(actual)) { return InvalidArgument("want rank of %s got rank of %s", - ShapeUtil::HumanString(expected).c_str(), - ShapeUtil::HumanString(actual).c_str()); + ShapeUtil::HumanString(expected), + ShapeUtil::HumanString(actual)); } if (expected.element_type() != actual.element_type()) { - return InvalidArgument( - "mismatch in primitive type %s vs %s", - PrimitiveType_Name(expected.element_type()).c_str(), - PrimitiveType_Name(actual.element_type()).c_str()); + return InvalidArgument("mismatch in primitive type %s vs %s", + PrimitiveType_Name(expected.element_type()), + PrimitiveType_Name(actual.element_type())); } if (expected.dimensions_size() != actual.dimensions_size()) { return InvalidArgument("want dimensions_size %d got dimensions_size %d", @@ -648,8 +752,7 @@ Status EqualShapes(const Shape& expected, const Shape& actual) { if (expected.dimensions(i) != actual.dimensions(i)) { return InvalidArgument( "mismatch in dimension #%d expected: %s actual: %s", i, - ShapeUtil::HumanString(expected).c_str(), - ShapeUtil::HumanString(actual).c_str()); + ShapeUtil::HumanString(expected), ShapeUtil::HumanString(actual)); } } } @@ -657,83 +760,43 @@ Status EqualShapes(const Shape& expected, const Shape& actual) { return Status::OK(); } +namespace { + +// If result is an error, extend the error message with the expected and actual +// literals. +Status EmitLiteralsInErrorMessage(const Status& result, + const LiteralSlice& expected, + const LiteralSlice& actual) { + if (result.ok()) { + return result; + } + return InvalidArgument("%s\n\nExpected literal:\n%s\n\nActual literal:\n%s", + result.error_message(), ToStringTruncated(expected), + ToStringTruncated(actual)); +} + +} // namespace + Status Equal(const LiteralSlice& expected, const LiteralSlice& actual) { VLOG(1) << "expected:"; XLA_VLOG_LINES(1, expected.ToString()); VLOG(1) << "actual:"; XLA_VLOG_LINES(1, actual.ToString()); - - TF_RETURN_IF_ERROR(EqualShapes(expected.shape(), actual.shape())); - std::vector<int64> multi_index(expected.shape().dimensions_size(), 0); - Status result; - switch (expected.shape().element_type()) { - case PRED: - result = Equal<bool>(expected, actual, &multi_index, 0); - break; - case U8: - result = Equal<uint8>(expected, actual, &multi_index, 0); - break; - case S32: - result = Equal<int32>(expected, actual, &multi_index, 0); - break; - case S64: - result = Equal<int64>(expected, actual, &multi_index, 0); - break; - case U32: - result = Equal<uint32>(expected, actual, &multi_index, 0); - break; - case U64: - result = Equal<uint64>(expected, actual, &multi_index, 0); - break; - case BF16: - result = Equal<bfloat16>(expected, actual, &multi_index, 0); - break; - case F16: - result = Equal<half>(expected, actual, &multi_index, 0); - break; - case F32: - result = Equal<float>(expected, actual, &multi_index, 0); - break; - case F64: - result = Equal<double>(expected, actual, &multi_index, 0); - break; - case C64: - result = Equal<complex64>(expected, actual, &multi_index, 0); - break; - case TUPLE: { - for (int i = 0; i < ShapeUtil::TupleElementCount(expected.shape()); ++i) { - result.Update( - Equal(LiteralSlice(expected, {i}), LiteralSlice(actual, {i}))); - } - break; - } - case TOKEN: - // Tokens have no on-device representation and are trivially equal. - return Status::OK(); - default: - LOG(FATAL) - << "Unsupported primitive type in LiteralTestUtil::ExpectEqual: " - << PrimitiveType_Name(expected.shape().element_type()); - } - - if (result.ok()) { - return Status::OK(); - } - - return AppendStatus(result, - tensorflow::strings::Printf( - "\nat index: %s\nexpected: %s\nactual: %s", - LiteralUtil::MultiIndexAsString(multi_index).c_str(), - ToStringTruncated(expected).c_str(), - ToStringTruncated(actual).c_str())); + Status result = EqualHelper(expected, actual); + return EmitLiteralsInErrorMessage(result, expected, actual); } Status Near(const LiteralSlice& expected, const LiteralSlice& actual, const ErrorSpec& error, bool detailed_message, const MiscompareCallback& miscompare_callback) { - return NearHelper(expected, actual, error, detailed_message, - miscompare_callback, - /*shape_index=*/{}); + VLOG(1) << "Expected literal:"; + XLA_VLOG_LINES(1, expected.ToString()); + VLOG(1) << "Actual literal:"; + XLA_VLOG_LINES(1, actual.ToString()); + Status result = + NearHelper(expected, actual, error, detailed_message, miscompare_callback, + /*shape_index=*/{}); + return EmitLiteralsInErrorMessage(result, expected, actual); } string ToStringTruncated(const LiteralSlice& literal) { diff --git a/tensorflow/compiler/xla/literal_test.cc b/tensorflow/compiler/xla/literal_test.cc index e8f919950f..e08a9d6e41 100644 --- a/tensorflow/compiler/xla/literal_test.cc +++ b/tensorflow/compiler/xla/literal_test.cc @@ -17,6 +17,9 @@ limitations under the License. #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/tf2xla/shape_util.h" #include "tensorflow/compiler/xla/array3d.h" #include "tensorflow/compiler/xla/array4d.h" @@ -96,42 +99,42 @@ class LiteralUtilTest : public ::testing::Test { TEST_F(LiteralUtilTest, LiteralScalarToString) { auto true_lit = LiteralUtil::CreateR0<bool>(true); - ASSERT_EQ("true", true_lit->ToString()); + EXPECT_EQ("true", true_lit->ToString()); auto false_lit = LiteralUtil::CreateR0<bool>(false); - ASSERT_EQ("false", false_lit->ToString()); + EXPECT_EQ("false", false_lit->ToString()); auto u32_lit = LiteralUtil::CreateR0<uint32>(42); - ASSERT_EQ("42", u32_lit->ToString()); + EXPECT_EQ("42", u32_lit->ToString()); auto s32_lit = LiteralUtil::CreateR0<int32>(-999); - ASSERT_EQ("-999", s32_lit->ToString()); + EXPECT_EQ("-999", s32_lit->ToString()); auto f32_lit = LiteralUtil::CreateR0<float>(3.14f); - ASSERT_EQ("3.14", f32_lit->ToString()); + EXPECT_EQ("3.14", f32_lit->ToString()); auto f16_lit = LiteralUtil::CreateR0<half>(static_cast<half>(0.5f)); - ASSERT_EQ("0.5", f16_lit->ToString()); + EXPECT_EQ("0.5", f16_lit->ToString()); auto c64_lit = LiteralUtil::CreateR0<complex64>({3.14f, 2.78f}); - ASSERT_EQ("(3.14, 2.78)", c64_lit->ToString()); + EXPECT_EQ("(3.14, 2.78)", c64_lit->ToString()); auto bf16_lit = LiteralUtil::CreateR0<bfloat16>(static_cast<bfloat16>(0.5f)); - ASSERT_EQ("0.5", bf16_lit->ToString()); + EXPECT_EQ("0.5", bf16_lit->ToString()); // 3.14 will be truncated to 3.125 in bfloat16 format. auto bf16_lit_truncated = LiteralUtil::CreateR0<bfloat16>(static_cast<bfloat16>(3.14f)); - ASSERT_EQ("3.125", bf16_lit_truncated->ToString()); + EXPECT_EQ("3.125", bf16_lit_truncated->ToString()); auto bf16_lit_truncated2 = LiteralUtil::CreateR0<bfloat16>(static_cast<bfloat16>(9.001f)); - ASSERT_EQ("9", bf16_lit_truncated2->ToString()); + EXPECT_EQ("9", bf16_lit_truncated2->ToString()); } TEST_F(LiteralUtilTest, LiteralVectorToString) { auto pred_vec = LiteralUtil::CreateR1<bool>({true, false, true}); - ASSERT_EQ("{101}", pred_vec->ToString()); + EXPECT_EQ("{101}", pred_vec->ToString()); } TEST_F(LiteralUtilTest, R2ToString) { @@ -141,7 +144,7 @@ TEST_F(LiteralUtilTest, R2ToString) { { 3, 4 }, { 5, 6 } })"; - ASSERT_EQ(expected, literal->ToString()); + EXPECT_EQ(expected, literal->ToString()); } TEST_F(LiteralUtilTest, R3ToString) { @@ -155,7 +158,7 @@ TEST_F(LiteralUtilTest, R3ToString) { { { 5 }, { 6 } } })"; - ASSERT_EQ(expected, literal->ToString()); + EXPECT_EQ(expected, literal->ToString()); } TEST_F(LiteralUtilTest, TupleToString) { @@ -169,7 +172,7 @@ f32[2,2] { { 3, 4 } } ))"; - ASSERT_EQ(expected, tuple->ToString()); + EXPECT_EQ(expected, tuple->ToString()); } TEST_F(LiteralUtilTest, CreateR3FromArray3d) { @@ -195,7 +198,7 @@ TEST_F(LiteralUtilTest, CreateR3FromArray3d) { { 9, 10 }, { 11, 12 } } })"; - ASSERT_EQ(expected, result); + EXPECT_EQ(expected, result); } TEST_F(LiteralUtilTest, CreateSparse) { @@ -248,7 +251,7 @@ TEST_F(LiteralUtilTest, LiteralR4F32ProjectedStringifies) { } } })"; - ASSERT_EQ(expected, result); + EXPECT_EQ(expected, result); } TEST_F(LiteralUtilTest, LiteralR4F32Stringifies) { @@ -281,7 +284,7 @@ TEST_F(LiteralUtilTest, LiteralR4F32Stringifies) { } } })"; - ASSERT_EQ(expected, result); + EXPECT_EQ(expected, result); } TEST_F(LiteralUtilTest, EachCellR2F32) { @@ -355,15 +358,15 @@ TEST_F(LiteralUtilTest, TokenEquality) { TEST_F(LiteralUtilTest, DifferentLayoutEquality) { // Test equality with literals which have different layouts. - auto colmajor = - MakeUnique<Literal>(ShapeUtil::MakeShapeWithLayout(F32, {2, 2}, {0, 1})); + auto colmajor = absl::make_unique<Literal>( + ShapeUtil::MakeShapeWithLayout(F32, {2, 2}, {0, 1})); colmajor->Set<float>({0, 0}, 1.0); colmajor->Set<float>({0, 1}, 2.0); colmajor->Set<float>({1, 0}, 3.0); colmajor->Set<float>({1, 1}, 4.0); - auto rowmajor = - MakeUnique<Literal>(ShapeUtil::MakeShapeWithLayout(F32, {2, 2}, {1, 0})); + auto rowmajor = absl::make_unique<Literal>( + ShapeUtil::MakeShapeWithLayout(F32, {2, 2}, {1, 0})); rowmajor->Set<float>({0, 0}, 1.0); rowmajor->Set<float>({0, 1}, 2.0); rowmajor->Set<float>({1, 0}, 3.0); @@ -1036,7 +1039,7 @@ TEST_F(LiteralUtilTest, CopyFromDifferentShapes) { auto vector = LiteralUtil::CreateR1<float>({5.0, 7.0}); Status status = matrix->CopyFrom(*vector); ASSERT_FALSE(status.ok()); - ASSERT_THAT(status.error_message(), + EXPECT_THAT(status.error_message(), HasSubstr("Destination subshape incompatible")); } @@ -1089,7 +1092,7 @@ TEST_F(LiteralUtilTest, Populate) { Shape shape = ShapeUtil::MakeShapeWithLayout( primitive_util::NativeToPrimitiveType<uint32>(), data.dimensions, data.layout); - auto literal = MakeUnique<Literal>(shape); + auto literal = absl::make_unique<Literal>(shape); auto generator = [&](ArraySlice<int64> indexes) -> uint32 { // Offsets from linear index just to avoid R0 literals to be initialized // with zero. @@ -1131,7 +1134,7 @@ TEST_F(LiteralUtilTest, PopulateParallel) { Shape shape = ShapeUtil::MakeShapeWithLayout( primitive_util::NativeToPrimitiveType<uint32>(), data.dimensions, data.layout); - auto literal = MakeUnique<Literal>(shape); + auto literal = absl::make_unique<Literal>(shape); auto generator = [&](ArraySlice<int64> indexes) -> uint32 { // Offsets from linear index just to avoid R0 literals to be initialized // with zero. @@ -1323,8 +1326,8 @@ TEST_F(LiteralUtilTest, BitcastConvertBetweenInvalidTypes) { auto literal = LiteralUtil::CreateR0<uint32>(1234); Status status = literal->BitcastConvert(F64).status(); EXPECT_NE(Status::OK(), status); - EXPECT_TRUE(tensorflow::str_util::StrContains(status.error_message(), - "bit widths are different")); + EXPECT_TRUE( + absl::StrContains(status.error_message(), "bit widths are different")); } TEST_F(LiteralUtilTest, CopyFromProto_Bool) { @@ -1391,10 +1394,10 @@ TEST_F(LiteralUtilTest, CopyFromProto_f16) { Literal::CreateFromProto(p)); auto r = literal->data<half>(); ASSERT_EQ(4, r.size()); - ASSERT_EQ(h1, r[0]); - ASSERT_EQ(h2, r[1]); - ASSERT_EQ(h2, r[2]); - ASSERT_EQ(h1, r[3]); + EXPECT_EQ(h1, r[0]); + EXPECT_EQ(h2, r[1]); + EXPECT_EQ(h2, r[2]); + EXPECT_EQ(h1, r[3]); } TEST_F(LiteralUtilTest, LiteralSliceTest) { @@ -1577,7 +1580,7 @@ TEST_F(LiteralUtilTest, MoveIntoTuple) { TEST_F(LiteralUtilTest, MoveIntoEmptyTuple) { Literal literal = Literal::MoveIntoTuple({}); ASSERT_TRUE(ShapeUtil::IsTuple(literal.shape())); - ASSERT_EQ(ShapeUtil::TupleElementCount(literal.shape()), 0); + EXPECT_EQ(ShapeUtil::TupleElementCount(literal.shape()), 0); } TEST_F(LiteralUtilTest, LiteralMoveAssignment) { @@ -1690,7 +1693,7 @@ TEST_F(LiteralUtilTest, InvalidProtoNoValues) { *proto.mutable_shape() = ShapeUtil::MakeShape(F32, {3}); Status status = Literal::CreateFromProto(proto).status(); ASSERT_FALSE(status.ok()); - ASSERT_THAT(status.error_message(), + EXPECT_THAT(status.error_message(), HasSubstr("Expected 3 elements in LiteralProto")); } @@ -1702,7 +1705,7 @@ TEST_F(LiteralUtilTest, InvalidProtoNoShape) { proto.add_preds(false); Status status = Literal::CreateFromProto(proto).status(); ASSERT_FALSE(status.ok()); - ASSERT_THAT(status.error_message(), HasSubstr("LiteralProto has no shape")); + EXPECT_THAT(status.error_message(), HasSubstr("LiteralProto has no shape")); } TEST_F(LiteralUtilTest, InvalidProtoWrongContainer) { @@ -1714,7 +1717,7 @@ TEST_F(LiteralUtilTest, InvalidProtoWrongContainer) { proto.add_preds(false); Status status = Literal::CreateFromProto(proto).status(); ASSERT_FALSE(status.ok()); - ASSERT_THAT(status.error_message(), + EXPECT_THAT(status.error_message(), HasSubstr("Expected 3 elements in LiteralProto")); } @@ -1727,7 +1730,7 @@ TEST_F(LiteralUtilTest, InvalidProtoTooFewValues) { proto.add_f32s(3.0); Status status = Literal::CreateFromProto(proto).status(); ASSERT_FALSE(status.ok()); - ASSERT_THAT(status.error_message(), + EXPECT_THAT(status.error_message(), HasSubstr("Expected 84 elements in LiteralProto")); } @@ -1740,7 +1743,7 @@ TEST_F(LiteralUtilTest, InvalidProtoTooManyValues) { proto.add_s32s(100); Status status = Literal::CreateFromProto(proto).status(); ASSERT_FALSE(status.ok()); - ASSERT_THAT(status.error_message(), + EXPECT_THAT(status.error_message(), HasSubstr("Expected 2 elements in LiteralProto")); } @@ -1755,7 +1758,7 @@ TEST_F(LiteralUtilTest, InvalidProtoMissingLayout) { proto.add_preds(false); Status status = Literal::CreateFromProto(proto).status(); ASSERT_FALSE(status.ok()); - ASSERT_THAT(status.error_message(), HasSubstr("LiteralProto has no layout")); + EXPECT_THAT(status.error_message(), HasSubstr("LiteralProto has no layout")); } TEST_F(LiteralUtilTest, InvalidProtoTooFewTupleElements) { @@ -1771,7 +1774,7 @@ TEST_F(LiteralUtilTest, InvalidProtoTooFewTupleElements) { Status status = Literal::CreateFromProto(proto).status(); ASSERT_FALSE(status.ok()); - ASSERT_THAT(status.error_message(), HasSubstr("Expected 2 tuple elements")); + EXPECT_THAT(status.error_message(), HasSubstr("Expected 2 tuple elements")); } TEST_F(LiteralUtilTest, InvalidProtoTooManyTupleElements) { @@ -1794,7 +1797,7 @@ TEST_F(LiteralUtilTest, InvalidProtoTooManyTupleElements) { Status status = Literal::CreateFromProto(proto).status(); ASSERT_FALSE(status.ok()); - ASSERT_THAT(status.error_message(), HasSubstr("Expected 2 tuple elements")); + EXPECT_THAT(status.error_message(), HasSubstr("Expected 2 tuple elements")); } TEST_F(LiteralUtilTest, SortSparseElements) { @@ -1804,7 +1807,7 @@ TEST_F(LiteralUtilTest, SortSparseElements) { literal->AppendSparseElement<float>({3, 4, 5}, 3.0); literal->AppendSparseElement<float>({1, 2, 3}, 1.0); literal->SortSparseElements(); - ASSERT_EQ(literal->ToString(false), + EXPECT_EQ(literal->ToString(false), "f32[10,10,10]{[1, 2, 3]: 1, [2, 3, 4]: 2, [3, 4, 5]: 3}"); } @@ -1812,27 +1815,26 @@ TEST_F(LiteralUtilTest, GetSparseElementAsString) { std::vector<int64> dimensions = {10, 10, 10}; SparseIndexArray indices(10, {{1, 2, 3}, {2, 3, 4}, {3, 4, 5}}); - ASSERT_EQ( + EXPECT_EQ( LiteralUtil::CreateSparse<bool>(dimensions, indices, {true, false, true}) ->GetSparseElementAsString(1), "false"); - ASSERT_EQ(LiteralUtil::CreateSparse<int64>(dimensions, indices, {1, 2, 3}) + EXPECT_EQ(LiteralUtil::CreateSparse<int64>(dimensions, indices, {1, 2, 3}) ->GetSparseElementAsString(1), - tensorflow::strings::StrCat(int64{2})); - ASSERT_EQ( + absl::StrCat(int64{2})); + EXPECT_EQ( LiteralUtil::CreateSparse<double>(dimensions, indices, {1.0, 2.0, 3.0}) ->GetSparseElementAsString(1), - tensorflow::strings::StrCat(double{2.0})); - ASSERT_EQ(LiteralUtil::CreateSparse<half>(dimensions, indices, + absl::StrCat(double{2.0})); + EXPECT_EQ(LiteralUtil::CreateSparse<half>(dimensions, indices, {half{1.0}, half{2.0}, half{3.0}}) ->GetSparseElementAsString(1), - tensorflow::strings::StrCat(static_cast<float>(half{2.0}))); - ASSERT_EQ( - LiteralUtil::CreateSparse<complex64>( - dimensions, indices, - std::vector<complex64>{{1.0, 2.0}, {3.0, 4.0}, {5.0, 6.0}}) - ->GetSparseElementAsString(1), - tensorflow::strings::StrCat("(", float{3.0}, ", ", float{4.0}, ")")); + absl::StrCat(static_cast<float>(half{2.0}))); + EXPECT_EQ(LiteralUtil::CreateSparse<complex64>( + dimensions, indices, + std::vector<complex64>{{1.0, 2.0}, {3.0, 4.0}, {5.0, 6.0}}) + ->GetSparseElementAsString(1), + absl::StrCat("(", float{3.0}, ", ", float{4.0}, ")")); } TEST_F(LiteralUtilTest, BroadcastVectorToMatrix0) { diff --git a/tensorflow/compiler/xla/literal_util.cc b/tensorflow/compiler/xla/literal_util.cc index 5d33df7d40..931d2c631b 100644 --- a/tensorflow/compiler/xla/literal_util.cc +++ b/tensorflow/compiler/xla/literal_util.cc @@ -22,6 +22,9 @@ limitations under the License. #include <numeric> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/index_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -30,19 +33,15 @@ limitations under the License. #include "tensorflow/core/lib/core/casts.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/hash/hash.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/mem.h" #include "tensorflow/core/platform/types.h" -using tensorflow::strings::StrCat; - namespace xla { - namespace { +using absl::StrCat; + // Return a literal with all arrays of type FromNativeT converted to type // ToNativeT in the given literal. template <typename FromNativeT, typename ToNativeT> @@ -57,7 +56,7 @@ std::unique_ptr<Literal> ConvertType(LiteralSlice literal) { primitive_util::NativeToPrimitiveType<ToNativeT>()); } }); - auto result = MakeUnique<Literal>(result_shape); + auto result = absl::make_unique<Literal>(result_shape); // Then copy over the data from 'literal' converting FromNativeT values to // ToNativeT values as necessary. @@ -102,7 +101,7 @@ std::unique_ptr<Literal> ConvertType(LiteralSlice literal) { } /* static */ std::unique_ptr<Literal> LiteralUtil::CreateToken() { - return MakeUnique<Literal>(ShapeUtil::MakeTokenShape()); + return absl::make_unique<Literal>(ShapeUtil::MakeTokenShape()); } /* static */ Literal LiteralUtil::Zero(PrimitiveType primitive_type) { @@ -279,15 +278,15 @@ std::unique_ptr<Literal> ConvertType(LiteralSlice literal) { /* static */ std::unique_ptr<Literal> LiteralUtil::CreateR1( const tensorflow::core::Bitmap& values) { - auto literal = MakeUnique<Literal>( + auto literal = absl::make_unique<Literal>( ShapeUtil::MakeShape(PRED, {static_cast<int64>(values.bits())})); literal->PopulateR1(values); return literal; } /* static */ std::unique_ptr<Literal> LiteralUtil::CreateR1U8( - tensorflow::StringPiece value) { - auto literal = MakeUnique<Literal>( + absl::string_view value) { + auto literal = absl::make_unique<Literal>( ShapeUtil::MakeShape(U8, {static_cast<int64>(value.size())})); for (int i = 0; i < value.size(); ++i) { literal->Set<uint8>({i}, value[i]); @@ -312,7 +311,7 @@ std::unique_ptr<Literal> ConvertType(LiteralSlice literal) { CHECK_EQ(ShapeUtil::ElementsIn(literal.shape()), new_num_elements); CHECK_EQ(new_dimensions.size(), minor_to_major.size()); - auto new_literal = MakeUnique<Literal>( + auto new_literal = absl::make_unique<Literal>( ShapeUtil::MakeShape(literal.shape().element_type(), new_dimensions)); // Create a new shape with the given minor-to-major layout. This shape is used @@ -436,7 +435,8 @@ std::unique_ptr<Literal> ConvertType(LiteralSlice literal) { for (const auto* element : elements) { element_shapes.push_back(element->shape()); } - auto literal = MakeUnique<Literal>(ShapeUtil::MakeTupleShape(element_shapes)); + auto literal = + absl::make_unique<Literal>(ShapeUtil::MakeTupleShape(element_shapes)); for (int i = 0; i < elements.size(); ++i) { TF_CHECK_OK(literal->CopyFrom(*elements[i], /*dest_shape_index=*/{i})); } @@ -449,7 +449,8 @@ std::unique_ptr<Literal> ConvertType(LiteralSlice literal) { for (const auto& element : elements) { element_shapes.push_back(element.shape()); } - auto literal = MakeUnique<Literal>(ShapeUtil::MakeTupleShape(element_shapes)); + auto literal = + absl::make_unique<Literal>(ShapeUtil::MakeTupleShape(element_shapes)); for (int i = 0; i < elements.size(); ++i) { TF_CHECK_OK(literal->CopyFrom(elements[i], /*dest_shape_index=*/{i})); } @@ -463,7 +464,8 @@ std::unique_ptr<Literal> ConvertType(LiteralSlice literal) { for (const auto& element : elements) { element_shapes.push_back(element->shape()); } - auto literal = MakeUnique<Literal>(ShapeUtil::MakeTupleShape(element_shapes)); + auto literal = + absl::make_unique<Literal>(ShapeUtil::MakeTupleShape(element_shapes)); for (int64 i = 0; i < elements.size(); ++i) { TF_CHECK_OK( literal->MoveFrom(std::move(*elements[i]), /*dest_shape_index=*/{i})); @@ -473,7 +475,7 @@ std::unique_ptr<Literal> ConvertType(LiteralSlice literal) { /* static */ string LiteralUtil::MultiIndexAsString( tensorflow::gtl::ArraySlice<int64> multi_index) { - return StrCat("{", tensorflow::str_util::Join(multi_index, ","), "}"); + return StrCat("{", absl::StrJoin(multi_index, ","), "}"); } } // namespace xla diff --git a/tensorflow/compiler/xla/literal_util.h b/tensorflow/compiler/xla/literal_util.h index e3737a9d00..3d28c070f2 100644 --- a/tensorflow/compiler/xla/literal_util.h +++ b/tensorflow/compiler/xla/literal_util.h @@ -27,6 +27,8 @@ limitations under the License. #include <type_traits> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array3d.h" #include "tensorflow/compiler/xla/array4d.h" @@ -34,7 +36,6 @@ limitations under the License. #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/primitive_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/sparse_index_array.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -43,7 +44,6 @@ limitations under the License. #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/bitmap.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/macros.h" @@ -187,7 +187,7 @@ class LiteralUtil { const Array4D<NativeT>& values, const Layout& layout); // Creates a new vector of U8s literal value from a string. - static std::unique_ptr<Literal> CreateR1U8(tensorflow::StringPiece value); + static std::unique_ptr<Literal> CreateR1U8(absl::string_view value); // Creates a linspace-populated literal with the given number of rows and // columns. @@ -327,7 +327,7 @@ std::ostream& operator<<(std::ostream& out, const Literal& literal); template <typename NativeT> /* static */ std::unique_ptr<Literal> LiteralUtil::CreateR0(NativeT value) { - auto literal = MakeUnique<Literal>(ShapeUtil::MakeShape( + auto literal = absl::make_unique<Literal>(ShapeUtil::MakeShape( primitive_util::NativeToPrimitiveType<NativeT>(), {})); literal->Set({}, value); return literal; @@ -336,7 +336,7 @@ template <typename NativeT> template <typename NativeT> /* static */ std::unique_ptr<Literal> LiteralUtil::CreateR1( tensorflow::gtl::ArraySlice<NativeT> values) { - auto literal = MakeUnique<Literal>( + auto literal = absl::make_unique<Literal>( ShapeUtil::MakeShape(primitive_util::NativeToPrimitiveType<NativeT>(), {static_cast<int64>(values.size())})); literal->PopulateR1(values); @@ -347,7 +347,7 @@ template <typename NativeT> /* static */ std::unique_ptr<Literal> LiteralUtil::CreateR2WithLayout( std::initializer_list<std::initializer_list<NativeT>> values, const Layout& layout) { - auto literal = MakeUnique<Literal>(ShapeUtil::MakeShapeWithLayout( + auto literal = absl::make_unique<Literal>(ShapeUtil::MakeShapeWithLayout( primitive_util::NativeToPrimitiveType<NativeT>(), {static_cast<int64>(values.size()), static_cast<int64>(values.begin()->size())}, @@ -433,9 +433,10 @@ template <typename NativeT> int64 rank = dimensions.size(); CHECK_EQ(num_elements, indices.index_count()); CHECK_EQ(rank, indices.rank()); - auto literal = MakeUnique<Literal>(ShapeUtil::MakeShapeWithSparseLayout( - primitive_util::NativeToPrimitiveType<NativeT>(), dimensions, - indices.max_indices())); + auto literal = + absl::make_unique<Literal>(ShapeUtil::MakeShapeWithSparseLayout( + primitive_util::NativeToPrimitiveType<NativeT>(), dimensions, + indices.max_indices())); literal->PopulateSparse(indices, values, sort); return literal; } @@ -451,7 +452,7 @@ template <typename NativeT> template <typename NativeT> /* static */ std::unique_ptr<Literal> LiteralUtil::CreateFromArrayWithLayout( const Array<NativeT>& values, const Layout& layout) { - auto literal = MakeUnique<Literal>(ShapeUtil::MakeShapeWithLayout( + auto literal = absl::make_unique<Literal>(ShapeUtil::MakeShapeWithLayout( primitive_util::NativeToPrimitiveType<NativeT>(), values.dimensions(), AsInt64Slice(layout.minor_to_major()))); literal->PopulateFromArray(values); @@ -571,8 +572,9 @@ template <typename NativeT> /* static */ std::unique_ptr<Literal> LiteralUtil::CreateFullWithDescendingLayout( tensorflow::gtl::ArraySlice<int64> dimensions, NativeT value) { - auto literal = MakeUnique<Literal>(ShapeUtil::MakeShapeWithDescendingLayout( - primitive_util::NativeToPrimitiveType<NativeT>(), dimensions)); + auto literal = + absl::make_unique<Literal>(ShapeUtil::MakeShapeWithDescendingLayout( + primitive_util::NativeToPrimitiveType<NativeT>(), dimensions)); literal->PopulateWithValue(value); return literal; } @@ -584,7 +586,7 @@ LiteralUtil::CreateRandomLiteral( const std::function<T(tensorflow::gtl::ArraySlice<int64>)>& generator) { using NativeT = typename primitive_util::PrimitiveTypeToNative<type>::type; TF_RET_CHECK(shape.element_type() == type); - auto literal = MakeUnique<Literal>(shape); + auto literal = absl::make_unique<Literal>(shape); TF_RETURN_IF_ERROR(literal.get()->Populate<NativeT>( [&](tensorflow::gtl::ArraySlice<int64> indexes) { return generator(indexes); diff --git a/tensorflow/compiler/xla/map_util.h b/tensorflow/compiler/xla/map_util.h index 3c74e070da..fcff48b6b1 100644 --- a/tensorflow/compiler/xla/map_util.h +++ b/tensorflow/compiler/xla/map_util.h @@ -60,7 +60,7 @@ MaybeFind(const Collection& collection, if (it == collection.end()) { std::ostringstream os; os << key; - return NotFound("key not found: %s", os.str().c_str()); + return NotFound("key not found: %s", os.str()); } return {it->second}; } diff --git a/tensorflow/compiler/xla/metric_table_report.cc b/tensorflow/compiler/xla/metric_table_report.cc index 69ef4f7a2f..4eab4fa429 100644 --- a/tensorflow/compiler/xla/metric_table_report.cc +++ b/tensorflow/compiler/xla/metric_table_report.cc @@ -18,7 +18,8 @@ limitations under the License. #include <cctype> #include <unordered_map> -#include "tensorflow/core/lib/strings/stringprintf.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -84,7 +85,7 @@ void MetricTableReport::WriteReportToInfoLog(double expected_metric_sum) { if (end_of_line == string::npos) { end_of_line = report.size(); } - tensorflow::StringPiece line(report.data() + pos, end_of_line - pos); + absl::string_view line(report.data() + pos, end_of_line - pos); // TODO(b/34779244): Figure out how to do this without the verbose log-line // prefix. The usual way didn't compile on open source. @@ -152,8 +153,8 @@ void MetricTableReport::AppendCategoryTable() { if (text.empty()) { text = "[no category]"; } - tensorflow::strings::StrAppend(&text, " (", category.entries.size(), " ", - entry_name_, ")"); + absl::StrAppend(&text, " (", category.entries.size(), " ", entry_name_, + ")"); AppendTableRow(text, category.metric_sum, metric_sum); // Show the top entries in the category. @@ -177,9 +178,9 @@ void MetricTableReport::AppendCategoryTable() { } const int64 remaining_categories = categories.size() - categories_shown; if (remaining_categories > 0) { - AppendTableRow(tensorflow::strings::StrCat("... (", remaining_categories, - " more categories)"), - expected_metric_sum_ - metric_sum, expected_metric_sum_); + AppendTableRow( + absl::StrCat("... (", remaining_categories, " more categories)"), + expected_metric_sum_ - metric_sum, expected_metric_sum_); } } @@ -206,9 +207,9 @@ void MetricTableReport::AppendEntryTable() { } const int64 remaining_entries = entries_.size() - entries_shown; if (remaining_entries > 0) { - AppendTableRow(tensorflow::strings::StrCat("... (", remaining_entries, - " more ", entry_name_, ")"), - expected_metric_sum_ - metric_sum, expected_metric_sum_); + AppendTableRow( + absl::StrCat("... (", remaining_entries, " more ", entry_name_, ")"), + expected_metric_sum_ - metric_sum, expected_metric_sum_); } } @@ -241,10 +242,10 @@ double MetricTableReport::UnaccountedMetric() { string MetricTableReport::MetricString(double metric) { // Round to integer and stringify. - string s1 = tensorflow::strings::StrCat(std::llround(metric)); + string s1 = absl::StrCat(std::llround(metric)); // Code below commafies the string, e.g. "1234" becomes "1,234". - tensorflow::StringPiece sp1(s1); + absl::string_view sp1(s1); string output; // Copy leading non-digit characters unconditionally. // This picks up the leading sign. @@ -263,8 +264,7 @@ string MetricTableReport::MetricString(double metric) { } string MetricTableReport::MetricPercent(double metric) { - return tensorflow::strings::Printf("%5.2f%%", - metric / expected_metric_sum_ * 100.0); + return absl::StrFormat("%5.2f%%", metric / expected_metric_sum_ * 100.0); } } // namespace xla diff --git a/tensorflow/compiler/xla/metric_table_report.h b/tensorflow/compiler/xla/metric_table_report.h index 818fb1d3fe..062d8ed99b 100644 --- a/tensorflow/compiler/xla/metric_table_report.h +++ b/tensorflow/compiler/xla/metric_table_report.h @@ -18,9 +18,8 @@ limitations under the License. #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { @@ -108,7 +107,7 @@ class MetricTableReport { // Append all parameters to the report. template <typename... Args> void AppendLine(Args... args) { - tensorflow::strings::StrAppend(&report_, std::forward<Args>(args)..., "\n"); + absl::StrAppend(&report_, std::forward<Args>(args)..., "\n"); } // Represents a set of entries with the same category_text. diff --git a/tensorflow/compiler/xla/packed_literal_reader.cc b/tensorflow/compiler/xla/packed_literal_reader.cc index 6b7fd10d63..6e42775f6f 100644 --- a/tensorflow/compiler/xla/packed_literal_reader.cc +++ b/tensorflow/compiler/xla/packed_literal_reader.cc @@ -19,9 +19,9 @@ limitations under the License. #include <string> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" @@ -54,17 +54,17 @@ StatusOr<std::unique_ptr<Literal>> PackedLiteralReader::Read( if (shape.element_type() != F32) { return Unimplemented( "not yet implemented element type for packed literal reading: %s", - PrimitiveType_Name(shape.element_type()).c_str()); + PrimitiveType_Name(shape.element_type())); } - auto result = MakeUnique<Literal>(literal_shape); + auto result = absl::make_unique<Literal>(literal_shape); result->PopulateWithValue(std::numeric_limits<float>::quiet_NaN()); int64 elements = ShapeUtil::ElementsIn(shape); tensorflow::gtl::ArraySlice<float> field = result->data<float>(); char* data = tensorflow::bit_cast<char*>(field.data()); uint64 bytes = elements * sizeof(float); - tensorflow::StringPiece sp; + tensorflow::StringPiece sp; // non-absl OK auto s = file_->Read(offset_, bytes, &sp, data); offset_ += sp.size(); if (!s.ok()) { @@ -85,7 +85,7 @@ bool PackedLiteralReader::IsExhausted() const { // Try to read a single byte from offset_. If we can't, we've // exhausted the data. char single_byte[1]; - tensorflow::StringPiece sp; + tensorflow::StringPiece sp; // non-absl OK auto s = file_->Read(offset_, sizeof(single_byte), &sp, single_byte); return !s.ok(); } diff --git a/tensorflow/compiler/xla/python/BUILD b/tensorflow/compiler/xla/python/BUILD index c8f2d65c22..fe91dc0618 100644 --- a/tensorflow/compiler/xla/python/BUILD +++ b/tensorflow/compiler/xla/python/BUILD @@ -39,6 +39,8 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/python:numpy_lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -59,6 +61,7 @@ cc_library( "//tensorflow/compiler/xla/service:shaped_buffer", "//tensorflow/core:framework_lite", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) diff --git a/tensorflow/compiler/xla/python/local_computation_builder.cc b/tensorflow/compiler/xla/python/local_computation_builder.cc index 8246f76d34..b5fd747cfa 100644 --- a/tensorflow/compiler/xla/python/local_computation_builder.cc +++ b/tensorflow/compiler/xla/python/local_computation_builder.cc @@ -14,10 +14,10 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/python/local_computation_builder.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/client/lib/math.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/executable_run_options.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/platform/thread_annotations.h" @@ -137,8 +137,7 @@ static StatusOr<ScopedShapedBuffer> ToBuffer(LocalClient* client, /* static */ StatusOr<LocalShapedBuffer*> LocalShapedBuffer::FromLiteral( - const Literal& argument, - const tensorflow::gtl::optional<Shape>& shape_with_layout) { + const Literal& argument, const absl::optional<Shape>& shape_with_layout) { LocalClient* client = GetOrCreateLocalClient(); StatusOr<ScopedShapedBuffer> buf = [&] { if (shape_with_layout) { @@ -163,7 +162,7 @@ CompiledLocalComputation::CompiledLocalComputation( StatusOr<std::unique_ptr<Literal>> CompiledLocalComputation::Execute( const std::vector<Literal>& arguments, - const std::vector<tensorflow::gtl::optional<Shape>>& shapes_with_layout) { + const std::vector<absl::optional<Shape>>& shapes_with_layout) { LocalClient* client = GetOrCreateLocalClient(); VLOG(1) << "Execution requested with " << GetReplicaCount() << " replicas."; @@ -194,7 +193,7 @@ StatusOr<std::unique_ptr<Literal>> CompiledLocalComputation::Execute( scoped_buffers.reserve(arguments.size()); for (int i = 0; i < arguments.size(); ++i) { const Literal& argument = arguments[i]; - const tensorflow::gtl::optional<Shape>& shape_with_layout = + const absl::optional<Shape>& shape_with_layout = shapes_with_layout[i]; StatusOr<ScopedShapedBuffer> pushed; @@ -252,7 +251,7 @@ StatusOr<std::unique_ptr<Literal>> CompiledLocalComputation::Execute( return InternalError( "Failed running replica %d (other replicas may have failed as well): " "%s.", - replica, statusor.status().ToString().c_str()); + replica, statusor.status().ToString()); } } @@ -575,6 +574,16 @@ StatusOr<bool> LocalComputationBuilder::IsConstant(const LocalOp& operand) { return builder_.IsConstant(operand.op()); } +LocalOp LocalComputationBuilder::Sort(const LocalOp& operand, int64 dimension) { + return xla::Sort(operand.op(), absl::nullopt, dimension); +} + +LocalOp LocalComputationBuilder::SortKeyVal(const LocalOp& keys, + const LocalOp& values, + int64 dimension) { + return xla::Sort(keys.op(), values.op(), dimension); +} + StatusOr<LocalComputation*> LocalComputationBuilder::BuildConstantSubGraph( const LocalOp& operand) { TF_ASSIGN_OR_RETURN(XlaComputation computation, @@ -640,7 +649,6 @@ _FORWARD_UNOP(Sin) _FORWARD_UNOP(Tanh) _FORWARD_UNOP(IsFinite) _FORWARD_UNOP(Neg) -_FORWARD_UNOP(Sort) _FORWARD_UNOP(Sqrt) _FORWARD_UNOP(Rsqrt) _FORWARD_UNOP(Square) @@ -688,8 +696,7 @@ StatusOr<LocalShapedBufferTuple*> DestructureLocalShapedBufferTuple( "Attemped to destructure a LocalShapedBuffer that did not have a tuple " "shape; shape: %s", ShapeUtil::HumanString( - local_shaped_buffer->shaped_buffer()->on_device_shape()) - .c_str()); + local_shaped_buffer->shaped_buffer()->on_device_shape())); } DeviceMemoryAllocator* allocator = diff --git a/tensorflow/compiler/xla/python/local_computation_builder.h b/tensorflow/compiler/xla/python/local_computation_builder.h index a568c24c63..d9543b958d 100644 --- a/tensorflow/compiler/xla/python/local_computation_builder.h +++ b/tensorflow/compiler/xla/python/local_computation_builder.h @@ -60,8 +60,7 @@ StatusOr<std::unique_ptr<Literal> > TransferFromOutfeedLocalReplica( class LocalShapedBuffer { public: static StatusOr<LocalShapedBuffer*> FromLiteral( - const Literal& argument, - const tensorflow::gtl::optional<Shape>& shape_with_layout); + const Literal& argument, const absl::optional<Shape>& shape_with_layout); LocalShapedBuffer(ScopedShapedBuffer shaped_buffer); const ScopedShapedBuffer* shaped_buffer() const; @@ -120,7 +119,7 @@ class CompiledLocalComputation { // shapes_with_layout. StatusOr<std::unique_ptr<Literal> > Execute( const std::vector<Literal>& arguments, - const std::vector<tensorflow::gtl::optional<Shape> >& shapes_with_layout); + const std::vector<absl::optional<Shape> >& shapes_with_layout); LocalShapedBuffer* ExecuteWithShapedBuffers( tensorflow::gtl::ArraySlice<LocalShapedBuffer*> argument_handles); @@ -301,6 +300,11 @@ class LocalComputationBuilder { StatusOr<bool> IsConstant(const LocalOp& operand); + LocalOp Sort(const LocalOp& operand, int64 dimension); + + LocalOp SortKeyVal(const LocalOp& keys, const LocalOp& values, + int64 dimension); + StatusOr<LocalComputation*> BuildConstantSubGraph(const LocalOp& operand); #define _FORWARD(method_name, return_sig, args_sig) \ @@ -357,7 +361,6 @@ class LocalComputationBuilder { _FORWARD_UNOP(Tanh) _FORWARD_UNOP(IsFinite) _FORWARD_UNOP(Neg) - _FORWARD_UNOP(Sort) _FORWARD_UNOP(Sqrt) _FORWARD_UNOP(Rsqrt) _FORWARD_UNOP(Square) diff --git a/tensorflow/compiler/xla/python/local_computation_builder.i b/tensorflow/compiler/xla/python/local_computation_builder.i index 5d5a955bfe..f6169ebf19 100644 --- a/tensorflow/compiler/xla/python/local_computation_builder.i +++ b/tensorflow/compiler/xla/python/local_computation_builder.i @@ -109,6 +109,8 @@ limitations under the License. // Must be included first #include "tensorflow/python/lib/core/numpy.h" +#include "third_party/absl/strings/str_cat.h" +#include "third_party/absl/strings/str_format.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" @@ -154,8 +156,8 @@ bool HandleStringAttribute(PyObject* o, return true; // The attribute is None, which we consider ok. } if (!PyString_Check(attr)) { - string message = tensorflow::strings::Printf("%s must be a string or none; got %s", - attr_name, numpy::PyObjectCppRepr(attr).c_str()); + string message = absl::StrFormat("%s must be a string or none; got %s", + attr_name, numpy::PyObjectCppRepr(attr)); PyErr_SetString(PyExc_TypeError, message.c_str()); Py_DECREF(attr); return false; // Type error, not ok. @@ -409,10 +411,10 @@ tensorflow::ImportNumpy(); $1 = &temp; } -%typemap(in) const tensorflow::gtl::optional<Shape>& ( - tensorflow::gtl::optional<Shape> temp) { +%typemap(in) const absl::optional<Shape>& ( + absl::optional<Shape> temp) { if ($input == Py_None) { - temp = tensorflow::gtl::nullopt; + temp = absl::nullopt; $1 = &temp; } else { StatusOr<Shape> statusor = numpy::XlaShapeFromPyShape($input); @@ -448,8 +450,8 @@ tensorflow::ImportNumpy(); $1 = &temps; } -%typemap(in) const std::vector<tensorflow::gtl::optional<Shape> >& ( - std::vector<tensorflow::gtl::optional<Shape> > temps) { +%typemap(in) const std::vector<absl::optional<Shape> >& ( + std::vector<absl::optional<Shape> > temps) { if (!PySequence_Check($input)) { PyErr_SetString(PyExc_TypeError, "Argument is not a sequence"); SWIG_fail; @@ -458,7 +460,7 @@ tensorflow::ImportNumpy(); for (int i = 0; i < size; ++i) { PyObject* o = PySequence_GetItem($input, i); if (o == Py_None) { - temps.push_back(tensorflow::gtl::nullopt); + temps.push_back(absl::nullopt); } else { StatusOr<Shape> statusor = numpy::XlaShapeFromPyShape(o); Py_DECREF(o); @@ -896,7 +898,7 @@ tensorflow::ImportNumpy(); if (o != Py_None) { StatusOr<Shape> statusor = numpy::XlaShapeFromPyShape(o); if (!statusor.ok()) { - PyErr_SetString(PyExc_TypeError, tensorflow::strings::StrCat("ExecutableBuildOptions.result_shape could not be created from Python shape value: ", statusor.status().ToString()).c_str()); + PyErr_SetString(PyExc_TypeError, absl::StrCat("ExecutableBuildOptions.result_shape could not be created from Python shape value: ", statusor.status().ToString()).c_str()); Py_DECREF(o); SWIG_fail; } @@ -1011,6 +1013,7 @@ tensorflow::ImportNumpy(); %unignore xla::swig::LocalComputationBuilder::Pow; %unignore xla::swig::LocalComputationBuilder::Neg; %unignore xla::swig::LocalComputationBuilder::Sort; +%unignore xla::swig::LocalComputationBuilder::SortKeyVal; %unignore xla::swig::LocalComputationBuilder::Sqrt; %unignore xla::swig::LocalComputationBuilder::Rsqrt; %unignore xla::swig::LocalComputationBuilder::Square; diff --git a/tensorflow/compiler/xla/python/numpy_bridge.cc b/tensorflow/compiler/xla/python/numpy_bridge.cc index 6f665faf61..fc6511bef5 100644 --- a/tensorflow/compiler/xla/python/numpy_bridge.cc +++ b/tensorflow/compiler/xla/python/numpy_bridge.cc @@ -14,6 +14,8 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/python/numpy_bridge.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/core/platform/logging.h" @@ -149,9 +151,7 @@ static int NumpyTypenum(PyObject* o) { // // NOTE: this is an internal helper for conversion to a C++, and so decrefs r. static string ExtractStringAndDecref(PyObject* r) { - auto error = [r] { - return tensorflow::strings::Printf("<failed conversion of %p>", r); - }; + auto error = [r] { return absl::StrFormat("<failed conversion of %p>", r); }; if (r == nullptr) { return error(); } @@ -191,8 +191,8 @@ StatusOr<Shape> XlaShapeFromPyShape(PyObject* o) { PyObject* result = PyObject_CallMethod(o, const_cast<char*>(method.c_str()), nullptr); if (result == nullptr) { - return error(tensorflow::strings::StrCat( - "Failed to call method of shape object:", method)); + return error( + absl::StrCat("Failed to call method of shape object:", method)); } return result; }; @@ -281,15 +281,15 @@ StatusOr<Shape> XlaShapeFromPyShape(PyObject* o) { // Helper that retrieves the member with attr_name, stringifies it if is not // None, and returns it as a C++ string. -static tensorflow::gtl::optional<string> GetAttrAsString( - PyObject* o, const string& attr_name) { +static absl::optional<string> GetAttrAsString(PyObject* o, + const string& attr_name) { if (!PyObject_HasAttrString(o, attr_name.c_str())) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } PyObject* attr = PyObject_GetAttrString(o, attr_name.c_str()); if (attr == Py_None) { Py_DECREF(attr); - return tensorflow::gtl::nullopt; + return absl::nullopt; } string result = PyObjectCppStr(attr); Py_DECREF(attr); @@ -298,48 +298,46 @@ static tensorflow::gtl::optional<string> GetAttrAsString( // Helper that retrieves the member with attr_name, checks that it is an integer // if it is not None, and returns it as an int32 value. -static tensorflow::gtl::optional<int32> GetAttrAsInt32( - PyObject* o, const string& attr_name) { +static absl::optional<int32> GetAttrAsInt32(PyObject* o, + const string& attr_name) { if (!PyObject_HasAttrString(o, attr_name.c_str())) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } PyObject* attr = PyObject_GetAttrString(o, attr_name.c_str()); if (attr == Py_None) { Py_DECREF(attr); - return tensorflow::gtl::nullopt; + return absl::nullopt; } if (!CheckPyIntOrLong(attr)) { Py_DECREF(attr); - return tensorflow::gtl::nullopt; + return absl::nullopt; } long value = PyIntOrPyLongToLong(attr); // NOLINT Py_DECREF(attr); if (value == -1 && PyErr_Occurred() != nullptr) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } if (static_cast<int32>(value) != value) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } return value; } StatusOr<OpMetadata> OpMetadataFromPyObject(PyObject* o) { OpMetadata result; - tensorflow::gtl::optional<string> op_type = GetAttrAsString(o, "op_type"); + absl::optional<string> op_type = GetAttrAsString(o, "op_type"); if (op_type.has_value()) { result.set_op_type(op_type.value()); } - tensorflow::gtl::optional<string> op_name = GetAttrAsString(o, "op_name"); + absl::optional<string> op_name = GetAttrAsString(o, "op_name"); if (op_name.has_value()) { result.set_op_name(op_name.value()); } - tensorflow::gtl::optional<string> source_file = - GetAttrAsString(o, "source_file"); + absl::optional<string> source_file = GetAttrAsString(o, "source_file"); if (source_file.has_value()) { result.set_source_file(source_file.value()); } - tensorflow::gtl::optional<int32> source_line = - GetAttrAsInt32(o, "source_line"); + absl::optional<int32> source_line = GetAttrAsInt32(o, "source_line"); if (source_line.has_value()) { result.set_source_line(source_line.value()); } diff --git a/tensorflow/compiler/xla/python/xla_client.py b/tensorflow/compiler/xla/python/xla_client.py index a2c6fc344d..fa4366ff07 100644 --- a/tensorflow/compiler/xla/python/xla_client.py +++ b/tensorflow/compiler/xla/python/xla_client.py @@ -105,7 +105,6 @@ _UNARY_OPS = [ 'Square', 'Reciprocal', 'Neg', - 'Sort', 'Erf', 'Erfc', 'ErfInv', @@ -1218,6 +1217,14 @@ class ComputationBuilder(object): lhs_dilation, rhs_dilation, dimension_numbers) + def Sort(self, operand, dimension=-1): + """Enqueues a sort operation onto the computation.""" + return self._client.Sort(operand, dimension) + + def SortKeyVal(self, keys, values, dimension=-1): + """Enqueues a key-value sort operation onto the computation.""" + return self._client.SortKeyVal(keys, values, dimension) + def _forward_methods_to_local_builder(): """Forward remaining ComputationBuilder methods to the C API. diff --git a/tensorflow/compiler/xla/reference_util.cc b/tensorflow/compiler/xla/reference_util.cc index a803520876..3de7ee2bc8 100644 --- a/tensorflow/compiler/xla/reference_util.cc +++ b/tensorflow/compiler/xla/reference_util.cc @@ -18,6 +18,7 @@ limitations under the License. #include <array> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/cpu/runtime_single_threaded_matmul.h" @@ -43,7 +44,7 @@ std::unique_ptr<Array2D<T>> MatmulArray2DImpl( int m = lhs.height(); int n = rhs.width(); int k = lhs.width(); - auto result = MakeUnique<Array2D<T>>(m, n); + auto result = absl::make_unique<Array2D<T>>(m, n); // Because Eigen is a header-oriented library, make sure that the Eigen code // is the same as the code used by the CPU backend (otherwise the linker will // randomly pick *some* definition). @@ -77,7 +78,8 @@ std::unique_ptr<Array2D<T>> MatmulArray2DImpl( /* static */ std::unique_ptr<Array2D<double>> ReferenceUtil::Array2DF32ToF64( const Array2D<float>& input) { - auto result = MakeUnique<Array2D<double>>(input.height(), input.width()); + auto result = + absl::make_unique<Array2D<double>>(input.height(), input.width()); for (int64 rowno = 0; rowno < input.height(); ++rowno) { for (int64 colno = 0; colno < input.height(); ++colno) { (*result)(rowno, colno) = input(rowno, colno); @@ -126,8 +128,8 @@ ReferenceUtil::ConvArray3DGeneralDimensionsDilated( a4dlhs, a4drhs, {kernel_stride, 1}, padding, {lhs_dilation, 1}, {rhs_dilation, 1}, dnums2d); - auto convr3 = MakeUnique<Array3D<float>>(convr4->planes(), convr4->depth(), - convr4->height()); + auto convr3 = absl::make_unique<Array3D<float>>( + convr4->planes(), convr4->depth(), convr4->height()); convr4->Each( [&](tensorflow::gtl::ArraySlice<int64> indices, float* value_ptr) { CHECK_EQ(indices[3], 0); @@ -201,7 +203,7 @@ ReferenceUtil::ReduceWindow1DGeneric( window_util::StridedBound(padded_width, window[i], stride[i]); pad_low[i] = padding[i].first; } - auto result = MakeUnique<std::vector<float>>(window_counts[0]); + auto result = absl::make_unique<std::vector<float>>(window_counts[0]); // Do a full 1D reduce window. for (int64 i0 = 0; i0 < window_counts[0]; ++i0) { @@ -247,7 +249,8 @@ ReferenceUtil::ReduceWindow2DGeneric( window_util::StridedBound(padded_width, window[i], stride[i]); pad_low[i] = padding[i].first; } - auto result = MakeUnique<Array2D<float>>(window_counts[0], window_counts[1]); + auto result = + absl::make_unique<Array2D<float>>(window_counts[0], window_counts[1]); // Do a full 2D reduce window. for (int64 i0 = 0; i0 < window_counts[0]; ++i0) { @@ -296,8 +299,8 @@ ReferenceUtil::ReduceWindow2DGeneric( WindowCount(dim_lengths[i], window[i], stride[i], padding); pad_low[i] = padding_both[i].first; } - auto result = MakeUnique<Array3D<float>>(window_counts[0], window_counts[1], - window_counts[2]); + auto result = absl::make_unique<Array3D<float>>( + window_counts[0], window_counts[1], window_counts[2]); for (int64 i0 = 0; i0 < window_counts[0]; ++i0) { for (int64 i1 = 0; i1 < window_counts[1]; ++i1) { @@ -358,8 +361,8 @@ ReferenceUtil::ReduceWindow4DGeneric( window_util::StridedBound(padded_width, window[i], stride[i]); pad_low[i] = padding[i].first; } - auto result = MakeUnique<Array4D<float>>(window_counts[0], window_counts[1], - window_counts[2], window_counts[3]); + auto result = absl::make_unique<Array4D<float>>( + window_counts[0], window_counts[1], window_counts[2], window_counts[3]); // Do a full 4D reduce window. for (int64 i0 = 0; i0 < window_counts[0]; ++i0) { for (int64 i1 = 0; i1 < window_counts[1]; ++i1) { @@ -426,8 +429,8 @@ ReferenceUtil::SelectAndScatter4DGePlus( const tensorflow::gtl::ArraySlice<int64>& window, const tensorflow::gtl::ArraySlice<int64>& stride, bool same_padding) { Padding padding = same_padding ? Padding::kSame : Padding::kValid; - auto result = MakeUnique<Array4D<float>>(operand.n1(), operand.n2(), - operand.n3(), operand.n4()); + auto result = absl::make_unique<Array4D<float>>(operand.n1(), operand.n2(), + operand.n3(), operand.n4()); std::vector<int64> dim_lengths{operand.n1(), operand.n2(), operand.n3(), operand.n4()}; auto padding_both = xla::MakePadding(dim_lengths, window, stride, padding); @@ -583,10 +586,10 @@ ReferenceUtil::ConvArray4DGeneralDimensionsDilated( CHECK_EQ(ShapeUtil::Rank(result_literal->shape()), 4); auto result = - MakeUnique<Array4D<float>>(result_literal->shape().dimensions(0), - result_literal->shape().dimensions(1), - result_literal->shape().dimensions(2), - result_literal->shape().dimensions(3)); + absl::make_unique<Array4D<float>>(result_literal->shape().dimensions(0), + result_literal->shape().dimensions(1), + result_literal->shape().dimensions(2), + result_literal->shape().dimensions(3)); result->Each([&](tensorflow::gtl::ArraySlice<int64> indices, float* value) { *value = result_literal->Get<float>(indices); @@ -601,7 +604,7 @@ ReferenceUtil::ReduceToColArray2D( const std::function<float(float, float)>& reduce_function) { int64 rows = matrix.height(); int64 cols = matrix.width(); - auto result = MakeUnique<std::vector<float>>(); + auto result = absl::make_unique<std::vector<float>>(); for (int64 i = 0; i < rows; ++i) { float acc = init; for (int64 j = 0; j < cols; ++j) { @@ -618,7 +621,7 @@ ReferenceUtil::ReduceToRowArray2D( const std::function<float(float, float)>& reduce_function) { int64 rows = matrix.height(); int64 cols = matrix.width(); - auto result = MakeUnique<std::vector<float>>(); + auto result = absl::make_unique<std::vector<float>>(); for (int64 i = 0; i < cols; ++i) { float acc = init; for (int64 j = 0; j < rows; ++j) { @@ -674,8 +677,8 @@ ReferenceUtil::ReduceToRowArray2D( /* static */ std::unique_ptr<Array4D<float>> ReferenceUtil::Broadcast1DTo4D( const std::vector<float>& array, const std::vector<int64>& bounds, int64 broadcast_from_dim) { - auto result = - MakeUnique<Array4D<float>>(bounds[0], bounds[1], bounds[2], bounds[3]); + auto result = absl::make_unique<Array4D<float>>(bounds[0], bounds[1], + bounds[2], bounds[3]); for (int64 i = 0; i < result->n1(); ++i) { for (int64 j = 0; j < result->n2(); ++j) { for (int64 k = 0; k < result->n3(); ++k) { @@ -710,7 +713,7 @@ ReferenceUtil::ReduceToRowArray2D( CHECK_EQ(dims.size(), 1); int64 rows = dims[0] == 0 ? array.n2() : array.n1(); int64 cols = dims[0] == 2 ? array.n2() : array.n3(); - auto result = MakeUnique<Array2D<float>>(rows, cols); + auto result = absl::make_unique<Array2D<float>>(rows, cols); result->Fill(init); for (int i0 = 0; i0 < array.n1(); ++i0) { for (int i1 = 0; i1 < array.n2(); ++i1) { @@ -730,7 +733,7 @@ ReferenceUtil::ReduceToRowArray2D( const std::function<float(float)>& map_function) { int64 rows = matrix.height(); int64 cols = matrix.width(); - auto result = MakeUnique<Array2D<float>>(rows, cols); + auto result = absl::make_unique<Array2D<float>>(rows, cols); for (int64 i = 0; i < rows; ++i) { for (int64 j = 0; j < cols; ++j) { (*result)(i, j) = map_function(matrix(i, j)); @@ -746,7 +749,7 @@ ReferenceUtil::ReduceToRowArray2D( CHECK_EQ(lhs.width(), rhs.width()); int64 rows = lhs.height(); int64 cols = rhs.width(); - auto result = MakeUnique<Array2D<float>>(rows, cols); + auto result = absl::make_unique<Array2D<float>>(rows, cols); for (int64 i = 0; i < rows; ++i) { for (int64 j = 0; j < cols; ++j) { (*result)(i, j) = map_function(lhs(i, j), rhs(i, j)); @@ -760,7 +763,7 @@ ReferenceUtil::ReduceToRowArray2D( const std::function<float(float, int64, int64)>& map_function) { int64 rows = matrix.height(); int64 cols = matrix.width(); - auto result = MakeUnique<Array2D<float>>(rows, cols); + auto result = absl::make_unique<Array2D<float>>(rows, cols); for (int64 i = 0; i < rows; ++i) { for (int64 j = 0; j < cols; ++j) { (*result)(i, j) = map_function(matrix(i, j), i, j); diff --git a/tensorflow/compiler/xla/reference_util.h b/tensorflow/compiler/xla/reference_util.h index 8fa6961d19..88f853a359 100644 --- a/tensorflow/compiler/xla/reference_util.h +++ b/tensorflow/compiler/xla/reference_util.h @@ -22,11 +22,11 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array3d.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/client/padding.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/gtl/array_slice.h" @@ -42,7 +42,8 @@ class ReferenceUtil { template <typename T> static std::unique_ptr<Array2D<T>> TransposeArray2D( const Array2D<T>& operand) { - auto result = MakeUnique<Array2D<T>>(operand.width(), operand.height()); + auto result = + absl::make_unique<Array2D<T>>(operand.width(), operand.height()); for (int64 w = 0; w < operand.width(); ++w) { for (int64 h = 0; h < operand.height(); ++h) { (*result)(w, h) = operand(h, w); @@ -242,7 +243,7 @@ class ReferenceUtil { const Array2D<T>& rhs, int concatenate_dimension) { CHECK(0 <= concatenate_dimension && concatenate_dimension < 2); - auto result = MakeUnique<Array2D<T>>( + auto result = absl::make_unique<Array2D<T>>( concatenate_dimension == 0 ? lhs.n1() + rhs.n1() : lhs.n1(), concatenate_dimension == 1 ? lhs.n2() + rhs.n2() : lhs.n2()); for (int64 i0 = 0; i0 < result->n1(); ++i0) { @@ -276,7 +277,8 @@ class ReferenceUtil { out_dims[i] = lhs_dims[i] + rhs_dims[i]; } } - auto result = MakeUnique<Array3D<T>>(out_dims[0], out_dims[1], out_dims[2]); + auto result = + absl::make_unique<Array3D<T>>(out_dims[0], out_dims[1], out_dims[2]); for (int64 i0 = 0; i0 < result->n1(); ++i0) { for (int64 i1 = 0; i1 < result->n2(); ++i1) { for (int64 i2 = 0; i2 < result->n3(); ++i2) { @@ -310,8 +312,8 @@ class ReferenceUtil { out_dims[i] = lhs_dims[i] + rhs_dims[i]; } } - auto result = MakeUnique<Array4D<T>>(out_dims[0], out_dims[1], out_dims[2], - out_dims[3]); + auto result = absl::make_unique<Array4D<T>>(out_dims[0], out_dims[1], + out_dims[2], out_dims[3]); for (int64 i0 = 0; i0 < result->n1(); ++i0) { for (int64 i1 = 0; i1 < result->n2(); ++i1) { for (int64 i2 = 0; i2 < result->n3(); ++i2) { @@ -355,9 +357,9 @@ class ReferenceUtil { CHECK_LE(limits[1], input.n2()); CHECK_GE(strides[0], 1); CHECK_GE(strides[1], 1); - auto result = - MakeUnique<Array2D<T>>(CeilOfRatio(limits[0] - starts[0], strides[0]), - CeilOfRatio(limits[1] - starts[1], strides[1])); + auto result = absl::make_unique<Array2D<T>>( + CeilOfRatio(limits[0] - starts[0], strides[0]), + CeilOfRatio(limits[1] - starts[1], strides[1])); for (int64 i0 = 0; i0 < result->n1(); ++i0) { for (int64 i1 = 0; i1 < result->n2(); ++i1) { (*result)(i0, i1) = @@ -381,10 +383,10 @@ class ReferenceUtil { CHECK_GE(strides[0], 1); CHECK_GE(strides[1], 1); CHECK_GE(strides[2], 1); - auto result = - MakeUnique<Array3D<T>>(CeilOfRatio(limits[0] - starts[0], strides[0]), - CeilOfRatio(limits[1] - starts[1], strides[1]), - CeilOfRatio(limits[2] - starts[2], strides[2])); + auto result = absl::make_unique<Array3D<T>>( + CeilOfRatio(limits[0] - starts[0], strides[0]), + CeilOfRatio(limits[1] - starts[1], strides[1]), + CeilOfRatio(limits[2] - starts[2], strides[2])); for (int64 i0 = 0; i0 < result->n1(); ++i0) { for (int64 i1 = 0; i1 < result->n2(); ++i1) { @@ -415,11 +417,11 @@ class ReferenceUtil { CHECK_GE(strides[1], 1); CHECK_GE(strides[2], 1); CHECK_GE(strides[3], 1); - auto result = - MakeUnique<Array4D<T>>(CeilOfRatio(limits[0] - starts[0], strides[0]), - CeilOfRatio(limits[1] - starts[1], strides[1]), - CeilOfRatio(limits[2] - starts[2], strides[2]), - CeilOfRatio(limits[3] - starts[3], strides[3])); + auto result = absl::make_unique<Array4D<T>>( + CeilOfRatio(limits[0] - starts[0], strides[0]), + CeilOfRatio(limits[1] - starts[1], strides[1]), + CeilOfRatio(limits[2] - starts[2], strides[2]), + CeilOfRatio(limits[3] - starts[3], strides[3])); for (int64 i0 = 0; i0 < result->n1(); ++i0) { for (int64 i1 = 0; i1 < result->n2(); ++i1) { for (int64 i2 = 0; i2 < result->n3(); ++i2) { @@ -460,8 +462,8 @@ class ReferenceUtil { template <typename F> static std::unique_ptr<Array4D<float>> MapWithIndexArray4D( const Array4D<float>& input, F&& map_function) { - auto result = MakeUnique<Array4D<float>>(input.planes(), input.depth(), - input.height(), input.width()); + auto result = absl::make_unique<Array4D<float>>( + input.planes(), input.depth(), input.height(), input.width()); for (int64 plane = 0; plane < input.planes(); ++plane) { for (int64 depth = 0; depth < input.depth(); ++depth) { for (int64 height = 0; height < input.height(); ++height) { @@ -495,8 +497,8 @@ class ReferenceUtil { template <typename F> static std::unique_ptr<Array4D<float>> MapWithIndexArray4D( const Array4D<float>& lhs, const Array4D<float>& rhs, F&& map_function) { - auto result = MakeUnique<Array4D<float>>(lhs.planes(), lhs.depth(), - lhs.height(), lhs.width()); + auto result = absl::make_unique<Array4D<float>>(lhs.planes(), lhs.depth(), + lhs.height(), lhs.width()); for (int64 plane = 0; plane < lhs.planes(); ++plane) { for (int64 depth = 0; depth < lhs.depth(); ++depth) { for (int64 height = 0; height < lhs.height(); ++height) { @@ -530,7 +532,7 @@ class ReferenceUtil { int64 out1 = in1 + low_padding1 + high_padding1 + (in1 - 1) * interior_padding1; - auto result = MakeUnique<Array2D<NativeT>>(out0, out1); + auto result = absl::make_unique<Array2D<NativeT>>(out0, out1); result->Fill(pad); int64 o0 = low_padding0; for (int64 i0 = 0; i0 < in0; ++i0) { @@ -669,7 +671,7 @@ class ReferenceUtil { static std::unique_ptr<Array2D<T1>> ApplyElementwise2D( F&& f, const Array2D<T1>& array1, const Array2D<Ts>&... arrays) { AssertSameSize2D(array1, arrays...); - auto result = MakeUnique<Array2D<T1>>(array1.n1(), array1.n2()); + auto result = absl::make_unique<Array2D<T1>>(array1.n1(), array1.n2()); for (int64 i = 0; i < array1.n1(); ++i) { for (int64 j = 0; j < array1.n2(); ++j) { (*result)(i, j) = f(array1(i, j), arrays(i, j)...); diff --git a/tensorflow/compiler/xla/reference_util_test.cc b/tensorflow/compiler/xla/reference_util_test.cc index 8091bed499..3ec0192148 100644 --- a/tensorflow/compiler/xla/reference_util_test.cc +++ b/tensorflow/compiler/xla/reference_util_test.cc @@ -18,12 +18,12 @@ limitations under the License. #include <cmath> #include <memory> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array3d.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/client/padding.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/tests/literal_test_util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" @@ -36,7 +36,7 @@ namespace { class ReferenceUtilTest : public ::testing::Test { protected: ReferenceUtilTest() { - matrix_ = MakeUnique<Array2D<float>>(rows_, cols_); + matrix_ = absl::make_unique<Array2D<float>>(rows_, cols_); // [1.f 2.f 3.f] // [4.f 5.f 6.f] for (int64 i = 0; i < rows_; ++i) { @@ -112,8 +112,8 @@ TEST_F(ReferenceUtilTest, MapWithIndexArray2D) { } TEST_F(ReferenceUtilTest, MapArray4D) { - auto input = MakeUnique<Array4D<float>>(/*planes=*/2, /*depth=*/3, - /*height=*/4, /*width=*/5); + auto input = absl::make_unique<Array4D<float>>(/*planes=*/2, /*depth=*/3, + /*height=*/4, /*width=*/5); input->FillWithMultiples(1.0f); auto multiply_by_two = [](float value) { return 2 * value; }; auto result = ReferenceUtil::MapArray4D(*input, multiply_by_two); @@ -126,8 +126,8 @@ TEST_F(ReferenceUtilTest, MapArray4D) { } TEST_F(ReferenceUtilTest, MapWithIndexArray4D) { - auto input = MakeUnique<Array4D<float>>(/*planes=*/2, /*depth=*/3, - /*height=*/4, /*width=*/5); + auto input = absl::make_unique<Array4D<float>>(/*planes=*/2, /*depth=*/3, + /*height=*/4, /*width=*/5); input->FillWithMultiples(1.0f); auto subtract_index = [](float value, int64 plane, int64 depth, int64 height, int64 width) { diff --git a/tensorflow/compiler/xla/rpc/BUILD b/tensorflow/compiler/xla/rpc/BUILD index 44b22a5586..97fcd37f6b 100644 --- a/tensorflow/compiler/xla/rpc/BUILD +++ b/tensorflow/compiler/xla/rpc/BUILD @@ -43,6 +43,7 @@ tf_cc_binary( "//tensorflow/compiler/xla/service:cpu_plugin", "//tensorflow/core:framework_internal", "//tensorflow/core:lib", + "@com_google_absl//absl/strings:str_format", ], ) @@ -62,6 +63,7 @@ tf_cc_test( "//tensorflow/core:lib", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/strings:str_format", ], ) diff --git a/tensorflow/compiler/xla/rpc/grpc_client_test.cc b/tensorflow/compiler/xla/rpc/grpc_client_test.cc index 6788676181..43fd8fe1bd 100644 --- a/tensorflow/compiler/xla/rpc/grpc_client_test.cc +++ b/tensorflow/compiler/xla/rpc/grpc_client_test.cc @@ -23,12 +23,12 @@ limitations under the License. #include "grpcpp/create_channel.h" #include "grpcpp/security/credentials.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/client/client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/rpc/grpc_stub.h" #include "tensorflow/compiler/xla/tests/literal_test_util.h" #include "tensorflow/core/lib/io/path.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/net.h" #include "tensorflow/core/platform/subprocess.h" @@ -46,7 +46,7 @@ class GRPCClientTestBase : public ::testing::Test { int port = tensorflow::internal::PickUnusedPortOrDie(); subprocess_.SetProgram( service_main_path, - {service_main_path, tensorflow::strings::Printf("--port=%d", port)}); + {service_main_path, absl::StrFormat("--port=%d", port)}); subprocess_.SetChannelAction(tensorflow::CHAN_STDOUT, tensorflow::ACTION_DUPPARENT); subprocess_.SetChannelAction(tensorflow::CHAN_STDERR, @@ -54,9 +54,8 @@ class GRPCClientTestBase : public ::testing::Test { CHECK(subprocess_.Start()); LOG(INFO) << "Launched subprocess"; - auto channel = - ::grpc::CreateChannel(tensorflow::strings::Printf("localhost:%d", port), - ::grpc::InsecureChannelCredentials()); + auto channel = ::grpc::CreateChannel(absl::StrFormat("localhost:%d", port), + ::grpc::InsecureChannelCredentials()); channel->WaitForConnected(gpr_time_add( gpr_now(GPR_CLOCK_REALTIME), gpr_time_from_seconds(10, GPR_TIMESPAN))); LOG(INFO) << "Channel to server is connected on port " << port; diff --git a/tensorflow/compiler/xla/rpc/grpc_service_main.cc b/tensorflow/compiler/xla/rpc/grpc_service_main.cc index c68c857c30..d6b5149a24 100644 --- a/tensorflow/compiler/xla/rpc/grpc_service_main.cc +++ b/tensorflow/compiler/xla/rpc/grpc_service_main.cc @@ -18,8 +18,8 @@ limitations under the License. #include "grpcpp/security/server_credentials.h" #include "grpcpp/server.h" #include "grpcpp/server_builder.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/rpc/grpc_service.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/init_main.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/util/command_line_flags.h" @@ -44,7 +44,7 @@ int RealMain(int argc, char** argv) { xla::GRPCService::NewService().ConsumeValueOrDie(); ::grpc::ServerBuilder builder; - string server_address(tensorflow::strings::Printf("localhost:%d", port)); + string server_address(absl::StrFormat("localhost:%d", port)); builder.AddListeningPort(server_address, ::grpc::InsecureServerCredentials()); builder.RegisterService(service.get()); diff --git a/tensorflow/compiler/xla/service/BUILD b/tensorflow/compiler/xla/service/BUILD index a65bdebf51..4aef093b04 100644 --- a/tensorflow/compiler/xla/service/BUILD +++ b/tensorflow/compiler/xla/service/BUILD @@ -99,6 +99,7 @@ cc_library( ":bfloat16_support", ":hlo", ":hlo_pass", + "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", @@ -175,6 +176,9 @@ cc_library( "//tensorflow/compiler/xla:window_util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -226,6 +230,7 @@ cc_library( hdrs = ["hlo_evaluator.h"], deps = [ ":hlo", + ":hlo_casting_utils", ":hlo_query", ":shape_inference", "//tensorflow/compiler/xla:literal", @@ -237,6 +242,11 @@ cc_library( "//tensorflow/compiler/xla:window_util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", ], ) @@ -263,6 +273,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", # fixdeps: keep "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -311,6 +322,10 @@ cc_library( "//tensorflow/core:human_readable_json", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -337,7 +352,7 @@ cc_library( deps = [ ":hlo", "//tensorflow/compiler/xla:shape_util", - "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -389,7 +404,8 @@ cc_library( "//tensorflow/compiler/xla:test", "//tensorflow/compiler/xla/service:hlo_parser", "//tensorflow/compiler/xla/tests:xla_internal_test_main", - "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", ], ) @@ -449,6 +465,9 @@ cc_library( "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -517,6 +536,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -552,6 +572,7 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/strings", ], ) @@ -574,6 +595,8 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", "//third_party/eigen3", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -615,6 +638,9 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:ptr_util", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], alwayslink = 1, ) @@ -647,6 +673,9 @@ cc_library( "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -669,6 +698,7 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:lib_internal", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/strings", ], ) @@ -719,6 +749,9 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -736,6 +769,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:ptr_util", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -766,6 +800,8 @@ cc_library( "//tensorflow/core:lib_internal", "//tensorflow/core:stream_executor_no_cuda", "//tensorflow/stream_executor", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings:str_format", ], ) @@ -813,6 +849,8 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -831,6 +869,8 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -847,6 +887,7 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", ], ) @@ -864,6 +905,8 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -874,6 +917,7 @@ cc_library( deps = [ "//tensorflow/compiler/xla:types", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -908,6 +952,8 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -917,12 +963,14 @@ tf_cc_test( deps = [ ":buffer_liveness", ":hlo", + ":hlo_dataflow_analysis", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", + "@com_google_absl//absl/memory", ], ) @@ -950,6 +998,9 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -977,6 +1028,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -996,6 +1048,8 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -1031,6 +1085,7 @@ cc_library( "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -1049,6 +1104,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -1059,12 +1115,15 @@ cc_library( deps = [ ":hlo", ":hlo_casting_utils", + ":tuple_points_to_analysis", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/types:optional", ], ) @@ -1074,6 +1133,7 @@ cc_library( hdrs = ["hlo_module_group_util.h"], deps = [ ":hlo", + ":hlo_casting_utils", ":hlo_module_group_metadata", ":hlo_reachability", "//tensorflow/compiler/xla:status", @@ -1082,6 +1142,8 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1101,6 +1163,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "//tensorflow/core:lib_internal", ], ) @@ -1108,17 +1171,18 @@ tf_cc_test( name = "hlo_scheduling_test", srcs = ["hlo_scheduling_test.cc"], deps = [ - ":buffer_value", ":heap_simulator", ":hlo", + ":hlo_dce", ":hlo_ordering", + ":hlo_parser", ":hlo_scheduling", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:xla_data_proto", - "//tensorflow/compiler/xla/service:hlo_parser", "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", + "//tensorflow/core:test", ], ) @@ -1142,6 +1206,7 @@ cc_library( ":hlo_pass", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", ], ) @@ -1167,6 +1232,7 @@ cc_library( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/compiler/xla/service:hlo_pass", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -1181,6 +1247,9 @@ cc_library( "//tensorflow/compiler/xla:literal_util", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:util", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1198,6 +1267,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -1216,6 +1286,7 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/types:optional", ], ) @@ -1231,6 +1302,7 @@ cc_library( "//tensorflow/compiler/xla:literal_util", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:util", + "@com_google_absl//absl/algorithm:container", ], ) @@ -1245,6 +1317,7 @@ cc_library( ":while_util", "//tensorflow/compiler/xla:literal_util", "//tensorflow/compiler/xla:statusor", + "@com_google_absl//absl/algorithm:container", ], ) @@ -1267,6 +1340,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -1276,6 +1350,7 @@ cc_library( hdrs = ["algebraic_simplifier.h"], deps = [ ":hlo", + ":hlo_casting_utils", ":hlo_creation_utils", ":hlo_pass", ":hlo_query", @@ -1289,6 +1364,10 @@ cc_library( "//tensorflow/compiler/xla:window_util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", ], ) @@ -1298,6 +1377,7 @@ tf_cc_test( deps = [ ":algebraic_simplifier", ":hlo", + ":hlo_casting_utils", ":hlo_matchers", ":hlo_pass", "//tensorflow/compiler/xla:literal", @@ -1312,6 +1392,8 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", # fixdeps: keep "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1323,8 +1405,7 @@ cc_library( ":hlo", ":hlo_creation_utils", ":hlo_pass", - "//tensorflow/compiler/xla:xla_data_proto", - "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", ], ) @@ -1377,6 +1458,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -1414,6 +1496,8 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1439,8 +1523,7 @@ cc_library( deps = [ ":hlo", ":hlo_evaluator", - "//tensorflow/compiler/xla:literal", - "//tensorflow/core:lib", + "@com_google_absl//absl/types:optional", ], ) @@ -1455,6 +1538,8 @@ cc_library( ":while_loop_analysis", "//tensorflow/compiler/xla:statusor", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", ], ) @@ -1468,6 +1553,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_verified_test_base", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -1582,6 +1668,7 @@ cc_library( "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", ], ) @@ -1602,6 +1689,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_verified_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -1635,6 +1723,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/compiler/xla/tests:xla_internal_test_main", + "@com_google_absl//absl/memory", ], ) @@ -1654,6 +1743,8 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], alwayslink = True, # Contains per-platform computation placer registration ) @@ -1667,6 +1758,8 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -1744,6 +1837,8 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/memory", ], ) @@ -1758,6 +1853,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -1789,6 +1885,8 @@ tf_cc_binary( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1805,6 +1903,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -1820,6 +1919,7 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/strings", ], ) @@ -1847,6 +1947,7 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/strings", ], ) @@ -1864,6 +1965,8 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1882,6 +1985,9 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1923,6 +2029,8 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1959,6 +2067,7 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -1979,6 +2088,7 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -2016,6 +2126,7 @@ cc_library( "//tensorflow/compiler/xla:statusor", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/memory", ], ) @@ -2028,7 +2139,6 @@ cc_library( ":hlo_dataflow_analysis", ":logical_buffer", ":logical_buffer_analysis", - "//tensorflow/compiler/xla:literal_util", "//tensorflow/compiler/xla:shape_tree", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:statusor", @@ -2036,6 +2146,10 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -2086,6 +2200,9 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -2108,6 +2225,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -2175,7 +2293,10 @@ cc_library( ":hlo_pass", ":shape_inference", "//tensorflow/compiler/xla:status_macros", + "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -2212,13 +2333,16 @@ cc_library( ":hlo_scheduling", ":logical_buffer", ":tuple_points_to_analysis", - ":tuple_simplifier", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "//tensorflow/core:lib_internal", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -2258,6 +2382,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -2339,6 +2464,9 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -2376,6 +2504,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/compiler/xla/tests:test_utils", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -2392,6 +2521,7 @@ cc_library( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:types", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -2402,6 +2532,7 @@ tf_cc_test( ":hlo", ":hlo_constant_folding", ":hlo_matchers", + ":hlo_parser", ":hlo_pass", "//tensorflow/compiler/xla:literal", "//tensorflow/compiler/xla:shape_util", @@ -2423,6 +2554,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -2437,6 +2569,7 @@ cc_library( "//tensorflow/compiler/xla:shape_tree", "//tensorflow/compiler/xla:shape_util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -2497,6 +2630,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_verified_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -2552,6 +2686,7 @@ cc_library( hdrs = ["elemental_ir_emitter.h"], deps = [ ":hlo", + ":hlo_casting_utils", ":hlo_module_config", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status_macros", @@ -2560,11 +2695,14 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service/llvm_ir:ir_array", + "//tensorflow/compiler/xla/service/llvm_ir:ir_builder_mixin", "//tensorflow/compiler/xla/service/llvm_ir:llvm_loop", "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/compiler/xla/service/llvm_ir:loop_emitter", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/strings", "@llvm//:core", "@llvm//:transform_utils", ], @@ -2596,10 +2734,11 @@ cc_library( ":computation_layout", "//tensorflow/compiler/xla:shape_layout", "//tensorflow/compiler/xla:types", - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla:xla_proto", - "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", ], ) @@ -2612,6 +2751,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -2648,8 +2788,8 @@ cc_library( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:xla_proto", "//tensorflow/core:framework", - "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/strings", ], ) @@ -2683,6 +2823,9 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:lib_internal", "//tensorflow/core:regexp_internal", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", + "@com_google_absl//absl/types:optional", ], alwayslink = 1, ) @@ -2699,6 +2842,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:test_utils", "//tensorflow/compiler/xla/tests:xla_internal_test_main", # fixdeps: keep "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -2780,9 +2924,9 @@ cc_library( hdrs = ["stream_pool.h"], deps = [ "//tensorflow/compiler/xla:types", - "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", ], ) @@ -2880,6 +3024,7 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", "//third_party/eigen3", + "@com_google_absl//absl/memory", ], ) @@ -2926,7 +3071,8 @@ cc_library( ":hlo_creation_utils", ":tuple_util", "//tensorflow/compiler/xla:literal_util", - "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/strings", ], ) @@ -2940,6 +3086,7 @@ tf_cc_test( "//tensorflow/compiler/xla/service:hlo_matchers", "//tensorflow/compiler/xla/service:hlo_parser", "//tensorflow/compiler/xla/tests:xla_internal_test_main", + "@com_google_absl//absl/algorithm:container", ], ) @@ -2955,6 +3102,8 @@ cc_library( "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/container:inlined_vector", ], ) @@ -2982,6 +3131,7 @@ cc_library( "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", ], ) @@ -3015,13 +3165,13 @@ cc_library( cc_library( name = "source_map_util", - srcs = ["source_map_util.cc"], + srcs = [], hdrs = ["source_map_util.h"], deps = [ ":executable", "//tensorflow/compiler/xla:status", - "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings:str_format", ], ) @@ -3036,6 +3186,10 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", "//tensorflow/core:ptr_util", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", ], ) @@ -3067,8 +3221,11 @@ cc_library( "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", - "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -3077,11 +3234,13 @@ tf_cc_test( size = "small", srcs = ["hlo_parser_test.cc"], deps = [ + ":hlo_matchers", ":hlo_parser", "//tensorflow/compiler/xla:window_util", "//tensorflow/core:lib", "//tensorflow/core:test", "//tensorflow/core:test_main", # fixdeps: keep + "@com_google_absl//absl/strings", ], ) @@ -3100,6 +3259,8 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:regexp_internal", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", ], ) diff --git a/tensorflow/compiler/xla/service/algebraic_simplifier.cc b/tensorflow/compiler/xla/service/algebraic_simplifier.cc index f7812d9661..19bb4da9a6 100644 --- a/tensorflow/compiler/xla/service/algebraic_simplifier.cc +++ b/tensorflow/compiler/xla/service/algebraic_simplifier.cc @@ -22,13 +22,19 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h" +#include "tensorflow/compiler/xla/service/hlo_casting_utils.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_creation_utils.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" +#include "tensorflow/compiler/xla/service/hlo_instructions.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/service/hlo_query.h" #include "tensorflow/compiler/xla/service/pattern_matcher.h" @@ -41,7 +47,6 @@ limitations under the License. #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -266,7 +271,7 @@ class AlgebraicSimplifierVisitor : public DfsHloVisitorWithDefault { StatusOr<HloInstruction*> OptimizeDotOfConcat(HloInstruction* dot); StatusOr<HloInstruction*> OptimizeDotOfConcatHelper( - const Shape& dot_shape, HloInstruction* lhs, int64 lhs_contracting_dim, + const HloInstruction& dot, HloInstruction* lhs, int64 lhs_contracting_dim, HloInstruction* rhs, int64 rhs_contracting_dim, bool swapped); StatusOr<HloInstruction*> OptimizeDotOfGather(HloInstruction* dot); @@ -540,7 +545,7 @@ Status AlgebraicSimplifierVisitor::HandleConstant(HloInstruction* constant) { // If a literal is all the same element replace it with a scalar broadcast. if (ShapeUtil::ElementsIn(constant->shape()) > 1 && constant->literal().IsAllFirst()) { - std::unique_ptr<Literal> unique_scalar = MakeUnique<Literal>( + std::unique_ptr<Literal> unique_scalar = absl::make_unique<Literal>( LiteralUtil::GetFirstScalarLiteral(constant->literal())); HloInstruction* scalar = computation_->AddInstruction( HloInstruction::CreateConstant(std::move(unique_scalar))); @@ -827,18 +832,18 @@ StatusOr<HloInstruction*> AlgebraicSimplifierVisitor::OptimizeDotOfConcat( TF_ASSIGN_OR_RETURN( HloInstruction * optimized_lhs_concat, - OptimizeDotOfConcatHelper(dot->shape(), lhs, lhs_contracting_dim, rhs, + OptimizeDotOfConcatHelper(*dot, lhs, lhs_contracting_dim, rhs, rhs_contracting_dim, /*swapped=*/false)); if (optimized_lhs_concat) { return optimized_lhs_concat; } - return OptimizeDotOfConcatHelper(dot->shape(), rhs, rhs_contracting_dim, lhs, + return OptimizeDotOfConcatHelper(*dot, rhs, rhs_contracting_dim, lhs, lhs_contracting_dim, /*swapped=*/true); } StatusOr<HloInstruction*> AlgebraicSimplifierVisitor::OptimizeDotOfConcatHelper( - const Shape& dot_shape, HloInstruction* lhs, int64 lhs_contracting_dim, + const HloInstruction& dot, HloInstruction* lhs, int64 lhs_contracting_dim, HloInstruction* rhs, int64 rhs_contracting_dim, bool swapped) { bool can_optimize = lhs->opcode() == HloOpcode::kConcatenate && lhs->concatenate_dimension() == lhs_contracting_dim && @@ -937,11 +942,12 @@ StatusOr<HloInstruction*> AlgebraicSimplifierVisitor::OptimizeDotOfConcatHelper( } auto* new_dot = computation_->AddInstruction(HloInstruction::CreateDot( - dot_shape, new_dot_lhs, new_dot_rhs, new_dot_dnums)); + dot.shape(), new_dot_lhs, new_dot_rhs, new_dot_dnums)); + new_dot->set_precision_config(dot.precision_config()); if (add_result) { add_result = computation_->AddInstruction(HloInstruction::CreateBinary( - dot_shape, HloOpcode::kAdd, add_result, new_dot)); + dot.shape(), HloOpcode::kAdd, add_result, new_dot)); } else { add_result = new_dot; } @@ -1040,6 +1046,7 @@ StatusOr<HloInstruction*> AlgebraicSimplifierVisitor::OptimizeDotOfGather( auto memoized_shape = ShapeUtil::MakeShape(F32, {m, n}); auto* memoized_inst = computation_->AddInstruction(HloInstruction::CreateDot( memoized_shape, left_operand, right_operand, dnums)); + memoized_inst->set_precision_config(dot->precision_config()); // Get pair {start, 0} or {0, start}. HloInstruction* original_start_indices = lhs_is_dynamic_slice ? lhs->mutable_operand(1) : rhs->mutable_operand(1); @@ -1137,6 +1144,7 @@ Status AlgebraicSimplifierVisitor::HandleDot(HloInstruction* dot) { ShapeUtil::PermuteDimensions({1, 0}, dot->shape()), rhs->mutable_operand(0), lhs->mutable_operand(0), dot_dimension_numbers)); + new_dot->set_precision_config(dot->precision_config()); return ReplaceWithNewInstruction( dot, HloInstruction::CreateTranspose(dot->shape(), new_dot, {1, 0})); } @@ -1232,7 +1240,7 @@ namespace { // return value = {1, 3} // // Precondition: input_dim_indices is sorted. -std::pair<bool, std::vector<int64>> ReshapeLeavesDimensionsUnmodified( +absl::optional<std::vector<int64>> ReshapeLeavesDimensionsUnmodified( const HloInstruction* hlo, tensorflow::gtl::ArraySlice<int64> input_dim_indices) { CHECK_EQ(HloOpcode::kReshape, hlo->opcode()); @@ -1252,11 +1260,11 @@ std::pair<bool, std::vector<int64>> ReshapeLeavesDimensionsUnmodified( } if (i >= unmodified_dims.size() || unmodified_dims[i].first != input_dim_index) { - return std::make_pair(false, std::vector<int64>()); + return absl::nullopt; } output_dim_indices.push_back(unmodified_dims[i].second); } - return std::make_pair(true, output_dim_indices); + return output_dim_indices; } // Returns true if the output of "instruction" is a permutation of the @@ -1385,6 +1393,15 @@ Status AlgebraicSimplifierVisitor::HandleBroadcast(HloInstruction* broadcast) { return Status::OK(); } + // broadcast(iota) -> iota. + if (operand->opcode() == HloOpcode::kIota) { + return ReplaceWithNewInstruction( + broadcast, + HloInstruction::CreateIota( + broadcast->shape(), + dims[Cast<HloIotaInstruction>(operand)->iota_dimension()])); + } + // Merge two consecutive broadcasts into a single one. if (operand->opcode() == HloOpcode::kBroadcast) { std::vector<int64> new_dimensions; @@ -1713,12 +1730,25 @@ Status AlgebraicSimplifierVisitor::HandleReshape(HloInstruction* reshape) { if (HloOpcode::kBroadcast == reshape->operand(0)->opcode()) { auto opt_dims = ReshapeLeavesDimensionsUnmodified( reshape, reshape->operand(0)->dimensions()); - if (opt_dims.first) { + if (opt_dims.has_value()) { return ReplaceWithNewInstruction( reshape, HloInstruction::CreateBroadcast( reshape->shape(), reshape->mutable_operand(0)->mutable_operand(0), - opt_dims.second)); + *opt_dims)); + } + } + + // reshape(iota) -> iota. + if (operand->opcode() == HloOpcode::kIota) { + auto* iota = Cast<HloIotaInstruction>(operand); + auto opt_dims = + ReshapeLeavesDimensionsUnmodified(reshape, {iota->iota_dimension()}); + if (opt_dims.has_value()) { + CHECK_EQ(opt_dims->size(), 1); + return ReplaceWithNewInstruction( + reshape, + HloInstruction::CreateIota(reshape->shape(), opt_dims->front())); } } @@ -1752,8 +1782,8 @@ Status AlgebraicSimplifierVisitor::HandleSlice(HloInstruction* slice) { } auto is_unstrided_slice = [](const HloInstruction* hlo) { - return c_all_of(hlo->slice_strides(), - [](int64 stride) { return stride == 1; }); + return absl::c_all_of(hlo->slice_strides(), + [](int64 stride) { return stride == 1; }); }; if (slice->operand(0)->opcode() == HloOpcode::kSlice && is_unstrided_slice(slice) && is_unstrided_slice(slice->operand(0))) { @@ -1930,7 +1960,8 @@ Status AlgebraicSimplifierVisitor::HandleReduce(HloInstruction* reduce) { // This should make fusion easier or use less memory bandwidth in the unfused // case. if (arg->opcode() == HloOpcode::kConcatenate && - c_linear_search(reduce->dimensions(), arg->concatenate_dimension())) { + absl::c_linear_search(reduce->dimensions(), + arg->concatenate_dimension())) { HloInstruction* old_reduce = nullptr; for (HloInstruction* operand : arg->operands()) { HloInstruction* new_reduce = computation_->AddInstruction( @@ -1983,9 +2014,9 @@ Status AlgebraicSimplifierVisitor::HandleReduceWindow( VLOG(10) << "Considering folding Pad: " << pad->ToString() << "\ninto reduce-window: " << reduce_window->ToString() - << (convert != nullptr ? tensorflow::strings::StrCat( - "\nvia convert: ", convert->ToString()) - : ""); + << (convert != nullptr + ? absl::StrCat("\nvia convert: ", convert->ToString()) + : ""); // Do not fold interior padding into ReduceWindow since the backends do not // support it. @@ -2294,6 +2325,8 @@ Status AlgebraicSimplifierVisitor::HandleConvolution( dot_dimension_numbers.add_rhs_contracting_dimensions(0); auto dot = computation_->AddInstruction(HloInstruction::CreateDot( dot_output_shape, new_lhs, new_rhs, dot_dimension_numbers)); + dot->set_precision_config(convolution->precision_config()); + return ReplaceInstruction(convolution, add_bitcast(convolution_shape, dot)); } diff --git a/tensorflow/compiler/xla/service/algebraic_simplifier.h b/tensorflow/compiler/xla/service/algebraic_simplifier.h index c48196e861..b864c372fa 100644 --- a/tensorflow/compiler/xla/service/algebraic_simplifier.h +++ b/tensorflow/compiler/xla/service/algebraic_simplifier.h @@ -47,7 +47,7 @@ class AlgebraicSimplifier : public HloPassInterface { enable_dot_strength_reduction_(enable_dot_strength_reduction), enable_conv_simplification_(enable_conv_simplification) {} ~AlgebraicSimplifier() override = default; - tensorflow::StringPiece name() const override { return "algsimp"; } + absl::string_view name() const override { return "algsimp"; } // Run algebraic simplification on the given computation. Returns whether the // computation was changed. diff --git a/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc b/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc index 5837391d75..1900a05750 100644 --- a/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc +++ b/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc @@ -18,11 +18,15 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "tensorflow/compiler/xla/service/hlo_casting_utils.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" +#include "tensorflow/compiler/xla/service/hlo_instructions.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/service/hlo_pass_fix.h" @@ -34,13 +38,12 @@ limitations under the License. #include "tensorflow/compiler/xla/window_util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" - -using ::testing::ElementsAre; namespace xla { namespace { +using ::testing::ElementsAre; + namespace op = xla::testing::opcode_matchers; AlgebraicSimplifier::ValidBitcastCallback bitcasting_callback() { @@ -51,7 +54,12 @@ AlgebraicSimplifier::ValidBitcastCallback non_bitcasting_callback() { return [](const Shape&, const Shape&) { return false; }; } -class AlgebraicSimplifierTest : public HloVerifiedTestBase {}; +class AlgebraicSimplifierTest : public HloVerifiedTestBase { + public: + AlgebraicSimplifierTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} +}; // Test that A + 0 is simplified to A TEST_F(AlgebraicSimplifierTest, AddZero) { @@ -1820,6 +1828,105 @@ TEST_F(AlgebraicSimplifierTest, BroadcastAndReshape_4_3x2x4x2_6x8) { op::Reshape(op::Broadcast(param))); } +TEST_F(AlgebraicSimplifierTest, IotaAndReshapeMerged) { + HloComputation::Builder builder(TestName()); + auto iota = builder.AddInstruction(HloInstruction::CreateIota( + ShapeUtil::MakeShape(F32, {1, 2, 3, 7, 12, 1}), 2)); + Shape result_shape = ShapeUtil::MakeShape(F32, {2, 3, 7, 2, 1, 3, 2}); + builder.AddInstruction(HloInstruction::CreateReshape(result_shape, iota)); + + auto computation = module().AddEntryComputation(builder.Build()); + + EXPECT_THAT(computation->root_instruction(), op::Reshape(op::Iota())); + + AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, + non_bitcasting_callback()); + ASSERT_TRUE(simplifier.Run(&module()).ValueOrDie()); + + EXPECT_THAT(computation->root_instruction(), op::Iota()); + EXPECT_TRUE( + ShapeUtil::Equal(computation->root_instruction()->shape(), result_shape)); +} + +TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x1_3) { + HloComputation::Builder builder(TestName()); + auto iota = builder.AddInstruction( + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 1}), 1)); + builder.AddInstruction( + HloInstruction::CreateReshape(ShapeUtil::MakeShape(F32, {3}), iota)); + + auto computation = module().AddEntryComputation(builder.Build()); + + EXPECT_THAT(computation->root_instruction(), op::Reshape(op::Iota())); + + AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, + non_bitcasting_callback()); + EXPECT_FALSE(simplifier.Run(&module()).ValueOrDie()); + + EXPECT_THAT(computation->root_instruction(), op::Reshape(op::Iota())); +} + +TEST_F(AlgebraicSimplifierTest, IotaAndReshape_4_3x2x4_6x1x1x4) { + HloComputation::Builder builder(TestName()); + auto iota = builder.AddInstruction( + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 2, 4}), 2)); + builder.AddInstruction(HloInstruction::CreateReshape( + ShapeUtil::MakeShape(F32, {6, 1, 1, 4}), iota)); + + HloComputation* computation = module().AddEntryComputation(builder.Build()); + + EXPECT_THAT(computation->root_instruction(), op::Reshape(op::Iota())); + + AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, + non_bitcasting_callback()); + ASSERT_TRUE(simplifier.Run(&module()).ValueOrDie()); + + EXPECT_THAT(computation->root_instruction(), op::Iota()); + EXPECT_EQ(Cast<HloIotaInstruction>(computation->root_instruction()) + ->iota_dimension(), + 3); +} + +TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x2x1_6x1x1x1) { + HloComputation::Builder builder(TestName()); + auto iota = builder.AddInstruction( + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 2, 1}), 2)); + builder.AddInstruction(HloInstruction::CreateReshape( + ShapeUtil::MakeShape(F32, {6, 1, 1, 1}), iota)); + + HloComputation* computation = module().AddEntryComputation(builder.Build()); + + EXPECT_THAT(computation->root_instruction(), op::Reshape(op::Iota())); + + AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, + non_bitcasting_callback()); + ASSERT_TRUE(simplifier.Run(&module()).ValueOrDie()); + + EXPECT_THAT(computation->root_instruction(), op::Iota()); + const int64 iota_dim = + Cast<HloIotaInstruction>(computation->root_instruction()) + ->iota_dimension(); + EXPECT_THAT(iota_dim, ::testing::AnyOf(1, 2, 3)); +} + +TEST_F(AlgebraicSimplifierTest, IotaAndReshape_4_3x2x4x2_6x8) { + HloComputation::Builder builder(TestName()); + auto iota = builder.AddInstruction( + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 2, 4, 2}), 2)); + builder.AddInstruction( + HloInstruction::CreateReshape(ShapeUtil::MakeShape(F32, {6, 8}), iota)); + + HloComputation* computation = module().AddEntryComputation(builder.Build()); + + EXPECT_THAT(computation->root_instruction(), op::Reshape(op::Iota())); + + AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, + non_bitcasting_callback()); + EXPECT_FALSE(simplifier.Run(&module()).ValueOrDie()); + + EXPECT_THAT(computation->root_instruction(), op::Reshape(op::Iota())); +} + TEST_F(AlgebraicSimplifierTest, RemoveNoopPad) { HloComputation::Builder builder(TestName()); HloInstruction* param = @@ -2037,7 +2144,7 @@ TEST_F(AlgebraicSimplifierTest, ConvertConvToMatmul) { // Builds a convolution from <options> and runs algebraic simplification on // the computation. Returns a string description of the result of // simplification. - auto build_and_simplify = [&options]() -> string { + auto build_and_simplify = [&]() -> string { HloComputation::Builder b(TestName()); Window window; @@ -2143,9 +2250,8 @@ TEST_F(AlgebraicSimplifierTest, ConvertConvToMatmul) { root->operand(0)->opcode() == HloOpcode::kDot) { auto lhs_shape = root->operand(0)->operand(0)->shape(); auto rhs_shape = root->operand(0)->operand(1)->shape(); - return tensorflow::strings::StrCat( - tensorflow::str_util::Join(lhs_shape.dimensions(), "x"), " DOT ", - tensorflow::str_util::Join(rhs_shape.dimensions(), "x")); + return absl::StrCat(absl::StrJoin(lhs_shape.dimensions(), "x"), " DOT ", + absl::StrJoin(rhs_shape.dimensions(), "x")); } return "UNEXPECTED CHANGE"; }; @@ -2648,6 +2754,47 @@ TEST_F(AlgebraicSimplifierTest, MergeBroadcasts2) { EXPECT_THAT(root->dimensions(), ElementsAre(1, 3)); } +// Test that a broadcast of an iota can be merged to one iota. +TEST_F(AlgebraicSimplifierTest, MergeBroadcastAndIota) { + HloComputation::Builder builder(TestName()); + Shape r2f32 = ShapeUtil::MakeShape(F32, {2, 2}); + HloInstruction* iota = + builder.AddInstruction(HloInstruction::CreateIota(r2f32, 1)); + Shape r3f32 = ShapeUtil::MakeShape(F32, {2, 2, 2}); + builder.AddInstruction(HloInstruction::CreateBroadcast(r3f32, iota, {0, 2})); + + auto computation = module().AddEntryComputation(builder.Build()); + HloInstruction* root = computation->root_instruction(); + EXPECT_EQ(root->opcode(), HloOpcode::kBroadcast); + AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, + non_bitcasting_callback()); + ASSERT_TRUE(simplifier.Run(&module()).ValueOrDie()); + root = computation->root_instruction(); + EXPECT_THAT(root, op::Iota()); + EXPECT_EQ(Cast<HloIotaInstruction>(root)->iota_dimension(), 2); +} + +// Test that a broadcast of an iota can be merged to one iota. +TEST_F(AlgebraicSimplifierTest, MergeBroadcastAndIota2) { + HloComputation::Builder builder(TestName()); + Shape r3f32 = ShapeUtil::MakeShape(F32, {2, 5, 3}); + HloInstruction* iota = + builder.AddInstruction(HloInstruction::CreateIota(r3f32, 1)); + Shape r4f32 = ShapeUtil::MakeShape(F32, {4, 2, 5, 3}); + builder.AddInstruction( + HloInstruction::CreateBroadcast(r4f32, iota, {1, 2, 3})); + + auto computation = module().AddEntryComputation(builder.Build()); + HloInstruction* root = computation->root_instruction(); + EXPECT_EQ(root->opcode(), HloOpcode::kBroadcast); + AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, + non_bitcasting_callback()); + ASSERT_TRUE(simplifier.Run(&module()).ValueOrDie()); + root = computation->root_instruction(); + EXPECT_THAT(root, op::Iota()); + EXPECT_EQ(Cast<HloIotaInstruction>(root)->iota_dimension(), 2); +} + struct PadReduceWindowEffectiveBroadcastCase { std::vector<int64> input_spatials; std::vector<int64> symmetric_pad_spatials; @@ -2660,11 +2807,10 @@ struct PadReduceWindowEffectiveBroadcastCase { bool should_become_broadcast; string ToTestCaseName() const { - return tensorflow::strings::StrCat( - tensorflow::str_util::Join(input_spatials, ","), ";", - tensorflow::str_util::Join(symmetric_pad_spatials, ","), ";", - tensorflow::str_util::Join(reduce_window_spatials, ","), ";", prepend_a, - ";", should_become_broadcast); + return absl::StrCat(absl::StrJoin(input_spatials, ","), ";", + absl::StrJoin(symmetric_pad_spatials, ","), ";", + absl::StrJoin(reduce_window_spatials, ","), ";", + prepend_a, ";", should_become_broadcast); } }; @@ -2852,7 +2998,12 @@ struct DotOfConcatTestSpec { class DotOfConcatSimplificationTest : public HloVerifiedTestBase, - public ::testing::WithParamInterface<DotOfConcatTestSpec> {}; + public ::testing::WithParamInterface<DotOfConcatTestSpec> { + public: + DotOfConcatSimplificationTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} +}; // Test that we transform // dot(const, concat(A, B, C)) @@ -3025,7 +3176,12 @@ struct DotOfGatherTestSpec { class DotOfGatherSimplificationTest : public HloVerifiedTestBase, - public ::testing::WithParamInterface<DotOfGatherTestSpec> {}; + public ::testing::WithParamInterface<DotOfGatherTestSpec> { + public: + DotOfGatherSimplificationTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} +}; // input: dot(DS(ctA), ctB)) // where DS(ctA) = DS({M x K}, {s, 0}, {1, K}) and ctB = {K x N}. diff --git a/tensorflow/compiler/xla/service/allocation_tracker.cc b/tensorflow/compiler/xla/service/allocation_tracker.cc index 51ebc4763b..1ed6142dce 100644 --- a/tensorflow/compiler/xla/service/allocation_tracker.cc +++ b/tensorflow/compiler/xla/service/allocation_tracker.cc @@ -17,15 +17,15 @@ limitations under the License. #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/device_memory_allocator.h" #include "tensorflow/compiler/xla/service/transfer_manager.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" namespace xla { @@ -69,8 +69,7 @@ StatusOr<GlobalDataHandle> AllocationTracker::RegisterInternal( return InvalidArgument( "AllocationTracker for platform %s cannot register buffer from " "platform %s", - backend_->platform()->Name().c_str(), - shaped_buffer.platform()->Name().c_str()); + backend_->platform()->Name(), shaped_buffer.platform()->Name()); } } @@ -91,8 +90,9 @@ StatusOr<GlobalDataHandle> AllocationTracker::RegisterInternal( // If ShapedBufferTy is ScopedShapedBuffer, release the ScopedShapedBuffer // into a regular ShapedBuffer, which is stored in // handle_to_shaped_buffers_. - handle_to_shaped_buffers_[handle].emplace_back(MakeUnique<ShapedBuffer>( - ReleaseIfScopedShapedBuffer(std::move(shaped_buffer)))); + handle_to_shaped_buffers_[handle].emplace_back( + absl::make_unique<ShapedBuffer>( + ReleaseIfScopedShapedBuffer(std::move(shaped_buffer)))); } GlobalDataHandle result; @@ -124,7 +124,7 @@ Status AllocationTracker::Unregister(const GlobalDataHandle& data) { // "handle does not exist". auto it = handle_to_shaped_buffers_.find(data.handle()); if (it == handle_to_shaped_buffers_.end()) { - return NotFound("no allocation record for global data handle: %lld", + return NotFound("no allocation record for global data handle: %d", data.handle()); } for (auto& shaped_buffer : it->second) { @@ -143,7 +143,7 @@ StatusOr<std::vector<GlobalDataHandle>> AllocationTracker::DeconstructTuple( // the same for all buffers across replicas. const ShapedBuffer* shaped_buffer = replicated_buffers[0]; if (!ShapeUtil::IsTuple(shaped_buffer->on_host_shape())) { - return InvalidArgument("global data handle %lld is not a tuple", + return InvalidArgument("global data handle %d is not a tuple", data.handle()); } // If the on-host representation is a tuple, then the on-device one should be @@ -200,14 +200,14 @@ StatusOr<std::vector<const ShapedBuffer*>> AllocationTracker::ResolveInternal( VLOG(2) << "resolve:" << data.handle(); auto it = handle_to_shaped_buffers_.find(data.handle()); if (it == handle_to_shaped_buffers_.end()) { - return NotFound("no allocation record for global data handle: %lld", + return NotFound("no allocation record for global data handle: %d", data.handle()); } std::vector<const ShapedBuffer*> replicated_buffers; for (const auto& shaped_buffer : it->second) { if (shaped_buffer == nullptr) { - return InvalidArgument( - "global data handle %lld was previously deallocated", data.handle()); + return InvalidArgument("global data handle %d was previously deallocated", + data.handle()); } replicated_buffers.push_back(shaped_buffer.get()); } diff --git a/tensorflow/compiler/xla/service/backend.cc b/tensorflow/compiler/xla/service/backend.cc index d12be3e007..a6889cb171 100644 --- a/tensorflow/compiler/xla/service/backend.cc +++ b/tensorflow/compiler/xla/service/backend.cc @@ -21,6 +21,7 @@ limitations under the License. #include <string> #include <utility> +#include "absl/memory/memory.h" #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/compiler/xla/service/compiler.h" #include "tensorflow/compiler/xla/service/platform_util.h" @@ -127,8 +128,8 @@ Backend::Backend( } } // Create a memory allocator for the valid stream executors. - memory_allocator_ = - MakeUnique<StreamExecutorMemoryAllocator>(platform, stream_executors); + memory_allocator_ = absl::make_unique<StreamExecutorMemoryAllocator>( + platform, stream_executors); CHECK(!stream_executors_.empty()) << "Service found no devices for backend " << platform_->Name() << '.'; @@ -176,7 +177,7 @@ StatusOr<se::StreamExecutor*> Backend::stream_executor( } } return InvalidArgument("device %s not supported by XLA service", - device_name(device_ordinal).c_str()); + device_name(device_ordinal)); } StatusOr<bool> Backend::devices_equivalent(int device_ordinal_a, diff --git a/tensorflow/compiler/xla/service/backend.h b/tensorflow/compiler/xla/service/backend.h index 1bc3796fa4..4a6a78daf0 100644 --- a/tensorflow/compiler/xla/service/backend.h +++ b/tensorflow/compiler/xla/service/backend.h @@ -21,6 +21,7 @@ limitations under the License. #include <string> #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/compiler.h" #include "tensorflow/compiler/xla/service/computation_placer.h" #include "tensorflow/compiler/xla/service/device_memory_allocator.h" @@ -29,7 +30,6 @@ limitations under the License. #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/mutex.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" #include "tensorflow/core/platform/thread_annotations.h" @@ -130,7 +130,7 @@ class Backend { // Return a string identifier for the given device, eg: "GPU:3". string device_name(int device_ordinal) const { - return tensorflow::strings::StrCat(platform_->Name(), ":", device_ordinal); + return absl::StrCat(platform_->Name(), ":", device_ordinal); } // Returns true if the devices with the given ordinals are equivalent from diff --git a/tensorflow/compiler/xla/service/batch_dot_simplification.cc b/tensorflow/compiler/xla/service/batch_dot_simplification.cc index 2099916509..a16b85a0a5 100644 --- a/tensorflow/compiler/xla/service/batch_dot_simplification.cc +++ b/tensorflow/compiler/xla/service/batch_dot_simplification.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/batch_dot_simplification.h" +#include "absl/algorithm/container.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_creation_utils.h" @@ -63,6 +64,7 @@ BatchDotSimplification::ElideDegenerateBatchDimensionFromBatchDot( TF_ASSIGN_OR_RETURN(HloInstruction * new_dot, MakeDotHlo(new_lhs, new_rhs, new_dim_numbers)); + new_dot->set_precision_config(batch_dot->precision_config()); TF_ASSIGN_OR_RETURN(HloInstruction * new_dot_reshaped, MakeReshapeHlo(batch_dot->shape(), new_dot)); @@ -76,7 +78,7 @@ BatchDotSimplification::ElideDegenerateBatchDimensionFromBatchDot( return true; } -tensorflow::StringPiece BatchDotSimplification::name() const { +absl::string_view BatchDotSimplification::name() const { return "batch-dot-simplification"; } @@ -84,10 +86,10 @@ StatusOr<bool> BatchDotSimplification::Run(HloModule* module) { bool changed = false; std::vector<HloInstruction*> dot_instrs; for (HloComputation* computation : module->MakeNonfusionComputations()) { - c_copy_if(computation->instructions(), std::back_inserter(dot_instrs), - [](HloInstruction* instr) { - return instr->opcode() == HloOpcode::kDot; - }); + absl::c_copy_if(computation->instructions(), std::back_inserter(dot_instrs), + [](HloInstruction* instr) { + return instr->opcode() == HloOpcode::kDot; + }); } for (HloInstruction* dot_instr : dot_instrs) { TF_ASSIGN_OR_RETURN(bool elided_batch_dim_from_one, diff --git a/tensorflow/compiler/xla/service/batch_dot_simplification.h b/tensorflow/compiler/xla/service/batch_dot_simplification.h index c0ca8d8eba..79d37f08d3 100644 --- a/tensorflow/compiler/xla/service/batch_dot_simplification.h +++ b/tensorflow/compiler/xla/service/batch_dot_simplification.h @@ -28,7 +28,7 @@ namespace xla { class BatchDotSimplification : public HloPassInterface { public: StatusOr<bool> Run(HloModule* module) override; - tensorflow::StringPiece name() const override; + absl::string_view name() const override; private: StatusOr<bool> ElideDegenerateBatchDimensionFromBatchDot( diff --git a/tensorflow/compiler/xla/service/batch_dot_simplification_test.cc b/tensorflow/compiler/xla/service/batch_dot_simplification_test.cc index 38f1a5d3a6..b342acb025 100644 --- a/tensorflow/compiler/xla/service/batch_dot_simplification_test.cc +++ b/tensorflow/compiler/xla/service/batch_dot_simplification_test.cc @@ -24,7 +24,12 @@ namespace { namespace op = xla::testing::opcode_matchers; -class BatchDotSimplificationTest : public HloVerifiedTestBase {}; +class BatchDotSimplificationTest : public HloVerifiedTestBase { + public: + BatchDotSimplificationTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} +}; TEST_F(BatchDotSimplificationTest, ElideSingleDegenerateBatchDotDim_VectorVector) { diff --git a/tensorflow/compiler/xla/service/batchnorm_expander.cc b/tensorflow/compiler/xla/service/batchnorm_expander.cc index c4cd60c120..01931b2d02 100644 --- a/tensorflow/compiler/xla/service/batchnorm_expander.cc +++ b/tensorflow/compiler/xla/service/batchnorm_expander.cc @@ -20,6 +20,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h" @@ -35,7 +36,6 @@ limitations under the License. #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/lib/gtl/flatmap.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -43,7 +43,7 @@ namespace xla { namespace { -using tensorflow::gtl::optional; +using absl::optional; // BatchNormExpanderVisitor traverses the HLO computation and rewrites BatchNorm // operations into smaller operations. diff --git a/tensorflow/compiler/xla/service/batchnorm_expander.h b/tensorflow/compiler/xla/service/batchnorm_expander.h index 7ae202c583..76e32174f3 100644 --- a/tensorflow/compiler/xla/service/batchnorm_expander.h +++ b/tensorflow/compiler/xla/service/batchnorm_expander.h @@ -36,7 +36,7 @@ class BatchNormExpander : public HloPassInterface { rewrite_inference_op_(rewrite_inference_op), rewrite_grad_op_(rewrite_grad_op) {} ~BatchNormExpander() = default; - tensorflow::StringPiece name() const override { return "batchnorm_expander"; } + absl::string_view name() const override { return "batchnorm_expander"; } // Run operation expander on the given computation. Returns whether the // computation was changed. diff --git a/tensorflow/compiler/xla/service/batchnorm_expander_test.cc b/tensorflow/compiler/xla/service/batchnorm_expander_test.cc index a725351462..aba0d9bb5b 100644 --- a/tensorflow/compiler/xla/service/batchnorm_expander_test.cc +++ b/tensorflow/compiler/xla/service/batchnorm_expander_test.cc @@ -18,9 +18,9 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" @@ -32,7 +32,6 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/hlo_test_base.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace xla { namespace { diff --git a/tensorflow/compiler/xla/service/bfloat16_conversion_folding.h b/tensorflow/compiler/xla/service/bfloat16_conversion_folding.h index c939838709..5dcd31b83d 100644 --- a/tensorflow/compiler/xla/service/bfloat16_conversion_folding.h +++ b/tensorflow/compiler/xla/service/bfloat16_conversion_folding.h @@ -37,7 +37,7 @@ class BFloat16ConversionFolding : public HloPassInterface { : bfloat16_support_(bfloat16_support) {} ~BFloat16ConversionFolding() override = default; - tensorflow::StringPiece name() const override { return "bfloat16-fold"; } + absl::string_view name() const override { return "bfloat16-fold"; } // Run BF16 conversion folding on the given computation. Returns whether the // computation was changed. diff --git a/tensorflow/compiler/xla/service/bfloat16_conversion_folding_test.cc b/tensorflow/compiler/xla/service/bfloat16_conversion_folding_test.cc index 7cf05ca443..6363a21c3b 100644 --- a/tensorflow/compiler/xla/service/bfloat16_conversion_folding_test.cc +++ b/tensorflow/compiler/xla/service/bfloat16_conversion_folding_test.cc @@ -235,8 +235,8 @@ TEST_F(BFloat16ConversionFoldingTest, FoldCrossReplicaSumTupleOutput) { HloInstruction* crs = builder.AddInstruction(HloInstruction::CreateCrossReplicaSum( ShapeUtil::MakeTupleShape({f32_shape, f32_shape}), {convert_a, b}, - sum, /*replica_group_ids=*/{}, /*barrier=*/"", - /*all_reduce_id=*/tensorflow::gtl::nullopt)); + sum, /*replica_groups=*/{}, /*barrier=*/"", + /*all_reduce_id=*/absl::nullopt)); HloInstruction* gte_a = builder.AddInstruction( HloInstruction::CreateGetTupleElement(f32_shape, crs, 0)); HloInstruction* gte_b = builder.AddInstruction( diff --git a/tensorflow/compiler/xla/service/bfloat16_normalization.cc b/tensorflow/compiler/xla/service/bfloat16_normalization.cc index 16e99b5722..32573ed355 100644 --- a/tensorflow/compiler/xla/service/bfloat16_normalization.cc +++ b/tensorflow/compiler/xla/service/bfloat16_normalization.cc @@ -18,6 +18,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" +#include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/gtl/array_slice.h" @@ -34,11 +35,6 @@ class BFloat16NormalizationVisitor : public DfsHloVisitorWithDefault { Status DefaultAction(HloInstruction* hlo) override; - // Special handling for cross-replica-sum and sort which can have a tuple - // output. - Status HandleCrossReplicaSum(HloInstruction* crs) override; - Status HandleSort(HloInstruction* sort) override; - static bool Run(HloComputation* computation, const BFloat16Support* bfloat16_support) { BFloat16NormalizationVisitor visitor(computation, bfloat16_support); @@ -150,23 +146,6 @@ Status BFloat16NormalizationVisitor::ConvertCalledComputations( return Status::OK(); } -Status BFloat16NormalizationVisitor::HandleCrossReplicaSum( - HloInstruction* crs) { - if (!ShapeUtil::IsTuple(crs->shape())) { - return HandleInstruction(crs); - } else { - return HandleMultipleOutputs(crs); - } -} - -Status BFloat16NormalizationVisitor::HandleSort(HloInstruction* sort) { - if (!ShapeUtil::IsTuple(sort->shape())) { - return HandleInstruction(sort); - } else { - return HandleMultipleOutputs(sort); - } -} - Status BFloat16NormalizationVisitor::HandleMultipleOutputs( HloInstruction* hlo) { std::vector<PrimitiveType> operand_types(hlo->operand_count()); @@ -380,6 +359,11 @@ Status BFloat16NormalizationVisitor::DefaultAction(HloInstruction* hlo) { hlo->opcode() == HloOpcode::kConditional) { return Status::OK(); } + if ((hlo->opcode() == HloOpcode::kSort || + hlo->opcode() == HloOpcode::kCrossReplicaSum) && + ShapeUtil::IsTuple(hlo->shape())) { + return HandleMultipleOutputs(hlo); + } return HandleInstruction(hlo); } diff --git a/tensorflow/compiler/xla/service/bfloat16_normalization.h b/tensorflow/compiler/xla/service/bfloat16_normalization.h index 2a60fe0af3..30b6346312 100644 --- a/tensorflow/compiler/xla/service/bfloat16_normalization.h +++ b/tensorflow/compiler/xla/service/bfloat16_normalization.h @@ -31,7 +31,7 @@ class BFloat16Normalization : public HloPassInterface { : bfloat16_support_(bfloat16_support) {} ~BFloat16Normalization() override = default; - tensorflow::StringPiece name() const override { return "bf16-normalization"; } + absl::string_view name() const override { return "bf16-normalization"; } // Run BF16 normalization on the given computation. Returns whether the // computation was changed. @@ -54,7 +54,7 @@ class BFloat16MixedPrecisionRemoval : public HloPassInterface { ~BFloat16MixedPrecisionRemoval() override = default; - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "bf16-mixed-precision-removal"; } diff --git a/tensorflow/compiler/xla/service/bfloat16_normalization_test.cc b/tensorflow/compiler/xla/service/bfloat16_normalization_test.cc index f9f1f64998..b08705d4c2 100644 --- a/tensorflow/compiler/xla/service/bfloat16_normalization_test.cc +++ b/tensorflow/compiler/xla/service/bfloat16_normalization_test.cc @@ -76,7 +76,8 @@ class BFloat16NormalizationTest : public HloTestBase { StatusOr<bool> result = normalization.Run(module); EXPECT_IS_OK(result.status()); - HloVerifier verifier(/*allow_mixed_precision=*/true); + HloVerifier verifier(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/true); EXPECT_IS_OK(verifier.Run(module).status()); return result.ValueOrDie(); @@ -251,8 +252,8 @@ TEST_F(BFloat16NormalizationTest, ResolveMixedPrecisionTupleCrossReplicaSum) { HloInstruction* crs = builder.AddInstruction(HloInstruction::CreateCrossReplicaSum( ShapeUtil::MakeTupleShape({f32_shape, bf16_shape}), {a, b}, reduction, - /*replica_group_ids=*/{}, /*barrier=*/"", - /*all_reduce_id=*/tensorflow::gtl::nullopt)); + /*replica_groups=*/{}, /*barrier=*/"", + /*all_reduce_id=*/absl::nullopt)); HloInstruction* gte = builder.AddInstruction( HloInstruction::CreateGetTupleElement(bf16_shape, crs, 1)); diff --git a/tensorflow/compiler/xla/service/bfloat16_propagation.h b/tensorflow/compiler/xla/service/bfloat16_propagation.h index 02b8cad089..1ee64971ab 100644 --- a/tensorflow/compiler/xla/service/bfloat16_propagation.h +++ b/tensorflow/compiler/xla/service/bfloat16_propagation.h @@ -64,9 +64,7 @@ class BFloat16Propagation : public HloPassInterface { ~BFloat16Propagation() override = default; - tensorflow::StringPiece name() const override { - return "bfloat16-propagation"; - } + absl::string_view name() const override { return "bfloat16-propagation"; } // Runs the pass on the given module. Returns whether the module was changed // (precision reductions were added). diff --git a/tensorflow/compiler/xla/service/buffer_assignment.cc b/tensorflow/compiler/xla/service/buffer_assignment.cc index cfd26fc778..b11f15ec7b 100644 --- a/tensorflow/compiler/xla/service/buffer_assignment.cc +++ b/tensorflow/compiler/xla/service/buffer_assignment.cc @@ -22,8 +22,10 @@ limitations under the License. #include <ostream> #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/buffer_value_containers.h" #include "tensorflow/compiler/xla/service/heap_simulator.h" #include "tensorflow/compiler/xla/service/hlo.pb.h" @@ -36,20 +38,15 @@ limitations under the License. #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/hash/hash.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" namespace xla { +namespace { +using absl::StrAppend; +using absl::StrAppendFormat; using ::tensorflow::gtl::FlatMap; using ::tensorflow::gtl::FlatSet; -using ::tensorflow::strings::Appendf; using ::tensorflow::strings::HumanReadableNumBytes; -using ::tensorflow::strings::Printf; -using ::tensorflow::strings::StrAppend; - -namespace { template <typename T> string ColocatedBufferSetsToString(const T& container, const char* title) { @@ -107,7 +104,7 @@ Status GatherComputationsByAllocationType( return InvalidArgument( "computation %s has conflicting allocation requirements (global " "and thread-local)", - computation->name().c_str()); + computation->name()); } if (is_thread_local) { @@ -130,7 +127,7 @@ Status GatherComputationsByAllocationType( return InvalidArgument( "computation %s cannot contain call/while op because it " "requires thread-local buffer allocations", - computation->name().c_str()); + computation->name()); } worklist.push_back(std::make_pair(subcomputation, false)); // Not thread local. @@ -147,9 +144,8 @@ Status GatherComputationsByAllocationType( true)); // Thread local. break; default: - return InternalError( - "Unexpected calling opcode: %s", - HloOpcodeString(instruction->opcode()).c_str()); + return InternalError("Unexpected calling opcode: %s", + HloOpcodeString(instruction->opcode())); } } } @@ -236,8 +232,8 @@ size_t BufferAllocation::Slice::Hasher::operator()(Slice s) const { } string BufferAllocation::Slice::ToString() const { - return tensorflow::strings::StrCat("{index:", index(), ", offset:", offset_, - ", size:", size_, "}"); + return absl::StrCat("{index:", index(), ", offset:", offset_, + ", size:", size_, "}"); } BufferAllocation::Slice BufferAllocation::GetSlice( @@ -298,7 +294,7 @@ BufferAllocationProto BufferAllocation::ToProto() const { string BufferAllocation::ToString() const { string output; - Appendf(&output, "allocation %lld: %p, size %lld", index_, this, size()); + StrAppendFormat(&output, "allocation %d: %p, size %d", index_, this, size()); if (color().value() != 0) { StrAppend(&output, ", color ", color().value()); } @@ -330,11 +326,10 @@ string BufferAllocation::ToString() const { }); for (const LogicalBuffer* buffer : sorted_buffers) { const OffsetSize& offset_size = FindOrDie(assigned_buffers_, buffer); - StrAppend(&output, - tensorflow::strings::Printf( - " %s [%lld,%lld]: %s\n", buffer->ToString().c_str(), - offset_size.offset, offset_size.size, - ShapeUtil::HumanStringWithLayout(buffer->shape()).c_str())); + StrAppend(&output, absl::StrFormat( + " %s [%d,%d]: %s\n", buffer->ToString(), + offset_size.offset, offset_size.size, + ShapeUtil::HumanStringWithLayout(buffer->shape()))); } return output; } @@ -427,7 +422,7 @@ StatusOr<BufferAllocation::Slice> BufferAssignment::GetUniqueSlice( return FailedPrecondition( "BufferAllocation::Slice for instruction %s at index %s cannot " "be determined at compile-time.", - instruction->name().c_str(), index.ToString().c_str()); + instruction->name(), index.ToString()); } } else { VLOG(3) << "No allocation"; @@ -436,7 +431,7 @@ StatusOr<BufferAllocation::Slice> BufferAssignment::GetUniqueSlice( if (result.allocation() == nullptr) { return FailedPrecondition( "BufferAllocation::Slice not assigned for instruction %s at index %s", - instruction->name().c_str(), index.ToString().c_str()); + instruction->name(), index.ToString()); } return result; } @@ -627,7 +622,7 @@ Status BufferAssignment::ComputeSummaryStats() { stats_.total_allocation_bytes += allocation.size(); } - // Only compute total fragmentation if all computations are sequential. + // Only compute total fragmentation if all computations have schedules. SequentialHloOrdering::HloModuleSequence module_sequence; for (const auto& computation : module_->computations()) { const std::vector<const HloInstruction*>* sequence = @@ -648,39 +643,38 @@ Status BufferAssignment::ComputeSummaryStats() { string BufferAssignment::Stats::ToString() const { string s; - Appendf(&s, "BufferAssignment stats:\n"); - Appendf(&s, " parameter allocation: %10s\n", - HumanReadableNumBytes(parameter_allocation_bytes).c_str()); - Appendf(&s, " constant allocation: %10s\n", - HumanReadableNumBytes(constant_allocation_bytes).c_str()); - Appendf(&s, " maybe_live_out allocation: %10s\n", - HumanReadableNumBytes(maybe_live_out_allocation_bytes).c_str()); - Appendf(&s, " preallocated temp allocation: %10s\n", - HumanReadableNumBytes(preallocated_temp_allocation_bytes).c_str()); + StrAppendFormat(&s, "BufferAssignment stats:\n"); + StrAppendFormat(&s, " parameter allocation: %10s\n", + HumanReadableNumBytes(parameter_allocation_bytes)); + StrAppendFormat(&s, " constant allocation: %10s\n", + HumanReadableNumBytes(constant_allocation_bytes)); + StrAppendFormat(&s, " maybe_live_out allocation: %10s\n", + HumanReadableNumBytes(maybe_live_out_allocation_bytes)); + StrAppendFormat(&s, " preallocated temp allocation: %10s\n", + HumanReadableNumBytes(preallocated_temp_allocation_bytes)); if (preallocated_temp_fragmentation_bytes >= 0) { const double percent = 100. * preallocated_temp_fragmentation_bytes / preallocated_temp_allocation_bytes; - Appendf( + StrAppendFormat( &s, " preallocated temp fragmentation: %10s (%.2f%%)\n", - HumanReadableNumBytes(preallocated_temp_fragmentation_bytes).c_str(), - percent); + HumanReadableNumBytes(preallocated_temp_fragmentation_bytes), percent); } - Appendf(&s, " total allocation: %10s\n", - HumanReadableNumBytes(total_allocation_bytes).c_str()); + StrAppendFormat(&s, " total allocation: %10s\n", + HumanReadableNumBytes(total_allocation_bytes)); if (total_fragmentation_bytes >= 0) { const double percent = 100. * total_fragmentation_bytes / total_allocation_bytes; - Appendf(&s, " total fragmentation: %10s (%.2f%%)\n", - HumanReadableNumBytes(total_fragmentation_bytes).c_str(), percent); + StrAppendFormat(&s, " total fragmentation: %10s (%.2f%%)\n", + HumanReadableNumBytes(total_fragmentation_bytes), percent); } return s; } string BufferAssignment::ToString() const { string output; - tensorflow::strings::StrAppend(&output, "BufferAssignment:\n"); + absl::StrAppend(&output, "BufferAssignment:\n"); for (auto& allocation : allocations_) { - tensorflow::strings::StrAppend(&output, allocation.ToString()); + absl::StrAppend(&output, allocation.ToString()); } return output; } @@ -1100,8 +1094,8 @@ Status BufferAssigner::AssignBuffersWithSequentialOrdering( options.buffers_to_assign = &buffer_value_set; TF_ASSIGN_OR_RETURN( const HeapSimulator::Result result, - HeapSimulator::Run(MakeUnique<DecreasingSizeRunsHeap>( - MakeUnique<LazyBestFitHeap>(alignment)), + HeapSimulator::Run(absl::make_unique<DecreasingSizeRunsHeap>( + absl::make_unique<LazyBestFitHeap>(alignment)), assignment->module(), module_sequence, assignment->points_to_analysis(), assignment->buffer_size_, options)); @@ -1130,11 +1124,12 @@ Status BufferAssigner::AssignBuffersWithSequentialOrdering( options.buffers_to_assign = &buffer_value_set; TF_ASSIGN_OR_RETURN( const HeapSimulator::Result result, - HeapSimulator::Run(MakeUnique<DecreasingSizeRunsHeap>( - MakeUnique<LazyBestFitHeap>(alignment)), - *computation, *instruction_sequence, - assignment->points_to_analysis(), - assignment->buffer_size_, options)); + HeapSimulator::Run( + absl::make_unique<DecreasingSizeRunsHeap>( + absl::make_unique<LazyBestFitHeap>(alignment)), + *computation, *instruction_sequence, + assignment->points_to_analysis(), assignment->buffer_size_, + options)); AssignBuffersFromHeapSimulator(result, assignment, single_colored_set.first); } @@ -1646,7 +1641,8 @@ StatusOr<std::unique_ptr<BufferAssignment>> BufferAssigner::CreateAssignment( XLA_VLOG_LINES(3, liveness->ToString()); XLA_VLOG_LINES(3, liveness->points_to_analysis().ToString()); - // Can't use MakeUnique because BufferAssignment constructor is private. + // Can't use absl::make_unique because BufferAssignment constructor is + // private. std::unique_ptr<BufferAssignment> assignment( new BufferAssignment(module, std::move(liveness), std::move(buffer_size), std::move(color_alignment))); diff --git a/tensorflow/compiler/xla/service/buffer_assignment_test.cc b/tensorflow/compiler/xla/service/buffer_assignment_test.cc index eccb146a0d..52abda16c4 100644 --- a/tensorflow/compiler/xla/service/buffer_assignment_test.cc +++ b/tensorflow/compiler/xla/service/buffer_assignment_test.cc @@ -21,8 +21,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/buffer_value.h" #include "tensorflow/compiler/xla/service/call_graph.h" #include "tensorflow/compiler/xla/service/copy_insertion.h" @@ -87,7 +87,7 @@ class BufferAssignmentTest : public HloTestBase { std::unique_ptr<BufferAssignment> RunBufferAssignment(HloModule* module, int64 alignment = 1) { return BufferAssigner::Run( - module, xla::MakeUnique<DependencyHloOrdering>(module), + module, absl::make_unique<DependencyHloOrdering>(module), backend().compiler()->BufferSizeBytesFunction(), [alignment](LogicalBuffer::Color) { return alignment; }, /*allow_input_output_aliasing=*/false, @@ -98,7 +98,7 @@ class BufferAssignmentTest : public HloTestBase { std::unique_ptr<BufferAssignment> RunBufferAssignmentNoBuffersForConstants( HloModule* module, int64 alignment = 1) { return BufferAssigner::Run( - module, xla::MakeUnique<DependencyHloOrdering>(module), + module, absl::make_unique<DependencyHloOrdering>(module), backend().compiler()->BufferSizeBytesFunction(), [alignment](LogicalBuffer::Color) { return alignment; }, /*allow_input_output_aliasing=*/false, @@ -109,7 +109,7 @@ class BufferAssignmentTest : public HloTestBase { std::unique_ptr<BufferAssignment> RunColoredBufferAssignment( HloModule* module, BufferLiveness::Colorer colorer, int64 alignment = 1) { return BufferAssigner::Run( - module, xla::MakeUnique<DependencyHloOrdering>(module), + module, absl::make_unique<DependencyHloOrdering>(module), backend().compiler()->BufferSizeBytesFunction(), [alignment](LogicalBuffer::Color) { return alignment; }, /*allow_input_output_aliasing=*/false, @@ -127,7 +127,8 @@ class BufferAssignmentTest : public HloTestBase { instruction_sequence.end()); return BufferAssigner::Run( module, - xla::MakeUnique<SequentialHloOrdering>(module, module_sequence), + absl::make_unique<SequentialHloOrdering>(module, + module_sequence), backend().compiler()->BufferSizeBytesFunction(), [alignment](LogicalBuffer::Color) { return alignment; }, /*allow_input_output_aliasing=*/false, @@ -1769,7 +1770,8 @@ class WhileBufferAssignmentTest : public HloTestBase { auto sequence = ScheduleComputationsInModule(*module, ByteSizeOf).ConsumeValueOrDie(); return BufferAssigner::Run( - module, xla::MakeUnique<SequentialHloOrdering>(module, sequence), + module, + absl::make_unique<SequentialHloOrdering>(module, sequence), ByteSizeOf, [alignment](LogicalBuffer::Color) { return alignment; }, /*allow_input_output_aliasing=*/false, @@ -2083,7 +2085,7 @@ TEST_F(WhileBufferAssignmentTest, ColocatedBuffers) { auto assignment, BufferAssigner::Run( module.get(), - xla::MakeUnique<SequentialHloOrdering>(module.get(), sequence), + absl::make_unique<SequentialHloOrdering>(module.get(), sequence), backend().compiler()->BufferSizeBytesFunction(), [](LogicalBuffer::Color) { return 1; }, /*allow_input_output_aliasing=*/false, @@ -2340,7 +2342,7 @@ TEST_F(WhileBufferAssignmentTest, WhileLoopsInterferingResultRange) { auto assignment = BufferAssigner::Run( module.get(), - xla::MakeUnique<SequentialHloOrdering>(module.get(), sequence), + absl::make_unique<SequentialHloOrdering>(module.get(), sequence), ByteSizeOf, [](LogicalBuffer::Color) { return 1; }, /*allow_input_output_aliasing=*/false, /*allocate_buffers_for_constants=*/true) diff --git a/tensorflow/compiler/xla/service/buffer_liveness.cc b/tensorflow/compiler/xla/service/buffer_liveness.cc index 810d597e73..9b2783a214 100644 --- a/tensorflow/compiler/xla/service/buffer_liveness.cc +++ b/tensorflow/compiler/xla/service/buffer_liveness.cc @@ -20,6 +20,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/logical_buffer.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -28,8 +30,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" namespace xla { @@ -75,27 +75,25 @@ Status BufferLiveness::Analyze() { string BufferLiveness::ToString() const { std::vector<string> pieces; - pieces.push_back(tensorflow::strings::Printf("BufferLiveness(module=%s):", - module_->name().c_str())); + pieces.push_back( + absl::StrFormat("BufferLiveness(module=%s):", module_->name())); pieces.push_back("HloOrdering:"); pieces.push_back(hlo_ordering_->ToString()); - pieces.push_back(tensorflow::strings::Printf("Aliased buffers:")); + pieces.push_back("Aliased buffers:"); for (const LogicalBuffer* buffer : aliased_buffers_) { - pieces.push_back( - tensorflow::strings::Printf(" %s", buffer->ToString().c_str())); + pieces.push_back(absl::StrFormat(" %s", buffer->ToString())); } - pieces.push_back(tensorflow::strings::Printf("Live out buffers:")); + pieces.push_back("Live out buffers:"); for (const LogicalBuffer* buffer : maybe_live_out_buffers_) { - pieces.push_back( - tensorflow::strings::Printf(" %s", buffer->ToString().c_str())); + pieces.push_back(absl::StrFormat(" %s", buffer->ToString())); } - return tensorflow::str_util::Join(pieces, "\n"); + return absl::StrJoin(pieces, "\n"); } bool BufferLiveness::live_range_strictly_before(const LogicalBuffer& a, const LogicalBuffer& b) const { - TF_CHECK_OK(points_to_analysis_->VerifyBuffer(a)); - TF_CHECK_OK(points_to_analysis_->VerifyBuffer(b)); + TF_DCHECK_OK(points_to_analysis_->VerifyBuffer(a)); + TF_DCHECK_OK(points_to_analysis_->VerifyBuffer(b)); if (!hlo_ordering_->ExecutesBefore(a.instruction(), b.instruction())) { return false; diff --git a/tensorflow/compiler/xla/service/buffer_liveness_test.cc b/tensorflow/compiler/xla/service/buffer_liveness_test.cc index 4a927b5767..26e26e316d 100644 --- a/tensorflow/compiler/xla/service/buffer_liveness_test.cc +++ b/tensorflow/compiler/xla/service/buffer_liveness_test.cc @@ -18,8 +18,9 @@ limitations under the License. #include <memory> #include <string> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" +#include "tensorflow/compiler/xla/service/hlo_dataflow_analysis.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -119,8 +120,8 @@ TEST_F(BufferLivenessTest, ElementwiseChain) { module->AddEntryComputation(builder.Build()); auto liveness = - BufferLiveness::Run(module.get(), - xla::MakeUnique<DependencyHloOrdering>(module.get())) + BufferLiveness::Run( + module.get(), absl::make_unique<DependencyHloOrdering>(module.get())) .ConsumeValueOrDie(); EXPECT_FALSE(InstructionsMayInterfere(*liveness, param, negate)); @@ -167,10 +168,10 @@ TEST_F(BufferLivenessTest, MultipleEntryParameters_Sequential) { SequentialHloOrdering::HloModuleSequence sequence; sequence.insert({entry, {param0, negate, param1, exp, add}}); - auto liveness = - BufferLiveness::Run(module.get(), xla::MakeUnique<SequentialHloOrdering>( - module.get(), sequence)) - .ConsumeValueOrDie(); + auto liveness = BufferLiveness::Run(module.get(), + absl::make_unique<SequentialHloOrdering>( + module.get(), sequence)) + .ConsumeValueOrDie(); // Entry parameters interfere as if they are defined simultaneously at // the very beginning. @@ -215,8 +216,8 @@ TEST_F(BufferLivenessTest, NonElementwiseOperand) { module->AddEntryComputation(builder.Build()); auto liveness = - BufferLiveness::Run(module.get(), - xla::MakeUnique<DependencyHloOrdering>(module.get())) + BufferLiveness::Run( + module.get(), absl::make_unique<DependencyHloOrdering>(module.get())) .ConsumeValueOrDie(); EXPECT_FALSE(InstructionsMayInterfere(*liveness, param, exp)); @@ -249,8 +250,8 @@ TEST_F(BufferLivenessTest, OverlappedBuffers) { module->AddEntryComputation(builder.Build()); auto liveness = - BufferLiveness::Run(module.get(), - xla::MakeUnique<DependencyHloOrdering>(module.get())) + BufferLiveness::Run( + module.get(), absl::make_unique<DependencyHloOrdering>(module.get())) .ConsumeValueOrDie(); EXPECT_TRUE(InstructionsMayInterfere(*liveness, param, negate)); @@ -293,10 +294,10 @@ TEST_F(BufferLivenessTest, OverlappedBuffersSequentialOrder) { SequentialHloOrdering::HloModuleSequence module_sequence; std::vector<const HloInstruction*> order = {param, negate, exp, add}; module_sequence.emplace(computation, order); - auto liveness = - BufferLiveness::Run(module.get(), xla::MakeUnique<SequentialHloOrdering>( - module.get(), module_sequence)) - .ConsumeValueOrDie(); + auto liveness = BufferLiveness::Run(module.get(), + absl::make_unique<SequentialHloOrdering>( + module.get(), module_sequence)) + .ConsumeValueOrDie(); EXPECT_TRUE(InstructionsMayInterfere(*liveness, param, negate)); EXPECT_FALSE(InstructionsMayInterfere(*liveness, param, exp)); @@ -342,10 +343,10 @@ TEST_F(BufferLivenessTest, RootInstructionIsNotLastInSequentialOrder) { std::vector<const HloInstruction*> order = {param, add, recv, recv_done, send, send_done}; module_sequence.emplace(computation, order); - auto liveness = - BufferLiveness::Run(module.get(), xla::MakeUnique<SequentialHloOrdering>( - module.get(), module_sequence)) - .ConsumeValueOrDie(); + auto liveness = BufferLiveness::Run(module.get(), + absl::make_unique<SequentialHloOrdering>( + module.get(), module_sequence)) + .ConsumeValueOrDie(); EXPECT_FALSE(InstructionsMayInterfere(*liveness, param, add)); // Check the root instruction (add) buffer interferes with the recv buffer. @@ -376,8 +377,8 @@ TEST_F(BufferLivenessTest, TupleLiveOut) { module->AddEntryComputation(builder.Build()); auto liveness = - BufferLiveness::Run(module.get(), - xla::MakeUnique<DependencyHloOrdering>(module.get())) + BufferLiveness::Run( + module.get(), absl::make_unique<DependencyHloOrdering>(module.get())) .ConsumeValueOrDie(); // All buffers should be live out except the param @@ -412,8 +413,8 @@ TEST_F(BufferLivenessTest, EmbeddedComputation) { module->AddEntryComputation(builder.Build()); auto liveness = - BufferLiveness::Run(module.get(), - xla::MakeUnique<DependencyHloOrdering>(module.get())) + BufferLiveness::Run( + module.get(), absl::make_unique<DependencyHloOrdering>(module.get())) .ConsumeValueOrDie(); // Buffers in different computations should always interfere. @@ -453,8 +454,8 @@ TEST_F(BufferLivenessTest, TupleConstantLiveOut) { module->AddEntryComputation(builder.Build()); auto liveness = - BufferLiveness::Run(module.get(), - xla::MakeUnique<DependencyHloOrdering>(module.get())) + BufferLiveness::Run( + module.get(), absl::make_unique<DependencyHloOrdering>(module.get())) .ConsumeValueOrDie(); // Only the element buffers of the tuple constant which are pointed to by @@ -518,8 +519,8 @@ TEST_F(BufferLivenessTest, IndependentTupleElements) { module->AddEmbeddedComputation(builder.Build()); auto liveness = - BufferLiveness::Run(module.get(), - xla::MakeUnique<DependencyHloOrdering>(module.get())) + BufferLiveness::Run( + module.get(), absl::make_unique<DependencyHloOrdering>(module.get())) .ConsumeValueOrDie(); // We compare tuple element pairs that are input/output to the computation: @@ -580,8 +581,8 @@ TEST_F(BufferLivenessTest, DependentTupleElements) { module->AddEmbeddedComputation(builder.Build()); auto liveness = - BufferLiveness::Run(module.get(), - xla::MakeUnique<DependencyHloOrdering>(module.get())) + BufferLiveness::Run( + module.get(), absl::make_unique<DependencyHloOrdering>(module.get())) .ConsumeValueOrDie(); // We compare tuple element pairs that are input/output to the computation: @@ -610,11 +611,8 @@ TEST_F(BufferLivenessTest, DependentTupleElements) { class FusedDynamicUpdateSliceLivenessTest : public BufferLivenessTest { protected: // Builds and runs a computation (see test case computation graphs below). - // Runs BufferLiveness on this computation. - // Returns whether buffer interference is detected between tuple-shaped - // parameter and root instructions at tuple element 1. - bool Run(const bool update_uses_tuple_element1, - const bool fuse_gte0 = false) { + std::unique_ptr<HloModule> BuildModule(const bool update_uses_tuple_element1, + const bool fuse_gte0) { auto builder = HloComputation::Builder(TestName()); // Create param0 Tuple. Shape data_shape = ShapeUtil::MakeShape(F32, {8}); @@ -645,12 +643,12 @@ class FusedDynamicUpdateSliceLivenessTest : public BufferLivenessTest { builder.AddInstruction(HloInstruction::CreateDynamicUpdateSlice( data_shape, gte1, update, starts)); // Create output tuple. - auto tuple_root = builder.AddInstruction( + builder.AddInstruction( HloInstruction::CreateTuple({gte0, dynamic_update_slice})); // Build module and get reference to entry computation. auto module = CreateNewModule(); - module->AddEntryComputation(BuildDummyComputation()); - auto* computation = module->AddEmbeddedComputation(builder.Build()); + module->AddEntryComputation(builder.Build()); + auto* computation = module->entry_computation(); // Create fusion instruction based on number of tuple element 1 users. if (update_uses_tuple_element1) { computation->CreateFusionInstruction( @@ -666,16 +664,39 @@ class FusedDynamicUpdateSliceLivenessTest : public BufferLivenessTest { computation->CreateFusionInstruction({gte0}, HloInstruction::FusionKind::kLoop); } + return module; + } + // Returns whether buffer interference is detected between tuple-shaped + // parameter and root instructions at tuple element 1. + bool Run(const bool update_uses_tuple_element1, + const bool fuse_gte0 = false) { + auto module = BuildModule(update_uses_tuple_element1, fuse_gte0); // Run BufferLiveness on 'module'. - auto liveness = - BufferLiveness::Run( - module.get(), xla::MakeUnique<DependencyHloOrdering>(module.get())) - .ConsumeValueOrDie(); + auto liveness = BufferLiveness::Run( + module.get(), + absl::make_unique<DependencyHloOrdering>(module.get())) + .ConsumeValueOrDie(); // Return whether or not buffers interference is detected between // 'tuple_param0' and 'tuple_root' at shape index '{1}'. + auto tuple_param0 = FindInstruction(module.get(), "param0"); + auto tuple_root = module->entry_computation()->root_instruction(); return TupleElementsMayInterfere(*liveness, tuple_param0, tuple_root, {1}); } + bool RunWithHloDataflowAnalysis(const bool update_uses_tuple_element1, + const bool fuse_gte0 = false) { + auto module = BuildModule(update_uses_tuple_element1, fuse_gte0); + // Run BufferLiveness on 'module'. + auto dataflow = HloDataflowAnalysis::Run(*module).ConsumeValueOrDie(); + auto hlo_ordering = absl::make_unique<DependencyHloOrdering>(module.get()); + // Return whether or not buffers interference is detected between + // 'tuple_param0' and 'tuple_root' at shape index '{1}'. + auto tuple_param0 = FindInstruction(module.get(), "param0"); + auto tuple_root = module->entry_computation()->root_instruction(); + return hlo_ordering->MayInterfere( + dataflow->GetUniqueValueAt(tuple_param0, {1}), + dataflow->GetUniqueValueAt(tuple_root, {1}), *dataflow); + } }; // Tests that live ranges of buffers Param0[1] and Tuple[1] (which alias fusion) @@ -693,6 +714,8 @@ class FusedDynamicUpdateSliceLivenessTest : public BufferLivenessTest { // TEST_F(FusedDynamicUpdateSliceLivenessTest, NoInterference) { EXPECT_FALSE(Run(/*update_uses_tuple_element1=*/false)); + EXPECT_FALSE( + RunWithHloDataflowAnalysis(/*update_uses_tuple_element1=*/false)); } // Tests that live ranges of buffers Param0[1] and Tuple[1] (which aliases @@ -712,6 +735,8 @@ TEST_F(FusedDynamicUpdateSliceLivenessTest, NoInterference) { // TEST_F(FusedDynamicUpdateSliceLivenessTest, NoInterferenceWithUnrelatedFusion) { EXPECT_FALSE(Run(/*update_uses_tuple_element1=*/false, /*fuse_gte0=*/true)); + EXPECT_FALSE(RunWithHloDataflowAnalysis(/*update_uses_tuple_element1=*/false, + /*fuse_gte0=*/true)); } // Tests that live ranges of buffers Param0[1] and Tuple[1] (which alias fusion) @@ -736,6 +761,7 @@ TEST_F(FusedDynamicUpdateSliceLivenessTest, NoInterferenceWithUnrelatedFusion) { // TEST_F(FusedDynamicUpdateSliceLivenessTest, WithInterference) { EXPECT_TRUE(Run(/*update_uses_tuple_element1=*/true)); + EXPECT_TRUE(RunWithHloDataflowAnalysis(/*update_uses_tuple_element1=*/true)); } class DynamicUpdateSliceLivenessTest : public BufferLivenessTest { @@ -780,10 +806,10 @@ class DynamicUpdateSliceLivenessTest : public BufferLivenessTest { module->AddEntryComputation(BuildDummyComputation()); module->AddEmbeddedComputation(builder.Build()); // Run BufferLiveness on 'module'. - auto liveness = - BufferLiveness::Run( - module.get(), xla::MakeUnique<DependencyHloOrdering>(module.get())) - .ConsumeValueOrDie(); + auto liveness = BufferLiveness::Run( + module.get(), + absl::make_unique<DependencyHloOrdering>(module.get())) + .ConsumeValueOrDie(); // Return whether or not buffers interference is detected between // 'tuple_param0' and 'tuple_root' at shape index '{1}'. return TupleElementsMayInterfere(*liveness, tuple_param0, tuple_root, {1}); diff --git a/tensorflow/compiler/xla/service/buffer_value.cc b/tensorflow/compiler/xla/service/buffer_value.cc index 2bc556a9e2..fdf822c666 100644 --- a/tensorflow/compiler/xla/service/buffer_value.cc +++ b/tensorflow/compiler/xla/service/buffer_value.cc @@ -17,11 +17,10 @@ limitations under the License. #include <iosfwd> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/types.h" namespace xla { diff --git a/tensorflow/compiler/xla/service/call_graph.cc b/tensorflow/compiler/xla/service/call_graph.cc index 985ff30e80..23b2a32709 100644 --- a/tensorflow/compiler/xla/service/call_graph.cc +++ b/tensorflow/compiler/xla/service/call_graph.cc @@ -17,21 +17,21 @@ limitations under the License. #include <queue> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/types.h" namespace xla { -using ::tensorflow::strings::Appendf; -using ::tensorflow::strings::StrCat; +using absl::StrAppendFormat; +using absl::StrCat; string CallContextToString(CallContext context) { switch (context) { @@ -71,10 +71,10 @@ CallContext GetInstructionCallContext(HloOpcode opcode) { } string CallSite::ToString() const { - return StrCat(instruction()->name(), " calls in context ", - CallContextToString(context()), ": ", - tensorflow::str_util::Join( - called_computations(), ", ", + return StrCat( + instruction()->name(), " calls in context ", + CallContextToString(context()), ": ", + absl::StrJoin(called_computations(), ", ", [](string* out, const HloComputation* computation) { out->append(computation->name()); })); @@ -237,8 +237,8 @@ void CallGraph::SetCallContexts() { /* static */ std::unique_ptr<CallGraph> CallGraph::Build(const HloModule* module) { - // Constructor for CallGraph is private so MakeUnique can't be used. - auto call_graph = WrapUnique<CallGraph>(new CallGraph(module)); + // Constructor for CallGraph is private so absl::make_unique can't be used. + auto call_graph = absl::WrapUnique<CallGraph>(new CallGraph(module)); VLOG(2) << "Building call graph for:"; XLA_VLOG_LINES(2, module->ToString()); @@ -356,20 +356,20 @@ CallGraph::NearestAncestorsInSameComputation(HloInstruction* a, string CallGraph::ToString() const { string out; - Appendf(&out, "Call graph for module %s:\n", module_->name().c_str()); + StrAppendFormat(&out, "Call graph for module %s:\n", module_->name()); for (const CallGraphNode& node : nodes()) { - Appendf(&out, "Computation %s:\n", node.computation()->name().c_str()); - Appendf(&out, " calls:\n"); + StrAppendFormat(&out, "Computation %s:\n", node.computation()->name()); + StrAppendFormat(&out, " calls:\n"); for (const HloComputation* callee : node.callees()) { - Appendf(&out, " %s\n", callee->name().c_str()); + StrAppendFormat(&out, " %s\n", callee->name()); } - Appendf(&out, " called by:\n"); + StrAppendFormat(&out, " called by:\n"); for (const HloComputation* caller : node.callers()) { - Appendf(&out, " %s\n", caller->name().c_str()); + StrAppendFormat(&out, " %s\n", caller->name()); } - Appendf(&out, " callsites:\n"); + StrAppendFormat(&out, " callsites:\n"); for (const CallSite& callsite : node.callsites()) { - Appendf(&out, " %s\n", callsite.ToString().c_str()); + StrAppendFormat(&out, " %s\n", callsite.ToString()); } } return out; diff --git a/tensorflow/compiler/xla/service/call_graph.h b/tensorflow/compiler/xla/service/call_graph.h index 97d3811508..3af2ab5edf 100644 --- a/tensorflow/compiler/xla/service/call_graph.h +++ b/tensorflow/compiler/xla/service/call_graph.h @@ -15,8 +15,8 @@ limitations under the License. // Call graph for an HLO module. -#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_HLO_CALL_GRAPH_H_ -#define TENSORFLOW_COMPILER_XLA_SERVICE_HLO_CALL_GRAPH_H_ +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CALL_GRAPH_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_CALL_GRAPH_H_ #include <ostream> @@ -272,4 +272,4 @@ class CallGraph { } // namespace xla -#endif // TENSORFLOW_COMPILER_XLA_SERVICE_HLO_CALL_GRAPH_H_ +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_CALL_GRAPH_H_ diff --git a/tensorflow/compiler/xla/service/call_inliner.cc b/tensorflow/compiler/xla/service/call_inliner.cc index 256d05a73e..1d42140444 100644 --- a/tensorflow/compiler/xla/service/call_inliner.cc +++ b/tensorflow/compiler/xla/service/call_inliner.cc @@ -96,7 +96,7 @@ class SubcomputationInsertionVisitor : public DfsHloVisitorWithDefault { if (it == subcomputation_hlo_to_new_hlo_.end()) { return NotFound( "Could not find mapping from subcomputation HLO %s to a cloned HLO.", - subcomputation_hlo->ToString().c_str()); + subcomputation_hlo->ToString()); } return it->second; } diff --git a/tensorflow/compiler/xla/service/call_inliner.h b/tensorflow/compiler/xla/service/call_inliner.h index a8345a394d..c5cd88b9ea 100644 --- a/tensorflow/compiler/xla/service/call_inliner.h +++ b/tensorflow/compiler/xla/service/call_inliner.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_XLA_SERVICE__CALL_INLINER_H_ -#define TENSORFLOW_COMPILER_XLA_SERVICE__CALL_INLINER_H_ +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CALL_INLINER_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_CALL_INLINER_H_ #include <deque> @@ -35,11 +35,11 @@ class CallInliner : public HloPassInterface { static StatusOr<InlinedInstructionMap> Inline(HloInstruction* call); ~CallInliner() override = default; - tensorflow::StringPiece name() const override { return "CallInliner"; } + absl::string_view name() const override { return "CallInliner"; } StatusOr<bool> Run(HloModule* module) override; }; } // namespace xla -#endif // TENSORFLOW_COMPILER_XLA_SERVICE__CALL_INLINER_H_ +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_CALL_INLINER_H_ diff --git a/tensorflow/compiler/xla/service/call_inliner_test.cc b/tensorflow/compiler/xla/service/call_inliner_test.cc index ff968bca29..5d85a3f173 100644 --- a/tensorflow/compiler/xla/service/call_inliner_test.cc +++ b/tensorflow/compiler/xla/service/call_inliner_test.cc @@ -18,9 +18,9 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" @@ -32,7 +32,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace op = xla::testing::opcode_matchers; diff --git a/tensorflow/compiler/xla/service/channel_tracker.cc b/tensorflow/compiler/xla/service/channel_tracker.cc index 13008efed1..3c2d1ae6d8 100644 --- a/tensorflow/compiler/xla/service/channel_tracker.cc +++ b/tensorflow/compiler/xla/service/channel_tracker.cc @@ -15,14 +15,14 @@ limitations under the License. #include "tensorflow/compiler/xla/service/channel_tracker.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/status.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/mutex.h" #include "tensorflow/core/platform/types.h" @@ -73,20 +73,20 @@ ChannelHandle ChannelTracker::AllocateHandle(ChannelHandle::ChannelType type) { Status ChannelTracker::RegisterSendInternal(const ChannelHandle& handle) { if (opaque_to_channel_.count(handle.handle()) == 0) { - return NotFound("channel handle not found: %lld", handle.handle()); + return NotFound("channel handle not found: %d", handle.handle()); } Channel& channel = opaque_to_channel_[handle.handle()]; if (channel.type == ChannelHandle::HOST_TO_DEVICE) { return FailedPrecondition( "host-to-device channels cannot be used with a Send operation; " - "channel handle: %lld", + "channel handle: %d", handle.handle()); } if (channel.has_sender) { return FailedPrecondition( "when registering send, passed a channel handle that is already used " - "by a sender: %lld", + "by a sender: %d", handle.handle()); } channel.has_sender = true; @@ -95,13 +95,13 @@ Status ChannelTracker::RegisterSendInternal(const ChannelHandle& handle) { Status ChannelTracker::RegisterRecvInternal(const ChannelHandle& handle) { if (opaque_to_channel_.count(handle.handle()) == 0) { - return NotFound("channel handle not found: %lld", handle.handle()); + return NotFound("channel handle not found: %d", handle.handle()); } Channel& channel = opaque_to_channel_[handle.handle()]; if (channel.type == ChannelHandle::DEVICE_TO_HOST) { return FailedPrecondition( "device-to-host channels cannot be used with a Recv operation; " - "channel handle: %lld", + "channel handle: %d", handle.handle()); } @@ -109,7 +109,7 @@ Status ChannelTracker::RegisterRecvInternal(const ChannelHandle& handle) { if (channel.receiver_count >= 1) { return FailedPrecondition( "when registering recv, passed a channel handle that is already used " - "by a receiver: %lld", + "by a receiver: %d", handle.handle()); } channel.receiver_count += 1; diff --git a/tensorflow/compiler/xla/service/compile_only_service.cc b/tensorflow/compiler/xla/service/compile_only_service.cc index 7426672a7a..3079695e96 100644 --- a/tensorflow/compiler/xla/service/compile_only_service.cc +++ b/tensorflow/compiler/xla/service/compile_only_service.cc @@ -19,6 +19,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/legacy_flags/debug_options_flags.h" #include "tensorflow/compiler/xla/service/backend.h" #include "tensorflow/compiler/xla/service/computation_layout.h" @@ -28,7 +29,6 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/cleanup.h" #include "tensorflow/core/lib/io/path.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/host_info.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" @@ -76,9 +76,9 @@ CompileOnlyService::CompileAheadOfTime( if (!directory_path.empty()) { HloSnapshot hlo_snapshot; *hlo_snapshot.mutable_hlo()->mutable_hlo_module() = instance.computation; - string filename = tensorflow::strings::StrCat( - "computation_", instance.computation.id(), "__", - instance.computation.entry_computation_name()); + string filename = + absl::StrCat("computation_", instance.computation.id(), "__", + instance.computation.entry_computation_name()); const string& per_host_path = tensorflow::io::JoinPath( directory_path, tensorflow::port::Hostname()); diff --git a/tensorflow/compiler/xla/service/compiler.cc b/tensorflow/compiler/xla/service/compiler.cc index 6b3b9820f0..687ecafe0c 100644 --- a/tensorflow/compiler/xla/service/compiler.cc +++ b/tensorflow/compiler/xla/service/compiler.cc @@ -101,7 +101,7 @@ Compiler::GetPlatformCompilers() { return NotFound( "could not find registered compiler for platform %s -- check " "target linkage", - platform->Name().c_str()); + platform->Name()); } // And then we invoke the factory, placing the result into the mapping. diff --git a/tensorflow/compiler/xla/service/computation_layout.cc b/tensorflow/compiler/xla/service/computation_layout.cc index cb61f3da39..af8f7f1027 100644 --- a/tensorflow/compiler/xla/service/computation_layout.cc +++ b/tensorflow/compiler/xla/service/computation_layout.cc @@ -17,9 +17,9 @@ limitations under the License. #include <algorithm> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { @@ -52,9 +52,8 @@ string ComputationLayout::ToString() const { for (auto& param_layout : parameter_layouts_) { params.push_back(param_layout.ToString()); } - return tensorflow::strings::StrCat("(", - tensorflow::str_util::Join(params, ", "), - ") => ", result_layout_.ToString()); + return absl::StrCat("(", absl::StrJoin(params, ", "), ") => ", + result_layout_.ToString()); } } // namespace xla diff --git a/tensorflow/compiler/xla/service/computation_placer.cc b/tensorflow/compiler/xla/service/computation_placer.cc index 187ce568cb..2210a8578a 100644 --- a/tensorflow/compiler/xla/service/computation_placer.cc +++ b/tensorflow/compiler/xla/service/computation_placer.cc @@ -19,8 +19,9 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -29,12 +30,11 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" -using tensorflow::strings::StrAppend; -using tensorflow::strings::StrCat; +using absl::StrAppend; +using absl::StrCat; namespace xla { @@ -60,8 +60,8 @@ DeviceAssignment::Deserialize(const DeviceAssignmentProto& proto) { "computation_count=%d", proto.replica_count(), proto.computation_count()); } - auto assignment = MakeUnique<DeviceAssignment>(proto.replica_count(), - proto.computation_count()); + auto assignment = absl::make_unique<DeviceAssignment>( + proto.replica_count(), proto.computation_count()); for (int computation = 0; computation < proto.computation_count(); ++computation) { const auto& computation_device = proto.computation_devices(computation); @@ -132,7 +132,7 @@ StatusOr<DeviceAssignment> ComputationPlacer::AssignDevices( return NotFound( "could not find registered computation placer for platform %s -- check " "target linkage", - platform->Name().c_str()); + platform->Name()); } if (it->second.placer == nullptr) { @@ -156,7 +156,7 @@ ComputationPlacer::GetPlatformComputationPlacers() { } // namespace xla static std::unique_ptr<xla::ComputationPlacer> CreateComputationPlacer() { - return xla::MakeUnique<xla::ComputationPlacer>(); + return absl::make_unique<xla::ComputationPlacer>(); } static bool InitModule() { diff --git a/tensorflow/compiler/xla/service/conditional_simplifier.cc b/tensorflow/compiler/xla/service/conditional_simplifier.cc index b7be3ba605..4ea3a13f28 100644 --- a/tensorflow/compiler/xla/service/conditional_simplifier.cc +++ b/tensorflow/compiler/xla/service/conditional_simplifier.cc @@ -19,6 +19,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/service/call_inliner.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" @@ -28,8 +29,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { diff --git a/tensorflow/compiler/xla/service/conditional_simplifier.h b/tensorflow/compiler/xla/service/conditional_simplifier.h index 063261e26d..3de50cbd7f 100644 --- a/tensorflow/compiler/xla/service/conditional_simplifier.h +++ b/tensorflow/compiler/xla/service/conditional_simplifier.h @@ -16,10 +16,10 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CONDITIONAL_SIMPLIFIER_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_CONDITIONAL_SIMPLIFIER_H_ +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/hlo_pass_interface.h" #include "tensorflow/compiler/xla/statusor.h" -#include "tensorflow/core/lib/core/stringpiece.h" namespace xla { @@ -27,9 +27,7 @@ namespace xla { // with their true or false computation as appropriate. class ConditionalSimplifier : public HloPassInterface { public: - tensorflow::StringPiece name() const override { - return "simplify-conditional"; - } + absl::string_view name() const override { return "simplify-conditional"; } StatusOr<bool> Run(HloModule* module) override; }; diff --git a/tensorflow/compiler/xla/service/conditional_simplifier_test.cc b/tensorflow/compiler/xla/service/conditional_simplifier_test.cc index c43a31b167..6c477da038 100644 --- a/tensorflow/compiler/xla/service/conditional_simplifier_test.cc +++ b/tensorflow/compiler/xla/service/conditional_simplifier_test.cc @@ -39,6 +39,10 @@ namespace op = xla::testing::opcode_matchers; class ConditionalSimplifierTest : public HloVerifiedTestBase { public: + ConditionalSimplifierTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} + // Makes a computation that contains a conditional with constant predicate. HloComputation* MakeConditional(HloModule* module); }; diff --git a/tensorflow/compiler/xla/service/convolution_feature_group_converter.cc b/tensorflow/compiler/xla/service/convolution_feature_group_converter.cc index 45252fc1ee..9c81a86bbb 100644 --- a/tensorflow/compiler/xla/service/convolution_feature_group_converter.cc +++ b/tensorflow/compiler/xla/service/convolution_feature_group_converter.cc @@ -18,9 +18,9 @@ limitations under the License. #include <memory> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -214,7 +214,7 @@ Status ConvolutionVisitor::HandleConvolution(HloInstruction* convolution) { expanded_filter = add(HloInstruction::CreateConcatenate( expanded_filter_shape, concat_operands, input_feature_dim)); } - auto zero = add(HloInstruction::CreateConstant(MakeUnique<Literal>( + auto zero = add(HloInstruction::CreateConstant(absl::make_unique<Literal>( LiteralUtil::Zero(expanded_filter_shape.element_type())))); auto zero_filter = add(HloInstruction::CreateBroadcast(expanded_filter_shape, zero, {})); @@ -224,6 +224,7 @@ Status ConvolutionVisitor::HandleConvolution(HloInstruction* convolution) { auto new_convolution = HloInstruction::CreateConvolve( convolution->shape(), convolution->mutable_operand(0), new_filter, convolution->window(), dim_numbers, /*feature_group_count=*/1); + new_convolution->set_precision_config(convolution->precision_config()); TF_RETURN_IF_ERROR(computation_->ReplaceWithNewInstruction( convolution, std::move(new_convolution))); return Status::OK(); diff --git a/tensorflow/compiler/xla/service/convolution_feature_group_converter.h b/tensorflow/compiler/xla/service/convolution_feature_group_converter.h index f213cc8709..498894737f 100644 --- a/tensorflow/compiler/xla/service/convolution_feature_group_converter.h +++ b/tensorflow/compiler/xla/service/convolution_feature_group_converter.h @@ -16,10 +16,10 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CONVOLUTION_FEATURE_GROUP_CONVERTER_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_CONVOLUTION_FEATURE_GROUP_CONVERTER_H_ +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/hlo_pass_interface.h" #include "tensorflow/compiler/xla/status_macros.h" -#include "tensorflow/core/lib/core/stringpiece.h" namespace xla { @@ -29,7 +29,7 @@ class ConvolutionFeatureGroupConverter : public HloPassInterface { public: ConvolutionFeatureGroupConverter() {} - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "convolution-feature-group-converter"; } diff --git a/tensorflow/compiler/xla/service/copy_insertion.cc b/tensorflow/compiler/xla/service/copy_insertion.cc index 3e39c1bab1..1b7a7b36ea 100644 --- a/tensorflow/compiler/xla/service/copy_insertion.cc +++ b/tensorflow/compiler/xla/service/copy_insertion.cc @@ -15,6 +15,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/copy_insertion.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/hlo_alias_analysis.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_dce.h" @@ -31,18 +33,13 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/flatmap.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" namespace xla { - -using ::tensorflow::str_util::Join; -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; - namespace { +using absl::StrAppend; + bool IsEntryParameterValue(const HloValue& value) { const HloComputation* computation = value.defining_instruction()->parent(); return value.defining_instruction()->opcode() == HloOpcode::kParameter && @@ -381,7 +378,7 @@ class CopyRemover { } string ToString() const { - string out = StrCat("CopyRemover, module ", module_->name(), "\n"); + string out = absl::StrCat("CopyRemover, module ", module_->name(), "\n"); StrAppend(&out, " Buffer values, in dependency order:\n"); for (const HloBuffer& buffer : alias_analysis_.buffers()) { StrAppend(&out, " HloBuffer ", buffer.id(), ":\n"); @@ -863,16 +860,16 @@ class CopyRemover { for (const ValueNode* p = head; p != nullptr; p = Next(*p)) { values.push_back(p->value); } - return StrCat("{", - Join(values, ", ", - [](string* s, const HloValue* value) { - StrAppend(s, value->ToShortString()); - }), - "}"); + return absl::StrCat("{", + absl::StrJoin(values, ", ", + [](string* s, const HloValue* value) { + StrAppend(s, value->ToShortString()); + }), + "}"); } string ToString() const { - string out = StrCat("BufferValueTracker:\n"); + string out = absl::StrCat("BufferValueTracker:\n"); StrAppend(&out, " Def-use chains in each buffer:\n"); for (const ValueNode* head : value_lists_) { StrAppend(&out, " Buffer defined by ", head->value->ToShortString(), @@ -880,10 +877,10 @@ class CopyRemover { const ValueNode* p = head; do { StrAppend(&out, " ", p->value->ToShortString(), ", uses: ", - Join(p->uses, "; ", - [](string* s, const HloUse* use) { - StrAppend(s, use->ToString()); - }), + absl::StrJoin(p->uses, "; ", + [](string* s, const HloUse* use) { + StrAppend(s, use->ToString()); + }), "\n"); p = p->next; @@ -960,16 +957,11 @@ Status CopyInsertion::AddCopiesToResolveInterference(HloModule* module) { return Status::OK(); } -// Add copies to address special constraints on the roots of computations not -// related to live range interference: -// -// (1) Entry computation root must be unambiguous and distinct. -// -// (2) Any computation called by a kCall instruction must have an -// unambiguous root. -// -// (3) Constants and parameters cannot be live out of the entry computation -// +Status CopyInsertion::AddSpecialCaseCopies(HloModule* module) { + std::unique_ptr<CallGraph> call_graph = CallGraph::Build(module); + return AddSpecialCaseCopies(*call_graph, module); +} + Status CopyInsertion::AddSpecialCaseCopies(const CallGraph& call_graph, HloModule* module) { TF_ASSIGN_OR_RETURN(std::unique_ptr<HloAliasAnalysis> alias_analysis, @@ -1065,15 +1057,6 @@ Status CopyInsertion::AddSpecialCaseCopies(const CallGraph& call_graph, for (HloInstruction* user : users) { TF_RETURN_IF_ERROR(instruction->ReplaceUseWith(user, deep_copy)); } - // Special case copies are not eligible for later copy elision passes. - indices_to_copy.ForEachElement([&](const ShapeIndex& index, bool has_copy) { - if (has_copy) { - HloInstruction* copy = *copies_added.mutable_element(index); - if (copy != nullptr) { - copy->SetCopyElisionAllowed(false); - } - } - }); if (instruction == instruction->parent()->root_instruction()) { instruction->parent()->set_root_instruction(deep_copy); } @@ -1081,10 +1064,10 @@ Status CopyInsertion::AddSpecialCaseCopies(const CallGraph& call_graph, return Status::OK(); } -Status CopyInsertion::VerifyNoLiveRangeInterference(HloModule* module) { +Status CopyInsertion::VerifyNoLiveRangeInterference(const HloOrdering& ordering, + HloModule* module) { TF_ASSIGN_OR_RETURN(std::unique_ptr<HloAliasAnalysis> alias_analysis, HloAliasAnalysis::Run(module, fusion_can_share_buffer_)); - DependencyHloOrdering ordering(module); TF_RET_CHECK(!alias_analysis->HasLiveRangeInterference(ordering)); return Status::OK(); } @@ -1101,8 +1084,7 @@ Status CopyInsertion::RemoveUnnecessaryCopies(const HloOrdering& ordering, std::unique_ptr<CallGraph> call_graph = CallGraph::Build(module); for (HloComputation* computation : module->computations()) { for (HloInstruction* instruction : computation->instructions()) { - if (instruction->opcode() == HloOpcode::kCopy && - instruction->CopyElisionAllowed()) { + if (instruction->opcode() == HloOpcode::kCopy) { TF_RETURN_IF_ERROR(copy_remover.TryElideCopy(instruction).status()); } } @@ -1168,10 +1150,10 @@ StatusOr<bool> CopyInsertion::Run(HloModule* module) { TF_RETURN_IF_ERROR(tuple_simplifier.Run(module).status()); TF_RETURN_IF_ERROR(dce.Run(module).status()); - TF_DCHECK_OK(VerifyNoLiveRangeInterference(module)); + DependencyHloOrdering dep_ordering(module); + TF_DCHECK_OK(VerifyNoLiveRangeInterference(dep_ordering, module)); - DependencyHloOrdering ordering(module); - TF_RETURN_IF_ERROR(RemoveUnnecessaryCopies(ordering, module)); + TF_RETURN_IF_ERROR(RemoveUnnecessaryCopies(dep_ordering, module)); TF_RETURN_IF_ERROR(AddSpecialCaseCopies(*call_graph, module)); @@ -1179,7 +1161,8 @@ StatusOr<bool> CopyInsertion::Run(HloModule* module) { TF_RETURN_IF_ERROR(tuple_simplifier.Run(module).status()); TF_RETURN_IF_ERROR(dce.Run(module).status()); - TF_DCHECK_OK(VerifyNoLiveRangeInterference(module)); + TF_DCHECK_OK( + VerifyNoLiveRangeInterference(DependencyHloOrdering(module), module)); MaybeDumpModule("after copy insertion", *module); diff --git a/tensorflow/compiler/xla/service/copy_insertion.h b/tensorflow/compiler/xla/service/copy_insertion.h index 5ba64b78a3..d308f6bc84 100644 --- a/tensorflow/compiler/xla/service/copy_insertion.h +++ b/tensorflow/compiler/xla/service/copy_insertion.h @@ -45,7 +45,7 @@ namespace xla { // InstructionAliasSet::IsDistinct return true. class CopyInsertion : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "copy-insertion"; } + absl::string_view name() const override { return "copy-insertion"; } // fusion_can_share_buffer: backend specific function that decides whether a // fusion can share buffer with its operand. @@ -77,15 +77,29 @@ class CopyInsertion : public HloPassInterface { Status RemoveUnnecessaryCopies(const HloOrdering& ordering, HloModule* module); - private: - // Verifies that no HLO values have interfering live ranged assuming the - // ordering used by copy insertion. - Status VerifyNoLiveRangeInterference(HloModule* module); + // Add copies to address special constraints on the roots of computations not + // related to live range interference: + // + // (1) Entry computation root must be unambiguous and distinct. + // + // (2) Any computation called by a kCall instruction must have an + // unambiguous root. + // + // (3) Constants and parameters cannot be live out of the entry computation + // + Status AddSpecialCaseCopies(HloModule* module); - Status AddCopiesToResolveInterference(HloModule* module); + // Verifies that no HLO values have interfering live ranges using the given + // ordering. + Status VerifyNoLiveRangeInterference(const HloOrdering& ordering, + HloModule* module); + private: + // Override which requires the caller to pass in a call graph. Status AddSpecialCaseCopies(const CallGraph& call_graph, HloModule* module); + Status AddCopiesToResolveInterference(HloModule* module); + // Backend specific function that decides whether a fusion can share buffer // with its operand. HloDataflowAnalysis::FusionCanShareBufferFunction fusion_can_share_buffer_; diff --git a/tensorflow/compiler/xla/service/cpu/BUILD b/tensorflow/compiler/xla/service/cpu/BUILD index fe1ef78533..4cd192873f 100644 --- a/tensorflow/compiler/xla/service/cpu/BUILD +++ b/tensorflow/compiler/xla/service/cpu/BUILD @@ -50,6 +50,7 @@ cc_library( "//tensorflow/compiler/xla/service/cpu:cpu_runtime", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", ], alwayslink = True, # Contains per-platform transfer manager registration ) @@ -85,6 +86,9 @@ cc_library( ":ir_emitter", ":parallel_task_assignment", ":simple_orc_jit", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + ":target_machine_features", "//tensorflow/compiler/tf2xla:cpu_function_runtime", "//tensorflow/compiler/xla/service:scatter_expander", "//tensorflow/compiler/xla:literal", @@ -178,6 +182,7 @@ cc_library( ":runtime_single_threaded_conv2d", ":runtime_single_threaded_fft", ":runtime_single_threaded_matmul", + "@com_google_absl//absl/memory", "@llvm//:execution_engine", "@llvm//:core", "@llvm//:mc", # fixdeps: keep @@ -229,6 +234,8 @@ cc_library( "//tensorflow/compiler/xla/service:tuple_points_to_analysis", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", "@llvm//:orc_jit", ], ) @@ -271,11 +278,14 @@ cc_library( "//tensorflow/compiler/xla/service/llvm_ir:dynamic_update_slice_util", "//tensorflow/compiler/xla/service/llvm_ir:fused_ir_emitter", "//tensorflow/compiler/xla/service/llvm_ir:ir_array", + "//tensorflow/compiler/xla/service/llvm_ir:ir_builder_mixin", "//tensorflow/compiler/xla/service/llvm_ir:llvm_loop", "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/compiler/xla/service/llvm_ir:loop_emitter", "//tensorflow/compiler/xla/service/llvm_ir:tuple_ops", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", "@llvm//:code_gen", "@llvm//:core", "@llvm//:support", @@ -320,6 +330,7 @@ cc_library( "//tensorflow/compiler/xla/service/cpu:cpu_runtime", "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", "@llvm//:core", ], ) @@ -330,12 +341,12 @@ cc_library( hdrs = ["parallel_loop_emitter.h"], deps = [ ":ir_emission_utils", - "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service/llvm_ir:ir_array", "//tensorflow/compiler/xla/service/llvm_ir:llvm_loop", "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/compiler/xla/service/llvm_ir:loop_emitter", "//tensorflow/core:lib", + "@com_google_absl//absl/strings:str_format", "@llvm//:core", ], ) @@ -362,6 +373,7 @@ cc_library( "//tensorflow/compiler/xla/service/llvm_ir:llvm_loop", "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", "@llvm//:core", ], ) @@ -382,6 +394,7 @@ tf_cc_binary( "//tensorflow/compiler/xla/client:xla_builder", "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/core:lib", + "@com_google_absl//absl/strings:str_format", ], ) @@ -395,6 +408,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/strings:str_format", "@llvm//:mc", "@llvm//:mc_disassembler", "@llvm//:object", @@ -418,6 +432,7 @@ cc_library( "//tensorflow/compiler/xla/service:llvm_compiler", "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", "@llvm//:analysis", "@llvm//:core", "@llvm//:ipo", @@ -634,6 +649,8 @@ tf_cc_test( "//tensorflow/core:lib", "//tensorflow/core:test", "//third_party/eigen3", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings:str_format", ], ) @@ -648,6 +665,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -810,6 +828,8 @@ cc_library( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/compiler/xla/service:hlo_cost_analysis", "//tensorflow/compiler/xla/service:hlo_pass", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -846,6 +866,7 @@ cc_library( deps = [ "//tensorflow/compiler/xla/service:hlo_module_config", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -893,6 +914,7 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", "@llvm//:core", "@llvm//:support", ], diff --git a/tensorflow/compiler/xla/service/cpu/compiler_functor.cc b/tensorflow/compiler/xla/service/cpu/compiler_functor.cc index 128eea4828..73b03440cb 100644 --- a/tensorflow/compiler/xla/service/cpu/compiler_functor.cc +++ b/tensorflow/compiler/xla/service/cpu/compiler_functor.cc @@ -22,6 +22,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "llvm/ADT/StringRef.h" #include "llvm/Analysis/TargetLibraryInfo.h" #include "llvm/Analysis/TargetTransformInfo.h" @@ -35,7 +36,6 @@ limitations under the License. #include "llvm/Transforms/IPO.h" #include "llvm/Transforms/IPO/AlwaysInliner.h" #include "llvm/Transforms/IPO/PassManagerBuilder.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/cpu/cpu_runtime.h" #include "tensorflow/compiler/xla/service/cpu/llvm_ir_runtime.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_util.h" @@ -205,7 +205,7 @@ void CompilerFunctor::AddTargetInfoPasses( llvm::legacy::PassManagerBase* passes) const { llvm::Triple target_triple(target_machine_->getTargetTriple()); auto target_library_info_impl = - MakeUnique<llvm::TargetLibraryInfoImpl>(target_triple); + absl::make_unique<llvm::TargetLibraryInfoImpl>(target_triple); target_library_info_impl->addVectorizableFunctions( VectorFunctionsForTargetLibraryInfoImpl()); passes->add( diff --git a/tensorflow/compiler/xla/service/cpu/conv_canonicalization.cc b/tensorflow/compiler/xla/service/cpu/conv_canonicalization.cc index 0985b9297f..098ce17a56 100644 --- a/tensorflow/compiler/xla/service/cpu/conv_canonicalization.cc +++ b/tensorflow/compiler/xla/service/cpu/conv_canonicalization.cc @@ -132,6 +132,7 @@ StatusOr<bool> ConvCanonicalization::Run(HloModule* module) { HloInstruction* new_conv = module->entry_computation()->AddInstruction( HloInstruction::CreateConvolve(new_conv_shape, new_input, new_kernel, hlo->window(), new_dnums)); + new_conv->set_precision_config(hlo->precision_config()); // Reshape the output back to the shape of the original convolution. TF_RETURN_IF_ERROR(module->entry_computation()->ReplaceWithNewInstruction( diff --git a/tensorflow/compiler/xla/service/cpu/conv_canonicalization.h b/tensorflow/compiler/xla/service/cpu/conv_canonicalization.h index e6fd1499ed..59437e88af 100644 --- a/tensorflow/compiler/xla/service/cpu/conv_canonicalization.h +++ b/tensorflow/compiler/xla/service/cpu/conv_canonicalization.h @@ -38,7 +38,7 @@ class ConvCanonicalization : public HloPassInterface { : target_machine_features_(*target_machine_features) {} ~ConvCanonicalization() override {} - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "convolution-canonicalization"; } diff --git a/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc b/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc index fde8fbd486..6420180b13 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc @@ -26,6 +26,8 @@ limitations under the License. // IWYU pragma: no_include "llvm/Config/Disassemblers.def.inc" // IWYU pragma: no_include "llvm/Config/Targets.def.inc" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "llvm/ADT/StringRef.h" #include "llvm/ADT/Triple.h" #include "llvm/IR/Function.h" @@ -42,7 +44,6 @@ limitations under the License. #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/protobuf_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/algebraic_simplifier.h" #include "tensorflow/compiler/xla/service/batch_dot_simplification.h" #include "tensorflow/compiler/xla/service/batchnorm_expander.h" @@ -101,8 +102,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { namespace cpu { @@ -235,15 +234,15 @@ class CollectProfileCandidates : public DfsHloVisitorWithDefault { std::unordered_map<const HloInstruction*, int64>* hlo_to_profile_idx_; const std::unordered_map<const HloInstruction*, int64>& assigned_indices_; }; -} // namespace -Status CpuCompiler::RunHloPasses(HloModule* module, bool is_aot_compile, - llvm::TargetMachine* target_machine) { - LLVMTargetMachineFeatures target_machine_features(target_machine); +} // namespace - // Optimization pipeline. - HloPassPipeline pipeline("CPU"); - pipeline.AddInvariantChecker<HloVerifier>(); +Status CpuCompiler::RunHloPassesThroughLayoutAssn( + HloModule* module, bool /*is_aot_compile*/, + LLVMTargetMachineFeatures* target_machine_features) { + HloPassPipeline pipeline("HLO passes through layout assignment"); + pipeline.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false); pipeline.AddPass<CpuHloSupportChecker>(); ReducePrecisionInsertion::AddPasses( @@ -260,11 +259,12 @@ Status CpuCompiler::RunHloPasses(HloModule* module, bool is_aot_compile, pipeline.AddPass<BatchDotSimplification>(); pipeline.AddPass<DotDecomposer>(); pipeline.AddPass<ConvolutionFeatureGroupConverter>(); - pipeline.AddPass<ConvCanonicalization>(&target_machine_features); + pipeline.AddPass<ConvCanonicalization>(target_machine_features); { auto& pass = pipeline.AddPass<HloPassFix<HloPassPipeline>>("simplification"); - pass.AddInvariantChecker<HloVerifier>(); + pass.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false); pass.AddPass<BatchNormExpander>( /*rewrite_training_op=*/true, @@ -291,10 +291,9 @@ Status CpuCompiler::RunHloPasses(HloModule* module, bool is_aot_compile, } pipeline.AddPass<IndexedArrayAnalysisPrinterPass>(); pipeline.AddPass<TransposeFolding>( - [&target_machine_features]( - const HloInstruction& dot, + [&](const HloInstruction& dot, const TransposeFolding::OperandIndices& candidate_operands) { - return PotentiallyImplementedAsEigenDot(dot, target_machine_features) + return PotentiallyImplementedAsEigenDot(dot, *target_machine_features) ? candidate_operands : TransposeFolding::OperandIndices{}; }, @@ -309,12 +308,28 @@ Status CpuCompiler::RunHloPasses(HloModule* module, bool is_aot_compile, ReducePrecisionInsertion::PassTiming::AFTER_FUSION); pipeline.AddPass<CpuLayoutAssignment>( - module->mutable_entry_computation_layout(), &target_machine_features); + module->mutable_entry_computation_layout(), target_machine_features); + return pipeline.Run(module).status(); +} + +Status CpuCompiler::RunHloPassesAfterLayoutAssn( + HloModule* module, bool is_aot_compile, + LLVMTargetMachineFeatures* target_machine_features) { + HloPassPipeline pipeline("HLO passes after layout assignment"); + // After layout assignment, use a layout-sensitive verifier. + auto& after_layout_assn = + pipeline.AddPass<HloPassPipeline>("after layout assignment"); + after_layout_assn.AddInvariantChecker<HloVerifier>( + /*layout_sensitive=*/true, + /*allow_mixed_precision=*/false); + // The LayoutAssignment pass may leave behind kCopy instructions which are // duplicate or NOPs, so remove them with algebraic simplification and CSE. { auto& pass = pipeline.AddPass<HloPassFix<HloPassPipeline>>( - "after layout assignement"); + "simplification after layout assignement"); + pass.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/true, + /*allow_mixed_precision=*/false); pass.AddPass<HloPassFix<AlgebraicSimplifier>>( /*is_layout_sensitive=*/true, [](const Shape&, const Shape&) { return true; }, @@ -322,7 +337,9 @@ Status CpuCompiler::RunHloPasses(HloModule* module, bool is_aot_compile, pass.AddPass<HloDCE>(); pass.AddPass<HloCSE>(/*is_layout_sensitive=*/true); } + pipeline.AddPass<HloElementTypeConverter>(BF16, F32); + // Outline ops in the entry computation into calls to subcomputations. const int max_parallelism = module->config().intra_op_parallelism_threads() > 0 @@ -335,14 +352,14 @@ Status CpuCompiler::RunHloPasses(HloModule* module, bool is_aot_compile, // binary size (and most AOT applications are single-threaded). // TODO(b/29630486) Support multi-threaded AOT. pipeline.AddPass<ParallelTaskAssigner>( - max_parallelism, ShapeSizeBytesFunction(), &target_machine_features); + max_parallelism, ShapeSizeBytesFunction(), target_machine_features); } - // Copy insertion should be performed immediately before IR emission to avoid - // inserting unnecessary copies (later pass adds an instruction which - // materializes the value) or missing a necessary copy (later pass removes an - // instruction which materializes a value). DCE must be run immediately before - // (and sometime after) copy insertion, to avoid dead code from interfering - // with the rewrites. + // Copy insertion should be performed immediately before IR emission to + // avoid inserting unnecessary copies (later pass adds an instruction which + // materializes the value) or missing a necessary copy (later pass removes + // an instruction which materializes a value). DCE must be run immediately + // before (and sometime after) copy insertion, to avoid dead code from + // interfering with the rewrites. pipeline.AddPass<HloDCE>(); pipeline.AddPass<FlattenCallGraph>(); pipeline.AddPass<CpuCopyInsertion>(); @@ -350,6 +367,15 @@ Status CpuCompiler::RunHloPasses(HloModule* module, bool is_aot_compile, return pipeline.Run(module).status(); } +Status CpuCompiler::RunHloPasses(HloModule* module, bool is_aot_compile, + llvm::TargetMachine* target_machine) { + LLVMTargetMachineFeatures target_machine_features(target_machine); + TF_RETURN_IF_ERROR(RunHloPassesThroughLayoutAssn(module, is_aot_compile, + &target_machine_features)); + return RunHloPassesAfterLayoutAssn(module, is_aot_compile, + &target_machine_features); +} + namespace { // Align buffers to 16-byte boundaries. @@ -453,7 +479,7 @@ Status CreateHloProfilingArtifacts( computation_to_profile_idx, std::unique_ptr<HloProfileIndexMap>* hlo_profile_index_map, std::unique_ptr<HloProfilePrinterData>* hlo_profile_printer_data) { - *hlo_profile_index_map = MakeUnique<HloProfileIndexMap>(module); + *hlo_profile_index_map = absl::make_unique<HloProfileIndexMap>(module); const HloComputation& entry_computation = *module.entry_computation(); TF_ASSIGN_OR_RETURN( @@ -520,11 +546,11 @@ StatusOr<std::unique_ptr<Executable>> CpuCompiler::RunBackend( &pre_optimization_ir_hook, &post_optimization_ir_hook)); // Compile must be thread-safe so create a new LLVM context for the module. - auto llvm_context = xla::MakeUnique<llvm::LLVMContext>(); + auto llvm_context = absl::make_unique<llvm::LLVMContext>(); auto llvm_module = - xla::MakeUnique<llvm::Module>("__compute_module", *llvm_context); + absl::make_unique<llvm::Module>("__compute_module", *llvm_context); - auto jit = xla::MakeUnique<SimpleOrcJIT>( + auto jit = absl::make_unique<SimpleOrcJIT>( CompilerTargetOptions(module->config()), CodeGenOptLevel(module->config()), options::OptimizeForSizeRequested(module->config()), @@ -566,12 +592,12 @@ StatusOr<std::unique_ptr<Executable>> CpuCompiler::RunBackend( // temporary buffers are required to run the computation. TF_ASSIGN_OR_RETURN( std::unique_ptr<BufferAssignment> assignment, - BufferAssigner::Run( - module.get(), - xla::MakeUnique<SequentialHloOrdering>(module.get(), module_sequence), - BufferSizeBytesFunction(), memory_alignment, - /*allow_input_output_aliasing=*/false, - /*allocate_buffers_for_constants=*/true)); + BufferAssigner::Run(module.get(), + absl::make_unique<SequentialHloOrdering>( + module.get(), module_sequence), + BufferSizeBytesFunction(), memory_alignment, + /*allow_input_output_aliasing=*/false, + /*allocate_buffers_for_constants=*/true)); // BufferAssignment::ToString() includes a header, so no need for us to // print one ourselves. XLA_VLOG_LINES(2, assignment->ToString()); @@ -679,8 +705,7 @@ CpuCompiler::CompileAheadOfTime(std::vector<std::unique_ptr<HloModule>> modules, const llvm::Target* target = llvm::TargetRegistry::lookupTarget(triple.getTriple(), error); if (target == nullptr) { - return InternalError("TargetRegistry::lookupTarget failed: %s", - error.c_str()); + return InternalError("TargetRegistry::lookupTarget failed: %s", error); } llvm::Reloc::Model reloc_model = llvm::Reloc::Static; @@ -716,7 +741,7 @@ CpuCompiler::CompileAheadOfTime(std::vector<std::unique_ptr<HloModule>> modules, llvm::StringRef cpu_name = llvm_ir::AsStringRef(options.cpu_name()); llvm::StringRef features = llvm_ir::AsStringRef(options.features()); llvm::CodeGenOpt::Level opt_level = CodeGenOptLevel(modules[0]->config()); - std::unique_ptr<llvm::TargetMachine> target_machine = WrapUnique( + std::unique_ptr<llvm::TargetMachine> target_machine = absl::WrapUnique( target->createTargetMachine(triple.getTriple(), cpu_name, features, CompilerTargetOptions(modules[0]->config()), reloc_model, llvm::None, opt_level)); @@ -757,7 +782,7 @@ CpuCompiler::CompileAheadOfTime(std::vector<std::unique_ptr<HloModule>> modules, std::unique_ptr<BufferAssignment> assignment, BufferAssigner::Run( module, - xla::MakeUnique<SequentialHloOrdering>(module, module_sequence), + absl::make_unique<SequentialHloOrdering>(module, module_sequence), BufferSizeBytesFunction(), memory_alignment, /*allow_input_output_aliasing=*/false, /*allocate_buffers_for_constants=*/true)); @@ -851,7 +876,7 @@ CpuCompiler::CompileAheadOfTime(std::vector<std::unique_ptr<HloModule>> modules, TF_ASSIGN_OR_RETURN(const BufferAllocation::Slice result_slice, assignment->GetUniqueTopLevelOutputSlice()); - results.emplace_back(MakeUnique<CpuAotCompilationResult>( + results.emplace_back(absl::make_unique<CpuAotCompilationResult>( std::move(object_file_data), std::move(buffer_infos), result_slice.index(), std::move(hlo_profile_printer_data))); } @@ -874,7 +899,7 @@ HloCostAnalysis::ShapeSizeFunction CpuCompiler::ShapeSizeBytesFunction() const { static bool InitModule() { xla::Compiler::RegisterCompilerFactory( stream_executor::host::kHostPlatformId, - []() { return xla::MakeUnique<xla::cpu::CpuCompiler>(); }); + []() { return absl::make_unique<xla::cpu::CpuCompiler>(); }); return true; } static bool module_initialized = InitModule(); diff --git a/tensorflow/compiler/xla/service/cpu/cpu_compiler.h b/tensorflow/compiler/xla/service/cpu/cpu_compiler.h index 04e1c48872..47b5edabff 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_compiler.h +++ b/tensorflow/compiler/xla/service/cpu/cpu_compiler.h @@ -20,6 +20,7 @@ limitations under the License. #include "llvm/Target/TargetMachine.h" #include "tensorflow/compiler/tf2xla/cpu_function_runtime.h" +#include "tensorflow/compiler/xla/service/cpu/target_machine_features.h" #include "tensorflow/compiler/xla/service/executable.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/llvm_compiler.h" @@ -157,6 +158,16 @@ class CpuCompiler : public LLVMCompiler { Status RunHloPasses(HloModule* module, bool is_aot_compile, llvm::TargetMachine* target_machine); + // Runs HLO passes up to and including layout assignment. + Status RunHloPassesThroughLayoutAssn( + HloModule* module, bool /*is_aot_compile*/, + LLVMTargetMachineFeatures* target_machine_features); + + // Runs HLO passes after layout assignment. + Status RunHloPassesAfterLayoutAssn( + HloModule* module, bool is_aot_compile, + LLVMTargetMachineFeatures* target_machine_features); + TF_DISALLOW_COPY_AND_ASSIGN(CpuCompiler); }; diff --git a/tensorflow/compiler/xla/service/cpu/cpu_copy_insertion.h b/tensorflow/compiler/xla/service/cpu/cpu_copy_insertion.h index 3313d1e6eb..d49f7d7cc2 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_copy_insertion.h +++ b/tensorflow/compiler/xla/service/cpu/cpu_copy_insertion.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CPU_COPY_INSERTION_H_ -#define TENSORFLOW_COMPILER_XLA_SERVICE_CPU_COPY_INSERTION_H_ +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CPU_CPU_COPY_INSERTION_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_CPU_CPU_COPY_INSERTION_H_ #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/hlo_pass_interface.h" @@ -32,11 +32,11 @@ namespace xla { // (module-scoped). class CpuCopyInsertion : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "copy-insertion"; } + absl::string_view name() const override { return "copy-insertion"; } StatusOr<bool> Run(HloModule* module) override; }; } // namespace xla -#endif // TENSORFLOW_COMPILER_XLA_SERVICE_CPU_COPY_INSERTION_H_ +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_CPU_CPU_COPY_INSERTION_H_ diff --git a/tensorflow/compiler/xla/service/cpu/cpu_executable.cc b/tensorflow/compiler/xla/service/cpu/cpu_executable.cc index c376864c3e..08773693fb 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_executable.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_executable.cc @@ -22,6 +22,9 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "llvm/ExecutionEngine/Orc/IRCompileLayer.h" #include "tensorflow/compiler/xla/service/buffer_assignment.h" #include "tensorflow/compiler/xla/service/computation_layout.h" @@ -35,9 +38,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/mem.h" @@ -171,20 +171,18 @@ Status CpuExecutable::ExecuteComputeFunction( void* result_buffer = buffer_pointers[result_slice.index()]; if (VLOG_IS_ON(3)) { VLOG(3) << "Executing compute function:"; - VLOG(3) << tensorflow::strings::Printf( - " func(void* result, void* params[null], void* temps[%zu], " - "uint64 profile_counters[%zu])", + VLOG(3) << absl::StrFormat( + " func(void* result, void* params[null], void* temps[%u], " + "uint64 profile_counters[%u])", buffer_pointers.size(), profile_counters_size); - VLOG(3) << tensorflow::strings::Printf(" result = %p", result_buffer); + VLOG(3) << absl::StrFormat(" result = %p", result_buffer); auto ptr_printer = [](string* out, const void* p) { - tensorflow::strings::StrAppend(out, tensorflow::strings::Printf("%p", p)); + absl::StrAppend(out, absl::StrFormat("%p", p)); }; VLOG(3) << " params = nullptr"; - VLOG(3) << tensorflow::strings::Printf( - " temps = [%s]", - tensorflow::str_util::Join(buffer_pointers, ", ", ptr_printer).c_str()); - VLOG(3) << tensorflow::strings::Printf(" profile_counters = %p", - profile_counters); + VLOG(3) << absl::StrFormat( + " temps = [%s]", absl::StrJoin(buffer_pointers, ", ", ptr_printer)); + VLOG(3) << absl::StrFormat(" profile_counters = %p", profile_counters); } compute_function_(result_buffer, run_options, nullptr, buffer_pointers.data(), diff --git a/tensorflow/compiler/xla/service/cpu/cpu_hlo_support_checker.cc b/tensorflow/compiler/xla/service/cpu/cpu_hlo_support_checker.cc index 7bd4741a04..7fbe0fa157 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_hlo_support_checker.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_hlo_support_checker.cc @@ -34,9 +34,8 @@ StatusOr<bool> CpuHloSupportChecker::Run(HloModule* module) { return xla::Unimplemented( "CPU backend does not support HLO instruction %s with shape " "containing a sparse layout: %s", - instruction->ToString().c_str(), - ShapeUtil::HumanStringWithLayout(instruction->shape()) - .c_str()); + instruction->ToString(), + ShapeUtil::HumanStringWithLayout(instruction->shape())); } return Status::OK(); })); diff --git a/tensorflow/compiler/xla/service/cpu/cpu_hlo_support_checker.h b/tensorflow/compiler/xla/service/cpu/cpu_hlo_support_checker.h index 2924b63659..6af724b2a5 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_hlo_support_checker.h +++ b/tensorflow/compiler/xla/service/cpu/cpu_hlo_support_checker.h @@ -28,9 +28,7 @@ class CpuHloSupportChecker : public HloPassInterface { CpuHloSupportChecker() = default; ~CpuHloSupportChecker() override = default; - tensorflow::StringPiece name() const override { - return "cpu_hlo_support_checker"; - } + absl::string_view name() const override { return "cpu_hlo_support_checker"; } // Note: always returns false (no instructions are ever modified by this // pass). diff --git a/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion.cc b/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion.cc index b40d264c03..7f867fa149 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion.cc @@ -78,7 +78,7 @@ bool CpuInstructionFusion::ShouldFuse(HloInstruction* consumer, } if (!CanBeLoopFused(*producer)) { - VLOG(2) << "Producer is not fusile."; + VLOG(2) << "Producer is not fusible."; return false; } @@ -140,7 +140,7 @@ bool CpuInstructionFusion::ShouldFuse(HloInstruction* consumer, } if (CanBeLoopFused(*consumer)) { - VLOG(2) << "Fusing: consumer is elementwise or fusile."; + VLOG(2) << "Fusing: consumer is elementwise or fusible."; return true; } diff --git a/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion_test.cc b/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion_test.cc index e6130c7d76..28aaa28cdb 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion_test.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion_test.cc @@ -18,6 +18,7 @@ limitations under the License. #include <algorithm> #include <set> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/service/transpose_folding.h" @@ -566,7 +567,7 @@ TEST_F(OpcodeFusionTest, DynamicSliceWithDynamicUpdateSlice) { HloOpcode::kParameter, HloOpcode::kParameter}); } -TEST_F(OpcodeFusionTest, MessOfFusileNodes) { +TEST_F(OpcodeFusionTest, MessOfFusibleNodes) { auto module = CreateNewModule(); HloComputation::Builder builder(TestName()); @@ -773,8 +774,8 @@ class GatherLoopFusionTest TEST_P(GatherLoopFusionTest, GatherLoopFusion) { const GatherLoopFusionTestSpec& spec = GetParam(); - string hlo_string = tensorflow::strings::StrCat( - "HloModule ", spec.test_name, "\n\n", spec.hlo_computation_text); + string hlo_string = absl::StrCat("HloModule ", spec.test_name, "\n\n", + spec.hlo_computation_text); TF_ASSERT_OK_AND_ASSIGN(std::unique_ptr<HloModule> module, ParseHloString(hlo_string)); diff --git a/tensorflow/compiler/xla/service/cpu/cpu_layout_assignment.cc b/tensorflow/compiler/xla/service/cpu/cpu_layout_assignment.cc index aa872d5ec9..bfecbd6e01 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_layout_assignment.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_layout_assignment.cc @@ -34,8 +34,8 @@ namespace cpu { // instruction stream. namespace { -using ::tensorflow::gtl::nullopt; -using ::tensorflow::gtl::optional; +using absl::nullopt; +using absl::optional; using ShouldMakeOperandColMajorCache = tensorflow::gtl::FlatMap<const HloInstruction*, bool>; diff --git a/tensorflow/compiler/xla/service/cpu/cpu_options.cc b/tensorflow/compiler/xla/service/cpu/cpu_options.cc index 3ed7876715..b8ace57026 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_options.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_options.cc @@ -15,8 +15,9 @@ limitations under the License. #include "tensorflow/compiler/xla/service/cpu/cpu_options.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_split.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace { @@ -45,17 +46,16 @@ bool VectorizedReduceDisabled(const HloModuleConfig& config) { return extra_options_map.count(kXlaOptimizeForSizeCpuOption) > 0; } -tensorflow::gtl::optional<int64> LlvmIrGemvTilingFactor( - const HloModuleConfig& config) { +absl::optional<int64> LlvmIrGemvTilingFactor(const HloModuleConfig& config) { const auto& extra_options_map = config.debug_options().xla_backend_extra_options(); auto it = extra_options_map.find(kLlvmIrDotTilingFactor); int64 tiling_factor; if (it != extra_options_map.end() && - tensorflow::strings::safe_strto64(it->second, &tiling_factor)) { + absl::SimpleAtoi(it->second, &tiling_factor)) { return tiling_factor; } - return tensorflow::gtl::nullopt; + return absl::nullopt; } bool EnableExperimentalLlvmIrGemm(const HloModuleConfig& config) { @@ -64,38 +64,37 @@ bool EnableExperimentalLlvmIrGemm(const HloModuleConfig& config) { return extra_options_map.count(kXlaEnableExperimentalLlvmIrGemm) > 0; } -static tensorflow::StringPiece RemoveSuffix(tensorflow::StringPiece str, - tensorflow::StringPiece suffix) { +static absl::string_view RemoveSuffix(absl::string_view str, + absl::string_view suffix) { CHECK_GE(str.size(), suffix.size()); CHECK_EQ(str.substr(str.size() - suffix.size()), suffix); return str.substr(0, str.size() - suffix.size()); } -tensorflow::gtl::optional<std::tuple<int64, int64, int64>> LlvmIrGemmTileSize( +absl::optional<std::tuple<int64, int64, int64>> LlvmIrGemmTileSize( const HloModuleConfig& config) { const auto& extra_options_map = config.debug_options().xla_backend_extra_options(); auto it = extra_options_map.find(kLlvmIrGemmTileSize); if (it == extra_options_map.end()) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } - std::vector<string> tile_components = - tensorflow::str_util::Split(it->second, ':'); + std::vector<string> tile_components = absl::StrSplit(it->second, ':'); CHECK_EQ(tile_components.size(), 3); int64 tile_size_m; int64 tile_size_k; int64 tile_size_n_in_vector_width; - CHECK(tensorflow::strings::safe_strto64(tile_components[0], &tile_size_m)); - CHECK(tensorflow::strings::safe_strto64(tile_components[1], &tile_size_k)); + CHECK(absl::SimpleAtoi(tile_components[0], &tile_size_m)); + CHECK(absl::SimpleAtoi(tile_components[1], &tile_size_k)); - tensorflow::StringPiece tile_size_n_in_vector_width_str = + absl::string_view tile_size_n_in_vector_width_str = RemoveSuffix(tile_components[2], "*vectwidth"); - CHECK(tensorflow::strings::safe_strto64(tile_size_n_in_vector_width_str, - &tile_size_n_in_vector_width)); + CHECK(absl::SimpleAtoi(tile_size_n_in_vector_width_str, + &tile_size_n_in_vector_width)); return std::tuple<int64, int64, int64>(tile_size_m, tile_size_k, tile_size_n_in_vector_width); diff --git a/tensorflow/compiler/xla/service/cpu/cpu_options.h b/tensorflow/compiler/xla/service/cpu/cpu_options.h index 429b9e16cb..47c7eb13b6 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_options.h +++ b/tensorflow/compiler/xla/service/cpu/cpu_options.h @@ -27,9 +27,8 @@ namespace options { bool OptimizeForSizeRequested(const HloModuleConfig& config); bool VectorizedReduceDisabled(const HloModuleConfig& config); bool EnableExperimentalLlvmIrGemm(const HloModuleConfig& config); -tensorflow::gtl::optional<int64> LlvmIrGemvTilingFactor( - const HloModuleConfig& config); -tensorflow::gtl::optional<std::tuple<int64, int64, int64>> LlvmIrGemmTileSize( +absl::optional<int64> LlvmIrGemvTilingFactor(const HloModuleConfig& config); +absl::optional<std::tuple<int64, int64, int64>> LlvmIrGemmTileSize( const HloModuleConfig& config); } // namespace options diff --git a/tensorflow/compiler/xla/service/cpu/cpu_runtime_test.cc b/tensorflow/compiler/xla/service/cpu/cpu_runtime_test.cc index 2ac950e6d9..1ae3aa5711 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_runtime_test.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_runtime_test.cc @@ -19,16 +19,16 @@ limitations under the License. #include <string> #include <tuple> +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/client/local_client.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/cpu/runtime_matmul.h" #include "tensorflow/compiler/xla/service/cpu/runtime_matmul_mkl.h" #include "tensorflow/compiler/xla/service/cpu/runtime_single_threaded_matmul.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/common_runtime/eigen_thread_pool.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/test.h" @@ -46,7 +46,7 @@ std::unique_ptr<Array2D<float>> MaybeTransposeArray2D(const Array2D<T>& array, if (transpose) { std::swap(output_width, output_height); } - auto output = MakeUnique<Array2D<float>>(output_height, output_width); + auto output = absl::make_unique<Array2D<float>>(output_height, output_width); for (int y = 0; y < array.height(); y++) { for (int x = 0; x < array.width(); x++) { if (transpose) { @@ -93,7 +93,7 @@ std::unique_ptr<Array2D<float>> EigenMatrixMultiply(const Array2D<float>& a, // Since we're going to transpose c before returning it. Swap the order of the // dimension sizes to ensure the returned array is properly dimensioned. - auto c_transpose = MakeUnique<Array2D<float>>(n, m); + auto c_transpose = absl::make_unique<Array2D<float>>(n, m); if (single_threaded) { __xla_cpu_runtime_EigenSingleThreadedMatMulF32( nullptr, c_transpose->data(), a_transpose->data(), b_transpose->data(), @@ -142,10 +142,10 @@ class EigenMatMulTest : public CpuRuntimeTest, bool transpose_rhs = std::get<2>(info.param); bool single_threaded = std::get<3>(info.param); - return tensorflow::strings::Printf( - "EigenMatMul_%lld_%lld_%lld_%s%s%s_threaded", shape.m, shape.k, shape.n, - transpose_lhs ? "Tlhs_" : "", transpose_rhs ? "Trhs_" : "", - single_threaded ? "single" : "multi"); + return absl::StrFormat("EigenMatMul_%d_%d_%d_%s%s%s_threaded", shape.m, + shape.k, shape.n, transpose_lhs ? "Tlhs_" : "", + transpose_rhs ? "Trhs_" : "", + single_threaded ? "single" : "multi"); } }; @@ -178,10 +178,10 @@ class MKLMatMulTest : public CpuRuntimeTest, bool transpose_rhs = std::get<2>(info.param); bool single_threaded = std::get<3>(info.param); - return tensorflow::strings::Printf( - "MKLMatMul_%lld_%lld_%lld_%s%s%s_threaded", shape.m, shape.k, shape.n, - transpose_lhs ? "Tlhs_" : "", transpose_rhs ? "Trhs_" : "", - single_threaded ? "single" : "multi"); + return absl::StrFormat("MKLMatMul_%d_%d_%d_%s%s%s_threaded", shape.m, + shape.k, shape.n, transpose_lhs ? "Tlhs_" : "", + transpose_rhs ? "Trhs_" : "", + single_threaded ? "single" : "multi"); } }; @@ -204,7 +204,7 @@ std::unique_ptr<Array2D<float>> MKLMatrixMultiply(const Array2D<float>& a, // Since we're going to transpose c before returning it, swap the order of the // dimension sizes to ensure the returned array is properly dimensioned. - auto c_transpose = MakeUnique<Array2D<float>>(n, m); + auto c_transpose = absl::make_unique<Array2D<float>>(n, m); if (single_threaded) { __xla_cpu_runtime_MKLSingleThreadedMatMulF32( nullptr, c_transpose->data(), a_transpose->data(), b_transpose->data(), diff --git a/tensorflow/compiler/xla/service/cpu/cpu_transfer_manager.cc b/tensorflow/compiler/xla/service/cpu/cpu_transfer_manager.cc index 59bc7e0e16..0df2abf001 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_transfer_manager.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_transfer_manager.cc @@ -19,6 +19,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/cpu/cpu_runtime.h" @@ -103,7 +104,7 @@ Status CpuTransferManager::TransferLiteralToInfeed( if (ShapeUtil::IsNestedTuple(shape)) { return Unimplemented( "Infeed with a nested tuple shape is not supported: %s", - ShapeUtil::HumanString(literal.shape()).c_str()); + ShapeUtil::HumanString(literal.shape())); } // For a tuple, we transfer each of its elements to the device and @@ -151,11 +152,11 @@ CpuTransferManager::TransferBufferToInfeedInternal(se::StreamExecutor* executor, int64 size, const void* source) { if (size > std::numeric_limits<int32>::max()) { - return InvalidArgument("Infeed shape is too large: needs %lld bytes", size); + return InvalidArgument("Infeed shape is too large: needs %d bytes", size); } if (size <= 0) { - return InvalidArgument("Infeed shape must have positive size; got %lld", + return InvalidArgument("Infeed shape must have positive size; got %d", size); } @@ -243,12 +244,12 @@ StatusOr<Shape> CpuTransferManager::TransferBuffersFromOutfeedInternal( for (auto b : buffer_data) { int64 size = b.second; if (size > std::numeric_limits<int32>::max()) { - return InvalidArgument("Outfeed shape is too large: needs %lld bytes", + return InvalidArgument("Outfeed shape is too large: needs %d bytes", size); } if (size <= 0) { - return InvalidArgument("Outfeed shape must have positive size; got %lld", + return InvalidArgument("Outfeed shape must have positive size; got %d", size); } @@ -256,7 +257,7 @@ StatusOr<Shape> CpuTransferManager::TransferBuffersFromOutfeedInternal( VLOG(2) << "Enqueueing outfeed buffer (for the device to populate) of length " << size_32 << "B"; - buffers.emplace_back(MakeUnique<CpuOutfeedBuffer>(b.first, size_32)); + buffers.emplace_back(absl::make_unique<CpuOutfeedBuffer>(b.first, size_32)); } std::vector<cpu::runtime::XfeedBuffer*> buffer_pointers; @@ -283,7 +284,7 @@ StatusOr<Shape> CpuTransferManager::TransferBuffersFromOutfeedInternal( } // namespace xla static std::unique_ptr<xla::TransferManager> CreateCpuTransferManager() { - return xla::MakeUnique<xla::CpuTransferManager>(); + return absl::make_unique<xla::CpuTransferManager>(); } static bool InitModule() { diff --git a/tensorflow/compiler/xla/service/cpu/cpu_transfer_manager.h b/tensorflow/compiler/xla/service/cpu/cpu_transfer_manager.h index 80ef953d53..7b938e9fd7 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_transfer_manager.h +++ b/tensorflow/compiler/xla/service/cpu/cpu_transfer_manager.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CPU_TRANSFER_MANAGER_H_ -#define TENSORFLOW_COMPILER_XLA_SERVICE_CPU_TRANSFER_MANAGER_H_ +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CPU_CPU_TRANSFER_MANAGER_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_CPU_CPU_TRANSFER_MANAGER_H_ #include <vector> @@ -76,4 +76,4 @@ class CpuTransferManager : public GenericTransferManager { } // namespace xla -#endif // TENSORFLOW_COMPILER_XLA_SERVICE_CPU_TRANSFER_MANAGER_H_ +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_CPU_CPU_TRANSFER_MANAGER_H_ diff --git a/tensorflow/compiler/xla/service/cpu/disassembler.cc b/tensorflow/compiler/xla/service/cpu/disassembler.cc index e4c674e227..3ae64142cd 100644 --- a/tensorflow/compiler/xla/service/cpu/disassembler.cc +++ b/tensorflow/compiler/xla/service/cpu/disassembler.cc @@ -21,13 +21,13 @@ limitations under the License. #include <type_traits> #include <vector> +#include "absl/strings/str_format.h" #include "llvm/MC/MCInst.h" #include "llvm/Support/TargetRegistry.h" #include "llvm/Support/raw_ostream.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -151,7 +151,7 @@ StatusOr<DisassemblerResult> Disassembler::DisassembleObjectFile( size = 1; } - ostream << tensorflow::strings::Printf("0x%08lx", index) << " "; + ostream << absl::StrFormat("0x%08lx", index) << " "; if (decode_status == llvm::MCDisassembler::Success) { // For branches, try to determine the actual address and emit it as an @@ -163,7 +163,7 @@ StatusOr<DisassemblerResult> Disassembler::DisassembleObjectFile( uint64_t target; if (inst_analysis_->evaluateBranch( instruction, section_address + index, size, target)) { - annotation = tensorflow::strings::Printf("[0x%08lx]", target); + annotation = absl::StrFormat("[0x%08lx]", target); } } inst_printer_->printInst(&instruction, ostream, annotation.c_str(), diff --git a/tensorflow/compiler/xla/service/cpu/dot_op_emitter.cc b/tensorflow/compiler/xla/service/cpu/dot_op_emitter.cc index f2ac742b6e..dd060f54a2 100644 --- a/tensorflow/compiler/xla/service/cpu/dot_op_emitter.cc +++ b/tensorflow/compiler/xla/service/cpu/dot_op_emitter.cc @@ -18,6 +18,7 @@ limitations under the License. #include <memory> #include <vector> +#include "absl/strings/str_cat.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Instructions.h" #include "llvm/IR/Module.h" @@ -146,9 +147,9 @@ class GemvConfig { bool has_addend() const { return has_addend_; } string GetCacheKey() const { - return tensorflow::strings::StrCat( - name_, "_", PrimitiveType_Name(scalar_type()), "_", tile_rows(), "_", - tile_cols(), "_", m(), "_", k(), has_addend() ? "_with_addend" : ""); + return absl::StrCat(name_, "_", PrimitiveType_Name(scalar_type()), "_", + tile_rows(), "_", tile_cols(), "_", m(), "_", k(), + has_addend() ? "_with_addend" : ""); } protected: @@ -621,19 +622,19 @@ void RowMajorMatrixVectorProductEmitter::EmitInnerLoopEpilogue( } // This class implements a tiled matrix multiplication algorithm, intended for -// use as the innermost GEBP loop in a GEMM kernel (GEBP is described in "Goto, -// Kazushige, and Robert Van De Geijn. "High-performance implementation of the -// level-3 BLAS." ACM Transactions on Mathematical Software (TOMS) 35.1 (2008): -// 4). +// multiplying small matrices that don't need cache tiling. +// +// In the future this can be used as the innermost GEBP loop in a GEMM kernel as +// described in "Goto, Kazushige, and Robert A. Geijn. "Anatomy of +// high-performance matrix multiplication." ACM Transactions on Mathematical +// Software (TOMS) 34.3 (2008): 12.". // // This only supports canonical dot operations (i.e. where the lhs contraction // dimension is 1 and the rhs contraction dimension is 0) over row major // matrices. -class MatrixMatrixBlockPanelEmitter { +class TiledSmallGemmEmitter { public: - // Describe the dimensions of the GEBP kernel. These will usually not be the - // dimensions of the GEMM itself, the GEMM will usually be broken up into GEBP - // kernels with smaller dimensions. + // Describe the dimensions of the kernel. class Dimensions { public: explicit Dimensions(int64 m, int64 k, int64 n) : m_(m), k_(k), n_(n) {} @@ -642,9 +643,7 @@ class MatrixMatrixBlockPanelEmitter { int64 k() const { return k_; } int64 n() const { return n_; } - string ToString() const { - return tensorflow::strings::StrCat(m(), "x", k(), "x", n()); - } + string ToString() const { return absl::StrCat(m(), "x", k(), "x", n()); } private: const int64 m_; @@ -652,9 +651,9 @@ class MatrixMatrixBlockPanelEmitter { const int64 n_; }; - // Represents the configuration of the GEBP emitter. The LLVM IR emitted by - // the emitter, modulo the LLVM values holding the input and output buffers, - // must be a function of the instance of `Config` passed to it. + // Represents the configuration of the emitter. The LLVM IR emitted by the + // emitter, modulo the LLVM values holding the input and output buffers, must + // be a function of the instance of `Config` passed to it. // // `dims` holds the matrix multiplication dimensions. // @@ -687,10 +686,10 @@ class MatrixMatrixBlockPanelEmitter { tile_size_k_(tile_size_k) {} string GetCacheKey() const { - return tensorflow::strings::StrCat( - "gebp_", PrimitiveType_Name(scalar_type()), "_", dims().ToString(), - "_", max_vectorization_width(), "_", min_vectorization_width(), "_", - tile_size_m(), "_", tile_size_k()); + return absl::StrCat("gemm_", PrimitiveType_Name(scalar_type()), "_", + dims().ToString(), "_", max_vectorization_width(), + "_", min_vectorization_width(), "_", tile_size_m(), + "_", tile_size_k()); } PrimitiveType scalar_type() const { return scalar_type_; } @@ -712,11 +711,11 @@ class MatrixMatrixBlockPanelEmitter { int64 tile_size_k_; }; - // Creates an instance of MatrixMatrixBlockPanelEmitter that matrix-multiplies + // Creates an instance of TiledSmallGemmEmitter that matrix-multiplies // `lhs` with `rhs` and stores the result in `result`. - explicit MatrixMatrixBlockPanelEmitter(Config config, llvm::Value* lhs, - llvm::Value* rhs, llvm::Value* result, - llvm::IRBuilder<>* b) + explicit TiledSmallGemmEmitter(Config config, llvm::Value* lhs, + llvm::Value* rhs, llvm::Value* result, + llvm::IRBuilder<>* b) : lhs_(lhs), rhs_(rhs), result_(result), @@ -780,9 +779,9 @@ class MatrixMatrixBlockPanelEmitter { KernelSupportLibrary ksl_; }; -void MatrixMatrixBlockPanelEmitter::Emit() { HandleResiduesOnN(); } +void TiledSmallGemmEmitter::Emit() { HandleResiduesOnN(); } -void MatrixMatrixBlockPanelEmitter::HandleResiduesOnN() { +void TiledSmallGemmEmitter::HandleResiduesOnN() { // We can only iterate the `n` dimension for an extent that is divisible by // the vectorization width. So we emit an outer loop that first processes the // largest extent in `n` that is divisible by max_vectorization_width, then @@ -799,7 +798,7 @@ void MatrixMatrixBlockPanelEmitter::HandleResiduesOnN() { int64 n_end = dims().n() - (dims().n() % current_vectorization_width); if (n_start != n_end) { VectorSupportLibrary vsl(scalar_type(), current_vectorization_width, b_, - "gebp"); + "gemm"); HandleResiduesOnK(&vsl, GetInt64(n_start), GetInt64(n_end)); n_start = n_end; } @@ -813,7 +812,7 @@ void MatrixMatrixBlockPanelEmitter::HandleResiduesOnN() { } if (n_start != dims().n()) { - VectorSupportLibrary vsl(scalar_type(), 1, b_, "gebp"); + VectorSupportLibrary vsl(scalar_type(), 1, b_, "gemm"); ksl_.ForReturnVoid("epi.n", n_start, dims().n(), 1, [&](llvm::Value* n_i) { llvm::Value* n_i_next = b_->CreateAdd(n_i, b_->getInt64(1)); HandleResiduesOnK(&vsl, n_i, n_i_next); @@ -821,9 +820,9 @@ void MatrixMatrixBlockPanelEmitter::HandleResiduesOnN() { } } -void MatrixMatrixBlockPanelEmitter::HandleResiduesOnK(VectorSupportLibrary* vsl, - llvm::Value* n_start, - llvm::Value* n_end) { +void TiledSmallGemmEmitter::HandleResiduesOnK(VectorSupportLibrary* vsl, + llvm::Value* n_start, + llvm::Value* n_end) { int64 k_start = 0; int64 k_end = dims().k() - (dims().k() % tile_size_k()); if (k_end != k_start) { @@ -838,7 +837,7 @@ void MatrixMatrixBlockPanelEmitter::HandleResiduesOnK(VectorSupportLibrary* vsl, } } -void MatrixMatrixBlockPanelEmitter::HandleResiduesOnM( +void TiledSmallGemmEmitter::HandleResiduesOnM( VectorSupportLibrary* vsl, int64 tile_size_k, llvm::Value* k_start, llvm::Value* k_end, llvm::Value* n_start, llvm::Value* n_end) { const int64 m_end = dims().m() - dims().m() % tile_size_m(); @@ -921,7 +920,7 @@ void MatrixMatrixBlockPanelEmitter::HandleResiduesOnM( // +-------------------+-------------------+-------------------+--------- // | a0*p0+b0*q0+c0*r0 | a0*p1+b0*q1+c0*r1 | a0*p2+b0*q2+c0*r2 | ... // +-------------------+-------------------+-------------------+--------- -void MatrixMatrixBlockPanelEmitter::EmitTiledGemm( +void TiledSmallGemmEmitter::EmitTiledGemm( VectorSupportLibrary* vsl, int64 tile_size_k, llvm::Value* k_start, llvm::Value* k_end, llvm::Value* n_start, llvm::Value* n_end, int64 tile_size_m, llvm::Value* m_start, llvm::Value* m_end) { @@ -1001,12 +1000,22 @@ DotOpEmitter::DotOpEmitter(const HloInstruction& dot, return dot_emitter.Emit(); } -bool DotOpEmitter::EmitExperimentalGebpDotIfEnabled( +bool DotOpEmitter::EmitSmallGemmIfProfitable( const DotOpEmitter::MatMultDims& mat_mult_dims) { - if (!EnableExperimentalLlvmIrGemm() || ShouldUseMultiThreadedEigen()) { + if (ShouldUseMultiThreadedEigen()) { return false; } + if (!EnableExperimentalLlvmIrGemm()) { + // TODO(sanjoy): We should make these numbers micro-arch specific. + bool small_gemm = mat_mult_dims.k <= 128 && + ((mat_mult_dims.m <= 32 && mat_mult_dims.n <= 128) || + (mat_mult_dims.m <= 128 && mat_mult_dims.n <= 32)); + if (!small_gemm) { + return false; + } + } + if (mat_mult_dims.lhs_non_canonical || mat_mult_dims.rhs_non_canonical) { return false; } @@ -1054,15 +1063,15 @@ bool DotOpEmitter::EmitExperimentalGebpDotIfEnabled( std::tie(tile_size_m, tile_size_k, tile_size_n_in_vector_width) = GetGemmTileSize(); - MatrixMatrixBlockPanelEmitter::Config config( + TiledSmallGemmEmitter::Config config( /*scalar_type=*/primitive_type, - MatrixMatrixBlockPanelEmitter::Dimensions{/*m=*/m, /*k=*/k, /*n=*/n}, + TiledSmallGemmEmitter::Dimensions{/*m=*/m, /*k=*/k, /*n=*/n}, /*max_vectorization_width=*/max_target_vector_width, /*max_vector_count=*/tile_size_n_in_vector_width, /*min_vectorization_width=*/std::min<int64>(4, max_target_vector_width), /*tile_size_m=*/tile_size_m, /*tile_size_k=*/tile_size_k); - VLOG(2) << "Emitting GEBP kernel in LLVM IR with config " + VLOG(2) << "Emitting GEMM kernel in LLVM IR with config " << config.GetCacheKey(); const bool enable_fast_math = @@ -1075,10 +1084,10 @@ bool DotOpEmitter::EmitExperimentalGebpDotIfEnabled( /*optimize_for_size=*/optimize_for_size, b_, config.GetCacheKey(), lhs, rhs, target, [this, config](llvm::Value* lhs, llvm::Value* rhs, llvm::Value* target) { - MatrixMatrixBlockPanelEmitter gebp_emitter(config, /*lhs=*/lhs, - /*rhs=*/rhs, - /*result=*/target, b_); - gebp_emitter.Emit(); + TiledSmallGemmEmitter small_gemm_emitter(config, /*lhs=*/lhs, + /*rhs=*/rhs, + /*result=*/target, b_); + small_gemm_emitter.Emit(); }); return true; @@ -1136,7 +1145,7 @@ bool DotOpEmitter::EmitLlvmIrDotIfProfitable() { } if (!is_column_major_matrix_vector && !is_row_major_matrix_vector) { - return EmitExperimentalGebpDotIfEnabled(mat_mult_dims); + return EmitSmallGemmIfProfitable(mat_mult_dims); } int64 tiling_factor = GetGemvTilingFactor(); @@ -1458,7 +1467,7 @@ Status DotOpEmitter::EmitCallToRuntime() { break; default: return Unimplemented("Invalid type %s for dot operation", - PrimitiveType_Name(type).c_str()); + PrimitiveType_Name(type)); } llvm::Type* float_ptr_type = float_type->getPointerTo(); @@ -1610,7 +1619,7 @@ bool PotentiallyImplementedAsEigenDot( // For vector-matrix dot products, it is always profitable to make the Rhs // column major. -tensorflow::gtl::optional<int64> ProfitableToMakeDotOperandColumnMajor( +absl::optional<int64> ProfitableToMakeDotOperandColumnMajor( const HloInstruction& hlo) { if (hlo.opcode() == HloOpcode::kDot && hlo.shape().dimensions_size() == 2 && hlo.shape().dimensions(0) == 1) { diff --git a/tensorflow/compiler/xla/service/cpu/dot_op_emitter.h b/tensorflow/compiler/xla/service/cpu/dot_op_emitter.h index 590032fbe9..4c2041b556 100644 --- a/tensorflow/compiler/xla/service/cpu/dot_op_emitter.h +++ b/tensorflow/compiler/xla/service/cpu/dot_op_emitter.h @@ -16,6 +16,7 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CPU_DOT_OP_EMITTER_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_CPU_DOT_OP_EMITTER_H_ +#include "absl/strings/string_view.h" #include "llvm/IR/IRBuilder.h" #include "tensorflow/compiler/xla/service/cpu/cpu_options.h" #include "tensorflow/compiler/xla/service/cpu/target_machine_features.h" @@ -25,7 +26,6 @@ limitations under the License. #include "tensorflow/compiler/xla/service/llvm_ir/llvm_loop.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/types.h" namespace xla { @@ -38,7 +38,7 @@ bool PotentiallyImplementedAsEigenDot( // Returns the index for an operand to `hlo` that should ideally be column // major. Returns nullopt if there is no such operand or if `hlo` is not a dot // or a fusion containing a dot. -tensorflow::gtl::optional<int64> ProfitableToMakeDotOperandColumnMajor( +absl::optional<int64> ProfitableToMakeDotOperandColumnMajor( const HloInstruction& hlo); // Returns true to indicate that we can generate a tiled LLVM IR implementation @@ -121,7 +121,7 @@ class DotOpEmitter { // of rank 2 as well). MatMultDims GetMatMultDims() const; - bool EmitExperimentalGebpDotIfEnabled(const MatMultDims& mat_mult_dims); + bool EmitSmallGemmIfProfitable(const MatMultDims& mat_mult_dims); // When doing a tiled GEMV in LLVM IR, a "tile" consists of this many vector // registers. diff --git a/tensorflow/compiler/xla/service/cpu/elemental_ir_emitter.cc b/tensorflow/compiler/xla/service/cpu/elemental_ir_emitter.cc index db54454707..c8312d80bd 100644 --- a/tensorflow/compiler/xla/service/cpu/elemental_ir_emitter.cc +++ b/tensorflow/compiler/xla/service/cpu/elemental_ir_emitter.cc @@ -30,15 +30,16 @@ limitations under the License. namespace xla { namespace cpu { -StatusOr<llvm::Value*> CpuElementalIrEmitter::EmitAtan2( - PrimitiveType prim_type, llvm::Value* lhs, llvm::Value* rhs) const { +StatusOr<llvm::Value*> CpuElementalIrEmitter::EmitAtan2(PrimitiveType prim_type, + llvm::Value* lhs, + llvm::Value* rhs) { string function_name; bool cast_result_to_fp16 = false; switch (prim_type) { case F16: cast_result_to_fp16 = true; - lhs = b_->CreateFPCast(lhs, b_->getFloatTy()); - rhs = b_->CreateFPCast(rhs, b_->getFloatTy()); + lhs = FPCast(lhs, b_->getFloatTy()); + rhs = FPCast(rhs, b_->getFloatTy()); TF_FALLTHROUGH_INTENDED; case F32: function_name = "atan2f"; @@ -58,21 +59,21 @@ StatusOr<llvm::Value*> CpuElementalIrEmitter::EmitAtan2( function->setDoesNotThrow(); function->setDoesNotAccessMemory(); // Create an instruction to call the function. - llvm::Value* result = b_->CreateCall(function, {lhs, rhs}); + llvm::Value* result = Call(function, {lhs, rhs}); if (cast_result_to_fp16) { - result = b_->CreateFPCast(result, b_->getHalfTy()); + result = FPCast(result, b_->getHalfTy()); } return result; } -StatusOr<llvm::Value*> CpuElementalIrEmitter::EmitTanh( - PrimitiveType prim_type, llvm::Value* value) const { +StatusOr<llvm::Value*> CpuElementalIrEmitter::EmitTanh(PrimitiveType prim_type, + llvm::Value* value) { bool cast_result_to_fp16 = false; string function_name; switch (prim_type) { case F16: cast_result_to_fp16 = true; - value = b_->CreateFPCast(value, b_->getFloatTy()); + value = FPCast(value, b_->getFloatTy()); TF_FALLTHROUGH_INTENDED; case F32: function_name = "tanhf"; @@ -91,16 +92,16 @@ StatusOr<llvm::Value*> CpuElementalIrEmitter::EmitTanh( function->setDoesNotThrow(); function->setDoesNotAccessMemory(); // Create an instruction to call the function. - llvm::Value* result = b_->CreateCall(function, value); + llvm::Value* result = Call(function, value); if (cast_result_to_fp16) { - result = b_->CreateFPCast(result, b_->getHalfTy()); + result = FPCast(result, b_->getHalfTy()); } return result; } llvm_ir::ElementGenerator CpuElementalIrEmitter::MakeElementGenerator( const HloInstruction* hlo, - const HloToElementGeneratorMap& operand_to_generator) const { + const HloToElementGeneratorMap& operand_to_generator) { if (hlo->opcode() == HloOpcode::kMap) { return [this, hlo, &operand_to_generator]( const llvm_ir::IrArray::Index& index) -> StatusOr<llvm::Value*> { diff --git a/tensorflow/compiler/xla/service/cpu/elemental_ir_emitter.h b/tensorflow/compiler/xla/service/cpu/elemental_ir_emitter.h index 76833e765d..e3fba9306b 100644 --- a/tensorflow/compiler/xla/service/cpu/elemental_ir_emitter.h +++ b/tensorflow/compiler/xla/service/cpu/elemental_ir_emitter.h @@ -36,13 +36,13 @@ class CpuElementalIrEmitter : public ElementalIrEmitter { llvm_ir::ElementGenerator MakeElementGenerator( const HloInstruction* hlo, - const HloToElementGeneratorMap& operand_to_generator) const override; + const HloToElementGeneratorMap& operand_to_generator) override; protected: StatusOr<llvm::Value*> EmitAtan2(PrimitiveType prim_type, llvm::Value* lhs, - llvm::Value* rhs) const override; + llvm::Value* rhs) override; StatusOr<llvm::Value*> EmitTanh(PrimitiveType prim_type, - llvm::Value* value) const override; + llvm::Value* value) override; IrEmitter* ir_emitter_; }; diff --git a/tensorflow/compiler/xla/service/cpu/ir_emitter.cc b/tensorflow/compiler/xla/service/cpu/ir_emitter.cc index 6f433b4f30..460363e18f 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_emitter.cc +++ b/tensorflow/compiler/xla/service/cpu/ir_emitter.cc @@ -27,6 +27,8 @@ limitations under the License. #include "tensorflow/core/lib/math/math_util.h" #include "tensorflow/core/platform/logging.h" // IWYU pragma: no_include "llvm/IR/Intrinsics.gen.inc" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "llvm/CodeGen/TargetRegisterInfo.h" #include "llvm/CodeGen/TargetSubtargetInfo.h" #include "llvm/IR/BasicBlock.h" @@ -67,8 +69,6 @@ limitations under the License. #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/lib/gtl/flatmap.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" namespace xla { @@ -170,9 +170,9 @@ IrEmitter::~IrEmitter() {} Status IrEmitter::HandleBitcast(HloInstruction* bitcast) { VLOG(2) << "HandleBitcast: " << bitcast->ToString(); emitted_value_[bitcast] = - b_.CreateBitCast(GetEmittedValueFor(bitcast->operand(0)), - IrShapeType(bitcast->shape())->getPointerTo(), - AsStringRef(IrName(bitcast))); + BitCast(GetEmittedValueFor(bitcast->operand(0)), + IrShapeType(bitcast->shape())->getPointerTo(), + AsStringRef(IrName(bitcast))); return Status::OK(); } @@ -230,9 +230,8 @@ Status IrEmitter::HandleCopy(HloInstruction* copy) { // Use the elemental emitter for array shapes. return DefaultAction(copy); } - return Unimplemented( - "unsupported operand type %s for copy instruction", - PrimitiveType_Name(copy->shape().element_type()).c_str()); + return Unimplemented("unsupported operand type %s for copy instruction", + PrimitiveType_Name(copy->shape().element_type())); } // Calculate the alignment of a buffer allocated for a given primitive type. @@ -389,7 +388,7 @@ Status IrEmitter::EmitXfeedTransfer(XfeedKind kind, const Shape& shape, int64 length = ByteSizeOf(shape); if (length <= 0 || length > std::numeric_limits<int32>::max()) { return InvalidArgument( - "xfeed (infeed or outfeed) buffer length %lld is outside the valid " + "xfeed (infeed or outfeed) buffer length %d is outside the valid " "size range", length); } @@ -440,22 +439,22 @@ Status IrEmitter::EmitXfeedTransfer(XfeedKind kind, const Shape& shape, // of size exactly 'length_32', and the runtime is responsible for // check-failing the process if there is a mismatch, versus passing us back a // buffer that we might overrun. - llvm::Value* acquired_pointer = b_.CreateCall( - acquire_func, - {b_.getInt32(length_32), shape_ptr, b_.getInt32(shape_length)}); + llvm::Value* acquired_pointer = + Call(acquire_func, + {b_.getInt32(length_32), shape_ptr, b_.getInt32(shape_length)}); if (kind == XfeedKind::kInfeed) { // Copy to the program buffer address from the acquired buffer. - b_.CreateMemCpy(program_buffer_address, /*DstAlign=*/1, acquired_pointer, - /*SrcAlign=*/1, length_32); + MemCpy(program_buffer_address, /*DstAlign=*/1, acquired_pointer, + /*SrcAlign=*/1, length_32); } else { // Outfeed -- copy from the in-program address to the acquired buffer. - b_.CreateMemCpy(acquired_pointer, /*DstAlign=*/1, program_buffer_address, - /*SrcAlign=*/1, length_32); + MemCpy(acquired_pointer, /*DstAlign=*/1, program_buffer_address, + /*SrcAlign=*/1, length_32); } - b_.CreateCall(release_func, {b_.getInt32(length_32), acquired_pointer, - shape_ptr, b_.getInt32(shape_length)}); + Call(release_func, {b_.getInt32(length_32), acquired_pointer, shape_ptr, + b_.getInt32(shape_length)}); return Status::OK(); } @@ -502,7 +501,7 @@ Status IrEmitter::HandleTuple(HloInstruction* tuple) { llvm::Value* IrEmitter::EmitElementalMap( const HloMapInstruction& map_instr, tensorflow::gtl::ArraySlice<llvm::Value*> elemental_operands, - tensorflow::StringPiece name) { + absl::string_view name) { return EmitThreadLocalCall(*map_instr.to_apply(), elemental_operands, name); } @@ -519,8 +518,8 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForReduceWindow( llvm_ir::PrimitiveTypeToIrType(operand_element_type, module_), "reduce_window_accumulator_address", &b_, MinimumAlignmentForPrimitiveType(operand_element_type)); - b_.CreateStore(b_.CreateLoad(GetEmittedValueFor(reduce_window->operand(1))), - accumulator_address); + Store(Load(GetEmittedValueFor(reduce_window->operand(1))), + accumulator_address); llvm_ir::ForLoopNest loops(IrName(reduce_window, "inner"), &b_); std::vector<int64> window_size; @@ -537,22 +536,21 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForReduceWindow( llvm::Value* in_bounds_condition = nullptr; for (size_t i = 0; i < index.size(); ++i) { llvm::Value* strided_index = - b_.CreateNSWMul(index[i], b_.getInt64(window.dimensions(i).stride())); - input_index[i] = - b_.CreateNSWSub(b_.CreateNSWAdd(strided_index, window_index[i]), - b_.getInt64(window.dimensions(i).padding_low())); + NSWMul(index[i], b_.getInt64(window.dimensions(i).stride())); + input_index[i] = NSWSub(NSWAdd(strided_index, window_index[i]), + b_.getInt64(window.dimensions(i).padding_low())); // We need to check if 0 <= input_index[i] < bound, as otherwise we are in // the padding so that we can skip the computation. That is equivalent to // input_index[i] < bound as an *unsigned* comparison, since a negative // value will wrap to a large positive value. - llvm::Value* index_condition = b_.CreateICmpULT( - input_index[i], - b_.getInt64(ShapeUtil::GetDimension(operand->shape(), i))); + llvm::Value* index_condition = + ICmpULT(input_index[i], + b_.getInt64(ShapeUtil::GetDimension(operand->shape(), i))); if (in_bounds_condition == nullptr) { in_bounds_condition = index_condition; } else { - in_bounds_condition = b_.CreateAnd(in_bounds_condition, index_condition); + in_bounds_condition = And(in_bounds_condition, index_condition); } } CHECK(in_bounds_condition != nullptr); @@ -565,12 +563,12 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForReduceWindow( llvm_ir::IrArray input_array(GetIrArrayFor(operand)); llvm::Value* input_value = input_array.EmitReadArrayElement(input_index, &b_); llvm::Value* result = EmitThreadLocalCall( - *reduce_window->to_apply(), - {b_.CreateLoad(accumulator_address), input_value}, "reducer_function"); - b_.CreateStore(result, accumulator_address); + *reduce_window->to_apply(), {Load(accumulator_address), input_value}, + "reducer_function"); + Store(result, accumulator_address); SetToFirstInsertPoint(loops.GetOuterLoopExitBasicBlock(), &b_); - return b_.CreateLoad(accumulator_address); + return Load(accumulator_address); } Status IrEmitter::HandleReduceWindow(HloInstruction* reduce_window) { @@ -647,7 +645,7 @@ Status IrEmitter::HandleSelectAndScatter(HloInstruction* select_and_scatter) { select_and_scatter, /*desc=*/IrName(select_and_scatter, "init"), [this, init_value](const llvm_ir::IrArray::Index& target_index) { llvm::Value* init_value_addr = GetEmittedValueFor(init_value); - return b_.CreateLoad(init_value_addr); + return Load(init_value_addr); })); // Create a loop to iterate over the source array to scatter to the output. @@ -667,7 +665,7 @@ Status IrEmitter::HandleSelectAndScatter(HloInstruction* select_and_scatter) { b_.getInt64Ty(), b_.getInt32(rank), "selected_index_address", &b_); llvm::Value* initialized_flag_address = llvm_ir::EmitAllocaAtFunctionEntry( b_.getInt1Ty(), "initialized_flag_address", &b_); - b_.CreateStore(b_.getInt1(false), initialized_flag_address); + Store(b_.getInt1(false), initialized_flag_address); // Create the inner loop to iterate over the window. llvm_ir::ForLoopNest window_loops(IrName(select_and_scatter, "window"), &b_); @@ -685,15 +683,14 @@ Status IrEmitter::HandleSelectAndScatter(HloInstruction* select_and_scatter) { llvm_ir::IrArray::Index operand_index(b_.getInt64Ty(), source_index.size()); llvm::Value* in_bounds_condition = b_.getTrue(); for (int64 i = 0; i < rank; ++i) { - llvm::Value* strided_index = b_.CreateNSWMul( - source_index[i], b_.getInt64(window.dimensions(i).stride())); - operand_index[i] = - b_.CreateNSWSub(b_.CreateNSWAdd(strided_index, window_index[i]), - b_.getInt64(window.dimensions(i).padding_low())); - llvm::Value* index_condition = b_.CreateICmpULT( - operand_index[i], - b_.getInt64(ShapeUtil::GetDimension(operand->shape(), i))); - in_bounds_condition = b_.CreateAnd(in_bounds_condition, index_condition); + llvm::Value* strided_index = + NSWMul(source_index[i], b_.getInt64(window.dimensions(i).stride())); + operand_index[i] = NSWSub(NSWAdd(strided_index, window_index[i]), + b_.getInt64(window.dimensions(i).padding_low())); + llvm::Value* index_condition = + ICmpULT(operand_index[i], + b_.getInt64(ShapeUtil::GetDimension(operand->shape(), i))); + in_bounds_condition = And(in_bounds_condition, index_condition); } CHECK(in_bounds_condition != nullptr); @@ -703,7 +700,7 @@ Status IrEmitter::HandleSelectAndScatter(HloInstruction* select_and_scatter) { llvm_ir::EmitIfThenElse(in_bounds_condition, "in-bounds", &b_); SetToFirstInsertPoint(if_in_bounds.true_block, &b_); llvm_ir::LlvmIfData if_initialized = llvm_ir::EmitIfThenElse( - b_.CreateLoad(initialized_flag_address), "initialized", &b_); + Load(initialized_flag_address), "initialized", &b_); // If the initialized_flag is false, initialize the selected value and index // with the currently visiting operand. @@ -712,38 +709,37 @@ Status IrEmitter::HandleSelectAndScatter(HloInstruction* select_and_scatter) { [&](const llvm_ir::IrArray::Index& operand_index) { for (int64 i = 0; i < rank; ++i) { llvm::Value* selected_index_address_slot = - b_.CreateInBoundsGEP(selected_index_address, {b_.getInt32(i)}); - b_.CreateStore(operand_index[i], selected_index_address_slot); + InBoundsGEP(selected_index_address, {b_.getInt32(i)}); + Store(operand_index[i], selected_index_address_slot); } }; llvm_ir::IrArray operand_array(GetIrArrayFor(operand)); llvm::Value* operand_data = operand_array.EmitReadArrayElement(operand_index, &b_); - b_.CreateStore(operand_data, selected_value_address); + Store(operand_data, selected_value_address); save_operand_index(operand_index); - b_.CreateStore(b_.getInt1(true), initialized_flag_address); + Store(b_.getInt1(true), initialized_flag_address); // If the initialized_flag is true, call the `select` function to potentially // update the selected value and index with the currently visiting operand. SetToFirstInsertPoint(if_initialized.true_block, &b_); llvm::Value* operand_address = operand_array.EmitArrayElementAddress(operand_index, &b_); - llvm::Value* operand_element = b_.CreateLoad(operand_address); + llvm::Value* operand_element = Load(operand_address); llvm::Value* result = EmitThreadLocalCall( *select_and_scatter->select(), - {b_.CreateLoad(selected_value_address), operand_element}, - "select_function"); + {Load(selected_value_address), operand_element}, "select_function"); // If the 'select' function returns false, update the selected value and the // index to the currently visiting operand. - llvm::Value* cond = b_.CreateICmpNE( + llvm::Value* cond = ICmpNE( result, llvm::ConstantInt::get(llvm_ir::PrimitiveTypeToIrType(PRED, module_), 0), "boolean_predicate"); llvm_ir::LlvmIfData if_select_lhs = llvm_ir::EmitIfThenElse(cond, "if-select-lhs", &b_); SetToFirstInsertPoint(if_select_lhs.false_block, &b_); - b_.CreateStore(b_.CreateLoad(operand_address), selected_value_address); + Store(Load(operand_address), selected_value_address); save_operand_index(operand_index); // After iterating over the window elements, scatter the source element to @@ -754,8 +750,8 @@ Status IrEmitter::HandleSelectAndScatter(HloInstruction* select_and_scatter) { llvm_ir::IrArray::Index selected_index(source_index.GetType()); for (int64 i = 0; i < rank; ++i) { llvm::Value* selected_index_address_slot = - b_.CreateInBoundsGEP(selected_index_address, {b_.getInt32(i)}); - selected_index.push_back(b_.CreateLoad(selected_index_address_slot)); + InBoundsGEP(selected_index_address, {b_.getInt32(i)}); + selected_index.push_back(Load(selected_index_address_slot)); } llvm_ir::IrArray source_array(GetIrArrayFor(source)); llvm::Value* source_value = @@ -837,7 +833,7 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForConvolution( lhs_llvm_type, "convolution_sum_address", &b_, MinimumAlignmentForPrimitiveType(lhs_element_type)); llvm::Value* constant_zero = llvm::Constant::getNullValue(lhs_llvm_type); - b_.CreateStore(constant_zero, sum_address); + Store(constant_zero, sum_address); llvm_ir::ForLoopNest loops(IrName(convolution, "inner"), &b_); std::vector<llvm::Value*> kernel_spatial(num_spatial_dims); @@ -846,7 +842,7 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForConvolution( loops .AddLoop( 0, rhs->shape().dimensions(dnums.kernel_spatial_dimensions(i)), - tensorflow::strings::StrCat("k", i)) + absl::StrCat("k", i)) ->GetIndVarValue(); } llvm::Value* input_feature = @@ -864,11 +860,11 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForConvolution( llvm::Value* kernel_index, const WindowDimension& window_dim) { llvm::Value* strided_index = - b_.CreateNSWMul(output_index, b_.getInt64(window_dim.stride())); - llvm::Value* dilated_kernel_index = b_.CreateNSWMul( - kernel_index, b_.getInt64(window_dim.window_dilation())); - return b_.CreateNSWSub(b_.CreateNSWAdd(strided_index, dilated_kernel_index), - b_.getInt64(window_dim.padding_low())); + NSWMul(output_index, b_.getInt64(window_dim.stride())); + llvm::Value* dilated_kernel_index = + NSWMul(kernel_index, b_.getInt64(window_dim.window_dilation())); + return NSWSub(NSWAdd(strided_index, dilated_kernel_index), + b_.getInt64(window_dim.padding_low())); }; std::vector<llvm::Value*> input_spatial(num_spatial_dims); for (int i = 0; i < num_spatial_dims; ++i) { @@ -885,9 +881,8 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForConvolution( // Also need to check that the input coordinates are not in one of the // holes created by base dilation. const auto not_in_hole = [&](llvm::Value* input_index, int64 base_dilation) { - llvm::Value* remainder = - b_.CreateSRem(input_index, b_.getInt64(base_dilation)); - return b_.CreateICmpEQ(remainder, b_.getInt64(0)); + llvm::Value* remainder = SRem(input_index, b_.getInt64(base_dilation)); + return ICmpEQ(remainder, b_.getInt64(0)); }; llvm::Value* in_bounds_condition = b_.getInt1(true); @@ -895,17 +890,17 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForConvolution( llvm::ConstantInt* input_bound = b_.getInt64(window_util::DilatedBound( lhs->shape().dimensions(dnums.input_spatial_dimensions(i)), window.dimensions(i).base_dilation())); - llvm::Value* dim_in_bound = b_.CreateICmpULT(input_spatial[i], input_bound); + llvm::Value* dim_in_bound = ICmpULT(input_spatial[i], input_bound); llvm::Value* dim_not_in_hole = not_in_hole(input_spatial[i], window.dimensions(i).base_dilation()); - llvm::Value* dim_ok = b_.CreateAnd(dim_in_bound, dim_not_in_hole); - in_bounds_condition = b_.CreateAnd(in_bounds_condition, dim_ok); + llvm::Value* dim_ok = And(dim_in_bound, dim_not_in_hole); + in_bounds_condition = And(in_bounds_condition, dim_ok); } // Now we need to map the dilated base coordinates back to the actual // data indices on the lhs. const auto undilate = [&](llvm::Value* input_index, int64 base_dilation) { - return b_.CreateSDiv(input_index, b_.getInt64(base_dilation)); + return SDiv(input_index, b_.getInt64(base_dilation)); }; for (int i = 0; i < num_spatial_dims; ++i) { input_spatial[i] = @@ -930,8 +925,8 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForConvolution( for (int i = 0; i < num_spatial_dims; ++i) { kernel_index[dnums.kernel_spatial_dimensions(i)] = window.dimensions(i).window_reversal() - ? b_.CreateNSWSub(b_.getInt64(window.dimensions(i).size() - 1), - kernel_spatial[i]) + ? NSWSub(b_.getInt64(window.dimensions(i).size() - 1), + kernel_spatial[i]) : kernel_spatial[i]; } @@ -940,13 +935,13 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForConvolution( llvm_ir::IrArray input_array(GetIrArrayFor(lhs)); llvm::Value* product = - b_.CreateFMul(input_array.EmitReadArrayElement(input_index, &b_), - kernel_array.EmitReadArrayElement(kernel_index, &b_)); - llvm::Value* sum = b_.CreateFAdd(b_.CreateLoad(sum_address), product); - b_.CreateStore(sum, sum_address); + FMul(input_array.EmitReadArrayElement(input_index, &b_), + kernel_array.EmitReadArrayElement(kernel_index, &b_)); + llvm::Value* sum = FAdd(Load(sum_address), product); + Store(sum, sum_address); SetToFirstInsertPoint(loops.GetOuterLoopExitBasicBlock(), &b_); - return b_.CreateLoad(sum_address); + return Load(sum_address); } Status IrEmitter::HandleConvolution(HloInstruction* convolution) { @@ -1072,34 +1067,32 @@ Status IrEmitter::HandleConvolution(HloInstruction* convolution) { conv_func->setCallingConv(llvm::CallingConv::C); conv_func->setDoesNotThrow(); conv_func->setOnlyAccessesArgMemory(); - b_.CreateCall( - conv_func, - { - GetExecutableRunOptionsArgument(), - b_.CreateBitCast(GetEmittedValueFor(convolution), ir_ptr_type), - b_.CreateBitCast(lhs_address, ir_ptr_type), - b_.CreateBitCast(rhs_address, ir_ptr_type), - b_.getInt64(input_batch), - b_.getInt64(input_rows), - b_.getInt64(input_cols), - b_.getInt64(input_channels), - b_.getInt64(kernel_rows), - b_.getInt64(kernel_cols), - b_.getInt64(kernel_channels), - b_.getInt64(kernel_filters), - b_.getInt64(output_rows), - b_.getInt64(output_cols), - b_.getInt64(row_stride), - b_.getInt64(col_stride), - b_.getInt64(padding_top), - b_.getInt64(padding_bottom), - b_.getInt64(padding_left), - b_.getInt64(padding_right), - b_.getInt64(lhs_row_dilation), - b_.getInt64(lhs_col_dilation), - b_.getInt64(rhs_row_dilation), - b_.getInt64(rhs_col_dilation), - }); + Call(conv_func, { + GetExecutableRunOptionsArgument(), + BitCast(GetEmittedValueFor(convolution), ir_ptr_type), + BitCast(lhs_address, ir_ptr_type), + BitCast(rhs_address, ir_ptr_type), + b_.getInt64(input_batch), + b_.getInt64(input_rows), + b_.getInt64(input_cols), + b_.getInt64(input_channels), + b_.getInt64(kernel_rows), + b_.getInt64(kernel_cols), + b_.getInt64(kernel_channels), + b_.getInt64(kernel_filters), + b_.getInt64(output_rows), + b_.getInt64(output_cols), + b_.getInt64(row_stride), + b_.getInt64(col_stride), + b_.getInt64(padding_top), + b_.getInt64(padding_bottom), + b_.getInt64(padding_left), + b_.getInt64(padding_right), + b_.getInt64(lhs_row_dilation), + b_.getInt64(lhs_col_dilation), + b_.getInt64(rhs_row_dilation), + b_.getInt64(rhs_col_dilation), + }); return Status::OK(); } @@ -1159,15 +1152,14 @@ Status IrEmitter::HandleFft(HloInstruction* fft) { fft_func->setDoesNotThrow(); fft_func->setOnlyAccessesInaccessibleMemOrArgMem(); const int fft_rank = fft_length.size(); - b_.CreateCall( - fft_func, - {GetExecutableRunOptionsArgument(), - b_.CreateBitCast(GetEmittedValueFor(fft), int8_ptr_type), - b_.CreateBitCast(operand_address, int8_ptr_type), - b_.getInt32(fft->fft_type()), b_.getInt32(fft_rank), - b_.getInt64(input_batch), b_.getInt64(fft_rank > 0 ? fft_length[0] : 0), - b_.getInt64(fft_rank > 1 ? fft_length[1] : 0), - b_.getInt64(fft_rank > 2 ? fft_length[2] : 0)}); + Call(fft_func, + {GetExecutableRunOptionsArgument(), + BitCast(GetEmittedValueFor(fft), int8_ptr_type), + BitCast(operand_address, int8_ptr_type), b_.getInt32(fft->fft_type()), + b_.getInt32(fft_rank), b_.getInt64(input_batch), + b_.getInt64(fft_rank > 0 ? fft_length[0] : 0), + b_.getInt64(fft_rank > 1 ? fft_length[1] : 0), + b_.getInt64(fft_rank > 2 ? fft_length[2] : 0)}); return Status::OK(); } @@ -1206,8 +1198,8 @@ Status IrEmitter::HandleCrossReplicaSum(HloInstruction* crs) { operand_ptrs.push_back(EmitTempBufferPointer(out_slice, operand_shape)); // TODO(b/63762267): Be more aggressive about specifying alignment. - b_.CreateMemCpy(operand_ptrs.back(), /*DstAlign=*/1, in_ptr, - /*SrcAlign=*/1, ShapeUtil::ByteSizeOf(operand_shape)); + MemCpy(operand_ptrs.back(), /*DstAlign=*/1, in_ptr, + /*SrcAlign=*/1, ShapeUtil::ByteSizeOf(operand_shape)); } llvm_ir::EmitTuple(GetIrArrayFor(crs), operand_ptrs, &b_, module_); return Status::OK(); @@ -1466,19 +1458,19 @@ IrEmitter::EmitInnerLoopForVectorizedReduction( accumulator_shard_type, "accumulator", &b_, 0)); } - llvm::Value* init_value_ssa = b_.CreateLoad(GetEmittedValueFor(init_value)); + llvm::Value* init_value_ssa = Load(GetEmittedValueFor(init_value)); for (llvm::Value* accumulator_shard : accumulator) { llvm::Value* initial_value; auto shard_type = accumulator_shard->getType()->getPointerElementType(); if (auto vector_type = llvm::dyn_cast<llvm::VectorType>(shard_type)) { initial_value = - b_.CreateVectorSplat(vector_type->getNumElements(), init_value_ssa); + VectorSplat(vector_type->getNumElements(), init_value_ssa); } else { initial_value = init_value_ssa; } - b_.CreateAlignedStore(initial_value, accumulator_shard, element_alignment); + AlignedStore(initial_value, accumulator_shard, element_alignment); } llvm_ir::ForLoopNest reduction_loop_nest(IrName(arg, "vectorized_inner"), @@ -1500,24 +1492,24 @@ IrEmitter::EmitInnerLoopForVectorizedReduction( } CHECK(output_index.end() == it); - llvm::Value* input_address = b_.CreateBitCast( + llvm::Value* input_address = BitCast( arg_array.EmitArrayElementAddress(input_index, &b_), b_.getInt8PtrTy()); for (int i = 0; i < accumulator.size(); i++) { auto input_address_typed = - b_.CreateBitCast(input_address, accumulator[i]->getType()); + BitCast(input_address, accumulator[i]->getType()); auto current_accumulator_value = - b_.CreateAlignedLoad(accumulator[i], element_alignment); - auto addend = b_.CreateAlignedLoad(input_address_typed, element_alignment); + AlignedLoad(accumulator[i], element_alignment); + auto addend = AlignedLoad(input_address_typed, element_alignment); arg_array.AnnotateLoadStoreInstructionWithMetadata(addend); auto reduced_result = reduction_generator(&b_, current_accumulator_value, addend); - b_.CreateAlignedStore(reduced_result, accumulator[i], element_alignment); + AlignedStore(reduced_result, accumulator[i], element_alignment); if (i != (accumulator.size() - 1)) { - input_address = b_.CreateConstInBoundsGEP1_32(reduced_result->getType(), - input_address_typed, 1); + input_address = ConstInBoundsGEP1_32(reduced_result->getType(), + input_address_typed, 1); } } @@ -1526,8 +1518,7 @@ IrEmitter::EmitInnerLoopForVectorizedReduction( ShardedVector result_ssa; result_ssa.reserve(accumulator.size()); for (auto accumulator_shard : accumulator) { - result_ssa.push_back( - b_.CreateAlignedLoad(accumulator_shard, element_alignment)); + result_ssa.push_back(AlignedLoad(accumulator_shard, element_alignment)); } return result_ssa; } @@ -1536,18 +1527,18 @@ void IrEmitter::EmitShardedVectorStore( llvm::Value* store_address, const std::vector<llvm::Value*>& value_to_store, const int alignment, const llvm_ir::IrArray& containing_array) { for (int i = 0; i < value_to_store.size(); i++) { - auto store_address_typed = b_.CreateBitCast( - store_address, - llvm::PointerType::getUnqual(value_to_store[i]->getType())); + auto store_address_typed = + BitCast(store_address, + llvm::PointerType::getUnqual(value_to_store[i]->getType())); - auto store_instruction = b_.CreateAlignedStore( - value_to_store[i], store_address_typed, alignment); + auto store_instruction = + AlignedStore(value_to_store[i], store_address_typed, alignment); containing_array.AnnotateLoadStoreInstructionWithMetadata( store_instruction); if (i != (value_to_store.size() - 1)) { - store_address = b_.CreateConstInBoundsGEP1_32( - value_to_store[i]->getType(), store_address_typed, 1); + store_address = ConstInBoundsGEP1_32(value_to_store[i]->getType(), + store_address_typed, 1); } } } @@ -1620,9 +1611,8 @@ StatusOr<bool> IrEmitter::EmitVectorizedReduce( int64 dimension = LayoutUtil::Minor(reduce->shape().layout(), i); int64 start_index = 0; int64 end_index = reduce->shape().dimensions(dimension); - std::unique_ptr<llvm_ir::ForLoop> loop = - loop_nest.AddLoop(start_index, end_index, - tensorflow::strings::Printf("dim.%lld", dimension)); + std::unique_ptr<llvm_ir::ForLoop> loop = loop_nest.AddLoop( + start_index, end_index, absl::StrFormat("dim.%d", dimension)); array_index[dimension] = loop->GetIndVarValue(); } @@ -1641,9 +1631,9 @@ StatusOr<bool> IrEmitter::EmitVectorizedReduce( int64 start_index = 0; int64 end_index = (innermost_dimension_size / vectorization_factor) * vectorization_factor; - std::unique_ptr<llvm_ir::ForLoop> loop = loop_nest.AddLoop( - start_index, end_index, vectorization_factor, - tensorflow::strings::Printf("dim.%lld", innermost_dimension)); + std::unique_ptr<llvm_ir::ForLoop> loop = + loop_nest.AddLoop(start_index, end_index, vectorization_factor, + absl::StrFormat("dim.%d", innermost_dimension)); array_index[innermost_dimension] = loop->GetIndVarValue(); SetToFirstInsertPoint(loop->GetBodyBasicBlock(), &b_); @@ -1713,8 +1703,8 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForReduce( llvm_ir::PrimitiveTypeToIrType(accumulator_type, module_), "accumulator", &b_, MinimumAlignmentForPrimitiveType(accumulator_type)); llvm::Value* init_value_addr = GetEmittedValueFor(init_value); - llvm::Value* load_init_value = b_.CreateLoad(init_value_addr); - b_.CreateStore(load_init_value, accumulator_addr); + llvm::Value* load_init_value = Load(init_value_addr); + Store(load_init_value, accumulator_addr); // The enclosing loops go over all the target elements. Now we have to compute // the actual target element. For this, we build a new loop nest to iterate @@ -1747,12 +1737,12 @@ StatusOr<llvm::Value*> IrEmitter::EmitTargetElementLoopBodyForReduce( // Apply the reduction function to the loaded value. llvm::Value* input_element = arg_array.EmitReadArrayElement(input_index, &b_); llvm::Value* result = EmitThreadLocalCall( - *reduce->to_apply(), {b_.CreateLoad(accumulator_addr), input_element}, + *reduce->to_apply(), {Load(accumulator_addr), input_element}, "reduce_function"); - b_.CreateStore(result, accumulator_addr); + Store(result, accumulator_addr); SetToFirstInsertPoint(loops.GetOuterLoopExitBasicBlock(), &b_); - return b_.CreateLoad(accumulator_addr); + return Load(accumulator_addr); } Status IrEmitter::HandleReduce(HloInstruction* reduce) { @@ -1990,7 +1980,7 @@ Status IrEmitter::HandlePad(HloInstruction* pad) { [this, pad](const llvm_ir::IrArray::Index& target_index) { const HloInstruction* padding_value = pad->operand(1); llvm::Value* padding_value_addr = GetEmittedValueFor(padding_value); - return b_.CreateLoad(padding_value_addr); + return Load(padding_value_addr); })); // Create a loop to iterate over the operand elements and update the output @@ -2012,10 +2002,10 @@ Status IrEmitter::HandlePad(HloInstruction* pad) { const PaddingConfig& padding_config = pad->padding_config(); llvm_ir::IrArray::Index output_index(operand_index.GetType()); for (size_t i = 0; i < operand_index.size(); ++i) { - llvm::Value* offset = b_.CreateMul( - operand_index[i], - b_.getInt64(padding_config.dimensions(i).interior_padding() + 1)); - llvm::Value* index = b_.CreateAdd( + llvm::Value* offset = + Mul(operand_index[i], + b_.getInt64(padding_config.dimensions(i).interior_padding() + 1)); + llvm::Value* index = Add( offset, b_.getInt64(padding_config.dimensions(i).edge_padding_low())); output_index.push_back(index); } @@ -2118,7 +2108,7 @@ Status IrEmitter::HandleCall(HloInstruction* call) { Status IrEmitter::HandleCustomCall(HloInstruction* custom_call) { gtl::ArraySlice<HloInstruction*> operands(custom_call->operands()); - tensorflow::StringPiece custom_call_target(custom_call->custom_call_target()); + absl::string_view custom_call_target(custom_call->custom_call_target()); llvm::Type* i8_ptr_type = b_.getInt8PtrTy(); llvm::AllocaInst* operands_alloca = llvm_ir::EmitAllocaAtFunctionEntryWithCount( @@ -2126,10 +2116,10 @@ Status IrEmitter::HandleCustomCall(HloInstruction* custom_call) { for (size_t i = 0; i < operands.size(); ++i) { const HloInstruction* operand = operands[i]; llvm::Value* operand_as_i8ptr = - b_.CreatePointerCast(GetEmittedValueFor(operand), i8_ptr_type); + PointerCast(GetEmittedValueFor(operand), i8_ptr_type); llvm::Value* slot_in_operands_alloca = - b_.CreateInBoundsGEP(operands_alloca, {b_.getInt64(i)}); - b_.CreateStore(operand_as_i8ptr, slot_in_operands_alloca); + InBoundsGEP(operands_alloca, {b_.getInt64(i)}); + Store(operand_as_i8ptr, slot_in_operands_alloca); } auto* custom_call_ir_function = llvm::cast<llvm::Function>(module_->getOrInsertFunction( @@ -2141,9 +2131,9 @@ Status IrEmitter::HandleCustomCall(HloInstruction* custom_call) { TF_RETURN_IF_ERROR(EmitTargetAddressForOp(custom_call)); auto* output_address_arg = - b_.CreatePointerCast(GetEmittedValueFor(custom_call), i8_ptr_type); + PointerCast(GetEmittedValueFor(custom_call), i8_ptr_type); - b_.CreateCall(custom_call_ir_function, {output_address_arg, operands_alloca}); + Call(custom_call_ir_function, {output_address_arg, operands_alloca}); return Status::OK(); } @@ -2170,8 +2160,8 @@ Status IrEmitter::HandleWhile(HloInstruction* xla_while) { return InternalError( "instruction %s %s does not share slice with " "instruction %s %s", - a->ToString().c_str(), slice_a.ToString().c_str(), - b->ToString().c_str(), slice_b.ToString().c_str()); + a->ToString(), slice_a.ToString(), b->ToString(), + slice_b.ToString()); } return Status::OK(); }; @@ -2202,15 +2192,14 @@ Status IrEmitter::HandleWhile(HloInstruction* xla_while) { llvm::BasicBlock* header_bb = llvm::BasicBlock::Create( module_->getContext(), AsStringRef(IrName(xla_while, "header")), compute_function_->function()); - b_.CreateBr(header_bb); + Br(header_bb); b_.SetInsertPoint(header_bb); // Calls the condition function to determine whether to proceed with the // body. It must return a bool, so use the scalar call form. EmitGlobalCall(*xla_while->while_condition(), IrName(xla_while, "cond")); - llvm::Value* while_predicate = b_.CreateICmpNE( - b_.CreateLoad( - GetBufferForGlobalCallReturnValue(*xla_while->while_condition())), + llvm::Value* while_predicate = ICmpNE( + Load(GetBufferForGlobalCallReturnValue(*xla_while->while_condition())), llvm::ConstantInt::get(llvm_ir::PrimitiveTypeToIrType(PRED, module_), 0)); // Branches to the body or to the while exit depending on the condition. @@ -2219,7 +2208,7 @@ Status IrEmitter::HandleWhile(HloInstruction* xla_while) { compute_function_->function()); llvm::BasicBlock* exit_bb = llvm::BasicBlock::Create( module_->getContext(), AsStringRef(IrName(xla_while, "exit"))); - b_.CreateCondBr(while_predicate, body_bb, exit_bb); + CondBr(while_predicate, body_bb, exit_bb); // Calls the body function from the body block. b_.SetInsertPoint(body_bb); @@ -2228,7 +2217,7 @@ Status IrEmitter::HandleWhile(HloInstruction* xla_while) { EmitGlobalCall(*xla_while->while_body(), IrName(xla_while, "body")); // Finishes with a branch back to the header. - b_.CreateBr(header_bb); + Br(header_bb); // Adds the exit block to the function and sets the insert point there. compute_function_->function()->getBasicBlockList().push_back(exit_bb); @@ -2275,7 +2264,6 @@ StatusOr<bool> IrEmitter::EmitFastConcatenate( output_min2maj.end()); llvm::Type* i8_ptr_type = b_.getInt8PtrTy(); - llvm::Type* i8_type = b_.getInt8Ty(); TF_RETURN_IF_ERROR(EmitTargetAddressForOp(concatenate)); llvm_ir::IrArray target_array = GetIrArrayFor(concatenate); @@ -2298,9 +2286,9 @@ StatusOr<bool> IrEmitter::EmitFastConcatenate( // Contiguous subregions from each operand to the concatenate contribute to a // contiguous subregion in the target buffer starting at target_region_begin. llvm::Value* target_region_begin = - b_.CreateBitCast(target_array.EmitArrayElementAddress( - outer_dims_index, &b_, "target_region"), - i8_ptr_type); + BitCast(target_array.EmitArrayElementAddress(outer_dims_index, &b_, + "target_region"), + i8_ptr_type); int64 byte_offset_into_target_region = 0; int64 inner_dims_product = @@ -2314,13 +2302,12 @@ StatusOr<bool> IrEmitter::EmitFastConcatenate( for (HloInstruction* operand : operands) { const Shape& input_shape = operand->shape(); llvm_ir::IrArray source_array = GetIrArrayFor(operand); - llvm::Value* copy_source_address = b_.CreateBitCast( + llvm::Value* copy_source_address = BitCast( source_array.EmitArrayElementAddress(outer_dims_index, &b_, "src_addr"), i8_ptr_type); llvm::Value* copy_target_address = - b_.CreateGEP(i8_type, target_region_begin, - b_.getInt64(byte_offset_into_target_region)); + GEP(target_region_begin, b_.getInt64(byte_offset_into_target_region)); EmitTransferElements( copy_target_address, copy_source_address, @@ -2352,15 +2339,15 @@ void IrEmitter::EmitTransferElements(llvm::Value* target, llvm::Value* source, llvm_ir::PrimitiveTypeToIrType(primitive_type, module_)); if (element_count == 1) { - auto* load_instruction = b_.CreateAlignedLoad( - b_.CreateBitCast(source, primitive_ptr_type), element_alignment); + auto* load_instruction = + AlignedLoad(BitCast(source, primitive_ptr_type), element_alignment); source_array.AnnotateLoadStoreInstructionWithMetadata(load_instruction); - auto* store_instruction = b_.CreateAlignedStore( - load_instruction, b_.CreateBitCast(target, primitive_ptr_type), - element_alignment); + auto* store_instruction = + AlignedStore(load_instruction, BitCast(target, primitive_ptr_type), + element_alignment); target_array.AnnotateLoadStoreInstructionWithMetadata(store_instruction); } else { - auto* memcpy_instruction = b_.CreateMemCpy( + auto* memcpy_instruction = MemCpy( target, /*DstAlign=*/element_alignment, source, /*SrcAlign=*/element_alignment, element_count * primitive_type_size); @@ -2422,9 +2409,9 @@ Status IrEmitter::HandleConditional(HloInstruction* conditional) { // cond_result = true_computation(true_operand) // else // cond_result = false_computation(false_operand) - llvm::LoadInst* pred_value = b_.CreateLoad( - GetIrArrayFor(pred).GetBasePointer(), "load_predicate_value"); - llvm::Value* pred_cond = b_.CreateICmpNE( + llvm::LoadInst* pred_value = + Load(GetIrArrayFor(pred).GetBasePointer(), "load_predicate_value"); + llvm::Value* pred_cond = ICmpNE( pred_value, llvm::ConstantInt::get(llvm_ir::PrimitiveTypeToIrType(PRED, module_), 0), "boolean_predicate"); @@ -2450,11 +2437,6 @@ Status IrEmitter::HandleAfterAll(HloInstruction* gen_token) { return Status::OK(); } -Status IrEmitter::HandleIota(HloInstruction* iota) { - // TODO(b/64798317): implement iota on CPU. - return Unimplemented("Iota is not implemented on CPU."); -} - Status IrEmitter::HandleRng(HloInstruction* rng) { ElementalIrEmitter::HloToElementGeneratorMap operand_to_generator; for (const HloInstruction* operand : rng->operands()) { @@ -2511,8 +2493,8 @@ llvm::Value* IrEmitter::GetProfileCounterCommon( int64 prof_counter_idx = it->second; string counter_name = IrName("prof_counter", hlo.name()); - return b_.CreateGEP(GetProfileCountersArgument(), - b_.getInt64(prof_counter_idx), AsStringRef(counter_name)); + return GEP(GetProfileCountersArgument(), b_.getInt64(prof_counter_idx), + AsStringRef(counter_name)); } void IrEmitter::ProfilingState::UpdateProfileCounter(llvm::IRBuilder<>* b, @@ -2666,8 +2648,7 @@ llvm::Value* IrEmitter::EmitThreadLocalTempBufferPointer( llvm::Value* params = compute_function_->parameters_arg(); llvm::Value* param_address_offset = llvm_ir::EmitBufferIndexingGEP(params, param_number, &b_); - llvm::LoadInst* param_address_untyped = - b_.CreateLoad(param_address_offset); + llvm::LoadInst* param_address_untyped = Load(param_address_offset); if (!ShapeUtil::IsOpaque(target_shape)) { AttachAlignmentMetadataForLoad(param_address_untyped, target_shape); @@ -2687,17 +2668,15 @@ llvm::Value* IrEmitter::EmitThreadLocalTempBufferPointer( auto buf_it = thread_local_buffers_.find(key); if (buf_it == thread_local_buffers_.end()) { llvm::Value* buffer = llvm_ir::EmitAllocaAtFunctionEntry( - IrShapeType(shape), - tensorflow::strings::StrCat("thread_local", slice.ToString()), &b_, - MinimumAlignmentForShape(target_shape)); + IrShapeType(shape), absl::StrCat("thread_local", slice.ToString()), + &b_, MinimumAlignmentForShape(target_shape)); auto it_inserted_pair = thread_local_buffers_.insert({key, buffer}); CHECK(it_inserted_pair.second); buf_it = it_inserted_pair.first; } return buf_it->second; }(); - return b_.CreateBitCast(tempbuf_address, - IrShapeType(target_shape)->getPointerTo()); + return BitCast(tempbuf_address, IrShapeType(target_shape)->getPointerTo()); } llvm::Value* IrEmitter::EmitGlobalTempBufferPointer( @@ -2705,7 +2684,7 @@ llvm::Value* IrEmitter::EmitGlobalTempBufferPointer( const BufferAllocation& allocation = *slice.allocation(); llvm::Value* tempbuf_address_ptr = llvm_ir::EmitBufferIndexingGEP( GetTempBuffersArgument(), slice.index(), &b_); - llvm::LoadInst* tempbuf_address_base = b_.CreateLoad(tempbuf_address_ptr); + llvm::LoadInst* tempbuf_address_base = Load(tempbuf_address_ptr); if (hlo_module_config_.debug_options() .xla_llvm_enable_invariant_load_metadata()) { tempbuf_address_base->setMetadata( @@ -2719,10 +2698,10 @@ llvm::Value* IrEmitter::EmitGlobalTempBufferPointer( if (slice.offset() > 0) { // Adjust the address to account for the slice offset. tempbuf_address_untyped = - b_.CreateInBoundsGEP(tempbuf_address_base, b_.getInt64(slice.offset())); + InBoundsGEP(tempbuf_address_base, b_.getInt64(slice.offset())); } - return b_.CreateBitCast(tempbuf_address_untyped, - IrShapeType(target_shape)->getPointerTo()); + return BitCast(tempbuf_address_untyped, + IrShapeType(target_shape)->getPointerTo()); } llvm::Value* IrEmitter::EmitTempBufferPointer( @@ -2753,7 +2732,7 @@ Status IrEmitter::EmitTargetElementLoop( } Status IrEmitter::EmitTargetElementLoop( - HloInstruction* target_op, tensorflow::StringPiece desc, + HloInstruction* target_op, absl::string_view desc, const llvm_ir::ElementGenerator& element_generator) { VLOG(2) << "EmitTargetElementLoop: " << target_op->ToString(); @@ -2808,8 +2787,8 @@ Status IrEmitter::EmitMemcpy(const HloInstruction& source, llvm::Value* destination_value = GetEmittedValueFor(&destination); int64 source_size = ByteSizeOf(source.shape()); // TODO(b/63762267): Be more aggressive about specifying alignment. - b_.CreateMemCpy(destination_value, /*DstAlign=*/1, source_value, - /*SrcAlign=*/1, source_size); + MemCpy(destination_value, /*DstAlign=*/1, source_value, + /*SrcAlign=*/1, source_size); return Status::OK(); } @@ -2827,8 +2806,8 @@ Status IrEmitter::ElementTypesSameAndSupported( if (std::find(supported_types.begin(), supported_types.end(), primitive_type) == supported_types.end()) { return Unimplemented("unsupported operand type %s in op %s", - PrimitiveType_Name(primitive_type).c_str(), - HloOpcodeString(instruction.opcode()).c_str()); + PrimitiveType_Name(primitive_type), + HloOpcodeString(instruction.opcode())); } return Status::OK(); } @@ -2848,7 +2827,7 @@ Status IrEmitter::DefaultAction(HloInstruction* hlo) { llvm::Value* IrEmitter::EmitThreadLocalCall( const HloComputation& callee, tensorflow::gtl::ArraySlice<llvm::Value*> parameters, - tensorflow::StringPiece name) { + absl::string_view name) { const Shape& return_shape = callee.root_instruction()->shape(); // Lifting this restriction to allow "small" arrays should be easy. Allowing @@ -2863,38 +2842,37 @@ llvm::Value* IrEmitter::EmitThreadLocalCall( CHECK(!parameter->getType()->isPointerTy()); llvm::Value* parameter_addr = llvm_ir::EmitAllocaAtFunctionEntry( parameter->getType(), "arg_addr", &b_); - b_.CreateStore(parameter, parameter_addr); + Store(parameter, parameter_addr); parameter_addrs.push_back(parameter_addr); } llvm::Value* return_value_buffer = llvm_ir::EmitAllocaAtFunctionEntry( llvm_ir::PrimitiveTypeToIrType(return_type, module_), - tensorflow::strings::StrCat(name, "_retval_addr"), &b_, + absl::StrCat(name, "_retval_addr"), &b_, MinimumAlignmentForPrimitiveType(return_type)); - b_.CreateCall( - FindOrDie(emitted_functions_, &callee), - GetArrayFunctionCallArguments( - parameter_addrs, &b_, name, - /*return_value_buffer=*/return_value_buffer, - /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), - /*temp_buffers_arg=*/ - llvm::Constant::getNullValue(b_.getInt8PtrTy()->getPointerTo()), - /*profile_counters_arg=*/GetProfileCountersArgument())); + Call(FindOrDie(emitted_functions_, &callee), + GetArrayFunctionCallArguments( + parameter_addrs, &b_, name, + /*return_value_buffer=*/return_value_buffer, + /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), + /*temp_buffers_arg=*/ + llvm::Constant::getNullValue(b_.getInt8PtrTy()->getPointerTo()), + /*profile_counters_arg=*/GetProfileCountersArgument())); - return b_.CreateLoad(return_value_buffer); + return Load(return_value_buffer); } void IrEmitter::EmitGlobalCall(const HloComputation& callee, - tensorflow::StringPiece name) { - b_.CreateCall(FindOrDie(emitted_functions_, &callee), - GetArrayFunctionCallArguments( - /*parameter_addresses=*/{}, &b_, name, - /*return_value_buffer=*/ - llvm::Constant::getNullValue(b_.getInt8PtrTy()), - /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), - /*temp_buffers_arg=*/GetTempBuffersArgument(), - /*profile_counters_arg=*/GetProfileCountersArgument())); + absl::string_view name) { + Call(FindOrDie(emitted_functions_, &callee), + GetArrayFunctionCallArguments( + /*parameter_addresses=*/{}, &b_, name, + /*return_value_buffer=*/ + llvm::Constant::getNullValue(b_.getInt8PtrTy()), + /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), + /*temp_buffers_arg=*/GetTempBuffersArgument(), + /*profile_counters_arg=*/GetProfileCountersArgument())); } llvm::Value* IrEmitter::GetBufferForGlobalCallReturnValue( diff --git a/tensorflow/compiler/xla/service/cpu/ir_emitter.h b/tensorflow/compiler/xla/service/cpu/ir_emitter.h index c9a1dab62d..f98891246b 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_emitter.h +++ b/tensorflow/compiler/xla/service/cpu/ir_emitter.h @@ -23,6 +23,7 @@ limitations under the License. #include <unordered_map> #include <vector> +#include "absl/strings/string_view.h" #include "llvm/ADT/Triple.h" #include "llvm/IR/Function.h" #include "llvm/IR/IRBuilder.h" @@ -39,12 +40,12 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_module_config.h" #include "tensorflow/compiler/xla/service/llvm_ir/alias_analysis.h" #include "tensorflow/compiler/xla/service/llvm_ir/ir_array.h" +#include "tensorflow/compiler/xla/service/llvm_ir/ir_builder_mixin.h" #include "tensorflow/compiler/xla/service/llvm_ir/loop_emitter.h" #include "tensorflow/compiler/xla/service/name_uniquer.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/lib/gtl/flatmap.h" #include "tensorflow/core/platform/macros.h" @@ -55,7 +56,8 @@ namespace cpu { // This class is the top-level API for the XLA HLO --> LLVM IR compiler. It // implements the DfsHloVisitor interface and emits HLO computations as LLVM IR // functions. -class IrEmitter : public DfsHloVisitorWithDefault { +class IrEmitter : public DfsHloVisitorWithDefault, + public IrBuilderMixin<IrEmitter> { public: // Create a new LLVM IR emitter. // @@ -100,6 +102,9 @@ class IrEmitter : public DfsHloVisitorWithDefault { llvm::IRBuilder<>* b() { return &b_; } + // builder() is for IrBuilderMixin. + llvm::IRBuilder<>* builder() { return &b_; } + // Emit an LLVM global variable for every constant buffer allocation. Status EmitConstantGlobals(); @@ -107,7 +112,7 @@ class IrEmitter : public DfsHloVisitorWithDefault { llvm::Value* EmitElementalMap( const HloMapInstruction& map_instr, tensorflow::gtl::ArraySlice<llvm::Value*> elemental_operands, - tensorflow::StringPiece name); + absl::string_view name); protected: // @@ -152,7 +157,6 @@ class IrEmitter : public DfsHloVisitorWithDefault { Status HandleConditional(HloInstruction* conditional) override; Status HandleScatter(HloInstruction* scatter) override; Status HandleAfterAll(HloInstruction* gen_token) override; - Status HandleIota(HloInstruction* iota) override; Status HandleRng(HloInstruction* rng) override; Status FinishVisit(HloInstruction* root) override; @@ -239,7 +243,7 @@ class IrEmitter : public DfsHloVisitorWithDefault { // function that a map operation applies. StatusOr<llvm::Function*> EmitFunction( HloComputation* function, // The function to emit. - tensorflow::StringPiece + absl::string_view function_name_suffix); // Used for LLVM IR register names. // Emits a call to a thread local function (e.g. to the computation nested @@ -251,14 +255,13 @@ class IrEmitter : public DfsHloVisitorWithDefault { llvm::Value* EmitThreadLocalCall( const HloComputation& callee, tensorflow::gtl::ArraySlice<llvm::Value*> parameters, - tensorflow::StringPiece name); + absl::string_view name); // Emits a call to a "global" function (e.g. to the computation nested within // a kWhile or a kCall). Buffer assignment unabiguously assignes buffers to // the parameters and return values for these computations so there is no need // to explicitly pass parameters or return results. - void EmitGlobalCall(const HloComputation& callee, - tensorflow::StringPiece name); + void EmitGlobalCall(const HloComputation& callee, absl::string_view name); // Returns the buffer to which a global call to `callee` would have written // its result. @@ -285,7 +288,7 @@ class IrEmitter : public DfsHloVisitorWithDefault { HloInstruction* target_op, const llvm_ir::ElementGenerator& element_generator); Status EmitTargetElementLoop( - HloInstruction* target_op, tensorflow::StringPiece desc, + HloInstruction* target_op, absl::string_view desc, const llvm_ir::ElementGenerator& element_generator); // Emits a memcpy from the source instruction's result value to the diff --git a/tensorflow/compiler/xla/service/cpu/ir_function.cc b/tensorflow/compiler/xla/service/cpu/ir_function.cc index 2db4d000f5..784045313d 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_function.cc +++ b/tensorflow/compiler/xla/service/cpu/ir_function.cc @@ -17,6 +17,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/cpu/ir_function.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/cpu/cpu_runtime.h" #include "tensorflow/compiler/xla/service/cpu/shape_partition.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_util.h" @@ -189,7 +190,7 @@ void IrFunction::Initialize(const string& function_name, llvm::Value* IrFunction::GetDynamicLoopBound(const int64 offset) { CHECK_GT(num_dynamic_loop_bounds_, 0); CHECK_LT(offset, num_dynamic_loop_bounds_ * 2); - string name = tensorflow::strings::StrCat("dynamic_loop_bound_", offset); + string name = absl::StrCat("dynamic_loop_bound_", offset); return b_->CreateLoad(b_->CreateGEP(CHECK_NOTNULL(dynamic_loop_bounds_arg_), b_->getInt64(offset), AsStringRef(name))); } @@ -200,7 +201,7 @@ llvm::Value* IrFunction::GetDynamicLoopBound(const int64 offset) { // address buffer). std::vector<llvm::Value*> GetArrayFunctionCallArguments( tensorflow::gtl::ArraySlice<llvm::Value*> parameter_addresses, - llvm::IRBuilder<>* b, tensorflow::StringPiece name, + llvm::IRBuilder<>* b, absl::string_view name, llvm::Value* return_value_buffer, llvm::Value* exec_run_options_arg, llvm::Value* temp_buffers_arg, llvm::Value* profile_counters_arg) { llvm::Value* parameter_addresses_buffer; @@ -211,13 +212,13 @@ std::vector<llvm::Value*> GetArrayFunctionCallArguments( } else { parameter_addresses_buffer = llvm_ir::EmitAllocaAtFunctionEntryWithCount( b->getInt8PtrTy(), b->getInt32(parameter_addresses.size()), - tensorflow::strings::StrCat(name, "_parameter_addresses"), b); + absl::StrCat(name, "_parameter_addresses"), b); for (size_t i = 0; i < parameter_addresses.size(); ++i) { llvm::Value* parameter_as_i8ptr = b->CreateBitCast(parameter_addresses[i], b->getInt8PtrTy(), - AsStringRef(tensorflow::strings::StrCat( - name, "_parameter_", i, "_address_as_i8ptr"))); + AsStringRef(absl::StrCat(name, "_parameter_", i, + "_address_as_i8ptr"))); llvm::Value* slot_in_param_addresses = b->CreateInBoundsGEP(parameter_addresses_buffer, {b->getInt64(i)}); b->CreateStore(parameter_as_i8ptr, slot_in_param_addresses); @@ -320,8 +321,7 @@ Status EmitCallToParallelForkJoin( /*Linkage=*/llvm::GlobalValue::PrivateLinkage, /*Initializer=*/partitions_array, /*Name=*/ - AsStringRef( - tensorflow::strings::StrCat(name, "_parallel_dimension_partitions"))); + AsStringRef(absl::StrCat(name, "_parallel_dimension_partitions"))); // Add argument specifying parallel dimension partitions. fork_join_arguments.push_back( diff --git a/tensorflow/compiler/xla/service/cpu/ir_function.h b/tensorflow/compiler/xla/service/cpu/ir_function.h index a41cbb64cd..ee7595f6e9 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_function.h +++ b/tensorflow/compiler/xla/service/cpu/ir_function.h @@ -116,7 +116,7 @@ class IrFunction { // Returns an array of compute function call argument ir values. std::vector<llvm::Value*> GetArrayFunctionCallArguments( tensorflow::gtl::ArraySlice<llvm::Value*> parameter_addresses, - llvm::IRBuilder<>* b, tensorflow::StringPiece name, + llvm::IRBuilder<>* b, absl::string_view name, llvm::Value* return_value_buffer, llvm::Value* exec_run_options_arg, llvm::Value* temp_buffers_arg, llvm::Value* profile_counters_arg); diff --git a/tensorflow/compiler/xla/service/cpu/parallel_loop_emitter.cc b/tensorflow/compiler/xla/service/cpu/parallel_loop_emitter.cc index 8560e4296a..f8441c3e34 100644 --- a/tensorflow/compiler/xla/service/cpu/parallel_loop_emitter.cc +++ b/tensorflow/compiler/xla/service/cpu/parallel_loop_emitter.cc @@ -15,9 +15,9 @@ limitations under the License. #include "tensorflow/compiler/xla/service/cpu/parallel_loop_emitter.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_loop.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_util.h" -#include "tensorflow/core/lib/strings/stringprintf.h" namespace xla { namespace cpu { @@ -30,8 +30,8 @@ ParallelLoopEmitter::ParallelLoopEmitter( dynamic_loop_bounds_(dynamic_loop_bounds) {} std::vector<llvm_ir::IrArray::Index> -ParallelLoopEmitter::EmitIndexAndSetExitBasicBlock( - tensorflow::StringPiece loop_name, llvm::Type* index_type) { +ParallelLoopEmitter::EmitIndexAndSetExitBasicBlock(absl::string_view loop_name, + llvm::Type* index_type) { CHECK_NE(index_type, nullptr); CHECK(!ShapeUtil::IsTuple(shape_)); @@ -52,15 +52,15 @@ ParallelLoopEmitter::EmitIndexAndSetExitBasicBlock( llvm::Value* end_index = (*dynamic_loop_bounds_)[bounds_index].second; std::unique_ptr<llvm_ir::ForLoop> loop = loop_nest.AddLoop( - /*suffix=*/tensorflow::strings::Printf("dim.%lld", dimension), - start_index, end_index); + /*suffix=*/absl::StrFormat("dim.%d", dimension), start_index, + end_index); array_index[dimension] = loop->GetIndVarValue(); } else { // Emit static loop bounds for this dimension. std::unique_ptr<llvm_ir::ForLoop> loop = loop_nest.AddLoop( /*start_index=*/0, /*end_index=*/shape_.dimensions(dimension), - /*suffix=*/tensorflow::strings::Printf("dim.%lld", dimension)); + /*suffix=*/absl::StrFormat("dim.%d", dimension)); array_index[dimension] = loop->GetIndVarValue(); } } diff --git a/tensorflow/compiler/xla/service/cpu/parallel_loop_emitter.h b/tensorflow/compiler/xla/service/cpu/parallel_loop_emitter.h index 076c683ca5..a604e1db22 100644 --- a/tensorflow/compiler/xla/service/cpu/parallel_loop_emitter.h +++ b/tensorflow/compiler/xla/service/cpu/parallel_loop_emitter.h @@ -61,7 +61,7 @@ class ParallelLoopEmitter : public llvm_ir::LoopEmitter { ~ParallelLoopEmitter() override = default; std::vector<llvm_ir::IrArray::Index> EmitIndexAndSetExitBasicBlock( - tensorflow::StringPiece loop_name, llvm::Type* index_type) override; + absl::string_view loop_name, llvm::Type* index_type) override; private: const DynamicLoopBounds* dynamic_loop_bounds_; diff --git a/tensorflow/compiler/xla/service/cpu/parallel_task_assignment.cc b/tensorflow/compiler/xla/service/cpu/parallel_task_assignment.cc index 4fa5984b04..b4c0c09ec0 100644 --- a/tensorflow/compiler/xla/service/cpu/parallel_task_assignment.cc +++ b/tensorflow/compiler/xla/service/cpu/parallel_task_assignment.cc @@ -15,6 +15,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/cpu/parallel_task_assignment.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/cpu/dot_op_emitter.h" #include "tensorflow/compiler/xla/service/cpu/ir_emission_utils.h" #include "tensorflow/compiler/xla/service/cpu/shape_partition.h" @@ -109,7 +111,7 @@ ParallelTaskAssignment::ParallelTaskAssignment( : target_machine_features_(*target_machine_features) { VLOG(1) << "ParallelTaskAssignment max_parallelism: " << max_parallelism; // Run cost analysis on 'module'. - auto cost_analysis = MakeUnique<HloCostAnalysis>(shape_size); + auto cost_analysis = absl::make_unique<HloCostAnalysis>(shape_size); HloComputation* computation = module->entry_computation(); Status status = computation->root_instruction()->Accept(cost_analysis.get()); if (status.ok()) { @@ -216,8 +218,7 @@ bool ParallelTaskAssigner::AssignParallelTasksHelper( // Outline 'instruction' in 'computation' for parallel task assignment. auto* call = module->OutlineExpressionFromComputation( - {instruction}, - tensorflow::strings::StrCat("parallel_", instruction->name()), + {instruction}, absl::StrCat("parallel_", instruction->name()), computation); // Set assigned dimension partitioning to 'instruction'. diff --git a/tensorflow/compiler/xla/service/cpu/parallel_task_assignment.h b/tensorflow/compiler/xla/service/cpu/parallel_task_assignment.h index 8becc8fa23..a99cd99c14 100644 --- a/tensorflow/compiler/xla/service/cpu/parallel_task_assignment.h +++ b/tensorflow/compiler/xla/service/cpu/parallel_task_assignment.h @@ -73,7 +73,7 @@ class ParallelTaskAssigner : public HloPassInterface { target_machine_features_(*target_machine_features) {} ~ParallelTaskAssigner() override {} - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "cpu-parallel-task-assigner"; } diff --git a/tensorflow/compiler/xla/service/cpu/parallel_task_assignment_test.cc b/tensorflow/compiler/xla/service/cpu/parallel_task_assignment_test.cc index ee272b5f4f..a84ee78b19 100644 --- a/tensorflow/compiler/xla/service/cpu/parallel_task_assignment_test.cc +++ b/tensorflow/compiler/xla/service/cpu/parallel_task_assignment_test.cc @@ -19,7 +19,6 @@ limitations under the License. #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/tests/hlo_verified_test_base.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace xla { namespace { @@ -36,7 +35,9 @@ class ParallelTaskAssignmentTest : public HloVerifiedTestBase { cpu::TargetMachineFeaturesWithFakeAlignmentLogic target_machine_features_; ParallelTaskAssignmentTest() - : target_machine_features_([](int64 shape_size) { + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false), + target_machine_features_([](int64 shape_size) { return cpu::TargetMachineFeatures::kEigenExpectedTensorAlignment; }) {} diff --git a/tensorflow/compiler/xla/service/cpu/sample_harness.cc b/tensorflow/compiler/xla/service/cpu/sample_harness.cc index f227e4ae13..942e2ddd39 100644 --- a/tensorflow/compiler/xla/service/cpu/sample_harness.cc +++ b/tensorflow/compiler/xla/service/cpu/sample_harness.cc @@ -16,6 +16,7 @@ limitations under the License. #include <memory> #include <string> +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/client/client.h" #include "tensorflow/compiler/xla/client/client_library.h" @@ -27,7 +28,6 @@ limitations under the License. #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/init_main.h" #include "tensorflow/core/platform/logging.h" @@ -67,8 +67,8 @@ int main(int argc, char** argv) { /*execution_profile=*/&profile); std::unique_ptr<xla::Literal> actual = result.ConsumeValueOrDie(); - LOG(INFO) << tensorflow::strings::Printf("computation took %lldns", - profile.compute_time_ns()); + LOG(INFO) << absl::StrFormat("computation took %dns", + profile.compute_time_ns()); LOG(INFO) << actual->ToString(); return 0; diff --git a/tensorflow/compiler/xla/service/cpu/simple_orc_jit.cc b/tensorflow/compiler/xla/service/cpu/simple_orc_jit.cc index be772cfb7e..bf98064647 100644 --- a/tensorflow/compiler/xla/service/cpu/simple_orc_jit.cc +++ b/tensorflow/compiler/xla/service/cpu/simple_orc_jit.cc @@ -20,13 +20,13 @@ limitations under the License. #include <list> #include <utility> +#include "absl/memory/memory.h" #include "llvm/ExecutionEngine/ExecutionEngine.h" #include "llvm/ExecutionEngine/JITSymbol.h" #include "llvm/ExecutionEngine/SectionMemoryManager.h" #include "llvm/IR/Mangler.h" #include "llvm/Support/CodeGen.h" #include "llvm/Support/Host.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/cpu/cpu_runtime.h" #include "tensorflow/compiler/xla/service/cpu/custom_call_target_registry.h" #include "tensorflow/compiler/xla/service/cpu/orc_jit_memory_mapper.h" @@ -170,15 +170,14 @@ namespace { bool RegisterKnownJITSymbols() { CustomCallTargetRegistry* registry = CustomCallTargetRegistry::Global(); -#define REGISTER_CPU_RUNTIME_SYMBOL(base_name) \ - do { \ - auto* function_address = \ - reinterpret_cast<void*>(__xla_cpu_runtime_##base_name); \ - registry->Register(xla::cpu::runtime::k##base_name##SymbolName, \ - function_address); \ - CHECK_EQ( \ - tensorflow::StringPiece(xla::cpu::runtime::k##base_name##SymbolName), \ - "__xla_cpu_runtime_" #base_name); \ +#define REGISTER_CPU_RUNTIME_SYMBOL(base_name) \ + do { \ + auto* function_address = \ + reinterpret_cast<void*>(__xla_cpu_runtime_##base_name); \ + registry->Register(xla::cpu::runtime::k##base_name##SymbolName, \ + function_address); \ + CHECK_EQ(absl::string_view(xla::cpu::runtime::k##base_name##SymbolName), \ + "__xla_cpu_runtime_" #base_name); \ } while (false) REGISTER_CPU_RUNTIME_SYMBOL(AcquireInfeedBufferForDequeue); diff --git a/tensorflow/compiler/xla/service/cpu/tests/BUILD b/tensorflow/compiler/xla/service/cpu/tests/BUILD index 181cec3cdd..2384166fd2 100644 --- a/tensorflow/compiler/xla/service/cpu/tests/BUILD +++ b/tensorflow/compiler/xla/service/cpu/tests/BUILD @@ -51,6 +51,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", ], ) @@ -94,6 +95,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:filecheck", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", "@llvm//:core", ], ) @@ -108,6 +110,7 @@ tf_cc_test( "//tensorflow/core:lib", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/strings", ], ) @@ -121,6 +124,7 @@ tf_cc_test( "//tensorflow/core:lib", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/xla/service/cpu/tests/cpu_eigen_dot_operation_test.cc b/tensorflow/compiler/xla/service/cpu/tests/cpu_eigen_dot_operation_test.cc index 6fcce42eaa..fcd87b36b3 100644 --- a/tensorflow/compiler/xla/service/cpu/tests/cpu_eigen_dot_operation_test.cc +++ b/tensorflow/compiler/xla/service/cpu/tests/cpu_eigen_dot_operation_test.cc @@ -19,10 +19,10 @@ limitations under the License. #include <cctype> #include <string> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/cpu/cpu_compiler.h" #include "tensorflow/compiler/xla/service/cpu/tests/cpu_codegen_test.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/test.h" namespace xla { diff --git a/tensorflow/compiler/xla/service/cpu/tests/cpu_fusion_test.cc b/tensorflow/compiler/xla/service/cpu/tests/cpu_fusion_test.cc index d98856fdbf..22721051e5 100644 --- a/tensorflow/compiler/xla/service/cpu/tests/cpu_fusion_test.cc +++ b/tensorflow/compiler/xla/service/cpu/tests/cpu_fusion_test.cc @@ -17,8 +17,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -129,8 +129,8 @@ TEST_F(CpuFusionTest, FuseElementwiseOpChain) { error_spec_); } -TEST_F(CpuFusionTest, ElementwiseOpChainWithNonfusableInstruction) { - // Test a chain of fusable ops with a non-fusable op (a reduce) thrown in the +TEST_F(CpuFusionTest, ElementwiseOpChainWithNonfusibleInstruction) { + // Test a chain of fusible ops with a non-fusible op (a reduce) thrown in the // middle. auto module = CreateNewModule(); auto builder = HloComputation::Builder(TestName()); diff --git a/tensorflow/compiler/xla/service/cpu/tests/cpu_intrinsic_test.cc b/tensorflow/compiler/xla/service/cpu/tests/cpu_intrinsic_test.cc index 973aac8766..a434c04a98 100644 --- a/tensorflow/compiler/xla/service/cpu/tests/cpu_intrinsic_test.cc +++ b/tensorflow/compiler/xla/service/cpu/tests/cpu_intrinsic_test.cc @@ -17,10 +17,10 @@ limitations under the License. #include <cctype> #include <string> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/cpu/cpu_compiler.h" #include "tensorflow/compiler/xla/service/cpu/tests/cpu_codegen_test.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/test.h" namespace xla { @@ -32,9 +32,9 @@ const char* const kTriple_android_arm = "armv7-none-android"; struct IntrinsicTestSpec { HloOpcode opcode; - tensorflow::StringPiece triple; - tensorflow::StringPiece features; - tensorflow::StringPiece check_lines; + absl::string_view triple; + absl::string_view features; + absl::string_view check_lines; }; // Tests that unary functions get lowered using intrinsic calls. @@ -65,9 +65,8 @@ class CpuUnaryIntrinsicTest features = ""; } - return tensorflow::strings::StrCat(opcode.c_str(), "_On_", triple.c_str(), - features.empty() ? "" : "_With", - features.c_str()); + return absl::StrCat(opcode, "_On_", triple, + (features.empty() ? "" : "_With"), features); } }; diff --git a/tensorflow/compiler/xla/service/cpu/tests/cpu_noalias_test.cc b/tensorflow/compiler/xla/service/cpu/tests/cpu_noalias_test.cc index 01daed4bcd..bb105194f1 100644 --- a/tensorflow/compiler/xla/service/cpu/tests/cpu_noalias_test.cc +++ b/tensorflow/compiler/xla/service/cpu/tests/cpu_noalias_test.cc @@ -16,9 +16,9 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "llvm/IR/Module.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/buffer_assignment.h" #include "tensorflow/compiler/xla/service/cpu/tests/cpu_codegen_test.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" @@ -62,7 +62,8 @@ TEST_F(CpuNoAliasTest, Concat) { // Now that we have an HLO module, build an llvm_ir::AliasAnalysis for it. auto status_or_buffer_assn = BufferAssigner::Run( - hlo_module.get(), MakeUnique<DependencyHloOrdering>(hlo_module.get()), + hlo_module.get(), + absl::make_unique<DependencyHloOrdering>(hlo_module.get()), backend().compiler()->BufferSizeBytesFunction(), [](LogicalBuffer::Color) { return /*alignment=*/1; }); ASSERT_EQ(status_or_buffer_assn.status(), Status::OK()); diff --git a/tensorflow/compiler/xla/service/cpu/vector_support_library.cc b/tensorflow/compiler/xla/service/cpu/vector_support_library.cc index 3274be8d9d..962ea69c09 100644 --- a/tensorflow/compiler/xla/service/cpu/vector_support_library.cc +++ b/tensorflow/compiler/xla/service/cpu/vector_support_library.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/cpu/vector_support_library.h" +#include "absl/algorithm/container.h" #include "llvm/Support/raw_ostream.h" #include "tensorflow/compiler/xla/service/cpu/target_machine_features.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_util.h" @@ -422,8 +423,8 @@ TileVariable::TileVariable(VectorSupportLibrary* vector_support, std::vector<llvm::Value*> TileVariable::Get() const { std::vector<llvm::Value*> result; - c_transform(storage_, std::back_inserter(result), - [&](VectorVariable vect_var) { return vect_var.Get(); }); + absl::c_transform(storage_, std::back_inserter(result), + [&](VectorVariable vect_var) { return vect_var.Get(); }); return result; } diff --git a/tensorflow/compiler/xla/service/defuser.h b/tensorflow/compiler/xla/service/defuser.h index 56b28fd22d..c326beb899 100644 --- a/tensorflow/compiler/xla/service/defuser.h +++ b/tensorflow/compiler/xla/service/defuser.h @@ -29,7 +29,7 @@ class Defuser : public HloPassInterface { public: Defuser() {} ~Defuser() override {} - tensorflow::StringPiece name() const override { return "defuser"; } + absl::string_view name() const override { return "defuser"; } // Run defusion on the given module. Returns whether the module was // changed. diff --git a/tensorflow/compiler/xla/service/defuser_test.cc b/tensorflow/compiler/xla/service/defuser_test.cc index e727ba49cb..37d1895d41 100644 --- a/tensorflow/compiler/xla/service/defuser_test.cc +++ b/tensorflow/compiler/xla/service/defuser_test.cc @@ -26,6 +26,11 @@ namespace xla { namespace { class DefuserTest : public HloVerifiedTestBase { + public: + DefuserTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} + protected: // Returns the number of fusion instructions in the module. int FusionCount() { diff --git a/tensorflow/compiler/xla/service/despecializer.cc b/tensorflow/compiler/xla/service/despecializer.cc index 48e4471499..ba2a674d9a 100644 --- a/tensorflow/compiler/xla/service/despecializer.cc +++ b/tensorflow/compiler/xla/service/despecializer.cc @@ -27,9 +27,7 @@ namespace { class ControlDepRemover : public HloPassInterface { public: ControlDepRemover() = default; - tensorflow::StringPiece name() const override { - return "control-dep-remover"; - } + absl::string_view name() const override { return "control-dep-remover"; } StatusOr<bool> Run(HloModule* module) override { bool changed = false; diff --git a/tensorflow/compiler/xla/service/despecializer.h b/tensorflow/compiler/xla/service/despecializer.h index cc1695b7f8..7be70add2f 100644 --- a/tensorflow/compiler/xla/service/despecializer.h +++ b/tensorflow/compiler/xla/service/despecializer.h @@ -33,7 +33,7 @@ namespace xla { class Despecializer : public HloPassInterface { public: Despecializer(); - tensorflow::StringPiece name() const override { return "despecializer"; } + absl::string_view name() const override { return "despecializer"; } StatusOr<bool> Run(HloModule* module) override; private: diff --git a/tensorflow/compiler/xla/service/device_memory_allocator.cc b/tensorflow/compiler/xla/service/device_memory_allocator.cc index e228bb56bc..1d0297cfbf 100644 --- a/tensorflow/compiler/xla/service/device_memory_allocator.cc +++ b/tensorflow/compiler/xla/service/device_memory_allocator.cc @@ -36,9 +36,8 @@ StatusOr<OwningDeviceMemory> StreamExecutorMemoryAllocator::Allocate( se::DeviceMemoryBase result = stream_executor->AllocateArray<uint8>(size); if (size > 0 && result == nullptr) { return ResourceExhausted( - "Failed to allocate request for %s (%lluB) on device ordinal %d", - tensorflow::strings::HumanReadableNumBytes(size).c_str(), size, - device_ordinal); + "Failed to allocate request for %s (%uB) on device ordinal %d", + tensorflow::strings::HumanReadableNumBytes(size), size, device_ordinal); } return OwningDeviceMemory(result, device_ordinal, this); } @@ -61,12 +60,12 @@ StatusOr<se::StreamExecutor*> StreamExecutorMemoryAllocator::GetStreamExecutor( } if (device_ordinal >= stream_executors_.size()) { return InvalidArgument( - "device ordinal value (%d) >= number of devices (%zu)", device_ordinal, + "device ordinal value (%d) >= number of devices (%u)", device_ordinal, stream_executors_.size()); } if (stream_executors_[device_ordinal] == nullptr) { return NotFound("Device %s:%d present but not supported", - platform()->Name().c_str(), device_ordinal); + platform()->Name(), device_ordinal); } return stream_executors_[device_ordinal]; } diff --git a/tensorflow/compiler/xla/service/dfs_hlo_visitor.cc b/tensorflow/compiler/xla/service/dfs_hlo_visitor.cc index 2172ae0a29..3e7373adc5 100644 --- a/tensorflow/compiler/xla/service/dfs_hlo_visitor.cc +++ b/tensorflow/compiler/xla/service/dfs_hlo_visitor.cc @@ -28,14 +28,14 @@ template <typename HloInstructionPtr> Status DfsHloVisitorBase<HloInstructionPtr>::HandleElementwiseUnary( HloInstructionPtr hlo) { return Unimplemented("DfsHloVisitor::HandleElementwiseUnary: %s", - HloOpcodeString(hlo->opcode()).c_str()); + HloOpcodeString(hlo->opcode())); } template <typename HloInstructionPtr> Status DfsHloVisitorBase<HloInstructionPtr>::HandleElementwiseBinary( HloInstructionPtr hlo) { return Unimplemented("DfsHloVisitor::HandleElementwiseBinary: %s", - HloOpcodeString(hlo->opcode()).c_str()); + HloOpcodeString(hlo->opcode())); } template <typename HloInstructionPtr> diff --git a/tensorflow/compiler/xla/service/dfs_hlo_visitor.h b/tensorflow/compiler/xla/service/dfs_hlo_visitor.h index 86d57581f8..f6f8fc5a2a 100644 --- a/tensorflow/compiler/xla/service/dfs_hlo_visitor.h +++ b/tensorflow/compiler/xla/service/dfs_hlo_visitor.h @@ -19,13 +19,13 @@ limitations under the License. #include <type_traits> #include <vector> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/status.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/lib/gtl/flatmap.h" #include "tensorflow/core/platform/macros.h" @@ -107,6 +107,7 @@ class DfsHloVisitorBase { virtual Status HandleFft(HloInstructionPtr fft) = 0; virtual Status HandleCrossReplicaSum(HloInstructionPtr hlo) = 0; virtual Status HandleAllToAll(HloInstructionPtr hlo) = 0; + virtual Status HandleCollectivePermute(HloInstructionPtr hlo) = 0; virtual Status HandleCompare(HloInstructionPtr hlo) { return HandleElementwiseBinary(hlo); } @@ -208,7 +209,6 @@ class DfsHloVisitorBase { virtual Status HandleInfeed(HloInstructionPtr hlo) = 0; virtual Status HandleOutfeed(HloInstructionPtr hlo) = 0; - virtual Status HandleHostCompute(HloInstructionPtr hlo) = 0; virtual Status HandleRng(HloInstructionPtr hlo) = 0; virtual Status HandleReverse(HloInstructionPtr hlo) = 0; virtual Status HandleSort(HloInstructionPtr hlo) = 0; diff --git a/tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h b/tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h index 617a5a2eb4..4f620e4c3a 100644 --- a/tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h +++ b/tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h @@ -16,13 +16,13 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_DFS_HLO_VISITOR_WITH_DEFAULT_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_DFS_HLO_VISITOR_WITH_DEFAULT_H_ +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/types.h" @@ -94,8 +94,11 @@ class DfsHloVisitorWithDefaultBase Status HandleCrossReplicaSum(HloInstructionPtr crs) override { return DefaultAction(crs); } - Status HandleAllToAll(HloInstructionPtr crs) override { - return DefaultAction(crs); + Status HandleAllToAll(HloInstructionPtr hlo) override { + return DefaultAction(hlo); + } + Status HandleCollectivePermute(HloInstructionPtr hlo) override { + return DefaultAction(hlo); } Status HandleRng(HloInstructionPtr random) override { return DefaultAction(random); @@ -106,9 +109,6 @@ class DfsHloVisitorWithDefaultBase Status HandleOutfeed(HloInstructionPtr outfeed) override { return DefaultAction(outfeed); } - Status HandleHostCompute(HloInstructionPtr host_compute) override { - return DefaultAction(host_compute); - } Status HandleReverse(HloInstructionPtr reverse) override { return DefaultAction(reverse); } diff --git a/tensorflow/compiler/xla/service/dot_decomposer.cc b/tensorflow/compiler/xla/service/dot_decomposer.cc index 12faed6967..09cb10d6ee 100644 --- a/tensorflow/compiler/xla/service/dot_decomposer.cc +++ b/tensorflow/compiler/xla/service/dot_decomposer.cc @@ -136,6 +136,7 @@ Status DecomposeBatchDot(HloInstruction* dot) { dot_dnums.add_rhs_contracting_dimensions(0); auto dot_r2 = computation->AddInstruction(HloInstruction::CreateDot( dot_shape_r2, lhs_slice_r2, rhs_slice_r2, dot_dnums)); + dot_r2->set_precision_config(dot->precision_config()); // Reshape Dot to R3 so we can concat along batch dimension. auto dot_r3 = computation->AddInstruction( diff --git a/tensorflow/compiler/xla/service/dot_decomposer.h b/tensorflow/compiler/xla/service/dot_decomposer.h index 1959b687f1..fc38e31700 100644 --- a/tensorflow/compiler/xla/service/dot_decomposer.h +++ b/tensorflow/compiler/xla/service/dot_decomposer.h @@ -29,7 +29,7 @@ class DotDecomposer : public HloPassInterface { DotDecomposer(bool decompose_batch_dot = true) : decompose_batch_dot_(decompose_batch_dot) {} ~DotDecomposer() = default; - tensorflow::StringPiece name() const override { return "dot_decomposer"; } + absl::string_view name() const override { return "dot_decomposer"; } // Run DotDecomposer pass on computations in 'module'. // Returns whether the 'module' was changed. diff --git a/tensorflow/compiler/xla/service/elemental_ir_emitter.cc b/tensorflow/compiler/xla/service/elemental_ir_emitter.cc index 891ae42141..813e93fafa 100644 --- a/tensorflow/compiler/xla/service/elemental_ir_emitter.cc +++ b/tensorflow/compiler/xla/service/elemental_ir_emitter.cc @@ -21,11 +21,15 @@ limitations under the License. #include <vector> // IWYU pragma: no_include "llvm/IR/Intrinsics.gen.inc" +#include "absl/algorithm/container.h" +#include "absl/strings/str_cat.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Instructions.h" #include "llvm/IR/Intrinsics.h" #include "llvm/Transforms/Utils/BasicBlockUtils.h" #include "tensorflow/compiler/xla/primitive_util.h" +#include "tensorflow/compiler/xla/service/hlo_casting_utils.h" +#include "tensorflow/compiler/xla/service/hlo_instructions.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/service/llvm_ir/ir_array.h" @@ -38,17 +42,16 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/random/random.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" namespace xla { +using absl::StrCat; using llvm_ir::AsStringRef; using llvm_ir::IrArray; using llvm_ir::IrName; using llvm_ir::SetToFirstInsertPoint; -using tensorflow::strings::StrCat; namespace { @@ -203,7 +206,7 @@ llvm::Value* EmitIntegralToFloating(llvm::Value* integer_value, } // namespace StatusOr<llvm::Value*> ElementalIrEmitter::EmitUnaryOp( - const HloInstruction* op, llvm::Value* operand_value) const { + const HloInstruction* op, llvm::Value* operand_value) { if (op->opcode() == HloOpcode::kCopy) { return operand_value; } else if (ShapeUtil::ElementIsIntegral(op->operand(0)->shape()) || @@ -217,7 +220,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitUnaryOp( } StatusOr<llvm::Value*> ElementalIrEmitter::EmitIntegerUnaryOp( - const HloInstruction* op, llvm::Value* operand_value) const { + const HloInstruction* op, llvm::Value* operand_value) { switch (op->opcode()) { case HloOpcode::kConvert: { PrimitiveType from_type = op->operand(0)->shape().element_type(); @@ -229,14 +232,14 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitIntegerUnaryOp( } if (to_type == PRED) { return b_->CreateZExt( - b_->CreateICmpNE(operand_value, llvm::ConstantInt::get( - operand_value->getType(), 0)), + ICmpNE(operand_value, + llvm::ConstantInt::get(operand_value->getType(), 0)), llvm_ir::PrimitiveTypeToIrType(PRED, module_)); } if (primitive_util::IsIntegralType(to_type)) { - return b_->CreateIntCast( - operand_value, llvm_ir::PrimitiveTypeToIrType(to_type, module_), - primitive_util::IsSignedIntegralType(from_type)); + return IntCast(operand_value, + llvm_ir::PrimitiveTypeToIrType(to_type, module_), + primitive_util::IsSignedIntegralType(from_type)); } if (primitive_util::IsFloatingPointType(to_type)) { if (to_type == BF16) { @@ -252,19 +255,17 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitIntegerUnaryOp( primitive_util::ComplexComponentType(to_type), module_); if (primitive_util::IsSignedIntegralType(from_type)) { return EmitComposeComplex( - op, b_->CreateSIToFP(operand_value, to_ir_component_type), - nullptr); + op, SIToFP(operand_value, to_ir_component_type), nullptr); } if (primitive_util::IsUnsignedIntegralType(from_type) || from_type == PRED) { return EmitComposeComplex( - op, b_->CreateUIToFP(operand_value, to_ir_component_type), - nullptr); + op, UIToFP(operand_value, to_ir_component_type), nullptr); } } return Unimplemented("conversion from primitive type %s to %s", - PrimitiveType_Name(from_type).c_str(), - PrimitiveType_Name(to_type).c_str()); + PrimitiveType_Name(from_type), + PrimitiveType_Name(to_type)); } case HloOpcode::kBitcastConvert: { PrimitiveType from_type = op->operand(0)->shape().element_type(); @@ -275,14 +276,13 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitIntegerUnaryOp( } if (primitive_util::BitWidth(from_type) == primitive_util::BitWidth(to_type)) { - return b_->CreateBitCast( - operand_value, llvm_ir::PrimitiveTypeToIrType(to_type, module_)); + return BitCast(operand_value, + llvm_ir::PrimitiveTypeToIrType(to_type, module_)); } return InvalidArgument( "bitcast conversion from primitive type %s to %s with unequal " "bit-widths (%u versus %u) ", - PrimitiveType_Name(from_type).c_str(), - PrimitiveType_Name(to_type).c_str(), + PrimitiveType_Name(from_type), PrimitiveType_Name(to_type), primitive_util::BitWidth(from_type), primitive_util::BitWidth(to_type)); } @@ -292,10 +292,8 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitIntegerUnaryOp( if (is_signed) { auto type = llvm_ir::PrimitiveTypeToIrType(op->shape().element_type(), module_); - auto zero = llvm::ConstantInt::get(type, 0); - auto cmp = b_->CreateICmpSGE(operand_value, zero); - return b_->CreateSelect(cmp, operand_value, - b_->CreateNeg(operand_value)); + auto cmp = ICmpSGE(operand_value, GetZero(type)); + return Select(cmp, operand_value, Neg(operand_value)); } else { return operand_value; } @@ -307,44 +305,37 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitIntegerUnaryOp( {operand_value->getType()}, b_); } case HloOpcode::kSign: { - bool is_signed = - primitive_util::IsSignedIntegralType(op->shape().element_type()); + CHECK(primitive_util::IsSignedIntegralType(op->shape().element_type())) + << op->shape().element_type(); auto type = llvm_ir::PrimitiveTypeToIrType(op->shape().element_type(), module_); - auto zero = llvm::ConstantInt::get(type, 0); - auto cmp = b_->CreateICmpEQ(operand_value, zero); - if (is_signed) { - auto ashr = - b_->CreateAShr(operand_value, type->getIntegerBitWidth() - 1); - return b_->CreateSelect(cmp, zero, b_->CreateOr(ashr, 1)); - } else { - return b_->CreateSelect(cmp, zero, llvm::ConstantInt::get(type, 1)); - } + auto cmp = ICmpEQ(operand_value, GetZero(type)); + auto ashr = AShr(operand_value, type->getIntegerBitWidth() - 1); + return Select(cmp, GetZero(type), Or(ashr, 1)); } case HloOpcode::kNegate: - return b_->CreateNeg(operand_value); + return Neg(operand_value); case HloOpcode::kNot: { auto type = op->shape().element_type(); if (type == PRED) { // It is not sufficient to just call CreateNot() here because a PRED // is represented as an i8 and the truth value is stored only in the // bottom bit. - return b_->CreateZExt( - b_->CreateNot(b_->CreateTrunc(operand_value, b_->getInt1Ty())), - llvm_ir::PrimitiveTypeToIrType(PRED, module_)); + return b_->CreateZExt(Not(Trunc(operand_value, b_->getInt1Ty())), + llvm_ir::PrimitiveTypeToIrType(PRED, module_)); } else if (primitive_util::IsIntegralType(type)) { - return b_->CreateNot(operand_value); + return Not(operand_value); } return Unimplemented("unary op Not is not defined for type '%d'", type); } default: return Unimplemented("unary integer op '%s'", - HloOpcodeString(op->opcode()).c_str()); + HloOpcodeString(op->opcode())); } } StatusOr<llvm::Value*> ElementalIrEmitter::EmitFloatUnaryOp( - const HloInstruction* op, llvm::Value* operand_value) const { + const HloInstruction* op, llvm::Value* operand_value) { switch (op->opcode()) { case HloOpcode::kConvert: { PrimitiveType from_type = op->operand(0)->shape().element_type(); @@ -361,8 +352,8 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitFloatUnaryOp( } return EmitComposeComplex( op, - b_->CreateFPCast(operand_value, llvm_ir::PrimitiveTypeToIrType( - to_component_type, module_)), + FPCast(operand_value, + llvm_ir::PrimitiveTypeToIrType(to_component_type, module_)), nullptr); } if (from_type == BF16) { @@ -378,26 +369,25 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitFloatUnaryOp( } if (to_type == PRED) { return b_->CreateZExt( - b_->CreateFCmpUNE( - operand_value, - llvm::ConstantFP::get(operand_value->getType(), 0.0)), + FCmpUNE(operand_value, + llvm::ConstantFP::get(operand_value->getType(), 0.0)), llvm_ir::PrimitiveTypeToIrType(PRED, module_)); } if (primitive_util::IsFloatingPointType(to_type)) { - return b_->CreateFPCast( - operand_value, llvm_ir::PrimitiveTypeToIrType(to_type, module_)); + return FPCast(operand_value, + llvm_ir::PrimitiveTypeToIrType(to_type, module_)); } if (primitive_util::IsSignedIntegralType(to_type)) { - return b_->CreateFPToSI( - operand_value, llvm_ir::PrimitiveTypeToIrType(to_type, module_)); + return FPToSI(operand_value, + llvm_ir::PrimitiveTypeToIrType(to_type, module_)); } if (primitive_util::IsUnsignedIntegralType(to_type)) { - return b_->CreateFPToUI( - operand_value, llvm_ir::PrimitiveTypeToIrType(to_type, module_)); + return FPToUI(operand_value, + llvm_ir::PrimitiveTypeToIrType(to_type, module_)); } return Unimplemented("unhandled conversion operation: %s => %s", - PrimitiveType_Name(from_type).c_str(), - PrimitiveType_Name(to_type).c_str()); + PrimitiveType_Name(from_type), + PrimitiveType_Name(to_type)); } case HloOpcode::kBitcastConvert: { PrimitiveType from_type = op->operand(0)->shape().element_type(); @@ -408,14 +398,13 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitFloatUnaryOp( } if (primitive_util::BitWidth(from_type) == primitive_util::BitWidth(to_type)) { - return b_->CreateBitCast( - operand_value, llvm_ir::PrimitiveTypeToIrType(to_type, module_)); + return BitCast(operand_value, + llvm_ir::PrimitiveTypeToIrType(to_type, module_)); } return InvalidArgument( "bitcast conversion from primitive type %s to %s with unequal " "bit-widths (%u versus %u) ", - PrimitiveType_Name(from_type).c_str(), - PrimitiveType_Name(to_type).c_str(), + PrimitiveType_Name(from_type), PrimitiveType_Name(to_type), primitive_util::BitWidth(from_type), primitive_util::BitWidth(to_type)); } @@ -453,11 +442,10 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitFloatUnaryOp( // TODO(b/32151903): Ensure consistent sign behavior for -0.0. auto type = operand_value->getType(); auto zero = llvm::ConstantFP::get(type, 0.0); - auto oeq = b_->CreateFCmpOEQ(operand_value, zero); - auto olt = b_->CreateFCmpOLT(operand_value, zero); - return b_->CreateSelect( - oeq, zero, - b_->CreateSelect(olt, llvm::ConstantFP::get(type, -1.0), + auto oeq = FCmpOEQ(operand_value, zero); + auto olt = FCmpOLT(operand_value, zero); + return Select(oeq, zero, + Select(olt, llvm::ConstantFP::get(type, -1.0), llvm::ConstantFP::get(type, 1.0))); } case HloOpcode::kIsFinite: { @@ -467,24 +455,24 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitFloatUnaryOp( auto abs_value = llvm_ir::EmitCallToIntrinsic( llvm::Intrinsic::fabs, {operand_value}, {type}, b_); auto infinity = llvm::ConstantFP::getInfinity(type); - auto not_infinite = b_->CreateFCmpONE(abs_value, infinity); + auto not_infinite = FCmpONE(abs_value, infinity); return b_->CreateZExt(not_infinite, llvm_ir::PrimitiveTypeToIrType(PRED, module_)); } case HloOpcode::kNegate: - return b_->CreateFNeg(operand_value); + return FNeg(operand_value); case HloOpcode::kReal: return operand_value; case HloOpcode::kImag: return llvm::ConstantFP::get(operand_value->getType(), 0.0); default: return Unimplemented("unary floating-point op '%s'", - HloOpcodeString(op->opcode()).c_str()); + HloOpcodeString(op->opcode())); } } StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexUnaryOp( - const HloInstruction* op, llvm::Value* operand_value) const { + const HloInstruction* op, llvm::Value* operand_value) { PrimitiveType input_type = op->operand(0)->shape().element_type(); PrimitiveType component_type = primitive_util::IsComplexType(input_type) @@ -496,12 +484,11 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexUnaryOp( auto a = EmitExtractReal(operand_value); auto b = EmitExtractImag(operand_value); llvm::Type* llvm_ty = a->getType(); - auto sum_sq = b_->CreateFAdd(b_->CreateFMul(a, a), b_->CreateFMul(b, b)); + auto sum_sq = FAdd(FMul(a, a), FMul(b, b)); TF_ASSIGN_OR_RETURN(auto log_sum_sq, EmitLog(component_type, sum_sq)); TF_ASSIGN_OR_RETURN(auto angle, EmitAtan2(component_type, b, a)); auto one_half = llvm::ConstantFP::get(llvm_ty, 0.5); - return EmitComposeComplex(op, b_->CreateFMul(one_half, log_sum_sq), - angle); + return EmitComposeComplex(op, FMul(one_half, log_sum_sq), angle); } case HloOpcode::kLog1p: { // log1p(a+bi) = .5*log((a+1)^2+b^2) + i*atan2(b, a + 1) @@ -509,14 +496,12 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexUnaryOp( auto b = EmitExtractImag(operand_value); llvm::Type* llvm_ty = a->getType(); auto one = llvm::ConstantFP::get(llvm_ty, 1.0); - auto a_plus_one = b_->CreateFAdd(a, one); - auto sum_sq = b_->CreateFAdd(b_->CreateFMul(a_plus_one, a_plus_one), - b_->CreateFMul(b, b)); + auto a_plus_one = FAdd(a, one); + auto sum_sq = FAdd(FMul(a_plus_one, a_plus_one), FMul(b, b)); TF_ASSIGN_OR_RETURN(auto log_sum_sq, EmitLog(component_type, sum_sq)); TF_ASSIGN_OR_RETURN(auto angle, EmitAtan2(component_type, b, a_plus_one)); auto one_half = llvm::ConstantFP::get(llvm_ty, 0.5); - return EmitComposeComplex(op, b_->CreateFMul(one_half, log_sum_sq), - angle); + return EmitComposeComplex(op, FMul(one_half, log_sum_sq), angle); } case HloOpcode::kConvert: { PrimitiveType from_type = op->operand(0)->shape().element_type(); @@ -530,11 +515,9 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexUnaryOp( primitive_util::ComplexComponentType(to_type); auto to_ir_component_type = llvm_ir::PrimitiveTypeToIrType(to_component_type, module_); - return EmitComposeComplex(op, - b_->CreateFPCast(EmitExtractReal(operand_value), - to_ir_component_type), - b_->CreateFPCast(EmitExtractImag(operand_value), - to_ir_component_type)); + return EmitComposeComplex( + op, FPCast(EmitExtractReal(operand_value), to_ir_component_type), + FPCast(EmitExtractImag(operand_value), to_ir_component_type)); } case HloOpcode::kExp: { // e^(a+bi) = e^a*(cos(b)+sin(b)i) @@ -544,8 +527,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexUnaryOp( auto cos_b, EmitCos(component_type, EmitExtractImag(operand_value))); TF_ASSIGN_OR_RETURN( auto sin_b, EmitSin(component_type, EmitExtractImag(operand_value))); - return EmitComposeComplex(op, b_->CreateFMul(exp_a, cos_b), - b_->CreateFMul(exp_a, sin_b)); + return EmitComposeComplex(op, FMul(exp_a, cos_b), FMul(exp_a, sin_b)); } case HloOpcode::kExpm1: { // e^(a+bi)-1 = (e^a*cos(b)-1)+e^a*sin(b)i @@ -556,8 +538,8 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexUnaryOp( TF_ASSIGN_OR_RETURN( auto sin_b, EmitSin(component_type, EmitExtractImag(operand_value))); auto one = llvm::ConstantFP::get(exp_a->getType(), 1.0); - auto real_result = b_->CreateFSub(b_->CreateFMul(exp_a, cos_b), one); - auto imag_result = b_->CreateFMul(exp_a, sin_b); + auto real_result = FSub(FMul(exp_a, cos_b), one); + auto imag_result = FMul(exp_a, sin_b); return EmitComposeComplex(op, real_result, imag_result); } case HloOpcode::kCos: { @@ -572,14 +554,13 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexUnaryOp( auto b = EmitExtractImag(operand_value); auto type = a->getType(); TF_ASSIGN_OR_RETURN(auto exp_b, EmitExp(component_type, b)); - auto half_exp_b = b_->CreateFMul(llvm::ConstantFP::get(type, 0.5), exp_b); - auto half_exp_neg_b = - b_->CreateFDiv(llvm::ConstantFP::get(type, 0.5), exp_b); + auto half_exp_b = FMul(llvm::ConstantFP::get(type, 0.5), exp_b); + auto half_exp_neg_b = FDiv(llvm::ConstantFP::get(type, 0.5), exp_b); TF_ASSIGN_OR_RETURN(auto cos_a, EmitCos(component_type, a)); TF_ASSIGN_OR_RETURN(auto sin_a, EmitSin(component_type, a)); - return EmitComposeComplex( - op, b_->CreateFMul(cos_a, b_->CreateFAdd(half_exp_neg_b, half_exp_b)), - b_->CreateFMul(sin_a, b_->CreateFSub(half_exp_neg_b, half_exp_b))); + return EmitComposeComplex(op, + FMul(cos_a, FAdd(half_exp_neg_b, half_exp_b)), + FMul(sin_a, FSub(half_exp_neg_b, half_exp_b))); } case HloOpcode::kSin: { // sin(z) = .5i(e^(-iz) - e^(iz)) @@ -595,14 +576,13 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexUnaryOp( auto b = EmitExtractImag(operand_value); auto type = a->getType(); TF_ASSIGN_OR_RETURN(auto exp_b, EmitExp(component_type, b)); - auto half_exp_b = b_->CreateFMul(llvm::ConstantFP::get(type, 0.5), exp_b); - auto half_exp_neg_b = - b_->CreateFDiv(llvm::ConstantFP::get(type, 0.5), exp_b); + auto half_exp_b = FMul(llvm::ConstantFP::get(type, 0.5), exp_b); + auto half_exp_neg_b = FDiv(llvm::ConstantFP::get(type, 0.5), exp_b); TF_ASSIGN_OR_RETURN(auto cos_a, EmitCos(component_type, a)); TF_ASSIGN_OR_RETURN(auto sin_a, EmitSin(component_type, a)); - return EmitComposeComplex( - op, b_->CreateFMul(sin_a, b_->CreateFAdd(half_exp_b, half_exp_neg_b)), - b_->CreateFMul(cos_a, b_->CreateFSub(half_exp_b, half_exp_neg_b))); + return EmitComposeComplex(op, + FMul(sin_a, FAdd(half_exp_b, half_exp_neg_b)), + FMul(cos_a, FSub(half_exp_b, half_exp_neg_b))); } case HloOpcode::kTanh: { /* @@ -630,74 +610,63 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexUnaryOp( TF_ASSIGN_OR_RETURN(auto exp_a, EmitExp(component_type, a)); TF_ASSIGN_OR_RETURN(auto cos_b, EmitCos(component_type, b)); TF_ASSIGN_OR_RETURN(auto sin_b, EmitSin(component_type, b)); - auto exp_neg_a = - b_->CreateFDiv(llvm::ConstantFP::get(exp_a->getType(), 1), exp_a); - auto exp_2a_minus_exp_neg_2a = b_->CreateFSub( - b_->CreateFMul(exp_a, exp_a), b_->CreateFMul(exp_neg_a, exp_neg_a)); - auto cos_b_sq = b_->CreateFMul(cos_b, cos_b); - auto sin_b_sq = b_->CreateFMul(sin_b, sin_b); - auto real_num = - b_->CreateFAdd(b_->CreateFMul(cos_b_sq, exp_2a_minus_exp_neg_2a), - b_->CreateFMul(sin_b_sq, exp_2a_minus_exp_neg_2a)); - auto cos_b_sin_b = b_->CreateFMul(cos_b, sin_b); - auto exp_a_plus_exp_neg_a = b_->CreateFAdd(exp_a, exp_neg_a); + auto exp_neg_a = FDiv(llvm::ConstantFP::get(exp_a->getType(), 1), exp_a); + auto exp_2a_minus_exp_neg_2a = + FSub(FMul(exp_a, exp_a), FMul(exp_neg_a, exp_neg_a)); + auto cos_b_sq = FMul(cos_b, cos_b); + auto sin_b_sq = FMul(sin_b, sin_b); + auto real_num = FAdd(FMul(cos_b_sq, exp_2a_minus_exp_neg_2a), + FMul(sin_b_sq, exp_2a_minus_exp_neg_2a)); + auto cos_b_sin_b = FMul(cos_b, sin_b); + auto exp_a_plus_exp_neg_a = FAdd(exp_a, exp_neg_a); auto exp_a_plus_exp_neg_a_sq = - b_->CreateFMul(exp_a_plus_exp_neg_a, exp_a_plus_exp_neg_a); - auto exp_a_minus_exp_neg_a = b_->CreateFSub(exp_a, exp_neg_a); + FMul(exp_a_plus_exp_neg_a, exp_a_plus_exp_neg_a); + auto exp_a_minus_exp_neg_a = FSub(exp_a, exp_neg_a); auto exp_a_minus_exp_neg_a_sq = - b_->CreateFMul(exp_a_minus_exp_neg_a, exp_a_minus_exp_neg_a); - auto imag_num = b_->CreateFMul( - cos_b_sin_b, - b_->CreateFSub(exp_a_plus_exp_neg_a_sq, exp_a_minus_exp_neg_a_sq)); - auto denom = - b_->CreateFAdd(b_->CreateFMul(cos_b_sq, exp_a_plus_exp_neg_a_sq), - b_->CreateFMul(sin_b_sq, exp_a_minus_exp_neg_a_sq)); - return EmitComposeComplex(op, b_->CreateFDiv(real_num, denom), - b_->CreateFDiv(imag_num, denom)); + FMul(exp_a_minus_exp_neg_a, exp_a_minus_exp_neg_a); + auto imag_num = FMul( + cos_b_sin_b, FSub(exp_a_plus_exp_neg_a_sq, exp_a_minus_exp_neg_a_sq)); + auto denom = FAdd(FMul(cos_b_sq, exp_a_plus_exp_neg_a_sq), + FMul(sin_b_sq, exp_a_minus_exp_neg_a_sq)); + return EmitComposeComplex(op, FDiv(real_num, denom), + FDiv(imag_num, denom)); } case HloOpcode::kAbs: { - auto sum_sq = - b_->CreateFAdd(b_->CreateFMul(EmitExtractReal(operand_value), - EmitExtractReal(operand_value)), - b_->CreateFMul(EmitExtractImag(operand_value), - EmitExtractImag(operand_value))); + auto sum_sq = FAdd( + FMul(EmitExtractReal(operand_value), EmitExtractReal(operand_value)), + FMul(EmitExtractImag(operand_value), EmitExtractImag(operand_value))); return llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::sqrt, {sum_sq}, {sum_sq->getType()}, b_); } case HloOpcode::kSign: { // Sign(c) = c / |c| - auto sum_sq = - b_->CreateFAdd(b_->CreateFMul(EmitExtractReal(operand_value), - EmitExtractReal(operand_value)), - b_->CreateFMul(EmitExtractImag(operand_value), - EmitExtractImag(operand_value))); + auto sum_sq = FAdd( + FMul(EmitExtractReal(operand_value), EmitExtractReal(operand_value)), + FMul(EmitExtractImag(operand_value), EmitExtractImag(operand_value))); auto cplx_abs = llvm_ir::EmitCallToIntrinsic( llvm::Intrinsic::sqrt, {sum_sq}, {sum_sq->getType()}, b_); auto type = cplx_abs->getType(); auto zero = llvm::ConstantFP::get(type, 0.0); - auto oeq = b_->CreateFCmpOEQ(cplx_abs, zero); - return b_->CreateSelect( + auto oeq = FCmpOEQ(cplx_abs, zero); + return Select( oeq, EmitComposeComplex(op, zero, zero), - EmitComposeComplex( - op, b_->CreateFDiv(EmitExtractReal(operand_value), cplx_abs), - b_->CreateFDiv(EmitExtractImag(operand_value), cplx_abs))); + EmitComposeComplex(op, FDiv(EmitExtractReal(operand_value), cplx_abs), + FDiv(EmitExtractImag(operand_value), cplx_abs))); } case HloOpcode::kNegate: - return EmitComposeComplex(op, - b_->CreateFNeg(EmitExtractReal(operand_value)), - b_->CreateFNeg(EmitExtractImag(operand_value))); + return EmitComposeComplex(op, FNeg(EmitExtractReal(operand_value)), + FNeg(EmitExtractImag(operand_value))); case HloOpcode::kReal: return EmitExtractReal(operand_value); case HloOpcode::kImag: return EmitExtractImag(operand_value); default: return Unimplemented("unary complex op '%s'", - HloOpcodeString(op->opcode()).c_str()); + HloOpcodeString(op->opcode())); } } StatusOr<llvm::Value*> ElementalIrEmitter::EmitBinaryOp( - const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const { + const HloInstruction* op, llvm::Value* lhs_value, llvm::Value* rhs_value) { PrimitiveType operand_type = op->operand(0)->shape().element_type(); if (ShapeUtil::ElementIsIntegral(op->operand(0)->shape()) || operand_type == PRED) { @@ -712,21 +681,20 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitBinaryOp( } StatusOr<llvm::Value*> ElementalIrEmitter::EmitFloatBinaryOp( - const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const { + const HloInstruction* op, llvm::Value* lhs_value, llvm::Value* rhs_value) { switch (op->opcode()) { case HloOpcode::kComplex: return EmitComposeComplex(op, lhs_value, rhs_value); case HloOpcode::kAdd: - return b_->CreateFAdd(lhs_value, rhs_value); + return FAdd(lhs_value, rhs_value); case HloOpcode::kSubtract: - return b_->CreateFSub(lhs_value, rhs_value); + return FSub(lhs_value, rhs_value); case HloOpcode::kMultiply: - return b_->CreateFMul(lhs_value, rhs_value); + return FMul(lhs_value, rhs_value); case HloOpcode::kDivide: - return b_->CreateFDiv(lhs_value, rhs_value); + return FDiv(lhs_value, rhs_value); case HloOpcode::kRemainder: - return b_->CreateFRem(lhs_value, rhs_value); + return FRem(lhs_value, rhs_value); // LLVM comparisons can be "unordered" (U) or "ordered" (O) -- ordered // comparisons always return false when one of the operands is NaN, whereas // unordered comparisons return true. @@ -763,66 +731,52 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitFloatBinaryOp( return EmitAtan2(op->shape().element_type(), lhs_value, rhs_value); default: return Unimplemented("binary floating point op '%s'", - HloOpcodeString(op->opcode()).c_str()); + HloOpcodeString(op->opcode())); } } StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexBinaryOp( - const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const { + const HloInstruction* op, llvm::Value* lhs_value, llvm::Value* rhs_value) { switch (op->opcode()) { case HloOpcode::kAdd: - return EmitComposeComplex(op, - b_->CreateFAdd(EmitExtractReal(lhs_value), - EmitExtractReal(rhs_value)), - b_->CreateFAdd(EmitExtractImag(lhs_value), - EmitExtractImag(rhs_value))); + return EmitComposeComplex( + op, FAdd(EmitExtractReal(lhs_value), EmitExtractReal(rhs_value)), + FAdd(EmitExtractImag(lhs_value), EmitExtractImag(rhs_value))); case HloOpcode::kSubtract: - return EmitComposeComplex(op, - b_->CreateFSub(EmitExtractReal(lhs_value), - EmitExtractReal(rhs_value)), - b_->CreateFSub(EmitExtractImag(lhs_value), - EmitExtractImag(rhs_value))); + return EmitComposeComplex( + op, FSub(EmitExtractReal(lhs_value), EmitExtractReal(rhs_value)), + FSub(EmitExtractImag(lhs_value), EmitExtractImag(rhs_value))); case HloOpcode::kMultiply: return EmitComposeComplex( op, - b_->CreateFSub(b_->CreateFMul(EmitExtractReal(lhs_value), - EmitExtractReal(rhs_value)), - b_->CreateFMul(EmitExtractImag(lhs_value), - EmitExtractImag(rhs_value))), - b_->CreateFAdd(b_->CreateFMul(EmitExtractReal(lhs_value), - EmitExtractImag(rhs_value)), - b_->CreateFMul(EmitExtractImag(lhs_value), - EmitExtractReal(rhs_value)))); + FSub(FMul(EmitExtractReal(lhs_value), EmitExtractReal(rhs_value)), + FMul(EmitExtractImag(lhs_value), EmitExtractImag(rhs_value))), + FAdd(FMul(EmitExtractReal(lhs_value), EmitExtractImag(rhs_value)), + FMul(EmitExtractImag(lhs_value), EmitExtractReal(rhs_value)))); case HloOpcode::kDivide: { // (a+bi) / (c+di) = ((a+bi)(c-di)) / ((c+di)(c-di)) // = ((ac + bd) + (bc - ad)i) / (c^2 + d^2) auto rhs_sum_sq = - b_->CreateFAdd(b_->CreateFMul(EmitExtractReal(rhs_value), - EmitExtractReal(rhs_value)), - b_->CreateFMul(EmitExtractImag(rhs_value), - EmitExtractImag(rhs_value))); + FAdd(FMul(EmitExtractReal(rhs_value), EmitExtractReal(rhs_value)), + FMul(EmitExtractImag(rhs_value), EmitExtractImag(rhs_value))); auto type = rhs_sum_sq->getType(); auto zero = llvm::ConstantFP::get(type, 0.0); - auto oeq = b_->CreateFCmpOEQ(rhs_sum_sq, zero); - auto real_inf_or_nan = b_->CreateFDiv(EmitExtractReal(lhs_value), zero); - auto imag_inf_or_nan = b_->CreateFDiv(EmitExtractImag(lhs_value), zero); - return b_->CreateSelect( + auto oeq = FCmpOEQ(rhs_sum_sq, zero); + auto real_inf_or_nan = FDiv(EmitExtractReal(lhs_value), zero); + auto imag_inf_or_nan = FDiv(EmitExtractImag(lhs_value), zero); + return Select( oeq, EmitComposeComplex(op, real_inf_or_nan, imag_inf_or_nan), - EmitComposeComplex( - op, - b_->CreateFDiv( - b_->CreateFAdd(b_->CreateFMul(EmitExtractReal(lhs_value), - EmitExtractReal(rhs_value)), - b_->CreateFMul(EmitExtractImag(lhs_value), - EmitExtractImag(rhs_value))), - rhs_sum_sq), - b_->CreateFDiv( - b_->CreateFSub(b_->CreateFMul(EmitExtractImag(lhs_value), - EmitExtractReal(rhs_value)), - b_->CreateFMul(EmitExtractReal(lhs_value), - EmitExtractImag(rhs_value))), - rhs_sum_sq))); + EmitComposeComplex(op, + FDiv(FAdd(FMul(EmitExtractReal(lhs_value), + EmitExtractReal(rhs_value)), + FMul(EmitExtractImag(lhs_value), + EmitExtractImag(rhs_value))), + rhs_sum_sq), + FDiv(FSub(FMul(EmitExtractImag(lhs_value), + EmitExtractReal(rhs_value)), + FMul(EmitExtractReal(lhs_value), + EmitExtractImag(rhs_value))), + rhs_sum_sq))); } // LLVM comparisons can be "unordered" (U) or "ordered" (O) -- ordered // comparisons always return false when one of the operands is NaN, whereas @@ -832,21 +786,19 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexBinaryOp( // unordered comparison. This makes x != y equivalent to !(x == y), and // matches C++'s semantics. case HloOpcode::kEq: - return b_->CreateAnd( - llvm_ir::EmitComparison(llvm::CmpInst::FCMP_OEQ, - EmitExtractReal(lhs_value), - EmitExtractReal(rhs_value), b_), - llvm_ir::EmitComparison(llvm::CmpInst::FCMP_OEQ, - EmitExtractImag(lhs_value), - EmitExtractImag(rhs_value), b_)); + return And(llvm_ir::EmitComparison(llvm::CmpInst::FCMP_OEQ, + EmitExtractReal(lhs_value), + EmitExtractReal(rhs_value), b_), + llvm_ir::EmitComparison(llvm::CmpInst::FCMP_OEQ, + EmitExtractImag(lhs_value), + EmitExtractImag(rhs_value), b_)); case HloOpcode::kNe: - return b_->CreateOr( - llvm_ir::EmitComparison(llvm::CmpInst::FCMP_UNE, - EmitExtractReal(lhs_value), - EmitExtractReal(rhs_value), b_), - llvm_ir::EmitComparison(llvm::CmpInst::FCMP_UNE, - EmitExtractImag(lhs_value), - EmitExtractImag(rhs_value), b_)); + return Or(llvm_ir::EmitComparison(llvm::CmpInst::FCMP_UNE, + EmitExtractReal(lhs_value), + EmitExtractReal(rhs_value), b_), + llvm_ir::EmitComparison(llvm::CmpInst::FCMP_UNE, + EmitExtractImag(lhs_value), + EmitExtractImag(rhs_value), b_)); case HloOpcode::kPower: { // (a+bi)^(c+di) = @@ -858,45 +810,43 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitComplexBinaryOp( auto b = EmitExtractImag(lhs_value); auto c = EmitExtractReal(rhs_value); auto d = EmitExtractImag(rhs_value); - auto aa_p_bb = b_->CreateFAdd(b_->CreateFMul(a, a), b_->CreateFMul(b, b)); + auto aa_p_bb = FAdd(FMul(a, a), FMul(b, b)); auto one_half = llvm::ConstantFP::get(a->getType(), 0.5); - auto half_c = b_->CreateFMul(one_half, c); + auto half_c = FMul(one_half, c); TF_ASSIGN_OR_RETURN(auto aa_p_bb_to_half_c, EmitPow(component_type, aa_p_bb, half_c)); - auto neg_d = b_->CreateFNeg(d); + auto neg_d = FNeg(d); TF_ASSIGN_OR_RETURN(auto arg_lhs, EmitAtan2(component_type, b, a)); - auto neg_d_arg_lhs = b_->CreateFMul(neg_d, arg_lhs); + auto neg_d_arg_lhs = FMul(neg_d, arg_lhs); TF_ASSIGN_OR_RETURN(auto e_to_neg_d_arg_lhs, EmitExp(component_type, neg_d_arg_lhs)); - auto coeff = b_->CreateFMul(aa_p_bb_to_half_c, e_to_neg_d_arg_lhs); + auto coeff = FMul(aa_p_bb_to_half_c, e_to_neg_d_arg_lhs); TF_ASSIGN_OR_RETURN(auto ln_aa_p_bb, EmitLog(component_type, aa_p_bb)); - auto half_d = b_->CreateFMul(one_half, d); - auto q = b_->CreateFAdd(b_->CreateFMul(c, arg_lhs), - b_->CreateFMul(half_d, ln_aa_p_bb)); + auto half_d = FMul(one_half, d); + auto q = FAdd(FMul(c, arg_lhs), FMul(half_d, ln_aa_p_bb)); TF_ASSIGN_OR_RETURN(auto cos_q, EmitCos(component_type, q)); TF_ASSIGN_OR_RETURN(auto sin_q, EmitSin(component_type, q)); - return EmitComposeComplex(op, b_->CreateFMul(coeff, cos_q), - b_->CreateFMul(coeff, sin_q)); + return EmitComposeComplex(op, FMul(coeff, cos_q), FMul(coeff, sin_q)); } default: return Unimplemented("binary complex op '%s'", - HloOpcodeString(op->opcode()).c_str()); + HloOpcodeString(op->opcode())); } } llvm::Value* ElementalIrEmitter::EmitFloatMax(llvm::Value* lhs_value, - llvm::Value* rhs_value) const { + llvm::Value* rhs_value) { return llvm_ir::EmitFloatMax(lhs_value, rhs_value, b_); } llvm::Value* ElementalIrEmitter::EmitFloatMin(llvm::Value* lhs_value, - llvm::Value* rhs_value) const { + llvm::Value* rhs_value) { return llvm_ir::EmitFloatMin(lhs_value, rhs_value, b_); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitErfInv(PrimitiveType prim_type, - llvm::Value* x) const { + llvm::Value* x) { if (prim_type != F32) { // TODO(b/34339814): Implement inverse erf for F64. return Unimplemented( @@ -909,9 +859,9 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitErfInv(PrimitiveType prim_type, auto multiply_add = [&](tensorflow::gtl::ArraySlice<float> coefficients, llvm::Value* w) { llvm::Value* p = getFloat(coefficients.front()); - coefficients.pop_front(); + coefficients.remove_prefix(1); for (float coefficient : coefficients) { - p = b_->CreateFAdd(b_->CreateFMul(p, w), getFloat(coefficient)); + p = FAdd(FMul(p, w), getFloat(coefficient)); } return p; }; @@ -931,25 +881,24 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitErfInv(PrimitiveType prim_type, llvm::Function* logf_fn = llvm::Intrinsic::getDeclaration( module_, llvm::Intrinsic::log, {b_->getFloatTy()}); - llvm::Value* w = b_->CreateFNeg(b_->CreateCall( - logf_fn, {b_->CreateFMul(b_->CreateFSub(getFloat(1.0f), x), - b_->CreateFAdd(getFloat(1.0f), x))})); + llvm::Value* w = FNeg( + Call(logf_fn, {FMul(FSub(getFloat(1.0f), x), FAdd(getFloat(1.0f), x))})); llvm::Value* p_addr = llvm_ir::EmitAllocaAtFunctionEntry(b_->getFloatTy(), "p.addr", b_); llvm_ir::LlvmIfData if_data = llvm_ir::EmitIfThenElse( - b_->CreateFCmpOLT(w, getFloat(5.0f)), "w_less_than_five", b_); + FCmpOLT(w, getFloat(5.0f)), "w_less_than_five", b_); // Handle true BB. SetToFirstInsertPoint(if_data.true_block, b_); { - llvm::Value* lw = b_->CreateFSub(w, getFloat(2.5f)); + llvm::Value* lw = FSub(w, getFloat(2.5f)); tensorflow::gtl::ArraySlice<float> lq{ 2.81022636e-08f, 3.43273939e-07f, -3.5233877e-06f, -4.39150654e-06f, 0.00021858087f, -0.00125372503f, -0.00417768164f, 0.246640727f, 1.50140941f}; llvm::Value* p = multiply_add(lq, lw); - b_->CreateStore(p, p_addr); + Store(p, p_addr); } // Handle false BB. @@ -958,76 +907,73 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitErfInv(PrimitiveType prim_type, llvm::Function* sqrtf_fn = llvm::Intrinsic::getDeclaration( module_, llvm::Intrinsic::sqrt, {b_->getFloatTy()}); - llvm::Value* gw = - b_->CreateFSub(b_->CreateCall(sqrtf_fn, {w}), getFloat(3.0f)); + llvm::Value* gw = FSub(Call(sqrtf_fn, w), getFloat(3.0f)); tensorflow::gtl::ArraySlice<float> gq{ -0.000200214257f, 0.000100950558f, 0.00134934322f, -0.00367342844f, 0.00573950773f, -0.0076224613f, 0.00943887047f, 1.00167406f, 2.83297682f}; llvm::Value* p = multiply_add(gq, gw); - b_->CreateStore(p, p_addr); + Store(p, p_addr); } SetToFirstInsertPoint(if_data.after_block, b_); - llvm::Value* p = b_->CreateLoad(p_addr); - return b_->CreateFMul(p, x); + llvm::Value* p = Load(p_addr); + return FMul(p, x); } -StatusOr<llvm::Value*> ElementalIrEmitter::EmitErfcInv( - PrimitiveType prim_type, llvm::Value* value) const { +StatusOr<llvm::Value*> ElementalIrEmitter::EmitErfcInv(PrimitiveType prim_type, + llvm::Value* value) { // Compute erfcinv(value) by calculating erfinv(1.0 - value). auto type = llvm_ir::PrimitiveTypeToIrType(prim_type, module_); auto one = llvm::ConstantFP::get(type, 1.0); - return EmitErfInv(prim_type, b_->CreateFSub(one, value)); + return EmitErfInv(prim_type, FSub(one, value)); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitLog(PrimitiveType prim_type, - llvm::Value* value) const { + llvm::Value* value) { return llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::log, {value}, {value->getType()}, b_); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitLog1p(PrimitiveType prim_type, - llvm::Value* value) const { + llvm::Value* value) { auto x = value; auto type = llvm_ir::PrimitiveTypeToIrType(prim_type, module_); auto one = llvm::ConstantFP::get(type, 1.0); auto negative_half = llvm::ConstantFP::get(type, -0.5); // When x is large, the naive evaluation of ln(x + 1) is more // accurate than the Taylor series. - TF_ASSIGN_OR_RETURN(auto for_large_x, - EmitLog(prim_type, b_->CreateFAdd(x, one))); + TF_ASSIGN_OR_RETURN(auto for_large_x, EmitLog(prim_type, FAdd(x, one))); // The Taylor series for ln(x+1) is x - x^2/2 - x^3/3 + …. - auto for_small_x = - b_->CreateFMul(b_->CreateFAdd(b_->CreateFMul(negative_half, x), one), x); + auto for_small_x = FMul(FAdd(FMul(negative_half, x), one), x); const auto kAntilogarithmIsSmallThreshold = 1e-4; auto abs_x = llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::fabs, {value}, {type}, b_); - auto x_is_small = b_->CreateFCmpOLT( + auto x_is_small = FCmpOLT( abs_x, llvm::ConstantFP::get(type, kAntilogarithmIsSmallThreshold)); - return b_->CreateSelect(x_is_small, for_small_x, for_large_x); + return Select(x_is_small, for_small_x, for_large_x); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitSin(PrimitiveType prim_type, - llvm::Value* value) const { + llvm::Value* value) { return llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::sin, {value}, {value->getType()}, b_); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitCos(PrimitiveType prim_type, - llvm::Value* value) const { + llvm::Value* value) { return llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::cos, {value}, {value->getType()}, b_); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitExp(PrimitiveType prim_type, - llvm::Value* value) const { + llvm::Value* value) { return llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::exp, {value}, {value->getType()}, b_); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitExpm1(PrimitiveType prim_type, - llvm::Value* value) const { + llvm::Value* value) { auto x = value; auto type = llvm_ir::PrimitiveTypeToIrType(prim_type, module_); auto one = llvm::ConstantFP::get(type, 1.0); @@ -1035,40 +981,40 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitExpm1(PrimitiveType prim_type, // When the exponent is large, the naive evaluation of e^(x) - 1 is more // accurate than the Taylor series. TF_ASSIGN_OR_RETURN(auto exp_x, EmitExp(prim_type, value)); - auto for_large_x = b_->CreateFSub(exp_x, one); + auto for_large_x = FSub(exp_x, one); // The Taylor series for exp(x) is 1 + x + x^2/2 + x^3/6 + …. // We want exp(x)-1 which is x + x^2/2 + x^3/6 + …. - auto x_squared = b_->CreateFAdd(x, x); - auto x_squared_over_two = b_->CreateFMul(x_squared, half); - auto for_small_x = b_->CreateFAdd(x, x_squared_over_two); + auto x_squared = FAdd(x, x); + auto x_squared_over_two = FMul(x_squared, half); + auto for_small_x = FAdd(x, x_squared_over_two); const auto kExponentIsSmallThreshold = 1e-5; auto abs_x = llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::fabs, {value}, {type}, b_); - auto x_is_small = b_->CreateFCmpOLT( - abs_x, llvm::ConstantFP::get(type, kExponentIsSmallThreshold)); - return b_->CreateSelect(x_is_small, for_small_x, for_large_x); + auto x_is_small = + FCmpOLT(abs_x, llvm::ConstantFP::get(type, kExponentIsSmallThreshold)); + return Select(x_is_small, for_small_x, for_large_x); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitPow(PrimitiveType prim_type, llvm::Value* lhs, - llvm::Value* rhs) const { + llvm::Value* rhs) { return llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::pow, {lhs, rhs}, {lhs->getType()}, b_); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitAtan2(PrimitiveType prim_type, llvm::Value* lhs, - llvm::Value* rhs) const { + llvm::Value* rhs) { return Unimplemented("atan2"); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitTanh(PrimitiveType prim_type, - llvm::Value* value) const { + llvm::Value* value) { return Unimplemented("tanh"); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitReducePrecision( - const HloInstruction* hlo, llvm::Value* x) const { + const HloInstruction* hlo, llvm::Value* x) { if (hlo->operand(0)->shape().element_type() != F32) { return Unimplemented("reduce-precision only implemented for F32"); } @@ -1099,23 +1045,103 @@ static llvm::Value* SaturateShiftIfNecessary(llvm::IRBuilder<>* b, return b->CreateSelect(shift_amt_in_range, shift_result, saturated_value); } +llvm::Value* ElementalIrEmitter::GetOne(llvm::Type* type) { + return llvm::ConstantInt::get(llvm::cast<llvm::IntegerType>(type), 1); +} + +llvm::Value* ElementalIrEmitter::GetZero(llvm::Type* type) { + return llvm::ConstantInt::get(llvm::cast<llvm::IntegerType>(type), 0); +} + +llvm::Value* ElementalIrEmitter::GetIntSMin(llvm::Type* type) { + auto* integer_type = llvm::cast<llvm::IntegerType>(type); + return llvm::ConstantInt::get(integer_type, llvm::APInt::getSignedMinValue( + integer_type->getBitWidth())); +} + +llvm::Value* ElementalIrEmitter::GetMinusOne(llvm::Type* type) { + auto* integer_type = llvm::cast<llvm::IntegerType>(type); + return llvm::ConstantInt::get( + integer_type, llvm::APInt::getAllOnesValue(integer_type->getBitWidth())); +} + +llvm::Value* ElementalIrEmitter::IsZero(llvm::Value* v) { + return ICmpEQ(v, llvm::ConstantInt::get(v->getType(), 0)); +} + +llvm::Value* ElementalIrEmitter::IsIntMinDivisionOverflow(llvm::Value* lhs, + llvm::Value* rhs) { + return And(ICmpEQ(lhs, GetIntSMin(lhs->getType())), + ICmpEQ(rhs, GetMinusOne(rhs->getType()))); +} + +llvm::Value* ElementalIrEmitter::EmitIntegerDivide(llvm::Value* lhs, + llvm::Value* rhs, + bool is_signed) { + // Integer division overflow behavior: + // + // X / 0 == -1 + // INT_SMIN /s -1 = INT_SMIN + + if (!is_signed) { + llvm::Value* udiv_is_unsafe = IsZero(rhs); + llvm::Value* safe_rhs = Select(udiv_is_unsafe, GetOne(lhs->getType()), rhs); + llvm::Value* safe_div = UDiv(lhs, safe_rhs); + return Select(udiv_is_unsafe, GetMinusOne(lhs->getType()), safe_div); + } + + llvm::Value* has_zero_divisor = IsZero(rhs); + llvm::Value* has_int_min_overflow = IsIntMinDivisionOverflow(lhs, rhs); + llvm::Value* sdiv_is_unsafe = Or(has_int_min_overflow, has_zero_divisor); + llvm::Value* safe_rhs = Select(sdiv_is_unsafe, GetOne(lhs->getType()), rhs); + llvm::Value* safe_div = SDiv(lhs, safe_rhs); + + return Select( + has_zero_divisor, GetMinusOne(lhs->getType()), + Select(has_int_min_overflow, GetIntSMin(lhs->getType()), safe_div)); +} + +llvm::Value* ElementalIrEmitter::EmitIntegerRemainder(llvm::Value* lhs, + llvm::Value* rhs, + bool is_signed) { + // Integer remainder overflow behavior: + // + // X % 0 == X + // INT_SMIN %s -1 = 0 + + if (!is_signed) { + llvm::Value* urem_is_unsafe = IsZero(rhs); + llvm::Value* safe_rhs = Select(urem_is_unsafe, GetOne(lhs->getType()), rhs); + llvm::Value* safe_rem = URem(lhs, safe_rhs); + return Select(urem_is_unsafe, lhs, safe_rem); + } + + llvm::Value* has_zero_divisor = IsZero(rhs); + llvm::Value* has_int_min_overflow = IsIntMinDivisionOverflow(lhs, rhs); + llvm::Value* srem_is_unsafe = Or(has_int_min_overflow, has_zero_divisor); + llvm::Value* safe_rhs = Select(srem_is_unsafe, GetOne(lhs->getType()), rhs); + llvm::Value* safe_rem = SRem(lhs, safe_rhs); + + return Select( + has_zero_divisor, lhs, + Select(has_int_min_overflow, GetZero(lhs->getType()), safe_rem)); +} + StatusOr<llvm::Value*> ElementalIrEmitter::EmitIntegerBinaryOp( const HloInstruction* op, llvm::Value* lhs_value, llvm::Value* rhs_value, - bool is_signed) const { + bool is_signed) { switch (op->opcode()) { // TODO(jingyue): add the "nsw" attribute for signed types. case HloOpcode::kAdd: - return b_->CreateAdd(lhs_value, rhs_value); + return Add(lhs_value, rhs_value); case HloOpcode::kSubtract: - return b_->CreateSub(lhs_value, rhs_value); + return Sub(lhs_value, rhs_value); case HloOpcode::kMultiply: - return b_->CreateMul(lhs_value, rhs_value); + return Mul(lhs_value, rhs_value); case HloOpcode::kDivide: - return is_signed ? b_->CreateSDiv(lhs_value, rhs_value) - : b_->CreateUDiv(lhs_value, rhs_value); + return EmitIntegerDivide(lhs_value, rhs_value, is_signed); case HloOpcode::kRemainder: - return is_signed ? b_->CreateSRem(lhs_value, rhs_value) - : b_->CreateURem(lhs_value, rhs_value); + return EmitIntegerRemainder(lhs_value, rhs_value, is_signed); case HloOpcode::kEq: return llvm_ir::EmitComparison(llvm::CmpInst::ICMP_EQ, lhs_value, rhs_value, b_); @@ -1143,11 +1169,11 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitIntegerBinaryOp( case HloOpcode::kMaximum: return EmitIntegralMax(lhs_value, rhs_value, is_signed); case HloOpcode::kAnd: - return b_->CreateAnd(lhs_value, rhs_value); + return And(lhs_value, rhs_value); case HloOpcode::kOr: - return b_->CreateOr(lhs_value, rhs_value); + return Or(lhs_value, rhs_value); case HloOpcode::kXor: - return b_->CreateXor(lhs_value, rhs_value); + return Xor(lhs_value, rhs_value); // Shifting out bits >= the number of bits in the type being shifted // produces a poison value in LLVM which is basically "deferred undefined @@ -1156,43 +1182,43 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitIntegerBinaryOp( // UB. case HloOpcode::kShiftRightArithmetic: return SaturateShiftIfNecessary(b_, lhs_value, rhs_value, - b_->CreateAShr(lhs_value, rhs_value), + AShr(lhs_value, rhs_value), /*saturate_to_sign_bit=*/true); case HloOpcode::kShiftLeft: return SaturateShiftIfNecessary(b_, lhs_value, rhs_value, - b_->CreateShl(lhs_value, rhs_value), + Shl(lhs_value, rhs_value), /*saturate_to_sign_bit=*/false); case HloOpcode::kShiftRightLogical: return SaturateShiftIfNecessary(b_, lhs_value, rhs_value, - b_->CreateLShr(lhs_value, rhs_value), + LShr(lhs_value, rhs_value), /*saturate_to_sign_bit=*/false); default: return Unimplemented("binary integer op '%s'", - HloOpcodeString(op->opcode()).c_str()); + HloOpcodeString(op->opcode())); } } llvm::Value* ElementalIrEmitter::EmitIntegralMax(llvm::Value* lhs_value, llvm::Value* rhs_value, - bool is_signed) const { - return b_->CreateSelect(b_->CreateICmp(is_signed ? llvm::ICmpInst::ICMP_SGE - : llvm::ICmpInst::ICMP_UGE, - lhs_value, rhs_value), - lhs_value, rhs_value); + bool is_signed) { + return Select(b_->CreateICmp(is_signed ? llvm::ICmpInst::ICMP_SGE + : llvm::ICmpInst::ICMP_UGE, + lhs_value, rhs_value), + lhs_value, rhs_value); } llvm::Value* ElementalIrEmitter::EmitIntegralMin(llvm::Value* lhs_value, llvm::Value* rhs_value, - bool is_signed) const { - return b_->CreateSelect(b_->CreateICmp(is_signed ? llvm::ICmpInst::ICMP_SLE - : llvm::ICmpInst::ICMP_ULE, - lhs_value, rhs_value), - lhs_value, rhs_value); + bool is_signed) { + return Select(b_->CreateICmp(is_signed ? llvm::ICmpInst::ICMP_SLE + : llvm::ICmpInst::ICMP_ULE, + lhs_value, rhs_value), + lhs_value, rhs_value); } llvm_ir::IrArray::Index ElementalIrEmitter::ElementwiseSourceIndex( const llvm_ir::IrArray::Index& target_index, const HloInstruction& hlo, - int64 operand_no) const { + int64 operand_no) { CHECK(hlo.IsElementwise()) << "HLO " << hlo.ToString() << " is not elementwise."; @@ -1233,7 +1259,7 @@ llvm_ir::IrArray::Index ElementalIrEmitter::ElementwiseSourceIndex( StatusOr<llvm::Value*> ElementalIrEmitter::ConvertValueForDistribution( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index, llvm::Value* raw_value) const { + const llvm_ir::IrArray::Index& index, llvm::Value* raw_value) { TF_ASSIGN_OR_RETURN(llvm::Value * a_or_mean, operand_to_generator.at(hlo->operand(0))(index)); TF_ASSIGN_OR_RETURN(llvm::Value * b_or_sigma, @@ -1251,17 +1277,17 @@ StatusOr<llvm::Value*> ElementalIrEmitter::ConvertValueForDistribution( // Perform the division using the float type with the same number of bits // as the raw value to avoid overflow. if (raw_value_size_in_bits == 32) { - elem_value = b_->CreateUIToFP(elem_value, b_->getFloatTy()); - elem_value = b_->CreateFDiv( - elem_value, llvm::ConstantFP::get(b_->getFloatTy(), std::exp2(32))); + elem_value = UIToFP(elem_value, b_->getFloatTy()); + elem_value = FDiv(elem_value, + llvm::ConstantFP::get(b_->getFloatTy(), std::exp2(32))); } else { - elem_value = b_->CreateUIToFP(elem_value, b_->getDoubleTy()); - elem_value = b_->CreateFDiv( + elem_value = UIToFP(elem_value, b_->getDoubleTy()); + elem_value = FDiv( elem_value, llvm::ConstantFP::get(b_->getDoubleTy(), std::exp2(64))); } if (elem_ir_ty != elem_value->getType()) { - elem_value = b_->CreateFPTrunc(elem_value, elem_ir_ty); + elem_value = FPTrunc(elem_value, elem_ir_ty); } } @@ -1269,9 +1295,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::ConvertValueForDistribution( switch (hlo->random_distribution()) { case RNG_UNIFORM: { if (elem_ir_ty->isFloatingPointTy()) { - return b_->CreateFAdd( - b_->CreateFMul(b_->CreateFSub(b_or_sigma, a_or_mean), elem_value), - a_or_mean); + return FAdd(FMul(FSub(b_or_sigma, a_or_mean), elem_value), a_or_mean); } else { // To generate a uniform random value in [a, b) from a raw random sample // in range [0, 2^N), we let range = b - a and return @@ -1284,22 +1308,21 @@ StatusOr<llvm::Value*> ElementalIrEmitter::ConvertValueForDistribution( // the same cost as if the whole warp were to re-sample. So an // efficient re-sampling implementation on GPU would need to do // nontrivial work to share entropy between threads in the warp. - auto range = b_->CreateSub(b_or_sigma, a_or_mean); - return b_->CreateAdd(a_or_mean, b_->CreateURem(elem_value, range)); + auto range = Sub(b_or_sigma, a_or_mean); + return Add(a_or_mean, URem(elem_value, range)); } } case RNG_NORMAL: { TF_ASSIGN_OR_RETURN( llvm::Value * r, - EmitErfcInv(elem_prim_ty, - b_->CreateFMul(llvm::ConstantFP::get(elem_ir_ty, 2.0), - elem_value))); - return b_->CreateFAdd(b_->CreateFMul(r, b_or_sigma), a_or_mean); + EmitErfcInv(elem_prim_ty, FMul(llvm::ConstantFP::get(elem_ir_ty, 2.0), + elem_value))); + return FAdd(FMul(r, b_or_sigma), a_or_mean); } default: return InvalidArgument( "unhandled distribution %s", - RandomDistribution_Name(hlo->random_distribution()).c_str()); + RandomDistribution_Name(hlo->random_distribution())); } } @@ -1414,8 +1437,7 @@ std::array<llvm::Value*, 4> CalculateSampleValues( // Precondition: the RNG instruction is not fused. llvm_ir::ElementGenerator ElementalIrEmitter::MakePhiloxRngElementGenerator( const HloInstruction* hlo, - const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator) - const { + const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator) { VLOG(3) << "Using philox RNG algorithm"; CHECK(!hlo->IsFused()); // A random number generated by the per module random number generator. @@ -1438,7 +1460,7 @@ llvm_ir::ElementGenerator ElementalIrEmitter::MakePhiloxRngElementGenerator( // Load the global state variable for the Philox RNG algorithm. llvm::GlobalVariable* rng_state_ptr = llvm_ir::GetOrCreateVariableForPhiloxRngState(module_, b_); - llvm::Value* rng_state = b_->CreateLoad(rng_state_ptr, "rng_state_value"); + llvm::Value* rng_state = Load(rng_state_ptr, "rng_state_value"); // Build and return the elemental IR generator to generate a random value for // the element corresponding to the current thread. @@ -1464,8 +1486,8 @@ llvm_ir::ElementGenerator ElementalIrEmitter::MakePhiloxRngElementGenerator( // element within the sample. llvm::Value* elems_per_sample_value = llvm::ConstantInt::get(index_ty, elems_per_sample); - llvm::Value* sample_idx = b_->CreateUDiv(elem_idx, elems_per_sample_value); - llvm::Value* elem_offset = b_->CreateURem(elem_idx, elems_per_sample_value); + llvm::Value* sample_idx = UDiv(elem_idx, elems_per_sample_value); + llvm::Value* elem_offset = URem(elem_idx, elems_per_sample_value); std::array<llvm::Value*, 4> counter_values = CalculateSampleValues( sample_idx, hlo_random_value, global_random_number, rng_state, b_); @@ -1473,18 +1495,17 @@ llvm_ir::ElementGenerator ElementalIrEmitter::MakePhiloxRngElementGenerator( // Store the four counter_values into the sample_address alloca so we can // load the elem_offset'th one below. for (int idx = 0; idx < 4; ++idx) { - b_->CreateStore(counter_values[idx], - b_->CreateInBoundsGEP(sample_address, b_->getInt32(idx))); + Store(counter_values[idx], + InBoundsGEP(sample_address, b_->getInt32(idx))); } llvm::Type* int64_ty = b_->getInt64Ty(); CHECK(elems_per_sample == 2 || elems_per_sample == 4); llvm::Type* raw_value_ty = elems_per_sample == 2 ? int64_ty : int32_ty; // Retrieve the raw value for the current element from the current sample. - llvm::Value* raw_elem_value = b_->CreateLoad( - b_->CreateInBoundsGEP( - b_->CreatePointerCast(sample_address, raw_value_ty->getPointerTo()), - elem_offset), + llvm::Value* raw_elem_value = Load( + InBoundsGEP(PointerCast(sample_address, raw_value_ty->getPointerTo()), + elem_offset), "raw_elem_value"); return ConvertValueForDistribution(hlo, operand_to_generator, index, @@ -1495,7 +1516,7 @@ llvm_ir::ElementGenerator ElementalIrEmitter::MakePhiloxRngElementGenerator( StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalSelect( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const { + const llvm_ir::IrArray::Index& index) { TF_ASSIGN_OR_RETURN(llvm::Value * pred_value, operand_to_generator.at(hlo->operand(0))( ElementwiseSourceIndex(index, *hlo, 0))); @@ -1505,14 +1526,14 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalSelect( TF_ASSIGN_OR_RETURN(llvm::Value * on_false_value, operand_to_generator.at(hlo->operand(2))( ElementwiseSourceIndex(index, *hlo, 2))); - return b_->CreateSelect(b_->CreateTrunc(pred_value, b_->getInt1Ty()), - on_true_value, on_false_value); + return Select(Trunc(pred_value, b_->getInt1Ty()), on_true_value, + on_false_value); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalClamp( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const { + const llvm_ir::IrArray::Index& index) { TF_ASSIGN_OR_RETURN(llvm::Value * min_value, operand_to_generator.at(hlo->operand(0))( ElementwiseSourceIndex(index, *hlo, 0))); @@ -1531,14 +1552,14 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalClamp( max_value, EmitIntegralMax(min_value, arg_value, is_signed), is_signed); } else { return Unimplemented("Clamp unimplemented for %s", - PrimitiveType_Name(prim_type).c_str()); + PrimitiveType_Name(prim_type)); } } StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalConcatenate( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& target_index) const { + const llvm_ir::IrArray::Index& target_index) { const int64 concat_dim = hlo->dimensions(0); auto source_index = target_index; @@ -1560,9 +1581,9 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalConcatenate( } llvm_ir::SetToFirstInsertPoint(exit_block, b_); - llvm::PHINode* output = b_->CreatePHI( - llvm_ir::PrimitiveTypeToIrType(hlo->shape().element_type(), module_), - hlo->operands().size()); + llvm::PHINode* output = + PHI(llvm_ir::PrimitiveTypeToIrType(hlo->shape().element_type(), module_), + hlo->operands().size()); auto prior_insert_point = b_->GetInsertPoint(); b_->SetInsertPoint(init_block); @@ -1577,9 +1598,8 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalConcatenate( auto concat_dim_size = llvm::ConstantInt::get(source_index[concat_dim]->getType(), operand->shape().dimensions(concat_dim)); - b_->CreateCondBr( - b_->CreateICmpULT(source_index[concat_dim], concat_dim_size), - true_block, false_block); + CondBr(ICmpULT(source_index[concat_dim], concat_dim_size), true_block, + false_block); // Create the terminator of the true block before calling operand // generators, because they require non-degenerate basic blocks. @@ -1592,11 +1612,10 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalConcatenate( // Subtract the size of the concat dimension of the current operand // from the source index. b_->SetInsertPoint(false_block); - source_index[concat_dim] = - b_->CreateSub(source_index[concat_dim], concat_dim_size); + source_index[concat_dim] = Sub(source_index[concat_dim], concat_dim_size); } - b_->CreateUnreachable(); + Unreachable(); b_->SetInsertPoint(exit_block, prior_insert_point); return output; } @@ -1604,7 +1623,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalConcatenate( StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDynamicSlice( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const { + const llvm_ir::IrArray::Index& index) { // Emit IR to read dynamic start indices from hlo->operand(1). const HloInstruction* input_hlo = hlo->operand(0); const int64 rank = ShapeUtil::Rank(input_hlo->shape()); @@ -1621,7 +1640,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDynamicSlice( // Clamp the start index so that the sliced portion fits in the operand: // start_index = clamp(start_index, 0, operand_dim_size - output_dim_size) - start_index_value = b_->CreateSExtOrTrunc(start_index_value, index_type); + start_index_value = SExtOrTrunc(start_index_value, index_type); int64 largest_valid_start_index = input_hlo->shape().dimensions(i) - hlo->shape().dimensions(i); CHECK_GE(largest_valid_start_index, 0); @@ -1641,7 +1660,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDynamicSlice( for (int64 i = 0; i < rank; ++i) { // Emit IR which computes: // input_index = start_index + offset_index - input_index[i] = b_->CreateAdd(slice_start_index[i], index[i]); + input_index[i] = Add(slice_start_index[i], index[i]); } return operand_to_generator.at(input_hlo)(input_index); } @@ -1649,7 +1668,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDynamicSlice( StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalGather( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const { + const llvm_ir::IrArray::Index& index) { const Shape& operand_shape = hlo->operand(0)->shape(); const Shape& indices_shape = hlo->operand(1)->shape(); const Shape& output_shape = hlo->shape(); @@ -1672,7 +1691,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalGather( std::vector<int64> operand_to_output_dim(operand_shape.dimensions_size(), -1); for (int64 i = 0, e = operand_shape.dimensions_size(), operand_index_dim = 0; i < e; i++) { - if (c_binary_search(dim_numbers.collapsed_slice_dims(), i)) { + if (absl::c_binary_search(dim_numbers.collapsed_slice_dims(), i)) { operand_index.push_back(index.GetConstantWithIndexType(0)); } else { int64 output_window_dim = dim_numbers.offset_dims(operand_index_dim++); @@ -1686,7 +1705,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalGather( { std::vector<llvm::Value*> gather_index_index_components; for (int64 i = 0, e = output_shape.dimensions_size(); i < e; i++) { - if (!c_binary_search(dim_numbers.offset_dims(), i)) { + if (!absl::c_binary_search(dim_numbers.offset_dims(), i)) { gather_index_index.push_back(index[i]); } } @@ -1698,7 +1717,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalGather( auto add_to_operand_index = [&](llvm::Value* index_component, int64 dim) { llvm::Value* gather_dim_component_extended = - b_->CreateSExtOrTrunc(index_component, index_type); + SExtOrTrunc(index_component, index_type); int64 operand_dim = dim_numbers.start_index_map(dim); int64 output_dim = operand_to_output_dim[operand_dim]; // If 'output_dim' is -1, it means 'operand_dim' is an elided window dim. @@ -1722,8 +1741,8 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalGather( gather_dim_component_extended, is_signed), is_signed); - operand_index[operand_dim] = b_->CreateAdd( - operand_index[operand_dim], gather_dim_component_extended_inbound); + operand_index[operand_dim] = + Add(operand_index[operand_dim], gather_dim_component_extended_inbound); }; if (indices_shape.dimensions_size() == dim_numbers.index_vector_dim()) { @@ -1747,7 +1766,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalGather( StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDynamicUpdateSlice( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const { + const llvm_ir::IrArray::Index& index) { const HloInstruction* input_hlo = hlo->operand(0); const HloInstruction* update_hlo = hlo->operand(1); const HloInstruction* start_hlo = hlo->operand(2); @@ -1770,7 +1789,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDynamicUpdateSlice( // Clamp the start index so that the update region fits in the operand. // start_index = clamp(start_index, 0, input_dim_size - update_dim_size) - start_index_value = b_->CreateSExtOrTrunc(start_index_value, index_type); + start_index_value = SExtOrTrunc(start_index_value, index_type); llvm::Value* update_dim_size = index_typed_const(update_hlo->shape().dimensions(i)); int64 largest_valid_start_index = @@ -1786,14 +1805,14 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDynamicUpdateSlice( start_index_value->setName( AsStringRef(IrName(hlo, StrCat("start_idx", i)))); slice_start_index[i] = start_index_value; - slice_limit_index[i] = b_->CreateAdd(slice_start_index[i], update_dim_size); - - slice_intersection = b_->CreateAnd( - slice_intersection, b_->CreateICmpSGE(index[i], slice_start_index[i]), - "slice_intersection"); - slice_intersection = b_->CreateAnd( - slice_intersection, b_->CreateICmpSLT(index[i], slice_limit_index[i]), - "slice_intersection"); + slice_limit_index[i] = Add(slice_start_index[i], update_dim_size); + + slice_intersection = + And(slice_intersection, ICmpSGE(index[i], slice_start_index[i]), + "slice_intersection"); + slice_intersection = + And(slice_intersection, ICmpSLT(index[i], slice_limit_index[i]), + "slice_intersection"); } // Emit: @@ -1810,26 +1829,26 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDynamicUpdateSlice( // Compute update index for intersection case. llvm_ir::IrArray::Index update_index(index.GetType(), rank); for (int64 i = 0; i < rank; ++i) { - update_index[i] = b_->CreateSub(index[i], slice_start_index[i]); + update_index[i] = Sub(index[i], slice_start_index[i]); } TF_ASSIGN_OR_RETURN(llvm::Value * true_value, operand_to_generator.at(update_hlo)(update_index)); - b_->CreateStore(true_value, ret_value_addr); + Store(true_value, ret_value_addr); // Handle false BB (return data from 'input') SetToFirstInsertPoint(if_data.false_block, b_); TF_ASSIGN_OR_RETURN(llvm::Value * false_value, operand_to_generator.at(input_hlo)(index)); - b_->CreateStore(false_value, ret_value_addr); + Store(false_value, ret_value_addr); SetToFirstInsertPoint(if_data.after_block, b_); - return b_->CreateLoad(ret_value_addr); + return Load(ret_value_addr); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalPad( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& padded_index) const { + const llvm_ir::IrArray::Index& padded_index) { auto index = padded_index; llvm::Value* in_bounds = b_->getTrue(); for (size_t i = 0; i < index.size(); ++i) { @@ -1837,26 +1856,22 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalPad( return llvm::ConstantInt::get(index[i]->getType(), n); }; const auto& pad_dim = hlo->padding_config().dimensions(i); - index[i] = - b_->CreateSub(index[i], index_typed_const(pad_dim.edge_padding_low())); - in_bounds = b_->CreateAnd(in_bounds, - b_->CreateICmpSGE(index[i], index_typed_const(0)), - "in_bounds"); - in_bounds = b_->CreateAnd( + index[i] = Sub(index[i], index_typed_const(pad_dim.edge_padding_low())); + in_bounds = + And(in_bounds, ICmpSGE(index[i], index_typed_const(0)), "in_bounds"); + in_bounds = And( in_bounds, - b_->CreateICmpEQ( + ICmpEQ( index_typed_const(0), - b_->CreateURem(index[i], - index_typed_const(pad_dim.interior_padding() + 1))), - "in_bounds"); - index[i] = b_->CreateSDiv( - index[i], index_typed_const(pad_dim.interior_padding() + 1)); - in_bounds = b_->CreateAnd( - in_bounds, - b_->CreateICmpSLT( - index[i], - index_typed_const(hlo->operand(0)->shape().dimensions(i))), + URem(index[i], index_typed_const(pad_dim.interior_padding() + 1))), "in_bounds"); + index[i] = + SDiv(index[i], index_typed_const(pad_dim.interior_padding() + 1)); + in_bounds = + And(in_bounds, + ICmpSLT(index[i], + index_typed_const(hlo->operand(0)->shape().dimensions(i))), + "in_bounds"); } // if (in_bounds) { @@ -1872,26 +1887,26 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalPad( SetToFirstInsertPoint(if_data.true_block, b_); TF_ASSIGN_OR_RETURN(llvm::Value * operand_value, operand_to_generator.at(hlo->operand(0))(index)); - b_->CreateStore(operand_value, ret_value_addr); + Store(operand_value, ret_value_addr); SetToFirstInsertPoint(if_data.false_block, b_); TF_ASSIGN_OR_RETURN(llvm::Value * padding_value, operand_to_generator.at(hlo->operand(1))( IrArray::Index(index.GetType()))); - b_->CreateStore(padding_value, ret_value_addr); + Store(padding_value, ret_value_addr); SetToFirstInsertPoint(if_data.after_block, b_); // Don't create phi(operand_value, padding_value) here, because invoking // operand_to_generator may create new basic blocks, making the parent // of operand_value or padding_value no longer a predecessor of // if_data.after_block. - return b_->CreateLoad(ret_value_addr); + return Load(ret_value_addr); } StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDot( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& dot_result_index) const { + const llvm_ir::IrArray::Index& dot_result_index) { auto lhs_generator = operand_to_generator.at(hlo->operand(0)); auto rhs_generator = operand_to_generator.at(hlo->operand(1)); @@ -1919,8 +1934,7 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDot( llvm_ir::PrimitiveTypeToIrType(primitive_type, module_); llvm::Value* accumulator_alloca = llvm_ir::EmitAllocaAtFunctionEntry(primitive_type_llvm, "dot_acc", b_); - b_->CreateStore(llvm::Constant::getNullValue(primitive_type_llvm), - accumulator_alloca); + Store(llvm::Constant::getNullValue(primitive_type_llvm), accumulator_alloca); SetToFirstInsertPoint(inner_loop->GetBodyBasicBlock(), b_); @@ -1942,42 +1956,37 @@ StatusOr<llvm::Value*> ElementalIrEmitter::EmitElementalDot( } rhs_index.InsertAt(rhs_contracting_dim, inner_loop->GetIndVarValue()); - llvm::Value* current_accumulator = b_->CreateLoad(accumulator_alloca); + llvm::Value* current_accumulator = Load(accumulator_alloca); TF_ASSIGN_OR_RETURN(llvm::Value * lhs_value, lhs_generator(lhs_index)); TF_ASSIGN_OR_RETURN(llvm::Value * rhs_value, rhs_generator(rhs_index)); llvm::Value* next_accumulator; if (primitive_util::IsComplexType(primitive_type)) { - llvm::Value* product_real = b_->CreateFSub( - b_->CreateFMul(EmitExtractReal(lhs_value), EmitExtractReal(rhs_value)), - b_->CreateFMul(EmitExtractImag(lhs_value), EmitExtractImag(rhs_value))); - llvm::Value* product_imag = b_->CreateFAdd( - b_->CreateFMul(EmitExtractReal(lhs_value), EmitExtractImag(rhs_value)), - b_->CreateFMul(EmitExtractImag(lhs_value), EmitExtractReal(rhs_value))); - next_accumulator = b_->CreateInsertValue( + llvm::Value* product_real = + FSub(FMul(EmitExtractReal(lhs_value), EmitExtractReal(rhs_value)), + FMul(EmitExtractImag(lhs_value), EmitExtractImag(rhs_value))); + llvm::Value* product_imag = + FAdd(FMul(EmitExtractReal(lhs_value), EmitExtractImag(rhs_value)), + FMul(EmitExtractImag(lhs_value), EmitExtractReal(rhs_value))); + next_accumulator = InsertValue( current_accumulator, - b_->CreateFAdd(EmitExtractReal(current_accumulator), product_real), - {0}); - next_accumulator = b_->CreateInsertValue( + FAdd(EmitExtractReal(current_accumulator), product_real), {0}); + next_accumulator = InsertValue( next_accumulator, - b_->CreateFAdd(EmitExtractImag(current_accumulator), product_imag), - {1}); + FAdd(EmitExtractImag(current_accumulator), product_imag), {1}); } else if (primitive_util::IsFloatingPointType(primitive_type)) { - next_accumulator = b_->CreateFAdd(current_accumulator, - b_->CreateFMul(lhs_value, rhs_value)); + next_accumulator = FAdd(current_accumulator, FMul(lhs_value, rhs_value)); } else { - next_accumulator = - b_->CreateAdd(current_accumulator, b_->CreateMul(lhs_value, rhs_value)); + next_accumulator = Add(current_accumulator, Mul(lhs_value, rhs_value)); } - b_->CreateStore(next_accumulator, accumulator_alloca); + Store(next_accumulator, accumulator_alloca); SetToFirstInsertPoint(inner_loop->GetExitBasicBlock(), b_); - return b_->CreateLoad(accumulator_alloca); + return Load(accumulator_alloca); } llvm_ir::ElementGenerator ElementalIrEmitter::MakeElementGenerator( const HloInstruction* hlo, - const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator) - const { + const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator) { switch (hlo->opcode()) { case HloOpcode::kAbs: case HloOpcode::kRoundNearestAfz: @@ -2071,10 +2080,10 @@ llvm_ir::ElementGenerator ElementalIrEmitter::MakeElementGenerator( const HloInstruction* operand = hlo->operand(0); auto source_index = target_index; for (int64 dim : hlo->dimensions()) { - source_index[dim] = b_->CreateSub( - llvm::ConstantInt::get(target_index[dim]->getType(), - hlo->shape().dimensions(dim) - 1), - target_index[dim]); + source_index[dim] = + Sub(llvm::ConstantInt::get(target_index[dim]->getType(), + hlo->shape().dimensions(dim) - 1), + target_index[dim]); } return operand_to_generator.at(operand)(source_index); }; @@ -2088,6 +2097,50 @@ llvm_ir::ElementGenerator ElementalIrEmitter::MakeElementGenerator( target_index.SourceIndexOfBroadcast(hlo->shape(), operand->shape(), hlo->dimensions(), b_)); }; + case HloOpcode::kIota: + return [this, hlo]( + const IrArray::Index& target_index) -> StatusOr<llvm::Value*> { + auto* iota = Cast<HloIotaInstruction>(hlo); + PrimitiveType element_type = iota->shape().element_type(); + IrArray::Index elem_index = + ShapeUtil::Rank(iota->shape()) > 1 + ? target_index.SourceIndexOfBroadcast( + iota->shape(), + ShapeUtil::MakeShapeWithDescendingLayout( + element_type, + {iota->shape().dimensions(iota->iota_dimension())}), + {iota->iota_dimension()}, b_) + : target_index; + llvm::Value* elem_index_linear = elem_index.linear(); + if (elem_index_linear == nullptr) { + std::vector<int64> iota_bound = { + iota->shape().dimensions(iota->iota_dimension())}; + elem_index_linear = elem_index.Linearize(iota_bound, b_); + } + if (ShapeUtil::ElementIsIntegral(iota->shape())) { + return b_->CreateIntCast( + elem_index_linear, + llvm_ir::PrimitiveTypeToIrType(element_type, module_), + /*isSigned=*/false); + } else { + TF_RET_CHECK(ShapeUtil::ElementIsFloating(iota->shape())) + << element_type; + llvm::Type* float_ir_type; + if (element_type == BF16) { + float_ir_type = llvm_ir::PrimitiveTypeToIrType(F32, module_); + } else { + float_ir_type = + llvm_ir::PrimitiveTypeToIrType(element_type, module_); + } + llvm::Value* float_val = + b_->CreateUIToFP(elem_index_linear, float_ir_type); + if (element_type == BF16) { + return EmitF32ToBF16(float_val, b_); + } else { + return float_val; + } + } + }; case HloOpcode::kSlice: return [this, hlo, &operand_to_generator]( const IrArray::Index& index) -> StatusOr<llvm::Value*> { @@ -2153,28 +2206,28 @@ llvm_ir::ElementGenerator ElementalIrEmitter::MakeElementGenerator( default: return [hlo](const IrArray::Index& index) { return Unimplemented("Unhandled opcode for elemental IR emission: %s", - HloOpcodeString(hlo->opcode()).c_str()); + HloOpcodeString(hlo->opcode())); }; } } -llvm::Value* ElementalIrEmitter::EmitExtractReal(llvm::Value* value) const { - return b_->CreateExtractValue(value, {0}); +llvm::Value* ElementalIrEmitter::EmitExtractReal(llvm::Value* value) { + return ExtractValue(value, {0}); } -llvm::Value* ElementalIrEmitter::EmitExtractImag(llvm::Value* value) const { - return b_->CreateExtractValue(value, {1}); +llvm::Value* ElementalIrEmitter::EmitExtractImag(llvm::Value* value) { + return ExtractValue(value, {1}); } llvm::Value* ElementalIrEmitter::EmitComposeComplex(const HloInstruction* op, llvm::Value* real, - llvm::Value* imag) const { + llvm::Value* imag) { auto cplx_type = llvm_ir::PrimitiveTypeToIrType(op->shape().element_type(), module_); - auto complex = b_->CreateInsertValue( - llvm::ConstantAggregateZero::get(cplx_type), real, {0}); + auto complex = + InsertValue(llvm::ConstantAggregateZero::get(cplx_type), real, {0}); if (imag != nullptr) { - complex = b_->CreateInsertValue(complex, imag, {1}); + complex = InsertValue(complex, imag, {1}); } return complex; } diff --git a/tensorflow/compiler/xla/service/elemental_ir_emitter.h b/tensorflow/compiler/xla/service/elemental_ir_emitter.h index 1598a4dd85..d3e2acaabd 100644 --- a/tensorflow/compiler/xla/service/elemental_ir_emitter.h +++ b/tensorflow/compiler/xla/service/elemental_ir_emitter.h @@ -23,12 +23,13 @@ limitations under the License. #include "llvm/IR/Value.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module_config.h" +#include "tensorflow/compiler/xla/service/llvm_ir/ir_builder_mixin.h" #include "tensorflow/compiler/xla/service/llvm_ir/loop_emitter.h" #include "tensorflow/compiler/xla/statusor.h" namespace xla { -class ElementalIrEmitter { +class ElementalIrEmitter : public IrBuilderMixin<ElementalIrEmitter> { public: using HloToElementGeneratorMap = std::unordered_map<const HloInstruction*, llvm_ir::ElementGenerator>; @@ -40,100 +41,114 @@ class ElementalIrEmitter { virtual ~ElementalIrEmitter() = default; virtual StatusOr<llvm::Value*> EmitUnaryOp(const HloInstruction* op, - llvm::Value* operand_value) const; + llvm::Value* operand_value); virtual StatusOr<llvm::Value*> EmitBinaryOp(const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const; + llvm::Value* rhs_value); // Returns a function to generate an element of the output of `hlo`, given a // map of functions to generate elements of its operands. virtual llvm_ir::ElementGenerator MakeElementGenerator( const HloInstruction* hlo, - const HloToElementGeneratorMap& operand_to_generator) const; + const HloToElementGeneratorMap& operand_to_generator); - llvm::IRBuilder<>* b() const { return b_; } - llvm::Module* module() const { return module_; } + llvm::IRBuilder<>* b() { return b_; } + + // builder() is for IrBuilderMixin. + llvm::IRBuilder<>* builder() { return b_; } + + llvm::Module* module() { return module_; } protected: - virtual StatusOr<llvm::Value*> EmitIntegerUnaryOp( - const HloInstruction* op, llvm::Value* operand_value) const; + virtual StatusOr<llvm::Value*> EmitIntegerUnaryOp(const HloInstruction* op, + llvm::Value* operand_value); + + virtual StatusOr<llvm::Value*> EmitFloatUnaryOp(const HloInstruction* op, + llvm::Value* operand_value); - virtual StatusOr<llvm::Value*> EmitFloatUnaryOp( - const HloInstruction* op, llvm::Value* operand_value) const; + virtual StatusOr<llvm::Value*> EmitComplexUnaryOp(const HloInstruction* op, + llvm::Value* operand_value); - virtual StatusOr<llvm::Value*> EmitComplexUnaryOp( - const HloInstruction* op, llvm::Value* operand_value) const; + llvm::Value* IsZero(llvm::Value* v); + llvm::Value* IsIntMinDivisionOverflow(llvm::Value* lhs, llvm::Value* rhs); + llvm::Value* GetZero(llvm::Type* type); + llvm::Value* GetOne(llvm::Type* type); + llvm::Value* GetIntSMin(llvm::Type* type); + llvm::Value* GetMinusOne(llvm::Type* type); + + llvm::Value* EmitIntegerDivide(llvm::Value* lhs, llvm::Value* rhs, + bool is_signed); + llvm::Value* EmitIntegerRemainder(llvm::Value* lhs, llvm::Value* rhs, + bool is_signed); virtual StatusOr<llvm::Value*> EmitIntegerBinaryOp(const HloInstruction* op, llvm::Value* lhs_value, llvm::Value* rhs_value, - bool is_signed) const; + bool is_signed); - virtual StatusOr<llvm::Value*> EmitFloatBinaryOp( - const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const; + virtual StatusOr<llvm::Value*> EmitFloatBinaryOp(const HloInstruction* op, + llvm::Value* lhs_value, + llvm::Value* rhs_value); - virtual StatusOr<llvm::Value*> EmitComplexBinaryOp( - const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const; + virtual StatusOr<llvm::Value*> EmitComplexBinaryOp(const HloInstruction* op, + llvm::Value* lhs_value, + llvm::Value* rhs_value); virtual llvm::Value* EmitFloatMax(llvm::Value* lhs_value, - llvm::Value* rhs_value) const; + llvm::Value* rhs_value); virtual llvm::Value* EmitFloatMin(llvm::Value* lhs_value, - llvm::Value* rhs_value) const; + llvm::Value* rhs_value); llvm::Value* EmitIntegralMax(llvm::Value* lhs_value, llvm::Value* rhs_value, - bool is_signed) const; + bool is_signed); llvm::Value* EmitIntegralMin(llvm::Value* lhs_value, llvm::Value* rhs_value, - bool is_signed) const; + bool is_signed); virtual StatusOr<llvm::Value*> EmitErfInv(PrimitiveType prim_type, - llvm::Value* value) const; + llvm::Value* value); virtual StatusOr<llvm::Value*> EmitErfcInv(PrimitiveType prim_type, - llvm::Value* value) const; + llvm::Value* value); virtual StatusOr<llvm::Value*> EmitAtan2(PrimitiveType prim_type, - llvm::Value* lhs, - llvm::Value* rhs) const; + llvm::Value* lhs, llvm::Value* rhs); virtual StatusOr<llvm::Value*> EmitLog(PrimitiveType prim_type, - llvm::Value* value) const; + llvm::Value* value); virtual StatusOr<llvm::Value*> EmitLog1p(PrimitiveType prim_type, - llvm::Value* value) const; + llvm::Value* value); virtual StatusOr<llvm::Value*> EmitSin(PrimitiveType prim_type, - llvm::Value* value) const; + llvm::Value* value); virtual StatusOr<llvm::Value*> EmitCos(PrimitiveType prim_type, - llvm::Value* value) const; + llvm::Value* value); virtual StatusOr<llvm::Value*> EmitExp(PrimitiveType prim_type, - llvm::Value* value) const; + llvm::Value* value); virtual StatusOr<llvm::Value*> EmitExpm1(PrimitiveType prim_type, - llvm::Value* value) const; + llvm::Value* value); virtual StatusOr<llvm::Value*> EmitPow(PrimitiveType prim_type, - llvm::Value* lhs, - llvm::Value* rhs) const; + llvm::Value* lhs, llvm::Value* rhs); virtual StatusOr<llvm::Value*> EmitTanh(PrimitiveType prim_type, - llvm::Value* value) const; + llvm::Value* value); virtual StatusOr<llvm::Value*> EmitReducePrecision(const HloInstruction* hlo, - llvm::Value* x) const; + llvm::Value* x); - virtual llvm::Value* EmitExtractReal(llvm::Value* value) const; - virtual llvm::Value* EmitExtractImag(llvm::Value* value) const; + virtual llvm::Value* EmitExtractReal(llvm::Value* value); + virtual llvm::Value* EmitExtractImag(llvm::Value* value); // Composes a complex struct. imag may be nullptr for simple cast operations. llvm::Value* EmitComposeComplex(const HloInstruction* op, llvm::Value* real, - llvm::Value* imag) const; + llvm::Value* imag); // A helper method for MakeElementGenerator. Given an elementwise op `hlo` and // the target array index, computes the source array index of its @@ -142,50 +157,50 @@ class ElementalIrEmitter { // Precondition: `hlo` is an elementwise op. llvm_ir::IrArray::Index ElementwiseSourceIndex( const llvm_ir::IrArray::Index& target_index, const HloInstruction& hlo, - int64 operand_no) const; + int64 operand_no); // Identifier of the thread unique among all threads on the device - virtual llvm::Value* EmitThreadId() const { return b_->getIntN(128, 0); } + virtual llvm::Value* EmitThreadId() { return b_->getIntN(128, 0); } StatusOr<llvm::Value*> EmitElementalSelect( const HloInstruction* hlo, const HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const; + const llvm_ir::IrArray::Index& index); StatusOr<llvm::Value*> EmitElementalClamp( const HloInstruction* hlo, const HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const; + const llvm_ir::IrArray::Index& index); StatusOr<llvm::Value*> EmitElementalConcatenate( const HloInstruction* hlo, const HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& target_index) const; + const llvm_ir::IrArray::Index& target_index); StatusOr<llvm::Value*> EmitElementalDynamicSlice( const HloInstruction* hlo, const HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const; + const llvm_ir::IrArray::Index& index); StatusOr<llvm::Value*> EmitElementalGather( const HloInstruction* hlo, const HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const; + const llvm_ir::IrArray::Index& index); StatusOr<llvm::Value*> EmitElementalDynamicUpdateSlice( const HloInstruction* hlo, const HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index) const; + const llvm_ir::IrArray::Index& index); StatusOr<llvm::Value*> EmitElementalPad( const HloInstruction* hlo, const HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& padded_index) const; + const llvm_ir::IrArray::Index& padded_index); StatusOr<llvm::Value*> EmitElementalDot( const HloInstruction* hlo, const HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& dot_result_index) const; + const llvm_ir::IrArray::Index& dot_result_index); llvm::IRBuilder<>* const b_; @@ -200,13 +215,13 @@ class ElementalIrEmitter { // random number generation algorithm. llvm_ir::ElementGenerator MakePhiloxRngElementGenerator( const HloInstruction* hlo, - const HloToElementGeneratorMap& operand_to_generator) const; + const HloToElementGeneratorMap& operand_to_generator); // Converts the raw value generated by a random number generation algorithm // to the distribution requested by the RNG HloInstruction. StatusOr<llvm::Value*> ConvertValueForDistribution( const HloInstruction* hlo, const ElementalIrEmitter::HloToElementGeneratorMap& operand_to_generator, - const llvm_ir::IrArray::Index& index, llvm::Value* raw_value) const; + const llvm_ir::IrArray::Index& index, llvm::Value* raw_value); }; } // namespace xla diff --git a/tensorflow/compiler/xla/service/elemental_ir_emitter_test.cc b/tensorflow/compiler/xla/service/elemental_ir_emitter_test.cc index addb016b04..5ab0756219 100644 --- a/tensorflow/compiler/xla/service/elemental_ir_emitter_test.cc +++ b/tensorflow/compiler/xla/service/elemental_ir_emitter_test.cc @@ -24,7 +24,7 @@ limitations under the License. namespace xla { namespace { -using tensorflow::gtl::nullopt; +using absl::nullopt; class ElementalIrEmitterExecutionTest : public HloTestBase { protected: diff --git a/tensorflow/compiler/xla/service/executable.cc b/tensorflow/compiler/xla/service/executable.cc index fd75847d0c..78edf918a4 100644 --- a/tensorflow/compiler/xla/service/executable.cc +++ b/tensorflow/compiler/xla/service/executable.cc @@ -15,6 +15,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/executable.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/legacy_flags/debug_options_flags.h" #include "tensorflow/compiler/xla/service/hlo_graph_dumper.h" #include "tensorflow/compiler/xla/status.h" @@ -22,7 +24,6 @@ limitations under the License. #include "tensorflow/core/lib/hash/hash.h" #include "tensorflow/core/lib/io/path.h" #include "tensorflow/core/lib/strings/proto_serialization.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/env.h" using tensorflow::gtl::ArraySlice; @@ -76,8 +77,8 @@ StatusOr<ScopedShapedBuffer> Executable::ExecuteOnStreamWrapper( std::unique_ptr<HloExecutionProfile> profile_ptr = module_config().debug_options().xla_hlo_profile() && hlo_profiling_enabled() - ? MakeUnique<HloExecutionProfile>(&hlo_profile_printer_data(), - &hlo_profile_index_map()) + ? absl::make_unique<HloExecutionProfile>(&hlo_profile_printer_data(), + &hlo_profile_index_map()) : nullptr; StatusOr<ScopedShapedBuffer> return_value = @@ -154,9 +155,9 @@ Status Executable::DumpHloSnapshot() { const string& directory_path = module_config().debug_options().xla_dump_executions_to(); const auto& module = hlo_snapshot_->hlo().hlo_module(); - string filename = tensorflow::strings::Printf( - "computation_%lld__%s__execution_%lld", module.id(), - module.entry_computation_name().c_str(), ++execution_count_); + string filename = + absl::StrFormat("computation_%d__%s__execution_%d", module.id(), + module.entry_computation_name(), ++execution_count_); return Executable::DumpToDirectory(directory_path, filename, *hlo_snapshot_); } diff --git a/tensorflow/compiler/xla/service/execution_tracker.cc b/tensorflow/compiler/xla/service/execution_tracker.cc index 228c3fac95..997db7c058 100644 --- a/tensorflow/compiler/xla/service/execution_tracker.cc +++ b/tensorflow/compiler/xla/service/execution_tracker.cc @@ -17,7 +17,7 @@ limitations under the License. #include <utility> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" @@ -53,8 +53,8 @@ ExecutionHandle ExecutionTracker::Register(Backend* backend, tensorflow::mutex_lock lock(execution_mutex_); int64 handle = next_handle_++; auto inserted = handle_to_execution_.emplace( - handle, - MakeUnique<AsyncExecution>(backend, std::move(streams), profile, result)); + handle, absl::make_unique<AsyncExecution>(backend, std::move(streams), + profile, result)); CHECK(inserted.second); ExecutionHandle execution_handle; @@ -66,7 +66,7 @@ Status ExecutionTracker::Unregister(const ExecutionHandle& handle) { tensorflow::mutex_lock lock(execution_mutex_); auto it = handle_to_execution_.find(handle.handle()); if (it == handle_to_execution_.end()) { - return NotFound("no execution record for execution handle: %lld", + return NotFound("no execution record for execution handle: %d", handle.handle()); } handle_to_execution_.erase(handle.handle()); @@ -78,7 +78,7 @@ StatusOr<const AsyncExecution*> ExecutionTracker::Resolve( tensorflow::mutex_lock lock(execution_mutex_); auto it = handle_to_execution_.find(handle.handle()); if (it == handle_to_execution_.end()) { - return NotFound("no execution record for execution handle: %lld", + return NotFound("no execution record for execution handle: %d", handle.handle()); } return it->second.get(); diff --git a/tensorflow/compiler/xla/service/flatten_call_graph.h b/tensorflow/compiler/xla/service/flatten_call_graph.h index d3efab3614..3cccec9862 100644 --- a/tensorflow/compiler/xla/service/flatten_call_graph.h +++ b/tensorflow/compiler/xla/service/flatten_call_graph.h @@ -28,7 +28,7 @@ namespace xla { // points-to analysis (see b/36865746 for details). class FlattenCallGraph : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "flatten-call-graph"; } + absl::string_view name() const override { return "flatten-call-graph"; } // Duplicates computations called from multiple call- or while-nodes to // flatten the call graph. diff --git a/tensorflow/compiler/xla/service/gather_expander.cc b/tensorflow/compiler/xla/service/gather_expander.cc index 9370c88710..3f1a881372 100644 --- a/tensorflow/compiler/xla/service/gather_expander.cc +++ b/tensorflow/compiler/xla/service/gather_expander.cc @@ -15,6 +15,7 @@ limitations under the License. #include <utility> +#include "absl/algorithm/container.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/gather_expander.h" #include "tensorflow/compiler/xla/service/hlo_creation_utils.h" @@ -230,7 +231,7 @@ static StatusOr<HloInstruction*> CreateGatherLoopAccumulatorInitValue( accumulator_state_shape_dims.reserve(1 + slice_sizes.size()); accumulator_state_shape_dims.push_back(gather_loop_trip_count); for (int64 i = 0; i < slice_sizes.size(); i++) { - if (!c_binary_search(dim_numbers.collapsed_slice_dims(), i)) { + if (!absl::c_binary_search(dim_numbers.collapsed_slice_dims(), i)) { accumulator_state_shape_dims.push_back(slice_sizes[i]); } } @@ -251,7 +252,7 @@ static StatusOr<HloInstruction*> PermuteBatchAndOffsetDims( int64 batch_idx_counter = 0; int64 offset_idx_counter = output_rank - offset_dims.size(); for (int64 i = 0; i < output_rank; i++) { - bool is_offset_dim = c_binary_search(offset_dims, i); + bool is_offset_dim = absl::c_binary_search(offset_dims, i); if (is_offset_dim) { permutation.push_back(offset_idx_counter++); } else { @@ -322,7 +323,7 @@ StatusOr<HloInstruction*> GatherExpander::ExpandGather( return Unimplemented( "Gather operations with more than 2147483647 gather indices are not " "supported. This error occurred for %s.", - gather_instr->ToString().c_str()); + gather_instr->ToString()); } TF_ASSIGN_OR_RETURN( @@ -373,8 +374,8 @@ StatusOr<bool> GatherExpander::Run(HloModule* module) { std::vector<HloInstruction*> gather_instrs; for (HloComputation* computation : module->MakeNonfusionComputations()) { - c_copy_if(computation->instructions(), std::back_inserter(gather_instrs), - is_nontrivial_gather); + absl::c_copy_if(computation->instructions(), + std::back_inserter(gather_instrs), is_nontrivial_gather); } for (HloInstruction* inst : gather_instrs) { diff --git a/tensorflow/compiler/xla/service/gather_expander.h b/tensorflow/compiler/xla/service/gather_expander.h index c1fc8574da..7bd9ea5984 100644 --- a/tensorflow/compiler/xla/service/gather_expander.h +++ b/tensorflow/compiler/xla/service/gather_expander.h @@ -25,7 +25,7 @@ namespace xla { // nevertheless have a minimum level of support. class GatherExpander : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "gather_expander"; } + absl::string_view name() const override { return "gather_expander"; } StatusOr<bool> Run(HloModule* module) override; private: diff --git a/tensorflow/compiler/xla/service/gpu/BUILD b/tensorflow/compiler/xla/service/gpu/BUILD index 8ef72850dc..82290bfea8 100644 --- a/tensorflow/compiler/xla/service/gpu/BUILD +++ b/tensorflow/compiler/xla/service/gpu/BUILD @@ -56,6 +56,8 @@ cc_library( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings:str_format", ], ) @@ -91,6 +93,7 @@ cc_library( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/compiler/xla/service:hlo_reachability", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -107,6 +110,8 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings:str_format", ], ) @@ -126,6 +131,7 @@ cc_library( "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/compiler/xla/service/llvm_ir:tuple_ops", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", "@llvm//:core", ], ) @@ -171,6 +177,7 @@ cc_library( "//tensorflow/compiler/xla/service/llvm_ir:dynamic_update_slice_util", "//tensorflow/compiler/xla/service/llvm_ir:fused_ir_emitter", "//tensorflow/compiler/xla/service/llvm_ir:ir_array", + "//tensorflow/compiler/xla/service/llvm_ir:ir_builder_mixin", "//tensorflow/compiler/xla/service/llvm_ir:kernel_support_library", "//tensorflow/compiler/xla/service/llvm_ir:kernel_tiling", "//tensorflow/compiler/xla/service/llvm_ir:llvm_loop", @@ -180,6 +187,11 @@ cc_library( "//tensorflow/compiler/xla/service/llvm_ir:tuple_ops", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", "@llvm//:core", "@llvm//:support", ], @@ -224,6 +236,7 @@ cc_library( "//tensorflow/compiler/xla/service/llvm_ir:loop_emitter", "//tensorflow/compiler/xla/service/llvm_ir:math_ops", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", "@llvm//:core", "@llvm//:support", ], @@ -243,6 +256,7 @@ cc_library( "//tensorflow/compiler/xla/service:device_memory_allocator", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", ], ) @@ -257,6 +271,7 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:ptr_util", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", ], ) @@ -337,6 +352,10 @@ cc_library( "//tensorflow/core/platform/default/build_config:cufft_plugin", "//tensorflow/core/platform/default/build_config:stream_executor_cuda", # build_cleaner: keep "//tensorflow/stream_executor", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", + "@com_google_absl//absl/types:optional", ], ) @@ -373,6 +392,9 @@ cc_library( "//tensorflow/compiler/xla/service:hlo_pass", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", + "@com_google_absl//absl/types:optional", ], ) @@ -390,6 +412,7 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/strings", ], ) @@ -420,7 +443,7 @@ tf_cc_test( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/compiler/xla/service:hlo_matchers", "//tensorflow/compiler/xla/service:shape_inference", - "//tensorflow/compiler/xla/tests:hlo_test_base", + "//tensorflow/compiler/xla/tests:hlo_verified_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", # fixdeps: keep "//tensorflow/core:test", ], @@ -466,6 +489,7 @@ cc_library( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/compiler/xla/service:multi_output_fusion", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", ], ) @@ -483,6 +507,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -513,6 +538,8 @@ cc_library( "//tensorflow/compiler/xla/service:hlo_cost_analysis", "//tensorflow/compiler/xla/service:hlo_pass", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/strings", ], ) @@ -544,6 +571,7 @@ cc_library( "//tensorflow/compiler/xla/service:hlo_creation_utils", "//tensorflow/compiler/xla/service:hlo_pass", "//tensorflow/compiler/xla/service:shape_inference", + "@com_google_absl//absl/memory", ], ) @@ -600,6 +628,7 @@ cc_library( "//tensorflow/compiler/xla/service/gpu:infeed_manager", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", "@llvm//:core", ], alwayslink = True, # Contains per-platform transfer manager registration @@ -670,6 +699,9 @@ cc_library( "//tensorflow/core:lib_internal", "//tensorflow/core:regexp_internal", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", "@llvm//:core", ], alwayslink = True, # Contains compiler registration @@ -702,8 +734,8 @@ cc_library( ":xfeed_queue", "//tensorflow/compiler/xla:shape_tree", "//tensorflow/compiler/xla:types", - "//tensorflow/compiler/xla:util", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", ], ) @@ -718,6 +750,7 @@ cc_library( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -756,6 +789,7 @@ tf_cc_test( "//tensorflow/compiler/xla/service:hlo_parser", "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", # build_cleaner: keep + "@com_google_absl//absl/strings", ], ) @@ -767,12 +801,12 @@ cc_library( ":stream_assignment", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:types", - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla/service:buffer_value", "//tensorflow/compiler/xla/service:hlo", "//tensorflow/compiler/xla/service:hlo_ordering", "//tensorflow/compiler/xla/service:hlo_reachability", "//tensorflow/compiler/xla/service:hlo_scheduling", + "@com_google_absl//absl/memory", ], ) @@ -789,6 +823,8 @@ tf_cc_test( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings:str_format", ], ) @@ -839,7 +875,9 @@ cc_library( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:types", + "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", + "//tensorflow/compiler/xla/service:hlo", "//tensorflow/core:stream_executor_no_cuda", ], ) @@ -868,9 +906,8 @@ cc_library( "//tensorflow/compiler/xla/service:compiler", "//tensorflow/compiler/xla/service:device_memory_allocator", "//tensorflow/compiler/xla/service:hlo_parser", - "//tensorflow/compiler/xla/service:hlo_runner", - "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/xla/service/gpu/buffer_allocations.cc b/tensorflow/compiler/xla/service/gpu/buffer_allocations.cc index 537295292b..528209abc7 100644 --- a/tensorflow/compiler/xla/service/gpu/buffer_allocations.cc +++ b/tensorflow/compiler/xla/service/gpu/buffer_allocations.cc @@ -17,8 +17,8 @@ limitations under the License. #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/gpu/gpu_constants.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" @@ -40,7 +40,7 @@ StatusOr<std::unique_ptr<BufferAllocations>> BufferAllocations::Builder::Build( const BufferAssignment* buffer_assignment, int device_ordinal, DeviceMemoryAllocator* memory_allocator) { const int64 num_buffers = buffer_assignment->Allocations().size(); - auto buffer_allocations = WrapUnique(new BufferAllocations( + auto buffer_allocations = absl::WrapUnique(new BufferAllocations( num_buffers, device_ordinal, memory_allocator, buffer_assignment)); for (BufferAllocation::Index i = 0; i < num_buffers; ++i) { @@ -62,7 +62,7 @@ StatusOr<std::unique_ptr<BufferAllocations>> BufferAllocations::Builder::Build( if (reinterpret_cast<uintptr_t>(address.opaque()) % expected_alignment != 0) { return InternalError( - "Address of registered buffer %lld must be a multiple of %llx, but " + "Address of registered buffer %d must be a multiple of %x, but " "was %p", i, kEntryParameterAlignBytes, address.opaque()); } @@ -83,7 +83,7 @@ StatusOr<std::unique_ptr<BufferAllocations>> BufferAllocations::Builder::Build( 0) { return InternalError( "Address returned by memory_allocator->Allocate must be a " - "multiple of %llx, but was %p", + "multiple of 0x%x, but was %p", kXlaAllocatedBufferAlignBytes, buffer.opaque()); } // We do manual memory management within BufferAllocations. Be sure not diff --git a/tensorflow/compiler/xla/service/gpu/buffer_comparator.cc b/tensorflow/compiler/xla/service/gpu/buffer_comparator.cc index 6a285a6b98..13c83c9199 100644 --- a/tensorflow/compiler/xla/service/gpu/buffer_comparator.cc +++ b/tensorflow/compiler/xla/service/gpu/buffer_comparator.cc @@ -16,9 +16,9 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/buffer_comparator.h" #include <cmath> +#include "absl/strings/str_replace.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/status_macros.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace xla { namespace gpu { @@ -74,9 +74,8 @@ ENTRY MaxDifference { %error = f32[SIZE] divide(%sub_abs, %denominator) ROOT %max_diff = f32[] reduce(%error, %zero_constant), dimensions={0}, to_apply=MaxF32 })"; - auto size_string = std::to_string(num_elements); - return tensorflow::str_util::StringReplace( - kF16CompHloText, "SIZE", {size_string.data(), size_string.size()}, true); + return absl::StrReplaceAll(kF16CompHloText, + {{"SIZE", absl::StrCat(num_elements)}}); } StatusOr<F16BufferComparator> F16BufferComparator::Create( @@ -125,7 +124,7 @@ StatusOr<F16BufferComparator> F16BufferComparator::Create( StatusOr<bool> F16BufferComparator::CompareEqualImpl( se::DeviceMemory<Eigen::half> test_buffer) { if (ref_buffer_.root_buffer().size() != test_buffer.size()) { - return InternalError("Mismatched buffer size: %lld vs %lld", + return InternalError("Mismatched buffer size: %d vs %d", ref_buffer_.root_buffer().size(), test_buffer.size()); } diff --git a/tensorflow/compiler/xla/service/gpu/conditional_thunk.cc b/tensorflow/compiler/xla/service/gpu/conditional_thunk.cc index 5780e0af40..9ed523998b 100644 --- a/tensorflow/compiler/xla/service/gpu/conditional_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/conditional_thunk.cc @@ -15,7 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/conditional_thunk.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" @@ -59,7 +59,7 @@ Status ConditionalThunk::ExecuteOnStream( Status block_status = stream->BlockHostUntilDone(); if (!block_status.ok()) { return InternalError("Failed to retrieve predicate value on stream %p: %s.", - stream, block_status.error_message().c_str()); + stream, block_status.error_message()); } // Execute the true or the false computation depending on the value of the diff --git a/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc b/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc index 7833a4077e..eea31f3de1 100644 --- a/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc @@ -17,12 +17,11 @@ limitations under the License. #include <string> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h" #include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" diff --git a/tensorflow/compiler/xla/service/gpu/convolution_thunk.h b/tensorflow/compiler/xla/service/gpu/convolution_thunk.h index d76ca6698d..f7952787c1 100644 --- a/tensorflow/compiler/xla/service/gpu/convolution_thunk.h +++ b/tensorflow/compiler/xla/service/gpu/convolution_thunk.h @@ -16,6 +16,7 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_GPU_CONVOLUTION_THUNK_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_GPU_CONVOLUTION_THUNK_H_ +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/buffer_assignment.h" #include "tensorflow/compiler/xla/service/gpu/buffer_allocations.h" #include "tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h" @@ -26,7 +27,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" namespace xla { diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_rewriter.h b/tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_rewriter.h index e09cde9abf..6e2e330edd 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_rewriter.h +++ b/tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_rewriter.h @@ -54,9 +54,7 @@ namespace gpu { // BatchNormRewriter. class CudnnBatchNormRewriter : public HloPassInterface { public: - tensorflow::StringPiece name() const override { - return "cudnn_batchnorm_rewriter"; - } + absl::string_view name() const override { return "cudnn_batchnorm_rewriter"; } StatusOr<bool> Run(HloModule* module) override; }; diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_thunk.cc b/tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_thunk.cc index 7b172812c3..bc3c6f72f6 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_thunk.cc @@ -17,12 +17,11 @@ limitations under the License. #include <string> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" #include "tensorflow/compiler/xla/service/gpu/ir_emission_utils.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc index caeb89d78e..dbdf8e7a0e 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc @@ -14,24 +14,25 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/gpu/backend_configs.pb.h" #include "tensorflow/compiler/xla/service/gpu/buffer_comparator.h" #include "tensorflow/compiler/xla/service/gpu/convolution_thunk.h" #include "tensorflow/compiler/xla/service/gpu/ir_emission_utils.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/mutex.h" namespace xla { namespace gpu { namespace { +using absl::optional; using se::DeviceMemoryBase; using se::dnn::AlgorithmConfig; using se::dnn::AlgorithmDesc; -using tensorflow::gtl::optional; class ScratchAllocator : public se::ScratchAllocator { public: @@ -59,8 +60,8 @@ StatusOr<se::DeviceMemory<uint8>> ScratchAllocator::AllocateBytes( if (byte_size > GetMemoryLimitInBytes(stream)) { return se::port::Status( se::port::error::RESOURCE_EXHAUSTED, - tensorflow::strings::Printf( - "Allocating %lld bytes exceeds the memory limit of %lld bytes.", + absl::StrFormat( + "Allocating %d bytes exceeds the memory limit of %d bytes.", byte_size, GetMemoryLimitInBytes(stream))); } @@ -128,14 +129,14 @@ std::vector<AlgorithmDesc> GetAlgorithms(CudnnConvKind kind, string AlgorithmToString(const AlgorithmDesc& algo) { if (algo.tensor_ops_enabled()) { - return tensorflow::strings::StrCat(algo.algo_id(), "+TC"); + return absl::StrCat(algo.algo_id(), "+TC"); } - return tensorflow::strings::StrCat(algo.algo_id()); + return absl::StrCat(algo.algo_id()); } string NumBytesToString(int64 bytes) { - return tensorflow::strings::StrCat( - tensorflow::strings::HumanReadableNumBytes(bytes), " (", bytes, "B)"); + return absl::StrCat(tensorflow::strings::HumanReadableNumBytes(bytes), " (", + bytes, "B)"); } // Acquires a process-global lock on the device pointed to by the given @@ -361,7 +362,7 @@ CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( return InternalError( "All algorithms tried for convolution %s failed. Falling back to " "default algorithm.", - instr->ToString().c_str()); + instr->ToString()); } StatusOr<bool> CudnnConvolutionAlgorithmPicker::RunOnInstruction( diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h index 8b7749628a..f76d273e8c 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h @@ -16,12 +16,12 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_GPU_CUDNN_CONVOLUTION_ALGORITHM_PICKER_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_GPU_CUDNN_CONVOLUTION_ALGORITHM_PICKER_H_ +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/compiler.h" #include "tensorflow/compiler/xla/service/device_memory_allocator.h" #include "tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/hlo_pass_interface.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" namespace xla { @@ -39,7 +39,7 @@ class CudnnConvolutionAlgorithmPicker : public HloPassInterface { Compiler* compiler) : stream_exec_(stream_exec), allocator_(allocator), compiler_(compiler) {} - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "cudnn-convolution-algorithm-picker"; } diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc index 905b5ee876..0b1ee2dc33 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc @@ -234,6 +234,23 @@ std::tuple<bool, Window, ConvolutionDimensionNumbers> MatchBackwardInput( << "Backward input convolution should reverse all kernel dimensions."; return no_match_result; } + } else if (reverse_filter->IsConstant()) { + // If the filter is a constant, we're willing to pattern-match to a + // backwards-input conv, on the theory that + // + // a) reversing a constant is free, and + // b) even if the user specified this filter as reverse(constant), we would + // long ago have constant-folded away the reverse. + // + // If the constant has any other uses, reversing it isn't entirely free, + // since we'd now have two constants to keep in memory. But hopefully it's + // free enough. + // + // TODO(jlebar): Should we do this even if the filter is not a constant? + // Reversing a non-constant filter is probably cheaper than padding the + // input! + + // Nothing to do, just fall through. } else { // Possibly 1x1 filter. for (int64 i = 0; i < kernel_spatial_dims.size(); ++i) { @@ -373,22 +390,25 @@ std::tuple<bool, Window, ConvolutionDimensionNumbers> MatchBackwardInput( } } - // Fuse the matched HLOs into a backward convolution instruction. - // - // If the reverse is omitted (for 1x1 filters) in the original pattern, we add - // it back in the fusion instruction so that later passes (such as - // PadInsertion) can handle such fusion instructions easily. + // OK, it's a match! Canonicalize the conv's filter so that it's a reverse. + // This simplifies things for our caller, and algebraic-simplifier will later + // remove any unnecessary reverses. if (reverse_filter->opcode() != HloOpcode::kReverse) { - reverse_filter = reverse_filter->parent()->AddInstruction( + // Create a double-reverse, which is a nop. + HloComputation* c = conv->parent(); + reverse_filter = c->AddInstruction( + HloInstruction::CreateReverse(reverse_filter->shape(), reverse_filter, + AsInt64Slice(kernel_spatial_dims))); + reverse_filter = c->AddInstruction( HloInstruction::CreateReverse(reverse_filter->shape(), reverse_filter, AsInt64Slice(kernel_spatial_dims))); TF_CHECK_OK(conv->ReplaceOperandWith(/*operand_no=*/1, reverse_filter)); } + dnums.set_kernel_input_feature_dimension( conv->convolution_dimension_numbers().kernel_output_feature_dimension()); dnums.set_kernel_output_feature_dimension( conv->convolution_dimension_numbers().kernel_input_feature_dimension()); - return std::make_tuple(true, new_window, dnums); } diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.h b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.h index 0c0578d888..fbe7e98494 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.h +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.h @@ -26,7 +26,7 @@ namespace gpu { // backwards-input convolutions into CustomCall HLOs that call into cuDNN. class CudnnConvolutionRewriter : public HloPassInterface { public: - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "cudnn-convolution-rewriter"; } diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter_test.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter_test.cc index 65588b6aaf..46c23db465 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter_test.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter_test.cc @@ -24,7 +24,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/shape_inference.h" #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/test_helpers.h" -#include "tensorflow/compiler/xla/tests/hlo_test_base.h" +#include "tensorflow/compiler/xla/tests/hlo_verified_test_base.h" #include "tensorflow/core/platform/test.h" namespace xla { @@ -32,10 +32,13 @@ namespace gpu { namespace { namespace op = xla::testing::opcode_matchers; +using ::testing::_; -class CudnnConvolutionRewriterTest : public HloTestBase { +class CudnnConvolutionRewriterTest : public HloVerifiedTestBase { public: - CudnnConvolutionRewriterTest() { + CudnnConvolutionRewriterTest() + : HloVerifiedTestBase(/*layout_sensitive=*/true, + /*allow_mixed_precision=*/false) { for (int i = 0; i < 2; ++i) { WindowDimension* window_dim = default_conv_window_.add_dimensions(); window_dim->set_size(1); @@ -114,7 +117,7 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardFilterConvolve) { auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); EXPECT_THAT(entry_computation->root_instruction(), op::GetTupleElement( op::CustomCall(kCudnnConvBackwardFilterCallTarget), 0)); @@ -142,7 +145,7 @@ TEST_F(CudnnConvolutionRewriterTest, auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); EXPECT_THAT(entry_computation->root_instruction(), op::GetTupleElement( op::CustomCall(kCudnnConvBackwardFilterCallTarget), 0)); @@ -172,7 +175,7 @@ TEST_F(CudnnConvolutionRewriterTest, auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); EXPECT_THAT(entry_computation->root_instruction(), op::GetTupleElement( op::CustomCall(kCudnnConvBackwardFilterCallTarget), 0)); @@ -202,7 +205,7 @@ TEST_F(CudnnConvolutionRewriterTest, auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); EXPECT_THAT(entry_computation->root_instruction(), op::GetTupleElement( op::CustomCall(kCudnnConvBackwardFilterCallTarget), 0)); @@ -230,7 +233,7 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardFilterConvolveWithUnevenPadding) { auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); EXPECT_THAT(entry_computation->root_instruction(), op::GetTupleElement( op::CustomCall(kCudnnConvBackwardFilterCallTarget), 0)); @@ -280,7 +283,7 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardInputConvolveEvenPadding) { auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); ASSERT_THAT(entry_computation->root_instruction(), op::GetTupleElement( @@ -325,7 +328,7 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardInputConvolve1x1Filter) { auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); EXPECT_THAT(entry_computation->root_instruction(), op::GetTupleElement( op::CustomCall(kCudnnConvBackwardInputCallTarget), 0)); @@ -357,7 +360,7 @@ TEST_F(CudnnConvolutionRewriterTest, auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); EXPECT_THAT( entry_computation->root_instruction(), op::GetTupleElement(op::CustomCall(kCudnnConvForwardCallTarget), 0)); @@ -410,7 +413,7 @@ TEST_F(CudnnConvolutionRewriterTest, auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); ASSERT_THAT(entry_computation->root_instruction(), op::GetTupleElement( op::CustomCall(kCudnnConvBackwardInputCallTarget), 0)); @@ -457,7 +460,7 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardInputConvolveLowPaddingTooLarge) { auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); EXPECT_THAT( entry_computation->root_instruction(), op::GetTupleElement(op::CustomCall(kCudnnConvForwardCallTarget), 0)); @@ -510,7 +513,7 @@ TEST_F(CudnnConvolutionRewriterTest, auto module = CreateNewModule(); const HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); ASSERT_THAT(entry_computation->root_instruction(), op::GetTupleElement( op::CustomCall(kCudnnConvBackwardInputCallTarget), 0)); @@ -562,12 +565,38 @@ TEST_F(CudnnConvolutionRewriterTest, auto module = CreateNewModule(); HloComputation* entry_computation = module->AddEntryComputation(builder.Build()); - EXPECT_TRUE(RunPass(module.get())); + EXPECT_TRUE(RunPass(module)); EXPECT_THAT( entry_computation->root_instruction(), op::GetTupleElement(op::CustomCall(kCudnnConvForwardCallTarget), 0)); } +// Check that we will materialize a reversed version of a constant in order to +// pattern-match a backwards input convolution. +TEST_F(CudnnConvolutionRewriterTest, BackwardInputConvolveConstantFilter) { + Array4D<float> constant_arr(4, 4, 2, 2); + constant_arr.FillIota(0); + string constant_str = + LiteralUtil::CreateR4FromArray4D(constant_arr)->ToString(); + ParseAndVerifyModule(absl::StrFormat(R"( + HloModule test + + ENTRY entry_computation { + param0 = f32[128,2,16,16]{3,2,1,0} parameter(0) + constant = f32[4,4,2,2]{3,2,1,0} constant(%s) + ROOT convolution = f32[128,2,32,32]{3,2,1,0} convolution(param0, constant), + window={size=4x4 pad=2_2x2_2 lhs_dilate=2x2}, + dim_labels=bf01_01oi->bf01, feature_group_count=1 + })", + constant_str)); + EXPECT_TRUE(RunPass(&module())); + EXPECT_THAT( + module().entry_computation()->root_instruction(), + op::GetTupleElement(op::CustomCall(kCudnnConvBackwardInputCallTarget, _, + op::Reverse(op::Constant())), + 0)); +} + } // anonymous namespace } // namespace gpu } // namespace xla diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc index 7b0d9e53d6..07b96fbd3f 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/service/gpu/stream_executor_util.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -56,7 +57,7 @@ class ScratchBufAllocator : public se::ScratchAllocator { "Can't allocate twice from a ScratchBufAllocator."); } if (byte_size > scratch_.size()) { - return se::port::InternalError(tensorflow::strings::StrCat( + return se::port::InternalError(absl::StrCat( "Can't allocate ", byte_size, " bytes from a ScratchBufAllocator of size ", scratch_.size())); } @@ -196,8 +197,8 @@ Status RunCudnnConvolution( if (!stream->ok()) { return InternalError( - "Unable to launch convolution with type %s and algorithm (%lld, %lld)", - CudnnConvKindToString(kind).c_str(), algorithm.algorithm().algo_id(), + "Unable to launch convolution with type %s and algorithm (%d, %d)", + CudnnConvKindToString(kind), algorithm.algorithm().algo_id(), algorithm.algorithm_no_scratch().algo_id()); } return Status::OK(); diff --git a/tensorflow/compiler/xla/service/gpu/elemental_ir_emitter.cc b/tensorflow/compiler/xla/service/gpu/elemental_ir_emitter.cc index 9b6de115ad..57a3a43a6f 100644 --- a/tensorflow/compiler/xla/service/gpu/elemental_ir_emitter.cc +++ b/tensorflow/compiler/xla/service/gpu/elemental_ir_emitter.cc @@ -23,6 +23,8 @@ limitations under the License. #include "tensorflow/core/platform/types.h" // IWYU pragma: no_include "llvm/IR/Attributes.gen.inc" // IWYU pragma: no_include "llvm/IR/Intrinsics.gen.inc" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" #include "llvm/ADT/APInt.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Instructions.h" @@ -43,16 +45,14 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/window_util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { namespace gpu { +using absl::StrAppend; using llvm_ir::IrArray; using llvm_ir::IrName; using llvm_ir::SetToFirstInsertPoint; -using tensorflow::strings::StrAppend; namespace { // Returns whether operand is a floating-point literal with the given value. @@ -77,7 +77,7 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitLibdeviceMathCall( const string& callee_name, tensorflow::gtl::ArraySlice<llvm::Value*> operands, tensorflow::gtl::ArraySlice<PrimitiveType> input_types, - PrimitiveType output_type) const { + PrimitiveType output_type) { // The libdevice math functions differentiate between "double" and "float" by // appending an 'f' to the function's name. libdevice doesn't have f16 math // functions, so we convert the operands to f32 before calling the function @@ -94,7 +94,7 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitLibdeviceMathCall( for (int64 i = 0; i < operands.size(); ++i) { if (input_types[i] == F16) { converted_operands[i] = - b_->CreateFPCast(converted_operands[i], b_->getFloatTy()); + FPCast(converted_operands[i], b_->getFloatTy()); converted_input_types[i] = F32; } } @@ -107,13 +107,13 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitLibdeviceMathCall( break; default: return Unimplemented("Bad type for libdevice math call: %s", - PrimitiveType_Name(output_type).c_str()); + PrimitiveType_Name(output_type)); } llvm::Value* result = EmitMathCall(munged_callee, converted_operands, converted_input_types, output_type) .ValueOrDie(); if (cast_result_to_fp16) { - result = b_->CreateFPCast(result, b_->getHalfTy()); + result = FPCast(result, b_->getHalfTy()); } return result; } @@ -122,7 +122,7 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitLlvmIntrinsicMathCall( const string& callee_name, tensorflow::gtl::ArraySlice<llvm::Value*> operands, tensorflow::gtl::ArraySlice<PrimitiveType> input_types, - PrimitiveType output_type) const { + PrimitiveType output_type) { // llvm intrinsics differentiate between half/float/double functions via // the suffixes ".f16", ".f32" and ".f64". string munged_callee = callee_name; @@ -138,7 +138,7 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitLlvmIntrinsicMathCall( break; default: return Unimplemented("Bad type for llvm intrinsic math call: %s", - PrimitiveType_Name(output_type).c_str()); + PrimitiveType_Name(output_type)); } return EmitMathCall(munged_callee, operands, input_types, output_type); } @@ -147,13 +147,13 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitMathCall( const string& callee_name, tensorflow::gtl::ArraySlice<llvm::Value*> operands, tensorflow::gtl::ArraySlice<PrimitiveType> input_types, - PrimitiveType output_type) const { + PrimitiveType output_type) { // Binary math functions transform are of type [T] -> T. for (PrimitiveType input_type : input_types) { if (output_type != input_type) { return Unimplemented("Input type ≠ output type: %s ≠ %s", - PrimitiveType_Name(input_type).c_str(), - PrimitiveType_Name(output_type).c_str()); + PrimitiveType_Name(input_type), + PrimitiveType_Name(output_type)); } } @@ -163,8 +163,7 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitMathCall( } StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitFloatBinaryOp( - const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const { + const HloInstruction* op, llvm::Value* lhs_value, llvm::Value* rhs_value) { PrimitiveType lhs_input_type = op->operand(0)->shape().element_type(); PrimitiveType rhs_input_type = op->operand(1)->shape().element_type(); PrimitiveType output_type = op->shape().element_type(); @@ -183,8 +182,7 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitFloatBinaryOp( } StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitPowerOp( - const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const { + const HloInstruction* op, llvm::Value* lhs_value, llvm::Value* rhs_value) { CHECK_EQ(op->opcode(), HloOpcode::kPower); PrimitiveType lhs_input_type = op->operand(0)->shape().element_type(); PrimitiveType rhs_input_type = op->operand(1)->shape().element_type(); @@ -218,7 +216,7 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitPowerOp( // TODO(jlebar): Does this happen with fastmath disabled? If not, should // we force-enable it? TF_ASSIGN_OR_RETURN(auto* sqrt, make_sqrt()); - return b_->CreateFDiv(llvm::ConstantFP::get(llvm_ty, 1), sqrt); + return FDiv(llvm::ConstantFP::get(llvm_ty, 1), sqrt); } VLOG(10) << "emitting pow as regular call to pow(): " << op->ToString(); @@ -227,55 +225,56 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitPowerOp( } StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitErfcInv( - PrimitiveType prim_type, llvm::Value* value) const { + PrimitiveType prim_type, llvm::Value* value) { return EmitLibdeviceMathCall("__nv_erfcinv", {value}, {prim_type}, prim_type); } -StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitLog( - PrimitiveType prim_type, llvm::Value* value) const { +StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitLog(PrimitiveType prim_type, + llvm::Value* value) { return EmitLibdeviceMathCall("__nv_log", {value}, {prim_type}, prim_type); } -StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitLog1p( - PrimitiveType prim_type, llvm::Value* value) const { +StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitLog1p(PrimitiveType prim_type, + llvm::Value* value) { return EmitLibdeviceMathCall("__nv_log1p", {value}, {prim_type}, prim_type); } -StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitSin( - PrimitiveType prim_type, llvm::Value* value) const { +StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitSin(PrimitiveType prim_type, + llvm::Value* value) { return EmitLibdeviceMathCall("__nv_sin", {value}, {prim_type}, prim_type); } -StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitCos( - PrimitiveType prim_type, llvm::Value* value) const { +StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitCos(PrimitiveType prim_type, + llvm::Value* value) { return EmitLibdeviceMathCall("__nv_cos", {value}, {prim_type}, prim_type); } -StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitExp( - PrimitiveType prim_type, llvm::Value* value) const { +StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitExp(PrimitiveType prim_type, + llvm::Value* value) { return EmitLibdeviceMathCall("__nv_exp", {value}, {prim_type}, prim_type); } -StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitExpm1( - PrimitiveType prim_type, llvm::Value* value) const { +StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitExpm1(PrimitiveType prim_type, + llvm::Value* value) { return EmitLibdeviceMathCall("__nv_expm1", {value}, {prim_type}, prim_type); } StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitPow(PrimitiveType prim_type, llvm::Value* lhs, - llvm::Value* rhs) const { + llvm::Value* rhs) { return EmitLibdeviceMathCall("__nv_pow", {lhs, rhs}, {prim_type, prim_type}, prim_type); } -StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitAtan2( - PrimitiveType prim_type, llvm::Value* lhs, llvm::Value* rhs) const { +StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitAtan2(PrimitiveType prim_type, + llvm::Value* lhs, + llvm::Value* rhs) { return EmitLibdeviceMathCall("__nv_atan2", {lhs, rhs}, {prim_type, prim_type}, prim_type); } -StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitTanh( - PrimitiveType prim_type, llvm::Value* value) const { +StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitTanh(PrimitiveType prim_type, + llvm::Value* value) { // Emit a fast approximation of tanh instead of calling __nv_tanh. // __nv_tanh is particularly bad because it contains branches, thus // preventing LLVM's load-store vectorizer from working its magic across a @@ -285,9 +284,9 @@ StatusOr<llvm::Value*> GpuElementalIrEmitter::EmitTanh( // Upcast F16 to F32 if necessary. llvm::Type* type = prim_type == F16 ? b_->getFloatTy() : value->getType(); - llvm::Value* input = b_->CreateFPCast(value, type); + llvm::Value* input = FPCast(value, type); llvm::Value* fast_tanh = llvm_ir::EmitFastTanh(b_, input); - return b_->CreateFPCast(fast_tanh, value->getType()); + return FPCast(fast_tanh, value->getType()); } llvm::Value* GpuElementalIrEmitter::EmitDeviceFunctionCall( @@ -295,7 +294,7 @@ llvm::Value* GpuElementalIrEmitter::EmitDeviceFunctionCall( tensorflow::gtl::ArraySlice<llvm::Value*> operands, tensorflow::gtl::ArraySlice<PrimitiveType> input_types, PrimitiveType output_type, - tensorflow::gtl::ArraySlice<llvm::Attribute::AttrKind> attributes) const { + tensorflow::gtl::ArraySlice<llvm::Attribute::AttrKind> attributes) { std::vector<llvm::Type*> ir_input_types; for (PrimitiveType input_type : input_types) { ir_input_types.push_back( @@ -315,29 +314,28 @@ llvm::Value* GpuElementalIrEmitter::EmitDeviceFunctionCall( callee->addFnAttr(attribute); } - return b_->CreateCall(callee, llvm_ir::AsArrayRef(operands)); + return Call(callee, llvm_ir::AsArrayRef(operands)); } -llvm::Value* GpuElementalIrEmitter::EmitThreadId() const { - llvm::Value* block_id = b_->CreateIntCast( - llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::nvvm_read_ptx_sreg_ctaid_x, - {}, {}, b_), - b_->getIntNTy(128), /*isSigned=*/true, "block.id"); - llvm::Value* thread_id_in_block = b_->CreateIntCast( - llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::nvvm_read_ptx_sreg_tid_x, - {}, {}, b_), - b_->getIntNTy(128), /*isSigned=*/true, "thread.id"); - llvm::Value* threads_per_block = b_->CreateIntCast( - llvm_ir::EmitCallToIntrinsic(llvm::Intrinsic::nvvm_read_ptx_sreg_ntid_x, - {}, {}, b_), - b_->getIntNTy(128), /*isSigned=*/true, "threads_per_block"); - return b_->CreateNSWAdd(b_->CreateNSWMul(block_id, threads_per_block), - thread_id_in_block); +llvm::Value* GpuElementalIrEmitter::EmitThreadId() { + llvm::Value* block_id = + IntCast(llvm_ir::EmitCallToIntrinsic( + llvm::Intrinsic::nvvm_read_ptx_sreg_ctaid_x, {}, {}, b_), + b_->getIntNTy(128), /*isSigned=*/true, "block.id"); + llvm::Value* thread_id_in_block = + IntCast(llvm_ir::EmitCallToIntrinsic( + llvm::Intrinsic::nvvm_read_ptx_sreg_tid_x, {}, {}, b_), + b_->getIntNTy(128), /*isSigned=*/true, "thread.id"); + llvm::Value* threads_per_block = + IntCast(llvm_ir::EmitCallToIntrinsic( + llvm::Intrinsic::nvvm_read_ptx_sreg_ntid_x, {}, {}, b_), + b_->getIntNTy(128), /*isSigned=*/true, "threads_per_block"); + return NSWAdd(NSWMul(block_id, threads_per_block), thread_id_in_block); } llvm_ir::ElementGenerator GpuElementalIrEmitter::MakeElementGenerator( const HloInstruction* hlo, - const HloToElementGeneratorMap& operand_to_generator) const { + const HloToElementGeneratorMap& operand_to_generator) { switch (hlo->opcode()) { case HloOpcode::kMap: return [=, &operand_to_generator]( @@ -383,7 +381,7 @@ llvm_ir::ElementGenerator GpuElementalIrEmitter::MakeElementGenerator( TF_ASSIGN_OR_RETURN(llvm::Value * init_value, operand_to_generator.at(hlo->operand(1))( IrArray::Index(index.GetType()))); - b_->CreateStore(init_value, accum_ptr); + Store(init_value, accum_ptr); } llvm::Type* index_type = index.GetType(); @@ -405,22 +403,21 @@ llvm_ir::ElementGenerator GpuElementalIrEmitter::MakeElementGenerator( IrArray::Index input_index(index_type, index.size()); llvm::Value* in_bounds = b_->getInt1(true); for (size_t i = 0; i < index.size(); ++i) { - llvm::Value* stridden_index = b_->CreateNSWMul( + llvm::Value* stridden_index = NSWMul( index[i], index_typed_const(window.dimensions(i).stride())); - input_index[i] = b_->CreateNSWSub( - b_->CreateNSWAdd(stridden_index, window_index[i]), - index_typed_const(window.dimensions(i).padding_low())); + input_index[i] = + NSWSub(NSWAdd(stridden_index, window_index[i]), + index_typed_const(window.dimensions(i).padding_low())); // We must check whether 0 ≤ input_index[i] < bound, as otherwise // we are in the pad and so can skip the computation. This // comparison is equivalent to the unsigned comparison // input_index[i] < bound, as a negative value wraps to a large // positive value. - in_bounds = b_->CreateAnd( - in_bounds, - b_->CreateICmpULT( - input_index[i], - index_typed_const(operand->shape().dimensions(i)))); + in_bounds = + And(in_bounds, + ICmpULT(input_index[i], + index_typed_const(operand->shape().dimensions(i)))); } llvm_ir::LlvmIfData if_data = @@ -432,12 +429,11 @@ llvm_ir::ElementGenerator GpuElementalIrEmitter::MakeElementGenerator( operand_to_generator.at(operand)(input_index)); TF_ASSIGN_OR_RETURN( llvm::Value * accum_value, - compute_nested_(*hlo->to_apply(), - {b_->CreateLoad(accum_ptr), input_value})); - b_->CreateStore(accum_value, accum_ptr); + compute_nested_(*hlo->to_apply(), {Load(accum_ptr), input_value})); + Store(accum_value, accum_ptr); SetToFirstInsertPoint(loops.GetOuterLoopExitBasicBlock(), b_); - return b_->CreateLoad(accum_ptr); + return Load(accum_ptr); }; case HloOpcode::kReduce: // TODO(b/112040122): This should be supported. diff --git a/tensorflow/compiler/xla/service/gpu/elemental_ir_emitter.h b/tensorflow/compiler/xla/service/gpu/elemental_ir_emitter.h index 84454d31bb..91942785d2 100644 --- a/tensorflow/compiler/xla/service/gpu/elemental_ir_emitter.h +++ b/tensorflow/compiler/xla/service/gpu/elemental_ir_emitter.h @@ -48,50 +48,50 @@ class GpuElementalIrEmitter : public ElementalIrEmitter { llvm_ir::ElementGenerator MakeElementGenerator( const HloInstruction* hlo, - const HloToElementGeneratorMap& operand_to_generator) const override; + const HloToElementGeneratorMap& operand_to_generator) override; protected: - StatusOr<llvm::Value*> EmitFloatBinaryOp( - const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const override; + StatusOr<llvm::Value*> EmitFloatBinaryOp(const HloInstruction* op, + llvm::Value* lhs_value, + llvm::Value* rhs_value) override; StatusOr<llvm::Value*> EmitErfcInv(PrimitiveType prim_type, - llvm::Value* value) const override; + llvm::Value* value) override; StatusOr<llvm::Value*> EmitLog(PrimitiveType prim_type, - llvm::Value* value) const override; + llvm::Value* value) override; StatusOr<llvm::Value*> EmitLog1p(PrimitiveType prim_type, - llvm::Value* value) const override; + llvm::Value* value) override; StatusOr<llvm::Value*> EmitSin(PrimitiveType prim_type, - llvm::Value* value) const override; + llvm::Value* value) override; StatusOr<llvm::Value*> EmitCos(PrimitiveType prim_type, - llvm::Value* value) const override; + llvm::Value* value) override; StatusOr<llvm::Value*> EmitExp(PrimitiveType prim_type, - llvm::Value* value) const override; + llvm::Value* value) override; StatusOr<llvm::Value*> EmitExpm1(PrimitiveType prim_type, - llvm::Value* value) const override; + llvm::Value* value) override; StatusOr<llvm::Value*> EmitPow(PrimitiveType prim_type, llvm::Value* lhs, - llvm::Value* rhs) const override; + llvm::Value* rhs) override; StatusOr<llvm::Value*> EmitAtan2(PrimitiveType prim_type, llvm::Value* lhs, - llvm::Value* rhs) const override; + llvm::Value* rhs) override; StatusOr<llvm::Value*> EmitTanh(PrimitiveType prim_type, - llvm::Value* value) const override; + llvm::Value* value) override; - llvm::Value* EmitThreadId() const override; + llvm::Value* EmitThreadId() override; private: // Emits IR for op, which must have opcode kPower. StatusOr<llvm::Value*> EmitPowerOp(const HloInstruction* op, llvm::Value* lhs_value, - llvm::Value* rhs_value) const; + llvm::Value* rhs_value); // Emits IR to call a device function named "callee_name" on the given // operand. Returns the IR value that represents the return value. @@ -100,7 +100,7 @@ class GpuElementalIrEmitter : public ElementalIrEmitter { tensorflow::gtl::ArraySlice<llvm::Value*> operands, tensorflow::gtl::ArraySlice<PrimitiveType> input_type, PrimitiveType output_type, - tensorflow::gtl::ArraySlice<llvm::Attribute::AttrKind> attributes) const; + tensorflow::gtl::ArraySlice<llvm::Attribute::AttrKind> attributes); // Emits IR to call an LLVM intrinsic of type [T] -> T. Adjusts // callee_name according to T. Returns the IR value that represents the @@ -109,7 +109,7 @@ class GpuElementalIrEmitter : public ElementalIrEmitter { const string& callee_name, tensorflow::gtl::ArraySlice<llvm::Value*> operands, tensorflow::gtl::ArraySlice<PrimitiveType> input_types, - PrimitiveType output_type) const; + PrimitiveType output_type); // Emits IR to call a libdevice function of type [T] -> T. Adjusts // callee_name according to T. Returns the IR value that represents the @@ -118,7 +118,7 @@ class GpuElementalIrEmitter : public ElementalIrEmitter { const string& callee_name, tensorflow::gtl::ArraySlice<llvm::Value*> operands, tensorflow::gtl::ArraySlice<PrimitiveType> input_types, - PrimitiveType output_type) const; + PrimitiveType output_type); // Emits IR to call a function of type [T] -> T. Does not munge callee_name. // Returns the IR value that represents the return value of the function. @@ -126,7 +126,7 @@ class GpuElementalIrEmitter : public ElementalIrEmitter { const string& callee_name, tensorflow::gtl::ArraySlice<llvm::Value*> operands, tensorflow::gtl::ArraySlice<PrimitiveType> input_types, - PrimitiveType output_type) const; + PrimitiveType output_type); const HloModuleConfig& hlo_module_config_; NestedComputer compute_nested_; diff --git a/tensorflow/compiler/xla/service/gpu/fft_thunk.cc b/tensorflow/compiler/xla/service/gpu/fft_thunk.cc index 0cdddf8bcf..11549cdac5 100644 --- a/tensorflow/compiler/xla/service/gpu/fft_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/fft_thunk.cc @@ -17,11 +17,11 @@ limitations under the License. #include <string> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" @@ -43,8 +43,8 @@ StatusOr<se::DeviceMemory<uint8>> FftScratchAllocator::AllocateBytes( if (byte_size > GetMemoryLimitInBytes(stream)) { return se::port::Status( se::port::error::RESOURCE_EXHAUSTED, - tensorflow::strings::Printf( - "Allocating %lld bytes exceeds the memory limit of %lld bytes.", + absl::StrFormat( + "Allocating %d bytes exceeds the memory limit of %d bytes.", byte_size, GetMemoryLimitInBytes(stream))); } @@ -213,7 +213,7 @@ Status FftThunk::ExecuteOnStream(const BufferAllocations& buffer_allocations, return Status::OK(); } return InternalError("Unable to launch fft for thunk %p with type %s", this, - FftTypeToString(fft_type_).c_str()); + FftTypeToString(fft_type_)); } } // namespace gpu diff --git a/tensorflow/compiler/xla/service/gpu/fft_thunk.h b/tensorflow/compiler/xla/service/gpu/fft_thunk.h index 8c53be5077..4adec7ee54 100644 --- a/tensorflow/compiler/xla/service/gpu/fft_thunk.h +++ b/tensorflow/compiler/xla/service/gpu/fft_thunk.h @@ -16,6 +16,7 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_GPU_FFT_THUNK_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_GPU_FFT_THUNK_H_ +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/buffer_assignment.h" #include "tensorflow/compiler/xla/service/gpu/buffer_allocations.h" #include "tensorflow/compiler/xla/service/gpu/gpu_executable.h" @@ -25,7 +26,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" namespace xla { diff --git a/tensorflow/compiler/xla/service/gpu/for_thunk.cc b/tensorflow/compiler/xla/service/gpu/for_thunk.cc index 2fd2206324..88f0b4d71c 100644 --- a/tensorflow/compiler/xla/service/gpu/for_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/for_thunk.cc @@ -15,7 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/for_thunk.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" @@ -28,7 +28,7 @@ ForThunk::ForThunk(const int64 loop_limit, const HloInstruction* hlo) : Thunk(Kind::kWhile, hlo), loop_limit_(loop_limit), - body_thunk_sequence_(MakeUnique<SequentialThunk>( + body_thunk_sequence_(absl::make_unique<SequentialThunk>( // Pass nullptr as the HloInstruction* to the body_thunk_sequence_ // constructor because this SequentialThunk is logically "part of" // this ForThunk, and shouldn't be profiled separately from it. diff --git a/tensorflow/compiler/xla/service/gpu/fusion_merger.cc b/tensorflow/compiler/xla/service/gpu/fusion_merger.cc index 3cd30b754c..1bd88233e1 100644 --- a/tensorflow/compiler/xla/service/gpu/fusion_merger.cc +++ b/tensorflow/compiler/xla/service/gpu/fusion_merger.cc @@ -18,12 +18,13 @@ limitations under the License. #include <algorithm> #include <vector> +#include "absl/algorithm/container.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/gpu/instruction_fusion.h" #include "tensorflow/compiler/xla/service/hlo_cost_analysis.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace xla { namespace gpu { @@ -64,10 +65,11 @@ double CalculateBytesReadByFusionParameter(HloInstruction* param) { // Slice for a more accurate estimate of bytes read. double bytes = 0.0; for (auto& instruction : instructions) { - if (c_all_of(instruction->users(), [](const HloInstruction* instruction) { - return instruction->opcode() == HloOpcode::kSlice || - instruction->opcode() == HloOpcode::kDynamicSlice; - })) { + if (absl::c_all_of( + instruction->users(), [](const HloInstruction* instruction) { + return instruction->opcode() == HloOpcode::kSlice || + instruction->opcode() == HloOpcode::kDynamicSlice; + })) { // All users are slice: accumulate bytes of all user slice instructions. for (auto& user : instruction->users()) { bytes += ShapeUtil::ByteSizeOf(user->shape()); @@ -223,7 +225,7 @@ Status FusionInstructionMerger::HandleFusion(HloInstruction* fusion) { // Skip 'fusion' instruction if we cannot merge into all of its users. // Merging into all users enables the removal of 'fusion' from the // computation. - if (!c_all_of(fusion->users(), [](const HloInstruction* user) { + if (!absl::c_all_of(fusion->users(), [](const HloInstruction* user) { return user->opcode() == HloOpcode::kFusion && (user->fusion_kind() == HloInstruction::FusionKind::kLoop || user->fusion_kind() == HloInstruction::FusionKind::kInput); @@ -241,11 +243,11 @@ Status FusionInstructionMerger::HandleFusion(HloInstruction* fusion) { // If 'fusion' has just one user, then an earlier fusion pass chose not to // fuse this producer/comsumer pair (likely because of expensive instruction // re-use by the consumer), and so we honor that choice here as well. - if (c_any_of(fusion->fused_instructions(), - [](const HloInstruction* instruction) { - return instruction->opcode() != HloOpcode::kParameter && - GpuInstructionFusion::IsExpensive(*instruction); - })) { + if (absl::c_any_of(fusion->fused_instructions(), + [](const HloInstruction* instruction) { + return instruction->opcode() != HloOpcode::kParameter && + GpuInstructionFusion::IsExpensive(*instruction); + })) { VLOG(3) << "Not merging " << fusion->name() << ": Contains one or more expensive instructions."; ++num_fail_expensive_fused_instruction_; @@ -287,11 +289,10 @@ Status FusionInstructionMerger::HandleFusion(HloInstruction* fusion) { << " flops_to_bytes_ratio: " << CalculateFlopsToBytesRatio(fusion) << " merged_to_current_bytes_ratio: " << merged_to_current_bytes_ratio << " into users { " - << tensorflow::str_util::Join(users, ", ", - [](string* out, HloInstruction* user) { - tensorflow::strings::StrAppend( - out, user->name()); - }) + << absl::StrJoin(users, ", ", + [](string* out, HloInstruction* user) { + absl::StrAppend(out, user->name()); + }) << " }"; // Remove 'fusion' instruction. CHECK_EQ(0, fusion->user_count()); diff --git a/tensorflow/compiler/xla/service/gpu/fusion_merger.h b/tensorflow/compiler/xla/service/gpu/fusion_merger.h index 4c523a66de..7e3f5775b8 100644 --- a/tensorflow/compiler/xla/service/gpu/fusion_merger.h +++ b/tensorflow/compiler/xla/service/gpu/fusion_merger.h @@ -34,7 +34,7 @@ namespace gpu { // class FusionMerger : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "fusion merger"; } + absl::string_view name() const override { return "fusion merger"; } StatusOr<bool> Run(HloModule* module) override; diff --git a/tensorflow/compiler/xla/service/gpu/gemm_thunk.cc b/tensorflow/compiler/xla/service/gpu/gemm_thunk.cc index 74282c568c..9c4a490366 100644 --- a/tensorflow/compiler/xla/service/gpu/gemm_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/gemm_thunk.cc @@ -17,8 +17,8 @@ limitations under the License. #include <functional> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" #include "tensorflow/core/platform/types.h" @@ -186,7 +186,7 @@ StatusOr<se::blas::AlgorithmType> DoGemmAutotune( } return InternalError( - "Unable to autotune cuBLAS gemm on stream %p; none of the %zu algorithms " + "Unable to autotune cuBLAS gemm on stream %p; none of the %u algorithms " "ran successfully", stream, algorithms.size()); } diff --git a/tensorflow/compiler/xla/service/gpu/gpu_copy_insertion.h b/tensorflow/compiler/xla/service/gpu/gpu_copy_insertion.h index 0c6f9b511f..8ffae18fe8 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_copy_insertion.h +++ b/tensorflow/compiler/xla/service/gpu/gpu_copy_insertion.h @@ -27,7 +27,7 @@ namespace gpu { // inserting kCopy instructions. class GpuCopyInsertion : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "copy-insertion"; } + absl::string_view name() const override { return "copy-insertion"; } StatusOr<bool> Run(HloModule* module) override; diff --git a/tensorflow/compiler/xla/service/gpu/gpu_executable.cc b/tensorflow/compiler/xla/service/gpu/gpu_executable.cc index 7060837904..71a02e70df 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_executable.cc +++ b/tensorflow/compiler/xla/service/gpu/gpu_executable.cc @@ -19,8 +19,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/gpu/buffer_allocations.h" #include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -112,7 +112,7 @@ Status GpuExecutable::ExecuteThunks( // // TODO(jlebar): Should we cache the results of HloInstruction::ToString(), // since we expect it to be an expensive call? - tensorflow::gtl::optional<ScopedAnnotation> op_annotation; + absl::optional<ScopedAnnotation> op_annotation; if (top_level_annotation.IsEnabled()) { op_annotation.emplace( thunk->hlo_instruction() != nullptr @@ -144,7 +144,7 @@ Status GpuExecutable::ExecuteThunks( TF_RETURN_IF_ERROR( thunk->ExecuteOnStream(buffer_allocations, stream, &profiler)); if (thunk_schedule_->Depended(thunk)) { - auto finish_event = MakeUnique<se::Event>(main_stream->parent()); + auto finish_event = absl::make_unique<se::Event>(main_stream->parent()); finish_event->Init(); stream->ThenRecordEvent(finish_event.get()); thunk_to_finish_event[thunk] = std::move(finish_event); @@ -160,7 +160,7 @@ Status GpuExecutable::ExecuteThunks( if (!block_status.ok()) { return InternalError( "Failed to complete all kernels launched on stream %p: %s", - main_stream, block_status.error_message().c_str()); + main_stream, block_status.error_message()); } } @@ -260,10 +260,9 @@ StatusOr<ScopedShapedBuffer> GpuExecutable::ExecuteOnStream( if (buffer.is_null() && buffer.size() > 0) { return FailedPrecondition( "Cannot run XLA computation because pointer to (sub-)buffer at " - "index %s of parameter %lld was null. All pointers to " - "(sub-)buffers must not be null, unless the (sub-)buffer has zero " - "elements.", - allocation.param_shape_index().ToString().c_str(), param_no); + "index %s of parameter %d was null. All pointers to (sub-)buffers " + "must not be null, unless the (sub-)buffer has zero elements.", + allocation.param_shape_index().ToString(), param_no); } buffer_allocations_builder.RegisterBuffer(i, buffer); diff --git a/tensorflow/compiler/xla/service/gpu/gpu_executable.h b/tensorflow/compiler/xla/service/gpu/gpu_executable.h index c7ce6d0acb..627a05e240 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_executable.h +++ b/tensorflow/compiler/xla/service/gpu/gpu_executable.h @@ -19,6 +19,8 @@ limitations under the License. #include <memory> #include <string> +#include "absl/strings/string_view.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/buffer_assignment.h" #include "tensorflow/compiler/xla/service/device_memory_allocator.h" #include "tensorflow/compiler/xla/service/executable.h" @@ -32,10 +34,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/tuple_points_to_analysis.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/lib/gtl/flatmap.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" diff --git a/tensorflow/compiler/xla/service/gpu/gpu_hlo_support_checker.cc b/tensorflow/compiler/xla/service/gpu/gpu_hlo_support_checker.cc index 4944c41f7d..4268fb2c7a 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_hlo_support_checker.cc +++ b/tensorflow/compiler/xla/service/gpu/gpu_hlo_support_checker.cc @@ -34,9 +34,8 @@ StatusOr<bool> GpuHloSupportChecker::Run(HloModule* module) { return xla::Unimplemented( "GPU backend does not support HLO instruction %s with shape " "containing a sparse layout: %s", - instruction->ToString().c_str(), - ShapeUtil::HumanStringWithLayout(instruction->shape()) - .c_str()); + instruction->ToString(), + ShapeUtil::HumanStringWithLayout(instruction->shape())); } return Status::OK(); })); diff --git a/tensorflow/compiler/xla/service/gpu/gpu_hlo_support_checker.h b/tensorflow/compiler/xla/service/gpu/gpu_hlo_support_checker.h index d63e213d2b..bbb3340760 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_hlo_support_checker.h +++ b/tensorflow/compiler/xla/service/gpu/gpu_hlo_support_checker.h @@ -28,9 +28,7 @@ class GpuHloSupportChecker : public HloPassInterface { GpuHloSupportChecker() = default; ~GpuHloSupportChecker() override = default; - tensorflow::StringPiece name() const override { - return "gpu_hlo_support_checker"; - } + absl::string_view name() const override { return "gpu_hlo_support_checker"; } // Note: always returns false (no instructions are ever modified by this // pass). diff --git a/tensorflow/compiler/xla/service/gpu/gpu_layout_assignment_test.cc b/tensorflow/compiler/xla/service/gpu/gpu_layout_assignment_test.cc index 286547ebae..fbc8ddf599 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_layout_assignment_test.cc +++ b/tensorflow/compiler/xla/service/gpu/gpu_layout_assignment_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/gpu_layout_assignment.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/service/computation_layout.h" #include "tensorflow/compiler/xla/service/gpu/ir_emission_utils.h" @@ -119,7 +120,7 @@ TEST_F(LayoutAssignmentTest, BatchNormInference) { for (const Shape& input_shape : AllLayoutsOf(shape)) { for (const Shape& result_shape : AllLayoutsOf(shape)) { - SCOPED_TRACE(tensorflow::strings::StrCat( + SCOPED_TRACE(absl::StrCat( "input_shape=", ShapeUtil::HumanStringWithLayout(input_shape), ", result_shape=", ShapeUtil::HumanStringWithLayout(result_shape))); @@ -192,7 +193,7 @@ TEST_F(LayoutAssignmentTest, BatchNormTraining) { // Enumerate all combinations of shapes. for (const Shape& input_shape : AllLayoutsOf(shape)) { for (const Shape& result_shape : AllLayoutsOf(shape)) { - SCOPED_TRACE(tensorflow::strings::StrCat( + SCOPED_TRACE(absl::StrCat( "input_shape=", ShapeUtil::HumanStringWithLayout(input_shape), ", result_shape=", ShapeUtil::HumanStringWithLayout(result_shape))); @@ -265,7 +266,7 @@ TEST_F(LayoutAssignmentTest, BatchNormGrad) { for (const Shape& input_shape : AllLayoutsOf(shape)) { for (const Shape& result_shape : AllLayoutsOf(shape)) { for (int constrained_param_no : {0, 4}) { - SCOPED_TRACE(tensorflow::strings::StrCat( + SCOPED_TRACE(absl::StrCat( "input_shape=", ShapeUtil::HumanStringWithLayout(input_shape), ", result_shape=", ShapeUtil::HumanStringWithLayout(result_shape))); diff --git a/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.cc b/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.cc index a2f53f8446..f3c2744292 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.cc +++ b/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.cc @@ -19,6 +19,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "llvm/IR/DataLayout.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" @@ -83,7 +84,7 @@ Status GpuTransferManager::EnqueueBuffersToInfeed( Status block_status = stream->BlockHostUntilDone(); if (!block_status.ok()) { return InternalError("Failed to complete data transfer on stream %p: %s", - stream, block_status.error_message().c_str()); + stream, block_status.error_message()); } infeed_manager->EnqueueDestination(std::move(buffers)); @@ -96,7 +97,7 @@ Status GpuTransferManager::EnqueueBuffersToInfeed( StatusOr<InfeedBuffer> GpuTransferManager::TransferBufferToInfeedInternal( se::StreamExecutor* executor, int64 size, const void* source) { if (size > std::numeric_limits<int32>::max()) { - return InvalidArgument("Infeed shape is too large: needs %lld bytes", size); + return InvalidArgument("Infeed shape is too large: needs %d bytes", size); } if (size == 0) { @@ -160,9 +161,10 @@ Status GpuTransferManager::TransferLiteralFromOutfeed( if (ShapeUtil::IsTuple(shape)) { return; } - *buffer = MakeUnique<gpu::OutfeedBuffer>(GetByteSizeRequirement(shape)); + *buffer = absl::make_unique<gpu::OutfeedBuffer>( + GetByteSizeRequirement(shape)); (*buffer)->set_destination( - MakeUnique<MutableBorrowingLiteral>(literal, index)); + absl::make_unique<MutableBorrowingLiteral>(literal, index)); }); // Give the tree of buffers to the outfeed mananger. The device will fill it @@ -179,7 +181,7 @@ Status GpuTransferManager::TransferLiteralFromOutfeed( } // namespace xla static std::unique_ptr<xla::TransferManager> CreateNVPTXTransferManager() { - return xla::MakeUnique<xla::gpu::GpuTransferManager>( + return absl::make_unique<xla::gpu::GpuTransferManager>( /*id=*/stream_executor::cuda::kCudaPlatformId, /*pointer_size=*/llvm::DataLayout(xla::gpu::NVPTXCompiler::kDataLayout) .getPointerSize(0 /* default address space */)); diff --git a/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.h b/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.h index 7929042869..fa88816bc8 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.h +++ b/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_GPU_TRANSFER_MANAGER_H_ -#define TENSORFLOW_COMPILER_XLA_SERVICE_GPU_TRANSFER_MANAGER_H_ +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_GPU_GPU_TRANSFER_MANAGER_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_GPU_GPU_TRANSFER_MANAGER_H_ #include <vector> @@ -61,4 +61,4 @@ class GpuTransferManager : public GenericTransferManager { } // namespace gpu } // namespace xla -#endif // TENSORFLOW_COMPILER_XLA_SERVICE_GPU_TRANSFER_MANAGER_H_ +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_GPU_GPU_TRANSFER_MANAGER_H_ diff --git a/tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.cc b/tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.cc index 1722676930..b9c21e8edb 100644 --- a/tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.cc +++ b/tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.cc @@ -20,6 +20,7 @@ limitations under the License. #include <unordered_set> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_execution_profile.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -33,7 +34,7 @@ namespace gpu { namespace { void InitAndStartTimer(std::stack<std::unique_ptr<se::Timer>>* timers, se::Stream* stream) { - timers->push(MakeUnique<se::Timer>(stream->parent())); + timers->push(absl::make_unique<se::Timer>(stream->parent())); stream->InitTimer(timers->top().get()).ThenStartTimer(timers->top().get()); } @@ -115,7 +116,7 @@ HloExecutionProfiler::MakeScopedInstructionProfiler( CHECK(hlo_instructions_.insert(hlo_instruction).second) << hlo_instruction->name(); } - return MakeUnique<ScopedInstructionProfiler>(this, hlo_instruction); + return absl::make_unique<ScopedInstructionProfiler>(this, hlo_instruction); } } // namespace gpu diff --git a/tensorflow/compiler/xla/service/gpu/hlo_schedule.cc b/tensorflow/compiler/xla/service/gpu/hlo_schedule.cc index 19de37b0fb..76055ff009 100644 --- a/tensorflow/compiler/xla/service/gpu/hlo_schedule.cc +++ b/tensorflow/compiler/xla/service/gpu/hlo_schedule.cc @@ -19,7 +19,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/hlo_schedule.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/buffer_value.h" #include "tensorflow/compiler/xla/service/hlo_reachability.h" #include "tensorflow/compiler/xla/service/hlo_scheduling.h" @@ -59,8 +59,8 @@ GpuHloOrdering::GpuHloOrdering( : PredecessorHloOrdering(module) { // The entry computation has a total order when there's only one stream. if (stream_assignment.StreamCount() == 1) { - entry_sequence_ = - MakeUnique<std::vector<const HloInstruction*>>(thunk_launch_order); + entry_sequence_ = absl::make_unique<std::vector<const HloInstruction*>>( + thunk_launch_order); } // The ordering of instructions for the entry computation is determined by the @@ -75,7 +75,7 @@ GpuHloOrdering::GpuHloOrdering( // same-stream predecessors of each instruction. // Compute the set of all instructions we will want to set reachability on. - auto predecessor_map = MakeUnique<HloReachabilityMap>( + auto predecessor_map = absl::make_unique<HloReachabilityMap>( module->entry_computation()->MakeInstructionPostOrder()); // The most recently visited instruction per stream. @@ -208,7 +208,7 @@ StatusOr<std::unique_ptr<HloSchedule>> HloSchedule::Build( BFSLaunchOrder(entry_computation, &schedule->thunk_launch_order_); } - schedule->hlo_ordering_ = MakeUnique<GpuHloOrdering>( + schedule->hlo_ordering_ = absl::make_unique<GpuHloOrdering>( &module, stream_assignment, schedule->thunk_launch_order_); return std::move(schedule); diff --git a/tensorflow/compiler/xla/service/gpu/hlo_schedule_test.cc b/tensorflow/compiler/xla/service/gpu/hlo_schedule_test.cc index 45f0a1c645..bb147c8d98 100644 --- a/tensorflow/compiler/xla/service/gpu/hlo_schedule_test.cc +++ b/tensorflow/compiler/xla/service/gpu/hlo_schedule_test.cc @@ -18,6 +18,8 @@ limitations under the License. #include <algorithm> #include <unordered_set> +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/service/gpu/stream_assignment.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -47,7 +49,7 @@ class HloScheduleTest : public HloTestBase { auto debug_options = GetDebugOptionsForTest(); debug_options.set_xla_gpu_disable_multi_streaming(false); config.set_debug_options(debug_options); - return MakeUnique<HloModule>("test_module", config); + return absl::make_unique<HloModule>("test_module", config); } HloVec RemoveHlo(const HloVec& input, @@ -265,7 +267,7 @@ TEST_F(HloScheduleTest, LatticeMatMul) { params.reserve(6); for (int i = 0; i < 6; ++i) { params.push_back(builder.AddInstruction(HloInstruction::CreateParameter( - i, f32_2x2_, /*name=*/tensorflow::strings::Printf("param%d", i)))); + i, f32_2x2_, /*name=*/absl::StrFormat("param%d", i)))); } HloInstruction* d00 = builder.AddInstruction( HloInstruction::CreateCanonicalDot(f32_2x2_, params[2], params[3])); diff --git a/tensorflow/compiler/xla/service/gpu/hlo_to_ir_bindings.cc b/tensorflow/compiler/xla/service/gpu/hlo_to_ir_bindings.cc index 8c11cd0541..0e205b9c02 100644 --- a/tensorflow/compiler/xla/service/gpu/hlo_to_ir_bindings.cc +++ b/tensorflow/compiler/xla/service/gpu/hlo_to_ir_bindings.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/hlo_to_ir_bindings.h" +#include "absl/strings/str_cat.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Function.h" #include "llvm/IR/Instructions.h" @@ -24,16 +25,14 @@ limitations under the License. #include "tensorflow/compiler/xla/service/llvm_ir/buffer_assignment_util.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_util.h" #include "tensorflow/compiler/xla/service/llvm_ir/tuple_ops.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" namespace xla { namespace gpu { -using tensorflow::strings::StrAppend; -using tensorflow::strings::StrCat; +using absl::StrAppend; +using absl::StrCat; void HloToIrBindings::EmitBasePointersForHlos( tensorflow::gtl::ArraySlice<const HloInstruction*> io_hlos, diff --git a/tensorflow/compiler/xla/service/gpu/infeed_manager.cc b/tensorflow/compiler/xla/service/gpu/infeed_manager.cc index c5f0cdf6cd..a4364b0deb 100644 --- a/tensorflow/compiler/xla/service/gpu/infeed_manager.cc +++ b/tensorflow/compiler/xla/service/gpu/infeed_manager.cc @@ -15,7 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/infeed_manager.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" namespace xla { namespace gpu { @@ -24,7 +24,7 @@ se::Stream* InfeedManager::GetStream(se::StreamExecutor* executor) { tensorflow::mutex_lock l(host_to_device_stream_mu_); if (host_to_device_executor_ == nullptr) { host_to_device_executor_ = executor; - host_to_device_stream_ = MakeUnique<se::Stream>(executor); + host_to_device_stream_ = absl::make_unique<se::Stream>(executor); host_to_device_stream_->Init(); } diff --git a/tensorflow/compiler/xla/service/gpu/infeed_thunk.cc b/tensorflow/compiler/xla/service/gpu/infeed_thunk.cc index fee6d2af3b..8c3a026740 100644 --- a/tensorflow/compiler/xla/service/gpu/infeed_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/infeed_thunk.cc @@ -96,7 +96,7 @@ Status InfeedThunk::ExecuteOnStream(const BufferAllocations& buffer_allocations, Status block_status = stream->BlockHostUntilDone(); if (!block_status.ok()) { return InternalError("Failed to complete data transfer on stream %p: %s", - stream, block_status.error_message().c_str()); + stream, block_status.error_message()); } VLOG(2) << "Infeeding to GPU complete"; diff --git a/tensorflow/compiler/xla/service/gpu/instruction_fusion.cc b/tensorflow/compiler/xla/service/gpu/instruction_fusion.cc index 0f2c83aeb2..0bcaaee2b7 100644 --- a/tensorflow/compiler/xla/service/gpu/instruction_fusion.cc +++ b/tensorflow/compiler/xla/service/gpu/instruction_fusion.cc @@ -26,7 +26,7 @@ namespace gpu { namespace { -bool IsFusile(const HloInstruction& hlo) { +bool IsFusible(const HloInstruction& hlo) { // Don't fuse get-tuple-element on GPU: We can, but it's slower than not // fusing. We never generate kernels for unfused GTEs. Instead, if an // unfused GTE is an input to a kernel (including a fusion kernel), we @@ -245,7 +245,7 @@ bool GpuInstructionFusion::ShouldFuse(HloInstruction* consumer, return true; } - if (!IsFusile(*producer) || !IsFusile(*consumer) || + if (!IsFusible(*producer) || !IsFusible(*consumer) || !InstructionFusion::ShouldFuse(consumer, operand_index)) { return false; } diff --git a/tensorflow/compiler/xla/service/gpu/instruction_fusion_test.cc b/tensorflow/compiler/xla/service/gpu/instruction_fusion_test.cc index 8d0522bd8f..f53dfaee3d 100644 --- a/tensorflow/compiler/xla/service/gpu/instruction_fusion_test.cc +++ b/tensorflow/compiler/xla/service/gpu/instruction_fusion_test.cc @@ -365,7 +365,7 @@ static StatusOr<const HloInstruction*> FindHloInstruction( } return NotFound( "Computation '%s' does not contain an instruction with op code '%s'.", - computation.name().c_str(), HloOpcodeString(op).c_str()); + computation.name(), HloOpcodeString(op)); } TEST_F(InstructionFusionTest, MultiOutputFusion) { diff --git a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc index c349063c71..f544bcc919 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc +++ b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc @@ -215,7 +215,7 @@ bool IsReductionToVector(const HloInstruction& reduce) { // This emits a device-side call to // "i32 vprintf(i8* fmt, arguments_type* arguments)" in the driver; see // http://docs.nvidia.com/cuda/ptx-writers-guide-to-interoperability/index.html#system-calls -llvm::Value* EmitPrintf(tensorflow::StringPiece fmt, +llvm::Value* EmitPrintf(absl::string_view fmt, tensorflow::gtl::ArraySlice<llvm::Value*> arguments, llvm::IRBuilder<>* builder) { std::vector<llvm::Type*> argument_types; diff --git a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h index 5d23a3d018..a35e250101 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h +++ b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h @@ -126,7 +126,7 @@ bool ImplementedAsLibraryCall(const HloInstruction& hlo); bool IsReductionToVector(const HloInstruction& reduce); // Emits call to "vprintf" with given format and arguments. -llvm::Value* EmitPrintf(tensorflow::StringPiece fmt, +llvm::Value* EmitPrintf(absl::string_view fmt, tensorflow::gtl::ArraySlice<llvm::Value*> arguments, llvm::IRBuilder<>* builder); diff --git a/tensorflow/compiler/xla/service/gpu/ir_emitter.cc b/tensorflow/compiler/xla/service/gpu/ir_emitter.cc index 6675dbd3f9..bdf6aadde6 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emitter.cc +++ b/tensorflow/compiler/xla/service/gpu/ir_emitter.cc @@ -21,6 +21,7 @@ limitations under the License. #include "tensorflow/core/platform/logging.h" // IWYU pragma: no_include "llvm/IR/Intrinsics.gen.inc" +#include "absl/algorithm/container.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Constants.h" #include "llvm/IR/Instructions.h" @@ -155,7 +156,7 @@ Status IrEmitter::EmitCallToNestedComputation( std::vector<llvm::Value*> arguments(operands.begin(), operands.end()); arguments.push_back(output); arguments.push_back(bindings_.GetTempBufferBase()); - b_.CreateCall(emitted_function, arguments); + Call(emitted_function, arguments); return Status::OK(); } @@ -177,7 +178,7 @@ bool IrEmitter::MaybeEmitDirectAtomicOperation( computation.root_instruction()->shape().element_type(); bool is_atomic_integral = element_type == S32 || element_type == U32 || element_type == S64 || element_type == U64; - llvm::Value* source = b_.CreateLoad(source_address, "source"); + llvm::Value* source = Load(source_address, "source"); if (root_opcode == HloOpcode::kAdd) { // NVPTX supports atomicAdd on F32 and integer types. if (element_type == F32) { @@ -189,8 +190,8 @@ bool IrEmitter::MaybeEmitDirectAtomicOperation( } if (is_atomic_integral) { // integral + integral - b_.CreateAtomicRMW(llvm::AtomicRMWInst::Add, output_address, source, - llvm::AtomicOrdering::SequentiallyConsistent); + AtomicRMW(llvm::AtomicRMWInst::Add, output_address, source, + llvm::AtomicOrdering::SequentiallyConsistent); return true; } } @@ -201,8 +202,8 @@ bool IrEmitter::MaybeEmitDirectAtomicOperation( auto opcode = primitive_util::IsSignedIntegralType(element_type) ? llvm::AtomicRMWInst::Max : llvm::AtomicRMWInst::UMax; - b_.CreateAtomicRMW(opcode, output_address, source, - llvm::AtomicOrdering::SequentiallyConsistent); + AtomicRMW(opcode, output_address, source, + llvm::AtomicOrdering::SequentiallyConsistent); return true; } @@ -211,8 +212,8 @@ bool IrEmitter::MaybeEmitDirectAtomicOperation( auto opcode = primitive_util::IsSignedIntegralType(element_type) ? llvm::AtomicRMWInst::Min : llvm::AtomicRMWInst::UMin; - b_.CreateAtomicRMW(opcode, output_address, source, - llvm::AtomicOrdering::SequentiallyConsistent); + AtomicRMW(opcode, output_address, source, + llvm::AtomicOrdering::SequentiallyConsistent); return true; } @@ -291,10 +292,10 @@ Status IrEmitter::EmitAtomicOperationUsingCAS(const HloComputation& computation, // cas_old_output_address and cas_new_output_address point to the scratch // memory where we store the old and new values for the repeated atomicCAS // operations. - llvm::Value* cas_old_output_address = b_.CreateAlloca( - atomic_type, /*ArraySize=*/nullptr, "cas_old_output_address"); - llvm::Value* cas_new_output_address = b_.CreateAlloca( - atomic_type, /*ArraySize=*/nullptr, "cas_new_output_address"); + llvm::Value* cas_old_output_address = + Alloca(atomic_type, /*ArraySize=*/nullptr, "cas_old_output_address"); + llvm::Value* cas_new_output_address = + Alloca(atomic_type, /*ArraySize=*/nullptr, "cas_new_output_address"); // Emit preparation code to the preheader. llvm::BasicBlock* loop_preheader_bb = b_.GetInsertBlock(); @@ -308,29 +309,26 @@ Status IrEmitter::EmitAtomicOperationUsingCAS(const HloComputation& computation, CHECK_EQ((element_size % sizeof(char)), 0); llvm::Type* address_int_type = module_->getDataLayout().getIntPtrType(output_address_type); - atomic_memory_address = b_.CreatePtrToInt(output_address, address_int_type); + atomic_memory_address = PtrToInt(output_address, address_int_type); llvm::Value* mask = llvm::ConstantInt::get(address_int_type, 3); - llvm::Value* offset = b_.CreateAnd(atomic_memory_address, mask); + llvm::Value* offset = And(atomic_memory_address, mask); mask = llvm::ConstantInt::get(address_int_type, -4); - atomic_memory_address = b_.CreateAnd(atomic_memory_address, mask); + atomic_memory_address = And(atomic_memory_address, mask); atomic_memory_address = - b_.CreateIntToPtr(atomic_memory_address, atomic_address_type); - binop_output_address = b_.CreateAdd( - b_.CreatePtrToInt(cas_new_output_address, address_int_type), offset); + IntToPtr(atomic_memory_address, atomic_address_type); binop_output_address = - b_.CreateIntToPtr(binop_output_address, element_address_type); + Add(PtrToInt(cas_new_output_address, address_int_type), offset); + binop_output_address = IntToPtr(binop_output_address, element_address_type); } else { - atomic_memory_address = - b_.CreateBitCast(output_address, atomic_address_type); + atomic_memory_address = BitCast(output_address, atomic_address_type); binop_output_address = - b_.CreateBitCast(cas_new_output_address, element_address_type); + BitCast(cas_new_output_address, element_address_type); } // Use the value from the memory that atomicCAS operates on to initialize // cas_old_output. - llvm::Value* cas_old_output = - b_.CreateLoad(atomic_memory_address, "cas_old_output"); - b_.CreateStore(cas_old_output, cas_old_output_address); + llvm::Value* cas_old_output = Load(atomic_memory_address, "cas_old_output"); + Store(cas_old_output, cas_old_output_address); llvm::BasicBlock* loop_exit_bb = loop_preheader_bb->splitBasicBlock( b_.GetInsertPoint(), "atomic_op_loop_exit"); @@ -343,32 +341,29 @@ Status IrEmitter::EmitAtomicOperationUsingCAS(const HloComputation& computation, // Emit the body of the loop that repeatedly invokes atomicCAS. // // Use cas_old_output to initialize cas_new_output. - cas_old_output = b_.CreateLoad(cas_old_output_address, "cas_old_output"); - b_.CreateStore(cas_old_output, cas_new_output_address); + cas_old_output = Load(cas_old_output_address, "cas_old_output"); + Store(cas_old_output, cas_new_output_address); // Emits code to calculate new_output = operation(old_output, source); TF_RETURN_IF_ERROR(EmitCallToNestedComputation( computation, {binop_output_address, source_address}, binop_output_address)); - llvm::Value* cas_new_output = - b_.CreateLoad(cas_new_output_address, "cas_new_output"); + llvm::Value* cas_new_output = Load(cas_new_output_address, "cas_new_output"); // Emit code to perform the atomicCAS operation // (cas_old_output, success) = atomicCAS(memory_address, cas_old_output, // cas_new_output); - llvm::Value* ret_value = b_.CreateAtomicCmpXchg( - atomic_memory_address, cas_old_output, cas_new_output, - llvm::AtomicOrdering::SequentiallyConsistent, - llvm::AtomicOrdering::SequentiallyConsistent); + llvm::Value* ret_value = + AtomicCmpXchg(atomic_memory_address, cas_old_output, cas_new_output, + llvm::AtomicOrdering::SequentiallyConsistent, + llvm::AtomicOrdering::SequentiallyConsistent); // Extract the memory value returned from atomicCAS and store it as // cas_old_output. - b_.CreateStore(b_.CreateExtractValue(ret_value, 0, "cas_old_output"), - cas_old_output_address); + Store(ExtractValue(ret_value, 0, "cas_old_output"), cas_old_output_address); // Extract the success bit returned from atomicCAS and generate a // conditional branch on the success bit. - b_.CreateCondBr(b_.CreateExtractValue(ret_value, 1, "success"), loop_exit_bb, - loop_body_bb); + CondBr(ExtractValue(ret_value, 1, "success"), loop_exit_bb, loop_body_bb); // Set the insertion point to the exit basic block so that the caller of // this method can continue emitting code to the right place. @@ -383,8 +378,8 @@ Status IrEmitter::EmitAtomicOperationForNestedComputation( // TODO(b/30258929): We only accept binary computations so far. return Unimplemented( "We only support atomic functions with exactly two parameters, but " - "computation %s has %lld.", - computation.name().c_str(), computation.num_parameters()); + "computation %s has %d.", + computation.name(), computation.num_parameters()); } if (MaybeEmitDirectAtomicOperation(computation, output_address, @@ -471,10 +466,10 @@ Status IrEmitter::HandleDot(HloInstruction* dot) { if (ShapeUtil::ElementIsComplex(lhs_shape)) { auto value = MultiplyComplex(lhs_value, rhs_value, &b_); result = llvm::ConstantAggregateZero::get(lhs_array.GetElementLlvmType()); - result = b_.CreateInsertValue(result, value.first, {0}); - result = b_.CreateInsertValue(result, value.second, {1}); + result = InsertValue(result, value.first, {0}); + result = InsertValue(result, value.second, {1}); } else { - result = b_.CreateFMul(lhs_value, rhs_value); + result = FMul(lhs_value, rhs_value); } target_array.EmitWriteArrayElement(/*index=*/element_index, result, &b_); return Status::OK(); @@ -518,7 +513,7 @@ Status IrEmitter::HandleDot(HloInstruction* dot) { // We don't have to iterate over the batch dimensions in both arrays, simplify // the loop nest of the rhs. for (int i = 0; i != dnums.lhs_batch_dimensions_size(); ++i) { - DCHECK(c_linear_search(dnums.lhs_batch_dimensions(), i)); + DCHECK(absl::c_linear_search(dnums.lhs_batch_dimensions(), i)); rhs_index[i] = lhs_index[i]; } @@ -558,21 +553,21 @@ Status IrEmitter::HandleDot(HloInstruction* dot) { &*reduction_loop->GetBodyBasicBlock()->getFirstInsertionPt()); llvm::Value* lhs_element = lhs_array.EmitReadArrayElement(lhs_index, &b_); llvm::Value* rhs_element = rhs_array.EmitReadArrayElement(rhs_index, &b_); - llvm::Value* accum = b_.CreateLoad(accum_address); + llvm::Value* accum = Load(accum_address); llvm::Value* updated_accum; if (ShapeUtil::ElementIsComplex(lhs_shape)) { auto value = MultiplyComplex(lhs_element, rhs_element, &b_); llvm::Value* accum_real = Real(accum, &b_); - llvm::Value* real_sum = b_.CreateFAdd(accum_real, value.first); - updated_accum = b_.CreateInsertValue(accum, real_sum, {0}); + llvm::Value* real_sum = FAdd(accum_real, value.first); + updated_accum = InsertValue(accum, real_sum, {0}); llvm::Value* accum_imag = Imag(accum, &b_); - llvm::Value* imag_sum = b_.CreateFAdd(accum_imag, value.second); - updated_accum = b_.CreateInsertValue(updated_accum, imag_sum, {1}); + llvm::Value* imag_sum = FAdd(accum_imag, value.second); + updated_accum = InsertValue(updated_accum, imag_sum, {1}); } else { - llvm::Value* product = b_.CreateFMul(lhs_element, rhs_element); - updated_accum = b_.CreateFAdd(accum, product); + llvm::Value* product = FMul(lhs_element, rhs_element); + updated_accum = FAdd(accum, product); } - b_.CreateStore(updated_accum, accum_address); + Store(updated_accum, accum_address); // After the reduction loop exits, store the accumulator into the target // address. The index into the target address is the concatenation of the rhs @@ -594,7 +589,7 @@ Status IrEmitter::HandleDot(HloInstruction* dot) { SetToFirstInsertPoint(reduction_loop->GetExitBasicBlock(), &b_); target_array.EmitWriteArrayElement( target_index, - b_.CreateLoad(accum_address), // The value written to the target array. + Load(accum_address), // The value written to the target array. &b_); // Set the IR builder insert point to the exit basic block of the outer most @@ -645,10 +640,9 @@ Status IrEmitter::HandleReduce(HloInstruction* reduce) { [=](const llvm_ir::IrArray::Index& index) -> StatusOr<llvm::Value*> { // Initialize an accumulator with init_value. llvm::AllocaInst* accumulator_addr = - b_.CreateAlloca(llvm_ir::PrimitiveTypeToIrType( + Alloca(llvm_ir::PrimitiveTypeToIrType( reduce->shape().element_type(), module_)); - b_.CreateStore(b_.CreateLoad(GetBasePointer(*init_value)), - accumulator_addr); + Store(Load(GetBasePointer(*init_value)), accumulator_addr); // The enclosing loops go over all the target elements. Now we have to // compute the actual target element. For this, we build a new loop nest @@ -685,7 +679,7 @@ Status IrEmitter::HandleReduce(HloInstruction* reduce) { *function, {accumulator_addr, input_address}, accumulator_addr)); SetToFirstInsertPoint(loops.GetOuterLoopExitBasicBlock(), &b_); - return b_.CreateLoad(accumulator_addr); + return Load(accumulator_addr); }); } @@ -752,11 +746,6 @@ Status IrEmitter::HandleBatchNormGrad(HloInstruction*) { "to a cudnn CustomCall using CudnnBatchNormRewriter."); } -Status IrEmitter::HandleIota(HloInstruction*) { - // TODO(b/64798317): implement iota on GPU. - return Unimplemented("Iota is not implemented on GPU."); -} - StatusOr<llvm::Value*> IrEmitter::ComputeNestedElement( const HloComputation& computation, tensorflow::gtl::ArraySlice<llvm::Value*> parameter_elements) { @@ -768,11 +757,11 @@ StatusOr<llvm::Value*> IrEmitter::ComputeNestedElement( for (llvm::Value* parameter_element : parameter_elements) { parameter_buffers.push_back(llvm_ir::EmitAllocaAtFunctionEntry( parameter_element->getType(), "parameter_buffer", &b_)); - b_.CreateStore(parameter_element, parameter_buffers.back()); + Store(parameter_element, parameter_buffers.back()); } TF_RETURN_IF_ERROR(EmitCallToNestedComputation(computation, parameter_buffers, return_buffer)); - return b_.CreateLoad(return_buffer); + return Load(return_buffer); } } // namespace gpu diff --git a/tensorflow/compiler/xla/service/gpu/ir_emitter.h b/tensorflow/compiler/xla/service/gpu/ir_emitter.h index 561c683879..3673b9f58d 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emitter.h +++ b/tensorflow/compiler/xla/service/gpu/ir_emitter.h @@ -22,6 +22,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/string_view.h" #include "llvm/IR/Function.h" #include "llvm/IR/IRBuilder.h" #include "llvm/IR/Value.h" @@ -35,12 +36,12 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/llvm_ir/ir_array.h" +#include "tensorflow/compiler/xla/service/llvm_ir/ir_builder_mixin.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_loop.h" #include "tensorflow/compiler/xla/service/llvm_ir/loop_emitter.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/platform/types.h" @@ -64,7 +65,8 @@ namespace gpu { // IrEmitterUnnested, but the code is generated using FusedIrEmitter, which is // not a subclass of gpu::IrEmitter, and in fact is better understood as an IR // generator generator. See comments on that class. -class IrEmitter : public DfsHloVisitorWithDefault { +class IrEmitter : public DfsHloVisitorWithDefault, + public IrBuilderMixin<IrEmitter> { public: IrEmitter(const IrEmitter&) = delete; IrEmitter& operator=(const IrEmitter&) = delete; @@ -95,10 +97,11 @@ class IrEmitter : public DfsHloVisitorWithDefault { Status HandleBatchNormInference(HloInstruction* batch_norm) override; Status HandleBatchNormTraining(HloInstruction* batch_norm) override; Status HandleBatchNormGrad(HloInstruction* batch_norm) override; - Status HandleIota(HloInstruction* iota) override; Status FinishVisit(HloInstruction* root) override { return Status::OK(); } + llvm::IRBuilder<>* builder() { return &b_; } + protected: // Constructs an IrEmitter with the given IrEmitter context. // ir_emitter_context is owned by the caller and should outlive the IrEmitter diff --git a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc index 1e81cbde35..c0c8ae181a 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc +++ b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc @@ -21,6 +21,11 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.h" +#include "absl/algorithm/container.h" +#include "absl/container/inlined_vector.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/types/optional.h" #include "llvm/ADT/StringRef.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Function.h" @@ -29,7 +34,6 @@ limitations under the License. #include "llvm/IR/LLVMContext.h" #include "llvm/IR/Module.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/buffer_assignment.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor.h" #include "tensorflow/compiler/xla/service/gpu/backend_configs.pb.h" @@ -77,7 +81,6 @@ limitations under the License. #include "tensorflow/core/lib/core/bits.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/logging.h" namespace xla { @@ -85,13 +88,13 @@ namespace gpu { namespace { +using absl::InlinedVector; +using absl::nullopt; +using absl::optional; +using absl::StrCat; using llvm_ir::IrArray; using llvm_ir::IrName; using tensorflow::gtl::ArraySlice; -using tensorflow::gtl::InlinedVector; -using tensorflow::gtl::nullopt; -using tensorflow::gtl::optional; -using tensorflow::strings::StrCat; // If a dimensions is smaller than this, untiled transposition may be more // efficient. @@ -314,13 +317,13 @@ llvm::Type* GetIndexTypeForKernel(const HloInstruction* hlo, int64 launch_size, }; // Check the size of input tensors - if (!c_all_of(unnested_hlo->operands(), hlo_shape_in_range)) { + if (!absl::c_all_of(unnested_hlo->operands(), hlo_shape_in_range)) { return i64_ty; } // Check the size of the internal result tensors if (unnested_hlo->opcode() == HloOpcode::kFusion) { - if (!c_all_of( + if (!absl::c_all_of( unnested_hlo->fused_instructions_computation()->instructions(), hlo_shape_in_range)) { return i64_ty; @@ -383,7 +386,7 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { int64 feature_index_value = feature_index->literal().Get<int64>({}); thunk_sequence_->emplace_back( - MakeUnique<CudnnBatchNormForwardInferenceThunk>( + absl::make_unique<CudnnBatchNormForwardInferenceThunk>( /*operand=*/GetAllocationSlice(*custom_call->operand(0)), /*scale=*/GetAllocationSlice(*custom_call->operand(1)), /*offset=*/GetAllocationSlice(*custom_call->operand(2)), @@ -413,7 +416,7 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { auto output_mean = assn.GetUniqueSlice(custom_call, {1}).ValueOrDie(); auto output_inv_stddev = assn.GetUniqueSlice(custom_call, {2}).ValueOrDie(); thunk_sequence_->emplace_back( - MakeUnique<CudnnBatchNormForwardTrainingThunk>( + absl::make_unique<CudnnBatchNormForwardTrainingThunk>( /*operand=*/GetAllocationSlice(*custom_call->operand(0)), /*scale=*/GetAllocationSlice(*custom_call->operand(1)), /*offset=*/GetAllocationSlice(*custom_call->operand(2)), @@ -443,19 +446,20 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { auto output_grad_scale = assn.GetUniqueSlice(custom_call, {1}).ValueOrDie(); auto output_grad_offset = assn.GetUniqueSlice(custom_call, {2}).ValueOrDie(); - thunk_sequence_->emplace_back(MakeUnique<CudnnBatchNormBackwardThunk>( - /*operand=*/GetAllocationSlice(*custom_call->operand(0)), - /*scale=*/GetAllocationSlice(*custom_call->operand(1)), - /*mean=*/GetAllocationSlice(*custom_call->operand(2)), - /*inv_stddev=*/GetAllocationSlice(*custom_call->operand(3)), - /*grad_output=*/GetAllocationSlice(*custom_call->operand(4)), - /*epsilon=*/epsilon_value, - /*feature_index=*/feature_index_value, - /*output_grad_data=*/output_grad_data, - /*output_grad_scale=*/output_grad_scale, - /*output_grad_offset=*/output_grad_offset, - /*output_tuple=*/GetAllocationSlice(*custom_call), - /*hlo=*/custom_call)); + thunk_sequence_->emplace_back( + absl::make_unique<CudnnBatchNormBackwardThunk>( + /*operand=*/GetAllocationSlice(*custom_call->operand(0)), + /*scale=*/GetAllocationSlice(*custom_call->operand(1)), + /*mean=*/GetAllocationSlice(*custom_call->operand(2)), + /*inv_stddev=*/GetAllocationSlice(*custom_call->operand(3)), + /*grad_output=*/GetAllocationSlice(*custom_call->operand(4)), + /*epsilon=*/epsilon_value, + /*feature_index=*/feature_index_value, + /*output_grad_data=*/output_grad_data, + /*output_grad_scale=*/output_grad_scale, + /*output_grad_offset=*/output_grad_offset, + /*output_tuple=*/GetAllocationSlice(*custom_call), + /*hlo=*/custom_call)); return Status::OK(); } @@ -475,7 +479,7 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { const auto& target = custom_call->custom_call_target(); std::unique_ptr<ConvolutionThunk> thunk; if (target == kCudnnConvForwardCallTarget) { - thunk = MakeUnique<ConvolutionThunk>( + thunk = absl::make_unique<ConvolutionThunk>( CudnnConvKind::kForward, /*input_buffer=*/lhs_slice, /*filter_buffer=*/rhs_slice, @@ -489,7 +493,7 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { backend_config.algorithm(), backend_config.tensor_ops_enabled(), custom_call); } else if (target == kCudnnConvBackwardInputCallTarget) { - thunk = MakeUnique<ConvolutionThunk>( + thunk = absl::make_unique<ConvolutionThunk>( CudnnConvKind::kBackwardInput, /*input_buffer=*/conv_result_slice, /*filter_buffer=*/rhs_slice, @@ -503,7 +507,7 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { backend_config.algorithm(), backend_config.tensor_ops_enabled(), custom_call); } else if (target == kCudnnConvBackwardFilterCallTarget) { - thunk = MakeUnique<ConvolutionThunk>( + thunk = absl::make_unique<ConvolutionThunk>( CudnnConvKind::kBackwardFilter, /*input_buffer=*/lhs_slice, /*filter_buffer=*/conv_result_slice, @@ -576,7 +580,7 @@ Status IrEmitterUnnested::HandleFusion(HloInstruction* fusion) { thunks.push_back( BuildKernelThunk(fusion, /*implements_whole_instruction=*/false)); thunk_sequence_->emplace_back( - MakeUnique<SequentialThunk>(std::move(thunks), fusion)); + absl::make_unique<SequentialThunk>(std::move(thunks), fusion)); std::vector<IrArray> parameter_arrays; for (HloInstruction* operand : fusion->operands()) { parameter_arrays.push_back(GetIrArray(*operand, *fusion)); @@ -725,7 +729,7 @@ Status IrEmitterUnnested::EmitExtraOutputsForReduce( "extra_output_element_address"); TF_ASSIGN_OR_RETURN(llvm::Value* const extra_output_ir_value, extra_output_gens[i].first(index)); - b_.CreateStore(extra_output_ir_value, extra_output_address); + Store(extra_output_ir_value, extra_output_address); } return Status::OK(); } @@ -798,8 +802,7 @@ Status IrEmitterUnnested::EmitReductionToScalar( // // RoundUpToNextMultipleOf(Ceil(num_elems / kTileSize), warpSize), // // // // and threads_per_block is a multiple of warpSize. - // reduce_kernel<<<num_blocks, threads_per_block>>>(); - // + // reduce_kernel // auto loop_body_emitter = [=](const IrArray::Index& tile_index) -> Status { const int num_reduces = reducers.size(); llvm::Type* element_ir_type = @@ -807,17 +810,17 @@ Status IrEmitterUnnested::EmitReductionToScalar( std::vector<llvm::Value*> partial_reduction_result_addresses; for (int i = 0; i != num_reduces; ++i) { llvm::Value* partial_reduction_result_address = - b_.CreateAlloca(element_ir_type, /*ArraySize=*/nullptr, - "partial_reduction_result." + llvm::Twine(i)); + Alloca(element_ir_type, /*ArraySize=*/nullptr, + "partial_reduction_result." + llvm::Twine(i)); TF_ASSIGN_OR_RETURN(llvm::Value* const init_ir_value, init_value_gens[i](IrArray::Index(index_ty))); - b_.CreateStore(init_ir_value, partial_reduction_result_address); + Store(init_ir_value, partial_reduction_result_address); partial_reduction_result_addresses.push_back( partial_reduction_result_address); } llvm::Value* x_in_tiles = tile_index[0]; - x_in_tiles = b_.CreateZExtOrTrunc(x_in_tiles, index_ty); + x_in_tiles = ZExtOrTrunc(x_in_tiles, index_ty); // Emit an inner for-loop that reduces the elements in the tile. auto emit_tile_element_loop = [=](bool tile_in_bounds) -> Status { @@ -829,15 +832,14 @@ Status IrEmitterUnnested::EmitReductionToScalar( // Emit the body of the partial reduction loop. llvm_ir::SetToFirstInsertPoint(tile_element_loop->GetBodyBasicBlock(), &b_); - llvm::Value* x = b_.CreateNSWAdd( - b_.CreateNSWMul(x_in_tiles, index_typed_constant(kTileSize)), - tile_element_loop->GetIndVarValue()); + llvm::Value* x = + NSWAdd(NSWMul(x_in_tiles, index_typed_constant(kTileSize)), + tile_element_loop->GetIndVarValue()); // Unless we know the tile is entirely in bounds, we have to emit a // x-in-bounds check before reading from the input. if (!tile_in_bounds) { llvm_ir::LlvmIfData if_data = llvm_ir::EmitIfThenElse( - b_.CreateICmpULT(x, index_typed_constant(num_elems)), "x_in_bounds", - &b_); + ICmpULT(x, index_typed_constant(num_elems)), "x_in_bounds", &b_); // Emit code that reads the input element and accumulates it to // the partial reduction result. @@ -846,11 +848,11 @@ Status IrEmitterUnnested::EmitReductionToScalar( IrArray::Index input_index( /*linear=*/x, input_shape, &b_); - llvm::Value* input_address = b_.CreateAlloca(element_ir_type); + llvm::Value* input_address = Alloca(element_ir_type); for (int i = 0; i != num_reduces; ++i) { TF_ASSIGN_OR_RETURN(llvm::Value* const input_ir_value, input_gens[i](input_index)); - b_.CreateStore(input_ir_value, input_address); + Store(input_ir_value, input_address); TF_RETURN_IF_ERROR(EmitCallToNestedComputation( *reducers[i], {partial_reduction_result_addresses[i], input_address}, @@ -861,14 +863,14 @@ Status IrEmitterUnnested::EmitReductionToScalar( // x_end = kTileSize + x_in_tiles * kTileSize, i.e., the location that's // immediately beyond the tile. - llvm::Value* x_end = b_.CreateNSWAdd( - index_typed_constant(kTileSize), - b_.CreateNSWMul(x_in_tiles, index_typed_constant(kTileSize))); + llvm::Value* x_end = + NSWAdd(index_typed_constant(kTileSize), + NSWMul(x_in_tiles, index_typed_constant(kTileSize))); // The tile is entirely in bound if all_threads_in_bounds or // x_end <= num_elems. llvm::Value* tile_in_bounds = - b_.CreateOr(b_.CreateICmpULE(x_end, index_typed_constant(num_elems)), - b_.getInt1(all_threads_in_bounds)); + Or(ICmpULE(x_end, index_typed_constant(num_elems)), + b_.getInt1(all_threads_in_bounds)); llvm_ir::LlvmIfData if_tile_in_bounds_data = llvm_ir::EmitIfThenElse(tile_in_bounds, "tile_in_bounds", &b_); llvm_ir::SetToFirstInsertPoint(if_tile_in_bounds_data.true_block, &b_); @@ -889,20 +891,18 @@ Status IrEmitterUnnested::EmitReductionToScalar( for (int shuffle_distance = kWarpSize / 2; shuffle_distance >= 1; shuffle_distance /= 2) { llvm::Value* result_from_other_lane = - b_.CreateAlloca(element_ir_type, nullptr, "result_from_other_lane"); + Alloca(element_ir_type, nullptr, "result_from_other_lane"); for (int i = 0; i != num_reduces; ++i) { - llvm::Value* partial_reduction_result = b_.CreateLoad( - b_.CreateBitCast(partial_reduction_result_addresses[i], - shuffle_ir_type->getPointerTo()), - "partial_reduction_result"); + llvm::Value* partial_reduction_result = + Load(BitCast(partial_reduction_result_addresses[i], + shuffle_ir_type->getPointerTo()), + "partial_reduction_result"); CHECK_EQ(launch_dimensions.threads_per_block() % kWarpSize, 0) << "Requires block size a multiple of the warp size, otherwise we " "will read undefined elements."; - b_.CreateStore( - EmitFullWarpShuffleDown(partial_reduction_result, - b_.getInt32(shuffle_distance), &b_), - b_.CreateBitCast(result_from_other_lane, - shuffle_ir_type->getPointerTo())); + Store(EmitFullWarpShuffleDown(partial_reduction_result, + b_.getInt32(shuffle_distance), &b_), + BitCast(result_from_other_lane, shuffle_ir_type->getPointerTo())); TF_RETURN_IF_ERROR(EmitCallToNestedComputation( *reducers[i], {partial_reduction_result_addresses[i], result_from_other_lane}, @@ -917,10 +917,9 @@ Status IrEmitterUnnested::EmitReductionToScalar( // lane 0 (which holds the partially accumulated result for its warp) to the // output element. llvm::Value* lane_id = - b_.CreateURem(x_in_tiles, index_typed_constant(kWarpSize), "lane_id"); + URem(x_in_tiles, index_typed_constant(kWarpSize), "lane_id"); llvm_ir::LlvmIfData if_lane_id_is_zero_data = llvm_ir::EmitIfThenElse( - b_.CreateICmpEQ(lane_id, index_typed_constant(0)), "lane_id_is_zero", - &b_); + ICmpEQ(lane_id, index_typed_constant(0)), "lane_id_is_zero", &b_); llvm_ir::SetToFirstInsertPoint(if_lane_id_is_zero_data.true_block, &b_); for (int i = 0; i != num_reduces; ++i) { @@ -1040,12 +1039,12 @@ Status IrEmitterUnnested::EmitColumnReduction( for (int i = 0; i != num_reduces; ++i) { for (int x_offset = 0; x_offset < kTileWidth; ++x_offset) { llvm::Value* partial_reduction_result_address = - b_.CreateAlloca(element_ir_type, /*ArraySize=*/nullptr, - "partial_reduction_result." + - llvm::Twine(i * kTileWidth + x_offset)); + Alloca(element_ir_type, /*ArraySize=*/nullptr, + "partial_reduction_result." + + llvm::Twine(i * kTileWidth + x_offset)); TF_ASSIGN_OR_RETURN(llvm::Value* const init_ir_value, init_value_gens[i](IrArray::Index(index_ty))); - b_.CreateStore(init_ir_value, partial_reduction_result_address); + Store(init_ir_value, partial_reduction_result_address); partial_reduction_result_addresses.push_back( partial_reduction_result_address); } @@ -1056,8 +1055,8 @@ Status IrEmitterUnnested::EmitColumnReduction( llvm::Value* y_in_tiles = tile_index[0]; llvm::Value* x_in_tiles = tile_index[1]; - y_in_tiles = b_.CreateZExtOrTrunc(y_in_tiles, index_ty); - x_in_tiles = b_.CreateZExtOrTrunc(x_in_tiles, index_ty); + y_in_tiles = ZExtOrTrunc(y_in_tiles, index_ty); + x_in_tiles = ZExtOrTrunc(x_in_tiles, index_ty); auto emit_tile_element_loop = [=](bool tile_in_y_bounds, bool tile_in_x_bounds) -> Status { @@ -1069,34 +1068,32 @@ Status IrEmitterUnnested::EmitColumnReduction( // Emit the body of the partial reduction loop. llvm_ir::SetToFirstInsertPoint(tile_element_loop->GetBodyBasicBlock(), &b_); - llvm::Value* y = b_.CreateNSWAdd( - b_.CreateNSWMul(y_in_tiles, index_typed_constant(kTileHeight)), - tile_element_loop->GetIndVarValue()); + llvm::Value* y = + NSWAdd(NSWMul(y_in_tiles, index_typed_constant(kTileHeight)), + tile_element_loop->GetIndVarValue()); // Unless we know that y is in bounds, we have to emit a check before // reading from the input. if (!tile_in_y_bounds) { llvm_ir::LlvmIfData if_data = llvm_ir::EmitIfThenElse( - b_.CreateICmpULT(y, index_typed_constant(height)), "y_in_bounds", - &b_); + ICmpULT(y, index_typed_constant(height)), "y_in_bounds", &b_); // Emit code that reads the input element and accumulates it to // the partial reduction result. llvm_ir::SetToFirstInsertPoint(if_data.true_block, &b_); } for (int x_offset = 0; x_offset < kTileWidth; ++x_offset) { - llvm::Value* x = b_.CreateNSWAdd( - b_.CreateNSWMul(x_in_tiles, index_typed_constant(kTileWidth)), - index_typed_constant(x_offset)); + llvm::Value* x = + NSWAdd(NSWMul(x_in_tiles, index_typed_constant(kTileWidth)), + index_typed_constant(x_offset)); // Unless we know that x is in bounds, we have to emit a check before // reading from the input. if (!tile_in_x_bounds) { llvm_ir::LlvmIfData if_data = llvm_ir::EmitIfThenElse( - b_.CreateICmpULT(x, index_typed_constant(width)), "x_in_bounds", - &b_); + ICmpULT(x, index_typed_constant(width)), "x_in_bounds", &b_); llvm_ir::SetToFirstInsertPoint(if_data.true_block, &b_); } - llvm::Value* input_address = b_.CreateAlloca(element_ir_type); + llvm::Value* input_address = Alloca(element_ir_type); // {y,x} is an index to input_matrix_shape [height,width]. We need to // convert that to an index to input_shape (the shape of the operand of // "reduce"). This conversion is composed of a transposition from @@ -1123,7 +1120,7 @@ Status IrEmitterUnnested::EmitColumnReduction( for (int i = 0; i != num_reduces; ++i) { TF_ASSIGN_OR_RETURN(llvm::Value* const input_ir_value, input_gens[i](input_index)); - b_.CreateStore(input_ir_value, input_address); + Store(input_ir_value, input_address); TF_RETURN_IF_ERROR(EmitCallToNestedComputation( *reducers[i], {partial_reduction_result_addresses[i * kTileWidth + x_offset], @@ -1138,20 +1135,20 @@ Status IrEmitterUnnested::EmitColumnReduction( // y_end = kTileHeight + y_in_tiles * kTileHeight, i.e., the y location // that's immediately beyond the tile. - llvm::Value* y_end = b_.CreateNSWAdd( - index_typed_constant(kTileHeight), - b_.CreateNSWMul(y_in_tiles, index_typed_constant(kTileHeight))); + llvm::Value* y_end = + NSWAdd(index_typed_constant(kTileHeight), + NSWMul(y_in_tiles, index_typed_constant(kTileHeight))); // x_end = kTileWidth + x_in_tiles * kTileWidth, i.e., the x location // that's immediately beyond the tile. - llvm::Value* x_end = b_.CreateNSWAdd( - index_typed_constant(kTileWidth), - b_.CreateNSWMul(x_in_tiles, index_typed_constant(kTileWidth))); + llvm::Value* x_end = + NSWAdd(index_typed_constant(kTileWidth), + NSWMul(x_in_tiles, index_typed_constant(kTileWidth))); llvm::Value* tile_in_y_bounds = - b_.CreateOr(b_.CreateICmpULE(y_end, index_typed_constant(height)), - b_.getInt1(height % kTileHeight == 0)); + Or(ICmpULE(y_end, index_typed_constant(height)), + b_.getInt1(height % kTileHeight == 0)); llvm::Value* tile_in_x_bounds = - b_.CreateOr(b_.CreateICmpULE(x_end, index_typed_constant(width)), - b_.getInt1(width % kTileWidth == 0)); + Or(ICmpULE(x_end, index_typed_constant(width)), + b_.getInt1(width % kTileWidth == 0)); // The tile is in y bounds if "height" is a multiple of kTileHeight or // y_end <= height. llvm_ir::LlvmIfData if_tile_in_y_bounds_data = @@ -1185,9 +1182,9 @@ Status IrEmitterUnnested::EmitColumnReduction( reduce->IsFused() ? reduce->parent()->FusionInstruction() : reduce; for (int i = 0; i != num_reduces; ++i) { for (int x_offset = 0; x_offset < kTileWidth; ++x_offset) { - llvm::Value* x = b_.CreateNSWAdd( - b_.CreateNSWMul(x_in_tiles, index_typed_constant(kTileWidth)), - index_typed_constant(x_offset)); + llvm::Value* x = + NSWAdd(NSWMul(x_in_tiles, index_typed_constant(kTileWidth)), + index_typed_constant(x_offset)); llvm::Value* output_address = GetIrArray(*output, *output, reduce_output_shapes[i]) .EmitArrayElementAddress( @@ -1376,11 +1373,11 @@ Status IrEmitterUnnested::EmitRowReduction( std::vector<llvm::Value*> partial_reduction_result_addresses; for (int i = 0; i != num_reduces; ++i) { llvm::Value* partial_reduction_result_address = - b_.CreateAlloca(element_ir_type, /*ArraySize=*/nullptr, - "partial_reduction_result." + llvm::Twine(i)); + Alloca(element_ir_type, /*ArraySize=*/nullptr, + "partial_reduction_result." + llvm::Twine(i)); TF_ASSIGN_OR_RETURN(llvm::Value* const init_ir_value, init_value_gens[i](IrArray::Index(index_ty))); - b_.CreateStore(init_ir_value, partial_reduction_result_address); + Store(init_ir_value, partial_reduction_result_address); partial_reduction_result_addresses.push_back( partial_reduction_result_address); } @@ -1389,22 +1386,20 @@ Status IrEmitterUnnested::EmitRowReduction( llvm::Value* y = tile_index[1]; llvm::Value* x_tile = tile_index[2]; - x_tile = b_.CreateZExtOrTrunc(x_tile, index_ty); + x_tile = ZExtOrTrunc(x_tile, index_ty); llvm::Value* warp_id = - b_.CreateUDiv(x_tile, index_typed_constant(kWarpSize), "warp_id"); + UDiv(x_tile, index_typed_constant(kWarpSize), "warp_id"); llvm::Value* lane_id = - b_.CreateURem(x_tile, index_typed_constant(kWarpSize), "lane_id"); + URem(x_tile, index_typed_constant(kWarpSize), "lane_id"); // The x-location of the last element in this z-x-tile. // last_x = lane_id + warpSize * (x_tile_size - 1 + warp_id * x_tile_size); - llvm::Value* last_x = b_.CreateNSWAdd( + llvm::Value* last_x = NSWAdd( lane_id, - b_.CreateNSWMul( - index_typed_constant(kWarpSize), - b_.CreateNSWAdd( - index_typed_constant(x_tile_size - 1), - b_.CreateNSWMul(warp_id, index_typed_constant(x_tile_size))))); + NSWMul(index_typed_constant(kWarpSize), + NSWAdd(index_typed_constant(x_tile_size - 1), + NSWMul(warp_id, index_typed_constant(x_tile_size))))); KernelSupportLibrary ksl( &b_, @@ -1416,9 +1411,8 @@ Status IrEmitterUnnested::EmitRowReduction( auto emit_z_x_tile_element_loop = [&](bool x_tile_in_bounds, int64 x_tile_loop_bound) -> Status { auto emit_z_tile_element_loop = [&](llvm::Value* z_indvar) -> Status { - llvm::Value* z = b_.CreateNSWAdd( - z_indvar, - b_.CreateNSWMul(index_typed_constant(z_tile_size), z_tile)); + llvm::Value* z = + NSWAdd(z_indvar, NSWMul(index_typed_constant(z_tile_size), z_tile)); TF_RETURN_IF_ERROR(ksl.For( "x_tile", /*start=*/index_typed_constant(0), @@ -1426,22 +1420,20 @@ Status IrEmitterUnnested::EmitRowReduction( /*step=*/1, [&](llvm::Value* x_indvar) -> Status { // x = lane_id + // warpSize * (element_id_in_x_tile + warp_id * x_tile_size); - llvm::Value* x = b_.CreateNSWAdd( + llvm::Value* x = NSWAdd( lane_id, - b_.CreateNSWMul( - index_typed_constant(kWarpSize), - b_.CreateNSWAdd( - x_indvar, b_.CreateNSWMul( - warp_id, llvm::ConstantInt::get( - index_ty, x_tile_size))))); + NSWMul(index_typed_constant(kWarpSize), + NSWAdd(x_indvar, + NSWMul(warp_id, llvm::ConstantInt::get( + index_ty, x_tile_size))))); // Unless we know the x-tile is entirely in bounds, we have to // emit a x-in-bounds check before reading from the input. if (!x_tile_in_bounds) { llvm_ir::LlvmIfData if_x_in_bounds_data = llvm_ir::EmitIfThenElse( - b_.CreateICmpULT(x, index_typed_constant(width)), - "x_in_bounds", &b_); + ICmpULT(x, index_typed_constant(width)), "x_in_bounds", + &b_); // Points b_ to the then-block. llvm_ir::SetToFirstInsertPoint(if_x_in_bounds_data.true_block, &b_); @@ -1449,7 +1441,7 @@ Status IrEmitterUnnested::EmitRowReduction( // Emit code that reads the input element and accumulates it // to the partial reduction result. - llvm::Value* input_address = b_.CreateAlloca(element_ir_type); + llvm::Value* input_address = Alloca(element_ir_type); { // {z,y,x} is an index to input_3d_tensor_shape // [depth,height,width]. We need to convert that to an index @@ -1480,7 +1472,7 @@ Status IrEmitterUnnested::EmitRowReduction( for (int i = 0; i != num_reduces; ++i) { TF_ASSIGN_OR_RETURN(llvm::Value* const input_ir_value, input_gens[i](input_index)); - b_.CreateStore(input_ir_value, input_address); + Store(input_ir_value, input_address); TF_RETURN_IF_ERROR(EmitCallToNestedComputation( *reducers[i], {partial_reduction_result_addresses[i], input_address}, @@ -1500,8 +1492,8 @@ Status IrEmitterUnnested::EmitRowReduction( }; llvm::Value* tile_in_bounds = - b_.CreateOr(b_.getInt1(width % (x_tile_size * kWarpSize) == 0), - b_.CreateICmpULT(last_x, index_typed_constant(width))); + Or(b_.getInt1(width % (x_tile_size * kWarpSize) == 0), + ICmpULT(last_x, index_typed_constant(width))); TF_RETURN_IF_ERROR( ksl.If(tile_in_bounds, @@ -1529,20 +1521,18 @@ Status IrEmitterUnnested::EmitRowReduction( for (int shuffle_distance = 16; shuffle_distance >= 1; shuffle_distance /= 2) { llvm::Value* result_from_other_lane = - b_.CreateAlloca(element_ir_type, nullptr, "result_from_other_lane"); + Alloca(element_ir_type, nullptr, "result_from_other_lane"); for (int i = 0; i != num_reduces; ++i) { - llvm::Value* partial_reduction_result = b_.CreateLoad( - b_.CreateBitCast(partial_reduction_result_addresses[i], - shuffle_ir_type->getPointerTo()), - "partial_reduction_result"); + llvm::Value* partial_reduction_result = + Load(BitCast(partial_reduction_result_addresses[i], + shuffle_ir_type->getPointerTo()), + "partial_reduction_result"); CHECK_EQ(launch_dimensions.threads_per_block() % kWarpSize, 0) << "Requires block size a multiple of the warp size, otherwise we " "will read undefined elements."; - b_.CreateStore( - EmitFullWarpShuffleDown(partial_reduction_result, - b_.getInt32(shuffle_distance), &b_), - b_.CreateBitCast(result_from_other_lane, - shuffle_ir_type->getPointerTo())); + Store(EmitFullWarpShuffleDown(partial_reduction_result, + b_.getInt32(shuffle_distance), &b_), + BitCast(result_from_other_lane, shuffle_ir_type->getPointerTo())); TF_RETURN_IF_ERROR(EmitCallToNestedComputation( *reducers[i], {partial_reduction_result_addresses[i], result_from_other_lane}, @@ -1557,8 +1547,7 @@ Status IrEmitterUnnested::EmitRowReduction( // lane 0 (which holds the partially accumulated result for its warp) to the // output element. llvm_ir::LlvmIfData if_lane_id_is_zero_data = llvm_ir::EmitIfThenElse( - b_.CreateICmpEQ(lane_id, index_typed_constant(0)), "lane_id_is_zero", - &b_); + ICmpEQ(lane_id, index_typed_constant(0)), "lane_id_is_zero", &b_); llvm_ir::SetToFirstInsertPoint(if_lane_id_is_zero_data.true_block, &b_); for (int i = 0; i != num_reduces; ++i) { llvm::Value* output_address = @@ -1718,7 +1707,7 @@ Status IrEmitterUnnested::HandleReduce(HloInstruction* reduce) { thunks.push_back( BuildKernelThunk(reduce, /*implements_whole_instruction=*/false)); thunk_sequence_->emplace_back( - MakeUnique<SequentialThunk>(std::move(thunks), reduce)); + absl::make_unique<SequentialThunk>(std::move(thunks), reduce)); return EmitReductionToVector( reduce, input->shape(), {[&](const IrArray::Index& index) { @@ -1738,7 +1727,7 @@ Status IrEmitterUnnested::HandleReduce(HloInstruction* reduce) { Status IrEmitterUnnested::HandleTuple(HloInstruction* tuple) { bool all_tuple_elements_have_buffer = - c_all_of(tuple->operands(), [&](HloInstruction* tuple_element) { + absl::c_all_of(tuple->operands(), [&](HloInstruction* tuple_element) { return ir_emitter_context_->buffer_assignment() .GetUniqueTopLevelSlice(tuple_element) .ok(); @@ -1760,7 +1749,7 @@ Status IrEmitterUnnested::HandleTuple(HloInstruction* tuple) { for (const HloInstruction* tuple_element : tuple->operands()) { tuple_element_buffers.push_back(GetAllocationSlice(*tuple_element)); } - thunk_sequence_->emplace_back(MakeUnique<TupleThunk>( + thunk_sequence_->emplace_back(absl::make_unique<TupleThunk>( tuple_element_buffers, GetAllocationSlice(*tuple), tuple)); return Status::OK(); } @@ -1792,8 +1781,8 @@ Status IrEmitterUnnested::HandleSelectAndScatter( thunks.push_back(std::move(initializer_thunk)); thunks.push_back(BuildKernelThunk(select_and_scatter, /*implements_whole_instruction=*/false)); - thunk_sequence_->emplace_back( - MakeUnique<SequentialThunk>(std::move(thunks), select_and_scatter)); + thunk_sequence_->emplace_back(absl::make_unique<SequentialThunk>( + std::move(thunks), select_and_scatter)); // TODO(b/31410564): Implement dilation rate for select-and-scatter. if (window_util::HasDilation(window)) { @@ -1842,7 +1831,7 @@ Status IrEmitterUnnested::HandleSelectAndScatter( &b_); llvm::Value* initialized_flag_address = llvm_ir::EmitAllocaAtFunctionEntry( b_.getInt1Ty(), "initialized_flag_address", &b_); - b_.CreateStore(b_.getInt1(false), initialized_flag_address); + Store(b_.getInt1(false), initialized_flag_address); // Create the inner loop to iterate over the window. llvm_ir::ForLoopNest window_loops(IrName(select_and_scatter, "inner"), &b_, @@ -1863,15 +1852,15 @@ Status IrEmitterUnnested::HandleSelectAndScatter( IrArray::Index operand_index(index_type, source_index.size()); llvm::Value* in_bounds_condition = b_.getInt1(true); for (int64 i = 0; i < rank; ++i) { - llvm::Value* strided_index = b_.CreateNSWMul( + llvm::Value* strided_index = NSWMul( source_index[i], index_typed_constant(window.dimensions(i).stride())); - operand_index[i] = b_.CreateNSWSub( - b_.CreateNSWAdd(strided_index, window_index[i]), - index_typed_constant(window.dimensions(i).padding_low())); - llvm::Value* index_condition = b_.CreateICmpULT( + operand_index[i] = + NSWSub(NSWAdd(strided_index, window_index[i]), + index_typed_constant(window.dimensions(i).padding_low())); + llvm::Value* index_condition = ICmpULT( operand_index[i], index_typed_constant(ShapeUtil::GetDimension(operand->shape(), i))); - in_bounds_condition = b_.CreateAnd(in_bounds_condition, index_condition); + in_bounds_condition = And(in_bounds_condition, index_condition); } CHECK(in_bounds_condition != nullptr); @@ -1881,7 +1870,7 @@ Status IrEmitterUnnested::HandleSelectAndScatter( llvm_ir::EmitIfThenElse(in_bounds_condition, "in-bounds", &b_); llvm_ir::SetToFirstInsertPoint(if_in_bounds.true_block, &b_); llvm_ir::LlvmIfData if_initialized = llvm_ir::EmitIfThenElse( - b_.CreateLoad(initialized_flag_address), "initialized", &b_); + Load(initialized_flag_address), "initialized", &b_); // If the initialized_flag is false, initialize the selected value and index // with the currently visiting operand. @@ -1889,16 +1878,16 @@ Status IrEmitterUnnested::HandleSelectAndScatter( const auto save_operand_index = [&](const IrArray::Index& operand_index) { for (int64 i = 0; i < rank; ++i) { llvm::Value* selected_index_address_slot = - b_.CreateInBoundsGEP(selected_index_address, {b_.getInt32(i)}); - b_.CreateStore(operand_index[i], selected_index_address_slot); + InBoundsGEP(selected_index_address, {b_.getInt32(i)}); + Store(operand_index[i], selected_index_address_slot); } }; IrArray operand_array = GetIrArray(*operand, *select_and_scatter); llvm::Value* operand_data = operand_array.EmitReadArrayElement(operand_index, &b_); - b_.CreateStore(operand_data, selected_value_address); + Store(operand_data, selected_value_address); save_operand_index(operand_index); - b_.CreateStore(b_.getInt1(true), initialized_flag_address); + Store(b_.getInt1(true), initialized_flag_address); // If the initialized_flag is true, call the `select` function to // potentially update the selected value and index with the currently @@ -1914,11 +1903,11 @@ Status IrEmitterUnnested::HandleSelectAndScatter( TF_RETURN_IF_ERROR(EmitCallToNestedComputation( *select_and_scatter->select(), {selected_value_address, operand_address}, select_return_buffer)); - llvm::Value* result = b_.CreateLoad(select_return_buffer); + llvm::Value* result = Load(select_return_buffer); // If the 'select' function returns false, update the selected value and the // index to the currently visiting operand. - llvm::Value* cond = b_.CreateICmpNE( + llvm::Value* cond = ICmpNE( result, llvm::ConstantInt::get(llvm_ir::PrimitiveTypeToIrType( PRED, ir_emitter_context_->llvm_module()), @@ -1927,7 +1916,7 @@ Status IrEmitterUnnested::HandleSelectAndScatter( llvm_ir::LlvmIfData if_select_lhs = llvm_ir::EmitIfThenElse(cond, "if-select-lhs", &b_); llvm_ir::SetToFirstInsertPoint(if_select_lhs.false_block, &b_); - b_.CreateStore(b_.CreateLoad(operand_address), selected_value_address); + Store(Load(operand_address), selected_value_address); save_operand_index(operand_index); // After iterating over the window elements, scatter the source element to @@ -1939,8 +1928,8 @@ Status IrEmitterUnnested::HandleSelectAndScatter( IrArray::Index selected_index(operand_index.GetType()); for (int64 i = 0; i < rank; ++i) { llvm::Value* selected_index_address_slot = - b_.CreateInBoundsGEP(selected_index_address, {b_.getInt32(i)}); - selected_index.push_back(b_.CreateLoad(selected_index_address_slot)); + InBoundsGEP(selected_index_address, {b_.getInt32(i)}); + selected_index.push_back(Load(selected_index_address_slot)); } llvm::Value* source_value_address = GetIrArray(*source, *select_and_scatter) @@ -2018,7 +2007,7 @@ Status IrEmitterUnnested::HandleRng(HloInstruction* rng) { thunks.push_back(std::move(rng_thunk)); thunks.push_back(std::move(increment_seed_thunk)); thunk_sequence_->emplace_back( - MakeUnique<SequentialThunk>(std::move(thunks), rng)); + absl::make_unique<SequentialThunk>(std::move(thunks), rng)); return Status::OK(); } @@ -2043,7 +2032,7 @@ Status IrEmitterUnnested::HandleSort(HloInstruction* sort) { auto values_destination = GetAllocationSlice(*sort, values_shape_index); if (keys_destination != GetAllocationSlice(*keys)) { - thunks.push_back(MakeUnique<DeviceToDeviceCopyThunk>( + thunks.push_back(absl::make_unique<DeviceToDeviceCopyThunk>( /*source_address=*/GetAllocationSlice(*keys), /*destination_buffer=*/keys_destination, /*mem_size=*/ShapeUtil::ByteSizeOf(keys->shape()), nullptr)); @@ -2051,7 +2040,7 @@ Status IrEmitterUnnested::HandleSort(HloInstruction* sort) { if (values != nullptr && values_destination != GetAllocationSlice(*values)) { // TODO(b/26783907): Figure out why we never seem to share buffers for // key/value sort. - thunks.push_back(MakeUnique<DeviceToDeviceCopyThunk>( + thunks.push_back(absl::make_unique<DeviceToDeviceCopyThunk>( /*source_address=*/GetAllocationSlice(*values), /*destination_buffer=*/values_destination, /*mem_size=*/ShapeUtil::ByteSizeOf(values->shape()), nullptr)); @@ -2095,15 +2084,15 @@ Status IrEmitterUnnested::HandleSort(HloInstruction* sort) { TF_RETURN_IF_ERROR(llvm_ir::EmitSortInPlace( dimension_to_sort, GetIrArray(*sort, *sort, keys_shape_index), - values != nullptr ? tensorflow::gtl::make_optional<IrArray>( + values != nullptr ? absl::make_optional<IrArray>( GetIrArray(*sort, *sort, values_shape_index)) - : tensorflow::gtl::nullopt, + : absl::nullopt, IrName(sort), xor_mask, &b_, &launch_dimensions)); } } thunk_sequence_->emplace_back( - MakeUnique<SequentialThunk>(std::move(thunks), sort)); + absl::make_unique<SequentialThunk>(std::move(thunks), sort)); return Status::OK(); } @@ -2130,7 +2119,7 @@ Status IrEmitterUnnested::HandleCrossReplicaSum(HloInstruction* crs) { if (crs->operand_count() == 1) { CHECK(ShapeUtil::IsArray(crs->operand(0)->shape())) << "Operands to cross-replica-sum must be arrays: " << crs->ToString(); - thunk_sequence_->push_back(MakeUnique<DeviceToDeviceCopyThunk>( + thunk_sequence_->push_back(absl::make_unique<DeviceToDeviceCopyThunk>( /*source_address=*/GetAllocationSlice(*crs->operand(0)), /*destination_buffer=*/GetAllocationSlice(*crs), /*mem_size=*/ShapeUtil::ByteSizeOf(crs->shape()), crs)); @@ -2145,17 +2134,17 @@ Status IrEmitterUnnested::HandleCrossReplicaSum(HloInstruction* crs) { tuple_element_buffers.push_back(ir_emitter_context_->buffer_assignment() .GetUniqueSlice(crs, {i}) .ValueOrDie()); - thunks.push_back(MakeUnique<DeviceToDeviceCopyThunk>( + thunks.push_back(absl::make_unique<DeviceToDeviceCopyThunk>( /*source_address=*/GetAllocationSlice(*crs->operand(i)), /*destination_buffer=*/tuple_element_buffers.back(), /*mem_size=*/ShapeUtil::ByteSizeOf(crs->operand(i)->shape()), nullptr)); } // Output a tuple of the buffers above. - thunks.push_back(MakeUnique<TupleThunk>(tuple_element_buffers, - GetAllocationSlice(*crs), nullptr)); + thunks.push_back(absl::make_unique<TupleThunk>( + tuple_element_buffers, GetAllocationSlice(*crs), nullptr)); thunk_sequence_->push_back( - MakeUnique<SequentialThunk>(std::move(thunks), crs)); + absl::make_unique<SequentialThunk>(std::move(thunks), crs)); return Status::OK(); } @@ -2305,7 +2294,7 @@ std::unique_ptr<KernelThunk> IrEmitterUnnested::BuildKernelThunk( for (const auto& kv : hlo_slices) { buffers_needed.insert(kv.second.first.allocation()); } - tensorflow::gtl::optional<const BufferAllocation*> temp_buffer; + absl::optional<const BufferAllocation*> temp_buffer; for (const BufferAllocation& alloc : buffer_assn.Allocations()) { if (alloc.IsPreallocatedTempBuffer()) { if (!temp_buffer.has_value()) { @@ -2322,10 +2311,10 @@ std::unique_ptr<KernelThunk> IrEmitterUnnested::BuildKernelThunk( // We'll pass a pointer to each of the elements of `buffers` to our kernel, in // this order. std::vector<const BufferAllocation*> non_constant_buffers; - c_copy_if(buffers_needed, std::back_inserter(non_constant_buffers), - [](const BufferAllocation* allocation) { - return !allocation->is_constant(); - }); + absl::c_copy_if(buffers_needed, std::back_inserter(non_constant_buffers), + [](const BufferAllocation* allocation) { + return !allocation->is_constant(); + }); std::sort(non_constant_buffers.begin(), non_constant_buffers.end(), [](const BufferAllocation* a, const BufferAllocation* b) { @@ -2364,8 +2353,8 @@ std::unique_ptr<KernelThunk> IrEmitterUnnested::BuildKernelThunk( *slice.allocation()))); CHECK_NE(loc, nullptr); } else { - loc = b_.CreateInBoundsGEP(kernel_args.at(slice.allocation()), - {b_.getInt64(slice.offset())}); + loc = InBoundsGEP(kernel_args.at(slice.allocation()), + {b_.getInt64(slice.offset())}); } // If gte_index is nonempty, we have to dereference `loc` to get to the @@ -2373,8 +2362,8 @@ std::unique_ptr<KernelThunk> IrEmitterUnnested::BuildKernelThunk( llvm::Type* int8_double_pointer = llvm::PointerType::get(b_.getInt8PtrTy(), /*AddressSpace=*/0); for (int64 idx : gte_index) { - loc = b_.CreateBitCast(loc, int8_double_pointer); - loc = b_.CreateLoad(b_.CreateInBoundsGEP(loc, {b_.getInt64(idx)})); + loc = BitCast(loc, int8_double_pointer); + loc = Load(InBoundsGEP(loc, {b_.getInt64(idx)})); } bindings_.BindHloToIrValue(*instr, loc, index); @@ -2389,7 +2378,7 @@ std::unique_ptr<KernelThunk> IrEmitterUnnested::BuildKernelThunk( llvm::ConstantPointerNull::get(b_.getInt8PtrTy())); } - return MakeUnique<KernelThunk>( + return absl::make_unique<KernelThunk>( non_constant_buffers, llvm_ir::AsString(kernel->getName()), implements_whole_instruction ? inst : nullptr, unroll_factor); } @@ -2398,7 +2387,7 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildHostToDeviceCopyThunk( const HloInstruction* inst) { const HloInstruction* operand = inst->operand(0); CHECK_EQ(HloOpcode::kConstant, operand->opcode()); - return MakeUnique<HostToDeviceCopyThunk>( + return absl::make_unique<HostToDeviceCopyThunk>( /*source_address=*/operand->literal().untyped_data(), /*destination_buffer=*/GetAllocationSlice(*inst), /*mem_size=*/ @@ -2410,7 +2399,7 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildHostToDeviceCopyThunk( std::unique_ptr<Thunk> IrEmitterUnnested::BuildDeviceToDeviceCopyThunk( const HloInstruction* inst) { const HloInstruction* operand = inst->operand(0); - return MakeUnique<DeviceToDeviceCopyThunk>( + return absl::make_unique<DeviceToDeviceCopyThunk>( /*source_address=*/GetAllocationSlice(*operand), /*destination_buffer=*/GetAllocationSlice(*inst), /*mem_size=*/ @@ -2430,7 +2419,7 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildInfeedThunk( .GetUniqueSlice(inst, index) .ConsumeValueOrDie(); }); - return MakeUnique<InfeedThunk>(slices, inst); + return absl::make_unique<InfeedThunk>(slices, inst); } std::unique_ptr<Thunk> IrEmitterUnnested::BuildOutfeedThunk( @@ -2447,7 +2436,7 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildOutfeedThunk( *slice = status_or_slice.ConsumeValueOrDie(); } }); - return MakeUnique<OutfeedThunk>(std::move(slices), inst); + return absl::make_unique<OutfeedThunk>(std::move(slices), inst); } namespace { @@ -2470,7 +2459,7 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildGemmThunk( if (inst->opcode() == HloOpcode::kDot) { const HloInstruction* lhs = inst->operand(0); const HloInstruction* rhs = inst->operand(1); - return MakeUnique<GemmThunk>( + return absl::make_unique<GemmThunk>( GetAllocationSlice(*lhs), // The buffer assigned to LHS. GetAllocationSlice(*rhs), // The buffer assigned to RHS. GetAllocationSlice(*inst), // The output buffer. @@ -2512,7 +2501,7 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildGemmThunk( const HloInstruction* rhs = inst->operand(rhs_parameter->parameter_number()); - return MakeUnique<GemmThunk>( + return absl::make_unique<GemmThunk>( GetAllocationSlice(*lhs), // The buffer assigned to LHS. GetAllocationSlice(*rhs), // The buffer assigned to RHS. GetAllocationSlice(*inst), // The output buffer. @@ -2529,11 +2518,12 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildGemmThunk( std::unique_ptr<Thunk> IrEmitterUnnested::BuildFftThunk( const HloInstruction* inst) { const HloInstruction* operand = inst->operand(0); - return MakeUnique<FftThunk>(inst->fft_type(), inst->fft_length(), - /*input_buffer=*/GetAllocationSlice(*operand), - /*output_buffer=*/GetAllocationSlice(*inst), - /*input_shape=*/operand->shape(), - /*output_shape=*/inst->shape(), inst); + return absl::make_unique<FftThunk>( + inst->fft_type(), inst->fft_length(), + /*input_buffer=*/GetAllocationSlice(*operand), + /*output_buffer=*/GetAllocationSlice(*inst), + /*input_shape=*/operand->shape(), + /*output_shape=*/inst->shape(), inst); } StatusOr<std::unique_ptr<Thunk>> IrEmitterUnnested::BuildInitializerThunk( @@ -2582,9 +2572,9 @@ StatusOr<std::unique_ptr<Thunk>> IrEmitterUnnested::BuildInitializerThunk( // MemzeroThunk. ArraySlice<uint8> literal_bytes( reinterpret_cast<const uint8*>(literal.untyped_data()), num_bytes); - if (c_all_of(literal_bytes, [](uint8 byte) { return byte == 0; })) { - return { - MakeUnique<MemzeroThunk>(GetAllocationSlice(*hlo, index), nullptr)}; + if (absl::c_all_of(literal_bytes, [](uint8 byte) { return byte == 0; })) { + return {absl::make_unique<MemzeroThunk>(GetAllocationSlice(*hlo, index), + nullptr)}; } // If the literal is 8 or 16 bits wide, we can emit a 32-bit memset by @@ -2601,7 +2591,7 @@ StatusOr<std::unique_ptr<Thunk>> IrEmitterUnnested::BuildInitializerThunk( memcpy(&pattern16, literal_bytes.data(), sizeof(pattern16)); } uint32 pattern32 = uint32{pattern16} | (uint32{pattern16} << 16); - return {MakeUnique<Memset32BitValueThunk>( + return {absl::make_unique<Memset32BitValueThunk>( pattern32, GetAllocationSlice(*hlo, index), nullptr)}; } @@ -2612,7 +2602,7 @@ StatusOr<std::unique_ptr<Thunk>> IrEmitterUnnested::BuildInitializerThunk( literal_bytes.size() - 4) == 0) { uint32 word; memcpy(&word, literal_bytes.data(), sizeof(word)); - return {MakeUnique<Memset32BitValueThunk>( + return {absl::make_unique<Memset32BitValueThunk>( word, GetAllocationSlice(*hlo, index), nullptr)}; } } @@ -2670,8 +2660,7 @@ Status CheckHloBuffersShareAllocation( if (slice_a != slice_b) { return InternalError( "instruction %s %s does not share allocation with instruction %s %s", - a->ToString().c_str(), slice_a.ToString().c_str(), - b->ToString().c_str(), slice_b.ToString().c_str()); + a->ToString(), slice_a.ToString(), b->ToString(), slice_b.ToString()); } return Status::OK(); } @@ -2764,7 +2753,7 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildWhileThunk( ir_emitter_context_); TF_CHECK_OK(body->Accept(&ir_emitter_body)); - return MakeUnique<WhileThunk>( + return absl::make_unique<WhileThunk>( GetAllocationSlice(*condition->root_instruction()), // cond result ir_emitter_condition.ConsumeThunkSequence(), ir_emitter_body.ConsumeThunkSequence(), hlo); @@ -2782,8 +2771,8 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildForThunk( ir_emitter_context_); TF_CHECK_OK(body->Accept(&ir_emitter_body)); - return MakeUnique<ForThunk>(loop_limit, - ir_emitter_body.ConsumeThunkSequence(), hlo); + return absl::make_unique<ForThunk>( + loop_limit, ir_emitter_body.ConsumeThunkSequence(), hlo); } std::unique_ptr<Thunk> IrEmitterUnnested::BuildConditionalThunk( @@ -2803,7 +2792,7 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildConditionalThunk( ir_emitter_context_); TF_CHECK_OK(false_computation->Accept(&ir_emitter_false)); - return MakeUnique<ConditionalThunk>( + return absl::make_unique<ConditionalThunk>( GetAllocationSlice(*hlo->operand(0)), GetAllocationSlice(*hlo->operand(1)), GetAllocationSlice(*hlo->operand(2)), @@ -3105,7 +3094,7 @@ LaunchDimensions IrEmitterUnnested::EmitHlo021Tile( CeilOfRatio<int64>(output_dims_in_tiles[i], kTileSize); } const int64 num_tiles = - c_accumulate(output_dims_in_tiles, 1, std::multiplies<int64>()); + absl::c_accumulate(output_dims_in_tiles, 1, std::multiplies<int64>()); LaunchDimensions launch_dimensions(num_tiles, kThreadsPerTile); llvm::Type* index_ty = @@ -3151,9 +3140,8 @@ LaunchDimensions IrEmitterUnnested::EmitHlo021Tile( const IrArray::Index output_tile_origin = [&] { IrArray::Index index = output_tile_index; for (int i = 1; i < 3; ++i) { - index[i] = - b_.CreateMul(output_tile_index[i], index_typed_constant(kTileSize), - "tile_origin." + std::to_string(i)); + index[i] = Mul(output_tile_index[i], index_typed_constant(kTileSize), + "tile_origin." + std::to_string(i)); } return index; }(); @@ -3166,12 +3154,12 @@ LaunchDimensions IrEmitterUnnested::EmitHlo021Tile( std::vector<llvm::Value*> output_tile_bounds(3); for (int i = 1; i < 3; ++i) { // Only last row or column may not have full size. - output_tile_bounds[i] = b_.CreateSelect( - b_.CreateICmpEQ(output_tile_index[i], - index_typed_constant(output_dims_in_tiles[i] - 1)), - index_typed_constant(reduced_output_dims[i] - - (output_dims_in_tiles[i] - 1) * kTileSize), - index_typed_constant(kTileSize), "kTileSize"); + output_tile_bounds[i] = + Select(ICmpEQ(output_tile_index[i], + index_typed_constant(output_dims_in_tiles[i] - 1)), + index_typed_constant(reduced_output_dims[i] - + (output_dims_in_tiles[i] - 1) * kTileSize), + index_typed_constant(kTileSize), "kTileSize"); } KernelSupportLibrary ksl(&b_, llvm_ir::UnrollMode::kDefaultUnroll); @@ -3189,7 +3177,7 @@ LaunchDimensions IrEmitterUnnested::EmitHlo021Tile( // Adds `addend` to the given `dim` of `index`. auto offset_dim = [&](IrArray::Index index, llvm::Value* addend, int64 dim) { - index[dim] = b_.CreateAdd(index[dim], addend); + index[dim] = Add(index[dim], addend); return index; }; const IrArray::Index input_index = @@ -3205,10 +3193,9 @@ LaunchDimensions IrEmitterUnnested::EmitHlo021Tile( llvm::Value* shmem_buffer = param_shmem_buffers[id]; // TODO(jlebar): Add AA metadata to this store. Tile buffers are // global variables, so LLVM can't infer much about it. - b_.CreateStore( - input_in_logical_shape.EmitReadArrayElement(index, &b_, - "input_element"), - b_.CreateGEP(shmem_buffer, {index_typed_constant(0), y_loc, x})); + Store(input_in_logical_shape.EmitReadArrayElement(index, &b_, + "input_element"), + GEP(shmem_buffer, {index_typed_constant(0), y_loc, x})); } }); @@ -3229,9 +3216,9 @@ LaunchDimensions IrEmitterUnnested::EmitHlo021Tile( output_index, "output", output_tile_bounds[2], output_tile_bounds[1], [&](const IrArray::Index& index, llvm::Value* y_loc) { // TODO(jlebar): Add AA metadata to this load. - llvm::Instruction* load_from_shmem_buffer = b_.CreateLoad( - b_.CreateGEP(param_shmem_buffers[0], {b_.getInt64(0), x, y_loc}), - "output_element"); + llvm::Instruction* load_from_shmem_buffer = + Load(GEP(param_shmem_buffers[0], {b_.getInt64(0), x, y_loc}), + "output_element"); output_in_reduced_shape_arrays[0].EmitWriteArrayElement( index, load_from_shmem_buffer, &b_); }); @@ -3259,7 +3246,7 @@ LaunchDimensions IrEmitterUnnested::EmitHlo021Tile( output_in_reduced_shape_arrays.size()); for (int64 i = 0; i < output_in_reduced_shape_arrays.size(); ++i) { output_in_reduced_shape_arrays[i].EmitWriteArrayElement( - index, b_.CreateExtractValue(output_value, i), &b_); + index, ExtractValue(output_value, i), &b_); } } else { output_in_reduced_shape_arrays[0].EmitWriteArrayElement( @@ -3341,7 +3328,7 @@ bool IrEmitterUnnested::CheckAndEmitHloWithTile021(HloInstruction* hlo) { // if there's a Right Choice. // // This is only sound if tiled transposes are the only place where we use - // shared memory in fusions. If in the future other fusile ops use shared + // shared memory in fusions. If in the future other fusible ops use shared // memory, we'll have to adjust this heuristic. constexpr int kMinBlocksPerCore = 3; constexpr int64 kShmemPerCore = 48 * 1024; diff --git a/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc b/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc index e76823ad10..3259eaa2a2 100644 --- a/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc @@ -15,12 +15,12 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/kernel_thunk.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/service/gpu/gpu_executable.h" #include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" @@ -41,8 +41,8 @@ Status KernelThunk::Initialize(const GpuExecutable& executable, tensorflow::mutex_lock lock(mutex_); if (!loader_spec_) { loader_spec_.reset(new se::MultiKernelLoaderSpec(args_.size())); - tensorflow::StringPiece ptx = executable.ptx(); - // Convert tensorflow::StringPiece to se::port::StringPiece because + absl::string_view ptx = executable.ptx(); + // Convert absl::string_view to se::port::StringPiece because // StreamExecutor uses the latter. loader_spec_->AddCudaPtxInMemory( se::port::StringPiece(ptx.data(), ptx.size()), kernel_name_); @@ -63,7 +63,7 @@ Status KernelThunk::Initialize(const GpuExecutable& executable, if (kernel_cache_.end() == it) { it = kernel_cache_.emplace(executor, se::KernelBase(executor)).first; if (!executor->GetKernel(*loader_spec_, &it->second)) { - return InternalError("Unable to load kernel %s", kernel_name_.c_str()); + return InternalError("Unable to load kernel %s", kernel_name_); } } @@ -95,7 +95,7 @@ Status KernelThunk::ExecuteOnStream(const BufferAllocations& buffer_allocations, VLOG(3) << "Launching " << kernel->name(); // Launch the kernel with potentially multiple blocks and threads. static constexpr int kKernelArgsLimit = 1024; - auto kernel_args = MakeUnique<se::KernelArgsArray<kKernelArgsLimit>>(); + auto kernel_args = absl::make_unique<se::KernelArgsArray<kKernelArgsLimit>>(); for (const BufferAllocation* arg : args_) { const auto& buf = buffer_allocations.GetDeviceAddress(arg->index()); kernel_args->add_device_memory_argument(buf); @@ -107,7 +107,7 @@ Status KernelThunk::ExecuteOnStream(const BufferAllocations& buffer_allocations, stream, se::ThreadDim(launch_dimensions.threads_per_block()), se::BlockDim(launch_dimensions.block_count()), *kernel, *kernel_args)) { - return InternalError("Unable to launch kernel %s", kernel_name_.c_str()); + return InternalError("Unable to launch kernel %s", kernel_name_); } return Status::OK(); } diff --git a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/BUILD b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/BUILD index eb93efc560..698d2d51cc 100644 --- a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/BUILD +++ b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/BUILD @@ -34,6 +34,9 @@ cc_library( "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", "@llvm//:amdgpu_code_gen", "@llvm//:analysis", "@llvm//:bit_reader", diff --git a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/dump_ir_pass.cc b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/dump_ir_pass.cc index 12a8a59488..85bc58cb44 100644 --- a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/dump_ir_pass.cc +++ b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/dump_ir_pass.cc @@ -15,14 +15,14 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/dump_ir_pass.h" +#include "absl/strings/str_format.h" +#include "absl/strings/string_view.h" #include "llvm/IR/Module.h" #include "llvm/Support/FileSystem.h" #include "llvm/Support/raw_ostream.h" #include "tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/io/path.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" namespace xla { @@ -86,10 +86,11 @@ void IrDumpingPassManager::run(llvm::Module &module) { const llvm::PassInfo *PI = llvm::PassRegistry::getPassRegistry()->getPassInfo(P->getPassID()); const string basename = ReplaceFilenameExtension( - tensorflow::io::Basename(input_filename_), - tensorflow::strings::Printf( + absl::string_view(tensorflow::io::Basename(input_filename_)), + absl::StrFormat( "pass-%02d.before.%s.ll", i, - (PI == nullptr ? "unknown" : PI->getPassArgument().data()))); + absl::string_view(PI == nullptr ? "unknown" + : PI->getPassArgument().data()))); llvm::legacy::PassManager::add( new DumpIrPass(tensorflow::io::JoinPath(output_dir_, basename))); } diff --git a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/nvptx_backend_lib.cc b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/nvptx_backend_lib.cc index ff4ae1f9ef..8751e3a9c2 100644 --- a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/nvptx_backend_lib.cc +++ b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/nvptx_backend_lib.cc @@ -20,13 +20,15 @@ limitations under the License. #include <string> #include <utility> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/dump_ir_pass.h" #include "tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/util.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" #include "llvm/ADT/STLExtras.h" #include "llvm/ADT/StringMap.h" #include "llvm/ADT/StringSet.h" @@ -54,10 +56,7 @@ limitations under the License. #include "llvm/Transforms/IPO/PassManagerBuilder.h" #include "llvm/Transforms/Scalar.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/io/path.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/tracing.h" @@ -107,8 +106,7 @@ static string GetLibdeviceFilename(const string& libdevice_dir_path, << ", " << compute_capability.second << ") ." << "Defaulting to libdevice for compute_" << libdevice_version; } - return tensorflow::strings::StrCat("libdevice.compute_", libdevice_version, - ".10.bc"); + return absl::StrCat("libdevice.compute_", libdevice_version, ".10.bc"); } // Gets the GPU name as it's known to LLVM for a given compute capability. If @@ -138,15 +136,16 @@ static string GetSmName(std::pair<int, int> compute_capability) { << "Defaulting to telling LLVM that we're compiling for sm_" << sm_version; } - return tensorflow::strings::StrCat("sm_", sm_version); + return absl::StrCat("sm_", sm_version); } // Convenience function for producing a name of a temporary compilation product // from the input filename. string MakeNameForTempProduct(const std::string& input_filename, - tensorflow::StringPiece extension) { - return ReplaceFilenameExtension( - tensorflow::io::Basename(llvm_ir::AsString(input_filename)), extension); + absl::string_view extension) { + return ReplaceFilenameExtension(absl::string_view(tensorflow::io::Basename( + llvm_ir::AsString(input_filename))), + extension); } // Initializes LLVM passes. Uses the PassRegistry mechanism. @@ -167,7 +166,7 @@ void InitializePasses(llvm::PassRegistry* pass_registry) { // Returns the TargetMachine, given a triple. std::unique_ptr<llvm::TargetMachine> GetTargetMachine( - llvm::Triple triple, tensorflow::StringPiece cpu_name, + llvm::Triple triple, absl::string_view cpu_name, const HloModuleConfig& hlo_module_config) { std::string error; const llvm::Target* target = TargetRegistry::lookupTarget("", triple, error); @@ -205,7 +204,7 @@ std::unique_ptr<llvm::TargetMachine> GetTargetMachine( default: codegen_opt_level = CodeGenOpt::None; } - return WrapUnique(target->createTargetMachine( + return absl::WrapUnique(target->createTargetMachine( triple.str(), llvm_ir::AsStringRef(cpu_name), "+ptx60", target_options, Optional<Reloc::Model>(RelocModel), Optional<CodeModel::Model>(CMModel), codegen_opt_level)); @@ -243,9 +242,9 @@ void AddOptimizationPasses(unsigned opt_level, unsigned size_level, } // Emits the given module to a bit code file. -void EmitBitcodeToFile(const Module& module, tensorflow::StringPiece filename) { +void EmitBitcodeToFile(const Module& module, absl::string_view filename) { std::error_code error_code; - llvm::ToolOutputFile outfile(filename.ToString().c_str(), error_code, + llvm::ToolOutputFile outfile(string(filename).c_str(), error_code, llvm::sys::fs::F_None); if (error_code) { LOG(FATAL) << "opening bitcode file for writing: " << error_code.message(); @@ -266,8 +265,9 @@ string EmitModuleToPTX(Module* module, llvm::TargetMachine* target_machine) { // get creative to add a suffix. string module_id(llvm_ir::AsString(module->getModuleIdentifier())); IrDumpingPassManager codegen_passes( - ReplaceFilenameExtension(tensorflow::io::Basename(module_id), - "-nvptx.dummy"), + ReplaceFilenameExtension( + absl::string_view(tensorflow::io::Basename(module_id)), + "-nvptx.dummy"), "", false); codegen_passes.add(new llvm::TargetLibraryInfoWrapperPass( llvm::Triple(module->getTargetTriple()))); @@ -332,8 +332,8 @@ Status LinkLibdeviceIfNecessary(llvm::Module* module, return !GV.hasName() || (GVS.count(GV.getName()) == 0); }); })) { - return tensorflow::errors::Internal(tensorflow::strings::StrCat( - "Error linking libdevice from ", libdevice_path)); + return tensorflow::errors::Internal( + absl::StrCat("Error linking libdevice from ", libdevice_path)); } return Status::OK(); } diff --git a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/nvptx_backend_lib.h b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/nvptx_backend_lib.h index 54e0e140de..9654175bfa 100644 --- a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/nvptx_backend_lib.h +++ b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/nvptx_backend_lib.h @@ -20,11 +20,11 @@ limitations under the License. #include <string> #include <utility> +#include "absl/strings/string_view.h" #include "llvm/IR/Module.h" #include "tensorflow/compiler/xla/service/hlo_module_config.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" namespace xla { namespace gpu { diff --git a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.cc b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.cc index 9ef9bc3a50..3b2c3591d9 100644 --- a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.cc +++ b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.cc @@ -17,13 +17,13 @@ limitations under the License. #include "tensorflow/core/platform/logging.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" #include "llvm/IR/LLVMContext.h" #include "llvm/IR/Module.h" #include "llvm/IRReader/IRReader.h" #include "llvm/Support/SourceMgr.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace { @@ -52,14 +52,13 @@ std::unique_ptr<llvm::Module> LoadIRModule(const string& filename, return module; } -string ReplaceFilenameExtension(tensorflow::StringPiece filename, - tensorflow::StringPiece new_extension) { +string ReplaceFilenameExtension(absl::string_view filename, + absl::string_view new_extension) { auto pos = filename.rfind('.'); - tensorflow::StringPiece stem = - pos == tensorflow::StringPiece::npos - ? filename - : tensorflow::StringPiece(filename.data(), pos); - return tensorflow::strings::StrCat(stem, ".", new_extension); + absl::string_view stem = pos == absl::string_view::npos + ? filename + : absl::string_view(filename.data(), pos); + return absl::StrCat(stem, ".", new_extension); } } // namespace gpu diff --git a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.h b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.h index a6daeca95a..60f4926849 100644 --- a/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.h +++ b/tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/utils.h @@ -18,8 +18,8 @@ limitations under the License. #include <memory> #include <string> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" namespace llvm { class LLVMContext; @@ -41,8 +41,8 @@ std::unique_ptr<llvm::Module> LoadIRModule(const string& filename, // // For example: // ReplaceFilenameExtension("/foo/baz.txt", "cc") --> "/foo/baz.cc" -string ReplaceFilenameExtension(tensorflow::StringPiece filename, - tensorflow::StringPiece new_extension); +string ReplaceFilenameExtension(absl::string_view filename, + absl::string_view new_extension); } // namespace gpu } // namespace xla diff --git a/tensorflow/compiler/xla/service/gpu/multi_output_fusion.cc b/tensorflow/compiler/xla/service/gpu/multi_output_fusion.cc index c62bae0628..7a43f0be54 100644 --- a/tensorflow/compiler/xla/service/gpu/multi_output_fusion.cc +++ b/tensorflow/compiler/xla/service/gpu/multi_output_fusion.cc @@ -23,6 +23,7 @@ limitations under the License. #include <string> #include <utility> +#include "absl/algorithm/container.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/service/gpu/instruction_fusion.h" #include "tensorflow/compiler/xla/service/gpu/ir_emission_utils.h" @@ -48,7 +49,7 @@ bool GpuMultiOutputFusion::ShapesCompatibleForFusion(HloInstruction* instr1, // If possible, we want to pick a reduce operand of the fusion root, // because it has the most constraints. for (const auto* inst : fused_expression_root->operands()) { - if (inst->opcode() == HloOpcode::kReduce) { + if (IsReductionToVector(*inst)) { return inst; } } @@ -63,7 +64,7 @@ bool GpuMultiOutputFusion::ShapesCompatibleForFusion(HloInstruction* instr1, auto get_element_shape = [&](const HloInstruction* element_instr) { // Special handling of kReduce instructions -- the fusion // applies to the first operand. - if (element_instr->opcode() == HloOpcode::kReduce) { + if (IsReductionToVector(*element_instr)) { return element_instr->operand(0)->shape(); } return element_instr->shape(); @@ -131,7 +132,7 @@ bool ReduceFriendlyInputLayouts(HloInstruction* instr) { max_rank_layout = ¶m->shape().layout(); } } - return c_all_of(params, [&](HloInstruction* param) { + return absl::c_all_of(params, [&](HloInstruction* param) { return (ShapeUtil::Rank(param->shape()) < max_rank) || (LayoutUtil::Equal(param->shape().layout(), *max_rank_layout)); }); @@ -140,10 +141,15 @@ bool ReduceFriendlyInputLayouts(HloInstruction* instr) { } // namespace bool GpuMultiOutputFusion::IsFusible(HloInstruction* instr) { - // We can fuse reduces and loop fusions. - return IsInputFusibleReduction(instr) || - (instr->opcode() == HloOpcode::kFusion && - instr->fusion_kind() == HloInstruction::FusionKind::kLoop); + // We can fuse reduces and loop fusions. Elementwise instructions can be fused + // with any other instruction. + // TODO(b/112957171): This should use the same isFusible logic as + // instruction_fusion. + return instr->IsFusible() && + (IsInputFusibleReduction(instr) || + (instr->opcode() == HloOpcode::kFusion && + instr->fusion_kind() == HloInstruction::FusionKind::kLoop) || + instr->IsElementwise()); } int64 GpuMultiOutputFusion::GetProfit(HloInstruction* instr1, @@ -177,11 +183,12 @@ bool GpuMultiOutputFusion::LegalToFuse(HloInstruction* instr1, // merge into bigger loop fusions and input (reduce) fusions become fusions // with multiple reduce outputs. We could fuse reduce and loop fusions // together too (the result being an input fusion) if we find cases where this - // improves things. + // improves things. Also disable fusing standalone input-fusible reduces into + // loop fusions. CHECK(instr1->opcode() == HloOpcode::kFusion); if ((instr2->opcode() == HloOpcode::kFusion && instr1->fusion_kind() != instr2->fusion_kind()) || - (instr2->opcode() != HloOpcode::kFusion && + (IsReductionToVector(*instr2) && instr1->fusion_kind() == HloInstruction::FusionKind::kLoop)) { return false; } @@ -197,7 +204,7 @@ bool GpuMultiOutputFusion::DoProducerConsumerMultiOutputFusion() { tensorflow::gtl::FlatSet<HloInstruction*> to_fuse; // Keep a list of the instructions to fuse after making all the fusion // decisions. We first aggressively add instructions to potential_fusion_list, - // then filter out instructions that will be no longer fusable because of + // then filter out instructions that will be no longer fusible because of // reachability change. This avoids recalculating reachability on a large set // of instructions. std::vector<std::pair<HloInstruction*, HloInstruction*>> @@ -213,7 +220,7 @@ bool GpuMultiOutputFusion::DoProducerConsumerMultiOutputFusion() { continue; } if (!IsInputFusibleReduction(consumer)) { - VLOG(3) << consumer->name() << " is not an input-fusable reduction."; + VLOG(3) << consumer->name() << " is not an input-fusible reduction."; continue; } VLOG(3) << consumer->name() @@ -222,8 +229,8 @@ bool GpuMultiOutputFusion::DoProducerConsumerMultiOutputFusion() { auto consumer_operands = consumer->operands(); for (size_t i = 0; i < consumer_operands.size(); ++i) { HloInstruction* producer = consumer_operands[i]; - if (!producer->IsFusable()) { - VLOG(3) << producer->name() << " is not fusable."; + if (!producer->IsFusible()) { + VLOG(3) << producer->name() << " is not fusible."; continue; } const bool is_loop_fusion = @@ -248,7 +255,7 @@ bool GpuMultiOutputFusion::DoProducerConsumerMultiOutputFusion() { } // Do not fuse a producer if the other operands of the fusion are // reachable from the producer, this would create a cycle. - if (c_any_of(consumer_operands, [&](HloInstruction* operand) { + if (absl::c_any_of(consumer_operands, [&](HloInstruction* operand) { return producer != operand && reachability()->IsReachable(producer, operand); })) { @@ -263,12 +270,12 @@ bool GpuMultiOutputFusion::DoProducerConsumerMultiOutputFusion() { } } - // Filter out pairs that will be no longer fusable because of reachability + // Filter out pairs that will be no longer fusible because of reachability // change. for (auto& fusion_pair : potential_fusion_list) { HloInstruction* producer = fusion_pair.first; HloInstruction* consumer = fusion_pair.second; - if (!c_any_of(consumer->operands(), [&](HloInstruction* operand) { + if (!absl::c_any_of(consumer->operands(), [&](HloInstruction* operand) { return producer != operand && reachability()->IsReachable(producer, operand); })) { diff --git a/tensorflow/compiler/xla/service/gpu/multi_output_fusion.h b/tensorflow/compiler/xla/service/gpu/multi_output_fusion.h index 67ca5d49ee..f0b4d67ab8 100644 --- a/tensorflow/compiler/xla/service/gpu/multi_output_fusion.h +++ b/tensorflow/compiler/xla/service/gpu/multi_output_fusion.h @@ -22,7 +22,7 @@ namespace xla { namespace gpu { // Multi-output fusion of sibling and producer-consumer instructions for the -// Jellyfish backend. +// GPU backend. class GpuMultiOutputFusion : public MultiOutputFusion { public: GpuMultiOutputFusion(); diff --git a/tensorflow/compiler/xla/service/gpu/multi_output_fusion_test.cc b/tensorflow/compiler/xla/service/gpu/multi_output_fusion_test.cc index 14f157a5e5..c822c94f1b 100644 --- a/tensorflow/compiler/xla/service/gpu/multi_output_fusion_test.cc +++ b/tensorflow/compiler/xla/service/gpu/multi_output_fusion_test.cc @@ -15,19 +15,19 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/multi_output_fusion.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/gpu/instruction_fusion.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/tests/hlo_test_base.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/str_util.h" - -namespace op = xla::testing::opcode_matchers; namespace xla { namespace gpu { +namespace op = xla::testing::opcode_matchers; + using MultiOutputFusionTest = HloTestBase; const char kModulePrefix[] = R"( @@ -47,7 +47,7 @@ const char kModulePrefix[] = R"( TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingReduceAndReduceFusion) { // Fusion with reduce instruction root and a sibling reduce instruction // sharing the same input param. - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation { p1.1 = f32[128,512,28,28]{3,2,1,0} parameter(1) mul = f32[128,512,28,28]{3,2,1,0} multiply(p1.1, p1.1) @@ -74,7 +74,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingReduceAndReduceFusion) { } TEST_F(MultiOutputFusionTest, MultiOutputFusionDifferentReduceInputShapes) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p1.1 = f32[6400]{0} parameter(1) mul = f32[6400]{0} multiply(p1.1, p1.1) @@ -101,7 +101,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionDifferentReduceInputShapes) { } TEST_F(MultiOutputFusionTest, MultiOutputFusionDifferentReduceOutputShapes) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p1.1 = f32[10,10]{1,0} parameter(1) mul = f32[10,10]{1,0} multiply(p1.1, p1.1) @@ -130,7 +130,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionDifferentReduceOutputShapes) { TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingReduceFusions) { // Two sibling fusions with reduce instruction roots sharing the same input // param. - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p1.1 = f32[128,512,28,28]{3,2,1,0} parameter(1) mul = f32[128,512,28,28]{3,2,1,0} multiply(p1.1, p1.1) @@ -165,7 +165,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingReduceAndReduceMultiOutputFusion) { // Multi-output fusion with two reduce instructions root and a sibling reduce // instruction sharing the same input param. - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation (p0: f32[128,512,28,28]) -> (f32[512], f32[512]) { const.1 = f32[] constant(1) p0.1 = f32[128,512,28,28]{3,2,1,0} parameter(0) @@ -198,7 +198,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingFusionCheckAgainstReduceOperand) { // Verify that if we already have a multi-output fusion that we prefer to pick // a reduce op from its operands for checking shape compatibility. - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p1.1 = f32[10,10]{1,0} parameter(1) mul = f32[10,10]{1,0} multiply(p1.1, p1.1) @@ -228,7 +228,7 @@ TEST_F(MultiOutputFusionTest, } TEST_F(MultiOutputFusionTest, MultiOutputFusionTwoLoops) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p0.1 = f32[6400]{0} parameter(0) ROOT mul = f32[6400]{0} multiply(p0.1, p0.1) @@ -256,8 +256,136 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionTwoLoops) { op::Tuple(op::Multiply(), op::Divide())); } -TEST_F(MultiOutputFusionTest, ProducerConsumerFusionElementwiseAndReduce) { +TEST_F(MultiOutputFusionTest, MultiOutputFusionLoopReduceToInputFusion) { + // Fusing a reduce into a loop fusion would require changing the fusion kind. + // That's not supported yet. auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + fused_computation_1 { + p0.1 = f32[6400]{0} parameter(0) + ROOT mul = f32[6400]{0} multiply(p0.1, p0.1) + } + + ENTRY entry { + p0 = f32[6400]{0} parameter(0) + fusion.1 = f32[6400]{0} fusion(p0), kind=kLoop, calls=fused_computation_1 + const.2 = f32[] constant(0) + reduce = f32[] reduce(p0, const.2), dimensions={0}, to_apply=scalar_add_computation + ROOT root = (f32[6400]{0}, f32[]) tuple(fusion.1, reduce) + })")) + .ValueOrDie(); + ASSERT_FALSE(GpuMultiOutputFusion().Run(module.get()).ValueOrDie()); +} + +TEST_F(MultiOutputFusionTest, MultiOutputFusionLoopElementwise) { + auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + fused_computation_1 { + p0.1 = f32[6400]{0} parameter(0) + ROOT mul = f32[6400]{0} multiply(p0.1, p0.1) + } + + ENTRY entry { + p0 = f32[6400]{0} parameter(0) + fusion.1 = f32[6400]{0} fusion(p0), kind=kLoop, calls=fused_computation_1 + const.2 = f32[] constant(1) + div = f32[6400]{0} divide(p0, const.2) + ROOT root = (f32[6400]{0}, f32[6400]{0}) tuple(fusion.1, div) + })")) + .ValueOrDie(); + ASSERT_TRUE(GpuMultiOutputFusion().Run(module.get()).ValueOrDie()); + SCOPED_TRACE(module->ToString()); + const HloInstruction* fusion = + module->entry_computation()->root_instruction()->operand(0)->operand(0); + ASSERT_TRUE(fusion->IsMultiOutputFusion()); + EXPECT_THAT(fusion->fused_expression_root(), + op::Tuple(op::Multiply(), op::Divide())); +} + +TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingLoopsDifferentShapes) { + auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + fused_computation_1 { + p0.1 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) + ROOT mul = f32[8,1,5,16,1,1]{5,4,3,2,1,0} multiply(p0.1, p0.1) + } + + fused_computation_2 { + p0.2 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) + const.2 = f32[] constant(0) + ROOT reduce = f32[8,1,5,1,1]{4,3,2,1,0} reduce(p0.2, const.2), dimensions={3}, to_apply=scalar_add_computation + } + + ENTRY entry { + p0 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) + fusion.1 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} fusion(p0), kind=kLoop, calls=fused_computation_1 + fusion.2 = f32[8,1,5,1,1]{4,3,2,1,0} fusion(p0), kind=kLoop, calls=fused_computation_2 + ROOT root = (f32[8,1,5,16,1,1]{5,4,3,2,1,0}, f32[8,1,5,1,1]{4,3,2,1,0}) tuple(fusion.1, fusion.2) + })")) + .ValueOrDie(); + ASSERT_FALSE(GpuMultiOutputFusion().Run(module.get()).ValueOrDie()); +} + +TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingLoopAndMultiOutputLoop) { + auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + fused_computation_1 { + p0.1 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) + mul = f32[8,1,5,16,1,1]{5,4,3,2,1,0} multiply(p0.1, p0.1) + exp = f32[8,1,5,16,1,1]{5,4,3,2,1,0} exponential(p0.1) + ROOT tuple = (f32[8,1,5,16,1,1]{5,4,3,2,1,0}, f32[8,1,5,16,1,1]{5,4,3,2,1,0}) tuple(mul, exp) + } + + fused_computation_2 { + p0.2 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) + const.2 = f32[] constant(0) + ROOT add = f32[8,1,5,16,1,1]{5,4,3,2,1,0} add(p0.2, const.2) + } + + ENTRY entry { + p0 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) + fusion.1 = (f32[8,1,5,16,1,1]{5,4,3,2,1,0}, f32[8,1,5,16,1,1]{5,4,3,2,1,0}) fusion(p0), kind=kLoop, calls=fused_computation_1 + fusion.2 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} fusion(p0), kind=kLoop, calls=fused_computation_2 + gte0 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} get-tuple-element(fusion.1), index=0 + gte1 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} get-tuple-element(fusion.1), index=1 + ROOT root = (f32[8,1,5,16,1,1]{5,4,3,2,1,0}, f32[8,1,5,16,1,1]{5,4,3,2,1,0}, f32[8,1,5,16,1,1]{5,4,3,2,1,0}) tuple(gte0, gte1, fusion.2) + })")) + .ValueOrDie(); + ASSERT_TRUE(GpuMultiOutputFusion().Run(module.get()).ValueOrDie()); + SCOPED_TRACE(module->ToString()); + const HloInstruction* fusion = + module->entry_computation()->root_instruction()->operand(0)->operand(0); + ASSERT_TRUE(fusion->IsMultiOutputFusion()); + EXPECT_THAT(fusion->fused_expression_root(), + op::Tuple(op::Multiply(), op::Exp(), op::Add())); +} + +TEST_F(MultiOutputFusionTest, + MultiOutputFusionSiblingLoopAndMultiOutputLoopDifferentShapes) { + auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + fused_computation_1 { + p0.1 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) + mul = f32[8,1,5,16,1,1]{5,4,3,2,1,0} multiply(p0.1, p0.1) + exp = f32[8,1,5,16,1,1]{5,4,3,2,1,0} exponential(p0.1) + ROOT tuple = (f32[8,1,5,16,1,1]{5,4,3,2,1,0}, f32[8,1,5,16,1,1]{5,4,3,2,1,0}) tuple(mul, exp) + } + + fused_computation_2 { + p0.2 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) + const.2 = f32[] constant(0) + ROOT reduce = f32[8,1,5,1,1]{4,3,2,1,0} reduce(p0.2, const.2), dimensions={3}, to_apply=scalar_add_computation + } + + ENTRY entry { + p0 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) + fusion.1 = (f32[8,1,5,16,1,1]{5,4,3,2,1,0}, f32[8,1,5,16,1,1]{5,4,3,2,1,0}) fusion(p0), kind=kLoop, calls=fused_computation_1 + fusion.2 = f32[8,1,5,1,1]{4,3,2,1,0} fusion(p0), kind=kLoop, calls=fused_computation_2 + gte0 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} get-tuple-element(fusion.1), index=0 + gte1 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} get-tuple-element(fusion.1), index=1 + ROOT root = (f32[8,1,5,16,1,1]{5,4,3,2,1,0}, f32[8,1,5,16,1,1]{5,4,3,2,1,0}, f32[8,1,5,1,1]{4,3,2,1,0}) tuple(gte0, gte1, fusion.2) + })")) + .ValueOrDie(); + ASSERT_FALSE(GpuMultiOutputFusion().Run(module.get()).ValueOrDie()); +} + +TEST_F(MultiOutputFusionTest, ProducerConsumerFusionElementwiseAndReduce) { + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( ENTRY reduce { p0 = f32[2,2,2]{2,1,0} parameter(0) c0 = f32[] constant(0) @@ -277,7 +405,7 @@ TEST_F(MultiOutputFusionTest, ProducerConsumerFusionElementwiseAndReduce) { } TEST_F(MultiOutputFusionTest, ProducerConsumerFusionLoopFusionAndReduce) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_add { p0.1 = f32[2,2,2]{2,1,0} parameter(0) p1.1 = f32[2,2,2]{2,1,0} parameter(1) @@ -304,7 +432,7 @@ TEST_F(MultiOutputFusionTest, ProducerConsumerFusionLoopFusionAndReduce) { } TEST_F(MultiOutputFusionTest, ProducerConsumerFusionLoopFusionAndReduceFusion) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_select { p1.1 = f32[2,2,2]{2,1,0} parameter(1) c0 = f32[] constant(0) @@ -345,7 +473,7 @@ TEST_F(MultiOutputFusionTest, ProducerConsumerFusionLoopFusionAndReduceFusion) { } TEST_F(MultiOutputFusionTest, ProducerConsumerFusionDoNotFuseLoopReduceFusion) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_element_wise { p0.1 = f32[2,2,2]{2,1,0} parameter(0) p1.1 = f32[2,2,2]{2,1,0} parameter(1) @@ -372,7 +500,7 @@ TEST_F(MultiOutputFusionTest, ProducerConsumerFusionDoNotFuseLoopReduceFusion) { TEST_F(MultiOutputFusionTest, ProducerConsumerFusionFp16LoopFusionAndReduceFusion) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_select { p1.1 = f16[2,2,2]{2,1,0} parameter(1) c0 = f16[] constant(0) @@ -413,7 +541,7 @@ TEST_F(MultiOutputFusionTest, TEST_F(MultiOutputFusionTest, ProducerConsumerFusionReduceUnfriendlyLoopFusion) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( mixed_input_layouts_computation { p0.1 = f16[128,1024,32,32]{1,3,2,0} parameter(0) p1.1 = f16[128,1024,32,32]{3,2,1,0} parameter(1) diff --git a/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc b/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc index 6c1eab4f8c..8e4a8e5f54 100644 --- a/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc +++ b/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc @@ -21,13 +21,15 @@ limitations under the License. #include <mutex> // NOLINT(build/c++11): only using std::call_once, not mutex. #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_cat.h" #include "llvm/IR/DiagnosticInfo.h" #include "llvm/IR/DiagnosticPrinter.h" #include "llvm/IR/LLVMContext.h" #include "llvm/IR/Module.h" #include "llvm/IR/Verifier.h" #include "tensorflow/compiler/xla/protobuf_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/algebraic_simplifier.h" #include "tensorflow/compiler/xla/service/batchnorm_expander.h" #include "tensorflow/compiler/xla/service/buffer_assignment.h" @@ -85,7 +87,6 @@ limitations under the License. #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/gtl/cleanup.h" #include "tensorflow/core/lib/io/path.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/cuda_libdevice_path.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/logging.h" @@ -140,7 +141,8 @@ Status OptimizeHloModule(HloModule* hlo_module, se::StreamExecutor* stream_exec, Compiler* compiler) { { HloPassPipeline pipeline("optimization"); - pipeline.AddInvariantChecker<HloVerifier>(); + pipeline.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false); pipeline.AddPass<GpuHloSupportChecker>(); ReducePrecisionInsertion::AddPasses( &pipeline, hlo_module->config().debug_options(), @@ -156,7 +158,8 @@ Status OptimizeHloModule(HloModule* hlo_module, se::StreamExecutor* stream_exec, { auto& pass = pipeline.AddPass<HloPassFix<HloPassPipeline>>("simplification"); - pass.AddInvariantChecker<HloVerifier>(); + pass.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false); // If cudnn batchnorms are enabled, rewrite batchnorm HLOs to cudnn calls // where possible. Not every batchnorm op can be implemented as a call to @@ -203,10 +206,15 @@ Status OptimizeHloModule(HloModule* hlo_module, se::StreamExecutor* stream_exec, // Convert convolutions into CustomCalls to cudnn, then canonicalize them // (PadInsertion). HloPassPipeline pipeline("conv_canonicalization"); - pipeline.AddInvariantChecker<HloVerifier>(); + pipeline.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false); // TODO(b/31709653): Directly use the grouped convolution support of Cudnn. pipeline.AddPass<ConvolutionFeatureGroupConverter>(); pipeline.AddPass<CudnnConvolutionRewriter>(); + // CudnnConvolutionRewriter may add instructions of the form + // reverse(constant), which it expects will be simplified by constant + // folding. + pipeline.AddPass<HloConstantFolding>(); pipeline.AddPass<PadInsertion>(); if (IsVoltaOrLater(*stream_exec)) { pipeline.AddPass<PadForTensorCores>(); @@ -218,9 +226,22 @@ Status OptimizeHloModule(HloModule* hlo_module, se::StreamExecutor* stream_exec, } { - HloPassPipeline pipeline("layout_assignment"); + // Run layout assignment in a separate pipeline from + // "post-layout-assignment" because we want everything after layout + // assignment to have a layout-sensitive invariant-checker, but + // HloPassPipeline also runs its invariant checker before any passes are + // run, meaning, the pipeline that contains layout assignment cannot contain + // a layout-sensitive verifier! + HloPassPipeline pipeline("layout assignment"); pipeline.AddPass<GpuLayoutAssignment>( hlo_module->mutable_entry_computation_layout(), stream_exec); + TF_RETURN_IF_ERROR(pipeline.Run(hlo_module).status()); + } + + { + HloPassPipeline pipeline("post-layout_assignment"); + pipeline.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/true, + /*allow_mixed_precision=*/false); // The LayoutAssignment pass may leave behind kCopy instructions which are // duplicate or NOPs, so remove them with algebraic simplification and CSE. @@ -266,17 +287,20 @@ Status OptimizeHloModule(HloModule* hlo_module, se::StreamExecutor* stream_exec, { HloPassFix<HloPassPipeline> fusion("fusion"); - fusion.AddInvariantChecker<HloVerifier>(); + fusion.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/true, + /*allow_mixed_precision=*/false); fusion.AddPass<GpuInstructionFusion>(/*may_duplicate=*/false); fusion.AddPass<GpuInstructionFusion>(/*may_duplicate=*/true); fusion.AddPass<FusionMerger>(); fusion.AddPass<GpuMultiOutputFusion>(); fusion.AddPass<HloCSE>(/*is_layout_sensitive=*/true, /*only_fusion_computations=*/true); + fusion.AddPass<HloDCE>(); TF_RETURN_IF_ERROR(fusion.Run(hlo_module).status()); HloPassPipeline reduce_pipeline("reduce-precision"); - reduce_pipeline.AddInvariantChecker<HloVerifier>(); + reduce_pipeline.AddInvariantChecker<HloVerifier>( + /*is_layout_sensitive=*/true, /*allow_mixed_precision=*/false); ReducePrecisionInsertion::AddPasses( &reduce_pipeline, hlo_module->config().debug_options(), ReducePrecisionInsertion::PassTiming::AFTER_FUSION); @@ -302,7 +326,8 @@ Status PrepareHloModuleForIrEmitting(HloModule* hlo_module) { // (b/27180329). Therefore, in that case, we set the output to be a copy of // the parameter. HloPassPipeline pipeline("GPU-ir-emit-prepare"); - pipeline.AddInvariantChecker<HloVerifier>(); + pipeline.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/true, + /*allow_mixed_precision=*/false); // Copy insertion should be performed immediately before IR emission to avoid // inserting unnecessary copies (later pass adds an instruction which @@ -352,9 +377,9 @@ void WarnIfBadPtxasVersion(const string& ptxas_path) { string vmaj_str, vmin_str, vdot_str; if (!RE2::PartialMatch(out, R"(\bV(\d+)\.(\d+)\.(\d+)\b)", &vmaj_str, &vmin_str, &vdot_str) || - !tensorflow::strings::safe_strto64(vmaj_str, &vmaj) || - !tensorflow::strings::safe_strto64(vmin_str, &vmin) || - !tensorflow::strings::safe_strto64(vdot_str, &vdot)) { + !absl::SimpleAtoi(vmaj_str, &vmaj) || + !absl::SimpleAtoi(vmin_str, &vmin) || + !absl::SimpleAtoi(vdot_str, &vdot)) { LOG(WARNING) << "Couldn't parse ptxas version in output of " << ptxas_path << " --version:\n" << out; @@ -466,7 +491,7 @@ StatusOr<std::vector<uint8>> CompilePtx(const string& ptx, int cc_major, tensorflow::SubProcess ptxas_info_dumper; std::vector<string> ptxas_args = { ptxas_path, ptx_path, "-o", cubin_path, - tensorflow::strings::StrCat("-arch=sm_", cc_major, cc_minor)}; + absl::StrCat("-arch=sm_", cc_major, cc_minor)}; if (VLOG_IS_ON(2)) { ptxas_args.push_back("-v"); } @@ -674,7 +699,7 @@ StatusOr<std::unique_ptr<Executable>> NVPTXCompiler::RunBackend( // Write PTX to IR dump directory, if IR dumping was requested. if (!ir_dump_directory.empty()) { const string ptx_outfile = tensorflow::io::JoinPath( - ir_dump_directory, tensorflow::strings::StrCat(module->name(), ".ptx")); + ir_dump_directory, absl::StrCat(module->name(), ".ptx")); auto status = [&] { auto* env = tensorflow::Env::Default(); TF_RETURN_IF_ERROR(env->RecursivelyCreateDir(ir_dump_directory)); @@ -690,7 +715,7 @@ StatusOr<std::unique_ptr<Executable>> NVPTXCompiler::RunBackend( const std::vector<uint8> cubin = CompilePtxOrGetCachedResult(ptx, cc_major, cc_minor); - auto thunk_schedule = MakeUnique<ThunkSchedule>( + auto thunk_schedule = absl::make_unique<ThunkSchedule>( ir_emitter.ConsumeThunkSequence(), std::move(stream_assignment), hlo_schedule->ThunkLaunchOrder()); VLOG(2) << "Printing the thunk schedule..."; @@ -704,7 +729,7 @@ StatusOr<std::unique_ptr<Executable>> NVPTXCompiler::RunBackend( cost_analysis.set_bytes_per_second( stream_exec->GetDeviceDescription().memory_bandwidth()); TF_RETURN_IF_ERROR(module->entry_computation()->Accept(&cost_analysis)); - profile_index_map = MakeUnique<HloProfileIndexMap>(*module); + profile_index_map = absl::make_unique<HloProfileIndexMap>(*module); profile_printer = CreateHloProfilePrinterData(*profile_index_map, cost_analysis); } @@ -813,7 +838,7 @@ se::Platform::Id NVPTXCompiler::PlatformId() const { static bool InitModule() { xla::Compiler::RegisterCompilerFactory( stream_executor::cuda::kCudaPlatformId, - []() { return xla::MakeUnique<xla::gpu::NVPTXCompiler>(); }); + []() { return absl::make_unique<xla::gpu::NVPTXCompiler>(); }); return true; } static bool module_initialized = InitModule(); diff --git a/tensorflow/compiler/xla/service/gpu/nvptx_compiler.h b/tensorflow/compiler/xla/service/gpu/nvptx_compiler.h index d4d2909f1b..08ef6ef56c 100644 --- a/tensorflow/compiler/xla/service/gpu/nvptx_compiler.h +++ b/tensorflow/compiler/xla/service/gpu/nvptx_compiler.h @@ -20,13 +20,13 @@ limitations under the License. #include <string> #include <vector> +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/executable.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/llvm_compiler.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/lib/hash/hash.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/mutex.h" diff --git a/tensorflow/compiler/xla/service/gpu/outfeed_manager.cc b/tensorflow/compiler/xla/service/gpu/outfeed_manager.cc index 4aaf0c9e14..2fa170964e 100644 --- a/tensorflow/compiler/xla/service/gpu/outfeed_manager.cc +++ b/tensorflow/compiler/xla/service/gpu/outfeed_manager.cc @@ -15,8 +15,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/outfeed_manager.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/core/platform/logging.h" diff --git a/tensorflow/compiler/xla/service/gpu/outfeed_thunk.cc b/tensorflow/compiler/xla/service/gpu/outfeed_thunk.cc index b99d998c4d..e0f3e84a4c 100644 --- a/tensorflow/compiler/xla/service/gpu/outfeed_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/outfeed_thunk.cc @@ -96,7 +96,7 @@ Status OutfeedThunk::ExecuteOnStream( Status block_status = stream->BlockHostUntilDone(); if (!block_status.ok()) { return InternalError("Failed to complete data transfer on stream %p: %s", - stream, block_status.error_message().c_str()); + stream, block_status.error_message()); } VLOG(2) << "Outfeeding from GPU complete"; diff --git a/tensorflow/compiler/xla/service/gpu/pad_for_tensor_cores.h b/tensorflow/compiler/xla/service/gpu/pad_for_tensor_cores.h index 192359f026..11dc56a64f 100644 --- a/tensorflow/compiler/xla/service/gpu/pad_for_tensor_cores.h +++ b/tensorflow/compiler/xla/service/gpu/pad_for_tensor_cores.h @@ -32,9 +32,7 @@ namespace gpu { // TODO(jlebar): Also pad dots. class PadForTensorCores : public HloPassInterface { public: - tensorflow::StringPiece name() const override { - return "pad for tensor cores"; - } + absl::string_view name() const override { return "pad for tensor cores"; } StatusOr<bool> Run(HloModule* module) override; }; diff --git a/tensorflow/compiler/xla/service/gpu/pad_for_tensor_cores_test.cc b/tensorflow/compiler/xla/service/gpu/pad_for_tensor_cores_test.cc index 99e7580b82..104af48c82 100644 --- a/tensorflow/compiler/xla/service/gpu/pad_for_tensor_cores_test.cc +++ b/tensorflow/compiler/xla/service/gpu/pad_for_tensor_cores_test.cc @@ -29,7 +29,12 @@ namespace { namespace op = xla::testing::opcode_matchers; using ::testing::_; -using PadForTensorCoresTest = HloVerifiedTestBase; +class PadForTensorCoresTest : public HloVerifiedTestBase { + public: + PadForTensorCoresTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} +}; TEST_F(PadForTensorCoresTest, PadF16ForwardConvInputChannels) { ParseAndVerifyModule(R"( diff --git a/tensorflow/compiler/xla/service/gpu/pad_insertion.cc b/tensorflow/compiler/xla/service/gpu/pad_insertion.cc index b22040eee1..98cc21ccac 100644 --- a/tensorflow/compiler/xla/service/gpu/pad_insertion.cc +++ b/tensorflow/compiler/xla/service/gpu/pad_insertion.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/pad_insertion.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/gpu/ir_emission_utils.h" @@ -69,7 +70,7 @@ HloInstruction* MaybePaddedAndSlicedInput( PrimitiveType element_type = input->shape().element_type(); HloInstruction* padding = computation->AddInstruction(HloInstruction::CreateConstant( - MakeUnique<Literal>(LiteralUtil::Zero(element_type)))); + absl::make_unique<Literal>(LiteralUtil::Zero(element_type)))); input = MakePadHlo(input, padding, padding_config).ValueOrDie(); } @@ -126,7 +127,7 @@ HloInstruction* MaybePaddedKernel(const Window& conv_window, PrimitiveType element_type = kernel->shape().element_type(); HloInstruction* padding = computation->AddInstruction(HloInstruction::CreateConstant( - MakeUnique<Literal>(LiteralUtil::Zero(element_type)))); + absl::make_unique<Literal>(LiteralUtil::Zero(element_type)))); return MakePadHlo(kernel, padding, padding_config).ValueOrDie(); } } // namespace @@ -236,7 +237,7 @@ bool PadInsertion::CanonicalizeBackwardFilterConvolution( HloComputation* computation = backward_conv->parent(); HloInstruction* output = backward_conv->mutable_operand(1); HloInstruction* padding = computation->AddInstruction( - HloInstruction::CreateConstant(MakeUnique<Literal>( + HloInstruction::CreateConstant(absl::make_unique<Literal>( LiteralUtil::Zero(input->shape().element_type())))); HloInstruction* padded_input = MakePadHlo(input, padding, input_padding_config).ValueOrDie(); diff --git a/tensorflow/compiler/xla/service/gpu/pad_insertion.h b/tensorflow/compiler/xla/service/gpu/pad_insertion.h index 67e51509e4..a622e894ed 100644 --- a/tensorflow/compiler/xla/service/gpu/pad_insertion.h +++ b/tensorflow/compiler/xla/service/gpu/pad_insertion.h @@ -26,7 +26,7 @@ namespace gpu { // padding, so that they can be lowered to cuDNN convolution. class PadInsertion : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "pad insertion"; } + absl::string_view name() const override { return "pad insertion"; } StatusOr<bool> Run(HloModule* module) override; diff --git a/tensorflow/compiler/xla/service/gpu/parallel_loop_emitter.cc b/tensorflow/compiler/xla/service/gpu/parallel_loop_emitter.cc index 3838fee674..ca57cacb98 100644 --- a/tensorflow/compiler/xla/service/gpu/parallel_loop_emitter.cc +++ b/tensorflow/compiler/xla/service/gpu/parallel_loop_emitter.cc @@ -57,8 +57,8 @@ ParallelLoopEmitter::ParallelLoopEmitter( unroll_factor_(unroll_factor) {} std::vector<llvm_ir::IrArray::Index> -ParallelLoopEmitter::EmitIndexAndSetExitBasicBlock( - tensorflow::StringPiece loop_name, llvm::Type* index_type) { +ParallelLoopEmitter::EmitIndexAndSetExitBasicBlock(absl::string_view loop_name, + llvm::Type* index_type) { // Emit the following code in LLVM IR: // linear_index = blockIdx.x * blockDim.x + threadIdx.x; // if (linear_index < num_elements) { diff --git a/tensorflow/compiler/xla/service/gpu/parallel_loop_emitter.h b/tensorflow/compiler/xla/service/gpu/parallel_loop_emitter.h index b82a23419d..cc7da2e73b 100644 --- a/tensorflow/compiler/xla/service/gpu/parallel_loop_emitter.h +++ b/tensorflow/compiler/xla/service/gpu/parallel_loop_emitter.h @@ -58,7 +58,7 @@ class ParallelLoopEmitter : public llvm_ir::LoopEmitter { ~ParallelLoopEmitter() override = default; std::vector<llvm_ir::IrArray::Index> EmitIndexAndSetExitBasicBlock( - tensorflow::StringPiece loop_name, llvm::Type* index_type) override; + absl::string_view loop_name, llvm::Type* index_type) override; private: // The thread and block dimension to parallelize the loop on. diff --git a/tensorflow/compiler/xla/service/gpu/partition_assignment.cc b/tensorflow/compiler/xla/service/gpu/partition_assignment.cc index d3fd0544fb..cf9f102d31 100644 --- a/tensorflow/compiler/xla/service/gpu/partition_assignment.cc +++ b/tensorflow/compiler/xla/service/gpu/partition_assignment.cc @@ -18,15 +18,15 @@ limitations under the License. #include <ostream> #include <string> +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/bits.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" namespace xla { @@ -34,9 +34,8 @@ namespace gpu { std::ostream& operator<<(std::ostream& out, const LaunchDimensions& launch_dims) { - out << tensorflow::strings::Printf("[block: %lld, thread: %lld]", - launch_dims.block_count(), - launch_dims.threads_per_block()); + out << absl::StrFormat("[block: %d, thread: %d]", launch_dims.block_count(), + launch_dims.threads_per_block()); return out; } @@ -91,9 +90,9 @@ LaunchDimensions CalculateLaunchDimensions( } int64 block_count = CeilOfRatio(num_elements, threads_per_block); - VLOG(2) << tensorflow::strings::Printf( + VLOG(2) << absl::StrFormat( "Initialized the block count to ceil(# of elements / threads per " - "block) = ceil(%lld/%lld) = %lld", + "block) = ceil(%d/%d) = %d", num_elements, threads_per_block, block_count); return LaunchDimensions(block_count, threads_per_block); diff --git a/tensorflow/compiler/xla/service/gpu/stream_assignment.cc b/tensorflow/compiler/xla/service/gpu/stream_assignment.cc index 0806dd5161..5b6cf2c04d 100644 --- a/tensorflow/compiler/xla/service/gpu/stream_assignment.cc +++ b/tensorflow/compiler/xla/service/gpu/stream_assignment.cc @@ -15,8 +15,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/stream_assignment.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/gpu/ir_emission_utils.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_reachability.h" @@ -119,7 +119,7 @@ int ComputeStreamToAssign( } // namespace std::unique_ptr<StreamAssignment> AssignStreams(const HloModule& module) { - auto stream_assignment = MakeUnique<StreamAssignment>(); + auto stream_assignment = absl::make_unique<StreamAssignment>(); const HloComputation& computation = *module.entry_computation(); std::unique_ptr<HloReachabilityMap> reachability = computation.ComputeReachability(); diff --git a/tensorflow/compiler/xla/service/gpu/stream_assignment_test.cc b/tensorflow/compiler/xla/service/gpu/stream_assignment_test.cc index 6f4bb0580e..091aca23e5 100644 --- a/tensorflow/compiler/xla/service/gpu/stream_assignment_test.cc +++ b/tensorflow/compiler/xla/service/gpu/stream_assignment_test.cc @@ -15,13 +15,14 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/stream_assignment.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/test_helpers.h" #include "tensorflow/compiler/xla/tests/hlo_test_base.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/stringprintf.h" namespace xla { namespace gpu { @@ -33,7 +34,7 @@ class StreamAssignmentTest : public HloTestBase { auto debug_options = GetDebugOptionsForTest(); debug_options.set_xla_gpu_disable_multi_streaming(false); config.set_debug_options(debug_options); - return MakeUnique<HloModule>("test_module", config); + return absl::make_unique<HloModule>("test_module", config); } // Pre-canned shapes. @@ -97,7 +98,7 @@ TEST_F(StreamAssignmentTest, LatticeMatMul) { params.reserve(6); for (int i = 0; i < 6; ++i) { params.push_back(builder.AddInstruction(HloInstruction::CreateParameter( - i, f32_2x2_, /*name=*/tensorflow::strings::Printf("param%d", i)))); + i, f32_2x2_, /*name=*/absl::StrFormat("param%d", i)))); } HloInstruction* d00 = builder.AddInstruction( HloInstruction::CreateCanonicalDot(f32_2x2_, params[2], params[3])); diff --git a/tensorflow/compiler/xla/service/gpu/stream_executor_util.cc b/tensorflow/compiler/xla/service/gpu/stream_executor_util.cc index 05b305ea4c..08ff52211a 100644 --- a/tensorflow/compiler/xla/service/gpu/stream_executor_util.cc +++ b/tensorflow/compiler/xla/service/gpu/stream_executor_util.cc @@ -16,6 +16,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/stream_executor_util.h" #include "tensorflow/compiler/xla/layout_util.h" +#include "tensorflow/compiler/xla/service/hlo_instruction.h" +#include "tensorflow/compiler/xla/util.h" namespace xla { namespace gpu { @@ -53,8 +55,9 @@ StreamExecutorConvLayoutsToXlaLayouts(const ConvolutionDimensionNumbers& dnums, input_layout.push_back(dnums.input_feature_dimension()); break; default: - return tensorflow::errors::Internal("Invalid input layout: ", - DataLayoutString(input)); + return InternalError("Invalid input layout %s for conv with dnums %s", + DataLayoutString(input), + ConvolutionDimensionNumbersToString(dnums)); } std::vector<int64> filter_layout; @@ -74,8 +77,9 @@ StreamExecutorConvLayoutsToXlaLayouts(const ConvolutionDimensionNumbers& dnums, filter_layout.push_back(dnums.kernel_input_feature_dimension()); break; default: - return tensorflow::errors::Internal("Invalid filter layout: ", - FilterLayoutString(filter)); + return InternalError("Invalid filter layout %s for conv with dnums %s", + FilterLayoutString(filter), + ConvolutionDimensionNumbersToString(dnums)); } std::vector<int64> output_layout; @@ -95,8 +99,9 @@ StreamExecutorConvLayoutsToXlaLayouts(const ConvolutionDimensionNumbers& dnums, output_layout.push_back(dnums.output_feature_dimension()); break; default: - return tensorflow::errors::Internal("Invalid output layout: ", - DataLayoutString(output)); + return InternalError("Invalid output layout %s for conv with dnums %s", + DataLayoutString(output), + ConvolutionDimensionNumbersToString(dnums)); } return std::make_tuple(LayoutUtil::MakeLayoutFromMajorToMinor(input_layout), @@ -128,8 +133,9 @@ XlaConvLayoutsToStreamExecutorLayouts(const ConvolutionDimensionNumbers& dnums, } else if (LayoutUtil::Equal(input, nhwc_input)) { input_layout = DataLayout::kBatchYXDepth; } else { - return tensorflow::errors::Internal("Invalid input layout: ", - input.ShortDebugString()); + return InternalError("Invalid input layout %s for conv with dnums %s", + LayoutUtil::HumanString(input), + ConvolutionDimensionNumbersToString(dnums)); } FilterLayout filter_layout; @@ -138,8 +144,9 @@ XlaConvLayoutsToStreamExecutorLayouts(const ConvolutionDimensionNumbers& dnums, } else if (LayoutUtil::Equal(filter, nhwc_filter)) { filter_layout = FilterLayout::kOutputYXInput; } else { - return tensorflow::errors::Internal("Invalid filter layout: ", - filter.ShortDebugString()); + return InternalError("Invalid filter layout %s for conv with dnums %s", + LayoutUtil::HumanString(filter), + ConvolutionDimensionNumbersToString(dnums)); } DataLayout output_layout; @@ -148,8 +155,9 @@ XlaConvLayoutsToStreamExecutorLayouts(const ConvolutionDimensionNumbers& dnums, } else if (LayoutUtil::Equal(output, nhwc_output)) { output_layout = DataLayout::kBatchYXDepth; } else { - return tensorflow::errors::Internal("Invalid output layout: ", - output.ShortDebugString()); + return InternalError("Invalid output layout %s for conv with dnums %s", + LayoutUtil::HumanString(output), + ConvolutionDimensionNumbersToString(dnums)); } return std::make_tuple(input_layout, filter_layout, output_layout); diff --git a/tensorflow/compiler/xla/service/gpu/tests/BUILD b/tensorflow/compiler/xla/service/gpu/tests/BUILD index 4fad3f46cf..db4a33dc56 100644 --- a/tensorflow/compiler/xla/service/gpu/tests/BUILD +++ b/tensorflow/compiler/xla/service/gpu/tests/BUILD @@ -35,13 +35,13 @@ cc_library( "requires-gpu-sm35", ], deps = [ - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla/legacy_flags:debug_options_flags", "//tensorflow/compiler/xla/service:gpu_plugin", "//tensorflow/compiler/xla/service/gpu:gpu_executable", "//tensorflow/compiler/xla/tests:filecheck", "//tensorflow/compiler/xla/tests:llvm_irgen_test_base", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], ) @@ -60,6 +60,7 @@ tf_cc_test( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", ], ) @@ -94,6 +95,7 @@ tf_cc_test( "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", ], ) @@ -150,6 +152,7 @@ tf_cc_test( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", ], ) @@ -168,6 +171,7 @@ tf_cc_test( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/memory", ], ) diff --git a/tensorflow/compiler/xla/service/gpu/tests/gpu_codegen_test.cc b/tensorflow/compiler/xla/service/gpu/tests/gpu_codegen_test.cc index 4b8415fe91..79e77d4c4d 100644 --- a/tensorflow/compiler/xla/service/gpu/tests/gpu_codegen_test.cc +++ b/tensorflow/compiler/xla/service/gpu/tests/gpu_codegen_test.cc @@ -14,8 +14,8 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/gpu/tests/gpu_codegen_test.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/legacy_flags/debug_options_flags.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/gpu/gpu_executable.h" #include "tensorflow/compiler/xla/tests/filecheck.h" #include "tensorflow/core/platform/logging.h" @@ -32,15 +32,14 @@ std::unique_ptr<HloModule> GpuCodegenTest::CreateNewModuleWithFTZ(bool ftz) { debug_options.add_xla_disable_hlo_passes("constant_folding"); config.set_debug_options(debug_options); - return MakeUnique<HloModule>(TestName(), config); + return absl::make_unique<HloModule>(TestName(), config); } void GpuCodegenTest::CompileAndVerifyPtx(std::unique_ptr<HloModule> hlo_module, const string& pattern) { std::unique_ptr<Executable> executable = std::move(CompileToExecutable(std::move(hlo_module)).ValueOrDie()); - string ptx_str = - std::string(static_cast<GpuExecutable*>(executable.get())->ptx()); + string ptx_str(static_cast<GpuExecutable*>(executable.get())->ptx()); StatusOr<bool> filecheck_result = RunFileCheck(ptx_str, pattern); ASSERT_TRUE(filecheck_result.ok()); EXPECT_TRUE(filecheck_result.ValueOrDie()); diff --git a/tensorflow/compiler/xla/service/gpu/tests/gpu_copy_test.cc b/tensorflow/compiler/xla/service/gpu/tests/gpu_copy_test.cc index ce69e058e6..4550f36fdf 100644 --- a/tensorflow/compiler/xla/service/gpu/tests/gpu_copy_test.cc +++ b/tensorflow/compiler/xla/service/gpu/tests/gpu_copy_test.cc @@ -16,9 +16,9 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/gpu/tests/gpu_codegen_test.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" diff --git a/tensorflow/compiler/xla/service/gpu/tests/gpu_index_test.cc b/tensorflow/compiler/xla/service/gpu/tests/gpu_index_test.cc index e5958165ef..a06576df7b 100644 --- a/tensorflow/compiler/xla/service/gpu/tests/gpu_index_test.cc +++ b/tensorflow/compiler/xla/service/gpu/tests/gpu_index_test.cc @@ -16,8 +16,8 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/gpu/tests/gpu_codegen_test.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" diff --git a/tensorflow/compiler/xla/service/gpu/tests/gpu_kernel_tiling_test.cc b/tensorflow/compiler/xla/service/gpu/tests/gpu_kernel_tiling_test.cc index cca35316f0..15d1e269cc 100644 --- a/tensorflow/compiler/xla/service/gpu/tests/gpu_kernel_tiling_test.cc +++ b/tensorflow/compiler/xla/service/gpu/tests/gpu_kernel_tiling_test.cc @@ -27,13 +27,22 @@ namespace { class GpuKernelTilingTest : public GpuCodegenTest { protected: - GpuKernelTilingTest() { + GpuKernelTilingTest() {} + + // Most tests in this file want to skip layout assignment, but a few need it + // enabled. + HloModuleConfig ConfigWithLayoutAssignment() { + return GetModuleConfigForTest(); + } + + HloModuleConfig ConfigWithoutLayoutAssignment() { + HloModuleConfig config; auto debug_options = HloTestBase::GetDebugOptionsForTest(); - config_.set_debug_options(debug_options); // Disable layout_assignment to use the preassigned layouts. - debug_options.add_xla_disable_hlo_passes("layout_assignment"); + debug_options.add_xla_disable_hlo_passes("layout-assignment"); + config.set_debug_options(debug_options); + return config; } - HloModuleConfig config_; }; TEST_F(GpuKernelTilingTest, UnnestedTransposeWithProperDimensionsTiled) { @@ -46,7 +55,13 @@ TEST_F(GpuKernelTilingTest, UnnestedTransposeWithProperDimensionsTiled) { })"; // Check that a call to llvm.nvvm.barrier0 is generated. - auto hlo_module = ParseHloString(kHloString, config_).ValueOrDie(); + // + // We must enable layout assignment in order for this test to work correctly. + // AlgebraicSimplifier removes copy1; it's added back by layout assignment, + // which respects the module's entry computation layout. But if we don't run + // layout assignment...well, nobody else adds the copy back. + auto hlo_module = + ParseHloString(kHloString, ConfigWithLayoutAssignment()).ValueOrDie(); CompileAndVerifyIr(std::move(hlo_module), R"( ; CHECK-LABEL: define void @copy @@ -68,8 +83,11 @@ TEST_F(GpuKernelTilingTest, UnnestedTransposeWithSmallDimensionsNotTiled) { ROOT copy1 = f16[2,3,64]{1,0,2} copy(para0) })"; - // Check that a call to llvm.nvvm.barrier0 is not generated. - auto hlo_module = ParseHloString(kHloString, config_).ValueOrDie(); + // Check that a call to llvm.nvvm.barrier0 is not generated. As in + // UnnestedTransposeWithProperDimensionsTiled, we must run layout assignment + // here. + auto hlo_module = + ParseHloString(kHloString, ConfigWithLayoutAssignment()).ValueOrDie(); CompileAndVerifyIr(std::move(hlo_module), R"( ; CHECK-LABEL: define void @copy @@ -95,7 +113,8 @@ TEST_F(GpuKernelTilingTest, SimpleFusionWithTransposeTiled) { })"; // Check that a call to llvm.nvvm.barrier0 is generated. - auto hlo_module = ParseHloString(kHloString, config_).ValueOrDie(); + auto hlo_module = + ParseHloString(kHloString, ConfigWithoutLayoutAssignment()).ValueOrDie(); CompileAndVerifyIr(std::move(hlo_module), R"( ; CHECK-LABEL: define void @fusion @@ -128,7 +147,8 @@ TEST_F(GpuKernelTilingTest, MultipleOutputFusionWithOnePossibleTransposeTiled) { })"; // Check that a call to llvm.nvvm.barrier0 is generated. - auto hlo_module = ParseHloString(kHloString, config_).ValueOrDie(); + auto hlo_module = + ParseHloString(kHloString, ConfigWithoutLayoutAssignment()).ValueOrDie(); CompileAndVerifyIr(std::move(hlo_module), R"( ; CHECK-LABEL: define void @fusion @@ -162,7 +182,8 @@ TEST_F(GpuKernelTilingTest, })"; // Check that a call to llvm.nvvm.barrier0 is not generated. - auto hlo_module = ParseHloString(kHloString, config_).ValueOrDie(); + auto hlo_module = + ParseHloString(kHloString, ConfigWithoutLayoutAssignment()).ValueOrDie(); CompileAndVerifyIr(std::move(hlo_module), R"( ; CHECK-LABEL: define void @fusion diff --git a/tensorflow/compiler/xla/service/gpu/tests/gpu_ldg_test.cc b/tensorflow/compiler/xla/service/gpu/tests/gpu_ldg_test.cc index 6c9ae7bada..6a9ecd9dae 100644 --- a/tensorflow/compiler/xla/service/gpu/tests/gpu_ldg_test.cc +++ b/tensorflow/compiler/xla/service/gpu/tests/gpu_ldg_test.cc @@ -20,8 +20,8 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/gpu/tests/gpu_codegen_test.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" diff --git a/tensorflow/compiler/xla/service/gpu/tests/gpu_noalias_test.cc b/tensorflow/compiler/xla/service/gpu/tests/gpu_noalias_test.cc index c42e5704a4..15198865bd 100644 --- a/tensorflow/compiler/xla/service/gpu/tests/gpu_noalias_test.cc +++ b/tensorflow/compiler/xla/service/gpu/tests/gpu_noalias_test.cc @@ -16,8 +16,8 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/gpu/tests/gpu_codegen_test.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" diff --git a/tensorflow/compiler/xla/service/gpu/tests/gpu_unrolling_test.cc b/tensorflow/compiler/xla/service/gpu/tests/gpu_unrolling_test.cc index 9622936306..0f2d5568ca 100644 --- a/tensorflow/compiler/xla/service/gpu/tests/gpu_unrolling_test.cc +++ b/tensorflow/compiler/xla/service/gpu/tests/gpu_unrolling_test.cc @@ -138,6 +138,9 @@ TEST_F(GpuUnrollingTest, UnrollMultiOutputFusion) { HloModuleConfig config; auto debug_options = HloTestBase::GetDebugOptionsForTest(); debug_options.set_xla_gpu_max_kernel_unroll_factor(2); + // Disable layout assignment for this test. Layout assignment does not expect + // fusions to be present, and so it does the wrong thing. + debug_options.add_xla_disable_hlo_passes("layout-assignment"); config.set_debug_options(debug_options); const char *const kMultiOutputFusionModule = R"( diff --git a/tensorflow/compiler/xla/service/gpu/thunk_schedule.cc b/tensorflow/compiler/xla/service/gpu/thunk_schedule.cc index bdb062837c..141f321938 100644 --- a/tensorflow/compiler/xla/service/gpu/thunk_schedule.cc +++ b/tensorflow/compiler/xla/service/gpu/thunk_schedule.cc @@ -144,16 +144,15 @@ const std::list<const Thunk*>& ThunkSchedule::DependsOn( string ThunkSchedule::ToString() const { string result = "Total order:\n"; for (Thunk* thunk : thunk_total_order_) { - tensorflow::strings::StrAppend(&result, "\t", - thunk->hlo_instruction()->ToString(), "\n"); + absl::StrAppend(&result, "\t", thunk->hlo_instruction()->ToString(), "\n"); } - tensorflow::strings::StrAppend(&result, "Dependencies:\n"); + absl::StrAppend(&result, "Dependencies:\n"); for (const auto& entry : depends_on_) { const Thunk* dependent = entry.first; for (const Thunk* dependency : entry.second) { - tensorflow::strings::StrAppend( - &result, "\t", dependent->hlo_instruction()->name(), " depends on ", - dependency->hlo_instruction()->name(), "\n"); + absl::StrAppend(&result, "\t", dependent->hlo_instruction()->name(), + " depends on ", dependency->hlo_instruction()->name(), + "\n"); } } return result; diff --git a/tensorflow/compiler/xla/service/gpu/tuple_thunk.cc b/tensorflow/compiler/xla/service/gpu/tuple_thunk.cc index 8579b1545f..989b542ff4 100644 --- a/tensorflow/compiler/xla/service/gpu/tuple_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/tuple_thunk.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/tuple_thunk.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" #include "tensorflow/compiler/xla/util.h" @@ -25,7 +26,7 @@ Status TupleThunk::ExecuteOnStream(const BufferAllocations& buffer_allocations, se::Stream* stream, HloExecutionProfiler* profiler) { auto size = tuple_element_buffers_.size(); - auto tuple_element_buffer_addresses = MakeUnique<void*[]>(size); + auto tuple_element_buffer_addresses = absl::make_unique<void*[]>(size); for (int i = 0; i != size; ++i) { tuple_element_buffer_addresses[i] = buffer_allocations.GetDeviceAddress(tuple_element_buffers_[i]).opaque(); diff --git a/tensorflow/compiler/xla/service/gpu/while_thunk.cc b/tensorflow/compiler/xla/service/gpu/while_thunk.cc index d81d87e7dc..c4754fe378 100644 --- a/tensorflow/compiler/xla/service/gpu/while_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/while_thunk.cc @@ -15,7 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/while_thunk.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" @@ -34,9 +34,9 @@ WhileThunk::WhileThunk( // and body_thunk_sequence_ constructors because these SequentialThunks // are logically "part of" this WhileThunk, and shouldn't be profiled // separately from it. - condition_thunk_sequence_(MakeUnique<SequentialThunk>( + condition_thunk_sequence_(absl::make_unique<SequentialThunk>( std::move(*condition_thunk_sequence), nullptr)), - body_thunk_sequence_(MakeUnique<SequentialThunk>( + body_thunk_sequence_(absl::make_unique<SequentialThunk>( std::move(*body_thunk_sequence), nullptr)) {} Status WhileThunk::Initialize(const GpuExecutable& executable, @@ -70,7 +70,7 @@ Status WhileThunk::ExecuteOnStream(const BufferAllocations& buffer_allocations, if (!block_status.ok()) { return InternalError( "Failed to complete all kernels launched on stream %p: %s", stream, - block_status.error_message().c_str()); + block_status.error_message()); } if (!condition_result) { diff --git a/tensorflow/compiler/xla/service/gpu/while_transformer_test.cc b/tensorflow/compiler/xla/service/gpu/while_transformer_test.cc index c5f3906356..40183de96e 100644 --- a/tensorflow/compiler/xla/service/gpu/while_transformer_test.cc +++ b/tensorflow/compiler/xla/service/gpu/while_transformer_test.cc @@ -118,7 +118,8 @@ class WhileTransformerTest : public HloTestBase { } void RunCopyInsertionPass() { - HloVerifier verifier; + HloVerifier verifier(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false); TF_ASSERT_OK(verifier.Run(module_.get()).status()); CopyInsertion copy_insertion; TF_ASSERT_OK(copy_insertion.Run(module_.get()).status()); diff --git a/tensorflow/compiler/xla/service/graphviz_example.cc b/tensorflow/compiler/xla/service/graphviz_example.cc index aa89567ee8..a2be89511b 100644 --- a/tensorflow/compiler/xla/service/graphviz_example.cc +++ b/tensorflow/compiler/xla/service/graphviz_example.cc @@ -22,9 +22,10 @@ limitations under the License. #include <memory> #include <string> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_graph_dumper.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -33,7 +34,6 @@ limitations under the License. #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/init_main.h" #include "tensorflow/core/platform/types.h" @@ -43,8 +43,7 @@ namespace { // Adds a computation to the given HLO module which adds a scalar constant to // its parameter and returns the result. HloComputation* AddScalarConstantComputation(int64 addend, HloModule* module) { - auto builder = - HloComputation::Builder(tensorflow::strings::StrCat("add_", addend)); + auto builder = HloComputation::Builder(absl::StrCat("add_", addend)); auto x_value = builder.AddInstruction(HloInstruction::CreateParameter( 0, ShapeUtil::MakeShape(F32, {}), "x_value")); auto half = builder.AddInstruction( @@ -84,7 +83,7 @@ HloComputation* CallForwardingComputation(HloComputation* computation, // the module. std::unique_ptr<HloModule> MakeBigGraph() { HloModuleConfig config; - auto module = MakeUnique<HloModule>("BigGraph", config); + auto module = absl::make_unique<HloModule>("BigGraph", config); auto builder = HloComputation::Builder("TestBigGraphvizGraph"); diff --git a/tensorflow/compiler/xla/service/heap_simulator.cc b/tensorflow/compiler/xla/service/heap_simulator.cc index 4005fc0d11..38c3982ebf 100644 --- a/tensorflow/compiler/xla/service/heap_simulator.cc +++ b/tensorflow/compiler/xla/service/heap_simulator.cc @@ -18,6 +18,7 @@ limitations under the License. #include <algorithm> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/util.h" @@ -45,7 +46,7 @@ StatusOr<int64> HeapSimulator::MinimumMemoryForModule( // bound, by minimizing the liveness of sub-computations. TF_ASSIGN_OR_RETURN( HeapSimulator::Result result, - HeapSimulator::Run(MakeUnique<NoFragmentationStatsHeap>(), *module, + HeapSimulator::Run(absl::make_unique<NoFragmentationStatsHeap>(), *module, module_sequence, *points_to_analysis, size_function)); return result.heap_size; } @@ -60,9 +61,10 @@ StatusOr<int64> HeapSimulator::MinimumMemoryForComputation( memory_by_computation) { TF_ASSIGN_OR_RETURN( HeapSimulator::Result result, - HeapSimulator::Run(MakeUnique<NoFragmentationStatsHeap>(), computation, - sequence, points_to_analysis, size_function, - HeapSimulator::Options(), memory_by_computation)); + HeapSimulator::Run(absl::make_unique<NoFragmentationStatsHeap>(), + computation, sequence, points_to_analysis, + size_function, HeapSimulator::Options(), + memory_by_computation)); return result.heap_size; } @@ -142,7 +144,7 @@ Status HeapSimulator::RunComputation( } } else { // A GetTupleElement doesn't need to keep all of its operand's buffers - // alive. It only needs the buffers that relate to the element its + // alive. It only needs the buffers that relate to the element it's // extracting, and the tuple it's extracting from, but not the buffers // for the other elements. for (const BufferValue* buffer : points_to.element({})) { @@ -275,13 +277,13 @@ Status HeapSimulator::RunComputation( *memory_by_computation_); } - // If the whole module is sequential, we can save memory by running the - // heap-simulation for sub-computations inline. E.g. the buffers for the - // condition and body of a kWhile instruction are only live for the duration - // of the instruction itself. + // If all computations in the module have been scheduled, we can save memory + // by running the heap-simulation for sub-computations inline. E.g. the + // buffers for the condition and body of a kWhile instruction are only live + // for the duration of the instruction itself. // // The order that the sub-computations are simulated does not affect - // correctness; since the whole module is sequential, we know that the + // correctness; since the whole module has been scheduled, we know that the // sub-computations will never be run concurrently. if (module_sequence_ != nullptr) { if (instruction->opcode() == HloOpcode::kCall || @@ -344,7 +346,7 @@ HeapSimulator::HeapSimulator( const SequentialHloOrdering::HloModuleSequence* module_sequence, const tensorflow::gtl::FlatMap<const HloComputation*, int64>* memory_by_computation) - : no_fragmentation_stats_(MakeUnique<NoFragmentationStatsHeap>()), + : no_fragmentation_stats_(absl::make_unique<NoFragmentationStatsHeap>()), algorithm_(std::move(algorithm)), size_fn_(size_fn), options_(options), @@ -378,9 +380,10 @@ void HeapSimulator::Alloc(const BufferValue* buffer, allocated_buffers_.insert(buffer); const int64 size = size_fn_(*buffer); - algorithm_->Alloc(buffer, size); - no_fragmentation_stats_->Alloc(buffer, size); - + const HloInstruction* instruction_to_calc_aliasing = + memory_by_computation_ == nullptr ? nullptr : instruction; + algorithm_->Alloc(buffer, size, instruction_to_calc_aliasing); + no_fragmentation_stats_->Alloc(buffer, size, instruction_to_calc_aliasing); FillDebugTrace(HeapSimulatorTrace::Event::ALLOC, buffer, instruction, nullptr); } @@ -518,6 +521,18 @@ void NoFragmentationStatsHeap::Alloc(const BufferValue* buffer, int64 size) { } } +void NoFragmentationStatsHeap::Alloc(const BufferValue* buffer, int64 size, + const HloInstruction* instruction) { + // The output buffer of while/call/conditional is always aliased with the + // output buffer of the root instruction in the body. Don't double count. + if (instruction == nullptr || + (instruction->opcode() != HloOpcode::kWhile && + instruction->opcode() != HloOpcode::kCall && + instruction->opcode() != HloOpcode::kConditional)) { + Alloc(buffer, size); + } +} + void NoFragmentationStatsHeap::AccountForSubcomputationMemory( const HloInstruction* instruction, const tensorflow::gtl::FlatMap<const HloComputation*, int64>& diff --git a/tensorflow/compiler/xla/service/heap_simulator.h b/tensorflow/compiler/xla/service/heap_simulator.h index 811a6042df..af05bedee7 100644 --- a/tensorflow/compiler/xla/service/heap_simulator.h +++ b/tensorflow/compiler/xla/service/heap_simulator.h @@ -36,6 +36,7 @@ namespace xla { // Forward declare classes defined below. class HeapAlgorithm; +class NoFragmentationStatsHeap; // HeapSimulator assigns buffer offsets by running a simulation of a regular // memory heap with Alloc and Free calls. It only works for completely @@ -161,7 +162,10 @@ class HeapSimulator { const HloInstruction* instruction, const BufferValue* shared_with_canonical); - const std::unique_ptr<HeapAlgorithm> no_fragmentation_stats_; + // Counterintuitive: the algorithm_ itself can be a NoFragmentationStatsHeap, + // in which case we are calculating the same allocs/frees twice in the + // simulation. + const std::unique_ptr<NoFragmentationStatsHeap> no_fragmentation_stats_; const std::unique_ptr<HeapAlgorithm> algorithm_; const BufferValue::SizeFunction size_fn_; const Options options_; @@ -216,6 +220,21 @@ class HeapAlgorithm { // Alloc allocates a buffer of 'size' bytes. virtual void Alloc(const BufferValue* buffer, int64 size) = 0; + // NoFragmentationStatsHeap overrides this method. + virtual void Alloc(const BufferValue* buffer, int64 size, + const HloInstruction* instruction) { + Alloc(buffer, size); + } + + // Takes memory usage of subcomputations into account when calculating the + // memory usage of a computation. Currently, we don't handle buffer aliasing + // between computations entirely correctly. We are careful to not double count + // for the output buffers of whiles/conds/calls. But we don't take into + // account other aliases, such as for the while init. A more thorough solution + // would require something like BufferAssignment::BuildColocatedBufferSets. + // TODO(b/65835246): + // Since TuplePointsToAnalysis is being replaced with a module-aware alias + // analysis, it's not worth making major changes to HeapSimulator now. virtual void AccountForSubcomputationMemory( const HloInstruction* instruction, const tensorflow::gtl::FlatMap<const HloComputation*, int64>& @@ -240,6 +259,9 @@ class NoFragmentationStatsHeap : public HeapAlgorithm { void Alloc(const BufferValue* buffer, int64 size) override; + void Alloc(const BufferValue* buffer, int64 size, + const HloInstruction* instruction) override; + void AccountForSubcomputationMemory( const HloInstruction* instruction, const tensorflow::gtl::FlatMap<const HloComputation*, int64>& diff --git a/tensorflow/compiler/xla/service/heap_simulator_test.cc b/tensorflow/compiler/xla/service/heap_simulator_test.cc index b41dc66fe9..5f85f14565 100644 --- a/tensorflow/compiler/xla/service/heap_simulator_test.cc +++ b/tensorflow/compiler/xla/service/heap_simulator_test.cc @@ -19,6 +19,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/service/buffer_value.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" @@ -137,7 +138,7 @@ class HeapSimulatorTracker { const string& name, std::unique_ptr<HloComputation> computation, const std::vector<const HloInstruction*>& instruction_sequence) { HloModuleConfig config; - module_ = MakeUnique<HloModule>(name, config); + module_ = absl::make_unique<HloModule>(name, config); module_->AddEntryComputation(std::move(computation)); points_to_analysis_ = TuplePointsToAnalysis::Run(module_.get()).ConsumeValueOrDie(); @@ -146,8 +147,8 @@ class HeapSimulatorTracker { // the secondary sorting criteria of DecreasingSizeRunsHeap to sort calls by // buffer id, for determinism in the tests. auto zero_size = [](const BufferValue& buffer) { return 0; }; - auto algorithm = MakeUnique<DecreasingSizeRunsHeap>( - MakeUnique<HeapCallRecorder>(&actual_calls_)); + auto algorithm = absl::make_unique<DecreasingSizeRunsHeap>( + absl::make_unique<HeapCallRecorder>(&actual_calls_)); result_ = HeapSimulator::Run( std::move(algorithm), *module_->entry_computation(), instruction_sequence, *points_to_analysis_, zero_size) @@ -156,7 +157,7 @@ class HeapSimulatorTracker { explicit HeapSimulatorTracker(const string& name) { HloModuleConfig config; - module_ = MakeUnique<HloModule>(name, config); + module_ = absl::make_unique<HloModule>(name, config); } // Similar to the single entry computation constructor above, but runs the @@ -182,8 +183,8 @@ class HeapSimulatorTracker { auto size_fn = [&reverse_position](const BufferValue& buffer) { return reverse_position[buffer.instruction()]; }; - auto algorithm = MakeUnique<DecreasingSizeRunsHeap>( - MakeUnique<HeapCallRecorder>(&actual_calls_)); + auto algorithm = absl::make_unique<DecreasingSizeRunsHeap>( + absl::make_unique<HeapCallRecorder>(&actual_calls_)); result_ = HeapSimulator::Run(std::move(algorithm), *module_, module_sequence, *points_to_analysis_, size_fn) .ConsumeValueOrDie(); @@ -675,7 +676,8 @@ class HeapAlgorithmTestBase : public ::testing::Test { const BufferValue::Id id = buffers_.size(); auto const0 = builder_.AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(1.0))); - buffers_.emplace_back(MakeUnique<HloValue>(id, const0, ShapeIndex{})); + buffers_.emplace_back( + absl::make_unique<HloValue>(id, const0, ShapeIndex{})); return buffers_.back().get(); } @@ -724,7 +726,8 @@ class DecreasingSizeRunsHeapTest : public HeapAlgorithmTestBase {}; TEST_F(DecreasingSizeRunsHeapTest, Empty) { CallSequence call_sequence; - DecreasingSizeRunsHeap heap(MakeUnique<HeapCallRecorder>(&call_sequence)); + DecreasingSizeRunsHeap heap( + absl::make_unique<HeapCallRecorder>(&call_sequence)); heap.Finish(); EXPECT_EQ(call_sequence, CallSequence({ {kFinish, nullptr}, @@ -733,7 +736,8 @@ TEST_F(DecreasingSizeRunsHeapTest, Empty) { TEST_F(DecreasingSizeRunsHeapTest, Simple) { CallSequence call_sequence; - DecreasingSizeRunsHeap heap(MakeUnique<HeapCallRecorder>(&call_sequence)); + DecreasingSizeRunsHeap heap( + absl::make_unique<HeapCallRecorder>(&call_sequence)); heap.Alloc(buffer_a_, 10); heap.Alloc(buffer_b_, 20); heap.Alloc(buffer_c_, 30); @@ -760,7 +764,8 @@ TEST_F(DecreasingSizeRunsHeapTest, Simple) { TEST_F(DecreasingSizeRunsHeapTest, Mixed) { CallSequence call_sequence; - DecreasingSizeRunsHeap heap(MakeUnique<HeapCallRecorder>(&call_sequence)); + DecreasingSizeRunsHeap heap( + absl::make_unique<HeapCallRecorder>(&call_sequence)); heap.Alloc(buffer_a_, 10); heap.Alloc(buffer_b_, 20); heap.Free(buffer_b_, 20); diff --git a/tensorflow/compiler/xla/service/hlo.proto b/tensorflow/compiler/xla/service/hlo.proto index fa218657fe..58b7af93eb 100644 --- a/tensorflow/compiler/xla/service/hlo.proto +++ b/tensorflow/compiler/xla/service/hlo.proto @@ -34,7 +34,7 @@ import "tensorflow/compiler/xla/xla_data.proto"; option cc_enable_arenas = true; // Serialization of HloInstruction. -// Next ID: 51 +// Next ID: 53 message HloInstructionProto { reserved 10; reserved "parameter_name"; @@ -46,6 +46,8 @@ message HloInstructionProto { reserved "control_predecessor_names"; reserved 6; reserved "called_computation_names"; + reserved 44; + reserved "replica_group_ids"; string name = 1; string opcode = 2; @@ -158,9 +160,6 @@ message HloInstructionProto { string backend_config = 43; // Cross replica op fields. - // TODO(b/112107579): remove replica_group_ids field and always use - // replica_groups. - repeated int64 replica_group_ids = 44; repeated ReplicaGroup replica_groups = 49; int64 all_reduce_id = 45; string cross_replica_sum_barrier = 46; @@ -171,6 +170,12 @@ message HloInstructionProto { bool is_host_transfer = 47; xla.ScatterDimensionNumbers scatter_dimension_numbers = 48; + + // Precision configuration for the instruction. Has backend-specific meaning. + xla.PrecisionConfigProto precision_config = 51; + + // Collective permute field. + repeated SourceTarget source_target_pairs = 52; } // Serialization of HloComputation. diff --git a/tensorflow/compiler/xla/service/hlo_alias_analysis.cc b/tensorflow/compiler/xla/service/hlo_alias_analysis.cc index e8a4b034b4..0986da65cb 100644 --- a/tensorflow/compiler/xla/service/hlo_alias_analysis.cc +++ b/tensorflow/compiler/xla/service/hlo_alias_analysis.cc @@ -20,6 +20,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/service/hlo_buffer.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -28,15 +30,11 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" namespace xla { -using ::tensorflow::str_util::Join; -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; +using absl::StrAppend; // Data structure used to construct the alias analysis. Thrown away after alias // analysis is complete. This data structure keeps track of which sets of @@ -414,7 +412,7 @@ Status HloAliasAnalysis::Verify() const { } string HloAliasAnalysis::ToString() const { - string out = StrCat("HloAliasAnalysis, module ", module_->name(), "\n"); + string out = absl::StrCat("HloAliasAnalysis, module ", module_->name(), "\n"); StrAppend(&out, " Buffers at each position:\n"); for (const HloComputation* computation : module_->computations()) { for (const HloInstruction* instruction : computation->instructions()) { @@ -457,7 +455,7 @@ StatusOr<std::unique_ptr<HloAliasAnalysis>> HloAliasAnalysis::Run( VLOG(2) << "HloAliasAnalysis::Run on module " << module->name(); XLA_VLOG_LINES(2, module->ToString()); - auto alias_analysis = WrapUnique(new HloAliasAnalysis(module)); + auto alias_analysis = absl::WrapUnique(new HloAliasAnalysis(module)); TF_ASSIGN_OR_RETURN(alias_analysis->dataflow_analysis_, HloDataflowAnalysis::Run(*module, /*ssa_form=*/true, /*bitcast_defines_value=*/false, @@ -537,10 +535,10 @@ bool HloAliasAnalysis::HasLiveRangeInterference( if (ordering.MayInterfere(*values[i - 1], *values[i], dataflow_analysis())) { VLOG(1) << "In buffer " << buffer.id() << " containing values:\n " - << Join(values, ", ", - [](string* out, const HloValue* value) { - StrAppend(out, value->ToShortString()); - }) + << absl::StrJoin(values, ", ", + [](string* out, const HloValue* value) { + StrAppend(out, value->ToShortString()); + }) << "\nValue " << values[i - 1]->ToShortString() << " may interfere with value " << values[i]->ToShortString(); diff --git a/tensorflow/compiler/xla/service/hlo_buffer.cc b/tensorflow/compiler/xla/service/hlo_buffer.cc index e16413f361..6c11a073b7 100644 --- a/tensorflow/compiler/xla/service/hlo_buffer.cc +++ b/tensorflow/compiler/xla/service/hlo_buffer.cc @@ -20,6 +20,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -27,15 +29,10 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" namespace xla { -using ::tensorflow::str_util::Join; -using ::tensorflow::strings::StrCat; - bool HloBuffer::operator==(const HloBuffer& other) const { bool equal = id() == other.id(); if (equal) { @@ -59,10 +56,11 @@ std::vector<HloPosition> HloBuffer::ComputePositions() const { } string HloBuffer::ToString() const { - return StrCat("HloBuffer ", id_, ", values: ", - Join(values_, ", ", [](string* result, const HloValue* value) { - result->append(value->ToShortString()); - })); + return absl::StrCat( + "HloBuffer ", id_, ", values: ", + absl::StrJoin(values_, ", ", [](string* result, const HloValue* value) { + result->append(value->ToShortString()); + })); } std::ostream& operator<<(std::ostream& out, const HloBuffer& buffer) { diff --git a/tensorflow/compiler/xla/service/hlo_computation.cc b/tensorflow/compiler/xla/service/hlo_computation.cc index 441288da1a..c2d0673f49 100644 --- a/tensorflow/compiler/xla/service/hlo_computation.cc +++ b/tensorflow/compiler/xla/service/hlo_computation.cc @@ -23,9 +23,13 @@ limitations under the License. #include <set> #include <sstream> +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" @@ -36,13 +40,11 @@ limitations under the License. #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" namespace xla { -using ::tensorflow::strings::StrCat; +using absl::StrCat; std::unique_ptr<HloComputation> HloComputation::Builder::Build( HloInstruction* root_instruction) { @@ -56,8 +58,8 @@ std::unique_ptr<HloComputation> HloComputation::Builder::Build( HloInstruction* root = root_instruction ? root_instruction : last_added_instruction_; CHECK_NE(nullptr, root); - return WrapUnique(new HloComputation(name_, parameter_count, &instructions_, - root, fusion_instruction_)); + return absl::WrapUnique(new HloComputation( + name_, parameter_count, &instructions_, root, fusion_instruction_)); } HloComputation::HloComputation( @@ -135,7 +137,7 @@ string RenameFusionParameter(const string& original_name, int64 new_param_no) { } string after_param = original_name.substr(index + param_underscore.size()); int64 numeric_suffix; - if (tensorflow::strings::safe_strto64(after_param, &numeric_suffix)) { + if (absl::SimpleAtoi(after_param, &numeric_suffix)) { return StrCat(original_name.substr(0, index + param_underscore.size()), new_param_no); } @@ -317,11 +319,12 @@ void ComputeComputationPostOrder( } } -enum State { kVisiting, kVisited }; +} // namespace -void ComputeInstructionPostOrder( +void HloComputation::ComputeInstructionPostOrder( + const HloComputation::ChannelDependencyMap& channel_dependency_map, std::vector<HloInstruction*>* post_order, HloInstruction* root, - tensorflow::gtl::FlatMap<HloInstruction*, State>* visited) { + tensorflow::gtl::FlatMap<HloInstruction*, VisitState>* visited) const { std::vector<HloInstruction*> dfs_stack; dfs_stack.push_back(root); while (!dfs_stack.empty()) { @@ -354,16 +357,71 @@ void ComputeInstructionPostOrder( for (HloInstruction* op : current->control_predecessors()) { dfs_stack.emplace_back(op); } + + // Add inputs for send->recv_done dependencies and cross-replica-sum + // dependencies. + switch (current->opcode()) { + case HloOpcode::kRecvDone: { + auto it = channel_dependency_map.find(current->channel_id()); + if (it != channel_dependency_map.end()) { + for (HloInstruction* op : it->second) { + dfs_stack.emplace_back(op); + } + } + break; + } + case HloOpcode::kCrossReplicaSum: { + auto all_reduce_id = current->all_reduce_id(); + if (all_reduce_id) { + auto it = channel_dependency_map.find(all_reduce_id.value()); + if (it != channel_dependency_map.end()) { + for (HloInstruction* op : it->second) { + dfs_stack.emplace_back(op); + } + } + } + break; + } + default: + break; + } } } -} // namespace +HloComputation::ChannelDependencyMap +HloComputation::ComputeChannelDependencies() const { + ChannelDependencyMap channel_dependency_map; + for (const auto& instruction : instructions_) { + switch (instruction->opcode()) { + case HloOpcode::kSend: { + channel_dependency_map[instruction->channel_id()].push_back( + instruction.get()); + break; + } + case HloOpcode::kCrossReplicaSum: { + auto all_reduce_id = instruction->all_reduce_id(); + if (all_reduce_id) { + auto& dependencies = channel_dependency_map[all_reduce_id.value()]; + absl::c_copy(instruction->operands(), + std::back_inserter(dependencies)); + absl::c_copy(instruction->control_predecessors(), + std::back_inserter(dependencies)); + } + break; + } + default: + break; + } + } + return channel_dependency_map; +} std::vector<HloInstruction*> HloComputation::MakeInstructionPostOrder() const { + auto channel_dependency_map = ComputeChannelDependencies(); std::vector<HloInstruction*> post_order; post_order.reserve(instruction_count()); std::vector<HloInstruction*> trace_instructions; - tensorflow::gtl::FlatMap<HloInstruction*, State> visited; + tensorflow::gtl::FlatMap<HloInstruction*, VisitState> visited; for (auto& instruction : instructions_) { if (instruction->opcode() == HloOpcode::kTrace) { // Trace instructions aren't handled by the DFS visitor. Add trace @@ -371,7 +429,8 @@ std::vector<HloInstruction*> HloComputation::MakeInstructionPostOrder() const { // users). trace_instructions.push_back(instruction.get()); } else if (instruction->users().empty()) { - ComputeInstructionPostOrder(&post_order, instruction.get(), &visited); + ComputeInstructionPostOrder(channel_dependency_map, &post_order, + instruction.get(), &visited); } } post_order.insert(post_order.end(), trace_instructions.begin(), @@ -493,9 +552,9 @@ HloComputation::CreateFromProto( return to_proto_id[a.get()] < to_proto_id[b.get()]; }); - return WrapUnique(new HloComputation(proto.name(), parameter_count, - &instructions, root, - /*fusion_instruction=*/nullptr)); + return absl::WrapUnique(new HloComputation(proto.name(), parameter_count, + &instructions, root, + /*fusion_instruction=*/nullptr)); } void HloComputation::FuseInstructionsInto( @@ -566,16 +625,15 @@ StatusOr<HloInstruction*> HloComputation::DeepCopyInstruction( if (instruction->parent() != this) { return FailedPrecondition( "Can't deep copy instruction %s: instruction is not in computation %s", - instruction->name().c_str(), name().c_str()); + instruction->name(), name()); } if (indices_to_copy != nullptr && !ShapeUtil::Compatible(instruction->shape(), indices_to_copy->shape())) { return FailedPrecondition( "Can't deep copy instruction %s: given shape tree of indices to copy " "has incompatible shapes: %s vs. %s", - instruction->name().c_str(), - ShapeUtil::HumanString(instruction->shape()).c_str(), - ShapeUtil::HumanString(indices_to_copy->shape()).c_str()); + instruction->name(), ShapeUtil::HumanString(instruction->shape()), + ShapeUtil::HumanString(indices_to_copy->shape())); } ShapeIndex index; @@ -605,7 +663,7 @@ StatusOr<HloInstruction*> HloComputation::DeepCopyInstructionWithCustomCopier( if (instruction->parent() != this) { return FailedPrecondition( "Can't deep copy instruction %s: instruction is not in computation %s", - instruction->name().c_str(), name().c_str()); + instruction->name(), name()); } ShapeIndex index; return DeepCopyHelper(instruction, &index, copy_leaf); @@ -624,6 +682,9 @@ ProgramShape HloComputation::ComputeProgramShape() const { } bool HloComputation::operator==(const HloComputation& other) const { + if (this == &other) { + return true; + } std::set<std::pair<const HloInstruction*, const HloInstruction*>> visited; std::function<bool(const HloInstruction*, const HloInstruction*)> eq = [&visited, &eq](const HloInstruction* a, const HloInstruction* b) { @@ -674,13 +735,37 @@ Status HloComputation::ReplaceInstruction(HloInstruction* old_instruction, std::unique_ptr<HloReachabilityMap> HloComputation::ComputeReachability() const { const auto& all = MakeInstructionPostOrder(); - auto result = MakeUnique<HloReachabilityMap>(all); + auto result = absl::make_unique<HloReachabilityMap>(all); + auto channel_dependency_map = ComputeChannelDependencies(); std::vector<HloInstruction*> inputs; for (const HloInstruction* hlo : all) { inputs.assign(hlo->operands().begin(), hlo->operands().end()); inputs.insert(inputs.end(), hlo->control_predecessors().begin(), hlo->control_predecessors().end()); + + switch (hlo->opcode()) { + case HloOpcode::kRecvDone: { + auto it = channel_dependency_map.find(hlo->channel_id()); + if (it != channel_dependency_map.end()) { + absl::c_copy(it->second, std::back_inserter(inputs)); + } + break; + } + case HloOpcode::kCrossReplicaSum: { + auto all_reduce_id = hlo->all_reduce_id(); + if (all_reduce_id) { + auto it = channel_dependency_map.find(all_reduce_id.value()); + if (it != channel_dependency_map.end()) { + absl::c_copy(it->second, std::back_inserter(inputs)); + } + } + break; + } + default: + break; + } + result->FastSetReachabilityToUnion(inputs, hlo); } return result; @@ -723,11 +808,10 @@ std::vector<HloInstruction*> HloComputation::CollectUnreachableRoots() const { } } VLOG(3) << "Unreachable roots:" - << tensorflow::str_util::Join( - unreachable_roots, "\n\t", - [](string* out, const HloInstruction* hlo) { - tensorflow::strings::StrAppend(out, hlo->ToString()); - }); + << absl::StrJoin(unreachable_roots, "\n\t", + [](string* out, const HloInstruction* hlo) { + absl::StrAppend(out, hlo->ToString()); + }); return unreachable_roots; } @@ -829,7 +913,7 @@ std::unique_ptr<HloComputation> HloComputation::CloneWithReplacements( HloCloneContext* context, const string& suffix) { std::unique_ptr<HloCloneContext> context_ptr; if (context == nullptr) { - context_ptr = MakeUnique<HloCloneContext>(parent(), suffix); + context_ptr = absl::make_unique<HloCloneContext>(parent(), suffix); context = context_ptr.get(); } @@ -898,12 +982,11 @@ void HloComputation::UniquifyName(NameUniquer* name_uniquer) { name_ = name_uniquer->GetUniqueName(name_); } -HloInstruction* HloComputation::GetInstructionWithName( - tensorflow::StringPiece name) { +HloInstruction* HloComputation::GetInstructionWithName(absl::string_view name) { auto instructions_in_computation = instructions(); - auto it = c_find_if(instructions_in_computation, [&](HloInstruction* instr) { - return instr->name() == name; - }); + auto it = absl::c_find_if( + instructions_in_computation, + [&](HloInstruction* instr) { return instr->name() == name; }); return it == instructions_in_computation.end() ? nullptr : *it; } diff --git a/tensorflow/compiler/xla/service/hlo_computation.h b/tensorflow/compiler/xla/service/hlo_computation.h index 49ed65910f..59016624f7 100644 --- a/tensorflow/compiler/xla/service/hlo_computation.h +++ b/tensorflow/compiler/xla/service/hlo_computation.h @@ -367,7 +367,7 @@ class HloComputation { // Returns the instruction in this computation that has name `name`. Returns // null if there is no such computation. - HloInstruction* GetInstructionWithName(tensorflow::StringPiece name); + HloInstruction* GetInstructionWithName(absl::string_view name); int64 unique_id() const { return unique_id_; } @@ -399,6 +399,20 @@ class HloComputation { // Internal helper to collect unreachable roots. std::vector<HloInstruction*> CollectUnreachableRoots() const; + // Returns a map from channel-id to directed dependencies of the channel + // instructions. For send&recv pairs it means the send instruction and for + // cross-replica-sum the union of the dependencies for all participating + // instructions. + using ChannelDependencyMap = + tensorflow::gtl::FlatMap<int64, absl::InlinedVector<HloInstruction*, 1>>; + ChannelDependencyMap ComputeChannelDependencies() const; + + enum VisitState { kVisiting, kVisited }; + void ComputeInstructionPostOrder( + const HloComputation::ChannelDependencyMap& channel_dependency_map, + std::vector<HloInstruction*>* post_order, HloInstruction* root, + tensorflow::gtl::FlatMap<HloInstruction*, VisitState>* visited) const; + string name_; int64 unique_id_; HloInstruction* root_instruction_; diff --git a/tensorflow/compiler/xla/service/hlo_computation_test.cc b/tensorflow/compiler/xla/service/hlo_computation_test.cc index e4c5470331..f7ed1b0316 100644 --- a/tensorflow/compiler/xla/service/hlo_computation_test.cc +++ b/tensorflow/compiler/xla/service/hlo_computation_test.cc @@ -691,6 +691,27 @@ TEST_F(HloComputationTest, StringificationCanonical) { EXPECT_EQ(computation->ToString(options), expected_computation2); } -} // namespace +TEST_F(HloComputationTest, ChannelReachability) { + const Shape shape = ShapeUtil::MakeShape(F32, {5, 7}); + HloComputation::Builder builder("ChannelReachability"); + auto param = builder.AddInstruction( + HloInstruction::CreateParameter(0, shape, "param")); + auto token0 = builder.AddInstruction(HloInstruction::CreateToken()); + auto send = + builder.AddInstruction(HloInstruction::CreateSend(param, token0, 1)); + auto send_done = builder.AddInstruction(HloInstruction::CreateSendDone(send)); + auto token1 = builder.AddInstruction(HloInstruction::CreateToken()); + auto recv = + builder.AddInstruction(HloInstruction::CreateRecv(shape, token1, 1)); + auto recv_done = builder.AddInstruction(HloInstruction::CreateRecvDone(recv)); + auto module = CreateNewModule(); + auto computation = module->AddEntryComputation(builder.Build(recv_done)); + auto reachability = computation->ComputeReachability(); + EXPECT_TRUE(reachability->IsReachable(param, recv_done)); + EXPECT_FALSE(reachability->IsReachable(send, recv)); + EXPECT_FALSE(reachability->IsReachable(send_done, recv)); +} + +} // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_constant_folding.cc b/tensorflow/compiler/xla/service/hlo_constant_folding.cc index 7229031c0c..2ed645c3ae 100644 --- a/tensorflow/compiler/xla/service/hlo_constant_folding.cc +++ b/tensorflow/compiler/xla/service/hlo_constant_folding.cc @@ -20,6 +20,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h" @@ -38,7 +39,7 @@ StatusOr<bool> HloConstantFolding::Run(HloModule* module) { // Limit the constant folding to 0 iterations to skip folding loops. This // retains the behavior from before while loop support in HloEvaluator and may // be revised. - auto evaluator = MakeUnique<HloEvaluator>(/*max_loop_iterations=*/0); + auto evaluator = absl::make_unique<HloEvaluator>(/*max_loop_iterations=*/0); XLA_VLOG_LINES(2, "HloConstantFolding::Run(), before:\n" + module->ToString()); @@ -51,9 +52,7 @@ StatusOr<bool> HloConstantFolding::Run(HloModule* module) { computation->root_instruction() != instruction) { continue; } - // Skip Constant, Parameter, Reduce, and AfterAll operation. - // TODO(b/35975797): Enable Reduce operation once arbitrary computation - // are supported by the evaluator. + // Skip Constant, Parameter, and AfterAll operation. // TODO(b/64407269): Enable Tuple once the timeout issue is resolved. // TODO(b/110532604): Enable AfterAll once AfterAll requires at least one // operand in which case constant folding will be impossible and this @@ -61,7 +60,6 @@ StatusOr<bool> HloConstantFolding::Run(HloModule* module) { if (instruction->opcode() == HloOpcode::kParameter || instruction->opcode() == HloOpcode::kConstant || instruction->opcode() == HloOpcode::kTuple || - instruction->opcode() == HloOpcode::kReduce || instruction->opcode() == HloOpcode::kAfterAll) { continue; } diff --git a/tensorflow/compiler/xla/service/hlo_constant_folding.h b/tensorflow/compiler/xla/service/hlo_constant_folding.h index 331480bd02..4557983a9c 100644 --- a/tensorflow/compiler/xla/service/hlo_constant_folding.h +++ b/tensorflow/compiler/xla/service/hlo_constant_folding.h @@ -25,7 +25,7 @@ namespace xla { // computation on constants. class HloConstantFolding : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "constant_folding"; } + absl::string_view name() const override { return "constant_folding"; } // Run constant folding operations on the given module. Returns whether the // module was changed (constant expressions folded). diff --git a/tensorflow/compiler/xla/service/hlo_constant_folding_test.cc b/tensorflow/compiler/xla/service/hlo_constant_folding_test.cc index 64a42c1efc..7cd1481a8a 100644 --- a/tensorflow/compiler/xla/service/hlo_constant_folding_test.cc +++ b/tensorflow/compiler/xla/service/hlo_constant_folding_test.cc @@ -24,6 +24,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" +#include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/service/hlo_pass_fix.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/test.h" @@ -202,5 +203,45 @@ TEST_F(HloConstantFoldingTest, TransposeConstantFold) { EXPECT_TRUE(matched); } +const char* const kConstantFoldReduce = R"( + HloModule ConstantFoldReduce + + add { + a = s32[] parameter(0) + b = s32[] parameter(1) + ROOT add = s32[] add(a, b) + } + + ENTRY r { + x = s32[3] constant({1, 2, 3}) + init = s32[] constant(0) + ROOT reduce = s32[] reduce(x, init), dimensions={0}, to_apply=add + })"; + +TEST_F(HloConstantFoldingTest, ConstantFoldReduce) { + TF_ASSERT_OK_AND_ASSIGN(std::unique_ptr<HloModule> module, + ParseHloString(kConstantFoldReduce)); + HloConstantFolding const_folder; + TF_ASSERT_OK_AND_ASSIGN(bool result, const_folder.Run(module.get())); + EXPECT_TRUE(result); + + EXPECT_EQ(6, module->entry_computation() + ->root_instruction() + ->literal() + .GetFirstElement<int32>()); +} + +TEST_F(HloConstantFoldingTest, ConstantFoldReduceNoLayout) { + TF_ASSERT_OK_AND_ASSIGN(std::unique_ptr<HloModule> module, + ParseHloString(kConstantFoldReduce)); + HloInstruction* add = module->computations().begin()->root_instruction(); + LayoutUtil::ClearLayout(add->mutable_shape()); + HloConstantFolding const_folder; + TF_ASSERT_OK_AND_ASSIGN(bool result, const_folder.Run(module.get())); + EXPECT_FALSE(result); + + EXPECT_THAT(module->entry_computation()->root_instruction(), op::Reduce()); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_cost_analysis.cc b/tensorflow/compiler/xla/service/hlo_cost_analysis.cc index 1bbb0ff08e..0e12a1ee03 100644 --- a/tensorflow/compiler/xla/service/hlo_cost_analysis.cc +++ b/tensorflow/compiler/xla/service/hlo_cost_analysis.cc @@ -258,10 +258,6 @@ Status HloCostAnalysis::HandleOutfeed(const HloInstruction*) { return Status::OK(); } -Status HloCostAnalysis::HandleHostCompute(const HloInstruction*) { - return Status::OK(); -} - Status HloCostAnalysis::HandleMap(const HloInstruction* map) { // Compute properties of the mapped function. TF_ASSIGN_OR_RETURN(const Properties sub_properties, @@ -544,15 +540,10 @@ Status HloCostAnalysis::HandleCrossReplicaSum(const HloInstruction* crs) { } Status HloCostAnalysis::HandleAllToAll(const HloInstruction* hlo) { - // TODO(b/110096724): Compute correct cost here. - double flops = 0.0; - ShapeUtil::ForEachSubshape(hlo->shape(), - [&](const Shape& subshape, const ShapeIndex&) { - if (ShapeUtil::IsArray(subshape)) { - flops += ShapeUtil::ElementsIn(subshape); - } - }); - current_properties_[kFlopsKey] = flops; + return Status::OK(); +} + +Status HloCostAnalysis::HandleCollectivePermute(const HloInstruction* /*hlo*/) { return Status::OK(); } diff --git a/tensorflow/compiler/xla/service/hlo_cost_analysis.h b/tensorflow/compiler/xla/service/hlo_cost_analysis.h index 193a04bea0..c6a2007904 100644 --- a/tensorflow/compiler/xla/service/hlo_cost_analysis.h +++ b/tensorflow/compiler/xla/service/hlo_cost_analysis.h @@ -72,9 +72,9 @@ class HloCostAnalysis : public ConstDfsHloVisitor { Status HandleFft(const HloInstruction* fft) override; Status HandleCrossReplicaSum(const HloInstruction* crs) override; Status HandleAllToAll(const HloInstruction* hlo) override; + Status HandleCollectivePermute(const HloInstruction* hlo) override; Status HandleInfeed(const HloInstruction* infeed) override; Status HandleOutfeed(const HloInstruction* outfeed) override; - Status HandleHostCompute(const HloInstruction* host_compute) override; Status HandleRng(const HloInstruction* random) override; Status HandleReverse(const HloInstruction* reverse) override; Status HandleSort(const HloInstruction* sort) override; diff --git a/tensorflow/compiler/xla/service/hlo_creation_utils.cc b/tensorflow/compiler/xla/service/hlo_creation_utils.cc index 858992a326..131846794d 100644 --- a/tensorflow/compiler/xla/service/hlo_creation_utils.cc +++ b/tensorflow/compiler/xla/service/hlo_creation_utils.cc @@ -14,15 +14,17 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/hlo_creation_utils.h" +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/shape_inference.h" #include "tensorflow/compiler/xla/util.h" namespace xla { +using absl::StrCat; using tensorflow::gtl::ArraySlice; -using tensorflow::strings::StrCat; StatusOr<HloInstruction*> MakeBinaryHlo(HloOpcode opcode, HloInstruction* lhs, HloInstruction* rhs) { @@ -149,13 +151,13 @@ StatusOr<HloInstruction*> MakeConcatHlo(ArraySlice<HloInstruction*> operands, CHECK_GT(operands.size(), 0); HloComputation* computation = operands[0]->parent(); - CHECK(c_all_of(operands, [&](HloInstruction* instr) { + CHECK(absl::c_all_of(operands, [&](HloInstruction* instr) { return instr->parent() == computation; })); std::vector<const Shape*> operand_shapes; - c_transform(operands, std::back_inserter(operand_shapes), - [](HloInstruction* instr) { return &instr->shape(); }); + absl::c_transform(operands, std::back_inserter(operand_shapes), + [](HloInstruction* instr) { return &instr->shape(); }); TF_ASSIGN_OR_RETURN(Shape concat_shape, ShapeInference::InferConcatOpShape( operand_shapes, dimension)); @@ -228,7 +230,7 @@ StatusOr<HloInstruction*> PrependDegenerateDims(HloInstruction* operand, const Shape& operand_shape = operand->shape(); new_shape_dims.reserve(n + operand_shape.dimensions_size()); new_shape_dims.insert(new_shape_dims.begin(), n, 1); - c_copy(operand_shape.dimensions(), std::back_inserter(new_shape_dims)); + absl::c_copy(operand_shape.dimensions(), std::back_inserter(new_shape_dims)); return MakeReshapeHlo(new_shape_dims, operand); } @@ -240,7 +242,7 @@ StatusOr<HloInstruction*> ExpandFirstDimIntoNDims( std::vector<int64> expanded_shape_dim_bounds; expanded_shape_dim_bounds.reserve(expanded_dims.size() + operand->shape().dimensions_size() - 1); - c_copy(expanded_dims, std::back_inserter(expanded_shape_dim_bounds)); + absl::c_copy(expanded_dims, std::back_inserter(expanded_shape_dim_bounds)); std::copy(operand->shape().dimensions().begin() + 1, operand->shape().dimensions().end(), std::back_inserter(expanded_shape_dim_bounds)); @@ -251,7 +253,7 @@ StatusOr<HloInstruction*> ExpandFirstDimIntoNDims( StatusOr<HloInstruction*> ElideDegenerateDims(HloInstruction* operand, ArraySlice<int64> dims_to_elide) { - CHECK(c_is_sorted(dims_to_elide)); + CHECK(absl::c_is_sorted(dims_to_elide)); const Shape& input_shape = operand->shape(); // First accumulate in reverse @@ -268,7 +270,7 @@ StatusOr<HloInstruction*> ElideDegenerateDims(HloInstruction* operand, } } - c_reverse(new_shape_dim_bounds); + absl::c_reverse(new_shape_dim_bounds); Shape output_shape = ShapeUtil::MakeShape(input_shape.element_type(), new_shape_dim_bounds); return MakeReshapeHlo(output_shape, operand); @@ -276,7 +278,7 @@ StatusOr<HloInstruction*> ElideDegenerateDims(HloInstruction* operand, StatusOr<HloInstruction*> InsertDegenerateDims( HloInstruction* operand, ArraySlice<int64> dims_to_insert) { - CHECK(c_is_sorted(dims_to_insert)); + CHECK(absl::c_is_sorted(dims_to_insert)); const Shape& operand_shape = operand->shape(); int64 output_shape_rank = @@ -318,7 +320,7 @@ StatusOr<HloInstruction*> PadVectorWithZeros(HloInstruction* operand, *padding_config.add_dimensions() = padding_config_dim; HloInstruction* zero = computation->AddInstruction( - HloInstruction::CreateConstant(MakeUnique<Literal>( + HloInstruction::CreateConstant(absl::make_unique<Literal>( LiteralUtil::Zero(operand->shape().element_type())))); return MakePadHlo(operand, zero, padding_config); } @@ -328,15 +330,15 @@ StatusOr<HloInstruction*> BroadcastZeros( ArraySlice<int64> broadcast_dimensions) { HloInstruction* zero = computation->AddInstruction(HloInstruction::CreateConstant( - MakeUnique<Literal>(LiteralUtil::Zero(element_type)))); + absl::make_unique<Literal>(LiteralUtil::Zero(element_type)))); return MakeBroadcastHlo(zero, /*broadcast_dimensions=*/{}, /*result_shape_bounds=*/broadcast_dimensions); } StatusOr<std::unique_ptr<HloComputation>> CreateComputationWithSignature( ArraySlice<const Shape*> domain, const Shape& range, - tensorflow::StringPiece name) { - HloComputation::Builder b{std::string(name)}; + absl::string_view name) { + HloComputation::Builder b{string(name)}; int64 param_idx = 0; for (const Shape* param_shape : domain) { b.AddInstruction(HloInstruction::CreateParameter( diff --git a/tensorflow/compiler/xla/service/hlo_creation_utils.h b/tensorflow/compiler/xla/service/hlo_creation_utils.h index 5ff8946fb0..1bc6d09b45 100644 --- a/tensorflow/compiler/xla/service/hlo_creation_utils.h +++ b/tensorflow/compiler/xla/service/hlo_creation_utils.h @@ -177,7 +177,7 @@ StatusOr<HloInstruction*> BroadcastZeros( // a value of type `range`. StatusOr<std::unique_ptr<HloComputation>> CreateComputationWithSignature( tensorflow::gtl::ArraySlice<const Shape*> domain, const Shape& range, - tensorflow::StringPiece name); + absl::string_view name); } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_creation_utils_test.cc b/tensorflow/compiler/xla/service/hlo_creation_utils_test.cc index 60d3e71757..a8de285d16 100644 --- a/tensorflow/compiler/xla/service/hlo_creation_utils_test.cc +++ b/tensorflow/compiler/xla/service/hlo_creation_utils_test.cc @@ -14,7 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/hlo_creation_utils.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/hlo_evaluator.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -28,7 +28,7 @@ using tensorflow::gtl::ArraySlice; class HloCreationUtilsTest : public HloTestBase { protected: - static std::unique_ptr<HloModule> CreateModuleWithProgramShape( + std::unique_ptr<HloModule> CreateModuleWithProgramShape( PrimitiveType primitive_type, ArraySlice<int64> input_shape_dims, ArraySlice<int64> output_shape_dims, HloInstruction** param, HloComputation** entry_computation) { diff --git a/tensorflow/compiler/xla/service/hlo_cse.cc b/tensorflow/compiler/xla/service/hlo_cse.cc index 06484f4012..cb367adf5e 100644 --- a/tensorflow/compiler/xla/service/hlo_cse.cc +++ b/tensorflow/compiler/xla/service/hlo_cse.cc @@ -35,6 +35,7 @@ limitations under the License. #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/lib/gtl/inlined_vector.h" +#include "tensorflow/core/lib/hash/hash.h" namespace xla { @@ -103,6 +104,9 @@ int64 CseHash(const HloInstruction* instruction) { for (auto operand : instruction->operands()) { hash = tensorflow::Hash64Combine(hash, operand->unique_id()); } + if (instruction->opcode() == HloOpcode::kConstant) { + hash = tensorflow::Hash64Combine(hash, instruction->literal().Hash()); + } return hash; } diff --git a/tensorflow/compiler/xla/service/hlo_cse.h b/tensorflow/compiler/xla/service/hlo_cse.h index 5e2b348bdd..a28c03599a 100644 --- a/tensorflow/compiler/xla/service/hlo_cse.h +++ b/tensorflow/compiler/xla/service/hlo_cse.h @@ -34,7 +34,7 @@ class HloCSE : public HloPassInterface { : is_layout_sensitive_(is_layout_sensitive), only_fusion_computations_(only_fusion_computations) {} ~HloCSE() override = default; - tensorflow::StringPiece name() const override { return "cse"; } + absl::string_view name() const override { return "cse"; } // Run CSE on the given module. Returns whether the module was changed (common // subexpressions were found and eliminated). diff --git a/tensorflow/compiler/xla/service/hlo_cse_test.cc b/tensorflow/compiler/xla/service/hlo_cse_test.cc index 90fbaa37c5..406d712ec6 100644 --- a/tensorflow/compiler/xla/service/hlo_cse_test.cc +++ b/tensorflow/compiler/xla/service/hlo_cse_test.cc @@ -20,9 +20,9 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" diff --git a/tensorflow/compiler/xla/service/hlo_dataflow_analysis.cc b/tensorflow/compiler/xla/service/hlo_dataflow_analysis.cc index bbfb0c253f..3376d170e6 100644 --- a/tensorflow/compiler/xla/service/hlo_dataflow_analysis.cc +++ b/tensorflow/compiler/xla/service/hlo_dataflow_analysis.cc @@ -19,8 +19,10 @@ limitations under the License. #include <queue> #include <vector> +#include "absl/container/inlined_vector.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" @@ -29,8 +31,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" namespace xla { @@ -78,8 +78,8 @@ bool MultiDynamicSliceUseShareSameIndices( } // namespace -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; +using absl::StrAppend; +using absl::StrCat; HloDataflowAnalysis::HloDataflowAnalysis( const HloModule& module, bool ssa_form, bool bitcast_defines_value, @@ -93,7 +93,7 @@ HloDataflowAnalysis::HloDataflowAnalysis( bool HloDataflowAnalysis::AreTransitiveUsesElementwiseOrTuple( const HloInstruction* inst) { tensorflow::gtl::FlatSet<const HloInstruction*> visited; - tensorflow::gtl::InlinedVector<const HloInstruction*, 4> stack; + absl::InlinedVector<const HloInstruction*, 4> stack; stack.push_back(inst); while (!stack.empty()) { const HloInstruction* current = stack.back(); @@ -837,7 +837,7 @@ Status HloDataflowAnalysis::InitializeInstructionValueSets() { return Unimplemented( "Computation %s is called in both a parallel (eg, kMap) and " "sequential (eg, kCall) context", - computation->name().c_str()); + computation->name()); } if (call_graph_node.caller_callsites().empty() || call_graph_node.context() == CallContext::kParallel) { @@ -886,7 +886,7 @@ StatusOr<std::unique_ptr<HloDataflowAnalysis>> HloDataflowAnalysis::Run( VLOG(1) << "HloDataflowAnalysis::Run on module " << module.name(); XLA_VLOG_LINES(2, module.ToString()); - auto dataflow_analysis = WrapUnique(new HloDataflowAnalysis( + auto dataflow_analysis = absl::WrapUnique(new HloDataflowAnalysis( module, ssa_form, bitcast_defines_value, fusion_can_share_buffer)); TF_RETURN_IF_ERROR(dataflow_analysis->InitializeInstructionValueSets()); @@ -976,28 +976,22 @@ Status HloDataflowAnalysis::Verify() const { bool HloDataflowAnalysis::DoesNotUseOperandBuffer( const HloInstruction* operand, const ShapeIndex& index, const HloInstruction* user) const { - CHECK(user->IsUserOf(operand)) - << "user: " << user->ToString() << " operand: " << operand->ToString(); - if (user->opcode() == HloOpcode::kFusion && - user->fusion_kind() == HloInstruction::FusionKind::kLoop) { - // Find fusion parameter associated with 'operand'. - HloInstruction* fusion_param = - user->fused_parameter(user->operand_index(operand)); - // Iterate through all users of all uses of the fusion parameter value. - // Return false if any uses are detected, returns true otherwise. - const HloValue& value = GetValueDefinedAt(fusion_param, index); - return value.uses().empty(); - } else { - // Return false if no value at 'operand' and 'index' is used at 'user'. - for (const HloValue* value : GetValueSet(operand, index).values()) { - for (const HloUse& use : value->uses()) { - if (use.instruction == user) { - return false; + // Return false if no value at 'operand' and 'index' is used at 'user'. + for (const HloValue* value : GetValueSet(operand, index).values()) { + for (const HloUse& use : value->uses()) { + if (use.instruction == user) { + if (user->opcode() == HloOpcode::kFusion && + user->fusion_kind() == HloInstruction::FusionKind::kLoop) { + HloInstruction* fusion_param = + user->fused_parameter(use.operand_number); + const HloValue& value = + GetValueDefinedAt(fusion_param, use.operand_index); + return value.uses().empty(); } + return false; } } } - return true; } diff --git a/tensorflow/compiler/xla/service/hlo_dataflow_analysis.h b/tensorflow/compiler/xla/service/hlo_dataflow_analysis.h index f4abc7a7c7..a1678d4943 100644 --- a/tensorflow/compiler/xla/service/hlo_dataflow_analysis.h +++ b/tensorflow/compiler/xla/service/hlo_dataflow_analysis.h @@ -138,7 +138,8 @@ class HloDataflowAnalysis { // Returns true if 'user' cannot possibly use the buffer at 'index' in // 'operand'. Returns false otherwise. // - // REQUIRES: 'operand' is an operand of 'user'. + // 'operand' does not have to be an operand of 'user'. This can be the case + // with indirect uses. bool DoesNotUseOperandBuffer(const HloInstruction* operand, const ShapeIndex& index, const HloInstruction* user) const; diff --git a/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc b/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc index 4755c4a0cf..d1a96c10f8 100644 --- a/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc +++ b/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc @@ -1963,6 +1963,54 @@ TEST_F(DoesNotUseOperandBufferTest, FusedDynamicUpdateSlice) { EXPECT_FALSE(dataflow_analysis_->DoesNotUseOperandBuffer(tuple, {1}, fusion)); } +// Similar to FusedDynamicUpdateSlice above, but tests indirect uses of the +// parameter tuple. +TEST_F(DoesNotUseOperandBufferTest, IndirectUses) { + auto builder = HloComputation::Builder(TestName()); + + Shape data_shape = ShapeUtil::MakeShape(F32, {8}); + auto tuple_param = builder.AddInstruction(HloInstruction::CreateParameter( + 0, ShapeUtil::MakeTupleShape({data_shape, data_shape}), "tuple")); + auto t0 = builder.AddInstruction( + HloInstruction::CreateGetTupleElement(data_shape, tuple_param, 0)); + auto t1 = builder.AddInstruction( + HloInstruction::CreateGetTupleElement(data_shape, tuple_param, 1)); + // Swap the tuple elements. + auto tuple = builder.AddInstruction(HloInstruction::CreateTuple({t1, t0})); + + auto gte0 = builder.AddInstruction( + HloInstruction::CreateGetTupleElement(data_shape, tuple, 0)); + auto gte1 = builder.AddInstruction( + HloInstruction::CreateGetTupleElement(data_shape, tuple, 1)); + + // Create a DynamicUpdateSlice instruction of tuple element 1. + auto starts = builder.AddInstruction( + HloInstruction::CreateConstant(LiteralUtil::CreateR1<int32>({2}))); + auto update = builder.AddInstruction(HloInstruction::CreateConstant( + LiteralUtil::CreateR1<float>({2.f, 2.f, 2.f}))); + auto dynamic_update_slice = + builder.AddInstruction(HloInstruction::CreateDynamicUpdateSlice( + data_shape, gte1, update, starts)); + builder.AddInstruction( + HloInstruction::CreateTuple({gte0, dynamic_update_slice})); + + BuildModule(builder.Build()); + auto fusion = computation_->CreateFusionInstruction( + {dynamic_update_slice, starts, update, gte1}, + HloInstruction::FusionKind::kLoop); + RunAnalysis(); + + // The fusion instruction never uses tuple element 0, but does use element 1. + EXPECT_TRUE(dataflow_analysis_->DoesNotUseOperandBuffer(tuple, {0}, fusion)); + EXPECT_FALSE(dataflow_analysis_->DoesNotUseOperandBuffer(tuple, {1}, fusion)); + // The same holds for the parameter tuple, except that the tuple elements are + // swapped in 'tuple'. + EXPECT_TRUE( + dataflow_analysis_->DoesNotUseOperandBuffer(tuple_param, {1}, fusion)); + EXPECT_FALSE( + dataflow_analysis_->DoesNotUseOperandBuffer(tuple_param, {0}, fusion)); +} + class CanShareOperandBufferWithUserTest : public HloDataflowAnalysisTestBase {}; TEST_F(CanShareOperandBufferWithUserTest, ElementWiseSameShape) { diff --git a/tensorflow/compiler/xla/service/hlo_dce.h b/tensorflow/compiler/xla/service/hlo_dce.h index 4e244494d6..1fe69b1395 100644 --- a/tensorflow/compiler/xla/service/hlo_dce.h +++ b/tensorflow/compiler/xla/service/hlo_dce.h @@ -36,7 +36,7 @@ namespace xla { class HloDCE : public HloPassInterface { public: ~HloDCE() override {} - tensorflow::StringPiece name() const override { return "dce"; } + absl::string_view name() const override { return "dce"; } // Run the pass on the given module. Returns whether the module was changed // (instructions were removed). diff --git a/tensorflow/compiler/xla/service/hlo_dce_test.cc b/tensorflow/compiler/xla/service/hlo_dce_test.cc index 26e3736e01..3b5cde2996 100644 --- a/tensorflow/compiler/xla/service/hlo_dce_test.cc +++ b/tensorflow/compiler/xla/service/hlo_dce_test.cc @@ -17,9 +17,9 @@ limitations under the License. #include <memory> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" diff --git a/tensorflow/compiler/xla/service/hlo_domain_isolator.cc b/tensorflow/compiler/xla/service/hlo_domain_isolator.cc index 78955db0da..72185698c9 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_isolator.cc +++ b/tensorflow/compiler/xla/service/hlo_domain_isolator.cc @@ -31,31 +31,10 @@ class HloDomainIsolator::RunContext { StatusOr<bool> Run(); private: - // Inserts a kDomain instruction between parent and operand, in case - // the attribute (ie, sharding) values change between instruction and operand. - // Returns the newly inserted kDomain instruction, or nullptr if no kDomain - // instruction was necessary. - StatusOr<HloInstruction*> CreateDomain(HloInstruction* instruction, - HloInstruction* parent, - HloInstruction* operand); - HloModule* module_; HloDomainIsolator* isolator_; }; -StatusOr<HloInstruction*> HloDomainIsolator::RunContext::CreateDomain( - HloInstruction* instruction, HloInstruction* parent, - HloInstruction* operand) { - HloInstruction* domain = nullptr; - std::unique_ptr<HloInstruction> domain_instruction = - isolator_->creator_(instruction, operand); - if (domain_instruction != nullptr) { - domain = operand->parent()->AddInstruction(std::move(domain_instruction)); - TF_RETURN_IF_ERROR(operand->ReplaceUseWith(parent, domain)); - } - return domain; -} - StatusOr<bool> HloDomainIsolator::RunContext::Run() { hlo_graph_dumper::MaybeDumpHloModule(*module_, "Before Domain Isolator"); @@ -71,16 +50,16 @@ StatusOr<bool> HloDomainIsolator::RunContext::Run() { // When applying multiple domains, we could end up stacking more than // one in one edge, so here we want to build the effective // (kDomain-less) instruction->operand edge. - HloInstruction* parent = instruction; - while (operand->opcode() == HloOpcode::kDomain) { - parent = operand; - operand = operand->mutable_operand(0); + HloInstruction* root = operand; + while (root->opcode() == HloOpcode::kDomain) { + root = root->mutable_operand(0); } // Check whether a kDomain is necessary between instruction and operand. - TF_ASSIGN_OR_RETURN(HloInstruction * domain, - CreateDomain(instruction, parent, operand)); + HloInstruction* domain = + isolator_->creator_(instruction, root, operand); if (domain != nullptr) { VLOG(4) << "New domain: " << domain->ToString(); + TF_RETURN_IF_ERROR(operand->ReplaceUseWith(instruction, domain)); ++added_domains; } } diff --git a/tensorflow/compiler/xla/service/hlo_domain_isolator.h b/tensorflow/compiler/xla/service/hlo_domain_isolator.h index eded3e78ee..d36631fc2f 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_isolator.h +++ b/tensorflow/compiler/xla/service/hlo_domain_isolator.h @@ -34,14 +34,16 @@ class HloDomainIsolator : public HloPassInterface { public: // Creates a new kDomain instruction for the edge between the use instruction // (the first HloInstruction argument), and the operand instruction (the - // second HloInstruction argument). + // third HloInstruction argument) if the interesting attribute of the + // instruction differes from the attribute of the root (the second + // HloInstruction argument). // Returns nullptr in case no domain separation is necessary. - using DomainCreator = std::function<std::unique_ptr<HloInstruction>( - HloInstruction*, HloInstruction*)>; + using DomainCreator = std::function<HloInstruction*( + HloInstruction*, HloInstruction*, HloInstruction*)>; explicit HloDomainIsolator(DomainCreator creator); - tensorflow::StringPiece name() const override { return "domain_isolator"; } + absl::string_view name() const override { return "domain_isolator"; } StatusOr<bool> Run(HloModule* module) override; diff --git a/tensorflow/compiler/xla/service/hlo_domain_map.cc b/tensorflow/compiler/xla/service/hlo_domain_map.cc index 9e096320db..8b2846e0c2 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_map.cc +++ b/tensorflow/compiler/xla/service/hlo_domain_map.cc @@ -17,6 +17,7 @@ limitations under the License. #include <algorithm> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/types.h" @@ -25,14 +26,14 @@ namespace xla { /* static */ StatusOr<std::unique_ptr<HloDomainMap>> HloDomainMap::Create( HloComputation* computation, string domain_kind) { - auto domain_map = WrapUnique(new HloDomainMap(std::move(domain_kind))); + auto domain_map = absl::WrapUnique(new HloDomainMap(std::move(domain_kind))); TF_RETURN_IF_ERROR(domain_map->Populate(computation)); return std::move(domain_map); } /* static */ StatusOr<std::unique_ptr<HloDomainMap>> HloDomainMap::Create( HloModule* module, string domain_kind) { - auto domain_map = WrapUnique(new HloDomainMap(std::move(domain_kind))); + auto domain_map = absl::WrapUnique(new HloDomainMap(std::move(domain_kind))); for (HloComputation* computation : module->computations()) { TF_RETURN_IF_ERROR(domain_map->Populate(computation)); } @@ -56,14 +57,14 @@ Status HloDomainMap::TryProcessEmptyDomain(HloInstruction* instruction) { // both sides. for (HloInstruction* operand : instruction->unique_operands()) { if (IsDomainInstruction(operand)) { - auto domain = MakeUnique<DomainMetadata::Domain>(); + auto domain = absl::make_unique<DomainMetadata::Domain>(); domain->enter_domains.insert(operand); domain->exit_domains.insert(instruction); TF_RETURN_IF_ERROR(InsertDomain(std::move(domain))); } } if (instruction == instruction->parent()->root_instruction()) { - auto domain = MakeUnique<DomainMetadata::Domain>(); + auto domain = absl::make_unique<DomainMetadata::Domain>(); domain->enter_domains.insert(instruction); TF_RETURN_IF_ERROR(InsertDomain(std::move(domain))); } @@ -71,6 +72,11 @@ Status HloDomainMap::TryProcessEmptyDomain(HloInstruction* instruction) { } Status HloDomainMap::Populate(HloComputation* computation) { + InstructionOrderMap instructions_post_order; + int64 count = 0; + for (HloInstruction* instruction : computation->MakeInstructionPostOrder()) { + instructions_post_order.insert(std::make_pair(instruction, count++)); + } for (HloInstruction* instruction : computation->instructions()) { if (IsDomainInstruction(instruction)) { // If this is a kDomain of the kind we are currently processing, check @@ -84,7 +90,7 @@ Status HloDomainMap::Populate(HloComputation* computation) { continue; } TF_ASSIGN_OR_RETURN(std::unique_ptr<DomainMetadata::Domain> domain, - CreateDomain(instruction)); + CreateDomain(instruction, instructions_post_order)); TF_RETURN_IF_ERROR(InsertDomain(std::move(domain))); } return Status::OK(); @@ -142,10 +148,12 @@ Status HloDomainMap::ExpandDomain(HloInstruction* instruction, } StatusOr<std::unique_ptr<DomainMetadata::Domain>> HloDomainMap::CreateDomain( - HloInstruction* instruction) const { - auto domain = MakeUnique<DomainMetadata::Domain>(); + HloInstruction* instruction, + const InstructionOrderMap& instructions_order) const { + auto domain = absl::make_unique<DomainMetadata::Domain>(); TF_RETURN_IF_ERROR(ExpandDomain(instruction, domain.get())); - domain->instructions = MakeNonDomainInstructions(domain->reach_set); + domain->instructions = + MakeNonDomainInstructions(domain->reach_set, instructions_order); return std::move(domain); } @@ -167,7 +175,8 @@ bool HloDomainMap::IsDomainInstruction(HloInstruction* instruction) const { /* static */ std::vector<HloInstruction*> HloDomainMap::MakeNonDomainInstructions( - const tensorflow::gtl::FlatSet<HloInstruction*>& instruction_set) { + const tensorflow::gtl::FlatSet<HloInstruction*>& instruction_set, + const InstructionOrderMap& instructions_order) { std::vector<HloInstruction*> instructions; instructions.reserve(instruction_set.size()); for (HloInstruction* instruction : instruction_set) { @@ -175,9 +184,10 @@ HloDomainMap::MakeNonDomainInstructions( instructions.push_back(instruction); } } + // sort instructions according to instructions_order std::sort(instructions.begin(), instructions.end(), - [](HloInstruction* a, HloInstruction* b) { - return a->unique_id() < b->unique_id(); + [&instructions_order](HloInstruction* a, HloInstruction* b) { + return instructions_order.at(a) < instructions_order.at(b); }); return instructions; } diff --git a/tensorflow/compiler/xla/service/hlo_domain_map.h b/tensorflow/compiler/xla/service/hlo_domain_map.h index 1ca7159725..633109249a 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_map.h +++ b/tensorflow/compiler/xla/service/hlo_domain_map.h @@ -70,6 +70,11 @@ class HloDomainMap { int64 GetDomainId(HloInstruction* instruction) const; private: + // Map used for representing instruction ordering, i.e. + // order_map[a] < order_map[b] means a must be ordered before b. + using InstructionOrderMap = + tensorflow::gtl::FlatMap<const HloInstruction*, int64>; + HloDomainMap(string domain_kind) : domain_kind_(std::move(domain_kind)) {} // Check if the kDomain instruction is facing (via its operand link) another @@ -95,12 +100,14 @@ class HloDomainMap { // Creates a domain data structure using the ExpandDomain() API. StatusOr<std::unique_ptr<DomainMetadata::Domain>> CreateDomain( - HloInstruction* instruction) const; + HloInstruction* instruction, + const InstructionOrderMap& instructions_order) const; // Out of an instruction set, returns a vector of all the ones which are not // a kDomain kind. static std::vector<HloInstruction*> MakeNonDomainInstructions( - const tensorflow::gtl::FlatSet<HloInstruction*>& instruction_set); + const tensorflow::gtl::FlatSet<HloInstruction*>& instruction_set, + const InstructionOrderMap& instructions_order); string domain_kind_; std::vector<std::unique_ptr<DomainMetadata::Domain>> instruction_domains_; diff --git a/tensorflow/compiler/xla/service/hlo_domain_metadata.h b/tensorflow/compiler/xla/service/hlo_domain_metadata.h index f855f2a1fc..6c142ee474 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_metadata.h +++ b/tensorflow/compiler/xla/service/hlo_domain_metadata.h @@ -20,10 +20,10 @@ limitations under the License. #include <string> #include <vector> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/flatset.h" namespace xla { @@ -44,7 +44,10 @@ class DomainMetadata { // two domains of different kind intersect each other. tensorflow::gtl::FlatSet<HloInstruction*> reach_set; - // The same instructions in reach_set, but purged from kDomain instructions. + // The same instructions in reach_set, but purged from kDomain instructions + // and ordered according to their computation graph post-order, i.e. + // if instructions[pos_a] depends on instructions[pos_b], then pos_a > + // pos_b. std::vector<HloInstruction*> instructions; // If we consider a graph edge as an arrow oriented from the operand to the @@ -63,7 +66,7 @@ class DomainMetadata { // Returns the metadata type. A unique identifier which describes the real // metadata type. - virtual tensorflow::StringPiece Kind() const = 0; + virtual absl::string_view Kind() const = 0; // Compares the metadata object with another one and returns true if the // two matches. diff --git a/tensorflow/compiler/xla/service/hlo_domain_remover.h b/tensorflow/compiler/xla/service/hlo_domain_remover.h index c859e05f02..97bc8ef604 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_remover.h +++ b/tensorflow/compiler/xla/service/hlo_domain_remover.h @@ -35,13 +35,13 @@ class HloDomainRemover : public HloPassInterface { // instructions in it with the same attributes (ie, sharding), a normalizer // function is tasked at applying attribute normalization on the instructions // within such domain. - HloDomainRemover(tensorflow::StringPiece kind, + HloDomainRemover(absl::string_view kind, std::function<Status(const DomainMetadata::Domain&, const DomainMetadata* metadata)> normalizer) - : kind_(kind.ToString()), normalizer_(std::move(normalizer)) {} + : kind_(kind), normalizer_(std::move(normalizer)) {} - tensorflow::StringPiece name() const override { return "domain_remover"; } + absl::string_view name() const override { return "domain_remover"; } StatusOr<bool> Run(HloModule* module) override; diff --git a/tensorflow/compiler/xla/service/hlo_domain_test.cc b/tensorflow/compiler/xla/service/hlo_domain_test.cc index 70271be304..c8e0a9e289 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_test.cc +++ b/tensorflow/compiler/xla/service/hlo_domain_test.cc @@ -13,6 +13,7 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/legacy_flags/debug_options_flags.h" #include "tensorflow/compiler/xla/service/hlo_domain_isolator.h" #include "tensorflow/compiler/xla/service/hlo_domain_metadata.h" @@ -28,6 +29,11 @@ namespace xla { namespace { class HloDomainTest : public HloVerifiedTestBase { + public: + HloDomainTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} + protected: bool FindUserViaDomainPath(HloInstruction* instruction, HloInstruction* operand) const { @@ -45,9 +51,8 @@ class HloDomainTest : public HloVerifiedTestBase { // Checks whether there is a kDomain instruction in the edge between the // instruction and the operand. - bool HasDomainEdge(HloModule* module, - tensorflow::StringPiece instruction_name, - tensorflow::StringPiece operand_name) { + bool HasDomainEdge(HloModule* module, absl::string_view instruction_name, + absl::string_view operand_name) { HloInstruction* instruction = FindInstruction(module, instruction_name); HloInstruction* operand = FindInstruction(module, operand_name); CHECK_NE(instruction, nullptr); @@ -65,7 +70,7 @@ class HloDomainTest : public HloVerifiedTestBase { return false; } - StatusOr<HloModule*> ParseModule(tensorflow::StringPiece hlo_string) { + StatusOr<HloModule*> ParseModule(absl::string_view hlo_string) { HloModuleConfig config; config.set_debug_options(legacy_flags::GetDebugOptionsFromFlags()); ParseAndVerifyModule(hlo_string, config); @@ -80,10 +85,10 @@ class OpNameMetadata : public DomainMetadata { explicit OpNameMetadata(string opname) : opname_(std::move(opname)) {} std::unique_ptr<DomainMetadata> Clone() const override { - return MakeUnique<OpNameMetadata>(opname_); + return absl::make_unique<OpNameMetadata>(opname_); } - tensorflow::StringPiece Kind() const override { return KindName(); } + absl::string_view Kind() const override { return KindName(); } bool Matches(const DomainMetadata& other) const override { const OpNameMetadata* other_ptr = @@ -97,25 +102,26 @@ class OpNameMetadata : public DomainMetadata { string ToString() const override { return opname_; } - static tensorflow::StringPiece KindName() { return "opname"; } + static absl::string_view KindName() { return "opname"; } private: string opname_; }; // Creator function for OpNameMetadata domains. -std::unique_ptr<HloInstruction> OpNameDomainCreator(HloInstruction* instruction, - HloInstruction* operand) { - if (instruction->metadata().op_name() == operand->metadata().op_name()) { +HloInstruction* OpNameDomainCreator(HloInstruction* instruction, + HloInstruction* root, + HloInstruction* operand) { + if (instruction->metadata().op_name() == root->metadata().op_name()) { return nullptr; } std::unique_ptr<DomainMetadata> operand_side_metadata = - MakeUnique<OpNameMetadata>(operand->metadata().op_name()); + absl::make_unique<OpNameMetadata>(root->metadata().op_name()); std::unique_ptr<DomainMetadata> user_side_metadata = - MakeUnique<OpNameMetadata>(instruction->metadata().op_name()); - return HloInstruction::CreateDomain(operand->shape(), operand, - std::move(operand_side_metadata), - std::move(user_side_metadata)); + absl::make_unique<OpNameMetadata>(instruction->metadata().op_name()); + return operand->parent()->AddInstruction(HloInstruction::CreateDomain( + operand->shape(), operand, std::move(operand_side_metadata), + std::move(user_side_metadata))); } Status OpNameDomainNormalizer(const DomainMetadata::Domain& domain, @@ -142,7 +148,7 @@ ENTRY entry { TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); LOG(INFO) << "Original module:\n" << module->ToString(); - HloDomainIsolator isolator(CreateShardingDomain); + HloDomainIsolator isolator(ShardingDomainCreator{}); TF_ASSERT_OK_AND_ASSIGN(bool isolator_changed, isolator.Run(module)); EXPECT_TRUE(isolator_changed); @@ -184,7 +190,7 @@ ENTRY entry { TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); LOG(INFO) << "Original module:\n" << module->ToString(); - HloDomainIsolator isolator(CreateShardingDomain); + HloDomainIsolator isolator(ShardingDomainCreator{}); TF_ASSERT_OK_AND_ASSIGN(bool isolator_changed, isolator.Run(module)); EXPECT_TRUE(!isolator_changed); } @@ -211,7 +217,7 @@ ENTRY entry { TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); LOG(INFO) << "Original module:\n" << module->ToString(); - HloDomainIsolator isolator(CreateShardingDomain); + HloDomainIsolator isolator(ShardingDomainCreator{}); TF_ASSERT_OK_AND_ASSIGN(bool isolator_changed, isolator.Run(module)); EXPECT_TRUE(isolator_changed); @@ -248,7 +254,7 @@ ENTRY entry { TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); LOG(INFO) << "Original module:\n" << module->ToString(); - HloDomainIsolator isolator(CreateShardingDomain); + HloDomainIsolator isolator(ShardingDomainCreator{}); TF_ASSERT_OK_AND_ASSIGN(bool isolator_changed, isolator.Run(module)); EXPECT_FALSE(isolator_changed); } @@ -302,7 +308,7 @@ ENTRY entry { TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); LOG(INFO) << "Original module:\n" << module->ToString(); - HloDomainIsolator sharding_isolator(CreateShardingDomain); + HloDomainIsolator sharding_isolator(ShardingDomainCreator{}); TF_ASSERT_OK_AND_ASSIGN(bool sharding_isolator_changed, sharding_isolator.Run(module)); EXPECT_TRUE(sharding_isolator_changed); @@ -344,7 +350,8 @@ ENTRY entry { token = token[] after-all() infeed = ((f32[4], f32[4]), token[]) infeed(token), sharding={{maximal device=1}, {maximal device=0}, {maximal device=0}} - infeed.data = (f32[4], f32[4]) get-tuple-element(infeed), index=0 + infeed.data = (f32[4], f32[4]) get-tuple-element(infeed), index=0, + sharding={{maximal device=1}, {maximal device=0}} gte0 = f32[4] get-tuple-element(infeed.data), index=0 gte1 = f32[4] get-tuple-element(infeed.data), index=1 copy0 = f32[4] copy(gte0) @@ -356,7 +363,7 @@ ENTRY entry { TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); LOG(INFO) << "Original module:\n" << module->ToString(); - HloDomainIsolator isolator(CreateShardingDomain); + HloDomainIsolator isolator(ShardingDomainCreator{}); TF_ASSERT_OK_AND_ASSIGN(bool isolator_changed, isolator.Run(module)); EXPECT_TRUE(isolator_changed); @@ -378,11 +385,8 @@ ENTRY entry { // \ / // TUPLE // | - HloInstruction* infeed = FindInstruction(module, "infeed"); - ASSERT_NE(infeed, nullptr); - HloInstruction* infeed_data = - infeed->parent()->AddInstruction(HloInstruction::CreateGetTupleElement( - ShapeUtil::GetTupleElementShape(infeed->shape(), 0), infeed, 0)); + HloInstruction* infeed_data = FindInstruction(module, "infeed.data"); + ASSERT_NE(infeed_data, nullptr); auto infeed_data_users = infeed_data->users(); HloInstruction* new_gte0 = infeed_data->parent()->AddInstruction( @@ -445,7 +449,7 @@ ENTRY entry { TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); - HloDomainIsolator isolator(CreateShardingDomain); + HloDomainIsolator isolator(ShardingDomainCreator{}); TF_ASSERT_OK_AND_ASSIGN(bool isolator_changed, isolator.Run(module)); EXPECT_TRUE(isolator_changed); @@ -474,8 +478,8 @@ ENTRY entry { TEST_F(HloDomainTest, DumpParseNullSharding) { auto builder = HloComputation::Builder(TestName()); Shape shape = ShapeUtil::MakeShape(F32, {}); - auto sharding_md_0 = MakeUnique<ShardingMetadata>(nullptr); - auto sharding_md_1 = MakeUnique<ShardingMetadata>(nullptr); + auto sharding_md_0 = absl::make_unique<ShardingMetadata>(nullptr); + auto sharding_md_1 = absl::make_unique<ShardingMetadata>(nullptr); HloInstruction* param = builder.AddInstruction(HloInstruction::CreateParameter(0, shape, "p")); HloInstruction* domain = builder.AddInstruction(HloInstruction::CreateDomain( @@ -490,6 +494,7 @@ TEST_F(HloDomainTest, DumpParseNullSharding) { ASSERT_TRUE(ParseModule(hlo_string).status().ok()); } +// Tuple inputs are domain instructions. TEST_F(HloDomainTest, DomainTuple) { const char* const hlo_string = R"( HloModule Module @@ -497,14 +502,15 @@ HloModule Module ENTRY entry { p0 = f32[4] parameter(0), sharding={maximal device=0} cst = u32[] constant(0), sharding={maximal device=1} - tpl = (u32[], f32[4]) tuple(cst, p0), sharding={{maximal device=1}, {maximal device=0}} + tpl = (u32[], f32[4]) tuple(cst, p0), + sharding={{maximal device=1}, {maximal device=0}} ROOT gte = f32[4] get-tuple-element(tpl), index=1, sharding={maximal device=0} } )"; TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); - HloDomainIsolator isolator(CreateShardingDomain); + HloDomainIsolator isolator(ShardingDomainCreator{}); TF_ASSERT_OK_AND_ASSIGN(bool isolator_changed, isolator.Run(module)); EXPECT_TRUE(isolator_changed); @@ -523,5 +529,168 @@ ENTRY entry { tpl->sharding()); } +TEST_F(HloDomainTest, MultiDomainMultiUser) { + const char* const hlo_string = R"( + HloModule Module + +ENTRY %entry (p0: (f32[4], f32[4])) -> (f32[4], f32[4], f32[4]) { + %p0 = (f32[4], f32[4]) parameter(0) + %a = f32[4]{0} get-tuple-element(%p0), index=0 + %domain = f32[4] domain(%a), + domain={kind="sharding", entry={maximal device=1}, exit={maximal device=0}} + %b = f32[4] get-tuple-element(%p0), index=1 + %domain.1 = f32[4] domain(%b), + domain={kind="sharding", entry={maximal device=1}, exit={maximal device=0}} + %c = f32[4] add(%domain, %domain.1), sharding={maximal device=1} + %domain.2 = f32[4] domain(%c), + domain={kind="sharding", entry={maximal device=0}, exit={maximal device=1}} + %d = f32[4] subtract(%domain, %c), + sharding={maximal device=1}, metadata={op_name="D"} + %domain.3 = f32[4] domain(%d), + domain={kind="sharding", entry={maximal device=0}, exit={maximal device=1}} + %e = f32[4] multiply(%c, %d), + sharding={maximal device=1}, metadata={op_name="D"} + %f = f32[4] add(f32[4]{0} %e, f32[4]{0} %c), sharding={maximal device=1} + %domain.4 = f32[4]{0} domain(%f), + domain={kind="sharding", entry={maximal device=0}, exit={maximal device=1}} + ROOT %g = (f32[4], f32[4], f32[4]) tuple(%domain.2, %domain.3, %domain.4) +})"; + + TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); + LOG(INFO) << "Original module:\n" << module->ToString(); + + HloDomainIsolator opname_isolator(OpNameDomainCreator); + TF_ASSERT_OK_AND_ASSIGN(bool opname_isolator_changed, + opname_isolator.Run(module)); + EXPECT_TRUE(opname_isolator_changed); + + EXPECT_TRUE(HasDomainEdge(module, "c", "a")); + EXPECT_TRUE(HasDomainEdge(module, "c", "b")); + EXPECT_TRUE(HasDomainEdge(module, "d", "a")); + EXPECT_TRUE(HasDomainEdge(module, "d", "c")); + EXPECT_FALSE(HasDomainEdge(module, "e", "d")); + + HloDomainRemover sharding_remover(ShardingMetadata::KindName(), + ShardingMetadata::NormalizeShardingDomain); + TF_ASSERT_OK_AND_ASSIGN(bool sharding_remover_changed, + sharding_remover.Run(module)); + EXPECT_TRUE(sharding_remover_changed); + + HloDomainRemover opname_remover(OpNameMetadata::KindName(), + OpNameDomainNormalizer); + TF_ASSERT_OK_AND_ASSIGN(bool opname_remover_changed, + opname_remover.Run(module)); + EXPECT_TRUE(opname_remover_changed); + + EXPECT_FALSE(HasDomainEdge(module, "c", "a")); + EXPECT_FALSE(HasDomainEdge(module, "c", "b")); + EXPECT_FALSE(HasDomainEdge(module, "d", "a")); + EXPECT_FALSE(HasDomainEdge(module, "d", "c")); +} + +// Emulate instructions inserted at top and bottom within nested tuple domain. +TEST_F(HloDomainTest, DomainTupleTopBottomInsert) { + const char* const hlo_string = R"( +HloModule Module + +ENTRY entry { + p0 = f32[4] parameter(0), sharding={maximal device=1} + p1 = (f32[5], f32[6]) parameter(1), + sharding={{maximal device=1}, {maximal device=0}} + tuple.0 = (f32[4], (f32[5], f32[6])) tuple(p0, p1), + sharding={{maximal device=1}, {maximal device=1}, {maximal device=0}} + ROOT res = (f32[5], f32[6]) get-tuple-element(tuple.0), index=1, + sharding={{maximal device=1}, {maximal device=0}} +} +)"; + + TF_ASSERT_OK_AND_ASSIGN(HloModule * module, ParseModule(hlo_string)); + + HloDomainIsolator isolator(ShardingDomainCreator{}); + TF_ASSERT_OK_AND_ASSIGN(bool isolator_changed, isolator.Run(module)); + EXPECT_TRUE(isolator_changed); + + // Clear sharding of tuple.0 instruction, in order to test domain sharding + // application. + auto tuple0 = FindInstruction(module, "tuple.0"); + tuple0->clear_sharding(); + + // Insert the following instructons above and below tuple.0, to emulate other + // passes effects: + // COPY.0 + // \ / + // TUPLE.0 + // / \ + // COPY.1 \ + // / \ + // GTE.0 GTE.1 + // | | + // | COPY.2 + // \ / + // \ / + // TUPLE.1 + // | + auto tuple0_users = tuple0->users(); + auto computation = tuple0->parent(); + HloInstruction* copy0 = computation->AddInstruction( + HloInstruction::CreateUnary(tuple0->operand(1)->shape(), HloOpcode::kCopy, + tuple0->mutable_operand(1))); + TF_EXPECT_OK(tuple0->ReplaceOperandWith(1, copy0)); + + HloInstruction* copy1 = computation->AddInstruction( + HloInstruction::CreateUnary(tuple0->shape(), HloOpcode::kCopy, tuple0)); + HloInstruction* gte0 = + computation->AddInstruction(HloInstruction::CreateGetTupleElement( + ShapeUtil::GetTupleElementShape(copy1->shape(), 0), copy1, 0)); + HloInstruction* gte1 = + computation->AddInstruction(HloInstruction::CreateGetTupleElement( + ShapeUtil::GetTupleElementShape(tuple0->shape(), 1), tuple0, 1)); + HloInstruction* copy2 = computation->AddInstruction( + HloInstruction::CreateUnary(gte1->shape(), HloOpcode::kCopy, gte1)); + HloInstruction* tuple1 = + computation->AddInstruction(HloInstruction::CreateTuple({gte0, copy2})); + + for (HloInstruction* user : tuple0_users) { + TF_EXPECT_OK(tuple0->ReplaceUseWith(user, tuple1)); + } + + HloDomainRemover remover(ShardingMetadata::KindName(), + ShardingMetadata::NormalizeShardingDomain); + TF_ASSERT_OK_AND_ASSIGN(bool remover_changed, remover.Run(module)); + EXPECT_TRUE(remover_changed); + + EXPECT_TRUE(tuple0->has_sharding()); + EXPECT_EQ(HloSharding::Tuple(tuple0->shape(), {HloSharding::AssignDevice(1), + HloSharding::AssignDevice(1), + HloSharding::AssignDevice(0)}), + tuple0->sharding()); + + EXPECT_TRUE(copy0->has_sharding()); + EXPECT_EQ(HloSharding::Tuple(copy0->shape(), {HloSharding::AssignDevice(1), + HloSharding::AssignDevice(0)}), + copy0->sharding()); + + // copy1 has partial information only from gte.0, so in the end it gets no + // sharding at all. During propagation it does propagate the information from + // gte.0 though, enabling Tuple.0 to be fully sharded. + EXPECT_FALSE(copy1->has_sharding()); + + EXPECT_TRUE(gte0->has_sharding()); + EXPECT_EQ(HloSharding::AssignDevice(1), gte0->sharding()); + + EXPECT_TRUE(gte1->has_sharding()); + EXPECT_EQ(HloSharding::Tuple(gte1->shape(), {HloSharding::AssignDevice(1), + HloSharding::AssignDevice(0)}), + gte1->sharding()); + + EXPECT_TRUE(copy2->has_sharding()); + EXPECT_EQ(HloSharding::Tuple(copy2->shape(), {HloSharding::AssignDevice(1), + HloSharding::AssignDevice(0)}), + copy2->sharding()); + + EXPECT_TRUE(tuple1->has_sharding()); + EXPECT_EQ(tuple0->sharding(), tuple1->sharding()); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_domain_verifier.cc b/tensorflow/compiler/xla/service/hlo_domain_verifier.cc index 751fc677e2..dc514ae3e5 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_verifier.cc +++ b/tensorflow/compiler/xla/service/hlo_domain_verifier.cc @@ -52,7 +52,7 @@ Status HloDomainVerifier::RunContext::PopulateDomainKinds() { TF_RET_CHECK(instruction->user_side_metadata().Kind() == instruction->operand_side_metadata().Kind()) << instruction->ToString(); - kinds.insert(instruction->user_side_metadata().Kind().ToString()); + kinds.insert(string(instruction->user_side_metadata().Kind())); } } } diff --git a/tensorflow/compiler/xla/service/hlo_domain_verifier.h b/tensorflow/compiler/xla/service/hlo_domain_verifier.h index 8e53cf97f8..81d6d69a8c 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_verifier.h +++ b/tensorflow/compiler/xla/service/hlo_domain_verifier.h @@ -33,7 +33,7 @@ class HloDomainVerifier : public HloPassInterface { public: HloDomainVerifier(std::vector<string> kinds) : kinds_(std::move(kinds)) {} - tensorflow::StringPiece name() const override { return "domain_verifier"; } + absl::string_view name() const override { return "domain_verifier"; } StatusOr<bool> Run(HloModule* module) override; diff --git a/tensorflow/compiler/xla/service/hlo_element_type_converter.h b/tensorflow/compiler/xla/service/hlo_element_type_converter.h index 2b109225d0..44ded2c2fa 100644 --- a/tensorflow/compiler/xla/service/hlo_element_type_converter.h +++ b/tensorflow/compiler/xla/service/hlo_element_type_converter.h @@ -32,9 +32,7 @@ class HloElementTypeConverter : public HloPassInterface { HloElementTypeConverter(PrimitiveType eliminate_type, PrimitiveType replace_with_type); - tensorflow::StringPiece name() const override { - return "element_type_converter"; - } + absl::string_view name() const override { return "element_type_converter"; } // Returns the pass on the module and returns whether the module was modified. StatusOr<bool> Run(HloModule* module) override; diff --git a/tensorflow/compiler/xla/service/hlo_evaluator.cc b/tensorflow/compiler/xla/service/hlo_evaluator.cc index 36d6a2eed6..71f91fde93 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator.cc +++ b/tensorflow/compiler/xla/service/hlo_evaluator.cc @@ -23,13 +23,15 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/index_util.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/primitive_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_evaluator_typed_visitor.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" @@ -43,7 +45,6 @@ limitations under the License. #include "tensorflow/core/lib/core/casts.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/types.h" @@ -95,7 +96,7 @@ StatusOr<std::unique_ptr<Literal>> Compare(const Shape& shape, HloOpcode opcode, << HloOpcodeString(opcode); } - auto result = MakeUnique<Literal>(shape); + auto result = absl::make_unique<Literal>(shape); TF_RETURN_IF_ERROR(result->Populate<bool>([&](ArraySlice<int64> multi_index) { return compare_op(lhs_literal.Get<OperandT>(multi_index), rhs_literal.Get<OperandT>(multi_index)); @@ -125,7 +126,7 @@ StatusOr<std::unique_ptr<Literal>> Compare<complex64>( << HloOpcodeString(opcode); } - auto result = MakeUnique<Literal>(shape); + auto result = absl::make_unique<Literal>(shape); TF_RETURN_IF_ERROR(result->Populate<bool>([&](ArraySlice<int64> multi_index) { return compare_op(lhs_literal.Get<complex64>(multi_index), rhs_literal.Get<complex64>(multi_index)); @@ -138,44 +139,57 @@ StatusOr<std::unique_ptr<Literal>> Compare<complex64>( HloEvaluator::HloEvaluator(int64 max_loop_iterations) : max_loop_iterations_(max_loop_iterations) { - typed_visitors_[PRED] = MakeUnique<HloEvaluatorTypedVisitor<bool>>(this); - typed_visitors_[U8] = MakeUnique<HloEvaluatorTypedVisitor<uint8>>(this); - typed_visitors_[U16] = MakeUnique<FunctionVisitor>([](HloInstruction*) { - return Unimplemented( - "HloEvaluator::HloEvaluatorTypedVisitor: unhandled primitive type: " - "U16."); - }); - typed_visitors_[U32] = MakeUnique<HloEvaluatorTypedVisitor<uint32>>(this); - typed_visitors_[U64] = MakeUnique<HloEvaluatorTypedVisitor<uint64>>(this); - typed_visitors_[S8] = MakeUnique<HloEvaluatorTypedVisitor<int8>>(this); - typed_visitors_[S16] = MakeUnique<FunctionVisitor>([](HloInstruction*) { - return Unimplemented( - "HloEvaluator::HloEvaluatorTypedVisitor: unhandled primitive type: " - "S16."); - }); - typed_visitors_[S32] = MakeUnique<HloEvaluatorTypedVisitor<int32>>(this); - typed_visitors_[S64] = MakeUnique<HloEvaluatorTypedVisitor<int64>>(this); + typed_visitors_[PRED] = + absl::make_unique<HloEvaluatorTypedVisitor<bool>>(this); + typed_visitors_[U8] = + absl::make_unique<HloEvaluatorTypedVisitor<uint8>>(this); + typed_visitors_[U16] = + absl::make_unique<FunctionVisitor>([](HloInstruction*) { + return Unimplemented( + "HloEvaluator::HloEvaluatorTypedVisitor: unhandled primitive type: " + "U16."); + }); + typed_visitors_[U32] = + absl::make_unique<HloEvaluatorTypedVisitor<uint32>>(this); + typed_visitors_[U64] = + absl::make_unique<HloEvaluatorTypedVisitor<uint64>>(this); + typed_visitors_[S8] = absl::make_unique<HloEvaluatorTypedVisitor<int8>>(this); + typed_visitors_[S16] = + absl::make_unique<FunctionVisitor>([](HloInstruction*) { + return Unimplemented( + "HloEvaluator::HloEvaluatorTypedVisitor: unhandled primitive type: " + "S16."); + }); + typed_visitors_[S32] = + absl::make_unique<HloEvaluatorTypedVisitor<int32>>(this); + typed_visitors_[S64] = + absl::make_unique<HloEvaluatorTypedVisitor<int64>>(this); typed_visitors_[F16] = - MakeUnique<HloEvaluatorTypedVisitor<Eigen::half, float>>(this); - typed_visitors_[F32] = MakeUnique<HloEvaluatorTypedVisitor<float>>(this); - typed_visitors_[F64] = MakeUnique<HloEvaluatorTypedVisitor<double>>(this); - typed_visitors_[C64] = MakeUnique<HloEvaluatorTypedVisitor<complex64>>(this); + absl::make_unique<HloEvaluatorTypedVisitor<Eigen::half, float>>(this); + typed_visitors_[F32] = + absl::make_unique<HloEvaluatorTypedVisitor<float>>(this); + typed_visitors_[F64] = + absl::make_unique<HloEvaluatorTypedVisitor<double>>(this); + typed_visitors_[C64] = + absl::make_unique<HloEvaluatorTypedVisitor<complex64>>(this); // Most of the evaluator computations we use don't support BF16 (e.g., // std::ceil, std::tanh). To make evaluator work with BF16, we set all // elementwise computations to be done in F32 and do BF16<->F32 conversion // around the input and the output of the computations. typed_visitors_[BF16] = - MakeUnique<HloEvaluatorTypedVisitor<bfloat16, float>>(this); - - typed_visitors_[TUPLE] = MakeUnique<FunctionVisitor>([](HloInstruction*) { - return Unimplemented( - "HloEvaluatorTypedVisitor: unhandled primitive type: TUPLE."); - }); - typed_visitors_[OPAQUE] = MakeUnique<FunctionVisitor>([](HloInstruction*) { - return Unimplemented( - "HloEvaluatorTypedVisitor: unhandled primitive type: OPAQUE."); - }); + absl::make_unique<HloEvaluatorTypedVisitor<bfloat16, float>>(this); + + typed_visitors_[TUPLE] = + absl::make_unique<FunctionVisitor>([](HloInstruction*) { + return Unimplemented( + "HloEvaluatorTypedVisitor: unhandled primitive type: TUPLE."); + }); + typed_visitors_[OPAQUE] = + absl::make_unique<FunctionVisitor>([](HloInstruction*) { + return Unimplemented( + "HloEvaluatorTypedVisitor: unhandled primitive type: OPAQUE."); + }); } template <typename LiteralPtr> @@ -216,7 +230,6 @@ template <typename LiteralPtr> StatusOr<std::unique_ptr<Literal>> HloEvaluator::Evaluate( HloInstruction* instruction, ArraySlice<LiteralPtr> arg_literals) { TF_RET_CHECK(hlo_query::AllOperandsAreParametersOrConstants(*instruction)); - TF_RETURN_IF_ERROR(ShapeUtil::ValidateShape(instruction->shape())); evaluated_.clear(); arg_literals_.clear(); @@ -253,7 +266,6 @@ StatusOr<std::unique_ptr<Literal>> HloEvaluator::Evaluate( return tensorflow::errors::FailedPrecondition( "Not all operands are constants."); } - TF_RETURN_IF_ERROR(ShapeUtil::ValidateShape(instruction->shape())); arg_literals_.clear(); evaluated_.clear(); @@ -423,7 +435,7 @@ Status HloEvaluator::HandleIsFinite(HloInstruction* is_finite) { if (!ShapeUtil::ElementIsFloating(operand->shape())) { return InvalidArgument( "expected element type in shape to be float for IsFinite op, got: %s", - PrimitiveType_Name(operand->shape().element_type()).c_str()); + PrimitiveType_Name(operand->shape().element_type())); } switch (operand->shape().element_type()) { @@ -464,9 +476,9 @@ Status HloEvaluator::HandleCompare(HloInstruction* compare) { return Unimplemented( "Implicit broadcasting is currently unsupported in HLO evaluator " "Shape Mismatch: %s vs %s vs %s", - ShapeUtil::HumanString(compare->shape()).c_str(), - ShapeUtil::HumanString(lhs->shape()).c_str(), - ShapeUtil::HumanString(rhs->shape()).c_str()); + ShapeUtil::HumanString(compare->shape()), + ShapeUtil::HumanString(lhs->shape()), + ShapeUtil::HumanString(rhs->shape())); } TF_RET_CHECK(lhs->shape().element_type() == rhs->shape().element_type()); @@ -564,7 +576,8 @@ ShapeUtil::IndexIterationSpace IterationSpaceForOutputBatchIndices( std::vector<int64> index_count; index_count.reserve(output_rank); for (int64 i = 0; i < output_rank; i++) { - bool is_output_batch_dim = !c_binary_search(dim_numbers.offset_dims(), i); + bool is_output_batch_dim = + !absl::c_binary_search(dim_numbers.offset_dims(), i); index_count.push_back(is_output_batch_dim ? output_shape.dimensions(i) : 1); } @@ -581,10 +594,11 @@ ShapeUtil::IndexIterationSpace IterationSpaceForOutputOffsetIndices( std::vector<int64> index_count(output_rank, 1); int64 slice_sizes_idx = 0; for (int64 i = 0; i < output_rank; i++) { - bool is_output_window_dim = c_binary_search(dim_numbers.offset_dims(), i); + bool is_output_window_dim = + absl::c_binary_search(dim_numbers.offset_dims(), i); if (is_output_window_dim) { - while (c_binary_search(dim_numbers.collapsed_slice_dims(), - slice_sizes_idx)) { + while (absl::c_binary_search(dim_numbers.collapsed_slice_dims(), + slice_sizes_idx)) { slice_sizes_idx++; } index_count[i] = slice_sizes[slice_sizes_idx++]; @@ -610,13 +624,13 @@ class OutputBatchIndexToInputIndex { : dim_numbers_(*dim_numbers), start_indices_(*start_indices) { for (int64 i = 0; i < output_shape.dimensions_size(); i++) { output_dim_is_batch_dims_.push_back( - !c_binary_search(dim_numbers_.offset_dims(), i)); + !absl::c_binary_search(dim_numbers_.offset_dims(), i)); } for (int64 i = 0; i < input_shape.dimensions_size(); i++) { int64 index_of_input_dim_in_index_vector = std::distance(dim_numbers_.start_index_map().begin(), - c_find(dim_numbers_.start_index_map(), i)); + absl::c_find(dim_numbers_.start_index_map(), i)); if (index_of_input_dim_in_index_vector == dim_numbers_.start_index_map_size()) { input_dim_value_to_index_vector_.push_back(-1); @@ -736,7 +750,7 @@ class OutputOffsetIndexToInputIndex { std::vector<int64> window_index_to_output_index; int64 output_index_count = 0; for (int64 i = 0; i < output_shape.dimensions_size(); i++) { - if (c_binary_search(dim_numbers.offset_dims(), i)) { + if (absl::c_binary_search(dim_numbers.offset_dims(), i)) { window_index_to_output_index.push_back(output_index_count++); } else { output_index_count++; @@ -745,7 +759,7 @@ class OutputOffsetIndexToInputIndex { int64 window_dim_count = 0; for (int64 i = 0; i < input_shape.dimensions_size(); i++) { - if (c_binary_search(dim_numbers.collapsed_slice_dims(), i)) { + if (absl::c_binary_search(dim_numbers.collapsed_slice_dims(), i)) { input_dim_value_to_output_index_.push_back(-1); } else { input_dim_value_to_output_index_.push_back( @@ -953,7 +967,7 @@ Status HloEvaluator::HandleGetTupleElement(HloInstruction* get_tuple_element) { const Literal& operand_tuple_literal = GetEvaluatedLiteralFor(operand); - evaluated_[get_tuple_element] = MakeUnique<Literal>( + evaluated_[get_tuple_element] = absl::make_unique<Literal>( ShapeUtil::GetTupleElementShape(operand->shape(), index)); return evaluated_[get_tuple_element]->CopyFrom(operand_tuple_literal, /*dest_shape_index=*/{}, @@ -1091,8 +1105,8 @@ Status HloEvaluator::HandleWhile(HloInstruction* while_hlo) { HloEvaluator loop_body_evaluator(max_loop_iterations_); while (keep_going) { if (max_loop_iterations_ >= 0 && iteration_count++ > max_loop_iterations_) { - return InvalidArgument("Loop %s exceeded loop iteration limit (%lld).", - while_hlo->name().c_str(), max_loop_iterations_); + return InvalidArgument("Loop %s exceeded loop iteration limit (%d).", + while_hlo->name(), max_loop_iterations_); } TF_ASSIGN_OR_RETURN(auto cond_val, cond_evaluator.Evaluate<Literal*>( *cond_comp, {lcv.get()})); @@ -1155,10 +1169,11 @@ StatusOr<std::unique_ptr<Literal>> EvaluateSortInternal( result_keys.push_back(key_value.first); result_values.push_back(key_value.second); } - auto result_keys_literal = MakeUnique<Literal>(keys_literal.shape()); + auto result_keys_literal = absl::make_unique<Literal>(keys_literal.shape()); result_keys_literal->PopulateR1( tensorflow::gtl::ArraySlice<KeyType>(result_keys)); - auto result_values_literal = MakeUnique<Literal>(values_literal.shape()); + auto result_values_literal = + absl::make_unique<Literal>(values_literal.shape()); result_values_literal->PopulateR1( tensorflow::gtl::ArraySlice<ValueType>(result_values)); return std::make_pair(std::move(result_keys_literal), @@ -1173,8 +1188,9 @@ StatusOr<std::unique_ptr<Literal>> EvaluateSortInternal( } else { // For R2 sort, the desired semantics are to sort each matrix row // independently. - auto keys_result_literal = MakeUnique<Literal>(keys_literal.shape()); - auto values_result_literal = MakeUnique<Literal>(values_literal.shape()); + auto keys_result_literal = absl::make_unique<Literal>(keys_literal.shape()); + auto values_result_literal = + absl::make_unique<Literal>(values_literal.shape()); int64 r1_length = keys_literal.shape().dimensions(1); for (int64 row = 0; row < keys_literal.shape().dimensions(0); ++row) { TF_ASSIGN_OR_RETURN(auto keys_r1_slice, @@ -1246,7 +1262,7 @@ Status HloEvaluator::HandleSort(HloInstruction* sort) { const int64 rank = ShapeUtil::Rank(sort->operand(0)->shape()); if (sort_dim != rank - 1) { return Unimplemented( - "Trying to support along dimension %lld, which is not the last " + "Trying to support along dimension %d, which is not the last " "dimension", sort_dim); } @@ -1267,7 +1283,7 @@ Status HloEvaluator::HandleSort(HloInstruction* sort) { Status HloEvaluator::Preprocess(HloInstruction* hlo) { VLOG(2) << "About to visit HLO: " << hlo->ToString(); - return Status::OK(); + return ShapeUtil::ValidateShape(hlo->shape()); } Status HloEvaluator::Postprocess(HloInstruction* hlo) { diff --git a/tensorflow/compiler/xla/service/hlo_evaluator.h b/tensorflow/compiler/xla/service/hlo_evaluator.h index a4c37ef328..0ea7089552 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator.h +++ b/tensorflow/compiler/xla/service/hlo_evaluator.h @@ -18,7 +18,7 @@ limitations under the License. #include <memory> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -222,11 +222,11 @@ class HloEvaluator : public DfsHloVisitorWithDefault { return Unimplemented( "Implicit broadcasting is currently unsupported in HLO evaluator " "Shape Mismatch: %s vs %s", - ShapeUtil::HumanString(shape).c_str(), - ShapeUtil::HumanString(operand->shape()).c_str()); + ShapeUtil::HumanString(shape), + ShapeUtil::HumanString(operand->shape())); } - auto result = MakeUnique<Literal>(shape); + auto result = absl::make_unique<Literal>(shape); TF_RETURN_IF_ERROR(result->Populate<ReturnT>( [&](tensorflow::gtl::ArraySlice<int64> multi_index) { return unary_op(operand_literal.Get<NativeT>(multi_index)); diff --git a/tensorflow/compiler/xla/service/hlo_evaluator_test.cc b/tensorflow/compiler/xla/service/hlo_evaluator_test.cc index 1394be68e4..c3af15c6a8 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator_test.cc +++ b/tensorflow/compiler/xla/service/hlo_evaluator_test.cc @@ -21,6 +21,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/reference_util.h" @@ -51,8 +52,11 @@ static std::array<bool, 2> use_bf16_params{true, false}; class HloEvaluatorTest : public ::testing::WithParamInterface<bool>, public HloVerifiedTestBase { protected: - HloEvaluatorTest() : use_bfloat16_(GetParam()) { - evaluator_ = MakeUnique<HloEvaluator>(); + HloEvaluatorTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false), + use_bfloat16_(GetParam()) { + evaluator_ = absl::make_unique<HloEvaluator>(); } std::unique_ptr<Literal> Evaluate( @@ -523,7 +527,7 @@ TEST_P(HloEvaluatorTest, Pad4DFloatArrayWithInteriorPadding) { std::unique_ptr<Literal> result = Evaluate(); - auto expected_array = MakeUnique<Array4D<float>>(8, 5, 1, 1); + auto expected_array = absl::make_unique<Array4D<float>>(8, 5, 1, 1); expected_array->Fill(kPadValue); (*expected_array)(1, 0, 0, 0) = 1.0f; (*expected_array)(1, 2, 0, 0) = 2.0f; @@ -547,7 +551,7 @@ TEST_P(HloEvaluatorTest, NegativePadding2D) { // { 9, 10, 11 }, // { 13, 14, 15 }, // } - auto input_array = MakeUnique<Array2D<float>>(4, 3); + auto input_array = absl::make_unique<Array2D<float>>(4, 3); input_array->FillUnique(1.0f); auto input = LiteralUtil::CreateR2FromArray2D<float>(*input_array); HloInstruction* input_instruction = @@ -568,7 +572,7 @@ TEST_P(HloEvaluatorTest, NegativePadding2D) { std::unique_ptr<Literal> result = Evaluate(); // f32[1,5] { 7.0, 2.718, 2.718, 2.718, 2.718 } - auto expected_array = MakeUnique<Array2D<float>>(1, 5); + auto expected_array = absl::make_unique<Array2D<float>>(1, 5); (*expected_array)(0, 0) = 7.0f; (*expected_array)(0, 1) = 2.718f; (*expected_array)(0, 2) = 2.718f; @@ -588,7 +592,7 @@ TEST_P(HloEvaluatorTest, NegativeAndInteriorPadding2D) { // { 9, 10, 11 }, // { 13, 14, 15 }, // } - auto input_array = MakeUnique<Array2D<float>>(4, 3); + auto input_array = absl::make_unique<Array2D<float>>(4, 3); input_array->FillUnique(1.0f); auto input = LiteralUtil::CreateR2FromArray2D<float>(*input_array); HloInstruction* input_instruction = @@ -612,7 +616,7 @@ TEST_P(HloEvaluatorTest, NegativeAndInteriorPadding2D) { std::unique_ptr<Literal> result = Evaluate(); - auto expected_array = MakeUnique<Array2D<float>>(0, 9); + auto expected_array = absl::make_unique<Array2D<float>>(0, 9); auto expected = LiteralUtil::CreateR2FromArray2D<float>(*expected_array); EXPECT_TRUE(LiteralTestUtil::Equal(*expected, *result)); @@ -628,7 +632,7 @@ TEST_P(HloEvaluatorTest, DotRank2AndRank1) { // { 3 }, // { 4 }, // } - auto lhs_array = MakeUnique<Array2D<float>>(4, 1); + auto lhs_array = absl::make_unique<Array2D<float>>(4, 1); lhs_array->FillUnique(1.0f); auto lhs_literal = LiteralUtil::CreateR2FromArray2D<float>(*lhs_array); HloInstruction* lhs_instruction = @@ -679,7 +683,7 @@ TEST_P(HloEvaluatorTest, DotRank1AndRank2) { // { 3, 4 }, // { 5, 6 }, // } - auto rhs_array = MakeUnique<Array2D<float>>(3, 2); + auto rhs_array = absl::make_unique<Array2D<float>>(3, 2); rhs_array->FillUnique(1.0f); auto rhs_literal = LiteralUtil::CreateR2FromArray2D<float>(*rhs_array); HloInstruction* rhs_instruction = @@ -710,7 +714,7 @@ TEST_P(HloEvaluatorTest, DotRank2AndRank2) { // { 9, 10, 11 }, // { 13, 14, 15 }, // } - auto lhs_array = MakeUnique<Array2D<float>>(4, 3); + auto lhs_array = absl::make_unique<Array2D<float>>(4, 3); lhs_array->FillUnique(1.0f); auto lhs_literal = LiteralUtil::CreateR2FromArray2D<float>(*lhs_array); HloInstruction* lhs_instruction = @@ -722,7 +726,7 @@ TEST_P(HloEvaluatorTest, DotRank2AndRank2) { // { 3, 4 }, // { 5, 6 }, // } - auto rhs_array = MakeUnique<Array2D<float>>(3, 2); + auto rhs_array = absl::make_unique<Array2D<float>>(3, 2); rhs_array->FillUnique(1.0f); auto rhs_literal = LiteralUtil::CreateR2FromArray2D<float>(*rhs_array); HloInstruction* rhs_instruction = @@ -1215,7 +1219,12 @@ TEST_P(HloEvaluatorTest, EXPECT_TRUE(LiteralTestUtil::Equal(*expected, *result)); } -class HloEvaluatorPreciseReduceTest : public HloVerifiedTestBase {}; +class HloEvaluatorPreciseReduceTest : public HloVerifiedTestBase { + public: + HloEvaluatorPreciseReduceTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} +}; // Tests that Reduce doesn't lose precision when adding many numbers (because // it accumulates its result in a double). @@ -1297,7 +1306,7 @@ TEST_P(HloEvaluatorTest, ReduceAdd) { // { 1, 2, 3 }, // { 5, 6, 7 }, // } - auto arg_array = MakeUnique<Array2D<float>>(2, 3); + auto arg_array = absl::make_unique<Array2D<float>>(2, 3); arg_array->FillUnique(1.0f); auto arg_literal = LiteralUtil::CreateR2FromArray2D<float>(*arg_array); @@ -1339,7 +1348,7 @@ TEST_P(HloEvaluatorTest, ReduceWindowMax) { // { 1, 2, 3 }, // { 5, 6, 7 }, // } - auto arg_array = MakeUnique<Array2D<float>>(2, 3); + auto arg_array = absl::make_unique<Array2D<float>>(2, 3); arg_array->FillUnique(1.0f); auto arg_literal = LiteralUtil::CreateR2FromArray2D<float>(*arg_array); @@ -1390,7 +1399,7 @@ TEST_P(HloEvaluatorTest, ReduceWindowAdd) { // { 1, 2, 3 }, // { 5, 6, 7 }, // } - auto arg_array = MakeUnique<Array2D<float>>(2, 3); + auto arg_array = absl::make_unique<Array2D<float>>(2, 3); arg_array->FillUnique(1.0f); auto arg_literal = LiteralUtil::CreateR2FromArray2D<float>(*arg_array); @@ -1511,7 +1520,7 @@ TEST_P(HloEvaluatorTest, StridedSlice) { // { 9, 10, 11, 12, 13 }, // { 17, 18, 19, 20, 21 }, // } - auto operand_array = MakeUnique<Array2D<float>>(3, 5); + auto operand_array = absl::make_unique<Array2D<float>>(3, 5); operand_array->FillUnique(1.0f); auto operand_literal = LiteralUtil::CreateR2FromArray2D<float>(*operand_array); @@ -1544,7 +1553,7 @@ TEST_P(HloEvaluatorTest, DynamicSlice) { // { 1, 2, 3, 4 }, // { 5, 6, 7, 8 }, // } - auto operand_array = MakeUnique<Array2D<float>>(2, 4); + auto operand_array = absl::make_unique<Array2D<float>>(2, 4); operand_array->FillUnique(1.0f); auto operand_literal = LiteralUtil::CreateR2FromArray2D<float>(*operand_array); @@ -1580,7 +1589,7 @@ TEST_P(HloEvaluatorTest, DynamicSliceModSlice) { // { 1, 2, 3, 4 }, // { 5, 6, 7, 8 }, // } - auto operand_array = MakeUnique<Array2D<float>>(2, 4); + auto operand_array = absl::make_unique<Array2D<float>>(2, 4); operand_array->FillUnique(1.0f); auto operand_literal = LiteralUtil::CreateR2FromArray2D<float>(*operand_array); @@ -1614,7 +1623,7 @@ TEST_P(HloEvaluatorTest, DynamicSliceUpdate) { // { 1, 2, 3 }, // { 5, 6, 7 }, // } - auto operand_array = MakeUnique<Array2D<double>>(2, 3); + auto operand_array = absl::make_unique<Array2D<double>>(2, 3); operand_array->FillUnique(1.0); auto operand_literal = LiteralUtil::CreateR2FromArray2D<double>(*operand_array); @@ -1651,7 +1660,7 @@ TEST_P(HloEvaluatorTest, SetAndGetTuples) { // { 1, 2, 3 }, // { 5, 6, 7 }, // } - auto operand_array = MakeUnique<Array2D<double>>(2, 3); + auto operand_array = absl::make_unique<Array2D<double>>(2, 3); operand_array->FillUnique(1.0); auto operand_literal2 = LiteralUtil::CreateR2FromArray2D<double>(*operand_array); @@ -1687,7 +1696,7 @@ TEST_P(HloEvaluatorTest, SetAndGetNestedTuples) { // { 1, 2, 3 }, // { 5, 6, 7 }, // } - auto operand_array = MakeUnique<Array2D<double>>(2, 3); + auto operand_array = absl::make_unique<Array2D<double>>(2, 3); operand_array->FillUnique(1.0); HloInstruction* operand2 = b.AddInstruction(HloInstruction::CreateConstant( diff --git a/tensorflow/compiler/xla/service/hlo_evaluator_typed_visitor.h b/tensorflow/compiler/xla/service/hlo_evaluator_typed_visitor.h index 7fdf4521de..f682e69ee9 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator_typed_visitor.h +++ b/tensorflow/compiler/xla/service/hlo_evaluator_typed_visitor.h @@ -16,11 +16,16 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_HLO_EVALUATOR_TYPED_VISITOR_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_HLO_EVALUATOR_TYPED_VISITOR_H_ +#include "absl/algorithm/container.h" +#include "absl/container/inlined_vector.h" +#include "absl/memory/memory.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/literal_util.h" +#include "tensorflow/compiler/xla/service/hlo_casting_utils.h" #include "tensorflow/compiler/xla/service/hlo_evaluator.h" +#include "tensorflow/compiler/xla/service/hlo_instructions.h" #include "tensorflow/compiler/xla/service/shape_inference.h" #include "tensorflow/core/lib/core/casts.h" -#include "tensorflow/core/lib/gtl/optional.h" namespace xla { @@ -105,7 +110,8 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { typename std::enable_if<is_complex_t<NativeT>::value>::type* = nullptr> double GetAsDouble(const Literal& literal, tensorflow::gtl::ArraySlice<int64> input_index) { - CHECK(false); + LOG(FATAL) << "Trying to get complex literal as double: " + << literal.ToString(); } public: @@ -139,7 +145,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { Status DefaultAction(HloInstruction* hlo_instruction) override { return Unimplemented("unhandled HLO ops for HloEvaluator: %s.", - HloOpcodeString(hlo_instruction->opcode()).c_str()); + HloOpcodeString(hlo_instruction->opcode())); } // TODO(b/35950897): many of the stl functions used in the handlers are not @@ -547,7 +553,11 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { return Status::OK(); } - Status HandleDivide(HloInstruction* divide) override { + template < + typename NativeT, + typename std::enable_if<std::is_floating_point<NativeT>::value || + is_complex_t<NativeT>::value>::type* = nullptr> + Status HandleDivide(HloInstruction* divide) { TF_ASSIGN_OR_RETURN(parent_->evaluated_[divide], ElementWiseBinaryOp(divide, [](ElementwiseT lhs_elem, ElementwiseT rhs_elem) { @@ -557,6 +567,46 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { } template <typename NativeT, + typename std::enable_if<std::is_signed<NativeT>::value && + std::is_integral<NativeT>::value>::type* = + nullptr> + Status HandleDivide(HloInstruction* divide) { + TF_ASSIGN_OR_RETURN( + parent_->evaluated_[divide], + ElementWiseBinaryOp( + divide, + [](ElementwiseT lhs_elem, ElementwiseT rhs_elem) -> ElementwiseT { + if (rhs_elem == 0) { + return static_cast<ElementwiseT>(-1); + } + if (rhs_elem == -1 && + lhs_elem == std::numeric_limits<ElementwiseT>::min()) { + return lhs_elem; + } + return lhs_elem / rhs_elem; + })); + return Status::OK(); + } + + template <typename NativeT, + typename std::enable_if<std::is_unsigned<NativeT>::value>::type* = + nullptr> + Status HandleDivide(HloInstruction* divide) { + TF_ASSIGN_OR_RETURN(parent_->evaluated_[divide], + ElementWiseBinaryOp(divide, [](ElementwiseT lhs_elem, + ElementwiseT rhs_elem) { + return rhs_elem == 0 + ? std::numeric_limits<ElementwiseT>::max() + : (lhs_elem / rhs_elem); + })); + return Status::OK(); + } + + Status HandleDivide(HloInstruction* divide) { + return HandleDivide<ElementwiseT>(divide); + } + + template <typename NativeT, typename std::enable_if<std::is_integral<NativeT>::value>::type* = nullptr> Status HandleMaximum(HloInstruction* maximum) { @@ -642,9 +692,8 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { return Status::OK(); } - template < - typename NativeT, - typename std::enable_if<!is_complex_t<NativeT>::value>::type* = nullptr> + template <typename NativeT, typename std::enable_if<std::is_floating_point< + NativeT>::value>::type* = nullptr> Status HandleRemainder(HloInstruction* remainder) { TF_ASSIGN_OR_RETURN(parent_->evaluated_[remainder], ElementWiseBinaryOp(remainder, [](ElementwiseT lhs_el, @@ -654,6 +703,40 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { return Status::OK(); } + template <typename NativeT, + typename std::enable_if<std::is_unsigned<NativeT>::value>::type* = + nullptr> + Status HandleRemainder(HloInstruction* remainder) { + TF_ASSIGN_OR_RETURN(parent_->evaluated_[remainder], + ElementWiseBinaryOp(remainder, [](ElementwiseT lhs_el, + ElementwiseT rhs_el) { + return rhs_el == 0 ? lhs_el : (lhs_el % rhs_el); + })); + return Status::OK(); + } + + template <typename NativeT, + typename std::enable_if<std::is_signed<NativeT>::value && + std::is_integral<NativeT>::value>::type* = + nullptr> + Status HandleRemainder(HloInstruction* remainder) { + TF_ASSIGN_OR_RETURN( + parent_->evaluated_[remainder], + ElementWiseBinaryOp( + remainder, + [](ElementwiseT lhs_el, ElementwiseT rhs_el) -> ElementwiseT { + if (rhs_el == 0) { + return lhs_el; + } + if (rhs_el == -1 && + lhs_el == std::numeric_limits<ElementwiseT>::min()) { + return 0; + } + return lhs_el % rhs_el; + })); + return Status::OK(); + } + template < typename NativeT, typename std::enable_if<is_complex_t<NativeT>::value>::type* = nullptr> @@ -895,7 +978,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { << ShapeUtil::HumanString(inferred_return_shape); const Literal& operand_literal = parent_->GetEvaluatedLiteralFor(operand); - auto result = MakeUnique<Literal>(result_shape); + auto result = absl::make_unique<Literal>(result_shape); TF_RETURN_IF_ERROR(result->Populate<ReturnT>( [&](tensorflow::gtl::ArraySlice<int64> out_index) { @@ -1052,7 +1135,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { return static_cast<ReturnT>(result_val); }; - auto result = MakeUnique<Literal>(result_shape); + auto result = absl::make_unique<Literal>(result_shape); TF_RETURN_IF_ERROR(result->PopulateParallel<ReturnT>(func)); parent_->evaluated_[conv] = std::move(result); @@ -1100,7 +1183,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { // result_index_locations[i] contains one or two pointers to the locations // in lhs_index or rhs_index where the i'th result index should go. - tensorflow::gtl::InlinedVector<std::pair<int64*, int64*>, kInlineRank> + absl::InlinedVector<std::pair<int64*, int64*>, kInlineRank> result_index_locations; result_index_locations.reserve(lhs_rank + rhs_rank - 2); @@ -1126,7 +1209,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { } } - auto result = MakeUnique<Literal>(dot->shape()); + auto result = absl::make_unique<Literal>(dot->shape()); TF_RETURN_IF_ERROR(result->Populate<ReturnT>( [&](tensorflow::gtl::ArraySlice<int64> result_index) { ElementwiseT result_val = static_cast<ElementwiseT>(0); @@ -1175,7 +1258,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { // Create new HLO of padded shape with padding value. ReturnT scalar = parent_->GetEvaluatedLiteralFor(pad->operand(1)).Get<ReturnT>({}); - auto result = MakeUnique<Literal>(pad->shape()); + auto result = absl::make_unique<Literal>(pad->shape()); TF_RETURN_IF_ERROR(result->Populate<ReturnT>( [&scalar](tensorflow::gtl::ArraySlice<int64> multi_index) { return scalar; @@ -1340,7 +1423,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { auto operands = map->operands(); HloComputation* computation = map->to_apply(); - auto result = MakeUnique<Literal>(map->shape()); + auto result = absl::make_unique<Literal>(map->shape()); HloEvaluator embedded_evaluator(parent_->max_loop_iterations_); TF_RETURN_IF_ERROR(result->Populate<ReturnT>( @@ -1454,7 +1537,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { [](const ReturnT& a, const ReturnT& b) { return SafeLess<ReturnT>(a, b); }); - auto result_literal = MakeUnique<Literal>(keys_literal.shape()); + auto result_literal = absl::make_unique<Literal>(keys_literal.shape()); result_literal->PopulateR1( tensorflow::gtl::ArraySlice<ReturnT>(result_data)); VLOG(3) << "HandleSort result_literal: " << result_literal->ToString(); @@ -1466,7 +1549,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { } else { // For R2 sort, the desired semantics are to sort each matrix row // independently. - auto result_literal = MakeUnique<Literal>(keys_literal.shape()); + auto result_literal = absl::make_unique<Literal>(keys_literal.shape()); int64 r1_length = keys->shape().dimensions(1); for (int64 row = 0; row < keys->shape().dimensions(0); ++row) { TF_ASSIGN_OR_RETURN(auto r1_slice, @@ -1540,11 +1623,15 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { } HloEvaluator embedded_evaluator(parent_->max_loop_iterations_); - auto result = MakeUnique<Literal>(reduce->shape()); + auto result = absl::make_unique<Literal>(reduce->shape()); + Status eval_status; // For each resulting dimension, calculate and assign computed value. TF_RETURN_IF_ERROR(result->Populate<ReturnT>( [&](tensorflow::gtl::ArraySlice<int64> multi_index) { ReturnT result_val = init_scalar; + if (!eval_status.ok()) { + return result_val; + } std::vector<int64> base(arg_dimensions.size()); for (int64 i = 0; i < multi_index.size(); ++i) { @@ -1565,7 +1652,8 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { arg_dim_steps, func); return static_cast<ReturnT>(computed_result); } - auto func = [&](tensorflow::gtl::ArraySlice<int64> input_index) { + auto func = [&](tensorflow::gtl::ArraySlice<int64> input_index) + -> StatusOr<bool> { auto curr_val = arg_literal.Get<ReturnT>(input_index); // Evaluate computation with specified literal operands. @@ -1573,12 +1661,10 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { auto result_val_literal = LiteralUtil::CreateR0<ReturnT>(result_val); - std::unique_ptr<Literal> computed_result = - embedded_evaluator - .Evaluate<const Literal*>( - *function, - {result_val_literal.get(), curr_val_literal.get()}) - .ConsumeValueOrDie(); + TF_ASSIGN_OR_RETURN(std::unique_ptr<Literal> computed_result, + embedded_evaluator.Evaluate<const Literal*>( + *function, {result_val_literal.get(), + curr_val_literal.get()})); // Clear visit states so that we can use the evaluator again on // the same computation. embedded_evaluator.ResetVisitStates(); @@ -1588,13 +1674,13 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { }; // Computes one element of the result, reducing all dimensions that // contribute to that element. - ShapeUtil::ForEachIndex(arg_literal.shape(), base, arg_dim_counts, - arg_dim_steps, func); + eval_status = ShapeUtil::ForEachIndexWithStatus( + arg_literal.shape(), base, arg_dim_counts, arg_dim_steps, func); return result_val; })); parent_->evaluated_[reduce] = std::move(result); - return Status::OK(); + return eval_status; } bool IsScalarAdd(HloComputation* computation) { @@ -1621,7 +1707,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { TF_RET_CHECK(ShapeUtil::IsScalar(init_literal.shape())); auto init_scalar = init_literal.Get<ReturnT>({}); - auto result = MakeUnique<Literal>(select_and_scatter->shape()); + auto result = absl::make_unique<Literal>(select_and_scatter->shape()); // Initialize result array with the init value. TF_RETURN_IF_ERROR(result->Populate<ReturnT>( @@ -1665,8 +1751,8 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { // 2. Using the selected index, scatter value from `source` to result. We // do this by iterating through the window, and compare each index with // the selected index. - tensorflow::gtl::optional<ReturnT> selected_val; - tensorflow::gtl::optional<std::vector<int64>> selected_index; + absl::optional<ReturnT> selected_val; + absl::optional<std::vector<int64>> selected_index; IterateThroughWindow( window_shape, window, operand_literal.shape(), source_index, @@ -1757,7 +1843,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { DimensionVector operand_index(ShapeUtil::Rank(operand_literal.shape())); HloEvaluator embedded_evaluator(parent_->max_loop_iterations_); - auto result = MakeUnique<Literal>(reduce_window->shape()); + auto result = absl::make_unique<Literal>(reduce_window->shape()); // For each resulting dimension, calculate and assign computed value. TF_RETURN_IF_ERROR(result->Populate<ReturnT>( [&](tensorflow::gtl::ArraySlice<int64> output_index) { @@ -1824,7 +1910,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { std::vector<int64> index_count(updates_rank, 1); for (int64 i = 0; i < updates_rank; i++) { bool is_update_scatter_dim = - !c_binary_search(dim_numbers.update_window_dims(), i); + !absl::c_binary_search(dim_numbers.update_window_dims(), i); if (is_update_scatter_dim) { index_count[i] = updates_shape.dimensions(i); } @@ -1843,7 +1929,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { std::vector<int64> index_count(updates_rank, 1); for (int64 i = 0; i < updates_rank; i++) { bool is_update_window_dim = - c_binary_search(dim_numbers.update_window_dims(), i); + absl::c_binary_search(dim_numbers.update_window_dims(), i); if (is_update_window_dim) { index_count[i] = updates_shape.dimensions(i); } @@ -1870,7 +1956,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { : dim_numbers_(*dim_numbers), scatter_indices_(*scatter_indices) { for (int64 i = 0; i < updates_shape.dimensions_size(); i++) { update_dim_is_scatter_dims_.push_back( - !c_binary_search(dim_numbers_.update_window_dims(), i)); + !absl::c_binary_search(dim_numbers_.update_window_dims(), i)); } for (int64 i = 0; i < input_shape.dimensions_size(); i++) { @@ -2000,7 +2086,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { std::vector<int64> window_index_to_update_index; int64 update_index_count = 0; for (int64 i = 0; i < updates_shape.dimensions_size(); i++) { - if (c_binary_search(dim_numbers.update_window_dims(), i)) { + if (absl::c_binary_search(dim_numbers.update_window_dims(), i)) { window_index_to_update_index.push_back(update_index_count++); } else { update_index_count++; @@ -2009,7 +2095,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { int64 window_dim_count = 0; for (int64 i = 0; i < input_shape.dimensions_size(); i++) { - if (c_binary_search(dim_numbers.inserted_window_dims(), i)) { + if (absl::c_binary_search(dim_numbers.inserted_window_dims(), i)) { input_dim_value_to_update_index_.push_back(-1); } else { input_dim_value_to_update_index_.push_back( @@ -2409,11 +2495,21 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { std::is_same<NativeT, float>::value || std::is_same<NativeT, int32>::value || std::is_same<NativeT, uint32>::value>::type* = nullptr> - Status HandleIota(HloInstruction* iota) { - auto result = MakeUnique<Literal>(iota->shape()); - auto data = result->data<ReturnT>(); + Status HandleIota(HloInstruction* instruction) { + auto* iota = Cast<HloIotaInstruction>(instruction); + std::vector<NativeT> data(iota->shape().dimensions(iota->iota_dimension())); std::iota(data.begin(), data.end(), 0); - parent_->evaluated_[iota] = std::move(result); + auto result = LiteralUtil::CreateR1<NativeT>(data); + + if (ShapeUtil::Rank(iota->shape()) > 1) { + TF_ASSIGN_OR_RETURN( + parent_->evaluated_[iota], + result->Broadcast(iota->shape(), {iota->iota_dimension()})); + } else { + TF_RET_CHECK(ShapeUtil::Rank(iota->shape()) == 1); + parent_->evaluated_[iota] = std::move(result); + } + return Status::OK(); } template <typename NativeT, @@ -2492,7 +2588,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { } std::vector<int64> operand_indices(start.size()); - auto result = MakeUnique<Literal>(result_shape); + auto result = absl::make_unique<Literal>(result_shape); TF_RETURN_IF_ERROR(result->Populate<ReturnT>( [&](tensorflow::gtl::ArraySlice<int64> multi_index) { for (int64 i = 0; i < operand_indices.size(); ++i) { @@ -2570,15 +2666,14 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { return Unimplemented( "Implicit broadcasting is currently unsupported in HLO evaluator " "Shape Mismatch: %s vs %s vs %s: ", - ShapeUtil::HumanString(shape).c_str(), - ShapeUtil::HumanString(lhs->shape()).c_str(), - ShapeUtil::HumanString(rhs->shape()).c_str()); + ShapeUtil::HumanString(shape), ShapeUtil::HumanString(lhs->shape()), + ShapeUtil::HumanString(rhs->shape())); } const Literal& lhs_literal = parent_->GetEvaluatedLiteralFor(lhs); const Literal& rhs_literal = parent_->GetEvaluatedLiteralFor(rhs); - auto result = MakeUnique<Literal>(shape); + auto result = absl::make_unique<Literal>(shape); TF_RETURN_IF_ERROR(result->Populate<ReturnT>( [&](tensorflow::gtl::ArraySlice<int64> multi_index) { @@ -2606,17 +2701,16 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { return Unimplemented( "Implicit broadcasting is currently unsupported in HLO evaluator " "Shape Mismatch: %s vs %s vs %s vs %s: ", - ShapeUtil::HumanString(shape).c_str(), - ShapeUtil::HumanString(lhs->shape()).c_str(), - ShapeUtil::HumanString(rhs->shape()).c_str(), - ShapeUtil::HumanString(ehs->shape()).c_str()); + ShapeUtil::HumanString(shape), ShapeUtil::HumanString(lhs->shape()), + ShapeUtil::HumanString(rhs->shape()), + ShapeUtil::HumanString(ehs->shape())); } const Literal& lhs_literal = parent_->GetEvaluatedLiteralFor(lhs); const Literal& rhs_literal = parent_->GetEvaluatedLiteralFor(rhs); const Literal& ehs_literal = parent_->GetEvaluatedLiteralFor(ehs); - auto result = MakeUnique<Literal>(shape); + auto result = absl::make_unique<Literal>(shape); TF_RETURN_IF_ERROR(result->Populate<ReturnT>( [&](tensorflow::gtl::ArraySlice<int64> multi_index) { diff --git a/tensorflow/compiler/xla/service/hlo_execution_profile.cc b/tensorflow/compiler/xla/service/hlo_execution_profile.cc index c3ccbf0f0c..de3d7a1677 100644 --- a/tensorflow/compiler/xla/service/hlo_execution_profile.cc +++ b/tensorflow/compiler/xla/service/hlo_execution_profile.cc @@ -19,6 +19,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/human_readable_profile_builder.h" @@ -49,7 +51,7 @@ std::unique_ptr<HloProfilePrinterData> CreateHloProfilePrinterData( size_t profile_counters_size = hlo_profile_index_map.total_count(); std::unique_ptr<HloProfilePrinterData> profile_printer_data = - MakeUnique<HloProfilePrinterData>(); + absl::make_unique<HloProfilePrinterData>(); profile_printer_data->set_profile_counters_size(profile_counters_size); profile_printer_data->mutable_computation_infos()->Reserve( hlo_profile_index_map.computation_count()); @@ -67,11 +69,11 @@ std::unique_ptr<HloProfilePrinterData> CreateHloProfilePrinterData( // The profile indices were computed deterministically in // HloProfileIndexMap::HloProfileIndexMap. - c_sort(computation_and_profile_idx_list, - [](const std::pair<const HloComputation*, int64>& left, - const std::pair<const HloComputation*, int64>& right) { - return left.second < right.second; - }); + absl::c_sort(computation_and_profile_idx_list, + [](const std::pair<const HloComputation*, int64>& left, + const std::pair<const HloComputation*, int64>& right) { + return left.second < right.second; + }); for (const auto& pair : computation_and_profile_idx_list) { CHECK_LT(pair.second, profile_counters_size); diff --git a/tensorflow/compiler/xla/service/hlo_execution_profile_test.cc b/tensorflow/compiler/xla/service/hlo_execution_profile_test.cc index eba80c0f19..460ae2b5ec 100644 --- a/tensorflow/compiler/xla/service/hlo_execution_profile_test.cc +++ b/tensorflow/compiler/xla/service/hlo_execution_profile_test.cc @@ -14,15 +14,15 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/hlo_execution_profile.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/hlo_cost_analysis.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/tests/hlo_test_base.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { namespace { -using tensorflow::strings::StrCat; +using absl::StrCat; using ::testing::AllOf; using ::testing::ContainsRegex; diff --git a/tensorflow/compiler/xla/service/hlo_graph_dumper.cc b/tensorflow/compiler/xla/service/hlo_graph_dumper.cc index 1efa6eb5bd..3041d94fa9 100644 --- a/tensorflow/compiler/xla/service/hlo_graph_dumper.cc +++ b/tensorflow/compiler/xla/service/hlo_graph_dumper.cc @@ -26,6 +26,12 @@ limitations under the License. #include <unordered_map> #include <vector> +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" +#include "absl/strings/str_replace.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/service/hlo_casting_utils.h" @@ -37,50 +43,25 @@ limitations under the License. #include "tensorflow/compiler/xla/window_util.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/gtl/map_util.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/lib/io/path.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/regexp.h" -using ::tensorflow::Env; -using ::tensorflow::WriteStringToFile; -using ::tensorflow::gtl::nullopt; -using ::tensorflow::gtl::optional; -using ::tensorflow::io::JoinPath; -using ::tensorflow::str_util::Join; -using ::tensorflow::str_util::StringReplace; -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; - namespace xla { namespace hlo_graph_dumper { namespace { -// Helpers for Printf and Appendf. -template <typename T> -struct PrintfConvert { - const T& operator()(const T& t) const { return t; } -}; -template <> -struct PrintfConvert<string> { - const char* operator()(const string& s) const { return s.c_str(); } -}; - -// Like tensorflow::strings::Printf/Appendf, but you don't need to call c_str() -// on strings. -template <typename... Ts> -string Printf(const char* fmt, const Ts&... ts) { - return tensorflow::strings::Printf(fmt, PrintfConvert<Ts>()(ts)...); -} -template <typename... Ts> -void Appendf(string* s, const char* fmt, const Ts&... ts) { - tensorflow::strings::Appendf(s, fmt, PrintfConvert<Ts>()(ts)...); -} +using absl::nullopt; +using absl::optional; +using absl::StrAppend; +using absl::StrCat; +using absl::StrFormat; +using absl::StrJoin; +using tensorflow::Env; +using tensorflow::WriteStringToFile; +using tensorflow::io::JoinPath; // Used to indicate how we should treat a given HLOInstruction in the graph. // should we treat it like normal, hide it, and so on? @@ -209,17 +190,15 @@ NodeColors NodeColorsForScheme(ColorScheme color) { string NodeColorAttributes(ColorScheme color) { NodeColors node_colors = NodeColorsForScheme(color); - return Printf( - R"(style="%s", fontcolor="%s", color="%s", fillcolor="%s")", - node_colors.style, node_colors.font_color, node_colors.stroke_color, - node_colors.fill_color); + return StrFormat(R"(style="%s", fontcolor="%s", color="%s", fillcolor="%s")", + node_colors.style, node_colors.font_color, + node_colors.stroke_color, node_colors.fill_color); } // Replaces <> with <>, so that this string is safe(er) for use in a // graphviz HTML-like string. -string HtmlLikeStringSanitize(tensorflow::StringPiece s) { - return StringReplace(StringReplace(s, "<", "<", /*replace_all=*/true), ">", - ">", /*replace_all=*/true); +string HtmlLikeStringSanitize(absl::string_view s) { + return absl::StrReplaceAll(s, {{"<", "<"}, {">", ">"}}); } // Tries to generates a human-readable one-word description of the given @@ -322,11 +301,11 @@ optional<string> MatchTrivialComputation(const HloComputation* computation) { // Encapsulates logic for dumping an HLO module to DOT (i.e. graphviz syntax). class HloDotDumper { public: - HloDotDumper(const HloComputation* computation, tensorflow::StringPiece label, + HloDotDumper(const HloComputation* computation, absl::string_view label, const DebugOptions& debug_options, bool show_backend_config, const HloExecutionProfile* profile, NodeFilter filter) : computation_(computation), - label_(std::string(label)), + label_(label), debug_options_(debug_options), show_backend_config_(show_backend_config), profile_(profile), @@ -448,7 +427,7 @@ string HloDotDumper::Dump() { } string HloDotDumper::Header() { - const char* fmt = R"(digraph G { + constexpr char fmt[] = R"(digraph G { rankdir = TB; compound = true; label = <<b>%s</b>>; @@ -457,7 +436,7 @@ labelloc = t; tooltip = " "; // DOT graphs accept a stylesheet as a URI. So naturally, an inline // stylesheet is a data URI! -stylesheet=" +stylesheet=< data:text/css, @import url(https://fonts.googleapis.com/css?family=Roboto:400,700); svg text { @@ -466,7 +445,7 @@ stylesheet=" } %s -" +> )"; @@ -481,8 +460,8 @@ stylesheet=" } if (profile_ != nullptr) { auto cycles = profile_->total_cycles_executed(*computation_); - Appendf(&graph_label, "<br/>total cycles = %lld (%s)", cycles, - tensorflow::strings::HumanReadableNum(cycles)); + absl::StrAppendFormat(&graph_label, "<br/>total cycles = %d (%s)", cycles, + tensorflow::strings::HumanReadableNum(cycles)); } // Create CSS rules that say, when you hover over the given node or cluster, @@ -509,14 +488,14 @@ stylesheet=" // One could imagine other ways of writing this CSS rule that involve // less duplication, but this way seems to be relatively performant. edge_css_rules.push_back( - Printf(" #%s%d:hover ~ #edge%lld text { fill: %s; }\n" - " #%s%d:hover ~ #edge%lld path { " - "stroke: %s; stroke-width: .2em; }\n" - " #%s%d:hover ~ #edge%lld polygon { " - "fill: %s; stroke: %s; stroke-width: .2em; }\n", - elem_type, elem_id, edge_id, color, // - elem_type, elem_id, edge_id, color, // - elem_type, elem_id, edge_id, color, color)); + StrFormat(" #%s%d:hover ~ #edge%d text { fill: %s; }\n" + " #%s%d:hover ~ #edge%d path { " + "stroke: %s; stroke-width: .2em; }\n" + " #%s%d:hover ~ #edge%d polygon { " + "fill: %s; stroke: %s; stroke-width: .2em; }\n", + elem_type, elem_id, edge_id, color, // + elem_type, elem_id, edge_id, color, // + elem_type, elem_id, edge_id, color, color)); }; // The "to_node" value may be a NULL, indicating that this points to the @@ -559,10 +538,10 @@ stylesheet=" } } - return Printf(fmt, graph_label, Join(edge_css_rules, "\n")); + return StrFormat(fmt, graph_label, StrJoin(edge_css_rules, "\n")); } -string HloDotDumper::Footer() { return StrCat(Join(edges_, "\n"), "\n}"); } +string HloDotDumper::Footer() { return StrCat(StrJoin(edges_, "\n"), "\n}"); } bool HloDotDumper::ShouldShowFusionSubcomputation(const HloInstruction* instr) { CHECK_EQ(instr->opcode(), HloOpcode::kFusion); @@ -600,9 +579,9 @@ string HloDotDumper::DumpSubcomputation(const HloComputation* subcomp, VLOG(2) << "Edge: from " << from->name() << " to " << parent_instr->name() << " as " << next_edge_id_; edge_ids_.insert({{from, parent_instr}, next_edge_id_++}); - const char* edge_fmt = + constexpr char edge_fmt[] = R"(%s -> %s [ltail="%s", style="dashed" tooltip="%s -> %s"];)"; - edges_.push_back(Printf( + edges_.push_back(StrFormat( edge_fmt, InstructionId(from), InstructionId(parent_instr), SubcomputationId(subcomp), subcomp->name(), parent_instr->name())); } @@ -619,9 +598,10 @@ string HloDotDumper::DumpSubcomputation(const HloComputation* subcomp, string subcomp_label, style; if (parent_instr->opcode() == HloOpcode::kFusion) { - subcomp_label = Printf("Fused expression for <b>%s</b><br/>%s", - HtmlLikeStringSanitize(parent_instr->name()), - HtmlLikeStringSanitize(parent_instr->ToCategory())); + subcomp_label = + StrFormat("Fused expression for <b>%s</b><br/>%s", + HtmlLikeStringSanitize(parent_instr->name()), + HtmlLikeStringSanitize(parent_instr->ToCategory())); string extra_info = GetInstructionNodeExtraInfo(parent_instr); if (!extra_info.empty()) { StrAppend(&subcomp_label, "<br/>", extra_info); @@ -647,18 +627,18 @@ string HloDotDumper::DumpSubcomputation(const HloComputation* subcomp, strokecolor = highlight ? "#b71c1c" : "#c2c2c2"; } style = - Printf(R"(style="rounded,filled,bold"; fillcolor="%s"; color="%s;")", - fillcolor, strokecolor); + StrFormat(R"(style="rounded,filled,bold"; fillcolor="%s"; color="%s;")", + fillcolor, strokecolor); } else { - subcomp_label = Printf("Subcomputation for <b>%s</b><br/>%s", - HtmlLikeStringSanitize(parent_instr->name()), - HtmlLikeStringSanitize(subcomp->name())); + subcomp_label = StrFormat("Subcomputation for <b>%s</b><br/>%s", + HtmlLikeStringSanitize(parent_instr->name()), + HtmlLikeStringSanitize(subcomp->name())); style = "style=rounded; color=black;"; } string comp_body = DumpComputation(subcomp); - const char* computation_fmt = R"(subgraph %s { + constexpr char computation_fmt[] = R"(subgraph %s { %s label = <%s>; labelloc = t; @@ -667,7 +647,7 @@ tooltip = " "; } // %s )"; - return Printf(computation_fmt, id, style, subcomp_label, comp_body, id); + return StrFormat(computation_fmt, id, style, subcomp_label, comp_body, id); } string HloDotDumper::DumpComputation(const HloComputation* comp) { @@ -718,11 +698,11 @@ string HloDotDumper::DumpRootTag() { VLOG(2) << "Adding edge from " << from->name() << " to root tag as " << next_edge_id_; edge_ids_.insert({{from, to}, next_edge_id_++}); - edges_.push_back(Printf(R"(%s -> %s [tooltip=" "];)", from_id, to_id)); + edges_.push_back(StrFormat(R"(%s -> %s [tooltip=" "];)", from_id, to_id)); - return Printf(R"(%s [label=<%s>, shape=%s, tooltip=" ", %s];)" - "\n", - to_id, node_body, node_shape, NodeColorAttributes(color)); + return StrFormat(R"(%s [label=<%s>, shape=%s, tooltip=" ", %s];)" + "\n", + to_id, node_body, node_shape, NodeColorAttributes(color)); } static const HloConstantInstruction* TryGetFusionParameterConstant( @@ -817,10 +797,10 @@ string HloDotDumper::DumpInstruction(const HloInstruction* instr) { } } - return Printf(R"(%s [label=<%s>, shape=%s, tooltip="%s", %s];)" - "\n", - InstructionId(instr), node_body, node_shape, node_metadata, - NodeColorAttributes(color)); + return StrFormat(R"(%s [label=<%s>, shape=%s, tooltip="%s", %s];)" + "\n", + InstructionId(instr), node_body, node_shape, node_metadata, + NodeColorAttributes(color)); } string HloDotDumper::GetInstructionNodeInlinedOperands( @@ -833,7 +813,7 @@ string HloDotDumper::GetInstructionNodeInlinedOperands( // enumerates all of its empty dimensions (e.g. "{ { {}, {} }, ..."), which // is just noise. if (ShapeUtil::IsZeroElementArray(shape)) { - return Printf("{} (%s)", ShapeUtil::HumanString(constant->shape())); + return StrFormat("{} (%s)", ShapeUtil::HumanString(constant->shape())); } // Print the literal value of constants with <= K elements. @@ -848,19 +828,19 @@ string HloDotDumper::GetInstructionNodeInlinedOperands( // collected from profiling tools. Those constants may not have a valid // literal. if (elem_count.has_value() && *elem_count <= 8 && constant->HasLiteral()) { - return Printf("%s (%s)", constant->literal().ToString(), - ShapeUtil::HumanString(constant->shape())); + return StrFormat("%s (%s)", constant->literal().ToString(), + ShapeUtil::HumanString(constant->shape())); } // Otherwise, print e.g. "%constant.42 (s32[100])". string constant_name; - if (tensorflow::str_util::StartsWith(constant->name(), "constant")) { + if (absl::StartsWith(constant->name(), "constant")) { constant_name = constant->name(); } else { constant_name = StrCat("constant ", constant->name()); } - return Printf("%s %s", constant_name, - ShapeUtil::HumanString(constant->shape())); + return StrFormat("%s %s", constant_name, + ShapeUtil::HumanString(constant->shape())); }; std::vector<string> lines; @@ -881,7 +861,7 @@ string HloDotDumper::GetInstructionNodeInlinedOperands( TryGetFusionParameterConstant(operand)) { operand_str = stringify_constant(constant); } else { - operand_str = Printf("Parameter %lld", operand->parameter_number()); + operand_str = StrFormat("Parameter %d", operand->parameter_number()); } } else { operand_str = operand->name(); @@ -890,13 +870,13 @@ string HloDotDumper::GetInstructionNodeInlinedOperands( if (operand_str) { if (instr->operand_count() > 1) { - lines.push_back(Printf("<b>operand %lld</b> = %s", i, *operand_str)); + lines.push_back(StrFormat("<b>operand %d</b> = %s", i, *operand_str)); } else { - lines.push_back(Printf("<b>operand</b> = %s", *operand_str)); + lines.push_back(StrFormat("<b>operand</b> = %s", *operand_str)); } } } - return Join(lines, "<br/>"); + return StrJoin(lines, "<br/>"); } ColorScheme HloDotDumper::GetInstructionColor(const HloInstruction* instr) { @@ -1049,6 +1029,7 @@ ColorScheme HloDotDumper::GetInstructionColor(const HloInstruction* instr) { return kGray; case HloOpcode::kCrossReplicaSum: case HloOpcode::kAllToAll: + case HloOpcode::kCollectivePermute: case HloOpcode::kInfeed: case HloOpcode::kOutfeed: case HloOpcode::kRecv: @@ -1059,7 +1040,6 @@ ColorScheme HloDotDumper::GetInstructionColor(const HloInstruction* instr) { case HloOpcode::kCall: case HloOpcode::kConditional: case HloOpcode::kCustomCall: - case HloOpcode::kHostCompute: case HloOpcode::kWhile: return kDarkGreen; case HloOpcode::kConstant: @@ -1080,14 +1060,13 @@ string HloDotDumper::GetInstructionNodeShape(const HloInstruction* instr) { string HloDotDumper::GetInstructionNodeLabel(const HloInstruction* instr) { // If we have a parameter, put the param number in the name. if (instr->opcode() == HloOpcode::kParameter) { - return Printf("<b>Parameter %lld</b>", instr->parameter_number()); + return StrFormat("<b>Parameter %d</b>", instr->parameter_number()); } // The HLO instruction name contains usually the opcode, e.g. "%add.42" is // an add instruction. In this case we render just the name. - if (tensorflow::str_util::StartsWith(instr->name(), - HloOpcodeString(instr->opcode()))) { - return Printf("<b>%s</b>", HtmlLikeStringSanitize(instr->name())); + if (absl::StartsWith(instr->name(), HloOpcodeString(instr->opcode()))) { + return StrFormat("<b>%s</b>", HtmlLikeStringSanitize(instr->name())); } string extended_opcode = StrCat(HloOpcodeString(instr->opcode()), @@ -1095,8 +1074,8 @@ string HloDotDumper::GetInstructionNodeLabel(const HloInstruction* instr) { ? "" : StrCat(":", xla::ToString(instr->fusion_kind()))); // If the name does not contain the opcode, render both. - return Printf("<b>%s</b><br/>%s", HtmlLikeStringSanitize(extended_opcode), - HtmlLikeStringSanitize(instr->name())); + return StrFormat("<b>%s</b><br/>%s", HtmlLikeStringSanitize(extended_opcode), + HtmlLikeStringSanitize(instr->name())); } string HloDotDumper::GetInstructionNodeMetadata(const HloInstruction* instr) { @@ -1105,16 +1084,16 @@ string HloDotDumper::GetInstructionNodeMetadata(const HloInstruction* instr) { lines.push_back(HtmlLikeStringSanitize(instr->metadata().op_name())); } if (!instr->metadata().op_type().empty()) { - lines.push_back(Printf( + lines.push_back(StrFormat( "op_type: %s", HtmlLikeStringSanitize(instr->metadata().op_type()))); } if (!instr->metadata().source_file().empty() && instr->metadata().source_line() != 0) { - lines.push_back(Printf("op_type: %s", instr->metadata().source_file(), - instr->metadata().source_line())); + lines.push_back(StrFormat("op_type: %s:%d", instr->metadata().source_file(), + instr->metadata().source_line())); } - return Join(lines, "<br/>"); + return StrJoin(lines, "<br/>"); } string HloDotDumper::GetInstructionNodeBackendConfig( @@ -1161,13 +1140,12 @@ string HloDotDumper::GetInstructionNodeExtraInfo(const HloInstruction* instr) { constexpr int kMaxShapeLen = 64; if (instr_shape.length() > kMaxShapeLen) { instr_shape = StrCat( - tensorflow::StringPiece(instr_shape).substr(0, kMaxShapeLen - 3), - "..."); + absl::string_view(instr_shape).substr(0, kMaxShapeLen - 3), "..."); } lines.push_back(instr_shape); } if (debug_options_.xla_hlo_graph_addresses()) { - lines.push_back(Printf("[%p]", instr)); + lines.push_back(StrFormat("[%p]", instr)); } if (profile_ != nullptr) { double hlo_cycles_executed = profile_->GetCyclesTakenBy(*instr); @@ -1175,11 +1153,11 @@ string HloDotDumper::GetInstructionNodeExtraInfo(const HloInstruction* instr) { profile_->total_cycles_executed(*instr->parent()); if (hlo_cycles_executed > 0 && total_cycles_executed > 0) { lines.push_back( - Printf("%% of cycles executed=%.2f", - 100 * hlo_cycles_executed / total_cycles_executed)); + StrFormat("%% of cycles executed=%.2f", + 100 * hlo_cycles_executed / total_cycles_executed)); } } - return Join(lines, "<br/>"); + return StrJoin(lines, "<br/>"); } // Gets the total number of array elements in the given shape. For tuples, this @@ -1211,7 +1189,8 @@ void HloDotDumper::AddInstructionIncomingEdges(const HloInstruction* instr) { string edge_label; if (instr->operand_count() > 1 && !control_edge) { - edge_label = Printf(R"( headlabel="%lld", labeldistance=2)", operand_num); + edge_label = + StrFormat(R"( headlabel="%d", labeldistance=2)", operand_num); } else if (control_edge) { edge_label = "style=\"dotted\" color=\"gray\" label=\"ctrl\""; } @@ -1221,10 +1200,11 @@ void HloDotDumper::AddInstructionIncomingEdges(const HloInstruction* instr) { // means. bool is_big_array = TotalElementsInShape(from->shape()) >= 4096; - const char* kEdgeFmt = R"(%s -> %s [arrowhead=%s tooltip="%s -> %s" %s];)"; - edges_.push_back(Printf(kEdgeFmt, InstructionId(from), InstructionId(to), - (is_big_array ? "normal" : "empty"), from->name(), - to->name(), edge_label)); + constexpr char kEdgeFmt[] = + R"(%s -> %s [arrowhead=%s tooltip="%s -> %s" %s];)"; + edges_.push_back(StrFormat(kEdgeFmt, InstructionId(from), InstructionId(to), + (is_big_array ? "normal" : "empty"), + from->name(), to->name(), edge_label)); }; // Add edges from instr's operands to instr. Parameters within fusion @@ -1265,14 +1245,14 @@ string HloDotDumper::GetInstructionTrivialComputationStr( continue; } if (instr->called_computations().size() == 1) { - lines.push_back(Printf("Subcomputation: <b>%s</b>", - HtmlLikeStringSanitize(*computation_type))); + lines.push_back(StrFormat("Subcomputation: <b>%s</b>", + HtmlLikeStringSanitize(*computation_type))); } else { - lines.push_back(Printf("Subcomputation %lld: <b>%s</b>", i, - HtmlLikeStringSanitize(*computation_type))); + lines.push_back(StrFormat("Subcomputation %d: <b>%s</b>", i, + HtmlLikeStringSanitize(*computation_type))); } } - return Join(lines, "<br/>"); + return StrJoin(lines, "<br/>"); } const HloInstruction* HloDotDumper::GetNodeForEdge( diff --git a/tensorflow/compiler/xla/service/hlo_graph_dumper_test.cc b/tensorflow/compiler/xla/service/hlo_graph_dumper_test.cc index 1d7a062c55..064c53252c 100644 --- a/tensorflow/compiler/xla/service/hlo_graph_dumper_test.cc +++ b/tensorflow/compiler/xla/service/hlo_graph_dumper_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_graph_dumper.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -23,12 +24,11 @@ limitations under the License. #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/tests/test_utils.h" #include "tensorflow/compiler/xla/xla.pb.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { namespace { -using ::tensorflow::strings::StrCat; +using absl::StrCat; using ::testing::HasSubstr; string TestName() { diff --git a/tensorflow/compiler/xla/service/hlo_instruction.cc b/tensorflow/compiler/xla/service/hlo_instruction.cc index 57e75cf931..ed4e159910 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.cc +++ b/tensorflow/compiler/xla/service/hlo_instruction.cc @@ -21,10 +21,17 @@ limitations under the License. #include <unordered_set> #include <utility> +#include "absl/algorithm/container.h" +#include "absl/container/inlined_vector.h" +#include "absl/memory/memory.h" +#include "absl/strings/ascii.h" +#include "absl/strings/escaping.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/protobuf_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor.h" #include "tensorflow/compiler/xla/service/hlo_casting_utils.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" @@ -39,17 +46,15 @@ limitations under the License. #include "tensorflow/core/lib/gtl/flatmap.h" #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/lib/gtl/map_util.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/human_readable_json.h" #include "tensorflow/core/platform/logging.h" namespace xla { -using tensorflow::str_util::CEscape; -using ::tensorflow::str_util::Join; -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; +using absl::CEscape; +using absl::StrAppend; +using absl::StrCat; +using absl::StrJoin; /* static */ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( @@ -224,7 +229,7 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( Literal::CreateFromProto(proto.literal())); instruction = CreateConstant(std::move(literal)); } else { - instruction = MakeUnique<HloConstantInstruction>(proto.shape()); + instruction = absl::make_unique<HloConstantInstruction>(proto.shape()); } break; } @@ -294,15 +299,15 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( TF_RET_CHECK(proto.called_computation_ids_size() == 1) << "CrossReplicaSum should have 1 called computation but sees " << proto.called_computation_ids_size(); - tensorflow::gtl::optional<int64> all_reduce_id; + absl::optional<int64> all_reduce_id; if (proto.all_reduce_id() > 0) { all_reduce_id = proto.all_reduce_id(); } instruction = CreateCrossReplicaSum( proto.shape(), all_operands(), computations(0), - /*replica_group_ids=*/ - std::vector<int64>(proto.replica_group_ids().begin(), - proto.replica_group_ids().end()), + /*replica_groups=*/ + std::vector<ReplicaGroup>(proto.replica_groups().begin(), + proto.replica_groups().end()), /*barrier=*/proto.cross_replica_sum_barrier(), /*all_reduce_id=*/all_reduce_id); break; @@ -312,8 +317,18 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( proto.shape(), all_operands(), /*replica_groups=*/ std::vector<ReplicaGroup>(proto.replica_groups().begin(), - proto.replica_groups().end()), - /*barrier=*/proto.cross_replica_sum_barrier()); + proto.replica_groups().end())); + break; + } + case HloOpcode::kCollectivePermute: { + std::vector<std::pair<int64, int64>> source_target_pairs( + proto.source_target_pairs_size()); + for (int i = 0; i < source_target_pairs.size(); i++) { + source_target_pairs[i].first = proto.source_target_pairs(i).source(); + source_target_pairs[i].second = proto.source_target_pairs(i).target(); + } + instruction = CreateCollectivePermute(proto.shape(), operands(0), + source_target_pairs); break; } case HloOpcode::kConvolution: @@ -361,11 +376,6 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( proto.convolution_dimension_numbers()); } break; - case HloOpcode::kHostCompute: - instruction = - CreateHostCompute(proto.shape(), all_operands(), proto.channel_name(), - proto.cost_estimate_ns()); - break; case HloOpcode::kPad: TF_RET_CHECK(proto.operand_ids_size() == 2) << "Pad instruction should have 2 operands but sees " @@ -379,7 +389,7 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( << "DynamicSlice instruction should have 2 operands but sees " << proto.operand_ids_size(); std::vector<int64> slice_sizes(proto.dynamic_slice_sizes_size()); - c_copy(proto.dynamic_slice_sizes(), slice_sizes.begin()); + absl::c_copy(proto.dynamic_slice_sizes(), slice_sizes.begin()); instruction = CreateDynamicSlice(proto.shape(), operands(0), operands(1), slice_sizes); break; @@ -391,7 +401,8 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( TF_RET_CHECK(proto.has_gather_dimension_numbers()) << "Gather instruction should have GatherDimensionNumbers set."; std::unique_ptr<GatherDimensionNumbers> gather_dimension_numbers = - MakeUnique<GatherDimensionNumbers>(proto.gather_dimension_numbers()); + absl::make_unique<GatherDimensionNumbers>( + proto.gather_dimension_numbers()); std::vector<int64> gather_slice_sizes; for (int64 bound : proto.gather_slice_sizes()) { gather_slice_sizes.push_back(bound); @@ -409,15 +420,22 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( TF_RET_CHECK(proto.called_computation_ids_size() == 1) << "Scatter instruction should have 1 called computation but sees " << proto.called_computation_ids_size(); - auto scatter_dimension_numbers = MakeUnique<ScatterDimensionNumbers>( - proto.scatter_dimension_numbers()); + auto scatter_dimension_numbers = + absl::make_unique<ScatterDimensionNumbers>( + proto.scatter_dimension_numbers()); instruction = CreateScatter(proto.shape(), operands(0), operands(1), operands(2), computations(0), *scatter_dimension_numbers); break; } + case HloOpcode::kIota: + TF_RET_CHECK(proto.dimensions_size() <= 1) + << "Iota instruction should have at most 1 dimension but sees " + << proto.dimensions_size(); + instruction = CreateIota(proto.shape(), proto.dimensions(0)); + break; default: { - instruction = WrapUnique(new HloInstruction(opcode, proto.shape())); + instruction = absl::WrapUnique(new HloInstruction(opcode, proto.shape())); for (const int64 operand_id : proto.operand_ids()) { TF_RET_CHECK(ContainsKey(instruction_map, operand_id)) << "No instruction with id " << operand_id; @@ -445,10 +463,11 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( instruction->SetAndSanitizeName(proto.name()); instruction->metadata_ = proto.metadata(); instruction->backend_config_ = proto.backend_config(); + instruction->precision_config_ = proto.precision_config(); if (proto.has_dot_dimension_numbers()) { instruction->dot_dimension_numbers_ = - MakeUnique<DotDimensionNumbers>(proto.dot_dimension_numbers()); + absl::make_unique<DotDimensionNumbers>(proto.dot_dimension_numbers()); } if (proto.has_sharding()) { @@ -462,34 +481,36 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateParameter( int64 parameter_number, const Shape& shape, const string& name) { - return MakeUnique<HloParameterInstruction>(parameter_number, shape, name); + return absl::make_unique<HloParameterInstruction>(parameter_number, shape, + name); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateTrace( const string& tag, HloInstruction* operand) { - return MakeUnique<HloTraceInstruction>(tag, operand); + return absl::make_unique<HloTraceInstruction>(tag, operand); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateConstant( std::unique_ptr<Literal> literal) { - return MakeUnique<HloConstantInstruction>(std::move(literal)); + return absl::make_unique<HloConstantInstruction>(std::move(literal)); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateIota( - const Shape& shape) { - return WrapUnique(new HloInstruction(HloOpcode::kIota, shape)); + const Shape& shape, int64 iota_dimension) { + return absl::make_unique<HloIotaInstruction>(shape, iota_dimension); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateGetTupleElement(const Shape& shape, HloInstruction* operand, int64 index) { - return MakeUnique<HloGetTupleElementInstruction>(shape, operand, index); + return absl::make_unique<HloGetTupleElementInstruction>(shape, operand, + index); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateRng( const Shape& shape, RandomDistribution distribution, tensorflow::gtl::ArraySlice<HloInstruction*> parameters) { - return MakeUnique<HloRngInstruction>(shape, distribution, parameters); + return absl::make_unique<HloRngInstruction>(shape, distribution, parameters); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateNary( @@ -499,7 +520,7 @@ HloInstruction::CreateGetTupleElement(const Shape& shape, // It is impossible to copy an opaque shape, we don't know how big it is. CHECK(!ShapeUtil::IsOpaque(shape)); } - auto instruction = WrapUnique(new HloInstruction(opcode, shape)); + auto instruction = absl::WrapUnique(new HloInstruction(opcode, shape)); for (auto operand : operands) { instruction->AppendOperand(operand); } @@ -604,31 +625,33 @@ HloInstruction::CreateGetTupleElement(const Shape& shape, /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateMap( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, HloComputation* map_computation) { - return MakeUnique<HloMapInstruction>(shape, operands, map_computation); + return absl::make_unique<HloMapInstruction>(shape, operands, map_computation); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateConvolve( const Shape& shape, HloInstruction* lhs, HloInstruction* rhs, const Window& window, const ConvolutionDimensionNumbers& dimension_numbers, int64 feature_group_count) { - return MakeUnique<HloConvolutionInstruction>( + return absl::make_unique<HloConvolutionInstruction>( shape, lhs, rhs, window, dimension_numbers, feature_group_count); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateFft( const Shape& shape, HloInstruction* operand, FftType fft_type, tensorflow::gtl::ArraySlice<int64> fft_length) { - return MakeUnique<HloFftInstruction>(shape, operand, fft_type, fft_length); + return absl::make_unique<HloFftInstruction>(shape, operand, fft_type, + fft_length); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateDot( const Shape& shape, HloInstruction* lhs, HloInstruction* rhs, const DotDimensionNumbers& dimension_numbers) { - auto instruction = WrapUnique(new HloInstruction(HloOpcode::kDot, shape)); + auto instruction = + absl::WrapUnique(new HloInstruction(HloOpcode::kDot, shape)); instruction->AppendOperand(lhs); instruction->AppendOperand(rhs); instruction->dot_dimension_numbers_ = - MakeUnique<DotDimensionNumbers>(dimension_numbers); + absl::make_unique<DotDimensionNumbers>(dimension_numbers); return instruction; } @@ -637,10 +660,12 @@ HloInstruction::CreateGetTupleElement(const Shape& shape, CHECK_EQ(ShapeUtil::Rank(lhs->shape()), 2); CHECK_EQ(ShapeUtil::Rank(rhs->shape()), 2); - auto instruction = WrapUnique(new HloInstruction(HloOpcode::kDot, shape)); + auto instruction = + absl::WrapUnique(new HloInstruction(HloOpcode::kDot, shape)); instruction->AppendOperand(lhs); instruction->AppendOperand(rhs); - instruction->dot_dimension_numbers_ = MakeUnique<DotDimensionNumbers>(); + instruction->dot_dimension_numbers_ = + absl::make_unique<DotDimensionNumbers>(); instruction->dot_dimension_numbers_->add_lhs_contracting_dimensions(1); instruction->dot_dimension_numbers_->add_rhs_contracting_dimensions(0); return instruction; @@ -651,7 +676,7 @@ HloInstruction::CreateReducePrecision(const Shape& shape, HloInstruction* operand, const int exponent_bits, const int mantissa_bits) { - return MakeUnique<HloReducePrecisionInstruction>( + return absl::make_unique<HloReducePrecisionInstruction>( shape, operand, exponent_bits, mantissa_bits); } @@ -659,40 +684,47 @@ HloInstruction::CreateReducePrecision(const Shape& shape, HloInstruction::CreateCrossReplicaSum( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, HloComputation* reduce_computation, - tensorflow::gtl::ArraySlice<int64> replica_group_ids, - tensorflow::StringPiece barrier, - const tensorflow::gtl::optional<int64>& all_reduce_id) { - return MakeUnique<HloAllReduceInstruction>( - shape, operands, reduce_computation, replica_group_ids, barrier, + const std::vector<ReplicaGroup>& replica_groups, absl::string_view barrier, + const absl::optional<int64>& all_reduce_id) { + return absl::make_unique<HloAllReduceInstruction>( + shape, operands, reduce_computation, replica_groups, barrier, all_reduce_id); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateAllToAll( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - const std::vector<ReplicaGroup>& replica_groups, - tensorflow::StringPiece barrier) { - return MakeUnique<HloAllToAllInstruction>(shape, operands, replica_groups, - barrier); + const std::vector<ReplicaGroup>& replica_groups) { + return absl::make_unique<HloAllToAllInstruction>(shape, operands, + replica_groups); +} + +/* static */ std::unique_ptr<HloInstruction> +HloInstruction::CreateCollectivePermute( + const Shape& shape, HloInstruction* operand, + const std::vector<std::pair<int64, int64>>& source_target_pairs) { + return absl::make_unique<HloCollectivePermuteInstruction>( + shape, operand, source_target_pairs); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateInfeed( const Shape& infeed_shape, HloInstruction* token_operand, const string& config) { - return MakeUnique<HloInfeedInstruction>(infeed_shape, token_operand, config); + return absl::make_unique<HloInfeedInstruction>(infeed_shape, token_operand, + config); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateOutfeed( const Shape& outfeed_shape, HloInstruction* operand, - HloInstruction* token_operand, tensorflow::StringPiece outfeed_config) { - return MakeUnique<HloOutfeedInstruction>(outfeed_shape, operand, - token_operand, outfeed_config); + HloInstruction* token_operand, absl::string_view outfeed_config) { + return absl::make_unique<HloOutfeedInstruction>( + outfeed_shape, operand, token_operand, outfeed_config); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateSend( HloInstruction* operand, HloInstruction* token, int64 channel_id, bool is_host_transfer) { - return MakeUnique<HloSendInstruction>(operand, token, channel_id, - is_host_transfer); + return absl::make_unique<HloSendInstruction>(operand, token, channel_id, + is_host_transfer); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateSendDone( @@ -700,14 +732,15 @@ HloInstruction::CreateCrossReplicaSum( auto send_operand = DynCast<HloSendInstruction>(operand); CHECK(send_operand != nullptr) << "SendDone must take the context operand from Send"; - return MakeUnique<HloSendDoneInstruction>(send_operand, is_host_transfer); + return absl::make_unique<HloSendDoneInstruction>(send_operand, + is_host_transfer); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateRecv( const Shape& shape, HloInstruction* token, int64 channel_id, bool is_host_transfer) { - return MakeUnique<HloRecvInstruction>(shape, token, channel_id, - is_host_transfer); + return absl::make_unique<HloRecvInstruction>(shape, token, channel_id, + is_host_transfer); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateRecvDone( @@ -715,19 +748,20 @@ HloInstruction::CreateCrossReplicaSum( auto recv_operand = DynCast<HloRecvInstruction>(operand); CHECK(recv_operand != nullptr) << "RecvDone must take the context operand from Recv"; - return MakeUnique<HloRecvDoneInstruction>(recv_operand, is_host_transfer); + return absl::make_unique<HloRecvDoneInstruction>(recv_operand, + is_host_transfer); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateReverse( const Shape& shape, HloInstruction* operand, tensorflow::gtl::ArraySlice<int64> dimensions) { - return MakeUnique<HloReverseInstruction>(shape, operand, dimensions); + return absl::make_unique<HloReverseInstruction>(shape, operand, dimensions); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateAfterAll( tensorflow::gtl::ArraySlice<HloInstruction*> operands) { CHECK(!operands.empty()); - auto instruction = WrapUnique( + auto instruction = absl::WrapUnique( new HloInstruction(HloOpcode::kAfterAll, ShapeUtil::MakeTokenShape())); for (auto operand : operands) { instruction->AppendOperand(operand); @@ -736,14 +770,15 @@ HloInstruction::CreateCrossReplicaSum( } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateToken() { - return WrapUnique( + return absl::WrapUnique( new HloInstruction(HloOpcode::kAfterAll, ShapeUtil::MakeTokenShape())); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateWhile( const Shape& shape, HloComputation* condition, HloComputation* body, HloInstruction* init) { - auto instruction = WrapUnique(new HloInstruction(HloOpcode::kWhile, shape)); + auto instruction = + absl::WrapUnique(new HloInstruction(HloOpcode::kWhile, shape)); instruction->AppendOperand(init); // Body comes before condition computation in the vector. instruction->called_computations_.push_back(body); @@ -756,7 +791,7 @@ HloInstruction::CreateCrossReplicaSum( HloInstruction* true_computation_arg, HloComputation* true_computation, HloInstruction* false_computation_arg, HloComputation* false_computation) { auto instruction = - WrapUnique(new HloInstruction(HloOpcode::kConditional, shape)); + absl::WrapUnique(new HloInstruction(HloOpcode::kConditional, shape)); instruction->AppendOperand(pred); instruction->AppendOperand(true_computation_arg); instruction->AppendOperand(false_computation_arg); @@ -773,15 +808,15 @@ HloInstruction::CreateCrossReplicaSum( tensorflow::gtl::ArraySlice<int64> start_indices, tensorflow::gtl::ArraySlice<int64> limit_indices, tensorflow::gtl::ArraySlice<int64> strides) { - return MakeUnique<HloSliceInstruction>(shape, operand, start_indices, - limit_indices, strides); + return absl::make_unique<HloSliceInstruction>(shape, operand, start_indices, + limit_indices, strides); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateDynamicSlice( const Shape& shape, HloInstruction* operand, HloInstruction* start_indices, tensorflow::gtl::ArraySlice<int64> slice_sizes) { - return MakeUnique<HloDynamicSliceInstruction>(shape, operand, start_indices, - slice_sizes); + return absl::make_unique<HloDynamicSliceInstruction>( + shape, operand, start_indices, slice_sizes); } /* static */ std::unique_ptr<HloInstruction> @@ -789,8 +824,8 @@ HloInstruction::CreateDynamicUpdateSlice(const Shape& shape, HloInstruction* operand, HloInstruction* update, HloInstruction* start_indices) { - auto instruction = - WrapUnique(new HloInstruction(HloOpcode::kDynamicUpdateSlice, shape)); + auto instruction = absl::WrapUnique( + new HloInstruction(HloOpcode::kDynamicUpdateSlice, shape)); instruction->AppendOperand(operand); instruction->AppendOperand(update); instruction->AppendOperand(start_indices); @@ -800,12 +835,14 @@ HloInstruction::CreateDynamicUpdateSlice(const Shape& shape, /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateConcatenate( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, int64 dimension) { - return MakeUnique<HloConcatenateInstruction>(shape, operands, dimension); + return absl::make_unique<HloConcatenateInstruction>(shape, operands, + dimension); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateConvert( const Shape& shape, HloInstruction* operand) { - auto instruction = WrapUnique(new HloInstruction(HloOpcode::kConvert, shape)); + auto instruction = + absl::WrapUnique(new HloInstruction(HloOpcode::kConvert, shape)); instruction->AppendOperand(operand); return instruction; } @@ -814,7 +851,7 @@ HloInstruction::CreateDynamicUpdateSlice(const Shape& shape, HloInstruction::CreateBitcastConvert(const Shape& shape, HloInstruction* operand) { auto instruction = - WrapUnique(new HloInstruction(HloOpcode::kBitcastConvert, shape)); + absl::WrapUnique(new HloInstruction(HloOpcode::kBitcastConvert, shape)); instruction->AppendOperand(operand); return instruction; } @@ -823,7 +860,7 @@ HloInstruction::CreateBitcastConvert(const Shape& shape, const Shape& shape, HloInstruction* operand, HloInstruction* init_value, tensorflow::gtl::ArraySlice<int64> dimensions_to_reduce, HloComputation* reduce_computation) { - auto instruction = WrapUnique(new HloReduceInstruction( + auto instruction = absl::WrapUnique(new HloReduceInstruction( shape, {operand, init_value}, dimensions_to_reduce, reduce_computation)); return std::move(instruction); } @@ -837,15 +874,15 @@ HloInstruction::CreateBitcastConvert(const Shape& shape, all_args.reserve(operands.size() * 2); all_args.insert(all_args.end(), operands.begin(), operands.end()); all_args.insert(all_args.end(), init_values.begin(), init_values.end()); - return MakeUnique<HloReduceInstruction>(shape, all_args, dimensions_to_reduce, - reduce_computation); + return absl::make_unique<HloReduceInstruction>( + shape, all_args, dimensions_to_reduce, reduce_computation); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateReduceWindow( const Shape& shape, HloInstruction* operand, HloInstruction* init_value, const Window& window, HloComputation* reduce_computation) { - return MakeUnique<HloReduceWindowInstruction>(shape, operand, init_value, - window, reduce_computation); + return absl::make_unique<HloReduceWindowInstruction>( + shape, operand, init_value, window, reduce_computation); } /* static */ std::unique_ptr<HloInstruction> @@ -854,7 +891,7 @@ HloInstruction::CreateBatchNormTraining(const Shape& shape, HloInstruction* scale, HloInstruction* offset, float epsilon, int64 feature_index) { - return MakeUnique<HloBatchNormTrainingInstruction>( + return absl::make_unique<HloBatchNormTrainingInstruction>( shape, operand, scale, offset, epsilon, feature_index); } @@ -863,7 +900,7 @@ HloInstruction::CreateBatchNormInference( const Shape& shape, HloInstruction* operand, HloInstruction* scale, HloInstruction* offset, HloInstruction* mean, HloInstruction* variance, float epsilon, int64 feature_index) { - return MakeUnique<HloBatchNormInferenceInstruction>( + return absl::make_unique<HloBatchNormInferenceInstruction>( shape, operand, scale, offset, mean, variance, epsilon, feature_index); } @@ -873,9 +910,9 @@ HloInstruction::CreateBatchNormGrad(const Shape& shape, HloInstruction* operand, HloInstruction* variance, HloInstruction* grad_output, float epsilon, int64 feature_index) { - return MakeUnique<HloBatchNormGradInstruction>(shape, operand, scale, mean, - variance, grad_output, epsilon, - feature_index); + return absl::make_unique<HloBatchNormGradInstruction>( + shape, operand, scale, mean, variance, grad_output, epsilon, + feature_index); } /* static */ std::unique_ptr<HloInstruction> @@ -883,15 +920,15 @@ HloInstruction::CreateSelectAndScatter( const Shape& shape, HloInstruction* operand, HloComputation* select, const Window& window, HloInstruction* source, HloInstruction* init_value, HloComputation* scatter) { - return MakeUnique<HloSelectAndScatterInstruction>( + return absl::make_unique<HloSelectAndScatterInstruction>( shape, operand, select, window, source, init_value, scatter); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateBroadcast( const Shape& shape, HloInstruction* operand, tensorflow::gtl::ArraySlice<int64> broadcast_dimensions) { - return MakeUnique<HloBroadcastInstruction>(shape, operand, - broadcast_dimensions); + return absl::make_unique<HloBroadcastInstruction>(shape, operand, + broadcast_dimensions); } /* static */ std::unique_ptr<HloInstruction> @@ -949,8 +986,8 @@ HloInstruction::CreateBroadcastSequence( /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreatePad( const Shape& shape, HloInstruction* operand, HloInstruction* padding_value, const PaddingConfig& padding_config) { - return MakeUnique<HloPadInstruction>(shape, operand, padding_value, - padding_config); + return absl::make_unique<HloPadInstruction>(shape, operand, padding_value, + padding_config); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateReshape( @@ -959,7 +996,8 @@ HloInstruction::CreateBroadcastSequence( ShapeUtil::ElementsIn(operand->shape())) << "shape: " << ShapeUtil::HumanString(shape) << " operand: " << ShapeUtil::HumanString(operand->shape()); - auto instruction = WrapUnique(new HloInstruction(HloOpcode::kReshape, shape)); + auto instruction = + absl::WrapUnique(new HloInstruction(HloOpcode::kReshape, shape)); instruction->AppendOperand(operand); return instruction; } @@ -967,26 +1005,27 @@ HloInstruction::CreateBroadcastSequence( /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateTranspose( const Shape& shape, HloInstruction* operand, tensorflow::gtl::ArraySlice<int64> dimensions) { - return MakeUnique<HloTransposeInstruction>(shape, operand, dimensions); + return absl::make_unique<HloTransposeInstruction>(shape, operand, dimensions); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateSort( const Shape& shape, int64 dimension, HloInstruction* keys, HloInstruction* values) { - return MakeUnique<HloSortInstruction>(shape, dimension, keys, values); + return absl::make_unique<HloSortInstruction>(shape, dimension, keys, values); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateFusion( const Shape& shape, FusionKind fusion_kind, HloInstruction* fused_root) { - return MakeUnique<HloFusionInstruction>(shape, fusion_kind, fused_root); + return absl::make_unique<HloFusionInstruction>(shape, fusion_kind, + fused_root); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateFusion( const Shape& shape, FusionKind fusion_kind, tensorflow::gtl::ArraySlice<HloInstruction*> operands, HloComputation* fusion_computation) { - return MakeUnique<HloFusionInstruction>(shape, fusion_kind, operands, - fusion_computation); + return absl::make_unique<HloFusionInstruction>(shape, fusion_kind, operands, + fusion_computation); } void HloInstruction::set_single_sharding(const HloSharding& sharding) { @@ -1006,6 +1045,7 @@ void HloInstruction::SetupDerivedInstruction( derived_instruction->clear_sharding(); } derived_instruction->set_metadata(metadata_); + derived_instruction->set_precision_config(precision_config_); } bool HloInstruction::HasSideEffectNoRecurse() const { @@ -1018,7 +1058,6 @@ bool HloInstruction::HasSideEffectNoRecurse() const { case HloOpcode::kInfeed: case HloOpcode::kOutfeed: case HloOpcode::kTrace: - case HloOpcode::kHostCompute: return true; case HloOpcode::kCrossReplicaSum: return all_reduce_id().has_value(); @@ -1044,7 +1083,7 @@ bool HloInstruction::HasSideEffect() const { const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, HloComputation* computation) { std::unique_ptr<HloInstruction> instruction = - WrapUnique(new HloInstruction(HloOpcode::kCall, shape)); + absl::WrapUnique(new HloInstruction(HloOpcode::kCall, shape)); for (auto operand : operands) { instruction->AppendOperand(operand); } @@ -1054,16 +1093,9 @@ bool HloInstruction::HasSideEffect() const { /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateCustomCall( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - tensorflow::StringPiece custom_call_target) { - return MakeUnique<HloCustomCallInstruction>(shape, operands, - custom_call_target); -} - -/* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateHostCompute( - const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - tensorflow::StringPiece channel_name, const int64 cost_estimate_ns) { - return MakeUnique<HloHostComputeInstruction>(shape, operands, channel_name, - cost_estimate_ns); + absl::string_view custom_call_target) { + return absl::make_unique<HloCustomCallInstruction>(shape, operands, + custom_call_target); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateTuple( @@ -1080,8 +1112,8 @@ bool HloInstruction::HasSideEffect() const { const Shape& shape, HloInstruction* operand, HloInstruction* start_indices, const GatherDimensionNumbers& gather_dim_numbers, tensorflow::gtl::ArraySlice<int64> slice_sizes) { - return MakeUnique<HloGatherInstruction>(shape, operand, start_indices, - gather_dim_numbers, slice_sizes); + return absl::make_unique<HloGatherInstruction>( + shape, operand, start_indices, gather_dim_numbers, slice_sizes); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateScatter( @@ -1089,16 +1121,17 @@ bool HloInstruction::HasSideEffect() const { HloInstruction* scatter_indices, HloInstruction* updates, HloComputation* update_computation, const ScatterDimensionNumbers& scatter_dim_numbers) { - return MakeUnique<HloScatterInstruction>(shape, operand, scatter_indices, - updates, update_computation, - scatter_dim_numbers); + return absl::make_unique<HloScatterInstruction>( + shape, operand, scatter_indices, updates, update_computation, + scatter_dim_numbers); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateDomain( const Shape& shape, HloInstruction* operand, std::unique_ptr<DomainMetadata> operand_side_metadata, std::unique_ptr<DomainMetadata> user_side_metadata) { - auto instruction = WrapUnique(new HloInstruction(HloOpcode::kDomain, shape)); + auto instruction = + absl::WrapUnique(new HloInstruction(HloOpcode::kDomain, shape)); instruction->operand_side_metadata_ = std::move(operand_side_metadata); instruction->user_side_metadata_ = std::move(user_side_metadata); instruction->AppendOperand(operand); @@ -1146,13 +1179,13 @@ std::unique_ptr<HloInstruction> HloInstruction::CloneWithNewOperands( case HloOpcode::kReducePrecision: case HloOpcode::kCrossReplicaSum: case HloOpcode::kAllToAll: + case HloOpcode::kCollectivePermute: case HloOpcode::kInfeed: case HloOpcode::kOutfeed: case HloOpcode::kConvolution: case HloOpcode::kCustomCall: case HloOpcode::kReduceWindow: case HloOpcode::kSelectAndScatter: - case HloOpcode::kHostCompute: case HloOpcode::kPad: case HloOpcode::kDynamicSlice: case HloOpcode::kSort: @@ -1274,6 +1307,7 @@ std::unique_ptr<HloInstruction> HloInstruction::CloneWithNewOperands( } break; } + // SetupDerivedInstruction will setup the precision_config_ field. SetupDerivedInstruction(clone.get()); clone->set_parent(parent_); clone->set_raw_backend_config_string(backend_config_); @@ -1339,7 +1373,7 @@ std::unique_ptr<HloInstruction> HloInstruction::Clone( // If names ends with .suffix[0-9]+ then replace with a suffix with the // numeric value incremented. int64 numeric_suffix; - if (tensorflow::strings::safe_strto64(after_suffix, &numeric_suffix)) { + if (absl::SimpleAtoi(after_suffix, &numeric_suffix)) { clone->name_ = StrCat(name().substr(0, index), dot_suffix, numeric_suffix + 1); } else { @@ -1614,11 +1648,11 @@ bool HloInstruction::IdenticalSlowPath( case HloOpcode::kOutfeed: case HloOpcode::kCrossReplicaSum: case HloOpcode::kAllToAll: + case HloOpcode::kCollectivePermute: case HloOpcode::kConvolution: case HloOpcode::kCustomCall: case HloOpcode::kReduceWindow: case HloOpcode::kSelectAndScatter: - case HloOpcode::kHostCompute: case HloOpcode::kPad: case HloOpcode::kDynamicSlice: case HloOpcode::kGather: @@ -1812,7 +1846,7 @@ void HloInstruction::set_false_computation(HloComputation* false_computation) { string HloInstruction::SignatureString() const { string operands = - Join(operands_, ", ", [](string* out, HloInstruction* operand) { + StrJoin(operands_, ", ", [](string* out, HloInstruction* operand) { StrAppend(out, ShapeUtil::HumanString(operand->shape())); }); return StrCat("(", operands, ") -> ", ShapeUtil::HumanString(shape())); @@ -1832,7 +1866,7 @@ string HloInstruction::ToString(const HloPrintOptions& options) const { } bool HloInstruction::IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const { + const absl::optional<int64>& operand_idx) const { switch (opcode_) { // Unary elementwise operations. case HloOpcode::kAbs: @@ -1959,7 +1993,7 @@ string HloInstruction::OperandsToStringWithCanonicalNameMap( slice.size() > kMaxOperandsToShowIfCompact) { slice.remove_suffix(slice.size() - kMaxOperandsToShowIfCompact); } - operands = Join(slice, ", ", [&](string* out, HloInstruction* operand) { + operands = StrJoin(slice, ", ", [&](string* out, HloInstruction* operand) { // If operand is already been deleted, put `null` to the string output. if (operand == nullptr) { StrAppend(out, "null "); @@ -1979,7 +2013,7 @@ string HloInstruction::OperandsToStringWithCanonicalNameMap( } else if (!options.compact_operands()) { str.push_back(PrintName(operand->name(), options)); } - StrAppend(out, Join(str, " ")); + StrAppend(out, StrJoin(str, " ")); }); const int64 remaining = operands_.size() - slice.size(); if (slice.size() != operands_.size()) { @@ -1996,6 +2030,11 @@ std::vector<string> HloInstruction::ExtraAttributesToString( extra.push_back(DotDimensionNumbersToString()); } + string precision_config_string = PrecisionConfigToString(); + if (!precision_config_string.empty()) { + extra.push_back(precision_config_string); + } + if (options.print_subcomputation_mode() == HloPrintOptions::PrintSubcomputationMode::kNameOnly) { if (opcode() == HloOpcode::kWhile) { @@ -2021,11 +2060,11 @@ std::vector<string> HloInstruction::ExtraAttributesToString( StrCat("to_apply=", PrintName(to_apply()->name(), options))); } else if (!called_computations().empty()) { extra.push_back(StrCat( - "calls=", Join(called_computations(), ", ", - [&](string* out, const HloComputation* computation) { - StrAppend(out, - PrintName(computation->name(), options)); - }))); + "calls=", + StrJoin(called_computations(), ", ", + [&](string* out, const HloComputation* computation) { + StrAppend(out, PrintName(computation->name(), options)); + }))); } } else if (options.print_subcomputation_mode() == HloPrintOptions::PrintSubcomputationMode::kFullBodies) { @@ -2058,12 +2097,12 @@ std::vector<string> HloInstruction::ExtraAttributesToString( break; default: if (!called_computations().empty()) { - extra.push_back( - StrCat("calls=\n", - Join(called_computations(), ", ", - [&](string* out, const HloComputation* computation) { - StrAppend(out, computation->ToString(new_options)); - }))); + extra.push_back(StrCat( + "calls=\n", + StrJoin(called_computations(), ", ", + [&](string* out, const HloComputation* computation) { + StrAppend(out, computation->ToString(new_options)); + }))); } break; } @@ -2074,11 +2113,11 @@ std::vector<string> HloInstruction::ExtraAttributesToString( } if (!control_predecessors_.empty()) { extra.push_back(StrCat("control-predecessors={", - Join(control_predecessors_, ", ", - [&](string* out, HloInstruction* pre) { - StrAppend(out, - PrintName(pre->name(), options)); - }), + StrJoin(control_predecessors_, ", ", + [&](string* out, HloInstruction* pre) { + StrAppend(out, + PrintName(pre->name(), options)); + }), "}")); } if (operand_side_metadata_ != nullptr && user_side_metadata_ != nullptr) { @@ -2092,10 +2131,10 @@ std::vector<string> HloInstruction::ExtraAttributesToString( string HloInstruction::ToShortString() const { return StrCat("%", name(), " = ", HloOpcodeString(opcode()), "(", - Join(operands_, ", ", - [](string* out, HloInstruction* operand) { - StrAppend(out, "%", operand->name()); - }), + StrJoin(operands_, ", ", + [](string* out, HloInstruction* operand) { + StrAppend(out, "%", operand->name()); + }), ")"); } @@ -2117,6 +2156,7 @@ HloInstructionProto HloInstruction::ToProto() const { *proto.mutable_metadata() = metadata_; proto.set_backend_config(backend_config_); + *proto.mutable_precision_config() = precision_config_; if (opcode() != HloOpcode::kFusion) { for (const HloComputation* computation : called_computations_) { proto.add_called_computation_ids(computation->unique_id()); @@ -2155,7 +2195,7 @@ void HloInstruction::set_tracing(HloInstruction* trace_instruction) { bool HloInstruction::IsFused() const { return parent_->IsFusionComputation(); } -bool HloInstruction::IsFusable() const { +bool HloInstruction::IsFusible() const { // Instructions which are traced should not be fused. if (tracing()) { return false; @@ -2261,6 +2301,8 @@ Status HloInstruction::Visit(DfsHloVisitorBase<HloInstructionPtr>* visitor) { return visitor->HandleCrossReplicaSum(this); case HloOpcode::kAllToAll: return visitor->HandleAllToAll(this); + case HloOpcode::kCollectivePermute: + return visitor->HandleCollectivePermute(this); case HloOpcode::kTuple: return visitor->HandleTuple(this); case HloOpcode::kMap: @@ -2329,8 +2371,6 @@ Status HloInstruction::Visit(DfsHloVisitorBase<HloInstructionPtr>* visitor) { return visitor->HandleInfeed(this); case HloOpcode::kOutfeed: return visitor->HandleOutfeed(this); - case HloOpcode::kHostCompute: - return visitor->HandleHostCompute(this); case HloOpcode::kRng: return visitor->HandleRng(this); case HloOpcode::kWhile: @@ -2369,15 +2409,14 @@ Status HloInstruction::Visit(DfsHloVisitorBase<HloInstructionPtr>* visitor) { return InternalError( "Unhandled HloOpcode for DfsHloVisitor: %s. This should not happen - " "please file a bug for XLA.", - HloOpcodeString(opcode_).c_str()); + HloOpcodeString(opcode_)); } // Explicit instantiations. template Status HloInstruction::Visit(DfsHloVisitor* visitor); template Status HloInstruction::Visit(ConstDfsHloVisitor* visitor); -using DFSStack = - tensorflow::gtl::InlinedVector<std::pair<int, HloInstruction*>, 16>; +using DFSStack = absl::InlinedVector<std::pair<int, HloInstruction*>, 16>; // Push "child" onto the dfs_stack if not already visited. Returns false if a // cycle was detected, and true otherwise. @@ -2453,7 +2492,7 @@ static Status PostOrderDFS(HloInstruction* root, Visitor* visitor, if (!TF_PREDICT_TRUE(PushDFSChild(visitor, &dfs_stack, child))) { return FailedPrecondition( "A cycle is detected while visiting instruction %s", - current_node->ToString().c_str()); + current_node->ToString()); } } @@ -2462,7 +2501,7 @@ static Status PostOrderDFS(HloInstruction* root, Visitor* visitor, if (!TF_PREDICT_TRUE(PushDFSChild(visitor, &dfs_stack, child))) { return FailedPrecondition( "A cycle is detected while visiting instruction %s", - current_node->ToString().c_str()); + current_node->ToString()); } } } @@ -2622,7 +2661,7 @@ bool HloInstruction::IsElementwiseBinary() const { } bool HloInstruction::IsElementwise() const { - return IsElementwiseImpl(tensorflow::gtl::nullopt); + return IsElementwiseImpl(absl::nullopt); } bool HloInstruction::ImplicitlyBroadcastsOperand(int64 operand_idx) const { @@ -2778,7 +2817,7 @@ StatusOr<HloInstruction::FusionKind> StringToFusionKind( if (kind_name == "kCustom") { return HloInstruction::FusionKind::kCustom; } - return InvalidArgument("Unknown fusion kind: %s", kind_name.c_str()); + return InvalidArgument("Unknown fusion kind: %s", kind_name); } string PaddingConfigToString(const PaddingConfig& padding) { @@ -2787,7 +2826,7 @@ string PaddingConfigToString(const PaddingConfig& padding) { [](const PaddingConfig::PaddingConfigDimension& dim) { return dim.interior_padding() != 0; }); - return Join( + return StrJoin( padding.dimensions(), "x", [&](string* out, const PaddingConfig::PaddingConfigDimension& dim) { StrAppend( @@ -2811,11 +2850,15 @@ string OpMetadataToString(const OpMetadata& metadata) { if (metadata.source_line() != 0) { result.push_back(StrCat("source_line=", metadata.source_line())); } - return Join(result, " "); + return StrJoin(result, " "); } string RandomDistributionToString(const RandomDistribution& distribution) { - return tensorflow::str_util::Lowercase(RandomDistribution_Name(distribution)); + return absl::AsciiStrToLower(RandomDistribution_Name(distribution)); +} + +string PrecisionToString(const PrecisionConfigProto::Precision& precision) { + return absl::AsciiStrToLower(PrecisionConfigProto::Precision_Name(precision)); } string ConvolutionDimensionNumbersToString( @@ -2843,8 +2886,8 @@ string ConvolutionDimensionNumbersToString( output_dims[dnums.output_spatial_dimensions(i)] = StrCat(i); } - return StrCat(Join(lhs_dims, ""), "_", Join(rhs_dims, ""), "->", - Join(output_dims, "")); + return StrCat(StrJoin(lhs_dims, ""), "_", StrJoin(rhs_dims, ""), "->", + StrJoin(output_dims, "")); } string HloInstruction::DotDimensionNumbersToString() const { @@ -2855,19 +2898,21 @@ string HloInstruction::DotDimensionNumbersToString() const { const DotDimensionNumbers& dnums = *dot_dimension_numbers_; if (!dnums.lhs_batch_dimensions().empty()) { result.push_back(StrCat("lhs_batch_dims={", - Join(dnums.lhs_batch_dimensions(), ","), "}")); + StrJoin(dnums.lhs_batch_dimensions(), ","), "}")); } result.push_back(StrCat("lhs_contracting_dims={", - Join(dnums.lhs_contracting_dimensions(), ","), "}")); + StrJoin(dnums.lhs_contracting_dimensions(), ","), + "}")); if (!dnums.rhs_batch_dimensions().empty()) { result.push_back(StrCat("rhs_batch_dims={", - Join(dnums.rhs_batch_dimensions(), ","), "}")); + StrJoin(dnums.rhs_batch_dimensions(), ","), "}")); } result.push_back(StrCat("rhs_contracting_dims={", - Join(dnums.rhs_contracting_dimensions(), ","), "}")); + StrJoin(dnums.rhs_contracting_dimensions(), ","), + "}")); - return Join(result, ", "); + return StrJoin(result, ", "); } StatusOr<RandomDistribution> StringToRandomDistribution(const string& name) { @@ -2881,7 +2926,44 @@ StatusOr<RandomDistribution> StringToRandomDistribution(const string& name) { } return map; }(); - auto found = map->find(tensorflow::str_util::Lowercase(name)); + auto found = map->find(absl::AsciiStrToLower(name)); + if (found == map->end()) { + return InvalidArgument("Unknown distribution"); + } + return found->second; +} + +string HloInstruction::PrecisionConfigToString() const { + if (precision_config_.operand_precision().empty()) { + return ""; + } + return StrCat( + "operand_precision={", + StrJoin(precision_config_.operand_precision(), ",", + [](string* out, int32 precision) { + CHECK(PrecisionConfigProto::Precision_IsValid(precision)) + << precision; + StrAppend(out, PrecisionToString( + static_cast<PrecisionConfigProto::Precision>( + precision))); + }), + "}"); +} + +StatusOr<PrecisionConfigProto::Precision> StringToPrecision( + const string& name) { + static std::unordered_map<string, PrecisionConfigProto::Precision>* map = [] { + static auto* map = + new std::unordered_map<string, PrecisionConfigProto::Precision>; + for (int i = 0; i < PrecisionConfigProto::Precision_ARRAYSIZE; i++) { + if (PrecisionConfigProto::Precision_IsValid(i)) { + auto value = static_cast<PrecisionConfigProto::Precision>(i); + (*map)[PrecisionToString(value)] = value; + } + } + return map; + }(); + auto found = map->find(absl::AsciiStrToLower(name)); if (found == map->end()) { return InvalidArgument("Unknown distribution"); } @@ -3131,31 +3213,25 @@ const string& HloInstruction::outfeed_config() const { return Cast<HloOutfeedInstruction>(this)->outfeed_config(); } -const std::vector<int64>& HloInstruction::replica_group_ids() const { - return Cast<HloAllReduceInstruction>(this)->replica_group_ids(); +const std::vector<ReplicaGroup>& HloInstruction::replica_groups() const { + return Cast<HloCollectiveInstruction>(this)->replica_groups(); } -const std::vector<ReplicaGroup>& HloInstruction::replica_groups() const { - return Cast<HloAllToAllInstruction>(this)->replica_groups(); +const std::vector<std::pair<int64, int64>>& +HloInstruction::source_target_pairs() const { + return Cast<HloCollectivePermuteInstruction>(this)->source_target_pairs(); } string HloInstruction::cross_replica_sum_barrier() const { - if (opcode() == HloOpcode::kCrossReplicaSum) { - return Cast<HloAllReduceInstruction>(this)->cross_replica_sum_barrier(); - } - return Cast<HloAllToAllInstruction>(this)->cross_replica_sum_barrier(); + return Cast<HloAllReduceInstruction>(this)->cross_replica_sum_barrier(); } void HloInstruction::set_cross_replica_sum_barrier(const string& barrier) { - if (opcode() == HloOpcode::kCrossReplicaSum) { - return Cast<HloAllReduceInstruction>(this)->set_cross_replica_sum_barrier( - barrier); - } - return Cast<HloAllToAllInstruction>(this)->set_cross_replica_sum_barrier( + return Cast<HloAllReduceInstruction>(this)->set_cross_replica_sum_barrier( barrier); } -tensorflow::gtl::optional<int64> HloInstruction::all_reduce_id() const { +absl::optional<int64> HloInstruction::all_reduce_id() const { return Cast<HloAllReduceInstruction>(this)->all_reduce_id(); } @@ -3205,10 +3281,6 @@ const string& HloInstruction::custom_call_target() const { return Cast<HloCustomCallInstruction>(this)->custom_call_target(); } -const string& HloInstruction::channel_name() const { - return Cast<HloHostComputeInstruction>(this)->channel_name(); -} - const PaddingConfig& HloInstruction::padding_config() const { return Cast<HloPadInstruction>(this)->padding_config(); } diff --git a/tensorflow/compiler/xla/service/hlo_instruction.h b/tensorflow/compiler/xla/service/hlo_instruction.h index 8d8f149ee3..4a424cebc0 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.h +++ b/tensorflow/compiler/xla/service/hlo_instruction.h @@ -32,6 +32,10 @@ limitations under the License. #include <unordered_set> #include <vector> +#include "absl/container/inlined_vector.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/iterator_util.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/map_util.h" @@ -45,10 +49,8 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/lib/gtl/flatmap.h" -#include "tensorflow/core/lib/gtl/inlined_vector.h" #include "tensorflow/core/lib/gtl/iterator_range.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/macros.h" @@ -101,6 +103,7 @@ class HloPrintOptions { return HloPrintOptions() .set_print_subcomputation_mode(PrintSubcomputationMode::kFullBodies) .set_print_metadata(false) + .set_print_backend_config(false) .set_compact_operands(true) .set_print_operand_shape(true) .set_print_program_shape(false) @@ -182,7 +185,7 @@ class HloPrintOptions { return print_subcomputation_mode_; } bool print_metadata() const { return print_metadata_; } - bool print_backend_config() const { return print_metadata_; } + bool print_backend_config() const { return print_backend_config_; } bool compact_operands() const { return compact_operands_; } bool print_operand_shape() const { return print_operand_shape_; } bool print_program_shape() const { return print_program_shape_; } @@ -220,7 +223,7 @@ class CanonicalNameMap { return iter->second; } - string new_name = tensorflow::strings::StrCat("tmp_", index++); + string new_name = absl::StrCat("tmp_", index++); canonical_name_map[old_name] = new_name; return new_name; } @@ -347,7 +350,8 @@ class HloInstruction { std::unique_ptr<Literal> literal); // Creates an Iota instruction. - static std::unique_ptr<HloInstruction> CreateIota(const Shape& shape); + static std::unique_ptr<HloInstruction> CreateIota(const Shape& shape, + int64 iota_dimension); // Creates a get tuple element instruction. static std::unique_ptr<HloInstruction> CreateGetTupleElement( @@ -433,9 +437,10 @@ class HloInstruction { // // `reduction_computation`: the reduction function. // - // `replica_group_ids`: maps replica ids to subgroup ids. If empty, all - // replicas belong to one group. Allreduce will be applied within subgroups. - // For example, we have 4 replicas, then replica_group_ids={0,1,0,1} means, + // `replica_groups`: each ReplicaGroup contains a list of replica id. If + // empty, all replicas belong to one group in the order of 0 - (n-1). + // Allreduce will be applied within subgroups. + // For example, we have 4 replicas, then replica_groups={{0,2},{1,3}} means, // replica 0 and 2 are in subgroup 0, replica 1 and 3 are in subgroup 1. // // `all_reduce_id`: for Allreduce nodes from different modules, if they have @@ -446,9 +451,8 @@ class HloInstruction { static std::unique_ptr<HloInstruction> CreateCrossReplicaSum( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, HloComputation* reduce_computation, - tensorflow::gtl::ArraySlice<int64> replica_group_ids, - tensorflow::StringPiece barrier, - const tensorflow::gtl::optional<int64>& all_reduce_id); + const std::vector<ReplicaGroup>& replica_groups, + absl::string_view barrier, const absl::optional<int64>& all_reduce_id); // This op handles the communication of an Alltoall operation. On each core, // the operands are N ops in the same shape, where N is the number of cores @@ -463,12 +467,18 @@ class HloInstruction { // within replica 1, 2, 3, and in the gather phase, the received blocks will // be concatenated in the order of 1, 2, 3; another Alltoall will be applied // within replica 4, 5, 0, and the concatenation order is 4, 5, 0. - // - // TODO(b/110096724): This is NOT YET ready to use. static std::unique_ptr<HloInstruction> CreateAllToAll( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - const std::vector<ReplicaGroup>& replica_groups, - tensorflow::StringPiece barrier); + const std::vector<ReplicaGroup>& replica_groups); + + // Creates a communitation instructions that permutes data cross replicas. + // Data is sent/received according to the (source_replica_id, + // target_replica_id) pairs in `source_target_pairs`. If a replica id is not a + // target_replica_id in any pair, the output on that replica is a tensor + // conssits of 0(s) in `shape`. + static std::unique_ptr<HloInstruction> CreateCollectivePermute( + const Shape& shape, HloInstruction* operand, + const std::vector<std::pair<int64, int64>>& source_target_pairs); // Creates a conversion instruction, where operand is the data to convert and // shape is the target shape for the conversion. @@ -493,7 +503,7 @@ class HloInstruction { // which is a TOKEN. static std::unique_ptr<HloInstruction> CreateOutfeed( const Shape& outfeed_shape, HloInstruction* operand, - HloInstruction* token_operand, tensorflow::StringPiece outfeed_config); + HloInstruction* token_operand, absl::string_view outfeed_config); // Creates an asynchronous send instruction with the given channel id, which // initiates sending the operand data to a unique receive instruction in @@ -706,13 +716,7 @@ class HloInstruction { // to the given operands. "shape" is the resultant shape. static std::unique_ptr<HloInstruction> CreateCustomCall( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - tensorflow::StringPiece custom_call_target); - - // Creates a HostCompute instruction, which records host-side control and - // data dependencies for use in instruction scheduling. - static std::unique_ptr<HloInstruction> CreateHostCompute( - const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - tensorflow::StringPiece channel_name, const int64 cost_estimate_ns); + absl::string_view custom_call_target); // Creates a tuple instruction with the given elements. This is a convenience // wrapper around CreateVariadic. @@ -766,7 +770,7 @@ class HloInstruction { int64 operand_count() const { return operands_.size(); } // Returns the vector of operands of this instruction. - using InstructionVector = tensorflow::gtl::InlinedVector<HloInstruction*, 2>; + using InstructionVector = absl::InlinedVector<HloInstruction*, 2>; const InstructionVector& operands() const { return operands_; } // Returns the vector of unique operands, in the same order they are found @@ -863,6 +867,11 @@ class HloInstruction { return false; } + if (!ContainersEqual(precision_config_.operand_precision(), + other.precision_config_.operand_precision())) { + return false; + } + return IdenticalSlowPath(other, eq_computations); } @@ -1030,7 +1039,7 @@ class HloInstruction { // Returns true if this instruction can be legally fused into a fusion // instruction. - bool IsFusable() const; + bool IsFusible() const; // Returns the sharding applied to this operator. // REQUIRES: has_sharding() is true. @@ -1038,21 +1047,26 @@ class HloInstruction { CHECK(has_sharding()); return *sharding_; } + std::shared_ptr<const HloSharding> sharding_ptr() const { return sharding_; } + // Returns the sharding applied to this operator, or default_ if none exists. const HloSharding& sharding_or_default(const HloSharding& default_) const { return sharding_ ? *sharding_ : default_; } // Returns the sharding unique device, if any. - tensorflow::gtl::optional<int64> sharding_unique_device() const { + absl::optional<int64> sharding_unique_device() const { if (sharding_ == nullptr) { - return tensorflow::gtl::optional<int64>(); + return absl::optional<int64>(); } return sharding_->UniqueDevice(); } // Sets the sharding of this operator. Should only be called by HloModule or // HloComputation methods. void set_sharding(const HloSharding& sharding) { - sharding_ = MakeUnique<HloSharding>(sharding); + sharding_ = std::make_shared<const HloSharding>(sharding); + } + void set_sharding(std::shared_ptr<const HloSharding> sharding) { + sharding_ = std::move(sharding); } void set_single_sharding(const HloSharding& sharding); // Sets a sharding that assigns the current instruction to device. @@ -1088,19 +1102,6 @@ class HloInstruction { // instruction. void SetupDerivedInstruction(HloInstruction* derived_instruction) const; - // TODO(b/80249101): Remove these methods once HLO scheduling and copy - // insertion are integrated, and we don't need to run a separate pass - // of copy elision anymore. - bool CopyElisionAllowed() const { - CHECK_EQ(HloOpcode::kCopy, opcode_); - return copy_elision_allowed_; - } - - void SetCopyElisionAllowed(bool value) { - CHECK_EQ(HloOpcode::kCopy, opcode_); - copy_elision_allowed_ = value; - } - // Returns data on the dimension numbers used for a dot operation. const DotDimensionNumbers& dot_dimension_numbers() const { CHECK(dot_dimension_numbers_ != nullptr); @@ -1110,6 +1111,9 @@ class HloInstruction { // Returns the dump string of the dot dimension numbers. string DotDimensionNumbersToString() const; + // Returns the dump string of the precision configuration. + string PrecisionConfigToString() const; + // Clones the HLO instruction. The clone will have the same opcode, shape, and // operands. After creation the clone has no uses. "this" (the instruction // cloned from) is not changed. Suffix is the string to append to the name of @@ -1253,6 +1257,20 @@ class HloInstruction { static StatusOr<string> BackendConfigToRawString( const tensorflow::protobuf::Message& proto); + // Returns the information used to tell the implementation information about + // what sort of precision is requested. The meaning of the field is backend + // specific. At the moment, it is only supported for kConvolution and kDot. + // Transformations on one kDot or kConvolution to another will preserve this + // information. Transformations to other HLOs will not preserve this + // information but it is presumed that the alternate lowering is strictly + // superior. + const PrecisionConfigProto& precision_config() const { + return precision_config_; + } + void set_precision_config(const PrecisionConfigProto& precision_config) { + precision_config_ = precision_config; + } + // Sets the debug metadata for this instruction. void set_metadata(const OpMetadata& metadata) { metadata_ = metadata; } const OpMetadata& metadata() const { return metadata_; } @@ -1421,18 +1439,18 @@ class HloInstruction { // Returns the shape for the Outfeed instruction. const Shape& outfeed_shape() const; - // Delegates to HloAllReduceInstruction::replica_group_ids. - const std::vector<int64>& replica_group_ids() const; - - // Delegates to HloAllToAllInstruction::replica_groups. + // Delegates to HloCollectiveInstruction::replica_groups. const std::vector<ReplicaGroup>& replica_groups() const; + // Delegates to HloCollectivePermuteInstruction::source_target_pairs. + const std::vector<std::pair<int64, int64>>& source_target_pairs() const; + // Delegates to HloAllReduceInstruction::cross_replica_sum_barrier. string cross_replica_sum_barrier() const; void set_cross_replica_sum_barrier(const string& barrier); // Delegates to HloAllReduceInstruction::all_reduce_id. - tensorflow::gtl::optional<int64> all_reduce_id() const; + absl::optional<int64> all_reduce_id() const; // Returns data on the window in a windowed operation such as // convolution. @@ -1475,9 +1493,6 @@ class HloInstruction { // Delegates to HloCustomCallInstruction::custom_call_target. const string& custom_call_target() const; - // Delegates to HloHostComputeInstruction::channel_name. - const string& channel_name() const; - // Delegates to HloPadInstruction::padding_config. const PaddingConfig& padding_config() const; @@ -1565,7 +1580,7 @@ class HloInstruction { // NOTE: For all instructions other than kFusion, being elementwise on one of // the operands is equivalent to being elementwise on all the operands. virtual bool IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const; + const absl::optional<int64>& operand_idx) const; // Prints an instruction to a string. // // The canonical string representation needs to name operands and instruction @@ -1642,7 +1657,10 @@ class HloInstruction { bool copy_elision_allowed_ = true; // The sharding, if one exists. - std::unique_ptr<HloSharding> sharding_; + // Uses std::shared_ptr to allow reuse of the same sharding object between + // HloInstructions and other components as HloSharding can be very large for + // many element tuples. + std::shared_ptr<const HloSharding> sharding_; // Fields used by the kDomain instruction. std::unique_ptr<DomainMetadata> operand_side_metadata_; @@ -1661,6 +1679,10 @@ class HloInstruction { // HLO. See the documentation on backend_config(). string backend_config_; + // Information used to communicate to the implementation about the algorithm + // used to produce results. See the documentation on precision_config(). + PrecisionConfigProto precision_config_; + // String identifier for instruction. string name_; @@ -1683,10 +1705,12 @@ StatusOr<HloInstruction::FusionKind> StringToFusionKind( string PaddingConfigToString(const PaddingConfig& padding); string OpMetadataToString(const OpMetadata& metadata); string RandomDistributionToString(const RandomDistribution& distribution); +string PrecisionToString(const PrecisionConfigProto::Precision& precision); string ConvolutionDimensionNumbersToString( const ConvolutionDimensionNumbers& dnums); StatusOr<RandomDistribution> StringToRandomDistribution(const string& name); +StatusOr<PrecisionConfigProto::Precision> StringToPrecision(const string& name); std::ostream& operator<<(std::ostream& os, HloInstruction::FusionKind kind); diff --git a/tensorflow/compiler/xla/service/hlo_instruction_test.cc b/tensorflow/compiler/xla/service/hlo_instruction_test.cc index 504b13043f..8b0b90dfb3 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction_test.cc +++ b/tensorflow/compiler/xla/service/hlo_instruction_test.cc @@ -53,7 +53,7 @@ class OpAndUserCollectingVisitor : public DfsHloVisitorWithDefault { public: Status DefaultAction(HloInstruction* hlo_instruction) override { return Unimplemented("not implemented %s", - HloOpcodeString(hlo_instruction->opcode()).c_str()); + HloOpcodeString(hlo_instruction->opcode())); } Status HandleParameter(HloInstruction* parameter) override { diff --git a/tensorflow/compiler/xla/service/hlo_instructions.cc b/tensorflow/compiler/xla/service/hlo_instructions.cc index 4fdf4360e6..ffc74cfedd 100644 --- a/tensorflow/compiler/xla/service/hlo_instructions.cc +++ b/tensorflow/compiler/xla/service/hlo_instructions.cc @@ -17,6 +17,12 @@ limitations under the License. #include <deque> +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" +#include "absl/strings/escaping.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" +#include "absl/strings/str_split.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/hlo_casting_utils.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" @@ -27,10 +33,10 @@ limitations under the License. namespace xla { namespace { -using ::tensorflow::str_util::CEscape; -using ::tensorflow::str_util::Join; -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; +using absl::CEscape; +using absl::StrAppend; +using absl::StrCat; +using absl::StrJoin; bool IsInstructionElementwiseOnOperand(const HloInstruction* instruction, const HloInstruction* operand) { @@ -89,7 +95,7 @@ HloBatchNormTrainingInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 3); - return MakeUnique<HloBatchNormTrainingInstruction>( + return absl::make_unique<HloBatchNormTrainingInstruction>( shape, new_operands[0], new_operands[1], new_operands[2], epsilon(), feature_index()); } @@ -111,7 +117,7 @@ HloBatchNormInferenceInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 5); - return MakeUnique<HloBatchNormInferenceInstruction>( + return absl::make_unique<HloBatchNormInferenceInstruction>( shape, new_operands[0], new_operands[1], new_operands[2], new_operands[3], new_operands[4], epsilon(), feature_index()); } @@ -133,7 +139,7 @@ HloBatchNormGradInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 5); - return MakeUnique<HloBatchNormGradInstruction>( + return absl::make_unique<HloBatchNormGradInstruction>( shape, new_operands[0], new_operands[1], new_operands[2], new_operands[3], new_operands[4], epsilon(), feature_index()); } @@ -158,7 +164,7 @@ HloInstructionProto HloFftInstruction::ToProto() const { std::vector<string> HloFftInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { return {StrCat("fft_type=", FftType_Name(fft_type())), - StrCat("fft_length={", Join(fft_length(), ","), "}")}; + StrCat("fft_length={", StrJoin(fft_length(), ","), "}")}; } bool HloFftInstruction::IdenticalSlowPath( @@ -175,8 +181,8 @@ std::unique_ptr<HloInstruction> HloFftInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloFftInstruction>(shape, new_operands[0], fft_type_, - fft_length_); + return absl::make_unique<HloFftInstruction>(shape, new_operands[0], fft_type_, + fft_length_); } HloSendRecvInstruction::HloSendRecvInstruction(HloOpcode opcode, @@ -230,8 +236,8 @@ std::unique_ptr<HloInstruction> HloSendInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 2); - return MakeUnique<HloSendInstruction>(new_operands[0], new_operands[1], - channel_id(), is_host_transfer()); + return absl::make_unique<HloSendInstruction>( + new_operands[0], new_operands[1], channel_id(), is_host_transfer()); } HloSendDoneInstruction::HloSendDoneInstruction(HloSendInstruction* operand, @@ -248,7 +254,7 @@ HloSendDoneInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloSendDoneInstruction>( + return absl::make_unique<HloSendDoneInstruction>( Cast<HloSendInstruction>(new_operands[0]), is_host_transfer()); } @@ -269,7 +275,7 @@ std::unique_ptr<HloInstruction> HloRecvInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloRecvInstruction>( + return absl::make_unique<HloRecvInstruction>( ShapeUtil::GetTupleElementShape(shape, 0), new_operands[0], channel_id(), is_host_transfer()); } @@ -291,31 +297,67 @@ HloRecvDoneInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloRecvDoneInstruction>( + return absl::make_unique<HloRecvDoneInstruction>( Cast<HloRecvInstruction>(new_operands[0]), is_host_transfer()); } +HloCollectiveInstruction::HloCollectiveInstruction( + HloOpcode opcode, const Shape& shape, + tensorflow::gtl::ArraySlice<HloInstruction*> operands, + const std::vector<ReplicaGroup>& replica_groups) + : HloInstruction(opcode, shape), replica_groups_(replica_groups) { + for (auto operand : operands) { + AppendOperand(operand); + } +} + +HloInstructionProto HloCollectiveInstruction::ToProto() const { + HloInstructionProto proto = HloInstruction::ToProto(); + *proto.mutable_replica_groups() = {replica_groups_.begin(), + replica_groups_.end()}; + return proto; +} + +std::vector<string> HloCollectiveInstruction::ExtraAttributesToStringImpl( + const HloPrintOptions& /*options*/) const { + std::vector<string> result; + std::vector<string> replica_group_str; + for (const ReplicaGroup& group : replica_groups()) { + replica_group_str.push_back( + StrCat("{", StrJoin(group.replica_ids(), ","), "}")); + } + result.push_back( + StrCat("replica_groups={", StrJoin(replica_group_str, ","), "}")); + return result; +} + +bool HloCollectiveInstruction::IdenticalSlowPath( + const HloInstruction& other, + const std::function<bool(const HloComputation*, const HloComputation*)>& + /*eq_computations*/) const { + const auto& casted_other = + static_cast<const HloCollectiveInstruction&>(other); + return ContainersEqual(replica_groups(), casted_other.replica_groups(), + [](const ReplicaGroup& a, const ReplicaGroup& b) { + return ContainersEqual(a.replica_ids(), + b.replica_ids()); + }); +} + HloAllReduceInstruction::HloAllReduceInstruction( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, HloComputation* reduce_computation, - tensorflow::gtl::ArraySlice<int64> replica_group_ids, - tensorflow::StringPiece barrier, - const tensorflow::gtl::optional<int64>& all_reduce_id) - : HloInstruction(HloOpcode::kCrossReplicaSum, shape), - replica_group_ids_(replica_group_ids.begin(), replica_group_ids.end()), - cross_replica_sum_barrier_(barrier.begin(), barrier.end()), + const std::vector<ReplicaGroup>& replica_groups, absl::string_view barrier, + const absl::optional<int64>& all_reduce_id) + : HloCollectiveInstruction(HloOpcode::kCrossReplicaSum, shape, operands, + replica_groups), + cross_replica_sum_barrier_(barrier), all_reduce_id_(all_reduce_id) { - for (auto operand : operands) { - AppendOperand(operand); - } AppendComputation(reduce_computation); } HloInstructionProto HloAllReduceInstruction::ToProto() const { - HloInstructionProto proto = HloInstruction::ToProto(); - for (int64 i : replica_group_ids_) { - proto.add_replica_group_ids(i); - } + HloInstructionProto proto = HloCollectiveInstruction::ToProto(); // Proto3 is so sad. if (all_reduce_id_) { proto.set_all_reduce_id(*all_reduce_id_); @@ -325,9 +367,9 @@ HloInstructionProto HloAllReduceInstruction::ToProto() const { } std::vector<string> HloAllReduceInstruction::ExtraAttributesToStringImpl( - const HloPrintOptions& /*options*/) const { - std::vector<string> result = { - StrCat("replica_group_ids={", Join(replica_group_ids(), ","), "}")}; + const HloPrintOptions& options) const { + std::vector<string> result = + HloCollectiveInstruction::ExtraAttributesToStringImpl(options); if (!cross_replica_sum_barrier().empty()) { result.push_back(StrCat("barrier=\"", cross_replica_sum_barrier(), "\"")); } @@ -342,7 +384,7 @@ bool HloAllReduceInstruction::IdenticalSlowPath( const std::function<bool(const HloComputation*, const HloComputation*)>& eq_computations) const { const auto& casted_other = static_cast<const HloAllReduceInstruction&>(other); - return replica_group_ids() == casted_other.replica_group_ids() && + return HloCollectiveInstruction::IdenticalSlowPath(other, eq_computations) && eq_computations(to_apply(), casted_other.to_apply()) && cross_replica_sum_barrier() == casted_other.cross_replica_sum_barrier() && @@ -354,70 +396,76 @@ HloAllReduceInstruction::CloneWithNewOperandsImpl( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* /*context*/) const { - return MakeUnique<HloAllReduceInstruction>( - shape, new_operands, to_apply(), replica_group_ids(), + return absl::make_unique<HloAllReduceInstruction>( + shape, new_operands, to_apply(), replica_groups(), cross_replica_sum_barrier(), all_reduce_id()); } HloAllToAllInstruction::HloAllToAllInstruction( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - const std::vector<ReplicaGroup>& replica_groups, - tensorflow::StringPiece barrier) - : HloInstruction(HloOpcode::kAllToAll, shape), - replica_groups_(replica_groups), - cross_replica_sum_barrier_(barrier.begin(), barrier.end()) { - for (auto operand : operands) { - AppendOperand(operand); - } -} - -bool HloAllToAllInstruction::IdenticalSlowPath( - const HloInstruction& other, - const std::function<bool(const HloComputation*, const HloComputation*)>& - eq_computations) const { - const auto& casted_other = static_cast<const HloAllToAllInstruction&>(other); - return ContainersEqual(replica_groups(), casted_other.replica_groups(), - [](const ReplicaGroup& a, const ReplicaGroup& b) { - return ContainersEqual(a.replica_ids(), - b.replica_ids()); - }) && - cross_replica_sum_barrier() == - casted_other.cross_replica_sum_barrier(); -} + const std::vector<ReplicaGroup>& replica_groups) + : HloCollectiveInstruction(HloOpcode::kAllToAll, shape, operands, + replica_groups) {} std::unique_ptr<HloInstruction> HloAllToAllInstruction::CloneWithNewOperandsImpl( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* /*context*/) const { - return MakeUnique<HloAllToAllInstruction>( - shape, new_operands, replica_groups(), cross_replica_sum_barrier()); + return absl::make_unique<HloAllToAllInstruction>(shape, new_operands, + replica_groups()); } -std::vector<string> HloAllToAllInstruction::ExtraAttributesToStringImpl( - const HloPrintOptions& options) const { - std::vector<string> result; - std::vector<string> replica_group_str; - for (const ReplicaGroup& group : replica_groups()) { - replica_group_str.push_back( - StrCat("{", Join(group.replica_ids(), ","), "}")); - } - result.push_back( - StrCat("replica_groups={", Join(replica_group_str, ","), "}")); +HloCollectivePermuteInstruction::HloCollectivePermuteInstruction( + const Shape& shape, HloInstruction* operand, + const std::vector<std::pair<int64, int64>>& source_target_pairs) + : HloInstruction(HloOpcode::kCollectivePermute, shape), + source_target_pairs_(source_target_pairs) { + AppendOperand(operand); +} - if (!cross_replica_sum_barrier().empty()) { - result.push_back(StrCat("barrier=\"", cross_replica_sum_barrier(), "\"")); +HloInstructionProto HloCollectivePermuteInstruction::ToProto() const { + HloInstructionProto proto = HloInstruction::ToProto(); + for (const auto& pair : source_target_pairs()) { + auto* proto_pair = proto.add_source_target_pairs(); + proto_pair->set_source(pair.first); + proto_pair->set_target(pair.second); } + return proto; +} +std::vector<string> +HloCollectivePermuteInstruction::ExtraAttributesToStringImpl( + const HloPrintOptions& /*options*/) const { + std::vector<string> result; + std::vector<string> strs; + for (const auto& pair : source_target_pairs()) { + strs.push_back(StrCat("{", pair.first, ",", pair.second, "}")); + } + result.push_back(StrCat("source_target_pairs={", StrJoin(strs, ","), "}")); return result; } -HloInstructionProto HloAllToAllInstruction::ToProto() const { - HloInstructionProto proto = HloInstruction::ToProto(); - *proto.mutable_replica_groups() = {replica_groups_.begin(), - replica_groups_.end()}; - proto.set_cross_replica_sum_barrier(cross_replica_sum_barrier_); - return proto; +bool HloCollectivePermuteInstruction::IdenticalSlowPath( + const HloInstruction& other, + const std::function<bool(const HloComputation*, const HloComputation*)>& + /*eq_computations*/) const { + const auto& casted_other = + static_cast<const HloCollectivePermuteInstruction&>(other); + return ContainersEqual( + source_target_pairs(), casted_other.source_target_pairs(), + [](const std::pair<int64, int64>& a, const std::pair<int64, int64>& b) { + return a == b; + }); +} + +std::unique_ptr<HloInstruction> +HloCollectivePermuteInstruction::CloneWithNewOperandsImpl( + const Shape& shape, + tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, + HloCloneContext* /*context*/) const { + return absl::make_unique<HloCollectivePermuteInstruction>( + shape, new_operands[0], source_target_pairs()); } HloReverseInstruction::HloReverseInstruction( @@ -438,7 +486,7 @@ HloInstructionProto HloReverseInstruction::ToProto() const { std::vector<string> HloReverseInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { - return {StrCat("dimensions={", Join(dimensions(), ","), "}")}; + return {StrCat("dimensions={", StrJoin(dimensions(), ","), "}")}; } bool HloReverseInstruction::IdenticalSlowPath( @@ -454,8 +502,8 @@ std::unique_ptr<HloInstruction> HloReverseInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloReverseInstruction>(shape, new_operands[0], - dimensions()); + return absl::make_unique<HloReverseInstruction>(shape, new_operands[0], + dimensions()); } HloConcatenateInstruction::HloConcatenateInstruction( @@ -477,7 +525,7 @@ HloInstructionProto HloConcatenateInstruction::ToProto() const { std::vector<string> HloConcatenateInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { - return {StrCat("dimensions={", Join(dimensions(), ","), "}")}; + return {StrCat("dimensions={", StrJoin(dimensions(), ","), "}")}; } bool HloConcatenateInstruction::IdenticalSlowPath( @@ -494,8 +542,8 @@ HloConcatenateInstruction::CloneWithNewOperandsImpl( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { - return MakeUnique<HloConcatenateInstruction>(shape, new_operands, - dimensions(0)); + return absl::make_unique<HloConcatenateInstruction>(shape, new_operands, + dimensions(0)); } HloReduceInstruction::HloReduceInstruction( @@ -520,7 +568,7 @@ HloInstructionProto HloReduceInstruction::ToProto() const { std::vector<string> HloReduceInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { - return {StrCat("dimensions={", Join(dimensions(), ","), "}")}; + return {StrCat("dimensions={", StrJoin(dimensions(), ","), "}")}; } bool HloReduceInstruction::IdenticalSlowPath( @@ -539,8 +587,8 @@ std::unique_ptr<HloInstruction> HloReduceInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 2); - return MakeUnique<HloReduceInstruction>(shape, new_operands, dimensions(), - to_apply()); + return absl::make_unique<HloReduceInstruction>(shape, new_operands, + dimensions(), to_apply()); } HloSortInstruction::HloSortInstruction(const Shape& shape, int64 dimension, @@ -563,7 +611,7 @@ HloInstructionProto HloSortInstruction::ToProto() const { std::vector<string> HloSortInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { - return {StrCat("dimensions={", Join(dimensions(), ","), "}")}; + return {StrCat("dimensions={", StrJoin(dimensions(), ","), "}")}; } bool HloSortInstruction::IdenticalSlowPath( @@ -580,7 +628,8 @@ std::unique_ptr<HloInstruction> HloSortInstruction::CloneWithNewOperandsImpl( HloCloneContext* context) const { HloInstruction* keys = new_operands[0]; HloInstruction* values = new_operands.size() == 2 ? new_operands[1] : nullptr; - return MakeUnique<HloSortInstruction>(shape, dimensions(0), keys, values); + return absl::make_unique<HloSortInstruction>(shape, dimensions(0), keys, + values); } HloTransposeInstruction::HloTransposeInstruction( @@ -595,7 +644,7 @@ HloTransposeInstruction::HloTransposeInstruction( Permute(dimensions, shape.dimensions()).begin())) << "shape: " << ShapeUtil::HumanString(shape) << ", operand->shape(): " << ShapeUtil::HumanString(shape) - << ", dimensions: {" << Join(dimensions, ", ") << "}"; + << ", dimensions: {" << StrJoin(dimensions, ", ") << "}"; AppendOperand(operand); } @@ -616,7 +665,7 @@ HloInstructionProto HloTransposeInstruction::ToProto() const { std::vector<string> HloTransposeInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { - return {StrCat("dimensions={", Join(dimensions(), ","), "}")}; + return {StrCat("dimensions={", StrJoin(dimensions(), ","), "}")}; } bool HloTransposeInstruction::IdenticalSlowPath( @@ -633,8 +682,8 @@ HloTransposeInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloTransposeInstruction>(shape, new_operands[0], - dimensions()); + return absl::make_unique<HloTransposeInstruction>(shape, new_operands[0], + dimensions()); } HloBroadcastInstruction::HloBroadcastInstruction( @@ -655,7 +704,7 @@ HloInstructionProto HloBroadcastInstruction::ToProto() const { std::vector<string> HloBroadcastInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { - return {StrCat("dimensions={", Join(dimensions(), ","), "}")}; + return {StrCat("dimensions={", StrJoin(dimensions(), ","), "}")}; } bool HloBroadcastInstruction::IdenticalSlowPath( @@ -672,8 +721,8 @@ HloBroadcastInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloBroadcastInstruction>(shape, new_operands[0], - dimensions()); + return absl::make_unique<HloBroadcastInstruction>(shape, new_operands[0], + dimensions()); } HloMapInstruction::HloMapInstruction( @@ -699,7 +748,7 @@ HloInstructionProto HloMapInstruction::ToProto() const { } bool HloMapInstruction::IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const { + const absl::optional<int64>& operand_idx) const { if (!dimensions().empty()) { // Check that the map is executed in elementwise compatible dimensions. if (dimensions().size() != shape().dimensions_size()) { @@ -716,7 +765,7 @@ bool HloMapInstruction::IsElementwiseImpl( std::vector<string> HloMapInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { - return {StrCat("dimensions={", Join(dimensions(), ","), "}")}; + return {StrCat("dimensions={", StrJoin(dimensions(), ","), "}")}; } bool HloMapInstruction::IdenticalSlowPath( @@ -730,7 +779,7 @@ std::unique_ptr<HloInstruction> HloMapInstruction::CloneWithNewOperandsImpl( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { - return MakeUnique<HloMapInstruction>(shape, new_operands, to_apply()); + return absl::make_unique<HloMapInstruction>(shape, new_operands, to_apply()); } HloSliceInstruction::HloSliceInstruction( @@ -774,7 +823,7 @@ std::vector<string> HloSliceInstruction::ExtraAttributesToStringImpl( bounds.push_back( StrCat("[", slice_starts_[i], ":", slice_limits_[i], stride_str, "]")); } - return {StrCat("slice={", Join(bounds, ", "), "}")}; + return {StrCat("slice={", StrJoin(bounds, ", "), "}")}; } bool HloSliceInstruction::IdenticalSlowPath( @@ -792,8 +841,8 @@ std::unique_ptr<HloInstruction> HloSliceInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloSliceInstruction>(shape, new_operands[0], slice_starts_, - slice_limits_, slice_strides_); + return absl::make_unique<HloSliceInstruction>( + shape, new_operands[0], slice_starts_, slice_limits_, slice_strides_); } HloConstantInstruction::HloConstantInstruction(std::unique_ptr<Literal> literal) @@ -812,7 +861,7 @@ HloInstructionProto HloConstantInstruction::ToProto() const { } bool HloConstantInstruction::IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const { + const absl::optional<int64>& operand_idx) const { return true; } @@ -845,7 +894,7 @@ HloConstantInstruction::CloneWithNewOperandsImpl( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { - return MakeUnique<HloConstantInstruction>(literal_->CloneToUnique()); + return absl::make_unique<HloConstantInstruction>(literal_->CloneToUnique()); } string HloConstantInstruction::OperandsToStringWithCanonicalNameMap( @@ -860,7 +909,7 @@ string HloConstantInstruction::OperandsToStringWithCanonicalNameMap( // lines. Compact this into one line by stripping out white space. string tmp = literal().ToString(); std::replace(tmp.begin(), tmp.end(), '\n', ' '); - std::vector<string> v = tensorflow::str_util::Split(tmp, ' '); + std::vector<string> v = absl::StrSplit(tmp, ' '); bool first = true; // Concatenate elements in "v" with spaces separating them, but ignoring // empty entries. @@ -952,7 +1001,7 @@ HloInstructionProto HloFusionInstruction::ToProto() const { } bool HloFusionInstruction::IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const { + const absl::optional<int64>& operand_idx) const { if (!operand_idx.has_value()) { for (auto* fused : fused_instructions()) { if (fused->opcode() != HloOpcode::kParameter && !fused->IsElementwise()) { @@ -1155,7 +1204,7 @@ HloInstruction* HloFusionInstruction::FuseInstructionInternal( HloInstruction* HloFusionInstruction::CloneAndFuseInternal( HloInstruction* instruction_to_fuse, bool add_output) { - CHECK(instruction_to_fuse->IsFusable()) << instruction_to_fuse->ToString(); + CHECK(instruction_to_fuse->IsFusible()) << instruction_to_fuse->ToString(); VLOG(3) << "CloneAndFuseInternal:\n" << instruction_to_fuse->ToString(); HloInstruction* clone = nullptr; if (called_computations().empty()) { @@ -1339,8 +1388,8 @@ std::unique_ptr<HloInstruction> HloFusionInstruction::CloneWithNewOperandsImpl( new_fused_computation = module->AddEmbeddedComputation( fused_instructions_computation()->Clone("clone", context)); } - return MakeUnique<HloFusionInstruction>(shape, fusion_kind(), new_operands, - new_fused_computation); + return absl::make_unique<HloFusionInstruction>( + shape, fusion_kind(), new_operands, new_fused_computation); } Status HloFusionInstruction::DeduplicateFusionOperands() { @@ -1384,7 +1433,7 @@ std::vector<string> HloRngInstruction::ExtraAttributesToStringImpl( } bool HloRngInstruction::IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const { + const absl::optional<int64>& operand_idx) const { return true; } @@ -1399,7 +1448,8 @@ std::unique_ptr<HloInstruction> HloRngInstruction::CloneWithNewOperandsImpl( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { - return MakeUnique<HloRngInstruction>(shape, distribution_, new_operands); + return absl::make_unique<HloRngInstruction>(shape, distribution_, + new_operands); } HloParameterInstruction::HloParameterInstruction(int64 parameter_number, @@ -1435,7 +1485,8 @@ HloParameterInstruction::CloneWithNewOperandsImpl( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { - return MakeUnique<HloParameterInstruction>(parameter_number_, shape, name()); + return absl::make_unique<HloParameterInstruction>(parameter_number_, shape, + name()); } HloGetTupleElementInstruction::HloGetTupleElementInstruction( @@ -1471,8 +1522,8 @@ HloGetTupleElementInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloGetTupleElementInstruction>(shape, new_operands[0], - tuple_index()); + return absl::make_unique<HloGetTupleElementInstruction>( + shape, new_operands[0], tuple_index()); } HloReducePrecisionInstruction::HloReducePrecisionInstruction( @@ -1514,7 +1565,7 @@ HloReducePrecisionInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloReducePrecisionInstruction>( + return absl::make_unique<HloReducePrecisionInstruction>( shape, new_operands[0], exponent_bits(), mantissa_bits()); } @@ -1555,16 +1606,17 @@ std::unique_ptr<HloInstruction> HloInfeedInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 1); - return MakeUnique<HloInfeedInstruction>(infeed_shape(), new_operands[0], - infeed_config()); + return absl::make_unique<HloInfeedInstruction>( + infeed_shape(), new_operands[0], infeed_config()); } -HloOutfeedInstruction::HloOutfeedInstruction( - const Shape& outfeed_shape, HloInstruction* operand, - HloInstruction* token_operand, tensorflow::StringPiece outfeed_config) +HloOutfeedInstruction::HloOutfeedInstruction(const Shape& outfeed_shape, + HloInstruction* operand, + HloInstruction* token_operand, + absl::string_view outfeed_config) : HloInstruction(HloOpcode::kOutfeed, ShapeUtil::MakeTokenShape()), outfeed_shape_(outfeed_shape), - outfeed_config_(outfeed_config.begin(), outfeed_config.end()) { + outfeed_config_(outfeed_config) { CHECK(ShapeUtil::Compatible(operand->shape(), outfeed_shape)) << "Outfeed shape " << outfeed_shape << " must be compatible with operand shape " << operand->shape(); @@ -1600,8 +1652,8 @@ std::unique_ptr<HloInstruction> HloOutfeedInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 2); - return MakeUnique<HloOutfeedInstruction>(outfeed_shape(), new_operands[0], - new_operands[1], outfeed_config()); + return absl::make_unique<HloOutfeedInstruction>( + outfeed_shape(), new_operands[0], new_operands[1], outfeed_config()); } HloConvolutionInstruction::HloConvolutionInstruction( @@ -1671,7 +1723,7 @@ HloConvolutionInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 2); - return MakeUnique<HloConvolutionInstruction>( + return absl::make_unique<HloConvolutionInstruction>( shape, new_operands[0], new_operands[1], window(), convolution_dimension_numbers_, feature_group_count_); } @@ -1716,7 +1768,7 @@ HloReduceWindowInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 2); - return MakeUnique<HloReduceWindowInstruction>( + return absl::make_unique<HloReduceWindowInstruction>( shape, new_operands[0], new_operands[1], window(), to_apply()); } @@ -1765,14 +1817,14 @@ HloSelectAndScatterInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 3); - return MakeUnique<HloSelectAndScatterInstruction>( + return absl::make_unique<HloSelectAndScatterInstruction>( shape, new_operands[0], select(), window(), new_operands[1], new_operands[2], scatter()); } HloCustomCallInstruction::HloCustomCallInstruction( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - tensorflow::StringPiece custom_call_target) + absl::string_view custom_call_target) : HloInstruction(HloOpcode::kCustomCall, shape), custom_call_target_(custom_call_target.begin(), custom_call_target.end()) { @@ -1840,8 +1892,8 @@ HloCustomCallInstruction::CloneWithNewOperandsImpl( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { - auto cloned = MakeUnique<HloCustomCallInstruction>(shape, new_operands, - custom_call_target()); + auto cloned = absl::make_unique<HloCustomCallInstruction>( + shape, new_operands, custom_call_target()); if (window_ != nullptr) { cloned->set_window(*window_); } @@ -1851,41 +1903,6 @@ HloCustomCallInstruction::CloneWithNewOperandsImpl( return std::move(cloned); } -HloHostComputeInstruction::HloHostComputeInstruction( - const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - tensorflow::StringPiece channel_name, const int64 cost_estimate_ns) - : HloInstruction(HloOpcode::kHostCompute, shape), - channel_name_(channel_name.begin(), channel_name.end()), - cost_estimate_ns_(cost_estimate_ns) { - for (auto operand : operands) { - AppendOperand(operand); - } -} - -HloInstructionProto HloHostComputeInstruction::ToProto() const { - HloInstructionProto proto = HloInstruction::ToProto(); - proto.set_channel_name(channel_name_); - proto.set_cost_estimate_ns(cost_estimate_ns_); - return proto; -} - -bool HloHostComputeInstruction::IdenticalSlowPath( - const HloInstruction& other, - const std::function<bool(const HloComputation*, const HloComputation*)>& - eq_computations) const { - // Not yet supported. - return false; -} - -std::unique_ptr<HloInstruction> -HloHostComputeInstruction::CloneWithNewOperandsImpl( - const Shape& shape, - tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, - HloCloneContext* context) const { - return MakeUnique<HloHostComputeInstruction>( - shape, new_operands, channel_name_, cost_estimate_ns_); -} - HloPadInstruction::HloPadInstruction(const Shape& shape, HloInstruction* operand, HloInstruction* padding_value, @@ -1920,8 +1937,8 @@ std::unique_ptr<HloInstruction> HloPadInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 2); - return MakeUnique<HloPadInstruction>(shape, new_operands[0], new_operands[1], - padding_config_); + return absl::make_unique<HloPadInstruction>(shape, new_operands[0], + new_operands[1], padding_config_); } HloDynamicSliceInstruction::HloDynamicSliceInstruction( @@ -1943,8 +1960,8 @@ HloInstructionProto HloDynamicSliceInstruction::ToProto() const { std::vector<string> HloDynamicSliceInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { - return { - StrCat("dynamic_slice_sizes={", Join(dynamic_slice_sizes(), ","), "}")}; + return {StrCat("dynamic_slice_sizes={", StrJoin(dynamic_slice_sizes(), ","), + "}")}; } bool HloDynamicSliceInstruction::IdenticalSlowPath( @@ -1960,7 +1977,7 @@ HloDynamicSliceInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 2); - return MakeUnique<HloDynamicSliceInstruction>( + return absl::make_unique<HloDynamicSliceInstruction>( shape, new_operands[0], new_operands[1], dynamic_slice_sizes_); } @@ -1972,25 +1989,25 @@ HloGatherInstruction::HloGatherInstruction( AppendOperand(operand); AppendOperand(start_indices); gather_dimension_numbers_ = - MakeUnique<GatherDimensionNumbers>(gather_dim_numbers); - c_copy(slice_sizes, std::back_inserter(gather_slice_sizes_)); + absl::make_unique<GatherDimensionNumbers>(gather_dim_numbers); + absl::c_copy(slice_sizes, std::back_inserter(gather_slice_sizes_)); } string HloGatherInstruction::GatherDimensionNumbersToString() const { CHECK(gather_dimension_numbers_ != nullptr); string offset_dims = StrCat("offset_dims={", - Join(gather_dimension_numbers_->offset_dims(), ","), "}"); - string collapsed_slice_dims = - StrCat("collapsed_slice_dims={", - Join(gather_dimension_numbers_->collapsed_slice_dims(), ","), "}"); + StrJoin(gather_dimension_numbers_->offset_dims(), ","), "}"); + string collapsed_slice_dims = StrCat( + "collapsed_slice_dims={", + StrJoin(gather_dimension_numbers_->collapsed_slice_dims(), ","), "}"); string start_index_map = StrCat("start_index_map={", - Join(gather_dimension_numbers_->start_index_map(), ","), "}"); + StrJoin(gather_dimension_numbers_->start_index_map(), ","), "}"); string index_vector_dim = StrCat( "index_vector_dim=", gather_dimension_numbers_->index_vector_dim()); - return Join<std::initializer_list<string>>( + return StrJoin<std::initializer_list<string>>( {offset_dims, collapsed_slice_dims, start_index_map, index_vector_dim}, ", "); } @@ -2027,7 +2044,7 @@ HloInstructionProto HloGatherInstruction::ToProto() const { std::vector<string> HloGatherInstruction::ExtraAttributesToStringImpl( const HloPrintOptions& options) const { return {GatherDimensionNumbersToString(), - StrCat("slice_sizes={", Join(gather_slice_sizes(), ","), "}")}; + StrCat("slice_sizes={", StrJoin(gather_slice_sizes(), ","), "}")}; } bool HloGatherInstruction::IdenticalSlowPath( @@ -2046,7 +2063,7 @@ std::unique_ptr<HloInstruction> HloGatherInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 2); - return MakeUnique<HloGatherInstruction>( + return absl::make_unique<HloGatherInstruction>( shape, new_operands[0], new_operands[1], gather_dimension_numbers(), gather_slice_sizes()); } @@ -2062,24 +2079,24 @@ HloScatterInstruction::HloScatterInstruction( AppendOperand(updates); AppendComputation(update_computation); scatter_dimension_numbers_ = - MakeUnique<ScatterDimensionNumbers>(scatter_dim_numbers); + absl::make_unique<ScatterDimensionNumbers>(scatter_dim_numbers); } string HloScatterInstruction::ScatterDimensionNumbersToString() const { - string update_window_dims = - StrCat("update_window_dims={", - Join(scatter_dimension_numbers().update_window_dims(), ","), "}"); + string update_window_dims = StrCat( + "update_window_dims={", + StrJoin(scatter_dimension_numbers().update_window_dims(), ","), "}"); string inserted_window_dims = StrCat( "inserted_window_dims={", - Join(scatter_dimension_numbers().inserted_window_dims(), ","), "}"); + StrJoin(scatter_dimension_numbers().inserted_window_dims(), ","), "}"); string scatter_dims_to_operand_dims = StrCat( "scatter_dims_to_operand_dims={", - Join(scatter_dimension_numbers().scatter_dims_to_operand_dims(), ","), + StrJoin(scatter_dimension_numbers().scatter_dims_to_operand_dims(), ","), "}"); string index_vector_dim = StrCat( "index_vector_dim=", scatter_dimension_numbers().index_vector_dim()); - return Join<std::initializer_list<string>>( + return StrJoin<std::initializer_list<string>>( {update_window_dims, inserted_window_dims, scatter_dims_to_operand_dims, index_vector_dim}, ", "); @@ -2133,9 +2150,39 @@ std::unique_ptr<HloInstruction> HloScatterInstruction::CloneWithNewOperandsImpl( tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 3); - return MakeUnique<HloScatterInstruction>( + return absl::make_unique<HloScatterInstruction>( shape, new_operands[0], new_operands[1], new_operands[2], to_apply(), scatter_dimension_numbers()); } +HloIotaInstruction::HloIotaInstruction(const Shape& shape, int64 iota_dimension) + : HloInstruction(HloOpcode::kIota, shape), + iota_dimension_(iota_dimension) {} + +HloInstructionProto HloIotaInstruction::ToProto() const { + HloInstructionProto proto = HloInstruction::ToProto(); + proto.add_dimensions(iota_dimension()); + return proto; +} + +std::vector<string> HloIotaInstruction::ExtraAttributesToStringImpl( + const HloPrintOptions& options) const { + return {StrCat("iota_dimension=", iota_dimension())}; +} + +bool HloIotaInstruction::IdenticalSlowPath( + const HloInstruction& other, + const std::function<bool(const HloComputation*, const HloComputation*)>& + eq_computations) const { + const auto& casted_other = static_cast<const HloIotaInstruction&>(other); + return iota_dimension() == casted_other.iota_dimension(); +} + +std::unique_ptr<HloInstruction> HloIotaInstruction::CloneWithNewOperandsImpl( + const Shape& shape, + tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, + HloCloneContext* context) const { + return absl::make_unique<HloIotaInstruction>(shape, iota_dimension()); +} + } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_instructions.h b/tensorflow/compiler/xla/service/hlo_instructions.h index 803dbeabeb..ee6e337b6a 100644 --- a/tensorflow/compiler/xla/service/hlo_instructions.h +++ b/tensorflow/compiler/xla/service/hlo_instructions.h @@ -18,6 +18,7 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_HLO_INSTRUCTIONS_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_HLO_INSTRUCTIONS_H_ +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" namespace xla { @@ -217,19 +218,37 @@ class HloRecvDoneInstruction : public HloSendRecvInstruction { HloCloneContext* context) const override; }; -class HloAllReduceInstruction : public HloInstruction { +class HloCollectiveInstruction : public HloInstruction { + public: + const std::vector<ReplicaGroup>& replica_groups() const { + return replica_groups_; + } + + protected: + explicit HloCollectiveInstruction( + HloOpcode opcode, const Shape& shape, + tensorflow::gtl::ArraySlice<HloInstruction*> operands, + const std::vector<ReplicaGroup>& replica_groups); + + HloInstructionProto ToProto() const override; + + std::vector<string> ExtraAttributesToStringImpl( + const HloPrintOptions& options) const override; + bool IdenticalSlowPath( + const HloInstruction& other, + const std::function<bool(const HloComputation*, const HloComputation*)>& + eq_computations) const override; + + std::vector<ReplicaGroup> replica_groups_; +}; + +class HloAllReduceInstruction : public HloCollectiveInstruction { public: explicit HloAllReduceInstruction( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, HloComputation* reduce_computation, - tensorflow::gtl::ArraySlice<int64> replica_group_ids, - tensorflow::StringPiece barrier, - const tensorflow::gtl::optional<int64>& all_reduce_id); - - // Returns the group ids of each replica for CrossReplicaSum op. - const std::vector<int64>& replica_group_ids() const { - return replica_group_ids_; - } + const std::vector<ReplicaGroup>& replica_groups, + absl::string_view barrier, const absl::optional<int64>& all_reduce_id); // Returns the barrier config used for the CrossReplicaSum implementation of // each backend. @@ -240,9 +259,7 @@ class HloAllReduceInstruction : public HloInstruction { cross_replica_sum_barrier_ = barrier; } - tensorflow::gtl::optional<int64> all_reduce_id() const { - return all_reduce_id_; - } + absl::optional<int64> all_reduce_id() const { return all_reduce_id_; } // Returns a serialized representation of this instruction. HloInstructionProto ToProto() const override; @@ -261,37 +278,40 @@ class HloAllReduceInstruction : public HloInstruction { tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const override; - // The group id of each replica for CrossReplicaSum. - std::vector<int64> replica_group_ids_; - // The string representation of the barrier config used for CrossReplicaSum. string cross_replica_sum_barrier_; // For Allreduce nodes from different modules, if they have the same // all_reduce_id, they will be 'Allreduce'd. If empty, Allreduce will not be // applied cross modules. - tensorflow::gtl::optional<int64> all_reduce_id_; + absl::optional<int64> all_reduce_id_; }; -class HloAllToAllInstruction : public HloInstruction { +class HloAllToAllInstruction : public HloCollectiveInstruction { public: explicit HloAllToAllInstruction( - const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operand, - const std::vector<ReplicaGroup>& replica_groups, - tensorflow::StringPiece barrier); + const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, + const std::vector<ReplicaGroup>& replica_groups); - const std::vector<ReplicaGroup>& replica_groups() const { - return replica_groups_; - } + private: + // Implementation for non-common logic of CloneWithNewOperands. + std::unique_ptr<HloInstruction> CloneWithNewOperandsImpl( + const Shape& shape, + tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, + HloCloneContext* context) const override; +}; - // TODO(b/110096724): rename this. - void set_cross_replica_sum_barrier(string barrier) { - cross_replica_sum_barrier_ = barrier; - } - string cross_replica_sum_barrier() const { - return cross_replica_sum_barrier_; +class HloCollectivePermuteInstruction : public HloInstruction { + public: + explicit HloCollectivePermuteInstruction( + const Shape& shape, HloInstruction* operand, + const std::vector<std::pair<int64, int64>>& source_target_pairs); + + const std::vector<std::pair<int64, int64>>& source_target_pairs() const { + return source_target_pairs_; } + // Returns a serialized representation of this instruction. HloInstructionProto ToProto() const override; private: @@ -308,10 +328,7 @@ class HloAllToAllInstruction : public HloInstruction { tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, HloCloneContext* context) const override; - std::vector<ReplicaGroup> replica_groups_; - - // The string representation of the barrier config. - string cross_replica_sum_barrier_; + const std::vector<std::pair<int64, int64>> source_target_pairs_; }; class HloReverseInstruction : public HloInstruction { @@ -507,7 +524,7 @@ class HloMapInstruction : public HloInstruction { private: bool IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const override; + const absl::optional<int64>& operand_idx) const override; std::vector<string> ExtraAttributesToStringImpl( const HloPrintOptions& options) const override; bool IdenticalSlowPath( @@ -600,7 +617,7 @@ class HloConstantInstruction : public HloInstruction { private: bool IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const override; + const absl::optional<int64>& operand_idx) const override; bool IdenticalSlowPath( const HloInstruction& other, const std::function<bool(const HloComputation*, const HloComputation*)>& @@ -751,7 +768,7 @@ class HloFusionInstruction : public HloInstruction { bool add_output = false); bool IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const override; + const absl::optional<int64>& operand_idx) const override; std::vector<string> ExtraAttributesToStringImpl( const HloPrintOptions& options) const override; bool IdenticalSlowPath( @@ -780,7 +797,7 @@ class HloRngInstruction : public HloInstruction { private: bool IsElementwiseImpl( - const tensorflow::gtl::optional<int64>& operand_idx) const override; + const absl::optional<int64>& operand_idx) const override; std::vector<string> ExtraAttributesToStringImpl( const HloPrintOptions& options) const override; bool IdenticalSlowPath( @@ -920,7 +937,7 @@ class HloOutfeedInstruction : public HloInstruction { explicit HloOutfeedInstruction(const Shape& outfeed_shape, HloInstruction* operand, HloInstruction* token_operand, - tensorflow::StringPiece outfeed_config); + absl::string_view outfeed_config); // Returns the shape for the Outfeed instruction. const Shape& outfeed_shape() const { TF_DCHECK_OK(ShapeUtil::ValidateShapeWithOptionalLayout(outfeed_shape_)); @@ -1073,14 +1090,14 @@ class HloCustomCallInstruction : public HloInstruction { public: explicit HloCustomCallInstruction( const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - tensorflow::StringPiece custom_call_target); + absl::string_view custom_call_target); const Window& window() const override { CHECK(window_ != nullptr); return *window_; } void set_window(const Window& window) override { - window_ = MakeUnique<Window>(window); + window_ = absl::make_unique<Window>(window); } const ConvolutionDimensionNumbers& convolution_dimension_numbers() const { @@ -1091,7 +1108,7 @@ class HloCustomCallInstruction : public HloInstruction { void set_convolution_dimension_numbers( const ConvolutionDimensionNumbers& dnums) { convolution_dimension_numbers_ = - MakeUnique<ConvolutionDimensionNumbers>(dnums); + absl::make_unique<ConvolutionDimensionNumbers>(dnums); } const string& custom_call_target() const { return custom_call_target_; } // Returns a serialized representation of this instruction. @@ -1117,33 +1134,6 @@ class HloCustomCallInstruction : public HloInstruction { std::unique_ptr<ConvolutionDimensionNumbers> convolution_dimension_numbers_; }; -class HloHostComputeInstruction : public HloInstruction { - public: - explicit HloHostComputeInstruction( - const Shape& shape, tensorflow::gtl::ArraySlice<HloInstruction*> operands, - tensorflow::StringPiece channel_name, const int64 cost_estimate_ns); - // Returns the channel name associated with the instruction. The name is - // used to identify host Send/Recv operations. - const string& channel_name() const { return channel_name_; } - // Returns a serialized representation of this instruction. - HloInstructionProto ToProto() const override; - - private: - bool IdenticalSlowPath( - const HloInstruction& other, - const std::function<bool(const HloComputation*, const HloComputation*)>& - eq_computations) const override; - // Implementation for non-common logic of CloneWithNewOperands. - std::unique_ptr<HloInstruction> CloneWithNewOperandsImpl( - const Shape& shape, - tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, - HloCloneContext* context) const override; - // Name to use for host send/recv channels. - string channel_name_; - // Estimate of the duration of a host computation in nanoseconds. - int64 cost_estimate_ns_ = 0; -}; - class HloPadInstruction : public HloInstruction { public: explicit HloPadInstruction(const Shape& shape, HloInstruction* operand, @@ -1289,6 +1279,30 @@ class HloScatterInstruction : public HloInstruction { std::unique_ptr<ScatterDimensionNumbers> scatter_dimension_numbers_; }; +class HloIotaInstruction : public HloInstruction { + public: + explicit HloIotaInstruction(const Shape& shape, int64 iota_dimension); + // Returns the dimension sizes or numbers associated with this instruction. + int64 iota_dimension() const { return iota_dimension_; } + // Returns a serialized representation of this instruction. + HloInstructionProto ToProto() const override; + + private: + std::vector<string> ExtraAttributesToStringImpl( + const HloPrintOptions& options) const override; + bool IdenticalSlowPath( + const HloInstruction& other, + const std::function<bool(const HloComputation*, const HloComputation*)>& + eq_computations) const override; + // Implementation for non-common logic of CloneWithNewOperands. + std::unique_ptr<HloInstruction> CloneWithNewOperandsImpl( + const Shape& shape, + tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, + HloCloneContext* context) const override; + + const int64 iota_dimension_; +}; + } // namespace xla #endif // TENSORFLOW_COMPILER_XLA_SERVICE_HLO_INSTRUCTIONS_H_ diff --git a/tensorflow/compiler/xla/service/hlo_lexer.cc b/tensorflow/compiler/xla/service/hlo_lexer.cc index 8e0d38b6a6..8350285e67 100644 --- a/tensorflow/compiler/xla/service/hlo_lexer.cc +++ b/tensorflow/compiler/xla/service/hlo_lexer.cc @@ -17,20 +17,20 @@ limitations under the License. #include <unordered_map> +#include "absl/strings/escaping.h" +#include "absl/strings/numbers.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/regexp.h" namespace xla { - -using ::tensorflow::StringPiece; - namespace { +using absl::string_view; + constexpr int kEOF = -1; constexpr int kError = -2; @@ -66,12 +66,12 @@ bool HloLexer::CanDereference(const char* ptr) const { return ptr < buf_.end() && ptr >= buf_.begin(); } -tensorflow::StringPiece HloLexer::StringPieceFromPointers( - const char* begin, const char* end) const { +absl::string_view HloLexer::StringPieceFromPointers(const char* begin, + const char* end) const { CHECK(begin <= end); CHECK(begin == buf_.end() || CanDereference(begin)); CHECK(end == buf_.end() || CanDereference(end)); - return tensorflow::StringPiece(begin, end - begin); + return absl::string_view(begin, end - begin); } tensorflow::RegexpStringPiece HloLexer::RegexpStringPieceFromPointers( @@ -235,7 +235,7 @@ TokKind HloLexer::LexIdentifier() { return TokKind::kAttributeName; } - tensorflow::StringPiece identifier = + absl::string_view identifier = StringPieceFromPointers(token_start_, current_ptr_); // See if this is a keyword. @@ -269,7 +269,7 @@ TokKind HloLexer::LexIdentifier() { } } - str_val_ = std::string(identifier); + str_val_ = string(identifier); return TokKind::kIdent; } @@ -306,8 +306,7 @@ TokKind HloLexer::LexNumberOrPattern() { R"([-]?((\d+|\d+[.]\d*|\d*[.]\d+)([eE][+-]?\d+))|[-]?(\d+[.]\d*|\d*[.]\d+))"}; if (RE2::Consume(&consumable, *float_pattern)) { current_ptr_ = consumable.begin(); - tensorflow::strings::safe_strtod(string(token_start_, current_ptr_).c_str(), - &decimal_val_); + CHECK(absl::SimpleAtod(string(token_start_, current_ptr_), &decimal_val_)); return TokKind::kDecimal; } @@ -339,7 +338,7 @@ TokKind HloLexer::LexNumberOrPattern() { if (RE2::Consume(&consumable, *int_pattern)) { current_ptr_ = consumable.begin(); auto slice = StringPieceFromPointers(token_start_, current_ptr_); - if (tensorflow::strings::safe_strto64(slice, &int64_val_)) { + if (absl::SimpleAtoi(slice, &int64_val_)) { return TokKind::kInt; } LOG(ERROR) << "Failed to parse int literal: " << slice; @@ -365,6 +364,7 @@ std::pair<unsigned, unsigned> HloLexer::GetLineAndColumn(LocTy location) const { line_no = line_no_cache_.line_no_of_query; } for (; ptr != location; ptr++) { + CHECK_LT(ptr, buf_.end()); if (*ptr == '\n') { line_no++; } @@ -374,24 +374,24 @@ std::pair<unsigned, unsigned> HloLexer::GetLineAndColumn(LocTy location) const { line_no_cache_.last_query = ptr; line_no_cache_.line_no_of_query = line_no; size_t line_offset = StringPieceFromPointers(start, ptr).rfind('\n'); - if (line_offset == tensorflow::StringPiece::npos) { + if (line_offset == absl::string_view::npos) { line_offset = 0; } return {line_no, ptr - start - line_offset}; } -tensorflow::StringPiece HloLexer::GetLine(LocTy loc) const { +absl::string_view HloLexer::GetLine(LocTy loc) const { if (!CanDereference(loc)) { return "LINE OUT OF RANGE"; } size_t line_start = StringPieceFromPointers(buf_.begin(), loc + 1).rfind('\n'); - const char* start = line_start == tensorflow::StringPiece::npos + const char* start = line_start == absl::string_view::npos ? buf_.begin() : buf_.begin() + line_start + 1; size_t line_end = StringPieceFromPointers(loc, buf_.end()).find('\n'); const char* end = - line_end == tensorflow::StringPiece::npos ? buf_.end() : loc + line_end; + line_end == absl::string_view::npos ? buf_.end() : loc + line_end; return StringPieceFromPointers(start, end); } @@ -403,10 +403,14 @@ TokKind HloLexer::LexString() { static LazyRE2 escaping_pattern = {R"("([^"\\]|\\.)*")"}; if (RE2::Consume(&consumable, *escaping_pattern)) { current_ptr_ = consumable.begin(); - tensorflow::StringPiece raw = + absl::string_view raw = StringPieceFromPointers(token_start_ + 1, current_ptr_ - 1); string error; - if (!tensorflow::str_util::CUnescape(raw, &str_val_, &error)) { + // TODO(b/113077997): Change to absl::CUnescape once it works properly with + // copy-on-write std::string implementations. + if (!tensorflow::str_util::CUnescape( // non-absl ok + tensorflow::StringPiece(raw.data(), raw.size()), // non-absl ok + &str_val_, &error)) { LOG(ERROR) << "Failed unescaping string: " << raw << ". error: " << error; return TokKind::kError; } diff --git a/tensorflow/compiler/xla/service/hlo_lexer.h b/tensorflow/compiler/xla/service/hlo_lexer.h index 003ac34ace..3e2f8bcd52 100644 --- a/tensorflow/compiler/xla/service/hlo_lexer.h +++ b/tensorflow/compiler/xla/service/hlo_lexer.h @@ -18,10 +18,10 @@ limitations under the License. #include <string> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/service/hlo_token.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/regexp.h" #include "tensorflow/core/platform/types.h" @@ -34,7 +34,7 @@ namespace xla { // it directly. class HloLexer { public: - explicit HloLexer(tensorflow::StringPiece buf) : buf_(buf) { + explicit HloLexer(absl::string_view buf) : buf_(buf) { current_ptr_ = buf_.begin(); } @@ -77,7 +77,7 @@ class HloLexer { std::pair<unsigned, unsigned> GetLineAndColumn(LocTy location) const; // Returns the whole line given the location. - tensorflow::StringPiece GetLine(LocTy loc) const; + absl::string_view GetLine(LocTy loc) const; private: // Returns the current character. If it's neither the end of input buffer nor @@ -89,8 +89,8 @@ class HloLexer { // Creates StringPiece with the given begin and end. Exits if the begin > end, // or it's out of the range of the current buffer. - tensorflow::StringPiece StringPieceFromPointers(const char* begin, - const char* end) const; + absl::string_view StringPieceFromPointers(const char* begin, + const char* end) const; tensorflow::RegexpStringPiece RegexpStringPieceFromPointers( const char* begin, const char* end) const; @@ -107,11 +107,11 @@ class HloLexer { TokKind LexNumberOrPattern(); TokKind LexString(); - const tensorflow::StringPiece buf_; + const absl::string_view buf_; const char* current_ptr_; // Information about the current token. - const char* token_start_; + const char* token_start_ = nullptr; TokKind current_kind_; string str_val_; Shape shape_val_; diff --git a/tensorflow/compiler/xla/service/hlo_liveness_analysis.cc b/tensorflow/compiler/xla/service/hlo_liveness_analysis.cc index 43c41ece6e..3a1dd471c6 100644 --- a/tensorflow/compiler/xla/service/hlo_liveness_analysis.cc +++ b/tensorflow/compiler/xla/service/hlo_liveness_analysis.cc @@ -17,8 +17,9 @@ limitations under the License. #include <deque> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/call_graph.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -29,17 +30,14 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" namespace xla { +namespace { using Worklist = std::deque<const HloInstruction*>; using Workset = std::unordered_set<const HloInstruction*>; -namespace { - void AddToWorklist(const HloInstruction* instruction, Worklist* worklist, Workset* workset) { if (workset->count(instruction) == 0) { @@ -296,7 +294,7 @@ StatusOr<std::unique_ptr<HloLivenessAnalysis>> HloLivenessAnalysis::Run( VLOG(1) << "HloLivenessAnalysis::Run on module " << module.name(); XLA_VLOG_LINES(2, module.ToString()); - auto liveness_analysis = WrapUnique(new HloLivenessAnalysis(module)); + auto liveness_analysis = absl::WrapUnique(new HloLivenessAnalysis(module)); liveness_analysis->RunAnalysis(); diff --git a/tensorflow/compiler/xla/service/hlo_matchers.cc b/tensorflow/compiler/xla/service/hlo_matchers.cc index 7e4b883435..5269cad94d 100644 --- a/tensorflow/compiler/xla/service/hlo_matchers.cc +++ b/tensorflow/compiler/xla/service/hlo_matchers.cc @@ -15,15 +15,13 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_matchers.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/test.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace xla { namespace testing { -using ::tensorflow::str_util::Join; - bool HloMatcher::MatchAndExplain( const HloInstruction* instruction, ::testing::MatchResultListener* listener) const { @@ -210,8 +208,8 @@ bool HloDotWithContractingDimsMatcher::MatchAndExplain( dim_nums.lhs_contracting_dimensions(0) != lhs_contracting_dim_) { *listener << instruction->ToString() << " has wrong lhs_contracting_dimensions (got {" - << Join(dim_nums.lhs_contracting_dimensions(), ",") << "} want {" - << lhs_contracting_dim_ << "})"; + << absl::StrJoin(dim_nums.lhs_contracting_dimensions(), ",") + << "} want {" << lhs_contracting_dim_ << "})"; return false; } @@ -219,8 +217,8 @@ bool HloDotWithContractingDimsMatcher::MatchAndExplain( dim_nums.rhs_contracting_dimensions(0) != rhs_contracting_dim_) { *listener << instruction->ToString() << " has wrong rhs_contracting_dimensions (got {" - << Join(dim_nums.rhs_contracting_dimensions(), ",") << "} want {" - << rhs_contracting_dim_ << "})"; + << absl::StrJoin(dim_nums.rhs_contracting_dimensions(), ",") + << "} want {" << rhs_contracting_dim_ << "})"; return false; } diff --git a/tensorflow/compiler/xla/service/hlo_matchers.h b/tensorflow/compiler/xla/service/hlo_matchers.h index c577b4359a..5502e565b6 100644 --- a/tensorflow/compiler/xla/service/hlo_matchers.h +++ b/tensorflow/compiler/xla/service/hlo_matchers.h @@ -16,10 +16,10 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_HLO_MATCHERS_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_HLO_MATCHERS_H_ +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/test.h" -#include "tensorflow/core/lib/gtl/optional.h" namespace xla { namespace testing { @@ -120,8 +120,7 @@ class HloShapeAndLayoutMatcher class HloShardingMatcher : public ::testing::MatcherInterface<const HloInstruction*> { public: - explicit HloShardingMatcher( - const tensorflow::gtl::optional<HloSharding>& sharding) + explicit HloShardingMatcher(const absl::optional<HloSharding>& sharding) : sharding_(sharding) {} bool MatchAndExplain(const HloInstruction* instruction, @@ -129,7 +128,7 @@ class HloShardingMatcher void DescribeTo(std::ostream* os) const override; private: - tensorflow::gtl::optional<HloSharding> sharding_; + absl::optional<HloSharding> sharding_; }; // Matches a Dot HLO instruction with specific LHS and RHS contracting @@ -189,6 +188,7 @@ HLO_MATCHER(Fusion); HLO_MATCHER(Ge); HLO_MATCHER(AfterAll); HLO_MATCHER(Gt); +HLO_MATCHER(Iota); HLO_MATCHER(Infeed); HLO_MATCHER(IsFinite); HLO_MATCHER(Le); @@ -307,7 +307,7 @@ inline ::testing::Matcher<const ::xla::HloInstruction*> Shape( return ::testing::MakeMatcher(new ::xla::testing::HloShapeMatcher(shape)); } inline ::testing::Matcher<const ::xla::HloInstruction*> Shape( - tensorflow::StringPiece shape) { + absl::string_view shape) { return ::testing::MakeMatcher(new ::xla::testing::HloShapeMatcher( ShapeUtil::ParseShapeString(shape).ValueOrDie())); } @@ -317,7 +317,7 @@ inline ::testing::Matcher<const ::xla::HloInstruction*> ShapeWithLayout( new ::xla::testing::HloShapeAndLayoutMatcher(shape)); } inline ::testing::Matcher<const ::xla::HloInstruction*> ShapeWithLayout( - tensorflow::StringPiece shape) { + absl::string_view shape) { return ::testing::MakeMatcher(new ::xla::testing::HloShapeAndLayoutMatcher( ShapeUtil::ParseShapeString(shape).ValueOrDie())); } @@ -330,14 +330,14 @@ inline ::testing::Matcher<const ::xla::HloInstruction*> Sharding( } // Matcher for Sharding from sharding string inline ::testing::Matcher<const ::xla::HloInstruction*> Sharding( - tensorflow::StringPiece sharding) { + absl::string_view sharding) { return ::testing::MakeMatcher(new ::xla::testing::HloShardingMatcher( ParseSharding(sharding).ValueOrDie())); } // Verifies that no HloSharding is set for an HLO instruction. inline ::testing::Matcher<const ::xla::HloInstruction*> NoSharding() { return ::testing::MakeMatcher( - new ::xla::testing::HloShardingMatcher(tensorflow::gtl::nullopt)); + new ::xla::testing::HloShardingMatcher(absl::nullopt)); } inline ::testing::Matcher<const ::xla::HloInstruction*> Dot( diff --git a/tensorflow/compiler/xla/service/hlo_module.cc b/tensorflow/compiler/xla/service/hlo_module.cc index 55ff073d3f..78167335c8 100644 --- a/tensorflow/compiler/xla/service/hlo_module.cc +++ b/tensorflow/compiler/xla/service/hlo_module.cc @@ -22,12 +22,13 @@ limitations under the License. #include <unordered_set> #include <utility> +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/gtl/map_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/types.h" namespace xla { @@ -274,7 +275,7 @@ StatusOr<std::unique_ptr<HloModule>> HloModule::CreateFromProto( } TF_RET_CHECK(entry != nullptr); - auto module = MakeUnique<HloModule>(proto.name(), module_config); + auto module = absl::make_unique<HloModule>(proto.name(), module_config); // Sort the computations in the proto id's order. std::sort(computations.begin(), computations.end(), @@ -409,7 +410,7 @@ HloInstruction* HloModule::OutlineExpressionFromComputation( string error_message = "The subcomputation to outline has multiple outputs:\n"; for (HloInstruction* output : outputs) { - tensorflow::strings::StrAppend(&error_message, output->ToString(), "\n"); + absl::StrAppend(&error_message, output->ToString(), "\n"); } LOG(FATAL) << error_message; } @@ -507,7 +508,7 @@ std::vector<HloComputation*> HloModule::MakeNonfusionComputations() const { std::unique_ptr<HloModule> HloModule::Clone(const string& suffix) const { VLOG(1) << "Cloning module :" << name_ << " --> " << suffix << "\n"; - auto module = MakeUnique<HloModule>(name_ + "-" + suffix, config_); + auto module = absl::make_unique<HloModule>(name_ + "-" + suffix, config_); HloCloneContext context(module.get(), suffix); auto cloned_computation = entry_computation_->Clone(suffix, &context); @@ -535,12 +536,11 @@ uint64 HloModule::RandomNew64() const { return rng_(); } -HloComputation* HloModule::GetComputationWithName( - tensorflow::StringPiece name) { +HloComputation* HloModule::GetComputationWithName(absl::string_view name) { auto computations_in_module = computations(); - auto it = c_find_if(computations_in_module, [&](HloComputation* computation) { - return computation->name() == name; - }); + auto it = absl::c_find_if( + computations_in_module, + [&](HloComputation* computation) { return computation->name() == name; }); return it == computations_in_module.end() ? nullptr : *it; } diff --git a/tensorflow/compiler/xla/service/hlo_module.h b/tensorflow/compiler/xla/service/hlo_module.h index d2e726a0db..cf129b835d 100644 --- a/tensorflow/compiler/xla/service/hlo_module.h +++ b/tensorflow/compiler/xla/service/hlo_module.h @@ -24,6 +24,7 @@ limitations under the License. #include <unordered_map> #include <vector> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/iterator_util.h" #include "tensorflow/compiler/xla/service/hlo.pb.h" #include "tensorflow/compiler/xla/service/hlo_clone_context.h" @@ -32,7 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_module_config.h" #include "tensorflow/compiler/xla/service/name_uniquer.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/lib/gtl/iterator_range.h" #include "tensorflow/core/platform/logging.h" @@ -142,7 +142,7 @@ class HloModule { // Returns the computation in this module that has the name `name`. Returns // null if there is no such computation. - HloComputation* GetComputationWithName(tensorflow::StringPiece name); + HloComputation* GetComputationWithName(absl::string_view name); // Gets the number of computations in this module. int64 computation_count() const { return computations_.size(); } diff --git a/tensorflow/compiler/xla/service/hlo_module_config.cc b/tensorflow/compiler/xla/service/hlo_module_config.cc index 07a8c798db..9bfa3a5f45 100644 --- a/tensorflow/compiler/xla/service/hlo_module_config.cc +++ b/tensorflow/compiler/xla/service/hlo_module_config.cc @@ -18,15 +18,15 @@ limitations under the License. #include <atomic> #include <vector> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/shape_layout.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { -using tensorflow::strings::StrAppend; +using absl::StrAppend; HloModuleConfig::HloModuleConfig(const ProgramShape& program_shape, bool ignore_layouts) @@ -39,15 +39,14 @@ void HloModuleConfig::SetDefaultComputationLayout( } string HloModuleConfig::compilation_cache_key() const { - string key = - tensorflow::strings::StrCat("profiling=", hlo_profiling_enabled()); + string key = absl::StrCat("profiling=", hlo_profiling_enabled()); StrAppend(&key, "::("); std::vector<string> params; for (const ShapeLayout& param_layout : entry_computation_layout_->parameter_layouts()) { params.push_back(param_layout.shape().DebugString()); } - StrAppend(&key, tensorflow::str_util::Join(params, ", "), ") => ", + StrAppend(&key, absl::StrJoin(params, ", "), ") => ", entry_computation_layout_->result_shape().SerializeAsString()); if (seed() != 0) { // TODO(b/32083678): force recompilation to reset global state. diff --git a/tensorflow/compiler/xla/service/hlo_module_config.h b/tensorflow/compiler/xla/service/hlo_module_config.h index 074e9c9070..3f1e1cc73e 100644 --- a/tensorflow/compiler/xla/service/hlo_module_config.h +++ b/tensorflow/compiler/xla/service/hlo_module_config.h @@ -18,11 +18,11 @@ limitations under the License. #include <string> +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/computation_layout.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla.pb.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/gtl/optional.h" namespace xla { @@ -72,15 +72,6 @@ class HloModuleConfig { return debug_options_.xla_hlo_profile(); } - // Sets/returns whether this is a "host module". Host modules are used to - // record the data- and control-flow dependencies of host side computation - // that communicates with compiled code. They are used for analysis and - // scheduling purposes, but no code is generated. - bool is_host_module() const { return is_host_module_; } - void set_is_host_module(bool is_host_module) { - is_host_module_ = is_host_module; - } - // Sets/returns the module seed set during execution. void set_seed(uint64 seed) { seed_ = seed; } uint64 seed() const { return seed_; } @@ -113,7 +104,7 @@ class HloModuleConfig { private: // If you add new members, be sure to update compilation_cache_key. - tensorflow::gtl::optional<ComputationLayout> entry_computation_layout_; + absl::optional<ComputationLayout> entry_computation_layout_; // Whether this is a 'host module'. bool is_host_module_ = false; diff --git a/tensorflow/compiler/xla/service/hlo_module_dce.h b/tensorflow/compiler/xla/service/hlo_module_dce.h index 29024085c1..12ca2340a6 100644 --- a/tensorflow/compiler/xla/service/hlo_module_dce.h +++ b/tensorflow/compiler/xla/service/hlo_module_dce.h @@ -31,7 +31,7 @@ namespace xla { class HloModuleDCE : public HloPassInterface { public: ~HloModuleDCE() override {} - tensorflow::StringPiece name() const override { return "hlo-module-dce"; } + absl::string_view name() const override { return "hlo-module-dce"; } // Run the pass on the given module. Returns whether the module was changed // (instructions were removed). diff --git a/tensorflow/compiler/xla/service/hlo_module_group_metadata.cc b/tensorflow/compiler/xla/service/hlo_module_group_metadata.cc index 10bf9ffd6c..9c01862a4b 100644 --- a/tensorflow/compiler/xla/service/hlo_module_group_metadata.cc +++ b/tensorflow/compiler/xla/service/hlo_module_group_metadata.cc @@ -19,9 +19,10 @@ limitations under the License. #include <string> #include <utility> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/hlo_casting_utils.h" #include "tensorflow/compiler/xla/service/hlo_instructions.h" +#include "tensorflow/compiler/xla/service/tuple_points_to_analysis.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/util.h" @@ -59,7 +60,7 @@ string HloModuleGroupMetadata::TrackedInstruction::ToString() const { /* static */ StatusOr<std::unique_ptr<HloModuleGroupMetadata>> HloModuleGroupMetadata::Build(const std::vector<HloModule*>& modules) { - auto metadata = MakeUnique<HloModuleGroupMetadata>(modules); + auto metadata = absl::make_unique<HloModuleGroupMetadata>(modules); TF_RETURN_IF_ERROR(metadata->Build()); return std::move(metadata); } @@ -131,6 +132,14 @@ Status HloModuleGroupMetadata::Build() { if (VLOG_IS_ON(4)) { DumpCollectedStats(); } + + for (HloModule* module : modules_) { + TF_ASSIGN_OR_RETURN( + std::unique_ptr<TuplePointsToAnalysis> points_to_analysis, + TuplePointsToAnalysis::Run(module)); + points_to_analyses_[module] = std::move(points_to_analysis); + } + return Status::OK(); } @@ -163,7 +172,7 @@ Status HloModuleGroupMetadata::VerifyCompanionSets() const { ss << " " << hlo->name() << std::endl; } ss << "has multiple instructions on the same device"; - return FailedPrecondition("%s", ss.str().c_str()); + return FailedPrecondition("%s", ss.str()); } } } @@ -204,6 +213,10 @@ const HloModuleGroupMetadata::Channel& HloModuleGroupMetadata::GetChannel( return channels_[channel_id_map_.at(channel_id)]; } +bool HloModuleGroupMetadata::HasChannel(int64 channel_id) const { + return channel_id_map_.find(channel_id) != channel_id_map_.end(); +} + HloComputation* HloModuleGroupMetadata::PeerComputation( const HloInstruction* instruction) const { CHECK(IsChannelInstruction(instruction)); @@ -267,15 +280,14 @@ int64 HloModuleGroupMetadata::GetModuleId(const HloModule* module) const { LOG(FATAL) << "unknown module"; } -tensorflow::gtl::optional<int64> HloModuleGroupMetadata::GetInstructionDevice( +absl::optional<int64> HloModuleGroupMetadata::GetInstructionDevice( const HloInstruction& instruction) const { // The module group metadata can be created in both "single module, multiple // devices" and "multiple modules, no explicit devices" fashions. // The API returns an optional even though the current implementation always // returns a device, to account for cases where we cannot guess a device. // In such cases the VerifyChannelInstructions() will return proper errors. - tensorflow::gtl::optional<int64> device = - instruction.sharding_unique_device(); + absl::optional<int64> device = instruction.sharding_unique_device(); if (!device) { device = GetModuleId(instruction.parent()->parent()); } @@ -283,10 +295,7 @@ tensorflow::gtl::optional<int64> HloModuleGroupMetadata::GetInstructionDevice( } int64 HloModuleGroupMetadata::GetDeviceModulesCount() const { - return std::count_if(modules_.begin(), modules_.end(), - [](const HloModule* module) { - return !module->config().is_host_module(); - }); + return modules_.size(); } Status HloModuleGroupMetadata::RecordInstructions() { @@ -383,7 +392,7 @@ Status HloModuleGroupMetadata::AddCompanion(HloInstruction* instruction1, if (!ContainsKey(companion_set_index_, instruction1) && !ContainsKey(companion_set_index_, instruction2)) { companion_sets_.push_back( - tensorflow::MakeUnique<std::unordered_set<HloInstruction*>>()); + absl::make_unique<std::unordered_set<HloInstruction*>>()); auto companion_set = companion_sets_.back().get(); companion_set->insert(instruction1); companion_set->insert(instruction2); @@ -411,16 +420,16 @@ Status HloModuleGroupMetadata::AddCompanion(HloInstruction* instruction1, Status HloModuleGroupMetadata::VerifyChannelInstructions() { for (const Channel& channel : channels_) { if (channel.send == nullptr) { - return FailedPrecondition("missing send for id : %lld", channel.id); + return FailedPrecondition("missing send for id : %d", channel.id); } if (channel.recv == nullptr) { - return FailedPrecondition("missing recv for id : %lld", channel.id); + return FailedPrecondition("missing recv for id : %d", channel.id); } if (channel.send_done == nullptr) { - return FailedPrecondition("missing send-done for id : %lld", channel.id); + return FailedPrecondition("missing send-done for id : %d", channel.id); } if (channel.recv_done == nullptr) { - return FailedPrecondition("missing recv-done for id : %lld", channel.id); + return FailedPrecondition("missing recv-done for id : %d", channel.id); } } @@ -436,33 +445,33 @@ Status HloModuleGroupMetadata::VerifyChannelInstructions() { auto send_done_device = GetInstructionDevice(*channel.send_done); if (!send_device) { return FailedPrecondition("send instruction must have a device: %s", - channel.send->ToString().c_str()); + channel.send->ToString()); } if (!send_done_device) { return FailedPrecondition("send_done instruction must have a device: %s", - channel.send_done->ToString().c_str()); + channel.send_done->ToString()); } if (*send_device != *send_done_device) { return FailedPrecondition( - "send and send-done (channel=%lld) must be on the same device: %lld " - "vs. %lld", + "send and send-done (channel=%d) must be on the same device: %d " + "vs. %d", channel.id, *send_device, *send_done_device); } auto recv_device = GetInstructionDevice(*channel.recv); auto recv_done_device = GetInstructionDevice(*channel.recv_done); if (!recv_done_device) { return FailedPrecondition("recv_done instruction must have a device: %s", - channel.recv_done->ToString().c_str()); + channel.recv_done->ToString()); } if (*recv_device != *recv_done_device) { return FailedPrecondition( - "recv and recv-done (channel=%lld) must be on the same device: %lld " - "vs. %lld", + "recv and recv-done (channel=%d) must be on the same device: %d " + "vs. %d", channel.id, *recv_device, *recv_done_device); } if (*send_device == *recv_device) { return FailedPrecondition( - "send and recv (channel=%lld) must be on different devices: %lld", + "send and recv (channel=%d) must be on different devices: %d", channel.id, *send_device); } } @@ -483,7 +492,7 @@ Status HloModuleGroupMetadata::VerifyChannelInstructions() { !CheckCompanionPathsCompatibility( path, GetCompanionsPath(channel.recv_done))) { return FailedPrecondition( - "Nest companion paths do not match for channel %lld", channel.id); + "Nest companion paths do not match for channel %d", channel.id); } } return Status::OK(); diff --git a/tensorflow/compiler/xla/service/hlo_module_group_metadata.h b/tensorflow/compiler/xla/service/hlo_module_group_metadata.h index 1b256cd00e..768b0c7eb3 100644 --- a/tensorflow/compiler/xla/service/hlo_module_group_metadata.h +++ b/tensorflow/compiler/xla/service/hlo_module_group_metadata.h @@ -22,14 +22,15 @@ limitations under the License. #include <unordered_set> #include <vector> +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" +#include "tensorflow/compiler/xla/service/tuple_points_to_analysis.h" #include "tensorflow/compiler/xla/status.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/gtl/flatmap.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/types.h" namespace xla { @@ -125,6 +126,9 @@ class HloModuleGroupMetadata { // Returns the Channel instance for the given channel id. const Channel& GetChannel(int64 channel_id) const; + // Returns if the given channel id exists in metadata. + bool HasChannel(int64 channel_id) const; + // Returns the all-reduce instructions with the same all_reduce_id. const std::vector<HloInstruction*>& GetAllReduceGroup( int64 all_reduce_id) const; @@ -156,7 +160,7 @@ class HloModuleGroupMetadata { // Retrieves the device an instruction is assigned to. Either from the // sharding information, or from the ordinal of the module the instruction // is in. - tensorflow::gtl::optional<int64> GetInstructionDevice( + absl::optional<int64> GetInstructionDevice( const HloInstruction& instruction) const; // Returns the number of modules for devices (excluding the host module). @@ -194,6 +198,10 @@ class HloModuleGroupMetadata { // Returns the maximum channel id or all_reduce_id used in the module group. int64 max_channel_id() const { return max_channel_id_; } + TuplePointsToAnalysis* points_to_analysis(HloModule* module) const { + return points_to_analyses_.at(module).get(); + } + private: Status Build(); @@ -268,6 +276,9 @@ class HloModuleGroupMetadata { // The modules that this metadata was built from. const std::vector<HloModule*>& modules_; + + tensorflow::gtl::FlatMap<HloModule*, std::unique_ptr<TuplePointsToAnalysis>> + points_to_analyses_; }; } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_module_group_util.cc b/tensorflow/compiler/xla/service/hlo_module_group_util.cc index 0dc5676148..d70328c8a3 100644 --- a/tensorflow/compiler/xla/service/hlo_module_group_util.cc +++ b/tensorflow/compiler/xla/service/hlo_module_group_util.cc @@ -22,7 +22,10 @@ limitations under the License. #include <string> #include <utility> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "tensorflow/compiler/xla/service/hlo_casting_utils.h" +#include "tensorflow/compiler/xla/service/hlo_instructions.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/service/hlo_reachability.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -30,7 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -94,12 +96,14 @@ std::vector<HloInstruction*> HloModuleGroupUtil::GlobalPredecessors( add_unique_predecessor(control_predecessor); } } - if (instruction->opcode() == HloOpcode::kRecvDone) { + if (instruction->opcode() == HloOpcode::kRecvDone && + !DynCast<HloRecvDoneInstruction>(instruction)->is_host_transfer()) { // Send is a remote predecessor of RecvDone. HloInstruction* send = metadata_.GetChannel(instruction->channel_id()).send; add_unique_predecessor(send); } - if (instruction->opcode() == HloOpcode::kSend) { + if (instruction->opcode() == HloOpcode::kSend && + !DynCast<HloSendInstruction>(instruction)->is_host_transfer()) { // Recv is a remote predecessor of Send. HloInstruction* recv_done = metadata_.GetChannel(instruction->channel_id()).recv_done; @@ -170,14 +174,16 @@ std::vector<HloInstruction*> HloModuleGroupUtil::GlobalSuccessors( add_unique_successor(control_successor); } } - if (instruction->opcode() == HloOpcode::kRecv) { + if (instruction->opcode() == HloOpcode::kRecv && + !DynCast<HloRecvInstruction>(instruction)->is_host_transfer()) { // Send is a remote successor of Recv. const HloInstruction* recv_done = instruction->users().front(); CHECK(recv_done->opcode() == HloOpcode::kRecvDone); HloInstruction* send = metadata_.GetChannel(instruction->channel_id()).send; add_unique_successor(send); } - if (instruction->opcode() == HloOpcode::kSend) { + if (instruction->opcode() == HloOpcode::kSend && + !DynCast<HloSendInstruction>(instruction)->is_host_transfer()) { // RecvDone is a remote successor of Send. HloInstruction* recv_done = metadata_.GetChannel(instruction->channel_id()).recv_done; @@ -264,8 +270,8 @@ Status HloModuleGroupUtil::VisitTopologicalOrder( string cyclic_instructions; for (const auto& state : *visit_state) { if (state.second == VisitState::kVisiting) { - tensorflow::strings::StrAppend(&cyclic_instructions, - state.first->ToString(), "\n"); + absl::StrAppend(&cyclic_instructions, state.first->ToString(), + "\n"); } } // TODO(b/64305524): Improve the error message to print out the @@ -276,7 +282,7 @@ Status HloModuleGroupUtil::VisitTopologicalOrder( "following nodes. Note that the order of the nodes is arbitrary " "and that the list may include nodes that are not part of the " "cycle.\n%s", - predecessor->ToString().c_str(), cyclic_instructions.c_str()); + predecessor->ToString(), cyclic_instructions); } stack.push(predecessor); } @@ -332,7 +338,7 @@ HloModuleGroupUtil::ComputeReachability( TF_RETURN_IF_ERROR( VisitTopologicalOrder(&visit_states, visit_function, root)); } - auto reachability = MakeUnique<HloReachabilityMap>(post_order); + auto reachability = absl::make_unique<HloReachabilityMap>(post_order); for (HloInstruction* hlo : post_order) { reachability->FastSetReachabilityToUnion(GlobalPredecessors(hlo), hlo); } diff --git a/tensorflow/compiler/xla/service/hlo_module_test.cc b/tensorflow/compiler/xla/service/hlo_module_test.cc index 236f450086..209ad5e58c 100644 --- a/tensorflow/compiler/xla/service/hlo_module_test.cc +++ b/tensorflow/compiler/xla/service/hlo_module_test.cc @@ -15,8 +15,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_module.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/shape_util.h" diff --git a/tensorflow/compiler/xla/service/hlo_opcode.cc b/tensorflow/compiler/xla/service/hlo_opcode.cc index d1eaf35785..2d4e38589f 100644 --- a/tensorflow/compiler/xla/service/hlo_opcode.cc +++ b/tensorflow/compiler/xla/service/hlo_opcode.cc @@ -39,7 +39,7 @@ StatusOr<HloOpcode> StringToHloOpcode(const string& opcode_name) { }); auto it = opcode_map->find(opcode_name); if (it == opcode_map->end()) { - return InvalidArgument("Unknown opcode: %s", opcode_name.c_str()); + return InvalidArgument("Unknown opcode: %s", opcode_name); } return it->second; } diff --git a/tensorflow/compiler/xla/service/hlo_opcode.h b/tensorflow/compiler/xla/service/hlo_opcode.h index ec279867e5..e6bfb8025d 100644 --- a/tensorflow/compiler/xla/service/hlo_opcode.h +++ b/tensorflow/compiler/xla/service/hlo_opcode.h @@ -58,6 +58,7 @@ namespace xla { V(kCall, "call", kHloOpcodeIsVariadic) \ V(kCeil, "ceil") \ V(kClamp, "clamp") \ + V(kCollectivePermute, "collective-permute") \ V(kClz, "count-leading-zeros") \ V(kComplex, "complex") \ V(kConcatenate, "concatenate", kHloOpcodeIsVariadic) \ @@ -85,7 +86,6 @@ namespace xla { V(kAfterAll, "after-all", kHloOpcodeIsVariadic) \ V(kGetTupleElement, "get-tuple-element") \ V(kGt, "greater-than", kHloOpcodeIsComparison) \ - V(kHostCompute, "host-compute") \ V(kImag, "imag") \ V(kInfeed, "infeed") \ V(kIota, "iota") \ @@ -156,7 +156,7 @@ enum HloOpcodeProperty { // Returns a string representation of the opcode. string HloOpcodeString(HloOpcode opcode); -// Returns a string representation of the opcode. +// Retrieves the opcode enum by name if the opcode exists. StatusOr<HloOpcode> StringToHloOpcode(const string& opcode_name); inline std::ostream& operator<<(std::ostream& os, HloOpcode opcode) { diff --git a/tensorflow/compiler/xla/service/hlo_ordering.cc b/tensorflow/compiler/xla/service/hlo_ordering.cc index 6c1e015f77..0581d5c404 100644 --- a/tensorflow/compiler/xla/service/hlo_ordering.cc +++ b/tensorflow/compiler/xla/service/hlo_ordering.cc @@ -18,6 +18,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -25,8 +27,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" namespace xla { @@ -254,6 +254,10 @@ bool HloOrdering::LiveRangeStrictlyBefore( } // All uses of 'a' must be before 'b' is defined. for (const HloUse& use : a.uses()) { + if (dataflow.DoesNotUseOperandBuffer(a.instruction(), a.index(), + use.instruction)) { + continue; + } if (!UseIsBeforeValueDefinition(use, b, dataflow)) { VLOG(4) << "use of " << a << " (" << use << ") not before " << b << " is defined"; @@ -302,22 +306,20 @@ string PredecessorHloOrdering::ToStringHelper(const string& name) const { std::vector<string> pieces; pieces.push_back(name); for (auto* computation : module_->MakeNonfusionComputations()) { - pieces.push_back(tensorflow::strings::Printf("computation %s:", - computation->name().c_str())); + pieces.push_back(absl::StrFormat("computation %s:", computation->name())); const auto all = computation->MakeInstructionPostOrder(); for (auto instruction : all) { - pieces.push_back(tensorflow::strings::Printf( - " %s predecessors:", instruction->name().c_str())); + pieces.push_back( + absl::StrFormat(" %s predecessors:", instruction->name())); for (auto predecessor : all) { if (predecessors_.at(computation) ->IsReachable(predecessor, instruction)) { - pieces.push_back( - tensorflow::strings::Printf(" %s", predecessor->name().c_str())); + pieces.push_back(absl::StrFormat(" %s", predecessor->name())); } } } } - return tensorflow::str_util::Join(pieces, "\n"); + return absl::StrJoin(pieces, "\n"); } DependencyHloOrdering::DependencyHloOrdering(const HloModule* module) @@ -368,8 +370,8 @@ string SequentialHloOrdering::ToString() const { std::vector<string> pieces; pieces.push_back("SequentialHloOrdering"); for (auto* computation : module_->computations()) { - pieces.push_back(tensorflow::strings::Printf("computation %s order:", - computation->name().c_str())); + pieces.push_back( + absl::StrFormat("computation %s order:", computation->name())); // Gather all instructions in the module sequence for this computation and // sort them by their position. std::vector<const HloInstruction*> instructions; @@ -384,11 +386,10 @@ string SequentialHloOrdering::ToString() const { return order_position_.at(a) < order_position_.at(b); }); for (auto instruction : instructions) { - pieces.push_back( - tensorflow::strings::Printf(" %s", instruction->name().c_str())); + pieces.push_back(absl::StrFormat(" %s", instruction->name())); } } - return tensorflow::str_util::Join(pieces, "\n"); + return absl::StrJoin(pieces, "\n"); } std::ostream& operator<<( diff --git a/tensorflow/compiler/xla/service/hlo_parser.cc b/tensorflow/compiler/xla/service/hlo_parser.cc index ab57a8b07f..eae4508b24 100644 --- a/tensorflow/compiler/xla/service/hlo_parser.cc +++ b/tensorflow/compiler/xla/service/hlo_parser.cc @@ -15,6 +15,12 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_parser.h" +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" +#include "absl/strings/str_split.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/hlo_domain_metadata.h" @@ -24,21 +30,17 @@ limitations under the License. #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/map_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" namespace xla { namespace { -using ::tensorflow::StringPiece; -using ::tensorflow::gtl::optional; -using ::tensorflow::str_util::Join; -using ::tensorflow::str_util::Split; -using ::tensorflow::str_util::SplitAndParseAsInts; -using ::tensorflow::strings::Printf; -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; +using absl::nullopt; +using absl::optional; +using absl::StrAppend; +using absl::StrCat; +using absl::StrFormat; +using absl::StrJoin; const double kF16max = 65504; @@ -47,7 +49,7 @@ class HloParser { public: using LocTy = HloLexer::LocTy; - explicit HloParser(StringPiece str, const HloModuleConfig& config) + explicit HloParser(absl::string_view str, const HloModuleConfig& config) : lexer_(str), config_(config) {} // Runs the parser. Returns false if an error occurred. @@ -57,14 +59,28 @@ class HloParser { std::unique_ptr<HloModule> ConsumeHloModule() { return std::move(module_); } // Returns the error information. - string GetError() const { return Join(error_, "\n"); } + string GetError() const { return StrJoin(error_, "\n"); } // Stand alone parsing utils for various aggregate data types. StatusOr<HloSharding> ParseShardingOnly(); StatusOr<Window> ParseWindowOnly(); StatusOr<ConvolutionDimensionNumbers> ParseConvolutionDimensionNumbersOnly(); + // Stand-alone parsing utility for a single instruction worth of text. + Status ParseSingleInstruction(HloComputation::Builder* builder, + string* root_name); + private: + // Locates an instruction with the given name in the instruction_pool_ or + // returns nullptr. + // + // If the missing_instruction_hook_ is registered and a "shape" is provided, + // the hook will be called and may satisfy the request for the given + // instruction. This is useful when we reify parameters as they're resolved; + // i.e. for ParseSingleInstruction. + std::pair<HloInstruction*, LocTy>* FindInstruction( + const string& name, const optional<Shape>& shape = nullopt); + // ParseXXX returns false if an error occurred. bool ParseHloModule(); bool ParseComputations(); @@ -138,6 +154,7 @@ class HloParser { kFusionKind, kDistribution, kDomain, + kPrecisionList, }; struct AttrConfig { @@ -203,6 +220,7 @@ class HloParser { bool ParseWindowPad(std::vector<std::vector<tensorflow::int64>>* pad); bool ParseSliceRanges(SliceRanges* result); + bool ParsePrecisionList(std::vector<PrecisionConfigProto::Precision>* result); bool ParseInt64List(const TokKind start, const TokKind end, const TokKind delim, std::vector<tensorflow::int64>* result); @@ -221,6 +239,7 @@ class HloParser { bool ParseFftType(FftType* result); bool ParseFusionKind(HloInstruction::FusionKind* result); bool ParseRandomDistribution(RandomDistribution* result); + bool ParsePrecision(PrecisionConfigProto::Precision* result); bool ParseInt64(tensorflow::int64* result); bool ParseDouble(double* result); bool ParseBool(bool* result); @@ -233,8 +252,8 @@ class HloParser { bool CanBeParamListToShape(); // Logs the current parsing line and the given message. Always returns false. - bool TokenError(StringPiece msg); - bool Error(LocTy loc, StringPiece msg); + bool TokenError(absl::string_view msg); + bool Error(LocTy loc, absl::string_view msg); // If the current token is 'kind', eats it (i.e. lexes the next token) and // returns true. @@ -265,24 +284,55 @@ class HloParser { std::vector<std::unique_ptr<HloComputation>> computations_; const HloModuleConfig config_; std::vector<string> error_; + + // Function that gets invoked when we try to resolve an instruction + // instruction_pool_ but fail to do so. + std::function<std::pair<HloInstruction*, LocTy>*(string, + const optional<Shape>&)> + missing_instruction_hook_; }; -bool HloParser::Error(LocTy loc, StringPiece msg) { +bool SplitToInt64s(absl::string_view s, char delim, std::vector<int64>* out) { + for (const auto& split : absl::StrSplit(s, delim)) { + int64 val; + if (!absl::SimpleAtoi(split, &val)) { + return false; + } + out->push_back(val); + } + return true; +} + +// Creates replica groups from the provided nested array. groups[i] represents +// the replica ids for group 'i'. +std::vector<ReplicaGroup> CreateReplicaGroups( + tensorflow::gtl::ArraySlice<std::vector<int64>> groups) { + std::vector<ReplicaGroup> replica_groups; + absl::c_transform(groups, std::back_inserter(replica_groups), + [](const std::vector<int64>& ids) { + ReplicaGroup group; + *group.mutable_replica_ids() = {ids.begin(), ids.end()}; + return group; + }); + return replica_groups; +} + +bool HloParser::Error(LocTy loc, absl::string_view msg) { auto line_col = lexer_.GetLineAndColumn(loc); const unsigned line = line_col.first; const unsigned col = line_col.second; std::vector<string> error_lines; error_lines.push_back( StrCat("was parsing ", line, ":", col, ": error: ", msg)); - error_lines.push_back(std::string(lexer_.GetLine(loc))); + error_lines.emplace_back(lexer_.GetLine(loc)); error_lines.push_back(col == 0 ? "" : StrCat(string(col - 1, ' '), "^")); - error_.push_back(Join(error_lines, "\n")); + error_.push_back(StrJoin(error_lines, "\n")); VLOG(1) << "Error: " << error_.back(); return false; } -bool HloParser::TokenError(StringPiece msg) { +bool HloParser::TokenError(absl::string_view msg) { return Error(lexer_.GetLoc(), msg); } @@ -291,6 +341,17 @@ bool HloParser::Run() { return ParseHloModule(); } +std::pair<HloInstruction*, HloParser::LocTy>* HloParser::FindInstruction( + const string& name, const optional<Shape>& shape) { + std::pair<HloInstruction*, LocTy>* instr = + tensorflow::gtl::FindOrNull(instruction_pool_, name); + // Potentially call the missing instruction hook. + if (instr == nullptr && missing_instruction_hook_ != nullptr) { + return missing_instruction_hook_(name, shape); + } + return instr; +} + // ::= 'HloModule' name computations bool HloParser::ParseHloModule() { if (lexer_.GetKind() != TokKind::kw_HloModule) { @@ -304,7 +365,7 @@ bool HloParser::ParseHloModule() { return false; } - module_ = MakeUnique<HloModule>(name, config_); + module_ = absl::make_unique<HloModule>(name, config_); return ParseComputations(); } @@ -357,7 +418,7 @@ bool HloParser::ParseComputation(HloComputation** entry_computation) { if (!ParseName(&name)) { return false; } - auto builder = MakeUnique<HloComputation::Builder>(name); + auto builder = absl::make_unique<HloComputation::Builder>(name); LocTy shape_loc = nullptr; Shape shape; @@ -370,8 +431,7 @@ bool HloParser::ParseComputation(HloComputation** entry_computation) { return false; } - std::pair<HloInstruction*, LocTy>* root_node = - tensorflow::gtl::FindOrNull(instruction_pool_, root_name); + std::pair<HloInstruction*, LocTy>* root_node = FindInstruction(root_name); // This means some instruction was marked as ROOT but we didn't find it in the // pool, which should not happen. if (!root_name.empty() && root_node == nullptr) { @@ -469,6 +529,10 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, attrs["backend_config"] = {/*required=*/false, AttrTy::kString, &backend_config}; + optional<std::vector<PrecisionConfigProto::Precision>> operand_precision; + attrs["operand_precision"] = {/*required=*/false, AttrTy::kPrecisionList, + &operand_precision}; + HloInstruction* instruction; switch (opcode) { case HloOpcode::kParameter: { @@ -498,11 +562,15 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, break; } case HloOpcode::kIota: { + optional<tensorflow::int64> iota_dimension; + attrs["iota_dimension"] = {/*required=*/true, AttrTy::kInt64, + &iota_dimension}; if (!ParseOperands(&operands, /*expected_size=*/0) || !ParseAttributes(attrs)) { return false; } - instruction = builder->AddInstruction(HloInstruction::CreateIota(shape)); + instruction = builder->AddInstruction( + HloInstruction::CreateIota(shape, *iota_dimension)); break; } // Unary ops. @@ -597,31 +665,29 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, break; } case HloOpcode::kCrossReplicaSum: { + optional<std::vector<std::vector<int64>>> tmp_groups; optional<HloComputation*> to_apply; optional<std::vector<int64>> replica_group_ids; optional<string> barrier; optional<int64> all_reduce_id; attrs["to_apply"] = {/*required=*/true, AttrTy::kHloComputation, &to_apply}; - attrs["replica_group_ids"] = { - /*required=*/false, AttrTy::kBracedInt64List, &replica_group_ids}; + attrs["replica_groups"] = {/*required=*/false, + AttrTy::kBracedInt64ListList, &tmp_groups}; attrs["barrier"] = {/*required=*/false, AttrTy::kString, &barrier}; attrs["all_reduce_id"] = {/*required=*/false, AttrTy::kInt64, &all_reduce_id}; if (!ParseOperands(&operands) || !ParseAttributes(attrs)) { return false; } - if (replica_group_ids) { - instruction = - builder->AddInstruction(HloInstruction::CreateCrossReplicaSum( - shape, operands, *to_apply, *replica_group_ids, - barrier ? *barrier : "", all_reduce_id)); - } else { - instruction = - builder->AddInstruction(HloInstruction::CreateCrossReplicaSum( - shape, operands, *to_apply, {}, barrier ? *barrier : "", - all_reduce_id)); + std::vector<ReplicaGroup> replica_groups; + if (tmp_groups) { + replica_groups = CreateReplicaGroups(*tmp_groups); } + instruction = + builder->AddInstruction(HloInstruction::CreateCrossReplicaSum( + shape, operands, *to_apply, replica_groups, + barrier ? *barrier : "", all_reduce_id)); break; } case HloOpcode::kAllToAll: { @@ -629,21 +695,36 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, optional<string> barrier; attrs["replica_groups"] = {/*required=*/false, AttrTy::kBracedInt64ListList, &tmp_groups}; - attrs["barrier"] = {/*required=*/false, AttrTy::kString, &barrier}; if (!ParseOperands(&operands) || !ParseAttributes(attrs)) { return false; } std::vector<ReplicaGroup> replica_groups; if (tmp_groups) { - c_transform(*tmp_groups, std::back_inserter(replica_groups), - [](const std::vector<int64>& ids) { - ReplicaGroup group; - *group.mutable_replica_ids() = {ids.begin(), ids.end()}; - return group; - }); + replica_groups = CreateReplicaGroups(*tmp_groups); } - instruction = builder->AddInstruction(HloInstruction::CreateAllToAll( - shape, operands, replica_groups, barrier ? *barrier : "")); + instruction = builder->AddInstruction( + HloInstruction::CreateAllToAll(shape, operands, replica_groups)); + break; + } + case HloOpcode::kCollectivePermute: { + optional<std::vector<std::vector<int64>>> source_targets; + attrs["source_target_pairs"] = { + /*required=*/true, AttrTy::kBracedInt64ListList, &source_targets}; + if (!ParseOperands(&operands, /*expected_size=*/1) || + !ParseAttributes(attrs)) { + return false; + } + std::vector<std::pair<int64, int64>> pairs(source_targets->size()); + for (int i = 0; i < pairs.size(); i++) { + if ((*source_targets)[i].size() != 2) { + return TokenError( + "expects 'source_target_pairs=' to be a list of pairs"); + } + pairs[i].first = (*source_targets)[i][0]; + pairs[i].second = (*source_targets)[i][1]; + } + instruction = builder->AddInstruction( + HloInstruction::CreateCollectivePermute(shape, operands[0], pairs)); break; } case HloOpcode::kReshape: { @@ -1177,20 +1258,6 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, } break; } - case HloOpcode::kHostCompute: { - optional<string> channel_name; - optional<tensorflow::int64> cost_estimate_ns; - attrs["channel_name"] = {/*required=*/true, AttrTy::kString, - &channel_name}; - attrs["cost_estimate_ns"] = {/*required=*/true, AttrTy::kInt64, - &cost_estimate_ns}; - if (!ParseOperands(&operands) || !ParseAttributes(attrs)) { - return false; - } - instruction = builder->AddInstruction(HloInstruction::CreateHostCompute( - shape, operands, *channel_name, *cost_estimate_ns)); - break; - } case HloOpcode::kDot: { optional<std::vector<tensorflow::int64>> lhs_contracting_dims; attrs["lhs_contracting_dims"] = { @@ -1346,6 +1413,12 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, if (backend_config) { instruction->set_raw_backend_config_string(std::move(*backend_config)); } + if (operand_precision) { + PrecisionConfigProto precision_config; + *precision_config.mutable_operand_precision() = {operand_precision->begin(), + operand_precision->end()}; + instruction->set_precision_config(precision_config); + } return AddInstruction(name, instruction, name_loc); } // NOLINT(readability/fn_size) @@ -1509,14 +1582,14 @@ bool HloParser::ParseDomain(DomainData* domain) { return false; } if (*kind == ShardingMetadata::KindName()) { - auto entry_sharding_ptr = MakeUnique<HloSharding>( + auto entry_sharding_ptr = absl::make_unique<HloSharding>( HloSharding::FromProto(*entry_sharding).ValueOrDie()); - auto exit_sharding_ptr = MakeUnique<HloSharding>( + auto exit_sharding_ptr = absl::make_unique<HloSharding>( HloSharding::FromProto(*exit_sharding).ValueOrDie()); domain->entry_metadata = - MakeUnique<ShardingMetadata>(std::move(entry_sharding_ptr)); + absl::make_unique<ShardingMetadata>(std::move(entry_sharding_ptr)); domain->exit_metadata = - MakeUnique<ShardingMetadata>(std::move(exit_sharding_ptr)); + absl::make_unique<ShardingMetadata>(std::move(exit_sharding_ptr)); } else { return TokenError(StrCat("unsupported domain kind: ", *kind)); } @@ -1536,11 +1609,9 @@ bool HloParser::ParseInstructionNames( if (!ParseName(&name)) { return Error(loc, "expects a instruction name"); } - std::pair<HloInstruction*, LocTy>* instr = - tensorflow::gtl::FindOrNull(instruction_pool_, name); + std::pair<HloInstruction*, LocTy>* instr = FindInstruction(name); if (!instr) { - return TokenError( - Printf("instruction '%s' is not defined", name.c_str())); + return TokenError(StrFormat("instruction '%s' is not defined", name)); } instructions->push_back(instr->first); } while (EatIfPresent(TokKind::kComma)); @@ -1769,10 +1840,10 @@ bool HloParser::ParseDenseLiteral(std::unique_ptr<Literal>* literal, std::vector<tensorflow::int64> elems_seen_until_dim( elems_seen_per_dim.begin(), elems_seen_per_dim.begin() + dim); return StrCat("[", - Join(elems_seen_until_dim, ",", - [](string* out, const tensorflow::int64& num_elems) { - StrAppend(out, num_elems - 1); - }), + StrJoin(elems_seen_until_dim, ",", + [](string* out, const tensorflow::int64& num_elems) { + StrAppend(out, num_elems - 1); + }), "]"); }; do { @@ -1782,17 +1853,17 @@ bool HloParser::ParseDenseLiteral(std::unique_ptr<Literal>* literal, case TokKind::kLbrace: { nest_level++; if (nest_level > rank) { - return TokenError(Printf( - "expects nested array in rank %lld, but sees larger", rank)); + return TokenError(absl::StrFormat( + "expects nested array in rank %d, but sees larger", rank)); } if (nest_level > 1) { elems_seen_per_dim[nest_level - 2]++; if (elems_seen_per_dim[nest_level - 2] > shape.dimensions(nest_level - 2)) { - return TokenError(Printf( - "expects %lld elements in the %sth element, but sees more", + return TokenError(absl::StrFormat( + "expects %d elements in the %sth element, but sees more", shape.dimensions(nest_level - 2), - get_index_str(nest_level - 2).c_str())); + get_index_str(nest_level - 2))); } } lexer_.Lex(); @@ -1801,9 +1872,9 @@ bool HloParser::ParseDenseLiteral(std::unique_ptr<Literal>* literal, case TokKind::kRbrace: { nest_level--; if (elems_seen_per_dim[nest_level] != shape.dimensions(nest_level)) { - return TokenError(Printf( - "expects %lld elements in the %sth element, but sees %lld", - shape.dimensions(nest_level), get_index_str(nest_level).c_str(), + return TokenError(absl::StrFormat( + "expects %d elements in the %sth element, but sees %d", + shape.dimensions(nest_level), get_index_str(nest_level), elems_seen_per_dim[nest_level])); } elems_seen_per_dim[nest_level] = 0; @@ -1824,15 +1895,15 @@ bool HloParser::ParseDenseLiteral(std::unique_ptr<Literal>* literal, if (rank > 0) { if (nest_level != rank) { return TokenError( - Printf("expects nested array in rank %lld, but sees %lld", rank, - nest_level)); + absl::StrFormat("expects nested array in rank %d, but sees %d", + rank, nest_level)); } elems_seen_per_dim[rank - 1]++; if (elems_seen_per_dim[rank - 1] > shape.dimensions(rank - 1)) { - return TokenError( - Printf("expects %lld elements on the minor-most dimension, but " - "sees more", - shape.dimensions(rank - 1))); + return TokenError(absl::StrFormat( + "expects %d elements on the minor-most dimension, but " + "sees more", + shape.dimensions(rank - 1))); } } if (lexer_.GetKind() == TokKind::kw_true || @@ -1925,7 +1996,7 @@ bool HloParser::ParseSparseLiteralHelper(std::unique_ptr<Literal>* literal, tensorflow::int64 rank = ShapeUtil::Rank(shape); - *literal = MakeUnique<Literal>(shape); + *literal = absl::make_unique<Literal>(shape); if (!ParseToken(TokKind::kLbrace, "expects '{' at the beginning of a sparse literal")) { @@ -1959,7 +2030,7 @@ bool HloParser::ParseSparseLiteralHelper(std::unique_ptr<Literal>* literal, return Error( index_loc, StrCat("invalid multi-dimension index for shape with rank ", rank, - ": [", Join(index, ", "), "]")); + ": [", StrJoin(index, ", "), "]")); } } if (!ParseToken(TokKind::kColon, @@ -2020,6 +2091,7 @@ bool HloParser::ParseSparseLiteralHelper(std::unique_ptr<Literal>* literal, // ::= operand (, operand)* // operand ::= (shape)? name bool HloParser::ParseOperands(std::vector<HloInstruction*>* operands) { + CHECK(operands != nullptr); if (!ParseToken(TokKind::kLparen, "expects '(' at the beginning of operands")) { return false; @@ -2030,9 +2102,10 @@ bool HloParser::ParseOperands(std::vector<HloInstruction*>* operands) { do { LocTy loc = lexer_.GetLoc(); string name; + optional<Shape> shape; if (CanBeShape()) { - Shape shape; - if (!ParseShape(&shape)) { + shape.emplace(); + if (!ParseShape(&shape.value())) { return false; } } @@ -2040,8 +2113,8 @@ bool HloParser::ParseOperands(std::vector<HloInstruction*>* operands) { return false; } std::pair<HloInstruction*, LocTy>* instruction = - tensorflow::gtl::FindOrNull(instruction_pool_, name); - if (!instruction) { + FindInstruction(name, shape); + if (instruction == nullptr) { return Error(loc, StrCat("instruction does not exist: ", name)); } operands->push_back(instruction->first); @@ -2052,6 +2125,7 @@ bool HloParser::ParseOperands(std::vector<HloInstruction*>* operands) { bool HloParser::ParseOperands(std::vector<HloInstruction*>* operands, const int expected_size) { + CHECK(operands != nullptr); LocTy loc = lexer_.GetLoc(); if (!ParseOperands(operands)) { return false; @@ -2085,8 +2159,8 @@ bool HloParser::ParseSubAttributes( for (const auto& attr_it : attrs) { if (attr_it.second.required && seen_attrs.find(attr_it.first) == seen_attrs.end()) { - return Error(loc, Printf("sub-attribute %s is expected but not seen", - attr_it.first.c_str())); + return Error(loc, StrFormat("sub-attribute %s is expected but not seen", + attr_it.first)); } } return ParseToken(TokKind::kRbrace, "expects '}' to end sub attributes"); @@ -2106,8 +2180,8 @@ bool HloParser::ParseAttributes( for (const auto& attr_it : attrs) { if (attr_it.second.required && seen_attrs.find(attr_it.first) == seen_attrs.end()) { - return Error(loc, Printf("attribute %s is expected but not seen", - attr_it.first.c_str())); + return Error(loc, StrFormat("attribute %s is expected but not seen", + attr_it.first)); } } return true; @@ -2123,7 +2197,7 @@ bool HloParser::ParseAttributeHelper( } VLOG(1) << "Parsing attribute " << name; if (!seen_attrs->insert(name).second) { - return Error(loc, Printf("attribute %s already exists", name.c_str())); + return Error(loc, StrFormat("attribute %s already exists", name)); } auto attr_it = attrs.find(name); if (attr_it == attrs.end()) { @@ -2133,13 +2207,13 @@ bool HloParser::ParseAttributeHelper( } else { allowed_attrs = StrCat( "Allowed attributes: ", - Join(attrs, ", ", - [&](string* out, const std::pair<string, AttrConfig>& kv) { - StrAppend(out, kv.first); - })); + StrJoin(attrs, ", ", + [&](string* out, const std::pair<string, AttrConfig>& kv) { + StrAppend(out, kv.first); + })); } - return Error(loc, Printf("unexpected attribute \"%s\". %s", name.c_str(), - allowed_attrs.c_str())); + return Error(loc, StrFormat("unexpected attribute \"%s\". %s", name, + allowed_attrs)); } AttrTy attr_type = attr_it->second.attr_type; void* attr_out_ptr = attr_it->second.result; @@ -2321,10 +2395,20 @@ bool HloParser::ParseAttributeHelper( case AttrTy::kDomain: { return ParseDomain(static_cast<DomainData*>(attr_out_ptr)); } + case AttrTy::kPrecisionList: { + std::vector<PrecisionConfigProto::Precision> result; + if (!ParsePrecisionList(&result)) { + return false; + } + static_cast<optional<std::vector<PrecisionConfigProto::Precision>>*>( + attr_out_ptr) + ->emplace(result); + return true; + } } }(); if (!success) { - return Error(loc, Printf("error parsing attribute %s", name.c_str())); + return Error(loc, StrFormat("error parsing attribute %s", name)); } return true; } @@ -2439,20 +2523,24 @@ bool HloParser::ParseConvolutionDimensionNumbers( } string str = lexer_.GetStrVal(); - // The str is expected to have 3 items, lhs, rhs, out, and it must looks like + // The str is expected to have 3 items, lhs, rhs, out, and it must look like // lhs_rhs->out, that is, the first separator is "_" and the second is "->". - // So we replace the "->" with "_" and then split on "_". - str = tensorflow::str_util::StringReplace(str, /*oldsub=*/"->", - /*newsub=*/"_", - /*replace_all=*/false); - std::vector<string> lhs_rhs_out = Split(str, "_"); - if (lhs_rhs_out.size() != 3) { + std::vector<string> split1 = absl::StrSplit(str, "_"); + if (split1.size() != 2) { + LOG(FATAL) << "expects 3 items: lhs, rhs, and output dims, but sees " + << str; + } + std::vector<string> split2 = absl::StrSplit(split1[1], "->"); + if (split2.size() != 2) { LOG(FATAL) << "expects 3 items: lhs, rhs, and output dims, but sees " << str; } + absl::string_view lhs = split1[0]; + absl::string_view rhs = split2[0]; + absl::string_view out = split2[1]; - const tensorflow::int64 rank = lhs_rhs_out[0].length(); - if (rank != lhs_rhs_out[1].length() || rank != lhs_rhs_out[2].length()) { + const tensorflow::int64 rank = lhs.length(); + if (rank != rhs.length() || rank != out.length()) { return TokenError( "convolution lhs, rhs, and output must have the same rank"); } @@ -2467,8 +2555,7 @@ bool HloParser::ParseConvolutionDimensionNumbers( // lhs { - const string& lhs = lhs_rhs_out[0]; - if (!is_unique(lhs)) { + if (!is_unique(string(lhs))) { return TokenError( StrCat("expects unique lhs dimension numbers, but sees ", lhs)); } @@ -2485,14 +2572,13 @@ bool HloParser::ParseConvolutionDimensionNumbers( dnums->set_input_spatial_dimensions(c - '0', i); } else { return TokenError( - Printf("expects [0-%lldbf] in lhs dimension numbers", rank - 1)); + StrFormat("expects [0-%dbf] in lhs dimension numbers", rank - 1)); } } } // rhs { - const string& rhs = lhs_rhs_out[1]; - if (!is_unique(rhs)) { + if (!is_unique(string(rhs))) { return TokenError( StrCat("expects unique rhs dimension numbers, but sees ", rhs)); } @@ -2509,14 +2595,13 @@ bool HloParser::ParseConvolutionDimensionNumbers( dnums->set_kernel_spatial_dimensions(c - '0', i); } else { return TokenError( - Printf("expects [0-%lldio] in rhs dimension numbers", rank - 1)); + StrFormat("expects [0-%dio] in rhs dimension numbers", rank - 1)); } } } // output { - const string& out = lhs_rhs_out[2]; - if (!is_unique(out)) { + if (!is_unique(string(out))) { return TokenError( StrCat("expects unique output dimension numbers, but sees ", out)); } @@ -2532,8 +2617,8 @@ bool HloParser::ParseConvolutionDimensionNumbers( } else if (c < '0' + rank && c >= '0') { dnums->set_output_spatial_dimensions(c - '0', i); } else { - return TokenError( - Printf("expects [0-%lldbf] in output dimension numbers", rank - 1)); + return TokenError(StrFormat( + "expects [0-%dbf] in output dimension numbers", rank - 1)); } } } @@ -2579,9 +2664,10 @@ bool HloParser::ParseSliceRanges(SliceRanges* result) { } const auto& range = ranges.back(); if (range.size() != 2 && range.size() != 3) { - return Error(loc, Printf("expects [start:limit:step] or [start:limit], " - "but sees %ld elements.", - range.size())); + return Error(loc, + StrFormat("expects [start:limit:step] or [start:limit], " + "but sees %d elements.", + range.size())); } } while (EatIfPresent(TokKind::kComma)); @@ -2593,6 +2679,24 @@ bool HloParser::ParseSliceRanges(SliceRanges* result) { return ParseToken(TokKind::kRbrace, "expects '}' to end ranges"); } +// precisionlist ::= start precision_elements end +// precision_elements +// ::= /*empty*/ +// ::= precision_val (delim precision_val)* +bool HloParser::ParsePrecisionList( + std::vector<PrecisionConfigProto::Precision>* result) { + auto parse_and_add_item = [&]() { + PrecisionConfigProto::Precision item; + if (!ParsePrecision(&item)) { + return false; + } + result->push_back(item); + return true; + }; + return ParseList(TokKind::kLbrace, TokKind::kRbrace, TokKind::kComma, + parse_and_add_item); +} + // int64list ::= start int64_elements end // int64_elements // ::= /*empty*/ @@ -2749,14 +2853,13 @@ bool HloParser::ParseDxD(const string& name, std::vector<tensorflow::int64>* result) { LocTy loc = lexer_.GetLoc(); if (!result->empty()) { - return Error(loc, - Printf("sub-attribute '%s=' already exists", name.c_str())); + return Error(loc, StrFormat("sub-attribute '%s=' already exists", name)); } // 1D if (lexer_.GetKind() == TokKind::kInt) { tensorflow::int64 number; if (!ParseInt64(&number)) { - return Error(loc, Printf("expects sub-attribute '%s=i'", name.c_str())); + return Error(loc, StrFormat("expects sub-attribute '%s=i'", name)); } result->push_back(number); return true; @@ -2764,9 +2867,8 @@ bool HloParser::ParseDxD(const string& name, // 2D or higher. if (lexer_.GetKind() == TokKind::kDxD) { string str = lexer_.GetStrVal(); - if (!SplitAndParseAsInts(str, 'x', result)) { - return Error(loc, - Printf("expects sub-attribute '%s=ixj...'", name.c_str())); + if (!SplitToInt64s(str, 'x', result)) { + return Error(loc, StrFormat("expects sub-attribute '%s=ixj...'", name)); } lexer_.Lex(); return true; @@ -2784,10 +2886,9 @@ bool HloParser::ParseWindowPad( return TokenError("expects window pad pattern, e.g., '0_0x3_3'"); } string str = lexer_.GetStrVal(); - std::vector<string> padding_str = Split(str, 'x'); - for (int i = 0; i < padding_str.size(); i++) { + for (const auto& padding_dim_str : absl::StrSplit(str, 'x')) { std::vector<tensorflow::int64> low_high; - if (!SplitAndParseAsInts(padding_str[i], '_', &low_high) || + if (!SplitToInt64s(padding_dim_str, '_', &low_high) || low_high.size() != 2) { return Error(loc, "expects padding_low and padding_high separated by '_'"); @@ -2808,10 +2909,9 @@ bool HloParser::ParsePaddingConfig(PaddingConfig* padding) { } LocTy loc = lexer_.GetLoc(); string str = lexer_.GetStrVal(); - std::vector<string> padding_str = Split(str, 'x'); - for (const auto& padding_dim_str : padding_str) { + for (const auto& padding_dim_str : absl::StrSplit(str, 'x')) { std::vector<tensorflow::int64> padding_dim; - if (!SplitAndParseAsInts(padding_dim_str, '_', &padding_dim) || + if (!SplitToInt64s(padding_dim_str, '_', &padding_dim) || (padding_dim.size() != 2 && padding_dim.size() != 3)) { return Error(loc, "expects padding config pattern like 'low_high_interior' or " @@ -2863,9 +2963,8 @@ bool HloParser::ParseOpcode(HloOpcode* result) { string val = lexer_.GetStrVal(); auto status_or_result = StringToHloOpcode(val); if (!status_or_result.ok()) { - return TokenError( - Printf("expects opcode but sees: %s, error: %s", val.c_str(), - status_or_result.status().error_message().c_str())); + return TokenError(StrFormat("expects opcode but sees: %s, error: %s", val, + status_or_result.status().error_message())); } *result = status_or_result.ValueOrDie(); lexer_.Lex(); @@ -2879,7 +2978,7 @@ bool HloParser::ParseFftType(FftType* result) { } string val = lexer_.GetStrVal(); if (!FftType_Parse(val, result) || !FftType_IsValid(*result)) { - return TokenError(Printf("expects fft type but sees: %s", val.c_str())); + return TokenError(StrFormat("expects fft type but sees: %s", val)); } lexer_.Lex(); return true; @@ -2893,9 +2992,9 @@ bool HloParser::ParseFusionKind(HloInstruction::FusionKind* result) { string val = lexer_.GetStrVal(); auto status_or_result = StringToFusionKind(val); if (!status_or_result.ok()) { - return TokenError( - Printf("expects fusion kind but sees: %s, error: %s", val.c_str(), - status_or_result.status().error_message().c_str())); + return TokenError(StrFormat("expects fusion kind but sees: %s, error: %s", + val, + status_or_result.status().error_message())); } *result = status_or_result.ValueOrDie(); lexer_.Lex(); @@ -2911,8 +3010,25 @@ bool HloParser::ParseRandomDistribution(RandomDistribution* result) { auto status_or_result = StringToRandomDistribution(val); if (!status_or_result.ok()) { return TokenError( - Printf("expects random distribution but sees: %s, error: %s", - val.c_str(), status_or_result.status().error_message().c_str())); + StrFormat("expects random distribution but sees: %s, error: %s", val, + status_or_result.status().error_message())); + } + *result = status_or_result.ValueOrDie(); + lexer_.Lex(); + return true; +} + +bool HloParser::ParsePrecision(PrecisionConfigProto::Precision* result) { + VLOG(1) << "ParsePrecision"; + if (lexer_.GetKind() != TokKind::kIdent) { + return TokenError("expects random distribution"); + } + string val = lexer_.GetStrVal(); + auto status_or_result = StringToPrecision(val); + if (!status_or_result.ok()) { + return TokenError(StrFormat("expects precision but sees: %s, error: %s", + val, + status_or_result.status().error_message())); } *result = status_or_result.ValueOrDie(); lexer_.Lex(); @@ -3006,7 +3122,7 @@ StatusOr<HloSharding> HloParser::ParseShardingOnly() { lexer_.Lex(); OpSharding op_sharding; if (!ParseSharding(&op_sharding)) { - return InvalidArgument("Syntax error:\n%s", GetError().c_str()); + return InvalidArgument("Syntax error:\n%s", GetError()); } if (lexer_.GetKind() != TokKind::kEof) { return InvalidArgument("Syntax error:\nExtra content after sharding"); @@ -3018,7 +3134,7 @@ StatusOr<Window> HloParser::ParseWindowOnly() { lexer_.Lex(); Window window; if (!ParseWindow(&window, /*expect_outer_curlies=*/false)) { - return InvalidArgument("Syntax error:\n%s", GetError().c_str()); + return InvalidArgument("Syntax error:\n%s", GetError()); } if (lexer_.GetKind() != TokKind::kEof) { return InvalidArgument("Syntax error:\nExtra content after window"); @@ -3031,7 +3147,7 @@ HloParser::ParseConvolutionDimensionNumbersOnly() { lexer_.Lex(); ConvolutionDimensionNumbers dnums; if (!ParseConvolutionDimensionNumbers(&dnums)) { - return InvalidArgument("Syntax error:\n%s", GetError().c_str()); + return InvalidArgument("Syntax error:\n%s", GetError()); } if (lexer_.GetKind() != TokKind::kEof) { return InvalidArgument( @@ -3040,37 +3156,83 @@ HloParser::ParseConvolutionDimensionNumbersOnly() { return dnums; } +Status HloParser::ParseSingleInstruction(HloComputation::Builder* builder, + string* root_name) { + TF_RET_CHECK(missing_instruction_hook_ == nullptr); + + // The missing instruction hook we register creates the shaped instruction on + // the fly as a parameter and returns it. + int64 parameter_count = 0; + missing_instruction_hook_ = + [this, builder, ¶meter_count]( + string name, + const optional<Shape>& shape) -> std::pair<HloInstruction*, LocTy>* { + if (!shape.has_value()) { + Error(lexer_.GetLoc(), + StrCat("Operand ", name, + " had no shape in HLO text; cannot create parameter for " + "single-instruction module.")); + return nullptr; + } + HloInstruction* parameter = builder->AddInstruction( + HloInstruction::CreateParameter(parameter_count++, *shape, name)); + instruction_pool_[name] = {parameter, lexer_.GetLoc()}; + return tensorflow::gtl::FindOrNull(instruction_pool_, name); + }; + + // Prime the lexer. + lexer_.Lex(); + + // Parse the instruction with the registered hook. + if (!ParseInstruction(builder, root_name)) { + return InvalidArgument("Syntax error:\n%s", GetError()); + } + return Status::OK(); +} + } // namespace StatusOr<std::unique_ptr<HloModule>> ParseHloString( - tensorflow::StringPiece str, const HloModuleConfig& config) { + absl::string_view str, const HloModuleConfig& config) { HloParser parser(str, config); if (!parser.Run()) { - return InvalidArgument("Syntax error:\n%s", parser.GetError().c_str()); + return InvalidArgument("Syntax error:\n%s", parser.GetError()); } return parser.ConsumeHloModule(); } -StatusOr<std::unique_ptr<HloModule>> ParseHloString( - tensorflow::StringPiece str) { +StatusOr<std::unique_ptr<HloModule>> ParseHloString(absl::string_view str) { HloModuleConfig config; return ParseHloString(str, config); } -StatusOr<HloSharding> ParseSharding(tensorflow::StringPiece str) { +StatusOr<std::unique_ptr<HloModule>> ParseHloOpToModule( + absl::string_view str, absl::string_view name) { + HloModuleConfig config; + HloParser parser(str, config); + auto builder = absl::make_unique<HloComputation::Builder>(string(name)); + string root_name; + TF_RETURN_IF_ERROR(parser.ParseSingleInstruction(builder.get(), &root_name)); + std::unique_ptr<HloComputation> computation = builder->Build(); + auto module = absl::make_unique<HloModule>(string(name), config); + module->AddEntryComputation(std::move(computation)); + return std::move(module); +} + +StatusOr<HloSharding> ParseSharding(absl::string_view str) { HloModuleConfig config; HloParser parser(str, config); return parser.ParseShardingOnly(); } -StatusOr<Window> ParseWindow(tensorflow::StringPiece str) { +StatusOr<Window> ParseWindow(absl::string_view str) { HloModuleConfig config; HloParser parser(str, config); return parser.ParseWindowOnly(); } StatusOr<ConvolutionDimensionNumbers> ParseConvolutionDimensionNumbers( - tensorflow::StringPiece str) { + absl::string_view str) { HloModuleConfig config; HloParser parser(str, config); return parser.ParseConvolutionDimensionNumbersOnly(); diff --git a/tensorflow/compiler/xla/service/hlo_parser.h b/tensorflow/compiler/xla/service/hlo_parser.h index 3f3a51215e..0c64b50481 100644 --- a/tensorflow/compiler/xla/service/hlo_parser.h +++ b/tensorflow/compiler/xla/service/hlo_parser.h @@ -16,7 +16,8 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_HLO_PARSER_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_HLO_PARSER_H_ -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_lexer.h" @@ -32,27 +33,31 @@ namespace xla { // The api of the hlo parser. Given a string in the HloModule::ToString() // format, parses the string and creates a HloModule with the given config. StatusOr<std::unique_ptr<HloModule>> ParseHloString( - tensorflow::StringPiece str, const HloModuleConfig& config); + absl::string_view str, const HloModuleConfig& config); + +// Parses the text for a single HLO operation into an HLO module with a function +// that runs that operation (with the same parameters) as its entry computation. +StatusOr<std::unique_ptr<HloModule>> ParseHloOpToModule( + absl::string_view str, absl::string_view name = "single_op"); // The api of the hlo parser. Given a string in the HloModule::ToString() // format, parses the string and creates a HloModule with default config. -StatusOr<std::unique_ptr<HloModule>> ParseHloString( - tensorflow::StringPiece str); +StatusOr<std::unique_ptr<HloModule>> ParseHloString(absl::string_view str); // Parses the result of HloSharding::ToString(), e.g. "{replicated}". -StatusOr<HloSharding> ParseSharding(tensorflow::StringPiece str); +StatusOr<HloSharding> ParseSharding(absl::string_view str); // Parses the result of window_util::ToString(const Window&). -StatusOr<Window> ParseWindow(tensorflow::StringPiece str); +StatusOr<Window> ParseWindow(absl::string_view str); // Parses the result of ConvolutionDimensionNumbersToString(), e.g. // "b0f_0io->b0f". StatusOr<ConvolutionDimensionNumbers> ParseConvolutionDimensionNumbers( - tensorflow::StringPiece str); + absl::string_view str); // ParseHloString sharding from str. str is supposed to contain the body of the // sharding, i.e. just the rhs of the "sharding={...}" attribute string. -StatusOr<HloSharding> ParseSharding(tensorflow::StringPiece str); +StatusOr<HloSharding> ParseSharding(absl::string_view str); } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_parser_test.cc b/tensorflow/compiler/xla/service/hlo_parser_test.cc index 0d7919346b..ba07ec432e 100644 --- a/tensorflow/compiler/xla/service/hlo_parser_test.cc +++ b/tensorflow/compiler/xla/service/hlo_parser_test.cc @@ -16,17 +16,19 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_parser.h" #include <string> +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" +#include "tensorflow/compiler/xla/service/hlo_matchers.h" #include "tensorflow/compiler/xla/window_util.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/test.h" namespace xla { - namespace { -using ::tensorflow::StringPiece; +namespace op = ::xla::testing::opcode_matchers; +using absl::string_view; struct TestData { string test_name; @@ -1049,7 +1051,7 @@ add { ENTRY CRS { input = f32[8]{0} parameter(0) - ROOT crs = f32[8]{0} cross-replica-sum(input), replica_group_ids={}, to_apply=add + ROOT crs = f32[8]{0} cross-replica-sum(input), replica_groups={}, to_apply=add } )" @@ -1067,7 +1069,7 @@ add { ENTRY CrossReplicaSumWithSubgroups { input = f32[128,32]{0,1} parameter(0) - ROOT cross-replica-sum = f32[128,32]{0,1} cross-replica-sum(input), replica_group_ids={0,0,1,1}, barrier="abc", to_apply=add + ROOT cross-replica-sum = f32[128,32]{0,1} cross-replica-sum(input), replica_groups={{0,1},{2,3}}, barrier="abc", to_apply=add } )" @@ -1091,7 +1093,19 @@ R"(HloModule AllToAllWithSubgroups ENTRY AllToAllWithSubgroups { input = f32[128,32]{0,1} parameter(0) - ROOT a2a = f32[128,32]{0,1} all-to-all(input), replica_groups={{1,2},{3,0}}, barrier="abc" + ROOT a2a = f32[128,32]{0,1} all-to-all(input), replica_groups={{1,2},{3,0}} +} + +)" +}, +// collective-permute +{ +"CollectivePermute", +R"(HloModule CollectivePermute + +ENTRY CollectivePermute { + input = f32[128,32]{0,1} parameter(0) + ROOT root = f32[128,32]{0,1} collective-permute(input), source_target_pairs={{0,1},{1,2},{2,3}} } )" @@ -1102,7 +1116,7 @@ ENTRY AllToAllWithSubgroups { R"(HloModule iota ENTRY Iota { - ROOT iota = f32[100]{0} iota() + ROOT iota = f32[100]{0} iota(), iota_dimension=0 } )" @@ -1125,8 +1139,8 @@ ENTRY Computation { class HloParserTest : public ::testing::Test, public ::testing::WithParamInterface<TestData> { protected: - static void ExpectHasSubstr(StringPiece s, StringPiece expected) { - EXPECT_TRUE(tensorflow::str_util::StrContains(s, expected)) + static void ExpectHasSubstr(string_view s, string_view expected) { + EXPECT_TRUE(absl::StrContains(s, expected)) << "'" << s << "' does not contain '" << expected << "'"; } @@ -1390,15 +1404,14 @@ ENTRY %Convolve1D1Window_0.v3 (input: f32[1,2,1], filter: f32[1,1,1]) -> f32[1,2 )"; - ExpectHasSubstr(ParseHloString(tensorflow::strings::StrCat( - prefix, ",dim_labels=00_01_10", suffix)) - .status() - .error_message(), - "expects dim labels pattern"); + ExpectHasSubstr( + ParseHloString(absl::StrCat(prefix, ",dim_labels=00_01_10", suffix)) + .status() + .error_message(), + "expects dim labels pattern"); ExpectHasSubstr( - ParseHloString(tensorflow::strings::StrCat( - prefix, ",dim_labels=010_1100->010", suffix)) + ParseHloString(absl::StrCat(prefix, ",dim_labels=010_1100->010", suffix)) .status() .error_message(), "must have the same rank"); @@ -1722,5 +1735,26 @@ ENTRY nontuple_infeed { "infeed must have a non-empty tuple shape"); } +TEST(HloParserSingleOpTest, SingleOp) { + const string text = + "%multiply = f32[2,4]{1,0} multiply(f32[2,4]{1,0} %broadcast, " + "f32[2,4]{1,0} %x)"; + TF_ASSERT_OK_AND_ASSIGN(auto module, ParseHloOpToModule(text)); + const HloComputation* computation = module->entry_computation(); + ASSERT_NE(computation, nullptr); + EXPECT_THAT(computation->root_instruction(), + op::Multiply(op::Parameter(0), op::Parameter(1))); +} + +TEST(HloParserSingleOpTest, SingleOpNoShapesProducesError) { + const string text = "%multiply = f32[2,4]{1,0} multiply(%broadcast, %x)"; + StatusOr<std::unique_ptr<HloModule>> module = ParseHloOpToModule(text); + ASSERT_TRUE(!module.status().ok()); + LOG(INFO) << "Status: " << module.status(); + EXPECT_THAT( + module.status().ToString(), + ::testing::HasSubstr("Operand broadcast had no shape in HLO text")); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_pass_interface.h b/tensorflow/compiler/xla/service/hlo_pass_interface.h index 0cddf8fb8f..f1ad0f9b01 100644 --- a/tensorflow/compiler/xla/service/hlo_pass_interface.h +++ b/tensorflow/compiler/xla/service/hlo_pass_interface.h @@ -29,7 +29,7 @@ namespace xla { class HloPassInterface { public: virtual ~HloPassInterface() = default; - virtual tensorflow::StringPiece name() const = 0; + virtual absl::string_view name() const = 0; // Run the pass on the given HLO module. Return whether it modified the // module. diff --git a/tensorflow/compiler/xla/service/hlo_pass_pipeline.cc b/tensorflow/compiler/xla/service/hlo_pass_pipeline.cc index d8f1ab916b..6e4ed0de62 100644 --- a/tensorflow/compiler/xla/service/hlo_pass_pipeline.cc +++ b/tensorflow/compiler/xla/service/hlo_pass_pipeline.cc @@ -17,22 +17,23 @@ limitations under the License. #include <functional> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/hlo_graph_dumper.h" #include "tensorflow/compiler/xla/service/hlo_proto_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; - namespace xla { - namespace { + +using absl::StrAppend; +using absl::StrCat; + void DumpModuleGraph(const HloModule& module, const string& message) { hlo_graph_dumper::MaybeDumpHloModule(module, message); VLOG(3) << "HLO " << message << ":"; @@ -48,9 +49,9 @@ void DumpModuleProto(const HloModule& module, const string& dump_to, tensorflow::mutex_lock lock(mu); const int64 pass_number = (*module_id_to_pass_number)[module.unique_id()]++; - const string mod_name = SanitizeFileName(tensorflow::strings::Printf( - "module_%04d.%04lld.%s.after_%s", module.unique_id(), pass_number, - pipeline_name.c_str(), pass_name.c_str())); + const string mod_name = SanitizeFileName( + absl::StrFormat("module_%04d.%04d.%s.after_%s", module.unique_id(), + pass_number, pipeline_name, pass_name)); TF_QCHECK_OK(protobuf_util::DumpProtoToDirectory(MakeHloProto(module), dump_to, mod_name)); @@ -68,7 +69,7 @@ StatusOr<bool> HloPassPipeline::Run(HloModule* module) { repeated_field.end()); if (!disabled_passes.empty()) { VLOG(1) << "Passes disabled by --xla_disable_hlo_passes: " - << tensorflow::str_util::Join(disabled_passes, ", "); + << absl::StrJoin(disabled_passes, ", "); } auto run_invariant_checkers = [this, @@ -90,7 +91,7 @@ StatusOr<bool> HloPassPipeline::Run(HloModule* module) { return Status::OK(); }; - string prefix = std::string(name()) + ": pipeline start"; + string prefix = StrCat(name(), ": pipeline start"); bool changed = false; string message; TF_RETURN_IF_ERROR( @@ -98,12 +99,12 @@ StatusOr<bool> HloPassPipeline::Run(HloModule* module) { const string xla_dump_per_pass_hlo_proto_to = module->config().debug_options().xla_dump_per_pass_hlo_proto_to(); if (!xla_dump_per_pass_hlo_proto_to.empty()) { - DumpModuleProto(*module, xla_dump_per_pass_hlo_proto_to, - std::string(name()), "pipeline_start"); + DumpModuleProto(*module, xla_dump_per_pass_hlo_proto_to, string(name()), + "pipeline_start"); } for (auto& pass : passes_) { - if (disabled_passes.count(std::string(pass->name())) > 0) { + if (disabled_passes.count(string(pass->name())) > 0) { VLOG(1) << " Skipping HLO pass " << pass->name() << ", disabled by --xla_disable_hlo_passes"; continue; @@ -120,8 +121,8 @@ StatusOr<bool> HloPassPipeline::Run(HloModule* module) { TF_RETURN_IF_ERROR( run_invariant_checkers(StrCat("after running pass: ", pass->name()))); if (!xla_dump_per_pass_hlo_proto_to.empty()) { - DumpModuleProto(*module, xla_dump_per_pass_hlo_proto_to, - std::string(name()), std::string(pass->name())); + DumpModuleProto(*module, xla_dump_per_pass_hlo_proto_to, string(name()), + string(pass->name())); } changed |= changed_this_pass; diff --git a/tensorflow/compiler/xla/service/hlo_pass_pipeline.h b/tensorflow/compiler/xla/service/hlo_pass_pipeline.h index a42d7e59fe..1d41a4dac1 100644 --- a/tensorflow/compiler/xla/service/hlo_pass_pipeline.h +++ b/tensorflow/compiler/xla/service/hlo_pass_pipeline.h @@ -21,7 +21,7 @@ limitations under the License. #include <string> #include <vector> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/hlo_pass_interface.h" #include "tensorflow/compiler/xla/statusor.h" @@ -34,7 +34,7 @@ namespace xla { class HloPassPipeline : public HloPassInterface { public: explicit HloPassPipeline(const string& name) : name_(name) {} - tensorflow::StringPiece name() const override { return name_; } + absl::string_view name() const override { return name_; } // Add a pass to the pipeline. It should be called with the arguments for the // pass constructor: diff --git a/tensorflow/compiler/xla/service/hlo_proto_util_test.cc b/tensorflow/compiler/xla/service/hlo_proto_util_test.cc index b9cca13870..c3cacd7ce6 100644 --- a/tensorflow/compiler/xla/service/hlo_proto_util_test.cc +++ b/tensorflow/compiler/xla/service/hlo_proto_util_test.cc @@ -22,7 +22,6 @@ limitations under the License. #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/tests/hlo_test_base.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace xla { namespace { diff --git a/tensorflow/compiler/xla/service/hlo_rematerialization.cc b/tensorflow/compiler/xla/service/hlo_rematerialization.cc index cf0be30c7a..569d2e5d2d 100644 --- a/tensorflow/compiler/xla/service/hlo_rematerialization.cc +++ b/tensorflow/compiler/xla/service/hlo_rematerialization.cc @@ -20,6 +20,10 @@ limitations under the License. #include <set> #include <string> +#include "absl/container/inlined_vector.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/primitive_util.h" #include "tensorflow/compiler/xla/service/buffer_value.h" @@ -37,17 +41,13 @@ limitations under the License. #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" -using ::tensorflow::strings::HumanReadableNumBytes; - namespace xla { - namespace { +using ::tensorflow::strings::HumanReadableNumBytes; + // Potential optimizations: // . TODO(b/35244891): Avoid N^2 behavior by keeping a priority queue // of candidates. @@ -88,7 +88,7 @@ bool CanBeRematerialized( // Type holding a unique identifier for each Buffer object. using BufferId = int64; -using BufferIdList = tensorflow::gtl::InlinedVector<BufferId, 3>; +using BufferIdList = absl::InlinedVector<BufferId, 3>; // We wrap HloInstruction* with an Item that holds auxiliary // per-instruction state. @@ -123,7 +123,7 @@ struct Item { int64 position; }; -using ItemList = tensorflow::gtl::InlinedVector<Item*, 3>; +using ItemList = absl::InlinedVector<Item*, 3>; // Class which maintains an ordered list of instructions with fast insertion // before arbitrary elements. @@ -206,11 +206,10 @@ class InstructionList { Item* to_insert, tensorflow::gtl::ArraySlice<Item*> before_instructions) { VLOG(3) << "InsertBeforeInstructions: " << to_insert->instruction->name() << " before {" - << tensorflow::str_util::Join(before_instructions, ", ", - [](string* out, Item* item) { - tensorflow::strings::StrAppend( - out, item->instruction->name()); - }) + << absl::StrJoin(before_instructions, ", ", + [](string* out, Item* item) { + absl::StrAppend(out, item->instruction->name()); + }) << "}"; // Find the minimal position number of any instruction in @@ -393,10 +392,9 @@ class MemoryUsageTracker { int64 unfinished_user_count; string ToString() const { - return tensorflow::strings::StrCat( - "Buffer ", id, " (defined by ", - defining_instruction->instruction->name(), ", size ", size, - " bytes)"); + return absl::StrCat("Buffer ", id, " (defined by ", + defining_instruction->instruction->name(), ", size ", + size, " bytes)"); } }; @@ -740,29 +738,27 @@ Status MemoryUsageTracker::AddRematerializedInstruction(Item* original_item, } string MemoryUsageTracker::ToString() const { - string output = tensorflow::strings::StrCat("MemoryUsageTracker for ", - computation_->name(), "\n"); - tensorflow::strings::StrAppend( - &output, "Memory usage: ", HumanReadableNumBytes(memory_usage()), " (", - memory_usage(), " bytes)"); + string output = + absl::StrCat("MemoryUsageTracker for ", computation_->name(), "\n"); + absl::StrAppend(&output, + "Memory usage: ", HumanReadableNumBytes(memory_usage()), " (", + memory_usage(), " bytes)"); for (auto* item = instruction_list_.first(); item != nullptr; item = instruction_list_.next(item)) { const HloInstruction* instruction = item->instruction; string inprogress = item == in_progress_item_ ? " in-progress" : ""; string placed = item->placed ? " placed" : ""; - tensorflow::strings::StrAppend(&output, " ", instruction->name(), - inprogress, placed, "\n Defines:\n"); + absl::StrAppend(&output, " ", instruction->name(), inprogress, placed, + "\n Defines:\n"); for (BufferId buffer_id : item->buffers_defined) { const Buffer& buffer = buffers_[buffer_id]; string live = IsCurrentlyLive(buffer_id) ? " live" : ""; - tensorflow::strings::StrAppend(&output, " ", buffer.ToString(), live, - ", ", buffer.unfinished_user_count, - " unfinished uses\n"); + absl::StrAppend(&output, " ", buffer.ToString(), live, ", ", + buffer.unfinished_user_count, " unfinished uses\n"); } - tensorflow::strings::StrAppend(&output, " Uses:\n"); + absl::StrAppend(&output, " Uses:\n"); for (BufferId buffer_id : item->buffers_used) { - tensorflow::strings::StrAppend(&output, " ", - buffers_[buffer_id].ToString(), "\n"); + absl::StrAppend(&output, " ", buffers_[buffer_id].ToString(), "\n"); } } return output; @@ -780,10 +776,9 @@ bool MemoryUsageTracker::Check() const { CHECK(elements_are_unique(defined_buffers)) << "Instruction " << instruction->name() << " does not have unique defined buffers: " - << tensorflow::str_util::Join( + << absl::StrJoin( defined_buffers, ", ", [this](string* out, BufferId buffer_id) { - tensorflow::strings::StrAppend( - out, buffers_.at(buffer_id).ToString()); + absl::StrAppend(out, buffers_.at(buffer_id).ToString()); }); for (const Buffer& buffer : buffers_) { @@ -803,10 +798,9 @@ bool MemoryUsageTracker::Check() const { CHECK(elements_are_unique(used_buffers)) << "Instruction " << instruction->name() << " does not have unique used buffers: " - << tensorflow::str_util::Join( + << absl::StrJoin( used_buffers, ", ", [this](string* out, BufferId buffer_id) { - tensorflow::strings::StrAppend( - out, buffers_.at(buffer_id).ToString()); + absl::StrAppend(out, buffers_.at(buffer_id).ToString()); }); } for (const Buffer& buffer : buffers_) { @@ -1209,6 +1203,49 @@ StatusOr<bool> HloRematerialization::Run( VLOG(1) << "HloRematerialization() with memory limit of " << HumanReadableNumBytes(memory_limit_bytes); + XLA_VLOG_LINES(3, "Before HloRematerialization:\n" + module->ToString()); + + // Create initial sequence of HLO instructions. + TF_ASSIGN_OR_RETURN(*sequence, ScheduleComputationsInModule( + *module, + [this](const BufferValue& buffer) { + return size_function_(buffer.shape()); + }, + scheduler_algorithm_)); + if (copy_insertion) { + // We run a separate pass of copy elision here because the sequential + // ordering from the HLO schedule allows for more copies to be eliminated. + // TODO(b/80249101): Instead of a separate copy elision pass, use the + // ordering from the HLO schedule directly for copy insertion. + + // First create a copy of the schedule which contains HloInstruction unique + // ids instead of HloInstruction*. This is necessary for updating the + // schedule below. + // TODO(b/113175018): Remove this when the HLO schedule is self-contained + // and can update itself. + tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>> + id_sequence = ComputeIdSchedule(*sequence); + + SequentialHloOrdering ordering(module, *sequence); + TF_RETURN_IF_ERROR( + copy_insertion->RemoveUnnecessaryCopies(ordering, module)); + + // RemoveUnnecessaryCopies only considers interference when determining + // whether it is legal to remove a copy. However, copies in the graph may be + // necessary for other reason such as preventing a constant from being live + // out of the graph. So run AddSpecialCaseCopies to re-insert these copies. + // TODO(b/80249101): Break copy insertion into several passes and run each + // one once in the regular HLO pipeline. + TF_RETURN_IF_ERROR(copy_insertion->AddSpecialCaseCopies(module)); + + // The passes above can add and remove copies, update the schedule to + // account for these transformations. Newly added instructions will be + // placed ASAP in the schedule. + TF_RETURN_IF_ERROR(UpdateSchedule(*module, id_sequence, sequence)); + + TF_DCHECK_OK(copy_insertion->VerifyNoLiveRangeInterference( + SequentialHloOrdering(module, *sequence), module)); + } TF_ASSIGN_OR_RETURN(points_to_analysis_, TuplePointsToAnalysis::Run(module)); @@ -1230,24 +1267,6 @@ StatusOr<bool> HloRematerialization::Run( << HumanReadableNumBytes(module_output_size) << "): " << HumanReadableNumBytes(adjusted_memory_limit_bytes); - XLA_VLOG_LINES(3, "Before HloRematerialization:\n" + module->ToString()); - // Create initial sequence of HLO instructions. - TF_ASSIGN_OR_RETURN(*sequence, ScheduleComputationsInModule( - *module, - [this](const BufferValue& buffer) { - return size_function_(buffer.shape()); - }, - scheduler_algorithm_)); - if (copy_insertion) { - // We run a separate pass of copy elision here because the sequential - // ordering from the HLO schedule allows for more copies to be eliminated. - // TODO(b/80249101): Instead of a separate copy elision pass, use the - // ordering from the HLO schedule directly for copy insertion. - SequentialHloOrdering ordering(module, *sequence); - TF_RETURN_IF_ERROR( - copy_insertion->RemoveUnnecessaryCopies(ordering, module)); - } - // Compute peak memory usage of all computations in the module called in a // sequential context. call_graph_ = CallGraph::Build(module); @@ -1334,12 +1353,11 @@ StatusOr<bool> HloRematerialization::Run( XLA_VLOG_LINES(3, "After HloRematerialization:\n" + module->ToString()); if (current_peak_memory > memory_limit_bytes) { - LOG(WARNING) << tensorflow::strings::Printf( - "Can't reduce memory use below %s (%lld bytes) by rematerialization; " - "only reduced to %s (%lld bytes)", - HumanReadableNumBytes(memory_limit_bytes).c_str(), memory_limit_bytes, - HumanReadableNumBytes(current_peak_memory).c_str(), - current_peak_memory); + LOG(WARNING) << absl::StrFormat( + "Can't reduce memory use below %s (%d bytes) by rematerialization; " + "only reduced to %s (%d bytes)", + HumanReadableNumBytes(memory_limit_bytes), memory_limit_bytes, + HumanReadableNumBytes(current_peak_memory), current_peak_memory); } return changed; diff --git a/tensorflow/compiler/xla/service/hlo_runner.cc b/tensorflow/compiler/xla/service/hlo_runner.cc index b2725e2918..7bd8a4a544 100644 --- a/tensorflow/compiler/xla/service/hlo_runner.cc +++ b/tensorflow/compiler/xla/service/hlo_runner.cc @@ -19,9 +19,9 @@ limitations under the License. #include <string> #include <utility> +#include "absl/memory/memory.h" #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/compiler/xla/layout_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/service/transfer_manager.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -32,7 +32,7 @@ limitations under the License. namespace xla { /*static*/ StatusOr<std::unique_ptr<HloModule>> -HloRunner::CreateModuleFromString(const tensorflow::StringPiece hlo_string, +HloRunner::CreateModuleFromString(const absl::string_view hlo_string, const DebugOptions& debug_options) { HloModuleConfig config; config.set_debug_options(debug_options); @@ -233,7 +233,7 @@ StatusOr<std::vector<std::unique_ptr<Literal>>> HloRunner::ExecuteReplicated( int64 device = device_assignment(i, 0); TF_ASSIGN_OR_RETURN(se::StreamExecutor * executor, backend().stream_executor(device)); - streams.push_back(MakeUnique<se::Stream>(executor)); + streams.push_back(absl::make_unique<se::Stream>(executor)); streams.back()->Init(); service_run_options.emplace_back(GetServiceRunOptionsForDevice( device, streams.back().get(), &device_assignment)); @@ -260,7 +260,7 @@ StatusOr<std::vector<std::unique_ptr<Literal>>> HloRunner::ExecuteReplicated( num_threads += options.num_replicas; } if (num_threads > 0) { - pool = MakeUnique<tensorflow::thread::ThreadPool>( + pool = absl::make_unique<tensorflow::thread::ThreadPool>( tensorflow::Env::Default(), "infeed_outfeed", /*num_threads=*/num_threads); } @@ -291,7 +291,7 @@ StatusOr<std::vector<std::unique_ptr<Literal>>> HloRunner::ExecuteReplicated( VLOG(1) << "Starting outfeed on device " << device; for (int64 step = 1; options.infeed_steps < 0 || step <= options.infeed_steps; ++step) { - auto literal = MakeUnique<Literal>(); + auto literal = absl::make_unique<Literal>(); TF_CHECK_OK(backend().transfer_manager()->TransferLiteralFromOutfeed( executor, options.outfeed_shape, literal.get())); if (options.outfeed_values != nullptr) { diff --git a/tensorflow/compiler/xla/service/hlo_runner.h b/tensorflow/compiler/xla/service/hlo_runner.h index 65537f07f5..cfc519063e 100644 --- a/tensorflow/compiler/xla/service/hlo_runner.h +++ b/tensorflow/compiler/xla/service/hlo_runner.h @@ -87,8 +87,7 @@ class HloRunner { // Converts an HloModule from the given hlo textual IR string (in // HloModule::ToString format). static StatusOr<std::unique_ptr<HloModule>> CreateModuleFromString( - const tensorflow::StringPiece hlo_string, - const DebugOptions& debug_options); + const absl::string_view hlo_string, const DebugOptions& debug_options); // Reads the proto file in xla.HloProto format, creates and returns the // HloModule. diff --git a/tensorflow/compiler/xla/service/hlo_scheduling.cc b/tensorflow/compiler/xla/service/hlo_scheduling.cc index 27cc5361cd..0fc3b268c0 100644 --- a/tensorflow/compiler/xla/service/hlo_scheduling.cc +++ b/tensorflow/compiler/xla/service/hlo_scheduling.cc @@ -16,6 +16,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_scheduling.h" #include <map> +#include <queue> #include <utility> #include <vector> @@ -28,16 +29,14 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/stringprintf.h" +#include "tensorflow/core/lib/gtl/map_util.h" #include "tensorflow/core/platform/logging.h" -using ::tensorflow::strings::HumanReadableNumBytes; - namespace xla { - namespace { +using ::tensorflow::strings::HumanReadableNumBytes; + // Class implementing a list scheduler of HLO instructions which produces a // sequence which minimizes memory usage by preferring to schedule the node that // frees bigger buffer and defines smaller outputs. @@ -582,4 +581,187 @@ StatusOr<std::vector<const HloInstruction*>> ScheduleOneComputation( size_function, nullptr, empty_map); } +tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>> +ComputeIdSchedule(const SequentialHloOrdering::HloModuleSequence& sequence) { + tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>> id_sequence; + for (const auto& computation_sequence : sequence) { + for (const HloInstruction* instruction : computation_sequence.second) { + id_sequence[computation_sequence.first].push_back( + instruction->unique_id()); + } + } + return id_sequence; +} + +Status UpdateSchedule( + const HloModule& module, + const tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>>& + id_sequence, + SequentialHloOrdering::HloModuleSequence* sequence) { + // Map from unique ID to HloInstruction pointer for instructions in the + // module. + tensorflow::gtl::FlatMap<int, const HloInstruction*> id_to_instruction; + // Set of all HloInstructions in the schedule. + tensorflow::gtl::FlatSet<int> ids_in_schedule; + std::vector<HloComputation*> nonfusion_computations = + module.MakeNonfusionComputations(); + for (const HloComputation* computation : nonfusion_computations) { + for (const HloInstruction* instruction : computation->instructions()) { + TF_RET_CHECK( + id_to_instruction.insert({instruction->unique_id(), instruction}) + .second); + } + for (int id : id_sequence.at(computation)) { + ids_in_schedule.insert(id); + } + } + + // Map from HloInstruction X to newly added instructions (instruction is in + // module, but not in schedule) which use X. If an instruction is not in the + // map, then it has no users which are newly added instructions. + tensorflow::gtl::FlatMap<const HloInstruction*, + std::vector<const HloInstruction*>> + new_instruction_uses; + + // For each newly added instruction, this is the count of the instruction's + // operands that have not yet been scheduled. When this value reaches zero, + // then the instruction may be placed in the schedule. + tensorflow::gtl::FlatMap<const HloInstruction*, int> + unscheduled_operand_count; + // For each computation, this is the set of newly added instructions which + // have no operands. These must be handled specially and are added to the + // beginning of the schedule. + tensorflow::gtl::FlatMap<const HloComputation*, + std::vector<const HloInstruction*>> + new_zero_operand_instructions; + for (const HloComputation* computation : nonfusion_computations) { + new_zero_operand_instructions[computation] = {}; + for (const HloInstruction* instruction : computation->instructions()) { + if (ids_in_schedule.count(instruction->unique_id()) == 0) { + // This is a newly added instruction which is not in the schedule. + for (const HloInstruction* operand : instruction->operands()) { + new_instruction_uses[operand].push_back(instruction); + } + if (instruction->operands().empty()) { + new_zero_operand_instructions[computation].push_back(instruction); + } + unscheduled_operand_count[instruction] = instruction->operand_count(); + } + } + } + + // Update the schedule with the newly added instructions, and remove any + // instructions no longer in the graph. + for (const HloComputation* computation : nonfusion_computations) { + std::vector<const HloInstruction*> old_computation_sequence = + std::move(sequence->at(computation)); + sequence->at(computation).clear(); + + // Create a worklist of newly added instructions which are ready to be added + // to the schedule. Initialize worklist with those that have zero operands. + std::queue<const HloInstruction*> worklist; + for (const HloInstruction* instruction : + new_zero_operand_instructions.at(computation)) { + worklist.push(instruction); + } + + // Lambda which schedules all instructions on the worklist. + auto schedule_worklist = [&]() { + while (!worklist.empty()) { + const HloInstruction* instruction = worklist.front(); + worklist.pop(); + sequence->at(computation).push_back(instruction); + std::vector<const HloInstruction*>* new_users = + tensorflow::gtl::FindOrNull(new_instruction_uses, instruction); + if (new_users != nullptr) { + // This just-scheduled instruction has users which are newly added to + // the module. Update the number of unscheduled operands and push the + // newly added instruction to the worklist if it is ready to + // schedule. + for (const HloInstruction* new_user : *new_users) { + unscheduled_operand_count.at(new_user)--; + CHECK_GE(unscheduled_operand_count.at(new_user), 0); + if (unscheduled_operand_count.at(new_user) == 0) { + worklist.push(new_user); + } + } + } + } + }; + + schedule_worklist(); + for (int id : id_sequence.at(computation)) { + auto it = id_to_instruction.find(id); + if (it == id_to_instruction.end()) { + // This instruction in the schedule is no longer in the module. + continue; + } + const HloInstruction* instruction = it->second; + worklist.push(instruction); + schedule_worklist(); + } + } + + TF_RETURN_IF_ERROR(VerifySchedule(module, *sequence)); + return Status::OK(); +} + +Status VerifySchedule( + const HloModule& module, + const SequentialHloOrdering::HloModuleSequence& sequence) { + VLOG(2) << "VerifySchedule()"; + XLA_VLOG_LINES(2, module.ToString()); + VLOG(2) << sequence; + + // Verify the set of computations in the sequence is exactly the set of + // computations in the module. + std::vector<HloComputation*> nonfusion_computations = + module.MakeNonfusionComputations(); + TF_RET_CHECK(nonfusion_computations.size() == sequence.size()); + tensorflow::gtl::FlatSet<const HloComputation*> computations_in_module( + module.computations().begin(), module.computations().end()); + for (const auto& computation_sequence : sequence) { + TF_RET_CHECK(computations_in_module.count(computation_sequence.first) == 1); + } + + // For each computation verify the set of instructions is the same and that + // each dependency and control edge is honored. + for (const HloComputation* computation : nonfusion_computations) { + tensorflow::gtl::FlatMap<const HloInstruction*, int> instruction_position; + int pos = 0; + for (const HloInstruction* instruction : sequence.at(computation)) { + TF_RET_CHECK(instruction_position.insert({instruction, pos}).second) + << "Instruction " << instruction->name() + << " appears more than once in the schedule"; + pos++; + } + + TF_RET_CHECK(instruction_position.size() == + computation->instruction_count()); + for (const HloInstruction* instruction : computation->instructions()) { + TF_RET_CHECK(instruction_position.count(instruction) == 1) + << "Instruction " << instruction->name() << " is not in schedule"; + } + + for (const HloInstruction* instruction : computation->instructions()) { + for (const HloInstruction* operand : instruction->operands()) { + TF_RET_CHECK(instruction_position.at(operand) < + instruction_position.at(instruction)) + << "Instruction " << instruction->name() + << " is not scheduled after its operand " << operand->name(); + } + + for (const HloInstruction* pred : instruction->control_predecessors()) { + TF_RET_CHECK(instruction_position.at(pred) < + instruction_position.at(instruction)) + << "Instruction " << instruction->name() + << " is not scheduled after its control predecessor " + << pred->name(); + } + } + } + + return Status::OK(); +} + } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_scheduling.h b/tensorflow/compiler/xla/service/hlo_scheduling.h index 2b33ccc8bf..d06b8d9a5c 100644 --- a/tensorflow/compiler/xla/service/hlo_scheduling.h +++ b/tensorflow/compiler/xla/service/hlo_scheduling.h @@ -85,6 +85,43 @@ StatusOr<std::vector<const HloInstruction*>> ScheduleOneComputation( const HloComputation& computation, const LogicalBuffer::SizeFunction& size_function); +// Transforms the given schedule such that it is (again) a valid schedule for +// the module. This is used to update a schedule after the HLO module has been +// transformed in some way. In general, the only transformations to the module +// for which a schedule can be updated is the addition or removal of +// instructions to/from the module. Updating the schedule after new dependencies +// between existing instructions in the module is not supported and may result +// in an error status returned. +// +// Instructions in the module which also exist in the given schedule will remain +// in the same order in the updated schedule. Instructions which exist in the +// module but not in the given schedule will be placed as early as possible in +// the updated schedule. +// +// 'id_sequence' is a mirror of the given schedule 'sequence' but with +// HloInstruction ids rather than HloInstruction pointers. This should be +// constructed using ComputeIdSchedule below after the schedule is constructed +// but before the HLO module is transformed. +Status UpdateSchedule( + const HloModule& module, + const tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>>& + id_sequence, + SequentialHloOrdering::HloModuleSequence* sequence); + +// Constructs a copy of the given schedule but with HloInstruction unique ids +// rather than HloInstruction pointers. This is necessary for updating a +// schedule as HloInstruction points in the schedule may become invalid if +// instructions are removed from the module. Used by UpdateSchedule above.. +// TODO(b/113175018): Remove this function when HLO schedule is its own class. +tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>> +ComputeIdSchedule(const SequentialHloOrdering::HloModuleSequence& sequence); + +// Verifies that the given schedule is valid for the given module. Specifically, +// the schedule contains exactly the instructions in the module and every +// dependency in the module is satisfied in the schedule. +Status VerifySchedule(const HloModule& module, + const SequentialHloOrdering::HloModuleSequence& sequence); + } // namespace xla #endif // TENSORFLOW_COMPILER_XLA_SERVICE_HLO_SCHEDULING_H_ diff --git a/tensorflow/compiler/xla/service/hlo_scheduling_test.cc b/tensorflow/compiler/xla/service/hlo_scheduling_test.cc index 9ec983c2bc..930801288a 100644 --- a/tensorflow/compiler/xla/service/hlo_scheduling_test.cc +++ b/tensorflow/compiler/xla/service/hlo_scheduling_test.cc @@ -20,6 +20,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/heap_simulator.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" +#include "tensorflow/compiler/xla/service/hlo_dce.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/service/hlo_ordering.h" @@ -28,6 +29,7 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/hlo_test_base.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" +#include "tensorflow/core/lib/core/status_test_util.h" namespace xla { namespace { @@ -244,9 +246,9 @@ TEST_F(HloSchedulingTest, ListAccountsForSubcomputations) { *entry_computation, sequence.at(entry_computation), *points_to_analysis, size_fn) .ValueOrDie()); - // HeapSimulator accounts for subcomputations. The max mem doesn't change - // because the while body isn't live during the peak. - EXPECT_EQ(80, HeapSimulator::MinimumMemoryForComputation( + // HeapSimulator accounts for subcomputations. The output buffer is aliased, + // so we don't double count. + EXPECT_EQ(64, HeapSimulator::MinimumMemoryForComputation( *entry_computation, sequence.at(entry_computation), *points_to_analysis, size_fn, &memory_by_computation) .ValueOrDie()); @@ -350,7 +352,6 @@ TEST_F(HloSchedulingTest, MultiOutputFusionAccountedCorrectly) { TEST_F(HloSchedulingTest, HeapSimulatorAccountsForSubcomputations) { auto module = CreateNewModule(); const Shape r1f32 = ShapeUtil::MakeShape(F32, {4}); - const Shape r2f32 = ShapeUtil::MakeShape(F32, {2, 4}); // param != 0 // Needs 17 bytes @@ -408,12 +409,259 @@ TEST_F(HloSchedulingTest, HeapSimulatorAccountsForSubcomputations) { *entry_computation, sequence.at(entry_computation), *points_to_analysis, size_fn) .ValueOrDie()); - // HeapSimulator accounts for subcomputations - EXPECT_EQ(33, HeapSimulator::MinimumMemoryForComputation( + // HeapSimulator accounts for subcomputations. Cond is the largest one. + // The output buffer of the while is aliased. + EXPECT_EQ(17, HeapSimulator::MinimumMemoryForComputation( *entry_computation, sequence.at(entry_computation), *points_to_analysis, size_fn, &memory_by_computation) .ValueOrDie()); } +TEST_F(HloSchedulingTest, UpdateScheduleUnchangedModule) { + // Updating the schedule of an unchanged HLO module should not affect the + // schedule at all. + const string module_str = R"( +HloModule UpdateScheduleUnchanged + +ENTRY main { + a = f32[] parameter(0) + b = f32[] parameter(1) + c = f32[] constant(42.0) + sum = f32[] add(a, b) + neg = f32[] negate(c) + ROOT root = f32[] multiply(sum, neg) +} +)"; + TF_ASSERT_OK_AND_ASSIGN(std::unique_ptr<HloModule> module, + ParseHloString(module_str)); + TF_ASSERT_OK_AND_ASSIGN( + SequentialHloOrdering::HloModuleSequence sequence, + ScheduleComputationsInModule(*module, [](const BufferValue& buffer) { + return ShapeUtil::ByteSizeOf(buffer.shape()); + })); + tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>> + id_sequence = ComputeIdSchedule(sequence); + std::vector<const HloInstruction*> entry_schedule = sequence.begin()->second; + + EXPECT_EQ(entry_schedule.size(), 6); + + TF_ASSERT_OK(UpdateSchedule(*module, id_sequence, &sequence)); + TF_ASSERT_OK(VerifySchedule(*module, sequence)); + + EXPECT_EQ(entry_schedule, sequence.begin()->second); +} + +TEST_F(HloSchedulingTest, UpdateScheduleWithNewInstructions) { + // Add some additional instructions to a module and verify the schedule can be + // updated. + const string module_str = R"( +HloModule UpdateScheduleWithNewInstructions + +ENTRY main { + a = f32[] parameter(0) + b = f32[] parameter(1) + c = f32[] constant(42.0) + sum = f32[] add(a, b) + neg = f32[] negate(c) + ROOT root = f32[] multiply(sum, neg) +} +)"; + TF_ASSERT_OK_AND_ASSIGN(std::unique_ptr<HloModule> module, + ParseHloString(module_str)); + TF_ASSERT_OK_AND_ASSIGN( + SequentialHloOrdering::HloModuleSequence sequence, + ScheduleComputationsInModule(*module, [](const BufferValue& buffer) { + return ShapeUtil::ByteSizeOf(buffer.shape()); + })); + tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>> + id_sequence = ComputeIdSchedule(sequence); + + HloComputation* entry = module->entry_computation(); + const Shape shape = entry->root_instruction()->shape(); + HloInstruction* constant = entry->AddInstruction( + HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(42.0))); + HloInstruction* sub = entry->AddInstruction(HloInstruction::CreateBinary( + shape, HloOpcode::kSubtract, constant, entry->root_instruction())); + entry->set_root_instruction(sub); + + auto in_schedule = [&](const HloInstruction* hlo) { + return std::find(sequence.at(entry).begin(), sequence.at(entry).end(), + hlo) != sequence.at(entry).end(); + }; + + EXPECT_EQ(sequence.at(entry).size(), 6); + EXPECT_FALSE(in_schedule(constant)); + EXPECT_FALSE(in_schedule(sub)); + + TF_ASSERT_OK(UpdateSchedule(*module, id_sequence, &sequence)); + TF_ASSERT_OK(VerifySchedule(*module, sequence)); + + EXPECT_EQ(sequence.at(entry).size(), 8); + EXPECT_TRUE(in_schedule(constant)); + EXPECT_TRUE(in_schedule(sub)); +} + +TEST_F(HloSchedulingTest, UpdateScheduleWithAddedAndDeletedInstruction) { + // Add and delete some instructions from a module and verify that the schedule + // can be updated successfully. + const string module_str = R"( +HloModule UpdateScheduleWithAddedAndDeletedInstruction + +ENTRY main { + a = f32[] parameter(0) + b = f32[] parameter(1) + c = f32[] constant(42.0) + sum = f32[] add(a, b) + neg = f32[] negate(c) + ROOT root = f32[] multiply(sum, neg) +} +)"; + + TF_ASSERT_OK_AND_ASSIGN(std::unique_ptr<HloModule> module, + ParseHloString(module_str)); + TF_ASSERT_OK_AND_ASSIGN( + SequentialHloOrdering::HloModuleSequence sequence, + ScheduleComputationsInModule(*module, [](const BufferValue& buffer) { + return ShapeUtil::ByteSizeOf(buffer.shape()); + })); + tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>> + id_sequence = ComputeIdSchedule(sequence); + + // Set the entry root to some expression containing just a parameter and a + // constant. + HloComputation* entry = module->entry_computation(); + HloInstruction* constant = entry->AddInstruction( + HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(42.0))); + HloInstruction* new_root = entry->AddInstruction( + HloInstruction::CreateBinary(constant->shape(), HloOpcode::kSubtract, + constant, entry->parameter_instruction(0))); + entry->set_root_instruction(new_root); + + // DCE should remove everything but the parameters and the newly added code. + HloDCE dce; + TF_ASSERT_OK(dce.Run(module.get()).status()); + + EXPECT_EQ(sequence.at(entry).size(), 6); + + TF_ASSERT_OK(UpdateSchedule(*module, id_sequence, &sequence)); + TF_ASSERT_OK(VerifySchedule(*module, sequence)); + + EXPECT_EQ(sequence.at(entry).size(), 4); +} + +TEST_F(HloSchedulingTest, UpdateScheduleWithCompletelyReplacedModule) { + // Completely replace a module with an entirely new set of instructions and + // verify that the schedule can be updated successfully. + const string module_str = R"( +HloModule UpdateScheduleWithCompletelyReplacedModule + +ENTRY main { + a = f32[] constant(42.0) + b = f32[] constant(123.0) + ROOT sum = f32[] add(a, b) +} +)"; + + TF_ASSERT_OK_AND_ASSIGN(std::unique_ptr<HloModule> module, + ParseHloString(module_str)); + TF_ASSERT_OK_AND_ASSIGN( + SequentialHloOrdering::HloModuleSequence sequence, + ScheduleComputationsInModule(*module, [](const BufferValue& buffer) { + return ShapeUtil::ByteSizeOf(buffer.shape()); + })); + tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>> + id_sequence = ComputeIdSchedule(sequence); + + // Replace the entry computation with the negation of a constant. + HloComputation* entry = module->entry_computation(); + HloInstruction* constant = entry->AddInstruction( + HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(1.0))); + HloInstruction* new_root = entry->AddInstruction(HloInstruction::CreateUnary( + constant->shape(), HloOpcode::kNegate, constant)); + entry->set_root_instruction(new_root); + + // DCE the old instructions. + HloDCE dce; + TF_ASSERT_OK(dce.Run(module.get()).status()); + + EXPECT_EQ(sequence.at(entry).size(), 3); + + TF_ASSERT_OK(UpdateSchedule(*module, id_sequence, &sequence)); + TF_ASSERT_OK(VerifySchedule(*module, sequence)); + + EXPECT_EQ(sequence.at(entry).size(), 2); +} + +TEST_F(HloSchedulingTest, UpdateScheduleWithMultipleComputations) { + // Create changes to more than one computation in an HLO module and verify + // that the schedule can be updated. + const string module_str = R"( +HloModule UpdateScheduleWithMultipleComputations + +%Body (param.1: (s32[], token[])) -> (s32[], token[]) { + %param.1 = (s32[], token[]) parameter(0) + %get-tuple-element.1 = s32[] get-tuple-element((s32[], token[]) %param.1), index=0 + %constant.1 = s32[] constant(1) + %add = s32[] add(s32[] %get-tuple-element.1, s32[] %constant.1) + %get-tuple-element.2 = token[] get-tuple-element((s32[], token[]) %param.1), index=1 + %after-all = token[] after-all(token[] %get-tuple-element.2) + ROOT %tuple = (s32[], token[]) tuple(s32[] %add, token[] %after-all) +} + +%Cond (param: (s32[], token[])) -> pred[] { + %param = (s32[], token[]) parameter(0) + %get-tuple-element = s32[] get-tuple-element((s32[], token[]) %param), index=0 + %constant = s32[] constant(42) + ROOT %less-than = pred[] less-than(s32[] %get-tuple-element, s32[] %constant) +} + +ENTRY %WhileLoop () -> s32[] { + %zero = s32[] constant(0) + %init_token = token[] after-all() + %init_tuple = (s32[], token[]) tuple(s32[] %zero, token[] %init_token) + %while = (s32[], token[]) while((s32[], token[]) %init_tuple), condition=%Cond, body=%Body + ROOT %root = s32[] get-tuple-element((s32[], token[]) %while), index=0 +} +)"; + + TF_ASSERT_OK_AND_ASSIGN(std::unique_ptr<HloModule> module, + ParseHloString(module_str)); + TF_ASSERT_OK_AND_ASSIGN( + SequentialHloOrdering::HloModuleSequence sequence, + ScheduleComputationsInModule(*module, [](const BufferValue& buffer) { + return ShapeUtil::ByteSizeOf(buffer.shape(), + /*pointer_size=*/sizeof(void*)); + })); + tensorflow::gtl::FlatMap<const HloComputation*, std::vector<int>> + id_sequence = ComputeIdSchedule(sequence); + + const HloInstruction* xla_while = + module->entry_computation()->root_instruction()->operand(0); + HloComputation* body = xla_while->while_body(); + HloComputation* cond = xla_while->while_condition(); + + // Negate the root of the cond. + cond->set_root_instruction(cond->AddInstruction( + HloInstruction::CreateUnary(ShapeUtil::MakeShape(PRED, {}), + HloOpcode::kNot, cond->root_instruction()))); + + // Replace the body with a computation which just passes through its + // parameter. + body->set_root_instruction(body->parameter_instruction(0)); + + // DCE the dead code in the body. + HloDCE dce; + TF_ASSERT_OK(dce.Run(module.get()).status()); + + EXPECT_EQ(sequence.at(body).size(), 7); + EXPECT_EQ(sequence.at(cond).size(), 4); + + TF_ASSERT_OK(UpdateSchedule(*module, id_sequence, &sequence)); + TF_ASSERT_OK(VerifySchedule(*module, sequence)); + + EXPECT_EQ(sequence.at(body).size(), 1); + EXPECT_EQ(sequence.at(cond).size(), 5); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_sharding.cc b/tensorflow/compiler/xla/service/hlo_sharding.cc index 0cba9ebbcb..980dae07ce 100644 --- a/tensorflow/compiler/xla/service/hlo_sharding.cc +++ b/tensorflow/compiler/xla/service/hlo_sharding.cc @@ -15,13 +15,14 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_sharding.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace xla { -using ::tensorflow::str_util::Join; -using ::tensorflow::strings::StrCat; +using absl::StrCat; +using absl::StrJoin; HloSharding HloSharding::AssignDevice(int64 device_id) { return HloSharding(device_id); @@ -71,12 +72,9 @@ HloSharding HloSharding::SingleTuple(const Shape& tuple_shape, const HloSharding& sharding) { CHECK(ShapeUtil::IsTuple(tuple_shape)) << ShapeUtil::HumanString(tuple_shape); CHECK(!sharding.IsTuple()) << sharding.ToString(); - int64 leaf_count = ShapeUtil::GetLeafCount(tuple_shape); + int64 leaf_count = RequiredLeaves(tuple_shape); std::vector<HloSharding> flattened_list; - flattened_list.reserve(leaf_count); - for (int64 i = 0; i < leaf_count; ++i) { - flattened_list.push_back(sharding); - } + flattened_list.resize(leaf_count, sharding); return HloSharding(flattened_list); } @@ -92,7 +90,7 @@ string HloSharding::ToString() const { for (const HloSharding& element : tuple_elements_) { parts.push_back(element.ToString()); } - return StrCat("{", tensorflow::str_util::Join(parts, ", "), "}"); + return StrCat("{", absl::StrJoin(parts, ", "), "}"); } if (replicated_) { @@ -101,8 +99,8 @@ string HloSharding::ToString() const { return StrCat( "{maximal device=", static_cast<int64>(*tile_assignment_.begin()), "}"); } else { - return StrCat("{devices=[", Join(tile_assignment_.dimensions(), ","), "]", - Join(tile_assignment_, ","), "}"); + return StrCat("{devices=[", StrJoin(tile_assignment_.dimensions(), ","), + "]", StrJoin(tile_assignment_, ","), "}"); } } @@ -244,16 +242,16 @@ StatusOr<HloSharding> HloSharding::GetTupleSharding(const Shape& shape) const { return Tuple(ShapeTree<HloSharding>(shape, *this)); } -tensorflow::gtl::optional<int64> HloSharding::UniqueDevice() const { +absl::optional<int64> HloSharding::UniqueDevice() const { if (IsTuple()) { if (tuple_elements_.empty()) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } - tensorflow::gtl::optional<int64> unique_device; + absl::optional<int64> unique_device; for (auto& tuple_sharding : tuple_elements_) { auto device = tuple_sharding.UniqueDevice(); if (!device || (unique_device && *device != *unique_device)) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } unique_device = device; } @@ -262,7 +260,7 @@ tensorflow::gtl::optional<int64> HloSharding::UniqueDevice() const { if (!replicated_ && maximal_) { return static_cast<int64>(*tile_assignment_.begin()); } - return tensorflow::gtl::nullopt; + return absl::nullopt; } int64 HloSharding::GetUniqueDevice() const { @@ -439,14 +437,13 @@ HloSharding HloSharding::GetSubSharding(const Shape& shape, : sub_shape_tree.element(ShapeIndex({})); } -tensorflow::gtl::optional<HloSharding> HloSharding::ExtractSingleSharding() - const { +absl::optional<HloSharding> HloSharding::ExtractSingleSharding() const { if (!IsTuple()) { return *this; } for (int64 i = 1; i < tuple_elements_.size(); ++i) { if (tuple_elements_[0] != tuple_elements_[i]) { - return tensorflow::gtl::optional<HloSharding>(); + return absl::nullopt; } } return tuple_elements_.front(); diff --git a/tensorflow/compiler/xla/service/hlo_sharding.h b/tensorflow/compiler/xla/service/hlo_sharding.h index 894783e5d1..be51c3f55b 100644 --- a/tensorflow/compiler/xla/service/hlo_sharding.h +++ b/tensorflow/compiler/xla/service/hlo_sharding.h @@ -151,7 +151,7 @@ class HloSharding { // span a single device, the return value will be empty. // In order for a sharding to span a single device, every leaf sharding must // be maximal and not replicated, and the used device must match. - tensorflow::gtl::optional<int64> UniqueDevice() const; + absl::optional<int64> UniqueDevice() const; // Retrieves the unique device or fails with a CHECK. int64 GetUniqueDevice() const; @@ -182,7 +182,7 @@ class HloSharding { // be returned. If it is a tuple, and all the tuple elements are common, the // common element will be returned. Otherwise the optional will contain no // value. - tensorflow::gtl::optional<HloSharding> ExtractSingleSharding() const; + absl::optional<HloSharding> ExtractSingleSharding() const; bool operator==(const HloSharding& other) const { return replicated_ == other.replicated_ && maximal_ == other.maximal_ && @@ -260,9 +260,9 @@ class HloSharding { bool maximal_; bool tuple_; Array<int64> tile_assignment_; - // Only non-empty when tuple_ is true, but because empty tuples are allowed - // may also be empty even then. This is a flattened list of all the leaf - // shardings in a tuple shape, by pre-order walk (ShapeTree iterator order). + // Only non-empty when tuple_ is true. If a tuple is empty then one entry is + // present for the root. This is a flattened list of all the leaf shardings in + // a tuple shape, by pre-order walk (ShapeTree iterator order). std::vector<HloSharding> tuple_elements_; }; diff --git a/tensorflow/compiler/xla/service/hlo_sharding_metadata.cc b/tensorflow/compiler/xla/service/hlo_sharding_metadata.cc index a2c1d39d0d..6e9b96488c 100644 --- a/tensorflow/compiler/xla/service/hlo_sharding_metadata.cc +++ b/tensorflow/compiler/xla/service/hlo_sharding_metadata.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_sharding_metadata.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/shape_tree.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -23,6 +24,23 @@ namespace xla { namespace { +// AssignmentKind and kUnassignedDevice are used during tuple domain sharding +// propagation in order to distinguish among three cases: +// kUnassigned: no assignment has occurred +// kAssigned: at least an assignment has occurred +// kConflict: no assignment has occurred because of conflicting propagations, +// which occurs when multiple users of an instruction have different +// shardings. +enum class AssignmentKind { kUnassigned, kAssigned, kConflict }; + +// kUnassignedDevice can only be assigned to tuple leaf shardings to indicate +// absence of sharding information for that particular sub-sharding during +// sharding propagation. It is used to be able to express tuple shardings with +// partial information. At the end of the propagation the sharding of +// tuple-shaped instructions using kUnassignedDevice's is cleared. +// TODO(b/112883246): Centralized enum of reserved devices. +constexpr int64 kUnassignedDevice = -2; + struct PassThrough { PassThrough(HloInstruction* user, HloInstruction* operand) : user(user), operand(operand) {} @@ -117,13 +135,17 @@ Status FixupPassThroughDomainLinks(const DomainMetadata::Domain& domain, return Status::OK(); } -std::unique_ptr<HloSharding> CloneShardingForDomain( - const HloSharding& sharding) { - auto single_sharding = sharding.ExtractSingleSharding(); +// For tuple shardings if every element have the same sharsing then we want to +// treat them as single element sharsings to insert less domain separation as a +// domain can prevent some optimizations and we want to minimize that from +// happening. +std::shared_ptr<const HloSharding> CloneShardingForDomain( + std::shared_ptr<const HloSharding> sharding) { + auto single_sharding = sharding->ExtractSingleSharding(); if (!single_sharding) { - return MakeUnique<HloSharding>(sharding); + return sharding; } - return MakeUnique<HloSharding>(*single_sharding); + return std::make_shared<const HloSharding>(*single_sharding); } Status ApplyDomainSingleSharding(const DomainMetadata::Domain& domain, @@ -142,108 +164,174 @@ Status ApplyDomainSingleSharding(const DomainMetadata::Domain& domain, return Status::OK(); } -// Retrieves the sharding of a tuple shaped instruction in form of a ShapeTree. -// If the instruction has no sharding, a ShapeTree with HloSharding::Replicate() -// sharding will be returned. -ShapeTree<HloSharding> GetTupleSharding(HloInstruction* tuple) { - if (tuple->has_sharding()) { - return tuple->sharding().GetAsShapeTree(tuple->shape()); +// Return the ShapeTree<HloSharding> of the user argument. The user argument +// is assumed to be a user of the instruction argument. +// If user is a tuple instruction, return the tuple subsharding corresponding to +// the operand matching the instruction argument, because that is the +// subsharding corresponding to instruction. +ShapeTree<HloSharding> GetShardingTreeFromUser( + const HloInstruction& instruction, const HloInstruction& user) { + if (user.opcode() == HloOpcode::kTuple) { + return user.sharding() + .GetSubSharding(user.shape(), {user.operand_index(&instruction)}) + .GetAsShapeTree(instruction.shape()); + } + return user.sharding().GetAsShapeTree(user.shape()); +} + +// Assign rhs to lhs. If rhs is unassigned (assigned to kUnassignedDevice) +// then no assignment is made. Therefore kUnassignedDevice is never propagated. +// kConflict is returned if lhs is already assigned and rhs is assigned to a +// different device. +StatusOr<AssignmentKind> AssignLeafSharding(HloSharding* lhs, + const HloSharding& rhs) { + TF_RET_CHECK(!lhs->IsTuple() && !rhs.IsTuple()); + if (rhs.UsesDevice(kUnassignedDevice)) { + return AssignmentKind::kUnassigned; + } + if (lhs->UsesDevice(kUnassignedDevice)) { + *lhs = rhs; + return AssignmentKind::kAssigned; + } + return lhs->UniqueDevice() != rhs.UniqueDevice() + ? AssignmentKind::kConflict + : AssignmentKind::kUnassigned; +} + +// Assigns the whole rhs tree to lhs_tree, starting at lhs_it. +// In case of conflicting assignment AssignmentKind::kConflict is returned. In +// this case lhs_tree is partially assigned, up to the conflicting leaf. It is +// up to the caller to discard the partial assignment in case of conflict. +StatusOr<AssignmentKind> AssignTreeSharding( + ShapeTree<HloSharding>* lhs_tree, ShapeTree<HloSharding>::iterator lhs_it, + const ShapeTree<HloSharding>& rhs_tree) { + AssignmentKind assigned = AssignmentKind::kUnassigned; + auto rhs_it = rhs_tree.begin(); + for (; lhs_it != lhs_tree->end() && rhs_it != rhs_tree.end(); + ++lhs_it, ++rhs_it) { + // TODO(b/112885211): Add ShapeTree::IsLeaf(const ShapeTreeIterator &it) + if (rhs_tree.IsLeaf(rhs_it->first)) { + TF_RET_CHECK(lhs_tree->IsLeaf(lhs_it->first)); + TF_ASSIGN_OR_RETURN(AssignmentKind sub_assigned, + AssignLeafSharding(&lhs_it->second, rhs_it->second)); + if (sub_assigned == AssignmentKind::kConflict) { + // In case of conflict we return conflict to the caller. At this point + // partial assignments to lhs_tree may have been made already. It is up + // to the caller to discard the partial assignment in case of conflict. + return AssignmentKind::kConflict; + } else if (sub_assigned == AssignmentKind::kAssigned) { + assigned = sub_assigned; + } + } } - return ShapeTree<HloSharding>(tuple->shape(), HloSharding::Replicate()); + TF_RET_CHECK(rhs_it == rhs_tree.end()); + return assigned; } -// Retrieves the sharding of operand, asked from a user instruction which is -// within domain. If operand is a kDomain, it means that sharding argument is -// the operand sharding, otherwise the operand's own sharding will be returned. -const HloSharding* GetOperandSharding(const HloInstruction* operand, +StatusOr<bool> ApplyShardingFromUsers(HloInstruction* instruction, const DomainMetadata::Domain& domain, - const HloSharding& sharding) { - // Here the user of operand is within the domain instruction set, and since it - // is user of operand, we need to look into the enter_domains set. If this is - // not a kDomain within the user domains set, then return the operand - // sharding, if any. - if (operand->opcode() != HloOpcode::kDomain || - domain.enter_domains.count(const_cast<HloInstruction*>(operand)) == 0) { - return operand->has_sharding() ? &operand->sharding() : nullptr; + const HloSharding& domain_sharding) { + if (instruction->users().empty()) { + // No sharding from users, use domain_sharding, after checking + // compatibility. + TF_RET_CHECK(ShapeUtil::IsTuple(instruction->shape()) && + ShapeUtil::GetLeafCount(instruction->shape()) == + domain_sharding.tuple_elements().size()); + instruction->set_sharding(domain_sharding); + return true; + } + AssignmentKind assigned = AssignmentKind::kUnassigned; + // The sharding_tree leaves are initialized to kUnassignedDevice. Only Tuple + // subshardings can result in a final sharding assignment containing + // kUnassignedDevice leaves, in case some tuple indexes are not used, or are + // used by users that don't have a sharding. + // Non-tuple shardings are either assigned to a real sharding, or are not + // assigned at all. As such they will never get assigned to kUnassignedDevice. + // In any case, kUnassignedDevice is never propagated, from the implementation + // of AssignLeafSharding. + ShapeTree<HloSharding> sharding_tree( + instruction->shape(), HloSharding::AssignDevice(kUnassignedDevice)); + for (HloInstruction* user : instruction->users()) { + if (user->opcode() == HloOpcode::kDomain && + domain.exit_domains.count(const_cast<HloInstruction*>(user)) > 0) { + // If a user is a domain and it is registered in the domain exits, then + // the instruction sharding is taken directly from the domain, and no + // further users need to be visited. + instruction->set_sharding(domain_sharding); + return true; + } + if (!user->has_sharding()) { + continue; + } + AssignmentKind sub_assigned = AssignmentKind::kUnassigned; + ShapeTree<HloSharding> user_sharding_tree = + GetShardingTreeFromUser(*instruction, *user); + if (ShapeUtil::IsTuple(instruction->shape())) { + // For tuple-shaped instructions collect individual tuple subshardings + // from the uses, and then combine them into the tuple sharding. + // If the user is a GTE its sharding concerns only the subtree of + // sharding_tree at index user->tuple_index, otherwise the whole + // sharding_tree is affected. + ShapeTree<HloSharding>::iterator sharding_tree_begin = + user->opcode() == HloOpcode::kGetTupleElement + ? sharding_tree.find({user->tuple_index()}) + : sharding_tree.begin(); + TF_ASSIGN_OR_RETURN( + sub_assigned, AssignTreeSharding(&sharding_tree, sharding_tree_begin, + user_sharding_tree)); + } else { + // Non-tuple shape: assign common users sharding. + TF_RET_CHECK(user_sharding_tree.leaf_count() == 1) + << "Expected non-tuple user sharding"; + TF_ASSIGN_OR_RETURN( + sub_assigned, + AssignTreeSharding(&sharding_tree, sharding_tree.begin(), + user_sharding_tree)); + } + + if (sub_assigned == AssignmentKind::kConflict) { + // In case of conflict we don't assign any sharding. + return false; + } else if (sub_assigned == AssignmentKind::kAssigned) { + assigned = sub_assigned; + } + } + + if (assigned == AssignmentKind::kAssigned) { + if (ShapeUtil::IsTuple(instruction->shape())) { + instruction->set_sharding(HloSharding::Tuple(sharding_tree)); + } else { + TF_RET_CHECK(sharding_tree.leaf_count() == 1); + instruction->set_sharding(sharding_tree.leaf_begin()->second); + } + return true; } - // At this point operand is a kDomain of the currently processed domain, so we - // can refer to sharding as the domain sharding. - return &sharding; + return false; } // Tries to propagate the sharding information into the instructions that are -// part of the domain, in a post order manner (operand propagate to user). +// part of the domain, in a reverse post order manner (users propoagate to +// instruction). StatusOr<int64> ApplyDomainShardingPass(const DomainMetadata::Domain& domain, - const HloSharding& sharding) { + const HloSharding& domain_sharding) { int64 assigned = 0; - for (HloInstruction* instruction : domain.instructions) { + // domain.instructions are ordered in a post-order manner. As we do + // user->operand propagation we process instructions in reverse order. In so + // doing we are guaranteed to process all users before their operands. + for (auto it = domain.instructions.rbegin(); it != domain.instructions.rend(); + ++it) { + HloInstruction* instruction = *it; if (instruction->has_sharding()) { continue; } - if (instruction->opcode() == HloOpcode::kGetTupleElement) { - HloInstruction* tuple = instruction->mutable_operand(0); - const HloSharding* tuple_sharding = - GetOperandSharding(tuple, domain, sharding); - if (tuple_sharding != nullptr) { - if (tuple_sharding->IsTuple()) { - HloSharding sub_sharding = tuple_sharding->GetSubSharding( - tuple->shape(), {instruction->tuple_index()}); - VLOG(4) << " " << instruction->name() << " to sharding " - << sub_sharding; - instruction->set_sharding(sub_sharding); - } else { - SetSingleSharding(instruction, *tuple_sharding); - } - ++assigned; - } - } else if (instruction->opcode() == HloOpcode::kTuple) { - int64 tuple_assigned = 0; - ShapeTree<HloSharding> shape_tree = GetTupleSharding(instruction); - for (int64 i = 0; i < instruction->operand_count(); ++i) { - const HloSharding* operand_sharding = - GetOperandSharding(instruction->operand(i), domain, sharding); - if (operand_sharding != nullptr) { - HloSharding operand_subsharding = HloSharding::Replicate(); - if (operand_sharding == &sharding) { - operand_subsharding = - sharding.GetSubSharding(instruction->shape(), {i}); - operand_sharding = &operand_subsharding; - } - if (shape_tree.element({i}) != *operand_sharding) { - *shape_tree.mutable_element({i}) = *operand_sharding; - ++tuple_assigned; - } - } - } - if (tuple_assigned > 0) { - HloSharding tuple_sharding = HloSharding::Tuple(shape_tree); - VLOG(4) << " " << instruction->name() << " to sharding " - << tuple_sharding; - instruction->set_sharding(tuple_sharding); - ++assigned; - } - } else { - // If all the operand of the given instruction has the same single device - // assignment, assign that device to this instruction as well. - const HloSharding* common_sharding = nullptr; - for (const HloInstruction* operand : instruction->operands()) { - const HloSharding* operand_sharding = - GetOperandSharding(operand, domain, sharding); - if (operand_sharding != nullptr) { - if (common_sharding != nullptr && - *common_sharding != *operand_sharding) { - common_sharding = nullptr; - break; - } - common_sharding = operand_sharding; - } - } - if (common_sharding != nullptr) { - VLOG(4) << " " << instruction->name() << " to sharding " - << *common_sharding; - instruction->set_sharding(*common_sharding); - ++assigned; - } + // Take the sharding from the users. + TF_ASSIGN_OR_RETURN( + bool instruction_assigned, + ApplyShardingFromUsers(instruction, domain, domain_sharding)); + if (instruction_assigned) { + ++assigned; + VLOG(4) << " " << instruction->name() << " to sharding " + << instruction->sharding(); } } return assigned; @@ -261,83 +349,40 @@ Status ApplyDomainSharding(const DomainMetadata::Domain& domain, return ApplyDomainSingleSharding(domain, *single_sharding); } VLOG(1) << "Assigning non-trivial sharding " << sharding; - for (;;) { - TF_ASSIGN_OR_RETURN(int64 assigned, - ApplyDomainShardingPass(domain, sharding)); - if (assigned == 0) { - break; - } - } + TF_RETURN_IF_ERROR(ApplyDomainShardingPass(domain, sharding).status()); + int64 unassigned = 0; for (HloInstruction* instruction : domain.instructions) { if (!instruction->has_sharding()) { LOG(WARNING) << "Unassigned instruction: " << instruction->ToString(); ++unassigned; + } else { + // Un-set sharding of tuples whose sub-sgardings are assigned to + // kUnassignedDevice. Indeed in case of doubt it is better to leave the + // entire tuple unassigned, and let the device placer decide for it. + if (instruction->sharding().UsesDevice(kUnassignedDevice)) { + TF_RET_CHECK(ShapeUtil::IsTuple(instruction->shape())) + << "Only tuples can have kUnassignedDevice sub shardings"; + instruction->clear_sharding(); + } } } // Should we error out if unassigned > 0? return Status::OK(); } -// Creates a kDomain instruction to be placed between instruction and operand. -// The kDomain instruction will be created only if the sharding differ between -// the instruction and the operand. -std::unique_ptr<HloInstruction> CreateDomain(HloInstruction* instruction, - HloInstruction* operand) { - const HloSharding* instruction_sharding = - instruction->has_sharding() ? &instruction->sharding() : nullptr; - const HloSharding* operand_sharding = - operand->has_sharding() ? &operand->sharding() : nullptr; - // No need for domain if they both have no sharding. - if (instruction_sharding == nullptr && operand_sharding == nullptr) { - return nullptr; - } - // No need for domain if they match. - if (instruction_sharding != nullptr && operand_sharding != nullptr && - ShardingMatches(*instruction_sharding, *operand_sharding)) { - return nullptr; - } - std::unique_ptr<HloSharding> real_instruction_sharding; - std::unique_ptr<HloSharding> real_operand_sharding; - if (instruction_sharding != nullptr) { - real_instruction_sharding = CloneShardingForDomain(*instruction_sharding); - } - if (operand_sharding != nullptr) { - real_operand_sharding = CloneShardingForDomain(*operand_sharding); - } - VLOG(3) << "Creating domain:"; - VLOG(3) << " Instruction: " << instruction->name(); - VLOG(3) << " Operand: " << operand->name(); - VLOG(3) << " User side sharding: " - << (real_instruction_sharding != nullptr - ? real_instruction_sharding->ToString() - : "None"); - VLOG(3) << " Operand side sharding: " - << (real_operand_sharding != nullptr - ? real_operand_sharding->ToString() - : "None"); - - std::unique_ptr<DomainMetadata> operand_side_metadata = - MakeUnique<ShardingMetadata>(std::move(real_operand_sharding)); - std::unique_ptr<DomainMetadata> user_side_metadata = - MakeUnique<ShardingMetadata>(std::move(real_instruction_sharding)); - return HloInstruction::CreateDomain(operand->shape(), operand, - std::move(operand_side_metadata), - std::move(user_side_metadata)); -} - -StatusOr<std::unique_ptr<HloSharding>> ExtractOriginalCommonSharding( +StatusOr<std::shared_ptr<const HloSharding>> ExtractOriginalCommonSharding( tensorflow::gtl::ArraySlice<HloInstruction*> instructions) { // If we are here, all the instructions being passed had the same sharding // (or no sharding), by the means of the ShardingMatches() API. // As such, no kDomain was inserted, and here we are asked to extract the // original common sharding. // All the instructions passed to this API are part of the same computation. - const HloSharding* sharding = nullptr; + std::shared_ptr<const HloSharding> sharding; for (HloInstruction* instruction : instructions) { if (instruction->has_sharding()) { if (sharding == nullptr) { - sharding = &instruction->sharding(); + sharding = instruction->sharding_ptr(); } else { TF_RET_CHECK(ShardingMatches(*sharding, instruction->sharding())) << "Sharding " << *sharding << " does not match the one in " @@ -346,10 +391,10 @@ StatusOr<std::unique_ptr<HloSharding>> ExtractOriginalCommonSharding( } } if (sharding == nullptr) { - return std::unique_ptr<HloSharding>(); + return std::shared_ptr<const HloSharding>(); } VLOG(4) << "Extracted sharding is " << *sharding; - return CloneShardingForDomain(*sharding); + return CloneShardingForDomain(sharding); } } // namespace @@ -357,9 +402,9 @@ StatusOr<std::unique_ptr<HloSharding>> ExtractOriginalCommonSharding( std::unique_ptr<DomainMetadata> ShardingMetadata::Clone() const { std::unique_ptr<HloSharding> sharding; if (sharding_ != nullptr) { - sharding = MakeUnique<HloSharding>(*sharding_); + sharding = absl::make_unique<HloSharding>(*sharding_); } - return MakeUnique<ShardingMetadata>(std::move(sharding)); + return absl::make_unique<ShardingMetadata>(std::move(sharding)); } bool ShardingMetadata::Matches(const DomainMetadata& other) const { @@ -403,7 +448,7 @@ Status ShardingMetadata::NormalizeShardingDomain( TF_RETURN_IF_ERROR(FixupPassThroughDomainLinks(domain, *sharding)); } } else { - TF_ASSIGN_OR_RETURN(std::unique_ptr<HloSharding> sharding, + TF_ASSIGN_OR_RETURN(std::shared_ptr<const HloSharding> sharding, ExtractOriginalCommonSharding(domain.instructions)); if (sharding != nullptr) { VLOG(4) << "Normalizing sharding-less domain to " << sharding->ToString(); @@ -415,9 +460,75 @@ Status ShardingMetadata::NormalizeShardingDomain( return Status::OK(); } -std::unique_ptr<HloInstruction> CreateShardingDomain( - HloInstruction* instruction, HloInstruction* operand) { - return CreateDomain(instruction, operand); +// Creates a kDomain instruction to be placed between instruction and operand. +// The kDomain instruction will be created only if the sharding differ between +// the instruction and the operand. +HloInstruction* ShardingDomainCreator::operator()(HloInstruction* instruction, + HloInstruction* root, + HloInstruction* operand) { + auto instruction_sharding = instruction->sharding_ptr(); + auto root_sharding = root->sharding_ptr(); + // No need for domain if they both have no sharding. + if (instruction_sharding == nullptr && root_sharding == nullptr) { + return nullptr; + } + // No need for domain if they match. + if (instruction_sharding != nullptr && root_sharding != nullptr && + ShardingMatches(*instruction_sharding, *root_sharding)) { + return nullptr; + } + + if (instruction_sharding != nullptr) { + instruction_sharding = CloneShardingForDomain(instruction_sharding); + } + if (root_sharding != nullptr) { + root_sharding = CloneShardingForDomain(root_sharding); + } + + auto it = domain_cse_map_.find({operand, instruction_sharding}); + if (it != domain_cse_map_.end()) { + return it->second; + } + + VLOG(3) << "Creating domain:"; + VLOG(3) << " Instruction: " << instruction->name(); + VLOG(3) << " Operand: " << operand->name(); + VLOG(3) << " User side sharding: " + << (instruction_sharding != nullptr ? instruction_sharding->ToString() + : "None"); + VLOG(3) << " Operand side sharding: " + << (root_sharding != nullptr ? root_sharding->ToString() : "None"); + + HloInstruction* domain = + operand->parent()->AddInstruction(HloInstruction::CreateDomain( + operand->shape(), operand, + absl::make_unique<ShardingMetadata>(root_sharding), + absl::make_unique<ShardingMetadata>(instruction_sharding))); + domain_cse_map_.emplace(DomainCseMapKey{operand, instruction_sharding}, + domain); + return domain; +} + +bool ShardingDomainCreator::DomainCseMapKey::operator==( + const ShardingDomainCreator::DomainCseMapKey& other) const { + if (instruction != other.instruction) { + return false; + } + if (sharding == nullptr && other.sharding == nullptr) { + return true; + } + if (sharding == nullptr || other.sharding == nullptr) { + return false; + } + return *sharding == *other.sharding; +} + +size_t ShardingDomainCreator::DomainCseMapHasher::operator()( + const ShardingDomainCreator::DomainCseMapKey& key) const { + return tensorflow::Hash64Combine( + std::hash<const HloInstruction*>{}(key.instruction), + key.sharding ? key.sharding->Hash() + : static_cast<size_t>(0x297814aaad196e6dULL)); } } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_sharding_metadata.h b/tensorflow/compiler/xla/service/hlo_sharding_metadata.h index 5e01fc0e22..7a6b0d9abc 100644 --- a/tensorflow/compiler/xla/service/hlo_sharding_metadata.h +++ b/tensorflow/compiler/xla/service/hlo_sharding_metadata.h @@ -27,12 +27,12 @@ namespace xla { // A DomainMetadata implementation that internally wraps a sharding attribute. class ShardingMetadata : public DomainMetadata { public: - explicit ShardingMetadata(std::unique_ptr<HloSharding> sharding) + explicit ShardingMetadata(std::shared_ptr<const HloSharding> sharding) : sharding_(std::move(sharding)) {} std::unique_ptr<DomainMetadata> Clone() const override; - tensorflow::StringPiece Kind() const override { return KindName(); } + absl::string_view Kind() const override { return KindName(); } bool Matches(const DomainMetadata& other) const override; @@ -40,7 +40,7 @@ class ShardingMetadata : public DomainMetadata { const HloSharding* sharding() const { return sharding_.get(); } - static tensorflow::StringPiece KindName() { return "sharding"; } + static absl::string_view KindName() { return "sharding"; } static StatusOr<const ShardingMetadata*> ToShardingMetadata( const DomainMetadata* metadata); @@ -55,15 +55,33 @@ class ShardingMetadata : public DomainMetadata { const DomainMetadata* metadata); private: - std::unique_ptr<HloSharding> sharding_; + std::shared_ptr<const HloSharding> sharding_; }; -// Given an HLO graph edge between instruction and one of its operands, creates -// a ShardingMetadata based kDomain instruction if the sharding between -// instruction and operand changes. Returns nullptr if there is no need for a -// domain separation. -std::unique_ptr<HloInstruction> CreateShardingDomain( - HloInstruction* instruction, HloInstruction* operand); +// If the sharding between root and instruction changes then returns a +// ShardingMetadata based kDomain instruction what can be used to separate +// operand and instruction. +// Returns nullptr if there is no need for a domain separation. +class ShardingDomainCreator { + public: + HloInstruction* operator()(HloInstruction* instruction, HloInstruction* root, + HloInstruction* operand); + + private: + // Map from instruction and user sharding to domain users to CSE identical + // domains. + struct DomainCseMapKey { + const HloInstruction* instruction; + std::shared_ptr<const HloSharding> sharding; + + bool operator==(const DomainCseMapKey& other) const; + }; + struct DomainCseMapHasher { + size_t operator()(const DomainCseMapKey& key) const; + }; + std::unordered_map<DomainCseMapKey, HloInstruction*, DomainCseMapHasher> + domain_cse_map_; +}; } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_sharding_test.cc b/tensorflow/compiler/xla/service/hlo_sharding_test.cc index 45fc300fca..2341f8ada0 100644 --- a/tensorflow/compiler/xla/service/hlo_sharding_test.cc +++ b/tensorflow/compiler/xla/service/hlo_sharding_test.cc @@ -115,6 +115,13 @@ TEST_F(HloShardingTest, Tile) { } } +// Tests that empty tuple is supported. +TEST_F(HloShardingTest, EmptySingleTuple) { + HloSharding sharding = HloSharding::SingleTuple(ShapeUtil::MakeTupleShape({}), + HloSharding::AssignDevice(0)); + EXPECT_TRUE(sharding.ExtractSingleSharding()); +} + TEST_F(HloShardingTest, NestedTuple) { // nested_tuple_shape = (f32[], (f32[3]), f32[4, 6]) Shape nested_tuple_shape = ShapeUtil::MakeTupleShape({ diff --git a/tensorflow/compiler/xla/service/hlo_subcomputation_unification.h b/tensorflow/compiler/xla/service/hlo_subcomputation_unification.h index 2ef38821af..d1cf644f82 100644 --- a/tensorflow/compiler/xla/service/hlo_subcomputation_unification.h +++ b/tensorflow/compiler/xla/service/hlo_subcomputation_unification.h @@ -24,7 +24,7 @@ namespace xla { // one arbitrarily to use and delete the others. class HloSubcomputationUnification : public HloPassInterface { public: - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "subcomputation-unification"; } diff --git a/tensorflow/compiler/xla/service/hlo_tfgraph_builder.cc b/tensorflow/compiler/xla/service/hlo_tfgraph_builder.cc index b78bfa0cdf..4876533449 100644 --- a/tensorflow/compiler/xla/service/hlo_tfgraph_builder.cc +++ b/tensorflow/compiler/xla/service/hlo_tfgraph_builder.cc @@ -14,6 +14,8 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/hlo_tfgraph_builder.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" @@ -21,28 +23,25 @@ limitations under the License. #include "tensorflow/core/framework/attr_value.pb.h" #include "tensorflow/core/framework/op.h" #include "tensorflow/core/framework/tensor_shape.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" - -using ::tensorflow::GraphDef; -using ::tensorflow::NodeDef; -using ::tensorflow::TensorShapeProto; -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; -using ::tensorflow::str_util::Join; namespace xla { namespace hlo_graph_dumper { namespace { +using absl::StrAppend; +using absl::StrCat; +using tensorflow::GraphDef; +using tensorflow::NodeDef; +using tensorflow::TensorShapeProto; + string GetOpDefName(const HloInstruction* instruction) { string name = StrCat("hlo-", HloOpcodeString(instruction->opcode())); - tensorflow::str_util::TitlecaseString(&name, "-"); + tensorflow::str_util::TitlecaseString(&name, "-"); // non-absl ok name.erase(std::remove(name.begin(), name.end(), '-'), name.end()); if (instruction->opcode() == HloOpcode::kFusion) { string fusion_name = ToString(instruction->fusion_kind()); - StrAppend(&name, tensorflow::StringPiece(fusion_name).substr(1)); + StrAppend(&name, absl::string_view(fusion_name).substr(1)); } return name; } @@ -166,7 +165,9 @@ void HloTfGraphBuilder::SetNodeAttrs(const HloInstruction* instruction, layout_string = ShapeUtil::HumanStringWithLayout(instruction->shape()); } else { layout_string = StrCat( - "{", Join(LayoutUtil::MinorToMajor(instruction->shape()), ","), "}"); + "{", + absl::StrJoin(LayoutUtil::MinorToMajor(instruction->shape()), ","), + "}"); } attrs["layout"].set_s(layout_string); } diff --git a/tensorflow/compiler/xla/service/hlo_value.cc b/tensorflow/compiler/xla/service/hlo_value.cc index 7fd99fc930..e0c1326177 100644 --- a/tensorflow/compiler/xla/service/hlo_value.cc +++ b/tensorflow/compiler/xla/service/hlo_value.cc @@ -18,8 +18,10 @@ limitations under the License. #include <algorithm> #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" @@ -30,16 +32,13 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" namespace xla { -using ::tensorflow::str_util::Join; -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; +using absl::StrAppend; +using absl::StrCat; const Shape& HloPosition::shape() const { return ShapeUtil::GetSubshape(instruction->shape(), index); @@ -216,10 +215,11 @@ void HloValueSet::SortAndUniquifyValues() { } string HloValueSet::ToString() const { - return StrCat("HloValueSet: ", - Join(values_, ", ", [](string* result, const HloValue* value) { - result->append(value->ToShortString()); - })); + return StrCat( + "HloValueSet: ", + absl::StrJoin(values_, ", ", [](string* result, const HloValue* value) { + result->append(value->ToShortString()); + })); } bool HloValueSet::AssignUnionOf( diff --git a/tensorflow/compiler/xla/service/hlo_verifier.cc b/tensorflow/compiler/xla/service/hlo_verifier.cc index ac1a663633..f1b29c2559 100644 --- a/tensorflow/compiler/xla/service/hlo_verifier.cc +++ b/tensorflow/compiler/xla/service/hlo_verifier.cc @@ -15,11 +15,13 @@ limitations under the License. #include <set> +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/hlo_casting_utils.h" #include "tensorflow/compiler/xla/service/hlo_instructions.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/service/hlo_verifier.h" #include "tensorflow/compiler/xla/status_macros.h" +#include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/gtl/flatmap.h" @@ -115,6 +117,11 @@ Status ShapeVerifier::HandleAllToAll(HloInstruction* hlo) { ShapeInference::InferAllToAllTupleShape(operand_shapes)); } +Status ShapeVerifier::HandleCollectivePermute(HloInstruction* hlo) { + return CheckShape(hlo, ShapeInference::InferCollectivePermuteShape( + hlo->operand(0)->shape())); +} + Status ShapeVerifier::HandleReducePrecision(HloInstruction* reduce_precision) { return CheckShape(reduce_precision, ShapeInference::InferReducePrecisionShape( reduce_precision->operand(0)->shape(), @@ -122,39 +129,32 @@ Status ShapeVerifier::HandleReducePrecision(HloInstruction* reduce_precision) { reduce_precision->mantissa_bits())); } -namespace { - -Status CheckIsTokenOperand(const HloInstruction* instruction, - int64 operand_no) { +Status ShapeVerifier::CheckIsTokenOperand(const HloInstruction* instruction, + int64 operand_no) { const HloInstruction* token = instruction->operand(operand_no); if (!ShapeUtil::Equal(token->shape(), ShapeUtil::MakeTokenShape())) { return InternalError( - "Expected operand %lld to be token-shaped, actual shape is " + "Expected operand %d to be token-shaped, actual shape is " "%s:\n%s", - operand_no, ShapeUtil::HumanString(token->shape()).c_str(), - instruction->ToString().c_str()); + operand_no, StringifyShape(token->shape()), instruction->ToString()); } return Status::OK(); } -Status CheckOperandAndParameter(const HloInstruction* instruction, - int64 operand_number, - const HloComputation* computation, - int64 parameter_number) { +Status ShapeVerifier::CheckOperandAndParameter( + const HloInstruction* instruction, int64 operand_number, + const HloComputation* computation, int64 parameter_number) { const HloInstruction* operand = instruction->operand(operand_number); const HloInstruction* parameter = computation->parameter_instruction(parameter_number); - if (!ShapeUtil::Compatible(operand->shape(), parameter->shape())) { + if (!ShapesSame(operand->shape(), parameter->shape())) { return InternalError("Operand %s shape does not match parameter's %s in %s", - operand->ToString().c_str(), - parameter->ToString().c_str(), - instruction->ToString().c_str()); + operand->ToString(), parameter->ToString(), + instruction->ToString()); } return Status::OK(); } -} // namespace - Status ShapeVerifier::HandleInfeed(HloInstruction* instruction) { HloInfeedInstruction* infeed = Cast<HloInfeedInstruction>(instruction); TF_RETURN_IF_ERROR(CheckIsTokenOperand(instruction, 0)); @@ -171,22 +171,16 @@ Status ShapeVerifier::HandleOutfeed(HloInstruction* instruction) { // Outfeed has a separate shape field for the value which is outfed to the // host. The shape of the instruction itself is always a token. - if (!ShapeUtil::Compatible(outfeed->outfeed_shape(), - outfeed->operand(0)->shape())) { + if (!ShapesSame(outfeed->outfeed_shape(), outfeed->operand(0)->shape())) { return InternalError( - "Expected outfeed shape to be compatible with operand's shape %s, " + "Expected outfeed shape to be equal to operand's shape %s, " "actual shape is %s:\n%s", - ShapeUtil::HumanString(outfeed->operand(0)->shape()).c_str(), - ShapeUtil::HumanString(outfeed->outfeed_shape()).c_str(), - outfeed->ToString().c_str()); + StringifyShape(outfeed->operand(0)->shape()), + StringifyShape(outfeed->outfeed_shape()), outfeed->ToString()); } return CheckShape(outfeed, ShapeUtil::MakeTokenShape()); } -Status ShapeVerifier::HandleHostCompute(HloInstruction*) { - return Status::OK(); -} - bool ShapeVerifier::HasCompatibleElementTypes(const Shape& shape_0, const Shape& shape_1, const Shape& result_shape) { @@ -200,7 +194,7 @@ bool ShapeVerifier::HasCompatibleElementTypes(const Shape& shape_0, Status ShapeVerifier::HandleRng(HloInstruction* instruction) { if (instruction->operand_count() != 2) { return InternalError("Expected two operands for Rng instruction: %s", - instruction->ToString().c_str()); + instruction->ToString()); } const Shape& shape_0 = instruction->operand(0)->shape(); @@ -208,14 +202,14 @@ Status ShapeVerifier::HandleRng(HloInstruction* instruction) { if (!ShapeUtil::IsScalar(shape_0) || !ShapeUtil::IsScalar(shape_1)) { return InternalError( "Expected scalar types for the two operands of Rng instruction: %s", - instruction->ToString().c_str()); + instruction->ToString()); } if (!HasCompatibleElementTypes(shape_0, shape_1, instruction->shape())) { return InternalError( "Expected compatible element types for the result and the two operands" " of Rng instruction: %s", - instruction->ToString().c_str()); + instruction->ToString()); } PrimitiveType element_type = shape_0.element_type(); @@ -228,7 +222,7 @@ Status ShapeVerifier::HandleRng(HloInstruction* instruction) { "Element type not supported." " Expected element to be of floating point type, integral type or" " predicate type for RngUniform: %s", - instruction->ToString().c_str()); + instruction->ToString()); } break; @@ -237,13 +231,13 @@ Status ShapeVerifier::HandleRng(HloInstruction* instruction) { return InternalError( "Element type not supported." " Expected element to be FloatingPointType for RngNormal: %s", - instruction->ToString().c_str()); + instruction->ToString()); } break; default: return InternalError( "Invalid Rng distribution %s", - RandomDistribution_Name(instruction->random_distribution()).c_str()); + RandomDistribution_Name(instruction->random_distribution())); } return Status::OK(); @@ -262,8 +256,8 @@ Status ShapeVerifier::HandleSort(HloInstruction* sort) { return InternalError( "Expected sort to have to have the same dimensions for the keys and " "the values. Keys shape is: %s\n, Values shape is: %s", - ShapeUtil::HumanString(sort->operand(0)->shape()).c_str(), - ShapeUtil::HumanString(sort->operand(1)->shape()).c_str()); + StringifyShape(sort->operand(0)->shape()), + StringifyShape(sort->operand(1)->shape())); } return CheckVariadicShape(sort); } @@ -272,10 +266,18 @@ Status ShapeVerifier::HandleConstant(HloInstruction* constant) { return CheckShape(constant, constant->literal().shape()); } -Status ShapeVerifier::HandleIota(HloInstruction* iota) { - return ShapeUtil::Rank(iota->shape()) == 1 - ? Status::OK() - : InternalError("Iota only supports arrays of rank 1."); +Status ShapeVerifier::HandleIota(HloInstruction* instruction) { + auto* iota = Cast<HloIotaInstruction>(instruction); + const int64 rank = ShapeUtil::Rank(iota->shape()); + if (rank == 0) { + return InternalError("Iota does not support scalars."); + } + int64 iota_dimension = iota->iota_dimension(); + if (iota_dimension >= rank) { + return InternalError( + "The iota dimension cannot go beyond the operation rank."); + } + return Status::OK(); } Status ShapeVerifier::HandleGetTupleElement(HloInstruction* get_tuple_element) { @@ -337,7 +339,18 @@ Status ShapeVerifier::HandleParameter(HloInstruction* hlo) { return Status::OK(); } -Status ShapeVerifier::HandleFusion(HloInstruction*) { return Status::OK(); } +Status ShapeVerifier::HandleFusion(HloInstruction* fusion) { + for (HloInstruction* fused_param : fusion->fused_parameters()) { + int64 param_no = fused_param->parameter_number(); + if (!ShapesSame(fused_param->shape(), fusion->operand(param_no)->shape())) { + return InternalError( + "Shape mismatch between parameter number %d and its operand in " + "%s.", + param_no, fusion->ToString().c_str()); + } + } + return Status::OK(); +} Status ShapeVerifier::HandleCall(HloInstruction* call) { for (int64 i = 0; i < call->to_apply()->num_parameters(); ++i) { @@ -419,12 +432,11 @@ Status ShapeVerifier::HandleWhile(HloInstruction* xla_while) { CheckOperandAndParameter(xla_while, 0, xla_while->while_condition(), 0)); const Shape& conditional_shape = xla_while->while_condition()->root_instruction()->shape(); - if (!ShapeUtil::Compatible(conditional_shape, - ShapeUtil::MakeShape(PRED, {}))) { + if (!ShapesSame(conditional_shape, ShapeUtil::MakeShape(PRED, {}))) { return InternalError( "Conditional computation shape does not lead to a scalar predicate " "shape: %s", - ShapeUtil::HumanString(conditional_shape).c_str()); + StringifyShape(conditional_shape)); } // The shape of kWhile should match the shape of the body computation it // calls. @@ -555,7 +567,7 @@ Status CheckMixedPrecisionOperands(const HloInstruction* instruction) { return InternalError( "Seen floating point types of different precisions in " "%s, but mixed precision is disallowed.", - instruction->ToString().c_str()); + instruction->ToString()); } return Status::OK(); })); @@ -602,53 +614,51 @@ Status ShapeVerifier::CheckShape(const HloInstruction* instruction, } // Check if the output shape matches the expected shape. - bool compatible; + // // We treat BF16 and F32 as compatible types if mixed precision is allowed, // but only when the instruction defines the BF16/F32 buffer. - switch (instruction->opcode()) { - case HloOpcode::kTupleSelect: - // TupleSelect only defines the top-level buffer, which in this case is - // the tuple, so we cannot allow mixed precision. - compatible = ShapeUtil::Compatible(instruction->shape(), inferred_shape); - break; - case HloOpcode::kGetTupleElement: - case HloOpcode::kTuple: - // Tuple and GetTupleElement do not define BF16/F32 buffers, so mixed - // precision is disallowed. - case HloOpcode::kConstant: - case HloOpcode::kBitcast: - case HloOpcode::kBitcastConvert: - case HloOpcode::kCall: - case HloOpcode::kConditional: - case HloOpcode::kConvert: - case HloOpcode::kCustomCall: - case HloOpcode::kInfeed: - case HloOpcode::kOutfeed: - case HloOpcode::kParameter: - case HloOpcode::kRecv: - case HloOpcode::kRecvDone: - case HloOpcode::kSend: - case HloOpcode::kSendDone: - case HloOpcode::kWhile: - // The above opcodes should match the expected shapes exactly. - compatible = ShapeUtil::Compatible(instruction->shape(), inferred_shape); - break; - default: - if (allow_mixed_precision_) { - compatible = ShapeUtil::CompatibleIgnoringFpPrecision( - instruction->shape(), inferred_shape); - } else { - compatible = - ShapeUtil::Compatible(instruction->shape(), inferred_shape); - } - } - if (!compatible) { + bool equal = [&] { + switch (instruction->opcode()) { + // The opcodes below can't have implicit layout conversions, nor can they + // implicitly transform f32 -> bf16. Fundamentally these are either + // reinterpreting existing data (e.g. kBitcast) or shuffling data around + // without modifying it (e.g. kGetTupleElement, kTupleSelect). + case HloOpcode::kBitcast: + case HloOpcode::kCall: + case HloOpcode::kConditional: + case HloOpcode::kConstant: + case HloOpcode::kCustomCall: + case HloOpcode::kGetTupleElement: + case HloOpcode::kInfeed: + case HloOpcode::kOutfeed: + case HloOpcode::kParameter: + case HloOpcode::kRecv: + case HloOpcode::kRecvDone: + case HloOpcode::kSend: + case HloOpcode::kSendDone: + case HloOpcode::kTuple: + case HloOpcode::kTupleSelect: + case HloOpcode::kWhile: + return ShapesSame(instruction->shape(), inferred_shape); + + // We allow arbitrary layout and f32->bf16 transformations on all other + // instructions, although this may be made more strict pending discussion + // in b/112709536. + default: + if (allow_mixed_precision_) { + return ShapeUtil::CompatibleIgnoringFpPrecision(instruction->shape(), + inferred_shape); + } else { + return ShapeUtil::Compatible(instruction->shape(), inferred_shape); + } + } + }(); + if (!equal) { return InternalError( - "Expected instruction to have shape compatible with %s, actual " + "Expected instruction to have shape equal to %s, actual " "shape is %s:\n%s", - ShapeUtil::HumanString(inferred_shape).c_str(), - ShapeUtil::HumanString(instruction->shape()).c_str(), - instruction->ToString().c_str()); + StringifyShape(inferred_shape), StringifyShape(instruction->shape()), + instruction->ToString()); } return Status::OK(); } @@ -692,10 +702,10 @@ Status ShapeVerifier::CheckVariadicShape(const HloInstruction* instruction) { string ComputationsToString( tensorflow::gtl::ArraySlice<HloComputation*> computations) { - return tensorflow::str_util::Join( - computations, ",", [](string* s, const HloComputation* computation) { - s->append(computation->name()); - }); + return absl::StrJoin(computations, ",", + [](string* s, const HloComputation* computation) { + s->append(computation->name()); + }); } // Verifies various invariants about the structure of the HLO: @@ -713,23 +723,23 @@ Status VerifyHloStructure(HloModule* module) { for (const HloComputation* computation : module->computations()) { if (computation->parent() == nullptr) { return InternalError("Computation %s has a null parent pointer", - computation->name().c_str()); + computation->name()); } if (computation->parent() != module) { return InternalError( "Computation %s parent() does not point to parent module", - computation->name().c_str()); + computation->name()); } for (const HloInstruction* instruction : computation->instructions()) { if (instruction->parent() == nullptr) { return InternalError("Instruction %s has a null parent pointer", - instruction->name().c_str()); + instruction->name()); } if (instruction->parent() != computation) { return InternalError( "Instruction %s parent() does not point to parent computation", - instruction->name().c_str()); + instruction->name()); } } } @@ -746,9 +756,8 @@ Status VerifyHloStructure(HloModule* module) { return InternalError( "Operand %d (%s) of instruction %s is in a different " "computation: %s vs %s", - i, operand->name().c_str(), instruction->name().c_str(), - operand->parent()->name().c_str(), - instruction->parent()->name().c_str()); + i, operand->name(), instruction->name(), + operand->parent()->name(), instruction->parent()->name()); } } } @@ -764,7 +773,7 @@ Status HloVerifier::CheckFusionInstruction(HloInstruction* fusion) const { "Instruction of fused computation does not match expected " "instruction " "%s.", - fusion->ToString().c_str()); + fusion->ToString()); } // Fused root instruction and fused parameters must all be owned by the @@ -778,7 +787,7 @@ Status HloVerifier::CheckFusionInstruction(HloInstruction* fusion) const { if (fused_root == instruction) { if (root_owned) { return InternalError("Root appears more than once in %s.", - fusion->ToString().c_str()); + fusion->ToString()); } root_owned = true; } @@ -786,7 +795,7 @@ Status HloVerifier::CheckFusionInstruction(HloInstruction* fusion) const { if (fused_parameters[i] == instruction) { if (parameter_owned[i]) { return InternalError("Parameter appears more than once in %s.", - fusion->ToString().c_str()); + fusion->ToString()); } parameter_owned[i] = true; } @@ -794,20 +803,19 @@ Status HloVerifier::CheckFusionInstruction(HloInstruction* fusion) const { } if (!root_owned) { return InternalError("Root not found in computation of %s.", - fusion->ToString().c_str()); + fusion->ToString()); } // Make sure all the parameter_owned entries are set for (int i = 0; i < parameter_owned.size(); i++) { if (!parameter_owned[i]) { return InternalError("Parameter %d not found in computation of %s.", i, - fusion->ToString().c_str()); + fusion->ToString()); } } // Fused root must have no users. if (fused_root->user_count() != 0) { - return InternalError("Root of %s may not have users.", - fusion->ToString().c_str()); + return InternalError("Root of %s may not have users.", fusion->ToString()); } // All uses of fused instructions must be in the fusion computation, and @@ -817,54 +825,46 @@ Status HloVerifier::CheckFusionInstruction(HloInstruction* fusion) const { if (instruction != fused_root) { if (instruction->user_count() == 0) { return InternalError("Non-root instruction %s in %s must have users.", - instruction->ToString().c_str(), - fusion->ToString().c_str()); + instruction->ToString(), fusion->ToString()); } for (auto& user : instruction->users()) { if (fused_computation != user->parent()) { return InternalError( "Non-root instruction %s in %s may not have external users.", - instruction->ToString().c_str(), fusion->ToString().c_str()); + instruction->ToString(), fusion->ToString()); } } } } // Fused parameter instructions must be numbered contiguously and match up - // (shapes compatible) with their respective operand. + // (shapes equal) with their respective operand. CHECK_EQ(fusion->operands().size(), fused_parameters.size()); std::vector<bool> parameter_numbers(fused_parameters.size(), false); for (auto fused_param : fused_parameters) { int64 param_no = fused_param->parameter_number(); if (param_no < 0) { - return InternalError("Unexpected negative parameter number %lld in %s.", - param_no, fusion->ToString().c_str()); + return InternalError("Unexpected negative parameter number %d in %s.", + param_no, fusion->ToString()); } if (param_no >= fused_parameters.size()) { return InternalError( - "Unexpected parameter number %lld in %s: higher then number of " + "Unexpected parameter number %d in %s: higher then number of " "parameters %lu.", - param_no, fusion->ToString().c_str(), fused_parameters.size()); + param_no, fusion->ToString(), fused_parameters.size()); } if (parameter_numbers[param_no]) { return InternalError( - "Did not expect parameter number %lld more than once in %s.", - param_no, fusion->ToString().c_str()); + "Did not expect parameter number %d more than once in %s.", param_no, + fusion->ToString()); } parameter_numbers[param_no] = true; - if (!ShapeUtil::Compatible(fused_param->shape(), - fusion->operand(param_no)->shape())) { - return InternalError( - "Shape mismatch between parameter number %lld and its operand in " - "%s.", - param_no, fusion->ToString().c_str()); - } } // Make sure all the parameter_numbers entries were seen. for (int i = 0; i < parameter_numbers.size(); i++) { if (!parameter_numbers[i]) { return InternalError("Did not see parameter number %d in %s.", i, - fusion->ToString().c_str()); + fusion->ToString()); } } @@ -879,18 +879,18 @@ Status HloVerifier::CheckWhileInstruction(HloInstruction* instruction) { auto* while_body = instruction->while_body(); if (while_cond->num_parameters() != 1) { return FailedPrecondition( - "While condition must have exactly 1 parameter; had %lld : %s", - while_cond->num_parameters(), while_cond->ToString().c_str()); + "While condition must have exactly 1 parameter; had %d : %s", + while_cond->num_parameters(), while_cond->ToString()); } if (while_body->num_parameters() != 1) { return FailedPrecondition( - "While body must have exactly 1 parameter; had %lld : %s", - while_body->num_parameters(), while_body->ToString().c_str()); + "While body must have exactly 1 parameter; had %d : %s", + while_body->num_parameters(), while_body->ToString()); } if (instruction->operand_count() != 1) { return FailedPrecondition( - "While loop must have exactly one operand; had %lld : %s", - instruction->operand_count(), instruction->ToString().c_str()); + "While loop must have exactly one operand; had %d : %s", + instruction->operand_count(), instruction->ToString()); } return Status::OK(); } @@ -898,16 +898,14 @@ Status HloVerifier::CheckWhileInstruction(HloInstruction* instruction) { Status HloVerifier::CheckConditionalInstruction(HloInstruction* instruction) { if (instruction->true_computation()->num_parameters() != 1) { return FailedPrecondition( - "True computation %s of %s must have 1 parameter insted of %lld", - instruction->true_computation()->name().c_str(), - instruction->ToString().c_str(), + "True computation %s of %s must have 1 parameter insted of %d", + instruction->true_computation()->name(), instruction->ToString(), instruction->true_computation()->num_parameters()); } if (instruction->false_computation()->num_parameters() != 1) { return FailedPrecondition( - "False computation %s of %s must have 1 parameter insted of %lld", - instruction->false_computation()->name().c_str(), - instruction->ToString().c_str(), + "False computation %s of %s must have 1 parameter insted of %d", + instruction->false_computation()->name(), instruction->ToString(), instruction->false_computation()->num_parameters()); } return Status::OK(); @@ -920,11 +918,11 @@ Status HloVerifier::CheckElementwiseInstruction(HloInstruction* instruction) { if (!ShapeUtil::CompatibleIgnoringElementType(operand_shape, out_shape)) { return FailedPrecondition( "Implicit broadcast is not allowed in HLO." - "Found non-compatible shapes for instruction %s.\n" + "Found different shapes for instruction %s.\n" "output: %s\noperand: %s\n", - HloOpcodeString(instruction->opcode()).c_str(), - ShapeUtil::HumanString(out_shape).c_str(), - ShapeUtil::HumanString(operand_shape).c_str()); + HloOpcodeString(instruction->opcode()), + ShapeUtil::HumanString(out_shape), + ShapeUtil::HumanString(operand_shape)); } } return Status::OK(); @@ -955,7 +953,7 @@ Status VerifyEntryAndExitShapes(const HloModule& module) { if (ShapeContainsToken(param->shape())) { return InternalError( "Entry parameter %d is or contains a token shape: %s", i, - ShapeUtil::HumanString(param->shape()).c_str()); + ShapeUtil::HumanString(param->shape())); } } return Status::OK(); @@ -967,9 +965,9 @@ Status CheckSameChannel(const HloInstruction* instr1, if (instr1->channel_id() != instr2->channel_id()) { return InternalError( "Expected to have the same channel id, actual channel ids are: %s " - "(%lld), %s (%lld)", - instr1->ToString().c_str(), instr1->channel_id(), - instr2->ToString().c_str(), instr2->channel_id()); + "(%d), %s (%d)", + instr1->ToString(), instr1->channel_id(), instr2->ToString(), + instr2->channel_id()); } return Status::OK(); } @@ -990,7 +988,7 @@ Status CheckSameIsHostTransfer(const HloInstruction* instr1, "Expected instructions to have the same is-host-transfer property: " "%s, " "%s ", - instr1->ToString().c_str(), instr2->ToString().c_str()); + instr1->ToString(), instr2->ToString()); } return Status::OK(); } @@ -1007,12 +1005,12 @@ Status VerifySendsAndRecvs(const HloModule& module) { host_channels.insert({sendrecv->channel_id(), sendrecv}); if (!it_inserted.second) { return FailedPrecondition( - "Channel %lld is used for multiple host send/recv instructions: " + "Channel %d is used for multiple host send/recv instructions: " "%s " "and " "%s", - sendrecv->channel_id(), sendrecv->ToString().c_str(), - it_inserted.first->second->ToString().c_str()); + sendrecv->channel_id(), sendrecv->ToString(), + it_inserted.first->second->ToString()); } } diff --git a/tensorflow/compiler/xla/service/hlo_verifier.h b/tensorflow/compiler/xla/service/hlo_verifier.h index c942fab08e..42e3027bf1 100644 --- a/tensorflow/compiler/xla/service/hlo_verifier.h +++ b/tensorflow/compiler/xla/service/hlo_verifier.h @@ -18,6 +18,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_pass_interface.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/shape_inference.h" namespace xla { @@ -27,9 +28,9 @@ namespace xla { // TODO(b/26024837): Check output shape for all instruction types. class ShapeVerifier : public DfsHloVisitor { public: - explicit ShapeVerifier() : allow_mixed_precision_(false) {} - explicit ShapeVerifier(bool allow_mixed_precision) - : allow_mixed_precision_(allow_mixed_precision) {} + explicit ShapeVerifier(bool layout_sensitive, bool allow_mixed_precision) + : layout_sensitive_(layout_sensitive), + allow_mixed_precision_(allow_mixed_precision) {} Status HandleElementwiseUnary(HloInstruction* hlo) override; Status HandleElementwiseBinary(HloInstruction* hlo) override; @@ -46,6 +47,7 @@ class ShapeVerifier : public DfsHloVisitor { Status HandleFft(HloInstruction* fft) override; Status HandleCrossReplicaSum(HloInstruction* crs) override; Status HandleAllToAll(HloInstruction* hlo) override; + Status HandleCollectivePermute(HloInstruction* hlo) override; Status HandleReducePrecision(HloInstruction* reduce_precision) override; Status HandleInfeed(HloInstruction*) override; Status HandleOutfeed(HloInstruction*) override; @@ -63,7 +65,6 @@ class ShapeVerifier : public DfsHloVisitor { Status HandleFusion(HloInstruction*) override; Status HandleCall(HloInstruction* call) override; Status HandleCustomCall(HloInstruction*) override; - Status HandleHostCompute(HloInstruction*) override; Status HandleSlice(HloInstruction* slice) override; Status HandleDynamicSlice(HloInstruction* dynamic_slice) override; Status HandleDynamicUpdateSlice( @@ -106,13 +107,42 @@ class ShapeVerifier : public DfsHloVisitor { Status CheckVariadicShape(const HloInstruction* instruction); private: - // Return true if the shapes of the two operands have the same element type, - // and the result shape either has the same element type as the operand - // shapes or mixed precision is allowed and the result shape and the operand - // shapes have floating point element types. + // Helpers that switch on layout_sensitive_. + bool ShapesSame(const Shape& a, const Shape& b) { + return layout_sensitive_ ? ShapeUtil::Equal(a, b) + : ShapeUtil::Compatible(a, b); + } + bool ShapesSameIgnoringFpPrecision(const Shape& a, const Shape& b) { + return layout_sensitive_ ? ShapeUtil::EqualIgnoringFpPrecision(a, b) + : ShapeUtil::CompatibleIgnoringFpPrecision(a, b); + } + string StringifyShape(const Shape& s) { + return layout_sensitive_ ? ShapeUtil::HumanStringWithLayout(s) + : ShapeUtil::HumanString(s); + } + + // Checks that the given operand of the given instruction is of type TOKEN. + Status CheckIsTokenOperand(const HloInstruction* instruction, + int64 operand_no); + + // Checks that the shape of the given operand of the given instruction matches + // the given parameter of the given computation. + Status CheckOperandAndParameter(const HloInstruction* instruction, + int64 operand_number, + const HloComputation* computation, + int64 parameter_number); + + // Returns true if the shapes of the two operands have the same element type, + // and the result shape either has the same element type as the operand shapes + // or mixed precision is allowed and the result shape and the operand shapes + // have floating point element types. bool HasCompatibleElementTypes(const Shape& shape_0, const Shape& shape_1, const Shape& result_shape); + // If the verifier is layout-sensitive, shapes must be equal to what's + // expected. Otherwise, the shapes must simply be compatible. + bool layout_sensitive_; + // Whether the inputs and output of an instruction can contain both F32s and // BF16s. Tuples that include both F32s and BF16s are allowed regardless of // this flag. @@ -125,14 +155,10 @@ class HloVerifier : public HloPassInterface { public: using ShapeVerifierFactory = std::function<std::unique_ptr<ShapeVerifier>()>; - // Uses standard shape inference. - explicit HloVerifier() - : shape_verifier_factory_( - [] { return MakeUnique<ShapeVerifier>(false); }) {} - - explicit HloVerifier(bool allow_mixed_precision) - : shape_verifier_factory_([allow_mixed_precision] { - return MakeUnique<ShapeVerifier>(allow_mixed_precision); + explicit HloVerifier(bool layout_sensitive, bool allow_mixed_precision) + : shape_verifier_factory_([layout_sensitive, allow_mixed_precision] { + return absl::make_unique<ShapeVerifier>(layout_sensitive, + allow_mixed_precision); }) {} // Uses custom shape verification. @@ -140,10 +166,9 @@ class HloVerifier : public HloPassInterface { : shape_verifier_factory_(std::move(shape_verifier_factory)) {} ~HloVerifier() override = default; - tensorflow::StringPiece name() const override { return "verifier"; } + absl::string_view name() const override { return "verifier"; } - // Note: always returns false (no instructions are ever modified by this - // pass). + // Never returns true; no instructions are ever modified by this pass. StatusOr<bool> Run(HloModule* module) override; private: diff --git a/tensorflow/compiler/xla/service/hlo_verifier_test.cc b/tensorflow/compiler/xla/service/hlo_verifier_test.cc index d764964f3c..fc1f81bdd2 100644 --- a/tensorflow/compiler/xla/service/hlo_verifier_test.cc +++ b/tensorflow/compiler/xla/service/hlo_verifier_test.cc @@ -37,13 +37,15 @@ using ::testing::HasSubstr; class HloVerifierTest : public HloTestBase { public: HloVerifierTest() - : HloTestBase(/*allow_mixed_precision_in_hlo_verifier=*/false) {} + : HloTestBase(/*verifier_layout_sensitive=*/false, + /*allow_mixed_precision_in_hlo_verifier=*/false) {} }; class HloVerifierTestAllowMixedPrecision : public HloTestBase { public: HloVerifierTestAllowMixedPrecision() - : HloTestBase(/*allow_mixed_precision_in_hlo_verifier=*/true) {} + : HloTestBase(/*verifier_layout_sensitive=*/false, + /*allow_mixed_precision_in_hlo_verifier=*/true) {} }; TEST_F(HloVerifierTest, NullInstructionParent) { @@ -275,5 +277,84 @@ TEST_F(HloVerifierTest, RngElementTypeNotSupported) { EXPECT_THAT(status.error_message(), HasSubstr("Element type not supported")); } +TEST_F(HloVerifierTest, NegativeInteriorPaddingNotAllowed) { + // This testcase can't be written using textual HLO, because it doesn't parse + // negative interior padding. That's probably a feature. :) + HloComputation::Builder builder(TestName()); + HloInstruction* param = + builder.AddInstruction(HloInstruction::CreateParameter( + 0, ShapeUtil::MakeShape(F32, {100}), "param")); + PaddingConfig padding_config; + padding_config.add_dimensions()->set_interior_padding(-1); + builder.AddInstruction(HloInstruction::CreatePad( + ShapeUtil::MakeShape(F32, {100}), param, + builder.AddInstruction(HloInstruction::CreateConstant( + LiteralUtil::Zero(F32).CloneToUnique())), + padding_config)); + + auto module = CreateNewModule(); + module->AddEntryComputation(builder.Build()); + + auto status = verifier().Run(module.get()).status(); + ASSERT_FALSE(status.ok()); + EXPECT_THAT(status.error_message(), + HasSubstr("Interior padding cannot be negative")); +} + +TEST_F(HloVerifierTest, PadNegativeInteriorDilationNotAllowed) { + // This testcase can't be written using textual HLO, because it doesn't parse + // negative interior padding. That's probably a feature. :) + HloComputation::Builder builder(TestName()); + HloInstruction* param = + builder.AddInstruction(HloInstruction::CreateParameter( + 0, ShapeUtil::MakeShape(F32, {100}), "param")); + PaddingConfig padding_config; + padding_config.add_dimensions()->set_interior_padding(-1); + builder.AddInstruction(HloInstruction::CreatePad( + ShapeUtil::MakeShape(F32, {100}), param, + builder.AddInstruction(HloInstruction::CreateConstant( + LiteralUtil::Zero(F32).CloneToUnique())), + padding_config)); + + auto module = CreateNewModule(); + module->AddEntryComputation(builder.Build()); + + EXPECT_THAT(verifier().Run(module.get()).status().error_message(), + HasSubstr("Interior padding cannot be negative")); +} + +// Simple module containing a convolution as the root. +static const char* const kConvHloString = R"( +HloModule module +ENTRY entry_computation { + param0 = f16[128,128,56,56] parameter(0) + param1 = f16[3,3,128,128] parameter(1) + zero_f16 = f16[] constant(0) + ROOT conv = f16[128,128,28,28] convolution(param0, param1), + window={size=3x3 stride=2x2}, dim_labels=bf01_01io->bf01 +})"; + +TEST_F(HloVerifierTest, ConvNegativeWindowDilationNotAllowed) { + TF_ASSERT_OK_AND_ASSIGN(auto module, ParseHloString(kConvHloString)); + auto* conv = module->entry_computation()->root_instruction(); + Window w = conv->window(); + w.mutable_dimensions(0)->set_window_dilation(-1); + conv->set_window(w); + + EXPECT_THAT(verifier().Run(module.get()).status().error_message(), + HasSubstr("non-positive window dilation factor")); +} + +TEST_F(HloVerifierTest, ConvNegativeBaseDilationNotAllowed) { + TF_ASSERT_OK_AND_ASSIGN(auto module, ParseHloString(kConvHloString)); + auto* conv = module->entry_computation()->root_instruction(); + Window w = conv->window(); + w.mutable_dimensions(0)->set_base_dilation(-1); + conv->set_window(w); + + EXPECT_THAT(verifier().Run(module.get()).status().error_message(), + HasSubstr("non-positive base area dilation factor")); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/human_readable_profile_builder.cc b/tensorflow/compiler/xla/service/human_readable_profile_builder.cc index bb5b40a8a8..e76b93107c 100644 --- a/tensorflow/compiler/xla/service/human_readable_profile_builder.cc +++ b/tensorflow/compiler/xla/service/human_readable_profile_builder.cc @@ -14,27 +14,27 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/human_readable_profile_builder.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/metric_table_report.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" namespace xla { -using tensorflow::strings::Appendf; +using absl::StrAppend; +using absl::StrAppendFormat; +using absl::StrCat; +using absl::StrFormat; using tensorflow::strings::HumanReadableElapsedTime; using tensorflow::strings::HumanReadableNumBytes; -using tensorflow::strings::Printf; -using tensorflow::strings::StrAppend; -using tensorflow::strings::StrCat; string HumanReadableProfileBuilder::ToString() const { string s; - Appendf(&s, "Execution profile for %s: (%s @ f_nom)\n", - computation_name_.c_str(), - HumanReadableElapsedTime(CyclesToSeconds(total_cycles_)).c_str()); + StrAppendFormat(&s, "Execution profile for %s: (%s @ f_nom)\n", + computation_name_, + HumanReadableElapsedTime(CyclesToSeconds(total_cycles_))); int64 cumulative_cycles = 0; auto print_op = [&](const OpInfo& op, bool is_total = false) { @@ -56,7 +56,7 @@ string HumanReadableProfileBuilder::ToString() const { if (op.bytes_accessed > op.cycles) { bytes_per_cycle = StrCat(HumanReadableNumBytes(bpc), "/cycle"); } else { - bytes_per_cycle = Printf("%.3fB/cycle", bpc); + bytes_per_cycle = StrFormat("%.3fB/cycle", bpc); } } @@ -77,27 +77,24 @@ string HumanReadableProfileBuilder::ToString() const { // columns in the output. cycles_percent_str = "100.% 100Σ"; } else { - cycles_percent_str = - Printf("%5.2f%% %2.0fΣ", cycles_percent, cumulative_cycles_percent); + cycles_percent_str = StrFormat("%5.2f%% %2.0fΣ", cycles_percent, + cumulative_cycles_percent); } double nsecs = op.cycles / clock_rate_ghz_; - Appendf( + StrAppendFormat( &s, - "%15lld cycles (%s) :: %12.1f usec %22s :: %18s :: %18s :: %14s :: " + "%15d cycles (%s) :: %12.1f usec %22s :: %18s :: %18s :: %14s :: " "%16s :: %s\n", - op.cycles, cycles_percent_str.c_str(), CyclesToMicroseconds(op.cycles), + op.cycles, cycles_percent_str, CyclesToMicroseconds(op.cycles), op.optimal_seconds < 0 ? "" - : Printf("(%12.1f optimal)", op.optimal_seconds * 1e6).c_str(), - op.flop_count <= 0 - ? "" - : HumanReadableNumFlops(op.flop_count, nsecs).c_str(), + : StrFormat("(%12.1f optimal)", op.optimal_seconds * 1e6), + op.flop_count <= 0 ? "" : HumanReadableNumFlops(op.flop_count, nsecs), op.transcendental_count <= 0 ? "" - : HumanReadableNumTranscendentalOps(op.transcendental_count, nsecs) - .c_str(), - bytes_per_sec.c_str(), bytes_per_cycle.c_str(), op.name.c_str()); + : HumanReadableNumTranscendentalOps(op.transcendental_count, nsecs), + bytes_per_sec, bytes_per_cycle, op.name); }; float optimal_seconds_sum = 0.0; diff --git a/tensorflow/compiler/xla/service/human_readable_profile_builder.h b/tensorflow/compiler/xla/service/human_readable_profile_builder.h index 6f56c3aa82..925111fa1f 100644 --- a/tensorflow/compiler/xla/service/human_readable_profile_builder.h +++ b/tensorflow/compiler/xla/service/human_readable_profile_builder.h @@ -18,8 +18,8 @@ limitations under the License. #include <vector> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -29,10 +29,10 @@ namespace xla { // computation, suitable for consumption by humans. class HumanReadableProfileBuilder { public: - explicit HumanReadableProfileBuilder(tensorflow::StringPiece computation_name, + explicit HumanReadableProfileBuilder(absl::string_view computation_name, int64 total_cycles, double clock_rate_ghz) - : computation_name_(std::string(computation_name)), + : computation_name_(computation_name), total_cycles_(total_cycles), clock_rate_ghz_(clock_rate_ghz) { CHECK_GE(clock_rate_ghz, 1e-9); @@ -43,15 +43,13 @@ class HumanReadableProfileBuilder { // Adds an operation to the profile. If you don't know the number of // floating-point ops or bytes touched by the op, or if you don't know how // fast it would run optimally, pass -1 for that param. - void AddOp(tensorflow::StringPiece op_name, - tensorflow::StringPiece short_name, - tensorflow::StringPiece category, int64 cycles, int64 flop_count, + void AddOp(absl::string_view op_name, absl::string_view short_name, + absl::string_view category, int64 cycles, int64 flop_count, int64 transcendental_count, int64 bytes_accessed, float optimal_seconds) { - op_infos_.push_back({std::string(op_name), std::string(short_name), - std::string(category), cycles, flop_count, - transcendental_count, bytes_accessed, - optimal_seconds}); + op_infos_.push_back({string(op_name), string(short_name), string(category), + cycles, flop_count, transcendental_count, + bytes_accessed, optimal_seconds}); } // Gets the human-readable profile. diff --git a/tensorflow/compiler/xla/service/implicit_broadcast_remover.h b/tensorflow/compiler/xla/service/implicit_broadcast_remover.h index aa325dc8a3..85bb4a8b24 100644 --- a/tensorflow/compiler/xla/service/implicit_broadcast_remover.h +++ b/tensorflow/compiler/xla/service/implicit_broadcast_remover.h @@ -30,7 +30,7 @@ class ImplicitBroadcastRemover : public HloPassInterface { ImplicitBroadcastRemover() {} ~ImplicitBroadcastRemover() override {} - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "implicit-broadcast-remover"; } diff --git a/tensorflow/compiler/xla/service/implicit_broadcast_remover_test.cc b/tensorflow/compiler/xla/service/implicit_broadcast_remover_test.cc index f85d31d522..df88587492 100644 --- a/tensorflow/compiler/xla/service/implicit_broadcast_remover_test.cc +++ b/tensorflow/compiler/xla/service/implicit_broadcast_remover_test.cc @@ -26,6 +26,11 @@ namespace xla { namespace { class ImplicitBroadcastRemoverTest : public HloVerifiedTestBase { + public: + ImplicitBroadcastRemoverTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} + protected: ImplicitBroadcastRemover remover_; }; diff --git a/tensorflow/compiler/xla/service/indexed_array_analysis.cc b/tensorflow/compiler/xla/service/indexed_array_analysis.cc index 8d17c03afc..43ef30d1eb 100644 --- a/tensorflow/compiler/xla/service/indexed_array_analysis.cc +++ b/tensorflow/compiler/xla/service/indexed_array_analysis.cc @@ -14,13 +14,16 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/indexed_array_analysis.h" + +#include "absl/algorithm/container.h" +#include "absl/container/inlined_vector.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/service/hlo_evaluator.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/gtl/inlined_vector.h" -#include "tensorflow/core/lib/gtl/optional.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { namespace gtl = ::tensorflow::gtl; @@ -31,32 +34,30 @@ using UnknownArray = Analysis::UnknownArray; using ConstantArray = Analysis::ConstantArray; using ReshapedArray = Analysis::ReshapedArray; using ScalarIndexedArray = Analysis::ScalarIndexedArray; +using absl::StrJoin; using tensorflow::gtl::ArraySlice; -using tensorflow::str_util::Join; } // namespace string IndexedArrayAnalysis::ToString(Array* root, bool print_constants) { switch (root->kind()) { case Array::kUnknown: { auto* unknown_tensor = root->as<UnknownArray>(); - return tensorflow::strings::StrCat("%", - unknown_tensor->instruction().name()); + return absl::StrCat("%", unknown_tensor->instruction().name()); } case Array::kConstant: { if (print_constants) { string contents = root->as<ConstantArray>()->literal()->ToString(); - return tensorflow::strings::StrCat( - "(constant ", ShapeUtil::HumanString(root->shape()), " ", contents, - ")"); + return absl::StrCat("(constant ", ShapeUtil::HumanString(root->shape()), + " ", contents, ")"); } - return tensorflow::strings::StrCat( - "(constant ", ShapeUtil::HumanString(root->shape()), ")"); + return absl::StrCat("(constant ", ShapeUtil::HumanString(root->shape()), + ")"); } case Array::kReshaped: { ReshapedArray* reshaped_array = root->as<ReshapedArray>(); - return tensorflow::strings::StrCat( + return absl::StrCat( "(reshape ", ToString(reshaped_array->operand(), print_constants), " to ", ShapeUtil::HumanString(reshaped_array->shape()), ")"); } @@ -67,11 +68,11 @@ string IndexedArrayAnalysis::ToString(Array* root, bool print_constants) { string name = root->kind() == Array::kScalarIndexedConstant ? "scalar-indexed-const" : "scalar-indexed"; - return tensorflow::strings::StrCat( + return absl::StrCat( "(", name, " ", ToString(indexed_array->source(), print_constants), " ", ToString(indexed_array->indices(), print_constants), " ", indexed_array->source_dim(), "->[", - Join(indexed_array->output_dims(), ","), "])"); + StrJoin(indexed_array->output_dims(), ","), "])"); } } } @@ -92,7 +93,7 @@ Status IndexedArrayAnalysis::TraverseAndPopulateCache( // Depth first search over the DAG, invoking ComputeArrayFor in post order. // The HLO instructions already in the cache are considered leaves. - gtl::InlinedVector<const HloInstruction*, 4> stack; + absl::InlinedVector<const HloInstruction*, 4> stack; enum DfsState { kDiscovered, kVisited }; gtl::FlatMap<const HloInstruction*, DfsState> dfs_state_map; @@ -290,13 +291,13 @@ StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayForGather( int64 source_dim = dim_numbers.start_index_map(0); std::vector<int64> output_dims; for (int64 i = 0, e = shape.dimensions_size(); i < e; i++) { - if (!c_binary_search(dim_numbers.offset_dims(), i)) { + if (!absl::c_binary_search(dim_numbers.offset_dims(), i)) { output_dims.push_back(i); } } if (auto* indexed = dynamic_cast<ScalarIndexedArray*>(source)) { - if (c_linear_search(indexed->output_dims(), source_dim)) { + if (absl::c_linear_search(indexed->output_dims(), source_dim)) { return FoldGatherOfGather(indexed, indices, source_dim, output_dims, shape); } @@ -314,7 +315,7 @@ namespace { // [values.begin()+index, values.end()) is equal to `product`. If there is no // such index, return -1. All integers in `values` must be positive. int64 FindSuffixWithProduct(ArraySlice<int64> values, int64 product) { - DCHECK(c_all_of(values, [](int64 value) { return value > 0; })); + DCHECK(absl::c_all_of(values, [](int64 value) { return value > 0; })); int64 current_product = 1; int64 i; @@ -377,8 +378,8 @@ std::vector<ReshapePassthroughDimPair> ComputeReshapePassthroughDimPairs( CHECK_NE(candidate_operand_dim, 0) << "result_dim = " << result_dim << ", result_subarray_size = " << result_subarray_size - << ", result_shape = [" << Join(result_shape, ",") << "]" - << ", operand_shape = [" << Join(operand_shape, ",") << "]"; + << ", result_shape = [" << StrJoin(result_shape, ",") << "]" + << ", operand_shape = [" << StrJoin(operand_shape, ",") << "]"; if (candidate_operand_dim != -1 && result_shape[result_dim] == operand_shape[candidate_operand_dim - 1]) { @@ -388,26 +389,27 @@ std::vector<ReshapePassthroughDimPair> ComputeReshapePassthroughDimPairs( result_subarray_size *= result_shape[result_dim]; } - c_reverse(result); + absl::c_reverse(result); if (VLOG_IS_ON(3)) { std::vector<string> result_strings; - c_transform(result, std::back_inserter(result_strings), - [](ReshapePassthroughDimPair value) { - return tensorflow::strings::StrCat(value.result_dim, "->", - value.operand_dim); - }); - VLOG(3) << "For a reshape from [" << Join(operand_shape, ",") << "] to [" - << Join(result_shape, ",") << "] passthrough indices are [" - << Join(result_strings, ",") << "] (legend: `result`->`operand`)"; + absl::c_transform(result, std::back_inserter(result_strings), + [](ReshapePassthroughDimPair value) { + return absl::StrCat(value.result_dim, "->", + value.operand_dim); + }); + VLOG(3) << "For a reshape from [" << StrJoin(operand_shape, ",") << "] to [" + << StrJoin(result_shape, ",") << "] passthrough indices are [" + << StrJoin(result_strings, ",") + << "] (legend: `result`->`operand`)"; } - DCHECK(c_is_sorted( + DCHECK(absl::c_is_sorted( result, [](ReshapePassthroughDimPair lhs, ReshapePassthroughDimPair rhs) { return lhs.result_dim < rhs.result_dim; })); - DCHECK(c_is_sorted( + DCHECK(absl::c_is_sorted( result, [](ReshapePassthroughDimPair lhs, ReshapePassthroughDimPair rhs) { return lhs.operand_dim < rhs.operand_dim; })); @@ -419,20 +421,20 @@ std::vector<ReshapePassthroughDimPair> ComputeReshapePassthroughDimPairs( // `passthrough_dims`. bool IsReshapePassthroughOperandDim( ArraySlice<ReshapePassthroughDimPair> passthrough_dims, int64 dim) { - return c_any_of(passthrough_dims, - [&](ReshapePassthroughDimPair passthrough_dim_pair) { - return passthrough_dim_pair.operand_dim == dim; - }); + return absl::c_any_of(passthrough_dims, + [&](ReshapePassthroughDimPair passthrough_dim_pair) { + return passthrough_dim_pair.operand_dim == dim; + }); } // Maps `operand_dim` which must be an passthrough operand dimension to its // corresponding passthrough result dimension based on `passthrough_dims`. int64 MapPassthroughOperandDimToResultDim( ArraySlice<ReshapePassthroughDimPair> passthrough_dims, int64 operand_dim) { - auto it = c_find_if(passthrough_dims, - [&](ReshapePassthroughDimPair passthrough_dim_pair) { - return passthrough_dim_pair.operand_dim == operand_dim; - }); + auto it = absl::c_find_if( + passthrough_dims, [&](ReshapePassthroughDimPair passthrough_dim_pair) { + return passthrough_dim_pair.operand_dim == operand_dim; + }); CHECK(it != passthrough_dims.end()); return it->result_dim; } @@ -441,7 +443,7 @@ int64 FindSourcePositionForPassthroughResultDim(ArraySlice<int64> operand_shape, ArraySlice<int64> result_shape, int64 source_passthrough_dim) { VLOG(3) << "FindSourcePositionForPassthroughResultDim([" - << Join(operand_shape, ",") << "], [" << Join(result_shape, ",") + << StrJoin(operand_shape, ",") << "], [" << StrJoin(result_shape, ",") << "], " << source_passthrough_dim << ")"; int64 indexed_source_subarray_size = @@ -453,8 +455,8 @@ int64 FindSourcePositionForPassthroughResultDim(ArraySlice<int64> operand_shape, Shape StripDegenerateDimensions(const Shape& shape) { DimensionVector new_dims; - c_copy_if(shape.dimensions(), std::back_inserter(new_dims), - [](int64 dim) { return dim != 1; }); + absl::c_copy_if(shape.dimensions(), std::back_inserter(new_dims), + [](int64 dim) { return dim != 1; }); return ShapeUtil::MakeShape(shape.element_type(), new_dims); } }; // namespace @@ -530,7 +532,7 @@ StatusOr<ScalarIndexedArray*> IndexedArrayAnalysis::ReshapeToAddDegenerateDims( // element is true iff the i'th component of the result index is an output // index. - gtl::InlinedVector<bool, 6> output_dims_bitvector( + absl::InlinedVector<bool, 6> output_dims_bitvector( operand->shape().dimensions_size()); for (int64 output_dim : operand->output_dims()) { output_dims_bitvector[output_dim] = true; @@ -552,8 +554,8 @@ StatusOr<ScalarIndexedArray*> IndexedArrayAnalysis::ReshapeToAddDegenerateDims( }(); DimensionVector new_result_shape_dims; - c_copy(operand->shape().dimensions(), - std::back_inserter(new_result_shape_dims)); + absl::c_copy(operand->shape().dimensions(), + std::back_inserter(new_result_shape_dims)); for (int64 degenerate_dim : degenerate_dims) { InsertAt(&new_result_shape_dims, degenerate_dim, 1); } @@ -694,8 +696,8 @@ IndexedArrayAnalysis::FoldReshapeOfGatherNoDegenerateDims( operand_dim); }; - if (!c_all_of(scalar_indexed->output_dims(), - is_reshape_passthrough_operand_dim)) { + if (!absl::c_all_of(scalar_indexed->output_dims(), + is_reshape_passthrough_operand_dim)) { VLOG(3) << "Not all output dims are passthrough dims " << ToString(scalar_indexed); return nullptr; @@ -753,9 +755,9 @@ IndexedArrayAnalysis::FoldReshapeOfGatherNoDegenerateDims( if (source_dim_for_new_scalar_indexed_node == -1) { VLOG(3) << "Could not compute the source dim for the new scalar indexed " "node: scalar_indexed_source_shape = [" - << Join(scalar_indexed_source_shape.dimensions(), ",") + << StrJoin(scalar_indexed_source_shape.dimensions(), ",") << "] and new_scalar_indexed_source_shape = [" - << Join(new_scalar_indexed_source_shape, ",") << "]"; + << StrJoin(new_scalar_indexed_source_shape, ",") << "]"; return nullptr; } @@ -763,8 +765,8 @@ IndexedArrayAnalysis::FoldReshapeOfGatherNoDegenerateDims( &new_scalar_indexed_source_shape, source_dim_for_new_scalar_indexed_node, scalar_indexed_source_shape.dimensions(scalar_indexed->source_dim())); - CHECK_EQ(c_accumulate(new_scalar_indexed_source_shape, 1LL, - std::multiplies<int64>()), + CHECK_EQ(absl::c_accumulate(new_scalar_indexed_source_shape, 1LL, + std::multiplies<int64>()), ShapeUtil::ElementsIn(scalar_indexed_source_shape)); CHECK(IsReshapePassthroughOperandDim( @@ -780,9 +782,9 @@ IndexedArrayAnalysis::FoldReshapeOfGatherNoDegenerateDims( }; std::vector<int64> output_dims_for_new_scalar_indexed_node; - c_transform(scalar_indexed->output_dims(), - std::back_inserter(output_dims_for_new_scalar_indexed_node), - map_passthrough_operand_dim_to_result_dim); + absl::c_transform(scalar_indexed->output_dims(), + std::back_inserter(output_dims_for_new_scalar_indexed_node), + map_passthrough_operand_dim_to_result_dim); TF_ASSIGN_OR_RETURN(const Literal* new_scalar_indexed_source_literal, TakeOwnership(scalar_indexed->literal().Reshape( @@ -873,11 +875,12 @@ IndexedArrayAnalysis::ComputeArrayForElementwiseBinaryOp(HloOpcode opcode, ArraySlice<int64> broadcast_dims = broadcast_instr->dimensions(); auto is_broadcasted_dim = [&](int64 output_dim) { - return c_find(broadcast_dims, output_dim) == broadcast_dims.end(); + return absl::c_find(broadcast_dims, output_dim) == broadcast_dims.end(); }; // All of the output dims must be "broadcasted" dims for the other operand. - if (!c_all_of(scalar_indexed_const->output_dims(), is_broadcasted_dim)) { + if (!absl::c_all_of(scalar_indexed_const->output_dims(), + is_broadcasted_dim)) { return nullptr; } @@ -969,15 +972,15 @@ namespace { // Returns the non-contracting non-batch dimension (as per `contracting_dims` // and `batch_dims`) if there is exactly one, otherwise returns nullopt. -gtl::optional<int64> GetOnlyNonContractingNonBatchDim( +absl::optional<int64> GetOnlyNonContractingNonBatchDim( int64 rank, ArraySlice<int64> contracting_dims, ArraySlice<int64> batch_dims) { - gtl::optional<int64> result; + absl::optional<int64> result; for (int64 dim = 0; dim < rank; dim++) { if (!ArrayContains(contracting_dims, dim) && !ArrayContains(batch_dims, dim)) { if (result.has_value()) { - return gtl::nullopt; + return absl::nullopt; } result = dim; } @@ -994,10 +997,9 @@ gtl::optional<int64> GetOnlyNonContractingNonBatchDim( // `contracting_dims` and `batch_dims` are the contracting and batch dimensions // of whatever operand `indexed_array` is to the dot (LHS or RHS). bool CanFoldDotIntoIndexedArray( - tensorflow::StringPiece tag, - Analysis::ScalarIndexedConstantArray* indexed_array, + absl::string_view tag, Analysis::ScalarIndexedConstantArray* indexed_array, ArraySlice<int64> contracting_dims, ArraySlice<int64> batch_dims) { - gtl::optional<int64> non_contracting_non_batch_dim = + absl::optional<int64> non_contracting_non_batch_dim = GetOnlyNonContractingNonBatchDim(ShapeUtil::Rank(indexed_array->shape()), contracting_dims, batch_dims); if (!non_contracting_non_batch_dim.has_value()) { @@ -1132,7 +1134,7 @@ StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayForDot( return nullptr; } -tensorflow::StringPiece IndexedArrayAnalysisPrinterPass::name() const { +absl::string_view IndexedArrayAnalysisPrinterPass::name() const { return "indexed-array-analysis-printer-pass"; } diff --git a/tensorflow/compiler/xla/service/indexed_array_analysis.h b/tensorflow/compiler/xla/service/indexed_array_analysis.h index 675eb31d26..3fa7d749e1 100644 --- a/tensorflow/compiler/xla/service/indexed_array_analysis.h +++ b/tensorflow/compiler/xla/service/indexed_array_analysis.h @@ -371,7 +371,7 @@ class IndexedArrayAnalysis { // unconditionally add to the regular HLO pass pipeline. class IndexedArrayAnalysisPrinterPass : public HloPassInterface { public: - tensorflow::StringPiece name() const override; + absl::string_view name() const override; StatusOr<bool> Run(HloModule* module) override; }; diff --git a/tensorflow/compiler/xla/service/indexed_array_analysis_test.cc b/tensorflow/compiler/xla/service/indexed_array_analysis_test.cc index 97052edf7d..c34c32f7d3 100644 --- a/tensorflow/compiler/xla/service/indexed_array_analysis_test.cc +++ b/tensorflow/compiler/xla/service/indexed_array_analysis_test.cc @@ -22,6 +22,11 @@ limitations under the License. namespace xla { namespace { class IndexedArrayAnalysisTest : public HloVerifiedTestBase { + public: + IndexedArrayAnalysisTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} + protected: void AssertArrayForRootExpressionIs(const string& hlo_text, const string& root_expression) { @@ -634,9 +639,9 @@ ENTRY main { AssertArrayWithConstantsForRootExpressionIs(hlo_text, 1 + R"( (scalar-indexed-const (constant f32[3,4] f32[3,4] { - { 0.761594176, 0.964027584, 0.995054781, 0.999329329 }, - { 0.761594176, 0.995054781, 0.964027584, 0.999329329 }, - { 0.999329329, 0.995054781, 0.964027584, 0.761594176 } + { 0.761594, 0.964028, 0.995055, 0.999329 }, + { 0.761594, 0.995055, 0.964028, 0.999329 }, + { 0.999329, 0.995055, 0.964028, 0.761594 } }) %indices 0->[0]))"); } diff --git a/tensorflow/compiler/xla/service/inliner.h b/tensorflow/compiler/xla/service/inliner.h index a523811f6c..efa8ed3abc 100644 --- a/tensorflow/compiler/xla/service/inliner.h +++ b/tensorflow/compiler/xla/service/inliner.h @@ -27,7 +27,7 @@ namespace xla { class Inliner : public HloPassInterface { public: ~Inliner() override = default; - tensorflow::StringPiece name() const override { return "inline"; } + absl::string_view name() const override { return "inline"; } // Run inlining on the given computation. Returns whether the computation was // changed. diff --git a/tensorflow/compiler/xla/service/inliner_test.cc b/tensorflow/compiler/xla/service/inliner_test.cc index 32937b33b3..5695bc2420 100644 --- a/tensorflow/compiler/xla/service/inliner_test.cc +++ b/tensorflow/compiler/xla/service/inliner_test.cc @@ -18,8 +18,8 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" diff --git a/tensorflow/compiler/xla/service/instruction_fusion.cc b/tensorflow/compiler/xla/service/instruction_fusion.cc index f33942d679..83313c7ec1 100644 --- a/tensorflow/compiler/xla/service/instruction_fusion.cc +++ b/tensorflow/compiler/xla/service/instruction_fusion.cc @@ -21,6 +21,7 @@ limitations under the License. #include <numeric> #include <vector> +#include "absl/algorithm/container.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/core/lib/core/errors.h" @@ -121,6 +122,7 @@ bool IsAlwaysDuplicable(const HloInstruction& instruction) { case HloOpcode::kConvolution: case HloOpcode::kCrossReplicaSum: case HloOpcode::kAllToAll: + case HloOpcode::kCollectivePermute: case HloOpcode::kCustomCall: case HloOpcode::kDivide: case HloOpcode::kDomain: @@ -130,7 +132,6 @@ bool IsAlwaysDuplicable(const HloInstruction& instruction) { case HloOpcode::kFft: case HloOpcode::kFusion: case HloOpcode::kGather: - case HloOpcode::kHostCompute: case HloOpcode::kLog: case HloOpcode::kLog1p: case HloOpcode::kMap: @@ -189,13 +190,13 @@ bool InstructionFusion::CanFuseOnAllPaths( if (consumer == producer) { return true; } - if (!consumer->IsFusable()) { + if (!consumer->IsFusible()) { return false; } for (int64 i = 0, e = consumer->operand_count(); i < e; ++i) { auto* consumer_operand = consumer->mutable_operand(i); // If the operand is not on a path to the producer, it doesn't matter - // whether it's fusable. + // whether it's fusible. if (!reachability_->IsReachable(producer, consumer_operand)) { continue; } @@ -205,7 +206,7 @@ bool InstructionFusion::CanFuseOnAllPaths( } // The producer is reachable from consumer_operand which means we need // to be able to fuse consumer_operand into consumer in order for - // producer to be fusable into consumer on all paths. + // producer to be fusible into consumer on all paths. // Perform the recursive step: make sure producer can be fused into // consumer_operand on all paths. if (!CanFuseOnAllPaths(producer, consumer_operand, do_not_duplicate)) { @@ -216,7 +217,7 @@ bool InstructionFusion::CanFuseOnAllPaths( } InstructionFusion::HloInstructionSet -InstructionFusion::ComputeGloballyUnfusable( +InstructionFusion::ComputeGloballyUnfusible( tensorflow::gtl::ArraySlice<HloInstruction*> post_order) { // Forbid fusion of producers that: // a) Need to be duplicated, unless they can be fused into all consumers @@ -270,19 +271,19 @@ InstructionFusion::ComputeGloballyUnfusable( // all of its consumers on all paths. // // That means, that for: - // A --> B (fusable) - // \-> C (non-fusable) + // A --> B (fusible) + // \-> C (non-fusible) // A will be not allowed to be fused into B, as it cannot be fused into C. // // Similarly, for: // A -------------> B // \-> C -> D -/ // If: - // - A is fusable into B and C, and D is fusable into B - // - C is *not* fusable into D + // - A is fusible into B and C, and D is fusible into B + // - C is *not* fusible into D // A will be not allowed to be fused into B, as it cannot be fused via // all paths. - if (producer->IsFusable() && + if (producer->IsFusible() && CanFuseOnAllPaths(producer, consumer, do_not_duplicate)) { continue; } @@ -318,7 +319,7 @@ StatusOr<bool> InstructionFusion::Run(HloModule* module) { InsertOrDie(&post_order_index, post_order[i], i); } - HloInstructionSet do_not_duplicate = ComputeGloballyUnfusable(post_order); + HloInstructionSet do_not_duplicate = ComputeGloballyUnfusible(post_order); // Instruction fusion effectively fuses edges in the computation graph // (producer instruction -> consumer instruction) so we iterate over all @@ -341,7 +342,7 @@ StatusOr<bool> InstructionFusion::Run(HloModule* module) { // consistent. post_order_index.erase(instruction); - if (!instruction->IsFusable() && + if (!instruction->IsFusible() && instruction->opcode() != HloOpcode::kFusion) { continue; } @@ -413,7 +414,7 @@ StatusOr<bool> InstructionFusion::Run(HloModule* module) { for (int64 i : sorted_operand_numbers) { HloInstruction* operand = instruction->mutable_operand(i); - if (!operand->IsFusable()) { + if (!operand->IsFusible()) { continue; } @@ -497,7 +498,7 @@ HloInstruction* InstructionFusion::FuseIntoMultiOutput( bool InstructionFusion::MultiOutputFusionCreatesCycle( HloInstruction* producer, HloInstruction* consumer) { - return c_any_of( + return absl::c_any_of( consumer->operands(), [&](const HloInstruction* consumer_operand) { // The fusion algorithm traverses the HLO graph in reverse post order. // Thus `cosumers` is visited before its operands (including diff --git a/tensorflow/compiler/xla/service/instruction_fusion.h b/tensorflow/compiler/xla/service/instruction_fusion.h index f73ca9adf7..9802d4cfc1 100644 --- a/tensorflow/compiler/xla/service/instruction_fusion.h +++ b/tensorflow/compiler/xla/service/instruction_fusion.h @@ -36,7 +36,7 @@ class InstructionFusion : public HloPassInterface { bool may_duplicate = true) : is_expensive_(is_expensive), may_duplicate_(may_duplicate) {} ~InstructionFusion() override = default; - tensorflow::StringPiece name() const override { return "fusion"; } + absl::string_view name() const override { return "fusion"; } // Run instruction fusion on the given computation. Returns whether the // computation was changed (instructions were fused). @@ -122,7 +122,7 @@ class InstructionFusion : public HloPassInterface { // Computes the set of nodes that we do not want to fuse into any of their // consumers based on a global analysis of the HLO graph. - HloInstructionSet ComputeGloballyUnfusable( + HloInstructionSet ComputeGloballyUnfusible( tensorflow::gtl::ArraySlice<HloInstruction*> post_order); // Used to determine if an HLO is expensive. Expensive operations will not be diff --git a/tensorflow/compiler/xla/service/instruction_fusion_test.cc b/tensorflow/compiler/xla/service/instruction_fusion_test.cc index 9e7a15f033..da1ad90959 100644 --- a/tensorflow/compiler/xla/service/instruction_fusion_test.cc +++ b/tensorflow/compiler/xla/service/instruction_fusion_test.cc @@ -158,7 +158,7 @@ TEST_F(InstructionFusionTest, PotentialBitcastTransposeOfParameterUnfused) { .ValueOrDie()); } -TEST_F(InstructionFusionTest, AvoidDuplicationIfNotAllFusable) { +TEST_F(InstructionFusionTest, AvoidDuplicationIfNotAllFusible) { HloComputation::Builder builder(TestName()); auto shape = ShapeUtil::MakeShape(F32, {16, 16}); auto param0 = @@ -216,7 +216,7 @@ TEST_F(InstructionFusionTest, FuseCheapNonDuplicatableOps) { EXPECT_EQ(Count(*module, HloOpcode::kAdd), 1) << module->ToString(); } -TEST_F(InstructionFusionTest, AvoidDuplicationIfNotAllFusableRecursively) { +TEST_F(InstructionFusionTest, AvoidDuplicationIfNotAllFusibleRecursively) { // Make sure we do not duplicate the add, as we cannot fuse through the rng. // // p0 -> add -------------------------> sub @@ -309,7 +309,7 @@ TEST_F(InstructionFusionTest, AvoidDuplicationIfNotAllFusableRecursively) { EXPECT_EQ(Count(*module, HloOpcode::kAdd), 2) << module->ToString(); // A variant of the above that allows the algorithm to put add2 into the set - // of unfusable ops to short-circuit the decision whether add1 should be fused + // of unfusible ops to short-circuit the decision whether add1 should be fused // into sub2. // // /---------------\ diff --git a/tensorflow/compiler/xla/service/interpreter/BUILD b/tensorflow/compiler/xla/service/interpreter/BUILD index 8652599dc6..581f8d2e92 100644 --- a/tensorflow/compiler/xla/service/interpreter/BUILD +++ b/tensorflow/compiler/xla/service/interpreter/BUILD @@ -12,12 +12,11 @@ cc_library( srcs = ["interpreter_transfer_manager.cc"], hdrs = ["interpreter_transfer_manager.h"], deps = [ - "//tensorflow/compiler/xla:util", - "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service:generic_transfer_manager", "//tensorflow/compiler/xla/service:transfer_manager", "//tensorflow/compiler/xla/service/interpreter:platform_id", "//tensorflow/core:lib", + "@com_google_absl//absl/memory", ], alwayslink = True, # Contains per-platform transfer manager registration ) @@ -32,8 +31,6 @@ cc_library( "//tensorflow/compiler/xla:status", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", - "//tensorflow/compiler/xla:util", - "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service:algebraic_simplifier", "//tensorflow/compiler/xla/service:compiler", "//tensorflow/compiler/xla/service:computation_placer", @@ -54,6 +51,7 @@ cc_library( "//tensorflow/compiler/xla/service:while_loop_simplifier", "//tensorflow/core:lib", "//tensorflow/stream_executor", + "@com_google_absl//absl/memory", ], alwayslink = True, # Contains compiler registration ) @@ -79,7 +77,6 @@ cc_library( "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:types", - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service:executable", "//tensorflow/compiler/xla/service:hlo", @@ -91,6 +88,7 @@ cc_library( "//tensorflow/compiler/xla/service:transfer_manager", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", + "@com_google_absl//absl/memory", ], ) diff --git a/tensorflow/compiler/xla/service/interpreter/compiler.cc b/tensorflow/compiler/xla/service/interpreter/compiler.cc index 9f8f4bda87..bb69cb9c47 100644 --- a/tensorflow/compiler/xla/service/interpreter/compiler.cc +++ b/tensorflow/compiler/xla/service/interpreter/compiler.cc @@ -18,7 +18,7 @@ limitations under the License. #include <string> #include <utility> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/algebraic_simplifier.h" #include "tensorflow/compiler/xla/service/computation_placer.h" #include "tensorflow/compiler/xla/service/flatten_call_graph.h" @@ -69,8 +69,8 @@ StatusOr<std::unique_ptr<Executable>> InterpreterCompiler::RunBackend( // Create executable from only the Hlo module. std::unique_ptr<Executable> executable = - xla::MakeUnique<InterpreterExecutable>(std::move(hlo_module), - xla::MakeUnique<HloEvaluator>()); + absl::make_unique<InterpreterExecutable>( + std::move(hlo_module), absl::make_unique<HloEvaluator>()); return std::move(executable); } @@ -103,11 +103,11 @@ HloCostAnalysis::ShapeSizeFunction InterpreterCompiler::ShapeSizeBytesFunction() static bool InitModule() { xla::Compiler::RegisterCompilerFactory( se::interpreter::kXlaInterpreterPlatformId, []() { - return xla::MakeUnique<xla::interpreter::InterpreterCompiler>(); + return absl::make_unique<xla::interpreter::InterpreterCompiler>(); }); xla::ComputationPlacer::RegisterComputationPlacer( se::interpreter::kXlaInterpreterPlatformId, - []() { return xla::MakeUnique<xla::ComputationPlacer>(); }); + []() { return absl::make_unique<xla::ComputationPlacer>(); }); return true; } diff --git a/tensorflow/compiler/xla/service/interpreter/executable.cc b/tensorflow/compiler/xla/service/interpreter/executable.cc index 8d40c08d55..2259dc1083 100644 --- a/tensorflow/compiler/xla/service/interpreter/executable.cc +++ b/tensorflow/compiler/xla/service/interpreter/executable.cc @@ -21,8 +21,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/interpreter/executor.h" diff --git a/tensorflow/compiler/xla/service/interpreter/interpreter_transfer_manager.cc b/tensorflow/compiler/xla/service/interpreter/interpreter_transfer_manager.cc index d27cd7502f..7955ee5cf3 100644 --- a/tensorflow/compiler/xla/service/interpreter/interpreter_transfer_manager.cc +++ b/tensorflow/compiler/xla/service/interpreter/interpreter_transfer_manager.cc @@ -17,7 +17,7 @@ limitations under the License. #include <memory> -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/interpreter/platform_id.h" #include "tensorflow/compiler/xla/service/transfer_manager.h" @@ -31,7 +31,7 @@ InterpreterTransferManager::InterpreterTransferManager() static std::unique_ptr<xla::TransferManager> CreateInterpreterTransferManager() { - return xla::MakeUnique<xla::InterpreterTransferManager>(); + return absl::make_unique<xla::InterpreterTransferManager>(); } static bool InitModule() { diff --git a/tensorflow/compiler/xla/service/interpreter/interpreter_transfer_manager.h b/tensorflow/compiler/xla/service/interpreter/interpreter_transfer_manager.h index 2b44f30821..b732230fdd 100644 --- a/tensorflow/compiler/xla/service/interpreter/interpreter_transfer_manager.h +++ b/tensorflow/compiler/xla/service/interpreter/interpreter_transfer_manager.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_INTERPRETER_TRANSFER_MANAGER_H_ -#define TENSORFLOW_COMPILER_XLA_SERVICE_INTERPRETER_TRANSFER_MANAGER_H_ +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_INTERPRETER_INTERPRETER_TRANSFER_MANAGER_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_INTERPRETER_INTERPRETER_TRANSFER_MANAGER_H_ #include "tensorflow/compiler/xla/service/generic_transfer_manager.h" #include "tensorflow/core/platform/macros.h" @@ -33,4 +33,4 @@ class InterpreterTransferManager : public GenericTransferManager { } // namespace xla -#endif // TENSORFLOW_COMPILER_XLA_SERVICE_INTERPRETER_TRANSFER_MANAGER_H_ +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_INTERPRETER_INTERPRETER_TRANSFER_MANAGER_H_ diff --git a/tensorflow/compiler/xla/service/interpreter/platform.cc b/tensorflow/compiler/xla/service/interpreter/platform.cc index 42c2c28997..c9b40d3c61 100644 --- a/tensorflow/compiler/xla/service/interpreter/platform.cc +++ b/tensorflow/compiler/xla/service/interpreter/platform.cc @@ -17,13 +17,14 @@ limitations under the License. #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/service/interpreter/executor.h" #include "tensorflow/stream_executor/device_options.h" #include "tensorflow/stream_executor/lib/initialize.h" #include "tensorflow/stream_executor/lib/ptr_util.h" #include "tensorflow/stream_executor/lib/status.h" #include "tensorflow/stream_executor/lib/status_macros.h" -#include "tensorflow/stream_executor/lib/stringprintf.h" #include "tensorflow/stream_executor/multi_platform_manager.h" #include "tensorflow/stream_executor/platform.h" @@ -70,15 +71,15 @@ port::StatusOr<StreamExecutor*> XlaInterpreterPlatform::GetExecutor( port::StatusOr<std::unique_ptr<StreamExecutor>> XlaInterpreterPlatform::GetUncachedExecutor( const StreamExecutorConfig& config) { - auto executor = MakeUnique<StreamExecutor>( - this, MakeUnique<XlaInterpreterExecutor>(config.plugin_config)); + auto executor = absl::make_unique<StreamExecutor>( + this, absl::make_unique<XlaInterpreterExecutor>(config.plugin_config)); auto init_status = executor->Init(config.ordinal, config.device_options); if (!init_status.ok()) { return port::Status{ port::error::INTERNAL, - port::Printf( + absl::StrFormat( "failed initializing StreamExecutor for device ordinal %d: %s", - config.ordinal, init_status.ToString().c_str())}; + config.ordinal, init_status.ToString())}; } return std::move(executor); diff --git a/tensorflow/compiler/xla/service/layout_assignment.cc b/tensorflow/compiler/xla/service/layout_assignment.cc index 805fdb2d5b..5e5c93e3a2 100644 --- a/tensorflow/compiler/xla/service/layout_assignment.cc +++ b/tensorflow/compiler/xla/service/layout_assignment.cc @@ -26,9 +26,12 @@ limitations under the License. #include <string> #include <tuple> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/computation_layout.h" #include "tensorflow/compiler/xla/service/hlo_casting_utils.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" @@ -49,20 +52,11 @@ limitations under the License. #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" namespace xla { -// For now moving only one API here, but we should have a single top level -// anonymous namespace, instead of three or four spread all over this file. -namespace { - -} // namespace - std::ostream& operator<<(std::ostream& out, const LayoutConstraint& constraint) { out << constraint.ToString(); @@ -77,9 +71,8 @@ BufferLayoutConstraint::BufferLayoutConstraint(const Layout& layout, } string BufferLayoutConstraint::ToString() const { - return tensorflow::strings::Printf("BufferLayoutConstraint %s: %s", - buffer_->ToString().c_str(), - LayoutUtil::HumanString(layout_).c_str()); + return absl::StrFormat("BufferLayoutConstraint %s: %s", buffer_->ToString(), + LayoutUtil::HumanString(layout_)); } OperandLayoutConstraint::OperandLayoutConstraint( @@ -98,15 +91,14 @@ OperandLayoutConstraint::OperandLayoutConstraint( } string OperandLayoutConstraint::ToString() const { - return tensorflow::strings::Printf( - "OperandLayoutConstraint %s, operand %lld: %s", - instruction_->name().c_str(), operand_no_, - shape_layout_.ToString().c_str()); + return absl::StrFormat("OperandLayoutConstraint %s, operand %d: %s", + instruction_->name(), operand_no_, + shape_layout_.ToString()); } string ResultLayoutConstraint::ToString() const { - return tensorflow::strings::Printf("ResultLayoutConstraint: %s", - shape_layout_.ToString().c_str()); + return absl::StrFormat("ResultLayoutConstraint: %s", + shape_layout_.ToString()); } LayoutConstraints::LayoutConstraints( @@ -137,7 +129,7 @@ PointsToSet::BufferSet* LayoutConstraints::GetBufferSet( } auto& buffer_set = buffer_sets_cache_ - .emplace(instruction, MakeUnique<PointsToSet::BufferSet>()) + .emplace(instruction, absl::make_unique<PointsToSet::BufferSet>()) .first->second; const auto& points_to_set = points_to_analysis_.GetPointsToSet(instruction); points_to_set.ForEachElement( @@ -174,8 +166,7 @@ Status LayoutConstraints::SetBufferLayout(const Layout& layout, return FailedPrecondition( "Layout of buffer %s cannot be constrained because buffer is not " "array-shaped, has shape: %s", - buffer.ToString().c_str(), - ShapeUtil::HumanString(buffer.shape()).c_str()); + buffer.ToString(), ShapeUtil::HumanString(buffer.shape())); } TF_RETURN_IF_ERROR( LayoutUtil::ValidateLayoutForShape(layout, buffer.shape())); @@ -191,9 +182,8 @@ Status LayoutConstraints::SetBufferLayout(const Layout& layout, return FailedPrecondition( "Buffer %s already has the layout constraint %s, cannot add " "incompatible constraint %s", - buffer.ToString().c_str(), - LayoutUtil::HumanString(curr_constraint.layout()).c_str(), - LayoutUtil::HumanString(layout).c_str()); + buffer.ToString(), LayoutUtil::HumanString(curr_constraint.layout()), + LayoutUtil::HumanString(layout)); } iter->second = BufferLayoutConstraint(layout, buffer, mandatory, dfs); } else { @@ -227,11 +217,11 @@ Status LayoutConstraints::SetOperandLayout(const Shape& shape_with_layout, } if (curr_shape_layout->mandatory()) { return FailedPrecondition( - "Operand %lld of instruction %s already has a layout constraint " + "Operand %d of instruction %s already has a layout constraint " "%s, cannot add incompatible constraint %s", - operand_no, instruction->name().c_str(), - curr_shape_layout->shape_layout().ToString().c_str(), - ShapeUtil::HumanStringWithLayout(shape_with_layout).c_str()); + operand_no, instruction->name(), + curr_shape_layout->shape_layout().ToString(), + ShapeUtil::HumanStringWithLayout(shape_with_layout)); } } @@ -240,9 +230,9 @@ Status LayoutConstraints::SetOperandLayout(const Shape& shape_with_layout, // layouts beyond this immediate use and is complicated to handle. if (OperandBufferForwarded(instruction, operand_no)) { return FailedPrecondition( - "Cannot constraint layout of operand %lld of instruction %s " + "Cannot constraint layout of operand %d of instruction %s " "because instruction forwards operand's LogicalBuffer(s)", - operand_no, instruction->name().c_str()); + operand_no, instruction->name()); } auto key = std::make_pair(instruction, operand_no); @@ -284,8 +274,8 @@ Status LayoutConstraints::SetResultLayout(const Shape& shape_with_layout, return FailedPrecondition( "Result of computation %s already has the layout constraint %s, " "cannot add incompatible constraint %s", - computation_->name().c_str(), curr_shape_layout->ToString().c_str(), - ShapeUtil::HumanStringWithLayout(shape_with_layout).c_str()); + computation_->name(), curr_shape_layout->ToString(), + ShapeUtil::HumanStringWithLayout(shape_with_layout)); } // New constraint matches existing constraint. Nothing to do. return Status::OK(); @@ -307,9 +297,8 @@ Status LayoutConstraints::SetInstructionLayout( if (!ShapeUtil::Compatible(shape_with_layout, instruction->shape())) { return FailedPrecondition( "Instruction %s of shape %s cannot be assigned incompatible layout %s", - instruction->name().c_str(), - ShapeUtil::HumanString(instruction->shape()).c_str(), - ShapeUtil::HumanStringWithLayout(shape_with_layout).c_str()); + instruction->name(), ShapeUtil::HumanString(instruction->shape()), + ShapeUtil::HumanStringWithLayout(shape_with_layout)); } // Create a BufferLayoutConstraint for each array shape in the output of the @@ -368,31 +357,27 @@ const ShapeLayout* LayoutConstraints::ResultLayout() const { string LayoutConstraints::ToString() const { string output; - tensorflow::strings::StrAppend(&output, "LayoutConstraints for computation ", - computation_->name(), ":\n"); + absl::StrAppend(&output, "LayoutConstraints for computation ", + computation_->name(), ":\n"); for (auto* instruction : computation_->MakeInstructionPostOrder()) { - tensorflow::strings::StrAppend(&output, " ", instruction->ToShortString(), - "\n"); + absl::StrAppend(&output, " ", instruction->ToShortString(), "\n"); for (int64 i = 0; i < instruction->operand_count(); ++i) { if (OperandLayout(instruction, i) != nullptr) { - tensorflow::strings::StrAppend( - &output, " operand (", i, - "): ", OperandLayout(instruction, i)->ToString(), "\n"); + absl::StrAppend(&output, " operand (", i, + "): ", OperandLayout(instruction, i)->ToString(), "\n"); } } for (const LogicalBuffer* buffer : points_to_analysis_.GetBuffersDefinedByInstruction(instruction)) { if (BufferLayout(*buffer) != nullptr) { - tensorflow::strings::StrAppend( - &output, " ", buffer->ToString(), " : ", - LayoutUtil::HumanString(*BufferLayout(*buffer)), "\n"); + absl::StrAppend(&output, " ", buffer->ToString(), " : ", + LayoutUtil::HumanString(*BufferLayout(*buffer)), "\n"); } } } if (ResultLayout() != nullptr) { - tensorflow::strings::StrAppend(&output, " => ", ResultLayout()->ToString(), - "\n"); + absl::StrAppend(&output, " => ", ResultLayout()->ToString(), "\n"); } return output; } @@ -763,7 +748,7 @@ Status CheckParameterLayout(HloInstruction* parameter, return InternalError( "parameter instruction %s does not match layout of computation " "shape: %s", - parameter->ToString().c_str(), parameter_layout.ToString().c_str()); + parameter->ToString(), parameter_layout.ToString()); } return Status::OK(); } @@ -774,8 +759,8 @@ Status CheckConstantLayout(HloInstruction* constant) { constant->shape())) { return InternalError( "constant instruction %s does not match the layout of its literal %s", - constant->ToString().c_str(), - ShapeUtil::HumanStringWithLayout(constant->literal().shape()).c_str()); + constant->ToString(), + ShapeUtil::HumanStringWithLayout(constant->literal().shape())); } return Status::OK(); } @@ -908,13 +893,10 @@ Status LayoutAssignment::CheckLayouts(HloModule* module) { return InternalError( "Layout of instruction %s at index {%s} does not match " "source LogicalBuffer %s: %s vs %s", - instruction->name().c_str(), - tensorflow::str_util::Join(index, ",").c_str(), - buffer->ToString().c_str(), - ShapeUtil::HumanStringWithLayout(instruction_subshape) - .c_str(), - ShapeUtil::HumanStringWithLayout(buffer->shape()) - .c_str()); + instruction->name(), absl::StrJoin(index, ","), + buffer->ToString(), + ShapeUtil::HumanStringWithLayout(instruction_subshape), + ShapeUtil::HumanStringWithLayout(buffer->shape())); } } } @@ -998,17 +980,18 @@ std::unique_ptr<Layout> LayoutAssignment::ChooseOperandLayoutFromOutputLayout( CHECK(ShapeUtil::IsArray(instruction->shape())); CHECK(ShapeUtil::IsArray(operand->shape())); - if (instruction->IsElementwiseOnOperand(operand_no) && - !ShapeUtil::IsScalar(operand->shape()) && + if (!ShapeUtil::IsScalar(operand->shape()) && ShapeUtil::Rank(operand->shape()) == - ShapeUtil::Rank(instruction->shape())) { - // Assign operands the same layout as the instruction, so that + ShapeUtil::Rank(instruction->shape()) && + InstructionRequiresInputLayoutEqualToOutputLayout(instruction)) { + // Propagate the result layout to the operand layout if the instruction + // requires the same layout out for the result and the operand. + // + // For elementwise operations, using the same layout for the operands and + // the result also has the following benefits: // 1) the elementwise operation can reuse its operand's buffer, and // 2) the input and output elements can reuse the same linear index. - // - // TODO(jingyue): Other operations, such as kSlice and kConcat, can benefit - // from assigning the same layout to input and output. - return MakeUnique<Layout>(output_layout); + return absl::make_unique<Layout>(output_layout); } if (instruction->opcode() == HloOpcode::kReshape) { @@ -1031,13 +1014,13 @@ std::unique_ptr<Layout> LayoutAssignment::ChooseOperandLayoutFromOutputLayout( *operand_shape.mutable_layout() = LayoutUtil::GetDefaultLayoutForShape(operand_shape); if (ShapeUtil::ReshapeIsBitcast(operand_shape, output_shape_with_layout)) { - return MakeUnique<Layout>(operand_shape.layout()); + return absl::make_unique<Layout>(operand_shape.layout()); } if (ShapeUtil::Rank(operand_shape) == ShapeUtil::Rank(output_shape)) { *operand_shape.mutable_layout() = output_layout; if (ShapeUtil::ReshapeIsBitcast(operand_shape, output_shape_with_layout)) { - return MakeUnique<Layout>(output_layout); + return absl::make_unique<Layout>(output_layout); } } auto aligned_operand_shape = @@ -1046,7 +1029,7 @@ std::unique_ptr<Layout> LayoutAssignment::ChooseOperandLayoutFromOutputLayout( auto operand_layout = aligned_operand_shape.value().layout(); TF_CHECK_OK( LayoutUtil::ValidateLayoutForShape(operand_layout, operand_shape)); - return MakeUnique<Layout>(operand_layout); + return absl::make_unique<Layout>(operand_layout); } } @@ -1062,7 +1045,7 @@ std::unique_ptr<Layout> LayoutAssignment::ChooseOperandLayoutFromOutputLayout( Layout operand_layout = LayoutUtil::MakeLayout(new_minor_to_major); TF_CHECK_OK( LayoutUtil::ValidateLayoutForShape(operand_layout, operand->shape())); - return MakeUnique<Layout>(operand_layout); + return absl::make_unique<Layout>(operand_layout); } return nullptr; @@ -1076,11 +1059,11 @@ std::unique_ptr<Layout> LayoutAssignment::ChooseOutputLayoutFromOperandLayout( CHECK(ShapeUtil::IsArray(user->shape()) && ShapeUtil::IsArray(operand->shape())); - if (user->IsElementwiseOnOperand(operand_no) && - !ShapeUtil::IsScalar(operand->shape()) && - ShapeUtil::Rank(operand->shape()) == ShapeUtil::Rank(user->shape())) { + if (!ShapeUtil::IsScalar(operand->shape()) && + ShapeUtil::Rank(operand->shape()) == ShapeUtil::Rank(user->shape()) && + InstructionRequiresInputLayoutEqualToOutputLayout(user)) { // Assign users the same layout as the operand. - return MakeUnique<Layout>(operand_layout); + return absl::make_unique<Layout>(operand_layout); } if (user->opcode() == HloOpcode::kReshape) { @@ -1103,13 +1086,13 @@ std::unique_ptr<Layout> LayoutAssignment::ChooseOutputLayoutFromOperandLayout( *output_shape.mutable_layout() = LayoutUtil::GetDefaultLayoutForShape(output_shape); if (ShapeUtil::ReshapeIsBitcast(output_shape, operand_shape_with_layout)) { - return MakeUnique<Layout>(output_shape.layout()); + return absl::make_unique<Layout>(output_shape.layout()); } if (ShapeUtil::Rank(operand->shape()) == ShapeUtil::Rank(output_shape)) { *output_shape.mutable_layout() = operand_layout; if (ShapeUtil::ReshapeIsBitcast(output_shape, operand_shape_with_layout)) { - return MakeUnique<Layout>(operand_layout); + return absl::make_unique<Layout>(operand_layout); } } auto aligned_user_shape = @@ -1118,7 +1101,7 @@ std::unique_ptr<Layout> LayoutAssignment::ChooseOutputLayoutFromOperandLayout( auto user_layout = aligned_user_shape.value().layout(); TF_CHECK_OK( LayoutUtil::ValidateLayoutForShape(user_layout, output_shape)); - return MakeUnique<Layout>(user_layout); + return absl::make_unique<Layout>(user_layout); } } @@ -1134,7 +1117,7 @@ std::unique_ptr<Layout> LayoutAssignment::ChooseOutputLayoutFromOperandLayout( } Layout user_layout = LayoutUtil::MakeLayout(new_minor_to_major); TF_CHECK_OK(LayoutUtil::ValidateLayoutForShape(user_layout, user->shape())); - return MakeUnique<Layout>(user_layout); + return absl::make_unique<Layout>(user_layout); } return nullptr; @@ -1385,7 +1368,7 @@ StatusOr<Layout> InferArrayLayout( // This should not happen because we've assigned layouts to all // instructions preceding this one. return InternalError("LogicalBuffer %s does not have a layout", - source_buffer->ToString().c_str()); + source_buffer->ToString()); } if (first_buffer_layout == nullptr) { @@ -1400,9 +1383,8 @@ StatusOr<Layout> InferArrayLayout( return FailedPrecondition( "Array at index {%s} in instruction %s aliases buffers %s " "and %s which have different layouts", - tensorflow::str_util::Join(index, ",").c_str(), - instruction->name().c_str(), source_buffers[0]->ToString().c_str(), - source_buffer->ToString().c_str()); + absl::StrJoin(index, ","), instruction->name(), + source_buffers[0]->ToString(), source_buffer->ToString()); } } @@ -1570,7 +1552,7 @@ Status LayoutAssignment::ClearComputationLayouts(HloComputation* computation) { // present in the IR before layout assignment is a bug. return InternalError( "Unexpected bitcast operation seen during layout assignment: %s.", - instruction->ToString().c_str()); + instruction->ToString()); } if (instruction->opcode() != HloOpcode::kInfeed) { LayoutUtil::ClearLayout(instruction->mutable_shape()); @@ -1822,6 +1804,107 @@ StatusOr<bool> LayoutAssignment::Run(HloModule* module) { return true; } +bool LayoutAssignment::InstructionRequiresInputLayoutEqualToOutputLayout( + const HloInstruction* instruction) { + switch (instruction->opcode()) { + case HloOpcode::kAbs: + case HloOpcode::kAdd: + case HloOpcode::kAnd: + case HloOpcode::kAtan2: + case HloOpcode::kBitcastConvert: + case HloOpcode::kCeil: + case HloOpcode::kClamp: + case HloOpcode::kClz: + case HloOpcode::kComplex: + case HloOpcode::kConcatenate: + case HloOpcode::kConditional: + case HloOpcode::kConvert: + case HloOpcode::kCos: + case HloOpcode::kCrossReplicaSum: + case HloOpcode::kAllToAll: + case HloOpcode::kCollectivePermute: + case HloOpcode::kCustomCall: + case HloOpcode::kDivide: + case HloOpcode::kDynamicSlice: + case HloOpcode::kDynamicUpdateSlice: + case HloOpcode::kEq: + case HloOpcode::kExp: + case HloOpcode::kExpm1: + case HloOpcode::kFft: + case HloOpcode::kFloor: + case HloOpcode::kGe: + case HloOpcode::kGt: + case HloOpcode::kImag: + case HloOpcode::kIsFinite: + case HloOpcode::kLe: + case HloOpcode::kLog: + case HloOpcode::kLog1p: + case HloOpcode::kLt: + case HloOpcode::kMap: + case HloOpcode::kMaximum: + case HloOpcode::kMinimum: + case HloOpcode::kMultiply: + case HloOpcode::kNe: + case HloOpcode::kNegate: + case HloOpcode::kNot: + case HloOpcode::kOr: + case HloOpcode::kXor: + case HloOpcode::kPad: + case HloOpcode::kPower: + case HloOpcode::kReal: + case HloOpcode::kReducePrecision: + case HloOpcode::kReduceWindow: + case HloOpcode::kRemainder: + case HloOpcode::kReverse: + case HloOpcode::kRoundNearestAfz: + case HloOpcode::kSelect: + case HloOpcode::kSelectAndScatter: + case HloOpcode::kShiftLeft: + case HloOpcode::kShiftRightArithmetic: + case HloOpcode::kShiftRightLogical: + case HloOpcode::kSign: + case HloOpcode::kSin: + case HloOpcode::kSlice: + case HloOpcode::kSort: + case HloOpcode::kSubtract: + case HloOpcode::kTanh: + case HloOpcode::kTupleSelect: + case HloOpcode::kWhile: + return true; + case HloOpcode::kBatchNormGrad: + case HloOpcode::kBatchNormInference: + case HloOpcode::kBatchNormTraining: + case HloOpcode::kBitcast: + case HloOpcode::kBroadcast: + case HloOpcode::kCall: + case HloOpcode::kConstant: + case HloOpcode::kConvolution: + case HloOpcode::kCopy: + case HloOpcode::kDomain: + case HloOpcode::kDot: + case HloOpcode::kFusion: + case HloOpcode::kGather: + case HloOpcode::kGetTupleElement: + case HloOpcode::kInfeed: + case HloOpcode::kIota: + case HloOpcode::kOutfeed: + case HloOpcode::kParameter: + case HloOpcode::kRecv: + case HloOpcode::kRecvDone: + case HloOpcode::kReduce: + case HloOpcode::kReshape: + case HloOpcode::kRng: + case HloOpcode::kScatter: + case HloOpcode::kSend: + case HloOpcode::kSendDone: + case HloOpcode::kAfterAll: + case HloOpcode::kTrace: + case HloOpcode::kTranspose: + case HloOpcode::kTuple: + return false; + } +} + Status LayoutAssignment::Init() { computation_layouts_.clear(); *entry_computation_layout_ = saved_entry_computation_layout_; diff --git a/tensorflow/compiler/xla/service/layout_assignment.h b/tensorflow/compiler/xla/service/layout_assignment.h index f9e8dbea2f..cf545031d3 100644 --- a/tensorflow/compiler/xla/service/layout_assignment.h +++ b/tensorflow/compiler/xla/service/layout_assignment.h @@ -297,12 +297,17 @@ class LayoutAssignment : public HloPassInterface { ComputationLayout* entry_computation_layout, ChannelLayoutConstraints* channel_constraints = nullptr); ~LayoutAssignment() override {} - tensorflow::StringPiece name() const override { return "layout-assignment"; } + absl::string_view name() const override { return "layout-assignment"; } // Assign layouts to the given module. Returns whether the module was changed // (any layouts were changed). StatusOr<bool> Run(HloModule* module) override; + // Returns true if the instruction requires that operands with the same rank + // as the output have to have the same layout as the output. + virtual bool InstructionRequiresInputLayoutEqualToOutputLayout( + const HloInstruction* instruction); + protected: // These methods, invoked by PropagateConstraints, propagate a layout // constraint to its neighbors (i.e. operands and users) in order to minimize diff --git a/tensorflow/compiler/xla/service/layout_assignment_test.cc b/tensorflow/compiler/xla/service/layout_assignment_test.cc index a16fa75e30..7505d7a5b3 100644 --- a/tensorflow/compiler/xla/service/layout_assignment_test.cc +++ b/tensorflow/compiler/xla/service/layout_assignment_test.cc @@ -59,7 +59,7 @@ class LayoutAssignmentTest : public HloTestBase { EXPECT_IS_OK(layout_assignment.Run(module).status()); } - std::vector<int64> LayoutOf(HloModule* module, tensorflow::StringPiece name) { + std::vector<int64> LayoutOf(HloModule* module, absl::string_view name) { auto minor_to_major = FindInstruction(module, name)->shape().layout().minor_to_major(); return std::vector<int64>(minor_to_major.begin(), minor_to_major.end()); @@ -861,5 +861,115 @@ TEST_F(LayoutAssignmentTest, ChannelLayoutMismatch) { ShapeUtil::MakeShapeWithLayout(F32, {2, 2}, {1, 0}))); } +TEST_F(LayoutAssignmentTest, CopySliceOperandToAvoidImplicitLayoutChange) { + const char* module_str = R"( + HloModule CopySliceOperandToAvoidImplicitLayoutChange + + ENTRY CopySliceOperandToAvoidImplicitLayoutChange { + par0 = f32[3,4]{1,0} parameter(0) + par1 = f32[4,5]{0,1} parameter(1) + slice0 = f32[3,4] slice(par1), slice={[1:4],[1:5]} + ROOT add0 = f32[3,4]{1,0} add(par0,slice0) + } + )"; + + auto module = ParseHloString(module_str).ValueOrDie(); + module = + backend() + .compiler() + ->RunHloPasses(std::move(module), backend().default_stream_executor(), + /*device_allocator=*/nullptr) + .ConsumeValueOrDie(); + + auto copy = FindInstruction(module.get(), "copy.1"); + auto slice = FindInstruction(module.get(), "slice0"); + EXPECT_EQ(slice->operand(0), copy); + EXPECT_TRUE( + LayoutUtil::Equal(slice->shape().layout(), copy->shape().layout())); +} + +TEST_F(LayoutAssignmentTest, CopyDSliceOperandToAvoidImplicitLayoutChange) { + const char* module_str = R"( + HloModule CopyDSliceOperandToAvoidImplicitLayoutChange + + ENTRY CopyDSliceOperandToAvoidImplicitLayoutChange { + par0 = f32[3,4]{1,0} parameter(0) + par1 = f32[4,5]{0,1} parameter(1) + par2 = s32[2] parameter(2) + dslice0 = f32[3,4] dynamic-slice(par1, par2), dynamic_slice_sizes={3,4} + ROOT add0 = f32[3,4]{1,0} add(par0,dslice0) + } + )"; + + auto module = ParseHloString(module_str).ValueOrDie(); + module = + backend() + .compiler() + ->RunHloPasses(std::move(module), backend().default_stream_executor(), + /*device_allocator=*/nullptr) + .ConsumeValueOrDie(); + + auto copy = FindInstruction(module.get(), "copy.1"); + auto dslice = FindInstruction(module.get(), "dslice0"); + EXPECT_EQ(dslice->operand(0), copy); + EXPECT_TRUE( + LayoutUtil::Equal(dslice->shape().layout(), copy->shape().layout())); +} + +TEST_F(LayoutAssignmentTest, CopyConcatOperandToAvoidImplicitLayoutChange) { + const char* module_str = R"( + HloModule CopyConcatOperandToAvoidImplicitLayoutChange + + ENTRY CopyConcatOperandToAvoidImplicitLayoutChange { + par0 = f32[3,8]{1,0} parameter(0) + par1 = f32[3,5]{0,1} parameter(1) + par2 = f32[3,3]{1,0} parameter(2) + concat0 = f32[3,8] concatenate(f32[3,5] par1, f32[3,3] par2), + dimensions={1} + ROOT add0 = f32[3,8]{1,0} add(par0,concat0) + } + )"; + + auto module = ParseHloString(module_str).ValueOrDie(); + module = + backend() + .compiler() + ->RunHloPasses(std::move(module), backend().default_stream_executor(), + /*device_allocator=*/nullptr) + .ConsumeValueOrDie(); + + auto copy = FindInstruction(module.get(), "copy.1"); + auto concat = FindInstruction(module.get(), "concat0"); + EXPECT_EQ(concat->operand(0), copy); + EXPECT_TRUE( + LayoutUtil::Equal(concat->shape().layout(), copy->shape().layout())); +} + +TEST_F(LayoutAssignmentTest, + ConvolutionOperandWithImplicitLayoutChangeNotCopied) { + const char* module_str = R"( + HloModule ConvolutionOperandWithImplicitLayoutChangeNotCopied + + ENTRY ConvolutionOperandWithImplicitLayoutChangeNotCopied { + par0 = f32[128,3,230,230]{2,3,1,0} parameter(0) + par1 = f32[7,7,3,64]{3,2,0,1} parameter(1) + ROOT convolution0 = f32[128,64,112,112]{3,2,1,0} convolution(par0, par1), + window={size=7x7 stride=2x2}, dim_labels=bf01_01io->bf01, + feature_group_count=1 + } + )"; + + auto module = ParseHloString(module_str).ValueOrDie(); + module = + backend() + .compiler() + ->RunHloPasses(std::move(module), backend().default_stream_executor(), + /*device_allocator=*/nullptr) + .ConsumeValueOrDie(); + + auto copy = FindInstruction(module.get(), "copy.1"); + EXPECT_EQ(copy, nullptr); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/llvm_ir/BUILD b/tensorflow/compiler/xla/service/llvm_ir/BUILD index cdd3daf73b..be12d7c90c 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/BUILD +++ b/tensorflow/compiler/xla/service/llvm_ir/BUILD @@ -38,6 +38,7 @@ cc_library( "//tensorflow/compiler/xla/service:hlo", "//tensorflow/compiler/xla/service:logical_buffer", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", "@llvm//:core", ], ) @@ -69,6 +70,7 @@ cc_library( "//tensorflow/compiler/xla/service:hlo_module_config", "//tensorflow/compiler/xla/service:name_uniquer", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", "@llvm//:core", "@llvm//:support", "@llvm//:target", @@ -88,6 +90,8 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/strings", "@llvm//:core", ], ) @@ -103,6 +107,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", "@llvm//:core", ], ) @@ -120,6 +125,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/strings:str_format", "@llvm//:core", ], ) @@ -133,9 +139,7 @@ cc_library( ":llvm_util", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:statusor", - "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:util", - "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/service:hlo", "//tensorflow/core:lib", "@llvm//:core", @@ -193,6 +197,8 @@ cc_library( "//tensorflow/compiler/xla/service/gpu:parallel_loop_emitter", "//tensorflow/compiler/xla/service/gpu:partition_assignment", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", "@llvm//:core", ], ) @@ -219,7 +225,7 @@ cc_library( deps = [ ":llvm_loop", "//tensorflow/compiler/xla/service/llvm_ir:llvm_util", - "//tensorflow/core:lib", + "@com_google_absl//absl/strings", "@llvm//:core", ], ) @@ -230,6 +236,7 @@ cc_library( hdrs = ["buffer_assignment_util.h"], deps = [ "//tensorflow/compiler/xla/service:buffer_assignment", + "@com_google_absl//absl/strings", ], ) @@ -242,3 +249,12 @@ cc_library( "@llvm//:core", ], ) + +cc_library( + name = "ir_builder_mixin", + srcs = [], + hdrs = ["ir_builder_mixin.h"], + deps = [ + "@llvm//:core", + ], +) diff --git a/tensorflow/compiler/xla/service/llvm_ir/alias_analysis.h b/tensorflow/compiler/xla/service/llvm_ir/alias_analysis.h index fe9eab93aa..8d9fa99d82 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/alias_analysis.h +++ b/tensorflow/compiler/xla/service/llvm_ir/alias_analysis.h @@ -16,6 +16,7 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_ALIAS_ANALYSIS_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_ALIAS_ANALYSIS_H_ +#include "absl/strings/str_cat.h" #include "llvm/IR/Module.h" #include "tensorflow/compiler/xla/service/buffer_assignment.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -23,7 +24,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/gtl/flatmap.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { namespace llvm_ir { diff --git a/tensorflow/compiler/xla/service/llvm_ir/buffer_assignment_util.cc b/tensorflow/compiler/xla/service/llvm_ir/buffer_assignment_util.cc index 4eb5d9fb47..bdce4a171b 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/buffer_assignment_util.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/buffer_assignment_util.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/llvm_ir/buffer_assignment_util.h" +#include "absl/strings/str_cat.h" namespace xla { namespace llvm_ir { @@ -48,7 +49,7 @@ string ConstantBufferAllocationToGlobalName( c = '_'; } } - return tensorflow::strings::StrCat("buffer_for_", instr_name); + return absl::StrCat("buffer_for_", instr_name); } const Literal& LiteralForConstantAllocation( diff --git a/tensorflow/compiler/xla/service/llvm_ir/dynamic_update_slice_util.cc b/tensorflow/compiler/xla/service/llvm_ir/dynamic_update_slice_util.cc index 27fbb11e2e..ad350613dd 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/dynamic_update_slice_util.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/dynamic_update_slice_util.cc @@ -40,7 +40,7 @@ static Status EmitDynamicUpdateSliceInPlaceImpl( const Shape& update_shape, const ElementGenerator& start_indices_generator, bool is_signed, ElementGenerator update_array_generator, const IrArray& output_array, const gpu::LaunchDimensions* launch_dimensions, - tensorflow::StringPiece name, llvm::IRBuilder<>* b) { + absl::string_view name, llvm::IRBuilder<>* b) { const Shape& output_shape = output_array.GetShape(); // Read start indices from start_indices_generator. @@ -101,8 +101,7 @@ static Status EmitDynamicUpdateSliceInPlaceImpl( Status EmitDynamicUpdateSliceInPlace( tensorflow::gtl::ArraySlice<IrArray> operand_arrays, - const IrArray& output_array, tensorflow::StringPiece name, - llvm::IRBuilder<>* b) { + const IrArray& output_array, absl::string_view name, llvm::IRBuilder<>* b) { VLOG(2) << "EmitDynamicUpdateSliceInPlace for " << name; // No need to use operand_arrays[0], the input array of the diff --git a/tensorflow/compiler/xla/service/llvm_ir/dynamic_update_slice_util.h b/tensorflow/compiler/xla/service/llvm_ir/dynamic_update_slice_util.h index 3502577d23..e1631a62ae 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/dynamic_update_slice_util.h +++ b/tensorflow/compiler/xla/service/llvm_ir/dynamic_update_slice_util.h @@ -65,8 +65,7 @@ inline bool CanEmitFusedDynamicUpdateSliceInPlace( // modify the input/output buffer without touching any of the other elements. Status EmitDynamicUpdateSliceInPlace( tensorflow::gtl::ArraySlice<IrArray> operand_arrays, - const IrArray& output_array, tensorflow::StringPiece name, - llvm::IRBuilder<>* b); + const IrArray& output_array, absl::string_view name, llvm::IRBuilder<>* b); // Given a loop-fusion node whose root is a dynamic-update-slice op whose // array-to-be-updated and output share the same buffer slice, emits diff --git a/tensorflow/compiler/xla/service/llvm_ir/fused_ir_emitter.cc b/tensorflow/compiler/xla/service/llvm_ir/fused_ir_emitter.cc index 72ede377e1..6d637cad6d 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/fused_ir_emitter.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/fused_ir_emitter.cc @@ -98,7 +98,7 @@ Status FusedIrEmitter::HandleGetTupleElement( return Unimplemented( "GetTupleElement fusion currently only supports" " parameter operands, but found operand: %s", - operand->name().c_str()); + operand->name()); } // Emit code to lookup tuple element pointer, and store it in 'gte_values_'. llvm::Value* tuple_element_ptr = llvm_ir::EmitGetTupleElement( diff --git a/tensorflow/compiler/xla/service/llvm_ir/ir_array.cc b/tensorflow/compiler/xla/service/llvm_ir/ir_array.cc index 2b6caee6aa..6971220022 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/ir_array.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/ir_array.cc @@ -342,9 +342,9 @@ llvm::Value* IrArray::Index::Linearize( return logical_linear_index; } -llvm::Value* IrArray::EmitArrayElementAddress( - const IrArray::Index& index, llvm::IRBuilder<>* b, - tensorflow::StringPiece name) const { +llvm::Value* IrArray::EmitArrayElementAddress(const IrArray::Index& index, + llvm::IRBuilder<>* b, + absl::string_view name) const { if (ShapeUtil::IsScalar(*shape_)) { // Special handling of scalars: a scalar pretends to have the same value for // every index, thus effectively implementing broadcasting of its value @@ -402,7 +402,7 @@ void IrArray::AnnotateLoadStoreInstructionWithMetadata( llvm::Value* IrArray::EmitReadArrayElement(const Index& index, llvm::IRBuilder<>* b, - tensorflow::StringPiece name) const { + absl::string_view name) const { llvm::Value* element_address = EmitArrayElementAddress(index, b, name); llvm::LoadInst* load = b->CreateLoad(element_address); AnnotateLoadStoreInstructionWithMetadata(load); diff --git a/tensorflow/compiler/xla/service/llvm_ir/ir_array.h b/tensorflow/compiler/xla/service/llvm_ir/ir_array.h index 28ca793e3e..e913c109b3 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/ir_array.h +++ b/tensorflow/compiler/xla/service/llvm_ir/ir_array.h @@ -19,12 +19,13 @@ limitations under the License. #include <map> #include <vector> +#include "absl/algorithm/container.h" +#include "absl/strings/string_view.h" #include "llvm/IR/IRBuilder.h" #include "llvm/IR/Value.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -81,7 +82,7 @@ class IrArray { } } CHECK_NE(index_type_, nullptr); - CHECK(c_all_of(multidim, [&](llvm::Value* v) { + CHECK(absl::c_all_of(multidim, [&](llvm::Value* v) { return index_type_ == v->getType(); })); } @@ -240,7 +241,7 @@ class IrArray { // The optional name is useful for debugging when looking at // the emitted LLVM IR. llvm::Value* EmitArrayElementAddress(const Index& index, llvm::IRBuilder<>* b, - tensorflow::StringPiece name = "") const; + absl::string_view name = "") const; // Attach metadata this IrArray instance knows about to "instruction". void AnnotateLoadStoreInstructionWithMetadata( @@ -254,7 +255,7 @@ class IrArray { // The optional name is useful for debugging when looking at // the emitted LLVM IR. llvm::Value* EmitReadArrayElement(const Index& index, llvm::IRBuilder<>* b, - tensorflow::StringPiece name = "") const; + absl::string_view name = "") const; // Emit IR to write the given value to the array element at the given index. void EmitWriteArrayElement(const Index& index, llvm::Value* value, diff --git a/tensorflow/compiler/xla/service/llvm_ir/ir_builder_mixin.h b/tensorflow/compiler/xla/service/llvm_ir/ir_builder_mixin.h new file mode 100644 index 0000000000..abc06fb7b4 --- /dev/null +++ b/tensorflow/compiler/xla/service/llvm_ir/ir_builder_mixin.h @@ -0,0 +1,400 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_IR_BUILDER_MIXIN_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_IR_BUILDER_MIXIN_H_ + +#include "llvm/IR/IRBuilder.h" + +namespace xla { + +// Mixin class that injects more ergonomic versions of llvm::IRBuilder methods +// into a class. Intended to be used as a CRTP base class, like: +// +// class MyIrEmitter : public IrBuilderMixin<MyIrEmitter> { +// llvm::IRBuilder<>* builder() { return builder_; } +// +// void EmitFoo(HloInstruction* foo) { +// Add(Mul(...), FPToUI(...)); +// } +// }; + +template <typename Derived> +class IrBuilderMixin { + protected: + template <class... Args> + llvm::Value* Add(Args&&... args) { + return mixin_builder()->CreateAdd(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::LoadInst* AlignedLoad(Args&&... args) { + return mixin_builder()->CreateAlignedLoad(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::StoreInst* AlignedStore(Args&&... args) { + return mixin_builder()->CreateAlignedStore(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::AllocaInst* Alloca(Args&&... args) { + return mixin_builder()->CreateAlloca(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* And(Args&&... args) { + return mixin_builder()->CreateAnd(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* AtomicCmpXchg(Args&&... args) { + return mixin_builder()->CreateAtomicCmpXchg(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* AtomicRMW(Args&&... args) { + return mixin_builder()->CreateAtomicRMW(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* BitCast(Args&&... args) { + return mixin_builder()->CreateBitCast(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Br(Args&&... args) { + return mixin_builder()->CreateBr(std::forward<Args>(args)...); + } + + llvm::CallInst* Call(llvm::Value* callee, + llvm::ArrayRef<llvm::Value*> args = llvm::None, + const llvm::Twine& name = "", + llvm::MDNode* fp_math_tag = nullptr) { + return mixin_builder()->CreateCall(callee, args, name, fp_math_tag); + } + + template <class... Args> + llvm::BranchInst* CondBr(Args&&... args) { + return mixin_builder()->CreateCondBr(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* ConstInBoundsGEP1_32(Args&&... args) { + return mixin_builder()->CreateConstInBoundsGEP1_32( + std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FAdd(Args&&... args) { + return mixin_builder()->CreateFAdd(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FMul(Args&&... args) { + return mixin_builder()->CreateFMul(std::forward<Args>(args)...); + } + + llvm::Value* GEP(llvm::Value* ptr, llvm::ArrayRef<llvm::Value*> idx_list, + const llvm::Twine& name = "") { + return mixin_builder()->CreateGEP(ptr, idx_list, name); + } + + template <class... Args> + llvm::Value* ICmpEQ(Args&&... args) { + return mixin_builder()->CreateICmpEQ(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* ICmpNE(Args&&... args) { + return mixin_builder()->CreateICmpNE(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* ICmpULE(Args&&... args) { + return mixin_builder()->CreateICmpULE(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* ICmpULT(Args&&... args) { + return mixin_builder()->CreateICmpULT(std::forward<Args>(args)...); + } + + llvm::Value* InBoundsGEP(llvm::Value* ptr, + llvm::ArrayRef<llvm::Value*> idx_list, + const llvm::Twine& name = "") { + return mixin_builder()->CreateInBoundsGEP(ptr, idx_list, name); + } + + llvm::Value* ExtractValue(llvm::Value* agg, llvm::ArrayRef<unsigned> idxs, + const llvm::Twine& name = "") { + return mixin_builder()->CreateExtractValue(agg, idxs, name); + } + + llvm::Value* InsertValue(llvm::Value* agg, llvm::Value* val, + llvm::ArrayRef<unsigned> idxs, + const llvm::Twine& name = "") { + return mixin_builder()->CreateInsertValue(agg, val, idxs, name); + } + + template <class... Args> + llvm::Value* IntToPtr(Args&&... args) { + return mixin_builder()->CreateIntToPtr(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::LoadInst* Load(Args&&... args) { + return mixin_builder()->CreateLoad(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::CallInst* MemCpy(Args&&... args) { + return mixin_builder()->CreateMemCpy(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Mul(Args&&... args) { + return mixin_builder()->CreateMul(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* NSWAdd(Args&&... args) { + return mixin_builder()->CreateNSWAdd(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* NSWMul(Args&&... args) { + return mixin_builder()->CreateNSWMul(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* NSWSub(Args&&... args) { + return mixin_builder()->CreateNSWSub(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Or(Args&&... args) { + return mixin_builder()->CreateOr(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* PointerCast(Args&&... args) { + return mixin_builder()->CreatePointerCast(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* PtrToInt(Args&&... args) { + return mixin_builder()->CreatePtrToInt(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* SDiv(Args&&... args) { + return mixin_builder()->CreateSDiv(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Select(Args&&... args) { + return mixin_builder()->CreateSelect(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* SRem(Args&&... args) { + return mixin_builder()->CreateSRem(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::StoreInst* Store(Args&&... args) { + return mixin_builder()->CreateStore(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* UDiv(Args&&... args) { + return mixin_builder()->CreateUDiv(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* URem(Args&&... args) { + return mixin_builder()->CreateURem(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* VectorSplat(Args&&... args) { + return mixin_builder()->CreateVectorSplat(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* ZExtOrTrunc(Args&&... args) { + return mixin_builder()->CreateZExtOrTrunc(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* AShr(Args&&... args) { + return mixin_builder()->CreateAShr(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FCmpOEQ(Args&&... args) { + return mixin_builder()->CreateFCmpOEQ(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FCmpOLT(Args&&... args) { + return mixin_builder()->CreateFCmpOLT(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FCmpONE(Args&&... args) { + return mixin_builder()->CreateFCmpONE(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FCmpUNE(Args&&... args) { + return mixin_builder()->CreateFCmpUNE(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FDiv(Args&&... args) { + return mixin_builder()->CreateFDiv(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FNeg(Args&&... args) { + return mixin_builder()->CreateFNeg(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FPCast(Args&&... args) { + return mixin_builder()->CreateFPCast(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FPToSI(Args&&... args) { + return mixin_builder()->CreateFPToSI(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FPToUI(Args&&... args) { + return mixin_builder()->CreateFPToUI(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FPTrunc(Args&&... args) { + return mixin_builder()->CreateFPTrunc(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FRem(Args&&... args) { + return mixin_builder()->CreateFRem(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* FSub(Args&&... args) { + return mixin_builder()->CreateFSub(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* ICmpSGE(Args&&... args) { + return mixin_builder()->CreateICmpSGE(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* ICmpSLT(Args&&... args) { + return mixin_builder()->CreateICmpSLT(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* IntCast(Args&&... args) { + return mixin_builder()->CreateIntCast(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* LShr(Args&&... args) { + return mixin_builder()->CreateLShr(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* MemSet(Args&&... args) { + return mixin_builder()->CreateMemSet(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Neg(Args&&... args) { + return mixin_builder()->CreateNeg(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Not(Args&&... args) { + return mixin_builder()->CreateNot(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::PHINode* PHI(Args&&... args) { + return mixin_builder()->CreatePHI(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* RetVoid(Args&&... args) { + return mixin_builder()->CreateRetVoid(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* SExtOrTrunc(Args&&... args) { + return mixin_builder()->CreateSExtOrTrunc(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Shl(Args&&... args) { + return mixin_builder()->CreateShl(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* SIToFP(Args&&... args) { + return mixin_builder()->CreateSIToFP(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Sub(Args&&... args) { + return mixin_builder()->CreateSub(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Trunc(Args&&... args) { + return mixin_builder()->CreateTrunc(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* UIToFP(Args&&... args) { + return mixin_builder()->CreateUIToFP(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Unreachable(Args&&... args) { + return mixin_builder()->CreateUnreachable(std::forward<Args>(args)...); + } + + template <class... Args> + llvm::Value* Xor(Args&&... args) { + return mixin_builder()->CreateXor(std::forward<Args>(args)...); + } + + private: + llvm::IRBuilder<>* mixin_builder() { + return static_cast<Derived*>(this)->builder(); + } +}; + +} // namespace xla + +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_IR_BUILDER_MIXIN_H_ diff --git a/tensorflow/compiler/xla/service/llvm_ir/kernel_support_library.cc b/tensorflow/compiler/xla/service/llvm_ir/kernel_support_library.cc index b79567369a..bd0139f85b 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/kernel_support_library.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/kernel_support_library.cc @@ -19,7 +19,7 @@ limitations under the License. namespace xla { Status KernelSupportLibrary::For( - tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, + absl::string_view name, llvm::Value* start, llvm::Value* end, llvm::Value* step, const std::function<Status(llvm::Value*, bool)>& for_body_generator) { return If(b_->CreateICmpSLT(start, end), [&]() -> Status { @@ -30,7 +30,7 @@ Status KernelSupportLibrary::For( } Status KernelSupportLibrary::For( - tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, + absl::string_view name, llvm::Value* start, llvm::Value* end, llvm::Value* step, bool peel_first_iteration, const std::function<Status(llvm::Value*, llvm::Value*)>& for_body_generator) { @@ -56,7 +56,7 @@ Status KernelSupportLibrary::For( } Status KernelSupportLibrary::If( - tensorflow::StringPiece name, llvm::Value* condition, + absl::string_view name, llvm::Value* condition, const std::function<Status()>& true_block_generator, const std::function<Status()>& false_block_generator) { llvm_ir::LlvmIfData if_data = llvm_ir::EmitIfThenElse(condition, name, b_); @@ -70,7 +70,7 @@ Status KernelSupportLibrary::If( void KernelSupportLibrary::EmitAndCallOutlinedKernel( bool enable_fast_math, bool optimize_for_size, llvm::IRBuilder<>* b, - tensorflow::StringPiece kernel_name, + absl::string_view kernel_name, KernelSupportLibrary::ArgumentVector arguments, const std::function<void(KernelSupportLibrary::ArgumentVector)>& kernel_body_generator) { diff --git a/tensorflow/compiler/xla/service/llvm_ir/kernel_support_library.h b/tensorflow/compiler/xla/service/llvm_ir/kernel_support_library.h index b00f903d56..b152cf9275 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/kernel_support_library.h +++ b/tensorflow/compiler/xla/service/llvm_ir/kernel_support_library.h @@ -13,17 +13,17 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_CPU_KERNEL_SUPPORT_LIBRARY_H_ -#define TENSORFLOW_COMPILER_XLA_SERVICE_CPU_KERNEL_SUPPORT_LIBRARY_H_ +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_KERNEL_SUPPORT_LIBRARY_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_KERNEL_SUPPORT_LIBRARY_H_ #include <string> +#include "absl/strings/string_view.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/IRBuilder.h" #include "llvm/IR/Value.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_loop.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_util.h" -#include "tensorflow/core/lib/core/stringpiece.h" namespace xla { // A thin wrapper around llvm_loop.h to make code generating structured control @@ -49,13 +49,13 @@ class KernelSupportLibrary { // `for_body_generator(/*ind_var=*/,i, /*is_first_iteration=*/false)`; // } Status For( - tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, + absl::string_view name, llvm::Value* start, llvm::Value* end, llvm::Value* step, const std::function<Status(llvm::Value* ind_var, bool is_first_iteration)>& for_body_generator); void ForReturnVoid( - tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, + absl::string_view name, llvm::Value* start, llvm::Value* end, llvm::Value* step, const std::function<void(llvm::Value* ind_var, bool is_first_iteration)>& for_body_generator) { @@ -67,7 +67,7 @@ class KernelSupportLibrary { })); } - Status For(tensorflow::StringPiece name, int64 start, int64 end, int64 step, + Status For(absl::string_view name, int64 start, int64 end, int64 step, const std::function<Status(llvm::Value* ind_var, bool is_first_iteration)>& for_body_generator) { @@ -77,7 +77,7 @@ class KernelSupportLibrary { } void ForReturnVoid( - tensorflow::StringPiece name, int64 start, int64 end, int64 step, + absl::string_view name, int64 start, int64 end, int64 step, const std::function<void(llvm::Value* ind_var, bool is_first_iteration)>& for_body_generator) { ForReturnVoid(name, /*start=*/b_->getInt64(start), @@ -99,13 +99,13 @@ class KernelSupportLibrary { // for (i64 i = `start`; i s< `end`; i += `step`) // `for_body_generator(/*ind_var=*/,i, // /*is_first_iteration=*/,(i != `start`))`; - Status For(tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, + Status For(absl::string_view name, llvm::Value* start, llvm::Value* end, llvm::Value* step, bool peel_first_iteration, const std::function<Status(llvm::Value* ind_var, llvm::Value* is_first_iteration)>& for_body_generator); - void ForReturnVoid(tensorflow::StringPiece name, llvm::Value* start, + void ForReturnVoid(absl::string_view name, llvm::Value* start, llvm::Value* end, llvm::Value* step, bool peel_first_iteration, const std::function<void(llvm::Value* ind_var, @@ -119,7 +119,7 @@ class KernelSupportLibrary { })); } - Status For(tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, + Status For(absl::string_view name, llvm::Value* start, llvm::Value* end, int64 step, bool peel_first_iteration, const std::function<Status(llvm::Value* ind_var, llvm::Value* is_first_iteration)>& @@ -129,7 +129,7 @@ class KernelSupportLibrary { peel_first_iteration, for_body_generator); } - void ForReturnVoid(tensorflow::StringPiece name, llvm::Value* start, + void ForReturnVoid(absl::string_view name, llvm::Value* start, llvm::Value* end, int64 step, bool peel_first_iteration, const std::function<void(llvm::Value* ind_var, llvm::Value* is_first_iteration)>& @@ -140,7 +140,7 @@ class KernelSupportLibrary { } Status For( - tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, + absl::string_view name, llvm::Value* start, llvm::Value* end, llvm::Value* step, const std::function<Status(llvm::Value* ind_var)>& for_body_generator) { return For(name, start, end, step, @@ -151,7 +151,7 @@ class KernelSupportLibrary { } void ForReturnVoid( - tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, + absl::string_view name, llvm::Value* start, llvm::Value* end, llvm::Value* step, const std::function<void(llvm::Value* ind_var)>& for_body_generator) { ForReturnVoid(name, start, end, step, @@ -162,8 +162,7 @@ class KernelSupportLibrary { } Status For( - tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, - int64 step, + absl::string_view name, llvm::Value* start, llvm::Value* end, int64 step, const std::function<Status(llvm::Value* ind_var)>& for_body_generator) { return For(name, start, end, llvm::ConstantInt::get(start->getType(), step), /*peel_first_iteration=*/false, @@ -173,8 +172,7 @@ class KernelSupportLibrary { } void ForReturnVoid( - tensorflow::StringPiece name, llvm::Value* start, llvm::Value* end, - int64 step, + absl::string_view name, llvm::Value* start, llvm::Value* end, int64 step, const std::function<void(llvm::Value* ind_var)>& for_body_generator) { ForReturnVoid(name, start, end, llvm::ConstantInt::get(start->getType(), step), @@ -182,7 +180,7 @@ class KernelSupportLibrary { } Status For( - tensorflow::StringPiece name, int64 start, int64 end, int64 step, + absl::string_view name, int64 start, int64 end, int64 step, const std::function<Status(llvm::Value* ind_var)>& for_body_generator) { return For(name, /*start=*/b_->getInt64(start), /*end=*/b_->getInt64(end), @@ -190,7 +188,7 @@ class KernelSupportLibrary { } void ForReturnVoid( - tensorflow::StringPiece name, int64 start, int64 end, int64 step, + absl::string_view name, int64 start, int64 end, int64 step, const std::function<void(llvm::Value* ind_var)>& for_body_generator) { ForReturnVoid(name, /*start=*/b_->getInt64(start), /*end=*/b_->getInt64(end), @@ -203,7 +201,7 @@ class KernelSupportLibrary { // `true_block_generator()`; // else // `false_block_generator()`; - Status If(tensorflow::StringPiece name, llvm::Value* condition, + Status If(absl::string_view name, llvm::Value* condition, const std::function<Status()>& true_block_generator, const std::function<Status()>& false_block_generator = []() -> Status { return Status::OK(); }); @@ -222,7 +220,7 @@ class KernelSupportLibrary { IfReturnVoid("", condition, true_block_generator, false_block_generator); } - void IfReturnVoid(tensorflow::StringPiece name, llvm::Value* condition, + void IfReturnVoid(absl::string_view name, llvm::Value* condition, const std::function<void()>& true_block_generator, const std::function<void()>& false_block_generator = []() { }) { @@ -259,13 +257,13 @@ class KernelSupportLibrary { // Currently we only support at most one nullptr value in `arguments`. static void EmitAndCallOutlinedKernel( bool enable_fast_math, bool optimize_for_size, llvm::IRBuilder<>* b, - tensorflow::StringPiece kernel_name, ArgumentVector arguments, + absl::string_view kernel_name, ArgumentVector arguments, const std::function<void(ArgumentVector)>& kernel_body_generator); // Thin wrappers around the more general EmitAndCallOutlinedKernel above. static void EmitAndCallOutlinedKernel( bool enable_fast_math, bool optimize_for_size, llvm::IRBuilder<>* b, - tensorflow::StringPiece kernel_name, llvm::Value* arg0, llvm::Value* arg1, + absl::string_view kernel_name, llvm::Value* arg0, llvm::Value* arg1, llvm::Value* arg2, const std::function<void(llvm::Value*, llvm::Value*, llvm::Value*)>& kernel_body_generator) { @@ -278,7 +276,7 @@ class KernelSupportLibrary { static void EmitAndCallOutlinedKernel( bool enable_fast_math, bool optimize_for_size, llvm::IRBuilder<>* b, - tensorflow::StringPiece kernel_name, llvm::Value* arg0, llvm::Value* arg1, + absl::string_view kernel_name, llvm::Value* arg0, llvm::Value* arg1, llvm::Value* arg2, llvm::Value* arg3, const std::function<void(llvm::Value*, llvm::Value*, llvm::Value*, llvm::Value*)>& kernel_body_generator) { @@ -296,4 +294,4 @@ class KernelSupportLibrary { }; } // namespace xla -#endif // TENSORFLOW_COMPILER_XLA_SERVICE_CPU_KERNEL_SUPPORT_LIBRARY_H_ +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_KERNEL_SUPPORT_LIBRARY_H_ diff --git a/tensorflow/compiler/xla/service/llvm_ir/kernel_tiling.cc b/tensorflow/compiler/xla/service/llvm_ir/kernel_tiling.cc index 35b3941272..cb4d1db997 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/kernel_tiling.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/kernel_tiling.cc @@ -55,10 +55,10 @@ Shape MergeDimensions(tensorflow::gtl::ArraySlice<size_t> segs, } } // namespace -tensorflow::gtl::optional<std::vector<int64> > FindTranspose021( - const Shape& a, const Shape& b) { +absl::optional<std::vector<int64> > FindTranspose021(const Shape& a, + const Shape& b) { if (!ShapeUtil::CompatibleIgnoringElementType(a, b)) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } std::vector<int64> perm(a.dimensions().size()); @@ -88,7 +88,7 @@ tensorflow::gtl::optional<std::vector<int64> > FindTranspose021( return dims_021; } - return tensorflow::gtl::nullopt; + return absl::nullopt; } IrArray::Index GetUnreducedOutputIndex( diff --git a/tensorflow/compiler/xla/service/llvm_ir/kernel_tiling.h b/tensorflow/compiler/xla/service/llvm_ir/kernel_tiling.h index ccb9b8ba3e..8bd06c42c3 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/kernel_tiling.h +++ b/tensorflow/compiler/xla/service/llvm_ir/kernel_tiling.h @@ -36,8 +36,8 @@ namespace llvm_ir { // If `b` is a 0-2-1 transpose of `a` in 0-1-2, return the dimensions for the // reduced shape of `b` or the 0-2-1 shape. -tensorflow::gtl::optional<std::vector<int64> > FindTranspose021(const Shape& a, - const Shape& b); +absl::optional<std::vector<int64> > FindTranspose021(const Shape& a, + const Shape& b); // Return the unreduced output index corresponding to the given reduced output // index. diff --git a/tensorflow/compiler/xla/service/llvm_ir/llvm_loop.cc b/tensorflow/compiler/xla/service/llvm_ir/llvm_loop.cc index ba7f94834c..9f3329e7f0 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/llvm_loop.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/llvm_loop.cc @@ -18,6 +18,7 @@ limitations under the License. #include <numeric> #include <vector> +#include "absl/strings/str_cat.h" #include "llvm/IR/Constants.h" #include "llvm/IR/Function.h" #include "llvm/IR/Instructions.h" @@ -25,19 +26,17 @@ limitations under the License. #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" namespace xla { namespace llvm_ir { -ForLoop::ForLoop(tensorflow::StringPiece prefix, tensorflow::StringPiece suffix, +ForLoop::ForLoop(absl::string_view prefix, absl::string_view suffix, llvm::Value* start_index, llvm::Value* end_index, llvm::Value* step, UnrollMode unroll_mode, bool prevent_vectorization) - : prefix_(std::string(prefix)), - suffix_(std::string(suffix)), + : prefix_(prefix), + suffix_(suffix), start_index_(start_index), end_index_(end_index), step_(step), @@ -46,9 +45,9 @@ ForLoop::ForLoop(tensorflow::StringPiece prefix, tensorflow::StringPiece suffix, prevent_vectorization_(prevent_vectorization) {} /* static */ std::unique_ptr<ForLoop> ForLoop::EmitForLoop( - tensorflow::StringPiece prefix, llvm::Value* start_index, - llvm::Value* end_index, llvm::Value* step, llvm::IRBuilder<>* b, - UnrollMode unroll_mode, bool prevent_vectorization) { + absl::string_view prefix, llvm::Value* start_index, llvm::Value* end_index, + llvm::Value* step, llvm::IRBuilder<>* b, UnrollMode unroll_mode, + bool prevent_vectorization) { std::unique_ptr<ForLoop> loop(new ForLoop(prefix, /*suffix=*/"", start_index, end_index, step, unroll_mode, prevent_vectorization)); @@ -168,16 +167,16 @@ std::vector<llvm::Metadata*> ForLoop::GetLoopMetadata(llvm::IRBuilder<>* b) { return result; } -string ForLoop::GetQualifiedName(tensorflow::StringPiece name) { +string ForLoop::GetQualifiedName(absl::string_view name) { return llvm_ir::IrName(prefix_, llvm_ir::IrName(name, suffix_)); } -llvm::BasicBlock* ForLoop::CreateLoopBB(tensorflow::StringPiece name, +llvm::BasicBlock* ForLoop::CreateLoopBB(absl::string_view name, llvm::IRBuilder<>* b) { return CreateBasicBlock(insert_before_bb_, GetQualifiedName(name), b); } -std::unique_ptr<ForLoop> ForLoopNest::AddLoop(tensorflow::StringPiece suffix, +std::unique_ptr<ForLoop> ForLoopNest::AddLoop(absl::string_view suffix, llvm::Value* start_index, llvm::Value* end_index, UnrollMode unroll_mode, @@ -186,12 +185,9 @@ std::unique_ptr<ForLoop> ForLoopNest::AddLoop(tensorflow::StringPiece suffix, unroll_mode, prevent_vectorization); } -std::unique_ptr<ForLoop> ForLoopNest::AddLoop(tensorflow::StringPiece suffix, - llvm::Value* start_index, - llvm::Value* end_index, - llvm::Value* stride, - UnrollMode unroll_mode, - bool prevent_vectorization) { +std::unique_ptr<ForLoop> ForLoopNest::AddLoop( + absl::string_view suffix, llvm::Value* start_index, llvm::Value* end_index, + llvm::Value* stride, UnrollMode unroll_mode, bool prevent_vectorization) { if (inner_loop_body_bb_ != nullptr) { // Create this loop inside the previous one. b_->SetInsertPoint(&*inner_loop_body_bb_->getFirstInsertionPt()); @@ -216,7 +212,7 @@ std::unique_ptr<ForLoop> ForLoopNest::AddLoop(tensorflow::StringPiece suffix, std::unique_ptr<ForLoop> ForLoopNest::AddLoop(int64 start_index, int64 end_index, - tensorflow::StringPiece suffix, + absl::string_view suffix, UnrollMode unroll_mode, bool prevent_vectorization) { CHECK_LE(start_index, end_index); @@ -227,7 +223,7 @@ std::unique_ptr<ForLoop> ForLoopNest::AddLoop(int64 start_index, std::unique_ptr<ForLoop> ForLoopNest::AddLoop(int64 start_index, int64 end_index, int64 stride, - tensorflow::StringPiece suffix, + absl::string_view suffix, UnrollMode unroll_mode, bool prevent_vectorization) { CHECK_LE(start_index, end_index); @@ -238,7 +234,7 @@ std::unique_ptr<ForLoop> ForLoopNest::AddLoop(int64 start_index, } IrArray::Index ForLoopNest::AddLoopsForShape(const Shape& shape, - tensorflow::StringPiece suffix) { + absl::string_view suffix) { std::vector<int64> dimensions(ShapeUtil::Rank(shape)); std::iota(dimensions.begin(), dimensions.end(), 0); return AddLoopsForShapeOnDimensions(shape, dimensions, suffix); @@ -246,14 +242,14 @@ IrArray::Index ForLoopNest::AddLoopsForShape(const Shape& shape, IrArray::Index ForLoopNest::AddLoopsForShapeOnDimensions( const Shape& shape, tensorflow::gtl::ArraySlice<int64> dimensions, - tensorflow::StringPiece suffix) { + absl::string_view suffix) { llvm_ir::IrArray::Index index(index_type_, shape.dimensions_size()); for (int64 dimension : dimensions) { std::unique_ptr<llvm_ir::ForLoop> loop = AddLoop( /*start_index=*/0, /*end_index=*/shape.dimensions(dimension), /*suffix=*/ - llvm_ir::IrName(suffix, tensorflow::strings::StrCat(dimension))); + llvm_ir::IrName(suffix, absl::StrCat(dimension))); index[dimension] = loop->GetIndVarValue(); } return index; @@ -261,7 +257,7 @@ IrArray::Index ForLoopNest::AddLoopsForShapeOnDimensions( IrArray::Index ForLoopNest::EmitOperandArrayLoopNest( const llvm_ir::IrArray& operand_array, int64 dimension_to_skip, - tensorflow::StringPiece name_suffix) { + absl::string_view name_suffix) { // Prepares the dimension list we will use to emit the loop nest. Outermost // loops are added first. Add loops in major-to-minor order, and skip the // 'dimension_to_skip' dimension. diff --git a/tensorflow/compiler/xla/service/llvm_ir/llvm_loop.h b/tensorflow/compiler/xla/service/llvm_ir/llvm_loop.h index a4fed5c8dc..0a406bd90b 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/llvm_loop.h +++ b/tensorflow/compiler/xla/service/llvm_ir/llvm_loop.h @@ -19,15 +19,15 @@ limitations under the License. #include <memory> #include <string> +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/IRBuilder.h" #include "llvm/IR/Value.h" #include "tensorflow/compiler/xla/service/llvm_ir/ir_array.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/types.h" @@ -78,7 +78,7 @@ class ForLoop { // `unroll_mode` specifies the desired LLVM unrolling behavior for generated // loop. static std::unique_ptr<ForLoop> EmitForLoop( - tensorflow::StringPiece prefix, llvm::Value* start_index, + absl::string_view prefix, llvm::Value* start_index, llvm::Value* end_index, llvm::Value* step, llvm::IRBuilder<>* b, UnrollMode unroll_mode = llvm_ir::UnrollMode::kDefaultUnroll, bool prevent_vectorization = false); @@ -133,19 +133,18 @@ class ForLoop { // Allow ForLoopNest to call this private constructor. friend class ForLoopNest; - ForLoop(tensorflow::StringPiece prefix, tensorflow::StringPiece suffix, + ForLoop(absl::string_view prefix, absl::string_view suffix, llvm::Value* start_index, llvm::Value* end_index, llvm::Value* step, UnrollMode unroll_mode, bool prevent_vectorization); // Emit the loop at the insert point of the builder. void Emit(llvm::IRBuilder<>* b); - llvm::BasicBlock* CreateLoopBB(tensorflow::StringPiece name, - llvm::IRBuilder<>* b); + llvm::BasicBlock* CreateLoopBB(absl::string_view name, llvm::IRBuilder<>* b); // Creates a name for an LLVM construct, appending prefix_ and suffix_, if // they are set. - string GetQualifiedName(tensorflow::StringPiece name); + string GetQualifiedName(absl::string_view name); // Return a list of metadata nodes that should be associated with the // llvm::Loop for this `ForLoop`. @@ -182,9 +181,9 @@ class ForLoopNest { SetIndexType(index_ty); } - ForLoopNest(tensorflow::StringPiece name, llvm::IRBuilder<>* b, + ForLoopNest(absl::string_view name, llvm::IRBuilder<>* b, llvm::Type* index_ty = nullptr) - : name_(std::string(name)), + : name_(name), outer_loop_preheader_bb_(nullptr), outer_loop_exit_bb_(nullptr), inner_loop_body_bb_(nullptr), @@ -197,14 +196,14 @@ class ForLoopNest { // been added then emit loop inside the body of the last added loop. // unroll_mode is used to emit metadata that controls LLVM unrolling. std::unique_ptr<ForLoop> AddLoop( - tensorflow::StringPiece suffix, llvm::Value* start_index, + absl::string_view suffix, llvm::Value* start_index, llvm::Value* end_index, llvm::Value* stride, UnrollMode unroll_mode = xla::llvm_ir::UnrollMode::kDefaultUnroll, bool prevent_vectorization = false); // Like the above, except that it defaults to a stride of one. std::unique_ptr<ForLoop> AddLoop( - tensorflow::StringPiece suffix, llvm::Value* start_index, + absl::string_view suffix, llvm::Value* start_index, llvm::Value* end_index, UnrollMode unroll_mode = xla::llvm_ir::UnrollMode::kDefaultUnroll, bool prevent_vectorization = false); @@ -213,13 +212,13 @@ class ForLoopNest { // end index are constant. std::unique_ptr<ForLoop> AddLoop( int64 start_index, int64 end_index, int64 stride, - tensorflow::StringPiece suffix, + absl::string_view suffix, UnrollMode unroll_mode = xla::llvm_ir::UnrollMode::kDefaultUnroll, bool prevent_vectorization = false); // Like the above, except that it defaults to a stride of one. std::unique_ptr<ForLoop> AddLoop( - int64 start_index, int64 end_index, tensorflow::StringPiece suffix, + int64 start_index, int64 end_index, absl::string_view suffix, UnrollMode unroll_mode = xla::llvm_ir::UnrollMode::kDefaultUnroll, bool prevent_vectorization = false); @@ -234,8 +233,7 @@ class ForLoopNest { // within the shape. One possible order for that sequence would be: // // (0,0), (0,1), (0,2), (1,0), (1,1), (1,2) - IrArray::Index AddLoopsForShape(const Shape& shape, - tensorflow::StringPiece suffix); + IrArray::Index AddLoopsForShape(const Shape& shape, absl::string_view suffix); // Add a loop for each dimension in "dimensions". "suffix" is the // name suffix of the indvar and basic blocks in this new loop nest. @@ -245,7 +243,7 @@ class ForLoopNest { // dimension that is not in "dimensions". IrArray::Index AddLoopsForShapeOnDimensions( const Shape& shape, tensorflow::gtl::ArraySlice<int64> dimensions, - tensorflow::StringPiece suffix); + absl::string_view suffix); // Emits a series of nested loops for iterating over an operand array. Loops // are constructed in major to minor dimension layout order. No loop is @@ -256,7 +254,7 @@ class ForLoopNest { // basic blocks) constructed by this method. IrArray::Index EmitOperandArrayLoopNest(const llvm_ir::IrArray& operand_array, int64 dimension_to_skip, - tensorflow::StringPiece name_suffix); + absl::string_view name_suffix); // Convenience methods which return particular basic blocks of the outermost // or innermost loops. These methods return nullptr if no loops have been diff --git a/tensorflow/compiler/xla/service/llvm_ir/llvm_util.cc b/tensorflow/compiler/xla/service/llvm_ir/llvm_util.cc index e6126881af..f0db2a3761 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/llvm_util.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/llvm_util.cc @@ -19,6 +19,8 @@ limitations under the License. #include <memory> #include <vector> +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" #include "llvm/IR/DerivedTypes.h" #include "llvm/IR/GlobalValue.h" #include "llvm/IR/MDBuilder.h" @@ -34,8 +36,6 @@ limitations under the License. #include "tensorflow/core/lib/core/casts.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/io/path.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/byte_order.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/logging.h" @@ -61,7 +61,7 @@ string AsString(const std::string& str) { return string(str.data(), str.length()); } -llvm::StringRef AsStringRef(tensorflow::StringPiece str) { +llvm::StringRef AsStringRef(absl::string_view str) { return llvm::StringRef(str.data(), str.size()); } @@ -262,15 +262,17 @@ llvm::Constant* ConvertLiteralToIrConstant(const Literal& literal, } llvm::AllocaInst* EmitAllocaAtFunctionEntry(llvm::Type* type, - tensorflow::StringPiece name, + absl::string_view name, llvm::IRBuilder<>* b, int alignment) { return EmitAllocaAtFunctionEntryWithCount(type, nullptr, name, b, alignment); } -llvm::AllocaInst* EmitAllocaAtFunctionEntryWithCount( - llvm::Type* type, llvm::Value* element_count, tensorflow::StringPiece name, - llvm::IRBuilder<>* b, int alignment) { +llvm::AllocaInst* EmitAllocaAtFunctionEntryWithCount(llvm::Type* type, + llvm::Value* element_count, + absl::string_view name, + llvm::IRBuilder<>* b, + int alignment) { llvm::IRBuilder<>::InsertPoint insert_point = b->saveIP(); llvm::Function* function = b->GetInsertBlock()->getParent(); b->SetInsertPoint(&function->getEntryBlock(), @@ -285,7 +287,7 @@ llvm::AllocaInst* EmitAllocaAtFunctionEntryWithCount( } llvm::BasicBlock* CreateBasicBlock(llvm::BasicBlock* insert_before, - tensorflow::StringPiece name, + absl::string_view name, llvm::IRBuilder<>* b) { return llvm::BasicBlock::Create( /*Context=*/b->getContext(), @@ -294,27 +296,25 @@ llvm::BasicBlock* CreateBasicBlock(llvm::BasicBlock* insert_before, /*InsertBefore*/ insert_before); } -LlvmIfData EmitIfThenElse(llvm::Value* condition, tensorflow::StringPiece name, +LlvmIfData EmitIfThenElse(llvm::Value* condition, absl::string_view name, llvm::IRBuilder<>* b, bool emit_else) { llvm_ir::LlvmIfData if_data; if_data.if_block = b->GetInsertBlock(); if_data.true_block = - CreateBasicBlock(nullptr, tensorflow::strings::StrCat(name, "-true"), b); + CreateBasicBlock(nullptr, absl::StrCat(name, "-true"), b); if_data.false_block = - emit_else ? CreateBasicBlock( - nullptr, tensorflow::strings::StrCat(name, "-false"), b) + emit_else ? CreateBasicBlock(nullptr, absl::StrCat(name, "-false"), b) : nullptr; // Add a terminator to the if block, if necessary. if (if_data.if_block->getTerminator() == nullptr) { b->SetInsertPoint(if_data.if_block); - if_data.after_block = CreateBasicBlock( - nullptr, tensorflow::strings::StrCat(name, "-after"), b); + if_data.after_block = + CreateBasicBlock(nullptr, absl::StrCat(name, "-after"), b); b->CreateBr(if_data.after_block); } else { if_data.after_block = if_data.if_block->splitBasicBlock( - b->GetInsertPoint(), - AsStringRef(tensorflow::strings::StrCat(name, "-after"))); + b->GetInsertPoint(), AsStringRef(absl::StrCat(name, "-after"))); } // Our basic block should now end with an unconditional branch. Remove it; @@ -413,14 +413,14 @@ string IrName(string a) { return a; } -string IrName(tensorflow::StringPiece a, tensorflow::StringPiece b) { +string IrName(absl::string_view a, absl::string_view b) { if (!a.empty() && !b.empty()) { - return IrName(tensorflow::strings::StrCat(a, ".", b)); + return IrName(absl::StrCat(a, ".", b)); } - return IrName(tensorflow::strings::StrCat(a, b)); + return IrName(absl::StrCat(a, b)); } -string IrName(const HloInstruction* a, tensorflow::StringPiece b) { +string IrName(const HloInstruction* a, absl::string_view b) { return IrName(a->name(), b); } @@ -556,7 +556,7 @@ std::map<int, llvm::MDNode*> MergeMetadata( return result; } -static string GetProcessUniqueIrFileName(tensorflow::StringPiece prefix) { +static string GetProcessUniqueIrFileName(absl::string_view prefix) { static tensorflow::mutex mu(tensorflow::LINKER_INITIALIZED); static NameUniquer* uniquer = new NameUniquer(/*separator=*/"-"); @@ -584,18 +584,16 @@ Status DumpIRToDirectory(const string& directory_name, // XlaJitCompiledCpuFunction::Compile. Avoid overwriting IR files previously // dumped from the same process in such cases. string unique_and_safe_file_name = GetProcessUniqueIrFileName( - tensorflow::strings::StrCat("ir-", SanitizeFileName(hlo_module_name), "-", - optimized ? "with" : "no", "-opt")); + absl::StrCat("ir-", SanitizeFileName(hlo_module_name), "-", + optimized ? "with" : "no", "-opt")); string ir_file_name = tensorflow::io::JoinPath( - directory_name, - tensorflow::strings::StrCat(unique_and_safe_file_name, ".ll")); + directory_name, absl::StrCat(unique_and_safe_file_name, ".ll")); // For some models the embedded constants can be huge, so also dump the module // with the constants stripped to get IR that is easier to manipulate. string ir_no_constant_initializers_file_name = tensorflow::io::JoinPath( - directory_name, - tensorflow::strings::StrCat(unique_and_safe_file_name, "-noconst.ll")); + directory_name, absl::StrCat(unique_and_safe_file_name, "-noconst.ll")); TF_RETURN_IF_ERROR(CreateAndWriteStringToFile( directory_name, ir_file_name, DumpModuleToString(llvm_module))); @@ -607,8 +605,7 @@ Status DumpIRToDirectory(const string& directory_name, llvm::Function* CreateFunction(llvm::FunctionType* function_type, llvm::GlobalValue::LinkageTypes linkage, bool enable_fast_math, bool optimize_for_size, - tensorflow::StringPiece name, - llvm::Module* module) { + absl::string_view name, llvm::Module* module) { llvm::Function* function = llvm::Function::Create(function_type, linkage, AsStringRef(name), module); function->setCallingConv(llvm::CallingConv::C); @@ -638,7 +635,7 @@ void InitializeLLVMCommandLineOptions(const HloModuleConfig& config) { fake_argv_storage.push_back(""); for (const auto& it : options) { // Skip options the XLA backend itself consumes. - if (!tensorflow::str_util::StartsWith(it.first, "xla_")) { + if (!absl::StartsWith(it.first, "xla_")) { if (it.second.empty()) { fake_argv_storage.push_back(it.first); } else { diff --git a/tensorflow/compiler/xla/service/llvm_ir/llvm_util.h b/tensorflow/compiler/xla/service/llvm_ir/llvm_util.h index 0958398534..dde50e19d1 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/llvm_util.h +++ b/tensorflow/compiler/xla/service/llvm_ir/llvm_util.h @@ -20,6 +20,7 @@ limitations under the License. #include <string> #include <vector> +#include "absl/strings/string_view.h" #include "llvm/ADT/StringRef.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/IRBuilder.h" @@ -32,7 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_module_config.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/platform/types.h" @@ -47,11 +47,11 @@ namespace llvm_ir { // Convert a std::string (used by LLVM's interfaces) to string. string AsString(const std::string& str); -// Convert a tensorflow::StringPiece to a llvm::StringRef. Note: both -// tensorflow::StringPiece and llvm::StringRef are non-owning pointers into a +// Convert a absl::string_view to a llvm::StringRef. Note: both +// absl::string_view and llvm::StringRef are non-owning pointers into a // string in memory. This method is used to feed strings to LLVM // & Clang APIs that expect llvm::StringRef. -llvm::StringRef AsStringRef(tensorflow::StringPiece str); +llvm::StringRef AsStringRef(absl::string_view str); template <typename T> llvm::ArrayRef<T> AsArrayRef(const std::vector<T>& vec) { @@ -88,8 +88,8 @@ string DumpModuleToString(const llvm::Module& module); // - removing all '%'s. // string IrName(string a); -string IrName(tensorflow::StringPiece a, tensorflow::StringPiece b); -string IrName(const HloInstruction* a, tensorflow::StringPiece b = ""); +string IrName(absl::string_view a, absl::string_view b); +string IrName(const HloInstruction* a, absl::string_view b = ""); // Removes special characters from a function name. // @@ -164,21 +164,23 @@ llvm::Constant* ConvertLiteralToIrConstant(const Literal& literal, // This can be useful to avoid e.g. executing an alloca every time // through a loop. llvm::AllocaInst* EmitAllocaAtFunctionEntry(llvm::Type* type, - tensorflow::StringPiece name, + absl::string_view name, llvm::IRBuilder<>* b, int alignment = 0); // As EmitAllocaAtFunctionEntry, but allocates element_count entries // instead of a single element. -llvm::AllocaInst* EmitAllocaAtFunctionEntryWithCount( - llvm::Type* type, llvm::Value* element_count, tensorflow::StringPiece name, - llvm::IRBuilder<>* b, int alignment = 0); +llvm::AllocaInst* EmitAllocaAtFunctionEntryWithCount(llvm::Type* type, + llvm::Value* element_count, + absl::string_view name, + llvm::IRBuilder<>* b, + int alignment = 0); // Creates a basic block with the same context and function as for the // builder. Inserts at the end of the function if insert_before is // null. llvm::BasicBlock* CreateBasicBlock(llvm::BasicBlock* insert_before, - tensorflow::StringPiece name, + absl::string_view name, llvm::IRBuilder<>* b); // Struct with data on a conditional branch in a diamond shape created @@ -210,7 +212,7 @@ struct LlvmIfData { // Currently the insertion point of the builder must be a well-formed // block with a terminator. If you need to use this for a // non-terminated block, just make the function able to do that too. -LlvmIfData EmitIfThenElse(llvm::Value* condition, tensorflow::StringPiece name, +LlvmIfData EmitIfThenElse(llvm::Value* condition, absl::string_view name, llvm::IRBuilder<>* b, bool emit_else = true); // Emits a compare operation between "lhs" and "rhs" with the given predicate, @@ -285,8 +287,7 @@ Status DumpIRToDirectory(const string& directory_name, llvm::Function* CreateFunction(llvm::FunctionType* function_type, llvm::GlobalValue::LinkageTypes linkage, bool enable_fast_math, bool optimize_for_size, - tensorflow::StringPiece name, - llvm::Module* module); + absl::string_view name, llvm::Module* module); // Extracts the xla_backend_extra_options from `config` and passes those that // don't start with xla_ to LLVM. diff --git a/tensorflow/compiler/xla/service/llvm_ir/loop_emitter.cc b/tensorflow/compiler/xla/service/llvm_ir/loop_emitter.cc index 36f5fa1952..1553b4fc91 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/loop_emitter.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/loop_emitter.cc @@ -18,13 +18,13 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/service/llvm_ir/llvm_loop.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/types.h" @@ -86,7 +86,7 @@ LoopEmitter::LoopEmitter(const ElementGenerator& target_element_generator, } std::vector<IrArray::Index> LoopEmitter::EmitIndexAndSetExitBasicBlock( - tensorflow::StringPiece loop_name, llvm::Type* index_type) { + absl::string_view loop_name, llvm::Type* index_type) { CHECK_NE(index_type, nullptr); if (ShapeUtil::IsScalar(shape_)) { // No loop needed, so set exit_bb_ to nullptr. @@ -105,7 +105,7 @@ std::vector<IrArray::Index> LoopEmitter::EmitIndexAndSetExitBasicBlock( std::unique_ptr<ForLoop> loop = loop_nest.AddLoop( /*start_index=*/0, /*end_index=*/shape_.dimensions(dimension), - /*suffix=*/tensorflow::strings::Printf("dim.%lld", dimension)); + /*suffix=*/absl::StrFormat("dim.%d", dimension)); array_index[dimension] = loop->GetIndVarValue(); } @@ -122,7 +122,7 @@ std::vector<IrArray::Index> LoopEmitter::EmitIndexAndSetExitBasicBlock( return {array_index}; } -Status LoopEmitter::EmitLoop(tensorflow::StringPiece loop_name, +Status LoopEmitter::EmitLoop(absl::string_view loop_name, llvm::Type* index_type) { if (index_type == nullptr) { index_type = b_->getInt64Ty(); diff --git a/tensorflow/compiler/xla/service/llvm_ir/loop_emitter.h b/tensorflow/compiler/xla/service/llvm_ir/loop_emitter.h index c4f5c82086..57d9d8bbc6 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/loop_emitter.h +++ b/tensorflow/compiler/xla/service/llvm_ir/loop_emitter.h @@ -69,10 +69,10 @@ class LoopEmitter { } virtual std::vector<IrArray::Index> EmitIndexAndSetExitBasicBlock( - tensorflow::StringPiece loop_name, llvm::Type* index_type); + absl::string_view loop_name, llvm::Type* index_type); // Emits a complete loop nest for every element in the given shape. - Status EmitLoop(tensorflow::StringPiece loop_name = "", + Status EmitLoop(absl::string_view loop_name = "", llvm::Type* index_type = nullptr); protected: diff --git a/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc b/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc index e546f5cc4a..00dd3f1638 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc @@ -16,6 +16,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/llvm_ir/sort_util.h" // IWYU pragma: no_include "llvm/IR/Intrinsics.gen.inc" +#include "absl/strings/string_view.h" +#include "absl/types/optional.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Constants.h" #include "llvm/IR/Instructions.h" @@ -29,8 +31,6 @@ limitations under the License. #include "tensorflow/compiler/xla/service/llvm_ir/loop_emitter.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/types.h" namespace xla { @@ -42,7 +42,7 @@ namespace { void EmitCompareLoop(int64 dimension_to_sort, const IrArray::Index& keys_index, const IrArray::Index& compare_keys_index, const IrArray& keys_array, - const tensorflow::gtl::optional<IrArray>& values_array, + const absl::optional<IrArray>& values_array, llvm::IRBuilder<>* b) { // if (is_smaller_index && // compare_keys[dimension_to_sort] < dimension_to_sort_bound) @@ -87,8 +87,8 @@ void EmitCompareLoop(int64 dimension_to_sort, const IrArray::Index& keys_index, } // namespace Status EmitSortInPlace(int64 dimension_to_sort, const IrArray& keys_array, - const tensorflow::gtl::optional<IrArray>& values_array, - tensorflow::StringPiece name, llvm::Value* xor_mask, + const absl::optional<IrArray>& values_array, + absl::string_view name, llvm::Value* xor_mask, llvm::IRBuilder<>* b, const gpu::LaunchDimensions* launch_dimensions) { const Shape& keys_shape = keys_array.GetShape(); diff --git a/tensorflow/compiler/xla/service/llvm_ir/sort_util.h b/tensorflow/compiler/xla/service/llvm_ir/sort_util.h index 8458744c6b..527ed10374 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/sort_util.h +++ b/tensorflow/compiler/xla/service/llvm_ir/sort_util.h @@ -16,12 +16,12 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_SORT_UTIL_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_LLVM_IR_SORT_UTIL_H_ +#include "absl/strings/string_view.h" +#include "absl/types/optional.h" #include "llvm/IR/Value.h" #include "tensorflow/compiler/xla/service/gpu/partition_assignment.h" #include "tensorflow/compiler/xla/service/llvm_ir/ir_array.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/types.h" namespace xla { @@ -31,8 +31,8 @@ namespace llvm_ir { // implements the inner loop of BitonicSort. If 'launch_dimensions' is nullptr, // the inner compare loop will not be parallelized. Status EmitSortInPlace(int64 dimension_to_sort, const IrArray& keys_array, - const tensorflow::gtl::optional<IrArray>& values_array, - tensorflow::StringPiece name, llvm::Value* xor_mask, + const absl::optional<IrArray>& values_array, + absl::string_view name, llvm::Value* xor_mask, llvm::IRBuilder<>* b, const gpu::LaunchDimensions* launch_dimensions); } // namespace llvm_ir diff --git a/tensorflow/compiler/xla/service/local_service.cc b/tensorflow/compiler/xla/service/local_service.cc index 5e02096ee5..768105d9e1 100644 --- a/tensorflow/compiler/xla/service/local_service.cc +++ b/tensorflow/compiler/xla/service/local_service.cc @@ -19,10 +19,12 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/client/executable_build_options.h" #include "tensorflow/compiler/xla/client/xla_computation.h" #include "tensorflow/compiler/xla/execution_options_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/backend.h" #include "tensorflow/compiler/xla/service/computation_layout.h" #include "tensorflow/compiler/xla/service/executable.h" @@ -37,7 +39,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/cleanup.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" @@ -73,7 +74,7 @@ namespace { // If the parameter number is invalid for this computation, nullopt is // returned. When the return value has_value(), nullptr will never be // the held value. -tensorflow::gtl::optional<const OpMetadata*> ParameterMetadata( +absl::optional<const OpMetadata*> ParameterMetadata( const XlaComputation& computation, int parameter_number) { for (const HloComputationProto& comp : computation.proto().computations()) { if (comp.id() == computation.proto().entry_computation_id()) { @@ -81,14 +82,14 @@ tensorflow::gtl::optional<const OpMetadata*> ParameterMetadata( if (instr.opcode() == HloOpcodeString(HloOpcode::kParameter) && instr.parameter_number() == parameter_number) { if (!instr.has_metadata()) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } return &instr.metadata(); } } } } - return tensorflow::gtl::nullopt; + return absl::nullopt; } ExecutionOptions CreateExecutionOptions( @@ -149,7 +150,7 @@ StatusOr<std::unique_ptr<Executable>> LocalService::CompileExecutable( // Validate incoming layouts. if (argument_layouts.size() != program_shape.parameters_size()) { return InvalidArgument( - "Invalid number of arguments for computation: expected %d, got %zu.", + "Invalid number of arguments for computation: expected %d, got %u.", program_shape.parameters_size(), argument_layouts.size()); } @@ -158,7 +159,7 @@ StatusOr<std::unique_ptr<Executable>> LocalService::CompileExecutable( TF_RETURN_IF_ERROR( ShapeUtil::ValidateShapeWithOptionalLayout(argument_shape)); if (!ShapeUtil::Compatible(argument_shape, program_shape.parameters(i))) { - tensorflow::gtl::optional<const OpMetadata*> metadata = + absl::optional<const OpMetadata*> metadata = ParameterMetadata(computation, /*parameter_number=*/i); auto metadata_string = [&metadata]() -> string { if (!metadata.has_value()) { @@ -167,16 +168,15 @@ StatusOr<std::unique_ptr<Executable>> LocalService::CompileExecutable( CHECK(metadata.value() != nullptr); const OpMetadata& m = *metadata.value(); if (!m.source_file().empty()) { - return tensorflow::strings::Printf( - " (%s:%d)", m.source_file().c_str(), m.source_line()); + return absl::StrFormat(" (%s:%d)", m.source_file(), m.source_line()); } return ""; }; return InvalidArgument( "Invalid argument shape for argument %d%s, expected %s, got %s.", i, - metadata_string().c_str(), - ShapeUtil::HumanString(program_shape.parameters(i)).c_str(), - ShapeUtil::HumanString(argument_shape).c_str()); + metadata_string(), + ShapeUtil::HumanString(program_shape.parameters(i)), + ShapeUtil::HumanString(argument_shape)); } } if (build_options.result_layout() != nullptr) { @@ -214,7 +214,7 @@ StatusOr<const ShapedBuffer*> LocalService::GlobalDataToShapedBuffer( TF_ASSIGN_OR_RETURN(auto buffers, allocation_tracker_.Resolve(data)); if (replica_number >= buffers.size()) { return InvalidArgument( - "replica_number %d out of range; must be less than num_replicas = %zu.", + "replica_number %d out of range; must be less than num_replicas = %u.", replica_number, buffers.size()); } return buffers[replica_number]; diff --git a/tensorflow/compiler/xla/service/logical_buffer.cc b/tensorflow/compiler/xla/service/logical_buffer.cc index c742d35a7b..e1f56727bd 100644 --- a/tensorflow/compiler/xla/service/logical_buffer.cc +++ b/tensorflow/compiler/xla/service/logical_buffer.cc @@ -15,11 +15,11 @@ limitations under the License. #include "tensorflow/compiler/xla/service/logical_buffer.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { @@ -34,11 +34,10 @@ LogicalBuffer::~LogicalBuffer() {} string LogicalBuffer::ToString() const { string color_string; if (has_color()) { - color_string = tensorflow::strings::StrCat(" @", color().value()); + color_string = absl::StrCat(" @", color().value()); } - return tensorflow::strings::StrCat(instruction_->name(), "[", - tensorflow::str_util::Join(index_, ","), - "](#", id(), color_string, ")"); + return absl::StrCat(instruction_->name(), "[", absl::StrJoin(index_, ","), + "](#", id(), color_string, ")"); } } // namespace xla diff --git a/tensorflow/compiler/xla/service/logical_buffer_analysis.cc b/tensorflow/compiler/xla/service/logical_buffer_analysis.cc index d631fb5ee4..eaa09591b7 100644 --- a/tensorflow/compiler/xla/service/logical_buffer_analysis.cc +++ b/tensorflow/compiler/xla/service/logical_buffer_analysis.cc @@ -17,6 +17,7 @@ limitations under the License. #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/platform/logging.h" @@ -89,7 +90,7 @@ void LogicalBufferAnalysis::NewLogicalBuffer(HloInstruction* instruction, const ShapeIndex& index) { CHECK_EQ(logical_buffers_.size(), next_buffer_id_); logical_buffers_.emplace_back( - MakeUnique<LogicalBuffer>(instruction, index, next_buffer_id_)); + absl::make_unique<LogicalBuffer>(instruction, index, next_buffer_id_)); output_buffers_[std::make_pair(instruction, index)] = logical_buffers_.back().get(); diff --git a/tensorflow/compiler/xla/service/multi_output_fusion.h b/tensorflow/compiler/xla/service/multi_output_fusion.h index 0019cd7254..4c8cb7d379 100644 --- a/tensorflow/compiler/xla/service/multi_output_fusion.h +++ b/tensorflow/compiler/xla/service/multi_output_fusion.h @@ -19,10 +19,10 @@ limitations under the License. #include <queue> #include <vector> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/hlo_pass_interface.h" #include "tensorflow/compiler/xla/statusor.h" -#include "tensorflow/core/lib/core/stringpiece.h" namespace xla { @@ -48,9 +48,7 @@ class MultiOutputFusion : public HloPassInterface { public: MultiOutputFusion(int64 fuel) : fuel_(fuel) {} - tensorflow::StringPiece name() const override { - return "multi_output_fusion"; - } + absl::string_view name() const override { return "multi_output_fusion"; } // Run multi-output fusion on the given module. Returns whether the module // was changed. @@ -104,17 +102,17 @@ class MultiOutputFusion : public HloPassInterface { // InstructionFusion instead. virtual bool DoProducerConsumerMultiOutputFusion(); - private: - // Update the internal data structures after instr1 and instr2 are fused into - // one fusion instruction. - void Update(HloInstruction* instr1, HloInstruction* instr2); - // Optimization fuel is a compiler debugging technique that makes an // optimization pass stop what it is doing after having made N changes to the // program, where N is the fuel. By varying N, this can be used to find the // first single change that makes a test fail. int64 fuel_; + private: + // Update the internal data structures after instr1 and instr2 are fused into + // one fusion instruction. + void Update(HloInstruction* instr1, HloInstruction* instr2); + // Computation for the pass. HloComputation* computation_; diff --git a/tensorflow/compiler/xla/service/name_uniquer.cc b/tensorflow/compiler/xla/service/name_uniquer.cc index f6e7578a89..bd8fb17a23 100644 --- a/tensorflow/compiler/xla/service/name_uniquer.cc +++ b/tensorflow/compiler/xla/service/name_uniquer.cc @@ -15,8 +15,9 @@ limitations under the License. #include "tensorflow/compiler/xla/service/name_uniquer.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -52,8 +53,8 @@ NameUniquer::NameUniquer(const string& separator) { return result; } -string NameUniquer::GetUniqueName(tensorflow::StringPiece prefix) { - string root = GetSanitizedName(prefix.empty() ? "name" : std::string(prefix)); +string NameUniquer::GetUniqueName(absl::string_view prefix) { + string root = GetSanitizedName(prefix.empty() ? "name" : string(prefix)); // Strip away numeric suffix (if any). Only recognize separator if it is in // the middle of the name. @@ -63,20 +64,22 @@ string NameUniquer::GetUniqueName(tensorflow::StringPiece prefix) { if (separator_index != string::npos && (separator_index > 0) && (separator_index < root.size() - 1)) { string after_suffix = root.substr(separator_index + 1); - if (tensorflow::strings::safe_strto64(after_suffix, &numeric_suffix)) { + if (absl::SimpleAtoi(after_suffix, &numeric_suffix)) { has_numeric_suffix = true; // Remove numeric suffix from root. root = root.substr(0, separator_index); + } else { + // absl::SimpleAtoi may modify numeric_suffix even if it returns false. + numeric_suffix = 0; } } SequentialIdGenerator& id_generator = generated_names_[root]; numeric_suffix = id_generator.RegisterId(numeric_suffix); if (numeric_suffix == 0) { - return has_numeric_suffix ? tensorflow::strings::StrCat(root, separator_, 0) - : root; + return has_numeric_suffix ? absl::StrCat(root, separator_, 0) : root; } - tensorflow::strings::StrAppend(&root, separator_, numeric_suffix); + absl::StrAppend(&root, separator_, numeric_suffix); return root; } diff --git a/tensorflow/compiler/xla/service/name_uniquer.h b/tensorflow/compiler/xla/service/name_uniquer.h index 4423d61069..6dd89c240f 100644 --- a/tensorflow/compiler/xla/service/name_uniquer.h +++ b/tensorflow/compiler/xla/service/name_uniquer.h @@ -18,8 +18,8 @@ limitations under the License. #include <string> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/flatmap.h" #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/platform/macros.h" @@ -38,7 +38,7 @@ class NameUniquer { // Get a sanitized unique name in a string, with an optional prefix for // convenience. - string GetUniqueName(tensorflow::StringPiece prefix = ""); + string GetUniqueName(absl::string_view prefix = ""); // Sanitizes and returns the name. Unallowed characters will be replaced with // '_'. The result will match the regexp "[a-zA-Z_][a-zA-Z0-9_.-]*". diff --git a/tensorflow/compiler/xla/service/pattern_matcher.h b/tensorflow/compiler/xla/service/pattern_matcher.h index ac6ea4c72f..4869db79e7 100644 --- a/tensorflow/compiler/xla/service/pattern_matcher.h +++ b/tensorflow/compiler/xla/service/pattern_matcher.h @@ -16,11 +16,11 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_PATTERN_MATCHER_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_PATTERN_MATCHER_H_ +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_opcode.h" #include "tensorflow/compiler/xla/shape_util.h" -#include "tensorflow/core/lib/core/stringpiece.h" namespace xla { @@ -622,7 +622,7 @@ template <typename Previous> class HloInstructionPatternNameImpl { public: explicit HloInstructionPatternNameImpl(const Previous& previous, - tensorflow::StringPiece name) + absl::string_view name) : previous_(previous), name_(name) {} bool Match(const ::xla::HloInstruction* inst) const { @@ -631,7 +631,7 @@ class HloInstructionPatternNameImpl { private: Previous previous_; - tensorflow::StringPiece name_; + absl::string_view name_; }; // An HloInstructionPattern implementation that matches only if the instruction @@ -784,7 +784,7 @@ class HloInstructionPattern { // Modifies the pattern to match only if the instruction has the given name. HloInstructionPattern<HloInstructionType, HloInstructionPatternNameImpl<Impl>> - WithName(tensorflow::StringPiece name) const { + WithName(absl::string_view name) const { return HloInstructionPattern<HloInstructionType, HloInstructionPatternNameImpl<Impl>>( HloInstructionPatternNameImpl<Impl>(impl_, name), matched_inst_); @@ -918,6 +918,7 @@ Op(::xla::HloInstruction** matched_inst) { } XLA_NULLOP_PATTERN(Constant) XLA_NULLOP_PATTERN(Parameter) +XLA_NULLOP_PATTERN(Iota) #undef XLA_NULLOP_PATTERN // Helpers for unary instructions. diff --git a/tensorflow/compiler/xla/service/platform_util.cc b/tensorflow/compiler/xla/service/platform_util.cc index 39fe3c7835..ae1e13d8a6 100644 --- a/tensorflow/compiler/xla/service/platform_util.cc +++ b/tensorflow/compiler/xla/service/platform_util.cc @@ -19,20 +19,19 @@ limitations under the License. #include <string> #include <utility> +#include "absl/strings/ascii.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/compiler.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/threadpool.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" namespace xla { -using tensorflow::str_util::Lowercase; - // Minimum supported CUDA compute capability is 3.5. constexpr int kMinCudaComputeCapabilityMajor = 3; constexpr int kMinCudaComputeCapabilityMinor = 5; @@ -43,7 +42,7 @@ constexpr char kInterpreter[] = "interpreter"; namespace { string CanonicalPlatformName(const string& name) { - string platform_str = Lowercase(name); + string platform_str = absl::AsciiStrToLower(name); // "cpu" and "host" mean the same thing. if (platform_str == "cpu") { platform_str = "host"; @@ -94,12 +93,12 @@ PlatformUtil::GetSupportedPlatforms() { } // Multiple platforms present and we can't pick a reasonable default. - string platforms_string = tensorflow::str_util::Join( + string platforms_string = absl::StrJoin( platforms, ", ", [](string* out, const se::Platform* p) { out->append(p->Name()); }); return InvalidArgument( "must specify platform because more than one platform found: %s", - platforms_string.c_str()); + platforms_string); } /* static */ StatusOr<se::Platform*> PlatformUtil::GetDefaultPlatform() { @@ -110,21 +109,21 @@ PlatformUtil::GetSupportedPlatforms() { return platforms[0]; } else if (platforms.size() == 2) { for (int i = 0; i < 2; i++) { - if (Lowercase(platforms[i]->Name()) == kInterpreter && - Lowercase(platforms[1 - i]->Name()) != kInterpreter) { + if (absl::AsciiStrToLower(platforms[i]->Name()) == kInterpreter && + absl::AsciiStrToLower(platforms[1 - i]->Name()) != kInterpreter) { return platforms[1 - i]; } } } // Multiple platforms present and we can't pick a reasonable default. - string platforms_string = tensorflow::str_util::Join( + string platforms_string = absl::StrJoin( platforms, ", ", [](string* out, const se::Platform* p) { out->append(p->Name()); }); return InvalidArgument( "must specify platform because more than one platform (except for the " "interpreter platform) found: %s", - platforms_string.c_str()); + platforms_string); } /*static*/ StatusOr<se::Platform*> PlatformUtil::GetPlatform( @@ -132,11 +131,11 @@ PlatformUtil::GetSupportedPlatforms() { string platform_str = CanonicalPlatformName(platform_name); TF_ASSIGN_OR_RETURN(auto platforms, PlatformUtil::GetSupportedPlatforms()); for (se::Platform* platform : platforms) { - if (Lowercase(platform->Name()) == platform_str) { + if (absl::AsciiStrToLower(platform->Name()) == platform_str) { return platform; } } - return InvalidArgument("platform %s not found", platform_name.c_str()); + return InvalidArgument("platform %s not found", platform_name); } /*static*/ StatusOr<se::Platform*> PlatformUtil::GetPlatformExceptFor( @@ -146,23 +145,23 @@ PlatformUtil::GetSupportedPlatforms() { TF_ASSIGN_OR_RETURN(auto platforms, PlatformUtil::GetSupportedPlatforms()); std::vector<se::Platform*> matched; for (se::Platform* platform : platforms) { - if (Lowercase(platform->Name()) != platform_name) { + if (absl::AsciiStrToLower(platform->Name()) != platform_name) { matched.push_back(platform); } } if (matched.empty()) { return InvalidArgument("unable to find platform that is not %s", - platform_name.c_str()); + platform_name); } if (matched.size() == 1) { return matched[0]; } - string matched_string = tensorflow::str_util::Join( + string matched_string = absl::StrJoin( matched, ", ", [](string* out, const se::Platform* p) { out->append(p->Name()); }); return InvalidArgument( "found multiple platforms %s, but expected one platform except for %s", - matched_string.c_str(), platform_name.c_str()); + matched_string, platform_name); } // Returns whether the device underlying the given StreamExecutor is supported @@ -193,7 +192,7 @@ static bool IsDeviceSupported(se::StreamExecutor* executor) { PlatformUtil::GetStreamExecutors(se::Platform* platform) { int device_count = platform->VisibleDeviceCount(); if (device_count <= 0) { - return NotFound("no %s devices found", platform->Name().c_str()); + return NotFound("no %s devices found", platform->Name()); } if (platform->id() == se::host::kHostPlatformId) { // On host "devices", StreamExecutor exports a device for each hardware @@ -232,7 +231,7 @@ PlatformUtil::GetStreamExecutors(se::Platform* platform) { if (std::all_of(stream_executors.begin(), stream_executors.end(), [](se::StreamExecutor* s) { return s == nullptr; })) { return InternalError("no supported devices found for platform %s", - platform->Name().c_str()); + platform->Name()); } return stream_executors; } diff --git a/tensorflow/compiler/xla/service/reduce_precision_insertion.h b/tensorflow/compiler/xla/service/reduce_precision_insertion.h index afde3cf95c..256b231e3a 100644 --- a/tensorflow/compiler/xla/service/reduce_precision_insertion.h +++ b/tensorflow/compiler/xla/service/reduce_precision_insertion.h @@ -59,7 +59,7 @@ class ReducePrecisionInsertion : public HloPassInterface { ~ReducePrecisionInsertion() override{}; - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "reduce-precision-insertion"; } diff --git a/tensorflow/compiler/xla/service/reshape_mover.cc b/tensorflow/compiler/xla/service/reshape_mover.cc index ca86c5d13e..4df746fca9 100644 --- a/tensorflow/compiler/xla/service/reshape_mover.cc +++ b/tensorflow/compiler/xla/service/reshape_mover.cc @@ -38,6 +38,8 @@ limitations under the License. #include "tensorflow/compiler/xla/service/reshape_mover.h" #include <algorithm> + +#include "absl/algorithm/container.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -374,7 +376,7 @@ StatusOr<bool> TryReshapeMoveOnCandidates( removed = false; for (auto operand : nontrivial_operands) { - if (c_any_of(operand->users(), [&](HloInstruction* user) { + if (absl::c_any_of(operand->users(), [&](HloInstruction* user) { return !reshape_candidates->count(user); })) { for (auto* user : operand->users()) { diff --git a/tensorflow/compiler/xla/service/reshape_mover.h b/tensorflow/compiler/xla/service/reshape_mover.h index 1f59e3b314..1e86a0823a 100644 --- a/tensorflow/compiler/xla/service/reshape_mover.h +++ b/tensorflow/compiler/xla/service/reshape_mover.h @@ -26,7 +26,7 @@ namespace xla { // them inputward also. class ReshapeMover : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "reshape-mover"; } + absl::string_view name() const override { return "reshape-mover"; } StatusOr<bool> Run(HloModule* module) override; }; diff --git a/tensorflow/compiler/xla/service/reshape_mover_test.cc b/tensorflow/compiler/xla/service/reshape_mover_test.cc index ccb9fb3e3a..a395dd5333 100644 --- a/tensorflow/compiler/xla/service/reshape_mover_test.cc +++ b/tensorflow/compiler/xla/service/reshape_mover_test.cc @@ -15,9 +15,9 @@ limitations under the License. #include "tensorflow/compiler/xla/service/reshape_mover.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" @@ -28,13 +28,18 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/hlo_verified_test_base.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" - -namespace op = xla::testing::opcode_matchers; namespace xla { namespace { -using ReshapeMoverTest = HloVerifiedTestBase; + +namespace op = xla::testing::opcode_matchers; + +class ReshapeMoverTest : public HloVerifiedTestBase { + public: + ReshapeMoverTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} +}; TEST_F(ReshapeMoverTest, ReshapesWithDifferentInputShapesNotMoved) { HloComputation::Builder builder(TestName()); diff --git a/tensorflow/compiler/xla/service/scatter_expander.cc b/tensorflow/compiler/xla/service/scatter_expander.cc index 45ca731153..2077b57c05 100644 --- a/tensorflow/compiler/xla/service/scatter_expander.cc +++ b/tensorflow/compiler/xla/service/scatter_expander.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/scatter_expander.h" +#include "absl/algorithm/container.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_creation_utils.h" @@ -92,7 +93,7 @@ static StatusOr<HloInstruction*> PermuteScatterAndWindowDims( permutation.reserve(updates_rank); for (int64 i = 0; i < updates_rank; ++i) { - bool is_scatter_dim = !c_binary_search(update_window_dims, i); + bool is_scatter_dim = !absl::c_binary_search(update_window_dims, i); if (is_scatter_dim) { permutation.push_back(i); } @@ -290,7 +291,7 @@ StatusOr<HloInstruction*> ScatterExpander::ExpandScatter( return Unimplemented( "Scatter operations with more than 2147483647 scatter indices are not " "supported. This error occurred for %s.", - scatter->ToString().c_str()); + scatter->ToString()); } // Canonicalize the scatter_indices, after which the size of its most-major diff --git a/tensorflow/compiler/xla/service/scatter_expander.h b/tensorflow/compiler/xla/service/scatter_expander.h index 8f735e877d..14f062c89c 100644 --- a/tensorflow/compiler/xla/service/scatter_expander.h +++ b/tensorflow/compiler/xla/service/scatter_expander.h @@ -22,7 +22,7 @@ namespace xla { class ScatterExpander : public HloPassInterface { public: - tensorflow::StringPiece name() const override { return "scatter_expander"; } + absl::string_view name() const override { return "scatter_expander"; } StatusOr<bool> Run(HloModule* module) override; private: diff --git a/tensorflow/compiler/xla/service/service.cc b/tensorflow/compiler/xla/service/service.cc index 1dbf540d13..e10c1d9927 100644 --- a/tensorflow/compiler/xla/service/service.cc +++ b/tensorflow/compiler/xla/service/service.cc @@ -20,10 +20,12 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/execution_options_util.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/legacy_flags/debug_options_flags.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/compiler.h" #include "tensorflow/compiler/xla/service/computation_layout.h" #include "tensorflow/compiler/xla/service/device_memory_allocator.h" @@ -46,8 +48,6 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/gtl/cleanup.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" @@ -55,13 +55,12 @@ limitations under the License. #include "tensorflow/core/platform/types.h" #include "tensorflow/core/util/ptr_util.h" -using ::tensorflow::strings::Printf; -using ::tensorflow::strings::StrCat; - namespace xla { - namespace { +using absl::StrCat; +using absl::StrFormat; + // Records the arguments used to invoke a computation in an HloSnapshot proto. Status RecordArguments( const tensorflow::gtl::ArraySlice<const ShapedBuffer*> arguments, @@ -148,19 +147,19 @@ Service::Service(const ServiceOptions& options, CHECK_GE(execute_backend_->device_count(), options_.number_of_replicas()) << "Requested more replicas than there are devices."; } - LOG(INFO) << Printf( + LOG(INFO) << StrFormat( "XLA service %p executing computations on platform %s. Devices:", this, - execute_backend_->platform()->Name().c_str()); + execute_backend_->platform()->Name()); for (int i = 0; i < execute_backend_->device_count(); ++i) { if (execute_backend_->device_ordinal_supported(i)) { se::StreamExecutor* executor = execute_backend_->stream_executor(i).ValueOrDie(); const auto& description = executor->GetDeviceDescription(); - LOG(INFO) << Printf(" StreamExecutor device (%d): %s, %s", i, - description.name().c_str(), - description.platform_version().c_str()); + LOG(INFO) << StrFormat(" StreamExecutor device (%d): %s, %s", i, + description.name(), + description.platform_version()); } else { - LOG(INFO) << Printf(" StreamExecutor device (%d) not supported", i); + LOG(INFO) << StrFormat(" StreamExecutor device (%d) not supported", i); } } } else { @@ -200,8 +199,8 @@ Status Service::ValidateResultShape(const Shape& client_shape, return InvalidArgument( "Shape used to set computation result layout %s is not compatible " "with result shape %s", - ShapeUtil::HumanStringWithLayout(client_shape).c_str(), - ShapeUtil::HumanString(result_shape).c_str()); + ShapeUtil::HumanStringWithLayout(client_shape), + ShapeUtil::HumanString(result_shape)); } return Status::OK(); } @@ -231,9 +230,9 @@ Service::ResolveAndValidateArguments( return InvalidArgument( "argument %lu is on device %s:%d but computation will be executed " "on device %s", - i, shaped_buffer->platform()->Name().c_str(), + i, shaped_buffer->platform()->Name(), shaped_buffer->device_ordinal(), - execute_backend_->device_name(replica_device_ordinal).c_str()); + execute_backend_->device_name(replica_device_ordinal)); } replicated_arguments[replica].push_back(shaped_buffer); } @@ -245,11 +244,11 @@ StatusOr<std::unique_ptr<HloModuleConfig>> Service::CreateModuleConfig( const ProgramShape& program_shape, tensorflow::gtl::ArraySlice<const Shape*> argument_shapes, const ExecutionOptions* execution_options) { - auto config = MakeUnique<HloModuleConfig>(program_shape); + auto config = absl::make_unique<HloModuleConfig>(program_shape); ComputationLayout* computation_layout = config->mutable_entry_computation_layout(); if (program_shape.parameters_size() != argument_shapes.size()) { - return InvalidArgument("computation takes %d parameters, but %zu given", + return InvalidArgument("computation takes %d parameters, but %u given", program_shape.parameters_size(), argument_shapes.size()); } @@ -261,8 +260,8 @@ StatusOr<std::unique_ptr<HloModuleConfig>> Service::CreateModuleConfig( return InvalidArgument( "Argument does not match shape of computation parameter %d: want " "%s, got %s", - i, ShapeUtil::HumanString(program_shape.parameters(i)).c_str(), - ShapeUtil::HumanString(*argument_shapes[i]).c_str()); + i, ShapeUtil::HumanString(program_shape.parameters(i)), + ShapeUtil::HumanString(*argument_shapes[i])); } TF_RETURN_IF_ERROR( computation_layout->mutable_parameter_layout(i)->CopyLayoutFromShape( @@ -314,7 +313,7 @@ StatusOr<std::vector<std::unique_ptr<Executable>>> Service::BuildExecutables( std::vector<std::unique_ptr<HloModuleConfig>> module_configs, Backend* backend, std::vector<std::vector<se::StreamExecutor*>> executors, DeviceMemoryAllocator* device_allocator) { - VLOG(1) << Printf("BuildExecutable on service %p", this); + VLOG(1) << StrFormat("BuildExecutable on service %p", this); // Dump computation proto state if flag is set. std::vector<std::unique_ptr<HloSnapshot>> hlo_snapshots; @@ -326,12 +325,11 @@ StatusOr<std::vector<std::unique_ptr<Executable>>> Service::BuildExecutables( if (directory_path.empty() && execution_directory_path.empty()) { continue; } - auto hlo_snapshot = MakeUnique<HloSnapshot>(); + auto hlo_snapshot = absl::make_unique<HloSnapshot>(); *hlo_snapshot->mutable_hlo()->mutable_hlo_module() = *module_protos[i]; if (!directory_path.empty()) { - string filename = - Printf("computation_%lld__%s", module_protos[i]->id(), - module_protos[i]->entry_computation_name().c_str()); + string filename = StrFormat("computation_%d__%s", module_protos[i]->id(), + module_protos[i]->entry_computation_name()); TF_RETURN_IF_ERROR( Executable::DumpToDirectory(directory_path, filename, *hlo_snapshot)); } @@ -409,7 +407,8 @@ Service::ExecuteParallelAndRegisterResult( streams.push_back(std::move(stream)); if (replica == 0 && profile != nullptr) { - timers.push_back(MakeUnique<se::Timer>(streams.back()->parent())); + timers.push_back( + absl::make_unique<se::Timer>(streams.back()->parent())); streams.back() ->InitTimer(timers.back().get()) .ThenStartTimer(timers.back().get()); @@ -453,8 +452,8 @@ Service::ExecuteParallelAndRegisterResult( for (int64 i = 0; i < streams.size(); ++i) { Status block_status = streams[i]->BlockHostUntilDone(); if (!block_status.ok()) { - return InternalError("failed to complete execution for stream %lld: %s", - i, block_status.error_message().c_str()); + return InternalError("failed to complete execution for stream %d: %s", i, + block_status.error_message()); } } @@ -579,7 +578,7 @@ StatusOr<std::vector<se::StreamExecutor*>> Service::GetExecutors( if (requests_size > 1 && execution_options.device_handles_size() > 1) { return InvalidArgument( "Parallel requests with multiple device handles is not supported. " - "Found %lld parallel requests, with request %lld containing %d device " + "Found %d parallel requests, with request %d containing %d device " "handles.", requests_size, request_index, execution_options.device_handles_size()); } @@ -744,8 +743,8 @@ Status Service::GetDeviceHandles(const GetDeviceHandlesRequest* arg, } if (available_device_count < arg->device_count() * replica_count) { return ResourceExhausted( - "Requested device count (%lld) exceeds the number of available devices " - "on the target (%lld)", + "Requested device count (%d) exceeds the number of available devices " + "on the target (%d)", arg->device_count(), available_device_count); } @@ -795,12 +794,12 @@ StatusOr<std::unique_ptr<Executable>> Service::BuildExecutable( const HloModuleProto& module_proto, std::unique_ptr<HloModuleConfig> module_config, Backend* backend, se::StreamExecutor* executor, DeviceMemoryAllocator* device_allocator) { - VLOG(1) << Printf( + VLOG(1) << StrFormat( "BuildExecutable on service %p with serialized module proto: %s", this, - module_proto.name().c_str()); + module_proto.name()); // Dump computation proto state if flag is set. - auto hlo_snapshot = MakeUnique<HloSnapshot>(); + auto hlo_snapshot = absl::make_unique<HloSnapshot>(); const string& directory_path = module_config->debug_options().xla_dump_computations_to(); const string& execution_directory_path = @@ -808,8 +807,8 @@ StatusOr<std::unique_ptr<Executable>> Service::BuildExecutable( if (!directory_path.empty() || !execution_directory_path.empty()) { *hlo_snapshot->mutable_hlo()->mutable_hlo_module() = module_proto; if (!directory_path.empty()) { - string filename = Printf("computation_%lld__%s", module_proto.id(), - module_proto.entry_computation_name().c_str()); + string filename = StrFormat("computation_%d__%s", module_proto.id(), + module_proto.entry_computation_name()); TF_RETURN_IF_ERROR( Executable::DumpToDirectory(directory_path, filename, *hlo_snapshot)); } @@ -954,7 +953,7 @@ namespace { // shape and DeviceMemoryBase values of the clone are identical to the original. std::unique_ptr<ShapedBuffer> CloneShapedBufferOnDevice( const ShapedBuffer& shaped_buffer, int device_ordinal) { - auto clone = MakeUnique<ShapedBuffer>( + auto clone = absl::make_unique<ShapedBuffer>( shaped_buffer.on_host_shape(), shaped_buffer.on_device_shape(), shaped_buffer.platform(), device_ordinal); clone->buffers() = shaped_buffer.buffers(); @@ -1009,8 +1008,7 @@ Status Service::TransferToInfeed(const TransferToInfeedRequest* arg, "%s", StrCat("The replica_id=", arg->replica_id(), " on TransferToInfeedRequest not in range [0, replica_count=", - replica_count, ").") - .c_str()); + replica_count, ").")); } se::StreamExecutor* executor; @@ -1036,8 +1034,7 @@ Status Service::TransferFromOutfeed(const TransferFromOutfeedRequest* arg, const int64 replica_count = options_.number_of_replicas(); if (arg->replica_id() < 0 || arg->replica_id() >= replica_count) { return FailedPrecondition( - "The replica_id=%lld on TransferFromOutfeedRequest not in range [0, " - "%lld)", + "The replica_id=%d on TransferFromOutfeedRequest not in range [0, %d)", arg->replica_id(), replica_count); } diff --git a/tensorflow/compiler/xla/service/shape_inference.cc b/tensorflow/compiler/xla/service/shape_inference.cc index cc1ec1704e..f5217c5a11 100644 --- a/tensorflow/compiler/xla/service/shape_inference.cc +++ b/tensorflow/compiler/xla/service/shape_inference.cc @@ -21,6 +21,11 @@ limitations under the License. #include <set> #include <string> +#include "absl/algorithm/container.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" @@ -28,32 +33,26 @@ limitations under the License. #include "tensorflow/compiler/xla/window_util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/lib/math/math_util.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" -using tensorflow::str_util::Join; -using tensorflow::strings::Printf; - namespace xla { - namespace { +using absl::StrFormat; +using absl::StrJoin; + // Returns true if no element is present in slice more than once. bool AllUnique(tensorflow::gtl::ArraySlice<int64> slice) { return std::set<int64>(slice.begin(), slice.end()).size() == slice.size(); } -Status ExpectArray(const Shape& shape, tensorflow::StringPiece op_type) { +Status ExpectArray(const Shape& shape, absl::string_view op_type) { if (!ShapeUtil::IsArray(shape)) { return InvalidArgument("Expected array argument for %s, but got %s.", - std::string(op_type).c_str(), - ShapeUtil::HumanString(shape).c_str()); + string(op_type), ShapeUtil::HumanString(shape)); } return Status::OK(); } @@ -65,7 +64,7 @@ Status VerifyReducerShape( int64 inputs) { if (reducer_shape.parameters_size() != inputs * 2) { return InvalidArgument( - "Reduction function must take %lld parameters, but " + "Reduction function must take %d parameters, but " "takes %d parameter(s).", inputs * 2, reducer_shape.parameters_size()); } @@ -75,7 +74,7 @@ Status VerifyReducerShape( if (ShapeUtil::IsArray(accumulator_shape)) { if (inputs != 1) { return InvalidArgument( - "Reduction function must produce a tuple with %lld elements, but " + "Reduction function must produce a tuple with %d elements, but " "produces a scalar", inputs); } @@ -83,8 +82,8 @@ Status VerifyReducerShape( } else if (ShapeUtil::IsTuple(accumulator_shape)) { if (ShapeUtil::TupleElementCount(accumulator_shape) != inputs) { return InvalidArgument( - "Reduction function must produce a tuple with %lld elements, but has " - "%lld elements", + "Reduction function must produce a tuple with %d elements, but has " + "%d elements", inputs, ShapeUtil::TupleElementCount(accumulator_shape)); } for (const Shape& element_shape : accumulator_shape.tuple_shapes()) { @@ -94,7 +93,7 @@ Status VerifyReducerShape( return InvalidArgument( "Reduction function must produce a scalar or tuple of scalars, but has " "shape: %s", - ShapeUtil::HumanString(accumulator_shape).c_str()); + ShapeUtil::HumanString(accumulator_shape)); } for (const Shape* element_shape : accumulator_subshapes) { @@ -102,7 +101,7 @@ Status VerifyReducerShape( return InvalidArgument( "Reduction function must return a scalar or tuple of scalars but " "returns shape: %s", - ShapeUtil::HumanString(accumulator_shape).c_str()); + ShapeUtil::HumanString(accumulator_shape)); } } @@ -113,19 +112,19 @@ Status VerifyReducerShape( if (!ShapeUtil::Compatible(*accumulator_subshapes[i], reducer_shape.parameters(i))) { return InvalidArgument( - "Reduction function's %lld-th parameter shape differs from the " + "Reduction function's %d-th parameter shape differs from the " "result shape: %s vs %s", - i, ShapeUtil::HumanString(reducer_shape.parameters(i)).c_str(), - ShapeUtil::HumanString(*accumulator_subshapes[i]).c_str()); + i, ShapeUtil::HumanString(reducer_shape.parameters(i)), + ShapeUtil::HumanString(*accumulator_subshapes[i])); } // Check that init_value's shapes are suitable for reducer_shape. if (!ShapeUtil::CompatibleIgnoringFpPrecision(*accumulator_subshapes[i], *init_value_shapes[i])) { return InvalidArgument( - "Reduction function's accumulator shape at index %lld differs from " + "Reduction function's accumulator shape at index %d differs from " "the init_value shape: %s vs %s", - i, ShapeUtil::HumanString(*accumulator_subshapes[i]).c_str(), - ShapeUtil::HumanString(*init_value_shapes[i]).c_str()); + i, ShapeUtil::HumanString(*accumulator_subshapes[i]), + ShapeUtil::HumanString(*init_value_shapes[i])); } // Check that the inputs can be passed in as the non-accumulator arguments. const Shape input_element_shape = @@ -133,11 +132,11 @@ Status VerifyReducerShape( if (!ShapeUtil::CompatibleIgnoringFpPrecision( input_element_shape, reducer_shape.parameters(inputs + i))) { return InvalidArgument( - "Reduction function's %lld-th parameter shape differs from the " + "Reduction function's %d-th parameter shape differs from the " "input type element type: %s vs %s", inputs + i, - ShapeUtil::HumanString(reducer_shape.parameters(inputs + i)).c_str(), - ShapeUtil::HumanString(input_element_shape).c_str()); + ShapeUtil::HumanString(reducer_shape.parameters(inputs + i)), + ShapeUtil::HumanString(input_element_shape)); } // Check that the accumulator and inputs to the reducer function match. // If the accumulator is scalar, it must have the same type as the inputs @@ -147,11 +146,11 @@ Status VerifyReducerShape( if (!ShapeUtil::CompatibleIgnoringFpPrecision( *accumulator_subshapes[i], reducer_shape.parameters(inputs + i))) { return InvalidArgument( - "Reduction function's %lld-th parameter shape must " + "Reduction function's %d-th parameter shape must " "match the result shape, but got %s vs %s.", inputs + i, - ShapeUtil::HumanString(reducer_shape.parameters(inputs + i)).c_str(), - ShapeUtil::HumanString(*accumulator_subshapes[i]).c_str()); + ShapeUtil::HumanString(reducer_shape.parameters(inputs + i)), + ShapeUtil::HumanString(*accumulator_subshapes[i])); } } @@ -164,7 +163,7 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, bool allow_negative_padding) { if (window.dimensions_size() != ShapeUtil::Rank(base_shape)) { return InvalidArgument( - "Window has dimension %d but base shape has dimension %lld.", + "Window has dimension %d but base shape has dimension %d.", window.dimensions_size(), ShapeUtil::Rank(base_shape)); } @@ -173,29 +172,29 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, const auto& dim = window.dimensions(i); if (dim.size() <= 0) { return InvalidArgument("Window %s has a non-positive dimension.", - window.DebugString().c_str()); + window.DebugString()); } if (dim.stride() <= 0) { return InvalidArgument("Window %s has a non-positive stride.", - window.DebugString().c_str()); + window.DebugString()); } if (!allow_negative_padding && dim.padding_low() < 0) { return InvalidArgument("Window %s has a negative low padding.", - window.DebugString().c_str()); + window.DebugString()); } if (!allow_negative_padding && dim.padding_high() < 0) { return InvalidArgument("Window %s has a negative high padding.", - window.DebugString().c_str()); + window.DebugString()); } if (dim.base_dilation() < 1) { return InvalidArgument( "Window %s has a non-positive base area dilation factor.", - window.DebugString().c_str()); + window.DebugString()); } if (dim.window_dilation() < 1) { return InvalidArgument( "Window %s has a non-positive window dilation factor.", - window.DebugString().c_str()); + window.DebugString()); } const int64 dilated_base = window_util::DilatedBound( @@ -233,11 +232,12 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, switch (opcode) { case HloOpcode::kFloor: case HloOpcode::kCeil: + case HloOpcode::kRoundNearestAfz: if (!ShapeUtil::ElementIsFloating(shape)) { return InvalidArgument( - "Expected element type in shape to be floating for floor/ceil " - "operation; got %s.", - PrimitiveType_Name(shape.element_type()).c_str()); + "Expected element type in shape to be floating for %s operation; " + "got %s.", + HloOpcodeString(opcode), PrimitiveType_Name(shape.element_type())); } return shape; case HloOpcode::kCos: @@ -250,9 +250,9 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, if (!ShapeUtil::ElementIsFloating(shape) && !ShapeUtil::ElementIsComplex(shape)) { return InvalidArgument( - "Expected element type in shape to be floating or complex for " - "sin/cos/exp/log/tanh operation; got %s.", - PrimitiveType_Name(shape.element_type()).c_str()); + "Expected element type in shape to be floating or complex for %s " + "operation; got %s.", + HloOpcodeString(opcode), PrimitiveType_Name(shape.element_type())); } return shape; case HloOpcode::kReal: @@ -264,19 +264,47 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, } else { return InvalidArgument( "Expected element type in shape to be floating or complex for " - "real/imag operation; got %s.", - PrimitiveType_Name(shape.element_type()).c_str()); + "%s operation; got %s.", + HloOpcodeString(opcode), PrimitiveType_Name(shape.element_type())); } case HloOpcode::kAbs: if (ShapeUtil::ElementIsComplex(shape)) { return ShapeUtil::ChangeElementType( shape, primitive_util::ComplexComponentType(shape.element_type())); + } else if (ShapeUtil::ElementIsSigned(shape)) { + return shape; + } else { + return InvalidArgument( + "Expected element type in shape to be floating or complex for " + "%s operation; got %s.", + HloOpcodeString(opcode), PrimitiveType_Name(shape.element_type())); } - return shape; case HloOpcode::kClz: + if (!ShapeUtil::ElementIsIntegral(shape)) { + return InvalidArgument( + "Expected an integral element type in argument to Clz " + "operation; got %s.", + PrimitiveType_Name(shape.element_type())); + } + return shape; case HloOpcode::kNegate: - case HloOpcode::kRoundNearestAfz: + if (!ShapeUtil::ElementIsIntegral(shape) && + !ShapeUtil::ElementIsFloating(shape) && + !ShapeUtil::ElementIsComplex(shape)) { + return InvalidArgument( + "Expected element type in shape to be integral, floating or " + "complex for %s operation; got %s.", + HloOpcodeString(opcode), PrimitiveType_Name(shape.element_type())); + } + return shape; case HloOpcode::kSign: + if (!ShapeUtil::ElementIsSigned(shape) && + !ShapeUtil::ElementIsComplex(shape)) { + return InvalidArgument( + "Expected element type in shape to be signed or complex for " + "%s operation; got %s.", + HloOpcodeString(opcode), PrimitiveType_Name(shape.element_type())); + } return shape; case HloOpcode::kNot: @@ -285,7 +313,7 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, return InvalidArgument( "Expected pred or an integral element type in argument to Not " "operation; got %s.", - PrimitiveType_Name(shape.element_type()).c_str()); + PrimitiveType_Name(shape.element_type())); } return shape; @@ -295,14 +323,14 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, "Expected element type in shape to be floating " "point for IsFinite " "operation; got %s.", - PrimitiveType_Name(shape.element_type()).c_str()); + PrimitiveType_Name(shape.element_type())); } return ShapeUtil::ChangeElementType(shape, PRED); default: return InvalidArgument( "Unknown operation for unary shape inference: \"%s\".", - HloOpcodeString(opcode).c_str()); + HloOpcodeString(opcode)); } } @@ -313,7 +341,7 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, return InvalidArgument("Concatenate expects at least one argument."); } if (dimension < 0 || dimension >= ShapeUtil::Rank(*arg_shapes[0])) { - return InvalidArgument("Concatenate dimension out of bounds: %lld.", + return InvalidArgument("Concatenate dimension out of bounds: %d.", dimension); } const Shape* arg_shape = nullptr; @@ -327,17 +355,16 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, } if (ShapeUtil::Rank(*arg_shape) != ShapeUtil::Rank(*shape)) { return InvalidArgument( - "Cannot concatenate arrays with different ranks: %lld (%s) vs %lld " + "Cannot concatenate arrays with different ranks: %d (%s) vs %d " "(%s).", - ShapeUtil::Rank(*arg_shape), - ShapeUtil::HumanString(*arg_shape).c_str(), ShapeUtil::Rank(*shape), - ShapeUtil::HumanString(*shape).c_str()); + ShapeUtil::Rank(*arg_shape), ShapeUtil::HumanString(*arg_shape), + ShapeUtil::Rank(*shape), ShapeUtil::HumanString(*shape)); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(*arg_shape, *shape)) { return InvalidArgument( "Cannot concatenate arrays with different element types: %s vs %s.", - PrimitiveType_Name(arg_shape->element_type()).c_str(), - PrimitiveType_Name(shape->element_type()).c_str()); + PrimitiveType_Name(arg_shape->element_type()), + PrimitiveType_Name(shape->element_type())); } for (int64 dimension_number = 0; dimension_number < ShapeUtil::Rank(*arg_shape); ++dimension_number) { @@ -350,9 +377,9 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, return InvalidArgument( "Cannot concatenate arrays that differ in dimensions other than " "the one being concatenated (the other array dimensions must be " - "the same): %s vs %s in dimension %lld.", - ShapeUtil::HumanString(*arg_shape).c_str(), - ShapeUtil::HumanString(*shape).c_str(), dimension); + "the same): %s vs %s in dimension %d.", + ShapeUtil::HumanString(*arg_shape), ShapeUtil::HumanString(*shape), + dimension); } } element_type = ShapeUtil::HigherPrecisionElementType(*shape, *arg_shape); @@ -384,8 +411,8 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, !primitive_util::IsComplexType(new_element_type)) { return Unimplemented( "Conversion from complex to real type %s => %s is not implemented.", - ShapeUtil::HumanString(operand_shape).c_str(), - PrimitiveType_Name(new_element_type).c_str()); + ShapeUtil::HumanString(operand_shape), + PrimitiveType_Name(new_element_type)); } if (!ShapeUtil::IsArray(operand_shape) || !primitive_util::IsArrayType(new_element_type)) { @@ -394,8 +421,8 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, // are valid. For now we just reject them, though. return InvalidArgument( "Convert does not allow non-arrays, so cannot convert from %s to %s.", - ShapeUtil::HumanString(operand_shape).c_str(), - PrimitiveType_Name(new_element_type).c_str()); + ShapeUtil::HumanString(operand_shape), + PrimitiveType_Name(new_element_type)); } return ShapeUtil::ChangeElementType(operand_shape, new_element_type); @@ -407,8 +434,8 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, if (primitive_util::IsComplexType(old_element_type) != primitive_util::IsComplexType(new_element_type)) { return InvalidArgument("Conversion from complex to real type %s => %s.", - ShapeUtil::HumanString(operand_shape).c_str(), - PrimitiveType_Name(new_element_type).c_str()); + ShapeUtil::HumanString(operand_shape), + PrimitiveType_Name(new_element_type)); } if (!ShapeUtil::IsArray(operand_shape) || !primitive_util::IsArrayType(new_element_type)) { @@ -417,15 +444,15 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, // are valid. For now we just reject them, though. return InvalidArgument( "Cannot convert from or to tuple type; requested conversion: %s => %s.", - ShapeUtil::HumanString(operand_shape).c_str(), - PrimitiveType_Name(new_element_type).c_str()); + ShapeUtil::HumanString(operand_shape), + PrimitiveType_Name(new_element_type)); } if (primitive_util::BitWidth(old_element_type) != primitive_util::BitWidth(new_element_type)) { return InvalidArgument( "Cannot bitcast types with different bit-widths: %s => %s.", - PrimitiveType_Name(old_element_type).c_str(), - PrimitiveType_Name(new_element_type).c_str()); + PrimitiveType_Name(old_element_type), + PrimitiveType_Name(new_element_type)); } return ShapeUtil::ChangeElementType(operand_shape, new_element_type); @@ -438,7 +465,7 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, return InvalidArgument( "Expected element type in shape to be floating point for " "ReducePrecision operation; got %s.", - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(operand_shape.element_type())); } if (exponent_bits < 1) { // One exponent bit is necessary to distinguish 0 from infinity. Having @@ -470,21 +497,29 @@ StatusOr<Shape> InferWindowOutputShape(const Shape& base_shape, return InvalidArgument( "The rank of the operand and the padding configuration do not match: " "%s vs %s.", - ShapeUtil::HumanString(operand_shape).c_str(), - padding_config.ShortDebugString().c_str()); + ShapeUtil::HumanString(operand_shape), + padding_config.ShortDebugString()); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(operand_shape, padding_value_shape)) { return InvalidArgument( "The element types of the operands to Pad do not match."); } + if (absl::c_any_of(padding_config.dimensions(), + [](const PaddingConfig::PaddingConfigDimension& p) { + return p.interior_padding() < 0; + })) { + return InvalidArgument("Interior padding cannot be negative: %s", + padding_config.ShortDebugString()); + } + std::vector<int64> dimensions(ShapeUtil::Rank(operand_shape)); for (int64 i = 0; i < operand_shape.dimensions_size(); ++i) { - dimensions[i] = operand_shape.dimensions(i) + - padding_config.dimensions(i).edge_padding_low() + - padding_config.dimensions(i).edge_padding_high() + + const auto& p = padding_config.dimensions(i); + dimensions[i] = operand_shape.dimensions(i) + p.edge_padding_low() + + p.edge_padding_high() + std::max<int64>(operand_shape.dimensions(i) - 1, 0LL) * - padding_config.dimensions(i).interior_padding(); + p.interior_padding(); } return ShapeUtil::MakeShape( ShapeUtil::HigherPrecisionElementType(operand_shape, padding_value_shape), @@ -538,7 +573,7 @@ Status ValidateDotDimensionNumbers( !dims_in_range(ShapeUtil::Rank(rhs), rhs_contracting_dimensions, rhs_batch_dimensions)) { return InvalidArgument("A dimension number is out of range in Dot: %s.", - dimension_numbers.DebugString().c_str()); + dimension_numbers.DebugString()); } // Check that dimension numbers are unique. @@ -556,7 +591,7 @@ Status ValidateDotDimensionNumbers( if (!dims_unique(lhs_contracting_dimensions, lhs_batch_dimensions) || !dims_unique(rhs_contracting_dimensions, rhs_batch_dimensions)) { return InvalidArgument("A dimension number is not unique in Dot: %s.", - dimension_numbers.DebugString().c_str()); + dimension_numbers.DebugString()); } // Check that the count of non-contracting-non-batch dimensions is in {0, 1}. @@ -601,14 +636,13 @@ Status ValidateDotDimensionNumbers( TF_RETURN_IF_ERROR(ExpectArray(rhs, "rhs of dot")); auto fail = [lhs, rhs](const string& addendum) -> Status { - string message = tensorflow::strings::Printf( - "Cannot infer shape for dot operation: %s <dot> %s.", - ShapeUtil::HumanString(lhs).c_str(), - ShapeUtil::HumanString(rhs).c_str()); + string message = + StrFormat("Cannot infer shape for dot operation: %s <dot> %s.", + ShapeUtil::HumanString(lhs), ShapeUtil::HumanString(rhs)); if (!addendum.empty()) { message += " " + addendum; } - return InvalidArgument("%s", message.c_str()); + return InvalidArgument("%s", message); }; // Check if both element types are the same. @@ -704,9 +738,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, } else { return InvalidArgument( "Binary op %s with incompatible shapes: %s and %s.", - HloOpcodeString(operation).c_str(), - ShapeUtil::HumanString(lhs).c_str(), - ShapeUtil::HumanString(rhs).c_str()); + HloOpcodeString(operation), ShapeUtil::HumanString(lhs), + ShapeUtil::HumanString(rhs)); } } return ShapeUtil::MakeShape(ShapeUtil::HigherPrecisionElementType(lhs, rhs), @@ -721,14 +754,14 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, // the user to provide an explicit broadcast dimension in this case. // See b/25177275 for more details. return InvalidArgument("Automatic shape inference not supported: %s and %s", - ShapeUtil::HumanString(smaller_shape).c_str(), - ShapeUtil::HumanString(larger_shape).c_str()); + ShapeUtil::HumanString(smaller_shape), + ShapeUtil::HumanString(larger_shape)); } else if (broadcast_dimensions.size() != ShapeUtil::Rank(smaller_shape)) { return InvalidArgument( "Size of broadcast_dimensions has to match lower-rank operand's " "rank; " - " lower-rank operand's rank is %lld, size of broadcast_dimensions is " - "%zu.", + " lower-rank operand's rank is %d, size of broadcast_dimensions is " + "%u.", ShapeUtil::Rank(smaller_shape), broadcast_dimensions.size()); } @@ -778,12 +811,12 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, int64 dimension_to_match = broadcast_dimensions.at(i); if (dimension_to_match < 0) { return InvalidArgument( - "Broadcast dimension number (%lld) cannot be negative.", + "Broadcast dimension number (%d) cannot be negative.", dimension_to_match); } if (dimension_to_match >= larger_shape.dimensions_size()) { return InvalidArgument( - "Broadcast dimension number (%lld) too large; higher-rank " + "Broadcast dimension number (%d) too large; higher-rank " "operand has rank %d.", dimension_to_match, larger_shape.dimensions_size()); } @@ -795,16 +828,16 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (small_dimension_size != large_dimension_size && small_dimension_size != 1 && large_dimension_size != 1) { return InvalidArgument( - "Broadcast dimension %d mismatch: %lld != %lld; %s and %s.", i, + "Broadcast dimension %d mismatch: %d != %d; %s and %s.", i, small_dimension_size, large_dimension_size, - ShapeUtil::HumanString(smaller_shape).c_str(), - ShapeUtil::HumanString(larger_shape).c_str()); + ShapeUtil::HumanString(smaller_shape), + ShapeUtil::HumanString(larger_shape)); } // Make sure the broadcast dimensions are listed in a strictly increasing // order. if (i > 0 && broadcast_dimensions.at(i - 1) >= dimension_to_match) { return InvalidArgument( - "Broadcast dimensions order is wrong: %lld comes after %lld.", + "Broadcast dimensions order is wrong: %d comes after %d.", dimension_to_match, broadcast_dimensions.at(i - 1)); } @@ -823,8 +856,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(lhs, rhs)) { return InvalidArgument( "Binary op %s with different element types: %s and %s.", - HloOpcodeString(operation).c_str(), ShapeUtil::HumanString(lhs).c_str(), - ShapeUtil::HumanString(rhs).c_str()); + HloOpcodeString(operation), ShapeUtil::HumanString(lhs), + ShapeUtil::HumanString(rhs)); } if (ShapeUtil::Rank(lhs) == ShapeUtil::Rank(rhs)) { @@ -874,20 +907,17 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, /* static */ StatusOr<Shape> ShapeInference::InferBinaryOpShape( HloOpcode opcode, const Shape& lhs, const Shape& rhs, tensorflow::gtl::ArraySlice<int64> broadcast_dimensions) { - VLOG(2) << tensorflow::strings::Printf( + VLOG(2) << StrFormat( "inferring shape for <%s>(%s, %s) with broadcast_dimensions={%s}", - HloOpcodeString(opcode).c_str(), ShapeUtil::HumanString(lhs).c_str(), - ShapeUtil::HumanString(rhs).c_str(), - Join(broadcast_dimensions, ", ").c_str()); + HloOpcodeString(opcode), ShapeUtil::HumanString(lhs), + ShapeUtil::HumanString(rhs), StrJoin(broadcast_dimensions, ", ")); TF_DCHECK_OK(ShapeUtil::ValidateShapeWithOptionalLayout(lhs)); TF_DCHECK_OK(ShapeUtil::ValidateShapeWithOptionalLayout(rhs)); - TF_RETURN_IF_ERROR( - ExpectArray(lhs, tensorflow::strings::StrCat("lhs of binary operation ", - HloOpcodeString(opcode)))); - TF_RETURN_IF_ERROR( - ExpectArray(rhs, tensorflow::strings::StrCat("rhs of binary operation ", - HloOpcodeString(opcode)))); + TF_RETURN_IF_ERROR(ExpectArray( + lhs, absl::StrCat("lhs of binary operation ", HloOpcodeString(opcode)))); + TF_RETURN_IF_ERROR(ExpectArray( + rhs, absl::StrCat("rhs of binary operation ", HloOpcodeString(opcode)))); switch (opcode) { case HloOpcode::kMaximum: case HloOpcode::kMinimum: @@ -909,7 +939,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Expected element type in shape to be floating for complex compose " "operation; got %s.", - PrimitiveType_Name(lhs.element_type()).c_str()); + PrimitiveType_Name(lhs.element_type())); } TF_ASSIGN_OR_RETURN(const Shape& shape, InferElementwiseBinaryOpShape(opcode, lhs, rhs, @@ -928,7 +958,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Expected pred or integral type in argument to and/or operation; " "got %s.", - PrimitiveType_Name(lhs.element_type()).c_str()); + PrimitiveType_Name(lhs.element_type())); } return InferElementwiseBinaryOpShape(opcode, lhs, rhs, broadcast_dimensions); @@ -946,8 +976,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, default: return Unimplemented( "Binary op shape inference: %s; lhs: %s; rhs: %s is not implemented.", - HloOpcodeString(opcode).c_str(), lhs.ShortDebugString().c_str(), - rhs.ShortDebugString().c_str()); + HloOpcodeString(opcode), lhs.ShortDebugString(), + rhs.ShortDebugString()); } } @@ -970,8 +1000,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, case HloOpcode::kTupleSelect: return InferTupleSelectShape(lhs, rhs, ehs); default: - return InvalidArgument("Unknown operation %s.", - HloOpcodeString(opcode).c_str()); + return InvalidArgument("Unknown operation %s.", HloOpcodeString(opcode)); } } @@ -1010,8 +1039,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Sort keys and values dimensions must match. " "Keys shape is: %s\n, Values shape is: %s", - ShapeUtil::HumanString(*operand_shapes[0]).c_str(), - ShapeUtil::HumanString(*operand_shapes[1]).c_str()); + ShapeUtil::HumanString(*operand_shapes[0]), + ShapeUtil::HumanString(*operand_shapes[1])); } return ShapeUtil::MakeTupleShape( {*operand_shapes[0], *operand_shapes[1]}); @@ -1019,8 +1048,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument("Unexpected number of operands for sort"); } default: - return InvalidArgument("Unknown operation %s.", - HloOpcodeString(opcode).c_str()); + return InvalidArgument("Unknown operation %s.", HloOpcodeString(opcode)); } } @@ -1058,7 +1086,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Map operation requires all operands to have the same shape; got: " "%s.", - Join(pieces, ", ").c_str()); + StrJoin(pieces, ", ")); } // Check that dimensions.size == arg_shape.dimensions_size() (we currently @@ -1066,7 +1094,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (dimensions.size() != arg_shape->dimensions_size()) { return InvalidArgument( "Map applied to a subset of dimensions currently not supported: " - "arg_dimension_size: %d, requested_map_dimensions_size: %zu.", + "arg_dimension_size: %d, requested_map_dimensions_size: %u.", arg_shape->dimensions_size(), dimensions.size()); } @@ -1075,7 +1103,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (dimensions[i] != i) { return InvalidArgument( "Map requires monotonically increasing dimension numbers; got: %s.", - Join(dimensions, ", ").c_str()); + StrJoin(dimensions, ", ")); } } @@ -1083,7 +1111,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (arg_shapes.size() != to_apply.parameters_size()) { return InvalidArgument( "Map applied function arity must match number of arguments; got: " - "arity: %d, arguments: %zu.", + "arity: %d, arguments: %u.", to_apply.parameters_size(), arg_shapes.size()); } @@ -1092,7 +1120,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (!ShapeUtil::IsScalar(output_shape)) { return InvalidArgument( "Mapped computation's result has to be a scalar; got: %s.", - ShapeUtil::HumanString(output_shape).c_str()); + ShapeUtil::HumanString(output_shape)); } for (int i = 0; i < to_apply.parameters_size(); ++i) { @@ -1102,7 +1130,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Mapped computation's parameter has to be a scalar; " "got parameter %d shape: %s.", - i, ShapeUtil::HumanString(parameter_shape).c_str()); + i, ShapeUtil::HumanString(parameter_shape)); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(parameter_shape, @@ -1110,8 +1138,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Mapped computation's parameter type has to match argument element " "type; got parameter %d shape: %s, argument shape: %s.", - i, ShapeUtil::HumanString(parameter_shape).c_str(), - ShapeUtil::HumanString(*arg_shape).c_str()); + i, ShapeUtil::HumanString(parameter_shape), + ShapeUtil::HumanString(*arg_shape)); } } @@ -1140,35 +1168,35 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Expected feature_index of batch-norm-training to be " "smaller than the rank of operand_shape; " - "got feature_index %lld, and rank %lld.", + "got feature_index %d, and rank %d.", feature_index, ShapeUtil::Rank(operand_shape)); } if (feature_index < 0) { return InvalidArgument( "Expected feature_index of batch-norm-training to " - "be a non-negative number, got %lld.", + "be a non-negative number, got %d.", feature_index); } if (ShapeUtil::Rank(operand_shape) < 1) { return InvalidArgument( "Expected the rank of operand to " - "batch-norm-training to be at least 1; got %lld.", + "batch-norm-training to be at least 1; got %d.", ShapeUtil::Rank(operand_shape)); } if (ShapeUtil::Rank(offset_shape) != 1) { return InvalidArgument( "Offset input of batch-norm-training must have" - " rank 1, but has rank %lld.", + " rank 1, but has rank %d.", ShapeUtil::Rank(offset_shape)); } if (ShapeUtil::Rank(scale_shape) != 1) { return InvalidArgument( "Scale input of batch-norm-training must have" - " rank 1, but has rank %lld.", + " rank 1, but has rank %d.", ShapeUtil::Rank(scale_shape)); } @@ -1176,7 +1204,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "The operand to batch-norm-training must have a floating point " "element type, but the shape is %s.", - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(offset_shape, @@ -1185,8 +1213,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "The inputs should have the same element type for batch-norm-training, " "but the shape of offset factor is %s " "and the shape of operand is %s.", - PrimitiveType_Name(offset_shape.element_type()).c_str(), - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(offset_shape.element_type()), + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(scale_shape, @@ -1195,8 +1223,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "The inputs should have the same element type for batch-norm-training, " "but the shape of scale factor is %s " "and the shape of operand is %s.", - PrimitiveType_Name(scale_shape.element_type()).c_str(), - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(scale_shape.element_type()), + PrimitiveType_Name(operand_shape.element_type())); } const int64 feature_count = operand_shape.dimensions(feature_index); @@ -1206,16 +1234,16 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (ShapeUtil::GetDimension(offset_shape, 0) != feature_count) { return InvalidArgument( "The size of offset factor should be the same as feature count," - "but the size of offset factor is %lld " - "and the feature count is %lld.", + "but the size of offset factor is %d " + "and the feature count is %d.", ShapeUtil::GetDimension(offset_shape, 0), feature_count); } if (ShapeUtil::GetDimension(scale_shape, 0) != feature_count) { return InvalidArgument( "The size of scale factor should be the same as feature count," - "but the size of scale factor is %lld " - "and the feature count is %lld.", + "but the size of scale factor is %d " + "and the feature count is %d.", ShapeUtil::GetDimension(scale_shape, 0), feature_count); } @@ -1250,35 +1278,35 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Expected feature_index of batch-norm-inference to be " "smaller than the rank of operand_shape; " - "got feature_index %lld, and rank %lld.", + "got feature_index %d, and rank %d.", feature_index, ShapeUtil::Rank(operand_shape)); } if (feature_index < 0) { return InvalidArgument( "Expected feature_index of batch-norm-inference to " - "be a non-negative number, got %lld.", + "be a non-negative number, got %d.", feature_index); } if (ShapeUtil::Rank(operand_shape) < 1) { return InvalidArgument( "Expected the rank of operand to " - "batch-norm-inference to be at least 1; got %lld.", + "batch-norm-inference to be at least 1; got %d.", ShapeUtil::Rank(operand_shape)); } if (ShapeUtil::Rank(offset_shape) != 1) { return InvalidArgument( "Offset input of batch-norm-inference must have" - " rank 1, but has rank %lld.", + " rank 1, but has rank %d.", ShapeUtil::Rank(offset_shape)); } if (ShapeUtil::Rank(scale_shape) != 1) { return InvalidArgument( "Scale input of batch-norm-inference must have" - " rank 1, but has rank %lld.", + " rank 1, but has rank %d.", ShapeUtil::Rank(scale_shape)); } @@ -1286,7 +1314,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "The operand to batch-norm-inference must have a floating point " "element type, but the shape is %s.", - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(offset_shape, @@ -1296,8 +1324,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "batch-norm-inference, " "but the shape of offset factor is %s " "and the shape of operand is %s.", - PrimitiveType_Name(offset_shape.element_type()).c_str(), - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(offset_shape.element_type()), + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(scale_shape, @@ -1307,8 +1335,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "batch-norm-inference, " "but the shape of scale factor is %s " "and the shape of operand is %s.", - PrimitiveType_Name(scale_shape.element_type()).c_str(), - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(scale_shape.element_type()), + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(mean_shape, @@ -1318,8 +1346,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "batch-norm-inference, " "but the shape of mean is %s " "and the shape of operand is %s.", - PrimitiveType_Name(mean_shape.element_type()).c_str(), - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(mean_shape.element_type()), + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(variance_shape, @@ -1329,8 +1357,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "batch-norm-inference, " "but the shape of variance is %s " "and the shape of operand is %s.", - PrimitiveType_Name(mean_shape.element_type()).c_str(), - PrimitiveType_Name(variance_shape.element_type()).c_str()); + PrimitiveType_Name(mean_shape.element_type()), + PrimitiveType_Name(variance_shape.element_type())); } const int64 feature_count = operand_shape.dimensions(feature_index); @@ -1340,32 +1368,32 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (ShapeUtil::GetDimension(offset_shape, 0) != feature_count) { return InvalidArgument( "The size of offset factor should be the same as feature count," - "but the size of offset factor is %lld " - "and the feature count is %lld.", + "but the size of offset factor is %d " + "and the feature count is %d.", ShapeUtil::GetDimension(offset_shape, 0), feature_count); } if (ShapeUtil::GetDimension(scale_shape, 0) != feature_count) { return InvalidArgument( "The size of scale factor should be the same as feature count," - "but the size of scale factor is %lld " - "and the feature count is %lld.", + "but the size of scale factor is %d " + "and the feature count is %d.", ShapeUtil::GetDimension(scale_shape, 0), feature_count); } if (ShapeUtil::GetDimension(mean_shape, 0) != feature_count) { return InvalidArgument( "The size of mean should be the same as feature count," - "but the size of mean is %lld " - "and the feature count is %lld.", + "but the size of mean is %d " + "and the feature count is %d.", ShapeUtil::GetDimension(mean_shape, 0), feature_count); } if (ShapeUtil::GetDimension(variance_shape, 0) != feature_count) { return InvalidArgument( "The size of variance should be the same as feature count," - "but the size of variance is %lld " - "and the feature count is %lld.", + "but the size of variance is %d " + "and the feature count is %d.", ShapeUtil::GetDimension(variance_shape, 0), feature_count); } @@ -1395,36 +1423,36 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Expected feature_index of batch-norm-grad to be " "smaller than the rank of operand_shape; " - "got feature_index %lld, and rank %lld.", + "got feature_index %d, and rank %d.", feature_index, ShapeUtil::Rank(operand_shape)); } if (ShapeUtil::Rank(operand_shape) != ShapeUtil::Rank(output_grad_shape)) { return InvalidArgument( "Expected operand_shape of batch-norm-grad to have the same rank as" - " output_grad_shape; got rank(oprand_shape) %lld, and" - " rank(output_grad_shape) %lld.", + " output_grad_shape; got rank(oprand_shape) %d, and" + " rank(output_grad_shape) %d.", ShapeUtil::Rank(operand_shape), ShapeUtil::Rank(output_grad_shape)); } if (ShapeUtil::Rank(mean_shape) != 1) { return InvalidArgument( "Mean input of batch-norm-grad must have" - " rank 1, but has rank %lld.", + " rank 1, but has rank %d.", ShapeUtil::Rank(mean_shape)); } if (ShapeUtil::Rank(scale_shape) != 1) { return InvalidArgument( "Scale input of batch-norm-grad must have" - " rank 1, but has rank %lld.", + " rank 1, but has rank %d.", ShapeUtil::Rank(scale_shape)); } if (ShapeUtil::Rank(var_shape) != 1) { return InvalidArgument( "Var input of batch-norm-grad must have" - " rank 1, but has rank %lld.", + " rank 1, but has rank %d.", ShapeUtil::Rank(var_shape)); } @@ -1432,14 +1460,14 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "The operand to batch-norm-grad must have a floating point " "element type, but the shape is %s.", - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::ElementIsFloating(output_grad_shape)) { return InvalidArgument( "The output_grad to batch-norm-grad must have a floating point " "element type, but the shape is %s.", - PrimitiveType_Name(output_grad_shape.element_type()).c_str()); + PrimitiveType_Name(output_grad_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(output_grad_shape, @@ -1448,8 +1476,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "The inputs should have the same element type for batch-norm-grad, " "but the element type of output_grad is %s " "and the element type of operand is %s.", - PrimitiveType_Name(output_grad_shape.element_type()).c_str(), - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(output_grad_shape.element_type()), + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(scale_shape, @@ -1458,8 +1486,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "The inputs should have the same element type for batch-norm-grad, " "but the element type of scale factor is %s " "and the element type of operand is %s.", - PrimitiveType_Name(scale_shape.element_type()).c_str(), - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(scale_shape.element_type()), + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(mean_shape, @@ -1468,8 +1496,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "The inputs should have the same element type for batch-norm-grad, " "but the element type of mean is %s " "and the element type of operand is %s.", - PrimitiveType_Name(mean_shape.element_type()).c_str(), - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(mean_shape.element_type()), + PrimitiveType_Name(operand_shape.element_type())); } if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(var_shape, @@ -1478,8 +1506,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "The inputs should have the same element type for batch-norm-grad, " "but the element type of mean is %s " "and the element type of operand is %s.", - PrimitiveType_Name(mean_shape.element_type()).c_str(), - PrimitiveType_Name(operand_shape.element_type()).c_str()); + PrimitiveType_Name(mean_shape.element_type()), + PrimitiveType_Name(operand_shape.element_type())); } const int64 feature_count = operand_shape.dimensions(feature_index); @@ -1490,24 +1518,24 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (ShapeUtil::GetDimension(mean_shape, 0) != feature_count) { return InvalidArgument( "The size of mean should be the same as feature count," - "but the size of offset factor is %lld " - "and the feature count is %lld.", + "but the size of offset factor is %d " + "and the feature count is %d.", ShapeUtil::GetDimension(mean_shape, 0), feature_count); } if (ShapeUtil::GetDimension(scale_shape, 0) != feature_count) { return InvalidArgument( "The size of scale factor should be the same as feature count," - "but the size of scale factor is %lld " - "and the feature count is %lld.", + "but the size of scale factor is %d " + "and the feature count is %d.", ShapeUtil::GetDimension(scale_shape, 0), feature_count); } if (ShapeUtil::GetDimension(var_shape, 0) != feature_count) { return InvalidArgument( "The size of variance should be the same as feature count," - "but the size of variance is %lld " - "and the feature count is %lld.", + "but the size of variance is %d " + "and the feature count is %d.", ShapeUtil::GetDimension(var_shape, 0), feature_count); } @@ -1517,8 +1545,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, ShapeUtil::GetDimension(output_grad_shape, i)) { return InvalidArgument( "The bounds of operand shape should be the same as output_grad's," - "but the bound of operand_shape at dimension %lld is %lld " - "and the bound of output_grad_shape is %lld.", + "but the bound of operand_shape at dimension %d is %d " + "and the bound of output_grad_shape is %d.", i, ShapeUtil::GetDimension(operand_shape, i), ShapeUtil::GetDimension(output_grad_shape, i)); } @@ -1537,15 +1565,14 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(lhs, rhs)) { return InvalidArgument( "Convolution with different element types: %s and %s.", - ShapeUtil::HumanString(lhs).c_str(), - ShapeUtil::HumanString(rhs).c_str()); + ShapeUtil::HumanString(lhs), ShapeUtil::HumanString(rhs)); } if (dnums.input_spatial_dimensions_size() != dnums.kernel_spatial_dimensions_size()) { return InvalidArgument( "Both arguments to convolution must have same number of dimensions.\n" "Window: %s", - window.DebugString().c_str()); + window.DebugString()); } const int num_spatial_dims = dnums.input_spatial_dimensions_size(); @@ -1553,19 +1580,19 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Window must have same number of dimensions as dimension numbers.\n" "Window: %s\nDimension numbers: %s.", - window.DebugString().c_str(), dnums.DebugString().c_str()); + window.DebugString(), dnums.DebugString()); } const int num_dims = num_spatial_dims + 2; if (ShapeUtil::Rank(lhs) != num_dims) { return InvalidArgument( "The LHS argument to a convolution should have rank %d; lhs: %s.", - num_dims, ShapeUtil::HumanString(lhs).c_str()); + num_dims, ShapeUtil::HumanString(lhs)); } if (ShapeUtil::Rank(rhs) != num_dims) { return InvalidArgument( "The RHS argument to a convolution should have rank %d; lhs: %s.", - num_dims, ShapeUtil::HumanString(lhs).c_str()); + num_dims, ShapeUtil::HumanString(lhs)); } TF_DCHECK_OK(ShapeUtil::ValidateShapeWithOptionalLayout(lhs)); TF_DCHECK_OK(ShapeUtil::ValidateShapeWithOptionalLayout(rhs)); @@ -1602,26 +1629,26 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, !std::all_of(output_dnums.begin(), output_dnums.end(), in_range)) { return InvalidArgument( "A dimension number is out of range in convolution: %s.", - dnums.DebugString().c_str()); + dnums.DebugString()); } if (input_dnums != expected_dnums) { return InvalidArgument( "Input dimensions of convolution must contain each dimension exactly " "once: %s.", - dnums.DebugString().c_str()); + dnums.DebugString()); } if (window_dnums != expected_dnums) { return InvalidArgument( "Window dimensions of convolution must contain each dimension exactly " "once: %s.", - dnums.DebugString().c_str()); + dnums.DebugString()); } if (output_dnums != expected_dnums) { return InvalidArgument( "Output dimensions of convolution must contain each dimension exactly " "once: %s.", - dnums.DebugString().c_str()); + dnums.DebugString()); } std::vector<int64> input_spatial_dims(num_spatial_dims); @@ -1642,13 +1669,13 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (input_features != kernel_input_features * feature_group_count) { return InvalidArgument( - "Expected LHS feature dimension (value %lld) to match RHS " - "input feature dimension * feature_group_count (value %lld); " + "Expected LHS feature dimension (value %d) to match RHS " + "input feature dimension * feature_group_count (value %d); " "got <conv>(%s, %s)\n" "Dimension numbers: {%s}.", input_features, kernel_input_features * feature_group_count, - ShapeUtil::HumanString(lhs).c_str(), - ShapeUtil::HumanString(rhs).c_str(), dnums.DebugString().c_str()); + ShapeUtil::HumanString(lhs), ShapeUtil::HumanString(rhs), + dnums.DebugString()); } std::vector<int64> window_dims(num_spatial_dims); for (int i = 0; i < num_spatial_dims; ++i) { @@ -1660,8 +1687,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, "RHS shape: %s\n\t" "Window: {%s}\n\t" "Dimension numbers: {%s}.", - ShapeUtil::HumanString(rhs).c_str(), window.ShortDebugString().c_str(), - dnums.ShortDebugString().c_str()); + ShapeUtil::HumanString(rhs), window.ShortDebugString(), + dnums.ShortDebugString()); } Shape base_shape = @@ -1687,29 +1714,29 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, const tensorflow::gtl::ArraySlice<int64> fft_length) { const int64 fft_rank = fft_length.size(); if (fft_rank < 1 || fft_rank > 3) { - return InvalidArgument("FFT only supports ranks 1-3; got %lld.", fft_rank); + return InvalidArgument("FFT only supports ranks 1-3; got %d.", fft_rank); } -#define RET_CHECK_RANK(x) \ - if (x.dimensions_size() < fft_rank) { \ - return InvalidArgument( \ - "FFT of rank %lld requires input of at least " \ - "same rank; got input of rank %d", \ - fft_rank, x.dimensions_size()); \ +#define RET_CHECK_RANK(x) \ + if (x.dimensions_size() < fft_rank) { \ + return InvalidArgument( \ + "FFT of rank %d requires input of at least " \ + "same rank; got input of rank %d", \ + fft_rank, x.dimensions_size()); \ } switch (fft_type) { case FFT: case IFFT: if (in.element_type() != C64) { return InvalidArgument("%s requires C64 input type, found %s.", - FftType_Name(fft_type).c_str(), - PrimitiveType_Name(in.element_type()).c_str()); + FftType_Name(fft_type), + PrimitiveType_Name(in.element_type())); } RET_CHECK_RANK(in); return in; case RFFT: { if (in.element_type() != F32) { return InvalidArgument("RFFT requires F32 input type, found %s.", - PrimitiveType_Name(in.element_type()).c_str()); + PrimitiveType_Name(in.element_type())); } RET_CHECK_RANK(in); for (int i = 0; i < fft_rank; i++) { @@ -1717,7 +1744,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, fft_length[i]) { return InvalidArgument( "RFFT requires innermost dimensions match fft_length but " - "dimension %lld is %lld and should be %lld.", + "dimension %d is %d and should be %d.", in.dimensions_size() - fft_rank + i, in.dimensions(in.dimensions_size() - fft_rank + i), fft_length[i]); @@ -1731,7 +1758,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, case IRFFT: { if (in.element_type() != C64) { return InvalidArgument("IRFFT requires C64 input type, found %s.", - PrimitiveType_Name(in.element_type()).c_str()); + PrimitiveType_Name(in.element_type())); } RET_CHECK_RANK(in); Shape result = ShapeUtil::ComplexComponentShape(in); @@ -1740,7 +1767,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, fft_length[i]) { return InvalidArgument( "IRFFT requires all but one innermost dimensions match " - "fft_length, but dimension %lld is %lld and should be %lld.", + "fft_length, but dimension %d is %d and should be %d.", in.dimensions_size() - fft_rank + i, in.dimensions(in.dimensions_size() - fft_rank + i), fft_length[i]); @@ -1750,7 +1777,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, fft_length[fft_rank - 1] / 2 + 1) { return InvalidArgument( "IRFFT requires innermost dimension matches fft_length/2+1, but " - "dimension %d is %lld and should be %lld.", + "dimension %d is %d and should be %d.", in.dimensions_size() - 1, in.dimensions(in.dimensions_size() - 1), fft_length[fft_rank - 1] / 2 + 1); } @@ -1786,18 +1813,18 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, TF_RET_CHECK(split_count > 0); if (split_dimension >= ShapeUtil::Rank(shape) || split_dimension < 0) { return InvalidArgument( - "AllToAll split_dimension %lld is out-of-bounds in shape %s.", - split_dimension, ShapeUtil::HumanString(shape).c_str()); + "AllToAll split_dimension %d is out-of-bounds in shape %s.", + split_dimension, ShapeUtil::HumanString(shape)); } if (concat_dimension >= ShapeUtil::Rank(shape) || concat_dimension < 0) { return InvalidArgument( - "AllToAll concat_dimension %lld is out-of-bounds in shape %s.", - concat_dimension, ShapeUtil::HumanString(shape).c_str()); + "AllToAll concat_dimension %d is out-of-bounds in shape %s.", + concat_dimension, ShapeUtil::HumanString(shape)); } if (shape.dimensions(split_dimension) % split_count != 0) { return InvalidArgument( - "AllToAll split dimension size %lld must be dividable by split_count " - "%lld.", + "AllToAll split dimension size %d must be dividable by split_count " + "%d.", shape.dimensions(split_dimension), split_count); } std::vector<int64> new_dimensions(shape.dimensions().begin(), @@ -1817,14 +1844,20 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "HLO all-to-all has operands with different shapes: the 0th " "operand shape %s, but the %dth operand has shape %s.", - ShapeUtil::HumanString(*operand_shapes[0]).c_str(), i, - ShapeUtil::HumanString(*operand_shapes[i]).c_str()); + ShapeUtil::HumanString(*operand_shapes[0]), i, + ShapeUtil::HumanString(*operand_shapes[i])); } } return InferVariadicOpShape(HloOpcode::kTuple, operand_shapes); } +/* static */ StatusOr<Shape> ShapeInference::InferCollectivePermuteShape( + const Shape& shape) { + TF_RET_CHECK(ShapeUtil::IsArray(shape)); + return shape; +} + /* static */ StatusOr<Shape> ShapeInference::InferReduceShape( tensorflow::gtl::ArraySlice<const Shape*> arg_shapes, tensorflow::gtl::ArraySlice<int64> dimensions_to_reduce, @@ -1847,9 +1880,9 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (!ShapeUtil::SameDimensions(*reduced_args[0], *reduced_args[i])) { return InvalidArgument( "All reduced tensors must have the sime dimension. Tensor 0 has " - "shape %s, Tensor %lld has shape %s", - ShapeUtil::HumanString(*reduced_args[0]).c_str(), i, - ShapeUtil::HumanString(*reduced_args[i]).c_str()); + "shape %s, Tensor %d has shape %s", + ShapeUtil::HumanString(*reduced_args[0]), i, + ShapeUtil::HumanString(*reduced_args[i])); } } @@ -1859,9 +1892,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, const Shape& arg = *reduced_args[0]; for (int64 dimension : dimensions_to_reduce) { if (dimension >= ShapeUtil::Rank(arg) || dimension < 0) { - return InvalidArgument( - "Reducing out-of-bounds dimension %lld in shape %s.", dimension, - ShapeUtil::HumanString(arg).c_str()); + return InvalidArgument("Reducing out-of-bounds dimension %d in shape %s.", + dimension, ShapeUtil::HumanString(arg)); } } @@ -1934,16 +1966,16 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Select function's first parameter shape currently must " "match the operand element shape, but got %s vs %s.", - ShapeUtil::HumanString(select_shape.parameters(0)).c_str(), - ShapeUtil::HumanString(operand_element_shape).c_str()); + ShapeUtil::HumanString(select_shape.parameters(0)), + ShapeUtil::HumanString(operand_element_shape)); } if (!ShapeUtil::CompatibleIgnoringFpPrecision(operand_element_shape, select_shape.parameters(1))) { return InvalidArgument( "Select function's second parameter shape currently must " "match the operand element shape, but got %s vs %s.", - ShapeUtil::HumanString(select_shape.parameters(1)).c_str(), - ShapeUtil::HumanString(operand_element_shape).c_str()); + ShapeUtil::HumanString(select_shape.parameters(1)), + ShapeUtil::HumanString(operand_element_shape)); } // Check if the scatter function has a proper shape as a reduction. @@ -1961,8 +1993,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Source shape does not match the shape of window-reduced operand: " "source(%s), window-reduced operand(%s).", - ShapeUtil::HumanString(source_shape).c_str(), - ShapeUtil::HumanString(window_result_shape).c_str()); + ShapeUtil::HumanString(source_shape), + ShapeUtil::HumanString(window_result_shape)); } return operand_shape; } @@ -1975,29 +2007,27 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "%s in slice operation; argument shape: %s; starts: {%s}; limits: " "{%s}; strides: {%s}.", - message.c_str(), ShapeUtil::HumanString(arg).c_str(), - Join(starts, ",").c_str(), Join(limits, ",").c_str(), - Join(strides, ",").c_str()); + message, ShapeUtil::HumanString(arg), StrJoin(starts, ","), + StrJoin(limits, ","), StrJoin(strides, ",")); }; TF_RETURN_IF_ERROR(ExpectArray(arg, "operand of slice")); - VLOG(2) << tensorflow::strings::Printf( - "slicing shape %s starts={%s} limits={%s}", - ShapeUtil::HumanString(arg).c_str(), Join(starts, ", ").c_str(), - Join(limits, ", ").c_str()); + VLOG(2) << StrFormat("slicing shape %s starts={%s} limits={%s}", + ShapeUtil::HumanString(arg), StrJoin(starts, ", "), + StrJoin(limits, ", ")); if (starts.size() != limits.size()) { - return error(Printf("slice start and limit sizes differ: %zu vs %zu", - starts.size(), limits.size())); + return error(StrFormat("slice start and limit sizes differ: %u vs %u", + starts.size(), limits.size())); } if (starts.size() != strides.size()) { - return error(Printf("slice start and strides sizes differ: %zu vs %zu", - starts.size(), strides.size())); + return error(StrFormat("slice start and strides sizes differ: %u vs %u", + starts.size(), strides.size())); } if (starts.size() != ShapeUtil::Rank(arg)) { return InvalidArgument( - "Slice index count does not match argument rank: %zu vs %lld.", + "Slice index count does not match argument rank: %u vs %d.", starts.size(), ShapeUtil::Rank(arg)); } @@ -2007,27 +2037,24 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, int64 limit_index = limits[dimension]; int64 stride = strides[dimension]; if (start_index < 0) { - return InvalidArgument("Negative start index to slice: %lld.", - start_index); + return InvalidArgument("Negative start index to slice: %d.", start_index); } if (limit_index > arg.dimensions(dimension)) { return error( - Printf("limit index (%lld) must be less than or equal to dimension " - "size (%lld)", - limit_index, arg.dimensions(dimension))); - } - VLOG(2) << tensorflow::strings::Printf("starts[%lld] = %lld", dimension, - start_index); - VLOG(2) << tensorflow::strings::Printf("limits[%lld] = %lld", dimension, - limit_index); + StrFormat("limit index (%d) must be less than or equal to dimension " + "size (%d)", + limit_index, arg.dimensions(dimension))); + } + VLOG(2) << StrFormat("starts[%d] = %d", dimension, start_index); + VLOG(2) << StrFormat("limits[%d] = %d", dimension, limit_index); if (start_index > limit_index) { return error( - Printf("limit index (%lld) must be greater or equal to " - "start index (%lld) in slice with positive stride", - limit_index, start_index)); + StrFormat("limit index (%d) must be greater or equal to " + "start index (%d) in slice with positive stride", + limit_index, start_index)); } if (stride <= 0) { - return InvalidArgument("Stride (%lld) must be positive.", stride); + return InvalidArgument("Stride (%d) must be positive.", stride); } sizes.push_back((limit_index - start_index + stride - 1) / stride); } @@ -2042,15 +2069,14 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, TF_RETURN_IF_ERROR( ExpectArray(start_indices_shape, "start indices of dynamic slice")); - VLOG(2) << tensorflow::strings::Printf( + VLOG(2) << StrFormat( "slicing shape %s at dynamic start_indices %s with slice_sizes={%s}", - ShapeUtil::HumanString(operand_shape).c_str(), - ShapeUtil::HumanString(start_indices_shape).c_str(), - Join(slice_sizes, ", ").c_str()); + ShapeUtil::HumanString(operand_shape), + ShapeUtil::HumanString(start_indices_shape), StrJoin(slice_sizes, ", ")); if (ShapeUtil::Rank(start_indices_shape) != 1) { return InvalidArgument( - "Dynamic slice start indices of rank %lld must be rank1.", + "Dynamic slice start indices of rank %d must be rank1.", ShapeUtil::Rank(start_indices_shape)); } @@ -2062,16 +2088,15 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, const int64 start_num_dims = start_indices_shape.dimensions(0); if (ShapeUtil::Rank(operand_shape) != start_num_dims) { return InvalidArgument( - "Dynamic slice start number of dimensions %lld (%s) must match rank " - "%lld of slice input (%s).", - start_num_dims, ShapeUtil::HumanString(start_indices_shape).c_str(), - ShapeUtil::Rank(operand_shape), - ShapeUtil::HumanString(operand_shape).c_str()); + "Dynamic slice start number of dimensions %d (%s) must match rank " + "%d of slice input (%s).", + start_num_dims, ShapeUtil::HumanString(start_indices_shape), + ShapeUtil::Rank(operand_shape), ShapeUtil::HumanString(operand_shape)); } if (slice_sizes.size() != ShapeUtil::Rank(operand_shape)) { return InvalidArgument( - "Dynamic slice index count does not match argument rank: %zu vs %lld.", + "Dynamic slice index count does not match argument rank: %u vs %d.", slice_sizes.size(), ShapeUtil::Rank(operand_shape)); } @@ -2079,16 +2104,15 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, const int64 input_dim_size = operand_shape.dimensions(dim); const int64 slice_dim_size = slice_sizes[dim]; if (slice_dim_size < 0) { - return InvalidArgument("Negative size index to dynamic slice: %lld.", + return InvalidArgument("Negative size index to dynamic slice: %d.", slice_dim_size); } if (slice_dim_size > input_dim_size) { return InvalidArgument( - "Slice dim size %lld greater than dynamic slice dimension: %lld.", + "Slice dim size %d greater than dynamic slice dimension: %d.", slice_dim_size, input_dim_size); } - VLOG(2) << tensorflow::strings::Printf("slice_sizes[%lld] = %lld", dim, - slice_dim_size); + VLOG(2) << StrFormat("slice_sizes[%d] = %d", dim, slice_dim_size); } return ShapeUtil::MakeShape(operand_shape.element_type(), slice_sizes); @@ -2104,16 +2128,16 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, TF_RETURN_IF_ERROR(ExpectArray(start_indices_shape, "start indices of dynamic update slice")); - VLOG(2) << tensorflow::strings::Printf( + VLOG(2) << StrFormat( "updating slice of shape %s at dynamic start_indices %s with update " "shape %s", - ShapeUtil::HumanString(operand_shape).c_str(), - ShapeUtil::HumanString(start_indices_shape).c_str(), - ShapeUtil::HumanString(update_shape).c_str()); + ShapeUtil::HumanString(operand_shape), + ShapeUtil::HumanString(start_indices_shape), + ShapeUtil::HumanString(update_shape)); if (ShapeUtil::Rank(start_indices_shape) != 1) { return InvalidArgument( - "Dynamic update slice start indices of rank %lld must be rank1.", + "Dynamic update slice start indices of rank %d must be rank1.", ShapeUtil::Rank(start_indices_shape)); } @@ -2125,17 +2149,16 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, const int64 start_num_dims = start_indices_shape.dimensions(0); if (ShapeUtil::Rank(operand_shape) != start_num_dims) { return InvalidArgument( - "Dynamic update slice start number of dimensions %lld (%s) must match " - "rank %lld of slice input (%s).", - start_num_dims, ShapeUtil::HumanString(start_indices_shape).c_str(), - ShapeUtil::Rank(operand_shape), - ShapeUtil::HumanString(operand_shape).c_str()); + "Dynamic update slice start number of dimensions %d (%s) must match " + "rank %d of slice input (%s).", + start_num_dims, ShapeUtil::HumanString(start_indices_shape), + ShapeUtil::Rank(operand_shape), ShapeUtil::HumanString(operand_shape)); } if (ShapeUtil::Rank(update_shape) != ShapeUtil::Rank(operand_shape)) { return InvalidArgument( "Dynamic update slice update rank does not match argument rank: " - "%lld vs %lld.", + "%d vs %d.", ShapeUtil::Rank(update_shape), ShapeUtil::Rank(operand_shape)); } @@ -2144,8 +2167,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Dynamic update slice update element type does not match argument. " "operand.element_type: %s vs update.element_type: %s.", - PrimitiveType_Name(operand_shape.element_type()).c_str(), - PrimitiveType_Name(update_shape.element_type()).c_str()); + PrimitiveType_Name(operand_shape.element_type()), + PrimitiveType_Name(update_shape.element_type())); } for (int64 dim = 0; dim < ShapeUtil::Rank(operand_shape); ++dim) { @@ -2153,16 +2176,15 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, const int64 update_dim_size = update_shape.dimensions(dim); if (update_dim_size < 0) { return InvalidArgument( - "Size index %lld to dynamic update slice must be >= 0.", + "Size index %d to dynamic update slice must be >= 0.", update_dim_size); } if (update_dim_size > input_dim_size) { return InvalidArgument( - "Update dim size %lld greater than dynamic slice dimension: %lld.", + "Update dim size %d greater than dynamic slice dimension: %d.", update_dim_size, input_dim_size); } - VLOG(2) << tensorflow::strings::Printf("update_sizes[%lld] = %lld", dim, - update_dim_size); + VLOG(2) << StrFormat("update_sizes[%d] = %d", dim, update_dim_size); } return operand_shape; @@ -2177,8 +2199,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, for (int64 dimension : dimensions) { if (dimension >= ShapeUtil::Rank(operand_shape) || dimension < 0) { return InvalidArgument( - "One of the reverse dimensions (%lld) is out-of-bounds in shape %s.", - dimension, ShapeUtil::HumanString(operand_shape).c_str()); + "One of the reverse dimensions (%d) is out-of-bounds in shape %s.", + dimension, ShapeUtil::HumanString(operand_shape)); } } return operand_shape; @@ -2189,14 +2211,14 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (!ShapeUtil::IsTuple(arg)) { return InvalidArgument( "Cannot infer shape: attempting to index into non-tuple: %s.", - ShapeUtil::HumanString(arg).c_str()); + ShapeUtil::HumanString(arg)); } if (index >= arg.tuple_shapes_size()) { return InvalidArgument( - "Cannot infer shape: attempt to index out of tuple bounds: %lld " + "Cannot infer shape: attempt to index out of tuple bounds: %d " ">= %d in shape %s.", - index, arg.tuple_shapes_size(), ShapeUtil::HumanString(arg).c_str()); + index, arg.tuple_shapes_size(), ShapeUtil::HumanString(arg)); } return arg.tuple_shapes(index); @@ -2216,17 +2238,15 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, } auto shape_string = [&]() { - return tensorflow::strings::Printf( - "Condition: %s; body: %s; init: %s.", - ShapeUtil::HumanString(condition).c_str(), - ShapeUtil::HumanString(body).c_str(), - ShapeUtil::HumanString(init).c_str()); + return StrFormat( + "Condition: %s; body: %s; init: %s.", ShapeUtil::HumanString(condition), + ShapeUtil::HumanString(body), ShapeUtil::HumanString(init)); }; // Check the shapes of computation parameters and return types. if (!ShapeUtil::ShapeIs(condition.result(), PRED, {})) { return InvalidArgument("Condition must return a boolean; got %s.", - shape_string().c_str()); + shape_string()); } if (!ShapeUtil::Compatible(body.result(), condition.parameters(0)) || !ShapeUtil::Compatible(body.result(), body.parameters(0)) || @@ -2234,7 +2254,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "The parameter of condition and body, the result of the body, and init " "must all have the same shape; got %s.", - shape_string().c_str()); + shape_string()); } return init; @@ -2246,7 +2266,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, const ProgramShape& false_computation) { if (!ShapeUtil::ShapeIs(predicate, PRED, {})) { return InvalidArgument("Predicate must be a boolean; got %s.", - ShapeUtil::HumanString(predicate).c_str()); + ShapeUtil::HumanString(predicate)); } if (true_computation.parameters_size() != 1) { @@ -2255,15 +2275,14 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, } if (!ShapeUtil::Compatible(true_computation.parameters(0), true_operand)) { auto true_shape_string = [&]() { - return tensorflow::strings::Printf( - "true_operand: %s; true_computation: %s", - ShapeUtil::HumanString(true_operand).c_str(), - ShapeUtil::HumanString(true_computation).c_str()); + return StrFormat("true_operand: %s; true_computation: %s", + ShapeUtil::HumanString(true_operand), + ShapeUtil::HumanString(true_computation)); }; return InvalidArgument( "true_operand must match the shape of the only parameter of " "true_computation: got %s.", - true_shape_string().c_str()); + true_shape_string()); } if (false_computation.parameters_size() != 1) { @@ -2272,28 +2291,27 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, } if (!ShapeUtil::Compatible(false_computation.parameters(0), false_operand)) { auto false_shape_string = [&]() { - return tensorflow::strings::Printf( - "false_operand: %s; false_computation: %s", - ShapeUtil::HumanString(false_operand).c_str(), - ShapeUtil::HumanString(false_computation).c_str()); + return StrFormat("false_operand: %s; false_computation: %s", + ShapeUtil::HumanString(false_operand), + ShapeUtil::HumanString(false_computation)); }; return InvalidArgument( "false_operand must match the shape of the only parameter of " "false_computation: got %s.", - false_shape_string().c_str()); + false_shape_string()); } if (!ShapeUtil::Compatible(true_computation.result(), false_computation.result())) { auto shape_string = [&]() { - return tensorflow::strings::Printf( + return StrFormat( "true_computation result: %s; false_computation result: %s.", - ShapeUtil::HumanString(true_computation.result()).c_str(), - ShapeUtil::HumanString(false_computation.result()).c_str()); + ShapeUtil::HumanString(true_computation.result()), + ShapeUtil::HumanString(false_computation.result())); }; return InvalidArgument( "the result of true_computation and false_computation must have the " "same shape: got %s.", - shape_string().c_str()); + shape_string()); } return true_computation.result(); } @@ -2303,7 +2321,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, TF_RETURN_IF_ERROR(ExpectArray(operand, "operand of broadcast")); for (int64 size : broadcast_sizes) { if (size < 0) { - return InvalidArgument("Broadcast with negative dimension size %lld.", + return InvalidArgument("Broadcast with negative dimension size %d.", size); } } @@ -2328,11 +2346,11 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (ShapeUtil::ElementsIn(operand) != ShapeUtil::ElementsIn(inferred_shape)) { return InvalidArgument( - "Reshape operation has mismatched element counts: from=%lld (%s) " - "to=%lld (%s).", - ShapeUtil::ElementsIn(operand), ShapeUtil::HumanString(operand).c_str(), + "Reshape operation has mismatched element counts: from=%d (%s) " + "to=%d (%s).", + ShapeUtil::ElementsIn(operand), ShapeUtil::HumanString(operand), ShapeUtil::ElementsIn(inferred_shape), - ShapeUtil::HumanString(inferred_shape).c_str()); + ShapeUtil::HumanString(inferred_shape)); } std::vector<int64> indices(ShapeUtil::Rank(operand)); @@ -2343,7 +2361,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Reshape dimensions [%s] are not a permutation of the operand " "dimensions (operand shape is %s).", - Join(dimensions, ",").c_str(), ShapeUtil::HumanString(operand).c_str()); + StrJoin(dimensions, ","), ShapeUtil::HumanString(operand)); } return inferred_shape; @@ -2378,9 +2396,9 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (!ShapeUtil::SameElementTypeIgnoringFpPrecision(min, operand) || !ShapeUtil::SameElementTypeIgnoringFpPrecision(max, operand)) { return InvalidArgument("Clamp with different operand types: %s, %s, %s.", - ShapeUtil::HumanString(min).c_str(), - ShapeUtil::HumanString(operand).c_str(), - ShapeUtil::HumanString(max).c_str()); + ShapeUtil::HumanString(min), + ShapeUtil::HumanString(operand), + ShapeUtil::HumanString(max)); } if (((ShapeUtil::CompatibleIgnoringFpPrecision(min, operand) || ShapeUtil::IsScalar(min)) && @@ -2397,9 +2415,9 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return ShapeUtil::ChangeElementType(min, operand.element_type()); } } - return Unimplemented( - "%s, %s <clamp> %s is not implemented.", min.ShortDebugString().c_str(), - max.ShortDebugString().c_str(), operand.ShortDebugString().c_str()); + return Unimplemented("%s, %s <clamp> %s is not implemented.", + min.ShortDebugString(), max.ShortDebugString(), + operand.ShortDebugString()); } // TODO(b/36794510): Make broadcast semantics more consistent, by supporting @@ -2410,13 +2428,12 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (!ShapeUtil::CompatibleIgnoringFpPrecision(on_true, on_false)) { return InvalidArgument( "Operands to select must be the same shape; got %s and %s.", - ShapeUtil::HumanString(on_true).c_str(), - ShapeUtil::HumanString(on_false).c_str()); + ShapeUtil::HumanString(on_true), ShapeUtil::HumanString(on_false)); } if (pred.element_type() != PRED) { return InvalidArgument( "Select's pred operand must have PRED element type; got %s.", - ShapeUtil::HumanString(pred).c_str()); + ShapeUtil::HumanString(pred)); } if (ShapeUtil::CompatibleIgnoringElementType(pred, on_true) || ShapeUtil::IsScalar(pred)) { @@ -2429,7 +2446,7 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Select operation with non-scalar predicate with dimensionality " " different from the other operands: %s.", - ShapeUtil::HumanString(pred).c_str()); + ShapeUtil::HumanString(pred)); } } @@ -2440,18 +2457,17 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (!ShapeUtil::Compatible(on_true, on_false)) { return InvalidArgument( "Operands to tuple-select must be the same shape; got %s and %s.", - ShapeUtil::HumanString(on_true).c_str(), - ShapeUtil::HumanString(on_false).c_str()); + ShapeUtil::HumanString(on_true), ShapeUtil::HumanString(on_false)); } if (pred.element_type() != PRED) { return InvalidArgument( "TupleSelect's pred operand must have PRED element type; got %s.", - ShapeUtil::HumanString(pred).c_str()); + ShapeUtil::HumanString(pred)); } if (!ShapeUtil::IsScalar(pred)) { return InvalidArgument( "TupleSelect operation with non-scalar predicate: %s.", - ShapeUtil::HumanString(pred).c_str()); + ShapeUtil::HumanString(pred)); } return on_true; } @@ -2463,15 +2479,15 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, if (arg_shapes.size() != to_apply.parameters_size()) { string computation_signature = ShapeUtil::HumanString(to_apply); string argument_shapes = - Join(arg_shapes, ", ", [](string* out, const Shape* shape) { - tensorflow::strings::StrAppend(out, ShapeUtil::HumanString(*shape)); + StrJoin(arg_shapes, ", ", [](string* out, const Shape* shape) { + absl::StrAppend(out, ShapeUtil::HumanString(*shape)); }); return InvalidArgument( "Call applied function arity must match number of arguments; got: " - "arity: %d, arguments: %zu; computation signature: %s; argument " + "arity: %d, arguments: %u; computation signature: %s; argument " "shapes: [%s].", - to_apply.parameters_size(), arg_shapes.size(), - computation_signature.c_str(), argument_shapes.c_str()); + to_apply.parameters_size(), arg_shapes.size(), computation_signature, + argument_shapes); } // All arguments must be compatible with the program shape. @@ -2482,8 +2498,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, return InvalidArgument( "Call parameter must match argument; got parameter %d shape: %s, " "argument shape: %s.", - i, ShapeUtil::HumanString(param_shape).c_str(), - ShapeUtil::HumanString(arg_shape).c_str()); + i, ShapeUtil::HumanString(param_shape), + ShapeUtil::HumanString(arg_shape)); } } @@ -2494,17 +2510,17 @@ static Status ValidateGatherDimensionNumbers( const Shape& input_shape, tensorflow::gtl::ArraySlice<int64> start_indices_shape, const GatherDimensionNumbers& dim_numbers) { - if (!c_is_sorted(dim_numbers.offset_dims())) { + if (!absl::c_is_sorted(dim_numbers.offset_dims())) { return InvalidArgument( "Output window dimensions in gather op must be ascending; got: %s.", - Join(dim_numbers.offset_dims(), ", ").c_str()); + StrJoin(dim_numbers.offset_dims(), ", ")); } - if (c_adjacent_find(dim_numbers.offset_dims()) != + if (absl::c_adjacent_find(dim_numbers.offset_dims()) != dim_numbers.offset_dims().end()) { return InvalidArgument( "Output window dimensions in gather op must not repeat; got: %s.", - Join(dim_numbers.offset_dims(), ", ").c_str()); + StrJoin(dim_numbers.offset_dims(), ", ")); } const int64 output_offset_dim_count = dim_numbers.offset_dims_size(); @@ -2515,9 +2531,9 @@ static Status ValidateGatherDimensionNumbers( int64 offset_dim = dim_numbers.offset_dims(i); if (offset_dim < 0 || offset_dim >= output_shape_rank) { return InvalidArgument( - "Offset dimension %d in gather op is out of bounds; got %lld, but " + "Offset dimension %d in gather op is out of bounds; got %d, but " "should " - "have been in [0,%lld).", + "have been in [0,%d).", i, offset_dim, output_shape_rank); } } @@ -2526,8 +2542,8 @@ static Status ValidateGatherDimensionNumbers( start_indices_shape[dim_numbers.index_vector_dim()]) { return InvalidArgument( "Gather op has %d elements in start_index_map and the " - "bound of dimension index_vector_dim=%lld of start_indices is " - "%lld. These two numbers must be equal.", + "bound of dimension index_vector_dim=%d of start_indices is " + "%d. These two numbers must be equal.", dim_numbers.start_index_map_size(), dim_numbers.index_vector_dim(), start_indices_shape[dim_numbers.index_vector_dim()]); } @@ -2537,7 +2553,7 @@ static Status ValidateGatherDimensionNumbers( if (operand_dim_for_start_index_i < 0 || operand_dim_for_start_index_i >= input_shape.dimensions_size()) { return InvalidArgument( - "Invalid start_index_map; domain is [0, %d), got: %d->%lld.", + "Invalid start_index_map; domain is [0, %d), got: %d->%d.", input_shape.dimensions_size(), i, operand_dim_for_start_index_i); } } @@ -2546,36 +2562,37 @@ static Status ValidateGatherDimensionNumbers( dim_numbers.start_index_map().begin(), dim_numbers.start_index_map().end()); - c_sort(sorted_start_index_map); + absl::c_sort(sorted_start_index_map); - if (c_adjacent_find(sorted_start_index_map) != sorted_start_index_map.end()) { + if (absl::c_adjacent_find(sorted_start_index_map) != + sorted_start_index_map.end()) { return InvalidArgument( "Repeated dimensions are not allowed in start_index_map; " "got: %s.", - Join(dim_numbers.start_index_map(), ", ").c_str()); + StrJoin(dim_numbers.start_index_map(), ", ")); } for (int64 collapsed_dim : dim_numbers.collapsed_slice_dims()) { if (collapsed_dim < 0 || collapsed_dim >= input_shape.dimensions_size()) { return InvalidArgument( "Invalid collapsed_slice_dims set in gather op; valid range is [0, " - "%d), got: %lld.", + "%d), got: %d.", input_shape.dimensions_size(), collapsed_dim); } } - if (!c_is_sorted(dim_numbers.collapsed_slice_dims())) { + if (!absl::c_is_sorted(dim_numbers.collapsed_slice_dims())) { return InvalidArgument( "collapsed_slice_dims in gather op must be sorted; got: %s", - Join(dim_numbers.collapsed_slice_dims(), ", ").c_str()); + StrJoin(dim_numbers.collapsed_slice_dims(), ", ")); } - if (c_adjacent_find(dim_numbers.collapsed_slice_dims()) != + if (absl::c_adjacent_find(dim_numbers.collapsed_slice_dims()) != dim_numbers.collapsed_slice_dims().end()) { return InvalidArgument( "Repeated dimensions not allowed in collapsed_slice_dims in gather op; " "got: %s.", - Join(dim_numbers.collapsed_slice_dims(), ", ").c_str()); + StrJoin(dim_numbers.collapsed_slice_dims(), ", ")); } return Status::OK(); @@ -2593,7 +2610,7 @@ static Status ValidateGatherDimensionNumbers( if (!ShapeUtil::ElementIsIntegral(start_indices_shape)) { return InvalidArgument( "Gather indices parameter must be an integral tensor; got %s.", - ShapeUtil::HumanString(start_indices_shape).c_str()); + ShapeUtil::HumanString(start_indices_shape)); } // We implicitly reshape gather indices of shape P[A,B,C] to P[A,B,C,1] if @@ -2606,15 +2623,15 @@ static Status ValidateGatherDimensionNumbers( return InvalidArgument( "Gather index leaf dimension must be within [0, rank(start_indices) + " "1). rank(start_indices) is %d and gather index leaf dimension is " - "%lld.", + "%d.", start_indices_shape.dimensions_size(), gather_dim_numbers.index_vector_dim()); } std::vector<int64> expanded_start_indices_shape; expanded_start_indices_shape.reserve(start_indices_shape.dimensions_size()); - c_copy(start_indices_shape.dimensions(), - std::back_inserter(expanded_start_indices_shape)); + absl::c_copy(start_indices_shape.dimensions(), + std::back_inserter(expanded_start_indices_shape)); if (expanded_start_indices_shape.size() == gather_dim_numbers.index_vector_dim()) { expanded_start_indices_shape.push_back(1); @@ -2637,8 +2654,8 @@ static Status ValidateGatherDimensionNumbers( "All components of the offset index in a gather op must either be a " "offset dimension or explicitly collapsed; got len(slice_sizes)=%lu, " "output_slice_sizes=%s, collapsed_slice_dims=%s.", - slice_sizes.size(), Join(gather_dim_numbers.offset_dims(), ",").c_str(), - Join(gather_dim_numbers.collapsed_slice_dims(), ",").c_str()); + slice_sizes.size(), StrJoin(gather_dim_numbers.offset_dims(), ","), + StrJoin(gather_dim_numbers.collapsed_slice_dims(), ",")); } for (int i = 0; i < slice_sizes.size(); i++) { @@ -2647,7 +2664,7 @@ static Status ValidateGatherDimensionNumbers( if (slice_size < 0 || slice_size > corresponding_input_size) { return InvalidArgument( "Slice size at index %d in gather op is out of range, must be " - "within [0, %lld), got %lld.", + "within [0, %d), got %d.", i, corresponding_input_size + 1, slice_size); } } @@ -2656,7 +2673,7 @@ static Status ValidateGatherDimensionNumbers( if (slice_sizes[gather_dim_numbers.collapsed_slice_dims(i)] != 1) { return InvalidArgument( "Gather op can only collapse slice dims with bound 1, but bound is " - "%lld for index %lld at position %d.", + "%d for index %d at position %d.", slice_sizes[gather_dim_numbers.collapsed_slice_dims(i)], gather_dim_numbers.collapsed_slice_dims(i), i); } @@ -2670,10 +2687,11 @@ static Status ValidateGatherDimensionNumbers( output_dim_bounds.reserve(result_rank); for (int64 i = 0; i < result_rank; i++) { int64 current_bound; - bool is_window_index = c_binary_search(gather_dim_numbers.offset_dims(), i); + bool is_window_index = + absl::c_binary_search(gather_dim_numbers.offset_dims(), i); if (is_window_index) { - while (c_binary_search(gather_dim_numbers.collapsed_slice_dims(), - offset_dims_seen)) { + while (absl::c_binary_search(gather_dim_numbers.collapsed_slice_dims(), + offset_dims_seen)) { offset_dims_seen++; } current_bound = slice_sizes[offset_dims_seen++]; @@ -2697,44 +2715,44 @@ Status ValidateScatterDimensionNumbers( tensorflow::gtl::ArraySlice<int64> scatter_indices_shape, const Shape& updates_shape, const ScatterDimensionNumbers& dim_numbers) { // Validate update_window_dims in ScatterDimensionNumbers. - if (!c_is_sorted(dim_numbers.update_window_dims())) { + if (!absl::c_is_sorted(dim_numbers.update_window_dims())) { return InvalidArgument( "update_window_dims in scatter op must be sorted; got: %s.", - Join(dim_numbers.update_window_dims(), ", ").c_str()); + StrJoin(dim_numbers.update_window_dims(), ", ")); } - if (c_adjacent_find(dim_numbers.update_window_dims()) != + if (absl::c_adjacent_find(dim_numbers.update_window_dims()) != dim_numbers.update_window_dims().end()) { return InvalidArgument( "update_window_dims in scatter op must not repeat; got: %s.", - Join(dim_numbers.update_window_dims(), ", ").c_str()); + StrJoin(dim_numbers.update_window_dims(), ", ")); } const int64 updates_rank = ShapeUtil::Rank(updates_shape); for (int64 window_dim : dim_numbers.update_window_dims()) { if (window_dim < 0 || window_dim >= updates_rank) { return InvalidArgument( "Invalid update_window_dims set in scatter op; valid range is [0, " - "%lld). got: %lld.", + "%d). got: %d.", updates_rank, window_dim); } } // Validate inserted_window_dims in ScatterDimensionNumbers. - if (!c_is_sorted(dim_numbers.inserted_window_dims())) { + if (!absl::c_is_sorted(dim_numbers.inserted_window_dims())) { return InvalidArgument( "inserted_window_dims in scatter op must be sorted; got: %s.", - Join(dim_numbers.inserted_window_dims(), ", ").c_str()); + StrJoin(dim_numbers.inserted_window_dims(), ", ")); } - if (c_adjacent_find(dim_numbers.inserted_window_dims()) != + if (absl::c_adjacent_find(dim_numbers.inserted_window_dims()) != dim_numbers.inserted_window_dims().end()) { return InvalidArgument( "inserted_window_dims in scatter op must not repeat; got: %s.", - Join(dim_numbers.inserted_window_dims(), ", ").c_str()); + StrJoin(dim_numbers.inserted_window_dims(), ", ")); } for (int64 inserted_dim : dim_numbers.inserted_window_dims()) { if (inserted_dim < 0 || inserted_dim >= operand_shape.dimensions_size()) { return InvalidArgument( "Invalid inserted_window_dims set in scatter op; valid range is [0, " - "%d), got: %lld.", + "%d), got: %d.", operand_shape.dimensions_size(), inserted_dim); } } @@ -2744,7 +2762,7 @@ Status ValidateScatterDimensionNumbers( scatter_indices_shape[dim_numbers.index_vector_dim()]) { return InvalidArgument( "Scatter op has %d elements in scatter_dims_to_operand_dims and the " - "bound of dimension index_vector_dim=%lld of scatter_indices is %lld. " + "bound of dimension index_vector_dim=%d of scatter_indices is %d. " "These two numbers must be equal.", dim_numbers.scatter_dims_to_operand_dims_size(), dim_numbers.index_vector_dim(), @@ -2757,20 +2775,20 @@ Status ValidateScatterDimensionNumbers( scatter_dim_to_operand_dim >= operand_shape.dimensions_size()) { return InvalidArgument( "Invalid scatter_dims_to_operand_dims mapping; domain is [0, %d), " - "got: %d->%lld.", + "got: %d->%d.", operand_shape.dimensions_size(), i, scatter_dim_to_operand_dim); } } std::vector<int64> sorted_scatter_dims_to_operand_dims( dim_numbers.scatter_dims_to_operand_dims().begin(), dim_numbers.scatter_dims_to_operand_dims().end()); - c_sort(sorted_scatter_dims_to_operand_dims); - if (c_adjacent_find(sorted_scatter_dims_to_operand_dims) != + absl::c_sort(sorted_scatter_dims_to_operand_dims); + if (absl::c_adjacent_find(sorted_scatter_dims_to_operand_dims) != sorted_scatter_dims_to_operand_dims.end()) { return InvalidArgument( "Repeated dimensions not allowed in scatter_dims_to_operand_dims; " "got: %s.", - Join(dim_numbers.scatter_dims_to_operand_dims(), ", ").c_str()); + StrJoin(dim_numbers.scatter_dims_to_operand_dims(), ", ")); } return Status::OK(); @@ -2791,7 +2809,7 @@ Status ValidateScatterDimensionNumbers( if (!ShapeUtil::ElementIsIntegral(scatter_indices_shape)) { return InvalidArgument( "Scatter indices parameter must be an integral tensor; got %s.", - ShapeUtil::HumanString(scatter_indices_shape).c_str()); + ShapeUtil::HumanString(scatter_indices_shape)); } if (scatter_indices_shape.dimensions_size() < @@ -2800,7 +2818,7 @@ Status ValidateScatterDimensionNumbers( return InvalidArgument( "Scatter index leaf dimension must be within [0, rank(scatter_indices)" " + 1). rank(scatter_indices) is %d and scatter index leaf dimension " - "is %lld.", + "is %d.", scatter_indices_shape.dimensions_size(), scatter_dim_numbers.index_vector_dim()); } @@ -2822,7 +2840,7 @@ Status ValidateScatterDimensionNumbers( int64 expected_updates_rank = expanded_scatter_indices_shape.size() - 1 + scatter_dim_numbers.update_window_dims_size(); if (ShapeUtil::Rank(updates_shape) != expected_updates_rank) { - return InvalidArgument("Updates tensor must be of rank %lld; got %lld.", + return InvalidArgument("Updates tensor must be of rank %d; got %d.", expected_updates_rank, ShapeUtil::Rank(updates_shape)); } @@ -2848,7 +2866,7 @@ Status ValidateScatterDimensionNumbers( return InvalidArgument( "Bounds of the window dimensions of updates must not exceed the " "bounds of the corresponding dimensions of operand. For dimension " - "%lld, updates bound is %lld, operand bound is %lld.", + "%d, updates bound is %d, operand bound is %d.", update_window_dim, updates_shape.dimensions(update_window_dim), max_update_slice_sizes[i]); } @@ -2857,7 +2875,7 @@ Status ValidateScatterDimensionNumbers( int64 scatter_dims_seen = 0; for (int64 i = 0; i < ShapeUtil::Rank(updates_shape); ++i) { bool is_update_window_dim = - c_binary_search(scatter_dim_numbers.update_window_dims(), i); + absl::c_binary_search(scatter_dim_numbers.update_window_dims(), i); if (is_update_window_dim) { continue; } @@ -2869,8 +2887,8 @@ Status ValidateScatterDimensionNumbers( return InvalidArgument( "Bounds of the scatter dimensions of updates must be same as the " "bounds of the corresponding dimensions of scatter indices. For " - "scatter dimension %lld, updates bound is %lld, scatter_indices " - "bound is %lld.", + "scatter dimension %d, updates bound is %d, scatter_indices " + "bound is %d.", i, updates_shape.dimensions(i), expanded_scatter_indices_shape[scatter_dims_seen]); } diff --git a/tensorflow/compiler/xla/service/shape_inference.h b/tensorflow/compiler/xla/service/shape_inference.h index 4974ac9916..235b1a4cf3 100644 --- a/tensorflow/compiler/xla/service/shape_inference.h +++ b/tensorflow/compiler/xla/service/shape_inference.h @@ -136,6 +136,9 @@ class ShapeInference { static StatusOr<Shape> InferAllToAllTupleShape( tensorflow::gtl::ArraySlice<const Shape*> operand_shapes); + // Infers the shape of a collective permute operation. + static StatusOr<Shape> InferCollectivePermuteShape(const Shape& shape); + // Infers the shape produced by applying the given reduction computation // shape to the given input operand shape. // diff --git a/tensorflow/compiler/xla/service/shaped_buffer.cc b/tensorflow/compiler/xla/service/shaped_buffer.cc index 7d7dcac10b..921a984589 100644 --- a/tensorflow/compiler/xla/service/shaped_buffer.cc +++ b/tensorflow/compiler/xla/service/shaped_buffer.cc @@ -18,20 +18,19 @@ limitations under the License. #include <string> #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/layout_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" namespace xla { -using ::tensorflow::strings::Appendf; - ShapedBuffer::ShapedBuffer(const Shape& on_host_shape, const Shape& on_device_shape, const se::Platform* platform, int device_ordinal) @@ -76,7 +75,7 @@ void ShapedBuffer::clear() { } string ShapedBuffer::ToString() const { - string s = tensorflow::strings::StrCat( + string s = absl::StrCat( "ShapedBuffer(", platform_->Name(), ":", device_ordinal(), "), on-host shape=" + ShapeUtil::HumanStringWithLayout(on_host_shape()), ", on-device shape=" + @@ -92,9 +91,9 @@ string ShapedBuffer::ToString() const { shape_str = ShapeUtil::HumanStringWithLayout(subshape); } const se::DeviceMemoryBase& memory = buffer(index); - Appendf(&s, " %s%p (%lld bytes) : %s\n", - string(index.size() * 2, ' ').c_str(), memory.opaque(), - memory.size(), shape_str.c_str()); + absl::StrAppendFormat(&s, " %s%p (%d bytes) : %s\n", + string(index.size() * 2, ' '), memory.opaque(), + memory.size(), shape_str); }); return s; } diff --git a/tensorflow/compiler/xla/service/shaped_buffer_test.cc b/tensorflow/compiler/xla/service/shaped_buffer_test.cc index 0fc2436679..d69e6362e9 100644 --- a/tensorflow/compiler/xla/service/shaped_buffer_test.cc +++ b/tensorflow/compiler/xla/service/shaped_buffer_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/shaped_buffer.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/device_memory_allocator.h" #include "tensorflow/compiler/xla/service/platform_util.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -34,7 +35,7 @@ TEST(ShapedBufferTest, ScopedShapeBufferAsShapedBufferB71629047) { xla::StreamExecutorMemoryAllocator allocator(platform, executors); const xla::Shape shape = xla::ShapeUtil::MakeShape(xla::F32, {}); const int kDeviceOrdinal = 0; - auto scoped_buffer = tensorflow::MakeUnique<xla::ScopedShapedBuffer>( + auto scoped_buffer = absl::make_unique<xla::ScopedShapedBuffer>( shape, shape, &allocator, kDeviceOrdinal); std::unique_ptr<xla::ShapedBuffer> buffer = std::move(scoped_buffer); buffer = nullptr; diff --git a/tensorflow/compiler/xla/service/source_map_util.cc b/tensorflow/compiler/xla/service/source_map_util.cc index 8cbaac7b37..dd53c7531b 100644 --- a/tensorflow/compiler/xla/service/source_map_util.cc +++ b/tensorflow/compiler/xla/service/source_map_util.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/source_map_util.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/util.h" namespace xla { @@ -26,11 +27,10 @@ Status InvalidParameterArgumentV(const OpMetadata& op_metadata, string message; tensorflow::strings::Appendv(&message, format, args); if (!op_metadata.source_file().empty()) { - tensorflow::strings::Appendf(&message, " (%s:%d)", - op_metadata.source_file().c_str(), - op_metadata.source_line()); + absl::StrAppendFormat(&message, " (%s:%d)", op_metadata.source_file(), + op_metadata.source_line()); } - return InvalidArgument("%s", message.c_str()); + return InvalidArgument("%s", message); } } // namespace diff --git a/tensorflow/compiler/xla/service/source_map_util.h b/tensorflow/compiler/xla/service/source_map_util.h index 18e2651abb..c5a7e17cb4 100644 --- a/tensorflow/compiler/xla/service/source_map_util.h +++ b/tensorflow/compiler/xla/service/source_map_util.h @@ -13,9 +13,10 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_XLA_SOURCE_MAP_UTIL_H_ -#define TENSORFLOW_COMPILER_XLA_SOURCE_MAP_UTIL_H_ +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_SOURCE_MAP_UTIL_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_SOURCE_MAP_UTIL_H_ +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/service/executable.h" #include "tensorflow/compiler/xla/status.h" #include "tensorflow/core/platform/macros.h" @@ -24,23 +25,40 @@ namespace xla { namespace source_map_util { // Creates an INVALID_ARGUMENT status with the given format string. +template <typename... Args> +Status InvalidParameterArgument(const OpMetadata& op_metadata, + const absl::FormatSpec<Args...>& format, + const Args&... args) { + string message = absl::StrFormat(format, args...); + if (!op_metadata.source_file().empty()) { + absl::StrAppendFormat(&message, " (%s:%d)", op_metadata.source_file(), + op_metadata.source_line()); + } + return InvalidArgument("%s", message); +} + +// Creates an INVALID_ARGUMENT status with the given format string. // // Also, attempts to extract the OpMetadata for parameter_number on executable // and append it to the status message for source mapping to user code. // // executable may be nullptr, but parameter_number should not be out of bounds // or a CHECK-failure may occur. +template <typename... Args> Status InvalidParameterArgument(Executable* executable, int parameter_number, - const char* format, ...) - TF_PRINTF_ATTRIBUTE(3, 4); - -// As above, but takes the parameter metadata directly instead of extracting it -// from the executable. -Status InvalidParameterArgument(const OpMetadata& op_metadata, - const char* format, ...) - TF_PRINTF_ATTRIBUTE(2, 3); + const absl::FormatSpec<Args...>& format, + const Args&... args) { + if (executable != nullptr && executable->has_module()) { + const HloModule& module = executable->module(); + const HloComputation& computation = *module.entry_computation(); + HloInstruction* param = computation.parameter_instruction(parameter_number); + const OpMetadata& metadata = param->metadata(); + return InvalidParameterArgument(metadata, format, args...); + } + return InvalidArgument(format, args...); +} } // namespace source_map_util } // namespace xla -#endif // TENSORFLOW_COMPILER_XLA_SOURCE_MAP_UTIL_H_ +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_SOURCE_MAP_UTIL_H_ diff --git a/tensorflow/compiler/xla/service/stream_pool.cc b/tensorflow/compiler/xla/service/stream_pool.cc index c0582c6a2d..5d1cd1c442 100644 --- a/tensorflow/compiler/xla/service/stream_pool.cc +++ b/tensorflow/compiler/xla/service/stream_pool.cc @@ -15,7 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/stream_pool.h" -#include "tensorflow/compiler/xla/ptr_util.h" +#include "absl/memory/memory.h" #include "tensorflow/core/platform/logging.h" namespace xla { @@ -35,7 +35,7 @@ StreamPool::Ptr StreamPool::BorrowStream(se::StreamExecutor* executor) { if (!stream) { // Create a new stream. - stream = MakeUnique<se::Stream>(executor); + stream = absl::make_unique<se::Stream>(executor); stream->Init(); VLOG(1) << stream->DebugStreamPointers() << " StreamPool created new stream"; diff --git a/tensorflow/compiler/xla/service/transfer_manager.cc b/tensorflow/compiler/xla/service/transfer_manager.cc index 32d368a904..b8d2d546e5 100644 --- a/tensorflow/compiler/xla/service/transfer_manager.cc +++ b/tensorflow/compiler/xla/service/transfer_manager.cc @@ -18,6 +18,8 @@ limitations under the License. #include <string> #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" @@ -27,7 +29,7 @@ limitations under the License. #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/notification.h" -using ::tensorflow::strings::StrCat; +using absl::StrCat; namespace xla { /* static */ tensorflow::mutex @@ -61,7 +63,7 @@ StatusOr<std::unique_ptr<Literal>> TransferManager::TransferLiteralFromDevice( if (!s.ok()) { return s; } - return MakeUnique<Literal>(std::move(literal)); + return absl::make_unique<Literal>(std::move(literal)); } Status TransferManager::TransferLiteralFromDevice( @@ -120,7 +122,7 @@ StatusOr<std::unique_ptr<Literal>> TransferManager::TransferArrayFromDevice( if (!s.ok()) { return s; } - return MakeUnique<Literal>(std::move(literal)); + return absl::make_unique<Literal>(std::move(literal)); } Status TransferManager::TransferArrayToDevice( @@ -147,7 +149,7 @@ Status TransferManager::TransferArrayToDeviceAsync( if (dest.size() < GetByteSizeRequirement(on_device_shape)) { return FailedPrecondition( "Allocation on device not large enough for array: " - "%lld < %lld", + "%d < %d", dest.size(), GetByteSizeRequirement(on_device_shape)); } ShapedBuffer shaped_buffer(/*on_host_shape=*/literal.shape(), on_device_shape, @@ -164,12 +166,12 @@ void TransferManager::TransferArrayFromDevice( auto error = StrCat("Shape ", ShapeUtil::HumanString(shape), " has a differently shaped representation on-device: ", ShapeUtil::HumanString(HostShapeToDeviceShape(shape))); - return done(FailedPrecondition("%s", error.c_str())); + return done(FailedPrecondition("%s", error)); } if (source.size() < GetByteSizeRequirement(shape)) { return done( FailedPrecondition("Allocation on device not large enough for array: " - "%lld < %lld", + "%d < %d", source.size(), GetByteSizeRequirement(shape))); } ShapedBuffer shaped_buffer(/*on_host_shape=*/shape, shape, @@ -201,7 +203,7 @@ void TransferManager::TransferArrayFromDevice( return NotFound( "could not find registered transfer manager for platform %s -- check " "target linkage", - platform->Name().c_str()); + platform->Name()); } if (it->second.manager == nullptr) { @@ -252,7 +254,7 @@ Status TransferManager::TransferBufferFromDevice( if (source.size() < size) { return FailedPrecondition( "Source allocation on device not large enough for data tranfer: " - "%lld < %lld", + "%d < %d", source.size(), size); } stream->ThenMemcpy(destination, source, size); @@ -265,7 +267,7 @@ Status TransferManager::TransferBufferToDevice( if (destination->size() < size) { return FailedPrecondition( "Destination allocation on device not large enough for data tranfer: " - "%lld < %lld", + "%d < %d", destination->size(), size); } stream->ThenMemcpy(destination, source, size); @@ -276,9 +278,8 @@ StatusOr<ScopedShapedBuffer> TransferManager::AllocateScopedShapedBuffer( const Shape& on_host_shape, DeviceMemoryAllocator* allocator, int device_ordinal) { if (!LayoutUtil::HasLayout(on_host_shape)) { - return InvalidArgument( - "Shape must have a layout: %s", - ShapeUtil::HumanStringWithLayout(on_host_shape).c_str()); + return InvalidArgument("Shape must have a layout: %s", + ShapeUtil::HumanStringWithLayout(on_host_shape)); } TF_RETURN_IF_ERROR(ShapeUtil::ValidateShape(on_host_shape)); const Shape on_device_shape = HostShapeToDeviceShape(on_host_shape); diff --git a/tensorflow/compiler/xla/service/transfer_manager.h b/tensorflow/compiler/xla/service/transfer_manager.h index 475a2e5c14..f77690a462 100644 --- a/tensorflow/compiler/xla/service/transfer_manager.h +++ b/tensorflow/compiler/xla/service/transfer_manager.h @@ -152,6 +152,26 @@ class TransferManager { const Shape& on_host_shape, DeviceMemoryAllocator* allocator, int device_ordinal); + // The given ShapedBuffer holds a handle to allocated memory, but it is not + // in the general case legal to immediately copy or access that allocated + // memory because queued operations on the device may alias that memory. + // Memory ordering is enforced by the Stream's happens-before relationship + // which allows eager deallocation and reallocation of buffers host-side even + // if the device hasn't finished with them. + // + // In certain cases, it can be known that a ShapedBuffer does not have any + // conflicting accesses on the device and thus is eligible to be accessed at + // any time from the host. + // + // This function returns true if device_buffer can be accessed immediately + // without waiting for the Stream's previously enqueued items. This only + // returns true if all subbuffers in device_buffer can be accessed + // immediately. + virtual bool CanShapedBufferBeAccessedNow( + se::StreamExecutor* executor, const ShapedBuffer& device_buffer) const { + return false; + } + ///// // The TransferManager class also serves as a point to register objects for // the various platforms. diff --git a/tensorflow/compiler/xla/service/transpose_folding.cc b/tensorflow/compiler/xla/service/transpose_folding.cc index 49e1f87319..530f40e4b2 100644 --- a/tensorflow/compiler/xla/service/transpose_folding.cc +++ b/tensorflow/compiler/xla/service/transpose_folding.cc @@ -109,6 +109,7 @@ Status FoldTransposeIntoDot(InstructionOperandsPair pair) { std::unique_ptr<HloInstruction> new_dot = HloInstruction::CreateDot( dot->shape(), new_lhs, new_rhs, new_dim_numbers); + new_dot->set_precision_config(dot->precision_config()); return dot->parent()->ReplaceWithNewInstruction(dot, std::move(new_dot)); } @@ -178,6 +179,7 @@ bool FoldTransposeIntoConvolution(InstructionOperandsPair pair) { auto new_conv = HloInstruction::CreateConvolve( convolution.shape(), new_lhs, new_rhs, convolution.window(), new_dnums); + new_conv->set_precision_config(convolution.precision_config()); TF_CHECK_OK(convolution.parent()->ReplaceWithNewInstruction( &convolution, std::move(new_conv))); diff --git a/tensorflow/compiler/xla/service/transpose_folding.h b/tensorflow/compiler/xla/service/transpose_folding.h index 71e8446452..3e5aa2db60 100644 --- a/tensorflow/compiler/xla/service/transpose_folding.h +++ b/tensorflow/compiler/xla/service/transpose_folding.h @@ -49,7 +49,7 @@ class TransposeFolding : public HloPassInterface { explicit TransposeFolding( TransposableGemmOperandsFn transposable_gemm_operands, TransposableConvOperandsFn transposable_conv_operands); - tensorflow::StringPiece name() const override { return "transpose-folding"; } + absl::string_view name() const override { return "transpose-folding"; } StatusOr<bool> Run(HloModule* module) override; diff --git a/tensorflow/compiler/xla/service/tuple_points_to_analysis.cc b/tensorflow/compiler/xla/service/tuple_points_to_analysis.cc index 0447807a41..cf00ca102b 100644 --- a/tensorflow/compiler/xla/service/tuple_points_to_analysis.cc +++ b/tensorflow/compiler/xla/service/tuple_points_to_analysis.cc @@ -19,6 +19,10 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/map_util.h" #include "tensorflow/compiler/xla/service/hlo_dataflow_analysis.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" @@ -26,17 +30,13 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" namespace xla { string BufferAlias::ToString() const { - return tensorflow::strings::StrCat("BufferAlias(", instruction_->name(), "[", - tensorflow::str_util::Join(index_, ","), - "])"); + return absl::StrCat("BufferAlias(", instruction_->name(), "[", + absl::StrJoin(index_, ","), "])"); } std::ostream& operator<<(std::ostream& out, const BufferAlias& buffer_alias) { @@ -441,7 +441,7 @@ PointsToSet& TuplePointsToAnalysis::CreateEmptyPointsToSet( PerInstruction* pi = PerInst(instruction); CHECK(pi->points_to_set == nullptr) << "instruction should not have been present in the map."; - auto set = MakeUnique<PointsToSet>(&instruction->shape()); + auto set = absl::make_unique<PointsToSet>(&instruction->shape()); pi->points_to_set = std::move(set); // Return *set using the iterator returned by emplace. return *pi->points_to_set; @@ -462,21 +462,20 @@ Status TuplePointsToAnalysis::VerifyBuffer(const LogicalBuffer& buffer) const { return FailedPrecondition( "LogicalBuffer %s is ill-defined: instruction %s does not define a " "buffer at that index", - buffer.ToString().c_str(), buffer.instruction()->name().c_str()); + buffer.ToString(), buffer.instruction()->name()); } } if (buffer.id() < 0 || buffer.id() >= logical_buffer_analysis_->num_logical_buffers()) { - return FailedPrecondition( - "LogicalBuffer %s is ill-defined: invalid id %lld", - buffer.ToString().c_str(), buffer.id()); + return FailedPrecondition("LogicalBuffer %s is ill-defined: invalid id %d", + buffer.ToString(), buffer.id()); } if (GetBuffer(buffer.id()).instruction() != buffer.instruction() || GetBuffer(buffer.id()).index() != buffer.index()) { return FailedPrecondition( "LogicalBuffer %s is ill-defined: buffer with same id differs: %s", - buffer.ToString().c_str(), GetBuffer(buffer.id()).ToString().c_str()); + buffer.ToString(), GetBuffer(buffer.id()).ToString()); } return Status::OK(); @@ -495,8 +494,7 @@ StatusOr<const LogicalBuffer*> TuplePointsToAnalysis::GetBufferDefinedAt( if (buffers.size() != 1 || buffers[0]->instruction() != instruction) { return FailedPrecondition( "instruction %s does not define buffer at index {%s}", - instruction->name().c_str(), - tensorflow::str_util::Join(index, ",").c_str()); + instruction->name(), absl::StrJoin(index, ",")); } return buffers[0]; } @@ -557,13 +555,12 @@ PointsToSet& TuplePointsToAnalysis::CreateCopiedPointsToSet( } string TuplePointsToAnalysis::ToString() const { - string output = tensorflow::strings::Printf( - "TuplePointsToSet for module %s:\n", module_->name().c_str()); + string output = + absl::StrFormat("TuplePointsToSet for module %s:\n", module_->name()); for (const auto* computation : module_->MakeNonfusionComputations()) { const char* entry = computation == module_->entry_computation() ? "entry " : ""; - tensorflow::strings::StrAppend(&output, entry, "computation ", - computation->name(), ":\n"); + absl::StrAppend(&output, entry, "computation ", computation->name(), ":\n"); for (const HloInstruction* instruction : computation->MakeInstructionPostOrder()) { InstructionToString(instruction, &output); @@ -575,12 +572,11 @@ string TuplePointsToAnalysis::ToString() const { } } - tensorflow::strings::StrAppend(&output, "LogicalBuffers:\n"); + absl::StrAppend(&output, "LogicalBuffers:\n"); for (const auto& b : logical_buffer_analysis_->logical_buffers()) { - tensorflow::strings::StrAppend(&output, " buffer ", b->ToString(), ":\n"); + absl::StrAppend(&output, " buffer ", b->ToString(), ":\n"); for (const BufferAlias& alias : logical_buffer_aliases_.at(b->id())) { - tensorflow::strings::StrAppend(&output, " alias ", alias.ToString(), - "\n"); + absl::StrAppend(&output, " alias ", alias.ToString(), "\n"); } } return output; @@ -589,20 +585,18 @@ string TuplePointsToAnalysis::ToString() const { void TuplePointsToAnalysis::InstructionToString( const HloInstruction* instruction, string* output) const { const string prefix = instruction->IsFused() ? " " : ""; - tensorflow::strings::StrAppend(output, prefix, " instruction ", - instruction->ToShortString(), ":\n"); + absl::StrAppend(output, prefix, " instruction ", + instruction->ToShortString(), ":\n"); const PointsToSet& points_to_set = GetPointsToSet(instruction); points_to_set.ForEachElement([&prefix, &output]( const ShapeIndex& index, const PointsToSet::BufferList& points_to) { - tensorflow::strings::StrAppend( - output, prefix, " {", tensorflow::str_util::Join(index, ","), "}: ", - tensorflow::str_util::Join( - points_to, ", ", - [](string* out, const LogicalBuffer* source) { - out->append(source->ToString()); - }), - "\n"); + absl::StrAppend(output, prefix, " {", absl::StrJoin(index, ","), "}: ", + absl::StrJoin(points_to, ", ", + [](string* out, const LogicalBuffer* source) { + out->append(source->ToString()); + }), + "\n"); }); } diff --git a/tensorflow/compiler/xla/service/tuple_points_to_analysis.h b/tensorflow/compiler/xla/service/tuple_points_to_analysis.h index 686bb05328..62c7bb685d 100644 --- a/tensorflow/compiler/xla/service/tuple_points_to_analysis.h +++ b/tensorflow/compiler/xla/service/tuple_points_to_analysis.h @@ -23,6 +23,7 @@ limitations under the License. #include <string> #include <vector> +#include "absl/container/inlined_vector.h" #include "tensorflow/compiler/xla/service/dfs_hlo_visitor_with_default.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" @@ -109,7 +110,7 @@ class PointsToSet { // Add a tuple source instruction for the given index. void add_tuple_source(const ShapeIndex& index, HloInstruction* tuple); - using BufferList = tensorflow::gtl::InlinedVector<const LogicalBuffer*, 1>; + using BufferList = absl::InlinedVector<const LogicalBuffer*, 1>; // Return the list of logical buffers for the subshape at index. const BufferList& element(const ShapeIndex& index) const { @@ -203,7 +204,7 @@ class TuplePointsToAnalysis : public DfsHloVisitorWithDefault { // logical buffer The buffer alias set is the inverse of the points-to set. // That is, LogicalBuffer B is in the points-to set of instruction I at index // N iff instruction I, index N is a BufferAlias of B. - using BufferAliasVector = tensorflow::gtl::InlinedVector<BufferAlias, 1>; + using BufferAliasVector = absl::InlinedVector<BufferAlias, 1>; const BufferAliasVector& GetBufferAliases(const LogicalBuffer& buffer) const; // Returns the number of logical buffers in the module @@ -226,8 +227,7 @@ class TuplePointsToAnalysis : public DfsHloVisitorWithDefault { // instructions produce a single buffer (the top-level buffer), some produce // no buffers (eg bitcast), and some produce more than one buffer (eg, // tuple-shaped parameters). - using BufferDefinitionVector = - tensorflow::gtl::InlinedVector<const LogicalBuffer*, 1>; + using BufferDefinitionVector = absl::InlinedVector<const LogicalBuffer*, 1>; const BufferDefinitionVector& GetBuffersDefinedByInstruction( const HloInstruction* instruction) const; diff --git a/tensorflow/compiler/xla/service/tuple_simplifier.h b/tensorflow/compiler/xla/service/tuple_simplifier.h index 7509501883..8c91d6e69d 100644 --- a/tensorflow/compiler/xla/service/tuple_simplifier.h +++ b/tensorflow/compiler/xla/service/tuple_simplifier.h @@ -30,7 +30,7 @@ class TupleSimplifier : public HloPassInterface { TupleSimplifier() : TupleSimplifier(/*exclude_entry_computation=*/false) {} explicit TupleSimplifier(bool exclude_entry_computation); ~TupleSimplifier() override {} - tensorflow::StringPiece name() const override { return "tuple-simplifier"; } + absl::string_view name() const override { return "tuple-simplifier"; } // Run tuple simplification on the given computation. Returns whether the // computation was changed. diff --git a/tensorflow/compiler/xla/service/while_loop_analysis.cc b/tensorflow/compiler/xla/service/while_loop_analysis.cc index af2cb6dc2a..7e4ac92a7c 100644 --- a/tensorflow/compiler/xla/service/while_loop_analysis.cc +++ b/tensorflow/compiler/xla/service/while_loop_analysis.cc @@ -18,8 +18,8 @@ limitations under the License. namespace xla { -using tensorflow::gtl::nullopt; -using tensorflow::gtl::optional; +using absl::nullopt; +using absl::optional; // Finds and returns the non-constant operand in instr. // diff --git a/tensorflow/compiler/xla/service/while_loop_analysis.h b/tensorflow/compiler/xla/service/while_loop_analysis.h index bf59813e8c..bf497f4892 100644 --- a/tensorflow/compiler/xla/service/while_loop_analysis.h +++ b/tensorflow/compiler/xla/service/while_loop_analysis.h @@ -16,8 +16,8 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_WHILE_LOOP_ANALYSIS_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_WHILE_LOOP_ANALYSIS_H_ +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" -#include "tensorflow/core/lib/gtl/optional.h" namespace xla { @@ -25,8 +25,8 @@ namespace xla { // nullopt otherwise. max_value_returned limits the number of steps that are // evaluated while trying to brute force a loop trip count, trip counts larger // than max_value_returned result in nullopt. -tensorflow::gtl::optional<int64> ComputeWhileLoopTripCount( - HloInstruction *while_op, int64 max_value_returned = 128); +absl::optional<int64> ComputeWhileLoopTripCount(HloInstruction *while_op, + int64 max_value_returned = 128); } // namespace xla diff --git a/tensorflow/compiler/xla/service/while_loop_constant_sinking.cc b/tensorflow/compiler/xla/service/while_loop_constant_sinking.cc index 62af45128a..aab1180662 100644 --- a/tensorflow/compiler/xla/service/while_loop_constant_sinking.cc +++ b/tensorflow/compiler/xla/service/while_loop_constant_sinking.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/while_loop_constant_sinking.h" +#include "absl/algorithm/container.h" #include "tensorflow/compiler/xla/service/while_util.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/flatmap.h" @@ -32,7 +33,7 @@ static Status ReplaceUsesWhileKeepingLoopInvariance( std::vector<HloInstruction*> users; users.reserve(old_instr->user_count()); - c_copy(old_instr->users(), std::back_inserter(users)); + absl::c_copy(old_instr->users(), std::back_inserter(users)); for (auto* user : users) { for (int64 i = 0, e = user->operand_count(); i < e; i++) { @@ -108,10 +109,10 @@ StatusOr<bool> WhileLoopConstantSinking::Run(HloModule* module) { // // This will let us sink the constant into the outer while first and then // into the inner while in a single run of this pass. - c_copy_if(comp->instructions(), std::back_inserter(while_instrs), - [](const HloInstruction* instr) { - return instr->opcode() == HloOpcode::kWhile; - }); + absl::c_copy_if(comp->instructions(), std::back_inserter(while_instrs), + [](const HloInstruction* instr) { + return instr->opcode() == HloOpcode::kWhile; + }); } for (HloInstruction* while_instr : while_instrs) { diff --git a/tensorflow/compiler/xla/service/while_loop_constant_sinking.h b/tensorflow/compiler/xla/service/while_loop_constant_sinking.h index 21fb8568a8..2dba7d7f75 100644 --- a/tensorflow/compiler/xla/service/while_loop_constant_sinking.h +++ b/tensorflow/compiler/xla/service/while_loop_constant_sinking.h @@ -54,7 +54,7 @@ class WhileLoopConstantSinking : public HloPassInterface { public: ~WhileLoopConstantSinking() override = default; - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "while-loop-invariant-code-motion"; } diff --git a/tensorflow/compiler/xla/service/while_loop_invariant_code_motion.cc b/tensorflow/compiler/xla/service/while_loop_invariant_code_motion.cc index 09ddcffb22..f4098f28b3 100644 --- a/tensorflow/compiler/xla/service/while_loop_invariant_code_motion.cc +++ b/tensorflow/compiler/xla/service/while_loop_invariant_code_motion.cc @@ -14,18 +14,19 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/while_loop_invariant_code_motion.h" +#include "absl/algorithm/container.h" +#include "absl/container/inlined_vector.h" #include "tensorflow/compiler/xla/service/tuple_util.h" #include "tensorflow/compiler/xla/service/while_util.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/flatmap.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/gtl/inlined_vector.h" namespace xla { +using absl::InlinedVector; using tensorflow::gtl::FlatMap; using tensorflow::gtl::FlatSet; -using tensorflow::gtl::InlinedVector; // Copies `to_hoist` to the computation containing `while_instr`, hoisting its // operands as needed. All of its transitive operands are expected to be either @@ -65,8 +66,8 @@ static void CreateLoopInvariantCopy( }; InlinedVector<HloInstruction*, 4> new_operands; - c_transform(old_instruction->operands(), std::back_inserter(new_operands), - get_new_operand); + absl::c_transform(old_instruction->operands(), + std::back_inserter(new_operands), get_new_operand); HloInstruction* new_instruction = parent_of_while->AddInstruction(old_instruction->CloneWithNewOperands( @@ -197,7 +198,7 @@ WhileLoopInvariantCodeMotion::TryHoistingInvariantInstructionsFromWhileBody( op->opcode() == HloOpcode::kConstant; }; - if (!c_all_of(instruction->operands(), is_invariant)) { + if (!absl::c_all_of(instruction->operands(), is_invariant)) { continue; } @@ -257,10 +258,10 @@ StatusOr<bool> WhileLoopInvariantCodeMotion::Run(HloModule* module) { bool changed = false; std::vector<HloInstruction*> while_instrs; for (auto* comp : module->computations()) { - c_copy_if(comp->instructions(), std::back_inserter(while_instrs), - [](const HloInstruction* instr) { - return instr->opcode() == HloOpcode::kWhile; - }); + absl::c_copy_if(comp->instructions(), std::back_inserter(while_instrs), + [](const HloInstruction* instr) { + return instr->opcode() == HloOpcode::kWhile; + }); } for (HloInstruction* while_instr : while_instrs) { diff --git a/tensorflow/compiler/xla/service/while_loop_invariant_code_motion.h b/tensorflow/compiler/xla/service/while_loop_invariant_code_motion.h index 8e6cc87875..2cdf20ce80 100644 --- a/tensorflow/compiler/xla/service/while_loop_invariant_code_motion.h +++ b/tensorflow/compiler/xla/service/while_loop_invariant_code_motion.h @@ -38,7 +38,7 @@ class WhileLoopInvariantCodeMotion : public HloPassInterface { : hoist_constants_(hoist_constants) {} ~WhileLoopInvariantCodeMotion() override = default; - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "while-loop-invariant-code-motion"; } StatusOr<bool> Run(HloModule* module) override; diff --git a/tensorflow/compiler/xla/service/while_loop_invariant_code_motion_test.cc b/tensorflow/compiler/xla/service/while_loop_invariant_code_motion_test.cc index 32e69c335b..e14014b961 100644 --- a/tensorflow/compiler/xla/service/while_loop_invariant_code_motion_test.cc +++ b/tensorflow/compiler/xla/service/while_loop_invariant_code_motion_test.cc @@ -28,6 +28,10 @@ namespace op = xla::testing::opcode_matchers; class WhileLoopInvariantCodeMotionTest : public HloVerifiedTestBase { public: + WhileLoopInvariantCodeMotionTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} + // Makes a computation which has one parameter, of the given shape, and always // returns PRED[]{true}. This is useful as a dummy loop condition. HloComputation* MakeAlwaysTrueComputation(const Shape& param_shape, diff --git a/tensorflow/compiler/xla/service/while_loop_simplifier.cc b/tensorflow/compiler/xla/service/while_loop_simplifier.cc index dd8697e680..6a7bfe3f12 100644 --- a/tensorflow/compiler/xla/service/while_loop_simplifier.cc +++ b/tensorflow/compiler/xla/service/while_loop_simplifier.cc @@ -14,17 +14,16 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/while_loop_simplifier.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/call_inliner.h" #include "tensorflow/compiler/xla/service/while_loop_analysis.h" #include "tensorflow/core/lib/gtl/flatmap.h" -#include "tensorflow/core/lib/gtl/optional.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { -using tensorflow::gtl::nullopt; -using tensorflow::gtl::optional; +using absl::optional; // Determines whether the given instruction is a send/recv node, or has a // subcomputation which contains a send/recv node. @@ -237,12 +236,11 @@ static StatusOr<bool> TryRemoveDeadWhileParams(HloInstruction* while_op) { << "Instruction " << user->ToString(print_no_metadata) << " should be unused (except by root of while body), but has " "users: {" - << tensorflow::str_util::Join( - user->users(), ", ", - [&](string* out, const HloInstruction* instr) { - tensorflow::strings::StrAppend( - out, instr->ToString(print_no_metadata)); - }) + << absl::StrJoin(user->users(), ", ", + [&](string* out, const HloInstruction* instr) { + absl::StrAppend( + out, instr->ToString(print_no_metadata)); + }) << "}"; replacements.emplace(user, nullptr); diff --git a/tensorflow/compiler/xla/service/while_loop_simplifier.h b/tensorflow/compiler/xla/service/while_loop_simplifier.h index 3d3e1d60f2..78024f14dc 100644 --- a/tensorflow/compiler/xla/service/while_loop_simplifier.h +++ b/tensorflow/compiler/xla/service/while_loop_simplifier.h @@ -33,9 +33,7 @@ namespace xla { class WhileLoopSimplifier : public HloPassInterface { public: ~WhileLoopSimplifier() override {} - tensorflow::StringPiece name() const override { - return "simplify-while-loops"; - } + absl::string_view name() const override { return "simplify-while-loops"; } StatusOr<bool> Run(HloModule* module) override; }; diff --git a/tensorflow/compiler/xla/service/while_loop_simplifier_test.cc b/tensorflow/compiler/xla/service/while_loop_simplifier_test.cc index 2e1571943e..cfe4104f6d 100644 --- a/tensorflow/compiler/xla/service/while_loop_simplifier_test.cc +++ b/tensorflow/compiler/xla/service/while_loop_simplifier_test.cc @@ -15,11 +15,12 @@ limitations under the License. #include "tensorflow/compiler/xla/service/while_loop_simplifier.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_replace.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/tests/hlo_verified_test_base.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" namespace xla { namespace { @@ -27,6 +28,11 @@ namespace { namespace op = xla::testing::opcode_matchers; class WhileLoopSimplifierTest : public HloVerifiedTestBase { + public: + WhileLoopSimplifierTest() + : HloVerifiedTestBase(/*layout_sensitive=*/false, + /*allow_mixed_precision=*/false) {} + protected: // Makes an HloModule that contains a loop with `num_iters` iteration. void MakeModuleWithSimpleLoop(int num_iters); @@ -64,10 +70,8 @@ void WhileLoopSimplifierTest::MakeModuleWithSimpleLoop(int num_iters) { } )"; - string hlo_string = tensorflow::str_util::StringReplace( - hlo_string_template, "{{LOOP_BOUND}}", - tensorflow::strings::StrCat(42 + num_iters), - /*replace_all=*/true); + string hlo_string = absl::StrReplaceAll( + hlo_string_template, {{"{{LOOP_BOUND}}", absl::StrCat(42 + num_iters)}}); ParseAndVerifyModule(hlo_string); } @@ -103,10 +107,8 @@ void WhileLoopSimplifierTest::MakeModuleWithSimpleLoopTupleElementLoopBound( } )"; - string hlo_string = tensorflow::str_util::StringReplace( - hlo_string_template, "{{LOOP_BOUND}}", - tensorflow::strings::StrCat(42 + num_iters), - /*replace_all=*/true); + string hlo_string = absl::StrReplaceAll( + hlo_string_template, {{"{{LOOP_BOUND}}", absl::StrCat(42 + num_iters)}}); ParseAndVerifyModule(hlo_string); } diff --git a/tensorflow/compiler/xla/service/while_util.cc b/tensorflow/compiler/xla/service/while_util.cc index 1ef17b9d7d..e8f76ff745 100644 --- a/tensorflow/compiler/xla/service/while_util.cc +++ b/tensorflow/compiler/xla/service/while_util.cc @@ -14,15 +14,16 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/while_util.h" +#include "absl/algorithm/container.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_creation_utils.h" #include "tensorflow/compiler/xla/service/tuple_util.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { -using tensorflow::strings::StrCat; +using absl::StrCat; static StatusOr<HloComputation*> WidenWhileCondition( HloComputation* narrow_condition, const Shape& wide_shape) { @@ -206,7 +207,7 @@ static StatusOr<HloInstruction*> MakeInitTupleFromInitValues( HloInstruction* zero = computation->AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<int32>(0))); init_values_with_indvar.push_back(zero); - c_copy(init_values, std::back_inserter(init_values_with_indvar)); + absl::c_copy(init_values, std::back_inserter(init_values_with_indvar)); return computation->AddInstruction( HloInstruction::CreateTuple(init_values_with_indvar)); } @@ -215,8 +216,9 @@ static Shape MakeLoopStateShape(const WhileUtil::LoopStateTy& init_values) { std::vector<Shape> loop_state_shape_components; loop_state_shape_components.reserve(init_values.size() + 1); loop_state_shape_components.push_back(ShapeUtil::MakeShape(S32, {})); - c_transform(init_values, std::back_inserter(loop_state_shape_components), - [](HloInstruction* instr) { return instr->shape(); }); + absl::c_transform(init_values, + std::back_inserter(loop_state_shape_components), + [](HloInstruction* instr) { return instr->shape(); }); return ShapeUtil::MakeTupleShape(loop_state_shape_components); } diff --git a/tensorflow/compiler/xla/service/while_util_test.cc b/tensorflow/compiler/xla/service/while_util_test.cc index 2ccb919acf..5e69419333 100644 --- a/tensorflow/compiler/xla/service/while_util_test.cc +++ b/tensorflow/compiler/xla/service/while_util_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/while_util.h" +#include "absl/algorithm/container.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/test.h" @@ -206,7 +207,7 @@ ENTRY main { auto is_while = [](const HloInstruction* instr) { return instr->opcode() == HloOpcode::kWhile; }; - EXPECT_EQ(c_count_if(main->instructions(), is_while), 1); + EXPECT_EQ(absl::c_count_if(main->instructions(), is_while), 1); } } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/zero_sized_hlo_elimination.h b/tensorflow/compiler/xla/service/zero_sized_hlo_elimination.h index 8763e588c4..a7f0e207eb 100644 --- a/tensorflow/compiler/xla/service/zero_sized_hlo_elimination.h +++ b/tensorflow/compiler/xla/service/zero_sized_hlo_elimination.h @@ -24,7 +24,7 @@ namespace xla { class ZeroSizedHloElimination : public HloPassInterface { public: StatusOr<bool> Run(HloModule* module) override; - tensorflow::StringPiece name() const override { + absl::string_view name() const override { return "zero_sized_hlo_elimination"; } }; diff --git a/tensorflow/compiler/xla/shape_layout.cc b/tensorflow/compiler/xla/shape_layout.cc index caad31d6ce..d44db89d57 100644 --- a/tensorflow/compiler/xla/shape_layout.cc +++ b/tensorflow/compiler/xla/shape_layout.cc @@ -25,8 +25,8 @@ namespace xla { Status ShapeLayout::CopyLayoutFromShape(const Shape& other_shape) { if (!ShapeUtil::Compatible(other_shape, shape_)) { return InvalidArgument("Shape %s is not compatible with shape %s", - ShapeUtil::HumanString(other_shape).c_str(), - ShapeUtil::HumanString(shape()).c_str()); + ShapeUtil::HumanString(other_shape), + ShapeUtil::HumanString(shape())); } shape_ = other_shape; return Status::OK(); @@ -35,8 +35,8 @@ Status ShapeLayout::CopyLayoutFromShape(const Shape& other_shape) { Status ShapeLayout::AssignLayoutToShape(Shape* to_shape) const { if (!ShapeUtil::Compatible(*to_shape, shape_)) { return InvalidArgument("Shape %s is not compatible with shape %s", - ShapeUtil::HumanString(*to_shape).c_str(), - ShapeUtil::HumanString(shape()).c_str()); + ShapeUtil::HumanString(*to_shape), + ShapeUtil::HumanString(shape())); } *to_shape = shape_; return Status::OK(); diff --git a/tensorflow/compiler/xla/shape_tree.h b/tensorflow/compiler/xla/shape_tree.h index c74dd648ad..c793a39c27 100644 --- a/tensorflow/compiler/xla/shape_tree.h +++ b/tensorflow/compiler/xla/shape_tree.h @@ -21,8 +21,9 @@ limitations under the License. #include <memory> #include <vector> +#include "absl/memory/memory.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/layout_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/xla_data.pb.h" @@ -30,7 +31,6 @@ limitations under the License. #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/lib/gtl/iterator_range.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" diff --git a/tensorflow/compiler/xla/shape_tree_test.cc b/tensorflow/compiler/xla/shape_tree_test.cc index c4c958be4a..c8ff55e784 100644 --- a/tensorflow/compiler/xla/shape_tree_test.cc +++ b/tensorflow/compiler/xla/shape_tree_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/shape_tree.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/xla_data.pb.h" @@ -242,7 +243,7 @@ TEST_F(ShapeTreeTest, InvalidIndexingNestedTuple) { TEST_F(ShapeTreeTest, ShapeTreeOfNonCopyableType) { ShapeTree<std::unique_ptr<int>> shape_tree{tuple_shape_}; EXPECT_EQ(shape_tree.element({2}).get(), nullptr); - *shape_tree.mutable_element({2}) = MakeUnique<int>(42); + *shape_tree.mutable_element({2}) = absl::make_unique<int>(42); EXPECT_EQ(*shape_tree.element({2}), 42); } diff --git a/tensorflow/compiler/xla/shape_util.cc b/tensorflow/compiler/xla/shape_util.cc index b69c346f1e..5477a78a9a 100644 --- a/tensorflow/compiler/xla/shape_util.cc +++ b/tensorflow/compiler/xla/shape_util.cc @@ -22,6 +22,14 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/ascii.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" +#include "absl/strings/str_split.h" +#include "absl/strings/string_view.h" +#include "absl/strings/strip.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/index_util.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/overflow_util.h" @@ -30,26 +38,22 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/iterator_range.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/lib/hash/hash.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/regexp.h" namespace xla { -using ::tensorflow::strings::StrAppend; -using ::tensorflow::strings::StrCat; +using absl::StrAppend; +using absl::StrCat; string ShapeIndex::ToString() const { return ShapeIndexView(*this).ToString(); } string ShapeIndexView::ToString() const { - return StrCat("{", tensorflow::str_util::Join(indices_, ","), "}"); + return StrCat("{", absl::StrJoin(indices_, ","), "}"); } bool ShapeIndexView::operator==(const ShapeIndexView& other) const { @@ -143,7 +147,7 @@ StatusOr<Shape> MakeShapeWithLayoutInternal( } if (element_type == OPAQUE || element_type == TUPLE) { return InvalidArgument("Unsupported element type: %s", - PrimitiveType_Name(element_type).c_str()); + PrimitiveType_Name(element_type)); } Shape shape = ShapeUtil::MakeShape(element_type, dimensions); auto min2maj = shape.mutable_layout()->mutable_minor_to_major(); @@ -449,14 +453,14 @@ ShapeUtil::MakeShapeWithDescendingLayoutAndSamePhysicalLayout( namespace { // Class to memoize the computation of -// tensorflow::str_util::Lowercase(PrimitiveType_Name(p)) +// absl::AsciiStrToLower(PrimitiveType_Name(p)) // for all PrimitiveType values "p" class PrimitiveTypeNameGenerator { public: PrimitiveTypeNameGenerator() { for (int i = 0; i < PrimitiveType_ARRAYSIZE; i++) { if (PrimitiveType_IsValid(i)) { - lowercase_name_[i] = tensorflow::str_util::Lowercase( + lowercase_name_[i] = absl::AsciiStrToLower( PrimitiveType_Name(static_cast<PrimitiveType>(i))); } } @@ -487,8 +491,7 @@ StatusOr<PrimitiveType> StringToPrimitiveType(const string& name) { }(); auto found = name_to_type->find(name); if (found == name_to_type->end()) { - return InvalidArgument("Invalid element type string: \"%s\".", - name.c_str()); + return InvalidArgument("Invalid element type string: \"%s\".", name); } return found->second; } @@ -507,7 +510,7 @@ StatusOr<PrimitiveType> StringToPrimitiveType(const string& name) { return text; } return StrCat(LowercasePrimitiveTypeName(shape.element_type()), "[", - tensorflow::str_util::Join(shape.dimensions(), ","), "]"); + absl::StrJoin(shape.dimensions(), ","), "]"); } /* static */ string ShapeUtil::HumanStringWithLayout(const Shape& shape) { @@ -543,30 +546,29 @@ StatusOr<PrimitiveType> StringToPrimitiveType(const string& name) { : "(unknown)", ": ", HumanString(shape))); } - return StrCat("(", tensorflow::str_util::Join(parameters, ", "), ") -> ", + return StrCat("(", absl::StrJoin(parameters, ", "), ") -> ", HumanString(program_shape.result())); } namespace { // Parses shapes with simple recursive descent structure -- consumes from the // front of s and passes that view recursively as required. -StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { - tensorflow::str_util::RemoveLeadingWhitespace(s); +StatusOr<Shape> ParseShapeStringInternal(absl::string_view* s) { + *s = StripLeadingAsciiWhitespace(*s); - if (tensorflow::str_util::ConsumePrefix(s, "(")) { // Tuple. + if (absl::ConsumePrefix(s, "(")) { // Tuple. std::vector<Shape> shapes; bool must_end = false; while (true) { - if (tensorflow::str_util::ConsumePrefix(s, ")")) { + if (absl::ConsumePrefix(s, ")")) { break; } else if (must_end) { - return InvalidArgument("Expected end of tuple; got: \"%s\"", - std::string(*s).c_str()); + return InvalidArgument("Expected end of tuple; got: \"%s\"", *s); } shapes.emplace_back(); TF_ASSIGN_OR_RETURN(shapes.back(), ParseShapeStringInternal(s)); - tensorflow::str_util::RemoveLeadingWhitespace(s); - must_end = !tensorflow::str_util::ConsumePrefix(s, ","); + *s = StripLeadingAsciiWhitespace(*s); + must_end = !absl::ConsumePrefix(s, ","); } return ShapeUtil::MakeTupleShape(shapes); } @@ -575,9 +577,9 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { string dimensions_string; string format_string; string layout_string; - // tensorflow::StringPiece is not compatible with internal RE2 StringPiece, so + // absl::string_view is not compatible with internal RE2 StringPiece, so // we convert in to the RE2-consumable type and then consume the corresponding - // amount from our StringPiece type. + // amount from our string_view type. static LazyRE2 shape_pattern = { "^(\\w*\\d*)\\[([\\d,]*)\\](?:\\s*(dense|sparse)?\\s*{([\\d,]+)})?"}; tensorflow::RegexpStringPiece s_consumable(s->data(), s->size()); @@ -585,12 +587,12 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { &dimensions_string, &format_string, &layout_string)) { size_t consumed = s->size() - s_consumable.size(); s->remove_prefix(consumed); - auto string_to_int64 = [&s](const string& input) -> StatusOr<int64> { + auto string_to_int64 = [&s](absl::string_view input) -> StatusOr<int64> { int64 element; - if (!tensorflow::strings::safe_strto64(input.c_str(), &element)) { + if (!absl::SimpleAtoi(input, &element)) { return InvalidArgument( - "Invalid s64 value in parsed shape string: \"%s\" in \"%s\"", - input.c_str(), std::string(*s).c_str()); + "Invalid s64 value in parsed shape string: \"%s\" in \"%s\"", input, + *s); } return element; }; @@ -598,7 +600,7 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { auto comma_list_to_int64s = [string_to_int64](const string& input) -> StatusOr<std::vector<int64>> { std::vector<int64> results; - for (const string& piece : tensorflow::str_util::Split(input, ',')) { + for (const auto& piece : absl::StrSplit(input, ',', absl::SkipEmpty())) { TF_ASSIGN_OR_RETURN(int64 element, string_to_int64(piece)); results.push_back(element); } @@ -614,7 +616,7 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { StringToPrimitiveType(element_type_string)); if (primitive_type == PRIMITIVE_TYPE_INVALID || primitive_type == TUPLE) { return InvalidArgument("Invalid element type string: \"%s\".", - element_type_string.c_str()); + element_type_string); } Shape result; @@ -644,17 +646,14 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { return std::move(result); } - return InvalidArgument("Invalid shape string to parse: \"%s\"", - std::string(*s).c_str()); + return InvalidArgument("Invalid shape string to parse: \"%s\"", *s); } } // namespace -/* static */ StatusOr<Shape> ShapeUtil::ParseShapeString( - tensorflow::StringPiece s) { +/* static */ StatusOr<Shape> ShapeUtil::ParseShapeString(absl::string_view s) { TF_ASSIGN_OR_RETURN(Shape shape, ParseShapeStringInternal(&s)); if (!s.empty()) { - return InvalidArgument("Invalid shape string to parse: \"%s\"", - std::string(s).c_str()); + return InvalidArgument("Invalid shape string to parse: \"%s\"", s); } return shape; } @@ -819,7 +818,7 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { const Shape& shape) { if (shape.element_type() == PRIMITIVE_TYPE_INVALID) { return InvalidArgument("shape has invalid element type: %s", - shape.ShortDebugString().c_str()); + shape.ShortDebugString()); } if (shape.element_type() == TUPLE) { if (shape.dimensions_size() != 0) { @@ -842,21 +841,21 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { if (shape.dimensions_size() != 0) { return InvalidArgument( "shape has %s element type, but has dimensions field: %s", - LowercasePrimitiveTypeName(shape.element_type()).c_str(), - shape.ShortDebugString().c_str()); + LowercasePrimitiveTypeName(shape.element_type()), + shape.ShortDebugString()); } if (shape.has_layout()) { return InvalidArgument( "shape has %s element type, but has layout field: %s", - LowercasePrimitiveTypeName(shape.element_type()).c_str(), - shape.ShortDebugString().c_str()); + LowercasePrimitiveTypeName(shape.element_type()), + shape.ShortDebugString()); } return Status::OK(); } if (Rank(shape) != shape.dimensions_size()) { return InvalidArgument( - "shape's rank is mismatched with dimension count; rank=%lld " + "shape's rank is mismatched with dimension count; rank=%d " "dimensions_size=%d", Rank(shape), shape.dimensions_size()); } @@ -864,9 +863,8 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { int64 dimension = shape.dimensions(i); if (dimension < 0) { return InvalidArgument( - "shape's dimensions must not be < 0; dimension at index %lld was " - "%lld", - i, dimension); + "shape's dimensions must not be < 0; dimension at index %d was %d", i, + dimension); } } @@ -931,7 +929,7 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { if (shape_size < 0) { return InvalidArgument("Shape %s size may overflow int64.", - ShapeUtil::HumanString(shape).c_str()); + ShapeUtil::HumanString(shape)); } VLOG(3) << "Shape size is valid: " << shape_size; @@ -991,7 +989,7 @@ StatusOr<Shape> ParseShapeStringInternal(tensorflow::StringPiece* s) { i >= return_shape->tuple_shapes_size()) { return InvalidArgument( "Shape index %s not a valid subshape index for tuple with shape %s", - index.ToString().c_str(), shape.DebugString().c_str()); + index.ToString(), shape.DebugString()); } return_shape = &return_shape->tuple_shapes(i); } @@ -1172,8 +1170,7 @@ Status ForEachMutableSubshapeHelper( CHECK(TransposeIsBitcast(shape, new_shape, InversePermutation(permutation))) << "shape=" << HumanStringWithLayout(shape) << ", new_shape=" << HumanStringWithLayout(new_shape) - << ", permutation={" << tensorflow::str_util::Join(permutation, ",") - << "}"; + << ", permutation={" << absl::StrJoin(permutation, ",") << "}"; } return new_shape; } @@ -1460,7 +1457,7 @@ ShapeUtil::DimensionsUnmodifiedByReshape(const Shape& input_shape, check_input_unit_indices(output_shape, input_shape); } -/* static */ tensorflow::gtl::optional<Shape> ShapeUtil::AlignLayouts( +/* static */ absl::optional<Shape> ShapeUtil::AlignLayouts( const Shape& input_shape, const Shape& output_shape) { CHECK(IsArray(input_shape)); CHECK(IsArray(output_shape)); @@ -1499,7 +1496,7 @@ ShapeUtil::DimensionsUnmodifiedByReshape(const Shape& input_shape, if (input_dimension_product < output_dimension_product || j == output_rank) { if (i == input_rank) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } dimension_to_alignment_index[i] = alignment.size() - 1; input_dimension_product *= input_shape.dimensions(i); @@ -1510,7 +1507,7 @@ ShapeUtil::DimensionsUnmodifiedByReshape(const Shape& input_shape, } } if (input_dimension_product != output_dimension_product) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } // We also need to store an end element so that we know where the last // alignment part ends. @@ -1554,7 +1551,7 @@ ShapeUtil::DimensionsUnmodifiedByReshape(const Shape& input_shape, for (int64 j = 0; j < num_non_trivial_dimensions_in_alignment_part; ++i, ++j) { if (i == input_rank) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } // Skip trivial dimensions with a bound of 1. if (input_shape.dimensions(input_dimension_numbers[i]) == 1) { @@ -1567,7 +1564,7 @@ ShapeUtil::DimensionsUnmodifiedByReshape(const Shape& input_shape, if (dimension_to_alignment_index[input_dimension_numbers[i]] != current_alignment_index || input_dimension_numbers[i] > current_dimension_number) { - return tensorflow::gtl::nullopt; + return absl::nullopt; } current_dimension_number = input_dimension_numbers[i]; } diff --git a/tensorflow/compiler/xla/shape_util.h b/tensorflow/compiler/xla/shape_util.h index d6f17fc965..83e58545bf 100644 --- a/tensorflow/compiler/xla/shape_util.h +++ b/tensorflow/compiler/xla/shape_util.h @@ -22,6 +22,8 @@ limitations under the License. #include <initializer_list> #include <string> +#include "absl/container/inlined_vector.h" +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/primitive_util.h" #include "tensorflow/compiler/xla/status_macros.h" @@ -31,8 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/threadpool.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/gtl/inlined_vector.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/cpu_info.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/macros.h" @@ -74,7 +74,7 @@ class ShapeIndex { // push_front is O(n^2), but shapes don't usually have a ton of dimensions. void push_front(int64 value) { indices_.insert(indices_.begin(), value); } - using container_type = tensorflow::gtl::InlinedVector<int64, 2>; + using container_type = absl::InlinedVector<int64, 2>; container_type::const_iterator begin() const { return indices_.begin(); } container_type::const_iterator end() const { return indices_.end(); } @@ -131,12 +131,12 @@ class ShapeIndexView { } ShapeIndexView ConsumeFront() const { ShapeIndexView result = *this; - result.indices_.pop_front(); + result.indices_.remove_prefix(1); return result; } ShapeIndexView ConsumeBack() const { ShapeIndexView result = *this; - result.indices_.pop_back(); + result.indices_.remove_suffix(1); return result; } ShapeIndex ToShapeIndex() const { return ShapeIndex(begin(), end()); } @@ -228,7 +228,7 @@ class ShapeUtil { // Parses a ShapeUtil::HumanString-format shape string back into a shape // object. - static StatusOr<Shape> ParseShapeString(tensorflow::StringPiece s); + static StatusOr<Shape> ParseShapeString(absl::string_view s); // Returns whether the LHS and RHS shapes have the same dimensions; note: does // not check element type. @@ -597,8 +597,8 @@ class ShapeUtil { // layout). The layout of 'input_shape' is kept fixed. Returns // 'output_shape_with_layout' if such a layout can be found, and an error // otherwise. - static tensorflow::gtl::optional<Shape> AlignLayouts( - const Shape& input_shape, const Shape& output_shape); + static absl::optional<Shape> AlignLayouts(const Shape& input_shape, + const Shape& output_shape); // Returns a shape with the given dimension deleted. // For example: @@ -737,13 +737,13 @@ class ShapeUtil { int64 n = -1; std::vector<int64> indexes(base.begin(), base.end()); const int kNumThreads = tensorflow::port::NumSchedulableCPUs(); - tensorflow::gtl::optional<tensorflow::thread::ThreadPool> pool; + absl::optional<tensorflow::thread::ThreadPool> pool; if (parallel) { pool.emplace(tensorflow::Env::Default(), "foreach", kNumThreads); } while (n < rank) { - if (pool != tensorflow::gtl::nullopt) { + if (pool != absl::nullopt) { pool->Schedule( [indexes, &visitor_function] { visitor_function(indexes); }); } else { diff --git a/tensorflow/compiler/xla/shape_util_test.cc b/tensorflow/compiler/xla/shape_util_test.cc index e5dd62ae9a..7549ba9c78 100644 --- a/tensorflow/compiler/xla/shape_util_test.cc +++ b/tensorflow/compiler/xla/shape_util_test.cc @@ -16,6 +16,8 @@ limitations under the License. #include "tensorflow/compiler/xla/shape_util.h" #include <numeric> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/test.h" @@ -23,8 +25,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace xla { namespace { @@ -849,13 +849,13 @@ TEST(ShapeUtilTest, PermuteDimensionsLayout) { std::iota(layout.begin(), layout.end(), 0); do { Shape s = ShapeUtil::MakeShapeWithLayout(F32, {10, 100, 1000}, layout); - SCOPED_TRACE(tensorflow::strings::StrCat("s=", ShapeUtil::HumanString(s))); + SCOPED_TRACE(absl::StrCat("s=", ShapeUtil::HumanString(s))); std::vector<int64> permutation(3); std::iota(permutation.begin(), permutation.end(), 0); do { - SCOPED_TRACE(tensorflow::strings::StrCat( - "permutation=", tensorflow::str_util::Join(permutation, ","))); + SCOPED_TRACE( + absl::StrCat("permutation=", absl::StrJoin(permutation, ","))); // TransposeIsBitcast takes the inverse of the permutation that // PermuteDimensions takes. diff --git a/tensorflow/compiler/xla/sparse_index_array.h b/tensorflow/compiler/xla/sparse_index_array.h index f2ce22d672..70fab3bea5 100644 --- a/tensorflow/compiler/xla/sparse_index_array.h +++ b/tensorflow/compiler/xla/sparse_index_array.h @@ -20,6 +20,7 @@ limitations under the License. #include <vector> +#include "absl/container/inlined_vector.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/index_util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" @@ -139,7 +140,7 @@ void SparseIndexArray::SortWithValues( // Reorder the array elements according to sort_order. Work through the array // and follow cycles so we can do the reorder in-place. - tensorflow::gtl::InlinedVector<int64, 8> saved_index(rank()); + absl::InlinedVector<int64, 8> saved_index(rank()); for (int64 i = 0; i < num_elements; ++i) { // sort_order[i] == -1 indicates the element has already been copied. if (sort_order[i] < 0) { diff --git a/tensorflow/compiler/xla/status_macros.cc b/tensorflow/compiler/xla/status_macros.cc index a6b1f9004f..b88fe367d7 100644 --- a/tensorflow/compiler/xla/status_macros.cc +++ b/tensorflow/compiler/xla/status_macros.cc @@ -17,9 +17,8 @@ limitations under the License. #include <algorithm> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/stacktrace.h" @@ -37,8 +36,7 @@ static void LogError(const Status& status, const char* filename, int line, if (TF_PREDICT_TRUE(log_severity != tensorflow::NUM_SEVERITIES)) { string stack_trace; if (should_log_stack_trace) { - stack_trace = - tensorflow::strings::StrCat("\n", tensorflow::CurrentStackTrace()); + stack_trace = absl::StrCat("\n", tensorflow::CurrentStackTrace()); } switch (log_severity) { case tensorflow::INFO: @@ -142,17 +140,15 @@ Status MakeErrorStream::Impl::GetStatus() { is_done_ = true; const string& stream_str = stream_.str(); - const string str = - prior_message_handling_ == kAppendToPriorMessage - ? tensorflow::strings::StrCat(prior_message_, stream_str) - : tensorflow::strings::StrCat(stream_str, prior_message_); + const string str = prior_message_handling_ == kAppendToPriorMessage + ? absl::StrCat(prior_message_, stream_str) + : absl::StrCat(stream_str, prior_message_); if (TF_PREDICT_FALSE(str.empty())) { - return MakeError(file_, line_, code_, - tensorflow::strings::StrCat( - str, "Error without message at ", file_, ":", line_), - true /* should_log */, - tensorflow::ERROR /* log_severity */, - should_log_stack_trace_); + return MakeError( + file_, line_, code_, + absl::StrCat(str, "Error without message at ", file_, ":", line_), + true /* should_log */, tensorflow::ERROR /* log_severity */, + should_log_stack_trace_); } else { return MakeError(file_, line_, code_, str, should_log_, log_severity_, should_log_stack_trace_); diff --git a/tensorflow/compiler/xla/test.h b/tensorflow/compiler/xla/test.h index 87a8c5f3a5..a657554dc2 100644 --- a/tensorflow/compiler/xla/test.h +++ b/tensorflow/compiler/xla/test.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPLIER_XLA_TEST_H_ -#define TENSORFLOW_COMPLIER_XLA_TEST_H_ +#ifndef TENSORFLOW_COMPILER_XLA_TEST_H_ +#define TENSORFLOW_COMPILER_XLA_TEST_H_ // This header includes gmock.h and enables the use of gmock matchers in tests // in third_party/tensorflow/compiler/xla. @@ -45,4 +45,4 @@ limitations under the License. #include "tensorflow/core/platform/test.h" -#endif // TENSORFLOW_COMPLIER_XLA_TEST_H_ +#endif // TENSORFLOW_COMPILER_XLA_TEST_H_ diff --git a/tensorflow/compiler/xla/test_helpers.h b/tensorflow/compiler/xla/test_helpers.h index 8918350135..3ede5e6e38 100644 --- a/tensorflow/compiler/xla/test_helpers.h +++ b/tensorflow/compiler/xla/test_helpers.h @@ -19,9 +19,9 @@ limitations under the License. #include <list> #include <vector> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/regexp.h" #include "tensorflow/core/platform/test.h" diff --git a/tensorflow/compiler/xla/tests/BUILD b/tensorflow/compiler/xla/tests/BUILD index e280492bd9..a0829b0d02 100644 --- a/tensorflow/compiler/xla/tests/BUILD +++ b/tensorflow/compiler/xla/tests/BUILD @@ -43,6 +43,7 @@ cc_library( "//tensorflow/compiler/xla/legacy_flags:debug_options_flags", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], alwayslink = True, ) @@ -98,6 +99,8 @@ cc_library( "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings:str_format", + "@com_google_absl//absl/types:optional", ], ) @@ -113,7 +116,6 @@ cc_library( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:types", - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/legacy_flags:debug_options_flags", "//tensorflow/compiler/xla/service:backend", @@ -127,6 +129,9 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", "//tensorflow/core:test", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/types:optional", ], ) @@ -144,6 +149,7 @@ cc_library( "//tensorflow/compiler/xla/service:hlo_verifier", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -187,7 +193,6 @@ cc_library( "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:test_helpers", - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:client_library", "//tensorflow/compiler/xla/client:global_data", @@ -201,6 +206,8 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", "//tensorflow/core:test", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -274,6 +281,7 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", "//third_party/eigen3", + "@com_google_absl//absl/memory", ], ) @@ -385,6 +393,8 @@ xla_test( "//tensorflow/core:lib", "//tensorflow/core:regexp_internal", "//tensorflow/core:test", + "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/strings", ], ) @@ -551,6 +561,7 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -665,6 +676,7 @@ xla_test( "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", ], ) @@ -683,7 +695,6 @@ xla_test( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla/client:local_client", "//tensorflow/compiler/xla/client:xla_builder", - "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/compiler/xla/tests:client_library_test_base", "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/compiler/xla/tests:test_utils", @@ -691,6 +702,7 @@ xla_test( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -715,10 +727,8 @@ xla_test( deps = [ ":client_library_test_base", ":hlo_test_base", - "//tensorflow/compiler/xla:execution_options_util", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:test", - "//tensorflow/compiler/xla/client:xla_builder", "//tensorflow/compiler/xla/service:hlo_parser", "//tensorflow/compiler/xla/tests:xla_internal_test_main", ], @@ -742,7 +752,6 @@ xla_test( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla/client:local_client", "//tensorflow/compiler/xla/client:xla_builder", - "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/compiler/xla/tests:client_library_test_base", "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/compiler/xla/tests:test_utils", @@ -750,6 +759,7 @@ xla_test( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -825,7 +835,10 @@ xla_test( timeout = "long", srcs = ["convolution_test.cc"], shard_count = 25, - deps = CONVOLUTION_TEST_DEPS, + deps = CONVOLUTION_TEST_DEPS + [ + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + ], ) xla_test( @@ -835,7 +848,10 @@ xla_test( backend_args = {"gpu": ["--xla_backend_extra_options=xla_gpu_experimental_conv_disable_layout_heuristic"]}, backends = ["gpu"], shard_count = 25, - deps = CONVOLUTION_TEST_DEPS, + deps = CONVOLUTION_TEST_DEPS + [ + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + ], ) xla_test( @@ -886,6 +902,7 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -919,6 +936,7 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -995,6 +1013,9 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/container:inlined_vector", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -1068,6 +1089,7 @@ xla_test( "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -1103,7 +1125,6 @@ xla_test( deps = [ "//tensorflow/compiler/xla:array2d", "//tensorflow/compiler/xla:array4d", - "//tensorflow/compiler/xla:literal", "//tensorflow/compiler/xla:literal_util", "//tensorflow/compiler/xla:reference_util", "//tensorflow/compiler/xla:shape_util", @@ -1121,6 +1142,8 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -1149,6 +1172,8 @@ xla_test_library( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1212,6 +1237,7 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -1222,12 +1248,12 @@ xla_test( "enable_for_xla_interpreter", ], deps = [ - ":client_library_test_base", "//tensorflow/compiler/xla/service:hlo_parser", "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -1238,12 +1264,12 @@ xla_test( "enable_for_xla_interpreter", ], deps = [ - ":client_library_test_base", "//tensorflow/compiler/xla/service:hlo_verifier", "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -1287,6 +1313,7 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", # fixdeps: keep "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -1352,6 +1379,7 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -1402,7 +1430,6 @@ xla_test( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:test_helpers", - "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:local_client", "//tensorflow/compiler/xla/client:xla_builder", @@ -1413,6 +1440,9 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -1482,6 +1512,8 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) @@ -1542,17 +1574,16 @@ xla_test( ], deps = [ "//tensorflow/compiler/xla:shape_util", - "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:local_client", "//tensorflow/compiler/xla/client:xla_builder", - "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/compiler/xla/tests:client_library_test_base", "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:stream_executor_no_cuda", "//tensorflow/core:test", + "@com_google_absl//absl/algorithm:container", ], ) @@ -1637,6 +1668,7 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -1649,7 +1681,6 @@ xla_test( "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:test", - "//tensorflow/compiler/xla:test_helpers", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:client_library", "//tensorflow/compiler/xla/client:global_data", @@ -1660,6 +1691,7 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/strings", ], ) @@ -1753,6 +1785,7 @@ xla_test( "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:test", + "@com_google_absl//absl/memory", ], ) @@ -1774,6 +1807,7 @@ tf_cc_test( "//tensorflow/core:test", "//tensorflow/core:test_main", "//tensorflow/stream_executor", + "@com_google_absl//absl/memory", "@llvm//:core", ], ) @@ -1825,6 +1859,7 @@ xla_test( "//tensorflow/core:lib", "//tensorflow/core:test", "//third_party/eigen3", + "@com_google_absl//absl/memory", ], ) @@ -1837,13 +1872,9 @@ xla_test( "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:util", "//tensorflow/compiler/xla:xla_data_proto", - "//tensorflow/compiler/xla/client:client_library", "//tensorflow/compiler/xla/client:local_client", - "//tensorflow/compiler/xla/client:xla_builder", - "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/compiler/xla/service:hlo", "//tensorflow/compiler/xla/service:hlo_runner", - "//tensorflow/compiler/xla/service:platform_util", "//tensorflow/compiler/xla/tests:client_library_test_base", "//tensorflow/compiler/xla/tests:hlo_test_base", "//tensorflow/compiler/xla/tests:literal_test_util", @@ -1851,6 +1882,8 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", ], ) @@ -1877,7 +1910,6 @@ xla_test( "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla/client:local_client", "//tensorflow/compiler/xla/client:xla_builder", - "//tensorflow/compiler/xla/client:xla_computation", "//tensorflow/compiler/xla/service:local_service", "//tensorflow/compiler/xla/service:shaped_buffer", "//tensorflow/compiler/xla/tests:literal_test_util", @@ -1885,6 +1917,7 @@ xla_test( "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", "//tensorflow/core:test", + "@com_google_absl//absl/types:optional", ], ) @@ -2011,6 +2044,7 @@ tf_cc_test( "//tensorflow/core:lib", "//tensorflow/core:test", "//tensorflow/core:test_main", + "@com_google_absl//absl/strings", ], ) @@ -2052,6 +2086,7 @@ xla_test( "//tensorflow/compiler/xla/tests:literal_test_util", "//tensorflow/compiler/xla/tests:xla_internal_test_main", "//tensorflow/core:lib", + "@com_google_absl//absl/types:optional", ], ) @@ -2096,19 +2131,13 @@ xla_test( xla_test( name = "iota_test", srcs = ["iota_test.cc"], - blacklisted_backends = [ - "cpu", - "gpu", - ], + shard_count = 30, tags = [ "enable_for_xla_interpreter", ], deps = [ ":client_library_test_base", - ":literal_test_util", ":xla_internal_test_main", - "//tensorflow/compiler/xla/client:xla_builder", "//tensorflow/core:lib", - "//tensorflow/core:test", ], ) diff --git a/tensorflow/compiler/xla/tests/array_elementwise_ops_test.cc b/tensorflow/compiler/xla/tests/array_elementwise_ops_test.cc index 74f2e36f82..577fd1ab3b 100644 --- a/tensorflow/compiler/xla/tests/array_elementwise_ops_test.cc +++ b/tensorflow/compiler/xla/tests/array_elementwise_ops_test.cc @@ -35,11 +35,14 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/casts.h" +#include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/platform/types.h" namespace xla { namespace { +using tensorflow::gtl::ArraySlice; + class ArrayElementwiseOpTest : public ClientLibraryTestBase { public: ErrorSpec error_spec_{0.0001, 0.0001}; @@ -293,6 +296,22 @@ XLA_TEST_F(ArrayElementwiseOpTest, SubTwoConstantS64s) { ComputeAndCompareR1<int64>(&b, expected, {lhs_data.get(), rhs_data.get()}); } +XLA_TEST_F(ArrayElementwiseOpTest, CmpTwoConstantU64s) { + XlaBuilder b(TestName()); + + std::vector<uint64> lhs{static_cast<uint64>(0x8000000000000000ULL)}; + std::unique_ptr<Literal> lhs_literal = LiteralUtil::CreateR1<uint64>({lhs}); + auto lhs_param = Parameter(&b, 0, lhs_literal->shape(), "lhs_param"); + + std::vector<uint64> rhs{static_cast<uint64>(0x7FFFFFFFFFFFFFFFULL)}; + std::unique_ptr<Literal> rhs_literal = LiteralUtil::CreateR1<uint64>({rhs}); + auto rhs_param = Parameter(&b, 1, rhs_literal->shape(), "rhs_param"); + + Lt(lhs_param, rhs_param); + + ComputeAndCompare(&b, {std::move(*lhs_literal), std::move(*rhs_literal)}); +} + TEST_P(ArrayElementwiseOpTestParamCount, AddManyValues) { const int count = GetParam(); XlaBuilder builder(TestName()); @@ -411,7 +430,64 @@ XLA_TEST_F(ArrayElementwiseOpTest, DivTwoConstantZeroElementF32s) { ComputeAndCompareR1<float>(&builder, {}, {}, error_spec_); } -XLA_TEST_F(ArrayElementwiseOpTest, DivS32s) { +class IntegerDivideOpTest : public ArrayElementwiseOpTest { + protected: + template <typename T> + void TestDivRem(ArraySlice<T> dividends, ArraySlice<T> divisors, + ArraySlice<T> quotients, ArraySlice<T> remainders) { + { + XlaBuilder builder(TestName()); + XlaOp dividend; + XlaOp divisor; + auto dividend_data = + CreateR1Parameter<T>(dividends, 0, "dividend", &builder, ÷nd); + auto divisor_data = + CreateR1Parameter<T>(divisors, 1, "divisor", &builder, &divisor); + Div(dividend, divisor); + + ComputeAndCompareR1<T>(&builder, quotients, + {dividend_data.get(), divisor_data.get()}); + } + + // Test with a compile-time constant divisor. + { + XlaBuilder builder(TestName()); + XlaOp dividend; + auto dividend_data = + CreateR1Parameter<T>(dividends, 0, "dividend", &builder, ÷nd); + Div(dividend, ConstantR1<T>(&builder, divisors)); + + ComputeAndCompareR1<T>(&builder, quotients, {dividend_data.get()}); + } + + { + XlaBuilder builder(TestName()); + XlaOp dividend; + XlaOp divisor; + auto dividend_data = + CreateR1Parameter<T>(dividends, 0, "dividend", &builder, ÷nd); + auto divisor_data = + CreateR1Parameter<T>(divisors, 1, "divisor", &builder, &divisor); + Rem(dividend, divisor); + + ComputeAndCompareR1<T>(&builder, remainders, + {dividend_data.get(), divisor_data.get()}); + } + + // Test with a compile-time constant divisor. + { + XlaBuilder builder(TestName()); + XlaOp dividend; + auto dividend_data = + CreateR1Parameter<T>(dividends, 0, "dividend", &builder, ÷nd); + Rem(dividend, ConstantR1<T>(&builder, divisors)); + + ComputeAndCompareR1<T>(&builder, remainders, {dividend_data.get()}); + } + } +}; + +XLA_TEST_F(IntegerDivideOpTest, DivS32s) { // clang-format off // Some interesting values to test. std::vector<int32> vals = { @@ -435,58 +511,17 @@ XLA_TEST_F(ArrayElementwiseOpTest, DivS32s) { } } - { - XlaBuilder builder(TestName()); - XlaOp dividend; - XlaOp divisor; - auto dividend_data = - CreateR1Parameter<int32>(dividends, 0, "dividend", &builder, ÷nd); - auto divisor_data = - CreateR1Parameter<int32>(divisors, 1, "divisor", &builder, &divisor); - Div(dividend, divisor); - - ComputeAndCompareR1<int32>(&builder, quotients, - {dividend_data.get(), divisor_data.get()}); - } - - // Test with a compile-time constant divisor. - { - XlaBuilder builder(TestName()); - XlaOp dividend; - auto dividend_data = - CreateR1Parameter<int32>(dividends, 0, "dividend", &builder, ÷nd); - Div(dividend, ConstantR1<int32>(&builder, divisors)); - - ComputeAndCompareR1<int32>(&builder, quotients, {dividend_data.get()}); - } - - { - XlaBuilder builder(TestName()); - XlaOp dividend; - XlaOp divisor; - auto dividend_data = - CreateR1Parameter<int32>(dividends, 0, "dividend", &builder, ÷nd); - auto divisor_data = - CreateR1Parameter<int32>(divisors, 1, "divisor", &builder, &divisor); - Rem(dividend, divisor); - - ComputeAndCompareR1<int32>(&builder, remainders, - {dividend_data.get(), divisor_data.get()}); - } + TestDivRem<int32>(dividends, divisors, quotients, remainders); +} - // Test with a compile-time constant divisor. - { - XlaBuilder builder(TestName()); - XlaOp dividend; - auto dividend_data = - CreateR1Parameter<int32>(dividends, 0, "dividend", &builder, ÷nd); - Rem(dividend, ConstantR1<int32>(&builder, divisors)); +XLA_TEST_F(IntegerDivideOpTest, SignedOverflow) { + std::vector<int32> dividends = {5, INT32_MIN}, divisors = {0, -1}, + quotients = {-1, INT32_MIN}, remainders = {5, 0}; - ComputeAndCompareR1<int32>(&builder, remainders, {dividend_data.get()}); - } + TestDivRem<int32>(dividends, divisors, quotients, remainders); } -XLA_TEST_F(ArrayElementwiseOpTest, DivU32s) { +XLA_TEST_F(IntegerDivideOpTest, DivU32s) { // clang-format off // Some interesting values to test. std::vector<uint32> vals = { @@ -506,53 +541,14 @@ XLA_TEST_F(ArrayElementwiseOpTest, DivU32s) { } } - { - XlaBuilder builder(TestName()); - XlaOp dividend; - XlaOp divisor; - auto dividend_data = CreateR1Parameter<uint32>(dividends, 0, "dividend", - &builder, ÷nd); - auto divisor_data = - CreateR1Parameter<uint32>(divisors, 1, "divisor", &builder, &divisor); - Div(dividend, divisor); - - ComputeAndCompareR1<uint32>(&builder, quotients, - {dividend_data.get(), divisor_data.get()}); - } - - { - XlaBuilder builder(TestName()); - XlaOp dividend; - auto dividend_data = CreateR1Parameter<uint32>(dividends, 0, "dividend", - &builder, ÷nd); - Div(dividend, ConstantR1<uint32>(&builder, divisors)); - - ComputeAndCompareR1<uint32>(&builder, quotients, {dividend_data.get()}); - } - - { - XlaBuilder builder(TestName()); - XlaOp dividend; - XlaOp divisor; - auto dividend_data = CreateR1Parameter<uint32>(dividends, 0, "dividend", - &builder, ÷nd); - auto divisor_data = - CreateR1Parameter<uint32>(divisors, 1, "divisor", &builder, &divisor); - Rem(dividend, divisor); - - ComputeAndCompareR1<uint32>(&builder, remainders, - {dividend_data.get(), divisor_data.get()}); - } + TestDivRem<uint32>(dividends, divisors, quotients, remainders); +} - { - XlaBuilder builder(TestName()); - XlaOp dividend; - auto dividend_data = CreateR1Parameter<uint32>(dividends, 0, "dividend", - &builder, ÷nd); - Rem(dividend, ConstantR1<uint32>(&builder, divisors)); +XLA_TEST_F(IntegerDivideOpTest, UnsignedOverflow) { + std::vector<int32> dividends = {5}, divisors = {0}, quotients = {-1}, + remainders = {5}; - ComputeAndCompareR1<uint32>(&builder, remainders, {dividend_data.get()}); - } + TestDivRem<int32>(dividends, divisors, quotients, remainders); } XLA_TEST_F(ArrayElementwiseOpTest, DivTwoConstantC64s) { diff --git a/tensorflow/compiler/xla/tests/batch_normalization_test.cc b/tensorflow/compiler/xla/tests/batch_normalization_test.cc index 24b17b7100..ac90a3adb6 100644 --- a/tensorflow/compiler/xla/tests/batch_normalization_test.cc +++ b/tensorflow/compiler/xla/tests/batch_normalization_test.cc @@ -17,6 +17,7 @@ limitations under the License. #include <memory> #include <vector> +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/client/lib/arithmetic.h" @@ -41,7 +42,6 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/math/math_util.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" @@ -382,7 +382,7 @@ struct BatchNormTestParam { friend ::std::ostream& operator<<(::std::ostream& os, const BatchNormTestParam& p) { - os << "bounds={" << tensorflow::str_util::Join(p.bounds, ", ") << "}, "; + os << "bounds={" << absl::StrJoin(p.bounds, ", ") << "}, "; os << "feature_index=" << p.feature_index << ", "; os << "random_value_mean=" << p.random_value_mean << ", "; os << "random_value_var=" << p.random_value_var; diff --git a/tensorflow/compiler/xla/tests/broadcast_test.cc b/tensorflow/compiler/xla/tests/broadcast_test.cc index c7b94b5bba..74d4d2eb10 100644 --- a/tensorflow/compiler/xla/tests/broadcast_test.cc +++ b/tensorflow/compiler/xla/tests/broadcast_test.cc @@ -16,8 +16,8 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" diff --git a/tensorflow/compiler/xla/tests/client_library_test_base.cc b/tensorflow/compiler/xla/tests/client_library_test_base.cc index 59d917054b..9cd974fd9b 100644 --- a/tensorflow/compiler/xla/tests/client_library_test_base.cc +++ b/tensorflow/compiler/xla/tests/client_library_test_base.cc @@ -17,18 +17,18 @@ limitations under the License. #include <string> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/client/client_library.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/execution_options_util.h" #include "tensorflow/compiler/xla/literal_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/platform_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/test_helpers.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -196,8 +196,8 @@ Status ClientLibraryTestBase::ComputeAndCompareLiteralWithAllOutputLayouts( AsInt64Slice(expected.shape().dimensions()), minor_to_major); TF_ASSIGN_OR_RETURN(auto actual, ExecuteAndTransfer(computation, arguments, &layout)); - verify_output(*actual, tensorflow::strings::StrCat( - "Test with output layout: ", + verify_output(*actual, + absl::StrCat("Test with output layout: ", ShapeUtil::HumanStringWithLayout(layout))); } while (std::next_permutation(minor_to_major.begin(), minor_to_major.end())); return Status::OK(); @@ -258,7 +258,7 @@ Status ClientLibraryTestBase::ComputeAndCompareLiteralWithAllInputLayouts( output_with_layout)); string error_message = "Test with input layouts: "; for (const auto& str : layout_strings) { - tensorflow::strings::StrAppend(&error_message, str, " "); + absl::StrAppend(&error_message, str, " "); } verify_output(*actual, error_message); return Status::OK(); @@ -391,7 +391,7 @@ Status ClientLibraryTestBase::ComputeAndCompareLiteralWithStatus( } void ClientLibraryTestBase::ComputeAndCompareR1U8( - XlaBuilder* builder, tensorflow::StringPiece expected, + XlaBuilder* builder, absl::string_view expected, tensorflow::gtl::ArraySlice<GlobalData*> arguments) { auto actual_status = ExecuteAndTransfer(builder, arguments); EXPECT_IS_OK(actual_status.status()); @@ -546,7 +546,7 @@ XlaComputation ClientLibraryTestBase::CreateScalarReluSensitivity() { std::unique_ptr<Array2D<float>> ClientLibraryTestBase::CreatePatternedMatrix( int rows, int cols, float offset) { - auto array = MakeUnique<Array2D<float>>(rows, cols); + auto array = absl::make_unique<Array2D<float>>(rows, cols); for (int64 row = 0; row < rows; ++row) { for (int64 col = 0; col < cols; ++col) { (*array)(row, col) = col + (row * 1000.0f) + offset; @@ -561,7 +561,7 @@ ClientLibraryTestBase::CreatePatternedMatrixWithZeroPadding(int rows, int cols, int cols_padded) { CHECK_GE(rows_padded, rows); CHECK_GE(cols_padded, cols); - auto array = MakeUnique<Array2D<float>>(rows_padded, cols_padded, 0.0); + auto array = absl::make_unique<Array2D<float>>(rows_padded, cols_padded, 0.0); for (int64 row = 0; row < rows; ++row) { for (int64 col = 0; col < cols; ++col) { (*array)(row, col) = col + (row * 1000.0f); diff --git a/tensorflow/compiler/xla/tests/client_library_test_base.h b/tensorflow/compiler/xla/tests/client_library_test_base.h index b04a3b105c..ac96d3e325 100644 --- a/tensorflow/compiler/xla/tests/client_library_test_base.h +++ b/tensorflow/compiler/xla/tests/client_library_test_base.h @@ -21,6 +21,8 @@ limitations under the License. #include <type_traits> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array3d.h" #include "tensorflow/compiler/xla/array4d.h" @@ -30,13 +32,11 @@ limitations under the License. #include "tensorflow/compiler/xla/client/xla_computation.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/literal_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/tests/literal_test_util.h" #include "tensorflow/compiler/xla/tests/test_utils.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/bitmap.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" #include "tensorflow/core/platform/test.h" @@ -202,7 +202,7 @@ class ClientLibraryTestBase : public ::testing::Test { // Compare the result of the computation to a strings. In XLA strings are // represented using rank-1 U8 shapes. void ComputeAndCompareR1U8( - XlaBuilder* builder, tensorflow::StringPiece expected, + XlaBuilder* builder, absl::string_view expected, tensorflow::gtl::ArraySlice<GlobalData*> arguments); // Convenience method for running a built computation, transferring the @@ -613,7 +613,7 @@ template <typename NativeT> std::unique_ptr<Array2D<NativeT>> ClientLibraryTestBase::CreatePseudorandomR2( const int rows, const int cols, NativeT min_value, NativeT max_value, uint32 seed) { - auto result = MakeUnique<Array2D<NativeT>>(rows, cols); + auto result = absl::make_unique<Array2D<NativeT>>(rows, cols); PseudorandomGenerator<NativeT> generator(min_value, max_value, seed); for (int y = 0; y < rows; ++y) { for (int x = 0; x < cols; ++x) { diff --git a/tensorflow/compiler/xla/tests/compute_constant_test.cc b/tensorflow/compiler/xla/tests/compute_constant_test.cc index 5a06d061f0..8226b6de3f 100644 --- a/tensorflow/compiler/xla/tests/compute_constant_test.cc +++ b/tensorflow/compiler/xla/tests/compute_constant_test.cc @@ -17,6 +17,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/match.h" #include "tensorflow/compiler/xla/client/client_library.h" #include "tensorflow/compiler/xla/client/global_data.h" #include "tensorflow/compiler/xla/client/xla_builder.h" @@ -32,7 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/test_utils.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/types.h" namespace xla { @@ -145,8 +145,8 @@ TEST_F(ComputeConstantTest, DirectParamMissing) { EXPECT_FALSE(IsConstant(computation, &b)); auto value = ComputeConstantScalar<float>(client, computation, &b); - EXPECT_TRUE(tensorflow::str_util::StrContains(value.status().ToString(), - "depends on a parameter")) + EXPECT_TRUE( + absl::StrContains(value.status().ToString(), "depends on a parameter")) << value.status(); } } @@ -161,8 +161,8 @@ TEST_F(ComputeConstantTest, IndirectParamMissing) { EXPECT_FALSE(IsConstant(computation, &b)); auto value = ComputeConstantScalar<float>(client, computation, &b); - EXPECT_TRUE(tensorflow::str_util::StrContains(value.status().ToString(), - "depends on a parameter")) + EXPECT_TRUE( + absl::StrContains(value.status().ToString(), "depends on a parameter")) << value.status(); } } diff --git a/tensorflow/compiler/xla/tests/conditional_test.cc b/tensorflow/compiler/xla/tests/conditional_test.cc index b27c1044ba..25d10ab00a 100644 --- a/tensorflow/compiler/xla/tests/conditional_test.cc +++ b/tensorflow/compiler/xla/tests/conditional_test.cc @@ -642,5 +642,57 @@ XLA_TEST_F(ConditionalOpTest, SwappedInputsInSequentialConditionals) { test_swap(11.24f, 5.55f); } +// Test conditional that duplicates tuple elements in the then and else +// computations. This is a regression test for b/112550242. +XLA_TEST_F(ConditionalOpTest, DuplicateElementsConditional) { + const Shape scalar = ShapeUtil::MakeShape(S32, {}); + const Shape tuple2 = ShapeUtil::MakeTupleShape({scalar, scalar}); + XlaComputation then_comp; + { + XlaBuilder builder(TestName() + ".then"); + auto p = Parameter(&builder, 0, tuple2, "then.p"); + auto e0 = GetTupleElement(p, 0); + auto e1 = GetTupleElement(p, 1); + Tuple(&builder, {e0, e1, e0}); + then_comp = builder.Build().ConsumeValueOrDie(); + } + XlaComputation else_comp; + { + XlaBuilder builder(TestName() + ".else"); + auto p = Parameter(&builder, 0, tuple2, "else.p"); + auto e0 = GetTupleElement(p, 0); + auto e1 = GetTupleElement(p, 1); + Tuple(&builder, {e0, e1, e1}); + else_comp = builder.Build().ConsumeValueOrDie(); + } + + { + // Pred is true case. + std::vector<Literal> args; + args.push_back(std::move( + *LiteralUtil::MakeTuple({LiteralUtil::CreateR0<int32>(123).get(), + LiteralUtil::CreateR0<int32>(-42).get()}))); + args.push_back(std::move(*LiteralUtil::CreateR0<bool>(true))); + XlaBuilder builder(TestName() + ".main"); + auto p = Parameter(&builder, 0, tuple2, "p0"); + auto p_pred = Parameter(&builder, 1, ShapeUtil::MakeShape(PRED, {}), "p1"); + Conditional(p_pred, p, then_comp, p, else_comp); + ComputeAndCompare(&builder, args); + } + { + // Pred is false case. + std::vector<Literal> args; + args.push_back(std::move( + *LiteralUtil::MakeTuple({LiteralUtil::CreateR0<int32>(123).get(), + LiteralUtil::CreateR0<int32>(-42).get()}))); + args.push_back(std::move(*LiteralUtil::CreateR0<bool>(false))); + XlaBuilder builder(TestName() + ".main"); + auto p = Parameter(&builder, 0, tuple2, "p0"); + auto p_pred = Parameter(&builder, 1, ShapeUtil::MakeShape(PRED, {}), "p1"); + Conditional(p_pred, p, then_comp, p, else_comp); + ComputeAndCompare(&builder, args); + } +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/tests/convert_test.cc b/tensorflow/compiler/xla/tests/convert_test.cc index 1adc68cc48..7a203d6873 100644 --- a/tensorflow/compiler/xla/tests/convert_test.cc +++ b/tensorflow/compiler/xla/tests/convert_test.cc @@ -19,6 +19,7 @@ limitations under the License. #include <memory> #include <vector> +#include "absl/algorithm/container.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -447,11 +448,11 @@ std::vector<float> GetInterestingF16ConversionTestCases() { XLA_TEST_F(ConvertTest, ConvertR1F16ToR1F32) { std::vector<float> test_cases = GetInterestingF16ConversionTestCases(); std::vector<half> input; - c_transform(test_cases, std::back_inserter(input), - [](float f) { return Eigen::half(f); }); + absl::c_transform(test_cases, std::back_inserter(input), + [](float f) { return Eigen::half(f); }); std::vector<float> expected_output; - c_transform(input, std::back_inserter(expected_output), - [](Eigen::half h) { return static_cast<float>(h); }); + absl::c_transform(input, std::back_inserter(expected_output), + [](Eigen::half h) { return static_cast<float>(h); }); TF_ASSERT_OK_AND_ASSIGN( std::unique_ptr<GlobalData> dot_lhs_handle, @@ -470,8 +471,8 @@ XLA_TEST_F(ConvertTest, ConvertR1F16ToR1F32) { XLA_TEST_F(ConvertTest, ConvertR1F32ToR1F16) { std::vector<float> input = GetInterestingF16ConversionTestCases(); std::vector<half> expected_output; - c_transform(input, std::back_inserter(expected_output), - [](float f) { return Eigen::half(f); }); + absl::c_transform(input, std::back_inserter(expected_output), + [](float f) { return Eigen::half(f); }); TF_ASSERT_OK_AND_ASSIGN( std::unique_ptr<GlobalData> dot_lhs_handle, diff --git a/tensorflow/compiler/xla/tests/convolution_dimension_numbers_test.cc b/tensorflow/compiler/xla/tests/convolution_dimension_numbers_test.cc index 7b6bbc4f57..38b6da4fa9 100644 --- a/tensorflow/compiler/xla/tests/convolution_dimension_numbers_test.cc +++ b/tensorflow/compiler/xla/tests/convolution_dimension_numbers_test.cc @@ -17,11 +17,11 @@ limitations under the License. #include <array> #include <memory> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/padding.h" #include "tensorflow/compiler/xla/client/xla_builder.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/reference_util.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/test.h" @@ -88,9 +88,9 @@ TEST_F(ConvolutionDimensionNumbersTest, InvalidOutputDimensionNumbers) { XLA_TEST_F(ConvolutionDimensionNumbersTest, TwoConvsWithDifferentDimensionNumbers) { - auto input_array = MakeUnique<Array4D<float>>(2, 3, 5, 5); + auto input_array = absl::make_unique<Array4D<float>>(2, 3, 5, 5); input_array->FillWithMultiples(0.1); - auto weight_array = MakeUnique<Array4D<float>>(4, 3, 1, 1); + auto weight_array = absl::make_unique<Array4D<float>>(4, 3, 1, 1); weight_array->FillWithMultiples(0.2); auto weight_data = client_ diff --git a/tensorflow/compiler/xla/tests/convolution_test.cc b/tensorflow/compiler/xla/tests/convolution_test.cc index 689928aee4..d2c6478b02 100644 --- a/tensorflow/compiler/xla/tests/convolution_test.cc +++ b/tensorflow/compiler/xla/tests/convolution_test.cc @@ -18,6 +18,8 @@ limitations under the License. #include <memory> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/client/global_data.h" @@ -26,7 +28,6 @@ limitations under the License. #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/reference_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/statusor.h" @@ -35,8 +36,6 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/literal_test_util.h" #include "tensorflow/compiler/xla/tests/test_macros.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" @@ -71,16 +70,16 @@ class ForwardPassConvolution_3x3x256_256_OutputZ_Iota : public ConvolutionTest { const int kKernelSizeY = 2; const int kOutputActivationSizeZ = 256; const int kMiniBatchSize = 4; - auto alhs = - MakeUnique<Array4D<T>>(kMiniBatchSize, kInputActivationSizeZ, - kInputActivationSizeY, kInputActivationSizeX); + auto alhs = absl::make_unique<Array4D<T>>( + kMiniBatchSize, kInputActivationSizeZ, kInputActivationSizeY, + kInputActivationSizeX); alhs->FillWithMultiples(static_cast<T>(1.0f)); ASSERT_EQ(3, alhs->width()); ASSERT_EQ(3, alhs->height()); - auto arhs = - MakeUnique<Array4D<T>>(kOutputActivationSizeZ, kInputActivationSizeZ, - kKernelSizeY, kKernelSizeX); + auto arhs = absl::make_unique<Array4D<T>>(kOutputActivationSizeZ, + kInputActivationSizeZ, + kKernelSizeY, kKernelSizeX); Array2D<T> rhs_raster({ {1.0f, 0.0f}, // row 0 {0.0f, 0.0f}, // row 1 diff --git a/tensorflow/compiler/xla/tests/copy_test.cc b/tensorflow/compiler/xla/tests/copy_test.cc index 5ef273e5a2..50a9ebc1e9 100644 --- a/tensorflow/compiler/xla/tests/copy_test.cc +++ b/tensorflow/compiler/xla/tests/copy_test.cc @@ -16,10 +16,10 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" diff --git a/tensorflow/compiler/xla/tests/custom_call_test.cc b/tensorflow/compiler/xla/tests/custom_call_test.cc index 13c777835e..6f7fc0e6e5 100644 --- a/tensorflow/compiler/xla/tests/custom_call_test.cc +++ b/tensorflow/compiler/xla/tests/custom_call_test.cc @@ -16,9 +16,9 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/literal_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/cpu/custom_call_target_registry.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" diff --git a/tensorflow/compiler/xla/tests/dot_operation_test.cc b/tensorflow/compiler/xla/tests/dot_operation_test.cc index 0e9e92ed99..5873516442 100644 --- a/tensorflow/compiler/xla/tests/dot_operation_test.cc +++ b/tensorflow/compiler/xla/tests/dot_operation_test.cc @@ -16,6 +16,7 @@ limitations under the License. #include <memory> #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array3d.h" #include "tensorflow/compiler/xla/client/local_client.h" @@ -261,16 +262,14 @@ string PrintDotTestParam( const ::testing::TestParamInfo<DotTestParam>& test_param) { const DotTestParam& param = test_param.param; if (param.has_addend) { - return tensorflow::strings::StrCat(param.m, "x", param.k, "x", param.n, - "_MajorToMinor", - param.dot_lhs_row_major ? "T" : "F", - param.dot_rhs_row_major ? "T" : "F", - param.addend_row_major ? "T" : "F"); + return absl::StrCat(param.m, "x", param.k, "x", param.n, "_MajorToMinor", + param.dot_lhs_row_major ? "T" : "F", + param.dot_rhs_row_major ? "T" : "F", + param.addend_row_major ? "T" : "F"); } else { - return tensorflow::strings::StrCat(param.m, "x", param.k, "x", param.n, - "_MajorToMinor", - param.dot_lhs_row_major ? "T" : "F", - param.dot_rhs_row_major ? "T" : "F"); + return absl::StrCat(param.m, "x", param.k, "x", param.n, "_MajorToMinor", + param.dot_lhs_row_major ? "T" : "F", + param.dot_rhs_row_major ? "T" : "F"); } } diff --git a/tensorflow/compiler/xla/tests/floor_ceil_test.cc b/tensorflow/compiler/xla/tests/floor_ceil_test.cc index 39cc6c5927..4a835a8e21 100644 --- a/tensorflow/compiler/xla/tests/floor_ceil_test.cc +++ b/tensorflow/compiler/xla/tests/floor_ceil_test.cc @@ -16,13 +16,13 @@ limitations under the License. #include <limits> #include <string> +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/tests/client_library_test_base.h" #include "tensorflow/compiler/xla/tests/literal_test_util.h" #include "tensorflow/compiler/xla/tests/test_macros.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/test.h" @@ -39,8 +39,7 @@ class FloorCeilTest : public ClientLibraryTestBase { // Runs a computation and comparison on expected vs f(input) void TestR1F32(tensorflow::gtl::ArraySlice<float> input, tensorflow::gtl::ArraySlice<float> expected, Function f) { - LOG(INFO) << "input: {" << tensorflow::str_util::Join(expected, ", ") - << "}"; + LOG(INFO) << "input: {" << absl::StrJoin(expected, ", ") << "}"; XlaBuilder builder(TestName()); auto c = ConstantR1<float>(&builder, input); if (f == kCeil) { diff --git a/tensorflow/compiler/xla/tests/fusion_test.cc b/tensorflow/compiler/xla/tests/fusion_test.cc index 792be0d3fc..341124170a 100644 --- a/tensorflow/compiler/xla/tests/fusion_test.cc +++ b/tensorflow/compiler/xla/tests/fusion_test.cc @@ -22,13 +22,13 @@ limitations under the License. #define EIGEN_USE_THREADS +#include "absl/memory/memory.h" #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/client/client_library.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/primitive_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" diff --git a/tensorflow/compiler/xla/tests/gather_operation_test.cc b/tensorflow/compiler/xla/tests/gather_operation_test.cc index f866ed6519..205d417f0c 100644 --- a/tensorflow/compiler/xla/tests/gather_operation_test.cc +++ b/tensorflow/compiler/xla/tests/gather_operation_test.cc @@ -25,7 +25,7 @@ limitations under the License. namespace xla { namespace { -using tensorflow::gtl::nullopt; +using absl::nullopt; class GatherOperationTest : public HloTestBase { protected: diff --git a/tensorflow/compiler/xla/tests/hlo_test_base.cc b/tensorflow/compiler/xla/tests/hlo_test_base.cc index 64e361f14f..93ea144438 100644 --- a/tensorflow/compiler/xla/tests/hlo_test_base.cc +++ b/tensorflow/compiler/xla/tests/hlo_test_base.cc @@ -20,9 +20,10 @@ limitations under the License. #include <string> #include <utility> +#include "absl/algorithm/container.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/legacy_flags/debug_options_flags.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/service/platform_util.h" @@ -41,9 +42,9 @@ namespace xla { namespace { -using tensorflow::StringPiece; +using absl::optional; +using absl::string_view; using tensorflow::gtl::ArraySlice; -using tensorflow::gtl::optional; constexpr char kInterpreter[] = "interpreter"; @@ -85,21 +86,24 @@ ProgramShape GetProgramShapeWithLayout(const HloModule& module) { } // namespace -HloTestBase::HloTestBase(bool allow_mixed_precision_in_hlo_verifier) +HloTestBase::HloTestBase(bool verifier_layout_sensitive, + bool allow_mixed_precision_in_hlo_verifier) : HloTestBase(GetTestPlatform(), GetReferencePlatform(), + verifier_layout_sensitive, allow_mixed_precision_in_hlo_verifier) {} HloTestBase::HloTestBase(se::Platform* test_platform, se::Platform* reference_platform, + bool verifier_layout_sensitive, bool allow_mixed_precision_in_hlo_verifier) : test_runner_(test_platform), reference_runner_(reference_platform) { - hlo_verifier_ = - MakeUnique<HloVerifier>(allow_mixed_precision_in_hlo_verifier); + hlo_verifier_ = absl::make_unique<HloVerifier>( + /*layout_sensitive=*/verifier_layout_sensitive, + /*allow_mixed_precision=*/allow_mixed_precision_in_hlo_verifier); } -/* static */ std::unique_ptr<HloModule> HloTestBase::CreateNewModule(const string& name) { - return MakeUnique<HloModule>(name, GetModuleConfigForTest()); + return absl::make_unique<HloModule>(name, GetModuleConfigForTest()); } /* static */ @@ -117,7 +121,6 @@ StatusOr<bool> HloTestBase::RunHloPass(HloPassInterface* hlo_pass, return status_or; } -/*static*/ DebugOptions HloTestBase::GetDebugOptionsForTest() { auto debug_options = legacy_flags::GetDebugOptionsFromFlags(); // TODO(b/38354253): Change tests to use Parameters instead of Constants. @@ -217,7 +220,7 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( MakeFakeArguments(module.get()).ConsumeValueOrDie(); std::vector<Literal*> fake_argument_ptrs; - c_transform( + absl::c_transform( fake_arguments, std::back_inserter(fake_argument_ptrs), [](const std::unique_ptr<Literal>& literal) { return literal.get(); }); @@ -231,7 +234,7 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( const auto& fake_arguments = MakeFakeArguments(module.get()).ConsumeValueOrDie(); std::vector<Literal*> fake_argument_ptrs; - c_transform( + absl::c_transform( fake_arguments, std::back_inserter(fake_argument_ptrs), [](const std::unique_ptr<Literal>& literal) { return literal.get(); }); @@ -240,8 +243,7 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( } ::testing::AssertionResult HloTestBase::RunAndCompare( - const StringPiece hlo_string, - const tensorflow::gtl::optional<ErrorSpec>& error, + string_view hlo_string, const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor) { auto module_or_status = HloRunner::CreateModuleFromString(hlo_string, GetDebugOptionsForTest()); @@ -254,7 +256,7 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( reference_preprocessor); } -::testing::AssertionResult HloTestBase::Run(const StringPiece hlo_string) { +::testing::AssertionResult HloTestBase::Run(string_view hlo_string) { auto module_or_status = HloRunner::CreateModuleFromString(hlo_string, GetDebugOptionsForTest()); if (!module_or_status.ok()) { @@ -266,7 +268,7 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( MakeFakeArguments(module_or_status.ValueOrDie().get()) .ConsumeValueOrDie(); std::vector<Literal*> fake_argument_ptrs; - c_transform( + absl::c_transform( fake_arguments, std::back_inserter(fake_argument_ptrs), [](const std::unique_ptr<Literal>& literal) { return literal.get(); }); return test_runner_ @@ -278,7 +280,7 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( } ::testing::AssertionResult HloTestBase::RunAndCompareFromFile( - const string& filename, const tensorflow::gtl::optional<ErrorSpec>& error, + const string& filename, const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor) { auto module_or_status = HloRunner::ReadModuleFromHloTextFile(filename, GetDebugOptionsForTest()); @@ -291,8 +293,7 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( } ::testing::AssertionResult HloTestBase::RunAndCompareNoHloPasses( - const StringPiece hlo_string, - const tensorflow::gtl::optional<ErrorSpec>& error, + string_view hlo_string, const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor) { auto module_or_status = HloRunner::CreateModuleFromString(hlo_string, GetDebugOptionsForTest()); @@ -306,7 +307,7 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( } ::testing::AssertionResult HloTestBase::RunAndCompareNoHloPassesFromFile( - const string& filename, const tensorflow::gtl::optional<ErrorSpec>& error, + const string& filename, const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor) { auto module_or_status = HloRunner::ReadModuleFromHloTextFile(filename, GetDebugOptionsForTest()); @@ -319,10 +320,10 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( } HloComputation* HloTestBase::FindComputation(HloModule* module, - tensorflow::StringPiece name) { + absl::string_view name) { auto computations = module->computations(); - auto it = c_find_if(computations, - [&](HloComputation* c) { return c->name() == name; }); + auto it = absl::c_find_if( + computations, [&](HloComputation* c) { return c->name() == name; }); if (it == computations.end()) { return nullptr; } @@ -330,11 +331,11 @@ HloComputation* HloTestBase::FindComputation(HloModule* module, } HloInstruction* HloTestBase::FindInstruction(HloModule* module, - tensorflow::StringPiece name) { + absl::string_view name) { for (const HloComputation* c : module->computations()) { auto instructions = c->instructions(); - auto it = c_find_if(instructions, - [&](HloInstruction* i) { return i->name() == name; }); + auto it = absl::c_find_if( + instructions, [&](HloInstruction* i) { return i->name() == name; }); if (it != instructions.end()) { return *it; } diff --git a/tensorflow/compiler/xla/tests/hlo_test_base.h b/tensorflow/compiler/xla/tests/hlo_test_base.h index c860c416f1..06bcc39741 100644 --- a/tensorflow/compiler/xla/tests/hlo_test_base.h +++ b/tensorflow/compiler/xla/tests/hlo_test_base.h @@ -20,6 +20,7 @@ limitations under the License. #include <string> #include <vector> +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/service/backend.h" #include "tensorflow/compiler/xla/service/computation_layout.h" #include "tensorflow/compiler/xla/service/hlo_module.h" @@ -32,7 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/stream_executor_no_cuda.h" #include "tensorflow/core/platform/test.h" @@ -72,8 +72,7 @@ class HloTestBase : public ::testing::Test { // options from command-line flags. If you want a fresh HloModule object and // then add HloComputations to it, it's recommended to use this method in your // tests. - static std::unique_ptr<HloModule> CreateNewModule( - const string& name = TestName()); + std::unique_ptr<HloModule> CreateNewModule(const string& name = TestName()); // Runs the hlo_pass with the provided module and returns the result. This // function also verifies that the module remains unchanged when hlo_pass @@ -86,12 +85,14 @@ class HloTestBase : public ::testing::Test { // automatically finds another supported backend as the test backend. If the // interpreter is the only supported backend, it will be both the test backend // and the reference backend. - HloTestBase(bool allow_mixed_precision_in_hlo_verifier = true); + HloTestBase(bool verifier_layout_sensitive = false, + bool allow_mixed_precision_in_hlo_verifier = true); // If your test doesn't use interpreter as the reference backend, you can use // this constructor. Note that your test target is responsible for linking in // both needed backends. HloTestBase(se::Platform* test_platform, se::Platform* reference_platform, + bool verifier_layout_sensitive = false, bool allow_mixed_precision_in_hlo_verifier = true); ~HloTestBase() override {} @@ -99,10 +100,13 @@ class HloTestBase : public ::testing::Test { // Populates debug options from command-line flags and adjusts the options for // testing. It is recommended to use this when you need to pass in // DebugOptions, e.g. when creating a module from a string or a file. - static DebugOptions GetDebugOptionsForTest(); + // + // This function is virtual so tests can specify an alternative set of debug + // options (e.g. disabling additional passes). + virtual DebugOptions GetDebugOptionsForTest(); // Gets an HloModuleConfig with options appropriate for tests. - static HloModuleConfig GetModuleConfigForTest() { + HloModuleConfig GetModuleConfigForTest() { HloModuleConfig config; config.set_debug_options(GetDebugOptionsForTest()); return config; @@ -137,7 +141,7 @@ class HloTestBase : public ::testing::Test { ::testing::AssertionResult RunAndCompare( std::unique_ptr<HloModule> module, const tensorflow::gtl::ArraySlice<Literal*> arguments, - const tensorflow::gtl::optional<ErrorSpec>& error, + const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor = nullptr) TF_MUST_USE_RESULT; @@ -146,22 +150,20 @@ class HloTestBase : public ::testing::Test { ::testing::AssertionResult RunAndCompareNoHloPasses( std::unique_ptr<HloModule> module, const tensorflow::gtl::ArraySlice<Literal*> arguments, - const tensorflow::gtl::optional<ErrorSpec>& error, + const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor = nullptr) TF_MUST_USE_RESULT; // Executes an hlo module with fake inputs and compares the results. ::testing::AssertionResult RunAndCompare( - std::unique_ptr<HloModule> module, - const tensorflow::gtl::optional<ErrorSpec>& error, + std::unique_ptr<HloModule> module, const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor = nullptr) TF_MUST_USE_RESULT; // Same as above, except that the module will be executed without Hlo // optimization. ::testing::AssertionResult RunAndCompareNoHloPasses( - std::unique_ptr<HloModule> module, - const tensorflow::gtl::optional<ErrorSpec>& error, + std::unique_ptr<HloModule> module, const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor = nullptr) TF_MUST_USE_RESULT; @@ -169,23 +171,23 @@ class HloTestBase : public ::testing::Test { // input. Module can be passed in directly, or parsed from an hlo_string, // or loaded from a file. ::testing::AssertionResult RunAndCompare( - const tensorflow::StringPiece hlo_string, - const tensorflow::gtl::optional<ErrorSpec>& error, + const absl::string_view hlo_string, + const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor = nullptr) TF_MUST_USE_RESULT; - ::testing::AssertionResult Run(const tensorflow::StringPiece hlo_string) + ::testing::AssertionResult Run(const absl::string_view hlo_string) TF_MUST_USE_RESULT; ::testing::AssertionResult RunAndCompareFromFile( - const string& filename, const tensorflow::gtl::optional<ErrorSpec>& error, + const string& filename, const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor = nullptr) TF_MUST_USE_RESULT; ::testing::AssertionResult RunAndCompareNoHloPasses( - const tensorflow::StringPiece hlo_string, - const tensorflow::gtl::optional<ErrorSpec>& error, + const absl::string_view hlo_string, + const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor = nullptr) TF_MUST_USE_RESULT; ::testing::AssertionResult RunAndCompareNoHloPassesFromFile( - const string& filename, const tensorflow::gtl::optional<ErrorSpec>& error, + const string& filename, const absl::optional<ErrorSpec>& error, const std::function<void(HloModule*)>& reference_preprocessor = nullptr) TF_MUST_USE_RESULT; @@ -228,10 +230,8 @@ class HloTestBase : public ::testing::Test { // // This is useful for tests which create HLOs from a string and then want to // inspect a particular computation or instruction. - HloComputation* FindComputation(HloModule* module, - tensorflow::StringPiece name); - HloInstruction* FindInstruction(HloModule* module, - tensorflow::StringPiece name); + HloComputation* FindComputation(HloModule* module, absl::string_view name); + HloInstruction* FindInstruction(HloModule* module, absl::string_view name); // Return an HLO verifier constructed for the test backend. HloVerifier& verifier() const { return *hlo_verifier_; } @@ -262,7 +262,7 @@ class HloTestBase : public ::testing::Test { StatusOr<::testing::AssertionResult> RunAndCompareInternal( std::unique_ptr<HloModule> module, const tensorflow::gtl::ArraySlice<Literal*> arguments, - const tensorflow::gtl::optional<ErrorSpec>& error, bool run_hlo_passes, + const absl::optional<ErrorSpec>& error, bool run_hlo_passes, const std::function<void(HloModule*)>& reference_preprocessor); }; diff --git a/tensorflow/compiler/xla/tests/hlo_verified_test_base.cc b/tensorflow/compiler/xla/tests/hlo_verified_test_base.cc index ad1f5b9eed..8f86c528d0 100644 --- a/tensorflow/compiler/xla/tests/hlo_verified_test_base.cc +++ b/tensorflow/compiler/xla/tests/hlo_verified_test_base.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/hlo_verified_test_base.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/service/hlo_verifier.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -24,8 +25,11 @@ limitations under the License. namespace xla { -HloVerifiedTestBase::HloVerifiedTestBase() - : shape_verifier_(MakeUnique<ShapeVerifier>()) {} +HloVerifiedTestBase::HloVerifiedTestBase(bool layout_sensitive, + bool allow_mixed_precision) + : HloTestBase( + /*verifier_layout_sensitive=*/layout_sensitive, + /*allow_mixed_precision_in_hlo_verifier=*/allow_mixed_precision) {} HloVerifiedTestBase::~HloVerifiedTestBase() { // We can't call the ASSERT or EXPECT test macros in destructors, so we @@ -50,8 +54,7 @@ void HloVerifiedTestBase::TearDown() { } void HloVerifiedTestBase::VerifyModule(HloModule* module) { - HloVerifier verifier(/*allow_mixed_precision=*/true); - xla::StatusOr<bool> mutated = verifier.Run(module); + xla::StatusOr<bool> mutated = verifier().Run(module); if (!mutated.ok()) { ADD_FAILURE() << "HloVerifier failed: " << mutated.status(); } else { @@ -72,7 +75,7 @@ HloModule* HloVerifiedTestBase::CreateNewModule(const string& name) { return modules_.back().get(); } -void HloVerifiedTestBase::ParseAndVerifyModule(tensorflow::StringPiece hlo_text, +void HloVerifiedTestBase::ParseAndVerifyModule(absl::string_view hlo_text, const HloModuleConfig& config) { CHECK(!module_) << "Called ParseModule when test already has a module."; TF_ASSERT_OK_AND_ASSIGN(module_, ParseHloString(hlo_text, config)); diff --git a/tensorflow/compiler/xla/tests/hlo_verified_test_base.h b/tensorflow/compiler/xla/tests/hlo_verified_test_base.h index 5b28c01c36..cc6967feed 100644 --- a/tensorflow/compiler/xla/tests/hlo_verified_test_base.h +++ b/tensorflow/compiler/xla/tests/hlo_verified_test_base.h @@ -29,7 +29,8 @@ namespace xla { // performs verification on that module on tear-down. class HloVerifiedTestBase : public HloTestBase { protected: - HloVerifiedTestBase(); + explicit HloVerifiedTestBase(bool layout_sensitive, + bool allow_mixed_precision); ~HloVerifiedTestBase() override; // Constructs a default shape verifier. @@ -44,32 +45,28 @@ class HloVerifiedTestBase : public HloTestBase { // Returns the default HloModule, lazily creating it if necessary via // HloTestBase::CreateNewModule(). HloModule& module(); - void ParseAndVerifyModule(tensorflow::StringPiece hlo_text, + void ParseAndVerifyModule(absl::string_view hlo_text, const HloModuleConfig& config = HloModuleConfig()); - // Sets the shape-size function used during hlo verification. If this isn't - // called, a default ShapeVerifier is used instead. - void SetShapeVerifier(std::unique_ptr<ShapeVerifier> shape_verifier) { - shape_verifier_ = std::move(shape_verifier); - } - // Creates a new module for a test, and stores it in modules_ so it can be // verified. Intentionally hides HloTestBase::CreateNewModule, to prevent // creation of unverified modules. HloModule* CreateNewModule(const string& name = TestName()); + private: + void VerifyModule(HloModule* module); + // It is confusing to store modules created by module() and CreateNewModule() // in different fields, but it allows us to migrate tests to // HloVerifiedTestBase more easily, so it's a win because we can verify more // modules. See b/80488902. - private: + // // Lazily populated. Access via module(). std::unique_ptr<HloModule> module_; // Populated by calls to CreateNewModule. std::vector<std::unique_ptr<HloModule>> modules_; - std::unique_ptr<ShapeVerifier> shape_verifier_; + bool tear_down_called_ = false; - static void VerifyModule(HloModule* module); }; } // namespace xla diff --git a/tensorflow/compiler/xla/tests/iota_test.cc b/tensorflow/compiler/xla/tests/iota_test.cc index 17ac95ae01..07c3c6b878 100644 --- a/tensorflow/compiler/xla/tests/iota_test.cc +++ b/tensorflow/compiler/xla/tests/iota_test.cc @@ -23,40 +23,95 @@ limitations under the License. namespace xla { namespace { -class IotaTest : public ClientLibraryTestBase { - public: - explicit IotaTest(se::Platform* platform = nullptr) - : ClientLibraryTestBase(platform) {} - template <typename T> - std::vector<T> GetExpected(const int64 num_elements) { - std::vector<T> result(num_elements); - std::iota(result.begin(), result.end(), 0); - return result; +template <typename T> +std::vector<T> GetR1Expected(const int64 num_elements) { + std::vector<T> result(num_elements); + std::iota(result.begin(), result.end(), 0); + return result; +} + +class IotaR1Test + : public ClientLibraryTestBase, + public ::testing::WithParamInterface<std::tuple<PrimitiveType, int>> {}; + +TEST_P(IotaR1Test, DoIt) { + const auto& spec = GetParam(); + const auto element_type = std::get<0>(spec); + const int64 num_elements = std::get<1>(spec); + XlaBuilder builder(TestName() + "_" + PrimitiveType_Name(element_type)); + IotaGen(&builder, element_type, num_elements); + if (element_type == F32) { + ComputeAndCompareR1<float>(&builder, GetR1Expected<float>(num_elements), {}, + ErrorSpec{0.0001}); + } else if (element_type == U32) { + ComputeAndCompareR1<uint32>(&builder, GetR1Expected<uint32>(num_elements), + {}); + } else { + CHECK_EQ(element_type, S32); + ComputeAndCompareR1<int32>(&builder, GetR1Expected<int32>(num_elements), + {}); } -}; - -XLA_TEST_F(IotaTest, SimpleR1) { - for (int num_elements = 1; num_elements < 10000001; num_elements *= 10) { - { - XlaBuilder builder(TestName() + "_f32"); - IotaGen(&builder, F32, num_elements); - ComputeAndCompareR1<float>(&builder, GetExpected<float>(num_elements), {}, - ErrorSpec{0.0001}); - } - { - XlaBuilder builder(TestName() + "_u32"); - IotaGen(&builder, U32, num_elements); - ComputeAndCompareR1<uint32>(&builder, GetExpected<uint32>(num_elements), - {}); - } - { - XlaBuilder builder(TestName() + "_s32"); - IotaGen(&builder, S32, num_elements); - ComputeAndCompareR1<int32>(&builder, GetExpected<int32>(num_elements), - {}); - } +} + +INSTANTIATE_TEST_CASE_P(IotaR1TestInstantiation, IotaR1Test, + ::testing::Combine(::testing::Values(F32, U32, S32), + ::testing::Range(/*start=*/10, + /*end=*/10001, + /*step=*/10))); + +class IotaR2Test : public ClientLibraryTestBase, + public ::testing::WithParamInterface< + std::tuple<PrimitiveType, int, int>> {}; + +TEST_P(IotaR2Test, DoIt) { + const auto& spec = GetParam(); + const auto element_type = std::get<0>(spec); + const int64 num_elements = std::get<1>(spec); + const int64 iota_dim = std::get<2>(spec); + XlaBuilder builder(TestName() + "_" + PrimitiveType_Name(element_type)); + std::vector<int64> dimensions = {42}; + dimensions.insert(dimensions.begin() + iota_dim, num_elements); + IotaGen(&builder, ShapeUtil::MakeShape(element_type, dimensions), iota_dim); + if (primitive_util::IsFloatingPointType(element_type)) { + ComputeAndCompare(&builder, {}, ErrorSpec{0.0001}); + } else { + ComputeAndCompare(&builder, {}); } } +INSTANTIATE_TEST_CASE_P(IotaR2TestInstantiation, IotaR2Test, + ::testing::Combine(::testing::Values(F32, S32), + ::testing::Range(/*start=*/10, + /*end=*/1001, + /*step=*/10), + ::testing::Values(0, 1))); + +class IotaR3Test : public ClientLibraryTestBase, + public ::testing::WithParamInterface< + std::tuple<PrimitiveType, int, int>> {}; + +TEST_P(IotaR3Test, DoIt) { + const auto& spec = GetParam(); + const auto element_type = std::get<0>(spec); + const int64 num_elements = std::get<1>(spec); + const int64 iota_dim = std::get<2>(spec); + XlaBuilder builder(TestName() + "_" + PrimitiveType_Name(element_type)); + std::vector<int64> dimensions = {42, 19}; + dimensions.insert(dimensions.begin() + iota_dim, num_elements); + IotaGen(&builder, ShapeUtil::MakeShape(element_type, dimensions), iota_dim); + if (primitive_util::IsFloatingPointType(element_type)) { + ComputeAndCompare(&builder, {}, ErrorSpec{0.0001}); + } else { + ComputeAndCompare(&builder, {}); + } +} + +INSTANTIATE_TEST_CASE_P(IotaR3TestInstantiation, IotaR3Test, + ::testing::Combine(::testing::Values(F32, S32), + ::testing::Range(/*start=*/10, + /*end=*/1001, + /*step=*/10), + ::testing::Values(0, 1, 2))); + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/tests/literal_test_util.cc b/tensorflow/compiler/xla/tests/literal_test_util.cc index cde1dcd9cd..554eb24d44 100644 --- a/tensorflow/compiler/xla/tests/literal_test_util.cc +++ b/tensorflow/compiler/xla/tests/literal_test_util.cc @@ -15,9 +15,9 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/literal_test_util.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/literal_comparison.h" #include "tensorflow/core/lib/io/path.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/test.h" namespace xla { @@ -35,8 +35,7 @@ void WriteLiteralToTempFile(const LiteralSlice& literal, const string& name) { int64 now_usec = tensorflow::Env::Default()->NowMicros(); string filename = tensorflow::io::JoinPath( tensorflow::testing::TmpDir(), - tensorflow::strings::Printf("tempfile-%s-%llx-%s", get_hostname().c_str(), - now_usec, name.c_str())); + absl::StrFormat("tempfile-%s-%x-%s", get_hostname(), now_usec, name)); TF_CHECK_OK(tensorflow::WriteBinaryProto(tensorflow::Env::Default(), filename, literal.ToProto())); LOG(ERROR) << "wrote to " << name << " file: " << filename; @@ -94,7 +93,7 @@ void OnMiscompare(const LiteralSlice& expected, const LiteralSlice& actual, /* static */ ::testing::AssertionResult LiteralTestUtil::NearOrEqual( const LiteralSlice& expected, const LiteralSlice& actual, - const tensorflow::gtl::optional<ErrorSpec>& error) { + const absl::optional<ErrorSpec>& error) { if (error.has_value()) { VLOG(1) << "Expects near"; return StatusToAssertion(literal_comparison::Near( diff --git a/tensorflow/compiler/xla/tests/literal_test_util.h b/tensorflow/compiler/xla/tests/literal_test_util.h index 31a099c15f..3dad91951e 100644 --- a/tensorflow/compiler/xla/tests/literal_test_util.h +++ b/tensorflow/compiler/xla/tests/literal_test_util.h @@ -21,6 +21,7 @@ limitations under the License. #include <random> #include <string> +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array3d.h" #include "tensorflow/compiler/xla/array4d.h" @@ -33,7 +34,6 @@ limitations under the License. #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" @@ -146,7 +146,7 @@ class LiteralTestUtil { // will be compared recursively. static ::testing::AssertionResult NearOrEqual( const LiteralSlice& expected, const LiteralSlice& actual, - const tensorflow::gtl::optional<ErrorSpec>& error) TF_MUST_USE_RESULT; + const absl::optional<ErrorSpec>& error) TF_MUST_USE_RESULT; private: TF_DISALLOW_COPY_AND_ASSIGN(LiteralTestUtil); diff --git a/tensorflow/compiler/xla/tests/literal_test_util_test.cc b/tensorflow/compiler/xla/tests/literal_test_util_test.cc index f297b2b847..4151bfae03 100644 --- a/tensorflow/compiler/xla/tests/literal_test_util_test.cc +++ b/tensorflow/compiler/xla/tests/literal_test_util_test.cc @@ -20,9 +20,9 @@ limitations under the License. #include <vector> +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/test_helpers.h" #include "tensorflow/core/lib/io/path.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/test.h" @@ -80,7 +80,7 @@ TEST(LiteralTestUtilTest, ExpectNearFailurePlacesResultsInTemporaryDirectory) { std::vector<string> results; TF_CHECK_OK(env->GetMatchingPaths(pattern, &results)); - LOG(INFO) << "results: [" << tensorflow::str_util::Join(results, ", ") << "]"; + LOG(INFO) << "results: [" << absl::StrJoin(results, ", ") << "]"; EXPECT_EQ(3, results.size()); for (const string& result : results) { LiteralProto literal_proto; @@ -105,8 +105,10 @@ TEST(LiteralTestUtilTest, NotEqualHasValuesInMessage) { auto actual = LiteralUtil::CreateR1<int32>({4, 5, 6}); ::testing::AssertionResult result = LiteralTestUtil::Equal(*expected, *actual); - EXPECT_THAT(result.message(), ::testing::HasSubstr("expected: {1, 2, 3}")); - EXPECT_THAT(result.message(), ::testing::HasSubstr("actual: {4, 5, 6}")); + EXPECT_THAT(result.message(), + ::testing::HasSubstr("Expected literal:\n{1, 2, 3}")); + EXPECT_THAT(result.message(), + ::testing::HasSubstr("Actual literal:\n{4, 5, 6}")); } TEST(LiteralTestUtilTest, NearComparatorR1) { diff --git a/tensorflow/compiler/xla/tests/llvm_compiler_test.cc b/tensorflow/compiler/xla/tests/llvm_compiler_test.cc index e719da54d4..8d65869557 100644 --- a/tensorflow/compiler/xla/tests/llvm_compiler_test.cc +++ b/tensorflow/compiler/xla/tests/llvm_compiler_test.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/xla/service/llvm_compiler.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/backend.h" #include "tensorflow/compiler/xla/service/cpu/cpu_compiler.h" @@ -125,7 +126,7 @@ class LLVMCompilerTest : public ::testing::Test { static std::unique_ptr<HloModule> CreateNewModule() { HloModuleConfig config; config.set_debug_options(legacy_flags::GetDebugOptionsFromFlags()); - return MakeUnique<HloModule>(TestName(), config); + return absl::make_unique<HloModule>(TestName(), config); } }; diff --git a/tensorflow/compiler/xla/tests/llvm_irgen_test_base.cc b/tensorflow/compiler/xla/tests/llvm_irgen_test_base.cc index 6fc1115097..0487d31409 100644 --- a/tensorflow/compiler/xla/tests/llvm_irgen_test_base.cc +++ b/tensorflow/compiler/xla/tests/llvm_irgen_test_base.cc @@ -51,8 +51,9 @@ void LlvmIrGenTestBase::CompileAndVerifyIr( std::unique_ptr<HloModule> hlo_module, const string& pattern, bool match_optimized_ir) { SetIrHook(match_optimized_ir); - TF_ASSERT_OK(CompileToExecutable(std::move(hlo_module)).status()); + Status status = CompileToExecutable(std::move(hlo_module)).status(); ResetIrHook(); + TF_ASSERT_OK(status); StatusOr<bool> filecheck_result = RunFileCheck(ir_, pattern); TF_ASSERT_OK(filecheck_result.status()); @@ -73,9 +74,10 @@ void LlvmIrGenTestBase::CompileAheadOfTimeAndVerifyIr( std::unique_ptr<HloModule> hlo_module, const AotCompilationOptions& options, const string& pattern, bool match_optimized_ir) { SetIrHook(match_optimized_ir); - TF_ASSERT_OK( - CompileToAotCompilationResult(std::move(hlo_module), options).status()); + Status status = + CompileToAotCompilationResult(std::move(hlo_module), options).status(); ResetIrHook(); + TF_ASSERT_OK(status); StatusOr<bool> filecheck_result = RunFileCheck(ir_, pattern); ASSERT_TRUE(filecheck_result.ok()); diff --git a/tensorflow/compiler/xla/tests/local_client_allocation_test.cc b/tensorflow/compiler/xla/tests/local_client_allocation_test.cc index e2cd5bcc5a..237a4a361e 100644 --- a/tensorflow/compiler/xla/tests/local_client_allocation_test.cc +++ b/tensorflow/compiler/xla/tests/local_client_allocation_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include <memory> +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/literal.h" @@ -24,7 +25,6 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/literal_test_util.h" #include "tensorflow/compiler/xla/tests/local_client_test_base.h" #include "tensorflow/compiler/xla/tests/test_macros.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" @@ -53,7 +53,7 @@ XLA_TEST_F(LocalClientAllocationTest, AddVectors) { // deallocation happen on the right allocator. ExecutableRunOptions options; options.set_allocator(allocator); - tensorflow::gtl::optional<ScopedShapedBuffer> result = + absl::optional<ScopedShapedBuffer> result = ExecuteLocallyOrDie(builder.Build().ValueOrDie(), {}, DefaultExecutableBuildOptions(), options); diff --git a/tensorflow/compiler/xla/tests/local_client_test_base.cc b/tensorflow/compiler/xla/tests/local_client_test_base.cc index eaddf756db..948b60061e 100644 --- a/tensorflow/compiler/xla/tests/local_client_test_base.cc +++ b/tensorflow/compiler/xla/tests/local_client_test_base.cc @@ -18,11 +18,11 @@ limitations under the License. #include <vector> +#include "absl/memory/memory.h" #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_computation.h" #include "tensorflow/compiler/xla/map_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/test_helpers.h" diff --git a/tensorflow/compiler/xla/tests/matrix_ops_simple_test.cc b/tensorflow/compiler/xla/tests/matrix_ops_simple_test.cc index da8c42d465..edb592f43e 100644 --- a/tensorflow/compiler/xla/tests/matrix_ops_simple_test.cc +++ b/tensorflow/compiler/xla/tests/matrix_ops_simple_test.cc @@ -17,12 +17,14 @@ limitations under the License. #include <memory> #include <string> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/client/xla_computation.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/reference_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/statusor.h" @@ -32,7 +34,6 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/test_macros.h" #include "tensorflow/compiler/xla/tests/test_utils.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" @@ -133,10 +134,9 @@ class TestLinspaceMaxParametric float from = -128.0, to = 256.0; std::unique_ptr<Array2D<T>> alhs = MakeLinspaceArray2D<T>(from, to, rows, cols); - auto arhs = MakeUnique<Array2D<T>>(rows, cols, static_cast<T>(1.0f)); + auto arhs = absl::make_unique<Array2D<T>>(rows, cols, static_cast<T>(1.0f)); - XlaBuilder builder( - tensorflow::strings::Printf("max_%lldx%lld_linspace", rows, cols)); + XlaBuilder builder(absl::StrFormat("max_%dx%d_linspace", rows, cols)); auto lhs = ConstantR2FromArray2D<T>(&builder, *alhs); auto rhs = ConstantR2FromArray2D<T>(&builder, *arhs); Max(lhs, rhs); @@ -158,7 +158,7 @@ class TestLinspaceMaxParametric string PrintTestLinspaceMaxParam( const ::testing::TestParamInfo<TestLinspaceMaxParam>& test_param) { const TestLinspaceMaxParam& param = test_param.param; - return tensorflow::strings::StrCat(param.rows, "r", param.cols, "c"); + return absl::StrCat(param.rows, "r", param.cols, "c"); } #ifndef XLA_BACKEND_DOES_NOT_SUPPORT_FLOAT16 diff --git a/tensorflow/compiler/xla/tests/multioutput_fusion_test.cc b/tensorflow/compiler/xla/tests/multioutput_fusion_test.cc index eb06b115da..16b77e965d 100644 --- a/tensorflow/compiler/xla/tests/multioutput_fusion_test.cc +++ b/tensorflow/compiler/xla/tests/multioutput_fusion_test.cc @@ -19,10 +19,11 @@ limitations under the License. #include <new> #include <utility> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/primitive_util.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" @@ -52,12 +53,22 @@ class MultiOutputFusionTest : public HloTestBase { protected: MultiOutputFusionTest() { error_spec_ = ErrorSpec{0.0001, 1e-2}; } + // Layout assignment assumes that there are no fusions in the input graph. + // Since the purpose of this test is to send pre-fused graphs to XLA, we have + // to do layout assignment ourselves. + DebugOptions GetDebugOptionsForTest() override { + auto opts = HloTestBase::GetDebugOptionsForTest(); + opts.add_xla_disable_hlo_passes("layout-assignment"); + return opts; + } + void RunTest2D(bool manual_fusion, int64 size) { auto builder = HloComputation::Builder(TestName()); auto hlo_module = CreateNewModule(); - const Shape elem_shape0 = ShapeUtil::MakeShape(F32, {}); - const Shape elem_shape2 = ShapeUtil::MakeShape(F32, {size, size}); + const Shape elem_shape0 = ShapeUtil::MakeShapeWithLayout(F32, {}, {}); + const Shape elem_shape2 = + ShapeUtil::MakeShapeWithLayout(F32, {size, size}, {1, 0}); auto const0 = builder.AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(8.0f))); @@ -100,10 +111,10 @@ class MultiOutputFusionTest : public HloTestBase { nullptr); } - Literal arg1(ShapeUtil::MakeShape(F32, {size, size})); + Literal arg1(ShapeUtil::MakeShapeWithDescendingLayout(F32, {size, size})); arg1.PopulateWithValue<float>(2.5f); - Literal expect(ShapeUtil::MakeShape(F32, {size, size})); + Literal expect(ShapeUtil::MakeShapeWithDescendingLayout(F32, {size, size})); expect.PopulateWithValue<float>(size * 1.5f * 3.5f); auto actual = ExecuteAndTransfer(std::move(hlo_module), @@ -115,8 +126,10 @@ class MultiOutputFusionTest : public HloTestBase { auto builder = HloComputation::Builder(TestName()); auto hlo_module = CreateNewModule(); - const Shape elem_shape_F32 = ShapeUtil::MakeShape(F32, {size}); - const Shape elem_shape_U8 = ShapeUtil::MakeShape(F64, {size}); + const Shape elem_shape_F32 = + ShapeUtil::MakeShapeWithDescendingLayout(F32, {size}); + const Shape elem_shape_U8 = + ShapeUtil::MakeShapeWithDescendingLayout(F64, {size}); auto param0 = builder.AddInstruction( HloInstruction::CreateParameter(0, elem_shape_F32, "0")); auto param1 = builder.AddInstruction( @@ -136,12 +149,13 @@ class MultiOutputFusionTest : public HloTestBase { HloInstruction* reshape = builder.AddInstruction(HloInstruction::CreateReshape( - ShapeUtil::MakeShape(F32, {size, 1}), add)); + ShapeUtil::MakeShapeWithDescendingLayout(F32, {size, 1}), add)); DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(0); dot_dnums.add_rhs_contracting_dimensions(0); HloInstruction* dot = builder.AddInstruction(HloInstruction::CreateDot( - ShapeUtil::MakeShape(F32, {1}), sub, reshape, dot_dnums)); + ShapeUtil::MakeShapeWithDescendingLayout(F32, {1}), sub, reshape, + dot_dnums)); auto computation = hlo_module->AddEntryComputation(builder.Build(dot)); if (manual_fusion) { @@ -161,9 +175,9 @@ class MultiOutputFusionTest : public HloTestBase { nullptr); } - Literal input0(ShapeUtil::MakeShape(F32, {size})); + Literal input0(ShapeUtil::MakeShapeWithDescendingLayout(F32, {size})); input0.PopulateWithValue(2.5f); - Literal input1(ShapeUtil::MakeShape(F64, {size})); + Literal input1(ShapeUtil::MakeShapeWithDescendingLayout(F64, {size})); input1.PopulateWithValue(1.); Literal expect = @@ -291,7 +305,7 @@ const char* const kScalarOps = R"( XLA_TEST_F(MultiOutputFusionTest, DISABLED_ON_CPU(MultiOutputReduceFusionMinor)) { - const string testcase = tensorflow::strings::StrCat(kScalarOps, R"( + const string testcase = absl::StrCat(kScalarOps, R"( fused_reduce { p0 = f32[2,2,2]{2,1,0} parameter(0) c0 = f32[] constant(0) @@ -323,7 +337,7 @@ XLA_TEST_F(MultiOutputFusionTest, XLA_TEST_F(MultiOutputFusionTest, DISABLED_ON_CPU(MultiOutputReduceFusionMajor)) { - const string testcase = tensorflow::strings::StrCat(kScalarOps, R"( + const string testcase = absl::StrCat(kScalarOps, R"( fused_reduce { p0 = f32[2,2,2]{2,1,0} parameter(0) c0 = f32[] constant(0) @@ -355,7 +369,7 @@ XLA_TEST_F(MultiOutputFusionTest, XLA_TEST_F(MultiOutputFusionTest, DISABLED_ON_CPU(MultiOutputReduceFusionScalar)) { - const string testcase = tensorflow::strings::StrCat(kScalarOps, R"( + const string testcase = absl::StrCat(kScalarOps, R"( fused_reduce { p0 = f32[2,2,2]{2,1,0} parameter(0) c0 = f32[] constant(0) @@ -388,7 +402,7 @@ XLA_TEST_F(MultiOutputFusionTest, XLA_TEST_F(MultiOutputFusionTest, DISABLED_ON_CPU(MultiOutputReduceFusionMinorWithExtraOutput)) { - const string testcase = tensorflow::strings::StrCat(kScalarOps, R"( + const string testcase = absl::StrCat(kScalarOps, R"( fused_reduce { p0 = f32[2,2,2]{2,1,0} parameter(0) c0 = f32[] constant(0) @@ -422,7 +436,7 @@ XLA_TEST_F(MultiOutputFusionTest, XLA_TEST_F(MultiOutputFusionTest, DISABLED_ON_CPU(MultiOutputReduceFusionMajorWithExtraOutput)) { - const string testcase = tensorflow::strings::StrCat(kScalarOps, R"( + const string testcase = absl::StrCat(kScalarOps, R"( fused_reduce { p0 = f32[2,2,2]{2,1,0} parameter(0) c0 = f32[] constant(0) @@ -457,7 +471,7 @@ XLA_TEST_F(MultiOutputFusionTest, XLA_TEST_F(MultiOutputFusionTest, DISABLED_ON_CPU(MultiOutputReduceFusionScalarWithExtraOutput)) { - const string testcase = tensorflow::strings::StrCat(kScalarOps, R"( + const string testcase = absl::StrCat(kScalarOps, R"( fused_reduce { p0 = f32[2,2,2]{2,1,0} parameter(0) c0 = f32[] constant(0) @@ -494,7 +508,7 @@ XLA_TEST_F(MultiOutputFusionTest, XLA_TEST_F(MultiOutputFusionTest, DISABLED_ON_CPU(MultiOutputReduceFusionNonConstInit)) { - const string testcase = tensorflow::strings::StrCat(kScalarOps, R"( + const string testcase = absl::StrCat(kScalarOps, R"( fused_reduce { p0 = f32[2,2,2]{2,1,0} parameter(0) init1 = f32[] parameter(1) @@ -529,7 +543,7 @@ XLA_TEST_F(MultiOutputFusionTest, XLA_TEST_F(MultiOutputFusionTest, DISABLED_ON_CPU(MultiOutputReduceFusionDifferentElementTypes)) { - const string testcase = tensorflow::strings::StrCat(kScalarOps, R"( + const string testcase = absl::StrCat(kScalarOps, R"( fused_reduce (p0: f16[2,2,2]) -> (f32[2,2], f32[2,2], f16[2,2,2]) { p0 = f16[2,2,2]{2,1,0} parameter(0) convert = f32[2,2,2]{2,1,0} convert(p0) diff --git a/tensorflow/compiler/xla/tests/pad_test.cc b/tensorflow/compiler/xla/tests/pad_test.cc index ca21b0b2ba..cbeddffacf 100644 --- a/tensorflow/compiler/xla/tests/pad_test.cc +++ b/tensorflow/compiler/xla/tests/pad_test.cc @@ -16,12 +16,12 @@ limitations under the License. #include <memory> #include <vector> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/client/lib/arithmetic.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/reference_util.h" #include "tensorflow/compiler/xla/tests/client_library_test_base.h" #include "tensorflow/compiler/xla/tests/literal_test_util.h" @@ -140,7 +140,7 @@ XLA_TEST_P(PadTestFloat, Pad4D_2x0x3x2_FloatArray) { TEST_P(PadTestFloat, Pad4DFloat_1x1x3x2_Array) { XlaBuilder b(TestName()); - auto input = MakeUnique<Array4D<float>>(1, 1, 3, 2); + auto input = absl::make_unique<Array4D<float>>(1, 1, 3, 2); Array2D<float> input_xy({ {1.0f, 2.0f}, // row 0 {3.0f, 4.0f}, // row 1 @@ -151,7 +151,7 @@ TEST_P(PadTestFloat, Pad4DFloat_1x1x3x2_Array) { Pad(AddParam(*input, &b), AddParam(*LiteralUtil::CreateR0<float>(1.5), &b), r4_padding_on_dim0_dim1_); - auto expected = MakeUnique<Array4D<float>>(2, 3, 3, 2); + auto expected = absl::make_unique<Array4D<float>>(2, 3, 3, 2); expected->Fill(1.5); (*expected)(1, 0, 0, 0) = 1.0f; (*expected)(1, 0, 0, 1) = 2.0f; @@ -171,7 +171,7 @@ TEST_P(PadTestFloat, Pad4DFloatArrayWithInteriorPadding) { AddParam(*LiteralUtil::CreateR0<float>(pad_value), &b), r4_padding_on_dim0_dim1_); - auto expected = MakeUnique<Array4D<float>>(8, 5, 1, 1); + auto expected = absl::make_unique<Array4D<float>>(8, 5, 1, 1); expected->Fill(pad_value); (*expected)(1, 0, 0, 0) = 1.0f; (*expected)(1, 2, 0, 0) = 2.0f; @@ -269,7 +269,7 @@ XLA_TEST_P(PadTestFloat, Pad4DFloatArrayMinorFirstNonTrivialMinorDimensions) { XLA_TEST_F(PadTest, Pad4DU8Array) { XlaBuilder b(TestName()); - auto input = MakeUnique<Array4D<uint8>>(1, 1, 3, 2); + auto input = absl::make_unique<Array4D<uint8>>(1, 1, 3, 2); Array2D<uint8> input_xy({ {1, 2}, // row 0 {3, 4}, // row 1 @@ -280,7 +280,7 @@ XLA_TEST_F(PadTest, Pad4DU8Array) { Pad(AddParam(*input, &b), ConstantR0<uint8>(&b, 35), r4_padding_on_dim0_dim1_); - auto expected = MakeUnique<Array4D<uint8>>(2, 3, 3, 2); + auto expected = absl::make_unique<Array4D<uint8>>(2, 3, 3, 2); expected->Fill(35); (*expected)(1, 0, 0, 0) = 1; (*expected)(1, 0, 0, 1) = 2; @@ -301,13 +301,13 @@ XLA_TEST_F(PadTest, Pad4DPredArray) { Pad(input, ConstantR0<bool>(&b, false), r4_padding_on_dim0_dim1_); // For the same reason, use Select to convert boolean values to int32. - auto zeros = MakeUnique<Array4D<int32>>(2, 3, 3, 2); - auto ones = MakeUnique<Array4D<int32>>(2, 3, 3, 2); + auto zeros = absl::make_unique<Array4D<int32>>(2, 3, 3, 2); + auto ones = absl::make_unique<Array4D<int32>>(2, 3, 3, 2); zeros->Fill(0); ones->Fill(1); Select(padded, AddParam(*ones, &b), AddParam(*zeros, &b)); - auto expected = MakeUnique<Array4D<int32>>(2, 3, 3, 2); + auto expected = absl::make_unique<Array4D<int32>>(2, 3, 3, 2); expected->Fill(0); (*expected)(1, 0, 0, 0) = 1; (*expected)(1, 0, 0, 1) = 1; @@ -321,7 +321,7 @@ XLA_TEST_F(PadTest, Pad4DPredArray) { XLA_TEST_P(PadTestFloat, Large2DPad) { XlaBuilder b(TestName()); - auto ones = MakeUnique<Array2D<float>>(4, 4); + auto ones = absl::make_unique<Array2D<float>>(4, 4); ones->Fill(1.0f); auto input = AddParam(*ones, &b); PaddingConfig padding_config = MakeNoPaddingConfig(2); @@ -342,7 +342,7 @@ XLA_TEST_P(PadTestFloat, AllTypes2DPad) { constexpr int64 in_rows = 35; constexpr int64 in_cols = 35; - auto operand = MakeUnique<Array2D<float>>(in_rows, in_cols); + auto operand = absl::make_unique<Array2D<float>>(in_rows, in_cols); operand->FillUnique(0.0f); auto input = AddParam(*operand, &b); @@ -368,7 +368,7 @@ XLA_TEST_P(PadTestFloat, High2DPad) { constexpr int64 low_padding = 0; int64 high_padding[2] = {5, 7}; constexpr int64 interior_padding = 0; - auto operand = MakeUnique<Array2D<float>>(in_rows, in_cols); + auto operand = absl::make_unique<Array2D<float>>(in_rows, in_cols); operand->FillUnique(1.0f); auto input = AddParam(*operand, &b); PaddingConfig padding_config = MakeNoPaddingConfig(2); @@ -395,7 +395,7 @@ XLA_TEST_P(PadTestFloat, NegativePadding2D) { int64 low_padding[2] = {-1, -2}; int64 high_padding[2] = {-3, 4}; constexpr int64 interior_padding = 0; - auto operand = MakeUnique<Array2D<float>>(in_rows, in_cols); + auto operand = absl::make_unique<Array2D<float>>(in_rows, in_cols); operand->FillUnique(1.0f); auto input = AddParam(*operand, &b); PaddingConfig padding_config = MakeNoPaddingConfig(2); @@ -423,7 +423,7 @@ XLA_TEST_P(PadTestFloat, NegativeAndInteriorPadding2D) { int64 low_padding[2] = {4, -1}; int64 high_padding[2] = {-2, -4}; int64 interior_padding[2] = {1, 2}; - auto operand = MakeUnique<Array2D<float>>(in_rows, in_cols); + auto operand = absl::make_unique<Array2D<float>>(in_rows, in_cols); operand->FillUnique(1.0f); auto input = AddParam(*operand, &b); PaddingConfig padding_config = MakeNoPaddingConfig(2); @@ -446,7 +446,7 @@ XLA_TEST_P(PadTestFloat, NegativeAndInteriorPadding2D) { // Regression test for b/31827337. XLA_TEST_P(PadTestFloat, ReducePad) { XlaBuilder b(TestName()); - auto ones = MakeUnique<Array4D<float>>(2, 2, 2, 2); + auto ones = absl::make_unique<Array4D<float>>(2, 2, 2, 2); ones->Fill(1.0); auto input = AddParam(*ones, &b); diff --git a/tensorflow/compiler/xla/tests/reduce_hlo_test.cc b/tensorflow/compiler/xla/tests/reduce_hlo_test.cc index a080dd1732..9af9ea4a22 100644 --- a/tensorflow/compiler/xla/tests/reduce_hlo_test.cc +++ b/tensorflow/compiler/xla/tests/reduce_hlo_test.cc @@ -15,11 +15,11 @@ limitations under the License. #include <array> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/service/hlo_parser.h" #include "tensorflow/compiler/xla/tests/hlo_test_base.h" #include "tensorflow/compiler/xla/tests/test_macros.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" @@ -29,16 +29,13 @@ limitations under the License. namespace xla { namespace { -namespace str_util = tensorflow::str_util; -namespace strings = tensorflow::strings; - struct ReduceLayout { std::array<int64, 4> input_minor_to_major; std::array<int64, 3> output_minor_to_major; string ToString() const { - return strings::StrCat(str_util::Join(input_minor_to_major, "x"), "_", - str_util::Join(output_minor_to_major, "x")); + return absl::StrCat(absl::StrJoin(input_minor_to_major, "x"), "_", + absl::StrJoin(output_minor_to_major, "x")); } }; diff --git a/tensorflow/compiler/xla/tests/reduce_precision_test.cc b/tensorflow/compiler/xla/tests/reduce_precision_test.cc index 531648fe3e..0916a07f4f 100644 --- a/tensorflow/compiler/xla/tests/reduce_precision_test.cc +++ b/tensorflow/compiler/xla/tests/reduce_precision_test.cc @@ -19,6 +19,7 @@ limitations under the License. #include <numeric> #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/client/global_data.h" #include "tensorflow/compiler/xla/client/local_client.h" @@ -57,8 +58,8 @@ static const int mantissa_sizes[] = {23, 10, 23, 10}; string TestDataToString(const ::testing::TestParamInfo<int> data) { int i = data.param; - return tensorflow::strings::StrCat(exponent_sizes[i], "_exponent_bits_", - mantissa_sizes[i], "_mantissa_bits"); + return absl::StrCat(exponent_sizes[i], "_exponent_bits_", mantissa_sizes[i], + "_mantissa_bits"); } // The FPVAL macro allows us to write out the binary representation of the diff --git a/tensorflow/compiler/xla/tests/reduce_test.cc b/tensorflow/compiler/xla/tests/reduce_test.cc index 2065271a7f..346f702488 100644 --- a/tensorflow/compiler/xla/tests/reduce_test.cc +++ b/tensorflow/compiler/xla/tests/reduce_test.cc @@ -32,6 +32,8 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/client/global_data.h" @@ -556,12 +558,11 @@ struct BoundsLayout { }; void PrintTo(const BoundsLayout& spec, std::ostream* os) { - *os << tensorflow::strings::Printf( - "R%luToR%lu%s_%s_Reduce%s", spec.bounds.size(), - spec.bounds.size() - spec.reduce_dims.size(), - tensorflow::str_util::Join(spec.bounds, "x").c_str(), - tensorflow::str_util::Join(spec.layout, "").c_str(), - tensorflow::str_util::Join(spec.reduce_dims, "").c_str()); + *os << absl::StrFormat("R%uToR%u%s_%s_Reduce%s", spec.bounds.size(), + spec.bounds.size() - spec.reduce_dims.size(), + absl::StrJoin(spec.bounds, "x"), + absl::StrJoin(spec.layout, ""), + absl::StrJoin(spec.reduce_dims, "")); } // Add-reduces a broadcasted scalar matrix among dimension 1 and 0. diff --git a/tensorflow/compiler/xla/tests/reduce_window_test.cc b/tensorflow/compiler/xla/tests/reduce_window_test.cc index cae029fd70..60167619a4 100644 --- a/tensorflow/compiler/xla/tests/reduce_window_test.cc +++ b/tensorflow/compiler/xla/tests/reduce_window_test.cc @@ -18,6 +18,9 @@ limitations under the License. #include <limits> #include <memory> +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array3d.h" #include "tensorflow/compiler/xla/array4d.h" @@ -357,7 +360,7 @@ XLA_TEST_P(ReduceWindowTest, R6AddMultipleStrides) { std::vector<int64> input_dims(6, 8); auto shape = ShapeUtil::MakeShape(F32, input_dims); - auto arg_literal = MakeUnique<Literal>(shape); + auto arg_literal = absl::make_unique<Literal>(shape); arg_literal->PopulateWithValue(1.0f); const auto input = CreateConstantFromLiteral(*arg_literal, &builder_); @@ -368,7 +371,7 @@ XLA_TEST_P(ReduceWindowTest, R6AddMultipleStrides) { std::vector<int64> output_dims = {6, 8, 6, 6, 8, 8}; Shape result_shape = ShapeUtil::MakeShapeWithLayout(F32, output_dims, output_layout); - auto expected = MakeUnique<Literal>(result_shape); + auto expected = absl::make_unique<Literal>(result_shape); expected->PopulateWithValue(27.0f); ComputeAndCompareLiteral(&builder_, *expected, {}, DefaultErrorSpec()); } @@ -578,21 +581,20 @@ string R4ReduceWindowTestDataToString( const ::testing::TestParamInfo< ::testing::tuple<R4ReduceWindowTestData, bool>>& data) { const auto& param = ::testing::get<0>(data.param); - string str = tensorflow::strings::StrCat( - "base_bounds_", tensorflow::str_util::Join(param.base_bounds, "x"), // - "__window_bounds_", - tensorflow::str_util::Join(param.window_bounds, "x"), // - "__strides_", tensorflow::str_util::Join(param.strides, "x"), // - "__pad_low_", tensorflow::str_util::Join(param.pad_low, "x"), // - "__pad_high_", tensorflow::str_util::Join(param.pad_high, "x"), // - "__layout_", tensorflow::str_util::Join(param.layout, "_"), // + string str = absl::StrCat( + "base_bounds_", absl::StrJoin(param.base_bounds, "x"), // + "__window_bounds_", absl::StrJoin(param.window_bounds, "x"), // + "__strides_", absl::StrJoin(param.strides, "x"), // + "__pad_low_", absl::StrJoin(param.pad_low, "x"), // + "__pad_high_", absl::StrJoin(param.pad_high, "x"), // + "__layout_", absl::StrJoin(param.layout, "_"), // (param.reducer == kAdd) ? "_add" : "_max"); CHECK(param.reducer == kAdd || param.reducer == kMax); // Test names are not allowed to contain the '-' character. std::replace(str.begin(), str.end(), '-', 'n'); if (::testing::get<1>(data.param)) { - str = tensorflow::strings::StrCat(str, "_bfloat16"); + str = absl::StrCat(str, "_bfloat16"); } return str; } @@ -934,15 +936,15 @@ string R3ReduceWindowTestDataToString( const ::testing::TestParamInfo< ::testing::tuple<R3ReduceWindowTestData, bool>>& data) { const auto& param = ::testing::get<0>(data.param); - string str = tensorflow::strings::StrCat( - "base_bounds_", tensorflow::str_util::Join(param.base_bounds, "x"), - "__window_bounds_", tensorflow::str_util::Join(param.window_bounds, "x"), - "__strides_", tensorflow::str_util::Join(param.strides, "x"), - "__padding_", param.padding == Padding::kSame ? "same" : "valid", - "__layout_", param.layout[0], "_", param.layout[1], "_", param.layout[2], - "__reducer_", param.reducer == kAdd ? "add" : "max"); + string str = absl::StrCat( + "base_bounds_", absl::StrJoin(param.base_bounds, "x"), "__window_bounds_", + absl::StrJoin(param.window_bounds, "x"), "__strides_", + absl::StrJoin(param.strides, "x"), "__padding_", + param.padding == Padding::kSame ? "same" : "valid", "__layout_", + param.layout[0], "_", param.layout[1], "_", param.layout[2], "__reducer_", + param.reducer == kAdd ? "add" : "max"); if (::testing::get<1>(data.param)) { - str = tensorflow::strings::StrCat(str, "_bfloat16"); + str = absl::StrCat(str, "_bfloat16"); } return str; } @@ -1068,17 +1070,16 @@ string R2ReduceWindowTestDataToString( const ::testing::TestParamInfo< ::testing::tuple<R2ReduceWindowTestData, bool>>& data) { const auto& param = ::testing::get<0>(data.param); - string str = tensorflow::strings::StrCat( - "base_bounds_", tensorflow::str_util::Join(param.base_bounds, "x"), // - "__window_bounds_", - tensorflow::str_util::Join(param.window_bounds, "x"), // - "__strides_", tensorflow::str_util::Join(param.strides, "x"), // - "__pad_low_", tensorflow::str_util::Join(param.pad_low, "x"), - "__pad_high_", tensorflow::str_util::Join(param.pad_high, "x"), - "__layout_", param.layout[0], "_", param.layout[1], // + string str = absl::StrCat( + "base_bounds_", absl::StrJoin(param.base_bounds, "x"), // + "__window_bounds_", absl::StrJoin(param.window_bounds, "x"), // + "__strides_", absl::StrJoin(param.strides, "x"), // + "__pad_low_", absl::StrJoin(param.pad_low, "x"), "__pad_high_", + absl::StrJoin(param.pad_high, "x"), "__layout_", param.layout[0], "_", + param.layout[1], // "__reducer_", param.reducer == kAdd ? "add" : "max"); if (::testing::get<1>(data.param)) { - str = tensorflow::strings::StrCat(str, "_bfloat16"); + str = absl::StrCat(str, "_bfloat16"); } return str; } @@ -1273,15 +1274,15 @@ string R1ReduceWindowTestDataToString( const ::testing::TestParamInfo< ::testing::tuple<R1ReduceWindowTestData, bool>>& data) { const auto& param = ::testing::get<0>(data.param); - string str = tensorflow::strings::StrCat( - "base_bounds_", tensorflow::str_util::Join(param.base_bounds, "x"), - "__window_bounds_", tensorflow::str_util::Join(param.window_bounds, "x"), - "__strides_", tensorflow::str_util::Join(param.strides, "x"), - "__pad_low_", tensorflow::str_util::Join(param.pad_low, "x"), - "__pad_high_", tensorflow::str_util::Join(param.pad_high, "x"), - "__reducer_", param.reducer == kAdd ? "add" : "max"); + string str = + absl::StrCat("base_bounds_", absl::StrJoin(param.base_bounds, "x"), + "__window_bounds_", absl::StrJoin(param.window_bounds, "x"), + "__strides_", absl::StrJoin(param.strides, "x"), + "__pad_low_", absl::StrJoin(param.pad_low, "x"), + "__pad_high_", absl::StrJoin(param.pad_high, "x"), + "__reducer_", param.reducer == kAdd ? "add" : "max"); if (::testing::get<1>(data.param)) { - str = tensorflow::strings::StrCat(str, "_bfloat16"); + str = absl::StrCat(str, "_bfloat16"); } return str; } @@ -1448,7 +1449,7 @@ ENTRY reduce-window-identity { } )"; - EXPECT_TRUE(RunAndCompare(hlo_string, tensorflow::gtl::nullopt)); + EXPECT_TRUE(RunAndCompare(hlo_string, absl::nullopt)); } XLA_TEST_F(HloTestBase, ReduceWindowS32) { @@ -1467,7 +1468,7 @@ ENTRY %reduce-window (parameter.0: s32[81,8], parameter.1: s32[]) -> s32[82,8] { } )"; - EXPECT_TRUE(RunAndCompare(hlo_string, tensorflow::gtl::nullopt)); + EXPECT_TRUE(RunAndCompare(hlo_string, absl::nullopt)); } XLA_TEST_F(HloTestBase, ReduceWindowF16) { @@ -1486,7 +1487,7 @@ ENTRY %reduce-window (parameter.0: f16[81,8], parameter.1: f16[]) -> f16[82,8] { } )"; - EXPECT_TRUE(RunAndCompare(hlo_string, tensorflow::gtl::nullopt)); + EXPECT_TRUE(RunAndCompare(hlo_string, absl::nullopt)); } } // namespace diff --git a/tensorflow/compiler/xla/tests/reverse_test.cc b/tensorflow/compiler/xla/tests/reverse_test.cc index 41e49b4003..c755ff63c9 100644 --- a/tensorflow/compiler/xla/tests/reverse_test.cc +++ b/tensorflow/compiler/xla/tests/reverse_test.cc @@ -15,6 +15,8 @@ limitations under the License. #include <memory> +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/array4d.h" #include "tensorflow/compiler/xla/client/local_client.h" @@ -42,11 +44,9 @@ struct ReverseSpec { bool use_bfloat16; string ToTestCaseName() const { - return tensorflow::strings::Printf( - "reverse_%s_in_dims_%s_%s", - tensorflow::str_util::Join(input_dims, "x").c_str(), - tensorflow::str_util::Join(reversal, "x").c_str(), - use_bfloat16 ? "bf16" : "f32"); + return absl::StrFormat( + "reverse_%s_in_dims_%s_%s", absl::StrJoin(input_dims, "x"), + absl::StrJoin(reversal, "x"), use_bfloat16 ? "bf16" : "f32"); } }; diff --git a/tensorflow/compiler/xla/tests/sample_text_test.cc b/tensorflow/compiler/xla/tests/sample_text_test.cc index b4f2b74e3d..2b03a0b0b2 100644 --- a/tensorflow/compiler/xla/tests/sample_text_test.cc +++ b/tensorflow/compiler/xla/tests/sample_text_test.cc @@ -19,18 +19,18 @@ limitations under the License. #include <string> #include <vector> +#include "absl/types/optional.h" #include "tensorflow/compiler/xla/test.h" #include "tensorflow/compiler/xla/tests/hlo_test_base.h" #include "tensorflow/compiler/xla/tests/literal_test_util.h" #include "tensorflow/compiler/xla/tests/test_macros.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/platform/types.h" namespace xla { namespace { -using tensorflow::gtl::nullopt; +using absl::nullopt; class SampleTextTest : public HloTestBase {}; diff --git a/tensorflow/compiler/xla/tests/scalar_computations_test.cc b/tensorflow/compiler/xla/tests/scalar_computations_test.cc index e42c71eb28..cf2d453f43 100644 --- a/tensorflow/compiler/xla/tests/scalar_computations_test.cc +++ b/tensorflow/compiler/xla/tests/scalar_computations_test.cc @@ -17,6 +17,7 @@ limitations under the License. #include <limits> #include <memory> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/client/global_data.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" @@ -31,7 +32,6 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/test_macros.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" diff --git a/tensorflow/compiler/xla/tests/scatter_test.cc b/tensorflow/compiler/xla/tests/scatter_test.cc index 922d70b752..99eeb12e2b 100644 --- a/tensorflow/compiler/xla/tests/scatter_test.cc +++ b/tensorflow/compiler/xla/tests/scatter_test.cc @@ -23,7 +23,7 @@ limitations under the License. namespace xla { namespace { -using tensorflow::gtl::nullopt; +using absl::nullopt; class ScatterTest : public HloTestBase { protected: diff --git a/tensorflow/compiler/xla/tests/slice_test.cc b/tensorflow/compiler/xla/tests/slice_test.cc index b8ad6668f8..69585ae39a 100644 --- a/tensorflow/compiler/xla/tests/slice_test.cc +++ b/tensorflow/compiler/xla/tests/slice_test.cc @@ -18,6 +18,10 @@ limitations under the License. #include <numeric> #include <vector> +#include "absl/container/inlined_vector.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" @@ -26,15 +30,12 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/literal_test_util.h" #include "tensorflow/compiler/xla/tests/test_macros.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" namespace xla { namespace { -using ::tensorflow::str_util::Join; - class SliceTest : public ClientLibraryTestBase {}; TEST_F(SliceTest, Slice3x3x3_To_3x3x1_F32) { @@ -195,7 +196,7 @@ class SliceR1Test : public ClientLibraryTestBase, void Run(const R1Spec& spec) { // This can't be an std::vector, since you can't grab an ArraySlice of a // vector<bool>. - tensorflow::gtl::InlinedVector<NativeT, 1> input(spec.input_dim0); + absl::InlinedVector<NativeT, 1> input(spec.input_dim0); std::iota(input.begin(), input.end(), NativeT()); auto literal = LiteralUtil::CreateR1<NativeT>(input); @@ -205,7 +206,7 @@ class SliceR1Test : public ClientLibraryTestBase, {spec.slice_stride}); // Ditto. - tensorflow::gtl::InlinedVector<NativeT, 1> expected; + absl::InlinedVector<NativeT, 1> expected; for (int i = spec.slice_start; i < spec.slice_limit; i += spec.slice_stride) { expected.push_back(i); @@ -222,9 +223,8 @@ class SliceR1LargeTest : public SliceR1Test {}; string SliceR1TestDataToString(const ::testing::TestParamInfo<R1Spec>& data) { const R1Spec& spec = data.param; - return ::tensorflow::strings::Printf("%lld_%lld_%lld_%lld", spec.input_dim0, - spec.slice_start, spec.slice_limit, - spec.slice_stride); + return absl::StrFormat("%d_%d_%d_%d", spec.input_dim0, spec.slice_start, + spec.slice_limit, spec.slice_stride); } XLA_TEST_P(SliceR1Test, DoIt_F32) { Run<float>(GetParam()); } @@ -448,13 +448,11 @@ struct R4Spec { string R4SpecToString(const ::testing::TestParamInfo<R4Spec>& data) { const R4Spec& spec = data.param; - return tensorflow::strings::StrCat( // - "input_", Join(spec.input_dims, "x"), // - "__layout_", Join(spec.input_layout, ""), // - "__starts_", Join(spec.slice_starts, "x"), // - "__limits_", Join(spec.slice_limits, "x"), // - "__strides_", Join(spec.slice_strides, "x") // - ); + return absl::StrCat("input_", absl::StrJoin(spec.input_dims, "x"), + "__layout_", absl::StrJoin(spec.input_layout, ""), + "__starts_", absl::StrJoin(spec.slice_starts, "x"), + "__limits_", absl::StrJoin(spec.slice_limits, "x"), + "__strides_", absl::StrJoin(spec.slice_strides, "x")); } class SliceR4Test : public ClientLibraryTestBase, diff --git a/tensorflow/compiler/xla/tests/test_macros.cc b/tensorflow/compiler/xla/tests/test_macros.cc index be35ec6c6e..a9874a9186 100644 --- a/tensorflow/compiler/xla/tests/test_macros.cc +++ b/tensorflow/compiler/xla/tests/test_macros.cc @@ -20,7 +20,9 @@ limitations under the License. #include <string> #include <unordered_map> -#include "tensorflow/core/lib/strings/str_util.h" +#include "absl/strings/ascii.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_split.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/regexp.h" @@ -44,7 +46,7 @@ ManifestT ReadManifest() { string contents((std::istreambuf_iterator<char>(file_stream)), std::istreambuf_iterator<char>()); - std::vector<string> lines = tensorflow::str_util::Split(contents, '\n'); + std::vector<string> lines = absl::StrSplit(contents, '\n'); for (string& line : lines) { auto comment = line.find("//"); if (comment != string::npos) { @@ -53,8 +55,8 @@ ManifestT ReadManifest() { if (line.empty()) { continue; } - tensorflow::str_util::StripTrailingWhitespace(&line); - std::vector<string> pieces = tensorflow::str_util::Split(line, ' '); + absl::StripTrailingAsciiWhitespace(&line); + std::vector<string> pieces = absl::StrSplit(line, ' '); CHECK_GE(pieces.size(), 1); auto& platforms = manifest[pieces[0]]; for (int64 i = 1; i < pieces.size(); ++i) { @@ -73,8 +75,7 @@ string PrependDisabledIfIndicated(const string& test_case_name, // First try full match: test_case_name.test_name // If that fails, try to find just the test_case_name; this would disable all // tests in the test case. - auto it = manifest.find( - tensorflow::strings::StrCat(test_case_name, ".", test_name)); + auto it = manifest.find(absl::StrCat(test_case_name, ".", test_name)); if (it == manifest.end()) { it = manifest.find(test_case_name); if (it == manifest.end()) { diff --git a/tensorflow/compiler/xla/tests/test_utils.cc b/tensorflow/compiler/xla/tests/test_utils.cc index f05421f8e1..776f93d9f7 100644 --- a/tensorflow/compiler/xla/tests/test_utils.cc +++ b/tensorflow/compiler/xla/tests/test_utils.cc @@ -15,12 +15,13 @@ limitations under the License. #include <cmath> -#include "tensorflow/compiler/xla/tests/test_utils.h" +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/primitive_util.h" #include "tensorflow/compiler/xla/service/hlo_dataflow_analysis.h" #include "tensorflow/compiler/xla/service/hlo_verifier.h" #include "tensorflow/compiler/xla/service/transfer_manager.h" +#include "tensorflow/compiler/xla/tests/test_utils.h" namespace xla { @@ -130,7 +131,7 @@ StatusOr<std::unique_ptr<Literal>> MakeFakeLiteralInternal( if (engine == nullptr) { return Literal::CreateFromShape(shape); } - auto literal = MakeUnique<Literal>(shape); + auto literal = absl::make_unique<Literal>(shape); switch (shape.element_type()) { case BF16: PopulateWithRandomFloatingPointData<bfloat16>(literal.get(), engine, @@ -193,7 +194,7 @@ StatusOr<std::unique_ptr<Literal>> MakeFakeLiteralInternal( break; default: return Unimplemented("Unsupported type for fake literal generation: %s", - ShapeUtil::HumanString(shape).c_str()); + ShapeUtil::HumanString(shape)); } return std::move(literal); } @@ -341,7 +342,7 @@ StatusOr<std::unique_ptr<Literal>> CreateLiteralForConstrainedUses( default: return Unimplemented( "Constrained operand generation not implemented for %s.", - use->ToString().c_str()); + use->ToString()); } } int constraint_count = 0; @@ -383,13 +384,15 @@ StatusOr<std::unique_ptr<Literal>> MakeConstrainedArgument( StatusOr<std::unique_ptr<Literal>> MakeFakeLiteral(const Shape& shape, bool pseudo_random) { - auto engine = pseudo_random ? MakeUnique<std::minstd_rand0>() : nullptr; + auto engine = + pseudo_random ? absl::make_unique<std::minstd_rand0>() : nullptr; return MakeFakeLiteralInternal(shape, engine.get(), /*no_duplicates=*/false); } StatusOr<std::vector<std::unique_ptr<Literal>>> MakeFakeArguments( HloModule* const module, bool pseudo_random) { - auto engine = pseudo_random ? MakeUnique<std::minstd_rand0>() : nullptr; + auto engine = + pseudo_random ? absl::make_unique<std::minstd_rand0>() : nullptr; return MakeFakeArguments(module, engine.get()); } @@ -405,8 +408,12 @@ StatusOr<std::vector<std::unique_ptr<Literal>>> MakeFakeArguments( return std::move(arguments); } -Status VerifyHloModule(HloModule* const module, bool allow_mixed_precision) { - return HloVerifier(allow_mixed_precision).Run(module).status(); +Status VerifyHloModule(HloModule* const module, bool layout_sensitive, + bool allow_mixed_precision) { + return HloVerifier(/*layout_sensitive=*/layout_sensitive, + /*allow_mixed_precision=*/allow_mixed_precision) + .Run(module) + .status(); } } // namespace xla diff --git a/tensorflow/compiler/xla/tests/test_utils.h b/tensorflow/compiler/xla/tests/test_utils.h index 3a8ad80ed1..277d53d423 100644 --- a/tensorflow/compiler/xla/tests/test_utils.h +++ b/tensorflow/compiler/xla/tests/test_utils.h @@ -20,9 +20,9 @@ limitations under the License. #include <memory> #include <random> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/service/hlo_module.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/gtl/array_slice.h" @@ -95,8 +95,8 @@ StatusOr<std::vector<std::unique_ptr<Literal>>> MakeFakeArguments( // Check that a given module satisfies various constraints before trying to // execute it. -Status VerifyHloModule(HloModule* const module, - bool allow_mixed_precision = false); +Status VerifyHloModule(HloModule* const module, bool layout_sensitive, + bool allow_mixed_precision); } // namespace xla diff --git a/tensorflow/compiler/xla/tests/token_hlo_test.cc b/tensorflow/compiler/xla/tests/token_hlo_test.cc index 2bdbd08309..c7eb9e2dbe 100644 --- a/tensorflow/compiler/xla/tests/token_hlo_test.cc +++ b/tensorflow/compiler/xla/tests/token_hlo_test.cc @@ -15,11 +15,10 @@ limitations under the License. #include <array> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/service/hlo_verifier.h" #include "tensorflow/compiler/xla/tests/hlo_test_base.h" #include "tensorflow/compiler/xla/tests/test_macros.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" @@ -67,7 +66,10 @@ XLA_TEST_F(TokenHloTest, InvalidTokenShapedEntryParameter) { HloInstruction::CreateConstant(LiteralUtil::CreateR0<int32>(42))); module->AddEntryComputation(builder.Build()); - Status status = HloVerifier().Run(module.get()).status(); + Status status = + HloVerifier(/*layout_sensitive=*/false, /*allow_mixed_precision=*/false) + .Run(module.get()) + .status(); ASSERT_IS_NOT_OK(status); EXPECT_THAT( status.error_message(), @@ -84,7 +86,10 @@ XLA_TEST_F(TokenHloTest, InvalidTupleTokenShapedEntryParameter) { "param")); module->AddEntryComputation(builder.Build()); - Status status = HloVerifier().Run(module.get()).status(); + Status status = + HloVerifier(/*layout_sensitive=*/false, /*allow_mixed_precision=*/false) + .Run(module.get()) + .status(); ASSERT_IS_NOT_OK(status); EXPECT_THAT( status.error_message(), @@ -101,7 +106,10 @@ XLA_TEST_F(TokenHloTest, InvalidOperandToTokenInstruction) { HloInstruction::CreateConstant(LiteralUtil::CreateR0<int32>(123))); module->AddEntryComputation(builder.Build()); - Status status = HloVerifier().Run(module.get()).status(); + Status status = + HloVerifier(/*layout_sensitive=*/false, /*allow_mixed_precision=*/false) + .Run(module.get()) + .status(); ASSERT_IS_NOT_OK(status); EXPECT_THAT(status.error_message(), ::testing::HasSubstr( diff --git a/tensorflow/compiler/xla/tests/tuple_test.cc b/tensorflow/compiler/xla/tests/tuple_test.cc index 97bbf80aff..c101cd2d20 100644 --- a/tensorflow/compiler/xla/tests/tuple_test.cc +++ b/tensorflow/compiler/xla/tests/tuple_test.cc @@ -16,6 +16,7 @@ limitations under the License. #include <initializer_list> #include <memory> +#include "absl/memory/memory.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" @@ -504,7 +505,7 @@ XLA_TEST_F(TupleTest, ComplexTuples) { LiteralUtil::CreateR2<complex64>({{{111, 222}, {331, 442}}, {{1011, 2022}, {3031, 4042}}, {{10011, 20022}, {30031, 40042}}}); - auto prod = MakeUnique<Literal>(sum->shape()); + auto prod = absl::make_unique<Literal>(sum->shape()); ASSERT_TRUE(prod->Populate<complex64>( [&sum](tensorflow::gtl::ArraySlice<int64> indexes) { return sum->Get<complex64>(indexes) * diff --git a/tensorflow/compiler/xla/tests/unary_op_test.cc b/tensorflow/compiler/xla/tests/unary_op_test.cc index 20ae68ab74..8f80a9f3e4 100644 --- a/tensorflow/compiler/xla/tests/unary_op_test.cc +++ b/tensorflow/compiler/xla/tests/unary_op_test.cc @@ -190,25 +190,6 @@ XLA_TEST_F(UnaryOpTest, SignAbsTestR1) { SignAbsTestHelper<complex64>(); } -XLA_TEST_F(UnaryOpTest, UnsignedAbsTestR1) { - XlaBuilder builder(TestName()); - auto arg = ConstantR1<unsigned int>( - &builder, {2, 25, 0, 123, std::numeric_limits<unsigned int>::max()}); - Abs(arg); - - ComputeAndCompareR1<unsigned int>( - &builder, {2, 25, 0, 123, std::numeric_limits<unsigned int>::max()}, {}); -} - -XLA_TEST_F(UnaryOpTest, UnsignedSignTestR1) { - XlaBuilder builder(TestName()); - auto arg = ConstantR1<unsigned int>( - &builder, {2, 25, 0, 123, std::numeric_limits<unsigned int>::max()}); - Sign(arg); - - ComputeAndCompareR1<unsigned int>(&builder, {1, 1, 0, 1, 1}, {}); -} - XLA_TEST_F(UnaryOpTest, SignAbsTestR2) { XlaBuilder builder(TestName()); auto arg = ConstantR2<float>(&builder, {{1.0, -2.0}, {-3.0, 4.0}}); diff --git a/tensorflow/compiler/xla/tests/xla_hlo_profile_test.cc b/tensorflow/compiler/xla/tests/xla_hlo_profile_test.cc index 11f3efb1f3..6a7ddd9b55 100644 --- a/tensorflow/compiler/xla/tests/xla_hlo_profile_test.cc +++ b/tensorflow/compiler/xla/tests/xla_hlo_profile_test.cc @@ -16,6 +16,10 @@ limitations under the License. #include <memory> #include <vector> +#include "absl/algorithm/container.h" +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_split.h" #include "tensorflow/compiler/xla/array2d.h" #include "tensorflow/compiler/xla/client/local_client.h" #include "tensorflow/compiler/xla/client/xla_builder.h" @@ -29,7 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/tests/test_utils.h" #include "tensorflow/core/lib/core/status_test_util.h" #include "tensorflow/core/lib/gtl/flatmap.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/regexp.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" @@ -81,8 +84,7 @@ struct ParsedProfileOutputLine { Status ParseOneProfileOutputLine( const string& line, bool expect_hlo, gtl::FlatMap<string, ParsedProfileOutputLine>* parsed_results, - tensorflow::gtl::ArraySlice<tensorflow::StringPiece> opcodes_to_ignore = - {}) { + tensorflow::gtl::ArraySlice<absl::string_view> opcodes_to_ignore = {}) { string separator = "[^:]*:: +"; string match_percentage = R"(\d+\.\d*% +\d+Σ)"; string match_cycles = R"((\d+) cycles +\( *()" + match_percentage + R"()\))"; @@ -99,7 +101,7 @@ Status ParseOneProfileOutputLine( string match_opcode = expect_hlo ? "%[^=]+= [^ ]+ ([^(]+)\\(.*" : "(\\[total\\])"; - string regexp_pattern = tensorflow::strings::StrCat( + string regexp_pattern = absl::StrCat( " +", match_cycles, separator, match_usecs, separator, match_flops, separator, match_trops, separator, match_bytes_per_sec, separator, match_bytes_per_cycle, separator, match_opcode); @@ -116,7 +118,7 @@ Status ParseOneProfileOutputLine( ", Regexp: ", regexp_pattern); } - if (!c_linear_search(opcodes_to_ignore, parsed_line.opcode)) { + if (!absl::c_linear_search(opcodes_to_ignore, parsed_line.opcode)) { InsertOrDie(parsed_results, parsed_line.opcode, parsed_line); } @@ -204,7 +206,7 @@ XLA_TEST_F(HloProfileTest, ProfileSingleComputation) { rhs_shape); std::vector<string> profile_output_lines = - tensorflow::str_util::Split(profile_output, '\n'); + absl::StrSplit(profile_output, '\n'); gtl::FlatMap<string, ParsedProfileOutputLine> parsed_profile_lines; @@ -291,22 +293,20 @@ XLA_TEST_F(HloProfileTest, ProfileWhileComputation) { matrix_shape); std::vector<string> profile_output_lines = - tensorflow::str_util::Split(profile_output, '\n'); + absl::StrSplit(profile_output, '\n'); auto while_body_profile_start = - c_find_if(profile_output_lines, [](tensorflow::StringPiece s) { - return tensorflow::str_util::StartsWith(s, - "Execution profile for body"); + absl::c_find_if(profile_output_lines, [](absl::string_view s) { + return absl::StartsWith(s, "Execution profile for body"); }); ASSERT_NE(while_body_profile_start, profile_output_lines.cend()); - auto while_body_profile_end = - std::find_if(while_body_profile_start, profile_output_lines.end(), - [](tensorflow::StringPiece s) { - return tensorflow::str_util::StartsWith( - s, "********** microseconds report **********"); - }); + auto while_body_profile_end = std::find_if( + while_body_profile_start, profile_output_lines.end(), + [](absl::string_view s) { + return absl::StartsWith(s, "********** microseconds report **********"); + }); // We emit a blank line before the "********** microseconds report **********" // line. diff --git a/tensorflow/compiler/xla/tests/xla_internal_test_main.cc b/tensorflow/compiler/xla/tests/xla_internal_test_main.cc index a075195618..15603619b6 100644 --- a/tensorflow/compiler/xla/tests/xla_internal_test_main.cc +++ b/tensorflow/compiler/xla/tests/xla_internal_test_main.cc @@ -13,9 +13,9 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#include "absl/strings/match.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/legacy_flags/debug_options_flags.h" -#include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/test_benchmark.h" @@ -32,16 +32,14 @@ GTEST_API_ int main(int argc, char** argv) { // If the --benchmarks flag is passed in then only run the benchmarks, not the // tests. for (int i = 1; i < argc; i++) { - tensorflow::StringPiece arg(argv[i]); - if (arg == "--benchmarks" || - tensorflow::str_util::StartsWith(arg, "--benchmarks=")) { + absl::string_view arg(argv[i]); + if (arg == "--benchmarks" || absl::StartsWith(arg, "--benchmarks=")) { const char* pattern = nullptr; - if (tensorflow::str_util::StartsWith(arg, "--benchmarks=")) { + if (absl::StartsWith(arg, "--benchmarks=")) { pattern = argv[i] + strlen("--benchmarks="); } else { // Handle flag of the form '--benchmarks foo' (no '='). - if (i + 1 >= argc || - tensorflow::str_util::StartsWith(argv[i + 1], "--")) { + if (i + 1 >= argc || absl::StartsWith(argv[i + 1], "--")) { LOG(ERROR) << "--benchmarks flag requires an argument."; return 2; } diff --git a/tensorflow/compiler/xla/text_literal_reader.cc b/tensorflow/compiler/xla/text_literal_reader.cc index 897123d760..442e66321e 100644 --- a/tensorflow/compiler/xla/text_literal_reader.cc +++ b/tensorflow/compiler/xla/text_literal_reader.cc @@ -20,25 +20,28 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/memory/memory.h" +#include "absl/strings/match.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_split.h" +#include "absl/strings/string_view.h" +#include "absl/strings/strip.h" #include "tensorflow/compiler/xla/literal.h" -#include "tensorflow/compiler/xla/ptr_util.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/io/buffered_inputstream.h" #include "tensorflow/core/lib/io/random_inputstream.h" -#include "tensorflow/core/lib/strings/str_util.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/types.h" namespace xla { StatusOr<std::unique_ptr<Literal>> TextLiteralReader::ReadPath( - tensorflow::StringPiece path) { - CHECK(!tensorflow::str_util::EndsWith(path, ".gz")) + absl::string_view path) { + CHECK(!absl::EndsWith(path, ".gz")) << "TextLiteralReader no longer supports reading .gz files"; std::unique_ptr<tensorflow::RandomAccessFile> file; Status s = @@ -54,33 +57,6 @@ StatusOr<std::unique_ptr<Literal>> TextLiteralReader::ReadPath( TextLiteralReader::TextLiteralReader(tensorflow::RandomAccessFile* file) : file_(file) {} -namespace { -// This is an optimized version of tensorflow::str_util::Split which uses -// StringPiece for the delimited strings and uses an out parameter for the -// result to avoid vector creation/destruction. -void SplitByDelimToStringPieces(tensorflow::StringPiece text, char delim, - std::vector<tensorflow::StringPiece>* result) { - result->clear(); - - if (text.empty()) { - return; - } - - // The following loop is a little strange: its bound is text.size() + 1 - // instead of the more typical text.size(). - // The final iteration of the loop (when i is equal to text.size()) handles - // the trailing token. - size_t token_start = 0; - for (size_t i = 0; i < text.size() + 1; i++) { - if (i == text.size() || text[i] == delim) { - tensorflow::StringPiece token(text.data() + token_start, i - token_start); - result->push_back(token); - token_start = i + 1; - } - } -} -} // namespace - StatusOr<std::unique_ptr<Literal>> TextLiteralReader::ReadAllLines() { tensorflow::io::RandomAccessInputStream stream(file_.get()); tensorflow::io::BufferedInputStream buf(&stream, 65536); @@ -90,61 +66,55 @@ StatusOr<std::unique_ptr<Literal>> TextLiteralReader::ReadAllLines() { return s; } - tensorflow::StringPiece sp(shape_string); - if (tensorflow::str_util::RemoveWhitespaceContext(&sp) > 0) { - string tmp = std::string(sp); - shape_string = tmp; - } + absl::StripAsciiWhitespace(&shape_string); TF_ASSIGN_OR_RETURN(Shape shape, ShapeUtil::ParseShapeString(shape_string)); if (shape.element_type() != F32) { return Unimplemented( "unsupported element type for text literal reading: %s", - ShapeUtil::HumanString(shape).c_str()); + ShapeUtil::HumanString(shape)); } - auto result = MakeUnique<Literal>(shape); + auto result = absl::make_unique<Literal>(shape); const float fill = std::numeric_limits<float>::quiet_NaN(); result->PopulateWithValue<float>(fill); - std::vector<tensorflow::StringPiece> pieces; - std::vector<tensorflow::StringPiece> coordinates; + std::vector<absl::string_view> pieces; + std::vector<absl::string_view> coordinates; std::vector<int64> coordinate_values; string line; while (buf.ReadLine(&line).ok()) { - SplitByDelimToStringPieces(line, ':', &pieces); - tensorflow::StringPiece coordinates_string = pieces[0]; - tensorflow::StringPiece value_string = pieces[1]; - tensorflow::str_util::RemoveWhitespaceContext(&coordinates_string); - tensorflow::str_util::RemoveWhitespaceContext(&value_string); - if (!tensorflow::str_util::ConsumePrefix(&coordinates_string, "(")) { + pieces = absl::StrSplit(line, ':'); + absl::string_view coordinates_string = + absl::StripAsciiWhitespace(pieces[0]); + absl::string_view value_string = absl::StripAsciiWhitespace(pieces[1]); + if (!absl::ConsumePrefix(&coordinates_string, "(")) { return InvalidArgument( - "expected '(' at the beginning of coordinates: \"%s\"", line.c_str()); + "expected '(' at the beginning of coordinates: \"%s\"", line); } - if (!tensorflow::str_util::ConsumeSuffix(&coordinates_string, ")")) { + if (!absl::ConsumeSuffix(&coordinates_string, ")")) { return InvalidArgument("expected ')' at the end of coordinates: \"%s\"", - line.c_str()); + line); } float value; - if (!tensorflow::strings::safe_strtof(std::string(value_string).c_str(), - &value)) { + if (!absl::SimpleAtof(value_string, &value)) { return InvalidArgument("could not parse value as float: \"%s\"", - std::string(value_string).c_str()); + value_string); } - SplitByDelimToStringPieces(coordinates_string, ',', &coordinates); + coordinates = absl::StrSplit(coordinates_string, ','); coordinate_values.clear(); - for (tensorflow::StringPiece piece : coordinates) { + for (absl::string_view piece : coordinates) { int64 coordinate_value; - if (!tensorflow::strings::safe_strto64(piece, &coordinate_value)) { + if (!absl::SimpleAtoi(piece, &coordinate_value)) { return InvalidArgument( "could not parse coordinate member as int64: \"%s\"", - std::string(piece).c_str()); + std::string(piece)); } coordinate_values.push_back(coordinate_value); } if (coordinate_values.size() != shape.dimensions_size()) { return InvalidArgument( - "line did not have expected number of coordinates; want %d got %zu: " + "line did not have expected number of coordinates; want %d got %u: " "\"%s\"", - shape.dimensions_size(), coordinate_values.size(), line.c_str()); + shape.dimensions_size(), coordinate_values.size(), line); } result->Set<float>(coordinate_values, value); } diff --git a/tensorflow/compiler/xla/text_literal_reader.h b/tensorflow/compiler/xla/text_literal_reader.h index 708e8c80d8..b265640802 100644 --- a/tensorflow/compiler/xla/text_literal_reader.h +++ b/tensorflow/compiler/xla/text_literal_reader.h @@ -18,11 +18,11 @@ limitations under the License. #include <memory> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/macros.h" @@ -41,8 +41,7 @@ class TextLiteralReader { public: // See class comment -- reads a file in its entirety (there must be only one // literal in the text file path provided). - static StatusOr<std::unique_ptr<Literal>> ReadPath( - tensorflow::StringPiece path); + static StatusOr<std::unique_ptr<Literal>> ReadPath(absl::string_view path); private: // Ownership of file is transferred. diff --git a/tensorflow/compiler/xla/text_literal_writer.cc b/tensorflow/compiler/xla/text_literal_writer.cc index 24e0784741..00147015a6 100644 --- a/tensorflow/compiler/xla/text_literal_writer.cc +++ b/tensorflow/compiler/xla/text_literal_writer.cc @@ -17,23 +17,23 @@ limitations under the License. #include <string> +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/types.h" namespace xla { -/* static */ Status TextLiteralWriter::WriteToPath( - const Literal& literal, tensorflow::StringPiece path) { +/* static */ Status TextLiteralWriter::WriteToPath(const Literal& literal, + absl::string_view path) { std::unique_ptr<tensorflow::WritableFile> f; - auto s = tensorflow::Env::Default()->NewWritableFile(std::string(path), &f); + auto s = tensorflow::Env::Default()->NewWritableFile(string(path), &f); if (!s.ok()) { return s; } @@ -51,11 +51,10 @@ namespace xla { if (!status.ok()) { return; } - string coordinates = tensorflow::strings::StrCat( - "(", tensorflow::str_util::Join(indices, ", "), ")"); + string coordinates = + absl::StrCat("(", absl::StrJoin(indices, ", "), ")"); - status = f_ptr->Append( - tensorflow::strings::StrCat(coordinates, ": ", value, "\n")); + status = f_ptr->Append(absl::StrCat(coordinates, ": ", value, "\n")); }); auto ignored = f->Close(); return status; diff --git a/tensorflow/compiler/xla/text_literal_writer.h b/tensorflow/compiler/xla/text_literal_writer.h index 159ac1b7e1..34de8572d6 100644 --- a/tensorflow/compiler/xla/text_literal_writer.h +++ b/tensorflow/compiler/xla/text_literal_writer.h @@ -16,11 +16,11 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_TEXT_LITERAL_WRITER_H_ #define TENSORFLOW_COMPILER_XLA_TEXT_LITERAL_WRITER_H_ +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/macros.h" namespace xla { @@ -37,8 +37,7 @@ namespace xla { // This should be readable by xla::TextLiteralReader. class TextLiteralWriter { public: - static Status WriteToPath(const Literal& literal, - tensorflow::StringPiece path); + static Status WriteToPath(const Literal& literal, absl::string_view path); private: TF_DISALLOW_COPY_AND_ASSIGN(TextLiteralWriter); diff --git a/tensorflow/compiler/xla/tools/BUILD b/tensorflow/compiler/xla/tools/BUILD index 40d28a57bf..f23c5b3ef1 100644 --- a/tensorflow/compiler/xla/tools/BUILD +++ b/tensorflow/compiler/xla/tools/BUILD @@ -24,6 +24,7 @@ tf_cc_binary( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/strings", ], ) @@ -191,6 +192,8 @@ tf_cc_binary( "//tensorflow/compiler/xla/service:hlo_proto", "//tensorflow/compiler/xla/service:interpreter_plugin", "//tensorflow/core:lib", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", ], ) diff --git a/tensorflow/compiler/xla/tools/dumped_computation_to_graphviz.cc b/tensorflow/compiler/xla/tools/dumped_computation_to_graphviz.cc index f20dcef382..d15b71b792 100644 --- a/tensorflow/compiler/xla/tools/dumped_computation_to_graphviz.cc +++ b/tensorflow/compiler/xla/tools/dumped_computation_to_graphviz.cc @@ -78,7 +78,7 @@ int main(int argc, char** argv) { tensorflow::port::InitMain(argv[0], &argc, &argv); tensorflow::gtl::ArraySlice<char*> args(argv, argc); - args.pop_front(); // Pop off the binary name, argv[0] + args.remove_prefix(1); // Pop off the binary name, argv[0] xla::tools::RealMain(args); return 0; } diff --git a/tensorflow/compiler/xla/tools/dumped_computation_to_operation_list.cc b/tensorflow/compiler/xla/tools/dumped_computation_to_operation_list.cc index f0af0580c1..c446b27a04 100644 --- a/tensorflow/compiler/xla/tools/dumped_computation_to_operation_list.cc +++ b/tensorflow/compiler/xla/tools/dumped_computation_to_operation_list.cc @@ -19,6 +19,8 @@ limitations under the License. #include <memory> #include <string> +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" #include "tensorflow/compiler/xla/client/client.h" #include "tensorflow/compiler/xla/client/client_library.h" #include "tensorflow/compiler/xla/client/local_client.h" @@ -30,8 +32,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/init_main.h" #include "tensorflow/core/platform/logging.h" @@ -44,16 +44,14 @@ class OperationDumper : public DfsHloVisitorWithDefault { explicit OperationDumper(const string& path) : path_(path) {} Status DefaultAction(HloInstruction* hlo) override { - string params = tensorflow::str_util::Join( + string params = absl::StrJoin( hlo->operands(), ", ", [](string* out, const HloInstruction* operand) { - tensorflow::strings::StrAppend( - out, ShapeUtil::HumanString(operand->shape())); + absl::StrAppend(out, ShapeUtil::HumanString(operand->shape())); }); // Spit `op_name(params...) -> result_type :: path` to stdout. - std::cout << tensorflow::strings::Printf( - "%s :: (%s) -> %s :: %s\n", HloOpcodeString(hlo->opcode()).c_str(), - params.c_str(), ShapeUtil::HumanString(hlo->shape()).c_str(), - path_.c_str()); + std::cout << absl::StrFormat("%s :: (%s) -> %s :: %s\n", + HloOpcodeString(hlo->opcode()), params, + ShapeUtil::HumanString(hlo->shape()), path_); return Status::OK(); } @@ -107,7 +105,7 @@ int main(int argc, char** argv) { tensorflow::port::InitMain(argv[0], &argc, &argv); tensorflow::gtl::ArraySlice<char*> args(argv, argc); - args.pop_front(); // Pop off the binary name, argv[0] + args.remove_prefix(1); // Pop off the binary name, argv[0] xla::tools::RealMain(args); return 0; } diff --git a/tensorflow/compiler/xla/tools/dumped_computation_to_text.cc b/tensorflow/compiler/xla/tools/dumped_computation_to_text.cc index f03e1b1f96..d86a4474b3 100644 --- a/tensorflow/compiler/xla/tools/dumped_computation_to_text.cc +++ b/tensorflow/compiler/xla/tools/dumped_computation_to_text.cc @@ -103,7 +103,7 @@ int main(int argc, char** argv) { QCHECK(argc > 1) << "\nERROR: must specify at least one module\n" << usage; tensorflow::gtl::ArraySlice<char*> args(argv, argc); - args.pop_front(); // Pop off the binary name, argv[0] + args.remove_prefix(1); // Pop off the binary name, argv[0] xla::tools::RealMain(args, compile); return 0; } diff --git a/tensorflow/compiler/xla/tools/dumped_computation_to_tf_graphdef.cc b/tensorflow/compiler/xla/tools/dumped_computation_to_tf_graphdef.cc index dc5c106d02..bd8b89542f 100644 --- a/tensorflow/compiler/xla/tools/dumped_computation_to_tf_graphdef.cc +++ b/tensorflow/compiler/xla/tools/dumped_computation_to_tf_graphdef.cc @@ -79,7 +79,7 @@ int main(int argc, char** argv) { tensorflow::port::InitMain(argv[0], &argc, &argv); tensorflow::gtl::ArraySlice<char*> args(argv, argc); - args.pop_front(); // Pop off the binary name, argv[0] + args.remove_prefix(1); // Pop off the binary name, argv[0] xla::tools::RealMain(args); return 0; } diff --git a/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc b/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc index eb7bff053b..75b63c3b84 100644 --- a/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc +++ b/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc @@ -17,10 +17,10 @@ limitations under the License. #include <string> #include <vector> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/core/casts.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/io/buffered_inputstream.h" #include "tensorflow/core/lib/io/random_inputstream.h" #include "tensorflow/core/platform/env.h" @@ -67,7 +67,7 @@ int main(int argc, char** argv) { floats.push_back(value); } - tensorflow::StringPiece content( + tensorflow::StringPiece content( // non-absl ok tensorflow::bit_cast<const char*>(floats.data()), floats.size() * sizeof(float)); TF_CHECK_OK(tensorflow::WriteStringToFile(tensorflow::Env::Default(), diff --git a/tensorflow/compiler/xla/tools/replay_computation.cc b/tensorflow/compiler/xla/tools/replay_computation.cc index b4774233e5..e826d6fa93 100644 --- a/tensorflow/compiler/xla/tools/replay_computation.cc +++ b/tensorflow/compiler/xla/tools/replay_computation.cc @@ -160,7 +160,7 @@ StatusOr<Literal> ReplayComputation(const HloSnapshot& module, // concurrent infeed occur via the fake_infeed_shape, or when // --generate_fake_infeed is passed and there exists an infeed operation in // the HloSnapshot. - tensorflow::gtl::optional<tensorflow::thread::ThreadPool> pool; + absl::optional<tensorflow::thread::ThreadPool> pool; std::unique_ptr<Literal> data; if (provide_infeed) { data = std::move(MakeFakeLiteral(infeed_shape)).ValueOrDie(); @@ -196,7 +196,7 @@ StatusOr<Literal> ReplayComputation(const HloSnapshot& module, StreamExecutorMemoryAllocator allocator( client->platform(), {client->platform()->ExecutorForDevice(0).ValueOrDie()}); - tensorflow::gtl::optional<ScopedShapedBuffer> result; + absl::optional<ScopedShapedBuffer> result; for (int i = 0; i < opts.num_runs; ++i) { // If xla_hlo_profile is enabled, print a noisy message before the last run, // making it easier to separate this profile from the others in the logspam. @@ -250,7 +250,7 @@ StatusOr<HloSnapshot> ParseInputFile(const string& filename, } fprintf(stderr, "%s: is not HLO text. Nothing left to try.\n", filename.c_str()); - return InvalidArgument("Could not parse %s.", filename.c_str()); + return InvalidArgument("Could not parse %s.", filename); } int RealMain(tensorflow::gtl::ArraySlice<char*> args, const Options& opts) { @@ -345,6 +345,6 @@ int main(int argc, char** argv) { } tensorflow::gtl::ArraySlice<char*> args(argv, argc); - args.pop_front(); // Pop off the binary name, argv[0] + args.remove_prefix(1); // Pop off the binary name, argv[0] return xla::tools::RealMain(args, opts); } diff --git a/tensorflow/compiler/xla/tools/show_signature.cc b/tensorflow/compiler/xla/tools/show_signature.cc index 4e53fafcc9..10e7202acf 100644 --- a/tensorflow/compiler/xla/tools/show_signature.cc +++ b/tensorflow/compiler/xla/tools/show_signature.cc @@ -67,7 +67,7 @@ int main(int argc, char** argv) { tensorflow::port::InitMain(argv[0], &argc, &argv); tensorflow::gtl::ArraySlice<char*> args(argv, argc); - args.pop_front(); // Pop off the binary name, argv[0] + args.remove_prefix(1); // Pop off the binary name, argv[0] xla::tools::RealMain(args); return 0; } diff --git a/tensorflow/compiler/xla/util.cc b/tensorflow/compiler/xla/util.cc index e43498e381..0f607a0c8a 100644 --- a/tensorflow/compiler/xla/util.cc +++ b/tensorflow/compiler/xla/util.cc @@ -18,12 +18,13 @@ limitations under the License. #include <stdarg.h> #include <numeric> +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" +#include "absl/strings/str_split.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/mutex.h" #include "tensorflow/core/platform/stacktrace.h" @@ -54,108 +55,25 @@ ScopedLoggingTimer::~ScopedLoggingTimer() { } } -Status AddStatus(Status prior, tensorflow::StringPiece context) { +Status AddStatus(Status prior, absl::string_view context) { CHECK(!prior.ok()); - return Status{prior.code(), tensorflow::strings::StrCat( - context, ": ", prior.error_message())}; + return Status{prior.code(), + absl::StrCat(context, ": ", prior.error_message())}; } -Status AppendStatus(Status prior, tensorflow::StringPiece context) { +Status AppendStatus(Status prior, absl::string_view context) { CHECK(!prior.ok()); - return Status{prior.code(), tensorflow::strings::StrCat(prior.error_message(), - ": ", context)}; + return Status{prior.code(), + absl::StrCat(prior.error_message(), ": ", context)}; } -// Implementation note: we can't common these out (without using macros) because -// they all need to va_start/va_end their varargs in their frame. - -Status InvalidArgumentV(const char* format, va_list args) { - string message; - tensorflow::strings::Appendv(&message, format, args); - return WithLogBacktrace(tensorflow::errors::InvalidArgument(message)); -} - -Status InvalidArgument(const char* format, ...) { - va_list args; - va_start(args, format); - Status result = InvalidArgumentV(format, args); - va_end(args); - return result; -} - -Status Unimplemented(const char* format, ...) { - string message; - va_list args; - va_start(args, format); - tensorflow::strings::Appendv(&message, format, args); - va_end(args); - return WithLogBacktrace(tensorflow::errors::Unimplemented(message)); -} - -Status InternalError(const char* format, ...) { - string message; - va_list args; - va_start(args, format); - tensorflow::strings::Appendv(&message, format, args); - va_end(args); - return WithLogBacktrace(tensorflow::errors::Internal(message)); -} - -Status FailedPrecondition(const char* format, ...) { - string message; - va_list args; - va_start(args, format); - tensorflow::strings::Appendv(&message, format, args); - va_end(args); - return WithLogBacktrace(tensorflow::errors::FailedPrecondition(message)); -} - -Status Cancelled(const char* format, ...) { - string message; - va_list args; - va_start(args, format); - tensorflow::strings::Appendv(&message, format, args); - va_end(args); - return WithLogBacktrace(tensorflow::errors::Cancelled(message)); -} - -Status ResourceExhausted(const char* format, ...) { - string message; - va_list args; - va_start(args, format); - tensorflow::strings::Appendv(&message, format, args); - va_end(args); - return WithLogBacktrace(tensorflow::errors::ResourceExhausted(message)); -} - -Status NotFound(const char* format, ...) { - string message; - va_list args; - va_start(args, format); - tensorflow::strings::Appendv(&message, format, args); - va_end(args); - return WithLogBacktrace(tensorflow::errors::NotFound(message)); -} - -Status Unavailable(const char* format, ...) { - string message; - va_list args; - va_start(args, format); - tensorflow::strings::Appendv(&message, format, args); - va_end(args); - return WithLogBacktrace(tensorflow::errors::Unavailable(message)); -} - -string Reindent(tensorflow::StringPiece original, - const tensorflow::StringPiece indentation) { - std::vector<string> pieces = tensorflow::str_util::Split( - tensorflow::StringPiece(original.data(), original.size()), '\n'); - return tensorflow::str_util::Join( - pieces, "\n", [indentation](string* out, string s) { - tensorflow::StringPiece piece(s); - tensorflow::str_util::RemoveWhitespaceContext(&piece); - tensorflow::strings::StrAppend(out, indentation, piece); - }); +string Reindent(absl::string_view original, + const absl::string_view indentation) { + std::vector<string> pieces = + absl::StrSplit(absl::string_view(original.data(), original.size()), '\n'); + return absl::StrJoin(pieces, "\n", [indentation](string* out, string s) { + absl::StrAppend(out, indentation, absl::StripAsciiWhitespace(s)); + }); } bool IsPermutation(tensorflow::gtl::ArraySlice<int64> permutation, int64 rank) { @@ -234,20 +152,20 @@ bool HasInteriorPadding(const PaddingConfig& config) { namespace { string HumanReadableNumOps(double flops, double nanoseconds, - tensorflow::StringPiece op_prefix) { + absl::string_view op_prefix) { if (nanoseconds == 0) { - return tensorflow::strings::StrCat("NaN ", op_prefix, "OP/s"); + return absl::StrCat("NaN ", op_prefix, "OP/s"); } double nano_flops = flops / nanoseconds; string throughput = tensorflow::strings::HumanReadableNum( static_cast<int64>(nano_flops * 1e9)); - tensorflow::StringPiece sp(throughput); + absl::string_view sp(throughput); // Use the more common "G(FLOPS)", rather than "B(FLOPS)" - if (tensorflow::str_util::EndsWith(sp, "B") || // Ends in 'B', ignoring case - tensorflow::str_util::EndsWith(sp, "b")) { + if (absl::EndsWith(sp, "B") || // Ends in 'B', ignoring case + absl::EndsWith(sp, "b")) { *throughput.rbegin() = 'G'; } - throughput += tensorflow::strings::StrCat(op_prefix, "OP/s"); + throughput += absl::StrCat(op_prefix, "OP/s"); return throughput; } } // namespace @@ -260,8 +178,7 @@ string HumanReadableNumTranscendentalOps(double trops, double nanoseconds) { return HumanReadableNumOps(trops, nanoseconds, "TR"); } -void LogLines(int sev, tensorflow::StringPiece text, const char* fname, - int lineno) { +void LogLines(int sev, absl::string_view text, const char* fname, int lineno) { const int orig_sev = sev; if (sev == tensorflow::FATAL) { sev = tensorflow::ERROR; @@ -275,7 +192,7 @@ void LogLines(int sev, tensorflow::StringPiece text, const char* fname, size_t cur = 0; while (cur < text.size()) { size_t eol = text.find('\n', cur); - if (eol == tensorflow::StringPiece::npos) { + if (eol == absl::string_view::npos) { eol = text.size(); } auto msg = text.substr(cur, eol - cur); diff --git a/tensorflow/compiler/xla/util.h b/tensorflow/compiler/xla/util.h index 5ae099a462..62f486369f 100644 --- a/tensorflow/compiler/xla/util.h +++ b/tensorflow/compiler/xla/util.h @@ -24,17 +24,20 @@ limitations under the License. #include <type_traits> #include <vector> +#include "absl/algorithm/container.h" +#include "absl/container/inlined_vector.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/status.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" +#include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/array_slice.h" -#include "tensorflow/core/lib/gtl/inlined_vector.h" #include "tensorflow/core/lib/math/math_util.h" #include "tensorflow/core/lib/strings/numbers.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/protobuf.h" @@ -54,7 +57,7 @@ Status WithLogBacktrace(const Status& status); // the InlinedVector will just behave like an std::vector<> and allocate the // memory to store its values. static constexpr int kInlineRank = 8; -using DimensionVector = tensorflow::gtl::InlinedVector<int64, kInlineRank>; +using DimensionVector = absl::InlinedVector<int64, kInlineRank>; // RAII timer that logs with a given label the wall clock time duration in human // readable form. This differs from base's ElapsedTimer primarily in that it @@ -201,46 +204,76 @@ void StridedCopy(tensorflow::gtl::MutableArraySlice<D> dest, int64 dest_base, // Adds some context information to the error message in a // Status. This is useful as Statuses are // propagated upwards. -Status AddStatus(Status prior, tensorflow::StringPiece context); -Status AppendStatus(Status prior, tensorflow::StringPiece context); - -// Status error shorthands -- printfs the arguments to be -// used as an error message and returns a status in the canonical -// error space. -Status InvalidArgument(const char* format, ...) TF_PRINTF_ATTRIBUTE(1, 2); -Status Unimplemented(const char* format, ...) TF_PRINTF_ATTRIBUTE(1, 2); -Status InternalError(const char* format, ...) TF_PRINTF_ATTRIBUTE(1, 2); -Status FailedPrecondition(const char* format, ...) TF_PRINTF_ATTRIBUTE(1, 2); -Status Cancelled(const char* format, ...) TF_PRINTF_ATTRIBUTE(1, 2); -Status ResourceExhausted(const char* format, ...) TF_PRINTF_ATTRIBUTE(1, 2); -Status NotFound(const char* format, ...) TF_PRINTF_ATTRIBUTE(1, 2); -Status Unavailable(const char* format, ...) TF_PRINTF_ATTRIBUTE(1, 2); - -// Passed-varargs variant of the InvalidArgument factory above. -Status InvalidArgumentV(const char* format, va_list args); +Status AddStatus(Status prior, absl::string_view context); +Status AppendStatus(Status prior, absl::string_view context); + +// Status error shorthands -- StrFormat's the arguments to be used as an error +// message and returns a status in the canonical error space. +template <typename... Args> +Status InvalidArgument(const absl::FormatSpec<Args...>& format, + const Args&... args) { + return WithLogBacktrace( + tensorflow::errors::InvalidArgument(absl::StrFormat(format, args...))); +} +template <typename... Args> +Status Unimplemented(const absl::FormatSpec<Args...>& format, + const Args&... args) { + return WithLogBacktrace( + tensorflow::errors::Unimplemented(absl::StrFormat(format, args...))); +} +template <typename... Args> +Status InternalError(const absl::FormatSpec<Args...>& format, + const Args&... args) { + return WithLogBacktrace( + tensorflow::errors::Internal(absl::StrFormat(format, args...))); +} +template <typename... Args> +Status FailedPrecondition(const absl::FormatSpec<Args...>& format, + const Args&... args) { + return WithLogBacktrace( + tensorflow::errors::FailedPrecondition(absl::StrFormat(format, args...))); +} +template <typename... Args> +Status Cancelled(const absl::FormatSpec<Args...>& format, const Args&... args) { + return WithLogBacktrace( + tensorflow::errors::Cancelled(absl::StrFormat(format, args...))); +} +template <typename... Args> +Status ResourceExhausted(const absl::FormatSpec<Args...>& format, + const Args&... args) { + return WithLogBacktrace( + tensorflow::errors::ResourceExhausted(absl::StrFormat(format, args...))); +} +template <typename... Args> +Status NotFound(const absl::FormatSpec<Args...>& format, const Args&... args) { + return WithLogBacktrace( + tensorflow::errors::NotFound(absl::StrFormat(format, args...))); +} +template <typename... Args> +Status Unavailable(const absl::FormatSpec<Args...>& format, + const Args&... args) { + return WithLogBacktrace( + tensorflow::errors::Unavailable(absl::StrFormat(format, args...))); +} template <typename... Args> Status InvalidArgumentStrCat(Args&&... concat) { - return InvalidArgument( - "%s", tensorflow::strings::StrCat(std::forward<Args>(concat)...).c_str()); + return InvalidArgument("%s", absl::StrCat(std::forward<Args>(concat)...)); } template <typename... Args> Status UnimplementedStrCat(Args&&... concat) { - return Unimplemented( - "%s", tensorflow::strings::StrCat(std::forward<Args>(concat)...).c_str()); + return Unimplemented("%s", absl::StrCat(std::forward<Args>(concat)...)); } template <typename... Args> Status InternalErrorStrCat(Args&&... concat) { - return InternalError( - "%s", tensorflow::strings::StrCat(std::forward<Args>(concat)...).c_str()); + return InternalError("%s", absl::StrCat(std::forward<Args>(concat)...)); } template <typename... Args> Status ResourceExhaustedStrCat(Args&&... concat) { - return ResourceExhausted( - "%s", tensorflow::strings::StrCat(std::forward<Args>(concat)...).c_str()); + return ResourceExhausted("%s", absl::StrCat(std::forward<Args>(concat)...)); } // Splits the lines of the original, replaces leading whitespace with the prefix @@ -249,8 +282,7 @@ Status ResourceExhaustedStrCat(Args&&... concat) { // // Note: even different amounts of leading whitespace on different lines will be // uniformly replaced with "indentation". -string Reindent(tensorflow::StringPiece original, - tensorflow::StringPiece indentation); +string Reindent(absl::string_view original, absl::string_view indentation); // Checks whether permutation is a permutation of the [0, rank) integer range. bool IsPermutation(tensorflow::gtl::ArraySlice<int64> permutation, int64 rank); @@ -312,7 +344,7 @@ string CommaSeparatedString(const Container& c, const char* prefix = "", string comma_separated = prefix; const char* separator = ""; for (const auto& entry : c) { - tensorflow::strings::StrAppend(&comma_separated, separator, entry); + absl::StrAppend(&comma_separated, separator, entry); separator = ", "; } comma_separated += suffix; @@ -394,8 +426,7 @@ string HumanReadableNumTranscendentalOps(double trops, double nanoseconds); // Split the text into multiple lines and log each line with the given // severity, filename, and line number. -void LogLines(int sev, tensorflow::StringPiece text, const char* fname, - int lineno); +void LogLines(int sev, absl::string_view text, const char* fname, int lineno); template <typename T> inline bool IsPowerOfTwo(T x) { @@ -434,122 +465,15 @@ std::vector<std::pair<int64, int64>> CommonFactors( // Removes illegal characters from filenames. string SanitizeFileName(string file_name); -template <typename Container, typename Predicate> -bool c_all_of(const Container& container, Predicate&& predicate) { - return std::all_of(std::begin(container), std::end(container), - std::forward<Predicate>(predicate)); -} - -template <typename Container, typename Predicate> -bool c_any_of(const Container& container, Predicate&& predicate) { - return std::any_of(std::begin(container), std::end(container), - std::forward<Predicate>(predicate)); -} - -template <typename InputContainer, typename OutputIterator, - typename UnaryOperation> -OutputIterator c_transform(const InputContainer& input_container, - OutputIterator output_iterator, - UnaryOperation&& unary_op) { - return std::transform(std::begin(input_container), std::end(input_container), - output_iterator, - std::forward<UnaryOperation>(unary_op)); -} - -template <class InputContainer, class OutputIterator, class UnaryPredicate> -OutputIterator c_copy_if(const InputContainer& input_container, - OutputIterator output_iterator, - UnaryPredicate&& predicate) { - return std::copy_if(std::begin(input_container), std::end(input_container), - output_iterator, std::forward<UnaryPredicate>(predicate)); -} - -template <class InputContainer, class OutputIterator> -OutputIterator c_copy(const InputContainer& input_container, - OutputIterator output_iterator) { - return std::copy(std::begin(input_container), std::end(input_container), - output_iterator); -} - -template <class InputContainer> -void c_sort(InputContainer& input_container) { - std::sort(std::begin(input_container), std::end(input_container)); -} - -template <class InputContainer, class Comparator> -void c_sort(InputContainer& input_container, Comparator&& comparator) { - std::sort(std::begin(input_container), std::end(input_container), - std::forward<Comparator>(comparator)); -} - -template <typename Sequence, typename T> -bool c_binary_search(const Sequence& sequence, T&& value) { - return std::binary_search(std::begin(sequence), std::end(sequence), - std::forward<T>(value)); -} - -template <typename C> -bool c_is_sorted(const C& c) { - return std::is_sorted(std::begin(c), std::end(c)); -} - -template <typename C, typename Compare> -bool c_is_sorted(const C& c, Compare&& comp) { - return std::is_sorted(std::begin(c), std::end(c), - std::forward<Compare>(comp)); -} - -template <typename C> -auto c_adjacent_find(C& c) -> decltype(std::begin(c)) { - return std::adjacent_find(std::begin(c), std::end(c)); -} - -template <typename C, typename Pred> -auto c_find_if(C& c, Pred&& pred) -> decltype(std::begin(c)) { - return std::find_if(std::begin(c), std::end(c), std::forward<Pred>(pred)); -} - -template <typename C, typename Value> -auto c_find(C& c, Value&& value) -> decltype(std::begin(c)) { - return std::find(std::begin(c), std::end(c), std::forward<Value>(value)); -} - -template <typename Sequence> -void c_reverse(Sequence& sequence) { - std::reverse(std::begin(sequence), std::end(sequence)); -} - -template <typename Sequence, typename T, typename BinaryOp> -typename std::decay<T>::type c_accumulate(const Sequence& sequence, T&& init, - BinaryOp&& binary_op) { - return std::accumulate(std::begin(sequence), std::end(sequence), - std::forward<T>(init), - std::forward<BinaryOp>(binary_op)); -} - -template <typename C, typename Pred> -typename std::iterator_traits< - decltype(std::begin(std::declval<C>()))>::difference_type -c_count_if(const C& c, Pred&& pred) { - return std::count_if(std::begin(c), std::end(c), std::forward<Pred>(pred)); -} - -// Determines whether `value` is present in `c`. -template <typename C, typename T> -bool c_linear_search(const C& c, T&& value) { - auto last = std::end(c); - return std::find(std::begin(c), last, std::forward<T>(value)) != last; -} - template <typename C, typename Value> int64 FindIndex(const C& c, Value&& value) { - auto it = c_find(c, std::forward<Value>(value)); + auto it = absl::c_find(c, std::forward<Value>(value)); return std::distance(c.begin(), it); } template <typename T> bool ArrayContains(tensorflow::gtl::ArraySlice<T> c, const T& value) { - return c_find(c, value) != c.end(); + return absl::c_find(c, value) != c.end(); } template <typename C, typename Value> @@ -567,9 +491,9 @@ std::vector<T> ArraySliceToVector(tensorflow::gtl::ArraySlice<T> slice) { return std::vector<T>(slice.begin(), slice.end()); } -template <typename T, int N> +template <typename T, size_t N> std::vector<T> InlinedVectorToVector( - const tensorflow::gtl::InlinedVector<T, N>& inlined_vector) { + const absl::InlinedVector<T, N>& inlined_vector) { return std::vector<T>(inlined_vector.begin(), inlined_vector.end()); } @@ -584,8 +508,8 @@ bool IsInt32(T x) { template <typename T> Status EraseElementFromVector(std::vector<T>* container, const T& value) { - // c_find returns a const_iterator which does not seem to work on gcc 4.8.4, - // and this breaks the ubuntu/xla_gpu build bot. + // absl::c_find returns a const_iterator which does not seem to work on + // gcc 4.8.4, and this breaks the ubuntu/xla_gpu build bot. auto it = std::find(container->begin(), container->end(), value); TF_RET_CHECK(it != container->end()); container->erase(it); diff --git a/tensorflow/compiler/xla/window_util.cc b/tensorflow/compiler/xla/window_util.cc index f11123ca24..268dc5db01 100644 --- a/tensorflow/compiler/xla/window_util.cc +++ b/tensorflow/compiler/xla/window_util.cc @@ -17,11 +17,9 @@ limitations under the License. #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/lib/strings/strcat.h" -#include "tensorflow/core/lib/strings/stringprintf.h" namespace xla { namespace window_util { @@ -49,8 +47,8 @@ PaddingConfig MakeSymmetricPadding(tensorflow::gtl::ArraySlice<int64> sizes) { } /* static */ string ToString(const WindowDimension& dim) { - using tensorflow::strings::StrAppend; - using tensorflow::strings::StrCat; + using absl::StrAppend; + using absl::StrCat; string str = StrCat("(size=", dim.size()); if (dim.stride() != 1) { StrAppend(&str, ",stride=", dim.stride()); @@ -75,8 +73,8 @@ PaddingConfig MakeSymmetricPadding(tensorflow::gtl::ArraySlice<int64> sizes) { } string ToString(const Window& window) { - using tensorflow::strings::StrAppend; - using tensorflow::strings::StrCat; + using absl::StrAppend; + using absl::StrCat; string str; const auto add_field = diff --git a/tensorflow/compiler/xla/xla_data.proto b/tensorflow/compiler/xla/xla_data.proto index 27aa94c2cb..8e43f275e1 100644 --- a/tensorflow/compiler/xla/xla_data.proto +++ b/tensorflow/compiler/xla/xla_data.proto @@ -105,13 +105,14 @@ enum PaddingValue { message PaddingConfig { // Describes the padding configuration for a dimension. message PaddingConfigDimension { - // Padding amount on the low-end (next to the index 0). + // Padding amount on the low-end (next to the index 0). May be negative. int64 edge_padding_low = 1; - // Padding amount on the high-end (next to the highest index). + // Padding amount on the high-end (next to the highest index). May be + // negative. int64 edge_padding_high = 2; - // Padding amount between the elements. + // Padding amount between the elements. May not be negative. int64 interior_padding = 3; } @@ -393,13 +394,14 @@ message WindowDimension { // Dilation factor of the sliding window in this dimension. A dilation factor // of 1 means no dilation. window_dilation - 1 no-op entries ("holes") are - // implicitly placed between each kernel element. See documentation for - // convolution. + // implicitly placed between each kernel element. This value may not be less + // than 1. See documentation for convolution. int64 window_dilation = 5; // Dilation factor of the base area in this dimension. A dilation factor of 1 // means no dilation. base_dilation - 1 no-op entries ("holes") are implicitly - // placed between each base area element. See documentation for convolution. + // placed between each base area element. This value may not be less than 1. + // See documentation for convolution. int64 base_dilation = 6; // Window reversal means that this dimension was logically reversed before the @@ -569,3 +571,24 @@ message ReplicaGroup { // ids matters in some op (e.g., all-to-all). repeated int64 replica_ids = 1; } + +// Describes the source target pair in the collective permute op. +message SourceTarget { + int64 source = 1; + int64 target = 2; +} + +// Used to indicate the precision configuration. It has backend specific +// meaning. +message PrecisionConfigProto { + enum Precision { + DEFAULT = 0; + HIGH = 1; + HIGHEST = 2; + + // Next: 3 + } + repeated Precision operand_precision = 1; + + // Next: 2 +} diff --git a/tensorflow/contrib/BUILD b/tensorflow/contrib/BUILD index 23bb783e22..66983801bf 100644 --- a/tensorflow/contrib/BUILD +++ b/tensorflow/contrib/BUILD @@ -20,7 +20,13 @@ py_library( ), srcs_version = "PY2AND3", visibility = ["//visibility:public"], - deps = [ + deps = if_not_windows([ + # TODO(aaroey): tensorrt dependency has to appear before tflite so the + # build can resolve its flatbuffers symbols within the tensorrt library. + # This is an issue with the tensorrt static library and will be fixed by + # the next tensorrt release, so fix the order here after that. + "//tensorflow/contrib/tensorrt:init_py", # doesn't compile on windows + ]) + [ "//tensorflow/contrib/all_reduce", "//tensorflow/contrib/batching:batch_py", "//tensorflow/contrib/bayesflow:bayesflow_py", @@ -55,7 +61,6 @@ py_library( "//tensorflow/contrib/integrate:integrate_py", "//tensorflow/contrib/keras", "//tensorflow/contrib/kernel_methods", - "//tensorflow/contrib/kfac", "//tensorflow/contrib/labeled_tensor", "//tensorflow/contrib/layers:layers_py", "//tensorflow/contrib/learn", @@ -64,6 +69,7 @@ py_library( "//tensorflow/contrib/linalg:linalg_py", "//tensorflow/contrib/linear_optimizer:sdca_estimator_py", "//tensorflow/contrib/linear_optimizer:sdca_ops_py", + "//tensorflow/contrib/lite/python:lite", "//tensorflow/contrib/lookup:lookup_py", "//tensorflow/contrib/losses:losses_py", "//tensorflow/contrib/losses:metric_learning_py", @@ -130,12 +136,6 @@ py_library( "//tensorflow/contrib/bigtable", # depends on bigtable "//tensorflow/contrib/cloud:cloud_py", # doesn't compile on Windows "//tensorflow/contrib/ffmpeg:ffmpeg_ops_py", - # TODO(aaroey): tensorrt dependency has to appear before tflite so the - # build can resolve its flatbuffers symbols within the tensorrt library. - # This is an issue with the tensorrt static library and will be fixed by - # the next tensorrt release, so fix the order here after that. - "//tensorflow/contrib/tensorrt:init_py", # doesn't compile on windows - "//tensorflow/contrib/lite/python:lite", # unix dependency, need to fix code ]), ) @@ -181,6 +181,7 @@ cc_library( "//tensorflow/contrib/boosted_trees:boosted_trees_ops_op_lib", "//tensorflow/contrib/coder:all_ops", "//tensorflow/contrib/data:dataset_ops_op_lib", + "//tensorflow/contrib/data:indexed_dataset_ops_op_lib", "//tensorflow/contrib/factorization:all_ops", "//tensorflow/contrib/framework:all_ops", "//tensorflow/contrib/hadoop:dataset_ops_op_lib", diff --git a/tensorflow/contrib/__init__.py b/tensorflow/contrib/__init__.py index e18ea8df4d..5f477a79a3 100644 --- a/tensorflow/contrib/__init__.py +++ b/tensorflow/contrib/__init__.py @@ -51,7 +51,6 @@ from tensorflow.contrib import input_pipeline from tensorflow.contrib import integrate from tensorflow.contrib import keras from tensorflow.contrib import kernel_methods -from tensorflow.contrib import kfac from tensorflow.contrib import labeled_tensor from tensorflow.contrib import layers from tensorflow.contrib import learn @@ -94,8 +93,7 @@ from tensorflow.contrib import tpu from tensorflow.contrib import training from tensorflow.contrib import util from tensorflow.contrib.eager.python import tfe as eager -if os.name != "nt": - from tensorflow.contrib.lite.python import lite +from tensorflow.contrib.lite.python import lite from tensorflow.contrib.optimizer_v2 import optimizer_v2_symbols as optimizer_v2 from tensorflow.contrib.receptive_field import receptive_field_api as receptive_field from tensorflow.contrib.recurrent.python import recurrent_api as recurrent diff --git a/tensorflow/contrib/android/asset_manager_filesystem.cc b/tensorflow/contrib/android/asset_manager_filesystem.cc index 513d519eab..d14b2126a0 100644 --- a/tensorflow/contrib/android/asset_manager_filesystem.cc +++ b/tensorflow/contrib/android/asset_manager_filesystem.cc @@ -28,7 +28,7 @@ string RemoveSuffix(const string& name, const string& suffix) { string output(name); StringPiece piece(output); str_util::ConsumeSuffix(&piece, suffix); - return piece.ToString(); + return string(piece); } // Closes the given AAsset when variable is destructed. @@ -231,7 +231,7 @@ string AssetManagerFileSystem::NormalizeDirectoryPath(const string& fname) { string AssetManagerFileSystem::RemoveAssetPrefix(const string& name) { StringPiece piece(name); str_util::ConsumePrefix(&piece, prefix_); - return piece.ToString(); + return string(piece); } bool AssetManagerFileSystem::DirectoryExists(const std::string& fname) { diff --git a/tensorflow/contrib/autograph/converters/builtin_functions_test.py b/tensorflow/contrib/autograph/converters/builtin_functions_test.py index d5c3e2c250..d0a0cbbeb6 100644 --- a/tensorflow/contrib/autograph/converters/builtin_functions_test.py +++ b/tensorflow/contrib/autograph/converters/builtin_functions_test.py @@ -36,7 +36,7 @@ class BuiltinFunctionsTest(converter_testing.TestCase): with self.converted(test_fn, builtin_functions, {'len': len}, array_ops.shape) as result: - with self.test_session() as sess: + with self.cached_session() as sess: ops = result.test_fn(constant_op.constant([0, 0, 0])) self.assertEqual(sess.run(ops), 3) @@ -49,7 +49,7 @@ class BuiltinFunctionsTest(converter_testing.TestCase): return print(a) with self.converted(test_fn, builtin_functions, {'print': print}) as result: - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertPrints('a\n'): sess.run(result.test_fn('a')) @@ -62,7 +62,7 @@ class BuiltinFunctionsTest(converter_testing.TestCase): return print(a, b, c) with self.converted(test_fn, builtin_functions, {'print': print}) as result: - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertPrints('a 1 [2, 3]\n'): sess.run( result.test_fn( diff --git a/tensorflow/contrib/autograph/converters/call_trees_test.py b/tensorflow/contrib/autograph/converters/call_trees_test.py index 8cdba659ee..ca4d1f2932 100644 --- a/tensorflow/contrib/autograph/converters/call_trees_test.py +++ b/tensorflow/contrib/autograph/converters/call_trees_test.py @@ -91,7 +91,7 @@ class CallTreesTest(converter_testing.TestCase): setattr(a, 'foo', 'bar') with self.converted(test_fn, call_trees, {'setattr': setattr}) as result: - with self.test_session() as sess: + with self.cached_session() as sess: class Dummy(object): pass @@ -110,7 +110,7 @@ class CallTreesTest(converter_testing.TestCase): with self.converted(test_fn, call_trees, {'np': np}, dtypes.int64) as result: - with self.test_session() as sess: + with self.cached_session() as sess: self.assertTrue(isinstance(result.test_fn(), ops.Tensor)) self.assertIn(sess.run(result.test_fn()), (0, 1, 2)) @@ -129,7 +129,7 @@ class CallTreesTest(converter_testing.TestCase): node = call_trees.transform(node, ctx) with self.compiled(node, ns) as result: - with self.test_session() as sess: + with self.cached_session() as sess: result_tensor = result.test_fn(constant_op.constant(1)) self.assertEquals(sess.run(result_tensor), 3) diff --git a/tensorflow/contrib/autograph/converters/control_flow.py b/tensorflow/contrib/autograph/converters/control_flow.py index 5a5a6ad63a..3530fbb2ec 100644 --- a/tensorflow/contrib/autograph/converters/control_flow.py +++ b/tensorflow/contrib/autograph/converters/control_flow.py @@ -95,6 +95,18 @@ class ControlFlowTransformer(converter.Base): return 'no variables' return ', '.join(map(str, symbol_set)) + def _validate_no_live_vars_created(self, node): + body_scope = anno.getanno(node, annos.NodeAnno.BODY_SCOPE) + live_vars_out = anno.getanno(node, anno.Static.LIVE_VARS_OUT) + live_vars_created_in_body = live_vars_out & body_scope.created + if live_vars_created_in_body: + raise ValueError( + 'The following variables are created inside the loop and used later:' + '\n%s\n' + 'Variables must be declared outside loops because loops may not' + ' necessarily execute.' % self._fmt_symbol_list( + live_vars_created_in_body)) + def visit_If(self, node): node = self.generic_visit(node) @@ -197,13 +209,15 @@ class ControlFlowTransformer(converter.Base): def visit_While(self, node): self.generic_visit(node) + self._validate_no_live_vars_created(node) + body_scope = anno.getanno(node, annos.NodeAnno.BODY_SCOPE) body_closure = body_scope.modified - body_scope.created all_referenced = body_scope.referenced cond_scope = anno.getanno(node, annos.NodeAnno.COND_SCOPE) cond_closure = set() - for s in cond_scope.referenced: + for s in cond_scope.used: for root in s.support_set: if root not in body_scope.created: cond_closure.add(root) @@ -236,6 +250,7 @@ class ControlFlowTransformer(converter.Base): node_body = ast_util.rename_symbols(node.body, ssf_map) test = ast_util.rename_symbols(node.test, ssf_map) + # TODO(b/113118541) investigate the need-for and correctness-of extra_deps template = """ def test_name(state_ssf): return test @@ -262,6 +277,8 @@ class ControlFlowTransformer(converter.Base): def visit_For(self, node): self.generic_visit(node) + self._validate_no_live_vars_created(node) + body_scope = anno.getanno(node, annos.NodeAnno.BODY_SCOPE) body_closure = body_scope.modified - body_scope.created all_referenced = body_scope.referenced @@ -294,7 +311,9 @@ class ControlFlowTransformer(converter.Base): template = """ def extra_test_name(state_ssf): return extra_test_expr - def body_name(iterate, state_ssf): + def body_name(loop_vars, state_ssf): + # Workaround for PEP-3113 + iterate = loop_vars body return state_ssf, state_ast_tuple = ag__.for_stmt( diff --git a/tensorflow/contrib/autograph/converters/control_flow_test.py b/tensorflow/contrib/autograph/converters/control_flow_test.py index ade3501426..1d04ba3ba6 100644 --- a/tensorflow/contrib/autograph/converters/control_flow_test.py +++ b/tensorflow/contrib/autograph/converters/control_flow_test.py @@ -33,7 +33,7 @@ class ControlFlowTest(converter_testing.TestCase): inputs = (inputs,) with self.converted(test_fn, control_flow, {}, constant_op.constant) as result: - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(result.test_fn(*inputs)), expected) def test_while_basic(self): @@ -48,6 +48,24 @@ class ControlFlowTest(converter_testing.TestCase): self.assertTransformedResult(test_fn, constant_op.constant(5), (10, 5, 5)) + def test_while_nested(self): + + def test_fn(n): + i = 0 + j = 0 + s = 0 + while i < n: + while j < i: + j += 3 + u = i + j # 'u' is not defined within the inner loop + s += u + i += 1 + j = 0 + return s, i, j, n + + self.assertTransformedResult(test_fn, constant_op.constant(5), + (25, 5, 0, 5)) + def test_while_single_output(self): def test_fn(n): @@ -57,6 +75,17 @@ class ControlFlowTest(converter_testing.TestCase): self.assertTransformedResult(test_fn, constant_op.constant(5), 0) + def test_while_variable_defined_in_body(self): + def bad_while_loop(n): + while n > 0: + n -= 1 + s = n + return s + + node, ctx = self.prepare(bad_while_loop, {}) + with self.assertRaises(transformer.AutographParseError): + control_flow.transform(node, ctx) + def test_if_basic(self): def test_fn(n): @@ -89,7 +118,7 @@ class ControlFlowTest(converter_testing.TestCase): return obj with self.converted(test_fn, control_flow, {}) as result: - with self.test_session() as sess: + with self.cached_session() as sess: res_obj = result.test_fn(constant_op.constant(1), TestClass(0, 0)) self.assertEqual(sess.run((res_obj.a, res_obj.b)), (-1, 0)) res_obj = result.test_fn(constant_op.constant(-1), TestClass(0, 0)) @@ -196,6 +225,23 @@ class ControlFlowTest(converter_testing.TestCase): self.assertEqual(result.test_fn(5), 10) self.assertEqual(eval_count[0], 1) + def test_for_variable_defined_in_body(self): + def bad_for_loop(n): + for i in range(n): + s = i + return s + + node, ctx = self.prepare(bad_for_loop, {}) + with self.assertRaises(transformer.AutographParseError): + control_flow.transform(node, ctx) + + def test_for_tuple_unpacking(self): + def test_fn(x_list): + z = tf.constant(0) # pylint:disable=undefined-variable + for i, x in enumerate(x_list): + z = z + x + i + return z + self.assertTransformedResult(test_fn, [3, 3], 7) if __name__ == '__main__': test.main() diff --git a/tensorflow/contrib/autograph/converters/lists_test.py b/tensorflow/contrib/autograph/converters/lists_test.py index 996e99ee61..c5e2dcf75e 100644 --- a/tensorflow/contrib/autograph/converters/lists_test.py +++ b/tensorflow/contrib/autograph/converters/lists_test.py @@ -65,7 +65,7 @@ class ListTest(converter_testing.TestCase): ns = {'special_functions': special_functions} with self.converted(test_fn, lists, ns) as result: - with self.test_session() as sess: + with self.cached_session() as sess: tl = result.test_fn() r = list_ops.tensor_list_stack(tl, dtypes.int32) self.assertAllEqual(sess.run(r), [1, 2, 3]) @@ -88,7 +88,7 @@ class ListTest(converter_testing.TestCase): node = lists.transform(node, ctx) with self.compiled(node, ns, dtypes.int32) as result: - with self.test_session() as sess: + with self.cached_session() as sess: ts, tl = result.test_fn() r = list_ops.tensor_list_stack(tl, dtypes.int32) self.assertAllEqual(sess.run(r), [1, 2]) @@ -122,7 +122,7 @@ class ListTest(converter_testing.TestCase): node = lists.transform(node, ctx) with self.compiled(node, {}, array_ops.stack, dtypes.int32) as result: - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual(sess.run(result.test_fn()), [1, 2, 3]) # TODO(mdan): Add a test with tf.stack with axis kwarg. diff --git a/tensorflow/contrib/autograph/converters/logical_expressions_test.py b/tensorflow/contrib/autograph/converters/logical_expressions_test.py index ca07de5e8a..8f9eee7081 100644 --- a/tensorflow/contrib/autograph/converters/logical_expressions_test.py +++ b/tensorflow/contrib/autograph/converters/logical_expressions_test.py @@ -33,7 +33,7 @@ class GradientsFunctionTest(converter_testing.TestCase): with self.converted(test_fn, logical_expressions, {}, math_ops.equal) as result: - with self.test_session() as sess: + with self.cached_session() as sess: self.assertTrue(sess.run(result.test_fn(1, 1))) self.assertFalse(sess.run(result.test_fn(1, 2))) @@ -44,7 +44,7 @@ class GradientsFunctionTest(converter_testing.TestCase): with self.converted(test_fn, logical_expressions, {}, math_ops.logical_or, math_ops.logical_and) as result: - with self.test_session() as sess: + with self.cached_session() as sess: self.assertTrue(sess.run(result.test_fn(True, False, True))) diff --git a/tensorflow/contrib/autograph/converters/side_effect_guards_test.py b/tensorflow/contrib/autograph/converters/side_effect_guards_test.py index bee512abbc..5fe5114d4b 100644 --- a/tensorflow/contrib/autograph/converters/side_effect_guards_test.py +++ b/tensorflow/contrib/autograph/converters/side_effect_guards_test.py @@ -46,7 +46,7 @@ class SideEffectGuardsTest(converter_testing.TestCase): self.assertEqual(len(node.body), 1) with self.compiled(node, {}, state_ops.assign) as result: - with self.test_session() as sess: + with self.cached_session() as sess: v = variable_scope.get_variable('test', initializer=2) sess.run(v.initializer) sess.run(result.test_fn(v)) @@ -67,7 +67,7 @@ class SideEffectGuardsTest(converter_testing.TestCase): self.assertEqual(len(node.body), 1) with self.compiled(node, {}, state_ops.assign) as result: - with self.test_session() as sess: + with self.cached_session() as sess: v = variable_scope.get_variable('test', initializer=2) sess.run(v.initializer) sess.run(result.test_fn(v)) @@ -87,7 +87,7 @@ class SideEffectGuardsTest(converter_testing.TestCase): self.assertEqual(len(node.body), 1) with self.compiled(node, {}, control_flow_ops.Assert) as result: - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaisesRegexp(errors_impl.InvalidArgumentError, 'expected in throw'): sess.run(result.test_fn(constant_op.constant(-1))) @@ -107,7 +107,7 @@ class SideEffectGuardsTest(converter_testing.TestCase): self.assertEqual(len(node.body), 1) with self.compiled(node, {}, state_ops.assign_add) as result: - with self.test_session() as sess: + with self.cached_session() as sess: v = variable_scope.get_variable('test', initializer=2) sess.run(v.initializer) sess.run(result.test_fn(v)) @@ -128,7 +128,7 @@ class SideEffectGuardsTest(converter_testing.TestCase): self.assertEqual(len(node.body[0].body), 1) with self.compiled(node, {}, state_ops.assign, ops.name_scope) as result: - with self.test_session() as sess: + with self.cached_session() as sess: v = variable_scope.get_variable('test', initializer=2) sess.run(v.initializer) sess.run(result.test_fn(v)) @@ -151,7 +151,7 @@ class SideEffectGuardsTest(converter_testing.TestCase): with self.compiled(node, {}, state_ops.assign, state_ops.assign_add) as result: - with self.test_session() as sess: + with self.cached_session() as sess: v = variable_scope.get_variable('test', initializer=2) sess.run(v.initializer) sess.run(result.test_fn(v)) diff --git a/tensorflow/contrib/autograph/converters/slices_test.py b/tensorflow/contrib/autograph/converters/slices_test.py index c822d53a4a..d74b2e025e 100644 --- a/tensorflow/contrib/autograph/converters/slices_test.py +++ b/tensorflow/contrib/autograph/converters/slices_test.py @@ -45,7 +45,7 @@ class SliceTest(converter_testing.TestCase): node = slices.transform(node, ctx) with self.compiled(node, {}, dtypes.int32) as result: - with self.test_session() as sess: + with self.cached_session() as sess: tl = list_ops.tensor_list_from_tensor( [1, 2], element_shape=constant_op.constant([], dtype=dtypes.int32)) y = result.test_fn(tl) diff --git a/tensorflow/contrib/autograph/examples/integration_tests/errors_test.py b/tensorflow/contrib/autograph/examples/integration_tests/errors_test.py index f4b9159942..04a968be10 100644 --- a/tensorflow/contrib/autograph/examples/integration_tests/errors_test.py +++ b/tensorflow/contrib/autograph/examples/integration_tests/errors_test.py @@ -97,7 +97,7 @@ class ErrorsTest(tf.test.TestCase): compiled_fn = ag.to_graph(test_fn) with self.assertRaises(ag.TfRuntimeError) as error: - with self.test_session() as sess: + with self.cached_session() as sess: x = compiled_fn(tf.constant([4, 8])) with ag.improved_errors(compiled_fn): sess.run(x) @@ -144,7 +144,7 @@ class ErrorsTest(tf.test.TestCase): # frame with "g" as the function name but because we don't yet add # try/except blocks to inner functions the name is "tf__g". with self.assertRaises(ag.TfRuntimeError) as error: - with self.test_session() as sess: + with self.cached_session() as sess: x = compiled_fn(tf.constant([4, 8])) with ag.improved_errors(compiled_fn): sess.run(x) diff --git a/tensorflow/contrib/autograph/examples/integration_tests/list_literals_test.py b/tensorflow/contrib/autograph/examples/integration_tests/list_literals_test.py index 680b6dbaf0..904246afb7 100644 --- a/tensorflow/contrib/autograph/examples/integration_tests/list_literals_test.py +++ b/tensorflow/contrib/autograph/examples/integration_tests/list_literals_test.py @@ -33,7 +33,7 @@ class ListLiteralsTest(tf.test.TestCase): converted = ag.to_graph(list_used_as_tuple) result = converted() - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual(sess.run(result), [1, 2, 3]) diff --git a/tensorflow/contrib/autograph/operators/control_flow_test.py b/tensorflow/contrib/autograph/operators/control_flow_test.py index b14d7edba3..677b7f8f62 100644 --- a/tensorflow/contrib/autograph/operators/control_flow_test.py +++ b/tensorflow/contrib/autograph/operators/control_flow_test.py @@ -34,7 +34,7 @@ class ForLoopTest(test.TestCase): extra_test=lambda s: True, body=lambda i, s: (s + i,), init_state=(0,)) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual((10,), sess.run(s)) def test_python(self): @@ -52,7 +52,7 @@ class ForLoopTest(test.TestCase): extra_test=lambda s: True, body=lambda i, s: (s + i,), init_state=(0,)) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual((10,), sess.run(s)) @@ -65,7 +65,7 @@ class WhileLoopTest(test.TestCase): body=lambda i, s: (i + 1, s + i,), init_state=(0, 0), extra_deps=(n,)) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual((5, 10), sess.run(results)) def test_python(self): @@ -86,7 +86,8 @@ class IfStmtTest(test.TestCase): cond=cond, body=lambda: 1, orelse=lambda: -1) - with self.test_session() as sess: + + with self.cached_session() as sess: self.assertEqual(1, sess.run(test_if_stmt(constant_op.constant(True)))) self.assertEqual(-1, sess.run(test_if_stmt(constant_op.constant(False)))) diff --git a/tensorflow/contrib/autograph/operators/data_structures_test.py b/tensorflow/contrib/autograph/operators/data_structures_test.py index 7ea11a839b..4b1e835d44 100644 --- a/tensorflow/contrib/autograph/operators/data_structures_test.py +++ b/tensorflow/contrib/autograph/operators/data_structures_test.py @@ -42,7 +42,7 @@ class ListTest(test.TestCase): def test_tf_tensor_list_new(self): l = data_structures.tf_tensor_list_new([3, 4, 5]) t = list_ops.tensor_list_stack(l, element_dtype=dtypes.int32) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual(sess.run(t), [3, 4, 5]) def test_tf_tensor_list_new_illegal_input(self): @@ -63,7 +63,7 @@ class ListTest(test.TestCase): def test_tf_tensor_array_new(self): l = data_structures.tf_tensor_array_new([3, 4, 5]) t = l.stack() - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual(sess.run(t), [3, 4, 5]) def test_tf_tensor_array_new_illegal_input(self): @@ -88,14 +88,14 @@ class ListTest(test.TestCase): l = data_structures.list_append(l, x) t = list_ops.tensor_list_stack(l, element_dtype=x.dtype) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual(sess.run(t), [[1, 2, 3]]) def test_append_tensorarray(self): l = tensor_array_ops.TensorArray(dtypes.int32, size=0, dynamic_size=True) l1 = data_structures.list_append(l, 1) l2 = data_structures.list_append(l1, 2) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual(sess.run(l1.stack()), [1]) self.assertAllEqual(sess.run(l2.stack()), [1, 2]) @@ -116,7 +116,7 @@ class ListTest(test.TestCase): with self.assertRaises(NotImplementedError): data_structures.list_pop(l, 0, opts) - with self.test_session() as sess: + with self.cached_session() as sess: l, x = data_structures.list_pop(l, None, opts) self.assertAllEqual(sess.run(x), [3, 4]) @@ -137,7 +137,7 @@ class ListTest(test.TestCase): opts = data_structures.ListStackOpts( element_dtype=initial_list.dtype, original_call=None) - with self.test_session() as sess: + with self.cached_session() as sess: t = data_structures.list_stack(l, opts) self.assertAllEqual(sess.run(t), sess.run(initial_list)) diff --git a/tensorflow/contrib/autograph/operators/slices_test.py b/tensorflow/contrib/autograph/operators/slices_test.py index d4aacb9d20..56aafe07c8 100644 --- a/tensorflow/contrib/autograph/operators/slices_test.py +++ b/tensorflow/contrib/autograph/operators/slices_test.py @@ -32,7 +32,7 @@ class SlicesTest(test.TestCase): l = list_ops.tensor_list_from_tensor(initial_list, element_shape=elem_shape) l = slices.set_item(l, 0, [5, 6]) - with self.test_session() as sess: + with self.cached_session() as sess: t = list_ops.tensor_list_stack(l, element_dtype=initial_list.dtype) self.assertAllEqual(sess.run(t), [[5, 6], [3, 4]]) @@ -43,7 +43,7 @@ class SlicesTest(test.TestCase): t = slices.get_item( l, 1, slices.GetItemOpts(element_dtype=initial_list.dtype)) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual(sess.run(t), [3, 4]) diff --git a/tensorflow/contrib/autograph/pyct/testing/BUILD b/tensorflow/contrib/autograph/pyct/testing/BUILD index 9ef1ac9663..29a92444bb 100644 --- a/tensorflow/contrib/autograph/pyct/testing/BUILD +++ b/tensorflow/contrib/autograph/pyct/testing/BUILD @@ -34,8 +34,10 @@ py_test( srcs = ["codegen_test.py"], srcs_version = "PY2AND3", tags = [ + "manual", "no_windows", "nomsan", + "notap", ], deps = [ ":testing", diff --git a/tensorflow/contrib/bigtable/README.md b/tensorflow/contrib/bigtable/README.md index b9abfa8295..f33eaf7e3d 100644 --- a/tensorflow/contrib/bigtable/README.md +++ b/tensorflow/contrib/bigtable/README.md @@ -324,8 +324,14 @@ If you encounter a log line that includes the following: "filename":"/usr/share/grpc/roots.pem" ``` -you likely need to copy the [gRPC `roots.pem` file][grpcPem] to -`/usr/share/grpc/roots.pem` on your local machine. +you can solve it via either of the following approaches: + +* copy the [gRPC `roots.pem` file][grpcPem] to + `/usr/share/grpc/roots.pem` on your local machine, which is the default + location where gRPC will look for this file +* export the environment variable `GRPC_DEFAULT_SSL_ROOTS_FILE_PATH` to point to + the full path of the gRPC `roots.pem` file on your file system if it's in a + different location [grpcPem]: https://github.com/grpc/grpc/blob/master/etc/roots.pem diff --git a/tensorflow/contrib/boosted_trees/BUILD b/tensorflow/contrib/boosted_trees/BUILD index 8eac1243ef..f03eab510c 100644 --- a/tensorflow/contrib/boosted_trees/BUILD +++ b/tensorflow/contrib/boosted_trees/BUILD @@ -445,6 +445,7 @@ tf_kernel_library( "//tensorflow/contrib/boosted_trees/proto:learner_proto_cc", "//tensorflow/contrib/boosted_trees/proto:quantiles_proto_cc", "//tensorflow/contrib/boosted_trees/proto:split_info_proto_cc", + "//tensorflow/contrib/boosted_trees/proto:tree_config_proto_cc", "//tensorflow/contrib/boosted_trees/resources:decision_tree_ensemble_resource", "//tensorflow/contrib/boosted_trees/resources:quantile_stream_resource", "//tensorflow/core:framework_headers_lib", diff --git a/tensorflow/contrib/boosted_trees/kernels/split_handler_ops.cc b/tensorflow/contrib/boosted_trees/kernels/split_handler_ops.cc index d9e7a0f466..3b28ed77f3 100644 --- a/tensorflow/contrib/boosted_trees/kernels/split_handler_ops.cc +++ b/tensorflow/contrib/boosted_trees/kernels/split_handler_ops.cc @@ -12,6 +12,7 @@ // See the License for the specific language governing permissions and // limitations under the License. // ============================================================================= +#include <limits> #include <memory> #include <string> #include <vector> @@ -325,13 +326,21 @@ class BuildDenseInequalitySplitsOp : public OpKernel { } float best_gain = std::numeric_limits<float>::lowest(); - int64 best_bucket_idx = 0; + int64 best_bucket_id = 0; std::vector<NodeStats> best_right_node_stats(num_elements, NodeStats(0)); std::vector<NodeStats> best_left_node_stats(num_elements, NodeStats(0)); std::vector<NodeStats> current_left_node_stats(num_elements, NodeStats(0)); std::vector<NodeStats> current_right_node_stats(num_elements, NodeStats(0)); - int64 current_bucket_id = 0; + int64 current_bucket_id = std::numeric_limits<int64>::max(); int64 last_bucket_id = -1; + // Find the lowest bucket id, this is going to be the first bucket id to + // try. + for (int root_idx = 0; root_idx < num_elements; root_idx++) { + const int start_index = partition_boundaries[root_idx]; + if (bucket_ids(start_index, 0) < current_bucket_id) { + current_bucket_id = bucket_ids(start_index, 0); + } + } // Indexes offsets for each of the partitions that can be used to access // gradients of a partition for a current bucket we consider. std::vector<int> current_layer_offsets(num_elements, 0); @@ -373,6 +382,7 @@ class BuildDenseInequalitySplitsOp : public OpKernel { best_gain = gain_of_split; best_left_node_stats = current_left_node_stats; best_right_node_stats = current_right_node_stats; + best_bucket_id = current_bucket_id; } current_bucket_id = next_bucket_id; } @@ -383,22 +393,23 @@ class BuildDenseInequalitySplitsOp : public OpKernel { best_gain -= num_elements * state->tree_complexity_regularization(); ObliviousSplitInfo oblivious_split_info; - auto* oblivious_dense_split = oblivious_split_info.mutable_split_node() - ->mutable_dense_float_binary_split(); + auto* oblivious_dense_split = + oblivious_split_info.mutable_split_node() + ->mutable_oblivious_dense_float_binary_split(); oblivious_dense_split->set_feature_column(state->feature_column_group_id()); - oblivious_dense_split->set_threshold( - bucket_boundaries(bucket_ids(best_bucket_idx, 0))); + oblivious_dense_split->set_threshold(bucket_boundaries(best_bucket_id)); (*gains)(0) = best_gain; for (int root_idx = 0; root_idx < num_elements; root_idx++) { - auto* left_children = oblivious_split_info.add_children_leaves(); - auto* right_children = oblivious_split_info.add_children_leaves(); + auto* left_child = oblivious_split_info.add_children(); + auto* right_child = oblivious_split_info.add_children(); - state->FillLeaf(best_left_node_stats[root_idx], left_children); - state->FillLeaf(best_right_node_stats[root_idx], right_children); + state->FillLeaf(best_left_node_stats[root_idx], left_child); + state->FillLeaf(best_right_node_stats[root_idx], right_child); const int start_index = partition_boundaries[root_idx]; (*output_partition_ids)(root_idx) = partition_ids(start_index); + oblivious_split_info.add_children_parent_id(partition_ids(start_index)); } oblivious_split_info.SerializeToString(&(*output_splits)(0)); } @@ -728,6 +739,11 @@ class BuildCategoricalEqualitySplitsOp : public OpKernel { context->input("bias_feature_id", &bias_feature_id_t)); int64 bias_feature_id = bias_feature_id_t->scalar<int64>()(); + const Tensor* weak_learner_type_t; + OP_REQUIRES_OK(context, + context->input("weak_learner_type", &weak_learner_type_t)); + const int32 weak_learner_type = weak_learner_type_t->scalar<int32>()(); + // Find the number of unique partitions before we allocate the output. std::vector<int32> partition_boundaries; std::vector<int32> non_empty_partitions; @@ -756,20 +772,63 @@ class BuildCategoricalEqualitySplitsOp : public OpKernel { tensorflow::TTypes<int32>::Vec output_partition_ids = output_partition_ids_t->vec<int32>(); + // For a normal tree, we output a split per partition. For an oblivious + // tree, we output one split for all partitions of the layer. + int size_output = num_elements; + if (weak_learner_type == LearnerConfig::OBLIVIOUS_DECISION_TREE && + num_elements > 0) { + size_output = 1; + } + Tensor* gains_t = nullptr; - OP_REQUIRES_OK( - context, context->allocate_output("gains", TensorShape({num_elements}), - &gains_t)); + OP_REQUIRES_OK(context, context->allocate_output( + "gains", TensorShape({size_output}), &gains_t)); tensorflow::TTypes<float>::Vec gains = gains_t->vec<float>(); Tensor* output_splits_t = nullptr; - OP_REQUIRES_OK(context, context->allocate_output( - "split_infos", TensorShape({num_elements}), - &output_splits_t)); + OP_REQUIRES_OK(context, context->allocate_output("split_infos", + TensorShape({size_output}), + &output_splits_t)); tensorflow::TTypes<string>::Vec output_splits = output_splits_t->vec<string>(); + if (num_elements == 0) { + return; + } SplitBuilderState state(context); + switch (weak_learner_type) { + case LearnerConfig::NORMAL_DECISION_TREE: { + ComputeNormalDecisionTree( + context, &state, normalizer_ratio, num_elements, + partition_boundaries, non_empty_partitions, bias_feature_id, + partition_ids, feature_ids, gradients_t, hessians_t, + &output_partition_ids, &gains, &output_splits); + break; + } + case LearnerConfig::OBLIVIOUS_DECISION_TREE: { + ComputeObliviousDecisionTree( + context, &state, normalizer_ratio, num_elements, + partition_boundaries, non_empty_partitions, bias_feature_id, + partition_ids, feature_ids, gradients_t, hessians_t, + &output_partition_ids, &gains, &output_splits); + break; + } + } + } + + private: + void ComputeNormalDecisionTree( + OpKernelContext* const context, SplitBuilderState* state, + const float normalizer_ratio, const int num_elements, + const std::vector<int32>& partition_boundaries, + const std::vector<int32>& non_empty_partitions, + const int64 bias_feature_id, + const tensorflow::TTypes<int32>::ConstVec& partition_ids, + const tensorflow::TTypes<int64>::ConstMatrix& feature_ids, + const Tensor* gradients_t, const Tensor* hessians_t, + tensorflow::TTypes<int32>::Vec* output_partition_ids, + tensorflow::TTypes<float>::Vec* gains, + tensorflow::TTypes<string>::Vec* output_splits) { for (int root_idx = 0; root_idx < num_elements; ++root_idx) { float best_gain = std::numeric_limits<float>::lowest(); int start_index = partition_boundaries[non_empty_partitions[root_idx]]; @@ -779,7 +838,7 @@ class BuildCategoricalEqualitySplitsOp : public OpKernel { errors::InvalidArgument("Bias feature ID missing.")); GradientStats root_gradient_stats(*gradients_t, *hessians_t, start_index); root_gradient_stats *= normalizer_ratio; - NodeStats root_stats = state.ComputeNodeStats(root_gradient_stats); + NodeStats root_stats = state->ComputeNodeStats(root_gradient_stats); int32 best_feature_idx = 0; NodeStats best_right_node_stats(0); NodeStats best_left_node_stats(0); @@ -790,8 +849,8 @@ class BuildCategoricalEqualitySplitsOp : public OpKernel { left_gradient_stats *= normalizer_ratio; GradientStats right_gradient_stats = root_gradient_stats - left_gradient_stats; - NodeStats left_stats = state.ComputeNodeStats(left_gradient_stats); - NodeStats right_stats = state.ComputeNodeStats(right_gradient_stats); + NodeStats left_stats = state->ComputeNodeStats(left_gradient_stats); + NodeStats right_stats = state->ComputeNodeStats(right_gradient_stats); if (left_stats.gain + right_stats.gain > best_gain) { best_gain = left_stats.gain + right_stats.gain; best_left_node_stats = left_stats; @@ -802,17 +861,132 @@ class BuildCategoricalEqualitySplitsOp : public OpKernel { SplitInfo split_info; auto* equality_split = split_info.mutable_split_node() ->mutable_categorical_id_binary_split(); - equality_split->set_feature_column(state.feature_column_group_id()); + equality_split->set_feature_column(state->feature_column_group_id()); equality_split->set_feature_id(feature_ids(best_feature_idx, 0)); auto* left_child = split_info.mutable_left_child(); auto* right_child = split_info.mutable_right_child(); - state.FillLeaf(best_left_node_stats, left_child); - state.FillLeaf(best_right_node_stats, right_child); - split_info.SerializeToString(&output_splits(root_idx)); - gains(root_idx) = - best_gain - root_stats.gain - state.tree_complexity_regularization(); - output_partition_ids(root_idx) = partition_ids(start_index); + state->FillLeaf(best_left_node_stats, left_child); + state->FillLeaf(best_right_node_stats, right_child); + split_info.SerializeToString(&(*output_splits)(root_idx)); + (*gains)(root_idx) = + best_gain - root_stats.gain - state->tree_complexity_regularization(); + (*output_partition_ids)(root_idx) = partition_ids(start_index); + } + } + + void ComputeObliviousDecisionTree( + OpKernelContext* const context, SplitBuilderState* state, + const float normalizer_ratio, const int num_elements, + const std::vector<int32>& partition_boundaries, + const std::vector<int32>& non_empty_partitions, + const int64 bias_feature_id, + const tensorflow::TTypes<int32>::ConstVec& partition_ids, + const tensorflow::TTypes<int64>::ConstMatrix& feature_ids, + const Tensor* gradients_t, const Tensor* hessians_t, + tensorflow::TTypes<int32>::Vec* output_partition_ids, + tensorflow::TTypes<float>::Vec* gains, + tensorflow::TTypes<string>::Vec* output_splits) { + // Holds the root stats per each node to be split. + std::vector<GradientStats> current_layer_stats; + current_layer_stats.reserve(num_elements); + for (int root_idx = 0; root_idx < num_elements; root_idx++) { + const int start_index = partition_boundaries[root_idx]; + // First feature ID in each partition should be the bias feature. + OP_REQUIRES(context, feature_ids(start_index, 0) == bias_feature_id, + errors::InvalidArgument("Bias feature ID missing.")); + GradientStats root_gradient_stats(*gradients_t, *hessians_t, start_index); + root_gradient_stats *= normalizer_ratio; + current_layer_stats.push_back(root_gradient_stats); } + float best_gain = std::numeric_limits<float>::lowest(); + int64 best_feature_id = 0; + std::vector<NodeStats> best_right_node_stats(num_elements, NodeStats(0)); + std::vector<NodeStats> best_left_node_stats(num_elements, NodeStats(0)); + std::vector<NodeStats> current_left_node_stats(num_elements, NodeStats(0)); + std::vector<NodeStats> current_right_node_stats(num_elements, NodeStats(0)); + int64 current_feature_id = std::numeric_limits<int64>::max(); + int64 last_feature_id = -1; + // Find the lowest feature id, this is going to be the first feature id to + // try. + for (int root_idx = 0; root_idx < num_elements; root_idx++) { + const int start_index = partition_boundaries[root_idx]; + if (feature_ids(start_index + 1, 0) < current_feature_id) { + current_feature_id = feature_ids(start_index + 1, 0); + } + } + // Indexes offsets for each of the partitions that can be used to access + // gradients of a partition for a current feature we consider. Start at one + // beacuse the zero index is for the bias. + std::vector<int> current_layer_offsets(num_elements, 1); + // The idea is to try every feature id in increasing order. In each + // iteration we calculate the gain of the layer using the current feature id + // as split value, and we also obtain the following feature id to try. + while (current_feature_id > last_feature_id) { + last_feature_id = current_feature_id; + int64 next_feature_id = -1; + // Left gradient stats per node. + std::vector<GradientStats> left_gradient_stats(num_elements); + for (int root_idx = 0; root_idx < num_elements; root_idx++) { + int idx = + current_layer_offsets[root_idx] + partition_boundaries[root_idx]; + const int end_index = partition_boundaries[root_idx + 1]; + if (idx < end_index && feature_ids(idx, 0) == current_feature_id) { + GradientStats g(*gradients_t, *hessians_t, idx); + g *= normalizer_ratio; + left_gradient_stats[root_idx] = g; + current_layer_offsets[root_idx]++; + idx++; + } + if (idx < end_index && + (feature_ids(idx, 0) < next_feature_id || next_feature_id == -1)) { + next_feature_id = feature_ids(idx, 0); + } + } + float gain_of_split = 0.0; + for (int root_idx = 0; root_idx < num_elements; root_idx++) { + GradientStats right_gradient_stats = + current_layer_stats[root_idx] - left_gradient_stats[root_idx]; + NodeStats left_stat = + state->ComputeNodeStats(left_gradient_stats[root_idx]); + NodeStats right_stat = state->ComputeNodeStats(right_gradient_stats); + gain_of_split += left_stat.gain + right_stat.gain; + current_left_node_stats[root_idx] = left_stat; + current_right_node_stats[root_idx] = right_stat; + } + if (gain_of_split > best_gain) { + best_gain = gain_of_split; + best_left_node_stats = current_left_node_stats; + best_right_node_stats = current_right_node_stats; + best_feature_id = current_feature_id; + } + current_feature_id = next_feature_id; + } + + for (int root_idx = 0; root_idx < num_elements; root_idx++) { + best_gain -= state->ComputeNodeStats(current_layer_stats[root_idx]).gain; + } + best_gain -= num_elements * state->tree_complexity_regularization(); + + ObliviousSplitInfo oblivious_split_info; + auto* equality_split = + oblivious_split_info.mutable_split_node() + ->mutable_oblivious_categorical_id_binary_split(); + equality_split->set_feature_column(state->feature_column_group_id()); + equality_split->set_feature_id(best_feature_id); + (*gains)(0) = best_gain; + + for (int root_idx = 0; root_idx < num_elements; root_idx++) { + auto* left_child = oblivious_split_info.add_children(); + auto* right_child = oblivious_split_info.add_children(); + + state->FillLeaf(best_left_node_stats[root_idx], left_child); + state->FillLeaf(best_right_node_stats[root_idx], right_child); + + const int start_index = partition_boundaries[root_idx]; + (*output_partition_ids)(root_idx) = partition_ids(start_index); + oblivious_split_info.add_children_parent_id(partition_ids(start_index)); + } + oblivious_split_info.SerializeToString(&(*output_splits)(0)); } }; diff --git a/tensorflow/contrib/boosted_trees/kernels/training_ops.cc b/tensorflow/contrib/boosted_trees/kernels/training_ops.cc index 6d9a6ee5a0..ab2853352a 100644 --- a/tensorflow/contrib/boosted_trees/kernels/training_ops.cc +++ b/tensorflow/contrib/boosted_trees/kernels/training_ops.cc @@ -12,9 +12,12 @@ // See the License for the specific language governing permissions and // limitations under the License. // ============================================================================= +#include <vector> + #include "tensorflow/contrib/boosted_trees/lib/utils/dropout_utils.h" #include "tensorflow/contrib/boosted_trees/proto/learner.pb.h" #include "tensorflow/contrib/boosted_trees/proto/split_info.pb.h" +#include "tensorflow/contrib/boosted_trees/proto/tree_config.pb.h" #include "tensorflow/contrib/boosted_trees/resources/decision_tree_ensemble_resource.h" #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/tensor_shape.h" @@ -26,6 +29,7 @@ namespace boosted_trees { namespace { +using boosted_trees::learner::LearnerConfig; using boosted_trees::learner::LearningRateConfig; using boosted_trees::trees::Leaf; using boosted_trees::trees::TreeNode; @@ -42,6 +46,9 @@ struct SplitCandidate { // Split info. learner::SplitInfo split_info; + + // Oblivious split info. + learner::ObliviousSplitInfo oblivious_split_info; }; // Checks that the leaf is not empty. @@ -343,7 +350,12 @@ class GrowTreeEnsembleOp : public OpKernel { OP_REQUIRES_OK(context, context->input("learning_rate", &learning_rate_t)); float learning_rate = learning_rate_t->scalar<float>()(); - // Read seed that was used for dropout. + // Read the weak learner type to use. + const Tensor* weak_learner_type_t; + OP_REQUIRES_OK(context, + context->input("weak_learner_type", &weak_learner_type_t)); + const int32 weak_learner_type = weak_learner_type_t->scalar<int32>()(); + const Tensor* seed_t; OP_REQUIRES_OK(context, context->input("dropout_seed", &seed_t)); // Cast seed to uint64. @@ -363,9 +375,18 @@ class GrowTreeEnsembleOp : public OpKernel { // Find best splits for each active partition. std::map<int32, SplitCandidate> best_splits; - FindBestSplitsPerPartition(context, partition_ids_list, gains_list, - splits_list, &best_splits); - + switch (weak_learner_type) { + case LearnerConfig::NORMAL_DECISION_TREE: { + FindBestSplitsPerPartitionNormal(context, partition_ids_list, + gains_list, splits_list, &best_splits); + break; + } + case LearnerConfig::OBLIVIOUS_DECISION_TREE: { + FindBestSplitsPerPartitionOblivious(context, gains_list, splits_list, + &best_splits); + break; + } + } // No-op if no new splits can be considered. if (best_splits.empty()) { LOG(WARNING) << "Not growing tree ensemble as no good splits were found."; @@ -377,25 +398,34 @@ class GrowTreeEnsembleOp : public OpKernel { OP_REQUIRES_OK(context, context->input("max_tree_depth", &max_tree_depth_t)); const int32 max_tree_depth = max_tree_depth_t->scalar<int32>()(); - // Update and retrieve the growable tree. // If the tree is fully built and dropout was applied, it also adjusts the // weights of dropped and the last tree. boosted_trees::trees::DecisionTreeConfig* const tree_config = UpdateAndRetrieveGrowableTree(ensemble_resource, learning_rate, - dropout_seed, max_tree_depth); - + dropout_seed, max_tree_depth, + weak_learner_type); // Split tree nodes. - for (auto& split_entry : best_splits) { - SplitTreeNode(split_entry.first, &split_entry.second, tree_config, - ensemble_resource); + switch (weak_learner_type) { + case LearnerConfig::NORMAL_DECISION_TREE: { + for (auto& split_entry : best_splits) { + SplitTreeNode(split_entry.first, &split_entry.second, tree_config, + ensemble_resource); + } + break; + } + case LearnerConfig::OBLIVIOUS_DECISION_TREE: { + SplitTreeLayer(&best_splits[0], tree_config, ensemble_resource); + } } - // Post-prune finalized tree if needed. if (learner_config_.pruning_mode() == boosted_trees::learner::LearnerConfig::POST_PRUNE && ensemble_resource->LastTreeMetadata()->is_finalized()) { VLOG(2) << "Post-pruning finalized tree."; + if (weak_learner_type == LearnerConfig::OBLIVIOUS_DECISION_TREE) { + LOG(FATAL) << "Post-prunning is not implemented for Oblivious trees."; + } PruneTree(tree_config); // If after post-pruning the whole tree has no gain, remove the tree @@ -409,10 +439,9 @@ class GrowTreeEnsembleOp : public OpKernel { private: // Helper method which effectively does a reduce over all split candidates // and finds the best split for each partition. - void FindBestSplitsPerPartition( - OpKernelContext* const context, - const OpInputList& partition_ids_list, const OpInputList& gains_list, - const OpInputList& splits_list, + void FindBestSplitsPerPartitionNormal( + OpKernelContext* const context, const OpInputList& partition_ids_list, + const OpInputList& gains_list, const OpInputList& splits_list, std::map<int32, SplitCandidate>* best_splits) { // Find best split per partition going through every feature candidate. // TODO(salehay): Is this worth parallelizing? @@ -446,6 +475,90 @@ class GrowTreeEnsembleOp : public OpKernel { } } + void FindBestSplitsPerPartitionOblivious( + OpKernelContext* const context, const OpInputList& gains_list, + const OpInputList& splits_list, + std::map<int32, SplitCandidate>* best_splits) { + // Find best split per partition going through every feature candidate. + for (int64 handler_id = 0; handler_id < num_handlers_; ++handler_id) { + const auto& gains = gains_list[handler_id].vec<float>(); + const auto& splits = splits_list[handler_id].vec<string>(); + OP_REQUIRES(context, gains.size() == 1, + errors::InvalidArgument( + "Gains size must be one for oblivious weak learner: ", + gains.size(), " != ", 1)); + OP_REQUIRES(context, splits.size() == 1, + errors::InvalidArgument( + "Splits size must be one for oblivious weak learner: ", + splits.size(), " != ", 1)); + // Get current split candidate. + const auto& gain = gains(0); + const auto& serialized_split = splits(0); + SplitCandidate split; + split.handler_id = handler_id; + split.gain = gain; + OP_REQUIRES( + context, split.oblivious_split_info.ParseFromString(serialized_split), + errors::InvalidArgument("Unable to parse oblivious split info.")); + + auto split_info = split.oblivious_split_info; + CHECK(split_info.children_size() % 2 == 0) + << "The oblivious split should generate an even number of children: " + << split_info.children_size(); + + // If every node is pure, then we shouldn't split. + bool only_pure_nodes = true; + for (int idx = 0; idx < split_info.children_size(); idx += 2) { + if (IsLeafWellFormed(*split_info.mutable_children(idx)) && + IsLeafWellFormed(*split_info.mutable_children(idx + 1))) { + only_pure_nodes = false; + break; + } + } + if (only_pure_nodes) { + VLOG(1) << "The oblivious split does not actually split anything."; + continue; + } + + // Don't consider negative splits if we're pre-pruning the tree. + if (learner_config_.pruning_mode() == learner::LearnerConfig::PRE_PRUNE && + gain < 0) { + continue; + } + + // Take the split if we don't have a candidate yet. + auto best_split_it = best_splits->find(0); + if (best_split_it == best_splits->end()) { + best_splits->insert(std::make_pair(0, std::move(split))); + continue; + } + + // Determine if we should update best split. + SplitCandidate& best_split = best_split_it->second; + trees::TreeNode current_node = split_info.split_node(); + trees::TreeNode best_node = best_split.oblivious_split_info.split_node(); + if (TF_PREDICT_FALSE(gain == best_split.gain)) { + // Tie break on node case preferring simpler tree node types. + VLOG(2) << "Attempting to tie break with smaller node case. " + << "(current split: " << current_node.node_case() + << ", best split: " << best_node.node_case() << ")"; + if (current_node.node_case() < best_node.node_case()) { + best_split = std::move(split); + } else if (current_node.node_case() == best_node.node_case()) { + // Tie break on handler Id. + VLOG(2) << "Tie breaking with higher handler Id. " + << "(current split: " << handler_id + << ", best split: " << best_split.handler_id << ")"; + if (handler_id > best_split.handler_id) { + best_split = std::move(split); + } + } + } else if (gain > best_split.gain) { + best_split = std::move(split); + } + } + } + void UpdateTreeWeightsIfDropout( boosted_trees::models::DecisionTreeEnsembleResource* const ensemble_resource, @@ -501,7 +614,7 @@ class GrowTreeEnsembleOp : public OpKernel { boosted_trees::models::DecisionTreeEnsembleResource* const ensemble_resource, const float learning_rate, const uint64 dropout_seed, - const int32 max_tree_depth) { + const int32 max_tree_depth, const int32 weak_learner_type) { const auto num_trees = ensemble_resource->num_trees(); if (num_trees <= 0 || ensemble_resource->LastTreeMetadata()->is_finalized()) { @@ -647,6 +760,71 @@ class GrowTreeEnsembleOp : public OpKernel { } } + void SplitTreeLayer( + SplitCandidate* split, + boosted_trees::trees::DecisionTreeConfig* tree_config, + boosted_trees::models::DecisionTreeEnsembleResource* ensemble_resource) { + int depth = 0; + while (depth < tree_config->nodes_size() && + tree_config->nodes(depth).node_case() != TreeNode::kLeaf) { + depth++; + } + CHECK(tree_config->nodes_size() > 0) + << "A tree must have at least one dummy leaf."; + // The number of new children. + int num_children = 1 << (depth + 1); + auto split_info = split->oblivious_split_info; + CHECK(num_children >= split_info.children_size()) + << "Too many new children, expected <= " << num_children << " and got " + << split_info.children_size(); + std::vector<trees::Leaf> new_leaves; + new_leaves.reserve(num_children); + int next_id = 0; + for (int idx = 0; idx < num_children / 2; idx++) { + trees::Leaf old_leaf = + *tree_config->mutable_nodes(depth + idx)->mutable_leaf(); + // Check if a split was made for this leaf. + if (next_id < split_info.children_parent_id_size() && + depth + idx == split_info.children_parent_id(next_id)) { + // Add left leaf. + new_leaves.push_back(*MergeLeafWeights( + old_leaf, split_info.mutable_children(2 * next_id))); + // Add right leaf. + new_leaves.push_back(*MergeLeafWeights( + old_leaf, split_info.mutable_children(2 * next_id + 1))); + next_id++; + } else { + // If there is no split for this leaf, just duplicate it. + new_leaves.push_back(old_leaf); + new_leaves.push_back(old_leaf); + } + } + CHECK(next_id == split_info.children_parent_id_size()); + TreeNodeMetadata* split_metadata = + split_info.mutable_split_node()->mutable_node_metadata(); + split_metadata->set_gain(split->gain); + + TreeNode new_split = *split_info.mutable_split_node(); + // Move old children to metadata. + for (int idx = depth; idx < tree_config->nodes_size(); idx++) { + *new_split.mutable_node_metadata()->add_original_oblivious_leaves() = + *tree_config->mutable_nodes(idx)->mutable_leaf(); + } + // Add the new split to the tree_config in place before the children start. + *tree_config->mutable_nodes(depth) = new_split; + // Add the new children + int nodes_size = tree_config->nodes_size(); + for (int idx = 0; idx < num_children; idx++) { + if (idx + depth + 1 < nodes_size) { + // Update leaves that were already there. + *tree_config->mutable_nodes(idx + depth + 1)->mutable_leaf() = + new_leaves[idx]; + } else { + // Add new leaves. + *tree_config->add_nodes()->mutable_leaf() = new_leaves[idx]; + } + } + } void PruneTree(boosted_trees::trees::DecisionTreeConfig* tree_config) { // No-op if tree is empty. if (tree_config->nodes_size() <= 0) { diff --git a/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler.py b/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler.py index efe29216c2..e6407174b1 100644 --- a/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler.py +++ b/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler.py @@ -19,6 +19,7 @@ from __future__ import division from __future__ import print_function from tensorflow.contrib.boosted_trees.lib.learner.batch import base_split_handler +from tensorflow.contrib.boosted_trees.proto import learner_pb2 from tensorflow.contrib.boosted_trees.python.ops import split_handler_ops from tensorflow.contrib.boosted_trees.python.ops import stats_accumulator_ops from tensorflow.python.framework import constant_op @@ -46,6 +47,7 @@ class EqualitySplitHandler(base_split_handler.BaseSplitHandler): multiclass_strategy, init_stamp_token=0, loss_uses_sum_reduction=False, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE, name=None): """Initialize the internal state for this split handler. @@ -66,6 +68,7 @@ class EqualitySplitHandler(base_split_handler.BaseSplitHandler): stamped objects. loss_uses_sum_reduction: A scalar boolean tensor that specifies whether SUM or MEAN reduction was used for the loss. + weak_learner_type: Specifies the type of weak learner to use. name: An optional handler name. """ super(EqualitySplitHandler, self).__init__( @@ -85,6 +88,7 @@ class EqualitySplitHandler(base_split_handler.BaseSplitHandler): hessian_shape, name="StatsAccumulator/{}".format(self._name)) self._sparse_int_column = sparse_int_column + self._weak_learner_type = weak_learner_type def update_stats(self, stamp_token, example_partition_ids, gradients, hessians, empty_gradients, empty_hessians, weights, @@ -197,7 +201,8 @@ class EqualitySplitHandler(base_split_handler.BaseSplitHandler): tree_complexity_regularization=self._tree_complexity_regularization, min_node_weight=self._min_node_weight, bias_feature_id=_BIAS_FEATURE_ID, - multiclass_strategy=self._multiclass_strategy)) + multiclass_strategy=self._multiclass_strategy, + weak_learner_type=self._weak_learner_type)) # There are no warm-up rounds needed in the equality column handler. So we # always return ready. are_splits_ready = constant_op.constant(True) diff --git a/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler_test.py b/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler_test.py index ef253e7cec..d9f03c3840 100644 --- a/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler_test.py +++ b/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler_test.py @@ -169,6 +169,117 @@ class EqualitySplitHandlerTest(test_util.TensorFlowTestCase): self.assertEqual(1, split_node.feature_id) + def testObliviousFeatureSplitGeneration(self): + with self.test_session() as sess: + # The data looks like the following: + # Example | Gradients | Partition | Feature ID | + # i0 | (0.2, 0.12) | 1 | 1 | + # i1 | (-0.5, 0.07) | 1 | 2 | + # i2 | (1.2, 0.2) | 1 | 1 | + # i3 | (4.0, 0.13) | 2 | 2 | + gradients = array_ops.constant([0.2, -0.5, 1.2, 4.0]) + hessians = array_ops.constant([0.12, 0.07, 0.2, 0.13]) + partition_ids = [1, 1, 1, 2] + indices = [[0, 0], [1, 0], [2, 0], [3, 0]] + values = array_ops.constant([1, 2, 1, 2], dtype=dtypes.int64) + + gradient_shape = tensor_shape.scalar() + hessian_shape = tensor_shape.scalar() + class_id = -1 + + split_handler = categorical_split_handler.EqualitySplitHandler( + l1_regularization=0.1, + l2_regularization=1, + tree_complexity_regularization=0, + min_node_weight=0, + sparse_int_column=sparse_tensor.SparseTensor(indices, values, [4, 1]), + feature_column_group_id=0, + gradient_shape=gradient_shape, + hessian_shape=hessian_shape, + multiclass_strategy=learner_pb2.LearnerConfig.TREE_PER_CLASS, + init_stamp_token=0, + weak_learner_type=learner_pb2.LearnerConfig.OBLIVIOUS_DECISION_TREE) + resources.initialize_resources(resources.shared_resources()).run() + + empty_gradients, empty_hessians = get_empty_tensors( + gradient_shape, hessian_shape) + example_weights = array_ops.ones([4, 1], dtypes.float32) + + update_1 = split_handler.update_stats_sync( + 0, + partition_ids, + gradients, + hessians, + empty_gradients, + empty_hessians, + example_weights, + is_active=array_ops.constant([True, True])) + update_2 = split_handler.update_stats_sync( + 0, + partition_ids, + gradients, + hessians, + empty_gradients, + empty_hessians, + example_weights, + is_active=array_ops.constant([True, True])) + + with ops.control_dependencies([update_1, update_2]): + are_splits_ready, partitions, gains, splits = ( + split_handler.make_splits(0, 1, class_id)) + are_splits_ready, partitions, gains, splits = ( + sess.run([are_splits_ready, partitions, gains, splits])) + self.assertTrue(are_splits_ready) + self.assertAllEqual([1, 2], partitions) + + # For partition 1. + # -(0.2 + 1.2 - 0.1) / (0.12 + 0.2 + 1) + expected_left_weight1 = -0.9848484848484846 + # (0.2 + 1.2 - 0.1) ** 2 / (0.12 + 0.2 + 1) + expected_left_gain1 = 1.2803030303030298 + + # -(-0.5 + 0.1) / (0.07 + 1) + expected_right_weight1 = 0.37383177570093457 + + # (-0.5 + 0.1) ** 2 / (0.07 + 1) + expected_right_gain1 = 0.14953271028037385 + + # (0.2 + -0.5 + 1.2 - 0.1) ** 2 / (0.12 + 0.07 + 0.2 + 1) + expected_bias_gain1 = 0.46043165467625885 + + split_info = split_info_pb2.ObliviousSplitInfo() + split_info.ParseFromString(splits[0]) + # Children of partition 1. + left_child = split_info.children[0].vector + right_child = split_info.children[1].vector + split_node = split_info.split_node.oblivious_categorical_id_binary_split + + self.assertEqual(0, split_node.feature_column) + self.assertEqual(1, split_node.feature_id) + self.assertAllClose([expected_left_weight1], left_child.value, 0.00001) + self.assertAllClose([expected_right_weight1], right_child.value, 0.00001) + + # For partition2. + expected_left_weight2 = 0 + expected_left_gain2 = 0 + # -(4 - 0.1) / (0.13 + 1) + expected_right_weight2 = -3.4513274336283186 + # (4 - 0.1) ** 2 / (0.13 + 1) + expected_right_gain2 = 13.460176991150442 + # (4 - 0.1) ** 2 / (0.13 + 1) + expected_bias_gain2 = 13.460176991150442 + + # Children of partition 2. + left_child = split_info.children[2].vector + right_child = split_info.children[3].vector + self.assertAllClose([expected_left_weight2], left_child.value, 0.00001) + self.assertAllClose([expected_right_weight2], right_child.value, 0.00001) + + self.assertAllClose( + expected_left_gain1 + expected_right_gain1 - expected_bias_gain1 + + expected_left_gain2 + expected_right_gain2 - expected_bias_gain2, + gains[0], 0.00001) + def testGenerateFeatureSplitCandidatesSumReduction(self): with self.test_session() as sess: # The data looks like the following: diff --git a/tensorflow/contrib/boosted_trees/lib/learner/batch/ordinal_split_handler_test.py b/tensorflow/contrib/boosted_trees/lib/learner/batch/ordinal_split_handler_test.py index 6572f2f414..5532bd026a 100644 --- a/tensorflow/contrib/boosted_trees/lib/learner/batch/ordinal_split_handler_test.py +++ b/tensorflow/contrib/boosted_trees/lib/learner/batch/ordinal_split_handler_test.py @@ -186,14 +186,15 @@ class DenseSplitHandlerTest(test_util.TensorFlowTestCase): with self.test_session() as sess: # The data looks like the following: # Example | Gradients | Partition | Dense Quantile | - # i0 | (0.2, 0.12) | 0 | 2 | - # i1 | (-0.5, 0.07) | 0 | 2 | - # i2 | (1.2, 0.2) | 0 | 0 | - # i3 | (4.0, 0.13) | 1 | 1 | - dense_column = array_ops.constant([0.62, 0.62, 0.3, 0.52]) + # i0 | (0.2, 0.12) | 1 | 3 | + # i1 | (-0.5, 0.07) | 1 | 3 | + # i2 | (1.2, 0.2) | 1 | 1 | + # i3 | (4.0, 0.13) | 2 | 2 | + dense_column = array_ops.placeholder( + dtypes.float32, shape=(4, 1), name="dense_column") gradients = array_ops.constant([0.2, -0.5, 1.2, 4.0]) hessians = array_ops.constant([0.12, 0.07, 0.2, 0.13]) - partition_ids = array_ops.constant([0, 0, 0, 1], dtype=dtypes.int32) + partition_ids = array_ops.constant([1, 1, 1, 2], dtype=dtypes.int32) class_id = -1 gradient_shape = tensor_shape.scalar() @@ -230,85 +231,94 @@ class DenseSplitHandlerTest(test_util.TensorFlowTestCase): with ops.control_dependencies([update_1]): are_splits_ready = split_handler.make_splits( np.int64(0), np.int64(1), class_id)[0] + # Forcing the creation of four buckets. + are_splits_ready = sess.run( + [are_splits_ready], + feed_dict={dense_column: [[0.2], [0.62], [0.3], [0.52]]})[0] - with ops.control_dependencies([are_splits_ready]): - update_2 = split_handler.update_stats_sync( - 1, - partition_ids, - gradients, - hessians, - empty_gradients, - empty_hessians, - example_weights, - is_active=array_ops.constant([True, True])) + update_2 = split_handler.update_stats_sync( + 1, + partition_ids, + gradients, + hessians, + empty_gradients, + empty_hessians, + example_weights, + is_active=array_ops.constant([True, True])) with ops.control_dependencies([update_2]): are_splits_ready2, partitions, gains, splits = ( split_handler.make_splits(np.int64(1), np.int64(2), class_id)) - are_splits_ready, are_splits_ready2, partitions, gains, splits = ( - sess.run([ - are_splits_ready, are_splits_ready2, partitions, gains, splits - ])) + # Only using the last three buckets. + are_splits_ready2, partitions, gains, splits = ( + sess.run( + [are_splits_ready2, partitions, gains, splits], + feed_dict={dense_column: [[0.62], [0.62], [0.3], [0.52]]})) # During the first iteration, inequality split handlers are not going to # have any splits. Make sure that we return not_ready in that case. self.assertFalse(are_splits_ready) self.assertTrue(are_splits_ready2) - self.assertAllEqual([0, 1], partitions) + self.assertAllEqual([1, 2], partitions) oblivious_split_info = split_info_pb2.ObliviousSplitInfo() oblivious_split_info.ParseFromString(splits[0]) - split_node = oblivious_split_info.split_node.dense_float_binary_split - + split_node = oblivious_split_info.split_node + split_node = split_node.oblivious_dense_float_binary_split self.assertAllClose(0.3, split_node.threshold, 0.00001) self.assertEqual(0, split_node.feature_column) - # Check the split on partition 0. + # Check the split on partition 1. # -(1.2 - 0.1) / (0.2 + 1) - expected_left_weight_0 = -0.9166666666666666 + expected_left_weight_1 = -0.9166666666666666 - # expected_left_weight_0 * -(1.2 - 0.1) - expected_left_gain_0 = 1.008333333333333 + # expected_left_weight_1 * -(1.2 - 0.1) + expected_left_gain_1 = 1.008333333333333 # (-0.5 + 0.2 + 0.1) / (0.19 + 1) - expected_right_weight_0 = 0.1680672 + expected_right_weight_1 = 0.1680672 - # expected_right_weight_0 * -(-0.5 + 0.2 + 0.1)) - expected_right_gain_0 = 0.033613445378151252 + # expected_right_weight_1 * -(-0.5 + 0.2 + 0.1)) + expected_right_gain_1 = 0.033613445378151252 # (0.2 + -0.5 + 1.2 - 0.1) ** 2 / (0.12 + 0.07 + 0.2 + 1) - expected_bias_gain_0 = 0.46043165467625896 + expected_bias_gain_1 = 0.46043165467625896 - left_child = oblivious_split_info.children_leaves[0].vector - right_child = oblivious_split_info.children_leaves[1].vector + left_child = oblivious_split_info.children[0].vector + right_child = oblivious_split_info.children[1].vector - self.assertAllClose([expected_left_weight_0], left_child.value, 0.00001) + self.assertAllClose([expected_left_weight_1], left_child.value, 0.00001) - self.assertAllClose([expected_right_weight_0], right_child.value, 0.00001) + self.assertAllClose([expected_right_weight_1], right_child.value, 0.00001) - # Check the split on partition 1. - expected_left_weight_1 = 0 - expected_left_gain_1 = 0 + # Check the split on partition 2. + expected_left_weight_2 = 0 + expected_left_gain_2 = 0 # -(4 - 0.1) / (0.13 + 1) - expected_right_weight_1 = -3.4513274336283186 - # expected_right_weight_1 * -(4 - 0.1) - expected_right_gain_1 = 13.460176991150442 + expected_right_weight_2 = -3.4513274336283186 + # expected_right_weight_2 * -(4 - 0.1) + expected_right_gain_2 = 13.460176991150442 # (-4 + 0.1) ** 2 / (0.13 + 1) - expected_bias_gain_1 = 13.460176991150442 + expected_bias_gain_2 = 13.460176991150442 - left_child = oblivious_split_info.children_leaves[2].vector - right_child = oblivious_split_info.children_leaves[3].vector + left_child = oblivious_split_info.children[2].vector + right_child = oblivious_split_info.children[3].vector - self.assertAllClose([expected_left_weight_1], left_child.value, 0.00001) + self.assertAllClose([expected_left_weight_2], left_child.value, 0.00001) - self.assertAllClose([expected_right_weight_1], right_child.value, 0.00001) + self.assertAllClose([expected_right_weight_2], right_child.value, 0.00001) # The layer gain is the sum of the gains of each partition layer_gain = ( - expected_left_gain_0 + expected_right_gain_0 - expected_bias_gain_0) + ( - expected_left_gain_1 + expected_right_gain_1 - expected_bias_gain_1) + expected_left_gain_1 + expected_right_gain_1 - expected_bias_gain_1) + ( + expected_left_gain_2 + expected_right_gain_2 - expected_bias_gain_2) self.assertAllClose(layer_gain, gains[0], 0.00001) + # We have examples in both partitions, then we get both ids. + self.assertEqual(2, len(oblivious_split_info.children_parent_id)) + self.assertEqual(1, oblivious_split_info.children_parent_id[0]) + self.assertEqual(2, oblivious_split_info.children_parent_id[1]) + def testGenerateFeatureSplitCandidatesLossUsesSumReduction(self): with self.test_session() as sess: # The data looks like the following: diff --git a/tensorflow/contrib/boosted_trees/lib/quantiles/weighted_quantiles_summary.h b/tensorflow/contrib/boosted_trees/lib/quantiles/weighted_quantiles_summary.h index 69bb8fd4ad..8d71a6cdbc 100644 --- a/tensorflow/contrib/boosted_trees/lib/quantiles/weighted_quantiles_summary.h +++ b/tensorflow/contrib/boosted_trees/lib/quantiles/weighted_quantiles_summary.h @@ -36,12 +36,6 @@ class WeightedQuantilesSummary { struct SummaryEntry { SummaryEntry(const ValueType& v, const WeightType& w, const WeightType& min, const WeightType& max) { - // Explicitly initialize all of memory (including padding from memory - // alignment) to allow the struct to be msan-resistant "plain old data". - // - // POD = http://en.cppreference.com/w/cpp/concept/PODType - memset(this, 0, sizeof(*this)); - value = v; weight = w; min_rank = min; @@ -49,8 +43,6 @@ class WeightedQuantilesSummary { } SummaryEntry() { - memset(this, 0, sizeof(*this)); - value = ValueType(); weight = 0; min_rank = 0; diff --git a/tensorflow/contrib/boosted_trees/lib/trees/decision_tree.cc b/tensorflow/contrib/boosted_trees/lib/trees/decision_tree.cc index 0e5578693a..64921faf81 100644 --- a/tensorflow/contrib/boosted_trees/lib/trees/decision_tree.cc +++ b/tensorflow/contrib/boosted_trees/lib/trees/decision_tree.cc @@ -12,11 +12,11 @@ // See the License for the specific language governing permissions and // limitations under the License. // ============================================================================= +#include <algorithm> + #include "tensorflow/contrib/boosted_trees/lib/trees/decision_tree.h" #include "tensorflow/core/platform/macros.h" -#include <algorithm> - namespace tensorflow { namespace boosted_trees { namespace trees { @@ -28,14 +28,15 @@ int DecisionTree::Traverse(const DecisionTreeConfig& config, if (TF_PREDICT_FALSE(config.nodes_size() <= sub_root_id)) { return kInvalidLeaf; } - // Traverse tree starting at the provided sub-root. int32 node_id = sub_root_id; + // The index of the leave that holds this example in the oblivious case. + int oblivious_leaf_idx = 0; while (true) { const auto& current_node = config.nodes(node_id); switch (current_node.node_case()) { case TreeNode::kLeaf: { - return node_id; + return node_id + oblivious_leaf_idx; } case TreeNode::kDenseFloatBinarySplit: { const auto& split = current_node.dense_float_binary_split(); @@ -100,6 +101,28 @@ int DecisionTree::Traverse(const DecisionTreeConfig& config, } break; } + case TreeNode::kObliviousDenseFloatBinarySplit: { + const auto& split = current_node.oblivious_dense_float_binary_split(); + oblivious_leaf_idx <<= 1; + if (example.dense_float_features[split.feature_column()] > + split.threshold()) { + oblivious_leaf_idx++; + } + node_id++; + break; + } + case TreeNode::kObliviousCategoricalIdBinarySplit: { + const auto& split = + current_node.oblivious_categorical_id_binary_split(); + oblivious_leaf_idx <<= 1; + const auto& features = + example.sparse_int_features[split.feature_column()]; + if (features.find(split.feature_id()) == features.end()) { + oblivious_leaf_idx++; + } + node_id++; + break; + } case TreeNode::NODE_NOT_SET: { LOG(QFATAL) << "Invalid node in tree: " << current_node.DebugString(); break; @@ -165,6 +188,16 @@ void DecisionTree::LinkChildren(const std::vector<int32>& children, split->set_right_id(*++children_it); break; } + case TreeNode::kObliviousDenseFloatBinarySplit: { + LOG(QFATAL) + << "Not implemented for the ObliviousDenseFloatBinarySplit case."; + break; + } + case TreeNode::kObliviousCategoricalIdBinarySplit: { + LOG(QFATAL) + << "Not implemented for the ObliviousCategoricalIdBinarySplit case."; + break; + } case TreeNode::NODE_NOT_SET: { LOG(QFATAL) << "A non-set node cannot have children."; break; @@ -199,6 +232,16 @@ std::vector<int32> DecisionTree::GetChildren(const TreeNode& node) { const auto& split = node.categorical_id_set_membership_binary_split(); return {split.left_id(), split.right_id()}; } + case TreeNode::kObliviousDenseFloatBinarySplit: { + LOG(QFATAL) + << "Not implemented for the ObliviousDenseFloatBinarySplit case."; + return {}; + } + case TreeNode::kObliviousCategoricalIdBinarySplit: { + LOG(QFATAL) + << "Not implemented for the ObliviousCategoricalIdBinarySplit case."; + break; + } case TreeNode::NODE_NOT_SET: { return {}; } diff --git a/tensorflow/contrib/boosted_trees/lib/utils/parallel_for.h b/tensorflow/contrib/boosted_trees/lib/utils/parallel_for.h index ec06787e1d..1f3672bf85 100644 --- a/tensorflow/contrib/boosted_trees/lib/utils/parallel_for.h +++ b/tensorflow/contrib/boosted_trees/lib/utils/parallel_for.h @@ -12,8 +12,8 @@ // See the License for the specific language governing permissions and // limitations under the License. // ============================================================================= -#ifndef TENSORFLOW_CONTRIB_LIB_UTILS_PARALLEL_FOR_H_ -#define TENSORFLOW_CONTRIB_LIB_UTILS_PARALLEL_FOR_H_ +#ifndef TENSORFLOW_CONTRIB_BOOSTED_TREES_LIB_UTILS_PARALLEL_FOR_H_ +#define TENSORFLOW_CONTRIB_BOOSTED_TREES_LIB_UTILS_PARALLEL_FOR_H_ #include "tensorflow/core/lib/core/threadpool.h" @@ -30,4 +30,4 @@ void ParallelFor(int64 batch_size, int64 desired_parallelism, } // namespace boosted_trees } // namespace tensorflow -#endif // TENSORFLOW_CONTRIB_LIB_UTILS_PARALLEL_FOR_H_ +#endif // TENSORFLOW_CONTRIB_BOOSTED_TREES_LIB_UTILS_PARALLEL_FOR_H_ diff --git a/tensorflow/contrib/boosted_trees/lib/utils/random.h b/tensorflow/contrib/boosted_trees/lib/utils/random.h index 546d344f55..249651e99e 100644 --- a/tensorflow/contrib/boosted_trees/lib/utils/random.h +++ b/tensorflow/contrib/boosted_trees/lib/utils/random.h @@ -12,8 +12,8 @@ // See the License for the specific language governing permissions and // limitations under the License. // ============================================================================= -#ifndef TENSORFLOW_CONTRIB_LIB_UTILS_RANDOM_H_ -#define TENSORFLOW_CONTRIB_LIB_UTILS_RANDOM_H_ +#ifndef TENSORFLOW_CONTRIB_BOOSTED_TREES_LIB_UTILS_RANDOM_H_ +#define TENSORFLOW_CONTRIB_BOOSTED_TREES_LIB_UTILS_RANDOM_H_ #include "tensorflow/core/lib/random/simple_philox.h" @@ -36,4 +36,4 @@ inline int32 PoissonBootstrap(random::SimplePhilox* rng) { } // namespace boosted_trees } // namespace tensorflow -#endif // TENSORFLOW_CONTRIB_LIB_UTILS_RANDOM_H_ +#endif // TENSORFLOW_CONTRIB_BOOSTED_TREES_LIB_UTILS_RANDOM_H_ diff --git a/tensorflow/contrib/boosted_trees/ops/split_handler_ops.cc b/tensorflow/contrib/boosted_trees/ops/split_handler_ops.cc index 9b68a9de96..f1e12a028a 100644 --- a/tensorflow/contrib/boosted_trees/ops/split_handler_ops.cc +++ b/tensorflow/contrib/boosted_trees/ops/split_handler_ops.cc @@ -179,6 +179,7 @@ REGISTER_OP("BuildCategoricalEqualitySplits") .Input("tree_complexity_regularization: float") .Input("min_node_weight: float") .Input("multiclass_strategy: int32") + .Input("weak_learner_type: int32") .Output("output_partition_ids: int32") .Output("gains: float32") .Output("split_infos: string") @@ -224,6 +225,8 @@ min_node_weight: A scalar, minimum sum of example hessian needed in a child. be considered. multiclass_strategy: A scalar, specifying the multiclass handling strategy. See LearnerConfig.MultiClassStrategy for valid values. +weak_learner_type: A scalar, specifying the weak learner type to use. + See LearnerConfig.WeakLearnerType for valid values. output_partition_ids: A rank 1 tensor, the partition IDs that we created splits for. gains: A rank 1 tensor, for the computed gain for the created splits. diff --git a/tensorflow/contrib/boosted_trees/ops/training_ops.cc b/tensorflow/contrib/boosted_trees/ops/training_ops.cc index 22ac9edb72..604ec8e0bf 100644 --- a/tensorflow/contrib/boosted_trees/ops/training_ops.cc +++ b/tensorflow/contrib/boosted_trees/ops/training_ops.cc @@ -57,6 +57,7 @@ REGISTER_OP("GrowTreeEnsemble") .Input("learning_rate: float") .Input("dropout_seed: int64") .Input("max_tree_depth: int32") + .Input("weak_learner_type: int32") .Input("partition_ids: num_handlers * int32") .Input("gains: num_handlers * float") .Input("splits: num_handlers * string") @@ -82,6 +83,7 @@ tree_ensemble_handle: Handle to the ensemble variable. stamp_token: Stamp token for validating operation consistency. next_stamp_token: Stamp token to be used for the next iteration. learning_rate: Scalar learning rate. +weak_learner_type: The type of weak learner to use. partition_ids: List of Rank 1 Tensors containing partition Id per candidate. gains: List of Rank 1 Tensors containing gains per candidate. splits: List of Rank 1 Tensors containing serialized SplitInfo protos per candidate. diff --git a/tensorflow/contrib/boosted_trees/proto/split_info.proto b/tensorflow/contrib/boosted_trees/proto/split_info.proto index 850340f5c2..784977af39 100644 --- a/tensorflow/contrib/boosted_trees/proto/split_info.proto +++ b/tensorflow/contrib/boosted_trees/proto/split_info.proto @@ -19,8 +19,10 @@ message SplitInfo { } message ObliviousSplitInfo { - // The split node with the feature_column and threshold defined. tensorflow.boosted_trees.trees.TreeNode split_node = 1; - // The new leaves of the tree. - repeated tensorflow.boosted_trees.trees.Leaf children_leaves = 2; + repeated tensorflow.boosted_trees.trees.Leaf children = 2; + // For each child, children_parent_id stores the node_id of its parent when it + // was a leaf. For the idx-th child it corresponds the idx/2-th + // children_parent_id. + repeated int32 children_parent_id = 3; } diff --git a/tensorflow/contrib/boosted_trees/proto/tree_config.proto b/tensorflow/contrib/boosted_trees/proto/tree_config.proto index 81411aa84a..520b4f8b11 100644 --- a/tensorflow/contrib/boosted_trees/proto/tree_config.proto +++ b/tensorflow/contrib/boosted_trees/proto/tree_config.proto @@ -15,6 +15,8 @@ message TreeNode { CategoricalIdBinarySplit categorical_id_binary_split = 5; CategoricalIdSetMembershipBinarySplit categorical_id_set_membership_binary_split = 6; + ObliviousDenseFloatBinarySplit oblivious_dense_float_binary_split = 7; + ObliviousCategoricalIdBinarySplit oblivious_categorical_id_binary_split = 8; } TreeNodeMetadata node_metadata = 777; } @@ -26,6 +28,9 @@ message TreeNodeMetadata { // The original leaf node before this node was split. Leaf original_leaf = 2; + + // The original layer of leaves before that layer was converted to a split. + repeated Leaf original_oblivious_leaves = 3; } // Leaves can either hold dense or sparse information. @@ -101,6 +106,28 @@ message CategoricalIdSetMembershipBinarySplit { int32 right_id = 4; } +// Split rule for dense float features in the oblivious case. +message ObliviousDenseFloatBinarySplit { + // Float feature column and split threshold describing + // the rule feature <= threshold. + int32 feature_column = 1; + float threshold = 2; + // We don't store children ids, because either the next node represents the + // whole next layer of the tree or starting with the next node we only have + // leaves. +} + +// Split rule for categorical features with a single feature Id in the oblivious +// case. +message ObliviousCategoricalIdBinarySplit { + // Categorical feature column and Id describing the rule feature == Id. + int32 feature_column = 1; + int64 feature_id = 2; + // We don't store children ids, because either the next node represents the + // whole next layer of the tree or starting with the next node we only have + // leaves. +} + // DecisionTreeConfig describes a list of connected nodes. // Node 0 must be the root and can carry any payload including a leaf // in the case of representing the bias. diff --git a/tensorflow/contrib/boosted_trees/python/kernel_tests/model_ops_test.py b/tensorflow/contrib/boosted_trees/python/kernel_tests/model_ops_test.py index 63b9c5fddf..42d69645ac 100644 --- a/tensorflow/contrib/boosted_trees/python/kernel_tests/model_ops_test.py +++ b/tensorflow/contrib/boosted_trees/python/kernel_tests/model_ops_test.py @@ -98,7 +98,7 @@ class ModelOpsTest(test_util.TensorFlowTestCase): self._seed = 123 def testCreate(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree = tree_ensemble_config.trees.add() _append_to_leaf(tree.nodes.add().leaf, 0, -0.4) @@ -133,7 +133,7 @@ class ModelOpsTest(test_util.TensorFlowTestCase): def testSerialization(self): with ops.Graph().as_default() as graph: - with self.test_session(graph): + with self.session(graph): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Bias tree only for second class. tree1 = tree_ensemble_config.trees.add() @@ -164,7 +164,7 @@ class ModelOpsTest(test_util.TensorFlowTestCase): serialized_config = serialized_config.eval() with ops.Graph().as_default() as graph: - with self.test_session(graph): + with self.session(graph): tree_ensemble_handle2 = model_ops.tree_ensemble_variable( stamp_token=9, tree_ensemble_config=serialized_config, @@ -204,14 +204,14 @@ class ModelOpsTest(test_util.TensorFlowTestCase): self.assertAllClose(result.eval(), [[0.5, -0.2], [0, 1.0]]) def testRestore(self): - # Calling self.test_session() without a graph specified results in + # Calling self.cached_session() without a graph specified results in # TensorFlowTestCase caching the session and returning the same one # every time. In this test, we need to create two different sessions - # which is why we also create a graph and pass it to self.test_session() + # which is why we also create a graph and pass it to self.cached_session() # to ensure no caching occurs under the hood. save_path = os.path.join(self.get_temp_dir(), "restore-test") with ops.Graph().as_default() as graph: - with self.test_session(graph) as sess: + with self.session(graph) as sess: # Prepare learner config. learner_config = learner_pb2.LearnerConfig() learner_config.num_classes = 2 @@ -288,7 +288,7 @@ class ModelOpsTest(test_util.TensorFlowTestCase): # Start a second session. In that session the parameter nodes # have not been initialized either. with ops.Graph().as_default() as graph: - with self.test_session(graph) as sess: + with self.session(graph) as sess: tree_ensemble_handle = model_ops.tree_ensemble_variable( stamp_token=0, tree_ensemble_config="", name="restore_tree") my_saver = saver.Saver() @@ -311,7 +311,7 @@ class ModelOpsTest(test_util.TensorFlowTestCase): self.assertAllClose(result.eval(), [[-1.1], [-1.1]]) def testUsedHandlers(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree_ensemble_config.growing_metadata.used_handler_ids.append(1) tree_ensemble_config.growing_metadata.used_handler_ids.append(5) diff --git a/tensorflow/contrib/boosted_trees/python/kernel_tests/prediction_ops_test.py b/tensorflow/contrib/boosted_trees/python/kernel_tests/prediction_ops_test.py index cf55759aaa..4278a30ba9 100644 --- a/tensorflow/contrib/boosted_trees/python/kernel_tests/prediction_ops_test.py +++ b/tensorflow/contrib/boosted_trees/python/kernel_tests/prediction_ops_test.py @@ -96,6 +96,20 @@ def _set_float_split(split, feat_col, thresh, l_id, r_id, feature_dim_id=None): split.dimension_id = feature_dim_id +def _set_float_oblivious_split(split, feat_col, thresh): + """Helper method for building tree float splits. + + Sets split feature column and threshold. + + Args: + split: split node to update. + feat_col: feature column for the split. + thresh: threshold to split on forming rule x <= thresh. + """ + split.feature_column = feat_col + split.threshold = thresh + + def _set_categorical_id_split(split, feat_col, feat_id, l_id, r_id): """Helper method for building tree categorical id splits. @@ -119,15 +133,17 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): def setUp(self): """Sets up the prediction tests. - Create a batch of two examples having one dense float, two sparse float + Creates, a batch of two examples having three dense float, two sparse float single valued, one sparse float multidimensional and one sparse int features. The data looks like the following: - | Instance | Dense0 | SparseF0 | SparseF1 | SparseI0 | SparseM - | 0 | 7 | -3 | | 9,1 | __, 5.0 - | 1 | -2 | | 4 | | 3, ___ + |Instance |Dense0 |Dense1 |Dense2 |SparseF0 |SparseF1 |SparseI0 |SparseM + | 0 | 7 | 1 | 2 | -3 | | 9,1 | __, 5.0 + | 1 | -2 | 2 | 0.5 | | 4 | | 3, ___ """ super(PredictionOpsTest, self).setUp() - self._dense_float_tensor = np.array([[7.0], [-2.0]]) + self._dense_float_tensor1 = np.array([[7.0], [-2.0]]) + self._dense_float_tensor2 = np.array([[1.0], [2.0]]) + self._dense_float_tensor3 = np.array([[2.0], [0.5]]) self._sparse_float_indices1 = np.array([[0, 0]]) self._sparse_float_values1 = np.array([-3.0]) self._sparse_float_shape1 = np.array([2, 1]) @@ -153,7 +169,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): reduce_dim=False): return prediction_ops.gradient_trees_prediction( tree_ensemble_handle, - self._seed, [self._dense_float_tensor], + self._seed, [self._dense_float_tensor1], [self._sparse_float_indices1, self._sparse_float_indices2], [self._sparse_float_values1, self._sparse_float_values2], [self._sparse_float_shape1, self._sparse_float_shape2], @@ -165,8 +181,27 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): center_bias=center_bias, reduce_dim=reduce_dim) + def _get_predictions_oblivious_case(self, + tree_ensemble_handle, + learner_config, + apply_dropout=False, + apply_averaging=False, + center_bias=False, + reduce_dim=False): + return prediction_ops.gradient_trees_prediction( + tree_ensemble_handle, + self._seed, [ + self._dense_float_tensor1, self._dense_float_tensor2, + self._dense_float_tensor3 + ], [], [], [], [], [], [], + learner_config=learner_config, + apply_dropout=apply_dropout, + apply_averaging=apply_averaging, + center_bias=center_bias, + reduce_dim=reduce_dim) + def testEmptyEnsemble(self): - with self.test_session(): + with self.cached_session(): # Empty tree ensenble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() @@ -189,7 +224,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): self.assertAllEqual([[], []], dropout_info.eval()) def testBiasEnsembleSingleClass(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree = tree_ensemble_config.trees.add() tree_ensemble_config.tree_metadata.add().is_finalized = True @@ -217,7 +252,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): self.assertAllEqual([[], []], dropout_info.eval()) def testBiasEnsembleMultiClass(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree = tree_ensemble_config.trees.add() tree_ensemble_config.tree_metadata.add().is_finalized = True @@ -247,7 +282,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): self.assertAllEqual([[], []], dropout_info.eval()) def testFullEnsembleSingleClass(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Bias tree. tree1 = tree_ensemble_config.trees.add() @@ -295,7 +330,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): # Empty dropout. self.assertAllEqual([[], []], dropout_info.eval()) - def testFullEnsembleWithMultidimensionalSparseSingleClass(self): + def testObliviousEnsemble(self): with self.test_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Bias tree. @@ -305,6 +340,53 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): # Depth 3 tree. tree2 = tree_ensemble_config.trees.add() + _set_float_oblivious_split( + tree2.nodes.add().oblivious_dense_float_binary_split, 0, 5.0) + _set_float_oblivious_split( + tree2.nodes.add().oblivious_dense_float_binary_split, 1, 3.0) + _set_float_oblivious_split( + tree2.nodes.add().oblivious_dense_float_binary_split, 2, 1.0) + for i in range(1, 9): + _append_to_leaf(tree2.nodes.add().leaf, 0, i / 10.0) + + tree_ensemble_config.tree_weights.append(1.0) + tree_ensemble_config.tree_weights.append(1.0) + + tree_ensemble_handle = model_ops.tree_ensemble_variable( + stamp_token=0, + tree_ensemble_config=tree_ensemble_config.SerializeToString(), + name="full_ensemble") + resources.initialize_resources(resources.shared_resources()).run() + + # Prepare learner config. + learner_config = learner_pb2.LearnerConfig() + learner_config.num_classes = 2 + + result, dropout_info = self._get_predictions_oblivious_case( + tree_ensemble_handle, + learner_config=learner_config.SerializeToString(), + reduce_dim=True) + + # The first example will get bias -0.4 from first tree and 0.6 from + # the 5th leaf of the second tree corresponding to node_id = 8, hence a + # prediction of 0.2. + # The second example will get bias -0.4 and 0.1 from the 0th leaf of the + # second tree corresponding to node_id = 3, hence a prediction of -0.3 + self.assertAllClose([[0.2], [-0.3]], result.eval()) + + # Empty dropout. + self.assertAllEqual([[], []], dropout_info.eval()) + + def testFullEnsembleWithMultidimensionalSparseSingleClass(self): + with self.cached_session(): + tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() + # Bias tree. + tree1 = tree_ensemble_config.trees.add() + tree_ensemble_config.tree_metadata.add().is_finalized = True + _append_to_leaf(tree1.nodes.add().leaf, 0, -0.4) + + # Depth 3 tree. + tree2 = tree_ensemble_config.trees.add() tree_ensemble_config.tree_metadata.add().is_finalized = True # Use feature column 2 (sparse multidimensional), split on first value # node 0. @@ -358,7 +440,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): result, dropout_info = prediction_ops.gradient_trees_prediction( tree_ensemble_handle, - self._seed, [self._dense_float_tensor], [ + self._seed, [self._dense_float_tensor1], [ self._sparse_float_indices1, self._sparse_float_indices2, self._sparse_float_indices_m ], [ @@ -384,7 +466,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): self.assertAllEqual([[], []], dropout_info.eval()) def testExcludeNonFinalTree(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Bias tree. tree1 = tree_ensemble_config.trees.add() @@ -431,7 +513,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): self.assertAllEqual([[], []], dropout_info.eval()) def testIncludeNonFinalTree(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Bias tree. tree1 = tree_ensemble_config.trees.add() @@ -482,7 +564,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): def testMetadataMissing(self): # Sometimes we want to do prediction on trees that are not added to ensemble # (for example in - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Bias tree. tree1 = tree_ensemble_config.trees.add() @@ -530,7 +612,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): # For TREE_PER_CLASS strategy, predictions size is num_classes-1 def testFullEnsembleMultiClassTreePerClassStrategy(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Bias tree only for second class. tree1 = tree_ensemble_config.trees.add() @@ -581,7 +663,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): # This test is when leafs have SPARSE weights stored (class id and # contribution). def testFullEnsembleMultiNotClassTreePerClassStrategySparseVector(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Bias tree only for second class. tree1 = tree_ensemble_config.trees.add() @@ -631,7 +713,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): # will have the size of the number of classes. # This test is when leafs have DENSE weights stored (weight for each class) def testFullEnsembleMultiNotClassTreePerClassStrategyDenseVector(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Bias tree only for second class. tree1 = tree_ensemble_config.trees.add() @@ -678,7 +760,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): self.assertAllEqual([[], []], dropout_info.eval()) def testDropout(self): - with self.test_session(): + with self.cached_session(): # Empty tree ensenble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Add 1000 trees with some weights. @@ -741,7 +823,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): # This is for normal non-batch mode where ensemble does not contain the tree # that is being built currently. num_trees = 10 - with self.test_session(): + with self.cached_session(): # Empty tree ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Add 10 trees with some weights. @@ -809,7 +891,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): # This is batch mode where ensemble already contains the tree that we are # building. This tree should never be dropped. num_trees = 10 - with self.test_session(): + with self.cached_session(): # Empty tree ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Add 10 trees with some weights. @@ -877,7 +959,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): dropout_info_center[0][num_dropped_center - 1]) def testDropoutSeed(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Add 10 trees with some weights. for i in range(0, 999): @@ -917,7 +999,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): # Different seed. _, dropout_info_3 = prediction_ops.gradient_trees_prediction( tree_ensemble_handle, - 112314, [self._dense_float_tensor], + 112314, [self._dense_float_tensor1], [self._sparse_float_indices1, self._sparse_float_indices2], [self._sparse_float_values1, self._sparse_float_values2], [self._sparse_float_shape1, self._sparse_float_shape2], @@ -950,7 +1032,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): len(dropout_info_4.eval()[0]) + 1, len(dropout_info_1.eval()[0])) def testDropOutZeroProb(self): - with self.test_session(): + with self.cached_session(): # Empty tree ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Add 1000 trees with some weights. @@ -993,7 +1075,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): self.assertAllClose(result.eval(), result_no_dropout.eval()) def testAveragingAllTrees(self): - with self.test_session(): + with self.cached_session(): # Empty tree ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() adjusted_tree_ensemble_config = ( @@ -1057,7 +1139,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): self.assertAllEqual(dropout_info.eval(), pattern_dropout_info.eval()) def testAveragingSomeTrees(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() adjusted_tree_ensemble_config = ( tree_config_pb2.DecisionTreeEnsembleConfig()) @@ -1138,7 +1220,7 @@ class PredictionOpsTest(test_util.TensorFlowTestCase): self.assertAllEqual(dropout_info_2.eval(), pattern_dropout_info.eval()) def testAverageMoreThanNumTreesExist(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() adjusted_tree_ensemble_config = ( tree_config_pb2.DecisionTreeEnsembleConfig()) @@ -1204,15 +1286,18 @@ class PartitionExamplesOpsTest(test_util.TensorFlowTestCase): def setUp(self): """Sets up the prediction tests. - Create a batch of two examples having one dense float, two sparse float and - one sparse int features. + Create a batch of two examples having three dense float, two sparse float + and one sparse int features. The data looks like the following: - | Instance | Dense0 | SparseF0 | SparseF1 | SparseI0 | - | 0 | 7 | -3 | | 9,1 | - | 1 | -2 | | 4 | | + |Instance |Dense0 |Dense1 |Dense2 |SparseF0 |SparseF1 |SparseI0 | + | 0 | 7 | 1 | 2 | -3 | | 9,1 | + | 1 | -2 | 2 | 0.5 | | 4 | | + """ super(PartitionExamplesOpsTest, self).setUp() - self._dense_float_tensor = np.array([[7.0], [-2.0]]) + self._dense_float_tensor1 = np.array([[7.0], [-2.0]]) + self._dense_float_tensor2 = np.array([[1.0], [2.0]]) + self._dense_float_tensor3 = np.array([[2.0], [0.5]]) self._sparse_float_indices1 = np.array([[0, 0]]) self._sparse_float_values1 = np.array([-3.0]) self._sparse_float_shape1 = np.array([2, 1]) @@ -1224,7 +1309,7 @@ class PartitionExamplesOpsTest(test_util.TensorFlowTestCase): self._sparse_int_shape1 = np.array([2, 2]) def testEnsembleEmpty(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree_ensemble_handle = model_ops.tree_ensemble_variable( @@ -1234,17 +1319,17 @@ class PartitionExamplesOpsTest(test_util.TensorFlowTestCase): resources.initialize_resources(resources.shared_resources()).run() result = prediction_ops.gradient_trees_partition_examples( - tree_ensemble_handle, [self._dense_float_tensor], [ - self._sparse_float_indices1, self._sparse_float_indices2 - ], [self._sparse_float_values1, self._sparse_float_values2], - [self._sparse_float_shape1, - self._sparse_float_shape2], [self._sparse_int_indices1], - [self._sparse_int_values1], [self._sparse_int_shape1]) + tree_ensemble_handle, [self._dense_float_tensor1], + [self._sparse_float_indices1, self._sparse_float_indices2], + [self._sparse_float_values1, self._sparse_float_values2], + [self._sparse_float_shape1, self._sparse_float_shape2], + [self._sparse_int_indices1], [self._sparse_int_values1], + [self._sparse_int_shape1]) self.assertAllEqual([0, 0], result.eval()) def testTreeNonFinalized(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Depth 3 tree. tree1 = tree_ensemble_config.trees.add() @@ -1269,17 +1354,17 @@ class PartitionExamplesOpsTest(test_util.TensorFlowTestCase): resources.initialize_resources(resources.shared_resources()).run() result = prediction_ops.gradient_trees_partition_examples( - tree_ensemble_handle, [self._dense_float_tensor], [ - self._sparse_float_indices1, self._sparse_float_indices2 - ], [self._sparse_float_values1, self._sparse_float_values2], - [self._sparse_float_shape1, - self._sparse_float_shape2], [self._sparse_int_indices1], - [self._sparse_int_values1], [self._sparse_int_shape1]) + tree_ensemble_handle, [self._dense_float_tensor1], + [self._sparse_float_indices1, self._sparse_float_indices2], + [self._sparse_float_values1, self._sparse_float_values2], + [self._sparse_float_shape1, self._sparse_float_shape2], + [self._sparse_int_indices1], [self._sparse_int_values1], + [self._sparse_int_shape1]) self.assertAllEqual([5, 3], result.eval()) def testTreeFinalized(self): - with self.test_session(): + with self.cached_session(): tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() # Depth 3 tree. tree1 = tree_ensemble_config.trees.add() @@ -1304,15 +1389,51 @@ class PartitionExamplesOpsTest(test_util.TensorFlowTestCase): resources.initialize_resources(resources.shared_resources()).run() result = prediction_ops.gradient_trees_partition_examples( - tree_ensemble_handle, [self._dense_float_tensor], [ - self._sparse_float_indices1, self._sparse_float_indices2 - ], [self._sparse_float_values1, self._sparse_float_values2], - [self._sparse_float_shape1, - self._sparse_float_shape2], [self._sparse_int_indices1], - [self._sparse_int_values1], [self._sparse_int_shape1]) + tree_ensemble_handle, [self._dense_float_tensor1], + [self._sparse_float_indices1, self._sparse_float_indices2], + [self._sparse_float_values1, self._sparse_float_values2], + [self._sparse_float_shape1, self._sparse_float_shape2], + [self._sparse_int_indices1], [self._sparse_int_values1], + [self._sparse_int_shape1]) self.assertAllEqual([0, 0], result.eval()) + def testObliviousTreeNonFinalized(self): + with self.test_session(): + tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() + # Depth 3 tree. + tree1 = tree_ensemble_config.trees.add() + _set_float_oblivious_split( + tree1.nodes.add().oblivious_dense_float_binary_split, 0, 5.0) + _set_float_oblivious_split( + tree1.nodes.add().oblivious_dense_float_binary_split, 1, 3.0) + _set_float_oblivious_split( + tree1.nodes.add().oblivious_dense_float_binary_split, 2, 1.0) + for i in range(1, 9): + _append_to_leaf(tree1.nodes.add().leaf, 0, i / 10.0) + tree_ensemble_config.tree_weights.append(1.0) + tree_ensemble_config.tree_metadata.add().is_finalized = False + + tree_ensemble_handle = model_ops.tree_ensemble_variable( + stamp_token=0, + tree_ensemble_config=tree_ensemble_config.SerializeToString(), + name="full_ensemble") + resources.initialize_resources(resources.shared_resources()).run() + + result = prediction_ops.gradient_trees_partition_examples( + tree_ensemble_handle, [ + self._dense_float_tensor1, + self._dense_float_tensor2, + self._dense_float_tensor3 + ], [], [], [], [], [], []) + + # The first example goes right, left, right in the tree and the second + # example goes lef, left, left. Since the depth of the tree is 3, the + # partition id's are as follows: + # First example: 3 + 5 = 8 + # Second exampel: 3 + 0 = 3 + self.assertAllEqual([8, 3], result.eval()) + if __name__ == "__main__": googletest.main() diff --git a/tensorflow/contrib/boosted_trees/python/kernel_tests/quantile_ops_test.py b/tensorflow/contrib/boosted_trees/python/kernel_tests/quantile_ops_test.py index 074623699d..848c42b686 100644 --- a/tensorflow/contrib/boosted_trees/python/kernel_tests/quantile_ops_test.py +++ b/tensorflow/contrib/boosted_trees/python/kernel_tests/quantile_ops_test.py @@ -77,7 +77,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): example_weights = constant_op.constant( [10, 1, 1, 1, 1, 1], dtype=dtypes.float32) - with self.test_session(): + with self.cached_session(): config = self._gen_config(0.33, 3) dense_buckets, sparse_buckets = quantile_ops.quantile_buckets( [dense_float_tensor_0], [sparse_indices_0, sparse_indices_m], @@ -107,7 +107,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): """ num_quantiles = 3 - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = quantile_ops.QuantileAccumulator( init_stamp_token=0, num_quantiles=num_quantiles, epsilon=0.001, name="q1") @@ -119,7 +119,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): column=input_column, example_weights=weights) - with self.test_session() as sess: + with self.cached_session() as sess: for i in range(1, 23): # start = 1, 2, 4, 7, 11, 16 ... (see comment above) start = int((i * (i-1) / 2) + 1) @@ -127,7 +127,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): {input_column: range(start, start+i), weights: [1] * i}) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(accumulator.flush(stamp_token=0, next_stamp_token=1)) are_ready_flush, buckets = (accumulator.get_buckets(stamp_token=1)) buckets, are_ready_flush = (sess.run( @@ -142,7 +142,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): num_quantiles = 3 # set generate_quantiles to True since the test will generate fewer # boundaries otherwise. - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = quantile_ops.QuantileAccumulator( init_stamp_token=0, num_quantiles=num_quantiles, epsilon=0.001, name="q1", generate_quantiles=True) @@ -154,7 +154,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): column=input_column, example_weights=weights) - with self.test_session() as sess: + with self.cached_session() as sess: # This input is generated by integer in the range [2030, 2060] # but represented by with float16 precision. Integers <= 2048 are # exactly represented, whereas numbers > 2048 are rounded; and hence @@ -174,7 +174,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): {input_column: inputs, weights: [1] * len(inputs)}) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(accumulator.flush(stamp_token=0, next_stamp_token=1)) are_ready_flush, buckets = (accumulator.get_buckets(stamp_token=1)) buckets, are_ready_flush = (sess.run( @@ -189,7 +189,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): # set generate_quantiles to True since the test will generate fewer # boundaries otherwise. - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = quantile_ops.QuantileAccumulator( init_stamp_token=0, num_quantiles=num_quantiles, epsilon=0.001, name="q1", generate_quantiles=True) @@ -201,12 +201,12 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): column=input_column, example_weights=weights) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(update, {input_column: inputs, weights: [1] * len(inputs)}) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(accumulator.flush(stamp_token=0, next_stamp_token=1)) are_ready_flush, buckets = (accumulator.get_buckets(stamp_token=1)) buckets, are_ready_flush = (sess.run( @@ -265,7 +265,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): [9900 9901 .. 9999] All the batches have 1 for all the example weights. """ - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = quantile_ops.QuantileAccumulator( init_stamp_token=0, num_quantiles=3, epsilon=0.01, name="q1") resources.initialize_resources(resources.shared_resources()).run() @@ -275,7 +275,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): stamp_token=0, column=dense_placeholder, example_weights=weight_placeholder) - with self.test_session() as sess: + with self.cached_session() as sess: for i in range(100): dense_float = np.linspace( i * 100, (i + 1) * 100 - 1, num=100).reshape(-1, 1) @@ -284,7 +284,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): weight_placeholder: np.ones(shape=(100, 1), dtype=np.float32) }) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(accumulator.flush(stamp_token=0, next_stamp_token=1)) are_ready_flush, buckets = (accumulator.get_buckets(stamp_token=1)) buckets, are_ready_flush = (sess.run([buckets, are_ready_flush])) @@ -301,7 +301,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): [9900 9901 .. 9999] All the batches have 1 for all the example weights. """ - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = quantile_ops.QuantileAccumulator( init_stamp_token=0, num_quantiles=3, epsilon=0.01, name="q1") accumulator_2 = quantile_ops.QuantileAccumulator( @@ -313,7 +313,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): stamp_token=0, column=dense_placeholder, example_weights=weight_placeholder) - with self.test_session() as sess: + with self.cached_session() as sess: for i in range(100): dense_float = np.linspace( i * 100, (i + 1) * 100 - 1, num=100).reshape(-1, 1) @@ -322,7 +322,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): weight_placeholder: np.ones(shape=(100, 1), dtype=np.float32) }) - with self.test_session() as sess: + with self.cached_session() as sess: summary = sess.run( accumulator.flush_summary(stamp_token=0, next_stamp_token=1)) sess.run( @@ -338,7 +338,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): save_dir = os.path.join(self.get_temp_dir(), "save_restore") save_path = os.path.join(tempfile.mkdtemp(prefix=save_dir), "hash") - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: accumulator = quantile_ops.QuantileAccumulator( init_stamp_token=0, num_quantiles=3, epsilon=0.33, name="q0") @@ -366,7 +366,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): self.assertEqual(True, are_ready_flush) self.assertAllEqual([2, 4, 6.], buckets) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: accumulator = quantile_ops.QuantileAccumulator( init_stamp_token=0, num_quantiles=3, epsilon=0.33, name="q0") save = saver.Saver() @@ -389,7 +389,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): save_dir = os.path.join(self.get_temp_dir(), "save_restore") save_path = os.path.join(tempfile.mkdtemp(prefix=save_dir), "hash") - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: accumulator = quantile_ops.QuantileAccumulator( init_stamp_token=0, num_quantiles=3, epsilon=0.33, name="q0") @@ -413,7 +413,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): self.assertAllEqual([1, 3, 5], buckets) save.save(sess, save_path) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: accumulator = quantile_ops.QuantileAccumulator( init_stamp_token=0, num_quantiles=3, epsilon=0.33, name="q0") save = saver.Saver() @@ -438,7 +438,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): [1] * (int(math.pow(2, 16)) + 1), dtype=dtypes.float32) config = self._gen_config(0.1, 10) - with self.test_session(): + with self.cached_session(): dense_buckets, _ = quantile_ops.quantile_buckets( [dense_float_tensor_0], [], [], [], example_weights=example_weights, @@ -464,7 +464,7 @@ class QuantileBucketsOpTest(test_util.TensorFlowTestCase): config = self._gen_config(0.1, 10) - with self.test_session(): + with self.cached_session(): dense_buckets, _ = quantile_ops.quantile_buckets( [dense_float_tensor_0], [], [], [], example_weights=example_weights, @@ -533,7 +533,7 @@ class QuantilesOpTest(test_util.TensorFlowTestCase): self._sparse_thresholds_m = [1, 2, 1000] def testDenseFeaturesOnly(self): - with self.test_session(): + with self.cached_session(): dense_quantiles, _ = quantile_ops.quantiles( [self._dense_float_tensor_0, self._dense_float_tensor_1], [], [self._dense_thresholds_0, self._dense_thresholds_1], [], []) @@ -546,7 +546,7 @@ class QuantilesOpTest(test_util.TensorFlowTestCase): dense_quantiles[1].eval()) def testSparseFeaturesOnly(self): - with self.test_session(): + with self.cached_session(): _, sparse_quantiles = quantile_ops.quantiles([], [ self._sparse_values_0, self._sparse_values_1, self._sparse_values_2, self._sparse_values_m @@ -571,7 +571,7 @@ class QuantilesOpTest(test_util.TensorFlowTestCase): sparse_quantiles[3].eval()) def testDenseAndSparseFeatures(self): - with self.test_session(): + with self.cached_session(): dense_quantiles, sparse_quantiles = quantile_ops.quantiles( [self._dense_float_tensor_0, self._dense_float_tensor_1], [ self._sparse_values_0, self._sparse_values_1, @@ -602,14 +602,14 @@ class QuantilesOpTest(test_util.TensorFlowTestCase): sparse_quantiles[3].eval()) def testBucketizeWithInputBoundaries(self): - with self.test_session(): + with self.cached_session(): buckets = quantile_ops.bucketize_with_input_boundaries( input=[1, 2, 3, 4, 5], boundaries=[3]) self.assertAllEqual([0, 0, 1, 1, 1], buckets.eval()) def testBucketizeWithInputBoundaries2(self): - with self.test_session(): + with self.cached_session(): boundaries = constant_op.constant([3], dtype=dtypes.float32) buckets = quantile_ops.bucketize_with_input_boundaries( input=[1, 2, 3, 4, 5], @@ -617,7 +617,7 @@ class QuantilesOpTest(test_util.TensorFlowTestCase): self.assertAllEqual([0, 0, 1, 1, 1], buckets.eval()) def testBucketizeWithInputBoundaries3(self): - with self.test_session(): + with self.cached_session(): b = array_ops.placeholder(dtypes.float32) buckets = quantile_ops.bucketize_with_input_boundaries( input=[1, 2, 3, 4, 5], diff --git a/tensorflow/contrib/boosted_trees/python/kernel_tests/split_handler_ops_test.py b/tensorflow/contrib/boosted_trees/python/kernel_tests/split_handler_ops_test.py index 2589504762..74917f7cde 100644 --- a/tensorflow/contrib/boosted_trees/python/kernel_tests/split_handler_ops_test.py +++ b/tensorflow/contrib/boosted_trees/python/kernel_tests/split_handler_ops_test.py @@ -33,7 +33,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): def testMakeDenseSplit(self): """Tests split handler op.""" - with self.test_session() as sess: + with self.cached_session() as sess: # The data looks like the following after dividing by number of steps (2). # Gradients | Partition | Dense Quantile | # (1.2, 0.2) | 0 | 0 | @@ -111,7 +111,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): def testMakeMulticlassDenseSplit(self): """Tests split handler op.""" - with self.test_session() as sess: + with self.cached_session() as sess: partition_ids = array_ops.constant([0, 0, 1], dtype=dtypes.int32) bucket_ids = array_ops.constant( [[0, 0], [1, 0], [1, 0]], dtype=dtypes.int64) @@ -153,7 +153,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): def testMakeDenseSplitEmptyInputs(self): """Tests empty inputs op.""" - with self.test_session() as sess: + with self.cached_session() as sess: partition_ids = array_ops.constant([], dtype=dtypes.int32) bucket_ids = array_ops.constant([[]], dtype=dtypes.int64) gradients = array_ops.constant([]) @@ -183,7 +183,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): def testMakeSparseSplit(self): """Tests split handler op.""" - with self.test_session() as sess: + with self.cached_session() as sess: # The data looks like the following after dividing by number of steps (2). # Gradients | Partition | bucket ID | # (0.9, 0.39) | 0 | -1 | @@ -274,7 +274,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): def testMakeSparseSplitAllEmptyDimensions(self): """Tests split handler op when all dimensions have only bias bucket id.""" - with self.test_session() as sess: + with self.cached_session() as sess: # The data looks like the following after dividing by number of steps (2). # Gradients | Partition | Dimension | bucket ID | # (0.9, 0.39) | 0 | 0 | -1 | @@ -307,7 +307,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): def testMakeSparseMultidimensionalSplit(self): """Tests split handler op.""" - with self.test_session() as sess: + with self.cached_session() as sess: # Num of steps is 2. # The feature column is three dimensional. # First dimension has bias bucket only, the second has bias bucket and @@ -408,7 +408,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): """Tests default direction is stable when no sparsity.""" random.seed(1123) for _ in range(50): - with self.test_session() as sess: + with self.cached_session() as sess: grad = random.random() hessian = random.random() # The data looks like the following (divide by the num of steps 2). @@ -465,7 +465,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): def testMakeMulticlassSparseSplit(self): """Tests split handler op.""" - with self.test_session() as sess: + with self.cached_session() as sess: partition_ids = array_ops.constant([0, 0, 0, 1, 1], dtype=dtypes.int32) bucket_ids = array_ops.constant( [[-1, 0], [0, 0], [1, 0], [-1, 0], [1, 0]], dtype=dtypes.int64) @@ -514,7 +514,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): def testMakeCategoricalEqualitySplit(self): """Tests split handler op for categorical equality split.""" - with self.test_session() as sess: + with self.cached_session() as sess: # The data looks like the following after dividing by number of steps (2). # Gradients | Partition | Feature ID | # (0.9, 0.39) | 0 | -1 | @@ -541,7 +541,8 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): feature_column_group_id=0, bias_feature_id=-1, class_id=-1, - multiclass_strategy=learner_pb2.LearnerConfig.TREE_PER_CLASS)) + multiclass_strategy=learner_pb2.LearnerConfig.TREE_PER_CLASS, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE)) partitions, gains, splits = sess.run([partitions, gains, splits]) self.assertAllEqual([0, 1], partitions) @@ -608,7 +609,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): def testMakeMulticlassCategoricalEqualitySplit(self): """Tests split handler op for categorical equality split in multiclass.""" - with self.test_session() as sess: + with self.cached_session() as sess: gradients = array_ops.constant([[1.8, 3.5], [2.4, 1.0], [0.4, 4.0], [9.0, 3.1], [3.0, 0.8]]) @@ -637,7 +638,8 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): feature_column_group_id=0, bias_feature_id=-1, class_id=-1, - multiclass_strategy=learner_pb2.LearnerConfig.FULL_HESSIAN)) + multiclass_strategy=learner_pb2.LearnerConfig.FULL_HESSIAN, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE)) partitions, gains, splits = sess.run([partitions, gains, splits]) self.assertAllEqual([0, 1], partitions) @@ -655,7 +657,7 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): self.assertEqual(1, split_node.feature_id) def testMakeCategoricalEqualitySplitEmptyInput(self): - with self.test_session() as sess: + with self.cached_session() as sess: gradients = [] hessians = [] partition_ids = [] @@ -674,7 +676,8 @@ class SplitHandlerOpsTest(test_util.TensorFlowTestCase): feature_column_group_id=0, bias_feature_id=-1, class_id=-1, - multiclass_strategy=learner_pb2.LearnerConfig.TREE_PER_CLASS)) + multiclass_strategy=learner_pb2.LearnerConfig.TREE_PER_CLASS, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE)) partitions, gains, splits = (sess.run([partitions, gains, splits])) self.assertEqual(0, len(partitions)) self.assertEqual(0, len(gains)) diff --git a/tensorflow/contrib/boosted_trees/python/kernel_tests/stats_accumulator_ops_test.py b/tensorflow/contrib/boosted_trees/python/kernel_tests/stats_accumulator_ops_test.py index 978bf530cd..05ce0884cc 100644 --- a/tensorflow/contrib/boosted_trees/python/kernel_tests/stats_accumulator_ops_test.py +++ b/tensorflow/contrib/boosted_trees/python/kernel_tests/stats_accumulator_ops_test.py @@ -29,7 +29,7 @@ class StatsAccumulatorScalarTest(test_util.TensorFlowTestCase): """Tests for scalar gradients and hessians accumulator.""" def testSimpleAcculumator(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.scalar(), @@ -57,7 +57,7 @@ class StatsAccumulatorScalarTest(test_util.TensorFlowTestCase): self.assertAllClose(result[(2, 3, 0)], [0.3, 0.4]) def testMultidimensionalAcculumator(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.scalar(), @@ -86,7 +86,7 @@ class StatsAccumulatorScalarTest(test_util.TensorFlowTestCase): self.assertAllClose(result[(2, 3, 1)], [0.1, 0.2]) def testDropStaleUpdate(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.scalar(), @@ -118,7 +118,7 @@ class StatsAccumulatorScalarTest(test_util.TensorFlowTestCase): self.assertAllClose(result[(2, 3, 0)], [0.3, 0.4]) def testSerialize(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.scalar(), @@ -159,7 +159,7 @@ class StatsAccumulatorScalarTest(test_util.TensorFlowTestCase): self.assertEqual(0, stamp_token) def testDeserialize(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.scalar(), @@ -196,7 +196,7 @@ class StatsAccumulatorScalarTest(test_util.TensorFlowTestCase): self.assertAllClose(result[(4, 6, 2)], [0.5, 0.7]) def testMakeSummary(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.scalar(), @@ -218,7 +218,7 @@ class StatsAccumulatorTensorTest(test_util.TensorFlowTestCase): """Tests for tensor gradients and hessians accumulator.""" def testSimpleAcculumator(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.TensorShape([2]), @@ -256,7 +256,7 @@ class StatsAccumulatorTensorTest(test_util.TensorFlowTestCase): self.assertAllClose(result[(2, 3, 0)][1], [[0.05, 0.06], [0.07, 0.08]]) def testMultidimensionalAcculumator(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.TensorShape([2]), @@ -294,7 +294,7 @@ class StatsAccumulatorTensorTest(test_util.TensorFlowTestCase): self.assertAllClose(result[(2, 3, 1)][1], [[0.05, 0.06], [0.07, 0.08]]) def testDropStaleUpdate(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.TensorShape([2]), @@ -331,7 +331,7 @@ class StatsAccumulatorTensorTest(test_util.TensorFlowTestCase): self.assertAllClose(result[(2, 3, 0)][1], [[0.05, 0.06], [0.07, 0.08]]) def testSerialize(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.TensorShape([2]), @@ -381,7 +381,7 @@ class StatsAccumulatorTensorTest(test_util.TensorFlowTestCase): self.assertAllEqual(result_1[2, 3, 0][1], result_2[2, 3, 0][1]) def testDeserialize(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.TensorShape([2]), @@ -425,7 +425,7 @@ class StatsAccumulatorTensorTest(test_util.TensorFlowTestCase): self.assertAllClose(result[(4, 5, 0)][1], [[0.07, 0.08], [0.09, 0.10]]) def testMakeSummary(self): - with self.test_session() as sess: + with self.cached_session() as sess: accumulator = stats_accumulator_ops.StatsAccumulator( stamp_token=0, gradient_shape=tensor_shape.TensorShape([2]), diff --git a/tensorflow/contrib/boosted_trees/python/kernel_tests/training_ops_test.py b/tensorflow/contrib/boosted_trees/python/kernel_tests/training_ops_test.py index e39e1de8d1..b3e4c2e5f7 100644 --- a/tensorflow/contrib/boosted_trees/python/kernel_tests/training_ops_test.py +++ b/tensorflow/contrib/boosted_trees/python/kernel_tests/training_ops_test.py @@ -91,6 +91,31 @@ def _gen_dense_split_info(fc, threshold, left_weight, right_weight): return split.SerializeToString() +def _gen_dense_oblivious_split_info(fc, threshold, leave_weights, + children_parent_id): + split_str = """ + split_node { + oblivious_dense_float_binary_split { + feature_column: %d + threshold: %f + } + }""" % (fc, threshold) + for weight in leave_weights: + split_str += """ + children { + vector { + value: %f + } + }""" % ( + weight) + for x in children_parent_id: + split_str += """ + children_parent_id: %d""" % (x) + split = split_info_pb2.ObliviousSplitInfo() + text_format.Merge(split_str, split) + return split.SerializeToString() + + def _gen_categorical_split_info(fc, feat_id, left_weight, right_weight): split_str = """ split_node { @@ -125,7 +150,7 @@ class CenterTreeEnsembleBiasOpTest(test_util.TensorFlowTestCase): def testCenterBias(self): """Tests bias centering for multiple iterations.""" - with self.test_session() as session: + with self.cached_session() as session: # Create empty ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree_ensemble_handle = model_ops.tree_ensemble_variable( @@ -276,7 +301,7 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): def testGrowEmptyEnsemble(self): """Test growing an empty ensemble.""" - with self.test_session() as session: + with self.cached_session() as session: # Create empty ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree_ensemble_handle = model_ops.tree_ensemble_variable( @@ -324,7 +349,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect the simpler split from handler 1 to be chosen. @@ -383,9 +409,122 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): self.assertEqual(stats.attempted_layers, 1) self.assertProtoEquals(expected_result, tree_ensemble_config) + def testGrowEmptyEnsembleObliviousCase(self): + """Test growing an empty ensemble in the oblivious case.""" + with self.test_session() as session: + # Create empty ensemble. + tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() + tree_ensemble_handle = model_ops.tree_ensemble_variable( + stamp_token=0, + tree_ensemble_config=tree_ensemble_config.SerializeToString(), + name="tree_ensemble") + resources.initialize_resources(resources.shared_resources()).run() + + # Prepare learner config. + learner_config = _gen_learner_config( + num_classes=2, + l1_reg=0, + l2_reg=0, + tree_complexity=0, + max_depth=1, + min_node_weight=0, + pruning_mode=learner_pb2.LearnerConfig.PRE_PRUNE, + growing_mode=learner_pb2.LearnerConfig.WHOLE_TREE) + + # Prepare handler inputs. + # Note that handlers 1 & 3 have the same gain but different splits. + handler1_partitions = np.array([0], dtype=np.int32) + handler1_gains = np.array([7.62], dtype=np.float32) + handler1_split = [ + _gen_dense_oblivious_split_info(0, 0.52, [-4.375, 7.143], [0]) + ] + handler2_partitions = np.array([0], dtype=np.int32) + handler2_gains = np.array([0.63], dtype=np.float32) + handler2_split = [ + _gen_dense_oblivious_split_info(0, 0.23, [-0.6, 0.24], [0]) + ] + handler3_partitions = np.array([0], dtype=np.int32) + handler3_gains = np.array([7.62], dtype=np.float32) + handler3_split = [ + _gen_dense_oblivious_split_info(0, 7, [-4.375, 7.143], [0]) + ] + + # Grow tree ensemble. + grow_op = training_ops.grow_tree_ensemble( + tree_ensemble_handle, + stamp_token=0, + next_stamp_token=1, + learning_rate=0.1, + partition_ids=[ + handler1_partitions, handler2_partitions, handler3_partitions + ], + gains=[handler1_gains, handler2_gains, handler3_gains], + splits=[handler1_split, handler2_split, handler3_split], + learner_config=learner_config.SerializeToString(), + dropout_seed=123, + center_bias=True, + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.OBLIVIOUS_DECISION_TREE) + session.run(grow_op) + + # Expect the split with bigger handler_id, i.e. handler 3 to be chosen. + # The grown tree should be finalized as max tree depth is 1. + new_stamp, serialized = session.run( + model_ops.tree_ensemble_serialize(tree_ensemble_handle)) + stats = session.run( + training_ops.tree_ensemble_stats(tree_ensemble_handle, stamp_token=1)) + tree_ensemble_config.ParseFromString(serialized) + expected_result = """ + trees { + nodes { + oblivious_dense_float_binary_split { + feature_column: 0 + threshold: 7 + } + node_metadata { + gain: 7.62 + original_oblivious_leaves { + } + } + } + nodes { + leaf { + vector { + value: -4.375 + } + } + } + nodes { + leaf { + vector { + value: 7.143 + } + } + } + } + tree_weights: 0.1 + tree_metadata { + num_tree_weight_updates: 1 + num_layers_grown: 1 + is_finalized: true + } + growing_metadata { + num_trees_attempted: 1 + num_layers_attempted: 1 + } + """ + self.assertEqual(new_stamp, 1) + self.assertEqual(stats.num_trees, 1) + self.assertEqual(stats.num_layers, 1) + self.assertEqual(stats.active_tree, 1) + self.assertEqual(stats.active_layer, 1) + self.assertEqual(stats.attempted_trees, 1) + self.assertEqual(stats.attempted_layers, 1) + self.assertProtoEquals(expected_result, tree_ensemble_config) + def testGrowExistingEnsembleTreeNotFinalized(self): """Test growing an existing ensemble with the last tree not finalized.""" - with self.test_session() as session: + with self.cached_session() as session: # Create existing ensemble with one root split tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() text_format.Merge(""" @@ -476,7 +615,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect the split for partition 1 to be chosen from handler 1 and @@ -575,7 +715,7 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): def testGrowExistingEnsembleTreeFinalized(self): """Test growing an existing ensemble with the last tree finalized.""" - with self.test_session() as session: + with self.cached_session() as session: # Create existing ensemble with one root split tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() text_format.Merge(""" @@ -661,7 +801,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect a new tree to be added with the split from handler 1. @@ -757,7 +898,7 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): def testGrowEnsemblePrePrune(self): """Test growing an ensemble with pre-pruning.""" - with self.test_session() as session: + with self.cached_session() as session: # Create empty ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree_ensemble_handle = model_ops.tree_ensemble_variable( @@ -798,7 +939,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect the ensemble to be empty. @@ -823,7 +965,7 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): def testGrowEnsemblePostPruneNone(self): """Test growing an empty ensemble.""" - with self.test_session() as session: + with self.cached_session() as session: # Create empty ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree_ensemble_handle = model_ops.tree_ensemble_variable( @@ -869,7 +1011,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect the simpler split from handler 1 to be chosen. @@ -930,7 +1073,7 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): def testGrowEnsemblePostPruneAll(self): """Test growing an ensemble with post-pruning.""" - with self.test_session() as session: + with self.cached_session() as session: # Create empty ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree_ensemble_handle = model_ops.tree_ensemble_variable( @@ -971,7 +1114,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect the split from handler 2 to be chosen despite the negative gain. @@ -1053,7 +1197,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect the ensemble to be empty as post-pruning will prune @@ -1079,7 +1224,7 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): def testGrowEnsemblePostPrunePartial(self): """Test growing an ensemble with post-pruning.""" - with self.test_session() as session: + with self.cached_session() as session: # Create empty ensemble. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() tree_ensemble_handle = model_ops.tree_ensemble_variable( @@ -1120,7 +1265,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect the split from handler 2 to be chosen despite the negative gain. @@ -1200,7 +1346,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect the negative gain split of partition 1 to be pruned and the @@ -1280,7 +1427,7 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): def testGrowEnsembleTreeLayerByLayer(self): """Test growing an existing ensemble with the last tree not finalized.""" - with self.test_session() as session: + with self.cached_session() as session: # Create existing ensemble with one root split tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() text_format.Merge(""" @@ -1371,7 +1518,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect the split for partition 1 to be chosen from handler 1 and @@ -1470,9 +1618,721 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): self.assertEqual(stats.attempted_layers, 2) self.assertProtoEquals(expected_result, tree_ensemble_config) + def testGrowEnsembleTreeLayerByLayerObliviousCase(self): + """Test growing an existing ensemble with the last tree not finalized.""" + with self.test_session() as session: + # Create existing ensemble with one root split + tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() + text_format.Merge( + """ + trees { + nodes { + oblivious_dense_float_binary_split { + feature_column: 4 + threshold: 7 + } + node_metadata { + gain: 7.62 + original_oblivious_leaves { + } + } + } + nodes { + leaf { + vector { + value: 7.143 + } + } + } + nodes { + leaf { + vector { + value: -4.375 + } + } + } + } + tree_weights: 0.1 + tree_metadata { + num_tree_weight_updates: 1 + num_layers_grown: 1 + } + growing_metadata { + num_trees_attempted: 1 + num_layers_attempted: 1 + } + """, tree_ensemble_config) + tree_ensemble_handle = model_ops.tree_ensemble_variable( + stamp_token=0, + tree_ensemble_config=tree_ensemble_config.SerializeToString(), + name="tree_ensemble") + resources.initialize_resources(resources.shared_resources()).run() + + # Prepare learner config. + learner_config = _gen_learner_config( + num_classes=2, + l1_reg=0, + l2_reg=0, + tree_complexity=0, + max_depth=3, + min_node_weight=0, + pruning_mode=learner_pb2.LearnerConfig.PRE_PRUNE, + growing_mode=learner_pb2.LearnerConfig.LAYER_BY_LAYER) + + # Prepare handler inputs. + handler1_partitions = np.array([0], dtype=np.int32) + handler1_gains = np.array([1.4], dtype=np.float32) + handler1_split = [ + _gen_dense_oblivious_split_info(0, 0.21, [-6.0, 1.65, 1.0, -0.5], + [1, 2]) + ] + handler2_partitions = np.array([0], dtype=np.int32) + handler2_gains = np.array([2.7], dtype=np.float32) + handler2_split = [ + _gen_dense_oblivious_split_info(0, 0.23, [-0.6, 0.24, 0.3, 0.4], + [1, 2]) + ] + handler3_partitions = np.array([0], dtype=np.int32) + handler3_gains = np.array([1.7], dtype=np.float32) + handler3_split = [ + _gen_dense_oblivious_split_info(0, 3, [-0.75, 1.93, 0.2, -0.1], + [1, 2]) + ] + + # Grow tree ensemble layer by layer. + grow_op = training_ops.grow_tree_ensemble( + tree_ensemble_handle, + stamp_token=0, + next_stamp_token=1, + learning_rate=0.1, + partition_ids=[ + handler1_partitions, handler2_partitions, handler3_partitions + ], + gains=[handler1_gains, handler2_gains, handler3_gains], + splits=[handler1_split, handler2_split, handler3_split], + learner_config=learner_config.SerializeToString(), + dropout_seed=123, + center_bias=True, + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.OBLIVIOUS_DECISION_TREE) + session.run(grow_op) + + # Expect the split for partition 1 to be chosen from handler 1 and + # the split for partition 2 to be chosen from handler 2. + # The grown tree should not be finalized as max tree depth is 3 and + # it's only grown 2 layers. + # The partition 1 split weights get added to original leaf weight 7.143. + # The partition 2 split weights get added to original leaf weight -4.375. + new_stamp, serialized = session.run( + model_ops.tree_ensemble_serialize(tree_ensemble_handle)) + stats = session.run( + training_ops.tree_ensemble_stats(tree_ensemble_handle, stamp_token=1)) + tree_ensemble_config.ParseFromString(serialized) + expected_result = """ + trees { + nodes { + oblivious_dense_float_binary_split { + feature_column: 4 + threshold: 7 + } + node_metadata { + gain: 7.62 + original_oblivious_leaves { + } + } + } + nodes { + oblivious_dense_float_binary_split { + feature_column: 0 + threshold: 0.23 + } + node_metadata { + gain: 2.7 + original_oblivious_leaves { + vector { + value: 7.143 + } + } + original_oblivious_leaves { + vector { + value: -4.375 + } + } + } + } + nodes { + leaf { + vector { + value: 6.543 + } + } + } + nodes { + leaf { + vector { + value: 7.383 + } + } + } + nodes { + leaf { + vector { + value: -4.075 + } + } + } + nodes { + leaf { + vector { + value: -3.975 + } + } + } + } + tree_weights: 0.1 + tree_metadata { + num_tree_weight_updates: 1 + num_layers_grown: 2 + } + growing_metadata { + num_trees_attempted: 1 + num_layers_attempted: 2 + } + """ + self.assertEqual(new_stamp, 1) + self.assertEqual(stats.num_trees, 0) + self.assertEqual(stats.num_layers, 2) + self.assertEqual(stats.active_tree, 1) + self.assertEqual(stats.active_layer, 2) + self.assertEqual(stats.attempted_trees, 1) + self.assertEqual(stats.attempted_layers, 2) + self.assertProtoEquals(expected_result, tree_ensemble_config) + + def testGrowEnsembleWithEmptyNodesMiddleCase(self): + """Test case: The middle existing leaves don't have examples.""" + with self.test_session() as session: + tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() + text_format.Merge( + """ + trees { + nodes { + oblivious_dense_float_binary_split { + feature_column: 4 + threshold: 7 + } + node_metadata { + gain: 7.62 + original_oblivious_leaves { + } + } + } + nodes { + oblivious_dense_float_binary_split { + feature_column: 1 + threshold: 0.23 + } + node_metadata { + gain: 2.7 + original_oblivious_leaves { + vector { + value: 7.143 + } + } + original_oblivious_leaves { + vector { + value: -4.375 + } + } + } + } + nodes { + leaf { + vector { + value: 6.543 + } + } + } + nodes { + leaf { + vector { + value: 7.5 + } + } + } + nodes { + leaf { + vector { + value: -4.075 + } + } + } + nodes { + leaf { + vector { + value: -3.975 + } + } + } + } + tree_weights: 0.1 + tree_metadata { + num_tree_weight_updates: 1 + num_layers_grown: 2 + } + growing_metadata { + num_trees_attempted: 1 + num_layers_attempted: 2 + } + """, tree_ensemble_config) + tree_ensemble_handle = model_ops.tree_ensemble_variable( + stamp_token=0, + tree_ensemble_config=tree_ensemble_config.SerializeToString(), + name="tree_ensemble") + resources.initialize_resources(resources.shared_resources()).run() + + # Prepare learner config. + learner_config = _gen_learner_config( + num_classes=2, + l1_reg=0, + l2_reg=0, + tree_complexity=0, + max_depth=6, + min_node_weight=0, + pruning_mode=learner_pb2.LearnerConfig.PRE_PRUNE, + growing_mode=learner_pb2.LearnerConfig.LAYER_BY_LAYER) + + # Prepare handler inputs. + handler1_partitions = np.array([0], dtype=np.int32) + handler1_gains = np.array([1.8], dtype=np.float32) + handler1_split = [ + _gen_dense_oblivious_split_info(0, 0.9, [1.0, 2.0, 3.0, 4.0], [2, 5]) + ] + # The tree currently has depth 2, so the ids for the four leaves are in + # the range [2, 6). In this test case we are assuming that our examples + # only fall in leaves 2 and 5. + + # Grow tree ensemble layer by layer. + grow_op = training_ops.grow_tree_ensemble( + tree_ensemble_handle, + stamp_token=0, + next_stamp_token=1, + learning_rate=0.1, + partition_ids=[handler1_partitions], + gains=[handler1_gains], + splits=[handler1_split], + learner_config=learner_config.SerializeToString(), + dropout_seed=123, + center_bias=True, + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.OBLIVIOUS_DECISION_TREE) + session.run(grow_op) + + new_stamp, serialized = session.run( + model_ops.tree_ensemble_serialize(tree_ensemble_handle)) + stats = session.run( + training_ops.tree_ensemble_stats(tree_ensemble_handle, stamp_token=1)) + tree_ensemble_config.ParseFromString(serialized) + expected_result = """ + trees { + nodes { + oblivious_dense_float_binary_split { + feature_column: 4 + threshold: 7 + } + node_metadata { + gain: 7.62 + original_oblivious_leaves { + } + } + } + nodes { + oblivious_dense_float_binary_split { + feature_column: 1 + threshold: 0.23 + } + node_metadata { + gain: 2.7 + original_oblivious_leaves { + vector { + value: 7.143 + } + } + original_oblivious_leaves { + vector { + value: -4.375 + } + } + } + } + nodes { + oblivious_dense_float_binary_split { + feature_column: 0 + threshold: 0.9 + } + node_metadata { + gain: 1.8 + original_oblivious_leaves { + vector { + value: 6.543 + } + } + original_oblivious_leaves { + vector { + value: 7.5 + } + } + original_oblivious_leaves { + vector { + value: -4.075 + } + } + original_oblivious_leaves { + vector { + value: -3.975 + } + } + } + } + nodes { + leaf { + vector { + value: 7.543 + } + } + } + nodes { + leaf { + vector { + value: 8.543 + } + } + } + nodes { + leaf { + vector { + value: 7.5 + } + } + } + nodes { + leaf { + vector { + value: 7.5 + } + } + } + nodes { + leaf { + vector { + value: -4.075 + } + } + } + nodes { + leaf { + vector { + value: -4.075 + } + } + } + nodes { + leaf { + vector { + value: -0.975 + } + } + } + nodes { + leaf { + vector { + value: 0.025 + } + } + } + } + tree_weights: 0.1 + tree_metadata { + num_tree_weight_updates: 1 + num_layers_grown: 3 + } + growing_metadata { + num_trees_attempted: 1 + num_layers_attempted: 3 + } + """ + self.assertEqual(new_stamp, 1) + self.assertEqual(stats.num_trees, 0) + self.assertEqual(stats.num_layers, 3) + self.assertEqual(stats.active_tree, 1) + self.assertEqual(stats.active_layer, 3) + self.assertEqual(stats.attempted_trees, 1) + self.assertEqual(stats.attempted_layers, 3) + self.assertProtoEquals(expected_result, tree_ensemble_config) + + def testGrowEnsembleWithEmptyNodesBorderCase(self): + """Test case: The first and last existing leaves don't have examples.""" + with self.test_session() as session: + tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() + text_format.Merge( + """ + trees { + nodes { + oblivious_dense_float_binary_split { + feature_column: 4 + threshold: 7 + } + node_metadata { + gain: 7.62 + original_oblivious_leaves { + } + } + } + nodes { + oblivious_dense_float_binary_split { + feature_column: 1 + threshold: 0.23 + } + node_metadata { + gain: 2.7 + original_oblivious_leaves { + vector { + value: 7.143 + } + } + original_oblivious_leaves { + vector { + value: -4.375 + } + } + } + } + nodes { + leaf { + vector { + value: 6.543 + } + } + } + nodes { + leaf { + vector { + value: 7.5 + } + } + } + nodes { + leaf { + vector { + value: -4.075 + } + } + } + nodes { + leaf { + vector { + value: -3.975 + } + } + } + } + tree_weights: 0.1 + tree_metadata { + num_tree_weight_updates: 1 + num_layers_grown: 2 + } + growing_metadata { + num_trees_attempted: 1 + num_layers_attempted: 2 + } + """, tree_ensemble_config) + tree_ensemble_handle = model_ops.tree_ensemble_variable( + stamp_token=0, + tree_ensemble_config=tree_ensemble_config.SerializeToString(), + name="tree_ensemble") + resources.initialize_resources(resources.shared_resources()).run() + + # Prepare learner config. + learner_config = _gen_learner_config( + num_classes=2, + l1_reg=0, + l2_reg=0, + tree_complexity=0, + max_depth=6, + min_node_weight=0, + pruning_mode=learner_pb2.LearnerConfig.PRE_PRUNE, + growing_mode=learner_pb2.LearnerConfig.LAYER_BY_LAYER) + + # Prepare handler inputs. + handler1_partitions = np.array([0], dtype=np.int32) + handler1_gains = np.array([1.8], dtype=np.float32) + handler1_split = [ + _gen_dense_oblivious_split_info(0, 0.9, [1.0, 2.0, 3.0, 4.0], [3, 4]) + ] + # The tree currently has depth 2, so the ids for the four leaves are in + # the range [2, 6). In this test case we are assuming that our examples + # only fall in leaves 3 and 4. + + # Grow tree ensemble layer by layer. + grow_op = training_ops.grow_tree_ensemble( + tree_ensemble_handle, + stamp_token=0, + next_stamp_token=1, + learning_rate=0.1, + partition_ids=[handler1_partitions], + gains=[handler1_gains], + splits=[handler1_split], + learner_config=learner_config.SerializeToString(), + dropout_seed=123, + center_bias=True, + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.OBLIVIOUS_DECISION_TREE) + session.run(grow_op) + + new_stamp, serialized = session.run( + model_ops.tree_ensemble_serialize(tree_ensemble_handle)) + stats = session.run( + training_ops.tree_ensemble_stats(tree_ensemble_handle, stamp_token=1)) + tree_ensemble_config.ParseFromString(serialized) + expected_result = """ + trees { + nodes { + oblivious_dense_float_binary_split { + feature_column: 4 + threshold: 7 + } + node_metadata { + gain: 7.62 + original_oblivious_leaves { + } + } + } + nodes { + oblivious_dense_float_binary_split { + feature_column: 1 + threshold: 0.23 + } + node_metadata { + gain: 2.7 + original_oblivious_leaves { + vector { + value: 7.143 + } + } + original_oblivious_leaves { + vector { + value: -4.375 + } + } + } + } + nodes { + oblivious_dense_float_binary_split { + feature_column: 0 + threshold: 0.9 + } + node_metadata { + gain: 1.8 + original_oblivious_leaves { + vector { + value: 6.543 + } + } + original_oblivious_leaves { + vector { + value: 7.5 + } + } + original_oblivious_leaves { + vector { + value: -4.075 + } + } + original_oblivious_leaves { + vector { + value: -3.975 + } + } + } + } + nodes { + leaf { + vector { + value: 6.543 + } + } + } + nodes { + leaf { + vector { + value: 6.543 + } + } + } + nodes { + leaf { + vector { + value: 8.5 + } + } + } + nodes { + leaf { + vector { + value: 9.5 + } + } + } + nodes { + leaf { + vector { + value: -1.075 + } + } + } + nodes { + leaf { + vector { + value: -0.075 + } + } + } + nodes { + leaf { + vector { + value: -3.975 + } + } + } + nodes { + leaf { + vector { + value: -3.975 + } + } + } + } + tree_weights: 0.1 + tree_metadata { + num_tree_weight_updates: 1 + num_layers_grown: 3 + } + growing_metadata { + num_trees_attempted: 1 + num_layers_attempted: 3 + } + """ + self.assertEqual(new_stamp, 1) + self.assertEqual(stats.num_trees, 0) + self.assertEqual(stats.num_layers, 3) + self.assertEqual(stats.active_tree, 1) + self.assertEqual(stats.active_layer, 3) + self.assertEqual(stats.attempted_trees, 1) + self.assertEqual(stats.attempted_layers, 3) + self.assertProtoEquals(expected_result, tree_ensemble_config) + def testGrowExistingEnsembleTreeFinalizedWithDropout(self): """Test growing an existing ensemble with the last tree finalized.""" - with self.test_session() as session: + with self.cached_session() as session: # Create existing ensemble with one root split and one bias tree. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() text_format.Merge(""" @@ -1575,7 +2435,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) # Expect a new tree to be added with the split from handler 1. @@ -1596,7 +2457,7 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): def testGrowExistingEnsembleTreeWithFeatureSelectionUsedHandlers(self): """Test growing a tree with feature selection.""" - with self.test_session() as session: + with self.cached_session() as session: # Create existing ensemble with one root split and one bias tree. tree_ensemble_config = tree_config_pb2.DecisionTreeEnsembleConfig() text_format.Merge(""" @@ -1700,7 +2561,8 @@ class GrowTreeEnsembleOpTest(test_util.TensorFlowTestCase): learner_config=learner_config.SerializeToString(), dropout_seed=123, center_bias=True, - max_tree_depth=learner_config.constraints.max_tree_depth) + max_tree_depth=learner_config.constraints.max_tree_depth, + weak_learner_type=learner_pb2.LearnerConfig.NORMAL_DECISION_TREE) session.run(grow_op) _, serialized = session.run( diff --git a/tensorflow/contrib/boosted_trees/python/training/functions/gbdt_batch.py b/tensorflow/contrib/boosted_trees/python/training/functions/gbdt_batch.py index 2f75d8aa99..b008c6e534 100644 --- a/tensorflow/contrib/boosted_trees/python/training/functions/gbdt_batch.py +++ b/tensorflow/contrib/boosted_trees/python/training/functions/gbdt_batch.py @@ -762,7 +762,8 @@ class GradientBoostedDecisionTreeModel(object): hessian_shape=self._hessian_shape, multiclass_strategy=strategy_tensor, init_stamp_token=init_stamp_token, - loss_uses_sum_reduction=loss_uses_sum_reduction)) + loss_uses_sum_reduction=loss_uses_sum_reduction, + weak_learner_type=weak_learner_type)) fc_name_idx += 1 # Create ensemble stats variables. @@ -1063,6 +1064,12 @@ class GradientBoostedDecisionTreeModel(object): # Grow the ensemble given the current candidates. sizes = array_ops.unstack(split_sizes) partition_ids_list = list(array_ops.split(partition_ids, sizes, axis=0)) + # When using the oblivious decision tree as weak learner, it produces + # one gain and one split per handler and not number of partitions. + if self._learner_config.weak_learner_type == ( + learner_pb2.LearnerConfig.OBLIVIOUS_DECISION_TREE): + sizes = len(training_state.handlers) + gains_list = list(array_ops.split(gains, sizes, axis=0)) split_info_list = list(array_ops.split(split_infos, sizes, axis=0)) return training_ops.grow_tree_ensemble( @@ -1076,7 +1083,8 @@ class GradientBoostedDecisionTreeModel(object): learner_config=self._learner_config_serialized, dropout_seed=dropout_seed, center_bias=self._center_bias, - max_tree_depth=self._max_tree_depth) + max_tree_depth=self._max_tree_depth, + weak_learner_type=self._learner_config.weak_learner_type) def _grow_ensemble_not_ready_fn(): # Don't grow the ensemble, just update the stamp. @@ -1091,7 +1099,8 @@ class GradientBoostedDecisionTreeModel(object): learner_config=self._learner_config_serialized, dropout_seed=dropout_seed, center_bias=self._center_bias, - max_tree_depth=self._max_tree_depth) + max_tree_depth=self._max_tree_depth, + weak_learner_type=self._learner_config.weak_learner_type) def _grow_ensemble_fn(): # Conditionally grow an ensemble depending on whether the splits diff --git a/tensorflow/contrib/boosted_trees/python/training/functions/gbdt_batch_test.py b/tensorflow/contrib/boosted_trees/python/training/functions/gbdt_batch_test.py index f7867d882d..73e41bc457 100644 --- a/tensorflow/contrib/boosted_trees/python/training/functions/gbdt_batch_test.py +++ b/tensorflow/contrib/boosted_trees/python/training/functions/gbdt_batch_test.py @@ -20,6 +20,7 @@ from __future__ import print_function from google.protobuf import text_format from tensorflow.contrib import layers +from tensorflow.contrib import learn from tensorflow.contrib.boosted_trees.proto import learner_pb2 from tensorflow.contrib.boosted_trees.proto import tree_config_pb2 from tensorflow.contrib.boosted_trees.python.ops import model_ops @@ -314,6 +315,162 @@ class GbdtTest(test_util.TensorFlowTestCase): }""" self.assertProtoEquals(expected_tree, output.trees[0]) + def testObliviousDecisionTreeAsWeakLearner(self): + with self.test_session(): + ensemble_handle = model_ops.tree_ensemble_variable( + stamp_token=0, tree_ensemble_config="", name="tree_ensemble") + learner_config = learner_pb2.LearnerConfig() + learner_config.num_classes = 2 + learner_config.learning_rate_tuner.fixed.learning_rate = 1 + learner_config.regularization.l1 = 0 + learner_config.regularization.l2 = 0 + learner_config.constraints.max_tree_depth = 2 + learner_config.constraints.min_node_weight = 0 + learner_config.weak_learner_type = ( + learner_pb2.LearnerConfig.OBLIVIOUS_DECISION_TREE) + learner_config.pruning_mode = learner_pb2.LearnerConfig.PRE_PRUNE + learner_config.growing_mode = learner_pb2.LearnerConfig.LAYER_BY_LAYER + features = {} + features["dense_float"] = array_ops.constant([[-2], [-1], [1], [2]], + dtypes.float32) + + gbdt_model = gbdt_batch.GradientBoostedDecisionTreeModel( + is_chief=True, + num_ps_replicas=0, + center_bias=False, + ensemble_handle=ensemble_handle, + examples_per_layer=1, + learner_config=learner_config, + logits_dimension=1, + features=features) + + predictions_dict = gbdt_model.predict(learn.ModeKeys.TRAIN) + predictions = predictions_dict["predictions"] + labels = array_ops.constant([[-2], [-1], [1], [2]], dtypes.float32) + weights = array_ops.ones([4, 1], dtypes.float32) + + train_op = gbdt_model.train( + loss=math_ops.reduce_mean( + _squared_loss(labels, weights, predictions)), + predictions_dict=predictions_dict, + labels=labels) + variables.global_variables_initializer().run() + resources.initialize_resources(resources.shared_resources()).run() + + # On first run, expect no splits to be chosen because the quantile + # buckets will not be ready. + train_op.run() + stamp_token, serialized = model_ops.tree_ensemble_serialize( + ensemble_handle) + output = tree_config_pb2.DecisionTreeEnsembleConfig() + output.ParseFromString(serialized.eval()) + self.assertEquals(len(output.trees), 0) + self.assertEquals(len(output.tree_weights), 0) + self.assertEquals(stamp_token.eval(), 1) + + # Second run. + train_op.run() + stamp_token, serialized = model_ops.tree_ensemble_serialize( + ensemble_handle) + output = tree_config_pb2.DecisionTreeEnsembleConfig() + output.ParseFromString(serialized.eval()) + self.assertEquals(len(output.trees), 1) + self.assertAllClose(output.tree_weights, [1]) + self.assertEquals(stamp_token.eval(), 2) + expected_tree = """ + nodes { + oblivious_dense_float_binary_split { + threshold: -1.0 + } + node_metadata { + gain: 4.5 + original_oblivious_leaves { + } + } + } + nodes { + leaf { + vector { + value: -1.5 + } + } + } + nodes { + leaf { + vector { + value: 1.5 + } + } + }""" + self.assertProtoEquals(expected_tree, output.trees[0]) + # Third run. + train_op.run() + stamp_token, serialized = model_ops.tree_ensemble_serialize( + ensemble_handle) + output = tree_config_pb2.DecisionTreeEnsembleConfig() + output.ParseFromString(serialized.eval()) + self.assertEquals(len(output.trees), 1) + self.assertAllClose(output.tree_weights, [1]) + self.assertEquals(stamp_token.eval(), 3) + expected_tree = """ + nodes { + oblivious_dense_float_binary_split { + threshold: -1.0 + } + node_metadata { + gain: 4.5 + original_oblivious_leaves { + } + } + } + nodes { + oblivious_dense_float_binary_split { + threshold: -2.0 + } + node_metadata { + gain: 0.25 + original_oblivious_leaves { + vector { + value: -1.5 + } + } + original_oblivious_leaves { + vector { + value: 1.5 + } + } + } + } + nodes { + leaf { + vector { + value: -2.0 + } + } + } + nodes { + leaf { + vector { + value: -1.0 + } + } + } + nodes { + leaf { + vector { + value: 1.5 + } + } + } + nodes { + leaf { + vector { + value: 1.5 + } + } + }""" + self.assertProtoEquals(expected_tree, output.trees[0]) + def testTrainFnChiefSparseAndDense(self): """Tests the train function with sparse and dense features.""" with self.test_session() as sess: diff --git a/tensorflow/contrib/checkpoint/__init__.py b/tensorflow/contrib/checkpoint/__init__.py index e92f0bb841..150d734db6 100644 --- a/tensorflow/contrib/checkpoint/__init__.py +++ b/tensorflow/contrib/checkpoint/__init__.py @@ -34,6 +34,9 @@ Checkpointable data structures: Checkpoint management: @@CheckpointManager + +Saving and restoring Python state: +@@NumpyState """ from __future__ import absolute_import @@ -41,6 +44,7 @@ from __future__ import division from __future__ import print_function from tensorflow.contrib.checkpoint.python.containers import UniqueNameTracker +from tensorflow.contrib.checkpoint.python.python_state import NumpyState from tensorflow.contrib.checkpoint.python.split_dependency import split_dependency from tensorflow.contrib.checkpoint.python.visualize import dot_graph_from_checkpoint from tensorflow.core.protobuf.checkpointable_object_graph_pb2 import CheckpointableObjectGraph diff --git a/tensorflow/contrib/checkpoint/python/BUILD b/tensorflow/contrib/checkpoint/python/BUILD index 7b200a29bf..ada4168726 100644 --- a/tensorflow/contrib/checkpoint/python/BUILD +++ b/tensorflow/contrib/checkpoint/python/BUILD @@ -9,6 +9,7 @@ py_library( srcs_version = "PY2AND3", deps = [ ":containers", + ":python_state", ":split_dependency", ":visualize", "//tensorflow/python/training/checkpointable:data_structures", @@ -41,6 +42,33 @@ py_test( ) py_library( + name = "python_state", + srcs = ["python_state.py"], + srcs_version = "PY2AND3", + visibility = ["//tensorflow:internal"], + deps = [ + "//tensorflow/python/training/checkpointable:base", + "//third_party/py/numpy", + "@six_archive//:six", + ], +) + +py_test( + name = "python_state_test", + srcs = ["python_state_test.py"], + deps = [ + ":python_state", + "//tensorflow/python:framework_ops", + "//tensorflow/python:framework_test_lib", + "//tensorflow/python:session", + "//tensorflow/python:variables", + "//tensorflow/python/eager:test", + "//tensorflow/python/training/checkpointable:util", + "//third_party/py/numpy", + ], +) + +py_library( name = "split_dependency", srcs = ["split_dependency.py"], srcs_version = "PY2AND3", diff --git a/tensorflow/contrib/checkpoint/python/python_state.py b/tensorflow/contrib/checkpoint/python/python_state.py new file mode 100644 index 0000000000..9b11035b6d --- /dev/null +++ b/tensorflow/contrib/checkpoint/python/python_state.py @@ -0,0 +1,166 @@ +"""Utilities for including Python state in TensorFlow checkpoints.""" +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import functools + +import numpy + +from tensorflow.python.training.checkpointable import base + +# pylint: disable=g-import-not-at-top +try: + # In Python 2.x, use the faster string buffering option. + from cStringIO import StringIO as BytesIO +except ImportError: + from io import BytesIO +# pylint: enable=g-import-not-at-top + + +class NumpyState(base.CheckpointableBase): + """A checkpointable object whose NumPy array attributes are saved/restored. + + Example usage: + + ```python + arrays = tf.contrib.checkpoint.NumpyState() + checkpoint = tf.train.Checkpoint(numpy_arrays=arrays) + arrays.x = numpy.zeros([3, 4]) + save_path = checkpoint.save("/tmp/ckpt") + arrays.x[1, 1] = 4. + checkpoint.restore(save_path) + assert (arrays.x == numpy.zeros([3, 4])).all() + + second_checkpoint = tf.train.Checkpoint( + numpy_arrays=tf.contrib.checkpoint.NumpyState()) + # Attributes of NumpyState objects are created automatically by restore() + second_checkpoint.restore(save_path) + assert (second_checkpoint.numpy_arrays.x == numpy.zeros([3, 4])).all() + ``` + + Note that `NumpyState` objects re-create the attributes of the previously + saved object on `restore()`. This is in contrast to TensorFlow variables, for + which a `Variable` object must be created and assigned to an attribute. + + This snippet works both when graph building and when executing eagerly. On + save, the NumPy array(s) are fed as strings to be saved in the checkpoint (via + a placeholder when graph building, or as a string constant when executing + eagerly). When restoring they skip the TensorFlow graph entirely, and so no + restore ops need be run. This means that restoration always happens eagerly, + rather than waiting for `checkpoint.restore(...).run_restore_ops()` like + TensorFlow variables when graph building. + """ + + def _lookup_dependency(self, name): + """Create placeholder NumPy arrays for to-be-restored attributes. + + Typically `_lookup_dependency` is used to check by name whether a dependency + exists. We cheat slightly by creating a checkpointable object for `name` if + we don't already have one, giving us attribute re-creation behavior when + loading a checkpoint. + + Args: + name: The name of the dependency being checked. + Returns: + An existing dependency if one exists, or a new `_NumpyWrapper` placeholder + dependency (which will generally be restored immediately). + """ + value = super(NumpyState, self)._lookup_dependency(name) + if value is None: + value = _NumpyWrapper(numpy.array([])) + new_reference = base.CheckpointableReference(name=name, ref=value) + self._unconditional_checkpoint_dependencies.append(new_reference) + self._unconditional_dependency_names[name] = value + super(NumpyState, self).__setattr__(name, value) + return value + + def __getattribute__(self, name): + """Un-wrap `_NumpyWrapper` objects when accessing attributes.""" + value = super(NumpyState, self).__getattribute__(name) + if isinstance(value, _NumpyWrapper): + return value.array + return value + + def __setattr__(self, name, value): + """Automatically wrap NumPy arrays assigned to attributes.""" + # TODO(allenl): Consider supporting lists/tuples, either ad-hoc or by making + # ndarrays checkpointable natively and using standard checkpointable list + # tracking. + if isinstance(value, numpy.ndarray): + try: + existing = super(NumpyState, self).__getattribute__(name) + existing.array = value + return + except AttributeError: + value = _NumpyWrapper(value) + self._track_checkpointable(value, name=name, overwrite=True) + elif (name not in ("_setattr_tracking", "_update_uid") + and getattr(self, "_setattr_tracking", True)): + # Mixing restore()-created attributes with user-added checkpointable + # objects is tricky, since we can't use the `_lookup_dependency` trick to + # re-create attributes (we might accidentally steal the restoration for + # another checkpointable object). For now `NumpyState` objects must be + # leaf nodes. Theoretically we could add some extra arguments to + # `_lookup_dependency` to figure out whether we should create a NumPy + # array for the attribute or not. + raise NotImplementedError( + ("Assigned %s to the %s property of %s, which is not a NumPy array. " + "Currently mixing NumPy arrays and other checkpointable objects is " + "not supported. File a feature request if this limitation bothers " + "you.") + % (value, name, self)) + super(NumpyState, self).__setattr__(name, value) + + +class _NumpyWrapper(base.CheckpointableBase): + """Wraps a NumPy array for storage in an object-based checkpoint.""" + + def __init__(self, array): + """Specify a NumPy array to wrap. + + Args: + array: The NumPy array to save and restore (may be overwritten). + """ + self.array = array + + def _serialize(self): + """Callback for `PythonStringStateSaveable` to serialize the array.""" + string_file = BytesIO() + try: + numpy.save(string_file, self.array, allow_pickle=False) + serialized = string_file.getvalue() + finally: + string_file.close() + return serialized + + def _deserialize(self, string_value): + """Callback for `PythonStringStateSaveable` to deserialize the array.""" + string_file = BytesIO(string_value) + try: + self.array = numpy.load(string_file, allow_pickle=False) + finally: + string_file.close() + + def _gather_saveables_for_checkpoint(self): + """Specify callbacks for saving and restoring `array`.""" + return { + "array": functools.partial( + base.PythonStringStateSaveable, + state_callback=self._serialize, + restore_callback=self._deserialize) + } diff --git a/tensorflow/contrib/checkpoint/python/python_state_test.py b/tensorflow/contrib/checkpoint/python/python_state_test.py new file mode 100644 index 0000000000..0439a4755e --- /dev/null +++ b/tensorflow/contrib/checkpoint/python/python_state_test.py @@ -0,0 +1,101 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os + +import numpy + +from tensorflow.contrib.checkpoint.python import python_state +from tensorflow.python.client import session +from tensorflow.python.eager import test +from tensorflow.python.framework import ops +from tensorflow.python.framework import test_util +from tensorflow.python.ops import variables +from tensorflow.python.training.checkpointable import util + + +class NumpyStateTests(test.TestCase): + + @test_util.run_in_graph_and_eager_modes + def testSaveRestoreNumpyState(self): + directory = self.get_temp_dir() + prefix = os.path.join(directory, "ckpt") + save_state = python_state.NumpyState() + saver = util.Checkpoint(numpy=save_state) + save_state.a = numpy.ones([2, 2]) + save_state.b = numpy.ones([2, 2]) + save_state.b = numpy.zeros([2, 2]) + self.assertAllEqual(numpy.ones([2, 2]), save_state.a) + self.assertAllEqual(numpy.zeros([2, 2]), save_state.b) + first_save_path = saver.save(prefix) + save_state.a[1, 1] = 2. + second_save_path = saver.save(prefix) + + load_state = python_state.NumpyState() + loader = util.Checkpoint(numpy=load_state) + loader.restore(first_save_path).initialize_or_restore() + self.assertAllEqual(numpy.ones([2, 2]), load_state.a) + self.assertAllEqual(numpy.zeros([2, 2]), load_state.b) + load_state.a[0, 0] = 42. + self.assertAllEqual([[42., 1.], [1., 1.]], load_state.a) + loader.restore(first_save_path).run_restore_ops() + self.assertAllEqual(numpy.ones([2, 2]), load_state.a) + loader.restore(second_save_path).run_restore_ops() + self.assertAllEqual([[1., 1.], [1., 2.]], load_state.a) + self.assertAllEqual(numpy.zeros([2, 2]), load_state.b) + + def testNoGraphPollution(self): + graph = ops.Graph() + with graph.as_default(), session.Session(): + directory = self.get_temp_dir() + prefix = os.path.join(directory, "ckpt") + save_state = python_state.NumpyState() + saver = util.Checkpoint(numpy=save_state) + save_state.a = numpy.ones([2, 2]) + save_path = saver.save(prefix) + saver.restore(save_path) + graph.finalize() + saver.save(prefix) + save_state.a = numpy.zeros([2, 2]) + saver.save(prefix) + saver.restore(save_path) + + @test_util.run_in_graph_and_eager_modes + def testNoMixedNumpyStateTF(self): + save_state = python_state.NumpyState() + save_state.a = numpy.ones([2, 2]) + with self.assertRaises(NotImplementedError): + save_state.v = variables.Variable(1.) + + @test_util.run_in_graph_and_eager_modes + def testDocstringExample(self): + arrays = python_state.NumpyState() + checkpoint = util.Checkpoint(numpy_arrays=arrays) + arrays.x = numpy.zeros([3, 4]) + save_path = checkpoint.save(os.path.join(self.get_temp_dir(), "ckpt")) + arrays.x[1, 1] = 4. + checkpoint.restore(save_path) + self.assertAllEqual(numpy.zeros([3, 4]), arrays.x) + + second_checkpoint = util.Checkpoint(numpy_arrays=python_state.NumpyState()) + second_checkpoint.restore(save_path) + self.assertAllEqual(numpy.zeros([3, 4]), second_checkpoint.numpy_arrays.x) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/cloud/kernels/bigquery_table_accessor.cc b/tensorflow/contrib/cloud/kernels/bigquery_table_accessor.cc index 58fadffce3..e57a66b99f 100644 --- a/tensorflow/contrib/cloud/kernels/bigquery_table_accessor.cc +++ b/tensorflow/contrib/cloud/kernels/bigquery_table_accessor.cc @@ -33,7 +33,7 @@ bool IsPartitionEmpty(const BigQueryTablePartition& partition) { Status ParseJson(StringPiece json, Json::Value* result) { Json::Reader reader; - if (!reader.parse(json.ToString(), *result)) { + if (!reader.parse(string(json), *result)) { return errors::Internal("Couldn't parse JSON response from BigQuery."); } return Status::OK(); diff --git a/tensorflow/contrib/cloud/kernels/bigquery_table_accessor.h b/tensorflow/contrib/cloud/kernels/bigquery_table_accessor.h index 1af43a3e10..f1fcaff73b 100644 --- a/tensorflow/contrib/cloud/kernels/bigquery_table_accessor.h +++ b/tensorflow/contrib/cloud/kernels/bigquery_table_accessor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_KERNELS_CLOUD_BIGQUERY_PARTITION_ACCESSOR_H_ -#define TENSORFLOW_CORE_KERNELS_CLOUD_BIGQUERY_PARTITION_ACCESSOR_H_ +#ifndef TENSORFLOW_CONTRIB_CLOUD_KERNELS_BIGQUERY_TABLE_ACCESSOR_H_ +#define TENSORFLOW_CONTRIB_CLOUD_KERNELS_BIGQUERY_TABLE_ACCESSOR_H_ #include <map> #include <memory> @@ -198,4 +198,4 @@ class BigQueryTableAccessor { }; } // namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_CLOUD_BIGQUERY_PARTITION_ACCESSOR_H_ +#endif // TENSORFLOW_CONTRIB_CLOUD_KERNELS_BIGQUERY_TABLE_ACCESSOR_H_ diff --git a/tensorflow/contrib/cloud/kernels/bigquery_table_accessor_test_data.h b/tensorflow/contrib/cloud/kernels/bigquery_table_accessor_test_data.h index fea6b15640..6f4d54ae4a 100644 --- a/tensorflow/contrib/cloud/kernels/bigquery_table_accessor_test_data.h +++ b/tensorflow/contrib/cloud/kernels/bigquery_table_accessor_test_data.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_KERNELS_CLOUD_BIGQUERY_TABLE_ACCESSOR_TEST_DATA_H_ -#define TENSORFLOW_CORE_KERNELS_CLOUD_BIGQUERY_TABLE_ACCESSOR_TEST_DATA_H_ +#ifndef TENSORFLOW_CONTRIB_CLOUD_KERNELS_BIGQUERY_TABLE_ACCESSOR_TEST_DATA_H_ +#define TENSORFLOW_CONTRIB_CLOUD_KERNELS_BIGQUERY_TABLE_ACCESSOR_TEST_DATA_H_ #include <string> @@ -401,4 +401,4 @@ const string kTestEmptyRow = R"({ } // namespace } // namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_CLOUD_BIGQUERY_TABLE_ACCESSOR_TEST_DATA_H_ +#endif // TENSORFLOW_CONTRIB_CLOUD_KERNELS_BIGQUERY_TABLE_ACCESSOR_TEST_DATA_H_ diff --git a/tensorflow/contrib/cmake/external/nsync.cmake b/tensorflow/contrib/cmake/external/nsync.cmake index 1d638e6402..479609458c 100644 --- a/tensorflow/contrib/cmake/external/nsync.cmake +++ b/tensorflow/contrib/cmake/external/nsync.cmake @@ -16,16 +16,16 @@ include (ExternalProject) set(nsync_INCLUDE_DIR ${CMAKE_CURRENT_BINARY_DIR}/external/nsync/public) set(nsync_URL https://github.com/google/nsync) -set(nsync_TAG 1.20.0) +set(nsync_TAG 1.20.1) set(nsync_BUILD ${CMAKE_CURRENT_BINARY_DIR}/nsync/src/nsync) set(nsync_INSTALL ${CMAKE_CURRENT_BINARY_DIR}/nsync/install) if(WIN32) set(nsync_HEADERS "${nsync_BUILD}/public/*.h") - set(nsync_STATIC_LIBRARIES ${nsync_INSTALL}/lib/nsync.lib) + set(nsync_STATIC_LIBRARIES ${nsync_INSTALL}/lib/nsync_cpp.lib) else() set(nsync_HEADERS "${nsync_BUILD}/public/*.h") - set(nsync_STATIC_LIBRARIES ${nsync_INSTALL}/lib/libnsync.a) + set(nsync_STATIC_LIBRARIES ${nsync_INSTALL}/lib/libnsync_cpp.a) endif() ExternalProject_Add(nsync @@ -35,12 +35,12 @@ ExternalProject_Add(nsync DOWNLOAD_DIR "${DOWNLOAD_LOCATION}" BUILD_IN_SOURCE 1 BUILD_BYPRODUCTS ${nsync_STATIC_LIBRARIES} - PATCH_COMMAND ${CMAKE_COMMAND} -E copy_if_different ${CMAKE_CURRENT_SOURCE_DIR}/patches/nsync/CMakeLists.txt ${nsync_BUILD} INSTALL_DIR ${nsync_INSTALL} CMAKE_CACHE_ARGS -DCMAKE_BUILD_TYPE:STRING=Release -DCMAKE_VERBOSE_MAKEFILE:BOOL=OFF -DCMAKE_INSTALL_PREFIX:STRING=${nsync_INSTALL} + -DCMAKE_INSTALL_LIBDIR:STRING=lib -DNSYNC_LANGUAGE:STRING=c++11) set(nsync_HEADERS diff --git a/tensorflow/contrib/cmake/patches/nsync/CMakeLists.txt b/tensorflow/contrib/cmake/patches/nsync/CMakeLists.txt deleted file mode 100644 index 6f059c7225..0000000000 --- a/tensorflow/contrib/cmake/patches/nsync/CMakeLists.txt +++ /dev/null @@ -1,325 +0,0 @@ -cmake_minimum_required (VERSION 2.8.12) - -# nsync provides portable synchronization primitives, such as mutexes and -# condition variables. -project (nsync) - -# Set variable NSYNC_LANGUAGE to "c++11" to build with C++11 -# rather than C. - -# Some builds need position-independent code. -set (CMAKE_POSITION_INDEPENDENT_CODE ON) - -# ----------------------------------------------------------------- -# Platform dependencies - -# Many platforms use these posix related sources; even Win32. -set (NSYNC_POSIX_SRC - "platform/posix/src/nsync_panic.c" - "platform/posix/src/per_thread_waiter.c" - "platform/posix/src/time_rep.c" - "platform/posix/src/yield.c" -) - -if (WIN32) - # Suppress warnings to reduce build log size. - add_definitions(/wd4267 /wd4244 /wd4800 /wd4503 /wd4554 /wd4996 /wd4348 /wd4018) - add_definitions(/wd4099 /wd4146 /wd4267 /wd4305 /wd4307) - add_definitions(/wd4715 /wd4722 /wd4723 /wd4838 /wd4309 /wd4334) - add_definitions(/wd4003 /wd4244 /wd4267 /wd4503 /wd4506 /wd4800 /wd4996) - add_definitions(/wd8029) -endif() - -# Many of the string matches below use a literal "X" suffix on both sides. -# This is because some versions of cmake treat (for example) "MSVC" (in quotes) -# as a reference to the variable MSVC, thus the expression -# "${CMAKE_C_COMPILER_ID}" STREQUAL "MSVC" -# is false when ${CMAKE_C_COMPILER_ID} has the value "MSVC"! See -# https://cmake.org/cmake/help/v3.1/policy/CMP0054.html - -# Pick the include directory for the operating system. -if ("${NSYNC_LANGUAGE}X" STREQUAL "c++11X") - include_directories ("${PROJECT_SOURCE_DIR}/platform/c++11") - add_definitions ("-DNSYNC_USE_CPP11_TIMEPOINT -DNSYNC_ATOMIC_CPP11") - set (NSYNC_OS_CPP_SRC - "platform/c++11/src/per_thread_waiter.cc" - "platform/c++11/src/yield.cc" - "platform/c++11/src/time_rep_timespec.cc" - "platform/c++11/src/nsync_panic.cc" - ) - if ("${CMAKE_SYSTEM_NAME}X" STREQUAL "WindowsX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/win32") - add_compile_options ("/TP") - set (NSYNC_OS_SRC - "platform/c++11/src/nsync_semaphore_mutex.cc" - "platform/win32/src/clock_gettime.c" - "platform/win32/src/pthread_key_win32.cc" - ${NSYNC_OS_CPP_SRC} - ) - set (NSYNC_TEST_OS_SRC - "platform/win32/src/start_thread.c" - ) - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "DarwinX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/macos") - include_directories ("${PROJECT_SOURCE_DIR}/platform/posix") - # Some versions of MacOS, such as Sierra, require _DARWIN_C_SOURCE - # when including certin C++ standard header files, such as <mutex>. - add_definitions ("-D_DARWIN_C_SOURCE") - add_compile_options ("-std=c++11") - set (NSYNC_OS_SRC - ${NSYNC_OS_CPP_SRC} - "platform/c++11/src/nsync_semaphore_mutex.cc" - "platform/posix/src/clock_gettime.c" - "platform/posix/src/nsync_semaphore_mutex.c" - ) - set (NSYNC_TEST_OS_SRC - "platform/posix/src/start_thread.c" - ) - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "LinuxX") - include_directories (BEFORE "${PROJECT_SOURCE_DIR}/platform/c++11.futex") - include_directories ("${PROJECT_SOURCE_DIR}/platform/posix") - add_compile_options ("-std=c++11") - set (NSYNC_OS_SRC - "platform/linux/src/nsync_semaphore_futex.c" - ${NSYNC_OS_CPP_SRC} - ) - set (NSYNC_TEST_OS_SRC - "platform/posix/src/start_thread.c" - ) - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "NetBSDX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/posix") - add_compile_options ("-std=c++11") - set (NSYNC_OS_SRC - "platform/c++11/src/nsync_semaphore_mutex.cc" - ${NSYNC_OS_CPP_SRC} - ) - set (NSYNC_TEST_OS_SRC - "platform/posix/src/start_thread.c" - ) - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "FreeBSDX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/posix") - add_compile_options ("-std=c++11") - set (NSYNC_OS_SRC - "platform/c++11/src/nsync_semaphore_mutex.cc" - ${NSYNC_OS_CPP_SRC} - ) - set (NSYNC_TEST_OS_SRC - "platform/posix/src/start_thread.c" - ) - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "OpenBSDX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/posix") - add_compile_options ("-std=c++11") - set (NSYNC_OS_SRC - "platform/c++11/src/nsync_semaphore_mutex.cc" - ${NSYNC_OS_CPP_SRC} - ) - set (NSYNC_TEST_OS_SRC - "platform/posix/src/start_thread.c" - ) - endif () -endif () - -# Pick the include directory for the compiler. -if ("${CMAKE_C_COMPILER_ID}X" STREQUAL "GNUX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/gcc") - set (THREADS_HAVE_PTHREAD_ARG ON) -elseif ("${CMAKE_C_COMPILER_ID}X" STREQUAL "ClangX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/clang") - set (THREADS_HAVE_PTHREAD_ARG ON) -elseif ("${CMAKE_C_COMPILER_ID}X" STREQUAL "MSVCX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/msvc") -else () - message (WARNING "CMAKE_C_COMPILER_ID (${CMAKE_C_COMPILER_ID}) matched NOTHING") -endif () - -if (NOT "${NSYNC_LANGUAGE}X" STREQUAL "c++11X") - if ("${CMAKE_SYSTEM_NAME}X" STREQUAL "WindowsX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/win32") - set (NSYNC_OS_SRC - ${NSYNC_POSIX_SRC} - "platform/win32/src/clock_gettime.c" - "platform/win32/src/init_callback_win32.c" - "platform/win32/src/nanosleep.c" - "platform/win32/src/nsync_semaphore_win32.c" - "platform/win32/src/pthread_cond_timedwait_win32.c" - "platform/win32/src/pthread_key_win32.cc" - ) - set (NSYNC_TEST_OS_SRC - "platform/win32/src/start_thread.c" - ) - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "DarwinX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/macos") - set (NSYNC_POSIX ON) - set (NSYNC_OS_EXTRA_SRC - "platform/posix/src/clock_gettime.c" - "platform/posix/src/nsync_semaphore_mutex.c" - ) - include_directories ("${PROJECT_SOURCE_DIR}/platform/posix") - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "LinuxX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/linux") - set (NSYNC_POSIX ON) - set (NSYNC_OS_EXTRA_SRC - "platform/linux/src/nsync_semaphore_futex.c" - ) - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "NetBSDX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/netbsd") - set (NSYNC_POSIX ON) - set (NSYNC_OS_EXTRA_SRC - "platform/posix/src/nsync_semaphore_mutex.c" - ) - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "FreeBSDX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/freebsd") - set (NSYNC_POSIX ON) - set (NSYNC_OS_EXTRA_SRC - "platform/posix/src/nsync_semaphore_mutex.c" - ) - elseif ("${CMAKE_SYSTEM_NAME}X" STREQUAL "OpenBSDX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/openbsd") - set (NSYNC_POSIX ON) - set (NSYNC_OS_EXTRA_SRC - "platform/posix/src/nsync_semaphore_mutex.c" - ) - endif () -endif () - -if (NSYNC_POSIX) - include_directories ("${PROJECT_SOURCE_DIR}/platform/posix") - set (NSYNC_OS_SRC - ${NSYNC_POSIX_SRC} - ${NSYNC_OS_EXTRA_SRC} - ) - set (NSYNC_TEST_OS_SRC - "platform/posix/src/start_thread.c" - ) -endif () - -# Pick the include directory for the architecture. -if (("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "x86_64X") OR - ("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "amd64X") OR - ("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "AMD64X")) - include_directories ("${PROJECT_SOURCE_DIR}/platform/x86_64") -elseif (("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "x86_32X") OR - ("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "i386X") OR - ("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "i686X")) - include_directories ("${PROJECT_SOURCE_DIR}/platform/x86_32") -elseif (("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "armv6lX") OR - ("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "armv7lX") OR - ("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "armX")) - include_directories ("${PROJECT_SOURCE_DIR}/platform/arm") -elseif (("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "aarch64X") OR - ("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "arm64X")) - include_directories ("${PROJECT_SOURCE_DIR}/platform/aarch64") -elseif (("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "ppcX") OR - ("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "ppc32X")) - include_directories ("${PROJECT_SOURCE_DIR}/platform/ppc32") -elseif (("${CMAKE_SYSTEM_PROCESSOR}X" STREQUAL "ppc64X")) - include_directories ("${PROJECT_SOURCE_DIR}/platform/ppc64") -endif () - -# Windows uses some include files from the posix directory also. -if ("${CMAKE_SYSTEM_NAME}X" STREQUAL "WindowsX") - include_directories ("${PROJECT_SOURCE_DIR}/platform/posix") -endif () - -# ----------------------------------------------------------------- - -include_directories ("${PROJECT_SOURCE_DIR}/public") -include_directories ("${PROJECT_SOURCE_DIR}/internal") - -set (NSYNC_SRC - "internal/common.c" - "internal/counter.c" - "internal/cv.c" - "internal/debug.c" - "internal/dll.c" - "internal/mu.c" - "internal/mu_wait.c" - "internal/note.c" - "internal/once.c" - "internal/sem_wait.c" - "internal/time_internal.c" - "internal/wait.c" - ${NSYNC_OS_SRC} -) -add_library (nsync ${NSYNC_SRC}) - -set (NSYNC_TEST_SRC - "testing/array.c" - "testing/atm_log.c" - "testing/closure.c" - "testing/smprintf.c" - "testing/testing.c" - "testing/time_extra.c" - ${NSYNC_TEST_OS_SRC} -) -add_library (nsync_test ${NSYNC_TEST_SRC}) - -set (NSYNC_TESTS - "counter_test" - "cv_mu_timeout_stress_test" - "cv_test" - "cv_wait_example_test" - "dll_test" - "mu_starvation_test" - "mu_test" - "mu_wait_example_test" - "mu_wait_test" - "note_test" - "once_test" - "pingpong_test" - "wait_test" -) - -if ("${NSYNC_LANGUAGE}X" STREQUAL "c++11X") - foreach (s IN ITEMS ${NSYNC_SRC} ${NSYNC_TEST_SRC}) - SET_SOURCE_FILES_PROPERTIES ("${s}" PROPERTIES LANGUAGE CXX) - endforeach (s) - foreach (t IN ITEMS ${NSYNC_TESTS}) - SET_SOURCE_FILES_PROPERTIES ("testing/${t}.c" PROPERTIES LANGUAGE CXX) - endforeach (t) -endif () - -enable_testing () -foreach (t IN ITEMS ${NSYNC_TESTS}) - add_executable (${t} "testing/${t}.c") -endforeach (t) - -find_package (Threads REQUIRED) -set (THREADS_PREFER_PTHREAD_FLAG ON) -foreach (t IN ITEMS "nsync" "nsync_test" ${NSYNC_TESTS}) - if (THREADS_HAVE_PTHREAD_ARG) - target_compile_options (${t} PUBLIC "-pthread") - endif () - if (CMAKE_THREAD_LIBS_INIT) - target_link_libraries (${t} "${CMAKE_THREAD_LIBS_INIT}") - endif () -endforeach (t) - -foreach (t IN ITEMS ${NSYNC_TESTS}) - target_link_libraries (${t} nsync_test nsync) - add_test (NAME ${t} COMMAND ${t}) -endforeach (t) - -install (TARGETS nsync - LIBRARY DESTINATION lib COMPONENT RuntimeLibraries - ARCHIVE DESTINATION lib COMPONENT Development) - -set (NSYNC_INCLUDES - "public/nsync.h" - "public/nsync_atomic.h" - "public/nsync_counter.h" - "public/nsync_cpp.h" - "public/nsync_cv.h" - "public/nsync_debug.h" - "public/nsync_mu.h" - "public/nsync_mu_wait.h" - "public/nsync_note.h" - "public/nsync_once.h" - "public/nsync_time.h" - "public/nsync_time_internal.h" - "public/nsync_waiter.h" -) - -foreach (NSYNC_INCLUDE ${NSYNC_INCLUDES}) - install (FILES ${NSYNC_INCLUDE} DESTINATION include COMPONENT Development) -endforeach () diff --git a/tensorflow/contrib/cmake/python_modules.txt b/tensorflow/contrib/cmake/python_modules.txt index a5a947f726..fb871acae9 100644 --- a/tensorflow/contrib/cmake/python_modules.txt +++ b/tensorflow/contrib/cmake/python_modules.txt @@ -4,6 +4,8 @@ tensorflow tensorflow/core tensorflow/core/example tensorflow/core/framework +tensorflow/core/kernels +tensorflow/core/kernels/boosted_trees tensorflow/core/lib tensorflow/core/lib/core tensorflow/core/profiler @@ -245,10 +247,6 @@ tensorflow/contrib/kernel_methods/python tensorflow/contrib/kernel_methods/python/mappers tensorflow/contrib/kinesis/python tensorflow/contrib/kinesis/python/ops -tensorflow/contrib/kfac -tensorflow/contrib/kfac/examples -tensorflow/contrib/kfac/python -tensorflow/contrib/kfac/python/ops tensorflow/contrib/labeled_tensor tensorflow/contrib/labeled_tensor/python tensorflow/contrib/labeled_tensor/python/ops diff --git a/tensorflow/contrib/coder/BUILD b/tensorflow/contrib/coder/BUILD index 855c824ead..4bfd753bb1 100644 --- a/tensorflow/contrib/coder/BUILD +++ b/tensorflow/contrib/coder/BUILD @@ -3,6 +3,7 @@ package(default_visibility = [ "//learning/brain:__subpackages__", + "//research/vision/piedpiper:__subpackages__", "//tensorflow:__subpackages__", ]) diff --git a/tensorflow/contrib/compiler/BUILD b/tensorflow/contrib/compiler/BUILD index bcee0b04c8..d7583be6d8 100644 --- a/tensorflow/contrib/compiler/BUILD +++ b/tensorflow/contrib/compiler/BUILD @@ -8,6 +8,7 @@ package_group( packages = ["//tensorflow/..."], ) +load("//tensorflow:tensorflow.bzl", "tf_py_test") load("//tensorflow:tensorflow.bzl", "cuda_py_test") py_library( @@ -46,3 +47,36 @@ cuda_py_test( ], xla_enabled = True, ) + +py_library( + name = "xla", + srcs = ["xla.py"], + srcs_version = "PY2AND3", + deps = [ + "//tensorflow/python:array_ops", + "//tensorflow/python:control_flow_ops", + "//tensorflow/python:framework_ops", + "//tensorflow/python:platform", + "//tensorflow/python:util", + "//tensorflow/python/estimator:model_fn", + ], +) + +tf_py_test( + name = "xla_test", + srcs = ["xla_test.py"], + additional_deps = [ + ":xla", + "@six_archive//:six", + "//tensorflow/python:constant_op", + "//tensorflow/python:control_flow_ops", + "//tensorflow/python:control_flow_util", + "//tensorflow/python:math_ops", + "//tensorflow/python:platform", + "//tensorflow/python:state_ops", + "//tensorflow/python:summary", + "//tensorflow/python:training", + "//tensorflow/python:variable_scope", + ], + tags = ["no_pip"], +) diff --git a/tensorflow/contrib/compiler/jit_test.py b/tensorflow/contrib/compiler/jit_test.py index a56a01b163..42b3b9f026 100644 --- a/tensorflow/contrib/compiler/jit_test.py +++ b/tensorflow/contrib/compiler/jit_test.py @@ -48,7 +48,7 @@ class JITTest(test.TestCase): def compute(self, use_jit, compute_fn): random_seed.set_random_seed(1234) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: with jit.experimental_jit_scope(use_jit): r = compute_fn() sess.run(variables.global_variables_initializer()) @@ -88,7 +88,7 @@ class JITTest(test.TestCase): self.assertAllClose(v_false_1, v_true_1) def testJITXlaScope(self): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): with jit.experimental_jit_scope(True): # XlaScope 0 a1 = constant_op.constant(1) @@ -138,7 +138,8 @@ class JITTest(test.TestCase): self.assertAllClose(v_false_1, v_true_1) def testDefunNoJitScope(self): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): + @function.Defun(compiled=True, noinline=True) def mulop(x1, x2): return x1 * x2 @@ -153,7 +154,7 @@ class JITTest(test.TestCase): self.assertEqual(b"function_mulop", func_attrs["_XlaScope"].s) def testDefunInheritsJitScope(self): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): with jit.experimental_jit_scope(True): @function.Defun(compiled=True, noinline=True) def mulop(x1, x2): @@ -195,7 +196,7 @@ class CompilationEnabledInGradientTest(test.TestCase): self.assertAllClose([[108]], x_grads.eval()) def testCompilationGradientScopeNames(self): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): with jit.experimental_jit_scope(): # XlaScope 0 a1 = constant_op.constant([[1.]]) @@ -217,7 +218,7 @@ class CompilationEnabledInGradientTest(test.TestCase): self.assertEqual(b"jit_scope_1", grad_a2.op.get_attr("_XlaScope")) def testCompilationSeparateGradientScopeNames(self): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): with jit.experimental_jit_scope(True, separate_compiled_gradients=True): # XlaScope 0 a1 = constant_op.constant([[1.]]) @@ -241,7 +242,7 @@ class CompilationEnabledInGradientTest(test.TestCase): grad_a2.op.get_attr("_XlaScope")) def testPlaysNicelyWithDefun(self): - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: with jit.experimental_jit_scope(True): @function.Defun(compiled=True, noinline=True) def mulop(x1, x2): @@ -266,7 +267,7 @@ class CompilationEnabledInGradientTest(test.TestCase): self.assertAllClose([1.0, 1.0, 2.0], sess.run([x, r, g_r])) def testPlaysNicelyWithDefunSeparateGradientScope(self): - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: with jit.experimental_jit_scope(True): @function.Defun( diff --git a/tensorflow/contrib/compiler/xla.py b/tensorflow/contrib/compiler/xla.py new file mode 100644 index 0000000000..60f5af1662 --- /dev/null +++ b/tensorflow/contrib/compiler/xla.py @@ -0,0 +1,208 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================= +"""xla provides experimental xla support API.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from six.moves import xrange # pylint: disable=redefined-builtin + +from tensorflow.core.framework import attr_value_pb2 +from tensorflow.python.framework import ops +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.platform import tf_logging as logging +from tensorflow.python.util import compat + +_XLA_COMPILE_ATTR = '_xla_compile_id' +_MAX_WARNING_LINES = 5 + +# Operations that indicate some error in the users graph. For example, XLA +# computation should not have any Placeholder op. +_BLACKLISTED_OPS = set([ + 'Placeholder', +]) + +# XLA doesn't currently support reading of intermediate tensors, thus some ops +# are not supported. +_UNSUPPORTED_OPS = set([ + 'AudioSummary', + 'AudioSummaryV2', + 'HistogramSummary', + 'ImageSummary', + 'MergeSummary', + 'Print', + 'ScalarSummary', + 'TensorSummary', + 'TensorSummaryV2', +]) + + +class XLACompileContext(control_flow_ops.XLAControlFlowContext): + """A `ControlFlowContext` for nodes inside an XLA computation cluster. + + THIS IS ONLY FOR TENSORFLOW INTERNAL IMPLEMENTATION, DO NO USE DIRECTLY. + + The primary role of `XLACompileContext` is to mark operators inside a + xla.compile() computation with attribute "_xla_compile_id=XYZ", where XYZ is + a unique name. + + `ControlFlowContext` is used to perform the annotation since it integrates + with Tensorflow constructs like ResourceVariables. For example, if a + `ResourceVariable` is constructed inside a xla.compile() block, the + `ResourceVariable` implementation can use + `with ops.control_dependencies(None)` to build the variable's definition + outside the compiled computation. + """ + + def __init__(self, name, pivot): + """Builds a new XLACompileContext. + + Args: + name: a unique name for the context, used to populate the + `_xla_compile_id` attribute. + pivot: a pivot node. Nodes in the XLACompileContext that do not have any + inputs will have a control dependency on the pivot node. This ensures + that nodes are correctly included in any enclosing control flow + contexts. + """ + super(XLACompileContext, self).__init__() + self._name = name + self._name_as_bytes = compat.as_bytes(name) + self._unsupported_ops = [] + self._pivot = pivot + + def report_unsupported_operations(self): + if self._unsupported_ops: + op_str = '\n'.join([ + ' %s (%s)' % (op.type, op.name) + for op in self._unsupported_ops[:_MAX_WARNING_LINES] + ]) + logging.warning('%d unsupported operations found: \n%s', + len(self._unsupported_ops), op_str) + if len(self._unsupported_ops) > _MAX_WARNING_LINES: + logging.warning('... and %d more', + len(self._unsupported_ops) - _MAX_WARNING_LINES) + + def AddOp(self, op): + """Create op in XLACompileContext and notifies outer context recursively.""" + # pylint: disable=protected-access + if op.type in _BLACKLISTED_OPS: + logging.error( + 'Operation of type %s (%s) is not supported in XLA. Execution will ' + 'fail if this op is used in the graph. ', op.type, op.name) + + # TODO(ycao): Automatically disable summaries instead of reporting them. + if op.type in _UNSUPPORTED_OPS: + self._unsupported_ops.append(op) + + if any(x.dtype._is_ref_dtype for x in op.inputs): + raise NotImplementedError( + 'Non-resource Variables are not supported inside XLA computations ' + '(operator name: %s)' % op.name) + + if _XLA_COMPILE_ATTR in op.node_def.attr: + raise ValueError('XLA compiled computations cannot be nested, (operator ' + 'name: %s)' % op.name) + + op._set_attr( + _XLA_COMPILE_ATTR, attr_value_pb2.AttrValue(s=self._name_as_bytes)) + + op.graph.prevent_feeding(op) + op.graph.prevent_fetching(op) + + # Remove any control edges from outer control flow contexts. These may cause + # mismatched frame errors. An example is when one of op's inputs is + # generated in a different While control flow context. + (internal_control_inputs, + external_control_inputs) = self._RemoveExternalControlEdges(op) + + if not op.inputs: + # Add a control edge from the control pivot to this op. + if not internal_control_inputs: + # pylint: disable=protected-access + op._add_control_input(self._pivot) + # pylint: enable=protected-access + else: + for index in xrange(len(op.inputs)): + x = op.inputs[index] + real_x = self.AddValue(x) + if real_x != x: + op._update_input(index, real_x) # pylint: disable=protected-access + + if external_control_inputs: + # Use an identity to pull control inputs as data inputs. Note that we + # ignore ops which don't have outputs. TODO(phawkins): fix that. + with ops.control_dependencies(None): + self.Enter() + external_control_inputs = [ + array_ops.identity(x.outputs[0]).op + for x in external_control_inputs + if x.outputs + ] + self.Exit() + # pylint: disable=protected-access + op._add_control_inputs(external_control_inputs) + # pylint: enable=protected-access + + # Mark op's outputs as seen by this context and any outer contexts. + output_names = [x.name for x in op.outputs] + context = self + while context is not None: + # pylint: disable=protected-access + context._values.update(output_names) + context = context._outer_context + # pylint: enable=protected-access + + if self._outer_context: + self._outer_context.AddInnerOp(op) + + def AddValue(self, val): + """Add `val` to the current context and its outer context recursively.""" + if val.name in self._values: + # Use the real value if it comes from outer context. + result = self._external_values.get(val.name) + return val if result is None else result + + result = val + self._values.add(val.name) + if self._outer_context: + result = self._outer_context.AddValue(val) + self._values.add(result.name) + + self._external_values[val.name] = result + + return result + + def AddInnerOp(self, op): + self.AddOp(op) + if self._outer_context: + self._outer_context.AddInnerOp(op) + + @property + def grad_state(self): + # Define the gradient loop state associated with the XLACompileContext to + # be None as the XLACompileContext does not get nested nor does the + # grad_state outside the XLACompileContext affect the graph inside so the + # grad_state should be as if this is the top-level gradient state. + return None + + @property + def back_prop(self): + """Forwards to the enclosing while context, if any.""" + if self.GetWhileContext(): + return self.GetWhileContext().back_prop + return False diff --git a/tensorflow/contrib/compiler/xla_test.py b/tensorflow/contrib/compiler/xla_test.py new file mode 100644 index 0000000000..a306b56f63 --- /dev/null +++ b/tensorflow/contrib/compiler/xla_test.py @@ -0,0 +1,180 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================= +"""Tests for contrib.compiler.xla.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.contrib.compiler import xla +from tensorflow.python import summary +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import ops +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import control_flow_util +from tensorflow.python.ops import logging_ops +from tensorflow.python.ops import math_ops +from tensorflow.python.ops import state_ops +from tensorflow.python.ops import summary_ops +from tensorflow.python.ops import variable_scope +from tensorflow.python.platform import test + + +class XLACompileContextTest(test.TestCase): + + def create_test_xla_compile_context(self): + computation_name = ops.get_default_graph().unique_name('computation') + pivot = control_flow_ops.no_op(name=computation_name + '/pivot') + return xla.XLACompileContext(name=computation_name, pivot=pivot) + + def test_report_unsupported_operations(self): + """Tests that unsupported operations are detected.""" + context = self.create_test_xla_compile_context() + context.Enter() + dummy_tensor = constant_op.constant(1.1) + audio_summary = summary.audio('audio_summary', dummy_tensor, 0.5) + histogram_summary = summary.histogram('histogram_summary', dummy_tensor) + image_summary = summary.image('image_summary', dummy_tensor) + scalar_summary = summary.scalar('scalar_summary', dummy_tensor) + tensor_summary = summary_ops.tensor_summary('tensor_summary', dummy_tensor) + summary.merge( + [ + audio_summary, histogram_summary, image_summary, scalar_summary, + tensor_summary + ], + name='merge_summary') + logging_ops.Print(dummy_tensor, [dummy_tensor], name='print_op') + context.Exit() + + unsupported_ops_names = [op.name for op in context._unsupported_ops] + self.assertEqual(unsupported_ops_names, [ + u'audio_summary', u'histogram_summary', u'image_summary', + u'scalar_summary', u'tensor_summary', u'merge_summary/merge_summary', + u'print_op' + ]) + + def test_resource_variable(self): + """Tests that resource variable usage is allowed.""" + a = variable_scope.get_variable( + name='variable_a', shape=(1), use_resource=True) + + context = self.create_test_xla_compile_context() + context.Enter() + state_ops.assign(a, a + 1) + context.Exit() + + def test_non_resource_variable_error(self): + """Tests that non-resource variable usage is disallowed.""" + a = variable_scope.get_variable( + name='variable_a', shape=(1), use_resource=False) + + context = self.create_test_xla_compile_context() + context.Enter() + with self.assertRaisesRegexp( + NotImplementedError, 'Non-resource Variables are not supported inside ' + r'XLA computations \(operator name: Assign\)'): + state_ops.assign(a, a + 1) + context.Exit() + + def test_nested_xla_compile_error(self): + """Tests that nested XLA computation leads to fatal error.""" + context1 = self.create_test_xla_compile_context() + context1.Enter() + + context2 = self.create_test_xla_compile_context() + context2.Enter() + with self.assertRaisesRegexp(ValueError, + 'XLA compiled computations cannot be nested'): + constant_op.constant(1) + context2.Exit() + context1.Exit() + + def test_xla_compile_attr(self): + """Tests that ops are tagged with XLA compile ID attribute.""" + context = self.create_test_xla_compile_context() + context.Enter() + op = constant_op.constant(1) + context.Exit() + self.assertIn('_xla_compile_id', op.op.node_def.attr) + + def test_op_without_input(self): + """Tests that ops without inputs depend on pivot correctly.""" + context = self.create_test_xla_compile_context() + context.Enter() + op = constant_op.constant(1) + context.Exit() + + self.assertIn(context._pivot, op.op.control_inputs) + + def test_external_control_edges(self): + """Tests that external control edges are handled correctly.""" + i = constant_op.constant(1) + op1 = constant_op.constant(1) + + with ops.control_dependencies([op1]): + op2 = constant_op.constant(1) + self.assertIn(op1.op, op2.op.control_inputs) + + def while_body(i): + del i # unused + context = self.create_test_xla_compile_context() + context.Enter() + with ops.control_dependencies([op1]): + op3 = constant_op.constant(1) + context.Exit() + self.assertNotIn(op1.op, op3.op.control_inputs) + return op3 + + control_flow_ops.while_loop( + cond=lambda i: math_ops.less(i, 10), body=while_body, loop_vars=[i]) + + def test_op_output_marked_as_seen(self): + """Tests that any op output is marked as seen in context.""" + context = self.create_test_xla_compile_context() + context.Enter() + op = constant_op.constant(1) + context.Exit() + + self.assertIn(op.name, context._values) + + def testOpIsInContext(self): + """Tests that XLACompileContext is recognized as an XLA context.""" + op1 = constant_op.constant(1) + context = self.create_test_xla_compile_context() + context.Enter() + op2 = constant_op.constant(2) + context.Exit() + self.assertFalse(control_flow_util.IsInXLAContext(op1.op)) + self.assertTrue(control_flow_util.IsInXLAContext(op2.op)) + + def testOpPreventFeeding(self): + """Tests that ops created inside XLACompileContext can not be fed.""" + context = self.create_test_xla_compile_context() + context.Enter() + op = constant_op.constant(1) + context.Exit() + self.assertFalse(op.graph.is_feedable(op.op)) + + def testOpPreventFetching(self): + """Tests that ops created inside XLACompileContext can not be fetched.""" + context = self.create_test_xla_compile_context() + context.Enter() + op = constant_op.constant(1) + context.Exit() + self.assertFalse(op.graph.is_fetchable(op.op)) + + +if __name__ == '__main__': + test.main() diff --git a/tensorflow/contrib/cudnn_rnn/python/kernel_tests/cudnn_rnn_test.py b/tensorflow/contrib/cudnn_rnn/python/kernel_tests/cudnn_rnn_test.py index 252ea1560d..fda1b9f1b3 100644 --- a/tensorflow/contrib/cudnn_rnn/python/kernel_tests/cudnn_rnn_test.py +++ b/tensorflow/contrib/cudnn_rnn/python/kernel_tests/cudnn_rnn_test.py @@ -802,7 +802,7 @@ class CudnnRNNTestSaveRestoreCheckpointable(test_util.TensorFlowTestCase): [single_cell_fn() for _ in range(num_layers)]) input_size = 3 save_graph = ops.Graph() - with save_graph.as_default(), self.test_session(graph=save_graph): + with save_graph.as_default(), self.session(graph=save_graph): save_layer = _MultiCellFn() save_layer(inputs=array_ops.ones([1, input_size]), state=save_layer.zero_state(1, dtypes.float32)) diff --git a/tensorflow/contrib/data/BUILD b/tensorflow/contrib/data/BUILD index 8bdbba83ef..9f710613dd 100644 --- a/tensorflow/contrib/data/BUILD +++ b/tensorflow/contrib/data/BUILD @@ -33,14 +33,22 @@ cc_library( tf_custom_op_library( name = "_dataset_ops.so", - srcs = ["ops/dataset_ops.cc"], - deps = ["//tensorflow/contrib/data/kernels:dataset_kernels"] + - if_static( - extra_deps = [":lib_proto_parsing_for_dataset_ops"], - otherwise = [], - ), + srcs = [ + "ops/dataset_ops.cc", + "ops/indexed_dataset_ops.cc", + ], + deps = [ + "//tensorflow/contrib/data/kernels:dataset_kernels", + "//tensorflow/contrib/data/kernels:indexed_dataset", + ] + if_static( + extra_deps = [":lib_proto_parsing_for_dataset_ops"], + otherwise = [], + ), ) tf_gen_op_libs( - op_lib_names = ["dataset_ops"], + op_lib_names = [ + "dataset_ops", + "indexed_dataset_ops", + ], ) diff --git a/tensorflow/contrib/data/__init__.py b/tensorflow/contrib/data/__init__.py index 5821d51bca..5e6c1520a2 100644 --- a/tensorflow/contrib/data/__init__.py +++ b/tensorflow/contrib/data/__init__.py @@ -25,6 +25,7 @@ See [Importing Data](https://tensorflow.org/guide/datasets) for an overview. @@Counter @@CheckpointInputPipelineHook @@CsvDataset +@@LMDBDataset @@RandomDataset @@Reducer @@SqlDataset @@ -49,6 +50,7 @@ See [Importing Data](https://tensorflow.org/guide/datasets) for an overview. @@map_and_batch @@padded_batch_and_drop_remainder @@parallel_interleave +@@parse_example_dataset @@prefetch_to_device @@read_batch_features @@rejection_resample @@ -89,10 +91,12 @@ from tensorflow.contrib.data.python.ops.interleave_ops import sample_from_datase from tensorflow.contrib.data.python.ops.interleave_ops import sloppy_interleave from tensorflow.contrib.data.python.ops.iterator_ops import CheckpointInputPipelineHook from tensorflow.contrib.data.python.ops.iterator_ops import make_saveable_from_iterator +from tensorflow.contrib.data.python.ops.parsing_ops import parse_example_dataset from tensorflow.contrib.data.python.ops.prefetching_ops import copy_to_device from tensorflow.contrib.data.python.ops.prefetching_ops import prefetch_to_device from tensorflow.contrib.data.python.ops.random_ops import RandomDataset from tensorflow.contrib.data.python.ops.readers import CsvDataset +from tensorflow.contrib.data.python.ops.readers import LMDBDataset from tensorflow.contrib.data.python.ops.readers import make_batched_features_dataset from tensorflow.contrib.data.python.ops.readers import make_csv_dataset from tensorflow.contrib.data.python.ops.readers import read_batch_features diff --git a/tensorflow/contrib/data/kernels/BUILD b/tensorflow/contrib/data/kernels/BUILD index 2e249f5c14..ec6cb37193 100644 --- a/tensorflow/contrib/data/kernels/BUILD +++ b/tensorflow/contrib/data/kernels/BUILD @@ -7,6 +7,31 @@ licenses(["notice"]) # Apache 2.0 exports_files(["LICENSE"]) cc_library( + name = "indexed_dataset_headers", + hdrs = ["indexed_dataset.h"], + deps = [ + "//tensorflow/core:framework_headers_lib", + "//third_party/eigen3", + "@protobuf_archive//:protobuf_headers", + ], +) + +cc_library( + name = "indexed_dataset", + srcs = [ + "identity_indexed_dataset.cc", + "indexed_dataset.cc", + ], + deps = [ + ":indexed_dataset_headers", + "//tensorflow/core:framework_headers_lib", + "//third_party/eigen3", + "@protobuf_archive//:protobuf_headers", + ], + alwayslink = 1, +) + +cc_library( name = "prefetching_kernels", srcs = ["prefetching_kernels.cc"], deps = [ @@ -52,6 +77,17 @@ cc_library( ) cc_library( + name = "lmdb_dataset_op", + srcs = ["lmdb_dataset_op.cc"], + deps = [ + "//tensorflow/core:framework_headers_lib", + "//third_party/eigen3", + "@lmdb", + "@protobuf_archive//:protobuf_headers", + ], +) + +cc_library( name = "threadpool_dataset_op", srcs = ["threadpool_dataset_op.cc"], deps = [ @@ -91,6 +127,8 @@ cc_library( ":csv_dataset_op", ":directed_interleave_dataset_op", ":ignore_errors_dataset_op", + ":indexed_dataset", + ":lmdb_dataset_op", ":prefetching_kernels", ":threadpool_dataset_op", ":unique_dataset_op", diff --git a/tensorflow/contrib/data/kernels/csv_dataset_op.cc b/tensorflow/contrib/data/kernels/csv_dataset_op.cc index d242cfdf49..0ba905b92e 100644 --- a/tensorflow/contrib/data/kernels/csv_dataset_op.cc +++ b/tensorflow/contrib/data/kernels/csv_dataset_op.cc @@ -713,7 +713,7 @@ class CSVDatasetOp : public DatasetOpKernel { component.scalar<string>()() = dataset()->record_defaults_[output_idx].flat<string>()(0); } else { - component.scalar<string>()() = field.ToString(); + component.scalar<string>()() = string(field); } break; } diff --git a/tensorflow/contrib/data/kernels/identity_indexed_dataset.cc b/tensorflow/contrib/data/kernels/identity_indexed_dataset.cc new file mode 100644 index 0000000000..4718c1c8b9 --- /dev/null +++ b/tensorflow/contrib/data/kernels/identity_indexed_dataset.cc @@ -0,0 +1,153 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/data/kernels/indexed_dataset.h" +#include "tensorflow/core/lib/core/errors.h" + +namespace tensorflow { +namespace { + +class IdentityIndexedDatasetOp : public IndexedDatasetOpKernel { + public: + using IndexedDatasetOpKernel::IndexedDatasetOpKernel; + + void MakeIndexedDataset(OpKernelContext* ctx, + IndexedDataset** output) override { + uint64 size = -1; + OP_REQUIRES_OK(ctx, ParseScalarArgument<uint64>(ctx, "size", &size)); + OP_REQUIRES(ctx, size > 0, errors::InvalidArgument("`size` must be > 0")); + *output = new Dataset(ctx, size); + } + + class Dataset : public IndexedDataset { + public: + Dataset(OpKernelContext* ctx, uint64 size) + : IndexedDataset(DatasetContext(ctx)), size_(size) {} + + Status MaterializeDataset( + std::shared_ptr<MaterializedIndexedDataset>* materialized) override { + materialized->reset(new Materialized(this)); + return Status::OK(); + } + + const DataTypeVector& output_dtypes() const override { + static DataTypeVector* dtypes = new DataTypeVector({DT_UINT64}); + return *dtypes; + } + + const std::vector<PartialTensorShape>& output_shapes() const override { + static std::vector<PartialTensorShape>* shapes = + new std::vector<PartialTensorShape>({{}}); + return *shapes; + } + + std::unique_ptr<IteratorBase> MakeIteratorInternal( + const string& prefix) const override { + return std::unique_ptr<IteratorBase>(new Iterator( + {this, strings::StrCat(prefix, "::IdentityIndexedDataset")})); + } + + string DebugString() const override { + return "IdentityIndexedDataset::Dataset"; + } + + Status AsGraphDefInternal(SerializationContext* ctx, + DatasetGraphDefBuilder* b, + Node** node) const override { + return errors::Unimplemented( + "identity_indexed_dataset.AsGraphDefInternal"); + } + + private: + class Iterator : public DatasetIterator<Dataset> { + public: + explicit Iterator(const Params& params) + : DatasetIterator<Dataset>(params) {} + Status GetNextInternal(IteratorContext* ctx, + std::vector<Tensor>* out_tensors, + bool* end_of_sequence) override { + mutex_lock l(mu_); + if (cur_ < dataset()->size_) { + Tensor result_tensor(ctx->allocator({}), DT_UINT64, {}); + result_tensor.scalar<uint64>()() = cur_++; + out_tensors->emplace_back(std::move(result_tensor)); + *end_of_sequence = false; + return Status::OK(); + } + *end_of_sequence = true; + return Status::OK(); + } + + private: + mutex mu_; + uint64 cur_ GUARDED_BY(mu_); + }; + + class Materialized : public MaterializedIndexedDataset { + public: + explicit Materialized(Dataset* dataset) : dataset_(dataset) { + dataset->Ref(); + } + + ~Materialized() override { + // TODO(saeta): Pull this into MaterializedIndexedDataset + dataset_->Unref(); + } + + const DataTypeVector& output_dtypes() const override { + return dataset_->output_dtypes(); + } + + const std::vector<PartialTensorShape>& output_shapes() const override { + return dataset_->output_shapes(); + } + + Status Get(IteratorContext&& ctx, uint64 index, + std::vector<Tensor>* out_tensors) const override { + LOG(INFO) << "Materialized(" << dataset_->size_ << ")::Get(" << index + << ")"; + if (index >= dataset_->size_) { + // Note: use InvalidArgument instead of OutOfRange error because many + // things consider OutOfRange to be a "clean termination" error. + return errors::InvalidArgument( + "Index ", index, + " is out of range for this dataset. (Size is: ", dataset_->size_, + ".)"); + } + Tensor result_tensor(ctx.allocator({}), DT_UINT64, {}); + result_tensor.scalar<uint64>()() = index; + out_tensors->emplace_back(std::move(result_tensor)); + return Status::OK(); + } + + Status Size(uint64* size) const override { + *size = dataset_->size_; + return Status::OK(); + } + + private: + const Dataset* const dataset_; // Not owned. + }; + + const uint64 size_; + std::shared_ptr<Materialized> materialized_; + }; +}; + +REGISTER_KERNEL_BUILDER(Name("IdentityIndexedDataset").Device(DEVICE_CPU), + IdentityIndexedDatasetOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/contrib/data/kernels/indexed_dataset.cc b/tensorflow/contrib/data/kernels/indexed_dataset.cc new file mode 100644 index 0000000000..c69564a31b --- /dev/null +++ b/tensorflow/contrib/data/kernels/indexed_dataset.cc @@ -0,0 +1,372 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include "tensorflow/contrib/data/kernels/indexed_dataset.h" + +#include "tensorflow/core/framework/resource_mgr.h" +#include "tensorflow/core/framework/tensor_shape.h" +#include "tensorflow/core/lib/core/errors.h" +#include "tensorflow/core/lib/gtl/cleanup.h" + +namespace tensorflow { + +namespace { + +Status VerifyTypesMatch(const DataTypeVector& expected, + const DataTypeVector& received) { + if (expected.size() != received.size()) { + return errors::InvalidArgument( + "Number of components does not match: expected ", expected.size(), + " types but got ", received.size(), "."); + } + for (size_t i = 0; i < expected.size(); ++i) { + if (expected[i] != received[i]) { + return errors::InvalidArgument("Data type mismatch at component ", i, + ": expected ", DataTypeString(expected[i]), + " but got ", DataTypeString(received[i]), + "."); + } + } + return Status::OK(); +} + +Status VerifyShapesCompatible(const std::vector<PartialTensorShape>& expected, + const std::vector<PartialTensorShape>& received) { + if (expected.size() != received.size()) { + return errors::InvalidArgument( + "Number of components does not match: expected ", expected.size(), + " shapes but got ", received.size(), "."); + } + for (size_t i = 0; i < expected.size(); ++i) { + if (!expected[i].IsCompatibleWith(received[i])) { + return errors::InvalidArgument("Incompatible shapes at component ", i, + ": expected ", expected[i].DebugString(), + " but got ", received[i].DebugString(), + "."); + } + } + + return Status::OK(); +} + +class MaterializedDatasetResource : public ResourceBase { + public: + MaterializedDatasetResource( + const DataTypeVector& output_dtypes, + const std::vector<PartialTensorShape>& output_shapes) + : output_dtypes_(output_dtypes), output_shapes_(output_shapes) {} + + string DebugString() override { + return "Materialized IndexedDataset resource"; + } + + Status Get(IteratorContext&& ctx, uint64 index, + std::vector<Tensor>* out_tensors) { + std::shared_ptr<MaterializedIndexedDataset> captured(materialized_); + if (captured) { + return captured->Get(std::move(ctx), index, out_tensors); + } else { + return errors::FailedPrecondition( + "Get() failed because the MaterializedIndexedDataset has not been " + "initialized. Ensure that you have run the materialization operation " + "for this MaterializedIndexedDataset before retrieving elements."); + } + } + + // TODO(saeta): Implement Save and Restore + + const DataTypeVector& output_dtypes() const { return output_dtypes_; } + const std::vector<PartialTensorShape>& output_shapes() const { + return output_shapes_; + } + + Status set_materialized_dataset( + const std::shared_ptr<MaterializedIndexedDataset>& dataset) { + if (dataset) { + TF_RETURN_IF_ERROR( + VerifyTypesMatch(output_dtypes_, dataset->output_dtypes())); + TF_RETURN_IF_ERROR( + VerifyShapesCompatible(output_shapes_, dataset->output_shapes())); + } + materialized_ = dataset; + return Status::OK(); + } + + private: + std::shared_ptr<MaterializedIndexedDataset> materialized_; + const DataTypeVector output_dtypes_; + const std::vector<PartialTensorShape> output_shapes_; +}; + +// A wrapper class for storing an `IndexedDataset` instance in a DT_VARIANT +// tensor. Objects of the wrapper class own a reference on an instance of an +// `IndexedTensor` and the wrapper's copy constructor and desctructor take care +// of managing the reference count. +// +// NOTE: This is not a feature-complete implementation of the DT_VARIANT +// specification. In particular, we cannot currently serialize an arbitrary +// `IndexedDataset` object, so the `Encode()` and `Decode()` methods are not +// implemented. +// +// NOTE(saeta): When `IndexedDataset`s get merged into core, we can instead just +// use `tensorflow::DatasetVariantWrapper`. +class IndexedDatasetVariantWrapper { + public: + IndexedDatasetVariantWrapper() : dataset_(nullptr) {} + + // Transfers ownership of `dataset` to `*this`. + explicit IndexedDatasetVariantWrapper(IndexedDataset* dataset) + : dataset_(dataset) {} + + IndexedDatasetVariantWrapper(const IndexedDatasetVariantWrapper& other) + : dataset_(other.dataset_) { + if (dataset_) dataset_->Ref(); + } + + ~IndexedDatasetVariantWrapper() { + if (dataset_) dataset_->Unref(); + } + + IndexedDataset* get() const { return dataset_; } + + string TypeName() const { return "tensorflow::IndexedDatasetVariantWrapper"; } + string DebugString() const { + if (dataset_) { + return dataset_->DebugString(); + } else { + return "<Uninitialized IndexedDatasetVariantWrapper>"; + } + } + + void Encode(VariantTensorData* data) const { + LOG(ERROR) << "The Encode() method is not implemented for " + "IndexedDatasetVariantWrapper objects."; + } + + bool Decode(const VariantTensorData& data) { + LOG(ERROR) << "The Decode() method is not implemented for " + "IndexedDatasetVariantWrapper objects."; + return false; + } + + private: + IndexedDataset* const dataset_; // Owns one reference. +}; + +} // namespace + +Status GetIndexedDatasetFromVariantTensor(const Tensor& tensor, + IndexedDataset** out_dataset) { + if (!(tensor.dtype() == DT_VARIANT || + TensorShapeUtils::IsScalar(tensor.shape()))) { + return errors::InvalidArgument( + "IndexedDataset tensor must be a scalar of dtype DT_VARIANT."); + } + const Variant& variant = tensor.scalar<Variant>()(); + const IndexedDatasetVariantWrapper* wrapper = + variant.get<IndexedDatasetVariantWrapper>(); + if (wrapper == nullptr) { + return errors::InvalidArgument("Tensor must be an IndexedDataset object."); + } + *out_dataset = wrapper->get(); + if (*out_dataset == nullptr) { + return errors::Internal("Read uninitialized IndexedDataset variant."); + } + return Status::OK(); +} + +Status StoreIndexedDatasetInVariantTensor(IndexedDataset* dataset, + Tensor* tensor) { + if (!(tensor->dtype() == DT_VARIANT || + TensorShapeUtils::IsScalar(tensor->shape()))) { + return errors::InvalidArgument( + "Dataset tensor must be a scalar of dtype DT_VARIANT."); + } + tensor->scalar<Variant>()() = IndexedDatasetVariantWrapper(dataset); + return Status::OK(); +} + +void IndexedDatasetOpKernel::Compute(OpKernelContext* ctx) { + IndexedDataset* dataset = nullptr; + MakeIndexedDataset(ctx, &dataset); + + if (ctx->status().ok()) { + OP_REQUIRES(ctx, dataset != nullptr, + errors::Internal("MakeIndexedDataset did not correctly " + "construct the IndexedDataset")); + Tensor* output = nullptr; + OP_REQUIRES_OK(ctx, ctx->allocate_output(0, TensorShape({}), &output)); + OP_REQUIRES_OK(ctx, StoreIndexedDatasetInVariantTensor(dataset, output)); + } +} + +namespace { + +class MaterializedHandleOp : public OpKernel { + public: + explicit MaterializedHandleOp(OpKernelConstruction* ctx) : OpKernel(ctx) { + OP_REQUIRES_OK(ctx, ctx->GetAttr("output_types", &output_dtypes_)); + OP_REQUIRES_OK(ctx, ctx->GetAttr("output_shapes", &output_shapes_)); + } + + ~MaterializedHandleOp() override { + if (resource_ != nullptr) { + resource_->Unref(); + if (cinfo_.resource_is_private_to_kernel()) { + if (!cinfo_.resource_manager() + ->template Delete<MaterializedDatasetResource>( + cinfo_.container(), cinfo_.name()) + .ok()) { + // Do nothing; the resource can have been deleted by session resets. + // Note: cargo-culted from $tf/core/framework/resource_op_kernel.h + } + } + } + } + + void Compute(OpKernelContext* context) override LOCKS_EXCLUDED(mu_) { + { + mutex_lock l(mu_); + if (resource_ == nullptr) { + ResourceMgr* mgr = context->resource_manager(); + OP_REQUIRES_OK(context, cinfo_.Init(mgr, def())); + + MaterializedDatasetResource* resource; + OP_REQUIRES_OK(context, + mgr->LookupOrCreate<MaterializedDatasetResource>( + cinfo_.container(), cinfo_.name(), &resource, + [this](MaterializedDatasetResource** ret) + EXCLUSIVE_LOCKS_REQUIRED(mu_) { + *ret = new MaterializedDatasetResource( + output_dtypes_, output_shapes_); + return Status::OK(); + })); + Status s = VerifyResource(resource); + if (TF_PREDICT_FALSE(!s.ok())) { + resource->Unref(); + context->SetStatus(s); + return; + } + + resource_ = resource; + } + } + OP_REQUIRES_OK(context, MakeResourceHandleToOutput( + context, 0, cinfo_.container(), cinfo_.name(), + MakeTypeIndex<MaterializedDatasetResource>())); + } + + private: + // During the first Compute(), resource is either created or looked up using + // shared_name. In the latter case, the resource found should be verified if + // it is compatible with this op's configuration. The verification may fail in + // cases such as two graphs asking queues of the same shared name to have + // inconsistent capacities. + Status VerifyResource(MaterializedDatasetResource* resource) { + TF_RETURN_IF_ERROR( + VerifyTypesMatch(output_dtypes_, resource->output_dtypes())); + TF_RETURN_IF_ERROR( + VerifyShapesCompatible(output_shapes_, resource->output_shapes())); + return Status::OK(); + } + + mutex mu_; + ContainerInfo cinfo_; // Written once under mu_ then constant afterwards. + MaterializedDatasetResource* resource_ GUARDED_BY(mu_) = nullptr; + DataTypeVector output_dtypes_; + std::vector<PartialTensorShape> output_shapes_; +}; + +// TODO(saeta): Make async. +class MaterializeDatasetOp : public OpKernel { + public: + explicit MaterializeDatasetOp(OpKernelConstruction* ctx) : OpKernel(ctx) {} + + void Compute(OpKernelContext* ctx) override { + IndexedDataset* dataset; + OP_REQUIRES_OK(ctx, + GetIndexedDatasetFromVariantTensor(ctx->input(0), &dataset)); + + MaterializedDatasetResource* materialized_resource; + OP_REQUIRES_OK(ctx, LookupResource(ctx, HandleFromInput(ctx, 1), + &materialized_resource)); + core::ScopedUnref unref(materialized_resource); + std::shared_ptr<MaterializedIndexedDataset> materialized; + OP_REQUIRES_OK(ctx, dataset->MaterializeDataset(&materialized)); + OP_REQUIRES_OK( + ctx, materialized_resource->set_materialized_dataset(materialized)); + } +}; + +// TODO(saeta): Make async +class IndexedDatasetGet : public OpKernel { + public: + explicit IndexedDatasetGet(OpKernelConstruction* ctx) : OpKernel(ctx) {} + + void Compute(OpKernelContext* ctx) override { + MaterializedDatasetResource* materialized_resource; + OP_REQUIRES_OK(ctx, LookupResource(ctx, HandleFromInput(ctx, 0), + &materialized_resource)); + auto cleanup = gtl::MakeCleanup([materialized_resource] { + materialized_resource->Unref(); // Note: can't use core::ScopedUnref. + }); + + const Tensor* index_t; + OP_REQUIRES_OK(ctx, ctx->input("index", &index_t)); + // TODO(saeta): Support batch reads (indexes should be non-scalar!) + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(index_t->shape()), + errors::InvalidArgument("index must be a scalar")); + const uint64 index = index_t->scalar<uint64>()(); + + std::vector<Tensor> out_tensors; + Status s = + materialized_resource->Get(IteratorContext(ctx), index, &out_tensors); + + // Note: Unref materialized_resource to avoid destruction races. (Important + // in a [future] async op implementation.) + cleanup.release()(); + + if (!s.ok()) { + ctx->SetStatus(s); + } else { + auto expected_shapes = materialized_resource->output_shapes(); + auto expected_types = materialized_resource->output_dtypes(); + for (size_t i = 0; i < out_tensors.size(); ++i) { + OP_REQUIRES( + ctx, expected_shapes[i].IsCompatibleWith(out_tensors[i].shape()), + errors::Internal( + "Materialized dataset output at index ", i, + " is incompatible with the expected shape. (Expected: ", + expected_shapes[i], ", got: ", out_tensors[i].shape(), ")")); + OP_REQUIRES(ctx, out_tensors[i].dtype() == expected_types[i], + errors::Internal("Materialized dataset output at index ", i, + " was not the expected dtype. (Expected: ", + expected_types[i], + ", got: ", out_tensors[i].dtype(), ")")); + ctx->set_output(i, out_tensors[i]); + } + } + } +}; + +REGISTER_KERNEL_BUILDER( + Name("MaterializedIndexDatasetHandle").Device(DEVICE_CPU), + MaterializedHandleOp); +REGISTER_KERNEL_BUILDER(Name("IndexedDatasetMaterialize").Device(DEVICE_CPU), + MaterializeDatasetOp); +REGISTER_KERNEL_BUILDER(Name("IndexedDatasetGet").Device(DEVICE_CPU), + IndexedDatasetGet); +} // namespace + +} // namespace tensorflow diff --git a/tensorflow/contrib/data/kernels/indexed_dataset.h b/tensorflow/contrib/data/kernels/indexed_dataset.h new file mode 100644 index 0000000000..6149de888c --- /dev/null +++ b/tensorflow/contrib/data/kernels/indexed_dataset.h @@ -0,0 +1,117 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#ifndef TENSORFLOW_CONTRIB_DATA_KERNELS_INDEXED_DATASET_H_ +#define TENSORFLOW_CONTRIB_DATA_KERNELS_INDEXED_DATASET_H_ + +#include "tensorflow/core/framework/dataset.h" +#include "tensorflow/core/framework/op_kernel.h" + +namespace tensorflow { + +// TODO(saeta): Urgh, this is ugly. +class MaterializedIndexedDataset { + public: + virtual ~MaterializedIndexedDataset() = default; + + // Retrieve the element at a given index. The output tensors are stored in + // out_tensors. + // + // If `index` is greater than `Size()`, tensorflow::errors::OutOfRangeError is + // returned. + // + // Get is thread-safe. + virtual Status Get(IteratorContext&& ctx, uint64 index, + std::vector<Tensor>* out_tensors) const = 0; + + // Size determines the number of elements in this IndexedDataset. + // + // Size is thread-safe. + virtual Status Size(uint64* size) const = 0; + + // Returns a vector of DataType values, representing the respective + // element types of each tuple component in the outputs of this dataset. + virtual const DataTypeVector& output_dtypes() const = 0; + + // Returns a vector of tensor shapes, representing the respective + // (and possibly partially defined) shapes of each tuple component + // in the outputs of this dataset. + virtual const std::vector<PartialTensorShape>& output_shapes() const = 0; +}; + +// IndexedDataset represents a dataset that supports random access in addition +// to iterator-based sequential access. +// +// Note: IndexedDatasets are HIGHLY experimental at this time. Expect +// significant (backwards incompatible) changes! +class IndexedDataset : public DatasetBase { + public: + IndexedDataset(DatasetContext&& ctx) : DatasetBase(std::move(ctx)) {} + + // Materialize (if necessary) the dataset, and return a pointer. + // TODO(saeta): Add in `IteratorContext* ctx` when materializing. + virtual Status MaterializeDataset( + std::shared_ptr<MaterializedIndexedDataset>* materialized) = 0; +}; + +// IndexedDatasetOpKernel abstracts away interfacing IndexedDatasets with the +// rest of the TensorFlow runtime. +// +// Most IndexedDataset's will be private members of classes inheriting from this +// class. +class IndexedDatasetOpKernel : public OpKernel { + public: + IndexedDatasetOpKernel(OpKernelConstruction* ctx) : OpKernel(ctx) {} + void Compute(OpKernelContext* ctx) final; + + protected: + // Subclasses should implement this method. It will be called during Compute + // execution. + virtual void MakeIndexedDataset(OpKernelContext* ctx, + IndexedDataset** output) = 0; + + template <typename T> + Status ParseScalarArgument(OpKernelContext* ctx, + const StringPiece& argument_name, T* output) { + const Tensor* argument_t; + TF_RETURN_IF_ERROR(ctx->input(argument_name, &argument_t)); + if (!TensorShapeUtils::IsScalar(argument_t->shape())) { + return errors::InvalidArgument(argument_name, " must be a scalar"); + } + *output = argument_t->scalar<T>()(); + return Status::OK(); + } +}; + +// Validates and extracts an `IndexedDataset` object from `tensor`. +// +// `tensor` must have been written by a call to +// `StoreIndexedDatasetInVariantTensor` +// +// The retrieved pointer isa borrowed reference to the dataset, which is owned +// by the tensor. The consumer must either acquire its own reference to the +// dataset by calling `(*out_dataset)->Ref()`, or ensure that `tensor` is not +// destroyed or mutated while the retrieved pointer is in use. +Status GetIndexedDatasetFromVariantTensor(const Tensor& tensor, + IndexedDataset** out_dataset); + +// Stores an `IndexedDataset` object in `tensor.` +// +// The ownership of `dataset` is transferred to `tensor`. +Status StoreIndexedDatasetInVariantTensor(IndexedDataset* dataset, + Tensor* tensor); + +} // namespace tensorflow + +#endif // TENSORFLOW_CONTRIB_DATA_KERNELS_INDEXED_DATASET_H_ diff --git a/tensorflow/contrib/data/kernels/lmdb_dataset_op.cc b/tensorflow/contrib/data/kernels/lmdb_dataset_op.cc new file mode 100644 index 0000000000..80f39992fb --- /dev/null +++ b/tensorflow/contrib/data/kernels/lmdb_dataset_op.cc @@ -0,0 +1,215 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include <sys/stat.h> + +#include "tensorflow/core/framework/dataset.h" +#include "tensorflow/core/lib/io/buffered_inputstream.h" +#include "tensorflow/core/platform/file_system.h" + +#include "lmdb.h" // NOLINT(build/include) + +namespace tensorflow { +namespace { + +class LMDBDatasetOp : public DatasetOpKernel { + public: + using DatasetOpKernel::DatasetOpKernel; + void MakeDataset(OpKernelContext* ctx, DatasetBase** output) override { + const Tensor* filenames_tensor; + OP_REQUIRES_OK(ctx, ctx->input("filenames", &filenames_tensor)); + OP_REQUIRES( + ctx, filenames_tensor->dims() <= 1, + errors::InvalidArgument("`filenames` must be a scalar or a vector.")); + + std::vector<string> filenames; + filenames.reserve(filenames_tensor->NumElements()); + for (int i = 0; i < filenames_tensor->NumElements(); ++i) { + filenames.push_back(filenames_tensor->flat<string>()(i)); + } + + *output = new Dataset(ctx, filenames); + } + + private: + class Dataset : public DatasetBase { + public: + Dataset(OpKernelContext* ctx, const std::vector<string>& filenames) + : DatasetBase(DatasetContext(ctx)), filenames_(filenames) {} + + std::unique_ptr<IteratorBase> MakeIteratorInternal( + const string& prefix) const override { + return std::unique_ptr<IteratorBase>( + new Iterator({this, strings::StrCat(prefix, "::LMDB")})); + } + + const DataTypeVector& output_dtypes() const override { + static DataTypeVector* dtypes = + new DataTypeVector({DT_STRING, DT_STRING}); + return *dtypes; + } + + const std::vector<PartialTensorShape>& output_shapes() const override { + static std::vector<PartialTensorShape>* shapes = + new std::vector<PartialTensorShape>({{}, {}}); + return *shapes; + } + + string DebugString() const override { return "LMDBDatasetOp::Dataset"; } + + protected: + Status AsGraphDefInternal(SerializationContext* ctx, + DatasetGraphDefBuilder* b, + Node** output) const override { + Node* filenames = nullptr; + TF_RETURN_IF_ERROR(b->AddVector(filenames_, &filenames)); + TF_RETURN_IF_ERROR(b->AddDataset(this, {filenames}, output)); + return Status::OK(); + } + + private: + class Iterator : public DatasetIterator<Dataset> { + public: + explicit Iterator(const Params& params) + : DatasetIterator<Dataset>(params) {} + + Status GetNextInternal(IteratorContext* ctx, + std::vector<Tensor>* out_tensors, + bool* end_of_sequence) override { + mutex_lock l(mu_); + do { + if (mdb_cursor_) { + Tensor key_tensor(ctx->allocator({}), DT_STRING, {}); + key_tensor.scalar<string>()() = string( + static_cast<const char*>(mdb_key_.mv_data), mdb_key_.mv_size); + out_tensors->emplace_back(std::move(key_tensor)); + + Tensor value_tensor(ctx->allocator({}), DT_STRING, {}); + value_tensor.scalar<string>()() = + string(static_cast<const char*>(mdb_value_.mv_data), + mdb_value_.mv_size); + out_tensors->emplace_back(std::move(value_tensor)); + + int val; + val = mdb_cursor_get(mdb_cursor_, &mdb_key_, &mdb_value_, MDB_NEXT); + if (val != MDB_SUCCESS && val != MDB_NOTFOUND) { + return errors::InvalidArgument(mdb_strerror(val)); + } + if (val == MDB_NOTFOUND) { + ResetStreamsLocked(); + ++current_file_index_; + } + *end_of_sequence = false; + return Status::OK(); + } + if (current_file_index_ == dataset()->filenames_.size()) { + *end_of_sequence = true; + return Status::OK(); + } + + TF_RETURN_IF_ERROR(SetupStreamsLocked(ctx->env())); + } while (true); + } + + protected: + Status SaveInternal(IteratorStateWriter* writer) override { + return errors::Unimplemented( + "Checkpointing is currently not supported for LMDBDataset."); + } + + Status RestoreInternal(IteratorContext* ctx, + IteratorStateReader* reader) override { + return errors::Unimplemented( + "Checkpointing is currently not supported for LMDBDataset."); + } + + private: + Status SetupStreamsLocked(Env* env) EXCLUSIVE_LOCKS_REQUIRED(mu_) { + if (current_file_index_ >= dataset()->filenames_.size()) { + return errors::InvalidArgument( + "current_file_index_:", current_file_index_, + " >= filenames_.size():", dataset()->filenames_.size()); + } + const string& filename = dataset()->filenames_[current_file_index_]; + + int val = mdb_env_create(&mdb_env_); + if (val != MDB_SUCCESS) { + return errors::InvalidArgument(mdb_strerror(val)); + } + int flags = MDB_RDONLY | MDB_NOTLS | MDB_NOLOCK; + + struct stat source_stat; + if (stat(filename.c_str(), &source_stat) == 0 && + (source_stat.st_mode & S_IFREG)) { + flags |= MDB_NOSUBDIR; + } + val = mdb_env_open(mdb_env_, filename.c_str(), flags, 0664); + if (val != MDB_SUCCESS) { + return errors::InvalidArgument(mdb_strerror(val)); + } + val = mdb_txn_begin(mdb_env_, nullptr, MDB_RDONLY, &mdb_txn_); + if (val != MDB_SUCCESS) { + return errors::InvalidArgument(mdb_strerror(val)); + } + val = mdb_dbi_open(mdb_txn_, nullptr, 0, &mdb_dbi_); + if (val != MDB_SUCCESS) { + return errors::InvalidArgument(mdb_strerror(val)); + } + val = mdb_cursor_open(mdb_txn_, mdb_dbi_, &mdb_cursor_); + if (val != MDB_SUCCESS) { + return errors::InvalidArgument(mdb_strerror(val)); + } + val = mdb_cursor_get(mdb_cursor_, &mdb_key_, &mdb_value_, MDB_FIRST); + if (val != MDB_SUCCESS && val != MDB_NOTFOUND) { + return errors::InvalidArgument(mdb_strerror(val)); + } + if (val == MDB_NOTFOUND) { + ResetStreamsLocked(); + } + return Status::OK(); + } + void ResetStreamsLocked() EXCLUSIVE_LOCKS_REQUIRED(mu_) { + if (mdb_env_ != nullptr) { + if (mdb_cursor_) { + mdb_cursor_close(mdb_cursor_); + mdb_cursor_ = nullptr; + } + mdb_dbi_close(mdb_env_, mdb_dbi_); + mdb_txn_abort(mdb_txn_); + mdb_env_close(mdb_env_); + mdb_txn_ = nullptr; + mdb_dbi_ = 0; + mdb_env_ = nullptr; + } + } + mutex mu_; + size_t current_file_index_ GUARDED_BY(mu_) = 0; + MDB_env* mdb_env_ GUARDED_BY(mu_) = nullptr; + MDB_txn* mdb_txn_ GUARDED_BY(mu_) = nullptr; + MDB_dbi mdb_dbi_ GUARDED_BY(mu_) = 0; + MDB_cursor* mdb_cursor_ GUARDED_BY(mu_) = nullptr; + + MDB_val mdb_key_ GUARDED_BY(mu_); + MDB_val mdb_value_ GUARDED_BY(mu_); + }; + + const std::vector<string> filenames_; + }; +}; + +REGISTER_KERNEL_BUILDER(Name("LMDBDataset").Device(DEVICE_CPU), LMDBDatasetOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/contrib/data/kernels/prefetching_kernels.cc b/tensorflow/contrib/data/kernels/prefetching_kernels.cc index 74df1e42a8..725f8933c9 100644 --- a/tensorflow/contrib/data/kernels/prefetching_kernels.cc +++ b/tensorflow/contrib/data/kernels/prefetching_kernels.cc @@ -548,7 +548,9 @@ class MultiDeviceIterator : public ResourceBase { devices_(devices), flib_def_(std::move(flib_def)), pflr_(std::move(pflr)), - lib_(lib) {} + lib_(lib) { + CHECK_NOTNULL(lib_); + } string DebugString() override { return strings::StrCat("MultiDeviceIterator for ", devices_.size(), @@ -600,6 +602,11 @@ class MultiDeviceIterator : public ResourceBase { return lib_def_; } + FunctionLibraryRuntime* const lib() { + tf_shared_lock l(mu_); + return lib_; + } + private: // A private class that uses a background thread to keep a per device buffer // full. @@ -930,8 +937,10 @@ class MultiDeviceIteratorInitOp : public OpKernel { core::ScopedUnref unref(resource); std::unique_ptr<IteratorBase> iterator; - OP_REQUIRES_OK(ctx, dataset->MakeIterator(IteratorContext(ctx), "Iterator", - &iterator)); + IteratorContext iter_ctx(ctx); + iter_ctx.set_lib(resource->lib()); + OP_REQUIRES_OK( + ctx, dataset->MakeIterator(std::move(iter_ctx), "Iterator", &iterator)); int64 incarnation_id; OP_REQUIRES_OK(ctx, resource->Init(std::move(iterator), max_buffer_size, &incarnation_id)); diff --git a/tensorflow/contrib/data/ops/dataset_ops.cc b/tensorflow/contrib/data/ops/dataset_ops.cc index cc5e250ea1..ae104d55bd 100644 --- a/tensorflow/contrib/data/ops/dataset_ops.cc +++ b/tensorflow/contrib/data/ops/dataset_ops.cc @@ -266,4 +266,13 @@ REGISTER_OP("AssertNextDataset") return shape_inference::ScalarShape(c); }); +REGISTER_OP("LMDBDataset") + .Input("filenames: string") + .Output("handle: variant") + .Attr("output_types: list(type) >= 1") + .Attr("output_shapes: list(shape) >= 1") + .SetIsStateful() // TODO(b/65524810): Source dataset ops must be marked + // stateful to inhibit constant folding. + .SetShapeFn(shape_inference::ScalarShape); + } // namespace tensorflow diff --git a/tensorflow/contrib/data/ops/indexed_dataset_ops.cc b/tensorflow/contrib/data/ops/indexed_dataset_ops.cc new file mode 100644 index 0000000000..cd9b7c68a0 --- /dev/null +++ b/tensorflow/contrib/data/ops/indexed_dataset_ops.cc @@ -0,0 +1,80 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include "tensorflow/core/framework/common_shape_fns.h" +#include "tensorflow/core/framework/op.h" + +namespace tensorflow { + +REGISTER_OP("IdentityIndexedDataset") + .Input("size: uint64") + .Output("handle: variant") + .SetIsStateful() + .SetShapeFn( + shape_inference::ScalarShape); // TODO(saeta): check input shapes. + +/////////////////////////////////////////////////////////////////////////////// +// IndexedDataset Internals +/////////////////////////////////////////////////////////////////////////////// + +// Creates the handle. +REGISTER_OP("MaterializedIndexDatasetHandle") + .Output("handle: resource") + .Attr("container: string") + .Attr("shared_name: string") + .Attr("output_types: list(type) >= 1") + .Attr("output_shapes: list(shape) >= 1") + .SetShapeFn(shape_inference::ScalarShape); + +// Actually materialize the materialize handle. +REGISTER_OP("IndexedDatasetMaterialize") + .Input("dataset: variant") + .Input("materialized: resource") + .SetShapeFn(shape_inference::NoOutputs); + +namespace { + +Status GetShapeFn(shape_inference::InferenceContext* c) { + shape_inference::ShapeHandle unused; + TF_RETURN_IF_ERROR(c->WithRank(c->input(0), 0, &unused)); + std::vector<PartialTensorShape> output_shapes; + TF_RETURN_IF_ERROR(c->GetAttr("output_shapes", &output_shapes)); + if (output_shapes.size() != c->num_outputs()) { + return errors::InvalidArgument( + "`output_shapes` must be the same length as `output_types` (", + output_shapes.size(), " vs. ", c->num_outputs()); + } + for (size_t i = 0; i < output_shapes.size(); ++i) { + shape_inference::ShapeHandle output_shape_handle; + TF_RETURN_IF_ERROR(c->MakeShapeFromPartialTensorShape( + output_shapes[i], &output_shape_handle)); + c->set_output(static_cast<int>(i), output_shape_handle); + } + return Status::OK(); +} + +} // namespace + +REGISTER_OP("IndexedDatasetGet") + .Input("materialized: resource") + .Input("index: uint64") + .Output("components: output_types") + .Attr("output_types: list(type) >= 1") + .Attr("output_shapes: list(shape) >= 1") + .SetShapeFn(GetShapeFn) + .Doc(R"doc( +Gets the element at `index` from `materialized` IndexedDataset. +)doc"); + +} // namespace tensorflow diff --git a/tensorflow/contrib/data/python/kernel_tests/BUILD b/tensorflow/contrib/data/python/kernel_tests/BUILD index 2b75aa2ca5..b86a543fc3 100644 --- a/tensorflow/contrib/data/python/kernel_tests/BUILD +++ b/tensorflow/contrib/data/python/kernel_tests/BUILD @@ -4,7 +4,8 @@ licenses(["notice"]) # Apache 2.0 exports_files(["LICENSE"]) -load("//tensorflow:tensorflow.bzl", "cuda_py_test", "py_test") +load("//tensorflow:tensorflow.bzl", "cuda_py_test") +load("//tensorflow:tensorflow.bzl", "py_test") py_test( name = "batch_dataset_op_test", @@ -134,12 +135,26 @@ py_test( ) py_test( + name = "indexed_dataset_ops_test", + srcs = ["indexed_dataset_ops_test.py"], + deps = [ + "//tensorflow/contrib/data/python/ops:contrib_op_loader", + "//tensorflow/contrib/data/python/ops:gen_dataset_ops", + "//tensorflow/contrib/data/python/ops:indexed_dataset_ops", + "//tensorflow/python:array_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:dtypes", + "//tensorflow/python/data/ops:dataset_ops", + "//third_party/py/numpy", + ], +) + +py_test( name = "interleave_dataset_op_test", size = "medium", srcs = ["interleave_dataset_op_test.py"], srcs_version = "PY2AND3", tags = [ - "manual", "no_oss", "no_pip", "notap", @@ -180,6 +195,31 @@ py_test( ) py_test( + name = "lmdb_dataset_op_test", + size = "medium", + srcs = ["lmdb_dataset_op_test.py"], + data = ["//tensorflow/core:lmdb_testdata"], + srcs_version = "PY2AND3", + tags = [ + "no_pip", + "no_windows", + ], + deps = [ + "//tensorflow/contrib/data/python/ops:readers", + "//tensorflow/python:client_testlib", + "//tensorflow/python:constant_op", + "//tensorflow/python:dtypes", + "//tensorflow/python:errors", + "//tensorflow/python:framework_ops", + "//tensorflow/python:parsing_ops", + "//tensorflow/python:platform", + "//tensorflow/python:platform_test", + "//tensorflow/python:session", + "//third_party/py/numpy", + ], +) + +py_test( name = "map_dataset_op_test", size = "medium", srcs = ["map_dataset_op_test.py"], @@ -206,6 +246,25 @@ py_test( ) py_test( + name = "filter_dataset_op_test", + size = "medium", + srcs = ["filter_dataset_op_test.py"], + srcs_version = "PY2AND3", + deps = [ + "//tensorflow/contrib/data/python/ops:optimization", + "//tensorflow/python:array_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:errors", + "//tensorflow/python:framework_ops", + "//tensorflow/python:io_ops", + "//tensorflow/python:math_ops", + "//tensorflow/python:util", + "//tensorflow/python/data/ops:dataset_ops", + "//third_party/py/numpy", + ], +) + +py_test( name = "map_defun_op_test", size = "small", srcs = ["map_defun_op_test.py"], @@ -230,19 +289,35 @@ py_test( srcs = ["optimize_dataset_op_test.py"], srcs_version = "PY2AND3", deps = [ - ":stats_dataset_test_base", "//tensorflow/contrib/data/python/ops:optimization", - "//tensorflow/contrib/data/python/ops:stats_ops", "//tensorflow/python:client_testlib", - "//tensorflow/python:constant_op", - "//tensorflow/python:dtypes", "//tensorflow/python:errors", - "//tensorflow/python:math_ops", "//tensorflow/python/data/ops:dataset_ops", "@absl_py//absl/testing:parameterized", ], ) +py_test( + name = "parsing_ops_test", + size = "small", + srcs = ["parsing_ops_test.py"], + srcs_version = "PY2AND3", + deps = [ + "//tensorflow/contrib/data/python/ops:parsing_ops", + "//tensorflow/core:protos_all_py", + "//tensorflow/python:client_testlib", + "//tensorflow/python:dtypes", + "//tensorflow/python:errors", + "//tensorflow/python:framework_ops", + "//tensorflow/python:parsing_ops", + "//tensorflow/python:platform", + "//tensorflow/python:sparse_tensor", + "//tensorflow/python/data/ops:dataset_ops", + "//tensorflow/python/data/util:nest", + "//third_party/py/numpy", + ], +) + cuda_py_test( name = "prefetching_ops_test", size = "small", @@ -329,6 +404,7 @@ py_test( "//tensorflow/python:parsing_ops", "//tensorflow/python:string_ops", "//tensorflow/python/data/ops:readers", + "//tensorflow/python/data/util:nest", "//third_party/py/numpy", ], ) @@ -549,3 +625,13 @@ py_test( "//tensorflow/python/data/ops:readers", ], ) + +py_library( + name = "test_utils", + srcs = ["test_utils.py"], + deps = [ + "//tensorflow/python:client_testlib", + "//tensorflow/python:errors", + "//tensorflow/python/data/util:nest", + ], +) diff --git a/tensorflow/contrib/data/python/kernel_tests/batch_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/batch_dataset_op_test.py index 42adfd17f0..9d8e955245 100644 --- a/tensorflow/contrib/data/python/kernel_tests/batch_dataset_op_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/batch_dataset_op_test.py @@ -720,6 +720,42 @@ class RestructuredDatasetTest(test.TestCase): def test_assert_element_shape(self): + def create_dataset(_): + return (array_ops.ones(2, dtype=dtypes.float32), + array_ops.zeros((3, 4), dtype=dtypes.int32)) + + dataset = dataset_ops.Dataset.range(5).map(create_dataset) + expected_shapes = (tensor_shape.TensorShape(2), + tensor_shape.TensorShape((3, 4))) + self.assertEqual(expected_shapes, dataset.output_shapes) + + result = dataset.apply(batching.assert_element_shape(expected_shapes)) + self.assertEqual(expected_shapes, result.output_shapes) + + iterator = result.make_initializable_iterator() + init_op = iterator.initializer + get_next = iterator.get_next() + with self.test_session() as sess: + sess.run(init_op) + for _ in range(5): + sess.run(get_next) + with self.assertRaises(errors.OutOfRangeError): + sess.run(get_next) + + def test_assert_wrong_element_shape(self): + + def create_dataset(_): + return (array_ops.ones(2, dtype=dtypes.float32), + array_ops.zeros((3, 4), dtype=dtypes.int32)) + + dataset = dataset_ops.Dataset.range(3).map(create_dataset) + wrong_shapes = (tensor_shape.TensorShape(2), + tensor_shape.TensorShape((3, 10))) + with self.assertRaises(ValueError): + dataset.apply(batching.assert_element_shape(wrong_shapes)) + + def test_assert_element_shape_on_unknown_shape_dataset(self): + def create_unknown_shape_dataset(x): return script_ops.py_func( lambda _: ( # pylint: disable=g-long-lambda @@ -748,7 +784,60 @@ class RestructuredDatasetTest(test.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(get_next) - def test_assert_wrong_element_shape(self): + def test_assert_wrong_element_shape_on_unknown_shape_dataset(self): + + def create_unknown_shape_dataset(x): + return script_ops.py_func( + lambda _: ( # pylint: disable=g-long-lambda + np.ones(2, dtype=np.float32), + np.zeros((3, 4), dtype=np.int32)), + [x], + [dtypes.float32, dtypes.int32]) + + dataset = dataset_ops.Dataset.range(3).map(create_unknown_shape_dataset) + unknown_shapes = (tensor_shape.TensorShape(None), + tensor_shape.TensorShape(None)) + self.assertEqual(unknown_shapes, dataset.output_shapes) + + wrong_shapes = (tensor_shape.TensorShape(2), + tensor_shape.TensorShape((3, 10))) + iterator = ( + dataset.apply(batching.assert_element_shape(wrong_shapes)) + .make_initializable_iterator()) + init_op = iterator.initializer + get_next = iterator.get_next() + with self.test_session() as sess: + sess.run(init_op) + with self.assertRaises(errors.InvalidArgumentError): + sess.run(get_next) + + def test_assert_partial_element_shape(self): + + def create_dataset(_): + return (array_ops.ones(2, dtype=dtypes.float32), + array_ops.zeros((3, 4), dtype=dtypes.int32)) + + dataset = dataset_ops.Dataset.range(5).map(create_dataset) + partial_expected_shape = (tensor_shape.TensorShape(None), # Unknown shape + tensor_shape.TensorShape((None, 4))) # Partial shape + result = dataset.apply( + batching.assert_element_shape(partial_expected_shape)) + # Partial shapes are merged with actual shapes: + actual_shapes = (tensor_shape.TensorShape(2), + tensor_shape.TensorShape((3, 4))) + self.assertEqual(actual_shapes, result.output_shapes) + + iterator = result.make_initializable_iterator() + init_op = iterator.initializer + get_next = iterator.get_next() + with self.test_session() as sess: + sess.run(init_op) + for _ in range(5): + sess.run(get_next) + with self.assertRaises(errors.OutOfRangeError): + sess.run(get_next) + + def test_assert_wrong_partial_element_shape(self): def create_dataset(_): return (array_ops.ones(2, dtype=dtypes.float32), @@ -756,11 +845,41 @@ class RestructuredDatasetTest(test.TestCase): dataset = dataset_ops.Dataset.range(3).map(create_dataset) wrong_shapes = (tensor_shape.TensorShape(2), - tensor_shape.TensorShape((3, 10))) + tensor_shape.TensorShape((None, 10))) with self.assertRaises(ValueError): dataset.apply(batching.assert_element_shape(wrong_shapes)) - def test_assert_wrong_element_shape_on_unknown_shape_dataset(self): + def test_assert_partial_element_shape_on_unknown_shape_dataset(self): + + def create_unknown_shape_dataset(x): + return script_ops.py_func( + lambda _: ( # pylint: disable=g-long-lambda + np.ones(2, dtype=np.float32), + np.zeros((3, 4), dtype=np.int32)), + [x], + [dtypes.float32, dtypes.int32]) + + dataset = dataset_ops.Dataset.range(5).map(create_unknown_shape_dataset) + unknown_shapes = (tensor_shape.TensorShape(None), + tensor_shape.TensorShape(None)) + self.assertEqual(unknown_shapes, dataset.output_shapes) + + expected_shapes = (tensor_shape.TensorShape(2), + tensor_shape.TensorShape((None, 4))) + result = dataset.apply(batching.assert_element_shape(expected_shapes)) + self.assertEqual(expected_shapes, result.output_shapes) + + iterator = result.make_initializable_iterator() + init_op = iterator.initializer + get_next = iterator.get_next() + with self.test_session() as sess: + sess.run(init_op) + for _ in range(5): + sess.run(get_next) + with self.assertRaises(errors.OutOfRangeError): + sess.run(get_next) + + def test_assert_wrong_partial_element_shape_on_unknown_shape_dataset(self): def create_unknown_shape_dataset(x): return script_ops.py_func( @@ -776,7 +895,7 @@ class RestructuredDatasetTest(test.TestCase): self.assertEqual(unknown_shapes, dataset.output_shapes) wrong_shapes = (tensor_shape.TensorShape(2), - tensor_shape.TensorShape((3, 10))) + tensor_shape.TensorShape((None, 10))) iterator = ( dataset.apply(batching.assert_element_shape(wrong_shapes)) .make_initializable_iterator()) diff --git a/tensorflow/contrib/data/python/kernel_tests/csv_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/csv_dataset_op_test.py index 2a0e64caeb..63bffd023f 100644 --- a/tensorflow/contrib/data/python/kernel_tests/csv_dataset_op_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/csv_dataset_op_test.py @@ -51,7 +51,7 @@ class CsvDatasetOpTest(test.TestCase): assert ds1.output_classes == ds2.output_classes next1 = ds1.make_one_shot_iterator().get_next() next2 = ds2.make_one_shot_iterator().get_next() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Run through datasets and check that outputs match, or errors match. while True: try: @@ -138,7 +138,7 @@ class CsvDatasetOpTest(test.TestCase): filenames = self._setup_files(inputs, linebreak, compression_type) kwargs['compression_type'] = compression_type with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: dataset = readers.CsvDataset(filenames, **kwargs) self._verify_output_or_err(sess, dataset, expected_output, expected_err_re) @@ -192,7 +192,7 @@ class CsvDatasetOpTest(test.TestCase): inputs = [['1,"2"3",4', '1,"2"3",4",5,5', 'a,b,"c"d"', 'e,f,g']] filenames = self._setup_files(inputs) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: dataset = readers.CsvDataset(filenames, record_defaults=record_defaults) dataset = dataset.apply(error_ops.ignore_errors()) self._verify_output_or_err(sess, dataset, [['e', 'f', 'g']]) @@ -202,7 +202,7 @@ class CsvDatasetOpTest(test.TestCase): inputs = [['1,2"3,4', 'a,b,c"d', '9,8"7,6,5', 'e,f,g']] filenames = self._setup_files(inputs) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: dataset = readers.CsvDataset(filenames, record_defaults=record_defaults) dataset = dataset.apply(error_ops.ignore_errors()) self._verify_output_or_err(sess, dataset, [['e', 'f', 'g']]) @@ -378,7 +378,7 @@ class CsvDatasetOpTest(test.TestCase): file_path, batch_size=1, shuffle=False, num_epochs=1) next_batch = ds.make_one_shot_iterator().get_next() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: result = list(sess.run(next_batch).values()) self.assertEqual(result, sorted(result)) diff --git a/tensorflow/contrib/data/python/kernel_tests/filter_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/filter_dataset_op_test.py new file mode 100644 index 0000000000..6d01bf585c --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/filter_dataset_op_test.py @@ -0,0 +1,76 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Benchmarks FilterDataset input pipeline op.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import time + +import numpy as np + +from tensorflow.contrib.data.python.ops import optimization +from tensorflow.python.client import session +from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.framework import ops +from tensorflow.python.ops import math_ops +from tensorflow.python.platform import test + + +class FilterBenchmark(test.Benchmark): + + # This benchmark compares the performance of pipeline with multiple chained + # filter with and without filter fusion. + def benchmarkFilters(self): + chain_lengths = [0, 1, 2, 5, 10, 20, 50] + for chain_length in chain_lengths: + self._benchmarkFilters(chain_length, False) + self._benchmarkFilters(chain_length, True) + + def _benchmarkFilters(self, chain_length, optimize_dataset): + with ops.Graph().as_default(): + dataset = dataset_ops.Dataset.from_tensors(5).repeat(None) + for _ in range(chain_length): + dataset = dataset.filter(lambda x: math_ops.greater_equal(x - 5, 0)) + if optimize_dataset: + dataset = dataset.apply(optimization.optimize(["filter_fusion"])) + + iterator = dataset.make_one_shot_iterator() + next_element = iterator.get_next() + + with session.Session() as sess: + for _ in range(10): + sess.run(next_element.op) + deltas = [] + for _ in range(100): + start = time.time() + for _ in range(100): + sess.run(next_element.op) + end = time.time() + deltas.append(end - start) + + median_wall_time = np.median(deltas) / 100 + opt_mark = "opt" if optimize_dataset else "no-opt" + print("Filter dataset {} chain length: {} Median wall time: {}".format( + opt_mark, chain_length, median_wall_time)) + self.report_benchmark( + iters=1000, + wall_time=median_wall_time, + name="benchmark_filter_dataset_chain_latency_{}_{}".format( + opt_mark, chain_length)) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/data/python/kernel_tests/indexed_dataset_ops_test.py b/tensorflow/contrib/data/python/kernel_tests/indexed_dataset_ops_test.py new file mode 100644 index 0000000000..db2ab815ee --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/indexed_dataset_ops_test.py @@ -0,0 +1,78 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for experimental indexed dataset ops.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import unittest + +from tensorflow.contrib.data.python.ops import contrib_op_loader # pylint: disable=unused-import +from tensorflow.contrib.data.python.ops import gen_dataset_ops +from tensorflow.contrib.data.python.ops import indexed_dataset_ops +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import errors +from tensorflow.python.framework import ops +from tensorflow.python.ops import array_ops +from tensorflow.python.platform import test + + +class IndexedDatasetOpsTest(test.TestCase): + + def testLowLevelIndexedDatasetOps(self): + identity = gen_dataset_ops.identity_indexed_dataset( + ops.convert_to_tensor(16, dtype=dtypes.uint64)) + handle = gen_dataset_ops.materialized_index_dataset_handle( + container="", + shared_name="", + output_types=[dtypes.uint64], + output_shapes=[[]]) + materialize = gen_dataset_ops.indexed_dataset_materialize(identity, handle) + index = array_ops.placeholder(dtypes.uint64) + get_op = gen_dataset_ops.indexed_dataset_get( + handle, index, output_types=[dtypes.uint64], output_shapes=[[]]) + + with self.test_session() as sess: + sess.run(materialize) + self.assertEqual([3], sess.run(get_op, feed_dict={index: 3})) + + def testIdentityIndexedDataset(self): + ds = indexed_dataset_ops.IdentityIndexedDataset(16) + materialized = ds.materialize() + with self.test_session() as sess: + sess.run(materialized.initializer) + placeholder = array_ops.placeholder(dtypes.uint64, shape=[]) + for i in range(16): + output = sess.run( + materialized.get(placeholder), feed_dict={placeholder: i}) + self.assertEqual([i], output) + with self.assertRaises(errors.InvalidArgumentError): + sess.run(materialized.get(placeholder), feed_dict={placeholder: 16}) + + @unittest.skip("Requisite functionality currently unimplemented.") + def testIdentityIndexedDatasetIterator(self): + ds = indexed_dataset_ops.IdentityIndexedDataset(16) + itr = ds.make_initializable_iterator() + n = itr.get_next() + with self.test_session() as sess: + sess.run(itr.initializer) + for i in range(16): + output = sess.run(n) + self.assertEqual(i, output) + with self.assertRaises(errors.OutOfRangeError): + sess.run(n) + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/data/python/kernel_tests/interleave_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/interleave_dataset_op_test.py index 44c3325a3d..7a3215f6cc 100644 --- a/tensorflow/contrib/data/python/kernel_tests/interleave_dataset_op_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/interleave_dataset_op_test.py @@ -777,6 +777,34 @@ class ParallelInterleaveDatasetTest(test.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(self.next_element) + def testShutdownRace(self): + dataset = dataset_ops.Dataset.range(20) + map_fn = lambda x: dataset_ops.Dataset.range(20 * x, 20 * (x + 1)) + dataset = dataset.apply( + interleave_ops.parallel_interleave( + map_fn, + cycle_length=3, + sloppy=False, + buffer_output_elements=1, + prefetch_input_elements=0)) + dataset = dataset.batch(32) + iterator = dataset.make_initializable_iterator() + next_element = iterator.get_next() + + results = [] + with self.test_session() as sess: + for _ in range(2): + elements = [] + sess.run(iterator.initializer) + try: + while True: + elements.extend(sess.run(next_element)) + except errors.OutOfRangeError: + pass + results.append(elements) + + self.assertAllEqual(results[0], results[1]) + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/data/python/kernel_tests/iterator_ops_test.py b/tensorflow/contrib/data/python/kernel_tests/iterator_ops_test.py index 77148aceec..704c0d1eb2 100644 --- a/tensorflow/contrib/data/python/kernel_tests/iterator_ops_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/iterator_ops_test.py @@ -60,7 +60,7 @@ class CheckpointInputPipelineHookTest(test.TestCase): meta_filename = ckpt_path + '.meta' saver_lib.import_meta_graph(meta_filename) saver = saver_lib.Saver() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: saver.restore(sess, ckpt_path) return sess.run(ops.get_collection('my_vars')) diff --git a/tensorflow/contrib/data/python/kernel_tests/lmdb_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/lmdb_dataset_op_test.py new file mode 100644 index 0000000000..7bc582ebaa --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/lmdb_dataset_op_test.py @@ -0,0 +1,66 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for LMDBDatasetOp.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os +import shutil + +from tensorflow.contrib.data.python.ops import readers +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import errors +from tensorflow.python.platform import test +from tensorflow.python.util import compat + +prefix_path = "tensorflow/core/lib" + + +class LMDBDatasetTest(test.TestCase): + + def setUp(self): + super(LMDBDatasetTest, self).setUp() + # Copy database out because we need the path to be writable to use locks. + path = os.path.join(prefix_path, "lmdb", "testdata", "data.mdb") + self.db_path = os.path.join(self.get_temp_dir(), "data.mdb") + shutil.copy(path, self.db_path) + + def testReadFromFile(self): + filename = self.db_path + + filenames = constant_op.constant([filename], dtypes.string) + num_repeats = 2 + + dataset = readers.LMDBDataset(filenames).repeat(num_repeats) + iterator = dataset.make_initializable_iterator() + init_op = iterator.initializer + get_next = iterator.get_next() + + with self.test_session() as sess: + sess.run(init_op) + for _ in range(num_repeats): # Dataset is repeated. + for i in range(10): # 10 records. + k = compat.as_bytes(str(i)) + v = compat.as_bytes(str(chr(ord("a") + i))) + self.assertEqual((k, v), sess.run(get_next)) + with self.assertRaises(errors.OutOfRangeError): + sess.run(get_next) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/data/python/kernel_tests/map_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/map_dataset_op_test.py index 009e21a34c..dc9d56dd53 100644 --- a/tensorflow/contrib/data/python/kernel_tests/map_dataset_op_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/map_dataset_op_test.py @@ -139,7 +139,7 @@ class MapDatasetTest(test.TestCase): with ops.Graph().as_default() as g: captured_init_op, init_op, get_next = _build_graph() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(captured_init_op) sess.run(init_op) for i in range(10): diff --git a/tensorflow/contrib/data/python/kernel_tests/map_defun_op_test.py b/tensorflow/contrib/data/python/kernel_tests/map_defun_op_test.py index a711325dae..73cde40305 100644 --- a/tensorflow/contrib/data/python/kernel_tests/map_defun_op_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/map_defun_op_test.py @@ -31,47 +31,57 @@ from tensorflow.python.platform import test class MapDefunTest(test.TestCase): - def testMapDefun_Simple(self): + def testMapDefunSimple(self): @function.Defun(dtypes.int32) def simple_fn(x): return x * 2 + 3 - with self.test_session(): - nums = [[1, 2], [3, 4], [5, 6]] - elems = constant_op.constant(nums, dtype=dtypes.int32, name="data") - r = map_defun.map_defun(simple_fn, [elems], [dtypes.int32], [(2,)])[0] - expected = elems * 2 + 3 - self.assertAllEqual(self.evaluate(r), self.evaluate(expected)) + nums = [[1, 2], [3, 4], [5, 6]] + elems = constant_op.constant(nums, dtype=dtypes.int32, name="data") + r = map_defun.map_defun(simple_fn, [elems], [dtypes.int32], [(2,)])[0] + expected = elems * 2 + 3 + self.assertAllEqual(self.evaluate(r), self.evaluate(expected)) - def testMapDefun_MismatchedTypes(self): + def testMapDefunMismatchedTypes(self): @function.Defun(dtypes.int32) def fn(x): return math_ops.cast(x, dtypes.float64) - with self.test_session(): - nums = [1, 2, 3, 4, 5, 6] - elems = constant_op.constant(nums, dtype=dtypes.int32, name="data") - r = map_defun.map_defun(fn, [elems], [dtypes.int32], [()])[0] - with self.assertRaises(errors.InvalidArgumentError): - self.evaluate(r) + nums = [1, 2, 3, 4, 5, 6] + elems = constant_op.constant(nums, dtype=dtypes.int32, name="data") + r = map_defun.map_defun(fn, [elems], [dtypes.int32], [()])[0] + with self.assertRaises(errors.InvalidArgumentError): + self.evaluate(r) + + def testMapDefunReduceDim(self): + # Tests where the output has a different rank from the input + + @function.Defun(dtypes.int32) + def fn(x): + return array_ops.gather(x, 0) + + nums = [[1, 2], [3, 4], [5, 6]] + elems = constant_op.constant(nums, dtype=dtypes.int32, name="data") + r = map_defun.map_defun(fn, [elems], [dtypes.int32], [()])[0] + expected = constant_op.constant([1, 3, 5]) + self.assertAllEqual(self.evaluate(r), self.evaluate(expected)) - def testMapDefun_MultipleOutputs(self): + def testMapDefunMultipleOutputs(self): @function.Defun(dtypes.int32) def fn(x): return (x, math_ops.cast(x * 2 + 3, dtypes.float64)) - with self.test_session(): - nums = [[1, 2], [3, 4], [5, 6]] - elems = constant_op.constant(nums, dtype=dtypes.int32, name="data") - r = map_defun.map_defun(fn, [elems], [dtypes.int32, dtypes.float64], - [(2,), (2,)]) - expected = [elems, elems * 2 + 3] - self.assertAllEqual(self.evaluate(r), self.evaluate(expected)) + nums = [[1, 2], [3, 4], [5, 6]] + elems = constant_op.constant(nums, dtype=dtypes.int32, name="data") + r = map_defun.map_defun(fn, [elems], [dtypes.int32, dtypes.float64], [(2,), + (2,)]) + expected = [elems, elems * 2 + 3] + self.assertAllEqual(self.evaluate(r), self.evaluate(expected)) - def testMapDefun_ShapeInference(self): + def testMapDefunShapeInference(self): @function.Defun(dtypes.int32) def fn(x): @@ -82,7 +92,7 @@ class MapDefunTest(test.TestCase): result = map_defun.map_defun(fn, [elems], [dtypes.int32], [(2,)])[0] self.assertEqual(result.get_shape(), (3, 2)) - def testMapDefun_PartialShapeInference(self): + def testMapDefunPartialShapeInference(self): @function.Defun(dtypes.int32) def fn(x): @@ -92,7 +102,7 @@ class MapDefunTest(test.TestCase): result = map_defun.map_defun(fn, [elems], [dtypes.int32], [(2,)]) self.assertEqual(result[0].get_shape().as_list(), [None, 2]) - def testMapDefun_RaisesErrorOnRuntimeShapeMismatch(self): + def testMapDefunRaisesErrorOnRuntimeShapeMismatch(self): @function.Defun(dtypes.int32, dtypes.int32) def fn(x, y): @@ -108,7 +118,7 @@ class MapDefunTest(test.TestCase): "All inputs must have the same dimension 0."): sess.run(result, feed_dict={elems1: [1, 2, 3, 4, 5], elems2: [1, 2, 3]}) - def testMapDefun_RaisesDefunError(self): + def testMapDefunRaisesDefunError(self): @function.Defun(dtypes.int32) def fn(x): @@ -117,9 +127,8 @@ class MapDefunTest(test.TestCase): elems = constant_op.constant([0, 0, 0, 37, 0]) result = map_defun.map_defun(fn, [elems], [dtypes.int32], [()]) - with self.test_session(): - with self.assertRaises(errors.InvalidArgumentError): - self.evaluate(result) + with self.assertRaises(errors.InvalidArgumentError): + self.evaluate(result) if __name__ == "__main__": diff --git a/tensorflow/contrib/data/python/kernel_tests/optimization/BUILD b/tensorflow/contrib/data/python/kernel_tests/optimization/BUILD new file mode 100644 index 0000000000..b299e0736f --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/optimization/BUILD @@ -0,0 +1,61 @@ +package(default_visibility = ["//tensorflow:internal"]) + +licenses(["notice"]) # Apache 2.0 + +exports_files(["LICENSE"]) + +load("//tensorflow:tensorflow.bzl", "py_test") + +py_test( + name = "map_vectorization_test", + size = "small", + srcs = ["map_vectorization_test.py"], + srcs_version = "PY2AND3", + deps = [ + "//tensorflow/contrib/data/python/kernel_tests:test_utils", + "//tensorflow/contrib/data/python/ops:optimization", + "//tensorflow/python:check_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:constant_op", + "//tensorflow/python:dtypes", + "//tensorflow/python:errors", + "//tensorflow/python:framework_ops", + "//tensorflow/python:math_ops", + "//tensorflow/python:session", + "//tensorflow/python/data/ops:dataset_ops", + "//third_party/py/numpy", + "@absl_py//absl/testing:parameterized", + ], +) + +py_test( + name = "map_and_filter_fusion_test", + size = "medium", + srcs = ["map_and_filter_fusion_test.py"], + srcs_version = "PY2AND3", + deps = [ + "//tensorflow/contrib/data/python/ops:optimization", + "//tensorflow/python:client_testlib", + "//tensorflow/python:constant_op", + "//tensorflow/python:dtypes", + "//tensorflow/python:errors", + "//tensorflow/python:math_ops", + "//tensorflow/python/data/ops:dataset_ops", + "@absl_py//absl/testing:parameterized", + ], +) + +py_test( + name = "latency_all_edges_test", + size = "small", + srcs = ["latency_all_edges_test.py"], + srcs_version = "PY2AND3", + deps = [ + "//tensorflow/contrib/data/python/kernel_tests:stats_dataset_test_base", + "//tensorflow/contrib/data/python/ops:optimization", + "//tensorflow/contrib/data/python/ops:stats_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:errors", + "//tensorflow/python/data/ops:dataset_ops", + ], +) diff --git a/tensorflow/contrib/data/python/kernel_tests/optimization/latency_all_edges_test.py b/tensorflow/contrib/data/python/kernel_tests/optimization/latency_all_edges_test.py new file mode 100644 index 0000000000..1850b6921a --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/optimization/latency_all_edges_test.py @@ -0,0 +1,58 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for the LatencyAllEdges optimization.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.contrib.data.python.kernel_tests import stats_dataset_test_base +from tensorflow.contrib.data.python.ops import optimization +from tensorflow.contrib.data.python.ops import stats_ops +from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.framework import errors +from tensorflow.python.platform import test + + +class OptimizeStatsDatasetTest(stats_dataset_test_base.StatsDatasetTestBase): + + def testLatencyStatsOptimization(self): + + stats_aggregator = stats_ops.StatsAggregator() + dataset = dataset_ops.Dataset.from_tensors(1).apply( + optimization.assert_next( + ["LatencyStats", "Map", "LatencyStats", "Prefetch", + "LatencyStats"])).map(lambda x: x * x).prefetch(1).apply( + optimization.optimize(["latency_all_edges"])).apply( + stats_ops.set_stats_aggregator(stats_aggregator)) + iterator = dataset.make_initializable_iterator() + get_next = iterator.get_next() + summary_t = stats_aggregator.get_summary() + + with self.test_session() as sess: + sess.run(iterator.initializer) + self.assertEqual(1 * 1, sess.run(get_next)) + with self.assertRaises(errors.OutOfRangeError): + sess.run(get_next) + summary_str = sess.run(summary_t) + self._assertSummaryHasCount(summary_str, + "record_latency_TensorDataset/_1", 1) + self._assertSummaryHasCount(summary_str, "record_latency_MapDataset/_4", + 1) + self._assertSummaryHasCount(summary_str, + "record_latency_PrefetchDataset/_6", 1) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/data/python/kernel_tests/optimization/map_and_filter_fusion_test.py b/tensorflow/contrib/data/python/kernel_tests/optimization/map_and_filter_fusion_test.py new file mode 100644 index 0000000000..586b4bee5f --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/optimization/map_and_filter_fusion_test.py @@ -0,0 +1,224 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for the MapAndFilterFusion optimization.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from absl.testing import parameterized + +from tensorflow.contrib.data.python.ops import optimization +from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import errors +from tensorflow.python.ops import math_ops +from tensorflow.python.platform import test + + +class MapAndFilterFusionTest(test.TestCase, parameterized.TestCase): + + @staticmethod + def map_functions(): + identity = lambda x: x + increment = lambda x: x + 1 + + def increment_and_square(x): + y = x + 1 + return y * y + + functions = [identity, increment, increment_and_square] + tests = [] + for i, fun1 in enumerate(functions): + for j, fun2 in enumerate(functions): + tests.append(( + "test_{}_{}".format(i, j), + [fun1, fun2], + )) + for k, fun3 in enumerate(functions): + tests.append(( + "test_{}_{}_{}".format(i, j, k), + [fun1, fun2, fun3], + )) + + swap = lambda x, n: (n, x) + tests.append(( + "swap1", + [lambda x: (x, 42), swap], + )) + tests.append(( + "swap2", + [lambda x: (x, 42), swap, swap], + )) + return tuple(tests) + + @parameterized.named_parameters(*map_functions.__func__()) + def testMapFusion(self, functions): + dataset = dataset_ops.Dataset.range(5).apply( + optimization.assert_next(["Map", "Prefetch"])) + for function in functions: + dataset = dataset.map(function) + + dataset = dataset.prefetch(0).apply(optimization.optimize(["map_fusion"])) + iterator = dataset.make_one_shot_iterator() + get_next = iterator.get_next() + with self.test_session() as sess: + for x in range(5): + result = sess.run(get_next) + r = x + for function in functions: + if isinstance(r, tuple): + r = function(*r) # Pass tuple as multiple arguments. + else: + r = function(r) + self.assertAllEqual(r, result) + + with self.assertRaises(errors.OutOfRangeError): + sess.run(get_next) + + @staticmethod + def map_and_filter_functions(): + identity = lambda x: x + increment = lambda x: x + 1 + minus_five = lambda x: x - 5 + + def increment_and_square(x): + y = x + 1 + return y * y + + take_all = lambda x: constant_op.constant(True) + is_zero = lambda x: math_ops.equal(x, 0) + is_odd = lambda x: math_ops.equal(x % 2, 0) + greater = lambda x: math_ops.greater(x + 5, 0) + + functions = [identity, increment, minus_five, increment_and_square] + filters = [take_all, is_zero, is_odd, greater] + tests = [] + + for x, fun in enumerate(functions): + for y, predicate in enumerate(filters): + tests.append(("mixed_{}_{}".format(x, y), fun, predicate)) + + # Multi output + tests.append(("multiOne", lambda x: (x, x), + lambda x, y: constant_op.constant(True))) + tests.append( + ("multiTwo", lambda x: (x, 2), + lambda x, y: math_ops.equal(x * math_ops.cast(y, dtypes.int64), 0))) + return tuple(tests) + + @parameterized.named_parameters(*map_and_filter_functions.__func__()) + def testMapFilterFusion(self, function, predicate): + dataset = dataset_ops.Dataset.range(10).apply( + optimization.assert_next( + ["Map", + "FilterByLastComponent"])).map(function).filter(predicate).apply( + optimization.optimize(["map_and_filter_fusion"])) + self._testMapAndFilter(dataset, function, predicate) + + def _testMapAndFilter(self, dataset, function, predicate): + iterator = dataset.make_one_shot_iterator() + get_next = iterator.get_next() + with self.test_session() as sess: + for x in range(10): + r = function(x) + if isinstance(r, tuple): + b = predicate(*r) # Pass tuple as multiple arguments. + else: + b = predicate(r) + if sess.run(b): + result = sess.run(get_next) + self.assertAllEqual(r, result) + with self.assertRaises(errors.OutOfRangeError): + sess.run(get_next) + + def testAdditionalInputs(self): + a = constant_op.constant(3, dtype=dtypes.int64) + b = constant_op.constant(4, dtype=dtypes.int64) + some_tensor = math_ops.mul(a, b) + function = lambda x: x * x + + def predicate(y): + return math_ops.less(math_ops.cast(y, dtypes.int64), some_tensor) + + # We are currently not supporting functions with additional inputs. + dataset = dataset_ops.Dataset.range(10).apply( + optimization.assert_next( + ["Map", "Filter"])).map(function).filter(predicate).apply( + optimization.optimize(["map_and_filter_fusion"])) + + self._testMapAndFilter(dataset, function, predicate) + + @staticmethod + def filter_functions(): + take_all = lambda x: constant_op.constant(True) + is_zero = lambda x: math_ops.equal(x, 0) + greater = lambda x: math_ops.greater(x + 5, 0) + + tests = [] + filters = [take_all, is_zero, greater] + identity = lambda x: x + for x, predicate_1 in enumerate(filters): + for y, predicate_2 in enumerate(filters): + tests.append(("mixed_{}_{}".format(x, y), identity, + [predicate_1, predicate_2])) + for z, predicate_3 in enumerate(filters): + tests.append(("mixed_{}_{}_{}".format(x, y, z), identity, + [predicate_1, predicate_2, predicate_3])) + + take_all_multiple = lambda x, y: constant_op.constant(True) + # Multi output + tests.append(("multiOne", lambda x: (x, x), + [take_all_multiple, take_all_multiple])) + tests.append(("multiTwo", lambda x: (x, 2), [ + take_all_multiple, + lambda x, y: math_ops.equal(x * math_ops.cast(y, dtypes.int64), 0) + ])) + return tuple(tests) + + @parameterized.named_parameters(*filter_functions.__func__()) + def testFilterFusion(self, map_function, predicates): + dataset = dataset_ops.Dataset.range(5).apply( + optimization.assert_next(["Map", "Filter", + "Prefetch"])).map(map_function) + for predicate in predicates: + dataset = dataset.filter(predicate) + + dataset = dataset.prefetch(0).apply( + optimization.optimize(["filter_fusion"])) + iterator = dataset.make_one_shot_iterator() + get_next = iterator.get_next() + with self.test_session() as sess: + for x in range(5): + r = map_function(x) + filtered = False + for predicate in predicates: + if isinstance(r, tuple): + b = predicate(*r) # Pass tuple as multiple arguments. + else: + b = predicate(r) + if not sess.run(b): + filtered = True + break + + if not filtered: + result = sess.run(get_next) + self.assertAllEqual(r, result) + with self.assertRaises(errors.OutOfRangeError): + sess.run(get_next) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/data/python/kernel_tests/optimization/map_vectorization_test.py b/tensorflow/contrib/data/python/kernel_tests/optimization/map_vectorization_test.py new file mode 100644 index 0000000000..e2c9bc82df --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/optimization/map_vectorization_test.py @@ -0,0 +1,219 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for the MapVectorization optimization.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import time + +from absl.testing import parameterized +import numpy as np + +from tensorflow.contrib.data.python.kernel_tests import test_utils +from tensorflow.contrib.data.python.ops import optimization +from tensorflow.python.client import session +from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import errors +from tensorflow.python.framework import ops +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import check_ops +from tensorflow.python.ops import math_ops +from tensorflow.python.platform import test + + +class MapVectorizationTest(test_utils.DatasetTestBase, parameterized.TestCase): + + def _get_test_datasets(self, + base_dataset, + map_fn, + num_parallel_calls=None, + expect_optimized=True): + """Given base dataset and map fn, creates test datasets. + + Returns a tuple of (unoptimized, dataset, optimized dataset). The + unoptimized dataset has the assertion that Batch follows Map. The optimized + dataset has the assertion that Map follows Batch, and has the + "map_vectorization" optimization applied. + + Args: + base_dataset: Input dataset to map->batch + map_fn: Map function to use + num_parallel_calls: (Optional.) num_parallel_calls argument for map + expect_optimized: (Optional.) Whether we expect the optimization to take + place, in which case we will assert that Batch is followed by Map, + otherwise Map followed by Batch. Defaults to True. + + Returns: + Tuple of (unoptimized dataset, optimized dataset). + """ + map_node_name = "Map" if num_parallel_calls is None else "ParallelMap" + batch_size = 100 + + def _make_dataset(node_names): + return base_dataset.apply(optimization.assert_next(node_names)).map( + map_fn, num_parallel_calls=num_parallel_calls).batch(batch_size) + + unoptimized = _make_dataset([map_node_name, "Batch"]) + optimized = _make_dataset(["Batch", map_node_name] if expect_optimized else + [map_node_name, "Batch"]).apply( + optimization.optimize(["map_vectorization"])) + + return unoptimized, optimized + + @parameterized.named_parameters( + ("Basic", lambda x: (x, x + 1), None), + ("Parallel", lambda x: (x, x + 1), 12), + ("Gather", lambda x: array_ops.gather(x, 0), 12), + ) + def testOptimization(self, map_fn, num_parallel_calls): + base_dataset = dataset_ops.Dataset.from_tensor_slices([[1, 2], + [3, 4]]).repeat(5) + unoptimized, optimized = self._get_test_datasets(base_dataset, map_fn, + num_parallel_calls) + self._assert_datasets_equal(unoptimized, optimized) + + def testOptimizationBadMapFn(self): + # Test map functions that give an error + def map_fn(x): + # x has leading dimension 5, this will raise an error + return array_ops.gather(x, 10) + + base_dataset = dataset_ops.Dataset.range(5).repeat(5).batch( + 5, drop_remainder=True) + _, optimized = self._get_test_datasets(base_dataset, map_fn) + nxt = optimized.make_one_shot_iterator().get_next() + with self.assertRaisesRegexp(errors.InvalidArgumentError, + r"indices = 10 is not in \[0, 5\)"): + self.evaluate(nxt) + + def testOptimizationWithCapturedInputs(self): + # Tests that vectorization works with captured inputs + def map_fn(x): + return x + y + + y = constant_op.constant(1, shape=(2,)) + base_dataset = dataset_ops.Dataset.from_tensor_slices([[1, 2], + [3, 4]]).repeat(5) + # TODO(rachelim): when this optimization works, turn on expect_optimized + unoptimized, optimized = self._get_test_datasets( + base_dataset, map_fn, expect_optimized=False) + self._assert_datasets_equal(optimized, unoptimized) + + def testOptimizationIgnoreStateful(self): + + def map_fn(x): + with ops.control_dependencies([check_ops.assert_equal(x, 0)]): + return array_ops.identity(x) + + base_dataset = dataset_ops.Dataset.from_tensor_slices([[1, 2], + [3, 4]]).repeat(5) + unoptimized, optimized = self._get_test_datasets( + base_dataset, map_fn, expect_optimized=False) + self._assert_datasets_raise_same_error( + unoptimized, optimized, errors.InvalidArgumentError, + [("OneShotIterator", "OneShotIterator_1", 1), + ("IteratorGetNext", "IteratorGetNext_1", 1)]) + + def testOptimizationIgnoreRagged(self): + # Make sure we ignore inputs that might not be uniformly sized + def map_fn(x): + return array_ops.gather(x, 0) + + # output_shape = (?,) + base_dataset = dataset_ops.Dataset.range(20).batch(3, drop_remainder=False) + unoptimized, optimized = self._get_test_datasets( + base_dataset, map_fn, expect_optimized=False) + self._assert_datasets_equal(unoptimized, optimized) + + def testOptimizationIgnoreRaggedMap(self): + # Don't optimize when the output of the map fn shapes are unknown. + def map_fn(x): + return array_ops.tile(x, x) + + base_dataset = dataset_ops.Dataset.range(20).batch(1, drop_remainder=True) + unoptimized, optimized = self._get_test_datasets( + base_dataset, map_fn, expect_optimized=False) + self._assert_datasets_raise_same_error( + unoptimized, optimized, errors.InvalidArgumentError, + [("OneShotIterator", "OneShotIterator_1", 1), + ("IteratorGetNext", "IteratorGetNext_1", 1)]) + + +class MapVectorizationBenchmark(test.Benchmark): + # TODO(rachelim): Add a benchmark for more expensive transformations, such as + # vgg_preprocessing. + + def _run(self, x, num_iters=100, name=None): + deltas = [] + with session.Session() as sess: + for _ in range(5): + # Warm up session... + sess.run(x) + for _ in range(num_iters): + start = time.time() + sess.run(x) + end = time.time() + deltas.append(end - start) + median_time = np.median(deltas) + self.report_benchmark(iters=num_iters, wall_time=median_time, name=name) + return median_time + + def benchmark_CheapFns(self): + + input_sizes = [(10, 10, 3), (10, 100, 300)] + batch_size = 1000 + for input_size in input_sizes: + input_dataset = dataset_ops.Dataset.from_tensor_slices( + (np.random.rand(*input_size), np.random.rand(*input_size))).repeat() + for map_fn, str_id in self._get_known_cheap_fns(): + self._compare(input_dataset, map_fn, batch_size, input_size, str_id) + + def _compare(self, input_dataset, map_fn, batch_size, input_size, str_id): + num_elems = np.prod(input_size) + name_template = "{}__batch_size_{}_input_size_{}_{}" + unoptimized = input_dataset.map(map_fn).batch(batch_size) + unoptimized_op = unoptimized.make_one_shot_iterator().get_next() + + optimized = unoptimized.apply(optimization.optimize(["map_vectorization"])) + optimized_op = optimized.make_one_shot_iterator().get_next() + + unoptimized_time = self._run( + unoptimized_op, + name=name_template.format(str_id, batch_size, num_elems, "unoptimized")) + optimized_time = self._run( + optimized_op, + name=name_template.format(str_id, batch_size, num_elems, "optimized")) + + print("Batch size: {}\n" + "Input size: {}\n" + "Transformation: {}\n" + "Speedup: {}\n".format(batch_size, input_size, str_id, + (unoptimized_time / optimized_time))) + + def _get_known_cheap_fns(self): + return [ + (lambda *args: [array_ops.identity(x) for x in args], "identity"), + (lambda *args: [x + 1 for x in args], "add_const"), + (lambda *args: args[0], "select"), + (lambda *args: [math_ops.cast(x, dtypes.float64) for x in args], + "cast"), + ] + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py index ae147b4fa7..446bf8d749 100644 --- a/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py @@ -19,14 +19,10 @@ from __future__ import print_function from absl.testing import parameterized -from tensorflow.contrib.data.python.kernel_tests import stats_dataset_test_base from tensorflow.contrib.data.python.ops import optimization -from tensorflow.contrib.data.python.ops import stats_ops from tensorflow.python.data.ops import dataset_ops -from tensorflow.python.framework import constant_op -from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors -from tensorflow.python.ops import math_ops +from tensorflow.python.ops import random_ops from tensorflow.python.platform import test @@ -105,176 +101,17 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(get_next) - def testFunctionLibraryDefinitionModification(self): - dataset = dataset_ops.Dataset.from_tensors(0).map(lambda x: x).apply( - optimization.optimize(["_test_only_function_rename"])) - iterator = dataset.make_one_shot_iterator() - get_next = iterator.get_next() - - with self.test_session() as sess: - with self.assertRaisesRegexp(errors.NotFoundError, - "Function .* is not defined."): - sess.run(get_next) - - @staticmethod - def map_functions(): - identity = lambda x: x - increment = lambda x: x + 1 - - def increment_and_square(x): - y = x + 1 - return y * y - - functions = [identity, increment, increment_and_square] - tests = [] - for i, fun1 in enumerate(functions): - for j, fun2 in enumerate(functions): - tests.append(( - "test_{}_{}".format(i, j), - [fun1, fun2], - )) - for k, fun3 in enumerate(functions): - tests.append(( - "test_{}_{}_{}".format(i, j, k), - [fun1, fun2, fun3], - )) - - swap = lambda x, n: (n, x) - tests.append(( - "swap1", - [lambda x: (x, 42), swap], - )) - tests.append(( - "swap2", - [lambda x: (x, 42), swap, swap], - )) - return tuple(tests) - - @parameterized.named_parameters(*map_functions.__func__()) - def testMapFusion(self, functions): - dataset = dataset_ops.Dataset.range(5).apply( - optimization.assert_next(["Map", "Prefetch"])) - for function in functions: - dataset = dataset.map(function) - - dataset = dataset.prefetch(0).apply(optimization.optimize(["map_fusion"])) - iterator = dataset.make_one_shot_iterator() - get_next = iterator.get_next() - with self.test_session() as sess: - for x in range(5): - result = sess.run(get_next) - r = x - for function in functions: - if isinstance(r, tuple): - r = function(*r) # Pass tuple as multiple arguments. - else: - r = function(r) - self.assertAllEqual(r, result) - - with self.assertRaises(errors.OutOfRangeError): - sess.run(get_next) - - @staticmethod - def map_and_filter_functions(): - identity = lambda x: x - increment = lambda x: x + 1 - minus_five = lambda x: x - 5 - - def increment_and_square(x): - y = x + 1 - return y * y - - take_all = lambda x: constant_op.constant(True) - is_zero = lambda x: math_ops.equal(x, 0) - is_odd = lambda x: math_ops.equal(x % 2, 0) - greater = lambda x: math_ops.greater(x + 5, 0) - - functions = [identity, increment, minus_five, increment_and_square] - filters = [take_all, is_zero, is_odd, greater] - tests = [] - - for x, fun in enumerate(functions): - for y, predicate in enumerate(filters): - tests.append(("mixed_{}_{}".format(x, y), fun, predicate)) - - # Multi output - tests.append(("multiOne", lambda x: (x, x), - lambda x, y: constant_op.constant(True))) - tests.append( - ("multiTwo", lambda x: (x, 2), - lambda x, y: math_ops.equal(x * math_ops.cast(y, dtypes.int64), 0))) - return tuple(tests) - - @parameterized.named_parameters(*map_and_filter_functions.__func__()) - def testMapFilterFusion(self, function, predicate): + def testStatefulFunctionOptimization(self): dataset = dataset_ops.Dataset.range(10).apply( - optimization.assert_next( - ["Map", - "FilterByLastComponent"])).map(function).filter(predicate).apply( - optimization.optimize(["map_and_filter_fusion"])) - self._testMapAndFilter(dataset, function, predicate) - - def _testMapAndFilter(self, dataset, function, predicate): + optimization.assert_next([ + "MapAndBatch" + ])).map(lambda _: random_ops.random_uniform([])).batch(10).apply( + optimization.optimize(["map_and_batch_fusion"])) iterator = dataset.make_one_shot_iterator() get_next = iterator.get_next() - with self.test_session() as sess: - for x in range(10): - r = function(x) - if isinstance(r, tuple): - b = predicate(*r) # Pass tuple as multiple arguments. - else: - b = predicate(r) - if sess.run(b): - result = sess.run(get_next) - self.assertAllEqual(r, result) - with self.assertRaises(errors.OutOfRangeError): - sess.run(get_next) - - def testAdditionalInputs(self): - a = constant_op.constant(3, dtype=dtypes.int64) - b = constant_op.constant(4, dtype=dtypes.int64) - some_tensor = math_ops.mul(a, b) - function = lambda x: x * x - - def predicate(y): - return math_ops.less(math_ops.cast(y, dtypes.int64), some_tensor) - - # We are currently not supporting functions with additional inputs. - dataset = dataset_ops.Dataset.range(10).apply( - optimization.assert_next( - ["Map", "Filter"])).map(function).filter(predicate).apply( - optimization.optimize(["map_and_filter_fusion"])) - - self._testMapAndFilter(dataset, function, predicate) - - -class OptimizeStatsDatasetTest(stats_dataset_test_base.StatsDatasetTestBase): - - def testLatencyStatsOptimization(self): - - stats_aggregator = stats_ops.StatsAggregator() - dataset = dataset_ops.Dataset.from_tensors(1).apply( - optimization.assert_next( - ["LatencyStats", "Map", "LatencyStats", "Prefetch", - "LatencyStats"])).map(lambda x: x * x).prefetch(1).apply( - optimization.optimize(["latency_all_edges"])).apply( - stats_ops.set_stats_aggregator(stats_aggregator)) - iterator = dataset.make_initializable_iterator() - get_next = iterator.get_next() - summary_t = stats_aggregator.get_summary() with self.test_session() as sess: - sess.run(iterator.initializer) - self.assertEqual(1 * 1, sess.run(get_next)) - with self.assertRaises(errors.OutOfRangeError): - sess.run(get_next) - summary_str = sess.run(summary_t) - self._assertSummaryHasCount(summary_str, - "record_latency_TensorDataset/_1", 1) - self._assertSummaryHasCount(summary_str, "record_latency_MapDataset/_4", - 1) - self._assertSummaryHasCount(summary_str, - "record_latency_PrefetchDataset/_6", 1) + sess.run(get_next) if __name__ == "__main__": diff --git a/tensorflow/contrib/data/python/kernel_tests/parsing_ops_test.py b/tensorflow/contrib/data/python/kernel_tests/parsing_ops_test.py new file mode 100644 index 0000000000..f6c4a984b8 --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/parsing_ops_test.py @@ -0,0 +1,850 @@ +# Copyright 2015 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for tensorflow.ops.parsing_ops.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import copy + +import numpy as np + +from tensorflow.contrib.data.python.ops import parsing_ops as contrib_parsing_ops +from tensorflow.core.example import example_pb2 +from tensorflow.core.example import feature_pb2 +from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.data.util import nest +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import errors_impl +from tensorflow.python.framework import ops +from tensorflow.python.framework import sparse_tensor +from tensorflow.python.ops import parsing_ops +from tensorflow.python.platform import test +from tensorflow.python.platform import tf_logging + +# Helpers for creating Example objects +example = example_pb2.Example +feature = feature_pb2.Feature +features = lambda d: feature_pb2.Features(feature=d) +bytes_feature = lambda v: feature(bytes_list=feature_pb2.BytesList(value=v)) +int64_feature = lambda v: feature(int64_list=feature_pb2.Int64List(value=v)) +float_feature = lambda v: feature(float_list=feature_pb2.FloatList(value=v)) +# Helpers for creating SequenceExample objects +feature_list = lambda l: feature_pb2.FeatureList(feature=l) +feature_lists = lambda d: feature_pb2.FeatureLists(feature_list=d) +sequence_example = example_pb2.SequenceExample + + +def _compare_output_to_expected(tester, dict_tensors, expected_tensors, + flat_output): + tester.assertEqual(set(dict_tensors.keys()), set(expected_tensors.keys())) + + i = 0 # Index into the flattened output of session.run() + for k, v in sorted(dict_tensors.items()): + # TODO(shivaniagrawal): flat_output is same as v. + expected_v = expected_tensors[k] + tf_logging.info("Comparing key: %s", k) + print("i", i, "flat_output", flat_output[i], "expected_v", expected_v) + if sparse_tensor.is_sparse(v): + # Three outputs for SparseTensor : indices, values, shape. + tester.assertEqual([k, len(expected_v)], [k, 3]) + print("i", i, "flat_output", flat_output[i].indices, "expected_v", + expected_v[0]) + tester.assertAllEqual(expected_v[0], flat_output[i].indices) + tester.assertAllEqual(expected_v[1], flat_output[i].values) + tester.assertAllEqual(expected_v[2], flat_output[i].dense_shape) + else: + # One output for standard Tensor. + tester.assertAllEqual(expected_v, flat_output[i]) + i += 1 + + +class ParseExampleTest(test.TestCase): + + def _test(self, + input_tensor, + feature_val, + expected_values=None, + expected_err=None): + + with self.test_session() as sess: + if expected_err: + with self.assertRaisesWithPredicateMatch(expected_err[0], + expected_err[1]): + dataset = dataset_ops.Dataset.from_tensors(input_tensor).apply( + contrib_parsing_ops.parse_example_dataset(feature_val)) + get_next = dataset.make_one_shot_iterator().get_next() + sess.run(get_next) + return + else: + # Returns dict w/ Tensors and SparseTensors. + # Check values. + dataset = dataset_ops.Dataset.from_tensors(input_tensor).apply( + contrib_parsing_ops.parse_example_dataset(feature_val)) + get_next = dataset.make_one_shot_iterator().get_next() + result = sess.run(get_next) + flattened = nest.flatten(result) + print("result", result, "expected_values", expected_values) + _compare_output_to_expected(self, result, expected_values, flattened) + + # Check shapes; if serialized is a Tensor we need its size to + # properly check. + batch_size = ( + input_tensor.eval().size if isinstance(input_tensor, ops.Tensor) else + np.asarray(input_tensor).size) + for k, f in feature_val.items(): + print("output_shapes as list ", + tuple(dataset.output_shapes[k].as_list())) + if isinstance(f, parsing_ops.FixedLenFeature) and f.shape is not None: + self.assertEqual(dataset.output_shapes[k].as_list()[0], batch_size) + elif isinstance(f, parsing_ops.VarLenFeature): + self.assertEqual(dataset.output_shapes[k].as_list()[1], None) + + def testEmptySerializedWithAllDefaults(self): + sparse_name = "st_a" + a_name = "a" + b_name = "b" + c_name = "c:has_a_tricky_name" + a_default = [0, 42, 0] + b_default = np.random.rand(3, 3).astype(bytes) + c_default = np.random.rand(2).astype(np.float32) + + expected_st_a = ( # indices, values, shape + np.empty( + (0, 2), dtype=np.int64), # indices + np.empty( + (0,), dtype=np.int64), # sp_a is DT_INT64 + np.array( + [2, 0], dtype=np.int64)) # batch == 2, max_elems = 0 + + expected_output = { + sparse_name: expected_st_a, + a_name: np.array(2 * [[a_default]]), + b_name: np.array(2 * [b_default]), + c_name: np.array(2 * [c_default]), + } + + self._test( + ops.convert_to_tensor(["", ""]), { + sparse_name: + parsing_ops.VarLenFeature(dtypes.int64), + a_name: + parsing_ops.FixedLenFeature( + (1, 3), dtypes.int64, default_value=a_default), + b_name: + parsing_ops.FixedLenFeature( + (3, 3), dtypes.string, default_value=b_default), + c_name: + parsing_ops.FixedLenFeature( + (2,), dtypes.float32, default_value=c_default), + }, + expected_values=expected_output) + + def testEmptySerializedWithoutDefaultsShouldFail(self): + input_features = { + "st_a": + parsing_ops.VarLenFeature(dtypes.int64), + "a": + parsing_ops.FixedLenFeature( + (1, 3), dtypes.int64, default_value=[0, 42, 0]), + "b": + parsing_ops.FixedLenFeature( + (3, 3), + dtypes.string, + default_value=np.random.rand(3, 3).astype(bytes)), + # Feature "c" is missing a default, this gap will cause failure. + "c": + parsing_ops.FixedLenFeature( + (2,), dtype=dtypes.float32), + } + + # Edge case where the key is there but the feature value is empty + original = example(features=features({"c": feature()})) + self._test( + [original.SerializeToString()], + input_features, + expected_err=(errors_impl.InvalidArgumentError, + "Feature: c \\(data type: float\\) is required")) + + # Standard case of missing key and value. + self._test( + ["", ""], + input_features, + expected_err=(errors_impl.InvalidArgumentError, + "Feature: c \\(data type: float\\) is required")) + + def testDenseNotMatchingShapeShouldFail(self): + original = [ + example(features=features({ + "a": float_feature([1, 1, 3]), + })), example(features=features({ + "a": float_feature([-1, -1]), + })) + ] + + serialized = [m.SerializeToString() for m in original] + + self._test( + ops.convert_to_tensor(serialized), + {"a": parsing_ops.FixedLenFeature((1, 3), dtypes.float32)}, + expected_err=(errors_impl.InvalidArgumentError, + "Key: a, Index: 1. Number of float values")) + + def testDenseDefaultNoShapeShouldFail(self): + original = [example(features=features({"a": float_feature([1, 1, 3]),})),] + + serialized = [m.SerializeToString() for m in original] + + self._test( + ops.convert_to_tensor(serialized), + {"a": parsing_ops.FixedLenFeature(None, dtypes.float32)}, + expected_err=(ValueError, "Missing shape for feature a")) + + def testSerializedContainingSparse(self): + original = [ + example(features=features({ + "st_c": float_feature([3, 4]) + })), + example(features=features({ + "st_c": float_feature([]), # empty float list + })), + example(features=features({ + "st_d": feature(), # feature with nothing in it + })), + example(features=features({ + "st_c": float_feature([1, 2, -1]), + "st_d": bytes_feature([b"hi"]) + })) + ] + + serialized = [m.SerializeToString() for m in original] + + expected_st_c = ( # indices, values, shape + np.array( + [[0, 0], [0, 1], [3, 0], [3, 1], [3, 2]], dtype=np.int64), np.array( + [3.0, 4.0, 1.0, 2.0, -1.0], dtype=np.float32), np.array( + [4, 3], dtype=np.int64)) # batch == 2, max_elems = 3 + + expected_st_d = ( # indices, values, shape + np.array( + [[3, 0]], dtype=np.int64), np.array( + ["hi"], dtype=bytes), np.array( + [4, 1], dtype=np.int64)) # batch == 2, max_elems = 1 + + expected_output = { + "st_c": expected_st_c, + "st_d": expected_st_d, + } + + self._test( + ops.convert_to_tensor(serialized), { + "st_c": parsing_ops.VarLenFeature(dtypes.float32), + "st_d": parsing_ops.VarLenFeature(dtypes.string) + }, + expected_values=expected_output) + + def testSerializedContainingSparseFeature(self): + original = [ + example(features=features({ + "val": float_feature([3, 4]), + "idx": int64_feature([5, 10]) + })), + example(features=features({ + "val": float_feature([]), # empty float list + "idx": int64_feature([]) + })), + example(features=features({ + "val": feature(), # feature with nothing in it + # missing idx feature + })), + example(features=features({ + "val": float_feature([1, 2, -1]), + "idx": + int64_feature([0, 9, 3]) # unsorted + })) + ] + + serialized = [m.SerializeToString() for m in original] + + expected_sp = ( # indices, values, shape + np.array( + [[0, 5], [0, 10], [3, 0], [3, 3], [3, 9]], dtype=np.int64), + np.array( + [3.0, 4.0, 1.0, -1.0, 2.0], dtype=np.float32), np.array( + [4, 13], dtype=np.int64)) # batch == 4, max_elems = 13 + + expected_output = {"sp": expected_sp,} + + self._test( + ops.convert_to_tensor(serialized), + {"sp": parsing_ops.SparseFeature(["idx"], "val", dtypes.float32, [13])}, + expected_values=expected_output) + + def testSerializedContainingSparseFeatureReuse(self): + original = [ + example(features=features({ + "val1": float_feature([3, 4]), + "val2": float_feature([5, 6]), + "idx": int64_feature([5, 10]) + })), + example(features=features({ + "val1": float_feature([]), # empty float list + "idx": int64_feature([]) + })), + ] + + serialized = [m.SerializeToString() for m in original] + + expected_sp1 = ( # indices, values, shape + np.array( + [[0, 5], [0, 10]], dtype=np.int64), np.array( + [3.0, 4.0], dtype=np.float32), np.array( + [2, 13], dtype=np.int64)) # batch == 2, max_elems = 13 + + expected_sp2 = ( # indices, values, shape + np.array( + [[0, 5], [0, 10]], dtype=np.int64), np.array( + [5.0, 6.0], dtype=np.float32), np.array( + [2, 7], dtype=np.int64)) # batch == 2, max_elems = 13 + + expected_output = { + "sp1": expected_sp1, + "sp2": expected_sp2, + } + + self._test( + ops.convert_to_tensor(serialized), { + "sp1": + parsing_ops.SparseFeature("idx", "val1", dtypes.float32, 13), + "sp2": + parsing_ops.SparseFeature( + "idx", "val2", dtypes.float32, size=7, already_sorted=True) + }, + expected_values=expected_output) + + def testSerializedContaining3DSparseFeature(self): + original = [ + example(features=features({ + "val": float_feature([3, 4]), + "idx0": int64_feature([5, 10]), + "idx1": int64_feature([0, 2]), + })), + example(features=features({ + "val": float_feature([]), # empty float list + "idx0": int64_feature([]), + "idx1": int64_feature([]), + })), + example(features=features({ + "val": feature(), # feature with nothing in it + # missing idx feature + })), + example(features=features({ + "val": float_feature([1, 2, -1]), + "idx0": int64_feature([0, 9, 3]), # unsorted + "idx1": int64_feature([1, 0, 2]), + })) + ] + + serialized = [m.SerializeToString() for m in original] + + expected_sp = ( + # indices + np.array( + [[0, 5, 0], [0, 10, 2], [3, 0, 1], [3, 3, 2], [3, 9, 0]], + dtype=np.int64), + # values + np.array([3.0, 4.0, 1.0, -1.0, 2.0], dtype=np.float32), + # shape batch == 4, max_elems = 13 + np.array([4, 13, 3], dtype=np.int64)) + + expected_output = {"sp": expected_sp,} + + self._test( + ops.convert_to_tensor(serialized), { + "sp": + parsing_ops.SparseFeature(["idx0", "idx1"], "val", + dtypes.float32, [13, 3]) + }, + expected_values=expected_output) + + def testSerializedContainingDense(self): + aname = "a" + bname = "b*has+a:tricky_name" + original = [ + example(features=features({ + aname: float_feature([1, 1]), + bname: bytes_feature([b"b0_str"]), + })), example(features=features({ + aname: float_feature([-1, -1]), + bname: bytes_feature([b""]), + })) + ] + + serialized = [m.SerializeToString() for m in original] + + expected_output = { + aname: + np.array( + [[1, 1], [-1, -1]], dtype=np.float32).reshape(2, 1, 2, 1), + bname: + np.array( + ["b0_str", ""], dtype=bytes).reshape(2, 1, 1, 1, 1), + } + + # No defaults, values required + self._test( + ops.convert_to_tensor(serialized), { + aname: + parsing_ops.FixedLenFeature((1, 2, 1), dtype=dtypes.float32), + bname: + parsing_ops.FixedLenFeature((1, 1, 1, 1), dtype=dtypes.string), + }, + expected_values=expected_output) + + # This test is identical as the previous one except + # for the creation of 'serialized'. + def testSerializedContainingDenseWithConcat(self): + aname = "a" + bname = "b*has+a:tricky_name" + # TODO(lew): Feature appearing twice should be an error in future. + original = [ + (example(features=features({ + aname: float_feature([10, 10]), + })), example(features=features({ + aname: float_feature([1, 1]), + bname: bytes_feature([b"b0_str"]), + }))), + ( + example(features=features({ + bname: bytes_feature([b"b100"]), + })), + example(features=features({ + aname: float_feature([-1, -1]), + bname: bytes_feature([b"b1"]), + })),), + ] + + serialized = [ + m.SerializeToString() + n.SerializeToString() for (m, n) in original + ] + + expected_output = { + aname: + np.array( + [[1, 1], [-1, -1]], dtype=np.float32).reshape(2, 1, 2, 1), + bname: + np.array( + ["b0_str", "b1"], dtype=bytes).reshape(2, 1, 1, 1, 1), + } + + # No defaults, values required + self._test( + ops.convert_to_tensor(serialized), { + aname: + parsing_ops.FixedLenFeature((1, 2, 1), dtype=dtypes.float32), + bname: + parsing_ops.FixedLenFeature((1, 1, 1, 1), dtype=dtypes.string), + }, + expected_values=expected_output) + + def testSerializedContainingDenseScalar(self): + original = [ + example(features=features({ + "a": float_feature([1]), + })), example(features=features({})) + ] + + serialized = [m.SerializeToString() for m in original] + + expected_output = { + "a": + np.array( + [[1], [-1]], dtype=np.float32) # 2x1 (column vector) + } + + self._test( + ops.convert_to_tensor(serialized), { + "a": + parsing_ops.FixedLenFeature( + (1,), dtype=dtypes.float32, default_value=-1), + }, + expected_values=expected_output) + + def testSerializedContainingDenseWithDefaults(self): + original = [ + example(features=features({ + "a": float_feature([1, 1]), + })), + example(features=features({ + "b": bytes_feature([b"b1"]), + })), + example(features=features({ + "b": feature() + })), + ] + + serialized = [m.SerializeToString() for m in original] + + expected_output = { + "a": + np.array( + [[1, 1], [3, -3], [3, -3]], dtype=np.float32).reshape(3, 1, 2, + 1), + "b": + np.array( + ["tmp_str", "b1", "tmp_str"], dtype=bytes).reshape(3, 1, 1, 1, + 1), + } + + self._test( + ops.convert_to_tensor(serialized), { + "a": + parsing_ops.FixedLenFeature( + (1, 2, 1), dtype=dtypes.float32, default_value=[3.0, -3.0]), + "b": + parsing_ops.FixedLenFeature( + (1, 1, 1, 1), dtype=dtypes.string, default_value="tmp_str"), + }, + expected_values=expected_output) + + def testSerializedContainingSparseAndSparseFeatureAndDenseWithNoDefault(self): + expected_st_a = ( # indices, values, shape + np.empty( + (0, 2), dtype=np.int64), # indices + np.empty( + (0,), dtype=np.int64), # sp_a is DT_INT64 + np.array( + [2, 0], dtype=np.int64)) # batch == 2, max_elems = 0 + expected_sp = ( # indices, values, shape + np.array( + [[0, 0], [0, 3], [1, 7]], dtype=np.int64), np.array( + ["a", "b", "c"], dtype="|S"), np.array( + [2, 13], dtype=np.int64)) # batch == 4, max_elems = 13 + + original = [ + example(features=features({ + "c": float_feature([3, 4]), + "val": bytes_feature([b"a", b"b"]), + "idx": int64_feature([0, 3]) + })), example(features=features({ + "c": float_feature([1, 2]), + "val": bytes_feature([b"c"]), + "idx": int64_feature([7]) + })) + ] + + serialized = [m.SerializeToString() for m in original] + + a_default = [1, 2, 3] + b_default = np.random.rand(3, 3).astype(bytes) + expected_output = { + "st_a": expected_st_a, + "sp": expected_sp, + "a": np.array(2 * [[a_default]]), + "b": np.array(2 * [b_default]), + "c": np.array( + [[3, 4], [1, 2]], dtype=np.float32), + } + + self._test( + ops.convert_to_tensor(serialized), + { + "st_a": + parsing_ops.VarLenFeature(dtypes.int64), + "sp": + parsing_ops.SparseFeature("idx", "val", dtypes.string, 13), + "a": + parsing_ops.FixedLenFeature( + (1, 3), dtypes.int64, default_value=a_default), + "b": + parsing_ops.FixedLenFeature( + (3, 3), dtypes.string, default_value=b_default), + # Feature "c" must be provided, since it has no default_value. + "c": + parsing_ops.FixedLenFeature((2,), dtypes.float32), + }, + expected_values=expected_output) + + def testSerializedContainingSparseAndSparseFeatureWithReuse(self): + expected_idx = ( # indices, values, shape + np.array( + [[0, 0], [0, 1], [1, 0], [1, 1]], dtype=np.int64), + np.array([0, 3, 7, 1]), np.array( + [2, 2], dtype=np.int64)) # batch == 4, max_elems = 2 + + expected_sp = ( # indices, values, shape + np.array( + [[0, 0], [0, 3], [1, 1], [1, 7]], dtype=np.int64), np.array( + ["a", "b", "d", "c"], dtype="|S"), np.array( + [2, 13], dtype=np.int64)) # batch == 4, max_elems = 13 + + original = [ + example(features=features({ + "val": bytes_feature([b"a", b"b"]), + "idx": int64_feature([0, 3]) + })), example(features=features({ + "val": bytes_feature([b"c", b"d"]), + "idx": int64_feature([7, 1]) + })) + ] + + serialized = [m.SerializeToString() for m in original] + + expected_output = { + "idx": expected_idx, + "sp": expected_sp, + } + + self._test( + ops.convert_to_tensor(serialized), { + "idx": + parsing_ops.VarLenFeature(dtypes.int64), + "sp": + parsing_ops.SparseFeature(["idx"], "val", dtypes.string, [13]), + }, + expected_values=expected_output) + + def _testSerializedContainingVarLenDenseLargerBatch(self, batch_size): + # During parsing, data read from the serialized proto is stored in buffers. + # For small batch sizes, a buffer will contain one minibatch entry. + # For larger batch sizes, a buffer may contain several minibatch + # entries. This test identified a bug where the code that copied + # data out of the buffers and into the output tensors assumed each + # buffer only contained one minibatch entry. The bug has since been fixed. + truth_int = [i for i in range(batch_size)] + truth_str = [[("foo%d" % i).encode(), ("bar%d" % i).encode()] + for i in range(batch_size)] + + expected_str = copy.deepcopy(truth_str) + + # Delete some intermediate entries + for i in range(batch_size): + col = 1 + if np.random.rand() < 0.25: + # w.p. 25%, drop out the second entry + expected_str[i][col] = b"default" + col -= 1 + truth_str[i].pop() + if np.random.rand() < 0.25: + # w.p. 25%, drop out the second entry (possibly again) + expected_str[i][col] = b"default" + truth_str[i].pop() + + expected_output = { + # Batch size batch_size, 1 time step. + "a": np.array(truth_int, dtype=np.int64).reshape(batch_size, 1), + # Batch size batch_size, 2 time steps. + "b": np.array(expected_str, dtype="|S").reshape(batch_size, 2), + } + + original = [ + example(features=features( + {"a": int64_feature([truth_int[i]]), + "b": bytes_feature(truth_str[i])})) + for i in range(batch_size) + ] + + serialized = [m.SerializeToString() for m in original] + + self._test( + ops.convert_to_tensor(serialized, dtype=dtypes.string), { + "a": + parsing_ops.FixedLenSequenceFeature( + shape=(), + dtype=dtypes.int64, + allow_missing=True, + default_value=-1), + "b": + parsing_ops.FixedLenSequenceFeature( + shape=[], + dtype=dtypes.string, + allow_missing=True, + default_value="default"), + }, + expected_values=expected_output) + + def testSerializedContainingVarLenDenseLargerBatch(self): + np.random.seed(3456) + for batch_size in (1, 10, 20, 100, 256): + self._testSerializedContainingVarLenDenseLargerBatch(batch_size) + + def testSerializedContainingVarLenDense(self): + aname = "a" + bname = "b" + cname = "c" + dname = "d" + original = [ + example(features=features({ + cname: int64_feature([2]), + })), + example(features=features({ + aname: float_feature([1, 1]), + bname: bytes_feature([b"b0_str", b"b1_str"]), + })), + example(features=features({ + aname: float_feature([-1, -1, 2, 2]), + bname: bytes_feature([b"b1"]), + })), + example(features=features({ + aname: float_feature([]), + cname: int64_feature([3]), + })), + ] + + serialized = [m.SerializeToString() for m in original] + + expected_output = { + aname: + np.array( + [ + [0, 0, 0, 0], + [1, 1, 0, 0], + [-1, -1, 2, 2], + [0, 0, 0, 0], + ], + dtype=np.float32).reshape(4, 2, 2, 1), + bname: + np.array( + [["", ""], ["b0_str", "b1_str"], ["b1", ""], ["", ""]], + dtype=bytes).reshape(4, 2, 1, 1, 1), + cname: + np.array([2, 0, 0, 3], dtype=np.int64).reshape(4, 1), + dname: + np.empty(shape=(4, 0), dtype=bytes), + } + + self._test( + ops.convert_to_tensor(serialized), { + aname: + parsing_ops.FixedLenSequenceFeature( + (2, 1), dtype=dtypes.float32, allow_missing=True), + bname: + parsing_ops.FixedLenSequenceFeature( + (1, 1, 1), dtype=dtypes.string, allow_missing=True), + cname: + parsing_ops.FixedLenSequenceFeature( + shape=[], dtype=dtypes.int64, allow_missing=True), + dname: + parsing_ops.FixedLenSequenceFeature( + shape=[], dtype=dtypes.string, allow_missing=True), + }, + expected_values=expected_output) + + # Test with padding values. + expected_output_custom_padding = dict(expected_output) + expected_output_custom_padding[aname] = np.array( + [ + [-2, -2, -2, -2], + [1, 1, -2, -2], + [-1, -1, 2, 2], + [-2, -2, -2, -2], + ], + dtype=np.float32).reshape(4, 2, 2, 1) + + self._test( + ops.convert_to_tensor(serialized), { + aname: + parsing_ops.FixedLenSequenceFeature( + (2, 1), + dtype=dtypes.float32, + allow_missing=True, + default_value=-2.0), + bname: + parsing_ops.FixedLenSequenceFeature( + (1, 1, 1), dtype=dtypes.string, allow_missing=True), + cname: + parsing_ops.FixedLenSequenceFeature( + shape=[], dtype=dtypes.int64, allow_missing=True), + dname: + parsing_ops.FixedLenSequenceFeature( + shape=[], dtype=dtypes.string, allow_missing=True), + }, expected_output_custom_padding) + + # Change number of required values so the inputs are not a + # multiple of this size. + self._test( + ops.convert_to_tensor(serialized), { + aname: + parsing_ops.FixedLenSequenceFeature( + (2, 1), dtype=dtypes.float32, allow_missing=True), + bname: + parsing_ops.FixedLenSequenceFeature( + (2, 1, 1), dtype=dtypes.string, allow_missing=True), + }, + expected_err=( + errors_impl.OpError, "Key: b, Index: 2. " + "Number of bytes values is not a multiple of stride length.")) + + self._test( + ops.convert_to_tensor(serialized), { + aname: + parsing_ops.FixedLenSequenceFeature( + (2, 1), + dtype=dtypes.float32, + allow_missing=True, + default_value=[]), + bname: + parsing_ops.FixedLenSequenceFeature( + (2, 1, 1), dtype=dtypes.string, allow_missing=True), + }, + expected_err=(ValueError, + "Cannot reshape a tensor with 0 elements to shape")) + + self._test( + ops.convert_to_tensor(serialized), { + aname: + parsing_ops.FixedLenFeature((None, 2, 1), dtype=dtypes.float32), + bname: + parsing_ops.FixedLenSequenceFeature( + (2, 1, 1), dtype=dtypes.string, allow_missing=True), + }, + expected_err=(ValueError, + "First dimension of shape for feature a unknown. " + "Consider using FixedLenSequenceFeature.")) + + self._test( + ops.convert_to_tensor(serialized), { + cname: + parsing_ops.FixedLenFeature( + (1, None), dtype=dtypes.int64, default_value=[[1]]), + }, + expected_err=(ValueError, + "All dimensions of shape for feature c need to be known " + r"but received \(1, None\).")) + + self._test( + ops.convert_to_tensor(serialized), { + aname: + parsing_ops.FixedLenSequenceFeature( + (2, 1), dtype=dtypes.float32, allow_missing=True), + bname: + parsing_ops.FixedLenSequenceFeature( + (1, 1, 1), dtype=dtypes.string, allow_missing=True), + cname: + parsing_ops.FixedLenSequenceFeature( + shape=[], dtype=dtypes.int64, allow_missing=False), + dname: + parsing_ops.FixedLenSequenceFeature( + shape=[], dtype=dtypes.string, allow_missing=True), + }, + expected_err=(ValueError, + "Unsupported: FixedLenSequenceFeature requires " + "allow_missing to be True.")) + + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/data/python/kernel_tests/reader_dataset_ops_test.py b/tensorflow/contrib/data/python/kernel_tests/reader_dataset_ops_test.py index 15b342d30f..64fe6dae24 100644 --- a/tensorflow/contrib/data/python/kernel_tests/reader_dataset_ops_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/reader_dataset_ops_test.py @@ -43,7 +43,7 @@ class ReadBatchFeaturesTest( for batch_size in [1, 2]: for num_epochs in [1, 10]: with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Basic test: read from file 0. self.outputs = self.make_batch_feature( filenames=self.test_filenames[0], @@ -54,7 +54,7 @@ class ReadBatchFeaturesTest( self._next_actual_batch(sess) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Basic test: read from file 1. self.outputs = self.make_batch_feature( filenames=self.test_filenames[1], @@ -65,7 +65,7 @@ class ReadBatchFeaturesTest( self._next_actual_batch(sess) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Basic test: read from both files. self.outputs = self.make_batch_feature( filenames=self.test_filenames, @@ -104,7 +104,7 @@ class ReadBatchFeaturesTest( for batch_size in [1, 2]: # Test that shuffling with same seed produces the same result. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: outputs1 = self.make_batch_feature( filenames=self.test_filenames[0], num_epochs=num_epochs, @@ -125,7 +125,7 @@ class ReadBatchFeaturesTest( # Test that shuffling with different seeds produces a different order. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: outputs1 = self.make_batch_feature( filenames=self.test_filenames[0], num_epochs=num_epochs, @@ -152,7 +152,7 @@ class ReadBatchFeaturesTest( for reader_num_threads in [2, 4]: for parser_num_threads in [2, 4]: with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: self.outputs = self.make_batch_feature( filenames=self.test_filenames, num_epochs=num_epochs, @@ -275,7 +275,7 @@ class MakeCsvDatasetTest(test.TestCase): filenames = self._setup_files( inputs, compression_type=kwargs.get("compression_type", None)) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: dataset = self._make_csv_dataset( filenames, batch_size=batch_size, @@ -740,7 +740,7 @@ class MakeCsvDatasetTest(test.TestCase): total_records = 20 for batch_size in [1, 2]: with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Test that shuffling with the same seed produces the same result dataset1 = self._make_csv_dataset( filenames, @@ -771,7 +771,7 @@ class MakeCsvDatasetTest(test.TestCase): self.assertAllEqual(batch1[i], batch2[i]) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Test that shuffling with a different seed produces different results dataset1 = self._make_csv_dataset( filenames, @@ -909,7 +909,7 @@ class MakeTFRecordDatasetTest( fn = None with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: outputs = readers.make_tf_record_dataset( file_pattern=file_pattern, num_epochs=num_epochs, @@ -965,7 +965,7 @@ class MakeTFRecordDatasetTest( def _shuffle_test(self, batch_size, num_epochs, num_parallel_reads=1, seed=None): with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: dataset = readers.make_tf_record_dataset( file_pattern=self.test_filenames, num_epochs=num_epochs, diff --git a/tensorflow/contrib/data/python/kernel_tests/serialization/BUILD b/tensorflow/contrib/data/python/kernel_tests/serialization/BUILD index 7b9ea191a4..4881f63ab9 100644 --- a/tensorflow/contrib/data/python/kernel_tests/serialization/BUILD +++ b/tensorflow/contrib/data/python/kernel_tests/serialization/BUILD @@ -318,6 +318,19 @@ py_test( ) py_test( + name = "parse_example_dataset_serialization_test", + size = "medium", + srcs = ["parse_example_dataset_serialization_test.py"], + srcs_version = "PY2AND3", + tags = ["no_pip"], + deps = [ + ":dataset_serialization_test_base", + "//tensorflow/contrib/data/python/kernel_tests:reader_dataset_ops_test_base", + "//tensorflow/python:client_testlib", + ], +) + +py_test( name = "prefetch_dataset_serialization_test", size = "small", srcs = ["prefetch_dataset_serialization_test.py"], diff --git a/tensorflow/contrib/data/python/kernel_tests/serialization/dataset_serialization_test_base.py b/tensorflow/contrib/data/python/kernel_tests/serialization/dataset_serialization_test_base.py index 3ed4dfb729..595cecef4d 100644 --- a/tensorflow/contrib/data/python/kernel_tests/serialization/dataset_serialization_test_base.py +++ b/tensorflow/contrib/data/python/kernel_tests/serialization/dataset_serialization_test_base.py @@ -252,7 +252,7 @@ class DatasetSerializationTestBase(test.TestCase): init_op, get_next_op = self._get_iterator_ops_from_collection( ds_fn, sparse_tensors=sparse_tensors) get_next_op = remove_variants(get_next_op) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: self._restore(saver, sess) self._initialize(init_op, sess) for _ in range(num_outputs): @@ -315,7 +315,7 @@ class DatasetSerializationTestBase(test.TestCase): _, get_next_op, saver = self._build_graph( ds_fn2, sparse_tensors=sparse_tensors) get_next_op = remove_variants(get_next_op) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: self._restore(saver, sess) for _ in range(num_outputs - break_point): actual.append(sess.run(get_next_op)) @@ -376,7 +376,7 @@ class DatasetSerializationTestBase(test.TestCase): get_next_op, saver = self._build_empty_graph( ds_fn, sparse_tensors=sparse_tensors) get_next_op = remove_variants(get_next_op) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: self._restore(saver, sess) for _ in range(num_outputs - break_point): actual.append(sess.run(get_next_op)) @@ -410,7 +410,7 @@ class DatasetSerializationTestBase(test.TestCase): init_op, get_next_op, saver = self._build_graph( ds_fn, sparse_tensors=sparse_tensors) get_next_op = remove_variants(get_next_op) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: self._initialize(init_op, sess) for _ in range(break_point): sess.run(get_next_op) @@ -510,14 +510,13 @@ class DatasetSerializationTestBase(test.TestCase): else: init_op, get_next_op, saver = self._build_graph( ds_fn, sparse_tensors=sparse_tensors) - get_next_op = remove_variants(get_next_op) return init_op, get_next_op, saver for i in range(len(break_points) + 1): with ops.Graph().as_default() as g: init_op, get_next_op, saver = get_ops() get_next_op = remove_variants(get_next_op) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: if ckpt_saved: if init_before_restore: self._initialize(init_op, sess) @@ -616,29 +615,40 @@ class DatasetSerializationTestBase(test.TestCase): # `get_next` may be a tuple e.g. in TensorSliceDataset. Since Collections # do not support tuples we flatten the tensors and restore the shape in # `_get_iterator_ops_from_collection`. - - # TODO(shivaniagrwal): `output_classes` is a nested structure of classes, - # this base class is specific to current test cases. Update when tests are - # added with `output_classes` as a nested structure with at least one of the - # component being `tf.SparseTensor`. - if (sparse_tensors or - self._get_output_classes(ds_fn) is sparse_tensor.SparseTensor): + if sparse_tensors: # specific for deprecated `from_sparse_tensor_slices`. ops.add_to_collection("iterator_ops", get_next.indices) ops.add_to_collection("iterator_ops", get_next.values) ops.add_to_collection("iterator_ops", get_next.dense_shape) - else: - for el in nest.flatten(get_next): - ops.add_to_collection("iterator_ops", el) + return + + get_next_list = nest.flatten(get_next) + for i, output_class in enumerate( + nest.flatten(self._get_output_classes(ds_fn))): + if output_class is sparse_tensor.SparseTensor: + ops.add_to_collection("iterator_ops", get_next_list[i].indices) + ops.add_to_collection("iterator_ops", get_next_list[i].values) + ops.add_to_collection("iterator_ops", get_next_list[i].dense_shape) + else: + ops.add_to_collection("iterator_ops", get_next_list[i]) def _get_iterator_ops_from_collection(self, ds_fn, sparse_tensors=False): all_ops = ops.get_collection("iterator_ops") - if (sparse_tensors or - self._get_output_classes(ds_fn) is sparse_tensor.SparseTensor): + if sparse_tensors: # specific for deprecated `from_sparse_tensor_slices`. init_op, indices, values, dense_shape = all_ops return init_op, sparse_tensor.SparseTensor(indices, values, dense_shape) - else: - return all_ops[0], nest.pack_sequence_as( - self._get_output_types(ds_fn), all_ops[1:]) + get_next_list = [] + i = 1 + for output_class in nest.flatten(self._get_output_classes(ds_fn)): + if output_class is sparse_tensor.SparseTensor: + indices, values, dense_shape = all_ops[i:i + 3] + i += 3 + get_next_list.append( + sparse_tensor.SparseTensor(indices, values, dense_shape)) + else: + get_next_list.append(all_ops[i]) + i += 1 + return all_ops[0], nest.pack_sequence_as( + self._get_output_types(ds_fn), get_next_list) def _get_output_types(self, ds_fn): with ops.Graph().as_default(): diff --git a/tensorflow/contrib/data/python/kernel_tests/serialization/parse_example_dataset_serialization_test.py b/tensorflow/contrib/data/python/kernel_tests/serialization/parse_example_dataset_serialization_test.py new file mode 100644 index 0000000000..d3fa84e74c --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/serialization/parse_example_dataset_serialization_test.py @@ -0,0 +1,50 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for the ParseExampleDataset serialization.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.contrib.data.python.kernel_tests import reader_dataset_ops_test_base +from tensorflow.contrib.data.python.kernel_tests.serialization import dataset_serialization_test_base +from tensorflow.python.platform import test + + +class ParseExampleDatasetSerializationTest( + reader_dataset_ops_test_base.ReadBatchFeaturesTestBase, + dataset_serialization_test_base.DatasetSerializationTestBase): + + def ParseExampleDataset(self, num_repeat, batch_size): + return self.make_batch_feature( + filenames=self.test_filenames, + num_epochs=num_repeat, + batch_size=batch_size, + reader_num_threads=5, + parser_num_threads=10) + + def testSerializationCore(self): + num_repeat = 5 + batch_size = 2 + num_outputs = self._num_records * self._num_files * num_repeat // batch_size + # pylint: disable=g-long-lambda + self.run_core_tests( + lambda: self.ParseExampleDataset( + num_repeat=num_repeat, batch_size=batch_size), + lambda: self.ParseExampleDataset(num_repeat=10, batch_size=4), + num_outputs) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/data/python/kernel_tests/serialization/range_dataset_serialization_test.py b/tensorflow/contrib/data/python/kernel_tests/serialization/range_dataset_serialization_test.py index e4f5b6cf5d..6341190847 100644 --- a/tensorflow/contrib/data/python/kernel_tests/serialization/range_dataset_serialization_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/serialization/range_dataset_serialization_test.py @@ -70,7 +70,7 @@ class RangeDatasetSerializationTest( break_point = 5 with ops.Graph().as_default() as g: init_op, get_next, save_op, _ = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) for i in range(start, break_point): @@ -79,7 +79,7 @@ class RangeDatasetSerializationTest( with ops.Graph().as_default() as g: init_op, get_next, _, restore_op = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) sess.run(restore_op) for i in range(break_point, stop): @@ -90,7 +90,7 @@ class RangeDatasetSerializationTest( # Saving and restoring in same session. with ops.Graph().as_default() as g: init_op, get_next, save_op, restore_op = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) for i in range(start, break_point): diff --git a/tensorflow/contrib/data/python/kernel_tests/serialization/serialization_integration_test.py b/tensorflow/contrib/data/python/kernel_tests/serialization/serialization_integration_test.py index 992d996a48..6aac50ecd9 100644 --- a/tensorflow/contrib/data/python/kernel_tests/serialization/serialization_integration_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/serialization/serialization_integration_test.py @@ -59,7 +59,7 @@ class SerializationIntegrationTest(test.TestCase): with ops.Graph().as_default() as g: init_ops, get_next_ops, saver = self._build_graph(num_pipelines, num_outputs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_ops) for _ in range(break_point): output = sess.run(get_next_ops) @@ -70,7 +70,7 @@ class SerializationIntegrationTest(test.TestCase): with ops.Graph().as_default() as g: init_ops, get_next_ops, saver = self._build_graph(num_pipelines, num_outputs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: saver.restore(sess, self._ckpt_path()) for _ in range(num_outputs - break_point): output = sess.run(get_next_ops) diff --git a/tensorflow/contrib/data/python/kernel_tests/serialization/shuffle_dataset_serialization_test.py b/tensorflow/contrib/data/python/kernel_tests/serialization/shuffle_dataset_serialization_test.py index d46c762aaa..a59fa94d66 100644 --- a/tensorflow/contrib/data/python/kernel_tests/serialization/shuffle_dataset_serialization_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/serialization/shuffle_dataset_serialization_test.py @@ -136,7 +136,7 @@ class ShuffleDatasetSerializationTest( for saveable in saveables: ops.add_to_collection(ops.GraphKeys.SAVEABLE_OBJECTS, saveable) saver = saver_lib.Saver(allow_empty=True) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: self._save(sess, saver) expected = [sess.run(get_next_ops) for _ in range(num_outputs)] self._restore(saver, sess) diff --git a/tensorflow/contrib/data/python/kernel_tests/shuffle_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/shuffle_dataset_op_test.py index 3c11d7a97f..077abd6b30 100644 --- a/tensorflow/contrib/data/python/kernel_tests/shuffle_dataset_op_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/shuffle_dataset_op_test.py @@ -106,7 +106,7 @@ class ShuffleAndRepeatTest(test.TestCase): ds = dataset_ops.Dataset.range(20).apply( shuffle_ops.shuffle_and_repeat(buffer_size=21)) get_next_op = ds.make_one_shot_iterator().get_next() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(get_next_op) diff --git a/tensorflow/contrib/data/python/kernel_tests/stats_dataset_ops_test.py b/tensorflow/contrib/data/python/kernel_tests/stats_dataset_ops_test.py index a41d21f8c1..53c22628c7 100644 --- a/tensorflow/contrib/data/python/kernel_tests/stats_dataset_ops_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/stats_dataset_ops_test.py @@ -190,7 +190,7 @@ class FeatureStatsDatasetTest( batch_size=batch_size, shuffle=True, shuffle_seed=5, - drop_final_batch=True).apply( + drop_final_batch=False).apply( stats_ops.set_stats_aggregator(stats_aggregator)) iterator = dataset.make_initializable_iterator() next_element = iterator.get_next() @@ -198,7 +198,8 @@ class FeatureStatsDatasetTest( with self.test_session() as sess: sess.run(iterator.initializer) - for _ in range(total_records // batch_size): + for _ in range(total_records // batch_size + 1 if total_records % + batch_size else total_records // batch_size): sess.run(next_element) with self.assertRaises(errors.OutOfRangeError): diff --git a/tensorflow/contrib/data/python/kernel_tests/test_utils.py b/tensorflow/contrib/data/python/kernel_tests/test_utils.py new file mode 100644 index 0000000000..1d70b16041 --- /dev/null +++ b/tensorflow/contrib/data/python/kernel_tests/test_utils.py @@ -0,0 +1,70 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Test utilities for tf.data functionality.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import re + +from tensorflow.python.data.util import nest +from tensorflow.python.framework import errors +from tensorflow.python.platform import test + + +class DatasetTestBase(test.TestCase): + """Base class for dataset tests.""" + + def _assert_datasets_equal(self, dataset1, dataset2): + # TODO(rachelim): support sparse tensor outputs + next1 = dataset1.make_one_shot_iterator().get_next() + next2 = dataset2.make_one_shot_iterator().get_next() + with self.test_session() as sess: + while True: + try: + op1 = sess.run(next1) + except errors.OutOfRangeError: + with self.assertRaises(errors.OutOfRangeError): + sess.run(next2) + break + op2 = sess.run(next2) + + op1 = nest.flatten(op1) + op2 = nest.flatten(op2) + assert len(op1) == len(op2) + for i in range(len(op1)): + self.assertAllEqual(op1[i], op2[i]) + + def _assert_datasets_raise_same_error(self, + dataset1, + dataset2, + exception_class, + replacements=None): + next1 = dataset1.make_one_shot_iterator().get_next() + next2 = dataset2.make_one_shot_iterator().get_next() + with self.test_session() as sess: + try: + sess.run(next1) + raise ValueError( + "Expected dataset to raise an error of type %s, but it did not." % + repr(exception_class)) + except exception_class as e: + expected_message = e.message + for old, new, count in replacements: + expected_message = expected_message.replace(old, new, count) + # Check that the first segment of the error messages are the same. + with self.assertRaisesRegexp(exception_class, + re.escape(expected_message)): + sess.run(next2) diff --git a/tensorflow/contrib/data/python/ops/BUILD b/tensorflow/contrib/data/python/ops/BUILD index ad9378dfb9..4b45cc7e36 100644 --- a/tensorflow/contrib/data/python/ops/BUILD +++ b/tensorflow/contrib/data/python/ops/BUILD @@ -80,17 +80,14 @@ py_library( ":batching", ":gen_dataset_ops", ":interleave_ops", + ":parsing_ops", ":shuffle_ops", - ":stats_ops", "//tensorflow/python:constant_op", "//tensorflow/python:dataset_ops_gen", "//tensorflow/python:dtypes", "//tensorflow/python:framework_ops", "//tensorflow/python:lib", - "//tensorflow/python:math_ops", - "//tensorflow/python:parsing_ops", "//tensorflow/python:platform", - "//tensorflow/python:string_ops", "//tensorflow/python:tensor_shape", "//tensorflow/python:util", "//tensorflow/python/data/ops:dataset_ops", @@ -211,6 +208,22 @@ py_library( ) py_library( + name = "parsing_ops", + srcs = ["parsing_ops.py"], + srcs_version = "PY2AND3", + deps = [ + "//tensorflow/python:dataset_ops_gen", + "//tensorflow/python:dtypes", + "//tensorflow/python:framework_ops", + "//tensorflow/python:parsing_ops", + "//tensorflow/python:sparse_tensor", + "//tensorflow/python:tensor_shape", + "//tensorflow/python/data/ops:dataset_ops", + "//tensorflow/python/data/util:nest", + ], +) + +py_library( name = "map_defun", srcs = ["map_defun.py"], srcs_version = "PY2AND3", @@ -331,7 +344,10 @@ py_library( tf_gen_op_wrapper_py( name = "gen_dataset_ops", out = "gen_dataset_ops.py", - deps = ["//tensorflow/contrib/data:dataset_ops_op_lib"], + deps = [ + "//tensorflow/contrib/data:dataset_ops_op_lib", + "//tensorflow/contrib/data:indexed_dataset_ops_op_lib", + ], ) tf_kernel_library( @@ -349,6 +365,7 @@ tf_custom_op_py_library( dso = ["//tensorflow/contrib/data:_dataset_ops.so"], kernels = [ ":dataset_ops_kernels", + "//tensorflow/contrib/data:indexed_dataset_ops_op_lib", "//tensorflow/contrib/data:dataset_ops_op_lib", ], srcs_version = "PY2AND3", @@ -360,6 +377,19 @@ tf_custom_op_py_library( ) py_library( + name = "indexed_dataset_ops", + srcs = ["indexed_dataset_ops.py"], + deps = [ + ":contrib_op_loader", + ":gen_dataset_ops", + "//tensorflow/python:framework_ops", + "//tensorflow/python/data/ops:dataset_ops", + "//tensorflow/python/data/util:nest", + "//tensorflow/python/data/util:sparse", + ], +) + +py_library( name = "prefetching_ops", srcs = ["prefetching_ops.py"], deps = [ @@ -380,6 +410,7 @@ py_library( ":error_ops", ":get_single_element", ":grouping", + ":indexed_dataset_ops", ":interleave_ops", ":map_defun", ":optimization", diff --git a/tensorflow/contrib/data/python/ops/batching.py b/tensorflow/contrib/data/python/ops/batching.py index 9f059942a6..9c2001c34f 100644 --- a/tensorflow/contrib/data/python/ops/batching.py +++ b/tensorflow/contrib/data/python/ops/batching.py @@ -647,15 +647,17 @@ def assert_element_shape(expected_shapes): """Assert the shape of this `Dataset`. ```python - shapes = [tf.TensorShape([16, 256]), tf.TensorShape(None)] + shapes = [tf.TensorShape([16, 256]), tf.TensorShape([None, 2])] result = dataset.apply(tf.contrib.data.assert_element_shape(shapes)) - print(result.output_shapes) # ==> "((16, 256), <unknown>)" + print(result.output_shapes) # ==> "((16, 256), (<unknown>, 2))" ``` If dataset shapes and expected_shape, are fully defined, assert they match. Otherwise, add assert op that will validate the shapes when tensors are evaluated, and set shapes on tensors, respectively. + Note that unknown dimension in `expected_shapes` will be ignored. + Args: expected_shapes: A nested structure of `tf.TensorShape` objects. @@ -664,20 +666,31 @@ def assert_element_shape(expected_shapes): `tf.data.Dataset.apply` """ + def _merge_output_shapes(original_shapes, expected_shapes): + flat_original_shapes = nest.flatten(original_shapes) + flat_new_shapes = nest.flatten_up_to(original_shapes, expected_shapes) + flat_merged_output_shapes = [ + original_shape.merge_with(new_shape) + for original_shape, new_shape in zip(flat_original_shapes, + flat_new_shapes)] + return nest.pack_sequence_as(original_shapes, flat_merged_output_shapes) + def _check_shape(*elements): flatten_tensors = nest.flatten(elements) flatten_shapes = nest.flatten(expected_shapes) checked_tensors = [ - with_shape(shape, tensor) + with_shape(shape, tensor) if shape else tensor # Ignore unknown shape for shape, tensor in zip(flatten_shapes, flatten_tensors) ] return nest.pack_sequence_as(elements, checked_tensors) def _apply_fn(dataset): + output_shapes = _merge_output_shapes(dataset.output_shapes, + expected_shapes) return _RestructuredDataset( dataset.map(_check_shape), dataset.output_types, - output_shapes=expected_shapes, + output_shapes=output_shapes, output_classes=dataset.output_classes) return _apply_fn diff --git a/tensorflow/contrib/data/python/ops/indexed_dataset_ops.py b/tensorflow/contrib/data/python/ops/indexed_dataset_ops.py new file mode 100644 index 0000000000..a0932b4081 --- /dev/null +++ b/tensorflow/contrib/data/python/ops/indexed_dataset_ops.py @@ -0,0 +1,173 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Python wrappers for indexed datasets.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import abc + +from tensorflow.contrib.data.python.ops import contrib_op_loader # pylint: disable=unused-import +from tensorflow.contrib.data.python.ops import gen_dataset_ops +from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.data.util import nest +from tensorflow.python.data.util import sparse +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops +from tensorflow.python.framework import tensor_shape + + +class MaterializedIndexedDataset(object): + """MaterializedIndexedDataset is highly experimental! + """ + + def __init__(self, materialized_resource, materializer, output_classes, + output_types, output_shapes): + self._materialized_resource = materialized_resource + self._materializer = materializer + self._output_classes = output_classes + self._output_types = output_types + self._output_shapes = output_shapes + + @property + def initializer(self): + if self._materializer is not None: + return self._materializer + raise ValueError("MaterializedDataset does not have a materializer") + + def get(self, index): + """Get retrieves a value (or set of values) from the IndexedDataset. + + Args: + index: A uint64 scalar or vector tensor with the indices to retrieve. + + Returns: + A tensor containing the values corresponding to `index`. + """ + # TODO(saeta): nest.pack_sequence_as(...) + return gen_dataset_ops.indexed_dataset_get( + self._materialized_resource, + index, + output_types=nest.flatten( + sparse.as_dense_types(self._output_types, self._output_classes)), + output_shapes=nest.flatten( + sparse.as_dense_types(self._output_shapes, self._output_classes))) + + +class IndexedDataset(dataset_ops.Dataset): + """IndexedDataset is highly experimental! + """ + + def __init__(self): + pass + + def materialize(self, shared_name=None, container=None): + """Materialize creates a MaterializedIndexedDataset. + + IndexedDatasets can be combined through operations such as TBD. Therefore, + they are only materialized when absolutely required. + + Args: + shared_name: a string for the shared name to use for the resource. + container: a string for the container to store the resource. + + Returns: + A MaterializedIndexedDataset. + """ + if container is None: + container = "" + if shared_name is None: + shared_name = "" + materialized_resource = gen_dataset_ops.materialized_index_dataset_handle( + container=container, + shared_name=shared_name, + output_types=nest.flatten( + sparse.as_dense_types(self.output_types, self.output_classes)), + output_shapes=nest.flatten( + sparse.as_dense_types(self.output_shapes, self.output_classes))) + + with ops.colocate_with(materialized_resource): + materializer = gen_dataset_ops.indexed_dataset_materialize( + self._as_variant_tensor(), materialized_resource) + return MaterializedIndexedDataset(materialized_resource, materializer, + self.output_classes, self.output_types, + self.output_shapes) + + @abc.abstractproperty + def output_types(self): + """Returns the type of each component of an element of this IndexedDataset. + + Returns: + A nested structure of `tf.DType` objects corresponding to each component + of an element of this IndexedDataset. + """ + raise NotImplementedError("IndexedDataset.output_types") + + @abc.abstractproperty + def output_classes(self): + """Returns the class of each component of an element of this IndexedDataset. + + The expected values are `tf.Tensor` and `tf.SparseTensor`. + + Returns: + A nested structure of Python `type` objects corresponding to each + component of an element of this IndexedDataset. + """ + raise NotImplementedError("IndexedDataset.output_classes") + + @abc.abstractproperty + def output_shapes(self): + """Returns the shape of each component of an element of this IndexedDataset. + + Returns: + A nested structure of `tf.TensorShape` objects corresponding to each + component of an element of this IndexedDataset. + """ + raise NotImplementedError("IndexedDataset.output_shapes") + + @abc.abstractmethod + def _as_variant_tensor(self): + """Creates a `tf.variant` `tf.Tensor` representing this IndexedDataset. + + Returns: + A scalar `tf.Tensor` of `tf.variant` type, which represents this + IndexedDataset. + """ + raise NotImplementedError("IndexedDataset._as_variant_tensor") + + +class IdentityIndexedDataset(IndexedDataset): + """IdentityIndexedDataset is a trivial indexed dataset used for testing. + """ + + def __init__(self, size): + super(IdentityIndexedDataset, self).__init__() + # TODO(saeta): Verify _size is a scalar! + self._size = ops.convert_to_tensor(size, dtype=dtypes.uint64, name="size") + + @property + def output_types(self): + return dtypes.uint64 + + @property + def output_classes(self): + return ops.Tensor + + @property + def output_shapes(self): + return tensor_shape.scalar() + + def _as_variant_tensor(self): + return gen_dataset_ops.identity_indexed_dataset(self._size) diff --git a/tensorflow/contrib/data/python/ops/interleave_ops.py b/tensorflow/contrib/data/python/ops/interleave_ops.py index 5a1a35199a..54a92ab185 100644 --- a/tensorflow/contrib/data/python/ops/interleave_ops.py +++ b/tensorflow/contrib/data/python/ops/interleave_ops.py @@ -163,7 +163,7 @@ class _DirectedInterleaveDataset(dataset_ops.Dataset): for data_input in data_inputs[1:]: if (data_input.output_types != data_inputs[0].output_types or data_input.output_classes != data_inputs[0].output_classes): - raise TypeError("All datasets must have the same type.") + raise TypeError("All datasets must have the same type and class.") def _as_variant_tensor(self): # pylint: disable=protected-access @@ -216,25 +216,46 @@ def sample_from_datasets(datasets, weights=None, seed=None): length of the `datasets` element. """ num_datasets = len(datasets) - if weights is None: - weights = dataset_ops.Dataset.from_tensors([1.0] * num_datasets).repeat() - elif not isinstance(weights, dataset_ops.Dataset): - weights = ops.convert_to_tensor(weights, name="weights") - if weights.dtype not in (dtypes.float32, dtypes.float64): - raise TypeError("`weights` must be convertible to a tensor of " - "`tf.float32` or `tf.float64` elements.") - if not weights.shape.is_compatible_with([num_datasets]): - raise ValueError("`weights` must be a vector of length `len(datasets)`.") - weights = dataset_ops.Dataset.from_tensors(weights).repeat() - - # The `stateless_multinomial()` op expects log-probabilities, as opposed to - # weights. - logits_ds = weights.map(lambda *p: math_ops.log(p, name="logits")) - def select_dataset(logits, seed): - return array_ops.squeeze( - stateless.stateless_multinomial(logits, 1, seed=seed), axis=[0, 1]) - selector_input = dataset_ops.Dataset.zip( - (logits_ds, random_ops.RandomDataset(seed).batch(2))).map(select_dataset) + if not isinstance(weights, dataset_ops.Dataset): + if weights is None: + # Select inputs with uniform probability. + logits = [[1.0] * num_datasets] + else: + # Use the given `weights` as the probability of choosing the respective + # input. + weights = ops.convert_to_tensor(weights, name="weights") + if weights.dtype not in (dtypes.float32, dtypes.float64): + raise TypeError("`weights` must be convertible to a tensor of " + "`tf.float32` or `tf.float64` elements.") + if not weights.shape.is_compatible_with([num_datasets]): + raise ValueError( + "`weights` must be a vector of length `len(datasets)`.") + + # The `stateless_multinomial()` op expects log-probabilities, as opposed + # to weights. + logits = array_ops.expand_dims(math_ops.log(weights, name="logits"), 0) + + def select_dataset_constant_logits(seed): + return array_ops.squeeze( + stateless.stateless_multinomial(logits, 1, seed=seed), axis=[0, 1]) + + selector_input = random_ops.RandomDataset(seed).batch(2).map( + select_dataset_constant_logits) + else: + # Use each element of the given `weights` dataset as the probability of + # choosing the respective input. + + # The `stateless_multinomial()` op expects log-probabilities, as opposed to + # weights. + logits_ds = weights.map(lambda *p: math_ops.log(p, name="logits")) + + def select_dataset_varying_logits(logits, seed): + return array_ops.squeeze( + stateless.stateless_multinomial(logits, 1, seed=seed), axis=[0, 1]) + + selector_input = dataset_ops.Dataset.zip( + (logits_ds, random_ops.RandomDataset(seed).batch(2) + )).map(select_dataset_varying_logits) return _DirectedInterleaveDataset(selector_input, datasets) diff --git a/tensorflow/contrib/data/python/ops/parsing_ops.py b/tensorflow/contrib/data/python/ops/parsing_ops.py new file mode 100644 index 0000000000..2701605e64 --- /dev/null +++ b/tensorflow/contrib/data/python/ops/parsing_ops.py @@ -0,0 +1,150 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Experimental `dataset` API for parsing example.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.data.util import nest +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops +from tensorflow.python.framework import sparse_tensor +from tensorflow.python.ops import gen_dataset_ops +from tensorflow.python.ops import parsing_ops + + +class _ParseExampleDataset(dataset_ops.Dataset): + """A `Dataset` that parses `example` dataset into a `dict` dataset.""" + + def __init__(self, input_dataset, features, num_parallel_calls): + super(_ParseExampleDataset, self).__init__() + self._input_dataset = input_dataset + if not all(types == dtypes.string + for types in nest.flatten(input_dataset.output_types)): + raise TypeError("Input dataset should be a dataset of vectors of strings") + self._num_parallel_calls = num_parallel_calls + # pylint: disable=protected-access + self._features = parsing_ops._prepend_none_dimension(features) + # sparse_keys and dense_keys come back sorted here. + (sparse_keys, sparse_types, dense_keys, dense_types, dense_defaults, + dense_shapes) = parsing_ops._features_to_raw_params( + self._features, [ + parsing_ops.VarLenFeature, parsing_ops.SparseFeature, + parsing_ops.FixedLenFeature, parsing_ops.FixedLenSequenceFeature + ]) + # TODO(b/112859642): Pass sparse_index and sparse_values for SparseFeature. + (_, dense_defaults_vec, sparse_keys, sparse_types, dense_keys, dense_shapes, + dense_shape_as_shape) = parsing_ops._process_raw_parameters( + None, dense_defaults, sparse_keys, sparse_types, dense_keys, + dense_types, dense_shapes) + # pylint: enable=protected-access + self._sparse_keys = sparse_keys + self._sparse_types = sparse_types + self._dense_keys = dense_keys + self._dense_defaults = dense_defaults_vec + self._dense_shapes = dense_shapes + self._dense_types = dense_types + dense_output_shapes = [ + self._input_dataset.output_shapes.concatenate(shape) + for shape in dense_shape_as_shape + ] + sparse_output_shapes = [ + self._input_dataset.output_shapes.concatenate([None]) + for _ in range(len(sparse_keys)) + ] + + self._output_shapes = dict( + zip(self._dense_keys + self._sparse_keys, + dense_output_shapes + sparse_output_shapes)) + self._output_types = dict( + zip(self._dense_keys + self._sparse_keys, + self._dense_types + self._sparse_types)) + self._output_classes = dict( + zip(self._dense_keys + self._sparse_keys, + [ops.Tensor for _ in range(len(self._dense_defaults))] + + [sparse_tensor.SparseTensor for _ in range(len(self._sparse_keys)) + ])) + + def _as_variant_tensor(self): + return gen_dataset_ops.parse_example_dataset( + self._input_dataset._as_variant_tensor(), # pylint: disable=protected-access + self._num_parallel_calls, + self._dense_defaults, + self._sparse_keys, + self._dense_keys, + self._sparse_types, + self._dense_shapes, + **dataset_ops.flat_structure(self)) + + @property + def output_shapes(self): + return self._output_shapes + + @property + def output_types(self): + return self._output_types + + @property + def output_classes(self): + return self._output_classes + + +# TODO(b/111553342): add arguments names and example names as well. +def parse_example_dataset(features, num_parallel_calls=1): + """A transformation that parses `Example` protos into a `dict` of tensors. + + Parses a number of serialized `Example` protos given in `serialized`. We refer + to `serialized` as a batch with `batch_size` many entries of individual + `Example` protos. + + This op parses serialized examples into a dictionary mapping keys to `Tensor` + and `SparseTensor` objects. `features` is a dict from keys to `VarLenFeature`, + `SparseFeature`, and `FixedLenFeature` objects. Each `VarLenFeature` + and `SparseFeature` is mapped to a `SparseTensor`, and each + `FixedLenFeature` is mapped to a `Tensor`. See `tf.parse_example` for more + details about feature dictionaries. + + Args: + features: A `dict` mapping feature keys to `FixedLenFeature`, + `VarLenFeature`, and `SparseFeature` values. + num_parallel_calls: (Optional.) A `tf.int32` scalar `tf.Tensor`, + representing the number of parsing processes to call in parallel. + + Returns: + A dataset transformation function, which can be passed to + `tf.data.Dataset.apply`. + + Raises: + ValueError: if features argument is None. + """ + if features is None: + raise ValueError("Missing: features was %s." % features) + + def _apply_fn(dataset): + """Function from `Dataset` to `Dataset` that applies the transformation.""" + out_dataset = _ParseExampleDataset(dataset, features, num_parallel_calls) + if any([ + isinstance(feature, parsing_ops.SparseFeature) + for _, feature in features.items() + ]): + # pylint: disable=protected-access + # pylint: disable=g-long-lambda + out_dataset = out_dataset.map( + lambda x: parsing_ops._construct_sparse_tensors_for_sparse_features( + features, x), num_parallel_calls=num_parallel_calls) + return out_dataset + + return _apply_fn diff --git a/tensorflow/contrib/data/python/ops/readers.py b/tensorflow/contrib/data/python/ops/readers.py index 3882d4bfdb..29005859d7 100644 --- a/tensorflow/contrib/data/python/ops/readers.py +++ b/tensorflow/contrib/data/python/ops/readers.py @@ -25,8 +25,8 @@ import numpy as np from tensorflow.contrib.data.python.ops import batching from tensorflow.contrib.data.python.ops import gen_dataset_ops as contrib_gen_dataset_ops from tensorflow.contrib.data.python.ops import interleave_ops +from tensorflow.contrib.data.python.ops import parsing_ops from tensorflow.contrib.data.python.ops import shuffle_ops -from tensorflow.contrib.data.python.ops import stats_ops from tensorflow.python.data.ops import dataset_ops from tensorflow.python.data.ops import readers as core_readers from tensorflow.python.data.util import convert @@ -37,7 +37,6 @@ from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_shape from tensorflow.python.lib.io import file_io from tensorflow.python.ops import gen_dataset_ops -from tensorflow.python.ops import parsing_ops from tensorflow.python.platform import gfile from tensorflow.python.util import deprecation @@ -326,7 +325,6 @@ def make_csv_dataset( shuffle_seed=None, prefetch_buffer_size=1, num_parallel_reads=1, - num_parallel_parser_calls=2, sloppy=False, num_rows_for_inference=100, compression_type=None, @@ -393,8 +391,6 @@ def make_csv_dataset( batches consumed per training step. num_parallel_reads: Number of threads used to read CSV records from files. If >1, the results will be interleaved. - num_parallel_parser_calls: Number of parallel invocations of the CSV parsing - function on CSV records. sloppy: If `True`, reading performance will be improved at the cost of non-deterministic ordering. If `False`, the order of elements produced is deterministic prior to shuffling (elements are still @@ -503,7 +499,7 @@ def make_csv_dataset( # indefinitely, and all batches will be full-sized. dataset = dataset.batch(batch_size=batch_size, drop_remainder=num_epochs is None) - dataset = dataset.map(map_fn, num_parallel_calls=num_parallel_parser_calls) + dataset = dataset.map(map_fn) dataset = dataset.prefetch(prefetch_buffer_size) return dataset @@ -778,8 +774,6 @@ def make_batched_features_dataset(file_pattern, dataset = _maybe_shuffle_and_repeat( dataset, num_epochs, shuffle, shuffle_buffer_size, shuffle_seed) - dataset = dataset.apply(stats_ops.feature_stats("record_stats")) - # NOTE(mrry): We set `drop_remainder=True` when `num_epochs is None` to # improve the shape inference, because it makes the batch dimension static. # It is safe to do this because in that case we are repeating the input @@ -788,9 +782,9 @@ def make_batched_features_dataset(file_pattern, batch_size, drop_remainder=drop_final_batch or num_epochs is None) # Parse `Example` tensors to a dictionary of `Feature` tensors. - dataset = dataset.map( - lambda x: parsing_ops.parse_example(x, features), - num_parallel_calls=parser_num_threads) + dataset = dataset.apply( + parsing_ops.parse_example_dataset( + features, num_parallel_calls=parser_num_threads)) # TODO(rachelim): Add an optional label_name argument for extracting the label # from the features dictionary, to comply with the type expected by the @@ -974,3 +968,49 @@ class SqlDataset(dataset_ops.Dataset): @property def output_types(self): return self._output_types + + +class LMDBDataset(dataset_ops.Dataset): + """A LMDB Dataset that reads the lmdb file.""" + + def __init__(self, filenames): + """Create a `LMDBDataset`. + + `LMDBDataset` allows a user to read data from a mdb file as + (key value) pairs sequentially. + For example: + ```python + dataset = tf.contrib.lmdb.LMDBDataset("/foo/bar.mdb") + iterator = dataset.make_one_shot_iterator() + next_element = iterator.get_next() + # Prints the (key, value) pairs inside a lmdb file. + while True: + try: + print(sess.run(next_element)) + except tf.errors.OutOfRangeError: + break + ``` + Args: + filenames: A `tf.string` tensor containing one or more filenames. + """ + super(LMDBDataset, self).__init__() + self._filenames = ops.convert_to_tensor( + filenames, dtype=dtypes.string, name="filenames") + + def _as_variant_tensor(self): + return contrib_gen_dataset_ops.lmdb_dataset( + self._filenames, + output_types=nest.flatten(self.output_types), + output_shapes=nest.flatten(self.output_shapes)) + + @property + def output_classes(self): + return ops.Tensor, ops.Tensor + + @property + def output_shapes(self): + return (tensor_shape.TensorShape([]), tensor_shape.TensorShape([])) + + @property + def output_types(self): + return dtypes.string, dtypes.string diff --git a/tensorflow/contrib/distribute/BUILD b/tensorflow/contrib/distribute/BUILD index d3628d480d..02feeafb60 100644 --- a/tensorflow/contrib/distribute/BUILD +++ b/tensorflow/contrib/distribute/BUILD @@ -29,12 +29,12 @@ py_library( "//tensorflow/contrib/distribute/python:cross_tower_ops", "//tensorflow/contrib/distribute/python:mirrored_strategy", "//tensorflow/contrib/distribute/python:monitor", - "//tensorflow/contrib/distribute/python:multi_worker_strategy", "//tensorflow/contrib/distribute/python:one_device_strategy", "//tensorflow/contrib/distribute/python:parameter_server_strategy", "//tensorflow/contrib/distribute/python:step_fn", "//tensorflow/contrib/distribute/python:tpu_strategy", "//tensorflow/python:training", "//tensorflow/python:util", + "//tensorflow/python/distribute:distribute_config", ], ) diff --git a/tensorflow/contrib/distribute/README.md b/tensorflow/contrib/distribute/README.md index 2f5dd10550..ba92ea0b12 100644 --- a/tensorflow/contrib/distribute/README.md +++ b/tensorflow/contrib/distribute/README.md @@ -1,6 +1,6 @@ # Distribution Strategy -> *NOTE*: This is a experimental feature. The API and performance +> *NOTE*: This is an experimental feature. The API and performance > characteristics are subject to change. ## Overview @@ -9,7 +9,7 @@ API is an easy way to distribute your training across multiple devices/machines. Our goal is to allow users to use existing models and training code with minimal changes to enable distributed training. -Moreover, we've design the API in such a way that it works with both eager and +Moreover, we've designed the API in such a way that it works with both eager and graph execution. Currently we support one type of strategy, called diff --git a/tensorflow/contrib/distribute/__init__.py b/tensorflow/contrib/distribute/__init__.py index 2c93ce92ce..bf763215ba 100644 --- a/tensorflow/contrib/distribute/__init__.py +++ b/tensorflow/contrib/distribute/__init__.py @@ -23,11 +23,11 @@ from tensorflow.contrib.distribute.python.collective_all_reduce_strategy import from tensorflow.contrib.distribute.python.cross_tower_ops import * from tensorflow.contrib.distribute.python.mirrored_strategy import MirroredStrategy from tensorflow.contrib.distribute.python.monitor import Monitor -from tensorflow.contrib.distribute.python.multi_worker_strategy import MultiWorkerMirroredStrategy from tensorflow.contrib.distribute.python.one_device_strategy import OneDeviceStrategy from tensorflow.contrib.distribute.python.parameter_server_strategy import ParameterServerStrategy from tensorflow.contrib.distribute.python.step_fn import * from tensorflow.contrib.distribute.python.tpu_strategy import TPUStrategy +from tensorflow.python.distribute.distribute_config import DistributeConfig from tensorflow.python.training.distribute import * from tensorflow.python.training.distribution_strategy_context import * @@ -38,9 +38,9 @@ _allowed_symbols = [ 'AllReduceCrossTowerOps', 'CollectiveAllReduceStrategy', 'CrossTowerOps', + 'DistributeConfig', 'DistributionStrategy', 'MirroredStrategy', - 'MultiWorkerMirroredStrategy', 'Monitor', 'OneDeviceStrategy', 'ParameterServerStrategy', diff --git a/tensorflow/contrib/distribute/python/BUILD b/tensorflow/contrib/distribute/python/BUILD index ae50d4e3fc..94deb2a432 100644 --- a/tensorflow/contrib/distribute/python/BUILD +++ b/tensorflow/contrib/distribute/python/BUILD @@ -23,8 +23,6 @@ py_library( deps = [ ":input_ops", ":prefetching_ops_v2", - "//tensorflow/contrib/data/python/ops:batching", - "//tensorflow/contrib/eager/python:datasets", "//tensorflow/python:array_ops", "//tensorflow/python:control_flow_ops", "//tensorflow/python:device_util", @@ -72,49 +70,72 @@ py_library( ":cross_tower_ops", ":shared_variable_creator", ":values", + "//tensorflow/core:protos_all_py", "//tensorflow/python:array_ops", + "//tensorflow/python:constant_op", + "//tensorflow/python:control_flow_ops", "//tensorflow/python:device", "//tensorflow/python:device_util", "//tensorflow/python:distribute", "//tensorflow/python:framework_ops", - "//tensorflow/python:math_ops", "//tensorflow/python:pywrap_tensorflow", "//tensorflow/python:training", + "//tensorflow/python:util", "//tensorflow/python:variable_scope", + "//tensorflow/python:variables", + "//tensorflow/python/distribute:multi_worker_util", "//tensorflow/python/eager:context", "//tensorflow/python/eager:tape", - "@six_archive//:six", ], ) py_library( - name = "multi_worker_strategy", - srcs = ["multi_worker_strategy.py"], + name = "parameter_server_strategy", + srcs = ["parameter_server_strategy.py"], visibility = ["//tensorflow:internal"], deps = [ + ":cross_tower_ops", ":mirrored_strategy", ":values", "//tensorflow/core:protos_all_py", + "//tensorflow/python:array_ops", + "//tensorflow/python:framework_ops", + "//tensorflow/python:resource_variable_ops", "//tensorflow/python:training", "//tensorflow/python:util", + "//tensorflow/python/distribute:multi_worker_util", + "//tensorflow/python/eager:context", ], ) -py_library( - name = "parameter_server_strategy", - srcs = ["parameter_server_strategy.py"], - visibility = ["//tensorflow:internal"], - deps = [ - ":cross_tower_ops", - ":mirrored_strategy", +cuda_py_test( + name = "parameter_server_strategy_test", + srcs = ["parameter_server_strategy_test.py"], + additional_deps = [ + ":combinations", + ":multi_worker_test_base", + ":parameter_server_strategy", ":values", + "@absl_py//absl/testing:parameterized", "//tensorflow/core:protos_all_py", "//tensorflow/python:array_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:constant_op", + "//tensorflow/python:control_flow_ops", "//tensorflow/python:framework_ops", - "//tensorflow/python:resource_variable_ops", + "//tensorflow/python:gradients", + "//tensorflow/python:layers", + "//tensorflow/python:session", "//tensorflow/python:training", - "//tensorflow/python:util", + "//tensorflow/python:variable_scope", + "//tensorflow/python:variables", "//tensorflow/python/distribute:multi_worker_util", + "//tensorflow/python/eager:context", + "//tensorflow/python/estimator:estimator_py", + ], + tags = [ + "multi_and_single_gpu", + "no_pip", ], ) @@ -148,6 +169,7 @@ py_library( "//tensorflow/python:collective_ops", "//tensorflow/python:framework_ops", "//tensorflow/python:training", + "//tensorflow/python/distribute:multi_worker_util", "//tensorflow/python/eager:context", ], ) @@ -185,7 +207,6 @@ py_library( ], deps = [ ":mirrored_strategy", - ":multi_worker_strategy", ":one_device_strategy", ":tpu_strategy", "//tensorflow/contrib/cluster_resolver:cluster_resolver_pip", @@ -220,9 +241,13 @@ py_test( ], deps = [ ":mirrored_strategy", + ":multi_worker_test_base", ":strategy_test_lib", + "//tensorflow/python:constant_op", "//tensorflow/python:distribute", + "//tensorflow/python:framework_ops", "//tensorflow/python:framework_test_lib", + "//tensorflow/python:training", "//tensorflow/python:variable_scope", "//tensorflow/python/eager:context", "//tensorflow/python/eager:test", @@ -244,40 +269,12 @@ py_test( ], ) -py_test( - name = "parameter_server_strategy_test", - srcs = ["parameter_server_strategy_test.py"], - srcs_version = "PY2AND3", - tags = [ - "no_pip", - ], - deps = [ - ":combinations", - ":multi_worker_test_base", - ":parameter_server_strategy", - "//tensorflow/core:protos_all_py", - "//tensorflow/python:array_ops", - "//tensorflow/python:client_testlib", - "//tensorflow/python:constant_op", - "//tensorflow/python:control_flow_ops", - "//tensorflow/python:framework_ops", - "//tensorflow/python:gradients", - "//tensorflow/python:layers", - "//tensorflow/python:session", - "//tensorflow/python:training", - "//tensorflow/python:variable_scope", - "//tensorflow/python:variables", - "//tensorflow/python/eager:context", - "//tensorflow/python/estimator:estimator_py", - "@absl_py//absl/testing:parameterized", - ], -) - cuda_py_test( name = "mirrored_strategy_multigpu_test", srcs = ["mirrored_strategy_multigpu_test.py"], additional_deps = [ ":mirrored_strategy", + ":multi_worker_test_base", ":values", ":strategy_test_lib", "//tensorflow/python:distribute", @@ -346,19 +343,17 @@ py_library( ], ) -py_test( +cuda_py_test( name = "collective_all_reduce_strategy_test", srcs = ["collective_all_reduce_strategy_test.py"], - srcs_version = "PY2AND3", - tags = [ - "no_pip", - ], - deps = [ + additional_deps = [ ":collective_all_reduce_strategy", ":combinations", ":cross_tower_utils", ":multi_worker_test_base", ":strategy_test_lib", + "@absl_py//absl/testing:parameterized", + "//third_party/py/numpy", "//tensorflow/core:protos_all_py", "//tensorflow/python:array_ops", "//tensorflow/python:client_testlib", @@ -372,8 +367,10 @@ py_test( "//tensorflow/python:variables", "//tensorflow/python/eager:context", "//tensorflow/python/estimator:estimator_py", - "//third_party/py/numpy", - "@absl_py//absl/testing:parameterized", + ], + tags = [ + "multi_and_single_gpu", + "no_pip", ], ) @@ -453,6 +450,35 @@ cuda_py_test( ], ) +cuda_py_test( + name = "estimator_training_test", + size = "large", + srcs = ["estimator_training_test.py"], + additional_deps = [ + ":combinations", + ":mirrored_strategy", + ":multi_worker_test_base", + ":parameter_server_strategy", + "//third_party/py/numpy", + "//tensorflow/contrib/optimizer_v2:training", + "//tensorflow/python/data/ops:dataset_ops", + "//tensorflow/python/distribute", + "//tensorflow/python/eager:test", + "//tensorflow/python/estimator:estimator_py", + "//tensorflow/python/feature_column", + "//tensorflow/python:framework_ops", + "//tensorflow/python:platform", + "//tensorflow/python:summary", + ], + tags = [ + "manual", + "multi_and_single_gpu", + "no_pip", + "nogpu", + "notap", + ], +) + py_library( name = "single_loss_example", srcs = ["single_loss_example.py"], @@ -608,6 +634,7 @@ cuda_py_test( ":combinations", ":cross_tower_ops", ":multi_worker_test_base", + ":mirrored_strategy", ":values", "@absl_py//absl/testing:parameterized", "//tensorflow/python:array_ops", diff --git a/tensorflow/contrib/distribute/python/checkpoint_utils_test.py b/tensorflow/contrib/distribute/python/checkpoint_utils_test.py index bcb977f640..865dba803f 100644 --- a/tensorflow/contrib/distribute/python/checkpoint_utils_test.py +++ b/tensorflow/contrib/distribute/python/checkpoint_utils_test.py @@ -48,7 +48,7 @@ class CheckpointUtilsWithDistributionStrategyTest( mode=["graph"])) def testInitFromCheckpoint(self, distribution, in_tower_mode): checkpoint_dir = self.get_temp_dir() - with self.test_session() as session: + with self.cached_session() as session: v1_value, v2_value, _, _ = checkpoint_utils_test._create_checkpoints( session, checkpoint_dir) @@ -62,7 +62,7 @@ class CheckpointUtilsWithDistributionStrategyTest( "var1": "new_var1", "var2": "new_var2" }) - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: session.run(variables.global_variables_initializer()) self.assertAllEqual(v1_value, self.evaluate(v1)) self.assertAllEqual(v2_value, self.evaluate(v2)) diff --git a/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py b/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py index 9afcaecf78..2331444261 100644 --- a/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py +++ b/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py @@ -18,30 +18,15 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function -import json -import os - from tensorflow.contrib.distribute.python import cross_tower_ops as cross_tower_ops_lib from tensorflow.contrib.distribute.python import cross_tower_utils from tensorflow.contrib.distribute.python import mirrored_strategy from tensorflow.contrib.distribute.python import values -from tensorflow.core.protobuf import cluster_pb2 +from tensorflow.python.distribute import multi_worker_util from tensorflow.python.eager import context from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops from tensorflow.python.ops import collective_ops -from tensorflow.python.training import server_lib - - -# TODO(yuefengz): move this function to a common util file. -def _normalize_cluster_spec(cluster_spec): - if isinstance(cluster_spec, (dict, cluster_pb2.ClusterDef)): - return server_lib.ClusterSpec(cluster_spec) - elif not isinstance(cluster_spec, server_lib.ClusterSpec): - raise ValueError( - "`cluster_spec' should be dict or a `tf.train.ClusterSpec` or a " - "`tf.train.ClusterDef` object") - return cluster_spec # TODO(yuefengz): shard the dataset. @@ -52,51 +37,45 @@ class CollectiveAllReduceStrategy(mirrored_strategy.MirroredStrategy): """Distribution strategy that uses collective ops for all-reduce. It is similar to the MirroredStrategy but it uses collective ops for - reduction. It currently only works for between-graph replication and its - reduction will reduce across all workers. + reduction. + + When `cluster_spec` is given by the `configure` method, it turns into the + mulit-worker version that works on multiple workers with between-graph + replication. + + Note: `configure` will be called by higher-level APIs if running in + distributed environment. """ - def __init__(self, - num_gpus_per_worker=0, - cluster_spec=None, - task_type="worker", - task_id=0): + def __init__(self, num_gpus_per_worker=0): """Initializes the object. Args: num_gpus_per_worker: number of local GPUs or GPUs per worker. - cluster_spec: a dict, ClusterDef or ClusterSpec object specifying the - cluster configurations. - task_type: the current task type, such as "worker". - task_id: the current task id. - - Raises: - ValueError: if `task_type` is not in the `cluster_spec`. """ self._num_gpus_per_worker = num_gpus_per_worker - self._initialize(cluster_spec, task_type, task_id) + self._initialize(None, None, None) def _initialize(self, cluster_spec, task_type, task_id): - if task_type not in ["chief", "worker"]: - raise ValueError( - "Unrecognized task_type: %r, valid task types are: \"chief\", " - "\"worker\"." % task_type) if cluster_spec: - self._cluster_spec = _normalize_cluster_spec(cluster_spec) + if task_type is None or task_id is None: + raise ValueError("When `cluster_spec` is given, you must also specify " + "`task_type` and `task_id`") + if task_type not in ["chief", "worker"]: + raise ValueError( + "Unrecognized task_type: %r, valid task types are: \"chief\", " + "\"worker\"." % task_type) + self._cluster_spec = multi_worker_util.normalize_cluster_spec( + cluster_spec) worker_device = "/job:%s/task:%d" % (task_type, task_id) - num_workers = len(self._cluster_spec.as_dict().get(task_type, [])) - if "chief" in self._cluster_spec.as_dict(): - num_workers += 1 + num_workers = len(self._cluster_spec.as_dict().get("worker", [])) + len( + self._cluster_spec.as_dict().get("chief", [])) if not num_workers: - raise ValueError("`task_type` shoud be in `cluster_spec`.") + raise ValueError("No `worker` or `chief` tasks can be found in " + "`cluster_spec`.") - # TODO(yuefengz): create a utility to infer chief. - if "chief" in self._cluster_spec.as_dict() and task_type == "chief": - assert task_id == 0 - self._is_chief = True - else: - assert task_type == "worker" - self._is_chief = task_id == 0 + self._is_chief = multi_worker_util.is_chief(cluster_spec, task_type, + task_id) else: self._cluster_spec = None self._is_chief = True @@ -187,19 +166,41 @@ class CollectiveAllReduceStrategy(mirrored_strategy.MirroredStrategy): return mirrored_strategy._create_mirrored_variable( devices, _real_mirrored_creator, *args, **kwargs) - def configure(self, session_config=None): - # Use TF_CONFIG to get the cluster spec and the current job. - if not self._cluster_spec: - tf_config = json.loads(os.environ.get("TF_CONFIG", "{}")) - cluster_spec = _normalize_cluster_spec(tf_config.get("cluster", {})) + def configure(self, + session_config=None, + cluster_spec=None, + task_type=None, + task_id=None): + """Configures the object. - task_env = tf_config.get("task", {}) - if task_env: - task_type = task_env.get("type", "worker") - task_id = int(task_env.get("index", "0")) - else: - task_type = "worker" - task_id = 0 + Args: + session_config: a @{tf.ConfigProto} + cluster_spec: a dict, ClusterDef or ClusterSpec object specifying the + cluster configurations. + task_type: the current task type, such as "worker". + task_id: the current task id. - if cluster_spec: - self._initialize(cluster_spec, task_type, task_id) + Raises: + ValueError: if `task_type` is not in the `cluster_spec`. + """ + # TODO(yuefengz): we'll need to mutate the session_config to add + # configurations for collective ops. + del session_config + if not self._cluster_spec and cluster_spec: + self._initialize(cluster_spec, task_type, task_id) + + @property + def between_graph(self): + return True + + @property + def should_init(self): + return True + + @property + def should_checkpoint(self): + return self._is_chief + + @property + def should_save_summary(self): + return self._is_chief diff --git a/tensorflow/contrib/distribute/python/collective_all_reduce_strategy_test.py b/tensorflow/contrib/distribute/python/collective_all_reduce_strategy_test.py index b5e54e3b7d..e284969b1a 100644 --- a/tensorflow/contrib/distribute/python/collective_all_reduce_strategy_test.py +++ b/tensorflow/contrib/distribute/python/collective_all_reduce_strategy_test.py @@ -25,10 +25,8 @@ from tensorflow.contrib.distribute.python import collective_all_reduce_strategy from tensorflow.contrib.distribute.python import combinations from tensorflow.contrib.distribute.python import cross_tower_utils from tensorflow.contrib.distribute.python import multi_worker_test_base -from tensorflow.contrib.distribute.python import strategy_test_lib from tensorflow.core.protobuf import config_pb2 from tensorflow.python.eager import context -from tensorflow.python.estimator import run_config from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops @@ -41,53 +39,43 @@ from tensorflow.python.ops import variables from tensorflow.python.platform import test -class DistributedCollectiveAllReduceStrategyTest( - multi_worker_test_base.MultiWorkerTestBase, parameterized.TestCase): +class CollectiveAllReduceStrategyTestBase( + multi_worker_test_base.MultiWorkerTestBase): collective_key_base = 0 - @classmethod - def setUpClass(cls): - """Create a local cluster with 2 workers.""" - cls._workers, cls._ps = multi_worker_test_base.create_in_process_cluster( - num_workers=3, num_ps=0) - cls._cluster_spec = { - run_config.TaskType.WORKER: [ - 'fake_worker_0', 'fake_worker_1', 'fake_worker_2' - ] - } - def setUp(self): self._run_options = config_pb2.RunOptions() self._run_options.experimental.collective_graph_key = 6 self._sess_config = config_pb2.ConfigProto() - self._sess_config.experimental.collective_group_leader = ( - '/job:worker/replica:0/task:0') # We use a different key_base for each test so that collective keys won't be # reused. # TODO(yuefengz, tucker): enable it to reuse collective keys in different # tests. - DistributedCollectiveAllReduceStrategyTest.collective_key_base += 100000 - super(DistributedCollectiveAllReduceStrategyTest, self).setUp() + CollectiveAllReduceStrategyTestBase.collective_key_base += 100000 + super(CollectiveAllReduceStrategyTestBase, self).setUp() def _get_test_object(self, task_type, task_id, num_gpus=0): distribution = collective_all_reduce_strategy.CollectiveAllReduceStrategy( - num_gpus_per_worker=num_gpus, - cluster_spec=self._cluster_spec, - task_type=task_type, - task_id=task_id) + num_gpus_per_worker=num_gpus) + if task_type and task_id is not None: + distribution.configure( + cluster_spec=self._cluster_spec, task_type=task_type, task_id=task_id) collective_keys = cross_tower_utils.CollectiveKeys( group_key_start=10 * num_gpus + - DistributedCollectiveAllReduceStrategyTest.collective_key_base, + CollectiveAllReduceStrategyTestBase.collective_key_base, instance_key_start=num_gpus * 100 + - DistributedCollectiveAllReduceStrategyTest.collective_key_base, + CollectiveAllReduceStrategyTestBase.collective_key_base, instance_key_with_id_start=num_gpus * 10000 + - DistributedCollectiveAllReduceStrategyTest.collective_key_base) + CollectiveAllReduceStrategyTestBase.collective_key_base) distribution._collective_keys = collective_keys distribution._cross_tower_ops._collective_keys = collective_keys - return distribution, self._workers[task_id].target + if task_type and task_id is not None: + return distribution, 'grpc://' + self._cluster_spec[task_type][task_id] + else: + return distribution, '' def _test_minimize_loss_graph(self, task_type, task_id, num_gpus): d, master_target = self._get_test_object(task_type, task_id, num_gpus) @@ -155,12 +143,6 @@ class DistributedCollectiveAllReduceStrategyTest( self.assertLess(error_after, error_before) return error_after < error_before - @combinations.generate( - combinations.combine(mode=['graph'], num_gpus=[0, 1, 2])) - def testMinimizeLossGraph(self, num_gpus): - self._run_between_graph_clients(self._test_minimize_loss_graph, - self._cluster_spec, num_gpus) - def _test_variable_initialization(self, task_type, task_id, num_gpus): distribution, master_target = self._get_test_object(task_type, task_id, num_gpus) @@ -182,16 +164,74 @@ class DistributedCollectiveAllReduceStrategyTest( distribution.reduce( variable_scope.VariableAggregation.MEAN, x, destinations='/cpu:0'))[0] + x = distribution.unwrap(x)[0] sess.run( variables.global_variables_initializer(), options=self._run_options) + x_value, reduced_x_value = sess.run( [x, reduced_x], options=self._run_options) - self.assertTrue(np.array_equal(x_value, reduced_x_value)) - return np.array_equal(x_value, reduced_x_value) + self.assertTrue( + np.allclose(x_value, reduced_x_value, atol=1e-5), + msg=('x_value = %r, reduced_x_value = %r' % (x_value, + reduced_x_value))) + return np.allclose(x_value, reduced_x_value, atol=1e-5) + + +class DistributedCollectiveAllReduceStrategyTest( + CollectiveAllReduceStrategyTestBase, parameterized.TestCase): + + @classmethod + def setUpClass(cls): + """Create a local cluster with 3 workers.""" + cls._cluster_spec = multi_worker_test_base.create_in_process_cluster( + num_workers=3, num_ps=0) + + def setUp(self): + super(DistributedCollectiveAllReduceStrategyTest, self).setUp() + self._sess_config.experimental.collective_group_leader = ( + '/job:worker/replica:0/task:0') + + @combinations.generate( + combinations.combine(mode=['graph'], num_gpus=[0, 1, 2], required_gpus=1)) + def testMinimizeLossGraph(self, num_gpus): + self._run_between_graph_clients(self._test_minimize_loss_graph, + self._cluster_spec, num_gpus) + + @combinations.generate( + combinations.combine(mode=['graph'], num_gpus=[0, 1, 2], required_gpus=1)) + def testVariableInitialization(self, num_gpus): + if context.num_gpus() < num_gpus: + return + self._run_between_graph_clients( + self._test_variable_initialization, + self._cluster_spec, + num_gpus=num_gpus) + + +class DistributedCollectiveAllReduceStrategyTestWithChief( + CollectiveAllReduceStrategyTestBase, parameterized.TestCase): + + @classmethod + def setUpClass(cls): + """Create a local cluster with 3 workers and 1 chief.""" + cls._cluster_spec = multi_worker_test_base.create_in_process_cluster( + num_workers=3, num_ps=0, has_chief=True) + + def setUp(self): + super(DistributedCollectiveAllReduceStrategyTestWithChief, self).setUp() + self._run_options.experimental.collective_graph_key = 7 + self._sess_config.experimental.collective_group_leader = ( + '/job:chief/replica:0/task:0') @combinations.generate( - combinations.combine(mode=['graph'], num_gpus=[0, 1, 2])) + combinations.combine(mode=['graph'], num_gpus=[0, 1, 2], required_gpus=1)) + def testMinimizeLossGraph(self, num_gpus): + self._run_between_graph_clients(self._test_minimize_loss_graph, + self._cluster_spec, num_gpus) + + @combinations.generate( + combinations.combine(mode=['graph'], num_gpus=[0, 1, 2], required_gpus=1)) def testVariableInitialization(self, num_gpus): if context.num_gpus() < num_gpus: return @@ -201,16 +241,14 @@ class DistributedCollectiveAllReduceStrategyTest( num_gpus=num_gpus) -class LocalCollectiveAllReduceStrategy(strategy_test_lib.DistributionTestBase, - parameterized.TestCase): +class LocalCollectiveAllReduceStrategy( + CollectiveAllReduceStrategyTestBase, parameterized.TestCase): def testMinimizeLossGraph(self, num_gpus=2): # Collective ops doesn't support strategy with one device. if context.num_gpus() < num_gpus: return - distribution = collective_all_reduce_strategy.CollectiveAllReduceStrategy( - num_gpus_per_worker=num_gpus) - self._test_minimize_loss_graph(distribution) + self._test_minimize_loss_graph(None, None, num_gpus) if __name__ == '__main__': diff --git a/tensorflow/contrib/distribute/python/combinations.py b/tensorflow/contrib/distribute/python/combinations.py index aeec9c44d7..2301ba9233 100644 --- a/tensorflow/contrib/distribute/python/combinations.py +++ b/tensorflow/contrib/distribute/python/combinations.py @@ -48,7 +48,6 @@ import six from tensorflow.contrib.cluster_resolver import TPUClusterResolver from tensorflow.contrib.distribute.python import mirrored_strategy as mirrored_lib -from tensorflow.contrib.distribute.python import multi_worker_strategy from tensorflow.contrib.distribute.python import one_device_strategy as one_device_lib from tensorflow.contrib.distribute.python import tpu_strategy as tpu_lib from tensorflow.contrib.optimizer_v2 import adam as adam_v2 @@ -342,33 +341,6 @@ mirrored_strategy_with_two_gpus = NamedDistribution( ["/gpu:0", "/gpu:1"], prefetch_on_device=False), required_gpus=2) -multi_worker_strategy_with_cpu = NamedDistribution( - "MultiWorkerCPU", - lambda: multi_worker_strategy.MultiWorkerMirroredStrategy( - cluster={ - "worker": [ - "/job:worker/replica:0/task:0", "/job:worker/replica:0/task:1" - ] - }, - num_gpus_per_worker=0), 0) -multi_worker_strategy_with_one_gpu = NamedDistribution( - "MultiWorker1GPU", - lambda: multi_worker_strategy.MultiWorkerMirroredStrategy( - cluster={ - "worker": [ - "/job:worker/replica:0/task:0", "/job:worker/replica:0/task:1" - ] - }, - num_gpus_per_worker=1), 1) -multi_worker_strategy_with_two_gpus = NamedDistribution( - "MultiWorker2GPUs", - lambda: multi_worker_strategy.MultiWorkerMirroredStrategy( - cluster={ - "worker": [ - "/job:worker/replica:0/task:0", "/job:worker/replica:0/task:1" - ] - }, - num_gpus_per_worker=2), 2) adam_optimizer_v1_fn = NamedObject( "AdamV1", lambda: adam.AdamOptimizer(0.2, epsilon=1)) diff --git a/tensorflow/contrib/distribute/python/cross_tower_ops.py b/tensorflow/contrib/distribute/python/cross_tower_ops.py index 3a7addf221..2a653b0f10 100644 --- a/tensorflow/contrib/distribute/python/cross_tower_ops.py +++ b/tensorflow/contrib/distribute/python/cross_tower_ops.py @@ -53,7 +53,7 @@ def validate_destinations(destinations): if not isinstance( destinations, (value_lib.DistributedValues, resource_variable_ops.ResourceVariable, - six.string_types, list)): + value_lib.AggregatingVariable, six.string_types, list)): raise ValueError("destinations must be one of a `DistributedValues` object," " a tf.Variable object, a device string, a list of device " "strings or None") @@ -62,7 +62,44 @@ def validate_destinations(destinations): raise ValueError("destinations can not be empty") +def _make_tensor_into_per_device(input_tensor): + """Converts a single tensor into a PerDevice object.""" + if isinstance(input_tensor, (tuple, list)): + raise ValueError("Cannot convert `input_tensor` to a `PerDevice` object, " + "got %r but expected a object that is not a tuple or list." + % (input_tensor,)) + if isinstance(input_tensor, value_lib.PerDevice): + return input_tensor + + try: + device = input_tensor.device + except AttributeError: + raise ValueError("Cannot convert `input_tensor` to a `PerDevice` object " + "because it doesn't have device set.") + + return value_lib.PerDevice({device: input_tensor}) + + +def _normalize_value_destination_pairs(value_destination_pairs): + """Converts each tensor into a PerDevice object in the input list.""" + result = [] + if not isinstance(value_destination_pairs, (list, tuple)): + raise ValueError("`value_destination_pairs` should be a list or tuple") + for pair in value_destination_pairs: + if not isinstance(pair, tuple): + raise ValueError( + "Each element of `value_destination_pairs` should be a tuple.") + if len(pair) != 2: + raise ValueError("Each element of `value_destination_pairs` should be a " + "tuple of size 2.") + + per_device = _make_tensor_into_per_device(pair[0]) + result.append((per_device, pair[1])) + return result + + def _validate_value_destination_pairs(value_destination_pairs): + # TODO(yuefengz): raise exceptions instead of returning False. # pylint: disable=g-missing-docstring if not value_destination_pairs: return False if not isinstance(value_destination_pairs, (list, tuple)): return False @@ -78,12 +115,15 @@ def _validate_value_destination_pairs(value_destination_pairs): def get_devices_from(destinations): if isinstance(destinations, value_lib.DistributedValues): return list(destinations.devices) - elif isinstance(destinations, resource_variable_ops.ResourceVariable): + elif isinstance(destinations, (resource_variable_ops.ResourceVariable, + value_lib.AggregatingVariable)): return [destinations.device] elif isinstance(destinations, six.string_types): return [device_util.resolve(destinations)] - else: + elif isinstance(destinations, (list, tuple)): return [device_util.resolve(destination) for destination in destinations] + else: + return [destinations.device] def _devices_match(left, right): @@ -158,7 +198,7 @@ class CrossTowerOps(object): Args: aggregation: Indicates how a variable will be aggregated. Accepted values are `tf.VariableAggregation.SUM`, `tf.VariableAggregation.MEAN`. - per_device_value: a PerDevice object. + per_device_value: a PerDevice object or a tensor with device set. destinations: the reduction destinations. Returns: @@ -168,7 +208,8 @@ class CrossTowerOps(object): ValueError: if per_device_value is not a PerDevice object. """ if not isinstance(per_device_value, value_lib.PerDevice): - raise ValueError("`per_device_value` must be a `PerDevice` object.") + per_device_value = _make_tensor_into_per_device(per_device_value) + if destinations is not None: validate_destinations(destinations) return self._reduce(aggregation, per_device_value, destinations) @@ -183,8 +224,9 @@ class CrossTowerOps(object): aggregation: Indicates how a variable will be aggregated. Accepted values are `tf.VariableAggregation.SUM`, `tf.VariableAggregation.MEAN`. value_destination_pairs: a list or a tuple of tuples of PerDevice objects - and destinations. If a destination is None, then the destinations - are set to match the devices of the input PerDevice object. + (or tensors with device set if there is one tower) and destinations. If + a destination is None, then the destinations are set to match the + devices of the input PerDevice object. Returns: a list of Mirrored objects. @@ -194,8 +236,11 @@ class CrossTowerOps(object): tuples of PerDevice objects and destinations """ if not _validate_value_destination_pairs(value_destination_pairs): - raise ValueError("`value_destination_pairs` must be a list or a tuple of " - "tuples of PerDevice objects and destinations") + # If the first element of each pair is a tensor, we try to turn it into a + # PerDevice object. + value_destination_pairs = _normalize_value_destination_pairs( + value_destination_pairs) + for _, d in value_destination_pairs: if d is not None: validate_destinations(d) @@ -756,7 +801,7 @@ class CollectiveAllReduce(CrossTowerOps): ) super(CollectiveAllReduce, self).__init__() - # TODO(yuefengz, tucker): is index slices supported by collective ops? + # TODO(yuefengz, tucker): is indexed slices supported by collective ops? def _reduce(self, aggregation, per_device_value, destinations): all_reduced = self._batch_all_reduce(aggregation, [per_device_value])[0] if destinations is None or _devices_match(per_device_value, destinations): @@ -768,8 +813,10 @@ class CollectiveAllReduce(CrossTowerOps): if d in all_reduced._index: index[d] = all_reduced._index[d] else: - with ops.device(d): + with ops.control_dependencies(list( + all_reduced._index.values())), ops.device(d): index[d] = array_ops.identity(list(all_reduced._index.values())[0]) + return value_lib.Mirrored(index) def _batch_reduce(self, aggregation, value_destination_pairs): diff --git a/tensorflow/contrib/distribute/python/cross_tower_ops_test.py b/tensorflow/contrib/distribute/python/cross_tower_ops_test.py index aec53b01d7..2ad91d56e9 100644 --- a/tensorflow/contrib/distribute/python/cross_tower_ops_test.py +++ b/tensorflow/contrib/distribute/python/cross_tower_ops_test.py @@ -26,12 +26,12 @@ import numpy as np from tensorflow.contrib.distribute.python import combinations from tensorflow.contrib.distribute.python import cross_tower_ops as cross_tower_ops_lib from tensorflow.contrib.distribute.python import cross_tower_utils +from tensorflow.contrib.distribute.python import mirrored_strategy from tensorflow.contrib.distribute.python import multi_worker_test_base from tensorflow.contrib.distribute.python import values as value_lib from tensorflow.core.protobuf import config_pb2 from tensorflow.python.eager import context from tensorflow.python.eager import test -from tensorflow.python.estimator import run_config from tensorflow.python.framework import constant_op from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops @@ -40,9 +40,17 @@ from tensorflow.python.ops import variable_scope as vs from tensorflow.python.training import device_util -def _make_per_device(values, devices): +def _make_per_device(values, devices, regroup=False): devices = cross_tower_ops_lib.get_devices_from(devices) assert len(values) == len(devices) + + # We simulate the result of regroup called on PerDevice which strips the + # PerDevice wrapper if it has only one value. + if len(values) == 1 and regroup: + with ops.device(devices[0]): + placed_v = array_ops.identity(values[0]) + return placed_v + index = {} for d, v in zip(devices, values): with ops.device(d): @@ -368,14 +376,27 @@ class MultiWorkerCrossTowerOpsTest(multi_worker_test_base.MultiWorkerTestBase, ("xring", 2, -1)], 0, 0, 0)), ], distribution=[ - combinations.multi_worker_strategy_with_cpu, - combinations.multi_worker_strategy_with_one_gpu, - combinations.multi_worker_strategy_with_two_gpus + combinations.NamedDistribution( + "MirroredCPU", + lambda: mirrored_strategy.MirroredStrategy(num_gpus=0), + required_gpus=0), + combinations.NamedDistribution( + "Mirrored1GPU", + lambda: mirrored_strategy.MirroredStrategy(num_gpus=1), + required_gpus=1), + combinations.NamedDistribution( + "Mirrored2GPUs", + lambda: mirrored_strategy.MirroredStrategy(num_gpus=2), + required_gpus=2), ], mode=["graph"]) @combinations.generate(multi_worker_allreduce_combinations) def testReductionAndBroadcast(self, cross_tower_ops, distribution): + distribution.configure(cluster_spec={ + "worker": + ["/job:worker/replica:0/task:0", "/job:worker/replica:0/task:1"] + }) with distribution.scope(): self._testReductionAndBroadcast(cross_tower_ops, distribution) @@ -388,13 +409,8 @@ class MultiWorkerCollectiveAllReduceTest( @classmethod def setUpClass(cls): """Create a local cluster with 2 workers.""" - cls._workers, cls._ps = multi_worker_test_base.create_in_process_cluster( + cls._cluster_spec = multi_worker_test_base.create_in_process_cluster( num_workers=3, num_ps=0) - cls._cluster_spec = { - run_config.TaskType.WORKER: [ - "fake_worker_0", "fake_worker_1", "fake_worker_2" - ] - } def setUp(self): super(MultiWorkerCollectiveAllReduceTest, self).setUp() @@ -417,7 +433,7 @@ class MultiWorkerCollectiveAllReduceTest( devices = ["/device:GPU:%d" % i for i in range(num_gpus)] else: devices = ["/device:CPU:0"] - return collective_all_reduce_ops, devices, "local" + return collective_all_reduce_ops, devices, "" else: collective_all_reduce_ops = cross_tower_ops_lib.CollectiveAllReduce( 3, num_gpus, collective_keys=collective_keys) @@ -428,7 +444,8 @@ class MultiWorkerCollectiveAllReduceTest( ] else: devices = ["/job:%s/task:%d" % (task_type, task_id)] - return collective_all_reduce_ops, devices, self._workers[task_id].target + return (collective_all_reduce_ops, devices, + "grpc://" + self._cluster_spec[task_type][task_id]) def _assert_values_equal(self, left, right, sess): if isinstance(left, list): @@ -455,7 +472,8 @@ class MultiWorkerCollectiveAllReduceTest( num_workers = 1 worker_device = None else: - num_workers = len(self._workers) + num_workers = len(self._cluster_spec.get("chief", [])) + len( + self._cluster_spec.get("worker", [])) worker_device = "/job:%s/task:%d" % (task_type, task_id) with ops.Graph().as_default(), \ ops.device(worker_device), \ @@ -463,7 +481,7 @@ class MultiWorkerCollectiveAllReduceTest( # Collective ops doesn't support scalar tensors, so we have to construct # 1-d tensors. values = [constant_op.constant([float(d)]) for d in range(len(devices))] - per_device = _make_per_device(values, devices) + per_device = _make_per_device(values, devices, regroup=True) mean = np.array([(len(devices) - 1.) / 2.]) values_2 = [constant_op.constant([d + 1.0]) for d in range(len(devices))] @@ -476,7 +494,7 @@ class MultiWorkerCollectiveAllReduceTest( destination_list = devices all_destinations = [ - None, destination_mirrored, destination_different, destination_str, + destination_different, None, destination_mirrored, destination_str, destination_list ] @@ -533,13 +551,19 @@ class MultiWorkerCollectiveAllReduceTest( return True @combinations.generate( - combinations.combine(mode=["graph"], num_gpus=[0, 1, 2])) + combinations.combine(mode=["graph"], num_gpus=[0, 1, 2], required_gpus=1)) def testReductionDistributed(self, num_gpus): if context.num_gpus() < num_gpus: return self._run_between_graph_clients(self._test_reduction, self._cluster_spec, num_gpus) + # Collective ops doesn't support strategy with one device. + def testReductionLocal(self, num_gpus=2): + if context.num_gpus() < num_gpus: + return + self._test_reduction(None, None, num_gpus, local_mode=True) + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/distribute/python/estimator_training_test.py b/tensorflow/contrib/distribute/python/estimator_training_test.py new file mode 100644 index 0000000000..5348512016 --- /dev/null +++ b/tensorflow/contrib/distribute/python/estimator_training_test.py @@ -0,0 +1,659 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests that show Distribute Coordinator works with Estimator.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import glob +import json +import os +import sys +import tempfile +import threading +from absl.testing import parameterized +import numpy as np +import six + +_portpicker_import_error = None +try: + import portpicker # pylint: disable=g-import-not-at-top +except ImportError as _error: # pylint: disable=invalid-name + _portpicker_import_error = _error + portpicker = None + +# pylint: disable=g-import-not-at-top +from tensorflow.contrib.distribute.python import combinations +from tensorflow.contrib.distribute.python import mirrored_strategy +from tensorflow.contrib.distribute.python import parameter_server_strategy +from tensorflow.contrib.optimizer_v2 import adagrad +from tensorflow.core.protobuf import config_pb2 +from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.distribute import distribute_coordinator as dc +from tensorflow.python.distribute import estimator_training as dc_training +from tensorflow.python.distribute.distribute_config import DistributeConfig +from tensorflow.python.eager import context +from tensorflow.python.estimator import exporter as exporter_lib +from tensorflow.python.estimator import run_config as run_config_lib +from tensorflow.python.estimator import training as estimator_training +from tensorflow.python.estimator.canned import dnn_linear_combined +from tensorflow.python.estimator.canned import prediction_keys +from tensorflow.python.estimator.export import export as export_lib +from tensorflow.python.feature_column import feature_column +from tensorflow.python.platform import gfile +from tensorflow.python.platform import test +from tensorflow.python.summary import summary_iterator +from tensorflow.python.summary.writer import writer_cache +from tensorflow.python.training import server_lib + +BATCH_SIZE = 10 +LABEL_DIMENSION = 2 +DATA = np.linspace( + 0., 2., BATCH_SIZE * LABEL_DIMENSION, dtype=np.float32).reshape( + BATCH_SIZE, LABEL_DIMENSION) +EVAL_NAME = "foo" +EXPORTER_NAME = "saved_model_exporter" +MAX_STEPS = 10 + +CHIEF = dc._TaskType.CHIEF +EVALUATOR = dc._TaskType.EVALUATOR +WORKER = dc._TaskType.WORKER +PS = dc._TaskType.PS + +original_run_distribute_coordinator = dc.run_distribute_coordinator + + +# TODO(yuefengz): merge this method back to test_util. +def _create_local_cluster(num_workers, + num_ps, + has_eval=False, + protocol="grpc", + worker_config=None, + ps_config=None): + if _portpicker_import_error: + raise _portpicker_import_error # pylint: disable=raising-bad-type + worker_ports = [portpicker.pick_unused_port() for _ in range(num_workers)] + ps_ports = [portpicker.pick_unused_port() for _ in range(num_ps)] + + cluster_dict = { + "worker": ["localhost:%s" % port for port in worker_ports], + "ps": ["localhost:%s" % port for port in ps_ports] + } + if has_eval: + cluster_dict["evaluator"] = ["localhost:%s" % portpicker.pick_unused_port()] + + cs = server_lib.ClusterSpec(cluster_dict) + + workers = [ + server_lib.Server( + cs, + job_name="worker", + protocol=protocol, + task_index=ix, + config=worker_config, + start=True) for ix in range(num_workers) + ] + ps_servers = [ + server_lib.Server( + cs, + job_name="ps", + protocol=protocol, + task_index=ix, + config=ps_config, + start=True) for ix in range(num_ps) + ] + if has_eval: + evals = [ + server_lib.Server( + cs, + job_name="evaluator", + protocol=protocol, + task_index=0, + config=worker_config, + start=True) + ] + else: + evals = [] + + return workers, ps_servers, evals + + +def _create_in_process_cluster(num_workers, num_ps, has_eval=False): + """Create an in-process cluster that consists of only standard server.""" + # Leave some memory for cuda runtime. + if has_eval: + gpu_mem_frac = 0.7 / (num_workers + 1) + else: + gpu_mem_frac = 0.7 / num_workers + + worker_config = config_pb2.ConfigProto() + worker_config.gpu_options.per_process_gpu_memory_fraction = gpu_mem_frac + + # Enable collective ops which has no impact on non-collective ops. + # TODO(yuefengz, tucker): removing this after we move the initialization of + # collective mgr to the session level. + worker_config.experimental.collective_group_leader = ( + "/job:worker/replica:0/task:0") + + ps_config = config_pb2.ConfigProto() + ps_config.device_count["GPU"] = 0 + + return _create_local_cluster( + num_workers, + num_ps=num_ps, + has_eval=has_eval, + worker_config=worker_config, + ps_config=ps_config, + protocol="grpc") + + +def _create_cluster_spec(has_chief=False, + num_workers=1, + num_ps=0, + has_eval=False): + if _portpicker_import_error: + raise _portpicker_import_error # pylint: disable=raising-bad-type + + cluster_spec = {} + if has_chief: + cluster_spec[CHIEF] = ["localhost:%s" % portpicker.pick_unused_port()] + if num_workers: + cluster_spec[WORKER] = [ + "localhost:%s" % portpicker.pick_unused_port() + for _ in range(num_workers) + ] + if num_ps: + cluster_spec[PS] = [ + "localhost:%s" % portpicker.pick_unused_port() for _ in range(num_ps) + ] + if has_eval: + cluster_spec[EVALUATOR] = ["localhost:%s" % portpicker.pick_unused_port()] + return cluster_spec + + +def _bytes_to_str(maybe_bytes): + if isinstance(maybe_bytes, six.string_types): + return maybe_bytes + else: + return str(maybe_bytes, "utf-8") + + +def _strip_protocol(target): + # cluster_spec expects "host:port" strings. + if "//" in target: + return target.split("//")[1] + else: + return target + + +class DistributeCoordinatorIntegrationTest(test.TestCase, + parameterized.TestCase): + + @classmethod + def setUpClass(cls): + """Create a local cluster with 2 workers.""" + cls._workers, cls._ps, cls._evals = _create_in_process_cluster( + num_workers=3, num_ps=2, has_eval=True) + cls._cluster_spec = { + "worker": [ + _strip_protocol(_bytes_to_str(w.target)) for w in cls._workers + ], + "ps": [_strip_protocol(_bytes_to_str(ps.target)) for ps in cls._ps], + "evaluator": [ + _strip_protocol(_bytes_to_str(e.target)) for e in cls._evals + ] + } + + def setUp(self): + self._model_dir = tempfile.mkdtemp() + self._event = threading.Event() + super(DistributeCoordinatorIntegrationTest, self).setUp() + + def dataset_input_fn(self, x, y, batch_size, shuffle): + + def input_fn(): + dataset = dataset_ops.Dataset.from_tensor_slices((x, y)) + if shuffle: + dataset = dataset.shuffle(batch_size) + dataset = dataset.repeat(100).batch(batch_size) + return dataset + + return input_fn + + def _get_exporter(self, name, fc): + feature_spec = feature_column.make_parse_example_spec(fc) + serving_input_receiver_fn = ( + export_lib.build_parsing_serving_input_receiver_fn(feature_spec)) + return exporter_lib.LatestExporter( + name, serving_input_receiver_fn=serving_input_receiver_fn) + + def _extract_loss_and_global_step(self, event_folder): + """Returns the loss and global step in last event.""" + event_paths = glob.glob(os.path.join(event_folder, "events*")) + + loss = None + global_step_count = None + + for e in summary_iterator.summary_iterator(event_paths[-1]): + current_loss = None + for v in e.summary.value: + if v.tag == "loss": + current_loss = v.simple_value + + # If loss is not found, global step is meaningless. + if current_loss is None: + continue + + current_global_step = e.step + if global_step_count is None or current_global_step > global_step_count: + global_step_count = current_global_step + loss = current_loss + + return (loss, global_step_count) + + def _get_estimator(self, + train_distribute, + eval_distribute, + remote_cluster=None): + input_dimension = LABEL_DIMENSION + linear_feature_columns = [ + feature_column.numeric_column("x", shape=(input_dimension,)) + ] + dnn_feature_columns = [ + feature_column.numeric_column("x", shape=(input_dimension,)) + ] + + return dnn_linear_combined.DNNLinearCombinedRegressor( + linear_feature_columns=linear_feature_columns, + dnn_hidden_units=(2, 2), + dnn_feature_columns=dnn_feature_columns, + label_dimension=LABEL_DIMENSION, + model_dir=self._model_dir, + dnn_optimizer=adagrad.AdagradOptimizer(0.001), + linear_optimizer=adagrad.AdagradOptimizer(0.001), + config=run_config_lib.RunConfig( + experimental_distribute=DistributeConfig( + train_distribute=train_distribute, + eval_distribute=eval_distribute, + remote_cluster=remote_cluster))) + + def _complete_flow(self, + train_distribute, + eval_distribute, + remote_cluster=None): + estimator = self._get_estimator(train_distribute, eval_distribute, + remote_cluster) + + input_dimension = LABEL_DIMENSION + train_input_fn = self.dataset_input_fn( + x={"x": DATA}, + y=DATA, + batch_size=BATCH_SIZE // len(train_distribute.worker_devices), + shuffle=True) + if eval_distribute: + eval_batch_size = BATCH_SIZE // len(eval_distribute.worker_devices) + else: + eval_batch_size = BATCH_SIZE + eval_input_fn = self.dataset_input_fn( + x={"x": DATA}, y=DATA, batch_size=eval_batch_size, shuffle=False) + + linear_feature_columns = [ + feature_column.numeric_column("x", shape=(input_dimension,)) + ] + dnn_feature_columns = [ + feature_column.numeric_column("x", shape=(input_dimension,)) + ] + feature_columns = linear_feature_columns + dnn_feature_columns + + estimator_training.train_and_evaluate( + estimator, + estimator_training.TrainSpec(train_input_fn, max_steps=MAX_STEPS), + estimator_training.EvalSpec( + name=EVAL_NAME, + input_fn=eval_input_fn, + steps=None, + exporters=self._get_exporter(EXPORTER_NAME, feature_columns), + start_delay_secs=0, + throttle_secs=1)) + return estimator + + def _inspect_train_and_eval_events(self, estimator): + # Make sure nothing is stuck in limbo. + writer_cache.FileWriterCache.clear() + + # Examine the training events. Use a range to check global step to avoid + # flakyness due to global step race condition. + training_loss, _ = self._extract_loss_and_global_step(self._model_dir) + self.assertIsNotNone(training_loss) + + # Examine the eval events. The global step should be accurate. + eval_dir = os.path.join(self._model_dir, "eval_" + EVAL_NAME) + eval_loss, eval_global_step = self._extract_loss_and_global_step( + event_folder=eval_dir) + self.assertIsNotNone(eval_loss) + self.assertGreaterEqual(eval_global_step, MAX_STEPS) + + # Examine the export folder. + export_dir = os.path.join( + os.path.join(self._model_dir, "export"), EXPORTER_NAME) + self.assertTrue(gfile.Exists(export_dir)) + + # Examine the ckpt for predict. + def predict_input_fn(): + return dataset_ops.Dataset.from_tensor_slices({ + "x": DATA + }).batch(BATCH_SIZE) + + predicted_proba = np.array([ + x[prediction_keys.PredictionKeys.PREDICTIONS] + for x in estimator.predict(predict_input_fn) + ]) + self.assertAllEqual((BATCH_SIZE, LABEL_DIMENSION), predicted_proba.shape) + + @combinations.generate( + combinations.combine( + mode=["graph"], + train_distribute_cls=[ + mirrored_strategy.MirroredStrategy, + parameter_server_strategy.ParameterServerStrategy + ], + eval_distribute_cls=[ + None, mirrored_strategy.MirroredStrategy, + parameter_server_strategy.ParameterServerStrategy + ], + required_gpus=1)) + def test_complete_flow_standalone_client(self, train_distribute_cls, + eval_distribute_cls): + try: + train_distribute = train_distribute_cls(num_gpus=context.num_gpus()) + except TypeError: + train_distribute = train_distribute_cls(num_gpus_per_worker=2) + + if eval_distribute_cls: + eval_distribute = eval_distribute_cls() + else: + eval_distribute = None + + estimator = self._complete_flow( + train_distribute, eval_distribute, remote_cluster=self._cluster_spec) + self._inspect_train_and_eval_events(estimator) + + def _mock_run_distribute_coordinator( + self, + worker_fn, + strategy, + eval_fn, + eval_strategy, + mode=dc.CoordinatorMode.STANDALONE_CLIENT, + cluster_spec=None, + session_config=None): + # Calls the origial `run_distribute_coordinator` method but gets task config + # from environment variables and then signals the caller. + task_type = None + task_id = None + if not cluster_spec: + cluster_spec = None + tf_config = json.loads(os.environ.get("TF_CONFIG", "{}")) + if not cluster_spec: + cluster_spec = tf_config.get("cluster", {}) + task_env = tf_config.get("task", {}) + if task_env: + task_type = task_env.get("type", task_type) + task_id = int(task_env.get("index", task_id)) + self._event.set() + original_run_distribute_coordinator( + worker_fn, + strategy, + eval_fn, + eval_strategy, + mode=mode, + cluster_spec=cluster_spec, + task_type=task_type, + task_id=task_id, + session_config=session_config) + + def _task_thread(self, train_distribute, eval_distribute): + with test.mock.patch.object(dc, "run_distribute_coordinator", + self._mock_run_distribute_coordinator): + self._complete_flow(train_distribute, eval_distribute) + + def _run_task_in_thread(self, cluster_spec, task_type, task_id, + train_distribute, eval_distribute): + if task_type: + tf_config = { + "cluster": cluster_spec, + "task": { + "type": task_type, + "index": task_id + } + } + else: + tf_config = { + "cluster": cluster_spec, + "task": { + "type": task_type, + "index": task_id + } + } + self._event.clear() + t = threading.Thread( + target=self._task_thread, args=(train_distribute, eval_distribute)) + with test.mock.patch.dict("os.environ", + {"TF_CONFIG": json.dumps(tf_config)}): + t.start() + self._event.wait() + return t + + def _run_multiple_tasks_in_threads(self, cluster_spec, train_distribute, + eval_distribute): + threads = {} + for task_type in cluster_spec.keys(): + threads[task_type] = [] + for task_id in range(len(cluster_spec[task_type])): + t = self._run_task_in_thread(cluster_spec, task_type, task_id, + train_distribute, eval_distribute) + threads[task_type].append(t) + return threads + + @combinations.generate( + combinations.combine( + mode=["graph"], + train_distribute_cls=[ + parameter_server_strategy.ParameterServerStrategy, + ], + eval_distribute_cls=[ + None, mirrored_strategy.MirroredStrategy, + parameter_server_strategy.ParameterServerStrategy + ], + required_gpus=1)) + def test_complete_flow_indepedent_worker_between_graph( + self, train_distribute_cls, eval_distribute_cls): + train_distribute = train_distribute_cls( + num_gpus_per_worker=context.num_gpus()) + + if eval_distribute_cls: + eval_distribute = eval_distribute_cls() + else: + eval_distribute = None + + cluster_spec = _create_cluster_spec(num_workers=3, num_ps=2, has_eval=True) + threads = self._run_multiple_tasks_in_threads( + cluster_spec, train_distribute, eval_distribute) + for task_type, ts in threads.items(): + if task_type == PS: + continue + for t in ts: + t.join() + + estimator = self._get_estimator(train_distribute, eval_distribute) + self._inspect_train_and_eval_events(estimator) + + @combinations.generate( + combinations.combine( + mode=["graph"], + train_distribute_cls=[mirrored_strategy.MirroredStrategy], + eval_distribute_cls=[None, mirrored_strategy.MirroredStrategy], + required_gpus=1)) + def test_complete_flow_indepedent_worker_in_graph(self, train_distribute_cls, + eval_distribute_cls): + train_distribute = train_distribute_cls(num_gpus=context.num_gpus()) + + if eval_distribute_cls: + eval_distribute = eval_distribute_cls() + else: + eval_distribute = None + + cluster_spec = _create_cluster_spec(num_workers=3, num_ps=2, has_eval=True) + threads = self._run_multiple_tasks_in_threads( + cluster_spec, train_distribute, eval_distribute) + threads[WORKER][0].join() + threads[EVALUATOR][0].join() + + estimator = self._get_estimator(train_distribute, eval_distribute) + self._inspect_train_and_eval_events(estimator) + + +TF_CONFIG_WITH_CHIEF = { + "cluster": { + "chief": ["fake_chief"], + }, + "task": { + "type": "chief", + "index": 0 + } +} + +TF_CONFIG_WITH_MASTER = { + "cluster": { + "master": ["fake_master"], + }, + "task": { + "type": "master", + "index": 0 + } +} + +TF_CONFIG_WITHOUT_TASK = {"cluster": {"chief": ["fake_worker"]}} + + +class RunConfigTest(test.TestCase): + + def test_previously_unexpected_cluster_spec(self): + with test.mock.patch.dict( + "os.environ", {"TF_CONFIG": json.dumps(TF_CONFIG_WITHOUT_TASK)}): + run_config_lib.RunConfig( + experimental_distribute=DistributeConfig( + train_distribute=mirrored_strategy.MirroredStrategy(num_gpus=2))) + + def test_should_run_distribute_coordinator(self): + """Tests that should_run_distribute_coordinator return a correct value.""" + # We don't use distribute coordinator for local training. + self.assertFalse( + dc_training.should_run_distribute_coordinator( + run_config_lib.RunConfig())) + + # When `train_distribute` is not specified, don't use distribute + # coordinator. + with test.mock.patch.dict("os.environ", + {"TF_CONFIG": json.dumps(TF_CONFIG_WITH_CHIEF)}): + self.assertFalse( + dc_training.should_run_distribute_coordinator( + run_config_lib.RunConfig())) + + # When `train_distribute` is specified and TF_CONFIG is detected, use + # distribute coordinator. + with test.mock.patch.dict("os.environ", + {"TF_CONFIG": json.dumps(TF_CONFIG_WITH_CHIEF)}): + config_with_train_distribute = run_config_lib.RunConfig( + experimental_distribute=DistributeConfig( + train_distribute=mirrored_strategy.MirroredStrategy(num_gpus=2))) + config_with_eval_distribute = run_config_lib.RunConfig( + experimental_distribute=DistributeConfig( + eval_distribute=mirrored_strategy.MirroredStrategy(num_gpus=2))) + self.assertTrue( + dc_training.should_run_distribute_coordinator( + config_with_train_distribute)) + self.assertFalse( + dc_training.should_run_distribute_coordinator( + config_with_eval_distribute)) + + # With a master in the cluster, don't run distribute coordinator. + with test.mock.patch.dict("os.environ", + {"TF_CONFIG": json.dumps(TF_CONFIG_WITH_MASTER)}): + config = run_config_lib.RunConfig( + experimental_distribute=DistributeConfig( + train_distribute=mirrored_strategy.MirroredStrategy(num_gpus=2))) + self.assertFalse(dc_training.should_run_distribute_coordinator(config)) + + def test_init_run_config_duplicate_distribute(self): + with self.assertRaises(ValueError): + run_config_lib.RunConfig( + train_distribute=mirrored_strategy.MirroredStrategy(), + experimental_distribute=DistributeConfig( + train_distribute=mirrored_strategy.MirroredStrategy())) + + with self.assertRaises(ValueError): + run_config_lib.RunConfig( + eval_distribute=mirrored_strategy.MirroredStrategy(), + experimental_distribute=DistributeConfig( + eval_distribute=mirrored_strategy.MirroredStrategy())) + + def test_init_run_config_none_distribute_coordinator_mode(self): + # We don't use distribute coordinator for local training. + config = run_config_lib.RunConfig( + train_distribute=mirrored_strategy.MirroredStrategy()) + dc_training.init_run_config(config, {}) + self.assertIsNone(config._distribute_coordinator_mode) + + # With a master in the cluster, don't run distribute coordinator. + with test.mock.patch.dict("os.environ", + {"TF_CONFIG": json.dumps(TF_CONFIG_WITH_MASTER)}): + config = run_config_lib.RunConfig( + train_distribute=mirrored_strategy.MirroredStrategy()) + self.assertIsNone(config._distribute_coordinator_mode) + + # When `train_distribute` is not specified, don't use distribute + # coordinator. + with test.mock.patch.dict("os.environ", + {"TF_CONFIG": json.dumps(TF_CONFIG_WITH_CHIEF)}): + config = run_config_lib.RunConfig() + self.assertFalse(hasattr(config, "_distribute_coordinator_mode")) + + def test_init_run_config_independent_worker(self): + # When `train_distribute` is specified and TF_CONFIG is detected, use + # distribute coordinator with INDEPENDENT_WORKER mode. + with test.mock.patch.dict("os.environ", + {"TF_CONFIG": json.dumps(TF_CONFIG_WITH_CHIEF)}): + config = run_config_lib.RunConfig( + train_distribute=mirrored_strategy.MirroredStrategy()) + self.assertEqual(config._distribute_coordinator_mode, + dc.CoordinatorMode.INDEPENDENT_WORKER) + + def test_init_run_config_standalone_client(self): + # When `train_distribute` is specified, TF_CONFIG is detected and + # `experimental.remote_cluster` is set use distribute coordinator with + # STANDALONE_CLIENT mode. + config = run_config_lib.RunConfig( + train_distribute=mirrored_strategy.MirroredStrategy(), + experimental_distribute=DistributeConfig( + remote_cluster={"chief": ["fake_worker"]})) + self.assertEqual(config._distribute_coordinator_mode, + dc.CoordinatorMode.STANDALONE_CLIENT) + + +if __name__ == "__main__": + with test.mock.patch.object(sys, "exit", os._exit): + test.main() diff --git a/tensorflow/contrib/distribute/python/examples/BUILD b/tensorflow/contrib/distribute/python/examples/BUILD index cbfd178502..84b106545e 100644 --- a/tensorflow/contrib/distribute/python/examples/BUILD +++ b/tensorflow/contrib/distribute/python/examples/BUILD @@ -19,9 +19,20 @@ py_binary( ) py_binary( - name = "simple_tfkeras_example", + name = "keras_model_with_estimator", srcs = [ - "simple_tfkeras_example.py", + "keras_model_with_estimator.py", + ], + deps = [ + "//tensorflow:tensorflow_py", + "//third_party/py/numpy", + ], +) + +py_binary( + name = "keras_mnist", + srcs = [ + "keras_mnist.py", ], deps = [ "//tensorflow:tensorflow_py", diff --git a/tensorflow/contrib/distribute/python/examples/keras_mnist.py b/tensorflow/contrib/distribute/python/examples/keras_mnist.py new file mode 100644 index 0000000000..a20069c4fe --- /dev/null +++ b/tensorflow/contrib/distribute/python/examples/keras_mnist.py @@ -0,0 +1,126 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""An example training a Keras Model using MirroredStrategy and native APIs.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import tensorflow as tf + + +NUM_CLASSES = 10 + + +def get_input_datasets(): + """Downloads the MNIST dataset and creates train and eval dataset objects. + + Returns: + Train dataset, eval dataset and input shape. + + """ + # input image dimensions + img_rows, img_cols = 28, 28 + + # the data, split between train and test sets + (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() + + if tf.keras.backend.image_data_format() == 'channels_first': + x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) + x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) + input_shape = (1, img_rows, img_cols) + else: + x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) + x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) + input_shape = (img_rows, img_cols, 1) + + x_train = x_train.astype('float32') + x_test = x_test.astype('float32') + x_train /= 255 + x_test /= 255 + + # convert class vectors to binary class matrices + y_train = tf.keras.utils.to_categorical(y_train, NUM_CLASSES) + y_test = tf.keras.utils.to_categorical(y_test, NUM_CLASSES) + + # train dataset + train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)) + train_ds = train_ds.repeat() + train_ds = train_ds.shuffle(100) + train_ds = train_ds.batch(64) + + # eval dataset + eval_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)) + eval_ds = eval_ds.repeat() + eval_ds = eval_ds.shuffle(100) + eval_ds = eval_ds.batch(64) + + return train_ds, eval_ds, input_shape + + +def get_model(input_shape): + """Builds a Sequential CNN model to recognize MNIST digits. + + Args: + input_shape: Shape of the input depending on the `image_data_format`. + + Returns: + a Keras model + + """ + # Define a CNN model to recognize MNIST digits. + model = tf.keras.models.Sequential() + model.add(tf.keras.layers.Conv2D(32, kernel_size=(3, 3), + activation='relu', + input_shape=input_shape)) + model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu')) + model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2))) + model.add(tf.keras.layers.Dropout(0.25)) + model.add(tf.keras.layers.Flatten()) + model.add(tf.keras.layers.Dense(128, activation='relu')) + model.add(tf.keras.layers.Dropout(0.5)) + model.add(tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')) + return model + + +def main(_): + # Build the train and eval datasets from the MNIST data. Also return the + # input shape which is constructed based on the `image_data_format` + # i.e channels_first or channels_last. + train_ds, eval_ds, input_shape = get_input_datasets() + model = get_model(input_shape) + + # Instantiate the MirroredStrategy object. If we don't specify `num_gpus` or + # the `devices` argument then all the GPUs available on the machine are used. + strategy = tf.contrib.distribute.MirroredStrategy() + + # Compile the model by passing the distribution strategy object to the + # `distribute` argument. `fit`, `evaluate` and `predict` will be distributed + # based on the strategy instantiated. + model.compile(loss=tf.keras.losses.categorical_crossentropy, + optimizer=tf.train.RMSPropOptimizer(learning_rate=0.001), + metrics=['accuracy'], + distribute=strategy) + + # Train the model with the train dataset. + model.fit(x=train_ds, epochs=20, steps_per_epoch=310) + + # Evaluate the model with the eval dataset. + score = model.evaluate(eval_ds, steps=10, verbose=0) + print('Test loss:', score[0]) + print('Test accuracy:', score[1]) + + +if __name__ == '__main__': + tf.app.run() diff --git a/tensorflow/contrib/distribute/python/examples/simple_tfkeras_example.py b/tensorflow/contrib/distribute/python/examples/keras_model_with_estimator.py index 518ec9c423..8d117eb7e8 100644 --- a/tensorflow/contrib/distribute/python/examples/simple_tfkeras_example.py +++ b/tensorflow/contrib/distribute/python/examples/keras_model_with_estimator.py @@ -42,19 +42,19 @@ def main(args): model_dir = args[1] print('Using %s to store checkpoints.' % model_dir) - # Define tf.keras Model. + # Define a Keras Model. model = tf.keras.Sequential() model.add(tf.keras.layers.Dense(16, activation='relu', input_shape=(10,))) model.add(tf.keras.layers.Dense(1, activation='sigmoid')) - # Compile tf.keras Model. + # Compile the model. optimizer = tf.train.GradientDescentOptimizer(0.2) model.compile(loss='binary_crossentropy', optimizer=optimizer) model.summary() tf.keras.backend.set_learning_phase(True) - # Define a DistributionStrategy and convert the tf.keras Model to a - # tf.Estimator that utilizes the DistributionStrategy. + # Define a DistributionStrategy and convert the Keras Model to an + # Estimator that utilizes the DistributionStrategy. strategy = tf.contrib.distribute.MirroredStrategy( ['/device:GPU:0', '/device:GPU:1']) config = tf.estimator.RunConfig( @@ -62,7 +62,7 @@ def main(args): keras_estimator = tf.keras.estimator.model_to_estimator( keras_model=model, config=config, model_dir=model_dir) - # Train and evaluate the tf.Estimator. + # Train and evaluate the model. keras_estimator.train(input_fn=input_fn, steps=10) eval_result = keras_estimator.evaluate(input_fn=input_fn) print('Eval result: {}'.format(eval_result)) diff --git a/tensorflow/contrib/distribute/python/input_ops_test.py b/tensorflow/contrib/distribute/python/input_ops_test.py index 16179c3a49..c5acb7ced4 100644 --- a/tensorflow/contrib/distribute/python/input_ops_test.py +++ b/tensorflow/contrib/distribute/python/input_ops_test.py @@ -91,7 +91,7 @@ class AutoShardDatasetTest(test.TestCase): def _verifySimpleShardingOutput(self, dataset, record_fn): iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: for f in range(self._shard_index, self._num_files, self._num_shards): for r in range(self._num_records): self.assertAllEqual(record_fn(r, f), sess.run(next_element)) @@ -150,7 +150,7 @@ class AutoShardDatasetTest(test.TestCase): iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: actual, expected = [], [] for f in range(self._shard_index, self._num_files, self._num_shards): for r in range(self._num_records): @@ -182,7 +182,7 @@ class AutoShardDatasetTest(test.TestCase): # Verify output. iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: actual = [] num_iterations = (self._num_files * self._num_records * num_epochs) // ( self._num_shards * batch_size) @@ -218,7 +218,7 @@ class AutoShardDatasetTest(test.TestCase): iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: for f in range(self._shard_index, self._num_files, self._num_shards): for r in range(self._num_records): self.assertAllEqual(self._record(r, f), sess.run(next_element)) diff --git a/tensorflow/contrib/distribute/python/keras_test.py b/tensorflow/contrib/distribute/python/keras_test.py index 4facd72d12..d39fd57294 100644 --- a/tensorflow/contrib/distribute/python/keras_test.py +++ b/tensorflow/contrib/distribute/python/keras_test.py @@ -116,7 +116,7 @@ class TestEstimatorDistributionStrategy(test_util.TensorFlowTestCase): model_dir=self._base_dir, train_distribute=dist, eval_distribute=dist) - with self.test_session(): + with self.cached_session(): est_keras = keras_lib.model_to_estimator( keras_model=keras_model, config=config) before_eval_results = est_keras.evaluate( @@ -139,7 +139,7 @@ class TestEstimatorDistributionStrategy(test_util.TensorFlowTestCase): config = run_config_lib.RunConfig(tf_random_seed=_RANDOM_SEED, model_dir=self._base_dir, train_distribute=dist) - with self.test_session(): + with self.cached_session(): est_keras = keras_lib.model_to_estimator( keras_model=keras_model, config=config) before_eval_results = est_keras.evaluate( @@ -163,7 +163,7 @@ class TestEstimatorDistributionStrategy(test_util.TensorFlowTestCase): config = run_config_lib.RunConfig(tf_random_seed=_RANDOM_SEED, model_dir=self._base_dir, train_distribute=dist) - with self.test_session(): + with self.cached_session(): est_keras = keras_lib.model_to_estimator(keras_model=keras_model, config=config) with self.assertRaisesRegexp(ValueError, @@ -178,7 +178,7 @@ class TestEstimatorDistributionStrategy(test_util.TensorFlowTestCase): class TestWithDistributionStrategy(test.TestCase): def test_validating_dataset_input_tensors_with_shape_mismatch(self): - with self.test_session(): + with self.cached_session(): strategy = mirrored_strategy.MirroredStrategy(['/device:GPU:0', '/device:CPU:0']) a = constant_op.constant([1, 2], shape=(1, 2)) @@ -197,7 +197,7 @@ class TestWithDistributionStrategy(test.TestCase): strategy, x, y) def test_validating_dataset_input_tensors_with_dtype_mismatch(self): - with self.test_session(): + with self.cached_session(): strategy = mirrored_strategy.MirroredStrategy(['/device:GPU:0', '/device:CPU:0']) a = constant_op.constant([1, 2], shape=(1, 2), dtype=dtypes.int32) @@ -216,7 +216,7 @@ class TestWithDistributionStrategy(test.TestCase): strategy, x, y) def test_calling_model_on_same_dataset(self): - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(3,), name='input') y = keras.layers.Dense(4, name='dense')(x) model = keras.Model(x, y) @@ -242,7 +242,7 @@ class TestWithDistributionStrategy(test.TestCase): model.predict(dataset, steps=2) def test_fit_with_tuple_and_dict_dataset_inputs(self): - with self.test_session(): + with self.cached_session(): a = keras.layers.Input(shape=(3,), name='input_a') b = keras.layers.Input(shape=(3,), name='input_b') @@ -283,7 +283,7 @@ class TestWithDistributionStrategy(test.TestCase): model.fit(dataset_dict, epochs=1, steps_per_epoch=2, verbose=1) def test_fit_eval_and_predict_methods_on_dataset(self): - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(3,), name='input') y = keras.layers.Dense(4, name='dense')(x) model = keras.Model(x, y) @@ -320,7 +320,7 @@ class TestWithDistributionStrategy(test.TestCase): def __call__(self, y_true, y_pred): return y_pred - y_true - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(3,), name='input') y = keras.layers.Dense(4, name='dense')(x) model = keras.Model(x, y) @@ -336,7 +336,7 @@ class TestWithDistributionStrategy(test.TestCase): model.compile(optimizer, loss, metrics=metrics, distribute=strategy) def test_unsupported_features(self): - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(3,), name='input') y = keras.layers.Dense(4, name='dense')(x) model = keras.Model(x, y) @@ -367,8 +367,8 @@ class TestWithDistributionStrategy(test.TestCase): # Test with sample weight. sample_weight = np.random.random((10,)) with self.assertRaisesRegexp( - NotImplementedError, 'sample_weight is currently not supported when ' - 'using DistributionStrategy.'): + NotImplementedError, '`sample_weight` is currently not supported ' + 'when using DistributionStrategy.'): model.fit( dataset, epochs=1, @@ -389,7 +389,7 @@ class TestWithDistributionStrategy(test.TestCase): model.predict(dataset, verbose=0) def test_calling_with_unsupported_predefined_callbacks(self): - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(3,), name='input') y = keras.layers.Dense(4, name='dense')(x) model = keras.Model(x, y) @@ -428,7 +428,7 @@ class TestWithDistributionStrategy(test.TestCase): callbacks=[keras.callbacks.TensorBoard(histogram_freq=10)]) def test_dataset_input_shape_validation(self): - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(3,), name='input') y = keras.layers.Dense(4, name='dense')(x) model = keras.Model(x, y) @@ -465,7 +465,7 @@ class TestWithDistributionStrategy(test.TestCase): # TODO(anjalisridhar): Modify this test to use Lambdas since we can compare # meaningful values. Currently we don't pass the learning phase if the # Lambda layer uses the learning phase. - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(16,), name='input') y = keras.layers.Dense(16)(x) z = keras.layers.Dropout(0.9999)(y) @@ -498,7 +498,7 @@ class TestWithDistributionStrategy(test.TestCase): class LossMaskingWithDistributionStrategyTest(test.TestCase): def test_masking(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1337) x = np.array([[[1], [1]], [[0], [0]]]) model = keras.models.Sequential() @@ -523,7 +523,7 @@ class LossMaskingWithDistributionStrategyTest(test.TestCase): class NormalizationLayerWithDistributionStrategyTest(test.TestCase): def test_batchnorm_correctness(self): - with self.test_session(): + with self.cached_session(): model = keras.models.Sequential() norm = keras.layers.BatchNormalization(input_shape=(10,), momentum=0.8) model.add(norm) @@ -550,7 +550,7 @@ class NormalizationLayerWithDistributionStrategyTest(test.TestCase): class CorrectnessWithDistributionStrategyTest(test.TestCase): def test_correctness(self): - with self.test_session(): + with self.cached_session(): keras.backend.set_image_data_format('channels_last') num_samples = 10000 x_train = np.random.rand(num_samples, 1) @@ -565,8 +565,7 @@ class CorrectnessWithDistributionStrategyTest(test.TestCase): dataset_with = dataset_ops.Dataset.from_tensor_slices((x_train, y_train)) dataset_with = dataset_with.batch(32) strategy = mirrored_strategy.MirroredStrategy(devices=['/device:CPU:0', - '/device:GPU:0'], - prefetch_on_device=False) + '/device:GPU:0']) model.compile(loss=keras.losses.mean_squared_error, optimizer=gradient_descent.GradientDescentOptimizer(0.5), diff --git a/tensorflow/contrib/distribute/python/minimize_loss_test.py b/tensorflow/contrib/distribute/python/minimize_loss_test.py index 516ede7ade..bdac4fb58c 100644 --- a/tensorflow/contrib/distribute/python/minimize_loss_test.py +++ b/tensorflow/contrib/distribute/python/minimize_loss_test.py @@ -71,7 +71,7 @@ class MinimizeLossStepTest(test.TestCase, parameterized.TestCase): self.evaluate(distribution.initialize()) if not context.executing_eagerly(): - with self.test_session() as sess: + with self.cached_session() as sess: run_step = sess.make_callable(run_step()) self.evaluate(variables_lib.global_variables_initializer()) @@ -108,7 +108,7 @@ class MinimizeLossStepTest(test.TestCase, parameterized.TestCase): model_fn, iterator.get_next(), run_concurrently=layer.built)) if not context.executing_eagerly(): - with self.test_session() as sess: + with self.cached_session() as sess: run_step = sess.make_callable(run_step()) self.evaluate(variables_lib.global_variables_initializer()) @@ -168,7 +168,7 @@ class MinimizeLossStepTest(test.TestCase, parameterized.TestCase): self.evaluate(distribution.initialize()) if not context.executing_eagerly(): - with self.test_session() as sess: + with self.cached_session() as sess: run_step = sess.make_callable(run_step()) self.evaluate(variables_lib.global_variables_initializer()) @@ -249,7 +249,7 @@ class MinimizeLossStepTest(test.TestCase, parameterized.TestCase): self.evaluate(distribution.initialize()) if not context.executing_eagerly(): - with self.test_session() as sess: + with self.cached_session() as sess: run_step = sess.make_callable(run_step()) self.evaluate(variables_lib.global_variables_initializer()) @@ -343,7 +343,7 @@ class MinimizeLossStepTest(test.TestCase, parameterized.TestCase): self.evaluate(distribution.initialize()) if not context.executing_eagerly(): - with self.test_session() as sess: + with self.cached_session() as sess: run_step = sess.make_callable(run_step()) self.evaluate(variables_lib.global_variables_initializer()) @@ -466,7 +466,7 @@ class MinimizeLossStepTest(test.TestCase, parameterized.TestCase): self.evaluate(distribution.initialize()) if not context.executing_eagerly(): - with self.test_session() as sess: + with self.cached_session() as sess: run_step = sess.make_callable(run_step()) self.evaluate(variables_lib.global_variables_initializer()) diff --git a/tensorflow/contrib/distribute/python/mirrored_strategy.py b/tensorflow/contrib/distribute/python/mirrored_strategy.py index edd5c6d17a..e87b48ba41 100644 --- a/tensorflow/contrib/distribute/python/mirrored_strategy.py +++ b/tensorflow/contrib/distribute/python/mirrored_strategy.py @@ -19,12 +19,14 @@ from __future__ import division from __future__ import print_function import contextlib +from functools import partial import threading from tensorflow.contrib.distribute.python import cross_tower_ops as cross_tower_ops_lib from tensorflow.contrib.distribute.python import shared_variable_creator from tensorflow.contrib.distribute.python import values from tensorflow.python import pywrap_tensorflow +from tensorflow.python.distribute import multi_worker_util from tensorflow.python.eager import context from tensorflow.python.eager import tape from tensorflow.python.framework import constant_op @@ -274,6 +276,9 @@ def _create_mirrored_variable(devices, real_mirrored_creator, *args, **kwargs): else: result = values.MirroredVariable(index, index[devices[0]], aggregation) + # Add the wrapped variable to the requested collections. + # The handling of eager mode and the global step matches + # ResourceVariable._init_from_args(). if not context.executing_eagerly(): g = ops.get_default_graph() # If "trainable" is True, next_creator() will add the member variables @@ -287,13 +292,55 @@ def _create_mirrored_variable(devices, real_mirrored_creator, *args, **kwargs): for v in index.values(): l.remove(v) g.add_to_collections(collections, result) + elif ops.GraphKeys.GLOBAL_STEP in collections: + ops.add_to_collections(ops.GraphKeys.GLOBAL_STEP, result) + return result class MirroredStrategy(distribute_lib.DistributionStrategy): - """Mirrors vars to distribute across multiple devices on a single machine. + """Mirrors vars to distribute across multiple devices and machines. + + This strategy uses one tower per device and sync replication for its multi-GPU + version. + + When `cluster_spec` is given by the `configure` method., it turns into the + mulit-worker version that works on multiple workers with in-graph replication. + Note: `configure` will be called by higher-level APIs if running in + distributed environment. + + There are several important concepts for distributed TensorFlow, e.g. + `client`, `job`, 'task', `cluster`, `in-graph replication` and + 'synchronous training' and they have already been defined in the + [TensorFlow's documentation](https://www.tensorflow.org/deploy/distributed). + The distribution strategy inherits these concepts as well and in addition to + that we also clarify several more concepts: + * **In-graph replication**: the `client` creates a single `tf.Graph` that + specifies tasks for devices on all workers. The `client` then creates a + client session which will talk to the `master` service of a `worker`. Then + the `master` will partition the graph and distribute the work to all + participating workers. + * **Worker**: A `worker` is a TensorFlow `task` that usually maps to one + physical machine. We will have multiple `worker`s with different `task` + index. They all do similar things except for one worker checkpointing model + variables, writing summaries, etc. in addition to its ordinary work. + + The multi-worker version of this class maps one tower to one device on a + worker. It mirrors all model variables on all towers. For example, if you have + two `worker`s and each `worker` has 4 GPUs, it will create 8 copies of the + model variables on these 8 GPUs. Then like in MirroredStrategy, each tower + performs their computation with their own copy of variables unless in + cross-tower model where variable or tensor reduction happens. - This strategy uses one tower per device and sync replication. + Args: + devices: a list of device strings. + num_gpus: number of GPUs. For local training, either specify `devices` or + `num_gpus`. In distributed training, this must be specified as number of + GPUs on each worker. + cross_tower_ops: optional, a descedant of `CrossTowerOps`. If this is not + set, the `configure` method will try to find the best one. + prefetch_on_device: optional boolean to specify whether to prefetch input + data to devices. """ def __init__(self, @@ -302,13 +349,73 @@ class MirroredStrategy(distribute_lib.DistributionStrategy): cross_tower_ops=None, prefetch_on_device=None): super(MirroredStrategy, self).__init__() + + self._cross_tower_ops = cross_tower_ops + self._prefetch_on_device = prefetch_on_device + # Rememeber num GPUs which might be needed by `configure` method. + self._num_gpus = num_gpus + + self._initialize_local(num_gpus, devices) + + def _initialize_local(self, num_gpus, devices): + """Initializes the object for local training.""" + self._cluster_spec = None # Convert `num_gpus` into `devices`, shouldn't specify both. if devices is None: if num_gpus is None: num_gpus = context.num_gpus() - devices = ["/device:GPU:%d" % d for d in range(num_gpus)] + if num_gpus == 0: + devices = ["/device:CPU:0"] + else: + devices = ["/device:GPU:%d" % d for d in range(num_gpus)] elif num_gpus is not None: raise ValueError("Must only specify one of `devices` and `num_gpus`.") + self._num_gpus = num_gpus + # TODO(yuefengz): consider setting the default device. + + assert devices, "Must specify at least one device." + assert len(set(devices)) == len(devices), ( + "No duplicates allowed in `devices` argument.") + # TODO(josh11b): Require at least 2 devices? + self._devices = [device_util.resolve(d) for d in devices] + self._canonical_device_set = set(self._devices) + self._device_index = values.PerDevice({d: i for i, d in enumerate(devices)}) + + def _initialize_multi_worker(self, num_gpus, cluster_spec): + """Initializes the object for multi-worker training.""" + cluster_spec = multi_worker_util.normalize_cluster_spec(cluster_spec) + self._cluster_spec = cluster_spec + + self._workers = [] + for job in ["chief", "worker"]: + for task in range(len(cluster_spec.as_dict().get(job, []))): + self._workers.append("/job:%s/task:%d" % (job, task)) + + if num_gpus is None: + raise ValueError("`num_gpus` is required if `cluster_spec` is given.") + if num_gpus > 0: + self._worker_device_map = { + worker: [ + device_util.canonicalize(worker + "/device:GPU:%d" % gpu) + for gpu in range(num_gpus) + ] for worker in self._workers + } + else: + self._worker_device_map = { + worker: [device_util.canonicalize(worker, "/device:CPU:0")] + for worker in self._workers + } + + devices = nest.flatten(self._worker_device_map) + + # Setting `_default_device` will add a device scope in the + # distribution.scope. We set the default device to the first worker. When + # users specify device under distribution.scope by + # with tf.device("/cpu:0"): + # ... + # their ops will end up on the cpu device of its first worker, e.g. + # "/job:worker/task:0/device:CPU:0". Note this is not used in tower mode. + self._default_device = self._workers[0] assert devices, "Must specify at least one device." assert len(set(devices)) == len(devices), ( @@ -318,9 +425,6 @@ class MirroredStrategy(distribute_lib.DistributionStrategy): self._canonical_device_set = set(self._devices) self._device_index = values.PerDevice( {d: i for i, d in enumerate(devices)}) - self._cross_tower_ops = cross_tower_ops - self._prefetch_on_device = prefetch_on_device - # TODO(yuefengz): consider setting the default device. def _create_variable(self, next_creator, *args, **kwargs): """Create a mirrored variable. See `DistributionStrategy.scope`.""" @@ -357,9 +461,14 @@ class MirroredStrategy(distribute_lib.DistributionStrategy): **kwargs) def distribute_dataset(self, dataset_fn): - return values.PerDeviceDataset( - self._call_dataset_fn(dataset_fn), self._devices, - self._prefetch_on_device) + if self._cluster_spec: + return values.MultiWorkerDataset( + partial(self._call_dataset_fn, dataset_fn), self._worker_device_map, + self._prefetch_on_device) + else: + return values.PerDeviceDataset( + self._call_dataset_fn(dataset_fn), self._devices, + self._prefetch_on_device) # TODO(priyag): Deal with OutOfRange errors once b/111349762 is fixed. def _run_steps_on_dataset(self, fn, iterator, iterations, @@ -444,10 +553,22 @@ class MirroredStrategy(distribute_lib.DistributionStrategy): # in addition to PerDevice data. return values.PerDevice({k: values.MapOutput(v) for k, v in index.items()}) - def configure(self, session_config=None): + def configure(self, + session_config=None, + cluster_spec=None, + task_type=None, + task_id=None): + del task_type, task_id + if cluster_spec: + self._initialize_multi_worker(self._num_gpus, cluster_spec) + if self._cross_tower_ops is None: - self._cross_tower_ops = cross_tower_ops_lib.choose_the_best( - self._devices, session_config=session_config) + if self._cluster_spec: + self._cross_tower_ops = cross_tower_ops_lib.MultiWorkerAllReduce( + self._workers, self._num_gpus) + else: + self._cross_tower_ops = cross_tower_ops_lib.choose_the_best( + self._devices, session_config=session_config) def _get_cross_tower_ops(self): if self._cross_tower_ops is None: @@ -532,6 +653,22 @@ class MirroredStrategy(distribute_lib.DistributionStrategy): def parameter_devices(self): return list(self._devices) + @property + def between_graph(self): + return False + + @property + def should_init(self): + return True + + @property + def should_checkpoint(self): + return True + + @property + def should_save_summary(self): + return True + def non_slot_devices(self, var_list): del var_list return list(self._devices) diff --git a/tensorflow/contrib/distribute/python/mirrored_strategy_multigpu_test.py b/tensorflow/contrib/distribute/python/mirrored_strategy_multigpu_test.py index 9a4cc0a897..a12ff662db 100644 --- a/tensorflow/contrib/distribute/python/mirrored_strategy_multigpu_test.py +++ b/tensorflow/contrib/distribute/python/mirrored_strategy_multigpu_test.py @@ -21,6 +21,7 @@ from __future__ import print_function import sys from tensorflow.contrib.distribute.python import mirrored_strategy +from tensorflow.contrib.distribute.python import multi_worker_test_base from tensorflow.contrib.distribute.python import strategy_test_lib from tensorflow.contrib.distribute.python import values from tensorflow.core.protobuf import config_pb2 @@ -41,6 +42,7 @@ from tensorflow.python.ops import variable_scope from tensorflow.python.ops import variables from tensorflow.python.training import device_util from tensorflow.python.training import distribution_strategy_context +from tensorflow.python.training import server_lib GPU_TEST = "test_gpu" in sys.argv[0] @@ -886,8 +888,18 @@ class MirroredVariableUpdateTest(test.TestCase): self.assertIsInstance(mirrored_var, values.MirroredVariable) self.evaluate(variables.global_variables_initializer()) self.assertEquals(1.0, self.evaluate(mirrored_var)) - mirrored_var_result = self.evaluate(mirrored_var.assign_add(6.0)) + + # read_value == True + mirrored_var_result = self.evaluate( + mirrored_var.assign_add(6.0, read_value=True)) self.assertEquals(7.0, mirrored_var_result) + self.assertEquals(7.0, self.evaluate(mirrored_var.get("/device:CPU:0"))) + self.assertEquals(7.0, self.evaluate(mirrored_var.get("/device:GPU:0"))) + + # read_value == False + self.evaluate(mirrored_var.assign_add(2.0, read_value=False)) + self.assertEquals(9.0, self.evaluate(mirrored_var.get("/device:CPU:0"))) + self.assertEquals(9.0, self.evaluate(mirrored_var.get("/device:GPU:0"))) @test_util.run_in_graph_and_eager_modes(config=config) def testAssignAddMirroredVarTowerContext(self): @@ -954,6 +966,8 @@ class MirroredVariableUpdateTest(test.TestCase): self.assertEquals(5.0, self.evaluate(mirrored_var)) mirrored_var_result = self.evaluate(mirrored_var.assign_sub(2.0)) self.assertEquals(3.0, mirrored_var_result) + self.assertEquals(3.0, self.evaluate(mirrored_var.get("/device:GPU:0"))) + self.assertEquals(3.0, self.evaluate(mirrored_var.get("/device:CPU:0"))) @test_util.run_in_graph_and_eager_modes(config=config) def testAssignSubMirroredVarTowerContext(self): @@ -1244,5 +1258,39 @@ class MirroredStrategyDefunTest(test.TestCase): self._call_and_check(fn1, [factors], expected_result, [fn1]) +class MultiWorkerMirroredStrategyTest( + multi_worker_test_base.MultiWorkerTestBase, + strategy_test_lib.DistributionTestBase): + + def _get_distribution_strategy(self): + cluster_spec = server_lib.ClusterSpec({ + "worker": ["/job:worker/task:0", "/job:worker/task:1"] + }) + strategy = mirrored_strategy.MirroredStrategy(num_gpus=context.num_gpus()) + strategy.configure(cluster_spec=cluster_spec) + return strategy + + def testMinimizeLossGraph(self): + self._test_minimize_loss_graph(self._get_distribution_strategy(), + learning_rate=0.05) + + +class MultiWorkerMirroredStrategyTestWithChief( + multi_worker_test_base.MultiWorkerTestBase, + strategy_test_lib.DistributionTestBase): + + @classmethod + def setUpClass(cls): + """Create a local cluster with 2 workers and 1 chief.""" + cls._cluster_spec = multi_worker_test_base.create_in_process_cluster( + num_workers=2, num_ps=0, has_chief=True) + cls._default_target = "grpc://" + cls._cluster_spec["chief"][0] + + def testMinimizeLossGraph(self): + strategy = mirrored_strategy.MirroredStrategy(num_gpus=context.num_gpus()) + strategy.configure(cluster_spec=self._cluster_spec) + self._test_minimize_loss_graph(strategy, learning_rate=0.05) + + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/distribute/python/mirrored_strategy_test.py b/tensorflow/contrib/distribute/python/mirrored_strategy_test.py index 5db2fff239..969e126956 100644 --- a/tensorflow/contrib/distribute/python/mirrored_strategy_test.py +++ b/tensorflow/contrib/distribute/python/mirrored_strategy_test.py @@ -22,6 +22,8 @@ from tensorflow.contrib.distribute.python import mirrored_strategy from tensorflow.contrib.distribute.python import strategy_test_lib from tensorflow.python.eager import context from tensorflow.python.eager import test +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import ops from tensorflow.python.framework import test_util from tensorflow.python.ops import variable_scope from tensorflow.python.training import distribution_strategy_context @@ -60,6 +62,7 @@ class VariableCreatorStackTest(test.TestCase): def model_fn(device_id): assert isinstance(device_id, int) + def thread_creator_fn(next_creator, *args, **kwargs): return next_creator(*args, **kwargs) + ":thread_" + str(device_id) @@ -86,5 +89,21 @@ class VariableCreatorStackTest(test.TestCase): self.assertEquals(expected, result) +class MultiWorkerMirroredStrategyTest(test.TestCase): + + def testDeviceScope(self): + """Test the device scope of multi-worker MirroredStrategy.""" + with context.graph_mode(): + strategy = mirrored_strategy.MirroredStrategy(num_gpus=context.num_gpus()) + strategy.configure( + cluster_spec={"worker": ["/job:worker/task:0", "/job:worker/task:1"]}) + with strategy.scope(): + a = constant_op.constant(1.) + with ops.device("/cpu:0"): + b = constant_op.constant(1.) + self.assertEqual(a.device, "/job:worker/task:0") + self.assertEqual(b.device, "/job:worker/task:0/device:CPU:0") + + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/distribute/python/monitor_test.py b/tensorflow/contrib/distribute/python/monitor_test.py index 2892ce4394..16be839e1d 100644 --- a/tensorflow/contrib/distribute/python/monitor_test.py +++ b/tensorflow/contrib/distribute/python/monitor_test.py @@ -45,7 +45,7 @@ class MonitorTest(test.TestCase, parameterized.TestCase): if context.executing_eagerly(): monitor = monitor_lib.Monitor(single_loss_step, None) else: - with self.test_session() as sess: + with self.cached_session() as sess: monitor = monitor_lib.Monitor(single_loss_step, sess) monitor.run_steps(1) diff --git a/tensorflow/contrib/distribute/python/multi_worker_strategy.py b/tensorflow/contrib/distribute/python/multi_worker_strategy.py deleted file mode 100644 index cbfe5df61d..0000000000 --- a/tensorflow/contrib/distribute/python/multi_worker_strategy.py +++ /dev/null @@ -1,141 +0,0 @@ -# Copyright 2018 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Classes implementing a mirrored DistributionStrategy for multiple workers.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from functools import partial - -from tensorflow.contrib.distribute.python import values -from tensorflow.contrib.distribute.python.mirrored_strategy import MirroredStrategy -from tensorflow.core.protobuf import cluster_pb2 -from tensorflow.python.training import device_util -from tensorflow.python.training import server_lib -from tensorflow.python.util import nest - - -# TODO(yuefengz): support between-graph replication. -# TODO(yuefengz): merge this class into its base class. -# TODO(yuefengz): in some cases, we probably want to use configure method to -# configure this class. -# TODO(yuefengz): MirroredStrategy.worker_devices may be confusing after the -# class is introduced. -class MultiWorkerMirroredStrategy(MirroredStrategy): - """Mirrored strategy that works on multiple workers with in-graph replication. - - There are several important concepts for distributed TensorFlow, e.g. - `client`, `job`, 'task', `cluster`, `in-graph replication` and - 'synchronous training' and they have already been defined in the - [TensorFlow's documentation](https://www.tensorflow.org/deploy/distributed). - The distribution strategy inherits these concepts as well and in addition to - that we also clarify several more concepts: - * **In-graph replication**: the `client` creates a single `tf.Graph` that - specifies tasks for devices on all workers. The `client` then creates a - client session which will talk to the `master` service of a `worker`. Then - the `master` will partition the graph and distribute the work to all - participating workers. - * **Worker**: A `worker` is a TensorFlow `task` that usually maps to one - physical machine. We will have multiple `worker`s with different `task` - index. They all do similar things except for one worker checkpointing model - variables, writing summaries, etc. in addition to its ordinary work. - - This class maps one tower to one device on a worker. It mirrors all model - variables on all towers. For example, if you have two `worker`s and each - `worker` has 4 GPUs, it will create 8 copies of the model variables on these 8 - GPUs. Then like in MirroredStrategy, each tower performs their computation - with their own copy of variables unless in cross-tower model where variable or - tensor reduction happens. - """ - - def __init__(self, - num_gpus_per_worker=1, - worker_job_name=None, - num_workers=None, - cluster=None, - cross_tower_ops=None, - prefetch_on_device=None): - """Initialize the strategy object. - - Args: - num_gpus_per_worker: number of GPUs per work. If it is zero, the local - CPU will be used. - worker_job_name: the job name for `worker`, typically just 'worker'. - num_workers: the number of workers. If it is 0, it regenerates to - single-worker MirroredStrategy. - cluster: a `tf.train.ClusterSpec` object or a dict that can be used to - construct a `tf.train.ClusterSpec` object or a `tf.train.ClusterDef` - proto buffer. It is an alternative way to initialize this object. - cross_tower_ops: the cross tower ops to use. If None, a default one will - be used. If configure method is called, a best one for the configuration - will be chosen. - prefetch_on_device: a boolean to specify whether to prefetech input to - each worker's devices. - - Raises: - ValueError: if got an unexpected `cluster`. - """ - if cluster is None: - self._workers = [ - '/job:%s/task:%d' % (worker_job_name, task_index) - for task_index in range(num_workers) - ] - else: - if isinstance(cluster, (dict, cluster_pb2.ClusterDef)): - cluster_spec = server_lib.ClusterSpec(cluster) - elif isinstance(cluster, server_lib.ClusterSpec): - cluster_spec = cluster - else: - raise ValueError( - "`cluster_spec' should be dict or a `tf.train.ClusterSpec` or a " - '`tf.train.ClusterDef` object') - - self._workers = [] - for job in sorted(cluster_spec.jobs): - for task in range(cluster_spec.num_tasks(job)): - self._workers.append('/job:%s/task:%d' % (job, task)) - - self._num_gpus_per_worker = num_gpus_per_worker - if num_gpus_per_worker > 0: - self._worker_device_map = { - worker: [ - device_util.canonicalize(worker + '/device:GPU:%d' % gpu) - for gpu in range(num_gpus_per_worker) - ] for worker in self._workers - } - else: - self._worker_device_map = { - worker: [device_util.canonicalize(worker, '/device:CPU:0')] - for worker in self._workers - } - self._devices = nest.flatten(self._worker_device_map) - - super(MultiWorkerMirroredStrategy, self).__init__( - devices=self._devices, prefetch_on_device=prefetch_on_device) - - # Setting `_default_device` will add a device scope in the - # distribution.scope. We set the default device to the first worker. When - # users specify device under distribution.scope by - # with tf.device("/cpu:0"): - # ... - # their ops will end up on the cpu device of its first worker, e.g. - # "/job:worker/task:0/device:CPU:0". Note this is not used in tower mode. - self._default_device = self._workers[0] - - def distribute_dataset(self, dataset_fn): - return values.MultiWorkerDataset( - partial(self._call_dataset_fn, dataset_fn), self._worker_device_map, - self._prefetch_on_device) diff --git a/tensorflow/contrib/distribute/python/multi_worker_strategy_test.py b/tensorflow/contrib/distribute/python/multi_worker_strategy_test.py deleted file mode 100644 index 09c859b32a..0000000000 --- a/tensorflow/contrib/distribute/python/multi_worker_strategy_test.py +++ /dev/null @@ -1,62 +0,0 @@ -# Copyright 2018 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for MultiWorkerMirroredStrategy.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from tensorflow.contrib.distribute.python import multi_worker_strategy -from tensorflow.contrib.distribute.python import multi_worker_test_base -from tensorflow.contrib.distribute.python import strategy_test_lib -from tensorflow.python.eager import context -from tensorflow.python.eager import test -from tensorflow.python.framework import constant_op -from tensorflow.python.framework import ops -from tensorflow.python.training import server_lib - - -class MultiWorkerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, - strategy_test_lib.DistributionTestBase): - - def _get_distribution_strategy(self): - return multi_worker_strategy.MultiWorkerMirroredStrategy( - cluster=server_lib.ClusterSpec({ - 'worker': ['/job:worker/task:0', '/job:worker/task:1'] - }), - num_gpus_per_worker=context.num_gpus()) - - def testMinimizeLossGraph(self): - self._test_minimize_loss_graph(self._get_distribution_strategy()) - - -class DeviceScopeTest(test.TestCase): - """Test the device scope of MultiWorkerMirroredStrategy.""" - - def testDeviceScope(self): - with context.graph_mode(): - strategy = multi_worker_strategy.MultiWorkerMirroredStrategy( - cluster={'worker': ['/job:worker/task:0', '/job:worker/task:1']}, - num_gpus_per_worker=context.num_gpus()) - with strategy.scope(): - a = constant_op.constant(1.) - with ops.device('/cpu:0'): - b = constant_op.constant(1.) - self.assertEqual(a.device, '/job:worker/task:0') - self.assertEqual(b.device, '/job:worker/task:0/device:CPU:0') - - -if __name__ == '__main__': - test.main() diff --git a/tensorflow/contrib/distribute/python/multi_worker_test_base.py b/tensorflow/contrib/distribute/python/multi_worker_test_base.py index 249de01f08..18b4503eff 100644 --- a/tensorflow/contrib/distribute/python/multi_worker_test_base.py +++ b/tensorflow/contrib/distribute/python/multi_worker_test_base.py @@ -23,26 +23,105 @@ import copy import threading import numpy as np +_portpicker_import_error = None +try: + import portpicker # pylint: disable=g-import-not-at-top +except ImportError as _error: # pylint: disable=invalid-name + _portpicker_import_error = _error + portpicker = None + +# pylint: disable=g-import-not-at-top from tensorflow.core.protobuf import config_pb2 from tensorflow.core.protobuf import rewriter_config_pb2 from tensorflow.python.client import session from tensorflow.python.estimator import run_config from tensorflow.python.platform import test -from tensorflow.python.framework import test_util - - -def create_in_process_cluster(num_workers, num_ps): +from tensorflow.python.training import server_lib + + +def _create_cluster(num_workers, + num_ps, + has_chief=False, + has_eval=False, + protocol='grpc', + worker_config=None, + ps_config=None): + """Creates and starts local servers and returns the cluster_spec dict.""" + if _portpicker_import_error: + raise _portpicker_import_error # pylint: disable=raising-bad-type + worker_ports = [portpicker.pick_unused_port() for _ in range(num_workers)] + ps_ports = [portpicker.pick_unused_port() for _ in range(num_ps)] + + cluster_dict = {} + if num_workers > 0: + cluster_dict['worker'] = ['localhost:%s' % port for port in worker_ports] + if num_ps > 0: + cluster_dict['ps'] = ['localhost:%s' % port for port in ps_ports] + if has_eval: + cluster_dict['evaluator'] = ['localhost:%s' % portpicker.pick_unused_port()] + if has_chief: + cluster_dict['chief'] = ['localhost:%s' % portpicker.pick_unused_port()] + + cs = server_lib.ClusterSpec(cluster_dict) + + for i in range(num_workers): + server_lib.Server( + cs, + job_name='worker', + protocol=protocol, + task_index=i, + config=worker_config, + start=True) + + for i in range(num_ps): + server_lib.Server( + cs, + job_name='ps', + protocol=protocol, + task_index=i, + config=ps_config, + start=True) + + if has_chief: + server_lib.Server( + cs, + job_name='chief', + protocol=protocol, + task_index=0, + config=worker_config, + start=True) + + if has_eval: + server_lib.Server( + cs, + job_name='evaluator', + protocol=protocol, + task_index=0, + config=worker_config, + start=True) + + return cluster_dict + + +def create_in_process_cluster(num_workers, + num_ps, + has_chief=False, + has_eval=False): """Create an in-process cluster that consists of only standard server.""" # Leave some memory for cuda runtime. - gpu_mem_frac = 0.7 / num_workers + gpu_mem_frac = 0.7 / (num_workers + int(has_chief) + int(has_eval)) worker_config = config_pb2.ConfigProto() worker_config.gpu_options.per_process_gpu_memory_fraction = gpu_mem_frac # Enable collective ops which has no impact on non-collective ops. # TODO(yuefengz, tucker): removing this after we move the initialization of # collective mgr to the session level. - worker_config.experimental.collective_group_leader = ( - '/job:worker/replica:0/task:0') + if has_chief: + worker_config.experimental.collective_group_leader = ( + '/job:chief/replica:0/task:0') + else: + worker_config.experimental.collective_group_leader = ( + '/job:worker/replica:0/task:0') ps_config = config_pb2.ConfigProto() ps_config.device_count['GPU'] = 0 @@ -56,9 +135,10 @@ def create_in_process_cluster(num_workers, num_ps): # 2) there is something global in CUDA such that if we initialize CUDA in the # parent process, the child process cannot initialize it again and thus cannot # use GPUs (https://stackoverflow.com/questions/22950047). - return test_util.create_local_cluster( + return _create_cluster( num_workers, num_ps=num_ps, + has_chief=has_chief, worker_config=worker_config, ps_config=ps_config, protocol='grpc') @@ -70,7 +150,8 @@ class MultiWorkerTestBase(test.TestCase): @classmethod def setUpClass(cls): """Create a local cluster with 2 workers.""" - cls._workers, cls._ps = create_in_process_cluster(num_workers=2, num_ps=0) + cls._cluster_spec = create_in_process_cluster(num_workers=2, num_ps=0) + cls._default_target = 'grpc://' + cls._cluster_spec['worker'][0] def setUp(self): # We only cache the session in one test because another test may have a @@ -111,17 +192,17 @@ class MultiWorkerTestBase(test.TestCase): config.graph_options.rewrite_options.constant_folding = ( rewriter_config_pb2.RewriterConfig.OFF) + if target is None: + target = self._default_target if graph is None: if getattr(self._thread_local, 'cached_session', None) is None: self._thread_local.cached_session = session.Session( - graph=None, config=config, target=target or self._workers[0].target) + graph=None, config=config, target=target) sess = self._thread_local.cached_session with sess.graph.as_default(), sess.as_default(): yield sess else: - with session.Session( - graph=graph, config=config, target=target or - self._workers[0].target) as sess: + with session.Session(graph=graph, config=config, target=target) as sess: yield sess def _run_client(self, client_fn, task_type, task_id, num_gpus, *args, diff --git a/tensorflow/contrib/distribute/python/optimizer_v2_test.py b/tensorflow/contrib/distribute/python/optimizer_v2_test.py index a2d736e422..6e9ba37a19 100644 --- a/tensorflow/contrib/distribute/python/optimizer_v2_test.py +++ b/tensorflow/contrib/distribute/python/optimizer_v2_test.py @@ -51,7 +51,7 @@ class MinimizeLossOptimizerV2Test(test.TestCase, parameterized.TestCase): model_fn, iterator.get_next(), run_concurrently=layer.built))) if not context.executing_eagerly(): - with self.test_session() as sess: + with self.cached_session() as sess: run_step = sess.make_callable(run_step()) self.evaluate(variables.global_variables_initializer()) diff --git a/tensorflow/contrib/distribute/python/parameter_server_strategy.py b/tensorflow/contrib/distribute/python/parameter_server_strategy.py index 8041eb0f34..361c8be590 100644 --- a/tensorflow/contrib/distribute/python/parameter_server_strategy.py +++ b/tensorflow/contrib/distribute/python/parameter_server_strategy.py @@ -22,10 +22,12 @@ from tensorflow.contrib.distribute.python import cross_tower_ops as cross_tower_ from tensorflow.contrib.distribute.python import mirrored_strategy from tensorflow.contrib.distribute.python import values from tensorflow.python.distribute import multi_worker_util +from tensorflow.python.eager import context from tensorflow.python.framework import device as tf_device from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops from tensorflow.python.ops import resource_variable_ops +from tensorflow.python.ops import variable_scope as vs from tensorflow.python.training import device_setter from tensorflow.python.training import device_util from tensorflow.python.training import distribute as distribute_lib @@ -55,7 +57,11 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): assigned to. This class assumes between-graph replication will be used and works on a graph - for a particular worker. + for a particular worker. Note that each graph and worker is independent. + This means that while each worker will synchronously compute a single gradient + update across all GPUs, updates between workers proceed asynchronously. + Operations that occur only on the first tower (such as incrementing the global + step), will occur on the first tower *of every worker*. It is expected to call `call_for_each_tower(fn, *args, **kwargs)` for any operations which potentially can be replicated across towers (i.e. multiple @@ -73,7 +79,7 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): 3) It is also not recommended to open a colocation scope (i.e. calling `tf.colocate_with`) under the strategy's scope. For colocating variables, use `distribution.colocate_vars_with` instead. Colocation of ops will possibly - create conflicts of device assignement. + create conflicts of device assignment. """ def __init__(self, @@ -81,7 +87,7 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): cluster_spec=None, task_type=None, task_id=None): - """Initiailizes this strategy. + """Initializes this strategy. Args: num_gpus_per_worker: number of local GPUs or GPUs per worker. @@ -89,11 +95,18 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): cluster configurations. task_type: the current task type. task_id: the current task id. + + Raises: + ValueError: if `cluster_spec` is given but `task_type` or `task_id` is + not. """ super(ParameterServerStrategy, self).__init__() self._num_gpus_per_worker = num_gpus_per_worker if cluster_spec: cluster_spec = multi_worker_util.normalize_cluster_spec(cluster_spec) + if task_type is None or task_id is None: + raise ValueError("When `cluster_spec` is given, must also specify " + "`task_type` and `task_id`.") self._cluster_spec = cluster_spec # We typically don't need to do all-reduce in this strategy. @@ -217,14 +230,57 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): # TODO(yuefengz): not all ops in device_setter.STANDARD_PS_OPS will go through # this creator, such as "MutableHashTable". def _create_variable(self, next_creator, *args, **kwargs): + if self.num_towers > 1: + aggregation = kwargs.pop("aggregation", vs.VariableAggregation.NONE) + if aggregation not in ( + vs.VariableAggregation.NONE, + vs.VariableAggregation.SUM, + vs.VariableAggregation.MEAN + ): + raise ValueError("Invalid variable aggregation mode: " + aggregation + + " for variable: " + kwargs["name"]) + + def var_creator(*args, **kwargs): + # Record what collections this variable should be added to. + collections = kwargs.pop("collections", None) + if collections is None: + collections = [ops.GraphKeys.GLOBAL_VARIABLES] + kwargs["collections"] = [] + + # Create and wrap the variable. + v = next_creator(*args, **kwargs) + wrapped = values.AggregatingVariable(v, aggregation) + + # Add the wrapped variable to the requested collections. + # The handling of eager mode and the global step matches + # ResourceVariable._init_from_args(). + if not context.executing_eagerly(): + g = ops.get_default_graph() + # If "trainable" is True, next_creator() will add the contained + # variable to the TRAINABLE_VARIABLES collection, so we manually + # remove it and replace with the wrapper. We can't set "trainable" + # to False for next_creator() since that causes functions like + # implicit_gradients to skip those variables. + if kwargs.get("trainable", True): + collections.append(ops.GraphKeys.TRAINABLE_VARIABLES) + l = g.get_collection_ref(ops.GraphKeys.TRAINABLE_VARIABLES) + l.remove(v) + g.add_to_collections(collections, wrapped) + elif ops.GraphKeys.GLOBAL_STEP in collections: + ops.add_to_collections(ops.GraphKeys.GLOBAL_STEP, wrapped) + + return wrapped + else: + var_creator = next_creator + if "colocate_with" in kwargs: with ops.device(None): with ops.colocate_with(kwargs["colocate_with"]): - return next_creator(*args, **kwargs) + return var_creator(*args, **kwargs) with ops.colocate_with(None, ignore_existing=True): with ops.device(self._variable_device): - return next_creator(*args, **kwargs) + return var_creator(*args, **kwargs) def _call_for_each_tower(self, fn, *args, **kwargs): # pylint: disable=protected-access @@ -246,7 +302,6 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): # pylint: disable=protected-access return mirrored_strategy._reduce_non_distributed_value( self, aggregation, value, destinations) - return self._cross_tower_ops.reduce( aggregation, value, destinations=destinations) @@ -279,6 +334,8 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): return nest.map_structure(_select_fn, structured) def _update(self, var, fn, *args, **kwargs): + if isinstance(var, values.AggregatingVariable): + var = var.get() if not isinstance(var, resource_variable_ops.ResourceVariable): raise ValueError( "You can not update `var` %r. It must be a Variable." % var) @@ -323,6 +380,10 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): cluster configurations. task_type: the current task type. task_id: the current task id. + + Raises: + ValueError: if `cluster_spec` is given but `task_type` or `task_id` is + not. """ del session_config @@ -331,6 +392,9 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): if not self._cluster_spec and cluster_spec: self._cluster_spec = multi_worker_util.normalize_cluster_spec( cluster_spec) + if task_type is None or task_id is None: + raise ValueError("When `cluster_spec` is given, must also specify " + "`task_type` and `task_id`.") self._initialize_devices(self._num_gpus_per_worker, self._cluster_spec, task_type, task_id) diff --git a/tensorflow/contrib/distribute/python/parameter_server_strategy_test.py b/tensorflow/contrib/distribute/python/parameter_server_strategy_test.py index 0df65714fb..0e2bfcec5f 100644 --- a/tensorflow/contrib/distribute/python/parameter_server_strategy_test.py +++ b/tensorflow/contrib/distribute/python/parameter_server_strategy_test.py @@ -24,6 +24,8 @@ from absl.testing import parameterized from tensorflow.contrib.distribute.python import combinations from tensorflow.contrib.distribute.python import multi_worker_test_base from tensorflow.contrib.distribute.python import parameter_server_strategy +from tensorflow.contrib.distribute.python import values +from tensorflow.python.distribute import multi_worker_util from tensorflow.python.eager import context from tensorflow.python.estimator import run_config from tensorflow.python.framework import constant_op @@ -37,21 +39,15 @@ from tensorflow.python.ops import variables from tensorflow.python.platform import test from tensorflow.python.training import device_util from tensorflow.python.training import distribution_strategy_context +from tensorflow.python.training import training_util +CHIEF = run_config.TaskType.CHIEF +WORKER = run_config.TaskType.WORKER +PS = run_config.TaskType.PS -class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, - parameterized.TestCase): - @classmethod - def setUpClass(cls): - cls._workers, cls._ps = multi_worker_test_base.create_in_process_cluster( - num_workers=3, num_ps=2) - cls._cluster_spec = { - run_config.TaskType.WORKER: [ - 'fake_worker_0', 'fake_worker_1', 'fake_worker_2' - ], - run_config.TaskType.PS: ['fake_ps_0', 'fake_ps_1'] - } +class ParameterServerStrategyTestBase( + multi_worker_test_base.MultiWorkerTestBase): def setUp(self): self._result = 0 @@ -60,7 +56,7 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, self._init_reached = 0 self._finish_condition = threading.Condition() self._finish_reached = 0 - super(ParameterServerStrategyTest, self).setUp() + super(ParameterServerStrategyTestBase, self).setUp() def _get_test_objects(self, task_type, task_id, num_gpus): distribution = parameter_server_strategy.ParameterServerStrategy( @@ -70,13 +66,13 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, distribution.configure( cluster_spec=self._cluster_spec, task_type=task_type, task_id=task_id) - return distribution, self._workers[task_id].target + return distribution, 'grpc://' + self._cluster_spec[WORKER][task_id] def _test_device_assignment_distributed(self, task_type, task_id, num_gpus): worker_device = '/job:%s/replica:0/task:%d' % (task_type, task_id) d, _ = self._get_test_objects(task_type, task_id, num_gpus) with ops.Graph().as_default(), \ - self.test_session(target=self._workers[0].target) as sess, \ + self.test_session(target=self._default_target) as sess, \ d.scope(): # Define a variable outside the call_for_each_tower scope. This is not @@ -101,7 +97,9 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, # The device scope is ignored for variables but not for normal ops. with ops.device('/job:worker/task:0'): - x = variable_scope.get_variable('x', initializer=10.0) + x = variable_scope.get_variable( + 'x', initializer=10.0, + aggregation=variable_scope.VariableAggregation.SUM) x_add = x.assign_add(c) e = a + c # The variable x is on the task 1 since the device_function has been @@ -113,18 +111,26 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, # The colocate_vars_with can override the distribution's device. with d.colocate_vars_with(x): - y = variable_scope.get_variable('y', initializer=20.0) - y_add = y.assign_add(x_add) + y = variable_scope.get_variable( + 'y', initializer=20.0, + aggregation=variable_scope.VariableAggregation.SUM) + # We add an identity here to avoid complaints about summing + # non-distributed values. + y_add = y.assign_add(array_ops.identity(x_add)) self.assertEqual(y.device, '/job:ps/task:1') self.assertEqual(y_add.device, y.device) self.assertEqual(y.device, x.device) - z = variable_scope.get_variable('z', initializer=10.0) + z = variable_scope.get_variable( + 'z', initializer=10.0, + aggregation=variable_scope.VariableAggregation.SUM) self.assertEqual(z.device, '/job:ps/task:0') self.assertNotEqual(z.device, x.device) with ops.control_dependencies([y_add]): - z_add = z.assign_add(y) + # We add an identity here to avoid complaints about summing + # non-distributed values. + z_add = z.assign_add(array_ops.identity(y)) with ops.control_dependencies([z_add]): f = z + c self.assertEqual(f.device, worker_device + '/' + last_part_device) @@ -162,18 +168,13 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, self.assertEqual(z_val, 43.0) self.assertEqual(f_val, 46.0) - @combinations.generate( - combinations.combine(mode=['graph'], num_gpus=[0, 1, 2])) - def testDeviceAssignmentDistributed(self, num_gpus): - self._test_device_assignment_distributed('worker', 1, num_gpus) - def _test_device_assignment_local(self, d, compute_device='CPU', variable_device='CPU', num_gpus=0): with ops.Graph().as_default(), \ - self.test_session(target=self._workers[0].target) as sess, \ + self.test_session(target=self._default_target) as sess, \ d.scope(): def model_fn(): @@ -202,7 +203,9 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, # The device scope is ignored for variables but not for normal ops. with ops.device('/device:GPU:2'): - x = variable_scope.get_variable('x', initializer=10.0) + x = variable_scope.get_variable( + 'x', initializer=10.0, + aggregation=variable_scope.VariableAggregation.SUM) x_add = x.assign_add(c) e = a + c self.assertEqual( @@ -212,19 +215,27 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, # The colocate_vars_with can override the distribution's device. with d.colocate_vars_with(x): - y = variable_scope.get_variable('y', initializer=20.0) - y_add = y.assign_add(x_add) + y = variable_scope.get_variable( + 'y', initializer=20.0, + aggregation=variable_scope.VariableAggregation.SUM) + # We add an identity here to avoid complaints about summing + # non-distributed values. + y_add = y.assign_add(array_ops.identity(x_add)) self.assertEqual( device_util.canonicalize(y.device), tower_variable_device) self.assertEqual(y_add.device, y.device) self.assertEqual(y.device, x.device) - z = variable_scope.get_variable('z', initializer=10.0) + z = variable_scope.get_variable( + 'z', initializer=10.0, + aggregation=variable_scope.VariableAggregation.SUM) self.assertEqual( device_util.canonicalize(z.device), tower_variable_device) with ops.control_dependencies([y_add]): - z_add = z.assign_add(y) + # We add an identity here to avoid complaints about summing + # non-distributed values. + z_add = z.assign_add(array_ops.identity(y)) with ops.control_dependencies([z_add]): f = z + c self.assertEqual(f.device, tower_compute_device) @@ -256,29 +267,12 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, self.assertEqual(z_val, 43.0) self.assertEqual(f_val, 46.0) - def testDeviceAssignmentLocalCPU(self): - distribution = parameter_server_strategy.ParameterServerStrategy( - num_gpus_per_worker=0) - self._test_device_assignment_local( - distribution, compute_device='CPU', variable_device='CPU', num_gpus=0) - - def testDeviceAssignmentLocalOneGPU(self): - distribution = parameter_server_strategy.ParameterServerStrategy( - num_gpus_per_worker=1) - self._test_device_assignment_local( - distribution, compute_device='GPU', variable_device='GPU', num_gpus=1) - - def testDeviceAssignmentLocalTwoGPUs(self): - distribution = parameter_server_strategy.ParameterServerStrategy( - num_gpus_per_worker=2) - self._test_device_assignment_local( - distribution, compute_device='GPU', variable_device='CPU', num_gpus=2) - def _test_simple_increment(self, task_type, task_id, num_gpus): d, master_target = self._get_test_objects(task_type, task_id, num_gpus) if hasattr(d, '_cluster_spec') and d._cluster_spec: - num_workers = len(d._cluster_spec.as_dict().get('worker', - ['dummy_worker'])) + num_workers = len(d._cluster_spec.as_dict().get(WORKER)) + if 'chief' in d._cluster_spec.as_dict(): + num_workers += 1 else: num_workers = 1 with ops.Graph().as_default(), \ @@ -286,11 +280,18 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, d.scope(): def model_fn(): - x = variable_scope.get_variable('x', initializer=10.0) - y = variable_scope.get_variable('y', initializer=20.0) - - x_add = x.assign_add(1.0, use_locking=True) - y_add = y.assign_add(1.0, use_locking=True) + x = variable_scope.get_variable( + 'x', initializer=10.0, + aggregation=variable_scope.VariableAggregation.SUM) + y = variable_scope.get_variable( + 'y', initializer=20.0, + aggregation=variable_scope.VariableAggregation.SUM) + + # We explicitly make a constant tensor here to avoid complaints about + # summing non-distributed values. + one = constant_op.constant(1.0) + x_add = x.assign_add(one, use_locking=True) + y_add = y.assign_add(one, use_locking=True) train_op = control_flow_ops.group([x_add, y_add]) return x, y, train_op @@ -330,6 +331,11 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, def _test_minimize_loss_graph(self, task_type, task_id, num_gpus): d, master_target = self._get_test_objects(task_type, task_id, num_gpus) + assert hasattr(d, '_cluster_spec') and d._cluster_spec + num_workers = len(d._cluster_spec.as_dict().get(WORKER)) + if CHIEF in d._cluster_spec.as_dict(): + num_workers += 1 + with ops.Graph().as_default(), \ self.test_session(target=master_target) as sess, \ d.scope(): @@ -378,13 +384,13 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, if context.num_gpus() < d._num_gpus_per_worker: return True - if task_id == 0: + if multi_worker_util.is_chief(d._cluster_spec, task_type, task_id): variables.global_variables_initializer().run() # Workers waiting for chief worker's initializing variables. self._init_condition.acquire() self._init_reached += 1 - while self._init_reached != 3: + while self._init_reached != num_workers: self._init_condition.wait() self._init_condition.notify_all() self._init_condition.release() @@ -401,9 +407,42 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, self.assertLess(error_after, error_before) return error_after < error_before + +class ParameterServerStrategyTest(ParameterServerStrategyTestBase, + parameterized.TestCase): + + @classmethod + def setUpClass(cls): + cls._cluster_spec = multi_worker_test_base.create_in_process_cluster( + num_workers=3, num_ps=2) + cls._default_target = 'grpc://' + cls._cluster_spec[WORKER][0] + + def testDeviceAssignmentLocalCPU(self): + distribution = parameter_server_strategy.ParameterServerStrategy( + num_gpus_per_worker=0) + self._test_device_assignment_local( + distribution, compute_device='CPU', variable_device='CPU', num_gpus=0) + + def testDeviceAssignmentLocalOneGPU(self): + distribution = parameter_server_strategy.ParameterServerStrategy( + num_gpus_per_worker=1) + self._test_device_assignment_local( + distribution, compute_device='GPU', variable_device='GPU', num_gpus=1) + + def testDeviceAssignmentLocalTwoGPUs(self): + distribution = parameter_server_strategy.ParameterServerStrategy( + num_gpus_per_worker=2) + self._test_device_assignment_local( + distribution, compute_device='GPU', variable_device='CPU', num_gpus=2) + + @combinations.generate( + combinations.combine(mode=['graph'], num_gpus=[0, 1, 2])) + def testDeviceAssignmentDistributed(self, num_gpus): + self._test_device_assignment_distributed('worker', 1, num_gpus) + def testSimpleBetweenGraph(self): self._run_between_graph_clients(self._test_simple_increment, - self._cluster_spec, 0) + self._cluster_spec, context.num_gpus()) @combinations.generate( combinations.combine(mode=['graph'], num_gpus=[0, 1, 2])) @@ -417,5 +456,38 @@ class ParameterServerStrategyTest(multi_worker_test_base.MultiWorkerTestBase, self._cluster_spec, num_gpus) +class ParameterServerStrategyWithChiefTest(ParameterServerStrategyTestBase, + parameterized.TestCase): + + @classmethod + def setUpClass(cls): + cls._cluster_spec = multi_worker_test_base.create_in_process_cluster( + num_workers=3, num_ps=2, has_chief=True) + cls._default_target = 'grpc://' + cls._cluster_spec[CHIEF][0] + + def testSimpleBetweenGraph(self): + self._run_between_graph_clients(self._test_simple_increment, + self._cluster_spec, context.num_gpus()) + + @combinations.generate( + combinations.combine(mode=['graph'], num_gpus=[0, 1, 2])) + def testMinimizeLossGraph(self, num_gpus): + self._run_between_graph_clients(self._test_minimize_loss_graph, + self._cluster_spec, num_gpus) + + def testGlobalStepIsWrapped(self): + distribution = parameter_server_strategy.ParameterServerStrategy( + num_gpus_per_worker=2) + with ops.Graph().as_default(), distribution.scope(): + created_step = training_util.create_global_step() + get_step = training_util.get_global_step() + self.assertEqual(created_step, get_step, + msg=('created_step %s type %s vs. get_step %s type %s' % + (id(created_step), created_step.__class__.__name__, + id(get_step), get_step.__class__.__name__))) + self.assertIs(values.AggregatingVariable, type(created_step)) + self.assertIs(values.AggregatingVariable, type(get_step)) + + if __name__ == '__main__': test.main() diff --git a/tensorflow/contrib/distribute/python/prefetching_ops_v2_test.py b/tensorflow/contrib/distribute/python/prefetching_ops_v2_test.py index a68dbce6c7..bb10b546a1 100644 --- a/tensorflow/contrib/distribute/python/prefetching_ops_v2_test.py +++ b/tensorflow/contrib/distribute/python/prefetching_ops_v2_test.py @@ -37,7 +37,7 @@ class PrefetchingOpsV2Test(test.TestCase): iterator = device_dataset.make_one_shot_iterator() next_element = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: for i in range(10): self.assertEqual(i, sess.run(next_element)) with self.assertRaises(errors.OutOfRangeError): @@ -55,7 +55,7 @@ class PrefetchingOpsV2Test(test.TestCase): next_element = iterator.get_next() output = [] - with self.test_session() as sess: + with self.cached_session() as sess: for _ in range(5): result = sess.run(next_element) self.assertEqual(2, len(result)) @@ -75,7 +75,7 @@ class PrefetchingOpsV2Test(test.TestCase): iterator = device_dataset.make_initializable_iterator() next_element = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(iterator.initializer) for _ in range(5): sess.run(next_element) diff --git a/tensorflow/contrib/distribute/python/step_fn_test.py b/tensorflow/contrib/distribute/python/step_fn_test.py index 8605ab1f7d..f1ada49fa3 100644 --- a/tensorflow/contrib/distribute/python/step_fn_test.py +++ b/tensorflow/contrib/distribute/python/step_fn_test.py @@ -49,7 +49,7 @@ class SingleLossStepTest(test.TestCase, parameterized.TestCase): if context.executing_eagerly(): run_step = single_loss_step else: - with self.test_session() as sess: + with self.cached_session() as sess: run_step = sess.make_callable(single_loss_step()) self.evaluate(variables.global_variables_initializer()) diff --git a/tensorflow/contrib/distribute/python/strategy_test_lib.py b/tensorflow/contrib/distribute/python/strategy_test_lib.py index 371b97ba96..6ee26e19ac 100644 --- a/tensorflow/contrib/distribute/python/strategy_test_lib.py +++ b/tensorflow/contrib/distribute/python/strategy_test_lib.py @@ -130,7 +130,8 @@ class DistributionTestBase(test.TestCase): # Error should go down self.assertLess(error_after, error_before) - def _test_minimize_loss_graph(self, d, soft_placement=False): + def _test_minimize_loss_graph(self, d, soft_placement=False, + learning_rate=0.2): config = config_pb2.ConfigProto() config.allow_soft_placement = soft_placement config.gpu_options.per_process_gpu_memory_fraction = 0.3 @@ -150,7 +151,7 @@ class DistributionTestBase(test.TestCase): grad_fn = backprop.implicit_grad(loss) def update(v, g): - return v.assign_sub(0.2 * g) + return v.assign_sub(learning_rate * g) one = d.broadcast(constant_op.constant([[1.]])) diff --git a/tensorflow/contrib/distribute/python/tpu_strategy.py b/tensorflow/contrib/distribute/python/tpu_strategy.py index 77fc56de36..6202a0750a 100644 --- a/tensorflow/contrib/distribute/python/tpu_strategy.py +++ b/tensorflow/contrib/distribute/python/tpu_strategy.py @@ -51,7 +51,7 @@ def get_tpu_system_metadata(tpu_cluster_resolver): tpu_system_metadata_lib._query_tpu_system_metadata( master, cluster_def=cluster_def, - query_topology=True)) + query_topology=False)) return tpu_system_metadata @@ -59,7 +59,7 @@ def get_tpu_system_metadata(tpu_cluster_resolver): class TPUStrategy(one_device_strategy.OneDeviceStrategy): """Experimental TPU distribution strategy implementation.""" - def __init__(self, tpu_cluster_resolver, steps_per_run): + def __init__(self, tpu_cluster_resolver, steps_per_run, num_cores=None): """Initializes the TPUStrategy object. Args: @@ -70,6 +70,8 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): metrics, summaries etc. This parameter is only used when Distribution Strategy is used with estimator or keras. + num_cores: Number of cores to use on the TPU. If None specified, then + auto-detect the cores and topology of the TPU system. """ # TODO(isaprykin): Generalize the defaults. They are currently tailored for # the unit test. @@ -77,13 +79,15 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): self._tpu_cluster_resolver = tpu_cluster_resolver self._tpu_metadata = get_tpu_system_metadata(self._tpu_cluster_resolver) + self._num_cores_override = num_cores - # TODO(priyag): This should not be hardcoded here. - self._host = '/device:CPU:0' # TODO(sourabhbajaj): Remove this once performance of running one step # at a time is comparable to multiple steps. self.steps_per_run = steps_per_run + # TODO(frankchn): This should not be hardcoded here for pod purposes. + self._host = self.tpu_host_cpu_device(0) + def distribute_dataset(self, dataset_fn): # TODO(priyag): Perhaps distribute across cores here. return self._call_dataset_fn(dataset_fn) @@ -106,6 +110,7 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): """Enqueue ops for one iteration.""" control_deps = [] sharded_inputs = [] + # TODO(sourabhbajaj): Add support for TPU pods with ops.device(self._host): for _ in range(self.num_towers): # Use control dependencies to ensure a deterministic ordering. @@ -258,4 +263,10 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): @property def num_towers(self): - return self._tpu_metadata.num_of_cores_per_host + return self._num_cores_override or self._tpu_metadata.num_cores + + def tpu_host_cpu_device(self, host_id): + if self._tpu_cluster_resolver.get_master() in ('', 'local'): + return '/replica:0/task:0/device:CPU:0' + return '/job:%s/task:%d/device:CPU:0' % ('tpu_worker', host_id) + diff --git a/tensorflow/contrib/distribute/python/values.py b/tensorflow/contrib/distribute/python/values.py index 8548a86421..3ccaa2690e 100644 --- a/tensorflow/contrib/distribute/python/values.py +++ b/tensorflow/contrib/distribute/python/values.py @@ -183,6 +183,14 @@ class Mirrored(DistributedDelegate): return self._index[device] return list(self._index.values())[0] + def _as_graph_element(self): + obj = self.get() + # pylint: disable=protected-access + conv_fn = getattr(obj, "_as_graph_element", None) + if conv_fn and callable(conv_fn): + return conv_fn() + return obj + def _assign_on_device(device, variable, tensor): with ops.device(device): @@ -296,6 +304,10 @@ class DistributedVariable(DistributedDelegate): self._primary_var.op.type) return self.get().op + @property + def _in_graph_mode(self): + return self._primary_var._in_graph_mode # pylint: disable=protected-access + def read_value(self): return distribution_strategy_context.get_distribution_strategy().read_var( self) @@ -308,26 +320,6 @@ class DistributedVariable(DistributedDelegate): ops.register_dense_tensor_like_type(DistributedVariable) -def _get_update_device(): - """Validate we are in update/update_non_slot() and return current device. - - This is used in MirroredVariable.assign* members, to make sure they - are only called via an update method, to make sure all components of the - variable are being updated in a consistent way. - - Returns: - A string device. - - Raises: - RuntimeError: If not in distribution.update()/.update_non_slot(). - """ - device = distribute_lib.get_update_device() - if device is None: - raise RuntimeError( - "Use DistributionStrategy.update() to modify a MirroredVariable.") - return device - - class _MirroredSaveable(saver.BaseSaverBuilder.ResourceVariableSaveable): """Class for defining how to restore a MirroredVariable.""" @@ -366,15 +358,27 @@ class MirroredVariable(DistributedVariable, Mirrored, f = kwargs.pop("f") if distribution_strategy_context.get_cross_tower_context(): update_device = distribute_lib.get_update_device() - # We are calling update on the mirrored variable in cross tower context. if update_device is not None: - # We are calling an assign function on the mirrored variable in cross - # tower context. + # We are calling an assign function on the mirrored variable in an + # update context. v = self.get(device=update_device) return f(v, *args, **kwargs) - return distribution_strategy_context.get_distribution_strategy().update( - self, f, *args, **kwargs) + # We are calling assign on the mirrored variable in cross tower context, + # use update to update the variable. + strategy = distribution_strategy_context.get_distribution_strategy() + updates = strategy.update(self, f, *args, **kwargs) + grouped = strategy.group(updates) + if isinstance(updates, DistributedValues) and updates.is_tensor_like: + # Make sure we run all updates. Without this, something like + # session.run(mirrored_var.assign*(...)) may only update one tower. + index = {} + for d in updates.devices: + with ops.device(d), ops.control_dependencies([grouped]): + index[d] = array_ops.identity(updates.get(d)) + return Mirrored(index) + else: + return grouped else: _assert_tower_context() # We are calling an assign function on the mirrored variable in tower @@ -1057,3 +1061,160 @@ def value_container(val): if container is not None: return container return val + + +# TODO(josh11b): Descend from Variable. +class AggregatingVariable(checkpointable.CheckpointableBase): + """A wrapper around a variable that aggregates updates across towers.""" + + def __init__(self, v, aggregation): + self._v = v + # TODO(josh11b): Set v._distributed_container? + # v._distributed_container = weakref.ref(self) # pylint: disable=protected-access + self._aggregation = aggregation + + def get(self): + return self._v + + def __getattr__(self, name): + return getattr(self._v, name) + + def _assign_func(self, *args, **kwargs): + f = kwargs.pop("f") + if distribution_strategy_context.get_cross_tower_context(): + update_device = distribute_lib.get_update_device() + if update_device is not None: + # We are calling an assign function in an update context. + return f(self._v, *args, **kwargs) + + # We are calling an assign function in cross tower context, wrap it in an + # update call. + return distribution_strategy_context.get_distribution_strategy().update( + self, f, *args, **kwargs) + else: + assert distribution_strategy_context.get_tower_context() + # We are calling an assign function in tower context. + # We reduce the value we want to assign/add/sub. More details about how we + # handle the different use cases can be found in the _reduce method. + # We call the function with the reduced value. + if self._aggregation == vs.VariableAggregation.NONE: + raise ValueError("You must specify an aggregation method to update a " + "a variable in Tower Context.") + + def merge_fn(strategy, value, *other_args, **other_kwargs): + return strategy.update( + self, f, + strategy.reduce( + aggregation=self._aggregation, value=value, destinations=self), + *other_args, **other_kwargs) + + return distribution_strategy_context.get_tower_context().merge_call( + merge_fn, *args, **kwargs) + + def assign_sub(self, *args, **kwargs): + assign_sub_fn = lambda var, *a, **kw: var.assign_sub(*a, **kw) + return self._assign_func(f=assign_sub_fn, *args, **kwargs) + + def assign_add(self, *args, **kwargs): + assign_add_fn = lambda var, *a, **kw: var.assign_add(*a, **kw) + return self._assign_func(f=assign_add_fn, *args, **kwargs) + + def assign(self, *args, **kwargs): + assign_fn = lambda var, *a, **kw: var.assign(*a, **kw) + return self._assign_func(f=assign_fn, *args, **kwargs) + + @property + def aggregation(self): + return self._aggregation + + @property + def name(self): + return self._v.name + + @property + def dtype(self): + return self._v.dtype + + # TODO(josh11b): Test saving & restoring. + def _gather_saveables_for_checkpoint(self): + return {checkpointable.VARIABLE_VALUE_KEY: self._v} + + # pylint: disable=multiple-statements + def __add__(self, o): return self._v + o + def __radd__(self, o): return o + self._v + def __sub__(self, o): return self._v - o + def __rsub__(self, o): return o - self._v + def __mul__(self, o): return self._v * o + def __rmul__(self, o): return o * self._v + def __truediv__(self, o): return self._v / o + def __rtruediv__(self, o): return o / self._v + def __floordiv__(self, o): return self._v // o + def __rfloordiv__(self, o): return o // self._v + def __mod__(self, o): return self._v % o + def __rmod__(self, o): return o % self._v + def __lt__(self, o): return self._v < o + def __le__(self, o): return self._v <= o + def __gt__(self, o): return self._v > o + def __ge__(self, o): return self._v >= o + def __and__(self, o): return self._v & o + def __rand__(self, o): return o & self._v + def __or__(self, o): return self._v | o + def __ror__(self, o): return o | self._v + def __xor__(self, o): return self._v ^ o + def __rxor__(self, o): return o ^ self._v + def __getitem__(self, o): return self._v[o] + def __pow__(self, o, modulo=None): return pow(self._v, o, modulo) + def __rpow__(self, o): return pow(o, self._v) + def __invert__(self): return ~self._v + def __neg__(self): return -self._v + def __abs__(self): return abs(self._v) + + def __div__(self, o): + try: + return self._v.__div__(o) + except AttributeError: + # See https://docs.python.org/3/library/constants.html#NotImplemented + return NotImplemented + + def __rdiv__(self, o): + try: + return self._v.__rdiv__(o) + except AttributeError: + # See https://docs.python.org/3/library/constants.html#NotImplemented + return NotImplemented + + def __matmul__(self, o): + try: + return self._v.__matmul__(o) + except AttributeError: + # See https://docs.python.org/3/library/constants.html#NotImplemented + return NotImplemented + + def __rmatmul__(self, o): + try: + return self._v.__rmatmul__(o) + except AttributeError: + # See https://docs.python.org/3/library/constants.html#NotImplemented + return NotImplemented + + def __str__(self): + return str(self._v) + + def __repr__(self): + return repr(self._v) + + def _should_act_as_resource_variable(self): + """Pass resource_variable_ops.is_resource_variable check.""" + pass + + +# Register a conversion function which reads the value of the variable, +# allowing instances of the class to be used as tensors. +def _tensor_conversion_aggregate(var, dtype=None, name=None, as_ref=False): + return ops.internal_convert_to_tensor( + var.get(), dtype=dtype, name=name, as_ref=as_ref) + + +ops.register_tensor_conversion_function( + AggregatingVariable, _tensor_conversion_aggregate) +ops.register_dense_tensor_like_type(AggregatingVariable) diff --git a/tensorflow/contrib/distribute/python/values_test.py b/tensorflow/contrib/distribute/python/values_test.py index 91a43d4999..3602f4d128 100644 --- a/tensorflow/contrib/distribute/python/values_test.py +++ b/tensorflow/contrib/distribute/python/values_test.py @@ -653,7 +653,7 @@ class MirroredVariableTest(test.TestCase): def _save_mirrored(self): """Save variables with mirroring, returns save_path.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v, devices, mirrored = _make_mirrored() # Overwrite the initial values. @@ -668,7 +668,7 @@ class MirroredVariableTest(test.TestCase): def _save_normal(self): """Save variables without mirroring, returns save_path.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: var = variable_scope.get_variable( name="v", initializer=1., use_resource=True) @@ -684,7 +684,7 @@ class MirroredVariableTest(test.TestCase): def _restore_normal(self, save_path): """Restore to variables without mirroring in a fresh graph.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: var = variable_scope.get_variable( name="v", initializer=7., use_resource=True) @@ -698,7 +698,7 @@ class MirroredVariableTest(test.TestCase): def _restore_mirrored(self, save_path): """Restore to variables with mirroring in a fresh graph.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v, devices, mirrored = _make_mirrored() # Overwrite the initial values. @@ -864,7 +864,7 @@ class TowerLocalVariableTest(test.TestCase): def _save_tower_local_mean(self): """Save variables with mirroring, returns save_path.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v, tower_local = _make_tower_local( variable_scope.VariableAggregation.MEAN) @@ -881,7 +881,7 @@ class TowerLocalVariableTest(test.TestCase): def _save_tower_local_sum(self): """Save variables with mirroring, returns save_path.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v, tower_local = _make_tower_local("sum") # Overwrite the initial values. @@ -897,7 +897,7 @@ class TowerLocalVariableTest(test.TestCase): def _save_normal(self): """Save variables without mirroring, returns save_path.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: var = variable_scope.get_variable( name="v", initializer=1., use_resource=True) @@ -913,7 +913,7 @@ class TowerLocalVariableTest(test.TestCase): def _restore_normal(self, save_path): """Restore to variables without mirroring in a fresh graph.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: var = variable_scope.get_variable( name="v", initializer=7., use_resource=True) @@ -927,7 +927,7 @@ class TowerLocalVariableTest(test.TestCase): def _restore_tower_local_mean(self, save_path): """Restore to variables with mirroring in a fresh graph.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v, tower_local = _make_tower_local( variable_scope.VariableAggregation.MEAN) @@ -942,7 +942,7 @@ class TowerLocalVariableTest(test.TestCase): def _restore_tower_local_sum(self, save_path): """Restore to variables with mirroring in a fresh graph.""" - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v, tower_local = _make_tower_local(variable_scope.VariableAggregation.SUM) # Overwrite the initial values. diff --git a/tensorflow/contrib/distribute/python/warm_starting_util_test.py b/tensorflow/contrib/distribute/python/warm_starting_util_test.py index d8bacdb338..5d57d144c1 100644 --- a/tensorflow/contrib/distribute/python/warm_starting_util_test.py +++ b/tensorflow/contrib/distribute/python/warm_starting_util_test.py @@ -56,7 +56,7 @@ class WarmStartingUtilWithDistributionStrategyTest( # Create variable and save checkpoint from which to warm-start. def create_var(g): - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: var = variable_scope.get_variable(var_name, initializer=original_value) sess.run(variables.global_variables_initializer()) saver = saver_lib.Saver() @@ -75,7 +75,7 @@ class WarmStartingUtilWithDistributionStrategyTest( self.assertAllEqual(original_value, prev_init_val) def warm_start(g): - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Initialize with zeros. var = variable_scope.get_variable( var_name, initializer=[[0., 0.], [0., 0.]]) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/autoregressive_test.py b/tensorflow/contrib/distributions/python/kernel_tests/autoregressive_test.py index 0928dc3f35..a22d4d825b 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/autoregressive_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/autoregressive_test.py @@ -53,7 +53,7 @@ class AutogressiveTest(test_util.VectorDistributionTestHelpers, test.TestCase): def testSampleAndLogProbConsistency(self): batch_shape = [] event_size = 2 - with self.test_session() as sess: + with self.cached_session() as sess: batch_event_shape = np.concatenate([batch_shape, [event_size]], axis=0) sample0 = array_ops.zeros(batch_event_shape) affine = Affine(scale_tril=self._random_scale_tril(event_size)) @@ -67,7 +67,7 @@ class AutogressiveTest(test_util.VectorDistributionTestHelpers, test.TestCase): sample_shape = np.int32([4, 5]) batch_shape = np.int32([]) event_size = np.int32(2) - with self.test_session() as sess: + with self.cached_session() as sess: batch_event_shape = np.concatenate([batch_shape, [event_size]], axis=0) sample0 = array_ops.zeros(batch_event_shape) affine = Affine(scale_tril=self._random_scale_tril(event_size)) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/batch_reshape_test.py b/tensorflow/contrib/distributions/python/kernel_tests/batch_reshape_test.py index f2bb2d3325..62623deccd 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/batch_reshape_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/batch_reshape_test.py @@ -76,7 +76,7 @@ class _BatchReshapeTest(object): wishart.log_prob(x), expected_log_prob_shape) actual_log_prob = reshape_wishart.log_prob(expected_sample) - with self.test_session() as sess: + with self.cached_session() as sess: [ batch_shape_, event_shape_, @@ -132,7 +132,7 @@ class _BatchReshapeTest(object): wishart.variance(), expected_matrix_stat_shape) actual_variance = reshape_wishart.variance() - with self.test_session() as sess: + with self.cached_session() as sess: [ expected_entropy_, actual_entropy_, expected_mean_, actual_mean_, @@ -202,7 +202,7 @@ class _BatchReshapeTest(object): normal.log_prob(x), expected_log_prob_shape) actual_log_prob = reshape_normal.log_prob(expected_sample) - with self.test_session() as sess: + with self.cached_session() as sess: [ batch_shape_, event_shape_, @@ -255,7 +255,7 @@ class _BatchReshapeTest(object): normal.variance(), expected_scalar_stat_shape) actual_variance = reshape_normal.variance() - with self.test_session() as sess: + with self.cached_session() as sess: [ expected_entropy_, actual_entropy_, expected_mean_, actual_mean_, @@ -323,7 +323,7 @@ class _BatchReshapeTest(object): mvn.log_prob(x), expected_log_prob_shape) actual_log_prob = reshape_mvn.log_prob(expected_sample) - with self.test_session() as sess: + with self.cached_session() as sess: [ batch_shape_, event_shape_, @@ -385,7 +385,7 @@ class _BatchReshapeTest(object): mvn.covariance(), expected_matrix_stat_shape) actual_covariance = reshape_mvn.covariance() - with self.test_session() as sess: + with self.cached_session() as sess: [ expected_entropy_, actual_entropy_, expected_mean_, actual_mean_, @@ -447,7 +447,7 @@ class _BatchReshapeTest(object): validate_args=True) else: - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError(r"Shape sizes do not match."): batch_reshape_lib.BatchReshape( distribution=mvn, @@ -482,7 +482,7 @@ class _BatchReshapeTest(object): validate_args=True) else: - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError(r".*must be >=-1.*"): batch_reshape_lib.BatchReshape( distribution=mvn, @@ -512,7 +512,7 @@ class _BatchReshapeTest(object): validate_args=True) else: - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError(r".*must be a vector.*"): batch_reshape_lib.BatchReshape( distribution=mvn, @@ -548,11 +548,11 @@ class _BatchReshapeTest(object): return with self.assertRaisesOpError("too few batch and event dims"): - with self.test_session(): + with self.cached_session(): poisson_141_reshaped.log_prob(x_4).eval() with self.assertRaisesOpError("unexpected batch and event shape"): - with self.test_session(): + with self.cached_session(): poisson_141_reshaped.log_prob(x_114).eval() diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/absolute_value_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/absolute_value_test.py index 042c8ebd51..372b7e37b7 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/absolute_value_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/absolute_value_test.py @@ -31,7 +31,7 @@ class AbsoluteValueTest(test.TestCase): """Tests correctness of the absolute value bijector.""" def testBijectorVersusNumpyRewriteOfBasicFunctionsEventNdims0(self): - with self.test_session() as sess: + with self.cached_session() as sess: bijector = AbsoluteValue(validate_args=True) self.assertEqual("absolute_value", bijector.name) x = array_ops.constant([[0., 1., -1], [0., -5., 3.]]) # Shape [2, 3] @@ -54,13 +54,13 @@ class AbsoluteValueTest(test.TestCase): y, event_ndims=0))) def testNegativeYRaisesForInverseIfValidateArgs(self): - with self.test_session() as sess: + with self.cached_session() as sess: bijector = AbsoluteValue(validate_args=True) with self.assertRaisesOpError("y was negative"): sess.run(bijector.inverse(-1.)) def testNegativeYRaisesForILDJIfValidateArgs(self): - with self.test_session() as sess: + with self.cached_session() as sess: bijector = AbsoluteValue(validate_args=True) with self.assertRaisesOpError("y was negative"): sess.run(bijector.inverse_log_det_jacobian(-1., event_ndims=0)) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_linear_operator_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_linear_operator_test.py index 1e4ad724d0..a7bd51430e 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_linear_operator_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_linear_operator_test.py @@ -28,7 +28,7 @@ from tensorflow.python.platform import test class AffineLinearOperatorTest(test.TestCase): def testIdentity(self): - with self.test_session(): + with self.cached_session(): affine = AffineLinearOperator( validate_args=True) x = np.array([[1, 0, -1], [2, 3, 4]], dtype=np.float32) @@ -45,7 +45,7 @@ class AffineLinearOperatorTest(test.TestCase): affine.forward_log_det_jacobian(x, event_ndims=2).eval()) def testDiag(self): - with self.test_session(): + with self.cached_session(): shift = np.array([-1, 0, 1], dtype=np.float32) diag = np.array([[1, 2, 3], [2, 5, 6]], dtype=np.float32) @@ -67,7 +67,7 @@ class AffineLinearOperatorTest(test.TestCase): affine.forward_log_det_jacobian(x, event_ndims=1).eval()) def testTriL(self): - with self.test_session(): + with self.cached_session(): shift = np.array([-1, 0, 1], dtype=np.float32) tril = np.array([[[3, 0, 0], [2, -1, 0], diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_scalar_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_scalar_test.py index d2533620be..bc6752a69d 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_scalar_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_scalar_test.py @@ -31,14 +31,14 @@ class AffineScalarBijectorTest(test.TestCase): """Tests correctness of the Y = scale @ x + shift transformation.""" def testProperties(self): - with self.test_session(): + with self.cached_session(): mu = -1. # scale corresponds to 1. bijector = AffineScalar(shift=mu) self.assertEqual("affine_scalar", bijector.name) def testNoBatchScalar(self): - with self.test_session() as sess: + with self.cached_session() as sess: def static_run(fun, x, **kwargs): return fun(x, **kwargs).eval() @@ -60,7 +60,7 @@ class AffineScalarBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=0)) def testOneBatchScalarViaIdentityIn64BitUserProvidesShiftOnly(self): - with self.test_session() as sess: + with self.cached_session() as sess: def static_run(fun, x, **kwargs): return fun(x, **kwargs).eval() @@ -83,7 +83,7 @@ class AffineScalarBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=0)) def testOneBatchScalarViaIdentityIn64BitUserProvidesScaleOnly(self): - with self.test_session() as sess: + with self.cached_session() as sess: def static_run(fun, x, **kwargs): return fun(x, **kwargs).eval() @@ -106,7 +106,7 @@ class AffineScalarBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=0)) def testTwoBatchScalarIdentityViaIdentity(self): - with self.test_session() as sess: + with self.cached_session() as sess: def static_run(fun, x, **kwargs): return fun(x, **kwargs).eval() @@ -129,7 +129,7 @@ class AffineScalarBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=0)) def testTwoBatchScalarIdentityViaScale(self): - with self.test_session() as sess: + with self.cached_session() as sess: def static_run(fun, x, **kwargs): return fun(x, **kwargs).eval() @@ -152,7 +152,7 @@ class AffineScalarBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=0)) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): bijector = AffineScalar(shift=3.6, scale=0.42) assert_scalar_congruency(bijector, lower_x=-2., upper_x=2.) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_test.py index 9e14b9a53e..dc18eb3df6 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/affine_test.py @@ -32,14 +32,14 @@ class AffineBijectorTest(test.TestCase): """Tests correctness of the Y = scale @ x + shift transformation.""" def testProperties(self): - with self.test_session(): + with self.cached_session(): mu = -1. # scale corresponds to 1. bijector = Affine(shift=mu) self.assertEqual("affine", bijector.name) def testNoBatchMultivariateIdentity(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -71,7 +71,7 @@ class AffineBijectorTest(test.TestCase): 0., run(bijector.inverse_log_det_jacobian, x, event_ndims=1)) def testNoBatchMultivariateDiag(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -114,7 +114,7 @@ class AffineBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=1)) def testNoBatchMultivariateFullDynamic(self): - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(dtypes.float32, name="x") mu = array_ops.placeholder(dtypes.float32, name="mu") scale_diag = array_ops.placeholder(dtypes.float32, name="scale_diag") @@ -137,7 +137,7 @@ class AffineBijectorTest(test.TestCase): feed_dict)) def testBatchMultivariateIdentity(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -161,7 +161,7 @@ class AffineBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=1)) def testBatchMultivariateDiag(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -185,7 +185,7 @@ class AffineBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=1)) def testBatchMultivariateFullDynamic(self): - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(dtypes.float32, name="x") mu = array_ops.placeholder(dtypes.float32, name="mu") scale_diag = array_ops.placeholder(dtypes.float32, name="scale_diag") @@ -209,7 +209,7 @@ class AffineBijectorTest(test.TestCase): x, event_ndims=1), feed_dict)) def testIdentityWithDiagUpdate(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -235,7 +235,7 @@ class AffineBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=1)) def testIdentityWithTriL(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -261,7 +261,7 @@ class AffineBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=1)) def testDiagWithTriL(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -285,7 +285,7 @@ class AffineBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=1)) def testIdentityAndDiagWithTriL(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -312,7 +312,7 @@ class AffineBijectorTest(test.TestCase): run(bijector.inverse_log_det_jacobian, x, event_ndims=1)) def testIdentityWithVDVTUpdate(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -349,7 +349,7 @@ class AffineBijectorTest(test.TestCase): run(bijector_ref.inverse_log_det_jacobian, x, event_ndims=1)) def testDiagWithVDVTUpdate(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -385,7 +385,7 @@ class AffineBijectorTest(test.TestCase): run(bijector_ref.inverse_log_det_jacobian, x, event_ndims=1)) def testTriLWithVDVTUpdate(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -422,7 +422,7 @@ class AffineBijectorTest(test.TestCase): run(bijector_ref.inverse_log_det_jacobian, x, event_ndims=1)) def testTriLWithVDVTUpdateNoDiagonal(self): - with self.test_session() as sess: + with self.cached_session() as sess: placeholder = array_ops.placeholder(dtypes.float32, name="x") def static_run(fun, x, **kwargs): @@ -459,7 +459,7 @@ class AffineBijectorTest(test.TestCase): run(bijector_ref.inverse_log_det_jacobian, x, event_ndims=1)) def testNoBatchMultivariateRaisesWhenSingular(self): - with self.test_session(): + with self.cached_session(): mu = [1., -1] bijector = Affine( shift=mu, @@ -531,7 +531,7 @@ class AffineBijectorTest(test.TestCase): itertools.combinations(s, r) for r in range(len(s) + 1)) for args in _powerset(scale_params.items()): - with self.test_session(): + with self.cached_session(): args = dict(args) scale_args = dict({"x": x}, **args) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/batch_normalization_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/batch_normalization_test.py index c832fcaa68..bf61e9f2fe 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/batch_normalization_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/batch_normalization_test.py @@ -69,7 +69,7 @@ class BatchNormTest(test_util.VectorDistributionTestHelpers, ] for input_shape, event_dims, training in params: x_ = np.arange(5 * 4 * 2).astype(np.float32).reshape(input_shape) - with self.test_session() as sess: + with self.cached_session() as sess: x = constant_op.constant(x_) # When training, memorize the exact mean of the last # minibatch that it normalized (instead of moving average assignment). @@ -145,7 +145,7 @@ class BatchNormTest(test_util.VectorDistributionTestHelpers, def testMaximumLikelihoodTraining(self): # Test Maximum Likelihood training with default bijector. - with self.test_session() as sess: + with self.cached_session() as sess: base_dist = distributions.MultivariateNormalDiag(loc=[0., 0.]) batch_norm = BatchNormalization(training=True) dist = transformed_distribution_lib.TransformedDistribution( @@ -176,7 +176,7 @@ class BatchNormTest(test_util.VectorDistributionTestHelpers, self.assertAllClose([1., 1.], moving_var_, atol=5e-2) def testLogProb(self): - with self.test_session() as sess: + with self.cached_session() as sess: layer = normalization.BatchNormalization(epsilon=0.) batch_norm = BatchNormalization(batchnorm_layer=layer, training=False) base_dist = distributions.MultivariateNormalDiag(loc=[0., 0.]) @@ -196,7 +196,7 @@ class BatchNormTest(test_util.VectorDistributionTestHelpers, def testMutuallyConsistent(self): # BatchNorm bijector is only mutually consistent when training=False. dims = 4 - with self.test_session() as sess: + with self.cached_session() as sess: layer = normalization.BatchNormalization(epsilon=0.) batch_norm = BatchNormalization(batchnorm_layer=layer, training=False) dist = transformed_distribution_lib.TransformedDistribution( @@ -215,7 +215,7 @@ class BatchNormTest(test_util.VectorDistributionTestHelpers, def testInvertMutuallyConsistent(self): # BatchNorm bijector is only mutually consistent when training=False. dims = 4 - with self.test_session() as sess: + with self.cached_session() as sess: layer = normalization.BatchNormalization(epsilon=0.) batch_norm = Invert( BatchNormalization(batchnorm_layer=layer, training=False)) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/chain_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/chain_test.py index dc45114b1c..ada99ec9c6 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/chain_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/chain_test.py @@ -46,7 +46,7 @@ class ChainBijectorTest(test.TestCase): """Tests the correctness of the Y = Chain(bij1, bij2, bij3) transformation.""" def testBijector(self): - with self.test_session(): + with self.cached_session(): chain = Chain((Exp(), Softplus())) self.assertEqual("chain_of_exp_of_softplus", chain.name) x = np.asarray([[[1., 2.], @@ -61,7 +61,7 @@ class ChainBijectorTest(test.TestCase): chain.forward_log_det_jacobian(x, event_ndims=1).eval()) def testBijectorIdentity(self): - with self.test_session(): + with self.cached_session(): chain = Chain() self.assertEqual("identity", chain.name) x = np.asarray([[[1., 2.], @@ -74,13 +74,13 @@ class ChainBijectorTest(test.TestCase): 0., chain.forward_log_det_jacobian(x, event_ndims=1).eval()) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): chain = Chain((Exp(), Softplus())) assert_scalar_congruency( chain, lower_x=1e-3, upper_x=1.5, rtol=0.05) def testShapeGetters(self): - with self.test_session(): + with self.cached_session(): chain = Chain([ SoftmaxCentered(validate_args=True), SoftmaxCentered(validate_args=True), @@ -195,7 +195,7 @@ class ChainBijectorTest(test.TestCase): dtype=np.float32, shape=[None, 10], name="samples") ildj = chain.inverse_log_det_jacobian(samples, event_ndims=0) self.assertTrue(ildj is not None) - with self.test_session(): + with self.cached_session(): ildj.eval({samples: np.zeros([2, 10], np.float32)}) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/cholesky_outer_product_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/cholesky_outer_product_test.py index d1ce273499..9681b64ced 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/cholesky_outer_product_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/cholesky_outer_product_test.py @@ -30,7 +30,7 @@ class CholeskyOuterProductBijectorTest(test.TestCase): """Tests the correctness of the Y = X @ X.T transformation.""" def testBijectorMatrix(self): - with self.test_session(): + with self.cached_session(): bijector = bijectors.CholeskyOuterProduct(validate_args=True) self.assertEqual("cholesky_outer_product", bijector.name) x = [[[1., 0], [2, 1]], [[np.sqrt(2.), 0], [np.sqrt(8.), 1]]] @@ -75,7 +75,7 @@ class CholeskyOuterProductBijectorTest(test.TestCase): bijector = bijectors.CholeskyOuterProduct() x_pl = array_ops.placeholder(dtypes.float32) - with self.test_session(): + with self.cached_session(): log_det_jacobian = bijector.forward_log_det_jacobian(x_pl, event_ndims=2) # The Jacobian matrix is 2 * tf.eye(2), which has jacobian determinant 4. @@ -86,7 +86,7 @@ class CholeskyOuterProductBijectorTest(test.TestCase): def testNoBatchStatic(self): x = np.array([[1., 0], [2, 1]]) # np.linalg.cholesky(y) y = np.array([[1., 2], [2, 5]]) # np.matmul(x, x.T) - with self.test_session() as sess: + with self.cached_session() as sess: y_actual = bijectors.CholeskyOuterProduct().forward(x=x) x_actual = bijectors.CholeskyOuterProduct().inverse(y=y) [y_actual_, x_actual_] = sess.run([y_actual, x_actual]) @@ -98,7 +98,7 @@ class CholeskyOuterProductBijectorTest(test.TestCase): def testNoBatchDeferred(self): x = np.array([[1., 0], [2, 1]]) # np.linalg.cholesky(y) y = np.array([[1., 2], [2, 5]]) # np.matmul(x, x.T) - with self.test_session() as sess: + with self.cached_session() as sess: x_pl = array_ops.placeholder(dtypes.float32) y_pl = array_ops.placeholder(dtypes.float32) y_actual = bijectors.CholeskyOuterProduct().forward(x=x_pl) @@ -119,7 +119,7 @@ class CholeskyOuterProductBijectorTest(test.TestCase): [2, 5]], [[9., 3], [3, 5]]]) # np.matmul(x, x.T) - with self.test_session() as sess: + with self.cached_session() as sess: y_actual = bijectors.CholeskyOuterProduct().forward(x=x) x_actual = bijectors.CholeskyOuterProduct().inverse(y=y) [y_actual_, x_actual_] = sess.run([y_actual, x_actual]) @@ -137,7 +137,7 @@ class CholeskyOuterProductBijectorTest(test.TestCase): [2, 5]], [[9., 3], [3, 5]]]) # np.matmul(x, x.T) - with self.test_session() as sess: + with self.cached_session() as sess: x_pl = array_ops.placeholder(dtypes.float32) y_pl = array_ops.placeholder(dtypes.float32) y_actual = bijectors.CholeskyOuterProduct().forward(x=x_pl) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/exp_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/exp_test.py index 7be939cd27..d2c00865e7 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/exp_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/exp_test.py @@ -30,7 +30,7 @@ class ExpBijectorTest(test.TestCase): """Tests correctness of the Y = g(X) = exp(X) transformation.""" def testBijector(self): - with self.test_session(): + with self.cached_session(): bijector = Exp() self.assertEqual("exp", bijector.name) x = [[[1.], [2.]]] @@ -48,13 +48,13 @@ class ExpBijectorTest(test.TestCase): x, event_ndims=1).eval()) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): bijector = Exp() assert_scalar_congruency( bijector, lower_x=-2., upper_x=1.5, rtol=0.05) def testBijectiveAndFinite(self): - with self.test_session(): + with self.cached_session(): bijector = Exp() x = np.linspace(-10, 10, num=10).astype(np.float32) y = np.logspace(-10, 10, num=10).astype(np.float32) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/gumbel_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/gumbel_test.py index 54e54c3296..b9cdbfb823 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/gumbel_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/gumbel_test.py @@ -31,7 +31,7 @@ class GumbelBijectorTest(test.TestCase): """Tests correctness of the Gumbel bijector.""" def testBijector(self): - with self.test_session(): + with self.cached_session(): loc = 0.3 scale = 5. bijector = Gumbel(loc=loc, scale=scale, validate_args=True) @@ -52,12 +52,12 @@ class GumbelBijectorTest(test.TestCase): atol=0.) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): assert_scalar_congruency( Gumbel(loc=0.3, scale=20.), lower_x=1., upper_x=100., rtol=0.02) def testBijectiveAndFinite(self): - with self.test_session(): + with self.cached_session(): bijector = Gumbel(loc=0., scale=3.0, validate_args=True) x = np.linspace(-10., 10., num=10).astype(np.float32) y = np.linspace(0.01, 0.99, num=10).astype(np.float32) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/inline_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/inline_test.py index 7d3bd758cd..c9bccb36fc 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/inline_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/inline_test.py @@ -32,7 +32,7 @@ class InlineBijectorTest(test.TestCase): """Tests correctness of the inline constructed bijector.""" def testBijector(self): - with self.test_session(): + with self.cached_session(): exp = Exp() inline = Inline( forward_fn=math_ops.exp, @@ -55,7 +55,7 @@ class InlineBijectorTest(test.TestCase): inline.forward_log_det_jacobian(x, event_ndims=1).eval()) def testShapeGetters(self): - with self.test_session(): + with self.cached_session(): bijector = Inline( forward_event_shape_tensor_fn=lambda x: array_ops.concat((x, [1]), 0), forward_event_shape_fn=lambda x: x.as_list() + [1], diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/invert_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/invert_test.py index 8b14c8327f..7e3340aeb0 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/invert_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/invert_test.py @@ -31,7 +31,7 @@ class InvertBijectorTest(test.TestCase): """Tests the correctness of the Y = Invert(bij) transformation.""" def testBijector(self): - with self.test_session(): + with self.cached_session(): for fwd in [ bijectors.Identity(), bijectors.Exp(), @@ -53,13 +53,13 @@ class InvertBijectorTest(test.TestCase): rev.forward_log_det_jacobian(x, event_ndims=1).eval()) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): bijector = bijectors.Invert(bijectors.Exp()) assert_scalar_congruency( bijector, lower_x=1e-3, upper_x=1.5, rtol=0.05) def testShapeGetters(self): - with self.test_session(): + with self.cached_session(): bijector = bijectors.Invert(bijectors.SoftmaxCentered(validate_args=True)) x = tensor_shape.TensorShape([2]) y = tensor_shape.TensorShape([1]) @@ -73,7 +73,7 @@ class InvertBijectorTest(test.TestCase): bijector.inverse_event_shape_tensor(y.as_list()).eval()) def testDocstringExample(self): - with self.test_session(): + with self.cached_session(): exp_gamma_distribution = ( transformed_distribution_lib.TransformedDistribution( distribution=gamma_lib.Gamma(concentration=1., rate=2.), diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/kumaraswamy_bijector_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/kumaraswamy_bijector_test.py index a8089881f6..b3fb50005e 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/kumaraswamy_bijector_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/kumaraswamy_bijector_test.py @@ -30,7 +30,7 @@ class KumaraswamyBijectorTest(test.TestCase): """Tests correctness of the Kumaraswamy bijector.""" def testBijector(self): - with self.test_session(): + with self.cached_session(): a = 2. b = 0.3 bijector = Kumaraswamy( @@ -54,13 +54,13 @@ class KumaraswamyBijectorTest(test.TestCase): atol=0.) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): assert_scalar_congruency( Kumaraswamy(concentration1=0.5, concentration0=1.1), lower_x=0., upper_x=1., n=int(10e3), rtol=0.02) def testBijectiveAndFinite(self): - with self.test_session(): + with self.cached_session(): concentration1 = 1.2 concentration0 = 2. bijector = Kumaraswamy( diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/masked_autoregressive_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/masked_autoregressive_test.py index 5ba5a2083b..ad4329d425 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/masked_autoregressive_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/masked_autoregressive_test.py @@ -71,7 +71,7 @@ class MaskedAutoregressiveFlowTest(test_util.VectorDistributionTestHelpers, def testBijector(self): x_ = np.arange(3 * 4 * 2).astype(np.float32).reshape(3, 4, 2) - with self.test_session() as sess: + with self.cached_session() as sess: ma = MaskedAutoregressiveFlow( validate_args=True, **self._autoregressive_flow_kwargs) @@ -102,7 +102,7 @@ class MaskedAutoregressiveFlowTest(test_util.VectorDistributionTestHelpers, def testMutuallyConsistent(self): dims = 4 - with self.test_session() as sess: + with self.cached_session() as sess: ma = MaskedAutoregressiveFlow( validate_args=True, **self._autoregressive_flow_kwargs) @@ -121,7 +121,7 @@ class MaskedAutoregressiveFlowTest(test_util.VectorDistributionTestHelpers, def testInvertMutuallyConsistent(self): dims = 4 - with self.test_session() as sess: + with self.cached_session() as sess: ma = Invert(MaskedAutoregressiveFlow( validate_args=True, **self._autoregressive_flow_kwargs)) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/matrix_inverse_tril_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/matrix_inverse_tril_test.py index 49a9afe3f6..31ee36f024 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/matrix_inverse_tril_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/matrix_inverse_tril_test.py @@ -26,6 +26,7 @@ from tensorflow.python.framework import test_util from tensorflow.python.platform import test +@test_util.run_all_in_graph_and_eager_modes class MatrixInverseTriLBijectorTest(test.TestCase): """Tests the correctness of the Y = inv(tril) transformation.""" @@ -40,7 +41,6 @@ class MatrixInverseTriLBijectorTest(test.TestCase): y[idx][np.triu_indices(y[idx].shape[-1], 1)] = 0 return y - @test_util.run_in_graph_and_eager_modes def testComputesCorrectValues(self): inv = bijectors.MatrixInverseTriL(validate_args=True) self.assertEqual("matrix_inverse_tril", inv.name) @@ -62,7 +62,6 @@ class MatrixInverseTriLBijectorTest(test.TestCase): self.assertNear(expected_fldj_, fldj_, err=1e-3) self.assertNear(-expected_fldj_, ildj_, err=1e-3) - @test_util.run_in_graph_and_eager_modes def testOneByOneMatrix(self): inv = bijectors.MatrixInverseTriL(validate_args=True) x_ = np.array([[5.]], dtype=np.float32) @@ -81,7 +80,6 @@ class MatrixInverseTriLBijectorTest(test.TestCase): self.assertNear(expected_fldj_, fldj_, err=1e-3) self.assertNear(-expected_fldj_, ildj_, err=1e-3) - @test_util.run_in_graph_and_eager_modes def testZeroByZeroMatrix(self): inv = bijectors.MatrixInverseTriL(validate_args=True) x_ = np.eye(0, dtype=np.float32) @@ -100,7 +98,6 @@ class MatrixInverseTriLBijectorTest(test.TestCase): self.assertNear(expected_fldj_, fldj_, err=1e-3) self.assertNear(-expected_fldj_, ildj_, err=1e-3) - @test_util.run_in_graph_and_eager_modes def testBatch(self): # Test batch computation with input shape (2, 1, 2, 2), i.e. batch shape # (2, 1). @@ -125,20 +122,18 @@ class MatrixInverseTriLBijectorTest(test.TestCase): self.assertAllClose(expected_fldj_, fldj_, atol=0., rtol=1e-3) self.assertAllClose(-expected_fldj_, ildj_, atol=0., rtol=1e-3) - @test_util.run_in_graph_and_eager_modes def testErrorOnInputRankTooLow(self): inv = bijectors.MatrixInverseTriL(validate_args=True) x_ = np.array([0.1], dtype=np.float32) rank_error_msg = "must have rank at least 2" - with self.test_session(): - with self.assertRaisesWithPredicateMatch(ValueError, rank_error_msg): - inv.forward(x_).eval() - with self.assertRaisesWithPredicateMatch(ValueError, rank_error_msg): - inv.inverse(x_).eval() - with self.assertRaisesWithPredicateMatch(ValueError, rank_error_msg): - inv.forward_log_det_jacobian(x_, event_ndims=2).eval() - with self.assertRaisesWithPredicateMatch(ValueError, rank_error_msg): - inv.inverse_log_det_jacobian(x_, event_ndims=2).eval() + with self.assertRaisesWithPredicateMatch(ValueError, rank_error_msg): + self.evaluate(inv.forward(x_)) + with self.assertRaisesWithPredicateMatch(ValueError, rank_error_msg): + self.evaluate(inv.inverse(x_)) + with self.assertRaisesWithPredicateMatch(ValueError, rank_error_msg): + self.evaluate(inv.forward_log_det_jacobian(x_, event_ndims=2)) + with self.assertRaisesWithPredicateMatch(ValueError, rank_error_msg): + self.evaluate(inv.inverse_log_det_jacobian(x_, event_ndims=2)) # TODO(b/80481923): Figure out why these assertions fail, and fix them. ## def testErrorOnInputNonSquare(self): @@ -146,55 +141,50 @@ class MatrixInverseTriLBijectorTest(test.TestCase): ## x_ = np.array([[1., 2., 3.], ## [4., 5., 6.]], dtype=np.float32) ## square_error_msg = "must be a square matrix" - ## with self.test_session(): - ## with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, - ## square_error_msg): - ## inv.forward(x_).eval() - ## with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, - ## square_error_msg): - ## inv.inverse(x_).eval() - ## with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, - ## square_error_msg): - ## inv.forward_log_det_jacobian(x_, event_ndims=2).eval() - ## with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, - ## square_error_msg): - ## inv.inverse_log_det_jacobian(x_, event_ndims=2).eval() - - @test_util.run_in_graph_and_eager_modes + ## with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, + ## square_error_msg): + ## self.evaluate(inv.forward(x_)) + ## with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, + ## square_error_msg): + ## self.evaluate(inv.inverse(x_)) + ## with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, + ## square_error_msg): + ## self.evaluate(inv.forward_log_det_jacobian(x_, event_ndims=2)) + ## with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, + ## square_error_msg): + ## self.evaluate(inv.inverse_log_det_jacobian(x_, event_ndims=2)) + def testErrorOnInputNotLowerTriangular(self): inv = bijectors.MatrixInverseTriL(validate_args=True) x_ = np.array([[1., 2.], [3., 4.]], dtype=np.float32) triangular_error_msg = "must be lower triangular" - with self.test_session(): - with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, - triangular_error_msg): - inv.forward(x_).eval() - with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, - triangular_error_msg): - inv.inverse(x_).eval() - with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, - triangular_error_msg): - inv.forward_log_det_jacobian(x_, event_ndims=2).eval() - with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, - triangular_error_msg): - inv.inverse_log_det_jacobian(x_, event_ndims=2).eval() - - @test_util.run_in_graph_and_eager_modes + with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, + triangular_error_msg): + self.evaluate(inv.forward(x_)) + with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, + triangular_error_msg): + self.evaluate(inv.inverse(x_)) + with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, + triangular_error_msg): + self.evaluate(inv.forward_log_det_jacobian(x_, event_ndims=2)) + with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, + triangular_error_msg): + self.evaluate(inv.inverse_log_det_jacobian(x_, event_ndims=2)) + def testErrorOnInputSingular(self): inv = bijectors.MatrixInverseTriL(validate_args=True) x_ = np.array([[1., 0.], [0., 0.]], dtype=np.float32) nonsingular_error_msg = "must have all diagonal entries nonzero" - with self.test_session(): - with self.assertRaisesOpError(nonsingular_error_msg): - inv.forward(x_).eval() - with self.assertRaisesOpError(nonsingular_error_msg): - inv.inverse(x_).eval() - with self.assertRaisesOpError(nonsingular_error_msg): - inv.forward_log_det_jacobian(x_, event_ndims=2).eval() - with self.assertRaisesOpError(nonsingular_error_msg): - inv.inverse_log_det_jacobian(x_, event_ndims=2).eval() + with self.assertRaisesOpError(nonsingular_error_msg): + self.evaluate(inv.forward(x_)) + with self.assertRaisesOpError(nonsingular_error_msg): + self.evaluate(inv.inverse(x_)) + with self.assertRaisesOpError(nonsingular_error_msg): + self.evaluate(inv.forward_log_det_jacobian(x_, event_ndims=2)) + with self.assertRaisesOpError(nonsingular_error_msg): + self.evaluate(inv.inverse_log_det_jacobian(x_, event_ndims=2)) if __name__ == "__main__": diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/ordered_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/ordered_test.py index cb42331a21..9a88f8f1bc 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/ordered_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/ordered_test.py @@ -38,26 +38,25 @@ class OrderedBijectorTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testBijectorVector(self): - with self.test_session(): - ordered = Ordered() - self.assertEqual("ordered", ordered.name) - x = np.asarray([[2., 3, 4], [4., 8, 13]]) - y = [[2., 0, 0], [4., np.log(4.), np.log(5.)]] - self.assertAllClose(y, self.evaluate(ordered.forward(x))) - self.assertAllClose(x, self.evaluate(ordered.inverse(y))) - self.assertAllClose( - np.sum(np.asarray(y)[..., 1:], axis=-1), - self.evaluate(ordered.inverse_log_det_jacobian(y, event_ndims=1)), - atol=0., - rtol=1e-7) - self.assertAllClose( - self.evaluate(-ordered.inverse_log_det_jacobian(y, event_ndims=1)), - self.evaluate(ordered.forward_log_det_jacobian(x, event_ndims=1)), - atol=0., - rtol=1e-7) + ordered = Ordered() + self.assertEqual("ordered", ordered.name) + x = np.asarray([[2., 3, 4], [4., 8, 13]]) + y = [[2., 0, 0], [4., np.log(4.), np.log(5.)]] + self.assertAllClose(y, self.evaluate(ordered.forward(x))) + self.assertAllClose(x, self.evaluate(ordered.inverse(y))) + self.assertAllClose( + np.sum(np.asarray(y)[..., 1:], axis=-1), + self.evaluate(ordered.inverse_log_det_jacobian(y, event_ndims=1)), + atol=0., + rtol=1e-7) + self.assertAllClose( + self.evaluate(-ordered.inverse_log_det_jacobian(y, event_ndims=1)), + self.evaluate(ordered.forward_log_det_jacobian(x, event_ndims=1)), + atol=0., + rtol=1e-7) def testBijectorUnknownShape(self): - with self.test_session(): + with self.cached_session(): ordered = Ordered() self.assertEqual("ordered", ordered.name) x = array_ops.placeholder(shape=[2, None], dtype=dtypes.float32) @@ -84,21 +83,20 @@ class OrderedBijectorTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testShapeGetters(self): - with self.test_session(): - x = tensor_shape.TensorShape([4]) - y = tensor_shape.TensorShape([4]) - bijector = Ordered(validate_args=True) - self.assertAllEqual(y, bijector.forward_event_shape(x)) - self.assertAllEqual(y.as_list(), - self.evaluate(bijector.forward_event_shape_tensor( - x.as_list()))) - self.assertAllEqual(x, bijector.inverse_event_shape(y)) - self.assertAllEqual(x.as_list(), - self.evaluate(bijector.inverse_event_shape_tensor( - y.as_list()))) + x = tensor_shape.TensorShape([4]) + y = tensor_shape.TensorShape([4]) + bijector = Ordered(validate_args=True) + self.assertAllEqual(y, bijector.forward_event_shape(x)) + self.assertAllEqual(y.as_list(), + self.evaluate(bijector.forward_event_shape_tensor( + x.as_list()))) + self.assertAllEqual(x, bijector.inverse_event_shape(y)) + self.assertAllEqual(x.as_list(), + self.evaluate(bijector.inverse_event_shape_tensor( + y.as_list()))) def testBijectiveAndFinite(self): - with self.test_session(): + with self.cached_session(): ordered = Ordered() x = np.sort(self._rng.randn(3, 10), axis=-1).astype(np.float32) y = (self._rng.randn(3, 10)).astype(np.float32) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/permute_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/permute_test.py index 7eef4ab599..e2062ed55d 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/permute_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/permute_test.py @@ -38,7 +38,7 @@ class PermuteBijectorTest(test.TestCase): expected_x = np.random.randn(4, 2, 3) expected_y = expected_x[..., expected_permutation] - with self.test_session() as sess: + with self.cached_session() as sess: permutation_ph = array_ops.placeholder(dtype=dtypes.int32) bijector = Permute( permutation=permutation_ph, @@ -64,7 +64,7 @@ class PermuteBijectorTest(test.TestCase): self.assertAllClose(0., ildj, rtol=1e-6, atol=0) def testRaisesOpError(self): - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaisesOpError("Permutation over `d` must contain"): permutation_ph = array_ops.placeholder(dtype=dtypes.int32) bijector = Permute( @@ -77,7 +77,7 @@ class PermuteBijectorTest(test.TestCase): permutation = np.int32([2, 0, 1]) x = np.random.randn(4, 2, 3) y = x[..., permutation] - with self.test_session(): + with self.cached_session(): bijector = Permute(permutation=permutation, validate_args=True) assert_bijective_and_finite( bijector, x, y, event_ndims=1, rtol=1e-6, atol=0) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/power_transform_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/power_transform_test.py index 85d2283013..ef303ab664 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/power_transform_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/power_transform_test.py @@ -30,7 +30,7 @@ class PowerTransformBijectorTest(test.TestCase): """Tests correctness of the power transformation.""" def testBijector(self): - with self.test_session(): + with self.cached_session(): c = 0.2 bijector = PowerTransform(power=c, validate_args=True) self.assertEqual("power_transform", bijector.name) @@ -48,13 +48,13 @@ class PowerTransformBijectorTest(test.TestCase): atol=0.) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): bijector = PowerTransform(power=0.2, validate_args=True) assert_scalar_congruency( bijector, lower_x=-2., upper_x=1.5, rtol=0.05) def testBijectiveAndFinite(self): - with self.test_session(): + with self.cached_session(): bijector = PowerTransform(power=0.2, validate_args=True) x = np.linspace(-4.999, 10, num=10).astype(np.float32) y = np.logspace(0.001, 10, num=10).astype(np.float32) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/real_nvp_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/real_nvp_test.py index 2d52895fbe..b3b7b8535e 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/real_nvp_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/real_nvp_test.py @@ -43,7 +43,7 @@ class RealNVPTest(test_util.VectorDistributionTestHelpers, test.TestCase): def testBijector(self): x_ = np.arange(3 * 4 * 2).astype(np.float32).reshape(3, 4 * 2) - with self.test_session() as sess: + with self.cached_session() as sess: nvp = RealNVP( num_masked=4, validate_args=True, @@ -78,7 +78,7 @@ class RealNVPTest(test_util.VectorDistributionTestHelpers, test.TestCase): def testMutuallyConsistent(self): dims = 4 - with self.test_session() as sess: + with self.cached_session() as sess: nvp = RealNVP( num_masked=3, validate_args=True, @@ -98,7 +98,7 @@ class RealNVPTest(test_util.VectorDistributionTestHelpers, test.TestCase): def testInvertMutuallyConsistent(self): dims = 4 - with self.test_session() as sess: + with self.cached_session() as sess: nvp = Invert(RealNVP( num_masked=3, validate_args=True, diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/reshape_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/reshape_test.py index d44e49b487..79eadf524b 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/reshape_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/reshape_test.py @@ -50,7 +50,7 @@ class _ReshapeBijectorTest(object): expected_x = np.random.randn(4, 3, 2) expected_y = np.reshape(expected_x, [4, 6]) - with self.test_session() as sess: + with self.cached_session() as sess: shape_in, shape_out, feed_dict = self.build_shapes([3, 2], [6,]) bijector = Reshape( event_shape_out=shape_out, @@ -84,7 +84,7 @@ class _ReshapeBijectorTest(object): # using the _tensor methods, we should always get a fully-specified # result since these are evaluated at graph runtime. - with self.test_session() as sess: + with self.cached_session() as sess: (shape_out_, shape_in_) = sess.run(( bijector.forward_event_shape_tensor(shape_in), @@ -103,7 +103,7 @@ class _ReshapeBijectorTest(object): expected_y_scalar = expected_x_scalar[0] shape_in, shape_out, feed_dict = self.build_shapes([], [1,]) - with self.test_session() as sess: + with self.cached_session() as sess: bijector = Reshape( event_shape_out=shape_in, event_shape_in=shape_out, validate_args=True) @@ -124,7 +124,7 @@ class _ReshapeBijectorTest(object): def testMultipleUnspecifiedDimensionsOpError(self): - with self.test_session() as sess: + with self.cached_session() as sess: shape_in, shape_out, feed_dict = self.build_shapes([2, 3], [4, -1, -1,]) bijector = Reshape( event_shape_out=shape_out, @@ -139,7 +139,7 @@ class _ReshapeBijectorTest(object): # pylint: disable=invalid-name def _testInvalidDimensionsOpError(self, expected_error_message): - with self.test_session() as sess: + with self.cached_session() as sess: shape_in, shape_out, feed_dict = self.build_shapes([2, 3], [1, 2, -2,]) bijector = Reshape( @@ -155,7 +155,7 @@ class _ReshapeBijectorTest(object): def testValidButNonMatchingInputOpError(self): x = np.random.randn(4, 3, 2) - with self.test_session() as sess: + with self.cached_session() as sess: shape_in, shape_out, feed_dict = self.build_shapes([2, 3], [1, 6, 1,]) bijector = Reshape( event_shape_out=shape_out, @@ -173,7 +173,7 @@ class _ReshapeBijectorTest(object): def testValidButNonMatchingInputPartiallySpecifiedOpError(self): x = np.random.randn(4, 3, 2) - with self.test_session() as sess: + with self.cached_session() as sess: shape_in, shape_out, feed_dict = self.build_shapes([2, -1], [1, 6, 1,]) bijector = Reshape( event_shape_out=shape_out, @@ -190,7 +190,7 @@ class _ReshapeBijectorTest(object): x1 = np.random.randn(4, 2, 3) x2 = np.random.randn(4, 1, 1, 5) - with self.test_session() as sess: + with self.cached_session() as sess: shape_in, shape_out, fd_mismatched = self.build_shapes([2, 3], [1, 1, 5]) bijector = Reshape( @@ -208,7 +208,7 @@ class _ReshapeBijectorTest(object): expected_x = np.random.randn(4, 6) expected_y = np.reshape(expected_x, [4, 2, 3]) - with self.test_session() as sess: + with self.cached_session() as sess: # one of input/output shapes is partially specified shape_in, shape_out, feed_dict = self.build_shapes([-1,], [2, 3]) bijector = Reshape( @@ -227,7 +227,7 @@ class _ReshapeBijectorTest(object): def testBothShapesPartiallySpecified(self): expected_x = np.random.randn(4, 2, 3) expected_y = np.reshape(expected_x, [4, 3, 2]) - with self.test_session() as sess: + with self.cached_session() as sess: shape_in, shape_out, feed_dict = self.build_shapes([-1, 3], [-1, 2]) bijector = Reshape( event_shape_out=shape_out, @@ -245,7 +245,7 @@ class _ReshapeBijectorTest(object): def testDefaultVectorShape(self): expected_x = np.random.randn(4, 4) expected_y = np.reshape(expected_x, [4, 2, 2]) - with self.test_session() as sess: + with self.cached_session() as sess: _, shape_out, feed_dict = self.build_shapes([-1,], [-1, 2]) bijector = Reshape(shape_out, validate_args=True) @@ -292,7 +292,7 @@ class ReshapeBijectorTestStatic(test.TestCase, _ReshapeBijectorTest): def testBijectiveAndFinite(self): x = np.random.randn(4, 2, 3) y = np.reshape(x, [4, 1, 2, 3]) - with self.test_session(): + with self.cached_session(): bijector = Reshape( event_shape_in=[2, 3], event_shape_out=[1, 2, 3], diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/sigmoid_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/sigmoid_test.py index cea4a62c22..a6d432753d 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/sigmoid_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/sigmoid_test.py @@ -31,7 +31,7 @@ class SigmoidBijectorTest(test.TestCase): """Tests correctness of the Y = g(X) = (1 + exp(-X))^-1 transformation.""" def testBijector(self): - with self.test_session(): + with self.cached_session(): self.assertEqual("sigmoid", Sigmoid().name) x = np.linspace(-10., 10., 100).reshape([2, 5, 10]).astype(np.float32) y = special.expit(x) @@ -45,11 +45,11 @@ class SigmoidBijectorTest(test.TestCase): x, event_ndims=0).eval(), atol=0., rtol=1e-4) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): assert_scalar_congruency(Sigmoid(), lower_x=-7., upper_x=7.) def testBijectiveAndFinite(self): - with self.test_session(): + with self.cached_session(): x = np.linspace(-7., 7., 100).astype(np.float32) eps = 1e-3 y = np.linspace(eps, 1. - eps, 100).astype(np.float32) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/sinh_arcsinh_bijector_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/sinh_arcsinh_bijector_test.py index 795f1993ba..282619a73b 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/sinh_arcsinh_bijector_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/sinh_arcsinh_bijector_test.py @@ -33,7 +33,7 @@ class SinhArcsinhBijectorTest(test.TestCase): """Tests correctness of the power transformation.""" def testBijectorVersusNumpyRewriteOfBasicFunctions(self): - with self.test_session(): + with self.cached_session(): skewness = 0.2 tailweight = 2.0 bijector = SinhArcsinh( @@ -58,7 +58,7 @@ class SinhArcsinhBijectorTest(test.TestCase): atol=0.) def testLargerTailWeightPutsMoreWeightInTails(self): - with self.test_session(): + with self.cached_session(): # Will broadcast together to shape [3, 2]. x = [-1., 1.] tailweight = [[0.5], [1.0], [2.0]] @@ -75,7 +75,7 @@ class SinhArcsinhBijectorTest(test.TestCase): self.assertLess(forward_1[1], forward_1[2]) def testSkew(self): - with self.test_session(): + with self.cached_session(): # Will broadcast together to shape [3, 2]. x = [-1., 1.] skewness = [[-1.], [0.], [1.]] @@ -92,24 +92,24 @@ class SinhArcsinhBijectorTest(test.TestCase): self.assertLess(np.abs(y[2, 0]), np.abs(y[2, 1])) def testScalarCongruencySkewness1Tailweight0p5(self): - with self.test_session(): + with self.cached_session(): bijector = SinhArcsinh(skewness=1.0, tailweight=0.5, validate_args=True) assert_scalar_congruency(bijector, lower_x=-2., upper_x=2.0, rtol=0.05) def testScalarCongruencySkewnessNeg1Tailweight1p5(self): - with self.test_session(): + with self.cached_session(): bijector = SinhArcsinh(skewness=-1.0, tailweight=1.5, validate_args=True) assert_scalar_congruency(bijector, lower_x=-2., upper_x=2.0, rtol=0.05) def testBijectiveAndFiniteSkewnessNeg1Tailweight0p5(self): - with self.test_session(): + with self.cached_session(): bijector = SinhArcsinh(skewness=-1., tailweight=0.5, validate_args=True) x = np.concatenate((-np.logspace(-2, 10, 1000), [0], np.logspace( -2, 10, 1000))).astype(np.float32) assert_bijective_and_finite(bijector, x, x, event_ndims=0, rtol=1e-3) def testBijectiveAndFiniteSkewness1Tailweight3(self): - with self.test_session(): + with self.cached_session(): bijector = SinhArcsinh(skewness=1., tailweight=3., validate_args=True) x = np.concatenate((-np.logspace(-2, 5, 1000), [0], np.logspace( -2, 5, 1000))).astype(np.float32) @@ -117,7 +117,7 @@ class SinhArcsinhBijectorTest(test.TestCase): bijector, x, x, event_ndims=0, rtol=1e-3) def testBijectorEndpoints(self): - with self.test_session(): + with self.cached_session(): for dtype in (np.float32, np.float64): bijector = SinhArcsinh( skewness=dtype(0.), tailweight=dtype(1.), validate_args=True) @@ -129,7 +129,7 @@ class SinhArcsinhBijectorTest(test.TestCase): bijector, bounds, bounds, event_ndims=0, atol=2e-6) def testBijectorOverRange(self): - with self.test_session(): + with self.cached_session(): for dtype in (np.float32, np.float64): skewness = np.array([1.2, 5.], dtype=dtype) tailweight = np.array([2., 10.], dtype=dtype) @@ -176,12 +176,12 @@ class SinhArcsinhBijectorTest(test.TestCase): atol=0.) def testZeroTailweightRaises(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("not positive"): SinhArcsinh(tailweight=0., validate_args=True).forward(1.0).eval() def testDefaultDtypeIsFloat32(self): - with self.test_session(): + with self.cached_session(): bijector = SinhArcsinh() self.assertEqual(bijector.tailweight.dtype, np.float32) self.assertEqual(bijector.skewness.dtype, np.float32) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softmax_centered_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softmax_centered_test.py index 0f0a2fa531..8d18400487 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softmax_centered_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softmax_centered_test.py @@ -35,7 +35,7 @@ class SoftmaxCenteredBijectorTest(test.TestCase): """Tests correctness of the Y = g(X) = exp(X) / sum(exp(X)) transformation.""" def testBijectorVector(self): - with self.test_session(): + with self.cached_session(): softmax = SoftmaxCentered() self.assertEqual("softmax_centered", softmax.name) x = np.log([[2., 3, 4], [4., 8, 12]]) @@ -54,7 +54,7 @@ class SoftmaxCenteredBijectorTest(test.TestCase): rtol=1e-7) def testBijectorUnknownShape(self): - with self.test_session(): + with self.cached_session(): softmax = SoftmaxCentered() self.assertEqual("softmax_centered", softmax.name) x = array_ops.placeholder(shape=[2, None], dtype=dtypes.float32) @@ -80,7 +80,7 @@ class SoftmaxCenteredBijectorTest(test.TestCase): rtol=1e-7) def testShapeGetters(self): - with self.test_session(): + with self.cached_session(): x = tensor_shape.TensorShape([4]) y = tensor_shape.TensorShape([5]) bijector = SoftmaxCentered(validate_args=True) @@ -94,7 +94,7 @@ class SoftmaxCenteredBijectorTest(test.TestCase): y.as_list()).eval()) def testBijectiveAndFinite(self): - with self.test_session(): + with self.cached_session(): softmax = SoftmaxCentered() x = np.linspace(-50, 50, num=10).reshape(5, 2).astype(np.float32) # Make y values on the simplex with a wide range. diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softplus_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softplus_test.py index 3d8a0a32bb..e805619041 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softplus_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softplus_test.py @@ -42,13 +42,13 @@ class SoftplusBijectorTest(test.TestCase): return -np.log(1 - np.exp(-y)) def testHingeSoftnessZeroRaises(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus(hinge_softness=0., validate_args=True) with self.assertRaisesOpError("must be non-zero"): bijector.forward([1., 1.]).eval() def testBijectorForwardInverseEventDimsZero(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus() self.assertEqual("softplus", bijector.name) x = 2 * rng.randn(2, 10) @@ -58,7 +58,7 @@ class SoftplusBijectorTest(test.TestCase): self.assertAllClose(x, bijector.inverse(y).eval()) def testBijectorForwardInverseWithHingeSoftnessEventDimsZero(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus(hinge_softness=1.5) x = 2 * rng.randn(2, 10) y = 1.5 * self._softplus(x / 1.5) @@ -67,7 +67,7 @@ class SoftplusBijectorTest(test.TestCase): self.assertAllClose(x, bijector.inverse(y).eval()) def testBijectorLogDetJacobianEventDimsZero(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus() y = 2 * rng.rand(2, 10) # No reduction needed if event_dims = 0. @@ -77,7 +77,7 @@ class SoftplusBijectorTest(test.TestCase): y, event_ndims=0).eval()) def testBijectorForwardInverseEventDimsOne(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus() self.assertEqual("softplus", bijector.name) x = 2 * rng.randn(2, 10) @@ -87,7 +87,7 @@ class SoftplusBijectorTest(test.TestCase): self.assertAllClose(x, bijector.inverse(y).eval()) def testBijectorLogDetJacobianEventDimsOne(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus() y = 2 * rng.rand(2, 10) ildj_before = self._softplus_ildj_before_reduction(y) @@ -97,25 +97,25 @@ class SoftplusBijectorTest(test.TestCase): y, event_ndims=1).eval()) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus() assert_scalar_congruency( bijector, lower_x=-2., upper_x=2.) def testScalarCongruencyWithPositiveHingeSoftness(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus(hinge_softness=1.3) assert_scalar_congruency( bijector, lower_x=-2., upper_x=2.) def testScalarCongruencyWithNegativeHingeSoftness(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus(hinge_softness=-1.3) assert_scalar_congruency( bijector, lower_x=-2., upper_x=2.) def testBijectiveAndFinite32bit(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus() x = np.linspace(-20., 20., 100).astype(np.float32) y = np.logspace(-10, 10, 100).astype(np.float32) @@ -123,7 +123,7 @@ class SoftplusBijectorTest(test.TestCase): bijector, x, y, event_ndims=0, rtol=1e-2, atol=1e-2) def testBijectiveAndFiniteWithPositiveHingeSoftness32Bit(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus(hinge_softness=1.23) x = np.linspace(-20., 20., 100).astype(np.float32) y = np.logspace(-10, 10, 100).astype(np.float32) @@ -131,7 +131,7 @@ class SoftplusBijectorTest(test.TestCase): bijector, x, y, event_ndims=0, rtol=1e-2, atol=1e-2) def testBijectiveAndFiniteWithNegativeHingeSoftness32Bit(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus(hinge_softness=-0.7) x = np.linspace(-20., 20., 100).astype(np.float32) y = -np.logspace(-10, 10, 100).astype(np.float32) @@ -139,7 +139,7 @@ class SoftplusBijectorTest(test.TestCase): bijector, x, y, event_ndims=0, rtol=1e-2, atol=1e-2) def testBijectiveAndFinite16bit(self): - with self.test_session(): + with self.cached_session(): bijector = Softplus() # softplus(-20) is zero, so we can't use such a large range as in 32bit. x = np.linspace(-10., 20., 100).astype(np.float16) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softsign_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softsign_test.py index d0098c3c10..8dad80aa64 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softsign_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/softsign_test.py @@ -43,16 +43,15 @@ class SoftsignBijectorTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testBijectorBounds(self): bijector = Softsign(validate_args=True) - with self.test_session(): - with self.assertRaisesOpError("greater than -1"): - bijector.inverse(-3.).eval() - with self.assertRaisesOpError("greater than -1"): - bijector.inverse_log_det_jacobian(-3., event_ndims=0).eval() - - with self.assertRaisesOpError("less than 1"): - bijector.inverse(3.).eval() - with self.assertRaisesOpError("less than 1"): - bijector.inverse_log_det_jacobian(3., event_ndims=0).eval() + with self.assertRaisesOpError("greater than -1"): + self.evaluate(bijector.inverse(-3.)) + with self.assertRaisesOpError("greater than -1"): + self.evaluate(bijector.inverse_log_det_jacobian(-3., event_ndims=0)) + + with self.assertRaisesOpError("less than 1"): + self.evaluate(bijector.inverse(3.)) + with self.assertRaisesOpError("less than 1"): + self.evaluate(bijector.inverse_log_det_jacobian(3., event_ndims=0)) @test_util.run_in_graph_and_eager_modes def testBijectorForwardInverse(self): diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/square_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/square_test.py index 30c7a738c3..e5550cc830 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/square_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/square_test.py @@ -29,7 +29,7 @@ class SquareBijectorTest(test.TestCase): """Tests the correctness of the Y = X ** 2 transformation.""" def testBijectorScalar(self): - with self.test_session(): + with self.cached_session(): bijector = bijectors.Square(validate_args=True) self.assertEqual("square", bijector.name) x = [[[1., 5], @@ -50,7 +50,7 @@ class SquareBijectorTest(test.TestCase): rtol=1e-7) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): bijector = bijectors.Square(validate_args=True) assert_scalar_congruency(bijector, lower_x=1e-3, upper_x=1.5, rtol=0.05) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/weibull_test.py b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/weibull_test.py index f57adcda89..424eb58fa0 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/bijectors/weibull_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/bijectors/weibull_test.py @@ -31,7 +31,7 @@ class WeibullBijectorTest(test.TestCase): """Tests correctness of the weibull bijector.""" def testBijector(self): - with self.test_session(): + with self.cached_session(): scale = 5. concentration = 0.3 bijector = Weibull( @@ -54,13 +54,13 @@ class WeibullBijectorTest(test.TestCase): atol=0.) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): assert_scalar_congruency( Weibull(scale=20., concentration=0.3), lower_x=1., upper_x=100., rtol=0.02) def testBijectiveAndFinite(self): - with self.test_session(): + with self.cached_session(): bijector = Weibull( scale=20., concentration=2., validate_args=True) x = np.linspace(1., 8., num=10).astype(np.float32) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/binomial_test.py b/tensorflow/contrib/distributions/python/kernel_tests/binomial_test.py index d30f6e418d..c317393fbc 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/binomial_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/binomial_test.py @@ -28,7 +28,7 @@ from tensorflow.python.platform import test class BinomialTest(test.TestCase): def testSimpleShapes(self): - with self.test_session(): + with self.cached_session(): p = np.float32(np.random.beta(1, 1)) binom = binomial.Binomial(total_count=1., probs=p) self.assertAllEqual([], binom.event_shape_tensor().eval()) @@ -37,7 +37,7 @@ class BinomialTest(test.TestCase): self.assertEqual(tensor_shape.TensorShape([]), binom.batch_shape) def testComplexShapes(self): - with self.test_session(): + with self.cached_session(): p = np.random.beta(1, 1, size=(3, 2)).astype(np.float32) n = [[3., 2], [4, 5], [6, 7]] binom = binomial.Binomial(total_count=n, probs=p) @@ -50,14 +50,14 @@ class BinomialTest(test.TestCase): def testNProperty(self): p = [[0.1, 0.2, 0.7], [0.2, 0.3, 0.5]] n = [[3.], [4]] - with self.test_session(): + with self.cached_session(): binom = binomial.Binomial(total_count=n, probs=p) self.assertEqual((2, 1), binom.total_count.get_shape()) self.assertAllClose(n, binom.total_count.eval()) def testPProperty(self): p = [[0.1, 0.2, 0.7]] - with self.test_session(): + with self.cached_session(): binom = binomial.Binomial(total_count=3., probs=p) self.assertEqual((1, 3), binom.probs.get_shape()) self.assertEqual((1, 3), binom.logits.get_shape()) @@ -65,7 +65,7 @@ class BinomialTest(test.TestCase): def testLogitsProperty(self): logits = [[0., 9., -0.5]] - with self.test_session(): + with self.cached_session(): binom = binomial.Binomial(total_count=3., logits=logits) self.assertEqual((1, 3), binom.probs.get_shape()) self.assertEqual((1, 3), binom.logits.get_shape()) @@ -74,7 +74,7 @@ class BinomialTest(test.TestCase): def testPmfAndCdfNandCountsAgree(self): p = [[0.1, 0.2, 0.7]] n = [[5.]] - with self.test_session(): + with self.cached_session(): binom = binomial.Binomial(total_count=n, probs=p, validate_args=True) binom.prob([2., 3, 2]).eval() binom.prob([3., 1, 2]).eval() @@ -92,7 +92,7 @@ class BinomialTest(test.TestCase): def testPmfAndCdfNonIntegerCounts(self): p = [[0.1, 0.2, 0.7]] n = [[5.]] - with self.test_session(): + with self.cached_session(): # No errors with integer n. binom = binomial.Binomial(total_count=n, probs=p, validate_args=True) binom.prob([2., 3, 2]).eval() @@ -116,7 +116,7 @@ class BinomialTest(test.TestCase): binom.cdf([1.0, 2.5, 1.5]).eval() def testPmfAndCdfBothZeroBatches(self): - with self.test_session(): + with self.cached_session(): # Both zero-batches. No broadcast p = 0.5 counts = 1. @@ -129,7 +129,7 @@ class BinomialTest(test.TestCase): self.assertEqual((), cdf.get_shape()) def testPmfAndCdfBothZeroBatchesNontrivialN(self): - with self.test_session(): + with self.cached_session(): # Both zero-batches. No broadcast p = 0.1 counts = 3. @@ -142,7 +142,7 @@ class BinomialTest(test.TestCase): self.assertEqual((), cdf.get_shape()) def testPmfAndCdfPStretchedInBroadcastWhenSameRank(self): - with self.test_session(): + with self.cached_session(): p = [[0.1, 0.9]] counts = [[1., 2.]] binom = binomial.Binomial(total_count=3., probs=p) @@ -154,7 +154,7 @@ class BinomialTest(test.TestCase): self.assertEqual((1, 2), cdf.get_shape()) def testPmfAndCdfPStretchedInBroadcastWhenLowerRank(self): - with self.test_session(): + with self.cached_session(): p = [0.1, 0.4] counts = [[1.], [0.]] binom = binomial.Binomial(total_count=1., probs=p) @@ -166,7 +166,7 @@ class BinomialTest(test.TestCase): self.assertEqual((2, 2), cdf.get_shape()) def testBinomialMean(self): - with self.test_session(): + with self.cached_session(): n = 5. p = [0.1, 0.2, 0.7] binom = binomial.Binomial(total_count=n, probs=p) @@ -175,7 +175,7 @@ class BinomialTest(test.TestCase): self.assertAllClose(expected_means, binom.mean().eval()) def testBinomialVariance(self): - with self.test_session(): + with self.cached_session(): n = 5. p = [0.1, 0.2, 0.7] binom = binomial.Binomial(total_count=n, probs=p) @@ -184,7 +184,7 @@ class BinomialTest(test.TestCase): self.assertAllClose(expected_variances, binom.variance().eval()) def testBinomialMode(self): - with self.test_session(): + with self.cached_session(): n = 5. p = [0.1, 0.2, 0.7] binom = binomial.Binomial(total_count=n, probs=p) @@ -193,7 +193,7 @@ class BinomialTest(test.TestCase): self.assertAllClose(expected_modes, binom.mode().eval()) def testBinomialMultipleMode(self): - with self.test_session(): + with self.cached_session(): n = 9. p = [0.1, 0.2, 0.7] binom = binomial.Binomial(total_count=n, probs=p) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/cauchy_test.py b/tensorflow/contrib/distributions/python/kernel_tests/cauchy_test.py index 73747db31c..4411d6f461 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/cauchy_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/cauchy_test.py @@ -56,7 +56,7 @@ class CauchyTest(test.TestCase): self.assertAllEqual(all_true, is_finite) def _testParamShapes(self, sample_shape, expected): - with self.test_session(): + with self.cached_session(): param_shapes = cauchy_lib.Cauchy.param_shapes(sample_shape) loc_shape, scale_shape = param_shapes["loc"], param_shapes["scale"] self.assertAllEqual(expected, loc_shape.eval()) @@ -85,7 +85,7 @@ class CauchyTest(test.TestCase): tensor_shape.TensorShape(sample_shape), sample_shape) def testCauchyLogPDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 loc = constant_op.constant([3.0] * batch_size) scale = constant_op.constant([np.sqrt(10.0)] * batch_size) @@ -112,7 +112,7 @@ class CauchyTest(test.TestCase): self.assertAllClose(np.exp(expected_log_pdf), pdf.eval()) def testCauchyLogPDFMultidimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 loc = constant_op.constant([[3.0, -3.0]] * batch_size) scale = constant_op.constant( @@ -144,7 +144,7 @@ class CauchyTest(test.TestCase): self.assertAllClose(np.exp(expected_log_pdf), pdf_values) def testCauchyCDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 50 loc = self._rng.randn(batch_size) scale = self._rng.rand(batch_size) + 1.0 @@ -162,7 +162,7 @@ class CauchyTest(test.TestCase): self.assertAllClose(expected_cdf, cdf.eval(), atol=0) def testCauchySurvivalFunction(self): - with self.test_session(): + with self.cached_session(): batch_size = 50 loc = self._rng.randn(batch_size) scale = self._rng.rand(batch_size) + 1.0 @@ -181,7 +181,7 @@ class CauchyTest(test.TestCase): self.assertAllClose(expected_sf, sf.eval(), atol=0) def testCauchyLogCDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 50 loc = self._rng.randn(batch_size) scale = self._rng.rand(batch_size) + 1.0 @@ -214,14 +214,14 @@ class CauchyTest(test.TestCase): ]: value = func(x) grads = gradients_impl.gradients(value, [loc, scale]) - with self.test_session(graph=g): + with self.session(graph=g): variables.global_variables_initializer().run() self.assertAllFinite(value) self.assertAllFinite(grads[0]) self.assertAllFinite(grads[1]) def testCauchyLogSurvivalFunction(self): - with self.test_session(): + with self.cached_session(): batch_size = 50 loc = self._rng.randn(batch_size) scale = self._rng.rand(batch_size) + 1.0 @@ -241,7 +241,7 @@ class CauchyTest(test.TestCase): self.assertAllClose(expected_sf, sf.eval(), atol=0, rtol=1e-5) def testCauchyEntropy(self): - with self.test_session(): + with self.cached_session(): loc = np.array([1.0, 1.0, 1.0]) scale = np.array([[1.0, 2.0, 3.0]]) cauchy = cauchy_lib.Cauchy(loc=loc, scale=scale) @@ -259,7 +259,7 @@ class CauchyTest(test.TestCase): self.assertAllClose(expected_entropy, entropy.eval()) def testCauchyMode(self): - with self.test_session(): + with self.cached_session(): # Mu will be broadcast to [7, 7, 7]. loc = [7.] scale = [11., 12., 13.] @@ -270,7 +270,7 @@ class CauchyTest(test.TestCase): self.assertAllEqual([7., 7, 7], cauchy.mode().eval()) def testCauchyMean(self): - with self.test_session(): + with self.cached_session(): loc = [1., 2., 3.] scale = [7.] cauchy = cauchy_lib.Cauchy(loc=loc, scale=scale) @@ -279,7 +279,7 @@ class CauchyTest(test.TestCase): self.assertAllEqual([np.nan] * 3, cauchy.mean().eval()) def testCauchyNanMean(self): - with self.test_session(): + with self.cached_session(): loc = [1., 2., 3.] scale = [7.] cauchy = cauchy_lib.Cauchy(loc=loc, scale=scale, allow_nan_stats=False) @@ -288,7 +288,7 @@ class CauchyTest(test.TestCase): cauchy.mean().eval() def testCauchyQuantile(self): - with self.test_session(): + with self.cached_session(): batch_size = 50 loc = self._rng.randn(batch_size) scale = self._rng.rand(batch_size) + 1.0 @@ -308,7 +308,7 @@ class CauchyTest(test.TestCase): self.assertAllClose(expected_x, x.eval(), atol=0.) def testCauchyVariance(self): - with self.test_session(): + with self.cached_session(): # scale will be broadcast to [7, 7, 7] loc = [1., 2., 3.] scale = [7.] @@ -318,7 +318,7 @@ class CauchyTest(test.TestCase): self.assertAllEqual([np.nan] * 3, cauchy.variance().eval()) def testCauchyNanVariance(self): - with self.test_session(): + with self.cached_session(): # scale will be broadcast to [7, 7, 7] loc = [1., 2., 3.] scale = [7.] @@ -328,7 +328,7 @@ class CauchyTest(test.TestCase): cauchy.variance().eval() def testCauchyStandardDeviation(self): - with self.test_session(): + with self.cached_session(): # scale will be broadcast to [7, 7, 7] loc = [1., 2., 3.] scale = [7.] @@ -338,7 +338,7 @@ class CauchyTest(test.TestCase): self.assertAllEqual([np.nan] * 3, cauchy.stddev().eval()) def testCauchyNanStandardDeviation(self): - with self.test_session(): + with self.cached_session(): # scale will be broadcast to [7, 7, 7] loc = [1., 2., 3.] scale = [7.] @@ -348,7 +348,7 @@ class CauchyTest(test.TestCase): cauchy.stddev().eval() def testCauchySample(self): - with self.test_session(): + with self.cached_session(): loc = constant_op.constant(3.0) scale = constant_op.constant(1.0) loc_v = 3.0 @@ -373,7 +373,7 @@ class CauchyTest(test.TestCase): self.assertAllEqual(expected_shape, sample_values.shape) def testCauchySampleMultiDimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 2 loc = constant_op.constant([[3.0, -3.0]] * batch_size) scale = constant_op.constant([[0.5, 1.0]] * batch_size) @@ -399,13 +399,13 @@ class CauchyTest(test.TestCase): self.assertAllEqual(expected_shape, sample_values.shape) def testCauchyNegativeLocFails(self): - with self.test_session(): + with self.cached_session(): cauchy = cauchy_lib.Cauchy(loc=[1.], scale=[-5.], validate_args=True) with self.assertRaisesOpError("Condition x > 0 did not hold"): cauchy.mode().eval() def testCauchyShape(self): - with self.test_session(): + with self.cached_session(): loc = constant_op.constant([-3.0] * 5) scale = constant_op.constant(11.0) cauchy = cauchy_lib.Cauchy(loc=loc, scale=scale) @@ -420,7 +420,7 @@ class CauchyTest(test.TestCase): scale = array_ops.placeholder(dtype=dtypes.float32) cauchy = cauchy_lib.Cauchy(loc=loc, scale=scale) - with self.test_session() as sess: + with self.cached_session() as sess: # get_batch_shape should return an "<unknown>" tensor. self.assertEqual(cauchy.batch_shape, tensor_shape.TensorShape(None)) self.assertEqual(cauchy.event_shape, ()) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/chi2_test.py b/tensorflow/contrib/distributions/python/kernel_tests/chi2_test.py index 75d48791ec..3b5a6aa90c 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/chi2_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/chi2_test.py @@ -29,7 +29,7 @@ from tensorflow.python.platform import test class Chi2Test(test.TestCase): def testChi2LogPDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 df = constant_op.constant([2.0] * batch_size, dtype=np.float64) df_v = 2.0 @@ -46,7 +46,7 @@ class Chi2Test(test.TestCase): self.assertAllClose(pdf.eval(), np.exp(expected_log_pdf)) def testChi2CDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 df = constant_op.constant([2.0] * batch_size, dtype=np.float64) df_v = 2.0 @@ -60,7 +60,7 @@ class Chi2Test(test.TestCase): self.assertAllClose(cdf.eval(), expected_cdf) def testChi2Mean(self): - with self.test_session(): + with self.cached_session(): df_v = np.array([1., 3, 5], dtype=np.float64) expected_mean = stats.chi2.mean(df_v) chi2 = chi2_lib.Chi2(df=df_v) @@ -68,7 +68,7 @@ class Chi2Test(test.TestCase): self.assertAllClose(chi2.mean().eval(), expected_mean) def testChi2Variance(self): - with self.test_session(): + with self.cached_session(): df_v = np.array([1., 3, 5], np.float64) expected_variances = stats.chi2.var(df_v) chi2 = chi2_lib.Chi2(df=df_v) @@ -76,7 +76,7 @@ class Chi2Test(test.TestCase): self.assertAllClose(chi2.variance().eval(), expected_variances) def testChi2Entropy(self): - with self.test_session(): + with self.cached_session(): df_v = np.array([1., 3, 5], dtype=np.float64) expected_entropy = stats.chi2.entropy(df_v) chi2 = chi2_lib.Chi2(df=df_v) @@ -84,7 +84,7 @@ class Chi2Test(test.TestCase): self.assertAllClose(chi2.entropy().eval(), expected_entropy) def testChi2WithAbsDf(self): - with self.test_session(): + with self.cached_session(): df_v = np.array([-1.3, -3.2, 5], dtype=np.float64) chi2 = chi2_lib.Chi2WithAbsDf(df=df_v) self.assertAllClose( diff --git a/tensorflow/contrib/distributions/python/kernel_tests/conditional_transformed_distribution_test.py b/tensorflow/contrib/distributions/python/kernel_tests/conditional_transformed_distribution_test.py index 4e8989b6c2..7e63b5ca5f 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/conditional_transformed_distribution_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/conditional_transformed_distribution_test.py @@ -69,7 +69,7 @@ class ConditionalTransformedDistributionTest( return ds.ConditionalTransformedDistribution def testConditioning(self): - with self.test_session(): + with self.cached_session(): conditional_normal = ds.ConditionalTransformedDistribution( distribution=ds.Normal(loc=0., scale=1.), bijector=_ChooseLocation(loc=[-100., 100.])) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/deterministic_test.py b/tensorflow/contrib/distributions/python/kernel_tests/deterministic_test.py index 200310bc41..36fc7a70c8 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/deterministic_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/deterministic_test.py @@ -29,7 +29,7 @@ rng = np.random.RandomState(0) class DeterministicTest(test.TestCase): def testShape(self): - with self.test_session(): + with self.cached_session(): loc = rng.rand(2, 3, 4) deterministic = deterministic_lib.Deterministic(loc) @@ -42,20 +42,20 @@ class DeterministicTest(test.TestCase): loc = rng.rand(2, 3, 4).astype(np.float32) deterministic = deterministic_lib.Deterministic( loc, atol=-1, validate_args=True) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Condition x >= 0"): deterministic.prob(0.).eval() def testProbWithNoBatchDimsIntegerType(self): deterministic = deterministic_lib.Deterministic(0) - with self.test_session(): + with self.cached_session(): self.assertAllClose(1, deterministic.prob(0).eval()) self.assertAllClose(0, deterministic.prob(2).eval()) self.assertAllClose([1, 0], deterministic.prob([0, 2]).eval()) def testProbWithNoBatchDims(self): deterministic = deterministic_lib.Deterministic(0.) - with self.test_session(): + with self.cached_session(): self.assertAllClose(1., deterministic.prob(0.).eval()) self.assertAllClose(0., deterministic.prob(2.).eval()) self.assertAllClose([1., 0.], deterministic.prob([0., 2.]).eval()) @@ -65,7 +65,7 @@ class DeterministicTest(test.TestCase): x = [[0., 1.1], [1.99, 3.]] deterministic = deterministic_lib.Deterministic(loc) expected_prob = [[1., 0.], [0., 1.]] - with self.test_session(): + with self.cached_session(): prob = deterministic.prob(x) self.assertAllEqual((2, 2), prob.get_shape()) self.assertAllEqual(expected_prob, prob.eval()) @@ -75,7 +75,7 @@ class DeterministicTest(test.TestCase): x = [[0., 1.1], [1.99, 3.]] deterministic = deterministic_lib.Deterministic(loc, atol=0.05) expected_prob = [[1., 0.], [1., 1.]] - with self.test_session(): + with self.cached_session(): prob = deterministic.prob(x) self.assertAllEqual((2, 2), prob.get_shape()) self.assertAllEqual(expected_prob, prob.eval()) @@ -85,7 +85,7 @@ class DeterministicTest(test.TestCase): x = [[0, 2], [4, 2]] deterministic = deterministic_lib.Deterministic(loc, atol=1) expected_prob = [[1, 1], [0, 1]] - with self.test_session(): + with self.cached_session(): prob = deterministic.prob(x) self.assertAllEqual((2, 2), prob.get_shape()) self.assertAllEqual(expected_prob, prob.eval()) @@ -95,7 +95,7 @@ class DeterministicTest(test.TestCase): x = [[0., 1.1], [100.1, 103.]] deterministic = deterministic_lib.Deterministic(loc, rtol=0.01) expected_prob = [[1., 0.], [1., 0.]] - with self.test_session(): + with self.cached_session(): prob = deterministic.prob(x) self.assertAllEqual((2, 2), prob.get_shape()) self.assertAllEqual(expected_prob, prob.eval()) @@ -107,7 +107,7 @@ class DeterministicTest(test.TestCase): # Batch 1 will have rtol = 1 (100% slack allowed) deterministic = deterministic_lib.Deterministic(loc, rtol=[[0], [1]]) expected_prob = [[1, 0, 0], [1, 1, 0]] - with self.test_session(): + with self.cached_session(): prob = deterministic.prob(x) self.assertAllEqual((2, 3), prob.get_shape()) self.assertAllEqual(expected_prob, prob.eval()) @@ -117,7 +117,7 @@ class DeterministicTest(test.TestCase): x = [[-1., -0.1], [-0.01, 1.000001]] deterministic = deterministic_lib.Deterministic(loc) expected_cdf = [[0., 0.], [0., 1.]] - with self.test_session(): + with self.cached_session(): cdf = deterministic.cdf(x) self.assertAllEqual((2, 2), cdf.get_shape()) self.assertAllEqual(expected_cdf, cdf.eval()) @@ -127,7 +127,7 @@ class DeterministicTest(test.TestCase): x = [[-1., -0.1], [-0.01, 1.000001]] deterministic = deterministic_lib.Deterministic(loc, atol=0.05) expected_cdf = [[0., 0.], [1., 1.]] - with self.test_session(): + with self.cached_session(): cdf = deterministic.cdf(x) self.assertAllEqual((2, 2), cdf.get_shape()) self.assertAllEqual(expected_cdf, cdf.eval()) @@ -137,7 +137,7 @@ class DeterministicTest(test.TestCase): x = [[0.9, 1.], [99.9, 97]] deterministic = deterministic_lib.Deterministic(loc, rtol=0.01) expected_cdf = [[0., 1.], [1., 0.]] - with self.test_session(): + with self.cached_session(): cdf = deterministic.cdf(x) self.assertAllEqual((2, 2), cdf.get_shape()) self.assertAllEqual(expected_cdf, cdf.eval()) @@ -145,7 +145,7 @@ class DeterministicTest(test.TestCase): def testSampleNoBatchDims(self): deterministic = deterministic_lib.Deterministic(0.) for sample_shape in [(), (4,)]: - with self.test_session(): + with self.cached_session(): sample = deterministic.sample(sample_shape) self.assertAllEqual(sample_shape, sample.get_shape()) self.assertAllClose( @@ -154,7 +154,7 @@ class DeterministicTest(test.TestCase): def testSampleWithBatchDims(self): deterministic = deterministic_lib.Deterministic([0., 0.]) for sample_shape in [(), (4,)]: - with self.test_session(): + with self.cached_session(): sample = deterministic.sample(sample_shape) self.assertAllEqual(sample_shape + (2,), sample.get_shape()) self.assertAllClose( @@ -166,7 +166,7 @@ class DeterministicTest(test.TestCase): deterministic = deterministic_lib.Deterministic(loc) for sample_shape_ in [(), (4,)]: - with self.test_session(): + with self.cached_session(): sample_ = deterministic.sample(sample_shape).eval( feed_dict={loc: [0., 0.], sample_shape: sample_shape_}) @@ -176,7 +176,7 @@ class DeterministicTest(test.TestCase): def testEntropy(self): loc = np.array([-0.1, -3.2, 7.]) deterministic = deterministic_lib.Deterministic(loc=loc) - with self.test_session() as sess: + with self.cached_session() as sess: entropy_ = sess.run(deterministic.entropy()) self.assertAllEqual(np.zeros(3), entropy_) @@ -184,7 +184,7 @@ class DeterministicTest(test.TestCase): class VectorDeterministicTest(test.TestCase): def testShape(self): - with self.test_session(): + with self.cached_session(): loc = rng.rand(2, 3, 4) deterministic = deterministic_lib.VectorDeterministic(loc) @@ -197,7 +197,7 @@ class VectorDeterministicTest(test.TestCase): loc = rng.rand(2, 3, 4).astype(np.float32) deterministic = deterministic_lib.VectorDeterministic( loc, atol=-1, validate_args=True) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Condition x >= 0"): deterministic.prob(loc).eval() @@ -205,14 +205,14 @@ class VectorDeterministicTest(test.TestCase): loc = rng.rand(2, 3, 4).astype(np.float32) deterministic = deterministic_lib.VectorDeterministic( loc, atol=-1, validate_args=True) - with self.test_session(): + with self.cached_session(): with self.assertRaisesRegexp(ValueError, "must have rank at least 1"): deterministic.prob(0.).eval() def testProbVectorDeterministicWithNoBatchDims(self): # 0 batch of deterministics on R^1. deterministic = deterministic_lib.VectorDeterministic([0.]) - with self.test_session(): + with self.cached_session(): self.assertAllClose(1., deterministic.prob([0.]).eval()) self.assertAllClose(0., deterministic.prob([2.]).eval()) self.assertAllClose([1., 0.], deterministic.prob([[0.], [2.]]).eval()) @@ -223,7 +223,7 @@ class VectorDeterministicTest(test.TestCase): x = [[0., 1.], [1.9, 3.], [3.99, 5.]] deterministic = deterministic_lib.VectorDeterministic(loc) expected_prob = [1., 0., 0.] - with self.test_session(): + with self.cached_session(): prob = deterministic.prob(x) self.assertAllEqual((3,), prob.get_shape()) self.assertAllEqual(expected_prob, prob.eval()) @@ -234,7 +234,7 @@ class VectorDeterministicTest(test.TestCase): x = [[0., 1.], [1.9, 3.], [3.99, 5.]] deterministic = deterministic_lib.VectorDeterministic(loc, atol=0.05) expected_prob = [1., 0., 1.] - with self.test_session(): + with self.cached_session(): prob = deterministic.prob(x) self.assertAllEqual((3,), prob.get_shape()) self.assertAllEqual(expected_prob, prob.eval()) @@ -245,7 +245,7 @@ class VectorDeterministicTest(test.TestCase): x = [[0., 1.], [0.9, 1.], [99.9, 100.1]] deterministic = deterministic_lib.VectorDeterministic(loc, rtol=0.01) expected_prob = [1., 0., 1.] - with self.test_session(): + with self.cached_session(): prob = deterministic.prob(x) self.assertAllEqual((3,), prob.get_shape()) self.assertAllEqual(expected_prob, prob.eval()) @@ -254,7 +254,7 @@ class VectorDeterministicTest(test.TestCase): # 0 batch of deterministics on R^0. deterministic = deterministic_lib.VectorDeterministic( [], validate_args=True) - with self.test_session(): + with self.cached_session(): self.assertAllClose(1., deterministic.prob([]).eval()) def testProbVectorDeterministicWithNoBatchDimsOnRZeroRaisesIfXNotInSameRk( @@ -262,14 +262,14 @@ class VectorDeterministicTest(test.TestCase): # 0 batch of deterministics on R^0. deterministic = deterministic_lib.VectorDeterministic( [], validate_args=True) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("not defined in the same space"): deterministic.prob([1.]).eval() def testSampleNoBatchDims(self): deterministic = deterministic_lib.VectorDeterministic([0.]) for sample_shape in [(), (4,)]: - with self.test_session(): + with self.cached_session(): sample = deterministic.sample(sample_shape) self.assertAllEqual(sample_shape + (1,), sample.get_shape()) self.assertAllClose( @@ -278,7 +278,7 @@ class VectorDeterministicTest(test.TestCase): def testSampleWithBatchDims(self): deterministic = deterministic_lib.VectorDeterministic([[0.], [0.]]) for sample_shape in [(), (4,)]: - with self.test_session(): + with self.cached_session(): sample = deterministic.sample(sample_shape) self.assertAllEqual(sample_shape + (2, 1), sample.get_shape()) self.assertAllClose( @@ -290,7 +290,7 @@ class VectorDeterministicTest(test.TestCase): deterministic = deterministic_lib.VectorDeterministic(loc) for sample_shape_ in [(), (4,)]: - with self.test_session(): + with self.cached_session(): sample_ = deterministic.sample(sample_shape).eval( feed_dict={loc: [[0.], [0.]], sample_shape: sample_shape_}) @@ -300,7 +300,7 @@ class VectorDeterministicTest(test.TestCase): def testEntropy(self): loc = np.array([[8.3, 1.2, 3.3], [-0.1, -3.2, 7.]]) deterministic = deterministic_lib.VectorDeterministic(loc=loc) - with self.test_session() as sess: + with self.cached_session() as sess: entropy_ = sess.run(deterministic.entropy()) self.assertAllEqual(np.zeros(2), entropy_) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/distribution_test.py b/tensorflow/contrib/distributions/python/kernel_tests/distribution_test.py index f42feae25d..f073f51a69 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/distribution_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/distribution_test.py @@ -47,7 +47,7 @@ class DistributionTest(test.TestCase): ] sample_shapes = [(), (10,), (10, 20, 30)] - with self.test_session(): + with self.cached_session(): for cls in classes: for sample_shape in sample_shapes: param_shapes = cls.param_shapes(sample_shape) @@ -62,7 +62,7 @@ class DistributionTest(test.TestCase): self.assertEqual(dist.parameters, dist_copy.parameters) def testCopyExtraArgs(self): - with self.test_session(): + with self.cached_session(): # Note: we cannot easily test all distributions since each requires # different initialization arguments. We therefore spot test a few. normal = tfd.Normal(loc=1., scale=2., validate_args=True) @@ -72,7 +72,7 @@ class DistributionTest(test.TestCase): self.assertEqual(wishart.parameters, wishart.copy().parameters) def testCopyOverride(self): - with self.test_session(): + with self.cached_session(): normal = tfd.Normal(loc=1., scale=2., validate_args=True) unused_normal_copy = normal.copy(validate_args=False) base_params = normal.parameters.copy() @@ -82,7 +82,7 @@ class DistributionTest(test.TestCase): self.assertEqual(base_params, copy_params) def testIsScalar(self): - with self.test_session(): + with self.cached_session(): mu = 1. sigma = 2. @@ -152,7 +152,7 @@ class DistributionTest(test.TestCase): def testSampleShapeHints(self): fake_distribution = self._GetFakeDistribution() - with self.test_session(): + with self.cached_session(): # Make a new session since we're playing with static shapes. [And below.] x = array_ops.placeholder(dtype=dtypes.float32) dist = fake_distribution(batch_shape=[2, 3], event_shape=[5]) @@ -162,28 +162,28 @@ class DistributionTest(test.TestCase): # unknown values, ie, Dimension(None). self.assertAllEqual([6, 7, 2, 3, 5], y.get_shape().as_list()) - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(dtype=dtypes.float32) dist = fake_distribution(batch_shape=[None, 3], event_shape=[5]) sample_shape = ops.convert_to_tensor([6, 7], dtype=dtypes.int32) y = dist._set_sample_static_shape(x, sample_shape) self.assertAllEqual([6, 7, None, 3, 5], y.get_shape().as_list()) - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(dtype=dtypes.float32) dist = fake_distribution(batch_shape=[None, 3], event_shape=[None]) sample_shape = ops.convert_to_tensor([6, 7], dtype=dtypes.int32) y = dist._set_sample_static_shape(x, sample_shape) self.assertAllEqual([6, 7, None, 3, None], y.get_shape().as_list()) - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(dtype=dtypes.float32) dist = fake_distribution(batch_shape=None, event_shape=None) sample_shape = ops.convert_to_tensor([6, 7], dtype=dtypes.int32) y = dist._set_sample_static_shape(x, sample_shape) self.assertTrue(y.get_shape().ndims is None) - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(dtype=dtypes.float32) dist = fake_distribution(batch_shape=[None, 3], event_shape=None) sample_shape = ops.convert_to_tensor([6, 7], dtype=dtypes.int32) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/distribution_util_test.py b/tensorflow/contrib/distributions/python/kernel_tests/distribution_util_test.py index 181c46d2e5..05f5d30666 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/distribution_util_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/distribution_util_test.py @@ -100,7 +100,7 @@ class MakeTrilScaleTest(test.TestCase): def _testLegalInputs( self, loc=None, shape_hint=None, scale_params=None): for args in _powerset(scale_params.items()): - with self.test_session(): + with self.cached_session(): args = dict(args) scale_args = dict({ @@ -143,19 +143,19 @@ class MakeTrilScaleTest(test.TestCase): }) def testZeroTriU(self): - with self.test_session(): + with self.cached_session(): scale = distribution_util.make_tril_scale(scale_tril=[[1., 1], [1., 1.]]) self.assertAllClose([[1., 0], [1., 1.]], scale.to_dense().eval()) def testValidateArgs(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("diagonal part must be non-zero"): scale = distribution_util.make_tril_scale( scale_tril=[[0., 1], [1., 1.]], validate_args=True) scale.to_dense().eval() def testAssertPositive(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("diagonal part must be positive"): scale = distribution_util.make_tril_scale( scale_tril=[[-1., 1], [1., 1.]], @@ -169,7 +169,7 @@ class MakeDiagScaleTest(test.TestCase): def _testLegalInputs( self, loc=None, shape_hint=None, scale_params=None): for args in _powerset(scale_params.items()): - with self.test_session(): + with self.cached_session(): args = dict(args) scale_args = dict({ @@ -204,14 +204,14 @@ class MakeDiagScaleTest(test.TestCase): }) def testValidateArgs(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("diagonal part must be non-zero"): scale = distribution_util.make_diag_scale( scale_diag=[[0., 1], [1., 1.]], validate_args=True) scale.to_dense().eval() def testAssertPositive(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("diagonal part must be positive"): scale = distribution_util.make_diag_scale( scale_diag=[[-1., 1], [1., 1.]], @@ -241,7 +241,7 @@ class ShapesFromLocAndScaleTest(test.TestCase): loc = constant_op.constant(np.zeros((2, 3))) diag = array_ops.placeholder(dtypes.float64) scale = linear_operator_diag.LinearOperatorDiag(diag) - with self.test_session() as sess: + with self.cached_session() as sess: batch_shape, event_shape = sess.run( distribution_util.shapes_from_loc_and_scale(loc, scale), feed_dict={diag: np.ones((5, 1, 3))}) @@ -252,7 +252,7 @@ class ShapesFromLocAndScaleTest(test.TestCase): loc = array_ops.placeholder(dtypes.float64) diag = constant_op.constant(np.ones((5, 2, 3))) scale = linear_operator_diag.LinearOperatorDiag(diag) - with self.test_session(): + with self.cached_session(): batch_shape, event_shape = distribution_util.shapes_from_loc_and_scale( loc, scale) # batch_shape depends on both args, and so is dynamic. Since loc did not @@ -266,7 +266,7 @@ class ShapesFromLocAndScaleTest(test.TestCase): loc = array_ops.placeholder(dtypes.float64) diag = array_ops.placeholder(dtypes.float64) scale = linear_operator_diag.LinearOperatorDiag(diag) - with self.test_session() as sess: + with self.cached_session() as sess: batch_shape, event_shape = sess.run( distribution_util.shapes_from_loc_and_scale(loc, scale), feed_dict={diag: np.ones((5, 2, 3)), loc: np.zeros((2, 3))}) @@ -286,7 +286,7 @@ class ShapesFromLocAndScaleTest(test.TestCase): loc = None diag = array_ops.placeholder(dtypes.float64) scale = linear_operator_diag.LinearOperatorDiag(diag) - with self.test_session() as sess: + with self.cached_session() as sess: batch_shape, event_shape = sess.run( distribution_util.shapes_from_loc_and_scale(loc, scale), feed_dict={diag: np.ones((5, 1, 3))}) @@ -307,7 +307,7 @@ class GetBroadcastShapeTest(test.TestCase): x = array_ops.ones((2, 1, 3)) y = array_ops.placeholder(x.dtype) z = array_ops.ones(()) - with self.test_session() as sess: + with self.cached_session() as sess: bcast_shape = sess.run( distribution_util.get_broadcast_shape(x, y, z), feed_dict={y: np.ones((1, 5, 3)).astype(np.float32)}) @@ -317,7 +317,7 @@ class GetBroadcastShapeTest(test.TestCase): class TridiagTest(test.TestCase): def testWorksCorrectlyNoBatches(self): - with self.test_session(): + with self.cached_session(): self.assertAllEqual( [[4., 8., 0., 0.], [1., 5., 9., 0.], @@ -329,7 +329,7 @@ class TridiagTest(test.TestCase): [8., 9., 10.]).eval()) def testWorksCorrectlyBatches(self): - with self.test_session(): + with self.cached_session(): self.assertAllClose( [[[4., 8., 0., 0.], [1., 5., 9., 0.], @@ -349,7 +349,7 @@ class TridiagTest(test.TestCase): rtol=1e-5, atol=0.) def testHandlesNone(self): - with self.test_session(): + with self.cached_session(): self.assertAllClose( [[[4., 0., 0., 0.], [0., 5., 0., 0.], @@ -396,7 +396,7 @@ class MixtureStddevTest(test.TestCase): means_tf, sigmas_tf) - with self.test_session() as sess: + with self.cached_session() as sess: actual_devs = sess.run(mix_dev) self.assertAllClose(actual_devs, expected_devs) @@ -405,7 +405,7 @@ class MixtureStddevTest(test.TestCase): class PadMixtureDimensionsTest(test.TestCase): def test_pad_mixture_dimensions_mixture(self): - with self.test_session() as sess: + with self.cached_session() as sess: gm = mixture.Mixture( cat=categorical.Categorical(probs=[[0.3, 0.7]]), components=[ @@ -422,7 +422,7 @@ class PadMixtureDimensionsTest(test.TestCase): self.assertAllEqual(x_out.reshape([-1]), x_pad_out.reshape([-1])) def test_pad_mixture_dimensions_mixture_same_family(self): - with self.test_session() as sess: + with self.cached_session() as sess: gm = mixture_same_family.MixtureSameFamily( mixture_distribution=categorical.Categorical(probs=[0.3, 0.7]), components_distribution=mvn_diag.MultivariateNormalDiag( @@ -444,7 +444,7 @@ class _PadTest(object): [4, 5, 6]]) value_ = np.float32(0.25) count_ = np.int32(2) - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder_with_default( x_, shape=x_.shape if self.is_static_shape else None) value = (constant_op.constant(value_) if self.is_static_shape @@ -491,7 +491,7 @@ class _PadTest(object): [4, 5, 6]]) value_ = np.float32(0.25) count_ = np.int32(2) - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder_with_default( x_, shape=x_.shape if self.is_static_shape else None) value = (constant_op.constant(value_) if self.is_static_shape @@ -542,9 +542,9 @@ class PadDynamicTest(_PadTest, test.TestCase): return False +@test_util.run_all_in_graph_and_eager_modes class TestMoveDimension(test.TestCase): - @test_util.run_in_graph_and_eager_modes def test_move_dimension_static_shape(self): x = random_ops.random_normal(shape=[200, 30, 4, 1, 6]) @@ -561,7 +561,6 @@ class TestMoveDimension(test.TestCase): x_perm = distribution_util.move_dimension(x, 4, 2) self.assertAllEqual(x_perm.shape.as_list(), [200, 30, 6, 4, 1]) - @test_util.run_in_graph_and_eager_modes def test_move_dimension_dynamic_shape(self): x_ = random_ops.random_normal(shape=[200, 30, 4, 1, 6]) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/geometric_test.py b/tensorflow/contrib/distributions/python/kernel_tests/geometric_test.py index 87cdd0485a..a627d85229 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/geometric_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/geometric_test.py @@ -34,7 +34,7 @@ from tensorflow.python.platform import test class GeometricTest(test.TestCase): def testGeometricShape(self): - with self.test_session(): + with self.cached_session(): probs = constant_op.constant([.1] * 5) geom = geometric.Geometric(probs=probs) @@ -45,19 +45,19 @@ class GeometricTest(test.TestCase): def testInvalidP(self): invalid_ps = [-.01, -0.01, -2.] - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Condition x >= 0"): geom = geometric.Geometric(probs=invalid_ps, validate_args=True) geom.probs.eval() invalid_ps = [1.1, 3., 5.] - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Condition x <= y"): geom = geometric.Geometric(probs=invalid_ps, validate_args=True) geom.probs.eval() def testGeomLogPmf(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 probs = constant_op.constant([.2] * batch_size) probs_v = .2 @@ -73,7 +73,7 @@ class GeometricTest(test.TestCase): self.assertAllClose(np.exp(expected_log_prob), pmf.eval()) def testGeometricLogPmf_validate_args(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 probs = constant_op.constant([.9] * batch_size) x = array_ops.placeholder(dtypes.float32, shape=[6]) @@ -95,7 +95,7 @@ class GeometricTest(test.TestCase): self.assertEqual([6,], pmf.get_shape()) def testGeometricLogPmfMultidimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 probs = constant_op.constant([[.2, .3, .5]] * batch_size) probs_v = np.array([.2, .3, .5]) @@ -113,7 +113,7 @@ class GeometricTest(test.TestCase): self.assertAllClose(np.exp(expected_log_prob), pmf_values) def testGeometricCDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 probs = constant_op.constant([[.2, .4, .5]] * batch_size) probs_v = np.array([.2, .4, .5]) @@ -127,7 +127,7 @@ class GeometricTest(test.TestCase): self.assertAllClose(expected_cdf, cdf.eval()) def testGeometricEntropy(self): - with self.test_session(): + with self.cached_session(): probs_v = np.array([.1, .3, .25], dtype=np.float32) geom = geometric.Geometric(probs=probs_v) expected_entropy = stats.geom.entropy(probs_v, loc=-1) @@ -135,7 +135,7 @@ class GeometricTest(test.TestCase): self.assertAllClose(expected_entropy, geom.entropy().eval()) def testGeometricMean(self): - with self.test_session(): + with self.cached_session(): probs_v = np.array([.1, .3, .25]) geom = geometric.Geometric(probs=probs_v) expected_means = stats.geom.mean(probs_v, loc=-1) @@ -143,7 +143,7 @@ class GeometricTest(test.TestCase): self.assertAllClose(expected_means, geom.mean().eval()) def testGeometricVariance(self): - with self.test_session(): + with self.cached_session(): probs_v = np.array([.1, .3, .25]) geom = geometric.Geometric(probs=probs_v) expected_vars = stats.geom.var(probs_v, loc=-1) @@ -151,7 +151,7 @@ class GeometricTest(test.TestCase): self.assertAllClose(expected_vars, geom.variance().eval()) def testGeometricStddev(self): - with self.test_session(): + with self.cached_session(): probs_v = np.array([.1, .3, .25]) geom = geometric.Geometric(probs=probs_v) expected_stddevs = stats.geom.std(probs_v, loc=-1) @@ -159,14 +159,14 @@ class GeometricTest(test.TestCase): self.assertAllClose(geom.stddev().eval(), expected_stddevs) def testGeometricMode(self): - with self.test_session(): + with self.cached_session(): probs_v = np.array([.1, .3, .25]) geom = geometric.Geometric(probs=probs_v) self.assertEqual([3,], geom.mode().get_shape()) self.assertAllClose([0.] * 3, geom.mode().eval()) def testGeometricSample(self): - with self.test_session(): + with self.cached_session(): probs_v = [.3, .9] probs = constant_op.constant(probs_v) n = constant_op.constant(100000) @@ -186,7 +186,7 @@ class GeometricTest(test.TestCase): rtol=.02) def testGeometricSampleMultiDimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 2 probs_v = [.3, .9] probs = constant_op.constant([probs_v] * batch_size) @@ -215,7 +215,7 @@ class GeometricTest(test.TestCase): rtol=.02) def testGeometricAtBoundary(self): - with self.test_session(): + with self.cached_session(): geom = geometric.Geometric(probs=1., validate_args=True) x = np.array([0., 2., 3., 4., 5., 6., 7.], dtype=np.float32) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/half_normal_test.py b/tensorflow/contrib/distributions/python/kernel_tests/half_normal_test.py index a4e7566008..686de9d246 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/half_normal_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/half_normal_test.py @@ -55,7 +55,7 @@ class HalfNormalTest(test.TestCase): self.assertAllEqual(all_true, is_finite) def _testParamShapes(self, sample_shape, expected): - with self.test_session(): + with self.cached_session(): param_shapes = hn_lib.HalfNormal.param_shapes(sample_shape) scale_shape = param_shapes["scale"] self.assertAllEqual(expected, scale_shape.eval()) @@ -87,7 +87,7 @@ class HalfNormalTest(test.TestCase): tensor_shape.TensorShape(sample_shape), sample_shape) def testHalfNormalLogPDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 scale = constant_op.constant([3.0] * batch_size) x = np.array([-2.5, 2.5, 4.0, 0.0, -1.0, 2.0], dtype=np.float32) @@ -106,7 +106,7 @@ class HalfNormalTest(test.TestCase): self.assertAllClose(np.exp(expected_log_pdf), pdf.eval()) def testHalfNormalLogPDFMultidimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 scale = constant_op.constant([[3.0, 1.0]] * batch_size) x = np.array([[-2.5, 2.5, 4.0, 0.0, -1.0, 2.0]], dtype=np.float32).T @@ -125,7 +125,7 @@ class HalfNormalTest(test.TestCase): self.assertAllClose(np.exp(expected_log_pdf), pdf.eval()) def testHalfNormalCDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 50 scale = self._rng.rand(batch_size) + 1.0 x = np.linspace(-8.0, 8.0, batch_size).astype(np.float64) @@ -144,7 +144,7 @@ class HalfNormalTest(test.TestCase): self.assertAllClose(np.exp(expected_logcdf), cdf.eval(), atol=0) def testHalfNormalSurvivalFunction(self): - with self.test_session(): + with self.cached_session(): batch_size = 50 scale = self._rng.rand(batch_size) + 1.0 x = np.linspace(-8.0, 8.0, batch_size).astype(np.float64) @@ -163,7 +163,7 @@ class HalfNormalTest(test.TestCase): self.assertAllClose(np.exp(expected_logsf), sf.eval(), atol=0) def testHalfNormalQuantile(self): - with self.test_session(): + with self.cached_session(): batch_size = 50 scale = self._rng.rand(batch_size) + 1.0 p = np.linspace(0., 1.0, batch_size).astype(np.float64) @@ -191,13 +191,13 @@ class HalfNormalTest(test.TestCase): print(func.__name__) value = func(x) grads = gradients_impl.gradients(value, [scale]) - with self.test_session(graph=g): + with self.session(graph=g): variables.global_variables_initializer().run() self.assertAllFinite(value) self.assertAllFinite(grads[0]) def testHalfNormalEntropy(self): - with self.test_session(): + with self.cached_session(): scale = np.array([[1.0, 2.0, 3.0]]) halfnorm = hn_lib.HalfNormal(scale=scale) @@ -210,7 +210,7 @@ class HalfNormalTest(test.TestCase): self.assertAllClose(expected_entropy, entropy.eval()) def testHalfNormalMeanAndMode(self): - with self.test_session(): + with self.cached_session(): scale = np.array([11., 12., 13.]) halfnorm = hn_lib.HalfNormal(scale=scale) @@ -223,7 +223,7 @@ class HalfNormalTest(test.TestCase): self.assertAllEqual([0., 0., 0.], halfnorm.mode().eval()) def testHalfNormalVariance(self): - with self.test_session(): + with self.cached_session(): scale = np.array([7., 7., 7.]) halfnorm = hn_lib.HalfNormal(scale=scale) expected_variance = scale ** 2.0 * (1.0 - 2.0 / np.pi) @@ -232,7 +232,7 @@ class HalfNormalTest(test.TestCase): self.assertAllEqual(expected_variance, halfnorm.variance().eval()) def testHalfNormalStandardDeviation(self): - with self.test_session(): + with self.cached_session(): scale = np.array([7., 7., 7.]) halfnorm = hn_lib.HalfNormal(scale=scale) expected_variance = scale ** 2.0 * (1.0 - 2.0 / np.pi) @@ -241,7 +241,7 @@ class HalfNormalTest(test.TestCase): self.assertAllEqual(np.sqrt(expected_variance), halfnorm.stddev().eval()) def testHalfNormalSample(self): - with self.test_session(): + with self.cached_session(): scale = constant_op.constant(3.0) n = constant_op.constant(100000) halfnorm = hn_lib.HalfNormal(scale=scale) @@ -263,7 +263,7 @@ class HalfNormalTest(test.TestCase): self.assertAllEqual(expected_shape_static, sample.eval().shape) def testHalfNormalSampleMultiDimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 2 scale = constant_op.constant([[2.0, 3.0]] * batch_size) n = constant_op.constant(100000) @@ -287,13 +287,13 @@ class HalfNormalTest(test.TestCase): self.assertAllEqual(expected_shape_static, sample.eval().shape) def testNegativeSigmaFails(self): - with self.test_session(): + with self.cached_session(): halfnorm = hn_lib.HalfNormal(scale=[-5.], validate_args=True, name="G") with self.assertRaisesOpError("Condition x > 0 did not hold"): halfnorm.mean().eval() def testHalfNormalShape(self): - with self.test_session(): + with self.cached_session(): scale = constant_op.constant([6.0] * 5) halfnorm = hn_lib.HalfNormal(scale=scale) @@ -306,7 +306,7 @@ class HalfNormalTest(test.TestCase): scale = array_ops.placeholder(dtype=dtypes.float32) halfnorm = hn_lib.HalfNormal(scale=scale) - with self.test_session() as sess: + with self.cached_session() as sess: # get_batch_shape should return an "<unknown>" tensor. self.assertEqual(halfnorm.batch_shape, tensor_shape.TensorShape(None)) self.assertEqual(halfnorm.event_shape, ()) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/independent_test.py b/tensorflow/contrib/distributions/python/kernel_tests/independent_test.py index 6a69f9e60b..ecf27289d7 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/independent_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/independent_test.py @@ -52,7 +52,7 @@ class ProductDistributionTest(test.TestCase): def testSampleAndLogProbUnivariate(self): loc = np.float32([-1., 1]) scale = np.float32([0.1, 0.5]) - with self.test_session() as sess: + with self.cached_session() as sess: ind = independent_lib.Independent( distribution=normal_lib.Normal(loc=loc, scale=scale), reinterpreted_batch_ndims=1) @@ -73,7 +73,7 @@ class ProductDistributionTest(test.TestCase): def testSampleAndLogProbMultivariate(self): loc = np.float32([[-1., 1], [1, -1]]) scale = np.float32([1., 0.5]) - with self.test_session() as sess: + with self.cached_session() as sess: ind = independent_lib.Independent( distribution=mvn_diag_lib.MultivariateNormalDiag( loc=loc, @@ -98,7 +98,7 @@ class ProductDistributionTest(test.TestCase): loc = np.float32([[-1., 1], [1, -1]]) scale = np.float32([1., 0.5]) n_samp = 1e4 - with self.test_session() as sess: + with self.cached_session() as sess: ind = independent_lib.Independent( distribution=mvn_diag_lib.MultivariateNormalDiag( loc=loc, @@ -231,7 +231,7 @@ class ProductDistributionTest(test.TestCase): def expected_log_prob(x, logits): return (x * logits - np.log1p(np.exp(logits))).sum(-1).sum(-1).sum(-1) - with self.test_session() as sess: + with self.cached_session() as sess: logits_ph = array_ops.placeholder( dtypes.float32, shape=logits.shape if static_shape else None) ind = independent_lib.Independent( diff --git a/tensorflow/contrib/distributions/python/kernel_tests/inverse_gamma_test.py b/tensorflow/contrib/distributions/python/kernel_tests/inverse_gamma_test.py index 6eb96ea9ff..70551d89d9 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/inverse_gamma_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/inverse_gamma_test.py @@ -30,7 +30,7 @@ from tensorflow.python.platform import test class InverseGammaTest(test.TestCase): def testInverseGammaShape(self): - with self.test_session(): + with self.cached_session(): alpha = constant_op.constant([3.0] * 5) beta = constant_op.constant(11.0) inv_gamma = inverse_gamma.InverseGamma(concentration=alpha, rate=beta) @@ -43,7 +43,7 @@ class InverseGammaTest(test.TestCase): [])) def testInverseGammaLogPDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 alpha = constant_op.constant([2.0] * batch_size) beta = constant_op.constant([3.0] * batch_size) @@ -61,7 +61,7 @@ class InverseGammaTest(test.TestCase): self.assertAllClose(pdf.eval(), np.exp(expected_log_pdf)) def testInverseGammaLogPDFMultidimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 alpha = constant_op.constant([[2.0, 4.0]] * batch_size) beta = constant_op.constant([[3.0, 4.0]] * batch_size) @@ -81,7 +81,7 @@ class InverseGammaTest(test.TestCase): self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) def testInverseGammaLogPDFMultidimensionalBroadcasting(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 alpha = constant_op.constant([[2.0, 4.0]] * batch_size) beta = constant_op.constant(3.0) @@ -101,7 +101,7 @@ class InverseGammaTest(test.TestCase): self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) def testInverseGammaCDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 alpha_v = 2.0 beta_v = 3.0 @@ -117,7 +117,7 @@ class InverseGammaTest(test.TestCase): self.assertAllClose(cdf.eval(), expected_cdf) def testInverseGammaMode(self): - with self.test_session(): + with self.cached_session(): alpha_v = np.array([5.5, 3.0, 2.5]) beta_v = np.array([1.0, 4.0, 5.0]) inv_gamma = inverse_gamma.InverseGamma(concentration=alpha_v, rate=beta_v) @@ -126,7 +126,7 @@ class InverseGammaTest(test.TestCase): self.assertAllClose(inv_gamma.mode().eval(), expected_modes) def testInverseGammaMeanAllDefined(self): - with self.test_session(): + with self.cached_session(): alpha_v = np.array([5.5, 3.0, 2.5]) beta_v = np.array([1.0, 4.0, 5.0]) inv_gamma = inverse_gamma.InverseGamma(concentration=alpha_v, rate=beta_v) @@ -135,7 +135,7 @@ class InverseGammaTest(test.TestCase): self.assertAllClose(inv_gamma.mean().eval(), expected_means) def testInverseGammaMeanAllowNanStats(self): - with self.test_session(): + with self.cached_session(): # Mean will not be defined for the first entry. alpha_v = np.array([1.0, 3.0, 2.5]) beta_v = np.array([1.0, 4.0, 5.0]) @@ -145,7 +145,7 @@ class InverseGammaTest(test.TestCase): inv_gamma.mean().eval() def testInverseGammaMeanNanStats(self): - with self.test_session(): + with self.cached_session(): # Mode will not be defined for the first two entries. alpha_v = np.array([0.5, 1.0, 3.0, 2.5]) beta_v = np.array([1.0, 2.0, 4.0, 5.0]) @@ -158,7 +158,7 @@ class InverseGammaTest(test.TestCase): self.assertAllClose(inv_gamma.mean().eval(), expected_means) def testInverseGammaVarianceAllDefined(self): - with self.test_session(): + with self.cached_session(): alpha_v = np.array([7.0, 3.0, 2.5]) beta_v = np.array([1.0, 4.0, 5.0]) inv_gamma = inverse_gamma.InverseGamma(concentration=alpha_v, rate=beta_v) @@ -167,7 +167,7 @@ class InverseGammaTest(test.TestCase): self.assertAllClose(inv_gamma.variance().eval(), expected_variances) def testInverseGammaVarianceAllowNanStats(self): - with self.test_session(): + with self.cached_session(): alpha_v = np.array([1.5, 3.0, 2.5]) beta_v = np.array([1.0, 4.0, 5.0]) inv_gamma = inverse_gamma.InverseGamma( @@ -176,7 +176,7 @@ class InverseGammaTest(test.TestCase): inv_gamma.variance().eval() def testInverseGammaVarianceNanStats(self): - with self.test_session(): + with self.cached_session(): alpha_v = np.array([1.5, 3.0, 2.5]) beta_v = np.array([1.0, 4.0, 5.0]) inv_gamma = inverse_gamma.InverseGamma( @@ -187,7 +187,7 @@ class InverseGammaTest(test.TestCase): self.assertAllClose(inv_gamma.variance().eval(), expected_variances) def testInverseGammaEntropy(self): - with self.test_session(): + with self.cached_session(): alpha_v = np.array([1.0, 3.0, 2.5]) beta_v = np.array([1.0, 4.0, 5.0]) expected_entropy = stats.invgamma.entropy(alpha_v, scale=beta_v) @@ -292,7 +292,7 @@ class InverseGammaTest(test.TestCase): self.assertNear(1., total, err=err) def testInverseGammaNonPositiveInitializationParamsRaises(self): - with self.test_session(): + with self.cached_session(): alpha_v = constant_op.constant(0.0, name="alpha") beta_v = constant_op.constant(1.0, name="beta") inv_gamma = inverse_gamma.InverseGamma( @@ -307,7 +307,7 @@ class InverseGammaTest(test.TestCase): inv_gamma.mean().eval() def testInverseGammaWithSoftplusConcentrationRate(self): - with self.test_session(): + with self.cached_session(): alpha = constant_op.constant([-0.1, -2.9], name="alpha") beta = constant_op.constant([1.0, -4.8], name="beta") inv_gamma = inverse_gamma.InverseGammaWithSoftplusConcentrationRate( diff --git a/tensorflow/contrib/distributions/python/kernel_tests/kumaraswamy_test.py b/tensorflow/contrib/distributions/python/kernel_tests/kumaraswamy_test.py index 2980e2bfe9..e39db51728 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/kumaraswamy_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/kumaraswamy_test.py @@ -77,7 +77,7 @@ def _kumaraswamy_pdf(a, b, x): class KumaraswamyTest(test.TestCase): def testSimpleShapes(self): - with self.test_session(): + with self.cached_session(): a = np.random.rand(3) b = np.random.rand(3) dist = kumaraswamy_lib.Kumaraswamy(a, b) @@ -87,7 +87,7 @@ class KumaraswamyTest(test.TestCase): self.assertEqual(tensor_shape.TensorShape([3]), dist.batch_shape) def testComplexShapes(self): - with self.test_session(): + with self.cached_session(): a = np.random.rand(3, 2, 2) b = np.random.rand(3, 2, 2) dist = kumaraswamy_lib.Kumaraswamy(a, b) @@ -97,7 +97,7 @@ class KumaraswamyTest(test.TestCase): self.assertEqual(tensor_shape.TensorShape([3, 2, 2]), dist.batch_shape) def testComplexShapesBroadcast(self): - with self.test_session(): + with self.cached_session(): a = np.random.rand(3, 2, 2) b = np.random.rand(2, 2) dist = kumaraswamy_lib.Kumaraswamy(a, b) @@ -109,7 +109,7 @@ class KumaraswamyTest(test.TestCase): def testAProperty(self): a = [[1., 2, 3]] b = [[2., 4, 3]] - with self.test_session(): + with self.cached_session(): dist = kumaraswamy_lib.Kumaraswamy(a, b) self.assertEqual([1, 3], dist.concentration1.get_shape()) self.assertAllClose(a, dist.concentration1.eval()) @@ -117,7 +117,7 @@ class KumaraswamyTest(test.TestCase): def testBProperty(self): a = [[1., 2, 3]] b = [[2., 4, 3]] - with self.test_session(): + with self.cached_session(): dist = kumaraswamy_lib.Kumaraswamy(a, b) self.assertEqual([1, 3], dist.concentration0.get_shape()) self.assertAllClose(b, dist.concentration0.eval()) @@ -125,7 +125,7 @@ class KumaraswamyTest(test.TestCase): def testPdfXProper(self): a = [[1., 2, 3]] b = [[2., 4, 3]] - with self.test_session(): + with self.cached_session(): dist = kumaraswamy_lib.Kumaraswamy(a, b, validate_args=True) dist.prob([.1, .3, .6]).eval() dist.prob([.2, .3, .5]).eval() @@ -136,7 +136,7 @@ class KumaraswamyTest(test.TestCase): dist.prob([.1, .2, 1.2]).eval() def testPdfTwoBatches(self): - with self.test_session(): + with self.cached_session(): a = [1., 2] b = [1., 2] x = [.5, .5] @@ -147,7 +147,7 @@ class KumaraswamyTest(test.TestCase): self.assertEqual((2,), pdf.get_shape()) def testPdfTwoBatchesNontrivialX(self): - with self.test_session(): + with self.cached_session(): a = [1., 2] b = [1., 2] x = [.3, .7] @@ -158,7 +158,7 @@ class KumaraswamyTest(test.TestCase): self.assertEqual((2,), pdf.get_shape()) def testPdfUniformZeroBatch(self): - with self.test_session(): + with self.cached_session(): # This is equivalent to a uniform distribution a = 1. b = 1. @@ -170,7 +170,7 @@ class KumaraswamyTest(test.TestCase): self.assertEqual((5,), pdf.get_shape()) def testPdfAStretchedInBroadcastWhenSameRank(self): - with self.test_session(): + with self.cached_session(): a = [[1., 2]] b = [[1., 2]] x = [[.5, .5], [.3, .7]] @@ -181,7 +181,7 @@ class KumaraswamyTest(test.TestCase): self.assertEqual((2, 2), pdf.get_shape()) def testPdfAStretchedInBroadcastWhenLowerRank(self): - with self.test_session(): + with self.cached_session(): a = [1., 2] b = [1., 2] x = [[.5, .5], [.2, .8]] @@ -191,7 +191,7 @@ class KumaraswamyTest(test.TestCase): self.assertEqual((2, 2), pdf.get_shape()) def testPdfXStretchedInBroadcastWhenSameRank(self): - with self.test_session(): + with self.cached_session(): a = [[1., 2], [2., 3]] b = [[1., 2], [2., 3]] x = [[.5, .5]] @@ -201,7 +201,7 @@ class KumaraswamyTest(test.TestCase): self.assertEqual((2, 2), pdf.get_shape()) def testPdfXStretchedInBroadcastWhenLowerRank(self): - with self.test_session(): + with self.cached_session(): a = [[1., 2], [2., 3]] b = [[1., 2], [2., 3]] x = [.5, .5] @@ -289,7 +289,7 @@ class KumaraswamyTest(test.TestCase): self.assertAllClose(expected_entropy, dist.entropy().eval()) def testKumaraswamySample(self): - with self.test_session(): + with self.cached_session(): a = 1. b = 2. kumaraswamy = kumaraswamy_lib.Kumaraswamy(a, b) @@ -316,7 +316,7 @@ class KumaraswamyTest(test.TestCase): # Test that sampling with the same seed twice gives the same results. def testKumaraswamySampleMultipleTimes(self): - with self.test_session(): + with self.cached_session(): a_val = 1. b_val = 2. n_val = 100 @@ -334,7 +334,7 @@ class KumaraswamyTest(test.TestCase): self.assertAllClose(samples1, samples2) def testKumaraswamySampleMultidimensional(self): - with self.test_session(): + with self.cached_session(): a = np.random.rand(3, 2, 2).astype(np.float32) b = np.random.rand(3, 2, 2).astype(np.float32) kumaraswamy = kumaraswamy_lib.Kumaraswamy(a, b) @@ -351,7 +351,7 @@ class KumaraswamyTest(test.TestCase): atol=1e-1) def testKumaraswamyCdf(self): - with self.test_session(): + with self.cached_session(): shape = (30, 40, 50) for dt in (np.float32, np.float64): a = 10. * np.random.random(shape).astype(dt) @@ -366,7 +366,7 @@ class KumaraswamyTest(test.TestCase): _kumaraswamy_cdf(a, b, x), actual, rtol=1e-4, atol=0) def testKumaraswamyLogCdf(self): - with self.test_session(): + with self.cached_session(): shape = (30, 40, 50) for dt in (np.float32, np.float64): a = 10. * np.random.random(shape).astype(dt) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/logistic_test.py b/tensorflow/contrib/distributions/python/kernel_tests/logistic_test.py index 251be9ed4f..12a2d4f8ec 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/logistic_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/logistic_test.py @@ -39,7 +39,7 @@ class LogisticTest(test.TestCase): dist.reparameterization_type == distribution.FULLY_REPARAMETERIZED) def testLogisticLogProb(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 np_loc = np.array([2.0] * batch_size, dtype=np.float32) loc = constant_op.constant(np_loc) @@ -57,7 +57,7 @@ class LogisticTest(test.TestCase): self.assertAllClose(prob.eval(), np.exp(expected_log_prob)) def testLogisticCDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 np_loc = np.array([2.0] * batch_size, dtype=np.float32) loc = constant_op.constant(np_loc) @@ -72,7 +72,7 @@ class LogisticTest(test.TestCase): self.assertAllClose(cdf.eval(), expected_cdf) def testLogisticLogCDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 np_loc = np.array([2.0] * batch_size, dtype=np.float32) loc = constant_op.constant(np_loc) @@ -87,7 +87,7 @@ class LogisticTest(test.TestCase): self.assertAllClose(logcdf.eval(), expected_logcdf) def testLogisticSurvivalFunction(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 np_loc = np.array([2.0] * batch_size, dtype=np.float32) loc = constant_op.constant(np_loc) @@ -102,7 +102,7 @@ class LogisticTest(test.TestCase): self.assertAllClose(survival_function.eval(), expected_survival_function) def testLogisticLogSurvivalFunction(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 np_loc = np.array([2.0] * batch_size, dtype=np.float32) loc = constant_op.constant(np_loc) @@ -118,7 +118,7 @@ class LogisticTest(test.TestCase): expected_logsurvival_function) def testLogisticMean(self): - with self.test_session(): + with self.cached_session(): loc = [2.0, 1.5, 1.0] scale = 1.5 expected_mean = stats.logistic.mean(loc, scale) @@ -126,7 +126,7 @@ class LogisticTest(test.TestCase): self.assertAllClose(dist.mean().eval(), expected_mean) def testLogisticVariance(self): - with self.test_session(): + with self.cached_session(): loc = [2.0, 1.5, 1.0] scale = 1.5 expected_variance = stats.logistic.var(loc, scale) @@ -134,7 +134,7 @@ class LogisticTest(test.TestCase): self.assertAllClose(dist.variance().eval(), expected_variance) def testLogisticEntropy(self): - with self.test_session(): + with self.cached_session(): batch_size = 3 np_loc = np.array([2.0] * batch_size, dtype=np.float32) loc = constant_op.constant(np_loc) @@ -144,7 +144,7 @@ class LogisticTest(test.TestCase): self.assertAllClose(dist.entropy().eval(), expected_entropy) def testLogisticSample(self): - with self.test_session(): + with self.cached_session(): loc = [3.0, 4.0, 2.0] scale = 1.0 dist = logistic.Logistic(loc, scale) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/mixture_same_family_test.py b/tensorflow/contrib/distributions/python/kernel_tests/mixture_same_family_test.py index ff6092fc26..faff42d243 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/mixture_same_family_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/mixture_same_family_test.py @@ -35,7 +35,7 @@ class MixtureSameFamilyTest(test_util.VectorDistributionTestHelpers, test.TestCase): def testSampleAndLogProbUnivariateShapes(self): - with self.test_session(): + with self.cached_session(): gm = mixture_same_family_lib.MixtureSameFamily( mixture_distribution=categorical_lib.Categorical(probs=[0.3, 0.7]), components_distribution=normal_lib.Normal( @@ -46,7 +46,7 @@ class MixtureSameFamilyTest(test_util.VectorDistributionTestHelpers, self.assertEqual([4, 5], log_prob_x.shape) def testSampleAndLogProbBatch(self): - with self.test_session(): + with self.cached_session(): gm = mixture_same_family_lib.MixtureSameFamily( mixture_distribution=categorical_lib.Categorical(probs=[[0.3, 0.7]]), components_distribution=normal_lib.Normal( @@ -59,7 +59,7 @@ class MixtureSameFamilyTest(test_util.VectorDistributionTestHelpers, def testSampleAndLogProbShapesBroadcastMix(self): mix_probs = np.float32([.3, .7]) bern_probs = np.float32([[.4, .6], [.25, .75]]) - with self.test_session(): + with self.cached_session(): bm = mixture_same_family_lib.MixtureSameFamily( mixture_distribution=categorical_lib.Categorical(probs=mix_probs), components_distribution=bernoulli_lib.Bernoulli(probs=bern_probs)) @@ -72,7 +72,7 @@ class MixtureSameFamilyTest(test_util.VectorDistributionTestHelpers, np.ones_like(x_, dtype=np.bool), np.logical_or(x_ == 0., x_ == 1.)) def testSampleAndLogProbMultivariateShapes(self): - with self.test_session(): + with self.cached_session(): gm = mixture_same_family_lib.MixtureSameFamily( mixture_distribution=categorical_lib.Categorical(probs=[0.3, 0.7]), components_distribution=mvn_diag_lib.MultivariateNormalDiag( @@ -83,7 +83,7 @@ class MixtureSameFamilyTest(test_util.VectorDistributionTestHelpers, self.assertEqual([4, 5], log_prob_x.shape) def testSampleAndLogProbBatchMultivariateShapes(self): - with self.test_session(): + with self.cached_session(): gm = mixture_same_family_lib.MixtureSameFamily( mixture_distribution=categorical_lib.Categorical(probs=[0.3, 0.7]), components_distribution=mvn_diag_lib.MultivariateNormalDiag( @@ -98,7 +98,7 @@ class MixtureSameFamilyTest(test_util.VectorDistributionTestHelpers, self.assertEqual([4, 5, 2], log_prob_x.shape) def testSampleConsistentLogProb(self): - with self.test_session() as sess: + with self.cached_session() as sess: gm = mixture_same_family_lib.MixtureSameFamily( mixture_distribution=categorical_lib.Categorical(probs=[0.3, 0.7]), components_distribution=mvn_diag_lib.MultivariateNormalDiag( @@ -111,7 +111,7 @@ class MixtureSameFamilyTest(test_util.VectorDistributionTestHelpers, sess.run, gm, radius=1., center=[1., -1], rtol=0.02) def testLogCdf(self): - with self.test_session() as sess: + with self.cached_session() as sess: gm = mixture_same_family_lib.MixtureSameFamily( mixture_distribution=categorical_lib.Categorical(probs=[0.3, 0.7]), components_distribution=normal_lib.Normal( @@ -128,7 +128,7 @@ class MixtureSameFamilyTest(test_util.VectorDistributionTestHelpers, rtol=1e-6, atol=0.0) def testSampleConsistentMeanCovariance(self): - with self.test_session() as sess: + with self.cached_session() as sess: gm = mixture_same_family_lib.MixtureSameFamily( mixture_distribution=categorical_lib.Categorical(probs=[0.3, 0.7]), components_distribution=mvn_diag_lib.MultivariateNormalDiag( @@ -136,7 +136,7 @@ class MixtureSameFamilyTest(test_util.VectorDistributionTestHelpers, self.run_test_sample_consistent_mean_covariance(sess.run, gm) def testVarianceConsistentCovariance(self): - with self.test_session() as sess: + with self.cached_session() as sess: gm = mixture_same_family_lib.MixtureSameFamily( mixture_distribution=categorical_lib.Categorical(probs=[0.3, 0.7]), components_distribution=mvn_diag_lib.MultivariateNormalDiag( diff --git a/tensorflow/contrib/distributions/python/kernel_tests/mixture_test.py b/tensorflow/contrib/distributions/python/kernel_tests/mixture_test.py index 0206489175..f8dbd34d02 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/mixture_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/mixture_test.py @@ -152,7 +152,7 @@ class MixtureTest(test.TestCase): use_static_graph = False def testShapes(self): - with self.test_session(): + with self.cached_session(): for batch_shape in ([], [1], [2, 3, 4]): dist = make_univariate_mixture(batch_shape, num_components=10, use_static_graph=self.use_static_graph) @@ -200,7 +200,7 @@ class MixtureTest(test.TestCase): use_static_graph=self.use_static_graph) def testBrokenShapesDynamic(self): - with self.test_session(): + with self.cached_session(): d0_param = array_ops.placeholder(dtype=dtypes.float32) d1_param = array_ops.placeholder(dtype=dtypes.float32) d = ds.Mixture( @@ -246,7 +246,7 @@ class MixtureTest(test.TestCase): # mixture are checked for equivalence. def testMeanUnivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: for batch_shape in ((), (2,), (2, 3)): dist = make_univariate_mixture( batch_shape=batch_shape, num_components=2, @@ -268,7 +268,7 @@ class MixtureTest(test.TestCase): self.assertAllClose(true_mean, mean_value) def testMeanMultivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: for batch_shape in ((), (2,), (2, 3)): dist = make_multivariate_mixture( batch_shape=batch_shape, num_components=2, event_shape=(4,), @@ -296,7 +296,7 @@ class MixtureTest(test.TestCase): def testStddevShapeUnivariate(self): num_components = 2 # This is the same shape test which is done in 'testMeanUnivariate'. - with self.test_session() as sess: + with self.cached_session() as sess: for batch_shape in ((), (2,), (2, 3)): dist = make_univariate_mixture( batch_shape=batch_shape, num_components=num_components, @@ -337,7 +337,7 @@ class MixtureTest(test.TestCase): num_components = 2 # This is the same shape test which is done in 'testMeanMultivariate'. - with self.test_session() as sess: + with self.cached_session() as sess: for batch_shape in ((), (2,), (2, 3)): dist = make_multivariate_mixture( batch_shape=batch_shape, @@ -392,12 +392,12 @@ class MixtureTest(test.TestCase): ], use_static_graph=self.use_static_graph) mix_dev = mixture_dist.stddev() - with self.test_session() as sess: + with self.cached_session() as sess: actual_stddev = sess.run(mix_dev) self.assertAllClose(actual_stddev, ground_truth_stddev) def testProbScalarUnivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: dist = make_univariate_mixture(batch_shape=[], num_components=2, use_static_graph=self.use_static_graph) for x in [ @@ -423,7 +423,7 @@ class MixtureTest(test.TestCase): self.assertAllClose(total_prob, p_x_value) def testProbScalarMultivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: dist = make_multivariate_mixture( batch_shape=[], num_components=2, event_shape=[3], use_static_graph=self.use_static_graph) @@ -452,7 +452,7 @@ class MixtureTest(test.TestCase): self.assertAllClose(total_prob, p_x_value) def testProbBatchUnivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: dist = make_univariate_mixture(batch_shape=[2, 3], num_components=2, use_static_graph=self.use_static_graph) @@ -479,7 +479,7 @@ class MixtureTest(test.TestCase): self.assertAllClose(total_prob, p_x_value) def testProbBatchMultivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: dist = make_multivariate_mixture( batch_shape=[2, 3], num_components=2, event_shape=[4], use_static_graph=self.use_static_graph) @@ -506,7 +506,7 @@ class MixtureTest(test.TestCase): self.assertAllClose(total_prob, p_x_value) def testSampleScalarBatchUnivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: num_components = 3 batch_shape = [] dist = make_univariate_mixture( @@ -539,7 +539,7 @@ class MixtureTest(test.TestCase): mus = [-5.0, 0.0, 5.0, 4.0, 20.0] sigmas = [0.1, 5.0, 3.0, 0.2, 4.0] - with self.test_session(): + with self.cached_session(): n = 100 random_seed.set_random_seed(654321) @@ -567,7 +567,7 @@ class MixtureTest(test.TestCase): self.assertAllClose(samples1, samples2) def testSampleScalarBatchMultivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: num_components = 3 dist = make_multivariate_mixture( batch_shape=[], num_components=num_components, event_shape=[2], @@ -592,7 +592,7 @@ class MixtureTest(test.TestCase): self.assertAllClose(which_dist_samples, sample_values[which_c, :]) def testSampleBatchUnivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: num_components = 3 dist = make_univariate_mixture( batch_shape=[2, 3], num_components=num_components, @@ -620,7 +620,7 @@ class MixtureTest(test.TestCase): sample_values[which_c_s, which_c_b0, which_c_b1]) def _testSampleBatchMultivariate(self, fully_known_batch_shape): - with self.test_session() as sess: + with self.cached_session() as sess: num_components = 3 if fully_known_batch_shape: batch_shape = [2, 3] @@ -672,7 +672,7 @@ class MixtureTest(test.TestCase): self._testSampleBatchMultivariate(fully_known_batch_shape=False) def testEntropyLowerBoundMultivariate(self): - with self.test_session() as sess: + with self.cached_session() as sess: for batch_shape in ((), (2,), (2, 3)): dist = make_multivariate_mixture( batch_shape=batch_shape, num_components=2, event_shape=(4,), @@ -732,7 +732,7 @@ class MixtureTest(test.TestCase): x_cdf_tf = mixture_tf.cdf(x_tensor) x_log_cdf_tf = mixture_tf.log_cdf(x_tensor) - with self.test_session() as sess: + with self.cached_session() as sess: for x_feed in xs_to_check: x_cdf_tf_result, x_log_cdf_tf_result = sess.run( [x_cdf_tf, x_log_cdf_tf], feed_dict={x_tensor: x_feed}) @@ -778,7 +778,7 @@ class MixtureTest(test.TestCase): x_cdf_tf = mixture_tf.cdf(x_tensor) x_log_cdf_tf = mixture_tf.log_cdf(x_tensor) - with self.test_session() as sess: + with self.cached_session() as sess: for x_feed in xs_to_check: x_cdf_tf_result, x_log_cdf_tf_result = sess.run( [x_cdf_tf, x_log_cdf_tf], @@ -802,7 +802,7 @@ class MixtureTest(test.TestCase): Mixture's use of dynamic partition requires `random_gamma` correctly returns an empty `Tensor`. """ - with self.test_session(): + with self.cached_session(): gm = ds.Mixture( cat=ds.Categorical(probs=[.3, .7]), components=[ds.Gamma(1., 2.), diff --git a/tensorflow/contrib/distributions/python/kernel_tests/moving_stats_test.py b/tensorflow/contrib/distributions/python/kernel_tests/moving_stats_test.py index 509fc66c05..3c988dad8a 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/moving_stats_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/moving_stats_test.py @@ -36,7 +36,7 @@ class MovingReduceMeanVarianceTest(test.TestCase): shape = [1, 2] true_mean = np.array([[0., 3.]]) true_stddev = np.array([[1.1, 0.5]]) - with self.test_session() as sess: + with self.cached_session() as sess: # Start "x" out with this mean. mean_var = variables.Variable(array_ops.zeros_like(true_mean)) variance_var = variables.Variable(array_ops.ones_like(true_stddev)) @@ -84,7 +84,7 @@ class MovingReduceMeanVarianceTest(test.TestCase): shape = [1, 2] true_mean = np.array([[0., 3.]]) true_stddev = np.array([[1.1, 0.5]]) - with self.test_session() as sess: + with self.cached_session() as sess: # Start "x" out with this mean. x = random_ops.random_normal(shape, dtype=np.float64, seed=0) x = true_stddev * x + true_mean @@ -111,7 +111,7 @@ class MovingLogExponentialMovingMeanExpTest(test.TestCase): true_mean = np.array([[0., 3.]]) true_stddev = np.array([[1.1, 0.5]]) decay = 0.99 - with self.test_session() as sess: + with self.cached_session() as sess: # Start "x" out with this mean. x = random_ops.random_normal(shape, dtype=np.float64, seed=0) x = true_stddev * x + true_mean diff --git a/tensorflow/contrib/distributions/python/kernel_tests/mvn_diag_plus_low_rank_test.py b/tensorflow/contrib/distributions/python/kernel_tests/mvn_diag_plus_low_rank_test.py index a924d2e383..88d0d346a4 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/mvn_diag_plus_low_rank_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/mvn_diag_plus_low_rank_test.py @@ -39,7 +39,7 @@ class MultivariateNormalDiagPlusLowRankTest(test.TestCase): diag = np.array([[1., 2], [3, 4], [5, 6]]) # batch_shape: [1], event_shape: [] identity_multiplier = np.array([5.]) - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiagPlusLowRank( scale_diag=diag, scale_identity_multiplier=identity_multiplier, @@ -61,7 +61,7 @@ class MultivariateNormalDiagPlusLowRankTest(test.TestCase): diag = np.array([[1., 2], [3, 4], [5, 6]]) # batch_shape: [3, 1], event_shape: [] identity_multiplier = np.array([[5.], [4], [3]]) - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiagPlusLowRank( scale_diag=diag, scale_identity_multiplier=identity_multiplier, @@ -75,7 +75,7 @@ class MultivariateNormalDiagPlusLowRankTest(test.TestCase): diag = np.array([[1., 2], [3, 4], [5, 6]]) # batch_shape: [3], event_shape: [] identity_multiplier = np.array([5., 4, 3]) - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiagPlusLowRank( scale_diag=diag, scale_identity_multiplier=identity_multiplier, @@ -94,7 +94,7 @@ class MultivariateNormalDiagPlusLowRankTest(test.TestCase): loc = np.array([1., 0, -1]) # batch_shape: [3], event_shape: [] identity_multiplier = np.array([5., 4, 3]) - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiagPlusLowRank( loc=loc, scale_identity_multiplier=identity_multiplier, @@ -116,7 +116,7 @@ class MultivariateNormalDiagPlusLowRankTest(test.TestCase): diag_large = [1.0, 5.0] v = [[2.0], [3.0]] diag_small = [3.0] - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiagPlusLowRank( loc=mu, scale_diag=diag_large, @@ -146,7 +146,7 @@ class MultivariateNormalDiagPlusLowRankTest(test.TestCase): true_variance = np.diag(true_covariance) true_stddev = np.sqrt(true_variance) - with self.test_session() as sess: + with self.cached_session() as sess: dist = ds.MultivariateNormalDiagPlusLowRank( loc=mu, scale_diag=diag_large, @@ -380,7 +380,7 @@ class MultivariateNormalDiagPlusLowRankTest(test.TestCase): cov = np.stack([np.matmul(scale[0], scale[0].T), np.matmul(scale[1], scale[1].T)]) logging.vlog(2, "expected_cov:\n{}".format(cov)) - with self.test_session(): + with self.cached_session(): mvn = ds.MultivariateNormalDiagPlusLowRank( loc=mu, scale_perturb_factor=u, diff --git a/tensorflow/contrib/distributions/python/kernel_tests/mvn_diag_test.py b/tensorflow/contrib/distributions/python/kernel_tests/mvn_diag_test.py index 9635134b08..6a3d171f6c 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/mvn_diag_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/mvn_diag_test.py @@ -45,14 +45,14 @@ class MultivariateNormalDiagTest(test.TestCase): def testScalarParams(self): mu = -1. diag = -5. - with self.test_session(): + with self.cached_session(): with self.assertRaisesRegexp(ValueError, "at least 1 dimension"): ds.MultivariateNormalDiag(mu, diag) def testVectorParams(self): mu = [-1.] diag = [-5.] - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiag(mu, diag, validate_args=True) self.assertAllEqual([3, 1], dist.sample(3).get_shape()) @@ -63,7 +63,7 @@ class MultivariateNormalDiagTest(test.TestCase): # Batch shape = [1], event shape = [3] mu = array_ops.zeros((1, 3)) diag = array_ops.ones((1, 3)) - with self.test_session(): + with self.cached_session(): base_dist = ds.MultivariateNormalDiag(mu, diag, validate_args=True) dist = ds.TransformedDistribution( base_dist, @@ -75,14 +75,14 @@ class MultivariateNormalDiagTest(test.TestCase): def testMean(self): mu = [-1., 1] diag = [1., -5] - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiag(mu, diag, validate_args=True) self.assertAllEqual(mu, dist.mean().eval()) def testMeanWithBroadcastLoc(self): mu = [-1.] diag = [1., -5] - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiag(mu, diag, validate_args=True) self.assertAllEqual([-1., -1.], dist.mean().eval()) @@ -91,14 +91,14 @@ class MultivariateNormalDiagTest(test.TestCase): diag = [-1., 5] diag_mat = np.diag(diag) scipy_mvn = stats.multivariate_normal(mean=mu, cov=diag_mat**2) - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiag(mu, diag, validate_args=True) self.assertAllClose(scipy_mvn.entropy(), dist.entropy().eval(), atol=1e-4) def testSample(self): mu = [-1., 1] diag = [1., -2] - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiag(mu, diag, validate_args=True) samps = dist.sample(int(1e3), seed=0).eval() cov_mat = array_ops.matrix_diag(diag).eval()**2 @@ -111,7 +111,7 @@ class MultivariateNormalDiagTest(test.TestCase): def testSingularScaleRaises(self): mu = [-1., 1] diag = [1., 0] - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiag(mu, diag, validate_args=True) with self.assertRaisesOpError("Singular"): dist.sample().eval() @@ -123,7 +123,7 @@ class MultivariateNormalDiagTest(test.TestCase): # diag corresponds to no batches of 3-variate normals diag = np.ones([3]) - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiag(mu, diag, validate_args=True) mean = dist.mean() @@ -142,7 +142,7 @@ class MultivariateNormalDiagTest(test.TestCase): atol=0.10, rtol=0.05) def testCovariance(self): - with self.test_session(): + with self.cached_session(): mvn = ds.MultivariateNormalDiag( loc=array_ops.zeros([2, 3], dtype=dtypes.float32)) self.assertAllClose( @@ -178,7 +178,7 @@ class MultivariateNormalDiagTest(test.TestCase): mvn.covariance().eval()) def testVariance(self): - with self.test_session(): + with self.cached_session(): mvn = ds.MultivariateNormalDiag( loc=array_ops.zeros([2, 3], dtype=dtypes.float32)) self.assertAllClose( @@ -203,7 +203,7 @@ class MultivariateNormalDiagTest(test.TestCase): mvn.variance().eval()) def testStddev(self): - with self.test_session(): + with self.cached_session(): mvn = ds.MultivariateNormalDiag( loc=array_ops.zeros([2, 3], dtype=dtypes.float32)) self.assertAllClose( @@ -229,7 +229,7 @@ class MultivariateNormalDiagTest(test.TestCase): def testMultivariateNormalDiagWithSoftplusScale(self): mu = [-1.0, 1.0] diag = [-1.0, -2.0] - with self.test_session(): + with self.cached_session(): dist = ds.MultivariateNormalDiagWithSoftplusScale( mu, diag, validate_args=True) samps = dist.sample(1000, seed=0).eval() @@ -241,7 +241,7 @@ class MultivariateNormalDiagTest(test.TestCase): def testMultivariateNormalDiagNegLogLikelihood(self): num_draws = 50 dims = 3 - with self.test_session() as sess: + with self.cached_session() as sess: x_pl = array_ops.placeholder(dtype=dtypes.float32, shape=[None, dims], name="x") @@ -291,7 +291,7 @@ class MultivariateNormalDiagTest(test.TestCase): def testKLDivIdenticalGradientDefined(self): dims = 3 - with self.test_session() as sess: + with self.cached_session() as sess: loc = array_ops.zeros([dims], dtype=dtypes.float32) mvn = ds.MultivariateNormalDiag( loc=loc, diff --git a/tensorflow/contrib/distributions/python/kernel_tests/mvn_full_covariance_test.py b/tensorflow/contrib/distributions/python/kernel_tests/mvn_full_covariance_test.py index b003526392..bbf803f045 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/mvn_full_covariance_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/mvn_full_covariance_test.py @@ -40,7 +40,7 @@ class MultivariateNormalFullCovarianceTest(test.TestCase): return math_ops.matmul(chol, chol, adjoint_b=True).eval() def testRaisesIfInitializedWithNonSymmetricMatrix(self): - with self.test_session(): + with self.cached_session(): mu = [1., 2.] sigma = [[1., 0.], [1., 1.]] # Nonsingular, but not symmetric mvn = ds.MultivariateNormalFullCovariance(mu, sigma, validate_args=True) @@ -48,14 +48,14 @@ class MultivariateNormalFullCovarianceTest(test.TestCase): mvn.covariance().eval() def testNamePropertyIsSetByInitArg(self): - with self.test_session(): + with self.cached_session(): mu = [1., 2.] sigma = [[1., 0.], [0., 1.]] mvn = ds.MultivariateNormalFullCovariance(mu, sigma, name="Billy") self.assertEqual(mvn.name, "Billy/") def testDoesNotRaiseIfInitializedWithSymmetricMatrix(self): - with self.test_session(): + with self.cached_session(): mu = rng.rand(10) sigma = self._random_pd_matrix(10, 10) mvn = ds.MultivariateNormalFullCovariance(mu, sigma, validate_args=True) @@ -63,7 +63,7 @@ class MultivariateNormalFullCovarianceTest(test.TestCase): mvn.covariance().eval() def testLogPDFScalarBatch(self): - with self.test_session(): + with self.cached_session(): mu = rng.rand(2) sigma = self._random_pd_matrix(2, 2) mvn = ds.MultivariateNormalFullCovariance(mu, sigma, validate_args=True) @@ -82,7 +82,7 @@ class MultivariateNormalFullCovarianceTest(test.TestCase): self.assertAllClose(expected_pdf, pdf.eval()) def testLogPDFScalarBatchCovarianceNotProvided(self): - with self.test_session(): + with self.cached_session(): mu = rng.rand(2) mvn = ds.MultivariateNormalFullCovariance( mu, covariance_matrix=None, validate_args=True) @@ -102,7 +102,7 @@ class MultivariateNormalFullCovarianceTest(test.TestCase): self.assertAllClose(expected_pdf, pdf.eval()) def testShapes(self): - with self.test_session(): + with self.cached_session(): mu = rng.rand(3, 5, 2) covariance = self._random_pd_matrix(3, 5, 2, 2) @@ -133,7 +133,7 @@ class MultivariateNormalFullCovarianceTest(test.TestCase): def testKLBatch(self): batch_shape = [2] event_shape = [3] - with self.test_session(): + with self.cached_session(): mu_a, sigma_a = self._random_mu_and_sigma(batch_shape, event_shape) mu_b, sigma_b = self._random_mu_and_sigma(batch_shape, event_shape) mvn_a = ds.MultivariateNormalFullCovariance( @@ -159,7 +159,7 @@ class MultivariateNormalFullCovarianceTest(test.TestCase): def testKLBatchBroadcast(self): batch_shape = [2] event_shape = [3] - with self.test_session(): + with self.cached_session(): mu_a, sigma_a = self._random_mu_and_sigma(batch_shape, event_shape) # No batch shape. mu_b, sigma_b = self._random_mu_and_sigma([], event_shape) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/mvn_tril_test.py b/tensorflow/contrib/distributions/python/kernel_tests/mvn_tril_test.py index b556d06123..776fc2ca9d 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/mvn_tril_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/mvn_tril_test.py @@ -45,7 +45,7 @@ class MultivariateNormalTriLTest(test.TestCase): return chol.eval(), sigma.eval() def testLogPDFScalarBatch(self): - with self.test_session(): + with self.cached_session(): mu = self._rng.rand(2) chol, sigma = self._random_chol(2, 2) chol[1, 1] = -chol[1, 1] @@ -65,7 +65,7 @@ class MultivariateNormalTriLTest(test.TestCase): self.assertAllClose(expected_pdf, pdf.eval()) def testLogPDFXIsHigherRank(self): - with self.test_session(): + with self.cached_session(): mu = self._rng.rand(2) chol, sigma = self._random_chol(2, 2) chol[0, 0] = -chol[0, 0] @@ -85,7 +85,7 @@ class MultivariateNormalTriLTest(test.TestCase): self.assertAllClose(expected_pdf, pdf.eval(), atol=0., rtol=0.03) def testLogPDFXLowerDimension(self): - with self.test_session(): + with self.cached_session(): mu = self._rng.rand(3, 2) chol, sigma = self._random_chol(3, 2, 2) chol[0, 0, 0] = -chol[0, 0, 0] @@ -108,7 +108,7 @@ class MultivariateNormalTriLTest(test.TestCase): self.assertAllClose(expected_pdf, pdf.eval()[1]) def testEntropy(self): - with self.test_session(): + with self.cached_session(): mu = self._rng.rand(2) chol, sigma = self._random_chol(2, 2) chol[0, 0] = -chol[0, 0] @@ -121,7 +121,7 @@ class MultivariateNormalTriLTest(test.TestCase): self.assertAllClose(expected_entropy, entropy.eval()) def testEntropyMultidimensional(self): - with self.test_session(): + with self.cached_session(): mu = self._rng.rand(3, 5, 2) chol, sigma = self._random_chol(3, 5, 2, 2) chol[1, 0, 0, 0] = -chol[1, 0, 0, 0] @@ -136,7 +136,7 @@ class MultivariateNormalTriLTest(test.TestCase): self.assertAllClose(expected_entropy, entropy.eval()[1, 1]) def testSample(self): - with self.test_session(): + with self.cached_session(): mu = self._rng.rand(2) chol, sigma = self._random_chol(2, 2) chol[0, 0] = -chol[0, 0] @@ -152,7 +152,7 @@ class MultivariateNormalTriLTest(test.TestCase): self.assertAllClose(np.cov(sample_values, rowvar=0), sigma, atol=0.06) def testSingularScaleRaises(self): - with self.test_session(): + with self.cached_session(): mu = None chol = [[1., 0.], [0., 0.]] mvn = ds.MultivariateNormalTriL(mu, chol, validate_args=True) @@ -160,7 +160,7 @@ class MultivariateNormalTriLTest(test.TestCase): mvn.sample().eval() def testSampleWithSampleShape(self): - with self.test_session(): + with self.cached_session(): mu = self._rng.rand(3, 5, 2) chol, sigma = self._random_chol(3, 5, 2, 2) chol[1, 0, 0, 0] = -chol[1, 0, 0, 0] @@ -185,7 +185,7 @@ class MultivariateNormalTriLTest(test.TestCase): self.assertAllClose(expected_log_pdf, x_log_pdf) def testSampleMultiDimensional(self): - with self.test_session(): + with self.cached_session(): mu = self._rng.rand(3, 5, 2) chol, sigma = self._random_chol(3, 5, 2, 2) chol[1, 0, 0, 0] = -chol[1, 0, 0, 0] @@ -205,7 +205,7 @@ class MultivariateNormalTriLTest(test.TestCase): atol=1e-1) def testShapes(self): - with self.test_session(): + with self.cached_session(): mu = self._rng.rand(3, 5, 2) chol, _ = self._random_chol(3, 5, 2, 2) chol[1, 0, 0, 0] = -chol[1, 0, 0, 0] @@ -237,7 +237,7 @@ class MultivariateNormalTriLTest(test.TestCase): def testKLNonBatch(self): batch_shape = [] event_shape = [2] - with self.test_session(): + with self.cached_session(): mu_a, sigma_a = self._random_mu_and_sigma(batch_shape, event_shape) mu_b, sigma_b = self._random_mu_and_sigma(batch_shape, event_shape) mvn_a = ds.MultivariateNormalTriL( @@ -259,7 +259,7 @@ class MultivariateNormalTriLTest(test.TestCase): def testKLBatch(self): batch_shape = [2] event_shape = [3] - with self.test_session(): + with self.cached_session(): mu_a, sigma_a = self._random_mu_and_sigma(batch_shape, event_shape) mu_b, sigma_b = self._random_mu_and_sigma(batch_shape, event_shape) mvn_a = ds.MultivariateNormalTriL( @@ -285,7 +285,7 @@ class MultivariateNormalTriLTest(test.TestCase): def testKLBatchBroadcast(self): batch_shape = [2] event_shape = [3] - with self.test_session(): + with self.cached_session(): mu_a, sigma_a = self._random_mu_and_sigma(batch_shape, event_shape) # No batch shape. mu_b, sigma_b = self._random_mu_and_sigma([], event_shape) @@ -312,7 +312,7 @@ class MultivariateNormalTriLTest(test.TestCase): def testKLTwoIdenticalDistributionsIsZero(self): batch_shape = [2] event_shape = [3] - with self.test_session(): + with self.cached_session(): mu_a, sigma_a = self._random_mu_and_sigma(batch_shape, event_shape) mvn_a = ds.MultivariateNormalTriL( loc=mu_a, @@ -336,7 +336,7 @@ class MultivariateNormalTriLTest(test.TestCase): true_variance = np.diag(true_covariance) true_stddev = np.sqrt(true_variance) - with self.test_session() as sess: + with self.cached_session() as sess: dist = ds.MultivariateNormalTriL( loc=mu, scale_tril=scale_tril, diff --git a/tensorflow/contrib/distributions/python/kernel_tests/negative_binomial_test.py b/tensorflow/contrib/distributions/python/kernel_tests/negative_binomial_test.py index 37edaa42cd..a46b81af35 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/negative_binomial_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/negative_binomial_test.py @@ -34,7 +34,7 @@ from tensorflow.python.platform import test class NegativeBinomialTest(test.TestCase): def testNegativeBinomialShape(self): - with self.test_session(): + with self.cached_session(): probs = [.1] * 5 total_count = [2.0] * 5 negbinom = negative_binomial.NegativeBinomial( @@ -46,7 +46,7 @@ class NegativeBinomialTest(test.TestCase): self.assertEqual(tensor_shape.TensorShape([]), negbinom.event_shape) def testNegativeBinomialShapeBroadcast(self): - with self.test_session(): + with self.cached_session(): probs = [[.1, .2, .3]] * 5 total_count = [[2.]] * 5 negbinom = negative_binomial.NegativeBinomial( @@ -60,7 +60,7 @@ class NegativeBinomialTest(test.TestCase): def testLogits(self): logits = [[0., 9., -0.5]] - with self.test_session(): + with self.cached_session(): negbinom = negative_binomial.NegativeBinomial( total_count=3., logits=logits) self.assertEqual([1, 3], negbinom.probs.get_shape()) @@ -69,14 +69,14 @@ class NegativeBinomialTest(test.TestCase): def testInvalidP(self): invalid_ps = [-.01, 0., -2.,] - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Condition x >= 0"): negbinom = negative_binomial.NegativeBinomial( 5., probs=invalid_ps, validate_args=True) negbinom.probs.eval() invalid_ps = [1.01, 2., 1.001,] - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("probs has components greater than 1."): negbinom = negative_binomial.NegativeBinomial( 5., probs=invalid_ps, validate_args=True) @@ -84,14 +84,14 @@ class NegativeBinomialTest(test.TestCase): def testInvalidNegativeCount(self): invalid_rs = [-.01, 0., -2.,] - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Condition x > 0"): negbinom = negative_binomial.NegativeBinomial( total_count=invalid_rs, probs=0.1, validate_args=True) negbinom.total_count.eval() def testNegativeBinomialLogCdf(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 probs = [.2] * batch_size probs_v = .2 @@ -109,7 +109,7 @@ class NegativeBinomialTest(test.TestCase): self.assertAllClose(np.exp(expected_log_cdf), cdf.eval()) def testNegativeBinomialLogCdfValidateArgs(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 probs = [.9] * batch_size total_count = 5. @@ -119,7 +119,7 @@ class NegativeBinomialTest(test.TestCase): negbinom.log_cdf(-1.).eval() def testNegativeBinomialLogPmf(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 probs = [.2] * batch_size probs_v = .2 @@ -137,7 +137,7 @@ class NegativeBinomialTest(test.TestCase): self.assertAllClose(np.exp(expected_log_pmf), pmf.eval()) def testNegativeBinomialLogPmfValidateArgs(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 probs = [.9] * batch_size total_count = 5. @@ -162,7 +162,7 @@ class NegativeBinomialTest(test.TestCase): self.assertEqual([6], pmf.get_shape()) def testNegativeBinomialLogPmfMultidimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 probs = constant_op.constant([[.2, .3, .5]] * batch_size) probs_v = np.array([.2, .3, .5]) @@ -183,7 +183,7 @@ class NegativeBinomialTest(test.TestCase): self.assertAllClose(np.exp(expected_log_pmf), pmf_values) def testNegativeBinomialMean(self): - with self.test_session(): + with self.cached_session(): total_count = 5. probs = np.array([.1, .3, .25], dtype=np.float32) negbinom = negative_binomial.NegativeBinomial( @@ -193,7 +193,7 @@ class NegativeBinomialTest(test.TestCase): self.assertAllClose(expected_means, negbinom.mean().eval()) def testNegativeBinomialVariance(self): - with self.test_session(): + with self.cached_session(): total_count = 5. probs = np.array([.1, .3, .25], dtype=np.float32) negbinom = negative_binomial.NegativeBinomial( @@ -203,7 +203,7 @@ class NegativeBinomialTest(test.TestCase): self.assertAllClose(expected_vars, negbinom.variance().eval()) def testNegativeBinomialStddev(self): - with self.test_session(): + with self.cached_session(): total_count = 5. probs = np.array([.1, .3, .25], dtype=np.float32) negbinom = negative_binomial.NegativeBinomial( @@ -213,7 +213,7 @@ class NegativeBinomialTest(test.TestCase): self.assertAllClose(expected_stds, negbinom.stddev().eval()) def testNegativeBinomialSample(self): - with self.test_session() as sess: + with self.cached_session() as sess: probs = [.3, .9] total_count = [4., 11.] n = int(100e3) @@ -242,7 +242,7 @@ class NegativeBinomialTest(test.TestCase): rtol=.02) def testLogProbOverflow(self): - with self.test_session() as sess: + with self.cached_session() as sess: logits = np.float32([20., 30., 40.]) total_count = np.float32(1.) x = np.float32(0.) @@ -253,7 +253,7 @@ class NegativeBinomialTest(test.TestCase): np.isfinite(log_prob_)) def testLogProbUnderflow(self): - with self.test_session() as sess: + with self.cached_session() as sess: logits = np.float32([-90, -100, -110]) total_count = np.float32(1.) x = np.float32(0.) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/onehot_categorical_test.py b/tensorflow/contrib/distributions/python/kernel_tests/onehot_categorical_test.py index 111f88eeb5..84ee19123c 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/onehot_categorical_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/onehot_categorical_test.py @@ -44,7 +44,7 @@ class OneHotCategoricalTest(test.TestCase): def testP(self): p = [0.2, 0.8] dist = onehot_categorical.OneHotCategorical(probs=p) - with self.test_session(): + with self.cached_session(): self.assertAllClose(p, dist.probs.eval()) self.assertAllEqual([2], dist.logits.get_shape()) @@ -52,14 +52,14 @@ class OneHotCategoricalTest(test.TestCase): p = np.array([0.2, 0.8], dtype=np.float32) logits = np.log(p) - 50. dist = onehot_categorical.OneHotCategorical(logits=logits) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([2], dist.probs.get_shape()) self.assertAllEqual([2], dist.logits.get_shape()) self.assertAllClose(dist.probs.eval(), p) self.assertAllClose(dist.logits.eval(), logits) def testShapes(self): - with self.test_session(): + with self.cached_session(): for batch_shape in ([], [1], [2, 3, 4]): dist = make_onehot_categorical(batch_shape, 10) self.assertAllEqual(batch_shape, dist.batch_shape.as_list()) @@ -97,7 +97,7 @@ class OneHotCategoricalTest(test.TestCase): np.array([1]+[0]*4, dtype=np.int64)).dtype) def testUnknownShape(self): - with self.test_session(): + with self.cached_session(): logits = array_ops.placeholder(dtype=dtypes.float32) dist = onehot_categorical.OneHotCategorical(logits) sample = dist.sample() @@ -112,7 +112,7 @@ class OneHotCategoricalTest(test.TestCase): def testEntropyNoBatch(self): logits = np.log([0.2, 0.8]) - 50. dist = onehot_categorical.OneHotCategorical(logits) - with self.test_session(): + with self.cached_session(): self.assertAllClose( dist.entropy().eval(), -(0.2 * np.log(0.2) + 0.8 * np.log(0.8))) @@ -120,7 +120,7 @@ class OneHotCategoricalTest(test.TestCase): def testEntropyWithBatch(self): logits = np.log([[0.2, 0.8], [0.6, 0.4]]) - 50. dist = onehot_categorical.OneHotCategorical(logits) - with self.test_session(): + with self.cached_session(): self.assertAllClose(dist.entropy().eval(), [ -(0.2 * np.log(0.2) + 0.8 * np.log(0.8)), -(0.6 * np.log(0.6) + 0.4 * np.log(0.4)) @@ -128,7 +128,7 @@ class OneHotCategoricalTest(test.TestCase): def testPmf(self): # check that probability of samples correspond to their class probabilities - with self.test_session(): + with self.cached_session(): logits = self._rng.random_sample(size=(8, 2, 10)) prob = np.exp(logits)/np.sum(np.exp(logits), axis=-1, keepdims=True) dist = onehot_categorical.OneHotCategorical(logits=logits) @@ -138,7 +138,7 @@ class OneHotCategoricalTest(test.TestCase): self.assertAllClose(expected_prob, np_prob.flatten()) def testSample(self): - with self.test_session(): + with self.cached_session(): probs = [[[0.2, 0.8], [0.4, 0.6]]] dist = onehot_categorical.OneHotCategorical(math_ops.log(probs) - 50.) n = 100 @@ -150,7 +150,7 @@ class OneHotCategoricalTest(test.TestCase): self.assertFalse(np.any(sample_values > 1)) def testSampleWithSampleShape(self): - with self.test_session(): + with self.cached_session(): probs = [[[0.2, 0.8], [0.4, 0.6]]] dist = onehot_categorical.OneHotCategorical(math_ops.log(probs) - 50.) samples = dist.sample((100, 100), seed=123) @@ -166,7 +166,7 @@ class OneHotCategoricalTest(test.TestCase): exp_logits = np.exp(logits) return exp_logits / exp_logits.sum(axis=-1, keepdims=True) - with self.test_session() as sess: + with self.cached_session() as sess: for categories in [2, 10]: for batch_size in [1, 2]: p_logits = self._rng.random_sample((batch_size, categories)) @@ -193,7 +193,7 @@ class OneHotCategoricalTest(test.TestCase): self.assertAllClose(kl_sample_, kl_expected, atol=1e-2, rtol=0.) def testSampleUnbiasedNonScalarBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: logits = self._rng.rand(4, 3, 2).astype(np.float32) dist = onehot_categorical.OneHotCategorical(logits=logits) n = int(3e3) @@ -221,7 +221,7 @@ class OneHotCategoricalTest(test.TestCase): actual_covariance_, sample_covariance_, atol=0., rtol=0.10) def testSampleUnbiasedScalarBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: logits = self._rng.rand(3).astype(np.float32) dist = onehot_categorical.OneHotCategorical(logits=logits) n = int(1e4) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/poisson_lognormal_test.py b/tensorflow/contrib/distributions/python/kernel_tests/poisson_lognormal_test.py index 1035cb00f7..e2d04c9c27 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/poisson_lognormal_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/poisson_lognormal_test.py @@ -29,7 +29,7 @@ class _PoissonLogNormalQuadratureCompoundTest( """Tests the PoissonLogNormalQuadratureCompoundTest distribution.""" def testSampleProbConsistent(self): - with self.test_session() as sess: + with self.cached_session() as sess: pln = poisson_lognormal.PoissonLogNormalQuadratureCompound( loc=array_ops.placeholder_with_default( -2., @@ -43,7 +43,7 @@ class _PoissonLogNormalQuadratureCompoundTest( sess.run, pln, batch_size=1, rtol=0.1) def testMeanVariance(self): - with self.test_session() as sess: + with self.cached_session() as sess: pln = poisson_lognormal.PoissonLogNormalQuadratureCompound( loc=array_ops.placeholder_with_default( 0., @@ -57,7 +57,7 @@ class _PoissonLogNormalQuadratureCompoundTest( sess.run, pln, rtol=0.02) def testSampleProbConsistentBroadcastScalar(self): - with self.test_session() as sess: + with self.cached_session() as sess: pln = poisson_lognormal.PoissonLogNormalQuadratureCompound( loc=array_ops.placeholder_with_default( [0., -0.5], @@ -71,7 +71,7 @@ class _PoissonLogNormalQuadratureCompoundTest( sess.run, pln, batch_size=2, rtol=0.1, atol=0.01) def testMeanVarianceBroadcastScalar(self): - with self.test_session() as sess: + with self.cached_session() as sess: pln = poisson_lognormal.PoissonLogNormalQuadratureCompound( loc=array_ops.placeholder_with_default( [0., -0.5], @@ -85,7 +85,7 @@ class _PoissonLogNormalQuadratureCompoundTest( sess.run, pln, rtol=0.1, atol=0.01) def testSampleProbConsistentBroadcastBoth(self): - with self.test_session() as sess: + with self.cached_session() as sess: pln = poisson_lognormal.PoissonLogNormalQuadratureCompound( loc=array_ops.placeholder_with_default( [[0.], [-0.5]], @@ -99,7 +99,7 @@ class _PoissonLogNormalQuadratureCompoundTest( sess.run, pln, batch_size=4, rtol=0.1, atol=0.08) def testMeanVarianceBroadcastBoth(self): - with self.test_session() as sess: + with self.cached_session() as sess: pln = poisson_lognormal.PoissonLogNormalQuadratureCompound( loc=array_ops.placeholder_with_default( [[0.], [-0.5]], diff --git a/tensorflow/contrib/distributions/python/kernel_tests/poisson_test.py b/tensorflow/contrib/distributions/python/kernel_tests/poisson_test.py index 19a7472d91..29eba5afca 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/poisson_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/poisson_test.py @@ -35,7 +35,7 @@ class PoissonTest(test.TestCase): return poisson_lib.Poisson(rate=rate, validate_args=validate_args) def testPoissonShape(self): - with self.test_session(): + with self.cached_session(): lam = constant_op.constant([3.0] * 5) poisson = self._make_poisson(rate=lam) @@ -47,13 +47,13 @@ class PoissonTest(test.TestCase): def testInvalidLam(self): invalid_lams = [-.01, 0., -2.] for lam in invalid_lams: - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Condition x > 0"): poisson = self._make_poisson(rate=lam, validate_args=True) poisson.rate.eval() def testPoissonLogPmf(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 lam = constant_op.constant([3.0] * batch_size) lam_v = 3.0 @@ -68,7 +68,7 @@ class PoissonTest(test.TestCase): self.assertAllClose(pmf.eval(), stats.poisson.pmf(x, lam_v)) def testPoissonLogPmfValidateArgs(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 lam = constant_op.constant([3.0] * batch_size) x = array_ops.placeholder(dtypes.float32, shape=[6]) @@ -91,7 +91,7 @@ class PoissonTest(test.TestCase): self.assertEqual(pmf.get_shape(), (6,)) def testPoissonLogPmfMultidimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 lam = constant_op.constant([[2.0, 4.0, 5.0]] * batch_size) lam_v = [2.0, 4.0, 5.0] @@ -107,7 +107,7 @@ class PoissonTest(test.TestCase): self.assertAllClose(pmf.eval(), stats.poisson.pmf(x, lam_v)) def testPoissonCDF(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 lam = constant_op.constant([3.0] * batch_size) lam_v = 3.0 @@ -123,7 +123,7 @@ class PoissonTest(test.TestCase): self.assertAllClose(cdf.eval(), stats.poisson.cdf(x, lam_v)) def testPoissonCDFNonIntegerValues(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 lam = constant_op.constant([3.0] * batch_size) lam_v = 3.0 @@ -142,7 +142,7 @@ class PoissonTest(test.TestCase): poisson_validate.cdf(x).eval() def testPoissonCdfMultidimensional(self): - with self.test_session(): + with self.cached_session(): batch_size = 6 lam = constant_op.constant([[2.0, 4.0, 5.0]] * batch_size) lam_v = [2.0, 4.0, 5.0] @@ -158,7 +158,7 @@ class PoissonTest(test.TestCase): self.assertAllClose(cdf.eval(), stats.poisson.cdf(x, lam_v)) def testPoissonMean(self): - with self.test_session(): + with self.cached_session(): lam_v = [1.0, 3.0, 2.5] poisson = self._make_poisson(rate=lam_v) self.assertEqual(poisson.mean().get_shape(), (3,)) @@ -166,7 +166,7 @@ class PoissonTest(test.TestCase): self.assertAllClose(poisson.mean().eval(), lam_v) def testPoissonVariance(self): - with self.test_session(): + with self.cached_session(): lam_v = [1.0, 3.0, 2.5] poisson = self._make_poisson(rate=lam_v) self.assertEqual(poisson.variance().get_shape(), (3,)) @@ -174,7 +174,7 @@ class PoissonTest(test.TestCase): self.assertAllClose(poisson.variance().eval(), lam_v) def testPoissonStd(self): - with self.test_session(): + with self.cached_session(): lam_v = [1.0, 3.0, 2.5] poisson = self._make_poisson(rate=lam_v) self.assertEqual(poisson.stddev().get_shape(), (3,)) @@ -182,14 +182,14 @@ class PoissonTest(test.TestCase): self.assertAllClose(poisson.stddev().eval(), np.sqrt(lam_v)) def testPoissonMode(self): - with self.test_session(): + with self.cached_session(): lam_v = [1.0, 3.0, 2.5, 3.2, 1.1, 0.05] poisson = self._make_poisson(rate=lam_v) self.assertEqual(poisson.mode().get_shape(), (6,)) self.assertAllClose(poisson.mode().eval(), np.floor(lam_v)) def testPoissonMultipleMode(self): - with self.test_session(): + with self.cached_session(): lam_v = [1.0, 3.0, 2.0, 4.0, 5.0, 10.0] poisson = self._make_poisson(rate=lam_v) # For the case where lam is an integer, the modes are: lam and lam - 1. @@ -198,7 +198,7 @@ class PoissonTest(test.TestCase): self.assertAllClose(lam_v, poisson.mode().eval()) def testPoissonSample(self): - with self.test_session(): + with self.cached_session(): lam_v = 4.0 lam = constant_op.constant(lam_v) # Choosing `n >= (k/rtol)**2, roughly ensures our sample mean should be @@ -215,7 +215,7 @@ class PoissonTest(test.TestCase): sample_values.var(), stats.poisson.var(lam_v), rtol=.01) def testPoissonSampleMultidimensionalMean(self): - with self.test_session(): + with self.cached_session(): lam_v = np.array([np.arange(1, 51, dtype=np.float32)]) # 1 x 50 poisson = self._make_poisson(rate=lam_v) # Choosing `n >= (k/rtol)**2, roughly ensures our sample mean should be @@ -232,7 +232,7 @@ class PoissonTest(test.TestCase): atol=0) def testPoissonSampleMultidimensionalVariance(self): - with self.test_session(): + with self.cached_session(): lam_v = np.array([np.arange(5, 15, dtype=np.float32)]) # 1 x 10 poisson = self._make_poisson(rate=lam_v) # Choosing `n >= 2 * lam * (k/rtol)**2, roughly ensures our sample diff --git a/tensorflow/contrib/distributions/python/kernel_tests/quantized_distribution_test.py b/tensorflow/contrib/distributions/python/kernel_tests/quantized_distribution_test.py index 6a7ee3a8bf..07528cafaf 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/quantized_distribution_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/quantized_distribution_test.py @@ -38,7 +38,7 @@ class QuantizedDistributionTest(test.TestCase): self.assertTrue(np.isfinite(array).all()) def testQuantizationOfUniformWithCutoffsHavingNoEffect(self): - with self.test_session() as sess: + with self.cached_session() as sess: # The Quantized uniform with cutoffs == None divides the real line into: # R = ...(-1, 0](0, 1](1, 2](2, 3](3, 4]... # j = ... 0 1 2 3 4 ... @@ -93,7 +93,7 @@ class QuantizedDistributionTest(test.TestCase): self.assertAllClose(3 / 3, cdf_5) def testQuantizationOfUniformWithCutoffsInTheMiddle(self): - with self.test_session() as sess: + with self.cached_session() as sess: # The uniform is supported on [-3, 3] # Consider partitions the real line in intervals # ...(-3, -2](-2, -1](-1, 0](0, 1](1, 2](2, 3] ... @@ -131,7 +131,7 @@ class QuantizedDistributionTest(test.TestCase): def testQuantizationOfBatchOfUniforms(self): batch_shape = (5, 5) - with self.test_session(): + with self.cached_session(): # The uniforms are supported on [0, 10]. The qdist considers the # intervals # ... (0, 1](1, 2]...(9, 10]... @@ -165,7 +165,7 @@ class QuantizedDistributionTest(test.TestCase): def testSamplingFromBatchOfNormals(self): batch_shape = (2,) - with self.test_session(): + with self.cached_session(): normal = distributions.Normal( loc=array_ops.zeros( batch_shape, dtype=dtypes.float32), @@ -199,7 +199,7 @@ class QuantizedDistributionTest(test.TestCase): # pretend that the cdf F is a bijection, and hence F(X) is uniform. # Note that F cannot be bijection since it is constant between the # integers. Hence, F(X) (see below) will not be uniform exactly. - with self.test_session(): + with self.cached_session(): qdist = distributions.QuantizedDistribution( distribution=distributions.Exponential(rate=0.01)) # X ~ QuantizedExponential @@ -222,7 +222,7 @@ class QuantizedDistributionTest(test.TestCase): # it makes sure the bin edges are consistent. # Make an exponential with mean 5. - with self.test_session(): + with self.cached_session(): qdist = distributions.QuantizedDistribution( distribution=distributions.Exponential(rate=0.2)) # Standard error should be less than 1 / (2 * sqrt(n_samples)) @@ -243,7 +243,7 @@ class QuantizedDistributionTest(test.TestCase): batch_shape = (3, 3) mu = rng.randn(*batch_shape) sigma = rng.rand(*batch_shape) + 1.0 - with self.test_session(): + with self.cached_session(): qdist = distributions.QuantizedDistribution( distribution=distributions.Normal( loc=mu, scale=sigma)) @@ -260,7 +260,7 @@ class QuantizedDistributionTest(test.TestCase): batch_shape = (3, 3) mu = rng.randn(*batch_shape) sigma = rng.rand(*batch_shape) + 1.0 - with self.test_session(): + with self.cached_session(): qdist = distributions.QuantizedDistribution( distribution=distributions.Normal( loc=mu, scale=sigma)) @@ -275,7 +275,7 @@ class QuantizedDistributionTest(test.TestCase): def testNormalProbWithCutoffs(self): # At integer values, the result should be the same as the standard normal. - with self.test_session(): + with self.cached_session(): qdist = distributions.QuantizedDistribution( distribution=distributions.Normal(loc=0., scale=1.), low=-2., @@ -297,7 +297,7 @@ class QuantizedDistributionTest(test.TestCase): def testNormalLogProbWithCutoffs(self): # At integer values, the result should be the same as the standard normal. - with self.test_session(): + with self.cached_session(): qdist = distributions.QuantizedDistribution( distribution=distributions.Normal(loc=0., scale=1.), low=-2., @@ -335,14 +335,14 @@ class QuantizedDistributionTest(test.TestCase): x = np.arange(-100, 100, 2).astype(dtype) proba = qdist.log_prob(x) grads = gradients_impl.gradients(proba, [mu, sigma]) - with self.test_session(graph=g): + with self.session(graph=g): variables.global_variables_initializer().run() self._assert_all_finite(proba.eval()) self._assert_all_finite(grads[0].eval()) self._assert_all_finite(grads[1].eval()) def testProbAndGradGivesFiniteResultsForCommonEvents(self): - with self.test_session(): + with self.cached_session(): mu = variables.Variable(0.0, name="mu") sigma = variables.Variable(1.0, name="sigma") qdist = distributions.QuantizedDistribution( @@ -360,7 +360,7 @@ class QuantizedDistributionTest(test.TestCase): self._assert_all_finite(grads[1].eval()) def testLowerCutoffMustBeBelowUpperCutoffOrWeRaise(self): - with self.test_session(): + with self.cached_session(): qdist = distributions.QuantizedDistribution( distribution=distributions.Normal(loc=0., scale=1.), low=1., # not strictly less than high. @@ -372,7 +372,7 @@ class QuantizedDistributionTest(test.TestCase): qdist.sample().eval() def testCutoffsMustBeIntegerValuedIfValidateArgsTrue(self): - with self.test_session(): + with self.cached_session(): low = array_ops.placeholder(dtypes.float32) qdist = distributions.QuantizedDistribution( distribution=distributions.Normal(loc=0., scale=1.), @@ -385,7 +385,7 @@ class QuantizedDistributionTest(test.TestCase): qdist.sample().eval(feed_dict={low: 1.5}) def testCutoffsCanBeFloatValuedIfValidateArgsFalse(self): - with self.test_session(): + with self.cached_session(): qdist = distributions.QuantizedDistribution( distribution=distributions.Normal( loc=0., scale=1., validate_args=False), @@ -399,7 +399,7 @@ class QuantizedDistributionTest(test.TestCase): def testDtypeAndShapeInheritedFromBaseDist(self): batch_shape = (2, 3) - with self.test_session(): + with self.cached_session(): qdist = distributions.QuantizedDistribution( distribution=distributions.Normal( loc=array_ops.zeros(batch_shape), diff --git a/tensorflow/contrib/distributions/python/kernel_tests/relaxed_bernoulli_test.py b/tensorflow/contrib/distributions/python/kernel_tests/relaxed_bernoulli_test.py index 2cf12bbe50..fec2374928 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/relaxed_bernoulli_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/relaxed_bernoulli_test.py @@ -34,29 +34,29 @@ class RelaxedBernoulliTest(test.TestCase): temperature = 1.0 p = [0.1, 0.4] dist = relaxed_bernoulli.RelaxedBernoulli(temperature, probs=p) - with self.test_session(): + with self.cached_session(): self.assertAllClose(p, dist.probs.eval()) def testLogits(self): temperature = 2.0 logits = [-42., 42.] dist = relaxed_bernoulli.RelaxedBernoulli(temperature, logits=logits) - with self.test_session(): + with self.cached_session(): self.assertAllClose(logits, dist.logits.eval()) - with self.test_session(): + with self.cached_session(): self.assertAllClose(scipy.special.expit(logits), dist.probs.eval()) p = [0.01, 0.99, 0.42] dist = relaxed_bernoulli.RelaxedBernoulli(temperature, probs=p) - with self.test_session(): + with self.cached_session(): self.assertAllClose(scipy.special.logit(p), dist.logits.eval()) def testInvalidP(self): temperature = 1.0 invalid_ps = [1.01, 2.] for p in invalid_ps: - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("probs has components greater than 1"): dist = relaxed_bernoulli.RelaxedBernoulli(temperature, probs=p, @@ -65,7 +65,7 @@ class RelaxedBernoulliTest(test.TestCase): invalid_ps = [-0.01, -3.] for p in invalid_ps: - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Condition x >= 0"): dist = relaxed_bernoulli.RelaxedBernoulli(temperature, probs=p, @@ -74,13 +74,13 @@ class RelaxedBernoulliTest(test.TestCase): valid_ps = [0.0, 0.5, 1.0] for p in valid_ps: - with self.test_session(): + with self.cached_session(): dist = relaxed_bernoulli.RelaxedBernoulli(temperature, probs=p) self.assertEqual(p, dist.probs.eval()) def testShapes(self): - with self.test_session(): + with self.cached_session(): for batch_shape in ([], [1], [2, 3, 4]): temperature = 1.0 p = np.random.random(batch_shape).astype(np.float32) @@ -96,7 +96,7 @@ class RelaxedBernoulliTest(test.TestCase): p = constant_op.constant([0.1, 0.4]) dist = relaxed_bernoulli.RelaxedBernoulli(temperature, probs=p, validate_args=True) - with self.test_session(): + with self.cached_session(): sample = dist.sample() with self.assertRaises(errors_impl.InvalidArgumentError): sample.eval() @@ -117,7 +117,7 @@ class RelaxedBernoulliTest(test.TestCase): self.assertEqual(dist64.dtype, dist64.sample(5).dtype) def testLogProb(self): - with self.test_session(): + with self.cached_session(): t = np.array(1.0, dtype=np.float64) p = np.array(0.1, dtype=np.float64) # P(x=1) dist = relaxed_bernoulli.RelaxedBernoulli(t, probs=p) @@ -131,7 +131,7 @@ class RelaxedBernoulliTest(test.TestCase): self.assertAllClose(expected_log_pdf, log_pdf) def testBoundaryConditions(self): - with self.test_session(): + with self.cached_session(): temperature = 1e-2 dist = relaxed_bernoulli.RelaxedBernoulli(temperature, probs=1.0) self.assertAllClose(np.nan, dist.log_prob(0.0).eval()) @@ -139,7 +139,7 @@ class RelaxedBernoulliTest(test.TestCase): def testSampleN(self): """mean of quantized samples still approximates the Bernoulli mean.""" - with self.test_session(): + with self.cached_session(): temperature = 1e-2 p = [0.2, 0.6, 0.5] dist = relaxed_bernoulli.RelaxedBernoulli(temperature, probs=p) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/relaxed_onehot_categorical_test.py b/tensorflow/contrib/distributions/python/kernel_tests/relaxed_onehot_categorical_test.py index faae9da6ad..ff13c2decc 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/relaxed_onehot_categorical_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/relaxed_onehot_categorical_test.py @@ -46,7 +46,7 @@ class ExpRelaxedOneHotCategoricalTest(test.TestCase): dist = relaxed_onehot_categorical.ExpRelaxedOneHotCategorical(temperature, logits) expected_p = np.exp(logits)/np.sum(np.exp(logits)) - with self.test_session(): + with self.cached_session(): self.assertAllClose(expected_p, dist.probs.eval()) self.assertAllEqual([3], dist.probs.get_shape()) @@ -57,7 +57,7 @@ class ExpRelaxedOneHotCategoricalTest(test.TestCase): p = np.exp(logits)/np.sum(np.exp(logits)) dist = relaxed_onehot_categorical.ExpRelaxedOneHotCategorical(temperature, logits) - with self.test_session(): + with self.cached_session(): x = dist.sample().eval() # analytical ExpConcrete density presented in Maddison et al. 2016 prod_term = p*np.exp(-temperature * x) @@ -74,14 +74,14 @@ class RelaxedOneHotCategoricalTest(test.TestCase): logits = [2.0, 3.0, -4.0] dist = relaxed_onehot_categorical.RelaxedOneHotCategorical(temperature, logits) - with self.test_session(): + with self.cached_session(): # check p for ExpRelaxed base distribution self.assertAllClose(logits, dist._distribution.logits.eval()) self.assertAllEqual([3], dist._distribution.logits.get_shape()) def testSample(self): temperature = 1.4 - with self.test_session(): + with self.cached_session(): # single logit logits = [.3, .1, .4] dist = relaxed_onehot_categorical.RelaxedOneHotCategorical(temperature, @@ -115,7 +115,7 @@ class RelaxedOneHotCategoricalTest(test.TestCase): expected_pdf = term1*np.power(term2, -k)*term3 return expected_pdf - with self.test_session(): + with self.cached_session(): temperature = .4 logits = np.array([[.3, .1, .4]]).astype(np.float32) dist = relaxed_onehot_categorical.RelaxedOneHotCategorical(temperature, @@ -136,7 +136,7 @@ class RelaxedOneHotCategoricalTest(test.TestCase): self.assertAllClose(expected_pdf.flatten(), pdf, rtol=1e-4) def testShapes(self): - with self.test_session(): + with self.cached_session(): for batch_shape in ([], [1], [2, 3, 4]): dist = make_relaxed_categorical(batch_shape, 10) self.assertAllEqual(batch_shape, dist.batch_shape.as_list()) @@ -153,12 +153,12 @@ class RelaxedOneHotCategoricalTest(test.TestCase): self.assertAllEqual([10], dist.event_shape_tensor().eval()) def testUnknownShape(self): - with self.test_session(): + with self.cached_session(): logits_pl = array_ops.placeholder(dtypes.float32) temperature = 1.0 dist = relaxed_onehot_categorical.ExpRelaxedOneHotCategorical(temperature, logits_pl) - with self.test_session(): + with self.cached_session(): feed_dict = {logits_pl: [.3, .1, .4]} self.assertAllEqual([3], dist.sample().eval(feed_dict=feed_dict).shape) self.assertAllEqual([5, 3], @@ -166,7 +166,7 @@ class RelaxedOneHotCategoricalTest(test.TestCase): def testDTypes(self): # check that sampling and log_prob work for a range of dtypes - with self.test_session(): + with self.cached_session(): for dtype in (dtypes.float16, dtypes.float32, dtypes.float64): logits = random_ops.random_uniform(shape=[3, 3], dtype=dtype) dist = relaxed_onehot_categorical.RelaxedOneHotCategorical( diff --git a/tensorflow/contrib/distributions/python/kernel_tests/sample_stats_test.py b/tensorflow/contrib/distributions/python/kernel_tests/sample_stats_test.py index ea04e8c29a..d6020e7866 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/sample_stats_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/sample_stats_test.py @@ -47,7 +47,7 @@ class _AutoCorrelationTest(object): input=x_, shape=x_.shape if self.use_static_shape else None) with spectral_ops_test_util.fft_kernel_label_map(): - with self.test_session() as sess: + with self.cached_session() as sess: # Setting normalize = True means we divide by zero. auto_corr = sample_stats.auto_correlation( x_ph, axis=1, center=False, normalize=False) @@ -65,7 +65,7 @@ class _AutoCorrelationTest(object): input=x_, shape=x_.shape if self.use_static_shape else None) with spectral_ops_test_util.fft_kernel_label_map(): - with self.test_session() as sess: + with self.cached_session() as sess: # Setting normalize = True means we divide by zero. auto_corr = sample_stats.auto_correlation( x_ph, axis=1, normalize=False, center=True) @@ -100,7 +100,7 @@ class _AutoCorrelationTest(object): x_ph = array_ops.placeholder_with_default( x, shape=x.shape if self.use_static_shape else None) with spectral_ops_test_util.fft_kernel_label_map(): - with self.test_session(): + with self.cached_session(): auto_corr = sample_stats.auto_correlation( x_ph, axis=axis, max_lags=max_lags, center=center, normalize=normalize) @@ -167,7 +167,7 @@ class _AutoCorrelationTest(object): x_ph = array_ops.placeholder_with_default( x, shape=(l,) if self.use_static_shape else None) with spectral_ops_test_util.fft_kernel_label_map(): - with self.test_session(): + with self.cached_session(): rxx = sample_stats.auto_correlation( x_ph, max_lags=l // 2, center=True, normalize=False) if self.use_static_shape: @@ -188,7 +188,7 @@ class _AutoCorrelationTest(object): x_ph = array_ops.placeholder_with_default( x, shape=(1000 * 10,) if self.use_static_shape else None) with spectral_ops_test_util.fft_kernel_label_map(): - with self.test_session(): + with self.cached_session(): rxx = sample_stats.auto_correlation( x_ph, max_lags=1000 * 10 // 2, center=True, normalize=False) if self.use_static_shape: @@ -209,7 +209,7 @@ class _AutoCorrelationTest(object): x_ph = array_ops.placeholder_with_default( x, shape=(l,) if self.use_static_shape else None) with spectral_ops_test_util.fft_kernel_label_map(): - with self.test_session(): + with self.cached_session(): rxx = sample_stats.auto_correlation( x_ph, max_lags=l // 2, center=True, normalize=True) if self.use_static_shape: @@ -271,7 +271,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): for q in [0, 10, 25, 49.9, 50, 50.01, 90, 95, 100]: expected_percentile = np.percentile( x, q=q, interpolation=self._interpolation, axis=0) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile( x, q=q, interpolation=self._interpolation, axis=[0]) self.assertAllEqual((), pct.get_shape()) @@ -282,7 +282,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): for q in [0, 10, 25, 49.9, 50, 50.01, 90, 95, 100]: expected_percentile = np.percentile( x, q=q, interpolation=self._interpolation) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile(x, q=q, interpolation=self._interpolation) self.assertAllEqual((), pct.get_shape()) self.assertAllClose(expected_percentile, pct.eval()) @@ -292,7 +292,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): for q in [0, 10, 25, 49.9, 50, 50.01, 90, 95, 100]: expected_percentile = np.percentile( x, q=q, interpolation=self._interpolation, axis=0) - with self.test_session(): + with self.cached_session(): # Get dim 1 with negative and positive indices. pct_neg_index = sample_stats.percentile( x, q=q, interpolation=self._interpolation, axis=[0]) @@ -308,7 +308,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): for q in [0, 10, 25, 49.9, 50, 50.01, 90, 95, 100]: expected_percentile = np.percentile( x, q=q, interpolation=self._interpolation, axis=0) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile( x, q=q, interpolation=self._interpolation, axis=[0]) self.assertAllEqual((2,), pct.get_shape()) @@ -319,7 +319,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): for q in [0, 10, 25, 49.9, 50, 50.01, 90, 95, 100]: expected_percentile = np.percentile( x, q=q, interpolation=self._interpolation, keepdims=True, axis=0) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile( x, q=q, @@ -334,7 +334,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): for axis in [None, 0, 1, -2, (0,), (-1,), (-1, 1), (3, 1), (-3, 0)]: expected_percentile = np.percentile( x, q=0.77, interpolation=self._interpolation, axis=axis) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile( x, q=0.77, @@ -352,7 +352,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): interpolation=self._interpolation, axis=axis, keepdims=True) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile( x, q=0.77, @@ -368,7 +368,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): for axis in [None, 0, 1, -2, (0,), (-1,), (-1, 1), (3, 1), (-3, 0)]: expected_percentile = np.percentile( x, q=0.77, interpolation=self._interpolation, axis=axis) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile( x_ph, q=0.77, @@ -386,7 +386,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): interpolation=self._interpolation, axis=axis, keepdims=True) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile( x_ph, q=0.77, @@ -400,7 +400,7 @@ class PercentileTestWithLowerInterpolation(test.TestCase): for q in [0, 10, 25, 49.9, 50, 50.01, 90, 95, 100]: expected_percentile = np.percentile( x, q=q, interpolation=self._interpolation) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile(x, q=q, interpolation=self._interpolation) self.assertEqual(dtypes.int32, pct.dtype) self.assertAllEqual((), pct.get_shape()) @@ -423,7 +423,7 @@ class PercentileTestWithNearestInterpolation(test.TestCase): for q in [0, 10.1, 25.1, 49.9, 50.1, 50.01, 89, 100]: expected_percentile = np.percentile( x, q=q, interpolation=self._interpolation) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile(x, q=q, interpolation=self._interpolation) self.assertAllEqual((), pct.get_shape()) self.assertAllClose(expected_percentile, pct.eval()) @@ -433,7 +433,7 @@ class PercentileTestWithNearestInterpolation(test.TestCase): for q in [0, 10.1, 25.1, 49.9, 50.1, 50.01, 89, 100]: expected_percentile = np.percentile( x, q=q, interpolation=self._interpolation) - with self.test_session(): + with self.cached_session(): pct = sample_stats.percentile(x, q=q, interpolation=self._interpolation) self.assertAllEqual((), pct.get_shape()) self.assertAllClose(expected_percentile, pct.eval()) @@ -452,7 +452,7 @@ class PercentileTestWithNearestInterpolation(test.TestCase): x = [1., 5., 3., 2., 4.] q_ph = array_ops.placeholder(dtypes.float32) pct = sample_stats.percentile(x, q=q_ph, validate_args=True) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("rank"): pct.eval(feed_dict={q_ph: [0.5]}) @@ -462,7 +462,7 @@ class PercentileTestWithNearestInterpolation(test.TestCase): # If float is used, it fails with InvalidArgumentError about an index out of # bounds. x = math_ops.linspace(0., 3e7, num=int(3e7)) - with self.test_session(): + with self.cached_session(): minval = sample_stats.percentile(x, q=0, validate_args=True) self.assertAllEqual(0, minval.eval()) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/shape_test.py b/tensorflow/contrib/distributions/python/kernel_tests/shape_test.py index 243b5a0348..a4d2aa381c 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/shape_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/shape_test.py @@ -73,7 +73,7 @@ class MakeBatchReadyTest(test.TestCase): return y, sample_shape, should_be_x_value def _test_dynamic(self, x, batch_ndims, event_ndims, expand_batch_dim=True): - with self.test_session() as sess: + with self.cached_session() as sess: x_pl = array_ops.placeholder(x.dtype) batch_ndims_pl = array_ops.placeholder(dtypes.int32) event_ndims_pl = array_ops.placeholder(dtypes.int32) @@ -91,7 +91,7 @@ class MakeBatchReadyTest(test.TestCase): self.assertAllEqual(x, should_be_x_value_) def _test_static(self, x, batch_ndims, event_ndims, expand_batch_dim): - with self.test_session() as sess: + with self.cached_session() as sess: [y_, sample_shape_, should_be_x_value_] = sess.run( self._build_graph(x, batch_ndims, event_ndims, expand_batch_dim)) expected_y, expected_sample_shape = self._get_expected( @@ -544,7 +544,7 @@ class DistributionShapeTest(test.TestCase): self.assertAllEqual(expected_item, next(actual_item)) def testDistributionShapeGetNdimsStatic(self): - with self.test_session(): + with self.cached_session(): shaper = _DistributionShape(batch_ndims=0, event_ndims=0) x = 1 self.assertEqual(0, shaper.get_sample_ndims(x).eval()) @@ -572,7 +572,7 @@ class DistributionShapeTest(test.TestCase): self.assertEqual(1, shaper.event_ndims.eval()) def testDistributionShapeGetNdimsDynamic(self): - with self.test_session() as sess: + with self.cached_session() as sess: batch_ndims = array_ops.placeholder(dtypes.int32) event_ndims = array_ops.placeholder(dtypes.int32) shaper = _DistributionShape( @@ -583,7 +583,7 @@ class DistributionShapeTest(test.TestCase): self.assertEqual(2, sess.run(shaper.get_ndims(y), feed_dict=feed_dict)) def testDistributionShapeGetDimsStatic(self): - with self.test_session(): + with self.cached_session(): shaper = _DistributionShape(batch_ndims=0, event_ndims=0) x = 1 self.assertAllEqual((_empty_shape, _empty_shape, _empty_shape), @@ -597,7 +597,7 @@ class DistributionShapeTest(test.TestCase): _constant(shaper.get_dims(x))) def testDistributionShapeGetDimsDynamic(self): - with self.test_session() as sess: + with self.cached_session() as sess: # Works for static {batch,event}_ndims despite unfed input. shaper = _DistributionShape(batch_ndims=1, event_ndims=2) y = array_ops.placeholder(dtypes.float32, shape=(10, None, 5, 5)) @@ -615,7 +615,7 @@ class DistributionShapeTest(test.TestCase): ([0], [1], [2, 3]), sess.run(shaper.get_dims(y), feed_dict=feed_dict)) def testDistributionShapeGetShapeStatic(self): - with self.test_session(): + with self.cached_session(): shaper = _DistributionShape(batch_ndims=0, event_ndims=0) self.assertAllEqual((_empty_shape, _empty_shape, _empty_shape), _constant(shaper.get_shape(1.))) @@ -657,7 +657,7 @@ class DistributionShapeTest(test.TestCase): _constant(shaper.get_shape(np.ones((3, 2, 1))))) def testDistributionShapeGetShapeDynamic(self): - with self.test_session() as sess: + with self.cached_session() as sess: # Works for static ndims despite unknown static shape. shaper = _DistributionShape(batch_ndims=1, event_ndims=1) y = array_ops.placeholder(dtypes.int32, shape=(None, None, 2)) diff --git a/tensorflow/contrib/distributions/python/kernel_tests/sinh_arcsinh_test.py b/tensorflow/contrib/distributions/python/kernel_tests/sinh_arcsinh_test.py index 88b48736dd..1811d85b7e 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/sinh_arcsinh_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/sinh_arcsinh_test.py @@ -34,7 +34,7 @@ class SinhArcsinhTest(test.TestCase): b = 10 scale = rng.rand(b) + 0.5 loc = rng.randn(b) - with self.test_session() as sess: + with self.cached_session() as sess: norm = ds.Normal( loc=loc, scale=scale, @@ -58,7 +58,7 @@ class SinhArcsinhTest(test.TestCase): norm_samps.std(axis=0), sasnorm_samps.std(axis=0), atol=0.1) def test_broadcast_params_dynamic(self): - with self.test_session() as sess: + with self.cached_session() as sess: loc = array_ops.placeholder(dtypes.float64) scale = array_ops.placeholder(dtypes.float64) skewness = array_ops.placeholder(dtypes.float64) @@ -78,7 +78,7 @@ class SinhArcsinhTest(test.TestCase): b = 10 scale = rng.rand(b) + 0.5 loc = rng.randn(b) - with self.test_session() as sess: + with self.cached_session() as sess: lap = ds.Laplace( loc=loc, scale=scale, @@ -106,7 +106,7 @@ class SinhArcsinhTest(test.TestCase): batch_size = 10 scale = rng.rand(batch_size) + 0.5 loc = 0.1 * rng.randn(batch_size) - with self.test_session() as sess: + with self.cached_session() as sess: norm = ds.Normal( loc=loc, scale=scale, @@ -148,7 +148,7 @@ class SinhArcsinhTest(test.TestCase): batch_size = 10 scale = rng.rand(batch_size) + 0.5 loc = np.float64(0.) - with self.test_session() as sess: + with self.cached_session() as sess: norm = ds.Normal( loc=loc, scale=scale, @@ -190,7 +190,7 @@ class SinhArcsinhTest(test.TestCase): batch_size = 10 scale = rng.rand(batch_size) + 0.5 loc = rng.randn(batch_size) - with self.test_session() as sess: + with self.cached_session() as sess: sasnorm = ds.SinhArcsinh( loc=loc, scale=scale, @@ -201,7 +201,7 @@ class SinhArcsinhTest(test.TestCase): np.testing.assert_array_less(loc, sasnorm_samps.mean(axis=0)) def test_pdf_reflected_for_negative_skewness(self): - with self.test_session() as sess: + with self.cached_session() as sess: sas_pos_skew = ds.SinhArcsinh( loc=0., scale=1., diff --git a/tensorflow/contrib/distributions/python/kernel_tests/transformed_distribution_test.py b/tensorflow/contrib/distributions/python/kernel_tests/transformed_distribution_test.py index 5fe1331d2c..196cc41335 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/transformed_distribution_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/transformed_distribution_test.py @@ -91,7 +91,7 @@ class TransformedDistributionTest(test.TestCase): # sample sample = log_normal.sample(100000, seed=235) self.assertAllEqual([], log_normal.event_shape) - with self.test_session(graph=g): + with self.session(graph=g): self.assertAllEqual([], log_normal.event_shape_tensor().eval()) self.assertAllClose( sp_dist.mean(), np.mean(sample.eval()), atol=0.0, rtol=0.05) @@ -107,7 +107,7 @@ class TransformedDistributionTest(test.TestCase): [log_normal.log_survival_function, sp_dist.logsf]]: actual = func[0](test_vals) expected = func[1](test_vals) - with self.test_session(graph=g): + with self.session(graph=g): self.assertAllClose(expected, actual.eval(), atol=0, rtol=0.01) def testNonInjectiveTransformedDistribution(self): @@ -123,7 +123,7 @@ class TransformedDistributionTest(test.TestCase): # sample sample = abs_normal.sample(100000, seed=235) self.assertAllEqual([], abs_normal.event_shape) - with self.test_session(graph=g): + with self.session(graph=g): sample_ = sample.eval() self.assertAllEqual([], abs_normal.event_shape_tensor().eval()) @@ -147,7 +147,7 @@ class TransformedDistributionTest(test.TestCase): abs_normal.log_prob(2.13).eval()) def testQuantile(self): - with self.test_session() as sess: + with self.cached_session() as sess: logit_normal = self._cls()( distribution=ds.Normal(loc=0., scale=1.), bijector=bs.Sigmoid(), @@ -169,7 +169,7 @@ class TransformedDistributionTest(test.TestCase): exp_forward_only._inverse_log_det_jacobian = self._make_unimplemented( "inverse_log_det_jacobian ") - with self.test_session() as sess: + with self.cached_session() as sess: mu = 3.0 sigma = 0.02 log_normal = self._cls()( @@ -195,7 +195,7 @@ class TransformedDistributionTest(test.TestCase): log_forward_only = bs.Invert(exp_inverse_only) - with self.test_session() as sess: + with self.cached_session() as sess: # The log bijector isn't defined over the whole real line, so we make # sigma sufficiently small so that the draws are positive. mu = 2. @@ -211,7 +211,7 @@ class TransformedDistributionTest(test.TestCase): self.assertAllClose(expected_log_pdf, log_pdf_val, atol=0.) def testShapeChangingBijector(self): - with self.test_session(): + with self.cached_session(): softmax = bs.SoftmaxCentered() standard_normal = ds.Normal(loc=0., scale=1.) multi_logit_normal = self._cls()( @@ -235,7 +235,7 @@ class TransformedDistributionTest(test.TestCase): def testCastLogDetJacobian(self): """Test log_prob when Jacobian and log_prob dtypes do not match.""" - with self.test_session(): + with self.cached_session(): # Create an identity bijector whose jacobians have dtype int32 int_identity = bs.Inline( forward_fn=array_ops.identity, @@ -257,7 +257,7 @@ class TransformedDistributionTest(test.TestCase): normal.entropy().eval() def testEntropy(self): - with self.test_session(): + with self.cached_session(): shift = np.array([[-1, 0, 1], [-1, -2, -3]], dtype=np.float32) diag = np.array([[1, 2, 3], [2, 3, 2]], dtype=np.float32) actual_mvn_entropy = np.concatenate([ @@ -277,7 +277,7 @@ class TransformedDistributionTest(test.TestCase): fake_mvn.entropy().eval()) def testScalarBatchScalarEventIdentityScale(self): - with self.test_session() as sess: + with self.cached_session() as sess: exp2 = self._cls()( ds.Exponential(rate=0.25), bijector=ds.bijectors.AffineScalar(scale=2.) @@ -310,7 +310,7 @@ class ScalarToMultiTest(test.TestCase): batch_shape=(), event_shape=(), not_implemented_message=None): - with self.test_session() as sess: + with self.cached_session() as sess: # Overriding shapes must be compatible w/bijector; most bijectors are # batch_shape agnostic and only care about event_ndims. # In the case of `Affine`, if we got it wrong then it would fire an @@ -428,7 +428,7 @@ class ScalarToMultiTest(test.TestCase): batch_shape=[2], not_implemented_message="not implemented") - with self.test_session(): + with self.cached_session(): # Can't override event_shape for scalar batch, non-scalar event. with self.assertRaisesRegexp(ValueError, "base distribution not scalar"): self._cls()( @@ -445,7 +445,7 @@ class ScalarToMultiTest(test.TestCase): event_shape=[3], not_implemented_message="not implemented when overriding event_shape") - with self.test_session(): + with self.cached_session(): # Can't override batch_shape for non-scalar batch, scalar event. with self.assertRaisesRegexp(ValueError, "base distribution not scalar"): self._cls()( @@ -456,7 +456,7 @@ class ScalarToMultiTest(test.TestCase): validate_args=True) def testNonScalarBatchNonScalarEvent(self): - with self.test_session(): + with self.cached_session(): # Can't override event_shape and/or batch_shape for non_scalar batch, # non-scalar event. with self.assertRaisesRegexp(ValueError, "base distribution not scalar"): @@ -469,7 +469,7 @@ class ScalarToMultiTest(test.TestCase): validate_args=True) def testMatrixEvent(self): - with self.test_session() as sess: + with self.cached_session() as sess: batch_shape = [2] event_shape = [2, 3, 3] batch_shape_pl = array_ops.placeholder( diff --git a/tensorflow/contrib/distributions/python/kernel_tests/vector_diffeomixture_test.py b/tensorflow/contrib/distributions/python/kernel_tests/vector_diffeomixture_test.py index 04f047aa0c..856579da32 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/vector_diffeomixture_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/vector_diffeomixture_test.py @@ -35,7 +35,7 @@ class VectorDiffeomixtureTest( """Tests the VectorDiffeomixture distribution.""" def testSampleProbConsistentBroadcastMixNoBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: dims = 4 vdm = vdm_lib.VectorDiffeomixture( mix_loc=[[0.], [1.]], @@ -64,7 +64,7 @@ class VectorDiffeomixtureTest( sess.run, vdm, radius=4., center=2., rtol=0.015) def testSampleProbConsistentBroadcastMixNonStandardBase(self): - with self.test_session() as sess: + with self.cached_session() as sess: dims = 4 vdm = vdm_lib.VectorDiffeomixture( mix_loc=[[0.], [1.]], @@ -93,7 +93,7 @@ class VectorDiffeomixtureTest( sess.run, vdm, radius=4., center=3., rtol=0.01) def testSampleProbConsistentBroadcastMixBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: dims = 4 vdm = vdm_lib.VectorDiffeomixture( mix_loc=[[0.], [1.]], @@ -128,7 +128,7 @@ class VectorDiffeomixtureTest( dims = 4 loc_1 = rng.randn(2, 3, dims).astype(np.float32) - with self.test_session() as sess: + with self.cached_session() as sess: vdm = vdm_lib.VectorDiffeomixture( mix_loc=(rng.rand(2, 3, 1) - 0.5).astype(np.float32), temperature=[1.], @@ -152,7 +152,7 @@ class VectorDiffeomixtureTest( sess.run, vdm, radius=3., center=loc_1, rtol=0.02) def testMeanCovarianceNoBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: dims = 3 vdm = vdm_lib.VectorDiffeomixture( mix_loc=[[0.], [4.]], @@ -179,7 +179,7 @@ class VectorDiffeomixtureTest( def testTemperatureControlsHowMuchThisLooksLikeDiscreteMixture(self): # As temperature decreases, this should approach a mixture of normals, with # components at -2, 2. - with self.test_session() as sess: + with self.cached_session() as sess: dims = 1 vdm = vdm_lib.VectorDiffeomixture( mix_loc=[0.], @@ -216,7 +216,7 @@ class VectorDiffeomixtureTest( sess.run, vdm, rtol=0.02, cov_rtol=0.08) def testConcentrationLocControlsHowMuchWeightIsOnEachComponent(self): - with self.test_session() as sess: + with self.cached_session() as sess: dims = 1 vdm = vdm_lib.VectorDiffeomixture( mix_loc=[[-1.], [0.], [1.]], @@ -259,7 +259,7 @@ class VectorDiffeomixtureTest( sess.run, vdm, rtol=0.02, cov_rtol=0.08) def testMeanCovarianceNoBatchUncenteredNonStandardBase(self): - with self.test_session() as sess: + with self.cached_session() as sess: dims = 3 vdm = vdm_lib.VectorDiffeomixture( mix_loc=[[0.], [4.]], @@ -284,7 +284,7 @@ class VectorDiffeomixtureTest( sess.run, vdm, num_samples=int(1e6), rtol=0.01, cov_atol=0.025) def testMeanCovarianceBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: dims = 3 vdm = vdm_lib.VectorDiffeomixture( mix_loc=[[0.], [4.]], @@ -312,7 +312,7 @@ class VectorDiffeomixtureTest( sess.run, vdm, rtol=0.02, cov_rtol=0.07) def testSampleProbConsistentQuadrature(self): - with self.test_session() as sess: + with self.cached_session() as sess: dims = 4 vdm = vdm_lib.VectorDiffeomixture( mix_loc=[0.], diff --git a/tensorflow/contrib/distributions/python/kernel_tests/vector_exponential_diag_test.py b/tensorflow/contrib/distributions/python/kernel_tests/vector_exponential_diag_test.py index fd05bd207f..db8186b79a 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/vector_exponential_diag_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/vector_exponential_diag_test.py @@ -37,42 +37,42 @@ class VectorExponentialDiagTest(test.TestCase): def testScalarParams(self): mu = -1. diag = -5. - with self.test_session(): + with self.cached_session(): with self.assertRaisesRegexp(ValueError, "at least 1 dimension"): ds.VectorExponentialDiag(mu, diag) def testVectorParams(self): mu = [-1.] diag = [-5.] - with self.test_session(): + with self.cached_session(): dist = ds.VectorExponentialDiag(mu, diag, validate_args=True) self.assertAllEqual([3, 1], dist.sample(3).get_shape()) def testMean(self): mu = [-1., 1] diag = [1., -5] - with self.test_session(): + with self.cached_session(): dist = ds.VectorExponentialDiag(mu, diag, validate_args=True) self.assertAllEqual([-1. + 1., 1. - 5.], dist.mean().eval()) def testMode(self): mu = [-1.] diag = [1., -5] - with self.test_session(): + with self.cached_session(): dist = ds.VectorExponentialDiag(mu, diag, validate_args=True) self.assertAllEqual([-1., -1.], dist.mode().eval()) def testMeanWithBroadcastLoc(self): mu = [-1.] diag = [1., -5] - with self.test_session(): + with self.cached_session(): dist = ds.VectorExponentialDiag(mu, diag, validate_args=True) self.assertAllEqual([-1. + 1, -1. - 5], dist.mean().eval()) def testSample(self): mu = [-2., 1] diag = [1., -2] - with self.test_session(): + with self.cached_session(): dist = ds.VectorExponentialDiag(mu, diag, validate_args=True) samps = dist.sample(int(1e4), seed=0).eval() cov_mat = array_ops.matrix_diag(diag).eval()**2 @@ -85,7 +85,7 @@ class VectorExponentialDiagTest(test.TestCase): def testSingularScaleRaises(self): mu = [-1., 1] diag = [1., 0] - with self.test_session(): + with self.cached_session(): dist = ds.VectorExponentialDiag(mu, diag, validate_args=True) with self.assertRaisesOpError("Singular"): dist.sample().eval() @@ -97,7 +97,7 @@ class VectorExponentialDiagTest(test.TestCase): # diag corresponds to no batches of 3-variate normals diag = np.ones([3]) - with self.test_session(): + with self.cached_session(): dist = ds.VectorExponentialDiag(mu, diag, validate_args=True) mean = dist.mean() @@ -117,7 +117,7 @@ class VectorExponentialDiagTest(test.TestCase): atol=0.10, rtol=0.05) def testCovariance(self): - with self.test_session(): + with self.cached_session(): vex = ds.VectorExponentialDiag( loc=array_ops.ones([2, 3], dtype=dtypes.float32)) self.assertAllClose( @@ -153,7 +153,7 @@ class VectorExponentialDiagTest(test.TestCase): vex.covariance().eval()) def testVariance(self): - with self.test_session(): + with self.cached_session(): vex = ds.VectorExponentialDiag( loc=array_ops.zeros([2, 3], dtype=dtypes.float32)) self.assertAllClose( @@ -178,7 +178,7 @@ class VectorExponentialDiagTest(test.TestCase): vex.variance().eval()) def testStddev(self): - with self.test_session(): + with self.cached_session(): vex = ds.VectorExponentialDiag( loc=array_ops.zeros([2, 3], dtype=dtypes.float32)) self.assertAllClose( diff --git a/tensorflow/contrib/distributions/python/kernel_tests/vector_laplace_diag_test.py b/tensorflow/contrib/distributions/python/kernel_tests/vector_laplace_diag_test.py index 1226c66113..9ee19b7e93 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/vector_laplace_diag_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/vector_laplace_diag_test.py @@ -38,14 +38,14 @@ class VectorLaplaceDiagTest(test.TestCase): def testScalarParams(self): mu = -1. diag = -5. - with self.test_session(): + with self.cached_session(): with self.assertRaisesRegexp(ValueError, "at least 1 dimension"): ds.VectorLaplaceDiag(mu, diag) def testVectorParams(self): mu = [-1.] diag = [-5.] - with self.test_session(): + with self.cached_session(): dist = ds.VectorLaplaceDiag(mu, diag, validate_args=True) self.assertAllEqual([3, 1], dist.sample(3).get_shape()) @@ -56,7 +56,7 @@ class VectorLaplaceDiagTest(test.TestCase): # Batch shape = [1], event shape = [3] mu = array_ops.zeros((1, 3)) diag = array_ops.ones((1, 3)) - with self.test_session(): + with self.cached_session(): base_dist = ds.VectorLaplaceDiag(mu, diag, validate_args=True) dist = ds.TransformedDistribution( base_dist, @@ -68,21 +68,21 @@ class VectorLaplaceDiagTest(test.TestCase): def testMean(self): mu = [-1., 1] diag = [1., -5] - with self.test_session(): + with self.cached_session(): dist = ds.VectorLaplaceDiag(mu, diag, validate_args=True) self.assertAllEqual(mu, dist.mean().eval()) def testMeanWithBroadcastLoc(self): mu = [-1.] diag = [1., -5] - with self.test_session(): + with self.cached_session(): dist = ds.VectorLaplaceDiag(mu, diag, validate_args=True) self.assertAllEqual([-1., -1.], dist.mean().eval()) def testSample(self): mu = [-1., 1] diag = [1., -2] - with self.test_session(): + with self.cached_session(): dist = ds.VectorLaplaceDiag(mu, diag, validate_args=True) samps = dist.sample(int(1e4), seed=0).eval() cov_mat = 2. * array_ops.matrix_diag(diag).eval()**2 @@ -95,7 +95,7 @@ class VectorLaplaceDiagTest(test.TestCase): def testSingularScaleRaises(self): mu = [-1., 1] diag = [1., 0] - with self.test_session(): + with self.cached_session(): dist = ds.VectorLaplaceDiag(mu, diag, validate_args=True) with self.assertRaisesOpError("Singular"): dist.sample().eval() @@ -107,7 +107,7 @@ class VectorLaplaceDiagTest(test.TestCase): # diag corresponds to no batches of 3-variate normals diag = np.ones([3]) - with self.test_session(): + with self.cached_session(): dist = ds.VectorLaplaceDiag(mu, diag, validate_args=True) mean = dist.mean() @@ -126,7 +126,7 @@ class VectorLaplaceDiagTest(test.TestCase): atol=0.10, rtol=0.05) def testCovariance(self): - with self.test_session(): + with self.cached_session(): vla = ds.VectorLaplaceDiag( loc=array_ops.zeros([2, 3], dtype=dtypes.float32)) self.assertAllClose( @@ -162,7 +162,7 @@ class VectorLaplaceDiagTest(test.TestCase): vla.covariance().eval()) def testVariance(self): - with self.test_session(): + with self.cached_session(): vla = ds.VectorLaplaceDiag( loc=array_ops.zeros([2, 3], dtype=dtypes.float32)) self.assertAllClose( @@ -187,7 +187,7 @@ class VectorLaplaceDiagTest(test.TestCase): vla.variance().eval()) def testStddev(self): - with self.test_session(): + with self.cached_session(): vla = ds.VectorLaplaceDiag( loc=array_ops.zeros([2, 3], dtype=dtypes.float32)) self.assertAllClose( diff --git a/tensorflow/contrib/distributions/python/kernel_tests/vector_sinh_arcsinh_diag_test.py b/tensorflow/contrib/distributions/python/kernel_tests/vector_sinh_arcsinh_diag_test.py index 2bc6a926dd..0dd7d23eb0 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/vector_sinh_arcsinh_diag_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/vector_sinh_arcsinh_diag_test.py @@ -35,7 +35,7 @@ class VectorSinhArcsinhDiagTest(test_util.VectorDistributionTestHelpers, scale_diag = rng.rand(d) scale_identity_multiplier = np.float64(1.0) loc = rng.randn(d) - with self.test_session() as sess: + with self.cached_session() as sess: norm = ds.MultivariateNormalDiag( loc=loc, scale_diag=scale_diag, @@ -65,7 +65,7 @@ class VectorSinhArcsinhDiagTest(test_util.VectorDistributionTestHelpers, scale_diag = rng.rand(d) scale_identity_multiplier = np.float64(1.2) loc = rng.randn(d) - with self.test_session() as sess: + with self.cached_session() as sess: vlap = ds.VectorLaplaceDiag( loc=loc, scale_diag=scale_diag, @@ -96,7 +96,7 @@ class VectorSinhArcsinhDiagTest(test_util.VectorDistributionTestHelpers, scale_diag = rng.rand(d) scale_identity_multiplier = np.float64(0.9) loc = rng.randn(d) - with self.test_session() as sess: + with self.cached_session() as sess: norm = ds.MultivariateNormalDiag( loc=loc, scale_diag=scale_diag, @@ -141,7 +141,7 @@ class VectorSinhArcsinhDiagTest(test_util.VectorDistributionTestHelpers, scale_diag = rng.rand(d) scale_identity_multiplier = np.float64(1.0) loc = rng.randn(d) - with self.test_session() as sess: + with self.cached_session() as sess: norm = ds.MultivariateNormalDiag( loc=loc, scale_diag=scale_diag, @@ -186,7 +186,7 @@ class VectorSinhArcsinhDiagTest(test_util.VectorDistributionTestHelpers, scale_diag = rng.rand(d) scale_identity_multiplier = np.float64(1.0) loc = rng.randn(d) - with self.test_session() as sess: + with self.cached_session() as sess: sasnorm = ds.VectorSinhArcsinhDiag( loc=loc, scale_diag=scale_diag, @@ -201,7 +201,7 @@ class VectorSinhArcsinhDiagTest(test_util.VectorDistributionTestHelpers, b, d = 5, 2 scale_diag = rng.rand(b, d) scale_identity_multiplier = np.float64(1.1) - with self.test_session() as sess: + with self.cached_session() as sess: sasnorm = ds.VectorSinhArcsinhDiag( scale_diag=scale_diag, scale_identity_multiplier=scale_identity_multiplier, @@ -228,7 +228,7 @@ class VectorSinhArcsinhDiagTest(test_util.VectorDistributionTestHelpers, d = 3 scale_diag = rng.rand(d) scale_identity_multiplier = np.float64(1.1) - with self.test_session() as sess: + with self.cached_session() as sess: sasnorm = ds.VectorSinhArcsinhDiag( scale_diag=scale_diag, scale_identity_multiplier=scale_identity_multiplier, @@ -252,7 +252,7 @@ class VectorSinhArcsinhDiagTest(test_util.VectorDistributionTestHelpers, rtol=0.1) def test_pdf_reflected_for_negative_skewness(self): - with self.test_session() as sess: + with self.cached_session() as sess: sas_pos_skew = ds.VectorSinhArcsinhDiag( loc=[0.], scale_identity_multiplier=1., diff --git a/tensorflow/contrib/distributions/python/kernel_tests/vector_student_t_test.py b/tensorflow/contrib/distributions/python/kernel_tests/vector_student_t_test.py index b8a3a262ce..aaec1f09d9 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/vector_student_t_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/vector_student_t_test.py @@ -75,7 +75,7 @@ class VectorStudentTTest(test.TestCase): self._rng = np.random.RandomState(42) def testProbStaticScalar(self): - with self.test_session(): + with self.cached_session(): # Scalar batch_shape. df = np.asarray(3., dtype=np.float32) # Scalar batch_shape. @@ -116,7 +116,7 @@ class VectorStudentTTest(test.TestCase): expected_mst = _FakeVectorStudentT( df=df, loc=loc, scale_tril=scale_tril) - with self.test_session(): + with self.cached_session(): actual_mst = _VectorStudentT(df=df, loc=loc, scale_diag=scale_diag, validate_args=True) self.assertAllClose(expected_mst.log_prob(x), @@ -145,7 +145,7 @@ class VectorStudentTTest(test.TestCase): expected_mst = _FakeVectorStudentT( df=df, loc=loc, scale_tril=scale_tril) - with self.test_session(): + with self.cached_session(): df_pl = array_ops.placeholder(dtypes.float32, name="df") loc_pl = array_ops.placeholder(dtypes.float32, name="loc") scale_diag_pl = array_ops.placeholder(dtypes.float32, name="scale_diag") @@ -180,7 +180,7 @@ class VectorStudentTTest(test.TestCase): loc=loc, scale_tril=scale_tril) - with self.test_session(): + with self.cached_session(): actual_mst = _VectorStudentT(df=df, loc=loc, scale_diag=scale_diag, validate_args=True) self.assertAllClose(expected_mst.log_prob(x), @@ -211,7 +211,7 @@ class VectorStudentTTest(test.TestCase): loc=loc, scale_tril=scale_tril) - with self.test_session(): + with self.cached_session(): df_pl = array_ops.placeholder(dtypes.float32, name="df") loc_pl = array_ops.placeholder(dtypes.float32, name="loc") scale_diag_pl = array_ops.placeholder(dtypes.float32, name="scale_diag") @@ -240,7 +240,7 @@ class VectorStudentTTest(test.TestCase): scale_tril=np.tile(scale_tril[array_ops.newaxis, :, :], reps=[len(df), 1, 1])) - with self.test_session(): + with self.cached_session(): actual_mst = _VectorStudentT(df=df, loc=loc, scale_diag=scale_diag, validate_args=True) self.assertAllClose(expected_mst.log_prob(x), @@ -266,7 +266,7 @@ class VectorStudentTTest(test.TestCase): scale_tril=np.tile(scale_tril[array_ops.newaxis, :, :], reps=[len(df), 1, 1])) - with self.test_session(): + with self.cached_session(): df_pl = array_ops.placeholder(dtypes.float32, name="df") loc_pl = array_ops.placeholder(dtypes.float32, name="loc") scale_diag_pl = array_ops.placeholder(dtypes.float32, name="scale_diag") diff --git a/tensorflow/contrib/distributions/python/kernel_tests/wishart_test.py b/tensorflow/contrib/distributions/python/kernel_tests/wishart_test.py index dcecce981f..a60056c444 100644 --- a/tensorflow/contrib/distributions/python/kernel_tests/wishart_test.py +++ b/tensorflow/contrib/distributions/python/kernel_tests/wishart_test.py @@ -52,7 +52,7 @@ def wishart_var(df, x): class WishartCholeskyTest(test.TestCase): def testEntropy(self): - with self.test_session(): + with self.cached_session(): scale = make_pd(1., 2) df = 4 w = distributions.WishartCholesky(df, chol(scale)) @@ -64,7 +64,7 @@ class WishartCholeskyTest(test.TestCase): self.assertAllClose(0.78375711047393404, w.entropy().eval()) def testMeanLogDetAndLogNormalizingConstant(self): - with self.test_session(): + with self.cached_session(): def entropy_alt(w): return ( @@ -80,35 +80,35 @@ class WishartCholeskyTest(test.TestCase): self.assertAllClose(w.entropy().eval(), entropy_alt(w)) def testMean(self): - with self.test_session(): + with self.cached_session(): scale = make_pd(1., 2) df = 4 w = distributions.WishartCholesky(df, chol(scale)) self.assertAllEqual(df * scale, w.mean().eval()) def testMode(self): - with self.test_session(): + with self.cached_session(): scale = make_pd(1., 2) df = 4 w = distributions.WishartCholesky(df, chol(scale)) self.assertAllEqual((df - 2. - 1.) * scale, w.mode().eval()) def testStd(self): - with self.test_session(): + with self.cached_session(): scale = make_pd(1., 2) df = 4 w = distributions.WishartCholesky(df, chol(scale)) self.assertAllEqual(chol(wishart_var(df, scale)), w.stddev().eval()) def testVariance(self): - with self.test_session(): + with self.cached_session(): scale = make_pd(1., 2) df = 4 w = distributions.WishartCholesky(df, chol(scale)) self.assertAllEqual(wishart_var(df, scale), w.variance().eval()) def testSample(self): - with self.test_session(): + with self.cached_session(): scale = make_pd(1., 2) df = 4 @@ -161,7 +161,7 @@ class WishartCholeskyTest(test.TestCase): # Test that sampling with the same seed twice gives the same results. def testSampleMultipleTimes(self): - with self.test_session(): + with self.cached_session(): df = 4. n_val = 100 @@ -184,7 +184,7 @@ class WishartCholeskyTest(test.TestCase): self.assertAllClose(samples1, samples2) def testProb(self): - with self.test_session(): + with self.cached_session(): # Generate some positive definite (pd) matrices and their Cholesky # factorizations. x = np.array( @@ -271,7 +271,7 @@ class WishartCholeskyTest(test.TestCase): w.log_prob(np.reshape(x, (2, 2, 2, 2))).get_shape()) def testBatchShape(self): - with self.test_session() as sess: + with self.cached_session() as sess: scale = make_pd(1., 2) chol_scale = chol(scale) @@ -295,7 +295,7 @@ class WishartCholeskyTest(test.TestCase): feed_dict={scale_deferred: [chol_scale, chol_scale]})) def testEventShape(self): - with self.test_session() as sess: + with self.cached_session() as sess: scale = make_pd(1., 2) chol_scale = chol(scale) @@ -320,7 +320,7 @@ class WishartCholeskyTest(test.TestCase): feed_dict={scale_deferred: [chol_scale, chol_scale]})) def testValidateArgs(self): - with self.test_session() as sess: + with self.cached_session() as sess: df_deferred = array_ops.placeholder(dtypes.float32) chol_scale_deferred = array_ops.placeholder(dtypes.float32) x = make_pd(1., 3) @@ -374,7 +374,7 @@ class WishartCholeskyTest(test.TestCase): chol_scale_deferred: np.ones((3, 3))}) def testStaticAsserts(self): - with self.test_session(): + with self.cached_session(): x = make_pd(1., 3) chol_scale = chol(x) @@ -404,7 +404,7 @@ class WishartCholeskyTest(test.TestCase): batch_shape + [dims, dims]) wishart = distributions.WishartFull(df=5, scale=scale) x = wishart.sample(sample_shape, seed=42) - with self.test_session() as sess: + with self.cached_session() as sess: x_ = sess.run(x) expected_shape = sample_shape + batch_shape + [dims, dims] self.assertAllEqual(expected_shape, x.shape) diff --git a/tensorflow/contrib/eager/python/BUILD b/tensorflow/contrib/eager/python/BUILD index f7933639a0..84517b57c7 100644 --- a/tensorflow/contrib/eager/python/BUILD +++ b/tensorflow/contrib/eager/python/BUILD @@ -14,6 +14,7 @@ py_library( ":datasets", ":metrics", ":network", + ":remote", ":saver", "//tensorflow/python:framework_ops", "//tensorflow/python:framework_test_lib", @@ -104,7 +105,6 @@ cuda_py_test( "//tensorflow/python:array_ops", "//tensorflow/python:client", "//tensorflow/python:client_testlib", - "//tensorflow/python/eager:graph_callable", "//tensorflow/python/eager:test", "//tensorflow/python:variables", ], @@ -224,11 +224,24 @@ py_test( ], ) +py_library( + name = "remote", + srcs = ["remote.py"], + srcs_version = "PY2AND3", + visibility = ["//tensorflow:internal"], + deps = [ + "//tensorflow/core:protos_all_py", + "//tensorflow/python:platform", + "//tensorflow/python/eager:context", + ], +) + py_test( name = "remote_test", srcs = ["remote_test.py"], srcs_version = "PY2AND3", deps = [ + ":remote", "//tensorflow/contrib/eager/python:tfe", "//tensorflow/python:array_ops", "//tensorflow/python:client", diff --git a/tensorflow/contrib/eager/python/examples/densenet/densenet_test.py b/tensorflow/contrib/eager/python/examples/densenet/densenet_test.py index 0736ed02b7..e5058bfd94 100644 --- a/tensorflow/contrib/eager/python/examples/densenet/densenet_test.py +++ b/tensorflow/contrib/eager/python/examples/densenet/densenet_test.py @@ -218,7 +218,7 @@ class DensenetBenchmark(tf.test.Benchmark): tf.constant(1.).cpu() def _benchmark_eager_apply(self, label, device_and_format, defun=False, - execution_mode=None, compiled=False): + execution_mode=None): with tfe.execution_mode(execution_mode): device, data_format = device_and_format model = densenet.DenseNet(self.depth, self.growth_rate, self.num_blocks, @@ -228,7 +228,7 @@ class DensenetBenchmark(tf.test.Benchmark): weight_decay=1e-4, dropout_rate=0, pool_initial=True, include_top=True) if defun: - model.call = tfe.defun(model.call, compiled=compiled) + model.call = tfe.defun(model.call) batch_size = 64 num_burn = 5 num_iters = 30 @@ -264,8 +264,7 @@ class DensenetBenchmark(tf.test.Benchmark): make_iterator, device_and_format, defun=False, - execution_mode=None, - compiled=False): + execution_mode=None): with tfe.execution_mode(execution_mode): device, data_format = device_and_format for batch_size in self._train_batch_sizes(): @@ -279,8 +278,8 @@ class DensenetBenchmark(tf.test.Benchmark): optimizer = tf.train.GradientDescentOptimizer(0.1) apply_grads = apply_gradients if defun: - model.call = tfe.defun(model.call, compiled=compiled) - apply_grads = tfe.defun(apply_gradients, compiled=compiled) + model.call = tfe.defun(model.call) + apply_grads = tfe.defun(apply_gradients) num_burn = 3 num_iters = 10 diff --git a/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb index 1a5a186e7a..315d7a4893 100644 --- a/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb +++ b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb @@ -1056,7 +1056,7 @@ "\n", " attention_plot[i] = tf.reshape(attention_weights, (-1, )).numpy()\n", "\n", - " predicted_id = tf.multinomial(tf.exp(predictions), num_samples=1)[0][0].numpy()\n", + " predicted_id = tf.multinomial(predictions, num_samples=1)[0][0].numpy()\n", " result.append(index_word[predicted_id])\n", "\n", " if index_word[predicted_id] == '<end>':\n", diff --git a/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb b/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb index 027097908f..40bc098724 100644 --- a/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb +++ b/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb @@ -610,7 +610,7 @@ "\n", " # using a multinomial distribution to predict the word returned by the model\n", " predictions = predictions / temperature\n", - " predicted_id = tf.multinomial(tf.exp(predictions), num_samples=1)[0][0].numpy()\n", + " predicted_id = tf.multinomial(predictions, num_samples=1)[0][0].numpy()\n", " \n", " # We pass the predicted word as the next input to the model\n", " # along with the previous hidden state\n", diff --git a/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb b/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb index 08d8364978..f1e1f99c57 100644 --- a/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb +++ b/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb @@ -466,10 +466,10 @@ " # passing the concatenated vector to the GRU\n", " output, state = self.gru(x)\n", " \n", - " # output shape == (batch_size * max_length, hidden_size)\n", + " # output shape == (batch_size * 1, hidden_size)\n", " output = tf.reshape(output, (-1, output.shape[2]))\n", " \n", - " # output shape == (batch_size * max_length, vocab)\n", + " # output shape == (batch_size * 1, vocab)\n", " x = self.fc(output)\n", " \n", " return x, state, attention_weights\n", @@ -677,7 +677,7 @@ " attention_weights = tf.reshape(attention_weights, (-1, ))\n", " attention_plot[t] = attention_weights.numpy()\n", "\n", - " predicted_id = tf.multinomial(tf.exp(predictions), num_samples=1)[0][0].numpy()\n", + " predicted_id = tf.multinomial(predictions, num_samples=1)[0][0].numpy()\n", "\n", " result += targ_lang.idx2word[predicted_id] + ' '\n", "\n", diff --git a/tensorflow/contrib/eager/python/examples/notebooks/README.md b/tensorflow/contrib/eager/python/examples/notebooks/README.md index 0d5ed84894..2778b228e9 100644 --- a/tensorflow/contrib/eager/python/examples/notebooks/README.md +++ b/tensorflow/contrib/eager/python/examples/notebooks/README.md @@ -1,11 +1,3 @@ -## Research and experimentation - -Eager execution provides an imperative, define-by-run interface for advanced -operations. Write custom layers, forward passes, and training loops with auto -differentiation. Start with these notebooks, then read the -[eager execution guide](https://www.tensorflow.org/guide/eager). - -1. [Eager execution basics](./eager_basics.ipynb) -2. [Automatic differentiation and gradient tapes](./automatic_differentiation.ipynb) -3. [Custom training: basics](./custom_training.ipynb) -4. [Custom layers](./custom_layers.ipynb) +The notebooks have been moved to the +[tensorflow/docs](https://github.com/tensorflow/docs/tree/master/site/en/tutorials/eager) +repository. diff --git a/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb b/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb index 51b7ffc4de..8fae622e12 100644 --- a/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb +++ b/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb @@ -15,12 +15,7 @@ "execution_count": 0, "metadata": { "cellView": "form", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, + "colab": {}, "colab_type": "code", "id": "GCCk8_dHpuNf" }, @@ -53,308 +48,35 @@ "cell_type": "markdown", "metadata": { "colab_type": "text", - "id": "idv0bPeCp325" - }, - "source": [ - "\u003ctable class=\"tfo-notebook-buttons\" align=\"left\"\u003e\u003ctd\u003e\n", - "\u003ca target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb\"\u003e\n", - " \u003cimg src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /\u003eRun in Google Colab\u003c/a\u003e\n", - "\u003c/td\u003e\u003ctd\u003e\n", - "\u003ca target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb\"\u003e\u003cimg width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /\u003eView source on GitHub\u003c/a\u003e\u003c/td\u003e\u003c/table\u003e" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "vDJ4XzMqodTy" - }, - "source": [ - "In the previous tutorial we introduced `Tensor`s and operations on them. In this tutorial we will cover [automatic differentiation](https://en.wikipedia.org/wiki/Automatic_differentiation), a key technique for optimizing machine learning models." - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "GQJysDM__Qb0" - }, - "source": [ - "## Setup\n" - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "colab_type": "code", - "id": "OiMPZStlibBv" - }, - "outputs": [], - "source": [ - "import tensorflow as tf\n", - "tf.enable_eager_execution()\n", - "\n", - "tfe = tf.contrib.eager # Shorthand for some symbols" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "1CLWJl0QliB0" - }, - "source": [ - "## Derivatives of a function\n", - "\n", - "TensorFlow provides APIs for automatic differentiation - computing the derivative of a function. The way that more closely mimics the math is to encapsulate the computation in a Python function, say `f`, and use `tfe.gradients_function` to create a function that computes the derivatives of `f` with respect to its arguments. If you're familiar with [autograd](https://github.com/HIPS/autograd) for differentiating numpy functions, this will be familiar. For example: " - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "colab_type": "code", - "id": "9FViq92UX7P8" - }, - "outputs": [], - "source": [ - "from math import pi\n", - "\n", - "def f(x):\n", - " return tf.square(tf.sin(x))\n", - "\n", - "assert f(pi/2).numpy() == 1.0\n", - "\n", - "\n", - "# grad_f will return a list of derivatives of f\n", - "# with respect to its arguments. Since f() has a single argument,\n", - "# grad_f will return a list with a single element.\n", - "grad_f = tfe.gradients_function(f)\n", - "assert tf.abs(grad_f(pi/2)[0]).numpy() \u003c 1e-7" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "v9fPs8RyopCf" - }, - "source": [ - "### Higher-order gradients\n", - "\n", - "The same API can be used to differentiate as many times as you like:\n" - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "colab_type": "code", - "id": "3D0ZvnGYo0rW" - }, - "outputs": [], - "source": [ - "def f(x):\n", - " return tf.square(tf.sin(x))\n", - "\n", - "def grad(f):\n", - " return lambda x: tfe.gradients_function(f)(x)[0]\n", - "\n", - "x = tf.lin_space(-2*pi, 2*pi, 100) # 100 points between -2π and +2π\n", - "\n", - "import matplotlib.pyplot as plt\n", - "\n", - "plt.plot(x, f(x), label=\"f\")\n", - "plt.plot(x, grad(f)(x), label=\"first derivative\")\n", - "plt.plot(x, grad(grad(f))(x), label=\"second derivative\")\n", - "plt.plot(x, grad(grad(grad(f)))(x), label=\"third derivative\")\n", - "plt.legend()\n", - "plt.show()" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "-39gouo7mtgu" - }, - "source": [ - "## Gradient tapes\n", - "\n", - "Every differentiable TensorFlow operation has an associated gradient function. For example, the gradient function of `tf.square(x)` would be a function that returns `2.0 * x`. To compute the gradient of a user-defined function (like `f(x)` in the example above), TensorFlow first \"records\" all the operations applied to compute the output of the function. We call this record a \"tape\". It then uses that tape and the gradients functions associated with each primitive operation to compute the gradients of the user-defined function using [reverse mode differentiation](https://en.wikipedia.org/wiki/Automatic_differentiation).\n", - "\n", - "Since operations are recorded as they are executed, Python control flow (using `if`s and `while`s for example) is naturally handled:\n", - "\n" - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "colab_type": "code", - "id": "MH0UfjympWf7" - }, - "outputs": [], - "source": [ - "def f(x, y):\n", - " output = 1\n", - " # Must use range(int(y)) instead of range(y) in Python 3 when\n", - " # using TensorFlow 1.10 and earlier. Can use range(y) in 1.11+\n", - " for i in range(int(y)):\n", - " output = tf.multiply(output, x)\n", - " return output\n", - "\n", - "def g(x, y):\n", - " # Return the gradient of `f` with respect to it's first parameter\n", - " return tfe.gradients_function(f)(x, y)[0]\n", - "\n", - "assert f(3.0, 2).numpy() == 9.0 # f(x, 2) is essentially x * x\n", - "assert g(3.0, 2).numpy() == 6.0 # And its gradient will be 2 * x\n", - "assert f(4.0, 3).numpy() == 64.0 # f(x, 3) is essentially x * x * x\n", - "assert g(4.0, 3).numpy() == 48.0 # And its gradient will be 3 * x * x" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "aNmR5-jhpX2t" - }, - "source": [ - "At times it may be inconvenient to encapsulate computation of interest into a function. For example, if you want the gradient of the output with respect to intermediate values computed in the function. In such cases, the slightly more verbose but explicit [tf.GradientTape](https://www.tensorflow.org/api_docs/python/tf/GradientTape) context is useful. All computation inside the context of a `tf.GradientTape` is \"recorded\".\n", - "\n", - "For example:" - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "colab_type": "code", - "id": "bAFeIE8EuVIq" + "id": "clNGnJ3u8Rl6" }, - "outputs": [], "source": [ - "x = tf.ones((2, 2))\n", - " \n", - "# TODO(b/78880779): Remove the 'persistent=True' argument and use\n", - "# a single t.gradient() call when the bug is resolved.\n", - "with tf.GradientTape(persistent=True) as t:\n", - " # TODO(ashankar): Explain with \"watch\" argument better?\n", - " t.watch(x)\n", - " y = tf.reduce_sum(x)\n", - " z = tf.multiply(y, y)\n", - "\n", - "# Use the same tape to compute the derivative of z with respect to the\n", - "# intermediate value y.\n", - "dz_dy = t.gradient(z, y)\n", - "assert dz_dy.numpy() == 8.0\n", - "\n", - "# Derivative of z with respect to the original input tensor x\n", - "dz_dx = t.gradient(z, x)\n", - "for i in [0, 1]:\n", - " for j in [0, 1]:\n", - " assert dz_dx[i][j].numpy() == 8.0" + "This file has moved." ] }, { "cell_type": "markdown", "metadata": { "colab_type": "text", - "id": "DK05KXrAAld3" - }, - "source": [ - "### Higher-order gradients\n", - "\n", - "Operations inside of the `GradientTape` context manager are recorded for automatic differentiation. If gradients are computed in that context, then the gradient computation is recorded as well. As a result, the exact same API works for higher-order gradients as well. For example:" - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "colab_type": "code", - "id": "cPQgthZ7ugRJ" - }, - "outputs": [], - "source": [ - "# TODO(ashankar): Should we use the persistent tape here instead? Follow up on Tom and Alex's discussion\n", - "\n", - "x = tf.constant(1.0) # Convert the Python 1.0 to a Tensor object\n", - "\n", - "with tf.GradientTape() as t:\n", - " with tf.GradientTape() as t2:\n", - " t2.watch(x)\n", - " y = x * x * x\n", - " # Compute the gradient inside the 't' context manager\n", - " # which means the gradient computation is differentiable as well.\n", - " dy_dx = t2.gradient(y, x)\n", - "d2y_dx2 = t.gradient(dy_dx, x)\n", - "\n", - "assert dy_dx.numpy() == 3.0\n", - "assert d2y_dx2.numpy() == 6.0" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "4U1KKzUpNl58" + "id": "idv0bPeCp325" }, "source": [ - "## Next Steps\n", - "\n", - "In this tutorial we covered gradient computation in TensorFlow. With that we have enough of the primitives required to build an train neural networks, which we will cover in the [next tutorial](https://github.com/tensorflow/models/tree/master/official/contrib/eager/python/examples/notebooks/3_neural_networks.ipynb)." + "\u003ctable class=\"tfo-notebook-buttons\" align=\"left\"\u003e\u003ctd\u003e\n", + "\u003ca target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/eager/automatic_differentiation.ipynb\"\u003e\n", + " \u003cimg src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /\u003eRun in Google Colab\u003c/a\u003e\n", + "\u003c/td\u003e\u003ctd\u003e\n", + "\u003ca target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/site/en/tutorials/eager/automatic_differentiation.ipynb\"\u003e\u003cimg width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /\u003eView source on GitHub\u003c/a\u003e\u003c/td\u003e\u003c/table\u003e" ] } ], "metadata": { "colab": { "collapsed_sections": [], - "default_view": {}, "name": "automatic_differentiation.ipynb", "private_outputs": true, "provenance": [], "toc_visible": true, - "version": "0.3.2", - "views": {} + "version": "0.3.2" }, "kernelspec": { "display_name": "Python 3", diff --git a/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb b/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb index a0bbbb6123..d89774c45e 100644 --- a/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb +++ b/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb @@ -1,46 +1,25 @@ { - "nbformat": 4, - "nbformat_minor": 0, - "metadata": { - "colab": { - "name": "custom_layers.ipynb", - "version": "0.3.2", - "views": {}, - "default_view": {}, - "provenance": [], - "private_outputs": true, - "collapsed_sections": [], - "toc_visible": true - }, - "kernelspec": { - "display_name": "Python 3", - "name": "python3" - } - }, "cells": [ { + "cell_type": "markdown", "metadata": { - "id": "tDnwEv8FtJm7", - "colab_type": "text" + "colab_type": "text", + "id": "tDnwEv8FtJm7" }, - "cell_type": "markdown", "source": [ "##### Copyright 2018 The TensorFlow Authors." ] }, { + "cell_type": "code", + "execution_count": 0, "metadata": { - "id": "JlknJBWQtKkI", + "cellView": "form", + "colab": {}, "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "cellView": "form" + "id": "JlknJBWQtKkI" }, - "cell_type": "code", + "outputs": [], "source": [ "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n", "# you may not use this file except in compliance with the License.\n", @@ -53,347 +32,57 @@ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n", "# See the License for the specific language governing permissions and\n", "# limitations under the License." - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "60RdWsg1tETW", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "# Custom layers" - ] - }, - { - "metadata": { - "id": "BcJg7Enms86w", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "<table class=\"tfo-notebook-buttons\" align=\"left\"><td>\n", - "<a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb\">\n", - " <img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n", - "</td><td>\n", - "<a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb\"><img width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a></td></table>" - ] - }, - { - "metadata": { - "id": "UEu3q4jmpKVT", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "We recommend using `tf.keras` as a high-level API for building neural networks. That said, most TensorFlow APIs are usable with eager execution.\n" ] }, { - "metadata": { - "id": "pwX7Fii1rwsJ", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "import tensorflow as tf\n", - "tfe = tf.contrib.eager\n", - "\n", - "tf.enable_eager_execution()" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "zSFfVVjkrrsI", - "colab_type": "text" - }, "cell_type": "markdown", - "source": [ - "## Layers: common sets of useful operations\n", - "\n", - "Most of the time when writing code for machine learning models you want to operate at a higher level of abstraction than individual operations and manipulation of individual variables.\n", - "\n", - "Many machine learning models are expressible as the composition and stacking of relatively simple layers, and TensorFlow provides both a set of many common layers as a well as easy ways for you to write your own application-specific layers either from scratch or as the composition of existing layers.\n", - "\n", - "TensorFlow includes the full [Keras](https://keras.io) API in the tf.keras package, and the Keras layers are very useful when building your own models.\n" - ] - }, - { "metadata": { - "id": "8PyXlPl-4TzQ", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } + "colab_type": "text", + "id": "60RdWsg1tETW" }, - "cell_type": "code", - "source": [ - "# In the tf.keras.layers package, layers are objects. To construct a layer,\n", - "# simply construct the object. Most layers take as a first argument the number\n", - "# of output dimensions / channels.\n", - "layer = tf.keras.layers.Dense(100)\n", - "# The number of input dimensions is often unnecessary, as it can be inferred\n", - "# the first time the layer is used, but it can be provided if you want to \n", - "# specify it manually, which is useful in some complex models.\n", - "layer = tf.keras.layers.Dense(10, input_shape=(None, 5))" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "Fn69xxPO5Psr", - "colab_type": "text" - }, - "cell_type": "markdown", "source": [ - "The full list of pre-existing layers can be seen in [the documentation](https://www.tensorflow.org/api_docs/python/tf/keras/layers). It includes Dense (a fully-connected layer),\n", - "Conv2D, LSTM, BatchNormalization, Dropout, and many others." + "# Custom layers" ] }, { - "metadata": { - "id": "E3XKNknP5Mhb", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "# To use a layer, simply call it.\n", - "layer(tf.zeros([10, 5]))" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "Wt_Nsv-L5t2s", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "# Layers have many useful methods. For example, you can inspect all variables\n", - "# in a layer by calling layer.variables. In this case a fully-connected layer\n", - "# will have variables for weights and biases.\n", - "layer.variables" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "6ilvKjz8_4MQ", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "# The variables are also accessible through nice accessors\n", - "layer.kernel, layer.bias" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "O0kDbE54-5VS", - "colab_type": "text" - }, "cell_type": "markdown", - "source": [ - "## Implementing custom layers\n", - "The best way to implement your own layer is extending the tf.keras.Layer class and implementing:\n", - " * `__init__` , where you can do all input-independent initialization\n", - " * `build`, where you know the shapes of the input tensors and can do the rest of the initialization\n", - " * `call`, where you do the forward computation\n", - "\n", - "Note that you don't have to wait until `build` is called to create your variables, you can also create them in `__init__`. However, the advantage of creating them in `build` is that it enables late variable creation based on the shape of the inputs the layer will operate on. On the other hand, creating variables in `__init__` would mean that shapes required to create the variables will need to be explicitly specified." - ] - }, - { - "metadata": { - "id": "5Byl3n1k5kIy", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "class MyDenseLayer(tf.keras.layers.Layer):\n", - " def __init__(self, num_outputs):\n", - " super(MyDenseLayer, self).__init__()\n", - " self.num_outputs = num_outputs\n", - " \n", - " def build(self, input_shape):\n", - " self.kernel = self.add_variable(\"kernel\", \n", - " shape=[input_shape[-1].value, \n", - " self.num_outputs])\n", - " \n", - " def call(self, input):\n", - " return tf.matmul(input, self.kernel)\n", - " \n", - "layer = MyDenseLayer(10)\n", - "print(layer(tf.zeros([10, 5])))\n", - "print(layer.variables)" - ], - "execution_count": 0, - "outputs": [] - }, - { "metadata": { - "id": "tk8E2vY0-z4Z", - "colab_type": "text" + "colab_type": "text", + "id": "9sFn_RV_8zM-" }, - "cell_type": "markdown", "source": [ - "Note that you don't have to wait until `build` is called to create your variables, you can also create them in `__init__`.\n", - "\n", - "Overall code is easier to read and maintain if it uses standard layers whenever possible, as other readers will be familiar with the behavior of standard layers. If you want to use a layer which is not present in tf.keras.layers or tf.contrib.layers, consider filing a [github issue](http://github.com/tensorflow/tensorflow/issues/new) or, even better, sending us a pull request!" + "This file has moved." ] }, { - "metadata": { - "id": "Qhg4KlbKrs3G", - "colab_type": "text" - }, "cell_type": "markdown", - "source": [ - "## Models: composing layers\n", - "\n", - "Many interesting layer-like things in machine learning models are implemented by composing existing layers. For example, each residual block in a resnet is a composition of convolutions, batch normalizations, and a shortcut.\n", - "\n", - "The main class used when creating a layer-like thing which contains other layers is tf.keras.Model. Implementing one is done by inheriting from tf.keras.Model." - ] - }, - { - "metadata": { - "id": "N30DTXiRASlb", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "class ResnetIdentityBlock(tf.keras.Model):\n", - " def __init__(self, kernel_size, filters):\n", - " super(ResnetIdentityBlock, self).__init__(name='')\n", - " filters1, filters2, filters3 = filters\n", - "\n", - " self.conv2a = tf.keras.layers.Conv2D(filters1, (1, 1))\n", - " self.bn2a = tf.keras.layers.BatchNormalization()\n", - "\n", - " self.conv2b = tf.keras.layers.Conv2D(filters2, kernel_size, padding='same')\n", - " self.bn2b = tf.keras.layers.BatchNormalization()\n", - "\n", - " self.conv2c = tf.keras.layers.Conv2D(filters3, (1, 1))\n", - " self.bn2c = tf.keras.layers.BatchNormalization()\n", - "\n", - " def call(self, input_tensor, training=False):\n", - " x = self.conv2a(input_tensor)\n", - " x = self.bn2a(x, training=training)\n", - " x = tf.nn.relu(x)\n", - "\n", - " x = self.conv2b(x)\n", - " x = self.bn2b(x, training=training)\n", - " x = tf.nn.relu(x)\n", - "\n", - " x = self.conv2c(x)\n", - " x = self.bn2c(x, training=training)\n", - "\n", - " x += input_tensor\n", - " return tf.nn.relu(x)\n", - "\n", - " \n", - "block = ResnetIdentityBlock(1, [1, 2, 3])\n", - "print(block(tf.zeros([1, 2, 3, 3])))\n", - "print([x.name for x in block.variables])" - ], - "execution_count": 0, - "outputs": [] - }, - { "metadata": { - "id": "wYfucVw65PMj", - "colab_type": "text" + "colab_type": "text", + "id": "BcJg7Enms86w" }, - "cell_type": "markdown", "source": [ - "Much of the time, however, models which compose many layers simply call one layer after the other. This can be done in very little code using tf.keras.Sequential" + "\u003ctable class=\"tfo-notebook-buttons\" align=\"left\"\u003e\u003ctd\u003e\n", + "\u003ca target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/eager/custom_layers.ipynb\"\u003e\n", + " \u003cimg src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /\u003eRun in Google Colab\u003c/a\u003e\n", + "\u003c/td\u003e\u003ctd\u003e\n", + "\u003ca target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/tutorials/eager/custom_layers.ipynb\"\u003e\u003cimg width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /\u003eView source on GitHub\u003c/a\u003e\u003c/td\u003e\u003c/table\u003e" ] + } + ], + "metadata": { + "colab": { + "collapsed_sections": [], + "name": "custom_layers.ipynb", + "private_outputs": true, + "provenance": [], + "toc_visible": true, + "version": "0.3.2" }, - { - "metadata": { - "id": "L9frk7Ur4uvJ", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - " my_seq = tf.keras.Sequential([tf.keras.layers.Conv2D(1, (1, 1)),\n", - " tf.keras.layers.BatchNormalization(),\n", - " tf.keras.layers.Conv2D(2, 1, \n", - " padding='same'),\n", - " tf.keras.layers.BatchNormalization(),\n", - " tf.keras.layers.Conv2D(3, (1, 1)),\n", - " tf.keras.layers.BatchNormalization()])\n", - "my_seq(tf.zeros([1, 2, 3, 3]))" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "c5YwYcnuK-wc", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "# Next steps\n", - "\n", - "Now you can go back to the previous notebook and adapt the linear regression example to use layers and models to be better structured." - ] + "kernelspec": { + "display_name": "Python 3", + "name": "python3" } - ] -}
\ No newline at end of file + }, + "nbformat": 4, + "nbformat_minor": 0 +} diff --git a/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb b/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb index 5f1b48fa0d..86dca0b423 100644 --- a/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb +++ b/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb @@ -1,46 +1,25 @@ { - "nbformat": 4, - "nbformat_minor": 0, - "metadata": { - "colab": { - "name": "Custom training: basics", - "version": "0.3.2", - "views": {}, - "default_view": {}, - "provenance": [], - "private_outputs": true, - "collapsed_sections": [], - "toc_visible": true - }, - "kernelspec": { - "name": "python3", - "display_name": "Python 3" - } - }, "cells": [ { + "cell_type": "markdown", "metadata": { - "id": "5rmpybwysXGV", - "colab_type": "text" + "colab_type": "text", + "id": "5rmpybwysXGV" }, - "cell_type": "markdown", "source": [ "##### Copyright 2018 The TensorFlow Authors." ] }, { + "cell_type": "code", + "execution_count": 0, "metadata": { - "id": "m8y3rGtQsYP2", + "cellView": "form", + "colab": {}, "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "cellView": "form" + "id": "m8y3rGtQsYP2" }, - "cell_type": "code", + "outputs": [], "source": [ "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n", "# you may not use this file except in compliance with the License.\n", @@ -53,425 +32,57 @@ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n", "# See the License for the specific language governing permissions and\n", "# limitations under the License." - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "hrXv0rU9sIma", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "# Custom training: basics" - ] - }, - { - "metadata": { - "id": "7S0BwJ_8sLu7", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "<table class=\"tfo-notebook-buttons\" align=\"left\"><td>\n", - "<a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb\">\n", - " <img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n", - "</td><td>\n", - "<a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb\"><img width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a></td></table>" - ] - }, - { - "metadata": { - "id": "k2o3TTG4TFpt", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "In the previous tutorial we covered the TensorFlow APIs for automatic differentiation, a basic building block for machine learning.\n", - "In this tutorial we will use the TensorFlow primitives introduced in the prior tutorials to do some simple machine learning.\n", - "\n", - "TensorFlow also includes a higher-level neural networks API (`tf.keras`) which provides useful abstractions to reduce boilerplate. We strongly recommend those higher level APIs for people working with neural networks. However, in this short tutorial we cover neural network training from first principles to establish a strong foundation." - ] - }, - { - "metadata": { - "id": "3LXMVuV0VhDr", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "## Setup" - ] - }, - { - "metadata": { - "id": "PJ64L90aVir3", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "import tensorflow as tf\n", - "\n", - "tf.enable_eager_execution()" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "eMAWbDJFVmMk", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "## Variables\n", - "\n", - "Tensors in TensorFlow are immutable stateless objects. Machine learning models, however, need to have changing state: as your model trains, the same code to compute predictions should behave differently over time (hopefully with a lower loss!). To represent this state which needs to change over the course of your computation, you can choose to rely on the fact that Python is a stateful programming language:\n" - ] - }, - { - "metadata": { - "id": "VkJwtLS_Jbn8", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "# Using python state\n", - "x = tf.zeros([10, 10])\n", - "x += 2 # This is equivalent to x = x + 2, which does not mutate the original\n", - " # value of x\n", - "print(x)" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "wfneTXy7JcUz", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "TensorFlow, however, has stateful operations built in, and these are often more pleasant to use than low-level Python representations of your state. To represent weights in a model, for example, it's often convenient and efficient to use TensorFlow variables.\n", - "\n", - "A Variable is an object which stores a value and, when used in a TensorFlow computation, will implicitly read from this stored value. There are operations (`tf.assign_sub`, `tf.scatter_update`, etc) which manipulate the value stored in a TensorFlow variable." ] }, { - "metadata": { - "id": "itxmrMil6DQi", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "v = tf.Variable(1.0)\n", - "assert v.numpy() == 1.0\n", - "\n", - "# Re-assign the value\n", - "v.assign(3.0)\n", - "assert v.numpy() == 3.0\n", - "\n", - "# Use `v` in a TensorFlow operation like tf.square() and reassign\n", - "v.assign(tf.square(v))\n", - "assert v.numpy() == 9.0" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "-paSaeq1JzwC", - "colab_type": "text" - }, "cell_type": "markdown", - "source": [ - "Computations using Variables are automatically traced when computing gradients. For Variables representing embeddings TensorFlow will do sparse updates by default, which are more computation and memory efficient.\n", - "\n", - "Using Variables is also a way to quickly let a reader of your code know that this piece of state is mutable." - ] - }, - { "metadata": { - "id": "BMiFcDzE7Qu3", - "colab_type": "text" + "colab_type": "text", + "id": "hrXv0rU9sIma" }, - "cell_type": "markdown", "source": [ - "## Example: Fitting a linear model\n", - "\n", - "Let's now put the few concepts we have so far ---`Tensor`, `GradientTape`, `Variable` --- to build and train a simple model. This typically involves a few steps:\n", - "\n", - "1. Define the model.\n", - "2. Define a loss function.\n", - "3. Obtain training data.\n", - "4. Run through the training data and use an \"optimizer\" to adjust the variables to fit the data.\n", - "\n", - "In this tutorial, we'll walk through a trivial example of a simple linear model: `f(x) = x * W + b`, which has two variables - `W` and `b`. Furthermore, we'll synthesize data such that a well trained model would have `W = 3.0` and `b = 2.0`." - ] - }, - { - "metadata": { - "id": "gFzH64Jn9PIm", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "### Define the model\n", - "\n", - "Let's define a simple class to encapsulate the variables and the computation." + "# Custom training: basics" ] }, { - "metadata": { - "id": "_WRu7Pze7wk8", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "class Model(object):\n", - " def __init__(self):\n", - " # Initialize variable to (5.0, 0.0)\n", - " # In practice, these should be initialized to random values.\n", - " self.W = tf.Variable(5.0)\n", - " self.b = tf.Variable(0.0)\n", - " \n", - " def __call__(self, x):\n", - " return self.W * x + self.b\n", - " \n", - "model = Model()\n", - "\n", - "assert model(3.0).numpy() == 15.0" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "xa6j_yXa-j79", - "colab_type": "text" - }, "cell_type": "markdown", - "source": [ - "### Define a loss function\n", - "\n", - "A loss function measures how well the output of a model for a given input matches the desired output. Let's use the standard L2 loss." - ] - }, - { - "metadata": { - "id": "Y0ysUFGY924U", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "def loss(predicted_y, desired_y):\n", - " return tf.reduce_mean(tf.square(predicted_y - desired_y))" - ], - "execution_count": 0, - "outputs": [] - }, - { "metadata": { - "id": "qutT_fkl_CBc", - "colab_type": "text" + "colab_type": "text", + "id": "IGPZTmwn9IT4" }, - "cell_type": "markdown", "source": [ - "### Obtain training data\n", - "\n", - "Let's synthesize the training data with some noise." + "This file has moved." ] }, { - "metadata": { - "id": "gxPTb-kt_N5m", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "TRUE_W = 3.0\n", - "TRUE_b = 2.0\n", - "NUM_EXAMPLES = 1000\n", - "\n", - "inputs = tf.random_normal(shape=[NUM_EXAMPLES])\n", - "noise = tf.random_normal(shape=[NUM_EXAMPLES])\n", - "outputs = inputs * TRUE_W + TRUE_b + noise" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "-50nq-wPBsAW", - "colab_type": "text" - }, "cell_type": "markdown", - "source": [ - "Before we train the model let's visualize where the model stands right now. We'll plot the model's predictions in red and the training data in blue." - ] - }, - { "metadata": { - "id": "_eb83LtrB4nt", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } + "colab_type": "text", + "id": "7S0BwJ_8sLu7" }, - "cell_type": "code", "source": [ - "import matplotlib.pyplot as plt\n", - "\n", - "plt.scatter(inputs, outputs, c='b')\n", - "plt.scatter(inputs, model(inputs), c='r')\n", - "plt.show()\n", - "\n", - "print('Current loss: '),\n", - "print(loss(model(inputs), outputs).numpy())" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "sSDP-yeq_4jE", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "### Define a training loop\n", - "\n", - "We now have our network and our training data. Let's train it, i.e., use the training data to update the model's variables (`W` and `b`) so that the loss goes down using [gradient descent](https://en.wikipedia.org/wiki/Gradient_descent). There are many variants of the gradient descent scheme that are captured in `tf.train.Optimizer` implementations. We'd highly recommend using those implementations, but in the spirit of building from first principles, in this particular example we will implement the basic math ourselves." + "\u003ctable class=\"tfo-notebook-buttons\" align=\"left\"\u003e\u003ctd\u003e\n", + "\u003ca target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/eager/custom_training.ipynb\"\u003e\n", + " \u003cimg src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /\u003eRun in Google Colab\u003c/a\u003e\n", + "\u003c/td\u003e\u003ctd\u003e\n", + "\u003ca target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/tutorials/eager/custom_training.ipynb\"\u003e\u003cimg width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /\u003eView source on GitHub\u003c/a\u003e\u003c/td\u003e\u003c/table\u003e" ] + } + ], + "metadata": { + "colab": { + "collapsed_sections": [], + "name": "Custom training: basics", + "private_outputs": true, + "provenance": [], + "toc_visible": true, + "version": "0.3.2" }, - { - "metadata": { - "id": "MBIACgdnA55X", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "def train(model, inputs, outputs, learning_rate):\n", - " with tf.GradientTape() as t:\n", - " current_loss = loss(model(inputs), outputs)\n", - " dW, db = t.gradient(current_loss, [model.W, model.b])\n", - " model.W.assign_sub(learning_rate * dW)\n", - " model.b.assign_sub(learning_rate * db)" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "RwWPaJryD2aN", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "Finally, let's repeatedly run through the training data and see how `W` and `b` evolve." - ] - }, - { - "metadata": { - "id": "XdfkR223D9dW", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "model = Model()\n", - "\n", - "# Collect the history of W-values and b-values to plot later\n", - "Ws, bs = [], []\n", - "epochs = range(10)\n", - "for epoch in epochs:\n", - " Ws.append(model.W.numpy())\n", - " bs.append(model.b.numpy())\n", - " current_loss = loss(model(inputs), outputs)\n", - "\n", - " train(model, inputs, outputs, learning_rate=0.1)\n", - " print('Epoch %2d: W=%1.2f b=%1.2f, loss=%2.5f' %\n", - " (epoch, Ws[-1], bs[-1], current_loss))\n", - "\n", - "# Let's plot it all\n", - "plt.plot(epochs, Ws, 'r',\n", - " epochs, bs, 'b')\n", - "plt.plot([TRUE_W] * len(epochs), 'r--',\n", - " [TRUE_b] * len(epochs), 'b--')\n", - "plt.legend(['W', 'b', 'true W', 'true_b'])\n", - "plt.show()\n", - " " - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "vPnIVuaSJwWz", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "## Next Steps\n", - "\n", - "In this tutorial we covered `Variable`s and built and trained a simple linear model using the TensorFlow primitives discussed so far.\n", - "\n", - "In theory, this is pretty much all you need to use TensorFlow for your machine learning research.\n", - "In practice, particularly for neural networks, the higher level APIs like `tf.keras` will be much more convenient since it provides higher level building blocks (called \"layers\"), utilities to save and restore state, a suite of loss functions, a suite of optimization strategies etc. \n", - "\n", - "The [next tutorial](TODO) will cover these higher level APIs." - ] + "kernelspec": { + "display_name": "Python 3", + "name": "python3" } - ] -}
\ No newline at end of file + }, + "nbformat": 4, + "nbformat_minor": 0 +} diff --git a/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb b/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb index f1e13de5de..c6d1a56604 100644 --- a/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb +++ b/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb @@ -1,46 +1,25 @@ { - "nbformat": 4, - "nbformat_minor": 0, - "metadata": { - "colab": { - "name": "eager_basics.ipynb", - "version": "0.3.2", - "views": {}, - "default_view": {}, - "provenance": [], - "private_outputs": true, - "collapsed_sections": [], - "toc_visible": true - }, - "kernelspec": { - "name": "python3", - "display_name": "Python 3" - } - }, "cells": [ { + "cell_type": "markdown", "metadata": { - "id": "iPpI7RaYoZuE", - "colab_type": "text" + "colab_type": "text", + "id": "iPpI7RaYoZuE" }, - "cell_type": "markdown", "source": [ "##### Copyright 2018 The TensorFlow Authors." ] }, { + "cell_type": "code", + "execution_count": 0, "metadata": { - "id": "hro2InpHobKk", + "cellView": "form", + "colab": {}, "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "cellView": "form" + "id": "hro2InpHobKk" }, - "cell_type": "code", + "outputs": [], "source": [ "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n", "# you may not use this file except in compliance with the License.\n", @@ -53,439 +32,47 @@ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n", "# See the License for the specific language governing permissions and\n", "# limitations under the License." - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "U9i2Dsh-ziXr", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "# Eager execution basics" - ] - }, - { - "metadata": { - "id": "Hndw-YcxoOJK", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "<table class=\"tfo-notebook-buttons\" align=\"left\"><td>\n", - "<a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb\">\n", - " <img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n", - "</td><td>\n", - "<a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb\"><img width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a></td></table>" - ] - }, - { - "metadata": { - "id": "6sILUVbHoSgH", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "This is an introductory tutorial for using TensorFlow. It will cover:\n", - "\n", - "* Importing required packages\n", - "* Creating and using Tensors\n", - "* Using GPU acceleration\n", - "* Datasets" - ] - }, - { - "metadata": { - "id": "z1JcS5iBXMRO", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "## Import TensorFlow\n", - "\n", - "To get started, import the `tensorflow` module and enable eager execution.\n", - "Eager execution enables a more interactive frontend to TensorFlow, the details of which we will discuss much later." - ] - }, - { - "metadata": { - "id": "RlIWhyeLoYnG", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "cellView": "code" - }, - "cell_type": "code", - "source": [ - "import tensorflow as tf\n", - "\n", - "tf.enable_eager_execution()" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "H9UySOPLXdaw", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "## Tensors\n", - "\n", - "A Tensor is a multi-dimensional array. Similar to NumPy `ndarray` objects, `Tensor` objects have a data type and a shape. Additionally, Tensors can reside in accelerator (like GPU) memory. TensorFlow offers a rich library of operations ([tf.add](https://www.tensorflow.org/api_docs/python/tf/add), [tf.matmul](https://www.tensorflow.org/api_docs/python/tf/matmul), [tf.linalg.inv](https://www.tensorflow.org/api_docs/python/tf/linalg/inv) etc.) that consume and produce Tensors. These operations automatically convert native Python types. For example:\n" - ] - }, - { - "metadata": { - "id": "ngUe237Wt48W", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "cellView": "code" - }, - "cell_type": "code", - "source": [ - "print(tf.add(1, 2))\n", - "print(tf.add([1, 2], [3, 4]))\n", - "print(tf.square(5))\n", - "print(tf.reduce_sum([1, 2, 3]))\n", - "print(tf.encode_base64(\"hello world\"))\n", - "\n", - "# Operator overloading is also supported\n", - "print(tf.square(2) + tf.square(3))" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "IDY4WsYRhP81", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "Each Tensor has a shape and a datatype" - ] - }, - { - "metadata": { - "id": "srYWH1MdJNG7", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "x = tf.matmul([[1]], [[2, 3]])\n", - "print(x.shape)\n", - "print(x.dtype)" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "eBPw8e8vrsom", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "The most obvious differences between NumPy arrays and TensorFlow Tensors are:\n", - "\n", - "1. Tensors can be backed by accelerator memory (like GPU, TPU).\n", - "2. Tensors are immutable." - ] - }, - { - "metadata": { - "id": "Dwi1tdW3JBw6", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "### NumPy Compatibility\n", - "\n", - "Conversion between TensorFlow Tensors and NumPy ndarrays is quite simple as:\n", - "* TensorFlow operations automatically convert NumPy ndarrays to Tensors.\n", - "* NumPy operations automatically convert Tensors to NumPy ndarrays.\n", - "\n", - "Tensors can be explicitly converted to NumPy ndarrays by invoking the `.numpy()` method on them.\n", - "These conversions are typically cheap as the array and Tensor share the underlying memory representation if possible. However, sharing the underlying representation isn't always possible since the Tensor may be hosted in GPU memory while NumPy arrays are always backed by host memory, and the conversion will thus involve a copy from GPU to host memory." - ] - }, - { - "metadata": { - "id": "lCUWzso6mbqR", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "import numpy as np\n", - "\n", - "ndarray = np.ones([3, 3])\n", - "\n", - "print(\"TensorFlow operations convert numpy arrays to Tensors automatically\")\n", - "tensor = tf.multiply(ndarray, 42)\n", - "print(tensor)\n", - "\n", - "\n", - "print(\"And NumPy operations convert Tensors to numpy arrays automatically\")\n", - "print(np.add(tensor, 1))\n", - "\n", - "print(\"The .numpy() method explicitly converts a Tensor to a numpy array\")\n", - "print(tensor.numpy())" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "PBNP8yTRfu_X", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "## GPU acceleration\n", - "\n", - "Many TensorFlow operations can be accelerated by using the GPU for computation. Without any annotations, TensorFlow automatically decides whether to use the GPU or CPU for an operation (and copies the tensor between CPU and GPU memory if necessary). Tensors produced by an operation are typically backed by the memory of the device on which the operation executed. For example:" - ] - }, - { - "metadata": { - "id": "3Twf_Rw-gQFM", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - }, - "cellView": "code" - }, - "cell_type": "code", - "source": [ - "x = tf.random_uniform([3, 3])\n", - "\n", - "print(\"Is there a GPU available: \"),\n", - "print(tf.test.is_gpu_available())\n", - "\n", - "print(\"Is the Tensor on GPU #0: \"),\n", - "print(x.device.endswith('GPU:0'))" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "vpgYzgVXW2Ud", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "### Device Names\n", - "\n", - "The `Tensor.device` property provides a fully qualified string name of the device hosting the contents of the Tensor. This name encodes a bunch of details, such as an identifier of the network address of the host on which this program is executing and the device within that host. This is required for distributed execution of TensorFlow programs, but we'll skip that for now. The string will end with `GPU:<N>` if the tensor is placed on the `N`-th tensor on the host." ] }, { - "metadata": { - "id": "ZWZQCimzuqyP", - "colab_type": "text" - }, "cell_type": "markdown", - "source": [ - "\n", - "\n", - "### Explicit Device Placement\n", - "\n", - "The term \"placement\" in TensorFlow refers to how individual operations are assigned (placed on) a device for execution. As mentioned above, when there is no explicit guidance provided, TensorFlow automatically decides which device to execute an operation, and copies Tensors to that device if needed. However, TensorFlow operations can be explicitly placed on specific devices using the `tf.device` context manager. For example:" - ] - }, - { - "metadata": { - "id": "RjkNZTuauy-Q", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "def time_matmul(x):\n", - " %timeit tf.matmul(x, x)\n", - "\n", - "# Force execution on CPU\n", - "print(\"On CPU:\")\n", - "with tf.device(\"CPU:0\"):\n", - " x = tf.random_uniform([1000, 1000])\n", - " assert x.device.endswith(\"CPU:0\")\n", - " time_matmul(x)\n", - "\n", - "# Force execution on GPU #0 if available\n", - "if tf.test.is_gpu_available():\n", - " with tf.device(\"GPU:0\"): # Or GPU:1 for the 2nd GPU, GPU:2 for the 3rd etc.\n", - " x = tf.random_uniform([1000, 1000])\n", - " assert x.device.endswith(\"GPU:0\")\n", - " time_matmul(x)" - ], - "execution_count": 0, - "outputs": [] - }, - { "metadata": { - "id": "o1K4dlhhHtQj", - "colab_type": "text" + "colab_type": "text", + "id": "U9i2Dsh-ziXr" }, - "cell_type": "markdown", "source": [ - "## Datasets\n", - "\n", - "This section demonstrates the use of the [`tf.data.Dataset` API](https://www.tensorflow.org/guide/datasets) to build pipelines to feed data to your model. It covers:\n", - "\n", - "* Creating a `Dataset`.\n", - "* Iteration over a `Dataset` with eager execution enabled.\n", - "\n", - "We recommend using the `Dataset`s API for building performant, complex input pipelines from simple, re-usable pieces that will feed your model's training or evaluation loops.\n", - "\n", - "If you're familiar with TensorFlow graphs, the API for constructing the `Dataset` object remains exactly the same when eager execution is enabled, but the process of iterating over elements of the dataset is slightly simpler.\n", - "You can use Python iteration over the `tf.data.Dataset` object and do not need to explicitly create an `tf.data.Iterator` object.\n", - "As a result, the discussion on iterators in the [TensorFlow Guide](https://www.tensorflow.org/guide/datasets) is not relevant when eager execution is enabled." - ] - }, - { - "metadata": { - "id": "zI0fmOynH-Ne", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "### Create a source `Dataset`\n", - "\n", - "Create a _source_ dataset using one of the factory functions like [`Dataset.from_tensors`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#from_tensors), [`Dataset.from_tensor_slices`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#from_tensor_slices) or using objects that read from files like [`TextLineDataset`](https://www.tensorflow.org/api_docs/python/tf/data/TextLineDataset) or [`TFRecordDataset`](https://www.tensorflow.org/api_docs/python/tf/data/TFRecordDataset). See the [TensorFlow Guide](https://www.tensorflow.org/guide/datasets#reading_input_data) for more information." + "# Eager execution basics" ] }, { - "metadata": { - "id": "F04fVOHQIBiG", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "ds_tensors = tf.data.Dataset.from_tensor_slices([1, 2, 3, 4, 5, 6])\n", - "\n", - "# Create a CSV file\n", - "import tempfile\n", - "_, filename = tempfile.mkstemp()\n", - "\n", - "with open(filename, 'w') as f:\n", - " f.write(\"\"\"Line 1\n", - "Line 2\n", - "Line 3\n", - " \"\"\")\n", - "\n", - "ds_file = tf.data.TextLineDataset(filename)" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "vbxIhC-5IPdf", - "colab_type": "text" - }, "cell_type": "markdown", - "source": [ - "### Apply transformations\n", - "\n", - "Use the transformations functions like [`map`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#map), [`batch`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#batch), [`shuffle`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#shuffle) etc. to apply transformations to the records of the dataset. See the [API documentation for `tf.data.Dataset`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset) for details." - ] - }, - { "metadata": { - "id": "uXSDZWE-ISsd", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } + "colab_type": "text", + "id": "Hndw-YcxoOJK" }, - "cell_type": "code", "source": [ - "ds_tensors = ds_tensors.map(tf.square).shuffle(2).batch(2)\n", - "\n", - "ds_file = ds_file.batch(2)" - ], - "execution_count": 0, - "outputs": [] - }, - { - "metadata": { - "id": "A8X1GNfoIZKJ", - "colab_type": "text" - }, - "cell_type": "markdown", - "source": [ - "### Iterate\n", - "\n", - "When eager execution is enabled `Dataset` objects support iteration.\n", - "If you're familiar with the use of `Dataset`s in TensorFlow graphs, note that there is no need for calls to `Dataset.make_one_shot_iterator()` or `get_next()` calls." + "\u003ctable class=\"tfo-notebook-buttons\" align=\"left\"\u003e\u003ctd\u003e\n", + "\u003ca target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/eager/eager_basics.ipynb\"\u003e\n", + " \u003cimg src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /\u003eRun in Google Colab\u003c/a\u003e\n", + "\u003c/td\u003e\u003ctd\u003e\n", + "\u003ca target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/tutorials/eager/eager_basics.ipynb\"\u003e\u003cimg width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /\u003eView source on GitHub\u003c/a\u003e\u003c/td\u003e\u003c/table\u003e" ] + } + ], + "metadata": { + "colab": { + "collapsed_sections": [], + "name": "eager_basics.ipynb", + "private_outputs": true, + "provenance": [], + "toc_visible": true, + "version": "0.3.2" }, - { - "metadata": { - "id": "ws-WKRk5Ic6-", - "colab_type": "code", - "colab": { - "autoexec": { - "startup": false, - "wait_interval": 0 - } - } - }, - "cell_type": "code", - "source": [ - "print('Elements of ds_tensors:')\n", - "for x in ds_tensors:\n", - " print(x)\n", - "\n", - "print('\\nElements in ds_file:')\n", - "for x in ds_file:\n", - " print(x)" - ], - "execution_count": 0, - "outputs": [] + "kernelspec": { + "display_name": "Python 3", + "name": "python3" } - ] -}
\ No newline at end of file + }, + "nbformat": 4, + "nbformat_minor": 0 +} diff --git a/tensorflow/contrib/eager/python/examples/resnet50/resnet50.py b/tensorflow/contrib/eager/python/examples/resnet50/resnet50.py index a28bc8a43d..3f70f573b1 100644 --- a/tensorflow/contrib/eager/python/examples/resnet50/resnet50.py +++ b/tensorflow/contrib/eager/python/examples/resnet50/resnet50.py @@ -272,8 +272,8 @@ class ResNet50(tf.keras.Model): else: self.global_pooling = None - def call(self, input_tensor, training): - x = self.conv1(input_tensor) + def call(self, inputs, training=True): + x = self.conv1(inputs) x = self.bn_conv1(x, training=training) x = tf.nn.relu(x) x = self.max_pool(x) diff --git a/tensorflow/contrib/eager/python/examples/resnet50/resnet50_test.py b/tensorflow/contrib/eager/python/examples/resnet50/resnet50_test.py index 07d8788882..d265169b5e 100644 --- a/tensorflow/contrib/eager/python/examples/resnet50/resnet50_test.py +++ b/tensorflow/contrib/eager/python/examples/resnet50/resnet50_test.py @@ -216,12 +216,12 @@ class ResNet50Benchmarks(tf.test.Benchmark): tf.constant(1.).cpu() def _benchmark_eager_apply(self, label, device_and_format, defun=False, - execution_mode=None, compiled=False): + execution_mode=None): with tfe.execution_mode(execution_mode): device, data_format = device_and_format model = resnet50.ResNet50(data_format) if defun: - model.call = tfe.defun(model.call, compiled=compiled) + model.call = tfe.defun(model.call) batch_size = 64 num_burn = 5 num_iters = 30 @@ -257,8 +257,7 @@ class ResNet50Benchmarks(tf.test.Benchmark): make_iterator, device_and_format, defun=False, - execution_mode=None, - compiled=False): + execution_mode=None): with tfe.execution_mode(execution_mode): device, data_format = device_and_format for batch_size in self._train_batch_sizes(): @@ -267,8 +266,8 @@ class ResNet50Benchmarks(tf.test.Benchmark): optimizer = tf.train.GradientDescentOptimizer(0.1) apply_grads = apply_gradients if defun: - model.call = tfe.defun(model.call, compiled=compiled) - apply_grads = tfe.defun(apply_gradients, compiled=compiled) + model.call = tfe.defun(model.call) + apply_grads = tfe.defun(apply_gradients) num_burn = 3 num_iters = 10 diff --git a/tensorflow/contrib/eager/python/examples/revnet/revnet_test.py b/tensorflow/contrib/eager/python/examples/revnet/revnet_test.py index 84b2ddf0de..6a921e1997 100644 --- a/tensorflow/contrib/eager/python/examples/revnet/revnet_test.py +++ b/tensorflow/contrib/eager/python/examples/revnet/revnet_test.py @@ -226,14 +226,13 @@ class RevNetBenchmark(tf.test.Benchmark): label, device_and_format, defun=False, - execution_mode=None, - compiled=False): + execution_mode=None): config = config_.get_hparams_imagenet_56() with tfe.execution_mode(execution_mode): device, data_format = device_and_format model = revnet.RevNet(config=config) if defun: - model.call = tfe.defun(model.call, compiled=compiled) + model.call = tfe.defun(model.call) batch_size = 64 num_burn = 5 num_iters = 10 @@ -271,8 +270,7 @@ class RevNetBenchmark(tf.test.Benchmark): make_iterator, device_and_format, defun=False, - execution_mode=None, - compiled=False): + execution_mode=None): config = config_.get_hparams_imagenet_56() with tfe.execution_mode(execution_mode): device, data_format = device_and_format diff --git a/tensorflow/contrib/eager/python/examples/rnn_colorbot/rnn_colorbot.py b/tensorflow/contrib/eager/python/examples/rnn_colorbot/rnn_colorbot.py index 5ee2176154..74ebb1ec77 100644 --- a/tensorflow/contrib/eager/python/examples/rnn_colorbot/rnn_colorbot.py +++ b/tensorflow/contrib/eager/python/examples/rnn_colorbot/rnn_colorbot.py @@ -243,8 +243,8 @@ def train_one_epoch(model, optimizer, train_data, log_interval=10): print("train/batch #%d\tloss: %.6f" % (batch, batch_model_loss())) -SOURCE_TRAIN_URL = "https://raw.githubusercontent.com/random-forests/tensorflow-workshop/master/extras/colorbot/data/train.csv" -SOURCE_TEST_URL = "https://raw.githubusercontent.com/random-forests/tensorflow-workshop/master/extras/colorbot/data/test.csv" +SOURCE_TRAIN_URL = "https://raw.githubusercontent.com/random-forests/tensorflow-workshop/master/archive/extras/colorbot/data/train.csv" +SOURCE_TEST_URL = "https://raw.githubusercontent.com/random-forests/tensorflow-workshop/master/archive/extras/colorbot/data/test.csv" def main(_): diff --git a/tensorflow/contrib/eager/python/metrics_impl.py b/tensorflow/contrib/eager/python/metrics_impl.py index 6efafccd6b..930e62b680 100644 --- a/tensorflow/contrib/eager/python/metrics_impl.py +++ b/tensorflow/contrib/eager/python/metrics_impl.py @@ -336,9 +336,27 @@ class Mean(Metric): return values return values, weights - def result(self): + def result(self, write_summary=True): + """Returns the result of the Metric. + + Args: + write_summary: bool indicating whether to feed the result to the summary + before returning. + Returns: + aggregated metric as float. + Raises: + ValueError: if the optional argument is not bool + """ + # Convert the boolean to tensor for tf.cond, if it is not. + if not isinstance(write_summary, ops.Tensor): + write_summary = ops.convert_to_tensor(write_summary) t = self.numer / self.denom - summary_ops.scalar(name=self.name, tensor=t) + def write_summary_f(): + summary_ops.scalar(name=self.name, tensor=t) + return t + control_flow_ops.cond(write_summary, + write_summary_f, + lambda: t) return t diff --git a/tensorflow/contrib/eager/python/metrics_test.py b/tensorflow/contrib/eager/python/metrics_test.py index 20d938d492..aa99616810 100644 --- a/tensorflow/contrib/eager/python/metrics_test.py +++ b/tensorflow/contrib/eager/python/metrics_test.py @@ -46,6 +46,18 @@ class MetricsTest(test.TestCase): self.assertEqual(dtypes.float64, m.dtype) self.assertEqual(dtypes.float64, m.result().dtype) + def testSummaryArg(self): + m = metrics.Mean() + m([1, 10, 100]) + m(1000) + m([10000.0, 100000.0]) + self.assertEqual(111111.0/6, m.result(write_summary=True).numpy()) + self.assertEqual(111111.0/6, m.result(write_summary=False).numpy()) + with self.assertRaises(ValueError): + m.result(write_summary=5) + with self.assertRaises(ValueError): + m.result(write_summary=[True]) + def testVariableCollections(self): with context.graph_mode(), ops.Graph().as_default(): m = metrics.Mean() @@ -93,6 +105,16 @@ class MetricsTest(test.TestCase): self.assertEqual(len(events), 2) self.assertEqual(events[1].summary.value[0].simple_value, 37.0) + # Get result without saving the summary. + logdir = tempfile.mkdtemp() + with summary_ops.create_file_writer( + logdir, max_queue=0, + name="t0").as_default(), summary_ops.always_record_summaries(): + m.result(write_summary=False) # As a side-effect will write summaries. + # events_from_logdir(_) asserts the directory exists. + events = summary_test_util.events_from_logdir(logdir) + self.assertEqual(len(events), 1) + def testWeightedMean(self): m = metrics.Mean() m([1, 100, 100000], weights=[1, 0.2, 0.3]) diff --git a/tensorflow/contrib/eager/python/remote.py b/tensorflow/contrib/eager/python/remote.py new file mode 100644 index 0000000000..b74cf394f6 --- /dev/null +++ b/tensorflow/contrib/eager/python/remote.py @@ -0,0 +1,73 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Helpers to connect to remote servers.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os + +from tensorflow.core.protobuf.cluster_pb2 import ClusterDef +from tensorflow.core.protobuf.tensorflow_server_pb2 import ServerDef +from tensorflow.python.eager import context + + +def connect_to_remote_host(remote_host=None, job_name="worker"): + """Connects to a single machine to enable remote execution on it. + + Will make devices on the remote host available to use. Note that calling this + more than once will work, but will invalidate any tensor handles on the old + remote devices. + + Using the default job_name of worker, you can schedule ops to run remotely as + follows: + ```python + # Enable eager execution, and connect to the remote host. + tf.enable_eager_execution() + tf.contrib.eager.connect_to_remote_host("exampleaddr.com:9876") + + with ops.device("job:worker/replica:0/task:1/device:CPU:0"): + # The following tensors should be resident on the remote device, and the op + # will also execute remotely. + x1 = array_ops.ones([2, 2]) + x2 = array_ops.ones([2, 2]) + y = math_ops.matmul(x1, x2) + ``` + + Args: + remote_host: The addr of the remote server in host-port format. + job_name: The job name under which the new server will be accessible. + + Raises: + ValueError: if remote_host is None. + """ + if remote_host is None: + raise ValueError("Must provide an remote_host") + cluster_def = ClusterDef() + job_def = cluster_def.job.add() + job_def.name = job_name + job_def.tasks[0] = "127.0.0.1:0" + job_def.tasks[1] = remote_host + + server_def = ServerDef( + cluster=cluster_def, + job_name=job_name, + task_index=0, + protocol="grpc") + + # TODO(nareshmodi): Make this default since it works in more situations. + os.environ["TF_EAGER_REMOTE_USE_SEND_TENSOR_RPC"] = "1" + context.set_server_def(server_def) diff --git a/tensorflow/contrib/eager/python/remote_test.py b/tensorflow/contrib/eager/python/remote_test.py index 76f48eeb1c..13029db975 100644 --- a/tensorflow/contrib/eager/python/remote_test.py +++ b/tensorflow/contrib/eager/python/remote_test.py @@ -23,6 +23,7 @@ import os import numpy as np +from tensorflow.contrib.eager.python import remote from tensorflow.core.protobuf import cluster_pb2 from tensorflow.core.protobuf import tensorflow_server_pb2 from tensorflow.python.eager import backprop @@ -85,6 +86,7 @@ class RemoteExecutionTest(test.TestCase): self._cached_server1_target = self._cached_server1.target[len("grpc://"):] self._cached_server2_target = self._cached_server2.target[len("grpc://"):] + def setUp(self): # Start the local server. context.set_server_def( server_def=get_server_def( @@ -172,6 +174,17 @@ class RemoteExecutionTest(test.TestCase): y = math_ops.matmul(x1, x1) np.testing.assert_array_equal([[2, 2], [2, 2]], y.numpy()) + @run_sync_and_async + def testConnectToRemoteServer(self): + """Basic server connection.""" + remote.connect_to_remote_host(self._cached_server1_target) + + with ops.device("job:worker/replica:0/task:1/device:CPU:0"): + x1 = array_ops.ones([2, 2]) + x2 = array_ops.ones([2, 2]) + y = math_ops.matmul(x1, x2) + np.testing.assert_array_equal([[2, 2], [2, 2]], y.numpy()) + if __name__ == "__main__": ops.enable_eager_execution() diff --git a/tensorflow/contrib/eager/python/saver_test.py b/tensorflow/contrib/eager/python/saver_test.py index 90a3711475..91bc75213c 100644 --- a/tensorflow/contrib/eager/python/saver_test.py +++ b/tensorflow/contrib/eager/python/saver_test.py @@ -21,15 +21,11 @@ import os from tensorflow.contrib.eager.python import saver as _saver from tensorflow.python.eager import context -from tensorflow.python.eager import graph_callable from tensorflow.python.eager import test -from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops -from tensorflow.python.ops import init_ops from tensorflow.python.ops import resource_variable_ops -from tensorflow.python.ops import variable_scope from tensorflow.python.training import adam from tensorflow.python.training import gradient_descent from tensorflow.python.training import momentum @@ -142,53 +138,6 @@ class SaverTest(test.TestCase): with _saver.restore_variables_on_create(ckpt_prefix): _ = model(resource_variable_ops.ResourceVariable(1.0, name='v2')) - def testSaveRestoreGraphCallable(self): - with ops.device(self._dev()): - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.float32)]) - def model(x): - v = variable_scope.get_variable( - 'v', initializer=init_ops.zeros_initializer(), shape=()) - return v + x - - # Default 2 + 0 = 2 - self.assertEqual( - 2, model(array_ops.constant(2, dtype=dtypes.float32)).numpy()) - - # Save the variable value 0. - ckpt_prefix = os.path.join(test.get_temp_dir(), 'ckpt') - _saver.Saver(model.variables).save(ckpt_prefix) - - # update variable to 1, so that 2 + 1 = 3 - model.variables[0].assign(1.) - self.assertEqual( - 3, model(array_ops.constant(2, dtype=dtypes.float32)).numpy()) - - # load the variable value 0, so that 2 + 0 = 2 - _saver.Saver(model.variables).restore(ckpt_prefix) - self.assertEqual( - 2, model(array_ops.constant(2, dtype=dtypes.float32)).numpy()) - - # update checkpoint variable to 1 and memory value to 2. - model.variables[0].assign(1.) - _saver.Saver(model.variables).save(ckpt_prefix) - model.variables[0].assign(2.) - self.assertEqual( - 4, model(array_ops.constant(2, dtype=dtypes.float32)).numpy()) - - # reset the graph and reload on create, so that 1 + 2 = 3 - ops.reset_default_graph() - with _saver.restore_variables_on_create(ckpt_prefix): - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.float32)]) - def model2(x): - v = variable_scope.get_variable( - 'v', initializer=init_ops.zeros_initializer(), shape=()) - return v + x - - self.assertEqual( - 3, model2(array_ops.constant(2, dtype=dtypes.float32)).numpy()) - class GetOptimizerTests(test.TestCase): diff --git a/tensorflow/contrib/eager/python/tfe.py b/tensorflow/contrib/eager/python/tfe.py index 4dfd083443..f5b8d95e4f 100644 --- a/tensorflow/contrib/eager/python/tfe.py +++ b/tensorflow/contrib/eager/python/tfe.py @@ -74,6 +74,8 @@ To use, at program startup, call `tf.enable_eager_execution()`. @@TensorSpec +@@connect_to_remote_host + @@DEVICE_PLACEMENT_EXPLICIT @@DEVICE_PLACEMENT_WARN @@DEVICE_PLACEMENT_SILENT @@ -94,6 +96,7 @@ from tensorflow.contrib.eager.python.network import Network from tensorflow.contrib.eager.python.network import Sequential from tensorflow.contrib.eager.python.network import save_network_checkpoint from tensorflow.contrib.eager.python.network import restore_network_checkpoint +from tensorflow.contrib.eager.python.remote import connect_to_remote_host from tensorflow.contrib.eager.python.saver import get_optimizer_variables from tensorflow.contrib.eager.python.saver import restore_variables_on_create from tensorflow.contrib.eager.python.saver import Saver diff --git a/tensorflow/contrib/estimator/python/estimator/extenders.py b/tensorflow/contrib/estimator/python/estimator/extenders.py index 26449b4651..e3c44bea66 100644 --- a/tensorflow/contrib/estimator/python/estimator/extenders.py +++ b/tensorflow/contrib/estimator/python/estimator/extenders.py @@ -26,6 +26,7 @@ from tensorflow.python.estimator.export.export_output import PredictOutput from tensorflow.python.framework import ops from tensorflow.python.framework import sparse_tensor as sparse_tensor_lib from tensorflow.python.ops import clip_ops +from tensorflow.python.ops import sparse_ops from tensorflow.python.training import optimizer as optimizer_lib from tensorflow.python.util import function_utils @@ -140,7 +141,7 @@ def clip_gradients_by_norm(optimizer, clip_norm): name='ClipByNorm' + optimizer.get_name()) -def forward_features(estimator, keys=None): +def forward_features(estimator, keys=None, sparse_default_values=None): """Forward features to predictions dictionary. In some cases, user wants to see some of the features in estimators prediction @@ -148,39 +149,36 @@ def forward_features(estimator, keys=None): runs inference on the users graph and returns the results. Keys are essential because there is no order guarantee on the outputs so they need to be rejoined to the inputs via keys or transclusion of the inputs in the outputs. - Example: - ```python def input_fn(): features, labels = ... features['unique_example_id'] = ... features, labels - estimator = tf.estimator.LinearClassifier(...) estimator = tf.contrib.estimator.forward_features( estimator, 'unique_example_id') estimator.train(...) assert 'unique_example_id' in estimator.predict(...) ``` - Args: estimator: A `tf.estimator.Estimator` object. - keys: a `string` or a `list` of `string`. If it is `None`, all of the + keys: A `string` or a `list` of `string`. If it is `None`, all of the `features` in `dict` is forwarded to the `predictions`. If it is a `string`, only given key is forwarded. If it is a `list` of strings, all the given `keys` are forwarded. + sparse_default_values: A dict of `str` keys mapping the name of the sparse + features to be converted to dense, to the default value to use. Only + sparse features indicated in the dictionary are converted to dense and the + provided default value is used. Returns: A new `tf.estimator.Estimator` which forwards features to predictions. - Raises: ValueError: * if `keys` is already part of `predictions`. We don't allow override. * if 'keys' does not exist in `features`. - * if feature key refers to a `SparseTensor`, since we don't support - `SparseTensor` in `predictions`. `SparseTensor` is common in `features`. TypeError: if `keys` type is not one of `string` or list/tuple of `string`. """ @@ -231,11 +229,18 @@ def forward_features(estimator, keys=None): for key in get_keys(features): feature = sparse_tensor_lib.convert_to_tensor_or_sparse_tensor( features[key]) + if sparse_default_values and (key in sparse_default_values): + if not isinstance(feature, sparse_tensor_lib.SparseTensor): + raise ValueError( + 'Feature ({}) is expected to be a `SparseTensor`.'.format(key)) + feature = sparse_ops.sparse_tensor_to_dense( + feature, default_value=sparse_default_values[key]) if not isinstance(feature, ops.Tensor): raise ValueError( - 'Forwarded feature ({}) should be a Tensor. Please use keys ' - 'argument of forward_features to filter unwanted features. Type of ' - 'features[{}] is {}.'.format(key, key, type(feature))) + 'Feature ({}) should be a Tensor. Please use `keys` ' + 'argument of forward_features to filter unwanted features, or' + 'add key to argument `sparse_default_values`.' + 'Type of features[{}] is {}.'.format(key, key, type(feature))) predictions[key] = feature spec = spec._replace(predictions=predictions) if spec.export_outputs: diff --git a/tensorflow/contrib/estimator/python/estimator/extenders_test.py b/tensorflow/contrib/estimator/python/estimator/extenders_test.py index 407af2deaf..c8fdaa8791 100644 --- a/tensorflow/contrib/estimator/python/estimator/extenders_test.py +++ b/tensorflow/contrib/estimator/python/estimator/extenders_test.py @@ -14,6 +14,7 @@ # ============================================================================== """extenders tests.""" + from __future__ import absolute_import from __future__ import division from __future__ import print_function @@ -23,6 +24,7 @@ import tempfile import numpy as np from tensorflow.contrib.estimator.python.estimator import extenders +from tensorflow.contrib.layers.python.layers import layers from tensorflow.contrib.predictor import from_saved_model from tensorflow.python.data.ops import dataset_ops from tensorflow.python.estimator import estimator_lib @@ -170,19 +172,53 @@ class ClipGradientsByNormTest(test.TestCase): class ForwardFeaturesTest(test.TestCase): """Tests forward_features.""" - def test_forward_single_key(self): - - def input_fn(): - return {'x': [[3.], [5.]], 'id': [[101], [102]]}, [[1.], [2.]] + def _export_estimator(self, estimator, serving_input_fn): + tmpdir = tempfile.mkdtemp() + export_dir_base = os.path.join( + compat.as_bytes(tmpdir), compat.as_bytes('export')) + export_dir = estimator.export_savedmodel(export_dir_base, serving_input_fn) + self.assertTrue(gfile.Exists(export_dir)) + return export_dir, tmpdir + def make_dummy_input_fn(self): + def _input_fn(): + dataset = dataset_ops.Dataset.from_tensors({ + 'x': [[3.], [5.]], + 'id': [[101], [102]], + 'sparse_id': sparse_tensor.SparseTensor( + values=[1, 2, 3], + indices=[[0, 0], [1, 0], [1, 1]], + dense_shape=[2, 2]), + 'labels': [[1.], [2.]] + }) + def _split(x): + labels = x.pop('labels') + return x, labels + dataset = dataset.map(_split) + return dataset + return _input_fn + + def test_forward_keys(self): + + input_fn = self.make_dummy_input_fn() estimator = linear.LinearRegressor([fc.numeric_column('x')]) estimator.train(input_fn=input_fn, steps=1) - self.assertNotIn('id', next(estimator.predict(input_fn=input_fn))) - estimator = extenders.forward_features(estimator, 'id') - predictions = next(estimator.predict(input_fn=input_fn)) - self.assertIn('id', predictions) - self.assertEqual(101, predictions['id']) + forwarded_keys = ['id', 'sparse_id'] + + for key in forwarded_keys: + self.assertNotIn(key, next(estimator.predict(input_fn=input_fn))) + + estimator = extenders.forward_features( + estimator, forwarded_keys, sparse_default_values={'sparse_id': 1}) + + expected_results = [101, 2, 102, 5] + predictions = estimator.predict(input_fn=input_fn) + for _ in range(2): + prediction = next(predictions) + for key in forwarded_keys: + self.assertIn(key, prediction) + self.assertEqual(expected_results.pop(0), sum(prediction[key])) def test_forward_in_exported(self): @@ -205,11 +241,7 @@ class ForwardFeaturesTest(test.TestCase): estimator = extenders.forward_features(estimator, 'id') # export saved model - tmpdir = tempfile.mkdtemp() - export_dir_base = os.path.join( - compat.as_bytes(tmpdir), compat.as_bytes('export')) - export_dir = estimator.export_savedmodel(export_dir_base, serving_input_fn) - self.assertTrue(gfile.Exists(export_dir)) + export_dir, tmpdir = self._export_estimator(estimator, serving_input_fn) # restore model predict_fn = from_saved_model(export_dir, signature_def_key='predict') @@ -222,6 +254,47 @@ class ForwardFeaturesTest(test.TestCase): # Clean up. gfile.DeleteRecursively(tmpdir) + def test_forward_in_exported_sparse(self): + features_columns = [fc.indicator_column( + fc.categorical_column_with_vocabulary_list('x', range(10)))] + + classifier = linear.LinearClassifier(feature_columns=features_columns) + + def train_input_fn(): + dataset = dataset_ops.Dataset.from_tensors({ + 'x': sparse_tensor.SparseTensor( + values=[1, 2, 3], + indices=[[0, 0], [1, 0], [1, 1]], + dense_shape=[2, 2]), + 'labels': [[0], [1]] + }) + def _split(x): + labels = x.pop('labels') + return x, labels + dataset = dataset.map(_split) + return dataset + + classifier.train(train_input_fn, max_steps=1) + + classifier = extenders.forward_features( + classifier, keys=['x'], sparse_default_values={'x': 0}) + + def serving_input_fn(): + features_ph = array_ops.placeholder(dtype=dtypes.int32, name='x', + shape=[None]) + features = {'x': layers.dense_to_sparse(features_ph)} + return estimator_lib.export.ServingInputReceiver(features, + {'x': features_ph}) + export_dir, tmpdir = self._export_estimator(classifier, serving_input_fn) + prediction_fn = from_saved_model(export_dir, signature_def_key='predict') + + features = (0, 2) + prediction = prediction_fn({'x': features}) + + self.assertIn('x', prediction) + self.assertEqual(features, tuple(prediction['x'])) + gfile.DeleteRecursively(tmpdir) + def test_forward_list(self): def input_fn(): @@ -266,7 +339,6 @@ class ForwardFeaturesTest(test.TestCase): extenders.forward_features(estimator, ['x', estimator]) def test_key_should_be_in_features(self): - def input_fn(): return {'x': [[3.], [5.]], 'id': [[101], [102]]}, [[1.], [2.]] @@ -279,27 +351,36 @@ class ForwardFeaturesTest(test.TestCase): next(estimator.predict(input_fn=input_fn)) def test_forwarded_feature_should_not_be_a_sparse_tensor(self): - def input_fn(): return { 'x': [[3.], [5.]], - 'id': - sparse_tensor.SparseTensor( - values=['1', '2'], - indices=[[0, 0], [1, 0]], - dense_shape=[2, 1]) - }, [[1.], [2.]] + 'id': sparse_tensor.SparseTensor( + values=['1', '2'], + indices=[[0, 0], [1, 0]], + dense_shape=[2, 1]) + }, [[1.], [2.]] estimator = linear.LinearRegressor([fc.numeric_column('x')]) estimator.train(input_fn=input_fn, steps=1) estimator = extenders.forward_features(estimator) with self.assertRaisesRegexp(ValueError, - 'Forwarded feature.* should be a Tensor.'): + 'Feature .* should be a Tensor.*'): next(estimator.predict(input_fn=input_fn)) - def test_predictions_should_be_dict(self): + def test_forwarded_feature_should_be_a_sparse_tensor(self): + input_fn = self.make_dummy_input_fn() + + estimator = linear.LinearRegressor([fc.numeric_column('x')]) + estimator.train(input_fn=input_fn, steps=1) + estimator = extenders.forward_features( + estimator, sparse_default_values={'id': 0, 'sparse_id': 0}) + with self.assertRaisesRegexp( + ValueError, 'Feature .* is expected to be a `SparseTensor`.'): + next(estimator.predict(input_fn=input_fn)) + + def test_predictions_should_be_dict(self): def input_fn(): return {'x': [[3.], [5.]], 'id': [[101], [102]]} diff --git a/tensorflow/contrib/estimator/python/estimator/head_test.py b/tensorflow/contrib/estimator/python/estimator/head_test.py index 2d367adb47..c6e75f8d46 100644 --- a/tensorflow/contrib/estimator/python/estimator/head_test.py +++ b/tensorflow/contrib/estimator/python/estimator/head_test.py @@ -215,7 +215,7 @@ class MultiLabelHead(test.TestCase): spec.export_outputs.keys()) # Assert predictions and export_outputs. - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNone(spec.scaffold.summary_op) predictions = sess.run(spec.predictions) @@ -246,7 +246,7 @@ class MultiLabelHead(test.TestCase): mode=model_fn.ModeKeys.PREDICT, logits=logits) - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertAllEqual( expected_export_classes, @@ -271,7 +271,7 @@ class MultiLabelHead(test.TestCase): logits=logits) # Assert predictions and export_outputs. - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNone(spec.scaffold.summary_op) predictions = sess.run(spec.predictions) @@ -297,7 +297,7 @@ class MultiLabelHead(test.TestCase): mode=model_fn.ModeKeys.EVAL, logits=logits, labels=labels)[0] - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) self.assertAllClose(expected_training_loss, actual_training_loss.eval()) @@ -321,7 +321,7 @@ class MultiLabelHead(test.TestCase): mode=model_fn.ModeKeys.EVAL, logits=logits, labels=labels)[0] - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) self.assertAllClose( expected_training_loss, actual_training_loss.eval(), atol=1e-4) @@ -338,7 +338,7 @@ class MultiLabelHead(test.TestCase): mode=model_fn.ModeKeys.EVAL, logits=logits, labels=labels_placeholder)[0] - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) with self.assertRaisesRegexp( errors.InvalidArgumentError, @@ -375,7 +375,7 @@ class MultiLabelHead(test.TestCase): mode=model_fn.ModeKeys.EVAL, logits=logits_input, labels=labels_input)[0] - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) self.assertAllClose(np.sum(loss) / 2., actual_training_loss.eval()) @@ -394,7 +394,7 @@ class MultiLabelHead(test.TestCase): mode=model_fn.ModeKeys.EVAL, logits=logits, labels=labels)[0] - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) with self.assertRaisesRegexp( errors.InvalidArgumentError, @@ -433,7 +433,7 @@ class MultiLabelHead(test.TestCase): # Assert predictions, loss, and metrics. tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNone(spec.scaffold.summary_op) value_ops = {k: spec.eval_metric_ops[k][0] for k in spec.eval_metric_ops} @@ -753,7 +753,7 @@ class MultiLabelHead(test.TestCase): # Assert predictions, loss, and metrics. tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNone(spec.scaffold.summary_op) value_ops = {k: spec.eval_metric_ops[k][0] for k in spec.eval_metric_ops} @@ -791,7 +791,7 @@ class MultiLabelHead(test.TestCase): mode=model_fn.ModeKeys.TRAIN, logits=logits, labels=labels) - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) self.assertAllClose( expected_training_loss, training_loss.eval(), atol=1e-4) @@ -825,7 +825,7 @@ class MultiLabelHead(test.TestCase): mode=model_fn.ModeKeys.TRAIN, logits=logits, labels=labels) - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) self.assertAllClose( expected_training_loss, training_loss.eval(), atol=1e-4) @@ -864,7 +864,7 @@ class MultiLabelHead(test.TestCase): logits=logits, labels=labels, train_op_fn=_train_op_fn) - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) with self.assertRaisesRegexp( errors.InvalidArgumentError, @@ -890,7 +890,7 @@ class MultiLabelHead(test.TestCase): logits=logits, labels=labels, train_op_fn=_train_op_fn) - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) with self.assertRaisesRegexp( errors.InvalidArgumentError, @@ -919,7 +919,7 @@ class MultiLabelHead(test.TestCase): # Assert predictions, loss, train_op, and summaries. tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNotNone(spec.scaffold.summary_op) loss, train_result, summary_str = sess.run((spec.loss, spec.train_op, @@ -1011,7 +1011,7 @@ class MultiLabelHead(test.TestCase): optimizer=_Optimizer()) tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) loss, train_result = sess.run((spec.loss, spec.train_op)) self.assertAllClose(expected_loss, loss, rtol=tol, atol=tol) @@ -1040,7 +1040,7 @@ class MultiLabelHead(test.TestCase): labels=np.array([[1, 0], [1, 1]], dtype=np.int64), train_op_fn=_train_op_fn) - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) sess.run(spec.train_op) w_value, t_value = sess.run([w, t]) @@ -1079,7 +1079,7 @@ class MultiLabelHead(test.TestCase): # Assert predictions, loss, train_op, and summaries. tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNotNone(spec.scaffold.summary_op) loss, train_result, summary_str = sess.run((spec.loss, spec.train_op, @@ -1127,7 +1127,7 @@ class MultiLabelHead(test.TestCase): # Assert predictions, loss, train_op, and summaries. tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNotNone(spec.scaffold.summary_op) loss, train_result, summary_str = sess.run((spec.loss, spec.train_op, @@ -1162,7 +1162,7 @@ class MultiLabelHead(test.TestCase): logits=logits, labels=labels) atol = 1.e-3 - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) self.assertAllClose( expected_training_loss, training_loss.eval(), atol=atol) @@ -1197,7 +1197,7 @@ class MultiLabelHead(test.TestCase): train_op_fn=_train_op_fn) atol = 1.e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, monitored_session.Scaffold()) loss, train_result = sess.run((spec.loss, spec.train_op)) self.assertAllClose(expected_loss, loss, atol=atol) @@ -1224,7 +1224,7 @@ class MultiLabelHead(test.TestCase): logits=logits, labels=labels, train_op_fn=_train_op_fn) - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) with self.assertRaisesRegexp( errors.InvalidArgumentError, @@ -1252,7 +1252,7 @@ class MultiLabelHead(test.TestCase): logits=logits, labels=labels, train_op_fn=_train_op_fn) - with self.test_session(): + with self.cached_session(): _initialize_variables(self, monitored_session.Scaffold()) with self.assertRaisesRegexp( errors.InvalidArgumentError, @@ -1327,7 +1327,7 @@ class PoissonRegressionHead(test.TestCase): labels=labels, train_op_fn=_train_op_fn) - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) loss, train_result = sess.run([spec.loss, spec.train_op]) self.assertAlmostEqual(expected_loss, loss, delta=atol) @@ -1352,7 +1352,7 @@ class PoissonRegressionHead(test.TestCase): self.assertEqual(dtypes.float32, spec.predictions[keys.LOGITS].dtype) # Assert predictions. - with self.test_session(): + with self.cached_session(): _initialize_variables(self, spec.scaffold) self.assertAllClose( expected_predictions, spec.predictions[keys.PREDICTIONS].eval()) @@ -1395,7 +1395,7 @@ class LogisticRegressionHead(test.TestCase): labels=labels, train_op_fn=_train_op_fn) - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) loss, train_result = sess.run([spec.loss, spec.train_op]) self.assertAlmostEqual(expected_loss, loss, delta=atol) @@ -1419,7 +1419,7 @@ class LogisticRegressionHead(test.TestCase): labels=labels, train_op_fn=_train_op_fn) - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) with self.assertRaisesRegexp( errors.InvalidArgumentError, @@ -1444,7 +1444,7 @@ class LogisticRegressionHead(test.TestCase): labels=labels, train_op_fn=_train_op_fn) - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) with self.assertRaisesRegexp( errors.InvalidArgumentError, @@ -1471,7 +1471,7 @@ class LogisticRegressionHead(test.TestCase): self.assertEqual(dtypes.float32, spec.predictions[keys.LOGITS].dtype) # Assert predictions. - with self.test_session(): + with self.cached_session(): _initialize_variables(self, spec.scaffold) self.assertAllClose( expected_predictions, spec.predictions[keys.PREDICTIONS].eval()) diff --git a/tensorflow/contrib/estimator/python/estimator/multi_head_test.py b/tensorflow/contrib/estimator/python/estimator/multi_head_test.py index 3d6fccb118..2b4d5f5261 100644 --- a/tensorflow/contrib/estimator/python/estimator/multi_head_test.py +++ b/tensorflow/contrib/estimator/python/estimator/multi_head_test.py @@ -132,7 +132,7 @@ class MultiHeadTest(test.TestCase): spec.export_outputs.keys()) # Assert predictions and export_outputs. - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNone(spec.scaffold.summary_op) predictions = sess.run(spec.predictions) @@ -202,7 +202,7 @@ class MultiHeadTest(test.TestCase): spec.export_outputs.keys()) # Assert predictions and export_outputs. - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNone(spec.scaffold.summary_op) predictions = sess.run(spec.predictions) @@ -259,7 +259,7 @@ class MultiHeadTest(test.TestCase): spec.export_outputs.keys()) # Assert predictions and export_outputs. - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNone(spec.scaffold.summary_op) predictions = sess.run(spec.predictions) @@ -336,7 +336,7 @@ class MultiHeadTest(test.TestCase): # Assert predictions, loss, and metrics. tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNone(spec.scaffold.summary_op) value_ops = {k: spec.eval_metric_ops[k][0] for k in spec.eval_metric_ops} @@ -362,7 +362,7 @@ class MultiHeadTest(test.TestCase): logits=logits, labels=labels)[0] tol = 1e-3 - with self.test_session(): + with self.cached_session(): # Unreduced loss of the head is [[(10 + 10) / 2], (15 + 0) / 2] # (averaged over classes, averaged over examples). self.assertAllClose(8.75, loss.eval(), rtol=tol, atol=tol) @@ -397,7 +397,7 @@ class MultiHeadTest(test.TestCase): logits=logits, labels=labels) tol = 1e-3 - with self.test_session(): + with self.cached_session(): # loss of the first head is [[(10 + 10) / 2], [(15 + 0) / 2]] # = [10, 7.5] # training_loss = (1 * 10 + 2 * 7.5) / 2 = 12.5 @@ -445,7 +445,7 @@ class MultiHeadTest(test.TestCase): logits=logits, labels=labels) tol = 1e-3 - with self.test_session(): + with self.cached_session(): # loss of the first head is [[(10 + 10) / 2], [(15 + 0) / 2]] # = [10, 7.5] # training_loss = (1 * 10 + 2 * 7.5) / 2 = 12.5 @@ -498,7 +498,7 @@ class MultiHeadTest(test.TestCase): logits=logits, labels=labels)[0] tol = 1e-3 - with self.test_session(): + with self.cached_session(): self.assertAllClose( expected_training_loss, training_loss.eval(), rtol=tol, atol=tol) @@ -535,7 +535,7 @@ class MultiHeadTest(test.TestCase): # Assert predictions, loss, train_op, and summaries. tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNotNone(spec.scaffold.summary_op) loss, train_result, summary_str = sess.run((spec.loss, spec.train_op, @@ -579,7 +579,7 @@ class MultiHeadTest(test.TestCase): optimizer=_Optimizer()) tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) loss, train_result = sess.run((spec.loss, spec.train_op)) self.assertAllClose(expected_loss, loss, rtol=tol, atol=tol) @@ -634,7 +634,7 @@ class MultiHeadTest(test.TestCase): # Assert predictions, loss, train_op, and summaries. tol = 1e-3 - with self.test_session() as sess: + with self.cached_session() as sess: _initialize_variables(self, spec.scaffold) self.assertIsNotNone(spec.scaffold.summary_op) loss, train_result, summary_str = sess.run((spec.loss, spec.train_op, diff --git a/tensorflow/contrib/estimator/python/estimator/replicate_model_fn_test.py b/tensorflow/contrib/estimator/python/estimator/replicate_model_fn_test.py index dd8a3a95f1..65229d67bb 100644 --- a/tensorflow/contrib/estimator/python/estimator/replicate_model_fn_test.py +++ b/tensorflow/contrib/estimator/python/estimator/replicate_model_fn_test.py @@ -209,7 +209,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[1.0], [2.0]]) labels = np.array([[1.0], [2.0]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, loss_reduction=losses.Reduction.SUM, @@ -233,7 +233,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[1.0], [2.0]]) labels = np.array([[1.0], [2.0]]) - with self.test_session() as session: + with self.cached_session() as session: # Add another trainable variable that doesn't produce a gradient to # verify that None gradients are supported. _ = variable_scope.get_variable( @@ -275,7 +275,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): # for the second. expected_c = 10.0 - 3.0, 7.0 - 4.0 - with self.test_session() as session, variable_scope.variable_scope( + with self.cached_session() as session, variable_scope.variable_scope( '', reuse=variable_scope.AUTO_REUSE): replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, @@ -299,7 +299,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[0.01], [0.002]]) labels = np.array([[0.01], [0.02]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, loss_reduction=losses.Reduction.SUM, @@ -330,7 +330,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[0.01], [0.002]]) labels = np.array([[0.01], [0.02]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, losses.Reduction.MEAN, devices=['/gpu:0', '/gpu:1']) estimator_spec = replicated_model_fn( @@ -359,7 +359,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[0.01], [0.002]]) labels = np.array([[0.01], [0.02]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, devices=['/gpu:0', '/gpu:1']) estimator_spec = replicated_model_fn( @@ -374,7 +374,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[1.0], [2.0]]) labels = np.array([[1.0], [2.0]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, devices=['/gpu:0']) estimator_spec = replicated_model_fn( @@ -396,7 +396,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[0.01], [0.002]]) labels = np.array([[0.01], [0.02]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, devices=['/gpu:0']) estimator_spec = replicated_model_fn( @@ -424,7 +424,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[0.01], [0.002]]) labels = np.array([[0.01], [0.02]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, devices=['/gpu:0']) estimator_spec = replicated_model_fn( @@ -456,7 +456,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[0.01], [0.002]]) labels = np.array([[0.01], [0.02]]) - with self.test_session(): + with self.cached_session(): replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, devices=['/GPU:0']) _ = replicated_model_fn( @@ -470,7 +470,7 @@ class ReplicateModelTest(test_util.TensorFlowTestCase): features = np.array([[0.01], [0.002]]) labels = np.array([[0.01], [0.02]]) - with self.test_session(): + with self.cached_session(): replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, devices=['/gpu:0']) _ = replicated_model_fn( @@ -521,7 +521,7 @@ class ReplicateAcrossASingleDeviceWithoutTowerOptimizer( features = np.array([[1.0], [2.0]]) labels = np.array([[1.0], [2.0]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, devices=['/gpu:0']) estimator_spec = replicated_model_fn( @@ -649,7 +649,7 @@ class ReplicateWithTwoOptimizersTest(test_util.TensorFlowTestCase): features = np.array([[1.0], [2.0]]) labels = np.array([[1.0], [2.0]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, loss_reduction=losses.Reduction.SUM, @@ -746,7 +746,7 @@ class ReplicateWithTwoLossesAndOneOptimizer(test_util.TensorFlowTestCase): features = np.array([[1.0], [2.0]]) labels = np.array([[1.0], [2.0]]) - with self.test_session() as session: + with self.cached_session() as session: replicated_model_fn = replicate_model_fn.replicate_model_fn( self.model_fn, loss_reduction=losses.Reduction.SUM, @@ -777,7 +777,7 @@ class ReplicateWithTwoLossesAndOneOptimizer(test_util.TensorFlowTestCase): features = np.array([[1.0], [2.0]]) labels = np.array([[1.0], [2.0]]) - with self.test_session(), ops_lib.Graph().as_default(): + with self.cached_session(), ops_lib.Graph().as_default(): with self.assertRaisesRegexp( ValueError, '.+was.+supposed.+to.+make.+same.+optimizer.+calls.+'): replicated_model_fn = replicate_model_fn.replicate_model_fn( @@ -819,7 +819,7 @@ class FailToWrapOptimizerInTheModelFn(test_util.TensorFlowTestCase): features = np.array([[1.0], [2.0]]) labels = np.array([[1.0], [2.0]]) - with self.test_session(): + with self.cached_session(): with self.assertRaisesRegexp(ValueError, 'Please.+wrap.+with.+TowerOptimizer'): replicated_model_fn = replicate_model_fn.replicate_model_fn( @@ -845,7 +845,7 @@ class GetLossTowersTest(test_util.TensorFlowTestCase): return model_fn_lib.EstimatorSpec(mode=mode, loss=math_ops.reduce_sum(loss)) def test_gradients_are_computed(self): - with self.test_session() as session: + with self.cached_session() as session: tower_specs = replicate_model_fn._get_loss_towers( self.model_fn, mode=None, @@ -879,7 +879,7 @@ class GetLossTowersTest(test_util.TensorFlowTestCase): self.assertEqual(0.25, session.run(c)) def test_gradients_are_computed_with_mean_reduction(self): - with self.test_session() as session: + with self.cached_session() as session: tower_specs = replicate_model_fn._get_loss_towers( self.model_fn, mode=model_fn_lib.ModeKeys.EVAL, @@ -932,7 +932,7 @@ class GetLossTowersTest(test_util.TensorFlowTestCase): return model_fn_lib.EstimatorSpec( mode=mode, loss=math_ops.reduce_sum(loss)) - with self.test_session() as session: + with self.cached_session() as session: tower_specs = replicate_model_fn._get_loss_towers( model_fn, mode=None, @@ -975,7 +975,7 @@ class SplitBatchTest(test_util.TensorFlowTestCase): self.assertAllEqual(a.dense_shape, b.dense_shape) def test_simple_half_split(self): - with self.test_session(): + with self.cached_session(): features = [0.0, 1.0, 2.0, 3.0] labels = [10.0, 11.0, 12.0, 13.0] feature_shards, label_shards = replicate_model_fn._split_batch( @@ -988,7 +988,7 @@ class SplitBatchTest(test_util.TensorFlowTestCase): self.assertAllEqual([[10.0, 11.0], [12.0, 13.0]], label_shards) def test_to_each_their_own(self): - with self.test_session(): + with self.cached_session(): features = [0.0, 1.0, 2.0, 3.0] labels = [10.0, 11.0, 12.0, 13.0] feature_shards, label_shards = replicate_model_fn._split_batch( @@ -1001,7 +1001,7 @@ class SplitBatchTest(test_util.TensorFlowTestCase): self.assertAllEqual([[10.0], [11.0], [12.0], [13.0]], label_shards) def test_one_batch(self): - with self.test_session(): + with self.cached_session(): features = [0.0, 1.0, 2.0, 3.0] labels = [10.0, 11.0, 12.0, 13.0] feature_shards, label_shards = replicate_model_fn._split_batch( @@ -1014,7 +1014,7 @@ class SplitBatchTest(test_util.TensorFlowTestCase): self.assertAllEqual([[10.0, 11.0, 12.0, 13.0]], label_shards) def test_half_split_in_dictionary(self): - with self.test_session(): + with self.cached_session(): features = {'first': [0.0, 1.0, 2.0, 3.0], 'second': [4.0, 5.0, 6.0, 7.0]} labels = [10.0, 11.0, 12.0, 13.0] @@ -1029,7 +1029,7 @@ class SplitBatchTest(test_util.TensorFlowTestCase): self.assertAllEqual([12.0, 13.0], label_shards[1].eval()) def test_sparse_tensor_can_be_split_unevenly(self): - with self.test_session(): + with self.cached_session(): features = { 'x': sparse_tensor.SparseTensor( @@ -1054,7 +1054,7 @@ class SplitBatchTest(test_util.TensorFlowTestCase): self.assertAllEqual([[2.0]], label_shards[1].eval()) def test_sparse_tensor_can_be_split_unevenly_repeated_row(self): - with self.test_session(): + with self.cached_session(): features = { 'x': sparse_tensor.SparseTensor( @@ -1081,7 +1081,7 @@ class SplitBatchTest(test_util.TensorFlowTestCase): self.assertAllEqual([[2.0]], label_shards[1].eval()) def test_one_batch_in_dictionary(self): - with self.test_session() as session: # pylint: disable=unused-variable + with self.cached_session() as session: # pylint: disable=unused-variable features = {'first': [0.0, 1.0, 2.0, 3.0], 'second': [4.0, 5.0, 6.0, 7.0]} labels = [10.0, 11.0, 12.0, 13.0] @@ -1095,7 +1095,7 @@ class SplitBatchTest(test_util.TensorFlowTestCase): self.assertAllEqual([10.0, 11.0, 12.0, 13.0], label_shards[0].eval()) def test_feature_and_label_dictionaries(self): - with self.test_session() as session: # pylint: disable=unused-variable + with self.cached_session() as session: # pylint: disable=unused-variable features = {'first': [0.0, 1.0, 2.0, 3.0], 'second': [4.0, 5.0, 6.0, 7.0]} labels = {'first': [10.0, 11.0], 'second': [12.0, 13.0]} @@ -1127,7 +1127,7 @@ class TrainSpecTest(test_util.TensorFlowTestCase): return constant_op.constant(loss_value, dtype=dtypes.float64) def test_example(self): - with self.test_session() as session: + with self.cached_session() as session: tower_losses = list(map(self.create_constant_loss, [2, 4, 6])) tower_specs = list(map(self.create_estimator_spec, tower_losses)) @@ -1161,7 +1161,7 @@ class EvalSpecTest(test_util.TensorFlowTestCase): return metrics def test_example(self): - with self.test_session() as session: + with self.cached_session() as session: tower_losses = map(self.create_constant_loss, [2, 4, 6]) tower_metrics = map(self.create_eval_metrics, [0, 0.2, 0.3]) tower_specs = [ @@ -1187,7 +1187,7 @@ class EvalSpecTest(test_util.TensorFlowTestCase): self.assertEqual(2 + 4 + 6, session.run(estimator_spec.loss)) def test_handles_single_tower(self): - with self.test_session() as session: + with self.cached_session() as session: tower_losses = map(self.create_constant_loss, [5]) tower_metrics = map(self.create_eval_metrics, [0.2]) tower_specs = [ @@ -1231,7 +1231,7 @@ class PredictSpecTest(test_util.TensorFlowTestCase): }) def test_example(self): - with self.test_session() as session: + with self.cached_session() as session: tower_specs = replicate_model_fn._get_loss_towers( self.model_fn, mode=None, @@ -1273,7 +1273,7 @@ class ReduceMetricVariablesTest(test_util.TensorFlowTestCase): np.array([3.3, 3.5, 3.7]) * (tower_id + 1), 'total') def test_example(self): - with self.test_session() as session: + with self.cached_session() as session: for tower_id in range(3): self.create_tower_metrics(tower_id) @@ -1303,7 +1303,7 @@ class ReduceMetricVariablesTest(test_util.TensorFlowTestCase): self.assertAllClose([0.0, 0.0, 0.0], local_metrics[8], 0.01) def test_reduce_is_idempotent(self): - with self.test_session() as session: + with self.cached_session() as session: for tower_id in range(3): self.create_tower_metrics(tower_id) @@ -1329,7 +1329,7 @@ class ReduceMetricVariablesTest(test_util.TensorFlowTestCase): self.assertAllClose([0.0, 0.0, 0.0], local_metrics[8], 0.01) def test_handles_single_tower(self): - with self.test_session() as session: + with self.cached_session() as session: self.create_tower_metrics(0) session.run( variables.variables_initializer( @@ -1346,7 +1346,7 @@ class ReduceMetricVariablesTest(test_util.TensorFlowTestCase): self.assertAllClose([3.3, 3.5, 3.7], local_metrics[2], 0.01) def test_doesnt_accept_uneven_number_of_variables(self): - with self.test_session() as session: + with self.cached_session() as session: for tower_id in range(3): self.create_tower_metrics(tower_id) self.create_metric_variable(-1.0, 'oddball') @@ -1418,7 +1418,7 @@ class MergeExportOutputsTest(test_util.TensorFlowTestCase): return estimator_spec def test_merge_predict_output(self): - with self.test_session() as session: + with self.cached_session() as session: estimator_spec = self.replicate_estimator_spec(session) self.assertAllClose( { @@ -1428,7 +1428,7 @@ class MergeExportOutputsTest(test_util.TensorFlowTestCase): signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY].outputs)) def test_merge_classification_output_scores_classes(self): - with self.test_session() as session: + with self.cached_session() as session: estimator_spec = self.replicate_estimator_spec(session) self.assertAllClose( [0.1, 0.02], @@ -1440,7 +1440,7 @@ class MergeExportOutputsTest(test_util.TensorFlowTestCase): estimator_spec.export_outputs['classification_output'].classes)) def test_merge_classification_output_scores(self): - with self.test_session() as session: + with self.cached_session() as session: estimator_spec = self.replicate_estimator_spec(session) self.assertAllClose( [0.1, 0.02], @@ -1450,7 +1450,7 @@ class MergeExportOutputsTest(test_util.TensorFlowTestCase): None, estimator_spec.export_outputs['classification_scores'].classes) def test_merge_classification_output_classes(self): - with self.test_session() as session: + with self.cached_session() as session: estimator_spec = self.replicate_estimator_spec(session) self.assertAllEqual( [b'split_inputs/split:0', b'split_inputs/split:1'], @@ -1460,7 +1460,7 @@ class MergeExportOutputsTest(test_util.TensorFlowTestCase): None, estimator_spec.export_outputs['classification_classes'].scores) def test_merge_regression_output(self): - with self.test_session() as session: + with self.cached_session() as session: estimator_spec = self.replicate_estimator_spec(session) self.assertAllClose( [0.1, 0.02], @@ -1548,7 +1548,7 @@ class LocalDeviceSetterTest(test_util.TensorFlowTestCase): class ComputeSumWithDevicePlacementTest(test_util.TensorFlowTestCase): def test_vectors(self): - with self.test_session() as session: + with self.cached_session() as session: total = replicate_model_fn._compute_sum_on_device( [1.0, 2.0, 3.0, 4.0], device='/device:GPU:0', name='test_sum') @@ -1557,7 +1557,7 @@ class ComputeSumWithDevicePlacementTest(test_util.TensorFlowTestCase): self.assertEqual(10.0, session.run(total)) def test_tensors(self): - with self.test_session() as session: + with self.cached_session() as session: total = replicate_model_fn._compute_sum_on_device( [[1.0, 2.0], [3.0, 4.0]], device='/device:GPU:0', name='test_sum') @@ -1566,7 +1566,7 @@ class ComputeSumWithDevicePlacementTest(test_util.TensorFlowTestCase): self.assertAllEqual([4.0, 6.0], session.run(total)) def test_indexedslices(self): - with self.test_session() as session: + with self.cached_session() as session: a = ops_lib.IndexedSlices( constant_op.constant([1.0, 2.0]), [0, 1], dense_shape=constant_op.constant([2])) @@ -1580,7 +1580,7 @@ class ComputeSumWithDevicePlacementTest(test_util.TensorFlowTestCase): session.run(ops_lib.convert_to_tensor(total))) def test_indexedslices_higher_dimensions(self): - with self.test_session() as session: + with self.cached_session() as session: a = ops_lib.IndexedSlices( constant_op.constant([[1.0, 5.0], [2.0, 6.0]]), [0, 1], dense_shape=constant_op.constant([2, 4])) @@ -1595,7 +1595,7 @@ class ComputeSumWithDevicePlacementTest(test_util.TensorFlowTestCase): session.run(ops_lib.convert_to_tensor(total))) def test_indexedslices_some_dont_overlap(self): - with self.test_session() as session: + with self.cached_session() as session: a = ops_lib.IndexedSlices( constant_op.constant([1.0, 2.0]), [0, 3], dense_shape=constant_op.constant([4])) @@ -1637,7 +1637,7 @@ class ConcatTensorDictsTest(test_util.TensorFlowTestCase): }, ] - with self.test_session() as session: + with self.cached_session() as session: self.assertAllClose({ 'a': np.array([1.0, 2.0, 3.0]), 'b': np.array([11.0, 12.0, 13.0, 14.0]), diff --git a/tensorflow/contrib/factorization/python/kernel_tests/clustering_ops_test.py b/tensorflow/contrib/factorization/python/kernel_tests/clustering_ops_test.py index 1322f7ce5f..db47073fcc 100644 --- a/tensorflow/contrib/factorization/python/kernel_tests/clustering_ops_test.py +++ b/tensorflow/contrib/factorization/python/kernel_tests/clustering_ops_test.py @@ -41,7 +41,7 @@ class KmeansPlusPlusInitializationTest(test.TestCase): [-1., -1.]]).astype(np.float32) def runTestWithSeed(self, seed): - with self.test_session(): + with self.cached_session(): sampled_points = clustering_ops.kmeans_plus_plus_initialization( self._points, 3, seed, (seed % 5) - 1) self.assertAllClose( @@ -58,7 +58,7 @@ class KmeansPlusPlusInitializationTest(test.TestCase): class KMC2InitializationTest(test.TestCase): def runTestWithSeed(self, seed): - with self.test_session(): + with self.cached_session(): distances = np.zeros(1000).astype(np.float32) distances[6] = 10e7 distances[4] = 10e3 @@ -82,7 +82,7 @@ class KMC2InitializationLargeTest(test.TestCase): self._distances[1000] = 50.0 def testBasic(self): - with self.test_session(): + with self.cached_session(): counts = {} seed = 0 for i in range(50): @@ -102,7 +102,7 @@ class KMC2InitializationCornercaseTest(test.TestCase): self._distances = np.zeros(10) def runTestWithSeed(self, seed): - with self.test_session(): + with self.cached_session(): sampled_point = clustering_ops.kmc2_chain_initialization( self._distances, seed) self.assertEquals(sampled_point.eval(), 0) @@ -128,14 +128,14 @@ class NearestCentersTest(test.TestCase): [1., 1.]]).astype(np.float32) def testNearest1(self): - with self.test_session(): + with self.cached_session(): [indices, distances] = clustering_ops.nearest_neighbors(self._points, self._centers, 1) self.assertAllClose(indices.eval(), [[0], [0], [1], [4]]) self.assertAllClose(distances.eval(), [[0.], [5.], [1.], [0.]]) def testNearest2(self): - with self.test_session(): + with self.cached_session(): [indices, distances] = clustering_ops.nearest_neighbors(self._points, self._centers, 2) self.assertAllClose(indices.eval(), [[0, 1], [0, 1], [1, 0], [4, 3]]) @@ -180,7 +180,7 @@ class NearestCentersLargeTest(test.TestCase): expected_nearest_neighbor_squared_distances)) def testNearest1(self): - with self.test_session(): + with self.cached_session(): [indices, distances] = clustering_ops.nearest_neighbors(self._points, self._centers, 1) self.assertAllClose(indices.eval(), @@ -190,7 +190,7 @@ class NearestCentersLargeTest(test.TestCase): self._expected_nearest_neighbor_squared_distances[:, [0]]) def testNearest5(self): - with self.test_session(): + with self.cached_session(): [indices, distances] = clustering_ops.nearest_neighbors(self._points, self._centers, 5) self.assertAllClose(indices.eval(), diff --git a/tensorflow/contrib/factorization/python/kernel_tests/masked_matmul_ops_test.py b/tensorflow/contrib/factorization/python/kernel_tests/masked_matmul_ops_test.py index 3a909e2373..dd115735d0 100644 --- a/tensorflow/contrib/factorization/python/kernel_tests/masked_matmul_ops_test.py +++ b/tensorflow/contrib/factorization/python/kernel_tests/masked_matmul_ops_test.py @@ -58,7 +58,7 @@ class MaskedProductOpsTest(test.TestCase): self._mask_ind, self._mask_shape = MakeMask() def _runTestMaskedProduct(self, transpose_a, transpose_b): - with ops.Graph().as_default(), self.test_session() as sess: + with ops.Graph().as_default(), self.cached_session() as sess: a = self._a if not transpose_a else array_ops.transpose(self._a) b = self._b if not transpose_b else array_ops.transpose(self._b) @@ -78,7 +78,7 @@ class MaskedProductOpsTest(test.TestCase): AssertClose(result, true_result) def _runTestEmptyMaskedProduct(self): - with ops.Graph().as_default(), self.test_session() as sess: + with ops.Graph().as_default(), self.cached_session() as sess: empty_mask = constant_op.constant(0, shape=[0, 2], dtype=dtypes.int64) values = gen_factorization_ops.masked_matmul( self._a, self._b, empty_mask, False, False) diff --git a/tensorflow/contrib/factorization/python/kernel_tests/wals_solver_ops_test.py b/tensorflow/contrib/factorization/python/kernel_tests/wals_solver_ops_test.py index 6c2f1d4608..8a16e22663 100644 --- a/tensorflow/contrib/factorization/python/kernel_tests/wals_solver_ops_test.py +++ b/tensorflow/contrib/factorization/python/kernel_tests/wals_solver_ops_test.py @@ -50,7 +50,7 @@ class WalsSolverOpsTest(test.TestCase): def testWalsSolverLhs(self): sparse_block = SparseBlock3x3() - with self.test_session(): + with self.cached_session(): [lhs_tensor, rhs_matrix] = gen_factorization_ops.wals_compute_partial_lhs_and_rhs( self._column_factors, self._column_weights, self._unobserved_weights, @@ -82,7 +82,7 @@ class WalsSolverOpsTest(test.TestCase): def testWalsSolverLhsEntryWeights(self): sparse_block = SparseBlock3x3() - with self.test_session(): + with self.cached_session(): [lhs_tensor, rhs_matrix] = gen_factorization_ops.wals_compute_partial_lhs_and_rhs( self._column_factors, [], self._unobserved_weights, diff --git a/tensorflow/contrib/ffmpeg/decode_audio_op_test.py b/tensorflow/contrib/ffmpeg/decode_audio_op_test.py index 3dc663bb6f..784da1c432 100644 --- a/tensorflow/contrib/ffmpeg/decode_audio_op_test.py +++ b/tensorflow/contrib/ffmpeg/decode_audio_op_test.py @@ -56,7 +56,7 @@ class DecodeAudioOpTest(test.TestCase): """ if samples_per_second_tensor is None: samples_per_second_tensor = samples_per_second - with self.test_session(): + with self.cached_session(): path = os.path.join(resource_loader.get_data_files_path(), 'testdata', filename) with open(path, 'rb') as f: @@ -123,7 +123,7 @@ class DecodeAudioOpTest(test.TestCase): self._loadFileAndTest('mono_10khz.ogg', 'ogg', 0.57, 10000, 1) def testInvalidFile(self): - with self.test_session(): + with self.cached_session(): contents = 'invalid file' audio_op = ffmpeg.decode_audio( contents, @@ -168,7 +168,7 @@ class DecodeAudioOpTest(test.TestCase): self._loadFileAndTest('mono_16khz.mp3', 'docx', 0.57, 20000, 1) def testStaticShapeInference_ConstantChannelCount(self): - with self.test_session(): + with self.cached_session(): audio_op = ffmpeg.decode_audio(b'~~~ wave ~~~', file_format='wav', samples_per_second=44100, @@ -176,7 +176,7 @@ class DecodeAudioOpTest(test.TestCase): self.assertEqual([None, 2], audio_op.shape.as_list()) def testStaticShapeInference_NonConstantChannelCount(self): - with self.test_session(): + with self.cached_session(): channel_count = array_ops.placeholder(dtypes.int32) audio_op = ffmpeg.decode_audio(b'~~~ wave ~~~', file_format='wav', @@ -185,7 +185,7 @@ class DecodeAudioOpTest(test.TestCase): self.assertEqual([None, None], audio_op.shape.as_list()) def testStaticShapeInference_ZeroChannelCountInvalid(self): - with self.test_session(): + with self.cached_session(): with six.assertRaisesRegex(self, Exception, r'channel_count must be positive'): ffmpeg.decode_audio(b'~~~ wave ~~~', @@ -194,7 +194,7 @@ class DecodeAudioOpTest(test.TestCase): channel_count=0) def testStaticShapeInference_NegativeChannelCountInvalid(self): - with self.test_session(): + with self.cached_session(): with six.assertRaisesRegex(self, Exception, r'channel_count must be positive'): ffmpeg.decode_audio(b'~~~ wave ~~~', diff --git a/tensorflow/contrib/ffmpeg/decode_video_op_test.py b/tensorflow/contrib/ffmpeg/decode_video_op_test.py index b43b6b8919..b734690756 100644 --- a/tensorflow/contrib/ffmpeg/decode_video_op_test.py +++ b/tensorflow/contrib/ffmpeg/decode_video_op_test.py @@ -42,7 +42,7 @@ class DecodeVideoOpTest(test.TestCase): bmp_filename: The filename for the bmp file. index: Index location inside the video. """ - with self.test_session(): + with self.cached_session(): path = os.path.join(resource_loader.get_data_files_path(), 'testdata', filename) with open(path, 'rb') as f: diff --git a/tensorflow/contrib/ffmpeg/encode_audio_op_test.py b/tensorflow/contrib/ffmpeg/encode_audio_op_test.py index 870290dc10..eb4325da82 100644 --- a/tensorflow/contrib/ffmpeg/encode_audio_op_test.py +++ b/tensorflow/contrib/ffmpeg/encode_audio_op_test.py @@ -61,7 +61,7 @@ class EncodeAudioOpTest(test.TestCase): def testRoundTrip(self): """Reads a wav file, writes it, and compares them.""" - with self.test_session(): + with self.cached_session(): audio_op = ffmpeg.decode_audio( self._contents, file_format='wav', @@ -73,7 +73,7 @@ class EncodeAudioOpTest(test.TestCase): self._compareWavFiles(self._contents, encoded_contents) def testRoundTripWithPlaceholderSampleRate(self): - with self.test_session(): + with self.cached_session(): placeholder = array_ops.placeholder(dtypes.int32) audio_op = ffmpeg.decode_audio( self._contents, @@ -86,7 +86,7 @@ class EncodeAudioOpTest(test.TestCase): self._compareWavFiles(self._contents, encoded_contents) def testFloatingPointSampleRateInvalid(self): - with self.test_session(): + with self.cached_session(): with self.assertRaises(TypeError): ffmpeg.encode_audio( [[0.0], [1.0]], @@ -94,7 +94,7 @@ class EncodeAudioOpTest(test.TestCase): samples_per_second=12345.678) def testZeroSampleRateInvalid(self): - with self.test_session() as sess: + with self.cached_session() as sess: encode_op = ffmpeg.encode_audio( [[0.0], [1.0]], file_format='wav', @@ -103,7 +103,7 @@ class EncodeAudioOpTest(test.TestCase): sess.run(encode_op) def testNegativeSampleRateInvalid(self): - with self.test_session() as sess: + with self.cached_session() as sess: encode_op = ffmpeg.encode_audio( [[0.0], [1.0]], file_format='wav', diff --git a/tensorflow/contrib/framework/python/framework/checkpoint_utils_test.py b/tensorflow/contrib/framework/python/framework/checkpoint_utils_test.py index 9396f027d3..4f591367fd 100644 --- a/tensorflow/contrib/framework/python/framework/checkpoint_utils_test.py +++ b/tensorflow/contrib/framework/python/framework/checkpoint_utils_test.py @@ -117,7 +117,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): my1 = variable_scope.get_variable("my1", [1, 10]) with variable_scope.variable_scope("some_other_scope"): @@ -158,7 +158,7 @@ class CheckpointsTest(test.TestCase): checkpoint_utils.init_from_checkpoint(checkpoint_dir, {"useful_scope/": "useful_scope/"}) - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: session.run(variables.global_variables_initializer()) self.assertAllEqual(my4.eval(session), v4) self.assertAllEqual(my5.eval(session), my5_init) @@ -170,7 +170,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): my1 = variable_scope.get_variable("var1", [1, 10]) my2 = variable_scope.get_variable("var2", [10, 10]) @@ -194,7 +194,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: my1 = variable_scope.get_variable("var1", [1, 10]) my2 = variable_scope.get_variable("var2", [10, 10]) my3 = variable_scope.get_variable("var3", [100, 100]) @@ -217,7 +217,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): my1 = variable_scope.get_variable( name="my1", @@ -247,7 +247,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): my1 = variable_scope.get_variable( name="my1", @@ -271,7 +271,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): _ = variable_scope.get_variable("my1", [10, 10]) _ = variable_scope.get_variable( diff --git a/tensorflow/contrib/framework/python/framework/tensor_util.py b/tensorflow/contrib/framework/python/framework/tensor_util.py index 4e6eea8884..bdf8aeb2b8 100644 --- a/tensorflow/contrib/framework/python/framework/tensor_util.py +++ b/tensorflow/contrib/framework/python/framework/tensor_util.py @@ -23,6 +23,7 @@ import numpy as np from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops from tensorflow.python.framework import sparse_tensor +from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import tensor_util from tensorflow.python.ops import array_ops from tensorflow.python.ops import check_ops @@ -129,10 +130,25 @@ def remove_squeezable_dimensions(predictions, labels, name=None): return predictions, labels -def _all_equal(tensor0, tensor1): - with ops.name_scope('all_equal', values=[tensor0, tensor1]) as scope: +def _shape_tensor_compatible(expected_shape, actual_shape): + """Returns whether actual_shape is compatible with expected_shape. + + Note that -1 in `expected_shape` is recognized as unknown dimension. + + Args: + expected_shape: Integer list defining the expected shape, or tensor of same. + actual_shape: Shape of the tensor to test. + Returns: + New tensor. + """ + with ops.name_scope('shape_tensor_equal', + values=[expected_shape, actual_shape]) as scope: return math_ops.reduce_all( - math_ops.equal(tensor0, tensor1, name='equal'), name=scope) + math_ops.logical_or( + math_ops.equal(expected_shape, -1), + math_ops.equal(expected_shape, actual_shape, 'equal'), + name='exclude_partial_shape'), + name=scope) def _is_rank(expected_rank, actual_tensor): @@ -153,6 +169,8 @@ def _is_rank(expected_rank, actual_tensor): def _is_shape(expected_shape, actual_tensor, actual_shape=None): """Returns whether actual_tensor's shape is expected_shape. + Note that -1 in `expected_shape` is recognized as unknown dimension. + Args: expected_shape: Integer list defining the expected shape, or tensor of same. actual_tensor: Tensor to test. @@ -164,15 +182,15 @@ def _is_shape(expected_shape, actual_tensor, actual_shape=None): is_rank = _is_rank(array_ops.size(expected_shape), actual_tensor) if actual_shape is None: actual_shape = array_ops.shape(actual_tensor, name='actual') - shape_equal = _all_equal( - ops.convert_to_tensor(expected_shape, name='expected'), - actual_shape) + shape_equal = _shape_tensor_compatible(expected_shape, actual_shape) return math_ops.logical_and(is_rank, shape_equal, name=scope) def _assert_shape_op(expected_shape, actual_tensor): """Asserts actual_tensor's shape is expected_shape. + Note that unknown dimension in `expected_shape` will be ignored. + Args: expected_shape: List of integers defining the expected shape, or tensor of same. @@ -182,6 +200,9 @@ def _assert_shape_op(expected_shape, actual_tensor): """ with ops.name_scope('assert_shape', values=[actual_tensor]) as scope: actual_shape = array_ops.shape(actual_tensor, name='actual') + if (isinstance(expected_shape, tensor_shape.TensorShape) + and not expected_shape.is_fully_defined()): + expected_shape = [d if d else -1 for d in expected_shape.as_list()] is_shape = _is_shape(expected_shape, actual_tensor, actual_shape) return control_flow_ops.Assert( is_shape, [ diff --git a/tensorflow/contrib/framework/python/framework/tensor_util_test.py b/tensorflow/contrib/framework/python/framework/tensor_util_test.py index af1b404cb5..2479fe5b8d 100644 --- a/tensorflow/contrib/framework/python/framework/tensor_util_test.py +++ b/tensorflow/contrib/framework/python/framework/tensor_util_test.py @@ -29,7 +29,7 @@ from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors_impl from tensorflow.python.framework import ops -from tensorflow.python.framework import sparse_tensor +from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops from tensorflow.python.ops import variables as variables_lib @@ -185,6 +185,16 @@ class WithShapeTest(test.TestCase): shape, unexpected_shapes) + def test_with_shape_2x2_with_partial_expected_shape(self): + with self.test_session(): + value = [[42, 43], [44, 45]] + actual_shape = [2, 2] + tensor = constant_op.constant(value, shape=actual_shape) + partial_expected_shape = tensor_shape.TensorShape([None, 2]) + # Won't raise any exception here: + tensor_with_shape = tensor_util.with_shape(partial_expected_shape, tensor) + np.testing.assert_array_equal(value, tensor_with_shape.eval()) + def test_with_shape_none(self): with self.test_session(): tensor_no_shape = array_ops.placeholder(dtypes.float32) @@ -366,7 +376,7 @@ class RemoveSqueezableDimensionsTest(test.TestCase): squeezed_predictions, squeezed_labels = ( tensor_util.remove_squeezable_dimensions(predictions, labels)) - with self.test_session(g): + with self.session(g): variables_lib.local_variables_initializer().run() self.assertAllClose( predictions_value, squeezed_predictions.eval(feed_dict=feed_dict)) diff --git a/tensorflow/contrib/framework/python/ops/arg_scope_test.py b/tensorflow/contrib/framework/python/ops/arg_scope_test.py index bcafc1a328..0e6c6f0e2f 100644 --- a/tensorflow/contrib/framework/python/ops/arg_scope_test.py +++ b/tensorflow/contrib/framework/python/ops/arg_scope_test.py @@ -52,7 +52,7 @@ def _key_op(op): class ArgScopeTest(test.TestCase): def testEmptyArgScope(self): - with self.test_session(): + with self.cached_session(): with arg_scope([]) as sc: self.assertEqual(sc, {}) @@ -60,7 +60,7 @@ class ArgScopeTest(test.TestCase): func1_kwargs = {'a': 1, 'b': None, 'c': [1]} key_op = _key_op(func1) func1_scope = {key_op: func1_kwargs.copy()} - with self.test_session(): + with self.cached_session(): with arg_scope([func1], a=1, b=None, c=[1]) as sc1: self.assertEqual(sc1, func1_scope) with arg_scope({}) as sc2: @@ -86,7 +86,7 @@ class ArgScopeTest(test.TestCase): func1_kwargs = {'a': 1, 'b': None, 'c': [1]} key_op = _key_op(func1) current_scope = {key_op: func1_kwargs.copy()} - with self.test_session(): + with self.cached_session(): with arg_scope([func1], a=1, b=None, c=[1]) as scope: self.assertDictEqual(scope, current_scope) @@ -102,7 +102,7 @@ class ArgScopeTest(test.TestCase): key(func1): func1_kwargs.copy(), key(func2): func2_kwargs.copy() } - with self.test_session(): + with self.cached_session(): with arg_scope([func1], a=1, b=None, c=[1]): with arg_scope([func2], b=2, d=[2]) as scope: self.assertDictEqual(scope, current_scope) @@ -111,7 +111,7 @@ class ArgScopeTest(test.TestCase): func1_kwargs = {'a': 1, 'b': None, 'c': [1]} key_op = _key_op(func1) current_scope = {key_op: func1_kwargs.copy()} - with self.test_session(): + with self.cached_session(): with arg_scope([func1], a=1, b=None, c=[1]) as scope1: pass with arg_scope(scope1) as scope: @@ -126,7 +126,7 @@ class ArgScopeTest(test.TestCase): key(func1): func1_kwargs.copy(), key(func2): func2_kwargs.copy() } - with self.test_session(): + with self.cached_session(): with arg_scope([func1], a=1, b=None, c=[1]) as scope1: with arg_scope([func2], b=2, d=[2]) as scope2: pass @@ -140,7 +140,7 @@ class ArgScopeTest(test.TestCase): def testSimpleArgScope(self): func1_args = (0,) func1_kwargs = {'a': 1, 'b': None, 'c': [1]} - with self.test_session(): + with self.cached_session(): with arg_scope([func1], a=1, b=None, c=[1]): args, kwargs = func1(0) self.assertTupleEqual(args, func1_args) @@ -149,7 +149,7 @@ class ArgScopeTest(test.TestCase): def testSimpleArgScopeWithTuple(self): func1_args = (0,) func1_kwargs = {'a': 1, 'b': None, 'c': [1]} - with self.test_session(): + with self.cached_session(): with arg_scope((func1,), a=1, b=None, c=[1]): args, kwargs = func1(0) self.assertTupleEqual(args, func1_args) @@ -240,7 +240,7 @@ class ArgScopeTest(test.TestCase): def testAddArgScopeRaceCondition(self): func4_kwargs = ('a', 'b', 'c', 'd', 'e', 'f', 'g', 'h') for i in range(4): - # redefine the function with different args + # redefine the function with different args @add_arg_scope def func4(a=1, b=2, c=3, d=4, e=5, f=6, g=7, h=8): pass diff --git a/tensorflow/contrib/framework/python/ops/checkpoint_ops_test.py b/tensorflow/contrib/framework/python/ops/checkpoint_ops_test.py index b7b9f5c59e..4036c87b6d 100644 --- a/tensorflow/contrib/framework/python/ops/checkpoint_ops_test.py +++ b/tensorflow/contrib/framework/python/ops/checkpoint_ops_test.py @@ -50,7 +50,7 @@ class LoadMulticlassBiasTest(test.TestCase): bias = variables.Variable( array_ops.reshape(flat_data, (num, dim)), name='bias') save = saver.Saver([bias]) - with self.test_session() as sess: + with self.cached_session() as sess: variables.global_variables_initializer().run() self.bundle_file = os.path.join(test.get_temp_dir(), 'bias_checkpoint') save.save(sess, self.bundle_file) @@ -90,7 +90,7 @@ class LoadMulticlassBiasTest(test.TestCase): initializer=bias_loading_initializer, partitioner=partitioned_variables.fixed_size_partitioner(3)) - with self.test_session(): + with self.cached_session(): variables.global_variables_initializer().run() self.assertAllClose(expected_remapped_bias_vector, remapped_bias_vector.as_tensor().eval()) @@ -109,7 +109,7 @@ class LoadVariableSlotTest(test.TestCase): accum = variables.Variable( array_ops.reshape(flat_data, (num, dim)), name='accum') save = saver.Saver([accum]) - with self.test_session() as sess: + with self.cached_session() as sess: variables.global_variables_initializer().run() self.bundle_file = os.path.join(test.get_temp_dir(), 'accum_checkpoint') save.save(sess, self.bundle_file) @@ -179,7 +179,7 @@ class LoadVariableSlotTest(test.TestCase): shape=[2, 1], initializer=variable_slot_initializer_part_1) - with self.test_session(): + with self.cached_session(): variables.global_variables_initializer().run() self.assertAllClose(expected_remapped_accum_vector_part_0, remapped_accum_vector_part_0.eval()) diff --git a/tensorflow/contrib/framework/python/ops/prettyprint_ops_test.py b/tensorflow/contrib/framework/python/ops/prettyprint_ops_test.py index 50bcbe625d..c104c51fef 100644 --- a/tensorflow/contrib/framework/python/ops/prettyprint_ops_test.py +++ b/tensorflow/contrib/framework/python/ops/prettyprint_ops_test.py @@ -34,7 +34,7 @@ class PrettyPrintOpsTest(test.TestCase): def testPrintTensorPassthrough(self): a = constant_op.constant([1]) a = prettyprint_ops.print_op(a) - with self.test_session(): + with self.cached_session(): self.assertEqual(a.eval(), constant_op.constant([1]).eval()) def testPrintSparseTensorPassthrough(self): @@ -43,7 +43,7 @@ class PrettyPrintOpsTest(test.TestCase): b = sparse_tensor.SparseTensor( indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]) a = prettyprint_ops.print_op(a) - with self.test_session(): + with self.cached_session(): self.assertAllEqual( sparse_ops.sparse_tensor_to_dense(a).eval(), sparse_ops.sparse_tensor_to_dense(b).eval()) @@ -54,13 +54,13 @@ class PrettyPrintOpsTest(test.TestCase): a = a.write(1, 1) a = a.write(0, 0) a = prettyprint_ops.print_op(a) - with self.test_session(): + with self.cached_session(): self.assertAllEqual(a.stack().eval(), constant_op.constant([0, 1]).eval()) def testPrintVariable(self): a = variables.Variable(1.0) a = prettyprint_ops.print_op(a) - with self.test_session(): + with self.cached_session(): variables.global_variables_initializer().run() a.eval() diff --git a/tensorflow/contrib/framework/python/ops/sort_ops_test.py b/tensorflow/contrib/framework/python/ops/sort_ops_test.py index a8fb94b245..791b32cd1e 100644 --- a/tensorflow/contrib/framework/python/ops/sort_ops_test.py +++ b/tensorflow/contrib/framework/python/ops/sort_ops_test.py @@ -48,7 +48,7 @@ class SortTest(test.TestCase): sort_axis = np.random.choice(rank) if negative_axis: sort_axis = -1 - sort_axis - with self.test_session(): + with self.cached_session(): self.assertAllEqual( np.sort(arr, axis=sort_axis), sort_ops.sort(constant_op.constant(arr), axis=sort_axis).eval()) @@ -60,7 +60,7 @@ class SortTest(test.TestCase): shape = [np.random.randint(1, 4) for _ in range(rank)] arr = np.random.random(shape) sort_axis = np.random.choice(rank) - with self.test_session(): + with self.cached_session(): self.assertAllEqual( np.sort(arr, axis=sort_axis), sort_ops.sort(constant_op.constant(arr), axis=sort_axis).eval()) @@ -73,7 +73,7 @@ class SortTest(test.TestCase): scalar = array_ops.zeros(zeros_length_1) sort = sort_ops.sort(scalar) - with self.test_session(): + with self.cached_session(): with self.assertRaises(errors.InvalidArgumentError): sort.eval() @@ -84,7 +84,7 @@ class SortTest(test.TestCase): def testDescending(self): arr = np.random.random((10, 5, 5)) - with self.test_session(): + with self.cached_session(): self.assertAllEqual( np.sort(arr, axis=0)[::-1], sort_ops.sort( @@ -111,7 +111,7 @@ class SortTest(test.TestCase): def testArgsort_1d(self): arr = np.random.random(42) - with self.test_session(): + with self.cached_session(): self.assertAllEqual( np.sort(arr), array_ops.gather(arr, sort_ops.argsort(arr)).eval()) @@ -119,7 +119,7 @@ class SortTest(test.TestCase): def testArgsort(self): arr = np.random.random((5, 6, 7, 8)) for axis in range(4): - with self.test_session(): + with self.cached_session(): self.assertAllEqual( np.argsort(arr, axis=axis), sort_ops.argsort(arr, axis=axis).eval()) diff --git a/tensorflow/contrib/framework/python/ops/variables_test.py b/tensorflow/contrib/framework/python/ops/variables_test.py index 3c44630a51..f9b0efd1da 100644 --- a/tensorflow/contrib/framework/python/ops/variables_test.py +++ b/tensorflow/contrib/framework/python/ops/variables_test.py @@ -45,7 +45,7 @@ from tensorflow.python.training import saver as saver_lib class LocalVariableTest(test.TestCase): def test_local_variable(self): - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEquals([], variables_lib.local_variables()) value0 = 42 variables_lib2.local_variable(value0) @@ -58,7 +58,7 @@ class LocalVariableTest(test.TestCase): self.assertAllEqual(set([value0, value1]), set(sess.run(variables))) def testLocalVariableNameAndShape(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.local_variable([1, 1, 1, 1, 1], name='a') self.assertEquals(a.op.name, 'A/a') @@ -66,21 +66,21 @@ class LocalVariableTest(test.TestCase): self.assertListEqual([a], variables_lib2.get_local_variables()) def testLocalVariableNotInAllVariables(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.local_variable(0) self.assertFalse(a in variables_lib.global_variables()) self.assertTrue(a in variables_lib.local_variables()) def testLocalVariableNotInVariablesToRestore(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.local_variable(0) self.assertFalse(a in variables_lib2.get_variables_to_restore()) self.assertTrue(a in variables_lib.local_variables()) def testGetVariablesDontReturnsTransients(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): variables_lib2.local_variable(0) with variable_scope.variable_scope('B'): @@ -89,7 +89,7 @@ class LocalVariableTest(test.TestCase): self.assertEquals([], variables_lib2.get_variables('B')) def testGetLocalVariablesReturnsTransients(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.local_variable(0) with variable_scope.variable_scope('B'): @@ -98,7 +98,7 @@ class LocalVariableTest(test.TestCase): self.assertEquals([b], variables_lib2.get_local_variables('B')) def testInitializedVariableValue(self): - with self.test_session() as sess: + with self.cached_session() as sess: a = variables_lib2.local_variable([0, 0, 0, 0, 0], name='a') sess.run(variables_lib.local_variables_initializer()) self.assertAllEqual(a.eval(), [0] * 5) @@ -114,7 +114,7 @@ class LocalVariableTest(test.TestCase): class GlobalVariableTest(test.TestCase): def test_global_variable(self): - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEquals([], variables_lib.global_variables()) value0 = 42 variables_lib2.global_variable(value0) @@ -129,7 +129,7 @@ class GlobalVariableTest(test.TestCase): self.assertAllEqual(set([value0, value1]), set(sess.run(variables))) def testVariableNameAndShape(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.global_variable([1, 1, 1, 1, 1], name='a') self.assertEquals(a.op.name, 'A/a') @@ -137,21 +137,21 @@ class GlobalVariableTest(test.TestCase): self.assertListEqual([a], variables_lib.global_variables()) def testGlobalVariableNotInLocalVariables(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.global_variable(0) self.assertFalse(a in variables_lib.local_variables()) self.assertTrue(a in variables_lib.global_variables()) def testGlobalVariableInVariablesToRestore(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.global_variable(0) self.assertFalse(a in variables_lib.local_variables()) self.assertTrue(a in variables_lib2.get_variables_to_restore()) def testGetVariablesReturnsThem(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.global_variable(0) with variable_scope.variable_scope('B'): @@ -160,7 +160,7 @@ class GlobalVariableTest(test.TestCase): self.assertEquals([b], variables_lib2.get_variables('B')) def testGetLocalVariablesDontReturnsThem(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): variables_lib2.global_variable(0) with variable_scope.variable_scope('B'): @@ -169,7 +169,7 @@ class GlobalVariableTest(test.TestCase): self.assertEquals([], variables_lib2.get_local_variables('B')) def testInitializedVariableValue(self): - with self.test_session() as sess: + with self.cached_session() as sess: a = variables_lib2.global_variable([0, 0, 0, 0, 0], name='a') sess.run(variables_lib.global_variables_initializer()) self.assertAllEqual(a.eval(), [0] * 5) @@ -249,7 +249,7 @@ class GlobalStepTest(test.TestCase): class VariablesTest(test.TestCase): def testCreateVariable(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) self.assertEquals(a.op.name, 'A/a') @@ -259,7 +259,7 @@ class VariablesTest(test.TestCase): self.assertFalse(a in variables_lib.local_variables()) def testGetVariables(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) with variable_scope.variable_scope('B'): @@ -269,7 +269,7 @@ class VariablesTest(test.TestCase): self.assertEquals([b], variables_lib2.get_variables('B')) def testGetVariablesWithScope(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A') as var_scope: a = variables_lib2.variable('a', [5]) b = variables_lib2.variable('b', [5]) @@ -277,7 +277,7 @@ class VariablesTest(test.TestCase): set([a, b]), set(variables_lib2.get_variables(var_scope))) def testGetVariablesSuffix(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) with variable_scope.variable_scope('A'): @@ -286,13 +286,13 @@ class VariablesTest(test.TestCase): self.assertEquals([b], variables_lib2.get_variables(suffix='b')) def testGetVariableWithSingleVar(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('parent'): a = variables_lib2.variable('child', [5]) self.assertEquals(a, variables_lib2.get_unique_variable('parent/child')) def testGetVariableWithDistractors(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('parent'): a = variables_lib2.variable('child', [5]) with variable_scope.variable_scope('child'): @@ -302,13 +302,13 @@ class VariablesTest(test.TestCase): def testGetVariableThrowsExceptionWithNoMatch(self): var_name = 'cant_find_me' - with self.test_session(): + with self.cached_session(): with self.assertRaises(ValueError): variables_lib2.get_unique_variable(var_name) def testGetThrowsExceptionWithChildrenButNoMatch(self): var_name = 'parent/child' - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope(var_name): variables_lib2.variable('grandchild1', [7]) variables_lib2.variable('grandchild2', [9]) @@ -316,7 +316,7 @@ class VariablesTest(test.TestCase): variables_lib2.get_unique_variable(var_name) def testGetVariablesToRestore(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) with variable_scope.variable_scope('B'): @@ -324,7 +324,7 @@ class VariablesTest(test.TestCase): self.assertEquals([a, b], variables_lib2.get_variables_to_restore()) def testIncludeGetVariablesToRestore(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) with variable_scope.variable_scope('B'): @@ -333,7 +333,7 @@ class VariablesTest(test.TestCase): self.assertEquals([a], variables_lib2.get_variables_to_restore(['A'])) def testExcludeGetVariablesToRestore(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) with variable_scope.variable_scope('B'): @@ -343,7 +343,7 @@ class VariablesTest(test.TestCase): [a], variables_lib2.get_variables_to_restore(exclude=['B'])) def testWrongIncludeGetVariablesToRestore(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) with variable_scope.variable_scope('B'): @@ -352,7 +352,7 @@ class VariablesTest(test.TestCase): self.assertEquals([], variables_lib2.get_variables_to_restore(['a'])) def testGetMixedVariablesToRestore(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) b = variables_lib2.variable('b', [5]) @@ -365,7 +365,7 @@ class VariablesTest(test.TestCase): variables_lib2.get_variables_to_restore(include=['A/a', 'B/c'])) def testExcludeGetMixedVariablesToRestore(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) b = variables_lib2.variable('b', [5]) @@ -378,7 +378,7 @@ class VariablesTest(test.TestCase): variables_lib2.get_variables_to_restore(exclude=['A/a', 'B/c'])) def testReuseVariable(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', []) with variable_scope.variable_scope('A', reuse=True): @@ -387,14 +387,14 @@ class VariablesTest(test.TestCase): self.assertListEqual([a], variables_lib2.get_variables()) def testVariableWithRegularizer(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [], regularizer=nn_ops.l2_loss) loss = ops.get_collection(ops.GraphKeys.REGULARIZATION_LOSSES)[0] self.assertDeviceEqual(loss.device, a.device) def testVariableWithRegularizerColocate(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable( 'a', [], device='gpu:0', regularizer=nn_ops.l2_loss) @@ -402,7 +402,7 @@ class VariablesTest(test.TestCase): self.assertDeviceEqual(loss.device, a.device) def testVariableWithDevice(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [], device='cpu:0') b = variables_lib2.variable('b', [], device='cpu:1') @@ -410,7 +410,7 @@ class VariablesTest(test.TestCase): self.assertDeviceEqual(b.device, 'cpu:1') def testVariableWithDeviceFromScope(self): - with self.test_session(): + with self.cached_session(): with ops.device('/cpu:0'): a = variables_lib2.variable('a', []) b = variables_lib2.variable('b', [], device='cpu:1') @@ -428,7 +428,7 @@ class VariablesTest(test.TestCase): self.counter += 1 return 'cpu:%d' % self.counter - with self.test_session(): + with self.cached_session(): with arg_scope([variables_lib2.variable], device=DevFn()): a = variables_lib2.variable('a', []) b = variables_lib2.variable('b', []) @@ -453,7 +453,7 @@ class VariablesTest(test.TestCase): self.assertDeviceEqual(e.initial_value.device, 'cpu:99') def testVariableWithReplicaDeviceSetter(self): - with self.test_session(): + with self.cached_session(): with ops.device(device_setter.replica_device_setter(ps_tasks=2)): a = variables_lib2.variable('a', []) b = variables_lib2.variable('b', []) @@ -570,7 +570,7 @@ class VariablesTest(test.TestCase): class ModelVariablesTest(test.TestCase): def testNameAndShape(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.model_variable('a', [5]) self.assertEquals(a.op.name, 'A/a') @@ -578,7 +578,7 @@ class ModelVariablesTest(test.TestCase): self.assertListEqual([a], variables_lib2.get_model_variables('A')) def testNotInLocalVariables(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.model_variable('a', [5]) self.assertTrue(a in variables_lib.global_variables()) @@ -586,7 +586,7 @@ class ModelVariablesTest(test.TestCase): self.assertFalse(a in variables_lib.local_variables()) def testGetVariablesReturns(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.model_variable('a', [5]) with variable_scope.variable_scope('B'): @@ -595,7 +595,7 @@ class ModelVariablesTest(test.TestCase): self.assertEquals([b], variables_lib2.get_variables('B')) def testGetModelVariables(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.model_variable('a', [5]) with variable_scope.variable_scope('B'): @@ -604,7 +604,7 @@ class ModelVariablesTest(test.TestCase): self.assertEquals([b], variables_lib2.get_model_variables('B')) def testGetTrainableVariables(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): variables_lib2.local_variable([5]) a = variables_lib.Variable([5]) @@ -615,7 +615,7 @@ class ModelVariablesTest(test.TestCase): self.assertEquals([b], variables_lib2.get_trainable_variables('B')) def testGetLocalVariables(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): _ = variables_lib2.model_variable('a', [5]) with variable_scope.variable_scope('B'): @@ -624,7 +624,7 @@ class ModelVariablesTest(test.TestCase): self.assertEquals([], variables_lib2.get_local_variables('B')) def testInitializedVariableValue(self): - with self.test_session() as sess: + with self.cached_session() as sess: a = variables_lib2.model_variable( 'a', [5], initializer=init_ops.ones_initializer()) sess.run(variables_lib.global_variables_initializer()) @@ -670,14 +670,14 @@ class ModelVariablesTest(test.TestCase): class GetVariablesCollections(test.TestCase): def testVariableCollection(self): - with self.test_session(): + with self.cached_session(): a = variables_lib2.variable('a', [], collections='A') b = variables_lib2.variable('b', [], collections='B') self.assertEquals(a, ops.get_collection('A')[0]) self.assertEquals(b, ops.get_collection('B')[0]) def testVariableCollections(self): - with self.test_session(): + with self.cached_session(): a = variables_lib2.variable('a', [], collections=['A', 'C']) b = variables_lib2.variable('b', [], collections=['B', 'C']) self.assertEquals(a, ops.get_collection('A')[0]) @@ -685,14 +685,14 @@ class GetVariablesCollections(test.TestCase): self.assertListEqual([a, b], ops.get_collection('C')) def testVariableCollectionsWithArgScope(self): - with self.test_session(): + with self.cached_session(): with arg_scope([variables_lib2.variable], collections='A'): a = variables_lib2.variable('a', []) b = variables_lib2.variable('b', []) self.assertListEqual([a, b], ops.get_collection('A')) def testVariableCollectionsWithArgScopeNested(self): - with self.test_session(): + with self.cached_session(): with arg_scope([variables_lib2.variable], collections='A'): a = variables_lib2.variable('a', []) with arg_scope([variables_lib2.variable], collections='B'): @@ -701,7 +701,7 @@ class GetVariablesCollections(test.TestCase): self.assertEquals(b, ops.get_collection('B')[0]) def testVariableCollectionsWithArgScopeNonNested(self): - with self.test_session(): + with self.cached_session(): with arg_scope([variables_lib2.variable], collections='A'): a = variables_lib2.variable('a', []) with arg_scope([variables_lib2.variable], collections='B'): @@ -711,7 +711,7 @@ class GetVariablesCollections(test.TestCase): self.assertListEqual([b], ops.get_collection('B')) def testVariableRestoreWithArgScopeNested(self): - with self.test_session(): + with self.cached_session(): a = variables_lib2.variable('a', []) with arg_scope( [variables_lib2.variable], trainable=False, collections=['A', 'B']): @@ -726,7 +726,7 @@ class GetVariablesCollections(test.TestCase): class GetVariablesBySuffixTest(test.TestCase): def testGetVariableGivenNameScoped(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) b = variables_lib2.variable('b', [5]) @@ -734,7 +734,7 @@ class GetVariablesBySuffixTest(test.TestCase): self.assertEquals([b], variables_lib2.get_variables_by_suffix('b')) def testGetVariableWithScope(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) fooa = variables_lib2.variable('fooa', [5]) @@ -748,7 +748,7 @@ class GetVariablesBySuffixTest(test.TestCase): self.assertEquals([a, fooa], matched_variables) def testGetVariableWithoutScope(self): - with self.test_session(): + with self.cached_session(): a = variables_lib2.variable('a', [5]) fooa = variables_lib2.variable('fooa', [5]) b_a = variables_lib2.variable('B/a', [5]) @@ -761,7 +761,7 @@ class GetVariablesBySuffixTest(test.TestCase): class GetVariablesByNameTest(test.TestCase): def testGetVariableGivenNameScoped(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) b = variables_lib2.variable('b', [5]) @@ -769,7 +769,7 @@ class GetVariablesByNameTest(test.TestCase): self.assertEquals([b], variables_lib2.get_variables_by_name('b')) def testGetVariableWithScope(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('A'): a = variables_lib2.variable('a', [5]) fooa = variables_lib2.variable('fooa', [5]) @@ -785,7 +785,7 @@ class GetVariablesByNameTest(test.TestCase): self.assertEquals([a], matched_variables) def testGetVariableWithoutScope(self): - with self.test_session(): + with self.cached_session(): a = variables_lib2.variable('a', [5]) fooa = variables_lib2.variable('fooa', [5]) b_a = variables_lib2.variable('B/a', [5]) @@ -818,7 +818,7 @@ class AssignFromValuesTest(test.TestCase): init_value0 = np.asarray([1.0, 3.0, 9.0]).reshape((1, 3, 1)) init_value1 = np.asarray([2.0, 4.0, 6.0, 8.0]).reshape((2, 1, 2)) - with self.test_session() as sess: + with self.cached_session() as sess: initializer = init_ops.truncated_normal_initializer(stddev=.1) var0 = variables_lib2.variable( 'my_var0', shape=[1, 3, 1], initializer=initializer) @@ -844,7 +844,7 @@ class AssignFromValuesTest(test.TestCase): init_value0 = np.asarray([1.0, 3.0, 9.0]).reshape((1, 3, 1)) init_value1 = np.asarray([2.0, 4.0, 6.0, 8.0]).reshape((2, 1, 2)) - with self.test_session() as sess: + with self.cached_session() as sess: initializer = init_ops.truncated_normal_initializer(stddev=.1) with variable_scope.variable_scope('my_model/my_layer0'): @@ -879,7 +879,7 @@ class AssignFromValuesFnTest(test.TestCase): init_value0 = np.asarray([1.0, 3.0, 9.0]).reshape((1, 3, 1)) init_value1 = np.asarray([2.0, 4.0, 6.0, 8.0]).reshape((2, 1, 2)) - with self.test_session() as sess: + with self.cached_session() as sess: initializer = init_ops.truncated_normal_initializer(stddev=.1) var0 = variables_lib2.variable( 'my_var0', shape=[1, 3, 1], initializer=initializer) @@ -904,7 +904,7 @@ class AssignFromValuesFnTest(test.TestCase): init_value0 = np.asarray([1.0, 3.0, 9.0]).reshape((1, 3, 1)) init_value1 = np.asarray([2.0, 4.0, 6.0, 8.0]).reshape((2, 1, 2)) - with self.test_session() as sess: + with self.cached_session() as sess: initializer = init_ops.truncated_normal_initializer(stddev=.1) with variable_scope.variable_scope('my_model/my_layer0'): @@ -968,7 +968,7 @@ class AssignFromCheckpointTest(test.TestCase): init_value1 = 20.0 var_names_to_values = {'v0': init_value0, 'v1': init_value1} - with self.test_session() as sess: + with self.cached_session() as sess: model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) var0 = variables_lib2.variable('my_var0', shape=[]) @@ -998,7 +998,7 @@ class AssignFromCheckpointTest(test.TestCase): init_value1 = np.array([20.0]) # Partitioned into 1 part, edge case. var_names_to_values = {'var0': init_value0, 'var1': init_value1} - with self.test_session() as sess: + with self.cached_session() as sess: model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) # var0 and var1 are PartitionedVariables. @@ -1039,7 +1039,7 @@ class AssignFromCheckpointTest(test.TestCase): init_value1 = 20.0 var_names_to_values = {'v0': init_value0, 'v1': init_value1} - with self.test_session(): + with self.cached_session(): model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) var0 = variables_lib2.variable('my_var0', shape=[]) @@ -1062,7 +1062,7 @@ class AssignFromCheckpointTest(test.TestCase): var_names_to_values = {'layer0/v0': init_value0, 'layer1/v1': init_value1} - with self.test_session() as sess: + with self.cached_session() as sess: model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) with variable_scope.variable_scope('my_model/my_layer0'): @@ -1123,7 +1123,7 @@ class AssignFromCheckpointFnTest(test.TestCase): init_value1 = 20.0 var_names_to_values = {'v0': init_value0, 'v1': init_value1} - with self.test_session() as sess: + with self.cached_session() as sess: model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) var0 = variables_lib2.variable('my_var0', shape=[]) @@ -1154,7 +1154,7 @@ class AssignFromCheckpointFnTest(test.TestCase): init_value1 = 20.0 var_names_to_values = {'v0': init_value0, 'v1': init_value1} - with self.test_session() as sess: + with self.cached_session() as sess: model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) var0 = variables_lib2.variable('my_var0', shape=[2, 1]) @@ -1183,7 +1183,7 @@ class AssignFromCheckpointFnTest(test.TestCase): init_value1 = 20.0 var_names_to_values = {'v0': init_value0, 'v1': init_value1} - with self.test_session() as sess: + with self.cached_session() as sess: model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) var0 = variables_lib2.variable('my_var0', shape=[2, 1]) @@ -1213,7 +1213,7 @@ class AssignFromCheckpointFnTest(test.TestCase): init_value1 = 20.0 var_names_to_values = {'v0': init_value0, 'v1': init_value1} - with self.test_session() as sess: + with self.cached_session() as sess: model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) var0 = variables_lib2.variable('my_var0', shape=[]) @@ -1241,7 +1241,7 @@ class AssignFromCheckpointFnTest(test.TestCase): init_value1 = 20.0 var_names_to_values = {'v0': init_value0, 'v1': init_value1} - with self.test_session() as sess: + with self.cached_session() as sess: model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) var0 = variables_lib2.variable('v0', shape=[]) @@ -1272,7 +1272,7 @@ class AssignFromCheckpointFnTest(test.TestCase): init_value1 = 20.0 var_names_to_values = {'v0': init_value0, 'v1': init_value1} - with self.test_session() as sess: + with self.cached_session() as sess: model_path = self.create_checkpoint_from_values(var_names_to_values, model_dir) var0 = variables_lib2.variable('my_var0', shape=[]) @@ -1299,7 +1299,7 @@ class ZeroInitializerOpTest(test.TestCase): def _testZeroInitializer(self, shape, initializer, use_init): var = variables_lib.Variable(initializer) var_zero = variables_lib2.zero_initializer(var) - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaisesOpError('Attempting to use uninitialized value'): var.eval() if use_init: @@ -1324,7 +1324,7 @@ class ZeroVarInitializerOpTest(test.TestCase): var = resource_variable_ops.ResourceVariable(initializer) var_zero = variables_lib2.zero_initializer(var) - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaisesOpError('Error while reading resource variable'): var.eval() if use_init: diff --git a/tensorflow/contrib/gan/BUILD b/tensorflow/contrib/gan/BUILD index 9866fccfba..9d0e6e1335 100644 --- a/tensorflow/contrib/gan/BUILD +++ b/tensorflow/contrib/gan/BUILD @@ -105,6 +105,7 @@ py_library( deps = [ ":gan_estimator", ":head", + ":stargan_estimator", "//tensorflow/python:util", ], ) @@ -534,6 +535,57 @@ py_test( ) py_library( + name = "stargan_estimator", + srcs = [ + "python/estimator/python/stargan_estimator.py", + "python/estimator/python/stargan_estimator_impl.py", + ], + srcs_version = "PY2AND3", + deps = [ + ":namedtuples", + ":summaries", + ":train", + "//tensorflow/contrib/framework:framework_py", + "//tensorflow/python:framework_ops", + "//tensorflow/python:metrics", + "//tensorflow/python:util", + "//tensorflow/python:variable_scope", + "//tensorflow/python/estimator:estimator_py", + ], +) + +py_test( + name = "stargan_estimator_test", + srcs = ["python/estimator/python/stargan_estimator_test.py"], + shard_count = 1, + srcs_version = "PY2AND3", + tags = ["notsan"], + deps = [ + ":namedtuples", + ":stargan_estimator", + ":tuple_losses", + "//tensorflow/contrib/layers:layers_py", + "//tensorflow/contrib/learn", + "//tensorflow/core:protos_all_py", + "//tensorflow/python:array_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:dtypes", + "//tensorflow/python:framework_ops", + "//tensorflow/python:math_ops", + "//tensorflow/python:metrics", + "//tensorflow/python:parsing_ops", + "//tensorflow/python:summary", + "//tensorflow/python:training", + "//tensorflow/python:training_util", + "//tensorflow/python:variable_scope", + "//tensorflow/python/estimator:estimator_py", + "//third_party/py/numpy", + "@absl_py//absl/testing:parameterized", + "@six_archive//:six", + ], +) + +py_library( name = "sliced_wasserstein", srcs = [ "python/eval/python/sliced_wasserstein.py", diff --git a/tensorflow/contrib/gan/python/estimator/__init__.py b/tensorflow/contrib/gan/python/estimator/__init__.py index c9f7bc61b2..99d38011ba 100644 --- a/tensorflow/contrib/gan/python/estimator/__init__.py +++ b/tensorflow/contrib/gan/python/estimator/__init__.py @@ -26,15 +26,18 @@ from __future__ import print_function # pylint: disable=unused-import,wildcard-import from tensorflow.contrib.gan.python.estimator.python import gan_estimator from tensorflow.contrib.gan.python.estimator.python import head +from tensorflow.contrib.gan.python.estimator.python import stargan_estimator from tensorflow.contrib.gan.python.estimator.python.gan_estimator import * from tensorflow.contrib.gan.python.estimator.python.head import * +from tensorflow.contrib.gan.python.estimator.python.stargan_estimator import * # pylint: enable=unused-import,wildcard-import from tensorflow.python.util.all_util import remove_undocumented _allowed_symbols = [ 'gan_estimator', + 'stargan_estimator', 'head', -] + gan_estimator.__all__ + head.__all__ +] + gan_estimator.__all__ + stargan_estimator.__all__ + head.__all__ remove_undocumented(__name__, _allowed_symbols) diff --git a/tensorflow/contrib/kfac/python/ops/optimizer_lib.py b/tensorflow/contrib/gan/python/estimator/python/stargan_estimator.py index 87d1866e06..341bdf9fbb 100644 --- a/tensorflow/contrib/kfac/python/ops/optimizer_lib.py +++ b/tensorflow/contrib/gan/python/estimator/python/stargan_estimator.py @@ -12,19 +12,17 @@ # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================== -"""The KFAC optimizer.""" +"""`tf.Learn` components for `GANEstimator`.""" from __future__ import absolute_import from __future__ import division from __future__ import print_function -# pylint: disable=unused-import,line-too-long,wildcard-import -from tensorflow.contrib.kfac.python.ops.optimizer import * +from tensorflow.contrib.gan.python.estimator.python import stargan_estimator_impl +# pylint: disable=wildcard-import +from tensorflow.contrib.gan.python.estimator.python.stargan_estimator_impl import * +# pylint: enable=wildcard-import from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long,wildcard-import -_allowed_symbols = [ - "KfacOptimizer", -] - -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) +__all__ = stargan_estimator_impl.__all__ +remove_undocumented(__name__, __all__) diff --git a/tensorflow/contrib/gan/python/estimator/python/stargan_estimator_impl.py b/tensorflow/contrib/gan/python/estimator/python/stargan_estimator_impl.py new file mode 100644 index 0000000000..f60e16bc04 --- /dev/null +++ b/tensorflow/contrib/gan/python/estimator/python/stargan_estimator_impl.py @@ -0,0 +1,363 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""A TFGAN-backed StarGAN Estimator.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import functools +import enum + +from tensorflow.contrib.framework.python.ops import variables as variable_lib +from tensorflow.contrib.gan.python import namedtuples as tfgan_tuples +from tensorflow.contrib.gan.python import train as tfgan_train +from tensorflow.contrib.gan.python.eval.python import summaries as tfgan_summaries +from tensorflow.python.estimator import estimator +from tensorflow.python.estimator import model_fn as model_fn_lib +from tensorflow.python.framework import ops +from tensorflow.python.ops import metrics as metrics_lib +from tensorflow.python.ops import variable_scope +from tensorflow.python.util import tf_inspect as inspect + +__all__ = ['StarGANEstimator', 'SummaryType'] + + +class SummaryType(enum.IntEnum): + NONE = 0 + VARIABLES = 1 + IMAGES = 2 + IMAGE_COMPARISON = 3 + + +_summary_type_map = { + SummaryType.VARIABLES: tfgan_summaries.add_gan_model_summaries, + SummaryType.IMAGES: tfgan_summaries.add_stargan_image_summaries, +} + + +class StarGANEstimator(estimator.Estimator): + """An estimator for Generative Adversarial Networks (GANs). + + This Estimator is backed by TFGAN. The network functions follow the TFGAN API + except for one exception: if either `generator_fn` or `discriminator_fn` have + an argument called `mode`, then the tf.Estimator mode is passed in for that + argument. This helps with operations like batch normalization, which have + different train and evaluation behavior. + + Example: + + ```python + import tensorflow as tf + tfgan = tf.contrib.gan + + # See TFGAN's `train.py` for a description of the generator and + # discriminator API. + def generator_fn(generator_inputs): + ... + return generated_data + + def discriminator_fn(data, conditioning): + ... + return logits + + # Create GAN estimator. + stargan_estimator = tfgan.estimator.StarGANEstimator( + model_dir, + generator_fn=generator_fn, + discriminator_fn=discriminator_fn, + loss_fn=loss_fn, + generator_optimizer=tf.train.AdamOptimizer(0.1, 0.5), + discriminator_optimizer=tf.train.AdamOptimizer(0.1, 0.5)) + + # Train estimator. + stargan_estimator.train(train_input_fn, steps) + + # Evaluate resulting estimator. + stargan_estimator.evaluate(eval_input_fn) + + # Generate samples from generator. + stargan_estimator = np.array([ + x for x in stargan_estimator.predict(predict_input_fn)]) + ``` + """ + + def __init__(self, + model_dir=None, + generator_fn=None, + discriminator_fn=None, + loss_fn=None, + generator_optimizer=None, + discriminator_optimizer=None, + get_hooks_fn=None, + get_eval_metric_ops_fn=None, + add_summaries=None, + use_loss_summaries=True, + config=None): + """Initializes a StarGANEstimator instance. + + Args: + model_dir: Directory to save model parameters, graph and etc. This can + also be used to load checkpoints from the directory into a estimator to + continue training a previously saved model. + generator_fn: A python function that takes a Tensor, Tensor list, or + Tensor dictionary as inputs and returns the outputs of the GAN + generator. See `TFGAN` for more details and examples. Additionally, if + it has an argument called `mode`, the Estimator's `mode` will be passed + in (ex TRAIN, EVAL, PREDICT). This is useful for things like batch + normalization. + discriminator_fn: A python function that takes the output of + `generator_fn` or real data in the GAN setup, and `input_data`. Outputs + a Tensor in the range [-inf, inf]. See `TFGAN` for more details and + examples. + loss_fn: The loss function on the generator. Takes a `StarGANModel` + namedtuple and return a `GANLoss` namedtuple. + generator_optimizer: The optimizer for generator updates, or a function + that takes no arguments and returns an optimizer. This function will be + called when the default graph is the `StarGANEstimator`'s graph, so + utilities like `tf.contrib.framework.get_or_create_global_step` will + work. + discriminator_optimizer: Same as `generator_optimizer`, but for the + discriminator updates. + get_hooks_fn: A function that takes a `GANTrainOps` tuple and returns a + list of hooks. These hooks are run on the generator and discriminator + train ops, and can be used to implement the GAN training scheme. + Defaults to `train.get_sequential_train_hooks()`. + get_eval_metric_ops_fn: A function that takes a `GANModel`, and returns a + dict of metric results keyed by name. The output of this function is + passed into `tf.estimator.EstimatorSpec` during evaluation. + add_summaries: `None`, a single `SummaryType`, or a list of `SummaryType`. + use_loss_summaries: If `True`, add loss summaries. If `False`, does not. + If `None`, uses defaults. + config: `RunConfig` object to configure the runtime settings. + + Raises: + ValueError: If loss functions aren't callable. + ValueError: If `use_loss_summaries` isn't boolean or `None`. + ValueError: If `get_hooks_fn` isn't callable or `None`. + """ + if not callable(loss_fn): + raise ValueError('loss_fn must be callable.') + if use_loss_summaries not in [True, False, None]: + raise ValueError('use_loss_summaries must be True, False or None.') + if get_hooks_fn is not None and not callable(get_hooks_fn): + raise TypeError('get_hooks_fn must be callable.') + + def _model_fn(features, labels, mode): + """StarGANEstimator model function.""" + if mode not in [ + model_fn_lib.ModeKeys.TRAIN, model_fn_lib.ModeKeys.EVAL, + model_fn_lib.ModeKeys.PREDICT + ]: + raise ValueError('Mode not recognized: %s' % mode) + + if mode == model_fn_lib.ModeKeys.PREDICT: + input_data = features[0] + input_data_domain_label = features[1] + else: + input_data = features # rename inputs for clarity + input_data_domain_label = labels # rename inputs for clarity + + # Make StarGANModel, which encapsulates the GAN model architectures. + gan_model = _get_gan_model(mode, generator_fn, discriminator_fn, + input_data, input_data_domain_label, + add_summaries) + + # Make the EstimatorSpec, which incorporates the StarGANModel, losses, + # eval, metrics, and optimizers (if required). + return _get_estimator_spec(mode, gan_model, loss_fn, + get_eval_metric_ops_fn, generator_optimizer, + discriminator_optimizer, get_hooks_fn) + + super(StarGANEstimator, self).__init__( + model_fn=_model_fn, model_dir=model_dir, config=config) + + +def _get_gan_model(mode, + generator_fn, + discriminator_fn, + input_data, + input_data_domain_label, + add_summaries, + generator_scope='Generator'): + """Makes the StarGANModel tuple.""" + if mode == model_fn_lib.ModeKeys.PREDICT: + gan_model = _make_prediction_gan_model(input_data, input_data_domain_label, + generator_fn, generator_scope) + else: # model_fn_lib.ModeKeys.TRAIN or model_fn_lib.ModeKeys.EVAL + gan_model = _make_gan_model(generator_fn, discriminator_fn, input_data, + input_data_domain_label, generator_scope, + add_summaries, mode) + + return gan_model + + +def _get_estimator_spec(mode, + gan_model, + loss_fn, + get_eval_metric_ops_fn, + generator_optimizer, + discriminator_optimizer, + get_hooks_fn=None): + """Get the EstimatorSpec for the current mode.""" + if mode == model_fn_lib.ModeKeys.PREDICT: + estimator_spec = model_fn_lib.EstimatorSpec( + mode=mode, predictions=gan_model.generated_data) + else: + gan_loss = loss_fn(gan_model) + if mode == model_fn_lib.ModeKeys.EVAL: + estimator_spec = _get_eval_estimator_spec(gan_model, gan_loss, + get_eval_metric_ops_fn) + else: # model_fn_lib.ModeKeys.TRAIN: + gopt = ( + generator_optimizer() + if callable(generator_optimizer) else generator_optimizer) + dopt = ( + discriminator_optimizer() + if callable(discriminator_optimizer) else discriminator_optimizer) + get_hooks_fn = get_hooks_fn or tfgan_train.get_sequential_train_hooks() + estimator_spec = _get_train_estimator_spec(gan_model, gan_loss, gopt, + dopt, get_hooks_fn) + + return estimator_spec + + +def _make_gan_model(generator_fn, discriminator_fn, input_data, + input_data_domain_label, generator_scope, add_summaries, + mode): + """Construct a `StarGANModel`, and optionally pass in `mode`.""" + # If network functions have an argument `mode`, pass mode to it. + if 'mode' in inspect.getargspec(generator_fn).args: + generator_fn = functools.partial(generator_fn, mode=mode) + if 'mode' in inspect.getargspec(discriminator_fn).args: + discriminator_fn = functools.partial(discriminator_fn, mode=mode) + gan_model = tfgan_train.stargan_model( + generator_fn, + discriminator_fn, + input_data, + input_data_domain_label, + generator_scope=generator_scope) + if add_summaries: + if not isinstance(add_summaries, (tuple, list)): + add_summaries = [add_summaries] + with ops.name_scope(None): + for summary_type in add_summaries: + _summary_type_map[summary_type](gan_model) + + return gan_model + + +def _make_prediction_gan_model(input_data, input_data_domain_label, + generator_fn, generator_scope): + """Make a `StarGANModel` from just the generator.""" + # If `generator_fn` has an argument `mode`, pass mode to it. + if 'mode' in inspect.getargspec(generator_fn).args: + generator_fn = functools.partial( + generator_fn, mode=model_fn_lib.ModeKeys.PREDICT) + with variable_scope.variable_scope(generator_scope) as gen_scope: + # pylint:disable=protected-access + input_data = tfgan_train._convert_tensor_or_l_or_d(input_data) + input_data_domain_label = tfgan_train._convert_tensor_or_l_or_d( + input_data_domain_label) + # pylint:enable=protected-access + generated_data = generator_fn(input_data, input_data_domain_label) + generator_variables = variable_lib.get_trainable_variables(gen_scope) + + return tfgan_tuples.StarGANModel( + input_data=input_data, + input_data_domain_label=None, + generated_data=generated_data, + generated_data_domain_target=input_data_domain_label, + reconstructed_data=None, + discriminator_input_data_source_predication=None, + discriminator_generated_data_source_predication=None, + discriminator_input_data_domain_predication=None, + discriminator_generated_data_domain_predication=None, + generator_variables=generator_variables, + generator_scope=generator_scope, + generator_fn=generator_fn, + discriminator_variables=None, + discriminator_scope=None, + discriminator_fn=None) + + +def _get_eval_estimator_spec(gan_model, + gan_loss, + get_eval_metric_ops_fn=None, + name=None): + """Return an EstimatorSpec for the eval case.""" + scalar_loss = gan_loss.generator_loss + gan_loss.discriminator_loss + with ops.name_scope(None, 'metrics', + [gan_loss.generator_loss, gan_loss.discriminator_loss]): + + def _summary_key(head_name, val): + return '%s/%s' % (val, head_name) if head_name else val + + eval_metric_ops = { + _summary_key(name, 'generator_loss'): + metrics_lib.mean(gan_loss.generator_loss), + _summary_key(name, 'discriminator_loss'): + metrics_lib.mean(gan_loss.discriminator_loss) + } + if get_eval_metric_ops_fn is not None: + custom_eval_metric_ops = get_eval_metric_ops_fn(gan_model) + if not isinstance(custom_eval_metric_ops, dict): + raise TypeError('get_eval_metric_ops_fn must return a dict, ' + 'received: {}'.format(custom_eval_metric_ops)) + eval_metric_ops.update(custom_eval_metric_ops) + return model_fn_lib.EstimatorSpec( + mode=model_fn_lib.ModeKeys.EVAL, + predictions=gan_model.generated_data, + loss=scalar_loss, + eval_metric_ops=eval_metric_ops) + + +def _get_train_estimator_spec(gan_model, + gan_loss, + generator_optimizer, + discriminator_optimizer, + get_hooks_fn, + train_op_fn=tfgan_train.gan_train_ops): + """Return an EstimatorSpec for the train case.""" + scalar_loss = gan_loss.generator_loss + gan_loss.discriminator_loss + train_ops = train_op_fn(gan_model, gan_loss, generator_optimizer, + discriminator_optimizer) + training_hooks = get_hooks_fn(train_ops) + return model_fn_lib.EstimatorSpec( + loss=scalar_loss, + mode=model_fn_lib.ModeKeys.TRAIN, + train_op=train_ops.global_step_inc_op, + training_hooks=training_hooks) + + +def stargan_prediction_input_fn_wrapper(fn): + """StarGAN Estimator prediction input_fn wrapper. + + Since estimator will disregard the "label" variable pass to the model, we will + use a wrapper to pack the (feature, label) tuple as feature passed to the + model. + + Args: + fn: input_fn for the prediction. + + Returns: + A tuple ((feature, label), None) where the second element is the dummy label + to be disregarded and the first element is the true input to the estimator. + """ + + def new_fn(): + return fn(), None + + return new_fn diff --git a/tensorflow/contrib/gan/python/estimator/python/stargan_estimator_test.py b/tensorflow/contrib/gan/python/estimator/python/stargan_estimator_test.py new file mode 100644 index 0000000000..2ec7938c7c --- /dev/null +++ b/tensorflow/contrib/gan/python/estimator/python/stargan_estimator_test.py @@ -0,0 +1,306 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for TFGAN's stargan_estimator.py.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import shutil +import tempfile + +from absl.testing import parameterized +import numpy as np +import six + +from tensorflow.contrib import layers +from tensorflow.contrib.gan.python import namedtuples as tfgan_tuples +from tensorflow.contrib.gan.python.estimator.python import stargan_estimator_impl as estimator +from tensorflow.python.estimator import model_fn as model_fn_lib +from tensorflow.python.estimator.inputs import numpy_io +from tensorflow.python.framework import ops +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import math_ops +from tensorflow.python.ops import metrics as metrics_lib +from tensorflow.python.ops import variable_scope +from tensorflow.python.platform import test +from tensorflow.python.summary.writer import writer_cache +from tensorflow.python.training import learning_rate_decay +from tensorflow.python.training import training +from tensorflow.python.training import training_util + + +def dummy_generator_fn(input_data, input_data_domain_label, mode): + del input_data_domain_label, mode + + return variable_scope.get_variable('dummy_g', initializer=0.5) * input_data + + +def dummy_discriminator_fn(input_data, num_domains, mode): + del mode + + hidden = layers.flatten(input_data) + output_src = math_ops.reduce_mean(hidden, axis=1) + output_cls = layers.fully_connected( + inputs=hidden, num_outputs=num_domains, scope='debug') + + return output_src, output_cls + + +class StarGetGANModelTest(test.TestCase, parameterized.TestCase): + """Tests that `StarGetGANModel` produces the correct model.""" + + @parameterized.named_parameters(('train', model_fn_lib.ModeKeys.TRAIN), + ('eval', model_fn_lib.ModeKeys.EVAL), + ('predict', model_fn_lib.ModeKeys.PREDICT)) + def test_get_gan_model(self, mode): + with ops.Graph().as_default(): + input_data = array_ops.ones([6, 4, 4, 3]) + input_data_domain_label = array_ops.one_hot([0] * 6, 5) + gan_model = estimator._get_gan_model( + mode, + dummy_generator_fn, + dummy_discriminator_fn, + input_data, + input_data_domain_label, + add_summaries=False) + + self.assertEqual(input_data, gan_model.input_data) + self.assertIsNotNone(gan_model.generated_data) + self.assertIsNotNone(gan_model.generated_data_domain_target) + self.assertEqual(1, len(gan_model.generator_variables)) + self.assertIsNotNone(gan_model.generator_scope) + self.assertIsNotNone(gan_model.generator_fn) + if mode == model_fn_lib.ModeKeys.PREDICT: + self.assertIsNone(gan_model.input_data_domain_label) + self.assertEqual(input_data_domain_label, + gan_model.generated_data_domain_target) + self.assertIsNone(gan_model.reconstructed_data) + self.assertIsNone(gan_model.discriminator_input_data_source_predication) + self.assertIsNone( + gan_model.discriminator_generated_data_source_predication) + self.assertIsNone(gan_model.discriminator_input_data_domain_predication) + self.assertIsNone( + gan_model.discriminator_generated_data_domain_predication) + self.assertIsNone(gan_model.discriminator_variables) + self.assertIsNone(gan_model.discriminator_scope) + self.assertIsNone(gan_model.discriminator_fn) + else: + self.assertEqual(input_data_domain_label, + gan_model.input_data_domain_label) + self.assertIsNotNone(gan_model.reconstructed_data.shape) + self.assertIsNotNone( + gan_model.discriminator_input_data_source_predication) + self.assertIsNotNone( + gan_model.discriminator_generated_data_source_predication) + self.assertIsNotNone( + gan_model.discriminator_input_data_domain_predication) + self.assertIsNotNone( + gan_model.discriminator_generated_data_domain_predication) + self.assertEqual(2, len(gan_model.discriminator_variables)) # 1 FC layer + self.assertIsNotNone(gan_model.discriminator_scope) + self.assertIsNotNone(gan_model.discriminator_fn) + + +def get_dummy_gan_model(): + """Similar to get_gan_model().""" + # TODO(joelshor): Find a better way of creating a variable scope. + with variable_scope.variable_scope('generator') as gen_scope: + gen_var = variable_scope.get_variable('dummy_var', initializer=0.0) + with variable_scope.variable_scope('discriminator') as dis_scope: + dis_var = variable_scope.get_variable('dummy_var', initializer=0.0) + return tfgan_tuples.StarGANModel( + input_data=array_ops.ones([1, 2, 2, 3]), + input_data_domain_label=array_ops.ones([1, 2]), + generated_data=array_ops.ones([1, 2, 2, 3]), + generated_data_domain_target=array_ops.ones([1, 2]), + reconstructed_data=array_ops.ones([1, 2, 2, 3]), + discriminator_input_data_source_predication=array_ops.ones([1]) * dis_var, + discriminator_generated_data_source_predication=array_ops.ones( + [1]) * gen_var * dis_var, + discriminator_input_data_domain_predication=array_ops.ones([1, 2 + ]) * dis_var, + discriminator_generated_data_domain_predication=array_ops.ones([1, 2]) * + gen_var * dis_var, + generator_variables=[gen_var], + generator_scope=gen_scope, + generator_fn=None, + discriminator_variables=[dis_var], + discriminator_scope=dis_scope, + discriminator_fn=None) + + +def dummy_loss_fn(gan_model): + loss = math_ops.reduce_sum( + gan_model.discriminator_input_data_domain_predication - + gan_model.discriminator_generated_data_domain_predication) + loss += math_ops.reduce_sum(gan_model.input_data - gan_model.generated_data) + return tfgan_tuples.GANLoss(loss, loss) + + +def get_metrics(gan_model): + return { + 'mse_custom_metric': + metrics_lib.mean_squared_error(gan_model.input_data, + gan_model.generated_data) + } + + +class GetEstimatorSpecTest(test.TestCase, parameterized.TestCase): + """Tests that the EstimatorSpec is constructed appropriately.""" + + @classmethod + def setUpClass(cls): + cls._generator_optimizer = training.GradientDescentOptimizer(1.0) + cls._discriminator_optimizer = training.GradientDescentOptimizer(1.0) + + @parameterized.named_parameters(('train', model_fn_lib.ModeKeys.TRAIN), + ('eval', model_fn_lib.ModeKeys.EVAL), + ('predict', model_fn_lib.ModeKeys.PREDICT)) + def test_get_estimator_spec(self, mode): + with ops.Graph().as_default(): + self._gan_model = get_dummy_gan_model() + spec = estimator._get_estimator_spec( + mode, + self._gan_model, + loss_fn=dummy_loss_fn, + get_eval_metric_ops_fn=get_metrics, + generator_optimizer=self._generator_optimizer, + discriminator_optimizer=self._discriminator_optimizer) + + self.assertEqual(mode, spec.mode) + if mode == model_fn_lib.ModeKeys.PREDICT: + self.assertEqual(self._gan_model.generated_data, spec.predictions) + elif mode == model_fn_lib.ModeKeys.TRAIN: + self.assertShapeEqual(np.array(0), spec.loss) # must be a scalar + self.assertIsNotNone(spec.train_op) + self.assertIsNotNone(spec.training_hooks) + elif mode == model_fn_lib.ModeKeys.EVAL: + self.assertEqual(self._gan_model.generated_data, spec.predictions) + self.assertShapeEqual(np.array(0), spec.loss) # must be a scalar + self.assertIsNotNone(spec.eval_metric_ops) + + +# TODO(joelshor): Add pandas test. +class StarGANEstimatorIntegrationTest(test.TestCase): + + def setUp(self): + self._model_dir = tempfile.mkdtemp() + + def tearDown(self): + if self._model_dir: + writer_cache.FileWriterCache.clear() + shutil.rmtree(self._model_dir) + + def _test_complete_flow(self, + train_input_fn, + eval_input_fn, + predict_input_fn, + prediction_size, + lr_decay=False): + + def make_opt(): + gstep = training_util.get_or_create_global_step() + lr = learning_rate_decay.exponential_decay(1.0, gstep, 10, 0.9) + return training.GradientDescentOptimizer(lr) + + gopt = make_opt if lr_decay else training.GradientDescentOptimizer(1.0) + dopt = make_opt if lr_decay else training.GradientDescentOptimizer(1.0) + est = estimator.StarGANEstimator( + generator_fn=dummy_generator_fn, + discriminator_fn=dummy_discriminator_fn, + loss_fn=dummy_loss_fn, + generator_optimizer=gopt, + discriminator_optimizer=dopt, + get_eval_metric_ops_fn=get_metrics, + model_dir=self._model_dir) + + # TRAIN + num_steps = 10 + est.train(train_input_fn, steps=num_steps) + + # EVALUTE + scores = est.evaluate(eval_input_fn) + self.assertEqual(num_steps, scores[ops.GraphKeys.GLOBAL_STEP]) + self.assertIn('loss', six.iterkeys(scores)) + self.assertEqual(scores['discriminator_loss'] + scores['generator_loss'], + scores['loss']) + self.assertIn('mse_custom_metric', six.iterkeys(scores)) + + # PREDICT + predictions = np.array([x for x in est.predict(predict_input_fn)]) + + self.assertAllEqual(prediction_size, predictions.shape) + + @staticmethod + def _numpy_input_fn_wrapper(numpy_input_fn, batch_size, label_size): + """Wrapper to remove the dictionary in numpy_input_fn. + + NOTE: + We create the domain_label here because the model expect a fully define + batch_size from the input. + + Args: + numpy_input_fn: input_fn created from numpy_io + batch_size: (int) number of items for each batch + label_size: (int) number of domains + + Returns: + a new input_fn + """ + + def new_input_fn(): + features = numpy_input_fn() + return features['x'], array_ops.one_hot([0] * batch_size, label_size) + + return new_input_fn + + def test_numpy_input_fn(self): + """Tests complete flow with numpy_input_fn.""" + batch_size = 5 + img_size = 8 + channel_size = 3 + label_size = 3 + image_data = np.zeros( + [batch_size, img_size, img_size, channel_size], dtype=np.float32) + train_input_fn = numpy_io.numpy_input_fn( + x={'x': image_data}, + batch_size=batch_size, + num_epochs=None, + shuffle=True) + eval_input_fn = numpy_io.numpy_input_fn( + x={'x': image_data}, batch_size=batch_size, shuffle=False) + predict_input_fn = numpy_io.numpy_input_fn( + x={'x': image_data}, shuffle=False) + + train_input_fn = self._numpy_input_fn_wrapper(train_input_fn, batch_size, + label_size) + eval_input_fn = self._numpy_input_fn_wrapper(eval_input_fn, batch_size, + label_size) + predict_input_fn = self._numpy_input_fn_wrapper(predict_input_fn, + batch_size, label_size) + + predict_input_fn = estimator.stargan_prediction_input_fn_wrapper( + predict_input_fn) + + self._test_complete_flow( + train_input_fn=train_input_fn, + eval_input_fn=eval_input_fn, + predict_input_fn=predict_input_fn, + prediction_size=[batch_size, img_size, img_size, channel_size]) + + +if __name__ == '__main__': + test.main() diff --git a/tensorflow/contrib/gan/python/eval/python/classifier_metrics_test.py b/tensorflow/contrib/gan/python/eval/python/classifier_metrics_test.py index 4fb8d58bc9..d64dfd1576 100644 --- a/tensorflow/contrib/gan/python/eval/python/classifier_metrics_test.py +++ b/tensorflow/contrib/gan/python/eval/python/classifier_metrics_test.py @@ -335,7 +335,7 @@ class ClassifierMetricsTest(test.TestCase, parameterized.TestCase): mofid_op = classifier_metrics.mean_only_frechet_classifier_distance_from_activations( # pylint: disable=line-too-long tf_pool_real_a, tf_pool_gen_a) - with self.test_session() as sess: + with self.cached_session() as sess: actual_mofid = sess.run(mofid_op) expected_mofid = _expected_mean_only_fid(pool_real_a, pool_gen_a) @@ -355,7 +355,7 @@ class ClassifierMetricsTest(test.TestCase, parameterized.TestCase): dofid_op = classifier_metrics.diagonal_only_frechet_classifier_distance_from_activations( # pylint: disable=line-too-long tf_pool_real_a, tf_pool_gen_a) - with self.test_session() as sess: + with self.cached_session() as sess: actual_dofid = sess.run(dofid_op) expected_dofid = _expected_diagonal_only_fid(pool_real_a, pool_gen_a) @@ -377,7 +377,7 @@ class ClassifierMetricsTest(test.TestCase, parameterized.TestCase): test_pool_gen_a, classifier_fn=lambda x: x) - with self.test_session() as sess: + with self.cached_session() as sess: actual_fid = sess.run(fid_op) expected_fid = _expected_fid(test_pool_real_a, test_pool_gen_a) @@ -404,7 +404,7 @@ class ClassifierMetricsTest(test.TestCase, parameterized.TestCase): classifier_fn=lambda x: x)) fids = [] - with self.test_session() as sess: + with self.cached_session() as sess: for fid_op in fid_ops: fids.append(sess.run(fid_op)) @@ -426,7 +426,7 @@ class ClassifierMetricsTest(test.TestCase, parameterized.TestCase): trace_sqrt_prod_op = _run_with_mock(classifier_metrics.trace_sqrt_product, cov_real, cov_gen) - with self.test_session() as sess: + with self.cached_session() as sess: # trace_sqrt_product: tsp actual_tsp = sess.run(trace_sqrt_prod_op) diff --git a/tensorflow/contrib/gan/python/eval/python/sliced_wasserstein_test.py b/tensorflow/contrib/gan/python/eval/python/sliced_wasserstein_test.py index 871f1ad54e..ab909feae3 100644 --- a/tensorflow/contrib/gan/python/eval/python/sliced_wasserstein_test.py +++ b/tensorflow/contrib/gan/python/eval/python/sliced_wasserstein_test.py @@ -65,7 +65,7 @@ class ClassifierMetricsTest(test.TestCase): pyramid = np_laplacian_pyramid(data, 3) data_tf = array_ops.placeholder(dtypes.float32, [256, 32, 32, 3]) pyramid_tf = swd._laplacian_pyramid(data_tf, 3) - with self.test_session() as sess: + with self.cached_session() as sess: pyramid_tf = sess.run( pyramid_tf, feed_dict={ data_tf: data.transpose(0, 2, 3, 1) @@ -79,7 +79,7 @@ class ClassifierMetricsTest(test.TestCase): d1 = random_ops.random_uniform([256, 32, 32, 3]) d2 = random_ops.random_normal([256, 32, 32, 3]) wfunc = swd.sliced_wasserstein_distance(d1, d2) - with self.test_session() as sess: + with self.cached_session() as sess: wscores = [sess.run(x) for x in wfunc] self.assertAllClose( np.array([0.014, 0.014], 'f'), @@ -95,7 +95,7 @@ class ClassifierMetricsTest(test.TestCase): d1 = random_ops.random_uniform([256, 32, 32, 3]) d2 = random_ops.random_normal([256, 32, 32, 3]) wfunc = swd.sliced_wasserstein_distance(d1, d2, use_svd=True) - with self.test_session() as sess: + with self.cached_session() as sess: wscores = [sess.run(x) for x in wfunc] self.assertAllClose( np.array([0.013, 0.013], 'f'), diff --git a/tensorflow/contrib/gdr/gdr_memory_manager.cc b/tensorflow/contrib/gdr/gdr_memory_manager.cc index 7e6a0f14f6..726f74c7b7 100644 --- a/tensorflow/contrib/gdr/gdr_memory_manager.cc +++ b/tensorflow/contrib/gdr/gdr_memory_manager.cc @@ -186,22 +186,22 @@ class GdrMemoryManager : public RemoteMemoryManager { // TODO(byronyi): remove this class and its registration when the default // cpu_allocator() returns visitable allocator, or cpu_allocator() is no // longer in use. -class BFCRdmaAllocator : public BFCAllocator { +class BFCGdrAllocator : public BFCAllocator { public: - BFCRdmaAllocator() + BFCGdrAllocator() : BFCAllocator(new BasicCPUAllocator(port::kNUMANoAffinity), 1LL << 36, - true, "cpu_rdma_bfc") {} + true, "cpu_gdr_bfc") {} }; -class BFCRdmaAllocatorFactory : public AllocatorFactory { +class BFCGdrAllocatorFactory : public AllocatorFactory { public: - Allocator* CreateAllocator() override { return new BFCRdmaAllocator; } + Allocator* CreateAllocator() override { return new BFCGdrAllocator; } virtual SubAllocator* CreateSubAllocator(int numa_node) { return new BasicCPUAllocator(numa_node); } }; -REGISTER_MEM_ALLOCATOR("BFCRdmaAllocator", 101, BFCRdmaAllocatorFactory); +REGISTER_MEM_ALLOCATOR("BFCGdrAllocator", 102, BFCGdrAllocatorFactory); GdrMemoryManager::GdrMemoryManager(const string& host, const string& port) : host_(host), diff --git a/tensorflow/contrib/gdr/gdr_memory_manager.h b/tensorflow/contrib/gdr/gdr_memory_manager.h index 9ac1aa96c4..c85886863e 100644 --- a/tensorflow/contrib/gdr/gdr_memory_manager.h +++ b/tensorflow/contrib/gdr/gdr_memory_manager.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef GDR_MEMORY_MANAGER_H_ -#define GDR_MEMORY_MANAGER_H_ +#ifndef TENSORFLOW_CONTRIB_GDR_GDR_MEMORY_MANAGER_H_ +#define TENSORFLOW_CONTRIB_GDR_GDR_MEMORY_MANAGER_H_ #include "google/protobuf/any.pb.h" #include "tensorflow/core/lib/core/status.h" @@ -57,4 +57,4 @@ RemoteMemoryManager* CreateRemoteMemoryManager(const string& host, } // namespace tensorflow -#endif // GDR_MEMORY_MANAGER_H_ +#endif // TENSORFLOW_CONTRIB_GDR_GDR_MEMORY_MANAGER_H_ diff --git a/tensorflow/contrib/gdr/gdr_rendezvous_mgr.h b/tensorflow/contrib/gdr/gdr_rendezvous_mgr.h index 7fedd04f54..47a36efdb7 100644 --- a/tensorflow/contrib/gdr/gdr_rendezvous_mgr.h +++ b/tensorflow/contrib/gdr/gdr_rendezvous_mgr.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef GDR_RENDEZVOUS_MGR_H_ -#define GDR_RENDEZVOUS_MGR_H_ +#ifndef TENSORFLOW_CONTRIB_GDR_GDR_RENDEZVOUS_MGR_H_ +#define TENSORFLOW_CONTRIB_GDR_GDR_RENDEZVOUS_MGR_H_ #include "tensorflow/contrib/gdr/gdr_memory_manager.h" #include "tensorflow/core/distributed_runtime/base_rendezvous_mgr.h" @@ -39,4 +39,4 @@ class GdrRendezvousMgr : public BaseRendezvousMgr { } // end namespace tensorflow -#endif // GDR_RENDEZVOUS_MGR_H_ +#endif // TENSORFLOW_CONTRIB_GDR_GDR_RENDEZVOUS_MGR_H_ diff --git a/tensorflow/contrib/gdr/gdr_server_lib.h b/tensorflow/contrib/gdr/gdr_server_lib.h index d6c40d429e..efa2390d33 100644 --- a/tensorflow/contrib/gdr/gdr_server_lib.h +++ b/tensorflow/contrib/gdr/gdr_server_lib.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef GDR_SERVER_LIB_H_ -#define GDR_SERVER_LIB_H_ +#ifndef TENSORFLOW_CONTRIB_GDR_GDR_SERVER_LIB_H_ +#define TENSORFLOW_CONTRIB_GDR_GDR_SERVER_LIB_H_ #include "tensorflow/contrib/gdr/gdr_memory_manager.h" #include "tensorflow/core/distributed_runtime/rpc/grpc_server_lib.h" @@ -49,4 +49,4 @@ class GdrServer : public GrpcServer { } // namespace tensorflow -#endif // GDR_SERVER_LIB_H_ +#endif // TENSORFLOW_CONTRIB_GDR_GDR_SERVER_LIB_H_ diff --git a/tensorflow/contrib/gdr/gdr_worker.h b/tensorflow/contrib/gdr/gdr_worker.h index 54081f655e..65105ed997 100644 --- a/tensorflow/contrib/gdr/gdr_worker.h +++ b/tensorflow/contrib/gdr/gdr_worker.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef GDR_WORKER_H_ -#define GDR_WORKER_H_ +#ifndef TENSORFLOW_CONTRIB_GDR_GDR_WORKER_H_ +#define TENSORFLOW_CONTRIB_GDR_GDR_WORKER_H_ #include "tensorflow/contrib/gdr/gdr_memory_manager.h" @@ -44,4 +44,4 @@ class GdrWorker : public GrpcWorker { } // namespace tensorflow -#endif // GDR_WORKER_H_ +#endif // TENSORFLOW_CONTRIB_GDR_GDR_WORKER_H_ diff --git a/tensorflow/contrib/image/python/kernel_tests/dense_image_warp_test.py b/tensorflow/contrib/image/python/kernel_tests/dense_image_warp_test.py index a58b6a247e..24b790977d 100644 --- a/tensorflow/contrib/image/python/kernel_tests/dense_image_warp_test.py +++ b/tensorflow/contrib/image/python/kernel_tests/dense_image_warp_test.py @@ -50,7 +50,7 @@ class DenseImageWarpTest(test_util.TensorFlowTestCase): interp = dense_image_warp._interpolate_bilinear(grid, query_points) - with self.test_session() as sess: + with self.cached_session() as sess: predicted = sess.run(interp) self.assertAllClose(expected_results, predicted) @@ -64,7 +64,7 @@ class DenseImageWarpTest(test_util.TensorFlowTestCase): interp = dense_image_warp._interpolate_bilinear( grid, query_points, indexing='xy') - with self.test_session() as sess: + with self.cached_session() as sess: predicted = sess.run(interp) self.assertAllClose(expected_results, predicted) @@ -78,7 +78,7 @@ class DenseImageWarpTest(test_util.TensorFlowTestCase): interp = dense_image_warp._interpolate_bilinear(grid, query_points) - with self.test_session() as sess: + with self.cached_session() as sess: predicted = sess.run(interp) self.assertAllClose(expected_results, predicted) @@ -160,7 +160,7 @@ class DenseImageWarpTest(test_util.TensorFlowTestCase): flow_type) interp = dense_image_warp.dense_image_warp(image, flows) - with self.test_session() as sess: + with self.cached_session() as sess: rand_image, rand_flows = self.get_random_image_and_flows( shape, image_type, flow_type) rand_flows *= 0 @@ -191,7 +191,7 @@ class DenseImageWarpTest(test_util.TensorFlowTestCase): flow_type) interp = dense_image_warp.dense_image_warp(image, flows) low_precision = image_type == 'float16' or flow_type == 'float16' - with self.test_session() as sess: + with self.cached_session() as sess: rand_image, rand_flows = self.get_random_image_and_flows( shape, image_type, flow_type) @@ -249,7 +249,7 @@ class DenseImageWarpTest(test_util.TensorFlowTestCase): opt_func = optimizer.apply_gradients(zip(grad, [flows])) init_op = variables.global_variables_initializer() - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(init_op) for _ in range(10): sess.run(opt_func) diff --git a/tensorflow/contrib/image/python/kernel_tests/distort_image_ops_test.py b/tensorflow/contrib/image/python/kernel_tests/distort_image_ops_test.py index a495b58b7f..ac8573445c 100644 --- a/tensorflow/contrib/image/python/kernel_tests/distort_image_ops_test.py +++ b/tensorflow/contrib/image/python/kernel_tests/distort_image_ops_test.py @@ -217,7 +217,7 @@ class AdjustSaturationInYiqTest(test_util.TensorFlowTestCase): 'gb_same', 'rgb_same', ] - with self.test_session(): + with self.cached_session(): for x_shape in x_shapes: for test_style in test_styles: x_np = np.random.rand(*x_shape) * 255. diff --git a/tensorflow/contrib/image/python/kernel_tests/image_ops_test.py b/tensorflow/contrib/image/python/kernel_tests/image_ops_test.py index f588eae923..70339d7612 100644 --- a/tensorflow/contrib/image/python/kernel_tests/image_ops_test.py +++ b/tensorflow/contrib/image/python/kernel_tests/image_ops_test.py @@ -39,7 +39,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): def test_zeros(self): for dtype in _DTYPES: - with self.test_session(): + with self.cached_session(): for shape in [(5, 5), (24, 24), (2, 24, 24, 3)]: for angle in [0, 1, np.pi / 2.0]: image = array_ops.zeros(shape, dtype) @@ -49,7 +49,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): def test_rotate_even(self): for dtype in _DTYPES: - with self.test_session(): + with self.cached_session(): image = array_ops.reshape( math_ops.cast(math_ops.range(36), dtype), (6, 6)) image_rep = array_ops.tile(image[None, :, :, None], [3, 1, 1, 1]) @@ -71,7 +71,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): def test_rotate_odd(self): for dtype in _DTYPES: - with self.test_session(): + with self.cached_session(): image = array_ops.reshape( math_ops.cast(math_ops.range(25), dtype), (5, 5)) image_rep = array_ops.tile(image[None, :, :, None], [3, 1, 1, 1]) @@ -91,7 +91,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): def test_translate(self): for dtype in _DTYPES: - with self.test_session(): + with self.cached_session(): image = constant_op.constant( [[1, 0, 1, 0], [0, 1, 0, 1], @@ -107,7 +107,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): def test_compose(self): for dtype in _DTYPES: - with self.test_session(): + with self.cached_session(): image = constant_op.constant( [[1, 1, 1, 0], [1, 0, 0, 0], @@ -131,7 +131,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): def test_extreme_projective_transform(self): for dtype in _DTYPES: - with self.test_session(): + with self.cached_session(): image = constant_op.constant( [[1, 0, 1, 0], [0, 1, 0, 1], @@ -147,7 +147,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): [0, 0, 0, 0]]) def test_bilinear(self): - with self.test_session(): + with self.cached_session(): image = constant_op.constant( [[0, 0, 0, 0, 0], [0, 1, 1, 1, 0], @@ -176,7 +176,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): [0, 0, 1, 0, 0]]) def test_bilinear_uint8(self): - with self.test_session(): + with self.cached_session(): image = constant_op.constant( np.asarray( [[0.0, 0.0, 0.0, 0.0, 0.0], @@ -209,7 +209,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): self.assertAllEqual([3, 5], result.get_shape()) def _test_grad(self, shape_to_test): - with self.test_session(): + with self.cached_session(): test_image_shape = shape_to_test test_image = np.random.randn(*test_image_shape) test_image_tensor = constant_op.constant( @@ -228,7 +228,7 @@ class ImageOpsTest(test_util.TensorFlowTestCase): self.assertLess(left_err, 1e-10) def _test_grad_different_shape(self, input_shape, output_shape): - with self.test_session(): + with self.cached_session(): test_image_shape = input_shape test_image = np.random.randn(*test_image_shape) test_image_tensor = constant_op.constant( @@ -276,7 +276,7 @@ class BipartiteMatchTest(test_util.TensorFlowTestCase): expected_col_to_row_match_np = np.array(expected_col_to_row_match, dtype=np.int32) - with self.test_session(): + with self.cached_session(): distance_mat_tf = constant_op.constant(distance_mat_np, shape=distance_mat_shape) location_to_prior, prior_to_location = image_ops.bipartite_match( diff --git a/tensorflow/contrib/image/python/kernel_tests/interpolate_spline_test.py b/tensorflow/contrib/image/python/kernel_tests/interpolate_spline_test.py index 1939caaa2d..d58a654292 100644 --- a/tensorflow/contrib/image/python/kernel_tests/interpolate_spline_test.py +++ b/tensorflow/contrib/image/python/kernel_tests/interpolate_spline_test.py @@ -26,6 +26,7 @@ from tensorflow.python.framework import constant_op from tensorflow.python.framework import ops from tensorflow.python.framework import test_util +from tensorflow.python.ops import array_ops from tensorflow.python.ops import clip_ops from tensorflow.python.ops import gradients from tensorflow.python.ops import math_ops @@ -164,7 +165,7 @@ class InterpolateSplineTest(test_util.TensorFlowTestCase): with ops.name_scope('interpolator'): interpolator = interpolate_spline.interpolate_spline( train_points, train_values, query_points, interpolation_order) - with self.test_session() as sess: + with self.cached_session() as sess: fetches = [query_points, train_points, train_values, interpolator] query_points_, train_points_, train_values_, interp_ = sess.run(fetches) @@ -204,7 +205,7 @@ class InterpolateSplineTest(test_util.TensorFlowTestCase): target_interpolation = tp.HARDCODED_QUERY_VALUES[(order, reg_weight)] target_interpolation = np.array(target_interpolation) - with self.test_session() as sess: + with self.cached_session() as sess: interp_val = sess.run(interpolator) self.assertAllClose(interp_val[0, :, 0], target_interpolation) @@ -222,10 +223,85 @@ class InterpolateSplineTest(test_util.TensorFlowTestCase): target_interpolation = tp.HARDCODED_QUERY_VALUES[(order, reg_weight)] target_interpolation = np.array(target_interpolation) - with self.test_session() as sess: + with self.cached_session() as sess: interp_val = sess.run(interpolator) self.assertAllClose(interp_val[0, :, 0], target_interpolation) + def test_nd_linear_interpolation_unspecified_shape(self): + """Ensure that interpolation supports dynamic batch_size and num_points.""" + + tp = _QuadraticPlusSinProblemND() + (query_points, _, train_points, + train_values) = tp.get_problem(dtype='float64') + + # Construct placeholders such that the batch size, number of train points, + # and number of query points are not known at graph construction time. + feature_dim = query_points.shape[-1] + value_dim = train_values.shape[-1] + train_points_ph = array_ops.placeholder( + dtype=train_points.dtype, shape=[None, None, feature_dim]) + train_values_ph = array_ops.placeholder( + dtype=train_values.dtype, shape=[None, None, value_dim]) + query_points_ph = array_ops.placeholder( + dtype=query_points.dtype, shape=[None, None, feature_dim]) + + order = 1 + reg_weight = 0.01 + + interpolator = interpolate_spline.interpolate_spline( + train_points_ph, train_values_ph, query_points_ph, order, reg_weight) + + target_interpolation = tp.HARDCODED_QUERY_VALUES[(order, reg_weight)] + target_interpolation = np.array(target_interpolation) + with self.cached_session() as sess: + + (train_points_value, train_values_value, query_points_value) = sess.run( + [train_points, train_values, query_points]) + + interp_val = sess.run( + interpolator, + feed_dict={ + train_points_ph: train_points_value, + train_values_ph: train_values_value, + query_points_ph: query_points_value + }) + self.assertAllClose(interp_val[0, :, 0], target_interpolation) + + def test_fully_unspecified_shape(self): + """Ensure that erreor is thrown when input/output dim unspecified.""" + + tp = _QuadraticPlusSinProblemND() + (query_points, _, train_points, + train_values) = tp.get_problem(dtype='float64') + + # Construct placeholders such that the batch size, number of train points, + # and number of query points are not known at graph construction time. + feature_dim = query_points.shape[-1] + value_dim = train_values.shape[-1] + train_points_ph = array_ops.placeholder( + dtype=train_points.dtype, shape=[None, None, feature_dim]) + train_points_ph_invalid = array_ops.placeholder( + dtype=train_points.dtype, shape=[None, None, None]) + train_values_ph = array_ops.placeholder( + dtype=train_values.dtype, shape=[None, None, value_dim]) + train_values_ph_invalid = array_ops.placeholder( + dtype=train_values.dtype, shape=[None, None, None]) + query_points_ph = array_ops.placeholder( + dtype=query_points.dtype, shape=[None, None, feature_dim]) + + order = 1 + reg_weight = 0.01 + + with self.assertRaises(ValueError): + _ = interpolate_spline.interpolate_spline( + train_points_ph_invalid, train_values_ph, query_points_ph, order, + reg_weight) + + with self.assertRaises(ValueError): + _ = interpolate_spline.interpolate_spline( + train_points_ph, train_values_ph_invalid, query_points_ph, order, + reg_weight) + def test_interpolation_gradient(self): """Make sure that backprop can run. Correctness of gradients is assumed. @@ -254,7 +330,7 @@ class InterpolateSplineTest(test_util.TensorFlowTestCase): opt_func = optimizer.apply_gradients(zip(grad, [train_points])) init_op = variables.global_variables_initializer() - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(init_op) for _ in range(100): sess.run([loss, opt_func]) diff --git a/tensorflow/contrib/image/python/kernel_tests/segmentation_test.py b/tensorflow/contrib/image/python/kernel_tests/segmentation_test.py index 48066cbace..3d39165ede 100644 --- a/tensorflow/contrib/image/python/kernel_tests/segmentation_test.py +++ b/tensorflow/contrib/image/python/kernel_tests/segmentation_test.py @@ -59,19 +59,19 @@ class SegmentationTest(test_util.TensorFlowTestCase): [7, 0, 8, 0, 0, 0, 9, 0, 0], [0, 0, 0, 0, 10, 0, 0, 0, 0], [0, 0, 11, 0, 0, 0, 0, 0, 0]]) # pyformat: disable - with self.test_session(): + with self.cached_session(): self.assertAllEqual(image_ops.connected_components(arr).eval(), expected) def testSimple(self): arr = [[0, 1, 0], [1, 1, 1], [0, 1, 0]] - with self.test_session(): + with self.cached_session(): # Single component with id 1. self.assertAllEqual( image_ops.connected_components(math_ops.cast( arr, dtypes.bool)).eval(), arr) def testSnake(self): - with self.test_session(): + with self.cached_session(): # Single component with id 1. self.assertAllEqual( image_ops.connected_components(math_ops.cast( @@ -80,7 +80,7 @@ class SegmentationTest(test_util.TensorFlowTestCase): def testSnake_disconnected(self): for i in range(SNAKE.shape[0]): for j in range(SNAKE.shape[1]): - with self.test_session(): + with self.cached_session(): # If we disconnect any part of the snake except for the endpoints, # there will be 2 components. if SNAKE[i, j] and (i, j) not in [(1, 1), (6, 3)]: @@ -121,27 +121,27 @@ class SegmentationTest(test_util.TensorFlowTestCase): [0, 6, 6, 0], [8, 0, 6, 0], [0, 0, 6, 6]]] # pyformat: disable - with self.test_session(): + with self.cached_session(): self.assertAllEqual( image_ops.connected_components(math_ops.cast( images, dtypes.bool)).eval(), expected) def testZeros(self): - with self.test_session(): + with self.cached_session(): self.assertAllEqual( image_ops.connected_components( array_ops.zeros((100, 20, 50), dtypes.bool)).eval(), np.zeros((100, 20, 50))) def testOnes(self): - with self.test_session(): + with self.cached_session(): self.assertAllEqual( image_ops.connected_components( array_ops.ones((100, 20, 50), dtypes.bool)).eval(), np.tile(np.arange(100)[:, None, None] + 1, [1, 20, 50])) def testOnes_small(self): - with self.test_session(): + with self.cached_session(): self.assertAllEqual( image_ops.connected_components(array_ops.ones((3, 5), dtypes.bool)).eval(), @@ -153,7 +153,7 @@ class SegmentationTest(test_util.TensorFlowTestCase): expected = connected_components_reference_implementation(images) if expected is None: return - with self.test_session(): + with self.cached_session(): self.assertAllEqual( image_ops.connected_components(images).eval(), expected) diff --git a/tensorflow/contrib/image/python/kernel_tests/single_image_random_dot_stereograms_ops_test.py b/tensorflow/contrib/image/python/kernel_tests/single_image_random_dot_stereograms_ops_test.py index 3f4029e558..e5980c53b2 100644 --- a/tensorflow/contrib/image/python/kernel_tests/single_image_random_dot_stereograms_ops_test.py +++ b/tensorflow/contrib/image/python/kernel_tests/single_image_random_dot_stereograms_ops_test.py @@ -47,7 +47,7 @@ class SingleImageRandomDotStereogramsTest(test_util.TensorFlowTestCase): normalize=True) shape_1 = sirds_1.get_shape().as_list() self.assertEqual(shape_1, [768, 1024, 1]) - with self.test_session(): + with self.cached_session(): r_tf_1 = sirds_1.eval() self.assertAllEqual(shape_1, r_tf_1.shape) @@ -59,7 +59,7 @@ class SingleImageRandomDotStereogramsTest(test_util.TensorFlowTestCase): normalize=True) shape_2 = sirds_2.get_shape().as_list() self.assertEqual(shape_2, [768, 1024, 3]) - with self.test_session(): + with self.cached_session(): r_tf_2 = sirds_2.eval() self.assertAllEqual(shape_2, r_tf_2.shape) @@ -73,7 +73,7 @@ class SingleImageRandomDotStereogramsTest(test_util.TensorFlowTestCase): output_image_shape=[1200, 800, 1]) shape_3 = sirds_3.get_shape().as_list() self.assertEqual(shape_3, [800, 1200, 1]) - with self.test_session(): + with self.cached_session(): r_tf_3 = sirds_3.eval() self.assertAllEqual(shape_3, r_tf_3.shape) diff --git a/tensorflow/contrib/image/python/kernel_tests/sparse_image_warp_test.py b/tensorflow/contrib/image/python/kernel_tests/sparse_image_warp_test.py index 0135c66e29..ce9e34df73 100644 --- a/tensorflow/contrib/image/python/kernel_tests/sparse_image_warp_test.py +++ b/tensorflow/contrib/image/python/kernel_tests/sparse_image_warp_test.py @@ -107,7 +107,7 @@ class SparseImageWarpTest(test_util.TensorFlowTestCase): regularization_weight=regularization, num_boundary_points=num_boundary_points) - with self.test_session() as sess: + with self.cached_session() as sess: warped_image, input_image, _ = sess.run( [warped_image_op, input_image_op, flow_field]) @@ -149,7 +149,7 @@ class SparseImageWarpTest(test_util.TensorFlowTestCase): interpolation_order=order, num_boundary_points=num_boundary_points) - with self.test_session() as sess: + with self.cached_session() as sess: warped_image, input_image, flow = sess.run( [warped_image_op, input_image_op, flow_field]) # Check that it moved the pixel correctly. @@ -176,7 +176,7 @@ class SparseImageWarpTest(test_util.TensorFlowTestCase): test_data_dir = test.test_src_dir_path('contrib/image/python/' 'kernel_tests/test_data/') input_file = test_data_dir + 'Yellow_Smiley_Face.png' - with self.test_session() as sess: + with self.cached_session() as sess: input_image = self.load_image(input_file, sess) control_points = np.asarray([[64, 59], [180 - 64, 59], [39, 111], [180 - 39, 111], [90, 143], [58, 134], @@ -199,7 +199,7 @@ class SparseImageWarpTest(test_util.TensorFlowTestCase): control_points_op + control_point_displacements_op, interpolation_order=interpolation_order, num_boundary_points=num_boundary_points) - with self.test_session() as sess: + with self.cached_session() as sess: warped_image = sess.run(warp_op) out_image = np.uint8(warped_image[0, :, :, :] * 255) target_file = ( @@ -244,7 +244,7 @@ class SparseImageWarpTest(test_util.TensorFlowTestCase): opt_func = optimizer.apply_gradients(zip(grad, [image])) init_op = variables.global_variables_initializer() - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(init_op) for _ in range(5): sess.run([loss, opt_func]) diff --git a/tensorflow/contrib/image/python/ops/interpolate_spline.py b/tensorflow/contrib/image/python/ops/interpolate_spline.py index daf8c56456..f0b408faa3 100644 --- a/tensorflow/contrib/image/python/ops/interpolate_spline.py +++ b/tensorflow/contrib/image/python/ops/interpolate_spline.py @@ -17,9 +17,6 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function -import numpy as np - -from tensorflow.python.framework import constant_op from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops from tensorflow.python.ops import linalg_ops @@ -95,10 +92,22 @@ def _solve_interpolation(train_points, train_values, order, Returns: w: `[b, n, k]` weights on each interpolation center v: `[b, d, k]` weights on each input dimension + Raises: + ValueError: if d or k is not fully specified. """ - b, n, d = train_points.get_shape().as_list() - _, _, k = train_values.get_shape().as_list() + # These dimensions are set dynamically at runtime. + b, n, _ = array_ops.unstack(array_ops.shape(train_points), num=3) + + d = train_points.shape[-1] + if d.value is None: + raise ValueError('The dimensionality of the input points (d) must be ' + 'statically-inferrable.') + + k = train_values.shape[-1] + if k.value is None: + raise ValueError('The dimensionality of the output values (k) must be ' + 'statically-inferrable.') # First, rename variables so that the notation (c, f, w, v, A, B, etc.) # follows https://en.wikipedia.org/wiki/Polyharmonic_spline. @@ -113,14 +122,12 @@ def _solve_interpolation(train_points, train_values, order, matrix_a = _phi(_pairwise_squared_distance_matrix(c), order) # [b, n, n] if regularization_weight > 0: - batch_identity_matrix = np.expand_dims(np.eye(n), 0) - batch_identity_matrix = constant_op.constant( - batch_identity_matrix, dtype=train_points.dtype) - + batch_identity_matrix = array_ops.expand_dims( + linalg_ops.eye(n, dtype=c.dtype), 0) matrix_a += regularization_weight * batch_identity_matrix # Append ones to the feature values for the bias term in the linear model. - ones = array_ops.ones([b, n, 1], train_points.dtype) + ones = array_ops.ones_like(c[..., :1], dtype=c.dtype) matrix_b = array_ops.concat([c, ones], 2) # [b, n, d + 1] # [b, n + d + 1, n] @@ -164,9 +171,6 @@ def _apply_interpolation(query_points, train_points, w, v, order): Polyharmonic interpolation evaluated at points defined in query_points. """ - batch_size = train_points.get_shape()[0].value - num_query_points = query_points.get_shape()[1].value - # First, compute the contribution from the rbf term. pairwise_dists = _cross_squared_distance_matrix(query_points, train_points) phi_pairwise_dists = _phi(pairwise_dists, order) @@ -177,7 +181,7 @@ def _apply_interpolation(query_points, train_points, w, v, order): # Pad query_points with ones, for the bias term in the linear model. query_points_pad = array_ops.concat([ query_points, - array_ops.ones([batch_size, num_query_points, 1], train_points.dtype) + array_ops.ones_like(query_points[..., :1], train_points.dtype) ], 2) linear_term = math_ops.matmul(query_points_pad, v) @@ -251,6 +255,9 @@ def interpolate_spline(train_points, Note the interpolation procedure is differentiable with respect to all inputs besides the order parameter. + We support dynamically-shaped inputs, where batch_size, n, and m are None + at graph construction time. However, d and k must be known. + Args: train_points: `[batch_size, n, d]` float `Tensor` of n d-dimensional locations. These do not need to be regularly-spaced. diff --git a/tensorflow/contrib/kfac/BUILD b/tensorflow/contrib/kfac/BUILD deleted file mode 100644 index b719046b37..0000000000 --- a/tensorflow/contrib/kfac/BUILD +++ /dev/null @@ -1,26 +0,0 @@ -# Description: -# Contains KfacOptimizer, an implementation of the K-FAC optimization -# algorithm in TensorFlow. -package(default_visibility = ["//visibility:public"]) - -licenses(["notice"]) # Apache 2.0 - -exports_files(["LICENSE"]) - -py_library( - name = "kfac", - srcs = ["__init__.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/kfac/python/ops:curvature_matrix_vector_products_lib", - "//tensorflow/contrib/kfac/python/ops:fisher_blocks_lib", - "//tensorflow/contrib/kfac/python/ops:fisher_estimator_lib", - "//tensorflow/contrib/kfac/python/ops:fisher_factors_lib", - "//tensorflow/contrib/kfac/python/ops:kfac_optimizer_lib", - "//tensorflow/contrib/kfac/python/ops:layer_collection_lib", - "//tensorflow/contrib/kfac/python/ops:loss_functions_lib", - "//tensorflow/contrib/kfac/python/ops:op_queue_lib", - "//tensorflow/contrib/kfac/python/ops:utils_lib", - "//tensorflow/python:util", - ], -) diff --git a/tensorflow/contrib/kfac/README.md b/tensorflow/contrib/kfac/README.md index 102626925d..42b91d0313 100644 --- a/tensorflow/contrib/kfac/README.md +++ b/tensorflow/contrib/kfac/README.md @@ -1,94 +1,3 @@ # K-FAC: Kronecker-Factored Approximate Curvature -# <font color="red", size=10><u>WARNING: </u></font> -# ==third_party/tensorflow/contrib/kfac is deprecated. This will be== -# ==removed on 15-07-2018. <!-- STY:begin_strip_and_replace -->Please import third_party/tensorflow_kfac.== -# ==<!-- STY:end_strip_and_replace Please check https://github.com/tensorflow/kfac. -->== - -**K-FAC in TensorFlow** is an implementation of [K-FAC][kfac-paper], an -approximate second-order optimization method, in TensorFlow. When applied to -feedforward and convolutional neural networks, K-FAC can converge `>3.5x` -faster in `>14x` fewer iterations than SGD with Momentum. - -[kfac-paper]: https://arxiv.org/abs/1503.05671 - -## What is K-FAC? - -K-FAC, short for "Kronecker-factored Approximate Curvature", is an approximation -to the [Natural Gradient][natural_gradient] algorithm designed specifically for -neural networks. It maintains a block-diagonal approximation to the [Fisher -Information matrix][fisher_information], whose inverse preconditions the -gradient. - -K-FAC can be used in place of SGD, Adam, and other `Optimizer` implementations. -Experimentally, K-FAC converges `>3.5x` faster than well-tuned SGD. - -Unlike most optimizers, K-FAC exploits structure in the model itself (e.g. "What -are the weights for layer i?"). As such, you must add some additional code while -constructing your model to use K-FAC. - -[natural_gradient]: http://www.mitpressjournals.org/doi/abs/10.1162/089976698300017746 -[fisher_information]: https://en.wikipedia.org/wiki/Fisher_information#Matrix_form - -## Why should I use K-FAC? - -K-FAC can take advantage of the curvature of the optimization problem, resulting -in **faster training**. For an 8-layer Autoencoder, K-FAC converges to the same -loss as SGD with Momentum in 3.8x fewer seconds and 14.7x fewer updates. See how -training loss changes as a function of number of epochs, steps, and seconds: - - - -## Is K-FAC for me? - -If you have a feedforward or convolutional model for classification that is -converging too slowly, K-FAC is for you. K-FAC can be used in your model if: - -* Your model defines a posterior distribution. -* Your model uses only fully-connected or convolutional layers (residual - connections OK). -* You are training on CPU or GPU. -* You can modify model code to register layers with K-FAC. - -## How do I use K-FAC? - -Using K-FAC requires three steps: - -1. Registering layer inputs, weights, and pre-activations with a - `LayerCollection`. -1. Minimizing the loss with a `KfacOptimizer`. -1. Keeping K-FAC's preconditioner updated. - -```python -# Build model. -w = tf.get_variable("w", ...) -b = tf.get_variable("b", ...) -logits = tf.matmul(x, w) + b -loss = tf.reduce_mean( - tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits)) - -# Register layers. -layer_collection = LayerCollection() -layer_collection.register_fully_connected((w, b), x, logits) -layer_collection.register_categorical_predictive_distribution(logits) - -# Construct training ops. -optimizer = KfacOptimizer(..., layer_collection=layer_collection) -train_op = optimizer.minimize(loss) - -# Minimize loss. -with tf.Session() as sess: - ... - sess.run([train_op, optimizer.cov_update_op, optimizer.inv_update_op]) -``` - -See [`examples/`](https://www.tensorflow.org/code/tensorflow/contrib/kfac/examples/) for runnable, end-to-end illustrations. - -## Authors - -- Alok Aggarwal -- Daniel Duckworth -- James Martens -- Matthew Johnson -- Olga Wichrowska -- Roger Grosse +## KFAC moved to third_party/tensorflow_kfac. diff --git a/tensorflow/contrib/kfac/__init__.py b/tensorflow/contrib/kfac/__init__.py deleted file mode 100644 index 1ea354e6cd..0000000000 --- a/tensorflow/contrib/kfac/__init__.py +++ /dev/null @@ -1,46 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Kronecker-factored Approximate Curvature Optimizer.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import,line-too-long -from tensorflow.contrib.kfac.python.ops import curvature_matrix_vector_products_lib as curvature_matrix_vector_products -from tensorflow.contrib.kfac.python.ops import estimator_lib as estimator -from tensorflow.contrib.kfac.python.ops import fisher_blocks_lib as fisher_blocks -from tensorflow.contrib.kfac.python.ops import fisher_factors_lib as fisher_factors -from tensorflow.contrib.kfac.python.ops import layer_collection_lib as layer_collection -from tensorflow.contrib.kfac.python.ops import loss_functions_lib as loss_functions -from tensorflow.contrib.kfac.python.ops import op_queue_lib as op_queue -from tensorflow.contrib.kfac.python.ops import optimizer_lib as optimizer -from tensorflow.contrib.kfac.python.ops import utils_lib as utils -from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long - -_allowed_symbols = [ - "curvature_matrix_vector_products", - "estimator", - "fisher_blocks", - "fisher_factors", - "layer_collection", - "loss_functions", - "op_queue", - "optimizer", - "utils", -] - -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) diff --git a/tensorflow/contrib/kfac/examples/BUILD b/tensorflow/contrib/kfac/examples/BUILD deleted file mode 100644 index 8186fa1c62..0000000000 --- a/tensorflow/contrib/kfac/examples/BUILD +++ /dev/null @@ -1,80 +0,0 @@ -package(default_visibility = [ - "//learning/brain/contrib/kfac/examples:__subpackages__", - "//tensorflow/contrib/kfac/examples:__subpackages__", -]) - -licenses(["notice"]) # Apache 2.0 - -exports_files(["LICENSE"]) - -py_binary( - name = "mlp_mnist_main", - srcs = ["mlp_mnist_main.py"], - srcs_version = "PY2AND3", - deps = [ - ":mlp", - "//tensorflow:tensorflow_py", - ], -) - -py_library( - name = "mlp", - srcs = ["mlp.py"], - srcs_version = "PY2AND3", - deps = [ - ":mnist", - "//tensorflow:tensorflow_py", - ], -) - -py_binary( - name = "convnet_mnist_single_main", - srcs = ["convnet_mnist_single_main.py"], - srcs_version = "PY2AND3", - deps = [ - ":convnet", - "//tensorflow:tensorflow_py", - ], -) - -py_binary( - name = "convnet_mnist_multi_tower_main", - srcs = ["convnet_mnist_multi_tower_main.py"], - srcs_version = "PY2AND3", - deps = [ - ":convnet", - "//tensorflow:tensorflow_py", - ], -) - -py_binary( - name = "convnet_mnist_distributed_main", - srcs = ["convnet_mnist_distributed_main.py"], - srcs_version = "PY2AND3", - deps = [ - ":convnet", - "//tensorflow:tensorflow_py", - ], -) - -py_library( - name = "convnet", - srcs = ["convnet.py"], - srcs_version = "PY2AND3", - deps = [ - ":mlp", - ":mnist", - "//tensorflow:tensorflow_py", - "//third_party/py/numpy", - ], -) - -py_library( - name = "mnist", - srcs = ["mnist.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow:tensorflow_py", - "//third_party/py/numpy", - ], -) diff --git a/tensorflow/contrib/kfac/examples/convnet.py b/tensorflow/contrib/kfac/examples/convnet.py deleted file mode 100644 index 44e01e1aeb..0000000000 --- a/tensorflow/contrib/kfac/examples/convnet.py +++ /dev/null @@ -1,667 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -r"""Train a ConvNet on MNIST using K-FAC. - -This library fits a 5-layer ConvNet on MNIST using K-FAC. The model has the -following structure, - -- Conv Layer: 5x5 kernel, 16 output channels. -- Max Pool: 3x3 kernel, stride 2. -- Conv Layer: 5x5 kernel, 16 output channels. -- Max Pool: 3x3 kernel, stride 2. -- Linear: 10 output dims. - -After 3k~6k steps, this should reach perfect accuracy on the training set. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import os - -import numpy as np -import tensorflow as tf - -from tensorflow.contrib.kfac.examples import mlp -from tensorflow.contrib.kfac.examples import mnist -from tensorflow.contrib.kfac.python.ops import optimizer as opt - - -lc = tf.contrib.kfac.layer_collection -oq = tf.contrib.kfac.op_queue -opt = tf.contrib.kfac.optimizer - -__all__ = [ - "conv_layer", - "max_pool_layer", - "linear_layer", - "build_model", - "minimize_loss_single_machine", - "distributed_grads_only_and_ops_chief_worker", - "distributed_grads_and_ops_dedicated_workers", - "train_mnist_single_machine", - "train_mnist_distributed_sync_replicas", - "train_mnist_multitower" -] - - -# Inverse update ops will be run every _INVERT_EVRY iterations. -_INVERT_EVERY = 10 - - -def conv_layer(layer_id, inputs, kernel_size, out_channels): - """Builds a convolutional layer with ReLU non-linearity. - - Args: - layer_id: int. Integer ID for this layer's variables. - inputs: Tensor of shape [num_examples, width, height, in_channels]. Each row - corresponds to a single example. - kernel_size: int. Width and height of the convolution kernel. The kernel is - assumed to be square. - out_channels: int. Number of output features per pixel. - - Returns: - preactivations: Tensor of shape [num_examples, width, height, out_channels]. - Values of the layer immediately before the activation function. - activations: Tensor of shape [num_examples, width, height, out_channels]. - Values of the layer immediately after the activation function. - params: Tuple of (kernel, bias), parameters for this layer. - """ - # TODO(b/67004004): Delete this function and rely on tf.layers exclusively. - layer = tf.layers.Conv2D( - out_channels, - kernel_size=[kernel_size, kernel_size], - kernel_initializer=tf.random_normal_initializer(stddev=0.01), - padding="SAME", - name="conv_%d" % layer_id) - preactivations = layer(inputs) - activations = tf.nn.relu(preactivations) - - # layer.weights is a list. This converts it a (hashable) tuple. - return preactivations, activations, (layer.kernel, layer.bias) - - -def max_pool_layer(layer_id, inputs, kernel_size, stride): - """Build a max-pooling layer. - - Args: - layer_id: int. Integer ID for this layer's variables. - inputs: Tensor of shape [num_examples, width, height, in_channels]. Each row - corresponds to a single example. - kernel_size: int. Width and height to pool over per input channel. The - kernel is assumed to be square. - stride: int. Step size between pooling operations. - - Returns: - Tensor of shape [num_examples, width/stride, height/stride, out_channels]. - Result of applying max pooling to 'inputs'. - """ - # TODO(b/67004004): Delete this function and rely on tf.layers exclusively. - with tf.variable_scope("pool_%d" % layer_id): - return tf.nn.max_pool( - inputs, [1, kernel_size, kernel_size, 1], [1, stride, stride, 1], - padding="SAME", - name="pool") - - -def linear_layer(layer_id, inputs, output_size): - """Builds the final linear layer for an MNIST classification problem. - - Args: - layer_id: int. Integer ID for this layer's variables. - inputs: Tensor of shape [num_examples, width, height, in_channels]. Each row - corresponds to a single example. - output_size: int. Number of output dims per example. - - Returns: - activations: Tensor of shape [num_examples, output_size]. Values of the - layer immediately after the activation function. - params: Tuple of (weights, bias), parameters for this layer. - """ - # TODO(b/67004004): Delete this function and rely on tf.layers exclusively. - pre, _, params = mlp.fc_layer(layer_id, inputs, output_size) - return pre, params - - -def build_model(examples, labels, num_labels, layer_collection): - """Builds a ConvNet classification model. - - Args: - examples: Tensor of shape [num_examples, num_features]. Represents inputs of - model. - labels: Tensor of shape [num_examples]. Contains integer IDs to be predicted - by softmax for each example. - num_labels: int. Number of distinct values 'labels' can take on. - layer_collection: LayerCollection instance. Layers will be registered here. - - Returns: - loss: 0-D Tensor representing loss to be minimized. - accuracy: 0-D Tensor representing model's accuracy. - """ - # Build a ConvNet. For each layer with parameters, we'll keep track of the - # preactivations, activations, weights, and bias. - tf.logging.info("Building model.") - pre0, act0, params0 = conv_layer( - layer_id=0, inputs=examples, kernel_size=5, out_channels=16) - act1 = max_pool_layer(layer_id=1, inputs=act0, kernel_size=3, stride=2) - pre2, act2, params2 = conv_layer( - layer_id=2, inputs=act1, kernel_size=5, out_channels=16) - act3 = max_pool_layer(layer_id=3, inputs=act2, kernel_size=3, stride=2) - flat_act3 = tf.reshape(act3, shape=[-1, int(np.prod(act3.shape[1:4]))]) - logits, params4 = linear_layer( - layer_id=4, inputs=flat_act3, output_size=num_labels) - loss = tf.reduce_mean( - tf.nn.sparse_softmax_cross_entropy_with_logits( - labels=labels, logits=logits)) - accuracy = tf.reduce_mean( - tf.cast(tf.equal(labels, tf.argmax(logits, axis=1)), dtype=tf.float32)) - - with tf.device("/cpu:0"): - tf.summary.scalar("loss", loss) - tf.summary.scalar("accuracy", accuracy) - - # Register parameters. K-FAC needs to know about the inputs, outputs, and - # parameters of each conv/fully connected layer and the logits powering the - # posterior probability over classes. - tf.logging.info("Building LayerCollection.") - layer_collection.register_conv2d(params0, (1, 1, 1, 1), "SAME", examples, - pre0) - layer_collection.register_conv2d(params2, (1, 1, 1, 1), "SAME", act1, pre2) - layer_collection.register_fully_connected(params4, flat_act3, logits) - layer_collection.register_categorical_predictive_distribution( - logits, name="logits") - - return loss, accuracy - - -def minimize_loss_single_machine(loss, - accuracy, - layer_collection, - device="/gpu:0", - session_config=None): - """Minimize loss with K-FAC on a single machine. - - A single Session is responsible for running all of K-FAC's ops. The covariance - and inverse update ops are placed on `device`. All model variables are on CPU. - - Args: - loss: 0-D Tensor. Loss to be minimized. - accuracy: 0-D Tensor. Accuracy of classifier on current minibatch. - layer_collection: LayerCollection instance describing model architecture. - Used by K-FAC to construct preconditioner. - device: string, Either '/cpu:0' or '/gpu:0'. The covariance and inverse - update ops are run on this device. - session_config: None or tf.ConfigProto. Configuration for tf.Session(). - - Returns: - final value for 'accuracy'. - """ - # Train with K-FAC. - g_step = tf.train.get_or_create_global_step() - optimizer = opt.KfacOptimizer( - learning_rate=0.0001, - cov_ema_decay=0.95, - damping=0.001, - layer_collection=layer_collection, - placement_strategy="round_robin", - cov_devices=[device], - inv_devices=[device], - momentum=0.9) - (cov_update_thunks, - inv_update_thunks) = optimizer.make_vars_and_create_op_thunks() - - def make_update_op(update_thunks): - update_ops = [thunk() for thunk in update_thunks] - return tf.group(*update_ops) - - cov_update_op = make_update_op(cov_update_thunks) - with tf.control_dependencies([cov_update_op]): - inverse_op = tf.cond( - tf.equal(tf.mod(g_step, _INVERT_EVERY), 0), - lambda: make_update_op(inv_update_thunks), tf.no_op) - with tf.control_dependencies([inverse_op]): - with tf.device(device): - train_op = optimizer.minimize(loss, global_step=g_step) - - tf.logging.info("Starting training.") - with tf.train.MonitoredTrainingSession(config=session_config) as sess: - while not sess.should_stop(): - global_step_, loss_, accuracy_, _ = sess.run( - [g_step, loss, accuracy, train_op]) - - if global_step_ % _INVERT_EVERY == 0: - tf.logging.info("global_step: %d | loss: %f | accuracy: %s", - global_step_, loss_, accuracy_) - - return accuracy_ - - -def _is_gradient_task(task_id, num_tasks): - """Returns True if this task should update the weights.""" - if num_tasks < 3: - return True - return 0 <= task_id < 0.6 * num_tasks - - -def _is_cov_update_task(task_id, num_tasks): - """Returns True if this task should update K-FAC's covariance matrices.""" - if num_tasks < 3: - return False - return 0.6 * num_tasks <= task_id < num_tasks - 1 - - -def _is_inv_update_task(task_id, num_tasks): - """Returns True if this task should update K-FAC's preconditioner.""" - if num_tasks < 3: - return False - return task_id == num_tasks - 1 - - -def _num_gradient_tasks(num_tasks): - """Number of tasks that will update weights.""" - if num_tasks < 3: - return num_tasks - return int(np.ceil(0.6 * num_tasks)) - - -def _make_distributed_train_op( - task_id, - num_worker_tasks, - num_ps_tasks, - layer_collection -): - """Creates optimizer and distributed training op. - - Constructs KFAC optimizer and wraps it in `sync_replicas` optimizer. Makes - the train op. - - Args: - task_id: int. Integer in [0, num_worker_tasks). ID for this worker. - num_worker_tasks: int. Number of workers in this distributed training setup. - num_ps_tasks: int. Number of parameter servers holding variables. If 0, - parameter servers are not used. - layer_collection: LayerCollection instance describing model architecture. - Used by K-FAC to construct preconditioner. - - Returns: - sync_optimizer: `tf.train.SyncReplicasOptimizer` instance which wraps KFAC - optimizer. - optimizer: Instance of `opt.KfacOptimizer`. - global_step: `tensor`, Global step. - """ - tf.logging.info("Task id : %d", task_id) - with tf.device(tf.train.replica_device_setter(num_ps_tasks)): - global_step = tf.train.get_or_create_global_step() - optimizer = opt.KfacOptimizer( - learning_rate=0.0001, - cov_ema_decay=0.95, - damping=0.001, - layer_collection=layer_collection, - momentum=0.9) - sync_optimizer = tf.train.SyncReplicasOptimizer( - opt=optimizer, - replicas_to_aggregate=_num_gradient_tasks(num_worker_tasks), - total_num_replicas=num_worker_tasks) - return sync_optimizer, optimizer, global_step - - -def distributed_grads_only_and_ops_chief_worker( - task_id, is_chief, num_worker_tasks, num_ps_tasks, master, checkpoint_dir, - loss, accuracy, layer_collection, invert_every=10): - """Minimize loss with a synchronous implementation of K-FAC. - - All workers perform gradient computation. Chief worker applies gradient after - averaging the gradients obtained from all the workers. All workers block - execution until the update is applied. Chief worker runs covariance and - inverse update ops. Covariance and inverse matrices are placed on parameter - servers in a round robin manner. For further details on synchronous - distributed optimization check `tf.train.SyncReplicasOptimizer`. - - Args: - task_id: int. Integer in [0, num_worker_tasks). ID for this worker. - is_chief: `boolean`, `True` if the worker is chief worker. - num_worker_tasks: int. Number of workers in this distributed training setup. - num_ps_tasks: int. Number of parameter servers holding variables. If 0, - parameter servers are not used. - master: string. IP and port of TensorFlow runtime process. Set to empty - string to run locally. - checkpoint_dir: string or None. Path to store checkpoints under. - loss: 0-D Tensor. Loss to be minimized. - accuracy: dict mapping strings to 0-D Tensors. Additional accuracy to - run with each step. - layer_collection: LayerCollection instance describing model architecture. - Used by K-FAC to construct preconditioner. - invert_every: `int`, Number of steps between update the inverse. - - Returns: - final value for 'accuracy'. - - Raises: - ValueError: if task_id >= num_worker_tasks. - """ - - sync_optimizer, optimizer, global_step = _make_distributed_train_op( - task_id, num_worker_tasks, num_ps_tasks, layer_collection) - (cov_update_thunks, - inv_update_thunks) = optimizer.make_vars_and_create_op_thunks() - - tf.logging.info("Starting training.") - hooks = [sync_optimizer.make_session_run_hook(is_chief)] - - def make_update_op(update_thunks): - update_ops = [thunk() for thunk in update_thunks] - return tf.group(*update_ops) - - if is_chief: - cov_update_op = make_update_op(cov_update_thunks) - with tf.control_dependencies([cov_update_op]): - inverse_op = tf.cond( - tf.equal(tf.mod(global_step, invert_every), 0), - lambda: make_update_op(inv_update_thunks), - tf.no_op) - with tf.control_dependencies([inverse_op]): - train_op = sync_optimizer.minimize(loss, global_step=global_step) - else: - train_op = sync_optimizer.minimize(loss, global_step=global_step) - - with tf.train.MonitoredTrainingSession( - master=master, - is_chief=is_chief, - checkpoint_dir=checkpoint_dir, - hooks=hooks, - stop_grace_period_secs=0) as sess: - while not sess.should_stop(): - global_step_, loss_, accuracy_, _ = sess.run( - [global_step, loss, accuracy, train_op]) - tf.logging.info("global_step: %d | loss: %f | accuracy: %s", global_step_, - loss_, accuracy_) - return accuracy_ - - -def distributed_grads_and_ops_dedicated_workers( - task_id, is_chief, num_worker_tasks, num_ps_tasks, master, checkpoint_dir, - loss, accuracy, layer_collection): - """Minimize loss with a synchronous implementation of K-FAC. - - Different workers are responsible for different parts of K-FAC's Ops. The - first 60% of tasks compute gradients; the next 20% accumulate covariance - statistics; the last 20% invert the matrices used to precondition gradients. - The chief worker applies the gradient . - - Args: - task_id: int. Integer in [0, num_worker_tasks). ID for this worker. - is_chief: `boolean`, `True` if the worker is chief worker. - num_worker_tasks: int. Number of workers in this distributed training setup. - num_ps_tasks: int. Number of parameter servers holding variables. If 0, - parameter servers are not used. - master: string. IP and port of TensorFlow runtime process. Set to empty - string to run locally. - checkpoint_dir: string or None. Path to store checkpoints under. - loss: 0-D Tensor. Loss to be minimized. - accuracy: dict mapping strings to 0-D Tensors. Additional accuracy to - run with each step. - layer_collection: LayerCollection instance describing model architecture. - Used by K-FAC to construct preconditioner. - - Returns: - final value for 'accuracy'. - - Raises: - ValueError: if task_id >= num_worker_tasks. - """ - sync_optimizer, optimizer, global_step = _make_distributed_train_op( - task_id, num_worker_tasks, num_ps_tasks, layer_collection) - _, cov_update_op, inv_update_ops, _, _, _ = optimizer.make_ops_and_vars() - train_op = sync_optimizer.minimize(loss, global_step=global_step) - inv_update_queue = oq.OpQueue(inv_update_ops) - - tf.logging.info("Starting training.") - is_chief = (task_id == 0) - hooks = [sync_optimizer.make_session_run_hook(is_chief)] - with tf.train.MonitoredTrainingSession( - master=master, - is_chief=is_chief, - checkpoint_dir=checkpoint_dir, - hooks=hooks, - stop_grace_period_secs=0) as sess: - while not sess.should_stop(): - # Choose which op this task is responsible for running. - if _is_gradient_task(task_id, num_worker_tasks): - learning_op = train_op - elif _is_cov_update_task(task_id, num_worker_tasks): - learning_op = cov_update_op - elif _is_inv_update_task(task_id, num_worker_tasks): - # TODO(duckworthd): Running this op before cov_update_op has been run a - # few times can result in "InvalidArgumentError: Cholesky decomposition - # was not successful." Delay running this op until cov_update_op has - # been run a few times. - learning_op = inv_update_queue.next_op(sess) - else: - raise ValueError("Which op should task %d do?" % task_id) - - global_step_, loss_, accuracy_, _ = sess.run( - [global_step, loss, accuracy, learning_op]) - tf.logging.info("global_step: %d | loss: %f | accuracy: %s", global_step_, - loss_, accuracy_) - - return accuracy_ - - -def train_mnist_single_machine(data_dir, - num_epochs, - use_fake_data=False, - device="/gpu:0"): - """Train a ConvNet on MNIST. - - Args: - data_dir: string. Directory to read MNIST examples from. - num_epochs: int. Number of passes to make over the training set. - use_fake_data: bool. If True, generate a synthetic dataset. - device: string, Either '/cpu:0' or '/gpu:0'. The covariance and inverse - update ops are run on this device. - - Returns: - accuracy of model on the final minibatch of training data. - """ - # Load a dataset. - tf.logging.info("Loading MNIST into memory.") - examples, labels = mnist.load_mnist( - data_dir, - num_epochs=num_epochs, - batch_size=128, - use_fake_data=use_fake_data, - flatten_images=False) - - # Build a ConvNet. - layer_collection = lc.LayerCollection() - loss, accuracy = build_model( - examples, labels, num_labels=10, layer_collection=layer_collection) - - # Fit model. - return minimize_loss_single_machine( - loss, accuracy, layer_collection, device=device) - - -def train_mnist_multitower(data_dir, num_epochs, num_towers, - use_fake_data=True, devices=None): - """Train a ConvNet on MNIST. - - Training data is split equally among the towers. Each tower computes loss on - its own batch of data and the loss is aggregated on the CPU. The model - variables are placed on first tower. The covariance and inverse update ops - and variables are placed on GPUs in a round robin manner. - - Args: - data_dir: string. Directory to read MNIST examples from. - num_epochs: int. Number of passes to make over the training set. - num_towers: int. Number of CPUs to split inference across. - use_fake_data: bool. If True, generate a synthetic dataset. - devices: string, Either list of CPU or GPU. The covariance and inverse - update ops are run on this device. - - Returns: - accuracy of model on the final minibatch of training data. - """ - if devices: - device_count = {"GPU": num_towers} - else: - device_count = {"CPU": num_towers} - - devices = devices or [ - "/cpu:{}".format(tower_id) for tower_id in range(num_towers) - ] - # Load a dataset. - tf.logging.info("Loading MNIST into memory.") - tower_batch_size = 128 - batch_size = tower_batch_size * num_towers - tf.logging.info( - ("Loading MNIST into memory. Using batch_size = %d = %d towers * %d " - "tower batch size.") % (batch_size, num_towers, tower_batch_size)) - examples, labels = mnist.load_mnist( - data_dir, - num_epochs=num_epochs, - batch_size=batch_size, - use_fake_data=use_fake_data, - flatten_images=False) - - # Split minibatch across towers. - examples = tf.split(examples, num_towers) - labels = tf.split(labels, num_towers) - - # Build an MLP. Each tower's layers will be added to the LayerCollection. - layer_collection = lc.LayerCollection() - tower_results = [] - for tower_id in range(num_towers): - with tf.device(devices[tower_id]): - with tf.name_scope("tower%d" % tower_id): - with tf.variable_scope(tf.get_variable_scope(), reuse=(tower_id > 0)): - tf.logging.info("Building tower %d." % tower_id) - tower_results.append( - build_model(examples[tower_id], labels[tower_id], 10, - layer_collection)) - losses, accuracies = zip(*tower_results) - - # Average across towers. - loss = tf.reduce_mean(losses) - accuracy = tf.reduce_mean(accuracies) - - # Fit model. - - session_config = tf.ConfigProto( - allow_soft_placement=False, - device_count=device_count, - ) - - g_step = tf.train.get_or_create_global_step() - optimizer = opt.KfacOptimizer( - learning_rate=0.0001, - cov_ema_decay=0.95, - damping=0.001, - layer_collection=layer_collection, - placement_strategy="round_robin", - cov_devices=devices, - inv_devices=devices, - momentum=0.9) - (cov_update_thunks, - inv_update_thunks) = optimizer.make_vars_and_create_op_thunks() - - def make_update_op(update_thunks): - update_ops = [thunk() for thunk in update_thunks] - return tf.group(*update_ops) - - cov_update_op = make_update_op(cov_update_thunks) - with tf.control_dependencies([cov_update_op]): - inverse_op = tf.cond( - tf.equal(tf.mod(g_step, _INVERT_EVERY), 0), - lambda: make_update_op(inv_update_thunks), tf.no_op) - with tf.control_dependencies([inverse_op]): - train_op = optimizer.minimize(loss, global_step=g_step) - - tf.logging.info("Starting training.") - with tf.train.MonitoredTrainingSession(config=session_config) as sess: - while not sess.should_stop(): - global_step_, loss_, accuracy_, _ = sess.run( - [g_step, loss, accuracy, train_op]) - - if global_step_ % _INVERT_EVERY == 0: - tf.logging.info("global_step: %d | loss: %f | accuracy: %s", - global_step_, loss_, accuracy_) - - -def train_mnist_distributed_sync_replicas(task_id, - is_chief, - num_worker_tasks, - num_ps_tasks, - master, - data_dir, - num_epochs, - op_strategy, - use_fake_data=False): - """Train a ConvNet on MNIST using Sync replicas optimizer. - - Args: - task_id: int. Integer in [0, num_worker_tasks). ID for this worker. - is_chief: `boolean`, `True` if the worker is chief worker. - num_worker_tasks: int. Number of workers in this distributed training setup. - num_ps_tasks: int. Number of parameter servers holding variables. - master: string. IP and port of TensorFlow runtime process. - data_dir: string. Directory to read MNIST examples from. - num_epochs: int. Number of passes to make over the training set. - op_strategy: `string`, Strategy to run the covariance and inverse - ops. If op_strategy == `chief_worker` then covariance and inverse - update ops are run on chief worker otherwise they are run on dedicated - workers. - - use_fake_data: bool. If True, generate a synthetic dataset. - - Returns: - accuracy of model on the final minibatch of training data. - - Raises: - ValueError: If `op_strategy` not in ["chief_worker", "dedicated_workers"]. - """ - # Load a dataset. - tf.logging.info("Loading MNIST into memory.") - examples, labels = mnist.load_mnist( - data_dir, - num_epochs=num_epochs, - batch_size=128, - use_fake_data=use_fake_data, - flatten_images=False) - - # Build a ConvNet. - layer_collection = lc.LayerCollection() - with tf.device(tf.train.replica_device_setter(num_ps_tasks)): - loss, accuracy = build_model( - examples, labels, num_labels=10, layer_collection=layer_collection) - - # Fit model. - checkpoint_dir = None if data_dir is None else os.path.join(data_dir, "kfac") - if op_strategy == "chief_worker": - return distributed_grads_only_and_ops_chief_worker( - task_id, is_chief, num_worker_tasks, num_ps_tasks, master, - checkpoint_dir, loss, accuracy, layer_collection) - elif op_strategy == "dedicated_workers": - return distributed_grads_and_ops_dedicated_workers( - task_id, is_chief, num_worker_tasks, num_ps_tasks, master, - checkpoint_dir, loss, accuracy, layer_collection) - else: - raise ValueError("Only supported op strategies are : {}, {}".format( - "chief_worker", "dedicated_workers")) - - -if __name__ == "__main__": - tf.app.run() diff --git a/tensorflow/contrib/kfac/examples/convnet_mnist_distributed_main.py b/tensorflow/contrib/kfac/examples/convnet_mnist_distributed_main.py deleted file mode 100644 index b4c2d4a9e9..0000000000 --- a/tensorflow/contrib/kfac/examples/convnet_mnist_distributed_main.py +++ /dev/null @@ -1,62 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -r"""Train a ConvNet on MNIST using K-FAC. - -Distributed training with sync replicas optimizer. See -`convnet.train_mnist_distributed_sync_replicas` for details. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - - -from absl import flags -import tensorflow as tf - -from tensorflow.contrib.kfac.examples import convnet - -FLAGS = flags.FLAGS -flags.DEFINE_integer("task", -1, "Task identifier") -flags.DEFINE_string("data_dir", "/tmp/mnist", "local mnist dir") -flags.DEFINE_string( - "cov_inv_op_strategy", "chief_worker", - "In dist training mode run the cov, inv ops on chief or dedicated workers." -) -flags.DEFINE_string("master", "local", "Session master.") -flags.DEFINE_integer("ps_tasks", 2, - "Number of tasks in the parameter server job.") -flags.DEFINE_integer("replicas_to_aggregate", 5, - "Number of replicas to aggregate.") -flags.DEFINE_integer("worker_replicas", 5, "Number of replicas in worker job.") -flags.DEFINE_integer("num_epochs", None, "Number of epochs.") - - -def _is_chief(): - """Determines whether a job is the chief worker.""" - if "chief_worker" in FLAGS.brain_jobs: - return FLAGS.brain_job_name == "chief_worker" - else: - return FLAGS.task == 0 - - -def main(unused_argv): - _ = unused_argv - convnet.train_mnist_distributed_sync_replicas( - FLAGS.task, _is_chief(), FLAGS.worker_replicas, FLAGS.ps_tasks, - FLAGS.master, FLAGS.data_dir, FLAGS.num_epochs, FLAGS.cov_inv_op_strategy) - -if __name__ == "__main__": - tf.app.run(main=main) diff --git a/tensorflow/contrib/kfac/examples/convnet_mnist_multi_tower_main.py b/tensorflow/contrib/kfac/examples/convnet_mnist_multi_tower_main.py deleted file mode 100644 index 4249bf8a8d..0000000000 --- a/tensorflow/contrib/kfac/examples/convnet_mnist_multi_tower_main.py +++ /dev/null @@ -1,48 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -r"""Train a ConvNet on MNIST using K-FAC. - -Multi tower training mode. See `convnet.train_mnist_multitower` for details. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - - -from absl import flags -import tensorflow as tf - -from tensorflow.contrib.kfac.examples import convnet - -FLAGS = flags.FLAGS -flags.DEFINE_string("data_dir", "/tmp/multitower_1/mnist", "local mnist dir") -flags.DEFINE_integer("num_towers", 2, - "Number of towers for multi tower training.") - - -def main(unused_argv): - _ = unused_argv - assert FLAGS.num_towers > 1 - devices = ["/gpu:{}".format(tower_id) for tower_id in range(FLAGS.num_towers)] - convnet.train_mnist_multitower( - FLAGS.data_dir, - num_epochs=200, - num_towers=FLAGS.num_towers, - devices=devices) - - -if __name__ == "__main__": - tf.app.run(main=main) diff --git a/tensorflow/contrib/kfac/examples/mlp.py b/tensorflow/contrib/kfac/examples/mlp.py deleted file mode 100644 index ea2b252a05..0000000000 --- a/tensorflow/contrib/kfac/examples/mlp.py +++ /dev/null @@ -1,354 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -r"""Train an MLP on MNIST using K-FAC. - -This library fits a 3-layer, tanh-activated MLP on MNIST using K-FAC. After -~25k steps, this should reach perfect accuracy on the training set. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import tensorflow as tf - -from tensorflow.contrib.kfac.examples import mnist - -lc = tf.contrib.kfac.layer_collection -opt = tf.contrib.kfac.optimizer - -__all__ = [ - "fc_layer", - "train_mnist", - "train_mnist_multitower", -] - - -def fc_layer(layer_id, inputs, output_size): - """Builds a fully connected layer. - - Args: - layer_id: int. Integer ID for this layer's variables. - inputs: Tensor of shape [num_examples, input_size]. Each row corresponds - to a single example. - output_size: int. Number of output dimensions after fully connected layer. - - Returns: - preactivations: Tensor of shape [num_examples, output_size]. Values of the - layer immediately before the activation function. - activations: Tensor of shape [num_examples, output_size]. Values of the - layer immediately after the activation function. - params: Tuple of (weights, bias), parameters for this layer. - """ - # TODO(b/67004004): Delete this function and rely on tf.layers exclusively. - layer = tf.layers.Dense( - output_size, - kernel_initializer=tf.random_normal_initializer(), - name="fc_%d" % layer_id) - preactivations = layer(inputs) - activations = tf.nn.tanh(preactivations) - - # layer.weights is a list. This converts it a (hashable) tuple. - return preactivations, activations, (layer.kernel, layer.bias) - - -def build_model(examples, labels, num_labels, layer_collection): - """Builds an MLP classification model. - - Args: - examples: Tensor of shape [num_examples, num_features]. Represents inputs of - model. - labels: Tensor of shape [num_examples]. Contains integer IDs to be predicted - by softmax for each example. - num_labels: int. Number of distinct values 'labels' can take on. - layer_collection: LayerCollection instance describing model architecture. - - Returns: - loss: 0-D Tensor representing loss to be minimized. - accuracy: 0-D Tensor representing model's accuracy. - """ - # Build an MLP. For each layer, we'll keep track of the preactivations, - # activations, weights, and bias. - pre0, act0, params0 = fc_layer(layer_id=0, inputs=examples, output_size=128) - pre1, act1, params1 = fc_layer(layer_id=1, inputs=act0, output_size=64) - pre2, act2, params2 = fc_layer(layer_id=2, inputs=act1, output_size=32) - logits, _, params3 = fc_layer(layer_id=3, inputs=act2, output_size=num_labels) - loss = tf.reduce_mean( - tf.nn.sparse_softmax_cross_entropy_with_logits( - labels=labels, logits=logits)) - accuracy = tf.reduce_mean( - tf.cast(tf.equal(labels, tf.argmax(logits, axis=1)), dtype=tf.float32)) - - # Register parameters. K-FAC needs to know about the inputs, outputs, and - # parameters of each layer and the logits powering the posterior probability - # over classes. - tf.logging.info("Building LayerCollection.") - layer_collection.register_fully_connected(params0, examples, pre0) - layer_collection.register_fully_connected(params1, act0, pre1) - layer_collection.register_fully_connected(params2, act1, pre2) - layer_collection.register_fully_connected(params3, act2, logits) - layer_collection.register_categorical_predictive_distribution( - logits, name="logits") - - return loss, accuracy - - -def minimize(loss, accuracy, layer_collection, num_towers, session_config=None): - """Minimize 'loss' with KfacOptimizer. - - Args: - loss: 0-D Tensor. Loss to be minimized. - accuracy: 0-D Tensor. Accuracy of classifier on current minibatch. - layer_collection: LayerCollection instance. Describes layers in model. - num_towers: int. Number of CPUs to split minibatch across. - session_config: tf.ConfigProto. Configuration for tf.Session(). - - Returns: - accuracy of classifier on final minibatch. - """ - devices = tuple("/cpu:%d" % tower_id for tower_id in range(num_towers)) - - # Train with K-FAC. We'll use a decreasing learning rate that's cut in 1/2 - # every 10k iterations. - tf.logging.info("Building KFAC Optimizer.") - global_step = tf.train.get_or_create_global_step() - optimizer = opt.KfacOptimizer( - learning_rate=tf.train.exponential_decay( - 0.00002, global_step, 10000, 0.5, staircase=True), - cov_ema_decay=0.95, - damping=0.0005, - layer_collection=layer_collection, - momentum=0.99, - placement_strategy="round_robin", - cov_devices=devices, - inv_devices=devices) - - (cov_update_thunks, - inv_update_thunks) = optimizer.make_vars_and_create_op_thunks() - - def make_update_op(update_thunks): - update_ops = [thunk() for thunk in update_thunks] - return tf.group(*update_ops) - - # TODO(b/78537047): change (some) examples to use PeriodicInvCovUpdateKfacOpt - # once that gets moved over? Could still leave more advanced examples as they - # are (e.g. train_mnist_estimator in this file) - - cov_update_op = make_update_op(cov_update_thunks) - with tf.control_dependencies([cov_update_op]): - # We update the inverses only every 20 iterations. - inverse_op = tf.cond( - tf.equal(tf.mod(global_step, 100), 0), - lambda: make_update_op(inv_update_thunks), tf.no_op) - with tf.control_dependencies([inverse_op]): - train_op = optimizer.minimize(loss, global_step=global_step) - - tf.logging.info("Starting training.") - with tf.train.MonitoredTrainingSession(config=session_config) as sess: - while not sess.should_stop(): - global_step_, loss_, accuracy_, _ = sess.run( - [global_step, loss, accuracy, train_op]) - - if global_step_ % 100 == 0: - tf.logging.info("global_step: %d | loss: %f | accuracy: %f", - global_step_, loss_, accuracy_) - - return accuracy_ - - -def train_mnist(data_dir, num_epochs, use_fake_data=False): - """Train an MLP on MNIST. - - Args: - data_dir: string. Directory to read MNIST examples from. - num_epochs: int. Number of passes to make over the training set. - use_fake_data: bool. If True, generate a synthetic dataset. - - Returns: - accuracy of model on the final minibatch of training data. - """ - # Load a dataset. - tf.logging.info("Loading MNIST into memory.") - examples, labels = mnist.load_mnist( - data_dir, - num_epochs=num_epochs, - batch_size=64, - flatten_images=True, - use_fake_data=use_fake_data) - - # Build an MLP. The model's layers will be added to the LayerCollection. - tf.logging.info("Building model.") - layer_collection = lc.LayerCollection() - loss, accuracy = build_model(examples, labels, 10, layer_collection) - - # Fit model. - minimize(loss, accuracy, layer_collection, 1) - - -def train_mnist_multitower(data_dir, - num_epochs, - num_towers, - use_fake_data=False): - """Train an MLP on MNIST, splitting the minibatch across multiple towers. - - Args: - data_dir: string. Directory to read MNIST examples from. - num_epochs: int. Number of passes to make over the training set. - num_towers: int. Number of CPUs to split minibatch across. - use_fake_data: bool. If True, generate a synthetic dataset. - - Returns: - accuracy of model on the final minibatch of training data. - """ - # Load a dataset. - tower_batch_size = 64 - batch_size = tower_batch_size * num_towers - tf.logging.info( - ("Loading MNIST into memory. Using batch_size = %d = %d towers * %d " - "tower batch size.") % (batch_size, num_towers, tower_batch_size)) - examples, labels = mnist.load_mnist( - data_dir, - num_epochs=num_epochs, - batch_size=batch_size, - flatten_images=True, - use_fake_data=use_fake_data) - - # Split minibatch across towers. - examples = tf.split(examples, num_towers) - labels = tf.split(labels, num_towers) - - # Build an MLP. Each tower's layers will be added to the LayerCollection. - layer_collection = lc.LayerCollection() - tower_results = [] - for tower_id in range(num_towers): - with tf.device("/cpu:%d" % tower_id): - with tf.name_scope("tower%d" % tower_id): - with tf.variable_scope(tf.get_variable_scope(), reuse=(tower_id > 0)): - tf.logging.info("Building tower %d." % tower_id) - tower_results.append( - build_model(examples[tower_id], labels[tower_id], 10, - layer_collection)) - losses, accuracies = zip(*tower_results) - - # Average across towers. - loss = tf.reduce_mean(losses) - accuracy = tf.reduce_mean(accuracies) - - # Fit model. - session_config = tf.ConfigProto( - allow_soft_placement=False, device_count={ - "CPU": num_towers - }) - return minimize( - loss, accuracy, layer_collection, num_towers, - session_config=session_config) - - -def train_mnist_estimator(data_dir, num_epochs, use_fake_data=False): - """Train an MLP on MNIST using tf.estimator. - - Args: - data_dir: string. Directory to read MNIST examples from. - num_epochs: int. Number of passes to make over the training set. - use_fake_data: bool. If True, generate a synthetic dataset. - - Returns: - accuracy of model on the final minibatch of training data. - """ - - # Load a dataset. - def input_fn(): - tf.logging.info("Loading MNIST into memory.") - return mnist.load_mnist( - data_dir, - num_epochs=num_epochs, - batch_size=64, - flatten_images=True, - use_fake_data=use_fake_data) - - def model_fn(features, labels, mode, params): - """Model function for MLP trained with K-FAC. - - Args: - features: Tensor of shape [batch_size, input_size]. Input features. - labels: Tensor of shape [batch_size]. Target labels for training. - mode: tf.estimator.ModeKey. Must be TRAIN. - params: ignored. - - Returns: - EstimatorSpec for training. - - Raises: - ValueError: If 'mode' is anything other than TRAIN. - """ - del params - - if mode != tf.estimator.ModeKeys.TRAIN: - raise ValueError("Only training is supposed with this API.") - - # Build a ConvNet. - layer_collection = lc.LayerCollection() - loss, accuracy = build_model( - features, labels, num_labels=10, layer_collection=layer_collection) - - # Train with K-FAC. - global_step = tf.train.get_or_create_global_step() - optimizer = opt.KfacOptimizer( - learning_rate=tf.train.exponential_decay( - 0.00002, global_step, 10000, 0.5, staircase=True), - cov_ema_decay=0.95, - damping=0.0001, - layer_collection=layer_collection, - momentum=0.99) - - (cov_update_thunks, - inv_update_thunks) = optimizer.make_vars_and_create_op_thunks() - - def make_update_op(update_thunks): - update_ops = [thunk() for thunk in update_thunks] - return tf.group(*update_ops) - - def make_batch_executed_op(update_thunks, batch_size=1): - return tf.group(*tf.contrib.kfac.utils.batch_execute( - global_step, update_thunks, batch_size=batch_size)) - - # Run cov_update_op every step. Run 1 inv_update_ops per step. - cov_update_op = make_update_op(cov_update_thunks) - with tf.control_dependencies([cov_update_op]): - # But make sure to execute all the inverse ops on the first step - inverse_op = tf.cond(tf.equal(global_step, 0), - lambda: make_update_op(inv_update_thunks), - lambda: make_batch_executed_op(inv_update_thunks)) - with tf.control_dependencies([inverse_op]): - train_op = optimizer.minimize(loss, global_step=global_step) - - # Print metrics every 5 sec. - hooks = [ - tf.train.LoggingTensorHook( - { - "loss": loss, - "accuracy": accuracy - }, every_n_secs=5), - ] - return tf.estimator.EstimatorSpec( - mode=mode, loss=loss, train_op=train_op, training_hooks=hooks) - - run_config = tf.estimator.RunConfig( - model_dir="/tmp/mnist", save_checkpoints_steps=1, keep_checkpoint_max=100) - - # Train until input_fn() is empty with Estimator. This is a prerequisite for - # TPU compatibility. - estimator = tf.estimator.Estimator(model_fn=model_fn, config=run_config) - estimator.train(input_fn=input_fn) diff --git a/tensorflow/contrib/kfac/examples/mlp_mnist_main.py b/tensorflow/contrib/kfac/examples/mlp_mnist_main.py deleted file mode 100644 index 9c34ade1d2..0000000000 --- a/tensorflow/contrib/kfac/examples/mlp_mnist_main.py +++ /dev/null @@ -1,64 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -r"""Train an MLP on MNIST using K-FAC. - -See mlp.py for details. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import argparse -import sys - -import tensorflow as tf - -from tensorflow.contrib.kfac.examples import mlp - -FLAGS = None - - -def main(argv): - _ = argv - if FLAGS.use_estimator: - if FLAGS.num_towers != 1: - raise ValueError("Only 1 device supported in tf.estimator example.") - mlp.train_mnist_estimator(FLAGS.data_dir, num_epochs=200) - elif FLAGS.num_towers > 1: - mlp.train_mnist_multitower( - FLAGS.data_dir, num_epochs=200, num_towers=FLAGS.num_towers) - else: - mlp.train_mnist(FLAGS.data_dir, num_epochs=200) - - -if __name__ == "__main__": - parser = argparse.ArgumentParser() - parser.add_argument( - "--data_dir", - type=str, - default="/tmp/mnist", - help="Directory to store dataset in.") - parser.add_argument( - "--num_towers", - type=int, - default=1, - help="Number of CPUs to split minibatch across.") - parser.add_argument( - "--use_estimator", - action="store_true", - help="Use tf.estimator API to train.") - FLAGS, unparsed = parser.parse_known_args() - tf.app.run(main=main, argv=[sys.argv[0]] + unparsed) diff --git a/tensorflow/contrib/kfac/examples/mnist.py b/tensorflow/contrib/kfac/examples/mnist.py deleted file mode 100644 index 547c4ab25d..0000000000 --- a/tensorflow/contrib/kfac/examples/mnist.py +++ /dev/null @@ -1,69 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Utilities for loading MNIST into TensorFlow.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf - -__all__ = [ - 'load_mnist', -] - - -def load_mnist(data_dir, - num_epochs, - batch_size, - flatten_images=True, - use_fake_data=False): - """Loads MNIST dataset into memory. - - Args: - data_dir: string. Directory to read MNIST examples from. - num_epochs: int. Number of passes to make over the dataset. - batch_size: int. Number of examples per minibatch. - flatten_images: bool. If True, [28, 28, 1]-shaped images are flattened into - [784]-shaped vectors. - use_fake_data: bool. If True, generate a synthetic dataset rather than - reading MNIST in. - - Returns: - examples: Tensor of shape [batch_size, 784] if 'flatten_images' is - True, else [batch_size, 28, 28, 1]. Each row is one example. - Values in [0, 1]. - labels: Tensor of shape [batch_size]. Indices of integer corresponding to - each example. Values in {0...9}. - """ - if use_fake_data: - rng = np.random.RandomState(42) - num_examples = batch_size * 4 - images = rng.rand(num_examples, 28 * 28) - if not flatten_images: - images = np.reshape(images, [num_examples, 28, 28, 1]) - labels = rng.randint(10, size=num_examples) - else: - mnist_data = tf.contrib.learn.datasets.mnist.read_data_sets( - data_dir, reshape=flatten_images) - num_examples = len(mnist_data.train.labels) - images = mnist_data.train.images - labels = mnist_data.train.labels - - dataset = tf.data.Dataset.from_tensor_slices((np.asarray( - images, dtype=np.float32), np.asarray(labels, dtype=np.int64))) - return (dataset.repeat(num_epochs).shuffle(num_examples).batch(batch_size) - .make_one_shot_iterator().get_next()) diff --git a/tensorflow/contrib/kfac/examples/tests/BUILD b/tensorflow/contrib/kfac/examples/tests/BUILD deleted file mode 100644 index ede7f183fe..0000000000 --- a/tensorflow/contrib/kfac/examples/tests/BUILD +++ /dev/null @@ -1,52 +0,0 @@ -package(default_visibility = ["//visibility:private"]) - -licenses(["notice"]) # Apache 2.0 - -exports_files(["LICENSE"]) - -load("//tensorflow:tensorflow.bzl", "py_test") - -py_test( - name = "mlp_test", - size = "large", - srcs = ["mlp_test.py"], - srcs_version = "PY2AND3", - tags = [ - "no_pip", - "notsan", - ], - deps = [ - "//tensorflow:tensorflow_py", - "//tensorflow/contrib/kfac/examples:mlp", - "//third_party/py/numpy", - ], -) - -py_test( - name = "convnet_test", - size = "large", - srcs = ["convnet_test.py"], - srcs_version = "PY2AND3", - tags = [ - "no_pip", - "notsan", - ], - deps = [ - "//tensorflow:tensorflow_py", - "//tensorflow/contrib/kfac", - "//tensorflow/contrib/kfac/examples:convnet", - "//third_party/py/numpy", - ], -) - -py_test( - name = "mnist_test", - srcs = ["mnist_test.py"], - srcs_version = "PY2AND3", - tags = ["no_pip"], - deps = [ - "//tensorflow:tensorflow_py", - "//tensorflow/contrib/kfac/examples:mnist", - "//third_party/py/numpy", - ], -) diff --git a/tensorflow/contrib/kfac/examples/tests/convnet_test.py b/tensorflow/contrib/kfac/examples/tests/convnet_test.py deleted file mode 100644 index adecda7166..0000000000 --- a/tensorflow/contrib/kfac/examples/tests/convnet_test.py +++ /dev/null @@ -1,166 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for convnet.py.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf - -from tensorflow.contrib.kfac import layer_collection as lc -from tensorflow.contrib.kfac.examples import convnet - - -class ConvNetTest(tf.test.TestCase): - - def testConvLayer(self): - with tf.Graph().as_default(): - pre, act, (w, b) = convnet.conv_layer( - layer_id=1, - inputs=tf.zeros([5, 3, 3, 2]), - kernel_size=3, - out_channels=5) - self.assertShapeEqual(np.zeros([5, 3, 3, 5]), pre) - self.assertShapeEqual(np.zeros([5, 3, 3, 5]), act) - self.assertShapeEqual(np.zeros([3, 3, 2, 5]), tf.convert_to_tensor(w)) - self.assertShapeEqual(np.zeros([5]), tf.convert_to_tensor(b)) - self.assertIsInstance(w, tf.Variable) - self.assertIsInstance(b, tf.Variable) - self.assertIn("conv_1", w.op.name) - self.assertIn("conv_1", b.op.name) - - def testMaxPoolLayer(self): - with tf.Graph().as_default(): - act = convnet.max_pool_layer( - layer_id=1, inputs=tf.zeros([5, 6, 6, 2]), kernel_size=5, stride=3) - self.assertShapeEqual(np.zeros([5, 2, 2, 2]), act) - self.assertEqual(act.op.name, "pool_1/pool") - - def testLinearLayer(self): - with tf.Graph().as_default(): - act, (w, b) = convnet.linear_layer( - layer_id=1, inputs=tf.zeros([5, 20]), output_size=5) - self.assertShapeEqual(np.zeros([5, 5]), act) - self.assertShapeEqual(np.zeros([20, 5]), tf.convert_to_tensor(w)) - self.assertShapeEqual(np.zeros([5]), tf.convert_to_tensor(b)) - self.assertIsInstance(w, tf.Variable) - self.assertIsInstance(b, tf.Variable) - self.assertIn("fc_1", w.op.name) - self.assertIn("fc_1", b.op.name) - - def testBuildModel(self): - with tf.Graph().as_default(): - x = tf.placeholder(tf.float32, [None, 6, 6, 3]) - y = tf.placeholder(tf.int64, [None]) - layer_collection = lc.LayerCollection() - loss, accuracy = convnet.build_model( - x, y, num_labels=5, layer_collection=layer_collection) - - # Ensure layers and logits were registered. - self.assertEqual(len(layer_collection.fisher_blocks), 3) - self.assertEqual(len(layer_collection.losses), 1) - - # Ensure inference doesn't crash. - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - feed_dict = { - x: np.random.randn(10, 6, 6, 3).astype(np.float32), - y: np.random.randint(5, size=10).astype(np.int64), - } - sess.run([loss, accuracy], feed_dict=feed_dict) - - def _build_toy_problem(self): - """Construct a toy linear regression problem. - - Initial loss should be, - 2.5 = 0.5 * (1^2 + 2^2) - - Returns: - loss: 0-D Tensor representing loss to be minimized. - accuracy: 0-D Tensors representing model accuracy. - layer_collection: LayerCollection instance describing model architecture. - """ - x = np.asarray([[1.], [2.]]).astype(np.float32) - y = np.asarray([1., 2.]).astype(np.float32) - x, y = (tf.data.Dataset.from_tensor_slices((x, y)) - .repeat(100).batch(2).make_one_shot_iterator().get_next()) - w = tf.get_variable("w", shape=[1, 1], initializer=tf.zeros_initializer()) - y_hat = tf.matmul(x, w) - loss = tf.reduce_mean(0.5 * tf.square(y_hat - y)) - accuracy = loss - - layer_collection = lc.LayerCollection() - layer_collection.register_fully_connected(params=w, inputs=x, outputs=y_hat) - layer_collection.register_normal_predictive_distribution(y_hat) - - return loss, accuracy, layer_collection - - def testMinimizeLossSingleMachine(self): - with tf.Graph().as_default(): - loss, accuracy, layer_collection = self._build_toy_problem() - accuracy_ = convnet.minimize_loss_single_machine( - loss, accuracy, layer_collection, device="/cpu:0") - self.assertLess(accuracy_, 2.0) - - def testMinimizeLossDistributed(self): - with tf.Graph().as_default(): - loss, accuracy, layer_collection = self._build_toy_problem() - accuracy_ = convnet.distributed_grads_only_and_ops_chief_worker( - task_id=0, - is_chief=True, - num_worker_tasks=1, - num_ps_tasks=0, - master="", - checkpoint_dir=None, - loss=loss, - accuracy=accuracy, - layer_collection=layer_collection) - self.assertLess(accuracy_, 2.0) - - def testTrainMnistSingleMachine(self): - with tf.Graph().as_default(): - # Ensure model training doesn't crash. - # - # Ideally, we should check that accuracy increases as the model converges, - # but there are too few parameters for the model to effectively memorize - # the training set the way an MLP can. - convnet.train_mnist_single_machine( - data_dir=None, num_epochs=1, use_fake_data=True, device="/cpu:0") - - def testTrainMnistMultitower(self): - with tf.Graph().as_default(): - # Ensure model training doesn't crash. - convnet.train_mnist_multitower( - data_dir=None, num_epochs=1, num_towers=2, use_fake_data=True) - - def testTrainMnistDistributed(self): - with tf.Graph().as_default(): - # Ensure model training doesn't crash. - convnet.train_mnist_distributed_sync_replicas( - task_id=0, - is_chief=True, - num_worker_tasks=1, - num_ps_tasks=0, - master="", - data_dir=None, - num_epochs=2, - op_strategy="chief_worker", - use_fake_data=True) - - -if __name__ == "__main__": - tf.test.main() diff --git a/tensorflow/contrib/kfac/examples/tests/mlp_test.py b/tensorflow/contrib/kfac/examples/tests/mlp_test.py deleted file mode 100644 index 22da6c29f1..0000000000 --- a/tensorflow/contrib/kfac/examples/tests/mlp_test.py +++ /dev/null @@ -1,63 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for mlp.py.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf - -from tensorflow.contrib.kfac.examples import mlp - - -class MlpTest(tf.test.TestCase): - - def testFcLayer(self): - with tf.Graph().as_default(): - pre, act, (w, b) = mlp.fc_layer( - layer_id=1, inputs=tf.zeros([5, 3]), output_size=10) - self.assertShapeEqual(np.zeros([5, 10]), pre) - self.assertShapeEqual(np.zeros([5, 10]), act) - self.assertShapeEqual(np.zeros([3, 10]), tf.convert_to_tensor(w)) - self.assertShapeEqual(np.zeros([10]), tf.convert_to_tensor(b)) - self.assertIsInstance(w, tf.Variable) - self.assertIsInstance(b, tf.Variable) - self.assertIn("fc_1/", w.op.name) - self.assertIn("fc_1/", b.op.name) - - def testTrainMnist(self): - with tf.Graph().as_default(): - # Ensure model training doesn't crash. - # - # Ideally, we should check that accuracy increases as the model converges, - # but that takes a non-trivial amount of compute. - mlp.train_mnist(data_dir=None, num_epochs=1, use_fake_data=True) - - def testTrainMnistMultitower(self): - with tf.Graph().as_default(): - # Ensure model training doesn't crash. - mlp.train_mnist_multitower( - data_dir=None, num_epochs=1, num_towers=2, use_fake_data=True) - - def testTrainMnistEstimator(self): - with tf.Graph().as_default(): - # Ensure model training doesn't crash. - mlp.train_mnist_estimator(data_dir=None, num_epochs=1, use_fake_data=True) - - -if __name__ == "__main__": - tf.test.main() diff --git a/tensorflow/contrib/kfac/examples/tests/mnist_test.py b/tensorflow/contrib/kfac/examples/tests/mnist_test.py deleted file mode 100644 index 92f8462357..0000000000 --- a/tensorflow/contrib/kfac/examples/tests/mnist_test.py +++ /dev/null @@ -1,72 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for mnist.py.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf - -from tensorflow.contrib.kfac.examples import mnist - - -class MnistTest(tf.test.TestCase): - - def testValues(self): - """Ensure values are in their expected range.""" - with tf.Graph().as_default(): - examples, labels = mnist.load_mnist( - data_dir=None, num_epochs=1, batch_size=64, use_fake_data=True) - - with self.test_session() as sess: - examples_, labels_ = sess.run([examples, labels]) - self.assertTrue(np.all((0 <= examples_) & (examples_ < 1))) - self.assertTrue(np.all((0 <= labels_) & (labels_ < 10))) - - def testFlattenedShapes(self): - """Ensure images are flattened into their appropriate shape.""" - with tf.Graph().as_default(): - examples, labels = mnist.load_mnist( - data_dir=None, - num_epochs=1, - batch_size=64, - flatten_images=True, - use_fake_data=True) - - with self.test_session() as sess: - examples_, labels_ = sess.run([examples, labels]) - self.assertEqual(examples_.shape, (64, 784)) - self.assertEqual(labels_.shape, (64,)) - - def testNotFlattenedShapes(self): - """Ensure non-flattened images are their appropriate shape.""" - with tf.Graph().as_default(): - examples, labels = mnist.load_mnist( - data_dir=None, - num_epochs=1, - batch_size=64, - flatten_images=False, - use_fake_data=True) - - with self.test_session() as sess: - examples_, labels_ = sess.run([examples, labels]) - self.assertEqual(examples_.shape, (64, 28, 28, 1)) - self.assertEqual(labels_.shape, (64,)) - - -if __name__ == '__main__': - tf.test.main() diff --git a/tensorflow/contrib/kfac/g3doc/autoencoder.png b/tensorflow/contrib/kfac/g3doc/autoencoder.png Binary files differdeleted file mode 100644 index 20f93c7703..0000000000 --- a/tensorflow/contrib/kfac/g3doc/autoencoder.png +++ /dev/null diff --git a/tensorflow/contrib/kfac/python/kernel_tests/BUILD b/tensorflow/contrib/kfac/python/kernel_tests/BUILD deleted file mode 100644 index 6e4a8d71ba..0000000000 --- a/tensorflow/contrib/kfac/python/kernel_tests/BUILD +++ /dev/null @@ -1,160 +0,0 @@ -package(default_visibility = ["//visibility:private"]) - -licenses(["notice"]) # Apache 2.0 - -exports_files(["LICENSE"]) - -load("//tensorflow:tensorflow.bzl", "py_test") - -py_test( - name = "estimator_test", - srcs = ["estimator_test.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/kfac/python/ops:fisher_estimator", - "//tensorflow/contrib/kfac/python/ops:layer_collection", - "//tensorflow/contrib/kfac/python/ops:utils", - "//tensorflow/python:array_ops", - "//tensorflow/python:client_testlib", - "//tensorflow/python:constant_op", - "//tensorflow/python:control_flow_ops", - "//tensorflow/python:dtypes", - "//tensorflow/python:framework_ops", - "//tensorflow/python:init_ops", - "//tensorflow/python:linalg_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:random_ops", - "//tensorflow/python:training", - "//tensorflow/python:variable_scope", - "//tensorflow/python:variables", - "//third_party/py/numpy", - ], -) - -py_test( - name = "fisher_factors_test", - srcs = ["fisher_factors_test.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/kfac/python/ops:fisher_blocks", - "//tensorflow/contrib/kfac/python/ops:fisher_factors", - "//tensorflow/python:array_ops", - "//tensorflow/python:client_testlib", - "//tensorflow/python:constant_op", - "//tensorflow/python:dtypes", - "//tensorflow/python:framework_ops", - "//tensorflow/python:gradients", - "//tensorflow/python:math_ops", - "//tensorflow/python:random_seed", - "//tensorflow/python:variables", - "//third_party/py/numpy", - ], -) - -py_test( - name = "fisher_blocks_test", - srcs = ["fisher_blocks_test.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/kfac/python/ops:fisher_blocks", - "//tensorflow/contrib/kfac/python/ops:layer_collection", - "//tensorflow/contrib/kfac/python/ops:linear_operator", - "//tensorflow/contrib/kfac/python/ops:utils", - "//tensorflow/python:array_ops", - "//tensorflow/python:client_testlib", - "//tensorflow/python:framework_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:random_ops", - "//tensorflow/python:random_seed", - "//tensorflow/python:state_ops", - "//tensorflow/python:variables", - "//third_party/py/numpy", - ], -) - -py_test( - name = "layer_collection_test", - srcs = ["layer_collection_test.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/kfac/python/ops:fisher_blocks", - "//tensorflow/contrib/kfac/python/ops:fisher_factors", - "//tensorflow/contrib/kfac/python/ops:layer_collection", - "//tensorflow/python:array_ops", - "//tensorflow/python:client_testlib", - "//tensorflow/python:dtypes", - "//tensorflow/python:framework_ops", - "//tensorflow/python:linalg_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:random_ops", - "//tensorflow/python:random_seed", - "//tensorflow/python:variable_scope", - ], -) - -py_test( - name = "optimizer_test", - srcs = ["optimizer_test.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/kfac/python/ops:fisher_factors", - "//tensorflow/contrib/kfac/python/ops:kfac_optimizer", - "//tensorflow/contrib/kfac/python/ops:layer_collection", - "//tensorflow/python:array_ops", - "//tensorflow/python:client_testlib", - "//tensorflow/python:framework_ops", - "//tensorflow/python:init_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:nn", - "//tensorflow/python:variable_scope", - "//tensorflow/python:variables", - "//third_party/py/numpy", - ], -) - -py_test( - name = "utils_test", - srcs = ["utils_test.py"], - srcs_version = "PY2AND3", - tags = ["no_windows"], # TODO: needs investigation on Windows - deps = [ - "//tensorflow/contrib/kfac/python/ops:utils", - "//tensorflow/contrib/tpu", - "//tensorflow/python:array_ops", - "//tensorflow/python:client_testlib", - "//tensorflow/python:dtypes", - "//tensorflow/python:framework_ops", - "//tensorflow/python:linalg_ops", - "//tensorflow/python:random_seed", - "//tensorflow/python:variable_scope", - "//tensorflow/python:variables", - "//third_party/py/numpy", - ], -) - -py_test( - name = "op_queue_test", - srcs = ["op_queue_test.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/kfac/python/ops:op_queue", - "//tensorflow/python:client_testlib", - "//tensorflow/python:framework_ops", - "//tensorflow/python:math_ops", - ], -) - -py_test( - name = "loss_functions_test", - srcs = ["loss_functions_test.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/kfac/python/ops:loss_functions", - "//tensorflow/python:array_ops", - "//tensorflow/python:client_testlib", - "//tensorflow/python:constant_op", - "//tensorflow/python:framework_ops", - "//tensorflow/python:random_ops", - "//third_party/py/numpy", - ], -) diff --git a/tensorflow/contrib/kfac/python/kernel_tests/estimator_test.py b/tensorflow/contrib/kfac/python/kernel_tests/estimator_test.py deleted file mode 100644 index 0e65d419a3..0000000000 --- a/tensorflow/contrib/kfac/python/kernel_tests/estimator_test.py +++ /dev/null @@ -1,310 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for tf.contrib.kfac.estimator.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np - -from tensorflow.contrib.kfac.python.ops import estimator -from tensorflow.contrib.kfac.python.ops import layer_collection as lc -from tensorflow.contrib.kfac.python.ops import utils -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import ops -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import control_flow_ops -from tensorflow.python.ops import init_ops -from tensorflow.python.ops import linalg_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import random_ops -from tensorflow.python.ops import variable_scope -from tensorflow.python.ops import variables -from tensorflow.python.platform import test -from tensorflow.python.training import training_util - -_ALL_ESTIMATION_MODES = ["gradients", "empirical", "curvature_prop", "exact"] - - -class EstimatorTest(test.TestCase): - - def setUp(self): - self._graph = ops.Graph() - with self._graph.as_default(): - self.layer_collection = lc.LayerCollection() - - self.inputs = random_ops.random_normal((2, 2), dtype=dtypes.float32) - self.weights = variable_scope.get_variable( - "w", shape=(2, 2), dtype=dtypes.float32) - self.bias = variable_scope.get_variable( - "b", initializer=init_ops.zeros_initializer(), shape=(2, 1)) - self.output = math_ops.matmul(self.inputs, self.weights) + self.bias - - # Only register the weights. - self.layer_collection.register_fully_connected( - params=(self.weights,), inputs=self.inputs, outputs=self.output) - - self.outputs = math_ops.tanh(self.output) - self.targets = array_ops.zeros_like(self.outputs) - self.layer_collection.register_categorical_predictive_distribution( - logits=self.outputs, targets=self.targets) - - def testEstimatorInitManualRegistration(self): - with self._graph.as_default(): - # We should be able to build an estimator for only the registered vars. - estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - cov_ema_decay=0.1, - damping=0.2, - layer_collection=self.layer_collection - ) - - # Check that we throw an error if we try to build an estimator for vars - # that were not manually registered. - with self.assertRaises(ValueError): - est = estimator.FisherEstimatorRoundRobin( - variables=[self.weights, self.bias], - cov_ema_decay=0.1, - damping=0.2, - layer_collection=self.layer_collection - ) - est.make_vars_and_create_op_thunks() - - # Check that we throw an error if we don't include registered variables, - # i.e. self.weights - with self.assertRaises(ValueError): - est = estimator.FisherEstimatorRoundRobin( - variables=[], - cov_ema_decay=0.1, - damping=0.2, - layer_collection=self.layer_collection) - est.make_vars_and_create_op_thunks() - - @test.mock.patch.object(utils.SubGraph, "variable_uses", return_value=42) - def testVariableWrongNumberOfUses(self, mock_uses): - with self.assertRaises(ValueError): - est = estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - cov_ema_decay=0.1, - damping=0.2, - layer_collection=self.layer_collection) - est.make_vars_and_create_op_thunks() - - def testInvalidEstimationMode(self): - with self.assertRaises(ValueError): - est = estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - cov_ema_decay=0.1, - damping=0.2, - layer_collection=self.layer_collection, - estimation_mode="not_a_real_mode") - est.make_vars_and_create_op_thunks() - - def testGradientsModeBuild(self): - with self._graph.as_default(): - est = estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - cov_ema_decay=0.1, - damping=0.2, - layer_collection=self.layer_collection, - estimation_mode="gradients") - est.make_vars_and_create_op_thunks() - - def testEmpiricalModeBuild(self): - with self._graph.as_default(): - est = estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - cov_ema_decay=0.1, - damping=0.2, - layer_collection=self.layer_collection, - estimation_mode="empirical") - est.make_vars_and_create_op_thunks() - - def testCurvaturePropModeBuild(self): - with self._graph.as_default(): - est = estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - cov_ema_decay=0.1, - damping=0.2, - layer_collection=self.layer_collection, - estimation_mode="curvature_prop") - est.make_vars_and_create_op_thunks() - - def testExactModeBuild(self): - with self._graph.as_default(): - est = estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - cov_ema_decay=0.1, - damping=0.2, - layer_collection=self.layer_collection, - estimation_mode="exact") - est.make_vars_and_create_op_thunks() - - def test_cov_update_thunks(self): - """Ensures covariance update ops run once per global_step.""" - with self._graph.as_default(), self.test_session() as sess: - fisher_estimator = estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - layer_collection=self.layer_collection, - damping=0.2, - cov_ema_decay=0.0) - - # Construct an op that executes one covariance update per step. - global_step = training_util.get_or_create_global_step() - (cov_variable_thunks, cov_update_op_thunks, _, - _) = fisher_estimator.create_ops_and_vars_thunks() - for thunk in cov_variable_thunks: - thunk() - cov_matrices = [ - fisher_factor.get_cov() - for fisher_factor in self.layer_collection.get_factors() - ] - cov_update_op = control_flow_ops.case( - [(math_ops.equal(global_step, i), thunk) - for i, thunk in enumerate(cov_update_op_thunks)]) - increment_global_step = global_step.assign_add(1) - - sess.run(variables.global_variables_initializer()) - initial_cov_values = sess.run(cov_matrices) - - # Ensure there's one update per covariance matrix. - self.assertEqual(len(cov_matrices), len(cov_update_op_thunks)) - - # Test is no-op if only 1 covariance matrix. - assert len(cov_matrices) > 1 - - for i in range(len(cov_matrices)): - # Compare new and old covariance values - new_cov_values = sess.run(cov_matrices) - is_cov_equal = [ - np.allclose(initial_cov_value, new_cov_value) - for (initial_cov_value, - new_cov_value) in zip(initial_cov_values, new_cov_values) - ] - num_cov_equal = sum(is_cov_equal) - - # Ensure exactly one covariance matrix changes per step. - self.assertEqual(num_cov_equal, len(cov_matrices) - i) - - # Run all covariance update ops. - sess.run(cov_update_op) - sess.run(increment_global_step) - - def test_round_robin_placement(self): - """Check if the ops and variables are placed on devices correctly.""" - with self._graph.as_default(): - fisher_estimator = estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - layer_collection=self.layer_collection, - damping=0.2, - cov_ema_decay=0.0, - cov_devices=["/cpu:{}".format(i) for i in range(2)], - inv_devices=["/cpu:{}".format(i) for i in range(2)]) - - # Construct an op that executes one covariance update per step. - (cov_update_thunks, - inv_update_thunks) = fisher_estimator.make_vars_and_create_op_thunks( - scope="test") - cov_update_ops = tuple(thunk() for thunk in cov_update_thunks) - inv_update_ops = tuple(thunk() for thunk in inv_update_thunks) - self.assertEqual(cov_update_ops[0].device, "/device:CPU:0") - self.assertEqual(cov_update_ops[1].device, "/device:CPU:1") - self.assertEqual(inv_update_ops[0].device, "/device:CPU:0") - self.assertEqual(inv_update_ops[1].device, "/device:CPU:1") - cov_matrices = [ - fisher_factor.get_cov() - for fisher_factor in self.layer_collection.get_factors() - ] - inv_matrices = [ - matrix - for fisher_factor in self.layer_collection.get_factors() - for matrix in fisher_factor._matpower_by_exp_and_damping.values() - ] - self.assertEqual(cov_matrices[0].device, "/device:CPU:0") - self.assertEqual(cov_matrices[1].device, "/device:CPU:1") - # Inverse matrices need to be explicitly placed. - self.assertEqual(inv_matrices[0].device, "") - self.assertEqual(inv_matrices[1].device, "") - - def test_inv_update_thunks(self): - """Ensures inverse update ops run once per global_step.""" - with self._graph.as_default(), self.test_session() as sess: - fisher_estimator = estimator.FisherEstimatorRoundRobin( - variables=[self.weights], - layer_collection=self.layer_collection, - damping=0.2, - cov_ema_decay=0.0) - - # Construct op that updates one inverse per global step. - global_step = training_util.get_or_create_global_step() - (cov_variable_thunks, _, inv_variable_thunks, - inv_update_op_thunks) = fisher_estimator.create_ops_and_vars_thunks() - for thunk in cov_variable_thunks: - thunk() - for thunk in inv_variable_thunks: - thunk() - inv_matrices = [ - matrix - for fisher_factor in self.layer_collection.get_factors() - for matrix in fisher_factor._matpower_by_exp_and_damping.values() - ] - inv_update_op = control_flow_ops.case( - [(math_ops.equal(global_step, i), thunk) - for i, thunk in enumerate(inv_update_op_thunks)]) - increment_global_step = global_step.assign_add(1) - - sess.run(variables.global_variables_initializer()) - initial_inv_values = sess.run(inv_matrices) - - # Ensure there's one update per inverse matrix. This is true as long as - # there's no fan-in/fan-out or parameter re-use. - self.assertEqual(len(inv_matrices), len(inv_update_op_thunks)) - - # Test is no-op if only 1 invariance matrix. - assert len(inv_matrices) > 1 - - # Assign each covariance matrix a value other than the identity. This - # ensures that the inverse matrices are updated to something different as - # well. - cov_matrices = [ - fisher_factor.get_cov() - for fisher_factor in self.layer_collection.get_factors() - ] - sess.run([ - cov_matrix.assign(2 * linalg_ops.eye(int(cov_matrix.shape[0]))) - for cov_matrix in cov_matrices - ]) - - for i in range(len(inv_matrices)): - # Compare new and old inverse values - new_inv_values = sess.run(inv_matrices) - is_inv_equal = [ - np.allclose(initial_inv_value, new_inv_value) - for (initial_inv_value, - new_inv_value) in zip(initial_inv_values, new_inv_values) - ] - num_inv_equal = sum(is_inv_equal) - - # Ensure exactly one inverse matrix changes per step. - self.assertEqual(num_inv_equal, len(inv_matrices) - i) - - # Run all inverse update ops. - sess.run(inv_update_op) - sess.run(increment_global_step) - - -if __name__ == "__main__": - test.main() diff --git a/tensorflow/contrib/kfac/python/kernel_tests/fisher_blocks_test.py b/tensorflow/contrib/kfac/python/kernel_tests/fisher_blocks_test.py deleted file mode 100644 index 86ec7a095a..0000000000 --- a/tensorflow/contrib/kfac/python/kernel_tests/fisher_blocks_test.py +++ /dev/null @@ -1,1018 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for tf.contrib.kfac.fisher_blocks.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np - -from tensorflow.contrib.kfac.python.ops import fisher_blocks as fb -from tensorflow.contrib.kfac.python.ops import fisher_factors as ff -from tensorflow.contrib.kfac.python.ops import layer_collection as lc -from tensorflow.contrib.kfac.python.ops import linear_operator as lo -from tensorflow.contrib.kfac.python.ops import utils -from tensorflow.python.framework import ops -from tensorflow.python.framework import random_seed -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import linalg_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import random_ops -from tensorflow.python.ops import state_ops -from tensorflow.python.ops import variables as tf_variables -from tensorflow.python.platform import test - - -# We need to set these constants since the numerical values used in the tests -# were chosen when these used to be the defaults. -ff.set_global_constants(init_covariances_at_zero=False, - zero_debias=False, - init_inverses_at_zero=False) - -# TODO(b/78538100): As far as I can tell, all the tests that say "Make sure our -# inverse is something other than the identity" are actually broken. They never -# run the covariance update ops and so the inverse actually is the identity -# (possible plus the damping term, which would still make it a multiple of the -# identity). - - -def _make_psd(dim): - """Constructs a PSD matrix of the given dimension.""" - mat = np.ones((dim, dim), dtype=np.float32) - mat[np.arange(dim), np.arange(dim)] = 2. + np.arange(dim) - return array_ops.constant(mat) - - -class UtilsTest(test.TestCase): - - def testComputePiTracenorm(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - diag = ops.convert_to_tensor([1., 2., 0., 1.]) - left_factor = lo.LinearOperatorDiag(diag) - right_factor = lo.LinearOperatorFullMatrix(array_ops.ones([2, 2])) - - # pi is the sqrt of the left trace norm divided by the right trace norm - pi = fb.compute_pi_tracenorm(left_factor, right_factor) - - pi_val = sess.run(pi) - self.assertEqual(1., pi_val) - - -class FullFBTest(test.TestCase): - - def testFullFBInitSingleTensor(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.FullFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - - self.assertAllEqual(params, block.tensors_to_compute_grads()) - - def testFullFBInitTensorTuple(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.FullFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - - self.assertAllEqual(params, block.tensors_to_compute_grads()) - - def testInstantiateFactors(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.FullFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - - grads = (params[0]**2, math_ops.sqrt(params[1])) - block.instantiate_factors(grads, 0.5) - - def testMultiplyInverseTuple(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.FullFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - grads = (params[0]**2, math_ops.sqrt(params[1])) - block.instantiate_factors((grads,), 0.5) - block._factor.instantiate_cov_variables() - block.register_inverse() - block._factor.instantiate_inv_variables() - - # Make sure our inverse is something other than the identity. - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._factor.make_inverse_update_ops()) - - vector = array_ops.ones(3,) * 2 - output = block.multiply_inverse(vector) - - self.assertAllClose(sess.run(vector * 2 / 3.), sess.run(output)) - - def testMultiplyInverseNotTuple(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = array_ops.constant([[1.], [2.]]) - block = fb.FullFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - grads = params**2 - block.instantiate_factors((grads,), 0.5) - block._factor.instantiate_cov_variables() - block.register_inverse() - block._factor.instantiate_inv_variables() - - # Make sure our inverse is something other than the identity. - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._factor.make_inverse_update_ops()) - - vector = array_ops.ones(2,) * 2 - output = block.multiply_inverse(vector) - - self.assertAllClose(sess.run(vector * 2 / 3.), sess.run(output)) - - def testMultiplyInverseAgainstExplicit(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.FullFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - grads = (array_ops.constant([2., 3.]), array_ops.constant(4.)) - damping = 0.5 - block.instantiate_factors((grads,), damping) - block._factor.instantiate_cov_variables() - block.register_inverse() - block._factor.instantiate_inv_variables() - - # Make sure our inverse is something other than the identity. - sess.run(state_ops.assign(block._factor._cov, _make_psd(3))) - sess.run(block._factor.make_inverse_update_ops()) - - v_flat = np.array([4., 5., 6.], dtype=np.float32) - vector = utils.column_to_tensors(params, array_ops.constant(v_flat)) - output = block.multiply_inverse(vector) - output_flat = sess.run(utils.tensors_to_column(output)).ravel() - - full = sess.run(block.full_fisher_block()) - explicit = np.dot(np.linalg.inv(full + damping * np.eye(3)), v_flat) - - self.assertAllClose(output_flat, explicit) - - -class NaiveDiagonalFBTest(test.TestCase): - - def testNaiveDiagonalFBInitSingleTensor(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.NaiveDiagonalFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - - self.assertAllEqual(params, block.tensors_to_compute_grads()) - - def testNaiveDiagonalFBInitTensorTuple(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.NaiveDiagonalFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - - self.assertAllEqual(params, block.tensors_to_compute_grads()) - - def testInstantiateFactors(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.NaiveDiagonalFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - - grads = (params[0]**2, math_ops.sqrt(params[1])) - block.instantiate_factors(grads, 0.5) - - def testMultiplyInverseTuple(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.NaiveDiagonalFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - grads = (params[0]**2, math_ops.sqrt(params[1])) - block.instantiate_factors((grads,), 0.5) - block._factor.instantiate_cov_variables() - - # Make sure our inverse is something other than the identity. - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._factor.make_inverse_update_ops()) - - vector = array_ops.ones(3,) * 2 - output = block.multiply_inverse(vector) - - self.assertAllClose(sess.run(vector * 2 / 3.), sess.run(output)) - - def testMultiplyInverseNotTuple(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = array_ops.constant([[1.], [2.]]) - block = fb.NaiveDiagonalFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - grads = params**2 - block.instantiate_factors((grads,), 0.5) - block._factor.instantiate_cov_variables() - - # Make sure our inverse is something other than the identity. - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._factor.make_inverse_update_ops()) - vector = array_ops.ones(2,) * 2 - output = block.multiply_inverse(vector) - - self.assertAllClose(sess.run(vector * 2 / 3.), sess.run(output)) - - def testMultiplyInverseAgainstExplicit(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = (array_ops.constant([1., 2.]), array_ops.constant(3.)) - block = fb.NaiveDiagonalFB(lc.LayerCollection(), params) - block.register_additional_tower(32) - grads = (params[0]**2, math_ops.sqrt(params[1])) - damping = 0.5 - block.instantiate_factors((grads,), damping) - block._factor.instantiate_cov_variables() - - cov = array_ops.reshape(array_ops.constant([2., 3., 4.]), [-1, 1]) - sess.run(state_ops.assign(block._factor._cov, cov)) - sess.run(block._factor.make_inverse_update_ops()) - - v_flat = np.array([4., 5., 6.], dtype=np.float32) - vector = utils.column_to_tensors(params, array_ops.constant(v_flat)) - output = block.multiply_inverse(vector) - output_flat = sess.run(utils.tensors_to_column(output)).ravel() - - full = sess.run(block.full_fisher_block()) - explicit = np.dot(np.linalg.inv(full + damping * np.eye(3)), v_flat) - self.assertAllClose(output_flat, explicit) - - -class FullyConnectedDiagonalFBTest(test.TestCase): - - def setUp(self): - super(FullyConnectedDiagonalFBTest, self).setUp() - - self.batch_size = 4 - self.input_size = 6 - self.output_size = 3 - - self.inputs = np.random.randn(self.batch_size, self.input_size).astype( - np.float32) - self.outputs = np.zeros([self.batch_size, self.output_size]).astype( - np.float32) - self.output_grads = np.random.randn(self.batch_size, - self.output_size).astype(np.float32) - self.w = np.random.randn(self.input_size, self.output_size).astype( - np.float32) - self.b = np.random.randn(self.output_size).astype(np.float32) - - def fisherApprox(self, has_bias=False): - """Fisher approximation using default inputs.""" - if has_bias: - inputs = np.concatenate( - [self.inputs, np.ones([self.batch_size, 1])], axis=1) - else: - inputs = self.inputs - return self.buildDiagonalFisherApproximation(inputs, self.output_grads) - - def buildDiagonalFisherApproximation(self, inputs, output_grads): - """Builds explicit diagonal Fisher approximation. - - Fisher's diagonal is (d loss / d w)'s elements squared for - d/dw = E[outer(input, output_grad)] - - where the expectation is taken over examples. - - Args: - inputs: np.array of shape [batch_size, input_size]. - output_grads: np.array of shape [batch_size, output_size]. - - Returns: - Diagonal np.array of shape [num_params, num_params] for num_params = - input_size * output_size. - """ - batch_size = inputs.shape[0] - assert output_grads.shape[0] == batch_size - input_size = inputs.shape[1] - output_size = output_grads.shape[1] - fisher_diag = np.zeros((input_size, output_size)) - for i in range(batch_size): - fisher_diag += np.square(np.outer(inputs[i], output_grads[i])) - return np.diag(fisher_diag.flatten()) / batch_size - - def testMultiply(self): - result, _ = self.runFisherBlockOps(self.w, [self.inputs], [self.outputs], - [self.output_grads]) - - # Construct Fisher-vector product. - expected_result = self.fisherApprox().dot(self.w.flatten()) - expected_result = expected_result.reshape( - [self.input_size, self.output_size]) - - self.assertAllClose(expected_result, result) - - def testMultiplyInverse(self): - _, result = self.runFisherBlockOps(self.w, [self.inputs], [self.outputs], - [self.output_grads]) - - # Construct inverse Fisher-vector product. - expected_result = np.linalg.inv(self.fisherApprox()).dot(self.w.flatten()) - expected_result = expected_result.reshape( - [self.input_size, self.output_size]) - - self.assertAllClose(expected_result, result) - - def testRegisterAdditionalTower(self): - """Ensure 1 big tower and 2 small towers are equivalent.""" - multiply_result_big, multiply_inverse_result_big = self.runFisherBlockOps( - self.w, [self.inputs], [self.outputs], [self.output_grads]) - multiply_result_small, multiply_inverse_result_small = ( - self.runFisherBlockOps(self.w, np.split(self.inputs, 2), - np.split(self.outputs, 2), - np.split(self.output_grads, 2))) - - self.assertAllClose(multiply_result_big, multiply_result_small) - self.assertAllClose(multiply_inverse_result_big, - multiply_inverse_result_small) - - def testMultiplyHasBias(self): - result, _ = self.runFisherBlockOps((self.w, self.b), [self.inputs], - [self.outputs], [self.output_grads]) - expected_result = self.fisherApprox(True).dot( - np.concatenate([self.w.flatten(), self.b.flatten()])) - expected_result = expected_result.reshape( - [self.input_size + 1, self.output_size]) - expected_result = (expected_result[:-1], expected_result[-1]) - - self.assertEqual(len(result), 2) - self.assertAllClose(expected_result[0], result[0]) - self.assertAllClose(expected_result[1], result[1]) - - def runFisherBlockOps(self, params, inputs, outputs, output_grads): - """Run Ops guaranteed by FisherBlock interface. - - Args: - params: Tensor or 2-tuple of Tensors. Represents weights or weights and - bias of this layer. - inputs: list of Tensors of shape [batch_size, input_size]. Inputs to - layer. - outputs: list of Tensors of shape [batch_size, output_size]. - Preactivations produced by layer. - output_grads: list of Tensors of shape [batch_size, output_size]. - Gradient of loss with respect to 'outputs'. - - Returns: - multiply_result: Result of FisherBlock.multiply(params) - multiply_inverse_result: Result of FisherBlock.multiply_inverse(params) - """ - with ops.Graph().as_default(), self.test_session() as sess: - inputs = as_tensors(inputs) - outputs = as_tensors(outputs) - output_grads = as_tensors(output_grads) - params = as_tensors(params) - - block = fb.FullyConnectedDiagonalFB( - lc.LayerCollection(), has_bias=isinstance(params, (tuple, list))) - for (i, o) in zip(inputs, outputs): - block.register_additional_tower(i, o) - - block.instantiate_factors((output_grads,), damping=0.0) - block._factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._factor.make_covariance_update_op(0.0)) - multiply_result = sess.run(block.multiply(params)) - multiply_inverse_result = sess.run(block.multiply_inverse(params)) - - return multiply_result, multiply_inverse_result - - -class EmbeddingKFACFBTest(test.TestCase): - - def testInstantiateFactors(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - - # Create a Fisher Block. - vocab_size = 5 - block = fb.EmbeddingKFACFB(lc.LayerCollection(), vocab_size) - - # Add some examples. - inputs = array_ops.constant([[0, 1], [1, 2], [2, 3]]) - outputs = array_ops.constant([[0.], [1.], [2.]]) - block.register_additional_tower(inputs, outputs) - - # Instantiate factor's variables. Ensure it doesn't fail. - grads = outputs**2. - damping = array_ops.constant(0.) - block.instantiate_factors(((grads,),), damping) - - def testMultiplyInverse(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - - # Create a Fisher Block. - vocab_size = 5 - block = fb.EmbeddingKFACFB(lc.LayerCollection(), vocab_size) - - # Add some examples. - inputs = array_ops.constant([[0, 1], [1, 2], [2, 3]]) - outputs = array_ops.constant([[0.], [1.], [2.]]) - block.register_additional_tower(inputs, outputs) - - # Instantiate factor's variables. Ensure it doesn't fail. - grads = outputs**2. - damping = array_ops.constant(0.) - block.instantiate_factors(((grads,),), damping) - block._input_factor.instantiate_cov_variables() - block._output_factor.instantiate_cov_variables() - block.register_inverse() - block._input_factor.instantiate_inv_variables() - block._output_factor.instantiate_inv_variables() - - # Create a sparse update. - indices = array_ops.constant([1, 3, 4]) - values = array_ops.constant([[1.], [1.], [1.]]) - sparse_vector = ops.IndexedSlices( - values, indices, dense_shape=[vocab_size, 1]) - dense_vector = array_ops.reshape([0., 1., 0., 1., 1.], [vocab_size, 1]) - - # Compare Fisher-vector product against explicit result. - result = block.multiply_inverse(sparse_vector) - expected_result = linalg_ops.matrix_solve(block.full_fisher_block(), - dense_vector) - - sess.run(tf_variables.global_variables_initializer()) - self.assertAlmostEqual( - sess.run(expected_result[1]), sess.run(result.values[0])) - self.assertAlmostEqual( - sess.run(expected_result[3]), sess.run(result.values[1])) - self.assertAlmostEqual( - sess.run(expected_result[4]), sess.run(result.values[2])) - - -class FullyConnectedKFACBasicFBTest(test.TestCase): - - def testFullyConnectedKFACBasicFBInit(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - inputs = array_ops.constant([1., 2.]) - outputs = array_ops.constant([3., 4.]) - block = fb.FullyConnectedKFACBasicFB(lc.LayerCollection()) - block.register_additional_tower(inputs, outputs) - - self.assertAllEqual([outputs], block.tensors_to_compute_grads()) - - def testInstantiateFactorsHasBias(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - inputs = array_ops.constant([[1., 2.], [3., 4.]]) - outputs = array_ops.constant([[3., 4.], [5., 6.]]) - block = fb.FullyConnectedKFACBasicFB(lc.LayerCollection(), has_bias=True) - block.register_additional_tower(inputs, outputs) - - grads = outputs**2 - block.instantiate_factors(((grads,),), 0.5) - - def testInstantiateFactorsNoBias(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - inputs = array_ops.constant([[1., 2.], [3., 4.]]) - outputs = array_ops.constant([[3., 4.], [5., 6.]]) - block = fb.FullyConnectedKFACBasicFB(lc.LayerCollection(), has_bias=False) - block.register_additional_tower(inputs, outputs) - - grads = outputs**2 - block.instantiate_factors(((grads,),), 0.5) - - def testMultiplyInverseTuple(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - inputs = array_ops.constant([[1., 2., 3.], [3., 4., 5.], [5., 6., 7.]]) - outputs = array_ops.constant([[3., 4.], [5., 6.]]) - block = fb.FullyConnectedKFACBasicFB(lc.LayerCollection(), has_bias=False) - block.register_additional_tower(inputs, outputs) - grads = outputs**2 - block.instantiate_factors(((grads,),), 0.5) - - block._input_factor.instantiate_cov_variables() - block._output_factor.instantiate_cov_variables() - block.register_inverse() - block._input_factor.instantiate_inv_variables() - block._output_factor.instantiate_inv_variables() - - # Make sure our inverse is something other than the identity. - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._input_factor.make_inverse_update_ops()) - sess.run(block._output_factor.make_inverse_update_ops()) - - vector = ( - np.arange(2, 6).reshape(2, 2).astype(np.float32), # - np.arange(1, 3).reshape(2, 1).astype(np.float32)) - output = block.multiply_inverse((array_ops.constant(vector[0]), - array_ops.constant(vector[1]))) - - output = sess.run(output) - self.assertAllClose([[0.686291, 1.029437], [1.372583, 1.715729]], - output[0]) - self.assertAllClose([0.343146, 0.686291], output[1]) - - def testMultiplyInverseNotTuple(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - inputs = array_ops.constant([[1., 2.], [3., 4.]]) - outputs = array_ops.constant([[3., 4.], [5., 6.]]) - block = fb.FullyConnectedKFACBasicFB(lc.LayerCollection(), has_bias=False) - block.register_additional_tower(inputs, outputs) - grads = outputs**2 - block.instantiate_factors(((grads,),), 0.5) - block._input_factor.instantiate_cov_variables() - block._output_factor.instantiate_cov_variables() - block.register_inverse() - block._input_factor.instantiate_inv_variables() - block._output_factor.instantiate_inv_variables() - - # Make sure our inverse is something other than the identity. - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._input_factor.make_inverse_update_ops()) - sess.run(block._output_factor.make_inverse_update_ops()) - - vector = np.arange(2, 6).reshape(2, 2).astype(np.float32) - output = block.multiply_inverse(array_ops.constant(vector)) - - self.assertAllClose([[0.686291, 1.029437], [1.372583, 1.715729]], - sess.run(output)) - - def testMultiplyInverseAgainstExplicit(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - input_dim, output_dim = 3, 2 - inputs = array_ops.zeros([32, input_dim]) - outputs = array_ops.zeros([32, output_dim]) - params = array_ops.zeros([input_dim, output_dim]) - block = fb.FullyConnectedKFACBasicFB(lc.LayerCollection(), has_bias=False) - block.register_additional_tower(inputs, outputs) - grads = outputs**2 - damping = 0. # This test is only valid without damping. - block.instantiate_factors(((grads,),), damping) - block._input_factor.instantiate_cov_variables() - block._output_factor.instantiate_cov_variables() - - sess.run(state_ops.assign(block._input_factor._cov, _make_psd(3))) - sess.run(state_ops.assign(block._output_factor._cov, _make_psd(2))) - - block.register_inverse() - block._input_factor.instantiate_inv_variables() - block._output_factor.instantiate_inv_variables() - - sess.run(block._input_factor.make_inverse_update_ops()) - sess.run(block._output_factor.make_inverse_update_ops()) - - v_flat = np.arange(6, dtype=np.float32) - vector = utils.column_to_tensors(params, array_ops.constant(v_flat)) - output = block.multiply_inverse(vector) - output_flat = sess.run(utils.tensors_to_column(output)).ravel() - - full = sess.run(block.full_fisher_block()) - explicit = np.dot(np.linalg.inv(full + damping * np.eye(6)), v_flat) - - self.assertAllClose(output_flat, explicit) - - -class ConvDiagonalFBTest(test.TestCase): - - def setUp(self): - super(ConvDiagonalFBTest, self).setUp() - - self.batch_size = 2 - self.height = 8 - self.width = 4 - self.input_channels = 6 - self.output_channels = 3 - self.kernel_size = 1 - - self.inputs = np.random.randn(self.batch_size, self.height, self.width, - self.input_channels).astype(np.float32) - self.outputs = np.zeros( - [self.batch_size, self.height, self.width, - self.output_channels]).astype(np.float32) - self.output_grads = np.random.randn( - self.batch_size, self.height, self.width, self.output_channels).astype( - np.float32) - self.w = np.random.randn(self.kernel_size, self.kernel_size, - self.input_channels, self.output_channels).astype( - np.float32) - self.b = np.random.randn(self.output_channels).astype(np.float32) - - def fisherApprox(self, has_bias=False): - """Fisher approximation using default inputs.""" - if has_bias: - inputs = np.concatenate( - [self.inputs, - np.ones([self.batch_size, self.height, self.width, 1])], - axis=-1) - else: - inputs = self.inputs - return self.buildDiagonalFisherApproximation(inputs, self.output_grads, - self.kernel_size) - - def buildDiagonalFisherApproximation(self, inputs, output_grads, kernel_size): - r"""Builds explicit diagonal Fisher approximation. - - Fisher's diagonal is (d loss / d w)'s elements squared for - d/dw = E[\sum_{loc} outer(input_{loc}, output_grad_{loc})] - - where the expectation is taken over examples and the sum over (x, y) - locations upon which the convolution is applied. - - Args: - inputs: np.array of shape [batch_size, height, width, input_channels]. - output_grads: np.array of shape [batch_size, height, width, - output_channels]. - kernel_size: int. height and width of kernel. - - Returns: - Diagonal np.array of shape [num_params, num_params] for num_params = - kernel_size^2 * input_channels * output_channels. - """ - batch_size, height, width, input_channels = inputs.shape - assert output_grads.shape[0] == batch_size - assert output_grads.shape[1] == height - assert output_grads.shape[2] == width - output_channels = output_grads.shape[3] - - # If kernel_size == 1, then we don't need to worry about capturing context - # around the pixel upon which a convolution is applied. This makes testing - # easier. - assert kernel_size == 1, "kernel_size != 1 isn't supported." - num_locations = height * width - inputs = np.reshape(inputs, [batch_size, num_locations, input_channels]) - output_grads = np.reshape(output_grads, - [batch_size, num_locations, output_channels]) - - fisher_diag = np.zeros((input_channels, output_channels)) - for i in range(batch_size): - # Each example's approximation is a square(sum-of-outer-products). - example_fisher_diag = np.zeros((input_channels, output_channels)) - for j in range(num_locations): - example_fisher_diag += np.outer(inputs[i, j], output_grads[i, j]) - fisher_diag += np.square(example_fisher_diag) - - # Normalize by batch_size (not num_locations). - return np.diag(fisher_diag.flatten()) / batch_size - - def testMultiply(self): - result, _ = self.runFisherBlockOps(self.w, [self.inputs], [self.outputs], - [self.output_grads]) - - # Construct Fisher-vector product. - expected_result = self.fisherApprox().dot(self.w.flatten()) - expected_result = expected_result.reshape([ - self.kernel_size, self.kernel_size, self.input_channels, - self.output_channels - ]) - - self.assertAllClose(expected_result, result) - - def testMultiplyInverse(self): - _, result = self.runFisherBlockOps(self.w, [self.inputs], [self.outputs], - [self.output_grads]) - - # Construct inverse Fisher-vector product. - expected_result = np.linalg.inv(self.fisherApprox()).dot(self.w.flatten()) - expected_result = expected_result.reshape([ - self.kernel_size, self.kernel_size, self.input_channels, - self.output_channels - ]) - - self.assertAllClose(expected_result, result, atol=1e-3) - - def testRegisterAdditionalTower(self): - """Ensure 1 big tower and 2 small towers are equivalent.""" - multiply_result_big, multiply_inverse_result_big = self.runFisherBlockOps( - self.w, [self.inputs], [self.outputs], [self.output_grads]) - multiply_result_small, multiply_inverse_result_small = ( - self.runFisherBlockOps(self.w, np.split(self.inputs, 2), - np.split(self.outputs, 2), - np.split(self.output_grads, 2))) - - self.assertAllClose(multiply_result_big, multiply_result_small) - self.assertAllClose(multiply_inverse_result_big, - multiply_inverse_result_small) - - def testMultiplyHasBias(self): - result, _ = self.runFisherBlockOps((self.w, self.b), [self.inputs], - [self.outputs], [self.output_grads]) - # Clone 'b' along 'input_channels' dimension. - b_filter = np.tile( - np.reshape(self.b, [1, 1, 1, self.output_channels]), - [self.kernel_size, self.kernel_size, 1, 1]) - params = np.concatenate([self.w, b_filter], axis=2) - expected_result = self.fisherApprox(True).dot(params.flatten()) - - # Extract 'b' from concatenated parameters. - expected_result = expected_result.reshape([ - self.kernel_size, self.kernel_size, self.input_channels + 1, - self.output_channels - ]) - expected_result = (expected_result[:, :, 0:-1, :], - np.reshape(expected_result[:, :, -1, :], - [self.output_channels])) - - self.assertEqual(len(result), 2) - self.assertAllClose(expected_result[0], result[0]) - self.assertAllClose(expected_result[1], result[1]) - - def runFisherBlockOps(self, params, inputs, outputs, output_grads): - """Run Ops guaranteed by FisherBlock interface. - - Args: - params: Tensor or 2-tuple of Tensors. Represents weights or weights and - bias of this layer. - inputs: list of Tensors of shape [batch_size, input_size]. Inputs to - layer. - outputs: list of Tensors of shape [batch_size, output_size]. - Preactivations produced by layer. - output_grads: list of Tensors of shape [batch_size, output_size]. - Gradient of loss with respect to 'outputs'. - - Returns: - multiply_result: Result of FisherBlock.multiply(params) - multiply_inverse_result: Result of FisherBlock.multiply_inverse(params) - """ - with ops.Graph().as_default(), self.test_session() as sess: - inputs = as_tensors(inputs) - outputs = as_tensors(outputs) - output_grads = as_tensors(output_grads) - params = as_tensors(params) - - block = fb.ConvDiagonalFB( - lc.LayerCollection(), params, strides=[1, 1, 1, 1], padding='SAME') - for (i, o) in zip(inputs, outputs): - block.register_additional_tower(i, o) - - block.instantiate_factors((output_grads,), damping=0.0) - block._factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._factor.make_covariance_update_op(0.0)) - multiply_result = sess.run(block.multiply(params)) - multiply_inverse_result = sess.run(block.multiply_inverse(params)) - - return multiply_result, multiply_inverse_result - - -class DepthwiseConvKFCBasicFBTest(test.TestCase): - - def testInstantiateFactors(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - params = random_ops.random_normal((3, 3, 8, 2)) - inputs = random_ops.random_normal((32, 5, 5, 8)) - outputs = random_ops.random_normal((32, 5, 5, 16)) - layer_collection = lc.LayerCollection() - block = fb.DepthwiseConvKFCBasicFB( - layer_collection, params=params, strides=[1, 1, 1, 1], padding='SAME') - block.register_additional_tower(inputs, outputs) - grads = outputs**2 - block.instantiate_factors(([grads],), 0.5) - - def testMultiplyInverse(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = random_ops.random_normal((3, 3, 8, 2)) - inputs = random_ops.random_normal((32, 5, 5, 8)) - outputs = random_ops.random_normal((32, 5, 5, 16)) - layer_collection = lc.LayerCollection() - block = fb.DepthwiseConvKFCBasicFB( - layer_collection, params=params, strides=[1, 1, 1, 1], padding='SAME') - block.register_additional_tower(inputs, outputs) - grads = outputs**2 - block.instantiate_factors(([grads],), 0.5) - block._input_factor.instantiate_cov_variables() - block._output_factor.instantiate_cov_variables() - block.register_inverse() - block._input_factor.instantiate_inv_variables() - block._output_factor.instantiate_inv_variables() - - # Ensure inverse update op doesn't crash. - sess.run(tf_variables.global_variables_initializer()) - sess.run([ - factor.make_inverse_update_ops() - for factor in layer_collection.get_factors() - ]) - - # Ensure inverse-vector multiply doesn't crash. - output = block.multiply_inverse(params) - sess.run(output) - - # Ensure same shape. - self.assertAllEqual(output.shape, params.shape) - - -class ConvKFCBasicFBTest(test.TestCase): - - def _testConvKFCBasicFBInitParams(self, params): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - if isinstance(params, (list, tuple)): - params = [array_ops.constant(param) for param in params] - else: - params = array_ops.constant(params) - inputs = random_ops.random_normal((2, 2, 2)) - outputs = random_ops.random_normal((2, 2, 2)) - block = fb.ConvKFCBasicFB( - lc.LayerCollection(), params=params, padding='SAME') - block.register_additional_tower(inputs, outputs) - - self.assertAllEqual([outputs], block.tensors_to_compute_grads()) - - def testConvKFCBasicFBInitParamsParamsTuple(self): - self._testConvKFCBasicFBInitParams([np.ones([1, 2, 2]), np.ones([2])]) - - def testConvKFCBasicFBInitParamsParamsSingle(self): - self._testConvKFCBasicFBInitParams([np.ones([1, 2, 2])]) - - def testMultiplyInverseTuple(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = random_ops.random_normal((2, 2, 2, 2)) - inputs = random_ops.random_normal((2, 2, 2, 2)) - outputs = random_ops.random_normal((2, 2, 2, 2)) - block = fb.ConvKFCBasicFB( - lc.LayerCollection(), params=params, padding='SAME') - block.register_additional_tower(inputs, outputs) - grads = outputs**2 - block.instantiate_factors(((grads,),), 0.5) - block._input_factor.instantiate_cov_variables() - block._output_factor.instantiate_cov_variables() - block.register_inverse() - block._input_factor.instantiate_inv_variables() - block._output_factor.instantiate_inv_variables() - - # Make sure our inverse is something other than the identity. - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._input_factor.make_inverse_update_ops()) - sess.run(block._output_factor.make_inverse_update_ops()) - - vector = (np.arange(1, 15).reshape(7, 2).astype(np.float32), - np.arange(2, 4).reshape(2, 1).astype(np.float32)) - output = block.multiply_inverse((array_ops.constant(vector[0]), - array_ops.constant(vector[1]))) - - output = sess.run(output) - self.assertAllClose([0.136455, 0.27291], output[0][0]) - self.assertAllClose([0.27291, 0.409365], output[1]) - - def testMultiplyInverseNotTuple(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = random_ops.random_normal((2, 2, 2, 2)) - inputs = random_ops.random_normal((2, 2, 2, 2)) - outputs = random_ops.random_normal((2, 2, 2, 2)) - block = fb.ConvKFCBasicFB( - lc.LayerCollection(), params=params, padding='SAME') - block.register_additional_tower(inputs, outputs) - self.assertFalse(block._has_bias) - grads = outputs**2 - block.instantiate_factors(((grads,),), 0.5) - block._input_factor.instantiate_cov_variables() - block._output_factor.instantiate_cov_variables() - block.register_inverse() - block._input_factor.instantiate_inv_variables() - block._output_factor.instantiate_inv_variables() - - # Make sure our inverse is something other than the identity. - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._input_factor.make_inverse_update_ops()) - sess.run(block._output_factor.make_inverse_update_ops()) - - vector = np.arange(1, 17).reshape(8, 2).astype(np.float32) - output = block.multiply_inverse(array_ops.constant(vector)) - - self.assertAllClose([0.136455, 0.27291], sess.run(output)[0]) - - def testMultiplyInverseNotTupleWithBias(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = [random_ops.random_normal((2, 2, 2, 2))] - inputs = random_ops.random_normal((2, 2, 2, 2)) - outputs = random_ops.random_normal((2, 2, 2, 2)) - block = fb.ConvKFCBasicFB( - lc.LayerCollection(), params=params, padding='SAME') - block.register_additional_tower(inputs, outputs) - self.assertTrue(block._has_bias) - grads = outputs**2 - block.instantiate_factors(((grads,),), 0.5) - block._input_factor.instantiate_cov_variables() - block._output_factor.instantiate_cov_variables() - block.register_inverse() - block._input_factor.instantiate_inv_variables() - block._output_factor.instantiate_inv_variables() - - # Make sure our inverse is something other than the identity. - sess.run(tf_variables.global_variables_initializer()) - sess.run(block._input_factor.make_inverse_update_ops()) - sess.run(block._output_factor.make_inverse_update_ops()) - - vector = np.arange(1, 19).reshape(9, 2).astype(np.float32) - output = block.multiply_inverse(array_ops.constant(vector)) - - self.assertAllClose([0.136455, 0.27291], sess.run(output)[0]) - - def testMultiplyInverseAgainstExplicit(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - params = array_ops.zeros((2, 2, 2, 2)) - inputs = array_ops.zeros((2, 2, 2, 2)) - outputs = array_ops.zeros((2, 2, 2, 2)) - block = fb.ConvKFCBasicFB( - lc.LayerCollection(), params=params, padding='SAME') - block.register_additional_tower(inputs, outputs) - grads = outputs**2 - damping = 0. # This test is only valid without damping. - block.instantiate_factors(((grads,),), damping) - block._input_factor.instantiate_cov_variables() - block._output_factor.instantiate_cov_variables() - block.register_inverse() - block._input_factor.instantiate_inv_variables() - block._output_factor.instantiate_inv_variables() - - sess.run(state_ops.assign(block._input_factor._cov, _make_psd(8))) - sess.run(state_ops.assign(block._output_factor._cov, _make_psd(2))) - sess.run(block._input_factor.make_inverse_update_ops()) - sess.run(block._output_factor.make_inverse_update_ops()) - - v_flat = np.arange(16, dtype=np.float32) - vector = utils.column_to_tensors(params, array_ops.constant(v_flat)) - output = block.multiply_inverse(vector) - output_flat = sess.run(utils.tensors_to_column(output)).ravel() - - full = sess.run(block.full_fisher_block()) - explicit = np.dot(np.linalg.inv(full + damping * np.eye(16)), v_flat) - - self.assertAllClose(output_flat, explicit) - - -class FullyConnectedSeriesFBTest(test.TestCase): - - def testFullyConnectedSeriesFBInit(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - inputs = array_ops.constant([1., 2.]) - outputs = array_ops.constant([3., 4.]) - block = fb.FullyConnectedSeriesFB(lc.LayerCollection()) - block.register_additional_tower([inputs], [outputs]) - self.assertAllEqual([[outputs]], block.tensors_to_compute_grads()) - - def testInstantiateFactorsHasBias(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - inputs = array_ops.constant([[1., 2.], [3., 4.]]) - outputs = array_ops.constant([[3., 4.], [5., 6.]]) - block = fb.FullyConnectedSeriesFB( - lc.LayerCollection(), - has_bias=True) - block.register_additional_tower([inputs], [outputs]) - grads = outputs**2 - block.instantiate_factors((((grads,),),), 0.5) - - def testInstantiateFactorsNoBias(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - inputs = array_ops.constant([[1., 2.], [3., 4.]]) - outputs = array_ops.constant([[3., 4.], [5., 6.]]) - block = fb.FullyConnectedSeriesFB( - lc.LayerCollection(), - has_bias=False) - block.register_additional_tower([inputs], [outputs]) - grads = outputs**2 - block.instantiate_factors((((grads,),),), 0.5) - - -def as_tensors(tensor_or_tuple): - """Converts a potentially nested tuple of np.array to Tensors.""" - if isinstance(tensor_or_tuple, (tuple, list)): - return tuple(as_tensors(t) for t in tensor_or_tuple) - return ops.convert_to_tensor(tensor_or_tuple) - - -if __name__ == '__main__': - test.main() diff --git a/tensorflow/contrib/kfac/python/kernel_tests/fisher_factors_test.py b/tensorflow/contrib/kfac/python/kernel_tests/fisher_factors_test.py deleted file mode 100644 index fad47cd02f..0000000000 --- a/tensorflow/contrib/kfac/python/kernel_tests/fisher_factors_test.py +++ /dev/null @@ -1,955 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for tf.contrib.kfac.fisher_factors.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import numpy.random as npr - -from tensorflow.contrib.kfac.python.ops import fisher_blocks as fb -from tensorflow.contrib.kfac.python.ops import fisher_factors as ff -from tensorflow.python.framework import constant_op -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import ops as tf_ops -from tensorflow.python.framework import random_seed -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import gradients_impl -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import random_ops -from tensorflow.python.ops import variables as tf_variables -from tensorflow.python.platform import test - - -# We need to set these constants since the numerical values used in the tests -# were chosen when these used to be the defaults. -ff.set_global_constants(init_covariances_at_zero=False, - zero_debias=False, - init_inverses_at_zero=False) - - -def make_damping_func(damping): - return fb._package_func(lambda: damping, damping) - - -class FisherFactorTestingDummy(ff.FisherFactor): - """Dummy class to test the non-abstract methods on ff.FisherFactor.""" - - @property - def _var_scope(self): - return 'dummy/a_b_c' - - @property - def _cov_shape(self): - raise NotImplementedError - - @property - def _num_sources(self): - return 1 - - @property - def _dtype(self): - return dtypes.float32 - - def _compute_new_cov(self): - raise NotImplementedError - - def instantiate_covariance(self): - pass - - def make_inverse_update_ops(self): - return [] - - def get_cov(self): - return NotImplementedError - - def instantiate_inv_variables(self): - return NotImplementedError - - def _num_towers(self): - raise NotImplementedError - - def _get_data_device(self): - raise NotImplementedError - - def register_matpower(self, exp, damping_func): - raise NotImplementedError - - def register_cholesky(self, damping_func): - raise NotImplementedError - - def register_cholesky_inverse(self, damping_func): - raise NotImplementedError - - def get_matpower(self, exp, damping_func): - raise NotImplementedError - - def get_cholesky(self, damping_func): - raise NotImplementedError - - def get_cholesky_inverse(self, damping_func): - raise NotImplementedError - - def get_cov_as_linear_operator(self): - raise NotImplementedError - - -class DenseSquareMatrixFactorTestingDummy(ff.DenseSquareMatrixFactor): - """Dummy class to test the non-abstract methods on ff.DenseSquareMatrixFactor. - """ - - def __init__(self, shape): - self._shape = shape - super(DenseSquareMatrixFactorTestingDummy, self).__init__() - - @property - def _var_scope(self): - return 'dummy/a_b_c' - - @property - def _cov_shape(self): - return self._shape - - @property - def _num_sources(self): - return 1 - - @property - def _dtype(self): - return dtypes.float32 - - def _compute_new_cov(self): - raise NotImplementedError - - def instantiate_covariance(self): - pass - - def _num_towers(self): - raise NotImplementedError - - def _get_data_device(self): - raise NotImplementedError - - -class NumericalUtilsTest(test.TestCase): - - def testComputeCovAgainstNumpy(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - npr.seed(0) - random_seed.set_random_seed(200) - - x = npr.randn(100, 3) - cov = ff.compute_cov(array_ops.constant(x)) - np_cov = np.dot(x.T, x) / x.shape[0] - - self.assertAllClose(sess.run(cov), np_cov) - - def testComputeCovAgainstNumpyWithAlternativeNormalizer(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - npr.seed(0) - random_seed.set_random_seed(200) - - normalizer = 10. - x = npr.randn(100, 3) - cov = ff.compute_cov(array_ops.constant(x), normalizer=normalizer) - np_cov = np.dot(x.T, x) / normalizer - - self.assertAllClose(sess.run(cov), np_cov) - - def testAppendHomog(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - npr.seed(0) - - m, n = 3, 4 - a = npr.randn(m, n) - a_homog = ff.append_homog(array_ops.constant(a)) - np_result = np.hstack([a, np.ones((m, 1))]) - - self.assertAllClose(sess.run(a_homog), np_result) - - -class NameStringUtilFunctionTest(test.TestCase): - - def _make_tensor(self): - x = array_ops.placeholder(dtypes.float64, (3, 1)) - w = array_ops.constant(npr.RandomState(0).randn(3, 3)) - y = math_ops.matmul(w, x) - g = gradients_impl.gradients(y, x)[0] - return g - - def testScopeStringFromParamsSingleTensor(self): - with tf_ops.Graph().as_default(): - g = self._make_tensor() - scope_string = ff.scope_string_from_params(g) - self.assertEqual('gradients_MatMul_grad_MatMul_1', scope_string) - - def testScopeStringFromParamsMultipleTensors(self): - with tf_ops.Graph().as_default(): - x = array_ops.constant(1,) - y = array_ops.constant(2,) - scope_string = ff.scope_string_from_params((x, y)) - self.assertEqual('Const_Const_1', scope_string) - - def testScopeStringFromParamsMultipleTypes(self): - with tf_ops.Graph().as_default(): - x = array_ops.constant(1,) - y = array_ops.constant(2,) - scope_string = ff.scope_string_from_params([[1, 2, 3], 'foo', True, 4, - (x, y)]) - self.assertEqual('1-2-3_foo_True_4_Const__Const_1', scope_string) - - def testScopeStringFromParamsUnsupportedType(self): - with tf_ops.Graph().as_default(): - x = array_ops.constant(1,) - y = array_ops.constant(2,) - unsupported = 1.2 # Floats are not supported. - with self.assertRaises(ValueError): - ff.scope_string_from_params([[1, 2, 3], 'foo', True, 4, (x, y), - unsupported]) - - def testScopeStringFromName(self): - with tf_ops.Graph().as_default(): - g = self._make_tensor() - scope_string = ff.scope_string_from_name(g) - self.assertEqual('gradients_MatMul_grad_MatMul_1', scope_string) - - def testScalarOrTensorToString(self): - with tf_ops.Graph().as_default(): - self.assertEqual(ff.scalar_or_tensor_to_string(5.), repr(5.)) - - g = self._make_tensor() - scope_string = ff.scope_string_from_name(g) - self.assertEqual(ff.scalar_or_tensor_to_string(g), scope_string) - - -class FisherFactorTest(test.TestCase): - - def testMakeInverseUpdateOps(self): - with tf_ops.Graph().as_default(): - random_seed.set_random_seed(200) - factor = FisherFactorTestingDummy() - - self.assertEqual(0, len(factor.make_inverse_update_ops())) - - -class DenseSquareMatrixFactorTest(test.TestCase): - - def testRegisterDampedInverse(self): - with tf_ops.Graph().as_default(): - random_seed.set_random_seed(200) - shape = [2, 2] - factor = DenseSquareMatrixFactorTestingDummy(shape) - factor_var_scope = 'dummy/a_b_c' - - damping_funcs = [make_damping_func(0.1), - make_damping_func(0.1), - make_damping_func(1e-5), - make_damping_func(1e-5)] - for damping_func in damping_funcs: - factor.register_inverse(damping_func) - - factor.instantiate_inv_variables() - - inv = factor.get_inverse(damping_funcs[0]).to_dense() - self.assertEqual(inv, factor.get_inverse(damping_funcs[1]).to_dense()) - self.assertNotEqual(inv, factor.get_inverse(damping_funcs[2]).to_dense()) - self.assertEqual(factor.get_inverse(damping_funcs[2]).to_dense(), - factor.get_inverse(damping_funcs[3]).to_dense()) - factor_vars = tf_ops.get_collection(tf_ops.GraphKeys.GLOBAL_VARIABLES, - factor_var_scope) - factor_tensors = (tf_ops.convert_to_tensor(var) for var in factor_vars) - - self.assertEqual(set([inv, - factor.get_inverse(damping_funcs[2]).to_dense()]), - set(factor_tensors)) - self.assertEqual(shape, inv.get_shape()) - - def testRegisterMatpower(self): - with tf_ops.Graph().as_default(): - random_seed.set_random_seed(200) - shape = [3, 3] - factor = DenseSquareMatrixFactorTestingDummy(shape) - factor_var_scope = 'dummy/a_b_c' - - # TODO(b/74201126): Change to using the same func for both once - # Topohash is in place. - damping_func_1 = make_damping_func(0.5) - damping_func_2 = make_damping_func(0.5) - - factor.register_matpower(-0.5, damping_func_1) - factor.register_matpower(2, damping_func_2) - - factor.instantiate_inv_variables() - - factor_vars = tf_ops.get_collection(tf_ops.GraphKeys.GLOBAL_VARIABLES, - factor_var_scope) - - factor_tensors = (tf_ops.convert_to_tensor(var) for var in factor_vars) - - matpower1 = factor.get_matpower(-0.5, damping_func_1).to_dense() - matpower2 = factor.get_matpower(2, damping_func_2).to_dense() - - self.assertEqual(set([matpower1, matpower2]), set(factor_tensors)) - - self.assertEqual(shape, matpower1.get_shape()) - self.assertEqual(shape, matpower2.get_shape()) - - def testMakeInverseUpdateOps(self): - with tf_ops.Graph().as_default(): - random_seed.set_random_seed(200) - factor = FisherFactorTestingDummy() - - self.assertEqual(0, len(factor.make_inverse_update_ops())) - - def testMakeInverseUpdateOpsManyInversesEigenDecomp(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - cov = np.array([[1., 2.], [3., 4.]]) - factor = DenseSquareMatrixFactorTestingDummy(cov.shape) - factor._cov = array_ops.constant(cov, dtype=dtypes.float32) - - damping_funcs = [] - for i in range(1, ff.EIGENVALUE_DECOMPOSITION_THRESHOLD + 1): - damping_funcs.append(make_damping_func(1./i)) - - for i in range(ff.EIGENVALUE_DECOMPOSITION_THRESHOLD): - factor.register_inverse(damping_funcs[i]) - - factor.instantiate_inv_variables() - ops = factor.make_inverse_update_ops() - self.assertEqual(1, len(ops)) - - sess.run(tf_variables.global_variables_initializer()) - new_invs = [] - sess.run(ops) - for i in range(ff.EIGENVALUE_DECOMPOSITION_THRESHOLD): - # The inverse op will assign the damped inverse of cov to the inv var. - new_invs.append( - sess.run(factor.get_inverse(damping_funcs[i]).to_dense())) - - # We want to see that the new invs are all different from each other. - for i in range(len(new_invs)): - for j in range(i + 1, len(new_invs)): - # Just check the first element. - self.assertNotEqual(new_invs[i][0][0], new_invs[j][0][0]) - - def testMakeInverseUpdateOpsMatPowerEigenDecomp(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - cov = np.array([[6., 2.], [2., 4.]]) - factor = DenseSquareMatrixFactorTestingDummy(cov.shape) - factor._cov = array_ops.constant(cov, dtype=dtypes.float32) - exp = 2 # NOTE(mattjj): must be int to test with np.linalg.matrix_power - damping = 0.5 - damping_func = make_damping_func(damping) - - factor.register_matpower(exp, damping_func) - factor.instantiate_inv_variables() - ops = factor.make_inverse_update_ops() - self.assertEqual(1, len(ops)) - - sess.run(tf_variables.global_variables_initializer()) - sess.run(ops[0]) - matpower = sess.run(factor.get_matpower(exp, damping_func).to_dense()) - matpower_np = np.linalg.matrix_power(cov + np.eye(2) * damping, exp) - self.assertAllClose(matpower, matpower_np) - - def testMakeInverseUpdateOpsNoEigenDecomp(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - cov = np.array([[5., 2.], [2., 4.]]) # NOTE(mattjj): must be symmetric - factor = DenseSquareMatrixFactorTestingDummy(cov.shape) - factor._cov = array_ops.constant(cov, dtype=dtypes.float32) - - damping_func = make_damping_func(0) - - factor.register_inverse(damping_func) - factor.instantiate_inv_variables() - ops = factor.make_inverse_update_ops() - self.assertEqual(1, len(ops)) - - sess.run(tf_variables.global_variables_initializer()) - # The inverse op will assign the damped inverse of cov to the inv var. - old_inv = sess.run(factor.get_inverse(damping_func).to_dense()) - self.assertAllClose( - sess.run(ff.inverse_initializer(cov.shape, dtypes.float32)), old_inv) - - sess.run(ops) - new_inv = sess.run(factor.get_inverse(damping_func).to_dense()) - self.assertAllClose(new_inv, np.linalg.inv(cov)) - - -class FullFactorTest(test.TestCase): - - def testFullFactorInit(self): - with tf_ops.Graph().as_default(): - random_seed.set_random_seed(200) - tensor = array_ops.ones((2, 3), name='a/b/c') - factor = ff.FullFactor((tensor,), 32) - factor.instantiate_cov_variables() - self.assertEqual([6, 6], factor.get_cov().get_shape().as_list()) - - def testFullFactorInitFloat64(self): - with tf_ops.Graph().as_default(): - dtype = dtypes.float64_ref - random_seed.set_random_seed(200) - tensor = array_ops.ones((2, 3), dtype=dtype, name='a/b/c') - factor = ff.FullFactor((tensor,), 32) - factor.instantiate_cov_variables() - cov = factor.get_cov() - self.assertEqual(cov.dtype, dtype) - self.assertEqual([6, 6], cov.get_shape().as_list()) - - def testMakeCovarianceUpdateOp(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - tensor = array_ops.constant([1., 2.], name='a/b/c') - factor = ff.FullFactor((tensor,), 2) - factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(factor.make_covariance_update_op(.5)) - self.assertAllClose([[0.75, 0.5], [0.5, 1.5]], new_cov) - - -class NaiveDiagonalFactorTest(test.TestCase): - - def testNaiveDiagonalFactorInit(self): - with tf_ops.Graph().as_default(): - random_seed.set_random_seed(200) - tensor = array_ops.ones((2, 3), name='a/b/c') - factor = ff.NaiveDiagonalFactor((tensor,), 32) - factor.instantiate_cov_variables() - self.assertEqual([6, 1], factor.get_cov().get_shape().as_list()) - - def testNaiveDiagonalFactorInitFloat64(self): - with tf_ops.Graph().as_default(): - dtype = dtypes.float64_ref - random_seed.set_random_seed(200) - tensor = array_ops.ones((2, 3), dtype=dtype, name='a/b/c') - factor = ff.NaiveDiagonalFactor((tensor,), 32) - factor.instantiate_cov_variables() - cov = factor.get_cov() - self.assertEqual(cov.dtype, dtype) - self.assertEqual([6, 1], cov.get_shape().as_list()) - - def testMakeCovarianceUpdateOp(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - tensor = array_ops.constant([1., 2.], name='a/b/c') - factor = ff.NaiveDiagonalFactor((tensor,), 2) - factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(factor.make_covariance_update_op(.5)) - self.assertAllClose([[0.75], [1.5]], new_cov) - - -class EmbeddingInputKroneckerFactorTest(test.TestCase): - - def testInitialization(self): - with tf_ops.Graph().as_default(): - input_ids = array_ops.constant([[0], [1], [4]]) - vocab_size = 5 - factor = ff.EmbeddingInputKroneckerFactor((input_ids,), vocab_size) - factor.instantiate_cov_variables() - cov = factor.get_cov() - self.assertEqual(cov.shape.as_list(), [vocab_size]) - - def testCovarianceUpdateOp(self): - with tf_ops.Graph().as_default(): - input_ids = array_ops.constant([[0], [1], [4]]) - vocab_size = 5 - factor = ff.EmbeddingInputKroneckerFactor((input_ids,), vocab_size) - factor.instantiate_cov_variables() - cov_update_op = factor.make_covariance_update_op(0.0) - - with self.test_session() as sess: - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(cov_update_op) - self.assertAllClose(np.array([1., 1., 0., 0., 1.]) / 3., new_cov) - - -class ConvDiagonalFactorTest(test.TestCase): - - def setUp(self): - self.batch_size = 10 - self.height = self.width = 32 - self.in_channels = 3 - self.out_channels = 1 - self.kernel_height = self.kernel_width = 3 - self.strides = [1, 2, 2, 1] - self.data_format = 'NHWC' - self.padding = 'SAME' - self.kernel_shape = [ - self.kernel_height, self.kernel_width, self.in_channels, - self.out_channels - ] - - def testInit(self): - with tf_ops.Graph().as_default(): - inputs = random_ops.random_uniform( - [self.batch_size, self.height, self.width, self.in_channels]) - outputs_grads = [ - random_ops.random_uniform([ - self.batch_size, self.height // self.strides[1], - self.width // self.strides[2], self.out_channels - ]) for _ in range(3) - ] - - factor = ff.ConvDiagonalFactor( - (inputs,), - (outputs_grads,), - self.kernel_shape, - self.strides, - self.padding, - data_format=self.data_format) - factor.instantiate_cov_variables() - - # Ensure covariance matrix's shape makes sense. - self.assertEqual([ - self.kernel_height * self.kernel_width * self.in_channels, - self.out_channels - ], - factor.get_cov().shape.as_list()) - - def testMakeCovarianceUpdateOp(self): - with tf_ops.Graph().as_default(): - # Construct all arguments such that convolution kernel is applied in - # exactly one spatial location. - inputs = np.random.randn( - 1, # batch_size - self.kernel_height, - self.kernel_width, - self.in_channels) # in_channels - outputs_grad = np.random.randn( - 1, # batch_size - 1, # output_height - 1, # output_width - self.out_channels) - - factor = ff.ConvDiagonalFactor( - (constant_op.constant(inputs),), - ((constant_op.constant(outputs_grad),),), - self.kernel_shape, - strides=[1, 1, 1, 1], - padding='VALID') - factor.instantiate_cov_variables() - - # Completely forget initial value on first update. - cov_update_op = factor.make_covariance_update_op(0.0) - - # Ensure new covariance value is same as outer-product of inputs/outputs - # vectorized, squared. - with self.test_session() as sess: - sess.run(tf_variables.global_variables_initializer()) - cov = sess.run(cov_update_op) - expected_cov = np.outer(inputs.flatten(), outputs_grad.flatten())**2 - self.assertAllClose(expected_cov, cov) - - def testHasBias(self): - with tf_ops.Graph().as_default(): - inputs = random_ops.random_uniform( - [self.batch_size, self.height, self.width, self.in_channels]) - outputs_grads = [ - random_ops.random_uniform([ - self.batch_size, self.height // self.strides[1], - self.width // self.strides[2], self.out_channels - ]) for _ in range(3) - ] - - factor = ff.ConvDiagonalFactor( - (inputs,), - (outputs_grads,), - self.kernel_shape, - self.strides, - self.padding, - data_format=self.data_format, - has_bias=True) - factor.instantiate_cov_variables() - - # Ensure shape accounts for bias. - self.assertEqual([ - self.kernel_height * self.kernel_width * self.in_channels + 1, - self.out_channels - ], - factor.get_cov().shape.as_list()) - - # Ensure update op doesn't crash. - cov_update_op = factor.make_covariance_update_op(0.0) - with self.test_session() as sess: - sess.run(tf_variables.global_variables_initializer()) - sess.run(cov_update_op) - - -class FullyConnectedKroneckerFactorTest(test.TestCase): - - def _testFullyConnectedKroneckerFactorInit(self, - has_bias, - final_shape, - dtype=dtypes.float32_ref): - with tf_ops.Graph().as_default(): - random_seed.set_random_seed(200) - tensor = array_ops.ones((2, 3), dtype=dtype, name='a/b/c') - factor = ff.FullyConnectedKroneckerFactor(((tensor,),), has_bias=has_bias) - factor.instantiate_cov_variables() - cov = factor.get_cov() - self.assertEqual(cov.dtype, dtype) - self.assertEqual(final_shape, cov.get_shape().as_list()) - - def testFullyConnectedKroneckerFactorInitNoBias(self): - for dtype in (dtypes.float32_ref, dtypes.float64_ref): - self._testFullyConnectedKroneckerFactorInit(False, [3, 3], dtype=dtype) - - def testFullyConnectedKroneckerFactorInitWithBias(self): - for dtype in (dtypes.float32_ref, dtypes.float64_ref): - self._testFullyConnectedKroneckerFactorInit(True, [4, 4], dtype=dtype) - - def testMakeCovarianceUpdateOpWithBias(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - tensor = array_ops.constant([[1., 2.], [3., 4.]], name='a/b/c') - factor = ff.FullyConnectedKroneckerFactor(((tensor,),), has_bias=True) - factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(factor.make_covariance_update_op(.5)) - self.assertAllClose([[3, 3.5, 1], [3.5, 5.5, 1.5], [1, 1.5, 1]], new_cov) - - def testMakeCovarianceUpdateOpNoBias(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - tensor = array_ops.constant([[1., 2.], [3., 4.]], name='a/b/c') - factor = ff.FullyConnectedKroneckerFactor(((tensor,),)) - factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(factor.make_covariance_update_op(.5)) - self.assertAllClose([[3, 3.5], [3.5, 5.5]], new_cov) - - -class ConvFactorTestCase(test.TestCase): - - def assertMatrixRank(self, rank, matrix, atol=1e-5): - assert rank <= matrix.shape[0], 'Rank cannot be larger than matrix size.' - eigvals = np.linalg.eigvals(matrix) - nnz_eigvals = np.sum(eigvals > atol) - self.assertEqual( - rank, - nnz_eigvals, - msg=('Found %d of %d expected non-zero eigenvalues: %s.' % - (nnz_eigvals, rank, eigvals))) - - -class ConvInputKroneckerFactorTest(ConvFactorTestCase): - - def test3DConvolution(self): - with tf_ops.Graph().as_default(): - batch_size = 1 - width = 3 - in_channels = 3**3 - out_channels = 4 - - factor = ff.ConvInputKroneckerFactor( - inputs=(random_ops.random_uniform( - (batch_size, width, width, width, in_channels), seed=0),), - filter_shape=(width, width, width, in_channels, out_channels), - padding='SAME', - strides=(2, 2, 2), - extract_patches_fn='extract_convolution_patches', - has_bias=False) - factor.instantiate_cov_variables() - - # Ensure shape of covariance matches input size of filter. - input_size = in_channels * (width**3) - self.assertEqual([input_size, input_size], - factor.get_cov().shape.as_list()) - - # Ensure cov_update_op doesn't crash. - with self.test_session() as sess: - sess.run(tf_variables.global_variables_initializer()) - sess.run(factor.make_covariance_update_op(0.0)) - cov = sess.run(factor.get_cov()) - - # Cov should be rank-8, as the filter will be applied at each corner of - # the 4-D cube. - self.assertMatrixRank(8, cov) - - def testPointwiseConv2d(self): - with tf_ops.Graph().as_default(): - batch_size = 1 - width = 3 - in_channels = 3**2 - out_channels = 4 - - factor = ff.ConvInputKroneckerFactor( - inputs=(random_ops.random_uniform( - (batch_size, width, width, in_channels), seed=0),), - filter_shape=(1, 1, in_channels, out_channels), - padding='SAME', - strides=(1, 1, 1, 1), - extract_patches_fn='extract_pointwise_conv2d_patches', - has_bias=False) - factor.instantiate_cov_variables() - - # Ensure shape of covariance matches input size of filter. - self.assertEqual([in_channels, in_channels], - factor.get_cov().shape.as_list()) - - # Ensure cov_update_op doesn't crash. - with self.test_session() as sess: - sess.run(tf_variables.global_variables_initializer()) - sess.run(factor.make_covariance_update_op(0.0)) - cov = sess.run(factor.get_cov()) - - # Cov should be rank-9, as the filter will be applied at each location. - self.assertMatrixRank(9, cov) - - def testStrides(self): - with tf_ops.Graph().as_default(): - batch_size = 1 - width = 3 - in_channels = 3**2 - out_channels = 4 - - factor = ff.ConvInputKroneckerFactor( - inputs=(random_ops.random_uniform( - (batch_size, width, width, in_channels), seed=0),), - filter_shape=(1, 1, in_channels, out_channels), - padding='SAME', - strides=(1, 2, 1, 1), - extract_patches_fn='extract_image_patches', - has_bias=False) - factor.instantiate_cov_variables() - - with self.test_session() as sess: - sess.run(tf_variables.global_variables_initializer()) - sess.run(factor.make_covariance_update_op(0.0)) - cov = sess.run(factor.get_cov()) - - # Cov should be the sum of 3 * 2 = 6 outer products. - self.assertMatrixRank(6, cov) - - def testDilationRate(self): - with tf_ops.Graph().as_default(): - batch_size = 1 - width = 3 - in_channels = 2 - out_channels = 4 - - factor = ff.ConvInputKroneckerFactor( - inputs=(random_ops.random_uniform( - (batch_size, width, width, in_channels), seed=0),), - filter_shape=(3, 3, in_channels, out_channels), - padding='SAME', - extract_patches_fn='extract_image_patches', - strides=(1, 1, 1, 1), - dilation_rate=(1, width, width, 1), - has_bias=False) - factor.instantiate_cov_variables() - - with self.test_session() as sess: - sess.run(tf_variables.global_variables_initializer()) - sess.run(factor.make_covariance_update_op(0.0)) - cov = sess.run(factor.get_cov()) - - # Cov should be rank = in_channels, as only the center of the filter - # receives non-zero input for each input channel. - self.assertMatrixRank(in_channels, cov) - - def testConvInputKroneckerFactorInitNoBias(self): - with tf_ops.Graph().as_default(): - tensor = array_ops.ones((64, 1, 2, 3), name='a/b/c') - factor = ff.ConvInputKroneckerFactor( - inputs=(tensor,), - filter_shape=(1, 2, 3, 4), - padding='SAME', - has_bias=False) - factor.instantiate_cov_variables() - self.assertEqual([1 * 2 * 3, 1 * 2 * 3], - factor.get_cov().get_shape().as_list()) - - def testConvInputKroneckerFactorInit(self): - with tf_ops.Graph().as_default(): - tensor = array_ops.ones((64, 1, 2, 3), name='a/b/c') - factor = ff.ConvInputKroneckerFactor( - (tensor,), filter_shape=(1, 2, 3, 4), padding='SAME', has_bias=True) - factor.instantiate_cov_variables() - self.assertEqual([1 * 2 * 3 + 1, 1 * 2 * 3 + 1], - factor.get_cov().get_shape().as_list()) - - def testConvInputKroneckerFactorInitFloat64(self): - with tf_ops.Graph().as_default(): - dtype = dtypes.float64_ref - tensor = array_ops.ones((64, 1, 2, 3), name='a/b/c', dtype=dtypes.float64) - factor = ff.ConvInputKroneckerFactor( - (tensor,), filter_shape=(1, 2, 3, 4), padding='SAME', has_bias=True) - factor.instantiate_cov_variables() - cov = factor.get_cov() - self.assertEqual(cov.dtype, dtype) - self.assertEqual([1 * 2 * 3 + 1, 1 * 2 * 3 + 1], - cov.get_shape().as_list()) - - def testMakeCovarianceUpdateOpWithBias(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - input_shape = (2, 1, 1, 1) - tensor = array_ops.constant( - np.arange(1, 1 + np.prod(input_shape)).reshape(input_shape).astype( - np.float32)) - factor = ff.ConvInputKroneckerFactor( - (tensor,), filter_shape=(1, 1, 1, 1), padding='SAME', has_bias=True) - factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(factor.make_covariance_update_op(0.)) - self.assertAllClose( - [ - [(1. + 4.) / 2., (1. + 2.) / 2.], # - [(1. + 2.) / 2., (1. + 1.) / 2.] - ], # - new_cov) - - def testMakeCovarianceUpdateOpNoBias(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - input_shape = (2, 1, 1, 1) - tensor = array_ops.constant( - np.arange(1, 1 + np.prod(input_shape)).reshape(input_shape).astype( - np.float32)) - factor = ff.ConvInputKroneckerFactor( - (tensor,), filter_shape=(1, 1, 1, 1), padding='SAME') - factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(factor.make_covariance_update_op(0.)) - self.assertAllClose([[(1. + 4.) / 2.]], new_cov) - - def testSubSample(self): - with tf_ops.Graph().as_default(): - patches_1 = array_ops.constant(1, shape=(10, 2)) - patches_2 = array_ops.constant(1, shape=(10, 8)) - patches_3 = array_ops.constant(1, shape=(3, 3)) - patches_1_sub = ff._subsample_for_cov_computation(patches_1) - patches_2_sub = ff._subsample_for_cov_computation(patches_2) - patches_3_sub = ff._subsample_for_cov_computation(patches_3) - patches_1_sub_batch_size = patches_1_sub.shape.as_list()[0] - patches_2_sub_batch_size = patches_2_sub.shape.as_list()[0] - patches_3_sub_batch_size = patches_3_sub.shape.as_list()[0] - self.assertEqual(2, patches_1_sub_batch_size) - self.assertEqual(8, patches_2_sub_batch_size) - self.assertEqual(3, patches_3_sub_batch_size) - - -class ConvOutputKroneckerFactorTest(ConvFactorTestCase): - - def test3DConvolution(self): - with tf_ops.Graph().as_default(): - batch_size = 1 - width = 3 - out_channels = width**3 - - factor = ff.ConvOutputKroneckerFactor(outputs_grads=([ - random_ops.random_uniform( - (batch_size, width, width, width, out_channels), seed=0) - ],)) - factor.instantiate_cov_variables() - - with self.test_session() as sess: - sess.run(tf_variables.global_variables_initializer()) - sess.run(factor.make_covariance_update_op(0.0)) - cov = sess.run(factor.get_cov()) - - # Cov should be rank 3^3, as each spatial position donates a rank-1 - # update. - self.assertMatrixRank(width**3, cov) - - def testConvOutputKroneckerFactorInit(self): - with tf_ops.Graph().as_default(): - random_seed.set_random_seed(200) - tensor = array_ops.ones((2, 3, 4, 5), name='a/b/c') - factor = ff.ConvOutputKroneckerFactor(((tensor,),)) - factor.instantiate_cov_variables() - self.assertEqual([5, 5], factor.get_cov().get_shape().as_list()) - - def testConvOutputKroneckerFactorInitFloat64(self): - with tf_ops.Graph().as_default(): - dtype = dtypes.float64_ref - random_seed.set_random_seed(200) - tensor = array_ops.ones((2, 3, 4, 5), dtype=dtype, name='a/b/c') - factor = ff.ConvOutputKroneckerFactor(((tensor,),)) - factor.instantiate_cov_variables() - cov = factor.get_cov() - self.assertEqual(cov.dtype, dtype) - self.assertEqual([5, 5], cov.get_shape().as_list()) - - def testMakeCovarianceUpdateOp(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - tensor = np.arange(1, 17).reshape(2, 2, 2, 2).astype(np.float32) - factor = ff.ConvOutputKroneckerFactor(((array_ops.constant(tensor),),)) - factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(factor.make_covariance_update_op(.5)) - self.assertAllClose([[43, 46.5], [46.5, 51.5]], new_cov) - - -class FullyConnectedMultiKFTest(test.TestCase): - - def testFullyConnectedMultiKFInit(self): - with tf_ops.Graph().as_default(): - random_seed.set_random_seed(200) - tensor = array_ops.ones((2, 3), name='a/b/c') - factor = ff.FullyConnectedMultiKF(((tensor,),), has_bias=False) - factor.instantiate_cov_variables() - self.assertEqual([3, 3], factor.get_cov().get_shape().as_list()) - - def testFullyConnectedMultiKFInitFloat64(self): - with tf_ops.Graph().as_default(): - dtype = dtypes.float64_ref - random_seed.set_random_seed(200) - tensor = array_ops.ones((2, 3), dtype=dtype, name='a/b/c') - factor = ff.FullyConnectedMultiKF(((tensor,),), has_bias=False) - factor.instantiate_cov_variables() - cov = factor.get_cov() - self.assertEqual(cov.dtype, dtype) - self.assertEqual([3, 3], cov.get_shape().as_list()) - - def testMakeCovarianceUpdateOpWithBias(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - tensor = array_ops.constant([[1., 2.], [3., 4.]], name='a/b/c') - factor = ff.FullyConnectedMultiKF(((tensor,),), has_bias=True) - factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(factor.make_covariance_update_op(.5)) - self.assertAllClose([[3, 3.5, 1], [3.5, 5.5, 1.5], [1, 1.5, 1]], new_cov) - - def testMakeCovarianceUpdateOpNoBias(self): - with tf_ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - tensor = array_ops.constant([[1., 2.], [3., 4.]], name='a/b/c') - factor = ff.FullyConnectedMultiKF(((tensor,),)) - factor.instantiate_cov_variables() - - sess.run(tf_variables.global_variables_initializer()) - new_cov = sess.run(factor.make_covariance_update_op(.5)) - self.assertAllClose([[3, 3.5], [3.5, 5.5]], new_cov) - - -if __name__ == '__main__': - test.main() diff --git a/tensorflow/contrib/kfac/python/kernel_tests/layer_collection_test.py b/tensorflow/contrib/kfac/python/kernel_tests/layer_collection_test.py deleted file mode 100644 index cb80fca370..0000000000 --- a/tensorflow/contrib/kfac/python/kernel_tests/layer_collection_test.py +++ /dev/null @@ -1,597 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for tf.contrib.kfac.layer_collection.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from tensorflow.contrib.kfac.python.ops import fisher_blocks -from tensorflow.contrib.kfac.python.ops import fisher_factors -from tensorflow.contrib.kfac.python.ops import layer_collection -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import ops -from tensorflow.python.framework import random_seed -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import linalg_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import random_ops -from tensorflow.python.ops import variable_scope -from tensorflow.python.platform import test - - -class MockFisherBlock(object): - """A fake FisherBlock.""" - - num_registered_towers = 2 - - def __init__(self, name='MockFisherBlock'): - self.name = name - - def __eq__(self, other): - return isinstance(other, MockFisherBlock) and other.name == self.name - - def __hash__(self): - return hash(self.name) - - -class LayerParametersDictTest(test.TestCase): - - def testSetItem(self): - """Ensure insertion, contains, retrieval works for supported key types.""" - with ops.Graph().as_default(): - lp_dict = layer_collection.LayerParametersDict() - - x = array_ops.constant(0) - y0 = array_ops.constant(0) - y1 = array_ops.constant(0) - z0 = array_ops.constant(0) - z1 = array_ops.constant(0) - keys = [x, (y0, y1), [z0, z1]] - for key in keys: - lp_dict[key] = key - - for key in keys: - self.assertTrue(key in lp_dict) - self.assertEqual(lp_dict[key], key) - - def testSetItemOverlap(self): - """Ensure insertion fails if key overlaps with existing key.""" - with ops.Graph().as_default(): - lp_dict = layer_collection.LayerParametersDict() - - x = array_ops.constant(0) - y = array_ops.constant(0) - lp_dict[x] = 'value' - - with self.assertRaises(ValueError): - lp_dict[(x, y)] = 'value' - - # Ensure 'y' wasn't inserted. - self.assertTrue(x in lp_dict) - self.assertFalse(y in lp_dict) - - -class LayerCollectionTest(test.TestCase): - - def testLayerCollectionInit(self): - lc = layer_collection.LayerCollection() - self.assertEqual(0, len(lc.get_blocks())) - self.assertEqual(0, len(lc.get_factors())) - self.assertFalse(lc.losses) - - def testRegisterBlocks(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - lc = layer_collection.LayerCollection() - lc.register_fully_connected( - array_ops.constant(1), array_ops.constant(2), array_ops.constant(3)) - lc.register_fully_connected( - array_ops.constant(1), - array_ops.constant(2), - array_ops.constant(3), - approx=layer_collection.APPROX_DIAGONAL_NAME) - lc.register_conv2d( - params=array_ops.ones((2, 3, 4, 5)), - strides=[1, 1, 1, 1], - padding='SAME', - inputs=array_ops.ones((1, 2, 3, 4)), - outputs=array_ops.ones((1, 1, 1, 5))) - lc.register_conv2d( - params=array_ops.ones((2, 3, 4, 5)), - strides=[1, 1, 1, 1], - padding='SAME', - inputs=array_ops.ones((1, 2, 3, 4)), - outputs=array_ops.ones((1, 1, 1, 5)), - approx=layer_collection.APPROX_DIAGONAL_NAME) - lc.register_separable_conv2d( - depthwise_params=array_ops.ones((3, 3, 1, 2)), - pointwise_params=array_ops.ones((1, 1, 2, 4)), - inputs=array_ops.ones((32, 5, 5, 1)), - depthwise_outputs=array_ops.ones((32, 5, 5, 2)), - pointwise_outputs=array_ops.ones((32, 5, 5, 4)), - strides=[1, 1, 1, 1], - padding='SAME') - lc.register_convolution( - params=array_ops.ones((3, 3, 1, 8)), - inputs=array_ops.ones((32, 5, 5, 1)), - outputs=array_ops.ones((32, 5, 5, 8)), - padding='SAME') - lc.register_generic( - array_ops.constant(5), 16, approx=layer_collection.APPROX_FULL_NAME) - lc.register_generic( - array_ops.constant(6), - 16, - approx=layer_collection.APPROX_DIAGONAL_NAME) - lc.register_fully_connected_multi( - array_ops.constant(1), - (array_ops.constant(2), array_ops.constant(3)), - (array_ops.constant(4), array_ops.constant(5))) - lc.register_conv2d_multi( - params=array_ops.ones((2, 3, 4, 5)), - strides=[1, 1, 1, 1], - padding='SAME', - inputs=(array_ops.ones((1, 2, 3, 4)), array_ops.ones((5, 6, 7, 8))), - outputs=(array_ops.ones((1, 1, 1, 5)), array_ops.ones((2, 2, 2, 10)))) - lc.register_embedding_multi( - array_ops.constant((1,)), - (array_ops.constant(2), array_ops.constant(3)), - (array_ops.constant(4), array_ops.constant(5))) - - self.assertEqual(12, len(lc.get_blocks())) - - def testRegisterBlocksMultipleRegistrations(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - lc = layer_collection.LayerCollection() - key = array_ops.constant(1) - lc.register_fully_connected(key, array_ops.constant(2), - array_ops.constant(3)) - with self.assertRaises(ValueError) as cm: - lc.register_generic(key, 16) - self.assertIn('already in LayerCollection', str(cm.exception)) - - def testRegisterSingleParamNotRegistered(self): - x = variable_scope.get_variable('x', initializer=array_ops.constant(1,)) - lc = layer_collection.LayerCollection() - lc.fisher_blocks = { - variable_scope.get_variable('y', initializer=array_ops.constant(1,)): - '1' - } - lc.register_block(x, 'foo') - - def testShouldRegisterSingleParamRegistered(self): - x = variable_scope.get_variable('x', initializer=array_ops.constant(1,)) - lc = layer_collection.LayerCollection() - lc.fisher_blocks = {x: '1'} - with self.assertRaises(ValueError) as cm: - lc.register_block(x, 'foo') - self.assertIn('already in LayerCollection', str(cm.exception)) - - def testRegisterSingleParamRegisteredInTuple(self): - x = variable_scope.get_variable('x', initializer=array_ops.constant(1,)) - y = variable_scope.get_variable('y', initializer=array_ops.constant(1,)) - lc = layer_collection.LayerCollection() - lc.fisher_blocks = {(x, y): '1'} - with self.assertRaises(ValueError) as cm: - lc.register_block(x, 'foo') - self.assertIn('was already registered', str(cm.exception)) - - def testRegisterTupleParamNotRegistered(self): - x = variable_scope.get_variable('x', initializer=array_ops.constant(1,)) - y = variable_scope.get_variable('y', initializer=array_ops.constant(1,)) - lc = layer_collection.LayerCollection() - lc.fisher_blocks = { - variable_scope.get_variable('z', initializer=array_ops.constant(1,)): - '1' - } - - lc.register_block((x, y), 'foo') - self.assertEqual(set(['1', 'foo']), set(lc.get_blocks())) - - def testRegisterTupleParamRegistered(self): - x = variable_scope.get_variable('x', initializer=array_ops.constant(1,)) - y = variable_scope.get_variable('y', initializer=array_ops.constant(1,)) - lc = layer_collection.LayerCollection() - lc.fisher_blocks = {(x, y): '1'} - - with self.assertRaises(ValueError) as cm: - lc.register_block((x, y), 'foo') - self.assertIn('already in LayerCollection', str(cm.exception)) - - def testRegisterTupleParamRegisteredInSuperset(self): - x = variable_scope.get_variable('x', initializer=array_ops.constant(1,)) - y = variable_scope.get_variable('y', initializer=array_ops.constant(1,)) - z = variable_scope.get_variable('z', initializer=array_ops.constant(1,)) - lc = layer_collection.LayerCollection() - lc.fisher_blocks = {(x, y, z): '1'} - - with self.assertRaises(ValueError) as cm: - lc.register_block((x, y), 'foo') - self.assertIn('was already registered', str(cm.exception)) - - def testRegisterTupleParamSomeRegistered(self): - x = variable_scope.get_variable('x', initializer=array_ops.constant(1,)) - y = variable_scope.get_variable('y', initializer=array_ops.constant(1,)) - z = variable_scope.get_variable('z', initializer=array_ops.constant(1,)) - lc = layer_collection.LayerCollection() - lc.fisher_blocks = {x: MockFisherBlock('1'), z: MockFisherBlock('2')} - - with self.assertRaises(ValueError) as cm: - lc.register_block((x, y), MockFisherBlock('foo')) - self.assertIn('was already registered', str(cm.exception)) - - def testRegisterTupleVarSomeRegisteredInOtherTuples(self): - x = variable_scope.get_variable('x', initializer=array_ops.constant(1,)) - y = variable_scope.get_variable('y', initializer=array_ops.constant(1,)) - z = variable_scope.get_variable('z', initializer=array_ops.constant(1,)) - w = variable_scope.get_variable('w', initializer=array_ops.constant(1,)) - lc = layer_collection.LayerCollection() - lc.fisher_blocks = {(x, z): '1', (z, w): '2'} - - with self.assertRaises(ValueError) as cm: - lc.register_block((x, y), 'foo') - self.assertIn('was already registered', str(cm.exception)) - - def testRegisterCategoricalPredictiveDistribution(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - logits = linalg_ops.eye(2) - - lc = layer_collection.LayerCollection() - lc.register_categorical_predictive_distribution(logits, seed=200) - single_loss = sess.run(lc.total_sampled_loss()) - - lc2 = layer_collection.LayerCollection() - lc2.register_categorical_predictive_distribution(logits, seed=200) - lc2.register_categorical_predictive_distribution(logits, seed=200) - double_loss = sess.run(lc2.total_sampled_loss()) - self.assertAlmostEqual(2 * single_loss, double_loss) - - def testLossFunctionByName(self): - """Ensure loss functions can be identified by name.""" - with ops.Graph().as_default(): - logits = linalg_ops.eye(2) - lc = layer_collection.LayerCollection() - - # Create a new loss function by name. - lc.register_categorical_predictive_distribution(logits, name='loss1') - self.assertEqual(1, len(lc.towers_by_loss)) - - # Add logits to same loss function. - lc.register_categorical_predictive_distribution( - logits, name='loss1', reuse=True) - self.assertEqual(1, len(lc.towers_by_loss)) - - # Add another new loss function. - lc.register_categorical_predictive_distribution(logits, name='loss2') - self.assertEqual(2, len(lc.towers_by_loss)) - - def testLossFunctionWithoutName(self): - """Ensure loss functions get unique names if 'name' not specified.""" - with ops.Graph().as_default(): - logits = linalg_ops.eye(2) - lc = layer_collection.LayerCollection() - - # Create a new loss function with default names. - lc.register_categorical_predictive_distribution(logits) - lc.register_categorical_predictive_distribution(logits) - self.assertEqual(2, len(lc.losses)) - - def testCategoricalPredictiveDistributionMultipleMinibatches(self): - """Ensure multiple minibatches are registered.""" - with ops.Graph().as_default(): - batch_size = 3 - output_size = 2 - logits = array_ops.zeros([batch_size, output_size]) - targets = array_ops.ones([batch_size], dtype=dtypes.int32) - lc = layer_collection.LayerCollection() - - # Create a new loss function. - lc.register_categorical_predictive_distribution( - logits, targets=targets, name='loss1') - - # Can add when reuse=True - lc.register_categorical_predictive_distribution( - logits, targets=targets, name='loss1', reuse=True) - - # Can add when reuse=VARIABLE_SCOPE and reuse=True there. - with variable_scope.variable_scope( - variable_scope.get_variable_scope(), reuse=True): - lc.register_categorical_predictive_distribution( - logits, - targets=targets, - name='loss1', - reuse=layer_collection.VARIABLE_SCOPE) - - # Can't add when reuse=False - with self.assertRaises(KeyError): - lc.register_categorical_predictive_distribution( - logits, targets=targets, name='loss1', reuse=False) - - # Can't add when reuse=VARIABLE_SCOPE and reuse=False there. - with self.assertRaises(KeyError): - lc.register_categorical_predictive_distribution( - logits, - targets=targets, - name='loss1', - reuse=layer_collection.VARIABLE_SCOPE) - - self.assertEqual(len(lc.towers_by_loss), 1) - # Three successful registrations. - self.assertEqual(len(lc.towers_by_loss[0]), 3) - - def testRegisterCategoricalPredictiveDistributionBatchSize1(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - logits = random_ops.random_normal((1, 2)) - lc = layer_collection.LayerCollection() - - lc.register_categorical_predictive_distribution(logits, seed=200) - - def testRegisterCategoricalPredictiveDistributionSpecifiedTargets(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - logits = array_ops.constant([[1., 2.], [3., 4.]], dtype=dtypes.float32) - lc = layer_collection.LayerCollection() - targets = array_ops.constant([0, 1], dtype=dtypes.int32) - - lc.register_categorical_predictive_distribution(logits, targets=targets) - single_loss = sess.run(lc.total_loss()) - self.assertAlmostEqual(1.6265233, single_loss) - - def testRegisterNormalPredictiveDistribution(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - predictions = array_ops.constant( - [[1., 2.], [3., 4]], dtype=dtypes.float32) - - lc = layer_collection.LayerCollection() - lc.register_normal_predictive_distribution(predictions, 1., seed=200) - single_loss = sess.run(lc.total_sampled_loss()) - - lc2 = layer_collection.LayerCollection() - lc2.register_normal_predictive_distribution(predictions, 1., seed=200) - lc2.register_normal_predictive_distribution(predictions, 1., seed=200) - double_loss = sess.run(lc2.total_sampled_loss()) - - self.assertAlmostEqual(2 * single_loss, double_loss) - - def testRegisterNormalPredictiveDistributionSpecifiedTargets(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - predictions = array_ops.constant( - [[1., 2.], [3., 4.]], dtype=dtypes.float32) - lc = layer_collection.LayerCollection() - targets = array_ops.constant([[3., 1.], [4., 2.]], dtype=dtypes.float32) - - lc.register_normal_predictive_distribution( - predictions, 2.**2, targets=targets) - single_loss = sess.run(lc.total_loss()) - self.assertAlmostEqual(7.6983433, single_loss) - - def ensureLayerReuseWorks(self, register_fn): - """Ensure the 'reuse' keyword argument function as intended. - - Args: - register_fn: function for registering a layer. Arguments are - layer_collection, reuse, and approx. - """ - # Fails on second if reuse=False. - lc = layer_collection.LayerCollection() - register_fn(lc) - with self.assertRaises(ValueError): - register_fn(lc, reuse=False) - - # Succeeds on second if reuse=True. - lc = layer_collection.LayerCollection() - register_fn(lc) - register_fn(lc, reuse=True) - - # Fails on second if reuse=VARIABLE_SCOPE and no variable reuse. - lc = layer_collection.LayerCollection() - register_fn(lc) - with self.assertRaises(ValueError): - register_fn(lc, reuse=layer_collection.VARIABLE_SCOPE) - - # Succeeds on second if reuse=VARIABLE_SCOPE and variable reuse. - lc = layer_collection.LayerCollection() - register_fn(lc) - with variable_scope.variable_scope( - variable_scope.get_variable_scope(), reuse=True): - register_fn(lc, reuse=layer_collection.VARIABLE_SCOPE) - - # Fails if block type changes. - lc = layer_collection.LayerCollection() - register_fn(lc, approx=layer_collection.APPROX_KRONECKER_NAME) - with self.assertRaises(ValueError): - register_fn(lc, approx=layer_collection.APPROX_DIAGONAL_NAME, reuse=True) - - # Fails if reuse requested but no FisherBlock exists. - lc = layer_collection.LayerCollection() - with self.assertRaises(KeyError): - register_fn(lc, reuse=True) - - def testRegisterFullyConnectedReuse(self): - """Ensure the 'reuse' works with register_fully_connected.""" - with ops.Graph().as_default(): - inputs = array_ops.ones([2, 10]) - outputs = array_ops.zeros([2, 5]) - params = ( - variable_scope.get_variable('w', [10, 5]), # - variable_scope.get_variable('b', [5])) - - def register_fn(lc, **kwargs): - lc.register_fully_connected( - params=params, inputs=inputs, outputs=outputs, **kwargs) - - self.ensureLayerReuseWorks(register_fn) - - def testRegisterConv2dReuse(self): - """Ensure the 'reuse' works with register_conv2d.""" - with ops.Graph().as_default(): - inputs = array_ops.ones([2, 5, 5, 10]) - outputs = array_ops.zeros([2, 5, 5, 3]) - params = ( - variable_scope.get_variable('w', [1, 1, 10, 3]), # - variable_scope.get_variable('b', [3])) - - def register_fn(lc, **kwargs): - lc.register_conv2d( - params=params, - strides=[1, 1, 1, 1], - padding='SAME', - inputs=inputs, - outputs=outputs, - **kwargs) - - self.ensureLayerReuseWorks(register_fn) - - def testReuseWithInvalidRegistration(self): - """Invalid registrations shouldn't overwrite existing blocks.""" - with ops.Graph().as_default(): - inputs = array_ops.ones([2, 5, 5, 10]) - outputs = array_ops.zeros([2, 5, 5, 3]) - w = variable_scope.get_variable('w', [1, 1, 10, 3]) - b = variable_scope.get_variable('b', [3]) - lc = layer_collection.LayerCollection() - lc.register_fully_connected(w, inputs, outputs) - self.assertEqual(lc.fisher_blocks[w].num_registered_towers, 1) - with self.assertRaises(KeyError): - lc.register_fully_connected((w, b), inputs, outputs, reuse=True) - self.assertNotIn((w, b), lc.fisher_blocks) - self.assertEqual(lc.fisher_blocks[w].num_registered_towers, 1) - lc.register_fully_connected(w, inputs, outputs, reuse=True) - self.assertEqual(lc.fisher_blocks[w].num_registered_towers, 2) - - def testMakeOrGetFactor(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - lc = layer_collection.LayerCollection() - key = array_ops.constant(1) - lc.make_or_get_factor(fisher_factors.FullFactor, ((key,), 16)) - lc.make_or_get_factor(fisher_factors.FullFactor, ((key,), 16)) - lc.make_or_get_factor(fisher_factors.FullFactor, - ((array_ops.constant(2),), 16)) - - self.assertEqual(2, len(lc.get_factors())) - variables = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - self.assertTrue( - all([var.name.startswith('LayerCollection') for var in variables])) - - def testMakeOrGetFactorCustomScope(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - scope = 'Foo' - lc = layer_collection.LayerCollection(name=scope) - key = array_ops.constant(1) - lc.make_or_get_factor(fisher_factors.FullFactor, ((key,), 16)) - lc.make_or_get_factor(fisher_factors.FullFactor, ((key,), 16)) - lc.make_or_get_factor(fisher_factors.FullFactor, - ((array_ops.constant(2),), 16)) - - self.assertEqual(2, len(lc.get_factors())) - variables = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - self.assertTrue(all([var.name.startswith(scope) for var in variables])) - - def testIdentifyLinkedParametersSomeRegisteredInOtherTuples(self): - x = variable_scope.get_variable('x', shape=()) - y = variable_scope.get_variable('y', shape=()) - z = variable_scope.get_variable('z', shape=()) - lc = layer_collection.LayerCollection() - lc.define_linked_parameters((x, y)) - - with self.assertRaises(ValueError): - lc.define_linked_parameters((x, z)) - - def testIdentifySubsetPreviouslyRegisteredTensor(self): - x = variable_scope.get_variable('x', shape=()) - y = variable_scope.get_variable('y', shape=()) - lc = layer_collection.LayerCollection() - lc.define_linked_parameters((x, y)) - - with self.assertRaises(ValueError): - lc.define_linked_parameters(x) - - def testSpecifyApproximation(self): - w_0 = variable_scope.get_variable('w_0', [10, 10]) - w_1 = variable_scope.get_variable('w_1', [10, 10]) - - b_0 = variable_scope.get_variable('b_0', [10]) - b_1 = variable_scope.get_variable('b_1', [10]) - - x_0 = array_ops.placeholder(dtypes.float32, shape=(32, 10)) - x_1 = array_ops.placeholder(dtypes.float32, shape=(32, 10)) - - pre_bias_0 = math_ops.matmul(x_0, w_0) - pre_bias_1 = math_ops.matmul(x_1, w_1) - - # Build the fully connected layers in the graph. - pre_bias_0 + b_0 # pylint: disable=pointless-statement - pre_bias_1 + b_1 # pylint: disable=pointless-statement - - lc = layer_collection.LayerCollection() - lc.define_linked_parameters( - w_0, approximation=layer_collection.APPROX_DIAGONAL_NAME) - lc.define_linked_parameters( - w_1, approximation=layer_collection.APPROX_DIAGONAL_NAME) - lc.define_linked_parameters( - b_0, approximation=layer_collection.APPROX_FULL_NAME) - lc.define_linked_parameters( - b_1, approximation=layer_collection.APPROX_FULL_NAME) - - lc.register_fully_connected(w_0, x_0, pre_bias_0) - lc.register_fully_connected( - w_1, x_1, pre_bias_1, approx=layer_collection.APPROX_KRONECKER_NAME) - self.assertIsInstance(lc.fisher_blocks[w_0], - fisher_blocks.FullyConnectedDiagonalFB) - self.assertIsInstance(lc.fisher_blocks[w_1], - fisher_blocks.FullyConnectedKFACBasicFB) - - lc.register_generic(b_0, batch_size=1) - lc.register_generic( - b_1, batch_size=1, approx=layer_collection.APPROX_DIAGONAL_NAME) - self.assertIsInstance(lc.fisher_blocks[b_0], fisher_blocks.FullFB) - self.assertIsInstance(lc.fisher_blocks[b_1], fisher_blocks.NaiveDiagonalFB) - - def testDefaultLayerCollection(self): - with ops.Graph().as_default(): - # Can't get default if there isn't one set. - with self.assertRaises(ValueError): - layer_collection.get_default_layer_collection() - - # Can't set default twice. - lc = layer_collection.LayerCollection() - layer_collection.set_default_layer_collection(lc) - with self.assertRaises(ValueError): - layer_collection.set_default_layer_collection(lc) - - # Same as one set. - self.assertTrue(lc is layer_collection.get_default_layer_collection()) - - # Can set to None. - layer_collection.set_default_layer_collection(None) - with self.assertRaises(ValueError): - layer_collection.get_default_layer_collection() - - # as_default() is the same as setting/clearing. - with lc.as_default(): - self.assertTrue(lc is layer_collection.get_default_layer_collection()) - with self.assertRaises(ValueError): - layer_collection.get_default_layer_collection() - - -if __name__ == '__main__': - test.main() diff --git a/tensorflow/contrib/kfac/python/kernel_tests/loss_functions_test.py b/tensorflow/contrib/kfac/python/kernel_tests/loss_functions_test.py deleted file mode 100644 index c00af5593f..0000000000 --- a/tensorflow/contrib/kfac/python/kernel_tests/loss_functions_test.py +++ /dev/null @@ -1,190 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for tf.contrib.kfac.loss_functions.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np - -from tensorflow.contrib.kfac.python.ops import loss_functions -from tensorflow.python.framework import constant_op -from tensorflow.python.framework import ops -from tensorflow.python.ops import array_ops -from tensorflow.python.platform import test - - -class InsertSliceInZerosTest(test.TestCase): - - def testBadShape(self): - bad_shaped_ones = array_ops.ones(shape=[1, 3]) # n.b. shape[1] != 1 - with self.assertRaises(ValueError): - loss_functions.insert_slice_in_zeros(bad_shaped_ones, 1, 42, 17) - - def test3d(self): - input_tensor = constant_op.constant([[[1, 2]], [[3, 4]]]) - expected_output_array = [[[1, 2], [0, 0]], [[3, 4], [0, 0]]] - op = loss_functions.insert_slice_in_zeros(input_tensor, 1, 2, 0) - with self.test_session() as sess: - actual_output_array = sess.run(op) - self.assertAllEqual(expected_output_array, actual_output_array) - - -class CategoricalLogitsNegativeLogProbLossTest(test.TestCase): - - def testSample(self): - """Ensure samples can be drawn.""" - with ops.Graph().as_default(), self.test_session() as sess: - logits = np.asarray([ - [0., 0., 0.], # - [1., -1., 0.] - ]).astype(np.float32) - loss = loss_functions.CategoricalLogitsNegativeLogProbLoss( - array_ops.constant(logits)) - sample = loss.sample(42) - sample = sess.run(sample) - self.assertEqual(sample.shape, (2,)) - - def testEvaluateOnTargets(self): - """Ensure log probability can be evaluated correctly.""" - with ops.Graph().as_default(), self.test_session() as sess: - logits = np.asarray([ - [0., 0., 0.], # - [1., -1., 0.] - ]).astype(np.float32) - targets = np.asarray([2, 1]).astype(np.int32) - loss = loss_functions.CategoricalLogitsNegativeLogProbLoss( - array_ops.constant(logits), targets=array_ops.constant(targets)) - neg_log_prob = loss.evaluate() - neg_log_prob = sess.run(neg_log_prob) - - # Calculate explicit log probability of targets. - probs = np.exp(logits) / np.sum(np.exp(logits), axis=1, keepdims=True) - log_probs = np.log([ - probs[0, targets[0]], # - probs[1, targets[1]] - ]) - expected_log_prob = np.sum(log_probs) - - self.assertAllClose(neg_log_prob, -expected_log_prob) - - def testEvaluateOnSample(self): - """Ensure log probability of a sample can be drawn.""" - with ops.Graph().as_default(), self.test_session() as sess: - logits = np.asarray([ - [0., 0., 0.], # - [1., -1., 0.] - ]).astype(np.float32) - loss = loss_functions.CategoricalLogitsNegativeLogProbLoss( - array_ops.constant(logits)) - neg_log_prob = loss.evaluate_on_sample(42) - - # Simply ensure this doesn't crash. As the output is random, it's - # difficult to say if the output is correct or not... - neg_log_prob = sess.run(neg_log_prob) - - def testMultiplyFisherSingleVector(self): - with ops.Graph().as_default(), self.test_session() as sess: - logits = np.array([1., 2., 3.]) - loss = loss_functions.CategoricalLogitsNegativeLogProbLoss(logits) - - # the LossFunction.multiply_fisher docstring only says it supports the - # case where the vector is the same shape as the input natural parameters - # (i.e. the logits here), but here we also test leading dimensions - vector = np.array([1., 2., 3.]) - vectors = [vector, vector.reshape(1, -1), np.stack([vector] * 4)] - - probs = np.exp(logits - np.logaddexp.reduce(logits)) - fisher = np.diag(probs) - np.outer(probs, probs) - - for vector in vectors: - result = loss.multiply_fisher(vector) - expected_result = np.dot(vector, fisher) - self.assertAllClose(expected_result, sess.run(result)) - - def testMultiplyFisherBatch(self): - with ops.Graph().as_default(), self.test_session() as sess: - logits = np.array([[1., 2., 3.], [4., 6., 8.]]) - loss = loss_functions.CategoricalLogitsNegativeLogProbLoss(logits) - - vector = np.array([[1., 2., 3.], [5., 3., 1.]]) - - na = np.newaxis - probs = np.exp(logits - np.logaddexp.reduce(logits, axis=-1, - keepdims=True)) - fishers = probs[..., na] * np.eye(3) - probs[..., na] * probs[..., na, :] - - result = loss.multiply_fisher(vector) - expected_result = np.matmul(vector[..., na, :], fishers)[..., 0, :] - self.assertEqual(sess.run(result).shape, logits.shape) - self.assertAllClose(expected_result, sess.run(result)) - - -class OnehotCategoricalLogitsNegativeLogProbLossTest(test.TestCase): - - def testSample(self): - """Ensure samples can be drawn.""" - with ops.Graph().as_default(), self.test_session() as sess: - logits = np.asarray([ - [0., 0., 0.], # - [1., -1., 0.] - ]).astype(np.float32) - loss = loss_functions.OnehotCategoricalLogitsNegativeLogProbLoss( - array_ops.constant(logits)) - sample = loss.sample(42) - sample = sess.run(sample) - self.assertEqual(sample.shape, (2, 3)) - - def testEvaluateOnTargets(self): - """Ensure log probability can be evaluated correctly.""" - with ops.Graph().as_default(), self.test_session() as sess: - logits = np.asarray([ - [0., 0., 0.], # - [1., -1., 0.] - ]).astype(np.float32) - targets = np.asarray([2, 1]).astype(np.int32) - loss = loss_functions.OnehotCategoricalLogitsNegativeLogProbLoss( - array_ops.constant(logits), targets=array_ops.one_hot(targets, 3)) - neg_log_prob = loss.evaluate() - neg_log_prob = sess.run(neg_log_prob) - - # Calculate explicit log probability of targets. - probs = np.exp(logits) / np.sum(np.exp(logits), axis=1, keepdims=True) - log_probs = np.log([ - probs[0, targets[0]], # - probs[1, targets[1]] - ]) - expected_log_prob = np.sum(log_probs) - - self.assertAllClose(neg_log_prob, -expected_log_prob) - - def testEvaluateOnSample(self): - """Ensure log probability of a sample can be drawn.""" - with ops.Graph().as_default(), self.test_session() as sess: - logits = np.asarray([ - [0., 0., 0.], # - [1., -1., 0.] - ]).astype(np.float32) - loss = loss_functions.OnehotCategoricalLogitsNegativeLogProbLoss( - array_ops.constant(logits)) - neg_log_prob = loss.evaluate_on_sample(42) - - # Simply ensure this doesn't crash. As the output is random, it's - # difficult to say if the output is correct or not... - neg_log_prob = sess.run(neg_log_prob) - -if __name__ == "__main__": - test.main() diff --git a/tensorflow/contrib/kfac/python/kernel_tests/op_queue_test.py b/tensorflow/contrib/kfac/python/kernel_tests/op_queue_test.py deleted file mode 100644 index b20a70e4ca..0000000000 --- a/tensorflow/contrib/kfac/python/kernel_tests/op_queue_test.py +++ /dev/null @@ -1,50 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for tf.contrib.kfac.op_queue.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from tensorflow.contrib.kfac.python.ops import op_queue -from tensorflow.python.framework import ops as tf_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.platform import test - - -class OpQueueTest(test.TestCase): - - def testNextOp(self): - """Ensures all ops get selected eventually.""" - with tf_ops.Graph().as_default(): - ops = [ - math_ops.add(1, 2), - math_ops.subtract(1, 2), - math_ops.reduce_mean([1, 2]), - ] - queue = op_queue.OpQueue(ops, seed=0) - - with self.test_session() as sess: - # Ensure every inv update op gets selected. - selected_ops = set([queue.next_op(sess) for _ in ops]) - self.assertEqual(set(ops), set(selected_ops)) - - # Ensure additional calls don't create any new ops. - selected_ops.add(queue.next_op(sess)) - self.assertEqual(set(ops), set(selected_ops)) - - -if __name__ == "__main__": - test.main() diff --git a/tensorflow/contrib/kfac/python/kernel_tests/optimizer_test.py b/tensorflow/contrib/kfac/python/kernel_tests/optimizer_test.py deleted file mode 100644 index 560a9b0b42..0000000000 --- a/tensorflow/contrib/kfac/python/kernel_tests/optimizer_test.py +++ /dev/null @@ -1,219 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for tf.contrib.kfac.optimizer.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np - -from tensorflow.contrib.kfac.python.ops import fisher_factors as ff -from tensorflow.contrib.kfac.python.ops import layer_collection as lc -from tensorflow.contrib.kfac.python.ops import optimizer -from tensorflow.python.framework import ops -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import init_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import nn -from tensorflow.python.ops import variable_scope -from tensorflow.python.ops import variables as tf_variables -from tensorflow.python.platform import test - - -# We need to set these constants since the numerical values used in the tests -# were chosen when these used to be the defaults. -ff.set_global_constants(init_covariances_at_zero=False, - zero_debias=False, - init_inverses_at_zero=False) - - -def dummy_layer_collection(): - lcoll = lc.LayerCollection() - dummy = array_ops.constant([1., 2.]) - lcoll.register_categorical_predictive_distribution(logits=dummy) - return lcoll - - -class OptimizerTest(test.TestCase): - - def testOptimizerInitInvalidMomentumRegistration(self): - with self.assertRaises(ValueError): - optimizer.KfacOptimizer( - 0.1, 0.2, 0.3, lc.LayerCollection(), momentum_type='foo') - - def testOptimizerInit(self): - with ops.Graph().as_default(): - layer_collection = lc.LayerCollection() - - inputs = array_ops.ones((2, 1)) * 2 - weights_val = np.ones((1, 1), dtype=np.float32) * 3. - weights = variable_scope.get_variable( - 'w', initializer=array_ops.constant(weights_val)) - bias = variable_scope.get_variable( - 'b', initializer=init_ops.zeros_initializer(), shape=(1, 1)) - output = math_ops.matmul(inputs, weights) + bias - - layer_collection.register_fully_connected((weights, bias), inputs, output) - - logits = math_ops.tanh(output) - targets = array_ops.constant([[0.], [1.]]) - output = math_ops.reduce_mean( - nn.softmax_cross_entropy_with_logits(logits=logits, labels=targets)) - - layer_collection.register_categorical_predictive_distribution(logits) - - optimizer.KfacOptimizer( - 0.1, - 0.2, - 0.3, - layer_collection, - momentum=0.5, - momentum_type='regular') - - def testSquaredFisherNorm(self): - with ops.Graph().as_default(), self.test_session() as sess: - grads_and_vars = [(array_ops.constant([[1., 2.], [3., 4.]]), None), - (array_ops.constant([[2., 3.], [4., 5.]]), None)] - pgrads_and_vars = [(array_ops.constant([[3., 4.], [5., 6.]]), None), - (array_ops.constant([[7., 8.], [9., 10.]]), None)] - opt = optimizer.KfacOptimizer(0.1, 0.2, 0.3, dummy_layer_collection()) - sq_norm = opt._squared_fisher_norm(grads_and_vars, pgrads_and_vars) - self.assertAlmostEqual(174., sess.run(sq_norm), places=5) - - def testUpdateClipCoeff(self): - with ops.Graph().as_default(), self.test_session() as sess: - grads_and_vars = [(array_ops.constant([[1., 2.], [3., 4.]]), None), - (array_ops.constant([[2., 3.], [4., 5.]]), None)] - pgrads_and_vars = [(array_ops.constant([[3., 4.], [5., 6.]]), None), - (array_ops.constant([[7., 8.], [9., 10.]]), None)] - lrate = 0.1 - - # Note: without rescaling, the squared Fisher norm of the update - # is 1.74 - - # If the update already satisfies the norm constraint, there should - # be no rescaling. - opt = optimizer.KfacOptimizer( - lrate, 0.2, 0.3, dummy_layer_collection(), norm_constraint=10.) - coeff = opt._update_clip_coeff(grads_and_vars, pgrads_and_vars) - self.assertAlmostEqual(1., sess.run(coeff), places=5) - - # If the update violates the constraint, it should be rescaled to - # be on the constraint boundary. - opt = optimizer.KfacOptimizer( - lrate, 0.2, 0.3, dummy_layer_collection(), norm_constraint=0.5) - coeff = opt._update_clip_coeff(grads_and_vars, pgrads_and_vars) - sq_norm_pgrad = opt._squared_fisher_norm(grads_and_vars, pgrads_and_vars) - sq_norm_update = lrate**2 * coeff**2 * sq_norm_pgrad - self.assertAlmostEqual(0.5, sess.run(sq_norm_update), places=5) - - def testComputeUpdateStepsRegular(self): - # TODO(olganw): implement this. - pass - - def testComputeUpdateStepsAdam(self): - # TODO(olganw): implement this. - pass - - def testUpdateVelocities(self): - with ops.Graph().as_default(), self.test_session() as sess: - layers = lc.LayerCollection() - layers.register_categorical_predictive_distribution( - array_ops.constant([1.0])) - opt = optimizer.KfacOptimizer( - 0.1, 0.2, 0.3, layers, momentum=0.5, momentum_type='regular') - x = variable_scope.get_variable('x', initializer=array_ops.ones((2, 2))) - y = variable_scope.get_variable( - 'y', initializer=array_ops.ones((2, 2)) * 2) - vec1 = array_ops.ones((2, 2)) * 3 - vec2 = array_ops.ones((2, 2)) * 4 - - model_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - update_op = opt._update_velocities([(vec1, x), (vec2, y)], 0.5) - opt_vars = [ - v for v in ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - if v not in model_vars - ] - - sess.run(tf_variables.global_variables_initializer()) - old_opt_vars = sess.run(opt_vars) - - # Optimizer vars start out at 0. - for opt_var in old_opt_vars: - self.assertAllEqual(sess.run(array_ops.zeros_like(opt_var)), opt_var) - - sess.run(update_op) - new_opt_vars = sess.run(opt_vars) - # After one update, the velocities are equal to the vectors. - for vec, opt_var in zip([vec1, vec2], new_opt_vars): - self.assertAllEqual(sess.run(vec), opt_var) - - sess.run(update_op) - final_opt_vars = sess.run(opt_vars) - for first, second in zip(new_opt_vars, final_opt_vars): - self.assertFalse(np.equal(first, second).all()) - - def testApplyGradients(self): - with ops.Graph().as_default(), self.test_session() as sess: - layer_collection = lc.LayerCollection() - - inputs = array_ops.ones((2, 1)) * 2 - weights_val = np.ones((1, 1), dtype=np.float32) * 3. - weights = variable_scope.get_variable( - 'w', initializer=array_ops.constant(weights_val)) - bias = variable_scope.get_variable( - 'b', initializer=init_ops.zeros_initializer(), shape=(1, 1)) - output = math_ops.matmul(inputs, weights) + bias - - layer_collection.register_fully_connected((weights, bias), inputs, output) - - logits = math_ops.tanh(output) - targets = array_ops.constant([[0.], [1.]]) - output = math_ops.reduce_mean( - nn.softmax_cross_entropy_with_logits(logits=logits, labels=targets)) - - layer_collection.register_categorical_predictive_distribution(logits) - - opt = optimizer.KfacOptimizer( - 0.1, - 0.2, - 0.3, - layer_collection, - momentum=0.5, - momentum_type='regular') - (cov_update_thunks, - inv_update_thunks) = opt.make_vars_and_create_op_thunks() - cov_update_ops = tuple(thunk() for thunk in cov_update_thunks) - inv_update_ops = tuple(thunk() for thunk in inv_update_thunks) - - grads_and_vars = opt.compute_gradients(output, [weights, bias]) - all_vars = [grad_and_var[1] for grad_and_var in grads_and_vars] - - op = opt.apply_gradients(grads_and_vars) - - sess.run(tf_variables.global_variables_initializer()) - old_vars = sess.run(all_vars) - sess.run(cov_update_ops) - sess.run(inv_update_ops) - sess.run(op) - new_vars = sess.run(all_vars) - - for old_var, new_var in zip(old_vars, new_vars): - self.assertNotEqual(old_var, new_var) - - -if __name__ == '__main__': - test.main() diff --git a/tensorflow/contrib/kfac/python/kernel_tests/utils_test.py b/tensorflow/contrib/kfac/python/kernel_tests/utils_test.py deleted file mode 100644 index 2cee01212a..0000000000 --- a/tensorflow/contrib/kfac/python/kernel_tests/utils_test.py +++ /dev/null @@ -1,410 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for tf.contrib.kfac.utils.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import numpy.random as npr - -from tensorflow.contrib.kfac.python.ops import utils -from tensorflow.contrib.tpu.python.tpu import tpu_function -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import ops -from tensorflow.python.framework import random_seed -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import linalg_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import nn_ops -from tensorflow.python.ops import random_ops -from tensorflow.python.ops import variable_scope -from tensorflow.python.ops import variables -from tensorflow.python.platform import test - - -class SequenceDictTest(test.TestCase): - - def testSequenceDictInit(self): - seq_dict = utils.SequenceDict() - self.assertFalse(seq_dict._dict) - - def testSequenceDictInitWithIterable(self): - reg_dict = {'a': 'foo', 'b': 'bar'} - itr = zip(reg_dict.keys(), reg_dict.values()) - seq_dict = utils.SequenceDict(itr) - self.assertEqual(reg_dict, seq_dict._dict) - - def testGetItemSingleKey(self): - seq_dict = utils.SequenceDict({'a': 'foo', 'b': 'bar'}) - self.assertEqual('foo', seq_dict['a']) - - def testGetItemMultipleKeys(self): - seq_dict = utils.SequenceDict({'a': 'foo', 'b': 'bar'}) - self.assertEqual(['foo', 'bar'], seq_dict[('a', 'b')]) - - def testSetItemSingleKey(self): - seq_dict = utils.SequenceDict() - seq_dict['a'] = 'foo' - self.assertEqual([('a', 'foo')], seq_dict.items()) - - def testSetItemMultipleKeys(self): - seq_dict = utils.SequenceDict() - keys = ('a', 'b', 'c') - values = ('foo', 'bar', 'baz') - seq_dict[keys] = values - self.assertItemsEqual(list(zip(keys, values)), seq_dict.items()) - - -class SubGraphTest(test.TestCase): - - def testBasicGraph(self): - a = array_ops.constant([[1., 2.], [3., 4.]]) - b = array_ops.constant([[5., 6.], [7., 8.]]) - c = a + b - d = a * b - sub_graph = utils.SubGraph((c,)) - self.assertTrue(sub_graph.is_member(a)) - self.assertTrue(sub_graph.is_member(b)) - self.assertTrue(sub_graph.is_member(c)) - self.assertFalse(sub_graph.is_member(d)) - - def testRepeatedAdds(self): - a = array_ops.constant([[1., 2.], [3., 4.]]) - b = array_ops.constant([[5., 6.], [7., 8.]]) - c = a + b + a # note that a appears twice in this graph - sub_graph = utils.SubGraph((c,)) - self.assertTrue(sub_graph.is_member(a)) - self.assertTrue(sub_graph.is_member(b)) - self.assertTrue(sub_graph.is_member(c)) - - def testFilterList(self): - a = array_ops.constant([[1., 2.], [3., 4.]]) - b = array_ops.constant([[5., 6.], [7., 8.]]) - c = a + b - d = a * b - sub_graph = utils.SubGraph((c,)) - input_list = [b, d] - filtered_list = sub_graph.filter_list(input_list) - self.assertEqual(filtered_list, [b]) - - def testVariableUses(self): - with ops.Graph().as_default(): - var = variable_scope.get_variable('var', shape=[10, 10]) - resource_var = variable_scope.get_variable( - 'resource_var', shape=[10, 10], use_resource=True) - x = array_ops.zeros([3, 10]) - z0 = math_ops.matmul(x, var) + math_ops.matmul(x, var) - z1 = math_ops.matmul(x, resource_var) - sub_graph = utils.SubGraph((z0, z1)) - self.assertEqual(2, sub_graph.variable_uses(var)) - self.assertEqual(1, sub_graph.variable_uses(resource_var)) - - -class UtilsTest(test.TestCase): - - def _fully_connected_layer_params(self): - weights_part = array_ops.constant([[1., 2.], [4., 3.]]) - bias_part = array_ops.constant([1., 2.]) - return (weights_part, bias_part) - - def _conv_layer_params(self): - weights_shape = 2, 2, 3, 4 - biases_shape = weights_shape[-1:] - weights = array_ops.constant(npr.RandomState(0).randn(*weights_shape)) - biases = array_ops.constant(npr.RandomState(1).randn(*biases_shape)) - return (weights, biases) - - def testFullyConnectedLayerParamsTupleToMat2d(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - layer_params = self._fully_connected_layer_params() - output = utils.layer_params_to_mat2d(layer_params) - self.assertListEqual([3, 2], output.get_shape().as_list()) - self.assertAllClose( - sess.run(output), np.array([[1., 2.], [4., 3.], [1., 2.]])) - - def testFullyConnectedLayerParamsTensorToMat2d(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - layer_params = self._fully_connected_layer_params() - output = utils.layer_params_to_mat2d(layer_params[0]) - self.assertListEqual([2, 2], output.get_shape().as_list()) - self.assertAllClose(sess.run(output), np.array([[1., 2.], [4., 3.]])) - - def testConvLayerParamsTupleToMat2d(self): - with ops.Graph().as_default(): - random_seed.set_random_seed(200) - layer_params = self._conv_layer_params() - output = utils.layer_params_to_mat2d(layer_params) - self.assertListEqual([2 * 2 * 3 + 1, 4], output.get_shape().as_list()) - - def testKron(self): - with ops.Graph().as_default(), self.test_session() as sess: - mat1 = np.array([[1., 2.], [3., 4.]]) - mat2 = np.array([[5., 6.], [7., 8.]]) - mat1_tf = array_ops.constant(mat1) - mat2_tf = array_ops.constant(mat2) - ans_tf = sess.run(utils.kronecker_product(mat1_tf, mat2_tf)) - ans_np = np.kron(mat1, mat2) - self.assertAllClose(ans_tf, ans_np) - - def testMat2dToFullyConnectedLayerParamsTuple(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - vector_template = self._fully_connected_layer_params() - mat2d = array_ops.constant([[5., 4.], [3., 2.], [1., 0.]]) - - output = sess.run(utils.mat2d_to_layer_params(vector_template, mat2d)) - - self.assertIsInstance(output, tuple) - self.assertEqual(len(output), 2) - a, b = output - self.assertAllClose(a, np.array([[5., 4.], [3., 2.]])) - self.assertAllClose(b, np.array([1., 0.])) - - def testMat2dToFullyConnectedLayerParamsTensor(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - vector_template = self._fully_connected_layer_params()[0] - mat2d = array_ops.constant([[5., 4.], [3., 2.]]) - - output = sess.run(utils.mat2d_to_layer_params(vector_template, mat2d)) - - self.assertAllClose(output, np.array([[5., 4.], [3., 2.]])) - - def testTensorsToColumn(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - - vector = array_ops.constant(np.array([[0., 1.], [2., 3.]])) - output = utils.tensors_to_column(vector) - self.assertListEqual([4, 1], output.get_shape().as_list()) - self.assertAllClose(sess.run(output), np.array([0., 1., 2., 3.])[:, None]) - - vector = self._fully_connected_layer_params() - output = utils.tensors_to_column(vector) - self.assertListEqual([6, 1], output.get_shape().as_list()) - self.assertAllClose( - sess.run(output), np.array([1., 2., 4., 3., 1., 2.])[:, None]) - - vector = list(vector) - vector.append(array_ops.constant([[6.], [7.], [8.], [9.]])) - - output = utils.tensors_to_column(vector) - self.assertListEqual([10, 1], output.get_shape().as_list()) - self.assertAllClose( - sess.run(output), - np.array([1., 2., 4., 3., 1., 2., 6., 7., 8., 9.])[:, None]) - - def testColumnToTensors(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - - vector_template = array_ops.constant(np.array([[0., 1.], [2., 3.]])) - colvec = array_ops.constant(np.arange(4.)[:, None]) - output = sess.run(utils.column_to_tensors(vector_template, colvec)) - self.assertAllClose(output, np.array([[0., 1.], [2., 3.]])) - - vector_template = self._fully_connected_layer_params() - colvec = array_ops.constant(np.arange(6.)[:, None]) - output = sess.run(utils.column_to_tensors(vector_template, colvec)) - - self.assertIsInstance(output, tuple) - self.assertEqual(len(output), 2) - a, b = output - self.assertAllClose(a, np.array([[0., 1.], [2., 3.]])) - self.assertAllClose(b, np.array([4., 5.])) - - vector_template = list(vector_template) - vector_template.append(array_ops.constant([[6.], [7.], [8.], [9.]])) - colvec = array_ops.constant(np.arange(10.)[:, None]) - output = sess.run(utils.column_to_tensors(vector_template, colvec)) - self.assertIsInstance(output, tuple) - self.assertEqual(len(output), 3) - a, b, c = output - self.assertAllClose(a, np.array([[0., 1.], [2., 3.]])) - self.assertAllClose(b, np.array([4., 5.])) - self.assertAllClose(c, np.array([[6.], [7.], [8.], [9.]])) - - def testPosDefInvCholesky(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - npr.seed(0) - square = lambda x: np.dot(x, x.T) - - size = 3 - x = square(npr.randn(size, size)) - damp = 0.1 - identity = linalg_ops.eye(size, dtype=dtypes.float64) - - tf_inv = utils.posdef_inv_cholesky(array_ops.constant(x), identity, damp) - np_inv = np.linalg.inv(x + damp * np.eye(size)) - self.assertAllClose(sess.run(tf_inv), np_inv) - - def testPosDefInvMatrixInverse(self): - with ops.Graph().as_default(), self.test_session() as sess: - random_seed.set_random_seed(200) - npr.seed(0) - square = lambda x: np.dot(x, x.T) - - size = 3 - x = square(npr.randn(size, size)) - damp = 0.1 - identity = linalg_ops.eye(size, dtype=dtypes.float64) - - tf_inv = utils.posdef_inv_matrix_inverse( - array_ops.constant(x), identity, damp) - np_inv = np.linalg.inv(x + damp * np.eye(size)) - self.assertAllClose(sess.run(tf_inv), np_inv) - - def testCrossReplicaMean(self): - """Ensures that cross_replica_mean() executes only when num_shards > 1.""" - with ops.Graph().as_default(): - with tpu_function.tpu_shard_context(4): - tensor = array_ops.zeros([], dtype=dtypes.float32) - mean = utils.cross_replica_mean(tensor) - self.assertNotEqual(mean, tensor) - - with ops.Graph().as_default(): - with tpu_function.tpu_shard_context(1): - tensor = array_ops.zeros([], dtype=dtypes.float32) - mean = utils.cross_replica_mean(tensor) - self.assertEqual(mean, tensor) - - with ops.Graph().as_default(): - with self.assertRaises(ValueError): # Outside of TPU context. - tensor = array_ops.zeros([], dtype=dtypes.float32) - mean = utils.cross_replica_mean(tensor) - - def testBatchExecute(self): - """Ensure batch_execute runs in a round-robin fashion.""" - - def increment_var(var): - return lambda: var.assign_add(1) - - with ops.Graph().as_default(), self.test_session() as sess: - i = variable_scope.get_variable('i', initializer=0) - accumulators = [ - variable_scope.get_variable('var%d' % j, initializer=0) - for j in range(3) - ] - thunks = [increment_var(var) for var in accumulators] - increment_accumulators = utils.batch_execute(i, thunks, 2) - increment_i = i.assign_add(1) - - sess.run(variables.global_variables_initializer()) - - # Ensure one op per thunk. - self.assertEqual(3, len(increment_accumulators)) - - # Ensure round-robin execution. - values = [] - for _ in range(5): - sess.run(increment_accumulators) - sess.run(increment_i) - values.append(sess.run(accumulators)) - self.assertAllClose( - [ - [1, 1, 0], # - [2, 1, 1], # - [2, 2, 2], # - [3, 3, 2], # - [4, 3, 3] - ], - values) - - def testExtractConvolutionPatches(self): - with ops.Graph().as_default(), self.test_session() as sess: - batch_size = 10 - image_spatial_shape = [9, 10, 11] - in_channels = out_channels = 32 - kernel_spatial_shape = [5, 3, 3] - spatial_strides = [1, 2, 1] - spatial_dilation = [1, 1, 1] - padding = 'SAME' - - images = random_ops.random_uniform( - [batch_size] + image_spatial_shape + [in_channels], seed=0) - kernel_shape = kernel_spatial_shape + [in_channels, out_channels] - kernel = random_ops.random_uniform(kernel_shape, seed=1) - - # Ensure shape matches expectation. - patches = utils.extract_convolution_patches( - images, - kernel_shape, - padding, - strides=spatial_strides, - dilation_rate=spatial_dilation) - result_spatial_shape = ( - patches.shape.as_list()[1:1 + len(image_spatial_shape)]) - self.assertEqual(patches.shape.as_list(), - [batch_size] + result_spatial_shape + - kernel_spatial_shape + [in_channels]) - - # Ensure extract...patches() + matmul() and convolution() implementation - # give the same answer. - outputs = nn_ops.convolution( - images, - kernel, - padding, - strides=spatial_strides, - dilation_rate=spatial_dilation) - - patches_flat = array_ops.reshape( - patches, [-1, np.prod(kernel_spatial_shape) * in_channels]) - kernel_flat = array_ops.reshape(kernel, [-1, out_channels]) - outputs_flat = math_ops.matmul(patches_flat, kernel_flat) - - outputs_, outputs_flat_ = sess.run([outputs, outputs_flat]) - self.assertAllClose(outputs_.flatten(), outputs_flat_.flatten()) - - def testExtractPointwiseConv2dPatches(self): - with ops.Graph().as_default(), self.test_session() as sess: - batch_size = 10 - image_height = image_width = 8 - in_channels = out_channels = 3 - kernel_height = kernel_width = 1 - strides = [1, 1, 1, 1] - padding = 'VALID' - - images = random_ops.random_uniform( - [batch_size, image_height, image_width, in_channels], seed=0) - kernel_shape = [kernel_height, kernel_width, in_channels, out_channels] - kernel = random_ops.random_uniform(kernel_shape, seed=1) - - # Ensure shape matches expectation. - patches = utils.extract_pointwise_conv2d_patches(images, kernel_shape) - self.assertEqual(patches.shape.as_list(), [ - batch_size, image_height, image_width, kernel_height, kernel_width, - in_channels - ]) - - # Ensure extract...patches() + matmul() and conv2d() implementation - # give the same answer. - outputs = nn_ops.conv2d(images, kernel, strides, padding) - - patches_flat = array_ops.reshape( - patches, [-1, kernel_height * kernel_width * in_channels]) - kernel_flat = array_ops.reshape(kernel, [-1, out_channels]) - outputs_flat = math_ops.matmul(patches_flat, kernel_flat) - - outputs_, outputs_flat_ = sess.run([outputs, outputs_flat]) - self.assertAllClose(outputs_.flatten(), outputs_flat_.flatten()) - - -if __name__ == '__main__': - test.main() diff --git a/tensorflow/contrib/kfac/python/ops/BUILD b/tensorflow/contrib/kfac/python/ops/BUILD deleted file mode 100644 index 3c01eb65e7..0000000000 --- a/tensorflow/contrib/kfac/python/ops/BUILD +++ /dev/null @@ -1,263 +0,0 @@ -package(default_visibility = [ - "//tensorflow/contrib/kfac:__pkg__", - "//tensorflow/contrib/kfac/python/kernel_tests:__pkg__", -]) - -licenses(["notice"]) # Apache 2.0 - -exports_files(["LICENSE"]) - -py_library( - name = "fisher_blocks", - srcs = ["fisher_blocks.py"], - srcs_version = "PY2AND3", - deps = [ - ":fisher_factors", - ":utils", - "//tensorflow/python:array_ops", - "//tensorflow/python:math_ops", - "@six_archive//:six", - ], -) - -py_library( - name = "fisher_blocks_lib", - srcs = ["fisher_blocks_lib.py"], - srcs_version = "PY2AND3", - deps = [ - ":fisher_blocks", - "//tensorflow/python:util", - ], -) - -py_library( - name = "fisher_factors", - srcs = ["fisher_factors.py"], - srcs_version = "PY2AND3", - deps = [ - ":linear_operator", - ":utils", - "//tensorflow/python:array_ops", - "//tensorflow/python:control_flow_ops", - "//tensorflow/python:dtypes", - "//tensorflow/python:framework_ops", - "//tensorflow/python:init_ops", - "//tensorflow/python:linalg_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:random_ops", - "//tensorflow/python:special_math_ops", - "//tensorflow/python:training", - "//tensorflow/python:variable_scope", - "//tensorflow/python:variables", - "//third_party/py/numpy", - "@six_archive//:six", - ], -) - -py_library( - name = "fisher_factors_lib", - srcs = ["fisher_factors_lib.py"], - srcs_version = "PY2AND3", - deps = [ - ":fisher_factors", - "//tensorflow/python:util", - ], -) - -py_library( - name = "linear_operator", - srcs = ["linear_operator.py"], - srcs_version = "PY2AND3", - deps = [ - ":utils", - "//tensorflow/python:framework_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python/ops/linalg", - "@six_archive//:six", - ], -) - -py_library( - name = "loss_functions", - srcs = ["loss_functions.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/distributions:distributions_py", - "//tensorflow/python:array_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:tensor_shape", - "//tensorflow/python/ops/distributions", - "@six_archive//:six", - ], -) - -py_library( - name = "loss_functions_lib", - srcs = ["loss_functions_lib.py"], - srcs_version = "PY2AND3", - deps = [ - ":loss_functions", - "//tensorflow/python:util", - ], -) - -py_library( - name = "curvature_matrix_vector_products", - srcs = ["curvature_matrix_vector_products.py"], - srcs_version = "PY2AND3", - deps = [ - ":utils", - "//tensorflow/python:gradients", - "//tensorflow/python:math_ops", - "//tensorflow/python:util", - ], -) - -py_library( - name = "curvature_matrix_vector_products_lib", - srcs = ["curvature_matrix_vector_products_lib.py"], - srcs_version = "PY2AND3", - deps = [ - ":curvature_matrix_vector_products", - "//tensorflow/python:util", - ], -) - -py_library( - name = "layer_collection", - srcs = ["layer_collection.py"], - srcs_version = "PY2AND3", - deps = [ - ":fisher_blocks", - ":loss_functions", - ":utils", - "//tensorflow/python:framework_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:platform", - "//tensorflow/python:util", - "//tensorflow/python:variable_scope", - "@six_archive//:six", - ], -) - -py_library( - name = "layer_collection_lib", - srcs = ["layer_collection_lib.py"], - srcs_version = "PY2AND3", - deps = [ - ":layer_collection", - "//tensorflow/python:util", - ], -) - -py_library( - name = "kfac_optimizer", - srcs = [ - "optimizer.py", - ], - srcs_version = "PY2AND3", - deps = [ - ":curvature_matrix_vector_products", - ":fisher_estimator", - "//tensorflow/python:array_ops", - "//tensorflow/python:control_flow_ops", - "//tensorflow/python:dtypes", - "//tensorflow/python:framework_ops", - "//tensorflow/python:linalg_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:state_ops", - "//tensorflow/python:training", - "//tensorflow/python:variable_scope", - "//tensorflow/python:variables", - ], -) - -py_library( - name = "kfac_optimizer_lib", - srcs = [ - "optimizer_lib.py", - ], - srcs_version = "PY2AND3", - deps = [ - ":kfac_optimizer", - "//tensorflow/python:util", - ], -) - -py_library( - name = "fisher_estimator", - srcs = [ - "estimator.py", - "placement.py", - ], - srcs_version = "PY2AND3", - deps = [ - ":utils", - "//tensorflow/python:control_flow_ops", - "//tensorflow/python:framework_ops", - "//tensorflow/python:gradients", - "//tensorflow/python:util", - "//third_party/py/numpy", - "@six_archive//:six", - ], -) - -py_library( - name = "fisher_estimator_lib", - srcs = [ - "estimator_lib.py", - ], - srcs_version = "PY2AND3", - deps = [ - ":fisher_estimator", - "//tensorflow/python:util", - ], -) - -py_library( - name = "utils", - srcs = ["utils.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/tpu", - "//tensorflow/python:array_ops", - "//tensorflow/python:control_flow_ops", - "//tensorflow/python:dtypes", - "//tensorflow/python:framework_ops", - "//tensorflow/python:gradients", - "//tensorflow/python:linalg_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:random_ops", - "//third_party/py/numpy", - ], -) - -py_library( - name = "utils_lib", - srcs = ["utils_lib.py"], - srcs_version = "PY2AND3", - deps = [ - ":utils", - "//tensorflow/python:util", - ], -) - -py_library( - name = "op_queue", - srcs = ["op_queue.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow/contrib/data/python/ops:dataset_ops", - "//tensorflow/python:framework_ops", - ], -) - -py_library( - name = "op_queue_lib", - srcs = ["op_queue_lib.py"], - srcs_version = "PY2AND3", - deps = [ - ":op_queue", - "//tensorflow/python:util", - ], -) diff --git a/tensorflow/contrib/kfac/python/ops/curvature_matrix_vector_products.py b/tensorflow/contrib/kfac/python/ops/curvature_matrix_vector_products.py deleted file mode 100644 index 21b5cde9b9..0000000000 --- a/tensorflow/contrib/kfac/python/ops/curvature_matrix_vector_products.py +++ /dev/null @@ -1,183 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Curvature matrix-vector multiplication.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from tensorflow.contrib.kfac.python.ops import utils -from tensorflow.python.ops import gradients_impl -from tensorflow.python.ops import math_ops -from tensorflow.python.util import nest - - -class CurvatureMatrixVectorProductComputer(object): - """Class for computing matrix-vector products for Fishers, GGNs and Hessians. - - In other words we compute M*v where M is the matrix, v is the vector, and - * refers to standard matrix/vector multiplication (not element-wise - multiplication). - - The matrices are defined in terms of some differential quantity of the total - loss function with respect to a provided list of tensors ("wrt_tensors"). - For example, the Fisher associated with a log-prob loss w.r.t. the - parameters. - - The 'vecs' argument to each method are lists of tensors that must be the - size as the corresponding ones from "wrt_tensors". They represent - the vector being multiplied. - - "factors" of the matrix M are defined as matrices B such that B*B^T = M. - Methods that multiply by the factor B take a 'loss_inner_vecs' argument - instead of 'vecs', which must be a list of tensors with shapes given by the - corresponding XXX_inner_shapes property. - - Note that matrix-vector products are not normalized by the batch size, nor - are any damping terms added to the results. These things can be easily - applied externally, if desired. - - See for example: www.cs.utoronto.ca/~jmartens/docs/HF_book_chapter.pdf - and https://arxiv.org/abs/1412.1193 for more information about the - generalized Gauss-Newton, Fisher, etc., and how to compute matrix-vector - products. - """ - - def __init__(self, losses, wrt_tensors): - """Create a CurvatureMatrixVectorProductComputer object. - - Args: - losses: A list of LossFunction instances whose sum defines the total loss. - wrt_tensors: A list of Tensors to compute the differential quantities - (defining the matrices) with respect to. See class description for more - info. - """ - self._losses = losses - self._inputs_to_losses = list(loss.inputs for loss in losses) - self._inputs_to_losses_flat = nest.flatten(self._inputs_to_losses) - self._wrt_tensors = wrt_tensors - - @property - def _total_loss(self): - return math_ops.add_n(tuple(loss.evaluate() for loss in self._losses)) - - # Jacobian multiplication functions: - def _multiply_jacobian(self, vecs): - """Multiply vecs by the Jacobian of losses.""" - # We stop gradients at wrt_tensors to produce partial derivatives (which is - # what we want for Jacobians). - jacobian_vecs_flat = utils.fwd_gradients( - self._inputs_to_losses_flat, self._wrt_tensors, grad_xs=vecs, - stop_gradients=self._wrt_tensors) - return nest.pack_sequence_as(self._inputs_to_losses, jacobian_vecs_flat) - - def _multiply_jacobian_transpose(self, loss_vecs): - """Multiply vecs by the transpose Jacobian of losses.""" - loss_vecs_flat = nest.flatten(loss_vecs) - # We stop gradients at wrt_tensors to produce partial derivatives (which is - # what we want for Jacobians). - return gradients_impl.gradients( - self._inputs_to_losses_flat, self._wrt_tensors, grad_ys=loss_vecs_flat, - stop_gradients=self._wrt_tensors) - - # Losses Fisher/Hessian multiplication functions: - def _multiply_loss_fisher(self, loss_vecs): - """Multiply loss_vecs by Fisher of total loss.""" - return tuple( - loss.multiply_fisher(loss_vec) - for loss, loss_vec in zip(self._losses, loss_vecs)) - - def _multiply_loss_fisher_factor(self, loss_inner_vecs): - """Multiply loss_inner_vecs by factor of Fisher of total loss.""" - return tuple( - loss.multiply_fisher_factor(loss_vec) - for loss, loss_vec in zip(self._losses, loss_inner_vecs)) - - def _multiply_loss_fisher_factor_transpose(self, loss_vecs): - """Multiply loss_vecs by transpose factor of Fisher of total loss.""" - return tuple( - loss.multiply_fisher_factor_transpose(loss_vec) - for loss, loss_vec in zip(self._losses, loss_vecs)) - - def _multiply_loss_hessian(self, loss_vecs): - """Multiply loss_vecs by Hessian of total loss.""" - return tuple( - loss.multiply_hessian(loss_vec) - for loss, loss_vec in zip(self._losses, loss_vecs)) - - def _multiply_loss_hessian_factor(self, loss_inner_vecs): - """Multiply loss_inner_vecs by factor of Hessian of total loss.""" - return tuple( - loss.multiply_hessian_factor(loss_vec) - for loss, loss_vec in zip(self._losses, loss_inner_vecs)) - - def _multiply_loss_hessian_factor_transpose(self, loss_vecs): - """Multiply loss_vecs by transpose factor of Hessian of total loss.""" - return tuple( - loss.multiply_hessian_factor_transpose(loss_vec) - for loss, loss_vec in zip(self._losses, loss_vecs)) - - # Matrix-vector product functions: - def multiply_fisher(self, vecs): - """Multiply vecs by Fisher of total loss.""" - jacobian_vecs = self._multiply_jacobian(vecs) - loss_fisher_jacobian_vecs = self._multiply_loss_fisher(jacobian_vecs) - return self._multiply_jacobian_transpose(loss_fisher_jacobian_vecs) - - def multiply_fisher_factor_transpose(self, vecs): - """Multiply vecs by transpose of factor of Fisher of total loss.""" - jacobian_vecs = self._multiply_jacobian(vecs) - return self._multiply_loss_fisher_factor_transpose(jacobian_vecs) - - def multiply_fisher_factor(self, loss_inner_vecs): - """Multiply loss_inner_vecs by factor of Fisher of total loss.""" - fisher_factor_transpose_vecs = self._multiply_loss_fisher_factor_transpose( - loss_inner_vecs) - return self._multiply_jacobian_transpose(fisher_factor_transpose_vecs) - - def multiply_hessian(self, vecs): - """Multiply vecs by Hessian of total loss.""" - return gradients_impl.gradients( - gradients_impl.gradients(self._total_loss, self._wrt_tensors), - self._wrt_tensors, - grad_ys=vecs) - - def multiply_generalized_gauss_newton(self, vecs): - """Multiply vecs by generalized Gauss-Newton of total loss.""" - jacobian_vecs = self._multiply_jacobian(vecs) - loss_hessian_jacobian_vecs = self._multiply_loss_hessian(jacobian_vecs) - return self._multiply_jacobian_transpose(loss_hessian_jacobian_vecs) - - def multiply_generalized_gauss_newton_factor_transpose(self, vecs): - """Multiply vecs by transpose of factor of GGN of total loss.""" - jacobian_vecs = self._multiply_jacobian(vecs) - return self._multiply_loss_hessian_factor_transpose(jacobian_vecs) - - def multiply_generalized_gauss_newton_factor(self, loss_inner_vecs): - """Multiply loss_inner_vecs by factor of GGN of total loss.""" - hessian_factor_transpose_vecs = ( - self._multiply_loss_hessian_factor_transpose(loss_inner_vecs)) - return self._multiply_jacobian_transpose(hessian_factor_transpose_vecs) - - # Shape properties for multiply_XXX_factor methods: - @property - def fisher_factor_inner_shapes(self): - """Shapes required by multiply_fisher_factor.""" - return tuple(loss.fisher_factor_inner_shape for loss in self._losses) - - @property - def generalized_gauss_newton_factor_inner_shapes(self): - """Shapes required by multiply_generalized_gauss_newton_factor.""" - return tuple(loss.hessian_factor_inner_shape for loss in self._losses) diff --git a/tensorflow/contrib/kfac/python/ops/curvature_matrix_vector_products_lib.py b/tensorflow/contrib/kfac/python/ops/curvature_matrix_vector_products_lib.py deleted file mode 100644 index 6e8c6404dc..0000000000 --- a/tensorflow/contrib/kfac/python/ops/curvature_matrix_vector_products_lib.py +++ /dev/null @@ -1,30 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Curvature matrix-vector multiplication.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import,line-too-long,wildcard-import -from tensorflow.contrib.kfac.python.ops.curvature_matrix_vector_products import * -from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long,wildcard-import - -_allowed_symbols = [ - 'CurvatureMatrixVectorProductComputer', -] - -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) diff --git a/tensorflow/contrib/kfac/python/ops/estimator.py b/tensorflow/contrib/kfac/python/ops/estimator.py deleted file mode 100644 index 323234c403..0000000000 --- a/tensorflow/contrib/kfac/python/ops/estimator.py +++ /dev/null @@ -1,516 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Defines the high-level Fisher estimator class.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import abc -import numpy as np -import six - -from tensorflow.contrib.kfac.python.ops import placement -from tensorflow.contrib.kfac.python.ops import utils -from tensorflow.python.framework import ops as tf_ops -from tensorflow.python.ops import control_flow_ops -from tensorflow.python.ops import gradients_impl -from tensorflow.python.ops import variable_scope -from tensorflow.python.util import nest - - -# The linter is confused. -# pylint: disable=abstract-class-instantiated -def make_fisher_estimator(placement_strategy=None, **kwargs): - """Creates Fisher estimator instances based on the placement strategy. - - For example if the `placement_strategy` is 'round_robin' then - `FisherEstimatorRoundRobin` instance is returned. - - Args: - placement_strategy: `string`, Strategy to be used for placing covariance - variables, covariance ops and inverse ops. Check - `placement.FisherEstimatorRoundRobin` for a concrete example. - **kwargs: Arguments to be passed into `FisherEstimator` class initializer. - - Returns: - An instance of class which inherits from `FisherEstimator` and the mixin - which implements specific placement strategy. See, - `FisherEstimatorRoundRobin` which inherits from `FisherEstimator` and - `RoundRobinPlacementMixin`. - - Raises: - ValueError: If the `placement_strategy` is not equal to 'round_robin'. - """ - if placement_strategy in [None, "round_robin"]: - return FisherEstimatorRoundRobin(**kwargs) - else: - raise ValueError("Unimplemented vars and ops " - "placement strategy : {}".format(placement_strategy)) -# pylint: enable=abstract-class-instantiated - - -@six.add_metaclass(abc.ABCMeta) -class FisherEstimator(object): - """Fisher estimator class supporting various approximations of the Fisher. - - This is an abstract base class which does not implement a strategy for - placing covariance variables, covariance update ops and inverse update ops. - The placement strategies are implemented in `placement.py`. See - `FisherEstimatorRoundRobin` for example of a concrete subclass with - a round-robin placement strategy. - """ - - def __init__(self, - variables, - cov_ema_decay, - damping, - layer_collection, - exps=(-1,), - estimation_mode="gradients", - colocate_gradients_with_ops=True, - name="FisherEstimator", - compute_cholesky=False, - compute_cholesky_inverse=False): - """Create a FisherEstimator object. - - Args: - variables: A `list` of variables or `callable` which returns the variables - for which to estimate the Fisher. This must match the variables - registered in layer_collection (if it is not None). - cov_ema_decay: The decay factor used when calculating the covariance - estimate moving averages. - damping: float. The damping factor used to stabilize training due to - errors in the local approximation with the Fisher information matrix, - and to regularize the update direction by making it closer to the - gradient. (Higher damping means the update looks more like a standard - gradient update - see Tikhonov regularization.) - layer_collection: The layer collection object, which holds the Fisher - blocks, Kronecker factors, and losses associated with the - graph. - exps: List of floats or ints. These represent the different matrix - powers of the approximate Fisher that the FisherEstimator will be able - to multiply vectors by. If the user asks for a matrix power other - one of these (or 1, which is always supported), there will be a - failure. (Default: (-1,)) - estimation_mode: The type of estimator to use for the Fishers. Can be - 'gradients', 'empirical', 'curvature_prop', or 'exact'. - (Default: 'gradients'). 'gradients' is the basic estimation approach - from the original K-FAC paper. 'empirical' computes the 'empirical' - Fisher information matrix (which uses the data's distribution for the - targets, as opposed to the true Fisher which uses the model's - distribution) and requires that each registered loss have specified - targets. 'curvature_propagation' is a method which estimates the - Fisher using self-products of random 1/-1 vectors times "half-factors" - of the Fisher, as described here: https://arxiv.org/abs/1206.6464 . - Finally, 'exact' is the obvious generalization of Curvature - Propagation to compute the exact Fisher (modulo any additional - diagonal or Kronecker approximations) by looping over one-hot vectors - for each coordinate of the output instead of using 1/-1 vectors. It - is more expensive to compute than the other three options by a factor - equal to the output dimension, roughly speaking. - colocate_gradients_with_ops: Whether we should request gradients be - colocated with their respective ops. (Default: True) - name: A string. A name given to this estimator, which is added to the - variable scope when constructing variables and ops. - (Default: "FisherEstimator") - compute_cholesky: Bool. Whether or not the FisherEstimator will be - able to multiply vectors by the Cholesky factor. - (Default: False) - compute_cholesky_inverse: Bool. Whether or not the FisherEstimator - will be able to multiply vectors by the Cholesky factor inverse. - (Default: False) - Raises: - ValueError: If no losses have been registered with layer_collection. - """ - self._variables = variables - self._cov_ema_decay = cov_ema_decay - self._damping = damping - self._estimation_mode = estimation_mode - self._layers = layer_collection - self._gradient_fns = { - "gradients": self._get_grads_lists_gradients, - "empirical": self._get_grads_lists_empirical, - "curvature_prop": self._get_grads_lists_curvature_prop, - "exact": self._get_grads_lists_exact - } - self._colocate_gradients_with_ops = colocate_gradients_with_ops - - self._made_vars = False - self._exps = exps - self._compute_cholesky = compute_cholesky - self._compute_cholesky_inverse = compute_cholesky_inverse - - self._name = name - - @property - def variables(self): - if callable(self._variables): - return self._variables() - else: - return self._variables - - @property - def damping(self): - return self._damping - - @property - def blocks(self): - """All registered FisherBlocks.""" - return self._layers.get_blocks() - - @property - def factors(self): - """All registered FisherFactors.""" - return self._layers.get_factors() - - @property - def name(self): - return self._name - - @abc.abstractmethod - def make_vars_and_create_op_thunks(self, scope=None): - """Make vars and create op thunks with a specific placement strategy. - - For each factor, all of that factor's cov variables and their associated - update ops will be placed on a particular device. A new device is chosen - for each factor by cycling through list of devices in the cov_devices - argument. If cov_devices is None then no explicit device placement occurs. - - An analogous strategy is followed for inverse update ops, with the list of - devices being given by the inv_devices argument. - - Inverse variables on the other hand are not placed on any specific device - (they will just use the current the device placement context, whatever - that happens to be). The idea is that the inverse variable belong where - they will be accessed most often, which is the device that actually applies - the preconditioner to the gradient. The user will be responsible for setting - the device context for this. - - Args: - scope: A string or None. If None it will be set to the name of this - estimator (given by the name property). All variables will be created, - and all thunks will execute, inside of a variable scope of the given - name. (Default: None) - - Returns: - cov_update_thunks: List of cov update thunks. Corresponds one-to-one with - the list of factors given by the "factors" property. - inv_update_thunks: List of inv update thunks. Corresponds one-to-one with - the list of factors given by the "factors" property. - """ - pass - - def _apply_transformation(self, vecs_and_vars, transform): - """Applies an block-wise transformation to the corresponding vectors. - - Args: - vecs_and_vars: List of (vector, variable) pairs. - transform: A function of the form f(fb, vec), where vec is the vector - to transform and fb is its corresponding block in the matrix, that - returns the transformed vector. - - Returns: - A list of (transformed vector, var) pairs in the same order as - vecs_and_vars. - """ - - vecs = utils.SequenceDict((var, vec) for vec, var in vecs_and_vars) - - trans_vecs = utils.SequenceDict() - - for params, fb in self._layers.fisher_blocks.items(): - trans_vecs[params] = transform(fb, vecs[params]) - - return [(trans_vecs[var], var) for _, var in vecs_and_vars] - - def multiply_inverse(self, vecs_and_vars): - """Multiplies the vecs by the corresponding (damped) inverses of the blocks. - - Args: - vecs_and_vars: List of (vector, variable) pairs. - - Returns: - A list of (transformed vector, var) pairs in the same order as - vecs_and_vars. - """ - return self.multiply_matpower(-1, vecs_and_vars) - - def multiply(self, vecs_and_vars): - """Multiplies the vectors by the corresponding (damped) blocks. - - Args: - vecs_and_vars: List of (vector, variable) pairs. - - Returns: - A list of (transformed vector, var) pairs in the same order as - vecs_and_vars. - """ - return self.multiply_matpower(1, vecs_and_vars) - - def multiply_matpower(self, exp, vecs_and_vars): - """Multiplies the vecs by the corresponding matrix powers of the blocks. - - Args: - exp: A float representing the power to raise the blocks by before - multiplying it by the vector. - vecs_and_vars: List of (vector, variable) pairs. - - Returns: - A list of (transformed vector, var) pairs in the same order as - vecs_and_vars. - """ - assert exp in self._exps - - fcn = lambda fb, vec: fb.multiply_matpower(vec, exp) - return self._apply_transformation(vecs_and_vars, fcn) - - def multiply_cholesky(self, vecs_and_vars, transpose=False): - """Multiplies the vecs by the corresponding Cholesky factors. - - Args: - vecs_and_vars: List of (vector, variable) pairs. - transpose: Bool. If true the Cholesky factors are transposed before - multiplying the vecs. (Default: False) - - Returns: - A list of (transformed vector, var) pairs in the same order as - vecs_and_vars. - """ - assert self._compute_cholesky - - fcn = lambda fb, vec: fb.multiply_cholesky(vec, transpose=transpose) - return self._apply_transformation(vecs_and_vars, fcn) - - def multiply_cholesky_inverse(self, vecs_and_vars, transpose=False): - """Mults the vecs by the inverses of the corresponding Cholesky factors. - - Note: if you are using Cholesky inverse multiplication to sample from - a matrix-variate Gaussian you will want to multiply by the transpose. - Let L be the Cholesky factor of F and observe that - - L^-T * L^-1 = (L * L^T)^-1 = F^-1 . - - Thus we want to multiply by L^-T in order to sample from Gaussian with - covariance F^-1. - - Args: - vecs_and_vars: List of (vector, variable) pairs. - transpose: Bool. If true the Cholesky factor inverses are transposed - before multiplying the vecs. (Default: False) - - Returns: - A list of (transformed vector, var) pairs in the same order as - vecs_and_vars. - """ - assert self._compute_cholesky_inverse - - fcn = lambda fb, vec: fb.multiply_cholesky_inverse(vec, transpose=transpose) - return self._apply_transformation(vecs_and_vars, fcn) - - def _instantiate_factors(self): - """Instantiates FisherFactors' variables. - - Raises: - ValueError: If estimation_mode was improperly specified at construction. - """ - blocks = self.blocks - tensors_to_compute_grads = [ - block.tensors_to_compute_grads() for block in blocks - ] - - try: - grads_lists = self._gradient_fns[self._estimation_mode]( - tensors_to_compute_grads) - except KeyError: - raise ValueError("Unrecognized value {} for estimation_mode.".format( - self._estimation_mode)) - - for grads_list, block in zip(grads_lists, blocks): - block.instantiate_factors(grads_list, self.damping) - - def _check_vars_unmade_and_set_made_flag(self): - if self._made_vars: - raise Exception("Already made variables.") - self._made_vars = True - - def made_vars(self): - return self._made_vars - - def _register_matrix_functions(self): - for block in self.blocks: - for exp in self._exps: - block.register_matpower(exp) - if self._compute_cholesky: - block.register_cholesky() - if self._compute_cholesky_inverse: - block.register_cholesky_inverse() - - def _finalize_layer_collection(self): - self._layers.create_subgraph() - self._layers.check_registration(self.variables) - self._instantiate_factors() - self._register_matrix_functions() - - def create_ops_and_vars_thunks(self, scope=None): - """Create thunks that make the ops and vars on demand. - - This function returns 4 lists of thunks: cov_variable_thunks, - cov_update_thunks, inv_variable_thunks, and inv_update_thunks. - - The length of each list is the number of factors and the i-th element of - each list corresponds to the i-th factor (given by the "factors" property). - - Note that the execution of these thunks must happen in a certain - partial order. The i-th element of cov_variable_thunks must execute - before the i-th element of cov_update_thunks (and also the i-th element - of inv_update_thunks). Similarly, the i-th element of inv_variable_thunks - must execute before the i-th element of inv_update_thunks. - - TL;DR (oversimplified): Execute the thunks according to the order that - they are returned. - - Args: - scope: A string or None. If None it will be set to the name of this - estimator (given by the name property). All thunks will execute inside - of a variable scope of the given name. (Default: None) - Returns: - cov_variable_thunks: A list of thunks that make the cov variables. - cov_update_thunks: A list of thunks that make the cov update ops. - inv_variable_thunks: A list of thunks that make the inv variables. - inv_update_thunks: A list of thunks that make the inv update ops. - """ - self._check_vars_unmade_and_set_made_flag() - - self._finalize_layer_collection() - - scope = self.name if scope is None else scope - - cov_variable_thunks = [ - self._create_cov_variable_thunk(factor, scope) - for factor in self.factors - ] - cov_update_thunks = [ - self._create_cov_update_thunk(factor, scope) for factor in self.factors - ] - inv_variable_thunks = [ - self._create_inv_variable_thunk(factor, scope) - for factor in self.factors - ] - inv_update_thunks = [ - self._create_inv_update_thunk(factor, scope) for factor in self.factors - ] - - return (cov_variable_thunks, cov_update_thunks, - inv_variable_thunks, inv_update_thunks) - - def _create_cov_variable_thunk(self, factor, scope): - """Constructs a covariance variable thunk for a single FisherFactor.""" - - def thunk(): - with variable_scope.variable_scope(scope): - return factor.instantiate_cov_variables() - - return thunk - - def _create_cov_update_thunk(self, factor, scope): - """Constructs a covariance update thunk for a single FisherFactor.""" - - def thunk(): - with variable_scope.variable_scope(scope): - return factor.make_covariance_update_op(self._cov_ema_decay) - - return thunk - - def _create_inv_variable_thunk(self, factor, scope): - """Constructs a inverse variable thunk for a single FisherFactor.""" - - def thunk(): - with variable_scope.variable_scope(scope): - return factor.instantiate_inv_variables() - - return thunk - - def _create_inv_update_thunk(self, factor, scope): - """Constructs an inverse update thunk for a single FisherFactor.""" - - def thunk(): - with variable_scope.variable_scope(scope): - return control_flow_ops.group(factor.make_inverse_update_ops()) - - return thunk - - def _get_grads_lists_gradients(self, tensors): - # Passing in a list of loss values is better than passing in the sum as - # the latter creates unnessesary ops on the default device - grads_flat = gradients_impl.gradients( - self._layers.eval_losses_on_samples(), - nest.flatten(tensors), - colocate_gradients_with_ops=self._colocate_gradients_with_ops) - grads_all = nest.pack_sequence_as(tensors, grads_flat) - return tuple((grad,) for grad in grads_all) - - def _get_grads_lists_empirical(self, tensors): - # Passing in a list of loss values is better than passing in the sum as - # the latter creates unnecessary ops on the default device - grads_flat = gradients_impl.gradients( - self._layers.eval_losses(), - nest.flatten(tensors), - colocate_gradients_with_ops=self._colocate_gradients_with_ops) - grads_all = nest.pack_sequence_as(tensors, grads_flat) - return tuple((grad,) for grad in grads_all) - - def _get_transformed_random_signs(self): - transformed_random_signs = [] - for loss in self._layers.losses: - with tf_ops.colocate_with(self._layers.loss_colocation_ops[loss]): - transformed_random_signs.append( - loss.multiply_fisher_factor( - utils.generate_random_signs(loss.fisher_factor_inner_shape))) - return transformed_random_signs - - def _get_grads_lists_curvature_prop(self, tensors): - loss_inputs = list(loss.inputs for loss in self._layers.losses) - transformed_random_signs = self._get_transformed_random_signs() - grads_flat = gradients_impl.gradients( - nest.flatten(loss_inputs), - nest.flatten(tensors), - grad_ys=nest.flatten(transformed_random_signs), - colocate_gradients_with_ops=self._colocate_gradients_with_ops) - grads_all = nest.pack_sequence_as(tensors, grads_flat) - return tuple((grad,) for grad in grads_all) - - def _get_grads_lists_exact(self, tensors): - """No docstring required.""" - # Loop over all coordinates of all losses. - grads_all = [] - for loss in self._layers.losses: - with tf_ops.colocate_with(self._layers.loss_colocation_ops[loss]): - for index in np.ndindex(*loss.fisher_factor_inner_static_shape[1:]): - transformed_one_hot = loss.multiply_fisher_factor_replicated_one_hot( - index) - grads_flat = gradients_impl.gradients( - loss.inputs, - nest.flatten(tensors), - grad_ys=transformed_one_hot, - colocate_gradients_with_ops=self._colocate_gradients_with_ops) - grads_all.append(nest.pack_sequence_as(tensors, grads_flat)) - return zip(*grads_all) - - -class FisherEstimatorRoundRobin(placement.RoundRobinPlacementMixin, - FisherEstimator): - """Fisher estimator which provides round robin device placement strategy.""" - pass diff --git a/tensorflow/contrib/kfac/python/ops/estimator_lib.py b/tensorflow/contrib/kfac/python/ops/estimator_lib.py deleted file mode 100644 index 9c9fef471f..0000000000 --- a/tensorflow/contrib/kfac/python/ops/estimator_lib.py +++ /dev/null @@ -1,31 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Defines the high-level Fisher estimator class.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import,line-too-long,wildcard-import -from tensorflow.contrib.kfac.python.ops.estimator import * -from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long,wildcard-import - -_allowed_symbols = [ - 'FisherEstimator', - 'make_fisher_estimator', -] - -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) diff --git a/tensorflow/contrib/kfac/python/ops/fisher_blocks.py b/tensorflow/contrib/kfac/python/ops/fisher_blocks.py deleted file mode 100644 index 9fa6eb7dcd..0000000000 --- a/tensorflow/contrib/kfac/python/ops/fisher_blocks.py +++ /dev/null @@ -1,1752 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""FisherBlock definitions. - -This library contains classes for estimating blocks in a model's Fisher -Information matrix. Suppose one has a model that parameterizes a posterior -distribution over 'y' given 'x' with parameters 'params', p(y | x, params). Its -Fisher Information matrix is given by, - - $$F(params) = E[ v(x, y, params) v(x, y, params)^T ]$$ - -where, - - $$v(x, y, params) = (d / d params) log p(y | x, params)$$ - -and the expectation is taken with respect to the data's distribution for 'x' and -the model's posterior distribution for 'y', - - x ~ p(x) - y ~ p(y | x, params) - -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import abc -import enum # pylint: disable=g-bad-import-order - -import numpy as np -import six - -from tensorflow.contrib.kfac.python.ops import fisher_factors -from tensorflow.contrib.kfac.python.ops import utils -from tensorflow.python.framework import ops -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.util import nest - -# For blocks corresponding to convolutional layers, or any type of block where -# the parameters can be thought of as being replicated in time or space, -# we want to adjust the scale of the damping by -# damping /= num_replications ** NORMALIZE_DAMPING_POWER -NORMALIZE_DAMPING_POWER = 1.0 - -# Methods for adjusting damping for FisherBlocks. See -# compute_pi_adjusted_damping() for details. -PI_OFF_NAME = "off" -PI_TRACENORM_NAME = "tracenorm" -PI_TYPE = PI_TRACENORM_NAME - - -def set_global_constants(normalize_damping_power=None, pi_type=None): - """Sets various global constants used by the classes in this module.""" - global NORMALIZE_DAMPING_POWER - global PI_TYPE - - if normalize_damping_power is not None: - NORMALIZE_DAMPING_POWER = normalize_damping_power - - if pi_type is not None: - PI_TYPE = pi_type - - -def normalize_damping(damping, num_replications): - """Normalize damping after adjusting scale by NORMALIZE_DAMPING_POWER.""" - if NORMALIZE_DAMPING_POWER: - return damping / (num_replications ** NORMALIZE_DAMPING_POWER) - return damping - - -def compute_pi_tracenorm(left_cov, right_cov): - r"""Computes the scalar constant pi for Tikhonov regularization/damping. - - $$\pi = \sqrt{ (trace(A) / dim(A)) / (trace(B) / dim(B)) }$$ - See section 6.3 of https://arxiv.org/pdf/1503.05671.pdf for details. - - Args: - left_cov: A LinearOperator object. The left Kronecker factor "covariance". - right_cov: A LinearOperator object. The right Kronecker factor "covariance". - - Returns: - The computed scalar constant pi for these Kronecker Factors (as a Tensor). - """ - # Instead of dividing by the dim of the norm, we multiply by the dim of the - # other norm. This works out the same in the ratio. - left_norm = left_cov.trace() * int(right_cov.domain_dimension) - right_norm = right_cov.trace() * int(left_cov.domain_dimension) - return math_ops.sqrt(left_norm / right_norm) - - -def compute_pi_adjusted_damping(left_cov, right_cov, damping): - - if PI_TYPE == PI_TRACENORM_NAME: - pi = compute_pi_tracenorm(left_cov, right_cov) - return (damping * pi, damping / pi) - - elif PI_TYPE == PI_OFF_NAME: - return (damping, damping) - - -class PackagedFunc(object): - """A Python thunk with a stable ID. - - Enables stable names for lambdas. - """ - - def __init__(self, func, func_id): - """Initializes PackagedFunc. - - Args: - func: a zero-arg Python function. - func_id: a hashable, function that produces a hashable, or a list/tuple - thereof. - """ - self._func = func - func_id = func_id if isinstance(func_id, (tuple, list)) else (func_id,) - self._func_id = func_id - - def __call__(self): - return self._func() - - @property - def func_id(self): - """A hashable identifier for this function.""" - return tuple(elt() if callable(elt) else elt for elt in self._func_id) - - -def _package_func(func, func_id): - return PackagedFunc(func, func_id) - - -@six.add_metaclass(abc.ABCMeta) -class FisherBlock(object): - """Abstract base class for objects modeling approximate Fisher matrix blocks. - - Subclasses must implement register_matpower, multiply_matpower, - instantiate_factors, tensors_to_compute_grads, and num_registered_towers - methods. - """ - - def __init__(self, layer_collection): - self._layer_collection = layer_collection - - @abc.abstractmethod - def instantiate_factors(self, grads_list, damping): - """Creates and registers the component factors of this Fisher block. - - Args: - grads_list: A list gradients (each a Tensor or tuple of Tensors) with - respect to the tensors returned by tensors_to_compute_grads() that - are to be used to estimate the block. - damping: The damping factor (float or Tensor). - """ - pass - - @abc.abstractmethod - def register_matpower(self, exp): - """Registers a matrix power to be computed by the block. - - Args: - exp: A float representing the power to raise the block by. - """ - pass - - @abc.abstractmethod - def register_cholesky(self): - """Registers a Cholesky factor to be computed by the block.""" - pass - - @abc.abstractmethod - def register_cholesky_inverse(self): - """Registers an inverse Cholesky factor to be computed by the block.""" - pass - - def register_inverse(self): - """Registers a matrix inverse to be computed by the block.""" - self.register_matpower(-1) - - @abc.abstractmethod - def multiply_matpower(self, vector, exp): - """Multiplies the vector by the (damped) matrix-power of the block. - - Args: - vector: The vector (a Tensor or tuple of Tensors) to be multiplied. - exp: A float representing the power to raise the block by before - multiplying it by the vector. - - Returns: - The vector left-multiplied by the (damped) matrix-power of the block. - """ - pass - - def multiply_inverse(self, vector): - """Multiplies the vector by the (damped) inverse of the block. - - Args: - vector: The vector (a Tensor or tuple of Tensors) to be multiplied. - - Returns: - The vector left-multiplied by the (damped) inverse of the block. - """ - return self.multiply_matpower(vector, -1) - - def multiply(self, vector): - """Multiplies the vector by the (damped) block. - - Args: - vector: The vector (a Tensor or tuple of Tensors) to be multiplied. - - Returns: - The vector left-multiplied by the (damped) block. - """ - return self.multiply_matpower(vector, 1) - - @abc.abstractmethod - def multiply_cholesky(self, vector, transpose=False): - """Multiplies the vector by the (damped) Cholesky-factor of the block. - - Args: - vector: The vector (a Tensor or tuple of Tensors) to be multiplied. - transpose: Bool. If true the Cholesky factor is transposed before - multiplying the vector. (Default: False) - - Returns: - The vector left-multiplied by the (damped) Cholesky-factor of the block. - """ - pass - - @abc.abstractmethod - def multiply_cholesky_inverse(self, vector, transpose=False): - """Multiplies vector by the (damped) inverse Cholesky-factor of the block. - - Args: - vector: The vector (a Tensor or tuple of Tensors) to be multiplied. - transpose: Bool. If true the Cholesky factor inverse is transposed - before multiplying the vector. (Default: False) - Returns: - Vector left-multiplied by (damped) inverse Cholesky-factor of the block. - """ - pass - - @abc.abstractmethod - def tensors_to_compute_grads(self): - """Returns the Tensor(s) with respect to which this FisherBlock needs grads. - """ - pass - - @abc.abstractproperty - def num_registered_towers(self): - """Number of towers registered for this FisherBlock. - - Typically equal to the number of towers in a multi-tower setup. - """ - pass - - -class FullFB(FisherBlock): - """FisherBlock using a full matrix estimate (no approximations). - - FullFB uses a full matrix estimate (no approximations), and should only ever - be used for very low dimensional parameters. - - Note that this uses the naive "square the sum estimator", and so is applicable - to any type of parameter in principle, but has very high variance. - """ - - def __init__(self, layer_collection, params): - """Creates a FullFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - params: The parameters of this layer (Tensor or tuple of Tensors). - """ - self._batch_sizes = [] - self._params = params - - super(FullFB, self).__init__(layer_collection) - - def instantiate_factors(self, grads_list, damping): - self._damping_func = _package_func(lambda: damping, (damping,)) - - self._factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullFactor, (grads_list, self._batch_size)) - - def register_matpower(self, exp): - self._factor.register_matpower(exp, self._damping_func) - - def register_cholesky(self): - self._factor.register_cholesky(self._damping_func) - - def register_cholesky_inverse(self): - self._factor.register_cholesky_inverse(self._damping_func) - - def _multiply_matrix(self, matrix, vector, transpose=False): - vector_flat = utils.tensors_to_column(vector) - out_flat = matrix.matmul(vector_flat, adjoint=transpose) - return utils.column_to_tensors(vector, out_flat) - - def multiply_matpower(self, vector, exp): - matrix = self._factor.get_matpower(exp, self._damping_func) - return self._multiply_matrix(matrix, vector) - - def multiply_cholesky(self, vector, transpose=False): - matrix = self._factor.get_cholesky(self._damping_func) - return self._multiply_matrix(matrix, vector, transpose=transpose) - - def multiply_cholesky_inverse(self, vector, transpose=False): - matrix = self._factor.get_cholesky_inverse(self._damping_func) - return self._multiply_matrix(matrix, vector, transpose=transpose) - - def full_fisher_block(self): - """Explicitly constructs the full Fisher block.""" - return self._factor.get_cov_as_linear_operator().to_dense() - - def tensors_to_compute_grads(self): - return self._params - - def register_additional_tower(self, batch_size): - """Register an additional tower. - - Args: - batch_size: The batch size, used in the covariance estimator. - """ - self._batch_sizes.append(batch_size) - - @property - def num_registered_towers(self): - return len(self._batch_sizes) - - @property - def _batch_size(self): - return math_ops.reduce_sum(self._batch_sizes) - - -@six.add_metaclass(abc.ABCMeta) -class DiagonalFB(FisherBlock): - """A base class for FisherBlocks that use diagonal approximations.""" - - def register_matpower(self, exp): - # Not needed for this. Matrix powers are computed on demand in the - # diagonal case - pass - - def register_cholesky(self): - # Not needed for this. Cholesky's are computed on demand in the - # diagonal case - pass - - def register_cholesky_inverse(self): - # Not needed for this. Cholesky inverses's are computed on demand in the - # diagonal case - pass - - def _multiply_matrix(self, matrix, vector): - vector_flat = utils.tensors_to_column(vector) - out_flat = matrix.matmul(vector_flat) - return utils.column_to_tensors(vector, out_flat) - - def multiply_matpower(self, vector, exp): - matrix = self._factor.get_matpower(exp, self._damping_func) - return self._multiply_matrix(matrix, vector) - - def multiply_cholesky(self, vector, transpose=False): - matrix = self._factor.get_cholesky(self._damping_func) - return self._multiply_matrix(matrix, vector) - - def multiply_cholesky_inverse(self, vector, transpose=False): - matrix = self._factor.get_cholesky_inverse(self._damping_func) - return self._multiply_matrix(matrix, vector) - - def full_fisher_block(self): - return self._factor.get_cov_as_linear_operator().to_dense() - - -class NaiveDiagonalFB(DiagonalFB): - """FisherBlock using a diagonal matrix approximation. - - This type of approximation is generically applicable but quite primitive. - - Note that this uses the naive "square the sum estimator", and so is applicable - to any type of parameter in principle, but has very high variance. - """ - - def __init__(self, layer_collection, params): - """Creates a NaiveDiagonalFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - params: The parameters of this layer (Tensor or tuple of Tensors). - """ - self._params = params - self._batch_sizes = [] - - super(NaiveDiagonalFB, self).__init__(layer_collection) - - def instantiate_factors(self, grads_list, damping): - self._damping_func = _package_func(lambda: damping, (damping,)) - - self._factor = self._layer_collection.make_or_get_factor( - fisher_factors.NaiveDiagonalFactor, (grads_list, self._batch_size)) - - def tensors_to_compute_grads(self): - return self._params - - def register_additional_tower(self, batch_size): - """Register an additional tower. - - Args: - batch_size: The batch size, used in the covariance estimator. - """ - self._batch_sizes.append(batch_size) - - @property - def num_registered_towers(self): - return len(self._batch_sizes) - - @property - def _batch_size(self): - return math_ops.reduce_sum(self._batch_sizes) - - -class InputOutputMultiTower(object): - """Mix-in class for blocks with inputs & outputs and multiple mini-batches.""" - - def __init__(self, *args, **kwargs): - self.__inputs = [] - self.__outputs = [] - super(InputOutputMultiTower, self).__init__(*args, **kwargs) - - def _process_data(self, grads_list): - """Process data into the format used by the factors. - - This function takes inputs and grads_lists data and processes it into - one of the formats expected by the FisherFactor classes (depending on - the value of the global configuration variable TOWER_STRATEGY). - - The initial format of self._inputs is expected to be a list of Tensors - over towers. Similarly grads_lists is expected to be a list over sources - of such lists. - - If TOWER_STRATEGY is "concat", 'inputs' becomes a tuple containing a single - tensor (represented as a PartitionedTensor object) equal to the - concatenation (across towers) of all of the elements of self._inputs. And - similarly grads_list is formatted into a tuple (over sources) of such - tensors (also represented as PartitionedTensors). - - If TOWER_STRATEGY is "separate", formatting of inputs and grads_list - remains unchanged from the initial format (although possibly converting - from lists into tuples). - - Args: - grads_list: grads_list in its initial format (see above). - - Returns: - inputs: self._inputs transformed into the appropriate format (see - above). - grads_list: grads_list transformed into the appropriate format (see - above). - - Raises: - ValueError: if TOWER_STRATEGY is not one of "separate" or "concat". - """ - inputs = self._inputs - # inputs is a list over towers of Tensors - # grads_list is a list of list with the first index being sources and the - # second being towers. - if fisher_factors.TOWER_STRATEGY == "concat": - # Merge towers together into a PartitionedTensor. We package it in - # a singleton tuple since the factors will expect a list over towers - inputs = (utils.PartitionedTensor(inputs),) - # Do the same for grads_list but preserve leading sources dimension - grads_list = tuple((utils.PartitionedTensor(grads),) - for grads in grads_list) - elif fisher_factors.TOWER_STRATEGY == "separate": - inputs = tuple(inputs) - grads_list = tuple(grads_list) - - else: - raise ValueError("Global config variable TOWER_STRATEGY must be one of " - "'concat' or 'separate'.") - - return inputs, grads_list - - def tensors_to_compute_grads(self): - """Tensors to compute derivative of loss with respect to.""" - return tuple(self._outputs) - - def register_additional_tower(self, inputs, outputs): - self._inputs.append(inputs) - self._outputs.append(outputs) - - @property - def num_registered_towers(self): - result = len(self._inputs) - assert result == len(self._outputs) - return result - - @property - def _inputs(self): - return self.__inputs - - @property - def _outputs(self): - return self.__outputs - - -class FullyConnectedDiagonalFB(InputOutputMultiTower, DiagonalFB): - """FisherBlock for fully-connected (dense) layers using a diagonal approx. - - Estimates the Fisher Information matrix's diagonal entries for a fully - connected layer. Unlike NaiveDiagonalFB this uses the low-variance "sum of - squares" estimator. - - Let 'params' be a vector parameterizing a model and 'i' an arbitrary index - into it. We are interested in Fisher(params)[i, i]. This is, - - $$Fisher(params)[i, i] = E[ v(x, y, params) v(x, y, params)^T ][i, i] - = E[ v(x, y, params)[i] ^ 2 ]$$ - - Consider fully connected layer in this model with (unshared) weight matrix - 'w'. For an example 'x' that produces layer inputs 'a' and output - preactivations 's', - - $$v(x, y, w) = vec( a (d loss / d s)^T )$$ - - This FisherBlock tracks Fisher(params)[i, i] for all indices 'i' corresponding - to the layer's parameters 'w'. - """ - - def __init__(self, layer_collection, has_bias=False): - """Creates a FullyConnectedDiagonalFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - has_bias: Whether the component Kronecker factors have an additive bias. - (Default: False) - """ - self._has_bias = has_bias - - super(FullyConnectedDiagonalFB, self).__init__(layer_collection) - - def instantiate_factors(self, grads_list, damping): - inputs, grads_list = self._process_data(grads_list) - - self._factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullyConnectedDiagonalFactor, - (inputs, grads_list, self._has_bias)) - - self._damping_func = _package_func(lambda: damping, (damping,)) - - -class ConvDiagonalFB(InputOutputMultiTower, DiagonalFB): - """FisherBlock for 2-D convolutional layers using a diagonal approx. - - Estimates the Fisher Information matrix's diagonal entries for a convolutional - layer. Unlike NaiveDiagonalFB this uses the low-variance "sum of squares" - estimator. - - Let 'params' be a vector parameterizing a model and 'i' an arbitrary index - into it. We are interested in Fisher(params)[i, i]. This is, - - $$Fisher(params)[i, i] = E[ v(x, y, params) v(x, y, params)^T ][i, i] - = E[ v(x, y, params)[i] ^ 2 ]$$ - - Consider a convoluational layer in this model with (unshared) filter matrix - 'w'. For an example image 'x' that produces layer inputs 'a' and output - preactivations 's', - - $$v(x, y, w) = vec( sum_{loc} a_{loc} (d loss / d s_{loc})^T )$$ - - where 'loc' is a single (x, y) location in an image. - - This FisherBlock tracks Fisher(params)[i, i] for all indices 'i' corresponding - to the layer's parameters 'w'. - """ - - def __init__(self, - layer_collection, - params, - strides, - padding, - data_format=None, - dilations=None): - """Creates a ConvDiagonalFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - params: The parameters (Tensor or tuple of Tensors) of this layer. If - kernel alone, a Tensor of shape [kernel_height, kernel_width, - in_channels, out_channels]. If kernel and bias, a tuple of 2 elements - containing the previous and a Tensor of shape [out_channels]. - strides: The stride size in this layer (1-D Tensor of length 4). - padding: The padding in this layer (e.g. "SAME"). - data_format: str or None. Format of input data. - dilations: List of 4 ints or None. Rate for dilation along all dimensions. - - Raises: - ValueError: if strides is not length-4. - ValueError: if dilations is not length-4. - ValueError: if channel is not last dimension. - """ - if len(strides) != 4: - raise ValueError("strides must contain 4 numbers.") - - if dilations is None: - dilations = [1, 1, 1, 1] - - if len(dilations) != 4: - raise ValueError("dilations must contain 4 numbers.") - - if not utils.is_data_format_channel_last(data_format): - raise ValueError("data_format must be channels-last.") - - self._strides = maybe_tuple(strides) - self._padding = padding - self._data_format = data_format - self._dilations = maybe_tuple(dilations) - self._has_bias = isinstance(params, (tuple, list)) - - fltr = params[0] if self._has_bias else params - self._filter_shape = tuple(fltr.shape.as_list()) - - if len(self._filter_shape) != 4: - raise ValueError( - "Convolution filter must be of shape" - " [filter_height, filter_width, in_channels, out_channels].") - - super(ConvDiagonalFB, self).__init__(layer_collection) - - def instantiate_factors(self, grads_list, damping): - inputs, grads_list = self._process_data(grads_list) - - # Infer number of locations upon which convolution is applied. - self._num_locations = num_conv_locations(inputs[0].shape.as_list(), - self._strides) - - self._factor = self._layer_collection.make_or_get_factor( - fisher_factors.ConvDiagonalFactor, - (inputs, grads_list, self._filter_shape, self._strides, self._padding, - self._data_format, self._dilations, self._has_bias)) - - def damping_func(): - return self._num_locations * normalize_damping(damping, - self._num_locations) - - damping_id = (self._num_locations, "mult", "normalize_damping", damping, - self._num_locations) - self._damping_func = _package_func(damping_func, damping_id) - - -class KroneckerProductFB(FisherBlock): - """A base class for blocks with separate input and output Kronecker factors. - - The Fisher block is approximated as a Kronecker product of the input and - output factors. - """ - - def _setup_damping(self, damping, normalization=None): - """Makes functions that compute the damping values for both factors.""" - def compute_damping(): - if normalization is not None: - maybe_normalized_damping = normalize_damping(damping, normalization) - else: - maybe_normalized_damping = damping - - return compute_pi_adjusted_damping( - self._input_factor.get_cov_as_linear_operator(), - self._output_factor.get_cov_as_linear_operator(), - maybe_normalized_damping**0.5) - - if normalization is not None: - damping_id = ("compute_pi_adjusted_damping", - "cov", self._input_factor.name, - "cov", self._output_factor.name, - "normalize_damping", damping, normalization, "power", 0.5) - else: - damping_id = ("compute_pi_adjusted_damping", - "cov", self._input_factor.name, - "cov", self._output_factor.name, - damping, "power", 0.5) - - self._input_damping_func = _package_func(lambda: compute_damping()[0], - damping_id + ("ref", 0)) - self._output_damping_func = _package_func(lambda: compute_damping()[1], - damping_id + ("ref", 1)) - - def register_matpower(self, exp): - self._input_factor.register_matpower(exp, self._input_damping_func) - self._output_factor.register_matpower(exp, self._output_damping_func) - - def register_cholesky(self): - self._input_factor.register_cholesky(self._input_damping_func) - self._output_factor.register_cholesky(self._output_damping_func) - - def register_cholesky_inverse(self): - self._input_factor.register_cholesky_inverse(self._input_damping_func) - self._output_factor.register_cholesky_inverse(self._output_damping_func) - - @property - def _renorm_coeff(self): - """Kronecker factor multiplier coefficient. - - If this FisherBlock is represented as 'FB = c * kron(left, right)', then - this is 'c'. - - Returns: - 0-D Tensor. - """ - return 1.0 - - def _multiply_factored_matrix(self, left_factor, right_factor, vector, - extra_scale=1.0, transpose_left=False, - transpose_right=False): - reshaped_vector = utils.layer_params_to_mat2d(vector) - reshaped_out = right_factor.matmul_right(reshaped_vector, - adjoint=transpose_right) - reshaped_out = left_factor.matmul(reshaped_out, - adjoint=transpose_left) - if extra_scale != 1.0: - reshaped_out *= math_ops.cast(extra_scale, dtype=reshaped_out.dtype) - return utils.mat2d_to_layer_params(vector, reshaped_out) - - def multiply_matpower(self, vector, exp): - left_factor = self._input_factor.get_matpower( - exp, self._input_damping_func) - right_factor = self._output_factor.get_matpower( - exp, self._output_damping_func) - extra_scale = float(self._renorm_coeff)**exp - return self._multiply_factored_matrix(left_factor, right_factor, vector, - extra_scale=extra_scale) - - def multiply_cholesky(self, vector, transpose=False): - left_factor = self._input_factor.get_cholesky(self._input_damping_func) - right_factor = self._output_factor.get_cholesky(self._output_damping_func) - extra_scale = float(self._renorm_coeff)**0.5 - return self._multiply_factored_matrix(left_factor, right_factor, vector, - extra_scale=extra_scale, - transpose_left=transpose, - transpose_right=not transpose) - - def multiply_cholesky_inverse(self, vector, transpose=False): - left_factor = self._input_factor.get_cholesky_inverse( - self._input_damping_func) - right_factor = self._output_factor.get_cholesky_inverse( - self._output_damping_func) - extra_scale = float(self._renorm_coeff)**-0.5 - return self._multiply_factored_matrix(left_factor, right_factor, vector, - extra_scale=extra_scale, - transpose_left=transpose, - transpose_right=not transpose) - - def full_fisher_block(self): - """Explicitly constructs the full Fisher block. - - Used for testing purposes. (In general, the result may be very large.) - - Returns: - The full Fisher block. - """ - left_factor = self._input_factor.get_cov_as_linear_operator().to_dense() - right_factor = self._output_factor.get_cov_as_linear_operator().to_dense() - return self._renorm_coeff * utils.kronecker_product(left_factor, - right_factor) - - -class EmbeddingKFACFB(InputOutputMultiTower, KroneckerProductFB): - """K-FAC FisherBlock for embedding layers. - - This FisherBlock is similar to FullyConnectedKFACBasicFB, except that its - input factor is approximated by a diagonal matrix. In the case that each - example references exactly one embedding, this approximation is exact. - - Does not support bias parameters. - """ - - def __init__(self, layer_collection, vocab_size): - """Creates a EmbeddingKFACFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - vocab_size: int. Size of vocabulary for this embedding layer. - """ - self._vocab_size = vocab_size - - super(EmbeddingKFACFB, self).__init__(layer_collection) - - def instantiate_factors(self, grads_list, damping): - """Instantiate Kronecker Factors for this FisherBlock. - - Args: - grads_list: List of list of Tensors. grads_list[i][j] is the - gradient of the loss with respect to 'outputs' from source 'i' and - tower 'j'. Each Tensor has shape [tower_minibatch_size, output_size]. - damping: 0-D Tensor or float. 'damping' * identity is approximately added - to this FisherBlock's Fisher approximation. - """ - inputs, grads_list = self._process_data(grads_list) - - self._input_factor = self._layer_collection.make_or_get_factor( - fisher_factors.EmbeddingInputKroneckerFactor, - (inputs, self._vocab_size)) - self._output_factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullyConnectedKroneckerFactor, (grads_list,)) - self._setup_damping(damping) - - -class FullyConnectedKFACBasicFB(InputOutputMultiTower, KroneckerProductFB): - """K-FAC FisherBlock for fully-connected (dense) layers. - - This uses the Kronecker-factorized approximation from the original - K-FAC paper (https://arxiv.org/abs/1503.05671) - """ - - def __init__(self, layer_collection, has_bias=False): - """Creates a FullyConnectedKFACBasicFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - has_bias: Whether the component Kronecker factors have an additive bias. - (Default: False) - """ - self._has_bias = has_bias - - super(FullyConnectedKFACBasicFB, self).__init__(layer_collection) - - def instantiate_factors(self, grads_list, damping): - """Instantiate Kronecker Factors for this FisherBlock. - - Args: - grads_list: List of list of Tensors. grads_list[i][j] is the - gradient of the loss with respect to 'outputs' from source 'i' and - tower 'j'. Each Tensor has shape [tower_minibatch_size, output_size]. - damping: 0-D Tensor or float. 'damping' * identity is approximately added - to this FisherBlock's Fisher approximation. - """ - inputs, grads_list = self._process_data(grads_list) - - self._input_factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullyConnectedKroneckerFactor, - ((inputs,), self._has_bias)) - self._output_factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullyConnectedKroneckerFactor, - (grads_list,)) - self._setup_damping(damping) - - -class ConvKFCBasicFB(InputOutputMultiTower, KroneckerProductFB): - r"""FisherBlock for convolutional layers using the basic KFC approx. - - Estimates the Fisher Information matrix's blog for a convolutional - layer. - - Consider a convolutional layer in this model with (unshared) filter matrix - 'w'. For a minibatch that produces inputs 'a' and output preactivations 's', - this FisherBlock estimates, - - $$F(w) = \#locations * kronecker(E[flat(a) flat(a)^T], - E[flat(ds) flat(ds)^T])$$ - - where - - $$ds = (d / ds) log p(y | x, w)$$ - #locations = number of (x, y) locations where 'w' is applied. - - where the expectation is taken over all examples and locations and flat() - concatenates an array's leading dimensions. - - See equation 23 in https://arxiv.org/abs/1602.01407 for details. - """ - - def __init__(self, - layer_collection, - params, - padding, - strides=None, - dilation_rate=None, - data_format=None, - extract_patches_fn=None): - """Creates a ConvKFCBasicFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - params: The parameters (Tensor or tuple of Tensors) of this layer. If - kernel alone, a Tensor of shape [..spatial_filter_shape.., - in_channels, out_channels]. If kernel and bias, a tuple of 2 elements - containing the previous and a Tensor of shape [out_channels]. - padding: str. Padding method. - strides: List of ints or None. Contains [..spatial_filter_strides..] if - 'extract_patches_fn' is compatible with tf.nn.convolution(), else - [1, ..spatial_filter_strides, 1]. - dilation_rate: List of ints or None. Rate for dilation along each spatial - dimension if 'extract_patches_fn' is compatible with - tf.nn.convolution(), else [1, ..spatial_dilation_rates.., 1]. - data_format: str or None. Format of input data. - extract_patches_fn: str or None. Name of function that extracts image - patches. One of "extract_convolution_patches", "extract_image_patches", - "extract_pointwise_conv2d_patches". - """ - self._padding = padding - self._strides = maybe_tuple(strides) - self._dilation_rate = maybe_tuple(dilation_rate) - self._data_format = data_format - self._extract_patches_fn = extract_patches_fn - self._has_bias = isinstance(params, (tuple, list)) - - fltr = params[0] if self._has_bias else params - self._filter_shape = tuple(fltr.shape.as_list()) - - super(ConvKFCBasicFB, self).__init__(layer_collection) - - def instantiate_factors(self, grads_list, damping): - inputs, grads_list = self._process_data(grads_list) - - # Infer number of locations upon which convolution is applied. - self._num_locations = num_conv_locations(inputs[0].shape.as_list(), - self._strides) - - self._input_factor = self._layer_collection.make_or_get_factor( - fisher_factors.ConvInputKroneckerFactor, - (inputs, self._filter_shape, self._padding, self._strides, - self._dilation_rate, self._data_format, self._extract_patches_fn, - self._has_bias)) - self._output_factor = self._layer_collection.make_or_get_factor( - fisher_factors.ConvOutputKroneckerFactor, (grads_list,)) - - self._setup_damping(damping, normalization=self._num_locations) - - @property - def _renorm_coeff(self): - return self._num_locations - - -class DepthwiseConvDiagonalFB(ConvDiagonalFB): - """FisherBlock for depthwise_conv2d(). - - Equivalent to ConvDiagonalFB applied to each input channel in isolation. - """ - - def __init__(self, - layer_collection, - params, - strides, - padding, - rate=None, - data_format=None): - """Creates a DepthwiseConvKFCBasicFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - params: Tensor of shape [filter_height, filter_width, in_channels, - channel_multiplier]. - strides: List of 4 ints. Strides along all dimensions. - padding: str. Padding method. - rate: List of 4 ints or None. Rate for dilation along all dimensions. - data_format: str or None. Format of input data. - - Raises: - NotImplementedError: If parameters contains bias. - ValueError: If filter is not 4-D. - ValueError: If strides is not length-4. - ValueError: If rates is not length-2. - ValueError: If channels are not last dimension. - """ - if isinstance(params, (tuple, list)): - raise NotImplementedError("Bias not yet supported.") - - if params.shape.ndims != 4: - raise ValueError("Filter must be 4-D.") - - if len(strides) != 4: - raise ValueError("strides must account for 4 dimensions.") - - if rate is not None: - if len(rate) != 2: - raise ValueError("rate must only account for spatial dimensions.") - rate = [1, rate[0], rate[1], 1] # conv2d expects 4-element rate. - - if not utils.is_data_format_channel_last(data_format): - raise ValueError("data_format must be channels-last.") - - super(DepthwiseConvDiagonalFB, self).__init__( - layer_collection=layer_collection, - params=params, - strides=strides, - padding=padding, - dilations=rate, - data_format=data_format) - - # This is a hack to overwrite the same setting in ConvKFCBasicFB.__init__(). - filter_height, filter_width, in_channels, channel_multiplier = ( - params.shape.as_list()) - self._filter_shape = (filter_height, filter_width, in_channels, - in_channels * channel_multiplier) - - def _multiply_matrix(self, matrix, vector): - conv2d_vector = depthwise_conv2d_filter_to_conv2d_filter(vector) - conv2d_result = super( - DepthwiseConvDiagonalFB, self)._multiply_matrix(matrix, conv2d_vector) - return conv2d_filter_to_depthwise_conv2d_filter(conv2d_result) - - -class DepthwiseConvKFCBasicFB(ConvKFCBasicFB): - """FisherBlock for depthwise_conv2d(). - - Equivalent to ConvKFCBasicFB applied to each input channel in isolation. - """ - - def __init__(self, - layer_collection, - params, - strides, - padding, - rate=None, - data_format=None): - """Creates a DepthwiseConvKFCBasicFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - params: Tensor of shape [filter_height, filter_width, in_channels, - channel_multiplier]. - strides: List of 4 ints. Strides along all dimensions. - padding: str. Padding method. - rate: List of 4 ints or None. Rate for dilation along all dimensions. - data_format: str or None. Format of input data. - - Raises: - NotImplementedError: If parameters contains bias. - ValueError: If filter is not 4-D. - ValueError: If strides is not length-4. - ValueError: If rates is not length-2. - ValueError: If channels are not last dimension. - """ - if isinstance(params, (tuple, list)): - raise NotImplementedError("Bias not yet supported.") - - if params.shape.ndims != 4: - raise ValueError("Filter must be 4-D.") - - if len(strides) != 4: - raise ValueError("strides must account for 4 dimensions.") - - if rate is not None: - if len(rate) != 2: - raise ValueError("rate must only account for spatial dimensions.") - rate = [1, rate[0], rate[1], 1] # conv2d expects 4-element rate. - - if not utils.is_data_format_channel_last(data_format): - raise ValueError("data_format must be channels-last.") - - super(DepthwiseConvKFCBasicFB, self).__init__( - layer_collection=layer_collection, - params=params, - padding=padding, - strides=strides, - dilation_rate=rate, - data_format=data_format, - extract_patches_fn="extract_image_patches") - - # This is a hack to overwrite the same setting in ConvKFCBasicFB.__init__(). - filter_height, filter_width, in_channels, channel_multiplier = ( - params.shape.as_list()) - self._filter_shape = (filter_height, filter_width, in_channels, - in_channels * channel_multiplier) - - def _multiply_factored_matrix(self, left_factor, right_factor, vector, - extra_scale=1.0, transpose_left=False, - transpose_right=False): - conv2d_vector = depthwise_conv2d_filter_to_conv2d_filter(vector) - conv2d_result = super( - DepthwiseConvKFCBasicFB, self)._multiply_factored_matrix( - left_factor, right_factor, conv2d_vector, extra_scale=extra_scale, - transpose_left=transpose_left, transpose_right=transpose_right) - return conv2d_filter_to_depthwise_conv2d_filter(conv2d_result) - - -def depthwise_conv2d_filter_to_conv2d_filter(filter, name=None): # pylint: disable=redefined-builtin - """Converts a convolution filter for use with conv2d. - - Transforms a filter for use with tf.nn.depthwise_conv2d() to one that's - compatible with tf.nn.conv2d(). - - Args: - filter: Tensor of shape [height, width, in_channels, channel_multiplier]. - name: None or str. Name of Op. - - Returns: - Tensor of shape [height, width, in_channels, out_channels]. - - """ - with ops.name_scope(name, "depthwise_conv2d_filter_to_conv2d_filter", - [filter]): - filter = ops.convert_to_tensor(filter) - filter_height, filter_width, in_channels, channel_multiplier = ( - filter.shape.as_list()) - - results = [] - for i in range(in_channels): - # Slice out one in_channel's filter. Insert zeros around it to force it - # to affect that channel and that channel alone. - elements = [] - if i > 0: - elements.append( - array_ops.zeros( - [filter_height, filter_width, i, channel_multiplier])) - elements.append(filter[:, :, i:(i + 1), :]) - if i + 1 < in_channels: - elements.append( - array_ops.zeros([ - filter_height, filter_width, in_channels - (i + 1), - channel_multiplier - ])) - - # Concat along in_channel. - results.append( - array_ops.concat(elements, axis=-2, name="in_channel_%d" % i)) - - # Concat along out_channel. - return array_ops.concat(results, axis=-1, name="out_channel") - - -def conv2d_filter_to_depthwise_conv2d_filter(filter, name=None): # pylint: disable=redefined-builtin - """Converts a convolution filter for use with depthwise_conv2d. - - Transforms a filter for use with tf.nn.conv2d() to one that's - compatible with tf.nn.depthwise_conv2d(). Ignores all filters but those along - the diagonal. - - Args: - filter: Tensor of shape [height, width, in_channels, out_channels]. - name: None or str. Name of Op. - - Returns: - Tensor of shape, - [height, width, in_channels, channel_multiplier] - - Raises: - ValueError: if out_channels is not evenly divisible by in_channels. - """ - with ops.name_scope(name, "conv2d_filter_to_depthwise_conv2d_filter", - [filter]): - filter = ops.convert_to_tensor(filter) - filter_height, filter_width, in_channels, out_channels = ( - filter.shape.as_list()) - - if out_channels % in_channels != 0: - raise ValueError("out_channels must be evenly divisible by in_channels.") - channel_multiplier = out_channels // in_channels - - results = [] - filter = array_ops.reshape(filter, [ - filter_height, filter_width, in_channels, in_channels, - channel_multiplier - ]) - for i in range(in_channels): - # Slice out output corresponding to the correct filter. - filter_slice = array_ops.reshape( - filter[:, :, i, i, :], - [filter_height, filter_width, 1, channel_multiplier]) - results.append(filter_slice) - - # Concat along out_channel. - return array_ops.concat(results, axis=-2, name="in_channels") - - -def maybe_tuple(obj): - if not isinstance(obj, list): - return obj - return tuple(obj) - - -def num_conv_locations(input_shape, strides): - """Returns the number of spatial locations a 2D Conv kernel is applied to. - - Args: - input_shape: List of ints representing shape of inputs to - tf.nn.convolution(). - strides: List of ints representing strides along spatial dimensions as - passed in to tf.nn.convolution(). - - Returns: - A scalar |T| denoting the number of spatial locations for the Conv layer. - """ - spatial_input_locations = np.prod(input_shape[1:-1]) - - if strides is None: - spatial_strides_divisor = 1 - else: - spatial_strides_divisor = np.prod(strides) - - return spatial_input_locations // spatial_strides_divisor - - -class InputOutputMultiTowerMultiUse(InputOutputMultiTower): - """Adds methods for multi-use/time-step case to InputOutputMultiTower.""" - - def __init__(self, num_uses=None, *args, **kwargs): - self._num_uses = num_uses - super(InputOutputMultiTowerMultiUse, self).__init__(*args, **kwargs) - - def _process_data(self, grads_list): - """Process temporal/multi-use data into the format used by the factors. - - This function takes inputs and grads_lists data and processes it into - one of the formats expected by the FisherFactor classes (depending on - the value of the global configuration variable TOWER_STRATEGY). - - It accepts the data in one of two initial formats. The first possible - format is where self._inputs is a list of list of Tensors. The first index - is tower, the second is use/time-step. grads_list, meanwhile, is a list - over sources of such lists of lists. - - The second possible data format is where self._inputs is a Tensor with - uses/times-steps folded into the batch dimension. i.e. it is a Tensor - of shape [num_uses * size_batch, ...] which represents a reshape of a - Tensor of shape [num_uses, size_batch, ...]. And similarly grads_list is - a list over sources of such Tensors. - - There are two possible formats which inputs and grads_list are transformed - into. - - If TOWER_STRATEGY is "concat", 'inputs' becomes a tuple containing - a single tensor (represented as a PartitionedTensor object) with all of - the data from the towers, as well as the uses/time-steps, concatenated - together. In this tensor the leading dimension is the batch and - use/time-step dimensions folded together (with 'use' being the major of - these two, so that the tensors can be thought of as reshapes of ones of - shape [num_uses, batch_size, ...]). grads_list is similarly formatted as a - tuple over sources of such tensors. - - If TOWER_STRATEGY is "separate" the inputs are formatted into lists of - tensors over towers. Each of these tensors has a similar format to - the tensor produced by the "concat" option, except that each contains - only the data from a single tower. grads_list is similarly formatted - into a tuple over sources of such tuples. - - Args: - grads_list: grads_list in its initial format (see above). - - Returns: - inputs: self._inputs transformed into the appropriate format (see - above). - grads_list: grads_list transformed into the appropriate format (see - above). - - Raises: - ValueError: If TOWER_STRATEGY is not one of "separate" or "concat". - ValueError: If the given/initial format of self._inputs and grads_list - isn't recognized, or doesn't agree with self._num_uses. - """ - - inputs = self._inputs - - if isinstance(inputs[0], (list, tuple)): - num_uses = len(inputs[0]) - if self._num_uses is not None and self._num_uses != num_uses: - raise ValueError("num_uses argument doesn't match length of inputs.") - else: - self._num_uses = num_uses - - # Check that all mini-batches/towers have the same number of uses - if not all(len(input_) == num_uses for input_ in inputs): - raise ValueError("Length of inputs argument is inconsistent across " - "towers.") - - if fisher_factors.TOWER_STRATEGY == "concat": - # Reverse the tower and use/time-step indices, so that use is now first, - # and towers is second - inputs = tuple(zip(*inputs)) - - # Flatten the two dimensions - inputs = nest.flatten(inputs) - - # Merge everything together into a PartitionedTensor. We package it in - # a singleton tuple since the factors will expect a list over towers - inputs = (utils.PartitionedTensor(inputs),) - - elif fisher_factors.TOWER_STRATEGY == "separate": - # Merge together the uses/time-step dimension into PartitionedTensors, - # but keep the leading dimension (towers) intact for the factors to - # process individually. - inputs = tuple(utils.PartitionedTensor(input_) for input_ in inputs) - - else: - raise ValueError("Global config variable TOWER_STRATEGY must be one of " - "'concat' or 'separate'.") - else: - inputs = tuple(inputs) - - # Now we perform the analogous processing for grads_list - if isinstance(grads_list[0][0], (list, tuple)): - num_uses = len(grads_list[0][0]) - if self._num_uses is not None and self._num_uses != num_uses: - raise ValueError("num_uses argument doesn't match length of outputs, " - "or length of outputs is inconsistent with length of " - "inputs.") - else: - self._num_uses = num_uses - - if not all(len(grad) == num_uses for grads in grads_list - for grad in grads): - raise ValueError("Length of outputs argument is inconsistent across " - "towers.") - - if fisher_factors.TOWER_STRATEGY == "concat": - # Reverse the tower and use/time-step indices, so that use is now first, - # and towers is second - grads_list = tuple(tuple(zip(*grads)) for grads in grads_list) - - # Flatten the two dimensions, leaving the leading dimension (source) - # intact - grads_list = tuple(nest.flatten(grads) for grads in grads_list) - - # Merge inner dimensions together into PartitionedTensors. We package - # them in a singleton tuple since the factors will expect a list over - # towers - grads_list = tuple((utils.PartitionedTensor(grads),) - for grads in grads_list) - - elif fisher_factors.TOWER_STRATEGY == "separate": - # Merge together the uses/time-step dimension into PartitionedTensors, - # but keep the leading dimension (towers) intact for the factors to - # process individually. - grads_list = tuple(tuple(utils.PartitionedTensor(grad) - for grad in grads) - for grads in grads_list) - - else: - raise ValueError("Global config variable TOWER_STRATEGY must be one of " - "'concat' or 'separate'.") - else: - grads_list = tuple(tuple(grads) for grads in grads_list) - - if self._num_uses is None: - raise ValueError("You must supply a value for the num_uses argument if " - "the number of uses cannot be inferred from inputs or " - "outputs arguments (e.g. if they are both given in the " - "single Tensor format, instead of as lists of Tensors.") - - return inputs, grads_list - - -class FullyConnectedMultiIndepFB(InputOutputMultiTowerMultiUse, - KroneckerProductFB): - """FisherBlock for fully-connected layers that share parameters. - - This class implements the "independence across time" approximation from the - following paper: - https://openreview.net/pdf?id=HyMTkQZAb - """ - - def __init__(self, layer_collection, has_bias=False, num_uses=None): - """Creates a FullyConnectedMultiIndepFB block. - - Args: - layer_collection: LayerCollection instance. - has_bias: bool. If True, estimates Fisher with respect to a bias - parameter as well as the layer's parameters. - num_uses: int or None. Number of uses of the layer in the model's graph. - Only required if the data is formatted with uses/time folded into the - batch dimension (instead of uses/time being a list dimension). - (Default: None) - """ - self._has_bias = has_bias - - super(FullyConnectedMultiIndepFB, self).__init__( - layer_collection=layer_collection, - num_uses=num_uses) - - def instantiate_factors(self, grads_list, damping): - inputs, grads_list = self._process_data(grads_list) - - self._input_factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullyConnectedMultiKF, - ((inputs,), self._num_uses, self._has_bias)) - - self._output_factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullyConnectedMultiKF, (grads_list, self._num_uses)) - - self._setup_damping(damping, normalization=self._num_uses) - - @property - def _renorm_coeff(self): - return float(self._num_uses) - - -class ConvKFCBasicMultiIndepFB(InputOutputMultiTowerMultiUse, - KroneckerProductFB): - """FisherBlock for 2D convolutional layers using the basic KFC approx. - - Similar to ConvKFCBasicFB except that this version supports multiple - uses/time-steps via a standard independence approximation. Similar to the - "independence across time" used in FullyConnectedMultiIndepFB but generalized - in the obvious way to conv layers. - """ - - def __init__(self, - layer_collection, - params, - padding, - strides=None, - dilation_rate=None, - data_format=None, - extract_patches_fn=None, - num_uses=None): - """Creates a ConvKFCBasicMultiIndepFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - params: The parameters (Tensor or tuple of Tensors) of this layer. If - kernel alone, a Tensor of shape [..spatial_filter_shape.., - in_channels, out_channels]. If kernel and bias, a tuple of 2 elements - containing the previous and a Tensor of shape [out_channels]. - padding: str. Padding method. - strides: List of ints or None. Contains [..spatial_filter_strides..] if - 'extract_patches_fn' is compatible with tf.nn.convolution(), else - [1, ..spatial_filter_strides, 1]. - dilation_rate: List of ints or None. Rate for dilation along each spatial - dimension if 'extract_patches_fn' is compatible with - tf.nn.convolution(), else [1, ..spatial_dilation_rates.., 1]. - data_format: str or None. Format of input data. - extract_patches_fn: str or None. Name of function that extracts image - patches. One of "extract_convolution_patches", "extract_image_patches", - "extract_pointwise_conv2d_patches". - num_uses: int or None. Number of uses of the layer in the model's graph. - Only required if the data is formatted with uses/time folded into the - batch dimension (instead of uses/time being a list dimension). - (Default: None) - """ - self._padding = padding - self._strides = maybe_tuple(strides) - self._dilation_rate = maybe_tuple(dilation_rate) - self._data_format = data_format - self._extract_patches_fn = extract_patches_fn - self._has_bias = isinstance(params, (tuple, list)) - - fltr = params[0] if self._has_bias else params - self._filter_shape = tuple(fltr.shape.as_list()) - - super(ConvKFCBasicMultiIndepFB, self).__init__( - layer_collection=layer_collection, - num_uses=num_uses) - - def instantiate_factors(self, grads_list, damping): - inputs, grads_list = self._process_data(grads_list) - - # Infer number of locations upon which convolution is applied. - self._num_locations = num_conv_locations(inputs[0].shape.as_list(), - self._strides) - - self._input_factor = self._layer_collection.make_or_get_factor( - fisher_factors.ConvInputKroneckerFactor, - (inputs, self._filter_shape, self._padding, self._strides, - self._dilation_rate, self._data_format, self._extract_patches_fn, - self._has_bias)) - self._output_factor = self._layer_collection.make_or_get_factor( - fisher_factors.ConvOutputKroneckerFactor, (grads_list,)) - - self._setup_damping(damping, normalization= - (self._num_locations * self._num_uses)) - - @property - def _renorm_coeff(self): - return self._num_locations * self._num_uses - - -class EmbeddingKFACMultiIndepFB(InputOutputMultiTowerMultiUse, - KroneckerProductFB): - """K-FAC FisherBlock for embedding layers used multiple times in the graph. - - Similar to EmbeddingKFACFB except that this version supports multiple uses - of the parameter within a single model. These uses could correspond to time - steps in an RNN architecture, but they don't have to. - - Does not support bias parameters. - """ - - def __init__(self, layer_collection, vocab_size, num_uses=None): - """Creates a EmbeddingKFACMultiIndepFB block. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - vocab_size: int. Size of vocabulary for this embedding layer. - num_uses: int or None. Number of uses of the layer in the model's graph. - Only required if the data is formatted with time folded into the batch - dimension (instead of time being a list dimension). (Default: None) - """ - self._vocab_size = vocab_size - - super(EmbeddingKFACMultiIndepFB, self).__init__( - layer_collection=layer_collection, - num_uses=num_uses) - - def instantiate_factors(self, grads_list, damping): - """Instantiate Kronecker Factors for this FisherBlock. - - Args: - grads_list: List of list of list of Tensors. grads_list[i][j][k] is the - gradient of the loss with respect to 'outputs' from source 'i', - tower/mini-batch 'j', and use/time-step 'k'. Each Tensor has shape - [tower_minibatch_size, output_size]. - damping: 0-D Tensor or float. 'damping' * identity is approximately added - to this FisherBlock's Fisher approximation. - """ - inputs, grads_list = self._process_data(grads_list) - - self._input_factor = self._layer_collection.make_or_get_factor( - fisher_factors.EmbeddingInputKroneckerFactor, - (inputs, self._vocab_size)) - self._output_factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullyConnectedMultiKF, (grads_list, self._num_uses)) - self._setup_damping(damping, normalization=self._num_uses) - - @property - def _renorm_coeff(self): - return float(self._num_uses) - - -class SeriesFBApproximation(enum.IntEnum): - """See FullyConnectedSeriesFB.__init__ for description and usage.""" - option1 = 1 - option2 = 2 - - -class FullyConnectedSeriesFB(InputOutputMultiTowerMultiUse, - KroneckerProductFB): - """FisherBlock for fully-connected layers that share parameters across time. - - This class implements the "Option 1" and "Option 2" approximation from the - following paper: - https://openreview.net/pdf?id=HyMTkQZAb - - See the end of the appendix of the paper for a pseudo-code of the - algorithm being implemented by multiply_matpower here. Note that we are - using pre-computed versions of certain matrix-matrix products to speed - things up. This is explicitly explained wherever it is done. - """ - - def __init__(self, - layer_collection, - has_bias=False, - num_uses=None, - option=SeriesFBApproximation.option2): - """Constructs a new `FullyConnectedSeriesFB`. - - Args: - layer_collection: The collection of all layers in the K-FAC approximate - Fisher information matrix to which this FisherBlock belongs. - has_bias: Whether the layer includes a bias parameter. - num_uses: int or None. Number of time-steps over which the layer - is used. Only required if the data is formatted with time folded into - the batch dimension (instead of time being a list dimension). - (Default: None) - option: A `SeriesFBApproximation` specifying the simplifying assumption - to be used in this block. `option1` approximates the cross-covariance - over time as a symmetric matrix, while `option2` makes - the assumption that training sequences are infinitely long. See section - 3.5 of the paper for more details. - """ - - self._has_bias = has_bias - self._option = option - - super(FullyConnectedSeriesFB, self).__init__( - layer_collection=layer_collection, - num_uses=num_uses) - - @property - def _num_timesteps(self): - return self._num_uses - - @property - def _renorm_coeff(self): - # This should no longer be used since the multiply_X functions from the base - # class have been overridden - assert False - - def instantiate_factors(self, grads_list, damping): - inputs, grads_list = self._process_data(grads_list) - - self._input_factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullyConnectedMultiKF, - ((inputs,), self._num_uses, self._has_bias)) - self._input_factor.register_cov_dt1() - - self._output_factor = self._layer_collection.make_or_get_factor( - fisher_factors.FullyConnectedMultiKF, (grads_list, self._num_uses)) - self._output_factor.register_cov_dt1() - - self._setup_damping(damping, normalization=self._num_uses) - - def register_matpower(self, exp): - if exp != -1: - raise NotImplementedError("FullyConnectedSeriesFB only supports inverse" - "multiplications.") - - if self._option == SeriesFBApproximation.option1: - self._input_factor.register_option1quants(self._input_damping_func) - self._output_factor.register_option1quants(self._output_damping_func) - elif self._option == SeriesFBApproximation.option2: - self._input_factor.register_option2quants(self._input_damping_func) - self._output_factor.register_option2quants(self._output_damping_func) - else: - raise ValueError( - "Unrecognized FullyConnectedSeriesFB approximation: {}".format( - self._option)) - - def multiply_matpower(self, vector, exp): - if exp != -1: - raise NotImplementedError("FullyConnectedSeriesFB only supports inverse" - "multiplications.") - - # pylint: disable=invalid-name - - Z = utils.layer_params_to_mat2d(vector) - - # Derivations were done for "batch_dim==1" case so we need to convert to - # that orientation: - Z = array_ops.transpose(Z) - - if self._option == SeriesFBApproximation.option1: - - # Note that \\(L_A = A0^{-1/2} * U_A and L_G = G0^{-1/2} * U_G.\\) - L_A, psi_A = self._input_factor.get_option1quants( - self._input_damping_func) - L_G, psi_G = self._output_factor.get_option1quants( - self._output_damping_func) - - def gamma(x): - # We are assuming that each case has the same number of time-steps. - # If this stops being the case one shouldn't simply replace this T - # with its average value. Instead, one needs to go back to the - # definition of the gamma function from the paper. - T = self._num_timesteps - return (1 - x)**2 / (T * (1 - x**2) - 2 * x * (1 - x**T)) - - # \\(Y = \gamma( psi_G*psi_A^T )\\) (computed element-wise) - # Even though Y is Z-independent we are recomputing it from the psi's - # each since Y depends on both A and G quantities, and it is relatively - # cheap to compute. - Y = gamma(array_ops.reshape(psi_G, [int(psi_G.shape[0]), -1]) * psi_A) - - # \\(Z = L_G^T * Z * L_A\\) - # This is equivalent to the following computation from the original - # pseudo-code: - # \\(Z = G0^{-1/2} * Z * A0^{-1/2}\\) - # \\(Z = U_G^T * Z * U_A\\) - Z = math_ops.matmul(L_G, math_ops.matmul(Z, L_A), transpose_a=True) - - # \\(Z = Z .* Y\\) - Z *= Y - - # \\(Z = L_G * Z * L_A^T\\) - # This is equivalent to the following computation from the original - # pseudo-code: - # \\(Z = U_G * Z * U_A^T\\) - # \\(Z = G0^{-1/2} * Z * A0^{-1/2}\\) - Z = math_ops.matmul(L_G, math_ops.matmul(Z, L_A, transpose_b=True)) - - elif self._option == SeriesFBApproximation.option2: - - # Note that \\(P_A = A_1^T * A_0^{-1} and P_G = G_1^T * G_0^{-1}\\), - # and \\(K_A = A_0^{-1/2} * E_A\ and\ K_G = G_0^{-1/2} * E_G.\\) - P_A, K_A, mu_A = self._input_factor.get_option2quants( - self._input_damping_func) - P_G, K_G, mu_G = self._output_factor.get_option2quants( - self._output_damping_func) - - # Our approach differs superficially from the pseudo-code in the paper - # in order to reduce the total number of matrix-matrix multiplies. - # In particular, the first three computations in the pseudo code are - # \\(Z = G0^{-1/2} * Z * A0^{-1/2}\\) - # \\(Z = Z - hPsi_G^T * Z * hPsi_A\\) - # \\(Z = E_G^T * Z * E_A\\) - # Noting that hPsi = C0^{-1/2} * C1 * C0^{-1/2}\\), so that - # \\(C0^{-1/2} * hPsi = C0^{-1} * C1 * C0^{-1/2} = P^T * C0^{-1/2}\\) - # the entire computation can be written as - # \\(Z = E_G^T * (G0^{-1/2} * Z * A0^{-1/2}\\) - # \\( - hPsi_G^T * G0^{-1/2} * Z * A0^{-1/2} * hPsi_A) * E_A\\) - # \\( = E_G^T * (G0^{-1/2} * Z * A0^{-1/2}\\) - # \\( - G0^{-1/2} * P_G * Z * P_A^T * A0^{-1/2}) * E_A\\) - # \\( = E_G^T * G0^{-1/2} * Z * A0^{-1/2} * E_A\\) - # \\( - E_G^T* G0^{-1/2} * P_G * Z * P_A^T * A0^{-1/2} * E_A\\) - # \\( = K_G^T * Z * K_A - K_G^T * P_G * Z * P_A^T * K_A\\) - # This final expression is computed by the following two lines: - # \\(Z = Z - P_G * Z * P_A^T\\) - Z -= math_ops.matmul(P_G, math_ops.matmul(Z, P_A, transpose_b=True)) - # \\(Z = K_G^T * Z * K_A\\) - Z = math_ops.matmul(K_G, math_ops.matmul(Z, K_A), transpose_a=True) - - # \\(Z = Z ./ (1*1^T - mu_G*mu_A^T)\\) - # Be careful with the outer product. We don't want to accidentally - # make it an inner-product instead. - tmp = 1.0 - array_ops.reshape(mu_G, [int(mu_G.shape[0]), -1]) * mu_A - # Prevent some numerical issues by setting any 0.0 eigs to 1.0 - tmp += 1.0 * math_ops.cast(math_ops.equal(tmp, 0.0), dtype=tmp.dtype) - Z /= tmp - - # We now perform the transpose/reverse version of the operations - # derived above, whose derivation from the original pseudo-code is - # analgous. - # \\(Z = K_G * Z * K_A^T\\) - Z = math_ops.matmul(K_G, math_ops.matmul(Z, K_A, transpose_b=True)) - - # \\(Z = Z - P_G^T * Z * P_A\\) - Z -= math_ops.matmul(P_G, math_ops.matmul(Z, P_A), transpose_a=True) - - # \\(Z = normalize (1/E[T]) * Z\\) - # Note that this normalization is done because we compute the statistics - # by averaging, not summing, over time. (And the gradient is presumably - # summed over time, not averaged, and thus their scales are different.) - Z /= math_ops.cast(self._num_timesteps, Z.dtype) - - # Convert back to the "batch_dim==0" orientation. - Z = array_ops.transpose(Z) - - return utils.mat2d_to_layer_params(vector, Z) - - # pylint: enable=invalid-name - - def multiply_cholesky(self, vector): - raise NotImplementedError("FullyConnectedSeriesFB does not support " - "Cholesky computations.") - - def multiply_cholesky_inverse(self, vector): - raise NotImplementedError("FullyConnectedSeriesFB does not support " - "Cholesky computations.") - diff --git a/tensorflow/contrib/kfac/python/ops/fisher_blocks_lib.py b/tensorflow/contrib/kfac/python/ops/fisher_blocks_lib.py deleted file mode 100644 index c04cf727fa..0000000000 --- a/tensorflow/contrib/kfac/python/ops/fisher_blocks_lib.py +++ /dev/null @@ -1,45 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""FisherBlock definitions.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import,line-too-long,wildcard-import -from tensorflow.contrib.kfac.python.ops.fisher_blocks import * -from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long,wildcard-import - -_allowed_symbols = [ - 'FisherBlock', - 'FullFB', - 'NaiveDiagonalFB', - 'FullyConnectedDiagonalFB', - 'KroneckerProductFB', - 'EmbeddingKFACFB', - 'FullyConnectedKFACBasicFB', - 'ConvKFCBasicFB', - 'ConvDiagonalFB', - 'set_global_constants', - 'compute_pi_tracenorm', - 'compute_pi_adjusted_damping', - 'num_conv_locations', - 'normalize_damping', - 'LEFT_MULTIPLY', - 'RIGHT_MULTIPLY', -] - -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) diff --git a/tensorflow/contrib/kfac/python/ops/fisher_factors.py b/tensorflow/contrib/kfac/python/ops/fisher_factors.py deleted file mode 100644 index afa2fd1ca7..0000000000 --- a/tensorflow/contrib/kfac/python/ops/fisher_factors.py +++ /dev/null @@ -1,1830 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""FisherFactor definitions.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import abc -import contextlib - -import numpy as np -import six - -from tensorflow.contrib.kfac.python.ops import linear_operator as lo -from tensorflow.contrib.kfac.python.ops import utils -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import ops as tf_ops -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import control_flow_ops -from tensorflow.python.ops import init_ops -from tensorflow.python.ops import linalg_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import random_ops -from tensorflow.python.ops import special_math_ops -from tensorflow.python.ops import variable_scope -from tensorflow.python.ops import variables -from tensorflow.python.training import moving_averages -from tensorflow.python.util import nest - - -# Whether to initialize covariance estimators at a zero matrix (or the identity -# matrix). -INIT_COVARIANCES_AT_ZERO = True - -# Whether to zero-debias the moving averages. -ZERO_DEBIAS = True - -# Whether to initialize inverse (and other such matrices computed from the cov -# matrices) to the zero matrix (or the identity matrix). -INIT_INVERSES_AT_ZERO = True - -# When the number of inverses requested from a FisherFactor exceeds this value, -# the inverses are computed using an eigenvalue decomposition. -EIGENVALUE_DECOMPOSITION_THRESHOLD = 2 - -# Numerical eigenvalues computed from covariance matrix estimates are clipped to -# be at least as large as this value before they are used to compute inverses or -# matrix powers. Must be nonnegative. -EIGENVALUE_CLIPPING_THRESHOLD = 0.0 - -# Used to subsample the flattened extracted image patches. The number of -# outer products per row of the covariance matrix should not exceed this -# value. This parameter is used only if `_SUB_SAMPLE_OUTER_PRODUCTS` is True. -_MAX_NUM_OUTER_PRODUCTS_PER_COV_ROW = 1 - -# Used to subsample the inputs passed to the extract image patches. The batch -# size of number of inputs to extract image patches is multiplied by this -# factor. This parameter is used only if `_SUB_SAMPLE_INPUTS` is True. -_INPUTS_TO_EXTRACT_PATCHES_FACTOR = 0.5 - -# If True, then subsamples the tensor passed to compute the covariance matrix. -_SUB_SAMPLE_OUTER_PRODUCTS = False - -# If True, then subsamples the tensor passed to compute the covariance matrix. -_SUB_SAMPLE_INPUTS = False - -# TOWER_STRATEGY can be one of "concat" or "separate". If "concat", the data -# passed to the factors from the blocks will be concatenated across towers -# (lazily via PartitionedTensor objects). Otherwise a tuple of tensors over -# towers will be passed in, and the factors will iterate over this and do the -# cov computations separately for each one, averaging the results together. -TOWER_STRATEGY = "concat" - - -def set_global_constants(init_covariances_at_zero=None, - zero_debias=None, - init_inverses_at_zero=None, - eigenvalue_decomposition_threshold=None, - eigenvalue_clipping_threshold=None, - max_num_outer_products_per_cov_row=None, - sub_sample_outer_products=None, - inputs_to_extract_patches_factor=None, - sub_sample_inputs=None, - tower_strategy=None): - """Sets various global constants used by the classes in this module.""" - global INIT_COVARIANCES_AT_ZERO - global ZERO_DEBIAS - global INIT_INVERSES_AT_ZERO - global EIGENVALUE_DECOMPOSITION_THRESHOLD - global EIGENVALUE_CLIPPING_THRESHOLD - global _MAX_NUM_OUTER_PRODUCTS_PER_COV_ROW - global _SUB_SAMPLE_OUTER_PRODUCTS - global _INPUTS_TO_EXTRACT_PATCHES_FACTOR - global _SUB_SAMPLE_INPUTS - global TOWER_STRATEGY - - if init_covariances_at_zero is not None: - INIT_COVARIANCES_AT_ZERO = init_covariances_at_zero - if zero_debias is not None: - ZERO_DEBIAS = zero_debias - if init_inverses_at_zero is not None: - INIT_INVERSES_AT_ZERO = init_inverses_at_zero - if eigenvalue_decomposition_threshold is not None: - EIGENVALUE_DECOMPOSITION_THRESHOLD = eigenvalue_decomposition_threshold - if eigenvalue_clipping_threshold is not None: - EIGENVALUE_CLIPPING_THRESHOLD = eigenvalue_clipping_threshold - if max_num_outer_products_per_cov_row is not None: - _MAX_NUM_OUTER_PRODUCTS_PER_COV_ROW = max_num_outer_products_per_cov_row - if sub_sample_outer_products is not None: - _SUB_SAMPLE_OUTER_PRODUCTS = sub_sample_outer_products - if inputs_to_extract_patches_factor is not None: - _INPUTS_TO_EXTRACT_PATCHES_FACTOR = inputs_to_extract_patches_factor - if sub_sample_inputs is not None: - _SUB_SAMPLE_INPUTS = sub_sample_inputs - if tower_strategy is not None: - TOWER_STRATEGY = tower_strategy - - -def inverse_initializer(shape, dtype, partition_info=None): # pylint: disable=unused-argument - if INIT_INVERSES_AT_ZERO: - return array_ops.zeros(shape, dtype=dtype) - return linalg_ops.eye(num_rows=shape[0], dtype=dtype) - - -def covariance_initializer(shape, dtype, partition_info=None): # pylint: disable=unused-argument - if INIT_COVARIANCES_AT_ZERO: - return array_ops.zeros(shape, dtype=dtype) - return linalg_ops.eye(num_rows=shape[0], dtype=dtype) - - -def diagonal_covariance_initializer(shape, dtype, partition_info=None): # pylint: disable=unused-argument - if INIT_COVARIANCES_AT_ZERO: - return array_ops.zeros(shape, dtype=dtype) - return array_ops.ones(shape, dtype=dtype) - - -@contextlib.contextmanager -def place_on_device(device): - if device is not None and len(device): - with tf_ops.device(device): - yield - else: - yield - - -def compute_cov(tensor, tensor_right=None, normalizer=None): - """Compute the empirical second moment of the rows of a 2D Tensor. - - This function is meant to be applied to random matrices for which the true row - mean is zero, so that the true second moment equals the true covariance. - - Args: - tensor: A 2D Tensor. - tensor_right: An optional 2D Tensor. If provided, this function computes - the matrix product tensor^T * tensor_right instead of tensor^T * tensor. - normalizer: optional scalar for the estimator (by default, the normalizer is - the number of rows of tensor). - - Returns: - A square 2D Tensor with as many rows/cols as the number of input columns. - """ - if normalizer is None: - normalizer = array_ops.shape(tensor)[0] - if tensor_right is None: - cov = ( - math_ops.matmul(tensor, tensor, transpose_a=True) / math_ops.cast( - normalizer, tensor.dtype)) - return (cov + array_ops.transpose(cov)) / math_ops.cast(2.0, cov.dtype) - else: - return (math_ops.matmul(tensor, tensor_right, transpose_a=True) / - math_ops.cast(normalizer, tensor.dtype)) - - -def append_homog(tensor): - """Appends a homogeneous coordinate to the last dimension of a Tensor. - - Args: - tensor: A Tensor. - - Returns: - A Tensor identical to the input but one larger in the last dimension. The - new entries are filled with ones. - """ - rank = len(tensor.shape.as_list()) - shape = array_ops.concat([array_ops.shape(tensor)[:-1], [1]], axis=0) - ones = array_ops.ones(shape, dtype=tensor.dtype) - return array_ops.concat([tensor, ones], axis=rank - 1) - - -def scope_string_from_params(params): - """Builds a variable scope string name from the given parameters. - - Supported parameters are: - * tensors - * booleans - * ints - * strings - * depth-1 tuples/lists of ints - * any depth tuples/lists of tensors - Other parameter types will throw an error. - - Args: - params: A parameter or list of parameters. - - Returns: - A string to use for the variable scope. - - Raises: - ValueError: if params includes an unsupported type. - """ - params = params if isinstance(params, (tuple, list)) else (params,) - - name_parts = [] - for param in params: - if param is None: - name_parts.append("None") - elif isinstance(param, (tuple, list)): - if all([isinstance(p, int) for p in param]): - name_parts.append("-".join([str(p) for p in param])) - else: - name_parts.append(scope_string_from_name(param)) - elif isinstance(param, (str, int, bool)): - name_parts.append(str(param)) - elif isinstance(param, (tf_ops.Tensor, variables.Variable)): - name_parts.append(scope_string_from_name(param)) - elif isinstance(param, utils.PartitionedTensor): - name_parts.append(scope_string_from_name(param.tensors)) - else: - raise ValueError("Encountered an unsupported param type {}".format( - type(param))) - return "_".join(name_parts) - - -def scope_string_from_name(tensor): - if isinstance(tensor, (tuple, list)): - return "__".join([scope_string_from_name(t) for t in tensor]) - # "gradients/add_4_grad/Reshape:0" -> "gradients_add_4_grad_Reshape" - return tensor.name.split(":")[0].replace("/", "_") - - -def scalar_or_tensor_to_string(val): - return repr(val) if np.isscalar(val) else scope_string_from_name(val) - - -def list_to_string(lst): - return "_".join(val if isinstance(val, six.string_types) - else scalar_or_tensor_to_string(val) for val in lst) - - -def graph_func_to_id(func): - """Returns a hashable object that represents func's computation.""" - # TODO(b/74201126): replace with Topohash of func's output - return func.func_id - - -def graph_func_to_string(func): - # TODO(b/74201126): replace with Topohash of func's output - return list_to_string(func.func_id) - - -def _subsample_for_cov_computation(array, name=None): - """Subsamples the first dimension of the array. - - `array`(A) is a tensor of shape `[batch_size, dim_2]`. Then the covariance - matrix(A^TA) is of shape `dim_2 ** 2`. Subsample only if the number of outer - products per row of the covariance matrix is greater than - `_MAX_NUM_OUTER_PRODUCTS_PER_COV_ROW`. - - Args: - array: Tensor, of shape `[batch_size, dim_2]`. - name: `string`, Default(None) - - Returns: - A tensor of shape `[max_samples, dim_2]`. - - Raises: - ValueError: If array's is not matrix-shaped. - ValueError: If array's batch_size cannot be inferred. - - """ - with tf_ops.name_scope(name, "subsample", [array]): - array = tf_ops.convert_to_tensor(array) - if len(array.shape) != 2: - raise ValueError("Input param array must be a matrix.") - - batch_size = array.shape.as_list()[0] - if batch_size is None: - raise ValueError("Unable to get batch_size from input param array.") - - num_cov_rows = array.shape.as_list()[-1] - max_batch_size = int(_MAX_NUM_OUTER_PRODUCTS_PER_COV_ROW * num_cov_rows) - if batch_size <= max_batch_size: - return array - - return _random_tensor_gather(array, max_batch_size) - - -def _random_tensor_gather(array, max_size): - """Generates a random set of indices and gathers the value at the indices. - - Args: - array: Tensor, of shape `[batch_size, dim_2]`. - max_size: int, Number of indices to sample. - - Returns: - A tensor of shape `[max_size, ...]`. - """ - batch_size = array.shape.as_list()[0] - indices = random_ops.random_shuffle(math_ops.range(0, batch_size))[:max_size] - return array_ops.gather(array, indices) - - -@six.add_metaclass(abc.ABCMeta) -class FisherFactor(object): - """Base class for objects modeling factors of approximate Fisher blocks. - - A FisherFactor represents part of an approximate Fisher Information matrix. - For example, one approximation to the Fisher uses the Kronecker product of two - FisherFactors A and B, F = kron(A, B). FisherFactors are composed with - FisherBlocks to construct a block-diagonal approximation to the full Fisher. - - FisherFactors are backed by a single, non-trainable variable that is updated - by running FisherFactor.make_covariance_update_op(). The shape and type of - this variable is implementation specific. - - Note that for blocks that aren't based on approximations, a 'factor' can - be the entire block itself, as is the case for the diagonal and full - representations. - """ - - def __init__(self): - self._cov = None - - @abc.abstractproperty - def _var_scope(self): - """Variable scope for this FisherFactor instance. - - Returns: - string that unique identifies this FisherFactor instance. - """ - pass - - @property - def name(self): - return self._var_scope - - @abc.abstractproperty - def _cov_shape(self): - """The shape of the variable backing this FisherFactor.""" - pass - - @abc.abstractproperty - def _num_sources(self): - """The number of things to sum over when updating covariance variable. - - The default make_covariance_update_op function will call _compute_new_cov - with indices ranging from 0 to _num_sources-1. The typical situation is - where the factor wants to sum the statistics it computes over multiple - backpropped "gradients" (typically passed in via "tensors" or - "outputs_grads" arguments). - """ - pass - - @abc.abstractproperty - def _num_towers(self): - pass - - @abc.abstractproperty - def _dtype(self): - """dtype for variable backing this factor.""" - pass - - @property - def _cov_initializer(self): - """Function for initializing covariance variable.""" - return covariance_initializer - - def instantiate_cov_variables(self): - """Makes the internal cov variable(s).""" - assert self._cov is None - with variable_scope.variable_scope(self._var_scope): - self._cov = variable_scope.get_variable( - "cov", - initializer=self._cov_initializer, - shape=self._cov_shape, - trainable=False, - dtype=self._dtype) - - @abc.abstractmethod - def _compute_new_cov(self, source, tower): - """Computes minibatch-estimated covariance for a single source. - - Args: - source: int in [0, self._num_sources). Which source to use when computing - the cov update. - tower: int in [0, self._num_towers). Which tower to use when computing - the cov update. - - Returns: - Tensor of same shape as self.get_cov(). - """ - pass - - def make_covariance_update_op(self, ema_decay): - """Constructs and returns the covariance update Op. - - Args: - ema_decay: The exponential moving average decay (float or Tensor). - Returns: - An Op for updating the covariance Variable referenced by _cov. - """ - new_cov_contribs = [] - for source in range(self._num_sources): - for tower in range(self._num_towers): - device = (self._get_data_device(tower) - if TOWER_STRATEGY == "separate" else None) - with place_on_device(device): - new_cov_contribs.append(self._compute_new_cov(source, tower)) - - new_cov = math_ops.add_n(new_cov_contribs) / float(self._num_towers) - - # Compute average of 'new_cov' across all TPU cores. On a TPU, each - # instance of 'new_cov' will be based on a different minibatch. This ensures - # that by the end of assign_moving_average(), all TPU cores see the same - # value for self._cov. - # - # Other implementations of make_covariance_update_op() that accumulate - # statistics in other variables should mimic this behavior. - if utils.on_tpu(): - new_cov = utils.cross_replica_mean(new_cov) - - return moving_averages.assign_moving_average( - self._cov, new_cov, ema_decay, zero_debias=ZERO_DEBIAS) - - @abc.abstractmethod - def _get_data_device(self, tower): - pass - - @abc.abstractmethod - def instantiate_inv_variables(self): - """Makes the internal "inverse" variable(s).""" - pass - - @abc.abstractmethod - def make_inverse_update_ops(self): - """Create and return update ops corresponding to registered computations.""" - pass - - def get_cov(self): - return self._cov - - @abc.abstractmethod - def get_cov_as_linear_operator(self): - pass - - @abc.abstractmethod - def register_matpower(self, exp, damping_func): - pass - - @abc.abstractmethod - def register_cholesky(self, damping_func): - pass - - @abc.abstractmethod - def register_cholesky_inverse(self, damping_func): - pass - - @abc.abstractmethod - def get_matpower(self, exp, damping_func): - pass - - @abc.abstractmethod - def get_cholesky(self, damping_func): - pass - - @abc.abstractmethod - def get_cholesky_inverse(self, damping_func): - pass - - -class DenseSquareMatrixFactor(FisherFactor): - """Base class for FisherFactors that are stored as dense square matrices. - - This class explicitly calculates and stores inverses of their `cov` matrices, - which must be square dense matrices. - - Subclasses must implement the _compute_new_cov method, and the _var_scope and - _cov_shape properties. - """ - - # TODO(b/69108481): This class (and its subclasses) should be refactored to - # serve the matrix quantities it computes as both (potentially stale) - # variables, updated by the inverse update ops, and fresh values stored in - # tensors that recomputed once every session.run() call. Currently matpower - # and damp_inverse have the former behavior, while eigendecomposition has - # the latter. - - def __init__(self): - self._matpower_by_exp_and_damping = {} # { (float, hashable): variable } - self._matpower_registrations = set() # { (float, hashable) } - self._eigendecomp = None - self._damping_funcs_by_id = {} # {hashable: lambda} - - self._cholesky_registrations = set() # { hashable } - self._cholesky_inverse_registrations = set() # { hashable } - - self._cholesky_by_damping = {} # { hashable: variable } - self._cholesky_inverse_by_damping = {} # { hashable: variable } - - super(DenseSquareMatrixFactor, self).__init__() - - def get_cov_as_linear_operator(self): - assert self.get_cov().shape.ndims == 2 - return lo.LinearOperatorFullMatrix(self.get_cov(), - is_self_adjoint=True, - is_square=True) - - def _register_damping(self, damping_func): - damping_id = graph_func_to_id(damping_func) - if damping_id not in self._damping_funcs_by_id: - self._damping_funcs_by_id[damping_id] = damping_func - return damping_id - - def register_inverse(self, damping_func): - # Just for backwards compatibility of some old code and tests - self.register_matpower(-1, damping_func) - - def register_matpower(self, exp, damping_func): - """Registers a matrix power to be maintained and served on demand. - - This creates a variable and signals make_inverse_update_ops to make the - corresponding update op. The variable can be read via the method - get_matpower. - - Args: - exp: float. The exponent to use in the matrix power. - damping_func: A function that computes a 0-D Tensor or a float which will - be the damping value used. i.e. damping = damping_func(). - """ - if exp == 1.0: - return - - damping_id = self._register_damping(damping_func) - - if (exp, damping_id) not in self._matpower_registrations: - self._matpower_registrations.add((exp, damping_id)) - - def register_cholesky(self, damping_func): - """Registers a Cholesky factor to be maintained and served on demand. - - This creates a variable and signals make_inverse_update_ops to make the - corresponding update op. The variable can be read via the method - get_cholesky. - - Args: - damping_func: A function that computes a 0-D Tensor or a float which will - be the damping value used. i.e. damping = damping_func(). - """ - damping_id = self._register_damping(damping_func) - - if damping_id not in self._cholesky_registrations: - self._cholesky_registrations.add(damping_id) - - def register_cholesky_inverse(self, damping_func): - """Registers an inverse Cholesky factor to be maintained/served on demand. - - This creates a variable and signals make_inverse_update_ops to make the - corresponding update op. The variable can be read via the method - get_cholesky_inverse. - - Args: - damping_func: A function that computes a 0-D Tensor or a float which will - be the damping value used. i.e. damping = damping_func(). - """ - damping_id = self._register_damping(damping_func) - - if damping_id not in self._cholesky_inverse_registrations: - self._cholesky_inverse_registrations.add(damping_id) - - def instantiate_inv_variables(self): - """Makes the internal "inverse" variable(s).""" - - for (exp, damping_id) in self._matpower_registrations: - exp_string = scalar_or_tensor_to_string(exp) - damping_func = self._damping_funcs_by_id[damping_id] - damping_string = graph_func_to_string(damping_func) - with variable_scope.variable_scope(self._var_scope): - matpower = variable_scope.get_variable( - "matpower_exp{}_damp{}".format(exp_string, damping_string), - initializer=inverse_initializer, - shape=self._cov_shape, - trainable=False, - dtype=self._dtype) - assert (exp, damping_id) not in self._matpower_by_exp_and_damping - self._matpower_by_exp_and_damping[(exp, damping_id)] = matpower - - for damping_id in self._cholesky_registrations: - damping_func = self._damping_funcs_by_id[damping_id] - damping_string = graph_func_to_string(damping_func) - with variable_scope.variable_scope(self._var_scope): - chol = variable_scope.get_variable( - "cholesky_damp{}".format(damping_string), - initializer=inverse_initializer, - shape=self._cov_shape, - trainable=False, - dtype=self._dtype) - assert damping_id not in self._cholesky_by_damping - self._cholesky_by_damping[damping_id] = chol - - for damping_id in self._cholesky_inverse_registrations: - damping_func = self._damping_funcs_by_id[damping_id] - damping_string = graph_func_to_string(damping_func) - with variable_scope.variable_scope(self._var_scope): - cholinv = variable_scope.get_variable( - "cholesky_inverse_damp{}".format(damping_string), - initializer=inverse_initializer, - shape=self._cov_shape, - trainable=False, - dtype=self._dtype) - assert damping_id not in self._cholesky_inverse_by_damping - self._cholesky_inverse_by_damping[damping_id] = cholinv - - def make_inverse_update_ops(self): - """Create and return update ops corresponding to registered computations.""" - ops = [] - - num_inverses = sum(1 for (exp, _) in self._matpower_by_exp_and_damping - if exp == -1) - - num_other_matpower = len(self._matpower_by_exp_and_damping) - num_inverses - - other_matrix_power_registered = num_other_matpower >= 1 - - use_eig = ( - self._eigendecomp or other_matrix_power_registered or - num_inverses >= EIGENVALUE_DECOMPOSITION_THRESHOLD) - - # We precompute these so we don't need to evaluate them multiple times (for - # each matrix power that uses them) - damping_value_by_id = {damping_id: math_ops.cast( - self._damping_funcs_by_id[damping_id](), self._dtype) - for damping_id in self._damping_funcs_by_id} - - if use_eig: - eigenvalues, eigenvectors = self.get_eigendecomp() # pylint: disable=unpacking-non-sequence - - for (exp, damping_id), matpower in ( - self._matpower_by_exp_and_damping.items()): - damping = damping_value_by_id[damping_id] - ops.append( - matpower.assign( - math_ops.matmul(eigenvectors * - (eigenvalues + damping)**exp, - array_ops.transpose(eigenvectors)))) - # These ops share computation and should be run on a single device. - ops = [control_flow_ops.group(*ops)] - else: - for (exp, damping_id), matpower in ( - self._matpower_by_exp_and_damping.items()): - assert exp == -1 - damping = damping_value_by_id[damping_id] - ops.append(matpower.assign(utils.posdef_inv(self.get_cov(), damping))) - - # TODO(b/77902055): If inverses are being computed with Cholesky's - # we can share the work. Instead this code currently just computes the - # Cholesky a second time. It does at least share work between requests for - # Cholesky's and Cholesky inverses with the same damping id. - for damping_id, cholesky_inv in self._cholesky_inverse_by_damping.items(): - cholesky_ops = [] - - damping = damping_value_by_id[damping_id] - cholesky_value = utils.cholesky(self.get_cov(), damping) - - if damping_id in self._cholesky_by_damping: - cholesky = self._cholesky_by_damping[damping_id] - cholesky_ops.append(cholesky.assign(cholesky_value)) - - identity = linalg_ops.eye(cholesky_value.shape.as_list()[0], - dtype=cholesky_value.dtype) - cholesky_inv_value = linalg_ops.matrix_triangular_solve(cholesky_value, - identity) - cholesky_ops.append(cholesky_inv.assign(cholesky_inv_value)) - - ops.append(control_flow_ops.group(*cholesky_ops)) - - for damping_id, cholesky in self._cholesky_by_damping.items(): - if damping_id not in self._cholesky_inverse_by_damping: - damping = damping_value_by_id[damping_id] - cholesky_value = utils.cholesky(self.get_cov(), damping) - ops.append(cholesky.assign(cholesky_value)) - - self._eigendecomp = False - return ops - - def get_inverse(self, damping_func): - # Just for backwards compatibility of some old code and tests - return self.get_matpower(-1, damping_func) - - def get_matpower(self, exp, damping_func): - # Note that this function returns a variable which gets updated by the - # inverse ops. It may be stale / inconsistent with the latest value of - # get_cov(). - if exp != 1: - damping_id = graph_func_to_id(damping_func) - matpower = self._matpower_by_exp_and_damping[(exp, damping_id)] - else: - matpower = self.get_cov() - identity = linalg_ops.eye(matpower.shape.as_list()[0], - dtype=matpower.dtype) - matpower += math_ops.cast(damping_func(), dtype=matpower.dtype)*identity - - assert matpower.shape.ndims == 2 - return lo.LinearOperatorFullMatrix(matpower, - is_non_singular=True, - is_self_adjoint=True, - is_positive_definite=True, - is_square=True) - - def get_cholesky(self, damping_func): - # Note that this function returns a variable which gets updated by the - # inverse ops. It may be stale / inconsistent with the latest value of - # get_cov(). - damping_id = graph_func_to_id(damping_func) - cholesky = self._cholesky_by_damping[damping_id] - assert cholesky.shape.ndims == 2 - return lo.LinearOperatorFullMatrix(cholesky, - is_non_singular=True, - is_square=True) - - def get_cholesky_inverse(self, damping_func): - # Note that this function returns a variable which gets updated by the - # inverse ops. It may be stale / inconsistent with the latest value of - # get_cov(). - damping_id = graph_func_to_id(damping_func) - cholesky_inv = self._cholesky_inverse_by_damping[damping_id] - assert cholesky_inv.shape.ndims == 2 - return lo.LinearOperatorFullMatrix(cholesky_inv, - is_non_singular=True, - is_square=True) - - def get_eigendecomp(self): - """Creates or retrieves eigendecomposition of self._cov.""" - # Unlike get_matpower this doesn't retrieve a stored variable, but instead - # always computes a fresh version from the current value of get_cov(). - if not self._eigendecomp: - eigenvalues, eigenvectors = linalg_ops.self_adjoint_eig(self.get_cov()) - - # The matrix self._cov is positive semidefinite by construction, but the - # numerical eigenvalues could be negative due to numerical errors, so here - # we clip them to be at least FLAGS.eigenvalue_clipping_threshold - clipped_eigenvalues = math_ops.maximum(eigenvalues, - EIGENVALUE_CLIPPING_THRESHOLD) - self._eigendecomp = (clipped_eigenvalues, eigenvectors) - - return self._eigendecomp - - -class FullFactor(DenseSquareMatrixFactor): - """FisherFactor for a full matrix representation of the Fisher of a parameter. - - Note that this uses the naive "square the sum estimator", and so is applicable - to any type of parameter in principle, but has very high variance. - """ - - def __init__(self, - params_grads, - batch_size): - self._batch_size = batch_size - self._params_grads = tuple(utils.ensure_sequence(params_grad) - for params_grad in params_grads) - super(FullFactor, self).__init__() - - @property - def _var_scope(self): - return "ff_full_" + scope_string_from_params( - [self._params_grads, self._batch_size]) - - @property - def _cov_shape(self): - size = sum(param_grad.shape.num_elements() - for param_grad in self._params_grads[0]) - return (size, size) - - @property - def _num_sources(self): - return len(self._params_grads) - - @property - def _num_towers(self): - return 1 - - @property - def _dtype(self): - return self._params_grads[0][0].dtype - - def _compute_new_cov(self, source, tower): - assert tower == 0 - - # This will be a very basic rank 1 estimate - params_grads_flat = utils.tensors_to_column(self._params_grads[source]) - return ((params_grads_flat * array_ops.transpose( - params_grads_flat)) / math_ops.cast(self._batch_size, - params_grads_flat.dtype)) - - def _get_data_device(self, tower): - return None - - -class DiagonalFactor(FisherFactor): - """A base class for FisherFactors that use diagonal approximations. - - A DiagonalFactor's covariance variable can be of any shape, but must contain - exactly one entry per parameter. - """ - - def __init__(self): - super(DiagonalFactor, self).__init__() - - def get_cov_as_linear_operator(self): - assert self._matrix_diagonal.shape.ndims == 1 - return lo.LinearOperatorDiag(self._matrix_diagonal, - is_self_adjoint=True, - is_square=True) - - @property - def _cov_initializer(self): - return diagonal_covariance_initializer - - @property - def _matrix_diagonal(self): - return array_ops.reshape(self.get_cov(), [-1]) - - def make_inverse_update_ops(self): - return [] - - def instantiate_inv_variables(self): - pass - - def register_matpower(self, exp, damping_func): - pass - - def register_cholesky(self, damping_func): - pass - - def register_cholesky_inverse(self, damping_func): - pass - - def get_matpower(self, exp, damping_func): - matpower_diagonal = (self._matrix_diagonal - + math_ops.cast(damping_func(), self._dtype))**exp - return lo.LinearOperatorDiag(matpower_diagonal, - is_non_singular=True, - is_self_adjoint=True, - is_positive_definite=True, - is_square=True) - - def get_cholesky(self, damping_func): - return self.get_matpower(0.5, damping_func) - - def get_cholesky_inverse(self, damping_func): - return self.get_matpower(-0.5, damping_func) - - -class NaiveDiagonalFactor(DiagonalFactor): - """FisherFactor for a diagonal approximation of any type of param's Fisher. - - Note that this uses the naive "square the sum estimator", and so is applicable - to any type of parameter in principle, but has very high variance. - """ - - def __init__(self, - params_grads, - batch_size): - """Initializes NaiveDiagonalFactor instance. - - Args: - params_grads: Sequence of Tensors, each with same shape as parameters this - FisherFactor corresponds to. For example, the gradient of the loss with - respect to parameters. - batch_size: int or 0-D Tensor. Size - """ - self._params_grads = tuple(utils.ensure_sequence(params_grad) - for params_grad in params_grads) - self._batch_size = batch_size - super(NaiveDiagonalFactor, self).__init__() - - @property - def _var_scope(self): - return "ff_naivediag_" + scope_string_from_params( - [self._params_grads, self._batch_size]) - - @property - def _cov_shape(self): - size = sum(param_grad.shape.num_elements() - for param_grad in self._params_grads[0]) - return [size, 1] - - @property - def _num_sources(self): - return len(self._params_grads) - - @property - def _num_towers(self): - return 1 - - @property - def _dtype(self): - return self._params_grads[0][0].dtype - - def _compute_new_cov(self, source, tower): - assert tower == 0 - - params_grads_flat = utils.tensors_to_column(self._params_grads[source]) - return (math_ops.square(params_grads_flat) / math_ops.cast( - self._batch_size, params_grads_flat.dtype)) - - def _get_data_device(self, tower): - return None - - -class EmbeddingInputKroneckerFactor(DiagonalFactor): - r"""FisherFactor for input to an embedding layer. - - Given input_ids = [batch_size, input_size] representing indices into an - [vocab_size, embedding_size] embedding matrix, approximate input covariance by - a diagonal matrix, - - Cov(input_ids, input_ids) = - (1/batch_size) sum_{i} diag(n_hot(input[i]) ** 2). - - where n_hot() constructs an n-hot binary vector and diag() constructs a - diagonal matrix of size [vocab_size, vocab_size]. - """ - - def __init__(self, input_ids, vocab_size, dtype=None): - """Instantiate EmbeddingInputKroneckerFactor. - - Args: - input_ids: List of Tensors of shape [batch_size, input_size] and dtype - int32. Indices into embedding matrix. List index is tower. - vocab_size: int or 0-D Tensor. Maximum value for entries in 'input_ids'. - dtype: dtype for covariance statistics. Must be a floating point type. - Defaults to float32. - """ - self._input_ids = input_ids - self._vocab_size = vocab_size - self._cov_dtype = dtype or dtypes.float32 - - super(EmbeddingInputKroneckerFactor, self).__init__() - - @property - def _var_scope(self): - return "ff_diag_embedding_" + scope_string_from_params(self._input_ids) - - @property - def _cov_shape(self): - return [self._vocab_size] - - @property - def _num_sources(self): - return 1 - - @property - def _num_towers(self): - return len(self._input_ids) - - @property - def _dtype(self): - return self._cov_dtype - - def _compute_new_cov(self, source, tower): - assert source == 0 - - input_ids = self._input_ids[tower] - - if len(input_ids.shape) > 2: - raise ValueError( - "Input to embeddings must have rank <= 2. Found rank %d." % len( - input_ids.shape)) - - batch_size = array_ops.shape(input_ids)[0] - - # Transform indices into one-hot vectors. - # - # TODO(b/72714822): There must be a faster way to construct the diagonal - # covariance matrix! This operation is O(batch_size * vocab_size), where - # it should be O(batch_size * input_size). - flat_input_ids = array_ops.reshape(input_ids, [-1]) - one_hots = array_ops.one_hot(flat_input_ids, - self._vocab_size) # [?, vocab_size] - - # Take average across examples. Note that, because all entries have - # magnitude zero or one, there's no need to square the entries. - # - # TODO(b/72714822): Support for SparseTensor, other kinds of aggregation - # within an example such as average. - # - # TODO(b/72714822): Support for partitioned embeddings. - new_cov = math_ops.reduce_sum(one_hots, axis=0) # [vocab_size] - new_cov /= math_ops.cast(batch_size, new_cov.dtype) - - return new_cov - - def _get_data_device(self, tower): - return self._input_ids[tower].device - - -class FullyConnectedDiagonalFactor(DiagonalFactor): - r"""FisherFactor for a diagonal approx of a fully-connected layer's Fisher. - - Given in = [batch_size, input_size] and out_grad = [batch_size, output_size], - approximates the covariance as, - - Cov(in, out) = (1/batch_size) sum_{i} outer(in[i], out_grad[i]) ** 2.0 - - where the square is taken element-wise. - """ - - def __init__(self, - inputs, - outputs_grads, - has_bias=False): - """Instantiate FullyConnectedDiagonalFactor. - - Args: - inputs: List of Tensors of shape [batch_size, input_size]. Inputs to this - layer. List index is towers. - outputs_grads: List of Tensors, each of shape [batch_size, output_size], - which are the gradients of the loss with respect to the layer's - outputs. First index is source, second is tower. - - has_bias: bool. If True, append '1' to each input. - """ - self._inputs = inputs - self._has_bias = has_bias - self._outputs_grads = outputs_grads - self._squared_inputs = None - - super(FullyConnectedDiagonalFactor, self).__init__() - - @property - def _var_scope(self): - return "ff_diagfc_" + scope_string_from_params( - tuple(self._inputs) + tuple(nest.flatten(self._outputs_grads))) - - @property - def _cov_shape(self): - input_size = self._inputs[0].shape[1] + self._has_bias - output_size = self._outputs_grads[0][0].shape[1] - return [input_size, output_size] - - @property - def _num_sources(self): - return len(self._outputs_grads) - - @property - def _num_towers(self): - return len(self._inputs) - - @property - def _dtype(self): - return self._outputs_grads[0][0].dtype - - def make_covariance_update_op(self, ema_decay): - - self._squared_inputs = [] - for tower in range(self._num_towers): - inputs = self._inputs[tower] - - with place_on_device(self._get_data_device(tower)): - if self._has_bias: - inputs = append_homog(inputs) - self._squared_inputs.append(math_ops.square(inputs)) - - return super(FullyConnectedDiagonalFactor, self).make_covariance_update_op( - ema_decay) - - def _compute_new_cov(self, source, tower): - batch_size = array_ops.shape(self._squared_inputs[tower])[0] - outputs_grad = self._outputs_grads[source][tower] - - # The well-known special formula that uses the fact that the entry-wise - # square of an outer product is the outer-product of the entry-wise squares. - # The gradient is the outer product of the input and the output gradients, - # so we just square both and then take their outer-product. - new_cov = math_ops.matmul( - self._squared_inputs[tower], - math_ops.square(outputs_grad), - transpose_a=True) - new_cov /= math_ops.cast(batch_size, new_cov.dtype) - return new_cov - - def _get_data_device(self, tower): - return self._inputs[tower].device - - -class ConvDiagonalFactor(DiagonalFactor): - """FisherFactor for a diagonal approx of a convolutional layer's Fisher.""" - - def __init__(self, - inputs, - outputs_grads, - filter_shape, - strides, - padding, - data_format=None, - dilations=None, - has_bias=False): - """Creates a ConvDiagonalFactor object. - - Args: - inputs: List of Tensors of shape [batch_size, height, width, in_channels]. - Input activations to this layer. List index is towers. - outputs_grads: List of Tensors, each of shape [batch_size, - height, width, out_channels], which are the gradients of the loss - with respect to the layer's outputs. First index is source, second - index is tower. - filter_shape: Tuple of 4 ints: (kernel_height, kernel_width, in_channels, - out_channels). Represents shape of kernel used in this layer. - strides: The stride size in this layer (1-D Tensor of length 4). - padding: The padding in this layer (1-D of Tensor length 4). - data_format: None or str. Format of conv2d inputs. - dilations: None or tuple of 4 ints. - has_bias: Python bool. If True, the layer is assumed to have a bias - parameter in addition to its filter parameter. - - Raises: - ValueError: If inputs, output_grads, and filter_shape do not agree on - in_channels or out_channels. - ValueError: If strides, dilations are not length-4 lists of ints. - ValueError: If data_format does not put channel last. - """ - if not utils.is_data_format_channel_last(data_format): - raise ValueError("Channel must be last.") - if any(input_.shape.ndims != 4 for input_ in inputs): - raise ValueError("inputs must be a list of 4-D Tensors.") - if any(input_.shape.as_list()[-1] != filter_shape[-2] for input_ in inputs): - raise ValueError("inputs and filter_shape must agree on in_channels.") - for i, outputs_grad in enumerate(outputs_grads): - if any(output_grad.shape.ndims != 4 for output_grad in outputs_grad): - raise ValueError("outputs[%d] must be 4-D Tensor." % i) - if any(output_grad.shape.as_list()[-1] != filter_shape[-1] - for output_grad in outputs_grad): - raise ValueError( - "outputs[%d] and filter_shape must agree on out_channels." % i) - if len(strides) != 4: - raise ValueError("strides must be length-4 list of ints.") - if dilations is not None and len(dilations) != 4: - raise ValueError("dilations must be length-4 list of ints.") - - self._inputs = inputs - self._outputs_grads = outputs_grads - self._filter_shape = filter_shape - self._strides = strides - self._padding = padding - self._data_format = data_format - self._dilations = dilations - self._has_bias = has_bias - self._patches = None - - super(ConvDiagonalFactor, self).__init__() - - @property - def _var_scope(self): - return "ff_convdiag_" + scope_string_from_params( - tuple(self._inputs) + tuple(nest.flatten(self._outputs_grads))) - - @property - def _cov_shape(self): - filter_height, filter_width, in_channels, out_channels = self._filter_shape - return [ - filter_height * filter_width * in_channels + self._has_bias, - out_channels - ] - - @property - def _num_sources(self): - return len(self._outputs_grads) - - @property - def _num_towers(self): - return len(self._inputs) - - @property - def _dtype(self): - return self._inputs[0].dtype - - def make_covariance_update_op(self, ema_decay): - filter_height, filter_width, _, _ = self._filter_shape - - # TODO(b/64144716): there is potential here for a big savings in terms - # of memory use. - if self._dilations is None: - rates = (1, 1, 1, 1) - else: - rates = tuple(self._dilations) - - self._patches = [] - for tower in range(self._num_towers): - with place_on_device(self._get_data_device(tower)): - patches = array_ops.extract_image_patches( - self._inputs[tower], - ksizes=[1, filter_height, filter_width, 1], - strides=self._strides, - rates=rates, - padding=self._padding) - - if self._has_bias: - patches = append_homog(patches) - - self._patches.append(patches) - - return super(ConvDiagonalFactor, self).make_covariance_update_op(ema_decay) - - def _compute_new_cov(self, source, tower): - patches = self._patches[tower] - batch_size = array_ops.shape(patches)[0] - outputs_grad = self._outputs_grads[source][tower] - - new_cov = self._convdiag_sum_of_squares(patches, outputs_grad) - new_cov /= math_ops.cast(batch_size, new_cov.dtype) - - return new_cov - - def _convdiag_sum_of_squares(self, patches, outputs_grad): - # This computes the sum of the squares of the per-training-case "gradients". - # It does this simply by computing a giant tensor containing all of these, - # doing an entry-wise square, and them summing along the batch dimension. - case_wise_gradients = special_math_ops.einsum("bijk,bijl->bkl", patches, - outputs_grad) - return math_ops.reduce_sum(math_ops.square(case_wise_gradients), axis=0) - - def _get_data_device(self, tower): - return self._inputs[tower].device - - -class FullyConnectedKroneckerFactor(DenseSquareMatrixFactor): - """Kronecker factor for the input or output side of a fully-connected layer. - """ - - def __init__(self, - tensors, - has_bias=False): - """Instantiate FullyConnectedKroneckerFactor. - - Args: - tensors: List of list of Tensors, each of shape [batch_size, n]. The - Tensors are typically either a layer's inputs or its output's gradients. - The first list index is source, the second is tower. - has_bias: bool. If True, append '1' to each row. - """ - # The tensor argument is either a tensor of input activations or a tensor of - # output pre-activation gradients. - self._has_bias = has_bias - self._tensors = tensors - super(FullyConnectedKroneckerFactor, self).__init__() - - @property - def _var_scope(self): - return "ff_fckron_" + scope_string_from_params( - tuple(nest.flatten(self._tensors)) + (self._has_bias,)) - - @property - def _cov_shape(self): - size = self._tensors[0][0].shape[1] + self._has_bias - return [size, size] - - @property - def _num_sources(self): - return len(self._tensors) - - @property - def _num_towers(self): - return len(self._tensors[0]) - - @property - def _dtype(self): - return self._tensors[0][0].dtype - - def _compute_new_cov(self, source, tower): - tensor = self._tensors[source][tower] - if self._has_bias: - tensor = append_homog(tensor) - return compute_cov(tensor) - - def _get_data_device(self, tower): - return self._tensors[0][tower].device - - -class ConvInputKroneckerFactor(DenseSquareMatrixFactor): - r"""Kronecker factor for the input side of a convolutional layer. - - Estimates E[ a a^T ] where a is the inputs to a convolutional layer given - example x. Expectation is taken over all examples and locations. - - Equivalent to Omega in https://arxiv.org/abs/1602.01407 for details. See - Section 3.1 Estimating the factors. - """ - - def __init__(self, - inputs, - filter_shape, - padding, - strides=None, - dilation_rate=None, - data_format=None, - extract_patches_fn=None, - has_bias=False, - sub_sample_inputs=None, - sub_sample_patches=None): - """Initializes ConvInputKroneckerFactor. - - Args: - inputs: List of Tensors of shape [batch_size, ..spatial_input_size.., - in_channels]. Inputs to layer. List index is tower. - filter_shape: List of ints. Contains [..spatial_filter_size.., - in_channels, out_channels]. Shape of convolution kernel. - padding: str. Padding method for layer. "SAME" or "VALID". - strides: List of ints or None. Contains [..spatial_filter_strides..] if - 'extract_patches_fn' is compatible with tf.nn.convolution(), else - [1, ..spatial_filter_strides, 1]. - dilation_rate: List of ints or None. Rate for dilation along each spatial - dimension if 'extract_patches_fn' is compatible with - tf.nn.convolution(), else [1, ..spatial_dilation_rates.., 1]. - data_format: str or None. Format of input data. - extract_patches_fn: str or None. Name of function that extracts image - patches. One of "extract_convolution_patches", "extract_image_patches", - "extract_pointwise_conv2d_patches". - has_bias: bool. If True, append 1 to in_channel. - sub_sample_inputs: `bool`. If True, then subsample the inputs from which - the image patches are extracted. (Default: None) - sub_sample_patches: `bool`, If `True` then subsample the extracted - patches.(Default: None) - """ - self._inputs = inputs - self._filter_shape = filter_shape - self._strides = strides - self._padding = padding - self._dilation_rate = dilation_rate - self._data_format = data_format - self._extract_patches_fn = extract_patches_fn - self._has_bias = has_bias - if sub_sample_inputs is None: - self._sub_sample_inputs = _SUB_SAMPLE_INPUTS - else: - self._sub_sample_inputs = sub_sample_inputs - - if sub_sample_patches is None: - self._sub_sample_patches = _SUB_SAMPLE_OUTER_PRODUCTS - else: - self._sub_sample_patches = sub_sample_patches - super(ConvInputKroneckerFactor, self).__init__() - - @property - def _var_scope(self): - return "ff_convinkron_" + scope_string_from_params( - tuple(self._inputs) + - tuple((self._filter_shape, self._strides, self._padding, - self._dilation_rate, self._data_format, self._has_bias))) - - @property - def _cov_shape(self): - spatial_filter_shape = self._filter_shape[0:-2] - in_channels = self._filter_shape[-2] - size = np.prod(spatial_filter_shape) * in_channels + self._has_bias - return [size, size] - - @property - def _num_sources(self): - return 1 - - @property - def _num_towers(self): - return len(self._inputs) - - @property - def _dtype(self): - return self._inputs[0].dtype - - def _compute_new_cov(self, source, tower): - assert source == 0 - - inputs = self._inputs[tower] - if self._sub_sample_inputs: - batch_size = inputs.shape.as_list()[0] - max_size = int(batch_size * _INPUTS_TO_EXTRACT_PATCHES_FACTOR) - inputs = _random_tensor_gather(inputs, max_size) - - # TODO(b/64144716): there is potential here for a big savings in terms of - # memory use. - if self._extract_patches_fn in [None, "extract_convolution_patches"]: - patches = utils.extract_convolution_patches( - inputs, - self._filter_shape, - padding=self._padding, - strides=self._strides, - dilation_rate=self._dilation_rate, - data_format=self._data_format) - - elif self._extract_patches_fn == "extract_image_patches": - assert inputs.shape.ndims == 4 - assert len(self._filter_shape) == 4 - assert len(self._strides) == 4, self._strides - if self._dilation_rate is None: - rates = [1, 1, 1, 1] - else: - rates = self._dilation_rate - assert len(rates) == 4 - assert rates[0] == rates[-1] == 1 - patches = array_ops.extract_image_patches( - inputs, - ksizes=[1] + list(self._filter_shape[0:-2]) + [1], - strides=self._strides, - rates=rates, - padding=self._padding) - - elif self._extract_patches_fn == "extract_pointwise_conv2d_patches": - assert self._strides in [None, [1, 1, 1, 1], (1, 1, 1, 1)] - assert self._filter_shape[0] == self._filter_shape[1] == 1 - patches = utils.extract_pointwise_conv2d_patches( - inputs, self._filter_shape, data_format=None) - - else: - raise NotImplementedError(self._extract_patches_fn) - - flatten_size = np.prod(self._filter_shape[0:-1]) - # patches_flat below is the matrix [[A_l]] from the KFC paper (tilde - # omitted over A for clarity). It has shape M|T| x J|Delta| (eq. 14), - # where M = minibatch size, |T| = number of spatial locations, - # |Delta| = number of spatial offsets, and J = number of input maps - # for convolutional layer l. - patches_flat = array_ops.reshape(patches, [-1, flatten_size]) - - # We append a homogenous coordinate to patches_flat if the layer has - # bias parameters. This gives us [[A_l]]_H from the paper. - if self._sub_sample_patches: - patches_flat = _subsample_for_cov_computation(patches_flat) - - if self._has_bias: - patches_flat = append_homog(patches_flat) - # We call compute_cov without passing in a normalizer. compute_cov uses - # the first dimension of patches_flat i.e. M|T| as the normalizer by - # default. Hence we end up computing 1/M|T| * [[A_l]]^T [[A_l]], with - # shape J|Delta| x J|Delta|. This is related to hat{Omega}_l from - # the paper but has a different scale here for consistency with - # ConvOutputKroneckerFactor. - # (Tilde omitted over A for clarity.) - return compute_cov(patches_flat) - - def _get_data_device(self, tower): - return self._inputs[tower].device - - -class ConvOutputKroneckerFactor(DenseSquareMatrixFactor): - r"""Kronecker factor for the output side of a convolutional layer. - - Estimates E[ ds ds^T ] where s is the preactivations of a convolutional layer - given example x and ds = (d / d s) log(p(y|x, w)). Expectation is taken over - all examples and locations. - - Equivalent to Gamma in https://arxiv.org/abs/1602.01407 for details. See - Section 3.1 Estimating the factors. - """ - - def __init__(self, outputs_grads, data_format=None): - """Initializes ConvOutputKroneckerFactor. - - Args: - outputs_grads: List of list of Tensors. Each Tensor is of shape - [batch_size, ..spatial_input_size.., out_channels]. First list index - is source, the second is tower. - data_format: None or str. Format of outputs_grads. - - Raises: - ValueError: If channels are not final dimension. - """ - if not utils.is_data_format_channel_last(data_format): - raise ValueError("Channel must be last.") - self._out_channels = outputs_grads[0][0].shape.as_list()[-1] - self._outputs_grads = outputs_grads - super(ConvOutputKroneckerFactor, self).__init__() - - @property - def _var_scope(self): - return "ff_convoutkron_" + scope_string_from_params( - nest.flatten(self._outputs_grads)) - - @property - def _cov_shape(self): - size = self._out_channels - return [size, size] - - @property - def _num_sources(self): - return len(self._outputs_grads) - - @property - def _num_towers(self): - return len(self._outputs_grads[0]) - - @property - def _dtype(self): - return self._outputs_grads[0][0].dtype - - def _compute_new_cov(self, source, tower): - outputs_grad = self._outputs_grads[source][tower] - - # reshaped_tensor below is the matrix DS_l defined in the KFC paper - # (tilde omitted over S for clarity). It has shape M|T| x I, where - # M = minibatch size, |T| = number of spatial locations, and - # I = number of output maps for convolutional layer l. - reshaped_tensor = array_ops.reshape(outputs_grad, [-1, self._out_channels]) - # Following the reasoning in ConvInputKroneckerFactor._compute_new_cov, - # compute_cov here returns 1/M|T| * DS_l^T DS_l = hat{Gamma}_l - # as defined in the paper, with shape I x I. - # (Tilde omitted over S for clarity.) - return compute_cov(reshaped_tensor) - - def _get_data_device(self, tower): - return self._outputs_grads[0][tower].device - - -class FullyConnectedMultiKF(FullyConnectedKroneckerFactor): - """Kronecker factor for a fully connected layer used multiple times.""" - - def __init__(self, - tensors, - num_uses=None, - has_bias=False): - """Constructs a new `FullyConnectedMultiKF`. - - Args: - tensors: List of list of Tensors of shape, each of shape - [num_uses * batch_size, n], and is a reshape version of a Tensor of - shape [num_uses, batch_size, n]. Each of these tensors is usually a - layer's inputs or its output's gradients. The first list index is - sources, the second is towers. - num_uses: int. The number of time-steps / uses. - has_bias: bool. If True, '1' is appended to each row. - """ - - self._num_uses = num_uses - - self._cov_dt1 = None - self._make_cov_dt1 = False - self._option1quants_by_damping = {} - self._option2quants_by_damping = {} - self._option1quants_registrations = set() - self._option2quants_registrations = set() - - super(FullyConnectedMultiKF, self).__init__(tensors=tensors, - has_bias=has_bias) - - @property - def _num_timesteps(self): - return self._num_uses - - @property - def _var_scope(self): - return "ff_fc_multi_" + scope_string_from_params( - tuple(nest.flatten(self._tensors)) - + (self._num_timesteps, self._has_bias,)) - - def make_covariance_update_op(self, ema_decay): - - op = super(FullyConnectedMultiKF, self).make_covariance_update_op(ema_decay) - - if self._cov_dt1 is not None: - new_cov_dt1_contribs = [] - for source in range(self._num_sources): - for tower in range(self._num_towers): - with place_on_device(self._get_data_device(tower)): - new_cov_dt1_contribs.append(self._compute_new_cov_dt1(source, - tower)) - - new_cov_dt1 = (math_ops.add_n(new_cov_dt1_contribs) - / float(self._num_towers)) - - # See comments in FisherFactor.make_covariance_update_op() for details. - if utils.on_tpu(): - new_cov_dt1 = utils.cross_replica_mean(new_cov_dt1) - - op2 = moving_averages.assign_moving_average( - self._cov_dt1, new_cov_dt1, ema_decay, zero_debias=ZERO_DEBIAS) - - # TODO(b/69112164): - # It's important that _cov and _cov_dt1 remain consistent with each - # other while the inverse ops are happening. How can we ensure this? - # We will need to add explicit synchronization for this to - # work with asynchronous training. - op = control_flow_ops.group(op, op2) - - return op - - def _compute_new_cov_dt1(self, source, tower): # pylint: disable=missing-docstring - tensor = self._tensors[source][tower] - if self._has_bias: - # This appending is technically done twice (the other time is for - # _compute_new_cov()) - tensor = append_homog(tensor) - - total_len = array_ops.shape(tensor)[0] - batch_size = total_len // self._num_timesteps - - tensor_present = tensor[:-batch_size, :] - tensor_future = tensor[batch_size:, :] - - # We specify a normalizer for this computation to ensure a PSD Fisher - # block estimate. This is equivalent to padding with zeros, as was done - # in Section B.2 of the appendix. - return compute_cov( - tensor_future, tensor_right=tensor_present, normalizer=total_len) - - def _get_data_device(self, tower): - return self._tensors[0][tower].device - - @property - def _vec_shape(self): - size = self._tensors[0][0].shape[1] + self._has_bias - return [size] - - def get_option1quants(self, damping_func): - damping_id = graph_func_to_id(damping_func) - return self._option1quants_by_damping[damping_id] - - def get_option2quants(self, damping_func): - damping_id = graph_func_to_id(damping_func) - return self._option2quants_by_damping[damping_id] - - def get_cov_dt1(self): - assert self._cov_dt1 is not None - return self._cov_dt1 - - def register_cov_dt1(self): - self._make_cov_dt1 = True - - def instantiate_cov_variables(self): - super(FullyConnectedMultiKF, self).instantiate_cov_variables() - assert self._cov_dt1 is None - if self._make_cov_dt1: - with variable_scope.variable_scope(self._var_scope): - self._cov_dt1 = variable_scope.get_variable( - "cov_dt1", - initializer=init_ops.zeros_initializer, - shape=self._cov_shape, - trainable=False, - dtype=self._dtype) - - def register_option1quants(self, damping_func): - damping_id = self._register_damping(damping_func) - if damping_id not in self._option1quants_registrations: - self._option1quants_registrations.add(damping_id) - - def register_option2quants(self, damping_func): - damping_id = self._register_damping(damping_func) - if damping_id not in self._option2quants_registrations: - self._option2quants_registrations.add(damping_id) - - def instantiate_inv_variables(self): - super(FullyConnectedMultiKF, self).instantiate_inv_variables() - - for damping_id in self._option1quants_registrations: - damping_func = self._damping_funcs_by_id[damping_id] - damping_string = graph_func_to_string(damping_func) - # It's questionable as to whether we should initialize with stuff like - # this at all. Ideally these values should never be used until they are - # updated at least once. - with variable_scope.variable_scope(self._var_scope): - Lmat = variable_scope.get_variable( # pylint: disable=invalid-name - "Lmat_damp{}".format(damping_string), - initializer=inverse_initializer, - shape=self._cov_shape, - trainable=False, - dtype=self._dtype) - psi = variable_scope.get_variable( - "psi_damp{}".format(damping_string), - initializer=init_ops.ones_initializer, - shape=self._vec_shape, - trainable=False, - dtype=self._dtype) - - assert damping_id not in self._option1quants_by_damping - self._option1quants_by_damping[damping_id] = (Lmat, psi) - - for damping_id in self._option2quants_registrations: - damping_func = self._damping_funcs_by_id[damping_id] - damping_string = graph_func_to_string(damping_func) - # It's questionable as to whether we should initialize with stuff like - # this at all. Ideally these values should never be used until they are - # updated at least once. - with variable_scope.variable_scope(self._var_scope): - Pmat = variable_scope.get_variable( # pylint: disable=invalid-name - "Lmat_damp{}".format(damping_string), - initializer=inverse_initializer, - shape=self._cov_shape, - trainable=False, - dtype=self._dtype) - Kmat = variable_scope.get_variable( # pylint: disable=invalid-name - "Kmat_damp{}".format(damping_string), - initializer=inverse_initializer, - shape=self._cov_shape, - trainable=False, - dtype=self._dtype) - mu = variable_scope.get_variable( - "mu_damp{}".format(damping_string), - initializer=init_ops.ones_initializer, - shape=self._vec_shape, - trainable=False, - dtype=self._dtype) - - assert damping_id not in self._option2quants_by_damping - self._option2quants_by_damping[damping_id] = (Pmat, Kmat, mu) - - def make_inverse_update_ops(self): - """Create and return update ops corresponding to registered computations.""" - # TODO(b/69918258): Add correctness tests for this method. - # pylint: disable=invalid-name - - ops = [] - - if (len(self._option1quants_by_damping) + - len(self._option2quants_by_damping)): - - # Note that C0 and C1 are stand-ins for A0 and A1, or G0 and G1, from - # the pseudo-code in the original paper. Because the computations for - # the A and G case are essentially the same they can both be performed by - # the same class (this one). - - C1 = self.get_cov_dt1() - - # Get the eigendecomposition of C0 (= self.get_cov()) - eigen_e, eigen_V = self.get_eigendecomp() - - # TODO(b/69678661): Note, there is an implicit assumption here that C1 - # and C0 (as represented here by its eigen-decomp) are consistent. This - # could fail to be the case if self._cov and self._cov_dt1 are not updated - # consistently, or are somehow read between or during the cov updates. - # Can this possibly happen? Is there a way to prevent it? - - for damping_id, (Lmat_var, - psi_var) in self._option1quants_by_damping.items(): - - damping = self._damping_funcs_by_id[damping_id]() - damping = math_ops.cast(damping, self._dtype) - - invsqrtC0 = math_ops.matmul( - eigen_V * (eigen_e + damping)**(-0.5), eigen_V, transpose_b=True) - - # Might need to enforce symmetry lost due to numerical issues. - invsqrtC0 = (invsqrtC0 + array_ops.transpose(invsqrtC0)) / 2.0 - - # The following line imposes the symmetry assumed by "Option 1" on C1. - # Strangely the code can work okay with this line commented out, - # depending on how psd_eig is defined. I'm not sure why. - C1 = (C1 + array_ops.transpose(C1)) / 2.0 - - # hPsi = C0^(-1/2) * C1 * C0^(-1/2) (hPsi means hat{Psi}) - hPsi = math_ops.matmul(math_ops.matmul(invsqrtC0, C1), invsqrtC0) - - # Compute the decomposition U*diag(psi)*U^T = hPsi - psi, U = utils.posdef_eig(hPsi) - - # L = C0^(-1/2) * U - Lmat = math_ops.matmul(invsqrtC0, U) - - ops.append(Lmat_var.assign(Lmat)) - ops.append(psi_var.assign(psi)) - - for damping_id, (Pmat_var, Kmat_var, - mu_var) in self._option2quants_by_damping.items(): - - damping = self._damping_funcs_by_id[damping_id]() - damping = math_ops.cast(damping, self._dtype) - - # compute C0^(-1/2) - invsqrtC0 = math_ops.matmul( - eigen_V * (eigen_e + damping)**(-0.5), eigen_V, transpose_b=True) - - # Might need to enforce symmetry lost due to numerical issues. - invsqrtC0 = (invsqrtC0 + array_ops.transpose(invsqrtC0)) / 2.0 - - # Compute the product C0^(-1/2) * C1 - invsqrtC0C1 = math_ops.matmul(invsqrtC0, C1) - - # hPsi = C0^(-1/2) * C1 * C0^(-1/2) (hPsi means hat{Psi}) - hPsi = math_ops.matmul(invsqrtC0C1, invsqrtC0) - - # Compute the decomposition E*diag(mu)*E^T = hPsi^T * hPsi - # Note that we using the notation mu instead of "m" for the eigenvalues. - # Instead of computing the product hPsi^T * hPsi and then doing an - # eigen-decomposition of this we just compute the SVD of hPsi and then - # square the singular values to get the eigenvalues. For a justification - # of this approach, see: - # https://en.wikipedia.org/wiki/Singular-value_decomposition#Relation_to_eigenvalue_decomposition - sqrtmu, _, E = linalg_ops.svd(hPsi) - mu = math_ops.square(sqrtmu) - - # Mathematically, the eigenvalues should not should not exceed 1.0, but - # due to numerical issues, or possible issues with inconsistent - # values of C1 and (the eigen-decomposition of) C0 they might. So - # we enforce this condition. - mu = math_ops.minimum(mu, 1.0) - - # P = (C0^(-1/2) * C1)^T * C0^(-1/2) = C_1^T * C_0^(-1) - Pmat = math_ops.matmul(invsqrtC0C1, invsqrtC0, transpose_a=True) - - # K = C_0^(-1/2) * E - Kmat = math_ops.matmul(invsqrtC0, E) - - ops.append(Pmat_var.assign(Pmat)) - ops.append(Kmat_var.assign(Kmat)) - ops.append(mu_var.assign(mu)) - - ops += super(FullyConnectedMultiKF, self).make_inverse_update_ops() - return [control_flow_ops.group(*ops)] - - # pylint: enable=invalid-name diff --git a/tensorflow/contrib/kfac/python/ops/fisher_factors_lib.py b/tensorflow/contrib/kfac/python/ops/fisher_factors_lib.py deleted file mode 100644 index 2d8e378a93..0000000000 --- a/tensorflow/contrib/kfac/python/ops/fisher_factors_lib.py +++ /dev/null @@ -1,38 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""FisherFactor definitions.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import,line-too-long,wildcard-import -from tensorflow.contrib.kfac.python.ops.fisher_factors import * -from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long,wildcard-import - -_allowed_symbols = [ - "inverse_initializer", "covariance_initializer", - "diagonal_covariance_initializer", "scope_string_from_params", - "scope_string_from_name", "scalar_or_tensor_to_string", "FisherFactor", - "InverseProvidingFactor", "FullFactor", "DiagonalFactor", - "NaiveDiagonalFactor", "EmbeddingInputKroneckerFactor", - "FullyConnectedDiagonalFactor", "FullyConnectedKroneckerFactor", - "ConvInputKroneckerFactor", "ConvOutputKroneckerFactor", - "ConvDiagonalFactor", "set_global_constants", "maybe_colocate_with", - "compute_cov", "append_homog" -] - -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) diff --git a/tensorflow/contrib/kfac/python/ops/layer_collection.py b/tensorflow/contrib/kfac/python/ops/layer_collection.py deleted file mode 100644 index 43aa713edc..0000000000 --- a/tensorflow/contrib/kfac/python/ops/layer_collection.py +++ /dev/null @@ -1,1269 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Registry for layers and their parameters/variables. - -This represents the collection of all layers in the approximate Fisher -information matrix to which a particular FisherBlock may belong. That is, we -might have several layer collections for one TF graph (if we have multiple K-FAC -optimizers being used, for example.) -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from collections import defaultdict -from collections import OrderedDict -from contextlib import contextmanager -from functools import partial -import warnings - -import math -import six - -from tensorflow.contrib.kfac.python.ops import fisher_blocks as fb -from tensorflow.contrib.kfac.python.ops import loss_functions as lf -from tensorflow.contrib.kfac.python.ops import utils -from tensorflow.python.framework import ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import variable_scope -from tensorflow.python.util import nest - -# Names for various approximations that can be requested for Fisher blocks. -APPROX_KRONECKER_NAME = "kron" -APPROX_DIAGONAL_NAME = "diagonal" -APPROX_FULL_NAME = "full" - -_GENERIC_APPROX_TO_BLOCK_TYPES = { - APPROX_FULL_NAME: fb.FullFB, - APPROX_DIAGONAL_NAME: fb.NaiveDiagonalFB, -} - -_FULLY_CONNECTED_APPROX_TO_BLOCK_TYPES = { - APPROX_KRONECKER_NAME: fb.FullyConnectedKFACBasicFB, - APPROX_DIAGONAL_NAME: fb.FullyConnectedDiagonalFB, -} - -_CONV2D_APPROX_TO_BLOCK_TYPES = { - APPROX_KRONECKER_NAME: fb.ConvKFCBasicFB, - APPROX_DIAGONAL_NAME: fb.ConvDiagonalFB, -} - -_EMBEDDING_APPROX_TO_BLOCK_TYPES = { - APPROX_KRONECKER_NAME: fb.EmbeddingKFACFB -} - -APPROX_KRONECKER_INDEP_NAME = "kron_indep" -APPROX_KRONECKER_SERIES_1_NAME = "kron_series_1" -APPROX_KRONECKER_SERIES_2_NAME = "kron_series_2" - -_FULLY_CONNECTED_MULTI_APPROX_TO_BLOCK_TYPES = { - APPROX_KRONECKER_INDEP_NAME: fb.FullyConnectedMultiIndepFB, - APPROX_KRONECKER_SERIES_1_NAME: partial(fb.FullyConnectedSeriesFB, - option=1), - APPROX_KRONECKER_SERIES_2_NAME: partial(fb.FullyConnectedSeriesFB, - option=2) -} - -_CONV2D_MULTI_APPROX_TO_BLOCK_TYPES = { - APPROX_KRONECKER_INDEP_NAME: fb.ConvKFCBasicMultiIndepFB -} - -_EMBEDDING_MULTI_APPROX_TO_BLOCK_TYPES = { - APPROX_KRONECKER_INDEP_NAME: fb.EmbeddingKFACMultiIndepFB -} - -# Possible value for `reuse` keyword argument. Sets `reuse` to -# tf.get_variable_scope().reuse. -VARIABLE_SCOPE = "VARIABLE_SCOPE" - -_DEFAULT_LAYER_COLLECTION = None - - -def get_default_layer_collection(): - """Get default LayerCollection.""" - if _DEFAULT_LAYER_COLLECTION is None: - raise ValueError( - "Attempted to retrieve default LayerCollection when none is set. Use " - "LayerCollection.as_default().") - - return _DEFAULT_LAYER_COLLECTION - - -def set_default_layer_collection(layer_collection): - global _DEFAULT_LAYER_COLLECTION - - if _DEFAULT_LAYER_COLLECTION is not None and layer_collection is not None: - raise ValueError("Default LayerCollection is already set.") - - _DEFAULT_LAYER_COLLECTION = layer_collection - - -class LayerParametersDict(OrderedDict): - """An OrderedDict where keys are Tensors or tuples of Tensors. - - Ensures that no Tensor is associated with two different keys. - """ - - def __init__(self, *args, **kwargs): - self._tensors = set() - super(LayerParametersDict, self).__init__(*args, **kwargs) - - def __setitem__(self, key, value): - key = self._canonicalize_key(key) - tensors = key if isinstance(key, (tuple, list)) else (key,) - key_collisions = self._tensors.intersection(tensors) - if key_collisions: - raise ValueError("Key(s) already present: {}".format(key_collisions)) - self._tensors.update(tensors) - super(LayerParametersDict, self).__setitem__(key, value) - - def __delitem__(self, key): - key = self._canonicalize_key(key) - self._tensors.remove(key) - super(LayerParametersDict, self).__delitem__(key) - - def __getitem__(self, key): - key = self._canonicalize_key(key) - return super(LayerParametersDict, self).__getitem__(key) - - def __contains__(self, key): - key = self._canonicalize_key(key) - return super(LayerParametersDict, self).__contains__(key) - - def _canonicalize_key(self, key): - if isinstance(key, (list, tuple)): - return tuple(key) - return key - - -# TODO(b/68034464): add capability for LayerCollection to be "finalized" -# and do this when it gets used by FisherEstimator / KfacOptimizer. - - -class LayerCollection(object): - """Registry of information about layers and losses. - - Note that you need to create a new one of these for each MatrixEstimator or - KfacOptimizer. - - Attributes: - fisher_blocks: a LayersParamsDict (subclass of OrderedDict) mapping layer - parameters (Tensors or tuples of Tensors) to FisherBlock instances. - fisher_factors: an OrderedDict mapping tuples to FisherFactor instances. - losses: a list of LossFunction objects. The loss to be optimized is their - sum. - loss_colocation_ops: ops to colocate loss function evaluations with. These - will typically be the inputs to the losses. - """ - - def __init__(self, - graph=None, - name="LayerCollection"): - warnings.warn( - "tf.contrib.kfac is deprecated and will be removed by 2018-11-01. " - "Use https://pypi.python.org/pypi/kfac instead.") - self.fisher_blocks = LayerParametersDict() - self.fisher_factors = OrderedDict() - self._linked_parameters = dict( - ) # dict mapping sets of variables to optionally specified approximations. - self._graph = graph or ops.get_default_graph() - self._loss_dict = {} # {str: LossFunction} - self._subgraph = None - self._default_generic_approximation = APPROX_DIAGONAL_NAME - self._default_embedding_approximation = APPROX_KRONECKER_NAME - self._default_fully_connected_approximation = APPROX_KRONECKER_NAME - self._default_conv2d_approximation = APPROX_KRONECKER_NAME - self._default_fully_connected_multi_approximation = ( - APPROX_KRONECKER_INDEP_NAME) - self._default_conv2d_multi_approximation = ( - APPROX_KRONECKER_INDEP_NAME) - self._default_embedding_multi_approximation = APPROX_KRONECKER_INDEP_NAME - self.loss_colocation_ops = {} - self._vars_to_uses = defaultdict(lambda: 0) - - with variable_scope.variable_scope(None, default_name=name) as scope: - self._var_scope = scope.name - - @property - def losses(self): - """Tuple of LossFunction objects registered with this LayerCollection.""" - return nest.flatten(self.towers_by_loss) - - @property - def towers_by_loss(self): - """Tuple across losses of LossFunction objects registered to each tower.""" - return tuple(tuple(lst) for lst in self._loss_dict.values()) - - @property - def registered_variables(self): - """A tuple of all of the variables currently registered.""" - tuple_of_tuples = (utils.ensure_sequence(key) for key, block - in six.iteritems(self.fisher_blocks)) - flat_tuple = tuple(item for tuple_ in tuple_of_tuples for item in tuple_) - return flat_tuple - - @property - def linked_parameters(self): - """Groups of parameters with an optionally specified approximation. - - Linked parameters can be added using `define_linked_parameters`. - If an approximation is specified, then this approximation will be used - when registering a layer with exactly these parameters, unless an - approximation is specified when calling the registration function. - - Returns: - A `dict` mapping tuples of parameters to an optional string. - """ - return self._linked_parameters - - @property - def default_embedding_approximation(self): - return self._default_embedding_approximation - - def set_default_embedding_approximation(self, value): - if value != APPROX_KRONECKER_NAME: - raise ValueError( - "{} is not a valid approximation for embedding variables.".format( - value)) - self._default_embedding_approximation = value - - @property - def default_generic_approximation(self): - return self._default_generic_approximation - - def set_default_generic_approximation(self, value): - if value not in _GENERIC_APPROX_TO_BLOCK_TYPES: - raise ValueError( - "{} is not a valid approximation for generic variables.".format( - value)) - self._default_generic_approximation = value - - @property - def default_fully_connected_approximation(self): - return self._default_fully_connected_approximation - - def set_default_fully_connected_approximation(self, value): - if value not in _FULLY_CONNECTED_APPROX_TO_BLOCK_TYPES: - raise ValueError( - "{} is not a valid approximation for fully connected layers.".format( - value)) - self._default_fully_connected_approximation = value - - @property - def default_conv2d_approximation(self): - return self._default_conv2d_approximation - - def set_default_conv2d_approximation(self, value): - if value not in _CONV2D_APPROX_TO_BLOCK_TYPES: - raise ValueError( - "{} is not a valid approximation for 2d convolutional layers.".format( - value)) - self._default_conv2d_approximation = value - - @property - def default_fully_connected_multi_approximation(self): - return self._default_fully_connected_multi_approximation - - def set_default_fully_connected_multi_approximation(self, value): - if value not in _FULLY_CONNECTED_MULTI_APPROX_TO_BLOCK_TYPES: - raise ValueError("{} is not a valid approximation for a fully-connected " - "multi layer.".format(value)) - self._default_fully_connected_multi_approximation = value - - @property - def default_conv2d_multi_approximation(self): - return self._default_conv2d_multi_approximation - - @property - def default_embedding_multi_approximation(self): - return self._default_embedding_multi_approximation - - def register_block(self, layer_key, fisher_block, reuse=VARIABLE_SCOPE): - """Validates and registers the layer_key associated with the fisher_block. - - Args: - layer_key: A variable or tuple of variables. The key to check for in - existing registrations and to register if valid. - fisher_block: The associated `FisherBlock`. - reuse: Method to use for inserting new `FisherBlock's. One of True, False, - or `VARIABLE_SCOPE`. - - Raises: - ValueError: If `layer_key` was already registered and reuse is `False`, - if `layer_key` was registered with a different block type, or if - `layer_key` shares any variables with but is not equal to a previously - registered key. - KeyError: If `reuse` is `True` but `layer_key` was not previously - registered. - - Returns: - The `FisherBlock` registered under `layer_key`. If `layer_key` was already - registered, this will be the previously registered `FisherBlock`. - """ - if reuse is VARIABLE_SCOPE: - reuse = variable_scope.get_variable_scope().reuse - - if reuse is True or (reuse is variable_scope.AUTO_REUSE and - layer_key in self.fisher_blocks): - result = self.fisher_blocks[layer_key] - if type(result) != type(fisher_block): # pylint: disable=unidiomatic-typecheck - raise ValueError( - "Attempted to register FisherBlock of type %s when existing " - "FisherBlock has type %s." % (type(fisher_block), type(result))) - return result - if reuse is False and layer_key in self.fisher_blocks: - raise ValueError("FisherBlock for %s is already in LayerCollection." % - (layer_key,)) - - # Insert fisher_block into self.fisher_blocks. - if layer_key in self.fisher_blocks: - raise ValueError("Duplicate registration: {}".format(layer_key)) - # Raise an error if any variable in layer_key has been registered in any - # other blocks. - variable_to_block = { - var: (params, block) - for (params, block) in self.fisher_blocks.items() - for var in utils.ensure_sequence(params) - } - for variable in utils.ensure_sequence(layer_key): - if variable in variable_to_block: - prev_key, prev_block = variable_to_block[variable] - raise ValueError( - "Attempted to register layer_key {} with block {}, but variable {}" - " was already registered in key {} with block {}.".format( - layer_key, fisher_block, variable, prev_key, prev_block)) - self.fisher_blocks[layer_key] = fisher_block - return fisher_block - - def register_loss_function(self, - loss, - colocation_op, - base_name, - name=None, - reuse=VARIABLE_SCOPE): - """Registers a LossFunction object. - - Args: - loss: The LossFunction object. - colocation_op: The op to colocate the loss function's computations with. - base_name: The name to derive a new unique name from is the name argument - is None. - name: (OPTIONAL) str or None. Unique name for this loss function. If None, - a new name is generated. (Default: None) - reuse: (OPTIONAL) bool or str. If True, adds `loss` as an additional - tower for the existing loss function. - - Raises: - ValueError: If reuse == True and name == None. - ValueError: If reuse == True and seed != None. - KeyError: If reuse == True and no existing LossFunction with `name` found. - KeyError: If reuse == False and existing LossFunction with `name` found. - """ - - name = name or self._graph.unique_name(base_name) - - if reuse == VARIABLE_SCOPE: - reuse = variable_scope.get_variable_scope().reuse - - if reuse: - if name is None: - raise ValueError( - "If reuse is enabled, loss function's name must be set.") - - loss_list = self._loss_dict.get(name, None) - - if loss_list is None: - raise KeyError( - "Unable to find loss function named {}. Register a new loss " - "function with reuse=False.".format(name)) - else: - if name in self._loss_dict: - raise KeyError( - "Loss function named {} already exists. Set reuse=True to append " - "another tower.".format(name)) - - loss_list = [] - self._loss_dict[name] = loss_list - - loss_list.append(loss) - self.loss_colocation_ops[loss] = colocation_op - - def _get_use_count_map(self): - """Returns a dict mapping variables to their number of registrations.""" - return self._vars_to_uses - - def _add_uses(self, params, uses): - """Register additional uses by params in the graph. - - Args: - params: Variable or tuple of Variables. Parameters for a layer. - uses: int or float. Number of additional uses for these parameters. - """ - params = params if isinstance(params, (tuple, list)) else (params,) - for var in params: - self._vars_to_uses[var] += uses - - def check_registration(self, variables): - """Checks that all variable uses have been registered properly. - - Args: - variables: List of variables. - - Raises: - ValueError: If any registered variables are not included in the list. - ValueError: If any variable in the list is not registered. - ValueError: If any variable in the list is registered with the wrong - number of "uses" in the subgraph recorded (vs the number of times that - variable is actually used in the subgraph). - """ - # Note that overlapping parameters (i.e. those that share variables) will - # be caught by layer_collection.LayerParametersDict during registration. - - reg_use_map = self._get_use_count_map() - - error_messages = [] - - for var in variables: - total_uses = self.subgraph.variable_uses(var) - reg_uses = reg_use_map[var] - - if reg_uses == 0: - error_messages.append("Variable {} not registered.".format(var)) - elif (not math.isinf(reg_uses)) and reg_uses != total_uses: - error_messages.append( - "Variable {} registered with wrong number of uses ({} " - "registrations vs {} uses).".format(var, reg_uses, total_uses)) - - num_get_vars = len(reg_use_map) - - if num_get_vars > len(variables): - error_messages.append("{} registered variables were not included in list." - .format(num_get_vars - len(variables))) - - if error_messages: - error_messages = [ - "Found the following errors with variable registration:" - ] + error_messages - raise ValueError("\n\t".join(error_messages)) - - def get_blocks(self): - return self.fisher_blocks.values() - - def get_factors(self): - return self.fisher_factors.values() - - @property - def graph(self): - return self._graph - - @property - def subgraph(self): - return self._subgraph - - def define_linked_parameters(self, params, approximation=None): - """Identify a set of parameters that should be grouped together. - - During automatic graph scanning, any matches containing variables that have - been identified as part of a linked group will be filtered out unless - the match parameters are exactly equal to the ones specified in the linked - group. - - Args: - params: A variable, or a tuple or list of variables. The variables - to be linked. - approximation: Optional string specifying the type of approximation to use - for these variables. If unspecified, this layer collection's default - approximation for the layer type will be used. - - Raises: - ValueError: If the parameters were already registered in a layer or - identified as part of an incompatible group. - """ - params = frozenset(utils.ensure_sequence(params)) - - # Check if any of the variables in `params` is already in - # 'self.fisher_blocks.keys()`. - for registered_params, fisher_block in self.fisher_blocks.items(): - registered_params_set = set(utils.ensure_sequence(registered_params)) - for variable in params: - if (variable in registered_params_set and - params != registered_params_set): - raise ValueError( - "Can`t link parameters {}, variable {} was already registered in " - "group {} with layer {}".format(params, variable, - registered_params, fisher_block)) - - # Check if any of the variables in `params` is already in - # 'self.linked_parameters`. - for variable in params: - for other_linked_params in self.linked_parameters: - if variable in other_linked_params: - raise ValueError("Can`t link parameters {}, variable {} was already " - "linked in group {}.".format(params, variable, - other_linked_params)) - self._linked_parameters[params] = approximation - - def create_subgraph(self): - if not self.losses: - raise ValueError("Must have at least one registered loss.") - inputs_to_losses = nest.flatten(tuple(loss.inputs for loss in self.losses)) - self._subgraph = utils.SubGraph(inputs_to_losses) - - def eval_losses(self): - """Return evaluated losses (colocated with inputs to losses).""" - evals = [] - for loss in self.losses: - with ops.colocate_with(self.loss_colocation_ops[loss]): - evals.append(loss.evaluate()) - return evals - - def eval_losses_on_samples(self): - """Return losses evaluated on samples (colocated with inputs to losses).""" - evals = [] - for loss in self.losses: - with ops.colocate_with(self.loss_colocation_ops[loss]): - evals.append(loss.evaluate_on_sample()) - return evals - - def total_loss(self): - return math_ops.add_n(self.eval_losses()) - - def total_sampled_loss(self): - return math_ops.add_n(self.eval_losses_on_samples()) - - def _get_linked_approx(self, params): - """If params were linked, return their specified approximation.""" - params_set = frozenset(utils.ensure_sequence(params)) - if params_set in self.linked_parameters: - return self.linked_parameters[params_set] - else: - return None - - def _get_block_type(self, params, approx, default, approx_to_type): - if approx is None: - approx = self._get_linked_approx(params) - if approx is None: - approx = default - - if approx not in approx_to_type: - raise ValueError("Bad value {} for approx.".format(approx)) - - return approx_to_type[approx], approx - - def register_embedding(self, - params, - inputs, - outputs, - approx=None, - reuse=VARIABLE_SCOPE): - """Registers an embedding layer. - - Args: - params: Embedding matrix of shape [vocab_size, embedding_size]. - inputs: Tensor of shape [batch_size, input_size] and dtype int32. Indices - into embedding matrix. - outputs: Tensor of shape [batch_size, embedding_size]. Outputs - produced by layer. - approx: str or None. If not None must be "kron". The Fisher - approximation to use. If None the default value is used. (Default: None) - reuse: bool or str. If True, this adds `inputs` and `outputs` as an - additional mini-batch/tower of data to use when estimating the Fisher - block for this layer (which must have already been registered). If - "VARIABLE_SCOPE", use tf.get_variable_scope().reuse. - (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - KeyError: If reuse == True but no FisherBlock found for `params`. - ValueError: If reuse == True and FisherBlock found but of the wrong type. - """ - block_type, approx = self._get_block_type( - params, approx, self.default_embedding_approximation, - _EMBEDDING_APPROX_TO_BLOCK_TYPES) - - if isinstance(params, (tuple, list)): - raise ValueError("Bias not supported.") - vocab_size = int(params.shape[0]) - block = self.register_block( - params, block_type(self, vocab_size), reuse=reuse) - block.register_additional_tower(inputs, outputs) - - self._add_uses(params, 1) - - def register_fully_connected(self, - params, - inputs, - outputs, - approx=None, - reuse=VARIABLE_SCOPE): - """Registers a fully connected layer. - - Args: - params: Tensor or 2-tuple of Tensors corresponding to weight and bias of - this layer. Weight matrix should have shape [input_size, output_size]. - Bias should have shape [output_size]. - inputs: Tensor of shape [batch_size, input_size]. Inputs to layer. - outputs: Tensor of shape [batch_size, output_size]. Outputs - produced by layer. - approx: str or None. If not None must be one of "kron" or "diagonal". - The Fisher approximation to use. If None the default value is used. - (Default: None) - reuse: bool or str. If True, this adds `inputs` and `outputs` as an - additional mini-batch/tower of data to use when estimating the Fisher - block for this layer (which must have already been registered). If - "VARIABLE_SCOPE", use tf.get_variable_scope().reuse. - (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - KeyError: If reuse == True but no FisherBlock found for `params`. - ValueError: If reuse == True and FisherBlock found but of the wrong type. - """ - - block_type, approx = self._get_block_type( - params, approx, self.default_fully_connected_approximation, - _FULLY_CONNECTED_APPROX_TO_BLOCK_TYPES) - - has_bias = isinstance(params, (tuple, list)) - block = self.register_block(params, block_type(self, has_bias=has_bias), - reuse=reuse) - block.register_additional_tower(inputs, outputs) - - self._add_uses(params, 1) - - def register_conv2d(self, - params, - strides, - padding, - inputs, - outputs, - data_format=None, - dilations=None, - approx=None, - reuse=VARIABLE_SCOPE): - """Registers a call to tf.nn.conv2d(). - - Args: - params: Tensor or 2-tuple of Tensors corresponding to weight and bias of - this layer. Weight matrix should have shape [kernel_height, - kernel_width, in_channels, out_channels]. Bias should have shape - [out_channels]. - strides: List of 4 ints. Strides for convolution kernel. - padding: string. see tf.nn.conv2d for valid values. - inputs: Tensor of shape [batch_size, height, width, in_channels]. Inputs - to layer. - outputs: Tensor of shape [batch_size, height, width, out_channels]. - Output produced by layer. - data_format: str or None. Format of data. - dilations: List of 4 ints. Dilations along each dimension. - approx: str or None. If not None must be one of "kron" or "diagonal". - The Fisher approximation to use. If None the default value is used. - (Default: None) - reuse: bool or str. If True, this adds `inputs` and `outputs` as an - additional mini-batch/tower of data to use when estimating the Fisher - block for this layer (which must have already been registered). If - "VARIABLE_SCOPE", use tf.get_variable_scope().reuse. - (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - KeyError: If reuse == True but no FisherBlock found for `params`. - ValueError: If reuse == True and FisherBlock found but of the wrong type. - """ - - block_type, approx = self._get_block_type( - params, approx, self.default_conv2d_approximation, - _CONV2D_APPROX_TO_BLOCK_TYPES) - - # It feels bad to pass in configuration that has to do with the internal - # implementation. And then we can`t use the same constructor for both - # anymore and are thus forced to use this ugly if-statement. - # TODO(b/74793309): Clean this up? - if approx == APPROX_KRONECKER_NAME: - block = self.register_block( - params, - block_type( - layer_collection=self, - params=params, - padding=padding, - strides=strides, - data_format=data_format, - dilation_rate=dilations, - extract_patches_fn="extract_image_patches"), - reuse=reuse) - elif approx == APPROX_DIAGONAL_NAME: - assert strides[0] == strides[-1] == 1 - block = self.register_block( - params, - block_type( - layer_collection=self, - params=params, - padding=padding, - strides=strides, - dilations=dilations, - data_format=data_format), - reuse=reuse) - else: - raise NotImplementedError(approx) - - block.register_additional_tower(inputs, outputs) - - self._add_uses(params, 1) - - def register_convolution(self, - params, - inputs, - outputs, - padding, - strides=None, - dilation_rate=None, - data_format=None, - approx=None, - reuse=VARIABLE_SCOPE): - """Register a call to tf.nn.convolution(). - - Args: - params: Tensor or 2-tuple of Tensors corresponding to weight and bias of - this layer. Weight matrix should have shape [..filter_spatial_size.., - in_channels, out_channels]. Bias should have shape [out_channels]. - inputs: Tensor of shape [batch_size, ..input_spatial_size.., in_channels]. - Inputs to layer. - outputs: Tensor of shape [batch_size, ..output_spatial_size.., - out_channels]. Output produced by layer. - padding: string. see tf.nn.conv2d for valid values. - strides: List of ints of length len(..input_spatial_size..). Strides for - convolution kernel in spatial dimensions. - dilation_rate: List of ints of length len(..input_spatial_size..). - Dilations along spatial dimension. - data_format: str or None. Format of data. - approx: str or None. If not None must be one of "kron" or "diagonal". - The Fisher approximation to use. If None the default value is used. - (Default: None) - reuse: bool or str. If True, this adds `inputs` and `outputs` as an - additional mini-batch/tower of data to use when estimating the Fisher - block for this layer (which must have already been registered). If - "VARIABLE_SCOPE", use tf.get_variable_scope().reuse. - (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - KeyError: If reuse == True but no FisherBlock found for `params`. - ValueError: If reuse == True and FisherBlock found but of the wrong type. - """ - # TODO(b/74793309): Have this use _get_block_type like the other - # registration functions? - assert approx is None or approx == APPROX_KRONECKER_NAME - - block = self.register_block( - params, - fb.ConvKFCBasicFB( - layer_collection=self, - params=params, - padding=padding, - strides=strides, - dilation_rate=dilation_rate, - data_format=data_format), - reuse=reuse) - block.register_additional_tower(inputs, outputs) - - self._add_uses(params, 1) - - def register_depthwise_conv2d(self, - params, - inputs, - outputs, - strides, - padding, - rate=None, - data_format=None, - approx=None, - reuse=VARIABLE_SCOPE): - """Register a call to tf.nn.depthwise_conv2d(). - - Args: - params: 4-D Tensor of shape [filter_height, filter_width, - in_channels, channel_multiplier]. Convolutional filter. - inputs: Tensor of shape [batch_size, input_height, input_width, - in_channels]. Inputs to layer. - outputs: Tensor of shape [batch_size, output_height, output_width, - in_channels * channel_multiplier]. Output produced by depthwise conv2d. - strides: List of ints of length 4. Strides along all dimensions. - padding: string. see tf.nn.conv2d for valid values. - rate: None or List of ints of length 2. Dilation rates in spatial - dimensions. - data_format: str or None. Format of data. - approx: str or None. If not None must "diagonal". The Fisher - approximation to use. If None the default value is used. (Default: None) - reuse: bool or str. If True, this adds `inputs` and `outputs` as an - additional mini-batch/tower of data to use when estimating the Fisher - block for this layer (which must have already been registered). If - "VARIABLE_SCOPE", use tf.get_variable_scope().reuse. - (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - KeyError: If reuse == True but no FisherBlock found for `params`. - ValueError: If reuse == True and FisherBlock found but of the wrong type. - """ - # TODO(b/74793309): Have this use _get_block_type like the other - # registration functions? - assert approx is None or approx == APPROX_DIAGONAL_NAME - assert data_format in [None, "NHWC"] - - block = self.register_block( - params, - fb.DepthwiseConvDiagonalFB( - layer_collection=self, - params=params, - strides=strides, - padding=padding, - rate=rate, - data_format=data_format), - reuse=reuse) - block.register_additional_tower(inputs, outputs) - - self._add_uses(params, 1) - - def register_separable_conv2d(self, - depthwise_params, - pointwise_params, - inputs, - depthwise_outputs, - pointwise_outputs, - strides, - padding, - rate=None, - data_format=None, - approx=None, - reuse=VARIABLE_SCOPE): - """Register a call to tf.nn.separable_conv2d(). - - Note: This requires access to intermediate outputs between depthwise and - pointwise convolutions. - - Args: - depthwise_params: 4-D Tensor of shape [filter_height, filter_width, - in_channels, channel_multiplier]. Filter for depthwise conv2d. - pointwise_params: 4-D Tensor of shape [1, 1, in_channels * - channel_multiplier, out_channels]. Filter for pointwise conv2d. - inputs: Tensor of shape [batch_size, input_height, input_width, - in_channels]. Inputs to layer. - depthwise_outputs: Tensor of shape [batch_size, output_height, - output_width, in_channels * channel_multiplier]. Output produced by - depthwise conv2d. - pointwise_outputs: Tensor of shape [batch_size, output_height, - output_width, out_channels]. Output produced by pointwise conv2d. - strides: List of ints of length 4. Strides for depthwise conv2d kernel in - all dimensions. - padding: string. see tf.nn.conv2d for valid values. - rate: None or List of ints of length 2. Dilation rate of depthwise conv2d - kernel in spatial dimensions. - data_format: str or None. Format of data. - approx: str or None. If not None must be one of "kron" or "diagonal". - The Fisher approximation to use. If None the default value is used. - (Default: None) - reuse: bool or str. If True, this adds `inputs` and `outputs` as an - additional mini-batch/tower of data to use when estimating the Fisher - block for this layer (which must have already been registered). If - "VARIABLE_SCOPE", use tf.get_variable_scope().reuse. - (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - KeyError: If reuse == True but no FisherBlock found for `params`. - ValueError: If reuse == True and FisherBlock found but of the wrong type. - """ - self.register_depthwise_conv2d( - params=depthwise_params, - inputs=inputs, - outputs=depthwise_outputs, - strides=strides, - padding=padding, - rate=rate, - data_format=data_format, - approx=APPROX_DIAGONAL_NAME, - reuse=reuse) - - self.register_conv2d( - params=pointwise_params, - inputs=depthwise_outputs, - outputs=pointwise_outputs, - strides=[1, 1, 1, 1], - padding="VALID", - data_format=data_format, - approx=approx, - reuse=reuse) - - def register_generic(self, - params, - batch_size, - approx=None, - reuse=VARIABLE_SCOPE): - """Registers a generic layer. - - Args: - params: Tensor or tuple of Tensors corresponding to the parameters. - batch_size: 0-D Tensor. Size of the minibatch (for this tower). - approx: str or None. It not None, must be one of "full" or "diagonal". - The Fisher approximation to use. If None the default value is used. - (Default: None) - reuse: bool or str. If True, this adds `batch_size` to the total - mini-batch size use when estimating the Fisher block for this layer - (which must have already been registered). If "VARIABLE_SCOPE", use - tf.get_variable_scope().reuse. (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - KeyError: If reuse == True but no FisherBlock found for `params`. - ValueError: If reuse == True and FisherBlock found but of the wrong type. - """ - block_type, approx = self._get_block_type( - params, approx, self.default_generic_approximation, - _GENERIC_APPROX_TO_BLOCK_TYPES) - - block = self.register_block(params, block_type(self, params), reuse=reuse) - block.register_additional_tower(batch_size) - - self._add_uses(params, float("inf")) - - def register_fully_connected_multi(self, params, inputs, outputs, - num_uses=None, approx=None, - reuse=VARIABLE_SCOPE): - """Register fully connected layers with shared parameters. - - This can handle general fully-connected layers with shared parameters, but - has specialized approximations to deal with the case where there is a - meaningful linear order to the share instances (such as in an RNN). - - Args: - params: Tensor or 2-tuple of Tensors corresponding to weight and bias of - this layer. Weight matrix should have shape [input_size, output_size]. - Bias should have shape [output_size]. - inputs: A list of Tensors, each of shape [batch_size, input_size]. Inputs - to layer. The list indexes each use in the graph (which might - correspond to a "time-step" in an RNN). OR, can be single Tensor, of - shape [num_uses * batch_size , input_size], which is a reshaped version - of a Tensor of shape [num_uses, batch_size, input_size]. - outputs: A list of Tensors, the same length as `inputs`, each of shape - [batch_size, output_size]. Outputs produced by layer. The list indexes - each use in the graph (which might correspond to a "time-step" in an - RNN). Needs to correspond with the order used in `inputs`. OR, can be - a single Tensor of shape [num_uses * batch_size, output_size], which is - a reshaped version of a Tensor of shape [num_uses, batch_size, - output_size]. - num_uses: int or None. The number uses/time-steps in the graph where the - layer appears. Only needed if both inputs and outputs are given in the - single Tensor format. (Default: None) - approx: str or None. If not None, must be of "kron_indep", "kron_series_1" - or "kron_series_2". The Fisher approximation to use. If None the default - value is used. (Default: None) - reuse: bool or str. If True, this adds `inputs` and `outputs` as an - additional mini-batch/tower of data to use when estimating the Fisher - block for this layer (which must have already been registered). If - "VARIABLE_SCOPE", use tf.get_variable_scope().reuse. (Note that the - word `use` here has a completely different meaning to "use in the graph" - as it pertains to the `inputs`, `outputs`, and `num_uses` arguments.) - (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - """ - block_type, approx = self._get_block_type( - params, approx, self.default_fully_connected_multi_approximation, - _FULLY_CONNECTED_MULTI_APPROX_TO_BLOCK_TYPES) - - # TODO(b/70283649): something along the lines of find_canonical_output - # should be added back in here (and for the other block types, arguably). - - has_bias = isinstance(params, (tuple, list)) - block = self.register_block(params, block_type(self, has_bias=has_bias, - num_uses=num_uses), - reuse=reuse) - block.register_additional_tower(inputs, outputs) - if isinstance(inputs, (tuple, list)): - assert len(inputs) == len(outputs) - self._add_uses(params, len(inputs)) - else: - self._add_uses(params, 1) - - def register_conv2d_multi(self, - params, - strides, - padding, - inputs, - outputs, - num_uses=None, - data_format=None, - dilations=None, - approx=None, - reuse=VARIABLE_SCOPE): - """Registers convolutional layers with shared parameters. - - Args: - params: Tensor or 2-tuple of Tensors corresponding to weight and bias of - this layer. Weight matrix should have shape [kernel_height, - kernel_width, in_channels, out_channels]. Bias should have shape - [out_channels]. - strides: 1-D Tensor of length 4. Strides for convolution kernel. - padding: string. see tf.nn.conv2d for valid values. - inputs: A list of Tensors, each of shape [batch_size, height, width, - in_channels]. Inputs to layer. The list indexes each use in the graph - (which might correspond to a "time-step" in an RNN). OR, can be single - Tensor, of shape [num_uses * batch_size, height, width, in_channels], - which is a reshaped version of a Tensor of shape [num_uses, batch_size, - height, width, in_channels]. - outputs: A list of Tensors, each of shape [batch_size, height, width, - out_channels]. Output produced by layer. The list indexes each use - in the graph (which might correspond to a "time-step" in an RNN). - Needs to correspond with the order used in `inputs`. OR, can be a - single Tensor, of shape [num_uses * batch_size, height, width, - out_channels], which is a reshaped version of a Tensor of shape - [num_uses, batch_size, height, width, out_channels]. - num_uses: int or None. The number uses/time-steps in the graph where the - layer appears. Only needed if both inputs and outputs are given in the - single Tensor format. (Default: None) - data_format: str or None. Format of data. - dilations: List of 4 ints. Dilations along each dimension. - approx: str or None. If not None must by "kron_indep". The Fisher - approximation to use. If None the default value is used. - (Default: None) - reuse: bool or str. If True, this adds `inputs` and `outputs` as an - additional mini-batch/tower of data to use when estimating the Fisher - block for this layer (which must have already been registered). If - "VARIABLE_SCOPE", use tf.get_variable_scope().reuse. (Note that the - word `use` here has a completely different meaning to "use in the graph" - as it pertains to the `inputs`, `outputs`, and `num_uses` arguments.) - (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - KeyError: If reuse == True but no FisherBlock found for `params`. - ValueError: If reuse == True and FisherBlock found but of the wrong type. - """ - block_type, approx = self._get_block_type( - params, approx, self.default_conv2d_multi_approximation, - _CONV2D_MULTI_APPROX_TO_BLOCK_TYPES) - - block = self.register_block( - params, - block_type( - layer_collection=self, - params=params, - padding=padding, - strides=strides, - data_format=data_format, - dilation_rate=dilations, - extract_patches_fn="extract_image_patches", - num_uses=num_uses), - reuse=reuse) - - block.register_additional_tower(inputs, outputs) - if isinstance(inputs, (tuple, list)): - assert len(inputs) == len(outputs) - self._add_uses(params, len(inputs)) - else: - self._add_uses(params, 1) - - # TODO(b/74108452): change the loss registration functions names to refer - # to "loss functions" instead of distributions. Following naming convention - # of the loss function classes themselves. - - def register_embedding_multi(self, - params, - inputs, - outputs, - num_uses=None, - approx=None, - reuse=VARIABLE_SCOPE): - """Registers embedding layers with shared parameters. - - Args: - params: Embedding matrix of shape [vocab_size, embedding_size]. - inputs: A list of Tensors, each of shape [batch_size, input_size] and - dtype int32. Indices into embedding matrix. The list indexes each use - in the graph (which might correspond to a "time-step" in an RNN). - OR, can be single Tensor, of shape [num_uses*batch_size, input_size], - which is a reshaped version of a Tensor of shape [num_uses, batch_size, - input_size]. - outputs: A list of Tensors, each of shape [batch_size, embedding_size]. - Outputs produced by layer. The list indexes each use in the graph - (which might correspond to a "time-step" in an RNN). Needs to - correspond with the order used in `inputs`. OR, can be a - single Tensor, of shape [num_uses * batch_size, embedding_size], which - is a reshaped version of a Tensor of shape [num_uses, batch_size, - embedding_size]. - num_uses: int or None. The number uses/time-steps in the graph where the - layer appears. Only needed if both inputs and outputs are given in the - single Tensor format. (Default: None) - approx: str or None. If not None must by "kron_indep". The Fisher - approximation to use. If None the default value is used. - (Default: None) - reuse: bool or str. If True, this adds `inputs` and `outputs` as an - additional mini-batch/tower of data to use when estimating the Fisher - block for this layer (which must have already been registered). If - "VARIABLE_SCOPE", use tf.get_variable_scope().reuse. (Note that the - word `use` here has a completely different meaning to "use in the graph" - as it pertains to the `inputs`, `outputs`, and `num_uses` arguments.) - (Default: "VARIABLE_SCOPE") - - Raises: - ValueError: For improper value to `approx`. - KeyError: If reuse == True but no FisherBlock found for `params`. - ValueError: If reuse == True and FisherBlock found but of the wrong type. - """ - block_type, approx = self._get_block_type( - params, approx, self.default_embedding_multi_approximation, - _EMBEDDING_MULTI_APPROX_TO_BLOCK_TYPES) - - if isinstance(params, (tuple, list)): - raise ValueError("Bias not supported.") - vocab_size = int(params.shape[0]) - - block = self.register_block( - params, block_type(self, vocab_size, num_uses=num_uses), reuse=reuse) - block.register_additional_tower(inputs, outputs) - - if isinstance(inputs, (tuple, list)): - self._add_uses(params, len(inputs)) - else: - self._add_uses(params, 1) - - def register_categorical_predictive_distribution(self, - logits, - seed=None, - targets=None, - name=None, - reuse=VARIABLE_SCOPE): - """Registers a categorical predictive distribution. - - Args: - logits: The logits of the distribution (i.e. its parameters). - seed: The seed for the RNG (for debugging) (Default: None) - targets: (OPTIONAL) The targets for the loss function. Only required if - one wants to call total_loss() instead of total_sampled_loss(). - total_loss() is required, for example, to estimate the - "empirical Fisher" (instead of the true Fisher). - (Default: None) - name: (OPTIONAL) str or None. Unique name for this loss function. If None, - a new name is generated. (Default: None) - reuse: bool or str. If True, this adds `logits` as an additional - mini-batch/tower of inputs to the loss-function/predictive distribution - (which must have already been registered). If "VARIABLE_SCOPE", use - tf.get_variable_scope().reuse. (Default: "VARIABLE_SCOPE") - """ - loss = lf.CategoricalLogitsNegativeLogProbLoss(logits, targets=targets, - seed=seed) - self.register_loss_function(loss, logits, - "categorical_predictive_distribution", - name=name, reuse=reuse) - - def register_normal_predictive_distribution(self, - mean, - var=0.5, - seed=None, - targets=None, - name=None, - reuse=VARIABLE_SCOPE): - """Registers a normal predictive distribution. - - Args: - mean: The mean vector defining the distribution. - var: The variance (must be a scalar). Note that the default value of - 0.5 corresponds to a standard squared error loss (target - - prediction)**2. If your squared error loss is of the form - 0.5*(target - prediction)**2 you should use var=1.0. (Default: 0.5) - seed: The seed for the RNG (for debugging) (Default: None) - targets: (OPTIONAL) The targets for the loss function. Only required if - one wants to call total_loss() instead of total_sampled_loss(). - total_loss() is required, for example, to estimate the - "empirical Fisher" (instead of the true Fisher). - (Default: None) - name: (OPTIONAL) str or None. Unique name for this loss function. If None, - a new name is generated. (Default: None) - reuse: bool or str. If True, this adds `mean` and `var` as an additional - mini-batch/tower of inputs to the loss-function/predictive distribution - (which must have already been registered). If "VARIABLE_SCOPE", use - tf.get_variable_scope().reuse. (Default: "VARIABLE_SCOPE") - """ - loss = lf.NormalMeanNegativeLogProbLoss(mean, var, targets=targets, - seed=seed) - self.register_loss_function(loss, mean, - "normal_predictive_distribution", - name=name, reuse=reuse) - - def register_multi_bernoulli_predictive_distribution(self, - logits, - seed=None, - targets=None, - name=None, - reuse=VARIABLE_SCOPE): - """Registers a multi-Bernoulli predictive distribution. - - Args: - logits: The logits of the distribution (i.e. its parameters). - seed: The seed for the RNG (for debugging) (Default: None) - targets: (OPTIONAL) The targets for the loss function. Only required if - one wants to call total_loss() instead of total_sampled_loss(). - total_loss() is required, for example, to estimate the - "empirical Fisher" (instead of the true Fisher). - (Default: None) - name: (OPTIONAL) str or None. Unique name for this loss function. If None, - a new name is generated. (Default: None) - reuse: bool or str. If True, this adds `logits` as an additional - mini-batch/tower of inputs to the loss-function/predictive distribution - (which must have already been registered). If "VARIABLE_SCOPE", use - tf.get_variable_scope().reuse. (Default: "VARIABLE_SCOPE") - """ - loss = lf.MultiBernoulliNegativeLogProbLoss(logits, targets=targets, - seed=seed) - self.register_loss_function(loss, logits, - "multi_bernoulli_predictive_distribution", - name=name, reuse=reuse) - - def make_or_get_factor(self, cls, args): - """Insert `cls(args)` into 'self.fisher_factors` if not already present. - - Wraps constructor in `tf.variable_scope()` to ensure variables constructed - in `cls.__init__` are placed under this LayerCollection's scope. - - Args: - cls: Class that implements FisherFactor. - args: Tuple of arguments to pass into `cls's constructor. Must be - hashable. - - Returns: - Instance of `cls` found in self.fisher_factors. - """ - try: - hash(args) - except TypeError: - raise TypeError( - ("Unable to use (cls, args) = ({}, {}) as a key in " - "LayerCollection.fisher_factors. The pair cannot be hashed.").format( - cls, args)) - - key = cls, args - if key not in self.fisher_factors: - with variable_scope.variable_scope(self._var_scope): - self.fisher_factors[key] = cls(*args) - return self.fisher_factors[key] - - @contextmanager - def as_default(self): - """Sets this LayerCollection as the default.""" - set_default_layer_collection(self) - yield - set_default_layer_collection(None) diff --git a/tensorflow/contrib/kfac/python/ops/layer_collection_lib.py b/tensorflow/contrib/kfac/python/ops/layer_collection_lib.py deleted file mode 100644 index 9f46853807..0000000000 --- a/tensorflow/contrib/kfac/python/ops/layer_collection_lib.py +++ /dev/null @@ -1,46 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Registry for layers and their parameters/variables. - -This represents the collection of all layers in the approximate Fisher -information matrix to which a particular FisherBlock may belong. That is, we -might have several layer collections for one TF graph (if we have multiple K-FAC -optimizers being used, for example.) -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import,line-too-long,wildcard-import -from tensorflow.contrib.kfac.python.ops.layer_collection import * -from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long,wildcard-import - -_allowed_symbols = [ - "get_default_layer_collection", - "set_default_layer_collection", - "LayerParametersDict", - "LayerCollection", - "APPROX_KRONECKER_NAME", - "APPROX_DIAGONAL_NAME", - "APPROX_FULL_NAME", - "VARIABLE_SCOPE", - "APPROX_KRONECKER_INDEP_NAME", - "APPROX_KRONECKER_SERIES_1_NAME", - "APPROX_KRONECKER_SERIES_2_NAME" -] - -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) diff --git a/tensorflow/contrib/kfac/python/ops/linear_operator.py b/tensorflow/contrib/kfac/python/ops/linear_operator.py deleted file mode 100644 index 61cb955ae8..0000000000 --- a/tensorflow/contrib/kfac/python/ops/linear_operator.py +++ /dev/null @@ -1,95 +0,0 @@ -# Copyright 2018 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""SmartMatrices definitions.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from tensorflow.contrib.kfac.python.ops import utils -from tensorflow.python.framework import ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops.linalg import linalg -from tensorflow.python.ops.linalg import linalg_impl -from tensorflow.python.ops.linalg import linear_operator_util as lou - - -class LinearOperatorExtras(object): # pylint: disable=missing-docstring - - def matmul(self, x, adjoint=False, adjoint_arg=False, name="matmul"): - - with self._name_scope(name, values=[x]): - if isinstance(x, ops.IndexedSlices): - return self._matmul_sparse(x, adjoint=adjoint, adjoint_arg=adjoint_arg) - - x = ops.convert_to_tensor(x, name="x") - self._check_input_dtype(x) - - self_dim = -2 if adjoint else -1 - arg_dim = -1 if adjoint_arg else -2 - self.shape[self_dim].assert_is_compatible_with(x.get_shape()[arg_dim]) - - return self._matmul(x, adjoint=adjoint, adjoint_arg=adjoint_arg) - - def matmul_right(self, x, adjoint=False, adjoint_arg=False, name="matmul"): - - with self._name_scope(name, values=[x]): - - if isinstance(x, ops.IndexedSlices): - return self._matmul_right_sparse( - x, adjoint=adjoint, adjoint_arg=adjoint_arg) - - x = ops.convert_to_tensor(x, name="x") - self._check_input_dtype(x) - - self_dim = -1 if adjoint else -2 - arg_dim = -2 if adjoint_arg else -1 - self.shape[self_dim].assert_is_compatible_with(x.get_shape()[arg_dim]) - - return self._matmul_right(x, adjoint=adjoint, adjoint_arg=adjoint_arg) - - -class LinearOperatorFullMatrix(LinearOperatorExtras, - linalg.LinearOperatorFullMatrix): - - # TODO(b/78117889) Remove this definition once core LinearOperator - # has _matmul_right. - def _matmul_right(self, x, adjoint=False, adjoint_arg=False): - return lou.matmul_with_broadcast( - x, self._matrix, adjoint_a=adjoint_arg, adjoint_b=adjoint) - - def _matmul_sparse(self, x, adjoint=False, adjoint_arg=False): - raise NotImplementedError - - def _matmul_right_sparse(self, x, adjoint=False, adjoint_arg=False): - assert not adjoint and not adjoint_arg - return utils.matmul_sparse_dense(x, self._matrix) - - -class LinearOperatorDiag(LinearOperatorExtras, # pylint: disable=missing-docstring - linalg.LinearOperatorDiag): - - def _matmul_right(self, x, adjoint=False, adjoint_arg=False): - diag_mat = math_ops.conj(self._diag) if adjoint else self._diag - x = linalg_impl.adjoint(x) if adjoint_arg else x - return diag_mat * x - - def _matmul_sparse(self, x, adjoint=False, adjoint_arg=False): - diag_mat = math_ops.conj(self._diag) if adjoint else self._diag - assert not adjoint_arg - return utils.matmul_diag_sparse(diag_mat, x) - - def _matmul_right_sparse(self, x, adjoint=False, adjoint_arg=False): - raise NotImplementedError diff --git a/tensorflow/contrib/kfac/python/ops/loss_functions.py b/tensorflow/contrib/kfac/python/ops/loss_functions.py deleted file mode 100644 index c8cebc42cb..0000000000 --- a/tensorflow/contrib/kfac/python/ops/loss_functions.py +++ /dev/null @@ -1,754 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Loss functions to be used by LayerCollection.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import abc - -import six - -from tensorflow.contrib.distributions.python.ops import onehot_categorical -from tensorflow.python.framework import tensor_shape -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops.distributions import bernoulli -from tensorflow.python.ops.distributions import categorical -from tensorflow.python.ops.distributions import normal - - -@six.add_metaclass(abc.ABCMeta) -class LossFunction(object): - """Abstract base class for loss functions. - - Note that unlike typical loss functions used in neural networks these are - summed and not averaged across cases in the batch, since this is what the - users of this class (FisherEstimator and MatrixVectorProductComputer) will - be expecting. The implication of this is that you will may want to - normalize things like Fisher-vector products by the batch size when you - use this class. It depends on the use case. - """ - - @abc.abstractproperty - def targets(self): - """The targets being predicted by the model. - - Returns: - None or Tensor of appropriate shape for calling self._evaluate() on. - """ - pass - - @abc.abstractproperty - def inputs(self): - """The inputs to the loss function (excluding the targets).""" - pass - - def evaluate(self): - """Evaluate the loss function on the targets.""" - if self.targets is not None: - # We treat the targets as "constant". It's only the inputs that get - # "back-propped" through. - return self._evaluate(array_ops.stop_gradient(self.targets)) - else: - raise Exception("Cannot evaluate losses with unspecified targets.") - - @abc.abstractmethod - def _evaluate(self, targets): - """Evaluates the negative log probability of the targets. - - Args: - targets: Tensor that distribution can calculate log_prob() of. - - Returns: - negative log probability of each target, summed across all targets. - """ - pass - - @abc.abstractmethod - def multiply_hessian(self, vector): - """Right-multiply a vector by the Hessian. - - Here the 'Hessian' is the Hessian matrix (i.e. matrix of 2nd-derivatives) - of the loss function with respect to its inputs. - - Args: - vector: The vector to multiply. Must be the same shape(s) as the - 'inputs' property. - - Returns: - The vector right-multiplied by the Hessian. Will be of the same shape(s) - as the 'inputs' property. - """ - pass - - @abc.abstractmethod - def multiply_hessian_factor(self, vector): - """Right-multiply a vector by a factor B of the Hessian. - - Here the 'Hessian' is the Hessian matrix (i.e. matrix of 2nd-derivatives) - of the loss function with respect to its inputs. Typically this will be - block-diagonal across different cases in the batch, since the loss function - is typically summed across cases. - - Note that B can be any matrix satisfying B * B^T = H where H is the Hessian, - but will agree with the one used in the other methods of this class. - - Args: - vector: The vector to multiply. Must be of the shape given by the - 'hessian_factor_inner_shape' property. - - Returns: - The vector right-multiplied by B. Will be of the same shape(s) as the - 'inputs' property. - """ - pass - - @abc.abstractmethod - def multiply_hessian_factor_transpose(self, vector): - """Right-multiply a vector by the transpose of a factor B of the Hessian. - - Here the 'Hessian' is the Hessian matrix (i.e. matrix of 2nd-derivatives) - of the loss function with respect to its inputs. Typically this will be - block-diagonal across different cases in the batch, since the loss function - is typically summed across cases. - - Note that B can be any matrix satisfying B * B^T = H where H is the Hessian, - but will agree with the one used in the other methods of this class. - - Args: - vector: The vector to multiply. Must be the same shape(s) as the - 'inputs' property. - - Returns: - The vector right-multiplied by B^T. Will be of the shape given by the - 'hessian_factor_inner_shape' property. - """ - pass - - @abc.abstractmethod - def multiply_hessian_factor_replicated_one_hot(self, index): - """Right-multiply a replicated-one-hot vector by a factor B of the Hessian. - - Here the 'Hessian' is the Hessian matrix (i.e. matrix of 2nd-derivatives) - of the loss function with respect to its inputs. Typically this will be - block-diagonal across different cases in the batch, since the loss function - is typically summed across cases. - - A 'replicated-one-hot' vector means a tensor which, for each slice along the - batch dimension (assumed to be dimension 0), is 1.0 in the entry - corresponding to the given index and 0 elsewhere. - - Note that B can be any matrix satisfying B * B^T = H where H is the Hessian, - but will agree with the one used in the other methods of this class. - - Args: - index: A tuple representing in the index of the entry in each slice that - is 1.0. Note that len(index) must be equal to the number of elements - of the 'hessian_factor_inner_shape' tensor minus one. - - Returns: - The vector right-multiplied by B^T. Will be of the same shape(s) as the - 'inputs' property. - """ - pass - - @abc.abstractproperty - def hessian_factor_inner_shape(self): - """The shape of the tensor returned by multiply_hessian_factor.""" - pass - - @abc.abstractproperty - def hessian_factor_inner_static_shape(self): - """Static version of hessian_factor_inner_shape.""" - pass - - -@six.add_metaclass(abc.ABCMeta) -class NegativeLogProbLoss(LossFunction): - """Abstract base class for loss functions that are negative log probs.""" - - def __init__(self, seed=None): - self._default_seed = seed - super(NegativeLogProbLoss, self).__init__() - - @property - def inputs(self): - return self.params - - @abc.abstractproperty - def params(self): - """Parameters to the underlying distribution.""" - pass - - @abc.abstractmethod - def multiply_fisher(self, vector): - """Right-multiply a vector by the Fisher. - - Args: - vector: The vector to multiply. Must be the same shape(s) as the - 'inputs' property. - - Returns: - The vector right-multiplied by the Fisher. Will be of the same shape(s) - as the 'inputs' property. - """ - pass - - @abc.abstractmethod - def multiply_fisher_factor(self, vector): - """Right-multiply a vector by a factor B of the Fisher. - - Here the 'Fisher' is the Fisher information matrix (i.e. expected outer- - product of gradients) with respect to the parameters of the underlying - probability distribution (whose log-prob defines the loss). Typically this - will be block-diagonal across different cases in the batch, since the - distribution is usually (but not always) conditionally iid across different - cases. - - Note that B can be any matrix satisfying B * B^T = F where F is the Fisher, - but will agree with the one used in the other methods of this class. - - Args: - vector: The vector to multiply. Must be of the shape given by the - 'fisher_factor_inner_shape' property. - - Returns: - The vector right-multiplied by B. Will be of the same shape(s) as the - 'inputs' property. - """ - pass - - @abc.abstractmethod - def multiply_fisher_factor_transpose(self, vector): - """Right-multiply a vector by the transpose of a factor B of the Fisher. - - Here the 'Fisher' is the Fisher information matrix (i.e. expected outer- - product of gradients) with respect to the parameters of the underlying - probability distribution (whose log-prob defines the loss). Typically this - will be block-diagonal across different cases in the batch, since the - distribution is usually (but not always) conditionally iid across different - cases. - - Note that B can be any matrix satisfying B * B^T = F where F is the Fisher, - but will agree with the one used in the other methods of this class. - - Args: - vector: The vector to multiply. Must be the same shape(s) as the - 'inputs' property. - - Returns: - The vector right-multiplied by B^T. Will be of the shape given by the - 'fisher_factor_inner_shape' property. - """ - pass - - @abc.abstractmethod - def multiply_fisher_factor_replicated_one_hot(self, index): - """Right-multiply a replicated-one-hot vector by a factor B of the Fisher. - - Here the 'Fisher' is the Fisher information matrix (i.e. expected outer- - product of gradients) with respect to the parameters of the underlying - probability distribution (whose log-prob defines the loss). Typically this - will be block-diagonal across different cases in the batch, since the - distribution is usually (but not always) conditionally iid across different - cases. - - A 'replicated-one-hot' vector means a tensor which, for each slice along the - batch dimension (assumed to be dimension 0), is 1.0 in the entry - corresponding to the given index and 0 elsewhere. - - Note that B can be any matrix satisfying B * B^T = H where H is the Fisher, - but will agree with the one used in the other methods of this class. - - Args: - index: A tuple representing in the index of the entry in each slice that - is 1.0. Note that len(index) must be equal to the number of elements - of the 'fisher_factor_inner_shape' tensor minus one. - - Returns: - The vector right-multiplied by B. Will be of the same shape(s) as the - 'inputs' property. - """ - pass - - @abc.abstractproperty - def fisher_factor_inner_shape(self): - """The shape of the tensor returned by multiply_fisher_factor.""" - pass - - @abc.abstractproperty - def fisher_factor_inner_static_shape(self): - """Static version of fisher_factor_inner_shape.""" - pass - - @abc.abstractmethod - def sample(self, seed): - """Sample 'targets' from the underlying distribution.""" - pass - - def evaluate_on_sample(self, seed=None): - """Evaluates the log probability on a random sample. - - Args: - seed: int or None. Random seed for this draw from the distribution. - - Returns: - Log probability of sampled targets, summed across examples. - """ - if seed is None: - seed = self._default_seed - # We treat the targets as "constant". It's only the inputs that get - # "back-propped" through. - return self._evaluate(array_ops.stop_gradient(self.sample(seed))) - - -# TODO(jamesmartens): should this just inherit from object to avoid "diamond" -# inheritance, or is there a better way? -class NaturalParamsNegativeLogProbLoss(NegativeLogProbLoss): - """Base class for neg log prob losses whose inputs are 'natural' parameters. - - Note that the Hessian and Fisher for natural parameters of exponential- - family models are the same, hence the purpose of this class. - See here: https://arxiv.org/abs/1412.1193 - - 'Natural parameters' are defined for exponential-family models. See for - example: https://en.wikipedia.org/wiki/Exponential_family - """ - - def multiply_hessian(self, vector): - return self.multiply_fisher(vector) - - def multiply_hessian_factor(self, vector): - return self.multiply_fisher_factor(vector) - - def multiply_hessian_factor_transpose(self, vector): - return self.multiply_fisher_factor_transpose(vector) - - def multiply_hessian_factor_replicated_one_hot(self, index): - return self.multiply_fisher_factor_replicated_one_hot(index) - - @property - def hessian_factor_inner_shape(self): - return self.fisher_factor_inner_shape - - @property - def hessian_factor_inner_static_shape(self): - return self.fisher_factor_inner_shape - - -class DistributionNegativeLogProbLoss(NegativeLogProbLoss): - """Base class for neg log prob losses that use the TF Distribution classes.""" - - def __init__(self, seed=None): - super(DistributionNegativeLogProbLoss, self).__init__(seed=seed) - - @abc.abstractproperty - def dist(self): - """The underlying tf.distributions.Distribution.""" - pass - - def _evaluate(self, targets): - return -math_ops.reduce_sum(self.dist.log_prob(targets)) - - def sample(self, seed): - return self.dist.sample(seed=seed) - - -class NormalMeanNegativeLogProbLoss(DistributionNegativeLogProbLoss, - NaturalParamsNegativeLogProbLoss): - """Neg log prob loss for a normal distribution parameterized by a mean vector. - - - Note that the covariance is treated as a constant 'var' times the identity. - Also note that the Fisher for such a normal distribution with respect the mean - parameter is given by: - - F = (1/var) * I - - See for example https://www.ii.pwr.edu.pl/~tomczak/PDF/[JMT]Fisher_inf.pdf. - """ - - def __init__(self, mean, var=0.5, targets=None, seed=None): - self._mean = mean - self._var = var - self._targets = targets - super(NormalMeanNegativeLogProbLoss, self).__init__(seed=seed) - - @property - def targets(self): - return self._targets - - @property - def dist(self): - return normal.Normal(loc=self._mean, scale=math_ops.sqrt(self._var)) - - @property - def params(self): - return self._mean - - def multiply_fisher(self, vector): - return (1. / self._var) * vector - - def multiply_fisher_factor(self, vector): - return self._var**-0.5 * vector - - def multiply_fisher_factor_transpose(self, vector): - return self.multiply_fisher_factor(vector) # it's symmetric in this case - - def multiply_fisher_factor_replicated_one_hot(self, index): - assert len(index) == 1, "Length of index was {}".format(len(index)) - ones_slice = array_ops.expand_dims( - array_ops.ones(array_ops.shape(self._mean)[:1], dtype=self._mean.dtype), - axis=-1) - output_slice = self._var**-0.5 * ones_slice - return insert_slice_in_zeros(output_slice, 1, int(self._mean.shape[1]), - index[0]) - - @property - def fisher_factor_inner_shape(self): - return array_ops.shape(self._mean) - - @property - def fisher_factor_inner_static_shape(self): - return self._mean.shape - - -class NormalMeanVarianceNegativeLogProbLoss(DistributionNegativeLogProbLoss): - """Negative log prob loss for a normal distribution with mean and variance. - - This class parameterizes a multivariate normal distribution with n independent - dimensions. Unlike `NormalMeanNegativeLogProbLoss`, this class does not - assume the variance is held constant. The Fisher Information for n = 1 - is given by, - - F = [[1 / variance, 0], - [ 0, 0.5 / variance^2]] - - where the parameters of the distribution are concatenated into a single - vector as [mean, variance]. For n > 1, the mean parameter vector is - concatenated with the variance parameter vector. - - See https://www.ii.pwr.edu.pl/~tomczak/PDF/[JMT]Fisher_inf.pdf for derivation. - """ - - def __init__(self, mean, variance, targets=None, seed=None): - assert len(mean.shape) == 2, "Expect 2D mean tensor." - assert len(variance.shape) == 2, "Expect 2D variance tensor." - self._mean = mean - self._variance = variance - self._targets = targets - super(NormalMeanVarianceNegativeLogProbLoss, self).__init__(seed=seed) - - @property - def targets(self): - return self._targets - - @property - def dist(self): - return normal.Normal(loc=self._mean, scale=math_ops.sqrt(self._variance)) - - @property - def params(self): - return self._mean, self._variance - - def _concat(self, mean, variance): - return array_ops.concat([mean, variance], axis=-1) - - def _split(self, params): - return array_ops.split(params, 2, axis=-1) - - @property - def _fisher_mean(self): - return 1. / self._variance - - @property - def _fisher_mean_factor(self): - return 1. / math_ops.sqrt(self._variance) - - @property - def _fisher_var(self): - return 1. / (2 * math_ops.square(self._variance)) - - @property - def _fisher_var_factor(self): - return 1. / (math_ops.sqrt(2.) * self._variance) - - def multiply_fisher(self, vecs): - mean_vec, var_vec = vecs - return (self._fisher_mean * mean_vec, self._fisher_var * var_vec) - - def multiply_fisher_factor(self, vecs): - mean_vec, var_vec = self._split(vecs) - return (self._fisher_mean_factor * mean_vec, - self._fisher_var_factor * var_vec) - - def multiply_fisher_factor_transpose(self, vecs): - mean_vec, var_vec = vecs - return self._concat(self._fisher_mean_factor * mean_vec, - self._fisher_var_factor * var_vec) - - def multiply_fisher_factor_replicated_one_hot(self, index): - assert len(index) == 1, "Length of index was {}".format(len(index)) - index = index[0] - - if index < int(self._mean.shape[-1]): - # Index corresponds to mean parameter. - mean_slice = self._fisher_mean_factor[:, index] - mean_slice = array_ops.expand_dims(mean_slice, axis=-1) - mean_output = insert_slice_in_zeros(mean_slice, 1, int( - self._mean.shape[1]), index) - var_output = array_ops.zeros_like(mean_output) - else: - index -= int(self._mean.shape[-1]) - # Index corresponds to variance parameter. - var_slice = self._fisher_var_factor[:, index] - var_slice = array_ops.expand_dims(var_slice, axis=-1) - var_output = insert_slice_in_zeros(var_slice, 1, - int(self._variance.shape[1]), index) - mean_output = array_ops.zeros_like(var_output) - - return mean_output, var_output - - @property - def fisher_factor_inner_shape(self): - return array_ops.concat( - [ - array_ops.shape(self._mean)[:-1], - 2 * array_ops.shape(self._mean)[-1:] - ], - axis=0) - - @property - def fisher_factor_inner_static_shape(self): - shape = self._mean.shape.as_list() - return tensor_shape.TensorShape(shape[-1:] + [2 * shape[-1]]) - - def multiply_hessian(self, vector): - raise NotImplementedError() - - def multiply_hessian_factor(self, vector): - raise NotImplementedError() - - def multiply_hessian_factor_transpose(self, vector): - raise NotImplementedError() - - def multiply_hessian_factor_replicated_one_hot(self, index): - raise NotImplementedError() - - @property - def hessian_factor_inner_shape(self): - raise NotImplementedError() - - @property - def hessian_factor_inner_static_shape(self): - raise NotImplementedError() - - -class CategoricalLogitsNegativeLogProbLoss(DistributionNegativeLogProbLoss, - NaturalParamsNegativeLogProbLoss): - """Neg log prob loss for a categorical distribution parameterized by logits. - - - Note that the Fisher (for a single case) of a categorical distribution, with - respect to the natural parameters (i.e. the logits), is given by: - - F = diag(p) - p*p^T - - where p = softmax(logits). F can be factorized as F = B * B^T where - - B = diag(q) - p*q^T - - where q is the entry-wise square root of p. This is easy to verify using the - fact that q^T*q = 1. - """ - - def __init__(self, logits, targets=None, seed=None): - """Instantiates a CategoricalLogitsNegativeLogProbLoss. - - Args: - logits: Tensor of shape [batch_size, output_size]. Parameters for - underlying distribution. - targets: None or Tensor of shape [output_size]. Each elements contains an - index in [0, output_size). - seed: int or None. Default random seed when sampling. - """ - self._logits = logits - self._targets = targets - super(CategoricalLogitsNegativeLogProbLoss, self).__init__(seed=seed) - - @property - def targets(self): - return self._targets - - @property - def dist(self): - return categorical.Categorical(logits=self._logits) - - @property - def _probs(self): - return self.dist.probs - - @property - def _sqrt_probs(self): - return math_ops.sqrt(self._probs) - - @property - def params(self): - return self._logits - - def multiply_fisher(self, vector): - probs = self._probs - return vector * probs - probs * math_ops.reduce_sum( - vector * probs, axis=-1, keepdims=True) - - def multiply_fisher_factor(self, vector): - probs = self._probs - sqrt_probs = self._sqrt_probs - return sqrt_probs * vector - probs * math_ops.reduce_sum( - sqrt_probs * vector, axis=-1, keepdims=True) - - def multiply_fisher_factor_transpose(self, vector): - probs = self._probs - sqrt_probs = self._sqrt_probs - return sqrt_probs * vector - sqrt_probs * math_ops.reduce_sum( - probs * vector, axis=-1, keepdims=True) - - def multiply_fisher_factor_replicated_one_hot(self, index): - assert len(index) == 1, "Length of index was {}".format(len(index)) - probs = self._probs - sqrt_probs = self._sqrt_probs - sqrt_probs_slice = array_ops.expand_dims(sqrt_probs[:, index[0]], -1) - padded_slice = insert_slice_in_zeros(sqrt_probs_slice, 1, - int(sqrt_probs.shape[1]), index[0]) - return padded_slice - probs * sqrt_probs_slice - - @property - def fisher_factor_inner_shape(self): - return array_ops.shape(self._logits) - - @property - def fisher_factor_inner_static_shape(self): - return self._logits.shape - - -class MultiBernoulliNegativeLogProbLoss(DistributionNegativeLogProbLoss, - NaturalParamsNegativeLogProbLoss): - """Neg log prob loss for multiple Bernoulli distributions param'd by logits. - - Represents N independent Bernoulli distributions where N = len(logits). Its - Fisher Information matrix is given by, - - F = diag(p * (1-p)) - p = sigmoid(logits) - - As F is diagonal with positive entries, its factor B is, - - B = diag(sqrt(p * (1-p))) - """ - - def __init__(self, logits, targets=None, seed=None): - self._logits = logits - self._targets = targets - super(MultiBernoulliNegativeLogProbLoss, self).__init__(seed=seed) - - @property - def targets(self): - return self._targets - - @property - def dist(self): - return bernoulli.Bernoulli(logits=self._logits) - - @property - def _probs(self): - return self.dist.probs - - @property - def params(self): - return self._logits - - def multiply_fisher(self, vector): - return self._probs * (1 - self._probs) * vector - - def multiply_fisher_factor(self, vector): - return math_ops.sqrt(self._probs * (1 - self._probs)) * vector - - def multiply_fisher_factor_transpose(self, vector): - return self.multiply_fisher_factor(vector) # it's symmetric in this case - - def multiply_fisher_factor_replicated_one_hot(self, index): - assert len(index) == 1, "Length of index was {}".format(len(index)) - probs_slice = array_ops.expand_dims(self._probs[:, index[0]], -1) - output_slice = math_ops.sqrt(probs_slice * (1 - probs_slice)) - return insert_slice_in_zeros(output_slice, 1, int(self._logits.shape[1]), - index[0]) - - @property - def fisher_factor_inner_shape(self): - return array_ops.shape(self._logits) - - @property - def fisher_factor_inner_static_shape(self): - return self._logits.shape - - -def insert_slice_in_zeros(slice_to_insert, dim, dim_size, position): - """Inserts slice into a larger tensor of zeros. - - Forms a new tensor which is the same shape as slice_to_insert, except that - the dimension given by 'dim' is expanded to the size given by 'dim_size'. - 'position' determines the position (index) at which to insert the slice within - that dimension. - - Assumes slice_to_insert.shape[dim] = 1. - - Args: - slice_to_insert: The slice to insert. - dim: The dimension which to expand with zeros. - dim_size: The new size of the 'dim' dimension. - position: The position of 'slice_to_insert' in the new tensor. - - Returns: - The new tensor. - - Raises: - ValueError: If the slice's shape at the given dim is not 1. - """ - slice_shape = slice_to_insert.shape - if slice_shape[dim] != 1: - raise ValueError("Expected slice_to_insert.shape to have {} dim of 1, but " - "was {}".format(dim, slice_to_insert.shape[dim])) - - before = [0] * int(len(slice_shape)) - after = before[:] - before[dim] = position - after[dim] = dim_size - position - 1 - - return array_ops.pad(slice_to_insert, list(zip(before, after))) - - -class OnehotCategoricalLogitsNegativeLogProbLoss( - CategoricalLogitsNegativeLogProbLoss): - """Neg log prob loss for a categorical distribution with onehot targets. - - Identical to CategoricalLogitsNegativeLogProbLoss except that the underlying - distribution is OneHotCategorical as opposed to Categorical. - """ - - @property - def dist(self): - return onehot_categorical.OneHotCategorical(logits=self._logits) diff --git a/tensorflow/contrib/kfac/python/ops/loss_functions_lib.py b/tensorflow/contrib/kfac/python/ops/loss_functions_lib.py deleted file mode 100644 index 4279cb2792..0000000000 --- a/tensorflow/contrib/kfac/python/ops/loss_functions_lib.py +++ /dev/null @@ -1,39 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Loss functions to be used by LayerCollection.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import,line-too-long,wildcard-import -from tensorflow.contrib.kfac.python.ops.loss_functions import * -from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long,wildcard-import - -_allowed_symbols = [ - "LossFunction", - "NegativeLogProbLoss", - "NaturalParamsNegativeLogProbLoss", - "DistributionNegativeLogProbLoss", - "NormalMeanNegativeLogProbLoss", - "NormalMeanVarianceNegativeLogProbLoss", - "CategoricalLogitsNegativeLogProbLoss", - "OnehotCategoricalLogitsNegativeLogProbLoss", - "MultiBernoulliNegativeLogProbLoss", - "insert_slice_in_zeros", -] - -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) diff --git a/tensorflow/contrib/kfac/python/ops/op_queue.py b/tensorflow/contrib/kfac/python/ops/op_queue.py deleted file mode 100644 index b6d9d37a31..0000000000 --- a/tensorflow/contrib/kfac/python/ops/op_queue.py +++ /dev/null @@ -1,69 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Helper for choosing which op to run next in a distributed setting.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from tensorflow.python.data.ops import dataset_ops -from tensorflow.python.framework import ops as tf_ops - - -class OpQueue(object): - """Class for choosing which Op to run next. - - Constructs an infinitely repeating sequence of Ops in shuffled order. - - In K-FAC, this can be used to distribute inverse update operations among - workers. - """ - - def __init__(self, ops, seed=None): - """Initializes an OpQueue. - - Args: - ops: list of TensorFlow Ops. Ops to be selected from. All workers must - initialize with the same set of ops. - seed: int or None. Random seed used when shuffling order of ops. - """ - self._ops_by_name = {op.name: op for op in ops} - - # Construct a (shuffled) Dataset with Op names. - op_names = tf_ops.convert_to_tensor(list(sorted(op.name for op in ops))) - op_names_dataset = (dataset_ops.Dataset.from_tensor_slices(op_names) - .shuffle(len(ops), seed=seed).repeat()) - self._next_op_name = op_names_dataset.make_one_shot_iterator().get_next() - - @property - def ops(self): - """Ops this OpQueue can return in next_op().""" - return self._ops_by_name.values() - - def next_op(self, sess): - """Chooses which op to run next. - - Note: This call will make a call to sess.run(). - - Args: - sess: tf.Session. - - Returns: - Next Op chosen from 'ops'. - """ - # In Python 3, type(next_op_name) == bytes. Calling bytes.decode('ascii') - # returns a str. - next_op_name = sess.run(self._next_op_name).decode('ascii') - return self._ops_by_name[next_op_name] diff --git a/tensorflow/contrib/kfac/python/ops/optimizer.py b/tensorflow/contrib/kfac/python/ops/optimizer.py deleted file mode 100644 index 38605259b5..0000000000 --- a/tensorflow/contrib/kfac/python/ops/optimizer.py +++ /dev/null @@ -1,727 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""The KFAC optimizer.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import warnings - -# pylint disable=long-line -from tensorflow.contrib.kfac.python.ops import curvature_matrix_vector_products as cmvp -from tensorflow.contrib.kfac.python.ops import estimator as est -# pylint enable=long-line - -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import ops -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import control_flow_ops -from tensorflow.python.ops import linalg_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import state_ops -from tensorflow.python.ops import variable_scope -from tensorflow.python.ops import variables as tf_variables -from tensorflow.python.training import gradient_descent - - -class KfacOptimizer(gradient_descent.GradientDescentOptimizer): - """The KFAC Optimizer (https://arxiv.org/abs/1503.05671).""" - - def __init__(self, - learning_rate, - cov_ema_decay, - damping, - layer_collection, - var_list=None, - momentum=0.9, - momentum_type="regular", - norm_constraint=None, - name="KFAC", - estimation_mode="gradients", - colocate_gradients_with_ops=True, - batch_size=None, - placement_strategy=None, - **kwargs): - """Initializes the KFAC optimizer with the given settings. - - Args: - learning_rate: The base learning rate for the optimizer. Should probably - be set to 1.0 when using momentum_type = 'qmodel', but can still be - set lowered if desired (effectively lowering the trust in the - quadratic model.) - cov_ema_decay: The decay factor used when calculating the covariance - estimate moving averages. - damping: The damping factor used to stabilize training due to errors in - the local approximation with the Fisher information matrix, and to - regularize the update direction by making it closer to the gradient. - If damping is adapted during training then this value is used for - initializing damping variable. - (Higher damping means the update looks more like a standard gradient - update - see Tikhonov regularization.) - layer_collection: The layer collection object, which holds the fisher - blocks, Kronecker factors, and losses associated with the - graph. The layer_collection cannot be modified after KfacOptimizer's - initialization. - var_list: Optional list or tuple of variables to train. Defaults to the - list of variables collected in the graph under the key - `GraphKeys.TRAINABLE_VARIABLES`. - momentum: The momentum decay constant to use. Only applies when - momentum_type is 'regular' or 'adam'. (Default: 0.9) - momentum_type: The type of momentum to use in this optimizer, one of - 'regular', 'adam', or 'qmodel'. (Default: 'regular') - norm_constraint: float or Tensor. If specified, the update is scaled down - so that its approximate squared Fisher norm v^T F v is at most the - specified value. May only be used with momentum type 'regular'. - (Default: None) - name: The name for this optimizer. (Default: 'KFAC') - estimation_mode: The type of estimator to use for the Fishers. Can be - 'gradients', 'empirical', 'curvature_propagation', or 'exact'. - (Default: 'gradients'). See the doc-string for FisherEstimator for - more a more detailed description of these options. - colocate_gradients_with_ops: Whether we should request gradients we - compute in the estimator be colocated with their respective ops. - (Default: True) - batch_size: The size of the mini-batch. Only needed when momentum_type - == 'qmodel' or when automatic adjustment is used. (Default: None) - placement_strategy: string, Device placement strategy used when creating - covariance variables, covariance ops, and inverse ops. - (Default: `None`) - **kwargs: Arguments to be passed to specific placement - strategy mixin. Check `placement.RoundRobinPlacementMixin` for example. - - Raises: - ValueError: If the momentum type is unsupported. - ValueError: If clipping is used with momentum type other than 'regular'. - ValueError: If no losses have been registered with layer_collection. - ValueError: If momentum is non-zero and momentum_type is not 'regular' - or 'adam'. - """ - warnings.warn( - "third_party.tensorflow.contrib.kfac is deprecated." - "This will be removed on 15-07-2018. Check README for further details.", - DeprecationWarning) - # Parameters to be passed to the Fisher estimator: - self._variables = var_list or tf_variables.trainable_variables - self._cov_ema_decay = cov_ema_decay - self._layers = layer_collection - self._estimation_mode = estimation_mode - self._colocate_gradients_with_ops = colocate_gradients_with_ops - - # The below parameters are required only if damping needs to be adapted. - # These parameters can be set by calling - # set_damping_adaptation_params() explicitly. - self._damping_adaptation_decay = 0.95 - self._damping_adaptation_interval = 5 - # Check section 6.5 KFAC paper. omega(1) = pow(damping decay, interval) - self._omega = ( - self._damping_adaptation_decay**self._damping_adaptation_interval) - self._adapt_damping = False - self._min_damping = 1e-5 - self._prev_train_batch = None - self._is_chief = False - self._loss_fn = None - self._damping_constant = damping - self._damping = None - self._rho = None - self._prev_loss = None - self._q_model_change = None - self._update_damping_op = None - - momentum_type = momentum_type.lower() - legal_momentum_types = ["regular", "adam", "qmodel"] - - if momentum_type not in legal_momentum_types: - raise ValueError("Unsupported momentum type {}. Must be one of {}." - .format(momentum_type, legal_momentum_types)) - if momentum_type != "regular" and norm_constraint is not None: - raise ValueError("Update clipping is only supported with momentum " - "type 'regular'.") - if momentum_type not in ["regular", "adam"] and momentum != 0: - raise ValueError("Momentum must be unspecified if using a momentum_type " - "other than 'regular' or 'adam'.") - - # Extra parameters of the optimizer - self._momentum = momentum - self._momentum_type = momentum_type - self._norm_constraint = norm_constraint - self._batch_size = batch_size - self._placement_strategy = placement_strategy - - with variable_scope.variable_scope(name): - self._fisher_est = est.make_fisher_estimator( - placement_strategy=placement_strategy, - variables=self._variables, - cov_ema_decay=self._cov_ema_decay, - damping=self.damping, - layer_collection=self._layers, - exps=(-1,), - estimation_mode=self._estimation_mode, - colocate_gradients_with_ops=self._colocate_gradients_with_ops, - **kwargs) - - super(KfacOptimizer, self).__init__(learning_rate, name=name) - - def set_damping_adaptation_params(self, - is_chief, - prev_train_batch, - loss_fn, - min_damping=1e-5, - damping_adaptation_decay=0.99, - damping_adaptation_interval=5): - """Sets parameters required to adapt damping during training. - - When called, enables damping adaptation according to the Levenberg-Marquardt - style rule described in Section 6.5 of "Optimizing Neural Networks with - Kronecker-factored Approximate Curvature". - - Note that this function creates Tensorflow variables which store a few - scalars and are accessed by the ops which update the damping (as part - of the training op returned by the minimize() method). - - Args: - is_chief: `Boolean`, `True` if the worker is chief. - prev_train_batch: Training data used to minimize loss in the previous - step. This will be used to evaluate loss by calling - `loss_fn(prev_train_batch)`. - loss_fn: `function` that takes as input training data tensor and returns - a scalar loss. - min_damping: `float`(Optional), Minimum value the damping parameter - can take. Default value 1e-5. - damping_adaptation_decay: `float`(Optional), The `damping` parameter is - multiplied by the `damping_adaptation_decay` every - `damping_adaptation_interval` number of iterations. Default value 0.99. - damping_adaptation_interval: `int`(Optional), Number of steps in between - updating the `damping` parameter. Default value 5. - - Raises: - ValueError: If `set_damping_adaptation_params` is already called and the - the `adapt_damping` is `True`. - """ - if self._adapt_damping: - raise ValueError("Damping adaptation parameters already set.") - - with variable_scope.variable_scope(self.get_name()): - self._adapt_damping = True - self._is_chief = is_chief - self._prev_train_batch = prev_train_batch - self._loss_fn = loss_fn - self._damping_adaptation_decay = damping_adaptation_decay - self._damping_adaptation_interval = damping_adaptation_interval - self._omega = ( - self._damping_adaptation_decay**self._damping_adaptation_interval) - self._min_damping = min_damping - - self._rho = variable_scope.get_variable( - "rho", shape=(), dtype=dtypes.float32, trainable=False) # LM ratio. - self._prev_loss = variable_scope.get_variable( - "prev_loss", shape=(), dtype=dtypes.float32, trainable=False) - self._q_model_change = variable_scope.get_variable( - "q_model_change", shape=(), dtype=dtypes.float32, trainable=False) - self._damping = variable_scope.get_variable( - "damping", initializer=self._damping_constant, trainable=False) - - @property - def variables(self): - return self._fisher_est.variables - - @property - def damping(self): - if self._damping: - return self._damping - else: - return self._damping_constant - - @property - def damping_adaptation_interval(self): - return self._damping_adaptation_interval - - def make_vars_and_create_op_thunks(self): - """Make vars and create op thunks. - - Returns: - cov_update_thunks: List of cov update thunks. Corresponds one-to-one with - the list of factors given by the "factors" property. - inv_update_thunks: List of inv update thunks. Corresponds one-to-one with - the list of factors given by the "factors" property. - """ - scope = self.get_name() + "/" + self._fisher_est.name - return self._fisher_est.make_vars_and_create_op_thunks(scope=scope) - - def create_ops_and_vars_thunks(self): - """Create thunks that make the ops and vars on demand. - - This function returns 4 lists of thunks: cov_variable_thunks, - cov_update_thunks, inv_variable_thunks, and inv_update_thunks. - - The length of each list is the number of factors and the i-th element of - each list corresponds to the i-th factor (given by the "factors" property). - - Note that the execution of these thunks must happen in a certain - partial order. The i-th element of cov_variable_thunks must execute - before the i-th element of cov_update_thunks (and also the i-th element - of inv_update_thunks). Similarly, the i-th element of inv_variable_thunks - must execute before the i-th element of inv_update_thunks. - - TL;DR (oversimplified): Execute the thunks according to the order that - they are returned. - - Returns: - cov_variable_thunks: A list of thunks that make the cov variables. - cov_update_thunks: A list of thunks that make the cov update ops. - inv_variable_thunks: A list of thunks that make the inv variables. - inv_update_thunks: A list of thunks that make the inv update ops. - """ - scope = self.get_name() + "/" + self._fisher_est.name - return self._fisher_est.create_ops_and_vars_thunks(scope=scope) - - def minimize(self, *args, **kwargs): - # Should this variable scope encompass everything below? Or will the super- - # class make another copy of the same name scope? - with variable_scope.variable_scope(self.get_name()): - kwargs["var_list"] = kwargs.get("var_list") or self.variables - if set(kwargs["var_list"]) != set(self.variables): - raise ValueError("var_list doesn't match with set of Fisher-estimating " - "variables.") - if self._adapt_damping and self._is_chief: - global_step = kwargs.get("global_step", None) - if not global_step: - raise KeyError("global_step needs to be passed to optimizer.minimize " - "if damping parameter is adapted.") - update_damping_op = self._update_damping(self._prev_train_batch, - global_step) - with ops.control_dependencies([update_damping_op]): - loss = args[0] - loss_assign_op = state_ops.assign(self._prev_loss, loss) - train_op = super(KfacOptimizer, self).minimize(*args, **kwargs) - return control_flow_ops.group(loss_assign_op, train_op) - else: - return super(KfacOptimizer, self).minimize(*args, **kwargs) - - def compute_gradients(self, *args, **kwargs): - # args[1] could be our var_list - if len(args) > 1: - var_list = args[1] - else: - kwargs["var_list"] = kwargs.get("var_list") or self.variables - var_list = kwargs["var_list"] - - if set(var_list) != set(self.variables): - raise ValueError("var_list doesn't match with set of Fisher-estimating " - "variables.") - return super(KfacOptimizer, self).compute_gradients(*args, **kwargs) - - def apply_gradients(self, grads_and_vars, *args, **kwargs): - """Applies gradients to variables. - - Args: - grads_and_vars: List of (gradient, variable) pairs. - *args: Additional arguments for super.apply_gradients. - **kwargs: Additional keyword arguments for super.apply_gradients. - - Returns: - An `Operation` that applies the specified gradients. - """ - # In Python 3, grads_and_vars can be a zip() object which can only be - # iterated over once. By converting it to a list, we ensure that it can be - # iterated over more than once. - grads_and_vars = list(grads_and_vars) - - # Compute step. - steps_and_vars = self._compute_update_steps(grads_and_vars) - - # Update trainable variables with this step. - return super(KfacOptimizer, self).apply_gradients(steps_and_vars, *args, - **kwargs) - - def _squared_fisher_norm(self, grads_and_vars, precon_grads_and_vars): - """Computes the squared (approximate) Fisher norm of the updates. - - This is defined as v^T F v, where F is the approximate Fisher matrix - as computed by the estimator, and v = F^{-1} g, where g is the gradient. - This is computed efficiently as v^T g. - - Args: - grads_and_vars: List of (gradient, variable) pairs. - precon_grads_and_vars: List of (preconditioned gradient, variable) pairs. - Must be the result of calling `self._fisher_est.multiply_inverse` - on `grads_and_vars`. - - Returns: - Scalar representing the squared norm. - - Raises: - ValueError: if the two list arguments do not contain the same variables, - in the same order. - """ - for (_, gvar), (_, pgvar) in zip(grads_and_vars, precon_grads_and_vars): - if gvar is not pgvar: - raise ValueError("The variables referenced by the two arguments " - "must match.") - terms = [ - math_ops.reduce_sum(grad * pgrad) - for (grad, _), (pgrad, _) in zip(grads_and_vars, precon_grads_and_vars) - ] - return math_ops.reduce_sum(terms) - - def _update_clip_coeff(self, grads_and_vars, precon_grads_and_vars): - """Computes the scale factor for the update to satisfy the norm constraint. - - Defined as min(1, sqrt(c / r^T F r)), where c is the norm constraint, - F is the approximate Fisher matrix, and r is the update vector, i.e. - -alpha * v, where alpha is the learning rate, and v is the preconditioned - gradient. - - This is based on Section 5 of Ba et al., Distributed Second-Order - Optimization using Kronecker-Factored Approximations. Note that they - absorb the learning rate alpha (which they denote eta_max) into the formula - for the coefficient, while in our implementation, the rescaling is done - before multiplying by alpha. Hence, our formula differs from theirs by a - factor of alpha. - - Args: - grads_and_vars: List of (gradient, variable) pairs. - precon_grads_and_vars: List of (preconditioned gradient, variable) pairs. - Must be the result of calling `self._fisher_est.multiply_inverse` - on `grads_and_vars`. - - Returns: - Scalar representing the coefficient which should be applied to the - preconditioned gradients to satisfy the norm constraint. - """ - sq_norm_grad = self._squared_fisher_norm(grads_and_vars, - precon_grads_and_vars) - sq_norm_up = sq_norm_grad * self._learning_rate**2 - return math_ops.minimum(1., - math_ops.sqrt(self._norm_constraint / sq_norm_up)) - - def _clip_updates(self, grads_and_vars, precon_grads_and_vars): - """Rescales the preconditioned gradients to satisfy the norm constraint. - - Rescales the preconditioned gradients such that the resulting update r - (after multiplying by the learning rate) will satisfy the norm constraint. - This constraint is that r^T F r <= C, where F is the approximate Fisher - matrix, and C is the norm_constraint attribute. See Section 5 of - Ba et al., Distributed Second-Order Optimization using Kronecker-Factored - Approximations. - - Args: - grads_and_vars: List of (gradient, variable) pairs. - precon_grads_and_vars: List of (preconditioned gradient, variable) pairs. - Must be the result of calling `self._fisher_est.multiply_inverse` - on `grads_and_vars`. - - Returns: - List of (rescaled preconditioned gradient, variable) pairs. - """ - coeff = self._update_clip_coeff(grads_and_vars, precon_grads_and_vars) - return [(pgrad * coeff, var) for pgrad, var in precon_grads_and_vars] - - def _compute_prev_updates(self, variables): - """Computes previous updates as negative velocities scaled by learning rate. - - Args: - variables: List of variables in the graph that the update will be - applied to. - - Returns: - List of previous updates applied to the `variables`. - """ - return list( - -1 * self._learning_rate * self._zeros_slot(var, "velocity", self._name) - for var in variables) - - def _compute_qmodel_hyperparams(self, precon_grads, prev_updates, grads, - variables): - """Compute optimal update hyperparameters from the quadratic model. - - More specifically, if L is the loss we minimize a quadratic approximation - of L(theta + d) which we denote by qmodel(d) with - d = alpha*precon_grad + mu*prev_update with respect to alpha and mu, where - - qmodel(d) = (1/2) * d^T * B * d + grad^T*d + L(theta) . - - Unlike in the KL clipping approach we use the non-approximated quadratic - model where the curvature matrix C is the true Fisher on the current - mini-batch (computed without any approximations beyond mini-batch sampling), - with the usual Tikhonov damping/regularization applied, - - C = F + damping * I - - See Section 7 of https://arxiv.org/abs/1503.05671 for a derivation of - the formula. See Appendix C for a discussion of the trick of using - a factorized Fisher matrix to more efficiently compute the required - vector-matrix-vector products. - - Note that the elements of all 4 lists passed to this function must - be in correspondence with each other. - - Args: - precon_grads: List of preconditioned gradients. - prev_updates: List of updates computed at the previous iteration. - grads: List of gradients. - variables: List of variables in the graph that the update will be - applied to. (Note that this function doesn't actually apply the - update.) - - Returns: - (alpha, mu, qmodel_change), where alpha and mu are chosen to optimize the - quadratic model, and - qmodel_change = qmodel(alpha*precon_grad + mu*prev_update) - qmodel(0) - = qmodel(alpha*precon_grad + mu*prev_update) - L(theta). - """ - - cmvpc = cmvp.CurvatureMatrixVectorProductComputer(self._layers.losses, - variables) - - # compute the matrix-vector products with the transposed Fisher factor - fft_precon_grads = cmvpc.multiply_fisher_factor_transpose(precon_grads) - fft_prev_updates = cmvpc.multiply_fisher_factor_transpose(prev_updates) - batch_size = math_ops.cast( - self._batch_size, dtype=fft_precon_grads[0].dtype) - - # compute the entries of the 2x2 matrix - m_11 = ( - _inner_product_list(fft_precon_grads, fft_precon_grads) / batch_size + - self.damping * _inner_product_list(precon_grads, precon_grads)) - - m_21 = ( - _inner_product_list(fft_prev_updates, fft_precon_grads) / batch_size + - self.damping * _inner_product_list(prev_updates, precon_grads)) - - m_22 = ( - _inner_product_list(fft_prev_updates, fft_prev_updates) / batch_size + - self.damping * _inner_product_list(prev_updates, prev_updates)) - - def non_zero_prevupd_case(): - r"""Computes optimal (alpha, mu) given non-zero previous update. - - We solve the full 2x2 linear system. See Martens & Grosse (2015), - Section 7, definition of $\alpha^*$ and $\mu^*$. - - Returns: - (alpha, mu, qmodel_change), where alpha and mu are chosen to optimize - the quadratic model, and - qmodel_change = qmodel(alpha*precon_grad + mu*prev_update) - qmodel(0). - """ - m = ops.convert_to_tensor([[m_11, m_21], [m_21, m_22]]) - - c = ops.convert_to_tensor([[_inner_product_list(grads, precon_grads)], - [_inner_product_list(grads, prev_updates)]]) - - sol = -1. * _two_by_two_solve(m, c) - alpha = sol[0] - mu = sol[1] - qmodel_change = 0.5 * math_ops.reduce_sum(sol * c) - - return alpha, mu, qmodel_change - - def zero_prevupd_case(): - r"""Computes optimal (alpha, mu) given all-zero previous update. - - The linear system reduces to 1x1. See Martens & Grosse (2015), - Section 6.4, definition of $\alpha^*$. - - Returns: - (alpha, 0.0, qmodel_change), where alpha is chosen to optimize the - quadratic model, and - qmodel_change = qmodel(alpha*precon_grad) - qmodel(0) - """ - m = m_11 - c = _inner_product_list(grads, precon_grads) - - alpha = -c / m - mu = 0.0 - qmodel_change = 0.5 * alpha * c - - return alpha, mu, qmodel_change - - return control_flow_ops.cond( - math_ops.equal(m_22, 0.0), zero_prevupd_case, non_zero_prevupd_case) - - def _assign_q_model_change(self, q_model_change): - """Assigns `q_model_change` to `self._q_model_change` if damping is adapted. - - Note only the chief worker does the assignment. - - Args: - q_model_change: Scalar tensor of type `float32`. - - Returns: - If `adapt_damping` is `True` then returns an assign op, Otherwise returns - a no_op(). - """ - if self._adapt_damping and self._is_chief: - q_model_assign_op = state_ops.assign(self._q_model_change, q_model_change) - else: - q_model_assign_op = control_flow_ops.no_op() - return q_model_assign_op - - def _compute_qmodel_hyperparams_wrapper(self, grads_and_vars, - precon_grads_and_vars): - """Wrapper function for `self._compute_qmodel_hyperparams`. - - Constructs a list of preconditioned gradients and variables. Also creates a - op to assign the computed q model change to `self._q_model_change`. - - Args: - grads_and_vars: List of (gradient, variable) pairs. - precon_grads_and_vars: List of (preconditioned gradients, variable) - pairs. - - Returns: - (alpha, mu, q_model_assign_op), where alpha and mu are chosen to optimize - the quadratic model, `q_model_assign_op` assigns the computed q model - change to `self._q_model_change`. - """ - precon_grads = list( - precon_grad for (precon_grad, _) in precon_grads_and_vars) - grads = list(grad for (grad, _) in grads_and_vars) - variables = list(var for (_, var) in grads_and_vars) - prev_updates = self._compute_prev_updates(variables) - # Compute optimal velocity update parameters according to quadratic model - alpha, mu, q_model_change = self._compute_qmodel_hyperparams( - precon_grads, prev_updates, grads, variables) - - return alpha, mu, self._assign_q_model_change(q_model_change) - - def _compute_update_steps(self, grads_and_vars): - """Computes the update steps for the variables given the gradients. - - Args: - grads_and_vars: List of (gradient, variable) pairs. - - Returns: - A list of tuple (assign_op ,var) where `assign_op` assigns the update - steps to `var`. - """ - - if self._momentum_type == "regular": - # Compute "preconditioned" gradient. - precon_grads_and_vars = self._fisher_est.multiply_inverse(grads_and_vars) - - # Apply "KL clipping" if asked for. - if self._norm_constraint is not None: - precon_grads_and_vars = self._clip_updates(grads_and_vars, - precon_grads_and_vars) - - # Update the velocity with this and return it as the step. - if self._adapt_damping and self._is_chief: - _, _, q_model_assign_op = self._compute_qmodel_hyperparams_wrapper( - grads_and_vars, precon_grads_and_vars) - with ops.control_dependencies([q_model_assign_op]): - return self._update_velocities(precon_grads_and_vars, self._momentum) - else: - return self._update_velocities(precon_grads_and_vars, self._momentum) - elif self._momentum_type == "adam": - # Update velocity. - velocities_and_vars = self._update_velocities(grads_and_vars, - self._momentum) - # Return "preconditioned" velocity vector as the step. - return self._fisher_est.multiply_inverse(velocities_and_vars) - - elif self._momentum_type == "qmodel": - # Compute "preconditioned" gradient. - precon_grads_and_vars = self._fisher_est.multiply_inverse(grads_and_vars) - - # Compute optimal velocity update parameters according to quadratic model - alpha, mu, q_model_assign_op = self._compute_qmodel_hyperparams_wrapper( - grads_and_vars, precon_grads_and_vars) - - with ops.control_dependencies([q_model_assign_op]): - return self._update_velocities( - precon_grads_and_vars, mu, vec_coeff=-alpha) - - def _update_velocities(self, vecs_and_vars, decay, vec_coeff=1.0): - """Updates the velocities of the variables with the given vectors. - - Args: - vecs_and_vars: List of (vector, variable) pairs. - decay: How much to decay the old velocity by. This is often referred to - as the 'momentum constant'. - vec_coeff: Coefficient to apply to the vectors before adding them to the - velocity. - - Returns: - A list of (velocity, var) indicating the new velocity for each var. - """ - - def _update_velocity(vec, var): - velocity = self._zeros_slot(var, "velocity", self._name) - with ops.colocate_with(velocity): - # NOTE(mattjj): read/modify/write race condition not suitable for async. - - # Compute the new velocity for this variable. - new_velocity = decay * velocity + vec_coeff * vec - - # Save the updated velocity. - return (array_ops.identity(velocity.assign(new_velocity)), var) - - # Go through variable and update its associated part of the velocity vector. - return [_update_velocity(vec, var) for vec, var in vecs_and_vars] - - def _update_damping(self, prev_batch, global_step): - """Adapts damping parameter. Check KFAC (Section 6.5) for the details. - - The damping parameter is updated according to the Levenberg-Marquardt rule - every `self._damping_adaptation_interval` iterations. - - Args: - prev_batch: Tensor or tuple of tensors which can be passed to - `self._loss_fn` to evaluate loss. - global_step: `Variable` which keeps track of number of times the training - variables have been updated. - Returns: - A `tf.cond` op which updates the damping parameter. - """ - def compute_damping(): - """"Adapts damping parameter based on "reduction ratio". - - Reduction ratio captures how closely the quadratic approximation to the - loss function approximates the actual loss within a trust region. The - damping update tries to make the damping as small as possible while - maintaining the property that the quadratic model remains a good local - approximation to the loss function. - - Returns: - An Op to assign newly computed damping value to `self._damping`. - """ - prev_batch_loss = self._loss_fn(prev_batch) - with ops.control_dependencies([prev_batch_loss]): - rho_assign = self._rho.assign( - (prev_batch_loss - self._prev_loss) / self._q_model_change) - with ops.control_dependencies([rho_assign]): - new_damping = control_flow_ops.case( - [(self._rho < 0.25, lambda: self.damping / self._omega), - (self._rho > 0.75, lambda: self.damping * self._omega)], - lambda: self.damping) - with ops.control_dependencies([new_damping]): - new_damping_min = math_ops.maximum(new_damping, self._min_damping) - return control_flow_ops.group(self._damping.assign(new_damping_min)) - - return control_flow_ops.cond( - math_ops.equal( - math_ops.mod(global_step + 1, self._damping_adaptation_interval), - 0), compute_damping, control_flow_ops.no_op) - - -def _inner_product_list(list1, list2): - return math_ops.add_n( - [math_ops.reduce_sum(elt1 * elt2) for elt1, elt2 in zip(list1, list2)]) - - -def _two_by_two_solve(m, c): - # it might be better just to crank out the exact formula for 2x2 inverses - return math_ops.matmul(linalg_ops.matrix_inverse(m), c) diff --git a/tensorflow/contrib/kfac/python/ops/placement.py b/tensorflow/contrib/kfac/python/ops/placement.py deleted file mode 100644 index c4454325ae..0000000000 --- a/tensorflow/contrib/kfac/python/ops/placement.py +++ /dev/null @@ -1,114 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Implements placement strategies for cov and inv ops, cov variables.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import itertools - -from tensorflow.python.framework import ops as tf_ops - - -def _make_thunk_on_device(func, device): - def thunk(): - with tf_ops.device(device): - return func() - return thunk - - -class RoundRobinPlacementMixin(object): - """Implements round robin placement strategy for ops and variables.""" - - def __init__(self, cov_devices=None, inv_devices=None, **kwargs): - """Initializes the RoundRobinPlacementMixin class. - - Args: - cov_devices: Iterable of device strings (e.g. '/gpu:0'). Covariance - computations will be placed on these devices in a round-robin fashion. - Can be None, which means that no devices are specified. - inv_devices: Iterable of device strings (e.g. '/gpu:0'). Inversion - computations will be placed on these devices in a round-robin fashion. - Can be None, which means that no devices are specified. - **kwargs: Need something here? - - """ - super(RoundRobinPlacementMixin, self).__init__(**kwargs) - self._cov_devices = cov_devices - self._inv_devices = inv_devices - - def make_vars_and_create_op_thunks(self, scope=None): - """Make vars and create op thunks w/ a round-robin device placement start. - - For each factor, all of that factor's cov variables and their associated - update ops will be placed on a particular device. A new device is chosen - for each factor by cycling through list of devices in the - `self._cov_devices` attribute. If `self._cov_devices` is `Non`e then no - explicit device placement occurs. - - An analogous strategy is followed for inverse update ops, with the list of - devices being given by the `self._inv_devices` attribute. - - Inverse variables on the other hand are not placed on any specific device - (they will just use the current the device placement context, whatever - that happens to be). The idea is that the inverse variable belong where - they will be accessed most often, which is the device that actually applies - the preconditioner to the gradient. The user will be responsible for setting - the device context for this. - - Args: - scope: A string or None. If None it will be set to the name of this - estimator (given by the name property). All variables will be created, - and all thunks will execute, inside of a variable scope of the given - name. (Default: None) - - Returns: - cov_update_thunks: List of cov update thunks. Corresponds one-to-one with - the list of factors given by the "factors" property. - inv_update_thunks: List of inv update thunks. Corresponds one-to-one with - the list of factors given by the "factors" property. - """ - # Note: `create_ops_and_vars_thunks` is implemented in `FisherEstimator`. - (cov_variable_thunks_raw, cov_update_thunks_raw, inv_variable_thunks_raw, - inv_update_thunks_raw) = self.create_ops_and_vars_thunks(scope=scope) - - if self._cov_devices: - cov_update_thunks = [] - for cov_variable_thunk, cov_update_thunk, device in zip( - cov_variable_thunks_raw, cov_update_thunks_raw, - itertools.cycle(self._cov_devices)): - with tf_ops.device(device): - cov_variable_thunk() - cov_update_thunks.append(_make_thunk_on_device(cov_update_thunk, - device)) - else: - for cov_variable_thunk in cov_variable_thunks_raw: - cov_variable_thunk() - cov_update_thunks = cov_update_thunks_raw - - for inv_variable_thunk in inv_variable_thunks_raw: - inv_variable_thunk() - - if self._inv_devices: - inv_update_thunks = [] - for inv_update_thunk, device in zip(inv_update_thunks_raw, - itertools.cycle(self._inv_devices)): - inv_update_thunks.append(_make_thunk_on_device(inv_update_thunk, - device)) - else: - inv_update_thunks = inv_update_thunks_raw - - return cov_update_thunks, inv_update_thunks diff --git a/tensorflow/contrib/kfac/python/ops/utils.py b/tensorflow/contrib/kfac/python/ops/utils.py deleted file mode 100644 index 144295f4c7..0000000000 --- a/tensorflow/contrib/kfac/python/ops/utils.py +++ /dev/null @@ -1,709 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Utility functions.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np - -from tensorflow.contrib.tpu.python.ops import tpu_ops -from tensorflow.contrib.tpu.python.tpu import tpu_function -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import ops -from tensorflow.python.framework import tensor_shape -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import control_flow_ops -from tensorflow.python.ops import gradients_impl -from tensorflow.python.ops import linalg_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import nn_ops -from tensorflow.python.ops import random_ops -from tensorflow.python.ops import resource_variable_ops -from tensorflow.python.ops import variables - -# Method used for inverting matrices. -POSDEF_INV_METHOD = "cholesky" -POSDEF_EIG_METHOD = "self_adjoint" - - -def set_global_constants(posdef_inv_method=None): - """Sets various global constants used by the classes in this module.""" - global POSDEF_INV_METHOD - - if posdef_inv_method is not None: - POSDEF_INV_METHOD = posdef_inv_method - - -class SequenceDict(object): - """A dict convenience wrapper that allows getting/setting with sequences.""" - - def __init__(self, iterable=None): - self._dict = dict(iterable or []) - - def __getitem__(self, key_or_keys): - if isinstance(key_or_keys, (tuple, list)): - return list(map(self.__getitem__, key_or_keys)) - else: - return self._dict[key_or_keys] - - def __setitem__(self, key_or_keys, val_or_vals): - if isinstance(key_or_keys, (tuple, list)): - for key, value in zip(key_or_keys, val_or_vals): - self[key] = value - else: - self._dict[key_or_keys] = val_or_vals - - def items(self): - return list(self._dict.items()) - - -def tensors_to_column(tensors): - """Converts a tensor or list of tensors to a column vector. - - Args: - tensors: A tensor or list of tensors. - - Returns: - The tensors reshaped into vectors and stacked on top of each other. - """ - if isinstance(tensors, (tuple, list)): - return array_ops.concat( - tuple(array_ops.reshape(tensor, [-1, 1]) for tensor in tensors), axis=0) - else: - return array_ops.reshape(tensors, [-1, 1]) - - -def column_to_tensors(tensors_template, colvec): - """Converts a column vector back to the shape of the given template. - - Args: - tensors_template: A tensor or list of tensors. - colvec: A 2d column vector with the same shape as the value of - tensors_to_column(tensors_template). - - Returns: - X, where X is tensor or list of tensors with the properties: - 1) tensors_to_column(X) = colvec - 2) X (or its elements) have the same shape as tensors_template (or its - elements) - """ - if isinstance(tensors_template, (tuple, list)): - offset = 0 - tensors = [] - for tensor_template in tensors_template: - sz = np.prod(tensor_template.shape.as_list(), dtype=np.int32) - tensor = array_ops.reshape(colvec[offset:(offset + sz)], - tensor_template.shape) - tensors.append(tensor) - offset += sz - - tensors = tuple(tensors) - else: - tensors = array_ops.reshape(colvec, tensors_template.shape) - - return tensors - - -def kronecker_product(mat1, mat2): - """Computes the Kronecker product two matrices.""" - m1, n1 = mat1.get_shape().as_list() - mat1_rsh = array_ops.reshape(mat1, [m1, 1, n1, 1]) - m2, n2 = mat2.get_shape().as_list() - mat2_rsh = array_ops.reshape(mat2, [1, m2, 1, n2]) - return array_ops.reshape(mat1_rsh * mat2_rsh, [m1 * m2, n1 * n2]) - - -def layer_params_to_mat2d(vector): - """Converts a vector shaped like layer parameters to a 2D matrix. - - In particular, we reshape the weights/filter component of the vector to be - 2D, flattening all leading (input) dimensions. If there is a bias component, - we concatenate it to the reshaped weights/filter component. - - Args: - vector: A Tensor or pair of Tensors shaped like layer parameters. - - Returns: - A 2D Tensor with the same coefficients and the same output dimension. - """ - if isinstance(vector, (tuple, list)): - w_part, b_part = vector - w_part_reshaped = array_ops.reshape(w_part, - [-1, w_part.shape.as_list()[-1]]) - return array_ops.concat( - (w_part_reshaped, array_ops.reshape(b_part, [1, -1])), axis=0) - elif isinstance(vector, ops.IndexedSlices): - return vector - else: # Tensor or Tensor-like. - return array_ops.reshape(vector, [-1, vector.shape.as_list()[-1]]) - - -def mat2d_to_layer_params(vector_template, mat2d): - """Converts a canonical 2D matrix representation back to a vector. - - Args: - vector_template: A Tensor or pair of Tensors shaped like layer parameters. - mat2d: A 2D Tensor with the same shape as the value of - layer_params_to_mat2d(vector_template). - - Returns: - A Tensor or pair of Tensors with the same coefficients as mat2d and the same - shape as vector_template. - """ - if isinstance(vector_template, (tuple, list)): - w_part, b_part = mat2d[:-1], mat2d[-1] - return array_ops.reshape(w_part, vector_template[0].shape), b_part - elif isinstance(vector_template, ops.IndexedSlices): - if not isinstance(mat2d, ops.IndexedSlices): - raise TypeError( - "If vector_template is an IndexedSlices, so should mat2d.") - return mat2d - else: - return array_ops.reshape(mat2d, vector_template.shape) - - -def posdef_inv(tensor, damping): - """Computes the inverse of tensor + damping * identity.""" - identity = linalg_ops.eye(tensor.shape.as_list()[0], dtype=tensor.dtype) - damping = math_ops.cast(damping, dtype=tensor.dtype) - return posdef_inv_functions[POSDEF_INV_METHOD](tensor, identity, damping) - - -def posdef_inv_matrix_inverse(tensor, identity, damping): - """Computes inverse(tensor + damping * identity) directly.""" - return linalg_ops.matrix_inverse(tensor + damping * identity) - - -def posdef_inv_cholesky(tensor, identity, damping): - """Computes inverse(tensor + damping * identity) with Cholesky.""" - chol = linalg_ops.cholesky(tensor + damping * identity) - return linalg_ops.cholesky_solve(chol, identity) - - -def posdef_inv_eig(tensor, identity, damping): - """Computes inverse(tensor + damping * identity) with eigendecomposition.""" - eigenvalues, eigenvectors = linalg_ops.self_adjoint_eig( - tensor + damping * identity) - return math_ops.matmul( - eigenvectors / eigenvalues, eigenvectors, transpose_b=True) - - -posdef_inv_functions = { - "matrix_inverse": posdef_inv_matrix_inverse, - "cholesky": posdef_inv_cholesky, - "eig": posdef_inv_eig, -} - - -def posdef_eig(mat): - """Computes the eigendecomposition of a positive semidefinite matrix.""" - return posdef_eig_functions[POSDEF_EIG_METHOD](mat) - - -def posdef_eig_svd(mat): - """Computes the singular values and left singular vectors of a matrix.""" - evals, evecs, _ = linalg_ops.svd(mat) - - return evals, evecs - - -def posdef_eig_self_adjoint(mat): - """Computes eigendecomposition using self_adjoint_eig.""" - evals, evecs = linalg_ops.self_adjoint_eig(mat) - evals = math_ops.abs(evals) # Should be equivalent to svd approach. - - return evals, evecs - - -posdef_eig_functions = { - "self_adjoint": posdef_eig_self_adjoint, - "svd": posdef_eig_svd, -} - - -def cholesky(tensor, damping): - """Computes the inverse of tensor + damping * identity.""" - identity = linalg_ops.eye(tensor.shape.as_list()[0], dtype=tensor.dtype) - damping = math_ops.cast(damping, dtype=tensor.dtype) - return linalg_ops.cholesky(tensor + damping * identity) - - -class SubGraph(object): - """Defines a subgraph given by all the dependencies of a given set of outputs. - """ - - def __init__(self, outputs): - # Set of all ancestor Tensors, Ops to 'outputs'. - self._members = set() - - self._iter_add(outputs) - - def _iter_add(self, root): - """Iteratively adds all of nodes' ancestors using depth first search.""" - stack = [root] - while stack: - nodes = stack.pop() - for node in nodes: - if node in self._members: - continue - self._members.add(node) - - if isinstance(node, ops.Tensor): - stack.append((node.op,)) - elif isinstance(node, ops.Operation): - stack.append(node.inputs) - - def is_member(self, node): - """Check if 'node' is in this subgraph.""" - return node in self._members - - def variable_uses(self, var): - """Computes number of times a variable is used. - - Args: - var: Variable or ResourceVariable instance. - - Returns: - Number of times a variable is used within this subgraph. - - Raises: - ValueError: If 'var' is not a variable type. - """ - if isinstance(var, resource_variable_ops.ResourceVariable): - var = var.handle - elif isinstance(var, variables.Variable): - var = var.value() - else: - raise ValueError("%s does not appear to be a variable." % str(var)) - - return len(self._members.intersection(set(var.consumers()))) - - def filter_list(self, node_list): - """Filters 'node_list' to nodes in this subgraph.""" - filtered_list = [] - for node in node_list: - if self.is_member(node): - filtered_list.append(node) - return filtered_list - - -def generate_random_signs(shape, dtype=dtypes.float32): - """Generate a random tensor with {-1, +1} entries.""" - ints = random_ops.random_uniform(shape, maxval=2, dtype=dtypes.int32) - return 2 * math_ops.cast(ints, dtype=dtype) - 1 - - -def fwd_gradients(ys, xs, grad_xs=None, stop_gradients=None): - """Compute forward-mode gradients.""" - # See b/37888268. - - # This version of forward-mode autodiff is based on code by Tim Cooijmans - # and handles list arguments and certain special cases such as when the - # ys doesn't depend on one or more of the xs, and when ops.IndexedSlices are - # generated by the first gradients_impl.gradients call. - - us = [array_ops.zeros_like(y) + float("nan") for y in ys] - dydxs = gradients_impl.gradients( - ys, xs, grad_ys=us, stop_gradients=stop_gradients) - - # Deal with strange types that gradients_impl.gradients returns but can't - # deal with. - dydxs = [ - ops.convert_to_tensor(dydx) - if isinstance(dydx, ops.IndexedSlices) else dydx for dydx in dydxs - ] - dydxs = [ - array_ops.zeros_like(x) if dydx is None else dydx - for x, dydx in zip(xs, dydxs) - ] - - dysdx = gradients_impl.gradients(dydxs, us, grad_ys=grad_xs) - - return dysdx - - -def on_tpu(): - """Returns True when building a TPU computation.""" - return tpu_function.get_tpu_context().number_of_shards is not None - - -def cross_replica_mean(tensor, name=None): - """Takes mean value of a Tensor across all TPU cores. - - Args: - tensor: Tensor to be synchronized. - name: None or string. Name of Op. - - Returns: - Average of Tensor across all TPU cores. - - Raises: - ValueError: If called outside of TPU context. - """ - with ops.name_scope(name, "cross_replica_mean", [tensor]): - num_shards = tpu_function.get_tpu_context().number_of_shards - if num_shards is None: - raise ValueError( - "Cannot take cross_replica_mean() outside of TPU Context.") - if num_shards == 1: - return tensor - return tpu_ops.cross_replica_sum(tensor / num_shards) - - -def ensure_sequence(obj): - """If `obj` isn't a tuple or list, return a tuple containing `obj`.""" - if isinstance(obj, (tuple, list)): - return obj - else: - return (obj,) - - -def batch_execute(global_step, thunks, batch_size, name=None): - """Executes a subset of ops per global step. - - Given a list of thunks, each of which produces a single stateful op, - ensures that exactly 'batch_size' ops are run per global step. Ops are - scheduled in a round-robin fashion. For example, with 3 ops - - global_step | op0 | op1 | op2 - ------------+-----+-----+----- - 0 | x | x | - ------------+-----+-----+----- - 1 | x | | x - ------------+-----+-----+----- - 2 | | x | x - ------------+-----+-----+----- - 3 | x | x | - ------------+-----+-----+----- - 4 | x | | x - - Does not guarantee order of op execution within a single global step. - - Args: - global_step: Tensor indicating time. Determines which ops run. - thunks: List of thunks. Each thunk encapsulates one op. Return values are - ignored. - batch_size: int. Number of ops to execute per global_step. - name: string or None. Name scope for newly added ops. - - Returns: - List of ops. Exactly 'batch_size' ops are guaranteed to have an effect - every global step. - """ - - def true_fn(thunk): - """Ensures thunk is executed and returns an Op (not a Tensor).""" - - def result(): - with ops.control_dependencies([thunk()]): - return control_flow_ops.no_op() - - return result - - def false_fn(_): - """Executes a no-op.""" - - def result(): - return control_flow_ops.no_op() - - return result - - with ops.name_scope(name, "batch_execute"): - true_fns = [true_fn(thunk) for thunk in thunks] - false_fns = [false_fn(thunk) for thunk in thunks] - num_thunks = len(thunks) - conditions = [ - math_ops.less( - math_ops.mod(batch_size - 1 + global_step * batch_size - j, - num_thunks), batch_size) for j in range(num_thunks) - ] - result = [ - control_flow_ops.cond(condition, true_fn, false_fn) - for (condition, true_fn, - false_fn) in zip(conditions, true_fns, false_fns) - ] - return result - - -def extract_convolution_patches(inputs, - filter_shape, - padding, - strides=None, - dilation_rate=None, - name=None, - data_format=None): - """Extracts inputs to each output coordinate in tf.nn.convolution. - - This is a generalization of tf.extract_image_patches() to tf.nn.convolution(), - where the number of spatial dimensions may be something other than 2. - - Assumes, - - First dimension of inputs is batch_size - - Convolution filter is applied to all input channels. - - Args: - inputs: Tensor of shape [batch_size, ..spatial_image_shape.., - ..spatial_filter_shape.., in_channels]. Inputs to tf.nn.convolution(). - filter_shape: List of ints. Shape of filter passed to tf.nn.convolution(). - padding: string. Padding method. One of "VALID", "SAME". - strides: None or list of ints. Strides along spatial dimensions. - dilation_rate: None or list of ints. Dilation along spatial dimensions. - name: None or str. Name of Op. - data_format: None or str. Format of data. - - Returns: - Tensor of shape [batch_size, ..spatial_image_shape.., - ..spatial_filter_shape.., in_channels] - - Raises: - ValueError: If data_format does not put channel last. - ValueError: If inputs and filter disagree on in_channels. - """ - if not is_data_format_channel_last(data_format): - raise ValueError("Channel must be last dimension.") - with ops.name_scope(name, "extract_convolution_patches", - [inputs, filter_shape, padding, strides, dilation_rate]): - batch_size = inputs.shape.as_list()[0] - in_channels = inputs.shape.as_list()[-1] - - # filter_shape = spatial_filter_shape + [in_channels, out_channels] - spatial_filter_shape = filter_shape[:-2] - if in_channels != filter_shape[-2]: - raise ValueError("inputs and filter_shape must agree on in_channels.") - - # Map each input feature to a location in the output. - out_channels = np.prod(spatial_filter_shape) * in_channels - filters = linalg_ops.eye(out_channels) - filters = array_ops.reshape( - filters, - list(spatial_filter_shape) + [in_channels, out_channels]) - - result = nn_ops.convolution( - inputs, - filters, - padding=padding, - strides=strides, - dilation_rate=dilation_rate) - spatial_output_shape = result.shape.as_list()[1:-1] - result = array_ops.reshape(result, - [batch_size or -1] + spatial_output_shape + - list(spatial_filter_shape) + [in_channels]) - - return result - - -def extract_pointwise_conv2d_patches(inputs, - filter_shape, - name=None, - data_format=None): - """Extract patches for a 1x1 conv2d. - - Args: - inputs: 4-D Tensor of shape [batch_size, height, width, in_channels]. - filter_shape: List of 4 ints. Shape of filter to apply with conv2d() - name: None or str. Name for Op. - data_format: None or str. Format for data. See 'data_format' in - tf.nn.conv2d() for details. - - Returns: - Tensor of shape [batch_size, ..spatial_input_shape.., - ..spatial_filter_shape.., in_channels] - - Raises: - ValueError: if inputs is not 4-D. - ValueError: if filter_shape is not [1, 1, ?, ?] - ValueError: if data_format is not channels-last. - """ - if inputs.shape.ndims != 4: - raise ValueError("inputs must have 4 dims.") - if len(filter_shape) != 4: - raise ValueError("filter_shape must have 4 dims.") - if filter_shape[0] != 1 or filter_shape[1] != 1: - raise ValueError("filter_shape must have shape 1 along spatial dimensions.") - if not is_data_format_channel_last(data_format): - raise ValueError("data_format must be channels last.") - with ops.name_scope(name, "extract_pointwise_conv2d_patches", - [inputs, filter_shape]): - ksizes = [1, 1, 1, 1] # Spatial shape is 1x1. - strides = [1, 1, 1, 1] # Operate on all pixels. - rates = [1, 1, 1, 1] # Dilation has no meaning with spatial shape = 1. - padding = "VALID" # Doesn't matter. - result = array_ops.extract_image_patches(inputs, ksizes, strides, rates, - padding) - - batch_size, input_height, input_width, in_channels = inputs.shape.as_list() - filter_height, filter_width, in_channels, _ = filter_shape - return array_ops.reshape(result, [ - batch_size, input_height, input_width, filter_height, filter_width, - in_channels - ]) - - -def is_data_format_channel_last(data_format): - """True if data_format puts channel last.""" - if data_format is None: - return True - return data_format.endswith("C") - - -def matmul_sparse_dense(A, B, name=None, transpose_a=False, transpose_b=False): # pylint: disable=invalid-name - """Computes matmul(A, B) where A is sparse, B is dense. - - Args: - A: tf.IndexedSlices with dense shape [m, n]. - B: tf.Tensor with shape [n, k]. - name: str. Name of op. - transpose_a: Bool. If true we transpose A before multiplying it by B. - (Default: False) - transpose_b: Bool. If true we transpose B before multiplying it by A. - (Default: False) - - Returns: - tf.IndexedSlices resulting from matmul(A, B). - - Raises: - ValueError: If A doesn't represent a matrix. - ValueError: If B is not rank-2. - """ - with ops.name_scope(name, "matmul_sparse_dense", [A, B]): - if A.indices.shape.ndims != 1 or A.values.shape.ndims != 2: - raise ValueError("A must represent a matrix. Found: %s." % A) - if B.shape.ndims != 2: - raise ValueError("B must be a matrix.") - new_values = math_ops.matmul( - A.values, B, transpose_a=transpose_a, transpose_b=transpose_b) - return ops.IndexedSlices( - new_values, - A.indices, - dense_shape=array_ops.stack([A.dense_shape[0], new_values.shape[1]])) - - -def matmul_diag_sparse(A_diag, B, name=None): # pylint: disable=invalid-name - """Computes matmul(A, B) where A is a diagonal matrix, B is sparse. - - Args: - A_diag: diagonal entries of matrix A of shape [m, m]. - B: tf.IndexedSlices. Represents matrix of shape [m, n]. - name: str. Name of op. - - Returns: - tf.IndexedSlices resulting from matmul(A, B). - - Raises: - ValueError: If A_diag is not rank-1. - ValueError: If B doesn't represent a matrix. - """ - with ops.name_scope(name, "matmul_diag_sparse", [A_diag, B]): - A_diag = ops.convert_to_tensor(A_diag) - if A_diag.shape.ndims != 1: - raise ValueError("A_diag must be a rank-1 Tensor.") - if B.indices.shape.ndims != 1 or B.values.shape.ndims != 2: - raise ValueError("B must represent a matrix. Found: %s." % B) - a = array_ops.gather(A_diag, B.indices) - a = array_ops.reshape(a, list(a.shape) + [1] * (B.values.shape.ndims - 1)) - return ops.IndexedSlices(a * B.values, B.indices, dense_shape=B.dense_shape) - - -class PartitionedTensor(object): - """A Tensor partitioned across its 0-th dimension.""" - - def __init__(self, tensors): - """Initializes PartitionedTensor. - - Args: - tensors: List of Tensors. All Tensors must agree on shape (excepting - batch dimension) and dtype. - - Raises: - ValueError: If 'tensors' has length zero. - ValueError: if contents of 'tensors' don't agree on shape or dtype. - """ - if not tensors: - raise ValueError("tensors must be a list of 1+ Tensors.") - - dtype = tensors[0].dtype - if not all(tensor.dtype == dtype for tensor in tensors): - raise ValueError("all tensors must have dtype = %s." % dtype) - - shape = tensors[0].shape[1:] - if not all(tensor.shape[1:] == shape for tensor in tensors): - raise ValueError("All tensors must have shape = %s (excluding batch " - "dimension)." % shape) - - self.tensors = tensors - self._concats = {} # {device: Tensor} - - @property - def shape(self): - feature_shape = self.tensors[0].shape[1:] - batch_size = sum([tensor.shape[0] for tensor in self.tensors], - tensor_shape.Dimension(0)) - return tensor_shape.TensorShape([batch_size]).concatenate(feature_shape) - - def get_shape(self): - return self.shape - - @property - def dtype(self): - return self.tensors[0].dtype - - def __str__(self): - return "PartitionedTensor([%s, ...], dtype=%s, shape=%s)" % ( - self.tensors[0].name, self.dtype.name, tuple(self.shape.as_list())) - - def __hash__(self): - return hash(tuple(self.tensors)) - - def __eq__(self, other): - if not isinstance(other, PartitionedTensor): - return False - return self.tensors == other.tensors - - def __ne__(self, other): - return not self == other # pylint: disable=g-comparison-negation - - def __getitem__(self, key): - return self.as_tensor()[key] - - def as_tensor(self, dtype=None, name=None, as_ref=False): - with ops.name_scope(name, "PartitionedTensor.as_tensor", self.tensors): - assert not as_ref - assert dtype in [None, self.dtype] - result = array_ops.concat(self.tensors, axis=0) - - # Cache 'result' if we haven't already cached a value for this device. - if result.device not in self._concats: - self._concats[result.device] = result - return self._concats[result.device] - - @property - def device(self): - # PartitionedTensors in general do not live on a single device. If the - # device cannot be determined unambiguously this property will return None. - device = self.tensors[0].device - if all(tensor.device == device for tensor in self.tensors): - return device - return None - - -ops.register_tensor_conversion_function( - PartitionedTensor, - lambda val, dtype, name, as_ref: val.as_tensor(dtype, name, as_ref)) - - -# TODO(b/69623235): Add a function for finding tensors that share gradients -# to eliminate redundant fisher factor computations. diff --git a/tensorflow/contrib/kfac/python/ops/utils_lib.py b/tensorflow/contrib/kfac/python/ops/utils_lib.py deleted file mode 100644 index 330d222dbf..0000000000 --- a/tensorflow/contrib/kfac/python/ops/utils_lib.py +++ /dev/null @@ -1,50 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Utility functions.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import,line-too-long,wildcard-import -from tensorflow.contrib.kfac.python.ops.utils import * -from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long,wildcard-import - -_allowed_symbols = [ - "set_global_constants", - "SequenceDict", - "tensors_to_column", - "column_to_tensors", - "kronecker_product", - "layer_params_to_mat2d", - "mat2d_to_layer_params", - "posdef_inv", - "posdef_inv_matrix_inverse", - "posdef_inv_cholesky", - "posdef_inv_funcs", - "SubGraph", - "generate_random_signs", - "fwd_gradients", - "ensure_sequence", - "batch_execute", - "extract_convolution_patches", - "extract_pointwise_conv2d_patches", - "is_data_format_channel_last", - "matmul_sparse_dense", - "matmul_diag_sparse", -] - -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) diff --git a/tensorflow/contrib/labeled_tensor/python/ops/ops_test.py b/tensorflow/contrib/labeled_tensor/python/ops/ops_test.py index 39e9d65407..9a402d888c 100644 --- a/tensorflow/contrib/labeled_tensor/python/ops/ops_test.py +++ b/tensorflow/contrib/labeled_tensor/python/ops/ops_test.py @@ -270,7 +270,7 @@ class ReshapeTest(Base): array_ops.placeholder(dtypes.float32, [None]), ['x']) reshape_lt = ops.reshape(orig_lt, ['x'], ['y', ('z', 1)]) self.assertEqual(reshape_lt.axes, core.Axes([('y', None), ('z', 1)])) - with self.test_session() as sess: + with self.cached_session() as sess: result = sess.run(reshape_lt, feed_dict={orig_lt.tensor: [1, 2]}) np.testing.assert_array_equal(result, [[1], [2]]) diff --git a/tensorflow/contrib/labeled_tensor/python/ops/test_util.py b/tensorflow/contrib/labeled_tensor/python/ops/test_util.py index 8f0416030f..900c9217c3 100644 --- a/tensorflow/contrib/labeled_tensor/python/ops/test_util.py +++ b/tensorflow/contrib/labeled_tensor/python/ops/test_util.py @@ -27,7 +27,7 @@ class Base(test.TestCase): """A class with some useful methods for testing.""" def eval(self, tensors): - with self.test_session() as sess: + with self.cached_session() as sess: coord = coordinator.Coordinator() threads = queue_runner_impl.start_queue_runners(sess=sess, coord=coord) diff --git a/tensorflow/contrib/layers/BUILD b/tensorflow/contrib/layers/BUILD index 7355a403ae..b4fe8cac74 100644 --- a/tensorflow/contrib/layers/BUILD +++ b/tensorflow/contrib/layers/BUILD @@ -185,7 +185,7 @@ py_test( py_test( name = "normalization_test", - size = "small", + size = "medium", srcs = ["python/layers/normalization_test.py"], srcs_version = "PY2AND3", tags = ["no_windows"], # TODO: needs investigation on Windows diff --git a/tensorflow/contrib/layers/python/layers/feature_column.py b/tensorflow/contrib/layers/python/layers/feature_column.py index 3ae07cedab..28d19a0445 100644 --- a/tensorflow/contrib/layers/python/layers/feature_column.py +++ b/tensorflow/contrib/layers/python/layers/feature_column.py @@ -997,9 +997,14 @@ class _OneHotColumn( # Remove (?, -1) index weighted_column = sparse_ops.sparse_slice( weighted_column, - [0, 0], + array_ops.zeros_like(weighted_column.dense_shape), weighted_column.dense_shape) - return sparse_ops.sparse_tensor_to_dense(weighted_column) + dense_tensor = sparse_ops.sparse_tensor_to_dense(weighted_column) + batch_shape = array_ops.shape(dense_tensor)[:-1] + dense_tensor_shape = array_ops.concat( + [batch_shape, [self.length]], axis=0) + dense_tensor = array_ops.reshape(dense_tensor, dense_tensor_shape) + return dense_tensor dense_id_tensor = sparse_ops.sparse_tensor_to_dense(sparse_id_column, default_value=-1) diff --git a/tensorflow/contrib/layers/python/layers/feature_column_test.py b/tensorflow/contrib/layers/python/layers/feature_column_test.py index 1de9ab7056..eaaf9f8d5f 100644 --- a/tensorflow/contrib/layers/python/layers/feature_column_test.py +++ b/tensorflow/contrib/layers/python/layers/feature_column_test.py @@ -57,6 +57,29 @@ def _sparse_id_tensor(shape, vocab_size, seed=112123): indices=indices, values=values, dense_shape=shape) +def _sparse_id_tensor_with_weights(shape, vocab_size, seed=112123): + # Returns a arbitrary `SparseTensor` with given shape and vocab size. + assert vocab_size >= shape[-1] + np.random.seed(seed) + indices = np.array(list(itertools.product(*[range(s) for s in shape]))) + + # Values must be distinct from the vocab + values = np.ndarray.flatten(np.array([ + np.random.choice(vocab_size, size=shape[-1], replace=False) + for _ in range(np.prod(shape[:-1]))])) + weights = np.sort(np.random.rand(*shape), axis=len(shape)-1) + + # Remove entries if weight < 0.5 for sparsity. + keep = np.ndarray.flatten(weights < 0.5) # Remove half of them + indices = indices[keep] + values = values[keep] + weights = np.ndarray.flatten(weights)[keep] + return (sparse_tensor_lib.SparseTensor( + indices=indices, values=values, dense_shape=shape), + sparse_tensor_lib.SparseTensor( + indices=indices, values=weights, dense_shape=shape)) + + class FeatureColumnTest(test.TestCase): def testImmutability(self): @@ -329,6 +352,34 @@ class FeatureColumnTest(test.TestCase): self.assertEqual(one_hot.sparse_id_column.name, "ids_weighted_by_weights") self.assertEqual(one_hot.length, 3) + def testIntegerizedOneHotColumnForWeightedSparseColumn(self): + vocab_size = 5 + ids = fc.sparse_column_with_integerized_feature("ids", vocab_size) + weighted_ids = fc.weighted_sparse_column(ids, "weights") + one_hot = fc.one_hot_column(weighted_ids) + self.assertEqual(one_hot.sparse_id_column.name, "ids_weighted_by_weights") + self.assertEqual(one_hot.length, vocab_size) + + def testIntegerizedOneHotWeightedSparseColumnShape(self): + vocab_size = 5 + for id_tensor_shape in [[4, 3], [2, 4], [3, 3, 3]]: + output_rank = len(id_tensor_shape) + a = fc.sparse_column_with_integerized_feature("a", vocab_size) + weighted = fc.weighted_sparse_column(a, "weights") + one_hot = fc.one_hot_column(weighted) + id_tensor, weight_tensor = _sparse_id_tensor_with_weights( + id_tensor_shape, vocab_size) + + one_hot_output = one_hot._to_dnn_input_layer( + (id_tensor, weight_tensor), + output_rank=output_rank) + one_hot_output_shape = one_hot_output.get_shape().as_list() + expected_shape = id_tensor_shape[:-1] + [vocab_size] + self.assertEquals(expected_shape, one_hot_output_shape) + with self.test_session() as sess: + one_hot_value = sess.run(one_hot_output) + self.assertEquals(expected_shape, list(one_hot_value.shape)) + def testOneHotColumnWithSparseColumnWithHashKeys(self): input_values = ["marlo", "unknown", "omar"] inputs = constant_op.constant(input_values) diff --git a/tensorflow/contrib/layers/python/layers/initializers_test.py b/tensorflow/contrib/layers/python/layers/initializers_test.py index b7fe878893..bd3692b258 100644 --- a/tensorflow/contrib/layers/python/layers/initializers_test.py +++ b/tensorflow/contrib/layers/python/layers/initializers_test.py @@ -85,7 +85,7 @@ class VarianceScalingInitializerTest(test.TestCase): def _test_variance(self, initializer, shape, variance, factor, mode, uniform): with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: var = variable_scope.get_variable( name='test', shape=shape, diff --git a/tensorflow/contrib/layers/python/layers/layers_test.py b/tensorflow/contrib/layers/python/layers/layers_test.py index 51c7abb105..eee90864b4 100644 --- a/tensorflow/contrib/layers/python/layers/layers_test.py +++ b/tensorflow/contrib/layers/python/layers/layers_test.py @@ -1067,7 +1067,7 @@ class Convolution2dTransposeTests(test.TestCase): conv = layers_lib.conv2d( transpose, num_filters, filter_size, stride=stride, padding='VALID') - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: sess.run(variables_lib.global_variables_initializer()) self.assertListEqual(list(conv.eval().shape), input_size) @@ -1460,14 +1460,14 @@ class DropoutTest(test.TestCase): class FlattenTest(test.TestCase): def testInvalidRank(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inputs = array_ops.placeholder(dtype=dtypes.float32) inputs.set_shape(tensor_shape.TensorShape((5,))) with self.assertRaisesRegexp(ValueError, 'incompatible with the layer'): _layers.flatten(inputs) def testUnknownLastDim(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inputs = array_ops.placeholder(dtype=dtypes.float32) inputs.set_shape(tensor_shape.TensorShape((5, None))) output = _layers.flatten(inputs) @@ -1629,7 +1629,7 @@ class FCTest(test.TestCase): def testCreateFC(self): height, width = 3, 3 for layer_fn in (_layers.fully_connected, layers_lib.relu): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inputs = np.random.uniform(size=(5, height * width * 3)) output = layer_fn(inputs, 32) self.assertEqual(output.op.name, 'fully_connected/Relu') @@ -1814,27 +1814,27 @@ class BatchNormTest(test.TestCase): a, center=False, data_format='NCHW', zero_debias_moving_mean=True) def testUnknownShape(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inputs = array_ops.placeholder(dtype=dtypes.float32) with self.assertRaisesRegexp(ValueError, 'undefined rank'): _layers.batch_norm(inputs) def testInvalidDataFormat(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inputs = array_ops.placeholder(dtype=dtypes.float32) with self.assertRaisesRegexp( ValueError, 'data_format has to be either NCHW or NHWC.'): _layers.batch_norm(inputs, data_format='CHWN') def testUnknownChannelsDimNHWC(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inputs = array_ops.placeholder(dtype=dtypes.float32) inputs.set_shape(tensor_shape.TensorShape((5, 3, 3, None))) with self.assertRaisesRegexp(ValueError, 'undefined'): _layers.batch_norm(inputs, data_format='NHWC') def testUnknownChannelsDimNCHW(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inputs = array_ops.placeholder(dtype=dtypes.float32) inputs.set_shape(tensor_shape.TensorShape((5, None, 3, 3))) with self.assertRaisesRegexp(ValueError, 'undefined'): @@ -2810,13 +2810,13 @@ class BatchNormTest(test.TestCase): class LayerNormTest(test.TestCase): def testUnknownShape(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inputs = array_ops.placeholder(dtype=dtypes.float32) with self.assertRaisesRegexp(ValueError, 'undefined rank'): _layers.layer_norm(inputs) def testParamsDimsNotFullyDefined(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inputs = array_ops.placeholder(dtype=dtypes.float32) inputs.set_shape(tensor_shape.TensorShape((5, 3, 3, None))) with self.assertRaisesRegexp(ValueError, 'is not fully defined'): @@ -2876,7 +2876,7 @@ class LayerNormTest(test.TestCase): for sigma in [1.0, 0.1]: input_values = np.random.randn(*input_shape) * sigma + mu with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: inputs = constant_op.constant( input_values, shape=input_shape, dtype=dtype) output_t = _layers.layer_norm( diff --git a/tensorflow/contrib/layers/python/layers/normalization.py b/tensorflow/contrib/layers/python/layers/normalization.py index c807ab0f2e..11033a2e9c 100644 --- a/tensorflow/contrib/layers/python/layers/normalization.py +++ b/tensorflow/contrib/layers/python/layers/normalization.py @@ -176,7 +176,8 @@ def group_norm(inputs, variables_collections=None, outputs_collections=None, trainable=True, - scope=None): + scope=None, + mean_close_to_zero=False): """Functional interface for the group normalization layer. Reference: https://arxiv.org/abs/1803.08494. @@ -222,6 +223,19 @@ def group_norm(inputs, trainable: If `True` also add variables to the graph collection `GraphKeys.TRAINABLE_VARIABLES` (see `tf.Variable`). scope: Optional scope for `variable_scope`. + mean_close_to_zero: The mean of `input` before ReLU will be close to zero + when batch size >= 4k for Resnet-50 on TPU. If `True`, use + `nn.sufficient_statistics` and `nn.normalize_moments` to calculate the + variance. This is the same behavior as `fused` equals `True` in batch + normalization. If `False`, use `nn.moments` to calculate the variance. + When `mean` is close to zero, like 1e-4, use `mean` to calculate the + variance may have poor result due to repeated roundoff error and + denormalization in `mean`. When `mean` is large, like 1e2, + sum(`input`^2) is so large that only the high-order digits of the elements + are being accumulated. Thus, use sum(`input` - `mean`)^2/n to calculate + the variance has better accuracy compared to (sum(`input`^2)/n - `mean`^2) + when `mean` is large. + Returns: A `Tensor` representing the output of the operation. @@ -333,7 +347,14 @@ def group_norm(inputs, gamma = array_ops.reshape(gamma, params_shape_broadcast) # Calculate the moments. - mean, variance = nn.moments(inputs, moments_axes, keep_dims=True) + if mean_close_to_zero: + # One pass algorithm returns better result when mean is close to zero. + counts, means_ss, variance_ss, _ = nn.sufficient_statistics( + inputs, moments_axes, keep_dims=True) + mean, variance = nn.normalize_moments( + counts, means_ss, variance_ss, shift=None) + else: + mean, variance = nn.moments(inputs, moments_axes, keep_dims=True) # Compute normalization. # TODO(shlens): Fix nn.batch_normalization to handle the 5-D Tensor diff --git a/tensorflow/contrib/layers/python/layers/normalization_test.py b/tensorflow/contrib/layers/python/layers/normalization_test.py index b6e96350db..55272e5fd1 100644 --- a/tensorflow/contrib/layers/python/layers/normalization_test.py +++ b/tensorflow/contrib/layers/python/layers/normalization_test.py @@ -293,8 +293,13 @@ class GroupNormTest(test.TestCase): train_np, eval_np = sess.run([output_train, output_eval]) self.assertAllClose(train_np, eval_np) - def doOutputTest(self, input_shape, channels_axis=None, reduction_axes=None, - groups=2, tol=1e-2): + def doOutputTest(self, + input_shape, + channels_axis=None, + reduction_axes=None, + mean_close_to_zero=False, + groups=2, + tol=1e-2): # Select the axis for the channel and the dimensions along which statistics # are accumulated. if channels_axis < 0: @@ -322,17 +327,28 @@ class GroupNormTest(test.TestCase): if i not in reduced_axes: reduced_shape.append(a) - for mu in (0.0, 1e2): - for sigma in (1.0, 0.1): + if mean_close_to_zero: + mu_tuple = (1e-4, 1e-2, 1.0) + sigma_tuple = (1e-2, 0.1, 1.0) + else: + mu_tuple = (1.0, 1e2) + sigma_tuple = (1.0, 0.1) + + for mu in mu_tuple: + for sigma in sigma_tuple: # Determine shape of Tensor after normalization. expected_mean = np.zeros(reduced_shape) expected_var = np.ones(reduced_shape) - inputs = random_ops.random_uniform(input_shape, seed=0) * sigma + mu + inputs = random_ops.random_normal(input_shape, seed=0) * sigma + mu output_op = normalization.group_norm( - inputs, groups=groups, center=False, scale=False, + inputs, + groups=groups, + center=False, + scale=False, channels_axis=channels_axis, - reduction_axes=reduction_axes) + reduction_axes=reduction_axes, + mean_close_to_zero=mean_close_to_zero) with self.test_session() as sess: sess.run(variables.global_variables_initializer()) outputs = sess.run(output_op) @@ -347,12 +363,32 @@ class GroupNormTest(test.TestCase): self.assertAllClose(expected_mean, mean, rtol=tol, atol=tol) self.assertAllClose(expected_var, var, rtol=tol, atol=tol) + def doOutputTestForMeanCloseToZero(self, + input_shape, + channels_axis=None, + reduction_axes=None, + groups=2, + tol=5e-2): + self.doOutputTest( + input_shape, + channels_axis=channels_axis, + reduction_axes=reduction_axes, + groups=groups, + tol=tol, + mean_close_to_zero=True) + def testOutputSmallInput4D_NHWC(self): input_shape = [10, 10, 10, 30] # Specify axes with positive values. self.doOutputTest(input_shape, channels_axis=3, reduction_axes=[1, 2]) # Specify axes with negative values. self.doOutputTest(input_shape, channels_axis=-1, reduction_axes=[-3, -2]) + # Specify axes with positive values. + self.doOutputTestForMeanCloseToZero( + input_shape, channels_axis=3, reduction_axes=[1, 2]) + # Specify axes with negative values. + self.doOutputTestForMeanCloseToZero( + input_shape, channels_axis=-1, reduction_axes=[-3, -2]) def testOutputSmallInput3D_NHWC(self): input_shape = [10, 10, 30] @@ -360,6 +396,12 @@ class GroupNormTest(test.TestCase): self.doOutputTest(input_shape, channels_axis=2, reduction_axes=[0, 1]) # Specify axes with negative values. self.doOutputTest(input_shape, channels_axis=-1, reduction_axes=[-3, -2]) + # Specify axes with positive values. + self.doOutputTestForMeanCloseToZero( + input_shape, channels_axis=2, reduction_axes=[0, 1]) + # Specify axes with negative values. + self.doOutputTestForMeanCloseToZero( + input_shape, channels_axis=-1, reduction_axes=[-3, -2]) def testOutputSmallInput4D_NCHW(self): input_shape = [10, 10, 10, 30] @@ -367,6 +409,12 @@ class GroupNormTest(test.TestCase): self.doOutputTest(input_shape, channels_axis=1, reduction_axes=[2, 3]) # Specify axes with negative values. self.doOutputTest(input_shape, channels_axis=-3, reduction_axes=[-2, -1]) + # Specify axes with positive values. + self.doOutputTestForMeanCloseToZero( + input_shape, channels_axis=1, reduction_axes=[2, 3]) + # Specify axes with negative values. + self.doOutputTestForMeanCloseToZero( + input_shape, channels_axis=-3, reduction_axes=[-2, -1]) def testOutputSmallInput3D_NCHW(self): input_shape = [10, 10, 30] @@ -374,23 +422,43 @@ class GroupNormTest(test.TestCase): self.doOutputTest(input_shape, channels_axis=0, reduction_axes=[1, 2]) # Specify axes with negative values. self.doOutputTest(input_shape, channels_axis=-3, reduction_axes=[-2, -1]) + # Specify axes with positive values. + self.doOutputTestForMeanCloseToZero( + input_shape, channels_axis=0, reduction_axes=[1, 2]) + # Specify axes with negative values. + self.doOutputTestForMeanCloseToZero( + input_shape, channels_axis=-3, reduction_axes=[-2, -1]) def testOutputBigInput4D_NHWC(self): - self.doOutputTest([5, 100, 100, 1], channels_axis=3, reduction_axes=[1, 2], - groups=1) + self.doOutputTest( + [5, 100, 100, 1], channels_axis=3, reduction_axes=[1, 2], groups=1) + self.doOutputTestForMeanCloseToZero( + [5, 100, 100, 1], channels_axis=3, reduction_axes=[1, 2], groups=1) def testOutputBigInput4D_NCHW(self): - self.doOutputTest([1, 100, 100, 4], channels_axis=1, reduction_axes=[2, 3], - groups=4) + self.doOutputTest( + [1, 100, 100, 4], channels_axis=1, reduction_axes=[2, 3], groups=4) + self.doOutputTestForMeanCloseToZero( + [1, 100, 100, 4], channels_axis=1, reduction_axes=[2, 3], groups=4) def testOutputSmallInput2D_NC(self): - self.doOutputTest([10, 7*100], channels_axis=1, reduction_axes=[], groups=7) + self.doOutputTest( + [10, 7 * 100], channels_axis=1, reduction_axes=[], groups=7) + self.doOutputTestForMeanCloseToZero( + [10, 7 * 100], channels_axis=1, reduction_axes=[], groups=7) def testOutputSmallInput5D_NCXXX(self): - self.doOutputTest([10, 10, 20, 40, 5], - channels_axis=1, - reduction_axes=[2, 3, 4], - groups=5) + self.doOutputTest( + [10, 10, 20, 40, 5], + channels_axis=1, + reduction_axes=[2, 3, 4], + groups=5) + self.doOutputTestForMeanCloseToZero( + [10, 10, 20, 40, 5], + channels_axis=1, + reduction_axes=[2, 3, 4], + groups=5) + if __name__ == '__main__': test.main() diff --git a/tensorflow/contrib/layers/python/layers/optimizers_test.py b/tensorflow/contrib/layers/python/layers/optimizers_test.py index a4461a20e5..0f037e24ad 100644 --- a/tensorflow/contrib/layers/python/layers/optimizers_test.py +++ b/tensorflow/contrib/layers/python/layers/optimizers_test.py @@ -66,7 +66,7 @@ class OptimizersTest(test.TestCase): ] for optimizer in optimizers: with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: x, var, loss, global_step = _setup_model() train = optimizers_lib.optimize_loss( loss, global_step, learning_rate=0.1, optimizer=optimizer) @@ -82,7 +82,7 @@ class OptimizersTest(test.TestCase): return gradient_descent.GradientDescentOptimizer(learning_rate=0.1) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: x, var, loss, global_step = _setup_model() train = optimizers_lib.optimize_loss( loss, global_step, learning_rate=None, optimizer=optimizer_fn) @@ -96,14 +96,14 @@ class OptimizersTest(test.TestCase): optimizers = ["blah", variables.Variable, object(), lambda x: None] for optimizer in optimizers: with ops.Graph().as_default() as g: - with self.test_session(graph=g): + with self.session(graph=g): _, _, loss, global_step = _setup_model() with self.assertRaises(ValueError): optimizers_lib.optimize_loss( loss, global_step, learning_rate=0.1, optimizer=optimizer) def testBadSummaries(self): - with ops.Graph().as_default() as g, self.test_session(graph=g): + with ops.Graph().as_default() as g, self.session(graph=g): _, _, loss, global_step = _setup_model() with self.assertRaises(ValueError): optimizers_lib.optimize_loss( @@ -111,7 +111,7 @@ class OptimizersTest(test.TestCase): summaries=["loss", "bad_summary"]) def testInvalidLoss(self): - with ops.Graph().as_default() as g, self.test_session(graph=g): + with ops.Graph().as_default() as g, self.session(graph=g): _, _, _, global_step = _setup_model() with self.assertRaises(ValueError): optimizers_lib.optimize_loss( @@ -121,7 +121,7 @@ class OptimizersTest(test.TestCase): [[1.0]], global_step, learning_rate=0.1, optimizer="SGD") def testInvalidGlobalStep(self): - with ops.Graph().as_default() as g, self.test_session(graph=g): + with ops.Graph().as_default() as g, self.session(graph=g): x = array_ops.placeholder(dtypes.float32, []) var = variable_scope.get_variable( "test", [], initializer=init_ops.constant_initializer(10)) @@ -157,7 +157,7 @@ class OptimizersTest(test.TestCase): optimizer="SGD") def testInvalidLearningRate(self): - with ops.Graph().as_default() as g, self.test_session(graph=g): + with ops.Graph().as_default() as g, self.session(graph=g): _, _, loss, global_step = _setup_model() with self.assertRaises(ValueError): optimizers_lib.optimize_loss( @@ -270,7 +270,7 @@ class OptimizersTest(test.TestCase): gradient_descent.GradientDescentOptimizer(learning_rate=0.1) ] for optimizer in optimizers: - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: x = array_ops.placeholder(dtypes.float32, []) var = variable_scope.get_variable( "test", [], initializer=init_ops.constant_initializer(10)) @@ -295,7 +295,7 @@ class OptimizersTest(test.TestCase): gradient_descent.GradientDescentOptimizer(learning_rate=0.1) ] for optimizer in optimizers: - with ops.Graph().as_default() as g, self.test_session(graph=g): + with ops.Graph().as_default() as g, self.session(graph=g): x = array_ops.placeholder(dtypes.float32, []) var = variable_scope.get_variable( "test", [], initializer=init_ops.constant_initializer(10)) @@ -319,7 +319,7 @@ class OptimizersTest(test.TestCase): gradient_descent.GradientDescentOptimizer(learning_rate=0.1) ] for optimizer in optimizers: - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: x, var, loss, global_step = _setup_model() update_var = variable_scope.get_variable( "update", [], initializer=init_ops.constant_initializer(10)) @@ -342,7 +342,7 @@ class OptimizersTest(test.TestCase): gradient_descent.GradientDescentOptimizer(learning_rate=0.1) ] for optimizer in optimizers: - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: x, var, loss, global_step = _setup_model() update_var = variable_scope.get_variable( "update", [], initializer=init_ops.constant_initializer(10)) @@ -365,7 +365,7 @@ class OptimizersTest(test.TestCase): gradient_descent.GradientDescentOptimizer(learning_rate=0.1) ] for optimizer in optimizers: - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: x, var, loss, global_step = _setup_model() update_var = variable_scope.get_variable( "update", [], initializer=init_ops.constant_initializer(10)) @@ -389,7 +389,7 @@ class OptimizersTest(test.TestCase): gradient_descent.GradientDescentOptimizer(learning_rate=0.1) ] for optimizer in optimizers: - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: x, var, loss, global_step = _setup_model() update_var = variable_scope.get_variable( "update", [], initializer=init_ops.constant_initializer(10)) @@ -413,7 +413,7 @@ class OptimizersTest(test.TestCase): gradient_descent.GradientDescentOptimizer(learning_rate=0.1) ] for optimizer in optimizers: - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: x, var, loss, global_step = _setup_model() update_var = variable_scope.get_variable( "update", [], initializer=init_ops.constant_initializer(10)) diff --git a/tensorflow/contrib/layers/python/layers/rev_block_lib.py b/tensorflow/contrib/layers/python/layers/rev_block_lib.py index dad3da3748..b25f11b5a6 100644 --- a/tensorflow/contrib/layers/python/layers/rev_block_lib.py +++ b/tensorflow/contrib/layers/python/layers/rev_block_lib.py @@ -151,9 +151,19 @@ def _rev_block_forward(x1, return y1, y2 +def _safe_wraps(fn): + if isinstance(fn, functools.partial): + # functools.partial objects cannot be wrapped as they are missing the + # necessary properties (__name__, __module__, __doc__). + def passthrough(f): + return f + return passthrough + return functools.wraps(fn) + + def _scope_wrap(fn, scope): - @functools.wraps(fn) + @_safe_wraps(fn) def wrap(*args, **kwargs): with variable_scope.variable_scope(scope, use_resource=True): return fn(*args, **kwargs) @@ -430,7 +440,7 @@ def rev_block(x1, def enable_with_args(dec): """A decorator for decorators to enable their usage with or without args.""" - @functools.wraps(dec) + @_safe_wraps(dec) def new_dec(*args, **kwargs): if len(args) == 1 and not kwargs and callable(args[0]): # Used as decorator without args @@ -477,7 +487,7 @@ def recompute_grad(fn, use_data_dep=_USE_DEFAULT, tupleize_grads=False): tf.gradients). """ - @functools.wraps(fn) + @_safe_wraps(fn) def wrapped(*args): return _recompute_grad( fn, args, use_data_dep=use_data_dep, tupleize_grads=tupleize_grads) diff --git a/tensorflow/contrib/layers/python/layers/utils_test.py b/tensorflow/contrib/layers/python/layers/utils_test.py index 645dc1291e..a9bd89532a 100644 --- a/tensorflow/contrib/layers/python/layers/utils_test.py +++ b/tensorflow/contrib/layers/python/layers/utils_test.py @@ -47,7 +47,7 @@ class ConstantValueTest(test.TestCase): def test_variable(self): for v in [True, False, 1, 0, 1.0]: - with ops.Graph().as_default() as g, self.test_session(g) as sess: + with ops.Graph().as_default() as g, self.session(g) as sess: x = variables.Variable(v) value = utils.constant_value(x) self.assertEqual(value, None) diff --git a/tensorflow/contrib/learn/python/learn/estimators/dynamic_rnn_estimator_test.py b/tensorflow/contrib/learn/python/learn/estimators/dynamic_rnn_estimator_test.py index c9a11f27f1..1d8a59281a 100644 --- a/tensorflow/contrib/learn/python/learn/estimators/dynamic_rnn_estimator_test.py +++ b/tensorflow/contrib/learn/python/learn/estimators/dynamic_rnn_estimator_test.py @@ -155,7 +155,7 @@ class DynamicRnnEstimatorTest(test.TestCase): sequence_input = dynamic_rnn_estimator.build_sequence_input( self.GetColumnsToTensors(), self.sequence_feature_columns, self.context_feature_columns) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) sess.run(lookup_ops.tables_initializer()) sequence_input_val = sess.run(sequence_input) @@ -330,7 +330,7 @@ class DynamicRnnEstimatorTest(test.TestCase): actual_state = dynamic_rnn_estimator.dict_to_state_tuple(state_dict, cell) flattened_state = dynamic_rnn_estimator.state_tuple_to_dict(actual_state) - with self.test_session() as sess: + with self.cached_session() as sess: (state_dict_val, actual_state_val, flattened_state_val) = sess.run( [state_dict, actual_state, flattened_state]) diff --git a/tensorflow/contrib/learn/python/learn/estimators/rnn_common_test.py b/tensorflow/contrib/learn/python/learn/estimators/rnn_common_test.py index 82563141cc..ebf5f5617d 100644 --- a/tensorflow/contrib/learn/python/learn/estimators/rnn_common_test.py +++ b/tensorflow/contrib/learn/python/learn/estimators/rnn_common_test.py @@ -44,7 +44,7 @@ class RnnCommonTest(test.TestCase): constant_op.constant(labels, dtype=dtypes.int32), constant_op.constant(sequence_length, dtype=dtypes.int32)) - with self.test_session() as sess: + with self.cached_session() as sess: activations_masked, labels_masked = sess.run( [activations_masked_t, labels_masked_t]) diff --git a/tensorflow/contrib/learn/python/learn/estimators/stability_test.py b/tensorflow/contrib/learn/python/learn/estimators/stability_test.py index 6d04543819..81376c0e2a 100644 --- a/tensorflow/contrib/learn/python/learn/estimators/stability_test.py +++ b/tensorflow/contrib/learn/python/learn/estimators/stability_test.py @@ -68,12 +68,12 @@ class StabilityTest(test.TestCase): minval = -0.3333 maxval = 0.3333 with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: g.seed = my_seed x = random_ops.random_uniform([10, 10], minval=minval, maxval=maxval) val1 = session.run(x) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: g.seed = my_seed x = random_ops.random_uniform([10, 10], minval=minval, maxval=maxval) val2 = session.run(x) diff --git a/tensorflow/contrib/learn/python/learn/estimators/state_saving_rnn_estimator_test.py b/tensorflow/contrib/learn/python/learn/estimators/state_saving_rnn_estimator_test.py index 442247409d..06c61554fa 100644 --- a/tensorflow/contrib/learn/python/learn/estimators/state_saving_rnn_estimator_test.py +++ b/tensorflow/contrib/learn/python/learn/estimators/state_saving_rnn_estimator_test.py @@ -53,7 +53,7 @@ class PrepareInputsForRnnTest(test.TestCase): sequence_feature_columns, num_unroll) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) sess.run(lookup_ops.tables_initializer()) features_val = sess.run(features_by_time) @@ -314,7 +314,7 @@ class StateSavingRnnEstimatorTest(test.TestCase): else: self.assertAllEqual(v, got[k]) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) sess.run(lookup_ops.tables_initializer()) actual_sequence, actual_context = sess.run( diff --git a/tensorflow/contrib/learn/python/learn/graph_actions_test.py b/tensorflow/contrib/learn/python/learn/graph_actions_test.py index df156da3f4..d5c02124ac 100644 --- a/tensorflow/contrib/learn/python/learn/graph_actions_test.py +++ b/tensorflow/contrib/learn/python/learn/graph_actions_test.py @@ -175,7 +175,7 @@ class GraphActionsTest(test.TestCase): return in0, in1, out def test_infer(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._assert_ckpt(self._output_dir, False) in0, in1, out = self._build_inference_graph() self.assertEqual({ @@ -193,7 +193,7 @@ class GraphActionsTest(test.TestCase): side_effect=learn.graph_actions.coordinator.Coordinator.request_stop, autospec=True) def test_coordinator_request_stop_called(self, request_stop): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): in0, in1, out = self._build_inference_graph() learn.graph_actions.infer(None, {'a': in0, 'b': in1, 'c': out}) self.assertTrue(request_stop.called) @@ -204,7 +204,7 @@ class GraphActionsTest(test.TestCase): side_effect=learn.graph_actions.coordinator.Coordinator.request_stop, autospec=True) def test_run_feeds_iter_cleanup_with_exceptions(self, request_stop): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): in0, in1, out = self._build_inference_graph() try: for _ in learn.graph_actions.run_feeds_iter({ @@ -249,7 +249,7 @@ class GraphActionsTest(test.TestCase): self._assert_ckpt(self._output_dir, False) def test_infer_invalid_feed(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._assert_ckpt(self._output_dir, False) in0, _, _ = self._build_inference_graph() with self.assertRaisesRegexp(TypeError, 'Can not convert a NoneType'): @@ -257,7 +257,7 @@ class GraphActionsTest(test.TestCase): self._assert_ckpt(self._output_dir, False) def test_infer_feed(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._assert_ckpt(self._output_dir, False) in0, _, out = self._build_inference_graph() self.assertEqual( @@ -271,7 +271,7 @@ class GraphActionsTest(test.TestCase): # TODO(ptucker): Test eval for 1 epoch. def test_evaluate_invalid_args(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._assert_ckpt(self._output_dir, False) with self.assertRaisesRegexp(ValueError, 'utput directory'): learn.graph_actions.evaluate( @@ -288,7 +288,7 @@ class GraphActionsTest(test.TestCase): self._assert_ckpt(self._output_dir, False) def test_evaluate(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): _, _, out = self._build_inference_graph() writer = learn.graph_actions.get_summary_writer(self._output_dir) self._assert_summaries(self._output_dir, writer, expected_session_logs=[]) @@ -310,7 +310,7 @@ class GraphActionsTest(test.TestCase): self._assert_ckpt(self._output_dir, False) def test_evaluate_ready_for_local_init(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): variables_lib.create_global_step() v = variables.Variable(1.0) variables.Variable( @@ -327,7 +327,7 @@ class GraphActionsTest(test.TestCase): max_steps=1) def test_evaluate_feed_fn(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): in0, _, out = self._build_inference_graph() writer = learn.graph_actions.get_summary_writer(self._output_dir) self._assert_summaries(self._output_dir, writer, expected_session_logs=[]) @@ -352,7 +352,7 @@ class GraphActionsTest(test.TestCase): self._assert_ckpt(self._output_dir, False) def test_evaluate_feed_fn_with_exhaustion(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): in0, _, out = self._build_inference_graph() writer = learn.graph_actions.get_summary_writer(self._output_dir) self._assert_summaries(self._output_dir, writer, expected_session_logs=[]) @@ -375,7 +375,7 @@ class GraphActionsTest(test.TestCase): expected_session_logs=[]) def test_evaluate_with_saver(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): _, _, out = self._build_inference_graph() ops.add_to_collection(ops.GraphKeys.SAVERS, saver_lib.Saver()) writer = learn.graph_actions.get_summary_writer(self._output_dir) @@ -469,7 +469,7 @@ class GraphActionsTrainTest(test.TestCase): return in0, in1, out def test_train_invalid_args(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): train_op = constant_op.constant(1.0) loss_op = constant_op.constant(2.0) with self.assertRaisesRegexp(ValueError, 'utput directory'): @@ -503,7 +503,7 @@ class GraphActionsTrainTest(test.TestCase): # TODO(ptucker): Mock supervisor, and assert all interactions. def test_train(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): with ops.control_dependencies(self._build_inference_graph()): train_op = state_ops.assign_add(variables_lib.get_global_step(), 1) self._assert_summaries(self._output_dir) @@ -522,7 +522,7 @@ class GraphActionsTrainTest(test.TestCase): self._assert_ckpt(self._output_dir, True) def test_train_steps_is_incremental(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): with ops.control_dependencies(self._build_inference_graph()): train_op = state_ops.assign_add(variables_lib.get_global_step(), 1) learn.graph_actions.train( @@ -535,7 +535,7 @@ class GraphActionsTrainTest(test.TestCase): self._output_dir, variables_lib.get_global_step().name) self.assertEqual(10, step) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): with ops.control_dependencies(self._build_inference_graph()): train_op = state_ops.assign_add(variables_lib.get_global_step(), 1) learn.graph_actions.train( @@ -549,7 +549,7 @@ class GraphActionsTrainTest(test.TestCase): self.assertEqual(25, step) def test_train_max_steps_is_not_incremental(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): with ops.control_dependencies(self._build_inference_graph()): train_op = state_ops.assign_add(variables_lib.get_global_step(), 1) learn.graph_actions.train( @@ -562,7 +562,7 @@ class GraphActionsTrainTest(test.TestCase): self._output_dir, variables_lib.get_global_step().name) self.assertEqual(10, step) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): with ops.control_dependencies(self._build_inference_graph()): train_op = state_ops.assign_add(variables_lib.get_global_step(), 1) learn.graph_actions.train( @@ -576,7 +576,7 @@ class GraphActionsTrainTest(test.TestCase): self.assertEqual(15, step) def test_train_loss(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): variables_lib.create_global_step() loss_var = variables_lib.local_variable(10.0) train_op = control_flow_ops.group( @@ -598,7 +598,7 @@ class GraphActionsTrainTest(test.TestCase): self._assert_ckpt(self._output_dir, True) def test_train_summaries(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): with ops.control_dependencies(self._build_inference_graph()): train_op = state_ops.assign_add(variables_lib.get_global_step(), 1) loss_op = constant_op.constant(2.0) @@ -624,7 +624,7 @@ class GraphActionsTrainTest(test.TestCase): self._assert_ckpt(self._output_dir, True) def test_train_chief_monitor(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): with ops.control_dependencies(self._build_inference_graph()): train_op = state_ops.assign_add(variables_lib.get_global_step(), 1) loss_op = constant_op.constant(2.0) @@ -663,7 +663,7 @@ class GraphActionsTrainTest(test.TestCase): # and the other chief exclusive. chief_exclusive_monitor = _BaseMonitorWrapper(False) all_workers_monitor = _BaseMonitorWrapper(True) - with self.test_session(g): + with self.session(g): loss = learn.graph_actions.train( g, output_dir=self._output_dir, diff --git a/tensorflow/contrib/learn/python/learn/learn_io/data_feeder_test.py b/tensorflow/contrib/learn/python/learn/learn_io/data_feeder_test.py index 1f439965da..5e07b9313f 100644 --- a/tensorflow/contrib/learn/python/learn/learn_io/data_feeder_test.py +++ b/tensorflow/contrib/learn/python/learn/learn_io/data_feeder_test.py @@ -58,7 +58,7 @@ class DataFeederTest(test.TestCase): self.assertEqual(expected_np_dtype, v) else: self.assertEqual(expected_np_dtype, feeder.input_dtype) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): inp, _ = feeder.input_builder() if isinstance(inp, dict): for v in list(inp.values()): diff --git a/tensorflow/contrib/learn/python/learn/learn_io/graph_io_test.py b/tensorflow/contrib/learn/python/learn/learn_io/graph_io_test.py index e11e8b698a..8e68a17e47 100644 --- a/tensorflow/contrib/learn/python/learn/learn_io/graph_io_test.py +++ b/tensorflow/contrib/learn/python/learn/learn_io/graph_io_test.py @@ -207,7 +207,7 @@ class GraphIOTest(test.TestCase): parsing_ops.FixedLenFeature(shape=shape, dtype=dtypes_lib.float32) } - with ops.Graph().as_default() as g, self.test_session(graph=g) as sess: + with ops.Graph().as_default() as g, self.session(graph=g) as sess: features = graph_io.read_batch_record_features( _VALID_FILE_PATTERN, batch_size, @@ -242,7 +242,7 @@ class GraphIOTest(test.TestCase): queue_capacity = 1234 name = "my_batch" - with ops.Graph().as_default() as g, self.test_session(graph=g) as sess: + with ops.Graph().as_default() as g, self.session(graph=g) as sess: inputs = graph_io.read_batch_examples( _VALID_FILE_PATTERN, batch_size, @@ -276,7 +276,7 @@ class GraphIOTest(test.TestCase): queue_capacity = 1234 name = "my_batch" - with ops.Graph().as_default() as g, self.test_session(graph=g) as sess: + with ops.Graph().as_default() as g, self.session(graph=g) as sess: inputs = graph_io.read_batch_examples( [_VALID_FILE_PATTERN, _VALID_FILE_PATTERN_2], batch_size, @@ -325,7 +325,7 @@ class GraphIOTest(test.TestCase): queue_capacity = 5 name = "my_batch" - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: inputs = graph_io.read_batch_examples( filename, batch_size, @@ -374,7 +374,7 @@ class GraphIOTest(test.TestCase): features = {"sequence": parsing_ops.FixedLenFeature([], dtypes_lib.string)} - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: keys, result = graph_io.read_keyed_batch_features( filename, batch_size, @@ -429,7 +429,7 @@ class GraphIOTest(test.TestCase): features = {"sequence": parsing_ops.FixedLenFeature([], dtypes_lib.string)} - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: result = graph_io.read_batch_features( filename, batch_size, @@ -475,7 +475,7 @@ class GraphIOTest(test.TestCase): queue_capacity = 5 name = "my_batch" - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: inputs = graph_io.read_batch_examples( filenames, batch_size, @@ -519,7 +519,7 @@ class GraphIOTest(test.TestCase): queue_capacity = 5 name = "my_batch" - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: keys, inputs = graph_io.read_keyed_batch_examples_shared_queue( filenames, batch_size, @@ -640,7 +640,7 @@ class GraphIOTest(test.TestCase): queue_capacity = 10 name = "my_batch" - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: inputs = graph_io.read_batch_examples( [filename], batch_size, @@ -672,7 +672,7 @@ class GraphIOTest(test.TestCase): queue_capacity = 5 name = "my_batch" - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: keys, inputs = graph_io.read_keyed_batch_examples( filename, batch_size, @@ -714,7 +714,7 @@ class GraphIOTest(test.TestCase): queue_capacity = 5 name = "my_batch" - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: dtypes = {"age": parsing_ops.FixedLenFeature([1], dtypes_lib.int64)} parse_fn = lambda example: parsing_ops.parse_single_example( # pylint: disable=g-long-lambda parsing_ops.decode_json_example(example), dtypes) @@ -773,7 +773,7 @@ class GraphIOTest(test.TestCase): examples = parsing_ops.parse_example(serialized, features) return math_ops.less(examples["age"], 2) - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: keys, inputs = graph_io._read_keyed_batch_examples_helper( filename, batch_size, @@ -812,7 +812,7 @@ class GraphIOTest(test.TestCase): coord.join(threads) def test_queue_parsed_features_single_tensor(self): - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: features = {"test": constant_op.constant([1, 2, 3])} _, queued_features = graph_io.queue_parsed_features(features) coord = coordinator.Coordinator() @@ -833,7 +833,7 @@ class GraphIOTest(test.TestCase): _, queued_feature = graph_io.read_keyed_batch_features_shared_queue( _VALID_FILE_PATTERN, batch_size, feature, reader) - with ops.Graph().as_default() as g, self.test_session(graph=g) as session: + with ops.Graph().as_default() as g, self.session(graph=g) as session: features_result = graph_io.read_batch_features( _VALID_FILE_PATTERN, batch_size, feature, reader) session.run(variables.local_variables_initializer()) diff --git a/tensorflow/contrib/learn/python/learn/monitors_test.py b/tensorflow/contrib/learn/python/learn/monitors_test.py index ff1da32c21..83e48a36e7 100644 --- a/tensorflow/contrib/learn/python/learn/monitors_test.py +++ b/tensorflow/contrib/learn/python/learn/monitors_test.py @@ -127,12 +127,12 @@ class MonitorsTest(test.TestCase): monitor.end() def test_base_monitor(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._run_monitor(learn.monitors.BaseMonitor()) def test_every_0(self): monitor = _MyEveryN(every_n_steps=0, first_n_steps=-1) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._run_monitor(monitor, num_epochs=3, num_steps_per_epoch=10) expected_steps = list(range(30)) self.assertAllEqual(expected_steps, monitor.steps_begun) @@ -141,7 +141,7 @@ class MonitorsTest(test.TestCase): def test_every_1(self): monitor = _MyEveryN(every_n_steps=1, first_n_steps=-1) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._run_monitor(monitor, num_epochs=3, num_steps_per_epoch=10) expected_steps = list(range(1, 30)) self.assertEqual(expected_steps, monitor.steps_begun) @@ -150,7 +150,7 @@ class MonitorsTest(test.TestCase): def test_every_2(self): monitor = _MyEveryN(every_n_steps=2, first_n_steps=-1) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._run_monitor(monitor, num_epochs=3, num_steps_per_epoch=10) expected_steps = list(range(2, 29, 2)) + [29] self.assertEqual(expected_steps, monitor.steps_begun) @@ -159,7 +159,7 @@ class MonitorsTest(test.TestCase): def test_every_8(self): monitor = _MyEveryN(every_n_steps=8, first_n_steps=2) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._run_monitor(monitor, num_epochs=3, num_steps_per_epoch=10) expected_steps = [0, 1, 2, 10, 18, 26, 29] self.assertEqual(expected_steps, monitor.steps_begun) @@ -168,7 +168,7 @@ class MonitorsTest(test.TestCase): def test_every_8_no_max_steps(self): monitor = _MyEveryN(every_n_steps=8, first_n_steps=2) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._run_monitor( monitor, num_epochs=3, num_steps_per_epoch=10, pass_max_steps=False) begin_end_steps = [0, 1, 2, 10, 18, 26] @@ -179,7 +179,7 @@ class MonitorsTest(test.TestCase): def test_every_8_recovered_after_step_begin(self): monitor = _MyEveryN(every_n_steps=8) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): for step in [8, 16]: monitor.step_begin(step) monitor.step_begin(step) @@ -192,7 +192,7 @@ class MonitorsTest(test.TestCase): def test_every_8_recovered_after_step_end(self): monitor = _MyEveryN(every_n_steps=8) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): for step in [8, 16]: monitor.step_begin(step) monitor.step_end(step, output=None) @@ -207,7 +207,7 @@ class MonitorsTest(test.TestCase): def test_every_8_call_post_step_at_the_end(self): monitor = _MyEveryN(every_n_steps=8) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): monitor.begin() for step in [8, 16]: monitor.step_begin(step) @@ -224,7 +224,7 @@ class MonitorsTest(test.TestCase): def test_every_8_call_post_step_should_not_be_called_twice(self): monitor = _MyEveryN(every_n_steps=8) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): monitor.begin() for step in [8, 16]: monitor.step_begin(step) @@ -240,13 +240,13 @@ class MonitorsTest(test.TestCase): self.assertEqual([8, 16], monitor.post_steps) def test_print(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): t = constant_op.constant(42.0, name='foo') self._run_monitor(learn.monitors.PrintTensor(tensor_names=[t.name])) self.assertRegexpMatches(str(self.logged_message), t.name) def test_logging_trainable(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): var = variables.Variable(constant_op.constant(42.0), name='foo') var.initializer.run() cof = constant_op.constant(1.0) @@ -258,7 +258,7 @@ class MonitorsTest(test.TestCase): self.assertRegexpMatches(str(self.logged_message), var.name) def test_summary_saver(self): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): log_dir = 'log/dir' summary_writer = testing.FakeSummaryWriter(log_dir, g) var = variables.Variable(0.0) @@ -312,7 +312,7 @@ class MonitorsTest(test.TestCase): monitor = learn.monitors.ValidationMonitor( x=constant_op.constant(2.0), every_n_steps=0) self._assert_validation_monitor(monitor) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): with self.assertRaisesRegexp(ValueError, 'set_estimator'): self._run_monitor(monitor) @@ -330,7 +330,7 @@ class MonitorsTest(test.TestCase): x=constant_op.constant(2.0), every_n_steps=0) self._assert_validation_monitor(monitor) monitor.set_estimator(estimator) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._run_monitor(monitor) self._assert_validation_monitor(monitor) mock_latest_checkpoint.assert_called_with(model_dir) @@ -351,7 +351,7 @@ class MonitorsTest(test.TestCase): x=constant_op.constant(2.0), every_n_steps=0) self._assert_validation_monitor(monitor) monitor.set_estimator(estimator) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): self._run_monitor(monitor) self._assert_validation_monitor(monitor) @@ -370,7 +370,7 @@ class MonitorsTest(test.TestCase): x=constant_op.constant(2.0), every_n_steps=0, early_stopping_rounds=1) self._assert_validation_monitor(monitor) monitor.set_estimator(estimator) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): with self.assertRaisesRegexp(ValueError, 'missing from outputs'): self._run_monitor(monitor, num_epochs=1, num_steps_per_epoch=1) @@ -392,7 +392,7 @@ class MonitorsTest(test.TestCase): self._assert_validation_monitor(monitor) monitor.set_estimator(estimator) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): monitor.begin(max_steps=100) monitor.epoch_begin(epoch=0) self.assertEqual(0, estimator.evaluate.call_count) @@ -477,7 +477,7 @@ class MonitorsTest(test.TestCase): every_n_steps=0, early_stopping_rounds=2) self._assert_validation_monitor(monitor) monitor.set_estimator(estimator) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): monitor.begin(max_steps=100) monitor.epoch_begin(epoch=0) self.assertEqual(0, estimator.evaluate.call_count) @@ -509,7 +509,7 @@ class MonitorsTest(test.TestCase): metrics=constant_op.constant(2.0), every_n_steps=0, early_stopping_rounds=2) monitor.set_estimator(estimator) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): monitor.begin(max_steps=100) monitor.epoch_begin(epoch=0) @@ -525,7 +525,7 @@ class MonitorsTest(test.TestCase): def test_graph_dump(self): monitor0 = learn.monitors.GraphDump() monitor1 = learn.monitors.GraphDump() - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): const_var = variables.Variable(42.0, name='my_const') counter_var = variables.Variable(0.0, name='my_counter') assign_add = state_ops.assign_add(counter_var, 1.0, name='my_assign_add') @@ -568,7 +568,7 @@ class MonitorsTest(test.TestCase): def test_capture_variable(self): monitor = learn.monitors.CaptureVariable( var_name='my_assign_add:0', every_n=8, first_n=2) - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): var = variables.Variable(0.0, name='my_var') var.initializer.run() state_ops.assign_add(var, 1.0, name='my_assign_add') diff --git a/tensorflow/contrib/legacy_seq2seq/python/kernel_tests/seq2seq_test.py b/tensorflow/contrib/legacy_seq2seq/python/kernel_tests/seq2seq_test.py index 7ce5fb2da6..2f33a2b74d 100644 --- a/tensorflow/contrib/legacy_seq2seq/python/kernel_tests/seq2seq_test.py +++ b/tensorflow/contrib/legacy_seq2seq/python/kernel_tests/seq2seq_test.py @@ -950,7 +950,7 @@ class Seq2SeqTest(test.TestCase): num_dec_timesteps = 3 def TestModel(seq2seq): - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: random_seed.set_random_seed(111) random.seed(111) np.random.seed(111) diff --git a/tensorflow/contrib/lite/BUILD b/tensorflow/contrib/lite/BUILD index 1e6f1e7da2..0091587bf7 100644 --- a/tensorflow/contrib/lite/BUILD +++ b/tensorflow/contrib/lite/BUILD @@ -154,6 +154,14 @@ cc_library( "optional_debug_tools.h", ], copts = tflite_copts(), + linkopts = [ + ] + select({ + "//tensorflow:android": [ + "-llog", + ], + "//conditions:default": [ + ], + }), deps = [ ":arena_planner", ":builtin_op_data", diff --git a/tensorflow/contrib/lite/build_def.bzl b/tensorflow/contrib/lite/build_def.bzl index 05d0b453ab..fc199f0a0e 100644 --- a/tensorflow/contrib/lite/build_def.bzl +++ b/tensorflow/contrib/lite/build_def.bzl @@ -235,6 +235,7 @@ def generated_test_models(): "exp", "expand_dims", "floor", + "floor_div", "fully_connected", "fused_batch_norm", "gather", @@ -266,7 +267,9 @@ def generated_test_models(): "padv2", "prelu", "pow", + "reduce_any", "reduce_max", + "reduce_min", "reduce_prod", "relu", "relu1", @@ -292,6 +295,7 @@ def generated_test_models(): "topk", "transpose", #"transpose_conv", # disabled due to b/111213074 + "unpack", "where", ] diff --git a/tensorflow/contrib/lite/builtin_op_data.h b/tensorflow/contrib/lite/builtin_op_data.h index 70178b2faa..e81f9e4f51 100644 --- a/tensorflow/contrib/lite/builtin_op_data.h +++ b/tensorflow/contrib/lite/builtin_op_data.h @@ -286,6 +286,11 @@ typedef struct { int axis; } TfLiteOneHotParams; +typedef struct { + int num; + int axis; +} TfLiteUnpackParams; + #ifdef __cplusplus } // extern "C" #endif // __cplusplus diff --git a/tensorflow/contrib/lite/builtin_ops.h b/tensorflow/contrib/lite/builtin_ops.h index 8a8eb98568..9cf4bea73e 100644 --- a/tensorflow/contrib/lite/builtin_ops.h +++ b/tensorflow/contrib/lite/builtin_ops.h @@ -113,6 +113,10 @@ typedef enum { kTfLiteBuiltinOneHot = 85, kTfLiteBuiltinLogicalAnd = 86, kTfLiteBuiltinLogicalNot = 87, + kTfLiteBuiltinUnpack = 88, + kTfLiteBuiltinReduceMin = 89, + kTfLiteBuiltinFloorDiv = 90, + kTfLiteBuiltinReduceAny = 91, } TfLiteBuiltinOperator; #ifdef __cplusplus diff --git a/tensorflow/contrib/lite/context.h b/tensorflow/contrib/lite/context.h index c265e7ce52..c7f4df3cdc 100644 --- a/tensorflow/contrib/lite/context.h +++ b/tensorflow/contrib/lite/context.h @@ -29,9 +29,6 @@ limitations under the License. #ifndef TENSORFLOW_CONTRIB_LITE_CONTEXT_H_ #define TENSORFLOW_CONTRIB_LITE_CONTEXT_H_ -#if defined(_MSC_VER) -#include <complex.h> -#endif #include <stdbool.h> #include <stdint.h> #include <stdlib.h> @@ -153,6 +150,11 @@ void TfLiteIntArrayFree(TfLiteIntArray* v); } \ } while (0) +// Single-precision complex data type compatible with the C99 definition. +typedef struct { + float re, im; // real and imaginary parts, respectively. +} TfLiteComplex64; + // Types supported by tensor typedef enum { kTfLiteNoType = 0, @@ -184,11 +186,7 @@ typedef union { uint8_t* uint8; bool* b; int16_t* i16; -#if defined(_MSC_VER) - _Fcomplex* c64; -#else - _Complex float* c64; -#endif + TfLiteComplex64* c64; } TfLitePtrUnion; // Memory allocation strategies. kTfLiteMmapRo is for read-only memory-mapped diff --git a/tensorflow/contrib/lite/delegates/eager/BUILD b/tensorflow/contrib/lite/delegates/eager/BUILD index 54231237d2..88c70fbb8a 100644 --- a/tensorflow/contrib/lite/delegates/eager/BUILD +++ b/tensorflow/contrib/lite/delegates/eager/BUILD @@ -19,7 +19,7 @@ cc_library( "//tensorflow/contrib/lite:kernel_api", ] + select({ "//tensorflow:android": [ - "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_lib_lite_no_runtime", ], "//conditions:default": [ "//tensorflow/core:framework", @@ -58,7 +58,7 @@ cc_library( "//tensorflow/contrib/lite:util", ] + select({ "//tensorflow:android": [ - "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_lib_lite_no_runtime", ], "//conditions:default": [ "//tensorflow/core:lib", @@ -87,7 +87,7 @@ cc_library( "//tensorflow/core/common_runtime/eager:context", ] + select({ "//tensorflow:android": [ - "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_lib_lite", ], "//conditions:default": [ "//tensorflow/core:core_cpu", @@ -124,11 +124,15 @@ cc_library( "//tensorflow/core/common_runtime/eager:execute", "//tensorflow/core/common_runtime/eager:tensor_handle", ] + select({ + # TODO(b/111881878): The android_tensorflow_lib target pulls in the full + # set of core TensorFlow kernels. We may want to revisit this dependency + # to allow selective registration via build targets. "//tensorflow:android": [ "//tensorflow/core:android_tensorflow_lib", ], "//conditions:default": [ "//tensorflow/core:protos_all_cc", + "//tensorflow/core:framework", ], }), ) @@ -168,7 +172,7 @@ cc_library( "//tensorflow/contrib/lite:kernel_api", ] + select({ "//tensorflow:android": [ - "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_lib_lite_no_runtime", ], "//conditions:default": [ "//tensorflow/core:lib", diff --git a/tensorflow/contrib/lite/delegates/eager/kernel.cc b/tensorflow/contrib/lite/delegates/eager/kernel.cc index b8e329275b..f8467c7cb2 100644 --- a/tensorflow/contrib/lite/delegates/eager/kernel.cc +++ b/tensorflow/contrib/lite/delegates/eager/kernel.cc @@ -14,7 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/contrib/lite/delegates/eager/kernel.h" -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers #include "tensorflow/contrib/lite/builtin_ops.h" #include "tensorflow/contrib/lite/context.h" #include "tensorflow/contrib/lite/context_util.h" @@ -26,6 +26,7 @@ limitations under the License. #include "tensorflow/core/common_runtime/eager/execute.h" #include "tensorflow/core/common_runtime/eager/tensor_handle.h" #include "tensorflow/core/framework/node_def.pb.h" +#include "tensorflow/core/framework/node_def_util.h" // Note: this is part of TF Lite's Eager delegation code which is to be // completed soon. @@ -189,6 +190,14 @@ void* Init(TfLiteContext* context, const char* buffer, size_t length) { } } + // Fill NodeDef with defaults if it's a valid op. + const tensorflow::OpRegistrationData* op_reg_data; + auto tf_status = tensorflow::OpRegistry::Global()->LookUp( + node_data.nodedef.op(), &op_reg_data); + if (tf_status.ok()) { + AddDefaultsToNodeDef(op_reg_data->op_def, &node_data.nodedef); + } + for (auto input_index : TfLiteIntArrayView(node->inputs)) { node_data.inputs.push_back(input_index); } diff --git a/tensorflow/contrib/lite/delegates/eager/test_util.cc b/tensorflow/contrib/lite/delegates/eager/test_util.cc index 203afa6abd..b8c9e2652a 100644 --- a/tensorflow/contrib/lite/delegates/eager/test_util.cc +++ b/tensorflow/contrib/lite/delegates/eager/test_util.cc @@ -16,7 +16,7 @@ limitations under the License. #include "tensorflow/contrib/lite/delegates/eager/test_util.h" #include "absl/memory/memory.h" -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers #include "tensorflow/contrib/lite/string.h" namespace tflite { diff --git a/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate.cc b/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate.cc index e6cc3dd99c..980a1cb4a0 100644 --- a/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate.cc +++ b/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate.cc @@ -238,7 +238,7 @@ class NNAPIOpBuilder { tensor->params.zero_point}; CHECK_NN(context_, ANeuralNetworksModel_addOperand(nn_model_, &operand_type)); - augmented_inputs_.push_back(ann_index); + augmented_outputs_.push_back(ann_index); *ann_tensor_index_out = ann_index; return kTfLiteOk; @@ -370,8 +370,8 @@ struct NNAPIOpMappingArgs { TfLiteContext* context; NNAPIOpBuilder* builder; TfLiteNode* node; - std::vector<int>* model_state_inputs; - std::vector<int>* model_state_tfl_outputs; + std::vector<int>* model_state_outputs; + std::vector<int>* model_state_tfl_inputs; }; // The kernel that represents the subgraph of TF Lite being run on NN API. @@ -781,8 +781,7 @@ class NNAPIDelegateKernel { break; case kTfLiteBuiltinRnn: // NNAPI only support float32 weights. - // TODO(miaowang): check the number of inputs before accessing it. - if (version == 1 && + if (version == 1 && node->inputs->size == 5 && context->tensors[node->inputs->data[/*kWeightsTensor*/ 1]].type == kTfLiteFloat32) { return [](const NNAPIOpMappingArgs& mapping_args) @@ -790,11 +789,11 @@ class NNAPIDelegateKernel { // NNAPI need both state_in and state_out. int ann_index; mapping_args.builder->AddStateFloat32Tensor( - mapping_args.node->outputs->data[/*kHiddenStateTensor*/ 0], + mapping_args.node->inputs->data[/*kHiddenStateTensor*/ 4], &ann_index); - mapping_args.model_state_inputs->push_back(ann_index); - mapping_args.model_state_tfl_outputs->push_back( - mapping_args.node->outputs->data[/*kHiddenStateTensor*/ 0]); + mapping_args.model_state_outputs->push_back(ann_index); + mapping_args.model_state_tfl_inputs->push_back( + mapping_args.node->inputs->data[/*kHiddenStateTensor*/ 4]); auto builtin = reinterpret_cast<TfLiteRNNParams*>( mapping_args.node->builtin_data); mapping_args.builder->AddScalarInt32Operand(builtin->activation); @@ -806,7 +805,7 @@ class NNAPIDelegateKernel { break; case kTfLiteBuiltinSvdf: // NNAPI only support float32 weights. - if (version == 1 && + if (version == 1 && node->inputs->size == 5 && context->tensors[node->inputs->data[/*kWeightsFeatureTensor*/ 1]] .type == kTfLiteFloat32) { return [](const NNAPIOpMappingArgs& mapping_args) @@ -814,11 +813,13 @@ class NNAPIDelegateKernel { // NNAPI need both state_in and state_out. int ann_index; mapping_args.builder->AddStateFloat32Tensor( - mapping_args.node->outputs->data[/*kStateTensor*/ 0], + mapping_args.node->inputs + ->data[/*kInputActivationStateTensor*/ 4], &ann_index); - mapping_args.model_state_inputs->push_back(ann_index); - mapping_args.model_state_tfl_outputs->push_back( - mapping_args.node->outputs->data[/*kStateTensor*/ 0]); + mapping_args.model_state_outputs->push_back(ann_index); + mapping_args.model_state_tfl_inputs->push_back( + mapping_args.node->inputs + ->data[/*kInputActivationStateTensor*/ 4]); auto builtin = reinterpret_cast<TfLiteSVDFParams*>( mapping_args.node->builtin_data); @@ -833,28 +834,12 @@ class NNAPIDelegateKernel { case kTfLiteBuiltinLstm: // NNAPI only support float32 weights. // TODO(miaowang): add loggings to indicate why the op is rejected. - if (version == 1 && node->inputs->size == 18 && + if (version == 1 && node->inputs->size == 20 && context->tensors[node->inputs ->data[/*kInputToOutputWeightsTensor*/ 4]] .type == kTfLiteFloat32) { return [](const NNAPIOpMappingArgs& mapping_args) -> ANeuralNetworksOperationType { - // NNAPI need both state_in and state_out for cell_state and - // output_state. - int ann_index; - mapping_args.builder->AddStateFloat32Tensor( - mapping_args.node->outputs->data[/*kOutputStateTensor*/ 0], - &ann_index); - mapping_args.model_state_inputs->push_back(ann_index); - mapping_args.model_state_tfl_outputs->push_back( - mapping_args.node->outputs->data[/*kOutputStateTensor*/ 0]); - mapping_args.builder->AddStateFloat32Tensor( - mapping_args.node->outputs->data[/*kCellStateTensor*/ 1], - &ann_index); - mapping_args.model_state_inputs->push_back(ann_index); - mapping_args.model_state_tfl_outputs->push_back( - mapping_args.node->outputs->data[/*kCellStateTensor*/ 1]); - auto builtin = reinterpret_cast<TfLiteLSTMParams*>( mapping_args.node->builtin_data); mapping_args.builder->AddScalarInt32Operand(builtin->activation); @@ -864,6 +849,25 @@ class NNAPIDelegateKernel { // Current NNAPI implementation requires the sratch_buffer as // output. mapping_args.builder->AddAdditionalFloat32OutputTensor(2); + + // NNAPI need both state_in and state_out for cell_state and + // output_state. + int ann_index; + mapping_args.builder->AddStateFloat32Tensor( + mapping_args.node->inputs + ->data[/*kInputActivationStateTensor*/ 18], + &ann_index); + mapping_args.model_state_outputs->push_back(ann_index); + mapping_args.model_state_tfl_inputs->push_back( + mapping_args.node->inputs + ->data[/*kInputActivationStateTensor*/ 18]); + mapping_args.builder->AddStateFloat32Tensor( + mapping_args.node->inputs->data[/*kInputCellStateTensor*/ 19], + &ann_index); + mapping_args.model_state_outputs->push_back(ann_index); + mapping_args.model_state_tfl_inputs->push_back( + mapping_args.node->inputs->data[/*kInputCellStateTensor*/ 19]); + return ANEURALNETWORKS_LSTM; }; } else { @@ -950,12 +954,10 @@ class NNAPIDelegateKernel { // Set the input tensor buffers. Note: we access tflite tensors using // absolute indices but NN api indices inputs by relative indices. int relative_input_index = 0; - int num_optional_tensors = 0; size_t input_offset = 0; for (auto absolute_input_index : TfLiteIntArrayView(node->inputs)) { if (absolute_input_index == kOptionalTensor) { - num_optional_tensors++; continue; } TfLiteTensor* tensor = &context->tensors[absolute_input_index]; @@ -989,16 +991,16 @@ class NNAPIDelegateKernel { // The state_out of previous invocation need to be mapped to state_in of // current invocation. - for (size_t i = 0; i < model_state_tfl_outputs_.size(); i++) { - int state_tensor_idx = model_state_tfl_outputs_[i]; + for (size_t i = 0; i < model_state_tfl_inputs_.size(); i++) { + int state_tensor_idx = model_state_tfl_inputs_[i]; TfLiteTensor* tensor = &context->tensors[state_tensor_idx]; // Here we are using a deep copy for state_in tensors so that we are not // reading and writing into the same buffer during a invocation. // TODO(110369471): using double shared buffer to minimize the copies. - CHECK_NN(context, - ANeuralNetworksExecution_setInput( - execution, i + node->inputs->size - num_optional_tensors, - nullptr, tensor->data.raw, tensor->bytes)); + CHECK_NN(context, ANeuralNetworksExecution_setOutput( + execution, relative_output_index, nullptr, + tensor->data.raw, tensor->bytes)); + relative_output_index++; } // Invoke ANN in blocking fashion. ANeuralNetworksEvent* event = nullptr; @@ -1030,8 +1032,8 @@ class NNAPIDelegateKernel { // Track indices we use OperandMapping operand_mapping_; - std::vector<int> model_state_inputs_; - std::vector<int> model_state_tfl_outputs_; + std::vector<int> model_state_outputs_; + std::vector<int> model_state_tfl_inputs_; std::unique_ptr<NNMemory> nn_input_memory_; std::unique_ptr<NNMemory> nn_output_memory_; @@ -1063,9 +1065,9 @@ class NNAPIDelegateKernel { } } // Get op type and operands - int nn_op_type = Map(context, reg->builtin_code, reg->version, - node)({context, &builder, node, &model_state_inputs_, - &model_state_tfl_outputs_}); + int nn_op_type = Map(context, reg->builtin_code, reg->version, node)( + {context, &builder, node, &model_state_outputs_, + &model_state_tfl_inputs_}); // Map outputs to NN API tensor indices. for (auto output_index : TfLiteIntArrayView(node->outputs)) { TF_LITE_ENSURE_STATUS(builder.AddTensorOutput(output_index)); @@ -1098,17 +1100,17 @@ class NNAPIDelegateKernel { } } - // Add state input tensors as model inputs - for (int i : model_state_inputs_) { - inputs.push_back(i); - } - size_t total_output_byte_size = 0; for (int i : TfLiteIntArrayView(output_tensors)) { outputs.push_back(operand_mapping_.lite_index_to_ann(i)); total_output_byte_size += context->tensors[i].bytes; } + // Add state output tensors as model inputs + for (int i : model_state_outputs_) { + outputs.push_back(i); + } + // Tell ANN to declare inputs/outputs CHECK_NN(context, ANeuralNetworksModel_identifyInputsAndOutputs( nn_model_.get(), inputs.size(), inputs.data(), diff --git a/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate_test.cc b/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate_test.cc index 3224b23a0c..4b01aefd6a 100644 --- a/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate_test.cc +++ b/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate_test.cc @@ -1773,15 +1773,16 @@ class RNNOpModel : public SingleOpModelWithNNAPI { weights_ = AddInput(weights); recurrent_weights_ = AddInput(recurrent_weights); bias_ = AddInput(TensorType_FLOAT32); - hidden_state_ = AddOutput(TensorType_FLOAT32); + hidden_state_ = AddInput(TensorType_FLOAT32, true); output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp( BuiltinOperator_RNN, BuiltinOptions_RNNOptions, CreateRNNOptions(builder_, ActivationFunctionType_RELU).Union()); - BuildInterpreter({{batches_, input_size_}, - {units_, input_size_}, - {units_, units_}, - {units_}}); + BuildInterpreter({{batches_, input_size_}, // input tensor + {units_, input_size_}, // weights tensor + {units_, units_}, // recurrent weights tensor + {units_}, // bias tensor + {batches_, units_}}); // hidden state tensor } void SetBias(std::initializer_list<float> f) { PopulateTensor(bias_, f); } @@ -1802,14 +1803,6 @@ class RNNOpModel : public SingleOpModelWithNNAPI { PopulateTensor(input_, offset, begin, end); } - void ResetHiddenState() { - const int zero_buffer_size = units_ * batches_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(hidden_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - std::vector<float> GetOutput() { return ExtractVector<float>(output_); } int input_size() { return input_size_; } @@ -1835,7 +1828,6 @@ TEST(NNAPIDelegate, RnnBlackBoxTest) { rnn.SetBias(rnn_bias); rnn.SetRecurrentWeights(rnn_recurrent_weights); - rnn.ResetHiddenState(); const int input_sequence_size = sizeof(rnn_input) / sizeof(float) / (rnn.input_size() * rnn.num_batches()); @@ -1968,16 +1960,20 @@ class BaseSVDFOpModel : public SingleOpModelWithNNAPI { weights_feature_ = AddInput(weights_feature_type); weights_time_ = AddInput(weights_time_type); bias_ = AddNullInput(); - state_ = AddOutput(TensorType_FLOAT32); + const int num_filters = units * rank; + activation_state_ = AddInput( + TensorData{TensorType_FLOAT32, {batches, memory_size * num_filters}}, + /*is_variable=*/true); output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp( BuiltinOperator_SVDF, BuiltinOptions_SVDFOptions, CreateSVDFOptions(builder_, rank, ActivationFunctionType_NONE).Union()); BuildInterpreter({ - {batches_, input_size_}, // Input tensor - {units_ * rank, input_size_}, // weights_feature tensor - {units_ * rank, memory_size_}, // weights_time tensor - {units_} // bias tensor + {batches_, input_size_}, // input tensor + {units_ * rank, input_size_}, // weights_feature tensor + {units_ * rank, memory_size_}, // weights_time tensor + {units_}, // bias tensor + {batches, memory_size * num_filters} // activation_state tensor }); } @@ -1996,15 +1992,6 @@ class BaseSVDFOpModel : public SingleOpModelWithNNAPI { PopulateTensor(input_, offset, begin, end); } - // Resets the state of SVDF op by filling it with 0's. - void ResetState() { - const int zero_buffer_size = rank_ * units_ * batches_ * memory_size_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - // Extracts the output tensor from the SVDF op. std::vector<float> GetOutput() { return ExtractVector<float>(output_); } @@ -2017,7 +2004,7 @@ class BaseSVDFOpModel : public SingleOpModelWithNNAPI { int weights_feature_; int weights_time_; int bias_; - int state_; + int activation_state_; int output_; int batches_; @@ -2081,7 +2068,6 @@ TEST(NNAPIDelegate, SVDFBlackBoxTestRank1) { -0.10781813, 0.27201805, 0.14324132, -0.23681851, -0.27115166, -0.01580888, -0.14943552, 0.15465137, 0.09784451, -0.0337657}); - svdf.ResetState(); svdf.VerifyGoldens(svdf_input, svdf_golden_output_rank_1, sizeof(svdf_input)); } @@ -2120,7 +2106,6 @@ TEST(NNAPIDelegate, SVDFBlackBoxTestRank2) { 0.27179423, -0.04710215, 0.31069002, 0.22672787, 0.09580326, 0.08682203, 0.1258215, 0.1851041, 0.29228821, 0.12366763}); - svdf.ResetState(); svdf.VerifyGoldens(svdf_input, svdf_golden_output_rank_2, sizeof(svdf_input)); } @@ -2192,8 +2177,12 @@ class LSTMOpModel : public SingleOpModelWithNNAPI { projection_bias_ = AddNullInput(); } - output_state_ = AddOutput(TensorType_FLOAT32); - cell_state_ = AddOutput(TensorType_FLOAT32); + // Adding the 2 input state tensors. + input_activation_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_batch_, n_output_}}, true); + input_cell_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_batch_, n_cell_}}, true); + output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp(BuiltinOperator_LSTM, BuiltinOptions_LSTMOptions, @@ -2271,22 +2260,6 @@ class LSTMOpModel : public SingleOpModelWithNNAPI { PopulateTensor(projection_bias_, f); } - void ResetOutputState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(output_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - - void ResetCellState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(cell_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - void SetInput(int offset, const float* begin, const float* end) { PopulateTensor(input_, offset, const_cast<float*>(begin), const_cast<float*>(end)); @@ -2495,10 +2468,6 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { lstm.SetRecurrentToForgetWeights(recurrent_to_forget_weights_); lstm.SetRecurrentToOutputWeights(recurrent_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -2602,10 +2571,6 @@ TEST_F(CifgNoPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { lstm.SetCellToForgetWeights(cell_to_forget_weights_); lstm.SetCellToOutputWeights(cell_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -3266,10 +3231,6 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, LstmBlackBoxTest) { lstm.SetProjectionWeights(projection_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } diff --git a/tensorflow/contrib/lite/examples/android/build.gradle b/tensorflow/contrib/lite/examples/android/build.gradle index a47fa4bbf6..66a62a921a 100644 --- a/tensorflow/contrib/lite/examples/android/build.gradle +++ b/tensorflow/contrib/lite/examples/android/build.gradle @@ -14,6 +14,7 @@ buildscript { allprojects { repositories { + google() jcenter() } } diff --git a/tensorflow/contrib/lite/examples/ios/simple/ios_image_load.h b/tensorflow/contrib/lite/examples/ios/simple/ios_image_load.h index 98934ce41d..96d2810937 100644 --- a/tensorflow/contrib/lite/examples/ios/simple/ios_image_load.h +++ b/tensorflow/contrib/lite/examples/ios/simple/ios_image_load.h @@ -12,12 +12,12 @@ // See the License for the specific language governing permissions and // limitations under the License. -#ifndef TENSORFLOW_EXAMPLES_IOS_IOS_IMAGE_LOAD_H_ -#define TENSORFLOW_EXAMPLES_IOS_IOS_IMAGE_LOAD_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_EXAMPLES_IOS_SIMPLE_IOS_IMAGE_LOAD_H_ +#define TENSORFLOW_CONTRIB_LITE_EXAMPLES_IOS_SIMPLE_IOS_IMAGE_LOAD_H_ #include <vector> std::vector<uint8_t> LoadImageFromFile(const char* file_name, int* out_width, int* out_height, int* out_channels); -#endif // TENSORFLOW_EXAMPLES_IOS_IOS_IMAGE_LOAD_H_ +#endif // TENSORFLOW_CONTRIB_LITE_EXAMPLES_IOS_SIMPLE_IOS_IMAGE_LOAD_H_ diff --git a/tensorflow/contrib/lite/examples/label_image/bitmap_helpers.h b/tensorflow/contrib/lite/examples/label_image/bitmap_helpers.h index 5fc75b1f72..7881ee80ca 100644 --- a/tensorflow/contrib/lite/examples/label_image/bitmap_helpers.h +++ b/tensorflow/contrib/lite/examples/label_image/bitmap_helpers.h @@ -39,4 +39,4 @@ template void resize<float>(float*, unsigned char*, int, int, int, int, int, } // namespace label_image } // namespace tflite -#endif // TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_BITMAP_HELPERS_H +#endif // TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_BITMAP_HELPERS_H_ diff --git a/tensorflow/contrib/lite/examples/label_image/get_top_n.h b/tensorflow/contrib/lite/examples/label_image/get_top_n.h index 70a7586fe6..adef434c00 100644 --- a/tensorflow/contrib/lite/examples/label_image/get_top_n.h +++ b/tensorflow/contrib/lite/examples/label_image/get_top_n.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_H -#define TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_H +#ifndef TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_H_ +#define TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_H_ #include "tensorflow/contrib/lite/examples/label_image/get_top_n_impl.h" @@ -35,4 +35,4 @@ template void get_top_n<float>(float*, int, size_t, float, } // namespace label_image } // namespace tflite -#endif // TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_H +#endif // TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_H_ diff --git a/tensorflow/contrib/lite/examples/label_image/get_top_n_impl.h b/tensorflow/contrib/lite/examples/label_image/get_top_n_impl.h index e416fbd39b..708cf2f2b1 100644 --- a/tensorflow/contrib/lite/examples/label_image/get_top_n_impl.h +++ b/tensorflow/contrib/lite/examples/label_image/get_top_n_impl.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_IMPL_H -#define TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_IMPL_H +#ifndef TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_IMPL_H_ +#define TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_IMPL_H_ #include <algorithm> #include <queue> @@ -67,4 +67,4 @@ void get_top_n(T* prediction, int prediction_size, size_t num_results, } // namespace label_image } // namespace tflite -#endif // TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_IMPL_H +#endif // TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_GET_TOP_N_IMPL_H_ diff --git a/tensorflow/contrib/lite/examples/label_image/label_image.h b/tensorflow/contrib/lite/examples/label_image/label_image.h index 34c223f713..f0be881b58 100644 --- a/tensorflow/contrib/lite/examples/label_image/label_image.h +++ b/tensorflow/contrib/lite/examples/label_image/label_image.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_LABEL_IMAGE_H -#define TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_LABEL_IMAGE_H +#ifndef TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_LABEL_IMAGE_H_ +#define TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_LABEL_IMAGE_H_ #include "tensorflow/contrib/lite/string.h" @@ -40,4 +40,4 @@ struct Settings { } // namespace label_image } // namespace tflite -#endif // TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_LABEL_IMAGE_H +#endif // TENSORFLOW_CONTRIB_LITE_EXAMPLES_LABEL_IMAGE_LABEL_IMAGE_H_ diff --git a/tensorflow/contrib/lite/experimental/examples/unity/TensorFlowLitePlugin/Assets/TensorFlowLite/SDK/Scripts/Interpreter.cs b/tensorflow/contrib/lite/experimental/examples/unity/TensorFlowLitePlugin/Assets/TensorFlowLite/SDK/Scripts/Interpreter.cs index b6905b5fbf..676783063d 100644 --- a/tensorflow/contrib/lite/experimental/examples/unity/TensorFlowLitePlugin/Assets/TensorFlowLite/SDK/Scripts/Interpreter.cs +++ b/tensorflow/contrib/lite/experimental/examples/unity/TensorFlowLitePlugin/Assets/TensorFlowLite/SDK/Scripts/Interpreter.cs @@ -29,15 +29,16 @@ namespace TensorFlowLite { private const string TensorFlowLibrary = "tensorflowlite_c"; - private TFL_Interpreter handle; + private TFL_Model model; + private TFL_Interpreter interpreter; public Interpreter(byte[] modelData) { GCHandle modelDataHandle = GCHandle.Alloc(modelData, GCHandleType.Pinned); IntPtr modelDataPtr = modelDataHandle.AddrOfPinnedObject(); - TFL_Model model = TFL_NewModel(modelDataPtr, modelData.Length); - handle = TFL_NewInterpreter(model, /*options=*/IntPtr.Zero); - TFL_DeleteModel(model); - if (handle == IntPtr.Zero) throw new Exception("Failed to create TensorFlowLite Interpreter"); + model = TFL_NewModel(modelDataPtr, modelData.Length); + if (model == IntPtr.Zero) throw new Exception("Failed to create TensorFlowLite Model"); + interpreter = TFL_NewInterpreter(model, /*options=*/IntPtr.Zero); + if (interpreter == IntPtr.Zero) throw new Exception("Failed to create TensorFlowLite Interpreter"); } ~Interpreter() { @@ -45,43 +46,45 @@ namespace TensorFlowLite } public void Dispose() { - if (handle != IntPtr.Zero) TFL_DeleteInterpreter(handle); - handle = IntPtr.Zero; + if (interpreter != IntPtr.Zero) TFL_DeleteInterpreter(interpreter); + interpreter = IntPtr.Zero; + if (model != IntPtr.Zero) TFL_DeleteModel(model); + model = IntPtr.Zero; } public void Invoke() { - ThrowIfError(TFL_InterpreterInvoke(handle)); + ThrowIfError(TFL_InterpreterInvoke(interpreter)); } public int GetInputTensorCount() { - return TFL_InterpreterGetInputTensorCount(handle); + return TFL_InterpreterGetInputTensorCount(interpreter); } public void SetInputTensorData(int inputTensorIndex, Array inputTensorData) { GCHandle tensorDataHandle = GCHandle.Alloc(inputTensorData, GCHandleType.Pinned); IntPtr tensorDataPtr = tensorDataHandle.AddrOfPinnedObject(); - TFL_Tensor tensor = TFL_InterpreterGetInputTensor(handle, inputTensorIndex); + TFL_Tensor tensor = TFL_InterpreterGetInputTensor(interpreter, inputTensorIndex); ThrowIfError(TFL_TensorCopyFromBuffer( tensor, tensorDataPtr, Buffer.ByteLength(inputTensorData))); } public void ResizeInputTensor(int inputTensorIndex, int[] inputTensorShape) { ThrowIfError(TFL_InterpreterResizeInputTensor( - handle, inputTensorIndex, inputTensorShape, inputTensorShape.Length)); + interpreter, inputTensorIndex, inputTensorShape, inputTensorShape.Length)); } public void AllocateTensors() { - ThrowIfError(TFL_InterpreterAllocateTensors(handle)); + ThrowIfError(TFL_InterpreterAllocateTensors(interpreter)); } public int GetOutputTensorCount() { - return TFL_InterpreterGetOutputTensorCount(handle); + return TFL_InterpreterGetOutputTensorCount(interpreter); } public void GetOutputTensorData(int outputTensorIndex, Array outputTensorData) { GCHandle tensorDataHandle = GCHandle.Alloc(outputTensorData, GCHandleType.Pinned); IntPtr tensorDataPtr = tensorDataHandle.AddrOfPinnedObject(); - TFL_Tensor tensor = TFL_InterpreterGetOutputTensor(handle, outputTensorIndex); + TFL_Tensor tensor = TFL_InterpreterGetOutputTensor(interpreter, outputTensorIndex); ThrowIfError(TFL_TensorCopyToBuffer( tensor, tensorDataPtr, Buffer.ByteLength(outputTensorData))); } diff --git a/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder.cc b/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder.cc index b6c9a28be6..121997dcb2 100644 --- a/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder.cc +++ b/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder.cc @@ -13,7 +13,7 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ #include <vector> -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers #include "tensorflow/contrib/lite/context.h" #include "tensorflow/contrib/lite/experimental/kernels/ctc_beam_search.h" #include "tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h" diff --git a/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder_test.cc b/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder_test.cc index 0da5532e66..32458305c4 100644 --- a/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder_test.cc +++ b/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder_test.cc @@ -18,7 +18,7 @@ limitations under the License. #include <vector> #include <gtest/gtest.h> -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers #include "tensorflow/contrib/lite/interpreter.h" #include "tensorflow/contrib/lite/kernels/register.h" #include "tensorflow/contrib/lite/kernels/test_util.h" diff --git a/tensorflow/contrib/lite/g3doc/_book.yaml b/tensorflow/contrib/lite/g3doc/_book.yaml index 98abd5743b..1dffe30790 100644 --- a/tensorflow/contrib/lite/g3doc/_book.yaml +++ b/tensorflow/contrib/lite/g3doc/_book.yaml @@ -1,6 +1,7 @@ upper_tabs: # Tabs left of dropdown menu - include: /_upper_tabs_left.yaml +- include: /versions/_upper_tabs_versions.yaml # Dropdown menu - name: Ecosystem path: /ecosystem diff --git a/tensorflow/contrib/lite/g3doc/apis.md b/tensorflow/contrib/lite/g3doc/apis.md index 776803da8c..f255017ad9 100644 --- a/tensorflow/contrib/lite/g3doc/apis.md +++ b/tensorflow/contrib/lite/g3doc/apis.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # TensorFlow Lite APIs diff --git a/tensorflow/contrib/lite/g3doc/custom_operators.md b/tensorflow/contrib/lite/g3doc/custom_operators.md index d979353bb3..ee6150b60e 100644 --- a/tensorflow/contrib/lite/g3doc/custom_operators.md +++ b/tensorflow/contrib/lite/g3doc/custom_operators.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # How to use custom operators diff --git a/tensorflow/contrib/lite/g3doc/demo_android.md b/tensorflow/contrib/lite/g3doc/demo_android.md index d79a2696b4..c38b928684 100644 --- a/tensorflow/contrib/lite/g3doc/demo_android.md +++ b/tensorflow/contrib/lite/g3doc/demo_android.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Android Demo App diff --git a/tensorflow/contrib/lite/g3doc/demo_ios.md b/tensorflow/contrib/lite/g3doc/demo_ios.md index a554898899..7579ad84a0 100644 --- a/tensorflow/contrib/lite/g3doc/demo_ios.md +++ b/tensorflow/contrib/lite/g3doc/demo_ios.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # iOS Demo App diff --git a/tensorflow/contrib/lite/g3doc/devguide.md b/tensorflow/contrib/lite/g3doc/devguide.md index dc9cc98c08..90e7915c52 100644 --- a/tensorflow/contrib/lite/g3doc/devguide.md +++ b/tensorflow/contrib/lite/g3doc/devguide.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Developer Guide diff --git a/tensorflow/contrib/lite/g3doc/ios.md b/tensorflow/contrib/lite/g3doc/ios.md index d78d373ccf..5ff0412209 100644 --- a/tensorflow/contrib/lite/g3doc/ios.md +++ b/tensorflow/contrib/lite/g3doc/ios.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # TensorFlow Lite for iOS diff --git a/tensorflow/contrib/lite/g3doc/models.md b/tensorflow/contrib/lite/g3doc/models.md index 4ceb9a53dc..b984671e89 100644 --- a/tensorflow/contrib/lite/g3doc/models.md +++ b/tensorflow/contrib/lite/g3doc/models.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # List of Hosted Models diff --git a/tensorflow/contrib/lite/g3doc/ops_versioning.md b/tensorflow/contrib/lite/g3doc/ops_versioning.md index b06f4fd3b8..0d571ce547 100644 --- a/tensorflow/contrib/lite/g3doc/ops_versioning.md +++ b/tensorflow/contrib/lite/g3doc/ops_versioning.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # TensorFlow Lite Ops Versioning diff --git a/tensorflow/contrib/lite/g3doc/overview.md b/tensorflow/contrib/lite/g3doc/overview.md index be60d7941a..8cf43496df 100644 --- a/tensorflow/contrib/lite/g3doc/overview.md +++ b/tensorflow/contrib/lite/g3doc/overview.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Introduction to TensorFlow Lite diff --git a/tensorflow/contrib/lite/g3doc/performance.md b/tensorflow/contrib/lite/g3doc/performance.md index 5cd0aab44f..28cb6aba6e 100644 --- a/tensorflow/contrib/lite/g3doc/performance.md +++ b/tensorflow/contrib/lite/g3doc/performance.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Performance diff --git a/tensorflow/contrib/lite/g3doc/rpi.md b/tensorflow/contrib/lite/g3doc/rpi.md index 9fcf79ba00..8ed8640582 100644 --- a/tensorflow/contrib/lite/g3doc/rpi.md +++ b/tensorflow/contrib/lite/g3doc/rpi.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # TensorFlow Lite for Raspberry Pi diff --git a/tensorflow/contrib/lite/g3doc/tf_ops_compatibility.md b/tensorflow/contrib/lite/g3doc/tf_ops_compatibility.md index aa65ec9988..8660d29855 100644 --- a/tensorflow/contrib/lite/g3doc/tf_ops_compatibility.md +++ b/tensorflow/contrib/lite/g3doc/tf_ops_compatibility.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # TensorFlow Lite & TensorFlow Compatibility Guide @@ -843,6 +841,31 @@ Outputs { } ``` +**UNPACK** + +``` +Inputs { + 0: a tensor. + 1: an integer. + 2: an integer. +} +Outputs { + 0-N: tensors of unpacked tensor. +} +``` + +**FLOOR_DIV** + +``` +Inputs { + 0: a list of tensors. + 1: a list of tensors. +} +Outputs { + 0: A tensor of floor_div output tensors. +} +``` + And these are TensorFlow Lite operations that are present but not ready for custom models yet: diff --git a/tensorflow/contrib/lite/g3doc/tfmobile/android_build.md b/tensorflow/contrib/lite/g3doc/tfmobile/android_build.md index 76e16fc9db..c7cdee07de 100644 --- a/tensorflow/contrib/lite/g3doc/tfmobile/android_build.md +++ b/tensorflow/contrib/lite/g3doc/tfmobile/android_build.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Building TensorFlow on Android diff --git a/tensorflow/contrib/lite/g3doc/tfmobile/index.md b/tensorflow/contrib/lite/g3doc/tfmobile/index.md index bd047bfcec..d003bb2f38 100644 --- a/tensorflow/contrib/lite/g3doc/tfmobile/index.md +++ b/tensorflow/contrib/lite/g3doc/tfmobile/index.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Overview diff --git a/tensorflow/contrib/lite/g3doc/tfmobile/ios_build.md b/tensorflow/contrib/lite/g3doc/tfmobile/ios_build.md index 6223707892..be8b4100c8 100644 --- a/tensorflow/contrib/lite/g3doc/tfmobile/ios_build.md +++ b/tensorflow/contrib/lite/g3doc/tfmobile/ios_build.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Building TensorFlow on iOS diff --git a/tensorflow/contrib/lite/g3doc/tfmobile/linking_libs.md b/tensorflow/contrib/lite/g3doc/tfmobile/linking_libs.md index 4c2071ed05..4d4bb3bc08 100644 --- a/tensorflow/contrib/lite/g3doc/tfmobile/linking_libs.md +++ b/tensorflow/contrib/lite/g3doc/tfmobile/linking_libs.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Integrating TensorFlow libraries diff --git a/tensorflow/contrib/lite/g3doc/tfmobile/optimizing.md b/tensorflow/contrib/lite/g3doc/tfmobile/optimizing.md index a0192c3541..7436594fd8 100644 --- a/tensorflow/contrib/lite/g3doc/tfmobile/optimizing.md +++ b/tensorflow/contrib/lite/g3doc/tfmobile/optimizing.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Optimizing for mobile diff --git a/tensorflow/contrib/lite/g3doc/tfmobile/prepare_models.md b/tensorflow/contrib/lite/g3doc/tfmobile/prepare_models.md index 6b4e4a92bd..d1c67d4c61 100644 --- a/tensorflow/contrib/lite/g3doc/tfmobile/prepare_models.md +++ b/tensorflow/contrib/lite/g3doc/tfmobile/prepare_models.md @@ -1,5 +1,3 @@ -book_path: /mobile/_book.yaml -project_path: /mobile/_project.yaml # Preparing models for mobile deployment diff --git a/tensorflow/contrib/lite/interpreter.cc b/tensorflow/contrib/lite/interpreter.cc index 362e588725..5ab53f4c1d 100644 --- a/tensorflow/contrib/lite/interpreter.cc +++ b/tensorflow/contrib/lite/interpreter.cc @@ -476,6 +476,10 @@ TfLiteStatus Interpreter::ResetVariableTensorsToZero() { return kTfLiteOk; } +void Interpreter::ReserveNodes(int count) { + nodes_and_registration_.reserve(count); +} + TfLiteStatus Interpreter::AddNodeWithParameters( const std::vector<int>& inputs, const std::vector<int>& outputs, const char* init_data, size_t init_data_size, void* builtin_data, diff --git a/tensorflow/contrib/lite/interpreter.h b/tensorflow/contrib/lite/interpreter.h index 7d69aa2ad3..2b1f1819b9 100644 --- a/tensorflow/contrib/lite/interpreter.h +++ b/tensorflow/contrib/lite/interpreter.h @@ -136,6 +136,11 @@ class Interpreter { // interpreter. TfLiteStatus SetVariables(std::vector<int> variables); + // Ensure the internal node storage memory allocates at least `count` + // spots for node. NOTE, this doesn't actually add operators. This is an + // efficiency optimization that is subject to change. + void ReserveNodes(int count); + // Adds a node with the given parameters and returns the index of the new // node in `node_index` (optionally). Interpreter will take ownership of // `builtin_data` and destroy it with `free`. Ownership of 'init_data' diff --git a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/DataType.java b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/DataType.java index 94a1ec65d6..41093e8ffe 100644 --- a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/DataType.java +++ b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/DataType.java @@ -15,8 +15,8 @@ limitations under the License. package org.tensorflow.lite; -/** Type of elements in a {@link TfLiteTensor}. */ -enum DataType { +/** Represents the type of elements in a TensorFlow Lite {@link Tensor} as an enum. */ +public enum DataType { /** 32-bit single precision floating point. */ FLOAT32(1), @@ -35,13 +35,29 @@ enum DataType { this.value = value; } - /** Corresponding value of the kTfLite* enum in the TensorFlow Lite CC API. */ - int getNumber() { + /** Returns the size of an element of this type, in bytes, or -1 if element size is variable. */ + public int byteSize() { + switch (this) { + case FLOAT32: + return 4; + case INT32: + return 4; + case UINT8: + return 1; + case INT64: + return 8; + } + throw new IllegalArgumentException( + "DataType error: DataType " + this + " is not supported yet"); + } + + /** Corresponding value of the TfLiteType enum in the TensorFlow Lite C API. */ + int c() { return value; } - /** Converts an integer to the corresponding type. */ - static DataType fromNumber(int c) { + /** Converts a C TfLiteType enum value to the corresponding type. */ + static DataType fromC(int c) { for (DataType t : values) { if (t.value == c) { return t; @@ -55,22 +71,6 @@ enum DataType { + ")"); } - /** Returns byte size of the type. */ - int elemByteSize() { - switch (this) { - case FLOAT32: - return 4; - case INT32: - return 4; - case UINT8: - return 1; - case INT64: - return 8; - } - throw new IllegalArgumentException( - "DataType error: DataType " + this + " is not supported yet"); - } - /** Gets string names of the data type. */ String toStringName() { switch (this) { diff --git a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Interpreter.java b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Interpreter.java index 7002f82677..b84720ae8e 100644 --- a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Interpreter.java +++ b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Interpreter.java @@ -162,9 +162,7 @@ public final class Interpreter implements AutoCloseable { */ public void runForMultipleInputsOutputs( @NonNull Object[] inputs, @NonNull Map<Integer, Object> outputs) { - if (wrapper == null) { - throw new IllegalStateException("Internal error: The Interpreter has already been closed."); - } + checkNotClosed(); wrapper.run(inputs, outputs); } @@ -174,12 +172,16 @@ public final class Interpreter implements AutoCloseable { * <p>IllegalArgumentException will be thrown if it fails to resize. */ public void resizeInput(int idx, @NonNull int[] dims) { - if (wrapper == null) { - throw new IllegalStateException("Internal error: The Interpreter has already been closed."); - } + checkNotClosed(); wrapper.resizeInput(idx, dims); } + /** Gets the number of input tensors. */ + public int getInputTensorCount() { + checkNotClosed(); + return wrapper.getInputTensorCount(); + } + /** * Gets index of an input given the op name of the input. * @@ -187,51 +189,65 @@ public final class Interpreter implements AutoCloseable { * to initialize the {@link Interpreter}. */ public int getInputIndex(String opName) { - if (wrapper == null) { - throw new IllegalStateException("Internal error: The Interpreter has already been closed."); - } + checkNotClosed(); return wrapper.getInputIndex(opName); } /** + * Gets the Tensor associated with the provdied input index. + * + * <p>IllegalArgumentException will be thrown if the provided index is invalid. + */ + public Tensor getInputTensor(int inputIndex) { + checkNotClosed(); + return wrapper.getInputTensor(inputIndex); + } + + /** Gets the number of output Tensors. */ + public int getOutputTensorCount() { + checkNotClosed(); + return wrapper.getOutputTensorCount(); + } + + /** * Gets index of an output given the op name of the output. * * <p>IllegalArgumentException will be thrown if the op name does not exist in the model file used * to initialize the {@link Interpreter}. */ public int getOutputIndex(String opName) { - if (wrapper == null) { - throw new IllegalStateException("Internal error: The Interpreter has already been closed."); - } + checkNotClosed(); return wrapper.getOutputIndex(opName); } /** + * Gets the Tensor associated with the provdied output index. + * + * <p>IllegalArgumentException will be thrown if the provided index is invalid. + */ + public Tensor getOutputTensor(int outputIndex) { + checkNotClosed(); + return wrapper.getOutputTensor(outputIndex); + } + + /** * Returns native inference timing. * <p>IllegalArgumentException will be thrown if the model is not initialized by the * {@link Interpreter}. */ public Long getLastNativeInferenceDurationNanoseconds() { - if (wrapper == null) { - throw new IllegalStateException("Internal error: The interpreter has already been closed."); - } + checkNotClosed(); return wrapper.getLastNativeInferenceDurationNanoseconds(); } /** Turns on/off Android NNAPI for hardware acceleration when it is available. */ public void setUseNNAPI(boolean useNNAPI) { - if (wrapper != null) { - wrapper.setUseNNAPI(useNNAPI); - } else { - throw new IllegalStateException( - "Internal error: NativeInterpreterWrapper has already been closed."); - } + checkNotClosed(); + wrapper.setUseNNAPI(useNNAPI); } public void setNumThreads(int numThreads) { - if (wrapper == null) { - throw new IllegalStateException("The interpreter has already been closed."); - } + checkNotClosed(); wrapper.setNumThreads(numThreads); } @@ -253,5 +269,11 @@ public final class Interpreter implements AutoCloseable { } } + private void checkNotClosed() { + if (wrapper == null) { + throw new IllegalStateException("Internal error: The Interpreter has already been closed."); + } + } + NativeInterpreterWrapper wrapper; } diff --git a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java index 767a220f8c..fa25082304 100644 --- a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java +++ b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java @@ -114,12 +114,10 @@ final class NativeInterpreterWrapper implements AutoCloseable { } } - if (!isMemoryAllocated) { + boolean needsAllocation = !isMemoryAllocated; + if (needsAllocation) { allocateTensors(interpreterHandle, errorHandle); isMemoryAllocated = true; - // Allocation can trigger dynamic resizing of output tensors, so clear the - // output tensor cache. - Arrays.fill(outputTensors, null); } for (int i = 0; i < inputs.length; ++i) { @@ -130,6 +128,14 @@ final class NativeInterpreterWrapper implements AutoCloseable { run(interpreterHandle, errorHandle); long inferenceDurationNanoseconds = System.nanoTime() - inferenceStartNanos; + // Allocation can trigger dynamic resizing of output tensors, so refresh all output shapes. + if (needsAllocation) { + for (int i = 0; i < outputTensors.length; ++i) { + if (outputTensors[i] != null) { + outputTensors[i].refreshShape(); + } + } + } for (Map.Entry<Integer, Object> output : outputs.entrySet()) { getOutputTensor(output.getKey()).copyTo(output.getValue()); } @@ -144,8 +150,9 @@ final class NativeInterpreterWrapper implements AutoCloseable { void resizeInput(int idx, int[] dims) { if (resizeInput(interpreterHandle, errorHandle, idx, dims)) { isMemoryAllocated = false; - // Resizing will invalidate the Tensor's shape, so invalidate the Tensor handle. - inputTensors[idx] = null; + if (inputTensors[idx] != null) { + inputTensors[idx].refreshShape(); + } } } @@ -230,6 +237,11 @@ final class NativeInterpreterWrapper implements AutoCloseable { return getOutputQuantizationScale(interpreterHandle, index); } + /** Gets the number of input tensors. */ + int getInputTensorCount() { + return inputTensors.length; + } + /** * Gets the input {@link Tensor} for the provided input index. * @@ -247,6 +259,11 @@ final class NativeInterpreterWrapper implements AutoCloseable { return inputTensor; } + /** Gets the number of output tensors. */ + int getOutputTensorCount() { + return inputTensors.length; + } + /** * Gets the output {@link Tensor} for the provided output index. * diff --git a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Tensor.java b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Tensor.java index 2403570c52..f174178d98 100644 --- a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Tensor.java +++ b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Tensor.java @@ -26,7 +26,7 @@ import java.util.Arrays; * <p>The native handle of a {@code Tensor} belongs to {@code NativeInterpreterWrapper}, thus not * needed to be closed here. */ -final class Tensor { +public final class Tensor { static Tensor fromHandle(long nativeHandle) { return new Tensor(nativeHandle); @@ -37,11 +37,26 @@ final class Tensor { return dtype; } + /** + * Returns the number of dimensions (sometimes referred to as <a + * href="https://www.tensorflow.org/resources/dims_types.html#rank">rank</a>) of the Tensor. + * + * <p>Will be 0 for a scalar, 1 for a vector, 2 for a matrix, 3 for a 3-dimensional tensor etc. + */ + public int numDimensions() { + return shapeCopy.length; + } + /** Returns the size, in bytes, of the tensor data. */ public int numBytes() { return numBytes(nativeHandle); } + /** Returns the number of elements in a flattened (1-D) view of the tensor. */ + public int numElements() { + return computeNumElements(shapeCopy); + } + /** * Returns the <a href="https://www.tensorflow.org/resources/dims_types.html#shape">shape</a> of * the Tensor, i.e., the sizes of each dimension. @@ -103,13 +118,22 @@ final class Tensor { if (isByteBuffer(input)) { return null; } - int[] inputShape = shapeOf(input); + int[] inputShape = computeShapeOf(input); if (Arrays.equals(shapeCopy, inputShape)) { return null; } return inputShape; } + /** + * Forces a refresh of the tensor's cached shape. + * + * <p>This is useful if the tensor is resized or has a dynamic shape. + */ + void refreshShape() { + this.shapeCopy = shape(nativeHandle); + } + /** Returns the type of the data. */ static DataType dataTypeOf(Object o) { if (o != null) { @@ -132,22 +156,31 @@ final class Tensor { } /** Returns the shape of an object as an int array. */ - static int[] shapeOf(Object o) { - int size = numDimensions(o); + static int[] computeShapeOf(Object o) { + int size = computeNumDimensions(o); int[] dimensions = new int[size]; fillShape(o, 0, dimensions); return dimensions; } + /** Returns the number of elements in a flattened (1-D) view of the tensor's shape. */ + static int computeNumElements(int[] shape) { + int n = 1; + for (int i = 0; i < shape.length; ++i) { + n *= shape[i]; + } + return n; + } + /** Returns the number of dimensions of a multi-dimensional array, otherwise 0. */ - static int numDimensions(Object o) { + static int computeNumDimensions(Object o) { if (o == null || !o.getClass().isArray()) { return 0; } if (Array.getLength(o) == 0) { throw new IllegalArgumentException("Array lengths cannot be 0."); } - return 1 + numDimensions(Array.get(o, 0)); + return 1 + computeNumDimensions(Array.get(o, 0)); } /** Recursively populates the shape dimensions for a given (multi-dimensional) array. */ @@ -188,7 +221,7 @@ final class Tensor { dtype, o.getClass().getName(), oType)); } - int[] oShape = shapeOf(o); + int[] oShape = computeShapeOf(o); if (!Arrays.equals(oShape, shapeCopy)) { throw new IllegalArgumentException( String.format( @@ -204,11 +237,11 @@ final class Tensor { private final long nativeHandle; private final DataType dtype; - private final int[] shapeCopy; + private int[] shapeCopy; private Tensor(long nativeHandle) { this.nativeHandle = nativeHandle; - this.dtype = DataType.fromNumber(dtype(nativeHandle)); + this.dtype = DataType.fromC(dtype(nativeHandle)); this.shapeCopy = shape(nativeHandle); } diff --git a/tensorflow/contrib/lite/java/src/main/native/exception_jni.h b/tensorflow/contrib/lite/java/src/main/native/exception_jni.h index 3ffff052df..2a4bbdbead 100644 --- a/tensorflow/contrib/lite/java/src/main/native/exception_jni.h +++ b/tensorflow/contrib/lite/java/src/main/native/exception_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_JAVA_EXCEPTION_JNI_H_ -#define TENSORFLOW_CONTRIB_LITE_JAVA_EXCEPTION_JNI_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_EXCEPTION_JNI_H_ +#define TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_EXCEPTION_JNI_H_ #include <jni.h> #include "tensorflow/contrib/lite/error_reporter.h" @@ -47,4 +47,4 @@ class BufferErrorReporter : public tflite::ErrorReporter { #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_CONTRIB_LITE_JAVA_EXCEPTION_JNI_H_ +#endif // TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_EXCEPTION_JNI_H_ diff --git a/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.h b/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.h index 618fba480e..55ca47fed7 100644 --- a/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.h +++ b/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_JAVA_NATIVEINTERPRETERWRAPPER_JNI_H_ -#define TENSORFLOW_CONTRIB_LITE_JAVA_NATIVEINTERPRETERWRAPPER_JNI_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_NATIVEINTERPRETERWRAPPER_JNI_H_ +#define TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_NATIVEINTERPRETERWRAPPER_JNI_H_ #include <jni.h> #include <stdio.h> @@ -230,4 +230,4 @@ JNIEXPORT void JNICALL Java_org_tensorflow_lite_NativeInterpreterWrapper_delete( #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_CONTRIB_LITE_JAVA_NATIVEINTERPRETERWRAPPER_JNI_H_ +#endif // TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_NATIVEINTERPRETERWRAPPER_JNI_H_ diff --git a/tensorflow/contrib/lite/java/src/main/native/tensor_jni.h b/tensorflow/contrib/lite/java/src/main/native/tensor_jni.h index 06e2546af8..c020f13d9c 100644 --- a/tensorflow/contrib/lite/java/src/main/native/tensor_jni.h +++ b/tensorflow/contrib/lite/java/src/main/native/tensor_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_JAVA_TENSOR_JNI_H_ -#define TENSORFLOW_CONTRIB_LITE_JAVA_TENSOR_JNI_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_TENSOR_JNI_H_ +#define TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_TENSOR_JNI_H_ #include <jni.h> #include "tensorflow/contrib/lite/context.h" @@ -92,4 +92,4 @@ Java_org_tensorflow_lite_Tensor_writeMultiDimensionalArray(JNIEnv* env, #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_CONTRIB_LITE_JAVA_TENSOR_JNI_H_ +#endif // TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_TENSOR_JNI_H_ diff --git a/tensorflow/contrib/lite/java/src/main/native/tensorflow_lite_jni.h b/tensorflow/contrib/lite/java/src/main/native/tensorflow_lite_jni.h index 65f8341149..5e2a7ded1b 100644 --- a/tensorflow/contrib/lite/java/src/main/native/tensorflow_lite_jni.h +++ b/tensorflow/contrib/lite/java/src/main/native/tensorflow_lite_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_JAVA_TENSORFLOW_LITE_JNI_H_ -#define TENSORFLOW_CONTRIB_LITE_JAVA_TENSORFLOW_LITE_JNI_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_TENSORFLOW_LITE_JNI_H_ +#define TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_TENSORFLOW_LITE_JNI_H_ #include <jni.h> @@ -33,4 +33,4 @@ Java_org_tensorflow_lite_TensorFlowLite_version(JNIEnv*, jclass); #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_CONTRIB_LITE_JAVA_TENSORFLOW_LITE_JNI_H_ +#endif // TENSORFLOW_CONTRIB_LITE_JAVA_SRC_MAIN_NATIVE_TENSORFLOW_LITE_JNI_H_ diff --git a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/DataTypeTest.java b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/DataTypeTest.java index cebc944200..6d6417f895 100644 --- a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/DataTypeTest.java +++ b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/DataTypeTest.java @@ -26,9 +26,16 @@ public final class DataTypeTest { @Test public void testElemByteSize() { - assertThat(DataType.FLOAT32.elemByteSize()).isEqualTo(4); - assertThat(DataType.INT32.elemByteSize()).isEqualTo(4); - assertThat(DataType.UINT8.elemByteSize()).isEqualTo(1); - assertThat(DataType.INT64.elemByteSize()).isEqualTo(8); + assertThat(DataType.FLOAT32.byteSize()).isEqualTo(4); + assertThat(DataType.INT32.byteSize()).isEqualTo(4); + assertThat(DataType.UINT8.byteSize()).isEqualTo(1); + assertThat(DataType.INT64.byteSize()).isEqualTo(8); + } + + @Test + public void testConversion() { + for (DataType dataType : DataType.values()) { + assertThat(DataType.fromC(dataType.c())).isEqualTo(dataType); + } } } diff --git a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/InterpreterTest.java b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/InterpreterTest.java index d66a73db94..9070b788b6 100644 --- a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/InterpreterTest.java +++ b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/InterpreterTest.java @@ -47,6 +47,10 @@ public final class InterpreterTest { public void testInterpreter() throws Exception { Interpreter interpreter = new Interpreter(MODEL_FILE); assertThat(interpreter).isNotNull(); + assertThat(interpreter.getInputTensorCount()).isEqualTo(1); + assertThat(interpreter.getInputTensor(0).dataType()).isEqualTo(DataType.FLOAT32); + assertThat(interpreter.getOutputTensorCount()).isEqualTo(1); + assertThat(interpreter.getOutputTensor(0).dataType()).isEqualTo(DataType.FLOAT32); interpreter.close(); } @@ -183,6 +187,19 @@ public final class InterpreterTest { } @Test + public void testResizeInput() { + try (Interpreter interpreter = new Interpreter(MODEL_FILE)) { + int[] inputDims = {1}; + interpreter.resizeInput(0, inputDims); + assertThat(interpreter.getInputTensor(0).shape()).isEqualTo(inputDims); + ByteBuffer input = ByteBuffer.allocateDirect(4).order(ByteOrder.nativeOrder()); + ByteBuffer output = ByteBuffer.allocateDirect(4).order(ByteOrder.nativeOrder()); + interpreter.run(input, output); + assertThat(interpreter.getOutputTensor(0).shape()).isEqualTo(inputDims); + } + } + + @Test public void testMobilenetRun() { // Create a gray image. float[][][][] img = new float[1][224][224][3]; @@ -199,6 +216,8 @@ public final class InterpreterTest { Interpreter interpreter = new Interpreter(MOBILENET_MODEL_FILE); interpreter.run(img, labels); + assertThat(interpreter.getInputTensor(0).shape()).isEqualTo(new int[] {1, 224, 224, 3}); + assertThat(interpreter.getOutputTensor(0).shape()).isEqualTo(new int[] {1, 1001}); interpreter.close(); assertThat(labels[0]) diff --git a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/TensorTest.java b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/TensorTest.java index 71ef044943..85ad393d89 100644 --- a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/TensorTest.java +++ b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/TensorTest.java @@ -64,6 +64,8 @@ public final class TensorTest { assertThat(tensor.shape()).isEqualTo(expectedShape); assertThat(tensor.dataType()).isEqualTo(DataType.FLOAT32); assertThat(tensor.numBytes()).isEqualTo(2 * 8 * 8 * 3 * 4); + assertThat(tensor.numElements()).isEqualTo(2 * 8 * 8 * 3); + assertThat(tensor.numDimensions()).isEqualTo(4); } @Test @@ -201,12 +203,12 @@ public final class TensorTest { @Test public void testNumDimensions() { int scalar = 1; - assertThat(Tensor.numDimensions(scalar)).isEqualTo(0); + assertThat(Tensor.computeNumDimensions(scalar)).isEqualTo(0); int[][] array = {{2, 4}, {1, 9}}; - assertThat(Tensor.numDimensions(array)).isEqualTo(2); + assertThat(Tensor.computeNumDimensions(array)).isEqualTo(2); try { int[] emptyArray = {}; - Tensor.numDimensions(emptyArray); + Tensor.computeNumDimensions(emptyArray); fail(); } catch (IllegalArgumentException e) { assertThat(e).hasMessageThat().contains("Array lengths cannot be 0."); @@ -214,9 +216,21 @@ public final class TensorTest { } @Test + public void testNumElements() { + int[] scalarShape = {}; + assertThat(Tensor.computeNumElements(scalarShape)).isEqualTo(1); + int[] vectorShape = {3}; + assertThat(Tensor.computeNumElements(vectorShape)).isEqualTo(3); + int[] matrixShape = {3, 4}; + assertThat(Tensor.computeNumElements(matrixShape)).isEqualTo(12); + int[] degenerateShape = {3, 4, 0}; + assertThat(Tensor.computeNumElements(degenerateShape)).isEqualTo(0); + } + + @Test public void testFillShape() { int[][][] array = {{{23}, {14}, {87}}, {{12}, {42}, {31}}}; - int num = Tensor.numDimensions(array); + int num = Tensor.computeNumDimensions(array); int[] shape = new int[num]; Tensor.fillShape(array, 0, shape); assertThat(num).isEqualTo(3); diff --git a/tensorflow/contrib/lite/kernels/BUILD b/tensorflow/contrib/lite/kernels/BUILD index 1f528fdab9..8287115f5c 100644 --- a/tensorflow/contrib/lite/kernels/BUILD +++ b/tensorflow/contrib/lite/kernels/BUILD @@ -172,6 +172,7 @@ cc_library( "expand_dims.cc", "fake_quant.cc", "floor.cc", + "floor_div.cc", "fully_connected.cc", "gather.cc", "hashtable_lookup.cc", @@ -211,6 +212,7 @@ cc_library( "transpose_conv.cc", "unidirectional_sequence_lstm.cc", "unidirectional_sequence_rnn.cc", + "unpack.cc", ], hdrs = [ "padding.h", @@ -1201,6 +1203,34 @@ tf_cc_test( ], ) +tf_cc_test( + name = "unpack_test", + size = "small", + srcs = ["unpack_test.cc"], + tags = ["tflite_not_portable_ios"], + deps = [ + ":builtin_ops", + "//tensorflow/contrib/lite:builtin_op_data", + "//tensorflow/contrib/lite:framework", + "//tensorflow/contrib/lite/kernels:test_util", + "@com_google_googletest//:gtest", + ], +) + +tf_cc_test( + name = "floor_div_test", + size = "small", + srcs = ["floor_div_test.cc"], + tags = ["tflite_not_portable_ios"], + deps = [ + ":builtin_ops", + "//tensorflow/contrib/lite:builtin_op_data", + "//tensorflow/contrib/lite:framework", + "//tensorflow/contrib/lite/kernels:test_util", + "@com_google_googletest//:gtest", + ], +) + filegroup( name = "all_files", srcs = glob( diff --git a/tensorflow/contrib/lite/kernels/audio_spectrogram.cc b/tensorflow/contrib/lite/kernels/audio_spectrogram.cc index fbbe172193..1170d84553 100644 --- a/tensorflow/contrib/lite/kernels/audio_spectrogram.cc +++ b/tensorflow/contrib/lite/kernels/audio_spectrogram.cc @@ -22,7 +22,7 @@ limitations under the License. #include "tensorflow/contrib/lite/kernels/kernel_util.h" #include "tensorflow/contrib/lite/kernels/op_macros.h" -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers namespace tflite { namespace ops { diff --git a/tensorflow/contrib/lite/kernels/audio_spectrogram_test.cc b/tensorflow/contrib/lite/kernels/audio_spectrogram_test.cc index b1e5f4f021..7346b9fd80 100644 --- a/tensorflow/contrib/lite/kernels/audio_spectrogram_test.cc +++ b/tensorflow/contrib/lite/kernels/audio_spectrogram_test.cc @@ -18,7 +18,7 @@ limitations under the License. #include <vector> #include <gtest/gtest.h> -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers #include "tensorflow/contrib/lite/interpreter.h" #include "tensorflow/contrib/lite/kernels/register.h" #include "tensorflow/contrib/lite/kernels/test_util.h" diff --git a/tensorflow/contrib/lite/kernels/basic_rnn.cc b/tensorflow/contrib/lite/kernels/basic_rnn.cc index c09b15b3d2..c5a5c0182f 100644 --- a/tensorflow/contrib/lite/kernels/basic_rnn.cc +++ b/tensorflow/contrib/lite/kernels/basic_rnn.cc @@ -31,8 +31,10 @@ constexpr int kInputTensor = 0; constexpr int kWeightsTensor = 1; constexpr int kRecurrentWeightsTensor = 2; constexpr int kBiasTensor = 3; -constexpr int kHiddenStateTensor = 0; -constexpr int kOutputTensor = 1; +constexpr int kHiddenStateTensor = 4; + +// Output tensor. +constexpr int kOutputTensor = 0; void* Init(TfLiteContext* context, const char* buffer, size_t length) { auto* scratch_tensor_index = new int; @@ -46,14 +48,16 @@ void Free(TfLiteContext* context, void* buffer) { TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { // Check we have all the inputs and outputs we need. - TF_LITE_ENSURE_EQ(context, node->inputs->size, 4); - TF_LITE_ENSURE_EQ(context, node->outputs->size, 2); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 5); + TF_LITE_ENSURE_EQ(context, node->outputs->size, 1); const TfLiteTensor* input = GetInput(context, node, kInputTensor); const TfLiteTensor* input_weights = GetInput(context, node, kWeightsTensor); const TfLiteTensor* recurrent_weights = GetInput(context, node, kRecurrentWeightsTensor); const TfLiteTensor* bias = GetInput(context, node, kBiasTensor); + const TfLiteTensor* hidden_state = + GetInput(context, node, kHiddenStateTensor); // Check all the parameters of tensor match within themselves and match the // input configuration. @@ -65,20 +69,12 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ASSERT_EQ(recurrent_weights->dims->data[1], bias->dims->data[0]); TF_LITE_ENSURE_EQ(context, input->type, kTfLiteFloat32); TF_LITE_ENSURE_EQ(context, input_weights->type, recurrent_weights->type); + TF_LITE_ENSURE_EQ(context, NumDimensions(hidden_state), 2); + TF_LITE_ENSURE_EQ(context, hidden_state->dims->data[0], batch_size); + TF_LITE_ENSURE_EQ(context, hidden_state->dims->data[1], num_units); - TfLiteTensor* hidden_state = GetOutput(context, node, kHiddenStateTensor); TfLiteTensor* output = GetOutput(context, node, kOutputTensor); - // Resize state. - TfLiteIntArray* hidden_state_size_array = TfLiteIntArrayCreate(2); - hidden_state_size_array->data[0] = batch_size; - hidden_state_size_array->data[1] = num_units; - TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, hidden_state, - hidden_state_size_array)); - - // Mark hidden state as a persistent tensor. - hidden_state->allocation_type = kTfLiteArenaRwPersistent; - // Resize output. TfLiteIntArray* output_size_array = TfLiteIntArrayCreate(2); output_size_array->data[0] = batch_size; @@ -205,7 +201,8 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { const TfLiteTensor* recurrent_weights = GetInput(context, node, kRecurrentWeightsTensor); const TfLiteTensor* bias = GetInput(context, node, kBiasTensor); - TfLiteTensor* hidden_state = GetOutput(context, node, kHiddenStateTensor); + TfLiteTensor* hidden_state = + &context->tensors[node->inputs->data[kHiddenStateTensor]]; TfLiteTensor* output = GetOutput(context, node, kOutputTensor); // We already checked that weight types are consistent, so branch on one. diff --git a/tensorflow/contrib/lite/kernels/basic_rnn_test.cc b/tensorflow/contrib/lite/kernels/basic_rnn_test.cc index 96465fcaf0..d179735404 100644 --- a/tensorflow/contrib/lite/kernels/basic_rnn_test.cc +++ b/tensorflow/contrib/lite/kernels/basic_rnn_test.cc @@ -181,15 +181,16 @@ class RNNOpModel : public SingleOpModel { weights_ = AddInput(weights); recurrent_weights_ = AddInput(recurrent_weights); bias_ = AddInput(TensorType_FLOAT32); - hidden_state_ = AddOutput(TensorType_FLOAT32); + hidden_state_ = AddInput(TensorType_FLOAT32, true); output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp( BuiltinOperator_RNN, BuiltinOptions_RNNOptions, CreateRNNOptions(builder_, ActivationFunctionType_RELU).Union()); - BuildInterpreter({{batches_, input_size_}, - {units_, input_size_}, - {units_, units_}, - {units_}}); + BuildInterpreter({{batches_, input_size_}, // input tensor + {units_, input_size_}, // weights tensor + {units_, units_}, // recurrent weights tensor + {units_}, // bias tensor + {batches_, units_}}); // hidden state tensor } void SetBias(std::initializer_list<float> f) { PopulateTensor(bias_, f); } @@ -210,14 +211,6 @@ class RNNOpModel : public SingleOpModel { PopulateTensor(input_, offset, begin, end); } - void ResetHiddenState() { - const int zero_buffer_size = units_ * batches_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(hidden_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - std::vector<float> GetOutput() { return ExtractVector<float>(output_); } int input_size() { return input_size_; } @@ -258,7 +251,6 @@ TEST(RnnOpTest, BlackBoxTest) { rnn.SetBias(rnn_bias); rnn.SetRecurrentWeights(rnn_recurrent_weights); - rnn.ResetHiddenState(); const int input_sequence_size = sizeof(rnn_input) / sizeof(float) / (rnn.input_size() * rnn.num_batches()); @@ -286,7 +278,6 @@ TEST(HybridRnnOpTest, BlackBoxTest) { rnn.SetBias(rnn_bias); rnn.SetRecurrentWeights(rnn_recurrent_weights); - rnn.ResetHiddenState(); const int input_sequence_size = sizeof(rnn_input) / sizeof(float) / (rnn.input_size() * rnn.num_batches()); diff --git a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc index 517309a226..4162d9bb88 100644 --- a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc +++ b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc @@ -23,6 +23,7 @@ limitations under the License. #include "tensorflow/contrib/lite/context.h" #include "tensorflow/contrib/lite/kernels/activation_functor.h" #include "tensorflow/contrib/lite/kernels/internal/kernel_utils.h" +#include "tensorflow/contrib/lite/kernels/kernel_util.h" #include "tensorflow/contrib/lite/kernels/op_macros.h" namespace tflite { @@ -44,25 +45,37 @@ constexpr int kFwOutputTensor = 1; constexpr int kBwHiddenStateTensor = 2; constexpr int kBwOutputTensor = 3; +void* Init(TfLiteContext* context, const char* buffer, size_t length) { + auto* scratch_tensor_index = new int; + context->AddTensors(context, /*tensors_to_add=*/3, scratch_tensor_index); + return scratch_tensor_index; +} + +void Free(TfLiteContext* context, void* buffer) { + delete reinterpret_cast<int*>(buffer); +} + TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { // Check we have all the inputs and outputs we need. TF_LITE_ENSURE_EQ(context, node->inputs->size, 7); TF_LITE_ENSURE_EQ(context, node->outputs->size, 4); - TfLiteTensor* input = &context->tensors[node->inputs->data[kInputTensor]]; - TfLiteTensor* fw_input_weights = - &context->tensors[node->inputs->data[kFwWeightsTensor]]; - TfLiteTensor* fw_recurrent_weights = - &context->tensors[node->inputs->data[kFwRecurrentWeightsTensor]]; - TfLiteTensor* fw_bias = &context->tensors[node->inputs->data[kFwBiasTensor]]; - TfLiteTensor* bw_input_weights = - &context->tensors[node->inputs->data[kBwWeightsTensor]]; - TfLiteTensor* bw_recurrent_weights = - &context->tensors[node->inputs->data[kBwRecurrentWeightsTensor]]; - TfLiteTensor* bw_bias = &context->tensors[node->inputs->data[kBwBiasTensor]]; + const TfLiteTensor* input = GetInput(context, node, kInputTensor); + const TfLiteTensor* fw_input_weights = + GetInput(context, node, kFwWeightsTensor); + const TfLiteTensor* fw_recurrent_weights = + GetInput(context, node, kFwRecurrentWeightsTensor); + const TfLiteTensor* fw_bias = GetInput(context, node, kFwBiasTensor); + const TfLiteTensor* bw_input_weights = + GetInput(context, node, kBwWeightsTensor); + const TfLiteTensor* bw_recurrent_weights = + GetInput(context, node, kBwRecurrentWeightsTensor); + const TfLiteTensor* bw_bias = GetInput(context, node, kBwBiasTensor); // Check all the parameters of tensor match within themselves and match the // input configuration. + TF_LITE_ENSURE_EQ(context, input->type, kTfLiteFloat32); + const int batch_size = input->dims->data[0]; const int max_time = input->dims->data[1]; const int fw_num_units = fw_input_weights->dims->data[0]; @@ -76,17 +89,15 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ASSERT_EQ(bw_recurrent_weights->dims->data[1], bw_bias->dims->data[0]); - TfLiteTensor* fw_output = - &context->tensors[node->outputs->data[kFwOutputTensor]]; - TfLiteTensor* bw_output = - &context->tensors[node->outputs->data[kBwOutputTensor]]; + TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); + TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); // Resize hidden states. TfLiteIntArray* fw_hidden_state_size_array = TfLiteIntArrayCreate(2); fw_hidden_state_size_array->data[0] = batch_size; fw_hidden_state_size_array->data[1] = fw_num_units; TfLiteTensor* fw_hidden_state = - &context->tensors[node->outputs->data[kFwHiddenStateTensor]]; + GetOutput(context, node, kFwHiddenStateTensor); TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, fw_hidden_state, fw_hidden_state_size_array)); @@ -94,7 +105,7 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { bw_hidden_state_size_array->data[0] = batch_size; bw_hidden_state_size_array->data[1] = fw_num_units; TfLiteTensor* bw_hidden_state = - &context->tensors[node->outputs->data[kBwHiddenStateTensor]]; + GetOutput(context, node, kBwHiddenStateTensor); TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, bw_hidden_state, bw_hidden_state_size_array)); @@ -102,6 +113,50 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { fw_hidden_state->allocation_type = kTfLiteArenaRwPersistent; bw_hidden_state->allocation_type = kTfLiteArenaRwPersistent; + const bool is_hybrid_op = + (fw_input_weights->type == kTfLiteUInt8 && input->type == kTfLiteFloat32); + + if (is_hybrid_op) { + int* scratch_tensor_index = reinterpret_cast<int*>(node->user_data); + TfLiteIntArrayFree(node->temporaries); + node->temporaries = TfLiteIntArrayCreate(2); + node->temporaries->data[0] = *scratch_tensor_index; + TfLiteTensor* input_quantized = GetTemporary(context, node, /*index=*/0); + input_quantized->type = kTfLiteUInt8; + input_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(input_quantized->dims, input->dims)) { + TfLiteIntArray* input_quantized_size = TfLiteIntArrayCopy(input->dims); + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, input_quantized, + input_quantized_size)); + } + node->temporaries->data[1] = *scratch_tensor_index + 1; + TfLiteTensor* fw_hidden_state_quantized = + GetTemporary(context, node, /*index=*/1); + fw_hidden_state_quantized->type = kTfLiteUInt8; + fw_hidden_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(fw_hidden_state_quantized->dims, + fw_hidden_state->dims)) { + TfLiteIntArray* fw_hidden_state_quantized_size = + TfLiteIntArrayCopy(fw_hidden_state->dims); + TF_LITE_ENSURE_OK( + context, context->ResizeTensor(context, fw_hidden_state_quantized, + fw_hidden_state_quantized_size)); + } + node->temporaries->data[2] = *scratch_tensor_index + 2; + TfLiteTensor* bw_hidden_state_quantized = + GetTemporary(context, node, /*index=*/2); + bw_hidden_state_quantized->type = kTfLiteUInt8; + bw_hidden_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(bw_hidden_state_quantized->dims, + bw_hidden_state->dims)) { + TfLiteIntArray* bw_hidden_state_quantized_size = + TfLiteIntArrayCopy(bw_hidden_state->dims); + TF_LITE_ENSURE_OK( + context, context->ResizeTensor(context, bw_hidden_state_quantized, + bw_hidden_state_quantized_size)); + } + } + // Resize outputs. TfLiteIntArray* fw_output_size_array = TfLiteIntArrayCreate(3); fw_output_size_array->data[0] = batch_size; @@ -119,30 +174,16 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { return kTfLiteOk; } -TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { - auto* params = reinterpret_cast<TfLiteSequenceRNNParams*>(node->builtin_data); - - TfLiteTensor* input = &context->tensors[node->inputs->data[kInputTensor]]; - TfLiteTensor* fw_input_weights = - &context->tensors[node->inputs->data[kFwWeightsTensor]]; - TfLiteTensor* fw_recurrent_weights = - &context->tensors[node->inputs->data[kFwRecurrentWeightsTensor]]; - TfLiteTensor* fw_bias = &context->tensors[node->inputs->data[kFwBiasTensor]]; - TfLiteTensor* fw_hidden_state = - &context->tensors[node->outputs->data[kFwHiddenStateTensor]]; - TfLiteTensor* fw_output = - &context->tensors[node->outputs->data[kFwOutputTensor]]; - - TfLiteTensor* bw_input_weights = - &context->tensors[node->inputs->data[kBwWeightsTensor]]; - TfLiteTensor* bw_recurrent_weights = - &context->tensors[node->inputs->data[kBwRecurrentWeightsTensor]]; - TfLiteTensor* bw_bias = &context->tensors[node->inputs->data[kBwBiasTensor]]; - TfLiteTensor* bw_hidden_state = - &context->tensors[node->outputs->data[kBwHiddenStateTensor]]; - TfLiteTensor* bw_output = - &context->tensors[node->outputs->data[kBwOutputTensor]]; - +TfLiteStatus EvalFloat(const TfLiteTensor* input, + const TfLiteTensor* fw_input_weights, + const TfLiteTensor* fw_recurrent_weights, + const TfLiteTensor* fw_bias, + const TfLiteTensor* bw_input_weights, + const TfLiteTensor* bw_recurrent_weights, + const TfLiteTensor* bw_bias, + const TfLiteSequenceRNNParams* params, + TfLiteTensor* fw_hidden_state, TfLiteTensor* fw_output, + TfLiteTensor* bw_hidden_state, TfLiteTensor* bw_output) { const int batch_size = input->dims->data[0]; const int max_time = input->dims->data[1]; const int input_size = input->dims->data[2]; @@ -190,12 +231,139 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { return kTfLiteOk; } +TfLiteStatus EvalHybrid( + const TfLiteTensor* input, const TfLiteTensor* fw_input_weights, + const TfLiteTensor* fw_recurrent_weights, const TfLiteTensor* fw_bias, + const TfLiteTensor* bw_input_weights, + const TfLiteTensor* bw_recurrent_weights, const TfLiteTensor* bw_bias, + const TfLiteSequenceRNNParams* params, TfLiteTensor* input_quantized, + TfLiteTensor* fw_hidden_state_quantized, TfLiteTensor* fw_scaling_factors, + TfLiteTensor* fw_hidden_state, TfLiteTensor* fw_output, + TfLiteTensor* bw_hidden_state_quantized, TfLiteTensor* bw_scaling_factors, + TfLiteTensor* bw_hidden_state, TfLiteTensor* bw_output) { + const int batch_size = input->dims->data[0]; + const int max_time = input->dims->data[1]; + const int input_size = input->dims->data[2]; + + const int fw_num_units = fw_input_weights->dims->data[0]; + const float* fw_bias_ptr = fw_bias->data.f; + const int8_t* fw_input_weights_ptr = + reinterpret_cast<const int8_t*>(fw_input_weights->data.uint8); + float fw_input_weights_scale = fw_input_weights->params.scale; + const int8_t* fw_recurrent_weights_ptr = + reinterpret_cast<const int8_t*>(fw_recurrent_weights->data.uint8); + float fw_recurrent_weights_scale = fw_recurrent_weights->params.scale; + + const int bw_num_units = bw_input_weights->dims->data[0]; + const float* bw_bias_ptr = bw_bias->data.f; + const int8_t* bw_input_weights_ptr = + reinterpret_cast<const int8_t*>(bw_input_weights->data.uint8); + float bw_input_weights_scale = bw_input_weights->params.scale; + const int8_t* bw_recurrent_weights_ptr = + reinterpret_cast<const int8_t*>(bw_recurrent_weights->data.uint8); + float bw_recurrent_weights_scale = bw_recurrent_weights->params.scale; + + // Initialize temporary storage for quantized values. + int8_t* quantized_input_ptr = + reinterpret_cast<int8_t*>(input_quantized->data.uint8); + int8_t* fw_quantized_hidden_state_ptr = + reinterpret_cast<int8_t*>(fw_hidden_state_quantized->data.uint8); + int8_t* bw_quantized_hidden_state_ptr = + reinterpret_cast<int8_t*>(bw_hidden_state_quantized->data.uint8); + float* fw_scaling_factors_ptr = fw_scaling_factors->data.f; + float* bw_scaling_factors_ptr = bw_scaling_factors->data.f; + + for (int b = 0; b < batch_size; b++) { + // Forward cell. + float* fw_hidden_state_ptr_batch = + fw_hidden_state->data.f + b * fw_num_units; + for (int s = 0; s < max_time; s++) { + const float* input_ptr_batch = + input->data.f + b * input_size * max_time + s * input_size; + float* output_ptr_batch = + fw_output->data.f + b * fw_num_units * max_time + s * fw_num_units; + + kernel_utils::RnnBatchStep( + input_ptr_batch, fw_input_weights_ptr, fw_input_weights_scale, + fw_recurrent_weights_ptr, fw_recurrent_weights_scale, fw_bias_ptr, + input_size, fw_num_units, /*batch_size=*/1, params->activation, + quantized_input_ptr, fw_quantized_hidden_state_ptr, + fw_scaling_factors_ptr, fw_hidden_state_ptr_batch, output_ptr_batch); + } + // Backward cell. + float* bw_hidden_state_ptr_batch = + bw_hidden_state->data.f + b * bw_num_units; + for (int s = max_time - 1; s >= 0; s--) { + const float* input_ptr_batch = + input->data.f + b * input_size * max_time + s * input_size; + float* output_ptr_batch = + bw_output->data.f + b * bw_num_units * max_time + s * bw_num_units; + + kernel_utils::RnnBatchStep( + input_ptr_batch, bw_input_weights_ptr, bw_input_weights_scale, + bw_recurrent_weights_ptr, bw_recurrent_weights_scale, bw_bias_ptr, + input_size, bw_num_units, /*batch_size=*/1, params->activation, + quantized_input_ptr, bw_quantized_hidden_state_ptr, + bw_scaling_factors_ptr, bw_hidden_state_ptr_batch, output_ptr_batch); + } + } + return kTfLiteOk; +} + +TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { + const auto* params = + reinterpret_cast<TfLiteSequenceRNNParams*>(node->builtin_data); + + const TfLiteTensor* input = GetInput(context, node, kInputTensor); + const TfLiteTensor* fw_input_weights = + GetInput(context, node, kFwWeightsTensor); + const TfLiteTensor* fw_recurrent_weights = + GetInput(context, node, kFwRecurrentWeightsTensor); + const TfLiteTensor* fw_bias = GetInput(context, node, kFwBiasTensor); + const TfLiteTensor* bw_input_weights = + GetInput(context, node, kBwWeightsTensor); + const TfLiteTensor* bw_recurrent_weights = + GetInput(context, node, kBwRecurrentWeightsTensor); + const TfLiteTensor* bw_bias = GetInput(context, node, kBwBiasTensor); + + TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); + TfLiteTensor* fw_hidden_state = + GetOutput(context, node, kFwHiddenStateTensor); + TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); + TfLiteTensor* bw_hidden_state = + GetOutput(context, node, kBwHiddenStateTensor); + + switch (fw_input_weights->type) { + case kTfLiteFloat32: + return EvalFloat(input, fw_input_weights, fw_recurrent_weights, fw_bias, + bw_input_weights, bw_recurrent_weights, bw_bias, params, + fw_hidden_state, fw_output, bw_hidden_state, bw_output); + case kTfLiteUInt8: { + TfLiteTensor* input_quantized = GetTemporary(context, node, 0); + TfLiteTensor* fw_hidden_state_quantized = GetTemporary(context, node, 1); + TfLiteTensor* bw_hidden_state_quantized = GetTemporary(context, node, 2); + TfLiteTensor* fw_scaling_factors = GetTemporary(context, node, 3); + TfLiteTensor* bw_scaling_factors = GetTemporary(context, node, 4); + return EvalHybrid(input, fw_input_weights, fw_recurrent_weights, fw_bias, + bw_input_weights, bw_recurrent_weights, bw_bias, params, + input_quantized, fw_hidden_state_quantized, + fw_scaling_factors, fw_hidden_state, fw_output, + bw_hidden_state_quantized, bw_scaling_factors, + bw_hidden_state, bw_output); + } + default: + context->ReportError(context, "Type not currently supported."); + return kTfLiteError; + } + return kTfLiteOk; +} + } // namespace bidirectional_sequence_rnn TfLiteRegistration* Register_BIDIRECTIONAL_SEQUENCE_RNN() { - static TfLiteRegistration r = {/*init=*/nullptr, /*free=*/nullptr, - bidirectional_sequence_rnn::Prepare, - bidirectional_sequence_rnn::Eval}; + static TfLiteRegistration r = { + bidirectional_sequence_rnn::Init, bidirectional_sequence_rnn::Free, + bidirectional_sequence_rnn::Prepare, bidirectional_sequence_rnn::Eval}; return &r; } diff --git a/tensorflow/contrib/lite/kernels/conv.cc b/tensorflow/contrib/lite/kernels/conv.cc index 50fe5c2e04..51989f541f 100644 --- a/tensorflow/contrib/lite/kernels/conv.cc +++ b/tensorflow/contrib/lite/kernels/conv.cc @@ -30,6 +30,7 @@ limitations under the License. #include "tensorflow/contrib/lite/kernels/internal/quantization_util.h" #include "tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h" #include "tensorflow/contrib/lite/kernels/internal/tensor.h" +#include "tensorflow/contrib/lite/kernels/internal/tensor_utils.h" #include "tensorflow/contrib/lite/kernels/kernel_util.h" #include "tensorflow/contrib/lite/kernels/op_macros.h" #include "tensorflow/contrib/lite/kernels/padding.h" @@ -60,6 +61,8 @@ struct OpData { // memory buffers. int im2col_id = kTensorNotAllocated; int hwcn_weights_id = kTensorNotAllocated; + int input_quantized_id = kTensorNotAllocated; + int scaling_factors_id = kTensorNotAllocated; TfLitePaddingValues padding; // The scaling factor from input to output (aka the 'real multiplier') can @@ -74,6 +77,8 @@ struct OpData { // of the allocated temporaries. int32_t im2col_index; int32_t hwcn_weights_index; + int32_t input_quantized_index; + int32_t scaling_factors_index; bool need_hwcn_weights; bool have_weights_been_transposed; bool need_im2col; @@ -125,6 +130,9 @@ static TfLiteStatus AllocateTemporaryTensorsIfRequired(TfLiteContext* context, TfLiteTensor* input = &context->tensors[node->inputs->data[0]]; TfLiteTensor* filter = &context->tensors[node->inputs->data[1]]; + const bool is_hybrid = + (input->type == kTfLiteFloat32 && filter->type == kTfLiteUInt8); + int filter_width = filter->dims->data[2]; int filter_height = filter->dims->data[1]; @@ -145,8 +153,8 @@ static TfLiteStatus AllocateTemporaryTensorsIfRequired(TfLiteContext* context, // buffer to store the results. // This path is only used for float processing, so only create the buffer if // we're running with that data type. - data->need_hwcn_weights = - (input->type == kTfLiteFloat32 && data->run_multithreaded_kernel); + data->need_hwcn_weights = (input->type == kTfLiteFloat32 && + data->run_multithreaded_kernel && !is_hybrid); int temporaries_count = 0; if (data->need_im2col) { @@ -164,6 +172,25 @@ static TfLiteStatus AllocateTemporaryTensorsIfRequired(TfLiteContext* context, ++temporaries_count; } + if (is_hybrid) { + // Allocate tensor to store the on-the-fly quantized inputs. + data->input_quantized_index = temporaries_count; + if (data->input_quantized_id == kTensorNotAllocated) { + TF_LITE_ENSURE_OK( + context, context->AddTensors(context, 1, &data->input_quantized_id)); + } + ++temporaries_count; + + // Allocate tensor to store the quantization params computed during + // on-the-fly input quantization. + data->scaling_factors_index = temporaries_count; + if (data->scaling_factors_id == kTensorNotAllocated) { + TF_LITE_ENSURE_OK( + context, context->AddTensors(context, 1, &data->scaling_factors_id)); + } + ++temporaries_count; + } + TfLiteIntArrayFree(node->temporaries); node->temporaries = TfLiteIntArrayCreate(temporaries_count); @@ -174,10 +201,6 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { auto* params = reinterpret_cast<TfLiteConvParams*>(node->builtin_data); OpData* data = reinterpret_cast<OpData*>(node->user_data); - data->run_multithreaded_kernel = context->recommended_num_threads != 1; - - TF_LITE_ENSURE_STATUS(AllocateTemporaryTensorsIfRequired(context, node)); - bool has_bias = node->inputs->size == 3; // Check number of inputs/outputs TF_LITE_ENSURE(context, has_bias || node->inputs->size == 2); @@ -193,11 +216,10 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_EQ(context, input->dims->data[3], filter->dims->data[3]); // Check types. (We assume that UINT8 refers to quantized tensors) - TfLiteType data_type = input->type; + TfLiteType input_type = input->type; TF_LITE_ENSURE(context, - data_type == kTfLiteFloat32 || data_type == kTfLiteUInt8); - TF_LITE_ENSURE_EQ(context, output->type, data_type); - TF_LITE_ENSURE_EQ(context, filter->type, data_type); + input_type == kTfLiteFloat32 || input_type == kTfLiteUInt8); + TF_LITE_ENSURE_EQ(context, output->type, input_type); TfLiteTensor* bias = nullptr; @@ -207,15 +229,26 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { if (has_bias) { bias = &context->tensors[node->inputs->data[2]]; - if (data_type == kTfLiteUInt8) { + if (input_type == kTfLiteUInt8) { TF_LITE_ENSURE_EQ(context, bias->type, kTfLiteInt32); TF_LITE_ENSURE_EQ(context, bias->params.zero_point, 0); } else { - TF_LITE_ENSURE_EQ(context, bias->type, data_type); + TF_LITE_ENSURE_EQ(context, bias->type, input_type); } TF_LITE_ENSURE_EQ(context, NumElements(bias), SizeOfDimension(filter, 0)); } + const bool is_hybrid = + (input->type == kTfLiteFloat32 && filter->type == kTfLiteUInt8); + + data->run_multithreaded_kernel = context->recommended_num_threads != 1; + // Hybrid kernels don't support multithreading yet. + if (is_hybrid) { + data->run_multithreaded_kernel = false; + } + + TF_LITE_ENSURE_STATUS(AllocateTemporaryTensorsIfRequired(context, node)); + int channels_out = filter->dims->data[0]; int width = input->dims->data[2]; int height = input->dims->data[1]; @@ -250,9 +283,9 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE(context, has_bias); - // Note that quantized inference requires that all tensors have their + // Note that full fixed-point inference requires that all tensors have their // parameters set. This is usually done during quantized training. - if (data_type != kTfLiteFloat32) { + if (input_type != kTfLiteFloat32) { double real_multiplier = 0.0; TF_LITE_ENSURE_STATUS(GetQuantizedConvolutionMultipler( context, input, filter, bias, output, &real_multiplier)); @@ -287,7 +320,10 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TfLiteTensor* im2col = &context->tensors[node->temporaries->data[data->im2col_index]]; - im2col->type = data_type; + im2col->type = input->type; + if (is_hybrid) { + im2col->type = kTfLiteUInt8; + } im2col->allocation_type = kTfLiteArenaRw; auto im2col_status = context->ResizeTensor(context, im2col, im2col_size); if (im2col_status != kTfLiteOk) return im2col_status; @@ -307,7 +343,7 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TfLiteTensor* hwcn_weights = &context->tensors[node->temporaries->data[data->hwcn_weights_index]]; - hwcn_weights->type = data_type; + hwcn_weights->type = input_type; hwcn_weights->allocation_type = kTfLiteArenaRwPersistent; auto hwcn_weights_status = @@ -319,6 +355,35 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { data->have_weights_been_transposed = false; } + if (is_hybrid) { + node->temporaries->data[data->input_quantized_index] = + data->input_quantized_id; + TfLiteTensor* input_quantized = + GetTemporary(context, node, data->input_quantized_index); + input_quantized->type = kTfLiteUInt8; + input_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(input_quantized->dims, input->dims)) { + TfLiteIntArray* input_quantized_size = TfLiteIntArrayCopy(input->dims); + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, input_quantized, + input_quantized_size)); + } + + node->temporaries->data[data->scaling_factors_index] = + data->scaling_factors_id; + TfLiteTensor* scaling_factors = + GetTemporary(context, node, data->scaling_factors_index); + scaling_factors->type = kTfLiteInt32; + scaling_factors->allocation_type = kTfLiteArenaRw; + TfLiteIntArray* scaling_factors_size = TfLiteIntArrayCreate(1); + // Only one scale factor per batch is typically necessary. See optimized + // implementation for why we need to allocate for height elements here. + scaling_factors_size->data[0] = height; + if (!TfLiteIntArrayEqual(scaling_factors->dims, scaling_factors_size)) { + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, scaling_factors, + scaling_factors_size)); + } + } + return kTfLiteOk; } @@ -456,6 +521,57 @@ void EvalFloat(TfLiteContext* context, TfLiteNode* node, } template <KernelType kernel_type> +void EvalHybrid(TfLiteContext* context, TfLiteNode* node, + TfLiteConvParams* params, OpData* data, TfLiteTensor* input, + TfLiteTensor* filter, TfLiteTensor* bias, TfLiteTensor* im2col, + TfLiteTensor* hwcn_weights, TfLiteTensor* output) { + float output_activation_min, output_activation_max; + CalculateActivationRange(params->activation, &output_activation_min, + &output_activation_max); + + const int input_size = NumElements(input) / SizeOfDimension(input, 0); + const int batch_size = SizeOfDimension(input, 0); + + const TfLiteTensor* input_quantized = + GetTemporary(context, node, data->input_quantized_index); + int8_t* quantized_input_ptr_batch = + reinterpret_cast<int8_t*>(input_quantized->data.uint8); + float* scaling_factors_ptr = + GetTemporary(context, node, data->scaling_factors_index)->data.f; + + // Per-batch input quantization for higher accuracy. + for (int b = 0; b < batch_size; ++b) { + float unused_min, unused_max; + const int offset = b * input_size; + tensor_utils::SymmetricQuantizeFloats( + input->data.f + offset, input_size, quantized_input_ptr_batch + offset, + &unused_min, &unused_max, &scaling_factors_ptr[b]); + scaling_factors_ptr[b] *= filter->params.scale; + } + + int8_t* im2col_ptr = reinterpret_cast<int8_t*>(im2col->data.uint8); + int8_t* filter_ptr = reinterpret_cast<int8_t*>(filter->data.uint8); + + switch (kernel_type) { + case kReference: + case kGenericOptimized: + case kMultithreadOptimized: + case kCblasOptimized: + // There is only one implementation for hybrid kernel. Note + // this does not make use of gemmlowp nor supports multithreading. + optimized_ops::HybridConv( + quantized_input_ptr_batch, GetTensorDims(input), filter_ptr, + GetTensorDims(filter), GetTensorData<float>(bias), + GetTensorDims(bias), params->stride_width, params->stride_height, + data->padding.width, data->padding.height, scaling_factors_ptr, + output_activation_min, output_activation_max, + GetTensorData<float>(output), GetTensorDims(output), im2col_ptr, + GetTensorDims(im2col)); + break; + } +} + +template <KernelType kernel_type> TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { auto* params = reinterpret_cast<TfLiteConvParams*>(node->builtin_data); OpData* data = reinterpret_cast<OpData*>(node->user_data); @@ -484,7 +600,10 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { // separate ops to avoid dispatch overhead here. switch (input->type) { // Already know in/outtypes are same. case kTfLiteFloat32: - if (data->run_multithreaded_kernel) { + if (filter->type == kTfLiteUInt8) { + EvalHybrid<kernel_type>(context, node, params, data, input, filter, + bias, im2col, hwcn_weights, output); + } else if (data->run_multithreaded_kernel) { EvalFloat<kernel_type>(context, node, params, data, input, filter, bias, im2col, hwcn_weights, output); } else { diff --git a/tensorflow/contrib/lite/kernels/conv_test.cc b/tensorflow/contrib/lite/kernels/conv_test.cc index 98152043c9..a4b9fb1a0b 100644 --- a/tensorflow/contrib/lite/kernels/conv_test.cc +++ b/tensorflow/contrib/lite/kernels/conv_test.cc @@ -142,6 +142,41 @@ TEST_P(ConvolutionOpTest, SimpleTestFloat32) { })); } +// This test's output is equivalent to the SimpleTestFloat32 +// because we break each input into two channels, each with half of the value, +// while keeping the filters for each channel equivalent. +// +// 2 * (A/2) * B = A * B, where the left side is this new test. +TEST_P(ConvolutionOpTest, SimpleTestFloat32WithChannels) { + ConvolutionOpModel m(GetRegistration(), {TensorType_FLOAT32, {2, 2, 4, 2}}, + {TensorType_FLOAT32, {3, 2, 2, 2}}, + {TensorType_FLOAT32, {}}); + + m.SetInput({ + // First batch + 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, // row = 1 + 1, 1, 1, 1, 1, 1, 1, 1, // row = 2 + // Second batch + 0.5, 0.5, 1, 1, 1.5, 1.5, 2, 2, // row = 1 + 0.5, 0.5, 1, 1, 1.5, 1.5, 2, 2 // row = 2 + }); + m.SetFilter({ + 1, 1, 2, 2, 3, 3, 4, 4, // first 2x2 filter + -1, -1, 1, 1, -1, -1, 1, 1, // second 2x2 filter + -1, -1, -1, -1, 1, 1, 1, 1 // third 2x2 filter + }); + m.SetBias({1, 2, 3}); + + m.Invoke(); + + EXPECT_THAT(m.GetOutput(), ElementsAreArray({ + 18, 2, 5, // first batch, left + 18, 2, 5, // first batch, right + 17, 4, 3, // second batch, left + 37, 4, 3, // second batch, right + })); +} + TEST_P(ConvolutionOpTest, SimpleTestFloat32WithAnisotropicStrides) { ConvolutionOpModel m(GetRegistration(), {TensorType_FLOAT32, {1, 3, 6, 1}}, {TensorType_FLOAT32, {1, 2, 2, 1}}, @@ -624,6 +659,116 @@ TEST_P(ConvolutionOpTest, SimpleTestQuantizedWithDilation) { ElementsAreArray({5, 5, 5, 5, 5, 5, 5, 5, 5})); } +class HybridConvolutionOpModel : public BaseConvolutionOpModel { + public: + using BaseConvolutionOpModel::BaseConvolutionOpModel; + + void SetInput(std::initializer_list<float> data) { + PopulateTensor(input_, data); + } + + void SetFilter(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(filter_, f); + } + + void SetBias(std::initializer_list<float> data) { + PopulateTensor(bias_, data); + } + + std::vector<float> GetOutput() { return ExtractVector<float>(output_); } +}; + +TEST_P(ConvolutionOpTest, SimpleTestHybrid) { + HybridConvolutionOpModel m( + GetRegistration(), {TensorType_FLOAT32, {2, 2, 4, 1}}, + {TensorType_UINT8, {3, 2, 2, 1}}, {TensorType_FLOAT32, {}}); + + m.SetInput({ + // First batch + 1, 1, 1, 1, // row = 1 + 2, 2, 2, 2, // row = 2 + // Second batch + 1, 2, 3, 4, // row = 1 + 1, 2, 3, 4, // row = 2 + }); + m.SetFilter({ + 1, 2, 3, 4, // first 2x2 filter + -1, 1, -1, 1, // second 2x2 filter + -1, -1, 1, 1, // third 2x2 filter + }); + m.SetBias({1, 2, 3}); + + m.Invoke(); + + // Example: we get 17.1577 instead of 17. + // + // Second batch: + // 1 2 3 4 -> 32 64 95 127 with scale factor 127/4. + // 1 2 3 4 32 64 95 127 + // + // First filter: + // 1 2 -> 32 64 with scale factor of 127/4. + // 3 4 95 127 + // + // The left half of the input gives us 16288. Multiply by (4/127)^2 for + // dequantization and adding 1 for the bias gives us the result. and adding + // the bias gives us the result. + // + // The optimized kernel converts the input into this matrix via Im2Col + // + // 1 1 2 2 + // 1 1 2 2 + // 1 2 1 2 + // 3 4 3 4 + // + // and multiplies it with the filter directly. + EXPECT_THAT(m.GetOutput(), ElementsAreArray(ArrayFloatNear( + { + 18, 2, 5, // first batch, left + 18, 2, 5, // first batch, right + 17, 4, 3, // second batch, left + 37, 4, 3, // second batch, right + }, + 0.16))); +} + +// This test's output is equivalent to the SimpleTestHybrid +// because we break each input into two channels, each with half of the value, +// while keeping the filters for each channel equivalent. +// +// 2 * (A/2) * B = A * B, where the left side is this new test. +TEST_P(ConvolutionOpTest, SimpleTestHybridWithChannels) { + HybridConvolutionOpModel m( + GetRegistration(), {TensorType_FLOAT32, {2, 2, 4, 2}}, + {TensorType_UINT8, {3, 2, 2, 2}}, {TensorType_FLOAT32, {}}); + + m.SetInput({ + // First batch + 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, // row = 1 + 1, 1, 1, 1, 1, 1, 1, 1, // row = 2 + // Second batch + 0.5, 0.5, 1, 1, 1.5, 1.5, 2, 2, // row = 1 + 0.5, 0.5, 1, 1, 1.5, 1.5, 2, 2 // row = 2 + }); + m.SetFilter({ + 1, 1, 2, 2, 3, 3, 4, 4, // first 2x2 filter + -1, -1, 1, 1, -1, -1, 1, 1, // second 2x2 filter + -1, -1, -1, -1, 1, 1, 1, 1 // third 2x2 filter + }); + m.SetBias({1, 2, 3}); + + m.Invoke(); + + EXPECT_THAT(m.GetOutput(), ElementsAreArray(ArrayFloatNear( + { + 18, 2, 5, // first batch, left + 18, 2, 5, // first batch, right + 17, 4, 3, // second batch, left + 37, 4, 3, // second batch, right + }, + 0.16))); +} + INSTANTIATE_TEST_CASE_P( ConvolutionOpTest, ConvolutionOpTest, ::testing::ValuesIn(SingleOpTest::GetKernelTags(*kKernelMap))); diff --git a/tensorflow/contrib/lite/kernels/detection_postprocess.cc b/tensorflow/contrib/lite/kernels/detection_postprocess.cc index 211d43a47a..136697f945 100644 --- a/tensorflow/contrib/lite/kernels/detection_postprocess.cc +++ b/tensorflow/contrib/lite/kernels/detection_postprocess.cc @@ -15,7 +15,7 @@ limitations under the License. #include <string.h> #include <numeric> #include <vector> -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers #include "tensorflow/contrib/lite/builtin_op_data.h" #include "tensorflow/contrib/lite/context.h" #include "tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h" diff --git a/tensorflow/contrib/lite/kernels/detection_postprocess_test.cc b/tensorflow/contrib/lite/kernels/detection_postprocess_test.cc index fe90e5d894..94c91a6bd6 100644 --- a/tensorflow/contrib/lite/kernels/detection_postprocess_test.cc +++ b/tensorflow/contrib/lite/kernels/detection_postprocess_test.cc @@ -17,7 +17,7 @@ limitations under the License. #include <vector> #include <gtest/gtest.h> -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers #include "tensorflow/contrib/lite/interpreter.h" #include "tensorflow/contrib/lite/kernels/register.h" #include "tensorflow/contrib/lite/kernels/test_util.h" diff --git a/tensorflow/contrib/lite/kernels/floor_div.cc b/tensorflow/contrib/lite/kernels/floor_div.cc new file mode 100644 index 0000000000..3c177ea330 --- /dev/null +++ b/tensorflow/contrib/lite/kernels/floor_div.cc @@ -0,0 +1,146 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include "tensorflow/contrib/lite/context.h" +#include "tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h" +#include "tensorflow/contrib/lite/kernels/internal/tensor.h" +#include "tensorflow/contrib/lite/kernels/kernel_util.h" +#include "tensorflow/contrib/lite/kernels/op_macros.h" + +namespace tflite { +namespace ops { +namespace builtin { +namespace floor_div { +namespace { + +// Input/output tensor index. +constexpr int kInputTensor1 = 0; +constexpr int kInputTensor2 = 1; +constexpr int kOutputTensor = 0; + +// Op data for floor_div op. +struct OpData { + bool requires_broadcast; +}; + +template <typename T> +T FloorDiv(T input1, T input2) { + return std::floor(std::divides<double>()(static_cast<double>(input1), + static_cast<double>(input2))); +} + +void* Init(TfLiteContext* context, const char* buffer, size_t length) { + auto* data = new OpData; + data->requires_broadcast = false; + return data; +} + +void Free(TfLiteContext* context, void* buffer) { + delete reinterpret_cast<OpData*>(buffer); +} + +TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { + TF_LITE_ENSURE_EQ(context, NumInputs(node), 2); + TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1); + + // Reinterprete the opaque data provided by user. + OpData* data = reinterpret_cast<OpData*>(node->user_data); + + const TfLiteTensor* input1 = GetInput(context, node, kInputTensor1); + const TfLiteTensor* input2 = GetInput(context, node, kInputTensor2); + TfLiteTensor* output = GetOutput(context, node, kOutputTensor); + + TF_LITE_ENSURE_EQ(context, input1->type, input2->type); + + const TfLiteType type = input1->type; + if (type != kTfLiteInt32) { + context->ReportError(context, "Currently floor_div only supports int32."); + return kTfLiteError; + } + output->type = type; + + data->requires_broadcast = !HaveSameShapes(input1, input2); + + TfLiteIntArray* output_size = nullptr; + if (data->requires_broadcast) { + TF_LITE_ENSURE_OK(context, CalculateShapeForBroadcast( + context, input1, input2, &output_size)); + } else { + output_size = TfLiteIntArrayCopy(input1->dims); + } + + return context->ResizeTensor(context, output, output_size); +} + +template <typename T> +TfLiteStatus EvalImpl(TfLiteContext* context, bool requires_broadcast, + const TfLiteTensor* input1, const TfLiteTensor* input2, + TfLiteTensor* output) { + const T* denominator_data = GetTensorData<T>(input2); + + // Validate the denominator. + for (int i = 0; i < NumElements(input2); ++i) { + if (std::equal_to<T>()(denominator_data[i], 0)) { + context->ReportError(context, "Division by 0"); + return kTfLiteError; + } + } + if (requires_broadcast) { + reference_ops::BroadcastBinaryFunction<T, T, T>( + GetTensorData<T>(input1), GetTensorDims(input1), denominator_data, + GetTensorDims(input2), GetTensorData<T>(output), GetTensorDims(output), + FloorDiv<T>); + } else { + reference_ops::BinaryFunction<T, T, T>( + GetTensorData<T>(input1), GetTensorDims(input1), + GetTensorData<T>(input2), GetTensorDims(input2), + GetTensorData<T>(output), GetTensorDims(output), FloorDiv<T>); + } + + return kTfLiteOk; +} + +TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { + OpData* data = reinterpret_cast<OpData*>(node->user_data); + + const TfLiteTensor* input1 = GetInput(context, node, kInputTensor1); + const TfLiteTensor* input2 = GetInput(context, node, kInputTensor2); + TfLiteTensor* output = GetOutput(context, node, kOutputTensor); + + switch (input1->type) { + case kTfLiteInt32: { + return EvalImpl<int32_t>(context, data->requires_broadcast, input1, + input2, output); + } + default: { + context->ReportError(context, "Currently floor_div only supports int32."); + return kTfLiteError; + } + } +} + +} // namespace +} // namespace floor_div + +TfLiteRegistration* Register_FLOOR_DIV() { + // Init, Free, Prepare, Eval are satisfying the Interface required by + // TfLiteRegistration. + static TfLiteRegistration r = {floor_div::Init, floor_div::Free, + floor_div::Prepare, floor_div::Eval}; + return &r; +} + +} // namespace builtin +} // namespace ops +} // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/floor_div_test.cc b/tensorflow/contrib/lite/kernels/floor_div_test.cc new file mode 100644 index 0000000000..eea69b61ac --- /dev/null +++ b/tensorflow/contrib/lite/kernels/floor_div_test.cc @@ -0,0 +1,90 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include <gtest/gtest.h> +#include "tensorflow/contrib/lite/interpreter.h" +#include "tensorflow/contrib/lite/kernels/register.h" +#include "tensorflow/contrib/lite/kernels/test_util.h" +#include "tensorflow/contrib/lite/model.h" + +namespace tflite { +namespace { + +using ::testing::ElementsAre; + +template <typename T> +class FloorDivModel : public SingleOpModel { + public: + FloorDivModel(const TensorData& input1, const TensorData& input2, + const TensorData& output) { + input1_ = AddInput(input1); + input2_ = AddInput(input2); + output_ = AddOutput(output); + SetBuiltinOp(BuiltinOperator_FLOOR_DIV, BuiltinOptions_FloorDivOptions, + CreateFloorDivOptions(builder_).Union()); + BuildInterpreter({GetShape(input1_), GetShape(input2_)}); + } + + int input1() { return input1_; } + int input2() { return input2_; } + + std::vector<T> GetOutput() { return ExtractVector<T>(output_); } + std::vector<int> GetOutputShape() { return GetTensorShape(output_); } + + private: + int input1_; + int input2_; + int output_; +}; + +TEST(PowOpModel, Simple) { + FloorDivModel<int32_t> model({TensorType_INT32, {1, 2, 2, 1}}, + {TensorType_INT32, {1, 2, 2, 1}}, + {TensorType_INT32, {}}); + model.PopulateTensor<int32_t>(model.input1(), {10, 9, 11, 3}); + model.PopulateTensor<int32_t>(model.input2(), {2, 2, 3, 4}); + model.Invoke(); + EXPECT_THAT(model.GetOutputShape(), ElementsAre(1, 2, 2, 1)); + EXPECT_THAT(model.GetOutput(), ElementsAre(5, 4, 3, 0)); +} + +TEST(PowOpModel, NegativeValue) { + FloorDivModel<int32_t> model({TensorType_INT32, {1, 2, 2, 1}}, + {TensorType_INT32, {1, 2, 2, 1}}, + {TensorType_INT32, {}}); + model.PopulateTensor<int32_t>(model.input1(), {10, -9, -11, 7}); + model.PopulateTensor<int32_t>(model.input2(), {2, 2, -3, -4}); + model.Invoke(); + EXPECT_THAT(model.GetOutputShape(), ElementsAre(1, 2, 2, 1)); + EXPECT_THAT(model.GetOutput(), ElementsAre(5, -5, 3, -2)); +} + +TEST(PowOpModel, BroadcastFloorDiv) { + FloorDivModel<int32_t> model({TensorType_INT32, {1, 2, 2, 1}}, + {TensorType_INT32, {1}}, {TensorType_INT32, {}}); + model.PopulateTensor<int32_t>(model.input1(), {10, -9, -11, 7}); + model.PopulateTensor<int32_t>(model.input2(), {-3}); + model.Invoke(); + EXPECT_THAT(model.GetOutputShape(), ElementsAre(1, 2, 2, 1)); + EXPECT_THAT(model.GetOutput(), ElementsAre(-4, 3, 3, -3)); +} + +} // namespace +} // namespace tflite + +int main(int argc, char** argv) { + ::tflite::LogToStderr(); + ::testing::InitGoogleTest(&argc, argv); + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/kernels/internal/BUILD b/tensorflow/contrib/lite/kernels/internal/BUILD index a97db6c6b2..464163bd78 100644 --- a/tensorflow/contrib/lite/kernels/internal/BUILD +++ b/tensorflow/contrib/lite/kernels/internal/BUILD @@ -160,6 +160,7 @@ cc_library( ":types", ":reference_base", ":round", + ":tensor_utils", "//third_party/eigen3", "@gemmlowp", "//tensorflow/contrib/lite:builtin_op_data", @@ -191,6 +192,7 @@ cc_library( deps = [ ":quantization_util", ":strided_slice_logic", + ":tensor_utils", ":types", ":legacy_reference_base", ":round", @@ -293,7 +295,6 @@ cc_library( ":round", ":strided_slice_logic", ":types", - "//third_party/eigen3", "@gemmlowp", "//tensorflow/contrib/lite:builtin_op_data", ] + select({ @@ -324,7 +325,6 @@ cc_library( ":round", ":strided_slice_logic", ":types", - "//third_party/eigen3", "@gemmlowp", "//tensorflow/contrib/lite:builtin_op_data", ] + select({ diff --git a/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc b/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc index 200f2f1515..88a0622286 100644 --- a/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc +++ b/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc @@ -127,6 +127,47 @@ void LstmStep( float* cell_state_ptr, float* input_gate_scratch, float* forget_gate_scratch, float* cell_scratch, float* output_gate_scratch, float* output_ptr_batch) { + LstmStepWithAuxInput( + input_ptr_batch, input_to_input_weights_ptr, input_to_forget_weights_ptr, + input_to_cell_weights_ptr, input_to_output_weights_ptr, + /*aux_input_ptr_batch=*/nullptr, + /*aux_input_to_input_weights_ptr=*/nullptr, + /*aux_input_to_forget_weights_ptr=*/nullptr, + /*aux_input_to_cell_weights_ptr=*/nullptr, + /*aux_input_to_output_weights_ptr=*/nullptr, + recurrent_to_input_weights_ptr, recurrent_to_forget_weights_ptr, + recurrent_to_cell_weights_ptr, recurrent_to_output_weights_ptr, + cell_to_input_weights_ptr, cell_to_forget_weights_ptr, + cell_to_output_weights_ptr, input_gate_bias_ptr, forget_gate_bias_ptr, + cell_bias_ptr, output_gate_bias_ptr, projection_weights_ptr, + projection_bias_ptr, params, n_batch, n_cell, n_input, n_output, + output_state_ptr, cell_state_ptr, input_gate_scratch, forget_gate_scratch, + cell_scratch, output_gate_scratch, output_ptr_batch); +} + +void LstmStepWithAuxInput( + const float* input_ptr_batch, const float* input_to_input_weights_ptr, + const float* input_to_forget_weights_ptr, + const float* input_to_cell_weights_ptr, + const float* input_to_output_weights_ptr, const float* aux_input_ptr_batch, + const float* aux_input_to_input_weights_ptr, + const float* aux_input_to_forget_weights_ptr, + const float* aux_input_to_cell_weights_ptr, + const float* aux_input_to_output_weights_ptr, + const float* recurrent_to_input_weights_ptr, + const float* recurrent_to_forget_weights_ptr, + const float* recurrent_to_cell_weights_ptr, + const float* recurrent_to_output_weights_ptr, + const float* cell_to_input_weights_ptr, + const float* cell_to_forget_weights_ptr, + const float* cell_to_output_weights_ptr, const float* input_gate_bias_ptr, + const float* forget_gate_bias_ptr, const float* cell_bias_ptr, + const float* output_gate_bias_ptr, const float* projection_weights_ptr, + const float* projection_bias_ptr, const TfLiteLSTMParams* params, + int n_batch, int n_cell, int n_input, int n_output, float* output_state_ptr, + float* cell_state_ptr, float* input_gate_scratch, + float* forget_gate_scratch, float* cell_scratch, float* output_gate_scratch, + float* output_ptr_batch) { // Since we have already checked that weights are all there or none, we can // check the existense of only one to the get the condition. const bool use_cifg = (input_to_input_weights_ptr == nullptr); @@ -160,6 +201,25 @@ void LstmStep( input_to_output_weights_ptr, n_cell, n_input, input_ptr_batch, n_batch, output_gate_scratch, /*result_stride=*/1); + // If auxiliary input is available then compute aux_input_weight * aux_input + if (aux_input_ptr_batch != nullptr) { + if (!use_cifg) { + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_to_input_weights_ptr, n_cell, n_input, aux_input_ptr_batch, + n_batch, input_gate_scratch, /*result_stride=*/1); + } + + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_to_forget_weights_ptr, n_cell, n_input, aux_input_ptr_batch, + n_batch, forget_gate_scratch, /*result_stride=*/1); + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_to_cell_weights_ptr, n_cell, n_input, aux_input_ptr_batch, + n_batch, cell_scratch, /*result_stride=*/1); + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_to_output_weights_ptr, n_cell, n_input, aux_input_ptr_batch, + n_batch, output_gate_scratch, /*result_stride=*/1); + } + // For each batch and cell: compute recurrent_weight * output_state. if (!use_cifg) { tensor_utils::MatrixBatchVectorMultiplyAccumulate( @@ -286,227 +346,362 @@ void LstmStep( int8_t* quantized_input_ptr_batch, int8_t* quantized_output_state_ptr, int8_t* quantized_cell_state_ptr, float* output_state_ptr, float* cell_state_ptr, float* output_ptr_batch) { - // Since we have already checked that weights are all there or none, we can - // check the existense of only one to the get the condition. - const bool use_cifg = (input_to_input_weights_ptr == nullptr); - const bool use_peephole = (cell_to_output_weights_ptr != nullptr); - // Initialize scratch buffers with bias. - if (!use_cifg) { - tensor_utils::VectorBatchVectorAssign(input_gate_bias_ptr, n_cell, n_batch, - input_gate_scratch); - } - tensor_utils::VectorBatchVectorAssign(forget_gate_bias_ptr, n_cell, n_batch, - forget_gate_scratch); - tensor_utils::VectorBatchVectorAssign(cell_bias_ptr, n_cell, n_batch, - cell_scratch); - tensor_utils::VectorBatchVectorAssign(output_gate_bias_ptr, n_cell, n_batch, - output_gate_scratch); - - if (!tensor_utils::IsZeroVector(input_ptr_batch, n_batch * n_input)) { - // Save quantization and matmul computation for all zero input. - float unused_min, unused_max; - for (int b = 0; b < n_batch; ++b) { - const int offset = b * n_input; - tensor_utils::SymmetricQuantizeFloats( - input_ptr_batch + offset, n_input, quantized_input_ptr_batch + offset, - &unused_min, &unused_max, &scaling_factors[b]); + LstmStepWithAuxInput( + input_ptr_batch, input_to_input_weights_ptr, input_to_input_weights_scale, + input_to_forget_weights_ptr, input_to_forget_weights_scale, + input_to_cell_weights_ptr, input_to_cell_weights_scale, + input_to_output_weights_ptr, input_to_output_weights_scale, + /*aux_input_ptr_batch=*/nullptr, + /*aux_input_to_input_weights_ptr=*/nullptr, + /*aux_input_to_input_weights_scale=*/0.0f, + /*aux_input_to_forget_weights_ptr=*/nullptr, + /*aux_input_to_forget_weights_scale=*/0.0f, + /*aux_input_to_cell_weights_ptr=*/nullptr, + /*aux_input_to_cell_weights_scale=*/0.0f, + /*aux_input_to_output_weights_ptr=*/nullptr, + /*aux_input_to_output_weights_scale=*/0.0f, + recurrent_to_input_weights_ptr, recurrent_to_input_weights_scale, + recurrent_to_forget_weights_ptr, recurrent_to_forget_weights_scale, + recurrent_to_cell_weights_ptr, recurrent_to_cell_weights_scale, + recurrent_to_output_weights_ptr, recurrent_to_output_weights_scale, + cell_to_input_weights_ptr, cell_to_input_weights_scale, + cell_to_forget_weights_ptr, cell_to_forget_weights_scale, + cell_to_output_weights_ptr, cell_to_output_weights_scale, + input_gate_bias_ptr, forget_gate_bias_ptr, cell_bias_ptr, + output_gate_bias_ptr, projection_weights_ptr, projection_weights_scale, + projection_bias_ptr, params, n_batch, n_cell, n_input, n_output, + input_gate_scratch, forget_gate_scratch, cell_scratch, + output_gate_scratch, scaling_factors, product_scaling_factors, + recovered_cell_weights, quantized_input_ptr_batch, + /*quantized_aux_input_ptr_batch=*/nullptr, quantized_output_state_ptr, + quantized_cell_state_ptr, output_state_ptr, cell_state_ptr, + output_ptr_batch); } - // For each batch and cell: compute input_weight * input. - if (!use_cifg) { - for (int b = 0; b < n_batch; ++b) { - product_scaling_factors[b] = - scaling_factors[b] * input_to_input_weights_scale; - } - tensor_utils::MatrixBatchVectorMultiplyAccumulate( - input_to_input_weights_ptr, n_cell, n_input, - quantized_input_ptr_batch, product_scaling_factors, n_batch, - input_gate_scratch, /*result_stride=*/1); - } - - for (int b = 0; b < n_batch; ++b) { - product_scaling_factors[b] = - scaling_factors[b] * input_to_forget_weights_scale; - } - tensor_utils::MatrixBatchVectorMultiplyAccumulate( - input_to_forget_weights_ptr, n_cell, n_input, quantized_input_ptr_batch, - product_scaling_factors, n_batch, forget_gate_scratch, - /*result_stride=*/1); - for (int b = 0; b < n_batch; ++b) { - product_scaling_factors[b] = - scaling_factors[b] * input_to_cell_weights_scale; - } - tensor_utils::MatrixBatchVectorMultiplyAccumulate( - input_to_cell_weights_ptr, n_cell, n_input, quantized_input_ptr_batch, - product_scaling_factors, n_batch, cell_scratch, /*result_stride=*/1); - - for (int b = 0; b < n_batch; ++b) { - product_scaling_factors[b] = - scaling_factors[b] * input_to_output_weights_scale; - } - tensor_utils::MatrixBatchVectorMultiplyAccumulate( - input_to_output_weights_ptr, n_cell, n_input, quantized_input_ptr_batch, - product_scaling_factors, n_batch, output_gate_scratch, - /*result_stride=*/1); - } - - if (!tensor_utils::IsZeroVector(output_state_ptr, n_batch * n_output)) { - // Save quantization and matmul computation for all zero input. - float unused_min, unused_max; - for (int b = 0; b < n_batch; ++b) { - const int offset = b * n_output; - tensor_utils::SymmetricQuantizeFloats(output_state_ptr + offset, n_output, - quantized_output_state_ptr + offset, - &unused_min, &unused_max, - &scaling_factors[b]); - } - // For each batch and cell: compute recurrent_weight * output_state. - if (!use_cifg) { - for (int b = 0; b < n_batch; ++b) { - product_scaling_factors[b] = - scaling_factors[b] * recurrent_to_input_weights_scale; + void LstmStepWithAuxInput( + const float* input_ptr_batch, const int8_t* input_to_input_weights_ptr, + float input_to_input_weights_scale, + const int8_t* input_to_forget_weights_ptr, + float input_to_forget_weights_scale, + const int8_t* input_to_cell_weights_ptr, + float input_to_cell_weights_scale, + const int8_t* input_to_output_weights_ptr, + float input_to_output_weights_scale, const float* aux_input_ptr_batch, + const int8_t* aux_input_to_input_weights_ptr, + float aux_input_to_input_weights_scale, + const int8_t* aux_input_to_forget_weights_ptr, + float aux_input_to_forget_weights_scale, + const int8_t* aux_input_to_cell_weights_ptr, + float aux_input_to_cell_weights_scale, + const int8_t* aux_input_to_output_weights_ptr, + float aux_input_to_output_weights_scale, + const int8_t* recurrent_to_input_weights_ptr, + float recurrent_to_input_weights_scale, + const int8_t* recurrent_to_forget_weights_ptr, + float recurrent_to_forget_weights_scale, + const int8_t* recurrent_to_cell_weights_ptr, + float recurrent_to_cell_weights_scale, + const int8_t* recurrent_to_output_weights_ptr, + float recurrent_to_output_weights_scale, + const int8_t* cell_to_input_weights_ptr, + float cell_to_input_weights_scale, + const int8_t* cell_to_forget_weights_ptr, + float cell_to_forget_weights_scale, + const int8_t* cell_to_output_weights_ptr, + float cell_to_output_weights_scale, const float* input_gate_bias_ptr, + const float* forget_gate_bias_ptr, const float* cell_bias_ptr, + const float* output_gate_bias_ptr, const int8_t* projection_weights_ptr, + float projection_weights_scale, const float* projection_bias_ptr, + const TfLiteLSTMParams* params, int n_batch, int n_cell, int n_input, + int n_output, float* input_gate_scratch, float* forget_gate_scratch, + float* cell_scratch, float* output_gate_scratch, float* scaling_factors, + float* product_scaling_factors, float* recovered_cell_weights, + int8_t* quantized_input_ptr_batch, + int8_t* quantized_aux_input_ptr_batch, + int8_t* quantized_output_state_ptr, int8_t* quantized_cell_state_ptr, + float* output_state_ptr, float* cell_state_ptr, + float* output_ptr_batch) { + // Since we have already checked that weights are all there or none, we + // can check the existense of only one to the get the condition. + const bool use_cifg = (input_to_input_weights_ptr == nullptr); + const bool use_peephole = (cell_to_output_weights_ptr != nullptr); + // Initialize scratch buffers with bias. + if (!use_cifg) { + tensor_utils::VectorBatchVectorAssign(input_gate_bias_ptr, n_cell, + n_batch, input_gate_scratch); + } + tensor_utils::VectorBatchVectorAssign(forget_gate_bias_ptr, n_cell, + n_batch, forget_gate_scratch); + tensor_utils::VectorBatchVectorAssign(cell_bias_ptr, n_cell, n_batch, + cell_scratch); + tensor_utils::VectorBatchVectorAssign(output_gate_bias_ptr, n_cell, + n_batch, output_gate_scratch); + + if (!tensor_utils::IsZeroVector(input_ptr_batch, n_batch * n_input)) { + // Save quantization and matmul computation for all zero input. + float unused_min, unused_max; + for (int b = 0; b < n_batch; ++b) { + const int offset = b * n_input; + tensor_utils::SymmetricQuantizeFloats( + input_ptr_batch + offset, n_input, + quantized_input_ptr_batch + offset, &unused_min, &unused_max, + &scaling_factors[b]); + } + // For each batch and cell: compute input_weight * input. + if (!use_cifg) { + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * input_to_input_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_input_weights_ptr, n_cell, n_input, + quantized_input_ptr_batch, product_scaling_factors, n_batch, + input_gate_scratch, /*result_stride=*/1); + } + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * input_to_forget_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_forget_weights_ptr, n_cell, n_input, + quantized_input_ptr_batch, product_scaling_factors, n_batch, + forget_gate_scratch, + /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * input_to_cell_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_cell_weights_ptr, n_cell, n_input, + quantized_input_ptr_batch, product_scaling_factors, n_batch, + cell_scratch, /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * input_to_output_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_output_weights_ptr, n_cell, n_input, + quantized_input_ptr_batch, product_scaling_factors, n_batch, + output_gate_scratch, + /*result_stride=*/1); } - tensor_utils::MatrixBatchVectorMultiplyAccumulate( - recurrent_to_input_weights_ptr, n_cell, n_output, - quantized_output_state_ptr, product_scaling_factors, n_batch, - input_gate_scratch, /*result_stride=*/1); - } - - for (int b = 0; b < n_batch; ++b) { - product_scaling_factors[b] = - scaling_factors[b] * recurrent_to_forget_weights_scale; - } - tensor_utils::MatrixBatchVectorMultiplyAccumulate( - recurrent_to_forget_weights_ptr, n_cell, n_output, - quantized_output_state_ptr, product_scaling_factors, n_batch, - forget_gate_scratch, /*result_stride=*/1); - - for (int b = 0; b < n_batch; ++b) { - product_scaling_factors[b] = - scaling_factors[b] * recurrent_to_cell_weights_scale; - } - tensor_utils::MatrixBatchVectorMultiplyAccumulate( - recurrent_to_cell_weights_ptr, n_cell, n_output, - quantized_output_state_ptr, product_scaling_factors, n_batch, - cell_scratch, /*result_stride=*/1); - - for (int b = 0; b < n_batch; ++b) { - product_scaling_factors[b] = - scaling_factors[b] * recurrent_to_output_weights_scale; - } - tensor_utils::MatrixBatchVectorMultiplyAccumulate( - recurrent_to_output_weights_ptr, n_cell, n_output, - quantized_output_state_ptr, product_scaling_factors, n_batch, - output_gate_scratch, /*result_stride=*/1); - } - - // Save quantization and matmul computation for all zero input. - bool is_cell_state_all_zeros = - tensor_utils::IsZeroVector(cell_state_ptr, n_batch * n_cell); - // For each batch and cell: update input gate. - if (!use_cifg) { - if (use_peephole && !is_cell_state_all_zeros) { - tensor_utils::VectorScalarMultiply(cell_to_input_weights_ptr, n_cell, - cell_to_input_weights_scale, - recovered_cell_weights); - tensor_utils::VectorBatchVectorCwiseProductAccumulate( - recovered_cell_weights, n_cell, cell_state_ptr, n_batch, - input_gate_scratch); - } - tensor_utils::ApplySigmoidToVector(input_gate_scratch, n_cell * n_batch, - input_gate_scratch); - } + if (aux_input_ptr_batch != nullptr && + !tensor_utils::IsZeroVector(aux_input_ptr_batch, n_batch * n_input)) { + // Save quantization and matmul computation for all zero input. + float unused_min, unused_max; + for (int b = 0; b < n_batch; ++b) { + const int offset = b * n_input; + tensor_utils::SymmetricQuantizeFloats( + aux_input_ptr_batch + offset, n_input, + quantized_aux_input_ptr_batch + offset, &unused_min, &unused_max, + &scaling_factors[b]); + } + // For each batch and cell: compute input_weight * input. + if (!use_cifg) { + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * aux_input_to_input_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_to_input_weights_ptr, n_cell, n_input, + quantized_aux_input_ptr_batch, product_scaling_factors, n_batch, + input_gate_scratch, /*result_stride=*/1); + } + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * aux_input_to_forget_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_to_forget_weights_ptr, n_cell, n_input, + quantized_aux_input_ptr_batch, product_scaling_factors, n_batch, + forget_gate_scratch, /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * aux_input_to_cell_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_to_cell_weights_ptr, n_cell, n_input, + quantized_aux_input_ptr_batch, product_scaling_factors, n_batch, + cell_scratch, /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * aux_input_to_output_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_to_output_weights_ptr, n_cell, n_input, + quantized_aux_input_ptr_batch, product_scaling_factors, n_batch, + output_gate_scratch, /*result_stride=*/1); + } - // For each batch and cell: update forget gate. - if (use_peephole && !is_cell_state_all_zeros) { - tensor_utils::VectorScalarMultiply(cell_to_forget_weights_ptr, n_cell, - cell_to_forget_weights_scale, - recovered_cell_weights); - tensor_utils::VectorBatchVectorCwiseProductAccumulate( - recovered_cell_weights, n_cell, cell_state_ptr, n_batch, - forget_gate_scratch); - } - tensor_utils::ApplySigmoidToVector(forget_gate_scratch, n_cell * n_batch, - forget_gate_scratch); + if (!tensor_utils::IsZeroVector(output_state_ptr, n_batch * n_output)) { + // Save quantization and matmul computation for all zero input. + float unused_min, unused_max; + for (int b = 0; b < n_batch; ++b) { + const int offset = b * n_output; + tensor_utils::SymmetricQuantizeFloats( + output_state_ptr + offset, n_output, + quantized_output_state_ptr + offset, &unused_min, &unused_max, + &scaling_factors[b]); + } + // For each batch and cell: compute recurrent_weight * output_state. + if (!use_cifg) { + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * recurrent_to_input_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_input_weights_ptr, n_cell, n_output, + quantized_output_state_ptr, product_scaling_factors, n_batch, + input_gate_scratch, /*result_stride=*/1); + } + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * recurrent_to_forget_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_forget_weights_ptr, n_cell, n_output, + quantized_output_state_ptr, product_scaling_factors, n_batch, + forget_gate_scratch, /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * recurrent_to_cell_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_cell_weights_ptr, n_cell, n_output, + quantized_output_state_ptr, product_scaling_factors, n_batch, + cell_scratch, /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * recurrent_to_output_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_output_weights_ptr, n_cell, n_output, + quantized_output_state_ptr, product_scaling_factors, n_batch, + output_gate_scratch, /*result_stride=*/1); + } - // For each batch and cell: update the cell. - tensor_utils::VectorVectorCwiseProduct(forget_gate_scratch, cell_state_ptr, - n_batch * n_cell, cell_state_ptr); - tensor_utils::ApplyActivationToVector(cell_scratch, n_batch * n_cell, - params->activation, cell_scratch); - if (use_cifg) { - tensor_utils::Sub1Vector(forget_gate_scratch, n_batch * n_cell, - forget_gate_scratch); - tensor_utils::VectorVectorCwiseProductAccumulate( - cell_scratch, forget_gate_scratch, n_batch * n_cell, cell_state_ptr); - } else { - tensor_utils::VectorVectorCwiseProductAccumulate( - cell_scratch, input_gate_scratch, n_batch * n_cell, cell_state_ptr); - } - if (params->cell_clip > 0.0) { - tensor_utils::ClipVector(cell_state_ptr, n_batch * n_cell, - params->cell_clip, cell_state_ptr); - } + // Save quantization and matmul computation for all zero input. + bool is_cell_state_all_zeros = + tensor_utils::IsZeroVector(cell_state_ptr, n_batch * n_cell); + + // For each batch and cell: update input gate. + if (!use_cifg) { + if (use_peephole && !is_cell_state_all_zeros) { + tensor_utils::VectorScalarMultiply(cell_to_input_weights_ptr, n_cell, + cell_to_input_weights_scale, + recovered_cell_weights); + tensor_utils::VectorBatchVectorCwiseProductAccumulate( + recovered_cell_weights, n_cell, cell_state_ptr, n_batch, + input_gate_scratch); + } + tensor_utils::ApplySigmoidToVector(input_gate_scratch, n_cell * n_batch, + input_gate_scratch); + } - is_cell_state_all_zeros = - tensor_utils::IsZeroVector(cell_state_ptr, n_batch * n_cell); - // For each batch and cell: update the output gate. - if (use_peephole && !is_cell_state_all_zeros) { - tensor_utils::VectorScalarMultiply(cell_to_output_weights_ptr, n_cell, - cell_to_output_weights_scale, - recovered_cell_weights); - tensor_utils::VectorBatchVectorCwiseProductAccumulate( - recovered_cell_weights, n_cell, cell_state_ptr, n_batch, - output_gate_scratch); - } - tensor_utils::ApplySigmoidToVector(output_gate_scratch, n_batch * n_cell, - output_gate_scratch); - tensor_utils::ApplyActivationToVector(cell_state_ptr, n_batch * n_cell, - params->activation, cell_scratch); - tensor_utils::VectorVectorCwiseProduct(output_gate_scratch, cell_scratch, - n_batch * n_cell, output_gate_scratch); + // For each batch and cell: update forget gate. + if (use_peephole && !is_cell_state_all_zeros) { + tensor_utils::VectorScalarMultiply(cell_to_forget_weights_ptr, n_cell, + cell_to_forget_weights_scale, + recovered_cell_weights); + tensor_utils::VectorBatchVectorCwiseProductAccumulate( + recovered_cell_weights, n_cell, cell_state_ptr, n_batch, + forget_gate_scratch); + } + tensor_utils::ApplySigmoidToVector(forget_gate_scratch, n_cell * n_batch, + forget_gate_scratch); + + // For each batch and cell: update the cell. + tensor_utils::VectorVectorCwiseProduct(forget_gate_scratch, + cell_state_ptr, n_batch * n_cell, + cell_state_ptr); + tensor_utils::ApplyActivationToVector(cell_scratch, n_batch * n_cell, + params->activation, cell_scratch); + if (use_cifg) { + tensor_utils::Sub1Vector(forget_gate_scratch, n_batch * n_cell, + forget_gate_scratch); + tensor_utils::VectorVectorCwiseProductAccumulate( + cell_scratch, forget_gate_scratch, n_batch * n_cell, + cell_state_ptr); + } else { + tensor_utils::VectorVectorCwiseProductAccumulate( + cell_scratch, input_gate_scratch, n_batch * n_cell, cell_state_ptr); + } + if (params->cell_clip > 0.0) { + tensor_utils::ClipVector(cell_state_ptr, n_batch * n_cell, + params->cell_clip, cell_state_ptr); + } - // For each batch: update the projection and output_state. - const bool use_projection_weight = (projection_weights_ptr != nullptr); - const bool use_projection_bias = (projection_bias_ptr != nullptr); - if (use_projection_weight) { - if (use_projection_bias) { - tensor_utils::VectorBatchVectorAssign(projection_bias_ptr, n_output, - n_batch, output_ptr_batch); - } else { - tensor_utils::ZeroVector(output_ptr_batch, n_batch * n_output); - } - if (!tensor_utils::IsZeroVector(output_gate_scratch, n_batch * n_cell)) { - // Save quantization and matmul computation for all zero input. - float unused_min, unused_max; - for (int b = 0; b < n_batch; ++b) { - const int offset = b * n_cell; - tensor_utils::SymmetricQuantizeFloats( - output_gate_scratch + offset, n_cell, - quantized_cell_state_ptr + offset, &unused_min, &unused_max, - &scaling_factors[b]); + is_cell_state_all_zeros = + tensor_utils::IsZeroVector(cell_state_ptr, n_batch * n_cell); + // For each batch and cell: update the output gate. + if (use_peephole && !is_cell_state_all_zeros) { + tensor_utils::VectorScalarMultiply(cell_to_output_weights_ptr, n_cell, + cell_to_output_weights_scale, + recovered_cell_weights); + tensor_utils::VectorBatchVectorCwiseProductAccumulate( + recovered_cell_weights, n_cell, cell_state_ptr, n_batch, + output_gate_scratch); } - for (int b = 0; b < n_batch; ++b) { - product_scaling_factors[b] = - scaling_factors[b] * projection_weights_scale; + tensor_utils::ApplySigmoidToVector(output_gate_scratch, n_batch * n_cell, + output_gate_scratch); + tensor_utils::ApplyActivationToVector(cell_state_ptr, n_batch * n_cell, + params->activation, cell_scratch); + tensor_utils::VectorVectorCwiseProduct(output_gate_scratch, cell_scratch, + n_batch * n_cell, + output_gate_scratch); + + // For each batch: update the projection and output_state. + const bool use_projection_weight = (projection_weights_ptr != nullptr); + const bool use_projection_bias = (projection_bias_ptr != nullptr); + if (use_projection_weight) { + if (use_projection_bias) { + tensor_utils::VectorBatchVectorAssign(projection_bias_ptr, n_output, + n_batch, output_ptr_batch); + } else { + tensor_utils::ZeroVector(output_ptr_batch, n_batch * n_output); + } + if (!tensor_utils::IsZeroVector(output_gate_scratch, + n_batch * n_cell)) { + // Save quantization and matmul computation for all zero input. + float unused_min, unused_max; + for (int b = 0; b < n_batch; ++b) { + const int offset = b * n_cell; + tensor_utils::SymmetricQuantizeFloats( + output_gate_scratch + offset, n_cell, + quantized_cell_state_ptr + offset, &unused_min, &unused_max, + &scaling_factors[b]); + } + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * projection_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + projection_weights_ptr, n_output, n_cell, + quantized_cell_state_ptr, product_scaling_factors, n_batch, + output_ptr_batch, + /*result_stride=*/1); + } + if (params->proj_clip > 0.0) { + tensor_utils::ClipVector(output_ptr_batch, n_batch * n_output, + params->proj_clip, output_ptr_batch); + } + } else { + tensor_utils::CopyVector(output_gate_scratch, n_batch * n_output, + output_ptr_batch); } - tensor_utils::MatrixBatchVectorMultiplyAccumulate( - projection_weights_ptr, n_output, n_cell, quantized_cell_state_ptr, - product_scaling_factors, n_batch, output_ptr_batch, - /*result_stride=*/1); - } - if (params->proj_clip > 0.0) { - tensor_utils::ClipVector(output_ptr_batch, n_batch * n_output, - params->proj_clip, output_ptr_batch); + tensor_utils::CopyVector(output_ptr_batch, n_batch * n_output, + output_state_ptr); } - } else { - tensor_utils::CopyVector(output_gate_scratch, n_batch * n_output, - output_ptr_batch); - } - tensor_utils::CopyVector(output_ptr_batch, n_batch * n_output, - output_state_ptr); -} } // namespace kernel_utils } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/internal/kernel_utils.h b/tensorflow/contrib/lite/kernels/internal/kernel_utils.h index 2a11b37a60..599850db60 100644 --- a/tensorflow/contrib/lite/kernels/internal/kernel_utils.h +++ b/tensorflow/contrib/lite/kernels/internal/kernel_utils.h @@ -66,8 +66,7 @@ void RnnBatchStep(const float* input_ptr_batch, const int8_t* input_weights_ptr, // - n_input: the input size, // - n_output: the output size. // -// The pointers to the cell and output state and the output are updated. Unless -// projection is specified output and output state contain the same data. +// The pointers to the cell and output state and the output are updated. // // The pointers with the suffix "_batch" point to data aligned in batch_major // order, and each step processes batch_size many inputs from input_ptr_batch, @@ -92,6 +91,31 @@ void LstmStep( float* forget_gate_scratch, float* cell_scratch, float* output_gate_scratch, float* output_ptr_batch); +// Same as above but includes an auxiliary input with the corresponding weights. +void LstmStepWithAuxInput( + const float* input_ptr_batch, const float* input_to_input_weights_ptr, + const float* input_to_forget_weights_ptr, + const float* input_to_cell_weights_ptr, + const float* input_to_output_weights_ptr, const float* aux_input_ptr_batch, + const float* aux_input_to_input_weights_ptr, + const float* aux_input_to_forget_weights_ptr, + const float* aux_input_to_cell_weights_ptr, + const float* aux_input_to_output_weights_ptr, + const float* recurrent_to_input_weights_ptr, + const float* recurrent_to_forget_weights_ptr, + const float* recurrent_to_cell_weights_ptr, + const float* recurrent_to_output_weights_ptr, + const float* cell_to_input_weights_ptr, + const float* cell_to_forget_weights_ptr, + const float* cell_to_output_weights_ptr, const float* input_gate_bias_ptr, + const float* forget_gate_bias_ptr, const float* cell_bias_ptr, + const float* output_gate_bias_ptr, const float* projection_weights_ptr, + const float* projection_bias_ptr, const TfLiteLSTMParams* params, + int n_batch, int n_cell, int n_input, int n_output, float* output_state_ptr, + float* cell_state_ptr, float* input_gate_scratch, + float* forget_gate_scratch, float* cell_scratch, float* output_gate_scratch, + float* output_ptr_batch); + // Same as above but with quantized weight matrices. In detail: // Input of size 'n_batch * n_input': // input_ptr_batch @@ -175,6 +199,46 @@ void LstmStep( int8_t* quantized_cell_state_ptr, float* output_state_ptr, float* cell_state_ptr, float* output_ptr_batch); +void LstmStepWithAuxInput( + const float* input_ptr_batch, const int8_t* input_to_input_weights_ptr, + float input_to_input_weights_scale, + const int8_t* input_to_forget_weights_ptr, + float input_to_forget_weights_scale, + const int8_t* input_to_cell_weights_ptr, float input_to_cell_weights_scale, + const int8_t* input_to_output_weights_ptr, + float input_to_output_weights_scale, const float* aux_input_ptr_batch, + const int8_t* aux_input_to_input_weights_ptr, + float aux_input_to_input_weights_scale, + const int8_t* aux_input_to_forget_weights_ptr, + float aux_input_to_forget_weights_scale, + const int8_t* aux_input_to_cell_weights_ptr, + float aux_input_to_cell_weights_scale, + const int8_t* aux_input_to_output_weights_ptr, + float aux_input_to_output_weights_scale, + const int8_t* recurrent_to_input_weights_ptr, + float recurrent_to_input_weights_scale, + const int8_t* recurrent_to_forget_weights_ptr, + float recurrent_to_forget_weights_scale, + const int8_t* recurrent_to_cell_weights_ptr, + float recurrent_to_cell_weights_scale, + const int8_t* recurrent_to_output_weights_ptr, + float recurrent_to_output_weights_scale, + const int8_t* cell_to_input_weights_ptr, float cell_to_input_weights_scale, + const int8_t* cell_to_forget_weights_ptr, + float cell_to_forget_weights_scale, + const int8_t* cell_to_output_weights_ptr, + float cell_to_output_weights_scale, const float* input_gate_bias_ptr, + const float* forget_gate_bias_ptr, const float* cell_bias_ptr, + const float* output_gate_bias_ptr, const int8_t* projection_weights_ptr, + float projection_weights_scale, const float* projection_bias_ptr, + const TfLiteLSTMParams* params, int n_batch, int n_cell, int n_input, + int n_output, float* input_gate_scratch, float* forget_gate_scratch, + float* cell_scratch, float* output_gate_scratch, float* scaling_factors, + float* product_scaling_factors, float* recovered_cell_weights, + int8_t* quantized_input_ptr_batch, int8_t* quantized_aux_input_ptr_batch, + int8_t* quantized_output_state_ptr, int8_t* quantized_cell_state_ptr, + float* output_state_ptr, float* cell_state_ptr, float* output_ptr_batch); + } // namespace kernel_utils } // namespace tflite #endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_KERNEL_UTILS_H_ diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/cpu_check.h b/tensorflow/contrib/lite/kernels/internal/optimized/cpu_check.h index 3a53d3ab07..934308ef29 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/cpu_check.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/cpu_check.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_CPU_CHECK_ -#define TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_CPU_CHECK_ +#ifndef TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_CPU_CHECK_H_ +#define TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_CPU_CHECK_H_ namespace tflite { @@ -58,4 +58,4 @@ inline bool TestCPUFeatureNeon() { return false; } : Portable##funcname(__VA_ARGS__) #endif -#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_CPU_CHECK_ +#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_CPU_CHECK_H_ diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/eigen_tensor_reduced_instantiations_google.h b/tensorflow/contrib/lite/kernels/internal/optimized/eigen_tensor_reduced_instantiations_google.h index 250872c422..6443f425b7 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/eigen_tensor_reduced_instantiations_google.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/eigen_tensor_reduced_instantiations_google.h @@ -140,4 +140,4 @@ limitations under the License. #include "third_party/eigen3/unsupported/Eigen/CXX11/src/Tensor/TensorIO.h" #include "Eigen/src/Core/util/ReenableStupidWarnings.h" -#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_EIGEN_TENSOR_REDUCED_INSTANTIATIONS_H +#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_EIGEN_TENSOR_REDUCED_INSTANTIATIONS_GOOGLE_H_ diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/legacy_optimized_ops.h b/tensorflow/contrib/lite/kernels/internal/optimized/legacy_optimized_ops.h index 7f0676be27..df4d871466 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/legacy_optimized_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/legacy_optimized_ops.h @@ -46,8 +46,8 @@ inline void L2Normalization(const uint8* input_data, const Dims<4>& input_dims, inline void Relu(const float* input_data, const Dims<4>& input_dims, float* output_data, const Dims<4>& output_dims) { - Relu(input_data, DimsToShape(input_dims), output_data, - DimsToShape(output_dims)); + Relu(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); } // legacy, for compatibility with old checked-in code @@ -580,8 +580,8 @@ inline void LogSoftmax(const uint8* input_data, const Dims<4>& input_dims, inline void Logistic(const float* input_data, const Dims<4>& input_dims, float* output_data, const Dims<4>& output_dims) { - Logistic(input_data, DimsToShape(input_dims), output_data, - DimsToShape(output_dims)); + Logistic(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); } inline void Logistic(const uint8* input_data, const Dims<4>& input_dims, @@ -601,8 +601,8 @@ inline void Logistic(const int16* input_data, const Dims<4>& input_dims, inline void Tanh(const float* input_data, const Dims<4>& input_dims, float* output_data, const Dims<4>& output_dims) { - Tanh(input_data, DimsToShape(input_dims), output_data, - DimsToShape(output_dims)); + Tanh(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); } inline void Tanh(const uint8* input_data, const Dims<4>& input_dims, diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/multithreaded_conv.h b/tensorflow/contrib/lite/kernels/internal/optimized/multithreaded_conv.h index 4a3545d47a..921aae1303 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/multithreaded_conv.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/multithreaded_conv.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_MULTITHREAD_CONV -#define TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_MULTITHREAD_CONV +#ifndef TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_MULTITHREADED_CONV_H_ +#define TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_MULTITHREADED_CONV_H_ #include <assert.h> #include <stdint.h> @@ -164,4 +164,4 @@ inline void Conv(const Eigen::ThreadPoolDevice& device, const float* input_data, } // namespace multithreaded_ops } // namespace tflite -#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_MULTITHREAD_CONV +#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_MULTITHREADED_CONV_H_ diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h b/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h index ca020215e6..e4bb4e0534 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_OPS_H_ -#define TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_OPS_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_OPTIMIZED_OPS_H_ +#define TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_OPTIMIZED_OPS_H_ #include <assert.h> #include <stdint.h> @@ -34,6 +34,7 @@ limitations under the License. #include "tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h" #include "tensorflow/contrib/lite/kernels/internal/round.h" #include "tensorflow/contrib/lite/kernels/internal/strided_slice_logic.h" +#include "tensorflow/contrib/lite/kernels/internal/tensor_utils.h" #include "tensorflow/contrib/lite/kernels/internal/types.h" namespace tflite { @@ -319,6 +320,7 @@ inline void AddBiasAndEvalActivationFunction(const float* bias_data, #endif } +// Note: This to be converted to RuntimeShapes along with Conv. // legacy, for compatibility with old checked-in code template <FusedActivationFunctionType Ac> void AddBiasAndEvalActivationFunction(const float* bias_data, @@ -1934,6 +1936,85 @@ inline void Conv(const float* input_data, const Dims<4>& input_dims, output_activation_max); } +inline void HybridConv(const int8_t* input_data, const Dims<4>& input_dims, + const int8_t* filter_data, const Dims<4>& filter_dims, + const float* bias_data, const Dims<4>& bias_dims, + int stride_width, int stride_height, int pad_width, + int pad_height, float* scaling_factors_ptr, + float output_activation_min, float output_activation_max, + float* output_data, const Dims<4>& output_dims, + int8_t* im2col_data, const Dims<4>& im2col_dims) { + const int batch_size = input_dims.sizes[3]; + const int filter_width = ArraySize(filter_dims, 1); + const int filter_height = ArraySize(filter_dims, 2); + + const int8* gemm_input_data = nullptr; + int num_input; + const bool need_im2col = stride_width != 1 || stride_height != 1 || + filter_width != 1 || filter_height != 1; + + if (need_im2col) { + TFLITE_DCHECK(im2col_data); + // symmetric quantization assumes zero point of 0. + const int input_zero_point = 0; + Im2col(input_data, input_dims, stride_width, stride_height, pad_width, + pad_height, filter_height, filter_width, input_zero_point, + im2col_data, im2col_dims); + gemm_input_data = im2col_data; + num_input = im2col_dims.sizes[0] * im2col_dims.sizes[1] * + im2col_dims.sizes[2] * im2col_dims.sizes[3]; + } else { + TFLITE_DCHECK(!im2col_data); + gemm_input_data = input_data; + num_input = input_dims.sizes[0] * input_dims.sizes[1] * + input_dims.sizes[2] * input_dims.sizes[3]; + } + + // Flatten 4D matrices into 2D matrices for matrix multiplication. + + // Flatten so that each filter has its own row. + const int filter_rows = filter_dims.sizes[3]; + const int filter_cols = + filter_dims.sizes[0] * filter_dims.sizes[1] * filter_dims.sizes[2]; + + // In MatrixBatchVectorMultiplyAccumulate, each output value is the + // dot product of one row of the first matrix with one row of the second + // matrix. Therefore, the number of cols in each matrix are equivalent. + // + // After Im2Col, each input patch becomes a row. + const int gemm_input_cols = filter_cols; + const int gemm_input_rows = num_input / gemm_input_cols; + + const int output_cols = output_dims.sizes[0]; + const int output_rows = + output_dims.sizes[1] * output_dims.sizes[2] * output_dims.sizes[3]; + TFLITE_DCHECK_EQ(output_cols, filter_rows); + TFLITE_DCHECK_EQ(output_rows, gemm_input_rows); + TFLITE_DCHECK_EQ(bias_dims.sizes[0], output_cols); + TFLITE_DCHECK_EQ(bias_dims.sizes[1], 1); + TFLITE_DCHECK_EQ(bias_dims.sizes[2], 1); + TFLITE_DCHECK_EQ(bias_dims.sizes[3], 1); + + // MatrixBatchVectorMultiplyAccumulate assumes that each row of the second + // input matrix has its own scale factor. This code duplicates the scale + // factors for each row in the same batch. + const int rows_per_batch = gemm_input_rows / batch_size; + for (int i = gemm_input_rows - 1; i >= 0; --i) { + scaling_factors_ptr[i] = scaling_factors_ptr[i / rows_per_batch]; + } + + tensor_utils::ZeroVector(output_data, output_rows * output_cols); + + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + filter_data, filter_rows, filter_cols, gemm_input_data, + scaling_factors_ptr, /*n_batch=*/gemm_input_rows, output_data, + /*result_stride=*/1); + + AddBiasAndEvalActivationFunction(bias_data, bias_dims, output_data, + output_dims, output_activation_min, + output_activation_max); +} + template <FusedActivationFunctionType Ac> void Conv(const float* input_data, const Dims<4>& input_dims, const float* filter_data, const Dims<4>& filter_dims, @@ -2142,38 +2223,6 @@ void Conv(const uint8* input_data, const Dims<4>& input_dims, im2col_data, im2col_dims, gemm_context); } -template <typename T> -inline void DepthToSpace(const T* input_data, const Dims<4>& input_dims, - int block_size, T* output_data, - const Dims<4>& output_dims) { - gemmlowp::ScopedProfilingLabel label("DepthToSpace"); - - const int input_depth = ArraySize(input_dims, 0); - const int input_width = ArraySize(input_dims, 1); - const int input_height = ArraySize(input_dims, 2); - - const int output_depth = ArraySize(output_dims, 0); - const int batch_size = ArraySize(output_dims, 3); - - // Number of continuous values that we can copy in one interation. - const int stride = block_size * output_depth; - - for (int batch = 0; batch < batch_size; ++batch) { - for (int in_h = 0; in_h < input_height; ++in_h) { - const T* input_ptr = input_data + Offset(input_dims, 0, 0, in_h, batch); - for (int offset_h = 0; offset_h < block_size; ++offset_h) { - const T* src = input_ptr; - for (int in_w = 0; in_w < input_width; ++in_w) { - memcpy(output_data, src, stride * sizeof(T)); - output_data += stride; - src += input_depth; - } - input_ptr += stride; - } - } - } -} - // legacy, for compatibility with old checked-in code template <FusedActivationFunctionType Ac, typename T> void Im2col(const T* input_data, const Dims<4>& input_dims, int stride, @@ -2249,25 +2298,87 @@ void ConvAsGemm(const uint8* input_data, const Dims<4>& input_dims, } template <typename T> -inline void SpaceToDepth(const T* input_data, const Dims<4>& input_dims, +inline void DepthToSpace(const tflite::DepthToSpaceParams& op_params, + const RuntimeShape& unextended_input_shape, + const T* input_data, + const RuntimeShape& unextended_output_shape, + T* output_data) { + gemmlowp::ScopedProfilingLabel label("DepthToSpace"); + + TFLITE_DCHECK_LE(unextended_input_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape input_shape = + RuntimeShape::ExtendedShape(4, unextended_input_shape); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + + const int input_depth = input_shape.Dims(3); + const int input_width = input_shape.Dims(2); + const int input_height = input_shape.Dims(1); + + const int output_depth = output_shape.Dims(3); + const int batch_size = output_shape.Dims(0); + + // Number of continuous values that we can copy in one interation. + const int stride = op_params.block_size * output_depth; + + for (int batch = 0; batch < batch_size; ++batch) { + for (int in_h = 0; in_h < input_height; ++in_h) { + const T* input_ptr = input_data + Offset(input_shape, batch, in_h, 0, 0); + for (int offset_h = 0; offset_h < op_params.block_size; ++offset_h) { + const T* src = input_ptr; + for (int in_w = 0; in_w < input_width; ++in_w) { + memcpy(output_data, src, stride * sizeof(T)); + output_data += stride; + src += input_depth; + } + input_ptr += stride; + } + } + } +} + +// Legacy Dims<4>. +template <typename T> +inline void DepthToSpace(const T* input_data, const Dims<4>& input_dims, int block_size, T* output_data, const Dims<4>& output_dims) { + tflite::DepthToSpaceParams op_params; + op_params.block_size = block_size; + + DepthToSpace(op_params, DimsToShape(input_dims), input_data, + DimsToShape(output_dims), output_data); +} + +template <typename T> +inline void SpaceToDepth(const tflite::SpaceToDepthParams& op_params, + const RuntimeShape& unextended_input_shape, + const T* input_data, + const RuntimeShape& unextended_output_shape, + T* output_data) { gemmlowp::ScopedProfilingLabel label("SpaceToDepth"); - const int output_depth = ArraySize(output_dims, 0); - const int output_width = ArraySize(output_dims, 1); - const int output_height = ArraySize(output_dims, 2); + TFLITE_DCHECK_LE(unextended_input_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape input_shape = + RuntimeShape::ExtendedShape(4, unextended_input_shape); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); - const int input_depth = ArraySize(input_dims, 0); - const int batch_size = ArraySize(input_dims, 3); + const int output_depth = output_shape.Dims(3); + const int output_width = output_shape.Dims(2); + const int output_height = output_shape.Dims(1); + + const int input_depth = input_shape.Dims(3); + const int batch_size = input_shape.Dims(0); // Number of continuous values that we can copy in one interation. - const int stride = block_size * input_depth; + const int stride = op_params.block_size * input_depth; for (int batch = 0; batch < batch_size; ++batch) { for (int out_h = 0; out_h < output_height; ++out_h) { - T* output_ptr = output_data + Offset(output_dims, 0, 0, out_h, batch); - for (int offset_h = 0; offset_h < block_size; ++offset_h) { + T* output_ptr = output_data + Offset(output_shape, batch, out_h, 0, 0); + for (int offset_h = 0; offset_h < op_params.block_size; ++offset_h) { T* dst = output_ptr; for (int out_w = 0; out_w < output_width; ++out_w) { memcpy(dst, input_data, stride * sizeof(T)); @@ -2280,55 +2391,20 @@ inline void SpaceToDepth(const T* input_data, const Dims<4>& input_dims, } } -template <FusedActivationFunctionType Ac> -void NonGlobalBatchNormalization( - const float* input_data, const Dims<4>& input_dims, const float* mean_data, - const Dims<4>& mean_dims, const float* multiplier_data, - const Dims<4>& multiplier_dims, const float* offset_data, - const Dims<4>& offset_dims, float* output_data, - const Dims<4>& output_dims) { - gemmlowp::ScopedProfilingLabel label("NonGlobalBatchNormalization"); - const int batches = MatchingArraySize(input_dims, 3, output_dims, 3); - const int inner_size = MatchingFlatSizeSkipDim( - input_dims, 3, mean_dims, multiplier_dims, offset_dims, output_dims); - - for (int b = 0; b < batches; ++b) { - for (int i = 0; i < inner_size; ++i) { - *output_data = ActivationFunction<Ac>( - (*input_data - mean_data[i]) * multiplier_data[i] + offset_data[i]); - ++output_data; - ++input_data; - } - } -} - -template <FusedActivationFunctionType Ac> -void GlobalBatchNormalization(const float* input_data, - const Dims<4>& input_dims, const float* mean_data, - const Dims<4>& mean_dims, - const float* multiplier_data, - const Dims<4>& multiplier_dims, - const float* offset_data, - const Dims<4>& offset_dims, float* output_data, - const Dims<4>& output_dims) { - gemmlowp::ScopedProfilingLabel label("GlobalBatchNormalization"); - const int outer_size = MatchingFlatSizeSkipDim(input_dims, 0, output_dims); - const int depth = - MatchingArraySize(input_dims, 0, mean_dims, 0, multiplier_dims, 0, - offset_dims, 0, output_dims, 0); +// Legacy Dims<4>. +template <typename T> +inline void SpaceToDepth(const T* input_data, const Dims<4>& input_dims, + int block_size, T* output_data, + const Dims<4>& output_dims) { + tflite::SpaceToDepthParams op_params; + op_params.block_size = block_size; - for (int i = 0; i < outer_size; ++i) { - for (int c = 0; c < depth; ++c) { - *output_data = ActivationFunction<Ac>( - (*input_data - mean_data[c]) * multiplier_data[c] + offset_data[c]); - ++output_data; - ++input_data; - } - } + SpaceToDepth(op_params, DimsToShape(input_dims), input_data, + DimsToShape(output_dims), output_data); } -inline void Relu(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { +inline void Relu(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { gemmlowp::ScopedProfilingLabel label("Relu (not fused)"); const auto input = MapAsVector(input_data, input_shape); @@ -2336,11 +2412,12 @@ inline void Relu(const float* input_data, const RuntimeShape& input_shape, output = input.cwiseMax(0.0f); } -template <FusedActivationFunctionType Ac> -void L2Normalization(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { +inline void L2Normalization(const tflite::L2NormalizationParams& op_params, + const RuntimeShape& input_shape, + const float* input_data, + const RuntimeShape& output_shape, + float* output_data) { gemmlowp::ScopedProfilingLabel label("L2Normalization"); - static_assert(Ac == FusedActivationFunctionType::kNone, ""); const int trailing_dim = input_shape.DimensionsCount() - 1; const int outer_size = MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape); @@ -2361,6 +2438,18 @@ void L2Normalization(const float* input_data, const RuntimeShape& input_shape, } } +// Legacy. +template <FusedActivationFunctionType Ac> +void L2Normalization(const float* input_data, const RuntimeShape& input_shape, + float* output_data, const RuntimeShape& output_shape) { + static_assert(Ac == FusedActivationFunctionType::kNone, ""); + tflite::L2NormalizationParams op_params; + // No params need to be set for float. + + L2Normalization(op_params, input_shape, input_data, output_shape, + output_data); +} + inline void GetInvSqrtQuantizedMultiplierExp(int32 input, int32* output_inv_sqrt, int* output_shift) { @@ -2409,16 +2498,18 @@ inline void GetInvSqrtQuantizedMultiplierExp(int32 input, *output_shift *= kReverseShift; } -inline void L2Normalization(const uint8* input_data, +inline void L2Normalization(const tflite::L2NormalizationParams& op_params, const RuntimeShape& input_shape, - int32 input_zero_point, uint8* output_data, - const RuntimeShape& output_shape) { + const uint8* input_data, + const RuntimeShape& output_shape, + uint8* output_data) { gemmlowp::ScopedProfilingLabel label("L2Normalization/8bit"); const int trailing_dim = input_shape.DimensionsCount() - 1; const int depth = MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim); const int outer_size = MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape); + const int32 input_zero_point = op_params.input_zero_point; for (int i = 0; i < outer_size; ++i) { int32 square_l2_norm = 0; for (int c = 0; c < depth; c++) { @@ -2444,6 +2535,18 @@ inline void L2Normalization(const uint8* input_data, } } +// Legacy. +inline void L2Normalization(const uint8* input_data, + const RuntimeShape& input_shape, + int32 input_zero_point, uint8* output_data, + const RuntimeShape& output_shape) { + tflite::L2NormalizationParams op_params; + op_params.input_zero_point = input_zero_point; + + L2Normalization(op_params, input_shape, input_data, output_shape, + output_data); +} + inline void Add(const ArithmeticParams& params, const RuntimeShape& input1_shape, const float* input1_data, const RuntimeShape& input2_shape, const float* input2_data, @@ -2725,17 +2828,16 @@ inline void BroadcastAddFivefold(const ArithmeticParams& unswitched_params, } } -inline void Mul(const float* input1_data, const Dims<4>& input1_dims, - const float* input2_data, const Dims<4>& input2_dims, - float output_activation_min, float output_activation_max, - float* output_data, const Dims<4>& output_dims) { +inline void Mul(const ArithmeticParams& params, + const RuntimeShape& input1_shape, const float* input1_data, + const RuntimeShape& input2_shape, const float* input2_data, + const RuntimeShape& output_shape, float* output_data) { gemmlowp::ScopedProfilingLabel label("Mul"); - TFLITE_DCHECK(IsPackedWithoutStrides(input1_dims)); - TFLITE_DCHECK(IsPackedWithoutStrides(input2_dims)); - TFLITE_DCHECK(IsPackedWithoutStrides(output_dims)); + const float output_activation_min = params.float_activation_min; + const float output_activation_max = params.float_activation_max; int i = 0; - const int size = MatchingFlatSize(input1_dims, input2_dims, output_dims); + const int size = MatchingFlatSize(input1_shape, input2_shape, output_shape); #ifdef USE_NEON const auto activation_min = vdupq_n_f32(output_activation_min); const auto activation_max = vdupq_n_f32(output_activation_max); @@ -2786,6 +2888,20 @@ inline void Mul(const float* input1_data, const Dims<4>& input1_dims, } } +// Legacy Dims<4>. +inline void Mul(const float* input1_data, const Dims<4>& input1_dims, + const float* input2_data, const Dims<4>& input2_dims, + float output_activation_min, float output_activation_max, + float* output_data, const Dims<4>& output_dims) { + tflite::ArithmeticParams op_params; + op_params.float_activation_min = output_activation_min; + op_params.float_activation_max = output_activation_max; + + Mul(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, DimsToShape(output_dims), + output_data); +} + // legacy, for compatibility with old checked-in code template <FusedActivationFunctionType Ac> void Mul(const float* input1_data, const Dims<4>& input1_dims, @@ -2798,13 +2914,16 @@ void Mul(const float* input1_data, const Dims<4>& input1_dims, output_activation_max, output_data, output_dims); } -inline void Mul(const int32* input1_data, const Dims<4>& input1_dims, - const int32* input2_data, const Dims<4>& input2_dims, - int32 output_activation_min, int32 output_activation_max, - int32* output_data, const Dims<4>& output_dims) { - gemmlowp::ScopedProfilingLabel label("Mul/int32"); +inline void Mul(const ArithmeticParams& params, + const RuntimeShape& input1_shape, const int32* input1_data, + const RuntimeShape& input2_shape, const int32* input2_data, + const RuntimeShape& output_shape, int32* output_data) { + gemmlowp::ScopedProfilingLabel label("Mul/int32/activation"); - const int flat_size = MatchingFlatSize(input1_dims, input2_dims, output_dims); + const int flat_size = + MatchingFlatSize(input1_shape, input2_shape, output_shape); + const int32 output_activation_min = params.quantized_activation_min; + const int32 output_activation_max = params.quantized_activation_max; for (int i = 0; i < flat_size; ++i) { output_data[i] = ActivationFunctionWithMinMax( input1_data[i] * input2_data[i], output_activation_min, @@ -2812,22 +2931,38 @@ inline void Mul(const int32* input1_data, const Dims<4>& input1_dims, } } -template <FusedActivationFunctionType Ac> -void Mul(const int32* input1_data, const Dims<4>& input1_dims, - const int32* input2_data, const Dims<4>& input2_dims, - int32* output_data, const Dims<4>& output_dims) { +// Legacy Dims<4>. +inline void Mul(const int32* input1_data, const Dims<4>& input1_dims, + const int32* input2_data, const Dims<4>& input2_dims, + int32 output_activation_min, int32 output_activation_max, + int32* output_data, const Dims<4>& output_dims) { + tflite::ArithmeticParams op_params; + op_params.quantized_activation_min = output_activation_min; + op_params.quantized_activation_max = output_activation_max; + + Mul(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, DimsToShape(output_dims), + output_data); +} + +inline void MulNoActivation(const ArithmeticParams& params, + const RuntimeShape& input1_shape, + const int32* input1_data, + const RuntimeShape& input2_shape, + const int32* input2_data, + const RuntimeShape& output_shape, + int32* output_data) { gemmlowp::ScopedProfilingLabel label("Mul/int32"); - TFLITE_DCHECK(Ac == FusedActivationFunctionType::kNone); - auto input1_map = MapAsVector(input1_data, input1_dims); - auto input2_map = MapAsVector(input2_data, input2_dims); - auto output_map = MapAsVector(output_data, output_dims); - if (AreSameDims(input1_dims, input2_dims)) { + auto input1_map = MapAsVector(input1_data, input1_shape); + auto input2_map = MapAsVector(input2_data, input2_shape); + auto output_map = MapAsVector(output_data, output_shape); + if (input1_shape == input2_shape) { output_map.array() = input1_map.array() * input2_map.array(); - } else if (FlatSize(input2_dims) == 1) { + } else if (input2_shape.FlatSize() == 1) { auto scalar = input2_data[0]; output_map.array() = input1_map.array() * scalar; - } else if (FlatSize(input1_dims) == 1) { + } else if (input1_shape.FlatSize() == 1) { auto scalar = input1_data[0]; output_map.array() = scalar * input2_map.array(); } else { @@ -2836,14 +2971,30 @@ void Mul(const int32* input1_data, const Dims<4>& input1_dims, } } -inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, - const int16* input2_data, const Dims<4>& input2_dims, - int16* output_data, const Dims<4>& output_dims) { - gemmlowp::ScopedProfilingLabel label("Mul/Int16"); +// Legacy Dims<4>. +template <FusedActivationFunctionType Ac> +void Mul(const int32* input1_data, const Dims<4>& input1_dims, + const int32* input2_data, const Dims<4>& input2_dims, + int32* output_data, const Dims<4>& output_dims) { + TFLITE_DCHECK(Ac == FusedActivationFunctionType::kNone); + tflite::ArithmeticParams op_params; + // No parameters needed. + + MulNoActivation(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); +} + +inline void Mul(const ArithmeticParams& params, + const RuntimeShape& input1_shape, const int16* input1_data, + const RuntimeShape& input2_shape, const int16* input2_data, + const RuntimeShape& output_shape, int16* output_data) { + gemmlowp::ScopedProfilingLabel label("Mul/Int16/NoActivation"); // This is a copy of the reference implementation. We do not currently have a // properly optimized version. - const int flat_size = MatchingFlatSize(output_dims, input1_dims, input2_dims); + const int flat_size = + MatchingFlatSize(input1_shape, input2_shape, output_shape); for (int i = 0; i < flat_size; i++) { // F0 uses 0 integer bits, range [-1, 1]. @@ -2855,17 +3006,32 @@ inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, } } +// Legacy Dims<4>. inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, const int16* input2_data, const Dims<4>& input2_dims, - int32 output_offset, int32 output_activation_min, - int32 output_activation_max, uint8* output_data, - const Dims<4>& output_dims) { + int16* output_data, const Dims<4>& output_dims) { + tflite::ArithmeticParams op_params; + // No parameters needed. + + Mul(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, DimsToShape(output_dims), + output_data); +} + +inline void Mul(const ArithmeticParams& params, + const RuntimeShape& input1_shape, const int16* input1_data, + const RuntimeShape& input2_shape, const int16* input2_data, + const RuntimeShape& output_shape, uint8* output_data) { gemmlowp::ScopedProfilingLabel label("Mul/Int16Uint8"); // This is a copy of the reference implementation. We do not currently have a // properly optimized version. + const int32 output_activation_min = params.quantized_activation_min; + const int32 output_activation_max = params.quantized_activation_max; + const int32 output_offset = params.output_offset; TFLITE_DCHECK_LE(output_activation_min, output_activation_max); - const int flat_size = MatchingFlatSize(output_dims, input1_dims, input2_dims); + const int flat_size = + MatchingFlatSize(input1_shape, input2_shape, output_shape); for (int i = 0; i < flat_size; i++) { // F0 uses 0 integer bits, range [-1, 1]. @@ -2883,62 +3049,51 @@ inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, } } -// TODO(jiawen): We can implement BroadcastMul on buffers of arbitrary -// dimensionality if the runtime code does a single loop over one dimension -// that handles broadcasting as the base case. The code generator would then -// generate max(D1, D2) nested for loops. -// TODO(benoitjacob): BroadcastMul is intentionally duplicated from -// reference_ops.h. Once an optimized version is implemented and NdArrayDesc<T> -// is no longer referenced in this file, move NdArrayDesc<T> from types.h to -// reference_ops.h. +// Legacy Dims<4>. +inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, + const int16* input2_data, const Dims<4>& input2_dims, + int32 output_offset, int32 output_activation_min, + int32 output_activation_max, uint8* output_data, + const Dims<4>& output_dims) { + tflite::ArithmeticParams op_params; + op_params.output_offset = output_offset; + op_params.quantized_activation_min = output_activation_min; + op_params.quantized_activation_max = output_activation_max; + + Mul(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, DimsToShape(output_dims), + output_data); +} + +// Legacy Dims<4>. template <typename T> void BroadcastMul(const T* input1_data, const Dims<4>& input1_dims, const T* input2_data, const Dims<4>& input2_dims, T output_activation_min, T output_activation_max, T* output_data, const Dims<4>& output_dims) { - gemmlowp::ScopedProfilingLabel label("BroadcastMul"); + tflite::ArithmeticParams op_params; + SetActivationParams(output_activation_min, output_activation_max, &op_params); - NdArrayDesc<4> desc1; - NdArrayDesc<4> desc2; - NdArrayDescsForElementwiseBroadcast(input1_dims, input2_dims, &desc1, &desc2); - - // In Tensorflow, the dimensions are canonically named (batch_number, row, - // col, channel), with extents (batches, height, width, depth), with the - // trailing dimension changing most rapidly (channels has the smallest stride, - // typically 1 element). - // - // In generated C code, we store arrays with the dimensions reversed. The - // first dimension has smallest stride. - // - // We name our variables by their Tensorflow convention, but generate C code - // nesting loops such that the innermost loop has the smallest stride for the - // best cache behavior. - for (int b = 0; b < ArraySize(output_dims, 3); ++b) { - for (int y = 0; y < ArraySize(output_dims, 2); ++y) { - for (int x = 0; x < ArraySize(output_dims, 1); ++x) { - for (int c = 0; c < ArraySize(output_dims, 0); ++c) { - output_data[Offset(output_dims, c, x, y, b)] = - ActivationFunctionWithMinMax( - input1_data[SubscriptToIndex(desc1, c, x, y, b)] * - input2_data[SubscriptToIndex(desc2, c, x, y, b)], - output_activation_min, output_activation_max); - } - } - } - } + BroadcastMul4DSlow(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); } +// Legacy Dims<4>. // legacy, for compatibility with old checked-in code -template <FusedActivationFunctionType Ac, typename T> -void BroadcastMul(const T* input1_data, const Dims<4>& input1_dims, - const T* input2_data, const Dims<4>& input2_dims, - T* output_data, const Dims<4>& output_dims) { - T output_activation_min, output_activation_max; - GetActivationMinMax(Ac, &output_activation_min, &output_activation_max); - - BroadcastMul(input1_data, input1_dims, input2_data, input2_dims, - output_activation_min, output_activation_max, output_data, - output_dims); +template <FusedActivationFunctionType Ac> +inline void BroadcastMul(const float* input1_data, const Dims<4>& input1_dims, + const float* input2_data, const Dims<4>& input2_dims, + float* output_data, const Dims<4>& output_dims) { + tflite::ArithmeticParams op_params; + float float_activation_min; + float float_activation_max; + GetActivationMinMax(Ac, &float_activation_min, &float_activation_max); + SetActivationParams(float_activation_min, float_activation_max, &op_params); + + BroadcastMul4DSlow(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); } // Element-wise mul that can often be used for inner loop of broadcast Mul as @@ -4034,29 +4189,28 @@ inline void L2Pool(const PoolParams& params, const RuntimeShape& input_shape, } } -inline void LocalResponseNormalization(const float* input_data, - const Dims<4>& input_dims, int range, - float bias, float alpha, float beta, - float* output_data, - const Dims<4>& output_dims) { +inline void LocalResponseNormalization( + const tflite::LocalResponseNormalizationParams& op_params, + const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { gemmlowp::ScopedProfilingLabel label("LocalResponseNormalization"); - MatchingFlatSize(input_dims, output_dims); + MatchingFlatSize(input_shape, output_shape); - const auto data_in = MapAsMatrixWithFirstDimAsRows(input_data, input_dims); - auto data_out = MapAsMatrixWithFirstDimAsRows(output_data, output_dims); + const auto data_in = MapAsMatrixWithLastDimAsRows(input_data, input_shape); + auto data_out = MapAsMatrixWithLastDimAsRows(output_data, output_shape); // Carry out local response normalization, vector by vector. // Since the data are stored column major, making row-wise operation // probably not memory efficient anyway, we do an explicit for loop over // the columns. - const int double_range = range * 2; + const int double_range = op_params.range * 2; Eigen::VectorXf padded_square(data_in.rows() + double_range); padded_square.setZero(); for (int r = 0; r < data_in.cols(); ++r) { // Do local response normalization for data_in(:, r) // first, compute the square and store them in buffer for repeated use - padded_square.block(range, 0, data_in.rows(), 1) = - data_in.col(r).cwiseProduct(data_in.col(r)) * alpha; + padded_square.block(op_params.range, 0, data_in.rows(), 1) = + data_in.col(r).cwiseProduct(data_in.col(r)) * op_params.alpha; // Then, compute the scale and writes them to data_out float accumulated_scale = 0; for (int i = 0; i < double_range; ++i) { @@ -4064,21 +4218,37 @@ inline void LocalResponseNormalization(const float* input_data, } for (int i = 0; i < data_in.rows(); ++i) { accumulated_scale += padded_square(i + double_range); - data_out(i, r) = bias + accumulated_scale; + data_out(i, r) = op_params.bias + accumulated_scale; accumulated_scale -= padded_square(i); } } // In a few cases, the pow computation could benefit from speedups. - if (beta == 1) { + if (op_params.beta == 1) { data_out.array() = data_in.array() * data_out.array().inverse(); - } else if (beta == 0.5) { + } else if (op_params.beta == 0.5) { data_out.array() = data_in.array() * data_out.array().sqrt().inverse(); } else { - data_out.array() = data_in.array() * data_out.array().pow(-beta); + data_out.array() = data_in.array() * data_out.array().pow(-op_params.beta); } } +// Legacy Dims<4>. +inline void LocalResponseNormalization(const float* input_data, + const Dims<4>& input_dims, int range, + float bias, float alpha, float beta, + float* output_data, + const Dims<4>& output_dims) { + tflite::LocalResponseNormalizationParams op_params; + op_params.range = range; + op_params.bias = bias; + op_params.alpha = alpha; + op_params.beta = beta; + + LocalResponseNormalization(op_params, DimsToShape(input_dims), input_data, + DimsToShape(output_dims), output_data); +} + inline void Softmax(const float* input_data, const RuntimeShape& input_shape, float beta, float* output_data, const RuntimeShape& output_shape) { @@ -4544,8 +4714,8 @@ inline void LogSoftmax(const uint8* input_data, const RuntimeShape& input_shape, } } -inline void Logistic(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { +inline void Logistic(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { gemmlowp::ScopedProfilingLabel label("Logistic"); auto input_map = MapAsVector(input_data, input_shape); auto output_map = MapAsVector(output_data, output_shape); @@ -4690,8 +4860,8 @@ inline void Logistic(const uint8* input_data, const RuntimeShape& input_shape, } } -inline void Logistic(const int16* input_data, const RuntimeShape& input_shape, - int16* output_data, const RuntimeShape& output_shape) { +inline void Logistic(const RuntimeShape& input_shape, const int16* input_data, + const RuntimeShape& output_shape, int16* output_data) { gemmlowp::ScopedProfilingLabel label("Logistic/Int16"); const int flat_size = MatchingFlatSize(input_shape, output_shape); @@ -4750,8 +4920,14 @@ inline void Logistic(const int16* input_data, const RuntimeShape& input_shape, } } -inline void Tanh(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { +// Legacy version. +inline void Logistic(const int16* input_data, const RuntimeShape& input_shape, + int16* output_data, const RuntimeShape& output_shape) { + Logistic(input_shape, input_data, output_shape, output_data); +} + +inline void Tanh(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { gemmlowp::ScopedProfilingLabel label("Tanh"); auto input_map = MapAsVector(input_data, input_shape); auto output_map = MapAsVector(output_data, output_shape); @@ -5006,22 +5182,37 @@ inline void Tanh(const int16* input_data, const RuntimeShape& input_shape, } template <typename SrcT, typename DstT> -inline void Cast(const SrcT* input_data, const Dims<4>& input_dims, - DstT* output_data, const Dims<4>& output_dims) { +inline void Cast(const RuntimeShape& input_shape, const SrcT* input_data, + const RuntimeShape& output_shape, DstT* output_data) { gemmlowp::ScopedProfilingLabel label("Cast"); - auto input_map = MapAsVector(input_data, input_dims); - auto output_map = MapAsVector(output_data, output_dims); + auto input_map = MapAsVector(input_data, input_shape); + auto output_map = MapAsVector(output_data, output_shape); output_map.array() = input_map.array().template cast<DstT>(); } -inline void Floor(const float* input_data, const Dims<4>& input_dims, - float* output_data, const Dims<4>& output_dims) { +// Legacy Dims<4> version. +template <typename SrcT, typename DstT> +void Cast(const SrcT* input_data, const Dims<4>& input_dims, DstT* output_data, + const Dims<4>& output_dims) { + Cast(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); +} + +inline void Floor(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { gemmlowp::ScopedProfilingLabel label("Floor"); - auto input_map = MapAsVector(input_data, input_dims); - auto output_map = MapAsVector(output_data, output_dims); + auto input_map = MapAsVector(input_data, input_shape); + auto output_map = MapAsVector(output_data, output_shape); output_map.array() = Eigen::floor(input_map.array()); } +// Legacy Dims<4> version. +inline void Floor(const float* input_data, const Dims<4>& input_dims, + float* output_data, const Dims<4>& output_dims) { + Floor(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); +} + #ifdef USE_NEON inline void ResizeBilinearKernel(const float* input_ptr, int32 depth, float scale, float* output_ptr) { @@ -5121,12 +5312,14 @@ inline void ResizeBilinearKernel(const float* input_ptr, int32 depth, inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, int32 x, int32 y, int32 depth, int32 batch, + const RuntimeShape& input_shape, const float* input_data, - const Dims<4>& input_dims, - float* output_data, - const Dims<4>& output_dims) { - const int32 input_width = ArraySize(input_dims, 1); - const int32 output_width = ArraySize(output_dims, 1); + const RuntimeShape& output_shape, + float* output_data) { + TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4); + TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4); + const int32 input_width = input_shape.Dims(2); + const int32 output_width = output_shape.Dims(2); const int32 input_x_offset = (x1 - x0) * depth; const int32 input_y_offset = (y1 - y0) * depth * input_width; @@ -5134,7 +5327,6 @@ inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, const int32 output_y_offset = depth * output_width; #ifdef USE_NEON - TFLITE_DCHECK(IsPackedWithoutStrides(input_dims)); TFLITE_DCHECK(x1 >= x0); TFLITE_DCHECK(y1 >= y0); @@ -5144,7 +5336,7 @@ inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, const float* input_ptr = nullptr; float32x4x2_t x0y0; - input_ptr = &input_data[Offset(input_dims, ic, x0, y0, batch)]; + input_ptr = &input_data[Offset(input_shape, batch, y0, x0, ic)]; x0y0.val[0] = vld1q_f32(input_ptr); x0y0.val[1] = vld1q_f32(input_ptr + 4); @@ -5164,7 +5356,7 @@ inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, x1y1.val[1] = vld1q_f32(input_ptr + 4); // Top left corner. - float* output_ptr = &output_data[Offset(output_dims, ic, x, y, batch)]; + float* output_ptr = &output_data[Offset(output_shape, batch, y, x, ic)]; vst1q_f32(output_ptr, x0y0.val[0]); vst1q_f32(output_ptr + 4, x0y0.val[1]); @@ -5203,14 +5395,15 @@ inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, } // Handle 4 input channels at a time. for (; ic <= depth - 4; ic += 4) { - const float* input_ptr = &input_data[Offset(input_dims, ic, x0, y0, batch)]; + const float* input_ptr = + &input_data[Offset(input_shape, batch, y0, x0, ic)]; float32x4_t x0y0 = vld1q_f32(input_ptr); float32x4_t x1y0 = vld1q_f32(input_ptr + input_x_offset); float32x4_t x0y1 = vld1q_f32(input_ptr + input_y_offset); float32x4_t x1y1 = vld1q_f32(input_ptr + input_x_offset + input_y_offset); // Top left corner. - float* output_ptr = &output_data[Offset(output_dims, ic, x, y, batch)]; + float* output_ptr = &output_data[Offset(output_shape, batch, y, x, ic)]; vst1q_f32(output_ptr, x0y0); // Top right corner. @@ -5234,7 +5427,7 @@ inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, } // Handle one input channel at a time. for (; ic < depth; ic++) { - const int32 input_offset = Offset(input_dims, ic, x0, y0, batch); + const int32 input_offset = Offset(input_shape, batch, y0, x0, ic); float x0y0 = input_data[input_offset]; float x1y0 = input_data[input_offset + input_x_offset]; @@ -5242,7 +5435,7 @@ inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, float x1y1 = input_data[input_offset + input_x_offset + input_y_offset]; // Top left corner. - const int32 output_offset = Offset(output_dims, ic, x, y, batch); + const int32 output_offset = Offset(output_shape, batch, y, x, ic); output_data[output_offset] = x0y0; // Top right corner. @@ -5258,7 +5451,7 @@ inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, } #else for (int ch = 0; ch < depth; ch++) { - const int32 input_offset = Offset(input_dims, ch, x0, y0, batch); + const int32 input_offset = Offset(input_shape, batch, y0, x0, ch); float x0y0 = input_data[input_offset]; float x1y0 = input_data[input_offset + input_x_offset]; @@ -5266,7 +5459,7 @@ inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, float x1y1 = input_data[input_offset + input_x_offset + input_y_offset]; // Top left corner. - const int32 output_offset = Offset(output_dims, ch, x, y, batch); + const int32 output_offset = Offset(output_shape, batch, y, x, ch); output_data[output_offset] = x0y0; // Top right corner. @@ -5283,31 +5476,30 @@ inline void ResizeBilinearKernel2x2(int32 x0, int32 x1, int32 y0, int32 y1, #endif } -inline void ResizeBilinear2x2(const float* input_data, - const Dims<4>& input_dims, float* output_data, - const Dims<4>& output_dims, int32 batches, - int32 input_height, int32 input_width, - int32 depth, int32 output_height, - int32 output_width) { +inline void ResizeBilinear2x2(int32 batches, int32 input_height, + int32 input_width, int32 depth, + int32 output_height, int32 output_width, + const RuntimeShape& input_shape, + const float* input_data, + const RuntimeShape& output_shape, + float* output_data) { for (int b = 0; b < batches; b++) { for (int y0 = 0, y = 0; y <= output_height - 2; y += 2, y0++) { for (int x0 = 0, x = 0; x <= output_width - 2; x += 2, x0++) { int32 x1 = std::min(x0 + 1, input_width - 1); int32 y1 = std::min(y0 + 1, input_height - 1); - ResizeBilinearKernel2x2(x0, x1, y0, y1, x, y, depth, b, input_data, - input_dims, output_data, output_dims); + ResizeBilinearKernel2x2(x0, x1, y0, y1, x, y, depth, b, input_shape, + input_data, output_shape, output_data); } } } } -inline void ResizeBilinearGeneric(const float* input_data, - const Dims<4>& input_dims, float* output_data, - const Dims<4>& output_dims, int32 batches, - int32 input_height, int32 input_width, - int32 depth, int32 output_height, - int32 output_width, float height_scale, - float width_scale) { +inline void ResizeBilinearGeneric( + int32 batches, int32 input_height, int32 input_width, int32 depth, + int32 output_height, int32 output_width, float height_scale, + float width_scale, const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { memset(output_data, 0, batches * output_height * output_width * depth * sizeof(float)); @@ -5324,22 +5516,22 @@ inline void ResizeBilinearGeneric(const float* input_data, float* output_ptr = &output_data[output_offset]; // Run kernel on the 4 corners of the bilinear resize algorithm. - int32 input_offset = Offset(input_dims, 0, x0, y0, b); + int32 input_offset = Offset(input_shape, b, y0, x0, 0); float scale = (1 - (input_y - y0)) * (1 - (input_x - x0)); const float* input_ptr = &input_data[input_offset]; ResizeBilinearKernel(input_ptr, depth, scale, output_ptr); - input_offset = Offset(input_dims, 0, x1, y0, b); + input_offset = Offset(input_shape, b, y0, x1, 0); scale = (1 - (input_y - y0)) * (input_x - x0); input_ptr = &input_data[input_offset]; ResizeBilinearKernel(input_ptr, depth, scale, output_ptr); - input_offset = Offset(input_dims, 0, x0, y1, b); + input_offset = Offset(input_shape, b, y1, x0, 0); scale = (input_y - y0) * (1 - (input_x - x0)); input_ptr = &input_data[input_offset]; ResizeBilinearKernel(input_ptr, depth, scale, output_ptr); - input_offset = Offset(input_dims, 0, x1, y1, b); + input_offset = Offset(input_shape, b, y1, x1, 0); scale = (input_y - y0) * (input_x - x0); input_ptr = &input_data[input_offset]; ResizeBilinearKernel(input_ptr, depth, scale, output_ptr); @@ -5352,10 +5544,10 @@ inline void ResizeBilinearGeneric(const float* input_data, template <typename T> inline void ResizeBilinearGenericSmallChannel( - const T* input_data, const Dims<4>& input_dims, T* output_data, - const Dims<4>& output_dims, int32 batches, int32 input_height, - int32 input_width, int32 depth, int32 output_height, int32 output_width, - float height_scale, float width_scale) { + int32 batches, int32 input_height, int32 input_width, int32 depth, + int32 output_height, int32 output_width, float height_scale, + float width_scale, const RuntimeShape& input_shape, const T* input_data, + const RuntimeShape& output_shape, T* output_data) { memset(output_data, 0, batches * output_height * output_width * depth * sizeof(T)); @@ -5370,9 +5562,10 @@ inline void ResizeBilinearGenericSmallChannel( int32 x0 = static_cast<int32>(input_x); int32 x1 = std::min(x0 + 1, input_width - 1); - int32 input_offset[4] = { - Offset(input_dims, 0, x0, y0, b), Offset(input_dims, 0, x1, y0, b), - Offset(input_dims, 0, x0, y1, b), Offset(input_dims, 0, x1, y1, b)}; + int32 input_offset[4] = {Offset(input_shape, b, y0, x0, 0), + Offset(input_shape, b, y0, x1, 0), + Offset(input_shape, b, y1, x0, 0), + Offset(input_shape, b, y1, x1, 0)}; float scale[4] = {(1 - (input_y - y0)) * (1 - (input_x - x0)), (1 - (input_y - y0)) * (input_x - x0), (input_y - y0) * (1 - (input_x - x0)), @@ -5390,79 +5583,123 @@ inline void ResizeBilinearGenericSmallChannel( } } -inline void ResizeBilinear(const float* input_data, const Dims<4>& input_dims, +inline void ResizeBilinear(const tflite::ResizeBilinearParams& op_params, + const RuntimeShape& unextended_input_shape, + const float* input_data, + const RuntimeShape& unextended_output_size_shape, const int32* output_size_data, - const Dims<4>& output_size_dims, float* output_data, - const Dims<4>& output_dims, bool align_corners) { + const RuntimeShape& unextended_output_shape, + float* output_data) { gemmlowp::ScopedProfilingLabel label("ResizeBilinear"); - int32 batches = MatchingArraySize(input_dims, 3, output_dims, 3); - int32 input_height = ArraySize(input_dims, 2); - int32 input_width = ArraySize(input_dims, 1); - int32 depth = MatchingArraySize(input_dims, 0, output_dims, 0); - - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 3), 1); - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 2), 1); - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 1), 1); - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 0), 2); - int32 output_height = output_size_data[Offset(output_size_dims, 0, 0, 0, 0)]; - int32 output_width = output_size_data[Offset(output_size_dims, 1, 0, 0, 0)]; + TFLITE_DCHECK_LE(unextended_input_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_size_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape input_shape = + RuntimeShape::ExtendedShape(4, unextended_input_shape); + RuntimeShape output_size_shape = + RuntimeShape::ExtendedShape(4, unextended_output_size_shape); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + + int32 batches = MatchingDim(input_shape, 0, output_shape, 0); + int32 input_height = input_shape.Dims(1); + int32 input_width = input_shape.Dims(2); + int32 depth = MatchingDim(input_shape, 3, output_shape, 3); + + TFLITE_DCHECK_EQ(output_size_shape.Dims(0), 1); + TFLITE_DCHECK_EQ(output_size_shape.Dims(1), 1); + TFLITE_DCHECK_EQ(output_size_shape.Dims(2), 1); + TFLITE_DCHECK_EQ(output_size_shape.Dims(3), 2); + int32 output_height = output_size_data[Offset(output_size_shape, 0, 0, 0, 0)]; + int32 output_width = output_size_data[Offset(output_size_shape, 0, 0, 0, 1)]; // Specialize for 2x2 upsample. - if (!align_corners && output_height == 2 * input_height && + if (!op_params.align_corners && output_height == 2 * input_height && output_width == 2 * input_width) { - ResizeBilinear2x2(input_data, input_dims, output_data, output_dims, batches, - input_height, input_width, depth, output_height, - output_width); + ResizeBilinear2x2(batches, input_height, input_width, depth, output_height, + output_width, input_shape, input_data, output_shape, + output_data); } else { float height_scale = static_cast<float>(input_height) / output_height; float width_scale = static_cast<float>(input_width) / output_width; - if (align_corners && output_height > 1) { + if (op_params.align_corners && output_height > 1) { height_scale = static_cast<float>(input_height - 1) / (output_height - 1); } - if (align_corners && output_width > 1) { + if (op_params.align_corners && output_width > 1) { width_scale = static_cast<float>(input_width - 1) / (output_width - 1); } - ResizeBilinearGeneric(input_data, input_dims, output_data, output_dims, - batches, input_height, input_width, depth, + ResizeBilinearGeneric(batches, input_height, input_width, depth, output_height, output_width, height_scale, - width_scale); + width_scale, input_shape, input_data, output_shape, + output_data); } } +// Legacy Dims<4> +inline void ResizeBilinear(const float* input_data, const Dims<4>& input_dims, + const int32* output_size_data, + const Dims<4>& output_size_dims, float* output_data, + const Dims<4>& output_dims, bool align_corners) { + tflite::ResizeBilinearParams op_params; + op_params.align_corners = align_corners; + ResizeBilinear(op_params, DimsToShape(input_dims), input_data, + DimsToShape(output_size_dims), output_size_data, + DimsToShape(output_dims), output_data); +} + // TODO(prabhumk): This is not a real quantized bilinear. It does not use int8 // or int16 arithmetic. -inline void ResizeBilinear(const uint8* input_data, const Dims<4>& input_dims, +inline void ResizeBilinear(const tflite::ResizeBilinearParams& op_params, + const RuntimeShape& input_shape, + const uint8* input_data, + const RuntimeShape& output_size_shape, const int32* output_size_data, - const Dims<4>& output_size_dims, uint8* output_data, - const Dims<4>& output_dims, bool align_corners) { + const RuntimeShape& output_shape, + uint8* output_data) { gemmlowp::ScopedProfilingLabel label("ResizeBilinear"); - int32 batches = MatchingArraySize(input_dims, 3, output_dims, 3); - int32 input_height = ArraySize(input_dims, 2); - int32 input_width = ArraySize(input_dims, 1); - int32 depth = MatchingArraySize(input_dims, 0, output_dims, 0); - - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 3), 1); - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 2), 1); - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 1), 1); - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 0), 2); - int32 output_height = output_size_data[Offset(output_size_dims, 0, 0, 0, 0)]; - int32 output_width = output_size_data[Offset(output_size_dims, 1, 0, 0, 0)]; + TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4); + TFLITE_DCHECK_EQ(output_size_shape.DimensionsCount(), 4); + TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4); + + int32 batches = MatchingDim(input_shape, 0, output_shape, 0); + int32 input_height = input_shape.Dims(1); + int32 input_width = input_shape.Dims(2); + int32 depth = MatchingDim(input_shape, 3, output_shape, 3); + + TFLITE_DCHECK_EQ(output_size_shape.Dims(0), 1); + TFLITE_DCHECK_EQ(output_size_shape.Dims(1), 1); + TFLITE_DCHECK_EQ(output_size_shape.Dims(2), 1); + TFLITE_DCHECK_EQ(output_size_shape.Dims(3), 2); + int32 output_height = output_size_data[Offset(output_size_shape, 0, 0, 0, 0)]; + int32 output_width = output_size_data[Offset(output_size_shape, 0, 0, 0, 1)]; float height_scale = - (align_corners && output_height > 1) + (op_params.align_corners && output_height > 1) ? (static_cast<float>(input_height - 1) / (output_height - 1)) : (static_cast<float>(input_height) / output_height); float width_scale = - (align_corners && output_width > 1) + (op_params.align_corners && output_width > 1) ? (static_cast<float>(input_width - 1) / (output_width - 1)) : (static_cast<float>(input_width) / output_width); ResizeBilinearGenericSmallChannel<uint8>( - input_data, input_dims, output_data, output_dims, batches, input_height, - input_width, depth, output_height, output_width, height_scale, - width_scale); + batches, input_height, input_width, depth, output_height, output_width, + height_scale, width_scale, input_shape, input_data, output_shape, + output_data); +} + +// Legacy Dims<4> +inline void ResizeBilinear(const uint8* input_data, const Dims<4>& input_dims, + const int32* output_size_data, + const Dims<4>& output_size_dims, uint8* output_data, + const Dims<4>& output_dims, bool align_corners) { + tflite::ResizeBilinearParams op_params; + op_params.align_corners = align_corners; + ResizeBilinear(op_params, DimsToShape(input_dims), input_data, + DimsToShape(output_size_dims), output_size_data, + DimsToShape(output_dims), output_data); } // legacy, for compatibility with old checked-in code @@ -5505,20 +5742,29 @@ inline void GetIndexRange(int spatial_index_dim, int block_shape_dim, } template <typename T> -inline void BatchToSpaceND(const T* input_data, const Dims<4>& input_dims, - const int32* block_shape_data, - const Dims<4>& block_shape_dims, - const int32* crops_data, const Dims<4>& crops_dims, - T* output_data, const Dims<4>& output_dims) { +inline void BatchToSpaceND( + const RuntimeShape& unextended_input1_shape, const T* input1_data, + const RuntimeShape& unextended_input2_shape, const int32* block_shape_data, + const RuntimeShape& unextended_input3_shape, const int32* crops_data, + const RuntimeShape& unextended_output_shape, T* output_data) { gemmlowp::ScopedProfilingLabel label("BatchToSpaceND"); - const int output_batch_size = ArraySize(output_dims, 3); - const int output_height = ArraySize(output_dims, 2); - const int output_width = ArraySize(output_dims, 1); - const int input_batch_size = ArraySize(input_dims, 3); - const int input_height = ArraySize(input_dims, 2); - const int input_width = ArraySize(input_dims, 1); - const int depth = ArraySize(input_dims, 0); + TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape input1_shape = + RuntimeShape::ExtendedShape(4, unextended_input1_shape); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + + const int output_width = output_shape.Dims(2); + const int output_height = output_shape.Dims(1); + const int output_batch_size = output_shape.Dims(0); + + const int depth = input1_shape.Dims(3); + const int input_width = input1_shape.Dims(2); + const int input_height = input1_shape.Dims(1); + const int input_batch_size = input1_shape.Dims(0); + const int block_shape_width = block_shape_data[1]; const int block_shape_height = block_shape_data[0]; const int crops_top = crops_data[0]; @@ -5553,14 +5799,28 @@ inline void BatchToSpaceND(const T* input_data, const Dims<4>& input_dims, spatial_offset % block_shape_width - crops_left; TFLITE_DCHECK_GE(out_w, 0); TFLITE_DCHECK_LT(out_w, output_width); - T* out = output_data + Offset(output_dims, 0, out_w, out_h, out_batch); - const T* in = input_data + Offset(input_dims, 0, in_w, in_h, in_batch); + T* out = output_data + Offset(output_shape, out_batch, out_h, out_w, 0); + const T* in = + input1_data + Offset(input1_shape, in_batch, in_h, in_w, 0); memcpy(out, in, depth * sizeof(T)); } } } } +// Legacy Dims<4>. +template <typename T> +inline void BatchToSpaceND(const T* input_data, const Dims<4>& input_dims, + const int32* block_shape_data, + const Dims<4>& block_shape_dims, + const int32* crops_data, const Dims<4>& crops_dims, + T* output_data, const Dims<4>& output_dims) { + BatchToSpaceND(DimsToShape(input_dims), input_data, + DimsToShape(block_shape_dims), block_shape_data, + DimsToShape(crops_dims), crops_data, DimsToShape(output_dims), + output_data); +} + template <typename T> void TypedMemset(void* ptr, T value, size_t num) { // Optimization for common cases where memset() will suffice. @@ -5598,12 +5858,14 @@ inline void PadImpl(const tflite::PadParams& op_params, // Runtime calls are currently fixed at 4 dimensions. Copy inputs so // we can pad them to 4 dims (yes, we are "padding the padding"). std::vector<int> left_padding_copy(4, 0); + const int left_padding_extend = 4 - op_params.left_padding_count; for (int i = 0; i < op_params.left_padding_count; ++i) { - left_padding_copy[i] = op_params.left_padding[i]; + left_padding_copy[left_padding_extend + i] = op_params.left_padding[i]; } std::vector<int> right_padding_copy(4, 0); + const int right_padding_extend = 4 - op_params.right_padding_count; for (int i = 0; i < op_params.right_padding_count; ++i) { - right_padding_copy[i] = op_params.right_padding[i]; + right_padding_copy[right_padding_extend + i] = op_params.right_padding[i]; } const int output_batch = ext_output_shape.Dims(0); @@ -5622,7 +5884,6 @@ inline void PadImpl(const tflite::PadParams& op_params, const int right_d_padding = right_padding_copy[3]; const int input_depth = ext_input_shape.Dims(3); - // const T pad_value = ExtractFloatOrInt<T>(op_params.pad_value); const T pad_value = *pad_value_ptr; if (left_b_padding != 0) { @@ -5732,7 +5993,6 @@ inline void PadV2(const T* input_data, const Dims<4>& input_dims, op_params.left_padding[i] = left_paddings[3 - i]; op_params.right_padding[i] = right_paddings[3 - i]; } - // SetFloatOrInt(pad_value, &op_params.pad_value); const T pad_value_copy = pad_value; Pad(op_params, DimsToShape(input_dims), input_data, &pad_value_copy, @@ -5978,4 +6238,4 @@ inline void TransposeConv(const float* input_data, const Dims<4>& input_dims, #pragma GCC diagnostic pop #endif -#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_OPS_H_ +#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_OPTIMIZED_OPTIMIZED_OPS_H_ diff --git a/tensorflow/contrib/lite/kernels/internal/reference/legacy_reference_ops.h b/tensorflow/contrib/lite/kernels/internal/reference/legacy_reference_ops.h index b862ae38c7..71ae74f34c 100644 --- a/tensorflow/contrib/lite/kernels/internal/reference/legacy_reference_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/reference/legacy_reference_ops.h @@ -42,20 +42,20 @@ inline void L2Normalization(const uint8* input_data, const Dims<4>& input_dims, inline void Relu(const float* input_data, const Dims<4>& input_dims, float* output_data, const Dims<4>& output_dims) { - Relu(input_data, DimsToShape(input_dims), output_data, - DimsToShape(output_dims)); + Relu(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); } inline void Relu1(const float* input_data, const Dims<4>& input_dims, float* output_data, const Dims<4>& output_dims) { - Relu1(input_data, DimsToShape(input_dims), output_data, - DimsToShape(output_dims)); + Relu1(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); } inline void Relu6(const float* input_data, const Dims<4>& input_dims, float* output_data, const Dims<4>& output_dims) { - Relu6(input_data, DimsToShape(input_dims), output_data, - DimsToShape(output_dims)); + Relu6(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); } template <FusedActivationFunctionType Ac> @@ -583,8 +583,8 @@ inline void LogSoftmax(const uint8* input_data, const Dims<4>& input_dims, inline void Logistic(const float* input_data, const Dims<4>& input_dims, float* output_data, const Dims<4>& output_dims) { - Logistic(input_data, DimsToShape(input_dims), output_data, - DimsToShape(output_dims)); + Logistic(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); } inline void Logistic(const uint8* input_data, const Dims<4>& input_dims, @@ -598,14 +598,14 @@ inline void Logistic(const uint8* input_data, const Dims<4>& input_dims, inline void Logistic(const int16* input_data, const Dims<4>& input_dims, int16* output_data, const Dims<4>& output_dims) { - Logistic(input_data, DimsToShape(input_dims), output_data, - DimsToShape(output_dims)); + Logistic(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); } inline void Tanh(const float* input_data, const Dims<4>& input_dims, float* output_data, const Dims<4>& output_dims) { - Tanh(input_data, DimsToShape(input_dims), output_data, - DimsToShape(output_dims)); + Tanh(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); } inline void Tanh(const uint8* input_data, const Dims<4>& input_dims, diff --git a/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h b/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h index 5634b8384a..3875b73e05 100644 --- a/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h @@ -19,11 +19,11 @@ limitations under the License. #include <sys/types.h> #include <algorithm> #include <cmath> +#include <functional> #include <limits> #include <memory> #include <type_traits> -#include "third_party/eigen3/Eigen/Core" #include "fixedpoint/fixedpoint.h" #include "public/gemmlowp.h" #include "tensorflow/contrib/lite/kernels/internal/common.h" @@ -407,18 +407,29 @@ void Conv(const uint8* input_data, const Dims<4>& input_dims, } template <typename T> -inline void DepthToSpace(const T* input_data, const Dims<4>& input_dims, - int block_size, T* output_data, - const Dims<4>& output_dims) { - const int input_depth = ArraySize(input_dims, 0); - const int input_width = ArraySize(input_dims, 1); - const int input_height = ArraySize(input_dims, 2); - const int input_batch = ArraySize(input_dims, 3); +inline void DepthToSpace(const tflite::DepthToSpaceParams& op_params, + const RuntimeShape& unextended_input_shape, + const T* input_data, + const RuntimeShape& unextended_output_shape, + T* output_data) { + TFLITE_DCHECK_LE(unextended_input_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape input_shape = + RuntimeShape::ExtendedShape(4, unextended_input_shape); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + + const int input_depth = input_shape.Dims(3); + const int input_width = input_shape.Dims(2); + const int input_height = input_shape.Dims(1); + const int input_batch = input_shape.Dims(0); - const int output_depth = ArraySize(output_dims, 0); - const int output_width = ArraySize(output_dims, 1); - const int output_height = ArraySize(output_dims, 2); - const int output_batch = ArraySize(output_dims, 3); + const int output_depth = output_shape.Dims(3); + const int output_width = output_shape.Dims(2); + const int output_height = output_shape.Dims(1); + const int output_batch = output_shape.Dims(0); + + const int32 block_size = op_params.block_size; TFLITE_DCHECK_EQ(input_width * block_size, output_width); TFLITE_DCHECK_EQ(input_height * block_size, output_height); @@ -437,9 +448,9 @@ inline void DepthToSpace(const T* input_data, const Dims<4>& input_dims, const int in_h = out_h / block_size; const int in_b = out_b; + const int input_index = Offset(input_shape, in_b, in_h, in_w, in_d); const int output_index = - Offset(output_dims, out_d, out_w, out_h, out_b); - const int input_index = Offset(input_dims, in_d, in_w, in_h, in_b); + Offset(output_shape, out_b, out_h, out_w, out_d); output_data[output_index] = input_data[input_index]; } @@ -448,19 +459,42 @@ inline void DepthToSpace(const T* input_data, const Dims<4>& input_dims, } } +// Legacy Dims<4>. template <typename T> -inline void SpaceToDepth(const T* input_data, const Dims<4>& input_dims, +inline void DepthToSpace(const T* input_data, const Dims<4>& input_dims, int block_size, T* output_data, const Dims<4>& output_dims) { - const int input_depth = ArraySize(input_dims, 0); - const int input_width = ArraySize(input_dims, 1); - const int input_height = ArraySize(input_dims, 2); - const int input_batch = ArraySize(input_dims, 3); + tflite::DepthToSpaceParams op_params; + op_params.block_size = block_size; - const int output_depth = ArraySize(output_dims, 0); - const int output_width = ArraySize(output_dims, 1); - const int output_height = ArraySize(output_dims, 2); - const int output_batch = ArraySize(output_dims, 3); + DepthToSpace(op_params, DimsToShape(input_dims), input_data, + DimsToShape(output_dims), output_data); +} + +template <typename T> +inline void SpaceToDepth(const tflite::SpaceToDepthParams& op_params, + const RuntimeShape& unextended_input_shape, + const T* input_data, + const RuntimeShape& unextended_output_shape, + T* output_data) { + TFLITE_DCHECK_LE(unextended_input_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape input_shape = + RuntimeShape::ExtendedShape(4, unextended_input_shape); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + + const int input_depth = input_shape.Dims(3); + const int input_width = input_shape.Dims(2); + const int input_height = input_shape.Dims(1); + const int input_batch = input_shape.Dims(0); + + const int output_depth = output_shape.Dims(3); + const int output_width = output_shape.Dims(2); + const int output_height = output_shape.Dims(1); + const int output_batch = output_shape.Dims(0); + + const int32 block_size = op_params.block_size; TFLITE_DCHECK_EQ(input_width, output_width * block_size); TFLITE_DCHECK_EQ(input_height, output_height * block_size); @@ -478,9 +512,9 @@ inline void SpaceToDepth(const T* input_data, const Dims<4>& input_dims, const int out_h = in_h / block_size; const int out_b = in_b; + const int input_index = Offset(input_shape, in_b, in_h, in_w, in_d); const int output_index = - Offset(output_dims, out_d, out_w, out_h, out_b); - const int input_index = Offset(input_dims, in_d, in_w, in_h, in_b); + Offset(output_shape, out_b, out_h, out_w, out_d); output_data[output_index] = input_data[input_index]; } @@ -489,6 +523,18 @@ inline void SpaceToDepth(const T* input_data, const Dims<4>& input_dims, } } +// Legacy Dims<4>. +template <typename T> +inline void SpaceToDepth(const T* input_data, const Dims<4>& input_dims, + int block_size, T* output_data, + const Dims<4>& output_dims) { + tflite::SpaceToDepthParams op_params; + op_params.block_size = block_size; + + SpaceToDepth(op_params, DimsToShape(input_dims), input_data, + DimsToShape(output_dims), output_data); +} + inline void FullyConnected(const float* input_data, const Dims<4>& input_dims, const float* weights_data, const Dims<4>& weights_dims, const float* bias_data, @@ -803,51 +849,8 @@ void FullyConnected(const uint8* input_data, const Dims<4>& input_dims, output_activation_max, output_data, output_dims, gemm_context); } -template <FusedActivationFunctionType Ac> -void NonGlobalBatchNormalization( - const float* input_data, const Dims<4>& input_dims, const float* mean_data, - const Dims<4>& mean_dims, const float* multiplier_data, - const Dims<4>& multiplier_dims, const float* offset_data, - const Dims<4>& offset_dims, float* output_data, - const Dims<4>& output_dims) { - const int batches = MatchingArraySize(input_dims, 3, output_dims, 3); - const int inner_size = MatchingFlatSizeSkipDim( - input_dims, 3, mean_dims, multiplier_dims, offset_dims, output_dims); - - for (int b = 0; b < batches; ++b) { - for (int i = 0; i < inner_size; ++i) { - output_data[b * inner_size + i] = ActivationFunction<Ac>( - (input_data[b * inner_size + i] - mean_data[i]) * multiplier_data[i] + - offset_data[i]); - } - } -} - -template <FusedActivationFunctionType Ac> -void GlobalBatchNormalization(const float* input_data, - const Dims<4>& input_dims, const float* mean_data, - const Dims<4>& mean_dims, - const float* multiplier_data, - const Dims<4>& multiplier_dims, - const float* offset_data, - const Dims<4>& offset_dims, float* output_data, - const Dims<4>& output_dims) { - const int outer_size = MatchingFlatSizeSkipDim(input_dims, 0, output_dims); - const int depth = - MatchingArraySize(input_dims, 0, mean_dims, 0, multiplier_dims, 0, - offset_dims, 0, output_dims, 0); - - for (int i = 0; i < outer_size; ++i) { - for (int c = 0; c < depth; ++c) { - output_data[depth * i + c] = ActivationFunction<Ac>( - (input_data[depth * i + c] - mean_data[c]) * multiplier_data[c] + - offset_data[c]); - } - } -} - -inline void Relu(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { +inline void Relu(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { const int flat_size = MatchingFlatSize(input_shape, output_shape); for (int i = 0; i < flat_size; ++i) { const float val = input_data[i]; @@ -857,8 +860,8 @@ inline void Relu(const float* input_data, const RuntimeShape& input_shape, } } -inline void Relu1(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { +inline void Relu1(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { gemmlowp::ScopedProfilingLabel label("Relu1 (not fused)"); const int flat_size = MatchingFlatSize(input_shape, output_shape); for (int i = 0; i < flat_size; ++i) { @@ -870,8 +873,8 @@ inline void Relu1(const float* input_data, const RuntimeShape& input_shape, } } -inline void Relu6(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { +inline void Relu6(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { gemmlowp::ScopedProfilingLabel label("Relu6 (not fused)"); const int flat_size = MatchingFlatSize(input_shape, output_shape); for (int i = 0; i < flat_size; ++i) { @@ -883,11 +886,14 @@ inline void Relu6(const float* input_data, const RuntimeShape& input_shape, } } -inline void ReluX(uint8 min_value, uint8 max_value, const uint8* input_data, - const RuntimeShape& input_shape, uint8* output_data, - const RuntimeShape& output_shape) { +inline void ReluX(const tflite::ActivationParams& params, + const RuntimeShape& input_shape, const uint8* input_data, + + const RuntimeShape& output_shape, uint8* output_data) { gemmlowp::ScopedProfilingLabel label("Quantized ReluX (not fused)"); const int flat_size = MatchingFlatSize(input_shape, output_shape); + const uint8 max_value = params.quantized_activation_max; + const uint8 min_value = params.quantized_activation_min; for (int i = 0; i < flat_size; ++i) { const uint8 val = input_data[i]; const uint8 clamped = @@ -896,10 +902,21 @@ inline void ReluX(uint8 min_value, uint8 max_value, const uint8* input_data, } } -template <FusedActivationFunctionType Ac> -void L2Normalization(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { - static_assert(Ac == FusedActivationFunctionType::kNone, ""); +// Legacy. +inline void ReluX(uint8 min_value, uint8 max_value, const uint8* input_data, + const RuntimeShape& input_shape, uint8* output_data, + const RuntimeShape& output_shape) { + tflite::ActivationParams params; + params.quantized_activation_max = max_value; + params.quantized_activation_min = min_value; + ReluX(params, input_shape, input_data, output_shape, output_data); +} + +inline void L2Normalization(const tflite::L2NormalizationParams& op_params, + const RuntimeShape& input_shape, + const float* input_data, + const RuntimeShape& output_shape, + float* output_data) { const int trailing_dim = input_shape.DimensionsCount() - 1; const int outer_size = MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape); @@ -918,6 +935,18 @@ void L2Normalization(const float* input_data, const RuntimeShape& input_shape, } } +// Legacy . +template <FusedActivationFunctionType Ac> +void L2Normalization(const float* input_data, const RuntimeShape& input_shape, + float* output_data, const RuntimeShape& output_shape) { + static_assert(Ac == FusedActivationFunctionType::kNone, ""); + tflite::L2NormalizationParams op_params; + // No params need to be set for float. + + L2Normalization(op_params, input_shape, input_data, output_shape, + output_data); +} + inline void GetInvSqrtQuantizedMultiplierExp(int32 input, int32* output_inv_sqrt, int* output_shift) { @@ -966,15 +995,17 @@ inline void GetInvSqrtQuantizedMultiplierExp(int32 input, *output_shift *= kReverseShift; } -inline void L2Normalization(const uint8* input_data, +inline void L2Normalization(const tflite::L2NormalizationParams& op_params, const RuntimeShape& input_shape, - int32 input_zero_point, uint8* output_data, - const RuntimeShape& output_shape) { + const uint8* input_data, + const RuntimeShape& output_shape, + uint8* output_data) { const int trailing_dim = input_shape.DimensionsCount() - 1; const int depth = MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim); const int outer_size = MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape); + const int32 input_zero_point = op_params.input_zero_point; for (int i = 0; i < outer_size; ++i) { int32 square_l2_norm = 0; for (int c = 0; c < depth; c++) { @@ -997,6 +1028,18 @@ inline void L2Normalization(const uint8* input_data, } } +// Legacy. +inline void L2Normalization(const uint8* input_data, + const RuntimeShape& input_shape, + int32 input_zero_point, uint8* output_data, + const RuntimeShape& output_shape) { + tflite::L2NormalizationParams op_params; + op_params.input_zero_point = input_zero_point; + + L2Normalization(op_params, input_shape, input_data, output_shape, + output_data); +} + template <typename T> inline void Add(const ArithmeticParams& params, const RuntimeShape& input1_shape, const T* input1_data, @@ -1320,11 +1363,16 @@ inline void BroadcastAddFivefold(const ArithmeticParams& unswitched_params, } template <typename T> -inline void Mul(const T* input1_data, const Dims<4>& input1_dims, - const T* input2_data, const Dims<4>& input2_dims, - T output_activation_min, T output_activation_max, - T* output_data, const Dims<4>& output_dims) { - const int flat_size = MatchingFlatSize(input1_dims, input2_dims, output_dims); +inline void Mul(const ArithmeticParams& params, + const RuntimeShape& input1_shape, const T* input1_data, + const RuntimeShape& input2_shape, const T* input2_data, + const RuntimeShape& output_shape, T* output_data) { + T output_activation_min; + T output_activation_max; + GetActivationParams(params, &output_activation_min, &output_activation_max); + + const int flat_size = + MatchingFlatSize(input1_shape, input2_shape, output_shape); for (int i = 0; i < flat_size; ++i) { output_data[i] = ActivationFunctionWithMinMax( input1_data[i] * input2_data[i], output_activation_min, @@ -1332,6 +1380,20 @@ inline void Mul(const T* input1_data, const Dims<4>& input1_dims, } } +// Legacy Dims<4>. +template <typename T> +inline void Mul(const T* input1_data, const Dims<4>& input1_dims, + const T* input2_data, const Dims<4>& input2_dims, + T output_activation_min, T output_activation_max, + T* output_data, const Dims<4>& output_dims) { + tflite::ArithmeticParams op_params; + SetActivationParams(output_activation_min, output_activation_max, &op_params); + + Mul(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, DimsToShape(output_dims), + output_data); +} + // legacy, for compatibility with old checked-in code template <FusedActivationFunctionType Ac> void Mul(const float* input1_data, const Dims<4>& input1_dims, @@ -1340,44 +1402,65 @@ void Mul(const float* input1_data, const Dims<4>& input1_dims, float output_activation_min, output_activation_max; GetActivationMinMax(Ac, &output_activation_min, &output_activation_max); - Mul(input1_data, input1_dims, input2_data, input2_dims, output_activation_min, - output_activation_max, output_data, output_dims); + tflite::ArithmeticParams op_params; + SetActivationParams(output_activation_min, output_activation_max, &op_params); + + Mul(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, DimsToShape(output_dims), + output_data); } // TODO(jiawen): We can implement BroadcastMul on buffers of arbitrary // dimensionality if the runtime code does a single loop over one dimension // that handles broadcasting as the base case. The code generator would then // generate max(D1, D2) nested for loops. +// TODO(benoitjacob): BroadcastMul is intentionally duplicated from +// reference_ops.h. Once an optimized version is implemented and NdArrayDesc<T> +// is no longer referenced in this file, move NdArrayDesc<T> from types.h to +// reference_ops.h. template <typename T> -void BroadcastMul(const T* input1_data, const Dims<4>& input1_dims, - const T* input2_data, const Dims<4>& input2_dims, - T output_activation_min, T output_activation_max, - T* output_data, const Dims<4>& output_dims) { - gemmlowp::ScopedProfilingLabel label("BroadcastMul"); +void BroadcastMul4DSlow(const ArithmeticParams& params, + const RuntimeShape& unextended_input1_shape, + const T* input1_data, + const RuntimeShape& unextended_input2_shape, + const T* input2_data, + const RuntimeShape& unextended_output_shape, + T* output_data) { + gemmlowp::ScopedProfilingLabel label("BroadcastMul4DSlow"); + T output_activation_min; + T output_activation_max; + GetActivationParams(params, &output_activation_min, &output_activation_max); + + TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_input2_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); NdArrayDesc<4> desc1; NdArrayDesc<4> desc2; - NdArrayDescsForElementwiseBroadcast(input1_dims, input2_dims, &desc1, &desc2); + NdArrayDescsForElementwiseBroadcast(unextended_input1_shape, + unextended_input2_shape, &desc1, &desc2); // In Tensorflow, the dimensions are canonically named (batch_number, row, // col, channel), with extents (batches, height, width, depth), with the - // trailing dimension changing most rapidly (channels has the smallest - // stride, typically 1 element). + // trailing dimension changing most rapidly (channels has the smallest stride, + // typically 1 element). // // In generated C code, we store arrays with the dimensions reversed. The // first dimension has smallest stride. // // We name our variables by their Tensorflow convention, but generate C code - // nesting loops such that the innermost loop has the smallest stride for - // the best cache behavior. - for (int b = 0; b < ArraySize(output_dims, 3); ++b) { - for (int y = 0; y < ArraySize(output_dims, 2); ++y) { - for (int x = 0; x < ArraySize(output_dims, 1); ++x) { - for (int c = 0; c < ArraySize(output_dims, 0); ++c) { - output_data[Offset(output_dims, c, x, y, b)] = + // nesting loops such that the innermost loop has the smallest stride for the + // best cache behavior. + for (int b = 0; b < output_shape.Dims(0); ++b) { + for (int y = 0; y < output_shape.Dims(1); ++y) { + for (int x = 0; x < output_shape.Dims(2); ++x) { + for (int c = 0; c < output_shape.Dims(3); ++c) { + output_data[Offset(output_shape, b, y, x, c)] = ActivationFunctionWithMinMax( - input1_data[SubscriptToIndex(desc1, c, x, y, b)] * - input2_data[SubscriptToIndex(desc2, c, x, y, b)], + input1_data[SubscriptToIndex(desc1, b, y, x, c)] * + input2_data[SubscriptToIndex(desc2, b, y, x, c)], output_activation_min, output_activation_max); } } @@ -1385,6 +1468,20 @@ void BroadcastMul(const T* input1_data, const Dims<4>& input1_dims, } } +// Legacy. +template <typename T> +void BroadcastMul(const T* input1_data, const Dims<4>& input1_dims, + const T* input2_data, const Dims<4>& input2_dims, + T output_activation_min, T output_activation_max, + T* output_data, const Dims<4>& output_dims) { + tflite::ArithmeticParams op_params; + SetActivationParams(output_activation_min, output_activation_max, &op_params); + + BroadcastMul4DSlow(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); +} + // legacy, for compatibility with old checked-in code template <FusedActivationFunctionType Ac, typename T> void BroadcastMul(const T* input1_data, const Dims<4>& input1_dims, @@ -1393,9 +1490,12 @@ void BroadcastMul(const T* input1_data, const Dims<4>& input1_dims, T output_activation_min, output_activation_max; GetActivationMinMax(Ac, &output_activation_min, &output_activation_max); - BroadcastMul(input1_data, input1_dims, input2_data, input2_dims, - output_activation_min, output_activation_max, output_data, - output_dims); + tflite::ArithmeticParams op_params; + SetActivationParams(output_activation_min, output_activation_max, &op_params); + + BroadcastMul4DSlow(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); } // Element-wise mul that can often be used for inner loop of broadcast Mul as @@ -1526,6 +1626,7 @@ inline void BroadcastMul4DSlow(const ArithmeticParams& params, } } +// Legacy. // Transitional version that will be moved shortly to legacy_reference_ops, as // part of RuntimeShape revisions. inline void BroadcastMul4DSlow(const uint8* input1_data, @@ -1536,52 +1637,27 @@ inline void BroadcastMul4DSlow(const uint8* input1_data, int output_shift, int32 output_activation_min, int32 output_activation_max, uint8* output_data, const Dims<4>& output_dims) { - gemmlowp::ScopedProfilingLabel label("BroadcastMul/8bit"); + tflite::ArithmeticParams op_params; + SetActivationParams(output_activation_min, output_activation_max, &op_params); + op_params.input1_offset = input1_offset; + op_params.input2_offset = input2_offset; + op_params.output_offset = output_offset; + op_params.output_multiplier = output_multiplier; + op_params.output_shift = output_shift; - NdArrayDesc<4> desc1; - NdArrayDesc<4> desc2; - NdArrayDescsForElementwiseBroadcast(input1_dims, input2_dims, &desc1, &desc2); - - // In Tensorflow, the dimensions are canonically named (batch_number, row, - // col, channel), with extents (batches, height, width, depth), with the - // trailing dimension changing most rapidly (channels has the smallest - // stride, typically 1 element). - // - // In generated C code, we store arrays with the dimensions reversed. The - // first dimension has smallest stride. - // - // We name our variables by their Tensorflow convention, but generate C code - // nesting loops such that the innermost loop has the smallest stride for - // the best cache behavior. - for (int b = 0; b < ArraySize(output_dims, 3); ++b) { - for (int y = 0; y < ArraySize(output_dims, 2); ++y) { - for (int x = 0; x < ArraySize(output_dims, 1); ++x) { - for (int c = 0; c < ArraySize(output_dims, 0); ++c) { - const int32 input1_val = - input1_offset + input1_data[SubscriptToIndex(desc1, c, x, y, b)]; - const int32 input2_val = - input2_offset + input2_data[SubscriptToIndex(desc2, c, x, y, b)]; - const int32 unclamped_result = - output_offset + - MultiplyByQuantizedMultiplierSmallerThanOneExp( - input1_val * input2_val, output_multiplier, output_shift); - const int32 clamped_output = - std::min(output_activation_max, - std::max(output_activation_min, unclamped_result)); - output_data[Offset(output_dims, c, x, y, b)] = - static_cast<uint8>(clamped_output); - } - } - } - } + BroadcastMul4DSlow(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); } -inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, - const int16* input2_data, const Dims<4>& input2_dims, - int16* output_data, const Dims<4>& output_dims) { +inline void Mul(const ArithmeticParams& params, + const RuntimeShape& input1_shape, const int16* input1_data, + const RuntimeShape& input2_shape, const int16* input2_data, + const RuntimeShape& output_shape, int16* output_data) { gemmlowp::ScopedProfilingLabel label("Mul/Int16"); - const int flat_size = MatchingFlatSize(output_dims, input1_dims, input2_dims); + const int flat_size = + MatchingFlatSize(input1_shape, input2_shape, output_shape); for (int i = 0; i < flat_size; i++) { // F0 uses 0 integer bits, range [-1, 1]. @@ -1593,15 +1669,30 @@ inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, } } +// Legacy Dims<4>. inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, const int16* input2_data, const Dims<4>& input2_dims, - int32 output_offset, int32 output_activation_min, - int32 output_activation_max, uint8* output_data, - const Dims<4>& output_dims) { + int16* output_data, const Dims<4>& output_dims) { + tflite::ArithmeticParams op_params; + // No params in this version. + + Mul(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, DimsToShape(output_dims), + output_data); +} + +inline void Mul(const ArithmeticParams& params, + const RuntimeShape& input1_shape, const int16* input1_data, + const RuntimeShape& input2_shape, const int16* input2_data, + const RuntimeShape& output_shape, uint8* output_data) { gemmlowp::ScopedProfilingLabel label("Mul/Int16Uint8"); + int32 output_offset = params.output_offset; + int32 output_activation_min = params.quantized_activation_min; + int32 output_activation_max = params.quantized_activation_max; TFLITE_DCHECK_LE(output_activation_min, output_activation_max); - const int flat_size = MatchingFlatSize(output_dims, input1_dims, input2_dims); + const int flat_size = + MatchingFlatSize(input1_shape, input2_shape, output_shape); for (int i = 0; i < flat_size; i++) { // F0 uses 0 integer bits, range [-1, 1]. @@ -1619,6 +1710,22 @@ inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, } } +// Legacy Dims<4>. +inline void Mul(const int16* input1_data, const Dims<4>& input1_dims, + const int16* input2_data, const Dims<4>& input2_dims, + int32 output_offset, int32 output_activation_min, + int32 output_activation_max, uint8* output_data, + const Dims<4>& output_dims) { + tflite::ArithmeticParams op_params; + op_params.quantized_activation_min = output_activation_min; + op_params.quantized_activation_max = output_activation_max; + op_params.output_offset = output_offset; + + Mul(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, DimsToShape(output_dims), + output_data); +} + // TODO(jiawen): We can implement BroadcastDiv on buffers of arbitrary // dimensionality if the runtime code does a single loop over one dimension // that handles broadcasting as the base case. The code generator would then @@ -2021,6 +2128,25 @@ void Pack(int dim, const Scalar* const* input_data, } } +template <typename Scalar> +void Unpack(int axis, const Scalar* input_data, const Dims<4>& input_dims, + int dimensions, int outputs_count, Scalar* const* output_datas, + const Dims<4>& output_dims) { + int outer_size = 1; + for (int i = dimensions - axis; i < 4; i++) { + outer_size *= input_dims.sizes[i]; + } + + const int copy_size = FlatSize(input_dims) / outer_size / outputs_count; + for (int k = 0; k < outer_size; k++) { + for (int i = 0; i < outputs_count; ++i) { + Scalar* output_ptr = output_datas[i] + copy_size * k; + int loc = k * outputs_count * copy_size + i * copy_size; + memcpy(output_ptr, input_data + loc, copy_size * sizeof(Scalar)); + } + } +} + // TODO(prabhumk): This is the same as the optimized implementation. // TODO(prabhumk): The quantized implementation of concatentation isn't fully // quantized as it takes scale as a floating point value. This should be fixed @@ -2076,6 +2202,44 @@ inline void Concatenation(int concat_dim, const uint8* const* input_data, } } +template <typename Scalar> +void Pack(int dim, const Scalar* const* input_data, + const Dims<4>* const* input_dims, const int32* input_zeropoint, + const float* input_scale, int inputs_count, Scalar* output_data, + const Dims<4>& output_dims, const int32 output_zeropoint, + const float output_scale) { + TFLITE_DCHECK(IsPackedWithoutStrides(output_dims)); + int outer_size = 1; + for (int i = dim + 1; i < 4; i++) { + outer_size *= output_dims.sizes[i]; + } + Scalar* output_ptr = output_data; + const int copy_size = FlatSize(**input_dims) / outer_size; + const float inverse_output_scale = 1.f / output_scale; + for (int k = 0; k < outer_size; k++) { + for (int i = 0; i < inputs_count; ++i) { + if (input_zeropoint[i] == output_zeropoint && + input_scale[i] == output_scale) { + memcpy(output_ptr, input_data[i] + k * copy_size, + copy_size * sizeof(Scalar)); + } else { + assert(false); + const float scale = input_scale[i] * inverse_output_scale; + const float bias = -input_zeropoint[i] * scale; + auto input_ptr = input_data[i]; + for (int j = 0; j < copy_size; ++j) { + const int32_t value = + static_cast<int32_t>(round(input_ptr[j] * scale + bias)) + + output_zeropoint; + output_ptr[j] = + static_cast<uint8_t>(std::max(std::min(255, value), 0)); + } + } + output_ptr += copy_size; + } + } +} + template <FusedActivationFunctionType Ac, typename Scalar> void DepthConcatenation(const Scalar* const* input_data, const Dims<4>* const* input_dims, int inputs_count, @@ -2448,36 +2612,6 @@ void TensorFlowSplit(const Scalar* input_data, const Dims<4>& input_dims, output_data, output_dims); } -// TODO(benoitjacob) make this a proper reference impl without Eigen! -template <typename Scalar> -using MatrixMap = typename std::conditional< - std::is_const<Scalar>::value, - Eigen::Map<const Eigen::Matrix<typename std::remove_const<Scalar>::type, - Eigen::Dynamic, Eigen::Dynamic>>, - Eigen::Map<Eigen::Matrix<Scalar, Eigen::Dynamic, Eigen::Dynamic>>>::type; - -template <typename Scalar, int N> -MatrixMap<Scalar> MapAsMatrixWithFirstDimAsRows(Scalar* data, - const Dims<N>& dims) { - const int rows = dims.sizes[0]; - int cols = 1; - for (int d = 1; d < N; d++) { - cols *= dims.sizes[d]; - } - return MatrixMap<Scalar>(data, rows, cols); -} - -template <typename Scalar, int N> -MatrixMap<Scalar> MapAsMatrixWithLastDimAsCols(Scalar* data, - const Dims<N>& dims) { - const int cols = dims.sizes[N - 1]; - int rows = 1; - for (int d = 0; d < N - 1; d++) { - rows *= dims.sizes[d]; - } - return MatrixMap<Scalar>(data, rows, cols); -} - inline int NodeOffset(int b, int h, int w, int height, int width) { return (b * height + h) * width + w; } @@ -2750,29 +2884,48 @@ inline void MaxPool(const PoolParams& params, const RuntimeShape& input_shape, } } -inline void LocalResponseNormalization(const float* input_data, - const Dims<4>& input_dims, int range, - float bias, float alpha, float beta, - float* output_data, - const Dims<4>& output_dims) { - const int outer_size = MatchingFlatSizeSkipDim(input_dims, 0, output_dims); - const int depth = MatchingArraySize(input_dims, 0, output_dims, 0); +inline void LocalResponseNormalization( + const tflite::LocalResponseNormalizationParams& op_params, + const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { + const int trailing_dim = input_shape.DimensionsCount() - 1; + const int outer_size = + MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape); + const int depth = + MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim); for (int i = 0; i < outer_size; ++i) { for (int c = 0; c < depth; ++c) { - const int begin_input_c = std::max(0, c - range); - const int end_input_c = std::min(depth, c + range); + const int begin_input_c = std::max(0, c - op_params.range); + const int end_input_c = std::min(depth, c + op_params.range); float accum = 0.f; for (int input_c = begin_input_c; input_c < end_input_c; ++input_c) { const float input_val = input_data[i * depth + input_c]; accum += input_val * input_val; } - const float multiplier = std::pow(bias + alpha * accum, -beta); + const float multiplier = + std::pow(op_params.bias + op_params.alpha * accum, -op_params.beta); output_data[i * depth + c] = input_data[i * depth + c] * multiplier; } } } +// Legacy Dims<4>. +inline void LocalResponseNormalization(const float* input_data, + const Dims<4>& input_dims, int range, + float bias, float alpha, float beta, + float* output_data, + const Dims<4>& output_dims) { + tflite::LocalResponseNormalizationParams op_params; + op_params.range = range; + op_params.bias = bias; + op_params.alpha = alpha; + op_params.beta = beta; + + LocalResponseNormalization(op_params, DimsToShape(input_dims), input_data, + DimsToShape(output_dims), output_data); +} + inline void Softmax(const float* input_data, const RuntimeShape& input_shape, float beta, float* output_data, const RuntimeShape& output_shape) { @@ -3118,8 +3271,8 @@ inline void LogSoftmax(const uint8* input_data, const RuntimeShape& input_shape, } } -inline void Logistic(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { +inline void Logistic(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { const int flat_size = MatchingFlatSize(input_shape, output_shape); for (int i = 0; i < flat_size; i++) { @@ -3167,8 +3320,8 @@ inline void Logistic(const uint8* input_data, const RuntimeShape& input_shape, } } -inline void Logistic(const int16* input_data, const RuntimeShape& input_shape, - int16* output_data, const RuntimeShape& output_shape) { +inline void Logistic(const RuntimeShape& input_shape, const int16* input_data, + const RuntimeShape& output_shape, int16* output_data) { const int flat_size = MatchingFlatSize(input_shape, output_shape); for (int i = 0; i < flat_size; i++) { @@ -3185,8 +3338,8 @@ inline void Logistic(const int16* input_data, const RuntimeShape& input_shape, } } -inline void Tanh(const float* input_data, const RuntimeShape& input_shape, - float* output_data, const RuntimeShape& output_shape) { +inline void Tanh(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { const int flat_size = MatchingFlatSize(input_shape, output_shape); for (int i = 0; i < flat_size; i++) { @@ -3302,9 +3455,9 @@ inline void FakeQuant(const float* input_data, const Dims<4>& input_dims, } template <typename SrcT, typename DstT> -inline void Cast(const SrcT* input_data, const Dims<4>& input_dims, - DstT* output_data, const Dims<4>& output_dims) { - const int flat_size = MatchingFlatSize(output_dims, input_dims); +inline void Cast(const RuntimeShape& input_shape, const SrcT* input_data, + const RuntimeShape& output_shape, DstT* output_data) { + const int flat_size = MatchingFlatSize(input_shape, output_shape); for (int i = 0; i < flat_size; i++) { int offset = i; @@ -3312,9 +3465,17 @@ inline void Cast(const SrcT* input_data, const Dims<4>& input_dims, } } -inline void Floor(const float* input_data, const Dims<4>& input_dims, - float* output_data, const Dims<4>& output_dims) { - const int flat_size = MatchingFlatSize(output_dims, input_dims); +// Legacy Dims<4> version. +template <typename SrcT, typename DstT> +void Cast(const SrcT* input_data, const Dims<4>& input_dims, DstT* output_data, + const Dims<4>& output_dims) { + Cast(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); +} + +inline void Floor(const RuntimeShape& input_shape, const float* input_data, + const RuntimeShape& output_shape, float* output_data) { + const int flat_size = MatchingFlatSize(input_shape, output_shape); for (int i = 0; i < flat_size; i++) { int offset = i; @@ -3322,6 +3483,13 @@ inline void Floor(const float* input_data, const Dims<4>& input_dims, } } +// Legacy Dims<4> version. +inline void Floor(const float* input_data, const Dims<4>& input_dims, + float* output_data, const Dims<4>& output_dims) { + Floor(DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data); +} + template <typename T> inline void Gather(const T* input_data, const Dims<4>& input_dims, int input_rank, const int32* coords_data, @@ -3341,27 +3509,41 @@ inline void Gather(const T* input_data, const Dims<4>& input_dims, } template <typename T> -inline void ResizeBilinear(const T* input_data, const Dims<4>& input_dims, +inline void ResizeBilinear(const tflite::ResizeBilinearParams& op_params, + const RuntimeShape& unextended_input_shape, + const T* input_data, + const RuntimeShape& unextended_output_size_shape, const int32* output_size_data, - const Dims<4>& output_size_dims, T* output_data, - const Dims<4>& output_dims, bool align_corners) { - int32 batches = MatchingArraySize(input_dims, 3, output_dims, 3); - int32 input_height = ArraySize(input_dims, 2); - int32 input_width = ArraySize(input_dims, 1); - int32 depth = MatchingArraySize(input_dims, 0, output_dims, 0); - - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 3), 1); - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 2), 1); - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 1), 1); - TFLITE_DCHECK_EQ(ArraySize(output_size_dims, 0), 2); - int32 output_height = output_size_data[Offset(output_size_dims, 0, 0, 0, 0)]; - int32 output_width = output_size_data[Offset(output_size_dims, 1, 0, 0, 0)]; + const RuntimeShape& unextended_output_shape, + T* output_data) { + TFLITE_DCHECK_LE(unextended_input_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_size_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape input_shape = + RuntimeShape::ExtendedShape(4, unextended_input_shape); + RuntimeShape output_size_shape = + RuntimeShape::ExtendedShape(4, unextended_output_size_shape); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + + int32 batches = MatchingDim(input_shape, 0, output_shape, 0); + int32 input_height = input_shape.Dims(1); + int32 input_width = input_shape.Dims(2); + int32 depth = MatchingDim(input_shape, 3, output_shape, 3); + + TFLITE_DCHECK_EQ(output_size_shape.Dims(0), 1); + TFLITE_DCHECK_EQ(output_size_shape.Dims(1), 1); + TFLITE_DCHECK_EQ(output_size_shape.Dims(2), 1); + TFLITE_DCHECK_EQ(output_size_shape.Dims(3), 2); + int32 output_height = output_size_data[Offset(output_size_shape, 0, 0, 0, 0)]; + int32 output_width = output_size_data[Offset(output_size_shape, 0, 0, 0, 1)]; + float height_scale = static_cast<float>(input_height) / output_height; float width_scale = static_cast<float>(input_width) / output_width; - if (align_corners && output_height > 1) { + if (op_params.align_corners && output_height > 1) { height_scale = static_cast<float>(input_height - 1) / (output_height - 1); } - if (align_corners && output_width > 1) { + if (op_params.align_corners && output_width > 1) { width_scale = static_cast<float>(input_width - 1) / (output_width - 1); } @@ -3376,21 +3558,34 @@ inline void ResizeBilinear(const T* input_data, const Dims<4>& input_dims, int32 x1 = std::min(x0 + 1, input_width - 1); for (int c = 0; c < depth; ++c) { T interpolation = - static_cast<T>(input_data[Offset(input_dims, c, x0, y0, b)] * + static_cast<T>(input_data[Offset(input_shape, b, y0, x0, c)] * (1 - (input_y - y0)) * (1 - (input_x - x0)) + - input_data[Offset(input_dims, c, x0, y1, b)] * + input_data[Offset(input_shape, b, y1, x0, c)] * (input_y - y0) * (1 - (input_x - x0)) + - input_data[Offset(input_dims, c, x1, y0, b)] * + input_data[Offset(input_shape, b, y0, x1, c)] * (1 - (input_y - y0)) * (input_x - x0) + - input_data[Offset(input_dims, c, x1, y1, b)] * + input_data[Offset(input_shape, b, y1, x1, c)] * (input_y - y0) * (input_x - x0)); - output_data[Offset(output_dims, c, x, y, b)] = interpolation; + output_data[Offset(output_shape, b, y, x, c)] = interpolation; } } } } } +// Legacy Dims<4>. +template <typename T> +inline void ResizeBilinear(const T* input_data, const Dims<4>& input_dims, + const int32* output_size_data, + const Dims<4>& output_size_dims, T* output_data, + const Dims<4>& output_dims, bool align_corners) { + tflite::ResizeBilinearParams op_params; + op_params.align_corners = align_corners; + ResizeBilinear(op_params, DimsToShape(input_dims), input_data, + DimsToShape(output_size_dims), output_size_data, + DimsToShape(output_dims), output_data); +} + // legacy, for compatibility with old checked-in code inline void ResizeBilinear(const float* input_data, const Dims<4>& input_dims, const int32* output_size_data, @@ -3401,6 +3596,7 @@ inline void ResizeBilinear(const float* input_data, const Dims<4>& input_dims, /*align_corners=*/false); } +// Legacy. inline void ResizeBilinear(const uint8* input_data, const Dims<4>& input_dims, const int32* output_size_data, const Dims<4>& output_size_dims, uint8* output_data, @@ -3411,45 +3607,56 @@ inline void ResizeBilinear(const uint8* input_data, const Dims<4>& input_dims, } template <typename T> -inline void SpaceToBatchND(const T* input_data, const Dims<4>& input_dims, - const int32* block_shape_data, - const Dims<4>& block_shape_dims, - const int32* paddings_data, - const Dims<4>& paddings_dims, T* output_data, - const Dims<4>& output_dims, - const int32_t pad_value) { - const int output_batch_size = ArraySize(output_dims, 3); - const int output_height = ArraySize(output_dims, 2); - const int output_width = ArraySize(output_dims, 1); - const int input_batch_size = ArraySize(input_dims, 3); - const int input_height = ArraySize(input_dims, 2); - const int input_width = ArraySize(input_dims, 1); - const int depth = ArraySize(input_dims, 0); +inline void SpaceToBatchND( + const SpaceToBatchParams& params, + const RuntimeShape& unextended_input1_shape, const T* input1_data, + const RuntimeShape& unextended_input2_shape, const int32* block_shape_data, + const RuntimeShape& unextended_input3_shape, const int32* paddings_data, + const RuntimeShape& unextended_output_shape, T* output_data) { + TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape input1_shape = + RuntimeShape::ExtendedShape(4, unextended_input1_shape); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + + const int depth = input1_shape.Dims(3); + const int input_width = input1_shape.Dims(2); + const int input_height = input1_shape.Dims(1); + const int input_batch_size = input1_shape.Dims(0); + + const int output_width = output_shape.Dims(2); + const int output_height = output_shape.Dims(1); + const int output_batch_size = output_shape.Dims(0); + const int block_shape_height = block_shape_data[0]; const int block_shape_width = block_shape_data[1]; const int padding_top = paddings_data[0]; const int padding_left = paddings_data[2]; + // For uint8 quantized, the correct padding "zero value" is the output offset. + const int32_t pad_value = params.output_offset; + for (int out_b = 0; out_b < output_batch_size; ++out_b) { int input_batch = out_b % input_batch_size; int shift_w = (out_b / input_batch_size) % block_shape_width; int shift_h = (out_b / input_batch_size) / block_shape_width; for (int out_h = 0; out_h < output_height; ++out_h) { for (int out_w = 0; out_w < output_width; ++out_w) { - T* out = output_data + Offset(output_dims, 0, out_w, out_h, out_b); + T* out = output_data + Offset(output_shape, out_b, out_h, out_w, 0); if (out_h * block_shape_height + shift_h < padding_top || out_h * block_shape_height + shift_h >= padding_top + input_height || out_w * block_shape_width + shift_w < padding_left || out_w * block_shape_width + shift_w >= padding_left + input_width) { + // This may not execute correctly when pad_value != 0 and T != uint8. memset(out, pad_value, depth * sizeof(T)); } else { const T* in = - input_data + - Offset(input_dims, 0, - (out_w * block_shape_width + shift_w) - padding_left, + input1_data + + Offset(input1_shape, input_batch, (out_h * block_shape_height + shift_h) - padding_top, - input_batch); + (out_w * block_shape_width + shift_w) - padding_left, 0); memcpy(out, in, depth * sizeof(T)); } } @@ -3457,30 +3664,63 @@ inline void SpaceToBatchND(const T* input_data, const Dims<4>& input_dims, } } +// Legacy Dims<4>. template <typename T> inline void SpaceToBatchND(const T* input_data, const Dims<4>& input_dims, const int32* block_shape_data, const Dims<4>& block_shape_dims, const int32* paddings_data, const Dims<4>& paddings_dims, T* output_data, - const Dims<4>& output_dims) { - SpaceToBatchND(input_data, input_dims, block_shape_data, block_shape_dims, - paddings_data, paddings_dims, output_data, output_dims, 0); + const Dims<4>& output_dims, + const int32_t pad_value) { + tflite::SpaceToBatchParams op_params; + op_params.output_offset = pad_value; + + SpaceToBatchND(op_params, DimsToShape(input_dims), input_data, + DimsToShape(block_shape_dims), block_shape_data, + DimsToShape(paddings_dims), paddings_data, + DimsToShape(output_dims), output_data); } +// Legacy if no good reason to have signature with pad_value=0. template <typename T> -inline void BatchToSpaceND(const T* input_data, const Dims<4>& input_dims, +inline void SpaceToBatchND(const T* input_data, const Dims<4>& input_dims, const int32* block_shape_data, const Dims<4>& block_shape_dims, - const int32* crops_data, const Dims<4>& crops_dims, - T* output_data, const Dims<4>& output_dims) { - const int output_batch_size = ArraySize(output_dims, 3); - const int output_height = ArraySize(output_dims, 2); - const int output_width = ArraySize(output_dims, 1); - const int input_batch_size = ArraySize(input_dims, 3); - const int input_height = ArraySize(input_dims, 2); - const int input_width = ArraySize(input_dims, 1); - const int depth = ArraySize(input_dims, 0); + const int32* paddings_data, + const Dims<4>& paddings_dims, T* output_data, + const Dims<4>& output_dims) { + tflite::SpaceToBatchParams op_params; + op_params.output_offset = 0; + + SpaceToBatchND(op_params, DimsToShape(input_dims), input_data, + DimsToShape(block_shape_dims), block_shape_data, + DimsToShape(paddings_dims), paddings_data, + DimsToShape(output_dims), output_data); +} + +template <typename T> +inline void BatchToSpaceND( + const RuntimeShape& unextended_input1_shape, const T* input1_data, + const RuntimeShape& unextended_input2_shape, const int32* block_shape_data, + const RuntimeShape& unextended_input3_shape, const int32* crops_data, + const RuntimeShape& unextended_output_shape, T* output_data) { + TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape input1_shape = + RuntimeShape::ExtendedShape(4, unextended_input1_shape); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + + const int output_width = output_shape.Dims(2); + const int output_height = output_shape.Dims(1); + const int output_batch_size = output_shape.Dims(0); + + const int depth = input1_shape.Dims(3); + const int input_width = input1_shape.Dims(2); + const int input_height = input1_shape.Dims(1); + const int input_batch_size = input1_shape.Dims(0); + const int block_shape_width = block_shape_data[1]; const int block_shape_height = block_shape_data[0]; const int crops_top = crops_data[0]; @@ -3502,14 +3742,28 @@ inline void BatchToSpaceND(const T* input_data, const Dims<4>& input_dims, if (out_w < 0 || out_w >= output_width) { continue; } - T* out = output_data + Offset(output_dims, 0, out_w, out_h, out_batch); - const T* in = input_data + Offset(input_dims, 0, in_w, in_h, in_batch); + T* out = output_data + Offset(output_shape, out_batch, out_h, out_w, 0); + const T* in = + input1_data + Offset(input1_shape, in_batch, in_h, in_w, 0); memcpy(out, in, depth * sizeof(T)); } } } } +// Legacy Dims<4>. +template <typename T> +inline void BatchToSpaceND(const T* input_data, const Dims<4>& input_dims, + const int32* block_shape_data, + const Dims<4>& block_shape_dims, + const int32* crops_data, const Dims<4>& crops_dims, + T* output_data, const Dims<4>& output_dims) { + BatchToSpaceND(DimsToShape(input_dims), input_data, + DimsToShape(block_shape_dims), block_shape_data, + DimsToShape(crops_dims), crops_data, DimsToShape(output_dims), + output_data); +} + // There are two versions of pad: Pad and PadV2. In PadV2 there is a second // scalar input that provides the padding value. Therefore pad_value_ptr can be // equivalent to a simple input1_data. For Pad, it should point to a zero @@ -3858,15 +4112,18 @@ inline bool InitTensorDataForReduce(const int* dims, const int num_dims, return true; } -// Computes the sum of elements across dimensions given in axis. +// Computes the generic value (i.e., sum/max/min/prod) of elements across +// dimensions given in axis. It needs to pass in init_value and reducer. template <typename T> -inline bool Sum(const T* input_data, const int* input_dims, - const int input_num_dims, T* output_data, - const int* output_dims, const int output_num_dims, - const int* axis, const int num_axis_dimensions, bool keep_dims, - int* temp_index, int* resolved_axis) { +inline bool ReduceGeneric(const T* input_data, const int* input_dims, + const int input_num_dims, T* output_data, + const int* output_dims, const int output_num_dims, + const int* axis, const int64_t num_axis_dimensions, + bool keep_dims, int* temp_index, int* resolved_axis, + T init_value, + T reducer(const T current, const T in)) { // Reset output data. - if (!InitTensorDataForReduce(output_dims, output_num_dims, static_cast<T>(0), + if (!InitTensorDataForReduce(output_dims, output_num_dims, init_value, output_data)) { return false; } @@ -3878,9 +4135,25 @@ inline bool Sum(const T* input_data, const int* input_dims, return false; } - return ReduceSumImpl<T, T>(input_data, input_dims, output_dims, - input_num_dims, output_num_dims, resolved_axis, - num_resolved_axis, temp_index, output_data); + return Reduce<T, T>(input_data, input_dims, output_dims, input_num_dims, + output_num_dims, resolved_axis, num_resolved_axis, + temp_index, reducer, output_data); +} + +// Computes the sum of elements across dimensions given in axis. +template <typename T> +inline bool Sum(const T* input_data, const int* input_dims, + const int input_num_dims, T* output_data, + const int* output_dims, const int output_num_dims, + const int* axis, const int num_axis_dimensions, bool keep_dims, + int* temp_index, int* resolved_axis) { + T init_value = static_cast<T>(0); + + auto reducer = [](const T current, const T in) -> T { return current + in; }; + return ReduceGeneric<T>(input_data, input_dims, input_num_dims, output_data, + output_dims, output_num_dims, axis, + num_axis_dimensions, keep_dims, temp_index, + resolved_axis, init_value, reducer); } // Computes the max of elements across dimensions given in axis. @@ -3891,25 +4164,32 @@ inline bool ReduceMax(const T* input_data, const int* input_dims, const int* axis, const int64_t num_axis_dimensions, bool keep_dims, int* temp_index, int* resolved_axis) { T init_value = std::numeric_limits<T>::lowest(); - // Reset output data. - if (!InitTensorDataForReduce(output_dims, output_num_dims, init_value, - output_data)) { - return false; - } - - // Resolve axis. - int num_resolved_axis = 0; - if (!ResolveAxis(input_num_dims, axis, num_axis_dimensions, resolved_axis, - &num_resolved_axis)) { - return false; - } auto reducer = [](const T current, const T in) -> T { return (in > current) ? in : current; }; - return Reduce<T, T>(input_data, input_dims, output_dims, input_num_dims, - output_num_dims, resolved_axis, num_resolved_axis, - temp_index, reducer, output_data); + return ReduceGeneric<T>(input_data, input_dims, input_num_dims, output_data, + output_dims, output_num_dims, axis, + num_axis_dimensions, keep_dims, temp_index, + resolved_axis, init_value, reducer); +} + +// Computes the min of elements across dimensions given in axis. +template <typename T> +inline bool ReduceMin(const T* input_data, const int* input_dims, + const int input_num_dims, T* output_data, + const int* output_dims, const int output_num_dims, + const int* axis, const int64_t num_axis_dimensions, + bool keep_dims, int* temp_index, int* resolved_axis) { + T init_value = std::numeric_limits<T>::max(); + + auto reducer = [](const T current, const T in) -> T { + return (in < current) ? in : current; + }; + return ReduceGeneric<T>(input_data, input_dims, input_num_dims, output_data, + output_dims, output_num_dims, axis, + num_axis_dimensions, keep_dims, temp_index, + resolved_axis, init_value, reducer); } // Computes the prod of elements across dimensions given in axis. @@ -3919,23 +4199,30 @@ inline bool ReduceProd(const T* input_data, const int* input_dims, const int* output_dims, const int output_num_dims, const int* axis, const int64_t num_axis_dimensions, bool keep_dims, int* temp_index, int* resolved_axis) { - // Reset output data. - if (!InitTensorDataForReduce(output_dims, output_num_dims, static_cast<T>(1), - output_data)) { - return false; - } - - // Resolve axis. - int num_resolved_axis = 0; - if (!ResolveAxis(input_num_dims, axis, num_axis_dimensions, resolved_axis, - &num_resolved_axis)) { - return false; - } + T init_value = static_cast<T>(1); auto reducer = [](const T current, const T in) -> T { return in * current; }; - return Reduce<T, T>(input_data, input_dims, output_dims, input_num_dims, - output_num_dims, resolved_axis, num_resolved_axis, - temp_index, reducer, output_data); + return ReduceGeneric<T>(input_data, input_dims, input_num_dims, output_data, + output_dims, output_num_dims, axis, + num_axis_dimensions, keep_dims, temp_index, + resolved_axis, init_value, reducer); +} + +// Computes the logical_or of elements across dimensions given in axis. +inline bool ReduceAny(const bool* input_data, const int* input_dims, + const int input_num_dims, bool* output_data, + const int* output_dims, const int output_num_dims, + const int* axis, const int64_t num_axis_dimensions, + bool keep_dims, int* temp_index, int* resolved_axis) { + bool init_value = false; + + auto reducer = [](const bool current, const bool in) -> bool { + return current || in; + }; + return ReduceGeneric<bool>(input_data, input_dims, input_num_dims, + output_data, output_dims, output_num_dims, axis, + num_axis_dimensions, keep_dims, temp_index, + resolved_axis, init_value, reducer); } // Computes the mean of elements across dimensions given in axis. @@ -4029,6 +4316,70 @@ inline void Mean(const T* input_data, const Dims<4>& input_dims, } } +// Computes the mean of elements across dimensions given in axis. +// It does so in two stages, first calculates the sum of elements along the axis +// then divides it by the number of element in axis for quantized values. +template <typename T, typename U> +inline bool Mean(const T* input_data, int32 input_zero_point, float input_scale, + const int* input_dims, const int input_num_dims, + T* output_data, int32 output_zero_point, float output_scale, + const int* output_dims, const int output_num_dims, + const int* axis, const int num_axis_dimensions, bool keep_dims, + int* temp_index, int* resolved_axis, U* temp_sum) { + // Reset output data. + size_t num_outputs = 1; + for (int idx = 0; idx < output_num_dims; ++idx) { + size_t current = static_cast<size_t>(output_dims[idx]); + // Overflow prevention. + if (num_outputs > std::numeric_limits<size_t>::max() / current) { + return false; + } + num_outputs *= current; + } + for (size_t idx = 0; idx < num_outputs; ++idx) { + output_data[idx] = T(); + temp_sum[idx] = U(); + } + + // Resolve axis. + int num_resolved_axis = 0; + if (!ResolveAxis(input_num_dims, axis, num_axis_dimensions, resolved_axis, + &num_resolved_axis)) { + return false; + } + + if (!ReduceSumImpl<T, U>(input_data, input_dims, output_dims, input_num_dims, + output_num_dims, resolved_axis, num_resolved_axis, + temp_index, temp_sum)) { + return false; + } + + // Calculate mean by dividing output_data by num of aggregated element. + U num_elements_in_axis = 1; + for (int idx = 0; idx < num_resolved_axis; ++idx) { + size_t current = static_cast<size_t>(input_dims[resolved_axis[idx]]); + // Overflow prevention. + if (current > (std::numeric_limits<U>::max() / num_elements_in_axis)) { + return false; + } + num_elements_in_axis *= current; + } + + if (num_elements_in_axis > 0) { + const float scale = input_scale / output_scale; + const float bias = -input_zero_point * scale; + for (size_t idx = 0; idx < num_outputs; ++idx) { + float float_mean = static_cast<float>(temp_sum[idx]) / + static_cast<float>(num_elements_in_axis); + + // Convert to float value. + output_data[idx] = + static_cast<T>(round(float_mean * scale + bias)) + output_zero_point; + } + } + return true; +} + template <typename T> void Minimum(const RuntimeShape& input1_shape, const T* input1_data, const T* input2_data, const RuntimeShape& output_shape, @@ -4070,21 +4421,24 @@ void TensorFlowMaximum(const T* input1_data, const Dims<4>& input1_dims, } template <typename T, typename Op> -void TensorFlowMaximumMinimum(const T* input1_data, const Dims<4>& input1_dims, - const T* input2_data, const Dims<4>& input2_dims, - T* output_data, const Dims<4>& output_dims, - Op op) { +void MaximumMinimumBroadcast4DSlow(const RuntimeShape& input1_shape, + const T* input1_data, + const RuntimeShape& input2_shape, + const T* input2_data, + const RuntimeShape& output_shape, + T* output_data, Op op) { NdArrayDesc<4> desc1; NdArrayDesc<4> desc2; - NdArrayDescsForElementwiseBroadcast(input1_dims, input2_dims, &desc1, &desc2); + NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1, + &desc2); - for (int b = 0; b < ArraySize(output_dims, 3); ++b) { - for (int y = 0; y < ArraySize(output_dims, 2); ++y) { - for (int x = 0; x < ArraySize(output_dims, 1); ++x) { - for (int c = 0; c < ArraySize(output_dims, 0); ++c) { - auto out_idx = Offset(output_dims, c, x, y, b); - auto in1_idx = SubscriptToIndex(desc1, c, x, y, b); - auto in2_idx = SubscriptToIndex(desc2, c, x, y, b); + for (int b = 0; b < output_shape.Dims(0); ++b) { + for (int y = 0; y < output_shape.Dims(1); ++y) { + for (int x = 0; x < output_shape.Dims(2); ++x) { + for (int c = 0; c < output_shape.Dims(3); ++c) { + auto out_idx = Offset(output_shape, b, y, x, c); + auto in1_idx = SubscriptToIndex(desc1, b, y, x, c); + auto in2_idx = SubscriptToIndex(desc2, b, y, x, c); auto in1_val = input1_data[in1_idx]; auto in2_val = input2_data[in2_idx]; output_data[out_idx] = op(in1_val, in2_val); @@ -4094,9 +4448,20 @@ void TensorFlowMaximumMinimum(const T* input1_data, const Dims<4>& input1_dims, } } +template <typename T, typename Op> +void TensorFlowMaximumMinimum(const T* input1_data, const Dims<4>& input1_dims, + const T* input2_data, const Dims<4>& input2_dims, + T* output_data, const Dims<4>& output_dims, + Op op) { + MaximumMinimumBroadcast4DSlow(DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data, op); +} + template <typename T1, typename T2, typename T3, typename Cmp> -void ArgMinMax(const T3* axis, const T1* input_data, const Dims<4>& input_dims, - T2* output_data, const Dims<4>& output_dims, const Cmp& cmp) { +void ArgMinMax(const T3* axis, const RuntimeShape& input_shape, + const T1* input_data, const RuntimeShape& output_shape, + T2* output_data, const Cmp& cmp) { // The current ArgMax implemention can only determine the index of the maximum // value in the last dimension. So the axis argument is ignored. @@ -4104,9 +4469,11 @@ void ArgMinMax(const T3* axis, const T1* input_data, const Dims<4>& input_dims, // 1). For the sake of simplicity, the output dimensions are equal to the // input dimensions here. We enforce the constraint that the last dimension // must always be 1. - TFLITE_DCHECK_EQ(ArraySize(output_dims, 0), 1); - const int outer_size = MatchingFlatSizeSkipDim(input_dims, 0, output_dims); - const int depth = ArraySize(input_dims, 0); + TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4); + TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4); + TFLITE_DCHECK_EQ(output_shape.Dims(3), 1); + const int outer_size = MatchingFlatSizeSkipDim(input_shape, 3, output_shape); + const int depth = input_shape.Dims(3); for (int i = 0; i < outer_size; ++i) { auto min_max_value = input_data[i * depth]; @@ -4122,6 +4489,15 @@ void ArgMinMax(const T3* axis, const T1* input_data, const Dims<4>& input_dims, } } +// Legacy Dims<4> version. +template <typename T1, typename T2, typename T3, typename Cmp> +void ArgMinMax(const T3* axis, const T1* input_data, const Dims<4>& input_dims, + T2* output_data, const Dims<4>& output_dims, const Cmp& cmp) { + ArgMinMax(axis, DimsToShape(input_dims), input_data, DimsToShape(output_dims), + output_data, cmp); +} + +// Legacy. // TODO(renjieliu): Remove this one. template <typename T1, typename T2, typename T3> void ArgMax(const T3* axis, const T1* input_data, @@ -4254,16 +4630,26 @@ template <typename T> using ComparisonFn = bool (*)(T, T); template <typename T, ComparisonFn<T> F> -inline void Comparison(const T* input1_data, const Dims<4>& input1_dims, - const T* input2_data, const Dims<4>& input2_dims, - bool* output_data, const Dims<4>& output_dims) { +inline void Comparison(const RuntimeShape& input1_shape, const T* input1_data, + const RuntimeShape& input2_shape, const T* input2_data, + const RuntimeShape& output_shape, bool* output_data) { const int64_t flatsize = - MatchingFlatSize(input1_dims, input2_dims, output_dims); + MatchingFlatSize(input1_shape, input2_shape, output_shape); for (int64_t i = 0; i < flatsize; ++i) { output_data[i] = F(input1_data[i], input2_data[i]); } } +// Legacy Dims<4> version. +template <typename T, ComparisonFn<T> F> +inline void Comparison(const T* input1_data, const Dims<4>& input1_dims, + const T* input2_data, const Dims<4>& input2_dims, + bool* output_data, const Dims<4>& output_dims) { + Comparison<T, F>(DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); +} + template <typename T, ComparisonFn<int32> F> inline void Comparison(int left_shift, const T* input1_data, const Dims<4>& input1_dims, int32 input1_offset, @@ -4474,69 +4860,156 @@ inline void SparseToDense(const std::vector<std::vector<TI>>& indices, } template <typename T> -inline void Pow(const T* input1_data, const Dims<4>& input1_dims, - const T* input2_data, const Dims<4>& input2_dims, - T* output_data, const Dims<4>& output_dims) { - const int flat_size = MatchingFlatSize(input1_dims, input2_dims, output_dims); +inline void Pow(const RuntimeShape& input1_shape, const T* input1_data, + const RuntimeShape& input2_shape, const T* input2_data, + const RuntimeShape& output_shape, T* output_data) { + const int flat_size = + MatchingFlatSize(input1_shape, input2_shape, output_shape); for (int i = 0; i < flat_size; ++i) { output_data[i] = std::pow(input1_data[i], input2_data[i]); } } +// Legacy Dims<4> version. template <typename T> -inline void BroadcastPow(const T* input1_data, const Dims<4>& input1_dims, - const T* input2_data, const Dims<4>& input2_dims, - T* output_data, const Dims<4>& output_dims) { +inline void Pow(const T* input1_data, const Dims<4>& input1_dims, + const T* input2_data, const Dims<4>& input2_dims, + T* output_data, const Dims<4>& output_dims) { + Pow(DimsToShape(input1_dims), input1_data, DimsToShape(input2_dims), + input2_data, DimsToShape(output_dims), output_data); +} + +template <typename T> +inline void BroadcastPow4DSlow(const RuntimeShape& input1_shape, + const T* input1_data, + const RuntimeShape& input2_shape, + const T* input2_data, + const RuntimeShape& output_shape, + T* output_data) { NdArrayDesc<4> desc1; NdArrayDesc<4> desc2; - NdArrayDescsForElementwiseBroadcast(input1_dims, input2_dims, &desc1, &desc2); - for (int b = 0; b < ArraySize(output_dims, 3); ++b) { - for (int y = 0; y < ArraySize(output_dims, 2); ++y) { - for (int x = 0; x < ArraySize(output_dims, 1); ++x) { - for (int c = 0; c < ArraySize(output_dims, 0); ++c) { - output_data[Offset(output_dims, c, x, y, b)] = - std::pow(input1_data[SubscriptToIndex(desc1, c, x, y, b)], - input2_data[SubscriptToIndex(desc2, c, x, y, b)]); + NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1, + &desc2); + + for (int b = 0; b < output_shape.Dims(0); ++b) { + for (int y = 0; y < output_shape.Dims(1); ++y) { + for (int x = 0; x < output_shape.Dims(2); ++x) { + for (int c = 0; c < output_shape.Dims(3); ++c) { + auto out_idx = Offset(output_shape, b, y, x, c); + auto in1_idx = SubscriptToIndex(desc1, b, y, x, c); + auto in2_idx = SubscriptToIndex(desc2, b, y, x, c); + auto in1_val = input1_data[in1_idx]; + auto in2_val = input2_data[in2_idx]; + output_data[out_idx] = std::pow(in1_val, in2_val); } } } } } +// Legacy Dims<4> version. +template <typename T> +inline void BroadcastPow(const T* input1_data, const Dims<4>& input1_dims, + const T* input2_data, const Dims<4>& input2_dims, + T* output_data, const Dims<4>& output_dims) { + BroadcastPow4DSlow(DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); +} + +inline void Logical(const RuntimeShape& input1_shape, const bool* input1_data, + const RuntimeShape& input2_shape, const bool* input2_data, + const RuntimeShape& output_shape, bool* output_data, + const std::function<bool(bool, bool)>& func) { + const int flat_size = + MatchingFlatSize(input1_shape, input2_shape, output_shape); + for (int i = 0; i < flat_size; ++i) { + output_data[i] = func(input1_data[i], input2_data[i]); + } +} + +// Legacy Dims<4> version. inline void Logical(const bool* input1_data, const Dims<4>& input1_dims, const bool* input2_data, const Dims<4>& input2_dims, bool* output_data, const Dims<4>& output_dims, const std::function<bool(bool, bool)>& func) { - const int flat_size = MatchingFlatSize(input1_dims, input2_dims, output_dims); - for (int i = 0; i < flat_size; ++i) { - output_data[i] = func(input1_data[i], input2_data[i]); + Logical(DimsToShape(input1_dims), input1_data, DimsToShape(input2_dims), + input2_data, DimsToShape(output_dims), output_data, func); +} + +inline void BroadcastLogical4DSlow( + const RuntimeShape& input1_shape, const bool* input1_data, + const RuntimeShape& input2_shape, const bool* input2_data, + const RuntimeShape& output_shape, bool* output_data, + const std::function<bool(bool, bool)>& func) { + NdArrayDesc<4> desc1; + NdArrayDesc<4> desc2; + NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1, + &desc2); + + for (int b = 0; b < output_shape.Dims(0); ++b) { + for (int y = 0; y < output_shape.Dims(1); ++y) { + for (int x = 0; x < output_shape.Dims(2); ++x) { + for (int c = 0; c < output_shape.Dims(3); ++c) { + auto out_idx = Offset(output_shape, b, y, x, c); + auto in1_idx = SubscriptToIndex(desc1, b, y, x, c); + auto in2_idx = SubscriptToIndex(desc2, b, y, x, c); + auto in1_val = input1_data[in1_idx]; + auto in2_val = input2_data[in2_idx]; + output_data[out_idx] = func(in1_val, in2_val); + } + } + } } } +// Legacy Dims<4> version. inline void BroadcastLogical(const bool* input1_data, const Dims<4>& input1_dims, const bool* input2_data, const Dims<4>& input2_dims, bool* output_data, const Dims<4>& output_dims, const std::function<bool(bool, bool)>& func) { + BroadcastLogical4DSlow(DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data, func); +} + +// TODO(ycling): Refactoring. Remove BroadcastLogical and use the more +// generalized and efficient BroadcastBinaryFunction. +// +// Also appears to duplicte MinimumMaximum. +// +// R: Result type. T1: Input 1 type. T2: Input 2 type. +template <typename R, typename T1, typename T2> +inline void BroadcastBinaryFunction4DSlow(const RuntimeShape& input1_shape, + const T1* input1_data, + const RuntimeShape& input2_shape, + const T2* input2_data, + const RuntimeShape& output_shape, + R* output_data, R (*func)(T1, T2)) { NdArrayDesc<4> desc1; NdArrayDesc<4> desc2; - NdArrayDescsForElementwiseBroadcast(input1_dims, input2_dims, &desc1, &desc2); - for (int b = 0; b < ArraySize(output_dims, 3); ++b) { - for (int y = 0; y < ArraySize(output_dims, 2); ++y) { - for (int x = 0; x < ArraySize(output_dims, 1); ++x) { - for (int c = 0; c < ArraySize(output_dims, 0); ++c) { - output_data[Offset(output_dims, c, x, y, b)] = - func(input1_data[SubscriptToIndex(desc1, c, x, y, b)], - input2_data[SubscriptToIndex(desc2, c, x, y, b)]); + NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1, + &desc2); + + for (int b = 0; b < output_shape.Dims(0); ++b) { + for (int y = 0; y < output_shape.Dims(1); ++y) { + for (int x = 0; x < output_shape.Dims(2); ++x) { + for (int c = 0; c < output_shape.Dims(3); ++c) { + auto out_idx = Offset(output_shape, b, y, x, c); + auto in1_idx = SubscriptToIndex(desc1, b, y, x, c); + auto in2_idx = SubscriptToIndex(desc2, b, y, x, c); + auto in1_val = input1_data[in1_idx]; + auto in2_val = input2_data[in2_idx]; + output_data[out_idx] = func(in1_val, in2_val); } } } } } -// TODO(ycling): Refactoring. Remove BroadcastLogical and use the more -// generalized and efficient BroadcastBinaryFunction. +// Legacy Dims<4> version. // // R: Result type. T1: Input 1 type. T2: Input 2 type. template <typename R, typename T1, typename T2> @@ -4546,19 +5019,23 @@ inline void BroadcastBinaryFunction(const T1* input1_data, const Dims<4>& input2_dims, R* output_data, const Dims<4>& output_dims, R (*func)(T1, T2)) { - NdArrayDesc<4> desc1; - NdArrayDesc<4> desc2; - NdArrayDescsForElementwiseBroadcast(input1_dims, input2_dims, &desc1, &desc2); - for (int b = 0; b < ArraySize(output_dims, 3); ++b) { - for (int y = 0; y < ArraySize(output_dims, 2); ++y) { - for (int x = 0; x < ArraySize(output_dims, 1); ++x) { - for (int c = 0; c < ArraySize(output_dims, 0); ++c) { - output_data[Offset(output_dims, c, x, y, b)] = - func(input1_data[SubscriptToIndex(desc1, c, x, y, b)], - input2_data[SubscriptToIndex(desc2, c, x, y, b)]); - } - } - } + BroadcastBinaryFunction4DSlow(DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data, func); +} + +// Legacy Dims<4> version. +// +// R: Result type. T1: Input 1 type. T2: Input 2 type. +// TODO(renjieliu): Refactor other binary functions to use this one. +template <typename R, typename T1, typename T2> +inline void BinaryFunction(const T1* input1_data, const Dims<4>& input1_dims, + const T2* input2_data, const Dims<4>& input2_dims, + R* output_data, const Dims<4>& output_dims, + R (*func)(T1, T2)) { + const int flat_size = MatchingFlatSize(input1_dims, input2_dims, output_dims); + for (int i = 0; i < flat_size; ++i) { + output_data[i] = func(input1_data[i], input2_data[i]); } } diff --git a/tensorflow/contrib/lite/kernels/internal/types.h b/tensorflow/contrib/lite/kernels/internal/types.h index 204df9ab19..8e17eaa964 100644 --- a/tensorflow/contrib/lite/kernels/internal/types.h +++ b/tensorflow/contrib/lite/kernels/internal/types.h @@ -668,9 +668,9 @@ static_assert(sizeof(MinMax) == 8, ""); struct ActivationParams { FusedActivationFunctionType activation_type; - // Quantized inference params. - int32 activation_min; - int32 activation_max; + // uint8, etc, activation params. + int32 quantized_activation_min; + int32 quantized_activation_max; }; // For Add, Sub, Mul ops. @@ -745,7 +745,7 @@ struct ConvParams { }; struct DepthToSpaceParams { - int16 block_size; + int32 block_size; }; struct DepthwiseParams { @@ -871,8 +871,13 @@ struct SoftmaxParams { int diff_min; }; +struct SpaceToBatchParams { + // "Zero" padding for uint8 means padding with the output offset. + int32 output_offset; +}; + struct SpaceToDepthParams { - int16 block_size; + int32 block_size; }; struct SplitParams { @@ -908,23 +913,30 @@ struct TanhParams { int input_left_shift; }; -template <typename T> -inline void SetActivationParams(T min, T max, ArithmeticParams* params); - -template <> -inline void SetActivationParams(float min, float max, - ArithmeticParams* params) { +template <typename P> +inline void SetActivationParams(float min, float max, P* params) { params->float_activation_min = min; params->float_activation_max = max; } -template <> -inline void SetActivationParams(int32 min, int32 max, - ArithmeticParams* params) { +template <typename P> +inline void SetActivationParams(int32 min, int32 max, P* params) { params->quantized_activation_min = min; params->quantized_activation_max = max; } +template <typename P> +inline void GetActivationParams(const P& params, int32* min, int32* max) { + *min = params.quantized_activation_min; + *max = params.quantized_activation_max; +} + +template <typename P> +inline void GetActivationParams(const P& params, float* min, float* max) { + *min = params.float_activation_min; + *max = params.float_activation_max; +} + } // namespace tflite #endif // TENSORFLOW_CONTRIB_LITE_KERNELS_INTERNAL_TYPES_H_ diff --git a/tensorflow/contrib/lite/kernels/lstm.cc b/tensorflow/contrib/lite/kernels/lstm.cc index ba251c451e..74dc3f25f9 100644 --- a/tensorflow/contrib/lite/kernels/lstm.cc +++ b/tensorflow/contrib/lite/kernels/lstm.cc @@ -37,7 +37,7 @@ namespace builtin { namespace lstm { struct OpData { - // Which kernel type to use. Full kernel (18 or 20 inputs) or basic kernel + // Which kernel type to use. Full kernel (20 inputs) or basic kernel // (5 inputs). TfLiteLSTMKernelType kernel_type; @@ -47,7 +47,7 @@ struct OpData { int scratch_tensor_index; }; -// For full inputs kernel (18 or 20 inputs). +// For full inputs kernel (20-inputs). namespace full { // Input Tensors of size {n_batch, n_input} @@ -81,19 +81,13 @@ constexpr int kProjectionWeightsTensor = 16; // Optional // Projection bias tensor of size {n_output} constexpr int kProjectionBiasTensor = 17; // Optional -// If the node has 20 inputs, the following 2 tensors are used as state tensors. -// These are defined as variable tensors, and will be modified by this op. +// These state tensors are defined as variable tensors, and will be modified by +// this op. constexpr int kInputActivationStateTensor = 18; constexpr int kInputCellStateTensor = 19; // Output tensors. -// * If the node has 18 inputs, these 2 tensors are used as state tensors. -// * If the node has 20 inputs, these 2 tensors are ignored. -// TODO(ycling): Make the 2 output state tensors optional, and propagate the -// state to output tensors when the 2 tensors present. -constexpr int kOutputStateTensor = 0; -constexpr int kCellStateTensor = 1; -constexpr int kOutputTensor = 2; +constexpr int kOutputTensor = 0; void* Init(TfLiteContext* context, const char* buffer, size_t length) { auto* op_data = new OpData(); @@ -258,30 +252,12 @@ TfLiteStatus CheckInputTensorDimensions(TfLiteContext* context, TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { OpData* op_data = reinterpret_cast<OpData*>(node->user_data); - TF_LITE_ENSURE_EQ(context, node->outputs->size, 3); - - // True if the node is using input variable state tensors. It means: - // * The state tensors are defined as inputs. In this case it would be the - // 19th and 20th input tensors. - // * Otherwise, the output tensors are used to store states. - bool use_input_variable_states; - if (node->inputs->size == 20) { - use_input_variable_states = true; - op_data->activation_state_tensor_index = - node->inputs->data[kInputActivationStateTensor]; - op_data->cell_state_tensor_index = - node->inputs->data[kInputCellStateTensor]; - } else if (node->inputs->size == 18) { - use_input_variable_states = false; - op_data->activation_state_tensor_index = - node->outputs->data[kOutputStateTensor]; - op_data->cell_state_tensor_index = node->outputs->data[kCellStateTensor]; - } else { - context->ReportError( - context, "The LSTM Full kernel expects 18 or 20 inputs. Got %d inputs", - node->inputs->size); - return kTfLiteError; - } + TF_LITE_ENSURE_EQ(context, node->outputs->size, 1); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 20); + + op_data->activation_state_tensor_index = + node->inputs->data[kInputActivationStateTensor]; + op_data->cell_state_tensor_index = node->inputs->data[kInputCellStateTensor]; // Inferring batch size, number of outputs and number of cells from the // input tensors. @@ -316,31 +292,11 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TfLiteTensor* cell_state = &context->tensors[op_data->cell_state_tensor_index]; - if (use_input_variable_states) { - // Check the shape of input state tensors. - // These tensor may be 1D or 2D. It's fine as long as the total size is - // correct. - TF_LITE_ENSURE_EQ(context, NumElements(activation_state), - n_batch * n_output); - TF_LITE_ENSURE_EQ(context, NumElements(cell_state), n_batch * n_cell); - } else { - // If the state tensors are outputs, this function takes the - // responsibility to resize the state tensors. - TfLiteIntArray* activation_state_size = TfLiteIntArrayCreate(2); - activation_state_size->data[0] = n_batch; - activation_state_size->data[1] = n_output; - TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, activation_state, - activation_state_size)); - - TfLiteIntArray* cell_size = TfLiteIntArrayCreate(2); - cell_size->data[0] = n_batch; - cell_size->data[1] = n_cell; - TF_LITE_ENSURE_OK(context, - context->ResizeTensor(context, cell_state, cell_size)); - // Mark state tensors as persistent tensors. - activation_state->allocation_type = kTfLiteArenaRwPersistent; - cell_state->allocation_type = kTfLiteArenaRwPersistent; - } + // Check the shape of input state tensors. + // These tensor may be 1D or 2D. It's fine as long as the total size is + // correct. + TF_LITE_ENSURE_EQ(context, NumElements(activation_state), n_batch * n_output); + TF_LITE_ENSURE_EQ(context, NumElements(cell_state), n_batch * n_cell); // Resize the output tensors. TfLiteIntArray* output_size = TfLiteIntArrayCreate(2); diff --git a/tensorflow/contrib/lite/kernels/lstm_test.cc b/tensorflow/contrib/lite/kernels/lstm_test.cc index 0266f5fe57..e7ddfceb45 100644 --- a/tensorflow/contrib/lite/kernels/lstm_test.cc +++ b/tensorflow/contrib/lite/kernels/lstm_test.cc @@ -106,14 +106,13 @@ class LSTMOpModel : public SingleOpModel { input_cell_state_ = AddInput(TensorData{TensorType_FLOAT32, {n_cell_ * n_batch_}}, true); - output_state_ = AddOutput(TensorType_FLOAT32); - cell_state_ = AddOutput(TensorType_FLOAT32); output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp(BuiltinOperator_LSTM, BuiltinOptions_LSTMOptions, CreateLSTMOptions(builder_, ActivationFunctionType_TANH, cell_clip, proj_clip) .Union()); + BuildInterpreter(input_shapes); } @@ -185,22 +184,6 @@ class LSTMOpModel : public SingleOpModel { PopulateTensor(projection_bias_, f); } - void ResetOutputState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(output_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - - void ResetCellState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(cell_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - void SetInput(int offset, const float* begin, const float* end) { PopulateTensor(input_, offset, const_cast<float*>(begin), const_cast<float*>(end)); @@ -469,10 +452,6 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { lstm.SetRecurrentToForgetWeights(recurrent_to_forget_weights_); lstm.SetRecurrentToOutputWeights(recurrent_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -529,10 +508,6 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { lstm.SetRecurrentToForgetWeights(recurrent_to_forget_weights_); lstm.SetRecurrentToOutputWeights(recurrent_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm, /*tolerance=*/0.0157651); } @@ -637,10 +612,6 @@ TEST_F(CifgNoPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { lstm.SetCellToForgetWeights(cell_to_forget_weights_); lstm.SetCellToOutputWeights(cell_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -698,14 +669,10 @@ TEST_F(CifgNoPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { lstm.SetCellToForgetWeights(cell_to_forget_weights_); lstm.SetCellToOutputWeights(cell_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm, /*tolerance=*/0.03573); } -class NoCifgPeepholeProjectionClippingLstmTest : public BaseLstmTest { +class NoCifgPeepholeProjectionNoClippingLstmTest : public BaseLstmTest { void SetUp() override { input_to_input_weights_ = { 0.021393683, 0.06124551, 0.046905167, -0.014657677, -0.03149463, @@ -1304,7 +1271,7 @@ class NoCifgPeepholeProjectionClippingLstmTest : public BaseLstmTest { } }; -TEST_F(NoCifgPeepholeProjectionClippingLstmTest, LstmBlackBoxTest) { +TEST_F(NoCifgPeepholeProjectionNoClippingLstmTest, LstmBlackBoxTest) { const int n_batch = 2; const int n_input = 5; const int n_cell = 20; @@ -1362,14 +1329,10 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, LstmBlackBoxTest) { lstm.SetProjectionWeights(projection_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } -TEST_F(NoCifgPeepholeProjectionClippingLstmTest, HybridLstmBlackBoxTest) { +TEST_F(NoCifgPeepholeProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { const int n_batch = 2; const int n_input = 5; const int n_cell = 20; @@ -1428,10 +1391,6 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, HybridLstmBlackBoxTest) { lstm.SetProjectionWeights(projection_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm, /*tolerance=*/0.00467); } diff --git a/tensorflow/contrib/lite/kernels/mfcc.cc b/tensorflow/contrib/lite/kernels/mfcc.cc index dd388df630..306f676619 100644 --- a/tensorflow/contrib/lite/kernels/mfcc.cc +++ b/tensorflow/contrib/lite/kernels/mfcc.cc @@ -13,7 +13,7 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ #include "tensorflow/contrib/lite/kernels/internal/mfcc.h" -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers #include "tensorflow/contrib/lite/builtin_op_data.h" #include "tensorflow/contrib/lite/context.h" #include "tensorflow/contrib/lite/kernels/internal/mfcc_dct.h" diff --git a/tensorflow/contrib/lite/kernels/mfcc_test.cc b/tensorflow/contrib/lite/kernels/mfcc_test.cc index 69aa19623b..c9124adcaf 100644 --- a/tensorflow/contrib/lite/kernels/mfcc_test.cc +++ b/tensorflow/contrib/lite/kernels/mfcc_test.cc @@ -18,7 +18,7 @@ limitations under the License. #include <vector> #include <gtest/gtest.h> -#include "include/flatbuffers/flexbuffers.h" // flatbuffers +#include "flatbuffers/flexbuffers.h" // flatbuffers #include "tensorflow/contrib/lite/interpreter.h" #include "tensorflow/contrib/lite/kernels/register.h" #include "tensorflow/contrib/lite/kernels/test_util.h" diff --git a/tensorflow/contrib/lite/kernels/op_macros.h b/tensorflow/contrib/lite/kernels/op_macros.h index 7568eaa88e..d66364c4d8 100644 --- a/tensorflow/contrib/lite/kernels/op_macros.h +++ b/tensorflow/contrib/lite/kernels/op_macros.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_KERNELS_OP_UTIL_H_ -#define TENSORFLOW_CONTRIB_LITE_KERNELS_OP_UTIL_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_KERNELS_OP_MACROS_H_ +#define TENSORFLOW_CONTRIB_LITE_KERNELS_OP_MACROS_H_ #include <cstdio> @@ -31,4 +31,4 @@ limitations under the License. if ((x) != (y)) TF_LITE_FATAL(#x " didn't equal " #y); \ } while (0) -#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_OP_UTIL_H_ +#endif // TENSORFLOW_CONTRIB_LITE_KERNELS_OP_MACROS_H_ diff --git a/tensorflow/contrib/lite/kernels/optional_tensor_test.cc b/tensorflow/contrib/lite/kernels/optional_tensor_test.cc index 1c728a4733..90a915bb02 100644 --- a/tensorflow/contrib/lite/kernels/optional_tensor_test.cc +++ b/tensorflow/contrib/lite/kernels/optional_tensor_test.cc @@ -101,8 +101,6 @@ class LSTMOpModel : public SingleOpModel { input_cell_state_ = AddInput(TensorData{TensorType_FLOAT32, {n_cell_ * n_batch_}}, true); - output_state_ = AddOutput(TensorType_FLOAT32); - cell_state_ = AddOutput(TensorType_FLOAT32); output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp(BuiltinOperator_LSTM, BuiltinOptions_LSTMOptions, @@ -180,22 +178,6 @@ class LSTMOpModel : public SingleOpModel { PopulateTensor(projection_bias_, f); } - void ResetOutputState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(output_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - - void ResetCellState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(cell_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - void SetInput(int offset, float* begin, float* end) { PopulateTensor(input_, offset, begin, end); } @@ -238,8 +220,6 @@ class LSTMOpModel : public SingleOpModel { int input_cell_state_; int output_; - int output_state_; - int cell_state_; int n_batch_; int n_input_; @@ -324,10 +304,6 @@ TEST(LSTMOpTest, BlackBoxTestWithCifgWithPeepholeNoProjectionNoClipping) { lstm.SetCellToOutputWeights( {-0.17135078, 0.82760304, 0.85573703, -0.77109635}); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - // Verify the model by unpacking it. lstm.Verify(); } diff --git a/tensorflow/contrib/lite/kernels/pack.cc b/tensorflow/contrib/lite/kernels/pack.cc index bb3416f6a6..cc326a7d51 100644 --- a/tensorflow/contrib/lite/kernels/pack.cc +++ b/tensorflow/contrib/lite/kernels/pack.cc @@ -27,24 +27,9 @@ namespace { constexpr int kOutputTensor = 0; -// Op data for pack op. -struct OpData { - int values_count; - int axis; -}; - -void* Init(TfLiteContext* context, const char* buffer, size_t length) { - auto* data = new OpData; - data->axis = 0; - return data; -} - -void Free(TfLiteContext* context, void* buffer) { - delete reinterpret_cast<OpData*>(buffer); -} - TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { - const OpData* data = reinterpret_cast<OpData*>(node->builtin_data); + const TfLitePackParams* data = + reinterpret_cast<TfLitePackParams*>(node->builtin_data); TF_LITE_ENSURE_EQ(context, NumInputs(node), data->values_count); TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1); @@ -54,9 +39,11 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE(context, NumDimensions(input0) >= data->axis); // TODO(renjieliu): Support negative axis. TF_LITE_ENSURE(context, data->axis >= 0); - if (input0->type != kTfLiteInt32 && input0->type != kTfLiteFloat32) { + if (input0->type != kTfLiteInt32 && input0->type != kTfLiteFloat32 && + input0->type != kTfLiteUInt8 && input0->type != kTfLiteInt16) { context->ReportError(context, - "Currently pack only supports int32 and float32."); + "Currently pack only supports " + "float32/uint8/int16/int32."); return kTfLiteError; } // Make sure all inputs have the same shape and type. @@ -82,6 +69,15 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TfLiteTensor* output = GetOutput(context, node, kOutputTensor); TF_LITE_ENSURE_EQ(context, output->type, input0->type); + // Guarantee input/output quantization params match as we do not support + // packing quantized tensors. + for (int i = 0; i < data->values_count; i++) { + const TfLiteTensor* input = GetInput(context, node, i); + TF_LITE_ENSURE_EQ(context, input->params.zero_point, + output->params.zero_point); + TF_LITE_ENSURE_EQ(context, input->params.scale, output->params.scale); + } + return context->ResizeTensor(context, output, output_shape); } @@ -95,7 +91,8 @@ void PackImpl(TfLiteContext* context, TfLiteNode* node, TfLiteTensor* output, } TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { - const OpData* data = reinterpret_cast<OpData*>(node->builtin_data); + const TfLitePackParams* data = + reinterpret_cast<TfLitePackParams*>(node->builtin_data); TfLiteTensor* output = GetOutput(context, node, kOutputTensor); switch (output->type) { @@ -103,13 +100,18 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { PackImpl<float>(context, node, output, data->values_count, data->axis); break; } + case kTfLiteUInt8: { + PackImpl<uint8_t>(context, node, output, data->values_count, data->axis); + break; + } case kTfLiteInt32: { PackImpl<int32_t>(context, node, output, data->values_count, data->axis); break; } default: { context->ReportError(context, - "Currently pack only supports int32 and float32."); + "Currently pack only supports " + "float32/uint8/int32."); return kTfLiteError; } } @@ -121,8 +123,7 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { } // namespace pack TfLiteRegistration* Register_PACK() { - static TfLiteRegistration r = {pack::Init, pack::Free, pack::Prepare, - pack::Eval}; + static TfLiteRegistration r = {nullptr, nullptr, pack::Prepare, pack::Eval}; return &r; } diff --git a/tensorflow/contrib/lite/kernels/pack_test.cc b/tensorflow/contrib/lite/kernels/pack_test.cc index 485a50ad3a..c70dbd2764 100644 --- a/tensorflow/contrib/lite/kernels/pack_test.cc +++ b/tensorflow/contrib/lite/kernels/pack_test.cc @@ -51,6 +51,7 @@ class PackOpModel : public SingleOpModel { int output_; }; +// float32 tests. TEST(PackOpTest, FloatThreeInputs) { PackOpModel<float> model({TensorType_FLOAT32, {2}}, 0, 3); model.SetInput(0, {1, 4}); @@ -81,7 +82,8 @@ TEST(PackOpTest, FloatMultilDimensions) { ElementsAreArray({1, 2, 3, 7, 8, 9, 4, 5, 6, 10, 11, 12})); } -TEST(PackOpTest, IntThreeInputs) { +// int32 tests. +TEST(PackOpTest, Int32ThreeInputs) { PackOpModel<int32_t> model({TensorType_INT32, {2}}, 0, 3); model.SetInput(0, {1, 4}); model.SetInput(1, {2, 5}); @@ -91,7 +93,7 @@ TEST(PackOpTest, IntThreeInputs) { EXPECT_THAT(model.GetOutput(), ElementsAreArray({1, 4, 2, 5, 3, 6})); } -TEST(PackOpTest, IntThreeInputsDifferentAxis) { +TEST(PackOpTest, Int32ThreeInputsDifferentAxis) { PackOpModel<int32_t> model({TensorType_INT32, {2}}, 1, 3); model.SetInput(0, {1, 4}); model.SetInput(1, {2, 5}); @@ -101,7 +103,7 @@ TEST(PackOpTest, IntThreeInputsDifferentAxis) { EXPECT_THAT(model.GetOutput(), ElementsAreArray({1, 2, 3, 4, 5, 6})); } -TEST(PackOpTest, IntMultilDimensions) { +TEST(PackOpTest, Int32MultilDimensions) { PackOpModel<int32_t> model({TensorType_INT32, {2, 3}}, 1, 2); model.SetInput(0, {1, 2, 3, 4, 5, 6}); model.SetInput(1, {7, 8, 9, 10, 11, 12}); @@ -110,6 +112,38 @@ TEST(PackOpTest, IntMultilDimensions) { EXPECT_THAT(model.GetOutput(), ElementsAreArray({1, 2, 3, 7, 8, 9, 4, 5, 6, 10, 11, 12})); } + +// uint8 +TEST(PackOpTest, Uint8ThreeInputs) { + PackOpModel<uint8_t> model({TensorType_UINT8, {2}}, 0, 3); + model.SetInput(0, {1, 4}); + model.SetInput(1, {2, 5}); + model.SetInput(2, {3, 6}); + model.Invoke(); + EXPECT_THAT(model.GetOutputShape(), ElementsAre(3, 2)); + EXPECT_THAT(model.GetOutput(), ElementsAreArray({1, 4, 2, 5, 3, 6})); +} + +TEST(PackOpTest, Uint8ThreeInputsDifferentAxis) { + PackOpModel<uint8_t> model({TensorType_UINT8, {2}}, 1, 3); + model.SetInput(0, {1, 4}); + model.SetInput(1, {2, 5}); + model.SetInput(2, {3, 6}); + model.Invoke(); + EXPECT_THAT(model.GetOutputShape(), ElementsAre(2, 3)); + EXPECT_THAT(model.GetOutput(), ElementsAreArray({1, 2, 3, 4, 5, 6})); +} + +TEST(PackOpTest, Uint8MultilDimensions) { + PackOpModel<uint8_t> model({TensorType_UINT8, {2, 3}}, 1, 2); + model.SetInput(0, {1, 2, 3, 4, 5, 6}); + model.SetInput(1, {7, 8, 9, 10, 11, 12}); + model.Invoke(); + EXPECT_THAT(model.GetOutputShape(), ElementsAre(2, 2, 3)); + EXPECT_THAT(model.GetOutput(), + ElementsAreArray({1, 2, 3, 7, 8, 9, 4, 5, 6, 10, 11, 12})); +} + } // namespace } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/reduce.cc b/tensorflow/contrib/lite/kernels/reduce.cc index e99f67c725..4001cf357f 100644 --- a/tensorflow/contrib/lite/kernels/reduce.cc +++ b/tensorflow/contrib/lite/kernels/reduce.cc @@ -177,6 +177,9 @@ TfLiteStatus InitializeTemporaries(TfLiteContext* context, TfLiteNode* node, case kTfLiteUInt8: temp_sum->type = kTfLiteInt32; break; + case kTfLiteBool: + temp_sum->type = kTfLiteBool; + break; default: return kTfLiteError; } @@ -204,6 +207,13 @@ TfLiteStatus PrepareSimple(TfLiteContext* context, TfLiteNode* node) { return kTfLiteOk; } +TfLiteStatus PrepareAny(TfLiteContext* context, TfLiteNode* node) { + TF_LITE_ENSURE_EQ(context, NumInputs(node), 2); + const TfLiteTensor* input = GetInput(context, node, 0); + TF_LITE_ENSURE_EQ(context, input->type, kTfLiteBool); + return PrepareSimple(context, node); +} + TfLiteStatus PrepareMean(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, PrepareSimple(context, node)); @@ -256,11 +266,27 @@ TfLiteStatus EvalMean(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE(context, TF_LITE_MEAN(reference_ops, int64_t, int64_t)); break; case kTfLiteUInt8: - TF_LITE_ENSURE_EQ(context, op_context.input->params.scale, - op_context.output->params.scale); - TF_LITE_ENSURE_EQ(context, op_context.input->params.zero_point, - op_context.output->params.zero_point); - TF_LITE_ENSURE(context, TF_LITE_MEAN(reference_ops, uint8_t, int)); + if (op_context.input->params.zero_point == + op_context.output->params.zero_point && + op_context.input->params.scale == op_context.output->params.scale) { + TF_LITE_ENSURE(context, TF_LITE_MEAN(reference_ops, uint8_t, int)); + } else { + TF_LITE_ENSURE( + context, + reference_ops::Mean<>( + GetTensorData<uint8_t>(op_context.input), + op_context.input->params.zero_point, + op_context.input->params.scale, op_context.input->dims->data, + op_context.input->dims->size, + GetTensorData<uint8_t>(op_context.output), + op_context.output->params.zero_point, + op_context.output->params.scale, + op_context.output->dims->data, op_context.output->dims->size, + GetTensorData<int>(op_context.axis), num_axis, + op_context.params->keep_dims, GetTensorData<int>(temp_index), + GetTensorData<int>(resolved_axis), + GetTensorData<int>(temp_sum))); + } break; default: return kTfLiteError; @@ -412,6 +438,79 @@ TfLiteStatus EvalMax(TfLiteContext* context, TfLiteNode* node) { return kTfLiteOk; } +template <KernelType kernel_type> +TfLiteStatus EvalMin(TfLiteContext* context, TfLiteNode* node) { + OpContext op_context(context, node); + int64_t num_axis = NumElements(op_context.axis); + TfLiteTensor* temp_index = GetTemporary(context, node, /*index=*/0); + TfLiteTensor* resolved_axis = GetTemporary(context, node, /*index=*/1); + // Resize the output tensor if the output tensor is dynamic. + if (IsDynamicTensor(op_context.output)) { + TF_LITE_ENSURE_OK(context, + ResizeTempAxis(context, &op_context, resolved_axis)); + TF_LITE_ENSURE_OK(context, ResizeOutputTensor(context, &op_context)); + } + +#define TF_LITE_MIN(kernel_type, data_type) \ + kernel_type::ReduceMin<>( \ + GetTensorData<data_type>(op_context.input), \ + op_context.input->dims->data, op_context.input->dims->size, \ + GetTensorData<data_type>(op_context.output), \ + op_context.output->dims->data, op_context.output->dims->size, \ + GetTensorData<int>(op_context.axis), num_axis, \ + op_context.params->keep_dims, GetTensorData<int>(temp_index), \ + GetTensorData<int>(resolved_axis)) + + if (kernel_type == kReference) { + switch (op_context.input->type) { + case kTfLiteFloat32: + TF_LITE_ENSURE(context, TF_LITE_MIN(reference_ops, float)); + break; + case kTfLiteInt32: + TF_LITE_ENSURE(context, TF_LITE_MIN(reference_ops, int)); + break; + case kTfLiteInt64: + TF_LITE_ENSURE(context, TF_LITE_MIN(reference_ops, int64_t)); + break; + case kTfLiteUInt8: + TF_LITE_ENSURE_EQ(context, op_context.input->params.scale, + op_context.output->params.scale); + TF_LITE_ENSURE_EQ(context, op_context.input->params.zero_point, + op_context.output->params.zero_point); + TF_LITE_ENSURE(context, TF_LITE_MIN(reference_ops, uint8_t)); + break; + default: + return kTfLiteError; + } + } +#undef TF_LITE_MIN + return kTfLiteOk; +} + +template <KernelType kernel_type> +TfLiteStatus EvalAny(TfLiteContext* context, TfLiteNode* node) { + OpContext op_context(context, node); + int64_t num_axis = NumElements(op_context.axis); + TfLiteTensor* temp_index = GetTemporary(context, node, /*index=*/0); + TfLiteTensor* resolved_axis = GetTemporary(context, node, /*index=*/1); + // Resize the output tensor if the output tensor is dynamic. + if (IsDynamicTensor(op_context.output)) { + TF_LITE_ENSURE_OK(context, + ResizeTempAxis(context, &op_context, resolved_axis)); + TF_LITE_ENSURE_OK(context, ResizeOutputTensor(context, &op_context)); + } + if (kernel_type == kReference) { + reference_ops::ReduceAny( + GetTensorData<bool>(op_context.input), op_context.input->dims->data, + op_context.input->dims->size, GetTensorData<bool>(op_context.output), + op_context.output->dims->data, op_context.output->dims->size, + GetTensorData<int>(op_context.axis), num_axis, + op_context.params->keep_dims, GetTensorData<int>(temp_index), + GetTensorData<int>(resolved_axis)); + } + + return kTfLiteOk; +} } // namespace reduce TfLiteRegistration* Register_MEAN_REF() { @@ -442,6 +541,19 @@ TfLiteRegistration* Register_REDUCE_MAX_REF() { return &r; } +TfLiteRegistration* Register_REDUCE_MIN_REF() { + static TfLiteRegistration r = {reduce::Init, reduce::Free, + reduce::PrepareSimple, + reduce::EvalMin<reduce::kReference>}; + return &r; +} + +TfLiteRegistration* Register_REDUCE_ANY_REF() { + static TfLiteRegistration r = {reduce::Init, reduce::Free, reduce::PrepareAny, + reduce::EvalAny<reduce::kReference>}; + return &r; +} + // TODO(kanlig): add optimized implementation of Mean. TfLiteRegistration* Register_MEAN() { return Register_MEAN_REF(); } TfLiteRegistration* Register_SUM() { return Register_SUM_REF(); } @@ -449,6 +561,8 @@ TfLiteRegistration* Register_REDUCE_PROD() { return Register_REDUCE_PROD_REF(); } TfLiteRegistration* Register_REDUCE_MAX() { return Register_REDUCE_MAX_REF(); } +TfLiteRegistration* Register_REDUCE_MIN() { return Register_REDUCE_MIN_REF(); } +TfLiteRegistration* Register_REDUCE_ANY() { return Register_REDUCE_ANY_REF(); } } // namespace builtin } // namespace ops diff --git a/tensorflow/contrib/lite/kernels/reduce_test.cc b/tensorflow/contrib/lite/kernels/reduce_test.cc index 5d432d34ef..6d289b14d8 100644 --- a/tensorflow/contrib/lite/kernels/reduce_test.cc +++ b/tensorflow/contrib/lite/kernels/reduce_test.cc @@ -169,6 +169,64 @@ class MaxOpDynamicModel : public BaseOpModel { } }; +// Model for the tests case where axis is a const tensor. +class MinOpConstModel : public BaseOpModel { + public: + MinOpConstModel(const TensorData& input, const TensorData& output, + std::initializer_list<int> axis_shape, + std::initializer_list<int> axis, bool keep_dims) { + input_ = AddInput(input); + axis_ = AddConstInput(TensorType_INT32, axis, axis_shape); + output_ = AddOutput(output); + SetBuiltinOp(BuiltinOperator_REDUCE_MIN, BuiltinOptions_ReducerOptions, + CreateReducerOptions(builder_, keep_dims).Union()); + BuildInterpreter({GetShape(input_)}); + } +}; + +// Model for the tests case where axis is a dynamic tensor. +class MinOpDynamicModel : public BaseOpModel { + public: + MinOpDynamicModel(const TensorData& input, const TensorData& output, + const TensorData& axis, bool keep_dims) { + input_ = AddInput(input); + axis_ = AddInput(axis); + output_ = AddOutput(output); + SetBuiltinOp(BuiltinOperator_REDUCE_MIN, BuiltinOptions_ReducerOptions, + CreateReducerOptions(builder_, keep_dims).Union()); + BuildInterpreter({GetShape(input_)}); + } +}; + +// Model for the tests case where axis is a const tensor. +class AnyOpConstModel : public BaseOpModel { + public: + AnyOpConstModel(const TensorData& input, const TensorData& output, + std::initializer_list<int> axis_shape, + std::initializer_list<int> axis, bool keep_dims) { + input_ = AddInput(input); + axis_ = AddConstInput(TensorType_INT32, axis, axis_shape); + output_ = AddOutput(output); + SetBuiltinOp(BuiltinOperator_REDUCE_ANY, BuiltinOptions_ReducerOptions, + CreateReducerOptions(builder_, keep_dims).Union()); + BuildInterpreter({GetShape(input_)}); + } +}; + +// Model for the tests case where axis is a dynamic tensor. +class AnyOpDynamicModel : public BaseOpModel { + public: + AnyOpDynamicModel(const TensorData& input, const TensorData& output, + const TensorData& axis, bool keep_dims) { + input_ = AddInput(input); + axis_ = AddInput(axis); + output_ = AddOutput(output); + SetBuiltinOp(BuiltinOperator_REDUCE_ANY, BuiltinOptions_ReducerOptions, + CreateReducerOptions(builder_, keep_dims).Union()); + BuildInterpreter({GetShape(input_)}); + } +}; + // for quantized Add, the error shouldn't exceed step float GetTolerance(int min, int max) { return (max - min) / 255.0; } @@ -309,6 +367,33 @@ TEST(DynamicUint8MeanOpTest, KeepDims) { ElementsAreArray(ArrayFloatNear({9.2815, 0.3695}, kQuantizedTolerance))); } +TEST(DynamicUint8MeanOpTest, QuantizedScalar) { + float kQuantizedTolerance = GetTolerance(-10.0, 12.0); + std::vector<float> data = {0.643}; + MeanOpDynamicModel m({TensorType_UINT8, {}, 0.0, 1.0}, + {TensorType_UINT8, {}, -10.0, 12.0}, + {TensorType_INT32, {1}}, true); + std::vector<int> axis = {0}; + m.QuantizeAndPopulate<uint8_t>(m.Input(), data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), IsEmpty()); + EXPECT_THAT(m.GetDequantizedOutput(), + ElementsAreArray(ArrayFloatNear({0.643}, kQuantizedTolerance))); +} + +TEST(ConstUint8MeanOpTest, QuantizedKeepDims) { + float kQuantizedTolerance = GetTolerance(-5.0, 5.0); + std::vector<float> data = {0.4, 0.2, 0.3, 0.4, 0.5, 0.6}; + MeanOpConstModel m({TensorType_UINT8, {3, 2}, 0.0, 1.0}, + {TensorType_UINT8, {3}, -5.0, 5.0}, {1}, {1}, true); + m.QuantizeAndPopulate<uint8_t>(m.Input(), data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({3, 1})); + EXPECT_THAT( + m.GetDequantizedOutput(), + ElementsAreArray(ArrayFloatNear({0.3, 0.35, 0.55}, kQuantizedTolerance))); +} + // Tests for reduce_sum TEST(ConstFloatSumOpTest, NotKeepDims) { @@ -665,6 +750,209 @@ TEST(DynamicUint8MaxOpTest, Scalar) { ElementsAreArray(ArrayFloatNear({11.1294}, kQuantizedTolerance))); } +// Tests for reduce_min + +TEST(ConstFloatMinOpTest, NotKeepDims) { + std::vector<float> data = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, + 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0, + 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0}; + MinOpConstModel m({TensorType_FLOAT32, {4, 3, 2}}, {TensorType_FLOAT32, {2}}, + {4}, {1, 0, -3, -3}, false); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({2})); + EXPECT_THAT(m.GetOutput<float>(), ElementsAreArray(ArrayFloatNear({1, 2}))); +} + +TEST(ConstFloatMinOpTest, KeepDims) { + std::vector<float> data = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, + 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0, + 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0}; + MinOpConstModel m({TensorType_FLOAT32, {4, 3, 2}}, {TensorType_FLOAT32, {3}}, + {2}, {0, 2}, true); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({1, 3, 1})); + EXPECT_THAT(m.GetOutput<float>(), + ElementsAreArray(ArrayFloatNear({1, 3, 5}))); +} + +TEST(DynamicFloatMinOpTest, NotKeepDims) { + std::vector<float> data = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, + 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0, + 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0}; + MinOpDynamicModel m({TensorType_FLOAT32, {4, 3, 2}}, + {TensorType_FLOAT32, {2}}, {TensorType_INT32, {4}}, + false); + std::vector<int> axis = {1, 0, -3, -3}; + m.SetAxis(axis); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({2})); + EXPECT_THAT(m.GetOutput<float>(), ElementsAreArray(ArrayFloatNear({1, 2}))); +} + +TEST(DynamicFloatMinOpTest, KeepDims) { + std::vector<float> data = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, + 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0, + 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0}; + MinOpDynamicModel m({TensorType_FLOAT32, {4, 3, 2}}, + {TensorType_FLOAT32, {3}}, {TensorType_INT32, {2}}, true); + std::vector<int> axis = {0, 2}; + m.SetAxis(axis); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({1, 3, 1})); + EXPECT_THAT(m.GetOutput<float>(), + ElementsAreArray(ArrayFloatNear({1, 3, 5}))); +} + +TEST(DynamicFloatMinOpTest, Scalar) { + std::vector<float> data = {9.527}; + MinOpDynamicModel m({TensorType_FLOAT32, {1}}, {TensorType_FLOAT32, {1}}, + {TensorType_INT32, {1}}, true); + std::vector<int> axis = {0}; + m.SetAxis(axis); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({1})); + EXPECT_THAT(m.GetOutput<float>(), ElementsAreArray(ArrayFloatNear({9.527}))); +} + +TEST(ConstUint8MinOpTest, NotKeepDims) { + float kQuantizedTolerance = GetTolerance(-1.0, 1.0); + std::vector<float> data = {0.4, 0.2, 0.3, 0.4, 0.5, 0.6}; + MinOpConstModel m({TensorType_UINT8, {1, 3, 2}, -1.0, 1.0}, + {TensorType_UINT8, {2}, -1.0, 1.0}, {1}, {1}, false); + m.QuantizeAndPopulate<uint8_t>(m.Input(), data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({1, 2})); + EXPECT_THAT( + m.GetDequantizedOutput(), + ElementsAreArray(ArrayFloatNear({0.294117, 0.2}, kQuantizedTolerance))); +} + +TEST(ConstUint8MinOpTest, KeepDims) { + float kQuantizedTolerance = GetTolerance(-1.0, 1.0); + std::vector<float> data = {0.4, 0.2, 0.3, 0.4, 0.5, 0.6}; + MinOpConstModel m({TensorType_UINT8, {3, 2}, -1.0, 1.0}, + {TensorType_UINT8, {3}, -1.0, 1.0}, {1}, {1}, true); + m.QuantizeAndPopulate<uint8_t>(m.Input(), data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({3, 1})); + EXPECT_THAT( + m.GetDequantizedOutput(), + ElementsAreArray(ArrayFloatNear({0.2, 0.3, 0.5}, kQuantizedTolerance))); +} + +TEST(DynamicUint8MinOpTest, NotKeepDims) { + float kQuantizedTolerance = GetTolerance(-5.0, 2.0); + std::vector<float> data = {1.3, -4.8, -3.6, 0.24}; + MinOpDynamicModel m({TensorType_UINT8, {2, 2}, -5.0, 2.0}, + {TensorType_UINT8, {2}, -5.0, 2.0}, + {TensorType_INT32, {1}}, false); + std::vector<int> axis = {1}; + m.SetAxis(axis); + m.QuantizeAndPopulate<uint8_t>(m.Input(), data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({2})); + EXPECT_THAT( + m.GetDequantizedOutput(), + ElementsAreArray(ArrayFloatNear({-4.807843, -3.6}, kQuantizedTolerance))); +} + +TEST(DynamicUint8MinOpTest, KeepDims) { + float kQuantizedTolerance = GetTolerance(-10.0, 12.0); + std::vector<float> data = {11.14, -0.14, 7.423, 0.879}; + MinOpDynamicModel m({TensorType_UINT8, {2, 2}, -10.0, 12.0}, + {TensorType_UINT8, {2}, -10.0, 12.0}, + {TensorType_INT32, {1}}, true); + std::vector<int> axis = {0}; + m.SetAxis(axis); + m.QuantizeAndPopulate<uint8_t>(m.Input(), data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({1, 2})); + EXPECT_THAT(m.GetDequantizedOutput(), + ElementsAreArray( + ArrayFloatNear({7.427451, -0.164706}, kQuantizedTolerance))); +} + +TEST(DynamicUint8MinOpTest, Scalar) { + float kQuantizedTolerance = GetTolerance(-10.0, 12.0); + std::vector<float> data = {11.14}; + MinOpDynamicModel m({TensorType_UINT8, {}, -10.0, 12.0}, + {TensorType_UINT8, {}, -10.0, 12.0}, + {TensorType_INT32, {1}}, true); + std::vector<int> axis = {0}; + m.QuantizeAndPopulate<uint8_t>(m.Input(), data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), IsEmpty()); + EXPECT_THAT(m.GetDequantizedOutput(), + ElementsAreArray(ArrayFloatNear({11.1294}, kQuantizedTolerance))); +} + +// Tests for reduce_any + +TEST(ConstAnyOpTest, NotKeepDims) { + std::vector<bool> data = {false, false, false, false, false, false, + false, true, false, false, false, true}; + AnyOpConstModel m({TensorType_BOOL, {2, 3, 2}}, {TensorType_BOOL, {2}}, {4}, + {1, 0, -3, -3}, false); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({2})); + EXPECT_THAT(m.GetOutput<bool>(), ElementsAreArray({false, true})); +} + +TEST(ConstAnyOpTest, KeepDims) { + std::vector<bool> data = {false, false, false, false, false, false, + false, true, false, false, false, true}; + AnyOpConstModel m({TensorType_BOOL, {2, 3, 2}}, {TensorType_BOOL, {3}}, {2}, + {0, 2}, true); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({1, 3, 1})); + EXPECT_THAT(m.GetOutput<bool>(), ElementsAreArray({true, false, true})); +} + +TEST(DynamicAnyOpTest, NotKeepDims) { + std::vector<bool> data = {false, false, false, false, false, false, + false, true, false, false, false, true}; + AnyOpDynamicModel m({TensorType_BOOL, {2, 3, 2}}, {TensorType_BOOL, {2}}, + {TensorType_INT32, {4}}, false); + std::vector<int> axis = {1, 0, -3, -3}; + m.SetAxis(axis); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({2})); + EXPECT_THAT(m.GetOutput<bool>(), ElementsAreArray({false, true})); +} + +TEST(DynamicAnyOpTest, KeepDims) { + std::vector<bool> data = {false, false, false, false, false, false, + false, true, false, false, false, true}; + AnyOpDynamicModel m({TensorType_BOOL, {2, 3, 2}}, {TensorType_BOOL, {3}}, + {TensorType_INT32, {2}}, true); + std::vector<int> axis = {0, 2}; + m.SetAxis(axis); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({1, 3, 1})); + EXPECT_THAT(m.GetOutput<bool>(), ElementsAreArray({true, false, true})); +} + +TEST(DynamicAnyOpTest, Scalar) { + std::vector<bool> data = {false}; + AnyOpDynamicModel m({TensorType_BOOL, {1}}, {TensorType_BOOL, {1}}, + {TensorType_INT32, {1}}, true); + std::vector<int> axis = {0}; + m.SetAxis(axis); + m.SetInput(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({1})); + EXPECT_THAT(m.GetOutput<bool>(), ElementsAreArray({false})); +} + } // namespace } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/register.cc b/tensorflow/contrib/lite/kernels/register.cc index 9681b900b7..7b859dc332 100644 --- a/tensorflow/contrib/lite/kernels/register.cc +++ b/tensorflow/contrib/lite/kernels/register.cc @@ -94,6 +94,8 @@ TfLiteRegistration* Register_NEG(); TfLiteRegistration* Register_SUM(); TfLiteRegistration* Register_REDUCE_PROD(); TfLiteRegistration* Register_REDUCE_MAX(); +TfLiteRegistration* Register_REDUCE_MIN(); +TfLiteRegistration* Register_REDUCE_ANY(); TfLiteRegistration* Register_SELECT(); TfLiteRegistration* Register_SLICE(); TfLiteRegistration* Register_SIN(); @@ -112,6 +114,8 @@ TfLiteRegistration* Register_ONE_HOT(); TfLiteRegistration* Register_LOGICAL_OR(); TfLiteRegistration* Register_LOGICAL_AND(); TfLiteRegistration* Register_LOGICAL_NOT(); +TfLiteRegistration* Register_UNPACK(); +TfLiteRegistration* Register_FLOOR_DIV(); TfLiteStatus UnsupportedTensorFlowOp(TfLiteContext* context, TfLiteNode* node) { context->ReportError( @@ -219,6 +223,8 @@ BuiltinOpResolver::BuiltinOpResolver() { AddBuiltin(BuiltinOperator_SUM, Register_SUM()); AddBuiltin(BuiltinOperator_REDUCE_PROD, Register_REDUCE_PROD()); AddBuiltin(BuiltinOperator_REDUCE_MAX, Register_REDUCE_MAX()); + AddBuiltin(BuiltinOperator_REDUCE_MIN, Register_REDUCE_MIN()); + AddBuiltin(BuiltinOperator_REDUCE_ANY, Register_REDUCE_ANY()); AddBuiltin(BuiltinOperator_EXPAND_DIMS, Register_EXPAND_DIMS()); AddBuiltin(BuiltinOperator_SPARSE_TO_DENSE, Register_SPARSE_TO_DENSE()); AddBuiltin(BuiltinOperator_EQUAL, Register_EQUAL()); @@ -233,6 +239,8 @@ BuiltinOpResolver::BuiltinOpResolver() { AddBuiltin(BuiltinOperator_LOGICAL_OR, Register_LOGICAL_OR()); AddBuiltin(BuiltinOperator_LOGICAL_AND, Register_LOGICAL_AND()); AddBuiltin(BuiltinOperator_LOGICAL_NOT, Register_LOGICAL_NOT()); + AddBuiltin(BuiltinOperator_UNPACK, Register_UNPACK()); + AddBuiltin(BuiltinOperator_FLOOR_DIV, Register_FLOOR_DIV()); // TODO(andrewharp, ahentz): Move these somewhere more appropriate so that // custom ops aren't always included by default. diff --git a/tensorflow/contrib/lite/kernels/svdf.cc b/tensorflow/contrib/lite/kernels/svdf.cc index 6d4912ce3a..6ba7959752 100644 --- a/tensorflow/contrib/lite/kernels/svdf.cc +++ b/tensorflow/contrib/lite/kernels/svdf.cc @@ -40,19 +40,22 @@ namespace { struct OpData { int scratch_tensor_index; bool float_weights_time_initialized; + + int activation_state_tensor_index; }; static inline void ApplyTimeWeightsBiasAndActivation( int batch_size, int memory_size, int num_filters, int num_units, int rank, const TfLiteTensor* weights_time, const TfLiteTensor* bias, - TfLiteFusedActivation activation, TfLiteTensor* state, + TfLiteFusedActivation activation, TfLiteTensor* activation_state, TfLiteTensor* scratch, TfLiteTensor* output) { // Compute matmul(state, weights_time). // The right most column is used to save temporary output (with the size of - // num_filters). This is achieved by starting at state->data.f and having the - // stride equal to memory_size. + // num_filters). This is achieved by starting at activation_state->data.f, + // and having the stride equal to memory_size. for (int b = 0; b < batch_size; ++b) { - float* state_ptr_batch = state->data.f + b * memory_size * num_filters; + float* state_ptr_batch = + activation_state->data.f + b * memory_size * num_filters; float* scratch_ptr_batch = scratch->data.f + b * num_filters; tensor_utils::BatchVectorBatchVectorDotProduct( weights_time->data.f, state_ptr_batch, memory_size, num_filters, @@ -82,13 +85,14 @@ static inline void ApplyTimeWeightsBiasAndActivation( activation, output_ptr_batch); } - // Left shift the state to make room for next cycle's activation. + // Left shift the activation_state to make room for next cycle's activation. // TODO(alanchiao): explore collapsing this into a single loop. for (int b = 0; b < batch_size; ++b) { - float* state_ptr_batch = state->data.f + b * memory_size * num_filters; + float* state_ptr_batch = + activation_state->data.f + b * memory_size * num_filters; for (int f = 0; f < num_filters; ++f) { tensor_utils::VectorShiftLeft(state_ptr_batch, memory_size, - /*shift_value=*/0.0); + /*shift_value=*/0.0f); state_ptr_batch += memory_size; } } @@ -96,12 +100,16 @@ static inline void ApplyTimeWeightsBiasAndActivation( } // namespace +// Input tensors. constexpr int kInputTensor = 0; constexpr int kWeightsFeatureTensor = 1; constexpr int kWeightsTimeTensor = 2; constexpr int kBiasTensor = 3; -constexpr int kStateTensor = 0; -constexpr int kOutputTensor = 1; +// This is a variable tensor, and will be modified by this op. +constexpr int kInputActivationStateTensor = 4; + +// Output tensor. +constexpr int kOutputTensor = 0; void* Init(TfLiteContext* context, const char* buffer, size_t length) { auto* op_data = new OpData(); @@ -121,8 +129,10 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { int scratch_tensor_index = op_data->scratch_tensor_index; // Check we have all the inputs and outputs we need. - TF_LITE_ENSURE_EQ(context, node->inputs->size, 4); - TF_LITE_ENSURE_EQ(context, node->outputs->size, 2); + TF_LITE_ENSURE_EQ(context, node->outputs->size, 1); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 5); + op_data->activation_state_tensor_index = + node->inputs->data[kInputActivationStateTensor]; const TfLiteTensor* input = GetInput(context, node, kInputTensor); const TfLiteTensor* weights_feature = @@ -148,22 +158,15 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ASSERT_EQ(bias->dims->data[0], num_units); } - TfLiteTensor* state = GetOutput(context, node, kStateTensor); + TfLiteTensor* activation_state = + &context->tensors[op_data->activation_state_tensor_index]; TfLiteTensor* output = GetOutput(context, node, kOutputTensor); - // Resize state. - // For each batch, the state is a 2-D tensor: memory_size * num_filters - // The left most column is used to save current cycle activation. - // The right most column is used to save temporary output which will be - // reduced to num_units outputs. - TfLiteIntArray* state_size_array = TfLiteIntArrayCreate(2); - state_size_array->data[0] = batch_size; - state_size_array->data[1] = memory_size * num_filters; - TF_LITE_ENSURE_OK(context, - context->ResizeTensor(context, state, state_size_array)); - - // Mark state as a persistent tensor. - state->allocation_type = kTfLiteArenaRwPersistent; + // Check the shape of input state tensors. + TF_LITE_ENSURE_EQ(context, NumDimensions(activation_state), 2); + TF_LITE_ENSURE_EQ(context, SizeOfDimension(activation_state, 0), batch_size); + TF_LITE_ENSURE_EQ(context, SizeOfDimension(activation_state, 1), + memory_size * num_filters); // Resize output. TfLiteIntArray* output_size_array = TfLiteIntArrayCreate(2); @@ -220,8 +223,8 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { scaling_factors_size)); } - // Used to store dequantized weights_time matrix for hybrid computation - // of matmul(state, weights_time), which occurs in floating point. + // Used to store dequantized weights_time matrix for hybrid computation of + // matmul(activation_state, weights_time), which occurs in floating point. node->temporaries->data[3] = scratch_tensor_index + 3; TfLiteTensor* float_weights_time = GetTemporary(context, node, /*index=*/3); float_weights_time->type = kTfLiteFloat32; @@ -253,13 +256,13 @@ TfLiteStatus EvalFloat(TfLiteContext* context, TfLiteNode* node, const int memory_size = weights_time->dims->data[1]; // Clear the activation (state left most column). - // TODO(ghodrat): Add a test which initialize state with invalid values in - // left most column and make sure it passes. + // TODO(ghodrat): Add a test which initialize activation_state with invalid + // values in left most column and make sure it passes. for (int b = 0; b < batch_size; ++b) { float* state_ptr_batch = state->data.f + b * memory_size * num_filters; for (int c = 0; c < num_filters; ++c) { float* state_ptr = state_ptr_batch + c * memory_size; - state_ptr[memory_size - 1] = 0.0; + state_ptr[memory_size - 1] = 0.0f; } } @@ -307,7 +310,7 @@ TfLiteStatus EvalHybrid( // Clear the activation (state left most column). // TODO(ghodrat): Add a test which initialize state with invalid values in - // left most column and make sure it passes. + // the left most column and make sure it passes. for (int b = 0; b < batch_size; ++b) { float* state_ptr_batch = state->data.f + b * memory_size * num_filters; for (int c = 0; c < num_filters; ++c) { @@ -329,9 +332,10 @@ TfLiteStatus EvalHybrid( } // Compute conv1d(inputs, weights_feature). - // The state right most column is used to save current cycle activation. - // This is achieved by starting at state->data.f[memory_size - 1] and having - // the stride equal to memory_size. + // The rightmost column of state is used to save the current cycle + // activation. + // This is achieved by starting at state->data.f[memory_size - 1] + // and having the stride equal to memory_size. tensor_utils::MatrixBatchVectorMultiplyAccumulate( weights_feature_ptr, num_filters, input_size, quantized_input_ptr_batch, scaling_factors_ptr, batch_size, &state->data.f[memory_size - 1], @@ -359,13 +363,14 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { TfLiteTensor* scratch = GetTemporary(context, node, /*index=*/0); - TfLiteTensor* state = GetOutput(context, node, kStateTensor); + TfLiteTensor* activation_state = + &context->tensors[op_data->activation_state_tensor_index]; TfLiteTensor* output = GetOutput(context, node, kOutputTensor); switch (weights_feature->type) { case kTfLiteFloat32: { return EvalFloat(context, node, input, weights_feature, weights_time, - bias, params, scratch, state, output); + bias, params, scratch, activation_state, output); break; } case kTfLiteUInt8: { @@ -392,7 +397,8 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { } return EvalHybrid(context, node, input, weights_feature, float_weights_time, bias, params, scratch, - scaling_factors, input_quantized, state, output); + scaling_factors, input_quantized, activation_state, + output); break; } default: diff --git a/tensorflow/contrib/lite/kernels/svdf_test.cc b/tensorflow/contrib/lite/kernels/svdf_test.cc index 5af3ff8500..6d60dc63f4 100644 --- a/tensorflow/contrib/lite/kernels/svdf_test.cc +++ b/tensorflow/contrib/lite/kernels/svdf_test.cc @@ -141,16 +141,20 @@ class BaseSVDFOpModel : public SingleOpModel { weights_feature_ = AddInput(weights_feature_type); weights_time_ = AddInput(weights_time_type); bias_ = AddNullInput(); - state_ = AddOutput(TensorType_FLOAT32); + const int num_filters = units * rank; + activation_state_ = AddInput( + TensorData{TensorType_FLOAT32, {batches, memory_size * num_filters}}, + /*is_variable=*/true); output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp( BuiltinOperator_SVDF, BuiltinOptions_SVDFOptions, CreateSVDFOptions(builder_, rank, ActivationFunctionType_NONE).Union()); BuildInterpreter({ - {batches_, input_size_}, // Input tensor - {units_ * rank, input_size_}, // weights_feature tensor - {units_ * rank, memory_size_}, // weights_time tensor - {units_} // bias tensor + {batches_, input_size_}, // input tensor + {units_ * rank, input_size_}, // weights_feature tensor + {units_ * rank, memory_size_}, // weights_time tensor + {units_}, // bias tensor + {batches, memory_size * num_filters} // activation_state tensor }); } @@ -169,15 +173,6 @@ class BaseSVDFOpModel : public SingleOpModel { PopulateTensor(input_, offset, begin, end); } - // Resets the state of SVDF op by filling it with 0's. - void ResetState() { - const int zero_buffer_size = rank_ * units_ * batches_ * memory_size_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - // Extracts the output tensor from the SVDF op. std::vector<float> GetOutput() { return ExtractVector<float>(output_); } @@ -190,7 +185,7 @@ class BaseSVDFOpModel : public SingleOpModel { int weights_feature_; int weights_time_; int bias_; - int state_; + int activation_state_; int output_; int batches_; @@ -274,7 +269,6 @@ TEST_F(SVDFOpTest, BlackBoxTestRank1) { -0.10781813, 0.27201805, 0.14324132, -0.23681851, -0.27115166, -0.01580888, -0.14943552, 0.15465137, 0.09784451, -0.0337657}); - svdf.ResetState(); VerifyGoldens(svdf_input, svdf_golden_output_rank_1, sizeof(svdf_input), &svdf); } @@ -314,7 +308,6 @@ TEST_F(SVDFOpTest, BlackBoxTestRank2) { 0.27179423, -0.04710215, 0.31069002, 0.22672787, 0.09580326, 0.08682203, 0.1258215, 0.1851041, 0.29228821, 0.12366763}); - svdf.ResetState(); VerifyGoldens(svdf_input, svdf_golden_output_rank_2, sizeof(svdf_input), &svdf); } @@ -339,7 +332,6 @@ TEST_F(SVDFOpTest, BlackBoxTestHybridRank1) { -0.10781813, 0.27201805, 0.14324132, -0.23681851, -0.27115166, -0.01580888, -0.14943552, 0.15465137, 0.09784451, -0.0337657}); - svdf.ResetState(); VerifyGoldens(svdf_input, svdf_golden_output_rank_1, sizeof(svdf_input), &svdf, /*tolerance=*/0.002945); @@ -380,7 +372,6 @@ TEST_F(SVDFOpTest, BlackBoxTestHybridRank2) { 0.27179423, -0.04710215, 0.31069002, 0.22672787, 0.09580326, 0.08682203, 0.1258215, 0.1851041, 0.29228821, 0.12366763}); - svdf.ResetState(); VerifyGoldens(svdf_input, svdf_golden_output_rank_2, sizeof(svdf_input), &svdf, /*tolerance=*/0.00625109); diff --git a/tensorflow/contrib/lite/kernels/unpack.cc b/tensorflow/contrib/lite/kernels/unpack.cc new file mode 100644 index 0000000000..4998f88b41 --- /dev/null +++ b/tensorflow/contrib/lite/kernels/unpack.cc @@ -0,0 +1,130 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/builtin_op_data.h" +#include "tensorflow/contrib/lite/context.h" +#include "tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h" +#include "tensorflow/contrib/lite/kernels/internal/tensor.h" +#include "tensorflow/contrib/lite/kernels/kernel_util.h" + +namespace tflite { +namespace ops { +namespace builtin { +namespace unpack { +namespace { + +constexpr int kInputTensor = 0; + +// Op data for unpack op. +struct OpData { + int num; + int axis; +}; + +void* Init(TfLiteContext* context, const char* buffer, size_t length) { + auto* data = new OpData; + data->axis = 0; + return data; +} + +void Free(TfLiteContext* context, void* buffer) { + delete reinterpret_cast<OpData*>(buffer); +} + +TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { + const OpData* data = reinterpret_cast<OpData*>(node->builtin_data); + + TF_LITE_ENSURE_EQ(context, NumInputs(node), 1); + TF_LITE_ENSURE_EQ(context, NumOutputs(node), data->num); + + const TfLiteTensor* input = GetInput(context, node, kInputTensor); + TF_LITE_ENSURE(context, NumDimensions(input) <= 4); + TF_LITE_ENSURE(context, NumDimensions(input) > 1); + TF_LITE_ENSURE(context, NumDimensions(input) > data->axis); + // TODO(renjieliu): Support negative axis. + TF_LITE_ENSURE(context, data->axis >= 0); + if (input->type != kTfLiteInt32 && input->type != kTfLiteFloat32) { + context->ReportError(context, + "Currently pack only supports int32 and float32."); + return kTfLiteError; + } + + const TfLiteIntArray* input_shape = input->dims; + // Num should be equal to the shape[axis]. + // Resize outputs. rank will be R - 1. + TfLiteIntArray* output_shape = TfLiteIntArrayCreate(NumDimensions(input) - 1); + int o = 0; + for (int index = 0; index < NumDimensions(input); ++index) { + if (index != data->axis) { + output_shape->data[o++] = input_shape->data[index]; + } + } + + TF_LITE_ENSURE_EQ(context, data->num, input_shape->data[data->axis]); + for (int i = 0; i < data->num; ++i) { + TfLiteIntArray* copied_output_shape = TfLiteIntArrayCopy(output_shape); + TfLiteTensor* output = GetOutput(context, node, i); + TF_LITE_ENSURE_EQ(context, output->type, input->type); + TF_LITE_ENSURE_OK( + context, context->ResizeTensor(context, output, copied_output_shape)); + } + + TfLiteIntArrayFree(output_shape); + return kTfLiteOk; +} + +template <typename T> +void UnpackImpl(TfLiteContext* context, TfLiteNode* node, + const TfLiteTensor* input, int output_count, int axis) { + VectorOfTensors<T> all_outputs(*context, *node->outputs); + reference_ops::Unpack<T>(axis, GetTensorData<T>(input), GetTensorDims(input), + NumDimensions(input), output_count, + all_outputs.data(), **all_outputs.dims()); +} + +TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { + const OpData* data = reinterpret_cast<OpData*>(node->builtin_data); + + const TfLiteTensor* input = GetInput(context, node, kInputTensor); + switch (input->type) { + case kTfLiteFloat32: { + UnpackImpl<float>(context, node, input, data->num, data->axis); + break; + } + case kTfLiteInt32: { + UnpackImpl<int32_t>(context, node, input, data->num, data->axis); + break; + } + default: { + context->ReportError(context, + "Currently pack only supports int32 and float32."); + return kTfLiteError; + } + } + + return kTfLiteOk; +} +} // namespace +} // namespace unpack + +TfLiteRegistration* Register_UNPACK() { + static TfLiteRegistration r = {unpack::Init, unpack::Free, unpack::Prepare, + unpack::Eval}; + return &r; +} + +} // namespace builtin +} // namespace ops +} // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/unpack_test.cc b/tensorflow/contrib/lite/kernels/unpack_test.cc new file mode 100644 index 0000000000..4efc92a0fd --- /dev/null +++ b/tensorflow/contrib/lite/kernels/unpack_test.cc @@ -0,0 +1,225 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include <vector> +#include <gtest/gtest.h> +#include "tensorflow/contrib/lite/interpreter.h" +#include "tensorflow/contrib/lite/kernels/register.h" +#include "tensorflow/contrib/lite/kernels/test_util.h" +#include "tensorflow/contrib/lite/model.h" + +namespace tflite { +namespace { + +using ::testing::ElementsAre; + +template <typename T> +class UnpackOpModel : public SingleOpModel { + public: + UnpackOpModel(const TensorData& input, int axis) { + CHECK_LE(axis, input.shape.size()); + const int num_outputs = input.shape[axis]; + input_ = AddInput(input); + for (int i = 0; i < num_outputs; ++i) { + outputs_.push_back(AddOutput(input.type)); + } + SetBuiltinOp(BuiltinOperator_UNPACK, BuiltinOptions_UnpackOptions, + CreatePackOptions(builder_, num_outputs, axis).Union()); + BuildInterpreter({GetShape(input_)}); + } + + void SetInput(std::initializer_list<T> data) { + PopulateTensor<T>(input_, data); + } + + std::vector<std::vector<T>> GetOutputDatas() { + std::vector<std::vector<T>> output_datas; + for (const int output : outputs_) { + std::cerr << "the output is " << output << std::endl; + output_datas.push_back(ExtractVector<T>(output)); + } + return output_datas; + } + + std::vector<std::vector<int>> GetOutputShapes() { + std::vector<std::vector<int>> output_shapes; + for (const int output : outputs_) { + output_shapes.push_back(GetTensorShape(output)); + } + return output_shapes; + } + + private: + int input_; + std::vector<int> outputs_; +}; + +// float32 tests. +TEST(UnpackOpTest, FloatThreeOutputs) { + UnpackOpModel<float> model({TensorType_FLOAT32, {3, 2}}, 0); + model.SetInput({1, 2, 3, 4, 5, 6}); + model.Invoke(); + + // Check outputs shapes. + const std::vector<std::vector<int>>& output_shapes = model.GetOutputShapes(); + EXPECT_EQ(output_shapes.size(), 3); + EXPECT_THAT(output_shapes[0], ElementsAre(2)); + EXPECT_THAT(output_shapes[1], ElementsAre(2)); + EXPECT_THAT(output_shapes[2], ElementsAre(2)); + + // Check outputs values. + const std::vector<std::vector<float>>& output_datas = model.GetOutputDatas(); + EXPECT_EQ(output_datas.size(), 3); + EXPECT_THAT(output_datas[0], ElementsAre(1, 2)); + EXPECT_THAT(output_datas[1], ElementsAre(3, 4)); + EXPECT_THAT(output_datas[2], ElementsAre(5, 6)); +} + +TEST(UnpackOpTest, FloatThreeOutputsAxisOne) { + UnpackOpModel<float> model({TensorType_FLOAT32, {3, 2}}, 1); + model.SetInput({1, 2, 3, 4, 5, 6}); + model.Invoke(); + + // Check outputs shapes. + const std::vector<std::vector<int>>& output_shapes = model.GetOutputShapes(); + EXPECT_EQ(output_shapes.size(), 2); + EXPECT_THAT(output_shapes[0], ElementsAre(3)); + EXPECT_THAT(output_shapes[1], ElementsAre(3)); + + // Check outputs values. + const std::vector<std::vector<float>>& output_datas = model.GetOutputDatas(); + EXPECT_EQ(output_datas.size(), 2); + EXPECT_THAT(output_datas[0], ElementsAre(1, 3, 5)); + EXPECT_THAT(output_datas[1], ElementsAre(2, 4, 6)); +} + +TEST(UnpackOpTest, FloatOneOutput) { + UnpackOpModel<float> model({TensorType_FLOAT32, {1, 6}}, 0); + model.SetInput({1, 2, 3, 4, 5, 6}); + model.Invoke(); + + // Check outputs shapes. + const std::vector<std::vector<int>>& output_shapes = model.GetOutputShapes(); + EXPECT_EQ(output_shapes.size(), 1); + EXPECT_THAT(output_shapes[0], ElementsAre(6)); + + // Check outputs values. + const std::vector<std::vector<float>>& output_datas = model.GetOutputDatas(); + EXPECT_EQ(output_datas.size(), 1); + EXPECT_THAT(output_datas[0], ElementsAre(1, 2, 3, 4, 5, 6)); +} + +TEST(UnpackOpTest, FloatThreeDimensionsOutputs) { + UnpackOpModel<float> model({TensorType_FLOAT32, {2, 2, 2}}, 2); + model.SetInput({1, 2, 3, 4, 5, 6, 7, 8}); + model.Invoke(); + + // Check outputs shapes. + const std::vector<std::vector<int>>& output_shapes = model.GetOutputShapes(); + EXPECT_EQ(output_shapes.size(), 2); + EXPECT_THAT(output_shapes[0], ElementsAre(2, 2)); + EXPECT_THAT(output_shapes[1], ElementsAre(2, 2)); + + // Check outputs values. + const std::vector<std::vector<float>>& output_datas = model.GetOutputDatas(); + EXPECT_EQ(output_datas.size(), 2); + EXPECT_THAT(output_datas[0], ElementsAre(1, 3, 5, 7)); + EXPECT_THAT(output_datas[1], ElementsAre(2, 4, 6, 8)); +} + +// int32 tests. +TEST(UnpackOpTest, IntThreeOutputs) { + UnpackOpModel<int32_t> model({TensorType_INT32, {3, 2}}, 0); + model.SetInput({1, 2, 3, 4, 5, 6}); + model.Invoke(); + + // Check outputs shapes. + const std::vector<std::vector<int>>& output_shapes = model.GetOutputShapes(); + EXPECT_EQ(output_shapes.size(), 3); + EXPECT_THAT(output_shapes[0], ElementsAre(2)); + EXPECT_THAT(output_shapes[1], ElementsAre(2)); + EXPECT_THAT(output_shapes[2], ElementsAre(2)); + + // Check outputs values. + const std::vector<std::vector<int32_t>>& output_datas = + model.GetOutputDatas(); + EXPECT_EQ(output_datas.size(), 3); + EXPECT_THAT(output_datas[0], ElementsAre(1, 2)); + EXPECT_THAT(output_datas[1], ElementsAre(3, 4)); + EXPECT_THAT(output_datas[2], ElementsAre(5, 6)); +} + +TEST(UnpackOpTest, IntThreeOutputsAxisOne) { + UnpackOpModel<int32_t> model({TensorType_INT32, {3, 2}}, 1); + model.SetInput({1, 2, 3, 4, 5, 6}); + model.Invoke(); + + // Check outputs shapes. + const std::vector<std::vector<int>>& output_shapes = model.GetOutputShapes(); + EXPECT_EQ(output_shapes.size(), 2); + EXPECT_THAT(output_shapes[0], ElementsAre(3)); + EXPECT_THAT(output_shapes[1], ElementsAre(3)); + + // Check outputs values. + const std::vector<std::vector<int32_t>>& output_datas = + model.GetOutputDatas(); + EXPECT_EQ(output_datas.size(), 2); + EXPECT_THAT(output_datas[0], ElementsAre(1, 3, 5)); + EXPECT_THAT(output_datas[1], ElementsAre(2, 4, 6)); +} + +TEST(UnpackOpTest, IntOneOutput) { + UnpackOpModel<int32_t> model({TensorType_INT32, {1, 6}}, 0); + model.SetInput({1, 2, 3, 4, 5, 6}); + model.Invoke(); + + // Check outputs shapes. + const std::vector<std::vector<int>>& output_shapes = model.GetOutputShapes(); + EXPECT_EQ(output_shapes.size(), 1); + EXPECT_THAT(output_shapes[0], ElementsAre(6)); + + // Check outputs values. + const std::vector<std::vector<int32_t>>& output_datas = + model.GetOutputDatas(); + EXPECT_EQ(output_datas.size(), 1); + EXPECT_THAT(output_datas[0], ElementsAre(1, 2, 3, 4, 5, 6)); +} + +TEST(UnpackOpTest, IntThreeDimensionsOutputs) { + UnpackOpModel<int32_t> model({TensorType_INT32, {2, 2, 2}}, 2); + model.SetInput({1, 2, 3, 4, 5, 6, 7, 8}); + model.Invoke(); + + // Check outputs shapes. + const std::vector<std::vector<int>>& output_shapes = model.GetOutputShapes(); + EXPECT_EQ(output_shapes.size(), 2); + EXPECT_THAT(output_shapes[0], ElementsAre(2, 2)); + EXPECT_THAT(output_shapes[1], ElementsAre(2, 2)); + + // Check outputs values. + const std::vector<std::vector<int32_t>>& output_datas = + model.GetOutputDatas(); + EXPECT_EQ(output_datas.size(), 2); + EXPECT_THAT(output_datas[0], ElementsAre(1, 3, 5, 7)); + EXPECT_THAT(output_datas[1], ElementsAre(2, 4, 6, 8)); +} + +} // namespace +} // namespace tflite + +int main(int argc, char** argv) { + ::tflite::LogToStderr(); + ::testing::InitGoogleTest(&argc, argv); + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/lib_package/create_ios_frameworks.sh b/tensorflow/contrib/lite/lib_package/create_ios_frameworks.sh index b58ae26601..6195426d6d 100755 --- a/tensorflow/contrib/lite/lib_package/create_ios_frameworks.sh +++ b/tensorflow/contrib/lite/lib_package/create_ios_frameworks.sh @@ -14,6 +14,7 @@ # limitations under the License. # ============================================================================== +# TODO(ycling): Refactoring - Move this script into `tools/make`. set -e echo "Starting" @@ -32,7 +33,7 @@ echo "Headers, populating: TensorFlow Lite" cd $TFLITE_DIR/../../.. find tensorflow/contrib/lite -name '*.h' \ - -not -path 'tensorflow/contrib/lite/downloads/*' \ + -not -path 'tensorflow/contrib/lite/tools/*' \ -not -path 'tensorflow/contrib/lite/examples/*' \ -not -path 'tensorflow/contrib/lite/gen/*' \ -not -path 'tensorflow/contrib/lite/toco/*' \ @@ -44,7 +45,7 @@ tar xf tmp.tar rm -f tmp.tar echo "Headers, populating: Flatbuffer" -cd $TFLITE_DIR/downloads/flatbuffers/include/ +cd $TFLITE_DIR/tools/make/downloads/flatbuffers/include/ find . -name '*.h' | tar -cf $FW_DIR_TFLITE_HDRS/tmp.tar -T - cd $FW_DIR_TFLITE_HDRS tar xf tmp.tar @@ -57,7 +58,7 @@ cp $TFLITE_DIR/../../../bazel-genfiles/tensorflow/tools/lib_package/include/tens $FW_DIR_TFLITE echo "Copying static libraries" -cp $TFLITE_DIR/gen/lib/libtensorflow-lite.a \ +cp $TFLITE_DIR/tools/make/gen/lib/libtensorflow-lite.a \ $FW_DIR_TFLITE/tensorflow_lite # This is required, otherwise they interfere with the documentation of the diff --git a/tensorflow/contrib/lite/model.cc b/tensorflow/contrib/lite/model.cc index 7b9413cd17..aa410ab002 100644 --- a/tensorflow/contrib/lite/model.cc +++ b/tensorflow/contrib/lite/model.cc @@ -622,8 +622,10 @@ TfLiteStatus ParseOpData(const Operator* op, BuiltinOperator op_type, } case BuiltinOperator_MEAN: case BuiltinOperator_REDUCE_MAX: + case BuiltinOperator_REDUCE_MIN: case BuiltinOperator_REDUCE_PROD: - case BuiltinOperator_SUM: { + case BuiltinOperator_SUM: + case BuiltinOperator_REDUCE_ANY: { auto* params = MallocPOD<TfLiteReducerParams>(); if (auto* schema_params = op->builtin_options_as_ReducerOptions()) { params->keep_dims = schema_params->keep_dims(); @@ -744,6 +746,15 @@ TfLiteStatus ParseOpData(const Operator* op, BuiltinOperator op_type, *builtin_data = static_cast<void*>(params); break; } + case BuiltinOperator_UNPACK: { + TfLiteUnpackParams* params = MallocPOD<TfLiteUnpackParams>(); + if (auto* unpack_params = op->builtin_options_as_UnpackOptions()) { + params->num = unpack_params->num(); + params->axis = unpack_params->axis(); + } + *builtin_data = reinterpret_cast<void*>(params); + break; + } // Below are the ops with no builtin_data strcture. case BuiltinOperator_BATCH_TO_SPACE_ND: @@ -789,6 +800,7 @@ TfLiteStatus ParseOpData(const Operator* op, BuiltinOperator op_type, case BuiltinOperator_LOGICAL_OR: case BuiltinOperator_LOGICAL_AND: case BuiltinOperator_LOGICAL_NOT: + case BuiltinOperator_FLOOR_DIV: break; } return kTfLiteOk; @@ -800,6 +812,10 @@ TfLiteStatus InterpreterBuilder::ParseNodes( const flatbuffers::Vector<flatbuffers::Offset<Operator>>* operators, Interpreter* interpreter) { TfLiteStatus status = kTfLiteOk; + + // Reduce the number of redundant allocations + interpreter->ReserveNodes(operators->Length()); + for (int i = 0; i < operators->Length(); ++i) { const auto* op = operators->Get(i); int index = op->opcode_index(); diff --git a/tensorflow/contrib/lite/models/speech_test.cc b/tensorflow/contrib/lite/models/speech_test.cc index 206de1962d..8ecf0b6154 100644 --- a/tensorflow/contrib/lite/models/speech_test.cc +++ b/tensorflow/contrib/lite/models/speech_test.cc @@ -102,7 +102,7 @@ class SpeechTest : public ::testing::TestWithParam<int> { int GetMaxInvocations() { return GetParam(); } }; -TEST_P(SpeechTest, HotwordOkGoogleRank1Test) { +TEST_P(SpeechTest, DISABLED_HotwordOkGoogleRank1Test) { std::stringstream os; ASSERT_TRUE(ConvertCsvData( "speech_hotword_model_rank1.tflite", "speech_hotword_model_in.csv", @@ -114,7 +114,7 @@ TEST_P(SpeechTest, HotwordOkGoogleRank1Test) { << test_driver.GetErrorMessage(); } -TEST_P(SpeechTest, HotwordOkGoogleRank2Test) { +TEST_P(SpeechTest, DISABLED_HotwordOkGoogleRank2Test) { std::stringstream os; ASSERT_TRUE(ConvertCsvData( "speech_hotword_model_rank2.tflite", "speech_hotword_model_in.csv", @@ -126,7 +126,7 @@ TEST_P(SpeechTest, HotwordOkGoogleRank2Test) { << test_driver.GetErrorMessage(); } -TEST_P(SpeechTest, SpeakerIdOkGoogleTest) { +TEST_P(SpeechTest, DISABLED_SpeakerIdOkGoogleTest) { std::stringstream os; ASSERT_TRUE(ConvertCsvData( "speech_speakerid_model.tflite", "speech_speakerid_model_in.csv", @@ -139,7 +139,7 @@ TEST_P(SpeechTest, SpeakerIdOkGoogleTest) { << test_driver.GetErrorMessage(); } -TEST_P(SpeechTest, AsrAmTest) { +TEST_P(SpeechTest, DISABLED_AsrAmTest) { std::stringstream os; ASSERT_TRUE( ConvertCsvData("speech_asr_am_model.tflite", "speech_asr_am_model_in.csv", @@ -156,7 +156,7 @@ TEST_P(SpeechTest, AsrAmTest) { // through the interpreter and stored the sum of all the output, which was them // compared for correctness. In this test we are comparing all the intermediate // results. -TEST_P(SpeechTest, AsrLmTest) { +TEST_P(SpeechTest, DISABLED_AsrLmTest) { std::ifstream in_file; testing::TfLiteDriver test_driver(/*use_nnapi=*/false); ASSERT_TRUE(Init("speech_asr_lm_model.test_spec", &test_driver, &in_file)); @@ -165,7 +165,7 @@ TEST_P(SpeechTest, AsrLmTest) { << test_driver.GetErrorMessage(); } -TEST_P(SpeechTest, EndpointerTest) { +TEST_P(SpeechTest, DISABLED_EndpointerTest) { std::stringstream os; ASSERT_TRUE(ConvertCsvData( "speech_endpointer_model.tflite", "speech_endpointer_model_in.csv", @@ -178,7 +178,7 @@ TEST_P(SpeechTest, EndpointerTest) { << test_driver.GetErrorMessage(); } -TEST_P(SpeechTest, TtsTest) { +TEST_P(SpeechTest, DISABLED_TtsTest) { std::stringstream os; ASSERT_TRUE(ConvertCsvData("speech_tts_model.tflite", "speech_tts_model_in.csv", diff --git a/tensorflow/contrib/lite/nnapi/NeuralNetworksShim.h b/tensorflow/contrib/lite/nnapi/NeuralNetworksShim.h index 42b8163445..81dd459223 100644 --- a/tensorflow/contrib/lite/nnapi/NeuralNetworksShim.h +++ b/tensorflow/contrib/lite/nnapi/NeuralNetworksShim.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef NN_API_SHIM_H0 -#define NN_API_SHIM_H0 +#ifndef TENSORFLOW_CONTRIB_LITE_NNAPI_NEURALNETWORKSSHIM_H_ +#define TENSORFLOW_CONTRIB_LITE_NNAPI_NEURALNETWORKSSHIM_H_ #include <dlfcn.h> #include <stdint.h> @@ -970,4 +970,4 @@ inline void ANeuralNetworksEvent_free(ANeuralNetworksEvent* event) { /**/ -#endif // NN_API_SHIM_H0 +#endif // TENSORFLOW_CONTRIB_LITE_NNAPI_NEURALNETWORKSSHIM_H_ diff --git a/tensorflow/contrib/lite/nnapi_delegate.cc b/tensorflow/contrib/lite/nnapi_delegate.cc index 45c92a8671..38f3e9881b 100644 --- a/tensorflow/contrib/lite/nnapi_delegate.cc +++ b/tensorflow/contrib/lite/nnapi_delegate.cc @@ -636,6 +636,7 @@ TfLiteStatus AddOpsAndParams( case tflite::BuiltinOperator_NOT_EQUAL: case tflite::BuiltinOperator_SUM: case tflite::BuiltinOperator_REDUCE_MAX: + case tflite::BuiltinOperator_REDUCE_MIN: case tflite::BuiltinOperator_REDUCE_PROD: case tflite::BuiltinOperator_SQRT: case tflite::BuiltinOperator_RSQRT: @@ -647,6 +648,9 @@ TfLiteStatus AddOpsAndParams( case tflite::BuiltinOperator_ONE_HOT: case tflite::BuiltinOperator_LOGICAL_AND: case tflite::BuiltinOperator_LOGICAL_NOT: + case tflite::BuiltinOperator_UNPACK: + case tflite::BuiltinOperator_FLOOR_DIV: + case tflite::BuiltinOperator_REDUCE_ANY: logError("Op code %d is currently not delegated to NNAPI", builtin); return kTfLiteError; break; diff --git a/tensorflow/contrib/lite/optional_debug_tools.h b/tensorflow/contrib/lite/optional_debug_tools.h index 7fb4b8d8b7..82a6e114a6 100644 --- a/tensorflow/contrib/lite/optional_debug_tools.h +++ b/tensorflow/contrib/lite/optional_debug_tools.h @@ -14,8 +14,8 @@ limitations under the License. ==============================================================================*/ // Optional debugging functionality. For small sized binaries, these are not // needed. -#ifndef TENSORFLOW_CONTRIB_LITE_DEBUG_TOOLS_H_ -#define TENSORFLOW_CONTRIB_LITE_DEBUG_TOOLS_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_OPTIONAL_DEBUG_TOOLS_H_ +#define TENSORFLOW_CONTRIB_LITE_OPTIONAL_DEBUG_TOOLS_H_ #include "tensorflow/contrib/lite/interpreter.h" @@ -26,4 +26,4 @@ void PrintInterpreterState(Interpreter* interpreter); } // namespace tflite -#endif // TENSORFLOW_CONTRIB_LITE_DEBUG_TOOLS_H_ +#endif // TENSORFLOW_CONTRIB_LITE_OPTIONAL_DEBUG_TOOLS_H_ diff --git a/tensorflow/contrib/lite/python/BUILD b/tensorflow/contrib/lite/python/BUILD index 47f0c8e9a2..6e30251eff 100644 --- a/tensorflow/contrib/lite/python/BUILD +++ b/tensorflow/contrib/lite/python/BUILD @@ -70,7 +70,7 @@ py_library( py_test( name = "lite_test", srcs = ["lite_test.py"], - data = [":interpreter_test_data"], + data = ["@tflite_mobilenet_ssd_quant_protobuf//:tflite_graph.pbtxt"], srcs_version = "PY2AND3", tags = [ "no_oss", @@ -130,6 +130,7 @@ py_test( ], deps = [ ":convert", + ":interpreter", ":op_hint", "//tensorflow/python:array_ops", "//tensorflow/python:client_testlib", diff --git a/tensorflow/contrib/lite/python/convert.py b/tensorflow/contrib/lite/python/convert.py index 11d4bdbe82..0b2192e031 100644 --- a/tensorflow/contrib/lite/python/convert.py +++ b/tensorflow/contrib/lite/python/convert.py @@ -19,6 +19,7 @@ from __future__ import division from __future__ import print_function import os as _os +import platform as _platform import subprocess as _subprocess import tempfile as _tempfile @@ -26,6 +27,7 @@ from tensorflow.contrib.lite.python import lite_constants from tensorflow.contrib.lite.toco import model_flags_pb2 as _model_flags_pb2 from tensorflow.contrib.lite.toco import toco_flags_pb2 as _toco_flags_pb2 from tensorflow.python.platform import resource_loader as _resource_loader +from tensorflow.python.util import deprecation from tensorflow.python.util.lazy_loader import LazyLoader @@ -90,12 +92,13 @@ def toco_convert_protos(model_flags_str, toco_flags_str, input_data_str): fp_output.name ] cmdline = " ".join(cmd) + is_windows = _platform.system() == "Windows" proc = _subprocess.Popen( cmdline, shell=True, stdout=_subprocess.PIPE, stderr=_subprocess.STDOUT, - close_fds=True) + close_fds=not is_windows) stdout, stderr = proc.communicate() exitcode = proc.returncode if exitcode == 0: @@ -223,7 +226,56 @@ def build_toco_convert_protos(input_tensors, return model, toco -def toco_convert(input_data, input_tensors, output_tensors, *args, **kwargs): +def toco_convert_graph_def(input_data, input_arrays_with_shape, output_arrays, + *args, **kwargs): + """"Convert a model using TOCO. + + This function is used to convert GraphDefs that cannot be loaded into + TensorFlow to TFLite. Conversion can be customized by providing arguments + that are forwarded to `build_toco_convert_protos` (see documentation for + details). + + Args: + input_data: Input data (i.e. often `sess.graph_def`), + input_arrays_with_shape: Tuple of strings representing input tensor names + and list of integers representing input shapes + (e.g., [("foo" : [1, 16, 16, 3])]). Use only when graph cannot be loaded + into TensorFlow and when `input_tensors` is None. (default None) + output_arrays: List of output tensors to freeze graph with. Use only when + graph cannot be loaded into TensorFlow and when `output_tensors` is None. + (default None) + *args: See `build_toco_convert_protos`, + **kwargs: See `build_toco_convert_protos`. + + Returns: + The converted data. For example if TFLite was the destination, then + this will be a tflite flatbuffer in a bytes array. + + Raises: + Defined in `build_toco_convert_protos`. + """ + model_flags, toco_flags = build_toco_convert_protos( + input_tensors=[], output_tensors=[], *args, **kwargs) + + for idx, (name, shape) in enumerate(input_arrays_with_shape): + input_array = model_flags.input_arrays.add() + if kwargs["inference_type"] == lite_constants.QUANTIZED_UINT8: + input_array.mean_value, input_array.std_value = kwargs[ + "quantized_input_stats"][idx] + input_array.name = name + input_array.shape.dims.extend(map(int, shape)) + + for name in output_arrays: + model_flags.output_arrays.append(name) + + data = toco_convert_protos(model_flags.SerializeToString(), + toco_flags.SerializeToString(), + input_data.SerializeToString()) + return data + + +def toco_convert_impl(input_data, input_tensors, output_tensors, *args, + **kwargs): """"Convert a model using TOCO. Typically this function is used to convert from TensorFlow GraphDef to TFLite. @@ -252,3 +304,30 @@ def toco_convert(input_data, input_tensors, output_tensors, *args, **kwargs): toco_flags.SerializeToString(), input_data.SerializeToString()) return data + + +@deprecation.deprecated(None, "Use `lite.TocoConverter` instead.") +def toco_convert(input_data, input_tensors, output_tensors, *args, **kwargs): + """"Convert a model using TOCO. + + Typically this function is used to convert from TensorFlow GraphDef to TFLite. + Conversion can be customized by providing arguments that are forwarded to + `build_toco_convert_protos` (see documentation for details). + + Args: + input_data: Input data (i.e. often `sess.graph_def`), + input_tensors: List of input tensors. Type and shape are computed using + `foo.get_shape()` and `foo.dtype`. + output_tensors: List of output tensors (only .name is used from this). + *args: See `build_toco_convert_protos`, + **kwargs: See `build_toco_convert_protos`. + + Returns: + The converted data. For example if TFLite was the destination, then + this will be a tflite flatbuffer in a bytes array. + + Raises: + Defined in `build_toco_convert_protos`. + """ + return toco_convert_impl(input_data, input_tensors, output_tensors, *args, + **kwargs) diff --git a/tensorflow/contrib/lite/python/convert_test.py b/tensorflow/contrib/lite/python/convert_test.py index bc05514cec..59f537b82a 100644 --- a/tensorflow/contrib/lite/python/convert_test.py +++ b/tensorflow/contrib/lite/python/convert_test.py @@ -17,9 +17,12 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import numpy as np + from tensorflow.contrib.lite.python import convert from tensorflow.contrib.lite.python import lite_constants from tensorflow.contrib.lite.python import op_hint +from tensorflow.contrib.lite.python.interpreter import Interpreter from tensorflow.python.client import session from tensorflow.python.framework import dtypes from tensorflow.python.framework import test_util @@ -37,9 +40,12 @@ class ConvertTest(test_util.TensorFlowTestCase): dtype=dtypes.float32) out_tensor = in_tensor + in_tensor sess = session.Session() + # Try running on valid graph - result = convert.toco_convert(sess.graph_def, [in_tensor], [out_tensor]) - self.assertTrue(result) + tflite_model = convert.toco_convert(sess.graph_def, [in_tensor], + [out_tensor]) + self.assertTrue(tflite_model) + # TODO(aselle): remove tests that fail (we must get TOCO to not fatal # all the time). # Try running on identity graph (known fail) @@ -52,11 +58,85 @@ class ConvertTest(test_util.TensorFlowTestCase): out_tensor = array_ops.fake_quant_with_min_max_args(in_tensor + in_tensor, min=0., max=1.) sess = session.Session() - result = convert.toco_convert( + + tflite_model = convert.toco_convert( sess.graph_def, [in_tensor], [out_tensor], inference_type=lite_constants.QUANTIZED_UINT8, quantized_input_stats=[(0., 1.)]) - self.assertTrue(result) + self.assertTrue(tflite_model) + + def testGraphDefBasic(self): + in_tensor = array_ops.placeholder( + shape=[1, 16, 16, 3], dtype=dtypes.float32, name="input") + _ = in_tensor + in_tensor + sess = session.Session() + + tflite_model = convert.toco_convert_graph_def( + sess.graph_def, [("input", [1, 16, 16, 3])], ["add"], + inference_type=lite_constants.FLOAT) + self.assertTrue(tflite_model) + + # Check values from converted model. + interpreter = Interpreter(model_content=tflite_model) + interpreter.allocate_tensors() + + input_details = interpreter.get_input_details() + self.assertEqual(1, len(input_details)) + self.assertEqual("input", input_details[0]["name"]) + self.assertEqual(np.float32, input_details[0]["dtype"]) + self.assertTrue(([1, 16, 16, 3] == input_details[0]["shape"]).all()) + self.assertEqual((0., 0.), input_details[0]["quantization"]) + + output_details = interpreter.get_output_details() + self.assertEqual(1, len(output_details)) + self.assertEqual("add", output_details[0]["name"]) + self.assertEqual(np.float32, output_details[0]["dtype"]) + self.assertTrue(([1, 16, 16, 3] == output_details[0]["shape"]).all()) + self.assertEqual((0., 0.), output_details[0]["quantization"]) + + def testGraphDefQuantization(self): + in_tensor_1 = array_ops.placeholder( + shape=[1, 16, 16, 3], dtype=dtypes.float32, name="inputA") + in_tensor_2 = array_ops.placeholder( + shape=[1, 16, 16, 3], dtype=dtypes.float32, name="inputB") + _ = array_ops.fake_quant_with_min_max_args( + in_tensor_1 + in_tensor_2, min=0., max=1., name="output") + sess = session.Session() + + input_arrays_map = [("inputA", [1, 16, 16, 3]), ("inputB", [1, 16, 16, 3])] + output_arrays = ["output"] + tflite_model = convert.toco_convert_graph_def( + sess.graph_def, + input_arrays_map, + output_arrays, + inference_type=lite_constants.QUANTIZED_UINT8, + quantized_input_stats=[(0., 1.), (0., 1.)]) + self.assertTrue(tflite_model) + + # Check values from converted model. + interpreter = Interpreter(model_content=tflite_model) + interpreter.allocate_tensors() + + input_details = interpreter.get_input_details() + self.assertEqual(2, len(input_details)) + self.assertEqual("inputA", input_details[0]["name"]) + self.assertEqual(np.uint8, input_details[0]["dtype"]) + self.assertTrue(([1, 16, 16, 3] == input_details[0]["shape"]).all()) + self.assertEqual((1., 0.), + input_details[0]["quantization"]) # scale, zero_point + + self.assertEqual("inputB", input_details[1]["name"]) + self.assertEqual(np.uint8, input_details[1]["dtype"]) + self.assertTrue(([1, 16, 16, 3] == input_details[1]["shape"]).all()) + self.assertEqual((1., 0.), + input_details[1]["quantization"]) # scale, zero_point + + output_details = interpreter.get_output_details() + self.assertEqual(1, len(output_details)) + self.assertEqual("output", output_details[0]["name"]) + self.assertEqual(np.uint8, output_details[0]["dtype"]) + self.assertTrue(([1, 16, 16, 3] == output_details[0]["shape"]).all()) + self.assertTrue(output_details[0]["quantization"][0] > 0) # scale class ConvertTestOpHint(test_util.TensorFlowTestCase): @@ -243,7 +323,6 @@ class ConvertTestOpHint(test_util.TensorFlowTestCase): with self.test_session() as sess: stubbed_graphdef = op_hint.convert_op_hints_to_stubs( graph_def=sess.graph_def) - print(stubbed_graphdef) self.assertCountEqual( self._getGraphOpTypes( stubbed_graphdef, diff --git a/tensorflow/contrib/lite/python/lite.py b/tensorflow/contrib/lite/python/lite.py index 5ec52035ad..a4c9a2381c 100644 --- a/tensorflow/contrib/lite/python/lite.py +++ b/tensorflow/contrib/lite/python/lite.py @@ -41,7 +41,9 @@ from google.protobuf.message import DecodeError from tensorflow.contrib.lite.python import lite_constants as constants from tensorflow.contrib.lite.python.convert import build_toco_convert_protos # pylint: disable=unused-import from tensorflow.contrib.lite.python.convert import tensor_name as _tensor_name -from tensorflow.contrib.lite.python.convert import toco_convert +from tensorflow.contrib.lite.python.convert import toco_convert # pylint: disable=unused-import +from tensorflow.contrib.lite.python.convert import toco_convert_graph_def as _toco_convert_graph_def +from tensorflow.contrib.lite.python.convert import toco_convert_impl as _toco_convert_impl from tensorflow.contrib.lite.python.convert import toco_convert_protos # pylint: disable=unused-import from tensorflow.contrib.lite.python.convert_saved_model import freeze_saved_model as _freeze_saved_model from tensorflow.contrib.lite.python.convert_saved_model import get_tensors_from_tensor_names as _get_tensors_from_tensor_names @@ -54,6 +56,7 @@ from tensorflow.python import keras as _keras from tensorflow.python.client import session as _session from tensorflow.python.framework import graph_util as _tf_graph_util from tensorflow.python.framework import ops as _ops +from tensorflow.python.framework.errors_impl import NotFoundError as _NotFoundError from tensorflow.python.framework.importer import import_graph_def as _import_graph_def from tensorflow.python.saved_model import signature_constants as _signature_constants from tensorflow.python.saved_model import tag_constants as _tag_constants @@ -110,6 +113,7 @@ class TocoConverter(object): Example usage: + ```python # Converting a GraphDef from session. converter = lite.TocoConverter.from_session(sess, in_tensors, out_tensors) tflite_model = converter.convert() @@ -124,9 +128,19 @@ class TocoConverter(object): # Converting a SavedModel. converter = lite.TocoConverter.from_saved_model(saved_model_dir) tflite_model = converter.convert() + + # Converting a tf.keras model. + converter = lite.TocoConverter.from_keras_model_file(keras_model) + tflite_model = converter.convert() + ``` """ - def __init__(self, graph_def, input_tensors, output_tensors): + def __init__(self, + graph_def, + input_tensors, + output_tensors, + input_arrays_with_shape=None, + output_arrays=None): """Constructor for TocoConverter. Args: @@ -135,6 +149,17 @@ class TocoConverter(object): input_tensors: List of input tensors. Type and shape are computed using `foo.get_shape()` and `foo.dtype`. output_tensors: List of output tensors (only .name is used from this). + input_arrays_with_shape: Tuple of strings representing input tensor names + and list of integers representing input shapes + (e.g., [("foo" : [1, 16, 16, 3])]). Use only when graph cannot be loaded + into TensorFlow and when `input_tensors` and `output_tensors` are None. + (default None) + output_arrays: List of output tensors to freeze graph with. Use only when + graph cannot be loaded into TensorFlow and when `input_tensors` and + `output_tensors` are None. (default None) + + Raises: + ValueError: Invalid arguments. """ self._graph_def = graph_def self._input_tensors = input_tensors @@ -152,6 +177,15 @@ class TocoConverter(object): self.dump_graphviz_dir = None self.dump_graphviz_video = False + # Attributes are used by models that cannot be loaded into TensorFlow. + if not self._has_valid_tensors(): + if not input_arrays_with_shape or not output_arrays: + raise ValueError( + "If input_tensors and output_tensors are None, both " + "input_arrays_with_shape and output_arrays must be defined.") + self._input_arrays_with_shape = input_arrays_with_shape + self._output_arrays = output_arrays + @classmethod def from_session(cls, sess, input_tensors, output_tensors): """Creates a TocoConverter class from a TensorFlow Session. @@ -193,6 +227,7 @@ class TocoConverter(object): Unable to parse input file. The graph is not frozen. input_arrays or output_arrays contains an invalid tensor name. + input_shapes is not correctly defined when required """ with _ops.Graph().as_default(): with _session.Session() as sess: @@ -215,20 +250,44 @@ class TocoConverter(object): except (_text_format.ParseError, DecodeError): raise ValueError( "Unable to parse input file '{}'.".format(graph_def_file)) - _import_graph_def(graph_def, name="") - - # Get input and output tensors. - input_tensors = _get_tensors_from_tensor_names(sess.graph, input_arrays) - output_tensors = _get_tensors_from_tensor_names(sess.graph, - output_arrays) - _set_tensor_shapes(input_tensors, input_shapes) - # Check if graph is frozen. - if not _is_frozen_graph(sess): - raise ValueError("Please freeze the graph using freeze_graph.py.") - - # Create TocoConverter class. - return cls(sess.graph_def, input_tensors, output_tensors) + # Handles models with custom TFLite ops that cannot be resolved in + # TensorFlow. + load_model_in_session = True + try: + _import_graph_def(graph_def, name="") + except _NotFoundError: + load_model_in_session = False + + if load_model_in_session: + # Check if graph is frozen. + if not _is_frozen_graph(sess): + raise ValueError("Please freeze the graph using freeze_graph.py.") + + # Get input and output tensors. + input_tensors = _get_tensors_from_tensor_names( + sess.graph, input_arrays) + output_tensors = _get_tensors_from_tensor_names( + sess.graph, output_arrays) + _set_tensor_shapes(input_tensors, input_shapes) + + return cls(sess.graph_def, input_tensors, output_tensors) + else: + if not input_shapes: + raise ValueError("input_shapes must be defined for this model.") + if set(input_arrays) != set(input_shapes.keys()): + raise ValueError("input_shapes must contain a value for each item " + "in input_array.") + + input_arrays_with_shape = [ + (name, input_shapes[name]) for name in input_arrays + ] + return cls( + graph_def, + input_tensors=None, + output_tensors=None, + input_arrays_with_shape=input_arrays_with_shape, + output_arrays=output_arrays) @classmethod def from_saved_model(cls, @@ -323,25 +382,25 @@ class TocoConverter(object): None value for dimension in input_tensor. """ # Checks dimensions in input tensor. - for tensor in self._input_tensors: - if not tensor.get_shape(): - raise ValueError("Provide an input shape for input array '{0}'.".format( - _tensor_name(tensor))) - shape = tensor.get_shape().as_list() - if None in shape[1:]: - raise ValueError( - "None is only supported in the 1st dimension. Tensor '{0}' has " - "invalid shape '{1}'.".format(_tensor_name(tensor), shape)) - elif shape[0] is None: - self._set_batch_size(batch_size=1) + if self._has_valid_tensors(): + for tensor in self._input_tensors: + if not tensor.get_shape(): + raise ValueError("Provide an input shape for input array " + "'{0}'.".format(_tensor_name(tensor))) + shape = tensor.get_shape().as_list() + if None in shape[1:]: + raise ValueError( + "None is only supported in the 1st dimension. Tensor '{0}' has " + "invalid shape '{1}'.".format(_tensor_name(tensor), shape)) + elif shape[0] is None: + self._set_batch_size(batch_size=1) # Get quantization stats. Ensures there is one stat per name if the stats # are specified. if self.quantized_input_stats: quantized_stats = [] invalid_stats = [] - for tensor in self._input_tensors: - name = _tensor_name(tensor) + for name in self.get_input_arrays(): if name in self.quantized_input_stats: quantized_stats.append(self.quantized_input_stats[name]) else: @@ -353,24 +412,35 @@ class TocoConverter(object): else: quantized_stats = None + converter_kwargs = { + "inference_type": self.inference_type, + "inference_input_type": self.inference_input_type, + "input_format": constants.TENSORFLOW_GRAPHDEF, + "output_format": self.output_format, + "quantized_input_stats": quantized_stats, + "default_ranges_stats": self.default_ranges_stats, + "drop_control_dependency": self.drop_control_dependency, + "reorder_across_fake_quant": self.reorder_across_fake_quant, + "change_concat_input_ranges": self.change_concat_input_ranges, + "allow_custom_ops": self.allow_custom_ops, + "quantize_weights": self.quantize_weights, + "dump_graphviz_dir": self.dump_graphviz_dir, + "dump_graphviz_video": self.dump_graphviz_video + } + # Converts model. - result = toco_convert( - input_data=self._graph_def, - input_tensors=self._input_tensors, - output_tensors=self._output_tensors, - inference_type=self.inference_type, - inference_input_type=self.inference_input_type, - input_format=constants.TENSORFLOW_GRAPHDEF, - output_format=self.output_format, - quantized_input_stats=quantized_stats, - default_ranges_stats=self.default_ranges_stats, - drop_control_dependency=self.drop_control_dependency, - reorder_across_fake_quant=self.reorder_across_fake_quant, - change_concat_input_ranges=self.change_concat_input_ranges, - allow_custom_ops=self.allow_custom_ops, - quantize_weights=self.quantize_weights, - dump_graphviz_dir=self.dump_graphviz_dir, - dump_graphviz_video=self.dump_graphviz_video) + if self._has_valid_tensors(): + result = _toco_convert_impl( + input_data=self._graph_def, + input_tensors=self._input_tensors, + output_tensors=self._output_tensors, + **converter_kwargs) + else: + result = _toco_convert_graph_def( + input_data=self._graph_def, + input_arrays_with_shape=self._input_arrays_with_shape, + output_arrays=self._output_arrays, + **converter_kwargs) return result def get_input_arrays(self): @@ -379,7 +449,18 @@ class TocoConverter(object): Returns: List of strings. """ - return [_tensor_name(tensor) for tensor in self._input_tensors] + if self._has_valid_tensors(): + return [_tensor_name(tensor) for tensor in self._input_tensors] + else: + return [name for name, _ in self._input_arrays_with_shape] + + def _has_valid_tensors(self): + """Checks if the input and output tensors have been initialized. + + Returns: + Bool. + """ + return self._input_tensors and self._output_tensors def _set_batch_size(self, batch_size): """Sets the first dimension of the input tensor to `batch_size`. @@ -387,7 +468,14 @@ class TocoConverter(object): Args: batch_size: Batch size for the model. Replaces the first dimension of an input size array if undefined. (default 1) + + Raises: + ValueError: input_tensor is not defined. """ + if not self._has_valid_tensors(): + raise ValueError("The batch size cannot be set for this model. Please " + "use input_shapes parameter.") + for tensor in self._input_tensors: shape = tensor.get_shape().as_list() shape[0] = batch_size diff --git a/tensorflow/contrib/lite/python/lite_test.py b/tensorflow/contrib/lite/python/lite_test.py index 2f13684228..8c9cfa943f 100644 --- a/tensorflow/contrib/lite/python/lite_test.py +++ b/tensorflow/contrib/lite/python/lite_test.py @@ -35,11 +35,51 @@ from tensorflow.python.ops import math_ops from tensorflow.python.ops import variable_scope from tensorflow.python.ops.variables import global_variables_initializer as _global_variables_initializer from tensorflow.python.platform import gfile +from tensorflow.python.platform import resource_loader from tensorflow.python.platform import test from tensorflow.python.saved_model import saved_model from tensorflow.python.training.training_util import write_graph +class FromConstructor(test_util.TensorFlowTestCase): + + # Tests invalid constructors using a dummy value for the GraphDef. + def testInvalidConstructor(self): + message = ('If input_tensors and output_tensors are None, both ' + 'input_arrays_with_shape and output_arrays must be defined.') + + # `output_arrays` is not defined. + with self.assertRaises(ValueError) as error: + lite.TocoConverter( + None, None, [], input_arrays_with_shape=[('input', [3, 9])]) + self.assertEqual(message, str(error.exception)) + + # `input_arrays_with_shape` is not defined. + with self.assertRaises(ValueError) as error: + lite.TocoConverter(None, [], None, output_arrays=['output']) + self.assertEqual(message, str(error.exception)) + + # Tests valid constructors using a dummy value for the GraphDef. + def testValidConstructor(self): + converter = lite.TocoConverter( + None, + None, + None, + input_arrays_with_shape=[('input', [3, 9])], + output_arrays=['output']) + self.assertFalse(converter._has_valid_tensors()) + self.assertEqual(converter.get_input_arrays(), ['input']) + + with self.assertRaises(ValueError) as error: + converter._set_batch_size(1) + self.assertEqual( + 'The batch size cannot be set for this model. Please use ' + 'input_shapes parameter.', str(error.exception)) + + converter = lite.TocoConverter(None, ['input_tensor'], ['output_tensor']) + self.assertTrue(converter._has_valid_tensors()) + + class FromSessionTest(test_util.TensorFlowTestCase): def testFloat(self): @@ -490,6 +530,79 @@ class FromFrozenGraphFile(test_util.TensorFlowTestCase): 'Unable to parse input file \'{}\'.'.format(graph_def_file), str(error.exception)) + # TODO(nupurgarg): Test model loading in open source. + def _initObjectDetectionArgs(self): + # Initializes the arguments required for the object detection model. + self._graph_def_file = resource_loader.get_path_to_datafile( + 'testdata/tflite_graph.pbtxt') + self._input_arrays = ['normalized_input_image_tensor'] + self._output_arrays = [ + 'TFLite_Detection_PostProcess', 'TFLite_Detection_PostProcess:1', + 'TFLite_Detection_PostProcess:2', 'TFLite_Detection_PostProcess:3' + ] + self._input_shapes = {'normalized_input_image_tensor': [1, 300, 300, 3]} + + def testTFLiteGraphDef(self): + # Tests the object detection model that cannot be loaded in TensorFlow. + self._initObjectDetectionArgs() + + converter = lite.TocoConverter.from_frozen_graph( + self._graph_def_file, self._input_arrays, self._output_arrays, + self._input_shapes) + converter.allow_custom_ops = True + tflite_model = converter.convert() + self.assertTrue(tflite_model) + + # Check values from converted model. + interpreter = Interpreter(model_content=tflite_model) + interpreter.allocate_tensors() + + input_details = interpreter.get_input_details() + self.assertEqual(1, len(input_details)) + self.assertEqual('normalized_input_image_tensor', input_details[0]['name']) + self.assertEqual(np.float32, input_details[0]['dtype']) + self.assertTrue(([1, 300, 300, 3] == input_details[0]['shape']).all()) + self.assertEqual((0., 0.), input_details[0]['quantization']) + + output_details = interpreter.get_output_details() + self.assertEqual(4, len(output_details)) + self.assertEqual('TFLite_Detection_PostProcess', output_details[0]['name']) + self.assertEqual(np.float32, output_details[0]['dtype']) + self.assertTrue(([1, 10, 4] == output_details[0]['shape']).all()) + self.assertEqual((0., 0.), output_details[0]['quantization']) + + self.assertEqual('TFLite_Detection_PostProcess:1', + output_details[1]['name']) + self.assertTrue(([1, 10] == output_details[1]['shape']).all()) + self.assertEqual('TFLite_Detection_PostProcess:2', + output_details[2]['name']) + self.assertTrue(([1, 10] == output_details[2]['shape']).all()) + self.assertEqual('TFLite_Detection_PostProcess:3', + output_details[3]['name']) + self.assertTrue(([1] == output_details[3]['shape']).all()) + + def testTFLiteGraphDefInvalid(self): + # Tests invalid cases for the model that cannot be loaded in TensorFlow. + self._initObjectDetectionArgs() + + # Missing `input_shapes`. + with self.assertRaises(ValueError) as error: + lite.TocoConverter.from_frozen_graph( + self._graph_def_file, self._input_arrays, self._output_arrays) + self.assertEqual('input_shapes must be defined for this model.', + str(error.exception)) + + # `input_shapes` does not contain the names in `input_arrays`. + with self.assertRaises(ValueError) as error: + lite.TocoConverter.from_frozen_graph( + self._graph_def_file, + self._input_arrays, + self._output_arrays, + input_shapes={'invalid-value': [1, 19]}) + self.assertEqual( + 'input_shapes must contain a value for each item in input_array.', + str(error.exception)) + class FromSavedModelTest(test_util.TensorFlowTestCase): diff --git a/tensorflow/contrib/lite/python/tflite_convert.py b/tensorflow/contrib/lite/python/tflite_convert.py index a76cc39635..ce12a9abde 100644 --- a/tensorflow/contrib/lite/python/tflite_convert.py +++ b/tensorflow/contrib/lite/python/tflite_convert.py @@ -47,6 +47,9 @@ def _get_toco_converter(flags): Returns: TocoConverter object. + + Raises: + ValueError: Invalid flags. """ # Parse input and output arrays. input_arrays = _parse_array(flags.input_arrays) @@ -77,6 +80,9 @@ def _get_toco_converter(flags): elif flags.keras_model_file: converter_fn = lite.TocoConverter.from_keras_model_file converter_kwargs["model_file"] = flags.keras_model_file + else: + raise ValueError("--graph_def_file, --saved_model_dir, or " + "--keras_model_file must be specified.") return converter_fn(**converter_kwargs) @@ -126,7 +132,8 @@ def _convert_model(flags): if flags.reorder_across_fake_quant: converter.reorder_across_fake_quant = flags.reorder_across_fake_quant if flags.change_concat_input_ranges: - converter.change_concat_input_ranges = flags.change_concat_input_ranges + converter.change_concat_input_ranges = ( + flags.change_concat_input_ranges == "TRUE") if flags.allow_custom_ops: converter.allow_custom_ops = flags.allow_custom_ops if flags.quantize_weights: @@ -306,7 +313,7 @@ def run_main(_): "quantization via \"dummy quantization\". (default None)")) parser.add_argument( "--quantize_weights", - type=bool, + action="store_true", help=("Store float weights as quantized weights followed by dequantize " "operations. Inference is still done in FLOAT, but reduces model " "size (at the cost of accuracy and latency).")) @@ -327,9 +334,14 @@ def run_main(_): "the graph. Results in a graph that differs from the quantized " "training graph, potentially causing differing arithmetic " "behavior. (default False)")) + # Usage for this flag is --change_concat_input_ranges=true or + # --change_concat_input_ranges=false in order to make it clear what the flag + # is set to. This keeps the usage consistent with other usages of the flag + # where the default is different. The default value here is False. parser.add_argument( "--change_concat_input_ranges", - action="store_true", + type=str.upper, + choices=["TRUE", "FALSE"], help=("Boolean to change behavior of min/max ranges for inputs and " "outputs of the concat operator for quantized models. Changes the " "ranges of concat operator overlap when true. (default False)")) diff --git a/tensorflow/contrib/lite/schema/flatbuffer_compatibility_test.cc b/tensorflow/contrib/lite/schema/flatbuffer_compatibility_test.cc index 4af6925709..11057203a8 100644 --- a/tensorflow/contrib/lite/schema/flatbuffer_compatibility_test.cc +++ b/tensorflow/contrib/lite/schema/flatbuffer_compatibility_test.cc @@ -15,7 +15,7 @@ limitations under the License. #include <fstream> #include <gtest/gtest.h> -#include "include/flatbuffers/flatc.h" // flatbuffers +#include "flatbuffers/flatc.h" // flatbuffers #include "tensorflow/core/platform/platform.h" #ifdef PLATFORM_GOOGLE diff --git a/tensorflow/contrib/lite/schema/schema.fbs b/tensorflow/contrib/lite/schema/schema.fbs index 14f88b4c00..cf66403ec9 100644 --- a/tensorflow/contrib/lite/schema/schema.fbs +++ b/tensorflow/contrib/lite/schema/schema.fbs @@ -169,6 +169,10 @@ enum BuiltinOperator : byte { ONE_HOT = 85, LOGICAL_AND = 86, LOGICAL_NOT = 87, + UNPACK = 88, + REDUCE_MIN = 89, + FLOOR_DIV = 90, + REDUCE_ANY = 91, } // Options for the builtin operators. @@ -236,6 +240,8 @@ union BuiltinOptions { OneHotOptions, LogicalAndOptions, LogicalNotOptions, + UnpackOptions, + FloorDivOptions, } enum Padding : byte { SAME, VALID } @@ -565,6 +571,14 @@ table LogicalAndOptions { table LogicalNotOptions { } +table UnpackOptions { + num:int; + axis:int; +} + +table FloorDivOptions { +} + // An OperatorCode can be an enum value (BuiltinOperator) if the operator is a // builtin, or a string if the operator is custom. table OperatorCode { @@ -631,9 +645,9 @@ table SubGraph { } // Table of raw data buffers (used for constant tensors). Referenced by tensors -// by index. +// by index. The generous alignment accommodates mmap-friendly data structures. table Buffer { - data:[ubyte]; + data:[ubyte] (force_align: 16); } table Model { diff --git a/tensorflow/contrib/lite/schema/schema_generated.h b/tensorflow/contrib/lite/schema/schema_generated.h index 3efa153e2c..6d9630d75e 100755 --- a/tensorflow/contrib/lite/schema/schema_generated.h +++ b/tensorflow/contrib/lite/schema/schema_generated.h @@ -220,6 +220,12 @@ struct LogicalAndOptionsT; struct LogicalNotOptions; struct LogicalNotOptionsT; +struct UnpackOptions; +struct UnpackOptionsT; + +struct FloorDivOptions; +struct FloorDivOptionsT; + struct OperatorCode; struct OperatorCodeT; @@ -373,11 +379,15 @@ enum BuiltinOperator { BuiltinOperator_ONE_HOT = 85, BuiltinOperator_LOGICAL_AND = 86, BuiltinOperator_LOGICAL_NOT = 87, + BuiltinOperator_UNPACK = 88, + BuiltinOperator_REDUCE_MIN = 89, + BuiltinOperator_FLOOR_DIV = 90, + BuiltinOperator_REDUCE_ANY = 91, BuiltinOperator_MIN = BuiltinOperator_ADD, - BuiltinOperator_MAX = BuiltinOperator_LOGICAL_NOT + BuiltinOperator_MAX = BuiltinOperator_REDUCE_ANY }; -inline BuiltinOperator (&EnumValuesBuiltinOperator())[87] { +inline BuiltinOperator (&EnumValuesBuiltinOperator())[91] { static BuiltinOperator values[] = { BuiltinOperator_ADD, BuiltinOperator_AVERAGE_POOL_2D, @@ -465,7 +475,11 @@ inline BuiltinOperator (&EnumValuesBuiltinOperator())[87] { BuiltinOperator_LOGICAL_OR, BuiltinOperator_ONE_HOT, BuiltinOperator_LOGICAL_AND, - BuiltinOperator_LOGICAL_NOT + BuiltinOperator_LOGICAL_NOT, + BuiltinOperator_UNPACK, + BuiltinOperator_REDUCE_MIN, + BuiltinOperator_FLOOR_DIV, + BuiltinOperator_REDUCE_ANY }; return values; } @@ -560,6 +574,10 @@ inline const char **EnumNamesBuiltinOperator() { "ONE_HOT", "LOGICAL_AND", "LOGICAL_NOT", + "UNPACK", + "REDUCE_MIN", + "FLOOR_DIV", + "REDUCE_ANY", nullptr }; return names; @@ -635,11 +653,13 @@ enum BuiltinOptions { BuiltinOptions_OneHotOptions = 61, BuiltinOptions_LogicalAndOptions = 62, BuiltinOptions_LogicalNotOptions = 63, + BuiltinOptions_UnpackOptions = 64, + BuiltinOptions_FloorDivOptions = 65, BuiltinOptions_MIN = BuiltinOptions_NONE, - BuiltinOptions_MAX = BuiltinOptions_LogicalNotOptions + BuiltinOptions_MAX = BuiltinOptions_FloorDivOptions }; -inline BuiltinOptions (&EnumValuesBuiltinOptions())[64] { +inline BuiltinOptions (&EnumValuesBuiltinOptions())[66] { static BuiltinOptions values[] = { BuiltinOptions_NONE, BuiltinOptions_Conv2DOptions, @@ -704,7 +724,9 @@ inline BuiltinOptions (&EnumValuesBuiltinOptions())[64] { BuiltinOptions_LogicalOrOptions, BuiltinOptions_OneHotOptions, BuiltinOptions_LogicalAndOptions, - BuiltinOptions_LogicalNotOptions + BuiltinOptions_LogicalNotOptions, + BuiltinOptions_UnpackOptions, + BuiltinOptions_FloorDivOptions }; return values; } @@ -775,6 +797,8 @@ inline const char **EnumNamesBuiltinOptions() { "OneHotOptions", "LogicalAndOptions", "LogicalNotOptions", + "UnpackOptions", + "FloorDivOptions", nullptr }; return names; @@ -1041,6 +1065,14 @@ template<> struct BuiltinOptionsTraits<LogicalNotOptions> { static const BuiltinOptions enum_value = BuiltinOptions_LogicalNotOptions; }; +template<> struct BuiltinOptionsTraits<UnpackOptions> { + static const BuiltinOptions enum_value = BuiltinOptions_UnpackOptions; +}; + +template<> struct BuiltinOptionsTraits<FloorDivOptions> { + static const BuiltinOptions enum_value = BuiltinOptions_FloorDivOptions; +}; + struct BuiltinOptionsUnion { BuiltinOptions type; void *value; @@ -1576,6 +1608,22 @@ struct BuiltinOptionsUnion { return type == BuiltinOptions_LogicalNotOptions ? reinterpret_cast<const LogicalNotOptionsT *>(value) : nullptr; } + UnpackOptionsT *AsUnpackOptions() { + return type == BuiltinOptions_UnpackOptions ? + reinterpret_cast<UnpackOptionsT *>(value) : nullptr; + } + const UnpackOptionsT *AsUnpackOptions() const { + return type == BuiltinOptions_UnpackOptions ? + reinterpret_cast<const UnpackOptionsT *>(value) : nullptr; + } + FloorDivOptionsT *AsFloorDivOptions() { + return type == BuiltinOptions_FloorDivOptions ? + reinterpret_cast<FloorDivOptionsT *>(value) : nullptr; + } + const FloorDivOptionsT *AsFloorDivOptions() const { + return type == BuiltinOptions_FloorDivOptions ? + reinterpret_cast<const FloorDivOptionsT *>(value) : nullptr; + } }; bool VerifyBuiltinOptions(flatbuffers::Verifier &verifier, const void *obj, BuiltinOptions type); @@ -5649,6 +5697,112 @@ inline flatbuffers::Offset<LogicalNotOptions> CreateLogicalNotOptions( flatbuffers::Offset<LogicalNotOptions> CreateLogicalNotOptions(flatbuffers::FlatBufferBuilder &_fbb, const LogicalNotOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); +struct UnpackOptionsT : public flatbuffers::NativeTable { + typedef UnpackOptions TableType; + int32_t num; + int32_t axis; + UnpackOptionsT() + : num(0), + axis(0) { + } +}; + +struct UnpackOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table { + typedef UnpackOptionsT NativeTableType; + enum { + VT_NUM = 4, + VT_AXIS = 6 + }; + int32_t num() const { + return GetField<int32_t>(VT_NUM, 0); + } + int32_t axis() const { + return GetField<int32_t>(VT_AXIS, 0); + } + bool Verify(flatbuffers::Verifier &verifier) const { + return VerifyTableStart(verifier) && + VerifyField<int32_t>(verifier, VT_NUM) && + VerifyField<int32_t>(verifier, VT_AXIS) && + verifier.EndTable(); + } + UnpackOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const; + void UnPackTo(UnpackOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const; + static flatbuffers::Offset<UnpackOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const UnpackOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); +}; + +struct UnpackOptionsBuilder { + flatbuffers::FlatBufferBuilder &fbb_; + flatbuffers::uoffset_t start_; + void add_num(int32_t num) { + fbb_.AddElement<int32_t>(UnpackOptions::VT_NUM, num, 0); + } + void add_axis(int32_t axis) { + fbb_.AddElement<int32_t>(UnpackOptions::VT_AXIS, axis, 0); + } + explicit UnpackOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb) + : fbb_(_fbb) { + start_ = fbb_.StartTable(); + } + UnpackOptionsBuilder &operator=(const UnpackOptionsBuilder &); + flatbuffers::Offset<UnpackOptions> Finish() { + const auto end = fbb_.EndTable(start_); + auto o = flatbuffers::Offset<UnpackOptions>(end); + return o; + } +}; + +inline flatbuffers::Offset<UnpackOptions> CreateUnpackOptions( + flatbuffers::FlatBufferBuilder &_fbb, + int32_t num = 0, + int32_t axis = 0) { + UnpackOptionsBuilder builder_(_fbb); + builder_.add_axis(axis); + builder_.add_num(num); + return builder_.Finish(); +} + +flatbuffers::Offset<UnpackOptions> CreateUnpackOptions(flatbuffers::FlatBufferBuilder &_fbb, const UnpackOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); + +struct FloorDivOptionsT : public flatbuffers::NativeTable { + typedef FloorDivOptions TableType; + FloorDivOptionsT() { + } +}; + +struct FloorDivOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table { + typedef FloorDivOptionsT NativeTableType; + bool Verify(flatbuffers::Verifier &verifier) const { + return VerifyTableStart(verifier) && + verifier.EndTable(); + } + FloorDivOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const; + void UnPackTo(FloorDivOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const; + static flatbuffers::Offset<FloorDivOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const FloorDivOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); +}; + +struct FloorDivOptionsBuilder { + flatbuffers::FlatBufferBuilder &fbb_; + flatbuffers::uoffset_t start_; + explicit FloorDivOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb) + : fbb_(_fbb) { + start_ = fbb_.StartTable(); + } + FloorDivOptionsBuilder &operator=(const FloorDivOptionsBuilder &); + flatbuffers::Offset<FloorDivOptions> Finish() { + const auto end = fbb_.EndTable(start_); + auto o = flatbuffers::Offset<FloorDivOptions>(end); + return o; + } +}; + +inline flatbuffers::Offset<FloorDivOptions> CreateFloorDivOptions( + flatbuffers::FlatBufferBuilder &_fbb) { + FloorDivOptionsBuilder builder_(_fbb); + return builder_.Finish(); +} + +flatbuffers::Offset<FloorDivOptions> CreateFloorDivOptions(flatbuffers::FlatBufferBuilder &_fbb, const FloorDivOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); + struct OperatorCodeT : public flatbuffers::NativeTable { typedef OperatorCode TableType; BuiltinOperator builtin_code; @@ -5971,6 +6125,12 @@ struct Operator FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table { const LogicalNotOptions *builtin_options_as_LogicalNotOptions() const { return builtin_options_type() == BuiltinOptions_LogicalNotOptions ? static_cast<const LogicalNotOptions *>(builtin_options()) : nullptr; } + const UnpackOptions *builtin_options_as_UnpackOptions() const { + return builtin_options_type() == BuiltinOptions_UnpackOptions ? static_cast<const UnpackOptions *>(builtin_options()) : nullptr; + } + const FloorDivOptions *builtin_options_as_FloorDivOptions() const { + return builtin_options_type() == BuiltinOptions_FloorDivOptions ? static_cast<const FloorDivOptions *>(builtin_options()) : nullptr; + } const flatbuffers::Vector<uint8_t> *custom_options() const { return GetPointer<const flatbuffers::Vector<uint8_t> *>(VT_CUSTOM_OPTIONS); } @@ -6254,6 +6414,14 @@ template<> inline const LogicalNotOptions *Operator::builtin_options_as<LogicalN return builtin_options_as_LogicalNotOptions(); } +template<> inline const UnpackOptions *Operator::builtin_options_as<UnpackOptions>() const { + return builtin_options_as_UnpackOptions(); +} + +template<> inline const FloorDivOptions *Operator::builtin_options_as<FloorDivOptions>() const { + return builtin_options_as_FloorDivOptions(); +} + struct OperatorBuilder { flatbuffers::FlatBufferBuilder &fbb_; flatbuffers::uoffset_t start_; @@ -8441,6 +8609,58 @@ inline flatbuffers::Offset<LogicalNotOptions> CreateLogicalNotOptions(flatbuffer _fbb); } +inline UnpackOptionsT *UnpackOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const { + auto _o = new UnpackOptionsT(); + UnPackTo(_o, _resolver); + return _o; +} + +inline void UnpackOptions::UnPackTo(UnpackOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const { + (void)_o; + (void)_resolver; + { auto _e = num(); _o->num = _e; }; + { auto _e = axis(); _o->axis = _e; }; +} + +inline flatbuffers::Offset<UnpackOptions> UnpackOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const UnpackOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) { + return CreateUnpackOptions(_fbb, _o, _rehasher); +} + +inline flatbuffers::Offset<UnpackOptions> CreateUnpackOptions(flatbuffers::FlatBufferBuilder &_fbb, const UnpackOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) { + (void)_rehasher; + (void)_o; + struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const UnpackOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va; + auto _num = _o->num; + auto _axis = _o->axis; + return tflite::CreateUnpackOptions( + _fbb, + _num, + _axis); +} + +inline FloorDivOptionsT *FloorDivOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const { + auto _o = new FloorDivOptionsT(); + UnPackTo(_o, _resolver); + return _o; +} + +inline void FloorDivOptions::UnPackTo(FloorDivOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const { + (void)_o; + (void)_resolver; +} + +inline flatbuffers::Offset<FloorDivOptions> FloorDivOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const FloorDivOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) { + return CreateFloorDivOptions(_fbb, _o, _rehasher); +} + +inline flatbuffers::Offset<FloorDivOptions> CreateFloorDivOptions(flatbuffers::FlatBufferBuilder &_fbb, const FloorDivOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) { + (void)_rehasher; + (void)_o; + struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const FloorDivOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va; + return tflite::CreateFloorDivOptions( + _fbb); +} + inline OperatorCodeT *OperatorCode::UnPack(const flatbuffers::resolver_function_t *_resolver) const { auto _o = new OperatorCodeT(); UnPackTo(_o, _resolver); @@ -8882,6 +9102,14 @@ inline bool VerifyBuiltinOptions(flatbuffers::Verifier &verifier, const void *ob auto ptr = reinterpret_cast<const LogicalNotOptions *>(obj); return verifier.VerifyTable(ptr); } + case BuiltinOptions_UnpackOptions: { + auto ptr = reinterpret_cast<const UnpackOptions *>(obj); + return verifier.VerifyTable(ptr); + } + case BuiltinOptions_FloorDivOptions: { + auto ptr = reinterpret_cast<const FloorDivOptions *>(obj); + return verifier.VerifyTable(ptr); + } default: return false; } } @@ -9152,6 +9380,14 @@ inline void *BuiltinOptionsUnion::UnPack(const void *obj, BuiltinOptions type, c auto ptr = reinterpret_cast<const LogicalNotOptions *>(obj); return ptr->UnPack(resolver); } + case BuiltinOptions_UnpackOptions: { + auto ptr = reinterpret_cast<const UnpackOptions *>(obj); + return ptr->UnPack(resolver); + } + case BuiltinOptions_FloorDivOptions: { + auto ptr = reinterpret_cast<const FloorDivOptions *>(obj); + return ptr->UnPack(resolver); + } default: return nullptr; } } @@ -9410,6 +9646,14 @@ inline flatbuffers::Offset<void> BuiltinOptionsUnion::Pack(flatbuffers::FlatBuff auto ptr = reinterpret_cast<const LogicalNotOptionsT *>(value); return CreateLogicalNotOptions(_fbb, ptr, _rehasher).Union(); } + case BuiltinOptions_UnpackOptions: { + auto ptr = reinterpret_cast<const UnpackOptionsT *>(value); + return CreateUnpackOptions(_fbb, ptr, _rehasher).Union(); + } + case BuiltinOptions_FloorDivOptions: { + auto ptr = reinterpret_cast<const FloorDivOptionsT *>(value); + return CreateFloorDivOptions(_fbb, ptr, _rehasher).Union(); + } default: return 0; } } @@ -9668,6 +9912,14 @@ inline BuiltinOptionsUnion::BuiltinOptionsUnion(const BuiltinOptionsUnion &u) FL value = new LogicalNotOptionsT(*reinterpret_cast<LogicalNotOptionsT *>(u.value)); break; } + case BuiltinOptions_UnpackOptions: { + value = new UnpackOptionsT(*reinterpret_cast<UnpackOptionsT *>(u.value)); + break; + } + case BuiltinOptions_FloorDivOptions: { + value = new FloorDivOptionsT(*reinterpret_cast<FloorDivOptionsT *>(u.value)); + break; + } default: break; } @@ -9990,6 +10242,16 @@ inline void BuiltinOptionsUnion::Reset() { delete ptr; break; } + case BuiltinOptions_UnpackOptions: { + auto ptr = reinterpret_cast<UnpackOptionsT *>(value); + delete ptr; + break; + } + case BuiltinOptions_FloorDivOptions: { + auto ptr = reinterpret_cast<FloorDivOptionsT *>(value); + delete ptr; + break; + } default: break; } value = nullptr; diff --git a/tensorflow/contrib/lite/testing/generate_examples.py b/tensorflow/contrib/lite/testing/generate_examples.py index 597ee8fb1e..57134ccd15 100644 --- a/tensorflow/contrib/lite/testing/generate_examples.py +++ b/tensorflow/contrib/lite/testing/generate_examples.py @@ -780,10 +780,15 @@ def make_binary_op_tests(zip_path, binary_operator): "input_shape_2": [[5]], "activation": [False, True] }, { - "dtype": [tf.float32], + "dtype": [tf.float32, tf.int32], "input_shape_1": [[1, 3, 4, 3]], "input_shape_2": [[3]], - "activation": [True] + "activation": [True, False] + }, { + "dtype": [tf.float32, tf.int32], + "input_shape_1": [[3]], + "input_shape_2": [[1, 3, 4, 3]], + "activation": [True, False] }, { "dtype": [tf.float32], "input_shape_1": [[]], @@ -821,13 +826,17 @@ def make_binary_op_tests(zip_path, binary_operator): make_zip_of_tests(zip_path, test_parameters, build_graph, build_inputs) -def make_reduce_tests(reduce_op, min_value=-10, max_value=10): +def make_reduce_tests(reduce_op, + min_value=-10, + max_value=10, + boolean_tensor_only=False): """Make a set of tests to do reduce operation. Args: reduce_op: TensorFlow reduce operation to test, i.e. `tf.reduce_mean`. min_value: min value for created tensor data. max_value: max value for created tensor data. + boolean_tensor_only: If true, will only generate tensor with boolean value. Returns: a function representing the true generator with `reduce_op_in` curried. @@ -867,10 +876,11 @@ def make_reduce_tests(reduce_op, min_value=-10, max_value=10): def build_graph(parameters): """Build the mean op testing graph.""" + dtype = parameters["input_dtype"] + if boolean_tensor_only: + dtype = tf.bool input_tensor = tf.placeholder( - dtype=parameters["input_dtype"], - name="input", - shape=parameters["input_shape"]) + dtype=dtype, name="input", shape=parameters["input_shape"]) # Get axis as either a placeholder or constants. if parameters["const_axis"]: @@ -889,9 +899,12 @@ def make_reduce_tests(reduce_op, min_value=-10, max_value=10): return input_tensors, [out] def build_inputs(parameters, sess, inputs, outputs): + dtype = parameters["input_dtype"] + if boolean_tensor_only: + dtype = tf.bool values = [ create_tensor_data( - parameters["input_dtype"], + dtype, parameters["input_shape"], min_value=min_value, max_value=max_value) @@ -926,6 +939,16 @@ def make_reduce_max_tests(zip_path): return make_reduce_tests(tf.reduce_max)(zip_path) +def make_reduce_min_tests(zip_path): + """Make a set of tests to do min.""" + return make_reduce_tests(tf.reduce_min)(zip_path) + + +def make_reduce_any_tests(zip_path): + """Make a set of tests to do any.""" + return make_reduce_tests(tf.reduce_any, boolean_tensor_only=True)(zip_path) + + def make_exp_tests(zip_path): """Make a set of tests to do exp.""" @@ -1080,6 +1103,10 @@ def make_pow_tests(zip_path): make_binary_op_tests(zip_path, tf.pow) +def make_floor_div_tests(zip_path): + make_binary_op_tests(zip_path, tf.floor_div) + + def make_gather_tests(zip_path): """Make a set of tests to do gather.""" @@ -2373,7 +2400,7 @@ def make_lstm_tests(zip_path): "time_step_size": [1], "input_vec_size": [3], "num_cells": [4], - "split_tflite_lstm_inputs": [True, False], + "split_tflite_lstm_inputs": [False], }, ] @@ -3144,6 +3171,36 @@ def make_pack_tests(zip_path): make_zip_of_tests(zip_path, test_parameters, build_graph, build_inputs) +def make_unpack_tests(zip_path): + """Make a set of tests to do unstack.""" + + test_parameters = [{ + "base_shape": [[3, 4, 3], [3, 4], [5, 6, 7, 8]], + "axis": [0, 1, 2, 3], + }] + + def get_valid_axis(parameters): + """Return a tweaked version of 'axis'.""" + axis = parameters["axis"] + shape = parameters["base_shape"][:] + while axis > len(shape) - 1: + axis -= 1 + return axis + + def build_graph(parameters): + input_tensor = tf.placeholder( + dtype=tf.float32, name=("input"), shape=parameters["base_shape"]) + outs = tf.unstack(input_tensor, axis=get_valid_axis(parameters)) + return [input_tensor], outs + + def build_inputs(parameters, sess, inputs, outputs): + input_value = create_tensor_data(np.float32, shape=parameters["base_shape"]) + return [input_value], sess.run( + outputs, feed_dict=dict(zip(inputs, [input_value]))) + + make_zip_of_tests(zip_path, test_parameters, build_graph, build_inputs) + + def _make_logical_tests(op): """Make a set of tests to do logical operations.""" diff --git a/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc b/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc index e67fee2a1c..37c7ae0e1c 100644 --- a/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc +++ b/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc @@ -101,6 +101,15 @@ std::map<string, string> kBrokenTests = { "77546240"}, {R"(^\/arg_min_max.*axis_is_last_dim=False.*input_shape=\[.,.\])", "77546240"}, + + // No Support for float. + {R"(^\/floor_div.*dtype=tf\.float32)", "112859002"}, + + // Relu does not support int32. + // These test cases appends a Relu after the tested ops when + // activation=True. The tests are failing since Relu doesn't support int32. + {R"(^\/div.*activation=True.*dtype=tf\.int32)", "112968789"}, + {R"(^\/floor_div.*activation=True.*dtype=tf\.int32)", "112968789"}, }; // Allows test data to be unarchived into a temporary directory and makes diff --git a/tensorflow/contrib/lite/testing/parse_testdata.h b/tensorflow/contrib/lite/testing/parse_testdata.h index d94361d735..26ee825866 100644 --- a/tensorflow/contrib/lite/testing/parse_testdata.h +++ b/tensorflow/contrib/lite/testing/parse_testdata.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_NNAPI_PARSE_TESTDATA_H_ -#define TENSORFLOW_CONTRIB_LITE_NNAPI_PARSE_TESTDATA_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_TESTING_PARSE_TESTDATA_H_ +#define TENSORFLOW_CONTRIB_LITE_TESTING_PARSE_TESTDATA_H_ #include <vector> #include "tensorflow/contrib/lite/interpreter.h" @@ -72,4 +72,4 @@ bool ParseAndRunTests(std::istream* input, TestRunner* test_runner, } // namespace testing } // namespace tflite -#endif // TENSORFLOW_CONTRIB_LITE_NNAPI_PARSE_TESTDATA_H_ +#endif // TENSORFLOW_CONTRIB_LITE_TESTING_PARSE_TESTDATA_H_ diff --git a/tensorflow/contrib/lite/testing/tflite_driver.cc b/tensorflow/contrib/lite/testing/tflite_driver.cc index 4dacf9c84b..1836eb53b9 100644 --- a/tensorflow/contrib/lite/testing/tflite_driver.cc +++ b/tensorflow/contrib/lite/testing/tflite_driver.cc @@ -302,28 +302,6 @@ bool TfLiteDriver::CheckResults() { void TfLiteDriver::ResetLSTMStateTensors() { interpreter_->ResetVariableTensorsToZero(); - - // Below is a workaround for initializing state tensors for LSTM. - // TODO(ycling): Remove the code below after nobody is using the 18-inputs - // definition. - for (auto node_index : interpreter_->execution_plan()) { - const auto& node_and_reg = interpreter_->node_and_registration(node_index); - const auto& node = node_and_reg->first; - const auto& registration = node_and_reg->second; - - if (registration.builtin_code == tflite::BuiltinOperator_LSTM) { - const auto* params = - reinterpret_cast<const TfLiteLSTMParams*>(node.builtin_data); - if (params->kernel_type == kTfLiteLSTMFullKernel && - node.inputs->size == 18 && node.outputs->size >= 2) { - // The first 2 outputs of LSTM are state tensors. - for (int i = 0; i < 2; ++i) { - int node_index = node.outputs->data[i]; - ResetTensor(node_index); - } - } - } - } } } // namespace testing diff --git a/tensorflow/contrib/lite/testing/tokenize.h b/tensorflow/contrib/lite/testing/tokenize.h index 7ed8eb96b7..8195391851 100644 --- a/tensorflow/contrib/lite/testing/tokenize.h +++ b/tensorflow/contrib/lite/testing/tokenize.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TESTING_TOKENIZER_H_ -#define TENSORFLOW_CONTRIB_LITE_TESTING_TOKENIZER_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_TESTING_TOKENIZE_H_ +#define TENSORFLOW_CONTRIB_LITE_TESTING_TOKENIZE_H_ #include <istream> #include <string> @@ -39,4 +39,4 @@ void Tokenize(std::istream* input, TokenProcessor* processor); } // namespace testing } // namespace tflite -#endif // TENSORFLOW_CONTRIB_LITE_TESTING_TOKENIZER_H_ +#endif // TENSORFLOW_CONTRIB_LITE_TESTING_TOKENIZE_H_ diff --git a/tensorflow/contrib/lite/toco/export_tensorflow.cc b/tensorflow/contrib/lite/toco/export_tensorflow.cc index 02671f0408..6fdf47dedc 100644 --- a/tensorflow/contrib/lite/toco/export_tensorflow.cc +++ b/tensorflow/contrib/lite/toco/export_tensorflow.cc @@ -1900,21 +1900,6 @@ void ConvertPowOperator(const Model& model, const PowOperator& src_op, (*pow_op->mutable_attr())["T"].set_type(data_type); } -void ConvertAnyOperator(const Model& model, const AnyOperator& src_op, - GraphDef* tensorflow_graph) { - tensorflow::NodeDef* any_op = tensorflow_graph->add_node(); - any_op->set_op("Any"); - any_op->set_name(src_op.outputs[0]); - CHECK_EQ(src_op.inputs.size(), 2); - for (int i = 0; i < 2; ++i) { - *any_op->add_input() = src_op.inputs[i]; - } - const tensorflow::DataType data_type = - GetTensorFlowDataType(model, src_op.inputs[1]); - (*any_op->mutable_attr())["Tidx"].set_type(data_type); - (*any_op->mutable_attr())["keep_dims"].set_b(src_op.keep_dims); -} - void ConvertLogicalAndOperator(const Model& model, const LogicalAndOperator& src_op, GraphDef* tensorflow_graph) { @@ -1967,6 +1952,20 @@ void ConvertCTCBeamSearchDecoderOperator( (*op->mutable_attr())["merge_repeated"].set_b(src_op.merge_repeated); } +void ConvertUnpackOperator(const Model& model, const UnpackOperator& src_op, + const char* op_name, GraphDef* tensorflow_graph) { + tensorflow::NodeDef* unpack_op = tensorflow_graph->add_node(); + unpack_op->set_op(op_name); + unpack_op->set_name(src_op.outputs[0]); + CHECK_EQ(src_op.inputs.size(), 2); + *unpack_op->add_input() = src_op.inputs[0]; + const tensorflow::DataType data_type = + GetTensorFlowDataType(model, src_op.inputs[0]); + (*unpack_op->mutable_attr())["T"].set_type(data_type); + (*unpack_op->mutable_attr())["num"].set_i(src_op.num); + (*unpack_op->mutable_attr())["axis"].set_i(src_op.axis); +} + void ConvertOperator(const Model& model, const Operator& src_op, GraphDef* tensorflow_graph) { if (src_op.fused_activation_function != FusedActivationFunctionType::kNone) { @@ -2118,7 +2117,7 @@ void ConvertOperator(const Model& model, const Operator& src_op, tensorflow_graph, "Prod"); } else if (src_op.type == OperatorType::kReduceMin) { ConvertReduceOperator(model, - static_cast<const TensorFlowMaxOperator&>(src_op), + static_cast<const TensorFlowMinOperator&>(src_op), tensorflow_graph, "Min"); } else if (src_op.type == OperatorType::kReduceMax) { ConvertReduceOperator(model, @@ -2207,8 +2206,9 @@ void ConvertOperator(const Model& model, const Operator& src_op, ConvertPowOperator(model, static_cast<const PowOperator&>(src_op), "Pow", tensorflow_graph); } else if (src_op.type == OperatorType::kAny) { - ConvertAnyOperator(model, static_cast<const AnyOperator&>(src_op), - tensorflow_graph); + ConvertReduceOperator(model, + static_cast<const TensorFlowAnyOperator&>(src_op), + tensorflow_graph, "Any"); } else if (src_op.type == OperatorType::kLogicalAnd) { ConvertLogicalAndOperator(model, static_cast<const LogicalAndOperator&>(src_op), @@ -2228,6 +2228,9 @@ void ConvertOperator(const Model& model, const Operator& src_op, ConvertCTCBeamSearchDecoderOperator( model, static_cast<const CTCBeamSearchDecoderOperator&>(src_op), "CTCBeamSearchDecoder", tensorflow_graph); + } else if (src_op.type == OperatorType::kUnpack) { + ConvertUnpackOperator(model, static_cast<const UnpackOperator&>(src_op), + "Unpack", tensorflow_graph); } else { LOG(FATAL) << "Unhandled operator type " << OperatorTypeName(src_op.type); } diff --git a/tensorflow/contrib/lite/toco/graph_transformations/propagate_array_data_types.cc b/tensorflow/contrib/lite/toco/graph_transformations/propagate_array_data_types.cc index c8310161cb..323eefcd3a 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/propagate_array_data_types.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/propagate_array_data_types.cc @@ -227,6 +227,15 @@ bool PropagateArrayDataTypes::Run(Model* model, std::size_t op_index) { ArrayDataType::kFloat; break; } + case OperatorType::kUnpack: { + CHECK_EQ(op->inputs.size(), 1); + const int output_size = op->outputs.size(); + for (int i = 0; i < output_size; ++i) { + model->GetArray(op->outputs[i]).data_type = + model->GetArray(op->inputs[0]).data_type; + } + break; + } default: { // These operators produce outputs with the same type as their 1st input CHECK_GT(op->inputs.size(), 0); diff --git a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc index 91e290439a..28effc2a67 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc @@ -539,6 +539,8 @@ bool KeepDims(const Operator& op) { return static_cast<const TensorFlowProdOperator&>(op).keep_dims; case OperatorType::kMean: return static_cast<const MeanOperator&>(op).keep_dims; + case OperatorType::kAny: + return static_cast<const TensorFlowAnyOperator&>(op).keep_dims; default: LOG(FATAL) << "Not a reduction operator!"; return false; @@ -1515,65 +1517,6 @@ void ProcessTileOperator(Model* model, TensorFlowTileOperator* op) { } } -void ProcessAnyOperator(Model* model, AnyOperator* op) { - CHECK_EQ(op->inputs.size(), 2); - CHECK_EQ(op->outputs.size(), 1); - - auto& output_array = model->GetArray(op->outputs[0]); - if (output_array.has_shape()) { - // We have already run. - return; - } - - const auto& input_array = model->GetArray(op->inputs[0]); - if (!input_array.has_shape()) { - // Yield until input dims have been resolved. - return; - } - const auto& input_shape = input_array.shape(); - - auto& reduction_indices_array = model->GetArray(op->inputs[1]); - if (!reduction_indices_array.has_shape()) { - // Yield until reduction indices shape been resolved. - return; - } - if (!reduction_indices_array.buffer) { - // Yield until the reduction indices are constant. - return; - } - CHECK(reduction_indices_array.data_type == ArrayDataType::kInt32) - << "Any reduction input must be int32"; - - int input_rank = input_shape.dimensions_count(); - std::set<int32> true_indices; - const auto& reduction_indices = - reduction_indices_array.GetBuffer<ArrayDataType::kInt32>().data; - for (int i = 0; i < reduction_indices.size(); ++i) { - const int32 reduction_index = reduction_indices[i]; - if (reduction_index < -input_rank || reduction_index >= input_rank) { - CHECK(false) << "Invalid reduction dimension " << reduction_index - << " for input with " << input_rank << " dimensions"; - } - int32 wrapped_index = reduction_index; - if (wrapped_index < 0) { - wrapped_index += input_rank; - } - true_indices.insert(wrapped_index); - } - - auto* mutable_dims = output_array.mutable_shape()->mutable_dims(); - mutable_dims->clear(); - for (int i = 0; i < input_rank; ++i) { - if (true_indices.count(i) > 0) { - if (op->keep_dims) { - mutable_dims->emplace_back(1); - } - } else { - mutable_dims->emplace_back(input_shape.dims(i)); - } - } -} - void ProcessOneHotOperator(Model* model, OneHotOperator* op) { CHECK_EQ(op->inputs.size(), 4); CHECK_EQ(op->outputs.size(), 1); @@ -1629,6 +1572,32 @@ void ProcessOneHotOperator(Model* model, OneHotOperator* op) { } } +void ProcessUnpackOperator(Model* model, UnpackOperator* op) { + CHECK_EQ(op->inputs.size(), 1); + const auto& input_array = model->GetArray(op->inputs[0]); + // Yield until input dims have been resolved. + if (!input_array.has_shape()) { + return; + } + + const std::vector<int>& input_dims = input_array.shape().dims(); + std::vector<int> output_dims; + + output_dims.reserve(input_dims.size() - 1); + for (int i = 0; i < input_dims.size(); ++i) { + if (i != op->axis) { + output_dims.push_back(input_dims[i]); + } + } + for (const string& output_name : op->outputs) { + auto& output_array = model->GetArray(output_name); + if (output_array.has_shape()) { + return; + } + *output_array.mutable_shape()->mutable_dims() = output_dims; + } +} + } // namespace bool PropagateFixedSizes::Run(Model* model, std::size_t op_index) { @@ -1743,6 +1712,7 @@ bool PropagateFixedSizes::Run(Model* model, std::size_t op_index) { case OperatorType::kSum: case OperatorType::kReduceProd: case OperatorType::kMean: + case OperatorType::kAny: ProcessTensorFlowReductionOperator(model, op); break; case OperatorType::kSelect: @@ -1874,12 +1844,13 @@ bool PropagateFixedSizes::Run(Model* model, std::size_t op_index) { case OperatorType::kTile: ProcessTileOperator(model, static_cast<TensorFlowTileOperator*>(op)); break; - case OperatorType::kAny: - ProcessAnyOperator(model, static_cast<AnyOperator*>(op)); break; case OperatorType::kOneHot: ProcessOneHotOperator(model, static_cast<OneHotOperator*>(op)); break; + case OperatorType::kUnpack: + ProcessUnpackOperator(model, static_cast<UnpackOperator*>(op)); + break; default: // Unimplemented, another graph transformation should drop it. LOG(FATAL) << "Unhandled operator type " << OperatorTypeName(op->type); diff --git a/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_fake_quant.cc b/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_fake_quant.cc index d395d7a6a0..f5f2f77460 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_fake_quant.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_fake_quant.cc @@ -117,6 +117,7 @@ bool ResolveConstantFakeQuant::Run(Model* model, std::size_t op_index) { &quantized_max); if (fakequant_op->narrow_range) { quantized_min++; + output_array.narrow_range = true; } // It is important for matching accuracy between TF training and TFLite diff --git a/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_reshape.cc b/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_reshape.cc index 41562ab393..a6f665b5f0 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_reshape.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_reshape.cc @@ -100,13 +100,7 @@ bool ResolveConstantReshape::Run(Model* model, std::size_t op_index) { AddMessageF("Resolving constant reshape of %s", LogName(*op)); - if (input_array.minmax) { - output_array.GetOrCreateMinMax() = input_array.GetMinMax(); - } - if (input_array.quantization_params) { - output_array.GetOrCreateQuantizationParams() = - input_array.GetQuantizationParams(); - } + CopyMinMaxAndQuantizationRelatedFields(input_array, &output_array); // Erase input arrays if no longer used. for (const auto& input : op->inputs) { diff --git a/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_tile.cc b/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_tile.cc index 0b0d070714..5cfa1a5582 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_tile.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_tile.cc @@ -128,15 +128,7 @@ bool ResolveConstantTile::Run(Model* model, std::size_t op_index) { multiples_array.data_type == ArrayDataType::kInt64) << "Only int32/int64 indices are supported"; - // Copy min/max info if present. The ranges of the selected values may be - // a subset of the original range but we want to ensure the quantization - // params stay the same. - if (input_array.minmax) { - const auto& input_minmax = input_array.GetMinMax(); - auto& output_minmax = output_array.GetOrCreateMinMax(); - output_minmax.min = input_minmax.min; - output_minmax.max = input_minmax.max; - } + CopyMinMaxAndQuantizationRelatedFields(input_array, &output_array); CHECK(!output_array.buffer); switch (output_array.data_type) { diff --git a/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_transpose.cc b/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_transpose.cc index 1fd20314b1..fe15dfa06f 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_transpose.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/resolve_constant_transpose.cc @@ -128,13 +128,7 @@ bool ResolveConstantTranspose::Run(Model* model, std::size_t op_index) { } const Array& input_array = model->GetArray(op->inputs[0]); - if (input_array.minmax) { - output_array.GetOrCreateMinMax() = input_array.GetMinMax(); - } - if (input_array.quantization_params) { - output_array.GetOrCreateQuantizationParams() = - input_array.GetQuantizationParams(); - } + CopyMinMaxAndQuantizationRelatedFields(input_array, &output_array); if (op->perm.empty()) { // Yield until perm has been populated by ResolveTransposeAttributes. diff --git a/tensorflow/contrib/lite/toco/graph_transformations/unroll_batch_matmul.cc b/tensorflow/contrib/lite/toco/graph_transformations/unroll_batch_matmul.cc index 5f0cece67a..fedf4441e2 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/unroll_batch_matmul.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/unroll_batch_matmul.cc @@ -154,6 +154,7 @@ bool UnrollBatchMatMul::Run(Model* model, std::size_t op_index) { pack_op->inputs = pack_inputs; pack_op->outputs = {batch_op->outputs[0]}; pack_op->axis = 0; + pack_op->values_count = pack_inputs.size(); model->operators.emplace(tail_it, pack_op); // Remove the old batch matmul now that we've unrolled. diff --git a/tensorflow/contrib/lite/toco/import_tensorflow.cc b/tensorflow/contrib/lite/toco/import_tensorflow.cc index b7fffbce22..cb6da21039 100644 --- a/tensorflow/contrib/lite/toco/import_tensorflow.cc +++ b/tensorflow/contrib/lite/toco/import_tensorflow.cc @@ -1576,6 +1576,26 @@ tensorflow::Status ConvertPackOperator( return tensorflow::Status::OK(); } +tensorflow::Status ConvertUnpackOperator( + const NodeDef& node, const TensorFlowImportFlags& tf_import_flags, + Model* model) { + CHECK_EQ(node.op(), "Unpack"); + auto op = absl::make_unique<UnpackOperator>(); + const int num_inputs = GetInputsCount(node, tf_import_flags); + QCHECK_EQ(num_inputs, 1); + op->inputs.push_back(node.input(0)); + op->num = GetIntAttr(node, "num"); + op->axis = HasAttr(node, "axis") ? GetIntAttr(node, "axis") : 0; + op->dtype = ConvertDataType(toco::GetDataTypeAttr(node, "T")); + + op->outputs.push_back(node.name()); // Implicit :0. + for (int i = 1; i < op->num; ++i) { + op->outputs.push_back(node.name() + ":" + std::to_string(i)); + } + model->operators.emplace_back(std::move(op)); + return tensorflow::Status::OK(); +} + // Some TensorFlow ops only occur in graph cycles, representing // control flow. We do not currently support control flow, so we wouldn't // be able to fully support such graphs, including performing inference, @@ -1618,24 +1638,6 @@ tensorflow::Status ConvertShapeOperator( return tensorflow::Status::OK(); } -tensorflow::Status ConvertAnyOperator( - const NodeDef& node, const TensorFlowImportFlags& tf_import_flags, - Model* model) { - CHECK_EQ(node.op(), "Any"); - TF_QCHECK_OK(CheckInputsCount(node, tf_import_flags, 2)); - const auto idx_type = - HasAttr(node, "Tidx") ? GetDataTypeAttr(node, "Tidx") : DT_INT32; - CHECK(idx_type == DT_INT32); - auto op = absl::make_unique<AnyOperator>(); - op->inputs.push_back(node.input(0)); - op->inputs.push_back(node.input(1)); - op->outputs.push_back(node.name()); - op->keep_dims = - HasAttr(node, "keep_dims") ? GetBoolAttr(node, "keep_dims") : false; - model->operators.push_back(std::move(op)); - return tensorflow::Status::OK(); -} - void StripCaretFromArrayNames(Model* model) { for (auto& op : model->operators) { for (auto& input : op->inputs) { @@ -1917,7 +1919,7 @@ ConverterMapType GetTensorFlowNodeConverterMap() { {"Add", ConvertSimpleOperator<AddOperator, 2>}, {"AddN", ConvertSimpleOperator<AddNOperator>}, {"All", ConvertSimpleOperator<TensorFlowAllOperator>}, - {"Any", ConvertAnyOperator}, + {"Any", ConvertReduceOperator<TensorFlowAnyOperator>}, {"ArgMax", ConvertArgMaxOperator}, {"ArgMin", ConvertArgMinOperator}, {"Assert", ConvertSimpleOperator<TensorFlowAssertOperator>}, @@ -2020,6 +2022,7 @@ ConverterMapType GetTensorFlowNodeConverterMap() { {"TopK", ConvertTopKV2Operator}, {"TopKV2", ConvertTopKV2Operator}, {"Transpose", ConvertSimpleOperator<TransposeOperator, 2>}, + {"Unpack", ConvertUnpackOperator}, }); } diff --git a/tensorflow/contrib/lite/toco/model.h b/tensorflow/contrib/lite/toco/model.h index 412e14c4ad..fa1c459f0e 100644 --- a/tensorflow/contrib/lite/toco/model.h +++ b/tensorflow/contrib/lite/toco/model.h @@ -149,6 +149,7 @@ enum class OperatorType : uint8 { kLogicalNot, kLogicalOr, kCTCBeamSearchDecoder, + kUnpack, }; // Helper to deal with TensorFlow arrays using a different ordering of @@ -1767,11 +1768,11 @@ struct PowOperator : Operator { // // Inputs: // Inputs[0]: required: A boolean input tensor. -// Inputs[1]: required: reduction_indices. // // TensorFlow equivalent: tf.reduce_any. -struct AnyOperator : Operator { - AnyOperator() : Operator(OperatorType::kAny) {} +struct TensorFlowAnyOperator : Operator { + TensorFlowAnyOperator() : Operator(OperatorType::kAny) {} + std::vector<int> axis; bool keep_dims = false; }; @@ -1828,6 +1829,20 @@ struct LogicalOrOperator : Operator { LogicalOrOperator() : Operator(OperatorType::kLogicalOr) {} }; +// Unpack operator: +// +// Inputs: +// Inputs[0]: required: A boolean input tensor. +// Inputs[1]: required: reduction_indices. +// +// TensorFlow equivalent: tf.unstack. +struct UnpackOperator : Operator { + UnpackOperator() : Operator(OperatorType::kUnpack) {} + int num; + int axis; + ArrayDataType dtype = ArrayDataType::kNone; +}; + // Alloc's are used for transient arrays only. An Alloc specifies which interval // of the "transient_data" workspace buffer passed to inference functions, is to // be used for the transient array at hand. The 'start' and 'end' values are diff --git a/tensorflow/contrib/lite/toco/tensorflow_graph_matching/cluster.h b/tensorflow/contrib/lite/toco/tensorflow_graph_matching/cluster.h index 18ff73ac39..fda7743a27 100644 --- a/tensorflow/contrib/lite/toco/tensorflow_graph_matching/cluster.h +++ b/tensorflow/contrib/lite/toco/tensorflow_graph_matching/cluster.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTER_H -#define TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTER_H +#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTER_H_ +#define TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTER_H_ #include <string> #include <vector> @@ -98,4 +98,4 @@ class ClusterFactoryInterface { } // end namespace toco -#endif // TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTER_H +#endif // TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTER_H_ diff --git a/tensorflow/contrib/lite/toco/tensorflow_graph_matching/cluster_utils.h b/tensorflow/contrib/lite/toco/tensorflow_graph_matching/cluster_utils.h index a15e480e70..b57bded305 100644 --- a/tensorflow/contrib/lite/toco/tensorflow_graph_matching/cluster_utils.h +++ b/tensorflow/contrib/lite/toco/tensorflow_graph_matching/cluster_utils.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTERUTILS_H -#define TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTERUTILS_H +#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTER_UTILS_H_ +#define TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTER_UTILS_H_ #include <string> @@ -30,4 +30,4 @@ void Transpose2DTensor(const float* tensor, int row, int col, } // end namespace toco -#endif // TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTERUTILS_H +#endif // TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_CLUSTER_UTILS_H_ diff --git a/tensorflow/contrib/lite/toco/tensorflow_graph_matching/resolve_cluster.h b/tensorflow/contrib/lite/toco/tensorflow_graph_matching/resolve_cluster.h index 7d33dd1885..3334552afb 100644 --- a/tensorflow/contrib/lite/toco/tensorflow_graph_matching/resolve_cluster.h +++ b/tensorflow/contrib/lite/toco/tensorflow_graph_matching/resolve_cluster.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_CLUSTER_H -#define TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_CLUSTER_H +#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_CLUSTER_H_ +#define TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_CLUSTER_H_ #include <string> #include <unordered_map> @@ -60,4 +60,4 @@ std::unique_ptr<tensorflow::GraphDef> MaybeReplaceCompositeSubgraph( } // end namespace toco -#endif // CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_CLUSTER_H +#endif // TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_CLUSTER_H_ diff --git a/tensorflow/contrib/lite/toco/tensorflow_graph_matching/resolve_svdf.h b/tensorflow/contrib/lite/toco/tensorflow_graph_matching/resolve_svdf.h index c4c6c34117..383fd99dff 100644 --- a/tensorflow/contrib/lite/toco/tensorflow_graph_matching/resolve_svdf.h +++ b/tensorflow/contrib/lite/toco/tensorflow_graph_matching/resolve_svdf.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_SVDF_H -#define TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_SVDF_H +#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_SVDF_H_ +#define TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_SVDF_H_ #include <string> #include <vector> @@ -79,4 +79,4 @@ class SvdfClusterFactory : public ClusterFactoryInterface { } // end namespace toco -#endif // TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_SVDF_H +#endif // TENSORFLOW_CONTRIB_LITE_TOCO_TENSORFLOW_GRAPH_MATCHING_RESOLVE_SVDF_H_ diff --git a/tensorflow/contrib/lite/toco/tflite/operator.cc b/tensorflow/contrib/lite/toco/tflite/operator.cc index 75808f2b69..a314c8d53a 100644 --- a/tensorflow/contrib/lite/toco/tflite/operator.cc +++ b/tensorflow/contrib/lite/toco/tflite/operator.cc @@ -769,7 +769,26 @@ class Sum }; class ReduceMax - : public BuiltinOperator<TensorFlowSumOperator, ::tflite::ReducerOptions, + : public BuiltinOperator<TensorFlowMaxOperator, ::tflite::ReducerOptions, + ::tflite::BuiltinOptions_ReducerOptions> { + public: + using BuiltinOperator::BuiltinOperator; + flatbuffers::Offset<TfLiteOptions> WriteOptions( + const TocoOperator& op, + flatbuffers::FlatBufferBuilder* builder) const override { + return ::tflite::CreateReducerOptions(*builder, op.keep_dims); + } + + void ReadOptions(const TfLiteOptions& options, + TocoOperator* op) const override { + op->keep_dims = options.keep_dims(); + } + + int GetVersion(const Operator& op) const override { return 1; } +}; + +class ReduceMin + : public BuiltinOperator<TensorFlowMinOperator, ::tflite::ReducerOptions, ::tflite::BuiltinOptions_ReducerOptions> { public: using BuiltinOperator::BuiltinOperator; @@ -788,7 +807,26 @@ class ReduceMax }; class ReduceProd - : public BuiltinOperator<TensorFlowSumOperator, ::tflite::ReducerOptions, + : public BuiltinOperator<TensorFlowProdOperator, ::tflite::ReducerOptions, + ::tflite::BuiltinOptions_ReducerOptions> { + public: + using BuiltinOperator::BuiltinOperator; + flatbuffers::Offset<TfLiteOptions> WriteOptions( + const TocoOperator& op, + flatbuffers::FlatBufferBuilder* builder) const override { + return ::tflite::CreateReducerOptions(*builder, op.keep_dims); + } + + void ReadOptions(const TfLiteOptions& options, + TocoOperator* op) const override { + op->keep_dims = options.keep_dims(); + } + + int GetVersion(const Operator& op) const override { return 1; } +}; + +class ReduceAny + : public BuiltinOperator<TensorFlowAnyOperator, ::tflite::ReducerOptions, ::tflite::BuiltinOptions_ReducerOptions> { public: using BuiltinOperator::BuiltinOperator; @@ -1091,6 +1129,24 @@ class CTCBeamSearchDecoder int GetVersion(const Operator& op) const override { return 1; } }; +class Unpack : public BuiltinOperator<UnpackOperator, ::tflite::UnpackOptions, + ::tflite::BuiltinOptions_UnpackOptions> { + public: + using BuiltinOperator::BuiltinOperator; + flatbuffers::Offset<TfLiteOptions> WriteOptions( + const TocoOperator& op, + flatbuffers::FlatBufferBuilder* builder) const override { + return ::tflite::CreateUnpackOptions(*builder, op.num, op.axis); + } + void ReadOptions(const TfLiteOptions& options, + TocoOperator* op) const override { + op->num = options.num(); + op->axis = options.axis(); + } + + int GetVersion(const Operator& op) const override { return 1; } +}; + class TensorFlowUnsupported : public BaseOperator { public: using BaseOperator::BaseOperator; @@ -1297,6 +1353,10 @@ std::vector<std::unique_ptr<BaseOperator>> BuildOperatorList() { OperatorType::kReduceProd)); ops.push_back(MakeUnique<ReduceMax>(::tflite::BuiltinOperator_REDUCE_MAX, OperatorType::kReduceMax)); + ops.push_back(MakeUnique<ReduceMin>(::tflite::BuiltinOperator_REDUCE_MIN, + OperatorType::kReduceMin)); + ops.push_back(MakeUnique<ReduceAny>(::tflite::BuiltinOperator_REDUCE_ANY, + OperatorType::kAny)); ops.push_back( MakeUnique<ResizeBilinear>(::tflite::BuiltinOperator_RESIZE_BILINEAR, OperatorType::kResizeBilinear)); @@ -1332,6 +1392,8 @@ std::vector<std::unique_ptr<BaseOperator>> BuildOperatorList() { MakeUnique<Pack>(::tflite::BuiltinOperator_PACK, OperatorType::kPack)); ops.push_back(MakeUnique<OneHot>(::tflite::BuiltinOperator_ONE_HOT, OperatorType::kOneHot)); + ops.push_back(MakeUnique<Unpack>(::tflite::BuiltinOperator_UNPACK, + OperatorType::kUnpack)); // Custom Operators. ops.push_back( @@ -1396,6 +1458,8 @@ std::vector<std::unique_ptr<BaseOperator>> BuildOperatorList() { "LOGICAL_AND", OperatorType::kLogicalAnd)); ops.emplace_back(new SimpleOperator<LogicalNotOperator>( "LOGICAL_NOT", OperatorType::kLogicalNot)); + ops.emplace_back(new SimpleOperator<FloorDivOperator>( + "FLOOR_DIV", OperatorType::kFloorDiv)); // Element-wise operator ops.push_back( MakeUnique<SimpleOperator<SinOperator>>("SIN", OperatorType::kSin)); diff --git a/tensorflow/contrib/lite/toco/tflite/operator_test.cc b/tensorflow/contrib/lite/toco/tflite/operator_test.cc index fc854461b4..519a3a4e01 100644 --- a/tensorflow/contrib/lite/toco/tflite/operator_test.cc +++ b/tensorflow/contrib/lite/toco/tflite/operator_test.cc @@ -97,6 +97,16 @@ class OperatorTest : public ::testing::Test { ASSERT_NE(nullptr, output_toco_op.get()); } + + template <typename T> + void CheckReducerOperator(const string& name, OperatorType type) { + T op; + + op.keep_dims = false; + + auto output_toco_op = SerializeAndDeserialize(GetOperator(name, type), op); + EXPECT_EQ(op.keep_dims, output_toco_op->keep_dims); + } }; TEST_F(OperatorTest, SimpleOperators) { @@ -133,6 +143,7 @@ TEST_F(OperatorTest, SimpleOperators) { OperatorType::kLogicalAnd); CheckSimpleOperator<LogicalNotOperator>("LOGICAL_NOT", OperatorType::kLogicalNot); + CheckSimpleOperator<FloorDivOperator>("FLOOR_DIV", OperatorType::kFloorDiv); } TEST_F(OperatorTest, BuiltinAdd) { @@ -144,13 +155,16 @@ TEST_F(OperatorTest, BuiltinAdd) { output_toco_op->fused_activation_function); } -TEST_F(OperatorTest, BuiltinMean) { - MeanOperator op; - op.keep_dims = false; - - auto output_toco_op = - SerializeAndDeserialize(GetOperator("MEAN", OperatorType::kMean), op); - EXPECT_EQ(op.keep_dims, output_toco_op->keep_dims); +TEST_F(OperatorTest, BuiltinReducerOps) { + CheckReducerOperator<MeanOperator>("MEAN", OperatorType::kMean); + CheckReducerOperator<TensorFlowSumOperator>("SUM", OperatorType::kSum); + CheckReducerOperator<TensorFlowProdOperator>("REDUCE_PROD", + OperatorType::kReduceProd); + CheckReducerOperator<TensorFlowMaxOperator>("REDUCE_MAX", + OperatorType::kReduceMax); + CheckReducerOperator<TensorFlowMinOperator>("REDUCE_MIN", + OperatorType::kReduceMin); + CheckReducerOperator<TensorFlowAnyOperator>("REDUCE_ANY", OperatorType::kAny); } TEST_F(OperatorTest, BuiltinCast) { @@ -476,6 +490,16 @@ TEST_F(OperatorTest, BuiltinOneHot) { EXPECT_EQ(op.axis, output_toco_op->axis); } +TEST_F(OperatorTest, BuiltinUnpack) { + UnpackOperator op; + op.num = 5; + op.axis = 2; + auto output_toco_op = + SerializeAndDeserialize(GetOperator("UNPACK", OperatorType::kUnpack), op); + EXPECT_EQ(op.num, output_toco_op->num); + EXPECT_EQ(op.axis, output_toco_op->axis); +} + TEST_F(OperatorTest, CustomCTCBeamSearchDecoder) { CTCBeamSearchDecoderOperator op; op.beam_width = 3; diff --git a/tensorflow/contrib/lite/toco/toco_types.h b/tensorflow/contrib/lite/toco/toco_types.h index d72a3bd1f3..319f1066cd 100644 --- a/tensorflow/contrib/lite/toco/toco_types.h +++ b/tensorflow/contrib/lite/toco/toco_types.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TYPES_H_ -#define TENSORFLOW_CONTRIB_LITE_TOCO_TYPES_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_TOCO_TOCO_TYPES_H_ +#define TENSORFLOW_CONTRIB_LITE_TOCO_TOCO_TYPES_H_ #include <string> #include "tensorflow/core/platform/platform.h" @@ -42,4 +42,4 @@ using tensorflow::uint8; } // namespace toco -#endif // TENSORFLOW_CONTRIB_LITE_TOCO_TYPES_H_ +#endif // TENSORFLOW_CONTRIB_LITE_TOCO_TOCO_TYPES_H_ diff --git a/tensorflow/contrib/lite/toco/tooling_util.cc b/tensorflow/contrib/lite/toco/tooling_util.cc index 2ad2719811..6ab93d9316 100644 --- a/tensorflow/contrib/lite/toco/tooling_util.cc +++ b/tensorflow/contrib/lite/toco/tooling_util.cc @@ -405,6 +405,7 @@ const char* OperatorTypeName(OperatorType type) { HANDLE_OPERATORTYPENAME_CASE(LogicalNot) HANDLE_OPERATORTYPENAME_CASE(LogicalOr) HANDLE_OPERATORTYPENAME_CASE(CTCBeamSearchDecoder) + HANDLE_OPERATORTYPENAME_CASE(Unpack) default: LOG(FATAL) << "Unhandled op type"; #undef HANDLE_OPERATORTYPENAME_CASE @@ -2278,4 +2279,14 @@ void UndoWeightsShuffling(Model* model) { } } +void CopyMinMaxAndQuantizationRelatedFields(const Array& src, Array* dst) { + if (src.minmax) { + dst->GetOrCreateMinMax() = src.GetMinMax(); + } + if (src.quantization_params) { + dst->GetOrCreateQuantizationParams() = src.GetQuantizationParams(); + } + dst->narrow_range = src.narrow_range; +} + } // namespace toco diff --git a/tensorflow/contrib/lite/toco/tooling_util.h b/tensorflow/contrib/lite/toco/tooling_util.h index b99e6111fe..bdeb203024 100644 --- a/tensorflow/contrib/lite/toco/tooling_util.h +++ b/tensorflow/contrib/lite/toco/tooling_util.h @@ -348,6 +348,9 @@ tensorflow::Status NumElements(const std::vector<T>& shape, U* num_elements) { // so that the rest of toco doesn't need to know about shuffled weights. void UndoWeightsShuffling(Model* model); +// Copies minmax, quantization_params, and narrow_range. +void CopyMinMaxAndQuantizationRelatedFields(const Array& src, Array* dst); + } // namespace toco #endif // TENSORFLOW_CONTRIB_LITE_TOCO_TOOLING_UTIL_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/BUILD b/tensorflow/contrib/lite/tools/accuracy/BUILD new file mode 100644 index 0000000000..21941f5c8b --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/BUILD @@ -0,0 +1,314 @@ +package(default_visibility = [ + "//visibility:public", +]) + +licenses(["notice"]) # Apache 2.0 + +load("//tensorflow:tensorflow.bzl", "tf_cc_binary", "tf_cc_test") +load("//tensorflow/contrib/lite:build_def.bzl", "tflite_copts", "tflite_linkopts") + +common_linkopts = tflite_linkopts() + select({ + "//conditions:default": [], + "//tensorflow:android": [ + "-pie", + "-llog", + ], +}) + +cc_library( + name = "utils", + srcs = ["utils.cc"], + hdrs = ["utils.h"], + copts = tflite_copts(), + deps = [ + "//tensorflow/contrib/lite:framework", + "//tensorflow/contrib/lite/kernels:builtin_ops", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + ], + "//conditions:default": [ + "//tensorflow/core:framework", + ], + }, + ), +) + +tf_cc_test( + name = "utils_test", + srcs = ["utils_test.cc"], + args = [ + "--test_model_file=$(location //tensorflow/contrib/lite:testdata/multi_add.bin)", + ], + data = ["//tensorflow/contrib/lite:testdata/multi_add.bin"], + linkopts = common_linkopts, + linkstatic = 1, + deps = [ + ":utils", + "@com_google_googletest//:gtest", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_test_lib", + ], + "//conditions:default": [ + "//tensorflow/core:framework_internal", + "//tensorflow/core:lib", + ], + }, + ), +) + +cc_library( + name = "run_tflite_model_op", + srcs = ["run_tflite_model_op.cc"], + copts = tflite_copts(), + deps = [ + ":utils", + "//tensorflow/contrib/lite:framework", + "//tensorflow/contrib/lite/kernels:builtin_ops", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + ], + "//conditions:default": [ + "//tensorflow/core:tensorflow", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:core_cpu", + "//tensorflow/core:framework", + "//tensorflow/core:lib", + "//tensorflow/core:ops", + ], + }, + ), + alwayslink = 1, +) + +cc_library( + name = "android_required_build_flags", + srcs = ["android_required_build_flags.cc"], + copts = tflite_copts(), +) + +tf_cc_test( + name = "run_tflite_model_op_test", + srcs = ["run_tflite_model_op_test.cc"], + args = [ + "--test_model_file=$(location //tensorflow/contrib/lite:testdata/multi_add.bin)", + ], + data = ["//tensorflow/contrib/lite:testdata/multi_add.bin"], + linkopts = common_linkopts, + linkstatic = 1, + deps = [ + "//tensorflow/cc:cc_ops", + "//tensorflow/cc:scope", + ":run_tflite_model_op", + ":android_required_build_flags", + "@com_google_googletest//:gtest", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_test_lib", + ], + "//conditions:default": [ + "//tensorflow/core:core_cpu", + "//tensorflow/core:framework", + "//tensorflow/core:framework_internal", + "//tensorflow/core:lib", + "//tensorflow/core:ops", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:tensorflow", + ], + }, + ), +) + +cc_library( + name = "stage", + hdrs = ["stage.h"], + copts = tflite_copts(), + deps = [ + "//tensorflow/cc:scope", + ], +) + +cc_library( + name = "file_reader_stage", + srcs = ["file_reader_stage.cc"], + hdrs = ["file_reader_stage.h"], + deps = [ + ":stage", + "//tensorflow/cc:cc_ops", + "//tensorflow/cc:scope", + ], +) + +tf_cc_test( + name = "file_reader_stage_test", + srcs = ["file_reader_stage_test.cc"], + linkopts = common_linkopts, + linkstatic = 1, + deps = [ + ":file_reader_stage", + "@com_google_googletest//:gtest", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core/kernels:android_whole_file_read_ops", + "//tensorflow/core:android_tensorflow_test_lib", + ], + "//conditions:default": [ + "//tensorflow/core:core_cpu", + "//tensorflow/core:tensorflow", + ], + }, + ), +) + +cc_library( + name = "run_tflite_model_stage", + srcs = ["run_tflite_model_stage.cc"], + hdrs = ["run_tflite_model_stage.h"], + copts = tflite_copts(), + deps = [ + ":run_tflite_model_op", + ":stage", + "//tensorflow/cc:cc_ops", + "//tensorflow/cc:scope", + ], +) + +cc_library( + name = "accuracy_eval_stage", + hdrs = ["accuracy_eval_stage.h"], + copts = tflite_copts(), + deps = [ + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + ], + "//conditions:default": [ + "//tensorflow/core:framework", + ], + }, + ), +) + +cc_library( + name = "eval_pipeline", + srcs = ["eval_pipeline.cc"], + hdrs = ["eval_pipeline.h"], + copts = tflite_copts(), + deps = [ + ":accuracy_eval_stage", + ":stage", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + ], + "//conditions:default": [ + "//tensorflow/core:framework", + "//tensorflow/core:core_cpu", + ], + }, + ), +) + +tf_cc_test( + name = "eval_pipeline_test", + srcs = ["eval_pipeline_test.cc"], + linkopts = common_linkopts, + linkstatic = 1, + deps = [ + ":eval_pipeline", + "//tensorflow/cc:cc_ops", + "@com_google_googletest//:gtest", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_test_lib", + ], + "//conditions:default": [ + "//tensorflow/core:framework", + "//tensorflow/core:core_cpu", + "//tensorflow/core:ops", + "//tensorflow/core:tensorflow", + ], + }, + ), +) + +cc_library( + name = "eval_pipeline_builder", + srcs = ["eval_pipeline_builder.cc"], + hdrs = ["eval_pipeline_builder.h"], + copts = tflite_copts(), + deps = [ + ":eval_pipeline", + ":accuracy_eval_stage", + ":stage", + "@com_google_absl//absl/memory", + "//tensorflow/cc:cc_ops", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + ], + "//conditions:default": [ + "//tensorflow/core:framework", + "//tensorflow/core:core_cpu", + "//tensorflow/core:ops", + "//tensorflow/core:tensorflow", + ], + }, + ), +) + +tf_cc_test( + name = "eval_pipeline_builder_test", + srcs = ["eval_pipeline_builder_test.cc"], + linkopts = common_linkopts, + linkstatic = 1, + deps = [ + ":eval_pipeline_builder", + "//tensorflow/cc:cc_ops", + "@com_google_googletest//:gtest", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_test_lib", + ], + "//conditions:default": [ + "//tensorflow/core:framework", + "//tensorflow/core:core_cpu", + "//tensorflow/core:ops", + "//tensorflow/core:tensorflow", + ], + }, + ), +) + +cc_library( + name = "csv_writer", + hdrs = ["csv_writer.h"], + copts = tflite_copts(), + deps = select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + ], + "//conditions:default": [ + "//tensorflow/core:lib", + ], + }, + ), +) diff --git a/tensorflow/contrib/lite/tools/accuracy/README.md b/tensorflow/contrib/lite/tools/accuracy/README.md new file mode 100644 index 0000000000..769ef201d2 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/README.md @@ -0,0 +1,40 @@ +## TFLite accuracy library. + +This library provides evaluation pipelines that can be used to evaluate +accuracy and other metrics of a model. The resulting binary can be run on +a desktop or on a mobile device. + +## Usage +The tool provides an evaluation pipeline with different stages. Each +stage outputs a Tensorflow graph. +A sample usage is shown below. + +```C++ +// First build the pipeline. +EvalPipelineBuilder builder; +std::unique_ptr<EvalPipeline> eval_pipeline; +auto status = builder.WithInput("pipeline_input", DT_FLOAT) + .WithInputStage(&input_stage) + .WithRunModelStage(&run_model_stage) + .WithPreprocessingStage(&preprocess_stage) + .WithAccuracyEval(&eval) + .Build(scope, &eval_pipeline); +TF_CHECK_OK(status); + +// Now run the pipeline with inputs and outputs. +std::unique_ptr<Session> session(NewSession(SessionOptions())); +TF_CHECK_OK(eval_pipeline.AttachSession(std::move(session))); +Tensor input = ... read input for the model ... +Tensor ground_truth = ... read ground truth for the model ... +TF_CHECK_OK(eval_pipeline.Run(input1, ground_truth1)); +``` +For further examples, check the usage in [imagenet accuracy evaluation binary] +(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_accuracy_eval.cc) + +## Measuring accuracy of published models. + +### ILSVRC (Imagenet Large Scale Visual Recognition Contest) classification task +For measuring accuracy for [ILSVRC 2012 image classification task] +(http://www.image-net.org/challenges/LSVRC/2012/), the binary can be built +using these +[instructions.](ilsvrc/) diff --git a/tensorflow/contrib/lite/tools/accuracy/accuracy_eval_stage.h b/tensorflow/contrib/lite/tools/accuracy/accuracy_eval_stage.h new file mode 100644 index 0000000000..9cb843729a --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/accuracy_eval_stage.h @@ -0,0 +1,49 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_ACCURACY_EVAL_STAGE_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_ACCURACY_EVAL_STAGE_H_ + +#include <vector> + +#include "tensorflow/core/framework/tensor.h" + +namespace tensorflow { +namespace metrics { + +// Base class for evaluation stage that evaluates the accuracy of the model. +// This stage calculates the accuracy metrics given the model outputs and +// expected ground truth. +class AccuracyEval { + public: + AccuracyEval() = default; + AccuracyEval(const AccuracyEval&) = delete; + AccuracyEval& operator=(const AccuracyEval&) = delete; + + AccuracyEval(const AccuracyEval&&) = delete; + AccuracyEval& operator=(const AccuracyEval&&) = delete; + + virtual ~AccuracyEval() = default; + + // Evaluates the accuracy of the model for given `model_outputs` and the + // `ground truth`. + // Derived classes can do additional book keeping, calculate aggregrate + // statistics etc for the given model. + virtual Status ComputeEval(const std::vector<Tensor>& model_outputs, + const Tensor& ground_truth) = 0; +}; +} // namespace metrics +} // namespace tensorflow +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_ACCURACY_EVAL_STAGE_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/android_required_build_flags.cc b/tensorflow/contrib/lite/tools/accuracy/android_required_build_flags.cc new file mode 100644 index 0000000000..7fa8986716 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/android_required_build_flags.cc @@ -0,0 +1,27 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +// Tensorflow on Android requires selective registration to be enabled in order +// for certain types (e.g. DT_UINT8) to work. +// Checks below ensure that for Android build, the right flags are passed to +// the compiler. + +#if defined(__ANDROID__) && (!defined(__ANDROID_TYPES_FULL__) || \ + !defined(SUPPORT_SELECTIVE_REGISTRATION)) +#error \ + "Binary needs custom kernel support. For enabling custom kernels on " \ + "Android, please pass -D__ANDROID_TYPES_FULL__ && " \ + "-DSUPPORT_SELECTIVE_REGISTRATION for including the kernel in the binary." +#endif diff --git a/tensorflow/contrib/lite/tools/accuracy/csv_writer.h b/tensorflow/contrib/lite/tools/accuracy/csv_writer.h new file mode 100644 index 0000000000..806b0d9418 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/csv_writer.h @@ -0,0 +1,79 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_CSV_WRITER_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_CSV_WRITER_H_ + +#include <fstream> +#include <vector> + +#include "tensorflow/core/lib/core/errors.h" +#include "tensorflow/core/lib/core/status.h" + +namespace tensorflow { +namespace metrics { +// A simple CSV writer that writes values of same type for fixed number of +// columns. This supports a very limited set of CSV spec and doesn't do any +// escaping. +// Usage: +// std::ofstream * output_stream = ... +// CSVWriter writer({"column1", "column2"}, output_stream); +// writer.WriteRow({4, 5}); +// writer.Flush(); // flush results immediately. +class CSVWriter { + public: + CSVWriter(const std::vector<string>& columns, std::ofstream* output_stream) + : num_columns_(columns.size()), output_stream_(output_stream) { + TF_CHECK_OK(WriteRow(columns, output_stream_)); + } + + template <typename T> + Status WriteRow(const std::vector<T>& values) { + if (values.size() != num_columns_) { + return errors::InvalidArgument("Invalid size for row:", values.size(), + " expected: ", num_columns_); + } + return WriteRow(values, output_stream_); + } + + void Flush() { output_stream_->flush(); } + + ~CSVWriter() { output_stream_->flush(); } + + private: + template <typename T> + static Status WriteRow(const std::vector<T>& values, + std::ofstream* output_stream) { + bool first = true; + for (const auto& v : values) { + if (!first) { + (*output_stream) << ", "; + } else { + first = false; + } + (*output_stream) << v; + } + (*output_stream) << "\n"; + if (!output_stream->good()) { + return errors::Internal("Writing to stream failed."); + } + return Status::OK(); + } + const size_t num_columns_; + std::ofstream* output_stream_; +}; +} // namespace metrics +} // namespace tensorflow +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_CSV_WRITER_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/eval_pipeline.cc b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline.cc new file mode 100644 index 0000000000..a03aba6a26 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline.cc @@ -0,0 +1,39 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/eval_pipeline.h" + +namespace tensorflow { +namespace metrics { + +Status EvalPipeline::AttachSession(std::unique_ptr<Session> session) { + session_ = std::move(session); + TF_RETURN_IF_ERROR(session_->Create(model_graph_)); + return Status::OK(); +} + +Status EvalPipeline::Run(const Tensor& input, const Tensor& ground_truth) { + if (session_ == nullptr) { + return errors::Internal("No session is associated with the graph."); + } + std::vector<Tensor> outputs; + TF_RETURN_IF_ERROR(session_->Run({{params_.model_input_node_name, input}}, + {params_.model_output_node_name}, {}, + &outputs)); + TF_RETURN_IF_ERROR(eval_->ComputeEval(outputs, ground_truth)); + return Status::OK(); +} +} // namespace metrics +} // namespace tensorflow diff --git a/tensorflow/contrib/lite/tools/accuracy/eval_pipeline.h b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline.h new file mode 100644 index 0000000000..c9cfc86613 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline.h @@ -0,0 +1,87 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_EVAL_PIPELINE_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_EVAL_PIPELINE_H_ + +#include <string> + +#include "tensorflow/contrib/lite/tools/accuracy/accuracy_eval_stage.h" +#include "tensorflow/contrib/lite/tools/accuracy/stage.h" +#include "tensorflow/core/public/session.h" + +namespace tensorflow { +namespace metrics { + +// Pipeline for evaluating a model. +// Runs the graph and passes the output of graph to +// the provided instance of AccuracyEval. +// Example usage: +// AccuracyEval *eval; +// GraphDef graph_def; +// ... populate graph_def... +// +// EvalPipeline eval_pipeline(&graph_def, +// {.model_input_node_name = "model_input", +// .model_output_node_name = "model_output"}, +// eval); +// std::unique_ptr<Session> session(NewSession(SessionOptions())); +// TF_CHECK_OK(eval_pipeline.AttachSession(std::move(session))); +// Tensor input = ... read input for the model ... +// Tensor ground_truth = ... read ground truth for the model ... +// TF_CHECK_OK(eval_pipeline.Run(input, ground_truth)); +// +class EvalPipeline { + public: + struct Params { + string model_input_node_name; + string model_output_node_name; + }; + + // Creates a new `EvalPipeline` object. The ownership of the `accuracy_eval` + // is retained by the caller. Lifetime of `accuracy_eval` instance should + // be longer than the lifetime of this instance of pipeline. + EvalPipeline(const GraphDef& graph, const Params& params, + AccuracyEval* accuracy_eval) + : model_graph_(graph), + params_(params), + eval_(accuracy_eval), + session_(nullptr) {} + + EvalPipeline(const EvalPipeline&) = delete; + EvalPipeline& operator=(const EvalPipeline&) = delete; + + EvalPipeline(const EvalPipeline&&) = delete; + EvalPipeline& operator=(const EvalPipeline&&) = delete; + + // Attaches the given session to this instance of pipeline. + // The provided session object will be reused for subsequent calls to + // EvalPipeline::Run. + Status AttachSession(std::unique_ptr<Session> session); + + // Runs the model by feeding `input` and then passes the output of the model + // along with provided `ground_truth` to the AccuracyEval instance by calling + // AccuracyEval::ComputeEval. + Status Run(const Tensor& input, const Tensor& ground_truth); + + private: + GraphDef model_graph_; + Params params_; + AccuracyEval* eval_; + std::unique_ptr<Session> session_; +}; +} // namespace metrics +} // namespace tensorflow +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_EVAL_PIPELINE_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder.cc b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder.cc new file mode 100644 index 0000000000..2e16437e15 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder.cc @@ -0,0 +1,100 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder.h" + +#include "absl/memory/memory.h" +#include "tensorflow/cc/ops/standard_ops.h" + +namespace tensorflow { +namespace metrics { + +EvalPipelineBuilder& EvalPipelineBuilder::WithInputStage(Stage* input_stage) { + input_stage_ = input_stage; + return *this; +} + +EvalPipelineBuilder& EvalPipelineBuilder::WithPreprocessingStage( + Stage* preprocessing_stage) { + preprocessing_stage_ = preprocessing_stage; + return *this; +} + +EvalPipelineBuilder& EvalPipelineBuilder::WithRunModelStage( + Stage* run_model_stage) { + run_model_stage_ = run_model_stage; + return *this; +} + +EvalPipelineBuilder& EvalPipelineBuilder::WithAccuracyEval( + AccuracyEval* accuracy_eval) { + accuracy_eval_ = accuracy_eval; + return *this; +} + +EvalPipelineBuilder& EvalPipelineBuilder::WithInput(const string& input_name, + DataType input_type) { + input_name_ = input_name; + input_type_ = input_type; + return *this; +} + +Status EvalPipelineBuilder::Build( + const Scope& scope, std::unique_ptr<EvalPipeline>* eval_pipeline) { + if (input_stage_ == nullptr) { + return errors::InvalidArgument("Input stage is null."); + } + if (preprocessing_stage_ == nullptr) { + return errors::InvalidArgument("Preprocessing stage is null."); + } + if (run_model_stage_ == nullptr) { + return errors::InvalidArgument("Run model stage is null."); + } + if (accuracy_eval_ == nullptr) { + return errors::InvalidArgument("accuracy_eval is null."); + } + if (input_name_.empty()) { + return errors::InvalidArgument("input name is not set."); + } + if (input_type_ == DT_INVALID) { + return errors::InvalidArgument("input type is not set."); + } + + auto input_placeholder = + ops::Placeholder(scope.WithOpName(input_name_), input_type_); + TF_RETURN_IF_ERROR(scope.status()); + + input_stage_->AddToGraph(scope, input_placeholder); + TF_RETURN_IF_ERROR(scope.status()); + + preprocessing_stage_->AddToGraph(scope, input_stage_->Output()); + TF_RETURN_IF_ERROR(scope.status()); + + run_model_stage_->AddToGraph(scope, preprocessing_stage_->Output()); + TF_RETURN_IF_ERROR(scope.status()); + + GraphDef graph_def; + TF_RETURN_IF_ERROR(scope.ToGraphDef(&graph_def)); + EvalPipeline::Params params; + params.model_input_node_name = input_name_; + params.model_output_node_name = run_model_stage_->output_name(); + *eval_pipeline = + absl::make_unique<EvalPipeline>(graph_def, params, accuracy_eval_); + + return Status::OK(); +} + +} // namespace metrics +} // namespace tensorflow diff --git a/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder.h b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder.h new file mode 100644 index 0000000000..692db022f8 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder.h @@ -0,0 +1,99 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_EVAL_PIPELINE_BUILDER_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_EVAL_PIPELINE_BUILDER_H_ + +#include <memory> +#include <string> + +#include "tensorflow/contrib/lite/tools/accuracy/accuracy_eval_stage.h" +#include "tensorflow/contrib/lite/tools/accuracy/eval_pipeline.h" +#include "tensorflow/contrib/lite/tools/accuracy/stage.h" + +namespace tensorflow { +namespace metrics { + +// A builder to simplify construction of an `EvalPipeline` instance. +// The `Build` method creates an |EvalPipeline| with the following structure: +// |input| -> |input_stage| +// |--> |preprocessing_stage| +// |--> |run_model_stage| -> |accuracy_eval_stage|. +// The stages are chained in the order shown above. Any missing stage results in +// an error. The ownership of the stage object is retained by the caller. Stage +// objects need to exist until the |Build| method is called. +// +// Currently only single inputs are supported. +// +// Example Usage: +// EvalPipelineBuilder builder; +// std::unique_ptr<EvalPipeline> eval_pipeline; +// auto status = builder.WithInput("pipeline_input", DT_FLOAT) +// .WithInputStage(&input_stage) +// .WithRunModelStage(&run_model_stage) +// .WithPreprocessingStage(&preprocess_stage) +// .WithAccuracyEval(&eval) +// .Build(scope, &eval_pipeline); +// TF_CHECK_OK(status); +class EvalPipelineBuilder { + public: + EvalPipelineBuilder() = default; + EvalPipelineBuilder(const EvalPipelineBuilder&) = delete; + EvalPipeline& operator=(const EvalPipelineBuilder&) = delete; + + EvalPipelineBuilder(const EvalPipelineBuilder&&) = delete; + EvalPipeline& operator=(const EvalPipelineBuilder&&) = delete; + + // Sets the input stage for the pipeline. + // Input stage converts the input, say filename into appropriate format + // that can be consumed by the preprocessing stage. + EvalPipelineBuilder& WithInputStage(Stage* input_stage); + + // Sets the preprocessing stage for the pipeline. + // Preprocessing stage converts the input into a format that can be used to + // run the model. + EvalPipelineBuilder& WithPreprocessingStage(Stage* preprocessing_stage); + + // Sets the run model stage for the pipeline. + // This stage receives the preprocessing input and output of this stage is + // fed to the accuracy eval stage. + EvalPipelineBuilder& WithRunModelStage(Stage* run_model_stage); + + // Sets the accuracy eval for the pipeline. + // Results of evaluating the pipeline are fed to the `accuracy_eval` instance. + EvalPipelineBuilder& WithAccuracyEval(AccuracyEval* accuracy_eval); + + // Sets the name and type of input for the pipeline. + // TODO(shashishekhar): Support multiple inputs for the pipeline, use a vector + // here. + EvalPipelineBuilder& WithInput(const string& input_name, DataType input_type); + + // Builds the pipeline and assigns the pipeline to `eval_pipeline`. + // If the pipeline creation fails `eval_pipeline` is untouched. + Status Build(const Scope& scope, + std::unique_ptr<EvalPipeline>* eval_pipeline); + + private: + Stage* input_stage_ = nullptr; + Stage* preprocessing_stage_ = nullptr; + Stage* run_model_stage_ = nullptr; + AccuracyEval* accuracy_eval_ = nullptr; + string input_name_; + DataType input_type_ = DT_INVALID; +}; + +} // namespace metrics +} // namespace tensorflow +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_EVAL_PIPELINE_BUILDER_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder_test.cc b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder_test.cc new file mode 100644 index 0000000000..2d41929b79 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder_test.cc @@ -0,0 +1,229 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder.h" +#include <gtest/gtest.h> +#include "tensorflow/cc/ops/standard_ops.h" +#include "tensorflow/core/public/session.h" + +namespace tensorflow { +namespace metrics { +namespace { + +class IdentityStage : public Stage { + public: + IdentityStage(const string& name, const string& output) + : name_(name), output_(output) {} + + void AddToGraph(const Scope& scope, const Input& input) override { + called_count_++; + inputs_.push_back(input.node()->name()); + stage_output_ = ops::Identity(scope.WithOpName(output_), input); + } + + string name() const override { return name_; } + string output_name() const override { return output_; } + + int times_called() const { return called_count_; } + + const std::vector<string> input_params() { return inputs_; } + + private: + string name_; + string output_; + int called_count_ = 0; + std::vector<string> inputs_; +}; + +class FailingStage : public Stage { + public: + FailingStage(const string& name, const string& output) + : name_(name), output_(output) {} + + void AddToGraph(const Scope& scope, const Input& input) override { + called_count_++; + scope.UpdateStatus(errors::Internal("Stage failed:", name_)); + } + + string name() const override { return name_; } + string output_name() const override { return output_; } + + int times_called() const { return called_count_; } + + private: + string name_; + string output_; + int called_count_ = 0; +}; + +class SimpleAccuracyEval : public AccuracyEval { + public: + SimpleAccuracyEval() {} + + Status ComputeEval(const std::vector<Tensor>& model_outputs, + const Tensor& ground_truth) override { + return Status::OK(); + } +}; + +TEST(EvalPipelineBuilder, MissingPipelineStages) { + IdentityStage input_stage("input_stage", "input_stage_out"); + IdentityStage run_model_stage("run_model", "run_model_out"); + IdentityStage preprocess_stage("preprocess_stage", "preprocess_stage_out"); + const string pipeline_input = "pipeline_input"; + + SimpleAccuracyEval eval; + + Scope scope = Scope::NewRootScope(); + std::unique_ptr<EvalPipeline> eval_pipeline; + EvalPipelineBuilder builder; + auto status = + builder.WithInputStage(&input_stage).Build(scope, &eval_pipeline); + EXPECT_FALSE(status.ok()); + EXPECT_FALSE(eval_pipeline); + + status = + builder.WithRunModelStage(&run_model_stage).Build(scope, &eval_pipeline); + EXPECT_FALSE(status.ok()); + EXPECT_FALSE(eval_pipeline); + + status = builder.WithPreprocessingStage(&preprocess_stage) + .Build(scope, &eval_pipeline); + EXPECT_FALSE(status.ok()); + EXPECT_FALSE(eval_pipeline); + + status = + builder.WithInput(pipeline_input, DT_FLOAT).Build(scope, &eval_pipeline); + EXPECT_FALSE(status.ok()); + EXPECT_FALSE(eval_pipeline); + + status = builder.WithAccuracyEval(&eval).Build(scope, &eval_pipeline); + TF_CHECK_OK(status); + EXPECT_TRUE(eval_pipeline); +} + +TEST(EvalPipeline, InputStageFailure) { + FailingStage input_stage("input_stage", "input_stage_out"); + IdentityStage run_model_stage("run_model", "run_model_out"); + IdentityStage preprocess_stage("preprocess_stage", "preprocess_stage_out"); + const string pipeline_input = "pipeline_input"; + + SimpleAccuracyEval eval; + + Scope scope = Scope::NewRootScope(); + std::unique_ptr<EvalPipeline> eval_pipeline; + EvalPipelineBuilder builder; + auto status = builder.WithInputStage(&input_stage) + .WithRunModelStage(&run_model_stage) + .WithPreprocessingStage(&preprocess_stage) + .WithInput(pipeline_input, DT_FLOAT) + .WithAccuracyEval(&eval) + .Build(scope, &eval_pipeline); + + EXPECT_FALSE(scope.status().ok()); + // None of the other stages would have been called. + EXPECT_EQ(1, input_stage.times_called()); + EXPECT_EQ(0, preprocess_stage.times_called()); + EXPECT_EQ(0, run_model_stage.times_called()); +} + +TEST(EvalPipeline, PreprocessingFailure) { + IdentityStage input_stage("input_stage", "input_stage_out"); + FailingStage preprocess_stage("preprocess_stage", "preprocess_stage_out"); + IdentityStage run_model_stage("run_model", "run_model_out"); + const string pipeline_input = "pipeline_input"; + + SimpleAccuracyEval eval; + + Scope scope = Scope::NewRootScope(); + std::unique_ptr<EvalPipeline> eval_pipeline; + EvalPipelineBuilder builder; + auto status = builder.WithInputStage(&input_stage) + .WithRunModelStage(&run_model_stage) + .WithPreprocessingStage(&preprocess_stage) + .WithInput(pipeline_input, DT_FLOAT) + .WithAccuracyEval(&eval) + .Build(scope, &eval_pipeline); + + EXPECT_FALSE(status.ok()); + // None of the other stages would have been called. + EXPECT_EQ(1, input_stage.times_called()); + EXPECT_EQ(1, preprocess_stage.times_called()); + EXPECT_EQ(0, run_model_stage.times_called()); +} + +TEST(EvalPipeline, GraphEvalFailure) { + IdentityStage input_stage("input_stage", "input_stage_out"); + IdentityStage preprocess_stage("preprocess_stage", "preprocess_stage_out"); + FailingStage run_model_stage("run_model", "run_model_out"); + const string pipeline_input = "pipeline_input"; + + SimpleAccuracyEval eval; + + Scope scope = Scope::NewRootScope(); + std::unique_ptr<EvalPipeline> eval_pipeline; + EvalPipelineBuilder builder; + auto status = builder.WithInputStage(&input_stage) + .WithRunModelStage(&run_model_stage) + .WithPreprocessingStage(&preprocess_stage) + .WithInput(pipeline_input, DT_FLOAT) + .WithAccuracyEval(&eval) + .Build(scope, &eval_pipeline); + + EXPECT_FALSE(status.ok()); + // None of the other stages would have been called. + EXPECT_EQ(1, input_stage.times_called()); + EXPECT_EQ(1, preprocess_stage.times_called()); + EXPECT_EQ(1, run_model_stage.times_called()); +} + +TEST(EvalPipeline, PipelineHasCorrectSequence) { + IdentityStage input_stage("input_stage", "input_stage_out"); + IdentityStage preprocess_stage("preprocess_stage", "preprocess_stage_out"); + IdentityStage run_model_stage("run_model", "run_model_out"); + const string pipeline_input = "pipeline_input"; + + SimpleAccuracyEval eval; + + Scope scope = Scope::NewRootScope(); + std::unique_ptr<EvalPipeline> eval_pipeline; + EvalPipelineBuilder builder; + auto status = builder.WithInputStage(&input_stage) + .WithRunModelStage(&run_model_stage) + .WithPreprocessingStage(&preprocess_stage) + .WithInput(pipeline_input, DT_FLOAT) + .WithAccuracyEval(&eval) + .Build(scope, &eval_pipeline); + TF_CHECK_OK(status); + + ASSERT_EQ(1, input_stage.times_called()); + ASSERT_EQ(1, run_model_stage.times_called()); + ASSERT_EQ(1, preprocess_stage.times_called()); + + EXPECT_EQ(pipeline_input, input_stage.input_params()[0]); + EXPECT_EQ(input_stage.output_name(), preprocess_stage.input_params()[0]); + EXPECT_EQ(preprocess_stage.output_name(), run_model_stage.input_params()[0]); +} + +} // namespace + +} // namespace metrics +} // namespace tensorflow + +int main(int argc, char** argv) { + ::testing::InitGoogleTest(&argc, argv); + + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_test.cc b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_test.cc new file mode 100644 index 0000000000..ea0f6e19df --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/eval_pipeline_test.cc @@ -0,0 +1,133 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/eval_pipeline.h" +#include <gtest/gtest.h> +#include "tensorflow/cc/ops/standard_ops.h" +#include "tensorflow/core/public/session.h" + +namespace tensorflow { +namespace metrics { +namespace { + +Tensor CreateFloatTensor(float value) { + Tensor tensor(DT_FLOAT, TensorShape({})); + tensor.scalar<float>()() = value; + return tensor; +} + +class NoOpAccuracyEval : public AccuracyEval { + public: + explicit NoOpAccuracyEval(const Status& status_to_return) + : status_to_return_(status_to_return) {} + + Status ComputeEval(const std::vector<Tensor>& model_outputs, + const Tensor& ground_truth) override { + model_outputs_ = model_outputs; + ground_truth_ = ground_truth; + was_called_ = true; + return status_to_return_; + } + + bool WasCalled() { return was_called_; } + std::vector<Tensor> model_outputs() { return model_outputs_; } + Tensor ground_truth() { return ground_truth_; } + + private: + std::vector<Tensor> model_outputs_; + Tensor ground_truth_; + Status status_to_return_; + bool was_called_ = false; +}; + +TEST(EvalPipeline, AccuracyEvalIsCalled) { + Scope scope = Scope::NewRootScope(); + // A graph that adds 1 to input. + auto input = ops::Placeholder(scope.WithOpName("input"), DT_FLOAT); + auto add_node = ops::Add(scope.WithOpName("output"), input, 1.0f); + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + EvalPipeline::Params params; + params.model_input_node_name = "input"; + params.model_output_node_name = "output"; + NoOpAccuracyEval accuracy_eval(Status::OK()); + + EvalPipeline eval_pipeline(graph_def, params, &accuracy_eval); + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(eval_pipeline.AttachSession(std::move(session))); + TF_CHECK_OK(eval_pipeline.Run(CreateFloatTensor(5), CreateFloatTensor(27))); + + EXPECT_TRUE(accuracy_eval.WasCalled()); + auto outputs = accuracy_eval.model_outputs(); + ASSERT_EQ(1, outputs.size()); + EXPECT_EQ(6.0f, outputs[0].scalar<float>()()); + // Ground truth is unchanged. + EXPECT_EQ(27, accuracy_eval.ground_truth().scalar<float>()()); +} + +TEST(EvalPipeline, EvalIsNotCalledOnGraphRunFailure) { + Scope scope = Scope::NewRootScope(); + // A graph that adds 1 to input. + auto input = ops::Placeholder(scope.WithOpName("input"), DT_FLOAT); + auto add_node = ops::Add(scope.WithOpName("output"), input, 1.0f); + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + EvalPipeline::Params params; + params.model_input_node_name = "input"; + params.model_output_node_name = "output"; + NoOpAccuracyEval accuracy_eval(Status::OK()); + + EvalPipeline eval_pipeline(graph_def, params, &accuracy_eval); + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(eval_pipeline.AttachSession(std::move(session))); + + // Pass a string tensor instead of a float tensor. + Tensor string_tensor(DT_STRING, TensorShape{}); + auto status = eval_pipeline.Run(string_tensor, CreateFloatTensor(27)); + EXPECT_FALSE(accuracy_eval.WasCalled()); + EXPECT_FALSE(status.ok()); +} + +TEST(EvalPipeline, AccuracyEvalFailureResultsInFailure) { + Scope scope = Scope::NewRootScope(); + // A graph that adds 1 to input. + auto input = ops::Placeholder(scope.WithOpName("input"), DT_FLOAT); + auto add_node = ops::Add(scope.WithOpName("output"), input, 1.0f); + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + EvalPipeline::Params params; + params.model_input_node_name = "input"; + params.model_output_node_name = "output"; + NoOpAccuracyEval accuracy_eval(errors::Internal("accuracy_fail")); + + EvalPipeline eval_pipeline(graph_def, params, &accuracy_eval); + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(eval_pipeline.AttachSession(std::move(session))); + auto status = eval_pipeline.Run(CreateFloatTensor(5), CreateFloatTensor(27)); + + EXPECT_TRUE(accuracy_eval.WasCalled()); + EXPECT_FALSE(status.ok()); +} + +} // namespace + +} // namespace metrics +} // namespace tensorflow + +int main(int argc, char** argv) { + ::testing::InitGoogleTest(&argc, argv); + + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/compiler/xla/ptr_util.h b/tensorflow/contrib/lite/tools/accuracy/file_reader_stage.cc index bfcdfc62f9..61bed369f8 100644 --- a/tensorflow/compiler/xla/ptr_util.h +++ b/tensorflow/contrib/lite/tools/accuracy/file_reader_stage.cc @@ -1,4 +1,4 @@ -/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. @@ -13,23 +13,17 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMPILER_XLA_PTR_UTIL_H_ -#define TENSORFLOW_COMPILER_XLA_PTR_UTIL_H_ +#include "tensorflow/contrib/lite/tools/accuracy/file_reader_stage.h" -// As this was moved to tensorflow/core/util, provide indirections here to -// maintain current functionality of the library. +#include "tensorflow/cc/framework/scope.h" +#include "tensorflow/cc/ops/standard_ops.h" -#include <stddef.h> - -#include <memory> -#include <type_traits> -#include <utility> - -#include "tensorflow/core/util/ptr_util.h" - -namespace xla { -using tensorflow::MakeUnique; -using tensorflow::WrapUnique; -} // namespace xla - -#endif // TENSORFLOW_COMPILER_XLA_PTR_UTIL_H_ +namespace tensorflow { +namespace metrics { +void FileReaderStage::AddToGraph(const Scope& scope, const Input& input) { + if (!scope.ok()) return; + Scope s = scope.WithOpName(name()); + this->stage_output_ = ops::ReadFile(s.WithOpName(output_name()), input); +} +} // namespace metrics +} // namespace tensorflow diff --git a/tensorflow/contrib/lite/tools/accuracy/file_reader_stage.h b/tensorflow/contrib/lite/tools/accuracy/file_reader_stage.h new file mode 100644 index 0000000000..18db5837c1 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/file_reader_stage.h @@ -0,0 +1,37 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_FILE_READER_STAGE_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_FILE_READER_STAGE_H_ + +#include <string> + +#include "tensorflow/contrib/lite/tools/accuracy/stage.h" + +namespace tensorflow { +namespace metrics { +// A stage for reading a file into |string|. +// Inputs: a string tensor: |file_name|. +// Outputs: a string tensor: contents of |file_name|. +class FileReaderStage : public Stage { + public: + string name() const override { return "stage_filereader"; } + string output_name() const override { return "stage_filereader_output"; } + + void AddToGraph(const Scope& scope, const Input& input) override; +}; +} // namespace metrics +} // namespace tensorflow +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_FILE_READER_STAGE_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/file_reader_stage_test.cc b/tensorflow/contrib/lite/tools/accuracy/file_reader_stage_test.cc new file mode 100644 index 0000000000..a75f99187d --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/file_reader_stage_test.cc @@ -0,0 +1,110 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include <cstdio> +#include <fstream> +#include <memory> + +#include <gtest/gtest.h> +#include "tensorflow/contrib/lite/tools/accuracy/file_reader_stage.h" +#include "tensorflow/core/public/session.h" + +namespace tensorflow { +namespace metrics { +namespace { + +class TempFile { + public: + TempFile() { + string file_path; + if (Env::Default()->LocalTempFilename(&file_path)) { + file_path_ = file_path; + created_ = true; + } + } + + string filepath() { return file_path_; } + bool CreateFileWithContents(const std::string& contents) { + if (!created_) { + return false; + } + std::fstream file(file_path_, std::ios_base::out); + if (file) { + file << contents; + } + return file.good(); + } + + ~TempFile() { + if (created_) { + std::remove(file_path_.c_str()); + } + } + + private: + bool created_ = false; + string file_path_; +}; + +TEST(FileReaderStageTest, FileIsRead) { + TempFile file; + const string kFileContents = "Hello world."; + ASSERT_TRUE(file.CreateFileWithContents(kFileContents)); + Scope scope = Scope::NewRootScope(); + FileReaderStage reader_stage; + reader_stage.AddToGraph(scope, file.filepath()); + TF_CHECK_OK(scope.status()); + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(session->Create(graph_def)); + std::vector<Tensor> outputs; + auto run_status = + session->Run({}, /*inputs*/ + {reader_stage.output_name()}, {}, /*target node names */ + &outputs); + TF_CHECK_OK(run_status); + EXPECT_EQ(1, outputs.size()); + string contents = outputs[0].scalar<string>()(); + EXPECT_EQ(kFileContents, contents); +} + +TEST(FileReaderStageTest, InvalidFile) { + Scope scope = Scope::NewRootScope(); + FileReaderStage reader_stage; + reader_stage.AddToGraph(scope, string("non_existent_file")); + TF_CHECK_OK(scope.status()); + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(session->Create(graph_def)); + std::vector<Tensor> outputs; + auto run_status = + session->Run({}, /*inputs*/ + {reader_stage.output_name()}, {}, /*target node names */ + &outputs); + EXPECT_FALSE(run_status.ok()); +} + +} // namespace + +} // namespace metrics +} // namespace tensorflow + +int main(int argc, char** argv) { + ::testing::InitGoogleTest(&argc, argv); + + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/BUILD b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/BUILD new file mode 100644 index 0000000000..db4b688a45 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/BUILD @@ -0,0 +1,171 @@ +package(default_visibility = [ + "//visibility:public", +]) + +licenses(["notice"]) # Apache 2.0 + +load("//tensorflow:tensorflow.bzl", "tf_cc_binary", "tf_cc_test") +load("//tensorflow/contrib/lite:build_def.bzl", "tflite_copts", "tflite_linkopts") + +common_linkopts = tflite_linkopts() + select({ + "//conditions:default": [], + "//tensorflow:android": [ + "-pie", + "-llog", + ], +}) + +cc_library( + name = "inception_preprocessing", + srcs = ["inception_preprocessing.cc"], + hdrs = ["inception_preprocessing.h"], + copts = tflite_copts(), + deps = [ + "//tensorflow/contrib/lite/tools/accuracy:android_required_build_flags", + "//tensorflow/contrib/lite/tools/accuracy:stage", + "//tensorflow/cc:cc_ops", + "//tensorflow/cc:scope", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core/kernels:android_tensorflow_image_op", + ], + "//conditions:default": [ + "//tensorflow/core:tensorflow", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:core_cpu", + "//tensorflow/core:framework", + "//tensorflow/core:lib", + "//tensorflow/core:ops", + ], + }, + ), +) + +tf_cc_test( + name = "inception_preprocessing_test", + srcs = ["inception_preprocessing_test.cc"], + args = [ + "--test_image=$(location :testdata/grace_hopper.jpg)", + ], + data = [":testdata/grace_hopper.jpg"], + linkopts = common_linkopts, + linkstatic = 1, + deps = [ + ":inception_preprocessing", + "//tensorflow/contrib/lite/tools/accuracy:android_required_build_flags", + "@com_google_googletest//:gtest", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_test_lib", + ], + "//conditions:default": [ + "//tensorflow/core:core_cpu", + "//tensorflow/core:framework_internal", + "//tensorflow/core:lib", + ], + }, + ), +) + +cc_library( + name = "imagenet_topk_eval", + srcs = ["imagenet_topk_eval.cc"], + hdrs = ["imagenet_topk_eval.h"], + copts = tflite_copts(), + deps = [ + "//tensorflow/contrib/lite/tools/accuracy:accuracy_eval_stage", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + ], + "//conditions:default": [ + "//tensorflow/core:framework", + ], + }, + ), +) + +tf_cc_test( + name = "imagenet_topk_eval_test", + srcs = ["imagenet_topk_eval_test.cc"], + linkopts = common_linkopts, + linkstatic = 1, + deps = [ + ":imagenet_topk_eval", + "@com_google_googletest//:gtest", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core:android_tensorflow_test_lib", + ], + "//conditions:default": [ + "//tensorflow/core:framework", + ], + }, + ), +) + +cc_library( + name = "imagenet_model_evaluator", + srcs = ["imagenet_model_evaluator.cc"], + hdrs = ["imagenet_model_evaluator.h"], + copts = tflite_copts(), + deps = [ + ":imagenet_topk_eval", + ":inception_preprocessing", + "//tensorflow/contrib/lite/tools/accuracy:android_required_build_flags", + "//tensorflow/contrib/lite/tools/accuracy:eval_pipeline", + "//tensorflow/contrib/lite/tools/accuracy:eval_pipeline_builder", + "//tensorflow/contrib/lite/tools/accuracy:file_reader_stage", + "//tensorflow/contrib/lite/tools/accuracy:run_tflite_model_stage", + "//tensorflow/contrib/lite/tools/accuracy:utils", + "@com_google_absl//absl/memory", + "//tensorflow/cc:cc_ops", + "//tensorflow/cc:scope", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + "//tensorflow/core/kernels:android_whole_file_read_ops", + "//tensorflow/core/kernels:android_tensorflow_image_op", + ], + "//conditions:default": [ + "//tensorflow/core:tensorflow", + "//tensorflow/core:framework_internal", + "//tensorflow/core:framework", + "//tensorflow/core:lib", + "//tensorflow/core:core_cpu", + ], + }, + ), +) + +tf_cc_binary( + name = "imagenet_accuracy_eval", + srcs = ["imagenet_accuracy_eval.cc"], + copts = tflite_copts(), + linkopts = common_linkopts, + deps = [ + ":imagenet_model_evaluator", + ":imagenet_topk_eval", + "@com_google_absl//absl/memory", + "//tensorflow/contrib/lite/tools/accuracy:android_required_build_flags", + "//tensorflow/contrib/lite/tools/accuracy:csv_writer", + ] + select( + { + "//tensorflow:android": [ + "//tensorflow/core:android_tensorflow_lib", + ], + "//conditions:default": [ + "//tensorflow/core:lib", + "//tensorflow/core:framework_internal", + ], + }, + ), +) diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/README.md b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/README.md new file mode 100644 index 0000000000..9b3b99451d --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/README.md @@ -0,0 +1,138 @@ +## Accuracy evaluation for ILSVRC 2012 (Imagenet Large Scale Visual Recognition Challenge) image classification task + +This binary can evaluate the accuracy of TFLite models trained for the [ILSVRC 2012 image classification task] +(http://www.image-net.org/challenges/LSVRC/2012/). +The binary takes the path to validation images and labels as inputs. It outputs the accuracy after running the TFLite model on the validation sets. + +To run the binary download the ILSVRC 2012 devkit [see instructions](#downloading-ilsvrc) and run the [`generate_validation_ground_truth` script](#ground-truth-label-generation) to generate the ground truth labels. + +## Parameters +The binary takes the following parameters: + +* `model_file` : `string` \ + Path to the TFlite model file. + +* `ground_truth_images_path`: `string` \ + The path to the directory containing ground truth images. + +* `ground_truth_labels`: `string` \ + Path to ground truth labels file. This file should contain the same number of labels as the number images in the ground truth directory. The labels are assumed to be in the + same order as the sorted filename of images. See [ground truth label generation](#ground-truth-label-generation) + section for more information about how to generate labels for images. + +* `model_output_labels`: `string` \ + Path to the file containing labels, that is used to interpret the output of + the model. E.g. in case of mobilenets, this is the path to + `mobilenet_labels.txt` where each label is in the same order as the output + 1001 dimension tensor. + +* `output_path`: `string` \ + This is the path to the output file. The output is a CSV file that has top-10 accuracies in each row. Each line of output file is the cumulative accuracy after processing images in a sorted order. So first line is accuracy after processing the first image, second line is accuracy after procesing first two images. The last line of the file is accuracy after processing the entire validation set. + +and the following optional parameters: +* `num_images`: `int` (default=0) \ + The number of images to process, if 0, all images in the directory are processed otherwise only num_images will be processed. + +## Downloading ILSVRC +In order to use this tool to run evaluation on the full 50K ImageNet dataset, +download the data set from http://image-net.org/request. + +## Ground truth label generation +The ILSVRC 2012 devkit `validation_ground_truth.txt` contains IDs that correspond to synset of the image. +The accuracy binary however expects the ground truth labels to contain the actual name of +category instead of synset ids. A conversion script has been provided to convert the validation ground truth to +category labels. The `validation_ground_truth.txt` can be converted by the following steps: + +``` +ILSVRC_2012_DEVKIT_DIR=[set to path to ILSVRC 2012 devkit] +VALIDATION_LABELS=[set to path to output] + +python generate_validation_labels.py -- \ +--ilsvrc_devkit_dir=${ILSVRC_2012_DEVKIT_DIR} \ +--validation_labels_output=${VALIDATION_LABELS} +``` + +## Running the binary + +### On Android + +(0) Refer to https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/android for configuring NDK and SDK. + +(1) Build using the following command: + +``` +bazel build -c opt \ + --config=android_arm \ + --config=monolithic \ + --cxxopt='--std=c++11' \ + --copt=-D__ANDROID_TYPES_FULL__ \ + --copt=-DSUPPORT_SELECTIVE_REGISTRATION \ + //tensorflow/contrib/lite/tools/accuracy/ilsvrc:imagenet_accuracy_eval +``` + +(2) Connect your phone. Push the binary to your phone with adb push + (make the directory if required): + +``` +adb push bazel-bin/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_accuracy_eval /data/local/tmp +``` + +(3) Make the binary executable. + +``` +adb shell chmod +x /data/local/tmp/imagenet_accuracy_eval +``` + +(4) Push the TFLite model that you need to test. For example: + +``` +adb push mobilenet_quant_v1_224.tflite /data/local/tmp +``` + +(5) Push the imagenet images to device, make sure device has sufficient storage available before pushing the dataset: + +``` +adb shell mkdir /data/local/tmp/ilsvrc_images && \ +adb push ${IMAGENET_IMAGES_DIR} /data/local/tmp/ilsvrc_images +``` + +(6) Push the generated validation ground labels to device. + +``` +adb push ${VALIDATION_LABELS} /data/local/tmp/ilsvrc_validation_labels.txt +``` + +(7) Push the model labels text file to device. + +``` +adb push ${MODEL_LABELS_TXT} /data/local/tmp/model_output_labels.txt +``` + +(8) Run the binary. + +``` +adb shell /data/local/tmp/imagenet_accuracy_eval \ + --model_file=/data/local/tmp/mobilenet_quant_v1_224.tflite \ + --ground_truth_images_path=/data/local/tmp/ilsvrc_images \ + --ground_truth_labels=/data/local/tmp/ilsvrc_validation_labels.txt \ + --model_output_labels=/data/local/tmp/model_output_labels.txt \ + --output_file_path=/data/local/tmp/accuracy_output.txt \ + --num_images=0 # Run on all images. +``` + +### On Desktop + +(1) Build and run using the following command: + +``` +bazel run -c opt \ + --cxxopt='--std=c++11' \ + -- \ + //tensorflow/contrib/lite/tools/accuracy/ilsvrc:imagenet_accuracy_eval \ + --model_file=mobilenet_quant_v1_224.tflite \ + --ground_truth_images_path=${IMAGENET_IMAGES_DIR} \ + --ground_truth_labels=${VALIDATION_LABELS} \ + --model_output_labels=${MODEL_LABELS_TXT} \ + --output_file_path=/tmp/accuracy_output.txt \ + --num_images=0 # Run on all images. +``` diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/generate_validation_labels.py b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/generate_validation_labels.py new file mode 100644 index 0000000000..c32a41e50d --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/generate_validation_labels.py @@ -0,0 +1,105 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tool to convert ILSVRC devkit validation ground truth to synset labels.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import argparse +from os import path +import sys +import scipy.io + +_SYNSET_ARRAYS_RELATIVE_PATH = 'data/meta.mat' +_VALIDATION_FILE_RELATIVE_PATH = 'data/ILSVRC2012_validation_ground_truth.txt' + + +def _synset_to_word(filepath): + """Returns synset to word dictionary by reading sysnset arrays.""" + mat = scipy.io.loadmat(filepath) + entries = mat['synsets'] + # These fields are listed in devkit readme.txt + fields = [ + 'synset_id', 'WNID', 'words', 'gloss', 'num_children', 'children', + 'wordnet_height', 'num_train_images' + ] + synset_index = fields.index('synset_id') + words_index = fields.index('words') + synset_to_word = {} + for entry in entries: + entry = entry[0] + synset_id = int(entry[synset_index][0]) + first_word = entry[words_index][0].split(',')[0] + synset_to_word[synset_id] = first_word + return synset_to_word + + +def _validation_file_path(ilsvrc_dir): + return path.join(ilsvrc_dir, _VALIDATION_FILE_RELATIVE_PATH) + + +def _synset_array_path(ilsvrc_dir): + return path.join(ilsvrc_dir, _SYNSET_ARRAYS_RELATIVE_PATH) + + +def _generate_validation_labels(ilsvrc_dir, output_file): + synset_to_word = _synset_to_word(_synset_array_path(ilsvrc_dir)) + with open(_validation_file_path(ilsvrc_dir), 'r') as synset_id_file, open( + output_file, 'w') as output: + for synset_id in synset_id_file: + synset_id = int(synset_id) + output.write('%s\n' % synset_to_word[synset_id]) + + +def _check_arguments(args): + if not args.validation_labels_output: + raise ValueError('Invalid path to output file.') + ilsvrc_dir = args.ilsvrc_devkit_dir + if not ilsvrc_dir or not path.isdir(ilsvrc_dir): + raise ValueError('Invalid path to ilsvrc_dir') + if not path.exists(_validation_file_path(ilsvrc_dir)): + raise ValueError('Invalid path to ilsvrc_dir, cannot find validation file.') + if not path.exists(_synset_array_path(ilsvrc_dir)): + raise ValueError( + 'Invalid path to ilsvrc_dir, cannot find synset arrays file.') + + +def main(): + parser = argparse.ArgumentParser( + description='Converts ILSVRC devkit validation_ground_truth.txt to synset' + ' labels file that can be used by the accuracy script.') + parser.add_argument( + '--validation_labels_output', + type=str, + help='Full path for outputting validation labels.') + parser.add_argument( + '--ilsvrc_devkit_dir', + type=str, + help='Full path to ILSVRC 2012 devikit directory.') + args = parser.parse_args() + try: + _check_arguments(args) + except ValueError as e: + parser.print_usage() + file_name = path.basename(sys.argv[0]) + sys.stderr.write('{0}: error: {1}\n'.format(file_name, str(e))) + sys.exit(1) + _generate_validation_labels(args.ilsvrc_devkit_dir, + args.validation_labels_output) + + +if __name__ == '__main__': + main() diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_accuracy_eval.cc b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_accuracy_eval.cc new file mode 100644 index 0000000000..f361341f7c --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_accuracy_eval.cc @@ -0,0 +1,148 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include <iomanip> +#include <memory> + +#include "absl/memory/memory.h" +#include "tensorflow/contrib/lite/tools/accuracy/csv_writer.h" +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.h" +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.h" +#include "tensorflow/core/platform/env.h" +#include "tensorflow/core/util/command_line_flags.h" + +namespace tensorflow { +namespace metrics { + +namespace { + +std::vector<double> GetAccuracies( + const ImagenetTopKAccuracy::AccuracyStats& accuracy_stats) { + std::vector<double> results; + results.reserve(accuracy_stats.number_of_images); + if (accuracy_stats.number_of_images > 0) { + for (int n : accuracy_stats.topk_counts) { + double accuracy = 0; + if (accuracy_stats.number_of_images > 0) { + accuracy = (n * 100.0) / accuracy_stats.number_of_images; + } + results.push_back(accuracy); + } + } + return results; +} + +} // namespace + +// Writes results to a CSV file. +class ResultsWriter : public ImagenetModelEvaluator::Observer { + public: + explicit ResultsWriter(std::unique_ptr<CSVWriter> writer) + : writer_(std::move(writer)) {} + + void OnEvaluationStart(int total_number_of_images) override {} + + void OnSingleImageEvaluationComplete( + const ImagenetTopKAccuracy::AccuracyStats& stats, + const string& image) override; + + private: + std::unique_ptr<CSVWriter> writer_; +}; + +void ResultsWriter::OnSingleImageEvaluationComplete( + const ImagenetTopKAccuracy::AccuracyStats& stats, const string& image) { + TF_CHECK_OK(writer_->WriteRow(GetAccuracies(stats))); + writer_->Flush(); +} + +// Logs results to standard output with `kLogDelayUs` microseconds. +class ResultsLogger : public ImagenetModelEvaluator::Observer { + public: + void OnEvaluationStart(int total_number_of_images) override; + + void OnSingleImageEvaluationComplete( + const ImagenetTopKAccuracy::AccuracyStats& stats, + const string& image) override; + + private: + int total_num_images_ = 0; + uint64 last_logged_time_us_ = 0; + static constexpr int kLogDelayUs = 500 * 1000; +}; + +void ResultsLogger::OnEvaluationStart(int total_number_of_images) { + total_num_images_ = total_number_of_images; + LOG(ERROR) << "Starting model evaluation: " << total_num_images_; +} + +void ResultsLogger::OnSingleImageEvaluationComplete( + const ImagenetTopKAccuracy::AccuracyStats& stats, const string& image) { + int num_evaluated = stats.number_of_images; + + double current_percent = num_evaluated * 100.0 / total_num_images_; + auto now_us = Env::Default()->NowMicros(); + + if ((now_us - last_logged_time_us_) >= kLogDelayUs) { + last_logged_time_us_ = now_us; + + LOG(ERROR) << "Evaluated " << num_evaluated << "/" << total_num_images_ + << " images, " << std::setprecision(2) << std::fixed + << current_percent << "%"; + } +} + +int Main(int argc, char* argv[]) { + // TODO(shashishekhar): Make this binary configurable and model + // agnostic. + string output_file_path; + std::vector<Flag> flag_list = { + Flag("output_file_path", &output_file_path, "Path to output file."), + }; + Flags::Parse(&argc, argv, flag_list); + + std::unique_ptr<ImagenetModelEvaluator> evaluator; + CHECK(!output_file_path.empty()) << "Invalid output file path."; + + TF_CHECK_OK(ImagenetModelEvaluator::Create(argc, argv, &evaluator)); + + std::ofstream output_stream(output_file_path, std::ios::out); + CHECK(output_stream) << "Unable to open output file path: '" + << output_file_path << "'"; + + output_stream << std::setprecision(3) << std::fixed; + std::vector<string> columns; + columns.reserve(evaluator->params().num_ranks); + for (int i = 0; i < evaluator->params().num_ranks; i++) { + string column_name = "Top "; + tensorflow::strings::StrAppend(&column_name, i + 1); + columns.push_back(column_name); + } + + ResultsWriter results_writer( + absl::make_unique<CSVWriter>(columns, &output_stream)); + ResultsLogger logger; + evaluator->AddObserver(&results_writer); + evaluator->AddObserver(&logger); + TF_CHECK_OK(evaluator->EvaluateModel()); + return 0; +} + +} // namespace metrics +} // namespace tensorflow + +int main(int argc, char* argv[]) { + return tensorflow::metrics::Main(argc, argv); +} diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc new file mode 100644 index 0000000000..a88a4a0fce --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc @@ -0,0 +1,206 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.h" + +#include <fstream> +#include <iomanip> +#include <string> +#include <vector> + +#include "absl/memory/memory.h" +#include "tensorflow/cc/framework/scope.h" +#include "tensorflow/contrib/lite/tools/accuracy/eval_pipeline.h" +#include "tensorflow/contrib/lite/tools/accuracy/eval_pipeline_builder.h" +#include "tensorflow/contrib/lite/tools/accuracy/file_reader_stage.h" +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.h" +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing.h" +#include "tensorflow/contrib/lite/tools/accuracy/run_tflite_model_stage.h" +#include "tensorflow/contrib/lite/tools/accuracy/utils.h" +#include "tensorflow/core/platform/init_main.h" +#include "tensorflow/core/public/session.h" +#include "tensorflow/core/util/command_line_flags.h" + +namespace { +using tensorflow::string; + +string StripTrailingSlashes(const string& path) { + int end = path.size(); + while (end > 0 && path[end - 1] == '/') { + end--; + } + return path.substr(0, end); +} + +tensorflow::Tensor CreateStringTensor(const string& value) { + tensorflow::Tensor tensor(tensorflow::DT_STRING, tensorflow::TensorShape({})); + tensor.scalar<string>()() = value; + return tensor; +} + +template <typename T> +std::vector<T> GetFirstN(const std::vector<T>& v, int n) { + if (n >= v.size()) return v; + std::vector<T> result(v.begin(), v.begin() + n); + return result; +} + +// File pattern for imagenet files. +const char* const kImagenetFilePattern = "*.[jJ][pP][eE][gG]"; + +} // namespace + +namespace tensorflow { +namespace metrics { + +/*static*/ Status ImagenetModelEvaluator::Create( + int argc, char* argv[], + std::unique_ptr<ImagenetModelEvaluator>* model_evaluator) { + Params params; + const std::vector<Flag> flag_list = { + Flag("model_output_labels", ¶ms.model_output_labels_path, + "Path to labels that correspond to output of model." + " E.g. in case of mobilenet, this is the path to label " + "file where each label is in the same order as the output" + " of the model."), + Flag("ground_truth_images_path", ¶ms.ground_truth_images_path, + "Path to ground truth images."), + Flag("ground_truth_labels", ¶ms.ground_truth_labels_path, + "Path to ground truth labels."), + Flag("num_images", ¶ms.number_of_images, + "Number of examples to evaluate, pass 0 for all " + "examples. Default: 100"), + tensorflow::Flag("model_file", ¶ms.model_file_path, + "Path to test tflite model file."), + }; + const bool parse_result = Flags::Parse(&argc, argv, flag_list); + if (!parse_result) + return errors::InvalidArgument("Invalid command line flags"); + ::tensorflow::port::InitMain(argv[0], &argc, &argv); + + TF_RETURN_WITH_CONTEXT_IF_ERROR( + Env::Default()->IsDirectory(params.ground_truth_images_path), + "Invalid ground truth data path."); + TF_RETURN_WITH_CONTEXT_IF_ERROR( + Env::Default()->FileExists(params.ground_truth_labels_path), + "Invalid ground truth labels path."); + TF_RETURN_WITH_CONTEXT_IF_ERROR( + Env::Default()->FileExists(params.model_output_labels_path), + "Invalid model output labels path."); + + if (params.number_of_images < 0) { + return errors::InvalidArgument("Invalid: num_examples"); + } + + utils::ModelInfo model_info; + TF_RETURN_WITH_CONTEXT_IF_ERROR( + utils::GetTFliteModelInfo(params.model_file_path, &model_info), + "Invalid TFLite model."); + + *model_evaluator = + absl::make_unique<ImagenetModelEvaluator>(model_info, params); + return Status::OK(); +} + +Status ImagenetModelEvaluator::EvaluateModel() { + if (model_info_.input_shapes.size() != 1) { + return errors::InvalidArgument("Invalid input shape"); + } + + const TensorShape& input_shape = model_info_.input_shapes[0]; + // Input should be of the shape {1, height, width, 3} + if (input_shape.dims() != 4 || input_shape.dim_size(3) != 3) { + return errors::InvalidArgument("Invalid input shape for the model."); + } + + const int image_height = input_shape.dim_size(1); + const int image_width = input_shape.dim_size(2); + const bool is_quantized = (model_info_.input_types[0] == DT_UINT8); + + RunTFLiteModelStage::Params tfl_model_params; + tfl_model_params.model_file_path = params_.model_file_path; + if (is_quantized) { + tfl_model_params.input_type = {DT_UINT8}; + tfl_model_params.output_type = {DT_UINT8}; + } else { + tfl_model_params.input_type = {DT_FLOAT}; + tfl_model_params.output_type = {DT_FLOAT}; + } + + Scope root = Scope::NewRootScope(); + FileReaderStage reader; + InceptionPreprocessingStage inc(image_height, image_width, is_quantized); + RunTFLiteModelStage tfl_model_stage(tfl_model_params); + EvalPipelineBuilder builder; + std::vector<string> model_labels; + TF_RETURN_IF_ERROR( + utils::ReadFileLines(params_.model_output_labels_path, &model_labels)); + if (model_labels.size() != 1001) { + return errors::InvalidArgument("Invalid number of labels: ", + model_labels.size()); + } + + ImagenetTopKAccuracy eval(model_labels, params_.num_ranks); + std::unique_ptr<EvalPipeline> eval_pipeline; + + auto build_status = builder.WithInputStage(&reader) + .WithPreprocessingStage(&inc) + .WithRunModelStage(&tfl_model_stage) + .WithAccuracyEval(&eval) + .WithInput("input_file", DT_STRING) + .Build(root, &eval_pipeline); + TF_RETURN_WITH_CONTEXT_IF_ERROR(build_status, + "Failure while building eval pipeline."); + + std::unique_ptr<Session> session(NewSession(SessionOptions())); + + TF_RETURN_IF_ERROR(eval_pipeline->AttachSession(std::move(session))); + string data_path = + StripTrailingSlashes(params_.ground_truth_images_path) + "/"; + + const string imagenet_file_pattern = data_path + kImagenetFilePattern; + std::vector<string> image_files; + TF_CHECK_OK( + Env::Default()->GetMatchingPaths(imagenet_file_pattern, &image_files)); + std::vector<string> image_labels; + TF_CHECK_OK( + utils::ReadFileLines(params_.ground_truth_labels_path, &image_labels)); + CHECK_EQ(image_files.size(), image_labels.size()); + + // Process files in filename sorted order. + std::sort(image_files.begin(), image_files.end()); + if (params_.number_of_images > 0) { + image_files = GetFirstN(image_files, params_.number_of_images); + image_labels = GetFirstN(image_labels, params_.number_of_images); + } + + for (Observer* observer : observers_) { + observer->OnEvaluationStart(image_files.size()); + } + + for (int i = 0; i < image_files.size(); i++) { + TF_CHECK_OK(eval_pipeline->Run(CreateStringTensor(image_files[i]), + CreateStringTensor(image_labels[i]))); + auto stats = eval.GetTopKAccuracySoFar(); + + for (Observer* observer : observers_) { + observer->OnSingleImageEvaluationComplete(stats, image_files[i]); + } + } + return Status::OK(); +} + +} // namespace metrics +} // namespace tensorflow diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.h b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.h new file mode 100644 index 0000000000..5f42b2a50e --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.h @@ -0,0 +1,113 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_IMAGENET_MODEL_EVALUATOR_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_IMAGENET_MODEL_EVALUATOR_H_ +#include <string> +#include <vector> + +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.h" +#include "tensorflow/contrib/lite/tools/accuracy/utils.h" +#include "tensorflow/core/framework/tensor_shape.h" +#include "tensorflow/core/lib/core/status.h" + +namespace tensorflow { +namespace metrics { + +// Evaluates models accuracy for ILSVRC dataset. +// +// Generates the top-1, top-k accuracy counts where k is +// controlled by |num_ranks|. +// Usage: +// ModelInfo model_info = .. +// ImagenetModelEvaluator::Params params; +// .. set params to image, label, output label and model file path.. +// SomeObserver observer; +// ImagenetModelEvaluator evaluator(model_info, params); +// evaluator.AddObserver(&observer); +// TF_CHECK_OK(evaluator.EvaluateModel()); +class ImagenetModelEvaluator { + public: + struct Params { + // Path to ground truth images. + string ground_truth_images_path; + + // Path to labels file for ground truth image. + // This file should be generated with the scripts. + string ground_truth_labels_path; + + // This is word labels generated by the model. The category + // indices of output probabilities generated by the model maybe different + // from the indices in the imagenet dataset. + string model_output_labels_path; + + // Path to the model file. + string model_file_path; + + // The maximum number of images to calculate accuracy. + // 0 means all images, a positive number means only the specified + // number of images. + int number_of_images = 0; + + // Number of ranks, top K. + int num_ranks = 10; + }; + + // An evaluation observer. + class Observer { + public: + Observer() = default; + Observer(const Observer&) = delete; + Observer& operator=(const Observer&) = delete; + + Observer(const Observer&&) = delete; + Observer& operator=(const Observer&&) = delete; + + // Called on start of evaluation. + virtual void OnEvaluationStart(int total_number_of_images) = 0; + + // Called when evaluation was complete for `image`. + virtual void OnSingleImageEvaluationComplete( + const ImagenetTopKAccuracy::AccuracyStats& stats, + const string& image) = 0; + + virtual ~Observer() = default; + }; + + ImagenetModelEvaluator(const utils::ModelInfo& model_info, + const Params& params) + : model_info_(model_info), params_(params) {} + + // Factory method to create the evaluator by parsing command line arguments. + static Status Create(int argc, char* argv[], + std::unique_ptr<ImagenetModelEvaluator>* evaluator); + + // Adds an observer that can observe evaluation events.. + void AddObserver(Observer* observer) { observers_.push_back(observer); } + + const Params& params() { return params_; } + + // Evaluates the provided model over the dataset. + Status EvaluateModel(); + + private: + std::vector<Observer*> observers_; + const utils::ModelInfo model_info_; + const Params params_; +}; + +} // namespace metrics +} // namespace tensorflow +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_IMAGENET_MODEL_EVALUATOR_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.cc b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.cc new file mode 100644 index 0000000000..d46075d234 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.cc @@ -0,0 +1,107 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.h" + +#include <numeric> + +namespace { +constexpr int kNumCategories = 1001; +std::vector<int> GetTopK(const std::vector<float>& values, int k) { + CHECK_LE(k, values.size()); + std::vector<int> indices(values.size()); + + std::iota(indices.begin(), indices.end(), 0); + std::sort(indices.begin(), indices.end(), + [&values](int a, int b) { return values[a] > values[b]; }); + + indices.resize(k); + return indices; +} +} // namespace + +namespace tensorflow { +namespace metrics { +ImagenetTopKAccuracy::ImagenetTopKAccuracy( + const std::vector<string>& ground_truth_labels, int k) + : ground_truth_labels_(ground_truth_labels), + k_(k), + accuracy_counts_(k_, 0), + num_samples_(0) { + CHECK_EQ(kNumCategories, ground_truth_labels.size()); +} + +Status ImagenetTopKAccuracy::ComputeEval( + const std::vector<Tensor>& model_outputs, const Tensor& ground_truth) { + if (model_outputs.size() != 1) { + return errors::InvalidArgument("Invalid model output: ", + model_outputs.size()); + } + const Tensor& output = model_outputs[0]; + if (!output.shape().IsSameSize({1, kNumCategories})) { + return errors::InvalidArgument("Invalid shape of model output: ", + output.shape().DebugString()); + } + if (ground_truth.dtype() != DT_STRING && ground_truth.dims() != 0) { + return errors::InvalidArgument("Invalid ground truth type: ", + ground_truth.DebugString()); + } + string ground_truth_label = ground_truth.scalar<string>()(); + + std::vector<float> probabilities; + probabilities.reserve(kNumCategories); + if (output.dtype() == DT_FLOAT) { + auto probs = output.flat<float>(); + for (size_t i = 0; i < probs.size(); i++) { + probabilities.push_back(probs(i)); + } + } else { + auto probs = output.flat<uint8>(); + for (size_t i = 0; i < probs.size(); i++) { + probabilities.push_back(probs(i)); + } + } + + CHECK_EQ(kNumCategories, probabilities.size()); + std::vector<int> topK = GetTopK(probabilities, k_); + int ground_truth_index = GroundTruthIndex(ground_truth_label); + for (size_t i = 0; i < topK.size(); ++i) { + if (ground_truth_index == topK[i]) { + for (size_t j = i; j < topK.size(); j++) { + accuracy_counts_[j] += 1; + } + break; + } + } + num_samples_++; + return Status::OK(); +} + +const ImagenetTopKAccuracy::AccuracyStats +ImagenetTopKAccuracy::GetTopKAccuracySoFar() const { + AccuracyStats stats; + stats.number_of_images = num_samples_; + stats.topk_counts = accuracy_counts_; + return stats; +} + +int ImagenetTopKAccuracy::GroundTruthIndex(const string& label) const { + auto index = std::find(ground_truth_labels_.cbegin(), + ground_truth_labels_.cend(), label); + CHECK(index != ground_truth_labels_.end()) << "Invalid label: " << label; + return std::distance(ground_truth_labels_.cbegin(), index); +} +} // namespace metrics +} // namespace tensorflow diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.h b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.h new file mode 100644 index 0000000000..5a575ff244 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.h @@ -0,0 +1,80 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_IMAGENET_TOPK_EVAL_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_IMAGENET_TOPK_EVAL_H_ + +#include <string> +#include <vector> + +#include "tensorflow/contrib/lite/tools/accuracy/accuracy_eval_stage.h" +#include "tensorflow/core/framework/tensor.h" + +namespace tensorflow { +namespace metrics { +// An |AccuracyEval| stage that calculates the top K error rate for model +// evaluations on imagenet like datasets. +// Inputs: A {1, 1001} shaped tensor that contains the probabilities for objects +// predicted by the model. +// Ground truth: A |string| label for the image. +// From the input object probabilities, the stage computes the predicted labels +// and finds the top K error rates by comparing the predictions with ground +// truths. +class ImagenetTopKAccuracy : public AccuracyEval { + public: + // Accuracy statistics. + struct AccuracyStats { + // Number of images evaluated. + int number_of_images; + // A vector of size |k| that contains the number of images + // that have correct labels in top K. + // E.g. topk_counts[0] contains number of images for which + // model returned the correct label as the first result. + // Similarly topk_counts[4] contains the number of images for which + // model returned the correct label in top 5 results. + // This can be used to compute the top K error-rate for the model. + std::vector<int> topk_counts; + }; + + // Creates a new instance of |ImagenetTopKAccuracy| with the given + // |ground_truth_labels| and |k|. + // Args: + // |ground_truth_labels| : an ordered vector of labels for images. This is + // used to compute the index for the predicted labels and ground_truth label. + ImagenetTopKAccuracy(const std::vector<string>& ground_truth_labels, int k); + + // Computes accuracy for a given image. The |model_outputs| should + // be a vector containing exactly one Tensor of shape: {1, 1001} where each + // item is a probability of the predicted object representing the image as + // output by the model. + // Uses |ground_truth_labels| to compute the index of |model_outputs| and + // |ground_truth| and computes the top K error rate. + Status ComputeEval(const std::vector<Tensor>& model_outputs, + const Tensor& ground_truth) override; + + // Gets the topK accuracy for images that have been evaluated till now. + const AccuracyStats GetTopKAccuracySoFar() const; + + private: + int GroundTruthIndex(const string& label) const; + std::vector<string> ground_truth_labels_; + const int k_; + std::vector<int> accuracy_counts_; + int num_samples_; +}; +} // namespace metrics +} // namespace tensorflow + +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_IMAGENET_TOPK_EVAL_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval_test.cc b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval_test.cc new file mode 100644 index 0000000000..ff332af5c5 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval_test.cc @@ -0,0 +1,151 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_topk_eval.h" +#include <gtest/gtest.h> + +namespace tensorflow { +namespace metrics { +namespace { + +const int kNumCategories = 1001; + +Tensor CreateStringTensor(const string& value) { + Tensor tensor(DT_STRING, TensorShape({})); + tensor.scalar<string>()() = value; + return tensor; +} + +Tensor CreateOutputTensor() { + Tensor tensor(DT_FLOAT, TensorShape({1, kNumCategories})); + for (int i = 0; i < kNumCategories; i++) { + tensor.flat<float>()(i) = 0; + } + return tensor; +} + +std::vector<string> CreateGroundTruth() { + std::vector<string> ground_truth; + ground_truth.reserve(kNumCategories); + for (int i = 0; i < kNumCategories; i++) { + string category; + strings::StrAppend(&category, i); + ground_truth.push_back(category); + } + return ground_truth; +} + +TEST(ImagenetTopKAccuracy, AllCorrect) { + ImagenetTopKAccuracy acc_top_5(CreateGroundTruth(), 5); + auto accuracies = acc_top_5.GetTopKAccuracySoFar(); + EXPECT_EQ(0, accuracies.number_of_images); + EXPECT_EQ(5, accuracies.topk_counts.size()); + + for (int i : accuracies.topk_counts) { + EXPECT_EQ(0, i); + } + // First image was correctly identified as "0". + Tensor tensor = CreateOutputTensor(); + tensor.flat<float>()(0) = 0.8; + + TF_CHECK_OK(acc_top_5.ComputeEval({tensor}, CreateStringTensor("0"))); + accuracies = acc_top_5.GetTopKAccuracySoFar(); + EXPECT_EQ(1, accuracies.number_of_images); + + for (int i : accuracies.topk_counts) { + EXPECT_EQ(1, i); + } + tensor.flat<float>()(1) = 0.9; + TF_CHECK_OK(acc_top_5.ComputeEval({tensor}, CreateStringTensor("1"))); + accuracies = acc_top_5.GetTopKAccuracySoFar(); + EXPECT_EQ(2, accuracies.number_of_images); + + for (int i : accuracies.topk_counts) { + EXPECT_EQ(2, i); + } +} + +TEST(ImagenetTopKAccuracy, Top5) { + ImagenetTopKAccuracy acc_top_5(CreateGroundTruth(), 5); + auto accuracies = acc_top_5.GetTopKAccuracySoFar(); + EXPECT_EQ(0, accuracies.number_of_images); + EXPECT_EQ(5, accuracies.topk_counts.size()); + + // For first image, with ground truth "0" probabilities were + // 0.5 for "0", + // "0.6" for 1, + // "0.7" for 2, + // "0.8" for 3, + // "0.9" for 4. + // remaining all zeroes. + + // First image was correctly identified as "0". + Tensor tensor = CreateOutputTensor(); + tensor.flat<float>()(0) = 0.5; + tensor.flat<float>()(1) = 0.6; + tensor.flat<float>()(2) = 0.7; + tensor.flat<float>()(3) = 0.8; + tensor.flat<float>()(4) = 0.9; + + TF_CHECK_OK(acc_top_5.ComputeEval({tensor}, CreateStringTensor("0"))); + accuracies = acc_top_5.GetTopKAccuracySoFar(); + EXPECT_EQ(1, accuracies.number_of_images); + EXPECT_EQ(1, accuracies.topk_counts[4]); + + for (int i = 0; i < 4; i++) { + EXPECT_EQ(0, accuracies.topk_counts[i]); + } + + // Now for "1" only last two buckets are going to be affected. + TF_CHECK_OK(acc_top_5.ComputeEval({tensor}, CreateStringTensor("1"))); + accuracies = acc_top_5.GetTopKAccuracySoFar(); + EXPECT_EQ(2, accuracies.number_of_images); + EXPECT_EQ(1, accuracies.topk_counts[3]); + EXPECT_EQ(2, accuracies.topk_counts[4]); + for (int i = 0; i < 3; i++) { + EXPECT_EQ(0, accuracies.topk_counts[i]); + } + + // All buckets will be affected. + TF_CHECK_OK(acc_top_5.ComputeEval({tensor}, CreateStringTensor("4"))); + accuracies = acc_top_5.GetTopKAccuracySoFar(); + EXPECT_EQ(3, accuracies.number_of_images); + EXPECT_EQ(1, accuracies.topk_counts[0]); + EXPECT_EQ(1, accuracies.topk_counts[1]); + EXPECT_EQ(1, accuracies.topk_counts[2]); + EXPECT_EQ(2, accuracies.topk_counts[3]); + EXPECT_EQ(3, accuracies.topk_counts[4]); + + // No buckets will be affected + TF_CHECK_OK(acc_top_5.ComputeEval({tensor}, CreateStringTensor("10"))); + accuracies = acc_top_5.GetTopKAccuracySoFar(); + EXPECT_EQ(4, accuracies.number_of_images); + EXPECT_EQ(1, accuracies.topk_counts[0]); + EXPECT_EQ(1, accuracies.topk_counts[1]); + EXPECT_EQ(1, accuracies.topk_counts[2]); + EXPECT_EQ(2, accuracies.topk_counts[3]); + EXPECT_EQ(3, accuracies.topk_counts[4]); +} + +} // namespace + +} // namespace metrics +} // namespace tensorflow + +int main(int argc, char** argv) { + ::testing::InitGoogleTest(&argc, argv); + + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing.cc b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing.cc new file mode 100644 index 0000000000..7512b39c32 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing.cc @@ -0,0 +1,80 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing.h" + +#include <memory> + +#include "tensorflow/cc/framework/scope.h" +#include "tensorflow/cc/ops/standard_ops.h" +#include "tensorflow/core/framework/graph.pb.h" +#include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/graph/graph_def_builder.h" +#include "tensorflow/core/lib/core/errors.h" +#include "tensorflow/core/platform/logging.h" +#include "tensorflow/core/platform/types.h" +#include "tensorflow/core/public/session.h" + +namespace tensorflow { +namespace metrics { + +namespace { +void CentralCropImage(const Scope& s, const tensorflow::Output& decoded_image, + double crop_fraction, tensorflow::Output* cropped_image) { + auto image_dims = ops::Slice(s, ops::Shape(s, decoded_image), {0}, {2}); + auto height_width = ops::Cast(s, image_dims, DT_DOUBLE); + auto cropped_begin = ops::Div( + s, ops::Sub(s, height_width, ops::Mul(s, height_width, crop_fraction)), + 2.0); + auto bbox_begin = ops::Cast(s, cropped_begin, DT_INT32); + auto bbox_size = ops::Sub(s, image_dims, ops::Mul(s, bbox_begin, 2)); + auto slice_begin = ops::Concat(s, {bbox_begin, Input({0})}, 0); + auto slice_size = ops::Concat(s, {bbox_size, {-1}}, 0); + *cropped_image = ops::Slice(s, decoded_image, slice_begin, slice_size); +} + +} // namespace + +void InceptionPreprocessingStage::AddToGraph(const Scope& scope, + const Input& input) { + if (!scope.ok()) return; + Scope s = scope.WithOpName(name()); + ops::DecodeJpeg::Attrs attrs; + attrs.channels_ = 3; + auto decoded_jpeg = ops::DecodeJpeg(s, input, attrs); + tensorflow::Output cropped_image; + CentralCropImage(s, decoded_jpeg, params_.cropping_fraction, &cropped_image); + auto dims_expander = ops::ExpandDims(s, cropped_image, 0); + auto resized_image = ops::ResizeBilinear( + s, dims_expander, + ops::Const(s.WithOpName("size"), {image_height_, image_width_})); + if (is_quantized_) { + this->stage_output_ = + ops::Cast(s.WithOpName(output_name()), resized_image, DT_UINT8); + } else { + auto squeezed_image = ops::Squeeze(s, resized_image); + auto normalized_image = + ops::Div(s, + ops::Sub(s, squeezed_image, + {params_.input_means[0], params_.input_means[1], + params_.input_means[2]}), + {params_.scale}); + this->stage_output_ = + ops::ExpandDims(s.WithOpName(output_name()), normalized_image, {0}); + } +} + +} // namespace metrics +} // namespace tensorflow diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing.h b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing.h new file mode 100644 index 0000000000..15df719817 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing.h @@ -0,0 +1,75 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_INCEPTION_PREPROCESSING_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_INCEPTION_PREPROCESSING_H_ + +#include <utility> + +#include "tensorflow/contrib/lite/tools/accuracy/stage.h" +#include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/lib/core/status.h" + +namespace tensorflow { +namespace metrics { + +// A stage that does inception preprocessing. +// Inputs: A tensor containing bytes of a JPEG image. +// Outputs: A tensor containing rescaled and preprocessed image that has +// shape {1, image_height, image_width, 3}, where 3 is the number of channels. +class InceptionPreprocessingStage : public Stage { + public: + struct Params { + std::vector<float> input_means; + float scale; + double cropping_fraction; + }; + + static Params DefaultParams() { + return {.input_means = {127.5, 127.5, 127.5}, + .scale = 127.5, + .cropping_fraction = 0.875}; + } + + // Creates a new preprocessing stage object with provided |image_width| + // |image_height| as the size of output image. + // If |is_quantized| is set to true then |params| is ignored since quantized + // images don't go through any preprocessing. + InceptionPreprocessingStage(int image_width, int image_height, + bool is_quantized, + Params params = DefaultParams()) + : image_width_(image_width), + image_height_(image_height), + is_quantized_(is_quantized), + params_(std::move(params)) {} + + string name() const override { return "stage_inception_preprocess"; } + string output_name() const override { + return "stage_inception_preprocess_output"; + } + + void AddToGraph(const Scope& scope, const Input& input) override; + + private: + int image_width_; + int image_height_; + bool is_quantized_; + Params params_; +}; + +} // namespace metrics +} // namespace tensorflow + +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_INCEPTION_PREPROCESSING_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing_test.cc b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing_test.cc new file mode 100644 index 0000000000..3587878ba3 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing_test.cc @@ -0,0 +1,123 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include <fstream> +#include <string> + +#include <gtest/gtest.h> +#include "tensorflow/contrib/lite/tools/accuracy/ilsvrc/inception_preprocessing.h" +#include "tensorflow/core/platform/init_main.h" +#include "tensorflow/core/public/session.h" +#include "tensorflow/core/util/command_line_flags.h" + +namespace { +tensorflow::string* g_test_image_file = nullptr; +} // namespace + +namespace tensorflow { +namespace metrics { + +namespace { + +using tensorflow::Status; +using tensorflow::Tensor; + +Status GetContents(const string& filename, string* output) { + std::ifstream input(filename, std::ios::binary); + const int kBufferSize = 2048; + char buffer[kBufferSize]; + while (true) { + input.read(buffer, kBufferSize); + output->append(buffer, input.gcount()); + if (!input.good()) { + if (input.eof()) return Status::OK(); + return Status(tensorflow::error::ABORTED, "Failed to read file."); + } + } +} + +TEST(InceptionPreprocessingTest, TestImagePreprocessQuantized) { + ASSERT_TRUE(g_test_image_file != nullptr); + string image_contents; + string image_path = *g_test_image_file; + auto status = GetContents(image_path, &image_contents); + ASSERT_TRUE(status.ok()) << status.error_message(); + const int width = 224; + const int height = 224; + const bool is_quantized = true; + InceptionPreprocessingStage preprocess_stage(width, height, is_quantized); + Scope scope = Scope::NewRootScope(); + preprocess_stage.AddToGraph(scope, image_contents); + TF_CHECK_OK(scope.status()); + + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(session->Create(graph_def)); + std::vector<Tensor> outputs; + auto run_status = + session->Run({}, /*inputs*/ + {preprocess_stage.output_name()}, {}, /*target node names */ + &outputs); + TF_CHECK_OK(run_status); + EXPECT_EQ(1, outputs.size()); + EXPECT_EQ(DT_UINT8, outputs[0].dtype()); + EXPECT_TRUE(outputs[0].shape().IsSameSize({1, 224, 224, 3})); +} + +TEST(InceptionPreprocessingTest, TestImagePreprocessFloat) { + ASSERT_TRUE(g_test_image_file != nullptr); + string image_contents; + string image_path = *g_test_image_file; + auto status = GetContents(image_path, &image_contents); + ASSERT_TRUE(status.ok()) << status.error_message(); + const int width = 224; + const int height = 224; + const bool is_quantized = false; + InceptionPreprocessingStage preprocess_stage(width, height, is_quantized); + Scope scope = Scope::NewRootScope(); + preprocess_stage.AddToGraph(scope, image_contents); + TF_CHECK_OK(scope.status()); + + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(session->Create(graph_def)); + std::vector<Tensor> outputs; + auto run_status = + session->Run({}, /*inputs*/ + {preprocess_stage.output_name()}, {}, /*target node names */ + &outputs); + TF_CHECK_OK(run_status); + EXPECT_EQ(1, outputs.size()); + EXPECT_EQ(DT_FLOAT, outputs[0].dtype()); + EXPECT_TRUE(outputs[0].shape().IsSameSize({1, 224, 224, 3})); +} + +} // namespace +} // namespace metrics +} // namespace tensorflow + +int main(int argc, char** argv) { + g_test_image_file = new tensorflow::string(); + const std::vector<tensorflow::Flag> flag_list = { + tensorflow::Flag("test_image", g_test_image_file, + "Path to image file for test."), + }; + const bool parse_result = tensorflow::Flags::Parse(&argc, argv, flag_list); + CHECK(parse_result) << "Required test_model_file"; + ::tensorflow::port::InitMain(argv[0], &argc, &argv); + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/testdata/grace_hopper.jpg b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/testdata/grace_hopper.jpg Binary files differnew file mode 100644 index 0000000000..d2a427810f --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/testdata/grace_hopper.jpg diff --git a/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_op.cc b/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_op.cc new file mode 100644 index 0000000000..da4258f1c1 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_op.cc @@ -0,0 +1,158 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include <memory> +#include <vector> + +#include "tensorflow/contrib/lite/context.h" +#include "tensorflow/contrib/lite/interpreter.h" +#include "tensorflow/contrib/lite/kernels/register.h" +#include "tensorflow/contrib/lite/model.h" +#include "tensorflow/contrib/lite/op_resolver.h" +#include "tensorflow/contrib/lite/tools/accuracy/utils.h" +#include "tensorflow/core/framework/common_shape_fns.h" +#include "tensorflow/core/framework/op_kernel.h" + +namespace tensorflow { + +namespace { +Status ValidateInputsMatch(const OpInputList& input_tensors, + const tflite::Interpreter& interpreter) { + std::vector<int> tflite_tensor_indices = interpreter.inputs(); + if (tflite_tensor_indices.size() != input_tensors.size()) { + return errors::InvalidArgument( + "size mismatch, interpreter size: ", tflite_tensor_indices.size(), + " actual: ", input_tensors.size()); + } + + for (int i = 0; i < input_tensors.size(); i++) { + const TfLiteTensor* tflite_tensor = + interpreter.tensor(tflite_tensor_indices[i]); + if (tflite_tensor == nullptr) { + return errors::InvalidArgument("Tensor is null at index: ", i); + } + + const Tensor& tensor = input_tensors[i]; + auto i_type = metrics::utils::GetTFDataType(tflite_tensor->type); + auto i_shape = metrics::utils::GetTFLiteTensorShape(*tflite_tensor); + if (i_type != tensor.dtype()) { + return errors::InvalidArgument("Data types mismatch for tensors: ", i, + " expected: ", i_type, + " got: ", tensor.dtype()); + } + + if (i_shape != tensor.shape()) { + return errors::InvalidArgument("Data shapes mismatch for tensors: ", i, + " expected: ", i_shape, + " got: ", tensor.shape()); + } + } + + return Status::OK(); +} + +} // namespace + +class RunTFLiteModelOp : public OpKernel { + public: + explicit RunTFLiteModelOp(OpKernelConstruction* ctx) : OpKernel(ctx) { + string model_file_path; + OP_REQUIRES_OK(ctx, ctx->GetAttr("model_file_path", &model_file_path)); + model_ = tflite::FlatBufferModel::BuildFromFile(model_file_path.data()); + OP_REQUIRES(ctx, model_, + errors::InvalidArgument( + "Model loading failed. Invalid model file path: ", + model_file_path)); + tflite::ops::builtin::BuiltinOpResolver resolver; + + tflite::InterpreterBuilder(*model_, resolver)(&interpreter_); + OP_REQUIRES(ctx, interpreter_, + errors::Internal("Interpreter creation failed.")); + } + + void Compute(OpKernelContext* context) override { + OpInputList input_tensors; + OP_REQUIRES_OK(context, context->input_list("model_input", &input_tensors)); + + OP_REQUIRES_OK(context, ValidateInputsMatch(input_tensors, *interpreter_)); + OpOutputList output_tensors; + OP_REQUIRES_OK(context, + context->output_list("model_output", &output_tensors)); + auto tfl_outputs = interpreter_->outputs(); + OP_REQUIRES(context, output_tensors.size() == tfl_outputs.size(), + errors::InvalidArgument( + "Invalid output size, expected: ", tfl_outputs.size(), + " got: ", output_tensors.size())); + for (int i = 0; i < output_tensors.size(); i++) { + DataType tfl_type = metrics::utils::GetTFDataType( + interpreter_->tensor(tfl_outputs[i])->type); + DataType otype = output_tensors.expected_output_dtype(i); + OP_REQUIRES( + context, tfl_type == otype, + errors::InvalidArgument("Invalid data type for output at index: ", i, + " expected: ", tfl_type, " got: ", otype)); + } + + auto allocation_status = interpreter_->AllocateTensors(); + OP_REQUIRES(context, allocation_status == kTfLiteOk, + errors::Internal("Unable to allocate tensors.")); + for (int i = 0; i < input_tensors.size(); i++) { + const int tfl_index = interpreter_->inputs()[i]; + TfLiteTensor* tflite_tensor = interpreter_->tensor(tfl_index); + auto tensor_bytes = input_tensors[i].tensor_data(); + OP_REQUIRES(context, tflite_tensor->bytes == tensor_bytes.size(), + errors::InvalidArgument( + "Size mismatch, expected: ", tflite_tensor->bytes, + " got: ", tensor_bytes.size())); + std::memcpy(tflite_tensor->data.raw, tensor_bytes.data(), + tensor_bytes.size()); + } + auto invocation_status = interpreter_->Invoke(); + OP_REQUIRES(context, invocation_status == kTfLiteOk, + errors::Internal("Interpreter invocation failed.")); + for (int i = 0; i < output_tensors.size(); i++) { + auto tfl_tensor = interpreter_->tensor(tfl_outputs[i]); + TensorShape shape = metrics::utils::GetTFLiteTensorShape(*tfl_tensor); + Tensor* output = nullptr; + OP_REQUIRES_OK(context, output_tensors.allocate(i, shape, &output)); + auto tensor_bytes = output->tensor_data(); + OP_REQUIRES(context, tensor_bytes.size() == tfl_tensor->bytes, + errors::Internal("Invalid size")); + std::memcpy(const_cast<char*>(tensor_bytes.data()), tfl_tensor->data.raw, + tfl_tensor->bytes); + } + } + + private: + std::unique_ptr<tflite::FlatBufferModel> model_; + std::unique_ptr<tflite::Interpreter> interpreter_; +}; + +REGISTER_KERNEL_BUILDER(Name("RunTFLiteModel").Device(DEVICE_CPU), + RunTFLiteModelOp); + +REGISTER_OP("RunTFLiteModel") + .Input("model_input: input_type") + .Output("model_output: output_type") + .Attr("model_file_path: string") + .Attr("input_type : list(type)") + .Attr("output_type: list(type)") + .SetShapeFn([](shape_inference::InferenceContext* c) { + // TODO(shashishekhar): Infer the correct shape based on output_type and + // maybe another attribute. + return shape_inference::UnknownShape(c); + }); + +} // namespace tensorflow diff --git a/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_op_test.cc b/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_op_test.cc new file mode 100644 index 0000000000..88175984a0 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_op_test.cc @@ -0,0 +1,200 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include <vector> + +#include <gmock/gmock.h> +#include <gtest/gtest.h> +#include "tensorflow/cc/framework/scope.h" +#include "tensorflow/cc/ops/standard_ops.h" +#include "tensorflow/core/platform/init_main.h" +#include "tensorflow/core/public/session.h" +#include "tensorflow/core/util/command_line_flags.h" + +namespace { +tensorflow::string* g_test_model_file = nullptr; +} + +namespace tensorflow { +namespace { + +TEST(RunTfliteModelOpTest, ModelIsRun) { + ASSERT_TRUE(g_test_model_file != nullptr); + string test_model_file = *g_test_model_file; + ASSERT_FALSE(test_model_file.empty()); + + Scope scope = Scope::NewRootScope(); + TF_CHECK_OK(scope.status()); + // Passed graph has 4 inputs : a,b,c,d and 2 outputs x,y + // x = a+b+c, y=b+c+d + + std::vector<Input> graph_inputs = { + ops::Const(scope, 1.0f, {1, 8, 8, 3}), // a + ops::Const(scope, 2.1f, {1, 8, 8, 3}), // b + ops::Const(scope, 3.2f, {1, 8, 8, 3}), // c + ops::Const(scope, 4.3f, {1, 8, 8, 3}), // d + }; + + std::vector<NodeBuilder::NodeOut> input_data; + std::transform(graph_inputs.begin(), graph_inputs.end(), + std::back_inserter(input_data), [&scope](Input model_input) { + return ops::AsNodeOut(scope, model_input); + }); + + std::vector<DataType> model_input_type = {DT_FLOAT, DT_FLOAT, DT_FLOAT, + DT_FLOAT}; + ::tensorflow::Node* ret; + auto builder = ::tensorflow::NodeBuilder("run_model_op", "RunTFLiteModel") + .Input(input_data) + .Attr("model_file_path", test_model_file) + .Attr("input_type", model_input_type) + .Attr("output_type", {DT_FLOAT, DT_FLOAT}); + + scope.UpdateBuilder(&builder); + scope.UpdateStatus(builder.Finalize(scope.graph(), &ret)); + TF_CHECK_OK(scope.status()); + + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(session->Create(graph_def)); + + std::vector<Tensor> outputs; + TF_CHECK_OK( + session->Run({}, {"run_model_op:0", "run_model_op:1"}, {}, &outputs)); + EXPECT_EQ(2, outputs.size()); + + for (const auto& tensor : outputs) { + EXPECT_TRUE(tensor.shape().IsSameSize({1, 8, 8, 3})); + } + auto output_x = outputs[0].flat<float>(); + auto output_y = outputs[1].flat<float>(); + EXPECT_EQ(1 * 8 * 8 * 3, output_x.size()); + EXPECT_EQ(1 * 8 * 8 * 3, output_y.size()); + for (int i = 0; i < output_x.size(); i++) { + EXPECT_NEAR(6.3f, output_x(i), 1e-6f); // a+b+c + EXPECT_NEAR(9.6f, output_y(i), 1e-6f); // b+c+d + } +} + +TEST(RunTfliteModelOpTest, NumInputsMismatch) { + ASSERT_TRUE(g_test_model_file != nullptr); + string test_model_file = *g_test_model_file; + ASSERT_FALSE(test_model_file.empty()); + + Scope scope = Scope::NewRootScope(); + TF_CHECK_OK(scope.status()); + // Passed graph has 4 inputs : a,b,c,d and 2 outputs x,y + // x = a+b+c, y=b+c+d + // Remove a from input. + + std::vector<Input> graph_inputs = { + ops::Const(scope, 2.1f, {1, 8, 8, 3}), // b + ops::Const(scope, 3.2f, {1, 8, 8, 3}), // c + ops::Const(scope, 4.3f, {1, 8, 8, 3}), // d + }; + + std::vector<NodeBuilder::NodeOut> input_data; + std::transform(graph_inputs.begin(), graph_inputs.end(), + std::back_inserter(input_data), [&scope](Input model_input) { + return ops::AsNodeOut(scope, model_input); + }); + + std::vector<DataType> model_input_type = {DT_FLOAT, DT_FLOAT, DT_FLOAT}; + + ::tensorflow::Node* ret; + auto builder = ::tensorflow::NodeBuilder("run_model_op", "RunTFLiteModel") + .Input(input_data) + .Attr("model_file_path", test_model_file) + .Attr("input_type", model_input_type) + .Attr("output_type", {DT_FLOAT, DT_FLOAT}); + + scope.UpdateBuilder(&builder); + scope.UpdateStatus(builder.Finalize(scope.graph(), &ret)); + TF_CHECK_OK(scope.status()); + + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(session->Create(graph_def)); + + std::vector<Tensor> outputs; + auto status = + (session->Run({}, {"run_model_op:0", "run_model_op:1"}, {}, &outputs)); + EXPECT_FALSE(status.ok()); +} + +TEST(RunTfliteModelOpTest, InputSizesMismatch) { + ASSERT_TRUE(g_test_model_file != nullptr); + string test_model_file = *g_test_model_file; + ASSERT_FALSE(test_model_file.empty()); + + Scope scope = Scope::NewRootScope(); + TF_CHECK_OK(scope.status()); + // Passed graph has 4 inputs : a,b,c,d and 2 outputs x,y + // x = a+b+c, y=b+c+d + // Set a to be invalid size. + std::vector<Input> graph_inputs = { + ops::Const(scope, 1.0f, {1, 8, 8, 4}), // a invalid size, + ops::Const(scope, 2.1f, {1, 8, 8, 3}), // b + ops::Const(scope, 3.2f, {1, 8, 8, 3}), // c + ops::Const(scope, 4.3f, {1, 8, 8, 3}), // d + }; + + std::vector<NodeBuilder::NodeOut> input_data; + std::transform(graph_inputs.begin(), graph_inputs.end(), + std::back_inserter(input_data), [&scope](Input model_input) { + return ops::AsNodeOut(scope, model_input); + }); + + std::vector<DataType> model_input_type = {DT_FLOAT, DT_FLOAT, DT_FLOAT, + DT_FLOAT}; + ::tensorflow::Node* ret; + auto builder = ::tensorflow::NodeBuilder("run_model_op", "RunTFLiteModel") + .Input(input_data) + .Attr("model_file_path", test_model_file) + .Attr("input_type", model_input_type) + .Attr("output_type", {DT_FLOAT, DT_FLOAT}); + + scope.UpdateBuilder(&builder); + scope.UpdateStatus(builder.Finalize(scope.graph(), &ret)); + TF_CHECK_OK(scope.status()); + + GraphDef graph_def; + TF_CHECK_OK(scope.ToGraphDef(&graph_def)); + std::unique_ptr<Session> session(NewSession(SessionOptions())); + TF_CHECK_OK(session->Create(graph_def)); + + std::vector<Tensor> outputs; + auto status = + (session->Run({}, {"run_model_op:0", "run_model_op:1"}, {}, &outputs)); + EXPECT_FALSE(status.ok()); +} + +} // namespace +} // namespace tensorflow + +int main(int argc, char** argv) { + g_test_model_file = new tensorflow::string(); + const std::vector<tensorflow::Flag> flag_list = { + tensorflow::Flag("test_model_file", g_test_model_file, + "Path to test tflite model file."), + }; + const bool parse_result = tensorflow::Flags::Parse(&argc, argv, flag_list); + CHECK(parse_result) << "Required test_model_file"; + ::tensorflow::port::InitMain(argv[0], &argc, &argv); + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_stage.cc b/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_stage.cc new file mode 100644 index 0000000000..c96795d499 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_stage.cc @@ -0,0 +1,45 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/run_tflite_model_stage.h" + +#include <vector> + +#include "tensorflow/cc/framework/scope.h" +#include "tensorflow/cc/ops/standard_ops.h" + +namespace tensorflow { +namespace metrics { +void RunTFLiteModelStage::AddToGraph(const Scope& scope, const Input& input) { + if (!scope.ok()) return; + Scope s = scope.WithOpName(name()); + + std::vector<NodeBuilder::NodeOut> _data = {ops::AsNodeOut(s, input)}; + ::tensorflow::Node* ret; + auto builder = NodeBuilder(output_name(), "RunTFLiteModel") + .Input(_data) + .Attr("model_file_path", params_.model_file_path) + .Attr("input_type", params_.input_type) + .Attr("output_type", params_.output_type); + + s.UpdateBuilder(&builder); + s.UpdateStatus(builder.Finalize(s.graph(), &ret)); + if (!s.ok()) return; + s.UpdateStatus(s.DoShapeInference(ret)); + this->stage_output_ = ::tensorflow::Output(ret, 0); +} + +} // namespace metrics +} // namespace tensorflow diff --git a/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_stage.h b/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_stage.h new file mode 100644 index 0000000000..90d12d6f42 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/run_tflite_model_stage.h @@ -0,0 +1,53 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_RUN_TFLITE_MODEL_STAGE_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_RUN_TFLITE_MODEL_STAGE_H_ + +#include <string> + +#include "tensorflow/contrib/lite/tools/accuracy/stage.h" + +namespace tensorflow { +namespace metrics { +// Stage that loads and runs a TFLite model. +// Inputs: The input to TFLite model. +// Outputs: The output of running the TFLite model. +class RunTFLiteModelStage : public Stage { + public: + // The parameters for the stage. + struct Params { + string model_file_path; + std::vector<TensorShape> output_shape; + std::vector<DataType> input_type; + std::vector<DataType> output_type; + }; + + explicit RunTFLiteModelStage(const Params& params) : params_(params) {} + + string name() const override { return "stage_run_tfl_model"; } + // TODO(shashishekhar): This stage can have multiple inputs and + // outputs, perhaps change the definition of stage. + string output_name() const override { return "stage_run_tfl_model_output"; } + + void AddToGraph(const Scope& scope, const Input& input) override; + + private: + Params params_; +}; + +} // namespace metrics +} // namespace tensorflow +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_RUN_TFLITE_MODEL_STAGE_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/stage.h b/tensorflow/contrib/lite/tools/accuracy/stage.h new file mode 100644 index 0000000000..8292ea2ec7 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/stage.h @@ -0,0 +1,56 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_STAGE_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_STAGE_H_ + +#include "tensorflow/cc/framework/scope.h" + +namespace tensorflow { +namespace metrics { + +// A stage in an evaluation pipeline. +// Each stage adds a subgraph to the pipeline. Stages can be chained +// together. +class Stage { + public: + Stage() = default; + Stage(const Stage&) = delete; + Stage& operator=(const Stage&) = delete; + + Stage(const Stage&&) = delete; + Stage& operator=(const Stage&&) = delete; + + // Adds a subgraph to given scope that takes in `input` as a parameter. + virtual void AddToGraph(const Scope& scope, const Input& input) = 0; + virtual ~Stage() {} + + // The name of the stage. + // Can be used by derived classes for naming the subscope for the stage + // graph. + virtual string name() const = 0; + + // The name of the output for the stage. + virtual string output_name() const = 0; + + const ::tensorflow::Output& Output() const { return stage_output_; } + + protected: + ::tensorflow::Output stage_output_; +}; +} // namespace metrics +} // namespace tensorflow + +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_STAGE_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/utils.cc b/tensorflow/contrib/lite/tools/accuracy/utils.cc new file mode 100644 index 0000000000..f5493301fc --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/utils.cc @@ -0,0 +1,102 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/lite/tools/accuracy/utils.h" + +#include <sys/stat.h> + +#include <cstring> +#include <fstream> +#include <memory> +#include <string> + +#include "tensorflow/contrib/lite/interpreter.h" +#include "tensorflow/contrib/lite/kernels/register.h" +#include "tensorflow/contrib/lite/model.h" +#include "tensorflow/contrib/lite/op_resolver.h" + +namespace tensorflow { +namespace metrics { + +namespace utils { + +DataType GetTFDataType(TfLiteType tflite_type) { + switch (tflite_type) { + case kTfLiteFloat32: + return DT_FLOAT; + case kTfLiteUInt8: + return DT_UINT8; + default: + return DT_INVALID; + } +} + +TensorShape GetTFLiteTensorShape(const TfLiteTensor& tflite_tensor) { + TensorShape shape; + for (int i = 0; i < tflite_tensor.dims->size; i++) { + shape.AddDim(tflite_tensor.dims->data[i]); + } + return shape; +} + +Status ReadFileLines(const string& file_path, + std::vector<string>* lines_output) { + if (!lines_output) { + return errors::InvalidArgument("Invalid output"); + } + std::vector<string> lines; + std::ifstream stream(file_path, std::ios_base::in); + if (!stream) { + return errors::InvalidArgument("Unable to open file: ", file_path); + } + std::string line; + while (std::getline(stream, line)) { + lines_output->push_back(line); + } + return Status::OK(); +} + +Status GetTFliteModelInfo(const string& model_file_path, + ModelInfo* model_info) { + if (model_file_path.empty()) { + return errors::InvalidArgument("Invalid model file."); + } + struct stat stat_buf; + if (stat(model_file_path.c_str(), &stat_buf) != 0) { + int error_num = errno; + return errors::InvalidArgument("Invalid model file: ", model_file_path, + std::strerror(error_num)); + } + + std::unique_ptr<tflite::FlatBufferModel> model; + std::unique_ptr<tflite::Interpreter> interpreter; + model = tflite::FlatBufferModel::BuildFromFile(model_file_path.data()); + tflite::ops::builtin::BuiltinOpResolver resolver; + + tflite::InterpreterBuilder(*model, resolver)(&interpreter); + if (!interpreter) { + return errors::InvalidArgument("Invalid model", model_file_path); + } + for (int i : interpreter->inputs()) { + TfLiteTensor* tensor = interpreter->tensor(i); + model_info->input_shapes.push_back(utils::GetTFLiteTensorShape(*tensor)); + model_info->input_types.push_back(utils::GetTFDataType(tensor->type)); + } + return Status::OK(); +} + +} // namespace utils +} // namespace metrics +} // namespace tensorflow diff --git a/tensorflow/contrib/lite/tools/accuracy/utils.h b/tensorflow/contrib/lite/tools/accuracy/utils.h new file mode 100644 index 0000000000..37cbad4d51 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/utils.h @@ -0,0 +1,46 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_UTILS_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_UTILS_H_ + +#include <string> +#include <vector> + +#include "tensorflow/contrib/lite/context.h" +#include "tensorflow/core/framework/tensor_shape.h" + +namespace tensorflow { +namespace metrics { + +namespace utils { + +struct ModelInfo { + std::vector<TensorShape> input_shapes; + std::vector<DataType> input_types; +}; + +Status GetTFliteModelInfo(const string& model_file_path, ModelInfo* model_info); + +DataType GetTFDataType(TfLiteType tflite_type); + +TensorShape GetTFLiteTensorShape(const TfLiteTensor& tflite_tensor); + +Status ReadFileLines(const string& file_path, + std::vector<string>* lines_output); +} // namespace utils +} // namespace metrics +} // namespace tensorflow +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_ACCURACY_UTILS_H_ diff --git a/tensorflow/contrib/lite/tools/accuracy/utils_test.cc b/tensorflow/contrib/lite/tools/accuracy/utils_test.cc new file mode 100644 index 0000000000..727eba21b6 --- /dev/null +++ b/tensorflow/contrib/lite/tools/accuracy/utils_test.cc @@ -0,0 +1,76 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include <string> +#include <vector> + +#include <gmock/gmock.h> +#include <gtest/gtest.h> +#include "tensorflow/contrib/lite/tools/accuracy/utils.h" +#include "tensorflow/core/platform/init_main.h" +#include "tensorflow/core/util/command_line_flags.h" + +namespace { +tensorflow::string* g_test_model_file = nullptr; +} + +namespace tensorflow { +namespace metrics { +namespace utils { +namespace { + +TEST(UtilsTest, GetTFLiteModelInfoReturnsCorrectly) { + ASSERT_TRUE(g_test_model_file != nullptr); + string test_model_file = *g_test_model_file; + ASSERT_FALSE(test_model_file.empty()); + // Passed graph has 4 inputs : a,b,c,d and 2 outputs x,y + // x = a+b+c, y=b+c+d + // Input and outputs have shape : {1,8,8,3} + ModelInfo model_info; + auto status = GetTFliteModelInfo(test_model_file, &model_info); + TF_CHECK_OK(status); + ASSERT_EQ(4, model_info.input_shapes.size()); + ASSERT_EQ(4, model_info.input_types.size()); + + for (int i = 0; i < 4; i++) { + const TensorShape& shape = model_info.input_shapes[i]; + DataType dataType = model_info.input_types[i]; + EXPECT_TRUE(shape.IsSameSize({1, 8, 8, 3})); + EXPECT_EQ(DT_FLOAT, dataType); + } +} + +TEST(UtilsTest, GetTFliteModelInfoIncorrectFile) { + ModelInfo model_info; + auto status = GetTFliteModelInfo("non_existent_file", &model_info); + EXPECT_FALSE(status.ok()); +} + +} // namespace +} // namespace utils +} // namespace metrics +} // namespace tensorflow + +int main(int argc, char** argv) { + g_test_model_file = new tensorflow::string(); + const std::vector<tensorflow::Flag> flag_list = { + tensorflow::Flag("test_model_file", g_test_model_file, + "Path to test tflite model file."), + }; + const bool parse_result = tensorflow::Flags::Parse(&argc, argv, flag_list); + CHECK(parse_result) << "Required test_model_file"; + ::tensorflow::port::InitMain(argv[0], &argc, &argv); + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/tools/benchmark/BUILD b/tensorflow/contrib/lite/tools/benchmark/BUILD index 2cb07eb6ec..dc97d22401 100644 --- a/tensorflow/contrib/lite/tools/benchmark/BUILD +++ b/tensorflow/contrib/lite/tools/benchmark/BUILD @@ -5,8 +5,8 @@ package(default_visibility = [ licenses(["notice"]) # Apache 2.0 load("//tensorflow/contrib/lite:special_rules.bzl", "tflite_portable_test_suite") -load("//tensorflow/contrib/lite:build_def.bzl", "tflite_linkopts") load("//tensorflow/contrib/lite:build_def.bzl", "tflite_copts") +load("//tensorflow/contrib/lite:build_def.bzl", "tflite_linkopts") common_copts = ["-Wall"] + tflite_copts() @@ -35,6 +35,25 @@ cc_binary( ], ) +cc_binary( + name = "benchmark_model_plus_eager", + srcs = [ + "benchmark_main.cc", + ], + copts = common_copts + ["-DTFLITE_EXTENDED"], + linkopts = tflite_linkopts() + select({ + "//tensorflow:android": [ + "-pie", # Android 5.0 and later supports only PIE + "-lm", # some builtin ops, e.g., tanh, need -lm + ], + "//conditions:default": [], + }), + deps = [ + ":benchmark_tflite_model_plus_eager_lib", + ":logging", + ], +) + cc_test( name = "benchmark_test", srcs = ["benchmark_test.cc"], @@ -88,7 +107,25 @@ cc_library( "//tensorflow/contrib/lite:string_util", "//tensorflow/contrib/lite/kernels:builtin_ops", "//tensorflow/contrib/lite/profiling:profile_summarizer", - "//tensorflow/contrib/lite/profiling:profiler", + ], +) + +cc_library( + name = "benchmark_tflite_model_plus_eager_lib", + srcs = [ + "benchmark_tflite_model.cc", + "logging.h", + ], + hdrs = ["benchmark_tflite_model.h"], + copts = common_copts + ["-DTFLITE_EXTENDED"], + deps = [ + ":benchmark_model_lib", + ":logging", + "//tensorflow/contrib/lite:framework", + "//tensorflow/contrib/lite:string_util", + "//tensorflow/contrib/lite/delegates/eager:delegate", + "//tensorflow/contrib/lite/kernels:builtin_ops", + "//tensorflow/contrib/lite/profiling:profile_summarizer", ], ) diff --git a/tensorflow/contrib/lite/tools/benchmark/benchmark_model.h b/tensorflow/contrib/lite/tools/benchmark/benchmark_model.h index 677a1ee68c..cc215a7b7f 100644 --- a/tensorflow/contrib/lite/tools/benchmark/benchmark_model.h +++ b/tensorflow/contrib/lite/tools/benchmark/benchmark_model.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_MODEL_H_ -#define TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_MODEL_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_BENCHMARK_MODEL_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_BENCHMARK_MODEL_H_ #include <cmath> #include <limits> diff --git a/tensorflow/contrib/lite/tools/benchmark/benchmark_tflite_model.cc b/tensorflow/contrib/lite/tools/benchmark/benchmark_tflite_model.cc index 7f97f5d0cd..02039922b4 100644 --- a/tensorflow/contrib/lite/tools/benchmark/benchmark_tflite_model.cc +++ b/tensorflow/contrib/lite/tools/benchmark/benchmark_tflite_model.cc @@ -23,6 +23,9 @@ limitations under the License. #include <unordered_set> #include <vector> +#ifdef TFLITE_EXTENDED +#include "tensorflow/contrib/lite/delegates/eager/delegate.h" +#endif // TFLITE_EXTENDED #include "tensorflow/contrib/lite/kernels/register.h" #include "tensorflow/contrib/lite/model.h" #include "tensorflow/contrib/lite/op_resolver.h" @@ -261,6 +264,16 @@ void BenchmarkTfLiteModel::Init() { bool use_nnapi = params_.Get<bool>("use_nnapi"); interpreter->UseNNAPI(use_nnapi); + +#ifdef TFLITE_EXTENDED + TFLITE_LOG(INFO) << "Instantiating Eager Delegate"; + delegate_ = EagerDelegate::Create(); + if (delegate_) { + interpreter->ModifyGraphWithDelegate(delegate_.get(), + /*allow_dynamic_tensors=*/true); + } +#endif // TFLITE_EXTENDED + auto interpreter_inputs = interpreter->inputs(); if (!inputs.empty()) { diff --git a/tensorflow/contrib/lite/tools/benchmark/benchmark_tflite_model.h b/tensorflow/contrib/lite/tools/benchmark/benchmark_tflite_model.h index 9931dcbafe..4c4320a998 100644 --- a/tensorflow/contrib/lite/tools/benchmark/benchmark_tflite_model.h +++ b/tensorflow/contrib/lite/tools/benchmark/benchmark_tflite_model.h @@ -13,13 +13,16 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_TFLITE_MODEL_H_ -#define TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_TFLITE_MODEL_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_BENCHMARK_TFLITE_MODEL_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_BENCHMARK_TFLITE_MODEL_H_ #include <memory> #include <string> #include <vector> +#ifdef TFLITE_EXTENDED +#include "tensorflow/contrib/lite/delegates/eager/delegate.h" +#endif // TFLITE_EXTENDED #include "tensorflow/contrib/lite/model.h" #include "tensorflow/contrib/lite/profiling/profile_summarizer.h" #include "tensorflow/contrib/lite/tools/benchmark/benchmark_model.h" @@ -52,6 +55,7 @@ class BenchmarkTfLiteModel : public BenchmarkModel { public: BenchmarkTfLiteModel(); BenchmarkTfLiteModel(BenchmarkParams params); + virtual ~BenchmarkTfLiteModel() {} std::vector<Flag> GetFlags() override; void LogParams() override; @@ -59,7 +63,6 @@ class BenchmarkTfLiteModel : public BenchmarkModel { uint64_t ComputeInputBytes() override; void Init() override; void RunImpl() override; - virtual ~BenchmarkTfLiteModel() {} struct InputLayerInfo { std::string name; @@ -67,6 +70,9 @@ class BenchmarkTfLiteModel : public BenchmarkModel { }; private: +#ifdef TFLITE_EXTENDED + std::unique_ptr<EagerDelegate> delegate_; +#endif // TFLITE_EXTENDED std::unique_ptr<tflite::FlatBufferModel> model; std::unique_ptr<tflite::Interpreter> interpreter; std::vector<InputLayerInfo> inputs; diff --git a/tensorflow/contrib/lite/tools/benchmark/command_line_flags.h b/tensorflow/contrib/lite/tools/benchmark/command_line_flags.h index 2e514ae3ea..6a0affd834 100644 --- a/tensorflow/contrib/lite/tools/benchmark/command_line_flags.h +++ b/tensorflow/contrib/lite/tools/benchmark/command_line_flags.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_COMMAND_LINE_FLAGS_H_ -#define TENSORFLOW_CONTRIB_LITE_TOOLS_COMMAND_LINE_FLAGS_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_COMMAND_LINE_FLAGS_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_COMMAND_LINE_FLAGS_H_ #include <functional> #include <string> diff --git a/tensorflow/contrib/lite/tools/benchmark/logging.h b/tensorflow/contrib/lite/tools/benchmark/logging.h index 9e9292e2fe..4045d1e731 100644 --- a/tensorflow/contrib/lite/tools/benchmark/logging.h +++ b/tensorflow/contrib/lite/tools/benchmark/logging.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_LOGGING_H_ -#define TENSORFLOW_CONTRIB_LITE_TOOLS_LOGGING_H_ +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_LOGGING_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_BENCHMARK_LOGGING_H_ // LOG and CHECK macros for benchmarks. diff --git a/tensorflow/contrib/lite/tools/optimize/BUILD b/tensorflow/contrib/lite/tools/optimize/BUILD new file mode 100644 index 0000000000..01fbce0ac7 --- /dev/null +++ b/tensorflow/contrib/lite/tools/optimize/BUILD @@ -0,0 +1,11 @@ +# TODO(suharshs): Write quantize_weights tests that use small exportable files. +# Then we can remove this file. +package( + default_visibility = ["//visibility:public"], +) + +licenses(["notice"]) # Apache 2.0 + +exports_files(["LICENSE"]) + +load("//tensorflow/contrib/lite:build_def.bzl", "tflite_copts") diff --git a/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc b/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc new file mode 100644 index 0000000000..0758514e39 --- /dev/null +++ b/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc @@ -0,0 +1,280 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include "tensorflow/contrib/lite/tools/optimize/quantize_weights.h" + +#include <algorithm> +#include <memory> +#include <string> +#include <vector> + +#include "flatbuffers/flexbuffers.h" +#include "tensorflow/contrib/lite/context.h" +#include "tensorflow/contrib/lite/model.h" +#include "tensorflow/contrib/lite/schema/schema_generated.h" +#include "tensorflow/core/platform/logging.h" + +namespace tflite { +namespace optimize { + +namespace { + +// The minimum number of elements a weights array must have to be quantized +// by this transformation. +// TODO(suharshs): Make this configurable. +const int kWeightsMinSize = 1024; + +// Nudge min and max so that floating point 0 falls exactly on a quantized +// value, returning the nudges scale and zero_point. +// +// Although this code originates from FakeQuantization in quantized training, +// we may deviate from that implementation as we please since we do not fine +// tune the weights with quantized training. +void GetQuantizationParams(const float min, const float max, + const int quant_min, const int quant_max, + QuantizationParametersT* quantization_params) { + // Adjust the boundaries to guarantee 0 is included. + const float quant_min_float = std::min(static_cast<float>(quant_min), 0.0f); + const float quant_max_float = std::max(static_cast<float>(quant_max), 0.0f); + const float scale = (max - min) / (quant_max_float - quant_min_float); + const float zero_point_from_min = quant_min_float - min / scale; + int64_t zero_point; + if (zero_point_from_min < quant_min_float) { + zero_point = static_cast<int64_t>(quant_min); + } else if (zero_point_from_min > quant_max_float) { + zero_point = static_cast<int64_t>(quant_max); + } else { + zero_point = static_cast<int64_t>(std::round(zero_point_from_min)); + } + quantization_params->scale = {scale}; + quantization_params->zero_point = {zero_point}; +} + +// Returns the number of elements in tensor. +uint64 NumElements(const TensorT* tensor) { + if (tensor->shape.empty()) { + LOG(FATAL) << "Tensor has no shape information."; + } + uint64 num_elements = 1; + for (const uint64 dim : tensor->shape) { + num_elements *= dim; + } + return num_elements; +} + +uint64 CountTensorConsumers(const ModelT* model, const SubGraphT* subgraph, + int32_t tensor_idx) { + uint64 count = 0; + for (int op_idx = 0; op_idx < subgraph->operators.size(); ++op_idx) { + const OperatorT* op = subgraph->operators[op_idx].get(); + if (op == nullptr) { + continue; + } + for (int i = 0; i < op->inputs.size(); ++i) { + if (op->inputs[i] == tensor_idx) { + count++; + } + } + } + return count; +} + +// Returns true if the Operator's weight tensor should be quantized. +bool GetQuantizableTensorFromOperator(const ModelT* model, const OperatorT* op, + TensorT** tensor, int32_t* tensor_idx, + int32_t* op_input_index) { + SubGraphT* subgraph = model->subgraphs.at(0).get(); + const BuiltinOperator op_code = + model->operator_codes[op->opcode_index]->builtin_code; + + if (op_code == BuiltinOperator_CONV_2D || + op_code == BuiltinOperator_DEPTHWISE_CONV_2D || + op_code == BuiltinOperator_FULLY_CONNECTED || + op_code == BuiltinOperator_SVDF) { + *op_input_index = 1; + } else if (op_code == BuiltinOperator_LSTM) { + // TODO(suharshs): Add RNN, and sequential/bidi versions. + *op_input_index = 2; + } else { + return false; + } + *tensor_idx = op->inputs[*op_input_index]; + + // TODO(suharshs): Support shared weights, i.e. If two tensors share the + // same weight array, things may break. (i.e. SSD object detection) + if (CountTensorConsumers(model, subgraph, *tensor_idx) != 1) { + LOG(INFO) << "Skipping quantization of tensor that is shared between " + "multiple multiple operations."; + return false; + } + + *tensor = subgraph->tensors[*tensor_idx].get(); + + if ((*tensor)->type != TensorType_FLOAT32) { + LOG(INFO) << "Skipping quantization of tensor that is not type float."; + return false; + } + const uint64 num_elements = NumElements(*tensor); + if (num_elements < kWeightsMinSize) { + LOG(INFO) << "Skipping quantization of tensor because it has fewer than " + << kWeightsMinSize << " elements (" << num_elements << ")."; + return false; + } + + return true; +} + +// Quantizes tensor using asymmetric quantization with the min and max elements +// of the tensor. This is needed to pass to Dequantize operations. +TfLiteStatus AsymmetricQuantizeTensor(ModelT* model, TensorT* tensor) { + BufferT* buffer = model->buffers[tensor->buffer].get(); + float* float_data = reinterpret_cast<float*>(buffer->data.data()); + const uint64 num_elements = NumElements(tensor); + LOG(INFO) << "Quantizing tensor with " << num_elements << " elements."; + + // Compute the quantization params. + float min_value = *std::min_element(float_data, float_data + num_elements); + float max_value = *std::max_element(float_data, float_data + num_elements); + GetQuantizationParams(min_value, max_value, 0, 255, + tensor->quantization.get()); + + // Quantize the buffer. + std::vector<uint8_t> quantized_buffer; + quantized_buffer.resize(num_elements); + const double inverse_scale = 1. / tensor->quantization->scale[0]; + for (std::size_t i = 0; i < num_elements; i++) { + const float src_val = float_data[i]; + double scaled_val; + if (tensor->quantization->scale[0] == 0) { + scaled_val = tensor->quantization->zero_point[0]; + } else { + scaled_val = + tensor->quantization->zero_point[0] + inverse_scale * src_val; + } + uint8_t integer_val = static_cast<uint8_t>(std::round(scaled_val)); + quantized_buffer[i] = integer_val; + } + model->buffers[tensor->buffer]->data = quantized_buffer; + + // Update the tensor type. + tensor->type = TensorType_UINT8; + + return kTfLiteOk; +} + +// Returns the index of the Dequantize op_code. +// If a Dequantize op_code doesn't exist, adds it and returns its index. +int32_t GetOrInsertDequantizeOpCodeIndex(ModelT* model) { + for (int i = 0; i < model->operator_codes.size(); ++i) { + if (model->operator_codes[i]->builtin_code == BuiltinOperator_DEQUANTIZE) { + return i; + } + } + model->operator_codes.push_back(std::make_unique<OperatorCodeT>()); + int op_code_idx = model->operator_codes.size() - 1; + model->operator_codes[op_code_idx]->builtin_code = BuiltinOperator_DEQUANTIZE; + // TODO(suharshs): How should the version be set in this op_code? + + // Return the index of the newly placed OperatorCodeT. + return op_code_idx; +} + +// Creates a Dequantize OperatorT object. +void MakeDequantizeOperator(ModelT* model, std::unique_ptr<OperatorT>* op, + int32_t input, int32_t output) { + OperatorT* op_raw = new OperatorT; + op_raw->opcode_index = GetOrInsertDequantizeOpCodeIndex(model); + op_raw->inputs = {input}; + op_raw->outputs = {output}; + + op->reset(op_raw); +} + +// Create a new TensorT object. +void MakeTensor(const string& name, const std::vector<int32_t>& shape, + std::unique_ptr<TensorT>* tensor) { + TensorT* tensor_raw = new TensorT; + tensor_raw->name = name; + tensor_raw->shape = shape; + + tensor->reset(tensor_raw); +} + +} // namespace + +TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, + const Model* input_model) { + std::unique_ptr<ModelT> model; + model.reset(input_model->UnPack()); + + // TODO(suharshs): When models support multiple subgraphs, add support. + if (model->subgraphs.size() != 1) { + LOG(ERROR) << "Quantize weights tool only supports tflite models with one " + "subgraph."; + return kTfLiteError; + } + + SubGraphT* subgraph = model->subgraphs.at(0).get(); + + std::vector<std::unique_ptr<OperatorT>> new_operators; + for (int i = 0; i < subgraph->operators.size(); ++i) { + OperatorT* op = subgraph->operators[i].get(); + + TensorT* tensor; + // The index of the weight tensor in subgraph->tensors. + int32_t tensor_idx; + int32_t op_input_idx; // The index of tensor_idx in the op->inputs. + // TODO(suharshs): Support hybrid ops that require symmetric quantization. + if (GetQuantizableTensorFromOperator(model.get(), op, &tensor, &tensor_idx, + &op_input_idx)) { + // Quantize the tensors. + TF_LITE_ENSURE_STATUS(AsymmetricQuantizeTensor(model.get(), tensor)); + + // Create a new tensor to be the output of the dequantize op. + std::unique_ptr<TensorT> dequantize_output; + MakeTensor(tensor->name + "_dequantize", tensor->shape, + &dequantize_output); + int32_t dequantize_output_idx = subgraph->tensors.size(); + subgraph->tensors.push_back(std::move(dequantize_output)); + + // Create the Dequantize operation. + std::unique_ptr<OperatorT> dequantize_op; + MakeDequantizeOperator(model.get(), &dequantize_op, tensor_idx, + dequantize_output_idx); + + // Update the op_input of tensor_idx to dequantize_output_idx. + op->inputs[op_input_idx] = dequantize_output_idx; + // Insert the updated op. + new_operators.push_back(std::move(subgraph->operators[i])); + + // Insert the newly created Dequantize operation. + new_operators.push_back(std::move(dequantize_op)); + } else { + // If this tensor wasn't quantizable, just copy the op over as-is. + new_operators.push_back(std::move(subgraph->operators[i])); + } + } + // At this point all unique_ptrs in the original operators are invalid, and + // we need to replace it with the new_operators vector. + subgraph->operators = std::move(new_operators); + + flatbuffers::Offset<Model> output_model_location = + Model::Pack(*builder, model.get()); + FinishModelBuffer(*builder, output_model_location); + + return kTfLiteOk; +} + +} // namespace optimize +} // namespace tflite diff --git a/tensorflow/contrib/lite/tools/optimize/quantize_weights.h b/tensorflow/contrib/lite/tools/optimize/quantize_weights.h new file mode 100644 index 0000000000..a408c1662d --- /dev/null +++ b/tensorflow/contrib/lite/tools/optimize/quantize_weights.h @@ -0,0 +1,38 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#ifndef TENSORFLOW_CONTRIB_LITE_TOOLS_OPTIMIZE_QUANTIZE_WEIGHTS_H_ +#define TENSORFLOW_CONTRIB_LITE_TOOLS_OPTIMIZE_QUANTIZE_WEIGHTS_H_ + +#include <memory> +#include "flatbuffers/flexbuffers.h" +#include "tensorflow/contrib/lite/context.h" +#include "tensorflow/contrib/lite/model.h" +#include "tensorflow/contrib/lite/schema/schema_generated.h" + +namespace tflite { +namespace optimize { + +// Quantizes input_model and populates the provided builder with the new model. +// +// A tflite::Model can be obtained from the builder with: +// const uint8_t* buffer = builder->GetBufferPointer(); +// tflite::Model* model = GetModel(buffer); +TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, + const Model* input_model); + +} // namespace optimize +} // namespace tflite + +#endif // TENSORFLOW_CONTRIB_LITE_TOOLS_OPTIMIZE_QUANTIZE_WEIGHTS_H_ diff --git a/tensorflow/contrib/lite/tools/optimize/quantize_weights_test.cc b/tensorflow/contrib/lite/tools/optimize/quantize_weights_test.cc new file mode 100644 index 0000000000..0e0676e5ff --- /dev/null +++ b/tensorflow/contrib/lite/tools/optimize/quantize_weights_test.cc @@ -0,0 +1,130 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include "tensorflow/contrib/lite/tools/optimize/quantize_weights.h" + +#include <memory> + +#include "flatbuffers/flexbuffers.h" +#include <gmock/gmock.h> +#include <gtest/gtest.h> +#include "tensorflow/contrib/lite/model.h" +#include "tensorflow/contrib/lite/schema/schema_generated.h" + +namespace tflite { +namespace optimize { +namespace { + +class QuantizeWeightsTest : public ::testing::Test { + protected: + int GetElementsNum(const TensorT* tensor) { + int tensor_size = 1; + for (const int dim : tensor->shape) { + tensor_size *= dim; + } + return tensor_size; + } + + const OperatorT* GetOpWithOutput(const SubGraphT* subgraph, + int32_t output_tensor_idx) { + for (int i = 0; i < subgraph->operators.size(); ++i) { + OperatorT* op = subgraph->operators[i].get(); + if (std::find(op->outputs.begin(), op->outputs.end(), + output_tensor_idx) != op->outputs.end()) { + return op; + } + } + return nullptr; + } + + void CheckWeights(const Model* model_packed) { + std::unique_ptr<ModelT> model; + model.reset(model_packed->UnPack()); + + SubGraphT* subgraph = model->subgraphs.at(0).get(); + + for (int i = 0; i < subgraph->operators.size(); ++i) { + OperatorT* op = subgraph->operators[i].get(); + const BuiltinOperator op_code = + model->operator_codes[op->opcode_index]->builtin_code; + + // These are the operations that should be quantized. + int32_t tensor_idx; + if (op_code == BuiltinOperator_CONV_2D || + op_code == BuiltinOperator_DEPTHWISE_CONV_2D || + op_code == BuiltinOperator_FULLY_CONNECTED) { + tensor_idx = op->inputs[1]; + } else if (op_code == BuiltinOperator_LSTM) { + // TODO(suharshs): Add tests for LSTMs. + tensor_idx = op->inputs[1]; + } else { + continue; + } + const TensorT* tensor = subgraph->tensors[tensor_idx].get(); + int tensor_size = GetElementsNum(tensor); + // If the tensor_size is less than 1024 we expect the tensor to remain + // unquantized. + if (tensor_size < 1024) { + ASSERT_TRUE(tensor->type == TensorType_FLOAT32) << tensor->name; + const OperatorT* preceding_op = GetOpWithOutput(subgraph, tensor_idx); + // The weight tensor should not come from a dequantize op. + ASSERT_TRUE(preceding_op == nullptr); + } else { + // The input to the op should still be float. + ASSERT_TRUE(tensor->type == TensorType_FLOAT32) << tensor->name; + const OperatorT* preceding_op = GetOpWithOutput(subgraph, tensor_idx); + ASSERT_TRUE(preceding_op != nullptr); + // The float input should be the dequantize output. + ASSERT_TRUE( + model->operator_codes[preceding_op->opcode_index]->builtin_code == + BuiltinOperator_DEQUANTIZE); + // Finally, ensure that the input to the dequantize operation is + // quantized. + ASSERT_TRUE(subgraph->tensors[preceding_op->inputs[0]]->type == + TensorType_UINT8); + // TODO(suharshs): Add more rigorous testing for the numerical values in + // the tensors. + } + } + } +}; + +TEST_F(QuantizeWeightsTest, SimpleTest) { + string model_path = + "third_party/tensorflow/contrib/lite/tools/optimize/testdata/" + "mobilenet_v1_0.25_128.tflite"; + std::unique_ptr<FlatBufferModel> input_fb = + FlatBufferModel::BuildFromFile(model_path.data()); + const Model* input_model = input_fb->GetModel(); + + flatbuffers::FlatBufferBuilder builder; + EXPECT_EQ(QuantizeWeights(&builder, input_model), kTfLiteOk); + + const uint8_t* buffer = builder.GetBufferPointer(); + const Model* output_model = GetModel(buffer); + + CheckWeights(output_model); +} + +// TODO(suharshs): Add tests that run the resulting model. + +} // namespace +} // namespace optimize +} // namespace tflite + +int main(int argc, char** argv) { + // On Linux, add: FLAGS_logtostderr = true; + ::testing::InitGoogleTest(&argc, argv); + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lookup/lookup_ops.py b/tensorflow/contrib/lookup/lookup_ops.py index 291972cce3..f83765a48d 100644 --- a/tensorflow/contrib/lookup/lookup_ops.py +++ b/tensorflow/contrib/lookup/lookup_ops.py @@ -18,6 +18,9 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import functools + +from tensorflow.python.eager import context from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops from tensorflow.python.ops import gen_lookup_ops @@ -39,6 +42,7 @@ from tensorflow.python.ops.lookup_ops import TextFileIndex from tensorflow.python.ops.lookup_ops import TextFileInitializer from tensorflow.python.ops.lookup_ops import TextFileStringTableInitializer # pylint: enable=unused-import +from tensorflow.python.training.checkpointable import base as checkpointable from tensorflow.python.training.saver import BaseSaverBuilder from tensorflow.python.util.deprecation import deprecated @@ -285,7 +289,7 @@ def index_to_string(tensor, mapping, default_value="UNK", name=None): return table.lookup(tensor) -class MutableHashTable(LookupInterface): +class MutableHashTable(LookupInterface, checkpointable.CheckpointableBase): """A generic mutable hash table implementation. Data can be inserted by calling the insert method. It does not support @@ -336,6 +340,13 @@ class MutableHashTable(LookupInterface): dtype=value_dtype) self._value_shape = self._default_value.get_shape() + executing_eagerly = context.executing_eagerly() + if executing_eagerly and shared_name is None: + # TODO(allenl): This will leak memory due to kernel caching by the + # shared_name attribute value (but is better than the alternative of + # sharing everything by default when executing eagerly; hopefully creating + # tables in a loop is uncommon). + shared_name = "table_%d" % (ops.uid(),) # The table must be shared if checkpointing is requested for multi-worker # training to work correctly. Use the node name if no shared_name has been # explicitly specified. @@ -355,9 +366,12 @@ class MutableHashTable(LookupInterface): value_dtype=value_dtype, value_shape=self._default_value.get_shape(), name=name) + if executing_eagerly: + op_name = None + else: + op_name = self._table_ref.op.name.split("/")[-1] super(MutableHashTable, self).__init__(key_dtype, value_dtype, - self._table_ref.op.name.split( - "/")[-1]) + op_name) if checkpoint: saveable = MutableHashTable._Saveable(self, name) @@ -446,6 +460,10 @@ class MutableHashTable(LookupInterface): self._table_ref, self._key_dtype, self._value_dtype, name=name) return exported_keys, exported_values + def _gather_saveables_for_checkpoint(self): + """For object-based checkpointing.""" + return {"table": functools.partial(MutableHashTable._Saveable, table=self)} + class _Saveable(BaseSaverBuilder.SaveableObject): """SaveableObject implementation for MutableHashTable.""" @@ -458,14 +476,15 @@ class MutableHashTable(LookupInterface): # pylint: disable=protected-access super(MutableHashTable._Saveable, self).__init__(table, specs, name) - def restore(self, restored_tensors, unused_restored_shapes): + def restore(self, restored_tensors, restored_shapes): + del restored_shapes # unused # pylint: disable=protected-access with ops.colocate_with(self.op._table_ref): return gen_lookup_ops.lookup_table_import_v2( self.op._table_ref, restored_tensors[0], restored_tensors[1]) -class MutableDenseHashTable(LookupInterface): +class MutableDenseHashTable(LookupInterface, checkpointable.CheckpointableBase): """A generic mutable hash table implementation using tensors as backing store. Data can be inserted by calling the insert method. It does not support @@ -536,6 +555,13 @@ class MutableDenseHashTable(LookupInterface): use_node_name_sharing = checkpoint and shared_name is None empty_key = ops.convert_to_tensor( empty_key, dtype=key_dtype, name="empty_key") + executing_eagerly = context.executing_eagerly() + if executing_eagerly and shared_name is None: + # TODO(allenl): This will leak memory due to kernel caching by the + # shared_name attribute value (but is better than the alternative of + # sharing everything by default when executing eagerly; hopefully creating + # tables in a loop is uncommon). + shared_name = "table_%d" % (ops.uid(),) self._table_ref = gen_lookup_ops.mutable_dense_hash_table_v2( empty_key=empty_key, shared_name=shared_name, @@ -544,8 +570,12 @@ class MutableDenseHashTable(LookupInterface): value_shape=self._value_shape, initial_num_buckets=initial_num_buckets, name=name) + if executing_eagerly: + op_name = None + else: + op_name = self._table_ref.op.name.split("/")[-1] super(MutableDenseHashTable, self).__init__( - key_dtype, value_dtype, self._table_ref.op.name.split("/")[-1]) + key_dtype, value_dtype, op_name) if checkpoint: saveable = MutableDenseHashTable._Saveable(self, name) @@ -636,6 +666,11 @@ class MutableDenseHashTable(LookupInterface): return exported_keys, exported_values + def _gather_saveables_for_checkpoint(self): + """For object-based checkpointing.""" + return {"table": functools.partial( + MutableDenseHashTable._Saveable, table=self)} + class _Saveable(BaseSaverBuilder.SaveableObject): """SaveableObject implementation for MutableDenseHashTable.""" @@ -648,7 +683,8 @@ class MutableDenseHashTable(LookupInterface): # pylint: disable=protected-access super(MutableDenseHashTable._Saveable, self).__init__(table, specs, name) - def restore(self, restored_tensors, unused_restored_shapes): + def restore(self, restored_tensors, restored_shapes): + del restored_shapes # unused # pylint: disable=protected-access with ops.colocate_with(self.op._table_ref): return gen_lookup_ops.lookup_table_import_v2( diff --git a/tensorflow/contrib/lookup/lookup_ops_test.py b/tensorflow/contrib/lookup/lookup_ops_test.py index 81257e1de5..0a54bb1f5e 100644 --- a/tensorflow/contrib/lookup/lookup_ops_test.py +++ b/tensorflow/contrib/lookup/lookup_ops_test.py @@ -38,6 +38,7 @@ from tensorflow.python.ops import variables from tensorflow.python.platform import test from tensorflow.python.training import saver from tensorflow.python.training import server_lib +from tensorflow.python.training.checkpointable import util as checkpointable class HashTableOpTest(test.TestCase): @@ -332,7 +333,7 @@ class MutableHashTableOpTest(test.TestCase): save_dir = os.path.join(self.get_temp_dir(), "save_restore") save_path = os.path.join(tempfile.mkdtemp(prefix=save_dir), "hash") - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v0 = variables.Variable(10.0, name="v0") v1 = variables.Variable(20.0, name="v1") @@ -357,7 +358,7 @@ class MutableHashTableOpTest(test.TestCase): self.assertTrue(isinstance(val, six.string_types)) self.assertEqual(save_path, val) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v0 = variables.Variable(-1.0, name="v0") v1 = variables.Variable(-1.0, name="v1") default_val = -1 @@ -383,6 +384,59 @@ class MutableHashTableOpTest(test.TestCase): output = table.lookup(input_string) self.assertAllEqual([-1, 0, 1, 2, -1], output.eval()) + @test_util.run_in_graph_and_eager_modes + def testObjectSaveRestore(self): + save_dir = os.path.join(self.get_temp_dir(), "save_restore") + save_prefix = os.path.join(tempfile.mkdtemp(prefix=save_dir), "hash") + + v0 = variables.Variable(10.0, name="v0") + v1 = variables.Variable(20.0, name="v1") + + default_val = -1 + keys = constant_op.constant(["b", "c", "d"], dtypes.string) + values = constant_op.constant([0, 1, 2], dtypes.int64) + table = lookup.MutableHashTable( + dtypes.string, dtypes.int64, default_val, name="t1", checkpoint=True) + + checkpoint = checkpointable.Checkpoint(table=table, v0=v0, v1=v1) + self.evaluate([v0.initializer, v1.initializer]) + + # Check that the parameter nodes have been initialized. + self.assertEqual(10.0, self.evaluate(v0)) + self.assertEqual(20.0, self.evaluate(v1)) + + self.assertAllEqual(0, self.evaluate(table.size())) + self.evaluate(table.insert(keys, values)) + self.assertAllEqual(3, self.evaluate(table.size())) + + save_path = checkpoint.save(save_prefix) + del table, checkpoint, v0, v1 + + v0 = variables.Variable(-1.0, name="v0") + v1 = variables.Variable(-1.0, name="v1") + default_val = -1 + table = lookup.MutableHashTable( + dtypes.string, dtypes.int64, default_val, name="t1", checkpoint=True) + self.evaluate(table.insert( + constant_op.constant(["a", "c"], dtypes.string), + constant_op.constant([12, 24], dtypes.int64))) + self.assertAllEqual(2, self.evaluate(table.size())) + + checkpoint = checkpointable.Checkpoint(table=table, v0=v0, v1=v1) + + # Restore the saved values in the parameter nodes. + checkpoint.restore(save_path).run_restore_ops() + # Check that the parameter nodes have been restored. + self.assertEqual(10.0, self.evaluate(v0)) + self.assertEqual(20.0, self.evaluate(v1)) + + self.assertAllEqual(3, self.evaluate(table.size())) + + input_string = constant_op.constant(["a", "b", "c", "d", "e"], + dtypes.string) + output = table.lookup(input_string) + self.assertAllEqual([-1, 0, 1, 2, -1], self.evaluate(output)) + def testSharing(self): # Start a server to store the table state server = server_lib.Server( @@ -958,7 +1012,7 @@ class MutableDenseHashTableOpTest(test.TestCase): save_dir = os.path.join(self.get_temp_dir(), "save_restore") save_path = os.path.join(tempfile.mkdtemp(prefix=save_dir), "hash") - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: default_value = -1 empty_key = 0 keys = constant_op.constant([11, 12, 13], dtypes.int64) @@ -983,7 +1037,7 @@ class MutableDenseHashTableOpTest(test.TestCase): self.assertTrue(isinstance(val, six.string_types)) self.assertEqual(save_path, val) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: table = lookup.MutableDenseHashTable( dtypes.int64, dtypes.int64, @@ -1010,11 +1064,65 @@ class MutableDenseHashTableOpTest(test.TestCase): output = table.lookup(input_string) self.assertAllEqual([-1, 0, 1, 2, -1], output.eval()) + @test_util.run_in_graph_and_eager_modes + def testObjectSaveRestore(self): + save_dir = os.path.join(self.get_temp_dir(), "save_restore") + save_prefix = os.path.join(tempfile.mkdtemp(prefix=save_dir), "hash") + + default_value = -1 + empty_key = 0 + keys = constant_op.constant([11, 12, 13], dtypes.int64) + values = constant_op.constant([0, 1, 2], dtypes.int64) + save_table = lookup.MutableDenseHashTable( + dtypes.int64, + dtypes.int64, + default_value=default_value, + empty_key=empty_key, + name="t1", + checkpoint=True, + initial_num_buckets=32) + + save_checkpoint = checkpointable.Checkpoint(table=save_table) + + self.assertAllEqual(0, self.evaluate(save_table.size())) + self.evaluate(save_table.insert(keys, values)) + self.assertAllEqual(3, self.evaluate(save_table.size())) + self.assertAllEqual(32, len(self.evaluate(save_table.export()[0]))) + + save_path = save_checkpoint.save(save_prefix) + del save_table, save_checkpoint + + load_table = lookup.MutableDenseHashTable( + dtypes.int64, + dtypes.int64, + default_value=default_value, + empty_key=empty_key, + name="t1", + checkpoint=True, + initial_num_buckets=64) + self.evaluate(load_table.insert( + constant_op.constant([11, 14], dtypes.int64), + constant_op.constant([12, 24], dtypes.int64))) + self.assertAllEqual(2, self.evaluate(load_table.size())) + self.assertAllEqual(64, len(self.evaluate(load_table.export()[0]))) + + restore_checkpoint = checkpointable.Checkpoint(table=load_table) + + # Restore the saved values in the parameter nodes. + restore_checkpoint.restore(save_path).run_restore_ops() + + self.assertAllEqual(3, self.evaluate(load_table.size())) + self.assertAllEqual(32, len(self.evaluate(load_table.export()[0]))) + + input_string = constant_op.constant([10, 11, 12, 13, 14], dtypes.int64) + output = load_table.lookup(input_string) + self.assertAllEqual([-1, 0, 1, 2, -1], self.evaluate(output)) + def testVectorSaveRestore(self): save_dir = os.path.join(self.get_temp_dir(), "vector_save_restore") save_path = os.path.join(tempfile.mkdtemp(prefix=save_dir), "hash") - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: empty_key = constant_op.constant([11, 13], dtypes.int64) default_value = constant_op.constant([-1, -2], dtypes.int64) keys = constant_op.constant([[11, 12], [11, 14], [13, 14]], dtypes.int64) @@ -1039,7 +1147,7 @@ class MutableDenseHashTableOpTest(test.TestCase): self.assertTrue(isinstance(val, six.string_types)) self.assertEqual(save_path, val) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: empty_key = constant_op.constant([11, 13], dtypes.int64) default_value = constant_op.constant([-1, -2], dtypes.int64) table = lookup.MutableDenseHashTable( @@ -1074,7 +1182,7 @@ class MutableDenseHashTableOpTest(test.TestCase): save_dir = os.path.join(self.get_temp_dir(), "vector_scalar_save_restore") save_path = os.path.join(tempfile.mkdtemp(prefix=save_dir), "hash") - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: empty_key = constant_op.constant([11, 13], dtypes.int64) default_value = constant_op.constant(-1, dtypes.int64) keys = constant_op.constant([[11, 12], [11, 14], [13, 14]], dtypes.int64) @@ -1099,7 +1207,7 @@ class MutableDenseHashTableOpTest(test.TestCase): self.assertTrue(isinstance(val, six.string_types)) self.assertEqual(save_path, val) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: empty_key = constant_op.constant([11, 13], dtypes.int64) default_value = constant_op.constant(-1, dtypes.int64) table = lookup.MutableDenseHashTable( diff --git a/tensorflow/contrib/makefile/Makefile b/tensorflow/contrib/makefile/Makefile index 1a1ab54a53..d962a5e12d 100644 --- a/tensorflow/contrib/makefile/Makefile +++ b/tensorflow/contrib/makefile/Makefile @@ -90,6 +90,7 @@ HOST_INCLUDES := \ -I$(MAKEFILE_DIR)/downloads/nsync/public \ -I$(MAKEFILE_DIR)/downloads/fft2d \ -I$(MAKEFILE_DIR)/downloads/double_conversion \ +-I$(MAKEFILE_DIR)/downloads/absl \ -I$(HOST_GENDIR) ifeq ($(HAS_GEN_HOST_PROTOC),true) HOST_INCLUDES += -I$(MAKEFILE_DIR)/gen/protobuf-host/include @@ -116,6 +117,25 @@ ifeq ($(HOST_OS),PI) HOST_LIBS += -ldl -lpthread endif +# Abseil sources. +ABSL_CC_ALL_SRCS := \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*/*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*/*/*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*/*/*/*.cc) + +ABSL_CC_EXCLUDE_SRCS := \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*test*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*/*test*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*/*/*test*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*/*/*/*test*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*benchmark*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*/*benchmark*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*/*/*benchmark*.cc) \ +$(wildcard tensorflow/contrib/makefile/downloads/absl/absl/*/*/*/*/*benchmark*.cc) \ +tensorflow/contrib/makefile/downloads/absl/absl/synchronization/internal/mutex_nonprod.cc + +ABSL_CC_SRCS := $(filter-out $(ABSL_CC_EXCLUDE_SRCS), $(ABSL_CC_ALL_SRCS)) # proto_text is a tool that converts protobufs into a form we can use more # compactly within TensorFlow. It's a bit like protoc, but is designed to @@ -125,7 +145,9 @@ endif PROTO_TEXT := $(HOST_BINDIR)proto_text # The list of dependencies is derived from the Bazel build file by running # the gen_file_lists.sh script on a system with a working Bazel setup. -PROTO_TEXT_CC_FILES := $(shell cat $(MAKEFILE_DIR)/proto_text_cc_files.txt) +PROTO_TEXT_CC_FILES := \ + $(ABSL_CC_SRCS) \ + $(shell cat $(MAKEFILE_DIR)/proto_text_cc_files.txt) PROTO_TEXT_PB_CC_LIST := \ $(shell cat $(MAKEFILE_DIR)/proto_text_pb_cc_files.txt) \ $(wildcard tensorflow/contrib/makefile/downloads/double_conversion/double-conversion/*.cc) @@ -175,6 +197,7 @@ INCLUDES := \ -I$(MAKEFILE_DIR)/downloads/nsync/public \ -I$(MAKEFILE_DIR)/downloads/fft2d \ -I$(MAKEFILE_DIR)/downloads/double_conversion \ +-I$(MAKEFILE_DIR)/downloads/absl \ -I$(PROTOGENDIR) \ -I$(PBTGENDIR) ifeq ($(HAS_GEN_HOST_PROTOC),true) @@ -236,7 +259,6 @@ ifeq ($(TARGET),PI) endif # Set up Android building -# LINT.IfChange ifeq ($(TARGET),ANDROID) # Override NDK_ROOT on the command line with your own NDK location, e.g. # make -f tensorflow/contrib/makefile/Makefile TARGET=ANDROID \ @@ -331,6 +353,7 @@ $(MARCH_OPTION) \ -I$(MAKEFILE_DIR)/downloads/nsync/public \ -I$(MAKEFILE_DIR)/downloads/fft2d \ -I$(MAKEFILE_DIR)/downloads/double_conversion \ +-I$(MAKEFILE_DIR)/downloads/absl \ -I$(MAKEFILE_DIR)/gen/protobuf_android/$(ANDROID_ARCH)/include \ -I$(PROTOGENDIR) \ -I$(PBTGENDIR) @@ -446,7 +469,6 @@ $(MARCH_OPTION) \ DEPDIR := $(DEPDIR)android_$(ANDROID_ARCH)/ endif # ifeq ($(BUILD_FOR_TEGRA),1) endif # ANDROID -# LINT.ThenChange(//tensorflow/contrib/android/cmake/CMakeLists.txt) # Settings for iOS. ifeq ($(TARGET),IOS) @@ -596,6 +618,7 @@ BENCHMARK_NAME := $(BINDIR)benchmark # gen_file_lists.sh script. CORE_CC_ALL_SRCS := \ +$(ABSL_CC_SRCS) \ $(wildcard tensorflow/core/*.cc) \ $(wildcard tensorflow/core/common_runtime/*.cc) \ $(wildcard tensorflow/core/framework/*.cc) \ diff --git a/tensorflow/contrib/makefile/compile_nsync.sh b/tensorflow/contrib/makefile/compile_nsync.sh index a28fc3a87f..cb4c94d92f 100755 --- a/tensorflow/contrib/makefile/compile_nsync.sh +++ b/tensorflow/contrib/makefile/compile_nsync.sh @@ -256,6 +256,7 @@ for arch in $archs; do esac makefile=' + AR := ${NDK_ROOT}/toolchains/'"$toolchain"'/prebuilt/'"$android_os_arch"'/bin/'"$bin_prefix"'-ar CC=${CC_PREFIX} \ ${NDK_ROOT}/toolchains/'"$toolchain"'/prebuilt/'"$android_os_arch"'/bin/'"$bin_prefix"'-g++ PLATFORM_CPPFLAGS=--sysroot \ diff --git a/tensorflow/contrib/makefile/tf_op_files.txt b/tensorflow/contrib/makefile/tf_op_files.txt index ecf2e120df..66a3315700 100644 --- a/tensorflow/contrib/makefile/tf_op_files.txt +++ b/tensorflow/contrib/makefile/tf_op_files.txt @@ -301,7 +301,6 @@ tensorflow/core/ops/array_grad.cc tensorflow/core/kernels/spacetobatch_functor.cc tensorflow/core/kernels/spacetobatch_op.cc tensorflow/core/kernels/batchtospace_op.cc -tensorflow/core/kernels/warn_about_ints.cc tensorflow/core/kernels/segment_reduction_ops.cc tensorflow/core/ops/audio_ops.cc tensorflow/core/kernels/decode_proto_op.cc diff --git a/tensorflow/contrib/metrics/python/ops/metric_ops.py b/tensorflow/contrib/metrics/python/ops/metric_ops.py index a328670526..bbf5d3f30c 100644 --- a/tensorflow/contrib/metrics/python/ops/metric_ops.py +++ b/tensorflow/contrib/metrics/python/ops/metric_ops.py @@ -2532,7 +2532,8 @@ def sparse_recall_at_top_k(labels, name=name_scope) -def _compute_recall_at_precision(tp, fp, fn, precision, name): +def _compute_recall_at_precision(tp, fp, fn, precision, name, + strict_mode=False): """Helper function to compute recall at a given `precision`. Args: @@ -2541,17 +2542,42 @@ def _compute_recall_at_precision(tp, fp, fn, precision, name): fn: The number of false negatives. precision: The precision for which the recall will be calculated. name: An optional variable_scope name. + strict_mode: If true and there exists a threshold where the precision is + no smaller than the target precision, return the corresponding recall at + the threshold. Otherwise, return 0. If false, find the threshold where the + precision is closest to the target precision and return the recall at the + threshold. Returns: The recall at a given `precision`. """ precisions = math_ops.div(tp, tp + fp + _EPSILON) - tf_index = math_ops.argmin( - math_ops.abs(precisions - precision), 0, output_type=dtypes.int32) + if not strict_mode: + tf_index = math_ops.argmin( + math_ops.abs(precisions - precision), 0, output_type=dtypes.int32) + # Now, we have the implicit threshold, so compute the recall: + return math_ops.div(tp[tf_index], tp[tf_index] + fn[tf_index] + _EPSILON, + name) + else: + # We aim to find the threshold where the precision is minimum but no smaller + # than the target precision. + # The rationale: + # 1. Compute the difference between precisions (by different thresholds) and + # the target precision. + # 2. Take the reciprocal of the values by the above step. The intention is + # to make the positive values rank before negative values and also the + # smaller positives rank before larger positives. + tf_index = math_ops.argmax( + math_ops.div(1.0, precisions - precision + _EPSILON), + 0, + output_type=dtypes.int32) + + def _return_good_recall(): + return math_ops.div(tp[tf_index], tp[tf_index] + fn[tf_index] + _EPSILON, + name) - # Now, we have the implicit threshold, so compute the recall: - return math_ops.div(tp[tf_index], tp[tf_index] + fn[tf_index] + _EPSILON, - name) + return control_flow_ops.cond(precisions[tf_index] >= precision, + _return_good_recall, lambda: .0) def recall_at_precision(labels, @@ -2561,7 +2587,8 @@ def recall_at_precision(labels, num_thresholds=200, metrics_collections=None, updates_collections=None, - name=None): + name=None, + strict_mode=False): """Computes `recall` at `precision`. The `recall_at_precision` function creates four local variables, @@ -2593,6 +2620,11 @@ def recall_at_precision(labels, updates_collections: An optional list of collections that `update_op` should be added to. name: An optional variable_scope name. + strict_mode: If true and there exists a threshold where the precision is + above the target precision, return the corresponding recall at the + threshold. Otherwise, return 0. If false, find the threshold where the + precision is closest to the target precision and return the recall at the + threshold. Returns: recall: A scalar `Tensor` representing the recall at the given @@ -2621,10 +2653,11 @@ def recall_at_precision(labels, predictions, labels, thresholds, weights) recall = _compute_recall_at_precision(values['tp'], values['fp'], - values['fn'], precision, 'value') + values['fn'], precision, 'value', + strict_mode) update_op = _compute_recall_at_precision(update_ops['tp'], update_ops['fp'], update_ops['fn'], precision, - 'update_op') + 'update_op', strict_mode) if metrics_collections: ops.add_to_collections(metrics_collections, recall) diff --git a/tensorflow/contrib/metrics/python/ops/metric_ops_test.py b/tensorflow/contrib/metrics/python/ops/metric_ops_test.py index 401fedcbed..024bd54912 100644 --- a/tensorflow/contrib/metrics/python/ops/metric_ops_test.py +++ b/tensorflow/contrib/metrics/python/ops/metric_ops_test.py @@ -3467,6 +3467,60 @@ class RecallAtPrecisionTest(test.TestCase): self.assertAlmostEqual(target_recall, sess.run(update_op)) self.assertAlmostEqual(target_recall, recall.eval()) + def _test_strict_mode(self, strict_mode, target_precision, expected_recall): + num_thresholds = 11 + predictions_values = [.2, .3, .5, .6, .7, .8, .9, .9, .9, .1] + labels_values = [1, 1, 0, 0, 0, 0, 0, 0, 0, 1] + # Resulting thresholds and the corresponding precision and recall values at + # each threshold: + # Thresholds [0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9] + # precisions: [0.3 0.2 0.1 0 0 0 0 0 0] + # recalls: [1.0 0.7 0.3 0 0 0 0 0 0] + predictions = constant_op.constant( + predictions_values, dtype=dtypes_lib.float32) + labels = constant_op.constant(labels_values) + recall, update_op = metrics.recall_at_precision( + labels, + predictions, + num_thresholds=num_thresholds, + precision=target_precision, + strict_mode=strict_mode) + + with self.test_session() as sess: + sess.run(variables.local_variables_initializer()) + self.assertAlmostEqual(expected_recall, sess.run(update_op)) + self.assertAlmostEqual(expected_recall, recall.eval()) + + def testStrictMode_Off(self): + # strict_mode is turned off and return the recall at the threshold where the + # precision (0.3) is closest to target precision (0.9). The recall + # corresponding to the threshold is 1.0. + self._test_strict_mode( + strict_mode=False, target_precision=0.9, expected_recall=1.0) + + def testStrictMode_OnAndFail(self): + # strict_mode is turned on and we fail to reach the target precision at any + # threshold. + # Target precision: 0.9 + # Diff: [-0.6 -0.7 -0.8 -0.9 -0.9 -0.9 -0.9 -0.9 -0.9] + # Reciprocal: [-1.6 -1.4 -1.3 -1.1 -1.1 -1.1 -1.1 -1.1 -1.1] + # Max index: 3 and corresponding precision is: 0 which is smaller than + # target precsion 0.9. As a result, the expected recall is 0. + self._test_strict_mode( + strict_mode=True, target_precision=0.9, expected_recall=.0) + + def testStrictMode_OnAndSucceed(self): + # strict_mode is on and we can reach the target precision at certain + # threshold. + # Target precision: 0.2 + # Diff: [0.1 0 -0.1 -0.2 -0.2 -0.2 -0.2 -0.2 -0.2] + # Reciprocal: [10 infty -10.0 -5.0 -5.0 -5.0 -5.0 -5.0 -5.0] + # Max index: 1 and corresponding precision is: 0.2 which is no smaller than + # target precsion 0.2. In this case, we return the recall at index 1, which + # is 2.0/3 (0.7). + self._test_strict_mode( + strict_mode=True, target_precision=0.2, expected_recall=2.0 / 3) + class PrecisionAtRecallTest(test.TestCase): @@ -3963,7 +4017,7 @@ class StreamingSparsePrecisionTest(test.TestCase): expected, class_id=None, weights=None): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): if weights is not None: weights = constant_op.constant(weights, dtypes_lib.float32) metric, update = metrics.streaming_sparse_precision_at_k( @@ -3992,7 +4046,7 @@ class StreamingSparsePrecisionTest(test.TestCase): expected, class_id=None, weights=None): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): if weights is not None: weights = constant_op.constant(weights, dtypes_lib.float32) metric, update = metrics.streaming_sparse_precision_at_top_k( @@ -4021,7 +4075,7 @@ class StreamingSparsePrecisionTest(test.TestCase): k, expected, weights=None): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): if weights is not None: weights = constant_op.constant(weights, dtypes_lib.float32) predictions = constant_op.constant(predictions, dtypes_lib.float32) @@ -4047,7 +4101,7 @@ class StreamingSparsePrecisionTest(test.TestCase): labels, expected, weights=None): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): if weights is not None: weights = constant_op.constant(weights, dtypes_lib.float32) metric, update = metrics.streaming_sparse_average_precision_at_top_k( @@ -4635,7 +4689,7 @@ class StreamingSparseRecallTest(test.TestCase): expected, class_id=None, weights=None): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): if weights is not None: weights = constant_op.constant(weights, dtypes_lib.float32) metric, update = metrics.streaming_sparse_recall_at_k( @@ -4664,7 +4718,7 @@ class StreamingSparseRecallTest(test.TestCase): expected, class_id=None, weights=None): - with ops.Graph().as_default() as g, self.test_session(g): + with ops.Graph().as_default() as g, self.session(g): if weights is not None: weights = constant_op.constant(weights, dtypes_lib.float32) metric, update = metric_ops.sparse_recall_at_top_k( diff --git a/tensorflow/contrib/model_pruning/BUILD b/tensorflow/contrib/model_pruning/BUILD index 16ddc38f5a..e662b11be8 100644 --- a/tensorflow/contrib/model_pruning/BUILD +++ b/tensorflow/contrib/model_pruning/BUILD @@ -119,6 +119,7 @@ py_test( deps = [ ":pruning_utils", "//tensorflow/python:client_testlib", + "@absl_py//absl/testing:parameterized", ], ) diff --git a/tensorflow/contrib/model_pruning/README.md b/tensorflow/contrib/model_pruning/README.md index a5267fd904..15d95896d9 100644 --- a/tensorflow/contrib/model_pruning/README.md +++ b/tensorflow/contrib/model_pruning/README.md @@ -53,7 +53,7 @@ The pruning library allows for specification of the following hyper parameters: | weight_sparsity_map | list of strings | [""] | list of weight variable name (or layer name):target sparsity pairs. Eg. [conv1:0.9,conv2/kernel:0.8]. For layers/weights not in this list, sparsity as specified by the target_sparsity hyperparameter is used. | | threshold_decay | float | 0.9 | The decay factor to use for exponential decay of the thresholds | | pruning_frequency | integer | 10 | How often should the masks be updated? (in # of global_steps) | -| nbins | integer | 256 | Number of bins to use for histogram computation | +| nbins | integer | 256 | Number of bins to use for histogram computation. Note: When running on TPUs, a large (>1024) value for `nbins` may adversely affect the training time. | | block_height|integer | 1 | Number of rows in a block for block sparse matrices| | block_width |integer | 1 | Number of cols in a block for block sparse matrices| | block_pooling_function| string | AVG | The function to use to pool weight values in a block: average (AVG) or max (MAX)| diff --git a/tensorflow/contrib/model_pruning/python/pruning.py b/tensorflow/contrib/model_pruning/python/pruning.py index cd58526ed3..a81abac2fa 100644 --- a/tensorflow/contrib/model_pruning/python/pruning.py +++ b/tensorflow/contrib/model_pruning/python/pruning.py @@ -476,8 +476,8 @@ class Pruning(object): smoothed_threshold, new_mask = self._update_mask(pooled_weights, threshold) - updated_mask = pruning_utils.kronecker_product( - new_mask, array_ops.ones(self._block_dim)) + + updated_mask = pruning_utils.expand_tensor(new_mask, self._block_dim) sliced_mask = array_ops.slice( updated_mask, [0, 0], [squeezed_weights.get_shape()[0], diff --git a/tensorflow/contrib/model_pruning/python/pruning_test.py b/tensorflow/contrib/model_pruning/python/pruning_test.py index 33c4ad58bd..cd3d8e76bb 100644 --- a/tensorflow/contrib/model_pruning/python/pruning_test.py +++ b/tensorflow/contrib/model_pruning/python/pruning_test.py @@ -61,14 +61,14 @@ class PruningHParamsTest(test.TestCase): self.assertEqual(p._weight_sparsity_map["conv2/kernel"], 0.8) def testInitWithExternalSparsity(self): - with self.test_session(): + with self.cached_session(): p = pruning.Pruning(spec=self.pruning_hparams, sparsity=self.sparsity) variables.global_variables_initializer().run() sparsity = p._sparsity.eval() self.assertAlmostEqual(sparsity, 0.5) def testInitWithVariableReuse(self): - with self.test_session(): + with self.cached_session(): p = pruning.Pruning(spec=self.pruning_hparams, sparsity=self.sparsity) p_copy = pruning.Pruning( spec=self.pruning_hparams, sparsity=self.sparsity) @@ -87,7 +87,7 @@ class PruningTest(test.TestCase): def testCreateMask2D(self): width = 10 height = 20 - with self.test_session(): + with self.cached_session(): weights = variables.Variable( random_ops.random_normal([width, height], stddev=1), name="weights") masked_weights = pruning.apply_mask(weights, @@ -98,7 +98,7 @@ class PruningTest(test.TestCase): self.assertAllEqual(weights_val, masked_weights_val) def testUpdateSingleMask(self): - with self.test_session() as session: + with self.cached_session() as session: weights = variables.Variable( math_ops.linspace(1.0, 100.0, 100), name="weights") masked_weights = pruning.apply_mask(weights) @@ -122,7 +122,7 @@ class PruningTest(test.TestCase): # Set up pruning p = pruning.Pruning(pruning_hparams, sparsity=sparsity) - with self.test_session(): + with self.cached_session(): variables.global_variables_initializer().run() _, new_mask = p._maybe_update_block_mask(weights, threshold) # Check if the mask is the same size as the weights @@ -167,7 +167,7 @@ class PruningTest(test.TestCase): def testPartitionedVariableMasking(self): partitioner = partitioned_variables.variable_axis_size_partitioner(40) - with self.test_session() as session: + with self.cached_session() as session: with variable_scope.variable_scope("", partitioner=partitioner): sparsity = variables.Variable(0.5, name="Sparsity") weights = variable_scope.get_variable( @@ -201,7 +201,7 @@ class PruningTest(test.TestCase): sparsity_val = math_ops.linspace(0.0, 0.9, 10) increment_global_step = state_ops.assign_add(self.global_step, 1) non_zero_count = [] - with self.test_session() as session: + with self.cached_session() as session: variables.global_variables_initializer().run() for i in range(10): session.run(state_ops.assign(sparsity, sparsity_val[i])) @@ -234,7 +234,7 @@ class PruningTest(test.TestCase): mask_update_op = p.conditional_mask_update_op() increment_global_step = state_ops.assign_add(self.global_step, 1) - with self.test_session() as session: + with self.cached_session() as session: variables.global_variables_initializer().run() for _ in range(110): session.run(mask_update_op) diff --git a/tensorflow/contrib/model_pruning/python/pruning_utils.py b/tensorflow/contrib/model_pruning/python/pruning_utils.py index ef6c6a3f5d..91b0bb7f60 100644 --- a/tensorflow/contrib/model_pruning/python/pruning_utils.py +++ b/tensorflow/contrib/model_pruning/python/pruning_utils.py @@ -69,7 +69,7 @@ def weight_threshold_variable(var, scope): scope: The variable scope of the variable var Returns: - a scalar threshold variable initialized to 0. + A scalar threshold variable initialized to 0. """ with variable_scope.variable_scope(scope): threshold = variable_scope.get_variable( @@ -97,6 +97,74 @@ def kronecker_product(mat1, mat2): return array_ops.reshape(mat1_rsh * mat2_rsh, [m1 * m2, n1 * n2]) +def expand_tensor(tensor, block_dims): + """Expands a 2D tensor by replicating the tensor values. + + This is equivalent to the kronecker product of the tensor and a matrix of + ones of size block_dims. + + Example: + + tensor = [[1,2] + [3,4]] + block_dims = [2,2] + + result = [[1 1 2 2] + [1 1 2 2] + [3 3 4 4] + [3 3 4 4]] + + Args: + tensor: A 2D tensor that needs to be expanded. + block_dims: List of integers specifying the expansion factor. + + Returns: + The expanded tensor + + Raises: + ValueError: if tensor is not rank-2 or block_dims is does not have 2 + elements. + """ + if tensor.get_shape().ndims != 2: + raise ValueError('Input tensor must be rank 2') + + if len(block_dims) != 2: + raise ValueError('block_dims must have 2 elements') + + block_height, block_width = block_dims + + def _tile_rows(tensor, multiple): + """Create a new tensor by tiling the tensor along rows.""" + return array_ops.tile(tensor, [multiple, 1]) + + def _generate_indices(num_rows, block_dim): + indices = np.zeros(shape=[num_rows * block_dim, 1], dtype=np.int32) + for k in range(block_dim): + for r in range(num_rows): + indices[k * num_rows + r] = r * block_dim + k + return indices + + def _replicate_rows(tensor, multiple): + tensor_shape = tensor.shape.as_list() + expanded_shape = [tensor_shape[0] * multiple, tensor_shape[1]] + indices = constant_op.constant(_generate_indices(tensor_shape[0], multiple)) + return array_ops.scatter_nd(indices, _tile_rows(tensor, multiple), + expanded_shape) + + expanded_tensor = tensor + + # Expand rows by factor block_height. + if block_height > 1: + expanded_tensor = _replicate_rows(tensor, block_height) + + # Transpose and expand by factor block_width. Transpose the result. + if block_width > 1: + expanded_tensor = array_ops.transpose( + _replicate_rows(array_ops.transpose(expanded_tensor), block_width)) + + return expanded_tensor + + def _histogram(values, value_range, nbins=100, dtype=dtypes.int32, name=None): """Return histogram of values. @@ -167,19 +235,18 @@ def compute_cdf_from_histogram(values, value_range, **kwargs): def compute_cdf(values, value_range, **kwargs): """Returns the normalized cumulative distribution of the given values tensor. - Uses tf.while_loop to directly compute the cdf of the values. Number of bins - for histogram is fixed at _NBINS=255 + Uses tf.while_loop to directly compute the cdf of the values. Args: values: Numeric `Tensor`. value_range: Shape [2] `Tensor` of same `dtype` as `values` - **kwargs: keyword arguments: name + **kwargs: keyword arguments: nbins, name Returns: A 1-D `Tensor` holding normalized cdf of values. """ - nbins = _NBINS + nbins = kwargs.get('nbins', _NBINS) name = kwargs.get('name', None) with ops.name_scope(name, 'cdf', [values, value_range, nbins]): values = ops.convert_to_tensor(values, name='values') @@ -213,7 +280,7 @@ def compute_cdf(values, value_range, **kwargs): cdf = math_ops.add( cdf, array_ops.one_hot( - loop_count, depth=_NBINS, on_value=temp, off_value=0.0)) + loop_count, depth=nbins, on_value=temp, off_value=0.0)) return [loop_count + 1, cdf] _, cdf = control_flow_ops.while_loop( diff --git a/tensorflow/contrib/model_pruning/python/pruning_utils_test.py b/tensorflow/contrib/model_pruning/python/pruning_utils_test.py index ccde5b4e8a..0aca843497 100644 --- a/tensorflow/contrib/model_pruning/python/pruning_utils_test.py +++ b/tensorflow/contrib/model_pruning/python/pruning_utils_test.py @@ -18,6 +18,7 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from absl.testing import parameterized import numpy as np from tensorflow.contrib.model_pruning.python import pruning_utils @@ -26,6 +27,7 @@ from tensorflow.python.ops import array_ops from tensorflow.python.ops import init_ops from tensorflow.python.ops import math_ops from tensorflow.python.ops import nn_ops +from tensorflow.python.ops import random_ops from tensorflow.python.ops import variable_scope from tensorflow.python.ops import variables from tensorflow.python.platform import test @@ -36,27 +38,13 @@ class PruningUtilsTest(test.TestCase): def _compare_cdf(self, values): abs_values = math_ops.abs(values) max_value = math_ops.reduce_max(abs_values) - with self.test_session(): + with self.cached_session(): variables.global_variables_initializer().run() cdf_from_histogram = pruning_utils.compute_cdf_from_histogram( abs_values, [0.0, max_value], nbins=pruning_utils._NBINS) cdf = pruning_utils.compute_cdf(abs_values, [0.0, max_value]) self.assertAllEqual(cdf.eval(), cdf_from_histogram.eval()) - def _compare_pooling_methods(self, weights, pooling_kwargs): - with self.test_session(): - variables.global_variables_initializer().run() - pooled_weights_tf = array_ops.squeeze( - nn_ops.pool( - array_ops.reshape( - weights, - [1, weights.get_shape()[0], - weights.get_shape()[1], 1]), **pooling_kwargs)) - pooled_weights_factorized_pool = pruning_utils.factorized_pool( - weights, **pooling_kwargs) - self.assertAllClose(pooled_weights_tf.eval(), - pooled_weights_factorized_pool.eval()) - def testHistogram(self): width = 10 height = 10 @@ -67,7 +55,7 @@ class PruningUtilsTest(test.TestCase): "weights", [width, height], initializer=init) histogram = pruning_utils._histogram( weights, [0, 1.0], nbins, dtype=np.float32) - with self.test_session(): + with self.cached_session(): variables.global_variables_initializer().run() computed_histogram = histogram.eval() self.assertAllEqual(expected_histogram, computed_histogram) @@ -79,7 +67,7 @@ class PruningUtilsTest(test.TestCase): norm_cdf = pruning_utils.compute_cdf_from_histogram( abs_weights, [0.0, 5.0], nbins=nbins) expected_cdf = np.array([0.1, 0.4, 0.5, 0.6, 1.0], dtype=np.float32) - with self.test_session() as sess: + with self.cached_session() as sess: variables.global_variables_initializer().run() norm_cdf_val = sess.run(norm_cdf) self.assertAllEqual(len(norm_cdf_val), nbins) @@ -95,26 +83,60 @@ class PruningUtilsTest(test.TestCase): weights = variable_scope.get_variable("weights", shape=[5, 5, 128, 128]) self._compare_cdf(weights) - def testFactorizedAvgPool(self): + +@parameterized.named_parameters( + ("1x1", [1, 1]), ("4x4", [4, 4]), ("6x6", [6, 6]), ("1x4", [1, 4]), + ("4x1", [4, 1]), ("1x8", [1, 8]), ("8x1", [8, 1])) +class PruningUtilsParameterizedTest(test.TestCase, parameterized.TestCase): + + def _compare_pooling_methods(self, weights, pooling_kwargs): + with self.cached_session(): + variables.global_variables_initializer().run() + pooled_weights_tf = array_ops.squeeze( + nn_ops.pool( + array_ops.reshape( + weights, + [1, weights.get_shape()[0], + weights.get_shape()[1], 1]), **pooling_kwargs)) + pooled_weights_factorized_pool = pruning_utils.factorized_pool( + weights, **pooling_kwargs) + self.assertAllClose(pooled_weights_tf.eval(), + pooled_weights_factorized_pool.eval()) + + def _compare_expand_tensor_with_kronecker_product(self, tensor, block_dim): + with self.cached_session() as session: + variables.global_variables_initializer().run() + expanded_tensor = pruning_utils.expand_tensor(tensor, block_dim) + kronecker_product = pruning_utils.kronecker_product( + tensor, array_ops.ones(block_dim)) + expanded_tensor_val, kronecker_product_val = session.run( + [expanded_tensor, kronecker_product]) + self.assertAllEqual(expanded_tensor_val, kronecker_product_val) + + def testFactorizedAvgPool(self, window_shape): weights = variable_scope.get_variable("weights", shape=[1024, 2048]) pooling_kwargs = { - "window_shape": [2, 4], + "window_shape": window_shape, "pooling_type": "AVG", - "strides": [2, 4], + "strides": window_shape, "padding": "SAME" } self._compare_pooling_methods(weights, pooling_kwargs) - def testFactorizedMaxPool(self): + def testFactorizedMaxPool(self, window_shape): weights = variable_scope.get_variable("weights", shape=[1024, 2048]) pooling_kwargs = { - "window_shape": [2, 4], + "window_shape": window_shape, "pooling_type": "MAX", - "strides": [2, 4], + "strides": window_shape, "padding": "SAME" } self._compare_pooling_methods(weights, pooling_kwargs) + def testExpandTensor(self, block_dim): + weights = random_ops.random_normal(shape=[1024, 512]) + self._compare_expand_tensor_with_kronecker_product(weights, block_dim) + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/model_pruning/python/strip_pruning_vars_test.py b/tensorflow/contrib/model_pruning/python/strip_pruning_vars_test.py index 255daa0360..237510cb0c 100644 --- a/tensorflow/contrib/model_pruning/python/strip_pruning_vars_test.py +++ b/tensorflow/contrib/model_pruning/python/strip_pruning_vars_test.py @@ -144,7 +144,7 @@ class StripPruningVarsTest(test.TestCase): return outputs def _get_initial_outputs(self, output_tensor_names_list): - with self.test_session(graph=self.initial_graph) as sess1: + with self.session(graph=self.initial_graph) as sess1: self._prune_model(sess1) reference_outputs = self._get_outputs(sess1, self.initial_graph, output_tensor_names_list) diff --git a/tensorflow/contrib/nccl/kernels/nccl_manager.h b/tensorflow/contrib/nccl/kernels/nccl_manager.h index 09fad35d23..7d158cc980 100644 --- a/tensorflow/contrib/nccl/kernels/nccl_manager.h +++ b/tensorflow/contrib/nccl/kernels/nccl_manager.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_KERNELS_NCCL_COMMUNICATOR_H_ -#define TENSORFLOW_CORE_KERNELS_NCCL_COMMUNICATOR_H_ +#ifndef TENSORFLOW_CONTRIB_NCCL_KERNELS_NCCL_MANAGER_H_ +#define TENSORFLOW_CONTRIB_NCCL_KERNELS_NCCL_MANAGER_H_ #ifdef GOOGLE_CUDA @@ -135,4 +135,4 @@ class NcclManager { #endif // GOOGLE_CUDA -#endif // TENSORFLOW_CORE_KERNELS_NCCL_COMMUNICATOR_H_ +#endif // TENSORFLOW_CONTRIB_NCCL_KERNELS_NCCL_MANAGER_H_ diff --git a/tensorflow/contrib/nn/python/ops/alpha_dropout_test.py b/tensorflow/contrib/nn/python/ops/alpha_dropout_test.py index 54a98e6f14..3aec88bcbf 100644 --- a/tensorflow/contrib/nn/python/ops/alpha_dropout_test.py +++ b/tensorflow/contrib/nn/python/ops/alpha_dropout_test.py @@ -32,7 +32,7 @@ class AlphaDropoutTest(test.TestCase): def testAlphaDropout(self): x_dim, y_dim = 40, 30 for keep_prob in [0.1, 0.5, 0.8]: - with self.test_session(): + with self.cached_session(): t = random_ops.random_normal([x_dim, y_dim]) output = alpha_dropout(t, keep_prob) self.assertEqual([x_dim, y_dim], output.get_shape()) diff --git a/tensorflow/contrib/nn/python/ops/fwd_gradients_test.py b/tensorflow/contrib/nn/python/ops/fwd_gradients_test.py index 56062c3cab..4cdac6a742 100644 --- a/tensorflow/contrib/nn/python/ops/fwd_gradients_test.py +++ b/tensorflow/contrib/nn/python/ops/fwd_gradients_test.py @@ -35,7 +35,7 @@ class ForwardAdTest(test.TestCase): dydx_tf = fwd_gradients.fwd_gradients([y], [x], [grad_x])[0] dydx_py = 2. * grad_x - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllClose(sess.run(dydx_tf), dydx_py, 1e-6) def testGather(self): @@ -44,7 +44,7 @@ class ForwardAdTest(test.TestCase): y.set_shape([2]) dydx = fwd_gradients.fwd_gradients([y], [x], assert_unused=True) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(dydx) diff --git a/tensorflow/contrib/nn/python/ops/sampling_ops_test.py b/tensorflow/contrib/nn/python/ops/sampling_ops_test.py index 1d4fe1321b..11738bb215 100644 --- a/tensorflow/contrib/nn/python/ops/sampling_ops_test.py +++ b/tensorflow/contrib/nn/python/ops/sampling_ops_test.py @@ -227,7 +227,7 @@ class RankSampledSoftmaxLossTest(test.TestCase): sampled_values=self._resampled_values, remove_accidental_hits=self._remove_accidental_hits, partition_strategy=partition_strategy) - with self.test_session() as sess: + with self.cached_session() as sess: loss_val = sess.run(loss) loss_nn_val = sess.run(loss_nn) @@ -299,7 +299,7 @@ class RankSampledSoftmaxLossTest(test.TestCase): sampled_values=resampled_values, remove_accidental_hits=remove_accidental_hits, partition_strategy='div') - with self.test_session() as sess: + with self.cached_session() as sess: loss_val = sess.run(loss) loss_nn_val = sess.run(loss_nn) diff --git a/tensorflow/contrib/opt/__init__.py b/tensorflow/contrib/opt/__init__.py index 781621dba0..ad7d7cfa6e 100644 --- a/tensorflow/contrib/opt/__init__.py +++ b/tensorflow/contrib/opt/__init__.py @@ -31,6 +31,7 @@ from tensorflow.contrib.opt.python.training.model_average_optimizer import * from tensorflow.contrib.opt.python.training.moving_average_optimizer import * from tensorflow.contrib.opt.python.training.multitask_optimizer_wrapper import * from tensorflow.contrib.opt.python.training.nadam_optimizer import * +from tensorflow.contrib.opt.python.training.reg_adagrad_optimizer import * from tensorflow.contrib.opt.python.training.shampoo import * from tensorflow.contrib.opt.python.training.weight_decay_optimizers import * from tensorflow.contrib.opt.python.training.powersign import * @@ -65,6 +66,7 @@ _allowed_symbols = [ 'ModelAverageCustomGetter', 'GGTOptimizer', 'ShampooOptimizer', + 'RegAdagradOptimizer', ] remove_undocumented(__name__, _allowed_symbols) diff --git a/tensorflow/contrib/opt/python/training/adamax_test.py b/tensorflow/contrib/opt/python/training/adamax_test.py index 915e6504e1..61d8b94eca 100644 --- a/tensorflow/contrib/opt/python/training/adamax_test.py +++ b/tensorflow/contrib/opt/python/training/adamax_test.py @@ -74,7 +74,7 @@ class AdaMaxOptimizerTest(test.TestCase): def doTestSparse(self, use_resource=False): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): # Initialize variables for numpy implementation. zero_slots = lambda: np.zeros((3), dtype=dtype.as_numpy_dtype) m0, v0, m1, v1 = zero_slots(), zero_slots(), zero_slots(), zero_slots() @@ -142,7 +142,7 @@ class AdaMaxOptimizerTest(test.TestCase): def testSparseRepeatedIndices(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): repeated_index_update_var = variables.Variable( [[1.0], [2.0]], dtype=dtype) aggregated_update_var = variables.Variable( @@ -172,7 +172,7 @@ class AdaMaxOptimizerTest(test.TestCase): def doTestBasic(self, use_resource=False): for i, dtype in enumerate([dtypes.half, dtypes.float32, dtypes.float64]): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) @@ -233,7 +233,7 @@ class AdaMaxOptimizerTest(test.TestCase): opt.get_slot(var=var0, name="m").name) def testBasic(self): - with self.test_session(): + with self.cached_session(): self.doTestBasic(use_resource=False) @test_util.run_in_graph_and_eager_modes(reset_test=True) @@ -242,7 +242,7 @@ class AdaMaxOptimizerTest(test.TestCase): def testTensorLearningRate(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) @@ -278,7 +278,7 @@ class AdaMaxOptimizerTest(test.TestCase): def testSharing(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) diff --git a/tensorflow/contrib/opt/python/training/elastic_average_optimizer.py b/tensorflow/contrib/opt/python/training/elastic_average_optimizer.py index 5763593b81..bbafd59aae 100644 --- a/tensorflow/contrib/opt/python/training/elastic_average_optimizer.py +++ b/tensorflow/contrib/opt/python/training/elastic_average_optimizer.py @@ -17,22 +17,23 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops -from tensorflow.python.ops import math_ops - -from tensorflow.python.ops import gen_nn_ops from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import data_flow_ops +from tensorflow.python.ops import gen_nn_ops +from tensorflow.python.ops import math_ops +from tensorflow.python.ops import state_ops from tensorflow.python.ops import variable_scope from tensorflow.python.ops import variables from tensorflow.python.training import optimizer +from tensorflow.python.training import saver from tensorflow.python.training import session_run_hook -from tensorflow.python.ops import state_ops -from tensorflow.python.ops import data_flow_ops -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import constant_op LOCAL_VARIABLE_NAME = 'local_center_variable' GLOBAL_VARIABLE_NAME = 'global_center_variable' +GLOBAL_STEP = 'global_step' class ElasticAverageCustomGetter(object): @@ -52,16 +53,32 @@ class ElasticAverageCustomGetter(object): with tf.device( tf.train.replica_device_setter( worker_device=worker_device, - ps_device="/job:ps/cpu:0", + ps_device="/job:ps", cluster=cluster)), tf.variable_scope('',custom_getter=ea_custom_getter): - hid_w = tf.get_variable( - initializer=tf.truncated_normal( - [IMAGE_PIXELS * IMAGE_PIXELS, FLAGS.hidden_units], - stddev=1.0 / IMAGE_PIXELS), - name="hid_w") - hid_b = tf.get_variable(initializer=tf.zeros([FLAGS.hidden_units]), - name="hid_b") + ... + create your model here + ... + with tf.device(worker_device): + opt = tf.train.MomentumOptimizer(...) + optimizer = ElasticAverageOptimizer( + opt, + num_worker=2, + moving_rate=0.01, # or use default value + communication_period=20, + ea_custom_getter=ea_custom_getter) + ... + train_op = optimizer.apply_gradients( + grads_vars, + global_step=global_step) + ... + hooks = [optimizer.make_session_run_hook(is_chief, task_index)] + ... + with tf.train.MonitoredTrainingSession(master=server.target, + is_chief=is_chief, + checkpoint_dir=("...), + save_checkpoint_secs=600, + hooks=hooks) as mon_sess: """ def __init__(self, worker_device): @@ -83,24 +100,40 @@ class ElasticAverageCustomGetter(object): collections=[ops.GraphKeys.LOCAL_VARIABLES], *args, **kwargs) - global_center_variable = variable_scope.variable( + if kwargs['reuse'] == True: + return local_var + global_center_variable = getter( name='%s/%s' % (GLOBAL_VARIABLE_NAME, name), - initial_value=local_var.initialized_value(), trainable=False, - collections=[ops.GraphKeys.GLOBAL_VARIABLES]) + collections=[ops.GraphKeys.GLOBAL_VARIABLES], + *args, + **kwargs) with ops.device(self._worker_device): - local_center_variable = variable_scope.variable( + local_center_variable = getter( name='%s/%s' % (LOCAL_VARIABLE_NAME, name), - initial_value=local_var.initialized_value(), trainable=False, - collections=[ops.GraphKeys.LOCAL_VARIABLES]) - - self._local_map[local_var] = local_center_variable - self._global_map[local_var] = global_center_variable + collections=[ops.GraphKeys.LOCAL_VARIABLES], + *args, + **kwargs) + if kwargs['partitioner'] is None: + self._local_map[local_var] = local_center_variable + self._global_map[local_var] = global_center_variable + else: + v_list = list(local_var) + for i in range(len(v_list)): + self._local_map[v_list[i]] \ + = list(local_center_variable)[i] + self._global_map[v_list[i]] \ + = list(global_center_variable)[i] return local_var else: - return getter(name, trainable, collections, *args, **kwargs) + return getter( + name, + trainable=trainable, + collections=collections, + *args, + **kwargs) class ElasticAverageOptimizer(optimizer.Optimizer): @@ -125,6 +158,7 @@ class ElasticAverageOptimizer(optimizer.Optimizer): moving_rate=None, rho=None, use_locking=True, + synchronous=False, name='ElasticAverageOptimizer'): """Construct a new gradient descent optimizer. @@ -136,9 +170,16 @@ class ElasticAverageOptimizer(optimizer.Optimizer): communication_period: An int point value to controls the frequency of the communication between every worker and the ps. moving_rate: A floating point value to control the elastic difference. - rho: the amount of exploration we allow ine the model. The default + rho: the amount of exploration we allow in the model. The default value is moving_rate/learning_rate + rho=0.0 is suggested in async mode. use_locking: If True use locks for update operations. + synchronous: Add_sync_queues_and_barrier or not. + True: all workers will wait for each other before start training + False: worker can start training when its initilization is done, + no need to wait for everyone is ready. + in case one worker is restarted, it can join and continue + training without being blocked. name: Optional name prefix for the operations created when applying gradients. Defaults to "ElasticAverageOptimizer". """ @@ -148,6 +189,7 @@ class ElasticAverageOptimizer(optimizer.Optimizer): self._period = communication_period self._local_map = ea_custom_getter._local_map self._global_map = ea_custom_getter._global_map + self._synchronous = synchronous if moving_rate is None: self._moving_rate = self.BETA / communication_period / num_worker @@ -241,11 +283,29 @@ class ElasticAverageOptimizer(optimizer.Optimizer): TypeError: If `grads_and_vars` is malformed. ValueError: If none of the variables have gradients. """ + global_old = set(n.op.name for n in variables.global_variables()) apply_updates = self._opt.apply_gradients(grads_and_vars) + global_new = set(n.op.name for n in variables.global_variables()) with ops.control_dependencies([apply_updates]): local_update = state_ops.assign_add( self._local_step, 1, name='local_step_update').op + # this is for place the variables created by optimizer to local collection + # e.g., AdamOptimizer will create beta as global variables + def _adjust_optimizer_variable_collection(opt_vars): + g = ops.get_default_graph() + idx = 0 + for _ in range(len(g._collections[ops.GraphKeys.GLOBAL_VARIABLES])): + var = g.get_collection_ref(ops.GraphKeys.GLOBAL_VARIABLES)[idx] + name = var.op.name + if name in opt_vars: + ops.add_to_collection(ops.GraphKeys.LOCAL_VARIABLES, var) + del g.get_collection_ref(ops.GraphKeys.GLOBAL_VARIABLES)[idx] + else: + idx += 1 + + _adjust_optimizer_variable_collection(global_new - global_old) + # update global variables. def _Update_global_variables(): local_vars = [v for g, v in grads_and_vars if g is not None] @@ -290,7 +350,7 @@ class ElasticAverageOptimizer(optimizer.Optimizer): variables equal to the global center variables before the training begins""" def _Add_sync_queues_and_barrier(enqueue_after_list): - """Adds ops to enqueu on all worker queues""" + """Adds ops to enqueue on all worker queues""" sync_queues = [ data_flow_ops.FIFOQueue( self._num_worker, [dtypes.bool], @@ -324,6 +384,9 @@ class ElasticAverageOptimizer(optimizer.Optimizer): init_ops.append(state_ops.assign(lc_var, gc_var)) init_op = control_flow_ops.group(*(init_ops)) + if self._synchronous == False: + return init_op + sync_queue_op = _Add_sync_queues_and_barrier([init_op]) return sync_queue_op @@ -331,6 +394,51 @@ class ElasticAverageOptimizer(optimizer.Optimizer): """Creates a hook to handle ElasticAverageOptimizerHook ops such as initialization.""" return _ElasticAverageOptimizerHook(self, is_chief, task_index) + def swapping_saver(self, var_list=None, name='swapping_saver', **kwargs): + """Create a saver copy global_center_variable to trainable variables + Please call this function after all your variables created with + ElasticAverageCustomGetter. For evaluations or inference, use this saver + during training. It will save the global_center_variable of the trained + parameters under the original parameter names. + Args: + var_list: List of variables to save, as per `Saver()`. + If set to None, save all the trainable_variables that have + been created before this call. + name: The name of the saver. + **kwargs: Keyword arguments of `Saver()`. + Returns: + A `tf.train.Saver` object. + Raises: + RuntimeError: global_center_variable is empty, please make sure + this is called after model created and + ElasticAverageCustomGetter is used when declaring you model + """ + if not self._global_map: + raise RuntimeError('global_center_variable is empty, please make sure ' + 'this is called after model created and ' + 'ElasticAverageCustomGetter is used when declaring ' + 'you model') + + if var_list is None: + var_list = variables.trainable_variables() + if not isinstance(var_list, dict): + var_list = saver.BaseSaverBuilder.OpListToDict(var_list) + + swapped_var_list = {} + for key, var in var_list.items(): + tensor = var + + if not isinstance(var, list): + for tvar in variables.trainable_variables(): + if tvar.op.name == var.op.name: + tensor = self._global_map.get(tvar, var) + break + else: #partitioned variable + tensor = [self._global_map.get(lvar, lvar) for lvar in var] + + swapped_var_list[key] = tensor + + return saver.Saver(swapped_var_list, name=name, **kwargs) class _ElasticAverageOptimizerHook(session_run_hook.SessionRunHook): @@ -351,3 +459,7 @@ class _ElasticAverageOptimizerHook(session_run_hook.SessionRunHook): if self._is_chief: self._global_init_op = variables.global_variables_initializer() self._variable_init_op = self._ea_optimizer.get_init_op(self._task_index) + + def after_create_session(self, session, coord): + """Run initialization ops""" + session.run(self._variable_init_op)
\ No newline at end of file diff --git a/tensorflow/contrib/opt/python/training/elastic_average_optimizer_test.py b/tensorflow/contrib/opt/python/training/elastic_average_optimizer_test.py index 5ed8057b86..5bf6a08de1 100644 --- a/tensorflow/contrib/opt/python/training/elastic_average_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/elastic_average_optimizer_test.py @@ -17,17 +17,22 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import os import portpicker +from tensorflow.python.client import session from tensorflow.python.framework import constant_op from tensorflow.python.framework import ops +from tensorflow.python.ops import init_ops +from tensorflow.python.ops import partitioned_variables +from tensorflow.python.ops import variable_scope from tensorflow.python.ops import variables from tensorflow.python.platform import test +from tensorflow.python.training import device_setter from tensorflow.python.training import gradient_descent +from tensorflow.python.training import saver from tensorflow.python.training import server_lib from tensorflow.python.training import training from tensorflow.python.training import training_util -from tensorflow.python.ops import variable_scope -from tensorflow.python.training import device_setter from tensorflow.contrib.opt.python.training.elastic_average_optimizer import \ ElasticAverageOptimizer, ElasticAverageCustomGetter, GLOBAL_VARIABLE_NAME @@ -59,29 +64,49 @@ def create_local_cluster(num_workers, num_ps, protocol="grpc"): # Creates the workers and return their sessions, graphs, train_ops. # Chief worker will update at last -def _get_workers(num_workers, period, workers, moving_rate): +def _get_workers(num_workers, period, workers, moving_rate, num_ps=1): sessions = [] graphs = [] train_ops = [] + savers = [] for worker_id in range(num_workers): graph = ops.Graph() is_chief = (worker_id == 0) with graph.as_default(): worker_device = "/job:worker/task:%d/cpu:0" % (worker_id) - ea_coustom = ElasticAverageCustomGetter(worker_device=worker_device) + ea_custom = ElasticAverageCustomGetter(worker_device=worker_device) with variable_scope.variable_scope( - "", custom_getter=ea_coustom), ops.device( + "", custom_getter=ea_custom), ops.device( device_setter.replica_device_setter( worker_device=worker_device, ps_device="/job:ps/task:0/cpu:0", ps_tasks=1)): - global_step = variables.Variable(0, name="global_step", trainable=False) + global_step = training_util.get_or_create_global_step() var_0 = variable_scope.get_variable(initializer=0.0, name="v0") var_1 = variable_scope.get_variable(initializer=1.0, name="v1") + if num_ps > 1: + with variable_scope.variable_scope( + "", + partitioner=partitioned_variables.fixed_size_partitioner( + num_ps, axis=0), + custom_getter=ea_custom), ops.device( + device_setter.replica_device_setter( + worker_device=worker_device, + ps_device="/job:ps/task:0/cpu:0", + ps_tasks=num_ps)): + + partition_var = variable_scope.get_variable( + 'partition_var', + shape=[2, 4], + initializer=init_ops.ones_initializer) + part_0 = list(partition_var)[0] + part_1 = list(partition_var)[1] with ops.device("/job:worker/task:" + str(worker_id)): grads_0 = constant_op.constant(-1.0) grads_1 = constant_op.constant(-1.0) + grads_part_0 = constant_op.constant([[-1., -1., -1., -1.]]) + grads_part_1 = constant_op.constant([[-1., -1., -1., -1.]]) sgd_opt = gradient_descent.GradientDescentOptimizer(1.0) opt = ElasticAverageOptimizer( @@ -89,12 +114,22 @@ def _get_workers(num_workers, period, workers, moving_rate): num_worker=num_workers, moving_rate=moving_rate, communication_period=period, - ea_custom_getter=ea_coustom) - train_op = [ - opt.apply_gradients(([grads_0, var_0], [grads_1, var_1]), - global_step) - ] + ea_custom_getter=ea_custom) + if num_ps == 1: + train_op = [ + opt.apply_gradients(([grads_0, var_0], [grads_1, var_1]), + global_step) + ] + else: + train_op = [ + opt.apply_gradients(([grads_0, var_0], + [grads_1, var_1], + [grads_part_0, part_0], + [grads_part_1, part_1]), + global_step) + ] easgd_hook = opt.make_session_run_hook(is_chief, worker_id) + saver = opt.swapping_saver() # Creates MonitoredSession sess = training.MonitoredTrainingSession( workers[worker_id].target, hooks=[easgd_hook]) @@ -102,8 +137,9 @@ def _get_workers(num_workers, period, workers, moving_rate): sessions.append(sess) graphs.append(graph) train_ops.append(train_op) + savers.append(saver) - return sessions, graphs, train_ops + return sessions, graphs, train_ops, savers class ElasticAverageOptimizerTest(test.TestCase): @@ -118,7 +154,7 @@ class ElasticAverageOptimizerTest(test.TestCase): cluster, workers, _ = create_local_cluster( num_workers=num_workers, num_ps=num_ps) - sessions, graphs, train_ops = _get_workers( + sessions, graphs, train_ops, savers = _get_workers( num_workers, communication_period, workers, 1.0) var_0 = graphs[0].get_tensor_by_name("v0:0") @@ -158,6 +194,21 @@ class ElasticAverageOptimizerTest(test.TestCase): self.assertAllEqual(2.0, sessions[0].run(var_0_g)) self.assertAllEqual(3.0, sessions[0].run(var_1_g)) self.assertAllEqual(1, sessions[0].run(global_step)) + sessions[0].run(train_ops[0]) + + # save, data will be global value + outfile = os.path.join(test.get_temp_dir(), "model") + savers[0].save(sessions[0]._sess._sess._sess._sess, + save_path=outfile) + ops.reset_default_graph() # restore on a new graph + with session.Session() as sess: + v0 = variable_scope.get_variable(initializer=0.0, name="v0") + v1 = variable_scope.get_variable(initializer=1.0, name="v1") + sess.run(variables.local_variables_initializer()) + saver_opt = saver.Saver(var_list=[v1, v0]) + saver_opt.restore(sess, outfile) + self.assertAllEqual(2.0, sess.run(v0)) + self.assertAllEqual(3.0, sess.run(v1)) def test2Worker1Period(self): num_workers = 2 @@ -166,8 +217,8 @@ class ElasticAverageOptimizerTest(test.TestCase): cluster, workers, _ = create_local_cluster( num_workers=num_workers, num_ps=num_ps) - sessions, graphs, train_ops = _get_workers( - num_workers, communication_period, workers, 0.5) + sessions, graphs, train_ops, savers = _get_workers( + num_workers, communication_period, workers, 0.5, num_ps=2) var_0 = graphs[0].get_tensor_by_name("v0:0") var_1 = graphs[0].get_tensor_by_name("v1:0") @@ -177,6 +228,9 @@ class ElasticAverageOptimizerTest(test.TestCase): var_0_g = graphs[0].get_tensor_by_name(GLOBAL_VARIABLE_NAME + "/v0:0") var_1_g = graphs[0].get_tensor_by_name(GLOBAL_VARIABLE_NAME + "/v1:0") + part_0_g = graphs[0].get_tensor_by_name( + GLOBAL_VARIABLE_NAME + "/partition_var/part_0:0") + # Verify the initialized value. self.assertAllEqual(0.0, sessions[0].run(var_0)) self.assertAllEqual(1.0, sessions[0].run(var_1)) @@ -194,22 +248,45 @@ class ElasticAverageOptimizerTest(test.TestCase): self.assertAllEqual(1.75, sessions[0].run(var_1_g)) self.assertAllEqual(0.75, sessions[1].run(var_0_1)) self.assertAllEqual(1.75, sessions[1].run(var_1_1)) + # part_0 of global_center copy + part_0_g = sessions[0].run(part_0_g) + + outfile = os.path.join(test.get_temp_dir(), "model") + savers[0].save(sessions[0]._sess._sess._sess._sess, + save_path=outfile) + + # verify restore of partitioned_variables + ops.reset_default_graph() # restore on a new graph + g = ops.get_default_graph() + with session.Session() as sess, g.as_default(): + with variable_scope.variable_scope( + "", + partitioner=partitioned_variables.fixed_size_partitioner( + num_ps, axis=0)): + partition_var = variable_scope.get_variable( + 'partition_var', + shape=[2, 4], + initializer=init_ops.ones_initializer) + s = saver.Saver(var_list=[partition_var]) + s.restore(sess, outfile) + part_0 = g.get_tensor_by_name('partition_var/part_0:0') + self.assertAllEqual(part_0_g, sess.run(part_0)) def testPS2TasksWithClusterSpecClass(self): cluster_spec = server_lib.ClusterSpec({ "ps": ["ps0:2222", "ps1:2222"], "worker": ["worker0:2222", "worker1:2222", "worker2:2222"] }) - ea_coustom = ElasticAverageCustomGetter(worker_device="/job:worker/task:0") + ea_custom = ElasticAverageCustomGetter(worker_device="/job:worker/task:0") from tensorflow.python.training import device_setter with ops.device( device_setter.replica_device_setter(cluster=cluster_spec, worker_device="/job:worker/task:0", ps_device="/job:ps")), \ - variable_scope.variable_scope("", custom_getter=ea_coustom): + variable_scope.variable_scope("", custom_getter=ea_custom): v = variable_scope.get_variable(initializer=[1, 2], name="v") w = variable_scope.get_variable(initializer=[2, 1], name="w") - v_g, w_g = ea_coustom._global_map[v], ea_coustom._global_map[w] + v_g, w_g = ea_custom._global_map[v], ea_custom._global_map[w] self.assertDeviceEqual("/job:worker/task:0", v.device) self.assertDeviceEqual("job:ps/task:0", v_g.device) self.assertDeviceEqual("/job:worker/task:0", w.device) diff --git a/tensorflow/contrib/opt/python/training/external_optimizer_test.py b/tensorflow/contrib/opt/python/training/external_optimizer_test.py index 953586ee70..9997103016 100644 --- a/tensorflow/contrib/opt/python/training/external_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/external_optimizer_test.py @@ -85,7 +85,7 @@ class ExternalOptimizerInterfaceTest(TestCase): optimizer = MockOptimizerInterface(loss) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) optimizer.minimize(sess) @@ -107,7 +107,7 @@ class ExternalOptimizerInterfaceTest(TestCase): optimizer = MockOptimizerInterface(loss) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) initial_vector_val = sess.run(vector) @@ -164,7 +164,7 @@ class ScipyOptimizerInterfaceTest(TestCase): optimizer = external_optimizer.ScipyOptimizerInterface( self._objective(x), method=method, options=options) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) optimizer.minimize(sess) @@ -176,7 +176,7 @@ class ScipyOptimizerInterfaceTest(TestCase): x = variables.Variable(array_ops.zeros(dimension)) optimizer = external_optimizer.ScipyOptimizerInterface(self._objective(x)) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) optimizer.minimize(sess) @@ -242,7 +242,7 @@ class ScipyOptimizerInterfaceTest(TestCase): optimizer = external_optimizer.ScipyOptimizerInterface( loss, equalities=equalities, inequalities=inequalities, method='SLSQP') - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) optimizer.minimize(sess) self.assertAllClose(np.ones(2), sess.run(vector)) @@ -260,7 +260,7 @@ class ScipyOptimizerInterfaceTest(TestCase): optimizer = external_optimizer.ScipyOptimizerInterface( loss, var_to_bounds=var_to_bounds) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) optimizer.minimize(sess) self.assertAllClose(np.ones(2), sess.run(vector)) @@ -277,7 +277,7 @@ class ScipyOptimizerInterfaceTest(TestCase): optimizer = external_optimizer.ScipyOptimizerInterface( loss, var_to_bounds=var_to_bounds) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) optimizer.minimize(sess) self.assertAllClose([0., 2.], sess.run(vector)) @@ -293,7 +293,7 @@ class ScipyOptimizerInterfaceTest(TestCase): optimizer = external_optimizer.ScipyOptimizerInterface( loss, method='SLSQP') - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) optimizer.minimize(sess) method = optimizer.optimizer_kwargs.get('method') @@ -312,7 +312,7 @@ class ScipyOptimizerInterfaceTest(TestCase): optimizer = external_optimizer.ScipyOptimizerInterface(loss, method='SLSQP') - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) initial_vector_val = sess.run(vector) diff --git a/tensorflow/contrib/opt/python/training/ggt_test.py b/tensorflow/contrib/opt/python/training/ggt_test.py index 42162960b0..1775edabb3 100644 --- a/tensorflow/contrib/opt/python/training/ggt_test.py +++ b/tensorflow/contrib/opt/python/training/ggt_test.py @@ -76,7 +76,7 @@ class GGTOptimizerTest(test.TestCase): def doTestBasic(self, use_resource=False): # SVD does not support float16 for i, dtype in enumerate([dtypes.float32, dtypes.float64]): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): # Initialize variables for numpy implementation. m0 = 0.0 window = 3 @@ -171,7 +171,7 @@ class GGTOptimizerTest(test.TestCase): self.assertAllCloseAccordingToType(var1_np, self.evaluate(var1)) def testBasic(self): - with self.test_session(): + with self.cached_session(): self.doTestBasic(use_resource=False) @test_util.run_in_graph_and_eager_modes(reset_test=True) diff --git a/tensorflow/contrib/opt/python/training/lars_optimizer_test.py b/tensorflow/contrib/opt/python/training/lars_optimizer_test.py index d94249b994..b76db763da 100644 --- a/tensorflow/contrib/opt/python/training/lars_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/lars_optimizer_test.py @@ -31,7 +31,7 @@ class LARSOptimizerTest(test.TestCase): def testLARSGradientOneStep(self): for _ in range(10): for dtype in [dtypes.float32, dtypes.float64]: - with self.test_session() as sess: + with self.cached_session() as sess: shape = [3, 3] var_np = np.ones(shape) grad_np = np.ones(shape) @@ -77,7 +77,7 @@ class LARSOptimizerTest(test.TestCase): def testLARSGradientMultiStep(self): for _ in range(10): for dtype in [dtypes.float32, dtypes.float64]: - with self.test_session() as sess: + with self.cached_session() as sess: shape = [3, 3] var_np = np.ones(shape) grad_np = np.ones(shape) diff --git a/tensorflow/contrib/opt/python/training/lazy_adam_optimizer_test.py b/tensorflow/contrib/opt/python/training/lazy_adam_optimizer_test.py index a16857db7d..dc4c462ce4 100644 --- a/tensorflow/contrib/opt/python/training/lazy_adam_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/lazy_adam_optimizer_test.py @@ -53,7 +53,7 @@ class AdamOptimizerTest(test.TestCase): def testSparse(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) @@ -109,7 +109,7 @@ class AdamOptimizerTest(test.TestCase): def testSparseRepeatedIndices(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): repeated_index_update_var = variables.Variable( [[1.0], [2.0]], dtype=dtype) aggregated_update_var = variables.Variable( diff --git a/tensorflow/contrib/opt/python/training/moving_average_optimizer_test.py b/tensorflow/contrib/opt/python/training/moving_average_optimizer_test.py index ac04ad9911..f22e724528 100644 --- a/tensorflow/contrib/opt/python/training/moving_average_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/moving_average_optimizer_test.py @@ -46,7 +46,7 @@ class MovingAverageOptimizerTest(test.TestCase): def _helpTestRun(self, use_resource=False): for sequential_update in [True, False]: for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: orig_val0 = [1.0, 2.0] orig_val1 = [3.0, 4.0] var0 = variable_scope.get_variable( @@ -165,7 +165,7 @@ class MovingAverageOptimizerTest(test.TestCase): self.assertLess(avg_val1[i], orig_val1[i]) def testFailWhenSaverCreatedBeforeInitialized(self): - with self.test_session(): + with self.cached_session(): var = variables.Variable([1.0], name='var', dtype=dtypes.float32) opt = moving_average_optimizer.MovingAverageOptimizer( gradient_descent.GradientDescentOptimizer(learning_rate=2.0)) @@ -187,7 +187,7 @@ class MovingAverageOptimizerTest(test.TestCase): self.apply_gradients_called = True return super(WrapperOptimizer, self).apply_gradients(*args, **kwargs) - with self.test_session() as sess: + with self.cached_session() as sess: var = variables.Variable([1.2], name='var', dtype=dtypes.float32) loss = var ** 2 wrapper_opt = WrapperOptimizer(learning_rate=2.0) diff --git a/tensorflow/contrib/opt/python/training/multitask_optimizer_wrapper_test.py b/tensorflow/contrib/opt/python/training/multitask_optimizer_wrapper_test.py index 618d8eb18d..904aa9ab13 100644 --- a/tensorflow/contrib/opt/python/training/multitask_optimizer_wrapper_test.py +++ b/tensorflow/contrib/opt/python/training/multitask_optimizer_wrapper_test.py @@ -34,7 +34,7 @@ class MultitaskOptimizerWrapperTest(test.TestCase): """ def testWrapper(self): - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtypes.float32) var1 = variables.Variable([3.0, 4.0], dtype=dtypes.float32) grads0 = constant_op.constant([0.1, 0.1], dtype=dtypes.float32) @@ -92,7 +92,7 @@ class MultitaskOptimizerWrapperTest(test.TestCase): self.evaluate(slot1)) def testGradientClipping(self): - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtypes.float32) var1 = variables.Variable([3.0, 4.0], dtype=dtypes.float32) var2 = variables.Variable([3.0, 4.0], dtype=dtypes.float32) diff --git a/tensorflow/contrib/opt/python/training/nadam_optimizer_test.py b/tensorflow/contrib/opt/python/training/nadam_optimizer_test.py index 825c08a09a..85e05ce71c 100644 --- a/tensorflow/contrib/opt/python/training/nadam_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/nadam_optimizer_test.py @@ -53,7 +53,7 @@ class NadamOptimizerTest(test.TestCase): def doTestSparse(self, use_resource=False): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) @@ -106,7 +106,7 @@ class NadamOptimizerTest(test.TestCase): def doTestBasic(self, use_resource=False): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) diff --git a/tensorflow/contrib/opt/python/training/powersign.py b/tensorflow/contrib/opt/python/training/powersign.py index 828f3c51c9..b4aa19264d 100644 --- a/tensorflow/contrib/opt/python/training/powersign.py +++ b/tensorflow/contrib/opt/python/training/powersign.py @@ -65,7 +65,7 @@ class PowerSignOptimizer(optimizer.Optimizer): Example usage for PowerSign-cd (PowerSign with cosine sign decay) ``` decay_steps = 1000 - linear_decay_fn = sign_decays.get_linear_decay_fn(decay_steps) + linear_decay_fn = sign_decays.get_cosine_decay_fn(decay_steps) opt = PowerSignOptimizer(learning_rate=0.1, sign_decay_fn=linear_decay_fn) ``` diff --git a/tensorflow/contrib/opt/python/training/reg_adagrad_optimizer_test.py b/tensorflow/contrib/opt/python/training/reg_adagrad_optimizer_test.py index ea56e1646a..c09e2ac76d 100644 --- a/tensorflow/contrib/opt/python/training/reg_adagrad_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/reg_adagrad_optimizer_test.py @@ -36,7 +36,7 @@ class RegAdagradOptimizerTest(test.TestCase): def doTestBasic(self, use_locking=False, use_resource=False): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): if use_resource: var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0, 4.0], dtype=dtype) @@ -73,7 +73,7 @@ class RegAdagradOptimizerTest(test.TestCase): def testMinimizeSparseResourceVariable(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = resource_variable_ops.ResourceVariable( [[1.0, 2.0], [3.0, 4.0]], dtype=dtype) x = constant_op.constant([[4.0], [5.0]], dtype=dtype) @@ -92,7 +92,7 @@ class RegAdagradOptimizerTest(test.TestCase): def testTensorLearningRate(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -116,7 +116,7 @@ class RegAdagradOptimizerTest(test.TestCase): def testSparseBasic(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([[1.0], [2.0]], dtype=dtype) var1 = variables.Variable([[3.0], [4.0]], dtype=dtype) grads0 = ops.IndexedSlices( @@ -144,7 +144,7 @@ class RegAdagradOptimizerTest(test.TestCase): def testSparseRepeatedIndices(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): repeated_index_update_var = variables.Variable( [[1.0], [2.0]], dtype=dtype) aggregated_update_var = variables.Variable([[1.0], [2.0]], dtype=dtype) @@ -170,7 +170,7 @@ class RegAdagradOptimizerTest(test.TestCase): def testSparseRepeatedIndicesResourceVariable(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var_repeated = resource_variable_ops.ResourceVariable( [1.0, 2.0], dtype=dtype) loss_repeated = math_ops.reduce_sum( @@ -194,7 +194,7 @@ class RegAdagradOptimizerTest(test.TestCase): def testSparseStability(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): shape = [1, 6] var0 = variables.Variable( [[ @@ -230,7 +230,7 @@ class RegAdagradOptimizerTest(test.TestCase): def testSharing(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -263,7 +263,7 @@ class RegAdagradOptimizerTest(test.TestCase): np.array([2.715679168701172, 3.715679168701172]), var1.eval()) def testDynamicShapeVariable_Ok(self): - with self.test_session(): + with self.cached_session(): v = variable_scope.get_variable( "v", initializer=constant_op.constant(1.), validate_shape=False) self.assertFalse(v.shape.is_fully_defined()) @@ -274,7 +274,7 @@ class RegAdagradOptimizerTest(test.TestCase): def testSkipUpdatingSlots(self): iav = 0.130005 # A value that works with float16 for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -306,7 +306,7 @@ class RegAdagradOptimizerTest(test.TestCase): def testSparseSkipUpdatingSlots(self): iav = 0.130005 # A value that works with float16 for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([[1.0], [2.0]], dtype=dtype) var1 = variables.Variable([[3.0], [4.0]], dtype=dtype) grads0 = ops.IndexedSlices( diff --git a/tensorflow/contrib/opt/python/training/shampoo_test.py b/tensorflow/contrib/opt/python/training/shampoo_test.py index 2e0a202ae2..b3688ab181 100644 --- a/tensorflow/contrib/opt/python/training/shampoo_test.py +++ b/tensorflow/contrib/opt/python/training/shampoo_test.py @@ -52,7 +52,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): grad_np = np.random.rand(size) grad_np_2 = np.random.rand(size) - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( @@ -103,7 +103,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): grad_np = np.random.rand(size[0], size[1]) grad_np_2 = np.random.rand(size[0], size[1]) - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( @@ -162,7 +162,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): grad_np = np.random.rand(size[0], size[1], size[2]) grad_np_2 = np.random.rand(size[0], size[1], size[2]) - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( @@ -240,7 +240,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): grad_np = np.random.rand(size) grad_np_2 = np.random.rand(size) - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( @@ -294,7 +294,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): grad_np = np.random.rand(size[0], size[1]) grad_np_2 = np.random.rand(size[0], size[1]) - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( @@ -365,7 +365,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): replace=False)) grad_np_2 = np.random.rand(sample_size_2, size[1]) - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( @@ -445,7 +445,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): replace=False)) grad_np = np.random.rand(sample_size, size[1], size[2]) - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( @@ -512,7 +512,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): gbar_decay = 0.9 gbar_weight = 0.1 - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( @@ -601,7 +601,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): mat_g3_a = np.eye(size[2]) mat_g3 = np.zeros_like(mat_g3_a) - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( @@ -672,7 +672,7 @@ class ShampooTest(test.TestCase, parameterized.TestCase): mat_g3_a = np.eye(size[2]) mat_g3 = np.zeros_like(mat_g3_a) - with self.test_session() as sess: + with self.cached_session() as sess: global_step = variables.Variable( 0, dtype=dtypes.int64, use_resource=use_resource_var) var = variables.Variable( diff --git a/tensorflow/contrib/opt/python/training/sign_decay_test.py b/tensorflow/contrib/opt/python/training/sign_decay_test.py index c31cb924ea..3a84789afd 100644 --- a/tensorflow/contrib/opt/python/training/sign_decay_test.py +++ b/tensorflow/contrib/opt/python/training/sign_decay_test.py @@ -66,7 +66,7 @@ class SignDecaysTest(test.TestCase): linear_decay_fn = sign_decay.get_linear_decay_fn(num_training_steps) for step in range(0, 1000, 100): - with self.test_session(): + with self.cached_session(): tf_decayed = linear_decay_fn(step).eval() py_decayed = py_linear_decay_fn(num_training_steps)(step) self.assertAlmostEqual(tf_decayed, py_decayed, places=4) @@ -78,7 +78,7 @@ class SignDecaysTest(test.TestCase): num_training_steps, num_periods=5, zero_after=2) for step in range(0, 1000, 100): - with self.test_session(): + with self.cached_session(): tf_decayed = cosine_decay_fn(step).eval() py_decayed = py_cosine_decay_fn(num_training_steps)(step) self.assertAlmostEqual(tf_decayed, py_decayed, places=4) @@ -95,7 +95,7 @@ class SignDecaysTest(test.TestCase): num_training_steps, num_periods=5, zero_after=2) for step in range(0, 1000, 100): - with self.test_session(): + with self.cached_session(): tf_decayed = restart_decay_fn(step).eval() py_decayed = py_restart_decay_fn(num_training_steps)(step) self.assertAlmostEqual(tf_decayed, py_decayed, places=4) diff --git a/tensorflow/contrib/opt/python/training/variable_clipping_optimizer_test.py b/tensorflow/contrib/opt/python/training/variable_clipping_optimizer_test.py index fdda86b0b5..ff0ea8d766 100644 --- a/tensorflow/contrib/opt/python/training/variable_clipping_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/variable_clipping_optimizer_test.py @@ -158,7 +158,7 @@ class VariableClippingOptimizerTest(test.TestCase): def testDenseLocal(self): for dtype in [dtypes.float32, dtypes.float64, dtypes.half]: - with self.test_session(): + with self.cached_session(): var0, var1, update_op = self._setupDense(False, dtype) self._assertDenseCorrect(var0, var1, update_op) @@ -171,7 +171,7 @@ class VariableClippingOptimizerTest(test.TestCase): def testSparseLocal(self): for dtype in [dtypes.float64, dtypes.float32, dtypes.half]: - with self.test_session(): + with self.cached_session(): var0, var1, update_op = self._setupSparse(False, dtype) self._assertSparseCorrect(var0, var1, update_op) diff --git a/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py b/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py index b9cf40eb7b..29acfc602e 100644 --- a/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py +++ b/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py @@ -26,6 +26,7 @@ from tensorflow.python.training import adam from tensorflow.python.training import momentum as momentum_opt from tensorflow.python.training import optimizer from tensorflow.python.util.tf_export import tf_export +from tensorflow.python.ops import array_ops class DecoupledWeightDecayExtension(object): @@ -159,8 +160,8 @@ class DecoupledWeightDecayExtension(object): def _decay_weights_sparse_op(self, var, indices, scatter_add): if not self._decay_var_list or var in self._decay_var_list: - return scatter_add(var, indices, -self._weight_decay * var, - self._use_locking) + update = -self._weight_decay * array_ops.gather(var, indices) + return scatter_add(var, indices, update, self._use_locking) return control_flow_ops.no_op() # Here, we overwrite the apply functions that the base optimizer calls. diff --git a/tensorflow/contrib/opt/python/training/weight_decay_optimizers_test.py b/tensorflow/contrib/opt/python/training/weight_decay_optimizers_test.py index 76d8a5697a..9c91078301 100644 --- a/tensorflow/contrib/opt/python/training/weight_decay_optimizers_test.py +++ b/tensorflow/contrib/opt/python/training/weight_decay_optimizers_test.py @@ -58,7 +58,7 @@ class WeightDecayOptimizerTest(test.TestCase): def doTest(self, optimizer, update_fn, optimizer_name, slot_name, use_resource=False, do_sparse=False): for i, dtype in enumerate([dtypes.half, dtypes.float32, dtypes.float64]): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) diff --git a/tensorflow/contrib/optimizer_v2/adadelta_test.py b/tensorflow/contrib/optimizer_v2/adadelta_test.py index 31cfec0d50..4c94b66679 100644 --- a/tensorflow/contrib/optimizer_v2/adadelta_test.py +++ b/tensorflow/contrib/optimizer_v2/adadelta_test.py @@ -37,7 +37,7 @@ class AdadeltaOptimizerTest(test.TestCase): for dtype in [dtypes.half, dtypes.float32]: for grad in [0.2, 0.1, 0.01]: for lr in [1.0, 0.5, 0.1]: - with self.test_session(): + with self.cached_session(): var0_init = [1.0, 2.0] var1_init = [3.0, 4.0] if use_resource: @@ -146,7 +146,7 @@ class AdadeltaOptimizerTest(test.TestCase): def testMinimizeSparseResourceVariable(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = resource_variable_ops.ResourceVariable([[1.0, 2.0]], dtype=dtype) x = constant_op.constant([[4.0], [5.0]], dtype=dtype) pred = math_ops.matmul(embedding_ops.embedding_lookup([var0], [0]), x) diff --git a/tensorflow/contrib/optimizer_v2/adagrad_test.py b/tensorflow/contrib/optimizer_v2/adagrad_test.py index 18191c3ef2..debaaaeeba 100644 --- a/tensorflow/contrib/optimizer_v2/adagrad_test.py +++ b/tensorflow/contrib/optimizer_v2/adagrad_test.py @@ -36,7 +36,7 @@ class AdagradOptimizerTest(test.TestCase): def doTestBasic(self, use_locking=False, use_resource=False): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): if use_resource: var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0, 4.0], dtype=dtype) @@ -73,7 +73,7 @@ class AdagradOptimizerTest(test.TestCase): def testMinimizeSparseResourceVariable(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = resource_variable_ops.ResourceVariable( [[1.0, 2.0], [3.0, 4.0]], dtype=dtype) x = constant_op.constant([[4.0], [5.0]], dtype=dtype) @@ -92,7 +92,7 @@ class AdagradOptimizerTest(test.TestCase): def testTensorLearningRate(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -116,7 +116,7 @@ class AdagradOptimizerTest(test.TestCase): def testSparseBasic(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([[1.0], [2.0]], dtype=dtype) var1 = variables.Variable([[3.0], [4.0]], dtype=dtype) grads0 = ops.IndexedSlices( @@ -147,7 +147,7 @@ class AdagradOptimizerTest(test.TestCase): def testSparseRepeatedIndices(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): repeated_index_update_var = variables.Variable( [[1.0], [2.0]], dtype=dtype) aggregated_update_var = variables.Variable( @@ -177,7 +177,7 @@ class AdagradOptimizerTest(test.TestCase): def testSparseRepeatedIndicesResourceVariable(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var_repeated = resource_variable_ops.ResourceVariable( [1.0, 2.0], dtype=dtype) loss_repeated = math_ops.reduce_sum( @@ -201,7 +201,7 @@ class AdagradOptimizerTest(test.TestCase): def testSparseStability(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): shape = [1, 6] var0 = variables.Variable( [[ @@ -237,7 +237,7 @@ class AdagradOptimizerTest(test.TestCase): def testSharing(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -270,7 +270,7 @@ class AdagradOptimizerTest(test.TestCase): np.array([2.715679168701172, 3.715679168701172]), var1.eval()) def testDynamicShapeVariable_Ok(self): - with self.test_session(): + with self.cached_session(): v = variable_scope.get_variable("v", initializer=constant_op.constant(1.), validate_shape=False) self.assertFalse(v.shape.is_fully_defined()) diff --git a/tensorflow/contrib/optimizer_v2/adam.py b/tensorflow/contrib/optimizer_v2/adam.py index 631d4f44df..04b1552b61 100644 --- a/tensorflow/contrib/optimizer_v2/adam.py +++ b/tensorflow/contrib/optimizer_v2/adam.py @@ -40,15 +40,14 @@ class AdamOptimizer(optimizer_v2.OptimizerV2): Initialization: - $$m_0 := 0 (Initialize initial 1st moment vector)$$ - $$v_0 := 0 (Initialize initial 2nd moment vector)$$ - $$t := 0 (Initialize timestep)$$ - + $$m_0 := 0 \text{(Initialize initial 1st moment vector)}$$ + $$v_0 := 0 \text{(Initialize initial 2nd moment vector)}$$ + $$t := 0 \text{(Initialize timestep)}$$ The update rule for `variable` with gradient `g` uses an optimization described at the end of section2 of the paper: $$t := t + 1$$ - $$lr_t := \text{learning_rate} * \sqrt{(1 - beta_2^t) / (1 - beta_1^t)}$$ + $$lr_t := \text{learning\_rate} * \sqrt{1 - beta_2^t} / (1 - beta_1^t)$$ $$m_t := beta_1 * m_{t-1} + (1 - beta_1) * g$$ $$v_t := beta_2 * v_{t-1} + (1 - beta_2) * g * g$$ diff --git a/tensorflow/contrib/optimizer_v2/adam_test.py b/tensorflow/contrib/optimizer_v2/adam_test.py index d9ad58b0a6..b1ad0ade42 100644 --- a/tensorflow/contrib/optimizer_v2/adam_test.py +++ b/tensorflow/contrib/optimizer_v2/adam_test.py @@ -56,7 +56,7 @@ class AdamOptimizerTest(test.TestCase): def doTestSparse(self, use_resource=False): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) @@ -122,7 +122,7 @@ class AdamOptimizerTest(test.TestCase): def testSparseRepeatedIndices(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): repeated_index_update_var = variables.Variable( [[1.0], [2.0]], dtype=dtype) aggregated_update_var = variables.Variable( @@ -152,7 +152,7 @@ class AdamOptimizerTest(test.TestCase): def doTestBasic(self, use_resource=False): for i, dtype in enumerate([dtypes.half, dtypes.float32, dtypes.float64]): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) @@ -215,7 +215,7 @@ class AdamOptimizerTest(test.TestCase): opt.get_slot(var=var0, name="m").name) def testBasic(self): - with self.test_session(): + with self.cached_session(): self.doTestBasic(use_resource=False) @test_util.run_in_graph_and_eager_modes(reset_test=True) @@ -224,7 +224,7 @@ class AdamOptimizerTest(test.TestCase): def testTensorLearningRate(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) @@ -261,7 +261,7 @@ class AdamOptimizerTest(test.TestCase): def testSharing(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) diff --git a/tensorflow/contrib/optimizer_v2/checkpointable_utils_test.py b/tensorflow/contrib/optimizer_v2/checkpointable_utils_test.py index 28a531dfec..e13b82d1d2 100644 --- a/tensorflow/contrib/optimizer_v2/checkpointable_utils_test.py +++ b/tensorflow/contrib/optimizer_v2/checkpointable_utils_test.py @@ -310,7 +310,7 @@ class CheckpointingTests(test.TestCase): global_step=root.global_step) checkpoint_path = checkpoint_management.latest_checkpoint( checkpoint_directory) - with self.test_session(graph=ops.get_default_graph()) as session: + with self.session(graph=ops.get_default_graph()) as session: status = root.restore(save_path=checkpoint_path) status.initialize_or_restore(session=session) if checkpoint_path is None: @@ -504,7 +504,7 @@ class CheckpointingTests(test.TestCase): """Saves after the first should not modify the graph.""" with context.graph_mode(): graph = ops.Graph() - with graph.as_default(), self.test_session(graph): + with graph.as_default(), self.session(graph): checkpoint_directory = self.get_temp_dir() checkpoint_prefix = os.path.join(checkpoint_directory, "ckpt") obj = tracking.Checkpointable() @@ -522,7 +522,7 @@ class CheckpointingTests(test.TestCase): """Restores after the first should not modify the graph.""" with context.graph_mode(): graph = ops.Graph() - with graph.as_default(), self.test_session(graph): + with graph.as_default(), self.session(graph): checkpoint_directory = self.get_temp_dir() checkpoint_prefix = os.path.join(checkpoint_directory, "ckpt") obj = tracking.Checkpointable() diff --git a/tensorflow/contrib/optimizer_v2/gradient_descent_test.py b/tensorflow/contrib/optimizer_v2/gradient_descent_test.py index ad9aef804f..4a77bce478 100644 --- a/tensorflow/contrib/optimizer_v2/gradient_descent_test.py +++ b/tensorflow/contrib/optimizer_v2/gradient_descent_test.py @@ -34,7 +34,7 @@ class GradientDescentOptimizerTest(test.TestCase): def testBasic(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -57,7 +57,7 @@ class GradientDescentOptimizerTest(test.TestCase): def testBasicResourceVariable(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -82,7 +82,7 @@ class GradientDescentOptimizerTest(test.TestCase): def testMinimizeResourceVariable(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = resource_variable_ops.ResourceVariable([[1.0, 2.0]], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0], dtype=dtype) x = constant_op.constant([[4.0], [5.0]], dtype=dtype) @@ -108,7 +108,7 @@ class GradientDescentOptimizerTest(test.TestCase): def testMinimizeSparseResourceVariable(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = resource_variable_ops.ResourceVariable([[1.0, 2.0]], dtype=dtype) var1 = resource_variable_ops.ResourceVariable([3.0], dtype=dtype) x = constant_op.constant([[4.0], [5.0]], dtype=dtype) @@ -135,7 +135,7 @@ class GradientDescentOptimizerTest(test.TestCase): def testTensorLearningRate(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -157,7 +157,7 @@ class GradientDescentOptimizerTest(test.TestCase): def testGradWrtRef(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): opt = gradient_descent.GradientDescentOptimizer(3.0) values = [1.0, 3.0] vars_ = [variables.Variable([v], dtype=dtype) for v in values] @@ -168,7 +168,7 @@ class GradientDescentOptimizerTest(test.TestCase): def testWithGlobalStep(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): global_step = variables.Variable(0, trainable=False) var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) @@ -191,7 +191,7 @@ class GradientDescentOptimizerTest(test.TestCase): def testSparseBasic(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([[1.0], [2.0]], dtype=dtype) var1 = variables.Variable([[3.0], [4.0]], dtype=dtype) grads0 = ops.IndexedSlices( diff --git a/tensorflow/contrib/optimizer_v2/momentum_test.py b/tensorflow/contrib/optimizer_v2/momentum_test.py index 24cdab4626..e69f12839e 100644 --- a/tensorflow/contrib/optimizer_v2/momentum_test.py +++ b/tensorflow/contrib/optimizer_v2/momentum_test.py @@ -123,7 +123,7 @@ class MomentumOptimizerTest(test.TestCase): ]), self.evaluate(var1)) def testBasic(self): - with self.test_session(): + with self.cached_session(): self.doTestBasic(use_resource=False) @test_util.run_in_graph_and_eager_modes(reset_test=True) @@ -162,7 +162,7 @@ class MomentumOptimizerTest(test.TestCase): def testNesterovMomentum(self): for dtype in [dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) @@ -188,7 +188,7 @@ class MomentumOptimizerTest(test.TestCase): def testSparseNesterovMomentum(self): for dtype in [dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) var1_np = np.array([3.0, 4.0], dtype=dtype.as_numpy_dtype) accum0_np = np.array([0.0, 0.0], dtype=dtype.as_numpy_dtype) @@ -282,7 +282,7 @@ class MomentumOptimizerTest(test.TestCase): def testTensorLearningRateAndMomentum(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) @@ -435,7 +435,7 @@ class MomentumOptimizerTest(test.TestCase): return db_grad, db_out def testLikeDistBeliefMom01(self): - with self.test_session(): + with self.cached_session(): db_grad, db_out = self._dbParamsMom01() num_samples = len(db_grad) var0 = variables.Variable([0.0] * num_samples) @@ -449,7 +449,7 @@ class MomentumOptimizerTest(test.TestCase): def testSparse(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable(array_ops.zeros([4, 2], dtype=dtype)) var1 = variables.Variable(constant_op.constant(1.0, dtype, [4, 2])) grads0 = ops.IndexedSlices( @@ -518,7 +518,7 @@ class MomentumOptimizerTest(test.TestCase): def testSharing(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) grads0 = constant_op.constant([0.1, 0.1], dtype=dtype) diff --git a/tensorflow/contrib/optimizer_v2/optimizer_v2_test.py b/tensorflow/contrib/optimizer_v2/optimizer_v2_test.py index a44bfd1bfd..dd7f2f4405 100644 --- a/tensorflow/contrib/optimizer_v2/optimizer_v2_test.py +++ b/tensorflow/contrib/optimizer_v2/optimizer_v2_test.py @@ -61,7 +61,7 @@ class OptimizerTest(test.TestCase): def testAggregationMethod(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) cost = 5 * var0 + 3 * var1 @@ -86,7 +86,7 @@ class OptimizerTest(test.TestCase): def testPrecomputedGradient(self): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], dtype=dtype) var1 = variables.Variable([3.0, 4.0], dtype=dtype) cost = 5 * var0 + 3 * var1 @@ -212,7 +212,7 @@ class OptimizerTest(test.TestCase): sgd_op.apply_gradients(grads_and_vars) def testTrainOp(self): - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0]) var1 = variables.Variable([3.0, 4.0]) cost = 5 * var0 + 3 * var1 @@ -225,7 +225,7 @@ class OptimizerTest(test.TestCase): def testConstraint(self): constraint_01 = lambda x: clip_ops.clip_by_value(x, -0.1, 0.) constraint_0 = lambda x: clip_ops.clip_by_value(x, 0., 1.) - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], constraint=constraint_01) var1 = variables.Variable([3.0, 4.0], @@ -247,7 +247,7 @@ class OptimizerTest(test.TestCase): self.assertAllClose([0., 0.], var1.eval()) def testStopGradients(self): - with self.test_session(): + with self.cached_session(): var0 = variables.Variable([1.0, 2.0], name='var0') var1 = variables.Variable([3.0, 4.0], name='var1') var0_id = array_ops.identity(var0) diff --git a/tensorflow/contrib/optimizer_v2/rmsprop_test.py b/tensorflow/contrib/optimizer_v2/rmsprop_test.py index 628d0418dd..44301ffe9e 100644 --- a/tensorflow/contrib/optimizer_v2/rmsprop_test.py +++ b/tensorflow/contrib/optimizer_v2/rmsprop_test.py @@ -162,7 +162,7 @@ class RMSPropOptimizerTest(test.TestCase, parameterized.TestCase): @parameterized.parameters([dtypes.float32, dtypes.float64]) def testMinimizeSparseResourceVariable(self, dtype): - with self.test_session(): + with self.cached_session(): var0 = resource_variable_ops.ResourceVariable([[1.0, 2.0]], dtype=dtype) x = constant_op.constant([[4.0], [5.0]], dtype=dtype) pred = math_ops.matmul(embedding_ops.embedding_lookup([var0], [0]), x) @@ -184,7 +184,7 @@ class RMSPropOptimizerTest(test.TestCase, parameterized.TestCase): @parameterized.parameters([dtypes.float32, dtypes.float64]) def testMinimizeSparseResourceVariableCentered(self, dtype): - with self.test_session(): + with self.cached_session(): var0 = resource_variable_ops.ResourceVariable([[1.0, 2.0]], dtype=dtype) x = constant_op.constant([[4.0], [5.0]], dtype=dtype) pred = math_ops.matmul(embedding_ops.embedding_lookup([var0], [0]), x) diff --git a/tensorflow/contrib/periodic_resample/kernels/periodic_resample_op.h b/tensorflow/contrib/periodic_resample/kernels/periodic_resample_op.h index 42fba81a5c..85b5a5a3b9 100644 --- a/tensorflow/contrib/periodic_resample/kernels/periodic_resample_op.h +++ b/tensorflow/contrib/periodic_resample/kernels/periodic_resample_op.h @@ -14,8 +14,8 @@ // limitations under the License. // ============================================================================= -#ifndef TENSORFLOW_KERNELS_PERIODICRESAMPLE_OP_H_ -#define TENSORFLOW_KERNELS_PERIODICRESAMPLE_OP_H_ +#ifndef TENSORFLOW_CONTRIB_PERIODIC_RESAMPLE_KERNELS_PERIODIC_RESAMPLE_OP_H_ +#define TENSORFLOW_CONTRIB_PERIODIC_RESAMPLE_KERNELS_PERIODIC_RESAMPLE_OP_H_ #include <cmath> #include <type_traits> @@ -421,4 +421,4 @@ class PeriodicResampleOpGrad : public tensorflow::OpKernel { tensorflow::PartialTensorShape desired_shape; }; -#endif // TENSORFLOW_KERNELS_PERIODICRESAMPLE_OP_H_ +#endif // TENSORFLOW_CONTRIB_PERIODIC_RESAMPLE_KERNELS_PERIODIC_RESAMPLE_OP_H_ diff --git a/tensorflow/contrib/proto/python/kernel_tests/decode_proto_op_test_base.py b/tensorflow/contrib/proto/python/kernel_tests/decode_proto_op_test_base.py index e3570e38a3..17b69c7b35 100644 --- a/tensorflow/contrib/proto/python/kernel_tests/decode_proto_op_test_base.py +++ b/tensorflow/contrib/proto/python/kernel_tests/decode_proto_op_test_base.py @@ -170,7 +170,7 @@ class DecodeProtoOpTestBase(test_base.ProtoOpTestBase, parameterized.TestCase): field_names = [f.name for f in fields] output_types = [f.dtype for f in fields] - with self.test_session() as sess: + with self.cached_session() as sess: sizes, vtensor = self._decode_module.decode_proto( batch, message_type=message_type, @@ -290,7 +290,7 @@ class DecodeProtoOpTestBase(test_base.ProtoOpTestBase, parameterized.TestCase): field_names = ['sizes'] field_types = [dtypes.int32] - with self.test_session() as sess: + with self.cached_session() as sess: ctensor, vtensor = self._decode_module.decode_proto( batch, message_type=msg_type, diff --git a/tensorflow/contrib/proto/python/kernel_tests/descriptor_source_test_base.py b/tensorflow/contrib/proto/python/kernel_tests/descriptor_source_test_base.py index 9a1c04af32..7e9b355c69 100644 --- a/tensorflow/contrib/proto/python/kernel_tests/descriptor_source_test_base.py +++ b/tensorflow/contrib/proto/python/kernel_tests/descriptor_source_test_base.py @@ -137,7 +137,7 @@ class DescriptorSourceTestBase(test.TestCase): field_names = ['values', 'shapes', 'sizes', 'fields'] tensor_types = [dtypes.string, dtypes.int32, dtypes.int32, dtypes.string] - with self.test_session() as sess: + with self.cached_session() as sess: sizes, field_tensors = self._decode_module.decode_proto( in_bufs, message_type=message_type, diff --git a/tensorflow/contrib/proto/python/kernel_tests/encode_proto_op_test_base.py b/tensorflow/contrib/proto/python/kernel_tests/encode_proto_op_test_base.py index 07dfb924d3..01b3ccc7fd 100644 --- a/tensorflow/contrib/proto/python/kernel_tests/encode_proto_op_test_base.py +++ b/tensorflow/contrib/proto/python/kernel_tests/encode_proto_op_test_base.py @@ -55,7 +55,7 @@ class EncodeProtoOpTestBase(test_base.ProtoOpTestBase, parameterized.TestCase): def testBadInputs(self): # Invalid field name - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError('Unknown field: non_existent_field'): self._encode_module.encode_proto( sizes=[[1]], @@ -64,7 +64,7 @@ class EncodeProtoOpTestBase(test_base.ProtoOpTestBase, parameterized.TestCase): field_names=['non_existent_field']).eval() # Incorrect types. - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError( 'Incompatible type for field double_value.'): self._encode_module.encode_proto( @@ -74,7 +74,7 @@ class EncodeProtoOpTestBase(test_base.ProtoOpTestBase, parameterized.TestCase): field_names=['double_value']).eval() # Incorrect shapes of sizes. - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError( r'sizes should be batch_size \+ \[len\(field_names\)\]'): sizes = array_ops.placeholder(dtypes.int32) @@ -89,7 +89,7 @@ class EncodeProtoOpTestBase(test_base.ProtoOpTestBase, parameterized.TestCase): }) # Inconsistent shapes of values. - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError( 'Values must match up to the last dimension'): sizes = array_ops.placeholder(dtypes.int32) @@ -109,7 +109,7 @@ class EncodeProtoOpTestBase(test_base.ProtoOpTestBase, parameterized.TestCase): field_names = [f.name for f in fields] out_types = [f.dtype for f in fields] - with self.test_session() as sess: + with self.cached_session() as sess: sizes, field_tensors = self._decode_module.decode_proto( in_bufs, message_type=message_type, diff --git a/tensorflow/contrib/quantize/BUILD b/tensorflow/contrib/quantize/BUILD index 23363617ed..499fec4ffa 100644 --- a/tensorflow/contrib/quantize/BUILD +++ b/tensorflow/contrib/quantize/BUILD @@ -244,7 +244,9 @@ py_test( "//tensorflow/python:framework_ops", "//tensorflow/python:framework_test_lib", "//tensorflow/python:init_ops", + "//tensorflow/python:math_ops", "//tensorflow/python:nn_ops", "//tensorflow/python:platform_test", + "//tensorflow/python:training", ], ) diff --git a/tensorflow/contrib/quantize/python/quantize_graph.py b/tensorflow/contrib/quantize/python/quantize_graph.py index 2944f964c7..484493f1b2 100644 --- a/tensorflow/contrib/quantize/python/quantize_graph.py +++ b/tensorflow/contrib/quantize/python/quantize_graph.py @@ -59,6 +59,10 @@ def _create_graph(input_graph=None, if input_graph is None: input_graph = ops.get_default_graph() + + # Add check to see if graph has training ops, if so provide error message and + # exit + _check_for_training_ops(input_graph) with input_graph.as_default(): fold_batch_norms.FoldBatchNorms( input_graph, @@ -78,6 +82,9 @@ def create_training_graph(input_graph=None, quant_delay=0): Variables added by the rewrite get added to the global variables collection. + This function must be invoked prior to insertion of gradient ops in a graph + as quantization should be modeled in both forward and backward passes. + The graph has fake quantization ops inserted to simulate the error introduced by quantization. Since the graph is transformed in place, the expected behavior of previously held references to nodes and tensors may @@ -104,7 +111,6 @@ def create_training_graph(input_graph=None, quant_delay=0): # Currently the values below are hardcoded for mobilenetV1 on imagenet # Please use the experimental API if you need to tune these values. freeze_bn_delay = None - _create_graph( input_graph=input_graph, is_training=True, @@ -141,6 +147,9 @@ def experimental_create_training_graph(input_graph=None, scope=None): """Rewrites a training input_graph in place for simulated quantization. + This function must be invoked prior to insertion of gradient ops in a graph + as quantization should be modeled in both forward and backward passes. + Variables added by the rewrite get added to the global variables collection. This function has additional experimental options not (yet) available to @@ -226,3 +235,45 @@ def experimental_create_eval_graph(input_graph=None, activation_bits=activation_bits, quant_delay=quant_delay, scope=scope) + + +def _check_for_training_ops(g): + """Check if training ops are present in the graph. + + Args: + g: The tf.Graph on which the check for training ops needs to be + performed. + + Raises: + ValueError: If a training op is seen in the graph; + """ + + # The list here is obtained + # from https://www.tensorflow.org/api_docs/cc/group/training-ops + training_ops = frozenset([ + 'ApplyAdagrad', 'ApplyAdagradDA', 'ApplyAdam', 'ApplyAddSign', + 'ApplyCenteredRMSProp', 'ApplyFtrl', 'ApplyFtrlV2', + 'ApplyGradientDescent', 'ApplyMomentum', 'ApplyPowerSign', + 'ApplyProximalAdagrad', 'ApplyProximalGradientDescent', 'ApplyRMSProp', + 'ResourceApplyAdadelta', 'ResourceApplyAdagrad', 'ResourceApplyAdagradDA', + 'ResourceApplyAdam', 'ResourceApplyAddSign', + 'ResourceApplyCenteredRMSProp', 'ResourceApplyFtrl', + 'ResourceApplyFtrlV2', 'ResourceApplyGradientDescent', + 'ResourceApplyMomentum', 'ResourceApplyPowerSign', + 'ResourceApplyProximalAdagrad', 'ResourceApplyProximalGradientDescent', + 'ResourceApplyRMSProp', 'ResourceSparseApplyAdadelta', + 'ResourceSparseApplyAdagrad', 'ResourceSparseApplyAdagradDA', + 'ResourceSparseApplyCenteredRMSProp', 'ResourceSparseApplyFtrl', + 'ResourceSparseApplyFtrlV2', 'ResourceSparseApplyMomentum', + 'ResourceSparseApplyProximalAdagrad', + 'ResourceSparseApplyProximalGradientDescent', + 'ResourceSparseApplyRMSProp', 'SparseApplyAdadelta', 'SparseApplyAdagrad', + 'SparseApplyAdagradDA', 'SparseApplyCenteredRMSProp', 'SparseApplyFtrl', + 'SparseApplyFtrlV2', 'SparseApplyMomentum', 'SparseApplyProximalAdagrad', + 'SparseApplyProximalGradientDescent', 'SparseApplyRMSProp' + ]) + + op_types = set([op.type for op in g.get_operations()]) + train_op_list = op_types.intersection(training_ops) + if train_op_list: + raise ValueError('Training op found in graph, exiting %s' % train_op_list) diff --git a/tensorflow/contrib/quantize/python/quantize_graph_test.py b/tensorflow/contrib/quantize/python/quantize_graph_test.py index 54faf582f1..e80d2183a6 100644 --- a/tensorflow/contrib/quantize/python/quantize_graph_test.py +++ b/tensorflow/contrib/quantize/python/quantize_graph_test.py @@ -20,10 +20,12 @@ from __future__ import print_function from tensorflow.contrib.layers.python.layers import layers from tensorflow.contrib.quantize.python import quantize_graph +from tensorflow.python import training from tensorflow.python.framework import ops from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops from tensorflow.python.ops import init_ops +from tensorflow.python.ops import math_ops from tensorflow.python.ops import nn_ops from tensorflow.python.platform import googletest @@ -145,6 +147,19 @@ class QuantizeGraphTest(test_util.TensorFlowTestCase): self.assertTrue(('int64_val: %i' % quant_delay) in const_value) self.assertTrue(quant_delay_found) + def testTrainingOpsCheck(self): + self._RunTestOverTrainingRewrites(self._TestTrainingOpsCheck) + + def _TestTrainingOpsCheck(self, rewrite_fn): + with ops.Graph().as_default(): + output = self._ConvLayer() + output_scalar = math_ops.reduce_sum(output) + loss = math_ops.square(output_scalar - 1) + opt = training.gradient_descent.GradientDescentOptimizer(0.0001) + opt.minimize(loss) + with self.assertRaisesRegexp(ValueError, 'Training op found in graph'): + rewrite_fn() + def testWeightBits(self): self._RunTestOverExperimentalRewrites(self._TestWeightBits) diff --git a/tensorflow/contrib/rate/BUILD b/tensorflow/contrib/rate/BUILD new file mode 100644 index 0000000000..c461a7145e --- /dev/null +++ b/tensorflow/contrib/rate/BUILD @@ -0,0 +1,48 @@ +# Description: +# contains parts of TensorFlow that are experimental or unstable and which are not supported. + +licenses(["notice"]) # Apache 2.0 + +package(default_visibility = ["//visibility:public"]) + +exports_files(["LICENSE"]) + +load("//tensorflow:tensorflow.bzl", "py_test") + +py_library( + name = "rate", + srcs = [ + "rate.py", + ], + srcs_version = "PY2AND3", + deps = [ + "//tensorflow/python:array_ops", + "//tensorflow/python:check_ops", + "//tensorflow/python:control_flow_ops", + "//tensorflow/python:framework", + "//tensorflow/python:framework_for_generated_wrappers", + "//tensorflow/python:math_ops", + "//tensorflow/python:sparse_ops", + "//tensorflow/python:state_ops", + "//tensorflow/python:util", + "//tensorflow/python:variable_scope", + "//tensorflow/python:variables", + ], +) + +py_test( + name = "rate_test", + size = "small", + srcs = ["rate_test.py"], + deps = [ + ":rate", + "//tensorflow/python:array_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:data_flow_ops", + "//tensorflow/python:errors", + "//tensorflow/python:framework", + "//tensorflow/python:framework_for_generated_wrappers", + "//tensorflow/python:variables", + "//tensorflow/python/eager:test", + ], +) diff --git a/tensorflow/contrib/rate/rate.py b/tensorflow/contrib/rate/rate.py new file mode 100644 index 0000000000..24d586479a --- /dev/null +++ b/tensorflow/contrib/rate/rate.py @@ -0,0 +1,151 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Implementation of tf.contrib.rate module.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import re + +from tensorflow.python.eager import context +from tensorflow.python.eager import function +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import math_ops +from tensorflow.python.ops import resource_variable_ops +from tensorflow.python.ops import state_ops +from tensorflow.python.ops import variable_scope + +_to_replace = re.compile("[^A-Za-z0-9.]") + + +class Rate(object): + """Computes the rate of change since the last rate call.""" + + def __init__(self, name=None): + self._built = False + self._vars = [] + self._initial_values = {} + name = name or self.__class__.__name__ + # Replace things like spaces in name to create a valid scope name. + scope_name = _to_replace.sub("_", name) + # We create the variable scope now to get the unique name that will + # be used as a variable prefix when build() calls _add_variable(). + with variable_scope.variable_scope( + scope_name, use_resource=True, reuse=False) as scope: + pos = scope.name.rfind(scope_name) + self._name = name + scope.name[pos + len(scope_name):] + self._scope = scope + + # Ensures that if the user calls build directly we still set self._built to + # True to prevent variables from being recreated. + self._build = self.build + if context.executing_eagerly(): + self._construction_scope = context.eager_mode + else: + # We make self.call() into a graph callable here, so that we can + # return a single op that performs all of the variable updates. + self._construction_scope = ops.get_default_graph().as_default + self.call = function.defun(self.call) + + def build(self, values, denominator): + """Method to create variables. + + Called by `__call__()` before `call()` for the first time. + + Args: + values: The numerator for rate. + denominator: Value to which the rate is taken with respect. + """ + self.numer = self._add_variable( + name="numer", shape=values.get_shape(), dtype=dtypes.float64) + self.denom = self._add_variable( + name="denom", shape=denominator.get_shape(), dtype=dtypes.float64) + self.prev_values = self._add_variable( + name="prev_values", shape=values.get_shape(), dtype=dtypes.float64) + self.prev_denominator = self._add_variable( + name="prev_denominator", + shape=denominator.get_shape(), + dtype=dtypes.float64) + self._built = True + + def __call__(self, *args, **kwargs): + """Returns op to execute to update. + + Returns None if eager execution is enabled. + Returns a graph-mode function if graph execution is enabled. + + Args: + *args: + **kwargs: A mini-batch of inputs to Rate, passed on to `call()`. + """ + if not self._built: + with variable_scope.variable_scope( + self._scope), self._construction_scope(): + self.build(*args, **kwargs) + self._built = True + return self.call(*args, **kwargs) + + @property + def name(self): + return self._name + + @property + def variables(self): + return self._vars + + def _safe_div(self, numerator, denominator, name): + t = math_ops.truediv(numerator, denominator) + zero = array_ops.zeros_like(t, dtype=denominator.dtype) + condition = math_ops.greater(denominator, zero) + zero = math_ops.cast(zero, t.dtype) + return array_ops.where(condition, t, zero, name=name) + + def _add_variable(self, name, shape=None, dtype=None): + """Private method for adding variables to the graph.""" + if self._built: + raise RuntimeError("Can't call add_variable() except in build().") + v = resource_variable_ops.ResourceVariable( + lambda: array_ops.zeros(shape, dtype), + trainable=False, + validate_shape=True, + name=name, + collections=[ops.GraphKeys.LOCAL_VARIABLES]) + return v + + def call(self, values, denominator): + """Computes the rate since the last call. + + Args: + values: Tensor with the per-example value. + denominator: Measure to take the rate with respect to. + + Returns: + The rate or 0 if denominator is unchanged since last call. + """ + if denominator.dtype != dtypes.float64: + denominator = math_ops.cast(denominator, dtypes.float64) + if values.dtype != dtypes.float64: + values = math_ops.cast(values, dtypes.float64) + + state_ops.assign(self.numer, math_ops.subtract(values, self.prev_values)) + state_ops.assign(self.denom, + math_ops.subtract(denominator, self.prev_denominator)) + state_ops.assign(self.prev_values, values) + state_ops.assign(self.prev_denominator, denominator) + + return self._safe_div(self.numer, self.denom, name="safe_rate") diff --git a/tensorflow/contrib/rate/rate_test.py b/tensorflow/contrib/rate/rate_test.py new file mode 100644 index 0000000000..08908104f4 --- /dev/null +++ b/tensorflow/contrib/rate/rate_test.py @@ -0,0 +1,97 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for Rate.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.contrib.rate import rate +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops +from tensorflow.python.framework import test_util +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import math_ops +from tensorflow.python.ops import variables +from tensorflow.python.platform import test + + +class RateTest(test.TestCase): + + @test_util.run_in_graph_and_eager_modes() + def testBuildRate(self): + m = rate.Rate() + m.build( + constant_op.constant([1], dtype=dtypes.float32), + constant_op.constant([2], dtype=dtypes.float32)) + old_numer = m.numer + m( + constant_op.constant([2], dtype=dtypes.float32), + constant_op.constant([2], dtype=dtypes.float32)) + self.assertTrue(old_numer is m.numer) + + @test_util.run_in_graph_and_eager_modes() + def testBasic(self): + with self.test_session(): + r_ = rate.Rate() + a = r_(array_ops.ones([1]), denominator=array_ops.ones([1])) + self.evaluate(variables.global_variables_initializer()) + self.evaluate(variables.local_variables_initializer()) + self.assertEqual([[1]], self.evaluate(a)) + b = r_(constant_op.constant([2]), denominator=constant_op.constant([2])) + self.assertEqual([[1]], self.evaluate(b)) + c = r_(constant_op.constant([4]), denominator=constant_op.constant([3])) + self.assertEqual([[2]], self.evaluate(c)) + d = r_(constant_op.constant([16]), denominator=constant_op.constant([3])) + self.assertEqual([[0]], self.evaluate(d)) # divide by 0 + + def testNamesWithSpaces(self): + m1 = rate.Rate(name="has space") + m1(array_ops.ones([1]), array_ops.ones([1])) + self.assertEqual(m1.name, "has space") + self.assertEqual(m1.prev_values.name, "has_space_1/prev_values:0") + + @test_util.run_in_graph_and_eager_modes() + def testWhileLoop(self): + with self.test_session(): + r_ = rate.Rate() + + def body(value, denom, i, ret_rate): + i += 1 + ret_rate = r_(value, denom) + with ops.control_dependencies([ret_rate]): + value = math_ops.add(value, 2) + denom = math_ops.add(denom, 1) + return [value, denom, i, ret_rate] + + def condition(v, d, i, r): + del v, d, r # unused vars by condition + return math_ops.less(i, 100) + + i = constant_op.constant(0) + value = constant_op.constant([1], dtype=dtypes.float64) + denom = constant_op.constant([1], dtype=dtypes.float64) + ret_rate = r_(value, denom) + self.evaluate(variables.global_variables_initializer()) + self.evaluate(variables.local_variables_initializer()) + loop = control_flow_ops.while_loop(condition, body, + [value, denom, i, ret_rate]) + self.assertEqual([[2]], self.evaluate(loop[3])) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/recurrent/python/kernel_tests/functional_rnn_test.py b/tensorflow/contrib/recurrent/python/kernel_tests/functional_rnn_test.py index f23194a6f2..1800edc05a 100644 --- a/tensorflow/contrib/recurrent/python/kernel_tests/functional_rnn_test.py +++ b/tensorflow/contrib/recurrent/python/kernel_tests/functional_rnn_test.py @@ -165,7 +165,7 @@ class FunctionalRnnTest(test_util.TensorFlowTestCase): fetches = self._CreateRnnGraph( fn, cell, tf_inputs, tf_slen, is_bidirectional, time_major=time_major) - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: sess.run(variables.global_variables_initializer()) # Note that cell.trainable_variables it not always set. self._MaybeResetVariables(variable_cache, sess, diff --git a/tensorflow/contrib/recurrent/python/ops/functional_rnn.py b/tensorflow/contrib/recurrent/python/ops/functional_rnn.py index 67a8f59c3c..c3db71359c 100644 --- a/tensorflow/contrib/recurrent/python/ops/functional_rnn.py +++ b/tensorflow/contrib/recurrent/python/ops/functional_rnn.py @@ -178,7 +178,8 @@ def _ApplyLengthsToBatch(sequence_lengths, tf_output): # TODO(drpng): just use Update so that we don't carry over the gradients? """Sets the output to be zero at the end of the sequence.""" # output is batch major. - batch_size, max_time, vector_size = tf_output.shape + shape = array_ops.shape(tf_output) + batch_size, max_time, vector_size = shape[0], shape[1], shape[2] output_time = array_ops.tile(math_ops.range(0, max_time), [batch_size]) output_time = array_ops.reshape(output_time, [batch_size, max_time]) lengths = array_ops.tile( @@ -278,11 +279,16 @@ def functional_rnn(cell, inputs, sequence_length=None, if initial_state is None: initial_state = cell.zero_state(batch_size, dtype) func_cell = _FunctionalRnnCell(cell, inputs, initial_state) + if sequence_length is not None: + max_length = math_ops.reduce_max(sequence_length) + else: + max_length = None extended_acc_state, extended_final_state = recurrent.Recurrent( theta=func_cell.theta, state0=func_cell.extended_initial_state, inputs=inputs, cell_fn=func_cell.cell_step, + max_input_length=max_length, use_tpu=use_tpu) tf_output, tf_state = _PostProcessOutput( extended_acc_state, extended_final_state, func_cell, diff --git a/tensorflow/contrib/reduce_slice_ops/kernels/reduce_slice_ops.h b/tensorflow/contrib/reduce_slice_ops/kernels/reduce_slice_ops.h index d8c0a0631d..69ef521c01 100644 --- a/tensorflow/contrib/reduce_slice_ops/kernels/reduce_slice_ops.h +++ b/tensorflow/contrib/reduce_slice_ops/kernels/reduce_slice_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_KERNELS_PARTIAL_REDUCTION_OPS_H_ -#define TENSORFLOW_CORE_KERNELS_PARTIAL_REDUCTION_OPS_H_ +#ifndef TENSORFLOW_CONTRIB_REDUCE_SLICE_OPS_KERNELS_REDUCE_SLICE_OPS_H_ +#define TENSORFLOW_CONTRIB_REDUCE_SLICE_OPS_KERNELS_REDUCE_SLICE_OPS_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor.h" @@ -81,4 +81,4 @@ CALL_ALL_REDUCEOPS(ReduceSliceFunctorReduceop) } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_PARTIAL_REDUCTION_OPS_H_ +#endif // TENSORFLOW_CONTRIB_REDUCE_SLICE_OPS_KERNELS_REDUCE_SLICE_OPS_H_ diff --git a/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py b/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py index 85f0f8ced9..15ce9d1ce7 100644 --- a/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py +++ b/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py @@ -225,7 +225,7 @@ class RNNCellTest(test.TestCase): def testBasicLSTMCell(self): for dtype in [dtypes.float16, dtypes.float32]: np_dtype = dtype.as_numpy_dtype - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2], dtype=dtype) @@ -395,7 +395,7 @@ class RNNCellTest(test.TestCase): def testIndyLSTMCell(self): for dtype in [dtypes.float16, dtypes.float32]: np_dtype = dtype.as_numpy_dtype - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2], dtype=dtype) diff --git a/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_test.py b/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_test.py index d62ec45d18..aa4562be7c 100644 --- a/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_test.py +++ b/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_test.py @@ -457,7 +457,7 @@ class LSTMTest(test.TestCase): input_size = 5 batch_size = 2 max_length = 8 - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: initializer = init_ops.random_uniform_initializer( -0.01, 0.01, seed=self._seed) state_saver = TestStateSaver(batch_size, num_units) @@ -491,7 +491,7 @@ class LSTMTest(test.TestCase): input_size = 5 batch_size = 2 max_length = 8 - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: initializer = init_ops.random_uniform_initializer( -0.01, 0.01, seed=self._seed) state_saver = TestStateSaver( @@ -588,7 +588,7 @@ class LSTMTest(test.TestCase): num_proj = 4 max_length = 8 sequence_length = [4, 6] - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: initializer = init_ops.random_uniform_initializer( -0.01, 0.01, seed=self._seed) inputs = max_length * [ @@ -834,7 +834,7 @@ class LSTMTest(test.TestCase): batch_size = 2 num_proj = 4 max_length = 8 - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: initializer = init_ops.random_uniform_initializer(-1, 1, seed=self._seed) initializer_d = init_ops.random_uniform_initializer( -1, 1, seed=self._seed + 1) @@ -884,7 +884,7 @@ class LSTMTest(test.TestCase): batch_size = 2 num_proj = 4 max_length = 8 - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: initializer = init_ops.random_uniform_initializer(-1, 1, seed=self._seed) inputs = max_length * [ array_ops.placeholder(dtypes.float32, shape=(None, input_size)) @@ -930,7 +930,7 @@ class LSTMTest(test.TestCase): max_length = 8 sequence_length = [4, 6] in_graph_mode = not context.executing_eagerly() - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: initializer = init_ops.random_uniform_initializer( -0.01, 0.01, seed=self._seed) if in_graph_mode: @@ -1006,7 +1006,7 @@ class LSTMTest(test.TestCase): max_length = 8 sequence_length = [4, 6] in_graph_mode = not context.executing_eagerly() - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: initializer = init_ops.random_uniform_initializer( -0.01, 0.01, seed=self._seed) if in_graph_mode: @@ -1612,7 +1612,7 @@ class MultiDimensionalLSTMTest(test.TestCase): batch_size = 2 max_length = 8 sequence_length = [4, 6] - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: inputs = max_length * [ array_ops.placeholder(dtypes.float32, shape=(None,) + input_size) ] @@ -1723,7 +1723,7 @@ class NestedLSTMTest(test.TestCase): state_size = 6 max_length = 8 sequence_length = [4, 6] - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: state_saver = TestStateSaver(batch_size, state_size) single_input = (array_ops.placeholder( dtypes.float32, shape=(None, input_size)), @@ -2017,7 +2017,7 @@ class RawRNNTest(test.TestCase): np.random.seed(self._seed) def _testRawRNN(self, max_time): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: batch_size = 16 input_depth = 4 num_units = 3 @@ -2126,7 +2126,7 @@ class RawRNNTest(test.TestCase): self._testRawRNN(max_time=10) def testLoopState(self): - with self.test_session(graph=ops_lib.Graph()): + with self.session(graph=ops_lib.Graph()): max_time = 10 batch_size = 16 input_depth = 4 @@ -2162,7 +2162,7 @@ class RawRNNTest(test.TestCase): self.assertEqual([10], loop_state.eval()) def testLoopStateWithTensorArray(self): - with self.test_session(graph=ops_lib.Graph()): + with self.session(graph=ops_lib.Graph()): max_time = 4 batch_size = 16 input_depth = 4 @@ -2205,7 +2205,7 @@ class RawRNNTest(test.TestCase): self.assertAllEqual([1, 2, 2 + 2, 4 + 3, 7 + 4], loop_state.eval()) def testEmitDifferentStructureThanCellOutput(self): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: max_time = 10 batch_size = 16 input_depth = 4 diff --git a/tensorflow/contrib/rnn/python/kernel_tests/rnn_cell_test.py b/tensorflow/contrib/rnn/python/kernel_tests/rnn_cell_test.py index c7d85862f6..2df8f0ec05 100644 --- a/tensorflow/contrib/rnn/python/kernel_tests/rnn_cell_test.py +++ b/tensorflow/contrib/rnn/python/kernel_tests/rnn_cell_test.py @@ -1440,7 +1440,7 @@ class CompiledWrapperTest(test.TestCase): atol = 1e-5 random_seed.set_random_seed(1234) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: xla_ops = _create_multi_lstm_cell_ops( batch_size=batch_size, num_units=num_units, @@ -1452,7 +1452,7 @@ class CompiledWrapperTest(test.TestCase): xla_results = sess.run(xla_ops) random_seed.set_random_seed(1234) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: non_xla_ops = _create_multi_lstm_cell_ops( batch_size=batch_size, num_units=num_units, diff --git a/tensorflow/contrib/saved_model/python/saved_model/reader_test.py b/tensorflow/contrib/saved_model/python/saved_model/reader_test.py index d10ec9cf0c..3e6ff65c33 100644 --- a/tensorflow/contrib/saved_model/python/saved_model/reader_test.py +++ b/tensorflow/contrib/saved_model/python/saved_model/reader_test.py @@ -43,7 +43,7 @@ class ReaderTest(test.TestCase): def testReadSavedModelValid(self): saved_model_dir = os.path.join(test.get_temp_dir(), "valid_saved_model") builder = saved_model_builder.SavedModelBuilder(saved_model_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) builder.add_meta_graph_and_variables(sess, [tag_constants.TRAINING]) builder.save() @@ -68,35 +68,35 @@ class ReaderTest(test.TestCase): # Graph with a single variable. SavedModel invoked to: # - add with weights. # - a single tag (from predefined constants). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) builder.add_meta_graph_and_variables(sess, [tag_constants.TRAINING]) # Graph that updates the single variable. SavedModel invoked to: # - simply add the model (weights are not updated). # - a single tag (from predefined constants). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 43) builder.add_meta_graph([tag_constants.SERVING]) # Graph that updates the single variable. SavedModel is invoked: # - to add the model (weights are not updated). # - multiple predefined tags. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 44) builder.add_meta_graph([tag_constants.SERVING, tag_constants.GPU]) # Graph that updates the single variable. SavedModel is invoked: # - to add the model (weights are not updated). # - multiple predefined tags for serving on TPU. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 44) builder.add_meta_graph([tag_constants.SERVING, tag_constants.TPU]) # Graph that updates the single variable. SavedModel is invoked: # - to add the model (weights are not updated). # - multiple custom tags. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 45) builder.add_meta_graph(["foo", "bar"]) diff --git a/tensorflow/contrib/seq2seq/python/kernel_tests/attention_wrapper_test.py b/tensorflow/contrib/seq2seq/python/kernel_tests/attention_wrapper_test.py index cd162bae25..f2c43f30d4 100644 --- a/tensorflow/contrib/seq2seq/python/kernel_tests/attention_wrapper_test.py +++ b/tensorflow/contrib/seq2seq/python/kernel_tests/attention_wrapper_test.py @@ -512,7 +512,7 @@ class AttentionWrapperTest(test.TestCase): for axis in [0, 1]: for exclusive in [True, False]: - with self.test_session(): + with self.cached_session(): # Compute cumprod with regular tf.cumprod cumprod_output = math_ops.cumprod( test_input, axis=axis, exclusive=exclusive).eval() @@ -548,7 +548,7 @@ class AttentionWrapperTest(test.TestCase): for p, a in zip(p_choose_i, previous_attention)]) # Compute output with TensorFlow function, for both calculation types - with self.test_session(): + with self.cached_session(): recursive_output = wrapper.monotonic_attention( p_choose_i, previous_attention, 'recursive').eval() @@ -569,7 +569,7 @@ class AttentionWrapperTest(test.TestCase): for p, a in zip(p_choose_i, previous_attention)]) # Compute output with TensorFlow function, for both calculation types - with self.test_session(): + with self.cached_session(): parallel_output = wrapper.monotonic_attention( p_choose_i, previous_attention, 'parallel').eval() @@ -594,7 +594,7 @@ class AttentionWrapperTest(test.TestCase): for p, a in zip(p_choose_i, previous_attention)]) # Compute output with TensorFlow function, for both calculation types - with self.test_session(): + with self.cached_session(): hard_output = wrapper.monotonic_attention( # TensorFlow is unhappy when these are not wrapped as tf.constant constant_op.constant(p_choose_i), @@ -634,7 +634,7 @@ class AttentionWrapperTest(test.TestCase): recursive_output = [np.array([1] + [0]*(p_choose_i.shape[1] - 1), np.float32)] # Compute output with TensorFlow function, for both calculation types - with self.test_session(): + with self.cached_session(): for j in range(p_choose_i.shape[0]): # Compute attention distribution for this output time step recursive_output.append(wrapper.monotonic_attention( diff --git a/tensorflow/contrib/seq2seq/python/kernel_tests/beam_search_decoder_test.py b/tensorflow/contrib/seq2seq/python/kernel_tests/beam_search_decoder_test.py index 4073b390fc..f5b6b1bde9 100644 --- a/tensorflow/contrib/seq2seq/python/kernel_tests/beam_search_decoder_test.py +++ b/tensorflow/contrib/seq2seq/python/kernel_tests/beam_search_decoder_test.py @@ -66,7 +66,7 @@ class TestGatherTree(test.TestCase): max_sequence_lengths=max_sequence_lengths, end_token=11) - with self.test_session() as sess: + with self.cached_session() as sess: res_ = sess.run(res) self.assertAllEqual(expected_result, res_) @@ -115,7 +115,7 @@ class TestGatherTree(test.TestCase): sorted_array = beam_search_decoder.gather_tree_from_array( array, parent_ids, sequence_length) - with self.test_session() as sess: + with self.cached_session() as sess: sorted_array = sess.run(sorted_array) expected_array = sess.run(expected_array) self.assertAllEqual(expected_array, sorted_array) @@ -170,7 +170,7 @@ class TestGatherTree(test.TestCase): sorted_array = beam_search_decoder.gather_tree_from_array( array, parent_ids, sequence_length) - with self.test_session() as sess: + with self.cached_session() as sess: sorted_array, expected_array = sess.run([sorted_array, expected_array]) self.assertAllEqual(expected_array, sorted_array) @@ -186,7 +186,7 @@ class TestArrayShapeChecks(test.TestCase): batch_size = array_ops.constant(batch_size) check_op = beam_search_decoder._check_batch_beam(t, batch_size, beam_width) # pylint: disable=protected-access - with self.test_session() as sess: + with self.cached_session() as sess: if is_valid: sess.run(check_op) else: @@ -220,7 +220,7 @@ class TestEosMasking(test.TestCase): masked = beam_search_decoder._mask_probs(probs, eos_token, previously_finished) - with self.test_session() as sess: + with self.cached_session() as sess: probs = sess.run(probs) masked = sess.run(masked) @@ -283,7 +283,7 @@ class TestBeamStep(test.TestCase): end_token=self.end_token, length_penalty_weight=self.length_penalty_weight) - with self.test_session() as sess: + with self.cached_session() as sess: outputs_, next_state_, state_, log_probs_ = sess.run( [outputs, next_beam_state, beam_state, log_probs]) @@ -338,7 +338,7 @@ class TestBeamStep(test.TestCase): end_token=self.end_token, length_penalty_weight=self.length_penalty_weight) - with self.test_session() as sess: + with self.cached_session() as sess: outputs_, next_state_, state_, log_probs_ = sess.run( [outputs, next_beam_state, beam_state, log_probs]) @@ -436,7 +436,7 @@ class TestLargeBeamStep(test.TestCase): end_token=self.end_token, length_penalty_weight=self.length_penalty_weight) - with self.test_session() as sess: + with self.cached_session() as sess: outputs_, next_state_, _, _ = sess.run( [outputs, next_beam_state, beam_state, log_probs]) @@ -471,7 +471,7 @@ class BeamSearchDecoderTest(test.TestCase): output_layer = layers_core.Dense(vocab_size, use_bias=True, activation=None) beam_width = 3 - with self.test_session() as sess: + with self.cached_session() as sess: batch_size_tensor = constant_op.constant(batch_size) embedding = np.random.randn(vocab_size, embedding_dim).astype(np.float32) cell = rnn_cell.LSTMCell(cell_depth) diff --git a/tensorflow/contrib/seq2seq/python/kernel_tests/beam_search_ops_test.py b/tensorflow/contrib/seq2seq/python/kernel_tests/beam_search_ops_test.py index 277c5b6ef7..9662a5780a 100644 --- a/tensorflow/contrib/seq2seq/python/kernel_tests/beam_search_ops_test.py +++ b/tensorflow/contrib/seq2seq/python/kernel_tests/beam_search_ops_test.py @@ -67,7 +67,7 @@ class GatherTreeTest(test.TestCase): parent_ids=parent_ids, max_sequence_lengths=max_sequence_lengths, end_token=end_token) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError( r"parent id -1 at \(batch, time, beam\) == \(0, 0, 1\)"): _ = beams.eval() diff --git a/tensorflow/contrib/session_bundle/session_bundle.cc b/tensorflow/contrib/session_bundle/session_bundle.cc index cf26e3cae7..a690d9b129 100644 --- a/tensorflow/contrib/session_bundle/session_bundle.cc +++ b/tensorflow/contrib/session_bundle/session_bundle.cc @@ -138,10 +138,10 @@ Status RunRestoreOp(const RunOptions& run_options, const StringPiece export_dir, Tensor variables_tensor = CreateStringTensor(GetVariablesFilename(export_dir)); std::vector<std::pair<string, Tensor>> inputs = { - {variables_filename_const_op_name.ToString(), variables_tensor}}; + {string(variables_filename_const_op_name), variables_tensor}}; AddAssetsTensorsToInputs(export_dir, asset_files, &inputs); RunMetadata run_metadata; - return session->Run(run_options, inputs, {}, {restore_op_name.ToString()}, + return session->Run(run_options, inputs, {}, {string(restore_op_name)}, nullptr /* outputs */, &run_metadata); } @@ -152,7 +152,7 @@ Status RunInitOp(const RunOptions& run_options, const StringPiece export_dir, std::vector<std::pair<string, Tensor>> inputs; AddAssetsTensorsToInputs(export_dir, asset_files, &inputs); RunMetadata run_metadata; - return session->Run(run_options, inputs, {}, {init_op_name.ToString()}, + return session->Run(run_options, inputs, {}, {string(init_op_name)}, nullptr /* outputs */, &run_metadata); } @@ -251,15 +251,14 @@ Status LoadSessionBundleFromPathUsingRunOptions(const SessionOptions& options, auto log_and_count = [&](const string& status_str) { LOG(INFO) << "Loading SessionBundle: " << status_str << ". Took " << load_latency_microsecs << " microseconds."; - load_attempt_count->GetCell(export_dir.ToString(), status_str) - ->IncrementBy(1); + load_attempt_count->GetCell(string(export_dir), status_str)->IncrementBy(1); }; if (status.ok()) { log_and_count(kLoadAttemptSuccess); } else { log_and_count(kLoadAttemptFail); } - load_latency->GetCell(export_dir.ToString()) + load_latency->GetCell(string(export_dir)) ->IncrementBy(load_latency_microsecs); return status; } diff --git a/tensorflow/contrib/session_bundle/session_bundle_test.py b/tensorflow/contrib/session_bundle/session_bundle_test.py index a57e8920c5..3c06ec048d 100644 --- a/tensorflow/contrib/session_bundle/session_bundle_test.py +++ b/tensorflow/contrib/session_bundle/session_bundle_test.py @@ -167,7 +167,7 @@ class SessionBundleLoadNoVarsTest(test.TestCase): y = math_ops.subtract(w * x, 7.0, name="y") # pylint: disable=unused-variable ops.add_to_collection("meta", "this is meta") - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: variables.global_variables_initializer().run() new_graph_def = graph_util.convert_variables_to_constants( session, g.as_graph_def(), ["y"]) diff --git a/tensorflow/contrib/slim/python/slim/evaluation_test.py b/tensorflow/contrib/slim/python/slim/evaluation_test.py index 2c97834523..cbfdaeb45d 100644 --- a/tensorflow/contrib/slim/python/slim/evaluation_test.py +++ b/tensorflow/contrib/slim/python/slim/evaluation_test.py @@ -100,7 +100,7 @@ class EvaluationTest(test.TestCase): # Save initialized variables to a checkpoint directory: saver = saver_lib.Saver() - with self.test_session() as sess: + with self.cached_session() as sess: init_op.run() saver.save(sess, os.path.join(chkpt_dir, 'chkpt')) @@ -211,7 +211,7 @@ class EvaluationTest(test.TestCase): # Save initialized variables to a checkpoint directory: saver = saver_lib.Saver() - with self.test_session() as sess: + with self.cached_session() as sess: init_op.run() saver.save(sess, os.path.join(chkpt_dir, 'chkpt')) @@ -248,7 +248,7 @@ class SingleEvaluationTest(test.TestCase): init_op = control_flow_ops.group(variables.global_variables_initializer(), variables.local_variables_initializer()) saver = saver_lib.Saver(write_version=saver_pb2.SaverDef.V1) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(init_op) saver.save(sess, checkpoint_path) diff --git a/tensorflow/contrib/slim/python/slim/learning_test.py b/tensorflow/contrib/slim/python/slim/learning_test.py index 831c6e427a..d92a7fbb47 100644 --- a/tensorflow/contrib/slim/python/slim/learning_test.py +++ b/tensorflow/contrib/slim/python/slim/learning_test.py @@ -73,7 +73,7 @@ class ClipGradientNormsTest(test.TestCase): # Ensure the variable passed through. self.assertEqual(gradients_to_variables[1], variable) - with self.test_session() as sess: + with self.cached_session() as sess: actual_gradient = sess.run(gradients_to_variables[0]) np_testing.assert_almost_equal(actual_gradient, self._clipped_grad_vec) @@ -164,7 +164,7 @@ class MultiplyGradientsTest(test.TestCase): # Ensure the variable passed through. self.assertEqual(grad_to_var[1], variable) - with self.test_session() as sess: + with self.cached_session() as sess: actual_gradient = sess.run(grad_to_var[0]) np_testing.assert_almost_equal(actual_gradient, self._multiplied_grad_vec, 5) @@ -188,7 +188,7 @@ class MultiplyGradientsTest(test.TestCase): self.assertEqual(grad_to_var[0].indices, indices) self.assertEqual(grad_to_var[0].dense_shape, dense_shape) - with self.test_session() as sess: + with self.cached_session() as sess: actual_gradient = sess.run(grad_to_var[0].values) np_testing.assert_almost_equal(actual_gradient, self._multiplied_grad_vec, 5) @@ -204,7 +204,7 @@ class MultiplyGradientsTest(test.TestCase): [grad_to_var] = learning.multiply_gradients([grad_to_var], gradient_multipliers) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables_lib.global_variables_initializer()) gradient_true_flag = sess.run(grad_to_var[0]) sess.run(multiplier_flag.assign(False)) diff --git a/tensorflow/contrib/slim/python/slim/nets/alexnet_test.py b/tensorflow/contrib/slim/python/slim/nets/alexnet_test.py index eb93f753ae..b6d1afd27d 100644 --- a/tensorflow/contrib/slim/python/slim/nets/alexnet_test.py +++ b/tensorflow/contrib/slim/python/slim/nets/alexnet_test.py @@ -33,7 +33,7 @@ class AlexnetV2Test(test.TestCase): batch_size = 5 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = alexnet.alexnet_v2(inputs, num_classes) self.assertEquals(logits.op.name, 'alexnet_v2/fc8/squeezed') @@ -44,7 +44,7 @@ class AlexnetV2Test(test.TestCase): batch_size = 1 height, width = 300, 400 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = alexnet.alexnet_v2(inputs, num_classes, spatial_squeeze=False) self.assertEquals(logits.op.name, 'alexnet_v2/fc8/BiasAdd') @@ -55,7 +55,7 @@ class AlexnetV2Test(test.TestCase): batch_size = 5 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) _, end_points = alexnet.alexnet_v2(inputs, num_classes) expected_names = [ @@ -70,7 +70,7 @@ class AlexnetV2Test(test.TestCase): batch_size = 5 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) alexnet.alexnet_v2(inputs, num_classes) expected_names = [ @@ -98,7 +98,7 @@ class AlexnetV2Test(test.TestCase): batch_size = 2 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): eval_inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = alexnet.alexnet_v2(eval_inputs, is_training=False) self.assertListEqual(logits.get_shape().as_list(), @@ -112,7 +112,7 @@ class AlexnetV2Test(test.TestCase): train_height, train_width = 224, 224 eval_height, eval_width = 300, 400 num_classes = 1000 - with self.test_session(): + with self.cached_session(): train_inputs = random_ops.random_uniform( (train_batch_size, train_height, train_width, 3)) logits, _ = alexnet.alexnet_v2(train_inputs) @@ -132,7 +132,7 @@ class AlexnetV2Test(test.TestCase): def testForward(self): batch_size = 1 height, width = 224, 224 - with self.test_session() as sess: + with self.cached_session() as sess: inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = alexnet.alexnet_v2(inputs) sess.run(variables.global_variables_initializer()) diff --git a/tensorflow/contrib/slim/python/slim/nets/inception_v1_test.py b/tensorflow/contrib/slim/python/slim/nets/inception_v1_test.py index 7a3d1c9703..34f12d7591 100644 --- a/tensorflow/contrib/slim/python/slim/nets/inception_v1_test.py +++ b/tensorflow/contrib/slim/python/slim/nets/inception_v1_test.py @@ -143,7 +143,7 @@ class InceptionV1Test(test.TestCase): height, width = 224, 224 num_classes = 1000 input_np = np.random.uniform(0, 1, (batch_size, height, width, 3)) - with self.test_session() as sess: + with self.cached_session() as sess: inputs = array_ops.placeholder( dtypes.float32, shape=(batch_size, None, None, 3)) logits, end_points = inception_v1.inception_v1(inputs, num_classes) @@ -167,7 +167,7 @@ class InceptionV1Test(test.TestCase): self.assertListEqual(logits.get_shape().as_list(), [None, num_classes]) images = random_ops.random_uniform((batch_size, height, width, 3)) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(logits, {inputs: images.eval()}) self.assertEquals(output.shape, (batch_size, num_classes)) @@ -182,7 +182,7 @@ class InceptionV1Test(test.TestCase): eval_inputs, num_classes, is_training=False) predictions = math_ops.argmax(logits, 1) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(predictions) self.assertEquals(output.shape, (batch_size,)) @@ -200,7 +200,7 @@ class InceptionV1Test(test.TestCase): logits, _ = inception_v1.inception_v1(eval_inputs, num_classes, reuse=True) predictions = math_ops.argmax(logits, 1) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(predictions) self.assertEquals(output.shape, (eval_batch_size,)) @@ -211,7 +211,7 @@ class InceptionV1Test(test.TestCase): logits, _ = inception_v1.inception_v1( images, num_classes=num_classes, spatial_squeeze=False) - with self.test_session() as sess: + with self.cached_session() as sess: variables.global_variables_initializer().run() logits_out = sess.run(logits) self.assertListEqual(list(logits_out.shape), [1, 1, 1, num_classes]) diff --git a/tensorflow/contrib/slim/python/slim/nets/inception_v2_test.py b/tensorflow/contrib/slim/python/slim/nets/inception_v2_test.py index 5fbc9e5aa3..66effba944 100644 --- a/tensorflow/contrib/slim/python/slim/nets/inception_v2_test.py +++ b/tensorflow/contrib/slim/python/slim/nets/inception_v2_test.py @@ -196,7 +196,7 @@ class InceptionV2Test(test.TestCase): height, width = 224, 224 num_classes = 1000 input_np = np.random.uniform(0, 1, (batch_size, height, width, 3)) - with self.test_session() as sess: + with self.cached_session() as sess: inputs = array_ops.placeholder( dtypes.float32, shape=(batch_size, None, None, 3)) logits, end_points = inception_v2.inception_v2(inputs, num_classes) @@ -220,7 +220,7 @@ class InceptionV2Test(test.TestCase): self.assertListEqual(logits.get_shape().as_list(), [None, num_classes]) images = random_ops.random_uniform((batch_size, height, width, 3)) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(logits, {inputs: images.eval()}) self.assertEquals(output.shape, (batch_size, num_classes)) @@ -235,7 +235,7 @@ class InceptionV2Test(test.TestCase): eval_inputs, num_classes, is_training=False) predictions = math_ops.argmax(logits, 1) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(predictions) self.assertEquals(output.shape, (batch_size,)) @@ -253,7 +253,7 @@ class InceptionV2Test(test.TestCase): logits, _ = inception_v2.inception_v2(eval_inputs, num_classes, reuse=True) predictions = math_ops.argmax(logits, 1) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(predictions) self.assertEquals(output.shape, (eval_batch_size,)) @@ -264,7 +264,7 @@ class InceptionV2Test(test.TestCase): logits, _ = inception_v2.inception_v2( images, num_classes=num_classes, spatial_squeeze=False) - with self.test_session() as sess: + with self.cached_session() as sess: variables.global_variables_initializer().run() logits_out = sess.run(logits) self.assertListEqual(list(logits_out.shape), [1, 1, 1, num_classes]) diff --git a/tensorflow/contrib/slim/python/slim/nets/inception_v3_test.py b/tensorflow/contrib/slim/python/slim/nets/inception_v3_test.py index 6ba02318ed..0f9cca7bbd 100644 --- a/tensorflow/contrib/slim/python/slim/nets/inception_v3_test.py +++ b/tensorflow/contrib/slim/python/slim/nets/inception_v3_test.py @@ -226,7 +226,7 @@ class InceptionV3Test(test.TestCase): height, width = 299, 299 num_classes = 1000 input_np = np.random.uniform(0, 1, (batch_size, height, width, 3)) - with self.test_session() as sess: + with self.cached_session() as sess: inputs = array_ops.placeholder( dtypes.float32, shape=(batch_size, None, None, 3)) logits, end_points = inception_v3.inception_v3(inputs, num_classes) @@ -249,7 +249,7 @@ class InceptionV3Test(test.TestCase): self.assertListEqual(logits.get_shape().as_list(), [None, num_classes]) images = random_ops.random_uniform((batch_size, height, width, 3)) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(logits, {inputs: images.eval()}) self.assertEquals(output.shape, (batch_size, num_classes)) @@ -264,7 +264,7 @@ class InceptionV3Test(test.TestCase): eval_inputs, num_classes, is_training=False) predictions = math_ops.argmax(logits, 1) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(predictions) self.assertEquals(output.shape, (batch_size,)) @@ -283,7 +283,7 @@ class InceptionV3Test(test.TestCase): eval_inputs, num_classes, is_training=False, reuse=True) predictions = math_ops.argmax(logits, 1) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(predictions) self.assertEquals(output.shape, (eval_batch_size,)) @@ -294,7 +294,7 @@ class InceptionV3Test(test.TestCase): logits, _ = inception_v3.inception_v3( images, num_classes=num_classes, spatial_squeeze=False) - with self.test_session() as sess: + with self.cached_session() as sess: variables.global_variables_initializer().run() logits_out = sess.run(logits) self.assertListEqual(list(logits_out.shape), [1, 1, 1, num_classes]) diff --git a/tensorflow/contrib/slim/python/slim/nets/overfeat_test.py b/tensorflow/contrib/slim/python/slim/nets/overfeat_test.py index 317af3cb29..44fa35ad14 100644 --- a/tensorflow/contrib/slim/python/slim/nets/overfeat_test.py +++ b/tensorflow/contrib/slim/python/slim/nets/overfeat_test.py @@ -33,7 +33,7 @@ class OverFeatTest(test.TestCase): batch_size = 5 height, width = 231, 231 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = overfeat.overfeat(inputs, num_classes) self.assertEquals(logits.op.name, 'overfeat/fc8/squeezed') @@ -44,7 +44,7 @@ class OverFeatTest(test.TestCase): batch_size = 1 height, width = 281, 281 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = overfeat.overfeat(inputs, num_classes, spatial_squeeze=False) self.assertEquals(logits.op.name, 'overfeat/fc8/BiasAdd') @@ -55,7 +55,7 @@ class OverFeatTest(test.TestCase): batch_size = 5 height, width = 231, 231 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) _, end_points = overfeat.overfeat(inputs, num_classes) expected_names = [ @@ -70,7 +70,7 @@ class OverFeatTest(test.TestCase): batch_size = 5 height, width = 231, 231 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) overfeat.overfeat(inputs, num_classes) expected_names = [ @@ -98,7 +98,7 @@ class OverFeatTest(test.TestCase): batch_size = 2 height, width = 231, 231 num_classes = 1000 - with self.test_session(): + with self.cached_session(): eval_inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = overfeat.overfeat(eval_inputs, is_training=False) self.assertListEqual(logits.get_shape().as_list(), @@ -112,7 +112,7 @@ class OverFeatTest(test.TestCase): train_height, train_width = 231, 231 eval_height, eval_width = 281, 281 num_classes = 1000 - with self.test_session(): + with self.cached_session(): train_inputs = random_ops.random_uniform( (train_batch_size, train_height, train_width, 3)) logits, _ = overfeat.overfeat(train_inputs) @@ -132,7 +132,7 @@ class OverFeatTest(test.TestCase): def testForward(self): batch_size = 1 height, width = 231, 231 - with self.test_session() as sess: + with self.cached_session() as sess: inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = overfeat.overfeat(inputs) sess.run(variables.global_variables_initializer()) diff --git a/tensorflow/contrib/slim/python/slim/nets/resnet_v1_test.py b/tensorflow/contrib/slim/python/slim/nets/resnet_v1_test.py index 576444214d..8ff44fe4b5 100644 --- a/tensorflow/contrib/slim/python/slim/nets/resnet_v1_test.py +++ b/tensorflow/contrib/slim/python/slim/nets/resnet_v1_test.py @@ -69,7 +69,7 @@ class ResnetUtilsTest(test.TestCase): x = resnet_utils.subsample(x, 2) expected = array_ops.reshape( constant_op.constant([0, 2, 6, 8]), [1, 2, 2, 1]) - with self.test_session(): + with self.cached_session(): self.assertAllClose(x.eval(), expected.eval()) def testSubsampleFourByFour(self): @@ -77,7 +77,7 @@ class ResnetUtilsTest(test.TestCase): x = resnet_utils.subsample(x, 2) expected = array_ops.reshape( constant_op.constant([0, 2, 8, 10]), [1, 2, 2, 1]) - with self.test_session(): + with self.cached_session(): self.assertAllClose(x.eval(), expected.eval()) def testConv2DSameEven(self): @@ -110,7 +110,7 @@ class ResnetUtilsTest(test.TestCase): y4_expected = math_ops.to_float([[48, 37], [37, 22]]) y4_expected = array_ops.reshape(y4_expected, [1, n2, n2, 1]) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) self.assertAllClose(y1.eval(), y1_expected.eval()) self.assertAllClose(y2.eval(), y2_expected.eval()) @@ -148,7 +148,7 @@ class ResnetUtilsTest(test.TestCase): y4 = layers.conv2d(x, 1, [3, 3], stride=2, scope='Conv') y4_expected = y2_expected - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) self.assertAllClose(y1.eval(), y1_expected.eval()) self.assertAllClose(y2.eval(), y2_expected.eval()) @@ -223,7 +223,7 @@ class ResnetUtilsTest(test.TestCase): with arg_scope([layers.batch_norm], is_training=False): for output_stride in [1, 2, 4, 8, None]: with ops.Graph().as_default(): - with self.test_session() as sess: + with self.cached_session() as sess: random_seed.set_random_seed(0) inputs = create_test_input(1, height, width, 3) # Dense feature extraction followed by subsampling. @@ -364,7 +364,7 @@ class ResnetCompleteNetworkTest(test.TestCase): for output_stride in [4, 8, 16, 32, None]: with arg_scope(resnet_utils.resnet_arg_scope()): with ops.Graph().as_default(): - with self.test_session() as sess: + with self.cached_session() as sess: random_seed.set_random_seed(0) inputs = create_test_input(2, 81, 81, 3) # Dense feature extraction followed by subsampling. @@ -401,7 +401,7 @@ class ResnetCompleteNetworkTest(test.TestCase): self.assertListEqual(logits.get_shape().as_list(), [None, 1, 1, num_classes]) images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(logits, {inputs: images.eval()}) self.assertEqual(output.shape, (batch, 1, 1, num_classes)) @@ -415,7 +415,7 @@ class ResnetCompleteNetworkTest(test.TestCase): output, _ = self._resnet_small(inputs, None, global_pool=global_pool) self.assertListEqual(output.get_shape().as_list(), [batch, None, None, 32]) images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(output, {inputs: images.eval()}) self.assertEqual(output.shape, (batch, 3, 3, 32)) @@ -431,7 +431,7 @@ class ResnetCompleteNetworkTest(test.TestCase): inputs, None, global_pool=global_pool, output_stride=output_stride) self.assertListEqual(output.get_shape().as_list(), [batch, None, None, 32]) images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(output, {inputs: images.eval()}) self.assertEqual(output.shape, (batch, 9, 9, 32)) diff --git a/tensorflow/contrib/slim/python/slim/nets/resnet_v2_test.py b/tensorflow/contrib/slim/python/slim/nets/resnet_v2_test.py index 6bdda18c5b..055ecff1c3 100644 --- a/tensorflow/contrib/slim/python/slim/nets/resnet_v2_test.py +++ b/tensorflow/contrib/slim/python/slim/nets/resnet_v2_test.py @@ -69,7 +69,7 @@ class ResnetUtilsTest(test.TestCase): x = resnet_utils.subsample(x, 2) expected = array_ops.reshape( constant_op.constant([0, 2, 6, 8]), [1, 2, 2, 1]) - with self.test_session(): + with self.cached_session(): self.assertAllClose(x.eval(), expected.eval()) def testSubsampleFourByFour(self): @@ -77,7 +77,7 @@ class ResnetUtilsTest(test.TestCase): x = resnet_utils.subsample(x, 2) expected = array_ops.reshape( constant_op.constant([0, 2, 8, 10]), [1, 2, 2, 1]) - with self.test_session(): + with self.cached_session(): self.assertAllClose(x.eval(), expected.eval()) def testConv2DSameEven(self): @@ -110,7 +110,7 @@ class ResnetUtilsTest(test.TestCase): y4_expected = math_ops.to_float([[48, 37], [37, 22]]) y4_expected = array_ops.reshape(y4_expected, [1, n2, n2, 1]) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) self.assertAllClose(y1.eval(), y1_expected.eval()) self.assertAllClose(y2.eval(), y2_expected.eval()) @@ -151,7 +151,7 @@ class ResnetUtilsTest(test.TestCase): y4 = layers.conv2d(x, 1, [3, 3], stride=2, scope='Conv') y4_expected = y2_expected - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) self.assertAllClose(y1.eval(), y1_expected.eval()) self.assertAllClose(y2.eval(), y2_expected.eval()) @@ -227,7 +227,7 @@ class ResnetUtilsTest(test.TestCase): with arg_scope([layers.batch_norm], is_training=False): for output_stride in [1, 2, 4, 8, None]: with ops.Graph().as_default(): - with self.test_session() as sess: + with self.cached_session() as sess: random_seed.set_random_seed(0) inputs = create_test_input(1, height, width, 3) # Dense feature extraction followed by subsampling. @@ -368,7 +368,7 @@ class ResnetCompleteNetworkTest(test.TestCase): for output_stride in [4, 8, 16, 32, None]: with arg_scope(resnet_utils.resnet_arg_scope()): with ops.Graph().as_default(): - with self.test_session() as sess: + with self.cached_session() as sess: random_seed.set_random_seed(0) inputs = create_test_input(2, 81, 81, 3) # Dense feature extraction followed by subsampling. @@ -405,7 +405,7 @@ class ResnetCompleteNetworkTest(test.TestCase): self.assertListEqual(logits.get_shape().as_list(), [None, 1, 1, num_classes]) images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(logits, {inputs: images.eval()}) self.assertEqual(output.shape, (batch, 1, 1, num_classes)) @@ -419,7 +419,7 @@ class ResnetCompleteNetworkTest(test.TestCase): output, _ = self._resnet_small(inputs, None, global_pool=global_pool) self.assertListEqual(output.get_shape().as_list(), [batch, None, None, 32]) images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(output, {inputs: images.eval()}) self.assertEqual(output.shape, (batch, 3, 3, 32)) @@ -435,7 +435,7 @@ class ResnetCompleteNetworkTest(test.TestCase): inputs, None, global_pool=global_pool, output_stride=output_stride) self.assertListEqual(output.get_shape().as_list(), [batch, None, None, 32]) images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) output = sess.run(output, {inputs: images.eval()}) self.assertEqual(output.shape, (batch, 9, 9, 32)) diff --git a/tensorflow/contrib/slim/python/slim/nets/vgg_test.py b/tensorflow/contrib/slim/python/slim/nets/vgg_test.py index 36628b32d1..71ce4b89cd 100644 --- a/tensorflow/contrib/slim/python/slim/nets/vgg_test.py +++ b/tensorflow/contrib/slim/python/slim/nets/vgg_test.py @@ -34,7 +34,7 @@ class VGGATest(test.TestCase): batch_size = 5 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_a(inputs, num_classes) self.assertEquals(logits.op.name, 'vgg_a/fc8/squeezed') @@ -45,7 +45,7 @@ class VGGATest(test.TestCase): batch_size = 1 height, width = 256, 256 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_a(inputs, num_classes, spatial_squeeze=False) self.assertEquals(logits.op.name, 'vgg_a/fc8/BiasAdd') @@ -73,7 +73,7 @@ class VGGATest(test.TestCase): batch_size = 5 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) vgg.vgg_a(inputs, num_classes) expected_names = [ @@ -107,7 +107,7 @@ class VGGATest(test.TestCase): batch_size = 2 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): eval_inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_a(eval_inputs, is_training=False) self.assertListEqual(logits.get_shape().as_list(), @@ -121,7 +121,7 @@ class VGGATest(test.TestCase): train_height, train_width = 224, 224 eval_height, eval_width = 256, 256 num_classes = 1000 - with self.test_session(): + with self.cached_session(): train_inputs = random_ops.random_uniform( (train_batch_size, train_height, train_width, 3)) logits, _ = vgg.vgg_a(train_inputs) @@ -141,7 +141,7 @@ class VGGATest(test.TestCase): def testForward(self): batch_size = 1 height, width = 224, 224 - with self.test_session() as sess: + with self.cached_session() as sess: inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_a(inputs) sess.run(variables.global_variables_initializer()) @@ -155,7 +155,7 @@ class VGG16Test(test.TestCase): batch_size = 5 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_16(inputs, num_classes) self.assertEquals(logits.op.name, 'vgg_16/fc8/squeezed') @@ -166,7 +166,7 @@ class VGG16Test(test.TestCase): batch_size = 1 height, width = 256, 256 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_16(inputs, num_classes, spatial_squeeze=False) self.assertEquals(logits.op.name, 'vgg_16/fc8/BiasAdd') @@ -197,7 +197,7 @@ class VGG16Test(test.TestCase): batch_size = 5 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) vgg.vgg_16(inputs, num_classes) expected_names = [ @@ -241,7 +241,7 @@ class VGG16Test(test.TestCase): batch_size = 2 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): eval_inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_16(eval_inputs, is_training=False) self.assertListEqual(logits.get_shape().as_list(), @@ -255,7 +255,7 @@ class VGG16Test(test.TestCase): train_height, train_width = 224, 224 eval_height, eval_width = 256, 256 num_classes = 1000 - with self.test_session(): + with self.cached_session(): train_inputs = random_ops.random_uniform( (train_batch_size, train_height, train_width, 3)) logits, _ = vgg.vgg_16(train_inputs) @@ -275,7 +275,7 @@ class VGG16Test(test.TestCase): def testForward(self): batch_size = 1 height, width = 224, 224 - with self.test_session() as sess: + with self.cached_session() as sess: inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_16(inputs) sess.run(variables.global_variables_initializer()) @@ -289,7 +289,7 @@ class VGG19Test(test.TestCase): batch_size = 5 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_19(inputs, num_classes) self.assertEquals(logits.op.name, 'vgg_19/fc8/squeezed') @@ -300,7 +300,7 @@ class VGG19Test(test.TestCase): batch_size = 1 height, width = 256, 256 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_19(inputs, num_classes, spatial_squeeze=False) self.assertEquals(logits.op.name, 'vgg_19/fc8/BiasAdd') @@ -332,7 +332,7 @@ class VGG19Test(test.TestCase): batch_size = 5 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((batch_size, height, width, 3)) vgg.vgg_19(inputs, num_classes) expected_names = [ @@ -382,7 +382,7 @@ class VGG19Test(test.TestCase): batch_size = 2 height, width = 224, 224 num_classes = 1000 - with self.test_session(): + with self.cached_session(): eval_inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_19(eval_inputs, is_training=False) self.assertListEqual(logits.get_shape().as_list(), @@ -396,7 +396,7 @@ class VGG19Test(test.TestCase): train_height, train_width = 224, 224 eval_height, eval_width = 256, 256 num_classes = 1000 - with self.test_session(): + with self.cached_session(): train_inputs = random_ops.random_uniform( (train_batch_size, train_height, train_width, 3)) logits, _ = vgg.vgg_19(train_inputs) @@ -416,7 +416,7 @@ class VGG19Test(test.TestCase): def testForward(self): batch_size = 1 height, width = 224, 224 - with self.test_session() as sess: + with self.cached_session() as sess: inputs = random_ops.random_uniform((batch_size, height, width, 3)) logits, _ = vgg.vgg_19(inputs) sess.run(variables.global_variables_initializer()) diff --git a/tensorflow/contrib/slim/python/slim/summaries_test.py b/tensorflow/contrib/slim/python/slim/summaries_test.py index 873ee78de2..c6017f073e 100644 --- a/tensorflow/contrib/slim/python/slim/summaries_test.py +++ b/tensorflow/contrib/slim/python/slim/summaries_test.py @@ -88,7 +88,7 @@ class SummariesTest(test.TestCase): summary_op = summary.merge_all() summary_writer = summary.FileWriter(output_dir) - with self.test_session() as sess: + with self.cached_session() as sess: new_summary = sess.run(summary_op) summary_writer.add_summary(new_summary, 1) summary_writer.flush() diff --git a/tensorflow/contrib/tensor_forest/BUILD b/tensorflow/contrib/tensor_forest/BUILD index 22d6e499d2..652f709fe2 100644 --- a/tensorflow/contrib/tensor_forest/BUILD +++ b/tensorflow/contrib/tensor_forest/BUILD @@ -534,10 +534,11 @@ py_library( py_test( name = "random_forest_test", - size = "medium", + size = "large", srcs = ["client/random_forest_test.py"], srcs_version = "PY2AND3", tags = [ + "noasan", "nomac", # b/63258195 "notsan", ], diff --git a/tensorflow/contrib/tensor_forest/hybrid/core/ops/utils.h b/tensorflow/contrib/tensor_forest/hybrid/core/ops/utils.h index 69a0143a4e..1ed3d8ca2e 100644 --- a/tensorflow/contrib/tensor_forest/hybrid/core/ops/utils.h +++ b/tensorflow/contrib/tensor_forest/hybrid/core/ops/utils.h @@ -13,8 +13,8 @@ // limitations under the License. // ============================================================================= -#ifndef LEARNING_LIB_TENSOR_FOREST_HYBRID_CORE_OPS_UTILS_H_ -#define LEARNING_LIB_TENSOR_FOREST_HYBRID_CORE_OPS_UTILS_H_ +#ifndef TENSORFLOW_CONTRIB_TENSOR_FOREST_HYBRID_CORE_OPS_UTILS_H_ +#define TENSORFLOW_CONTRIB_TENSOR_FOREST_HYBRID_CORE_OPS_UTILS_H_ #include <vector> #include "tensorflow/core/framework/tensor.h" @@ -43,4 +43,4 @@ void GetFeatureSet(int32 tree_num, int32 node_num, int32 random_seed, } // namespace tensorforest } // namespace tensorflow -#endif // LEARNING_LIB_TENSOR_FOREST_HYBRID_CORE_OPS_UTILS_H_ +#endif // TENSORFLOW_CONTRIB_TENSOR_FOREST_HYBRID_CORE_OPS_UTILS_H_ diff --git a/tensorflow/contrib/tensor_forest/hybrid/python/kernel_tests/k_feature_routing_function_op_test.py b/tensorflow/contrib/tensor_forest/hybrid/python/kernel_tests/k_feature_routing_function_op_test.py index 980f53253d..cc053f3b94 100644 --- a/tensorflow/contrib/tensor_forest/hybrid/python/kernel_tests/k_feature_routing_function_op_test.py +++ b/tensorflow/contrib/tensor_forest/hybrid/python/kernel_tests/k_feature_routing_function_op_test.py @@ -58,7 +58,7 @@ class KFeatureRoutingFunctionTest(test_util.TensorFlowTestCase): self.assertEquals(self.params.num_features_per_node, 2) def testRoutingFunction(self): - with self.test_session(): + with self.cached_session(): route_tensor = gen_training_ops.k_feature_routing_function( self.input_data, self.tree_weights, diff --git a/tensorflow/contrib/tensor_forest/hybrid/python/kernel_tests/routing_function_op_test.py b/tensorflow/contrib/tensor_forest/hybrid/python/kernel_tests/routing_function_op_test.py index a27fd49d32..554f7b0d7a 100644 --- a/tensorflow/contrib/tensor_forest/hybrid/python/kernel_tests/routing_function_op_test.py +++ b/tensorflow/contrib/tensor_forest/hybrid/python/kernel_tests/routing_function_op_test.py @@ -36,7 +36,7 @@ class RoutingFunctionTest(test_util.TensorFlowTestCase): self.ops = training_ops.Load() def testRoutingFunction(self): - with self.test_session(): + with self.cached_session(): route_tensor = gen_training_ops.routing_function( self.input_data, self.tree_weights, self.tree_thresholds, max_nodes=3) diff --git a/tensorflow/contrib/tensor_forest/kernels/data_spec.h b/tensorflow/contrib/tensor_forest/kernels/data_spec.h index bb33400214..336a7a3239 100644 --- a/tensorflow/contrib/tensor_forest/kernels/data_spec.h +++ b/tensorflow/contrib/tensor_forest/kernels/data_spec.h @@ -15,8 +15,8 @@ // This is a surrogate for using a proto, since it doesn't seem to be possible // to use protos in a dynamically-loaded/shared-linkage library, which is // what is used for custom ops in tensorflow/contrib. -#ifndef TENSORFLOW_CONTRIB_TENSOR_FOREST_CORE_OPS_DATA_SPEC_H_ -#define TENSORFLOW_CONTRIB_TENSOR_FOREST_CORE_OPS_DATA_SPEC_H_ +#ifndef TENSORFLOW_CONTRIB_TENSOR_FOREST_KERNELS_DATA_SPEC_H_ +#define TENSORFLOW_CONTRIB_TENSOR_FOREST_KERNELS_DATA_SPEC_H_ #include <unordered_map> #include "tensorflow/core/lib/strings/numbers.h" @@ -139,4 +139,4 @@ class TensorForestDataSpec { } // namespace tensorforest } // namespace tensorflow -#endif // TENSORFLOW_CONTRIB_TENSOR_FOREST_CORE_OPS_DATA_SPEC_H_ +#endif // TENSORFLOW_CONTRIB_TENSOR_FOREST_KERNELS_DATA_SPEC_H_ diff --git a/tensorflow/contrib/tensor_forest/kernels/tree_utils.h b/tensorflow/contrib/tensor_forest/kernels/tree_utils.h index 03aab1b61e..e04eb60f9b 100644 --- a/tensorflow/contrib/tensor_forest/kernels/tree_utils.h +++ b/tensorflow/contrib/tensor_forest/kernels/tree_utils.h @@ -12,8 +12,8 @@ // See the License for the specific language governing permissions and // limitations under the License. // ============================================================================= -#ifndef TENSORFLOW_CONTRIB_TENSOR_FOREST_CORE_OPS_TREE_UTILS_H_ -#define TENSORFLOW_CONTRIB_TENSOR_FOREST_CORE_OPS_TREE_UTILS_H_ +#ifndef TENSORFLOW_CONTRIB_TENSOR_FOREST_KERNELS_TREE_UTILS_H_ +#define TENSORFLOW_CONTRIB_TENSOR_FOREST_KERNELS_TREE_UTILS_H_ #include <limits> @@ -302,4 +302,4 @@ void GetParentWeightedMean(float leaf_sum, const float* leaf_data, } // namespace tensorforest } // namespace tensorflow -#endif // TENSORFLOW_CONTRIB_TENSOR_FOREST_CORE_OPS_TREE_UTILS_H_ +#endif // TENSORFLOW_CONTRIB_TENSOR_FOREST_KERNELS_TREE_UTILS_H_ diff --git a/tensorflow/contrib/tensor_forest/kernels/v4/input_data.cc b/tensorflow/contrib/tensor_forest/kernels/v4/input_data.cc index d43884481a..99c5800391 100644 --- a/tensorflow/contrib/tensor_forest/kernels/v4/input_data.cc +++ b/tensorflow/contrib/tensor_forest/kernels/v4/input_data.cc @@ -130,7 +130,11 @@ void TensorDataSet::RandomSample(int example, num_total_features += num_sparse; } } - int rand_feature = rng_->Uniform(num_total_features); + int rand_feature = 0; + { + mutex_lock lock(mu_); + rand_feature = rng_->Uniform(num_total_features); + } if (rand_feature < available_features_.size()) { // it's dense. *feature_id = available_features_[rand_feature]; *type = input_spec_.GetDenseFeatureType(rand_feature); diff --git a/tensorflow/contrib/tensor_forest/kernels/v4/input_data.h b/tensorflow/contrib/tensor_forest/kernels/v4/input_data.h index 95f75b4d7e..4945b53007 100644 --- a/tensorflow/contrib/tensor_forest/kernels/v4/input_data.h +++ b/tensorflow/contrib/tensor_forest/kernels/v4/input_data.h @@ -25,6 +25,7 @@ #include "tensorflow/core/lib/random/philox_random.h" #include "tensorflow/core/lib/random/random.h" #include "tensorflow/core/lib/random/simple_philox.h" +#include "tensorflow/core/platform/mutex.h" namespace tensorflow { namespace tensorforest { @@ -120,6 +121,8 @@ class TensorDataSet { int32 split_sampling_random_seed_; std::unique_ptr<random::PhiloxRandom> single_rand_; std::unique_ptr<random::SimplePhilox> rng_; + // Mutex for using random number generator. + mutable mutex mu_; }; } // namespace tensorforest } // namespace tensorflow diff --git a/tensorflow/contrib/tensorrt/BUILD b/tensorflow/contrib/tensorrt/BUILD index fc0d22d112..122a67a407 100644 --- a/tensorflow/contrib/tensorrt/BUILD +++ b/tensorflow/contrib/tensorrt/BUILD @@ -279,7 +279,9 @@ tf_cuda_library( "//tensorflow/core/grappler/optimizers:custom_graph_optimizer_registry", "//tensorflow/core/grappler:grappler_item", "//tensorflow/core/grappler:utils", + "//tensorflow/core:framework", "//tensorflow/core:framework_lite", + "//tensorflow/core:gpu_runtime", "//tensorflow/core:graph", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", @@ -293,6 +295,31 @@ tf_cuda_library( ]) + tf_custom_op_library_additional_deps(), ) +tf_cuda_cc_test( + name = "convert_graph_test", + size = "medium", + srcs = ["convert/convert_graph_test.cc"], + tags = [ + "no_cuda_on_cpu_tap", + "no_windows", + "nomac", + ], + deps = [ + ":trt_conversion", + "//tensorflow/core/grappler:grappler_item", + "//tensorflow/core/grappler/clusters:cluster", + "//tensorflow/core:core_cpu", + "//tensorflow/core:core_cpu_base", + "//tensorflow/core:direct_session", + "//tensorflow/core:lib", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + ] + if_tensorrt([ + "@local_config_tensorrt//:nv_infer", + ]), +) + # Library for the segmenting portion of TensorRT operation creation cc_library( name = "segment", @@ -387,17 +414,19 @@ cuda_py_tests( name = "tf_trt_integration_test", srcs = [ "test/base_test.py", - # "test/batch_matmul_test.py", - # "test/biasadd_matmul_test.py", - # "test/binary_tensor_weight_broadcast_test.py", # Blocked by trt4 installation - # "test/concatenation_test.py", # Blocked by trt4 installation + "test/batch_matmul_test.py", + "test/biasadd_matmul_test.py", + "test/binary_tensor_weight_broadcast_test.py", + "test/concatenation_test.py", "test/const_broadcast_test.py", + "test/manual_test.py", + "test/memory_alignment_test.py", "test/multi_connection_neighbor_engine_test.py", "test/neighboring_engine_test.py", - # "test/unary_test.py", # Blocked by trt4 installation - # "test/vgg_block_nchw_test.py", - # "test/vgg_block_test.py", - "test/memory_alignment_test.py", + "test/rank_two_test.py", + "test/unary_test.py", + "test/vgg_block_nchw_test.py", + "test/vgg_block_test.py", ], additional_deps = [ ":tf_trt_integration_test_base", diff --git a/tensorflow/contrib/tensorrt/convert/convert_graph.cc b/tensorflow/contrib/tensorrt/convert/convert_graph.cc index 21ec8b0b30..b019c99882 100644 --- a/tensorflow/contrib/tensorrt/convert/convert_graph.cc +++ b/tensorflow/contrib/tensorrt/convert/convert_graph.cc @@ -31,6 +31,9 @@ limitations under the License. #include "tensorflow/contrib/tensorrt/resources/trt_resources.h" #include "tensorflow/contrib/tensorrt/segment/segment.h" #include "tensorflow/contrib/tensorrt/test/utils.h" +#include "tensorflow/core/common_runtime/gpu/gpu_id.h" +#include "tensorflow/core/common_runtime/gpu/gpu_id_manager.h" +#include "tensorflow/core/common_runtime/gpu/gpu_process_state.h" #include "tensorflow/core/framework/function.h" #include "tensorflow/core/framework/graph_to_functiondef.h" #include "tensorflow/core/framework/node_def_builder.h" @@ -772,33 +775,55 @@ std::pair<int, tensorflow::Allocator*> GetDeviceAndAllocator( const ConversionParams& params, const EngineInfo& engine) { int cuda_device_id = -1; tensorflow::Allocator* dev_allocator = nullptr; - if (params.cluster) { - std::vector<tensorflow::Device*> devices; - if (!engine.device.empty() && params.cluster->GetDeviceSet()) { - DeviceNameUtils::ParsedName parsed_name; - if (DeviceNameUtils::ParseFullName(engine.device, &parsed_name) && - parsed_name.has_id) { - params.cluster->GetDeviceSet()->FindMatchingDevices(parsed_name, - &devices); + if (params.cluster == nullptr || params.cluster->GetDeviceSet() == nullptr || + engine.device.empty()) { + // If device is not set, use the first found GPU device for the conversion. + for (int tf_gpu_id_value = 0; tf_gpu_id_value < 100; ++tf_gpu_id_value) { + TfGpuId tf_gpu_id(tf_gpu_id_value); + CudaGpuId cuda_gpu_id; + Status s = GpuIdManager::TfToCudaGpuId(tf_gpu_id, &cuda_gpu_id); + if (s.ok()) { + VLOG(1) << "Found TF GPU " << tf_gpu_id.value() << " at cuda device " + << cuda_gpu_id.value(); + cuda_device_id = cuda_gpu_id.value(); + GPUOptions gpu_options; + // If the TF to Cuda gpu id mapping exist, the device and corresponding + // allocator must have been initialized already, so the + // GetGPUAllocator() call won't create a new allocator. + dev_allocator = GPUProcessState::singleton()->GetGPUAllocator( + gpu_options, tf_gpu_id, 1); + break; } + LOG(ERROR) << "TF GPU with id " << tf_gpu_id_value << " does not exist " + << s; } - if (!devices.empty()) { - if (devices.size() > 1) { - string msg = "Found multiple matching devices using name '"; - StrAppend(&msg, engine.device, "': "); - for (auto d : devices) StrAppend(&msg, d->name(), ", "); - StrAppend(&msg, ". Will get the allocator from first one."); - LOG(WARNING) << msg; - } - tensorflow::AllocatorAttributes alloc_attr; - cuda_device_id = devices[0]->tensorflow_gpu_device_info()->gpu_id; - dev_allocator = devices[0]->GetAllocator(alloc_attr); - VLOG(1) << "Using allocator " << dev_allocator->Name() - << " and cuda_device_id " << cuda_device_id; - } else { - LOG(WARNING) << "Cluster is set but device '" << engine.device - << "' is not found in the cluster"; + return std::make_pair(cuda_device_id, dev_allocator); + } + + // Use the device requested by the engine. + auto device_set = params.cluster->GetDeviceSet(); + std::vector<tensorflow::Device*> devices; + DeviceNameUtils::ParsedName parsed_name; + if (DeviceNameUtils::ParseFullName(engine.device, &parsed_name) && + parsed_name.has_id) { + device_set->FindMatchingDevices(parsed_name, &devices); + } + if (!devices.empty()) { + if (devices.size() > 1) { + string msg = "Found multiple matching devices using name '"; + StrAppend(&msg, engine.device, "': "); + for (auto d : devices) StrAppend(&msg, d->name(), ", "); + StrAppend(&msg, ". Will get the allocator from first one."); + LOG(WARNING) << msg; } + tensorflow::AllocatorAttributes alloc_attr; + cuda_device_id = devices[0]->tensorflow_gpu_device_info()->gpu_id; + dev_allocator = devices[0]->GetAllocator(alloc_attr); + VLOG(1) << "Using allocator " << dev_allocator->Name() + << " and cuda_device_id " << cuda_device_id; + } else { + LOG(WARNING) << "Cluster is set but device '" << engine.device + << "' is not found in the cluster"; } return std::make_pair(cuda_device_id, dev_allocator); } diff --git a/tensorflow/contrib/tensorrt/convert/convert_graph.h b/tensorflow/contrib/tensorrt/convert/convert_graph.h index 9d986e4890..3525202369 100644 --- a/tensorflow/contrib/tensorrt/convert/convert_graph.h +++ b/tensorflow/contrib/tensorrt/convert/convert_graph.h @@ -17,6 +17,7 @@ limitations under the License. #include <vector> +#include "tensorflow/contrib/tensorrt/convert/convert_nodes.h" #include "tensorflow/core/framework/graph.pb.h" #include "tensorflow/core/grappler/clusters/cluster.h" #include "tensorflow/core/grappler/costs/graph_properties.h" @@ -84,6 +85,11 @@ std::vector<int> GetLinkedTensorRTVersion(); // Return runtime time TensorRT library version information. std::vector<int> GetLoadedTensorRTVersion(); + +// Helper method for the conversion, expose for testing. +std::pair<int, tensorflow::Allocator*> GetDeviceAndAllocator( + const ConversionParams& params, const EngineInfo& engine); + } // namespace convert } // namespace tensorrt } // namespace tensorflow diff --git a/tensorflow/contrib/tensorrt/convert/convert_graph_test.cc b/tensorflow/contrib/tensorrt/convert/convert_graph_test.cc new file mode 100644 index 0000000000..8146bed4b0 --- /dev/null +++ b/tensorflow/contrib/tensorrt/convert/convert_graph_test.cc @@ -0,0 +1,140 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/tensorrt/convert/convert_graph.h" + +#include "tensorflow/contrib/tensorrt/convert/convert_nodes.h" +#include "tensorflow/core/common_runtime/device_mgr.h" +#include "tensorflow/core/common_runtime/device_set.h" +#include "tensorflow/core/grappler/clusters/cluster.h" +#include "tensorflow/core/grappler/grappler_item.h" +#include "tensorflow/core/lib/core/status.h" +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/platform/test.h" +#include "tensorflow/core/protobuf/config.pb.h" // NOLINT +#include "tensorflow/core/public/session.h" + +#if GOOGLE_CUDA +#if GOOGLE_TENSORRT + +namespace tensorflow { +namespace tensorrt { +namespace convert { + +class FakeCluster : public grappler::Cluster { + public: + FakeCluster() : Cluster(0) {} + + void SetDeviceSet(const DeviceSet* device_set) { device_set_ = device_set; } + + const DeviceSet* GetDeviceSet() const override { return device_set_; } + + string type() const override { return ""; } + Status Provision() override { return Status::OK(); } + Status Initialize(const grappler::GrapplerItem& item) override { + return Status::OK(); + } + Status Run(const GraphDef& graph_def, + const std::vector<std::pair<string, Tensor>>& feed, + const std::vector<string>& fetch, + RunMetadata* metadata) override { + return Status::OK(); + } + + private: + const DeviceSet* device_set_; +}; + +TEST(ConvertGraphTest, GetDeviceAndAllocator) { + ConversionParams params; + EngineInfo engine_info; + { + // params.cluster is not set, and no gpu device is available. + auto result = GetDeviceAndAllocator(params, engine_info); + EXPECT_EQ(-1, result.first); + EXPECT_EQ(nullptr, result.second); + } + + // Create a session with two (virtual) gpu device. + SessionOptions options; + ConfigProto* config = &options.config; + GPUOptions* gpu_options = config->mutable_gpu_options(); + auto virtual_devices = + gpu_options->mutable_experimental()->add_virtual_devices(); + virtual_devices->add_memory_limit_mb(200); + virtual_devices->add_memory_limit_mb(200); + std::unique_ptr<Session> session(NewSession(options)); + + { + // params.cluster is not set, should find and return first gpu id and + // corresponding allocator. + auto result = GetDeviceAndAllocator(params, engine_info); + EXPECT_EQ(0, result.first); + EXPECT_NE(nullptr, result.second); + EXPECT_EQ("GPU_0_bfc", result.second->Name()); + } + + FakeCluster cluster; + params.cluster = &cluster; + { + // params.cluster->GetDeviceSet() returns null, should find and return first + // gpu id and corresponding allocator. + auto result = GetDeviceAndAllocator(params, engine_info); + EXPECT_EQ(0, result.first); + EXPECT_NE(nullptr, result.second); + EXPECT_EQ("GPU_0_bfc", result.second->Name()); + } + + // Build the DeviceSet. + DeviceSet device_set; + const DeviceMgr* device_mgr = nullptr; + TF_ASSERT_OK(session->LocalDeviceManager(&device_mgr)); + for (auto d : device_mgr->ListDevices()) { + device_set.AddDevice(d); + } + cluster.SetDeviceSet(&device_set); + { + // engine_info.device is not set, should find and return first gpu id and + // corresponding allocator. + auto result = GetDeviceAndAllocator(params, engine_info); + EXPECT_EQ(0, result.first); + EXPECT_NE(nullptr, result.second); + EXPECT_EQ("GPU_0_bfc", result.second->Name()); + } + + engine_info.device = "/GPU:1"; + { + // Set to use second device. + auto result = GetDeviceAndAllocator(params, engine_info); + EXPECT_EQ(0, result.first); + EXPECT_NE(nullptr, result.second); + EXPECT_EQ("GPU_1_bfc", result.second->Name()); + } + + engine_info.device = "/GPU:3"; + { + // Set to use nonexistent device. + auto result = GetDeviceAndAllocator(params, engine_info); + EXPECT_EQ(-1, result.first); + EXPECT_EQ(nullptr, result.second); + } +} + +} // namespace convert +} // namespace tensorrt +} // namespace tensorflow + +#endif // GOOGLE_TENSORRT +#endif // GOOGLE_CUDA diff --git a/tensorflow/contrib/tensorrt/convert/convert_nodes.cc b/tensorflow/contrib/tensorrt/convert/convert_nodes.cc index 35fa590254..c98b07ad8b 100644 --- a/tensorflow/contrib/tensorrt/convert/convert_nodes.cc +++ b/tensorflow/contrib/tensorrt/convert/convert_nodes.cc @@ -33,6 +33,7 @@ limitations under the License. #include "tensorflow/contrib/tensorrt/resources/trt_resources.h" #include "tensorflow/core/framework/node_def.pb.h" // NOLINT #include "tensorflow/core/framework/node_def_builder.h" +#include "tensorflow/core/framework/tensor.pb.h" // NOLINT #include "tensorflow/core/framework/tensor_shape.pb.h" // NOLINT #include "tensorflow/core/framework/types.h" #include "tensorflow/core/graph/algorithm.h" @@ -77,6 +78,10 @@ limitations under the License. namespace tensorflow { namespace tensorrt { +// TODO(aaroey): put these constants into some class. +const char* const kInputPHName = "TensorRTInputPH_"; +const char* const kOutputPHName = "TensorRTOutputPH_"; + namespace convert { using ::tensorflow::str_util::Split; using ::tensorflow::strings::StrAppend; @@ -155,12 +160,22 @@ tensorflow::Status ValidateInputProperties(const PartialTensorShape& shape, for (int d = 1; d < shape.dims(); ++d) { if (shape.dim_size(d) < 0) { return tensorflow::errors::InvalidArgument( - "Input tensor has a unknown non-batch dimemension at dim ", d); + "Input tensor with shape ", shape.DebugString(), + " has an unknown non-batch dimemension at dim ", d); } } return Status::OK(); } +string DebugString(const nvinfer1::Dims& dims) { + string out = StrCat("nvinfer1::Dims(nbDims=", dims.nbDims, ", d="); + for (int i = 0; i < nvinfer1::Dims::MAX_DIMS; ++i) { + StrAppend(&out, dims.d[i], ","); + } + StrAppend(&out, ")"); + return out; +} + // Return whether or not the broadcast is feasible; bool TensorRTGetBroadcastShape(const nvinfer1::Dims& operand_l, const bool operand_l_is_tensor, @@ -353,6 +368,13 @@ class TRT_ShapedWeights { // Default converter operator nvinfer1::Weights() const { return GetWeightsForTRT(); } + string DebugString() const { + return StrCat( + "TRT_ShapedWeights(shape=", convert::DebugString(shape_), ", type=", + type_, ", values=", reinterpret_cast<uintptr_t>(values_), + ", empty_weight_flag=", empty_weight_flag_, ")"); + } + // TODO(aaroey): make these private. nvinfer1::Dims shape_; tensorflow::DataType type_; @@ -367,11 +389,14 @@ class TRT_TensorOrWeights { public: explicit TRT_TensorOrWeights(nvinfer1::ITensor* tensor) : tensor_(tensor), weights_(DT_FLOAT), variant_(TRT_NODE_TENSOR) {} + explicit TRT_TensorOrWeights(const TRT_ShapedWeights& weights) : tensor_(nullptr), weights_(weights), variant_(TRT_NODE_WEIGHTS) {} + // TODO(aaroey): use rvalue reference. TRT_TensorOrWeights(const TRT_TensorOrWeights& rhs) : tensor_(rhs.tensor_), weights_(rhs.weights_), variant_(rhs.variant_) {} + ~TRT_TensorOrWeights() {} bool is_tensor() const { return variant_ == TRT_NODE_TENSOR; } @@ -381,18 +406,22 @@ class TRT_TensorOrWeights { CHECK(is_tensor()); return tensor_; } + const nvinfer1::ITensor* tensor() const { CHECK(is_tensor()); return tensor_; } + TRT_ShapedWeights& weights() { CHECK(is_weights()); return weights_; } + const TRT_ShapedWeights& weights() const { CHECK(is_weights()); return weights_; } + nvinfer1::Dims shape() const { if (is_tensor()) { return tensor()->getDimensions(); @@ -401,6 +430,18 @@ class TRT_TensorOrWeights { } } + string DebugString() const { + string output = "TRT_TensorOrWeights(type="; + if (is_tensor()) { + StrAppend(&output, "tensor @", reinterpret_cast<uintptr_t>(tensor_), + ", shape=", convert::DebugString(tensor_->getDimensions())); + } else { + StrAppend(&output, "weights=", weights_.DebugString()); + } + StrAppend(&output, ")"); + return output; + } + private: nvinfer1::ITensor* tensor_; TRT_ShapedWeights weights_; @@ -555,7 +596,7 @@ void ReorderCKtoKC(const TRT_ShapedWeights& iweights, } void ReorderRSCKToKCRS(const TRT_ShapedWeights& iweights, - TRT_ShapedWeights* oweights, int num_groups) { + TRT_ShapedWeights* oweights, const int num_groups) { CHECK_EQ(iweights.type_, oweights->type_); CHECK_EQ(iweights.size_bytes(), oweights->size_bytes()); // K indexes over output channels, C over input channels, and R and S over the @@ -563,13 +604,13 @@ void ReorderRSCKToKCRS(const TRT_ShapedWeights& iweights, const int r = iweights.shape_.d[0]; const int s = iweights.shape_.d[1]; // TRT requires GKcRS, while TF depthwise has RSCK where c=1, C=G - VLOG(2) << "num_groups: " << num_groups; const int c = iweights.shape_.d[2] / num_groups; - VLOG(2) << "c" << iweights.shape_.d[2] << " then " << c; const int k = iweights.shape_.d[3] * num_groups; - VLOG(2) << "k" << iweights.shape_.d[3] << " then " << k; - VLOG(2) << "r" << iweights.shape_.d[0] << " then " << r; - VLOG(2) << "s" << iweights.shape_.d[1] << " then " << s; + VLOG(2) << "num_groups: " << num_groups + << "c" << iweights.shape_.d[2] << " then " << c + << "k" << iweights.shape_.d[3] << " then " << k + << "r" << iweights.shape_.d[0] << " then " << r + << "s" << iweights.shape_.d[1] << " then " << s; oweights->shape_.d[0] = k / num_groups; oweights->shape_.d[1] = c * num_groups; oweights->shape_.d[2] = r; @@ -607,63 +648,15 @@ using OpConverter = std::vector<TRT_TensorOrWeights>*)>; class Converter { - // TODO(aaroey): fix the order of members. - std::unordered_map<string, TRT_TensorOrWeights> trt_tensors_; - std::unordered_map<string, OpConverter> op_registry_; - OpConverter plugin_converter_; - nvinfer1::INetworkDefinition* trt_network_; - std::list<std::vector<uint8_t>> temp_bufs_; - // TODO(aaroey): inline the definition of TRTWeightStore here, and add APIs to - // operate the stored weights instead of operating it directly. - TRTWeightStore* weight_store_; - bool fp16_; - void register_op_converters(); - tensorflow::Status get_inputs(const tensorflow::NodeDef& node_def, - std::vector<TRT_TensorOrWeights>* inputs) { - for (auto const& input_name : node_def.input()) { - /************************************************************************* - * TODO(jie): handle case 1) here. - * Normalizes the inputs and extracts associated metadata: - * 1) Inputs can contain a colon followed by a suffix of characters. - * That suffix may be a single number (e.g. inputName:1) or several - * word characters separated from a number by a colon - * (e.g. inputName:foo:1). The - * latter case is used to denote inputs and outputs of functions. - * 2) Control dependency inputs contain caret at the beginning and we - * remove this and annotate the edge as a control dependency. - ************************************************************************/ - // skip control nodes - if (input_name[0] == '^') continue; - string name = input_name; - auto first = name.find_first_of(':'); - // TODO(aaroey): why removing the colon but not the zero? A bug? - if (first != string::npos && first + 2 == name.size() && - name[first + 1] == '0') - name.erase(first); - - VLOG(2) << "retrieve input: " << name; - if (trt_tensors_.count(name)) { - inputs->push_back(trt_tensors_.at(name)); - } else { - // TODO(aaroey): this should not happen, make it a CHECK. - // TODO(aaroey): use StrCat for pattern like this. - string msg("Node "); - StrAppend(&msg, node_def.name(), " should have an input named '", name, - "' but it is not available"); - LOG(ERROR) << msg; - return tensorflow::errors::InvalidArgument(msg); - } - } - return tensorflow::Status::OK(); - } - public: explicit Converter(nvinfer1::INetworkDefinition* trt_network, TRTWeightStore* ws, bool fp16) : trt_network_(trt_network), weight_store_(ws), fp16_(fp16) { this->register_op_converters(); } + TRTWeightStore* weight_store() { return weight_store_; } + TRT_ShapedWeights get_temp_weights(tensorflow::DataType type, nvinfer1::Dims shape) { TRT_ShapedWeights weights(type, nullptr, shape); @@ -672,8 +665,10 @@ class Converter { weights.SetValues(weight_store_->store_.back().data()); return weights; } + // TODO(aaroey): fix all the namings. bool isFP16() { return fp16_; } + TRT_ShapedWeights get_temp_weights_like(const TRT_ShapedWeights& weights) { return this->get_temp_weights(weights.type_, weights.shape_); } @@ -684,7 +679,6 @@ class Converter { const string& op = node_def.op(); std::vector<TRT_TensorOrWeights> outputs; if (PluginFactoryTensorRT::GetInstance()->IsPlugin(op)) { - // TODO(aaroey): plugin_converter_ is not set, fix it. TF_RETURN_IF_ERROR(plugin_converter_(*this, node_def, inputs, &outputs)); } else { if (!op_registry_.count(op)) { @@ -702,7 +696,8 @@ class Converter { if (output.is_tensor()) { output.tensor()->setName(output_name.c_str()); } - VLOG(2) << "Write out tensor: " << output_name; + VLOG(2) << "Adding out tensor " << output_name << ": " + << output.DebugString(); if (!trt_tensors_.insert({output_name, output}).second) { return tensorflow::errors::AlreadyExists( "Output tensor already exists for op: " + op); @@ -751,6 +746,63 @@ class Converter { layer->setReshapeDimensions(reshape_dims); return layer->getOutput(0); } + + private: + std::unordered_map<string, TRT_TensorOrWeights> trt_tensors_; + std::unordered_map<string, OpConverter> op_registry_; + OpConverter plugin_converter_; + nvinfer1::INetworkDefinition* trt_network_; + std::list<std::vector<uint8_t>> temp_bufs_; + + // TODO(aaroey): inline the definition of TRTWeightStore here, and add APIs to + // operate the stored weights instead of operating it directly. + TRTWeightStore* weight_store_; + + bool fp16_; + + void register_op_converters(); + + tensorflow::Status get_inputs(const tensorflow::NodeDef& node_def, + std::vector<TRT_TensorOrWeights>* inputs) { + for (auto const& input_name : node_def.input()) { + /************************************************************************* + * TODO(jie): handle case 1) here. + * Normalizes the inputs and extracts associated metadata: + * 1) Inputs can contain a colon followed by a suffix of characters. + * That suffix may be a single number (e.g. inputName:1) or several + * word characters separated from a number by a colon + * (e.g. inputName:foo:1). The + * latter case is used to denote inputs and outputs of functions. + * 2) Control dependency inputs contain caret at the beginning and we + * remove this and annotate the edge as a control dependency. + ************************************************************************/ + // skip control nodes + if (input_name[0] == '^') continue; + string name = input_name; + auto first = name.find_first_of(':'); + // TODO(aaroey): why removing the colon but not the zero? A bug? + // TODO(aaroey): use TensorId + if (first != string::npos && first + 2 == name.size() && + name[first + 1] == '0') { + name.erase(first); + } + + if (trt_tensors_.count(name)) { + TRT_TensorOrWeights& input = trt_tensors_.at(name); + inputs->push_back(input); + VLOG(2) << "Retrieved input " << name << ": " << input.DebugString(); + } else { + // TODO(aaroey): this should not happen, make it a CHECK. + // TODO(aaroey): use StrCat for pattern like this. + string msg("Node "); + StrAppend(&msg, node_def.name(), " should have an input named '", name, + "' but it is not available"); + LOG(ERROR) << msg; + return tensorflow::errors::InvalidArgument(msg); + } + } + return tensorflow::Status::OK(); + } }; TRT_ShapedWeights ConvertFP32ToFP16(Converter& ctx, @@ -1187,17 +1239,11 @@ tensorflow::Status ConvertConv2DHelper( VLOG(2) << "groups count: " << num_groups; TRT_ShapedWeights weights_rsck = inputs.at(1).weights(); - - VLOG(2) << "weight shape: " << weights_rsck.shape_.nbDims; - for (int i = 0; i < weights_rsck.shape_.nbDims; i++) { - VLOG(2) << weights_rsck.shape_.d[i]; - } - + VLOG(2) << "weight shape: " << weights_rsck.DebugString(); if (weights_rsck.shape_.nbDims != 4) { return tensorflow::errors::Internal( "Conv2D expects kernel of dimension 4, at: " + node_def.name()); } - if (ctx.isFP16()) { weights_rsck = ConvertFP32ToFP16(ctx, inputs.at(1).weights()); } @@ -1209,16 +1255,13 @@ tensorflow::Status ConvertConv2DHelper( nvinfer1::DimsHW kernel_size; kernel_size.h() = weights.shape_.d[2]; kernel_size.w() = weights.shape_.d[3]; - VLOG(2) << "RSCK: "; - for (int i = 0; i < 4; i++) { - VLOG(2) << " " << weights.shape_.d[i]; - } + VLOG(2) << "RSCK: " << weights.DebugString(); VLOG(2) << "kernel size: " << kernel_size.h() << ", " << kernel_size.w(); // TODO(jie): stride. (NHWC/NCHW) const auto tf_stride = attrs.get<std::vector<int>>("strides"); VLOG(2) << "h_INDEX" << h_index << ", w_index " << w_index; - VLOG(2) << "stride!!!: " << tf_stride[0] << tf_stride[1] << tf_stride[2] + VLOG(2) << "stride: " << tf_stride[0] << tf_stride[1] << tf_stride[2] << tf_stride[3]; const nvinfer1::DimsHW stride(tf_stride[h_index], tf_stride[w_index]); @@ -1240,10 +1283,7 @@ tensorflow::Status ConvertConv2DHelper( // TODO(jie): handle asymmetric padding VLOG(2) << "Padding!!!: " << padding[0].first << padding[0].second << padding[1].first << padding[1].second; - - auto dim_before = tensor->getDimensions(); - VLOG(2) << "TENSOR before: " << dim_before.d[0] << ", " << dim_before.d[1] - << dim_before.d[2] << ", " << dim_before.d[3]; + VLOG(2) << "TENSOR before: " << DebugString(tensor->getDimensions()); auto pad_layer = ctx.network()->addPadding( *const_cast<nvinfer1::ITensor*>(tensor), nvinfer1::DimsHW(padding[0].first, padding[1].first), @@ -1251,9 +1291,7 @@ tensorflow::Status ConvertConv2DHelper( TFTRT_RETURN_ERROR_IF_NULLPTR(pad_layer, node_def.name()); padding = {{0, 0}, {0, 0}}; tensor = pad_layer->getOutput(0); - auto dim_after = tensor->getDimensions(); - VLOG(2) << "TENSOR after: " << dim_after.d[0] << ", " << dim_after.d[1] - << dim_after.d[2] << ", " << dim_after.d[3]; + VLOG(2) << "TENSOR after: " << DebugString(tensor->getDimensions()); } nvinfer1::IConvolutionLayer* layer = @@ -1266,17 +1304,12 @@ tensorflow::Status ConvertConv2DHelper( layer->setName(node_def.name().c_str()); layer->setNbGroups(num_groups); nvinfer1::ITensor* output_tensor = layer->getOutput(0); - - auto dim_after = output_tensor->getDimensions(); - VLOG(2) << "TENSOR out: " << dim_after.d[0] << ", " << dim_after.d[1] << ", " - << dim_after.d[2] << ", " << dim_after.d[3]; - + VLOG(2) << "TENSOR out: " << DebugString(output_tensor->getDimensions()); + VLOG(2) << "data_format: " << data_format; if (data_format == "NHWC") { // TODO(jie): transpose it back! output_tensor = ctx.TransposeTensor(output_tensor, {0, 2, 3, 1}); TFTRT_RETURN_ERROR_IF_NULLPTR(output_tensor, node_def.name()); - } else { - VLOG(2) << "NCHW !!!!"; } outputs->push_back(TRT_TensorOrWeights(output_tensor)); return tensorflow::Status::OK(); @@ -1990,22 +2023,22 @@ tensorflow::Status ConvertReduce(Converter& ctx, return tensorflow::errors::Unimplemented("Tidx supports only DT_INT32"); } - const auto keep_dims = attrs.get<bool>("keep_dims"); - auto index_list_data = - static_cast<int*>(const_cast<void*>(index_list.GetValues())); - int axes = 0; if (index_list.count() == 0) { return tensorflow::errors::InvalidArgument( "TRT cannot support reduce on all (batch) dimensions, at", node_def.name()); } else { + auto index_list_data = + static_cast<int*>(const_cast<void*>(index_list.GetValues())); for (int i = 0; i < index_list.count(); i++) { - if (index_list_data[i] == 0) { + int axis = index_list_data[i]; + if (axis < 0) axis += tensor->getDimensions().nbDims + 1; + if (axis == 0) { return tensorflow::errors::InvalidArgument( "TRT cannot reduce at batch dimension, at", node_def.name()); } - axes |= (1 << (index_list_data[i] - 1)); + axes |= (1 << (axis - 1)); } } @@ -2025,6 +2058,7 @@ tensorflow::Status ConvertReduce(Converter& ctx, " , at ", node_def.name()); } + const auto keep_dims = attrs.get<bool>("keep_dims"); nvinfer1::ILayer* layer = ctx.network()->addReduce(*const_cast<nvinfer1::ITensor*>(tensor), reduce_operation, axes, keep_dims); @@ -2694,8 +2728,6 @@ tensorflow::Status ConvertGraphDefToEngine( VLOG(2) << "Converting op name=" << node_name << ", op=" << node_def.op(); if (tensorflow::str_util::StartsWith(node_name, kInputPHName) && (node_def.op() == "Placeholder")) { - nvinfer1::DimsCHW input_dim_pseudo_chw; - for (int i = 0; i < 8; i++) input_dim_pseudo_chw.d[i] = 0; int32 slot_number = -1; if (!tensorflow::strings::safe_strto32( node_name.c_str() + strlen(kInputPHName), &slot_number)) { @@ -2713,28 +2745,25 @@ tensorflow::Status ConvertGraphDefToEngine( LOG(WARNING) << error_message; return Status(status.code(), error_message); } - if (VLOG_IS_ON(1)) { - string dim_str("dims="); - StrAppend(&dim_str, "[ ", shape.dim_size(0)); - for (int i = 1; i < shape.dims(); i++) { - StrAppend(&dim_str, ", ", shape.dim_size(i)); - } - StrAppend(&dim_str, " ]"); - VLOG(1) << dim_str; - } + +#if NV_TENSORRT_MAJOR == 3 + nvinfer1::DimsCHW input_dim; +#elif NV_TENSORRT_MAJOR > 3 + nvinfer1::Dims input_dim; +#endif for (int i = 1; i < shape.dims(); i++) { - input_dim_pseudo_chw.d[i - 1] = shape.dim_size(i); + input_dim.d[i - 1] = shape.dim_size(i); } - - input_dim_pseudo_chw.nbDims = shape.dims() - 1; - nvinfer1::ITensor* input_tensor = converter.network()->addInput( - node_name.c_str(), dtype, input_dim_pseudo_chw); + input_dim.nbDims = shape.dims() - 1; + nvinfer1::ITensor* input_tensor = + converter.network()->addInput(node_name.c_str(), dtype, input_dim); if (!input_tensor) { return tensorflow::errors::InvalidArgument( "Failed to create Input layer tensor ", node_name, " rank=", shape.dims() - 1); } - VLOG(1) << "Input tensor name :" << node_name; + VLOG(2) << "Adding engine input tensor " << node_name << " with shape " + << DebugString(input_dim); if (!converter.insert_input_tensor(node_name, input_tensor)) { return tensorflow::errors::AlreadyExists( "Output tensor already exists for op: " + node_name); @@ -2937,10 +2966,25 @@ bool InputEdgeValidator::operator()(const tensorflow::Edge* in_edge) const { << ": " << status; return false; } - if (shape.dims() < 3 && in_edge->src()->type_string() != "Const") { + + + if (in_edge->src()->type_string() != "Const" && +#if NV_TENSORRT_MAJOR == 3 + // TRT 3.x only support 4 dimensional input tensor. + shape.dims() != 4) { +#else + // Single dimensional input tensor is not supported since the first + // dimension is treated as batch dimension. + shape.dims() < 2) { +#endif VLOG(1) << "--> Need to remove input node " << in_edge->dst()->name() - << " which has an input at port " << in_edge->dst_input() - << " with #dim<3 and is not a const: " << shape; + << " which has an input at port " << in_edge->dst_input() << " with" +#if NV_TENSORRT_MAJOR == 3 + << " #dim!=4" +#else + << " #dim<2" +#endif + << " and is not a const: " << shape; return false; } return true; diff --git a/tensorflow/contrib/tensorrt/convert/convert_nodes.h b/tensorflow/contrib/tensorrt/convert/convert_nodes.h index a60253740f..9274027e63 100644 --- a/tensorflow/contrib/tensorrt/convert/convert_nodes.h +++ b/tensorflow/contrib/tensorrt/convert/convert_nodes.h @@ -36,8 +36,9 @@ limitations under the License. namespace tensorflow { namespace tensorrt { -static const char* kInputPHName = "TensorRTInputPH_"; -static const char* kOutputPHName = "TensorRTOutputPH_"; +extern const char* const kInputPHName; +extern const char* const kOutputPHName; + namespace convert { struct EngineConnection { diff --git a/tensorflow/contrib/tensorrt/convert/trt_optimization_pass.cc b/tensorflow/contrib/tensorrt/convert/trt_optimization_pass.cc index f33f2cc4d6..ff4fba58bf 100644 --- a/tensorflow/contrib/tensorrt/convert/trt_optimization_pass.cc +++ b/tensorflow/contrib/tensorrt/convert/trt_optimization_pass.cc @@ -14,6 +14,7 @@ limitations under the License. #include "tensorflow/contrib/tensorrt/convert/trt_optimization_pass.h" #include "tensorflow/contrib/tensorrt/convert/convert_graph.h" +#include "tensorflow/contrib/tensorrt/convert/utils.h" #include "tensorflow/core/grappler/clusters/cluster.h" #include "tensorflow/core/grappler/grappler_item.h" #include "tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.h" @@ -37,7 +38,6 @@ tensorflow::Status TRTOptimizationPass::Init( const tensorflow::RewriterConfig_CustomGraphOptimizer* config) { VLOG(1) << "Called INIT for " << name_ << " with config = " << config; if (config == nullptr) { - maximum_workspace_size_ = 2 << 30; return tensorflow::Status::OK(); } const auto params = config->parameter_map(); @@ -47,7 +47,6 @@ tensorflow::Status TRTOptimizationPass::Init( if (params.count("max_batch_size")) { maximum_batch_size_ = params.at("max_batch_size").i(); } - is_dynamic_op_ = false; if (params.count("is_dynamic_op")) { is_dynamic_op_ = params.at("is_dynamic_op").b(); } @@ -58,27 +57,15 @@ tensorflow::Status TRTOptimizationPass::Init( batches_.push_back(i); } } - max_cached_batches_ = 1; if (params.count("maximum_cached_engines")) { max_cached_batches_ = params.at("maximum_cached_engines").i(); } if (params.count("max_workspace_size_bytes")) { - maximum_workspace_size_ = params.at("max_workspace_size_bytes").i(); + max_workspace_size_bytes_ = params.at("max_workspace_size_bytes").i(); } if (params.count("precision_mode")) { - string pm = Uppercase(params.at("precision_mode").s()); - if (pm == "FP32") { - precision_mode_ = 0; - } else if (pm == "FP16") { - precision_mode_ = 1; - } else if (pm == "INT8") { - precision_mode_ = 2; - } else { - LOG(ERROR) << "Unknown precision mode '" << pm << "'"; - return tensorflow::errors::InvalidArgument( - "Unknown precision mode argument" + pm + - " Valid values are FP32, FP16, INT8"); - } + TF_RETURN_IF_ERROR(GetPrecisionMode( + Uppercase(params.at("precision_mode").s()), &precision_mode_)); } return tensorflow::Status::OK(); } @@ -255,7 +242,7 @@ tensorflow::Status TRTOptimizationPass::Optimize( cp.input_graph_def = &item.graph; cp.output_names = &nodes_to_preserve; cp.max_batch_size = maximum_batch_size_; - cp.max_workspace_size_bytes = maximum_workspace_size_; + cp.max_workspace_size_bytes = max_workspace_size_bytes_; cp.output_graph_def = optimized_graph; cp.precision_mode = precision_mode_; cp.minimum_segment_size = minimum_segment_size_; diff --git a/tensorflow/contrib/tensorrt/convert/trt_optimization_pass.h b/tensorflow/contrib/tensorrt/convert/trt_optimization_pass.h index 463ed3883e..71b51d1368 100644 --- a/tensorflow/contrib/tensorrt/convert/trt_optimization_pass.h +++ b/tensorflow/contrib/tensorrt/convert/trt_optimization_pass.h @@ -36,7 +36,9 @@ class TRTOptimizationPass : public tensorflow::grappler::CustomGraphOptimizer { minimum_segment_size_(3), precision_mode_(0), maximum_batch_size_(-1), - maximum_workspace_size_(-1) { + is_dynamic_op_(false), + max_cached_batches_(1), + max_workspace_size_bytes_(256LL << 20) { VLOG(1) << "Constructing " << name_; } @@ -57,14 +59,14 @@ class TRTOptimizationPass : public tensorflow::grappler::CustomGraphOptimizer { const tensorflow::grappler::GrapplerItem& item); private: - string name_; + const string name_; int minimum_segment_size_; int precision_mode_; int maximum_batch_size_; bool is_dynamic_op_; std::vector<int> batches_; int max_cached_batches_; - int64_t maximum_workspace_size_; + int64_t max_workspace_size_bytes_; }; } // namespace convert diff --git a/tensorflow/contrib/tensorrt/resources/trt_resource_manager.h b/tensorflow/contrib/tensorrt/resources/trt_resource_manager.h index bc15b51e05..19f39e6d3d 100644 --- a/tensorflow/contrib/tensorrt/resources/trt_resource_manager.h +++ b/tensorflow/contrib/tensorrt/resources/trt_resource_manager.h @@ -42,4 +42,4 @@ class TRTResourceManager { } // namespace tensorrt } // namespace tensorflow -#endif // TENSORFLOW_CONTRIB_TENSORRT_RESOURCE_TRT_RESOURCE_MANAGER_H_ +#endif // TENSORFLOW_CONTRIB_TENSORRT_RESOURCES_TRT_RESOURCE_MANAGER_H_ diff --git a/tensorflow/contrib/tensorrt/segment/segment.cc b/tensorflow/contrib/tensorrt/segment/segment.cc index b43f1b190f..c82d4a0183 100644 --- a/tensorflow/contrib/tensorrt/segment/segment.cc +++ b/tensorflow/contrib/tensorrt/segment/segment.cc @@ -74,6 +74,7 @@ class SimpleNode { const std::vector<SimpleEdge*>& in_edges() const { return in_edges_; } const std::vector<SimpleEdge*>& out_edges() const { return out_edges_; } + std::vector<SimpleNode*> in_nodes() const { std::vector<SimpleNode*> res; res.reserve(in_edges_.size()); @@ -82,6 +83,16 @@ class SimpleNode { } return res; } + + std::vector<SimpleNode*> out_nodes() const { + std::vector<SimpleNode*> res; + res.reserve(out_edges_.size()); + for (const auto e : out_edges_) { + if (e) res.push_back(e->dst()); + } + return res; + } + const string& name() const { return node_->name(); } const tensorflow::Node* tf_node() const { return node_; } int id() const { return id_; } @@ -215,45 +226,53 @@ SimpleGraph::~SimpleGraph() { namespace { -bool CheckCycles(const std::unique_ptr<SimpleGraph>& g, const SimpleNode* src, - const std::vector<SimpleNode*>& start) { - // Copied from TF ReverseDFS, which only works for tensorflow::Graph. +// Copied from TF ReverseDFS, which only works for tensorflow::Graph. +void StableDFS(const SimpleGraph& g, bool reverse, + const std::vector<const SimpleNode*>& start, + const std::function<bool(const SimpleNode*)>& enter, + const std::function<bool(const SimpleNode*)>& leave) { + // Stack of work to do. struct Work { - SimpleNode* node; + const SimpleNode* node; bool leave; // Are we entering or leaving n? }; - std::vector<Work> stack(start.size()); for (int i = 0; i < start.size(); ++i) { stack[i] = Work{start[i], false}; } - std::vector<bool> visited(g->num_node_ids(), false); + auto get_nodes = reverse ? [](const SimpleNode* n) { return n->in_nodes(); } + : [](const SimpleNode* n) { return n->out_nodes(); }; + std::vector<bool> visited(g.num_node_ids(), false); while (!stack.empty()) { Work w = stack.back(); stack.pop_back(); auto n = w.node; if (w.leave) { - if (n == src) { - return true; - } + if (leave && !leave(n)) return; continue; } if (visited[n->id()]) continue; visited[n->id()] = true; - // Arrange to call leave(n) when all done with descendants. - stack.push_back(Work{n, true}); + if (enter && !enter(n)) return; - auto nodes = n->in_nodes(); - for (const auto node : nodes) { + // Arrange to call leave(n) when all done with descendants. + if (leave) stack.push_back(Work{n, true}); + + auto nodes = get_nodes(n); + std::vector<const SimpleNode*> nodes_sorted(nodes.begin(), nodes.end()); + std::sort(nodes_sorted.begin(), nodes_sorted.end(), + [](const SimpleNode* lhs, const SimpleNode* rhs) { + return lhs->name() < rhs->name(); + }); + for (const SimpleNode* node : nodes_sorted) { if (!visited[node->id()]) { stack.push_back(Work{node, false}); } } } - return false; } bool CanContractEdge(const SimpleEdge* edge, @@ -289,14 +308,21 @@ bool CanContractEdge(const SimpleEdge* edge, // To achieve this goal, the correct way seems to be: // 1. remove any direct edge from src->dst; // 2. detect if src can reach dst, if so they cannot be merged. - std::vector<SimpleNode*> dfs_start_nodes; - for (SimpleNode* node : dst->in_nodes()) { + std::vector<const SimpleNode*> dfs_start_nodes; + for (const SimpleNode* node : dst->in_nodes()) { if (node != src) { dfs_start_nodes.push_back(node); } } - - const bool has_cycle = CheckCycles(graph, src, dfs_start_nodes); + bool has_cycle = false; + StableDFS(*graph, /*reverse=*/true, dfs_start_nodes, /*enter=*/nullptr, + [&has_cycle, src](const SimpleNode* n) { + if (n == src) { + has_cycle = true; + return false; + } + return true; + }); return !has_cycle; } } // namespace @@ -403,15 +429,13 @@ tensorflow::Status SegmentGraph( // In the future if we have a measure of how beneficial it is to include a // given node in a TRT subgraph then we can revisit this algorithm to take // advantage of that information. - std::vector<tensorflow::Node*> tforder; - tensorflow::GetPostOrder(*tf_graph, &tforder); - // use postorder implementation from tensorflow and construct mirror in - // internal format - std::vector<SimpleNode*> order; - order.reserve(tforder.size()); - for (const auto tfnode : tforder) { - order.push_back(graph->FindNodeId(tfnode->id())); - } + std::vector<const SimpleNode*> order; + order.reserve(graph->num_node_ids()); + StableDFS(*graph, /*reverse=*/false, {graph->source_node()}, + /*enter=*/nullptr, [&order](const SimpleNode* n) { + order.push_back(n); + return true; + }); for (const SimpleNode* node : order) { // All output nodes of 'node' have been visited... VLOG(3) << "Trying node " << node->name() << " id=" << node->id(); diff --git a/tensorflow/contrib/tensorrt/test/base_test.py b/tensorflow/contrib/tensorrt/test/base_test.py index 8ea5a63735..e9ac833d55 100644 --- a/tensorflow/contrib/tensorrt/test/base_test.py +++ b/tensorflow/contrib/tensorrt/test/base_test.py @@ -40,6 +40,7 @@ class SimpleSingleEngineTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [100, 24, 24, 2] + output_name = "output" g = ops.Graph() with g.as_default(): inp = array_ops.placeholder( @@ -62,19 +63,21 @@ class SimpleSingleEngineTest(trt_test.TfTrtIntegrationTestBase): identity = array_ops.identity(relu, "identity") pool = nn_ops.max_pool( identity, [1, 2, 2, 1], [1, 2, 2, 1], "VALID", name="max_pool") - array_ops.squeeze(pool, name=self.output_name) + array_ops.squeeze(pool, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - # TODO(aaroey): LayoutOptimizer adds additional nodes to the graph which - # breaks the connection check, fix it. - # - my_trt_op_0 should have ["weights", "conv", "bias", "bias_add", - # "relu", "identity", "max_pool"] - expected_engines=["my_trt_op_0"], - expected_output_dims=(100, 6, 6, 6), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(100, 6, 6, 6)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + # TODO(aaroey): LayoutOptimizer adds additional nodes to the graph which + # breaks the connection check, fix it. + # - my_trt_op_0 should have ["weights", "conv", "bias", "bias_add", + # "relu", "identity", "max_pool"] + return ["my_trt_op_0"] class SimpleMultiEnginesTest(trt_test.TfTrtIntegrationTestBase): @@ -85,6 +88,7 @@ class SimpleMultiEnginesTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [100, 24, 24, 2] + output_name = "output" g = ops.Graph() with g.as_default(): inp = array_ops.placeholder( @@ -115,20 +119,22 @@ class SimpleMultiEnginesTest(trt_test.TfTrtIntegrationTestBase): q = math_ops.mul(q, edge, name="mul1") s = math_ops.add(p, q, name="add1") s = math_ops.sub(s, r, name="sub1") - array_ops.squeeze(s, name=self.output_name) + array_ops.squeeze(s, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - # TODO(aaroey): LayoutOptimizer adds additional nodes to the graph which - # breaks the connection check, fix it. - # - my_trt_op_0 should have ["mul", "sub", "div1", "mul1", "add1", - # "add", "sub1"]; - # - my_trt_op_1 should have ["weights","conv", "div"] - expected_engines=["my_trt_op_0", "my_trt_op_1"], - expected_output_dims=(100, 12, 12, 6), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(100, 12, 12, 6)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + # TODO(aaroey): LayoutOptimizer adds additional nodes to the graph which + # breaks the connection check, fix it. + # - my_trt_op_0 should have ["mul", "sub", "div1", "mul1", "add1", + # "add", "sub1"]; + # - my_trt_op_1 should have ["weights","conv", "div"] + return ["my_trt_op_0", "my_trt_op_1"] class PartiallyConvertedTestA(trt_test.TfTrtIntegrationTestBase): @@ -143,6 +149,7 @@ class PartiallyConvertedTestA(trt_test.TfTrtIntegrationTestBase): """Create a graph containing two segment.""" input_name = "input" input_dims = [2, 32, 32, 3] + output_name = "output" g = ops.Graph() with g.as_default(): inp = array_ops.placeholder( @@ -161,18 +168,20 @@ class PartiallyConvertedTestA(trt_test.TfTrtIntegrationTestBase): c = constant_op.constant(1.0, name="c3") n = math_ops.add(n, c, name="add3") n = math_ops.mul(n, n, name="mul3") - array_ops.squeeze(n, name=self.output_name) + array_ops.squeeze(n, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines={ - # Only the first engine is built. - "my_trt_op_0": ["c0", "c1", "add0", "add1", "mul0", "mul1"] - }, - expected_output_dims=tuple(input_dims), - allclose_atol=1.e-06, - allclose_rtol=1.e-06) + output_names=[output_name], + expected_output_dims=[tuple(input_dims)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return { + # Only the first engine is built. + "my_trt_op_0": ["c0", "c1", "add0", "add1", "mul0", "mul1"] + } class PartiallyConvertedTestB(PartiallyConvertedTestA): @@ -184,13 +193,12 @@ class PartiallyConvertedTestB(PartiallyConvertedTestA): trt_convert.clear_test_values("") trt_convert.add_test_value("my_trt_op_0:CreateTRTNode", "fail") - def GetParams(self): - """Create a graph containing two segment.""" - return super(PartiallyConvertedTestB, self).GetParams()._replace( - expected_engines={ - # Only the second engine is built. - "my_trt_op_1": ["c2", "c3", "add2", "add3", "mul2", "mul3"] - }) + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return { + # Only the second engine is built. + "my_trt_op_1": ["c2", "c3", "add2", "add3", "mul2", "mul3"] + } class ConstInputTest(trt_test.TfTrtIntegrationTestBase): @@ -199,6 +207,7 @@ class ConstInputTest(trt_test.TfTrtIntegrationTestBase): """Create a graph containing multiple segment.""" input_name = "input" input_dims = [2, 32, 32, 3] + output_name = "output" g = ops.Graph() with g.as_default(): inp = array_ops.placeholder( @@ -221,18 +230,20 @@ class ConstInputTest(trt_test.TfTrtIntegrationTestBase): n = math_ops.add(n, c, name="add2") n = math_ops.mul(n, n, name="mul1") n = math_ops.add(n, n, name="add3") - array_ops.squeeze(n, name=self.output_name) + array_ops.squeeze(n, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines={ - "my_trt_op_0": ["add", "add1", "mul"], - "my_trt_op_1": ["add2", "add3", "mul1"] - }, - expected_output_dims=tuple(input_dims), - allclose_atol=1.e-06, - allclose_rtol=1.e-06) + output_names=[output_name], + expected_output_dims=[tuple(input_dims)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return { + "my_trt_op_0": ["add", "add1", "mul"], + "my_trt_op_1": ["add2", "add3", "mul1"] + } class ConstDataInputSingleEngineTest(trt_test.TfTrtIntegrationTestBase): @@ -241,6 +252,7 @@ class ConstDataInputSingleEngineTest(trt_test.TfTrtIntegrationTestBase): """Create a graph containing single segment.""" input_name = "input" input_dims = [2, 32, 32, 3] + output_name = "output" g = ops.Graph() with g.as_default(): inp = array_ops.placeholder( @@ -251,15 +263,17 @@ class ConstDataInputSingleEngineTest(trt_test.TfTrtIntegrationTestBase): n = math_ops.add(n, c, name="add") n = math_ops.mul(n, n, name="mul") n = math_ops.add(n, n, name="add1") - array_ops.squeeze(n, name=self.output_name) + array_ops.squeeze(n, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines={"my_trt_op_0": ["c", "add", "add1", "mul"]}, - expected_output_dims=tuple(input_dims), - allclose_atol=1.e-06, - allclose_rtol=1.e-06) + output_names=[output_name], + expected_output_dims=[tuple(input_dims)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return {"my_trt_op_0": ["c", "add", "add1", "mul"]} class ConstDataInputMultipleEnginesTest(trt_test.TfTrtIntegrationTestBase): @@ -268,6 +282,7 @@ class ConstDataInputMultipleEnginesTest(trt_test.TfTrtIntegrationTestBase): """Create a graph containing multiple segment.""" input_name = "input" input_dims = [2, 32, 32, 3] + output_name = "output" g = ops.Graph() with g.as_default(): inp = array_ops.placeholder( @@ -282,22 +297,24 @@ class ConstDataInputMultipleEnginesTest(trt_test.TfTrtIntegrationTestBase): n = math_ops.add(n, c, name="add2") n = math_ops.mul(n, n, name="mul1") n = math_ops.add(n, n, name="add3") - array_ops.squeeze(n, name=self.output_name) + array_ops.squeeze(n, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines={ - "my_trt_op_0": ["add2", "add3", "mul1"], - # Why segment ["add", "add1", "mul"] was assigned segment id 1 - # instead of 0: the parent node of this segment is actually const - # node 'c', but it's removed later since it's const output of the - # segment which is not allowed. - "my_trt_op_1": ["add", "add1", "mul"] - }, - expected_output_dims=tuple(input_dims), - allclose_atol=1.e-06, - allclose_rtol=1.e-06) + output_names=[output_name], + expected_output_dims=[tuple(input_dims)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return { + "my_trt_op_0": ["add2", "add3", "mul1"], + # Why segment ["add", "add1", "mul"] was assigned segment id 1 + # instead of 0: the parent node of this segment is actually const + # node 'c', but it's removed later since it's const output of the + # segment which is not allowed. + "my_trt_op_1": ["add", "add1", "mul"] + } class ControlDependencyTest(trt_test.TfTrtIntegrationTestBase): @@ -306,6 +323,7 @@ class ControlDependencyTest(trt_test.TfTrtIntegrationTestBase): """Create a graph containing multiple segment.""" input_name = "input" input_dims = [2, 32, 32, 3] + output_name = "output" g = ops.Graph() with g.as_default(): inp = array_ops.placeholder( @@ -328,18 +346,20 @@ class ControlDependencyTest(trt_test.TfTrtIntegrationTestBase): mul1 = math_ops.mul(add2, add2, name="mul1") with g.control_dependencies([d1, d2, add, add1]): add3 = math_ops.add(mul1, mul1, name="add3") - array_ops.squeeze(add3, name=self.output_name) + array_ops.squeeze(add3, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines={ - "my_trt_op_0": ["c1", "add", "add1", "mul"], - "my_trt_op_1": ["c2", "add2", "add3", "mul1"] - }, - expected_output_dims=tuple(input_dims), - allclose_atol=1.e-06, - allclose_rtol=1.e-06) + output_names=[output_name], + expected_output_dims=[tuple(input_dims)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return { + "my_trt_op_0": ["c1", "add", "add1", "mul"], + "my_trt_op_1": ["c2", "add2", "add3", "mul1"] + } if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/batch_matmul_test.py b/tensorflow/contrib/tensorrt/test/batch_matmul_test.py index 2e1107e303..2f153c6f2f 100644 --- a/tensorflow/contrib/tensorrt/test/batch_matmul_test.py +++ b/tensorflow/contrib/tensorrt/test/batch_matmul_test.py @@ -37,6 +37,7 @@ class BatchMatMulTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [12, 5, 8, 12] + output_name = "output" w1_name = "matmul_w1" w1_dims = [12, 5, 12, 7] w2_name = "matmul_w2" @@ -61,15 +62,46 @@ class BatchMatMulTest(trt_test.TfTrtIntegrationTestBase): x3 = x3 + f x3 = gen_array_ops.reshape(x3, [12, 5, 8, 7]) out = x1 + x2 + x3 - array_ops.squeeze(out, name=self.output_name) + array_ops.squeeze(out, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name, w1_name, w2_name], input_dims=[input_dims, w1_dims, w2_dims], - expected_engines=["my_trt_op_0"], - expected_output_dims=(12, 5, 8, 7), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(12, 5, 8, 7)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + if (run_params.dynamic_engine and + not trt_test.IsQuantizationMode(run_params.precision_mode)): + return ["my_trt_op_0", "my_trt_op_1"] + return ["my_trt_op_1"] + + def ExpectedEnginesToRun(self, run_params): + """Return the expected engines to run.""" + return ["my_trt_op_1"] + + def ShouldRunTest(self, run_params): + """Whether to run the test.""" + # TODO(aaroey): Trt library will fail like: + # + # ../builder/cudnnBuilder2.cpp:685: + # virtual std::vector<nvinfer1::query::Ports< + # nvinfer1::query::TensorRequirements>> + # nvinfer1::builder::Node::getSupportedFormats( + # const nvinfer1::query::Ports<nvinfer1::query::AbstractTensor>&, + # const nvinfer1::cudnn::HardwareContext&, + # nvinfer1::builder::Format::Type, + # const nvinfer1::builder::FormatTypeHack&) const: + # Assertion `sf' failed. + # + # To reproduce, run: + # bazel test -c opt --copt=-mavx \ + # --test_arg=BatchMatMulTest.testTfTrt_ToolConversion_INT8_DynamicEngine \ + # tensorflow/contrib/tensorrt:batch_matmul_test + # + # Investigate and fix it. + return not trt_test.IsQuantizationMode(run_params.precision_mode) if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/biasadd_matmul_test.py b/tensorflow/contrib/tensorrt/test/biasadd_matmul_test.py index 8be32f59b4..62f4e525f7 100644 --- a/tensorflow/contrib/tensorrt/test/biasadd_matmul_test.py +++ b/tensorflow/contrib/tensorrt/test/biasadd_matmul_test.py @@ -38,6 +38,7 @@ class BiasaddMatMulTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [48, 12] + output_name = "output" g = ops.Graph() with g.as_default(): x = array_ops.placeholder(dtype=dtype, shape=input_dims, name=input_name) @@ -97,18 +98,59 @@ class BiasaddMatMulTest(trt_test.TfTrtIntegrationTestBase): out = array_ops.concat( [x1, x2, x3, x4, x5, x6, x7, x8, x9, x10, x11], axis=-1) - out = array_ops.squeeze(out, name=self.output_name) + out = array_ops.squeeze(out, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines=[ - "my_trt_op_0", "my_trt_op_1", "my_trt_op_2", "my_trt_op_3", - "my_trt_op_4", "my_trt_op_5", "my_trt_op_6" - ], - expected_output_dims=(48, 89), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(48, 89)]) + + def GetConversionParams(self, run_params): + """Return a ConversionParams for test.""" + return super(BiasaddMatMulTest, + self).GetConversionParams(run_params)._replace( + max_batch_size=48, maximum_cached_engines=2) + + def _ValidEngines(self): + """Engines expected to build and run.""" + return [ + "my_trt_op_0", "my_trt_op_1", "my_trt_op_2", "my_trt_op_6", + "my_trt_op_7", "my_trt_op_8", "my_trt_op_9" + ] + + def _InvalidEngines(self): + """Engines that will cause conversion error at building time.""" + return ["my_trt_op_3", "my_trt_op_4", "my_trt_op_5"] + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + # In dynamic engine mode the engines are built in execution time, not in + # conversion time, so build errors occurs later. Here three of the engines + # will be failed to built but the corresponding engine op are still created. + # TODO(aaroey, jjsjann123): fix this. + if (run_params.dynamic_engine and + not trt_test.IsQuantizationMode(run_params.precision_mode)): + return self._ValidEngines() + self._InvalidEngines() + return self._ValidEngines() + + def ExpectedEnginesToRun(self, run_params): + """Return the expected engines to run.""" + return self._ValidEngines() + + def ShouldRunTest(self, run_params): + """Whether to run the test.""" + # TODO(aaroey): Trt 4.0 forbids conversion for tensors with rank <3 in int8 + # mode, which is a bug. Re-enable this when trt library is fixed. + return not trt_test.IsQuantizationMode(run_params.precision_mode) + + def ExpectedAbsoluteTolerance(self, run_params): + """The absolute tolerance to compare floating point results.""" + return 1.e-05 if run_params.precision_mode == "FP32" else 1.e-03 + + def ExpectedRelativeTolerance(self, run_params): + """The relative tolerance to compare floating point results.""" + return 1.e-05 if run_params.precision_mode == "FP32" else 1.e-03 if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/binary_tensor_weight_broadcast_test.py b/tensorflow/contrib/tensorrt/test/binary_tensor_weight_broadcast_test.py index 9316b14da0..f126ed4238 100644 --- a/tensorflow/contrib/tensorrt/test/binary_tensor_weight_broadcast_test.py +++ b/tensorflow/contrib/tensorrt/test/binary_tensor_weight_broadcast_test.py @@ -37,6 +37,7 @@ class BinaryTensorWeightBroadcastTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [10, 24, 24, 20] + output_name = "output" g = ops.Graph() with g.as_default(): x = array_ops.placeholder(dtype=dtype, shape=input_dims, name=input_name) @@ -104,32 +105,34 @@ class BinaryTensorWeightBroadcastTest(trt_test.TfTrtIntegrationTestBase): a = constant_op.constant(np.random.randn(24, 20), dtype=dtype) f = x + a x = math_ops.sigmoid(f) - gen_array_ops.reshape(x, [5, -1], name=self.output_name) + gen_array_ops.reshape(x, [5, -1], name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines=[ - "my_trt_op_0", - "my_trt_op_1", - "my_trt_op_2", - "my_trt_op_3", - "my_trt_op_4", - "my_trt_op_5", - "my_trt_op_6", - "my_trt_op_7", - "my_trt_op_8", - "my_trt_op_9", - "my_trt_op_10", - "my_trt_op_11", - "my_trt_op_12", - "my_trt_op_13", - "my_trt_op_14", - "my_trt_op_15", - ], - expected_output_dims=(5, 23040), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(5, 23040)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return [ + "my_trt_op_0", + "my_trt_op_1", + "my_trt_op_2", + "my_trt_op_3", + "my_trt_op_4", + "my_trt_op_5", + "my_trt_op_6", + "my_trt_op_7", + "my_trt_op_8", + "my_trt_op_9", + "my_trt_op_10", + "my_trt_op_11", + "my_trt_op_12", + "my_trt_op_13", + "my_trt_op_14", + "my_trt_op_15", + ] if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/concatenation_test.py b/tensorflow/contrib/tensorrt/test/concatenation_test.py index 1874b9dd45..465cb02296 100644 --- a/tensorflow/contrib/tensorrt/test/concatenation_test.py +++ b/tensorflow/contrib/tensorrt/test/concatenation_test.py @@ -37,6 +37,7 @@ class ConcatenationTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [2, 3, 3, 1] + output_name = "output" g = ops.Graph() with g.as_default(): x = array_ops.placeholder(dtype=dtype, shape=input_dims, name=input_name) @@ -68,15 +69,17 @@ class ConcatenationTest(trt_test.TfTrtIntegrationTestBase): concat1 = array_ops.concat([r1, r2, r3, r4, r5, r6], axis=-1) concat2 = array_ops.concat([r7, r8, r9, r10, r11, r12], axis=3) x = array_ops.concat([concat1, concat2], axis=-1) - gen_array_ops.reshape(x, [2, -1], name=self.output_name) + gen_array_ops.reshape(x, [2, -1], name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines=["my_trt_op_0"], - expected_output_dims=(2, 126), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(2, 126)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return ["my_trt_op_0"] if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/const_broadcast_test.py b/tensorflow/contrib/tensorrt/test/const_broadcast_test.py index 8c59000b70..e32f047866 100644 --- a/tensorflow/contrib/tensorrt/test/const_broadcast_test.py +++ b/tensorflow/contrib/tensorrt/test/const_broadcast_test.py @@ -36,6 +36,7 @@ class ConstBroadcastTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = 'input' input_dims = [5, 12, 12, 2] + output_name = 'output' g = ops.Graph() with g.as_default(): x = array_ops.placeholder(dtype=dtype, shape=input_dims, name=input_name) @@ -53,15 +54,25 @@ class ConstBroadcastTest(trt_test.TfTrtIntegrationTestBase): dtype=dtype, name='filt3') y3 = nn.conv2d(z2, filt3, strides=[1, 1, 1, 1], padding='SAME', name='y3') - nn.relu(y3, name='output') + nn.relu(y3, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines=['my_trt_op_0'], - expected_output_dims=(5, 12, 12, 1), - allclose_atol=1.e-02, - allclose_rtol=1.e-02) + output_names=[output_name], + expected_output_dims=[(5, 12, 12, 1)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return ['my_trt_op_0'] + + def ExpectedAbsoluteTolerance(self, run_params): + """The absolute tolerance to compare floating point results.""" + return 1.e-04 if run_params.precision_mode == 'FP32' else 1.e-02 + + def ExpectedRelativeTolerance(self, run_params): + """The relative tolerance to compare floating point results.""" + return 1.e-04 if run_params.precision_mode == 'FP32' else 1.e-02 if __name__ == '__main__': diff --git a/tensorflow/contrib/tensorrt/test/manual_test.py b/tensorflow/contrib/tensorrt/test/manual_test.py new file mode 100644 index 0000000000..1187c759b4 --- /dev/null +++ b/tensorflow/contrib/tensorrt/test/manual_test.py @@ -0,0 +1,114 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Basic tests for TF-TensorRT integration.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import ast +import os + +from tensorflow.contrib.tensorrt.test import tf_trt_integration_test_base as trt_test +from tensorflow.core.framework import graph_pb2 +from tensorflow.python.platform import gfile +from tensorflow.python.platform import test + + +class ManualTest(trt_test.TfTrtIntegrationTestBase): + + def __init__(self, methodName='runTest'): # pylint: disable=invalid-name + super(ManualTest, self).__init__(methodName) + self._params_map = None + + def _GetEnv(self): + """Get an environment variable specifying the manual test parameters. + + The value of the environment variable is the string representation of a dict + which should contain the following keys: + - 'graph_path': the file path to the serialized frozen graphdef + - 'input_names': TfTrtIntegrationTestParams.input_names + - 'input_dims': TfTrtIntegrationTestParams.input_dims + - 'expected_output_dims': TfTrtIntegrationTestParams.expected_output_dims + - 'output_name': the name of op to fetch + - 'expected_engines_to_run': ExpectedEnginesToRun() will return this + - 'expected_engines_to_build': ExpectedEnginesToBuild() will return this + - 'max_batch_size': ConversionParams.max_batch_size + + Returns: + The value of the environment variable. + """ + return os.getenv('TRT_MANUAL_TEST_PARAMS', '') + + def _GetParamsMap(self): + """Parse the environment variable as a dict and return it.""" + if self._params_map is None: + self._params_map = ast.literal_eval(self._GetEnv()) + return self._params_map + + def GetParams(self): + """Testing conversion of manually provided frozen graph.""" + params_map = self._GetParamsMap() + gdef = graph_pb2.GraphDef() + with gfile.Open(params_map['graph_path'], 'rb') as f: + gdef.ParseFromString(f.read()) + return trt_test.TfTrtIntegrationTestParams( + gdef=gdef, + input_names=params_map['input_names'], + input_dims=params_map['input_dims'], + output_names=params_map['output_names'], + expected_output_dims=params_map['expected_output_dims']) + + def GetConversionParams(self, run_params): + """Return a ConversionParams for test.""" + conversion_params = super(ManualTest, self).GetConversionParams(run_params) + params_map = self._GetParamsMap() + if 'max_batch_size' in params_map: + conversion_params = conversion_params._replace( + max_batch_size=params_map['max_batch_size']) + return conversion_params + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return self._GetParamsMap()['expected_engines_to_build'] + + def ExpectedEnginesToRun(self, run_params): + """Return the expected engines to run.""" + params_map = self._GetParamsMap() + if 'expected_engines_to_run' in params_map: + return params_map['expected_engines_to_run'] + return self.ExpectedEnginesToBuild(run_params) + + def ExpectedAbsoluteTolerance(self, run_params): + """The absolute tolerance to compare floating point results.""" + params_map = self._GetParamsMap() + if 'atol' in params_map: + return params_map['atol'] + return 1.e-3 + + def ExpectedRelativeTolerance(self, run_params): + """The relative tolerance to compare floating point results.""" + params_map = self._GetParamsMap() + if 'rtol' in params_map: + return params_map['rtol'] + return 1.e-3 + + def ShouldRunTest(self, run_params): + """Whether to run the test.""" + return len(self._GetEnv()) + + +if __name__ == '__main__': + test.main() diff --git a/tensorflow/contrib/tensorrt/test/memory_alignment_test.py b/tensorflow/contrib/tensorrt/test/memory_alignment_test.py index 66eb6be757..bc7c90081f 100644 --- a/tensorflow/contrib/tensorrt/test/memory_alignment_test.py +++ b/tensorflow/contrib/tensorrt/test/memory_alignment_test.py @@ -36,6 +36,7 @@ class MemoryAlignmentTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [2, 15, 15, 3] + output_name = "output" g = ops.Graph() with g.as_default(): inp = array_ops.placeholder( @@ -57,15 +58,25 @@ class MemoryAlignmentTest(trt_test.TfTrtIntegrationTestBase): strides=[1, 1, 1, 1], padding="VALID", name="conv_2") - array_ops.squeeze(out, name=self.output_name) + array_ops.squeeze(out, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines=["my_trt_op_0"], - expected_output_dims=(2, 15, 15, 10), - allclose_atol=1.e-02, - allclose_rtol=1.e-02) + output_names=[output_name], + expected_output_dims=[(2, 15, 15, 10)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return ["my_trt_op_0"] + + def ExpectedAbsoluteTolerance(self, run_params): + """The absolute tolerance to compare floating point results.""" + return 1.e-06 if run_params.precision_mode == "FP32" else 1.e-02 + + def ExpectedRelativeTolerance(self, run_params): + """The relative tolerance to compare floating point results.""" + return 0.1 if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/multi_connection_neighbor_engine_test.py b/tensorflow/contrib/tensorrt/test/multi_connection_neighbor_engine_test.py index fd55b8cd99..11be4feaf7 100644 --- a/tensorflow/contrib/tensorrt/test/multi_connection_neighbor_engine_test.py +++ b/tensorflow/contrib/tensorrt/test/multi_connection_neighbor_engine_test.py @@ -38,6 +38,7 @@ class MultiConnectionNeighborEngineTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [2, 3, 7, 5] + output_name = "output" g = ops.Graph() with g.as_default(): x = array_ops.placeholder(dtype=dtype, shape=input_dims, name=input_name) @@ -72,15 +73,17 @@ class MultiConnectionNeighborEngineTest(trt_test.TfTrtIntegrationTestBase): t = t + q t = t + d t = t - edge3 - array_ops.squeeze(t, name=self.output_name) + array_ops.squeeze(t, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines=["my_trt_op_0", "my_trt_op_1"], - expected_output_dims=(2, 4, 5, 4), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(2, 4, 5, 4)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return ["my_trt_op_0", "my_trt_op_1"] if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/neighboring_engine_test.py b/tensorflow/contrib/tensorrt/test/neighboring_engine_test.py index 51c905a50b..eddeafa38b 100644 --- a/tensorflow/contrib/tensorrt/test/neighboring_engine_test.py +++ b/tensorflow/contrib/tensorrt/test/neighboring_engine_test.py @@ -37,6 +37,7 @@ class NeighboringEngineTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [2, 3, 7, 5] + output_name = "output" g = ops.Graph() with g.as_default(): x = array_ops.placeholder(dtype=dtype, shape=input_dims, name=input_name) @@ -54,18 +55,20 @@ class NeighboringEngineTest(trt_test.TfTrtIntegrationTestBase): t = math_ops.mul(conv, b, name="mul") e = self.trt_incompatible_op(conv, name="incompatible") t = math_ops.sub(t, e, name="sub") - array_ops.squeeze(t, name=self.output_name) + array_ops.squeeze(t, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines={ - "my_trt_op_0": ["bias", "mul", "sub"], - "my_trt_op_1": ["weights", "conv"] - }, - expected_output_dims=(2, 4, 5, 4), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(2, 4, 5, 4)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return { + "my_trt_op_0": ["bias", "mul", "sub"], + "my_trt_op_1": ["weights", "conv"] + } if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/rank_two_test.py b/tensorflow/contrib/tensorrt/test/rank_two_test.py new file mode 100644 index 0000000000..74a4a05925 --- /dev/null +++ b/tensorflow/contrib/tensorrt/test/rank_two_test.py @@ -0,0 +1,89 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Model script to test TF-TensorRT integration.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.contrib.tensorrt.test import tf_trt_integration_test_base as trt_test +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import gen_math_ops +from tensorflow.python.ops import math_ops +from tensorflow.python.platform import test + + +class RankTwoTest(trt_test.TfTrtIntegrationTestBase): + + def GetParams(self): + """Test for rank 2 input in TF-TRT.""" + input_names = ["input", "input2"] + # Two paths: first with rank 2 input, second with rank 4 input. + input_dims = [[12, 5], [12, 5, 2, 2]] + output_name = "output" + g = ops.Graph() + with g.as_default(): + outputs = [] + for i in range(2): + x = array_ops.placeholder( + dtype=dtypes.float32, shape=input_dims[i], name=input_names[i]) + c = constant_op.constant(1.0, name="c%d_1" % i) + q = math_ops.add(x, c, name="add%d_1" % i) + q = math_ops.abs(q, name="abs%d_1" % i) + c = constant_op.constant(2.2, name="c%d_2" % i) + q = math_ops.add(q, c, name="add%d_2" % i) + q = math_ops.abs(q, name="abs%d_2" % i) + c = constant_op.constant(3.0, name="c%d_3" % i) + q = math_ops.add(q, c, name="add%d_3" % i) + if i == 0: + for j in range(2): + q = array_ops.expand_dims(q, -1, name="expand%d_%d" % (i, j)) + q = gen_math_ops.reciprocal(q, name="reciprocal%d" % i) + outputs.append(q) + # Combine both paths + q = math_ops.add(outputs[0], outputs[1], name="add") + array_ops.squeeze(q, name=output_name) + return trt_test.TfTrtIntegrationTestParams( + gdef=g.as_graph_def(), + input_names=input_names, + input_dims=input_dims, + output_names=[output_name], + expected_output_dims=[tuple(input_dims[1])]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return { + "my_trt_op_0": [ + "add0_1", "add0_2", "add0_3", "c0_1", "c0_2", "c0_3", "abs0_1", + "abs0_2" + ], + "my_trt_op_1": [ + "add", "add1_1", "add1_2", "add1_3", "c1_1", "c1_2", "c1_3", + "abs1_1", "abs1_2", "reciprocal0", "reciprocal1" + ], + } + + def ShouldRunTest(self, run_params): + """Whether to run the test.""" + # TODO(aaroey): Trt 4.0 forbids conversion for tensors with rank <3 in int8 + # mode, which is a bug. Re-enable this when trt library is fixed. + return not trt_test.IsQuantizationMode(run_params.precision_mode) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/contrib/tensorrt/test/tf_trt_integration_test_base.py b/tensorflow/contrib/tensorrt/test/tf_trt_integration_test_base.py index 6f85ada464..65ca21cf37 100644 --- a/tensorflow/contrib/tensorrt/test/tf_trt_integration_test_base.py +++ b/tensorflow/contrib/tensorrt/test/tf_trt_integration_test_base.py @@ -31,6 +31,7 @@ from tensorflow.contrib.tensorrt.python.ops import trt_engine_op # pylint: enable=unused-import from tensorflow.core.protobuf import config_pb2 from tensorflow.core.protobuf import rewriter_config_pb2 +from tensorflow.python.framework import dtypes from tensorflow.python.framework import graph_io from tensorflow.python.framework import importer from tensorflow.python.framework import ops @@ -39,18 +40,23 @@ from tensorflow.python.ops import math_ops from tensorflow.python.platform import tf_logging as logging TfTrtIntegrationTestParams = namedtuple("TfTrtIntegrationTestParams", [ - "gdef", "input_names", "input_dims", "expected_engines", - "expected_output_dims", "allclose_atol", "allclose_rtol" + "gdef", "input_names", "input_dims", "output_names", "expected_output_dims" ]) RunParams = namedtuple( "RunParams", ["use_optimizer", "precision_mode", "dynamic_engine", "test_name"]) +ConversionParams = namedtuple("ConversionParams", [ + "max_batch_size", "max_workspace_size_bytes", "precision_mode", + "minimum_segment_size", "is_dynamic_op", "maximum_cached_engines", + "cached_engine_batches" +]) + PRECISION_MODES = ["FP32", "FP16", "INT8"] -def _IsQuantizationMode(mode): +def IsQuantizationMode(mode): return mode == "INT8" @@ -64,10 +70,6 @@ class TfTrtIntegrationTestBase(test_util.TensorFlowTestCase): """Class to test Tensorflow-TensorRT integration.""" @property - def output_name(self): - return "output" - - @property def trt_incompatible_op(self): return math_ops.sin @@ -112,6 +114,10 @@ class TfTrtIntegrationTestBase(test_util.TensorFlowTestCase): super(TfTrtIntegrationTestBase, cls).setUpClass() trt_convert.enable_test_value() + def __init__(self, methodName="runTest"): # pylint: disable=invalid-name + super(TfTrtIntegrationTestBase, self).__init__(methodName) + self._trt_test_params = None + def setUp(self): """Setup method.""" super(TfTrtIntegrationTestBase, self).setUp() @@ -122,43 +128,97 @@ class TfTrtIntegrationTestBase(test_util.TensorFlowTestCase): """Return a TfTrtIntegrationTestParams for test, implemented by subclass.""" raise NotImplementedError() - def _PrepareRun(self, params, graph_state): + def GetConversionParams(self, run_params): + """Return a ConversionParams for test.""" + return ConversionParams( + max_batch_size=max([ + dims[0] for dims in self._GetParamsCached().input_dims if len(dims) + ]), + max_workspace_size_bytes=1 << 25, + precision_mode=self._ToBytes(run_params.precision_mode), + minimum_segment_size=2, + is_dynamic_op=run_params.dynamic_engine, + maximum_cached_engines=1, + cached_engine_batches=None) + + def ShouldRunTest(self, run_params): + """Whether to run the test.""" + return True + + def VerifyRunForEngine(self, engine_name, graph_state, expect_run=True): + """Verify the state of a particular engine after sess.run().""" + if graph_state == GraphState.ORIGINAL: + self._ExpectCalibration(engine_name, "") + self._ExpectNativeSegment(engine_name, "") + self._ExpectTrtEngine(engine_name, "") + elif graph_state == GraphState.CALIBRATE: + self._ExpectCalibration(engine_name, "done") + self._ExpectNativeSegment(engine_name, "done") + self._ExpectTrtEngine(engine_name, "") + elif graph_state == GraphState.INFERENCE: + self._ExpectCalibration(engine_name, "") + if expect_run: + self._ExpectNativeSegment(engine_name, "") + self._ExpectTrtEngine(engine_name, "done") + else: + self._ExpectNativeSegment(engine_name, "done") + self._ExpectTrtEngine(engine_name, "") + + def VerifyRun(self, run_params, graph_state): + """Verify the state of all engines after sess.run().""" + for engine_name in self.ExpectedEnginesToBuild(run_params): + expect_run = (engine_name in self.ExpectedEnginesToRun(run_params)) + self.VerifyRunForEngine(engine_name, graph_state, expect_run) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build, implemented by subclass.""" + raise NotImplementedError() + + def ExpectedEnginesToRun(self, run_params): + """Return the expected engines to run.""" + return self.ExpectedEnginesToBuild(run_params) + + def ExpectedAbsoluteTolerance(self, run_params): + """The absolute tolerance to compare floating point results.""" + return 1.e-06 if run_params.precision_mode == "FP32" else 1.e-03 + + def ExpectedRelativeTolerance(self, run_params): + """The relative tolerance to compare floating point results.""" + return 1.e-06 if run_params.precision_mode == "FP32" else 1.e-03 + + def _GetParamsCached(self): + if self._trt_test_params is None: + self._trt_test_params = self.GetParams() + return self._trt_test_params + + def _PrepareRun(self, graph_state): """Set up necessary testing environment before calling sess.run().""" # Clear test values added by TRTEngineOp. trt_convert.clear_test_values("my_trt_op_.*:ExecuteTrtEngine") trt_convert.clear_test_values("my_trt_op_.*:ExecuteCalibration") trt_convert.clear_test_values("my_trt_op_.*:ExecuteNativeSegment") - def _VerifyRun(self, params, graph_state): - """Verify the state after sess.run().""" - for engine_name in params.expected_engines: - if graph_state == GraphState.ORIGINAL: - self._ExpectCalibration(engine_name, "") - self._ExpectNativeSegment(engine_name, "") - self._ExpectTrtEngine(engine_name, "") - elif graph_state == GraphState.CALIBRATE: - self._ExpectCalibration(engine_name, "done") - self._ExpectNativeSegment(engine_name, "done") - self._ExpectTrtEngine(engine_name, "") - elif graph_state == GraphState.INFERENCE: - self._ExpectCalibration(engine_name, "") - self._ExpectNativeSegment(engine_name, "") - self._ExpectTrtEngine(engine_name, "done") - - def _GetConfigProto(self, params, run_params, graph_state): + def _GetConfigProto(self, run_params, graph_state): """Get config proto based on specific settings.""" if graph_state != GraphState.ORIGINAL and run_params.use_optimizer: rewriter_cfg = rewriter_config_pb2.RewriterConfig() rewriter_cfg.optimizers.extend(["constfold", "layout"]) custom_op = rewriter_cfg.custom_optimizers.add() custom_op.name = "TensorRTOptimizer" - custom_op.parameter_map["minimum_segment_size"].i = 2 - custom_op.parameter_map["max_batch_size"].i = max( - [dims[0] for dims in params.input_dims]) - custom_op.parameter_map["is_dynamic_op"].b = run_params.dynamic_engine - custom_op.parameter_map["max_workspace_size_bytes"].i = 1 << 25 - custom_op.parameter_map["precision_mode"].s = self._ToBytes( - run_params.precision_mode) + trt_params = self.GetConversionParams(run_params) + custom_op.parameter_map["max_batch_size"].i = trt_params.max_batch_size + custom_op.parameter_map["max_workspace_size_bytes"].i = ( + trt_params.max_workspace_size_bytes) + custom_op.parameter_map["precision_mode"].s = trt_params.precision_mode + custom_op.parameter_map["minimum_segment_size"].i = ( + trt_params.minimum_segment_size) + custom_op.parameter_map["is_dynamic_op"].b = trt_params.is_dynamic_op + custom_op.parameter_map["maximum_cached_engines"].i = ( + trt_params.maximum_cached_engines) + if trt_params.cached_engine_batches: + custom_op.parameter_map["cached_engine_batches"].list.i.extend( + trt_params.cached_engine_batches) + graph_options = config_pb2.GraphOptions(rewrite_options=rewriter_cfg) else: graph_options = config_pb2.GraphOptions() @@ -190,53 +250,67 @@ class TfTrtIntegrationTestBase(test_util.TensorFlowTestCase): def _ExpectNativeSegment(self, engine_name, value): self._ExpectTestValue(engine_name, "ExecuteNativeSegment", value) - def _RunGraph(self, params, gdef, input_data, config, graph_state, + def _RunGraph(self, + run_params, + gdef, + input_data, + config, + graph_state, num_runs=2): """Run given graphdef multiple times.""" + params = self._GetParamsCached() assert len(params.input_names) == len(input_data) g = ops.Graph() with g.as_default(): io_ops = importer.import_graph_def( graph_def=gdef, - return_elements=params.input_names + [self.output_name], + return_elements=params.input_names + params.output_names, name="") - inp = [i.outputs[0] for i in io_ops[:-1]] - assert len(inp) == len(input_data) - out = io_ops[-1].outputs[0] + inputs = [op.outputs[0] for op in io_ops[:len(params.input_names)]] + assert len(inputs) == len(input_data) + outputs = [op.outputs[0] for op in io_ops[len(params.input_names):]] with self.test_session( graph=g, config=config, use_gpu=True, force_gpu=True) as sess: val = None # Defaults to 2 runs to verify result across multiple runs is same. for _ in range(num_runs): - self._PrepareRun(params, graph_state) - new_val = sess.run(out, - {inp[i]: input_data[i] for i in range(len(inp))}) - self.assertEqual(params.expected_output_dims, new_val.shape) + self._PrepareRun(graph_state) + new_val = sess.run( + outputs, {inputs[i]: input_data[i] for i in range(len(inputs))}) + output_len = len(params.expected_output_dims) + self.assertEqual(output_len, len(new_val)) + for i in range(output_len): + self.assertEqual(params.expected_output_dims[i], new_val[i].shape) if val is not None: - self.assertAllEqual(val, new_val) + self.assertAllClose(val, new_val, atol=1.e-06, rtol=1.e-06) val = new_val - self._VerifyRun(params, graph_state) + self.VerifyRun(run_params, graph_state) return val # Use real data that is representative of the inference dataset # for calibration. For this test script it is random data. - def _RunCalibration(self, params, gdef, input_data, config): + def _RunCalibration(self, run_params, gdef, input_data, config): """Run calibration on given graph.""" return self._RunGraph( - params, gdef, input_data, config, GraphState.CALIBRATE, num_runs=5) + run_params, gdef, input_data, config, GraphState.CALIBRATE, num_runs=5) - def _GetTrtGraphDef(self, params, run_params, gdef): + def _GetTrtGraphDef(self, run_params, gdef): """Return trt converted graphdef.""" + params = self._GetParamsCached() + trt_params = self.GetConversionParams(run_params) + logging.info(trt_params) return trt_convert.create_inference_graph( input_graph_def=gdef, - outputs=[self.output_name], - max_batch_size=max([dims[0] for dims in params.input_dims]), - max_workspace_size_bytes=1 << 25, - precision_mode=run_params.precision_mode, - minimum_segment_size=2, - is_dynamic_op=run_params.dynamic_engine) - - def _WriteGraph(self, params, run_params, gdef, graph_state): + outputs=params.input_names + params.output_names, + max_batch_size=trt_params.max_batch_size, + max_workspace_size_bytes=trt_params.max_workspace_size_bytes, + precision_mode=trt_params.precision_mode, + minimum_segment_size=trt_params.minimum_segment_size, + is_dynamic_op=trt_params.is_dynamic_op, + maximum_cached_engines=trt_params.maximum_cached_engines, + cached_engine_batches=trt_params.cached_engine_batches) + + def _WriteGraph(self, run_params, gdef, graph_state): if graph_state == GraphState.ORIGINAL: label = "Original" elif graph_state == GraphState.CALIBRATE: @@ -247,15 +321,17 @@ class TfTrtIntegrationTestBase(test_util.TensorFlowTestCase): self.__class__.__name__ + "_" + run_params.test_name + "_" + label + ".pbtxt") temp_dir = os.getenv("TRT_TEST_TMPDIR", self.get_temp_dir()) - logging.info("Writing graph to %s/%s", temp_dir, graph_name) - graph_io.write_graph(gdef, temp_dir, graph_name) + if temp_dir: + logging.info("Writing graph to %s/%s", temp_dir, graph_name) + graph_io.write_graph(gdef, temp_dir, graph_name) - def _VerifyConnections(self, params, converted_gdef): + def _VerifyConnections(self, expected_engines, converted_gdef): + params = self._GetParamsCached() old_to_new_node_map = { self._ToString(node.name): self._ToString(node.name) for node in params.gdef.node } - for engine_name, node_names in params.expected_engines.items(): + for engine_name, node_names in expected_engines.items(): for node_name in node_names: old_to_new_node_map[node_name] = engine_name name_to_node_map = { @@ -310,97 +386,114 @@ class TfTrtIntegrationTestBase(test_util.TensorFlowTestCase): msg="expected:\n%s\nvs actual:\n%s" % (sorted( expected_input_map.items()), sorted(actual_input_map.items()))) - def _VerifyGraphDef(self, params, run_params, gdef, graph_state): - self._WriteGraph(params, run_params, gdef, graph_state) + def _VerifyGraphDef(self, run_params, gdef, graph_state): + self._WriteGraph(run_params, gdef, graph_state) + expected_engines = self.ExpectedEnginesToBuild(run_params) num_engines = 0 for node in gdef.node: if node.op == "TRTEngineOp": + logging.info("Found TRTEngineOp: " + node.name) + for node in gdef.node: + if node.op == "TRTEngineOp": num_engines += 1 - self.assertTrue(node.name in params.expected_engines) - self.assertTrue(len(node.attr["serialized_segment"].s)) - self.assertTrue(len(node.attr["segment_funcdef_name"].s)) + self.assertTrue(node.name in expected_engines, node.name) + self.assertTrue(len(node.attr["serialized_segment"].s), node.name) + self.assertTrue(len(node.attr["segment_funcdef_name"].s), node.name) self.assertEqual( self._ToBytes(run_params.precision_mode), - node.attr["precision_mode"].s) + node.attr["precision_mode"].s, node.name) is_dynamic_engine = not node.attr["static_engine"].b - self.assertEqual(run_params.dynamic_engine, is_dynamic_engine) + self.assertEqual(run_params.dynamic_engine, is_dynamic_engine, + node.name) has_calibration_data = len(node.attr["calibration_data"].s) - if (_IsQuantizationMode(run_params.precision_mode) and + if (IsQuantizationMode(run_params.precision_mode) and graph_state == GraphState.INFERENCE): - self.assertTrue(has_calibration_data) + self.assertTrue(has_calibration_data, node.name) else: - self.assertFalse(has_calibration_data) + self.assertFalse(has_calibration_data, node.name) if graph_state == GraphState.ORIGINAL: self.assertEqual(0, num_engines) else: - self.assertEqual(num_engines, len(params.expected_engines)) - if isinstance(params.expected_engines, dict): - self._VerifyConnections(params, gdef) + self.assertEqual(num_engines, len(expected_engines)) + if isinstance(expected_engines, dict): + self._VerifyConnections(expected_engines, gdef) # TODO(aaroey): consider verifying the corresponding TF function. - def RunTest(self, params, run_params): + def RunTest(self, run_params): + if not self.ShouldRunTest(run_params): + return assert run_params.precision_mode in PRECISION_MODES - input_data = [np.random.random_sample(dims) for dims in params.input_dims] + + params = self._GetParamsCached() input_gdef = params.gdef - self._VerifyGraphDef(params, run_params, input_gdef, GraphState.ORIGINAL) + input_dtypes = {} + for node in input_gdef.node: + if self._ToString(node.name) in params.input_names: + assert self._ToString(node.op) == "Placeholder" + input_dtypes[self._ToString(node.name)] = ( + dtypes.as_dtype(node.attr["dtype"].type).as_numpy_dtype()) + assert len(params.input_names) == len(input_dtypes) + + input_data = [] + for i in range(len(params.input_names)): + dtype = input_dtypes[params.input_names[i]] + # Multiply the input by some constant to avoid all zeros input for integer + # types. + scale = 10.0 if np.issubdtype(dtype, np.integer) else 1.0 + dims = params.input_dims[i] + input_data.append((scale * np.random.random_sample(dims)).astype(dtype)) + self._VerifyGraphDef(run_params, input_gdef, GraphState.ORIGINAL) # Get reference result without running trt. - config_no_trt = self._GetConfigProto(params, run_params, - GraphState.ORIGINAL) + config_no_trt = self._GetConfigProto(run_params, GraphState.ORIGINAL) logging.info("Running original graph w/o trt, config:\n%s", str(config_no_trt)) - ref_result = self._RunGraph(params, input_gdef, input_data, config_no_trt, - GraphState.ORIGINAL) + ref_result = self._RunGraph(run_params, input_gdef, input_data, + config_no_trt, GraphState.ORIGINAL) # Run calibration if necessary. - if _IsQuantizationMode(run_params.precision_mode): + if IsQuantizationMode(run_params.precision_mode): - calib_config = self._GetConfigProto(params, run_params, - GraphState.CALIBRATE) + calib_config = self._GetConfigProto(run_params, GraphState.CALIBRATE) logging.info("Running calibration graph, config:\n%s", str(calib_config)) if run_params.use_optimizer: - result = self._RunCalibration(params, input_gdef, input_data, + result = self._RunCalibration(run_params, input_gdef, input_data, calib_config) else: - calib_gdef = self._GetTrtGraphDef(params, run_params, input_gdef) - self._VerifyGraphDef(params, run_params, calib_gdef, - GraphState.CALIBRATE) - result = self._RunCalibration(params, calib_gdef, input_data, + calib_gdef = self._GetTrtGraphDef(run_params, input_gdef) + self._VerifyGraphDef(run_params, calib_gdef, GraphState.CALIBRATE) + result = self._RunCalibration(run_params, calib_gdef, input_data, calib_config) - infer_gdef = trt_convert.calib_graph_to_infer_graph(calib_gdef) - self._VerifyGraphDef(params, run_params, infer_gdef, GraphState.INFERENCE) + infer_gdef = trt_convert.calib_graph_to_infer_graph( + calib_gdef, run_params.dynamic_engine) + self._VerifyGraphDef(run_params, infer_gdef, GraphState.INFERENCE) self.assertAllClose( ref_result, result, - atol=params.allclose_atol, - rtol=params.allclose_rtol) + atol=self.ExpectedAbsoluteTolerance(run_params), + rtol=self.ExpectedRelativeTolerance(run_params)) else: infer_gdef = input_gdef # Run inference. - infer_config = self._GetConfigProto(params, run_params, - GraphState.INFERENCE) + infer_config = self._GetConfigProto(run_params, GraphState.INFERENCE) logging.info("Running final inference graph, config:\n%s", str(infer_config)) - if run_params.use_optimizer: - result = self._RunGraph(params, infer_gdef, input_data, infer_config, - GraphState.INFERENCE) - else: - trt_infer_gdef = self._GetTrtGraphDef(params, run_params, infer_gdef) - self._VerifyGraphDef(params, run_params, trt_infer_gdef, - GraphState.INFERENCE) - result = self._RunGraph(params, trt_infer_gdef, input_data, infer_config, - GraphState.INFERENCE) + if not run_params.use_optimizer: + infer_gdef = self._GetTrtGraphDef(run_params, infer_gdef) + self._VerifyGraphDef(run_params, infer_gdef, GraphState.INFERENCE) + result = self._RunGraph(run_params, infer_gdef, input_data, infer_config, + GraphState.INFERENCE) self.assertAllClose( ref_result, result, - atol=params.allclose_atol, - rtol=params.allclose_rtol) + atol=self.ExpectedAbsoluteTolerance(run_params), + rtol=self.ExpectedRelativeTolerance(run_params)) def testIdempotence(self): # Test that applying tensorrt optimizer or offline conversion tools multiple @@ -421,13 +514,12 @@ def _AddTests(test_class): """Gets a single test method based on the parameters.""" def _Test(self): - params = self.GetParams() logging.info( "Running test %s with parameters: use_optimizer=%s, " "precision_mode=%s, dynamic_engine=%s", "testTfTrt_" + run_params.test_name, run_params.use_optimizer, run_params.precision_mode, run_params.dynamic_engine) - self.RunTest(params, run_params) + self.RunTest(run_params) return _Test @@ -435,7 +527,7 @@ def _AddTests(test_class): dynamic_engine_options = [False, True] for (use_optimizer, precision_mode, dynamic_engine) in itertools.product( use_optimizer_options, PRECISION_MODES, dynamic_engine_options): - if _IsQuantizationMode(precision_mode): + if IsQuantizationMode(precision_mode): if use_optimizer: # TODO(aaroey): if use_optimizer is True we need to get the inference # graphdef using custom python wrapper class, which is not currently diff --git a/tensorflow/contrib/tensorrt/test/unary_test.py b/tensorflow/contrib/tensorrt/test/unary_test.py index 500057a36d..8736bfb644 100644 --- a/tensorflow/contrib/tensorrt/test/unary_test.py +++ b/tensorflow/contrib/tensorrt/test/unary_test.py @@ -38,6 +38,7 @@ class UnaryTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [12, 5, 8, 1, 1, 12] + output_name = "output" input2_name = "input_2" input2_dims = [12, 5, 8, 1, 12, 1, 1] g = ops.Graph() @@ -95,18 +96,20 @@ class UnaryTest(trt_test.TfTrtIntegrationTestBase): q = a * b q = q / c - array_ops.squeeze(q, name=self.output_name) + array_ops.squeeze(q, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name, input2_name], input_dims=[input_dims, input2_dims], - expected_engines=[ - "my_trt_op_0", "my_trt_op_1", "my_trt_op_2", "my_trt_op_3", - "my_trt_op_4" - ], - expected_output_dims=(12, 5, 8, 12), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(12, 5, 8, 12)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return [ + "my_trt_op_0", "my_trt_op_1", "my_trt_op_2", "my_trt_op_3", + "my_trt_op_4" + ] if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/vgg_block_nchw_test.py b/tensorflow/contrib/tensorrt/test/vgg_block_nchw_test.py index ab4d224db4..b0271a04b3 100644 --- a/tensorflow/contrib/tensorrt/test/vgg_block_nchw_test.py +++ b/tensorflow/contrib/tensorrt/test/vgg_block_nchw_test.py @@ -38,15 +38,14 @@ class VGGBlockNCHWTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [5, 2, 8, 8] + output_name = "output" g = ops.Graph() with g.as_default(): x = array_ops.placeholder(dtype=dtype, shape=input_dims, name=input_name) x, _, _ = nn_impl.fused_batch_norm( - x, - np.random.randn(2).astype(np.float32), - np.random.randn(2).astype(np.float32), - mean=np.random.randn(2).astype(np.float32), - variance=np.random.randn(2).astype(np.float32), + x, [1.0, 1.0], [0.0, 0.0], + mean=[0.5, 0.5], + variance=[1.0, 1.0], data_format="NCHW", is_training=False) e = constant_op.constant( @@ -67,15 +66,17 @@ class VGGBlockNCHWTest(trt_test.TfTrtIntegrationTestBase): "VALID", data_format="NCHW", name="max_pool") - array_ops.squeeze(v, name="output") + array_ops.squeeze(v, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines=["my_trt_op_0"], - expected_output_dims=(5, 6, 2, 2), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(5, 6, 2, 2)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return ["my_trt_op_0"] if __name__ == "__main__": diff --git a/tensorflow/contrib/tensorrt/test/vgg_block_test.py b/tensorflow/contrib/tensorrt/test/vgg_block_test.py index 56bdf848ea..d7c165784b 100644 --- a/tensorflow/contrib/tensorrt/test/vgg_block_test.py +++ b/tensorflow/contrib/tensorrt/test/vgg_block_test.py @@ -38,15 +38,14 @@ class VGGBlockTest(trt_test.TfTrtIntegrationTestBase): dtype = dtypes.float32 input_name = "input" input_dims = [5, 8, 8, 2] + output_name = "output" g = ops.Graph() with g.as_default(): x = array_ops.placeholder(dtype=dtype, shape=input_dims, name=input_name) x, _, _ = nn_impl.fused_batch_norm( - x, - np.random.randn(2).astype(np.float32), - np.random.randn(2).astype(np.float32), - mean=np.random.randn(2).astype(np.float32), - variance=np.random.randn(2).astype(np.float32), + x, [1.0, 1.0], [0.0, 0.0], + mean=[0.5, 0.5], + variance=[1.0, 1.0], is_training=False) e = constant_op.constant( np.random.randn(1, 1, 2, 6), name="weights", dtype=dtype) @@ -58,15 +57,17 @@ class VGGBlockTest(trt_test.TfTrtIntegrationTestBase): idty = array_ops.identity(relu, "ID") v = nn_ops.max_pool( idty, [1, 2, 2, 1], [1, 2, 2, 1], "VALID", name="max_pool") - array_ops.squeeze(v, name="output") + array_ops.squeeze(v, name=output_name) return trt_test.TfTrtIntegrationTestParams( gdef=g.as_graph_def(), input_names=[input_name], input_dims=[input_dims], - expected_engines=["my_trt_op_0"], - expected_output_dims=(5, 2, 2, 6), - allclose_atol=1.e-03, - allclose_rtol=1.e-03) + output_names=[output_name], + expected_output_dims=[(5, 2, 2, 6)]) + + def ExpectedEnginesToBuild(self, run_params): + """Return the expected engines to build.""" + return ["my_trt_op_0"] if __name__ == "__main__": diff --git a/tensorflow/contrib/timeseries/examples/BUILD b/tensorflow/contrib/timeseries/examples/BUILD index 355303acf6..21c0c30c19 100644 --- a/tensorflow/contrib/timeseries/examples/BUILD +++ b/tensorflow/contrib/timeseries/examples/BUILD @@ -16,6 +16,7 @@ config_setting( py_binary( name = "predict", srcs = ["predict.py"], + data = ["data/period_trend.csv"], srcs_version = "PY2AND3", tags = ["no_pip"], deps = select({ diff --git a/tensorflow/contrib/timeseries/examples/known_anomaly.py b/tensorflow/contrib/timeseries/examples/known_anomaly.py index 71621abc71..1226433625 100644 --- a/tensorflow/contrib/timeseries/examples/known_anomaly.py +++ b/tensorflow/contrib/timeseries/examples/known_anomaly.py @@ -41,7 +41,7 @@ _MODULE_PATH = path.dirname(__file__) _DATA_FILE = path.join(_MODULE_PATH, "data/changepoints.csv") -def state_space_esitmator(exogenous_feature_columns): +def state_space_estimator(exogenous_feature_columns): """Constructs a StructuralEnsembleRegressor.""" def _exogenous_update_condition(times, features): @@ -68,7 +68,7 @@ def state_space_esitmator(exogenous_feature_columns): 4, 64) -def autoregressive_esitmator(exogenous_feature_columns): +def autoregressive_estimator(exogenous_feature_columns): input_window_size = 8 output_window_size = 2 return ( @@ -169,10 +169,10 @@ def main(unused_argv): "Please install matplotlib to generate a plot from this example.") make_plot("Ignoring a known anomaly (state space)", *train_and_evaluate_exogenous( - estimator_fn=state_space_esitmator)) + estimator_fn=state_space_estimator)) make_plot("Ignoring a known anomaly (autoregressive)", *train_and_evaluate_exogenous( - estimator_fn=autoregressive_esitmator, train_steps=3000)) + estimator_fn=autoregressive_estimator, train_steps=3000)) pyplot.show() diff --git a/tensorflow/contrib/timeseries/examples/known_anomaly_test.py b/tensorflow/contrib/timeseries/examples/known_anomaly_test.py index 8c64f2e186..57ccf8f260 100644 --- a/tensorflow/contrib/timeseries/examples/known_anomaly_test.py +++ b/tensorflow/contrib/timeseries/examples/known_anomaly_test.py @@ -28,7 +28,7 @@ class KnownAnomalyExampleTest(test.TestCase): def test_shapes_and_variance_structural_ar(self): (times, observed, all_times, mean, upper_limit, lower_limit, anomaly_locations) = known_anomaly.train_and_evaluate_exogenous( - train_steps=1, estimator_fn=known_anomaly.autoregressive_esitmator) + train_steps=1, estimator_fn=known_anomaly.autoregressive_estimator) self.assertAllEqual( anomaly_locations, [25, 50, 75, 100, 125, 150, 175, 249]) @@ -40,7 +40,7 @@ class KnownAnomalyExampleTest(test.TestCase): def test_shapes_and_variance_structural_ssm(self): (times, observed, all_times, mean, upper_limit, lower_limit, anomaly_locations) = known_anomaly.train_and_evaluate_exogenous( - train_steps=50, estimator_fn=known_anomaly.state_space_esitmator) + train_steps=50, estimator_fn=known_anomaly.state_space_estimator) self.assertAllEqual( anomaly_locations, [25, 50, 75, 100, 125, 150, 175, 249]) diff --git a/tensorflow/contrib/timeseries/examples/predict.py b/tensorflow/contrib/timeseries/examples/predict.py index 8147d40caa..b036911314 100644 --- a/tensorflow/contrib/timeseries/examples/predict.py +++ b/tensorflow/contrib/timeseries/examples/predict.py @@ -19,6 +19,7 @@ from __future__ import division from __future__ import print_function import argparse +import os import sys import numpy as np @@ -40,6 +41,10 @@ except ImportError: FLAGS = None +_MODULE_PATH = os.path.dirname(__file__) +_DEFAULT_DATA_FILE = os.path.join(_MODULE_PATH, "data/period_trend.csv") + + def structural_ensemble_train_and_predict(csv_file_name): # Cycle between 5 latent values over a period of 100. This leads to a very # smooth periodic component (and a small model), which is a good fit for our @@ -115,9 +120,12 @@ def main(unused_argv): if not HAS_MATPLOTLIB: raise ImportError( "Please install matplotlib to generate a plot from this example.") + input_filename = FLAGS.input_filename + if input_filename is None: + input_filename = _DEFAULT_DATA_FILE make_plot("Structural ensemble", - *structural_ensemble_train_and_predict(FLAGS.input_filename)) - make_plot("AR", *ar_train_and_predict(FLAGS.input_filename)) + *structural_ensemble_train_and_predict(input_filename)) + make_plot("AR", *ar_train_and_predict(input_filename)) pyplot.show() @@ -126,7 +134,7 @@ if __name__ == "__main__": parser.add_argument( "--input_filename", type=str, - required=True, - help="Input csv file.") + required=False, + help="Input csv file (omit to use the data/period_trend.csv).") FLAGS, unparsed = parser.parse_known_args() tf.app.run(main=main, argv=[sys.argv[0]] + unparsed) diff --git a/tensorflow/contrib/timeseries/python/timeseries/ar_model_test.py b/tensorflow/contrib/timeseries/python/timeseries/ar_model_test.py index 5eb4deefb9..de547f835d 100644 --- a/tensorflow/contrib/timeseries/python/timeseries/ar_model_test.py +++ b/tensorflow/contrib/timeseries/python/timeseries/ar_model_test.py @@ -195,7 +195,7 @@ class ARModelTest(test.TestCase): self.train_helper(input_window_size=10, loss=ar_model.ARModel.NORMAL_LIKELIHOOD_LOSS, train_steps=300, - max_loss=2.5, + max_loss=50., # Just make sure there are no exceptions. anomaly_distribution=None) def test_autoregression_normal_multiple_periods(self): diff --git a/tensorflow/contrib/timeseries/python/timeseries/estimators_test.py b/tensorflow/contrib/timeseries/python/timeseries/estimators_test.py index 983455f63d..461fe22210 100644 --- a/tensorflow/contrib/timeseries/python/timeseries/estimators_test.py +++ b/tensorflow/contrib/timeseries/python/timeseries/estimators_test.py @@ -69,8 +69,10 @@ class TimeSeriesRegressorTest(test.TestCase): input_pipeline.NumpyReader(features), shuffle_seed=3, num_threads=1, batch_size=16, window_size=16) first_estimator.train(input_fn=train_input_fn, steps=1) - first_loss_before_fit = first_estimator.evaluate( - input_fn=eval_input_fn, steps=1)["loss"] + first_evaluation = first_estimator.evaluate( + input_fn=eval_input_fn, steps=1) + first_loss_before_fit = first_evaluation["loss"] + self.assertAllEqual(first_loss_before_fit, first_evaluation["average_loss"]) self.assertAllEqual([], first_loss_before_fit.shape) first_estimator.train(input_fn=train_input_fn, steps=1) first_loss_after_fit = first_estimator.evaluate( diff --git a/tensorflow/contrib/timeseries/python/timeseries/head.py b/tensorflow/contrib/timeseries/python/timeseries/head.py index 32194e400e..1f9f9b7aa6 100644 --- a/tensorflow/contrib/timeseries/python/timeseries/head.py +++ b/tensorflow/contrib/timeseries/python/timeseries/head.py @@ -30,6 +30,7 @@ from tensorflow.python.framework import sparse_tensor from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import math_ops +from tensorflow.python.ops import metrics_impl from tensorflow.python.ops import state_ops from tensorflow.python.ops import variable_scope from tensorflow.python.summary import summary @@ -123,6 +124,8 @@ class TimeSeriesRegressionHead(head_lib._Head): # pylint:disable=protected-acce metrics[feature_keys.FilteringResults.STATE_TUPLE] = ( _identity_metric_nested(feature_keys.FilteringResults.STATE_TUPLE, model_outputs.end_state)) + metrics[metric_keys.MetricKeys.LOSS_MEAN] = metrics_impl.mean( + model_outputs.loss, name="average_loss") return estimator_lib.EstimatorSpec( loss=model_outputs.loss, mode=mode, diff --git a/tensorflow/contrib/timeseries/python/timeseries/head_test.py b/tensorflow/contrib/timeseries/python/timeseries/head_test.py index bda3b53aca..e65e7b74d4 100644 --- a/tensorflow/contrib/timeseries/python/timeseries/head_test.py +++ b/tensorflow/contrib/timeseries/python/timeseries/head_test.py @@ -172,6 +172,7 @@ class EvaluationMetricsTests(test.TestCase): evaluation = estimator.evaluate(input_fn, steps=1) self.assertIn("plain_boring_metric386", evaluation) self.assertIn("fun_metric101", evaluation) + self.assertIn("average_loss", evaluation) # The values are deterministic because of fixed tf_random_seed. # However if they become flaky, remove such exacts comparisons. self.assertAllClose(evaluation["plain_boring_metric386"], 1.130380) @@ -398,6 +399,7 @@ class OneShotTests(parameterized.TestCase): num_threads=1, batch_size=16, window_size=16) estimator.train(input_fn=train_input_fn, steps=5) result = estimator.evaluate(input_fn=train_input_fn, steps=1) + self.assertIn("average_loss", result) self.assertNotIn(feature_keys.State.STATE_TUPLE, result) input_receiver_fn = estimator.build_raw_serving_input_receiver_fn() export_location = estimator.export_savedmodel(_new_temp_dir(), diff --git a/tensorflow/contrib/timeseries/python/timeseries/math_utils_test.py b/tensorflow/contrib/timeseries/python/timeseries/math_utils_test.py index b9f8620fd8..02d2524b66 100644 --- a/tensorflow/contrib/timeseries/python/timeseries/math_utils_test.py +++ b/tensorflow/contrib/timeseries/python/timeseries/math_utils_test.py @@ -290,7 +290,7 @@ class InputStatisticsTests(test.TestCase): time_series_reader=input_pipeline.NumpyReader(features)) statistics = stat_object.initialize_graph( features=input_fn()[0]) - with self.test_session(graph=graph) as session: + with self.session(graph=graph) as session: variables.global_variables_initializer().run() coordinator = coordinator_lib.Coordinator() queue_runner_impl.start_queue_runners(session, coord=coordinator) diff --git a/tensorflow/contrib/timeseries/python/timeseries/state_space_models/state_space_model_test.py b/tensorflow/contrib/timeseries/python/timeseries/state_space_models/state_space_model_test.py index 1fb4a3c121..c2eaa78493 100644 --- a/tensorflow/contrib/timeseries/python/timeseries/state_space_models/state_space_model_test.py +++ b/tensorflow/contrib/timeseries/python/timeseries/state_space_models/state_space_model_test.py @@ -190,13 +190,13 @@ class StateSpaceEquivalenceTests(test.TestCase): estimator.build_raw_serving_input_receiver_fn()) with ops.Graph().as_default() as graph: random_model.initialize_graph() - with self.test_session(graph=graph) as session: + with self.session(graph=graph) as session: variables.global_variables_initializer().run() evaled_start_state = session.run(random_model.get_start_state()) evaled_start_state = [ state_element[None, ...] for state_element in evaled_start_state] with ops.Graph().as_default() as graph: - with self.test_session(graph=graph) as session: + with self.session(graph=graph) as session: signatures = loader.load( session, [tag_constants.SERVING], export_location) first_split_filtering = saved_model_utils.filter_continuation( diff --git a/tensorflow/contrib/tpu/BUILD b/tensorflow/contrib/tpu/BUILD index 56e451e2e3..a9e338ee59 100644 --- a/tensorflow/contrib/tpu/BUILD +++ b/tensorflow/contrib/tpu/BUILD @@ -16,6 +16,7 @@ package( "//cloud/vmm/testing/tests/tpu:__subpackages__", "//learning/brain:__subpackages__", "//learning/deepmind:__subpackages__", + "//medical/pathology:__subpackages__", "//tensorflow:__subpackages__", ], ) diff --git a/tensorflow/contrib/tpu/ops/cross_replica_ops.cc b/tensorflow/contrib/tpu/ops/cross_replica_ops.cc index 06553929dc..9ee5ecb123 100644 --- a/tensorflow/contrib/tpu/ops/cross_replica_ops.cc +++ b/tensorflow/contrib/tpu/ops/cross_replica_ops.cc @@ -21,9 +21,9 @@ namespace tensorflow { REGISTER_OP("CrossReplicaSum") .Input("input: T") + .Input("group_assignment: int32") .Output("output: T") .Attr("T: {bfloat16, float}") - .Attr("group_assignment: list(int) = []") .SetShapeFn(shape_inference::UnchangedShape) .Doc(R"doc( An Op to sum inputs across replicated TPU instances. Each @@ -31,15 +31,17 @@ instance supplies its own input. If group_assignment is empty, the output of each is the sum of all the inputs, otherwise the output of each is the sum of the inputs belonging to the same group. -For example, suppose there are 4 TPU instances: `[A, B, C, D]`. Passing -group_assignment=`[0,1,0,1]` sets `A, C` as group 0, and `B, D` as group 1. -Thus we get the outputs: `[A+C, B+D, A+C, B+D]`. +For example, suppose there are 8 TPU instances: `[A, B, C, D, E, F, G, H]`. +Passing group_assignment=`[[0,2,4,6],[1,3,5,7]]` sets `A, C, E, G` as group 0, +and `B, D, F, H` as group 1. Thus we get the outputs: +`[A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H]`. input: The local input to the sum. +group_assignment: An int32 tensor with shape + [num_groups, num_replicas_per_group]. `group_assignment[i]` represents the + replica ids in the ith subgroup. output: The sum of all the distributed inputs. T: The type of elements to be summed. -group_assignment: The list of group ids. `group_assignment[i]` represents the - group id of replica i. )doc"); } // namespace tensorflow diff --git a/tensorflow/contrib/tpu/profiler/op_profile.proto b/tensorflow/contrib/tpu/profiler/op_profile.proto index 1f249de314..feb177a7da 100644 --- a/tensorflow/contrib/tpu/profiler/op_profile.proto +++ b/tensorflow/contrib/tpu/profiler/op_profile.proto @@ -8,6 +8,8 @@ message Profile { Node by_category = 1; // Root of a profile broken down by program structure. Node by_program_structure = 2; + // Per program profile, indexed by hlo module name of the program. + map<string, Node> per_program = 3; } // An entry in the profile tree. (An instruction, or set of instructions). diff --git a/tensorflow/contrib/tpu/proto/optimization_parameters.proto b/tensorflow/contrib/tpu/proto/optimization_parameters.proto index 2cc17d6d92..bf807af68b 100644 --- a/tensorflow/contrib/tpu/proto/optimization_parameters.proto +++ b/tensorflow/contrib/tpu/proto/optimization_parameters.proto @@ -119,7 +119,9 @@ message OptimizationParameters { // Whether to use gradient accumulation (do two passes over the input // gradients: one to accumulate them into a temporary array and another to - // apply them using the actual optimization algorithm). + // apply them using the actual optimization algorithm). This feature is + // experimental -- it has not been fully verified and may cause training + // crashes and/or failures. bool use_gradient_accumulation = 15; // Optimization algorithm parameters; which field is selected determines which diff --git a/tensorflow/contrib/tpu/python/ops/tpu_ops.py b/tensorflow/contrib/tpu/python/ops/tpu_ops.py index bf442d9116..3ed571aff9 100644 --- a/tensorflow/contrib/tpu/python/ops/tpu_ops.py +++ b/tensorflow/contrib/tpu/python/ops/tpu_ops.py @@ -21,8 +21,10 @@ from __future__ import print_function import platform +from tensorflow.contrib.tpu.python.tpu import tpu_function from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops +from tensorflow.python.platform import tf_logging as logging if platform.system() != "Windows": # pylint: disable=wildcard-import,unused-import,g-import-not-at-top @@ -36,10 +38,35 @@ if platform.system() != "Windows": _tpu_ops = loader.load_op_library( resource_loader.get_path_to_datafile("_tpu_ops.so")) + def cross_replica_sum(x, group_assignment=None, name=None): + """Sum the input tensor accorss replicas according to group_assignment. + + Args: + x: The local tensor to the sum. + group_assignment: Optional 2d int32 lists with shape [num_groups, + num_replicas_per_group]. `group_assignment[i]` represents the replica + ids in the ith subgroup. + name: Optional op name. + + Returns: + A `Tensor` which is summed across replicas. + """ + if group_assignment is None: + num_shards = tpu_function.get_tpu_context().number_of_shards + if num_shards is None: + logging.warning( + "cross_replica_sum should be used within a tpu_shard_context, but " + "got unset number_of_shards. Assuming 1.") + num_shards = 1 + group_assignment = [list(range(num_shards))] + + return gen_tpu_ops.cross_replica_sum(x, group_assignment, name=name) + @ops.RegisterGradient("CrossReplicaSum") def _cross_replica_sum_grad(op, grad): # The gradient of a cross replica sum is also a cross-replica sum. - return gen_tpu_ops.cross_replica_sum(grad, op.get_attr("group_assignment")) + # The graident with respect to group_assignment is None. + return [gen_tpu_ops.cross_replica_sum(grad, op.inputs[1]), None] # This extra type checking exists to give a more helpful error message in # the common case that uint8 and int64 values are infed. Remove when both diff --git a/tensorflow/contrib/tpu/python/tpu/keras_support.py b/tensorflow/contrib/tpu/python/tpu/keras_support.py index a5e8277ba5..dbf5c66c9e 100644 --- a/tensorflow/contrib/tpu/python/tpu/keras_support.py +++ b/tensorflow/contrib/tpu/python/tpu/keras_support.py @@ -61,6 +61,7 @@ from tensorflow.contrib.tpu.python.ops import tpu_ops from tensorflow.contrib.tpu.python.tpu import tpu from tensorflow.contrib.tpu.python.tpu import tpu_function from tensorflow.contrib.tpu.python.tpu import tpu_optimizer +from tensorflow.contrib.tpu.python.tpu import tpu_system_metadata as tpu_system_metadata_lib from tensorflow.core.protobuf import config_pb2 from tensorflow.python.client import session as tf_session from tensorflow.python.data.ops import dataset_ops @@ -80,7 +81,6 @@ from tensorflow.python.ops import math_ops from tensorflow.python.ops import random_ops from tensorflow.python.ops import variable_scope from tensorflow.python.platform import tf_logging as logging -from tensorflow.python.util import tf_inspect _SESSIONS = {} @@ -110,24 +110,52 @@ def reset_tpu_sessions(): _SESSIONS.clear() -# Work-around dependency cycle between DistributionStrategy and TPU lib. -def TPUDistributionStrategy(tpu_cluster_resolver=None): # pylint: disable=invalid-name - """Construct a TPUDistributionStrategy.""" - from tensorflow.contrib.distribute.python import tpu_strategy # pylint: disable=g-import-not-at-top - # TODO -- remove this when TPUStrategy API is consistent (b/112705069) - if tpu_cluster_resolver is None: - tpu_cluster_resolver = tpu_cluster_resolver_lib.TPUClusterResolver('') +def get_tpu_system_metadata(tpu_cluster_resolver): + """Retrieves TPU system metadata given a TPUClusterResolver.""" + master = tpu_cluster_resolver.master() - args, _, _, _ = tf_inspect.getargspec(tpu_strategy.TPUStrategy.__init__) - if len(args) == 3: - logging.info('Detected new TPUStrategy API.') - return tpu_strategy.TPUStrategy(tpu_cluster_resolver, steps_per_run=1) - else: - logging.info('Detected old TPUStrategy API.') - strategy = tpu_strategy.TPUStrategy(num_cores_per_host=8) - strategy._tpu_cluster_resolver = tpu_cluster_resolver + # pylint: disable=protected-access + cluster_spec = tpu_cluster_resolver.cluster_spec() + cluster_def = cluster_spec.as_cluster_def() if cluster_spec else None + tpu_system_metadata = ( + tpu_system_metadata_lib._query_tpu_system_metadata( + master, + cluster_def=cluster_def, + query_topology=False)) + + return tpu_system_metadata + + +class TPUDistributionStrategy(object): + """The strategy to run Keras model on TPU.""" - return strategy + def __init__(self, tpu_cluster_resolver=None, using_single_core=False): + """Construct a TPUDistributionStrategy. + + Args: + tpu_cluster_resolver: Any instance of `TPUClusterResolver`. If None, will + create one with '' as master address. + using_single_core: Bool. This is the debugging option, which might be + removed in future once the model replication functionality is mature + enough. If `False` (default behavior), the system automatically finds + the best configuration, in terms of number of TPU cores, for the model + replication, typically using all avaiable TPU cores. If overwrites as + `True`, force the model replication using single core, i.e., no + replication. + """ + + if tpu_cluster_resolver is None: + tpu_cluster_resolver = tpu_cluster_resolver_lib.TPUClusterResolver('') + + num_cores = (1 if using_single_core else + get_tpu_system_metadata(tpu_cluster_resolver).num_cores) + + self._tpu_cluster_resolver = tpu_cluster_resolver + self._num_cores = num_cores + + @property + def num_towers(self): + return self._num_cores class TPUEmbedding(embeddings.Embedding): @@ -612,7 +640,7 @@ class TPUDatasetInfeedManager(TPUInfeedManager): 'currently requires static shapes. The provided ' 'dataset only has a partially defined shape. ' '(Dimension %d of output tensor %d is not statically known ' - 'for output shapes: %s.%s)' % (i, j, dataset.output_shapes, hint)) + 'for output shapes: %s.%s)' % (j, i, dataset.output_shapes, hint)) @property def dummy_x(self): @@ -1205,5 +1233,10 @@ def tpu_model(model, strategy=None): if strategy is None: strategy = TPUDistributionStrategy() + else: + if not isinstance(strategy, TPUDistributionStrategy): + raise TypeError( + '`strategy` must have type `tf.contrib.tpu.TPUDistributionStrategy`. ' + 'Got: {}'.format(type(strategy))) return KerasTPUModel(cpu_model=model, strategy=strategy) diff --git a/tensorflow/contrib/tpu/python/tpu/tpu.py b/tensorflow/contrib/tpu/python/tpu/tpu.py index 7fa06d6d56..3c735a0b85 100644 --- a/tensorflow/contrib/tpu/python/tpu/tpu.py +++ b/tensorflow/contrib/tpu/python/tpu/tpu.py @@ -42,9 +42,9 @@ _BLACKLISTED_OPS = set([ "Placeholder", ]) -# These operations will currently fail to compile, but we should be able to -# support them eventually via CPU offload or extending our operation set. -_NOT_IMPLEMENTED_OPS = set([ +# XLA doesn't currently support reading of intermediate tensors, thus some ops +# are not supported. +_UNSUPPORTED_OPS = set([ "AudioSummary", "AudioSummaryV2", "HistogramSummary", @@ -149,6 +149,7 @@ class TPUReplicateContext(control_flow_ops.XLAControlFlowContext): self._gradient_colocation_stack = [] self._host_compute_core = [] self._name = name + self._name_as_bytes = compat.as_bytes(name) self._unsupported_ops = [] self._pivot = pivot self._replicated_vars = {} @@ -323,16 +324,13 @@ class TPUReplicateContext(control_flow_ops.XLAControlFlowContext): return self._host_compute_core def AddOp(self, op): - self._AddOpInternal(op) - - def _AddOpInternal(self, op): # pylint: disable=protected-access if op.type in _BLACKLISTED_OPS: logging.error("Operation of type %s (%s) is not supported on the TPU. " "Execution will fail if this op is used in the graph. " % (op.type, op.name)) - if op.type in _NOT_IMPLEMENTED_OPS: + if op.type in _UNSUPPORTED_OPS: self._unsupported_ops.append(op) if any(x.dtype._is_ref_dtype for x in op.inputs): @@ -342,7 +340,7 @@ class TPUReplicateContext(control_flow_ops.XLAControlFlowContext): if _TPU_REPLICATE_ATTR in op.node_def.attr: raise ValueError("TPU computations cannot be nested") op._set_attr(_TPU_REPLICATE_ATTR, - attr_value_pb2.AttrValue(s=compat.as_bytes(self._name))) + attr_value_pb2.AttrValue(s=self._name_as_bytes)) if self._outside_compilation_cluster: op._set_attr( _OUTSIDE_COMPILATION_ATTR, @@ -356,11 +354,12 @@ class TPUReplicateContext(control_flow_ops.XLAControlFlowContext): # Remove any control edges from outer control flow contexts. These may cause # mismatched frame errors. - control_inputs, external_inputs = self._RemoveExternalControlEdges(op) + (internal_control_inputs, + external_control_inputs) = self._RemoveExternalControlEdges(op) if not op.inputs: # Add a control edge from the control pivot to this op. - if not control_inputs: + if not internal_control_inputs: # pylint: disable=protected-access op._add_control_input(self.GetControlPivot()) # pylint: enable=protected-access @@ -371,19 +370,19 @@ class TPUReplicateContext(control_flow_ops.XLAControlFlowContext): if real_x != x: op._update_input(index, real_x) # pylint: disable=protected-access - if external_inputs: + if external_control_inputs: # Use an identity to pull control inputs as data inputs. Note that we # ignore ops which don't have outputs. TODO(phawkins): fix that. with ops.control_dependencies(None): self.Enter() - external_inputs = [ + external_control_inputs = [ array_ops.identity(x.outputs[0]).op - for x in external_inputs + for x in external_control_inputs if x.outputs ] self.Exit() # pylint: disable=protected-access - op._add_control_inputs(external_inputs) + op._add_control_inputs(external_control_inputs) # pylint: enable=protected-access # Mark op's outputs as seen by this context and any outer contexts. @@ -399,6 +398,7 @@ class TPUReplicateContext(control_flow_ops.XLAControlFlowContext): self._outer_context.AddInnerOp(op) def AddValue(self, val): + """Add `val` to the current context and its outer context recursively.""" if val.name in self._values: # Use the real value if it comes from outer context. result = self._external_values.get(val.name) @@ -415,7 +415,7 @@ class TPUReplicateContext(control_flow_ops.XLAControlFlowContext): return result def AddInnerOp(self, op): - self._AddOpInternal(op) + self.AddOp(op) if self._outer_context: self._outer_context.AddInnerOp(op) diff --git a/tensorflow/contrib/tpu/python/tpu/tpu_config.py b/tensorflow/contrib/tpu/python/tpu/tpu_config.py index 8d05e081a7..18e0abdda2 100644 --- a/tensorflow/contrib/tpu/python/tpu/tpu_config.py +++ b/tensorflow/contrib/tpu/python/tpu/tpu_config.py @@ -65,7 +65,7 @@ class TPUConfig( The number of model replicas in the system. For non-model-parallelism case, this number equals the total number of TPU cores. For model-parallelism, the total number of TPU cores equals - product(computation_shape) * num_shards. + num_cores_per_replica * num_shards. num_cores_per_replica: Defaults to `None`, which disables model parallelism. An integer which describes the number of TPU cores per model replica. This is required by model-parallelism which enables partitioning @@ -103,7 +103,7 @@ class TPUConfig( input mode. Raises: - ValueError: If `computation_shape` or `computation_shape` are invalid. + ValueError: If `num_cores_per_replica` is not 1, 2, 4 or 8. """ def __new__(cls, @@ -137,7 +137,7 @@ class TPUConfig( raise ValueError( 'input_partition_dims requires setting num_cores_per_replica.') - # Parse computation_shape + # Check num_cores_per_replica if num_cores_per_replica is not None: if num_cores_per_replica not in [1, 2, 4, 8]: raise ValueError( diff --git a/tensorflow/contrib/tpu/python/tpu/tpu_context.py b/tensorflow/contrib/tpu/python/tpu/tpu_context.py index 806ae1c4c9..19359cb612 100644 --- a/tensorflow/contrib/tpu/python/tpu/tpu_context.py +++ b/tensorflow/contrib/tpu/python/tpu/tpu_context.py @@ -390,12 +390,6 @@ class _InternalTPUContext(object): logging.info('_is_running_on_cpu: eval_on_tpu disabled') return True - if mode != model_fn_lib.ModeKeys.PREDICT: - return False - - # There are actually 2 use cases when running with mode.PREDICT: prediction - # and saving the model. We run actual predictions on the TPU, but - # model export is run on the CPU. if is_export_mode: return True diff --git a/tensorflow/contrib/tpu/python/tpu/tpu_estimator.py b/tensorflow/contrib/tpu/python/tpu/tpu_estimator.py index f221155568..1ff04f5c26 100644 --- a/tensorflow/contrib/tpu/python/tpu/tpu_estimator.py +++ b/tensorflow/contrib/tpu/python/tpu/tpu_estimator.py @@ -762,9 +762,13 @@ def generate_per_host_v2_enqueue_ops_fn_for_host( if not is_dataset: raise TypeError('`input_fn` must return a `Dataset` for the PER_HOST_V2 ' 'input pipeline configuration.') + if ctx.mode == model_fn_lib.ModeKeys.PREDICT: - # TODO(b/XXX): Add predict support for PER_HOST_V2 - raise TypeError('Most PREDICT not yet supported in PER_HOST_V2 mode.') + inputs = _InputsWithStoppingSignals( + dataset=inputs.dataset, + batch_size=ctx.batch_size_for_input_fn, + add_padding=True, + num_invocations_per_step=ctx.num_of_replicas_per_host) hooks.append(inputs.dataset_initializer_hook()) tpu_ordinal_function_impl = ctx.tpu_ordinal_function(host_id) @@ -774,6 +778,7 @@ def generate_per_host_v2_enqueue_ops_fn_for_host( control_deps = [] per_host_sharded_inputs = [] num_replicas_per_host = ctx.num_of_replicas_per_host + cached_signals = None with ops.device(device): if not inputs.is_dataset: raise TypeError('`input_fn` must return a `Dataset` for this mode.') @@ -781,21 +786,32 @@ def generate_per_host_v2_enqueue_ops_fn_for_host( # Use control dependencies to ensure a deterministic ordering. with ops.control_dependencies(control_deps): features, labels = inputs.features_and_labels() # Calls get_next() + signals = inputs.signals() + + # All the replicas share the replica 0's stopping singal. + # This avoids inconsistent state among different model replcias. + if cached_signals: + signals['stopping'] = cached_signals['stopping'] + else: + cached_signals = signals inputs_structure_recorder.validate_and_record_structure( features, labels) flattened_inputs = ( inputs_structure_recorder.flatten_features_and_labels( - features, labels)) + features, labels, signals)) control_deps.extend(flattened_inputs) per_host_sharded_inputs.append(flattened_inputs) if inputs_structure_recorder.flattened_input_dims: + input_partition_dims = inputs_structure_recorder.flattened_input_dims + if signals: + input_partition_dims += [None] * len(signals) # pylint: disable=protected-access infeed_queue = tpu_feed._PartitionedInfeedQueue( number_of_tuple_elements=len(per_host_sharded_inputs[0]), host_id=host_id, - input_partition_dims=inputs_structure_recorder.flattened_input_dims, + input_partition_dims=input_partition_dims, device_assignment=ctx.device_assignment) per_host_enqueue_ops = infeed_queue.generate_enqueue_ops( per_host_sharded_inputs) @@ -807,7 +823,13 @@ def generate_per_host_v2_enqueue_ops_fn_for_host( tpu_ordinal_function=tpu_ordinal_function_impl) captured_infeed_queue.capture(infeed_queue) - return per_host_enqueue_ops + if signals is None: + return per_host_enqueue_ops + else: + return { + 'ops': per_host_enqueue_ops, + 'signals': signals, + } return enqueue_ops_fn, captured_infeed_queue, hooks, is_dataset @@ -2124,9 +2146,10 @@ class TPUEstimator(estimator_lib.Estimator): mode=model_fn_lib.ModeKeys.PREDICT, export_tags=None, check_variables=True): - if mode != model_fn_lib.ModeKeys.PREDICT: + if self._export_to_tpu and mode != model_fn_lib.ModeKeys.PREDICT: raise NotImplementedError( - 'TPUEstimator only handles mode PREDICT for export_savedmodel(); ' + 'TPUEstimator only handles mode PREDICT for exporting ' + 'when `export_to_tpu` is `True`; ' 'got {}.'.format(mode)) (super(TPUEstimator, self). @@ -2424,16 +2447,12 @@ class TPUEstimator(estimator_lib.Estimator): with self._ctx.with_mode(mode) as ctx: model_fn_wrapper = _ModelFnWrapper(model_fn, config, params, ctx) - if mode != model_fn_lib.ModeKeys.PREDICT: + # `input_fn` is called in `train()`, `evaluate()`, and `predict()`, + # but not in `export_savedmodel()`. + if self._is_input_fn_invoked: is_export_mode = False else: - # For export_savedmodel, input_fn is never passed to Estimator. So, by - # checking the self._is_input_fn_invoked bit, we can know, given the - # mode == PREDICT, it is the .predict API, not export_savedmodel API. - if self._is_input_fn_invoked: - is_export_mode = False - else: - is_export_mode = True + is_export_mode = True # Clear the bit. self._is_input_fn_invoked = None @@ -2805,8 +2824,6 @@ def _train_on_tpu_system(ctx, model_fn_wrapper, dequeue_fn): def _predict_on_tpu_system(ctx, model_fn_wrapper, dequeue_fn): """Executes `model_fn_wrapper` multiple times on all TPU shards.""" - num_cores = ctx.num_cores - (single_tpu_predict_step, host_calls, captured_scaffold_fn, captured_predict_hooks ) = model_fn_wrapper.convert_to_single_tpu_predict_step(dequeue_fn) @@ -2825,7 +2842,7 @@ def _predict_on_tpu_system(ctx, model_fn_wrapper, dequeue_fn): (dummy_predict_op,) = tpu.shard( multi_tpu_predict_steps_on_single_shard, inputs=[], - num_shards=num_cores, + num_shards=ctx.num_replicas, outputs_from_all_shards=False, device_assignment=ctx.device_assignment) @@ -3043,16 +3060,48 @@ class _Inputs(object): class _InputsWithStoppingSignals(_Inputs): """Inputs with `_StopSignals` inserted into the dataset.""" - def __init__(self, dataset, batch_size, add_padding=False): + def __init__(self, + dataset, + batch_size, + add_padding=False, + num_invocations_per_step=1): assert dataset is not None - user_provided_dataset = dataset.map( _InputsWithStoppingSignals.insert_stopping_signal( stop=False, batch_size=batch_size, add_padding=add_padding)) - final_batch_dataset = dataset.take(1).map( - _InputsWithStoppingSignals.insert_stopping_signal( - stop=True, batch_size=batch_size, add_padding=add_padding)) + if num_invocations_per_step == 1: + final_batch_dataset = dataset.take(1).map( + _InputsWithStoppingSignals.insert_stopping_signal( + stop=True, batch_size=batch_size, add_padding=add_padding)) + else: + # We append (2 * num_invocations_per_step - 1) batches for exhausting the + # user_provided_dataset and stop properly. + # For example, if num_invocations_per_step is 2, we append 3 additional + # padding batches: b1, b2, b3. + # If user_provided_dataset contains two batches: a1, a2 + # Step 1: [a1, a2] + # Step 2: [b1, b2] -> STOP + # If user_provided_dataset contains three batches: a1, a2, a3. + # The training loops: + # Step 1: [a1, a2] + # Step 2: [a3, b1] + # Step 3: [b2, b3] -> STOP. + final_batch_dataset = dataset.take(1).map( + _InputsWithStoppingSignals.insert_stopping_signal( + stop=True, batch_size=batch_size, add_padding=add_padding)) + final_batch_dataset = final_batch_dataset.repeat( + 2 * num_invocations_per_step - 1) + + def _set_mask(data_dict): + signals = data_dict['signals'] + signals['padding_mask'] = array_ops.ones_like(signals['padding_mask']) + data_dict['signals'] = signals + return data_dict + + # Mask out the extra batch. + final_batch_dataset = final_batch_dataset.map(_set_mask) + dataset = user_provided_dataset.concatenate(final_batch_dataset).prefetch(2) super(_InputsWithStoppingSignals, self).__init__(dataset=dataset) diff --git a/tensorflow/contrib/tpu/python/tpu/tpu_estimator_signals_test.py b/tensorflow/contrib/tpu/python/tpu/tpu_estimator_signals_test.py index 3e90957e6d..bd530fdc3a 100644 --- a/tensorflow/contrib/tpu/python/tpu/tpu_estimator_signals_test.py +++ b/tensorflow/contrib/tpu/python/tpu/tpu_estimator_signals_test.py @@ -286,6 +286,59 @@ class TPUEstimatorStoppingSignalsWithPaddingTest(test.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(sliced_features) + def test_slice_with_multi_invocations_per_step(self): + num_samples = 3 + batch_size = 2 + + params = {'batch_size': batch_size} + input_fn, (a, b) = make_input_fn(num_samples=num_samples) + + with ops.Graph().as_default(): + dataset = input_fn(params) + inputs = tpu_estimator._InputsWithStoppingSignals( + dataset, batch_size, add_padding=True, num_invocations_per_step=2) + hook = inputs.dataset_initializer_hook() + features, _ = inputs.features_and_labels() + signals = inputs.signals() + + sliced_features = ( + tpu_estimator._PaddingSignals.slice_tensor_or_dict(features, signals)) + + with session.Session() as sess: + hook.begin() + hook.after_create_session(sess, coord=None) + + result, evaluated_signals = sess.run([sliced_features, signals]) + self.assertAllEqual(a[:batch_size], result['a']) + self.assertAllEqual(b[:batch_size], result['b']) + self.assertAllEqual([[0.]] * batch_size, evaluated_signals['stopping']) + + # This is the final partial batch. + result, evaluated_signals = sess.run([sliced_features, signals]) + self.assertEqual(1, len(result['a'])) + self.assertAllEqual(a[batch_size:num_samples], result['a']) + self.assertAllEqual(b[batch_size:num_samples], result['b']) + self.assertAllEqual([[0.]] * batch_size, evaluated_signals['stopping']) + + # We should see 3 continuous batches with STOP ('1') as signals and all + # of them have mask 1. + _, evaluated_signals = sess.run([sliced_features, signals]) + self.assertAllEqual([[1.]] * batch_size, evaluated_signals['stopping']) + self.assertAllEqual([1.] * batch_size, + evaluated_signals['padding_mask']) + + _, evaluated_signals = sess.run([sliced_features, signals]) + self.assertAllEqual([[1.]] * batch_size, evaluated_signals['stopping']) + self.assertAllEqual([1.] * batch_size, + evaluated_signals['padding_mask']) + + _, evaluated_signals = sess.run([sliced_features, signals]) + self.assertAllEqual([[1.]] * batch_size, evaluated_signals['stopping']) + self.assertAllEqual([1.] * batch_size, + evaluated_signals['padding_mask']) + with self.assertRaises(errors.OutOfRangeError): + sess.run(sliced_features) + if __name__ == '__main__': test.main() diff --git a/tensorflow/contrib/tpu/python/tpu/tpu_optimizer.py b/tensorflow/contrib/tpu/python/tpu/tpu_optimizer.py index 53d33f4077..1e11de6421 100644 --- a/tensorflow/contrib/tpu/python/tpu/tpu_optimizer.py +++ b/tensorflow/contrib/tpu/python/tpu/tpu_optimizer.py @@ -19,7 +19,6 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function -import collections from tensorflow.contrib.tpu.python.ops import tpu_ops from tensorflow.contrib.tpu.python.tpu import tpu_function @@ -44,8 +43,9 @@ class CrossShardOptimizer(optimizer.Optimizer): reduction: The reduction to apply to the shard losses. name: Optional name prefix for the operations created when applying gradients. Defaults to "CrossShardOptimizer". - group_assignment: Optional list of group ids for applying the optimizer - to subgroups. + group_assignment: Optional 2d int32 lists with shape + [num_groups, num_replicas_per_group] which describles how to apply + optimizer to subgroups. Raises: ValueError: If reduction is not a valid cross-shard reduction. @@ -74,11 +74,22 @@ class CrossShardOptimizer(optimizer.Optimizer): """ if not group_assignment: return None - if len(group_assignment) != num_shards: - raise ValueError("The size of group_assignment does not equal to " - "num_shard({0}). Got group_assignment={1}".format( - num_shards, self._group_assignment)) - subgroup_size_list = dict(collections.Counter(group_assignment)).values() + if not (isinstance(group_assignment, list) and + all(isinstance(i, list) for i in group_assignment)): + raise ValueError("group_assignment must be a list of list. Got {}".format( + group_assignment)) + + replica_ids = set() + for g in group_assignment: + for i in g: + replica_ids.add(i) + + if set(range(num_shards)) != replica_ids: + raise ValueError("group_assignment must be a permutation of range({0})." + " Got group_assignment={1}".format( + num_shards, group_assignment)) + + subgroup_size_list = [len(group) for group in group_assignment] if all(subgroup_size_list[0] == size for size in subgroup_size_list): return subgroup_size_list[0] else: @@ -186,3 +197,7 @@ class CrossShardOptimizer(optimizer.Optimizer): A list of strings. """ return self._opt.get_slot_names(*args, **kwargs) + + def variables(self): + """Forwarding the variables from the underlying optimizer.""" + return self._opt.variables() diff --git a/tensorflow/contrib/training/python/training/batch_sequences_with_states_test.py b/tensorflow/contrib/training/python/training/batch_sequences_with_states_test.py index df07ff44ee..afeef978f3 100644 --- a/tensorflow/contrib/training/python/training/batch_sequences_with_states_test.py +++ b/tensorflow/contrib/training/python/training/batch_sequences_with_states_test.py @@ -108,7 +108,7 @@ class BatchSequencesWithStatesTest(test.TestCase): expected_seq4_batch1, expected_seq4_batch2, key=None, make_keys_unique=False): - with self.test_session() as sess: + with self.cached_session() as sess: next_batch = sqss.batch_sequences_with_states( input_key=key if key is not None else self.key, input_sequences=self.sequences, @@ -332,7 +332,7 @@ class BatchSequencesWithStatesTest(test.TestCase): "seq4": self.sequences["seq4"], } - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaisesRegexp(errors_impl.InvalidArgumentError, ".*should be a multiple of: 3, but saw " "value: 4. Consider setting pad=True."): @@ -508,7 +508,7 @@ class BatchSequencesWithStatesTest(test.TestCase): class PaddingTest(test.TestCase): def testPaddingInvalidLengths(self): - with ops.Graph().as_default() as g, self.test_session(graph=g): + with ops.Graph().as_default() as g, self.session(graph=g): sequences = { "key_1": constant_op.constant([1, 2, 3]), # length 3 "key_2": constant_op.constant([1.5, 2.5]) # length 2 @@ -520,7 +520,7 @@ class PaddingTest(test.TestCase): padded_seq["key_1"].eval() def testPadding(self): - with ops.Graph().as_default() as g, self.test_session(graph=g): + with ops.Graph().as_default() as g, self.session(graph=g): sequences = { "key_1": constant_op.constant([1, 2]), "key_2": constant_op.constant([0.5, -1.0]), @@ -549,7 +549,7 @@ class PaddingTest(test.TestCase): val2 = np.array([9, 12]) shape2 = np.array([5]) - with ops.Graph().as_default() as g, self.test_session(graph=g): + with ops.Graph().as_default() as g, self.session(graph=g): sp_tensor1 = sparse_tensor.SparseTensor( indices=array_ops.constant(ind1, dtypes.int64), values=array_ops.constant(val1, dtypes.int64), diff --git a/tensorflow/contrib/training/python/training/bucket_ops_test.py b/tensorflow/contrib/training/python/training/bucket_ops_test.py index 504f1fcd41..b259e0ee83 100644 --- a/tensorflow/contrib/training/python/training/bucket_ops_test.py +++ b/tensorflow/contrib/training/python/training/bucket_ops_test.py @@ -112,7 +112,7 @@ class BucketTest(test.TestCase): self.assertAllEqual( [[32], [32, None], [32, 3], [None, None]], [out.get_shape().as_list() for out in bucketed_dynamic[1]]) - with self.test_session() as sess: + with self.cached_session() as sess: for v in range(32): self.enqueue_inputs(sess, { self.scalar_int_feed: v, @@ -162,7 +162,7 @@ class BucketTest(test.TestCase): self.assertAllEqual( [[None], [None, None], [None, 3], [None, None]], [out.get_shape().as_list() for out in bucketed_dynamic[1]]) - with self.test_session() as sess: + with self.cached_session() as sess: for v in range(15): self.enqueue_inputs(sess, { self.scalar_int_feed: v, @@ -204,7 +204,7 @@ class BucketTest(test.TestCase): self.assertAllEqual( [[32], [32, None], [32, 3], [None, None]], [out.get_shape().as_list() for out in bucketed_dynamic[1]]) - with self.test_session() as sess: + with self.cached_session() as sess: for v in range(64): self.enqueue_inputs(sess, { self.scalar_int_feed: v, @@ -286,7 +286,7 @@ class BucketTest(test.TestCase): self.assertAllEqual( [[32], [32, None], [32, 3]], [out.get_shape().as_list() for out in bucketed_dynamic[1]]) - with self.test_session() as sess: + with self.cached_session() as sess: for v in range(128): self.enqueue_inputs(sess, { self.scalar_int_feed: v, @@ -405,7 +405,7 @@ class BucketBySequenceLengthTest(test.TestCase): num_pairs_to_enqueue - (batch_size - 1) * num_buckets, num_pairs_dequeued) - with self.test_session() as sess: + with self.cached_session() as sess: coord = coordinator.Coordinator() # Feed the inputs, then close the input thread. diff --git a/tensorflow/contrib/training/python/training/evaluation_test.py b/tensorflow/contrib/training/python/training/evaluation_test.py index c36d00e842..ec47fe5d97 100644 --- a/tensorflow/contrib/training/python/training/evaluation_test.py +++ b/tensorflow/contrib/training/python/training/evaluation_test.py @@ -67,7 +67,7 @@ class CheckpointIteratorTest(test.TestCase): global_step = variables.get_or_create_global_step() saver = saver_lib.Saver() # Saves the global step. - with self.test_session() as session: + with self.cached_session() as session: session.run(variables_lib.global_variables_initializer()) save_path = os.path.join(checkpoint_dir, 'model.ckpt') saver.save(session, save_path, global_step=global_step) diff --git a/tensorflow/contrib/training/python/training/resample_test.py b/tensorflow/contrib/training/python/training/resample_test.py index 774241a816..8665a24883 100644 --- a/tensorflow/contrib/training/python/training/resample_test.py +++ b/tensorflow/contrib/training/python/training/resample_test.py @@ -44,7 +44,7 @@ class ResampleTest(test.TestCase): ([3], [0, 0, 0]), ([0, 1, 2, 3], [1, 2, 2, 3, 3, 3]), ] - with self.test_session() as sess: + with self.cached_session() as sess: for inputs, expected in cases: array_inputs = numpy.array(inputs, dtype=numpy.int32) actual = sess.run(resample._repeat_range(array_inputs)) @@ -65,7 +65,7 @@ class ResampleTest(test.TestCase): init = control_flow_ops.group(variables.local_variables_initializer(), variables.global_variables_initializer()) - with self.test_session() as s: + with self.cached_session() as s: s.run(init) # initialize # outputs @@ -112,7 +112,7 @@ class ResampleTest(test.TestCase): init = control_flow_ops.group(variables.local_variables_initializer(), variables.global_variables_initializer()) expected_sum_op = math_ops.reduce_sum(vals) - with self.test_session() as s: + with self.cached_session() as s: s.run(init) expected_sum = n * s.run(expected_sum_op) @@ -147,7 +147,7 @@ class ResampleTest(test.TestCase): resampled = resample.resample_at_rate([vals], rates) - with self.test_session() as s: + with self.cached_session() as s: rs, = s.run(resampled, { vals: list(range(count)), rates: numpy.zeros( diff --git a/tensorflow/contrib/training/python/training/sampling_ops_test.py b/tensorflow/contrib/training/python/training/sampling_ops_test.py index bf7fb4fd48..1aeff7dc80 100644 --- a/tensorflow/contrib/training/python/training/sampling_ops_test.py +++ b/tensorflow/contrib/training/python/training/sampling_ops_test.py @@ -146,7 +146,7 @@ class StratifiedSampleTest(test.TestCase): for illegal_label in illegal_labels: # Run session that should fail. - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaises(errors_impl.InvalidArgumentError): sess.run([val_tf, lbl_tf], feed_dict={label_ph: illegal_label, @@ -154,7 +154,7 @@ class StratifiedSampleTest(test.TestCase): for illegal_prob in illegal_probs: # Run session that should fail. - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaises(errors_impl.InvalidArgumentError): sess.run([prob_tf], feed_dict={label_ph: valid_labels, @@ -172,7 +172,7 @@ class StratifiedSampleTest(test.TestCase): summary_op = logging_ops.merge_summary( ops.get_collection(ops.GraphKeys.SUMMARIES)) - with self.test_session() as sess: + with self.cached_session() as sess: coord = coordinator.Coordinator() threads = queue_runner_impl.start_queue_runners(coord=coord) @@ -197,7 +197,7 @@ class StratifiedSampleTest(test.TestCase): batch_size, init_probs=[0, .3, 0, .7, 0], enqueue_many=True) - with self.test_session() as sess: + with self.cached_session() as sess: coord = coordinator.Coordinator() threads = queue_runner_impl.start_queue_runners(coord=coord) @@ -228,7 +228,7 @@ class StratifiedSampleTest(test.TestCase): # Run graph to make sure there are no shape-related runtime errors. for vals, labels in legal_input_pairs: - with self.test_session() as sess: + with self.cached_session() as sess: sess.run([val_tf, labels_tf], feed_dict={vals_ph: vals, labels_ph: labels}) @@ -253,7 +253,7 @@ class StratifiedSampleTest(test.TestCase): self.assertEqual(len(val_list), len(val_input_batch)) self.assertTrue(isinstance(lbls, ops.Tensor)) - with self.test_session() as sess: + with self.cached_session() as sess: coord = coordinator.Coordinator() threads = queue_runner_impl.start_queue_runners(coord=coord) @@ -283,7 +283,7 @@ class StratifiedSampleTest(test.TestCase): # Run session and keep track of how frequently the labels and values appear. data_l = [] label_l = [] - with self.test_session() as sess: + with self.cached_session() as sess: # Need to initialize variables that keep running total of classes seen. variables.global_variables_initializer().run() @@ -374,7 +374,7 @@ class RejectionSampleTest(test.TestCase): 'rejection_sample/prob_with_checks:0') # Run session that should fail. - with self.test_session() as sess: + with self.cached_session() as sess: for illegal_prob in [-0.1, 1.1]: with self.assertRaises(errors_impl.InvalidArgumentError): sess.run(prob_tensor, feed_dict={prob_ph: illegal_prob}) @@ -393,7 +393,7 @@ class RejectionSampleTest(test.TestCase): sample = sampling_ops.rejection_sample(tensor_list, accept_prob_fn, batch_size) - with self.test_session() as sess: + with self.cached_session() as sess: coord = coordinator.Coordinator() threads = queue_runner_impl.start_queue_runners(coord=coord) diff --git a/tensorflow/contrib/training/python/training/sampling_ops_threading_test.py b/tensorflow/contrib/training/python/training/sampling_ops_threading_test.py index ca78c0029e..73ad859ab3 100644 --- a/tensorflow/contrib/training/python/training/sampling_ops_threading_test.py +++ b/tensorflow/contrib/training/python/training/sampling_ops_threading_test.py @@ -59,7 +59,7 @@ class SamplingOpsThreadingTest(test.TestCase): out_tensor = queue.dequeue() # Run the multi-threaded session. - with self.test_session() as sess: + with self.cached_session() as sess: # Need to initialize variables that keep running total of classes seen. variables.global_variables_initializer().run() diff --git a/tensorflow/contrib/training/python/training/sequence_queueing_state_saver_test.py b/tensorflow/contrib/training/python/training/sequence_queueing_state_saver_test.py index 7aebd9d9fe..8932b905c9 100644 --- a/tensorflow/contrib/training/python/training/sequence_queueing_state_saver_test.py +++ b/tensorflow/contrib/training/python/training/sequence_queueing_state_saver_test.py @@ -36,7 +36,7 @@ from tensorflow.python.platform import test class SequenceQueueingStateSaverTest(test.TestCase): def testSequenceInputWrapper(self): - with self.test_session(): + with self.cached_session(): length = 3 key = "key" padded_length = 4 @@ -54,7 +54,7 @@ class SequenceQueueingStateSaverTest(test.TestCase): self.assertTrue(isinstance(input_wrapper.context["context1"], ops.Tensor)) def testStateSaverWithTwoSimpleSteps(self): - with self.test_session() as sess: + with self.cached_session() as sess: batch_size_value = 2 batch_size = constant_op.constant(batch_size_value) num_unroll = 2 @@ -159,7 +159,7 @@ class SequenceQueueingStateSaverTest(test.TestCase): self.assertEqual(0, state_saver.barrier.ready_size().eval()) def testStateSaverFailsIfPaddedLengthIsNotMultipleOfNumUnroll(self): - with self.test_session() as sess: + with self.cached_session() as sess: batch_size = constant_op.constant(32) num_unroll = 17 bad_padded_length = 3 @@ -194,7 +194,7 @@ class SequenceQueueingStateSaverTest(test.TestCase): }) def _testStateSaverFailsIfCapacityTooSmall(self, batch_size): - with self.test_session() as sess: + with self.cached_session() as sess: num_unroll = 2 length = array_ops.placeholder(dtypes.int32) key = array_ops.placeholder(dtypes.string) @@ -243,7 +243,7 @@ class SequenceQueueingStateSaverTest(test.TestCase): self._testStateSaverFailsIfCapacityTooSmall(batch_size) def testStateSaverFailsIfInconsistentPaddedLength(self): - with self.test_session() as sess: + with self.cached_session() as sess: batch_size = constant_op.constant(32) num_unroll = 17 length = array_ops.placeholder(dtypes.int32) @@ -282,7 +282,7 @@ class SequenceQueueingStateSaverTest(test.TestCase): def testStateSaverFailsIfInconsistentWriteState(self): # TODO(b/26910386): Identify why this infrequently causes timeouts. - with self.test_session() as sess: + with self.cached_session() as sess: batch_size = constant_op.constant(1) num_unroll = 17 length = array_ops.placeholder(dtypes.int32) @@ -326,7 +326,7 @@ class SequenceQueueingStateSaverTest(test.TestCase): def testStateSaverWithManyInputsReadWriteThread(self): batch_size_value = 32 num_proc_threads = 100 - with self.test_session() as sess: + with self.cached_session() as sess: batch_size = constant_op.constant(batch_size_value) num_unroll = 17 length = array_ops.placeholder(dtypes.int32) @@ -490,7 +490,7 @@ class SequenceQueueingStateSaverTest(test.TestCase): self.assertGreater(processed_count[0], 2 * 20 * batch_size_value) def testStateSaverProcessesExamplesInOrder(self): - with self.test_session() as sess: + with self.cached_session() as sess: batch_size_value = 32 batch_size = constant_op.constant(batch_size_value) num_unroll = 17 @@ -563,7 +563,7 @@ class SequenceQueueingStateSaverTest(test.TestCase): self.assertEqual(get_ready_size.eval(), 0) def testStateSaverCanHandleVariableBatchsize(self): - with self.test_session() as sess: + with self.cached_session() as sess: batch_size = array_ops.placeholder(dtypes.int32) num_unroll = 17 length = array_ops.placeholder(dtypes.int32) diff --git a/tensorflow/contrib/training/python/training/sgdr_learning_rate_decay_test.py b/tensorflow/contrib/training/python/training/sgdr_learning_rate_decay_test.py index 4a46e9a49e..3269d5fef2 100644 --- a/tensorflow/contrib/training/python/training/sgdr_learning_rate_decay_test.py +++ b/tensorflow/contrib/training/python/training/sgdr_learning_rate_decay_test.py @@ -62,7 +62,7 @@ class SGDRDecayTest(test_util.TensorFlowTestCase): def get_sgdr_values(self, lr, initial_period_steps, t_mul, iters): """Get an array with learning rate values from the consecutive steps using current tensorflow implementation.""" - with self.test_session(): + with self.cached_session(): step = placeholder(dtypes.int32) decay = sgdr_decay(lr, step, initial_period_steps, t_mul) @@ -76,7 +76,7 @@ class SGDRDecayTest(test_util.TensorFlowTestCase): """Compare values generated by tensorflow implementation to the values generated by the original implementation (https://github.com/loshchil/SGDR/blob/master/SGDR_WRNs.py).""" - with self.test_session(): + with self.cached_session(): lr = 10.0 init_steps = 2 t_mul = 3 @@ -92,7 +92,7 @@ class SGDRDecayTest(test_util.TensorFlowTestCase): def testMDecay(self): """Test m_mul argument. Check values for learning rate at the beginning of the first, second, third and fourth period. """ - with self.test_session(): + with self.cached_session(): step = placeholder(dtypes.int32) lr = 0.1 @@ -121,7 +121,7 @@ class SGDRDecayTest(test_util.TensorFlowTestCase): def testCos(self): """Check learning rate values at the beginning, in the middle and at the end of the period.""" - with self.test_session(): + with self.cached_session(): step = placeholder(dtypes.int32) lr = 0.2 t_e = 1000 diff --git a/tensorflow/contrib/training/python/training/tensor_queue_dataset_test.py b/tensorflow/contrib/training/python/training/tensor_queue_dataset_test.py index df0a186f4f..d9b0511a98 100644 --- a/tensorflow/contrib/training/python/training/tensor_queue_dataset_test.py +++ b/tensorflow/contrib/training/python/training/tensor_queue_dataset_test.py @@ -79,7 +79,7 @@ class PrependFromQueueAndPaddedBatchDatasetTest(test.TestCase): iterator = dataset.make_one_shot_iterator() queue_handle, value = iterator.get_next() enqueue_negative = tqd.enqueue_in_queue_dataset(queue_handle, -value) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual([[0, 0, 0]], sess.run(value)) value_1, _ = sess.run([value, enqueue_negative]) self.assertAllEqual([[1, 0, 0]], value_1) @@ -101,7 +101,7 @@ class PrependFromQueueAndPaddedBatchDatasetTest(test.TestCase): iterator = dataset.make_one_shot_iterator() queue_handle, value = iterator.get_next() enqueue_negative = tqd.enqueue_in_queue_dataset(queue_handle, -value) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual([0], sess.run(value)) value_1, _ = sess.run([value, enqueue_negative]) self.assertEqual([1], value_1) @@ -126,7 +126,7 @@ class PrependFromQueueAndPaddedBatchDatasetTest(test.TestCase): enqueue_zeroth = tqd.enqueue_in_queue_dataset([queue_handle[0]], array_ops.expand_dims( value[0], axis=0)) - with self.test_session() as sess: + with self.cached_session() as sess: value_0, _ = sess.run([value, enqueue_negative]) self.assertAllEqual([0, 1], value_0) value_1, _ = sess.run([value, enqueue_zeroth]) @@ -147,7 +147,7 @@ class PrependFromQueueAndPaddedBatchDatasetTest(test.TestCase): tqd.enqueue_in_queue_dataset(queue_handle, value + 100 + i) for i in range(1000) ] - with self.test_session() as sess: + with self.cached_session() as sess: value_0, _ = sess.run((value, enqueue_many_more)) self.assertEqual([0], value_0) rest = [] @@ -174,7 +174,7 @@ class PrependFromQueueAndPaddedBatchDatasetTest(test.TestCase): iterator = dataset.make_one_shot_iterator() queue_handle, value = iterator.get_next() enqueue = tqd.enqueue_in_queue_dataset(queue_handle, value + 1) - with self.test_session() as sess: + with self.cached_session() as sess: i = 0 while i < 4: received, _ = sess.run((value, enqueue)) @@ -199,7 +199,7 @@ class PrependFromQueueAndPaddedBatchDatasetTest(test.TestCase): batch_size=1, padded_shapes=[2])) iterator = dataset.make_one_shot_iterator() _, value = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaisesOpError( r"Incompatible input shapes at component 0 between " r"input dataset this dataset: \[3\] vs. \[2\]"): @@ -224,7 +224,7 @@ class PrependFromQueueAndPaddedBatchDatasetTest(test.TestCase): np.array( [[1]], dtype=np.int32)) - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaisesOpError( "mismatched number of tensors. Queue expects 1 tensors but " "tried to insert 2"): @@ -274,7 +274,7 @@ class PrependFromQueueAndPaddedBatchDatasetTest(test.TestCase): with ops.control_dependencies([enqueue_rest_op]): calc = array_ops.identity(value_head) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual([[0, 0], [2, 2], [4, 4]], sess.run(calc)) self.assertAllEqual([[4, 4], [6, 6]], sess.run(calc)) self.assertAllEqual([[6, 6]], sess.run(calc)) @@ -304,7 +304,7 @@ class PrependFromQueueAndPaddedBatchDatasetTest(test.TestCase): iterator = dataset.make_one_shot_iterator() _, (unused_count, padded_value) = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual([[-1, -1, -1, -1], [2, 2, -1, -1], [4, 4, 4, 4]], sess.run(padded_value)) self.assertAllEqual([[6] * 6], sess.run(padded_value)) diff --git a/tensorflow/contrib/training/python/training/training_test.py b/tensorflow/contrib/training/python/training/training_test.py index 94cf7788b2..3b524ac8c7 100644 --- a/tensorflow/contrib/training/python/training/training_test.py +++ b/tensorflow/contrib/training/python/training/training_test.py @@ -62,7 +62,7 @@ class ClipGradsTest(test.TestCase): clipped_gradients_to_variables = training.clip_gradient_norms( gradients_to_variables, 3.0) - with self.test_session() as session: + with self.cached_session() as session: session.run(variables_lib2.global_variables_initializer()) self.assertAlmostEqual(4.0, gradients_to_variables[0][0].eval()) self.assertAlmostEqual(3.0, clipped_gradients_to_variables[0][0].eval()) @@ -75,7 +75,7 @@ class ClipGradsTest(test.TestCase): clipped_gradients_to_variables = training.clip_gradient_norms_fn(3.0)( gradients_to_variables) - with self.test_session() as session: + with self.cached_session() as session: session.run(variables_lib2.global_variables_initializer()) self.assertAlmostEqual(4.0, gradients_to_variables[0][0].eval()) self.assertAlmostEqual(3.0, clipped_gradients_to_variables[0][0].eval()) @@ -122,7 +122,7 @@ class CreateTrainOpTest(test.TestCase): moving_variance = variables_lib.get_variables_by_name('moving_variance')[ 0] - with self.test_session() as session: + with self.cached_session() as session: # Initialize all variables session.run(variables_lib2.global_variables_initializer()) mean, variance = session.run([moving_mean, moving_variance]) @@ -155,7 +155,7 @@ class CreateTrainOpTest(test.TestCase): moving_variance = variables_lib.get_variables_by_name('moving_variance')[ 0] - with self.test_session() as session: + with self.cached_session() as session: # Initialize all variables session.run(variables_lib2.global_variables_initializer()) mean, variance = session.run([moving_mean, moving_variance]) @@ -186,7 +186,7 @@ class CreateTrainOpTest(test.TestCase): global_step = variables_lib.get_or_create_global_step() - with self.test_session() as session: + with self.cached_session() as session: # Initialize all variables session.run(variables_lib2.global_variables_initializer()) @@ -209,7 +209,7 @@ class CreateTrainOpTest(test.TestCase): global_step = variables_lib.get_or_create_global_step() - with self.test_session() as session: + with self.cached_session() as session: # Initialize all variables session.run(variables_lib2.global_variables_initializer()) @@ -535,7 +535,7 @@ class TrainTest(test.TestCase): train_biases = training.create_train_op( total_loss, optimizer, variables_to_train=[biases]) - with self.test_session() as session: + with self.cached_session() as session: # Initialize the variables. session.run(variables_lib2.global_variables_initializer()) diff --git a/tensorflow/contrib/verbs/grpc_verbs_client.h b/tensorflow/contrib/verbs/grpc_verbs_client.h index 2cfaa4986c..e07085502f 100644 --- a/tensorflow/contrib/verbs/grpc_verbs_client.h +++ b/tensorflow/contrib/verbs/grpc_verbs_client.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_GRPC_VERBS_CLIENT_H_ -#define TENSORFLOW_CONTRIB_GRPC_VERBS_CLIENT_H_ +#ifndef TENSORFLOW_CONTRIB_VERBS_GRPC_VERBS_CLIENT_H_ +#define TENSORFLOW_CONTRIB_VERBS_GRPC_VERBS_CLIENT_H_ #include "tensorflow/contrib/verbs/grpc_verbs_service_impl.h" #include "tensorflow/contrib/verbs/verbs_service.pb.h" @@ -47,4 +47,4 @@ class GrpcVerbsClient { } // namespace tensorflow -#endif // TENSORFLOW_CONTRIB_GRPC_VERBS_CLIENT_H_ +#endif // TENSORFLOW_CONTRIB_VERBS_GRPC_VERBS_CLIENT_H_ diff --git a/tensorflow/contrib/verbs/grpc_verbs_service_impl.h b/tensorflow/contrib/verbs/grpc_verbs_service_impl.h index abe5e08b07..cfb9b7ddd7 100644 --- a/tensorflow/contrib/verbs/grpc_verbs_service_impl.h +++ b/tensorflow/contrib/verbs/grpc_verbs_service_impl.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_GRPC_VERBS_SERVICE_IMPL_H_ -#define TENSORFLOW_CONTRIB_GRPC_VERBS_SERVICE_IMPL_H_ +#ifndef TENSORFLOW_CONTRIB_VERBS_GRPC_VERBS_SERVICE_IMPL_H_ +#define TENSORFLOW_CONTRIB_VERBS_GRPC_VERBS_SERVICE_IMPL_H_ #include "grpcpp/impl/codegen/async_stream.h" #include "grpcpp/impl/codegen/async_unary_call.h" @@ -86,4 +86,4 @@ class VerbsService GRPC_FINAL { } // namespace tensorflow -#endif // TENSORFLOW_CONTRIB_GRPC_VERBS_SERVICE_IMPL_H_ +#endif // TENSORFLOW_CONTRIB_VERBS_GRPC_VERBS_SERVICE_IMPL_H_ diff --git a/tensorflow/contrib/verbs/verbs_util.h b/tensorflow/contrib/verbs/verbs_util.h index 5cd0a3533a..6277bc4b41 100644 --- a/tensorflow/contrib/verbs/verbs_util.h +++ b/tensorflow/contrib/verbs/verbs_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CONTRIB_RDMA_UTIL_H_ -#define TENSORFLOW_CONTRIB_RDMA_UTIL_H_ +#ifndef TENSORFLOW_CONTRIB_VERBS_VERBS_UTIL_H_ +#define TENSORFLOW_CONTRIB_VERBS_VERBS_UTIL_H_ #include <string> @@ -30,4 +30,4 @@ class VerbsUtil { }; } // namespace tensorflow -#endif // TENSORFLOW_CONTRIB_RDMA_UTIL_H_ +#endif // TENSORFLOW_CONTRIB_VERBS_VERBS_UTIL_H_ diff --git a/tensorflow/core/BUILD b/tensorflow/core/BUILD index 64430a1418..51225f34bc 100644 --- a/tensorflow/core/BUILD +++ b/tensorflow/core/BUILD @@ -375,6 +375,7 @@ cc_library( ":lib_platform", ":platform_base", "//tensorflow/core/platform/default/build_config:port", + "@com_google_absl//absl/base", "@snappy", ], ) @@ -668,8 +669,11 @@ cc_library( "lib/io/table_builder.h", "lib/io/table_options.h", "lib/math/math_util.h", + "lib/monitoring/collected_metrics.h", + "lib/monitoring/collection_registry.h", "lib/monitoring/counter.h", "lib/monitoring/gauge.h", + "lib/monitoring/metric_def.h", "lib/monitoring/sampler.h", "lib/random/distribution_sampler.h", "lib/random/philox_random.h", @@ -1572,6 +1576,7 @@ cc_library( ], visibility = ["//visibility:public"], deps = [ + ":mobile_additional_lib_deps", ":protos_all_cc_impl", ":stats_calculator_portable", "//third_party/eigen3", @@ -1582,6 +1587,11 @@ cc_library( alwayslink = 1, ) +cc_library( + name = "mobile_additional_lib_deps", + deps = tf_additional_lib_deps(), +) + # Native library support for iOS applications. # # bazel build --config=ios_x86_64 \ @@ -1613,6 +1623,7 @@ cc_library( copts = tf_copts() + ["-Os"] + ["-std=c++11"], visibility = ["//visibility:public"], deps = [ + ":mobile_additional_lib_deps", ":protos_all_cc_impl", ":stats_calculator_portable", "//third_party/eigen3", @@ -2009,9 +2020,6 @@ LIB_INTERNAL_PUBLIC_HEADERS = tf_additional_lib_hdrs() + [ "lib/io/zlib_compression_options.h", "lib/io/zlib_inputstream.h", "lib/io/zlib_outputbuffer.h", - "lib/monitoring/collected_metrics.h", - "lib/monitoring/collection_registry.h", - "lib/monitoring/metric_def.h", "lib/monitoring/mobile_counter.h", "lib/monitoring/mobile_gauge.h", "lib/monitoring/mobile_sampler.h", @@ -2260,6 +2268,8 @@ cc_library( srcs = if_android([ "lib/gif/gif_io.cc", "platform/gif.h", + "lib/strings/strcat.h", + "lib/strings/numbers.h", ]), hdrs = [ "lib/bfloat16/bfloat16.h", @@ -2350,6 +2360,7 @@ tf_generate_proto_text_sources( srcs = COMMON_PROTO_SRCS, protodeps = ERROR_CODES_PROTO_SRCS, srcs_relative_dir = "tensorflow/core/", + visibility = ["//visibility:public"], deps = [ ":error_codes_proto_text", ":lib_internal", @@ -2462,6 +2473,7 @@ cc_header_only_library( cc_header_only_library( name = "core_cpu_headers_lib", + visibility = ["//visibility:public"], deps = [ ":core_cpu_lib", ], @@ -2585,6 +2597,7 @@ tf_cuda_library( # TODO(josh11b): Is this needed, or can we just use ":protos_all_cc"? cc_library( name = "protos_cc", + visibility = ["//visibility:public"], deps = ["//tensorflow/core/platform/default/build_config:protos_cc"], ) @@ -2694,12 +2707,13 @@ CORE_CPU_LIB_HEADERS = CORE_CPU_BASE_HDRS + [ "common_runtime/allocator_retry.h", "common_runtime/base_collective_executor.h", "common_runtime/bfc_allocator.h", - "common_runtime/broadcaster.h", + "common_runtime/hierarchical_tree_broadcaster.h", "common_runtime/buf_rendezvous.h", "common_runtime/build_graph_options.h", "common_runtime/collective_executor_mgr.h", "common_runtime/collective_param_resolver_local.h", "common_runtime/collective_rma_local.h", + "common_runtime/collective_util.h", "common_runtime/constant_folding.h", "common_runtime/copy_tensor.h", "common_runtime/costmodel_manager.h", @@ -2730,6 +2744,7 @@ CORE_CPU_LIB_HEADERS = CORE_CPU_BASE_HDRS + [ "common_runtime/stats_publisher_interface.h", "common_runtime/step_stats_collector.h", "common_runtime/threadpool_device.h", + "common_runtime/tracing_device.h", "common_runtime/visitable_allocator.h", "common_runtime/process_state.h", "common_runtime/pool_allocator.h", @@ -2744,12 +2759,12 @@ tf_cuda_library( "common_runtime/allocator_retry.cc", "common_runtime/base_collective_executor.cc", "common_runtime/bfc_allocator.cc", - "common_runtime/broadcaster.cc", "common_runtime/buf_rendezvous.cc", "common_runtime/build_graph_options.cc", "common_runtime/collective_executor_mgr.cc", "common_runtime/collective_param_resolver_local.cc", "common_runtime/collective_rma_local.cc", + "common_runtime/collective_util.cc", "common_runtime/constant_folding.cc", "common_runtime/copy_tensor.cc", "common_runtime/costmodel_manager.cc", @@ -2764,6 +2779,7 @@ tf_cuda_library( "common_runtime/function.cc", "common_runtime/graph_optimizer.cc", "common_runtime/graph_runner.cc", + "common_runtime/hierarchical_tree_broadcaster.cc", "common_runtime/local_device.cc", "common_runtime/lower_if_op.cc", "common_runtime/memory_types.cc", @@ -3650,10 +3666,10 @@ tf_cc_tests_gpu( ) tf_cc_tests_gpu( - name = "broadcaster_test", + name = "hierarchical_tree_broadcaster_test", size = "small", srcs = [ - "common_runtime/broadcaster_test.cc", + "common_runtime/hierarchical_tree_broadcaster_test.cc", ], linkstatic = tf_kernel_tests_linkstatic(), tags = tf_cuda_tests_tags(), diff --git a/tensorflow/core/api_def/base_api/api_def_ApplyAdam.pbtxt b/tensorflow/core/api_def/base_api/api_def_ApplyAdam.pbtxt index b90f5473c8..6341eeda32 100644 --- a/tensorflow/core/api_def/base_api/api_def_ApplyAdam.pbtxt +++ b/tensorflow/core/api_def/base_api/api_def_ApplyAdam.pbtxt @@ -82,7 +82,7 @@ END } summary: "Update \'*var\' according to the Adam algorithm." description: <<END -$$lr_t := \text{learning_rate} * \sqrt{(1 - beta_2^t) / (1 - beta_1^t)}$$ +$$lr_t := \text{learning\_rate} * \sqrt{1 - beta_2^t} / (1 - beta_1^t)$$ $$m_t := beta_1 * m_{t-1} + (1 - beta_1) * g$$ $$v_t := beta_2 * v_{t-1} + (1 - beta_2) * g * g$$ $$variable := variable - lr_t * m_t / (\sqrt{v_t} + \epsilon)$$ diff --git a/tensorflow/core/api_def/base_api/api_def_DivNoNan.pbtxt b/tensorflow/core/api_def/base_api/api_def_DivNoNan.pbtxt new file mode 100644 index 0000000000..5604a1a89e --- /dev/null +++ b/tensorflow/core/api_def/base_api/api_def_DivNoNan.pbtxt @@ -0,0 +1,9 @@ +op { + graph_op_name: "DivNoNan" + summary: "Returns 0 if the denominator is zero." + description: <<END + +*NOTE*: `DivNoNan` supports broadcasting. More about broadcasting +[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) +END +} diff --git a/tensorflow/core/api_def/base_api/api_def_EnsureShape.pbtxt b/tensorflow/core/api_def/base_api/api_def_EnsureShape.pbtxt new file mode 100644 index 0000000000..1658472209 --- /dev/null +++ b/tensorflow/core/api_def/base_api/api_def_EnsureShape.pbtxt @@ -0,0 +1,26 @@ +op { + graph_op_name: "EnsureShape" + in_arg { + name: "input" + description: <<END +A tensor, whose shape is to be validated. +END + } + out_arg { + name: "output" + description: <<END +A tensor with the same shape and contents as the input tensor or value. +END + } + attr { + name: "shape" + description: <<END +The expected (possibly partially specified) shape of the input tensor. +END + } + summary: "Ensures that the tensor's shape matches the expected shape." + description: <<END +Raises an error if the input tensor's shape does not match the specified shape. +Returns the input tensor otherwise. +END +} diff --git a/tensorflow/core/api_def/base_api/api_def_MatrixExponential.pbtxt b/tensorflow/core/api_def/base_api/api_def_MatrixExponential.pbtxt index d7b56aec87..46da1de1c3 100644 --- a/tensorflow/core/api_def/base_api/api_def_MatrixExponential.pbtxt +++ b/tensorflow/core/api_def/base_api/api_def_MatrixExponential.pbtxt @@ -1,32 +1,5 @@ op { graph_op_name: "MatrixExponential" - in_arg { - name: "input" - description: <<END -Shape is `[..., M, M]`. -END - } - out_arg { - name: "output" - description: <<END -Shape is `[..., M, M]`. - -@compatibility(scipy) -Equivalent to scipy.linalg.expm -@end_compatibility -END - } - summary: "Computes the matrix exponential of one or more square matrices:" - description: <<END -\\(exp(A) = \sum_{n=0}^\infty A^n/n!\\) - -The exponential is computed using a combination of the scaling and squaring -method and the Pade approximation. Details can be founds in: -Nicholas J. Higham, "The scaling and squaring method for the matrix exponential -revisited," SIAM J. Matrix Anal. Applic., 26:1179-1193, 2005. - -The input is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions -form square matrices. The output is a tensor of the same shape as the input -containing the exponential for all input submatrices `[..., :, :]`. -END + visibility: SKIP + summary: "Deprecated, use python implementation tf.linalg.matrix_exponential." } diff --git a/tensorflow/core/api_def/base_api/api_def_ParseExampleDataset.pbtxt b/tensorflow/core/api_def/base_api/api_def_ParseExampleDataset.pbtxt new file mode 100644 index 0000000000..3de2f18fc2 --- /dev/null +++ b/tensorflow/core/api_def/base_api/api_def_ParseExampleDataset.pbtxt @@ -0,0 +1,69 @@ +op { + graph_op_name: "ParseExampleDataset" + in_arg { + name: "dense_defaults" + description: <<END +A dict mapping string keys to `Tensor`s. +The keys of the dict must match the dense_keys of the feature. +END + } + attr { + name: "sparse_keys" + description: <<END +A list of string keys in the examples features. +The results for these keys will be returned as `SparseTensor` objects. +END + } + attr { + name: "dense_keys" + description: <<END +A list of Ndense string Tensors (scalars). +The keys expected in the Examples features associated with dense values. +END + } + attr { + name: "sparse_types" + description: <<END +A list of `DTypes` of the same length as `sparse_keys`. +Only `tf.float32` (`FloatList`), `tf.int64` (`Int64List`), +and `tf.string` (`BytesList`) are supported. +END + } + attr { + name: "Tdense" + description: <<END +A list of DTypes of the same length as `dense_keys`. +Only `tf.float32` (`FloatList`), `tf.int64` (`Int64List`), +and `tf.string` (`BytesList`) are supported. + +END + } + attr { + name: "dense_shapes" + description: <<END +List of tuples with the same length as `dense_keys`. +The shape of the data for each dense feature referenced by `dense_keys`. +Required for any input tensors identified by `dense_keys`. Must be +either fully defined, or may contain an unknown first dimension. +An unknown first dimension means the feature is treated as having +a variable number of blocks, and the output shape along this dimension +is considered unknown at graph build time. Padding is applied for +minibatch elements smaller than the maximum number of blocks for the +given feature along this dimension. +END + } + attr { + name: "output_types" + description: <<END +The type list for the return values. +END + } + attr { + name: "output_shapes" + description: <<END +The list of shapes being produced. +END + } + summary: "Transforms `input_dataset` containing `Example` protos as vectors of DT_STRING into a dataset of `Tensor` or `SparseTensor` objects representing the parsed features." +} + diff --git a/tensorflow/core/api_def/base_api/api_def_ResourceApplyAdam.pbtxt b/tensorflow/core/api_def/base_api/api_def_ResourceApplyAdam.pbtxt index ad0aeac004..2dcd136ae3 100644 --- a/tensorflow/core/api_def/base_api/api_def_ResourceApplyAdam.pbtxt +++ b/tensorflow/core/api_def/base_api/api_def_ResourceApplyAdam.pbtxt @@ -76,7 +76,7 @@ END } summary: "Update \'*var\' according to the Adam algorithm." description: <<END -$$lr_t := \text{learning_rate} * \sqrt{(1 - beta_2^t) / (1 - beta_1^t)}$$ +$$lr_t := \text{learning\_rate} * \sqrt{1 - beta_2^t} / (1 - beta_1^t)$$ $$m_t := beta_1 * m_{t-1} + (1 - beta_1) * g$$ $$v_t := beta_2 * v_{t-1} + (1 - beta_2) * g * g$$ $$variable := variable - lr_t * m_t / (\sqrt{v_t} + \epsilon)$$ diff --git a/tensorflow/core/api_def/base_api/api_def_ScatterNdUpdate.pbtxt b/tensorflow/core/api_def/base_api/api_def_ScatterNdUpdate.pbtxt index 1a75e67c0c..e400c7402b 100644 --- a/tensorflow/core/api_def/base_api/api_def_ScatterNdUpdate.pbtxt +++ b/tensorflow/core/api_def/base_api/api_def_ScatterNdUpdate.pbtxt @@ -70,5 +70,7 @@ The resulting update to ref would look like this: See `tf.scatter_nd` for more details about how to make updates to slices. + +See also `tf.scatter_update` and `tf.batch_scatter_update`. END } diff --git a/tensorflow/core/api_def/base_api/api_def_ScatterUpdate.pbtxt b/tensorflow/core/api_def/base_api/api_def_ScatterUpdate.pbtxt index 4804908afc..4037dee432 100644 --- a/tensorflow/core/api_def/base_api/api_def_ScatterUpdate.pbtxt +++ b/tensorflow/core/api_def/base_api/api_def_ScatterUpdate.pbtxt @@ -59,5 +59,7 @@ Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []` <div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/ScatterUpdate.png" alt> </div> + +See also `tf.batch_scatter_update` and `tf.scatter_nd_update`. END } diff --git a/tensorflow/core/api_def/base_api/api_def_StaticRegexReplace.pbtxt b/tensorflow/core/api_def/base_api/api_def_StaticRegexReplace.pbtxt new file mode 100644 index 0000000000..e382bcec81 --- /dev/null +++ b/tensorflow/core/api_def/base_api/api_def_StaticRegexReplace.pbtxt @@ -0,0 +1,26 @@ +op { + graph_op_name: "StaticRegexReplace" + in_arg { + name: "input" + description: "The text to be processed." + } + out_arg { + name: "output" + description: "The text after applying pattern and rewrite." + } + attr { + name: "pattern" + description: "The regular expression to match the input." + } + attr { + name: "rewrite" + description: "The rewrite to be applied to the matched expresion." + } + attr { + name: "replace_global" + description: "If True, the replacement is global, otherwise the replacement\nis done only on the first match." + } + summary: "Replaces the match of pattern in input with rewrite." + description: "It follows the re2 syntax (https://github.com/google/re2/wiki/Syntax)" + visibility: HIDDEN +} diff --git a/tensorflow/core/api_def/base_api/api_def_UnsafeDiv.pbtxt b/tensorflow/core/api_def/base_api/api_def_UnsafeDiv.pbtxt deleted file mode 100644 index 82c913d15e..0000000000 --- a/tensorflow/core/api_def/base_api/api_def_UnsafeDiv.pbtxt +++ /dev/null @@ -1,5 +0,0 @@ -op { - graph_op_name: "UnsafeDiv" - summary: "Returns 0 if the denominator is zero." - description: "" -} diff --git a/tensorflow/core/api_def/python_api/api_def_DivNoNan.pbtxt b/tensorflow/core/api_def/python_api/api_def_DivNoNan.pbtxt new file mode 100644 index 0000000000..1bf3fba3c6 --- /dev/null +++ b/tensorflow/core/api_def/python_api/api_def_DivNoNan.pbtxt @@ -0,0 +1,4 @@ +op { + graph_op_name: "DivNoNan" + visibility: HIDDEN +} diff --git a/tensorflow/core/api_def/python_api/api_def_EnsureShape.pbtxt b/tensorflow/core/api_def/python_api/api_def_EnsureShape.pbtxt new file mode 100644 index 0000000000..4414d973ac --- /dev/null +++ b/tensorflow/core/api_def/python_api/api_def_EnsureShape.pbtxt @@ -0,0 +1,4 @@ +op { + graph_op_name: "EnsureShape" + visibility: HIDDEN +} diff --git a/tensorflow/core/api_def/python_api/api_def_ParseExampleDataset.pbtxt b/tensorflow/core/api_def/python_api/api_def_ParseExampleDataset.pbtxt new file mode 100644 index 0000000000..45826b6fdc --- /dev/null +++ b/tensorflow/core/api_def/python_api/api_def_ParseExampleDataset.pbtxt @@ -0,0 +1,4 @@ +op { + graph_op_name: "ParseExampleDataset" + visibility: HIDDEN +} diff --git a/tensorflow/core/api_def/python_api/api_def_ScatterNdSub.pbtxt b/tensorflow/core/api_def/python_api/api_def_ScatterNdSub.pbtxt new file mode 100644 index 0000000000..c1edef8c9d --- /dev/null +++ b/tensorflow/core/api_def/python_api/api_def_ScatterNdSub.pbtxt @@ -0,0 +1,4 @@ +op { + graph_op_name: "ScatterNdSub" + visibility: HIDDEN +} diff --git a/tensorflow/core/api_def/python_api/api_def_UnsafeDiv.pbtxt b/tensorflow/core/api_def/python_api/api_def_UnsafeDiv.pbtxt deleted file mode 100644 index 56caabcf3c..0000000000 --- a/tensorflow/core/api_def/python_api/api_def_UnsafeDiv.pbtxt +++ /dev/null @@ -1,4 +0,0 @@ -op { - graph_op_name: "UnsafeDiv" - visibility: HIDDEN -} diff --git a/tensorflow/core/common_runtime/base_collective_executor.cc b/tensorflow/core/common_runtime/base_collective_executor.cc index 637b43c844..5b01f7fa03 100644 --- a/tensorflow/core/common_runtime/base_collective_executor.cc +++ b/tensorflow/core/common_runtime/base_collective_executor.cc @@ -14,13 +14,28 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/core/common_runtime/base_collective_executor.h" -#include "tensorflow/core/common_runtime/broadcaster.h" +#include <algorithm> +#include <functional> +#include <utility> + #include "tensorflow/core/common_runtime/copy_tensor.h" #include "tensorflow/core/common_runtime/device_mgr.h" #include "tensorflow/core/common_runtime/dma_helper.h" +#include "tensorflow/core/common_runtime/hierarchical_tree_broadcaster.h" #include "tensorflow/core/common_runtime/process_util.h" #include "tensorflow/core/common_runtime/ring_reducer.h" +#include "tensorflow/core/framework/allocator.h" +#include "tensorflow/core/framework/op_kernel.h" +#include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/framework/tensor_shape.h" +#include "tensorflow/core/framework/types.h" +#include "tensorflow/core/framework/types.pb.h" +#include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/notification.h" +#include "tensorflow/core/lib/core/status.h" +#include "tensorflow/core/lib/strings/strcat.h" +#include "tensorflow/core/platform/macros.h" +#include "tensorflow/core/platform/types.h" #define VALUE_IN_DEBUG_STRING false @@ -83,7 +98,7 @@ class CollectiveAdapterImpl : public CollectiveAdapter { // If necessary, flatten output. void Flatten() { - if (old_shape_.dims() > 1) { + if (old_shape_.dims() != 1) { TensorShape new_shape = TensorShape({old_shape_.num_elements()}); DMAHelper::UnsafeSetShape(&output_, new_shape); } @@ -211,104 +226,67 @@ void BaseCollectiveExecutor::ExecuteAsync(OpKernelContext* ctx, }; Tensor* output = ctx->mutable_output(0); - string error; - switch (col_params.instance.type) { - case REDUCTION_COLLECTIVE: { - // TODO(tucker): support other reduction algorithms, - // e.g. tree-reduce, hybrid tree/ring, delegate-to-NCCL, etc. - const Tensor* input = &ctx->input(0); - RingReducer* reducer = - CreateReducer(ctx, CtxParams(ctx), col_params, exec_key, step_id_, - input, output, &error); - if (!reducer) { - done_safe(errors::Internal(error)); - return; - } - // Run in an I/O thread, so as not to starve the executor threads. - // TODO(tucker): Instead of forking every per-device Collective - // Op off into its own thread, consider queuing them on a - // fixed-size thread-pool dedicated to running CollectiveOps. - SchedClosure([reducer, done_safe]() { - reducer->Run([reducer, done_safe](const Status& s) { - done_safe(s); - delete reducer; - }); - }); - } break; - - case BROADCAST_COLLECTIVE: { - Broadcaster* broadcaster = CreateBroadcaster( - ctx, CtxParams(ctx), col_params, exec_key, step_id_, output, &error); - if (!broadcaster) { - done_safe(errors::Internal(error)); - return; - } - // Run in an I/O thread, so as not to starve the executor threads. - SchedClosure([broadcaster, done_safe]() { - broadcaster->Run([broadcaster, done_safe](const Status& s) { - done_safe(s); - delete broadcaster; - }); - }); - } break; - - default: - done_safe(errors::Internal("Unimplemented CollectiveType ", - col_params.instance.type)); + const Tensor* input = (col_params.instance.type == REDUCTION_COLLECTIVE || + (col_params.instance.type == BROADCAST_COLLECTIVE && + col_params.is_source)) + ? &ctx->input(0) + : nullptr; + CollectiveImplementationInterface* col_impl = nullptr; + Status status = CreateCollective(col_params, &col_impl); + if (!status.ok()) { + done_safe(status); + DCHECK_EQ(nullptr, col_impl); + return; } -} - -RingReducer* BaseCollectiveExecutor::CreateReducer( - OpKernelContext* ctx, OpKernelContext::Params* params, - const CollectiveParams& col_params, const string& exec_key, int64 step_id, - const Tensor* input, Tensor* output, string* error) { - switch (col_params.instance.data_type) { - case DT_INT32: - if (col_params.group.device_type == DEVICE_GPU) { - *error = - "Collective Reduce does not support datatype DT_INT32 on " - "DEVICE_GPU"; - return nullptr; - } - TF_FALLTHROUGH_INTENDED; - case DT_FLOAT: - case DT_DOUBLE: - case DT_INT64: - return new RingReducer(this, dev_mgr_, ctx, params, col_params, exec_key, - step_id, input, output); - break; - default: - *error = strings::StrCat("Collective Reduce does not support datatype ", - col_params.instance.data_type); - return nullptr; + CollectiveContext* col_ctx = + new CollectiveContext(this, dev_mgr_, ctx, CtxParams(ctx), col_params, + exec_key, step_id_, input, output); + status = col_impl->InitializeCollectiveContext(col_ctx); + if (!status.ok()) { + done_safe(status); + delete col_ctx; + delete col_impl; + return; } + // Run in an I/O thread, so as not to starve the executor threads. + // TODO(b/80529858): Instead of forking every per-device Collective + // Op off into its own thread, consider queuing them on a + // fixed-size thread-pool dedicated to running CollectiveOps. + SchedClosure([col_impl, col_ctx, done_safe]() { + col_impl->Run([col_impl, col_ctx, done_safe](const Status& s) { + done_safe(s); + delete col_ctx; + delete col_impl; + }); + }); } -Broadcaster* BaseCollectiveExecutor::CreateBroadcaster( - OpKernelContext* ctx, OpKernelContext::Params* params, - const CollectiveParams& col_params, const string& exec_key, int64 step_id, - Tensor* output, string* error) { +Status BaseCollectiveExecutor::CreateCollective( + const CollectiveParams& col_params, + CollectiveImplementationInterface** col_impl) { + *col_impl = nullptr; + Status status; switch (col_params.instance.data_type) { case DT_INT32: if (col_params.group.device_type == DEVICE_GPU) { - *error = - "Collective Broadcast does not support datatype DT_INT32 on " - "DEVICE_GPU"; - return nullptr; + status = errors::Internal( + "CollectiveImplementation does not support datatype DT_INT32 on " + "DEVICE_GPU"); } TF_FALLTHROUGH_INTENDED; case DT_FLOAT: case DT_DOUBLE: case DT_INT64: { - return new Broadcaster(this, dev_mgr_, ctx, params, col_params, exec_key, - step_id, output); - } break; + status = CollectiveRegistry::Lookup( + col_params.instance.impl_details.collective_name, col_impl); + break; + } default: - *error = - strings::StrCat("Collective Broadcast does not support datatype ", - DataTypeString(col_params.instance.data_type)); - return nullptr; + status = errors::Internal( + "CollectiveImplementation does not support datatype ", + col_params.instance.data_type); } + return status; } } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/base_collective_executor.h b/tensorflow/core/common_runtime/base_collective_executor.h index 3af9286264..360ce4db7b 100644 --- a/tensorflow/core/common_runtime/base_collective_executor.h +++ b/tensorflow/core/common_runtime/base_collective_executor.h @@ -15,15 +15,17 @@ limitations under the License. #ifndef TENSORFLOW_CORE_COMMON_RUNTIME_BASE_COLLECTIVE_EXECUTOR_H_ #define TENSORFLOW_CORE_COMMON_RUNTIME_BASE_COLLECTIVE_EXECUTOR_H_ +#include <memory> #include <string> + #include "tensorflow/core/common_runtime/buf_rendezvous.h" #include "tensorflow/core/framework/collective.h" #include "tensorflow/core/framework/device_attributes.pb.h" namespace tensorflow { -class Broadcaster; +class CollectiveImplementation; class DeviceMgr; -class RingReducer; +class Device; // Helper interface that aliases regular subfields of a Tensor as separate // Tensors for in-place update. @@ -133,18 +135,8 @@ class BaseCollectiveExecutor : public CollectiveExecutor { std::unique_ptr<PerStepCollectiveRemoteAccess> remote_access_; private: - RingReducer* CreateReducer(OpKernelContext* ctx, - OpKernelContext::Params* params, - const CollectiveParams& col_params, - const string& exec_key, int64 step_id, - const Tensor* input, Tensor* output, - string* error); - - Broadcaster* CreateBroadcaster(OpKernelContext* ctx, - OpKernelContext::Params* params, - const CollectiveParams& col_params, - const string& exec_key, int64 step_id, - Tensor* output, string* error); + Status CreateCollective(const CollectiveParams& col_params, + CollectiveImplementationInterface** col_impl); }; } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/bfc_allocator.h b/tensorflow/core/common_runtime/bfc_allocator.h index 580e61e2ea..20e1dab1d5 100644 --- a/tensorflow/core/common_runtime/bfc_allocator.h +++ b/tensorflow/core/common_runtime/bfc_allocator.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_BFC_ALLOCATOR_H_ -#define TENSORFLOW_COMMON_RUNTIME_BFC_ALLOCATOR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_BFC_ALLOCATOR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_BFC_ALLOCATOR_H_ #include <array> #include <memory> @@ -451,4 +451,4 @@ class BFCAllocator : public VisitableAllocator { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_BFC_ALLOCATOR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_BFC_ALLOCATOR_H_ diff --git a/tensorflow/core/common_runtime/broadcaster.cc b/tensorflow/core/common_runtime/broadcaster.cc deleted file mode 100644 index e1c6b21939..0000000000 --- a/tensorflow/core/common_runtime/broadcaster.cc +++ /dev/null @@ -1,300 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ -#include "tensorflow/core/common_runtime/broadcaster.h" - -#include "tensorflow/core/common_runtime/collective_rma_local.h" -#include "tensorflow/core/common_runtime/device_mgr.h" -#include "tensorflow/core/common_runtime/dma_helper.h" -#include "tensorflow/core/lib/core/notification.h" -#include "tensorflow/core/platform/env.h" - -// Set true for greater intelligibility of debug mode log messages. -#define READABLE_KEYS false - -namespace tensorflow { - -namespace { -// Key to be used for BufRendezvous by Broadcaster. -string BroadcastBufKey(const string& exec_key, int subdiv, int src_rank, - int dst_rank) { - if (READABLE_KEYS) { - return strings::StrCat("broadcast(", exec_key, "):subdiv(", subdiv, - "):src(", src_rank, "):dst(", dst_rank, ")"); - } else { - // TODO(tucker): Try a denser format, e.g. a 64 or 128 bit hash. - return strings::StrCat(exec_key, ":", subdiv, ":", src_rank, ":", dst_rank); - } -} -} // namespace - -Broadcaster::Broadcaster(CollectiveExecutor* col_exec, const DeviceMgr* dev_mgr, - OpKernelContext* ctx, OpKernelContext::Params* params, - const CollectiveParams& col_params, - const string& exec_key, int64 step_id, Tensor* output) - : col_exec_(col_exec), - dev_mgr_(dev_mgr), - ctx_(ctx), - col_params_(col_params), - exec_key_(exec_key), - rank_(col_params.subdiv_rank[0]), - is_source_(col_params.is_source), - output_(output), - done_(nullptr), - device_(nullptr) {} - -void Broadcaster::Run(StatusCallback done) { - // The optimal data transfer choreography is going to very platform dependent. - // That will be addressed by later improvements here or by platform-specific - // overrides of collective broadcast. The initial version is simply - // a binary tree that completely ignores DeviceLocality. - done_ = std::move(done); - - // Get the device for which we're executing and look up its locality. - status_ = dev_mgr_->LookupDevice( - col_params_.instance.device_names[col_params_.default_rank], &device_); - if (!status_.ok()) { - done_(status_); - return; - } - CHECK(device_); - device_locality_ = device_->attributes().locality(); - - RunTree(); -} - -// Binary tree parent/child relations are trivial to calculate, i.e. -// device at rank r is the parent of 2r+1 and 2r+2. The one exception -// is if the source is not rank 0. We treat that case as though the -// source is appended to the front of the rank ordering as well as -// continuing to occupy its current position. Hence we calculate as -// though each device's rank is actually r+1, then subtract 1 again to -// get the descendent ranks. If the source is not rank 0 then its -// descendants include both {0,1} and the descendents of its current -// position. Where a non-0-rank source is a descendent of another -// device, no send to it is necessary. - -/* static*/ -int Broadcaster::TreeRecvFrom(const CollectiveParams& cp, int subdiv) { - DCHECK_LT(subdiv, static_cast<int>(cp.subdiv_rank.size())); - int my_rank = cp.subdiv_rank[subdiv]; - if (-1 == my_rank) return -1; - - const auto& impl = cp.instance.impl_details; - DCHECK_LT(subdiv, static_cast<int>(impl.subdiv_source_rank.size())); - int source_rank = impl.subdiv_source_rank[subdiv]; - if (my_rank == source_rank) return -1; - if (source_rank == 0) { - return (my_rank - 1) / 2; - } else { - int predecessor_rank = (my_rank / 2) - 1; - return (predecessor_rank < 0) ? source_rank : predecessor_rank; - } -} - -/* static */ -void Broadcaster::TreeSendTo(const CollectiveParams& cp, int subdiv, - std::vector<int>* targets) { - DCHECK_LT(subdiv, static_cast<int>(cp.subdiv_rank.size())); - int my_rank = cp.subdiv_rank[subdiv]; - if (-1 == my_rank) return; - - const auto& impl = cp.instance.impl_details; - DCHECK_LT(subdiv, static_cast<int>(impl.subdiv_source_rank.size())); - int source_rank = impl.subdiv_source_rank[subdiv]; - - int group_size = 0; - for (int i = 0; i < impl.subdiv_permutations[subdiv].size(); i++) { - if (impl.subdiv_permutations[subdiv][i] >= 0) { - group_size++; - } - } - - targets->clear(); - int successor_rank = 0; - if (source_rank == 0) { - successor_rank = (2 * my_rank) + 1; - } else { - successor_rank = (2 * (my_rank + 1)); - } - DCHECK_NE(successor_rank, my_rank); - if (cp.is_source && source_rank != 0) { - // The source sends to rank 0,1 in addition to its positional - // descendants. - if (group_size > 1) { - targets->push_back(0); - } - if (group_size > 2 && source_rank != 1) { - targets->push_back(1); - } - } - for (int i = 0; i < 2; ++i) { - if (successor_rank < group_size && successor_rank != source_rank) { - targets->push_back(successor_rank); - } - ++successor_rank; - } -} - -// Executes a hierarchical tree broadcast. -// Each subdiv is a broadcast between a subset of the devices. -// If there is only one task, there is one subdiv comprising a broadcast between -// all devices belonging to the task. -// If there are n tasks, n>1, then there are n+1 subdivs. In the first (global) -// subdiv, one device from each task participates in a binary tree broadcast. -// Each task receives a copy of the tensor on one device via this broadcast. -// Subsequent subdivs correspond to intra-task broadcasts. Subdiv i+1 -// corresponds to broadcast between all devices on task i. Thus, each task -// participates in at most 2 subdivs. -void Broadcaster::RunTree() { - int num_subdivs = static_cast<int>(col_params_.subdiv_rank.size()); - // TODO(ayushd): this is easily improved when a node participates in both - // first and second subdivision. It would first send to its descendents in - // the first subdiv, then wait until all pending ops are finished before - // sending to descendents in second subdiv. A better implementation would - // collapse the two send blocks. - for (int si = 0; si < num_subdivs; si++) { - int my_rank = col_params_.subdiv_rank[si]; - // If rank is -1, this device does not participate in this subdiv. - if (-1 == my_rank) continue; - int source_rank = col_params_.instance.impl_details.subdiv_source_rank[si]; - if (VLOG_IS_ON(1)) { - string subdiv_buf; - for (int r : col_params_.instance.impl_details.subdiv_permutations[si]) { - strings::StrAppend(&subdiv_buf, r, ","); - } - VLOG(1) << "Running Broadcast tree device=" << device_->name() - << " subdiv=" << si << " perm=" << subdiv_buf - << " my_rank=" << my_rank << " source_rank=" << source_rank; - } - - mutex mu; // also guards status_ while callbacks are pending - int pending_count = 0; // GUARDED_BY(mu) - condition_variable all_done; - - if (my_rank >= 0 && my_rank != source_rank) { - // Begin by receiving the value. - int recv_from_rank = TreeRecvFrom(col_params_, si); - Notification note; - DispatchRecv(si, recv_from_rank, my_rank, output_, - [this, &mu, ¬e](const Status& s) { - mutex_lock l(mu); - status_.Update(s); - note.Notify(); - }); - note.WaitForNotification(); - } - - // Then forward value to all descendent devices. - if (my_rank >= 0 && status_.ok()) { - std::vector<int> send_to_ranks; - TreeSendTo(col_params_, si, &send_to_ranks); - for (int i = 0; i < send_to_ranks.size(); ++i) { - int target_rank = send_to_ranks[i]; - { - mutex_lock l(mu); - ++pending_count; - } - DispatchSend(si, target_rank, my_rank, - (is_source_ ? &ctx_->input(0) : output_), - [this, &mu, &pending_count, &all_done](const Status& s) { - mutex_lock l(mu); - status_.Update(s); - --pending_count; - if (pending_count == 0) { - all_done.notify_all(); - } - }); - } - } - - // For the original source device, we copy input to output if they are - // different. - // If there is only 1 subdiv, we do this in that subdiv. If there is more - // than 1 subdiv, then the original source device will participate in 2 - // subdivs - the global inter-task broadcast and one local intra-task - // broadcast. In this case, we perform the copy in the second subdiv for - // this device. - if (status_.ok() && is_source_ && (1 == num_subdivs || 0 != si)) { - VLOG(2) << "copying input to output for device=" << device_->name() - << " subdiv=" << si; - const Tensor* input = &ctx_->input(0); - if (input != output_ && - (DMAHelper::base(input) != DMAHelper::base(output_))) { - { - mutex_lock l(mu); - ++pending_count; - } - DeviceContext* op_dev_ctx = ctx_->op_device_context(); - CollectiveRemoteAccessLocal::MemCpyAsync( - op_dev_ctx, op_dev_ctx, device_, device_, ctx_->input_alloc_attr(0), - ctx_->output_alloc_attr(0), input, output_, 0, /*stream_index*/ - [this, &mu, &pending_count, &all_done](const Status& s) { - mutex_lock l(mu); - status_.Update(s); - --pending_count; - if (0 == pending_count) { - all_done.notify_all(); - } - }); - } - } - - // Then wait for all pending actions to complete. - { - mutex_lock l(mu); - if (pending_count > 0) { - all_done.wait(l); - } - } - } - VLOG(2) << "device=" << device_->name() << " return status " << status_; - done_(status_); -} - -void Broadcaster::DispatchSend(int subdiv, int dst_rank, int src_rank, - const Tensor* src_tensor, - const StatusCallback& done) { - string send_buf_key = BroadcastBufKey(exec_key_, subdiv, src_rank, dst_rank); - int dst_idx = - col_params_.instance.impl_details.subdiv_permutations[subdiv][dst_rank]; - VLOG(1) << "DispatchSend " << send_buf_key << " from_device " - << device_->name() << " to_device " - << col_params_.instance.device_names[dst_idx] << " subdiv=" << subdiv - << " dst_rank=" << dst_rank << " dst_idx=" << dst_idx; - col_exec_->PostToPeer(col_params_.instance.device_names[dst_idx], - col_params_.instance.task_names[dst_idx], send_buf_key, - device_, ctx_->op_device_context(), - ctx_->output_alloc_attr(0), src_tensor, - device_locality_, done); -} - -void Broadcaster::DispatchRecv(int subdiv, int src_rank, int dst_rank, - Tensor* dst_tensor, const StatusCallback& done) { - string recv_buf_key = BroadcastBufKey(exec_key_, subdiv, src_rank, dst_rank); - int src_idx = - col_params_.instance.impl_details.subdiv_permutations[subdiv][src_rank]; - VLOG(1) << "DispatchRecv " << recv_buf_key << " from_device " - << col_params_.instance.device_names[src_idx] << " to_device " - << device_->name() << " subdiv=" << subdiv << " src_rank=" << src_rank - << " src_idx=" << src_idx; - col_exec_->RecvFromPeer(col_params_.instance.device_names[src_idx], - col_params_.instance.task_names[src_idx], - col_params_.task.is_local[src_idx], recv_buf_key, - device_, ctx_->op_device_context(), - ctx_->output_alloc_attr(0), dst_tensor, - device_locality_, 0 /*stream_index*/, done); -} - -} // namespace tensorflow diff --git a/tensorflow/core/common_runtime/buf_rendezvous.h b/tensorflow/core/common_runtime/buf_rendezvous.h index 9eb9f060f6..065bbd008b 100644 --- a/tensorflow/core/common_runtime/buf_rendezvous.h +++ b/tensorflow/core/common_runtime/buf_rendezvous.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_BUF_RENDEZVOUS_H_ -#define TENSORFLOW_COMMON_RUNTIME_BUF_RENDEZVOUS_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_BUF_RENDEZVOUS_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_BUF_RENDEZVOUS_H_ #include <functional> #include <string> @@ -100,4 +100,4 @@ class BufRendezvous { void PurgeTable(const Status& s, HookTable* table); }; } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_BUF_RENDEZVOUS_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_BUF_RENDEZVOUS_H_ diff --git a/tensorflow/core/common_runtime/collective_executor_mgr.h b/tensorflow/core/common_runtime/collective_executor_mgr.h index 9de6ab8968..d53aca85b9 100644 --- a/tensorflow/core/common_runtime/collective_executor_mgr.h +++ b/tensorflow/core/common_runtime/collective_executor_mgr.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_COLLECTIVE_EXECUTOR_MGR_H_ -#define TENSORFLOW_COMMON_RUNTIME_COLLECTIVE_EXECUTOR_MGR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_EXECUTOR_MGR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_EXECUTOR_MGR_H_ #include "tensorflow/core/framework/collective.h" #include "tensorflow/core/lib/gtl/flatmap.h" @@ -72,4 +72,4 @@ class CollectiveExecutorMgr : public CollectiveExecutorMgrInterface { }; } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_COLLECTIVE_EXECUTOR_MGR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_EXECUTOR_MGR_H_ diff --git a/tensorflow/core/common_runtime/collective_param_resolver_local.cc b/tensorflow/core/common_runtime/collective_param_resolver_local.cc index 2a14493a67..52eedae9b7 100644 --- a/tensorflow/core/common_runtime/collective_param_resolver_local.cc +++ b/tensorflow/core/common_runtime/collective_param_resolver_local.cc @@ -14,7 +14,20 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/core/common_runtime/collective_param_resolver_local.h" +#include <stddef.h> +#include <algorithm> +#include <unordered_map> +#include <utility> + #include "tensorflow/core/common_runtime/device_mgr.h" +#include "tensorflow/core/framework/cancellation.h" +#include "tensorflow/core/framework/device_attributes.pb.h" +#include "tensorflow/core/framework/types.h" +#include "tensorflow/core/lib/core/errors.h" +#include "tensorflow/core/lib/core/status.h" +#include "tensorflow/core/lib/strings/strcat.h" +#include "tensorflow/core/platform/types.h" +#include "tensorflow/core/util/device_name_utils.h" namespace tensorflow { @@ -319,206 +332,6 @@ void SortDevicesAndTasks(CollectiveParams* cp) { } } // namespace -int GetDeviceTask(int device_rank, const std::vector<int>& dev_per_task) { - int num_tasks = static_cast<int>(dev_per_task.size()); - int task_lo = 0; - int task_hi; - for (int ti = 0; ti < num_tasks; ti++) { - task_hi = task_lo + dev_per_task[ti]; - if (task_lo <= device_rank && device_rank < task_hi) return ti; - task_lo += dev_per_task[ti]; - } - LOG(FATAL) << "Unexpected device rank " << device_rank << " for " << task_hi - << " devices"; - return -1; -} - -void CollectiveParamResolverLocal::GenerateBcastSubdivPerms( - const string& device, int source_rank, const std::vector<int>& dev_per_task, - CollectiveParams* cp) { - if (VLOG_IS_ON(1)) { - string dpt_buf; - for (int dpt : dev_per_task) strings::StrAppend(&dpt_buf, dpt, ";"); - VLOG(1) << "GenerateBcastSubdivPerms device=" << device - << " source_rank=" << source_rank << " dev_per_task=" << dpt_buf; - } - int num_tasks = cp->group.num_tasks; - // If there is just 1 task, then execute binary tree broadcast over all - // devices. Otherwise, the first subdiv is inter-task broadcast, and then - // there are N more subdivs, where N is #task. - int num_subdivs = num_tasks + (num_tasks > 1 ? 1 : 0); - int total_num_devices = 0; - for (int num_dev : dev_per_task) total_num_devices += num_dev; - - cp->instance.impl_details.subdiv_permutations.resize(num_subdivs); - cp->subdiv_rank.reserve(num_subdivs); - cp->instance.impl_details.subdiv_source_rank.reserve(num_subdivs); - - // Inter-task subdiv. Pick one device from each task - this is the source - // device if it belongs to that task, or device 0 for that task. If a device - // does not participate in the subdiv, set subdiv_rank to -1. - if (num_tasks > 1) { - const int sdi = 0; - std::vector<int>& perm = cp->instance.impl_details.subdiv_permutations[sdi]; - CHECK_EQ(perm.size(), 0); - int device_count = 0; - int source_task = GetDeviceTask(source_rank, dev_per_task); - for (int ti = 0; ti < cp->group.num_tasks; ti++) { - bool participate = false; - if (source_task == ti) { - // Source device belongs to this task. - perm.push_back(source_rank); - participate = cp->instance.device_names[source_rank] == device; - } else { - // Source does not belong to this task, choose dev 0. - perm.push_back(device_count); - participate = cp->instance.device_names[device_count] == device; - } - if (participate) cp->subdiv_rank.push_back(ti); - device_count += dev_per_task[ti]; - } - if (cp->subdiv_rank.empty()) cp->subdiv_rank.push_back(-1); - cp->instance.impl_details.subdiv_source_rank.push_back(source_task); - } - - // Intra-task subdivs. Pick all devices in task ti for subdiv sdi. Set - // source to dev 0 for that task if it does not contain original source, else - // set to rank of original source. If a device does not participate in the - // subdiv, set subdiv_rank to -1; - int abs_di = 0; - for (int ti = 0; ti < cp->group.num_tasks; ti++) { - const int sdi = ti + (num_tasks > 1 ? 1 : 0); - std::vector<int>& perm = cp->instance.impl_details.subdiv_permutations[sdi]; - CHECK_EQ(perm.size(), 0); - bool participate = false; - int subdiv_source = 0; - for (int di = 0; di < dev_per_task[ti]; di++) { - perm.push_back(abs_di); - if (cp->instance.device_names[abs_di] == device) { - participate = true; - cp->subdiv_rank.push_back(di); - } - if (abs_di == source_rank) subdiv_source = di; - abs_di++; - } - if (!participate) cp->subdiv_rank.push_back(-1); - cp->instance.impl_details.subdiv_source_rank.push_back(subdiv_source); - } - - for (int sri = 0; sri < num_subdivs; sri++) { - CHECK_GE(cp->instance.impl_details.subdiv_source_rank[sri], 0); - } -} - -// Establish the requested number of subdivision permutations based on the -// ring order implicit in the device order. -/*static*/ -void CollectiveParamResolverLocal::GenerateSubdivPerms(const string& device, - int source_rank, - CollectiveParams* cp) { - // Each subdiv permutation is a ring formed by rotating each - // single-task subsequence of devices by an offset. This makes most - // sense when each task has the same number of devices but we can't - // depend on that being the case so we'll compute something that - // works in any case. - - // Start by counting the devices in each task. - // Precondition: device_names must be sorted so that all devices in - // the same task are adjacent. - VLOG(2) << "Sorted task names: " - << str_util::Join(cp->instance.task_names, ", "); - std::vector<int> dev_per_task; - const string* prior_task_name = &cp->instance.task_names[0]; - int dev_count = 1; - for (int di = 1; di < cp->group.group_size; ++di) { - if (cp->instance.task_names[di] != *prior_task_name) { - dev_per_task.push_back(dev_count); - dev_count = 1; - prior_task_name = &cp->instance.task_names[di]; - } else { - ++dev_count; - } - } - dev_per_task.push_back(dev_count); - CHECK_EQ(cp->group.num_tasks, dev_per_task.size()); - - CHECK(cp->instance.type == REDUCTION_COLLECTIVE || - cp->instance.type == BROADCAST_COLLECTIVE); - if (cp->instance.type == REDUCTION_COLLECTIVE) { - // Generate a ring permutation for each requested offset. - CHECK_GT(cp->instance.impl_details.subdiv_offsets.size(), 0); - VLOG(2) << "Setting up perms for cp " << cp << " subdiv_permutations " - << &cp->instance.impl_details.subdiv_permutations; - cp->instance.impl_details.subdiv_permutations.resize( - cp->instance.impl_details.subdiv_offsets.size()); - cp->subdiv_rank.resize(cp->instance.impl_details.subdiv_offsets.size(), -1); - for (int sdi = 0; sdi < cp->instance.impl_details.subdiv_offsets.size(); - ++sdi) { - std::vector<int>& perm = - cp->instance.impl_details.subdiv_permutations[sdi]; - CHECK_EQ(perm.size(), 0); - int offset = cp->instance.impl_details.subdiv_offsets[sdi]; - // A negative subdivision offset is interpreted as follows: - // 1. Reverse the local device ordering. - // 2. Begin the subdivision at abs(offset) in the reversed ordering. - bool reverse = false; - if (offset < 0) { - offset = abs(offset); - reverse = true; - } - int prior_dev_count = 0; // sum over prior worker device counts - for (int ti = 0; ti < cp->group.num_tasks; ++ti) { - for (int di = 0; di < dev_per_task[ti]; ++di) { - int di_offset = (di + offset) % dev_per_task[ti]; - int offset_di = - reverse ? (dev_per_task[ti] - (di_offset + 1)) : di_offset; - // Device index in global subdivision permutation. - int permuted_di = prior_dev_count + offset_di; - int rank = static_cast<int>(perm.size()); - perm.push_back(permuted_di); - if (cp->instance.device_names[permuted_di] == device) { - CHECK_EQ(permuted_di, cp->default_rank); - cp->subdiv_rank[sdi] = rank; - } - } - prior_dev_count += dev_per_task[ti]; - } - CHECK_EQ(cp->group.group_size, perm.size()); - } - } else if (cp->instance.type == BROADCAST_COLLECTIVE) { - GenerateBcastSubdivPerms(device, source_rank, dev_per_task, cp); - } - - if (VLOG_IS_ON(1)) { - // Log the computed ring order for each subdiv. - string buf; - for (int sdi = 0; - sdi < cp->instance.impl_details.subdiv_permutations.size(); ++sdi) { - buf = strings::StrCat("Subdiv ", sdi, " device order:\n"); - for (int di = 0; - di < cp->instance.impl_details.subdiv_permutations[sdi].size(); - ++di) { - int idx = cp->instance.impl_details.subdiv_permutations[sdi][di]; - if (idx >= 0) { - CHECK_GT(cp->instance.device_names.size(), idx); - strings::StrAppend(&buf, cp->instance.device_names[idx], "\n"); - } - } - strings::StrAppend(&buf, " subdiv_offsets: "); - for (auto o : cp->instance.impl_details.subdiv_offsets) - strings::StrAppend(&buf, o, " "); - strings::StrAppend(&buf, " SubdivRank: "); - for (auto d : cp->subdiv_rank) strings::StrAppend(&buf, d, " "); - if (cp->instance.type == BROADCAST_COLLECTIVE) { - strings::StrAppend(&buf, " subdiv_source_rank: "); - for (auto src : cp->instance.impl_details.subdiv_source_rank) - strings::StrAppend(&buf, src, " "); - } - VLOG(1) << buf; - } - } -} - void CollectiveParamResolverLocal::CompleteTaskIsLocal(const string& task_name, CollectiveParams* cp) { cp->task.is_local.resize(cp->group.group_size, false); @@ -785,29 +598,39 @@ void CollectiveParamResolverLocal::CompleteInstanceFromInitializedIRec( // Populate the fields common across task, also default_rank. SetDefaultRank(device, cp); CompleteTaskIsLocal(task_name_, cp); + // TODO(b/113171733): we need a better way to pick the collective + // implementation. The ideal way would depend upon the topology and link + // strength before picking a particular implementation. + cp->instance.impl_details.collective_name = + (cp->instance.type == BROADCAST_COLLECTIVE) ? "HierarchicalTreeBroadcast" + : "RingReduce"; + CollectiveImplementationInterface* col_impl; + Status lookup_status = CollectiveRegistry::LookupParamResolverInstance( + cp->instance.impl_details.collective_name, &col_impl); + if (!lookup_status.ok()) { + done(lookup_status); + return; + } // If broadcast, may need to wait for source discovery. if (cp->instance.type == BROADCAST_COLLECTIVE) { CompleteInstanceSource(ir, cp, is_source, - [this, ir, device, cp, done](InstanceRec* irec) { + [col_impl, ir, device, cp, done](InstanceRec* irec) { CHECK_EQ(ir, irec); Status s; - int source_rank; { mutex_lock l(irec->out_mu); irec->WaitForOutMu(l); s = irec->status; - source_rank = irec->source_rank; + cp->source_rank = irec->source_rank; } if (s.ok()) { - GenerateSubdivPerms(device, source_rank, cp); + s = col_impl->InitializeCollectiveParams(cp); } done(s); }); - return; } else { - GenerateSubdivPerms(device, 0, cp); + done(col_impl->InitializeCollectiveParams(cp)); } - done(Status::OK()); } void CollectiveParamResolverLocal::CompleteInstanceSource(InstanceRec* ir, diff --git a/tensorflow/core/common_runtime/collective_param_resolver_local.h b/tensorflow/core/common_runtime/collective_param_resolver_local.h index 2e2aa801d9..c5c3497e28 100644 --- a/tensorflow/core/common_runtime/collective_param_resolver_local.h +++ b/tensorflow/core/common_runtime/collective_param_resolver_local.h @@ -12,10 +12,14 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_COLLECTIVE_PARAM_RESOLVER_LOCAL_H_ -#define TENSORFLOW_COMMON_RUNTIME_COLLECTIVE_PARAM_RESOLVER_LOCAL_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_PARAM_RESOLVER_LOCAL_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_PARAM_RESOLVER_LOCAL_H_ +#include <functional> +#include <memory> +#include <set> #include <string> +#include <vector> #include "tensorflow/core/framework/collective.h" #include "tensorflow/core/lib/gtl/flatmap.h" @@ -79,6 +83,7 @@ class CollectiveParamResolverLocal : public ParamResolverInterface { // Used to complete/verify CollInstance. struct InstanceRec; + typedef std::function<void(InstanceRec*)> IRConsumer; struct InstanceRec { // This structure has two mutexes so that a possibly long @@ -212,18 +217,6 @@ class CollectiveParamResolverLocal : public ParamResolverInterface { void CallbackWithStatus(const InstanceRecCallback& done, InstanceRec* irec) LOCKS_EXCLUDED(irec->out_mu); - friend class CollectiveParamResolverLocalTest; - // Establishes the requested number of subdivision permutations based on the - // ring order implicit in the device order. - static void GenerateSubdivPerms(const string& device, int source_rank, - CollectiveParams* cp); - // Establishes the subdivisions for broadcast op. The first subdiv executes - // binary tree bcast with one device per task. Each subsequent subdiv - // executes intra-task binary tree broadcast. - static void GenerateBcastSubdivPerms(const string& device, int source_rank, - const std::vector<int>& dev_per_task, - CollectiveParams* cp); - const DeviceMgr* dev_mgr_; DeviceResolverInterface* dev_resolver_; // Not owned. string task_name_; @@ -237,4 +230,4 @@ class CollectiveParamResolverLocal : public ParamResolverInterface { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_COLLECTIVE_PARAM_RESOLVER_LOCAL_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_PARAM_RESOLVER_LOCAL_H_ diff --git a/tensorflow/core/common_runtime/collective_param_resolver_local_test.cc b/tensorflow/core/common_runtime/collective_param_resolver_local_test.cc index 9ea23b72d2..9e1e2e8d5b 100644 --- a/tensorflow/core/common_runtime/collective_param_resolver_local_test.cc +++ b/tensorflow/core/common_runtime/collective_param_resolver_local_test.cc @@ -44,31 +44,6 @@ class CollectiveParamResolverLocalTest : public ::testing::Test { task_name)); } - void GenSubdivPerms(const string& device, int source_rank, - CollectiveParams* cp) { - CollectiveParamResolverLocal::GenerateSubdivPerms(device, source_rank, cp); - } - - // Calls GenerateBcastSubdivPerms for device at `device_rank`. Checks if the - // generated subdiv perms, ranks, and source ranks match the expected values. - void BcastSubdivPerms( - CollectiveParams* cp, const std::vector<int>& dev_per_task, - int device_rank, int source_rank, - const std::vector<std::vector<int>>& expected_subdiv_perms, - const std::vector<int>& expected_subdiv_rank, - const std::vector<int>& expected_subdiv_source_rank) { - cp->subdiv_rank.clear(); - cp->instance.impl_details.subdiv_permutations.clear(); - cp->instance.impl_details.subdiv_source_rank.clear(); - CollectiveParamResolverLocal::GenerateBcastSubdivPerms( - cp->instance.device_names[device_rank], source_rank, dev_per_task, cp); - EXPECT_EQ(expected_subdiv_perms, - cp->instance.impl_details.subdiv_permutations); - EXPECT_EQ(expected_subdiv_rank, cp->subdiv_rank); - EXPECT_EQ(expected_subdiv_source_rank, - cp->instance.impl_details.subdiv_source_rank); - } - std::vector<Device*> devices_; std::unique_ptr<DeviceMgr> device_mgr_; std::unique_ptr<DeviceResolverLocal> drl_; @@ -114,7 +89,6 @@ TEST_F(CollectiveParamResolverLocalTest, CompleteParamsReduction1Task) { cps[i].instance.device_names[j]); EXPECT_TRUE(cps[i].task.is_local[j]); } - EXPECT_EQ(cps[i].subdiv_rank[0], i); EXPECT_EQ(cps[i].instance.impl_details.subdiv_source_rank.size(), 0); EXPECT_FALSE(cps[i].is_source); EXPECT_EQ(cps[i].default_rank, i); @@ -161,188 +135,10 @@ TEST_F(CollectiveParamResolverLocalTest, CompleteParamsBroadcast1Task) { cps[i].instance.device_names[j]); EXPECT_TRUE(cps[i].task.is_local[j]); } - ASSERT_GT(cps[i].subdiv_rank.size(), 0); - EXPECT_EQ(cps[i].subdiv_rank[0], i); - ASSERT_GT(cps[i].instance.impl_details.subdiv_source_rank.size(), 0); - EXPECT_EQ(cps[i].instance.impl_details.subdiv_source_rank[0], 1); EXPECT_EQ(cps[i].is_source, (i == 1)); EXPECT_EQ(cps[i].default_rank, i); EXPECT_TRUE(cps[i].instance.same_num_devices_per_task); } } -TEST_F(CollectiveParamResolverLocalTest, GenerateSubdivPerms) { - static const int kNumDevsPerTask = 8; - static const int kNumTasks = 3; - static const int kNumDevs = kNumDevsPerTask * kNumTasks; - CollectiveParams cp; - std::vector<string> device_names; - std::vector<string> task_names; - cp.group.group_key = 1; - cp.group.group_size = kNumDevs; - cp.group.device_type = DeviceType("GPU"); - cp.group.num_tasks = kNumTasks; - cp.instance.instance_key = 3; - cp.instance.type = REDUCTION_COLLECTIVE; - cp.instance.data_type = DataType(DT_FLOAT); - cp.instance.shape = TensorShape({5}); - cp.instance.impl_details.subdiv_offsets.push_back(0); - cp.is_source = false; - for (int i = 0; i < kNumDevs; ++i) { - int task_id = i / kNumDevsPerTask; - int dev_id = i % kNumDevsPerTask; - string task_name = strings::StrCat("/job:worker/replica:0/task:", task_id); - task_names.push_back(task_name); - string device_name = strings::StrCat(task_name, "/device:GPU:", dev_id); - device_names.push_back(device_name); - cp.instance.task_names.push_back(task_name); - cp.instance.device_names.push_back(device_name); - } - - int test_rank = 0; - cp.default_rank = test_rank; - cp.instance.impl_details.subdiv_offsets = {0, 4}; - GenSubdivPerms(cp.instance.device_names[test_rank], 0, &cp); - std::vector<int> expected_0 = {0, 1, 2, 3, 4, 5, 6, 7, - 8, 9, 10, 11, 12, 13, 14, 15, - 16, 17, 18, 19, 20, 21, 22, 23}; - std::vector<int> expected_1 = {4, 5, 6, 7, 0, 1, 2, 3, 12, 13, 14, 15, - 8, 9, 10, 11, 20, 21, 22, 23, 16, 17, 18, 19}; - for (int i = 0; i < kNumDevs; ++i) { - EXPECT_EQ(expected_0[i], - cp.instance.impl_details.subdiv_permutations[0][i]); - EXPECT_EQ(expected_1[i], - cp.instance.impl_details.subdiv_permutations[1][i]); - } - EXPECT_EQ(0, cp.subdiv_rank[0]); - EXPECT_EQ(4, cp.subdiv_rank[1]); - - test_rank = 3; - cp.default_rank = test_rank; - cp.instance.impl_details.subdiv_offsets = {3, -3}; - cp.instance.impl_details.subdiv_permutations.clear(); - GenSubdivPerms(cp.instance.device_names[test_rank], 0, &cp); - expected_0 = {3, 4, 5, 6, 7, 0, 1, 2, 11, 12, 13, 14, - 15, 8, 9, 10, 19, 20, 21, 22, 23, 16, 17, 18}; - expected_1 = {4, 3, 2, 1, 0, 7, 6, 5, 12, 11, 10, 9, - 8, 15, 14, 13, 20, 19, 18, 17, 16, 23, 22, 21}; - for (int i = 0; i < kNumDevs; ++i) { - EXPECT_EQ(expected_0[i], - cp.instance.impl_details.subdiv_permutations[0][i]); - EXPECT_EQ(expected_1[i], - cp.instance.impl_details.subdiv_permutations[1][i]); - } - EXPECT_EQ(0, cp.subdiv_rank[0]); - EXPECT_EQ(1, cp.subdiv_rank[1]); -} - -TEST_F(CollectiveParamResolverLocalTest, GenerateBcastSubdivPerms1Task8GPU) { - CollectiveParams cp; - cp.group.device_type = DeviceType("GPU"); - cp.group.num_tasks = 1; - cp.instance.type = BROADCAST_COLLECTIVE; - for (int i = 0; i < 8; i++) { - string dev_name = - strings::StrCat("/job:worker/replica:0/task:0/device:GPU:", i); - cp.instance.device_names.push_back(dev_name); - } - std::vector<int> dev_per_task = {8}; - - // source 0 device 0 - BcastSubdivPerms(&cp, dev_per_task, 0, 0, {{0, 1, 2, 3, 4, 5, 6, 7}}, {0}, - {0}); - - // source 2 device 2 - BcastSubdivPerms(&cp, dev_per_task, 2, 2, {{0, 1, 2, 3, 4, 5, 6, 7}}, {2}, - {2}); - - // source 2 device 0 - BcastSubdivPerms(&cp, dev_per_task, 0, 2, {{0, 1, 2, 3, 4, 5, 6, 7}}, {0}, - {2}); -} - -TEST_F(CollectiveParamResolverLocalTest, GenerateBcastSubdivPerms4Tasks8GPU) { - CollectiveParams cp; - cp.group.device_type = DeviceType("GPU"); - cp.group.num_tasks = 4; - cp.instance.type = BROADCAST_COLLECTIVE; - for (int ti = 0; ti < cp.group.num_tasks; ti++) { - for (int di = 0; di < 8; di++) { - string dev_name = strings::StrCat("/job:worker/replica:0/task:", ti, - "/device:GPU:", di); - cp.instance.device_names.push_back(dev_name); - } - } - std::vector<int> dev_per_task = {8, 8, 8, 8}; - - // source 0 device 0 - BcastSubdivPerms(&cp, dev_per_task, 0, 0, - {{0, 8, 16, 24}, - {0, 1, 2, 3, 4, 5, 6, 7}, - {8, 9, 10, 11, 12, 13, 14, 15}, - {16, 17, 18, 19, 20, 21, 22, 23}, - {24, 25, 26, 27, 28, 29, 30, 31}}, - {0, 0, -1, -1, -1}, {0, 0, 0, 0, 0}); - - // source 2 device 0 - BcastSubdivPerms(&cp, dev_per_task, 0, 2, - {{2, 8, 16, 24}, - {0, 1, 2, 3, 4, 5, 6, 7}, - {8, 9, 10, 11, 12, 13, 14, 15}, - {16, 17, 18, 19, 20, 21, 22, 23}, - {24, 25, 26, 27, 28, 29, 30, 31}}, - {-1, 0, -1, -1, -1}, {0, 2, 0, 0, 0}); - - // source 9 device 9 - BcastSubdivPerms(&cp, dev_per_task, 9, 9, - {{0, 9, 16, 24}, - {0, 1, 2, 3, 4, 5, 6, 7}, - {8, 9, 10, 11, 12, 13, 14, 15}, - {16, 17, 18, 19, 20, 21, 22, 23}, - {24, 25, 26, 27, 28, 29, 30, 31}}, - {1, -1, 1, -1, -1}, {1, 0, 1, 0, 0}); -} - -TEST_F(CollectiveParamResolverLocalTest, - GenerateBcastSubdivPerms4TasksVariableGPU) { - CollectiveParams cp; - cp.group.device_type = DeviceType("GPU"); - cp.group.num_tasks = 4; - std::vector<int> dev_per_task = {4, 4, 6, 8}; - for (int ti = 0; ti < cp.group.num_tasks; ti++) { - for (int di = 0; di < dev_per_task[ti]; di++) { - string dev_name = strings::StrCat("/job:worker/replica:0/task:", ti, - "/device:GPU:", di); - cp.instance.device_names.push_back(dev_name); - } - } - - // source 0 device 0 - BcastSubdivPerms(&cp, dev_per_task, 0, 0, - {{0, 4, 8, 14}, - {0, 1, 2, 3}, - {4, 5, 6, 7}, - {8, 9, 10, 11, 12, 13}, - {14, 15, 16, 17, 18, 19, 20, 21}}, - {0, 0, -1, -1, -1}, {0, 0, 0, 0, 0}); - - // source 2 device 0 - BcastSubdivPerms(&cp, dev_per_task, 0, 2, - {{2, 4, 8, 14}, - {0, 1, 2, 3}, - {4, 5, 6, 7}, - {8, 9, 10, 11, 12, 13}, - {14, 15, 16, 17, 18, 19, 20, 21}}, - {-1, 0, -1, -1, -1}, {0, 2, 0, 0, 0}); - - // source 9 device 5 - BcastSubdivPerms(&cp, dev_per_task, 5, 9, - {{0, 4, 9, 14}, - {0, 1, 2, 3}, - {4, 5, 6, 7}, - {8, 9, 10, 11, 12, 13}, - {14, 15, 16, 17, 18, 19, 20, 21}}, - {-1, -1, 1, -1, -1}, {2, 0, 0, 1, 0}); -} - } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/collective_rma_local.h b/tensorflow/core/common_runtime/collective_rma_local.h index 44408438b9..2188087957 100644 --- a/tensorflow/core/common_runtime/collective_rma_local.h +++ b/tensorflow/core/common_runtime/collective_rma_local.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_COLLECTIVE_RMA_LOCAL_ACCESS_H_ -#define TENSORFLOW_COMMON_RUNTIME_COLLECTIVE_RMA_LOCAL_ACCESS_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_RMA_LOCAL_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_RMA_LOCAL_H_ #include "tensorflow/core/common_runtime/buf_rendezvous.h" #include "tensorflow/core/common_runtime/device_mgr.h" #include "tensorflow/core/framework/collective.h" @@ -89,4 +89,4 @@ class CollectiveRemoteAccessLocal : public PerStepCollectiveRemoteAccess { }; } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_COLLECTIVE_RMA_LOCAL_ACCESS_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_RMA_LOCAL_H_ diff --git a/tensorflow/core/common_runtime/collective_util.cc b/tensorflow/core/common_runtime/collective_util.cc new file mode 100644 index 0000000000..195521a078 --- /dev/null +++ b/tensorflow/core/common_runtime/collective_util.cc @@ -0,0 +1,83 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include "tensorflow/core/common_runtime/collective_util.h" + +#include <memory> +#include <vector> + +#include "tensorflow/core/common_runtime/device.h" +#include "tensorflow/core/common_runtime/device_mgr.h" +#include "tensorflow/core/framework/collective.h" +#include "tensorflow/core/framework/device_attributes.pb.h" +#include "tensorflow/core/lib/core/errors.h" +#include "tensorflow/core/lib/strings/strcat.h" +#include "tensorflow/core/platform/types.h" + +namespace tensorflow { +namespace collective_util { + +/*static*/ +Status InitializeDeviceAndLocality(const DeviceMgr* dev_mgr, + const string& device_name, Device** device, + DeviceLocality* device_locality) { + if (!dev_mgr) { + return errors::Internal("Required non-null dev_mgr ", dev_mgr, + " for InitializeDeviceAndLocality"); + } + + Status status = dev_mgr->LookupDevice(device_name, device); + if (status.ok()) { + CHECK(*device); + *device_locality = (*device)->attributes().locality(); + } else { + LOG(ERROR) << "Failed to find device " << device_name; + for (auto d : dev_mgr->ListDevices()) { + LOG(ERROR) << "Available devices " << d->name(); + } + } + return status; +} + +/*static*/ +string SubdivPermDebugString(const CollectiveParams& col_params) { + const auto& subdiv_perms = + col_params.instance.impl_details.subdiv_permutations; + string buf; + for (int sdi = 0; sdi < subdiv_perms.size(); ++sdi) { + strings::StrAppend(&buf, "Subdiv ", sdi, " device order:\n"); + for (int di = 0; di < subdiv_perms[sdi].size(); ++di) { + int idx = subdiv_perms[sdi][di]; + if (idx >= 0) { + CHECK_GT(col_params.instance.device_names.size(), idx); + strings::StrAppend(&buf, col_params.instance.device_names[idx], "\n"); + } + } + strings::StrAppend(&buf, " subdiv_offsets: "); + for (auto o : col_params.instance.impl_details.subdiv_offsets) + strings::StrAppend(&buf, o, " "); + strings::StrAppend(&buf, " SubdivRank: "); + for (auto d : col_params.subdiv_rank) strings::StrAppend(&buf, d, " "); + if (col_params.instance.type == BROADCAST_COLLECTIVE) { + strings::StrAppend(&buf, " subdiv_source_rank: "); + for (auto src : col_params.instance.impl_details.subdiv_source_rank) + strings::StrAppend(&buf, src, " "); + } + strings::StrAppend(&buf, "\n"); + } + return buf; +} + +} // namespace collective_util +} // namespace tensorflow diff --git a/tensorflow/core/common_runtime/collective_util.h b/tensorflow/core/common_runtime/collective_util.h new file mode 100644 index 0000000000..ebb5731bec --- /dev/null +++ b/tensorflow/core/common_runtime/collective_util.h @@ -0,0 +1,38 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_UTIL_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_UTIL_H_ + +#include <string> + +#include "tensorflow/core/common_runtime/device.h" +#include "tensorflow/core/common_runtime/device_mgr.h" +#include "tensorflow/core/framework/collective.h" +#include "tensorflow/core/framework/device_attributes.pb.h" +#include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/lib/core/status.h" + +namespace tensorflow { +namespace collective_util { + +Status InitializeDeviceAndLocality(const DeviceMgr* dev_mgr, + const string& device_name, Device** device, + DeviceLocality* device_locality); +string SubdivPermDebugString(const CollectiveParams& col_params); + +} // namespace collective_util +} // namespace tensorflow + +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_COLLECTIVE_UTIL_H_ diff --git a/tensorflow/core/common_runtime/constant_folding.cc b/tensorflow/core/common_runtime/constant_folding.cc index b5a51d2526..97b6971c5b 100644 --- a/tensorflow/core/common_runtime/constant_folding.cc +++ b/tensorflow/core/common_runtime/constant_folding.cc @@ -37,6 +37,8 @@ limitations under the License. #include "tensorflow/core/lib/gtl/cleanup.h" #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/lib/strings/strcat.h" +#include "tensorflow/core/platform/denormal.h" +#include "tensorflow/core/platform/setround.h" #include "tensorflow/core/public/session_options.h" namespace tensorflow { @@ -553,6 +555,11 @@ bool ReplaceTensorWithConstant( Status ConstantFold(const ConstantFoldingOptions& opts, FunctionLibraryRuntime* function_library, Env* env, Device* partition_device, Graph* graph, bool* was_mutated) { + // TensorFlow flushes denormals to zero and rounds to nearest, so we do + // the same here. + port::ScopedFlushDenormal flush; + port::ScopedSetRound round(FE_TONEAREST); + DumpGraph("Before", graph); ConstantFoldNameGenerator generate_new_name = opts.generate_new_name; if (generate_new_name == nullptr) { diff --git a/tensorflow/core/common_runtime/constant_folding.h b/tensorflow/core/common_runtime/constant_folding.h index 84598880bb..a9a84f761b 100644 --- a/tensorflow/core/common_runtime/constant_folding.h +++ b/tensorflow/core/common_runtime/constant_folding.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_CONSTANT_FOLDING_H_ -#define TENSORFLOW_COMMON_RUNTIME_CONSTANT_FOLDING_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_CONSTANT_FOLDING_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_CONSTANT_FOLDING_H_ #include "tensorflow/core/common_runtime/device.h" #include "tensorflow/core/framework/function.h" @@ -66,4 +66,4 @@ Status ConstantFold(const ConstantFoldingOptions& opts, } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_CONSTANT_FOLDING_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_CONSTANT_FOLDING_H_ diff --git a/tensorflow/core/common_runtime/debugger_state_interface.h b/tensorflow/core/common_runtime/debugger_state_interface.h index e0fa983373..797a0ade53 100644 --- a/tensorflow/core/common_runtime/debugger_state_interface.h +++ b/tensorflow/core/common_runtime/debugger_state_interface.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_DEBUGGER_STATE_INTERFACE_H_ -#define TENSORFLOW_COMMON_RUNTIME_DEBUGGER_STATE_INTERFACE_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_DEBUGGER_STATE_INTERFACE_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_DEBUGGER_STATE_INTERFACE_H_ #include <memory> @@ -117,4 +117,4 @@ class DebugGraphDecoratorRegistry { } // end namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_DEBUGGER_STATE_INTERFACE_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_DEBUGGER_STATE_INTERFACE_H_ diff --git a/tensorflow/core/common_runtime/device.h b/tensorflow/core/common_runtime/device.h index b537666492..81d68e3be4 100644 --- a/tensorflow/core/common_runtime/device.h +++ b/tensorflow/core/common_runtime/device.h @@ -26,8 +26,8 @@ limitations under the License. // * Task numbers are within the specified replica, so there are as // many "task zeros" as replicas. -#ifndef TENSORFLOW_COMMON_RUNTIME_DEVICE_H_ -#define TENSORFLOW_COMMON_RUNTIME_DEVICE_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_H_ #include <memory> #include <string> @@ -183,4 +183,4 @@ class Device : public DeviceBase { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_DEVICE_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_H_ diff --git a/tensorflow/core/common_runtime/device_factory.h b/tensorflow/core/common_runtime/device_factory.h index 10eb62afa8..db50226fe8 100644 --- a/tensorflow/core/common_runtime/device_factory.h +++ b/tensorflow/core/common_runtime/device_factory.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_DEVICE_FACTORY_H_ -#define TENSORFLOW_COMMON_RUNTIME_DEVICE_FACTORY_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_FACTORY_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_FACTORY_H_ #include <string> #include <vector> @@ -126,4 +126,4 @@ class Registrar { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_DEVICE_FACTORY_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_FACTORY_H_ diff --git a/tensorflow/core/common_runtime/device_mgr.h b/tensorflow/core/common_runtime/device_mgr.h index cd93f76324..c1ff10d9b5 100644 --- a/tensorflow/core/common_runtime/device_mgr.h +++ b/tensorflow/core/common_runtime/device_mgr.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_DEVICE_MGR_H_ -#define TENSORFLOW_COMMON_RUNTIME_DEVICE_MGR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_MGR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_MGR_H_ #include <string> #include <unordered_map> @@ -77,4 +77,4 @@ class DeviceMgr { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_DEVICE_MGR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_MGR_H_ diff --git a/tensorflow/core/common_runtime/device_resolver_local.h b/tensorflow/core/common_runtime/device_resolver_local.h index 098eccdf84..bb6ff2efa0 100644 --- a/tensorflow/core/common_runtime/device_resolver_local.h +++ b/tensorflow/core/common_runtime/device_resolver_local.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_DEVICE_RESOLVER_LOCAL_H_ -#define TENSORFLOW_COMMON_RUNTIME_DEVICE_RESOLVER_LOCAL_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_RESOLVER_LOCAL_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_RESOLVER_LOCAL_H_ #include <string> @@ -45,4 +45,4 @@ class DeviceResolverLocal : public DeviceResolverInterface { }; } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_DEVICE_RESOLVER_LOCAL_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_RESOLVER_LOCAL_H_ diff --git a/tensorflow/core/common_runtime/device_set.h b/tensorflow/core/common_runtime/device_set.h index 4cd56e583c..c384d46e97 100644 --- a/tensorflow/core/common_runtime/device_set.h +++ b/tensorflow/core/common_runtime/device_set.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_DEVICE_SET_H_ -#define TENSORFLOW_COMMON_RUNTIME_DEVICE_SET_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_SET_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_SET_H_ #include <memory> #include <unordered_map> @@ -86,4 +86,4 @@ class DeviceSet { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_DEVICE_SET_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_DEVICE_SET_H_ diff --git a/tensorflow/core/common_runtime/direct_session.h b/tensorflow/core/common_runtime/direct_session.h index 72a2be4816..55a6fbce6d 100644 --- a/tensorflow/core/common_runtime/direct_session.h +++ b/tensorflow/core/common_runtime/direct_session.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_DIRECT_SESSION_H_ -#define TENSORFLOW_COMMON_RUNTIME_DIRECT_SESSION_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_DIRECT_SESSION_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_DIRECT_SESSION_H_ #include <atomic> #include <memory> @@ -399,4 +399,4 @@ class DirectSession : public Session { } // end namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_DIRECT_SESSION_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_DIRECT_SESSION_H_ diff --git a/tensorflow/core/common_runtime/dma_helper.h b/tensorflow/core/common_runtime/dma_helper.h index cdfce1f366..4a76cff1e3 100644 --- a/tensorflow/core/common_runtime/dma_helper.h +++ b/tensorflow/core/common_runtime/dma_helper.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_DMA_HELPER_H_ -#define TENSORFLOW_COMMON_RUNTIME_DMA_HELPER_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_DMA_HELPER_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_DMA_HELPER_H_ #include "tensorflow/core/framework/tensor.h" @@ -35,4 +35,4 @@ class DMAHelper { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_DMA_HELPER_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_DMA_HELPER_H_ diff --git a/tensorflow/core/common_runtime/eager/attr_builder.h b/tensorflow/core/common_runtime/eager/attr_builder.h index fc50bed3c0..cbe6a1cb50 100644 --- a/tensorflow/core/common_runtime/eager/attr_builder.h +++ b/tensorflow/core/common_runtime/eager/attr_builder.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_C_EAGER_RUNTIME_H_ -#define TENSORFLOW_C_EAGER_RUNTIME_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_EAGER_ATTR_BUILDER_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_EAGER_ATTR_BUILDER_H_ // Support for eager execution of TensorFlow kernels. @@ -122,12 +122,12 @@ class AttrBuilder { AttrValue attr_value; if (found == nullptr) { SetAttrValue(value, &attr_value); - m->insert(AttrValueMap::value_type(attr_name.ToString(), attr_value)); + m->insert(AttrValueMap::value_type(string(attr_name), attr_value)); } else { // TODO(ashankar): Do what is done in // NodeDefBuilder::CheckInconsistency(attr_name, *found, attr_value); SetAttrValue(std::forward<T>(value), &attr_value); - (*m)[attr_name.ToString()] = attr_value; + (*m)[string(attr_name)] = attr_value; } } @@ -154,4 +154,4 @@ AttrBuilder& AttrBuilder::Set(StringPiece attr_name, } // namespace tensorflow -#endif // TENSORFLOW_C_EAGER_RUNTIME_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_EAGER_ATTR_BUILDER_H_ diff --git a/tensorflow/core/common_runtime/eager/context.cc b/tensorflow/core/common_runtime/eager/context.cc index 5bdd547c7f..b859b06fa0 100644 --- a/tensorflow/core/common_runtime/eager/context.cc +++ b/tensorflow/core/common_runtime/eager/context.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/core/common_runtime/eager/context.h" +#include "tensorflow/core/common_runtime/device_set.h" #include "tensorflow/core/common_runtime/process_util.h" #include "tensorflow/core/framework/resource_mgr.h" #include "tensorflow/core/lib/core/blocking_counter.h" @@ -78,6 +79,12 @@ void EagerContext::InitDeviceMapAndAsync() { } } } + + DeviceSet ds; + for (Device* d : devices_) { + ds.AddDevice(d); + } + prioritized_device_type_list_ = ds.PrioritizedDeviceTypeList(); } bool EagerContext::Async() const { diff --git a/tensorflow/core/common_runtime/eager/context.h b/tensorflow/core/common_runtime/eager/context.h index 9835b19511..3c95ac590d 100644 --- a/tensorflow/core/common_runtime/eager/context.h +++ b/tensorflow/core/common_runtime/eager/context.h @@ -93,6 +93,9 @@ class EagerContext { // TODO(apassos) make this return a constant reference std::vector<Device*>* devices() { return &devices_; } + const std::vector<DeviceType>& prioritized_device_type_list() { + return prioritized_device_type_list_; + } // Clears the kernel caches. void ClearCaches(); @@ -210,6 +213,7 @@ class EagerContext { // Devices owned by device_manager std::vector<Device*> devices_; + std::vector<DeviceType> prioritized_device_type_list_; // All devices are not owned. gtl::FlatMap<string, Device*, StringPieceHasher> devices_map_; Rendezvous* rendezvous_; diff --git a/tensorflow/core/common_runtime/eager/execute.cc b/tensorflow/core/common_runtime/eager/execute.cc index 46065f399c..5b3a64ba98 100644 --- a/tensorflow/core/common_runtime/eager/execute.cc +++ b/tensorflow/core/common_runtime/eager/execute.cc @@ -192,17 +192,14 @@ Status ValidateInputTypeAndPlacement(EagerContext* ctx, Device* op_device, } Status SelectDevice(const NodeDef& ndef, EagerContext* ctx, Device** device) { - DeviceSet ds; - for (Device* d : *ctx->devices()) { - ds.AddDevice(d); - } DeviceTypeVector final_devices; - auto status = SupportedDeviceTypesForNode(ds.PrioritizedDeviceTypeList(), - ndef, &final_devices); - if (!status.ok()) return status; + TF_RETURN_IF_ERROR(SupportedDeviceTypesForNode( + ctx->prioritized_device_type_list(), ndef, &final_devices)); if (final_devices.empty()) { - return errors::Internal("Could not find valid device for node ", - ndef.DebugString()); + return errors::Internal( + "Could not find valid device for node.\nNode: ", SummarizeNodeDef(ndef), + "\nAll kernels registered for op ", ndef.op(), " :\n", + KernelsRegisteredForOp(ndef.op())); } for (Device* d : *ctx->devices()) { if (d->device_type() == final_devices[0].type_string()) { @@ -211,7 +208,7 @@ Status SelectDevice(const NodeDef& ndef, EagerContext* ctx, Device** device) { } } return errors::Unknown("Could not find a device for node ", - ndef.DebugString()); + SummarizeNodeDef(ndef)); } Status GetOutputDTypes(EagerOperation* op, DataTypeVector* output_dtypes) { diff --git a/tensorflow/core/common_runtime/eager/tensor_handle.cc b/tensorflow/core/common_runtime/eager/tensor_handle.cc index 85b0b79bce..b912f7d37b 100644 --- a/tensorflow/core/common_runtime/eager/tensor_handle.cc +++ b/tensorflow/core/common_runtime/eager/tensor_handle.cc @@ -193,7 +193,6 @@ Status TensorHandle::CopyToDevice(EagerContext* ctx, tensorflow::Device* dstd, // has device type XLA_CPU, and the other CPU. const bool both_on_cpu = src_cpu && dst_cpu; if (is_same_device || both_on_cpu) { - dstd = dst_cpu ? nullptr : dstd; *output = new tensorflow::TensorHandle(*src, dstd, dstd, ctx); return tensorflow::Status::OK(); } diff --git a/tensorflow/core/common_runtime/executor.cc b/tensorflow/core/common_runtime/executor.cc index 63ed860b9f..02193dae5a 100644 --- a/tensorflow/core/common_runtime/executor.cc +++ b/tensorflow/core/common_runtime/executor.cc @@ -1618,7 +1618,7 @@ void ExecutorState::Process(TaggedNode tagged_node, int64 scheduled_nsec) { if (vlog_) { VLOG(1) << "Process node: " << id << " step " << params.step_id << " " - << SummarizeNode(*node) << " is dead: " << tagged_node.is_dead + << SummarizeNode(*node) << (tagged_node.is_dead ? " is dead" : "") << " device: " << device->name(); } @@ -1680,7 +1680,7 @@ void ExecutorState::Process(TaggedNode tagged_node, int64 scheduled_nsec) { VLOG(2) << "Async kernel done: " << state->item->node->id() << " step " << step_id_ << " " << SummarizeNode(*state->item->node) - << " is dead: " << state->tagged_node.is_dead + << (state->tagged_node.is_dead ? " is dead" : "") << " device: " << device->name(); } @@ -1734,7 +1734,7 @@ void ExecutorState::Process(TaggedNode tagged_node, int64 scheduled_nsec) { if (vlog_) { VLOG(2) << "Synchronous kernel done: " << id << " step " << params.step_id << " " << SummarizeNode(*node) - << " is dead: " << tagged_node.is_dead + << (tagged_node.is_dead ? " is dead: " : "") << " device: " << device->name(); } diff --git a/tensorflow/core/common_runtime/executor.h b/tensorflow/core/common_runtime/executor.h index a238a6763a..6cd4fd22ea 100644 --- a/tensorflow/core/common_runtime/executor.h +++ b/tensorflow/core/common_runtime/executor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_EXECUTOR_H_ -#define TENSORFLOW_COMMON_RUNTIME_EXECUTOR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_EXECUTOR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_EXECUTOR_H_ #include "tensorflow/core/common_runtime/device.h" #include "tensorflow/core/framework/rendezvous.h" @@ -235,4 +235,4 @@ void DeleteNonCachedKernel(OpKernel* kernel); } // end namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_EXECUTOR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_EXECUTOR_H_ diff --git a/tensorflow/core/common_runtime/function.cc b/tensorflow/core/common_runtime/function.cc index 54bbe84b57..fb89bcc0df 100644 --- a/tensorflow/core/common_runtime/function.cc +++ b/tensorflow/core/common_runtime/function.cc @@ -555,6 +555,12 @@ Status FunctionLibraryRuntimeImpl::Instantiate( next_handle_++; } } + + if (options.create_kernels_eagerly) { + Item* item; + TF_RETURN_IF_ERROR(GetOrCreateItem(*handle, &item)); + } + return Status::OK(); } diff --git a/tensorflow/core/common_runtime/function.h b/tensorflow/core/common_runtime/function.h index a274f1ef51..eeca66f5d0 100644 --- a/tensorflow/core/common_runtime/function.h +++ b/tensorflow/core/common_runtime/function.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_FUNCTION_H_ -#define TENSORFLOW_COMMON_RUNTIME_FUNCTION_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_FUNCTION_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_FUNCTION_H_ #include <functional> #include <memory> @@ -170,4 +170,4 @@ Status FunctionDefToBodyHelper( FunctionBody** fbody); } // end namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_FUNCTION_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_FUNCTION_H_ diff --git a/tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.h b/tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.h index a3e0d0734f..f1cc2eace1 100644 --- a/tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.h +++ b/tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_GPU_GPU_BFC_ALLOCATOR_H_ -#define TENSORFLOW_COMMON_RUNTIME_GPU_GPU_BFC_ALLOCATOR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_BFC_ALLOCATOR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_BFC_ALLOCATOR_H_ #include <memory> #include <string> @@ -89,4 +89,4 @@ class GPUMemAllocator : public SubAllocator { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_GPU_GPU_BFC_ALLOCATOR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_BFC_ALLOCATOR_H_ diff --git a/tensorflow/core/common_runtime/gpu/gpu_cudamalloc_allocator.h b/tensorflow/core/common_runtime/gpu/gpu_cudamalloc_allocator.h index 5043fac797..856fdc34b4 100644 --- a/tensorflow/core/common_runtime/gpu/gpu_cudamalloc_allocator.h +++ b/tensorflow/core/common_runtime/gpu/gpu_cudamalloc_allocator.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_GPU_GPU_CUDA_MALLOC_ALLOCATOR_H_ -#define TENSORFLOW_COMMON_RUNTIME_GPU_GPU_CUDA_MALLOC_ALLOCATOR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_CUDAMALLOC_ALLOCATOR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_CUDAMALLOC_ALLOCATOR_H_ #include <memory> @@ -51,4 +51,4 @@ class GPUcudaMallocAllocator : public VisitableAllocator { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_GPU_GPU_CUDAMALLOC_ALLOCATOR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_CUDAMALLOC_ALLOCATOR_H_ diff --git a/tensorflow/core/common_runtime/gpu/gpu_debug_allocator.h b/tensorflow/core/common_runtime/gpu/gpu_debug_allocator.h index c49ec2a566..0f9b72040c 100644 --- a/tensorflow/core/common_runtime/gpu/gpu_debug_allocator.h +++ b/tensorflow/core/common_runtime/gpu/gpu_debug_allocator.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_GPU_GPU_DEBUG_ALLOCATOR_H_ -#define TENSORFLOW_COMMON_RUNTIME_GPU_GPU_DEBUG_ALLOCATOR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_DEBUG_ALLOCATOR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_DEBUG_ALLOCATOR_H_ #include <memory> #include <string> @@ -88,4 +88,4 @@ class GPUNanResetAllocator : public VisitableAllocator { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_GPU_GPU_DEBUG_ALLOCATOR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_DEBUG_ALLOCATOR_H_ diff --git a/tensorflow/core/common_runtime/gpu/gpu_event_mgr.h b/tensorflow/core/common_runtime/gpu/gpu_event_mgr.h index f0a109cc10..2d406b676e 100644 --- a/tensorflow/core/common_runtime/gpu/gpu_event_mgr.h +++ b/tensorflow/core/common_runtime/gpu/gpu_event_mgr.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_GPU_GPU_EVENT_MGR_H_ -#define TENSORFLOW_COMMON_RUNTIME_GPU_GPU_EVENT_MGR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_EVENT_MGR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_EVENT_MGR_H_ #include <deque> #include <vector> @@ -203,4 +203,4 @@ class EventMgr { }; } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_GPU_GPU_EVENT_MGR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_EVENT_MGR_H_ diff --git a/tensorflow/core/common_runtime/gpu/gpu_init.h b/tensorflow/core/common_runtime/gpu/gpu_init.h index bfd7a77f83..4e1f06ac83 100644 --- a/tensorflow/core/common_runtime/gpu/gpu_init.h +++ b/tensorflow/core/common_runtime/gpu/gpu_init.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_GPU_GPU_INIT_H_ -#define TENSORFLOW_COMMON_RUNTIME_GPU_GPU_INIT_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_INIT_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_INIT_H_ #include "tensorflow/core/lib/core/status.h" @@ -36,4 +36,4 @@ stream_executor::Platform* GPUMachineManager(); } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_GPU_GPU_INIT_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_INIT_H_ diff --git a/tensorflow/core/common_runtime/gpu/gpu_stream_util.h b/tensorflow/core/common_runtime/gpu/gpu_stream_util.h index 771c158267..c61ada96ef 100644 --- a/tensorflow/core/common_runtime/gpu/gpu_stream_util.h +++ b/tensorflow/core/common_runtime/gpu/gpu_stream_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_GPU_GPU_STREAM_UTIL_H_ -#define TENSORFLOW_COMMON_RUNTIME_GPU_GPU_STREAM_UTIL_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_STREAM_UTIL_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_STREAM_UTIL_H_ #include <unordered_map> @@ -42,4 +42,4 @@ Status AssignStreams(const Graph* graph, const AssignStreamsOpts& opts, } // namespace gpu_stream_util } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_GPU_GPU_STREAM_UTIL_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_STREAM_UTIL_H_ diff --git a/tensorflow/core/common_runtime/gpu/gpu_util.h b/tensorflow/core/common_runtime/gpu/gpu_util.h index 57687a8364..8ac3febb01 100644 --- a/tensorflow/core/common_runtime/gpu/gpu_util.h +++ b/tensorflow/core/common_runtime/gpu/gpu_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_GPU_GPU_UTIL_H_ -#define TENSORFLOW_COMMON_RUNTIME_GPU_GPU_UTIL_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_UTIL_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_UTIL_H_ #include "tensorflow/core/common_runtime/device.h" #include "tensorflow/core/common_runtime/dma_helper.h" @@ -108,4 +108,4 @@ class GPUUtil { }; } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_GPU_GPU_UTIL_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_GPU_GPU_UTIL_H_ diff --git a/tensorflow/core/common_runtime/gpu/gpu_util_platform_specific.cc b/tensorflow/core/common_runtime/gpu/gpu_util_platform_specific.cc index ea1b04feeb..4bc88ffc8c 100644 --- a/tensorflow/core/common_runtime/gpu/gpu_util_platform_specific.cc +++ b/tensorflow/core/common_runtime/gpu/gpu_util_platform_specific.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/core/common_runtime/device.h" +#include "tensorflow/core/common_runtime/gpu/gpu_event_mgr.h" #include "tensorflow/core/common_runtime/gpu/gpu_util.h" #include "tensorflow/core/common_runtime/gpu_device_context.h" #include "tensorflow/core/framework/tensor.h" @@ -36,4 +37,12 @@ void GPUDeviceContext::CopyDeviceTensorToCPU(const Tensor* device_tensor, GPUUtil::CopyGPUTensorToCPU(device, this, device_tensor, cpu_tensor, done); } +Status GPUDeviceContext::ThenExecute(Device* device, se::Stream* stream, + std::function<void()> func) { + const DeviceBase::GpuDeviceInfo* gpu_info = + device->tensorflow_gpu_device_info(); + gpu_info->event_mgr->ThenExecute(stream, func); + return Status::OK(); +} + } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/gpu_device_context.h b/tensorflow/core/common_runtime/gpu_device_context.h index d697d878dc..3603808152 100644 --- a/tensorflow/core/common_runtime/gpu_device_context.h +++ b/tensorflow/core/common_runtime/gpu_device_context.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_GPU_DEVICE_CONTEXT_H_ -#define TENSORFLOW_COMMON_RUNTIME_GPU_DEVICE_CONTEXT_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_GPU_DEVICE_CONTEXT_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_GPU_DEVICE_CONTEXT_H_ #include "tensorflow/core/common_runtime/device.h" #include "tensorflow/core/framework/device_base.h" @@ -60,6 +60,9 @@ class GPUDeviceContext : public DeviceContext { void MaintainLifetimeOnStream(const Tensor* t, se::Stream* stream) const override {} + Status ThenExecute(Device* device, se::Stream* stream, + std::function<void()> func) override; + private: int stream_id_; // The default primary stream to use for this context. @@ -75,4 +78,4 @@ class GPUDeviceContext : public DeviceContext { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_GPU_DEVICE_CONTEXT_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_GPU_DEVICE_CONTEXT_H_ diff --git a/tensorflow/core/common_runtime/graph_execution_state.cc b/tensorflow/core/common_runtime/graph_execution_state.cc index c23b7d3699..346befc255 100644 --- a/tensorflow/core/common_runtime/graph_execution_state.cc +++ b/tensorflow/core/common_runtime/graph_execution_state.cc @@ -581,7 +581,7 @@ Status GraphExecutionState::OptimizeGraph( if (id.second != 0) { return errors::InvalidArgument("Unsupported feed: ", feed); } - feeds.insert(id.first.ToString()); + feeds.emplace(id.first); } for (const TensorConnection& tensor_connection : options.callable_options.tensor_connection()) { @@ -590,7 +590,7 @@ Status GraphExecutionState::OptimizeGraph( return errors::InvalidArgument("Unsupported feed: ", tensor_connection.to_tensor()); } - feeds.insert(id.first.ToString()); + feeds.emplace(id.first); } for (const NodeDef& node : original_graph_def_.node()) { if (feeds.find(node.name()) == feeds.end()) { diff --git a/tensorflow/core/common_runtime/hierarchical_tree_broadcaster.cc b/tensorflow/core/common_runtime/hierarchical_tree_broadcaster.cc new file mode 100644 index 0000000000..eae34997d9 --- /dev/null +++ b/tensorflow/core/common_runtime/hierarchical_tree_broadcaster.cc @@ -0,0 +1,440 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include "tensorflow/core/common_runtime/hierarchical_tree_broadcaster.h" + +#include <functional> +#include <memory> +#include <string> +#include <utility> + +#include "tensorflow/core/common_runtime/collective_rma_local.h" +#include "tensorflow/core/common_runtime/collective_util.h" +#include "tensorflow/core/common_runtime/device_mgr.h" +#include "tensorflow/core/common_runtime/dma_helper.h" +#include "tensorflow/core/framework/device_base.h" +#include "tensorflow/core/framework/op_kernel.h" +#include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/lib/core/notification.h" +#include "tensorflow/core/lib/core/status.h" +#include "tensorflow/core/lib/strings/str_util.h" +#include "tensorflow/core/lib/strings/strcat.h" +#include "tensorflow/core/platform/env.h" +#include "tensorflow/core/platform/types.h" + +// Set true for greater intelligibility of debug mode log messages. +#define READABLE_KEYS false + +namespace tensorflow { + +namespace { +// Key to be used for BufRendezvous by Broadcaster. +string BroadcastBufKey(const string& exec_key, int subdiv, int src_rank, + int dst_rank) { + if (READABLE_KEYS) { + return strings::StrCat("broadcast(", exec_key, "):subdiv(", subdiv, + "):src(", src_rank, "):dst(", dst_rank, ")"); + } else { + // TODO(b/78352018): Try a denser format, e.g. a 64 or 128 bit hash. + return strings::StrCat(exec_key, ":", subdiv, ":", src_rank, ":", dst_rank); + } +} +} // namespace + +HierarchicalTreeBroadcaster::HierarchicalTreeBroadcaster() + : col_ctx_(nullptr), + col_params_(nullptr), + done_(nullptr), + is_source_(false) {} + +int HierarchicalTreeBroadcaster::GetDeviceTask( + int device_rank, const std::vector<int>& dev_per_task) { + int num_tasks = static_cast<int>(dev_per_task.size()); + int task_lo = 0; + int task_hi; + for (int ti = 0; ti < num_tasks; ti++) { + task_hi = task_lo + dev_per_task[ti]; + if (task_lo <= device_rank && device_rank < task_hi) return ti; + task_lo = task_hi; + } + LOG(FATAL) << "Unexpected device rank " << device_rank << " for " << task_hi + << " devices"; + return -1; +} + +Status HierarchicalTreeBroadcaster::InitializeCollectiveParams( + CollectiveParams* col_params) { + CHECK_EQ(col_params->instance.type, BROADCAST_COLLECTIVE); + CHECK_EQ(col_params->instance.impl_details.collective_name, + "HierarchicalTreeBroadcast"); + const string& device_name = + col_params->instance.device_names[col_params->default_rank]; + // Start by counting the devices in each task. + // Precondition: device_names must be sorted so that all devices in + // the same task are adjacent. + VLOG(2) << "Sorted task names: " + << str_util::Join(col_params->instance.task_names, ", "); + std::vector<int> dev_per_task; + const string* prior_task_name = &col_params->instance.task_names[0]; + int dev_count = 1; + for (int di = 1; di < col_params->group.group_size; ++di) { + if (col_params->instance.task_names[di] != *prior_task_name) { + dev_per_task.push_back(dev_count); + dev_count = 1; + prior_task_name = &col_params->instance.task_names[di]; + } else { + ++dev_count; + } + } + dev_per_task.push_back(dev_count); + CHECK_EQ(col_params->group.num_tasks, dev_per_task.size()); + + if (VLOG_IS_ON(2)) { + string dpt_buf; + for (int dpt : dev_per_task) strings::StrAppend(&dpt_buf, dpt, ";"); + VLOG(2) << "HierarchicalTreeBroadcaster::InitializeCollectiveParams device=" + << device_name << " source_rank=" << col_params->source_rank + << " dev_per_task=" << dpt_buf; + } + int num_tasks = col_params->group.num_tasks; + // If there is just 1 task, then execute binary tree broadcast over all + // devices. Otherwise, the first subdiv is inter-task broadcast, and then + // there are N more subdivs, where N is #task. + int num_subdivs = num_tasks + (num_tasks > 1 ? 1 : 0); + int total_num_devices = 0; + for (int num_dev : dev_per_task) total_num_devices += num_dev; + + col_params->instance.impl_details.subdiv_permutations.resize(num_subdivs); + col_params->subdiv_rank.reserve(num_subdivs); + col_params->instance.impl_details.subdiv_source_rank.reserve(num_subdivs); + + // Inter-task subdiv. Pick one device from each task - this is the source + // device if it belongs to that task, or device 0 for that task. If a device + // does not participate in the subdiv, set subdiv_rank to -1. + if (num_tasks > 1) { + const int sdi = 0; + std::vector<int>& perm = + col_params->instance.impl_details.subdiv_permutations[sdi]; + CHECK_EQ(perm.size(), 0); + int device_count = 0; + int source_task = GetDeviceTask(col_params->source_rank, dev_per_task); + for (int ti = 0; ti < col_params->group.num_tasks; ti++) { + bool participate = false; + if (source_task == ti) { + // Source device belongs to this task. + perm.push_back(col_params->source_rank); + participate = + col_params->instance.device_names[col_params->source_rank] == + device_name; + } else { + // Source does not belong to this task, choose dev 0. + perm.push_back(device_count); + participate = + col_params->instance.device_names[device_count] == device_name; + } + if (participate) col_params->subdiv_rank.push_back(ti); + device_count += dev_per_task[ti]; + } + if (col_params->subdiv_rank.empty()) col_params->subdiv_rank.push_back(-1); + col_params->instance.impl_details.subdiv_source_rank.push_back(source_task); + } + + // Intra-task subdivs. Pick all devices in task ti for subdiv sdi. Set + // source to dev 0 for that task if it does not contain original source, else + // set to rank of original source. If a device does not participate in + // the subdiv, set subdiv_rank to -1; + int abs_di = 0; + for (int ti = 0; ti < col_params->group.num_tasks; ti++) { + const int sdi = ti + (num_tasks > 1 ? 1 : 0); + std::vector<int>& perm = + col_params->instance.impl_details.subdiv_permutations[sdi]; + CHECK_EQ(perm.size(), 0); + bool participate = false; + int subdiv_source = 0; + for (int di = 0; di < dev_per_task[ti]; di++) { + perm.push_back(abs_di); + if (col_params->instance.device_names[abs_di] == device_name) { + participate = true; + col_params->subdiv_rank.push_back(di); + } + if (abs_di == col_params->source_rank) subdiv_source = di; + abs_di++; + } + if (!participate) col_params->subdiv_rank.push_back(-1); + col_params->instance.impl_details.subdiv_source_rank.push_back( + subdiv_source); + } + + for (int sri = 0; sri < num_subdivs; sri++) { + CHECK_GE(col_params->instance.impl_details.subdiv_source_rank[sri], 0); + } + + VLOG(2) << collective_util::SubdivPermDebugString(*col_params); + return Status::OK(); +} + +Status HierarchicalTreeBroadcaster::InitializeCollectiveContext( + CollectiveContext* col_ctx) { + CHECK(col_ctx->dev_mgr); + col_ctx_ = col_ctx; + col_params_ = &col_ctx->col_params; + return collective_util::InitializeDeviceAndLocality( + col_ctx->dev_mgr, col_ctx->device_name, &col_ctx->device, + &col_ctx->device_locality); +} + +void HierarchicalTreeBroadcaster::Run(StatusCallback done) { + CHECK(col_ctx_); + CHECK(col_params_); + done_ = std::move(done); + is_source_ = col_params_->is_source; + RunTree(); +} + +// Binary tree parent/child relations are trivial to calculate, i.e. +// device at rank r is the parent of 2r+1 and 2r+2. The one exception +// is if the source is not rank 0. We treat that case as though the +// source is appended to the front of the rank ordering as well as +// continuing to occupy its current position. Hence we calculate as +// though each device's rank is actually r+1, then subtract 1 again to +// get the descendent ranks. If the source is not rank 0 then its +// descendants include both {0,1} and the descendents of its current +// position. Where a non-0-rank source is a descendent of another +// device, no send to it is necessary. + +/* static*/ +int HierarchicalTreeBroadcaster::TreeRecvFrom(const CollectiveParams& cp, + int subdiv) { + DCHECK_LT(subdiv, static_cast<int>(cp.subdiv_rank.size())); + int my_rank = cp.subdiv_rank[subdiv]; + if (-1 == my_rank) return -1; + + const auto& impl = cp.instance.impl_details; + DCHECK_LT(subdiv, static_cast<int>(impl.subdiv_source_rank.size())); + int source_rank = impl.subdiv_source_rank[subdiv]; + if (my_rank == source_rank) return -1; + if (source_rank == 0) { + return (my_rank - 1) / 2; + } else { + int predecessor_rank = (my_rank / 2) - 1; + return (predecessor_rank < 0) ? source_rank : predecessor_rank; + } +} + +/* static */ +void HierarchicalTreeBroadcaster::TreeSendTo(const CollectiveParams& cp, + int subdiv, + std::vector<int>* targets) { + DCHECK_LT(subdiv, static_cast<int>(cp.subdiv_rank.size())); + int my_rank = cp.subdiv_rank[subdiv]; + if (-1 == my_rank) return; + + const auto& impl = cp.instance.impl_details; + DCHECK_LT(subdiv, static_cast<int>(impl.subdiv_source_rank.size())); + int source_rank = impl.subdiv_source_rank[subdiv]; + + int group_size = 0; + for (int i = 0; i < impl.subdiv_permutations[subdiv].size(); i++) { + if (impl.subdiv_permutations[subdiv][i] >= 0) { + group_size++; + } + } + + targets->clear(); + int successor_rank = 0; + if (source_rank == 0) { + successor_rank = (2 * my_rank) + 1; + } else { + successor_rank = (2 * (my_rank + 1)); + } + DCHECK_NE(successor_rank, my_rank); + if (cp.is_source && source_rank != 0) { + // The source sends to rank 0,1 in addition to its positional + // descendants. + if (group_size > 1) { + targets->push_back(0); + } + if (group_size > 2 && source_rank != 1) { + targets->push_back(1); + } + } + for (int i = 0; i < 2; ++i) { + if (successor_rank < group_size && successor_rank != source_rank) { + targets->push_back(successor_rank); + } + ++successor_rank; + } +} + +// Executes a hierarchical tree broadcast. +// Each subdiv is a broadcast between a subset of the devices. +// If there is only one task, there is one subdiv comprising a broadcast between +// all devices belonging to the task. +// If there are n tasks, n>1, then there are n+1 subdivs. In the first (global) +// subdiv, one device from each task participates in a binary tree broadcast. +// Each task receives a copy of the tensor on one device via this broadcast. +// Subsequent subdivs correspond to intra-task broadcasts. Subdiv i+1 +// corresponds to broadcast between all devices on task i. Thus, each task +// participates in at most 2 subdivs. +void HierarchicalTreeBroadcaster::RunTree() { + int num_subdivs = static_cast<int>(col_params_->subdiv_rank.size()); + // TODO(b/78352018): this is easily improved when a node participates in both + // first and second subdivision. It would first send to its descendents in + // the first subdiv, then wait until all pending ops are finished before + // sending to descendents in second subdiv. A better implementation would + // collapse the two send blocks. + for (int si = 0; si < num_subdivs; si++) { + int my_rank = col_params_->subdiv_rank[si]; + // If rank is -1, this device does not participate in this subdiv. + if (-1 == my_rank) continue; + int source_rank = col_params_->instance.impl_details.subdiv_source_rank[si]; + if (VLOG_IS_ON(1)) { + string subdiv_buf; + for (int r : col_params_->instance.impl_details.subdiv_permutations[si]) { + strings::StrAppend(&subdiv_buf, r, ","); + } + VLOG(1) << "Running Broadcast tree device=" << col_ctx_->device_name + << " subdiv=" << si << " perm=" << subdiv_buf + << " my_rank=" << my_rank << " source_rank=" << source_rank; + } + + mutex mu; // also guards status_ while callbacks are pending + int pending_count = 0; // GUARDED_BY(mu) + condition_variable all_done; + + if (my_rank >= 0 && my_rank != source_rank) { + // Begin by receiving the value. + int recv_from_rank = TreeRecvFrom(*col_params_, si); + Notification note; + DispatchRecv(si, recv_from_rank, my_rank, col_ctx_->output, + [this, &mu, ¬e](const Status& s) { + mutex_lock l(mu); + status_.Update(s); + note.Notify(); + }); + note.WaitForNotification(); + } + + // Then forward value to all descendent devices. + if (my_rank >= 0 && status_.ok()) { + std::vector<int> send_to_ranks; + TreeSendTo(*col_params_, si, &send_to_ranks); + for (int i = 0; i < send_to_ranks.size(); ++i) { + int target_rank = send_to_ranks[i]; + { + mutex_lock l(mu); + ++pending_count; + } + DispatchSend(si, target_rank, my_rank, + (is_source_ ? col_ctx_->input : col_ctx_->output), + [this, &mu, &pending_count, &all_done](const Status& s) { + mutex_lock l(mu); + status_.Update(s); + --pending_count; + if (pending_count == 0) { + all_done.notify_all(); + } + }); + } + } + + // For the original source device, we copy input to output if they are + // different. + // If there is only 1 subdiv, we do this in that subdiv. If there is more + // than 1 subdiv, then the original source device will participate in 2 + // subdivs - the global inter-task broadcast and one local intra-task + // broadcast. In this case, we perform the copy in the second subdiv for + // this device. + if (status_.ok() && is_source_ && (1 == num_subdivs || 0 != si)) { + VLOG(2) << "copying input to output for device=" << col_ctx_->device_name + << " subdiv=" << si; + if (col_ctx_->input != col_ctx_->output && + (DMAHelper::base(col_ctx_->input) != + DMAHelper::base(col_ctx_->output))) { + { + mutex_lock l(mu); + ++pending_count; + } + DeviceContext* op_dev_ctx = col_ctx_->op_ctx->op_device_context(); + CollectiveRemoteAccessLocal::MemCpyAsync( + op_dev_ctx, op_dev_ctx, col_ctx_->device, col_ctx_->device, + col_ctx_->op_ctx->input_alloc_attr(0), + col_ctx_->op_ctx->output_alloc_attr(0), col_ctx_->input, + col_ctx_->output, 0, /*stream_index*/ + [this, &mu, &pending_count, &all_done](const Status& s) { + mutex_lock l(mu); + status_.Update(s); + --pending_count; + if (0 == pending_count) { + all_done.notify_all(); + } + }); + } + } + + // Then wait for all pending actions to complete. + { + mutex_lock l(mu); + if (pending_count > 0) { + all_done.wait(l); + } + } + } + VLOG(2) << "device=" << col_ctx_->device_name << " return status " << status_; + done_(status_); +} + +void HierarchicalTreeBroadcaster::DispatchSend(int subdiv, int dst_rank, + int src_rank, + const Tensor* src_tensor, + const StatusCallback& done) { + string send_buf_key = + BroadcastBufKey(col_ctx_->exec_key, subdiv, src_rank, dst_rank); + int dst_idx = + col_params_->instance.impl_details.subdiv_permutations[subdiv][dst_rank]; + VLOG(3) << "DispatchSend " << send_buf_key << " from_device " + << col_ctx_->device_name << " to_device " + << col_params_->instance.device_names[dst_idx] << " subdiv=" << subdiv + << " dst_rank=" << dst_rank << " dst_idx=" << dst_idx; + col_ctx_->col_exec->PostToPeer(col_params_->instance.device_names[dst_idx], + col_params_->instance.task_names[dst_idx], + send_buf_key, col_ctx_->device, + col_ctx_->op_ctx->op_device_context(), + col_ctx_->op_ctx->output_alloc_attr(0), + src_tensor, col_ctx_->device_locality, done); +} + +void HierarchicalTreeBroadcaster::DispatchRecv(int subdiv, int src_rank, + int dst_rank, Tensor* dst_tensor, + const StatusCallback& done) { + string recv_buf_key = + BroadcastBufKey(col_ctx_->exec_key, subdiv, src_rank, dst_rank); + int src_idx = + col_params_->instance.impl_details.subdiv_permutations[subdiv][src_rank]; + VLOG(3) << "DispatchRecv " << recv_buf_key << " from_device " + << col_params_->instance.device_names[src_idx] << " to_device " + << col_ctx_->device_name << " subdiv=" << subdiv + << " src_rank=" << src_rank << " src_idx=" << src_idx; + col_ctx_->col_exec->RecvFromPeer( + col_params_->instance.device_names[src_idx], + col_params_->instance.task_names[src_idx], + col_params_->task.is_local[src_idx], recv_buf_key, col_ctx_->device, + col_ctx_->op_ctx->op_device_context(), + col_ctx_->op_ctx->output_alloc_attr(0), dst_tensor, + col_ctx_->device_locality, 0 /*stream_index*/, done); +} + +REGISTER_COLLECTIVE(HierarchicalTreeBroadcast, HierarchicalTreeBroadcaster); + +} // namespace tensorflow diff --git a/tensorflow/core/common_runtime/broadcaster.h b/tensorflow/core/common_runtime/hierarchical_tree_broadcaster.h index 799228b161..ceb9baad30 100644 --- a/tensorflow/core/common_runtime/broadcaster.h +++ b/tensorflow/core/common_runtime/hierarchical_tree_broadcaster.h @@ -12,25 +12,40 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_BROADCASTER_H_ -#define TENSORFLOW_CORE_COMMON_RUNTIME_BROADCASTER_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_HIERARCHICAL_TREE_BROADCASTER_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_HIERARCHICAL_TREE_BROADCASTER_H_ #include <vector> + #include "tensorflow/core/common_runtime/base_collective_executor.h" #include "tensorflow/core/framework/collective.h" -#include "tensorflow/core/framework/device_attributes.pb.h" namespace tensorflow { -// Tree-algorithm implementation of collective broadcast. -class Broadcaster { +// Hierarchical tree-algorithm implementation of collective broadcast. +class HierarchicalTreeBroadcaster : public CollectiveImplementationInterface { public: - Broadcaster(CollectiveExecutor* col_exec, const DeviceMgr* dev_mgr, - OpKernelContext* ctx, OpKernelContext::Params* params, - const CollectiveParams& col_params, const string& exec_key, - int64 step_id, Tensor* output); + HierarchicalTreeBroadcaster(); + ~HierarchicalTreeBroadcaster() override = default; + + // Establishes the subdiv permutations needed for a hierarchical broadcast. + // If all devices are local, establishes a single subdiv comprising all + // devices. If any devices are on a different task, establishes n+1 subdivs + // for n tasks. + // The first subdiv comprises one device per task which gets the tensor on + // each task. Subdiv i+1 corresponds to a task-local tree-broadcast for task + // i. + Status InitializeCollectiveParams(CollectiveParams* col_params) override; - void Run(StatusCallback done); + // Initializes members of CollectiveContext not yet initialized, i.e. device + // and device_locality. Also saves the CollectiveContext in this object. + Status InitializeCollectiveContext(CollectiveContext* col_ctx) override; + + // Begins async execution of the hierarchical tree broadcast. + // Must be called in a blockable thread. + // TODO(b/80529858): remove the previous warning when we have a dedicated + // collective threadpool. + void Run(StatusCallback done) override; // Returns the rank of the device from which this device should receive // its value, -1 if no value should be received. @@ -42,32 +57,29 @@ class Broadcaster { std::vector<int>* targets); private: + // Get the task to which the device at `device_rank` belongs. + int GetDeviceTask(int device_rank, const std::vector<int>& dev_per_task); + // Sends `src_tensor` asynchronously from this device to device at `dst_rank` // in `subdiv`. Calls `done` upon completion. void DispatchSend(int subdiv, int dst_rank, int src_rank, const Tensor* src_tensor, const StatusCallback& done); + // Receives a tensor into the memory buffer owned by `dst_tensor` at this // device from device at `src_rank` in `subdiv`. Calls `done` upon // completion. void DispatchRecv(int subdiv, int src_rank, int dst_rank, Tensor* dst_tensor, const StatusCallback& done); + // Executes the hierarchical broadcast defined by this op. void RunTree(); - Status status_; - CollectiveExecutor* col_exec_; // Not owned - const DeviceMgr* dev_mgr_; // Not owned - OpKernelContext* ctx_; // Not owned - const CollectiveParams& col_params_; - const string exec_key_; - const int rank_; - const bool is_source_; - Tensor* output_; // Not owned - std::unique_ptr<CollectiveAdapter> ca_; + CollectiveContext* col_ctx_; // Not owned + const CollectiveParams* col_params_; // Not owned StatusCallback done_; - Device* device_; // The device for which this instance labors - DeviceLocality device_locality_; + Status status_; + bool is_source_; }; } // namespace tensorflow -#endif // TENSORFLOW_CORE_COMMON_RUNTIME_BROADCASTER_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_HIERARCHICAL_TREE_BROADCASTER_H_ diff --git a/tensorflow/core/common_runtime/broadcaster_test.cc b/tensorflow/core/common_runtime/hierarchical_tree_broadcaster_test.cc index 3960fc6c97..da0e359cf8 100644 --- a/tensorflow/core/common_runtime/broadcaster_test.cc +++ b/tensorflow/core/common_runtime/hierarchical_tree_broadcaster_test.cc @@ -12,7 +12,7 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#include "tensorflow/core/common_runtime/broadcaster.h" +#include "tensorflow/core/common_runtime/hierarchical_tree_broadcaster.h" #include <algorithm> #include "tensorflow/core/common_runtime/base_collective_executor.h" @@ -41,7 +41,7 @@ static int64 kStepId = 123; // The test harness won't allow a mixture of fixture and non-fixture // tests in one file, so this is a trival fixture for tests that don't -// need the heavy-weight BroadcasterTest fixture. +// need the heavy-weight HierarchicalTreeBroadcasterTest fixture. class TrivialTest : public ::testing::Test { protected: TrivialTest() {} @@ -53,23 +53,23 @@ class TrivialTest : public ::testing::Test { // R = tested rank // RF = receive-from rank // ST = send_to rank vector -#define DEF_TL_TEST(D, S, R, RF, ST) \ - TEST_F(TrivialTest, TreeLinks_##D##Devs_##S##Source_##R##Rank) { \ - CollectiveParams cp; \ - cp.group.group_size = D; \ - cp.instance.impl_details.subdiv_source_rank = {S}; \ - cp.instance.impl_details.subdiv_permutations.push_back( \ - std::vector<int>(D, 0)); \ - cp.subdiv_rank = {R}; \ - cp.is_source = (S == R); \ - EXPECT_EQ(RF, Broadcaster::TreeRecvFrom(cp, 0)); \ - std::vector<int> expected = ST; \ - std::vector<int> send_to; \ - Broadcaster::TreeSendTo(cp, 0, &send_to); \ - ASSERT_EQ(expected.size(), send_to.size()); \ - for (int i = 0; i < expected.size(); ++i) { \ - EXPECT_EQ(expected[i], send_to[i]); \ - } \ +#define DEF_TL_TEST(D, S, R, RF, ST) \ + TEST_F(TrivialTest, TreeLinks_##D##Devs_##S##Source_##R##Rank) { \ + CollectiveParams cp; \ + cp.group.group_size = D; \ + cp.instance.impl_details.subdiv_source_rank = {S}; \ + cp.instance.impl_details.subdiv_permutations.push_back( \ + std::vector<int>(D, 0)); \ + cp.subdiv_rank = {R}; \ + cp.is_source = (S == R); \ + EXPECT_EQ(RF, HierarchicalTreeBroadcaster::TreeRecvFrom(cp, 0)); \ + std::vector<int> expected = ST; \ + std::vector<int> send_to; \ + HierarchicalTreeBroadcaster::TreeSendTo(cp, 0, &send_to); \ + ASSERT_EQ(expected.size(), send_to.size()); \ + for (int i = 0; i < expected.size(); ++i) { \ + EXPECT_EQ(expected[i], send_to[i]); \ + } \ } #define V(...) std::vector<int>({__VA_ARGS__}) @@ -130,7 +130,7 @@ DEF_TL_TEST(8, 7, 7, -1, V(0, 1)) // Wraps CollectiveRemoteAccessLocal with the ability to return an // error status to the N'th action. -// TODO(tucker): factor out of this file and ring_reducer_test.cc +// TODO(b/113171733): factor out of this file and ring_reducer_test.cc // into a single common source. class FailTestRMA : public CollectiveRemoteAccessLocal { public: @@ -187,31 +187,32 @@ class FailTestRMA : public CollectiveRemoteAccessLocal { int fail_after_ GUARDED_BY(mu_); }; -class BroadcasterTest : public ::testing::Test { +class HierarchicalTreeBroadcasterTest : public ::testing::Test { protected: - BroadcasterTest() : device_type_(DEVICE_CPU) {} + HierarchicalTreeBroadcasterTest() : device_type_(DEVICE_CPU) {} - ~BroadcasterTest() override { + ~HierarchicalTreeBroadcasterTest() override { stop_ = true; - for (auto i : instances_) { - delete i; - } + for (auto i : instances_) delete i; if (col_exec_) col_exec_->Unref(); } - void SetUp() override { -#if GOOGLE_CUDA +#ifdef GOOGLE_CUDA + void InitGPUDevices() { auto device_factory = DeviceFactory::GetFactory("GPU"); CHECK(device_factory); SessionOptions options; Status s = device_factory->CreateDevices( options, "/job:worker/replica:0/task:0", &gpu_devices_); CHECK(s.ok()); -#endif } +#endif void Init(int num_workers, int num_devices_per_worker, DataType dtype, const DeviceType& device_type, int fail_after) { +#ifdef GOOGLE_CUDA + InitGPUDevices(); +#endif VLOG(2) << "num_workers=" << num_workers << " num_devices_per_worker=" << num_devices_per_worker; int total_num_devices = num_workers * num_devices_per_worker; @@ -400,8 +401,6 @@ class BroadcasterTest : public ::testing::Test { return GetKernel(node_def, device_type, device); } - void BuildColParams() {} - template <typename T> void RunTest(DataType dtype, const DeviceType& device_type, int num_workers, int num_devices, int tensor_len, int fail_after, @@ -511,10 +510,47 @@ class BroadcasterTest : public ::testing::Test { } } + void RunSubdivPermsTest( + CollectiveParams* cp, + const std::vector<std::vector<int>>& expected_subdiv_perms, + const std::vector<int>& expected_subdiv_rank, + const std::vector<int>& expected_subdiv_source_rank) { + col_exec_ = nullptr; + cp->instance.impl_details.subdiv_permutations.clear(); + cp->subdiv_rank.clear(); + cp->instance.impl_details.subdiv_source_rank.clear(); + // Create a stub broadcaster only for testing param initialization. + HierarchicalTreeBroadcaster broadcaster; + TF_CHECK_OK(broadcaster.InitializeCollectiveParams(cp)); + EXPECT_EQ(expected_subdiv_perms, + cp->instance.impl_details.subdiv_permutations); + EXPECT_EQ(expected_subdiv_rank, cp->subdiv_rank); + EXPECT_EQ(expected_subdiv_source_rank, + cp->instance.impl_details.subdiv_source_rank); + } + + void PrepColParamsForSubdivPermsTest(CollectiveParams* cp, int num_tasks, + int num_gpus) { + cp->group.device_type = DeviceType("GPU"); + cp->group.num_tasks = num_tasks; + cp->group.group_size = num_tasks * num_gpus; + cp->instance.type = BROADCAST_COLLECTIVE; + cp->instance.impl_details.collective_name = "HierarchicalTreeBroadcast"; + for (int ti = 0; ti < num_tasks; ti++) { + string task_name = strings::StrCat("/job:worker/replica:0/task:", ti); + for (int di = 0; di < num_gpus; di++) { + string dev_name = strings::StrCat(task_name, "/device:GPU:", di); + cp->instance.task_names.push_back(task_name); + cp->instance.device_names.push_back(dev_name); + } + } + } + class DeviceInstance { public: DeviceInstance(int rank, const string& dev_name, - const DeviceType& device_type, BroadcasterTest* parent) + const DeviceType& device_type, + HierarchicalTreeBroadcasterTest* parent) : parent_(parent), dev_name_(dev_name), device_type_(device_type), @@ -636,21 +672,20 @@ class BroadcasterTest : public ::testing::Test { ctx.allocate_output(0, tensor_.shape(), &output_tensor_ptr)); } CHECK_EQ(output_tensor_ptr, ctx.mutable_output(0)); + const Tensor* input_tensor_ptr = + col_params_.is_source ? &tensor_ : nullptr; // Prepare a Broadcaster instance. string exec_key = strings::StrCat(col_params_.instance.instance_key, ":0:0"); - Broadcaster broadcaster(parent_->col_exec_, parent_->dev_mgr_.get(), &ctx, - &op_params, col_params_, exec_key, kStepId, - output_tensor_ptr); - - // Start execution in a threadpool then wait for completion. - Notification notification; - broadcaster.Run([this, ¬ification](Status s) { - status_ = s; - notification.Notify(); - }); - notification.WaitForNotification(); + HierarchicalTreeBroadcaster broadcaster; + CollectiveContext col_ctx(parent_->col_exec_, parent_->dev_mgr_.get(), + &ctx, &op_params, col_params_, exec_key, + kStepId, input_tensor_ptr, output_tensor_ptr); + TF_CHECK_OK(broadcaster.InitializeCollectiveContext(&col_ctx)); + + // Run the broadcast. + broadcaster.Run([this](Status s) { status_ = s; }); if (status_.ok()) { CHECK(tensor_.CopyFrom(*ctx.mutable_output(0), tensor_.shape())); } @@ -658,15 +693,13 @@ class BroadcasterTest : public ::testing::Test { dev_ctx->Unref(); } - BroadcasterTest* parent_; + HierarchicalTreeBroadcasterTest* parent_; string dev_name_; DeviceType device_type_ = DEVICE_CPU; int rank_; Tensor tensor_; Device* device_; CollectiveParams col_params_; - std::unique_ptr<CollectiveAdapter> ca_; - std::unique_ptr<OpKernelContext> ctx_; Status status_; }; // class DeviceInstance @@ -688,6 +721,118 @@ class BroadcasterTest : public ::testing::Test { int failure_count_ GUARDED_BY(mu_) = 0; }; +TEST_F(HierarchicalTreeBroadcasterTest, InitializeParams1Task8GPU) { + CollectiveParams cp; + PrepColParamsForSubdivPermsTest(&cp, 1, 8); + + // source 0 device 0 + cp.source_rank = 0; + cp.default_rank = 0; + RunSubdivPermsTest(&cp, {{0, 1, 2, 3, 4, 5, 6, 7}}, {0}, {0}); + + // source 2 device 2 + cp.source_rank = 2; + cp.default_rank = 2; + RunSubdivPermsTest(&cp, {{0, 1, 2, 3, 4, 5, 6, 7}}, {2}, {2}); + + // source 2 device 0 + cp.source_rank = 2; + cp.default_rank = 0; + RunSubdivPermsTest(&cp, {{0, 1, 2, 3, 4, 5, 6, 7}}, {0}, {2}); +} + +TEST_F(HierarchicalTreeBroadcasterTest, InitializeParams4Tasks8GPU) { + CollectiveParams cp; + PrepColParamsForSubdivPermsTest(&cp, 4, 8); + + // source 0 device 0 + cp.source_rank = 0; + cp.default_rank = 0; + RunSubdivPermsTest(&cp, + {{0, 8, 16, 24}, + {0, 1, 2, 3, 4, 5, 6, 7}, + {8, 9, 10, 11, 12, 13, 14, 15}, + {16, 17, 18, 19, 20, 21, 22, 23}, + {24, 25, 26, 27, 28, 29, 30, 31}}, + {0, 0, -1, -1, -1}, {0, 0, 0, 0, 0}); + + // source 2 device 0 + cp.source_rank = 2; + cp.default_rank = 0; + RunSubdivPermsTest(&cp, + {{2, 8, 16, 24}, + {0, 1, 2, 3, 4, 5, 6, 7}, + {8, 9, 10, 11, 12, 13, 14, 15}, + {16, 17, 18, 19, 20, 21, 22, 23}, + {24, 25, 26, 27, 28, 29, 30, 31}}, + {-1, 0, -1, -1, -1}, {0, 2, 0, 0, 0}); + + // source 9 device 9 + cp.source_rank = 9; + cp.default_rank = 9; + RunSubdivPermsTest(&cp, + {{0, 9, 16, 24}, + {0, 1, 2, 3, 4, 5, 6, 7}, + {8, 9, 10, 11, 12, 13, 14, 15}, + {16, 17, 18, 19, 20, 21, 22, 23}, + {24, 25, 26, 27, 28, 29, 30, 31}}, + {1, -1, 1, -1, -1}, {1, 0, 1, 0, 0}); +} + +TEST_F(HierarchicalTreeBroadcasterTest, InitializeParams4TasksVariableGPU) { + CollectiveParams cp; + int num_tasks = 4; + cp.group.device_type = DeviceType("GPU"); + cp.group.num_tasks = num_tasks; + cp.group.group_size = 0; + cp.instance.type = BROADCAST_COLLECTIVE; + cp.instance.impl_details.collective_name = "HierarchicalTreeBroadcast"; + std::vector<int> dev_per_task = {4, 4, 6, 8}; + for (int ti = 0; ti < cp.group.num_tasks; ti++) { + string task_name = strings::StrCat("/job:worker/replica:0/task:", ti); + for (int di = 0; di < dev_per_task[ti]; di++) { + string dev_name = strings::StrCat(task_name, "/device:GPU:", di); + cp.instance.task_names.push_back(task_name); + cp.instance.device_names.push_back(dev_name); + cp.group.group_size++; + } + } + + // source 0 device 0 + cp.source_rank = 0; + cp.default_rank = 0; + RunSubdivPermsTest(&cp, + {{0, 4, 8, 14}, + {0, 1, 2, 3}, + {4, 5, 6, 7}, + {8, 9, 10, 11, 12, 13}, + {14, 15, 16, 17, 18, 19, 20, 21}}, + {0, 0, -1, -1, -1}, {0, 0, 0, 0, 0}); + + // source 2 device 0 + cp.source_rank = 2; + cp.default_rank = 0; + RunSubdivPermsTest(&cp, + {{2, 4, 8, 14}, + {0, 1, 2, 3}, + {4, 5, 6, 7}, + {8, 9, 10, 11, 12, 13}, + {14, 15, 16, 17, 18, 19, 20, 21}}, + {-1, 0, -1, -1, -1}, {0, 2, 0, 0, 0}); + + // source 9 device 5 + cp.source_rank = 9; + cp.default_rank = 5; + RunSubdivPermsTest(&cp, + {{0, 4, 9, 14}, + {0, 1, 2, 3}, + {4, 5, 6, 7}, + {8, 9, 10, 11, 12, 13}, + {14, 15, 16, 17, 18, 19, 20, 21}}, + {-1, -1, 1, -1, -1}, {2, 0, 0, 1, 0}); +} + +// TODO(b/113171733): change to use TEST_P. // Tests of full broadcast algorithm, with different device and // data types. // B = data element type @@ -697,7 +842,7 @@ class BroadcasterTest : public ::testing::Test { // L = tensor length // A = abort after count #define DEF_TEST(B, T, W, D, L, A, F) \ - TEST_F(BroadcasterTest, \ + TEST_F(HierarchicalTreeBroadcasterTest, \ DaTy##B##_DevTy##T##_Wkr##W##_Dev##D##_Len##L##_Abt##A##_Fw##F) { \ DataType dtype = DT_##B; \ switch (dtype) { \ diff --git a/tensorflow/core/common_runtime/kernel_benchmark_testlib.h b/tensorflow/core/common_runtime/kernel_benchmark_testlib.h index 995a15a299..555b43f655 100644 --- a/tensorflow/core/common_runtime/kernel_benchmark_testlib.h +++ b/tensorflow/core/common_runtime/kernel_benchmark_testlib.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_KERNEL_BENCHMARK_TESTLIB_H_ -#define TENSORFLOW_COMMON_RUNTIME_KERNEL_BENCHMARK_TESTLIB_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_KERNEL_BENCHMARK_TESTLIB_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_KERNEL_BENCHMARK_TESTLIB_H_ #include <string> #include <vector> @@ -65,4 +65,4 @@ class Benchmark { } // end namespace test } // end namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_KERNEL_BENCHMARK_TESTLIB_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_KERNEL_BENCHMARK_TESTLIB_H_ diff --git a/tensorflow/core/common_runtime/local_device.cc b/tensorflow/core/common_runtime/local_device.cc index 873182371e..db5022d56e 100644 --- a/tensorflow/core/common_runtime/local_device.cc +++ b/tensorflow/core/common_runtime/local_device.cc @@ -62,7 +62,7 @@ struct LocalDevice::EigenThreadPoolInfo { LocalDevice::LocalDevice(const SessionOptions& options, const DeviceAttributes& attributes) - : Device(options.env, attributes), owned_tp_info_(nullptr) { + : TracingDevice(options.env, attributes), owned_tp_info_(nullptr) { // Log info messages if TensorFlow is not compiled with instructions that // could speed up performance and are available on the current CPU. port::InfoAboutUnusedCPUFeatures(); diff --git a/tensorflow/core/common_runtime/local_device.h b/tensorflow/core/common_runtime/local_device.h index 84a4f66db4..9a82fb7204 100644 --- a/tensorflow/core/common_runtime/local_device.h +++ b/tensorflow/core/common_runtime/local_device.h @@ -13,10 +13,11 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_LOCAL_DEVICE_H_ -#define TENSORFLOW_COMMON_RUNTIME_LOCAL_DEVICE_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_LOCAL_DEVICE_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_LOCAL_DEVICE_H_ #include "tensorflow/core/common_runtime/device.h" +#include "tensorflow/core/common_runtime/tracing_device.h" #include "tensorflow/core/framework/device_attributes.pb.h" #include "tensorflow/core/platform/macros.h" @@ -31,7 +32,7 @@ struct SessionOptions; // initializes a shared Eigen compute device used by both. This // should eventually be removed once we refactor ThreadPoolDevice and // GPUDevice into more 'process-wide' abstractions. -class LocalDevice : public Device { +class LocalDevice : public TracingDevice { public: LocalDevice(const SessionOptions& options, const DeviceAttributes& attributes); @@ -54,4 +55,4 @@ class LocalDevice : public Device { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_LOCAL_DEVICE_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_LOCAL_DEVICE_H_ diff --git a/tensorflow/core/common_runtime/optimization_registry.h b/tensorflow/core/common_runtime/optimization_registry.h index f5d265aa24..6fcd2afd27 100644 --- a/tensorflow/core/common_runtime/optimization_registry.h +++ b/tensorflow/core/common_runtime/optimization_registry.h @@ -132,11 +132,12 @@ class OptimizationPassRegistration { #define REGISTER_OPTIMIZATION_UNIQ_HELPER(ctr, grouping, phase, optimization) \ REGISTER_OPTIMIZATION_UNIQ(ctr, grouping, phase, optimization) -#define REGISTER_OPTIMIZATION_UNIQ(ctr, grouping, phase, optimization) \ - static optimization_registration::OptimizationPassRegistration \ - register_optimization_##ctr( \ - grouping, phase, \ - std::unique_ptr<GraphOptimizationPass>(new optimization()), \ +#define REGISTER_OPTIMIZATION_UNIQ(ctr, grouping, phase, optimization) \ + static ::tensorflow::optimization_registration::OptimizationPassRegistration \ + register_optimization_##ctr( \ + grouping, phase, \ + ::std::unique_ptr<::tensorflow::GraphOptimizationPass>( \ + new optimization()), \ #optimization) } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/placer.h b/tensorflow/core/common_runtime/placer.h index fce87269c5..cefcdd25db 100644 --- a/tensorflow/core/common_runtime/placer.h +++ b/tensorflow/core/common_runtime/placer.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_PLACER_H_ -#define TENSORFLOW_COMMON_RUNTIME_PLACER_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_PLACER_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_PLACER_H_ #include <string> #include <unordered_map> @@ -100,4 +100,4 @@ class Placer { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_PLACER_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_PLACER_H_ diff --git a/tensorflow/core/common_runtime/rendezvous_mgr.h b/tensorflow/core/common_runtime/rendezvous_mgr.h index cb5848ede3..b4d8ab4eb2 100644 --- a/tensorflow/core/common_runtime/rendezvous_mgr.h +++ b/tensorflow/core/common_runtime/rendezvous_mgr.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_RENDEZVOUS_MGR_H_ -#define TENSORFLOW_COMMON_RUNTIME_RENDEZVOUS_MGR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_RENDEZVOUS_MGR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_RENDEZVOUS_MGR_H_ #include <string> #include <unordered_map> @@ -87,4 +87,4 @@ class IntraProcessRendezvous : public Rendezvous { } // end namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_RENDEZVOUS_MGR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_RENDEZVOUS_MGR_H_ diff --git a/tensorflow/core/common_runtime/ring_reducer.cc b/tensorflow/core/common_runtime/ring_reducer.cc index e26761703b..bb8eeb141a 100644 --- a/tensorflow/core/common_runtime/ring_reducer.cc +++ b/tensorflow/core/common_runtime/ring_reducer.cc @@ -14,13 +14,29 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/core/common_runtime/ring_reducer.h" +#include <stdlib.h> +#include <atomic> +#include <functional> +#include <utility> + #include "tensorflow/core/common_runtime/collective_rma_local.h" +#include "tensorflow/core/common_runtime/collective_util.h" #include "tensorflow/core/common_runtime/copy_tensor.h" +#include "tensorflow/core/common_runtime/device.h" #include "tensorflow/core/common_runtime/device_mgr.h" #include "tensorflow/core/common_runtime/dma_helper.h" +#include "tensorflow/core/framework/allocator.h" +#include "tensorflow/core/framework/device_base.h" +#include "tensorflow/core/framework/op_kernel.h" +#include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/framework/types.h" +#include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/notification.h" +#include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/strings/str_util.h" +#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/env.h" +#include "tensorflow/core/platform/types.h" // Set true for greater intelligibility of debug mode log messages. #define READABLE_KEYS false @@ -36,7 +52,8 @@ string RingReduceBufKey(const string& exec_key, int pass, int section, return strings::StrCat("rred(", exec_key, "):pass(", pass, "):section(", section, "):srcrank(", source_rank, ")"); } else { - // TODO(tucker): Try out some kind of denser encoding, e.g. 128 bit hash. + // TODO(b/78352018): Try out some kind of denser encoding, e.g. 128 bit + // hash. return strings::StrCat(exec_key, ":", pass, ":", section, ":", source_rank); } } @@ -65,105 +82,149 @@ RingReducer::RingField* RingReducer::PCQueue::Dequeue() { return rf; } -RingReducer::RingReducer(CollectiveExecutor* col_exec, const DeviceMgr* dev_mgr, - OpKernelContext* ctx, - OpKernelContext::Params* op_params, - const CollectiveParams& col_params, - const string& exec_key, int64 step_id, - const Tensor* input, Tensor* output) - : col_exec_(col_exec), - dev_mgr_(dev_mgr), - ctx_(ctx), - op_params_(op_params), - col_params_(col_params), - exec_key_(exec_key), - input_(input), - output_(output), - rank_(col_params.subdiv_rank[0]), - step_id_(step_id), - group_size_(col_params.group.group_size), - num_subdivs_(static_cast<int>( - col_params.instance.impl_details.subdiv_permutations.size())), +RingReducer::RingReducer() + : col_ctx_(nullptr), + col_params_(nullptr), done_(nullptr), - device_(nullptr), - device_name_( - col_params_.instance.device_names[col_params_.default_rank]) { - CHECK_GT(group_size_, 0); - CHECK_GT(num_subdivs_, 0); -} + group_size_(-1), + num_subdivs_(-1) {} RingReducer::~RingReducer() { group_size_tensor_ready_.WaitForNotification(); } -string RingReducer::TensorDebugString(Tensor tensor) { - const DeviceBase::GpuDeviceInfo* gpu_device_info = - ctx_->device()->tensorflow_gpu_device_info(); - if (gpu_device_info) { - Tensor cpu_tensor(tensor.dtype(), tensor.shape()); - Notification note; - gpu_device_info->default_context->CopyDeviceTensorToCPU( - &tensor, "" /*tensor_name*/, device_, &cpu_tensor, - [¬e](const Status& s) { - CHECK(s.ok()); - note.Notify(); - }); - note.WaitForNotification(); - return cpu_tensor.SummarizeValue(64); - } else { - return tensor.SummarizeValue(64); +Status RingReducer::InitializeCollectiveParams(CollectiveParams* col_params) { + CHECK_EQ(col_params->instance.type, REDUCTION_COLLECTIVE); + CHECK_EQ(col_params->instance.impl_details.collective_name, "RingReduce"); + const string& device_name = + col_params->instance.device_names[col_params->default_rank]; + // Each subdiv permutation is a ring formed by rotating each + // single-task subsequence of devices by an offset. This makes most + // sense when each task has the same number of devices but we can't + // depend on that being the case so we'll compute something that + // works in any case. + + // Start by counting the devices in each task. + // Precondition: device_names must be sorted so that all devices in + // the same task are adjacent. + VLOG(2) << "Sorted task names: " + << str_util::Join(col_params->instance.task_names, ", "); + std::vector<int> dev_per_task; + const string* prior_task_name = &col_params->instance.task_names[0]; + int dev_count = 1; + for (int di = 1; di < col_params->group.group_size; ++di) { + if (col_params->instance.task_names[di] != *prior_task_name) { + dev_per_task.push_back(dev_count); + dev_count = 1; + prior_task_name = &col_params->instance.task_names[di]; + } else { + ++dev_count; + } + } + dev_per_task.push_back(dev_count); + CHECK_EQ(col_params->group.num_tasks, dev_per_task.size()); + + // Generate a ring permutation for each requested offset. + if (col_params->instance.impl_details.subdiv_offsets.empty()) { + return errors::Internal( + "Subdiv offsets should be non-empty for ring reducer, size=", + col_params->instance.impl_details.subdiv_offsets.size()); + } + VLOG(2) << "Setting up perms for col_params " << col_params + << " subdiv_permutations " + << &col_params->instance.impl_details.subdiv_permutations; + col_params->instance.impl_details.subdiv_permutations.resize( + col_params->instance.impl_details.subdiv_offsets.size()); + col_params->subdiv_rank.resize( + col_params->instance.impl_details.subdiv_offsets.size(), -1); + for (int sdi = 0; + sdi < col_params->instance.impl_details.subdiv_offsets.size(); ++sdi) { + std::vector<int>& perm = + col_params->instance.impl_details.subdiv_permutations[sdi]; + CHECK_EQ(perm.size(), 0); + int offset = col_params->instance.impl_details.subdiv_offsets[sdi]; + // A negative subdivision offset is interpreted as follows: + // 1. Reverse the local device ordering. + // 2. Begin the subdivision at abs(offset) in the reversed ordering. + bool reverse = false; + if (offset < 0) { + offset = abs(offset); + reverse = true; + } + int prior_dev_count = 0; // sum over prior worker device counts + for (int ti = 0; ti < col_params->group.num_tasks; ++ti) { + for (int di = 0; di < dev_per_task[ti]; ++di) { + int di_offset = (di + offset) % dev_per_task[ti]; + int offset_di = + reverse ? (dev_per_task[ti] - (di_offset + 1)) : di_offset; + // Device index in global subdivision permutation. + int permuted_di = prior_dev_count + offset_di; + int rank = static_cast<int>(perm.size()); + perm.push_back(permuted_di); + if (col_params->instance.device_names[permuted_di] == device_name) { + CHECK_EQ(permuted_di, col_params->default_rank); + col_params->subdiv_rank[sdi] = rank; + } + } + prior_dev_count += dev_per_task[ti]; + } + CHECK_EQ(col_params->group.group_size, perm.size()); } + + VLOG(2) << collective_util::SubdivPermDebugString(*col_params); + return Status::OK(); +} + +Status RingReducer::InitializeCollectiveContext(CollectiveContext* col_ctx) { + CHECK(col_ctx->dev_mgr); + col_ctx_ = col_ctx; + col_params_ = &col_ctx->col_params; + return collective_util::InitializeDeviceAndLocality( + col_ctx->dev_mgr, col_ctx->device_name, &col_ctx->device, + &col_ctx->device_locality); } void RingReducer::Run(StatusCallback done) { + CHECK(col_ctx_); + CHECK(col_params_); done_ = std::move(done); + group_size_ = col_params_->group.group_size; + num_subdivs_ = static_cast<int>( + col_params_->instance.impl_details.subdiv_permutations.size()); + CHECK_GT(num_subdivs_, 0); - // Get local execution device. if (VLOG_IS_ON(1)) { string buf; - for (int r = 0; r < col_params_.instance.device_names.size(); ++r) { + for (int r = 0; r < col_params_->instance.device_names.size(); ++r) { strings::StrAppend(&buf, "dev ", r, " : ", - col_params_.instance.device_names[r], "\n"); + col_params_->instance.device_names[r], "\n"); } for (int sd = 0; - sd < col_params_.instance.impl_details.subdiv_permutations.size(); + sd < col_params_->instance.impl_details.subdiv_permutations.size(); ++sd) { strings::StrAppend(&buf, "\nsubdiv ", sd, " perm: "); - for (auto x : col_params_.instance.impl_details.subdiv_permutations[sd]) { + for (auto x : + col_params_->instance.impl_details.subdiv_permutations[sd]) { strings::StrAppend(&buf, x, ", "); } } - VLOG(1) << "RingReducer::Run for device " << device_name_ - << " default_rank " << col_params_.default_rank << "\n" + VLOG(1) << "RingReducer::Run for device " << col_ctx_->device_name + << " default_rank " << col_params_->default_rank << "\n" << buf; } - CHECK(dev_mgr_); - Status status = dev_mgr_->LookupDevice( - col_params_.instance.device_names[col_params_.default_rank], &device_); - if (!status.ok()) { - LOG(ERROR) << "Failed to find device " - << col_params_.instance.device_names[col_params_.default_rank]; - for (auto d : dev_mgr_->ListDevices()) { - LOG(ERROR) << "Available device " << d->name(); - } - done_(status); - return; - } - CHECK(device_); - device_locality_ = device_->attributes().locality(); - - VLOG(1) << this << " default_rank " << col_params_.default_rank << " cp " - << &col_params_ << ": " << col_params_.ToString(); // Start by copying input to output if they're not already the same, i.e. if // we're not computing in-place on the input tensor. - if ((input_ != output_) && - (DMAHelper::base(input_) != DMAHelper::base(output_))) { + if ((col_ctx_->input != col_ctx_->output) && + (DMAHelper::base(col_ctx_->input) != DMAHelper::base(col_ctx_->output))) { // We are running in a blockable thread and the callback can't block so // just wait here on the copy. Notification note; + Status status; CollectiveRemoteAccessLocal::MemCpyAsync( - ctx_->input_device_context(0), ctx_->op_device_context(), device_, - device_, ctx_->input_alloc_attr(0), ctx_->output_alloc_attr(0), input_, - output_, 0 /*dev_to_dev_stream_index*/, + col_ctx_->op_ctx->input_device_context(0), + col_ctx_->op_ctx->op_device_context(), col_ctx_->device, + col_ctx_->device, col_ctx_->op_ctx->input_alloc_attr(0), + col_ctx_->op_ctx->output_alloc_attr(0), col_ctx_->input, + col_ctx_->output, 0 /*dev_to_dev_stream_index*/, [this, ¬e, &status](const Status& s) { status.Update(s); note.Notify(); @@ -177,24 +238,43 @@ void RingReducer::Run(StatusCallback done) { ContinueAfterInputCopy(); } +string RingReducer::TensorDebugString(const Tensor& tensor) { + const DeviceBase::GpuDeviceInfo* gpu_device_info = + col_ctx_->op_ctx->device()->tensorflow_gpu_device_info(); + if (gpu_device_info) { + Tensor cpu_tensor(tensor.dtype(), tensor.shape()); + Notification note; + gpu_device_info->default_context->CopyDeviceTensorToCPU( + &tensor, "" /*tensor_name*/, col_ctx_->device, &cpu_tensor, + [¬e](const Status& s) { + CHECK(s.ok()); + note.Notify(); + }); + note.WaitForNotification(); + return cpu_tensor.SummarizeValue(64); + } else { + return tensor.SummarizeValue(64); + } +} + // Note that this function is blocking and must not run in any thread // which cannot be blocked. void RingReducer::ContinueAfterInputCopy() { - AllocatorAttributes attr = ctx_->output_alloc_attr(0); - ca_.reset(MakeCollectiveAdapter(output_, group_size_ * num_subdivs_, - device_->GetAllocator(attr))); + AllocatorAttributes attr = col_ctx_->op_ctx->output_alloc_attr(0); + ca_.reset(MakeCollectiveAdapter(col_ctx_->output, group_size_ * num_subdivs_, + col_ctx_->device->GetAllocator(attr))); - if (col_params_.final_op) { + if (col_params_->final_op) { // Create an on-device scalar value from group_size_ that may be needed // later. // TODO(tucker): Cache and reuse across invocations? Or maybe the scalar // can be provided to the kernel in host memory? Tensor group_size_val = ca_->Scalar(group_size_); - if (col_params_.group.device_type != "CPU") { - group_size_tensor_ = - ca_->Scalar(device_->GetAllocator(ctx_->input_alloc_attr(0))); - DeviceContext* op_dev_ctx = ctx_->op_device_context(); - op_dev_ctx->CopyCPUTensorToDevice(&group_size_val, device_, + if (col_params_->group.device_type != "CPU") { + group_size_tensor_ = ca_->Scalar(col_ctx_->device->GetAllocator( + col_ctx_->op_ctx->input_alloc_attr(0))); + DeviceContext* op_dev_ctx = col_ctx_->op_ctx->op_device_context(); + op_dev_ctx->CopyCPUTensorToDevice(&group_size_val, col_ctx_->device, &group_size_tensor_, [this](const Status& s) { if (!s.ok()) { @@ -231,14 +311,14 @@ void RingReducer::StartAbort(const Status& s) { // cancellation on all of the outstanding CollectiveRemoteAccess // actions. if (abort_started) { - col_exec_->StartAbort(s); + col_ctx_->col_exec->StartAbort(s); } } void RingReducer::Finish(bool ok) { if (ok) { // Recover the output from the adaptor. - ca_->ConsumeFinalValue(output_); + ca_->ConsumeFinalValue(col_ctx_->output); } Status s; { @@ -275,7 +355,7 @@ Status RingReducer::ComputeBinOp(Device* device, OpKernel* op, Tensor* output, // TODO(tucker): Is it possible to cache and reuse these objects? They're // mostly identical inside one device execution. std::unique_ptr<SubContext> sub_ctx( - new SubContext(ctx_, op_params_, op, output, input)); + new SubContext(col_ctx_->op_ctx, col_ctx_->op_params, op, output, input)); device->Compute(op, sub_ctx->sub_ctx_); return sub_ctx->sub_ctx_->status(); } @@ -295,18 +375,18 @@ void RingReducer::InitRingField(RingField* rf, int chunk_idx, int subdiv_idx, rf->chunk_idx = chunk_idx; rf->subdiv_idx = subdiv_idx; rf->sc_idx = field_idx; - rf->rank = col_params_.subdiv_rank[subdiv_idx]; + rf->rank = col_params_->subdiv_rank[subdiv_idx]; rf->second_pass = false; rf->action = RF_INIT; // Recv from the device with preceding rank within the subdivision. int recv_from_rank = (rf->rank + (group_size_ - 1)) % group_size_; int send_to_rank = (rf->rank + 1) % group_size_; - rf->recv_dev_idx = col_params_.instance.impl_details + rf->recv_dev_idx = col_params_->instance.impl_details .subdiv_permutations[subdiv_idx][recv_from_rank]; - int send_dev_idx = col_params_.instance.impl_details + int send_dev_idx = col_params_->instance.impl_details .subdiv_permutations[subdiv_idx][send_to_rank]; - rf->recv_is_remote = !col_params_.task.is_local[rf->recv_dev_idx]; - rf->send_is_remote = !col_params_.task.is_local[send_dev_idx]; + rf->recv_is_remote = !col_params_->task.is_local[rf->recv_dev_idx]; + rf->send_is_remote = !col_params_->task.is_local[send_dev_idx]; if (ca_->ChunkBytes(rf->sc_idx) > 0) { // In pass 0 we skip Recv when rank = chunk_idx rf->do_recv = (rf->chunk_idx != rf->rank); @@ -360,45 +440,47 @@ string RingReducer::RingField::DebugString() const { void RingReducer::DispatchSend(RingField* rf, const StatusCallback& done) { CHECK(rf->do_send); - string send_buf_key = - RingReduceBufKey(exec_key_, rf->second_pass, rf->sc_idx, rf->rank); - VLOG(3) << "DispatchSend rank=" << col_params_.default_rank << " send key " + string send_buf_key = RingReduceBufKey(col_ctx_->exec_key, rf->second_pass, + rf->sc_idx, rf->rank); + VLOG(3) << "DispatchSend rank=" << col_params_->default_rank << " send key " << send_buf_key << " chunk " << ca_->TBounds(rf->chunk) << " sc_idx " << rf->sc_idx; int send_to_rank = (rf->rank + 1) % group_size_; - int send_to_dev_idx = col_params_.instance.impl_details + int send_to_dev_idx = col_params_->instance.impl_details .subdiv_permutations[rf->subdiv_idx][send_to_rank]; - col_exec_->PostToPeer(col_params_.instance.device_names[send_to_dev_idx], - col_params_.instance.task_names[send_to_dev_idx], - send_buf_key, device_, ctx_->op_device_context(), - ctx_->output_alloc_attr(0), &rf->chunk, - device_locality_, done); + col_ctx_->col_exec->PostToPeer( + col_params_->instance.device_names[send_to_dev_idx], + col_params_->instance.task_names[send_to_dev_idx], send_buf_key, + col_ctx_->device, col_ctx_->op_ctx->op_device_context(), + col_ctx_->op_ctx->output_alloc_attr(0), &rf->chunk, + col_ctx_->device_locality, done); } void RingReducer::DispatchRecv(RingField* rf, const StatusCallback& done) { CHECK(rf->do_recv); string recv_buf_key = - RingReduceBufKey(exec_key_, rf->second_pass, rf->sc_idx, + RingReduceBufKey(col_ctx_->exec_key, rf->second_pass, rf->sc_idx, (rf->rank + (group_size_ - 1)) % group_size_); - VLOG(3) << "DispatchRecv rank=" << col_params_.default_rank << " recv key " + VLOG(3) << "DispatchRecv rank=" << col_params_->default_rank << " recv key " << recv_buf_key << " chunk " << ca_->TBounds(rf->chunk) << " into " - << ((col_params_.merge_op != nullptr) ? "tmp_chunk" : "chunk"); - Tensor* dst_tensor = (!rf->second_pass && (col_params_.merge_op != nullptr)) + << ((col_params_->merge_op != nullptr) ? "tmp_chunk" : "chunk"); + Tensor* dst_tensor = (!rf->second_pass && (col_params_->merge_op != nullptr)) ? &rf->tmp_chunk : &rf->chunk; - col_exec_->RecvFromPeer(col_params_.instance.device_names[rf->recv_dev_idx], - col_params_.instance.task_names[rf->recv_dev_idx], - col_params_.task.is_local[rf->recv_dev_idx], - recv_buf_key, device_, ctx_->op_device_context(), - ctx_->output_alloc_attr(0), dst_tensor, - device_locality_, rf->subdiv_idx, done); + col_ctx_->col_exec->RecvFromPeer( + col_params_->instance.device_names[rf->recv_dev_idx], + col_params_->instance.task_names[rf->recv_dev_idx], + col_params_->task.is_local[rf->recv_dev_idx], recv_buf_key, + col_ctx_->device, col_ctx_->op_ctx->op_device_context(), + col_ctx_->op_ctx->output_alloc_attr(0), dst_tensor, + col_ctx_->device_locality, rf->subdiv_idx, done); } string RingReducer::FieldState() { - string s = strings::StrCat("RingReducer ", - strings::Hex(reinterpret_cast<uint64>(this)), - " exec ", exec_key_, " step_id=", step_id_, - " state of all ", rfv_.size(), " fields:"); + string s = strings::StrCat( + "RingReducer ", strings::Hex(reinterpret_cast<uint64>(this)), " exec ", + col_ctx_->exec_key, " step_id=", col_ctx_->step_id, " state of all ", + rfv_.size(), " fields:"); for (int i = 0; i < rfv_.size(); ++i) { s.append("\n"); s.append(rfv_[i].DebugString()); @@ -468,8 +550,9 @@ bool RingReducer::RunAsyncParts() { --recv_pending_count; if (!rf->second_pass) { rf->action = RF_REDUCE; - Status s = ComputeBinOp(device_, col_params_.merge_op.get(), - &rf->chunk, &rf->tmp_chunk); + Status s = + ComputeBinOp(col_ctx_->device, col_params_->merge_op.get(), + &rf->chunk, &rf->tmp_chunk); if (!s.ok()) { aborted = true; StartAbort(s); @@ -479,11 +562,12 @@ bool RingReducer::RunAsyncParts() { } break; case RF_REDUCE: - if (!rf->second_pass && col_params_.final_op.get() && rf->is_final) { + if (!rf->second_pass && col_params_->final_op.get() && rf->is_final) { rf->action = RF_FINALIZE; group_size_tensor_ready_.WaitForNotification(); - Status s = ComputeBinOp(device_, col_params_.final_op.get(), - &rf->chunk, &group_size_tensor_); + Status s = + ComputeBinOp(col_ctx_->device, col_params_->final_op.get(), + &rf->chunk, &group_size_tensor_); if (!s.ok()) { aborted = true; StartAbort(s); @@ -552,9 +636,11 @@ bool RingReducer::RunAsyncParts() { CHECK_EQ(send_pending_count, 0); CHECK_EQ(recv_pending_count, 0); - VLOG(2) << this << " rank=" << rank_ << " finish;" + VLOG(2) << this << " device=" << col_ctx_->device_name << " finish;" << " final value " << TensorDebugString(ca_->Value()); return !aborted; } +REGISTER_COLLECTIVE(RingReduce, RingReducer); + } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/ring_reducer.h b/tensorflow/core/common_runtime/ring_reducer.h index 3e1988e787..0848e37b52 100644 --- a/tensorflow/core/common_runtime/ring_reducer.h +++ b/tensorflow/core/common_runtime/ring_reducer.h @@ -16,25 +16,35 @@ limitations under the License. #define TENSORFLOW_CORE_COMMON_RUNTIME_RING_REDUCER_H_ #include <deque> +#include <memory> +#include <string> +#include <vector> #include "tensorflow/core/common_runtime/base_collective_executor.h" #include "tensorflow/core/framework/collective.h" -#include "tensorflow/core/framework/device_attributes.pb.h" namespace tensorflow { -class DeviceMgr; +class Device; // Ring-algorithm implementation of collective all-reduce. -class RingReducer { +class RingReducer : public CollectiveImplementationInterface { public: - RingReducer(CollectiveExecutor* col_exec, const DeviceMgr* dev_mgr, - OpKernelContext* ctx, OpKernelContext::Params* op_params, - const CollectiveParams& col_params, const string& exec_key, - int64 step_id, const Tensor* input, Tensor* output); + RingReducer(); + ~RingReducer() override; - virtual ~RingReducer(); + // Establishes the requested number of subdivision permutations based on the + // ring order implicit in the device order. + Status InitializeCollectiveParams(CollectiveParams* col_params) override; - void Run(StatusCallback done); + // Initializes members of CollectiveContext not yet initialized, i.e. device + // and device_locality. Also saves the CollectiveContext in this object. + Status InitializeCollectiveContext(CollectiveContext* col_ctx) override; + + // Begins async execution of the ring reduce algorithm. + // Must be called in a blockable thread. + // TODO(b/80529858): remove the previous warning when we have a dedicated + // collective threadpool. + void Run(StatusCallback done) override; private: // Called when a bad status is received that implies we should terminate @@ -101,7 +111,7 @@ class RingReducer { // For constructing log messages for debugging. string FieldState(); - string TensorDebugString(Tensor tensor); + string TensorDebugString(const Tensor& tensor); // Producer/Consumer Queue of RingField structs. class PCQueue { @@ -116,30 +126,19 @@ class RingReducer { std::deque<RingField*> deque_ GUARDED_BY(pcq_mu_); }; - CollectiveExecutor* col_exec_; // Not owned - const DeviceMgr* dev_mgr_; // Not owned - OpKernelContext* ctx_; // Not owned - OpKernelContext::Params* op_params_; // Not owned - const CollectiveParams& col_params_; - const string exec_key_; - const Tensor* input_; // Not owned - Tensor* output_; // Not owned - const int rank_; - const int64 step_id_; - const int group_size_; - const int num_subdivs_; + CollectiveContext* col_ctx_; // Not owned + const CollectiveParams* col_params_; // Not owned + StatusCallback done_; + int group_size_; + int num_subdivs_; Tensor group_size_tensor_; Notification group_size_tensor_ready_; std::unique_ptr<CollectiveAdapter> ca_; - StatusCallback done_; - Device* device_; // The device for which this instance labors - const string device_name_; - DeviceLocality device_locality_; - mutex status_mu_; Status status_ GUARDED_BY(status_mu_); - std::vector<RingField> rfv_; + + friend class RingReducerTest; }; } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/ring_reducer_test.cc b/tensorflow/core/common_runtime/ring_reducer_test.cc index fcdf9deff8..5e079dbce6 100644 --- a/tensorflow/core/common_runtime/ring_reducer_test.cc +++ b/tensorflow/core/common_runtime/ring_reducer_test.cc @@ -37,7 +37,6 @@ limitations under the License. #include "tensorflow/core/public/version.h" namespace tensorflow { -namespace { // Wraps CollectiveRemoteAccessLocal with the ability to return an // error status to the N'th action. @@ -135,27 +134,28 @@ class RingReducerTest : public ::testing::Test { protected: RingReducerTest() : device_type_(DEVICE_CPU) {} - void SetUp() override { -#if GOOGLE_CUDA +#ifdef GOOGLE_CUDA + void InitGPUDevices() { auto device_factory = DeviceFactory::GetFactory("GPU"); CHECK(device_factory); SessionOptions options; Status s = device_factory->CreateDevices( options, "/job:worker/replica:0/task:0", &gpu_devices_); CHECK(s.ok()); -#endif } +#endif ~RingReducerTest() override { stop_ = true; - for (auto i : instances_) { - delete i; - } + for (auto i : instances_) delete i; if (col_exec_) col_exec_->Unref(); } void Init(int num_workers, int num_devices, DataType dtype, const DeviceType& device_type, int num_subdivs, int fail_after) { +#ifdef GOOGLE_CUDA + InitGPUDevices(); +#endif device_type_ = device_type; std::vector<Device*> local_devices; SessionOptions sess_opts; @@ -201,6 +201,7 @@ class RingReducerTest : public ::testing::Test { col_params_.instance.instance_key = kInstanceKey; col_params_.instance.impl_details.subdiv_offsets.clear(); col_params_.instance.type = REDUCTION_COLLECTIVE; + col_params_.instance.impl_details.collective_name = "RingReduce"; col_params_.instance.data_type = dtype; col_params_.instance.impl_details.subdiv_permutations.resize(num_subdivs); col_params_.subdiv_rank.resize(num_subdivs); @@ -373,6 +374,22 @@ class RingReducerTest : public ::testing::Test { return GetKernel(node_def, device_type, device); } + void RunSubdivPermsTest( + CollectiveParams* cp, + const std::vector<std::vector<int>>& expected_subdiv_perms, + const std::vector<int>& expected_subdiv_rank) { + col_exec_ = nullptr; + cp->instance.impl_details.subdiv_permutations.clear(); + cp->subdiv_rank.clear(); + // Create a stub ring reducer only for testing param initialization. + RingReducer reducer; + TF_CHECK_OK(reducer.InitializeCollectiveParams(cp)); + EXPECT_EQ(expected_subdiv_perms, + cp->instance.impl_details.subdiv_permutations); + EXPECT_EQ(expected_subdiv_rank, cp->subdiv_rank); + reducer.group_size_tensor_ready_.Notify(); // To unblock destructor. + } + class DeviceInstance { public: DeviceInstance(int rank, const string& dev_name, @@ -475,8 +492,8 @@ class RingReducerTest : public ::testing::Test { op_params.op_kernel = op.get(); OpKernelContext ctx(&op_params, 1); - // We never actually execute the kernel, so we need to do the - // output allocation that it would do, ourselves. + // We never actually execute the kernel, so we need to do the output + // allocation it would do, ourselves. Tensor* output_tensor_ptr = nullptr; TF_CHECK_OK(ctx.forward_input_or_allocate_output({0}, 0, tensor_.shape(), &output_tensor_ptr)); @@ -485,20 +502,17 @@ class RingReducerTest : public ::testing::Test { // Prepare a RingReducer instance. string exec_key = strings::StrCat(col_params_.instance.instance_key, ":0:0"); - RingReducer rr(parent_->col_exec_, parent_->dev_mgr_.get(), &ctx, - &op_params, col_params_, exec_key, kStepId, &tensor_, - &tensor_); - - // Start execution in a threadpool then wait for completion. - Notification notification; - SchedClosure([this, ¬ification, &rr]() { - rr.Run([this, ¬ification](Status s) { - status_ = s; - notification.Notify(); - }); - }); - notification.WaitForNotification(); - CHECK(tensor_.CopyFrom(*ctx.mutable_output(0), tensor_.shape())); + RingReducer reducer; + CollectiveContext col_ctx(parent_->col_exec_, parent_->dev_mgr_.get(), + &ctx, &op_params, col_params_, exec_key, + kStepId, &tensor_, &tensor_); + TF_CHECK_OK(reducer.InitializeCollectiveContext(&col_ctx)); + + // Run the all-reduce. + reducer.Run([this](Status s) { status_ = s; }); + if (status_.ok()) { + CHECK(tensor_.CopyFrom(*ctx.mutable_output(0), tensor_.shape())); + } dev_ctx->Unref(); } @@ -531,6 +545,57 @@ class RingReducerTest : public ::testing::Test { int32 reduce_counter_ GUARDED_BY(mu_) = 0; }; +TEST_F(RingReducerTest, InitializeParams) { + static const int kNumDevsPerTask = 8; + static const int kNumTasks = 3; + static const int kNumDevs = kNumDevsPerTask * kNumTasks; + CollectiveParams cp; + std::vector<string> device_names; + std::vector<string> task_names; + cp.group.group_key = 1; + cp.group.group_size = kNumDevs; + cp.group.device_type = DeviceType("GPU"); + cp.group.num_tasks = kNumTasks; + cp.instance.instance_key = 3; + cp.instance.type = REDUCTION_COLLECTIVE; + cp.instance.data_type = DataType(DT_FLOAT); + cp.instance.shape = TensorShape({5}); + cp.instance.impl_details.collective_name = "RingReduce"; + cp.instance.impl_details.subdiv_offsets.push_back(0); + cp.is_source = false; + for (int i = 0; i < kNumDevs; ++i) { + int task_id = i / kNumDevsPerTask; + int dev_id = i % kNumDevsPerTask; + string task_name = strings::StrCat("/job:worker/replica:0/task:", task_id); + task_names.push_back(task_name); + string device_name = strings::StrCat(task_name, "/device:GPU:", dev_id); + device_names.push_back(device_name); + cp.instance.task_names.push_back(task_name); + cp.instance.device_names.push_back(device_name); + } + + int test_rank = 0; + cp.default_rank = test_rank; + cp.instance.impl_details.subdiv_offsets = {0, 4}; + RunSubdivPermsTest(&cp, + {{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, + 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23}, + {4, 5, 6, 7, 0, 1, 2, 3, 12, 13, 14, 15, + 8, 9, 10, 11, 20, 21, 22, 23, 16, 17, 18, 19}}, + {0, 4}); + + test_rank = 3; + cp.default_rank = test_rank; + cp.instance.impl_details.subdiv_offsets = {3, -3}; + RunSubdivPermsTest(&cp, + {{3, 4, 5, 6, 7, 0, 1, 2, 11, 12, 13, 14, + 15, 8, 9, 10, 19, 20, 21, 22, 23, 16, 17, 18}, + {4, 3, 2, 1, 0, 7, 6, 5, 12, 11, 10, 9, + 8, 15, 14, 13, 20, 19, 18, 17, 16, 23, 22, 21}}, + {0, 1}); +} + +// TODO(b/113171733): change to use TEST_P. #define DEF_TEST(B, T, W, D, S, L, A) \ TEST_F(RingReducerTest, \ DaTy##B##_DevTy##T##_Wkr##W##_Dev##D##_Sdiv##S##_Len##L##_Abrt##A) { \ @@ -604,5 +669,4 @@ DEF_TEST(FLOAT, GPU, 1, 8, 1, 9408, 2) DEF_TEST(FLOAT, GPU, 1, 8, 2, 9408, 5) #endif -} // namespace } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/session_factory.h b/tensorflow/core/common_runtime/session_factory.h index 81c172c6ae..8565088afc 100644 --- a/tensorflow/core/common_runtime/session_factory.h +++ b/tensorflow/core/common_runtime/session_factory.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_SESSION_FACTORY_H_ -#define TENSORFLOW_COMMON_RUNTIME_SESSION_FACTORY_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_SESSION_FACTORY_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_SESSION_FACTORY_H_ #include <string> @@ -73,4 +73,4 @@ class SessionFactory { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_SESSION_FACTORY_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_SESSION_FACTORY_H_ diff --git a/tensorflow/core/common_runtime/sycl/sycl_allocator.h b/tensorflow/core/common_runtime/sycl/sycl_allocator.h index 550f193332..cc5909de17 100644 --- a/tensorflow/core/common_runtime/sycl/sycl_allocator.h +++ b/tensorflow/core/common_runtime/sycl/sycl_allocator.h @@ -17,8 +17,8 @@ limitations under the License. #error This file must only be included when building TensorFlow with SYCL support #endif -#ifndef TENSORFLOW_COMMON_RUNTIME_SYCL_SYCL_ALLOCATOR_H_ -#define TENSORFLOW_COMMON_RUNTIME_SYCL_SYCL_ALLOCATOR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_SYCL_SYCL_ALLOCATOR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_SYCL_SYCL_ALLOCATOR_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/allocator.h" @@ -72,4 +72,4 @@ class SYCLAllocator : public Allocator { } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_SYCL_SYCL_ALLOCATOR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_SYCL_SYCL_ALLOCATOR_H_ diff --git a/tensorflow/core/common_runtime/threadpool_device.cc b/tensorflow/core/common_runtime/threadpool_device.cc index 7406ecf4f8..0fbc20b34b 100644 --- a/tensorflow/core/common_runtime/threadpool_device.cc +++ b/tensorflow/core/common_runtime/threadpool_device.cc @@ -70,17 +70,6 @@ ThreadPoolDevice::ThreadPoolDevice(const SessionOptions& options, ThreadPoolDevice::~ThreadPoolDevice() {} -void ThreadPoolDevice::Compute(OpKernel* op_kernel, OpKernelContext* context) { - // When Xprof/ThreadScape profiling is off (which is the default), the - // following code is simple enough that its overhead is negligible. - tracing::ScopedActivity activity(op_kernel->name(), op_kernel->type_string(), - op_kernel->IsExpensive()); - tracing::ScopedRegion region(tracing::EventCategory::kCompute, - op_kernel->name()); - - op_kernel->Compute(context); -} - Allocator* ThreadPoolDevice::GetAllocator(AllocatorAttributes attr) { return allocator_; } diff --git a/tensorflow/core/common_runtime/threadpool_device.h b/tensorflow/core/common_runtime/threadpool_device.h index afc5d15ebc..51bd038a1c 100644 --- a/tensorflow/core/common_runtime/threadpool_device.h +++ b/tensorflow/core/common_runtime/threadpool_device.h @@ -29,7 +29,6 @@ class ThreadPoolDevice : public LocalDevice { Allocator* allocator); ~ThreadPoolDevice() override; - void Compute(OpKernel* op_kernel, OpKernelContext* context) override; Allocator* GetAllocator(AllocatorAttributes attr) override; Allocator* GetScopedAllocator(AllocatorAttributes attr, int64 step_id) override; diff --git a/tensorflow/core/common_runtime/tracing_device.h b/tensorflow/core/common_runtime/tracing_device.h new file mode 100644 index 0000000000..39215efa35 --- /dev/null +++ b/tensorflow/core/common_runtime/tracing_device.h @@ -0,0 +1,57 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_TRACING_DEVICE_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_TRACING_DEVICE_H_ + +#include "tensorflow/core/common_runtime/device.h" +#include "tensorflow/core/platform/macros.h" +#include "tensorflow/core/platform/tracing.h" + +namespace tensorflow { + +namespace test { +class Benchmark; +} +struct SessionOptions; + +// This class implements tracing functionality that is shared by its subclasses +// (including ThreadPoolDevice and XlaDevice). +class TracingDevice : public Device { + public: + TracingDevice(Env* env, const DeviceAttributes& attributes) + : Device(env, attributes) {} + + void Compute(OpKernel* op_kernel, OpKernelContext* context) override { + if (TF_PREDICT_FALSE( + tracing::GetTraceCollector() || + tracing::GetEventCollector(tracing::EventCategory::kCompute))) { + const string& op_name = op_kernel->name(); + tracing::ScopedActivity activity(op_name, op_kernel->type_string(), + op_kernel->IsExpensive()); + tracing::ScopedRegion region(tracing::EventCategory::kCompute, op_name); + op_kernel->Compute(context); + } else { + op_kernel->Compute(context); + } + } + + private: + TF_DISALLOW_COPY_AND_ASSIGN(TracingDevice); +}; + +} // namespace tensorflow + +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_TRACING_DEVICE_H_ diff --git a/tensorflow/core/common_runtime/visitable_allocator.h b/tensorflow/core/common_runtime/visitable_allocator.h index 8edf922d11..ae0563a96a 100644 --- a/tensorflow/core/common_runtime/visitable_allocator.h +++ b/tensorflow/core/common_runtime/visitable_allocator.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_COMMON_RUNTIME_VISITABLE_ALLOCATOR_H_ -#define TENSORFLOW_COMMON_RUNTIME_VISITABLE_ALLOCATOR_H_ +#ifndef TENSORFLOW_CORE_COMMON_RUNTIME_VISITABLE_ALLOCATOR_H_ +#define TENSORFLOW_CORE_COMMON_RUNTIME_VISITABLE_ALLOCATOR_H_ #include <functional> #include "tensorflow/core/framework/allocator.h" @@ -76,4 +76,4 @@ class TrackingVisitableAllocator : public TrackingAllocator, VisitableAllocator* allocator_; }; } // namespace tensorflow -#endif // TENSORFLOW_COMMON_RUNTIME_VISITABLE_ALLOCATOR_H_ +#endif // TENSORFLOW_CORE_COMMON_RUNTIME_VISITABLE_ALLOCATOR_H_ diff --git a/tensorflow/core/debug/debug_callback_registry.h b/tensorflow/core/debug/debug_callback_registry.h index 8f08c656c2..bcd4ddc50c 100644 --- a/tensorflow/core/debug/debug_callback_registry.h +++ b/tensorflow/core/debug/debug_callback_registry.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_DEBUG_CALLBACK_REGISTRY_H_ -#define TENSORFLOW_DEBUG_CALLBACK_REGISTRY_H_ +#ifndef TENSORFLOW_CORE_DEBUG_DEBUG_CALLBACK_REGISTRY_H_ +#define TENSORFLOW_CORE_DEBUG_DEBUG_CALLBACK_REGISTRY_H_ #include <functional> #include <map> @@ -68,4 +68,4 @@ class DebugCallbackRegistry { } // namespace tensorflow -#endif // TENSORFLOW_DEBUG_CALLBACK_REGISTRY_H_ +#endif // TENSORFLOW_CORE_DEBUG_DEBUG_CALLBACK_REGISTRY_H_ diff --git a/tensorflow/core/debug/debug_graph_utils.cc b/tensorflow/core/debug/debug_graph_utils.cc index 7641edea52..5fc95a8f20 100644 --- a/tensorflow/core/debug/debug_graph_utils.cc +++ b/tensorflow/core/debug/debug_graph_utils.cc @@ -356,8 +356,8 @@ Status DebugNodeInserter::ParseDebugOpName( "Malformed attributes in debug op name \"", debug_op_name, "\""); } - const string key = std::string(seg.substr(0, eq_index)); - const string value = std::string( + const string key(seg.substr(0, eq_index)); + const string value( seg.substr(eq_index + 1, attribute_seg.size() - eq_index - 1)); if (key.empty() || value.empty()) { return errors::InvalidArgument( diff --git a/tensorflow/core/debug/debug_graph_utils.h b/tensorflow/core/debug/debug_graph_utils.h index 64deff1f00..86dc90a134 100644 --- a/tensorflow/core/debug/debug_graph_utils.h +++ b/tensorflow/core/debug/debug_graph_utils.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_DEBUG_NODE_INSERTER_H_ -#define TENSORFLOW_DEBUG_NODE_INSERTER_H_ +#ifndef TENSORFLOW_CORE_DEBUG_DEBUG_GRAPH_UTILS_H_ +#define TENSORFLOW_CORE_DEBUG_DEBUG_GRAPH_UTILS_H_ #include <unordered_map> #include <vector> @@ -123,4 +123,4 @@ class DebugNodeInserter { }; } // namespace tensorflow -#endif // TENSORFLOW_DEBUG_NODE_INSERTER_H_ +#endif // TENSORFLOW_CORE_DEBUG_DEBUG_GRAPH_UTILS_H_ diff --git a/tensorflow/core/debug/debug_grpc_testlib.h b/tensorflow/core/debug/debug_grpc_testlib.h index 8d3c9ff575..93376613b6 100644 --- a/tensorflow/core/debug/debug_grpc_testlib.h +++ b/tensorflow/core/debug/debug_grpc_testlib.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_DEBUG_GRPC_TESTLIB_H_ -#define TENSORFLOW_DEBUG_GRPC_TESTLIB_H_ +#ifndef TENSORFLOW_CORE_DEBUG_DEBUG_GRPC_TESTLIB_H_ +#define TENSORFLOW_CORE_DEBUG_DEBUG_GRPC_TESTLIB_H_ #include <atomic> #include <unordered_set> @@ -84,4 +84,4 @@ bool PollTillFirstRequestSucceeds(const string& server_url, } // namespace tensorflow -#endif // TENSORFLOW_DEBUG_GRPC_TESTLIB_H_ +#endif // TENSORFLOW_CORE_DEBUG_DEBUG_GRPC_TESTLIB_H_ diff --git a/tensorflow/core/debug/debug_io_utils.cc b/tensorflow/core/debug/debug_io_utils.cc index 9e8002d490..09c2b58168 100644 --- a/tensorflow/core/debug/debug_io_utils.cc +++ b/tensorflow/core/debug/debug_io_utils.cc @@ -18,6 +18,8 @@ limitations under the License. #include <stddef.h> #include <string.h> #include <cmath> +#include <cstdlib> +#include <cstring> #include <limits> #include <utility> #include <vector> @@ -399,8 +401,8 @@ Status DebugIO::PublishDebugMetadata( strings::Printf("%.14lld", session_run_index))), Env::Default()->NowMicros()); status.Update(DebugFileIO::DumpEventProtoToFile( - event, std::string(io::Dirname(core_metadata_path)), - std::string(io::Basename(core_metadata_path)))); + event, string(io::Dirname(core_metadata_path)), + string(io::Basename(core_metadata_path)))); } } @@ -418,6 +420,19 @@ Status DebugIO::PublishDebugTensor(const DebugNodeKey& debug_node_key, if (str_util::Lowercase(url).find(kFileURLScheme) == 0) { const string dump_root_dir = url.substr(strlen(kFileURLScheme)); + const int64 tensorBytes = + tensor.IsInitialized() ? tensor.TotalBytes() : 0; + if (!DebugFileIO::requestDiskByteUsage(tensorBytes)) { + return errors::ResourceExhausted( + "TensorFlow Debugger has exhausted file-system byte-size " + "allowance (", + DebugFileIO::globalDiskBytesLimit, "), therefore it cannot ", + "dump an additional ", tensorBytes, " byte(s) of tensor data ", + "for the debug tensor ", debug_node_key.node_name, ":", + debug_node_key.output_slot, ". You may use the environment ", + "variable TFDBG_DISK_BYTES_LIMIT to set a higher limit."); + } + Status s = DebugFileIO::DumpTensorToDir( debug_node_key, tensor, wall_time_us, dump_root_dir, nullptr); if (!s.ok()) { @@ -632,8 +647,8 @@ Status DebugFileIO::DumpTensorToEventFile(const DebugNodeKey& debug_node_key, std::vector<Event> events; TF_RETURN_IF_ERROR( WrapTensorAsEvents(debug_node_key, tensor, wall_time_us, 0, &events)); - return DumpEventProtoToFile(events[0], std::string(io::Dirname(file_path)), - std::string(io::Basename(file_path))); + return DumpEventProtoToFile(events[0], string(io::Dirname(file_path)), + string(io::Basename(file_path))); } Status DebugFileIO::RecursiveCreateDir(Env* env, const string& dir) { @@ -642,7 +657,7 @@ Status DebugFileIO::RecursiveCreateDir(Env* env, const string& dir) { return Status::OK(); } - string parent_dir = std::string(io::Dirname(dir)); + string parent_dir(io::Dirname(dir)); if (!env->FileExists(parent_dir).ok()) { // The parent path does not exist yet, create it first. Status s = RecursiveCreateDir(env, parent_dir); // Recursive call @@ -670,6 +685,36 @@ Status DebugFileIO::RecursiveCreateDir(Env* env, const string& dir) { } } +// Default total disk usage limit: 100 GBytes +const uint64 DebugFileIO::defaultGlobalDiskBytesLimit = 107374182400L; +uint64 DebugFileIO::globalDiskBytesLimit = 0; +uint64 DebugFileIO::diskBytesUsed = 0; + +bool DebugFileIO::requestDiskByteUsage(uint64 bytes) { + if (globalDiskBytesLimit == 0) { + const char* env_tfdbg_disk_bytes_limit = getenv("TFDBG_DISK_BYTES_LIMIT"); + if (env_tfdbg_disk_bytes_limit == nullptr || + strlen(env_tfdbg_disk_bytes_limit) == 0) { + globalDiskBytesLimit = defaultGlobalDiskBytesLimit; + } else { + strings::safe_strtou64(string(env_tfdbg_disk_bytes_limit), + &globalDiskBytesLimit); + } + } + + if (bytes == 0) { + return true; + } + if (diskBytesUsed + bytes < globalDiskBytesLimit) { + diskBytesUsed += bytes; + return true; + } else { + return false; + } +} + +void DebugFileIO::resetDiskByteUsage() { diskBytesUsed = 0; } + #ifndef PLATFORM_WINDOWS DebugGrpcChannel::DebugGrpcChannel(const string& server_stream_addr) : server_stream_addr_(server_stream_addr), diff --git a/tensorflow/core/debug/debug_io_utils.h b/tensorflow/core/debug/debug_io_utils.h index c974a47051..56f8b74e18 100644 --- a/tensorflow/core/debug/debug_io_utils.h +++ b/tensorflow/core/debug/debug_io_utils.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_DEBUG_IO_UTILS_H_ -#define TENSORFLOW_DEBUG_IO_UTILS_H_ +#ifndef TENSORFLOW_CORE_DEBUG_DEBUG_IO_UTILS_H_ +#define TENSORFLOW_CORE_DEBUG_DEBUG_IO_UTILS_H_ #include <cstddef> #include <functional> @@ -193,6 +193,26 @@ class DebugFileIO { const string& dir_name, const string& file_name); + // Request additional bytes to be dumped to the file system. + // + // Does not actually dump the bytes, but instead just performs the + // bookkeeping necessary to prevent the total dumped amount of data from + // exceeding the limit (default 100 GBytes or set customly through the + // environment variable TFDBG_DISK_BYTES_LIMIT). + // + // Args: + // bytes: Number of bytes to request. + // + // Returns: + // Whether the request is approved given the total dumping + // limit. + static bool requestDiskByteUsage(uint64 bytes); + + // Reset the disk byte usage to zero. + static void resetDiskByteUsage(); + + static uint64 globalDiskBytesLimit; + private: // Encapsulates the Tensor in an Event protobuf and write it to file. static Status DumpTensorToEventFile(const DebugNodeKey& debug_node_key, @@ -204,6 +224,11 @@ class DebugFileIO { // TODO(cais): Replace with shared implementation once http://b/30497715 is // fixed. static Status RecursiveCreateDir(Env* env, const string& dir); + + static uint64 diskBytesUsed; + static const uint64 defaultGlobalDiskBytesLimit; + + friend class DiskUsageLimitTest; }; } // namespace tensorflow @@ -398,4 +423,4 @@ class DebugGrpcIO { } // namespace tensorflow #endif // #ifndef(PLATFORM_WINDOWS) -#endif // TENSORFLOW_DEBUG_IO_UTILS_H_ +#endif // TENSORFLOW_CORE_DEBUG_DEBUG_IO_UTILS_H_ diff --git a/tensorflow/core/debug/debug_io_utils_test.cc b/tensorflow/core/debug/debug_io_utils_test.cc index 0807a85b8b..82e0ae5edb 100644 --- a/tensorflow/core/debug/debug_io_utils_test.cc +++ b/tensorflow/core/debug/debug_io_utils_test.cc @@ -13,6 +13,7 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#include <cstdlib> #include <unordered_set> #include "tensorflow/core/debug/debug_io_utils.h" @@ -454,5 +455,50 @@ TEST_F(DebugIOUtilsTest, PublishTensorConcurrentlyToPartiallyOverlappingPaths) { } } +class DiskUsageLimitTest : public ::testing::Test { + public: + void Initialize() { + setenv("TFDBG_DISK_BYTES_LIMIT", "", 1); + DebugFileIO::resetDiskByteUsage(); + DebugFileIO::globalDiskBytesLimit = 0; + } +}; + +TEST_F(DiskUsageLimitTest, RequestWithZeroByteIsOkay) { + Initialize(); + ASSERT_TRUE(DebugFileIO::requestDiskByteUsage(0L)); +} + +TEST_F(DiskUsageLimitTest, ExceedingLimitAfterOneCall) { + Initialize(); + ASSERT_FALSE(DebugFileIO::requestDiskByteUsage(100L * 1024L * 1024L * 1024L)); +} + +TEST_F(DiskUsageLimitTest, ExceedingLimitAfterTwoCalls) { + Initialize(); + ASSERT_TRUE(DebugFileIO::requestDiskByteUsage(50L * 1024L * 1024L * 1024L)); + ASSERT_FALSE(DebugFileIO::requestDiskByteUsage(50L * 1024L * 1024L * 1024L)); + ASSERT_TRUE(DebugFileIO::requestDiskByteUsage(1024L)); +} + +TEST_F(DiskUsageLimitTest, ResetDiskByteUsageWorks) { + Initialize(); + ASSERT_TRUE(DebugFileIO::requestDiskByteUsage(50L * 1024L * 1024L * 1024L)); + ASSERT_FALSE(DebugFileIO::requestDiskByteUsage(50L * 1024L * 1024L * 1024L)); + DebugFileIO::resetDiskByteUsage(); + ASSERT_TRUE(DebugFileIO::requestDiskByteUsage(50L * 1024L * 1024L * 1024L)); +} + +TEST_F(DiskUsageLimitTest, CustomEnvVarIsObeyed) { + Initialize(); + setenv("TFDBG_DISK_BYTES_LIMIT", "1024", 1); + ASSERT_FALSE(DebugFileIO::requestDiskByteUsage(1024L)); + ASSERT_TRUE(DebugFileIO::requestDiskByteUsage(1000L)); + ASSERT_TRUE(DebugFileIO::requestDiskByteUsage(23L)); + ASSERT_FALSE(DebugFileIO::requestDiskByteUsage(1L)); + DebugFileIO::resetDiskByteUsage(); + ASSERT_TRUE(DebugFileIO::requestDiskByteUsage(1023L)); +} + } // namespace } // namespace tensorflow diff --git a/tensorflow/core/debug/debug_node_key.h b/tensorflow/core/debug/debug_node_key.h index b46054c013..eaeb369790 100644 --- a/tensorflow/core/debug/debug_node_key.h +++ b/tensorflow/core/debug/debug_node_key.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_DEBUG_NODE_KEY_H_ -#define TENSORFLOW_DEBUG_NODE_KEY_H_ +#ifndef TENSORFLOW_CORE_DEBUG_DEBUG_NODE_KEY_H_ +#define TENSORFLOW_CORE_DEBUG_DEBUG_NODE_KEY_H_ #include <string> @@ -48,4 +48,4 @@ struct DebugNodeKey { } // namespace tensorflow -#endif // TENSORFLOW_DEBUG_NODE_KEY_H_ +#endif // TENSORFLOW_CORE_DEBUG_DEBUG_NODE_KEY_H_ diff --git a/tensorflow/core/debug/debugger_state_impl.cc b/tensorflow/core/debug/debugger_state_impl.cc index 2f5aaf93fa..79798f9392 100644 --- a/tensorflow/core/debug/debugger_state_impl.cc +++ b/tensorflow/core/debug/debugger_state_impl.cc @@ -27,6 +27,9 @@ DebuggerState::DebuggerState(const DebugOptions& debug_options) { debug_urls_.insert(url); } } + if (debug_options.reset_disk_byte_usage()) { + DebugFileIO::resetDiskByteUsage(); + } } DebuggerState::~DebuggerState() { diff --git a/tensorflow/core/debug/debugger_state_impl.h b/tensorflow/core/debug/debugger_state_impl.h index 52e2663d08..8f6e53fafe 100644 --- a/tensorflow/core/debug/debugger_state_impl.h +++ b/tensorflow/core/debug/debugger_state_impl.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_DEBUGGER_STATE_IMPL_H_ -#define TENSORFLOW_DEBUGGER_STATE_IMPL_H_ +#ifndef TENSORFLOW_CORE_DEBUG_DEBUGGER_STATE_IMPL_H_ +#define TENSORFLOW_CORE_DEBUG_DEBUGGER_STATE_IMPL_H_ #include "tensorflow/core/common_runtime/debugger_state_interface.h" @@ -58,4 +58,4 @@ class DebugGraphDecorator : public DebugGraphDecoratorInterface { } // namespace tensorflow -#endif // TENSORFLOW_DEBUGGER_STATE_IMPL_H_ +#endif // TENSORFLOW_CORE_DEBUG_DEBUGGER_STATE_IMPL_H_ diff --git a/tensorflow/core/distributed_runtime/BUILD b/tensorflow/core/distributed_runtime/BUILD index b2192c5a80..37029f3f1a 100644 --- a/tensorflow/core/distributed_runtime/BUILD +++ b/tensorflow/core/distributed_runtime/BUILD @@ -562,6 +562,7 @@ cc_library( deps = [ ":worker_cache", ":worker_interface", + "//tensorflow/core:framework", ], ) diff --git a/tensorflow/core/distributed_runtime/master.cc b/tensorflow/core/distributed_runtime/master.cc index a48f734d3e..269f620e42 100644 --- a/tensorflow/core/distributed_runtime/master.cc +++ b/tensorflow/core/distributed_runtime/master.cc @@ -53,6 +53,7 @@ limitations under the License. #include "tensorflow/core/protobuf/master.pb.h" #include "tensorflow/core/protobuf/worker.pb.h" #include "tensorflow/core/public/session_options.h" +#include "tensorflow/core/util/device_name_utils.h" namespace tensorflow { @@ -167,13 +168,55 @@ class DeviceFinder { } // Enumerates all known workers' target. A target name is a // prefix of a device name. E.g., /job:mnist/replica:0/task:10. - CHECK_GT(env_->local_devices.size(), 0) << "No local devices provided."; - const string& local_device_name = env_->local_devices[0]->name(); - std::vector<string> workers; - worker_cache->ListWorkers(&workers); if (filters_.empty()) { + // If no filters were specified, we list all known workers in + // `worker_cache`. + std::vector<string> workers; + worker_cache->ListWorkers(&workers); std::swap(workers, targets_); } else { + // When applying filters, we must include the local worker, even if it + // does not match any of the filters. + CHECK_GT(env_->local_devices.size(), 0) << "No local devices provided."; + const string& local_device_name = env_->local_devices[0]->name(); + DeviceNameUtils::ParsedName local_parsed_name; + CHECK(DeviceNameUtils::ParseFullName(local_device_name, + &local_parsed_name)); + bool all_filters_have_job = true; + std::unordered_set<string> filter_job_names({local_parsed_name.job}); + for (const DeviceNameUtils::ParsedName& filter : filters_) { + all_filters_have_job = all_filters_have_job && filter.has_job; + if (filter.has_job) { + filter_job_names.insert(filter.job); + } + } + + std::vector<string> workers; + if (all_filters_have_job) { + // If all of the device filters have a job specified, then we only need + // to list the workers in the jobs named in the filter, because a worker + // in any other job would not match any filter. + for (const string& job_name : filter_job_names) { + VLOG(2) << "Selectively listing workers in job: " << job_name; + std::vector<string> workers_in_job; + worker_cache->ListWorkersInJob(job_name, &workers_in_job); + workers.insert(workers.end(), workers_in_job.begin(), + workers_in_job.end()); + } + } else { + // If any of the device filters does not have a job specified, then we + // must list the workers from all jobs. + VLOG(2) << "Listing workers in all jobs because some device " + << "filter has no job specified. Filters were:"; + if (device_filters.empty()) { + VLOG(2) << "- <NO FILTERS>"; + } else { + for (const string& filter : device_filters) { + VLOG(2) << "- " << filter; + } + } + worker_cache->ListWorkers(&workers); + } for (const string& name : workers) { if (MatchFilters(name) || DeviceNameUtils::IsSameAddressSpace(name, local_device_name)) { diff --git a/tensorflow/core/distributed_runtime/master_env.h b/tensorflow/core/distributed_runtime/master_env.h index da26c42aca..837ccd1dd4 100644 --- a/tensorflow/core/distributed_runtime/master_env.h +++ b/tensorflow/core/distributed_runtime/master_env.h @@ -99,4 +99,4 @@ struct MasterEnv { } // end namespace tensorflow -#endif // TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_MASTER_H_ +#endif // TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_MASTER_ENV_H_ diff --git a/tensorflow/core/distributed_runtime/master_session.cc b/tensorflow/core/distributed_runtime/master_session.cc index d34ca53f73..abd07e37b7 100644 --- a/tensorflow/core/distributed_runtime/master_session.cc +++ b/tensorflow/core/distributed_runtime/master_session.cc @@ -615,7 +615,7 @@ Status MasterSession::ReffedClientGraph::RunPartitionsHelper( // inadvertently slowing down the normal run path. if (is_partial_) { for (const auto& name_index : feeds) { - const auto iter = part.feed_key.find(std::string(name_index.first)); + const auto iter = part.feed_key.find(string(name_index.first)); if (iter == part.feed_key.end()) { // The provided feed must be for a different partition. continue; @@ -959,7 +959,7 @@ Status MasterSession::ReffedClientGraph::CheckFetches( // Skip if already fed. if (input.second) continue; TensorId id(ParseTensorName(input.first)); - const Node* n = execution_state->get_node_by_name(std::string(id.first)); + const Node* n = execution_state->get_node_by_name(string(id.first)); if (n == nullptr) { return errors::NotFound("Feed ", input.first, ": not found"); } @@ -975,7 +975,7 @@ Status MasterSession::ReffedClientGraph::CheckFetches( for (size_t i = 0; i < req.num_fetches(); ++i) { const string& fetch = req.fetch_name(i); const TensorId id(ParseTensorName(fetch)); - const Node* n = execution_state->get_node_by_name(std::string(id.first)); + const Node* n = execution_state->get_node_by_name(string(id.first)); if (n == nullptr) { return errors::NotFound("Fetch ", fetch, ": not found"); } diff --git a/tensorflow/core/distributed_runtime/message_wrappers.h b/tensorflow/core/distributed_runtime/message_wrappers.h index 72a0c7edd8..474ac0e186 100644 --- a/tensorflow/core/distributed_runtime/message_wrappers.h +++ b/tensorflow/core/distributed_runtime/message_wrappers.h @@ -721,4 +721,4 @@ class NonOwnedProtoRunStepResponse : public MutableRunStepResponseWrapper { } // namespace tensorflow -#endif // TENSORFLOW +#endif // TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_MESSAGE_WRAPPERS_H_ diff --git a/tensorflow/core/distributed_runtime/remote_device.cc b/tensorflow/core/distributed_runtime/remote_device.cc index 15e5919c54..a043c5dee6 100644 --- a/tensorflow/core/distributed_runtime/remote_device.cc +++ b/tensorflow/core/distributed_runtime/remote_device.cc @@ -37,7 +37,7 @@ string GetLocalDeviceName(StringPiece fullname) { auto pos = fullname.rfind('/'); CHECK_NE(pos, StringPiece::npos); fullname.remove_prefix(pos + 1); - return std::string(fullname); + return string(fullname); } class RemoteDevice : public Device { diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_channel.cc b/tensorflow/core/distributed_runtime/rpc/grpc_channel.cc index b7eb3c9015..456c30ecf4 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_channel.cc +++ b/tensorflow/core/distributed_runtime/rpc/grpc_channel.cc @@ -163,6 +163,13 @@ class MultiGrpcChannelCache : public CachingGrpcChannelCache { } } + void ListWorkersInJob(const string& job_name, + std::vector<string>* workers) override { + for (GrpcChannelCache* cache : caches_) { + cache->ListWorkersInJob(job_name, workers); + } + } + string TranslateTask(const string& target) override { mutex_lock l(mu_); // could use reader lock GrpcChannelCache* cache = gtl::FindPtrOrNull(target_caches_, target); @@ -223,6 +230,13 @@ class SparseGrpcChannelCache : public CachingGrpcChannelCache { } } + void ListWorkersInJob(const string& job_name, + std::vector<string>* workers) override { + if (job_name == job_id_) { + ListWorkers(workers); + } + } + string TranslateTask(const string& target) override { DeviceNameUtils::ParsedName parsed; if (!DeviceNameUtils::ParseFullName(target, &parsed)) { diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_channel.h b/tensorflow/core/distributed_runtime/rpc/grpc_channel.h index 4861cdb691..6fa99d7b14 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_channel.h +++ b/tensorflow/core/distributed_runtime/rpc/grpc_channel.h @@ -66,6 +66,8 @@ class GrpcChannelCache { // /job:<job identifier>/task:<task id> // e.g. /job:mnist/task:2 virtual void ListWorkers(std::vector<string>* workers) = 0; + virtual void ListWorkersInJob(const string& job_name, + std::vector<string>* workers) = 0; // If found, returns a gRPC channel that is connected to the remote // worker named by 'target'. 'target' is of the following diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_channel_test.cc b/tensorflow/core/distributed_runtime/rpc/grpc_channel_test.cc index f07a5a0974..a814ef85e2 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_channel_test.cc +++ b/tensorflow/core/distributed_runtime/rpc/grpc_channel_test.cc @@ -89,13 +89,33 @@ TEST(GrpcChannelTest, HostPorts) { EXPECT_NE(d_4_1.get(), e_5_2.get()); } - std::vector<string> workers; - cc->ListWorkers(&workers); - EXPECT_EQ(std::vector<string>( - {"/job:mnist/replica:0/task:0", "/job:mnist/replica:0/task:1", - "/job:mnist/replica:0/task:2", "/job:mnist/replica:0/task:3", - "/job:mnist/replica:0/task:4", "/job:mnist/replica:0/task:5"}), - workers); + { + std::vector<string> workers; + cc->ListWorkers(&workers); + EXPECT_EQ( + std::vector<string>( + {"/job:mnist/replica:0/task:0", "/job:mnist/replica:0/task:1", + "/job:mnist/replica:0/task:2", "/job:mnist/replica:0/task:3", + "/job:mnist/replica:0/task:4", "/job:mnist/replica:0/task:5"}), + workers); + } + + { + std::vector<string> workers; + cc->ListWorkersInJob("mnist", &workers); + EXPECT_EQ( + std::vector<string>( + {"/job:mnist/replica:0/task:0", "/job:mnist/replica:0/task:1", + "/job:mnist/replica:0/task:2", "/job:mnist/replica:0/task:3", + "/job:mnist/replica:0/task:4", "/job:mnist/replica:0/task:5"}), + workers); + } + + { + std::vector<string> workers; + cc->ListWorkersInJob("other", &workers); + EXPECT_TRUE(workers.empty()); + } } TEST(GrpcChannelTest, SparseHostPorts) { @@ -135,13 +155,30 @@ TEST(GrpcChannelTest, SparseHostPorts) { EXPECT_NE(d_4_1.get(), e_5_2.get()); } - std::vector<string> workers; - cc->ListWorkers(&workers); - std::sort(workers.begin(), workers.end()); - EXPECT_EQ(std::vector<string>({"/job:mnist/replica:0/task:0", - "/job:mnist/replica:0/task:3", - "/job:mnist/replica:0/task:4"}), - workers); + { + std::vector<string> workers; + cc->ListWorkers(&workers); + std::sort(workers.begin(), workers.end()); + EXPECT_EQ(std::vector<string>({"/job:mnist/replica:0/task:0", + "/job:mnist/replica:0/task:3", + "/job:mnist/replica:0/task:4"}), + workers); + } + + { + std::vector<string> workers; + cc->ListWorkersInJob("mnist", &workers); + EXPECT_EQ(std::vector<string>({"/job:mnist/replica:0/task:0", + "/job:mnist/replica:0/task:3", + "/job:mnist/replica:0/task:4"}), + workers); + } + + { + std::vector<string> workers; + cc->ListWorkersInJob("other", &workers); + EXPECT_TRUE(workers.empty()); + } } TEST(GrpcChannelTest, NewHostPortGrpcChannelValidation) { diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_remote_worker.h b/tensorflow/core/distributed_runtime/rpc/grpc_remote_worker.h index 709c3833e7..b85c1dc5b4 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_remote_worker.h +++ b/tensorflow/core/distributed_runtime/rpc/grpc_remote_worker.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_DISTRIBUTED_RUNTIME_RPC_GRPC_REMOTE_WORKER_H_ -#define TENSORFLOW_DISTRIBUTED_RUNTIME_RPC_GRPC_REMOTE_WORKER_H_ +#ifndef TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_GRPC_REMOTE_WORKER_H_ +#define TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_GRPC_REMOTE_WORKER_H_ #include <memory> @@ -35,4 +35,4 @@ WorkerInterface* NewGrpcRemoteWorker(SharedGrpcChannelPtr channel, } // namespace tensorflow -#endif // TENSORFLOW_DISTRIBUTED_RUNTIME_RPC_GRPC_REMOTE_WORKER_H_ +#endif // TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_GRPC_REMOTE_WORKER_H_ diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc b/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc index bcd46a4c06..c4f2247145 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc +++ b/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc @@ -190,6 +190,8 @@ Status GrpcServer::Init( builder.SetMaxMessageSize(std::numeric_limits<int32>::max()); builder.SetOption( std::unique_ptr<::grpc::ServerBuilderOption>(new NoReusePortOption)); + // Allow subclasses to specify more args to pass to the gRPC server. + MaybeMutateBuilder(&builder); master_impl_ = CreateMaster(&master_env_); master_service_ = NewGrpcMasterService(master_impl_.get(), config, &builder); worker_impl_ = diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.h b/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.h index 3366246afb..7979e96d3e 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.h +++ b/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.h @@ -59,6 +59,9 @@ typedef std::function<std::unique_ptr<GrpcWorker>(WorkerEnv*)> class GrpcServer : public ServerInterface { protected: GrpcServer(const ServerDef& server_def, Env* env); + // Allow children classes to override this and provide custom args to the + // server before it is constructed. Default behavior is to do nothing. + virtual void MaybeMutateBuilder(::grpc::ServerBuilder* builder) {} public: static Status Create(const ServerDef& server_def, Env* env, diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_testlib.h b/tensorflow/core/distributed_runtime/rpc/grpc_testlib.h index d5baaae353..98164e750b 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_testlib.h +++ b/tensorflow/core/distributed_runtime/rpc/grpc_testlib.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_TESTLIB_H_ -#define TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_TESTLIB_H_ +#ifndef TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_GRPC_TESTLIB_H_ +#define TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_GRPC_TESTLIB_H_ #include <memory> #include <string> @@ -71,4 +71,4 @@ class TestCluster { } // end namespace test } // end namespace tensorflow -#endif // TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_TESTLIB_H_ +#endif // TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_GRPC_TESTLIB_H_ diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_worker_cache.cc b/tensorflow/core/distributed_runtime/rpc/grpc_worker_cache.cc index b9f21ea211..e1541db69b 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_worker_cache.cc +++ b/tensorflow/core/distributed_runtime/rpc/grpc_worker_cache.cc @@ -54,6 +54,11 @@ class GrpcWorkerCache : public WorkerCachePartial { channel_cache_->ListWorkers(workers); } + void ListWorkersInJob(const string& job_name, + std::vector<string>* workers) const override { + channel_cache_->ListWorkersInJob(job_name, workers); + } + WorkerInterface* CreateWorker(const string& target) override { if (target == local_target_) { return local_worker_; diff --git a/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr_test.cc b/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr_test.cc index 25ff6512a0..b070dd13dd 100644 --- a/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr_test.cc +++ b/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr_test.cc @@ -50,6 +50,8 @@ namespace { // Fake cache implementation for WorkerEnv. class DummyWorkerCache : public WorkerCacheInterface { void ListWorkers(std::vector<string>* workers) const override {} + void ListWorkersInJob(const string& job_name, + std::vector<string>* workers) const override {} WorkerInterface* CreateWorker(const string& target) override { return nullptr; } diff --git a/tensorflow/core/distributed_runtime/test_utils.h b/tensorflow/core/distributed_runtime/test_utils.h index 48d83845dd..88a97da34d 100644 --- a/tensorflow/core/distributed_runtime/test_utils.h +++ b/tensorflow/core/distributed_runtime/test_utils.h @@ -18,6 +18,7 @@ limitations under the License. #include <unordered_map> #include "tensorflow/core/distributed_runtime/worker_cache.h" #include "tensorflow/core/distributed_runtime/worker_interface.h" +#include "tensorflow/core/util/device_name_utils.h" namespace tensorflow { @@ -138,6 +139,19 @@ class TestWorkerCache : public WorkerCacheInterface { } } + void ListWorkersInJob(const string& job_name, + std::vector<string>* workers) const override { + workers->clear(); + for (auto it : workers_) { + DeviceNameUtils::ParsedName device_name; + CHECK(DeviceNameUtils::ParseFullName(it.first, &device_name)); + CHECK(device_name.has_job); + if (job_name == device_name.job) { + workers->push_back(it.first); + } + } + } + WorkerInterface* CreateWorker(const string& target) override { auto it = workers_.find(target); if (it != workers_.end()) { diff --git a/tensorflow/core/distributed_runtime/worker_cache.h b/tensorflow/core/distributed_runtime/worker_cache.h index 8521f8956b..0c8575b4d5 100644 --- a/tensorflow/core/distributed_runtime/worker_cache.h +++ b/tensorflow/core/distributed_runtime/worker_cache.h @@ -36,6 +36,8 @@ class WorkerCacheInterface { // Updates *workers with strings naming the remote worker tasks to // which open channels have been established. virtual void ListWorkers(std::vector<string>* workers) const = 0; + virtual void ListWorkersInJob(const string& job_name, + std::vector<string>* workers) const = 0; // If "target" names a remote task for which an RPC channel exists // or can be constructed, returns a pointer to a WorkerInterface object diff --git a/tensorflow/core/distributed_runtime/worker_cache_wrapper.h b/tensorflow/core/distributed_runtime/worker_cache_wrapper.h index 43c3b6285b..1f309b4361 100644 --- a/tensorflow/core/distributed_runtime/worker_cache_wrapper.h +++ b/tensorflow/core/distributed_runtime/worker_cache_wrapper.h @@ -32,6 +32,10 @@ class WorkerCacheWrapper : public WorkerCacheInterface { virtual void ListWorkers(std::vector<string>* workers) const { return wrapped_->ListWorkers(workers); } + virtual void ListWorkersInJob(const string& job_name, + std::vector<string>* workers) const { + return wrapped_->ListWorkersInJob(job_name, workers); + } // If "target" names a remote task for which an RPC channel exists // or can be constructed, returns a pointer to a WorkerInterface object diff --git a/tensorflow/core/distributed_runtime/worker_session.cc b/tensorflow/core/distributed_runtime/worker_session.cc index ca6dc1b1de..c7d0c6b7f3 100644 --- a/tensorflow/core/distributed_runtime/worker_session.cc +++ b/tensorflow/core/distributed_runtime/worker_session.cc @@ -35,6 +35,11 @@ class WorkerFreeListCache : public WorkerCacheInterface { wrapped_->ListWorkers(workers); } + void ListWorkersInJob(const string& job_name, + std::vector<string>* workers) const override { + wrapped_->ListWorkersInJob(job_name, workers); + } + WorkerInterface* CreateWorker(const string& target) override { mutex_lock l(mu_); auto p = workers_.find(target); diff --git a/tensorflow/core/example/example_parser_configuration.h b/tensorflow/core/example/example_parser_configuration.h index 3d06bd55e2..8bbed28471 100644 --- a/tensorflow/core/example/example_parser_configuration.h +++ b/tensorflow/core/example/example_parser_configuration.h @@ -53,4 +53,4 @@ Status ExampleParserConfigurationProtoToFeatureVectors( } // namespace tensorflow -#endif // TENSORFLOW_CORE_EXAMPLE_EXAMPLE_PARSE_CONFIGURATION_H_ +#endif // TENSORFLOW_CORE_EXAMPLE_EXAMPLE_PARSER_CONFIGURATION_H_ diff --git a/tensorflow/core/example/feature_util.h b/tensorflow/core/example/feature_util.h index 2265498b5e..ec93b9aad9 100644 --- a/tensorflow/core/example/feature_util.h +++ b/tensorflow/core/example/feature_util.h @@ -97,8 +97,8 @@ limitations under the License. // GetFeatureValues<FeatureType>(feature) -> RepeatedField<FeatureType> // Returns values of the feature for the FeatureType. -#ifndef TENSORFLOW_EXAMPLE_FEATURE_H_ -#define TENSORFLOW_EXAMPLE_FEATURE_H_ +#ifndef TENSORFLOW_CORE_EXAMPLE_FEATURE_UTIL_H_ +#define TENSORFLOW_CORE_EXAMPLE_FEATURE_UTIL_H_ #include <iterator> #include <type_traits> @@ -322,4 +322,4 @@ bool ExampleHasFeature(const string& key, const Example& example) { } } // namespace tensorflow -#endif // TENSORFLOW_EXAMPLE_FEATURE_H_ +#endif // TENSORFLOW_CORE_EXAMPLE_FEATURE_UTIL_H_ diff --git a/tensorflow/core/framework/attr_value_util.h b/tensorflow/core/framework/attr_value_util.h index 0da9b1081b..9fce488793 100644 --- a/tensorflow/core/framework/attr_value_util.h +++ b/tensorflow/core/framework/attr_value_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_ATTR_VALUE_UTIL_H_ -#define TENSORFLOW_FRAMEWORK_ATTR_VALUE_UTIL_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_ATTR_VALUE_UTIL_H_ +#define TENSORFLOW_CORE_FRAMEWORK_ATTR_VALUE_UTIL_H_ #include <functional> #include <string> @@ -126,4 +126,4 @@ bool SubstitutePlaceholders(const SubstituteFunc& substitute, AttrValue* value); } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_ATTR_VALUE_UTIL_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_ATTR_VALUE_UTIL_H_ diff --git a/tensorflow/core/framework/bfloat16.h b/tensorflow/core/framework/bfloat16.h index 2f79d0fa70..e9e94024f5 100644 --- a/tensorflow/core/framework/bfloat16.h +++ b/tensorflow/core/framework/bfloat16.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_BFLOAT16_H_ -#define TENSORFLOW_FRAMEWORK_BFLOAT16_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_BFLOAT16_H_ +#define TENSORFLOW_CORE_FRAMEWORK_BFLOAT16_H_ #include "tensorflow/core/framework/numeric_types.h" #include "tensorflow/core/platform/byte_order.h" @@ -60,4 +60,4 @@ void BFloat16ToFloat(const bfloat16* src, float* dst, int64 size); } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_BFLOAT16_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_BFLOAT16_H_ diff --git a/tensorflow/core/framework/cancellation.h b/tensorflow/core/framework/cancellation.h index 90074c87b2..acdaaf6a90 100644 --- a/tensorflow/core/framework/cancellation.h +++ b/tensorflow/core/framework/cancellation.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_CANCELLATION_H_ -#define TENSORFLOW_FRAMEWORK_CANCELLATION_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_CANCELLATION_H_ +#define TENSORFLOW_CORE_FRAMEWORK_CANCELLATION_H_ #include <atomic> #include <functional> @@ -134,4 +134,4 @@ class CancellationManager { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_CANCELLATION_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_CANCELLATION_H_ diff --git a/tensorflow/core/framework/collective.cc b/tensorflow/core/framework/collective.cc index d4ac50cbbe..4cb277d5a8 100644 --- a/tensorflow/core/framework/collective.cc +++ b/tensorflow/core/framework/collective.cc @@ -21,6 +21,31 @@ limitations under the License. namespace tensorflow { +namespace { +// A RegistrationInfo object stores a collective implementation registration +// details. `factory` is used to create instances of the collective +// implementation. +struct RegistrationInfo { + // This constructor also creates, and stores in `param_resolver_instance`, + // what is effectively a static instance of the collective implementation. + // During param resolution of collective ops we return this static instance. + // The actual op execution gets a fresh instance using `factory`. + RegistrationInfo(const string& n, CollectiveRegistry::Factory f) + : name(n), + factory(std::move(f)), + param_resolver_instance(this->factory()) {} + string name; + CollectiveRegistry::Factory factory; + CollectiveImplementationInterface* param_resolver_instance; +}; + +std::vector<RegistrationInfo>* MutableCollectiveRegistry() { + static std::vector<RegistrationInfo>* registry = + new std::vector<RegistrationInfo>; + return registry; +} +} // namespace + string CollGroupParams::ToString() const { return strings::StrCat("CollGroupParams {group_key=", group_key, " group_size=", group_size, @@ -102,7 +127,8 @@ string CollectiveParams::ToString() const { strings::StrAppend(&v, " ", instance.ToString()); strings::StrAppend(&v, " ", task.ToString()); strings::StrAppend(&v, " default_rank=", default_rank, - " is_source=", is_source, " subdiv_rank={"); + " is_source=", is_source, " source_rank=", source_rank, + " subdiv_rank={"); for (const auto& r : subdiv_rank) { strings::StrAppend(&v, r, ","); } @@ -115,7 +141,81 @@ string CollectiveParams::ToString() const { return ctx->params_; } +CollectiveContext::CollectiveContext(CollectiveExecutor* col_exec, + const DeviceMgr* dev_mgr, + OpKernelContext* ctx, + OpKernelContext::Params* op_params, + const CollectiveParams& col_params, + const string& exec_key, int64 step_id, + const Tensor* input, Tensor* output) + : col_exec(col_exec), + dev_mgr(dev_mgr), + op_ctx(ctx), + op_params(op_params), + col_params(col_params), + exec_key(exec_key), + step_id(step_id), + input(input), + output(output), + device(nullptr), + device_name(col_params.instance.device_names[col_params.default_rank]) {} + /*static*/ int64 CollectiveExecutor::kInvalidId = -1; +/*static*/ +Status CollectiveRegistry::Lookup( + const string& collective_name, + CollectiveImplementationInterface** implementation) { + return LookupHelper(collective_name, implementation, false); +} + +/*static*/ +Status CollectiveRegistry::LookupParamResolverInstance( + const string& collective_name, + CollectiveImplementationInterface** implementation) { + return LookupHelper(collective_name, implementation, true); +} + +/*static*/ +void CollectiveRegistry::GetAll( + std::vector<CollectiveImplementationInterface*>* implementations) { + std::vector<RegistrationInfo>* registry = MutableCollectiveRegistry(); + for (const RegistrationInfo& reg_info : *registry) + implementations->emplace_back(reg_info.factory()); +} + +/*static*/ +Status CollectiveRegistry::Register(const string& collective_name, + Factory factory) { + std::vector<RegistrationInfo>* registry = MutableCollectiveRegistry(); + for (const RegistrationInfo& reg_info : *registry) { + if (reg_info.name == collective_name) + return errors::Internal("Already registered collective ", + collective_name); + } + registry->emplace_back(collective_name, std::move(factory)); + return Status::OK(); +} + +/*static*/ +Status CollectiveRegistry::LookupHelper( + const string& collective_name, + CollectiveImplementationInterface** implementation, bool param_resolver) { + std::vector<RegistrationInfo>* registry = MutableCollectiveRegistry(); + for (const RegistrationInfo& reg_info : *registry) { + if (reg_info.name == collective_name) { + if (param_resolver) { + *implementation = reg_info.param_resolver_instance; + } else { + *implementation = reg_info.factory(); + } + return Status::OK(); + } + } + return errors::Internal( + "CollectiveRegistry::Lookup did not find collective implementation ", + collective_name); +} + } // namespace tensorflow diff --git a/tensorflow/core/framework/collective.h b/tensorflow/core/framework/collective.h index c3e6388e28..e35edb09d0 100644 --- a/tensorflow/core/framework/collective.h +++ b/tensorflow/core/framework/collective.h @@ -12,12 +12,13 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_COLLECTIVE_EXECUTOR_H_ -#define TENSORFLOW_FRAMEWORK_COLLECTIVE_EXECUTOR_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_COLLECTIVE_H_ +#define TENSORFLOW_CORE_FRAMEWORK_COLLECTIVE_H_ #include <string> #include <vector> +#include "tensorflow/core/framework/device_attributes.pb.h" #include "tensorflow/core/framework/device_base.h" #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/lib/core/refcount.h" @@ -30,7 +31,8 @@ class CompleteGroupRequest; class CompleteGroupResponse; class CompleteInstanceRequest; class CompleteInstanceResponse; -class DeviceLocality; +class Device; +class DeviceMgr; class GetStepSequenceRequest; class GetStepSequenceResponse; class Op; @@ -64,10 +66,10 @@ struct CollGroupParams { // interpretation. On first execution the runtime will update this // structure with decisions that will guide all subsequent executions. struct CollImplDetails { + string collective_name; std::vector<std::vector<int>> subdiv_permutations; std::vector<int> subdiv_offsets; - // broadcast only: rank of source in each subdiv - std::vector<int> subdiv_source_rank; + std::vector<int> subdiv_source_rank; // rank of source in each subdiv }; // Data common to all members of a collective instance. @@ -104,6 +106,7 @@ struct CollectiveParams { string name = ""; // node name used only for log or error messages int default_rank = -1; // index of this op within device_names bool is_source = false; // broadcast only + int source_rank = -1; // broadcast only // Rank of this device in each subdivision permutation. std::vector<int> subdiv_rank; std::unique_ptr<OpKernel> merge_op; // reduction only @@ -306,6 +309,110 @@ class PerStepCollectiveRemoteAccess : public CollectiveRemoteAccess { virtual void StartAbort(const Status& s) = 0; }; +class CollectiveContext { + public: + CollectiveContext(CollectiveExecutor* col_exec, const DeviceMgr* dev_mgr, + OpKernelContext* ctx, OpKernelContext::Params* op_params, + const CollectiveParams& col_params, const string& exec_key, + int64 step_id, const Tensor* input, Tensor* output); + + virtual ~CollectiveContext() = default; + + CollectiveExecutor* col_exec; // Not owned + const DeviceMgr* dev_mgr; // Not owned + OpKernelContext* op_ctx; // Not owned + OpKernelContext::Params* op_params; // Not owned + const CollectiveParams& col_params; + const string exec_key; + const int64 step_id; + const Tensor* input; // Not owned + Tensor* output; // Not owned + Device* device; // The device for which this instance labors + const string device_name; + DeviceLocality device_locality; +}; + +// Interface of a Collective Op implementation. Each specific CollectiveOp will +// implement this interface and register the implementation via the +// CollectiveRegistry detailed below. See common_runtime/ring_reducer and +// common_runtime/hierarchical_tree_broadcaster for examples. +class CollectiveImplementationInterface { + public: + virtual ~CollectiveImplementationInterface() = default; + + // Initializes the portions of `col_params` specific to this + // implementation. Called exactly once for every Collective instance during + // the CollectiveParams resolution process when the graph is first executed. + // NOTE(ayushd): This is effectively a static function because it modifies the + // `col_params` passed in and should not manipulate any data members. However + // because it is virtual and needs to be implemented by every derived class we + // do not mark it as static. + virtual Status InitializeCollectiveParams(CollectiveParams* col_params) = 0; + + // Prepares the CollectiveContext for executing this CollectiveImplementation. + // Called from CollectiveExecutor right before calling Run(). The + // CollectiveContext passed in must outlive the CollectiveImplementation + // object. + virtual Status InitializeCollectiveContext(CollectiveContext* col_ctx) = 0; + + // Processes and moves data according to the logic of this Collective + // implementation. Relies on appropriate initialization of op-specific + // CollectiveParams in InitializeCollectiveParams(), as well as appropriate + // context initialization in InitializeCollectiveContext(). + virtual void Run(StatusCallback done) = 0; +}; + +// Static-methods only class for registering and looking up collective +// implementations. +class CollectiveRegistry { + public: + using Factory = std::function<CollectiveImplementationInterface*()>; + // Looks up a previously registered CollectiveImplementation under + // `collective_name`. If found, creates an instance of the implementation and + // assign to `implementation`. + static Status Lookup(const string& collective_name, + CollectiveImplementationInterface** implementation); + + // Looks up a previously registered CollectiveImplementation under + // `collective_name`. If found, returns the static instance of this + // implementation via `implementation`. This instance should only be used to + // call InitializateCollectiveParams. + static Status LookupParamResolverInstance( + const string& collective_name, + CollectiveImplementationInterface** implementation); + + // Returns all registered collective implementations. + static void GetAll( + std::vector<CollectiveImplementationInterface*>* implementations); + + private: + friend class CollectiveRegistration; + // Registers a CollectiveImplementation with name `collective_name` and + // factory `factory`. The latter is a function used to create instances of + // the CollectiveImplementation. Also creates a static instance of the + // implementation - this instance is used during param resolution and should + // only be used to call InitializeCollectiveParams. + static Status Register(const string& collective_name, Factory factory); + + static Status LookupHelper(const string& collective_name, + CollectiveImplementationInterface** implementation, + bool param_resolver); +}; + +// Class used to call CollectiveRegistry::Register. This should only be used to +// create a global static object. +class CollectiveRegistration { + public: + CollectiveRegistration(const string& collective_name, + CollectiveRegistry::Factory factory) { + TF_CHECK_OK(CollectiveRegistry::Register(collective_name, factory)); + } +}; + +#define REGISTER_COLLECTIVE(name, implementation) \ + static CollectiveRegistration register_##name##_collective( \ + #name, []() { return new implementation; }); + } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_COLLECTIVE_EXECUTOR_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_COLLECTIVE_H_ diff --git a/tensorflow/core/framework/common_shape_fns.h b/tensorflow/core/framework/common_shape_fns.h index 2bedce1d6a..e6f9f935f9 100644 --- a/tensorflow/core/framework/common_shape_fns.h +++ b/tensorflow/core/framework/common_shape_fns.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_OPS_COMMON_SHAPE_FNS_H_ -#define TENSORFLOW_CORE_OPS_COMMON_SHAPE_FNS_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_COMMON_SHAPE_FNS_H_ +#define TENSORFLOW_CORE_FRAMEWORK_COMMON_SHAPE_FNS_H_ #include <array> @@ -311,4 +311,4 @@ Status ExplicitShapes(InferenceContext* c); } // namespace tensorflow -#endif // TENSORFLOW_CORE_OPS_COMMON_SHAPE_FNS_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_COMMON_SHAPE_FNS_H_ diff --git a/tensorflow/core/framework/control_flow.h b/tensorflow/core/framework/control_flow.h index 4dad0b4fef..4839e02e22 100644 --- a/tensorflow/core/framework/control_flow.h +++ b/tensorflow/core/framework/control_flow.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_CONTROL_FLOW_H_ -#define TENSORFLOW_FRAMEWORK_CONTROL_FLOW_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_CONTROL_FLOW_H_ +#define TENSORFLOW_CORE_FRAMEWORK_CONTROL_FLOW_H_ #include "tensorflow/core/lib/hash/hash.h" #include "tensorflow/core/platform/logging.h" @@ -55,4 +55,4 @@ struct FrameAndIterHash { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_CONTROL_FLOW_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_CONTROL_FLOW_H_ diff --git a/tensorflow/core/framework/dataset.cc b/tensorflow/core/framework/dataset.cc index f3c7189292..b0b27ce94f 100644 --- a/tensorflow/core/framework/dataset.cc +++ b/tensorflow/core/framework/dataset.cc @@ -133,22 +133,25 @@ Status GraphDefBuilderWrapper::AddDataset( return Status::OK(); } -Status GraphDefBuilderWrapper::AddFunction( - const FunctionLibraryDefinition& flib_def, const string& function_name) { +Status GraphDefBuilderWrapper::AddFunction(SerializationContext* ctx, + const string& function_name) { if (b_->HasFunction(function_name)) { VLOG(1) << "Function with name " << function_name << "already exists in" << " the graph. It will not be added again."; return Status::OK(); } - TF_RETURN_IF_ERROR(EnsureFunctionIsStateless(flib_def, function_name)); - const FunctionDef* f_def = flib_def.Find(function_name); + if (!ctx->allow_stateful_functions()) { + TF_RETURN_IF_ERROR( + EnsureFunctionIsStateless(ctx->flib_def(), function_name)); + } + const FunctionDef* f_def = ctx->flib_def().Find(function_name); if (f_def == nullptr) { return errors::InvalidArgument("Unable to find FunctionDef for ", function_name, " in the registry."); } FunctionDefLibrary def; *def.add_function() = *f_def; - const string gradient_func = flib_def.FindGradient(function_name); + const string gradient_func = ctx->flib_def().FindGradient(function_name); if (!gradient_func.empty()) { GradientDef* g_def = def.add_gradient(); g_def->set_function_name(function_name); @@ -159,19 +162,19 @@ Status GraphDefBuilderWrapper::AddFunction( // Recursively add functions in inputs of function_name. for (const NodeDef& node_def : f_def->node_def()) { const OpRegistrationData* op_reg_data = nullptr; - TF_RETURN_IF_ERROR(flib_def.LookUp(node_def.op(), &op_reg_data)); + TF_RETURN_IF_ERROR(ctx->flib_def().LookUp(node_def.op(), &op_reg_data)); if (op_reg_data->is_function_op) { - TF_RETURN_IF_ERROR(AddFunction(flib_def, op_reg_data->op_def.name())); + TF_RETURN_IF_ERROR(AddFunction(ctx, op_reg_data->op_def.name())); } // Recursively add functions in attrs of this NodeDef. for (const auto& pair : node_def.attr()) { - TF_RETURN_IF_ERROR(AddAttrFunctions(pair.second, flib_def)); + TF_RETURN_IF_ERROR(AddAttrFunctions(ctx, pair.second)); } } // Recursively add functions in attrs of function_name. for (auto iter = f_def->attr().begin(); iter != f_def->attr().end(); iter++) { - TF_RETURN_IF_ERROR(AddAttrFunctions(iter->second, flib_def)); + TF_RETURN_IF_ERROR(AddAttrFunctions(ctx, iter->second)); } return Status::OK(); } diff --git a/tensorflow/core/framework/dataset.h b/tensorflow/core/framework/dataset.h index e0c26d9286..e06ca68bca 100644 --- a/tensorflow/core/framework/dataset.h +++ b/tensorflow/core/framework/dataset.h @@ -41,6 +41,7 @@ limitations under the License. namespace tensorflow { class DatasetBase; +class SerializationContext; // Interface for reading values from a key-value store. // Used for restoring iterator state. @@ -155,11 +156,11 @@ class GraphDefBuilderWrapper { // Adds a user-defined function with name `function_name` to the graph and // recursively adds all functions it references. If a function with a matching // name has already been added, returns with OK status. If a user-defined with - // name `function_name` is not found in the FunctionLibraryDefinition, returns - // an InvalidArgumentError. If the function with name `function_name` or any - // of its dependent functions are stateful, returns an InvalidArgument error. - Status AddFunction(const FunctionLibraryDefinition& flib_def, - const string& function_name); + // name `function_name` is not found in the context's function library, + // returns an InvalidArgumentError. If the function with name `function_name` + // or any of its dependent functions are stateful, and the context does not + // explicitly permit stateful functions, returns an InvalidArgument error. + Status AddFunction(SerializationContext* ctx, const string& function_name); template <typename T> void BuildAttrValue(const T& value, AttrValue* attr) { @@ -220,13 +221,13 @@ class GraphDefBuilderWrapper { return false; } - Status AddAttrFunctions(const AttrValue& attr_value, - const FunctionLibraryDefinition& flib_def) { + Status AddAttrFunctions(SerializationContext* ctx, + const AttrValue& attr_value) { if (attr_value.has_func()) { - TF_RETURN_IF_ERROR(AddFunction(flib_def, attr_value.func().name())); + TF_RETURN_IF_ERROR(AddFunction(ctx, attr_value.func().name())); } else if (attr_value.has_list()) { for (const NameAttrList& name_attr_list : attr_value.list().func()) { - TF_RETURN_IF_ERROR(AddFunction(flib_def, name_attr_list.name())); + TF_RETURN_IF_ERROR(AddFunction(ctx, name_attr_list.name())); } } return Status::OK(); @@ -332,11 +333,14 @@ class IteratorContext { class SerializationContext { public: struct Params { + bool allow_stateful_functions = false; const FunctionLibraryDefinition* flib_def; // Not owned. }; explicit SerializationContext(Params params) : params_(std::move(params)) {} + bool allow_stateful_functions() { return params_.allow_stateful_functions; } + const FunctionLibraryDefinition& flib_def() { return *params_.flib_def; } private: diff --git a/tensorflow/core/framework/device_base.h b/tensorflow/core/framework/device_base.h index b184fd91e1..794250a2c1 100644 --- a/tensorflow/core/framework/device_base.h +++ b/tensorflow/core/framework/device_base.h @@ -89,6 +89,15 @@ class DeviceContext : public core::RefCounted { Tensor* cpu_tensor, StatusCallback done) { done(errors::Internal("Unrecognized device type in device-to-CPU Copy")); } + + // If possible, wait for all events on *stream to complete then execute func. + // A non-OK Status is returned otherwise. The stream argument should be the + // one provided by GpuDeviceInfo. This function is not applicable to devices + // that don't provide such a value. + virtual Status ThenExecute(Device* device, stream_executor::Stream* stream, + std::function<void()> func) { + return errors::Internal("ThenExecute not supported by device"); + } }; // map[i] is the DeviceContext* for the node with id i, if i < map.size(). diff --git a/tensorflow/core/framework/fake_input.h b/tensorflow/core/framework/fake_input.h index 103db47a99..c3062762ff 100644 --- a/tensorflow/core/framework/fake_input.h +++ b/tensorflow/core/framework/fake_input.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_FAKE_INPUT_H_ -#define TENSORFLOW_FRAMEWORK_FAKE_INPUT_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_FAKE_INPUT_H_ +#define TENSORFLOW_CORE_FRAMEWORK_FAKE_INPUT_H_ #include "tensorflow/core/framework/node_def_builder.h" #include "tensorflow/core/framework/types.h" @@ -37,4 +37,4 @@ inline FakeInputFunctor FakeInput(std::initializer_list<DataType> dts) { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_FAKE_INPUT_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_FAKE_INPUT_H_ diff --git a/tensorflow/core/framework/function.cc b/tensorflow/core/framework/function.cc index 6b92e10d76..26f32677af 100644 --- a/tensorflow/core/framework/function.cc +++ b/tensorflow/core/framework/function.cc @@ -504,7 +504,7 @@ string Print(const NodeDef& n) { std::vector<string> dep; for (StringPiece s : n.input()) { if (str_util::ConsumePrefix(&s, "^")) { - dep.push_back(std::string(s)); + dep.emplace_back(s); } else { dat.push_back(s); } diff --git a/tensorflow/core/framework/function.h b/tensorflow/core/framework/function.h index edb7ed01e9..03296a7761 100644 --- a/tensorflow/core/framework/function.h +++ b/tensorflow/core/framework/function.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_FUNCTION_H_ -#define TENSORFLOW_FRAMEWORK_FUNCTION_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_FUNCTION_H_ +#define TENSORFLOW_CORE_FRAMEWORK_FUNCTION_H_ #include <vector> #include "tensorflow/core/framework/attr_value.pb.h" @@ -490,6 +490,11 @@ class FunctionLibraryRuntime { // Instantiates the function using an executor of the given type. If empty, // the default TensorFlow executor will be used. string executor_type; + + // If true, the runtime will attempt to create kernels for the function at + // instantiation time, rather than on the first run. This can be used to + // surface errors earlier. + bool create_kernels_eagerly = false; }; typedef uint64 Handle; virtual Status Instantiate(const string& function_name, AttrSlice attrs, @@ -705,9 +710,10 @@ Status ArgNumType(AttrSlice attrs, const OpDef::ArgDef& arg_def, #define REGISTER_OP_GRADIENT_UNIQ_HELPER(ctr, name, fn) \ REGISTER_OP_GRADIENT_UNIQ(ctr, name, fn) -#define REGISTER_OP_GRADIENT_UNIQ(ctr, name, fn) \ - static bool unused_grad_##ctr = SHOULD_REGISTER_OP_GRADIENT && \ - ::tensorflow::gradient::RegisterOp(name, fn) +#define REGISTER_OP_GRADIENT_UNIQ(ctr, name, fn) \ + static bool unused_grad_##ctr TF_ATTRIBUTE_UNUSED = \ + SHOULD_REGISTER_OP_GRADIENT && \ + ::tensorflow::gradient::RegisterOp(name, fn) namespace gradient { // Register a gradient creator for the "op". @@ -731,4 +737,4 @@ GET_ATTR(bool) } // end namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_FUNCTION_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_FUNCTION_H_ diff --git a/tensorflow/core/framework/function_testlib.cc b/tensorflow/core/framework/function_testlib.cc index 41270b8e5e..6e38256ba8 100644 --- a/tensorflow/core/framework/function_testlib.cc +++ b/tensorflow/core/framework/function_testlib.cc @@ -49,8 +49,8 @@ NodeDef NDef(StringPiece name, StringPiece op, gtl::ArraySlice<string> inputs, gtl::ArraySlice<std::pair<string, FDH::AttrValueWrapper>> attrs, const string& device) { NodeDef n; - n.set_name(name.ToString()); - n.set_op(op.ToString()); + n.set_name(string(name)); + n.set_op(string(op)); for (const auto& in : inputs) n.add_input(in); n.set_device(device); for (auto na : attrs) n.mutable_attr()->insert({na.first, na.second.proto}); diff --git a/tensorflow/core/framework/graph_def_util.h b/tensorflow/core/framework/graph_def_util.h index 525e84a989..2f8d5e8f51 100644 --- a/tensorflow/core/framework/graph_def_util.h +++ b/tensorflow/core/framework/graph_def_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_GRAPH_DEF_UTIL_H_ -#define TENSORFLOW_FRAMEWORK_GRAPH_DEF_UTIL_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_GRAPH_DEF_UTIL_H_ +#define TENSORFLOW_CORE_FRAMEWORK_GRAPH_DEF_UTIL_H_ #include <set> #include "tensorflow/core/framework/op.h" @@ -118,4 +118,4 @@ Status StrippedOpListForGraph(const GraphDef& graph_def, } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_GRAPH_DEF_UTIL_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_GRAPH_DEF_UTIL_H_ diff --git a/tensorflow/core/framework/kernel_def_builder.h b/tensorflow/core/framework/kernel_def_builder.h index 2966aa58de..32dd21f94e 100644 --- a/tensorflow/core/framework/kernel_def_builder.h +++ b/tensorflow/core/framework/kernel_def_builder.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_KERNEL_DEF_BUILDER_H_ -#define TENSORFLOW_FRAMEWORK_KERNEL_DEF_BUILDER_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_KERNEL_DEF_BUILDER_H_ +#define TENSORFLOW_CORE_FRAMEWORK_KERNEL_DEF_BUILDER_H_ #include "tensorflow/core/framework/types.h" #include "tensorflow/core/lib/gtl/array_slice.h" @@ -84,4 +84,4 @@ KernelDefBuilder& KernelDefBuilder::TypeConstraint(const char* attr_name) { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_KERNEL_DEF_BUILDER_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_KERNEL_DEF_BUILDER_H_ diff --git a/tensorflow/core/framework/log_memory.h b/tensorflow/core/framework/log_memory.h index faef7b8e98..1b926ddaa3 100644 --- a/tensorflow/core/framework/log_memory.h +++ b/tensorflow/core/framework/log_memory.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_LOG_MEMORY_H_ -#define TENSORFLOW_FRAMEWORK_LOG_MEMORY_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_LOG_MEMORY_H_ +#define TENSORFLOW_CORE_FRAMEWORK_LOG_MEMORY_H_ #include "tensorflow/core/framework/tensor.h" #include "tensorflow/core/platform/protobuf.h" @@ -108,4 +108,4 @@ class LogMemory { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_LOG_MEMORY_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_LOG_MEMORY_H_ diff --git a/tensorflow/core/framework/lookup_interface.h b/tensorflow/core/framework/lookup_interface.h index 1381dd66a5..0622dd06cb 100644 --- a/tensorflow/core/framework/lookup_interface.h +++ b/tensorflow/core/framework/lookup_interface.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_LOOKUP_INTERFACE_H_ -#define TENSORFLOW_FRAMEWORK_LOOKUP_INTERFACE_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_LOOKUP_INTERFACE_H_ +#define TENSORFLOW_CORE_FRAMEWORK_LOOKUP_INTERFACE_H_ #include "tensorflow/core/framework/resource_mgr.h" #include "tensorflow/core/framework/tensor.h" @@ -142,4 +142,4 @@ class LookupInterface : public ResourceBase { } // namespace lookup } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_LOOKUP_INTERFACE_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_LOOKUP_INTERFACE_H_ diff --git a/tensorflow/core/framework/memory_types.h b/tensorflow/core/framework/memory_types.h index d3918513d3..f719131bcb 100644 --- a/tensorflow/core/framework/memory_types.h +++ b/tensorflow/core/framework/memory_types.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_MEMORY_TYPES_H_ -#define TENSORFLOW_FRAMEWORK_MEMORY_TYPES_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_MEMORY_TYPES_H_ +#define TENSORFLOW_CORE_FRAMEWORK_MEMORY_TYPES_H_ #include "tensorflow/core/framework/op.h" #include "tensorflow/core/framework/types.h" @@ -35,4 +35,4 @@ Status MemoryTypesForNode(const OpRegistryInterface* op_registry, } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_MEMORY_TYPES_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_MEMORY_TYPES_H_ diff --git a/tensorflow/core/framework/node_def_builder.cc b/tensorflow/core/framework/node_def_builder.cc index 8e00bfe4f8..348a825af9 100644 --- a/tensorflow/core/framework/node_def_builder.cc +++ b/tensorflow/core/framework/node_def_builder.cc @@ -24,23 +24,22 @@ limitations under the License. namespace tensorflow { NodeDefBuilder::NodeOut::NodeOut(StringPiece n, int i, DataType dt) - : node(std::string(n)), index(i), data_type(dt) {} + : node(n), index(i), data_type(dt) {} NodeDefBuilder::NodeOut::NodeOut() { // uninitialized, call Reset() before use. } void NodeDefBuilder::NodeOut::Reset(StringPiece n, int i, DataType dt) { - node = std::string(n); + node = string(n); index = i; data_type = dt; } NodeDefBuilder::NodeDefBuilder(StringPiece name, StringPiece op_name, const OpRegistryInterface* op_registry) { - node_def_.set_name(std::string(name)); - const Status status = - op_registry->LookUpOpDef(std::string(op_name), &op_def_); + node_def_.set_name(string(name)); + const Status status = op_registry->LookUpOpDef(string(op_name), &op_def_); if (status.ok()) { Initialize(); } else { @@ -51,7 +50,7 @@ NodeDefBuilder::NodeDefBuilder(StringPiece name, StringPiece op_name, NodeDefBuilder::NodeDefBuilder(StringPiece name, const OpDef* op_def) : op_def_(op_def) { - node_def_.set_name(std::string(name)); + node_def_.set_name(string(name)); Initialize(); } @@ -171,7 +170,7 @@ void NodeDefBuilder::AddInput(StringPiece src_node, int src_index) { } else if (src_index > 0) { node_def_.add_input(strings::StrCat(src_node, ":", src_index)); } else { - node_def_.add_input(std::string(src_node)); + node_def_.add_input(string(src_node)); } } @@ -194,12 +193,12 @@ void NodeDefBuilder::VerifyInputRef(const OpDef::ArgDef* input_arg, } NodeDefBuilder& NodeDefBuilder::ControlInput(StringPiece src_node) { - control_inputs_.push_back(std::string(src_node)); + control_inputs_.emplace_back(src_node); return *this; } NodeDefBuilder& NodeDefBuilder::Device(StringPiece device_spec) { - node_def_.set_device(std::string(device_spec)); + node_def_.set_device(string(device_spec)); return *this; } diff --git a/tensorflow/core/framework/node_def_builder.h b/tensorflow/core/framework/node_def_builder.h index c138332beb..ad07ec5480 100644 --- a/tensorflow/core/framework/node_def_builder.h +++ b/tensorflow/core/framework/node_def_builder.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_NODE_DEF_BUILDER_H_ -#define TENSORFLOW_FRAMEWORK_NODE_DEF_BUILDER_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_NODE_DEF_BUILDER_H_ +#define TENSORFLOW_CORE_FRAMEWORK_NODE_DEF_BUILDER_H_ #include <functional> #include <vector> @@ -175,4 +175,4 @@ class NodeDefBuilder { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_NODE_DEF_BUILDER_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_NODE_DEF_BUILDER_H_ diff --git a/tensorflow/core/framework/node_def_util.cc b/tensorflow/core/framework/node_def_util.cc index 0bd79366eb..bacc1d72c4 100644 --- a/tensorflow/core/framework/node_def_util.cc +++ b/tensorflow/core/framework/node_def_util.cc @@ -254,7 +254,7 @@ DEFINE_GET_ATTR(NameAttrList, func, "func", emplace_back, v, ;); #undef DEFINE_GET_ATTR bool HasNodeAttr(const NodeDef& node_def, StringPiece attr_name) { - return node_def.attr().find(std::string(attr_name)) != node_def.attr().end(); + return node_def.attr().find(string(attr_name)) != node_def.attr().end(); } static const string& kEmptyString = *new string(); @@ -653,7 +653,7 @@ Status AttachDef(const Status& status, const Node& node) { void AddNodeAttr(StringPiece name, const AttrValue& value, NodeDef* node_def) { node_def->mutable_attr()->insert( - AttrValueMap::value_type(std::string(name), value)); + AttrValueMap::value_type(string(name), value)); } #define ADD_NODE_ATTR(T) \ @@ -691,7 +691,7 @@ ADD_NODE_ATTR(gtl::ArraySlice<NameAttrList>) #undef ADD_NODE_ATTR void AddAttr(StringPiece name, const AttrValue& value, AttrValueMap* map) { - map->insert(AttrValueMap::value_type(std::string(name), value)); + map->insert(AttrValueMap::value_type(string(name), value)); } #define ADD_ATTR(T) \ diff --git a/tensorflow/core/framework/node_def_util.h b/tensorflow/core/framework/node_def_util.h index c012b7c3d3..499034cab2 100644 --- a/tensorflow/core/framework/node_def_util.h +++ b/tensorflow/core/framework/node_def_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_NODE_DEF_UTIL_H_ -#define TENSORFLOW_FRAMEWORK_NODE_DEF_UTIL_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_NODE_DEF_UTIL_H_ +#define TENSORFLOW_CORE_FRAMEWORK_NODE_DEF_UTIL_H_ #include <string> #include <unordered_map> @@ -312,4 +312,4 @@ Status AddPrefixAndSuffixToNode(StringPiece prefix, StringPiece suffix, NodeDef* node_def); } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_NODE_DEF_UTIL_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_NODE_DEF_UTIL_H_ diff --git a/tensorflow/core/framework/numeric_op.h b/tensorflow/core/framework/numeric_op.h index 4538ff053c..0167e21f11 100644 --- a/tensorflow/core/framework/numeric_op.h +++ b/tensorflow/core/framework/numeric_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_NUMERIC_OP_H_ -#define TENSORFLOW_FRAMEWORK_NUMERIC_OP_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_NUMERIC_OP_H_ +#define TENSORFLOW_CORE_FRAMEWORK_NUMERIC_OP_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/tensor.h" @@ -110,4 +110,4 @@ class BinaryElementWiseOp : public BinaryOp<T> { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_NUMERIC_OP_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_NUMERIC_OP_H_ diff --git a/tensorflow/core/framework/numeric_types.h b/tensorflow/core/framework/numeric_types.h index b1d0127809..3236d1897c 100644 --- a/tensorflow/core/framework/numeric_types.h +++ b/tensorflow/core/framework/numeric_types.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_NUMERIC_TYPES_H_ -#define TENSORFLOW_FRAMEWORK_NUMERIC_TYPES_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_NUMERIC_TYPES_H_ +#define TENSORFLOW_CORE_FRAMEWORK_NUMERIC_TYPES_H_ #include <complex> #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -122,4 +122,4 @@ struct hash<Eigen::half> { } // namespace std #endif // _MSC_VER -#endif // TENSORFLOW_FRAMEWORK_NUMERIC_TYPES_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_NUMERIC_TYPES_H_ diff --git a/tensorflow/core/framework/op.h b/tensorflow/core/framework/op.h index 3ccca4090d..25f8de8dcc 100644 --- a/tensorflow/core/framework/op.h +++ b/tensorflow/core/framework/op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_OP_H_ -#define TENSORFLOW_FRAMEWORK_OP_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_OP_H_ +#define TENSORFLOW_CORE_FRAMEWORK_OP_H_ #include <functional> #include <unordered_map> @@ -309,4 +309,4 @@ struct OpDefBuilderReceiver { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_OP_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_OP_H_ diff --git a/tensorflow/core/framework/op_def_builder.cc b/tensorflow/core/framework/op_def_builder.cc index 91eb6c0672..34a7a43d38 100644 --- a/tensorflow/core/framework/op_def_builder.cc +++ b/tensorflow/core/framework/op_def_builder.cc @@ -527,7 +527,7 @@ void FinalizeDoc(const string& text, OpDef* op_def, } // namespace OpDefBuilder::OpDefBuilder(StringPiece op_name) { - op_def()->set_name(std::string(op_name)); // NOLINT + op_def()->set_name(string(op_name)); // NOLINT } OpDefBuilder& OpDefBuilder::Attr(StringPiece spec) { @@ -584,7 +584,7 @@ OpDefBuilder& OpDefBuilder::Deprecated(int version, StringPiece explanation) { } else { OpDeprecation* deprecation = op_def()->mutable_deprecation(); deprecation->set_version(version); - deprecation->set_explanation(std::string(explanation)); + deprecation->set_explanation(string(explanation)); } return *this; } diff --git a/tensorflow/core/framework/op_def_builder.h b/tensorflow/core/framework/op_def_builder.h index fbfb4018aa..0b39d6e848 100644 --- a/tensorflow/core/framework/op_def_builder.h +++ b/tensorflow/core/framework/op_def_builder.h @@ -16,8 +16,8 @@ limitations under the License. // Class and associated machinery for specifying an Op's OpDef and shape // inference function for Op registration. -#ifndef TENSORFLOW_FRAMEWORK_OP_DEF_BUILDER_H_ -#define TENSORFLOW_FRAMEWORK_OP_DEF_BUILDER_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_OP_DEF_BUILDER_H_ +#define TENSORFLOW_CORE_FRAMEWORK_OP_DEF_BUILDER_H_ #include <string> #include <vector> @@ -162,4 +162,4 @@ class OpDefBuilder { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_OP_DEF_BUILDER_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_OP_DEF_BUILDER_H_ diff --git a/tensorflow/core/framework/op_def_util.cc b/tensorflow/core/framework/op_def_util.cc index 9be0dc69d2..3597f43d51 100644 --- a/tensorflow/core/framework/op_def_util.cc +++ b/tensorflow/core/framework/op_def_util.cc @@ -172,6 +172,15 @@ const OpDef::ArgDef* FindInputArg(StringPiece name, const OpDef& op_def) { return nullptr; } +const ApiDef::Arg* FindInputArg(StringPiece name, const ApiDef& api_def) { + for (int i = 0; i < api_def.in_arg_size(); ++i) { + if (api_def.in_arg(i).name() == name) { + return &api_def.in_arg(i); + } + } + return nullptr; +} + #define VALIDATE(EXPR, ...) \ do { \ if (!(EXPR)) { \ diff --git a/tensorflow/core/framework/op_def_util.h b/tensorflow/core/framework/op_def_util.h index 0ba1325a03..85afe2bdea 100644 --- a/tensorflow/core/framework/op_def_util.h +++ b/tensorflow/core/framework/op_def_util.h @@ -16,10 +16,11 @@ limitations under the License. // TODO(josh11b): Probably not needed for OpKernel authors, so doesn't // need to be as publicly accessible as other files in framework/. -#ifndef TENSORFLOW_FRAMEWORK_OP_DEF_UTIL_H_ -#define TENSORFLOW_FRAMEWORK_OP_DEF_UTIL_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_OP_DEF_UTIL_H_ +#define TENSORFLOW_CORE_FRAMEWORK_OP_DEF_UTIL_H_ #include <string> +#include "tensorflow/core/framework/api_def.pb.h" #include "tensorflow/core/framework/op_def.pb.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/platform/protobuf.h" @@ -47,6 +48,10 @@ OpDef::AttrDef* FindAttrMutable(StringPiece name, OpDef* op_def); // Returns nullptr if no such attr is found. const OpDef::ArgDef* FindInputArg(StringPiece name, const OpDef& op_def); +// Searches api_def for input argument with the indicated name. +// Returns nullptr if no such attr is found. +const ApiDef::Arg* FindInputArg(StringPiece name, const ApiDef& api_def); + // Produce a human-readable version of an op_def that is more concise // than a text-format proto. Excludes descriptions. string SummarizeOpDef(const OpDef& op_def); @@ -98,4 +103,4 @@ uint64 OpDefHash(const OpDef& o); } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_OP_DEF_UTIL_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_OP_DEF_UTIL_H_ diff --git a/tensorflow/core/framework/op_gen_lib.cc b/tensorflow/core/framework/op_gen_lib.cc index 4b56d807df..505ab54775 100644 --- a/tensorflow/core/framework/op_gen_lib.cc +++ b/tensorflow/core/framework/op_gen_lib.cc @@ -186,7 +186,7 @@ static bool FindMultiline(StringPiece line, size_t colon, string* end) { while (str_util::ConsumePrefix(&line, " ")) { } if (str_util::ConsumePrefix(&line, "<<")) { - *end = std::string(line); + *end = string(line); return true; } return false; diff --git a/tensorflow/core/framework/op_gen_lib.h b/tensorflow/core/framework/op_gen_lib.h index 533dd64805..c269e2df04 100644 --- a/tensorflow/core/framework/op_gen_lib.h +++ b/tensorflow/core/framework/op_gen_lib.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_OP_GEN_LIB_H_ -#define TENSORFLOW_FRAMEWORK_OP_GEN_LIB_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_OP_GEN_LIB_H_ +#define TENSORFLOW_CORE_FRAMEWORK_OP_GEN_LIB_H_ #include <string> #include <unordered_map> @@ -97,4 +97,4 @@ class ApiDefMap { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_OP_GEN_LIB_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_OP_GEN_LIB_H_ diff --git a/tensorflow/core/framework/op_kernel.cc b/tensorflow/core/framework/op_kernel.cc index b285accce7..c694e10193 100644 --- a/tensorflow/core/framework/op_kernel.cc +++ b/tensorflow/core/framework/op_kernel.cc @@ -913,7 +913,7 @@ void OpKernelContext::clear_recorded_memory() { struct KernelRegistration { KernelRegistration(const KernelDef& d, StringPiece c, kernel_factory::OpKernelRegistrar::Factory f) - : def(d), kernel_class_name(std::string(c)), factory(f) {} + : def(d), kernel_class_name(c), factory(f) {} const KernelDef def; const string kernel_class_name; const kernel_factory::OpKernelRegistrar::Factory factory; diff --git a/tensorflow/core/framework/queue_interface.h b/tensorflow/core/framework/queue_interface.h index 4aeaab3d9b..4ca4416c5a 100644 --- a/tensorflow/core/framework/queue_interface.h +++ b/tensorflow/core/framework/queue_interface.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_QUEUE_INTERFACE_H_ -#define TENSORFLOW_FRAMEWORK_QUEUE_INTERFACE_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_QUEUE_INTERFACE_H_ +#define TENSORFLOW_CORE_FRAMEWORK_QUEUE_INTERFACE_H_ #include <string> #include <vector> @@ -99,4 +99,4 @@ class QueueInterface : public ResourceBase { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_QUEUE_INTERFACE_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_QUEUE_INTERFACE_H_ diff --git a/tensorflow/core/framework/reader_base.h b/tensorflow/core/framework/reader_base.h index cb44be4dee..5b82e9181f 100644 --- a/tensorflow/core/framework/reader_base.h +++ b/tensorflow/core/framework/reader_base.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_READER_BASE_H_ -#define TENSORFLOW_FRAMEWORK_READER_BASE_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_READER_BASE_H_ +#define TENSORFLOW_CORE_FRAMEWORK_READER_BASE_H_ #include <memory> #include <string> @@ -135,4 +135,4 @@ class ReaderBase : public ReaderInterface { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_READER_BASE_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_READER_BASE_H_ diff --git a/tensorflow/core/framework/reader_interface.h b/tensorflow/core/framework/reader_interface.h index dac6056b5a..f894acbe1d 100644 --- a/tensorflow/core/framework/reader_interface.h +++ b/tensorflow/core/framework/reader_interface.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_READER_INTERFACE_H_ -#define TENSORFLOW_FRAMEWORK_READER_INTERFACE_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_READER_INTERFACE_H_ +#define TENSORFLOW_CORE_FRAMEWORK_READER_INTERFACE_H_ #include <memory> #include <string> @@ -84,4 +84,4 @@ class ReaderInterface : public ResourceBase { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_READER_INTERFACE_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_READER_INTERFACE_H_ diff --git a/tensorflow/core/framework/reader_op_kernel.h b/tensorflow/core/framework/reader_op_kernel.h index ffd6a1a184..e65a8695be 100644 --- a/tensorflow/core/framework/reader_op_kernel.h +++ b/tensorflow/core/framework/reader_op_kernel.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_READER_OP_KERNEL_H_ -#define TENSORFLOW_FRAMEWORK_READER_OP_KERNEL_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_READER_OP_KERNEL_H_ +#define TENSORFLOW_CORE_FRAMEWORK_READER_OP_KERNEL_H_ #include <functional> #include <string> @@ -85,4 +85,4 @@ class ReaderOpKernel : public ResourceOpKernel<ReaderInterface> { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_READER_OP_KERNEL_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_READER_OP_KERNEL_H_ diff --git a/tensorflow/core/framework/register_types.h b/tensorflow/core/framework/register_types.h index f1cd37ecda..ddb5b10c18 100644 --- a/tensorflow/core/framework/register_types.h +++ b/tensorflow/core/framework/register_types.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_REGISTER_TYPES_H_ -#define TENSORFLOW_FRAMEWORK_REGISTER_TYPES_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_REGISTER_TYPES_H_ +#define TENSORFLOW_CORE_FRAMEWORK_REGISTER_TYPES_H_ // This file is used by cuda code and must remain compilable by nvcc. #include "tensorflow/core/framework/numeric_types.h" @@ -161,9 +161,12 @@ limitations under the License. TF_CALL_int64(m) TF_CALL_int32(m) TF_CALL_uint16(m) TF_CALL_int16(m) \ TF_CALL_uint8(m) TF_CALL_int8(m) +#define TF_CALL_FLOAT_TYPES(m) \ + TF_CALL_half(m) TF_CALL_bfloat16(m) TF_CALL_float(m) TF_CALL_double(m) + #define TF_CALL_REAL_NUMBER_TYPES(m) \ TF_CALL_INTEGRAL_TYPES(m) \ - TF_CALL_half(m) TF_CALL_bfloat16(m) TF_CALL_float(m) TF_CALL_double(m) + TF_CALL_FLOAT_TYPES(m) #define TF_CALL_REAL_NUMBER_TYPES_NO_BFLOAT16(m) \ TF_CALL_INTEGRAL_TYPES(m) TF_CALL_half(m) TF_CALL_float(m) TF_CALL_double(m) @@ -225,4 +228,4 @@ limitations under the License. #define TF_CALL_SYCL_NUMBER_TYPES(m) TF_CALL_float(m) TF_CALL_SYCL_double(m) #endif // __ANDROID_TYPES_SLIM__ -#endif // TENSORFLOW_FRAMEWORK_REGISTER_TYPES_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_REGISTER_TYPES_H_ diff --git a/tensorflow/core/framework/register_types_traits.h b/tensorflow/core/framework/register_types_traits.h index ab35c2f095..d475a1972d 100644 --- a/tensorflow/core/framework/register_types_traits.h +++ b/tensorflow/core/framework/register_types_traits.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_REGISTER_TYPES_TRAITS_H_ -#define TENSORFLOW_FRAMEWORK_REGISTER_TYPES_TRAITS_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_REGISTER_TYPES_TRAITS_H_ +#define TENSORFLOW_CORE_FRAMEWORK_REGISTER_TYPES_TRAITS_H_ // This file is used by cuda code and must remain compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -102,4 +102,4 @@ struct proxy_type { #endif // TENSORFLOW_USE_SYCL } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_REGISTER_TYPES_TRAITS_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_REGISTER_TYPES_TRAITS_H_ diff --git a/tensorflow/core/framework/resource_mgr.h b/tensorflow/core/framework/resource_mgr.h index 33d4cb77ff..f8a587c9b5 100644 --- a/tensorflow/core/framework/resource_mgr.h +++ b/tensorflow/core/framework/resource_mgr.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_RESOURCE_MGR_H_ -#define TENSORFLOW_FRAMEWORK_RESOURCE_MGR_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_RESOURCE_MGR_H_ +#define TENSORFLOW_CORE_FRAMEWORK_RESOURCE_MGR_H_ #include <string> #include <typeindex> @@ -61,8 +61,8 @@ namespace tensorflow { // // // Create a var. // MyVar* my_var = new MyVar; -// my_var.val = Tensor(DT_FLOAT, my_shape); -// my_var.val.flat<float>().setZeros(); // 0 initialized. +// my_var->val = Tensor(DT_FLOAT, my_shape); +// my_var->val.flat<float>().setZeros(); // 0 initialized. // ctx->SetStatus(rm.Create("my_container", "my_name", my_var)); // // // += a variable. @@ -555,4 +555,4 @@ void ResourceHandleOp<T>::Compute(OpKernelContext* ctx) { } // end namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_RESOURCE_MGR_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_RESOURCE_MGR_H_ diff --git a/tensorflow/core/framework/resource_op_kernel.h b/tensorflow/core/framework/resource_op_kernel.h index 0a8da8b3bf..fbcd439dea 100644 --- a/tensorflow/core/framework/resource_op_kernel.h +++ b/tensorflow/core/framework/resource_op_kernel.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_RESOURCE_OP_KERNEL_H_ -#define TENSORFLOW_FRAMEWORK_RESOURCE_OP_KERNEL_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_RESOURCE_OP_KERNEL_H_ +#define TENSORFLOW_CORE_FRAMEWORK_RESOURCE_OP_KERNEL_H_ #include <string> @@ -136,4 +136,4 @@ class ResourceOpKernel : public OpKernel { }; } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_RESOURCE_OP_KERNEL_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_RESOURCE_OP_KERNEL_H_ diff --git a/tensorflow/core/framework/selective_registration.h b/tensorflow/core/framework/selective_registration.h index 503947969d..4b281a04bf 100644 --- a/tensorflow/core/framework/selective_registration.h +++ b/tensorflow/core/framework/selective_registration.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_SELECTIVE_REGISTRATION_H_ -#define TENSORFLOW_FRAMEWORK_SELECTIVE_REGISTRATION_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_SELECTIVE_REGISTRATION_H_ +#define TENSORFLOW_CORE_FRAMEWORK_SELECTIVE_REGISTRATION_H_ #include <string.h> @@ -55,4 +55,4 @@ static_assert(false, "ops_to_register.h must define SHOULD_REGISTER macros"); #define SHOULD_REGISTER_OP_KERNEL(clz) true #endif -#endif // TENSORFLOW_FRAMEWORK_SELECTIVE_REGISTRATION_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_SELECTIVE_REGISTRATION_H_ diff --git a/tensorflow/core/framework/session_state.h b/tensorflow/core/framework/session_state.h index 653a661dd2..63568685f2 100644 --- a/tensorflow/core/framework/session_state.h +++ b/tensorflow/core/framework/session_state.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_SESSION_STATE_H_ -#define TENSORFLOW_FRAMEWORK_SESSION_STATE_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_SESSION_STATE_H_ +#define TENSORFLOW_CORE_FRAMEWORK_SESSION_STATE_H_ #include <string> #include <unordered_map> @@ -90,4 +90,4 @@ class TensorStore { } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_SESSION_STATE_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_SESSION_STATE_H_ diff --git a/tensorflow/core/framework/shape_inference_testutil.h b/tensorflow/core/framework/shape_inference_testutil.h index f6656b3b45..bb4dc25da4 100644 --- a/tensorflow/core/framework/shape_inference_testutil.h +++ b/tensorflow/core/framework/shape_inference_testutil.h @@ -32,7 +32,7 @@ class Tensor; struct ShapeInferenceTestOp { typedef std::pair<string, DataType> ShapeAndType; - explicit ShapeInferenceTestOp(StringPiece name) : name(std::string(name)) {} + explicit ShapeInferenceTestOp(StringPiece name) : name(string(name)) {} string name; NodeDef node_def; std::vector<const Tensor*> input_tensors; diff --git a/tensorflow/core/framework/tensor.cc b/tensorflow/core/framework/tensor.cc index a82beb7e8f..516afa517d 100644 --- a/tensorflow/core/framework/tensor.cc +++ b/tensorflow/core/framework/tensor.cc @@ -617,13 +617,13 @@ bool Tensor::IsInitialized() const { } void Tensor::CheckType(DataType expected_dtype) const { - CHECK_EQ(dtype(), expected_dtype) + CHECK_EQ(dtype(), expected_dtype) << " " << DataTypeString(expected_dtype) << " expected, got " << DataTypeString(dtype()); } void Tensor::CheckTypeAndIsAligned(DataType expected_dtype) const { - CHECK_EQ(dtype(), expected_dtype) + CHECK_EQ(dtype(), expected_dtype) << " " << DataTypeString(expected_dtype) << " expected, got " << DataTypeString(dtype()); CHECK(IsAligned()) << "ptr = " << base<void>(); diff --git a/tensorflow/core/framework/tensor_slice.h b/tensorflow/core/framework/tensor_slice.h index 6019737342..82f21fb17e 100644 --- a/tensorflow/core/framework/tensor_slice.h +++ b/tensorflow/core/framework/tensor_slice.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_TENSOR_SLICE_H_ -#define TENSORFLOW_FRAMEWORK_TENSOR_SLICE_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_TENSOR_SLICE_H_ +#define TENSORFLOW_CORE_FRAMEWORK_TENSOR_SLICE_H_ #include <string> #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -221,4 +221,4 @@ void TensorSlice::FillIndicesAndSizes( } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_TENSOR_SLICE_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_TENSOR_SLICE_H_ diff --git a/tensorflow/core/framework/tensor_types.h b/tensorflow/core/framework/tensor_types.h index a5c1a56bfc..6f981db189 100644 --- a/tensorflow/core/framework/tensor_types.h +++ b/tensorflow/core/framework/tensor_types.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_TENSOR_TYPES_H_ -#define TENSORFLOW_FRAMEWORK_TENSOR_TYPES_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_TENSOR_TYPES_H_ +#define TENSORFLOW_CORE_FRAMEWORK_TENSOR_TYPES_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -123,4 +123,4 @@ To32Bit(TensorType in) { } } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_TENSOR_TYPES_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_TENSOR_TYPES_H_ diff --git a/tensorflow/core/framework/tensor_util.h b/tensorflow/core/framework/tensor_util.h index 43d2d95311..4bda8f9eb8 100644 --- a/tensorflow/core/framework/tensor_util.h +++ b/tensorflow/core/framework/tensor_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_TENSOR_UTIL_H_ -#define TENSORFLOW_FRAMEWORK_TENSOR_UTIL_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_TENSOR_UTIL_H_ +#define TENSORFLOW_CORE_FRAMEWORK_TENSOR_UTIL_H_ #include "tensorflow/core/framework/tensor.h" #include "tensorflow/core/framework/tensor_shape.pb.h" @@ -160,4 +160,4 @@ CreateTensorProto(const std::vector<Type>& values, } // namespace tensor } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_TENSOR_UTIL_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_TENSOR_UTIL_H_ diff --git a/tensorflow/core/framework/tracking_allocator.h b/tensorflow/core/framework/tracking_allocator.h index 661c28969e..5eafce662e 100644 --- a/tensorflow/core/framework/tracking_allocator.h +++ b/tensorflow/core/framework/tracking_allocator.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_TRACKING_ALLOCATOR_H_ -#define TENSORFLOW_FRAMEWORK_TRACKING_ALLOCATOR_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_TRACKING_ALLOCATOR_H_ +#define TENSORFLOW_CORE_FRAMEWORK_TRACKING_ALLOCATOR_H_ #include <unordered_map> #include "tensorflow/core/framework/allocator.h" @@ -130,4 +130,4 @@ class TrackingAllocator : public Allocator { } // end namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_TRACKING_ALLOCATOR_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_TRACKING_ALLOCATOR_H_ diff --git a/tensorflow/core/framework/type_index.h b/tensorflow/core/framework/type_index.h index b978d90fa8..989fc42e26 100644 --- a/tensorflow/core/framework/type_index.h +++ b/tensorflow/core/framework/type_index.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_TYPE_INDEX_H_ -#define TENSORFLOW_FRAMEWORK_TYPE_INDEX_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_TYPE_INDEX_H_ +#define TENSORFLOW_CORE_FRAMEWORK_TYPE_INDEX_H_ #include <string> #if defined(__GXX_RTTI) || defined(_CPPRTTI) @@ -84,4 +84,4 @@ inline TypeIndex MakeTypeIndex() { #endif // __GXX_RTTI } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_TYPE_INDEX_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_TYPE_INDEX_H_ diff --git a/tensorflow/core/framework/type_traits.h b/tensorflow/core/framework/type_traits.h index e8351e494f..96fbf92938 100644 --- a/tensorflow/core/framework/type_traits.h +++ b/tensorflow/core/framework/type_traits.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_TYPE_TRAITS_H_ -#define TENSORFLOW_FRAMEWORK_TYPE_TRAITS_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_TYPE_TRAITS_H_ +#define TENSORFLOW_CORE_FRAMEWORK_TYPE_TRAITS_H_ #include <limits> #include <utility> @@ -106,4 +106,4 @@ struct is_signed<tensorflow::qint32> : public is_signed<tensorflow::int32> {}; } // namespace std -#endif // TENSORFLOW_FRAMEWORK_TYPE_TRAITS_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_TYPE_TRAITS_H_ diff --git a/tensorflow/core/framework/types.h b/tensorflow/core/framework/types.h index ff7c9855d6..15b1add2c1 100644 --- a/tensorflow/core/framework/types.h +++ b/tensorflow/core/framework/types.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_TYPES_H_ -#define TENSORFLOW_FRAMEWORK_TYPES_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_TYPES_H_ +#define TENSORFLOW_CORE_FRAMEWORK_TYPES_H_ #include <map> #include <set> @@ -481,4 +481,4 @@ bool DataTypeAlwaysOnHost(DataType dt); } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_TYPES_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_TYPES_H_ diff --git a/tensorflow/core/framework/variant.h b/tensorflow/core/framework/variant.h index c02391dae3..52732801a0 100644 --- a/tensorflow/core/framework/variant.h +++ b/tensorflow/core/framework/variant.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_VARIANT_H_ -#define TENSORFLOW_FRAMEWORK_VARIANT_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_VARIANT_H_ +#define TENSORFLOW_CORE_FRAMEWORK_VARIANT_H_ #include <functional> #include <iostream> @@ -351,4 +351,4 @@ const void* Variant::get() const; } // end namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_VARIANT_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_VARIANT_H_ diff --git a/tensorflow/core/framework/variant_encode_decode.h b/tensorflow/core/framework/variant_encode_decode.h index ded04b2a30..f155aa4892 100644 --- a/tensorflow/core/framework/variant_encode_decode.h +++ b/tensorflow/core/framework/variant_encode_decode.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_VARIANT_ENCODE_DECODE_H_ -#define TENSORFLOW_FRAMEWORK_VARIANT_ENCODE_DECODE_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_VARIANT_ENCODE_DECODE_H_ +#define TENSORFLOW_CORE_FRAMEWORK_VARIANT_ENCODE_DECODE_H_ #include <iostream> #include <type_traits> @@ -271,4 +271,4 @@ bool DecodeVariantList(std::unique_ptr<port::StringListDecoder> d, } // end namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_VARIANT_ENCODE_DECODE_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_VARIANT_ENCODE_DECODE_H_ diff --git a/tensorflow/core/framework/variant_op_registry.h b/tensorflow/core/framework/variant_op_registry.h index c9e8dd2217..e6a2665a56 100644 --- a/tensorflow/core/framework/variant_op_registry.h +++ b/tensorflow/core/framework/variant_op_registry.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_VARIANT_OP_REGISTRY_H_ -#define TENSORFLOW_FRAMEWORK_VARIANT_OP_REGISTRY_H_ +#ifndef TENSORFLOW_CORE_FRAMEWORK_VARIANT_OP_REGISTRY_H_ +#define TENSORFLOW_CORE_FRAMEWORK_VARIANT_OP_REGISTRY_H_ #include <string> #include <unordered_set> @@ -580,4 +580,4 @@ class UnaryVariantBinaryOpRegistration { } // end namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_VARIANT_OP_REGISTRY_H_ +#endif // TENSORFLOW_CORE_FRAMEWORK_VARIANT_OP_REGISTRY_H_ diff --git a/tensorflow/core/framework/variant_tensor_data.h b/tensorflow/core/framework/variant_tensor_data.h index 1d87bc341a..7500e77d43 100644 --- a/tensorflow/core/framework/variant_tensor_data.h +++ b/tensorflow/core/framework/variant_tensor_data.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_FRAMEWORK_VARIANT_TENSOR_DATA_H -#define TENSORFLOW_FRAMEWORK_VARIANT_TENSOR_DATA_H +#ifndef TENSORFLOW_CORE_FRAMEWORK_VARIANT_TENSOR_DATA_H_ +#define TENSORFLOW_CORE_FRAMEWORK_VARIANT_TENSOR_DATA_H_ #include <algorithm> #include <vector> @@ -112,4 +112,4 @@ string ProtoDebugString(const VariantTensorData& object); } // namespace tensorflow -#endif // TENSORFLOW_FRAMEWORK_VARIANT_TENSOR_DATA_H +#endif // TENSORFLOW_CORE_FRAMEWORK_VARIANT_TENSOR_DATA_H_ diff --git a/tensorflow/core/graph/algorithm.h b/tensorflow/core/graph/algorithm.h index 5bbbc6f6dc..45f8a29a92 100644 --- a/tensorflow/core/graph/algorithm.h +++ b/tensorflow/core/graph/algorithm.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_ALGORITHM_H_ -#define TENSORFLOW_GRAPH_ALGORITHM_H_ +#ifndef TENSORFLOW_CORE_GRAPH_ALGORITHM_H_ +#define TENSORFLOW_CORE_GRAPH_ALGORITHM_H_ #include <functional> #include <unordered_set> @@ -117,4 +117,4 @@ bool FixupSourceAndSinkEdges(Graph* g); } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_ALGORITHM_H_ +#endif // TENSORFLOW_CORE_GRAPH_ALGORITHM_H_ diff --git a/tensorflow/core/graph/colors.h b/tensorflow/core/graph/colors.h index c1e1940cac..43d2225571 100644 --- a/tensorflow/core/graph/colors.h +++ b/tensorflow/core/graph/colors.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_COLORS_H_ -#define TENSORFLOW_GRAPH_COLORS_H_ +#ifndef TENSORFLOW_CORE_GRAPH_COLORS_H_ +#define TENSORFLOW_CORE_GRAPH_COLORS_H_ namespace tensorflow { @@ -26,4 +26,4 @@ const char* ColorFor(int dindex); } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_COLORS_H_ +#endif // TENSORFLOW_CORE_GRAPH_COLORS_H_ diff --git a/tensorflow/core/graph/control_flow.h b/tensorflow/core/graph/control_flow.h index 548820720b..5abe77f5a1 100644 --- a/tensorflow/core/graph/control_flow.h +++ b/tensorflow/core/graph/control_flow.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_CONTROL_FLOW_H_ -#define TENSORFLOW_GRAPH_CONTROL_FLOW_H_ +#ifndef TENSORFLOW_CORE_GRAPH_CONTROL_FLOW_H_ +#define TENSORFLOW_CORE_GRAPH_CONTROL_FLOW_H_ #include <vector> @@ -48,4 +48,4 @@ Status BuildControlFlowInfo(const Graph* g, std::vector<ControlFlowInfo>* info, } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_CONTROL_FLOW_H_ +#endif // TENSORFLOW_CORE_GRAPH_CONTROL_FLOW_H_ diff --git a/tensorflow/core/graph/costmodel.h b/tensorflow/core/graph/costmodel.h index 9b703e4693..2d94dd5cdc 100644 --- a/tensorflow/core/graph/costmodel.h +++ b/tensorflow/core/graph/costmodel.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_COSTMODEL_H_ -#define TENSORFLOW_GRAPH_COSTMODEL_H_ +#ifndef TENSORFLOW_CORE_GRAPH_COSTMODEL_H_ +#define TENSORFLOW_CORE_GRAPH_COSTMODEL_H_ #include <unordered_map> #include <vector> @@ -229,4 +229,4 @@ class CostModel { } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_COSTMODEL_H_ +#endif // TENSORFLOW_CORE_GRAPH_COSTMODEL_H_ diff --git a/tensorflow/core/graph/default_device.h b/tensorflow/core/graph/default_device.h index 68d7c8e553..f0f53c91f4 100644 --- a/tensorflow/core/graph/default_device.h +++ b/tensorflow/core/graph/default_device.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_DEFAULT_DEVICE_H_ -#define TENSORFLOW_GRAPH_DEFAULT_DEVICE_H_ +#ifndef TENSORFLOW_CORE_GRAPH_DEFAULT_DEVICE_H_ +#define TENSORFLOW_CORE_GRAPH_DEFAULT_DEVICE_H_ #include <string> @@ -38,4 +38,4 @@ inline void SetDefaultDevice(const string& device, GraphDef* graph_def) { } // namespace graph } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_DEFAULT_DEVICE_H_ +#endif // TENSORFLOW_CORE_GRAPH_DEFAULT_DEVICE_H_ diff --git a/tensorflow/core/graph/graph.cc b/tensorflow/core/graph/graph.cc index 568f0870c0..1630ab7a15 100644 --- a/tensorflow/core/graph/graph.cc +++ b/tensorflow/core/graph/graph.cc @@ -483,7 +483,7 @@ const Edge* Graph::AddControlEdge(Node* source, Node* dest, void Graph::RemoveControlEdge(const Edge* e) { if (!e->src_->IsSource() && !e->dst_->IsSink()) { e->dst_->MaybeCopyOnWrite(); - std::string e_src_name = strings::StrCat("^", e->src_->name()); + string e_src_name = strings::StrCat("^", e->src_->name()); auto* inputs = e->dst_->props_->node_def.mutable_input(); for (auto it = inputs->begin(); it != inputs->end(); ++it) { if (*it == e_src_name) { @@ -495,6 +495,15 @@ void Graph::RemoveControlEdge(const Edge* e) { RemoveEdge(e); } +namespace { +const Edge* FindEdge(const Node* dst, int index) { + for (const Edge* e : dst->in_edges()) { + if (e->dst_input() == index) return e; + } + return nullptr; +} +} // namespace + Status Graph::UpdateEdge(Node* new_src, int new_src_index, Node* dst, int dst_index) { TF_RETURN_IF_ERROR(IsValidOutputTensor(new_src, new_src_index)); @@ -512,17 +521,6 @@ Status Graph::UpdateEdge(Node* new_src, int new_src_index, Node* dst, return Status::OK(); } -const Edge* Graph::FindEdge(const Node* dst, int index) { - for (const Edge* e : edges_) { - // edges_ will contain null edges if RemoveEdge() was called. - if (e == nullptr) continue; - if (e->dst() == dst && e->dst_input() == index) { - return e; - } - } - return nullptr; -} - Status Graph::AddFunctionLibrary(const FunctionDefLibrary& fdef_lib) { // Need a new-enough consumer to support the functions we add to the graph. if (fdef_lib.function_size() > 0 && versions_->min_consumer() < 12) { @@ -721,7 +719,7 @@ Status Graph::AddWhileContext(StringPiece frame_name, std::vector<OutputTensor> body_outputs, WhileContext** result) { auto pair = while_ctxs_.insert(std::pair<string, WhileContext>( - std::string(frame_name), + string(frame_name), WhileContext(frame_name, std::move(enter_nodes), std::move(exit_nodes), cond_output, std::move(body_inputs), std::move(body_outputs)))); diff --git a/tensorflow/core/graph/graph.h b/tensorflow/core/graph/graph.h index a147c94689..52e9f23a76 100644 --- a/tensorflow/core/graph/graph.h +++ b/tensorflow/core/graph/graph.h @@ -680,10 +680,6 @@ class Graph { // AddWhileContext() or Node::while_ctx(), but this manages the lifetime. std::map<string, WhileContext> while_ctxs_; - // Searches through edges_ for the Edge whose destination node and index - // matches dst. An edge with destination `dst` must exist in the graph. - const Edge* FindEdge(const Node* dst, int index); - TF_DISALLOW_COPY_AND_ASSIGN(Graph); }; diff --git a/tensorflow/core/graph/graph_constructor.cc b/tensorflow/core/graph/graph_constructor.cc index 8c73f8f712..ee10194142 100644 --- a/tensorflow/core/graph/graph_constructor.cc +++ b/tensorflow/core/graph/graph_constructor.cc @@ -513,7 +513,7 @@ Status GraphConstructor::InitFromEdges() { num_control_edges++; } else { TensorId id(ParseTensorName(input_name)); - if (next_iteration_nodes_.find(std::string(id.first)) != + if (next_iteration_nodes_.find(string(id.first)) != next_iteration_nodes_.end()) { has_loop_back_edge = true; } @@ -835,7 +835,7 @@ void GraphConstructor::UniquifyNames( // We require that UniquifyNames() is called on all NodeDefs in topological // order. This guarantees that node_def's inputs will already be uniquified // if necessary. - auto iter = uniquified_names_.find(std::string(id.first)); + auto iter = uniquified_names_.find(string(id.first)); if (iter == uniquified_names_.end()) continue; id.first = iter->second; node_def->set_input(i, id.ToString()); @@ -854,7 +854,7 @@ void GraphConstructor::UpdateUniquifiedColocationNames() { for (int i = 0; i < coloc_values.size(); ++i) { StringPiece val(coloc_values[i]); if (str_util::ConsumePrefix(&val, kColocationGroupPrefix)) { - const auto& name_pair = uniquified_names_.find(std::string(val)); + const auto& name_pair = uniquified_names_.find(string(val)); if (name_pair == uniquified_names_.end()) continue; updated = true; coloc_values[i] = @@ -880,7 +880,7 @@ bool GraphConstructor::NameExistsInGraphDef(StringPiece name) { } string GraphConstructor::FindUniqueName(StringPiece original_name) { - string name = std::string(original_name); + string name(original_name); int count = 0; // Check that any generated names don't collide with imported NodeDefs (as // well as nodes in g_). @@ -997,7 +997,7 @@ Status GraphConstructor::Convert() { src_node->num_outputs(), " outputs"); } - inputs.emplace_back(std::string(id.first), src_node, src_index); + inputs.emplace_back(string(id.first), src_node, src_index); } if (has_data_back_edge && !IsMerge(*node_def)) { diff --git a/tensorflow/core/graph/graph_constructor.h b/tensorflow/core/graph/graph_constructor.h index 889359a68a..f6e41faf9c 100644 --- a/tensorflow/core/graph/graph_constructor.h +++ b/tensorflow/core/graph/graph_constructor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_GRAPH_CONSTRUCTOR_H_ -#define TENSORFLOW_GRAPH_GRAPH_CONSTRUCTOR_H_ +#ifndef TENSORFLOW_CORE_GRAPH_GRAPH_CONSTRUCTOR_H_ +#define TENSORFLOW_CORE_GRAPH_GRAPH_CONSTRUCTOR_H_ #include "tensorflow/core/framework/graph.pb.h" #include "tensorflow/core/graph/graph.h" @@ -186,4 +186,4 @@ extern void CopyGraph(const Graph& src, Graph* dest); } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_GRAPH_CONSTRUCTOR_H_ +#endif // TENSORFLOW_CORE_GRAPH_GRAPH_CONSTRUCTOR_H_ diff --git a/tensorflow/core/graph/graph_constructor_test.cc b/tensorflow/core/graph/graph_constructor_test.cc index e338840eeb..73142ebde7 100644 --- a/tensorflow/core/graph/graph_constructor_test.cc +++ b/tensorflow/core/graph/graph_constructor_test.cc @@ -156,9 +156,8 @@ class GraphConstructorTest : public ::testing::Test { return ""; } StringPiece loc(value[0]); - return str_util::ConsumePrefix(&loc, kColocationGroupPrefix) - ? std::string(loc) - : ""; + return str_util::ConsumePrefix(&loc, kColocationGroupPrefix) ? string(loc) + : ""; } string GraphDebugString() const { diff --git a/tensorflow/core/graph/graph_def_builder.cc b/tensorflow/core/graph/graph_def_builder.cc index dd84c4f7c7..6d5df7efba 100644 --- a/tensorflow/core/graph/graph_def_builder.cc +++ b/tensorflow/core/graph/graph_def_builder.cc @@ -44,12 +44,12 @@ GraphDefBuilder::Options GraphDefBuilder::Options::WithControlInputs( } GraphDefBuilder::Options GraphDefBuilder::Options::WithNameImpl( StringPiece name) { - name_ = std::string(name); + name_ = string(name); return *this; } GraphDefBuilder::Options GraphDefBuilder::Options::WithDeviceImpl( StringPiece device) { - device_ = std::string(device); + device_ = string(device); return *this; } GraphDefBuilder::Options GraphDefBuilder::Options::WithControlInputImpl( diff --git a/tensorflow/core/graph/graph_def_builder.h b/tensorflow/core/graph/graph_def_builder.h index 0d6aae4355..400d8b6c84 100644 --- a/tensorflow/core/graph/graph_def_builder.h +++ b/tensorflow/core/graph/graph_def_builder.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_GRAPH_DEF_BUILDER_H_ -#define TENSORFLOW_GRAPH_GRAPH_DEF_BUILDER_H_ +#ifndef TENSORFLOW_CORE_GRAPH_GRAPH_DEF_BUILDER_H_ +#define TENSORFLOW_CORE_GRAPH_GRAPH_DEF_BUILDER_H_ #include <vector> #include "tensorflow/core/framework/graph.pb.h" @@ -128,7 +128,7 @@ class GraphDefBuilder { Options WithControlInputsImpl(gtl::ArraySlice<Node*> control_inputs); template <class T> Options WithAttrImpl(StringPiece name, T&& value) { - attrs_.emplace_back(std::string(name), AttrValue()); + attrs_.emplace_back(string(name), AttrValue()); SetAttrValue(std::forward<T>(value), &attrs_.back().second); return *this; } @@ -203,4 +203,4 @@ Node* BinaryOp(const string& op_name, NodeOut a, NodeOut b, } // namespace ops } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_GRAPH_DEF_BUILDER_H_ +#endif // TENSORFLOW_CORE_GRAPH_GRAPH_DEF_BUILDER_H_ diff --git a/tensorflow/core/graph/graph_partition.cc b/tensorflow/core/graph/graph_partition.cc index ea0a814ab8..1dbcebab59 100644 --- a/tensorflow/core/graph/graph_partition.cc +++ b/tensorflow/core/graph/graph_partition.cc @@ -793,7 +793,7 @@ Status TopologicalSortNodesWithTimePriority( for (int n = 0; n < gdef->node_size(); ++n) { const NodeDef* ndef = &gdef->node(n); for (int i = 0; i < ndef->input_size(); ++i) { - node_to_output_nodes[std::string(ParseTensorName(ndef->input(i)).first)] + node_to_output_nodes[string(ParseTensorName(ndef->input(i)).first)] .push_back(ndef); } int64 start_time; diff --git a/tensorflow/core/graph/graph_partition.h b/tensorflow/core/graph/graph_partition.h index 67fafddd51..8020c2d247 100644 --- a/tensorflow/core/graph/graph_partition.h +++ b/tensorflow/core/graph/graph_partition.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_GRAPH_PARTITION_H_ -#define TENSORFLOW_GRAPH_GRAPH_PARTITION_H_ +#ifndef TENSORFLOW_CORE_GRAPH_GRAPH_PARTITION_H_ +#define TENSORFLOW_CORE_GRAPH_GRAPH_PARTITION_H_ #include <functional> #include <string> @@ -95,4 +95,4 @@ Status AddControlEdges(const PartitionOptions& opts, } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_GRAPH_PARTITION_H_ +#endif // TENSORFLOW_CORE_GRAPH_GRAPH_PARTITION_H_ diff --git a/tensorflow/core/graph/mkl_layout_pass.cc b/tensorflow/core/graph/mkl_layout_pass.cc index 833592caab..7e501c1717 100644 --- a/tensorflow/core/graph/mkl_layout_pass.cc +++ b/tensorflow/core/graph/mkl_layout_pass.cc @@ -334,6 +334,7 @@ class MklLayoutRewritePass : public GraphOptimizationPass { rinfo_.push_back({csinfo_.conv2d_grad_input, mkl_op_registry::GetMklOpName(csinfo_.conv2d_grad_input), CopyAttrsConv2D, AlwaysRewrite, nullptr}); + rinfo_.push_back({csinfo_.fused_batch_norm, mkl_op_registry::GetMklOpName(csinfo_.fused_batch_norm), CopyAttrsFusedBatchNorm, AlwaysRewrite, nullptr}); @@ -546,14 +547,14 @@ class MklLayoutRewritePass : public GraphOptimizationPass { // If Op has been specifically assigned to a non-CPU device, then No. if (!n->assigned_device_name().empty() && - !str_util::StrContains(n->assigned_device_name(),kCPUDeviceSubStr)) { + !str_util::StrContains(n->assigned_device_name(), kCPUDeviceSubStr)) { result = false; reason = "Op has been assigned a runtime device that is not CPU."; } // If user has specifically assigned this op to a non-CPU device, then No. if (!n->def().device().empty() && - !str_util::StrContains(n->def().device(),kCPUDeviceSubStr)) { + !str_util::StrContains(n->def().device(), kCPUDeviceSubStr)) { result = false; reason = "User has assigned a device that is not CPU."; } @@ -2408,6 +2409,8 @@ class MklLayoutRewritePass : public GraphOptimizationPass { csinfo_.addn = "AddN"; csinfo_.avg_pool = "AvgPool"; csinfo_.avg_pool_grad = "AvgPoolGrad"; + csinfo_.avg_pool3d = "AvgPool3D"; + csinfo_.avg_pool3d_grad = "AvgPool3DGrad"; csinfo_.bias_add = "BiasAdd"; csinfo_.bias_add_grad = "BiasAddGrad"; csinfo_.concat = "Concat"; @@ -2429,6 +2432,8 @@ class MklLayoutRewritePass : public GraphOptimizationPass { csinfo_.matmul = "MatMul"; csinfo_.max_pool = "MaxPool"; csinfo_.max_pool_grad = "MaxPoolGrad"; + csinfo_.max_pool3d = "MaxPool3D"; + csinfo_.max_pool3d_grad = "MaxPool3DGrad"; csinfo_.mkl_conv2d = "_MklConv2D"; csinfo_.mkl_conv2d_grad_input = "_MklConv2DBackpropInput"; csinfo_.mkl_conv2d_grad_filter = "_MklConv2DBackpropFilter"; @@ -2463,6 +2468,12 @@ class MklLayoutRewritePass : public GraphOptimizationPass { rinfo_.push_back({csinfo_.avg_pool_grad, mkl_op_registry::GetMklOpName(csinfo_.avg_pool_grad), CopyAttrsPooling, AlwaysRewrite}); + rinfo_.push_back({csinfo_.avg_pool3d, + mkl_op_registry::GetMklOpName(csinfo_.avg_pool3d), + CopyAttrsPooling, AlwaysRewrite}); + rinfo_.push_back({csinfo_.avg_pool3d_grad, + mkl_op_registry::GetMklOpName(csinfo_.avg_pool3d_grad), + CopyAttrsPooling, AlwaysRewrite}); rinfo_.push_back({csinfo_.concat, mkl_op_registry::GetMklOpName(csinfo_.concat), CopyAttrsConcat, AlwaysRewrite}); @@ -2513,7 +2524,12 @@ class MklLayoutRewritePass : public GraphOptimizationPass { rinfo_.push_back({csinfo_.max_pool_grad, mkl_op_registry::GetMklOpName(csinfo_.max_pool_grad), CopyAttrsPooling, MaxpoolGradRewrite}); - + rinfo_.push_back({csinfo_.max_pool3d, + mkl_op_registry::GetMklOpName(csinfo_.max_pool3d), + CopyAttrsPooling, NonDepthBatchWisePoolRewrite}); + rinfo_.push_back({csinfo_.max_pool3d_grad, + mkl_op_registry::GetMklOpName(csinfo_.max_pool3d_grad), + CopyAttrsPooling, AlwaysRewrite}); rinfo_.push_back({csinfo_.maximum, mkl_op_registry::GetMklOpName(csinfo_.maximum), CopyAttrsDataType, AlwaysRewrite}); @@ -2550,6 +2566,8 @@ class MklLayoutRewritePass : public GraphOptimizationPass { // Add info about which ops to add workspace edge to and the slots. wsinfo_.push_back({csinfo_.lrn, csinfo_.lrn_grad, 0, 2, 1, 3}); wsinfo_.push_back({csinfo_.max_pool, csinfo_.max_pool_grad, 0, 1, 1, 3}); + wsinfo_.push_back + ({csinfo_.max_pool3d, csinfo_.max_pool3d_grad, 0, 1, 1, 3}); // Add a rule for merging nodes minfo_.push_back({csinfo_.conv2d, csinfo_.bias_add, @@ -2617,6 +2635,8 @@ class MklLayoutRewritePass : public GraphOptimizationPass { string add; string avg_pool; string avg_pool_grad; + string avg_pool3d; + string avg_pool3d_grad; string bias_add; string bias_add_grad; string concat; @@ -2637,6 +2657,8 @@ class MklLayoutRewritePass : public GraphOptimizationPass { string matmul; string max_pool; string max_pool_grad; + string max_pool3d; + string max_pool3d_grad; string maximum; string mkl_conv2d; string mkl_conv2d_grad_input; diff --git a/tensorflow/core/graph/mkl_layout_pass.h b/tensorflow/core/graph/mkl_layout_pass.h index ffe5c1ecfc..e7175149df 100644 --- a/tensorflow/core/graph/mkl_layout_pass.h +++ b/tensorflow/core/graph/mkl_layout_pass.h @@ -15,8 +15,8 @@ limitations under the License. // A graph pass that rewrites graph for propagating MKL layout as a tensor -#ifndef TENSORFLOW_GRAPH_MKL_LAYOUT_PASS_H_ -#define TENSORFLOW_GRAPH_MKL_LAYOUT_PASS_H_ +#ifndef TENSORFLOW_CORE_GRAPH_MKL_LAYOUT_PASS_H_ +#define TENSORFLOW_CORE_GRAPH_MKL_LAYOUT_PASS_H_ #ifdef INTEL_MKL @@ -33,4 +33,4 @@ extern bool RunMklLayoutRewritePass(std::unique_ptr<Graph>* g); #endif -#endif // TENSORFLOW_GRAPH_MKL_LAYOUT_PASS_H_ +#endif // TENSORFLOW_CORE_GRAPH_MKL_LAYOUT_PASS_H_ diff --git a/tensorflow/core/graph/mkl_tfconversion_pass.cc b/tensorflow/core/graph/mkl_tfconversion_pass.cc index aa39af637f..b67a321fc1 100644 --- a/tensorflow/core/graph/mkl_tfconversion_pass.cc +++ b/tensorflow/core/graph/mkl_tfconversion_pass.cc @@ -175,7 +175,11 @@ Status MklToTfConversionPass::InsertConversionNodeOnEdge( .Finalize(&**g, &conversion_node)); CHECK_NOTNULL(conversion_node); - if (GetNodeAttr(src->def(), "data_format", &data_format) == Status::OK()) { + // TODO(Intel-tf) MklToTf accepts only NHWC or NCHW, but doesn't seem to be + // using data_format. This code might be redundant. + if (GetNodeAttr(src->def(), "data_format", &data_format) == Status::OK() && + (data_format == ToString(FORMAT_NHWC) || + data_format == ToString(FORMAT_NCHW))) { conversion_node->AddAttr("data_format", data_format); } @@ -254,9 +258,13 @@ Status MklToTfConversionPass::InsertInputConversionNode( } } + // TODO(Intel-tf) MklInputConversion accepts only NHWC or NCHW, but doesn't + // seem to be using data_format. This code might be redundant. string data_format; if (GetNodeAttr(edges[0]->src()->def(), "data_format", &data_format) == - Status::OK()) { + Status::OK() && + (data_format == ToString(FORMAT_NHWC) || + data_format == ToString(FORMAT_NCHW))) { conversion_node->AddAttr("data_format", data_format); } diff --git a/tensorflow/core/graph/node_builder.cc b/tensorflow/core/graph/node_builder.cc index 03f3bbd663..a446e0d136 100644 --- a/tensorflow/core/graph/node_builder.cc +++ b/tensorflow/core/graph/node_builder.cc @@ -30,7 +30,7 @@ NodeBuilder::NodeOut::NodeOut(Node* n, int32 i) // NOLINT(runtime/explicit) dt(SafeGetOutput(node, i, &error)) {} NodeBuilder::NodeOut::NodeOut(StringPiece n, int32 i, DataType t) - : node(nullptr), error(false), name(std::string(n)), index(i), dt(t) {} + : node(nullptr), error(false), name(n), index(i), dt(t) {} NodeBuilder::NodeOut::NodeOut() : node(nullptr), error(true), index(0), dt(DT_FLOAT) {} diff --git a/tensorflow/core/graph/node_builder.h b/tensorflow/core/graph/node_builder.h index f6b7b5674b..4727ee7b56 100644 --- a/tensorflow/core/graph/node_builder.h +++ b/tensorflow/core/graph/node_builder.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_NODE_BUILDER_H_ -#define TENSORFLOW_GRAPH_NODE_BUILDER_H_ +#ifndef TENSORFLOW_CORE_GRAPH_NODE_BUILDER_H_ +#define TENSORFLOW_CORE_GRAPH_NODE_BUILDER_H_ #include <vector> #include "tensorflow/core/framework/node_def_builder.h" @@ -160,4 +160,4 @@ NodeBuilder& NodeBuilder::Attr(StringPiece attr_name, } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_NODE_BUILDER_H_ +#endif // TENSORFLOW_CORE_GRAPH_NODE_BUILDER_H_ diff --git a/tensorflow/core/graph/optimizer_cse.h b/tensorflow/core/graph/optimizer_cse.h index b8f3230c70..ef466fb788 100644 --- a/tensorflow/core/graph/optimizer_cse.h +++ b/tensorflow/core/graph/optimizer_cse.h @@ -15,8 +15,8 @@ limitations under the License. // An optimization pass that performs common subexpression elimination. -#ifndef TENSORFLOW_GRAPH_OPTIMIZER_CSE_H_ -#define TENSORFLOW_GRAPH_OPTIMIZER_CSE_H_ +#ifndef TENSORFLOW_CORE_GRAPH_OPTIMIZER_CSE_H_ +#define TENSORFLOW_CORE_GRAPH_OPTIMIZER_CSE_H_ #include <sys/types.h> #include "tensorflow/core/graph/graph.h" @@ -34,4 +34,4 @@ extern bool OptimizeCSE(Graph* g, } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_OPTIMIZER_CSE_H_ +#endif // TENSORFLOW_CORE_GRAPH_OPTIMIZER_CSE_H_ diff --git a/tensorflow/core/graph/quantize_training.h b/tensorflow/core/graph/quantize_training.h index 2bb4ee1cf0..dc3d7e3b1f 100644 --- a/tensorflow/core/graph/quantize_training.h +++ b/tensorflow/core/graph/quantize_training.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_QUANTIZE_TRAINING_H_ -#define TENSORFLOW_GRAPH_QUANTIZE_TRAINING_H_ +#ifndef TENSORFLOW_CORE_GRAPH_QUANTIZE_TRAINING_H_ +#define TENSORFLOW_CORE_GRAPH_QUANTIZE_TRAINING_H_ #include "tensorflow/core/graph/graph.h" @@ -53,4 +53,4 @@ Status DoQuantizeTrainingOnGraphDef(const GraphDef& input_graphdef, } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_QUANTIZE_TRAINING_H_ +#endif // TENSORFLOW_CORE_GRAPH_QUANTIZE_TRAINING_H_ diff --git a/tensorflow/core/graph/subgraph.h b/tensorflow/core/graph/subgraph.h index ba35846d93..3e99ff0c8c 100644 --- a/tensorflow/core/graph/subgraph.h +++ b/tensorflow/core/graph/subgraph.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_SUBGRAPH_H_ -#define TENSORFLOW_GRAPH_SUBGRAPH_H_ +#ifndef TENSORFLOW_CORE_GRAPH_SUBGRAPH_H_ +#define TENSORFLOW_CORE_GRAPH_SUBGRAPH_H_ #include <string> @@ -162,4 +162,4 @@ class SendFetchRewrite : public PruneRewrite { } // namespace subgraph } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_SUBGRAPH_H_ +#endif // TENSORFLOW_CORE_GRAPH_SUBGRAPH_H_ diff --git a/tensorflow/core/graph/tensor_id.cc b/tensorflow/core/graph/tensor_id.cc index 80c76df255..5a5b85e727 100644 --- a/tensorflow/core/graph/tensor_id.cc +++ b/tensorflow/core/graph/tensor_id.cc @@ -25,7 +25,7 @@ namespace tensorflow { TensorId::TensorId(const SafeTensorId& id) : TensorId(id.first, id.second) {} SafeTensorId::SafeTensorId(const TensorId& id) - : SafeTensorId(id.first.ToString(), id.second) {} + : SafeTensorId(string(id.first), id.second) {} TensorId ParseTensorName(const string& name) { return ParseTensorName(StringPiece(name.data(), name.size())); diff --git a/tensorflow/core/graph/testlib.h b/tensorflow/core/graph/testlib.h index eb9038d619..8585b35a19 100644 --- a/tensorflow/core/graph/testlib.h +++ b/tensorflow/core/graph/testlib.h @@ -15,8 +15,8 @@ limitations under the License. // DEPRECATED: Use the C++ API defined in tensorflow/cc instead. -#ifndef TENSORFLOW_GRAPH_TESTLIB_H_ -#define TENSORFLOW_GRAPH_TESTLIB_H_ +#ifndef TENSORFLOW_CORE_GRAPH_TESTLIB_H_ +#define TENSORFLOW_CORE_GRAPH_TESTLIB_H_ #include <string> #include <vector> @@ -213,4 +213,4 @@ Node* DiagPart(Graph* g, Node* in, DataType type); } // end namespace test } // end namespace tensorflow -#endif // TENSORFLOW_GRAPH_TESTLIB_H_ +#endif // TENSORFLOW_CORE_GRAPH_TESTLIB_H_ diff --git a/tensorflow/core/graph/types.h b/tensorflow/core/graph/types.h index c707809927..ac5a7f8229 100644 --- a/tensorflow/core/graph/types.h +++ b/tensorflow/core/graph/types.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_TYPES_H_ -#define TENSORFLOW_GRAPH_TYPES_H_ +#ifndef TENSORFLOW_CORE_GRAPH_TYPES_H_ +#define TENSORFLOW_CORE_GRAPH_TYPES_H_ #include "tensorflow/core/lib/gtl/int_type.h" #include "tensorflow/core/platform/types.h" @@ -32,4 +32,4 @@ TF_LIB_GTL_DEFINE_INT_TYPE(Bytes, int64); } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_TYPES_H_ +#endif // TENSORFLOW_CORE_GRAPH_TYPES_H_ diff --git a/tensorflow/core/graph/while_context.cc b/tensorflow/core/graph/while_context.cc index 1b38aac35d..8e89bc4c75 100644 --- a/tensorflow/core/graph/while_context.cc +++ b/tensorflow/core/graph/while_context.cc @@ -23,7 +23,7 @@ WhileContext::WhileContext(StringPiece frame_name, OutputTensor cond_output, std::vector<OutputTensor> body_inputs, std::vector<OutputTensor> body_outputs) - : frame_name_(std::string(frame_name)), + : frame_name_(frame_name), enter_nodes_(std::move(enter_nodes)), exit_nodes_(std::move(exit_nodes)), cond_output_(cond_output), diff --git a/tensorflow/core/graph/while_context.h b/tensorflow/core/graph/while_context.h index 2a83eb7bd8..5405e62be2 100644 --- a/tensorflow/core/graph/while_context.h +++ b/tensorflow/core/graph/while_context.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_GRAPH_WHILE_CONTEXT_H_ -#define TENSORFLOW_GRAPH_WHILE_CONTEXT_H_ +#ifndef TENSORFLOW_CORE_GRAPH_WHILE_CONTEXT_H_ +#define TENSORFLOW_CORE_GRAPH_WHILE_CONTEXT_H_ #include "tensorflow/core/graph/graph.h" @@ -73,4 +73,4 @@ class WhileContext { } // namespace tensorflow -#endif // TENSORFLOW_GRAPH_GRAPH_H_ +#endif // TENSORFLOW_CORE_GRAPH_WHILE_CONTEXT_H_ diff --git a/tensorflow/core/grappler/clusters/cluster.cc b/tensorflow/core/grappler/clusters/cluster.cc index 6ca379323e..7171ae059b 100644 --- a/tensorflow/core/grappler/clusters/cluster.cc +++ b/tensorflow/core/grappler/clusters/cluster.cc @@ -81,6 +81,8 @@ void Cluster::DisableOptimizer(bool disable) { rewriter_config->set_dependency_optimization(RewriterConfig::OFF); rewriter_config->set_constant_folding(RewriterConfig::OFF); rewriter_config->set_memory_optimization(RewriterConfig::NO_MEM_OPT); + rewriter_config->set_shape_optimization(RewriterConfig::OFF); + rewriter_config->set_remapping(RewriterConfig::OFF); rewriter_config->mutable_auto_parallel()->set_enable(false); rewriter_config->clear_optimizers(); } else { diff --git a/tensorflow/core/grappler/clusters/virtual_cluster.cc b/tensorflow/core/grappler/clusters/virtual_cluster.cc index 12e3e46f65..f543dca49e 100644 --- a/tensorflow/core/grappler/clusters/virtual_cluster.cc +++ b/tensorflow/core/grappler/clusters/virtual_cluster.cc @@ -45,6 +45,8 @@ VirtualCluster::VirtualCluster(const DeviceSet* device_set) for (const auto& device : device_set_->devices()) { DeviceProperties props = GetDeviceInfo(device->parsed_name()); if (props.type() == "UNKNOWN") continue; + auto attrs = device->attributes(); + props.set_memory_size(attrs.memory_limit()); devices_[device->name()] = props; } } diff --git a/tensorflow/core/grappler/costs/analytical_cost_estimator.cc b/tensorflow/core/grappler/costs/analytical_cost_estimator.cc index a60e3c7a9f..0690640ffa 100644 --- a/tensorflow/core/grappler/costs/analytical_cost_estimator.cc +++ b/tensorflow/core/grappler/costs/analytical_cost_estimator.cc @@ -18,6 +18,7 @@ limitations under the License. #include <limits> #include <unordered_map> +#include "tensorflow/core/framework/tensor.pb.h" // NOLINT #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/graph/types.h" #include "tensorflow/core/grappler/costs/graph_properties.h" diff --git a/tensorflow/core/grappler/costs/graph_memory.cc b/tensorflow/core/grappler/costs/graph_memory.cc index a5736d40b1..b01aca610a 100644 --- a/tensorflow/core/grappler/costs/graph_memory.cc +++ b/tensorflow/core/grappler/costs/graph_memory.cc @@ -20,6 +20,7 @@ limitations under the License. #include "tensorflow/core/framework/attr_value.pb.h" #include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/framework/step_stats.pb.h" +#include "tensorflow/core/framework/tensor.pb.h" // NOLINT #include "tensorflow/core/framework/tensor_description.pb.h" #include "tensorflow/core/framework/tensor_shape.h" #include "tensorflow/core/framework/tensor_shape.pb.h" diff --git a/tensorflow/core/grappler/costs/graph_properties.cc b/tensorflow/core/grappler/costs/graph_properties.cc index 231c7c63be..6710ff9df3 100644 --- a/tensorflow/core/grappler/costs/graph_properties.cc +++ b/tensorflow/core/grappler/costs/graph_properties.cc @@ -21,6 +21,7 @@ limitations under the License. #include "tensorflow/core/framework/common_shape_fns.h" #include "tensorflow/core/framework/function.pb.h" #include "tensorflow/core/framework/node_def_util.h" +#include "tensorflow/core/framework/tensor.pb.h" #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/framework/versions.pb.h" #include "tensorflow/core/graph/graph_constructor.h" @@ -804,8 +805,9 @@ class SymbolicShapeRefiner { CHECK_NOTNULL(function_library_.Find(function_node->op())); GrapplerFunctionItem grappler_function_item; - TF_RETURN_IF_ERROR(MakeGrapplerFunctionItem( - *function_def, function_library_, &grappler_function_item)); + TF_RETURN_IF_ERROR( + MakeGrapplerFunctionItem(*function_def, function_library_, + graph_def_version_, &grappler_function_item)); if (grappler_function_item.inputs().size() > function_node->input_size()) { return errors::FailedPrecondition( diff --git a/tensorflow/core/grappler/costs/graph_properties_test.cc b/tensorflow/core/grappler/costs/graph_properties_test.cc index 5acfb56b05..8938b7c32e 100644 --- a/tensorflow/core/grappler/costs/graph_properties_test.cc +++ b/tensorflow/core/grappler/costs/graph_properties_test.cc @@ -18,8 +18,10 @@ limitations under the License. #include "tensorflow/cc/ops/standard_ops.h" #include "tensorflow/core/framework/graph_def_util.h" #include "tensorflow/core/framework/node_def_builder.h" +#include "tensorflow/core/framework/tensor.pb.h" // NOLINT #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/framework/tensor_testutil.h" +#include "tensorflow/core/framework/versions.pb.h" #include "tensorflow/core/grappler/clusters/single_machine.h" #include "tensorflow/core/grappler/grappler_item.h" #include "tensorflow/core/grappler/inputs/trivial_test_graph_input_yielder.h" @@ -783,6 +785,46 @@ TEST_F(GraphPropertiesTest, InferRestoreOpShape_WithTwoNodesShareSameOutput) { EXPECT_EQ("float: [128,256]", PropToString(prop)); } +TEST_F(GraphPropertiesTest, FunctionWithScalarInputTest) { + // Create graph with a function that takes a scalar value so that we use + // Placeholder with scalar as for input to the function shape inference. + // Placeholder -> Identity -> MyFunc, where MyFunc simply takes Identity of + // the input; all tensors are scalars. + FunctionDefLibrary library; + *library.add_function() = FunctionDefHelper::Create( + "MyFunc", // Name + {"x: float"}, // Inputs + {"out: float"}, // Outputs + {}, // Attrs + {{{"a"}, "Identity", {"x"}, {{"T", DataType::DT_FLOAT}}}}, // Nodes + {{"out", "a:output:0"}}); // Returns + tensorflow::Scope s = tensorflow::Scope::NewRootScope(); + TF_CHECK_OK(s.graph()->AddFunctionLibrary(library)); + Output placeholder = + ops::Placeholder(s.WithOpName("Placeholder"), DataType::DT_FLOAT, + ops::Placeholder::Shape(TensorShape({}))); + Output identity = ops::Identity(s.WithOpName("Identity"), placeholder); + auto _identity = tensorflow::ops::AsNodeOut(s, identity); + auto builder = + tensorflow::NodeBuilder("MyFunc", "MyFunc", s.graph()->op_registry()); + tensorflow::Node* func_op; + TF_CHECK_OK(builder.Input(_identity).Finalize(s.graph(), &func_op)); + GrapplerItem item; + TF_CHECK_OK(s.ToGraphDef(&item.graph)); + + // Tensorflow version < 21 infers output shape of Placeholder with empty shape + // as unknown, instead of scalar. + EXPECT_GT(item.graph.versions().producer(), 21); + + // MyFunc output shouldn't be unknown rank. + GraphProperties properties(item); + TF_CHECK_OK(properties.InferStatically(false)); + const auto out_props = properties.GetOutputProperties("MyFunc"); + const OpInfo::TensorProperties out_prop0 = out_props[0]; + EXPECT_EQ(DT_FLOAT, out_prop0.dtype()); + EXPECT_FALSE(out_prop0.shape().unknown_rank()); +} + TEST_F(GraphPropertiesTest, SimpleFunctionStaticShapeInference) { // Test graph produced in python using: /* diff --git a/tensorflow/core/grappler/costs/op_level_cost_estimator.cc b/tensorflow/core/grappler/costs/op_level_cost_estimator.cc index 0341d7f8e1..71f4d9fd05 100644 --- a/tensorflow/core/grappler/costs/op_level_cost_estimator.cc +++ b/tensorflow/core/grappler/costs/op_level_cost_estimator.cc @@ -18,6 +18,7 @@ limitations under the License. #include "third_party/eigen3/Eigen/Core" #include "tensorflow/core/framework/attr_value.pb.h" #include "tensorflow/core/framework/attr_value_util.h" +#include "tensorflow/core/framework/tensor.pb.h" #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/framework/types.h" #include "tensorflow/core/grappler/clusters/utils.h" diff --git a/tensorflow/core/grappler/costs/op_level_cost_estimator_test.cc b/tensorflow/core/grappler/costs/op_level_cost_estimator_test.cc index 9e579098ef..998bd59dce 100644 --- a/tensorflow/core/grappler/costs/op_level_cost_estimator_test.cc +++ b/tensorflow/core/grappler/costs/op_level_cost_estimator_test.cc @@ -17,6 +17,7 @@ limitations under the License. #include "tensorflow/core/framework/attr_value.pb.h" #include "tensorflow/core/framework/attr_value_util.h" #include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/framework/tensor.pb.h" #include "tensorflow/core/framework/tensor_shape.h" #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/framework/types.h" diff --git a/tensorflow/core/grappler/costs/utils.cc b/tensorflow/core/grappler/costs/utils.cc index be54d98534..aad00ce039 100644 --- a/tensorflow/core/grappler/costs/utils.cc +++ b/tensorflow/core/grappler/costs/utils.cc @@ -99,7 +99,7 @@ static void ExtractExtraProperties( continue; } TensorId input_tensor_id = ParseTensorName(input_name); - const string input_node_name = input_tensor_id.first.ToString(); + const string input_node_name(input_tensor_id.first); auto iter = name_to_node.find(input_node_name); if (iter == name_to_node.end()) continue; @@ -172,7 +172,7 @@ std::vector<OpInfo::TensorProperties> FindInputFeatures( for (const auto& input_name : node.input()) { CHECK(!input_name.empty()); TensorId input_tensor_id = ParseTensorName(input_name); - const string input_node_name = input_tensor_id.first.ToString(); + const string input_node_name(input_tensor_id.first); const int output_index = input_tensor_id.second; // Skip control inputs. diff --git a/tensorflow/core/grappler/costs/virtual_scheduler.cc b/tensorflow/core/grappler/costs/virtual_scheduler.cc index 6e3ebdee12..037a823096 100644 --- a/tensorflow/core/grappler/costs/virtual_scheduler.cc +++ b/tensorflow/core/grappler/costs/virtual_scheduler.cc @@ -880,10 +880,15 @@ Costs VirtualScheduler::Summary() const { // Print per device summary VLOG(1) << "Devices:"; Costs critical_path_costs = Costs::ZeroCosts(); + std::vector<string> device_names; + device_names.reserve(device_.size()); + for (auto& it : device_) { + device_names.push_back(it.first); + } + std::sort(device_names.begin(), device_names.end()); - for (const auto& device : device_) { - const auto& name = device.first; - const auto& state = device.second; + for (const auto& name : device_names) { + const auto& state = device_.at(name); std::map<string, int64> op_to_memory; // First profile only persistent memory usage. diff --git a/tensorflow/core/grappler/costs/virtual_scheduler_test.cc b/tensorflow/core/grappler/costs/virtual_scheduler_test.cc index b1373d8317..02a379fca8 100644 --- a/tensorflow/core/grappler/costs/virtual_scheduler_test.cc +++ b/tensorflow/core/grappler/costs/virtual_scheduler_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/core/grappler/costs/virtual_scheduler.h" #include "tensorflow/cc/ops/standard_ops.h" +#include "tensorflow/core/framework/tensor.pb.h" // NOLINT #include "tensorflow/core/framework/tensor_description.pb.h" #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/grappler/clusters/virtual_cluster.h" diff --git a/tensorflow/core/grappler/graph_analyzer/BUILD b/tensorflow/core/grappler/graph_analyzer/BUILD new file mode 100644 index 0000000000..d56a08d3c8 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/BUILD @@ -0,0 +1,139 @@ +licenses(["notice"]) # Apache 2.0 + +load("//tensorflow:tensorflow.bzl", "tf_cc_test") + +cc_library( + name = "graph_analyzer_lib", + srcs = [ + "gen_node.cc", + "graph_analyzer.cc", + "sig_node.cc", + "subgraph.cc", + ], + hdrs = [ + "gen_node.h", + "graph_analyzer.h", + "hash_tools.h", + "map_tools.h", + "sig_node.h", + "subgraph.h", + ], + visibility = ["//visibility:public"], + deps = [ + "//tensorflow/core:framework", + "//tensorflow/core:lib", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:tensorflow", + "//tensorflow/core/grappler:op_types", + "//tensorflow/core/grappler:utils", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", + ], +) + +cc_library( + name = "graph_analyzer_tool", + srcs = ["graph_analyzer_tool.cc"], + hdrs = ["graph_analyzer_tool.h"], + visibility = ["//visibility:public"], + deps = [ + ":graph_analyzer_lib", + "//tensorflow/core:lib", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:tensorflow", + "//tensorflow/core/grappler:grappler_item", + "@com_google_absl//absl/strings", + ], +) + +cc_library( + name = "test_tools_lib", + testonly = 1, + srcs = [ + "test_tools.cc", + ], + hdrs = [ + "test_tools.h", + ], + visibility = ["//visibility:public"], + deps = [ + ":graph_analyzer_lib", + "//tensorflow/core:framework", + "//tensorflow/core:tensorflow", + "//tensorflow/core/grappler:op_types", + "@com_google_absl//absl/strings", + "@com_google_absl//absl/strings:str_format", + ], +) + +tf_cc_test( + name = "hash_tools_test", + testonly = 1, + srcs = [ + "hash_tools_test.cc", + ], + deps = [ + ":graph_analyzer_lib", + "@com_google_googletest//:gtest_main", + ], +) + +tf_cc_test( + name = "gen_node_test", + testonly = 1, + srcs = [ + "gen_node_test.cc", + ], + deps = [ + ":graph_analyzer_lib", + ":test_tools_lib", + "@com_google_absl//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +tf_cc_test( + name = "sig_node_test", + testonly = 1, + srcs = [ + "sig_node_test.cc", + ], + deps = [ + ":graph_analyzer_lib", + ":test_tools_lib", + "//tensorflow/core/grappler:utils", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings:str_format", + "@com_google_googletest//:gtest_main", + ], +) + +tf_cc_test( + name = "graph_analyzer_test", + testonly = 1, + srcs = [ + "graph_analyzer_test.cc", + ], + deps = [ + ":graph_analyzer_lib", + ":test_tools_lib", + "@com_google_absl//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +tf_cc_test( + name = "subgraph_test", + testonly = 1, + srcs = [ + "subgraph_test.cc", + ], + deps = [ + ":graph_analyzer_lib", + ":test_tools_lib", + "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings:str_format", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/tensorflow/core/grappler/graph_analyzer/gen_node.cc b/tensorflow/core/grappler/graph_analyzer/gen_node.cc new file mode 100644 index 0000000000..f8c15fd50e --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/gen_node.cc @@ -0,0 +1,148 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/graph_analyzer/gen_node.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" +#include "tensorflow/core/framework/op.h" +#include "tensorflow/core/grappler/graph_analyzer/hash_tools.h" +#include "tensorflow/core/grappler/op_types.h" +#include "tensorflow/core/grappler/utils.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +GenNode::GenNode(const NodeDef* node) : node_(node), op_(nullptr) {} + +Status GenNode::BuildGraphInMap(const GraphDef& source, GenNodeMap* map) { + for (const auto& n : source.node()) { + const string& name = n.name(); + if (map->find(name) != map->end()) { + // This error code looks more meaningful than ALREADY_EXISTS. + return Status(error::INVALID_ARGUMENT, + "Duplicate node name '" + name + "'."); + } + (*map)[name] = absl::make_unique<GenNode>(&n); + } + // Now parse the links. + for (const auto& mapit : *map) { + Status st = mapit.second->ParseInputs(map); + if (!st.ok()) { + return st; + } + } + return Status::OK(); +} + +Status GenNode::ParseInputs(const GenNodeMap* map) { + all_inputs_or_none_ = false; + Status st = OpRegistry::Global()->LookUpOpDef(opcode(), &op_); + if (!st.ok()) { + return Status( + error::INVALID_ARGUMENT, + absl::StrFormat("Node '%s' contains an undefined operation '%s': %s", + name(), opcode(), st.error_message())); + } + + int n_inputs = node_->input_size(); + + int n_named_inputs = op_->input_arg_size(); + + int n_multi_inputs = 0; + for (const auto& inarg : op_->input_arg()) { + if (!inarg.number_attr().empty() || !inarg.type_list_attr().empty()) { + ++n_multi_inputs; + } + } + bool is_commutative = grappler::IsCommutative(*node_); + + if (n_multi_inputs > 1 || (n_multi_inputs > 0 && n_named_inputs > 1)) { + // Can't handle more than one multi-input at a time. + // And can't handle the commutativeness of only some arguments + // rather than all of them. + is_commutative = false; + } + + if (is_commutative) { + // If truly commutative, can treat all the inputs as one multi-input. + // It's possible to just treat the commutative nodes as AllInputsOrNone + // but (1) this way is a bit more efficient and (2) I want to preserve this + // more efficient code path that does all-or-none by a single input and + // perhaps extend its use in the future. + n_named_inputs = 1; + all_inputs_or_none_ = false; + } else if (n_multi_inputs > 0) { + all_inputs_or_none_ = true; + } + + for (int i = 0; i < n_inputs; ++i) { + int other_position; + string other_name = ParseNodeName(node_->input(i), &other_position); + auto other_it = map->find(other_name); + if (other_it == map->end()) { + return Status( + error::INVALID_ARGUMENT, + absl::StrFormat( + "Node '%s' input %d refers to a non-existing node '%s'.", name(), + i, other_name)); + } + GenNode* other_node = other_it->second.get(); + + int this_position = other_position < 0 ? -1 : (is_commutative ? 0 : i); + + if (this_position >= 0 && n_multi_inputs == 0 && + this_position >= n_named_inputs) { + return Status( + error::INVALID_ARGUMENT, + absl::StrFormat( + "Node '%s' has a non-control input from '%s' at index %d but its " + "operation '%s' defines only %d inputs.", + name(), other_name, this_position, op_->name(), n_named_inputs)); + } + + Port this_port(/*inbound=*/true, this_position); + Port other_port(/*inbound=*/false, other_position); + + links_[this_port].emplace_back(LinkTarget(other_node, other_port)); + other_node->links_[other_port].emplace_back(LinkTarget(this, this_port)); + } + return Status::OK(); +} + +bool GenNode::IsMultiInput(Port port) const { + if (!port.IsInbound()) { + return false; + } + auto it = links_.find(port); + if (it == links_.end()) { + return false; // Shouldn't happen. + } + return (it->second.size() > 1); +} + +GenNode::Port::operator string() const { + string result = this->IsInbound() ? "i" : "o"; + if (this->IsControl()) { + result.append("C"); + } else { + result.append(absl::StrFormat("%d", this->Id())); + } + return result; +} + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/gen_node.h b/tensorflow/core/grappler/graph_analyzer/gen_node.h new file mode 100644 index 0000000000..faec9ecad8 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/gen_node.h @@ -0,0 +1,167 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_GEN_NODE_H_ +#define TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_GEN_NODE_H_ + +#include <map> +#include <memory> +#include <vector> + +#include "tensorflow/core/framework/graph.pb.h" +#include "tensorflow/core/framework/node_def.pb.h" +#include "tensorflow/core/framework/op_def.pb.h" +#include "tensorflow/core/lib/core/status.h" +#include "tensorflow/core/protobuf/meta_graph.pb.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +class GenNode; + +// To find nodes by name. +using GenNodeMap = std::unordered_map<string, std::unique_ptr<GenNode>>; + +// One node in the graph, in the form convenient for traversal and generation of +// subgraphs. It refers to the original NodeDef protobuf for most information +// and adds the extra enrichment. +// +// The graph building is 2-stage: first match a GenNode with each NodeDef and +// collect them into a map that finds them by name, then process the map, +// deep-parse the underlying NodeDefs and connect the GenNodes together. +class GenNode { + public: + // Will keep the pointer, so the underlying object must not be deleted while + // GenNode is alive. + explicit GenNode(const NodeDef* node); + + // Access wrappers. + const string& name() const { return node_->name(); } + const string& opcode() const { return node_->op(); } + const NodeDef* node_def() const { return node_; } + + // Parse the inputs of this node and update the map accordingly, creating the + // links (i.e. edges, connections between nodes) in itself and in the nodes + // it's linked to (the map itself is unchanged, only the nodes in it are + // updated). + Status ParseInputs(const GenNodeMap* map); + + // Does the full 2-stage build of the graph. The map should be initially + // empty. The map keeps pointers to the nodes in source, so the source must + // not be destroyed before the map. + static Status BuildGraphInMap(const GraphDef& source, GenNodeMap* map); + + // The enrichment that constitutes the point of this class. + + // Representation of a connection on a node. + class Port { + public: + // A port may be inbound or outbound. + // Negative ids (canonically -1) mean a control port. + Port(bool inbound, int32_t id) : value_(id << 1) { + if (inbound) { + value_ |= 1; + } + } + Port(const Port&) = default; + Port& operator=(const Port&) = default; + + bool IsInbound() const { return (value_ & 0x1); } + + bool IsControl() const { return (value_ < 0); } + + int32_t Id() const { + // Arithmetic shift preserves the sign. + return (value_ >> 1); + } + + // Integer type used to represent the encoded port value. + using IntPort = int32_t; + + // Returns the encoded form of this port, so that it can be used + // as various map indexes. + IntPort Encoded() const { return value_; } + + static Port Decode(IntPort encoded) { return Port(encoded); } + + bool operator==(const Port& other) const { return value_ == other.value_; } + bool operator<(const Port& other) const { return value_ < other.value_; } + + struct Hasher { + size_t operator()(const Port& port) const noexcept { + return hasher(port.Encoded()); + } + std::hash<int32_t> hasher; + }; + + // Convenient for printing. I've really wanted it to be implicit but + // ClangTidy insists on making it explicit. + explicit operator string() const; + + private: + explicit Port(IntPort value) : value_(value) {} + + IntPort value_; + }; + + struct LinkTarget { + GenNode* node; // Node where this link points. + Port port; // Port on the remote side of this link. + + LinkTarget(GenNode* a_node, Port a_port) : node(a_node), port(a_port) {} + }; + // All the links that are connected to the same port of this node + // are collected in one vector. A link is an edge of the graph that connects + // 2 nodes. Each of the connected nodes has its own perspective on the link, + // seeing its local port, remote port and the remote node. The direction of + // the link is encoded in the ports, one port is always incoming and another + // one outgoing. + using LinkTargetVector = std::vector<LinkTarget>; + // Both inputs and outputs are stored in the same map. + using LinkMap = std::unordered_map<Port, LinkTargetVector, Port::Hasher>; + + // Access to the link map. + const LinkMap& links() const { return links_; } + + // Check whether the port is an input (including the controls) with multiple + // connections. Such inputs get handled in a special way when building the + // subgraphs, in an "all or nothing" fashion. + bool IsMultiInput(Port port) const; + + // When building the subgraphs, must include either all non-control inputs of + // this node into the subgraph or none of them. This happens when at least one + // of the inputs is a multi-input (or if the opcode is commutative, thus + // treating all the inputs as one multi-input). + bool AllInputsOrNone() const { return all_inputs_or_none_; } + + private: + const NodeDef* node_; + // Becomes valid only after ParseInputs(). + const OpDef* op_; + + // The opcode has a complicated structure of input args, with multi-input args + // that are not commutative. This means that to make sense, the subgraphs that + // include this node must also include either all its inputs or none of them. + bool all_inputs_or_none_ = false; + + LinkMap links_; +}; + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow + +#endif // TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_GEN_NODE_H_ diff --git a/tensorflow/core/grappler/graph_analyzer/gen_node_test.cc b/tensorflow/core/grappler/graph_analyzer/gen_node_test.cc new file mode 100644 index 0000000000..d77daf7849 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/gen_node_test.cc @@ -0,0 +1,491 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/graph_analyzer/gen_node.h" + +#include <gmock/gmock.h> +#include <gtest/gtest.h> +#include "absl/memory/memory.h" +#include "tensorflow/core/grappler/graph_analyzer/test_tools.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { +namespace test { +namespace { + +using ::testing::ElementsAre; +using ::testing::Eq; +using ::testing::Ne; + +TEST(GenNodeTest, Port) { + { + GenNode::Port p(true, 100); + EXPECT_THAT(p.IsInbound(), Eq(true)); + EXPECT_THAT(p.IsControl(), Eq(false)); + EXPECT_THAT(p.Id(), Eq(100)); + GenNode::Port p2 = GenNode::Port::Decode(p.Encoded()); + EXPECT_THAT(p2.IsInbound(), Eq(true)); + EXPECT_THAT(p2.IsControl(), Eq(false)); + EXPECT_THAT(p2.Id(), Eq(100)); + } + { + GenNode::Port p(false, 0); + EXPECT_THAT(p.IsInbound(), Eq(false)); + EXPECT_THAT(p.IsControl(), Eq(false)); + EXPECT_THAT(p.Id(), Eq(0)); + GenNode::Port p2 = GenNode::Port::Decode(p.Encoded()); + EXPECT_THAT(p2.IsInbound(), Eq(false)); + EXPECT_THAT(p2.IsControl(), Eq(false)); + EXPECT_THAT(p2.Id(), Eq(0)); + } + { + GenNode::Port p(true, -100); + EXPECT_THAT(p.IsInbound(), Eq(true)); + EXPECT_THAT(p.IsControl(), Eq(true)); + EXPECT_THAT(p.Id(), Eq(-100)); + GenNode::Port p2 = GenNode::Port::Decode(p.Encoded()); + EXPECT_THAT(p2.IsInbound(), Eq(true)); + EXPECT_THAT(p2.IsControl(), Eq(true)); + EXPECT_THAT(p2.Id(), Eq(-100)); + } + { + GenNode::Port p(false, -1); + EXPECT_THAT(p.IsInbound(), Eq(false)); + EXPECT_THAT(p.IsControl(), Eq(true)); + EXPECT_THAT(p.Id(), Eq(-1)); + GenNode::Port p2 = GenNode::Port::Decode(p.Encoded()); + EXPECT_THAT(p2.IsInbound(), Eq(false)); + EXPECT_THAT(p2.IsControl(), Eq(true)); + EXPECT_THAT(p2.Id(), Eq(-1)); + } +} + +TEST(GenNodeTest, ParseNodeNoInputs) { + GenNodeMap map; + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + + auto gn1 = map["node1"].get(); + ASSERT_THAT(gn1->ParseInputs(&map), Eq(Status::OK())); + EXPECT_THAT(DumpLinkMap(gn1->links()), ElementsAre()); +} + +// A general operation, and a control link. +TEST(GenNodeTest, ParseNodeWithControl) { + GenNodeMap map; + + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + + NodeDef node2 = MakeNodeConst("node2"); + map["node2"] = absl::make_unique<GenNode>(&node2); + + NodeDef node3 = MakeNodeSub("node3", "node1", "node2"); + node3.add_input("^node1"); // The control link. + node3.add_input("^node2"); // The control link. + map["node3"] = absl::make_unique<GenNode>(&node3); + + auto gn1 = map["node1"].get(); + auto gn2 = map["node2"].get(); + auto gn3 = map["node3"].get(); + ASSERT_THAT(gn3->ParseInputs(&map), Eq(Status::OK())); + // clang-format off + EXPECT_THAT(DumpLinkMap(gn1->links()), ElementsAre( + "o0: node3[i0]", + "oC: node3[iC]" + )); + EXPECT_THAT(DumpLinkMap(gn2->links()), ElementsAre( + "o0: node3[i1]", + "oC: node3[iC]" + )); + EXPECT_THAT(DumpLinkMap(gn3->links()), ElementsAre( + "i0: node1[o0]", + "i1: node2[o0]", + "iC: node1[oC], node2[oC]" + )); + // clang-format on + + EXPECT_THAT(gn3->IsMultiInput(GenNode::Port(true, 0)), Eq(false)); + + // This is a multi-control-input. + EXPECT_THAT(gn3->IsMultiInput(GenNode::Port(true, -1)), Eq(true)); + + EXPECT_FALSE(gn1->AllInputsOrNone()); + EXPECT_FALSE(gn2->AllInputsOrNone()); + EXPECT_FALSE(gn3->AllInputsOrNone()); +} + +// Commutative nodes are treated as having a single input, +// because their inputs are equivalent. +TEST(GenNodeTest, ParseNodeCommutative) { + GenNodeMap map; + + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + + NodeDef node2 = MakeNodeConst("node2"); + map["node2"] = absl::make_unique<GenNode>(&node2); + + // TODO(babkin): grappler::IsCommutative() should return true for Add but + // apparently doesn't. So use Mul in the meantime. + NodeDef node3 = MakeNodeMul("node3", "node1", "node2"); + map["node3"] = absl::make_unique<GenNode>(&node3); + + auto gn1 = map["node1"].get(); + auto gn2 = map["node2"].get(); + auto gn3 = map["node3"].get(); + ASSERT_THAT(gn3->ParseInputs(&map), Eq(Status::OK())); + // clang-format off + EXPECT_THAT(DumpLinkMap(gn1->links()), ElementsAre( + "o0: node3[i0]" + )); + EXPECT_THAT(DumpLinkMap(gn2->links()), ElementsAre( + "o0: node3[i0]" + )); + EXPECT_THAT(DumpLinkMap(gn3->links()), ElementsAre( + "i0: node1[o0], node2[o0]" + )); + // clang-format on + + EXPECT_THAT(gn3->IsMultiInput(GenNode::Port(true, 0)), Eq(true)); + + EXPECT_FALSE(gn3->AllInputsOrNone()); +} + +TEST(GenNodeTest, ParseNodeMultiInputCommutative) { + GenNodeMap map; + + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + + NodeDef node2 = MakeNodeConst("node2"); + map["node2"] = absl::make_unique<GenNode>(&node2); + + NodeDef node3 = MakeNodeAddN("node3", "node1", "node2"); + map["node3"] = absl::make_unique<GenNode>(&node3); + + auto gn1 = map["node1"].get(); + auto gn2 = map["node2"].get(); + auto gn3 = map["node3"].get(); + ASSERT_THAT(gn3->ParseInputs(&map), Eq(Status::OK())); + // clang-format off + EXPECT_THAT(DumpLinkMap(gn1->links()), ElementsAre( + "o0: node3[i0]" + )); + EXPECT_THAT(DumpLinkMap(gn2->links()), ElementsAre( + "o0: node3[i0]" + )); + EXPECT_THAT(DumpLinkMap(gn3->links()), ElementsAre( + "i0: node1[o0], node2[o0]" + )); + // clang-format on + + // This is a multi-output. + EXPECT_THAT(gn2->IsMultiInput(GenNode::Port(false, 0)), Eq(false)); + // This is a multi-input. + EXPECT_THAT(gn3->IsMultiInput(GenNode::Port(true, 0)), Eq(true)); + + EXPECT_FALSE(gn3->AllInputsOrNone()); +} + +TEST(GenNodeTest, ParseNodeMultiInputNotCommutative) { + GenNodeMap map; + + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + + NodeDef node2 = MakeNodeConst("node2"); + map["node2"] = absl::make_unique<GenNode>(&node2); + + NodeDef node3 = MakeNodeShapeN("node3", "node1", "node2"); + map["node3"] = absl::make_unique<GenNode>(&node3); + + auto gn1 = map["node1"].get(); + auto gn2 = map["node2"].get(); + auto gn3 = map["node3"].get(); + ASSERT_THAT(gn3->ParseInputs(&map), Eq(Status::OK())); + // clang-format off + EXPECT_THAT(DumpLinkMap(gn1->links()), ElementsAre( + "o0: node3[i0]" + )); + EXPECT_THAT(DumpLinkMap(gn2->links()), ElementsAre( + "o0: node3[i1]" + )); + EXPECT_THAT(DumpLinkMap(gn3->links()), ElementsAre( + "i0: node1[o0]", + "i1: node2[o0]" + )); + // clang-format on + + // Non-commutative multi-input doesn't count. + EXPECT_THAT(gn3->IsMultiInput(GenNode::Port(true, 0)), Eq(false)); + EXPECT_TRUE(gn3->AllInputsOrNone()); +} + +TEST(GenNodeTest, ParseNodeMultiInputList) { + GenNodeMap map; + + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + + NodeDef node2 = MakeNodeConst("node2"); + map["node2"] = absl::make_unique<GenNode>(&node2); + + NodeDef node3 = MakeNodeIdentityN("node3", "node1", "node2"); + map["node3"] = absl::make_unique<GenNode>(&node3); + + auto gn1 = map["node1"].get(); + auto gn2 = map["node2"].get(); + auto gn3 = map["node3"].get(); + ASSERT_THAT(gn3->ParseInputs(&map), Eq(Status::OK())); + // clang-format off + EXPECT_THAT(DumpLinkMap(gn1->links()), ElementsAre( + "o0: node3[i0]" + )); + EXPECT_THAT(DumpLinkMap(gn2->links()), ElementsAre( + "o0: node3[i1]" + )); + EXPECT_THAT(DumpLinkMap(gn3->links()), ElementsAre( + "i0: node1[o0]", + "i1: node2[o0]" + )); + // clang-format on + + // Non-commutative multi-input doesn't count. + EXPECT_THAT(gn3->IsMultiInput(GenNode::Port(true, 0)), Eq(false)); + EXPECT_TRUE(gn3->AllInputsOrNone()); +} + +TEST(GenNodeTest, ParseNodeMultiMultiInput) { + GenNodeMap map; + + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + + NodeDef node2 = MakeNodeConst("node2"); + map["node2"] = absl::make_unique<GenNode>(&node2); + + NodeDef node3 = MakeNodeConst("node3"); + map["node3"] = absl::make_unique<GenNode>(&node3); + + NodeDef node4 = MakeNodeConst("node4"); + map["node4"] = absl::make_unique<GenNode>(&node4); + + NodeDef node5 = + MakeNodeQuantizedConcat("node5", "node1", "node2", "node3", "node4"); + map["node5"] = absl::make_unique<GenNode>(&node5); + + auto gn1 = map["node1"].get(); + auto gn2 = map["node2"].get(); + auto gn3 = map["node3"].get(); + auto gn4 = map["node4"].get(); + auto gn5 = map["node5"].get(); + ASSERT_THAT(gn5->ParseInputs(&map), Eq(Status::OK())); + // clang-format off + EXPECT_THAT(DumpLinkMap(gn1->links()), ElementsAre( + "o0: node5[i0]" + )); + EXPECT_THAT(DumpLinkMap(gn2->links()), ElementsAre( + "o0: node5[i1]" + )); + EXPECT_THAT(DumpLinkMap(gn3->links()), ElementsAre( + "o0: node5[i2]" + )); + EXPECT_THAT(DumpLinkMap(gn4->links()), ElementsAre( + "o0: node5[i3]" + )); + EXPECT_THAT(DumpLinkMap(gn5->links()), ElementsAre( + "i0: node1[o0]", + "i1: node2[o0]", + "i2: node3[o0]", + "i3: node4[o0]" + )); + // clang-format on + + // Non-commutative multi-input doesn't count. + EXPECT_THAT(gn5->IsMultiInput(GenNode::Port(true, 1)), Eq(false)); + EXPECT_THAT(gn5->IsMultiInput(GenNode::Port(true, 2)), Eq(false)); + EXPECT_TRUE(gn5->AllInputsOrNone()); +} + +TEST(GenNodeTest, ParseNodeMultiOutput) { + GenNodeMap map; + + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + + NodeDef node2 = MakeNodeConst("node2"); + map["node2"] = absl::make_unique<GenNode>(&node2); + + NodeDef node3 = MakeNodeBroadcastGradientArgs("node3", "node1", "node2"); + map["node3"] = absl::make_unique<GenNode>(&node3); + + NodeDef node4 = MakeNodeSub("node4", "node3:1", "node3:0"); + map["node4"] = absl::make_unique<GenNode>(&node4); + + auto gn4 = map["node4"].get(); + ASSERT_THAT(gn4->ParseInputs(&map), Eq(Status::OK())); + // clang-format off + EXPECT_THAT(DumpLinkMap(gn4->links()), ElementsAre( + "i0: node3[o1]", + "i1: node3[o0]" + )); + // clang-format on +} + +TEST(GenNodeTest, ParseNodeUndefinedOp) { + GenNodeMap map; + NodeDef node1; + node1.set_name("node1"); + node1.set_op("Zzzx"); + + map["node1"] = absl::make_unique<GenNode>(&node1); + + const OpDef* opdef; + Status nested_error = OpRegistry::Global()->LookUpOpDef("Zzzx", &opdef); + + auto gn = map["node1"].get(); + ASSERT_THAT( + gn->ParseInputs(&map), + Eq(Status(error::INVALID_ARGUMENT, + "Node 'node1' contains an undefined operation 'Zzzx': " + + nested_error.error_message()))); +} + +TEST(GenNodeTest, ParseNodeUnexpectedInputs) { + GenNodeMap map; + + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + node1.add_input("node1"); + + auto gn1 = map["node1"].get(); + EXPECT_THAT(gn1->ParseInputs(&map), + Eq(Status(error::INVALID_ARGUMENT, + "Node 'node1' has a non-control " + "input from 'node1' at index 0 but its operation " + "'Const' defines only 0 inputs."))); + + NodeDef node2 = MakeNodeConst("node2"); + map["node2"] = absl::make_unique<GenNode>(&node2); + + NodeDef node3 = MakeNodeSub("node3", "node1", "node2"); + map["node3"] = absl::make_unique<GenNode>(&node3); + node3.add_input("node1"); + + auto gn3 = map["node3"].get(); + EXPECT_THAT(gn3->ParseInputs(&map), + Eq(Status(error::INVALID_ARGUMENT, + "Node 'node3' has a non-control " + "input from 'node1' at index 2 but its operation " + "'Sub' defines only 2 inputs."))); +} + +// Even if an opcode defines no inputs, the node may still accept the control +// inputs. +TEST(GenNodeTest, ParseNodeControlInputsAlwaysOk) { + GenNodeMap map; + NodeDef node1 = MakeNodeConst("node1"); + map["node1"] = absl::make_unique<GenNode>(&node1); + node1.add_input("^node1"); + auto gn1 = map["node1"].get(); + ASSERT_THAT(gn1->ParseInputs(&map), Eq(Status::OK())); + // clang-format off + EXPECT_THAT(DumpLinkMap(gn1->links()), ElementsAre( + "iC: node1[oC]", + "oC: node1[iC]" + )); + // clang-format on +} + +TEST(GenNodeTest, ParseNodeInvalidInput) { + GenNodeMap map; + NodeDef node1 = MakeNodeAddN("node1", "node2", "node3"); + map["node1"] = absl::make_unique<GenNode>(&node1); + node1.add_input("node1"); + auto gn1 = map["node1"].get(); + ASSERT_THAT( + gn1->ParseInputs(&map), + Eq(Status( + error::INVALID_ARGUMENT, + "Node 'node1' input 0 refers to a non-existing node 'node2'."))); +} + +TEST(GenNodeTest, BuildGraphInMap) { + GraphDef graph; + // A topology with a loop. + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeSub("node2", "node3:1", "node3:0"); + (*graph.add_node()) = + MakeNodeBroadcastGradientArgs("node3", "node1", "node2"); + + GenNodeMap map; + ASSERT_THAT(GenNode::BuildGraphInMap(graph, &map), Eq(Status::OK())); + ASSERT_THAT(map.find("node1"), Ne(map.end())); + ASSERT_THAT(map.find("node2"), Ne(map.end())); + ASSERT_THAT(map.find("node3"), Ne(map.end())); + + EXPECT_THAT(map["node1"]->name(), Eq("node1")); + EXPECT_THAT(map["node2"]->name(), Eq("node2")); + EXPECT_THAT(map["node3"]->name(), Eq("node3")); + + // clang-format off + EXPECT_THAT(DumpLinkMap(map["node1"]->links()), ElementsAre( + "o0: node3[i0]" + )); + EXPECT_THAT(DumpLinkMap(map["node2"]->links()), ElementsAre( + "i0: node3[o1]", + "i1: node3[o0]", + "o0: node3[i1]" + )); + EXPECT_THAT(DumpLinkMap(map["node3"]->links()), ElementsAre( + "i0: node1[o0]", + "i1: node2[o0]", + "o0: node2[i1]", + "o1: node2[i0]" + )); + // clang-format on +} + +TEST(GenNodeTest, BuildGraphInMapDuplicateNode) { + GraphDef graph; + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeConst("node1"); + GenNodeMap map; + ASSERT_THAT( + GenNode::BuildGraphInMap(graph, &map), + Eq(Status(error::INVALID_ARGUMENT, "Duplicate node name 'node1'."))); +} + +TEST(GenNodeTest, BuildGraphInMapParseError) { + GraphDef graph; + // A topology with a loop. + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeSub("node2", "node3:1", "node3:0"); + + GenNodeMap map; + ASSERT_THAT( + GenNode::BuildGraphInMap(graph, &map), + Eq(Status( + error::INVALID_ARGUMENT, + "Node 'node2' input 0 refers to a non-existing node 'node3'."))); +} + +} // end namespace +} // end namespace test +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/graph_analyzer.cc b/tensorflow/core/grappler/graph_analyzer/graph_analyzer.cc new file mode 100644 index 0000000000..f3796fcf86 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/graph_analyzer.cc @@ -0,0 +1,341 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include <deque> +#include <iostream> + +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" +#include "tensorflow/core/grappler/graph_analyzer/gen_node.h" +#include "tensorflow/core/grappler/graph_analyzer/graph_analyzer.h" +#include "tensorflow/core/grappler/graph_analyzer/sig_node.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +GraphAnalyzer::GraphAnalyzer(const GraphDef& graph, int subgraph_size) + : graph_(graph), subgraph_size_(subgraph_size) {} + +GraphAnalyzer::~GraphAnalyzer() {} + +Status GraphAnalyzer::Run() { + // The signature computation code would detect this too, but better + // to report it up front than spend time computing all the graphs first. + if (subgraph_size_ > Signature::kMaxGraphSize) { + return Status(error::INVALID_ARGUMENT, + absl::StrFormat("Subgraphs of %d nodes are not supported, " + "the maximal supported node count is %d.", + subgraph_size_, Signature::kMaxGraphSize)); + } + + Status st = BuildMap(); + if (!st.ok()) { + return st; + } + + FindSubgraphs(); + DropInvalidSubgraphs(); + st = CollateResult(); + if (!st.ok()) { + return st; + } + + return Status::OK(); +} + +Status GraphAnalyzer::BuildMap() { + nodes_.clear(); + return GenNode::BuildGraphInMap(graph_, &nodes_); +} + +void GraphAnalyzer::FindSubgraphs() { + result_.clear(); + + if (subgraph_size_ < 1) { + return; + } + + partial_.clear(); + todo_.clear(); // Just in case. + + // Start with all subgraphs of size 1. + const Subgraph::Identity empty_parent; + for (const auto& node : nodes_) { + if (subgraph_size_ == 1) { + result_.ExtendParent(empty_parent, node.second.get()); + } else { + // At this point ExtendParent() is guaranteed to not return nullptr. + todo_.push_back(partial_.ExtendParent(empty_parent, node.second.get())); + } + } + + // Then extend the subgraphs until no more extensions are possible. + while (!todo_.empty()) { + ExtendSubgraph(todo_.front()); + todo_.pop_front(); + } + + partial_.clear(); +} + +void GraphAnalyzer::ExtendSubgraph(Subgraph* parent) { + bool will_complete = (parent->id().size() + 1 == subgraph_size_); + SubgraphPtrSet& sg_set = will_complete ? result_ : partial_; + + const GenNode* last_all_or_none_node = nullptr; + for (SubgraphIterator sit(parent); !sit.AtEnd(); sit.Next()) { + const GenNode* node = sit.GetNode(); + GenNode::Port port = sit.GetPort(); + const GenNode::LinkTarget& neighbor = sit.GetNeighbor(); + + if (node->AllInputsOrNone() && port.IsInbound() && !port.IsControl()) { + if (node != last_all_or_none_node) { + ExtendSubgraphAllOrNone(parent, node); + last_all_or_none_node = node; + } + sit.SkipPort(); + } else if (neighbor.node->AllInputsOrNone() && !port.IsInbound() && + !port.IsControl()) { + if (parent->id().find(neighbor.node) == parent->id().end()) { + // Not added yet. + ExtendSubgraphAllOrNone(parent, neighbor.node); + } + } else if (node->IsMultiInput(port)) { + ExtendSubgraphPortAllOrNone(parent, node, port); + sit.SkipPort(); + } else if (neighbor.node->IsMultiInput(neighbor.port)) { + // Would need to add all inputs of the neighbor node at this port at + // once. + if (parent->id().find(neighbor.node) != parent->id().end()) { + continue; // Already added. + } + ExtendSubgraphPortAllOrNone(parent, neighbor.node, neighbor.port); + } else { + Subgraph* sg = sg_set.ExtendParent(parent->id(), neighbor.node); + if (!will_complete && sg != nullptr) { + todo_.push_back(sg); + } + } + } +} + +void GraphAnalyzer::ExtendSubgraphAllOrNone(Subgraph* parent, + const GenNode* node) { + Subgraph::Identity id = parent->id(); + id.insert(node); + + auto range_end = node->links().end(); + + for (auto nbit = node->links().begin(); nbit != range_end; ++nbit) { + auto port = nbit->first; + if (!port.IsInbound() || port.IsControl()) { + continue; + } + + // Since there might be multiple links to the same nodes, + // have to add all links one-by-one to check whether the subgraph + // would grow too large. But if it does grow too large, there is no + // point in growing it more, can just skip over the rest of the links. + for (const auto& link : nbit->second) { + id.insert(link.node); + if (id.size() > subgraph_size_) { + return; // Too big. + } + } + } + + AddExtendedSubgraph(parent, id); +} + +void GraphAnalyzer::ExtendSubgraphPortAllOrNone(Subgraph* parent, + const GenNode* node, + GenNode::Port port) { + auto nbit = node->links().find(port); + if (nbit == node->links().end()) { + return; // Should never happen. + } + + Subgraph::Identity id = parent->id(); + id.insert(node); + + // Since there might be multiple links to the same nodes, + // have to add all links one-by-one to check whether the subgraph + // would grow too large. But if it does grow too large, there is no + // point in growing it more, can just skip over the rest of the links. + for (const auto& link : nbit->second) { + id.insert(link.node); + if (id.size() > subgraph_size_) { + return; // Too big. + } + } + + AddExtendedSubgraph(parent, id); +} + +void GraphAnalyzer::AddExtendedSubgraph(Subgraph* parent, + const Subgraph::Identity& id) { + if (id.size() == parent->id().size()) { + return; // Nothing new was added. + } + + auto sg = absl::make_unique<Subgraph>(id); + SubgraphPtrSet& spec_sg_set = + (id.size() == subgraph_size_) ? result_ : partial_; + if (spec_sg_set.find(sg) != spec_sg_set.end()) { + // This subgraph was already found by extending from a different path. + return; + } + + if (id.size() != subgraph_size_) { + todo_.push_back(sg.get()); + } + spec_sg_set.insert(std::move(sg)); +} + +void GraphAnalyzer::DropInvalidSubgraphs() { + auto resit = result_.begin(); + while (resit != result_.end()) { + if (HasInvalidMultiInputs(resit->get())) { + auto delit = resit; + ++resit; + result_.erase(delit); + } else { + ++resit; + } + } +} + +bool GraphAnalyzer::HasInvalidMultiInputs(Subgraph* sg) { + // Do the all-or-none-input nodes. + for (auto const& node : sg->id()) { + if (!node->AllInputsOrNone()) { + continue; + } + + bool anyIn = false; + bool anyOut = false; + + auto range_end = node->links().end(); + for (auto nbit = node->links().begin(); nbit != range_end; ++nbit) { + auto port = nbit->first; + if (!port.IsInbound() || port.IsControl()) { + continue; + } + + // Since there might be multiple links to the same nodes, + // have to add all links one-by-one to check whether the subgraph + // would grow too large. But if it does grow too large, there is no + // point in growing it more, can just skip over the rest of the links. + for (const auto& link : nbit->second) { + if (sg->id().find(link.node) == sg->id().end()) { + anyOut = true; + } else { + anyIn = true; + } + } + } + + if (anyIn && anyOut) { + return true; + } + } + + // Do the multi-input ports. + for (SubgraphIterator sit(sg); !sit.AtEnd(); sit.Next()) { + if (sit.GetNode()->IsMultiInput(sit.GetPort())) { + bool anyIn = false; + bool anyOut = false; + do { + GenNode* peer = sit.GetNeighbor().node; + if (sg->id().find(peer) == sg->id().end()) { + anyOut = true; + } else { + anyIn = true; + } + } while (sit.NextIfSamePort()); + + if (anyIn && anyOut) { + return true; + } + } + } + return false; +} + +Status GraphAnalyzer::CollateResult() { + ordered_collation_.clear(); + collation_map_.clear(); + + // Collate by the signatures of the graphs. + for (const auto& it : result_) { + auto sig = absl::make_unique<Signature>(); + it->ExtractForSignature(&sig->map); + Status status = sig->Compute(); + if (!status.ok()) { + return status; + } + + auto& coll_entry = collation_map_[sig.get()]; + if (coll_entry.sig == nullptr) { + coll_entry.sig = std::move(sig); + } + ++coll_entry.count; + } + + // Then order them by the count. + for (auto& entry : collation_map_) { + ordered_collation_.insert(&entry.second); + } + + result_.clear(); // Not needed after collation. + + return Status::OK(); +} + +std::vector<string> GraphAnalyzer::DumpRawSubgraphs() { + std::vector<string> result; + for (const auto& it : result_) { + result.emplace_back(it->Dump()); + } + return result; +} + +std::vector<string> GraphAnalyzer::DumpSubgraphs() { + std::vector<string> result; + for (auto ptr : ordered_collation_) { + result.emplace_back( + absl::StrFormat("%d %s", ptr->count, ptr->sig->ToString())); + } + return result; +} + +Status GraphAnalyzer::OutputSubgraphs() { + size_t total = 0; + for (auto ptr : ordered_collation_) { + std::cout << ptr->count << ' ' << ptr->sig->ToString() << '\n'; + total += ptr->count; + } + std::cout << "Total: " << total << '\n'; + if (std::cout.fail()) { + return Status(error::DATA_LOSS, "Failed to write to stdout"); + } else { + return Status::OK(); + } +} + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/graph_analyzer.h b/tensorflow/core/grappler/graph_analyzer/graph_analyzer.h new file mode 100644 index 0000000000..26d38a4931 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/graph_analyzer.h @@ -0,0 +1,154 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_GRAPH_ANALYZER_H_ +#define TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_GRAPH_ANALYZER_H_ + +#include <deque> +#include <vector> + +#include "tensorflow/core/framework/graph.pb.h" +#include "tensorflow/core/grappler/graph_analyzer/map_tools.h" +#include "tensorflow/core/grappler/graph_analyzer/sig_node.h" +#include "tensorflow/core/grappler/graph_analyzer/subgraph.h" +#include "tensorflow/core/lib/core/status.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +namespace test { +class GraphAnalyzerTest; +} // end namespace test + +// Finds all the subgraphs of a given size and groups them by equivalence. +class GraphAnalyzer { + public: + // Makes a copy of the graph. + GraphAnalyzer(const GraphDef& graph, int subgraph_size); + + virtual ~GraphAnalyzer(); + + // Performs the analysis and collects the subgraphs. + Status Run(); + + // Returns the subgraphs found in Run() printed to text. + std::vector<string> DumpSubgraphs(); + + // Prints the subgraphs found in Run() to stdout. + Status OutputSubgraphs(); + + // TODO(babkin): add a way to extract the subgraphs as direct data + // structures and as protobufs, and to write protobufs to a RecordIO. + + private: + GraphAnalyzer() = delete; + GraphAnalyzer(const GraphAnalyzer&) = delete; + void operator=(const GraphAnalyzer&) = delete; + + friend class tensorflow::grappler::graph_analyzer::test::GraphAnalyzerTest; + + // Builds the map of nodes from the original graph definition. + Status BuildMap(); + + // Using nodes_, finds all the subgraphs of size subgraph_size_ and places + // them into result_. + void FindSubgraphs(); + + // Deletes from result_ the unacceptable subgraphs. Those include the + // subgraphs where not all the inputs at a multi-input port are included (this + // could happen if some of these inputs were reached and included through + // different paths). + void DropInvalidSubgraphs(); + + // Deletes from result_ duplicate entries of equivalent topology. + Status CollateResult(); + + // Returns the raw subgraphs found in FindSubgraphs() printed to text. + std::vector<string> DumpRawSubgraphs(); + + // Finds and adds appropriately to either partial_ or result_ all the + // subgraphs that can be created by extending the parent subgraph by one node. + // Ignores the duplicates. + void ExtendSubgraph(Subgraph* parent); + + // Extends the parent subgraph by adding another node (if it wasn't already + // added) and all its non-control inputs in the link map range at once. + // If the subgraph would grow over subgraph_size_, it gets ignored. + void ExtendSubgraphAllOrNone(Subgraph* parent, const GenNode* node); + // Same but adds one specific inbound port (even control) all-or-none. + void ExtendSubgraphPortAllOrNone(Subgraph* parent, const GenNode* node, + GenNode::Port port); + // The common final step called by ExtendSubgraph*AllOrNone() methods. + void AddExtendedSubgraph(Subgraph* parent, const Subgraph::Identity& id); + + // Returns true if this subgraph has any multi-inputs that aren't all-in or + // all-out. + bool HasInvalidMultiInputs(Subgraph* sg); + + // Graph to run the analysis on. + GraphDef graph_; + int subgraph_size_; + + // The enriched graph of parsed nodes and connections. + GenNodeMap nodes_; + // The resulting set of subgraphs. + SubgraphPtrSet result_; + // The subgraphs of partial size, stored while finding the result. + SubgraphPtrSet partial_; + // The subgraphs of partial size (stored in partial_) that are still waiting + // to be extended. + // + // TODO(babkin): This is rather simple-minded, each subgraph is examined from + // scratch, which means that all its internal links get iterated too. But it's + // OK for the small subgraphs. This can be improved by keeping not just + // subgraphs but iterators on the list, each of them having the list not-yet + // examined nodes (and the link position of the next link to be examined for + // the first node). This would add extra constant overhead, so the break-even + // subgraph size is not clear yet. + std::deque<Subgraph*> todo_; + + // The collation map by signature is designed to allow the removal of entries + // and moving of the signature references from the keys of this map to the + // outside world. Must be careful at inserting and removal: make sure that + // when a new entry is inserted, its signature reference gets populated with + // the same data as the key of the map, and that if a reference is moved out, + // the map entry gets removed before that reference gets destroyed. + struct CollationEntry { + std::shared_ptr<Signature> sig; + size_t count = 0; + }; + using CollationMap = + std::unordered_map<Signature*, CollationEntry, HashAtPtr<Signature*>, + EqAtPtr<Signature*> >; + CollationMap collation_map_; + + // The entries are owned by collation_map_, so must be removed from + // ordered_collation_ before removing them from collation_map_. + struct ReverseLessByCount { + bool operator()(CollationEntry* left, CollationEntry* right) { + return left->count > right->count; // Reverse order. + } + }; + using CollationOrderByCount = + std::multiset<CollationEntry*, ReverseLessByCount>; + CollationOrderByCount ordered_collation_; +}; + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow + +#endif // TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_GRAPH_ANALYZER_H_ diff --git a/tensorflow/core/grappler/graph_analyzer/graph_analyzer_test.cc b/tensorflow/core/grappler/graph_analyzer/graph_analyzer_test.cc new file mode 100644 index 0000000000..e94c472056 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/graph_analyzer_test.cc @@ -0,0 +1,569 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/graph_analyzer/graph_analyzer.h" + +#include <algorithm> + +#include <gmock/gmock.h> +#include <gtest/gtest.h> +#include "absl/memory/memory.h" +#include "tensorflow/core/grappler/graph_analyzer/test_tools.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { +namespace test { + +using ::testing::ElementsAre; +using ::testing::Eq; +using ::testing::Ne; +using ::testing::SizeIs; +using ::testing::UnorderedElementsAre; + +class GraphAnalyzerTest : public ::testing::Test, protected TestGraphs { + protected: + Status BuildMap() { return gran_->BuildMap(); } + + void FindSubgraphs() { gran_->FindSubgraphs(); } + + void DropInvalidSubgraphs() { gran_->DropInvalidSubgraphs(); } + + Status CollateResult() { return gran_->CollateResult(); } + + void ExtendSubgraph(Subgraph* parent) { gran_->ExtendSubgraph(parent); } + + void ExtendSubgraphPortAllOrNone(Subgraph* parent, GenNode* node, + GenNode::Port port) { + gran_->ExtendSubgraphPortAllOrNone(parent, node, port); + } + + void ExtendSubgraphAllOrNone(Subgraph* parent, GenNode* node) { + gran_->ExtendSubgraphAllOrNone(parent, node); + } + + std::vector<string> DumpRawSubgraphs() { return gran_->DumpRawSubgraphs(); } + + std::vector<string> DumpPartials() { + std::vector<string> result; + for (const auto& it : gran_->partial_) { + result.emplace_back(it->Dump()); + } + return result; + } + + const GenNodeMap& GetNodes() { return gran_->nodes_; } + + GenNode* GetNode(const string& name) { return gran_->nodes_.at(name).get(); } + + SubgraphPtrSet& GetResult() { return gran_->result_; } + SubgraphPtrSet& GetPartial() { return gran_->partial_; } + std::deque<Subgraph*>& GetTodo() { return gran_->todo_; } + + // Gets initialized by a particular test from a suitable GraphDef. + std::unique_ptr<GraphAnalyzer> gran_; +}; + +TEST_F(GraphAnalyzerTest, BuildMap) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_3n_self_control_, 1); + Status st = BuildMap(); + EXPECT_THAT(st, Eq(Status::OK())); + + auto& map = GetNodes(); + EXPECT_THAT(map.find("node1"), Ne(map.end())); + EXPECT_THAT(map.find("node2"), Ne(map.end())); + EXPECT_THAT(map.find("node3"), Ne(map.end())); +} + +TEST_F(GraphAnalyzerTest, BuildMapError) { + // A duplicate node. + (*graph_3n_self_control_.add_node()) = MakeNodeConst("node1"); + gran_ = absl::make_unique<GraphAnalyzer>(graph_3n_self_control_, 1); + Status st = BuildMap(); + ASSERT_THAT( + st, Eq(Status(error::INVALID_ARGUMENT, "Duplicate node name 'node1'."))); +} + +TEST_F(GraphAnalyzerTest, FindSubgraphs0) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_3n_self_control_, 0); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + FindSubgraphs(); + auto& subgraphs = GetResult(); + EXPECT_THAT(subgraphs, SizeIs(0)); + EXPECT_THAT(DumpRawSubgraphs(), ElementsAre()); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +TEST_F(GraphAnalyzerTest, FindSubgraphs1) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_3n_self_control_, 1); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + FindSubgraphs(); + auto& subgraphs = GetResult(); + EXPECT_THAT(subgraphs, SizeIs(3)); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: BroadcastGradientArgs(node3)", + "1: Const(node1)", + "1: Sub(node2)" + )); + // clang-format on + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// The required subgraphs are larger than the graph. +TEST_F(GraphAnalyzerTest, FindSubgraphsTooLarge) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_3n_self_control_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + FindSubgraphs(); + EXPECT_THAT(DumpRawSubgraphs(), ElementsAre()); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +//=== + +// Successfully propagate backwards through a multi-input link, +// with the base (currently-extending) node already in the graph. +TEST_F(GraphAnalyzerTest, MultiInputSuccessBackwardsBaseIn) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_multi_input_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("add2")})); + + ExtendSubgraphPortAllOrNone(root.get(), GetNode("add2"), + GenNode::Port(true, 0)); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: AddN(add2), Const(const2_1), Const(const2_2), Const(const2_3)" + )); + // clang-format on + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// Successfully propagate backwards through a multi-input link, +// with the base (currently-extending) node not in the graph yet. +TEST_F(GraphAnalyzerTest, MultiInputSuccessBackwardsBaseOut) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_multi_input_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto parent = absl::make_unique<Subgraph>(Subgraph::Identity()); + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("add2")})); + + ExtendSubgraphPortAllOrNone(parent.get(), GetNode("add2"), + GenNode::Port(true, 0)); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: AddN(add2), Const(const2_1), Const(const2_2), Const(const2_3)" + )); + // clang-format on + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// Successfully propagate backwards through a multi-input link, +// where the target subgraph size is larger. +TEST_F(GraphAnalyzerTest, MultiInputSuccessBackwardsIncomplete) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_multi_input_, 5); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("add2")})); + + ExtendSubgraphPortAllOrNone(root.get(), GetNode("add2"), + GenNode::Port(true, 0)); + + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre()); + // clang-format off + EXPECT_THAT(DumpPartials(), UnorderedElementsAre( + "1: AddN(add2), Const(const2_1), Const(const2_2), Const(const2_3)" + )); + // clang-format on + EXPECT_THAT(GetTodo(), SizeIs(1)); +} + +// Propagate backwards through a multi-input link, finding that the +// resulting subgraph would be too large. +TEST_F(GraphAnalyzerTest, MultiInputTooLargeBackwards) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_multi_input_, 3); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("add2")})); + + ExtendSubgraphPortAllOrNone(root.get(), GetNode("add2"), + GenNode::Port(true, 0)); + + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre()); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// Propagate backwards through a multi-input link, finding that nothing +// would be added to the parent subgraph. +TEST_F(GraphAnalyzerTest, MultiInputNothingAddedBackwards) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_multi_input_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = absl::make_unique<Subgraph>( + Subgraph::Identity({GetNode("add2"), GetNode("const2_1"), + GetNode("const2_2"), GetNode("const2_3")})); + + ExtendSubgraphPortAllOrNone(root.get(), GetNode("add2"), + GenNode::Port(true, 0)); + + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre()); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// Successfully propagate forwards through a multi-input link, +// with the base (currently-extending) node not in the subgraph yet. +TEST_F(GraphAnalyzerTest, MultiInputSuccessForwardsBaseOut) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_multi_input_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("const2_1")})); + + ExtendSubgraphPortAllOrNone(root.get(), GetNode("add2"), + GenNode::Port(true, 0)); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: AddN(add2), Const(const2_1), Const(const2_2), Const(const2_3)" + )); + // clang-format on + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// Successfully propagate backwards through a multi-input link. +TEST_F(GraphAnalyzerTest, MultiInputSuccessBackwardsFull) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_multi_input_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("add2")})); + + ExtendSubgraph(root.get()); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: AddN(add2), Const(const2_1), Const(const2_2), Const(const2_3)" + )); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre( + "1: AddN(add2), Sub(sub)" + )); + // clang-format on + EXPECT_THAT(GetTodo(), SizeIs(1)); +} + +// Successfully propagate forwards through a multi-input link. +TEST_F(GraphAnalyzerTest, MultiInputSuccessForwardsFull) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_multi_input_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("const2_1")})); + + ExtendSubgraph(root.get()); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: AddN(add2), Const(const2_1), Const(const2_2), Const(const2_3)" + )); + // clang-format on + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +TEST_F(GraphAnalyzerTest, DropInvalidSubgraphsMulti) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_multi_input_, 3); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + // A good one, multi-input is all-in. + GetResult().insert(absl::make_unique<Subgraph>(Subgraph::Identity({ + GetNode("const1_1"), + GetNode("const1_2"), + GetNode("add1"), + }))); + // A good one, multi-input is all-out + GetResult().insert(absl::make_unique<Subgraph>(Subgraph::Identity({ + GetNode("add1"), + GetNode("add2"), + GetNode("sub"), + }))); + // A bad one, multi-input is partially in. + GetResult().insert(absl::make_unique<Subgraph>(Subgraph::Identity({ + GetNode("const1_1"), + GetNode("add1"), + GetNode("sub"), + }))); + // A bad one, multi-input is partially in. + GetResult().insert(absl::make_unique<Subgraph>(Subgraph::Identity({ + GetNode("add2"), + GetNode("const2_1"), + GetNode("const2_2"), + }))); + + DropInvalidSubgraphs(); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: AddN(add1), AddN(add2), Sub(sub)", + "1: AddN(add1), Const(const1_1), Const(const1_2)" + )); + // clang-format on + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +//=== + +// Successfully propagate backwards through a multi-input link, +// with the base (currently-extending) node already in the graph. +TEST_F(GraphAnalyzerTest, AllOrNoneInputSuccessBackwards) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_all_or_none_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("pass2")})); + + ExtendSubgraphAllOrNone(root.get(), GetNode("pass2")); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: Const(const2_1), Const(const2_2), Const(const2_3), IdentityN(pass2)" + )); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + // clang-format on + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// Successfully propagate backwards through a multi-input link, +// but no control links propagate. It also tests the situation +// where the target subgraph size is larger. +TEST_F(GraphAnalyzerTest, AllOrNoneInputSuccessBackwardsNoControl) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_all_or_none_, 5); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("pass1")})); + + ExtendSubgraphAllOrNone(root.get(), GetNode("pass1")); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre()); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre( + "1: Const(const1_1), Const(const1_2), IdentityN(pass1)" + )); + // clang-format on + EXPECT_THAT(GetTodo(), SizeIs(1)); +} + +// The control links propagate separately as all-or-none, even on the nodes +// that are all-or-none for the normal inputs. +TEST_F(GraphAnalyzerTest, AllOrNoneInputSeparateControl) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_all_or_none_, 5); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("pass1")})); + + ExtendSubgraphPortAllOrNone(root.get(), GetNode("pass1"), + GenNode::Port(true, -1)); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre()); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre( + "1: Const(const2_1), Const(const2_2), Const(const2_3), IdentityN(pass1)" + )); + // clang-format on + EXPECT_THAT(GetTodo(), SizeIs(1)); +} + +// Propagate backwards from all-or-none-input node, finding that the +// resulting subgraph would be too large. +TEST_F(GraphAnalyzerTest, AllOrNoneInputTooLargeBackwards) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_all_or_none_, 3); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("pass2")})); + + ExtendSubgraphAllOrNone(root.get(), GetNode("pass2")); + + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre()); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// Propagate backwards from all-or-none-input node, finding that nothing +// would be added to the parent subgraph. +TEST_F(GraphAnalyzerTest, AllOrNoneInputNothingAddedBackwards) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_all_or_none_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = absl::make_unique<Subgraph>( + Subgraph::Identity({GetNode("pass2"), GetNode("const2_1"), + GetNode("const2_2"), GetNode("const2_3")})); + + ExtendSubgraphAllOrNone(root.get(), GetNode("pass2")); + + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre()); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// Successfully propagate forwards to all-or-none-input node, +// with the base (currently-extending) node not in the subgraph yet. +TEST_F(GraphAnalyzerTest, AllOrNoneInputSuccessForwardsBaseOut) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_all_or_none_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("const2_1")})); + + ExtendSubgraphAllOrNone(root.get(), GetNode("pass2")); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: Const(const2_1), Const(const2_2), Const(const2_3), IdentityN(pass2)" + )); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + // clang-format on + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +// Successfully propagate backwards from all-or-none-input node. +TEST_F(GraphAnalyzerTest, AllOrNoneInputSuccessBackwardsFull) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_all_or_none_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("pass2")})); + + ExtendSubgraph(root.get()); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: Const(const2_1), Const(const2_2), Const(const2_3), IdentityN(pass2)" + )); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre( + "1: IdentityN(pass2), Sub(sub)" + )); + // clang-format on + EXPECT_THAT(GetTodo(), SizeIs(1)); +} + +// Successfully propagate forwards to all-or-none-input node. This includes +// both all-or-none-input for the normal inputs, and multi-input by the +// control path. +TEST_F(GraphAnalyzerTest, AllOrNoneInputSuccessForwardsFull) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_all_or_none_, 4); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + auto root = + absl::make_unique<Subgraph>(Subgraph::Identity({GetNode("const2_1")})); + + ExtendSubgraph(root.get()); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: Const(const2_1), Const(const2_2), Const(const2_3), IdentityN(pass2)", + "1: Const(const2_1), Const(const2_2), Const(const2_3), IdentityN(pass1)" + )); + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + // clang-format on + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +TEST_F(GraphAnalyzerTest, DropInvalidSubgraphsAllOrNone) { + gran_ = absl::make_unique<GraphAnalyzer>(graph_all_or_none_, 3); + Status st = BuildMap(); + ASSERT_THAT(st, Eq(Status::OK())); + + // A good one, all-or-none is all-in. + GetResult().insert(absl::make_unique<Subgraph>(Subgraph::Identity({ + GetNode("const1_1"), + GetNode("const1_2"), + GetNode("pass1"), + }))); + // A good one, all-or-none is all-out + GetResult().insert(absl::make_unique<Subgraph>(Subgraph::Identity({ + GetNode("pass1"), + GetNode("pass2"), + GetNode("sub"), + }))); + // A bad one, all-or-none is partially in. + GetResult().insert(absl::make_unique<Subgraph>(Subgraph::Identity({ + GetNode("const1_1"), + GetNode("pass1"), + GetNode("sub"), + }))); + // A bad one, all-or-none is partially in. + GetResult().insert(absl::make_unique<Subgraph>(Subgraph::Identity({ + GetNode("pass2"), + GetNode("const2_1"), + GetNode("const2_2"), + }))); + + DropInvalidSubgraphs(); + + // clang-format off + EXPECT_THAT(DumpRawSubgraphs(), UnorderedElementsAre( + "1: IdentityN(pass1), IdentityN(pass2), Sub(sub)", + "1: Const(const1_1), Const(const1_2), IdentityN(pass1)" + )); + // clang-format on + EXPECT_THAT(DumpPartials(), UnorderedElementsAre()); + EXPECT_THAT(GetTodo(), SizeIs(0)); +} + +} // end namespace test +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/graph_analyzer_tool.cc b/tensorflow/core/grappler/graph_analyzer/graph_analyzer_tool.cc new file mode 100644 index 0000000000..924ca11e61 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/graph_analyzer_tool.cc @@ -0,0 +1,98 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/framework/graph.pb.h" +#include "tensorflow/core/framework/node_def.pb.h" +#include "tensorflow/core/grappler/graph_analyzer/graph_analyzer.h" +#include "tensorflow/core/grappler/grappler_item.h" +#include "tensorflow/core/lib/core/status.h" +#include "tensorflow/core/platform/env.h" +#include "tensorflow/core/platform/init_main.h" +#include "tensorflow/core/protobuf/meta_graph.pb.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +// Dies on failure. +static void LoadModel(const string& filename, + tensorflow::MetaGraphDef* metagraph) { + LOG(INFO) << "Loading model from " << filename; + Status st; + st = ReadBinaryProto(Env::Default(), filename, metagraph); + if (!st.ok()) { + LOG(WARNING) << "Failed to read a binary metagraph: " << st; + st = ReadTextProto(Env::Default(), filename, metagraph); + if (!st.ok()) { + LOG(FATAL) << "Failed to read a text metagraph: " << st; + } + } +} + +// Prune the graph to only keep the transitive fanin part with respect to a set +// of train ops (if provided). +void MaybePruneGraph(const tensorflow::MetaGraphDef& metagraph, + tensorflow::GraphDef* graph) { + std::vector<string> fetch_nodes; + for (const auto& fetch : + metagraph.collection_def().at("train_op").node_list().value()) { + LOG(INFO) << "Fetch node: " << fetch; + fetch_nodes.push_back(fetch); + } + if (fetch_nodes.empty()) { + *graph = metagraph.graph_def(); + } else { + std::vector<const tensorflow::NodeDef*> fanin_nodes = + tensorflow::grappler::ComputeTransitiveFanin(metagraph.graph_def(), + fetch_nodes); + for (const tensorflow::NodeDef* node : fanin_nodes) { + *(graph->add_node()) = *node; + } + LOG(INFO) << "Pruned " + << metagraph.graph_def().node_size() - graph->node_size() + << " nodes. Original graph size: " + << metagraph.graph_def().node_size() + << ". New graph size: " << graph->node_size() << "."; + } +} + +void GraphAnalyzerTool(const string& file_name, int n) { + if (n < 1) { + LOG(FATAL) << "Invalid subgraph size " << n << ", must be at least 1"; + } + + tensorflow::MetaGraphDef metagraph; + LoadModel(file_name, &metagraph); + tensorflow::GraphDef graph; + MaybePruneGraph(metagraph, &graph); + tensorflow::grappler::graph_analyzer::GraphAnalyzer analyzer(graph, n); + LOG(INFO) << "Running the analysis"; + tensorflow::Status st = analyzer.Run(); + if (!st.ok()) { + LOG(FATAL) << "Analysis failed: " << st; + } + + LOG(INFO) << "Printing the result"; + st = analyzer.OutputSubgraphs(); + if (!st.ok()) { + LOG(FATAL) << "Failed to print the result: " << st; + } + + LOG(INFO) << "Completed"; +} + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/graph_analyzer_tool.h b/tensorflow/core/grappler/graph_analyzer/graph_analyzer_tool.h new file mode 100644 index 0000000000..5a91fe7dc8 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/graph_analyzer_tool.h @@ -0,0 +1,31 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_GRAPH_ANALYZER_TOOL_H_ +#define TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_GRAPH_ANALYZER_TOOL_H_ + +#include "tensorflow/core/lib/strings/str_util.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +void GraphAnalyzerTool(const string& file_name, int n); + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow + +#endif // TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_GRAPH_ANALYZER_TOOL_H_ diff --git a/tensorflow/core/grappler/graph_analyzer/hash_tools.h b/tensorflow/core/grappler/graph_analyzer/hash_tools.h new file mode 100644 index 0000000000..b0e79f9a68 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/hash_tools.h @@ -0,0 +1,47 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_HASH_TOOLS_H_ +#define TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_HASH_TOOLS_H_ + +#include <cstddef> + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +// Unfortunately, std::hash provides no way to combine hashes, so everyone +// is copying boost::hash_combine. This is a version that follows Google's +// guidelines on the arguments, and contains only the combination, without +// hashing. +inline void CombineHash(size_t from, size_t* to) { + *to ^= from + 0x9e3779b9 + (*to << 6) + (*to >> 2); +} + +// Combine two hashes in such a way that the order of combination doesn't matter +// (so it's really both commutative and associative). The result is not a very +// high-quality hash but can be used in case if the order of sub-elements must +// not matter in the following comparison. An alternative would be to sort the +// hashes of the sub-elements and then combine them normally in the sorted +// order. +inline void CombineHashCommutative(size_t from, size_t* to) { + *to = *to + from + 0x9e3779b9; +} + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow + +#endif // TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_HASH_TOOLS_H_ diff --git a/tensorflow/core/grappler/graph_analyzer/hash_tools_test.cc b/tensorflow/core/grappler/graph_analyzer/hash_tools_test.cc new file mode 100644 index 0000000000..b5e9ce6b8e --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/hash_tools_test.cc @@ -0,0 +1,46 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/graph_analyzer/hash_tools.h" + +#include <gmock/gmock.h> +#include <gtest/gtest.h> + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { +namespace test { +namespace { + +using ::testing::Eq; + +TEST(HashToolsTest, CombineHashCommutative) { + size_t a = 0; + size_t b = 999; + + size_t c = a; + CombineHashCommutative(b, &c); + + size_t d = b; + CombineHashCommutative(a, &d); + + EXPECT_THAT(c, Eq(d)); +} + +} // namespace +} // end namespace test +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/map_tools.h b/tensorflow/core/grappler/graph_analyzer/map_tools.h new file mode 100644 index 0000000000..584062c5f2 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/map_tools.h @@ -0,0 +1,46 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_MAP_TOOLS_H_ +#define TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_MAP_TOOLS_H_ + +#include <functional> + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +// Helpers for building maps of pointers. + +template <typename Ptr> +struct LessAtPtr : std::binary_function<Ptr, Ptr, bool> { + bool operator()(const Ptr& x, const Ptr& y) const { return *x < *y; } +}; + +template <typename Ptr> +struct EqAtPtr : std::binary_function<Ptr, Ptr, bool> { + bool operator()(const Ptr& x, const Ptr& y) const { return *x == *y; } +}; + +template <typename Ptr> +struct HashAtPtr : std::unary_function<Ptr, size_t> { + size_t operator()(const Ptr& x) const { return x->Hash(); } +}; + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow + +#endif // TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_MAP_TOOLS_H_ diff --git a/tensorflow/core/grappler/graph_analyzer/sig_node.cc b/tensorflow/core/grappler/graph_analyzer/sig_node.cc new file mode 100644 index 0000000000..b5cca6a512 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/sig_node.cc @@ -0,0 +1,453 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/graph_analyzer/sig_node.h" + +#include <algorithm> + +#include "absl/strings/str_format.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +static constexpr bool debug = false; + +//=== SigNode + +SigNode::SigNode(const NodeDef* node) : node_(node) {} + +void SigNode::CopyLinks(const GenNode& from, const TranslationMap& map) { + hash_to_link_.clear(); + hashed_peers_.clear(); + + std::map<LinkTag, Link> link_map; + CopyLinksPass1(from, map, &link_map); + CopyLinksPass2(&link_map); +} + +void SigNode::CopyLinksPass1(const GenNode& from, const TranslationMap& map, + std::map<LinkTag, Link>* link_map) { + LinkTag::Hasher link_hasher; + + for (const auto& entry : from.links()) { + for (const auto& target : entry.second) { + auto nodeit = map.find(target.node); + if (nodeit == map.end()) { + // Node is not in the subgraph, ignore. + continue; + } + + LinkTag tag(entry.first, target.port); + size_t hval = link_hasher(tag); + + // This instantiates the entry if it was not present. + Link& map_entry = (*link_map)[tag]; + if (map_entry.peers.empty()) { + map_entry.tag = tag; + map_entry.unique_hash = hval; + } + map_entry.peers.push_back(nodeit->second); + } + } +} + +void SigNode::CopyLinksPass2(std::map<LinkTag, Link>* link_map) { + for (auto& entry : *link_map) { + Link* hl_entry_ptr = &hash_to_link_[entry.second.unique_hash]; + // In case of a conflict, rehash. This should almost never happen. + // Because the order of iteration is predictable, the rehashed values + // will also be predictable. + while (!hl_entry_ptr->peers.empty()) { + CombineHash(1, &entry.second.unique_hash); + hl_entry_ptr = &hash_to_link_[entry.second.unique_hash]; + } + + for (const auto& peer : entry.second.peers) { + hashed_peers_.emplace_back(HashedPeer(entry.second.unique_hash, peer)); + } + + hl_entry_ptr->tag = entry.second.tag; + hl_entry_ptr->unique_hash = entry.second.unique_hash; + hl_entry_ptr->peers.swap(entry.second.peers); + } +} + +void SigNode::ComputeTopoHash0() { + topo_hash_.clear(); + last_hashed_nodes_ = next_hashed_nodes_ = node_mask_; + + // TODO(babkin): include the attrbutes too, as an option. + size_t hval = std::hash<string>()(opcode()); + + // Getting the topology of the links in to the hash early should get more + // conflicts resolved early. + for (const auto& entry : hashed_peers_) { + CombineHash(entry.link_hash, &hval); + } + + topo_hash_.push_back(hval); +} + +void SigNode::ComputeTopoHash(int distance) { + // The new starting point. + next_hashed_nodes_ = last_hashed_nodes_; + if (debug) { + LOG(INFO) << "DEBUG node " << name() << " mask=" << std::hex + << next_hashed_nodes_; + } + + if (hash_is_final_) { + return; + } + + CHECK(topo_hash_.size() == distance); + + int prev = distance - 1; + + // Start with own's local topology hash. This value is stable, so + // if the hashes of the surrounding nodes don't change on the following + // distances, the hash of this node won't change either. + size_t hval = topo_hash_[0]; + + if (!hashed_peers_.empty()) { + size_t last_link_hash = hashed_peers_[0].link_hash; + size_t comm_hash = 0; + + for (const auto& entry : hashed_peers_) { + if (entry.link_hash != last_link_hash) { + CombineHash(last_link_hash, &hval); + CombineHash(comm_hash, &hval); + comm_hash = 0; + last_link_hash = entry.link_hash; + } + + // The links in the same vector are commutative, so combine their + // hashes in a commutative way. + CombineHashCommutative(entry.peer->GetTopoHash(prev), &comm_hash); + next_hashed_nodes_ |= entry.peer->last_hashed_nodes_; + if (debug) { + LOG(INFO) << "DEBUG node " << name() << " += " << entry.peer->name() + << " mask=" << std::hex << next_hashed_nodes_; + } + } + + // The last commutative group. + CombineHash(last_link_hash, &hval); + CombineHash(comm_hash, &hval); + } + + topo_hash_.push_back(hval); +} + +size_t SigNode::GetTopoHash(int distance) const { + CHECK(!topo_hash_.empty()); + if (distance >= topo_hash_.size()) { + CHECK(hash_is_final_); + return topo_hash_.back(); + } else { + return topo_hash_[distance]; + } +} + +bool SigNode::operator==(const SigNode& other) const { + // TODO(babkin): add attributes too. + if (opcode() != other.opcode()) { + return false; + } + + // Normally the caller is expected to compare the nodes + // at the same rank in different graphs, but just in case... + if (unique_rank_ != other.unique_rank_) { + return false; + } + + if (hashed_peers_.size() != other.hashed_peers_.size()) { + return false; + } + + for (auto it1 = hashed_peers_.begin(), it2 = other.hashed_peers_.begin(); + it1 != hashed_peers_.end(); ++it1, ++it2) { + // TODO(babkin): might compare the actual values too + // but the hash is probably just as good. + if (it1->link_hash != it2->link_hash) { + return false; + } + if (it1->peer->unique_rank_ != it2->peer->unique_rank_) { + return false; + } + } + + return true; +} + +//=== Signature + +constexpr int Signature::kMaxGraphSize; + +string Signature::ToString() const { + string result; + for (size_t n = 0; n < nodes.size(); ++n) { + // TODO(babkin): add attributes too. + result += absl::StrFormat("%d:%s", n, nodes[n]->opcode()); + for (const auto& entry : nodes[n]->hashed_peers_) { + const auto& link = nodes[n]->hash_to_link_[entry.link_hash]; + + // The link entries are already sorted, by tags and then by the + // node ranks. + if (link.tag.local.IsInbound()) { + result += + absl::StrFormat("[%s:%s:%d]", string(link.tag.local), + string(link.tag.remote), entry.peer->unique_rank_); + } + } + result.push_back(','); + } + return result; +} + +Status Signature::Compute() { + if (map.size() > kMaxGraphSize) { + return Status( + error::INVALID_ARGUMENT, + absl::StrFormat( + "A graph of %d nodes is too big for signature computation, " + "the maximal supported node count is %d.", + map.size(), kMaxGraphSize)); + } + + // The value that will be assigned next as the unique node id. + // This also means that all the entries in nodes at indexes less than this + // have been finalized and don't need to be touched any more. + size_t next_node_id = 0; + + sig_short = 0; + sig_full.resize(0); // Keep the storage. + + // The main signature generation. + PrepareNodes(); + FindUniqueHashes(&next_node_id); + while (next_node_id < map.size()) { + ComputeOneRound(next_node_id); + FindUniqueHashes(&next_node_id); + } + + OrderLinks(); + + return Status::OK(); +} + +void Signature::PrepareNodes() { + nodes.resize(0); // Keep the storage. + + // Initialize the nodes. + int64_t mask = 1; + for (const auto& entry : map) { + SigNode* node = entry.second.get(); + node->last_hashed_nodes_ = node->node_mask_ = mask; + mask <<= 1; + node->unique_rank_ = ~0; + node->hash_is_final_ = false; + node->ComputeTopoHash0(); + if (node->GetHighTopoHash() <= map.size()) { + // Would conflict with one of the reserved values. + node->ReHighTopoHash(); + } + + // The initial order is random. + nodes.emplace_back(node); + } +} + +void Signature::FindUniqueHashes(size_t* next_node_id_p) { + // Start by sorting by the hash value. + std::sort(nodes.begin() + *next_node_id_p, nodes.end(), + SigNode::NodeOrderLess()); + + // At each call, if no nodes have unique hashes, one node that has a + // non-unique (shared) hash can be made unique by assigning a unique id. + // This node gets picked predictably by taking the last node. + // TODO(babkin): Technically, more than one node can be unshared, + // as long as their last_hashed_nodes_ overlap only by the nodes that + // already had the assigned ids before the current round. But it's not clear + // yet, how often would this beneficial, because it looks like for many + // subgraphs unsharing one node should be enough to untangle them. This + // would need more measurement before implementing. + bool found_unique = false; + for (size_t n = *next_node_id_p; n < nodes.size(); ++n) { + size_t cur_hash = nodes[n]->GetHighTopoHash(); + if (n + 1 < nodes.size() && nodes[n + 1]->GetHighTopoHash() == cur_hash) { + // A sequence of nodes sharing the same hash. Skip over it. + // TODO(babkin): check here for the arbitrary hash conflicts and resolve + // them. + for (++n; + n + 1 < nodes.size() && nodes[n + 1]->GetHighTopoHash() == cur_hash; + ++n) { + } + if (found_unique || n != nodes.size() - 1) { + // Either some unique nodes have already been found, or this is + // not the last chance, keep trying to find the unique nodes. + continue; + } + // Here we're at the last node and haven't found any unique ones. + // So fall through and make this last node unique. + } + + found_unique = true; + size_t id = (*next_node_id_p)++; + nodes[n]->unique_rank_ = id; + + size_t last_hash = nodes[n]->GetHighTopoHash(); + CombineHash(last_hash, &sig_short); + sig_full.push_back(last_hash); + + // Take the hash at 0 and mix the unique rank into it. After that it will + // stay fixed. + nodes[n]->topo_hash_.resize(1); + nodes[n]->topo_hash_[0] = id + 1; // Avoid the value of 0. + + nodes[n]->hash_is_final_ = true; + nodes[n]->last_hashed_nodes_ = nodes[n]->node_mask_; + if (n != id) { + std::swap(nodes[id], nodes[n]); + } + } +} + +void Signature::ComputeOneRound(size_t next_node_id) { + // Reset the state of the nodes. + int debug_i = 0; + for (auto it = nodes.begin() + next_node_id; it != nodes.end(); ++it) { + auto node = *it; + // The hash at distance 0 never changes, so preserve it. + node->topo_hash_.resize(1); + node->last_hashed_nodes_ = node->node_mask_; + node->hash_is_final_ = false; + if (debug) { + LOG(INFO) << "DEBUG distance=" << 0 << " node " << debug_i++ << " " + << node->name() << " mask=" << std::hex + << node->last_hashed_nodes_; + } + } + + bool stop = false; + // The distance can reach up to nodes.size()+1, to include not only all the + // nodes but also all the redundant paths. + for (int distance = 1; !stop; ++distance) { + for (auto it = nodes.begin() + next_node_id; it != nodes.end(); ++it) { + auto node = *it; + if (node->hash_is_final_) { + continue; + } + node->ComputeTopoHash(distance); + if (node->GetHighTopoHash() <= nodes.size()) { + // Would conflict with one of the reserved values. + node->ReHighTopoHash(); + } + } + + // Will be looking for the indications to not stop. + stop = true; + + debug_i = 0; + // The bitmasks get moved after all the hash computations are done. + for (auto it = nodes.begin() + next_node_id; it != nodes.end(); ++it) { + auto node = *it; + if (debug) { + LOG(INFO) << "DEBUG distance=" << distance << " node " << debug_i++ + << " " << node->name() << " oldmask=" << std::hex + << node->last_hashed_nodes_ << " mask=" << std::hex + << node->next_hashed_nodes_; + } + if (node->last_hashed_nodes_ == node->next_hashed_nodes_) { + // Stopped growing, this part of the graph must be fully + // surrounded by nodes that already have the unique ids. + node->hash_is_final_ = true; + } else { + node->last_hashed_nodes_ = node->next_hashed_nodes_; + stop = false; + } + } + } +} + +void Signature::OrderLinks() { + for (const auto& node : nodes) { + if (node->hashed_peers_.empty()) { + continue; + } + + size_t cur_link_hash = node->hashed_peers_[0].link_hash + 1; + int first_idx = -1; + + int idx; + for (idx = 0; idx < node->hashed_peers_.size(); ++idx) { + auto& entry = node->hashed_peers_[idx]; + if (entry.link_hash == cur_link_hash) { + continue; + } + if (idx - first_idx > 1) { + // Need to sort. + std::sort(node->hashed_peers_.begin() + first_idx, + node->hashed_peers_.begin() + idx, + SigNode::HashedPeer::LessByRank()); + } + + cur_link_hash = entry.link_hash; + first_idx = idx; + } + if (idx - first_idx > 1) { + // Sort the last bunch. + std::sort(node->hashed_peers_.begin() + first_idx, + node->hashed_peers_.begin() + idx, + SigNode::HashedPeer::LessByRank()); + } + } +} + +bool Signature::operator==(const Signature& other) const { + // Tries to find the differences as early as possible by + // comparing the hashes first. + + if (sig_short != other.sig_short) { + return false; + } + if (sig_full.size() != other.sig_full.size()) { + return false; + } + + for (auto it1 = sig_full.begin(), it2 = other.sig_full.begin(); + it1 != sig_full.end(); ++it1, ++it2) { + if (*it1 != *it2) { + return false; + } + } + + if (nodes.size() != other.nodes.size()) { + return false; + } + for (auto it1 = nodes.begin(), it2 = other.nodes.begin(); it1 != nodes.end(); + ++it1, ++it2) { + if (**it1 != **it2) { + return false; + } + } + + return true; +} + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/sig_node.h b/tensorflow/core/grappler/graph_analyzer/sig_node.h new file mode 100644 index 0000000000..45c0ed3162 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/sig_node.h @@ -0,0 +1,304 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_SIG_NODE_H_ +#define TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_SIG_NODE_H_ + +#include <map> +#include <memory> +#include <vector> + +#include "tensorflow/core/framework/graph.pb.h" +#include "tensorflow/core/framework/node_def.pb.h" +#include "tensorflow/core/grappler/graph_analyzer/gen_node.h" +#include "tensorflow/core/grappler/graph_analyzer/hash_tools.h" +#include "tensorflow/core/lib/core/status.h" +#include "tensorflow/core/protobuf/meta_graph.pb.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +namespace test { +class SigBaseTest; +} // end namespace test + +class SigNode; + +// To find nodes by name. Having the map ordered makes the tests easier, +// and it isn't used in production code often enough to get any win from +// using an unordered map. +using SigNodeMap = std::map<string, std::unique_ptr<SigNode>>; + +// One node in the graph, in the form convenient for generation of the signature +// of the graph, and comparison of two (sub)graphs for equivalence. It refers to +// the original NodeDef protobuf for most information and adds the extra +// enrichment. +// +// The graph building is 2-stage: first match a SigNode with each NodeDef and +// collect them into a map that finds them by name, then process the map, +// deep-parse the underlying NodeDefs and connect the SigNodes together. +class SigNode { + public: + friend struct Signature; + + // Will keep the pointer to the underlying NodeDef, so that + // underlying object must not be deleted while SigNode is alive. + explicit SigNode(const NodeDef* node); + + // Access wrappers. + const string& name() const { return node_->name(); } + const string& opcode() const { return node_->op(); } + const NodeDef* node_def() const { return node_; } + + // For extraction of subgraphs into a separate SigNodeMap, copies the links + // that point inside the subgraph from a full-graph SigNode to a subgraph + // SigNode. The translation map defines the subgraph and gives the mapping + // from the nodes in the full graph to the matching nodes in subgraph. + using TranslationMap = + std::unordered_map<const GenNode* /*full_graph*/, SigNode* /*subgraph*/>; + void CopyLinks(const GenNode& from, const TranslationMap& map); + + // A link is an edge of the graph that connects 2 nodes. Each of the connected + // nodes has its own perspective on the link, seeing its local port, remote + // port and the remote node. The direction of the link is encoded in the + // ports, one port is always incoming and another one outgoing. + // + // The link tag here contains both ports of the link viewed from the + // perspective of this node; consisting of both the local port (i.e. at this + // node) and remote port (i.e. on the other node), the local one going first. + struct LinkTag { + struct Hasher { + size_t operator()(const LinkTag& tag) const noexcept { + size_t hval = port_hasher(tag.local); + CombineHash(port_hasher(tag.remote), &hval); + return hval; + } + GenNode::Port::Hasher port_hasher; + }; + + LinkTag(GenNode::Port a_local, GenNode::Port a_remote) + : local(a_local), remote(a_remote) {} + + // The default constructor is used for the default values in maps. + // (false, 99) is an arbitrary value that makes the uninitialized + // links easy to tell when debugging (they should never happen). + LinkTag() : local(false, 99), remote(false, 99) {} + + // Port of the link on the local node. + GenNode::Port local; + // Port of the link on the remote node. + GenNode::Port remote; + + bool operator==(const LinkTag& other) const { + return local == other.local && remote == other.remote; + } + bool operator<(const LinkTag& other) const { + return local < other.local || + (local == other.local && remote < other.remote); + } + }; + + // Since the signature logic doesn't differentiate between the links + // with the same tag (other than by the "peer" nodes on their other ends), + // all the links with the same tag are grouped into a single structure. + struct Link { + LinkTag tag; + size_t unique_hash; // Hash of the tag after conflict resolution. + // The remote node(s) on the other side on the link(s). + using PeerVector = std::vector<SigNode*>; + PeerVector peers; + }; + + // A way to look up the link description by its hash. + using LinkHashMap = std::map<size_t, Link>; + const LinkHashMap& hash_to_link() const { return hash_to_link_; } + + // The enumeration of all the peer nodes in a predictable order. + // Before the signature generation, only the link values determine the + // order, after the signature generation the entries at the same + // links get further sorted by their peer node ranks. + struct HashedPeer { + HashedPeer(size_t l, SigNode* p) : link_hash(l), peer(p) {} + + struct LessByRank { + bool operator()(const SigNode::HashedPeer& left, + const SigNode::HashedPeer& right) { + return left.peer->unique_rank_ < right.peer->unique_rank_; + } + }; + + size_t link_hash; + SigNode* peer; + }; + using HashedPeerVector = std::vector<HashedPeer>; + const HashedPeerVector& hashed_peers() const { return hashed_peers_; } + + // Compares two nodes in two different graphs for equivalence (two nodes in + // the same graph would never be equivalent). Expects that the signatures of + // the graphs have already been computed, so unique_rank_ is filled in and + // the hashed_peers_ properly ordered. + bool operator==(const SigNode& other) const; + + bool operator!=(const SigNode& other) const { return !(*this == other); } + + private: + friend class test::SigBaseTest; + + // The CopyLinks code is split into 2 parts for testability. + // The first pass builds a map ordered by LinkTag for predictability. + void CopyLinksPass1(const GenNode& from, const TranslationMap& map, + std::map<LinkTag, Link>* link_map); + // The second pass converts to the map by hash value, + // resolves any hash conflicts, and builds the hashed peer vector. + void CopyLinksPass2(std::map<LinkTag, Link>* link_map); + + // Computes the topological hash at distance 0. Resets the topo_hash_ vector + // and hashed_nodes_; + void ComputeTopoHash0(); + + // Compute the topological has at the given distance. The hashes for all the + // lower distances must be already computed for all the nodes in the graph. + // Also computes next_hashed_nodes_ from last_hashed_nodes_. + void ComputeTopoHash(int distance); + + // Get the hash value for a particular distance. It must be previously + // computed. + size_t GetTopoHash(int distance) const; + + // The the hash value for the highest computed distance. It must be previously + // computed. + size_t GetHighTopoHash() const { + CHECK(!topo_hash_.empty()); + return topo_hash_.back(); + } + + // Rehash the topmost hash, to avoid conflicts. + void ReHighTopoHash() { + CHECK(!topo_hash_.empty()); + CombineHash(1, &topo_hash_.back()); + } + + // Ordering by node order and highest available hash (it must be + // previously computed). + struct NodeOrderLess { + bool operator()(const SigNode* left, const SigNode* right) { + return left->topo_hash_.back() < right->topo_hash_.back(); + } + }; + + private: + const NodeDef* node_; + + // The bitmap mask with 1 bit set that represents this node in the set + // during the computation of the signature. + uint64_t node_mask_ = 0; + + // The code that populates this map makes sure that there are no hash + // conflicts, rehashing if necessary. + LinkHashMap hash_to_link_; + + // The enumeration of all the direct peers in the predictable order (which + // happens to be the order ot their link tags, but the order of the hashes + // would do too). It is used for the quick enumeration during the signature + // computation. After the signature building is completed, the entries that + // have the same link tag get further sorted in the order of the ranks of + // their nodes. + HashedPeerVector hashed_peers_; + + // The unique rank represents the order in which the node will be included + // into the signature. It gets assigned in order either when the topo_hash_ of + // this node becomes unique in the graph, or when the nodes are completely + // equivalent, one of them is picked at random to assign the next rank, and + // then the rest of the nodes attempt to disambiguate based on that + // information. + size_t unique_rank_ = ~0; + // When hash_is_final_ is set, the topo_has_ vector stops growing, and the + // last value from it is used for all the further hashes. + bool hash_is_final_ = false; + // The hashes that include the topology of the nodes up to the distance N. The + // hash for distance 0 is produced from the attributes of this node itself and + // its general connectivity properties but no information about the + // neighboring nodes. The hash for distance D+1 is build from hashes at level + // D of this node and of all its immediate neighbors. The neighbors that are + // connected by equivalent links are included in a commutative way. + std::vector<size_t> topo_hash_; + // The set of nodes that got included into the computation of the + // last topo_hash_ entry. + uint64_t last_hashed_nodes_ = 0; + // The next set of nodes that gets used for the current topo_hash entry. + uint64_t next_hashed_nodes_ = 0; +}; + +// Signature of a graph. The computation is intertwined with the private methods +// of SigNode, so keeping both in the same file looks more convenient. +struct Signature { + friend class test::SigBaseTest; + + // Maximal size of the graphs for which the signature can be computed. + // Changing this constant won't magically add the support for a larger size, + // the rest of implementation would have to be extended. The value of 64 is + // driven by the size of a bitset in an uint64_t, and should be enough for our + // purposes, while having a high efficiency of implementation. + static constexpr int kMaxGraphSize = 64; + + // Using the map, computes the rest of the fields of a signature. + // Returns an error is the graph is too big. + Status Compute(); + + // Convert the computed signature to a string representation. + string ToString() const; + + SigNodeMap map; // The nodes in the graph, accessible by name. + size_t sig_short = 0; // Hash of the signature, for the quick equality check. + // The full signature: hashes of the nodes in a predictable order. + std::vector<size_t> sig_full; + // The nodes in the same order as they go in the signature. + std::vector<SigNode*> nodes; + + // For building the unordered maps. + size_t Hash() const { return sig_short; } + + // Returns true if the graphs are equivalent. The signature must be already + // computed. + bool operator==(const Signature& other) const; + + private: + // Populates the nodes vector from the map and initializes the state of the + // nodes for the signature computation. + void PrepareNodes(); + + // Finds the nodes with the hashes that are unique and assigns the unique ids + // to them. If there are nodes with non-unique hashes, exactly one node from + // the first such sequence (in the order of hash values) will be picked and + // assigned a unique id. Assumes that the nodes[0...(next_node_id-1)] have + // been already assigned the unique ids. Advances next_node_id by at least 1. + void FindUniqueHashes(size_t* next_node_id_p); + + // One round of the signature computation. Assumes that the + // nodes[0...(next_node_id-1)] have been already assigned the fixed + // positions, and thus computes the hashes only for the remaining nodes. + void ComputeOneRound(size_t next_node_id); + + // Additional ordering of the hashed_peers_ links in the nodes, so that they + // can be compared and printed in a predictable order. + void OrderLinks(); +}; + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow + +#endif // TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_SIG_NODE_H_ diff --git a/tensorflow/core/grappler/graph_analyzer/sig_node_test.cc b/tensorflow/core/grappler/graph_analyzer/sig_node_test.cc new file mode 100644 index 0000000000..4c6a9ba9e0 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/sig_node_test.cc @@ -0,0 +1,1235 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/graph_analyzer/sig_node.h" + +#include <gmock/gmock.h> +#include <gtest/gtest.h> +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" +#include "tensorflow/core/grappler/graph_analyzer/subgraph.h" +#include "tensorflow/core/grappler/graph_analyzer/test_tools.h" +#include "tensorflow/core/grappler/utils.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { +namespace test { + +using ::testing::ElementsAre; +using ::testing::Eq; +using ::testing::Gt; +using ::testing::Ne; +using ::testing::SizeIs; + +//=== + +TEST(SigNodeLinkTag, Compare) { + SigNode::LinkTag a(GenNode::Port(false, 1), GenNode::Port(false, 2)); + SigNode::LinkTag b(GenNode::Port(false, 1), GenNode::Port(false, 2)); + SigNode::LinkTag c(GenNode::Port(false, 2), GenNode::Port(false, 1)); + SigNode::LinkTag d(GenNode::Port(false, 1), GenNode::Port(false, 3)); + SigNode::LinkTag e(GenNode::Port(false, 2), GenNode::Port(false, 2)); + + EXPECT_TRUE(a == b); + EXPECT_FALSE(a == c); + EXPECT_FALSE(a == e); + + EXPECT_FALSE(a < b); + EXPECT_FALSE(b < a); + + EXPECT_TRUE(a < c); + EXPECT_FALSE(c < a); + + EXPECT_TRUE(a < d); + EXPECT_FALSE(d < a); +} + +//=== + +class SigBaseTest : public ::testing::Test, protected TestGraphs { + protected: + void BuildSigMap(const GraphDef& graph) { + gen_map_.clear(); + sig_.map.clear(); + CHECK(GenNode::BuildGraphInMap(graph, &gen_map_).ok()); + Subgraph::Identity id; + for (const auto& entry : gen_map_) { + id.insert(entry.second.get()); + } + Subgraph sg(id); + sg.ExtractForSignature(&sig_.map); + } + + static void CopyLinksPass2( + std::map<SigNode::LinkTag, SigNode::Link>* link_map, SigNode* node) { + node->CopyLinksPass2(link_map); + } + + static void ComputeTopoHash0(SigNode* node) { node->ComputeTopoHash0(); } + + static void ComputeTopoHash(int distance, SigNode* node) { + node->ComputeTopoHash(distance); + } + + static size_t GetTopoHash(int distance, SigNode* node) { + return node->GetTopoHash(distance); + } + + static size_t GetHighTopoHash(SigNode* node) { + return node->GetHighTopoHash(); + } + + static void ReHighTopoHash(SigNode* node) { node->ReHighTopoHash(); } + + static SigNode::HashedPeerVector& RefHashedPeers(SigNode* node) { + return node->hashed_peers_; + } + static size_t& RefUniqueRank(SigNode* node) { return node->unique_rank_; } + static bool& RefHashIsFinal(SigNode* node) { return node->hash_is_final_; } + static std::vector<size_t>& RefTopoHash(SigNode* node) { + return node->topo_hash_; + } + static uint64_t& RefNodeMask(SigNode* node) { return node->node_mask_; } + static uint64_t& RefLastHashedNodes(SigNode* node) { + return node->last_hashed_nodes_; + } + static uint64_t& RefNextHashedNodes(SigNode* node) { + return node->next_hashed_nodes_; + } + + static void PrepareNodes(Signature* signature) { signature->PrepareNodes(); } + + static void FindUniqueHashes(size_t* next_node_id_p, Signature* signature) { + signature->FindUniqueHashes(next_node_id_p); + } + + static void ComputeOneRound(size_t next_node_id, Signature* signature) { + signature->ComputeOneRound(next_node_id); + } + + static void OrderLinks(Signature* signature) { signature->OrderLinks(); } + + // These get initialized in BuildSigMap(). + GenNodeMap gen_map_; + Signature sig_; +}; + +//=== + +class SigNodeTest : public SigBaseTest {}; + +// Tests that the duplicate hashes get resolved by rehashing. +TEST_F(SigNodeTest, DuplicateHash) { + NodeDef node1 = MakeNodeConst("node1"); + NodeDef node2 = MakeNodeConst("node2"); + NodeDef node3 = MakeNodeShapeN("node3", "node1", "node2"); + + SigNode sn1(&node1); + SigNode sn2(&node2); + SigNode sn3(&node3); + + constexpr size_t kSameHash = 999; + + SigNode::Link link1; + link1.tag = SigNode::LinkTag(GenNode::Port(true, 0), GenNode::Port(false, 0)); + link1.unique_hash = kSameHash; + link1.peers.emplace_back(&sn1); + + SigNode::Link link2; + link2.tag = SigNode::LinkTag(GenNode::Port(true, 1), GenNode::Port(false, 0)); + link2.unique_hash = kSameHash; + link2.peers.emplace_back(&sn2); + + SigNode::Link link3; + link3.tag = SigNode::LinkTag(GenNode::Port(true, 2), GenNode::Port(false, 0)); + link3.unique_hash = kSameHash; + link3.peers.emplace_back(&sn3); + + std::map<SigNode::LinkTag, SigNode::Link> link_map; + link_map[link1.tag] = link1; + link_map[link2.tag] = link2; + link_map[link3.tag] = link3; + + CopyLinksPass2(&link_map, &sn3); + auto& hl = sn3.hash_to_link(); + EXPECT_THAT(hl, SizeIs(3)); + + // Check that the hashes are self_consistent, and put the entries into + // another map with a known order. + std::map<SigNode::LinkTag, SigNode::Link> rehashed; + auto hlit = hl.begin(); + ASSERT_THAT(hlit, Ne(hl.end())); + EXPECT_THAT(hlit->second.unique_hash, Eq(hlit->first)); + rehashed[hlit->second.tag] = hlit->second; + ++hlit; + ASSERT_THAT(hlit, Ne(hl.end())); + EXPECT_THAT(hlit->second.unique_hash, Eq(hlit->first)); + rehashed[hlit->second.tag] = hlit->second; + ++hlit; + ASSERT_THAT(hlit, Ne(hl.end())); + EXPECT_THAT(hlit->second.unique_hash, Eq(hlit->first)); + rehashed[hlit->second.tag] = hlit->second; + + // Just in case. + ASSERT_THAT(rehashed, SizeIs(3)); + + auto rhit = rehashed.begin(); + ASSERT_THAT(rhit, Ne(rehashed.end())); + EXPECT_TRUE(rhit->second.tag == link1.tag); + EXPECT_THAT(rhit->second.unique_hash, Eq(kSameHash)); + EXPECT_THAT(rhit->second.peers, ElementsAre(&sn1)); + + ++rhit; + ASSERT_THAT(rhit, Ne(rehashed.end())); + EXPECT_TRUE(rhit->second.tag == link2.tag); + // This hash must be rehashed. + EXPECT_THAT(rhit->second.unique_hash, Ne(kSameHash)); + size_t hash2 = rhit->second.unique_hash; + EXPECT_THAT(rhit->second.peers, ElementsAre(&sn2)); + + ++rhit; + ASSERT_THAT(rhit, Ne(rehashed.end())); + EXPECT_TRUE(rhit->second.tag == link3.tag); + // This hash must be rehashed. + EXPECT_THAT(rhit->second.unique_hash, Ne(kSameHash)); + EXPECT_THAT(rhit->second.unique_hash, Ne(hash2)); + size_t hash3 = rhit->second.unique_hash; + EXPECT_THAT(rhit->second.peers, ElementsAre(&sn3)); + + auto& peers = sn3.hashed_peers(); + EXPECT_THAT(peers, SizeIs(3)); + + auto peerit = peers.begin(); + ASSERT_THAT(peerit, Ne(peers.end())); + EXPECT_THAT(peerit->link_hash, Eq(kSameHash)); + EXPECT_THAT(peerit->peer, Eq(&sn1)); + + ++peerit; + ASSERT_THAT(peerit, Ne(peers.end())); + EXPECT_THAT(peerit->link_hash, Eq(hash2)); + EXPECT_THAT(peerit->peer, Eq(&sn2)); + + ++peerit; + ASSERT_THAT(peerit, Ne(peers.end())); + EXPECT_THAT(peerit->link_hash, Eq(hash3)); + EXPECT_THAT(peerit->peer, Eq(&sn3)); +} + +// The full CopyLinks() is tested in (SubgraphTest, ExtractForSignature). + +TEST_F(SigNodeTest, GetTopoHash) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + + // Fake some hash values. + RefTopoHash(&sn1).emplace_back(123); + RefTopoHash(&sn1).emplace_back(456); + + EXPECT_THAT(GetTopoHash(0, &sn1), Eq(123)); + EXPECT_THAT(GetTopoHash(1, &sn1), Eq(456)); + + RefHashIsFinal(&sn1) = true; + + EXPECT_THAT(GetTopoHash(0, &sn1), Eq(123)); + EXPECT_THAT(GetTopoHash(1, &sn1), Eq(456)); + EXPECT_THAT(GetTopoHash(2, &sn1), Eq(456)); + + EXPECT_THAT(GetHighTopoHash(&sn1), Eq(456)); +} + +TEST_F(SigNodeTest, ReTopoHash) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + + // Fake some hash values. + RefTopoHash(&sn1).emplace_back(123); + RefTopoHash(&sn1).emplace_back(456); + + EXPECT_THAT(GetTopoHash(0, &sn1), Eq(123)); + EXPECT_THAT(GetTopoHash(1, &sn1), Eq(456)); + + ReHighTopoHash(&sn1); + + size_t expected_hash = 456; + CombineHash(1, &expected_hash); + + EXPECT_THAT(GetTopoHash(0, &sn1), Eq(123)); + EXPECT_THAT(GetTopoHash(1, &sn1), Eq(expected_hash)); +} + +TEST_F(SigNodeTest, ComputeTopoHash0) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + + // Fake a topology. + RefUniqueRank(&sn1) = 10; + RefNodeMask(&sn1) = 0x02; + + RefTopoHash(&sn1).emplace_back(123); + RefTopoHash(&sn1).emplace_back(456); + + // Fake a state. + RefLastHashedNodes(&sn1) = 0xFF; + RefNextHashedNodes(&sn1) = 0xFF; + + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(1, nullptr)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(1, nullptr)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(2, nullptr)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(3, nullptr)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(3, nullptr)); + + // Run the test. + ComputeTopoHash0(&sn1); + + EXPECT_THAT(RefLastHashedNodes(&sn1), Eq(0x02)); + EXPECT_THAT(RefNextHashedNodes(&sn1), Eq(0x02)); + EXPECT_THAT(RefTopoHash(&sn1), SizeIs(1)); + + size_t exp_hval = std::hash<string>()(sn1.opcode()); + CombineHash(1, &exp_hval); + CombineHash(1, &exp_hval); + CombineHash(2, &exp_hval); + CombineHash(3, &exp_hval); + CombineHash(3, &exp_hval); + + EXPECT_THAT(GetTopoHash(0, &sn1), Eq(exp_hval)); +} + +TEST_F(SigNodeTest, ComputeTopoHashNotFinal) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + NodeDef node2 = MakeNodeConst("node2"); + SigNode sn2(&node2); + NodeDef node3 = MakeNodeConst("node3"); + SigNode sn3(&node3); + + // Fake a topology. + RefUniqueRank(&sn1) = 0; + RefNodeMask(&sn1) = 0x01; + RefUniqueRank(&sn2) = 0; + RefNodeMask(&sn2) = 0x02; + RefUniqueRank(&sn3) = 0; + RefNodeMask(&sn3) = 0x04; + + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(10, &sn2)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(10, &sn3)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(20, &sn2)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(30, &sn3)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(30, &sn2)); + + // Fake a state. + RefTopoHash(&sn1).emplace_back(123); + RefTopoHash(&sn1).emplace_back(321); + + RefTopoHash(&sn2).emplace_back(456); + RefTopoHash(&sn2).emplace_back(654); + + RefTopoHash(&sn3).emplace_back(789); + RefTopoHash(&sn3).emplace_back(987); + + // These values are not realistic in the way that they don't include the bits + // from the mask of nodes themselves, but that's the point of this test: only + // the previous nodes' node sets are used in the computation, not their own + // masks directly. + RefLastHashedNodes(&sn1) = 0x8; + RefLastHashedNodes(&sn2) = 0x10; + RefLastHashedNodes(&sn3) = 0x20; + + // A scratch value to get overwritten. + RefNextHashedNodes(&sn1) = 0x100; + + ComputeTopoHash(2, &sn1); + + EXPECT_THAT(RefLastHashedNodes(&sn1), Eq(0x8)); // Unchanged. + EXPECT_THAT(RefNextHashedNodes(&sn1), Eq(0x38)); + + // This computes the hash form the explicit numbers above. + size_t exp_hash = 123; // The 0th hash is the starting point. + size_t comm_hash; + + comm_hash = 0; + CombineHashCommutative(654, &comm_hash); + CombineHashCommutative(987, &comm_hash); + + CombineHash(10, &exp_hash); + CombineHash(comm_hash, &exp_hash); + + comm_hash = 0; + CombineHashCommutative(654, &comm_hash); + + CombineHash(20, &exp_hash); + CombineHash(comm_hash, &exp_hash); + + comm_hash = 0; + CombineHashCommutative(654, &comm_hash); + CombineHashCommutative(987, &comm_hash); + + CombineHash(30, &exp_hash); + CombineHash(comm_hash, &exp_hash); + + EXPECT_THAT(GetTopoHash(2, &sn1), Eq(exp_hash)); + EXPECT_THAT(RefTopoHash(&sn1), SizeIs(3)); +} + +TEST_F(SigNodeTest, ComputeTopoHashFinal) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + NodeDef node2 = MakeNodeConst("node2"); + SigNode sn2(&node2); + NodeDef node3 = MakeNodeConst("node3"); + SigNode sn3(&node3); + + // Fake a topology - same as for ComputeTopoHashNotFinal. + RefUniqueRank(&sn1) = 0; + RefNodeMask(&sn1) = 0x01; + RefUniqueRank(&sn2) = 0; + RefNodeMask(&sn2) = 0x02; + RefUniqueRank(&sn3) = 0; + RefNodeMask(&sn3) = 0x04; + + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(10, &sn2)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(10, &sn3)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(20, &sn2)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(30, &sn3)); + RefHashedPeers(&sn1).emplace_back(SigNode::HashedPeer(30, &sn2)); + + // Fake a state - mostly same as for ComputeTopoHashNotFinal. + RefTopoHash(&sn1).emplace_back(123); + RefTopoHash(&sn1).emplace_back(321); + + RefTopoHash(&sn2).emplace_back(456); + RefTopoHash(&sn2).emplace_back(654); + + RefTopoHash(&sn3).emplace_back(789); + RefTopoHash(&sn3).emplace_back(987); + + // These values are not realistic in the way that they don't include the bits + // from the mask of nodes themselves, but that's the point of this test: only + // the previous nodes' node sets are used in the computation, not their own + // masks directly. + RefLastHashedNodes(&sn1) = 0x8; + RefLastHashedNodes(&sn2) = 0x10; + RefLastHashedNodes(&sn3) = 0x20; + + // A scratch value to get overwritten. + RefNextHashedNodes(&sn1) = 0x100; + + // This is the difference in configuration. + RefHashIsFinal(&sn1) = true; + + ComputeTopoHash(2, &sn1); + + EXPECT_THAT(RefLastHashedNodes(&sn1), Eq(0x8)); // Unchanged. + EXPECT_THAT(RefNextHashedNodes(&sn1), Eq(0x8)); + EXPECT_THAT(RefTopoHash(&sn1), SizeIs(2)); + EXPECT_THAT(GetTopoHash(2, &sn1), Eq(321)); +} + +TEST_F(SigNodeTest, EqualsOpcode) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + + NodeDef node2 = MakeNodeConst("node2"); + SigNode sn2(&node2); + + EXPECT_TRUE(sn1 == sn2); + EXPECT_FALSE(sn1 != sn2); + + node2.set_op("Mul"); + + EXPECT_TRUE(sn1 != sn2); + EXPECT_FALSE(sn1 == sn2); +} + +TEST_F(SigNodeTest, EqualsRank) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + + NodeDef node2 = MakeNodeConst("node2"); + SigNode sn2(&node2); + + EXPECT_TRUE(sn1 == sn2); + EXPECT_FALSE(sn1 != sn2); + + RefUniqueRank(&sn1) = 1; + RefUniqueRank(&sn2) = 2; + + EXPECT_TRUE(sn1 != sn2); + EXPECT_FALSE(sn1 == sn2); +} + +// Checks that if the nodes have a different number of links, +// they will be considered unequal. +TEST_F(SigNodeTest, EqualsLinkSize) { + GraphDef graph1; + (*graph1.add_node()) = MakeNodeConst("node1"); + (*graph1.add_node()) = MakeNodeMul("node2", "node1", "node1"); + + GenNodeMap gen_map1; + ASSERT_THAT(GenNode::BuildGraphInMap(graph1, &gen_map1), Eq(Status::OK())); + + Subgraph::Identity id1; + id1.insert(gen_map1["node1"].get()); + id1.insert(gen_map1["node2"].get()); + Subgraph sg1(id1); + + SigNodeMap sig_map1; + sg1.ExtractForSignature(&sig_map1); + + GraphDef graph2; + (*graph2.add_node()) = MakeNodeConst("node1"); + // The difference between graph1 and graph2: one more input. + auto node22 = graph2.add_node(); + *node22 = MakeNodeMul("node2", "node1", "node1"); + node22->add_input("node2"); + + GenNodeMap gen_map2; + ASSERT_THAT(GenNode::BuildGraphInMap(graph2, &gen_map2), Eq(Status::OK())); + + Subgraph::Identity id2; + id2.insert(gen_map2["node1"].get()); + id2.insert(gen_map2["node2"].get()); + Subgraph sg2(id2); + + SigNodeMap sig_map2; + sg2.ExtractForSignature(&sig_map2); + + EXPECT_TRUE(*sig_map1["node1"] == *sig_map2["node1"]); + EXPECT_FALSE(*sig_map1["node2"] == *sig_map2["node2"]); + EXPECT_FALSE(*sig_map2["node2"] == *sig_map1["node2"]); +} + +TEST_F(SigNodeTest, EqualsLinks) { + // Start with 2 copies of the same graph. + GraphDef graph1; + (*graph1.add_node()) = MakeNodeConst("node1"); + (*graph1.add_node()) = MakeNodeMul("node2", "node1", "node1"); + + GenNodeMap gen_map1; + ASSERT_THAT(GenNode::BuildGraphInMap(graph1, &gen_map1), Eq(Status::OK())); + + Subgraph::Identity id1; + id1.insert(gen_map1["node1"].get()); + id1.insert(gen_map1["node2"].get()); + Subgraph sg1(id1); + + SigNodeMap sig_map1; + sg1.ExtractForSignature(&sig_map1); + + GenNodeMap gen_map2; + ASSERT_THAT(GenNode::BuildGraphInMap(graph1, &gen_map2), Eq(Status::OK())); + + Subgraph::Identity id2; + id2.insert(gen_map2["node1"].get()); + id2.insert(gen_map2["node2"].get()); + Subgraph sg2(id2); + + SigNodeMap sig_map2; + sg2.ExtractForSignature(&sig_map2); + + EXPECT_TRUE(*sig_map1["node1"] == *sig_map2["node1"]); + EXPECT_TRUE(*sig_map1["node2"] == *sig_map2["node2"]); + + // Alter the link hash of one of the nodes. + SigNode* sn2 = sig_map2["node2"].get(); + ++RefHashedPeers(sn2)[0].link_hash; + + EXPECT_FALSE(*sig_map1["node2"] == *sig_map2["node2"]); + + // Restore back. + --RefHashedPeers(sn2)[0].link_hash; + EXPECT_TRUE(*sig_map1["node2"] == *sig_map2["node2"]); + + // Alter the unique rank of a referenced node. + ++RefUniqueRank(sig_map2["node1"].get()); + + EXPECT_FALSE(*sig_map1["node2"] == *sig_map2["node2"]); +} + +//=== + +class SignatureTest : public SigBaseTest { + protected: + // Initializeds the state used to generate the permutations of a given size. + static void InitPermutation(size_t size, + std::vector<size_t>* plain_permutation, + std::vector<size_t>* countdown) { + plain_permutation->clear(); + countdown->clear(); + for (size_t i = 0; i < size; ++i) { + plain_permutation->emplace_back(i); + countdown->emplace_back(size - 1 - i); + } + } + + // Builds a permutation guided by the count-down value. + static void BuildPermutation(const std::vector<size_t>& plain_permutation, + const std::vector<size_t>& countdown, + std::vector<size_t>* result) { + *result = plain_permutation; + for (int i = 0; i < result->size(); ++i) { + std::swap((*result)[i], (*result)[i + countdown[i]]); + } + } + + // Returns false when the count-down is finished. + static bool CountDown(std::vector<size_t>* countdown) { + // The last position always contains 0, so skip it. + int pos; + for (pos = countdown->size() - 2; pos >= 0; --pos) { + if ((*countdown)[pos] > 0) { + --(*countdown)[pos]; + break; + } + (*countdown)[pos] = (countdown->size() - 1 - pos); + } + + return pos >= 0; + } + + // Permutes the nodes every which way and checks that all the signatures + // produced are the same. This is reasonable for the graphs up to the + // size 5, maybe 6 at the stretch. After that the number of permutation grows + // huge and the test becomes very slow. + void TestGraphEveryWay(const GraphDef& graph) { + size_t graph_size = graph.node_size(); + + gen_map_.clear(); + sig_.map.clear(); + Status result = GenNode::BuildGraphInMap(graph, &gen_map_); + ASSERT_THAT(result, Eq(Status::OK())); + Subgraph::Identity id; + for (const auto& entry : gen_map_) { + id.insert(entry.second.get()); + } + Subgraph sg(id); + sg.ExtractForSignature(&sig_.map); + + std::vector<size_t> plain_permutation; + std::vector<size_t> countdown; + InitPermutation(graph_size, &plain_permutation, &countdown); + + std::set<string> signatures; + std::vector<size_t> permutation; + do { + BuildPermutation(plain_permutation, countdown, &permutation); + + constexpr bool kDebugPermutation = false; + if (kDebugPermutation) { + string p; + for (int i = 0; i < permutation.size(); ++i) { + p.push_back('0' + permutation[i]); + } + LOG(INFO) << "Permutation: " << p; + } + + std::vector<std::unique_ptr<SigNode>> hold(graph_size); + int idx; + + // Permute the nodes. + sig_.nodes.clear(); + idx = 0; + if (kDebugPermutation) { + LOG(INFO) << " nodes before permutation:"; + } + for (auto& entry : sig_.map) { + if (kDebugPermutation) { + LOG(INFO) << " " << entry.second.get(); + } + hold[idx++] = std::move(entry.second); + } + idx = 0; + if (kDebugPermutation) { + LOG(INFO) << " nodes after permutation:"; + } + for (auto& entry : sig_.map) { + entry.second = std::move(hold[permutation[idx++]]); + if (kDebugPermutation) { + LOG(INFO) << " " << entry.second.get(); + } + // This is used to order the links per permutation. + sig_.nodes.emplace_back(entry.second.get()); + RefUniqueRank(entry.second.get()) = idx; + } + // Order the links with the same tags per permutation. + OrderLinks(&sig_); + + // The test as such. + ASSERT_THAT(sig_.Compute(), Eq(Status::OK())); + + signatures.insert(sig_.ToString()); + + EXPECT_THAT(sig_.sig_full, SizeIs(graph_size)); + size_t hval = 0; + for (size_t ih : sig_.sig_full) { + // The space 1..graph_size is reserved. + EXPECT_THAT(ih, Gt(graph_size)); + CombineHash(ih, &hval); + } + EXPECT_THAT(sig_.sig_short, Eq(hval)); + + // Un-permute the nodes for the next iteration. + idx = 0; + for (auto& entry : sig_.map) { + hold[permutation[idx++]] = std::move(entry.second); + } + idx = 0; + if (kDebugPermutation) { + LOG(INFO) << " nodes after un-permutation:"; + } + for (auto& entry : sig_.map) { + entry.second = std::move(hold[idx++]); + if (kDebugPermutation) { + LOG(INFO) << " " << entry.second.get(); + } + } + } while (CountDown(&countdown)); + + for (const auto& s : signatures) { + LOG(INFO) << "Signature: " << s; + } + + // All the permutations should produce the same signature. + EXPECT_THAT(signatures, SizeIs(1)); + } +}; + +TEST_F(SignatureTest, PrepareNodes) { + NodeDef node1 = MakeNodeConst("node1"); + sig_.map["node1"] = absl::make_unique<SigNode>(&node1); + NodeDef node2 = MakeNodeConst("node2"); + sig_.map["node2"] = absl::make_unique<SigNode>(&node2); + NodeDef node3 = MakeNodeConst("node3"); + sig_.map["node3"] = absl::make_unique<SigNode>(&node3); + + PrepareNodes(&sig_); + + ASSERT_THAT(sig_.nodes, SizeIs(3)); + + int idx = 0; + for (const auto& entry : sig_.map) { + EXPECT_THAT(RefNodeMask(entry.second.get()), Eq(1 << idx)) + << " at index " << idx; + EXPECT_THAT(RefUniqueRank(entry.second.get()), Eq(static_cast<size_t>(~0))) + << " at index " << idx; + EXPECT_THAT(RefHashIsFinal(entry.second.get()), false) + << " at index " << idx; + EXPECT_THAT(RefTopoHash(entry.second.get()), SizeIs(1)) + << " at index " << idx; + ++idx; + } +} + +TEST_F(SignatureTest, FindUniqueHashesAllDifferent) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + NodeDef node2 = MakeNodeConst("node2"); + SigNode sn2(&node2); + NodeDef node3 = MakeNodeConst("node3"); + SigNode sn3(&node3); + NodeDef node4 = MakeNodeConst("node4"); + SigNode sn4(&node4); + + // The last values in the arrays values go in the backwards order. + RefTopoHash(&sn1).emplace_back(100); + RefTopoHash(&sn1).emplace_back(900); + + RefTopoHash(&sn2).emplace_back(200); + RefTopoHash(&sn2).emplace_back(800); + + RefTopoHash(&sn3).emplace_back(300); + RefTopoHash(&sn3).emplace_back(700); + + RefTopoHash(&sn4).emplace_back(400); + RefTopoHash(&sn4).emplace_back(600); + + sig_.nodes.emplace_back(&sn1); + sig_.nodes.emplace_back(&sn2); + sig_.nodes.emplace_back(&sn3); + sig_.nodes.emplace_back(&sn4); + + size_t next = 1; // Skips over sn1. + + FindUniqueHashes(&next, &sig_); + EXPECT_THAT(next, Eq(4)); + + EXPECT_THAT(sig_.nodes[0], Eq(&sn1)); + // The nodes after first one get sorted by the high hash. + EXPECT_THAT(sig_.nodes[1], Eq(&sn4)); + EXPECT_THAT(sig_.nodes[2], Eq(&sn3)); + EXPECT_THAT(sig_.nodes[3], Eq(&sn2)); + + EXPECT_THAT(RefHashIsFinal(&sn1), Eq(false)); + // Nodes that get finalized are marked as such. + EXPECT_THAT(RefHashIsFinal(&sn2), Eq(true)); + EXPECT_THAT(RefHashIsFinal(&sn3), Eq(true)); + EXPECT_THAT(RefHashIsFinal(&sn4), Eq(true)); + + EXPECT_THAT(RefTopoHash(&sn1), SizeIs(2)); + ASSERT_THAT(RefTopoHash(&sn2), SizeIs(1)); + ASSERT_THAT(RefTopoHash(&sn3), SizeIs(1)); + ASSERT_THAT(RefTopoHash(&sn4), SizeIs(1)); + + EXPECT_THAT(RefTopoHash(&sn2)[0], Eq(4)); + EXPECT_THAT(RefTopoHash(&sn3)[0], Eq(3)); + EXPECT_THAT(RefTopoHash(&sn4)[0], Eq(2)); + + EXPECT_THAT(sig_.sig_full, ElementsAre(600, 700, 800)); + + size_t exp_short_hash = 0; + CombineHash(600, &exp_short_hash); + CombineHash(700, &exp_short_hash); + CombineHash(800, &exp_short_hash); + EXPECT_THAT(sig_.sig_short, Eq(exp_short_hash)); +} + +TEST_F(SignatureTest, FindUniqueHashesDuplicatesExceptOne) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + NodeDef node2 = MakeNodeConst("node2"); + SigNode sn2(&node2); + NodeDef node3 = MakeNodeConst("node3"); + SigNode sn3(&node3); + NodeDef node4 = MakeNodeConst("node4"); + SigNode sn4(&node4); + NodeDef node5 = MakeNodeConst("node5"); + SigNode sn5(&node5); + + RefTopoHash(&sn1).emplace_back(100); + RefTopoHash(&sn1).emplace_back(600); + + RefTopoHash(&sn2).emplace_back(200); + RefTopoHash(&sn2).emplace_back(600); + + RefTopoHash(&sn3).emplace_back(300); + RefTopoHash(&sn3).emplace_back(700); + + RefTopoHash(&sn4).emplace_back(400); + RefTopoHash(&sn4).emplace_back(800); + + RefTopoHash(&sn5).emplace_back(500); + RefTopoHash(&sn5).emplace_back(800); + + sig_.nodes.emplace_back(&sn1); + sig_.nodes.emplace_back(&sn2); + sig_.nodes.emplace_back(&sn3); + sig_.nodes.emplace_back(&sn4); + sig_.nodes.emplace_back(&sn5); + + size_t next = 0; + + FindUniqueHashes(&next, &sig_); + EXPECT_THAT(next, Eq(1)); + + // The unique node goes first. + EXPECT_THAT(sig_.nodes[0], Eq(&sn3)); + + // The rest of the nodes are assumed to be sorted in a stable order. + EXPECT_THAT(sig_.nodes[1], Eq(&sn2)); + // Node 1 gets swapped with node 3. + EXPECT_THAT(sig_.nodes[2], Eq(&sn1)); + EXPECT_THAT(sig_.nodes[3], Eq(&sn4)); + EXPECT_THAT(sig_.nodes[4], Eq(&sn5)); + + EXPECT_THAT(RefHashIsFinal(&sn1), Eq(false)); + EXPECT_THAT(RefHashIsFinal(&sn2), Eq(false)); + EXPECT_THAT(RefHashIsFinal(&sn3), Eq(true)); + EXPECT_THAT(RefHashIsFinal(&sn4), Eq(false)); + EXPECT_THAT(RefHashIsFinal(&sn5), Eq(false)); + + EXPECT_THAT(RefTopoHash(&sn1), SizeIs(2)); + EXPECT_THAT(RefTopoHash(&sn2), SizeIs(2)); + EXPECT_THAT(RefTopoHash(&sn3), SizeIs(1)); + EXPECT_THAT(RefTopoHash(&sn4), SizeIs(2)); + EXPECT_THAT(RefTopoHash(&sn5), SizeIs(2)); + + EXPECT_THAT(RefTopoHash(&sn3)[0], Eq(1)); +} + +TEST_F(SignatureTest, FindUniqueHashesDuplicates) { + NodeDef node1 = MakeNodeConst("node1"); + SigNode sn1(&node1); + NodeDef node2 = MakeNodeConst("node2"); + SigNode sn2(&node2); + NodeDef node3 = MakeNodeConst("node3"); + SigNode sn3(&node3); + NodeDef node4 = MakeNodeConst("node4"); + SigNode sn4(&node4); + NodeDef node5 = MakeNodeConst("node5"); + SigNode sn5(&node5); + + RefTopoHash(&sn1).emplace_back(100); + RefTopoHash(&sn1).emplace_back(600); + + RefTopoHash(&sn2).emplace_back(200); + RefTopoHash(&sn2).emplace_back(600); + + RefTopoHash(&sn3).emplace_back(300); + RefTopoHash(&sn3).emplace_back(700); + + RefTopoHash(&sn4).emplace_back(400); + RefTopoHash(&sn4).emplace_back(700); + + RefTopoHash(&sn5).emplace_back(500); + RefTopoHash(&sn5).emplace_back(700); + + sig_.nodes.emplace_back(&sn1); + sig_.nodes.emplace_back(&sn2); + sig_.nodes.emplace_back(&sn3); + sig_.nodes.emplace_back(&sn4); + sig_.nodes.emplace_back(&sn5); + + size_t next = 0; + + FindUniqueHashes(&next, &sig_); + EXPECT_THAT(next, Eq(1)); + + // The last copy of the last duplicate wins. + EXPECT_THAT(sig_.nodes[0], Eq(&sn5)); + + // The rest of the nodes are assumed to be sorted in a stable order. + // Node 1 gets swapped. + EXPECT_THAT(sig_.nodes[1], Eq(&sn2)); + EXPECT_THAT(sig_.nodes[2], Eq(&sn3)); + EXPECT_THAT(sig_.nodes[3], Eq(&sn4)); + EXPECT_THAT(sig_.nodes[4], Eq(&sn1)); + + EXPECT_THAT(RefHashIsFinal(&sn1), Eq(false)); + EXPECT_THAT(RefHashIsFinal(&sn2), Eq(false)); + EXPECT_THAT(RefHashIsFinal(&sn3), Eq(false)); + EXPECT_THAT(RefHashIsFinal(&sn4), Eq(false)); + EXPECT_THAT(RefHashIsFinal(&sn5), Eq(true)); + + EXPECT_THAT(RefTopoHash(&sn1), SizeIs(2)); + EXPECT_THAT(RefTopoHash(&sn2), SizeIs(2)); + EXPECT_THAT(RefTopoHash(&sn3), SizeIs(2)); + EXPECT_THAT(RefTopoHash(&sn4), SizeIs(2)); + EXPECT_THAT(RefTopoHash(&sn5), SizeIs(1)); + + EXPECT_THAT(RefTopoHash(&sn5)[0], Eq(1)); +} + +// On a circular topology. +TEST_F(SignatureTest, ComputeOneRoundCircular) { + BuildSigMap(graph_circular_onedir_); + PrepareNodes(&sig_); + + ASSERT_THAT(sig_.nodes, SizeIs(5)); + + // This skips FindUniqueHashes() which would pick one node, so that + // all the nodes are equivalent for ComputeOneRound(). + + ComputeOneRound(0, &sig_); + + // All the nodes are the same, so the computed hashes will also be the same. + size_t hval = GetHighTopoHash(sig_.nodes[0]); + for (int i = 0; i < 5; ++i) { + EXPECT_THAT(GetHighTopoHash(sig_.nodes[i]), Eq(hval)) << " at index " << i; + EXPECT_THAT(RefHashIsFinal(sig_.nodes[i]), Eq(true)) << " at index " << i; + EXPECT_THAT(RefLastHashedNodes(sig_.nodes[i]), Eq(0x1F)) + << " at index " << i; + EXPECT_THAT(RefNextHashedNodes(sig_.nodes[i]), Eq(0x1F)) + << " at index " << i; + // The sets of hashed nodes go like this: + // Step 0: self. + // Step 1: self, previous (-1) and next (+1) node. + // Step 2: self, (-1), (-2), (+1), (+2): all 5 nodes in the graph + // Step 3: still all 5 nodes in the graph + EXPECT_THAT(RefTopoHash(sig_.nodes[i]), SizeIs(4)) << " at index " << i; + } +} + +// On a linear topology. +TEST_F(SignatureTest, ComputeOneRoundLinear) { + BuildSigMap(graph_linear_); + PrepareNodes(&sig_); + + ASSERT_THAT(sig_.nodes, SizeIs(5)); + + // This skips FindUniqueHashes() which would pick one node, so that + // all the nodes are equivalent for ComputeOneRound(). + + ComputeOneRound(0, &sig_); + + std::vector<size_t> hash_size; + for (int i = 0; i < 5; ++i) { + EXPECT_THAT(RefHashIsFinal(sig_.nodes[i]), Eq(true)) << " at index " << i; + EXPECT_THAT(RefLastHashedNodes(sig_.nodes[i]), Eq(0x1F)) + << " at index " << i; + EXPECT_THAT(RefNextHashedNodes(sig_.nodes[i]), Eq(0x1F)) + << " at index " << i; + hash_size.emplace_back(RefTopoHash(sig_.nodes[i]).size()); + } + + // The sets of hashed nodes for the central node go like this: + // Step 0: self. + // Step 1: self, previous (-1) and next (+1) node. + // Step 2: self, (-1), (-2), (+1), (+2): all 5 nodes in the graph + // Step 3: still all 5 nodes in the graph + // + // The nodes one step closer to the ends require one more step. The end nodes + // require one more step yet. + std::sort(hash_size.begin(), hash_size.end()); + EXPECT_THAT(hash_size, ElementsAre(4, 5, 5, 6, 6)); +} + +// On a linear topology where the cental node has been already marked as unique +// (yeah, not a very realistic case but tests the situations when the +// disconnected subgraphs get created). +TEST_F(SignatureTest, ComputeOneRoundSplitLinear) { + BuildSigMap(graph_linear_); + PrepareNodes(&sig_); + + ASSERT_THAT(sig_.nodes, SizeIs(5)); + + // This test relies on the order of SigNodeMap imposed on sig_.nodes. + + // The middle node gets separated by moving it to the front. + std::swap(sig_.nodes[0], sig_.nodes[2]); + ASSERT_THAT(RefNodeMask(sig_.nodes[0]), Eq(0x04)); + ASSERT_THAT(RefLastHashedNodes(sig_.nodes[0]), Eq(0x04)); + ASSERT_THAT(RefNextHashedNodes(sig_.nodes[0]), Eq(0x04)); + RefHashIsFinal(sig_.nodes[0]) = true; + + ComputeOneRound(1, &sig_); + + // These should stay unchanged. + EXPECT_THAT(RefLastHashedNodes(sig_.nodes[0]), Eq(0x04)); + EXPECT_THAT(RefNextHashedNodes(sig_.nodes[0]), Eq(0x04)); + + std::vector<size_t> hash_size; + for (int i = 1; i < 5; ++i) { + EXPECT_THAT(RefHashIsFinal(sig_.nodes[i]), Eq(true)) << " at index " << i; + hash_size.emplace_back(RefTopoHash(sig_.nodes[i]).size()); + } + + std::sort(hash_size.begin(), hash_size.end()); + // The end nodes take 4 steps, closer to the center 3 steps. + EXPECT_THAT(hash_size, ElementsAre(3, 3, 4, 4)); + + EXPECT_THAT(RefLastHashedNodes(sig_.nodes[1]), Eq(0x07)); + EXPECT_THAT(RefNextHashedNodes(sig_.nodes[1]), Eq(0x07)); + EXPECT_THAT(RefLastHashedNodes(sig_.nodes[2]), Eq(0x07)); + EXPECT_THAT(RefNextHashedNodes(sig_.nodes[2]), Eq(0x07)); + + EXPECT_THAT(RefLastHashedNodes(sig_.nodes[3]), Eq(0x1C)); + EXPECT_THAT(RefNextHashedNodes(sig_.nodes[3]), Eq(0x1C)); + EXPECT_THAT(RefLastHashedNodes(sig_.nodes[4]), Eq(0x1C)); + EXPECT_THAT(RefNextHashedNodes(sig_.nodes[4]), Eq(0x1C)); +} + +TEST_F(SignatureTest, OrderLinks) { + gen_map_.clear(); + sig_.map.clear(); + Status result = GenNode::BuildGraphInMap(graph_for_link_order_, &gen_map_); + ASSERT_THAT(result, Eq(Status::OK())); + Subgraph::Identity id; + for (const auto& entry : gen_map_) { + id.insert(entry.second.get()); + } + Subgraph sg(id); + sg.ExtractForSignature(&sig_.map); + + // Populate the fake signature and assign the ranks in the backwards order. + for (auto it = sig_.map.rbegin(); it != sig_.map.rend(); ++it) { + auto& entry = *it; + RefUniqueRank(entry.second.get()) = sig_.nodes.size(); + sig_.nodes.emplace_back(entry.second.get()); + } + + // How it was ordered in the original graph. + string before = sig_.ToString(); + // clang-format off + EXPECT_THAT(before, Eq( + "0:Mul[i0:o0:5][i0:o0:4][i0:o1:4][i0:o2:3][i0:o2:2][i0:o3:2]," + "1:Mul[i0:o0:5][i0:o0:4][i0:o0:3][i0:o0:2]," + "2:Const," + "3:Const," + "4:Const," + "5:Const," + )); + // clang-format on + + OrderLinks(&sig_); + + string after = sig_.ToString(); + // clang-format off + EXPECT_THAT(after, Eq( + "0:Mul[i0:o0:4][i0:o0:5][i0:o1:4][i0:o2:2][i0:o2:3][i0:o3:2]," + "1:Mul[i0:o0:2][i0:o0:3][i0:o0:4][i0:o0:5]," + "2:Const," + "3:Const," + "4:Const," + "5:Const," + )); + // clang-format on +} + +TEST_F(SignatureTest, GraphTooBig) { + GraphDef graph; + for (int i = 0; i <= Signature::kMaxGraphSize; ++i) { + (*graph.add_node()) = MakeNodeConst(absl::StrFormat("node%d", i)); + } + + ASSERT_THAT(GenNode::BuildGraphInMap(graph, &gen_map_), Eq(Status::OK())); + + Subgraph::Identity id; + for (const auto& entry : gen_map_) { + id.insert(entry.second.get()); + } + Subgraph sg(id); + sg.ExtractForSignature(&sig_.map); + + ASSERT_THAT(sig_.Compute(), + Eq(Status(error::INVALID_ARGUMENT, + "A graph of 65 nodes is too big for signature " + "computation, the maximal supported node count is " + "64."))); +} + +TEST_F(SignatureTest, ToString) { + BuildSigMap(graph_circular_onedir_); + PrepareNodes(&sig_); + + ASSERT_THAT(sig_.nodes, SizeIs(5)); + + // Fake the works by assigning unique ranks as they go in the initial order. + for (int i = 0; i < 5; ++i) { + RefUniqueRank(sig_.nodes[i]) = i; + RefHashIsFinal(sig_.nodes[i]) = true; + } + + string result = sig_.ToString(); + + // clang-format off + ASSERT_THAT(result, Eq( + "0:Mul[i0:o0:4][i0:o0:4]," + "1:Mul[i0:o0:0][i0:o0:0]," + "2:Mul[i0:o0:1][i0:o0:1]," + "3:Mul[i0:o0:2][i0:o0:2]," + "4:Mul[i0:o0:3][i0:o0:3]," + )); + // clang-format on +} + +// This is a test of the permutation logic itself. +TEST_F(SignatureTest, Permutation) { + std::vector<size_t> plain_permutation; + std::vector<size_t> countdown; + InitPermutation(5, &plain_permutation, &countdown); + + std::set<string> results; + + std::vector<size_t> permutation; + do { + BuildPermutation(plain_permutation, countdown, &permutation); + EXPECT_THAT(permutation, SizeIs(5)); + + string p; + for (int i = 0; i < permutation.size(); ++i) { + p.push_back('0' + permutation[i]); + } + LOG(INFO) << "Permutation: " << p; + results.insert(p); + } while (CountDown(&countdown)); + + EXPECT_THAT(results, SizeIs(5 * 4 * 3 * 2 * 1)); +} + +TEST_F(SignatureTest, ComputeCircularOneDir) { + TestGraphEveryWay(graph_circular_onedir_); +} + +TEST_F(SignatureTest, ComputeCircularBiDir) { + TestGraphEveryWay(graph_circular_bidir_); +} + +TEST_F(SignatureTest, ComputeLinear) { TestGraphEveryWay(graph_linear_); } + +TEST_F(SignatureTest, ComputeMultiInput) { + TestGraphEveryWay(graph_multi_input_); +} + +TEST_F(SignatureTest, ComputeAllOrNone) { + TestGraphEveryWay(graph_all_or_none_); +} + +TEST_F(SignatureTest, ComputeCross) { TestGraphEveryWay(graph_small_cross_); } + +TEST_F(SignatureTest, Equals) { + // Start with 2 copies of the same graph. + GenNodeMap gen_map1; + ASSERT_THAT(GenNode::BuildGraphInMap(graph_circular_bidir_, &gen_map1), + Eq(Status::OK())); + + Subgraph::Identity id1; + id1.insert(gen_map1["node1"].get()); + id1.insert(gen_map1["node2"].get()); + Subgraph sg1(id1); + + Signature sig1; + sg1.ExtractForSignature(&sig1.map); + ASSERT_THAT(sig1.Compute(), Eq(Status::OK())); + + GenNodeMap gen_map2; + ASSERT_THAT(GenNode::BuildGraphInMap(graph_circular_bidir_, &gen_map2), + Eq(Status::OK())); + + Subgraph::Identity id2; + id2.insert(gen_map2["node1"].get()); + id2.insert(gen_map2["node2"].get()); + Subgraph sg2(id2); + + Signature sig2; + sg2.ExtractForSignature(&sig2.map); + ASSERT_THAT(sig2.Compute(), Eq(Status::OK())); + + EXPECT_TRUE(sig1 == sig2); + + // Change the short hash. + ++sig2.sig_short; + EXPECT_FALSE(sig1 == sig2); + + // Restore back. + --sig2.sig_short; + EXPECT_TRUE(sig1 == sig2); + + // Change the full hash. + ++sig2.sig_full[0]; + EXPECT_FALSE(sig1 == sig2); + + // Restore back. + --sig2.sig_full[0]; + EXPECT_TRUE(sig1 == sig2); + + // Make the nodes different. + std::swap(sig2.nodes[0], sig2.nodes[1]); + EXPECT_FALSE(sig1 == sig2); + + // Restore back. + std::swap(sig2.nodes[0], sig2.nodes[1]); + EXPECT_TRUE(sig1 == sig2); + + // Different number of nodes. + sig2.nodes.emplace_back(sig2.nodes[0]); + EXPECT_FALSE(sig1 == sig2); + EXPECT_FALSE(sig2 == sig1); +} + +} // end namespace test +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/subgraph.cc b/tensorflow/core/grappler/graph_analyzer/subgraph.cc new file mode 100644 index 0000000000..28a91e0f84 --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/subgraph.cc @@ -0,0 +1,235 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/graph_analyzer/subgraph.h" + +#include <functional> + +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" +#include "tensorflow/core/grappler/graph_analyzer/hash_tools.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +//=== Subgraph::Identity + +Subgraph::Identity::Identity(InitializerList init) { + for (auto element : init) { + insert(element); + } +} + +bool Subgraph::Identity::operator<(const Identity& other) const { + // Shorter sets go first. + if (this->size() < other.size()) { + return true; + } + if (this->size() > other.size()) { + return false; + } + for (auto lit = this->begin(), rit = other.begin(); lit != this->end(); + ++lit, ++rit) { + if (*lit < *rit) { + return true; + } + if (*lit > *rit) { + return false; + } + } + return false; // Equal. +} + +bool Subgraph::Identity::operator==(const Identity& other) const { + if (this->size() != other.size()) { + return false; + } + for (auto lit = this->begin(), rit = other.begin(); lit != this->end(); + ++lit, ++rit) { + if (*lit != *rit) { + return false; + } + } + return true; // Equal. +} + +size_t Subgraph::Identity::Hash() const { + std::hash<const GenNode*> hasher; + size_t result = 0; + for (auto ptr : *this) { + CombineHash(hasher(ptr), &result); + } + return result; +} + +string Subgraph::Dump() { + // TODO(babkin): this is simplified for now. + std::vector<string> nodes; + for (const auto& n : id_) { + if (specific_) { + nodes.emplace_back(absl::StrFormat("%s(%s)", n->opcode(), n->name())); + } else { + nodes.emplace_back(n->opcode()); + } + } + std::sort(nodes.begin(), nodes.end()); + + return absl::StrFormat("%d: ", collation_count_) + absl::StrJoin(nodes, ", "); +} + +void Subgraph::ExtractForSignature(SigNodeMap* result) { + // Mapping of nodes from the original graph to the new one. + SigNode::TranslationMap full_to_new; + + for (auto node : id_) { + auto newnode_ref = absl::make_unique<SigNode>(node->node_def()); + auto newnode = newnode_ref.get(); + (*result)[node->name()] = std::move(newnode_ref); + full_to_new[node] = newnode; + } + + for (const auto& mapping : full_to_new) { + mapping.second->CopyLinks(*mapping.first, full_to_new); + } +} + +//=== Subgraph + +Subgraph::Subgraph(const Identity& parent_id, GenNode* add_node) + : id_(parent_id) { + id_.insert(add_node); + hash_ = id_.Hash(); +} + +//=== SubgraphIterator + +SubgraphIterator::SubgraphIterator(const Subgraph::Identity* id) + : id_(id), id_it_(id_->begin()) { + if (!id_->empty()) { + link_map_it_ = (*id_it_)->links().begin(); + // In case if the node has no links. + while (link_map_it_ == (*id_it_)->links().end()) { + if (++id_it_ == id_->end()) { + return; + } + link_map_it_ = (*id_it_)->links().begin(); + } + link_idx_ = 0; + // The LinkTargetVector should never be empty but just in case safeguard + // against that too. + PropagateNext(); + } +} + +bool SubgraphIterator::Next() { + if (AtEnd()) { + return false; + } + ++link_idx_; + return PropagateNext(); +} + +bool SubgraphIterator::NextIfSamePort() { + if (AtEnd()) { + return false; + } + if (link_idx_ + 1 < link_map_it_->second.size()) { + ++link_idx_; + return true; + } else { + return false; + } +} + +void SubgraphIterator::SkipPort() { + if (AtEnd()) { + return; + } + link_idx_ = link_map_it_->second.size() - 1; +} + +void SubgraphIterator::SkipNode() { + if (AtEnd()) { + return; + } + for (auto next = link_map_it_; next != (*id_it_)->links().end(); ++next) { + link_map_it_ = next; + } + link_idx_ = link_map_it_->second.size() - 1; +} + +bool SubgraphIterator::PropagateNext() { + // Loops are used to skip over the empty entries. + while (link_idx_ >= link_map_it_->second.size()) { + ++link_map_it_; + while (link_map_it_ == (*id_it_)->links().end()) { + if (++id_it_ == id_->end()) { + return false; + } + link_map_it_ = (*id_it_)->links().begin(); + } + link_idx_ = 0; + } + return true; +} + +bool SubgraphIterator::operator==(const SubgraphIterator& other) const { + if (id_ != other.id_) { + return false; + } + if (id_it_ != other.id_it_) { + return false; + } + // When AtEnd(), the rest of the fields are not valid. + if (AtEnd()) { + return true; + } + if (link_map_it_ != other.link_map_it_) { + return false; + } + if (link_idx_ != other.link_idx_) { + return false; + } + return true; +} + +//=== SubgraphPtrSet + +Subgraph* SubgraphPtrSet::ExtendParent(const Subgraph::Identity& parent_id, + GenNode* node) { + if (parent_id.find(node) != parent_id.end()) { + // This was another link to the node that is already in the parent. + return nullptr; + } + + // Constructing an object just to check that an equivalent one is already + // present is kind of ugly but storing the references rather than the objects + // in the set avoids the need to make the object copyable. + auto sg = absl::make_unique<Subgraph>(parent_id, node); + if (find(sg) != end()) { + // This subgraph was already found by extending from a different path. + return nullptr; + } + + Subgraph* ptr = sg.get(); + insert(std::move(sg)); + return ptr; +} + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/subgraph.h b/tensorflow/core/grappler/graph_analyzer/subgraph.h new file mode 100644 index 0000000000..4de31d5dfa --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/subgraph.h @@ -0,0 +1,189 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_SUBGRAPH_H_ +#define TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_SUBGRAPH_H_ + +#include <initializer_list> +#include <set> + +#include "tensorflow/core/grappler/graph_analyzer/gen_node.h" +#include "tensorflow/core/grappler/graph_analyzer/map_tools.h" +#include "tensorflow/core/grappler/graph_analyzer/sig_node.h" +#include "tensorflow/core/lib/gtl/flatset.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { + +// The description of a single subgraph for processing. +class Subgraph { + public: + // Identity of a single subgraph as a set of nodes. + class Identity : public gtl::FlatSet<const GenNode*> { + public: + using InitializerList = std::initializer_list<GenNode*>; + + Identity() = default; + Identity(InitializerList init); + bool operator<(const Identity& other) const; + bool operator==(const Identity& other) const; + + // Compute the hash. + size_t Hash() const; + }; + + explicit Subgraph(Identity id) : id_(std::move(id)), hash_(id_.Hash()) {} + + // Construct by extending the parent identity with an extra node. + Subgraph(const Identity& parent_id, GenNode* add_node); + + Subgraph() = delete; + Subgraph(const Subgraph& other) = delete; + void operator=(const Subgraph& other) = delete; + + // Order for building sets of subgraphs. + bool operator<(const Subgraph& other) const { return this->id_ < other.id_; } + // Support for hashed sets. + bool operator==(const Subgraph& other) const { + return this->id_ == other.id_; + } + size_t Hash() const { return hash_; } + + // Dump the subgraph information to a string. + string Dump(); + + // Extract this subgraph into a separate graph representation for signature + // building, that includes only the links between the nodes in the subgraph + // and drops all the external links. The result map should be clear before the + // call. + void ExtractForSignature(SigNodeMap* result); + + const Identity& id() const { return id_; } + bool specific() const { return specific_; } + void SetSpecific(bool value) { specific_ = value; } + int32_t collation_count() const { return collation_count_; } + void AddCollation(int32_t n = 1) { collation_count_ += n; } + void ResetCollation() { collation_count_ = 1; } + void MergeCollation(const Subgraph& other) { + collation_count_ += other.collation_count_; + } + + private: + // Identity also serves as the list of nodes. It never changes throughout the + // life of subgraph. + Identity id_; + size_t hash_; // Cached from the identity. + // Whether the dump should include the specific names of the nodes. The + // non-specific (i.e. generic) subgraphs represent a collation of multiple + // subgraphs. + bool specific_ = true; + // How many collated subgraphs are represented by this subgraph. + int32_t collation_count_ = 1; +}; + +// Iteration of all links in a subgraph. This is more like Java iterators than +// the normal C++ iterators. It's simpler this way and there seems to be no +// major reason to make it a proper C++ iterator. +class SubgraphIterator { + public: + // Obviously an iterator is valid only until the original object + // gets destroyed. + explicit SubgraphIterator(const Subgraph::Identity* id); + explicit SubgraphIterator(const Subgraph* sg) : SubgraphIterator(&sg->id()) {} + + // Check whether the built-in iterator is at the end. + bool AtEnd() const { return id_it_ == id_->end(); } + + // Get the neighbor at the current iterator. + // MUST NOT be called when AtEnd(); + const GenNode::LinkTarget& GetNeighbor() const { + return link_map_it_->second[link_idx_]; + } + + // Get the node at the current iterator. + // MUST NOT be called when AtEnd(); + const GenNode* GetNode() const { return *id_it_; } + + // Get the port leading to the neighbor at the current iterator. + // MUST NOT be called when AtEnd(); + GenNode::Port GetPort() const { return link_map_it_->first; } + + // Increases the iterator. + // Returns true if NOT AtEnd() after increasing the iterator. + // Safe to call if already AtEnd(). + bool Next(); + + // If there are more links at the same port, increases the iterator and + // returns true. Otherwise leaves the iterator unchanged and returns false. + bool NextIfSamePort(); + + // Increases the iterator directly to the last position on the current port + // (or if already there then doesn't increase). Equivalent to calling + // NextIfSamePort() while it returns true, but faster. + // Safe to call if already AtEnd(). + void SkipPort(); + + // Increases the iterator directly to the last position on the current node. + // Safe to call if already AtEnd(). + void SkipNode(); + + // Returns true if the iterators are exactly the same. + bool operator==(const SubgraphIterator& other) const; + bool operator!=(const SubgraphIterator& other) const { + return !(*this == other); + } + + private: + // After link_idx_ has been increased, make sure that it points to the + // next valid element (or end) by increasing the higher levels of iteration if + // needed. + // Returns true if NOT AtEnd() after increasing the iterator. + // NOT safe to call if already AtEnd(). + bool PropagateNext(); + + // Identity of the subgraph being iterated over. + const Subgraph::Identity* id_; + + // The current position, allowing to iterate through the links (see the + // reasoning for it in the public section). + // + // (1) Iterator of the nodes in the subgraph. + Subgraph::Identity::const_iterator id_it_; + // (2) Iterator in the link map of the node. + GenNode::LinkMap::const_iterator link_map_it_; + // (3) Index in the vector of the links. + int32_t link_idx_; +}; + +// A convenient way to store subgraphs: in a set of unique_ptrs. This way the +// addresses of subgraph objects will stay stable, and the objects themselves +// won't be copied. +class SubgraphPtrSet + : public std::unordered_set<std::unique_ptr<Subgraph>, + HashAtPtr<std::unique_ptr<Subgraph>>, + EqAtPtr<std::unique_ptr<Subgraph>>> { + public: + // Attempts to extend the set by adding a new subgraph that gets created by + // adding one node to the parent subgraph. If such a subgraph already exists, + // returns nullptr, otherwise returns the pointer to the new subgraph. + Subgraph* ExtendParent(const Subgraph::Identity& parent_id, GenNode* node); +}; + +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow + +#endif // TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_SUBGRAPH_H_ diff --git a/tensorflow/core/grappler/graph_analyzer/subgraph_test.cc b/tensorflow/core/grappler/graph_analyzer/subgraph_test.cc new file mode 100644 index 0000000000..0f90dc8f0d --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/subgraph_test.cc @@ -0,0 +1,348 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/graph_analyzer/subgraph.h" + +#include <algorithm> +#include <string> +#include <vector> + +#include <gmock/gmock.h> +#include <gtest/gtest.h> +#include "absl/memory/memory.h" +#include "absl/strings/str_format.h" +#include "tensorflow/core/grappler/graph_analyzer/test_tools.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { +namespace test { +namespace { + +using ::testing::ElementsAre; +using ::testing::Eq; +using ::testing::Ne; + +TEST(SubgraphTest, Comparison) { + GraphDef graph; + // A topology with a loop. + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeConst("node2"); + GenNodeMap map; + ASSERT_THAT(GenNode::BuildGraphInMap(graph, &map), Eq(Status::OK())); + auto gn1 = map["node1"].get(); + auto gn2 = map["node2"].get(); + ASSERT_THAT(gn1, Ne(nullptr)); + ASSERT_THAT(gn2, Ne(nullptr)); + + Subgraph::Identity id1; + Subgraph::Identity id2; + + id1.insert(gn1); + id2.insert(gn2); + + Subgraph sg1(id1); + Subgraph sg2(id2); + + EXPECT_TRUE(id1 == sg1.id()); + EXPECT_TRUE(id2 == sg2.id()); + + EXPECT_THAT(sg1 < sg2, Eq(id1 < id2)); +} + +TEST(SubgraphTest, EmptyIteration) { + NodeDef node1 = MakeNodeConst("node1"); + auto gn1 = absl::make_unique<GenNode>(&node1); + Subgraph::Identity id1; + id1.insert(gn1.get()); + Subgraph sg1(id1); + SubgraphIterator sit(&sg1); + + EXPECT_TRUE(sit.AtEnd()); + EXPECT_FALSE(sit.Next()); + EXPECT_TRUE(sit.AtEnd()); + + SubgraphIterator sit2(&sg1); + EXPECT_TRUE(sit == sit2); +} + +TEST(SubgraphTest, Iteration) { + GraphDef graph; + // A topology with a loop. + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeSub("node2", "node3:1", "node3:0"); + auto node3 = graph.add_node(); + *node3 = MakeNodeBroadcastGradientArgs("node3", "node1", "node2"); + node3->add_input("^node3"); // The control link goes back to self. + + GenNodeMap map; + ASSERT_THAT(GenNode::BuildGraphInMap(graph, &map), Eq(Status::OK())); + ASSERT_THAT(map.find("node3"), Ne(map.end())); + + Subgraph::Identity id; + id.insert(map["node3"].get()); + Subgraph sg(id); + + // node3 has 2 incoming data links, 2 outgoing data , 1 control incoming, 1 + // control outgoing = total of 6 + { + SubgraphIterator sit(&sg); + EXPECT_FALSE(sit.AtEnd()); // 1 + EXPECT_TRUE(sit.Next()); + EXPECT_FALSE(sit.AtEnd()); // 2 + EXPECT_TRUE(sit.Next()); + EXPECT_FALSE(sit.AtEnd()); // 3 + EXPECT_TRUE(sit.Next()); + EXPECT_FALSE(sit.AtEnd()); // 4 + EXPECT_TRUE(sit.Next()); + EXPECT_FALSE(sit.AtEnd()); // 5 + EXPECT_TRUE(sit.Next()); + EXPECT_FALSE(sit.AtEnd()); // 6 + EXPECT_FALSE(sit.Next()); + EXPECT_TRUE(sit.AtEnd()); + } + + // Now get the values out. And more equality testing along the way. + { + SubgraphIterator sit(&sg); + SubgraphIterator sit2(&sg); + std::vector<string> links; + for (; !sit.AtEnd(); sit.Next()) { + EXPECT_TRUE(sit == sit2); + sit2.Next(); + EXPECT_FALSE(sit == sit2); + + links.push_back(absl::StrFormat("[%s,%s,%s]", string(sit.GetPort()), + sit.GetNeighbor().node->name(), + string(sit.GetNeighbor().port))); + } + EXPECT_TRUE(sit == sit2); + + std::sort(links.begin(), links.end()); + // clang-format off + EXPECT_THAT(links, ElementsAre( + "[i0,node1,o0]", + "[i1,node2,o0]", + "[iC,node3,oC]", + "[o0,node2,i1]", + "[o1,node2,i0]", + "[oC,node3,iC]" + )); + // clang-format on + } +} + +TEST(SubgraphTest, IterationSamePort) { + GraphDef graph; + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeSub("node2", "node3", "node3"); + (*graph.add_node()) = MakeNodeAddN("node3", "node1", "node2"); + + GenNodeMap map; + ASSERT_THAT(GenNode::BuildGraphInMap(graph, &map), Eq(Status::OK())); + ASSERT_THAT(map.find("node3"), Ne(map.end())); + + Subgraph::Identity id; + id.insert(map["node3"].get()); + Subgraph sg(id); + + int total_links = 0; + for (SubgraphIterator sit(&sg); !sit.AtEnd(); sit.Next()) { + ++total_links; + } + + // Initialize the port as control, which doesn't occur in this graph. + GenNode::Port last_port(false, -1); + int steps_total_same_port = 0; + int steps_with_same_port = 0; + for (SubgraphIterator sit(&sg); !sit.AtEnd(); sit.Next()) { + GenNode::Port new_port = sit.GetPort(); + EXPECT_THAT(last_port.Encoded(), Ne(new_port.Encoded())) + << "At step " << steps_total_same_port; + last_port = new_port; + + ++steps_total_same_port; + + SubgraphIterator sit2(sit); + sit2.SkipPort(); + + while (sit.NextIfSamePort()) { + new_port = sit.GetPort(); + EXPECT_THAT(last_port.Encoded(), Eq(new_port.Encoded())) + << "At step " << steps_total_same_port; + ++steps_total_same_port; + ++steps_with_same_port; + } + + EXPECT_TRUE(sit == sit2); + } + + EXPECT_THAT(steps_total_same_port, Eq(total_links)); + // There is one 2-way input and one 2-way output. + EXPECT_THAT(steps_with_same_port, Eq(2)); +} + +TEST(SubgraphTest, IterationSameNode) { + GraphDef graph; + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeSub("node2", "node3", "node3"); + (*graph.add_node()) = MakeNodeAddN("node3", "node1", "node2"); + + GenNodeMap map; + ASSERT_THAT(GenNode::BuildGraphInMap(graph, &map), Eq(Status::OK())); + ASSERT_THAT(map.find("node3"), Ne(map.end())); + + Subgraph::Identity id; + id.insert(map["node3"].get()); + Subgraph sg(id); + + const GenNode* last_node = nullptr; + SubgraphIterator sit(&sg); + while (!sit.AtEnd()) { + const GenNode* new_node = sit.GetNode(); + + EXPECT_THAT(new_node, Ne(last_node)) << "At node " << new_node->name(); + + SubgraphIterator sit2(sit); + sit2.SkipNode(); + + ASSERT_FALSE(sit2.AtEnd()); + EXPECT_THAT(sit2.GetNode(), Eq(new_node)) + << "At expected node " << new_node->name() << ", got " + << sit2.GetNode()->name(); + + while (sit != sit2 && !sit.AtEnd()) { + sit.Next(); + } + + ASSERT_FALSE(sit.AtEnd()); + EXPECT_THAT(sit.GetNode(), Eq(new_node)) + << "At expected node " << new_node->name() << ", got " + << sit2.GetNode()->name(); + + sit.Next(); + + last_node = new_node; + } + + // Check that it doesn't fail if already at end. + sit.SkipNode(); + EXPECT_TRUE(sit.AtEnd()); +} + +TEST(SubgraphTest, ExtendSet) { + GraphDef graph; + // A topology with a loop. + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeSub("node2", "node3:1", "node3:0"); + auto node3 = graph.add_node(); + *node3 = MakeNodeBroadcastGradientArgs("node3", "node1", "node2"); + node3->add_input("^node3"); // The control link goes back to self. + + GenNodeMap map; + ASSERT_THAT(GenNode::BuildGraphInMap(graph, &map), Eq(Status::OK())); + ASSERT_THAT(map.find("node2"), Ne(map.end())); + ASSERT_THAT(map.find("node3"), Ne(map.end())); + + Subgraph::Identity id_empty; + + Subgraph::Identity id3; + id3.insert(map["node3"].get()); + + Subgraph::Identity id23 = id3; + id23.insert(map["node2"].get()); + + Subgraph* sg; + SubgraphPtrSet set; + + // Extend an empty identity. + sg = set.ExtendParent(id_empty, map["node3"].get()); + EXPECT_THAT(set.size(), Eq(1)); + ASSERT_THAT(sg, Ne(nullptr)); + EXPECT_TRUE(sg->id() == id3); + + // Extend with a node that is already in the parent. + sg = set.ExtendParent(id3, map["node3"].get()); + EXPECT_THAT(set.size(), Eq(1)); + EXPECT_THAT(sg, Eq(nullptr)); + + // Extend to a 2-node subgraph. + sg = set.ExtendParent(id3, map["node2"].get()); + EXPECT_THAT(set.size(), Eq(2)); + ASSERT_THAT(sg, Ne(nullptr)); + EXPECT_TRUE(sg->id() == id23); + + // The second insert of the same node gets ignored. + sg = set.ExtendParent(id3, map["node2"].get()); + EXPECT_THAT(set.size(), Eq(2)); + EXPECT_THAT(sg, Eq(nullptr)); +} + +TEST(SubgraphTest, ExtractForSignature) { + GraphDef graph; + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeSub("node2", "node3:1", "node3:0"); + auto node3 = graph.add_node(); + *node3 = MakeNodeBroadcastGradientArgs("node3", "node1", "node2"); + node3->add_input("^node1"); + node3->add_input("^node2"); + node3->add_input("^node3"); // The control link goes back to self. + + GenNodeMap map; + ASSERT_THAT(GenNode::BuildGraphInMap(graph, &map), Eq(Status::OK())); + ASSERT_THAT(map.find("node1"), Ne(map.end())); + ASSERT_THAT(map.find("node2"), Ne(map.end())); + ASSERT_THAT(map.find("node3"), Ne(map.end())); + + Subgraph::Identity id; + id.insert(map["node1"].get()); + id.insert(map["node3"].get()); + + Subgraph sg(id); + + SigNodeMap map2; + sg.ExtractForSignature(&map2); + ASSERT_THAT(map2.find("node1"), Ne(map2.end())); + ASSERT_THAT(map2.find("node2"), Eq(map2.end())); + ASSERT_THAT(map2.find("node3"), Ne(map2.end())); + + // clang-format off + EXPECT_THAT(DumpLinkHashMap(map2["node1"]->hash_to_link()), ElementsAre( + "oC:iC: node3", + "o0:i0: node3" + )); + EXPECT_THAT(DumpHashedPeerVector(map2["node1"]->hashed_peers()), ElementsAre( + "node3", + "node3" + )); + EXPECT_THAT(DumpLinkHashMap(map2["node3"]->hash_to_link()), ElementsAre( + "oC:iC: node3", + "iC:oC: node1, node3", + "i0:o0: node1" + )); + EXPECT_THAT(DumpHashedPeerVector(map2["node3"]->hashed_peers()), ElementsAre( + "node3", + "node1", + "node3", + "node1" + )); + // clang-format on +} + +} // end namespace +} // end namespace test +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/test_tools.cc b/tensorflow/core/grappler/graph_analyzer/test_tools.cc new file mode 100644 index 0000000000..fc9495bc7d --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/test_tools.cc @@ -0,0 +1,296 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/graph_analyzer/test_tools.h" + +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { +namespace test { + +//=== Helper methods to construct the nodes. + +NodeDef MakeNodeConst(const string& name) { + NodeDef n; + n.set_name(name); + n.set_op("Const"); + return n; +} + +NodeDef MakeNode2Arg(const string& name, const string& opcode, + const string& arg1, const string& arg2) { + NodeDef n; + n.set_name(name); + n.set_op(opcode); + n.add_input(arg1); + n.add_input(arg2); + return n; +} + +NodeDef MakeNode4Arg(const string& name, const string& opcode, + const string& arg1, const string& arg2, const string& arg3, + const string& arg4) { + NodeDef n; + n.set_name(name); + n.set_op(opcode); + n.add_input(arg1); + n.add_input(arg2); + n.add_input(arg3); + n.add_input(arg4); + return n; +} + +// Not really a 2-argument but convenient to construct. +NodeDef MakeNodeShapeN(const string& name, const string& arg1, + const string& arg2) { + // This opcode is multi-input but not commutative. + return MakeNode2Arg(name, "ShapeN", arg1, arg2); +} + +// Not really a 2-argument but convenient to construct. +NodeDef MakeNodeIdentityN(const string& name, const string& arg1, + const string& arg2) { + // The argument is of a list type. + return MakeNode2Arg(name, "IdentityN", arg1, arg2); +} + +NodeDef MakeNodeQuantizedConcat(const string& name, const string& arg1, + const string& arg2, const string& arg3, + const string& arg4) { + // This opcode has multiple multi-inputs. + return MakeNode4Arg(name, "QuantizedConcat", arg1, arg2, arg3, arg4); +} + +//=== Helper methods for analysing the structures. + +std::vector<string> DumpLinkMap(const GenNode::LinkMap& link_map) { + // This will order the entries first. + std::map<string, string> ordered; + for (const auto& link : link_map) { + string key = string(link.first); + + // Order the other sides too. They may be repeating, so store them + // in a multiset. + std::multiset<string> others; + for (const auto& other : link.second) { + others.emplace( + absl::StrFormat("%s[%s]", other.node->name(), string(other.port))); + } + ordered[key] = absl::StrJoin(others, ", "); + } + // Now dump the result in a predictable order. + std::vector<string> result; + result.reserve(ordered.size()); + for (const auto& link : ordered) { + result.emplace_back(link.first + ": " + link.second); + } + return result; +} + +std::vector<string> DumpLinkHashMap(const SigNode::LinkHashMap& link_hash_map) { + // The entries in this map are ordered by hash value which might change + // at any point. Re-order them by the link tag. + std::map<SigNode::LinkTag, size_t> tags; + for (const auto& entry : link_hash_map) { + tags[entry.second.tag] = entry.first; + } + + std::vector<string> result; + for (const auto& id : tags) { + // For predictability, the nodes need to be sorted. + std::vector<string> nodes; + for (const auto& peer : link_hash_map.at(id.second).peers) { + nodes.emplace_back(peer->name()); + } + std::sort(nodes.begin(), nodes.end()); + result.emplace_back(string(id.first.local) + ":" + string(id.first.remote) + + ": " + absl::StrJoin(nodes, ", ")); + } + return result; +} + +std::vector<string> DumpHashedPeerVector( + const SigNode::HashedPeerVector& hashed_peers) { + std::vector<string> result; + + // Each subset of nodes with the same hash has to be sorted by name. + // Other than that, the vector is already ordered by full tags. + size_t last_hash = 0; + // Index, since iterators may get invalidated on append. + size_t subset_start = 0; + + for (const auto& entry : hashed_peers) { + if (entry.link_hash != last_hash) { + std::sort(result.begin() + subset_start, result.end()); + subset_start = result.size(); + } + result.emplace_back(entry.peer->name()); + } + std::sort(result.begin() + subset_start, result.end()); + + return result; +} + +TestGraphs::TestGraphs() { + { + GraphDef& graph = graph_3n_self_control_; + // The topology includes a loop and a link to self. + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeSub("node2", "node3:1", "node3:0"); + auto node3 = graph.add_node(); + *node3 = MakeNodeBroadcastGradientArgs("node3", "node1", "node2"); + node3->add_input("^node3"); // The control link goes back to self. + } + { + GraphDef& graph = graph_multi_input_; + // The topology includes a loop and a link to self. + (*graph.add_node()) = MakeNodeConst("const1_1"); + (*graph.add_node()) = MakeNodeConst("const1_2"); + (*graph.add_node()) = MakeNodeAddN("add1", "const1_1", "const1_2"); + + (*graph.add_node()) = MakeNodeConst("const2_1"); + (*graph.add_node()) = MakeNodeConst("const2_2"); + (*graph.add_node()) = MakeNodeConst("const2_3"); + + auto add2 = graph.add_node(); + *add2 = MakeNodeAddN("add2", "const2_1", "const2_2"); + // The 3rd node is connected twice, to 4 links total. + add2->add_input("const2_3"); + add2->add_input("const2_3"); + + (*graph.add_node()) = MakeNodeSub("sub", "add1", "add2"); + } + { + GraphDef& graph = graph_all_or_none_; + // The topology includes a loop and a link to self. + (*graph.add_node()) = MakeNodeConst("const1_1"); + (*graph.add_node()) = MakeNodeConst("const1_2"); + auto pass1 = graph.add_node(); + *pass1 = MakeNodeIdentityN("pass1", "const1_1", "const1_2"); + + (*graph.add_node()) = MakeNodeConst("const2_1"); + (*graph.add_node()) = MakeNodeConst("const2_2"); + (*graph.add_node()) = MakeNodeConst("const2_3"); + + auto pass2 = graph.add_node(); + *pass2 = MakeNodeIdentityN("pass2", "const2_1", "const2_2"); + // The 3rd node is connected twice, to 4 links total. + pass2->add_input("const2_3"); + pass2->add_input("const2_3"); + + // Add the control links, they get handled separately than the normal + // links. + pass1->add_input("^const2_1"); + pass1->add_input("^const2_2"); + pass1->add_input("^const2_3"); + + (*graph.add_node()) = MakeNodeSub("sub", "pass1", "pass2"); + } + { + GraphDef& graph = graph_circular_onedir_; + (*graph.add_node()) = MakeNodeMul("node1", "node5", "node5"); + (*graph.add_node()) = MakeNodeMul("node2", "node1", "node1"); + (*graph.add_node()) = MakeNodeMul("node3", "node2", "node2"); + (*graph.add_node()) = MakeNodeMul("node4", "node3", "node3"); + (*graph.add_node()) = MakeNodeMul("node5", "node4", "node4"); + } + { + GraphDef& graph = graph_circular_bidir_; + // The left and right links are intentionally mixed up. + (*graph.add_node()) = MakeNodeMul("node1", "node5", "node2"); + (*graph.add_node()) = MakeNodeMul("node2", "node3", "node1"); + (*graph.add_node()) = MakeNodeMul("node3", "node2", "node4"); + (*graph.add_node()) = MakeNodeMul("node4", "node5", "node3"); + (*graph.add_node()) = MakeNodeMul("node5", "node4", "node1"); + } + { + GraphDef& graph = graph_linear_; + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeMul("node2", "node1", "node1"); + (*graph.add_node()) = MakeNodeMul("node3", "node2", "node2"); + (*graph.add_node()) = MakeNodeMul("node4", "node3", "node3"); + (*graph.add_node()) = MakeNodeMul("node5", "node4", "node4"); + } + { + GraphDef& graph = graph_cross_; + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeMul("node2", "node1", "node1"); + (*graph.add_node()) = MakeNodeConst("node3"); + (*graph.add_node()) = MakeNodeMul("node4", "node3", "node3"); + (*graph.add_node()) = MakeNodeConst("node5"); + (*graph.add_node()) = MakeNodeMul("node6", "node5", "node5"); + (*graph.add_node()) = MakeNodeConst("node7"); + (*graph.add_node()) = MakeNodeMul("node8", "node7", "node7"); + + auto center = graph.add_node(); + *center = MakeNodeMul("node9", "node2", "node4"); + center->add_input("node6"); + center->add_input("node8"); + } + { + GraphDef& graph = graph_small_cross_; + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeConst("node2"); + (*graph.add_node()) = MakeNodeConst("node3"); + (*graph.add_node()) = MakeNodeConst("node4"); + + auto center = graph.add_node(); + *center = MakeNodeMul("node5", "node1", "node2"); + center->add_input("node3"); + center->add_input("node4"); + } + { + GraphDef& graph = graph_for_link_order_; + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeConst("node2"); + (*graph.add_node()) = MakeNodeConst("node3"); + (*graph.add_node()) = MakeNodeConst("node4"); + + // One group of equivalent links. + auto center = graph.add_node(); + *center = MakeNodeMul("node5", "node1", "node2"); + center->add_input("node3"); + center->add_input("node4"); + + // Multiple groups, separated by unique links. + auto center2 = graph.add_node(); + *center2 = MakeNodeMul("node6", "node1", "node2"); + center2->add_input("node2:1"); + center2->add_input("node3:2"); + center2->add_input("node4:2"); + center2->add_input("node4:3"); + } + { + GraphDef& graph = graph_sun_; + (*graph.add_node()) = MakeNodeConst("node1"); + (*graph.add_node()) = MakeNodeConst("node2"); + (*graph.add_node()) = MakeNodeConst("node3"); + (*graph.add_node()) = MakeNodeConst("node4"); + (*graph.add_node()) = MakeNodeConst("node5"); + (*graph.add_node()) = MakeNodeSub("node6", "node1", "node10"); + (*graph.add_node()) = MakeNodeSub("node7", "node2", "node6"); + (*graph.add_node()) = MakeNodeSub("node8", "node3", "node7"); + (*graph.add_node()) = MakeNodeSub("node9", "node4", "node8"); + (*graph.add_node()) = MakeNodeSub("node10", "node5", "node9"); + } +} + +} // end namespace test +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/test_tools.h b/tensorflow/core/grappler/graph_analyzer/test_tools.h new file mode 100644 index 0000000000..98e269d57e --- /dev/null +++ b/tensorflow/core/grappler/graph_analyzer/test_tools.h @@ -0,0 +1,120 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_TEST_TOOLS_H_ +#define TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_TEST_TOOLS_H_ + +#include <string> +#include <vector> + +#include "tensorflow/core/framework/op.h" +#include "tensorflow/core/grappler/graph_analyzer/gen_node.h" +#include "tensorflow/core/grappler/graph_analyzer/sig_node.h" +#include "tensorflow/core/grappler/op_types.h" + +namespace tensorflow { +namespace grappler { +namespace graph_analyzer { +namespace test { + +//=== Helper methods to construct the nodes. + +NodeDef MakeNodeConst(const string& name); + +NodeDef MakeNode2Arg(const string& name, const string& opcode, + const string& arg1, const string& arg2); + +NodeDef MakeNode4Arg(const string& name, const string& opcode, + const string& arg1, const string& arg2, const string& arg3, + const string& arg4); + +inline NodeDef MakeNodeMul(const string& name, const string& arg1, + const string& arg2) { + return MakeNode2Arg(name, "Mul", arg1, arg2); +} + +// Not really a 2-argument but convenient to construct. +inline NodeDef MakeNodeAddN(const string& name, const string& arg1, + const string& arg2) { + return MakeNode2Arg(name, "AddN", arg1, arg2); +} + +inline NodeDef MakeNodeSub(const string& name, const string& arg1, + const string& arg2) { + return MakeNode2Arg(name, "Sub", arg1, arg2); +} + +// Has 2 honest outputs. +inline NodeDef MakeNodeBroadcastGradientArgs(const string& name, + const string& arg1, + const string& arg2) { + return MakeNode2Arg(name, "BroadcastGradientArgs", arg1, arg2); +} + +NodeDef MakeNodeShapeN(const string& name, const string& arg1, + const string& arg2); + +NodeDef MakeNodeIdentityN(const string& name, const string& arg1, + const string& arg2); + +NodeDef MakeNodeQuantizedConcat(const string& name, const string& arg1, + const string& arg2, const string& arg3, + const string& arg4); + +//=== A container of pre-constructed graphs. + +class TestGraphs { + public: + TestGraphs(); + + // Graph with 3 nodes and a control link to self (which is not valid in + // reality but adds excitement to the tests). + GraphDef graph_3n_self_control_; + // Graph that has the multi-input links. + GraphDef graph_multi_input_; + // Graph that has the all-or-none nodes. + GraphDef graph_all_or_none_; + // All the nodes are connected in a circle that goes in one direction. + GraphDef graph_circular_onedir_; + // All the nodes are connected in a circle that goes in both directions. + GraphDef graph_circular_bidir_; + // The nodes are connected in a line. + GraphDef graph_linear_; + // The nodes are connected in a cross shape. + GraphDef graph_cross_; + GraphDef graph_small_cross_; + // For testing the ordering of links at the end of signature generation, + // a variation of a cross. + GraphDef graph_for_link_order_; + // Sun-shaped, a ring with "rays". + GraphDef graph_sun_; +}; + +//=== Helper methods for analysing the structures. + +std::vector<string> DumpLinkMap(const GenNode::LinkMap& link_map); + +// Also checks for the consistency of hash values. +std::vector<string> DumpLinkHashMap(const SigNode::LinkHashMap& link_hash_map); + +std::vector<string> DumpHashedPeerVector( + const SigNode::HashedPeerVector& hashed_peers); + +} // end namespace test +} // end namespace graph_analyzer +} // end namespace grappler +} // end namespace tensorflow + +#endif // TENSORFLOW_CORE_GRAPPLER_GRAPH_ANALYZER_TEST_TOOLS_H_ diff --git a/tensorflow/core/grappler/grappler_item_builder.cc b/tensorflow/core/grappler/grappler_item_builder.cc index 288587ce9b..029515ad3c 100644 --- a/tensorflow/core/grappler/grappler_item_builder.cc +++ b/tensorflow/core/grappler/grappler_item_builder.cc @@ -29,6 +29,7 @@ limitations under the License. #include "tensorflow/core/framework/graph_def_util.h" #include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/framework/op.h" +#include "tensorflow/core/framework/tensor.pb.h" #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/framework/types.pb.h" #include "tensorflow/core/framework/variable.pb.h" diff --git a/tensorflow/core/grappler/optimizers/BUILD b/tensorflow/core/grappler/optimizers/BUILD index caaa5ac8db..70ad9f9a9b 100644 --- a/tensorflow/core/grappler/optimizers/BUILD +++ b/tensorflow/core/grappler/optimizers/BUILD @@ -110,10 +110,10 @@ cc_library( ], ) -tf_cc_test( +tf_cuda_cc_test( name = "constant_folding_test", srcs = ["constant_folding_test.cc"], - shard_count = 5, + tags = ["requires-gpu-sm35"], deps = [ ":constant_folding", "//tensorflow/cc:cc_ops", @@ -827,11 +827,6 @@ cc_library( "//tensorflow/core:lib", "//tensorflow/core:lib_internal", "//tensorflow/core:protos_all_cc", - "//tensorflow/core/grappler:grappler_item", - "//tensorflow/core/grappler:op_types", - "//tensorflow/core/grappler:utils", - "//tensorflow/core/grappler/clusters:cluster", - "//tensorflow/core/grappler/costs:graph_properties", ], ) diff --git a/tensorflow/core/grappler/optimizers/arithmetic_optimizer.cc b/tensorflow/core/grappler/optimizers/arithmetic_optimizer.cc index 889445bbd6..4fb2fe6883 100644 --- a/tensorflow/core/grappler/optimizers/arithmetic_optimizer.cc +++ b/tensorflow/core/grappler/optimizers/arithmetic_optimizer.cc @@ -27,6 +27,7 @@ limitations under the License. #include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/framework/node_def_util.h" #include "tensorflow/core/framework/op.h" +#include "tensorflow/core/framework/tensor.pb.h" #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/framework/types.h" #include "tensorflow/core/grappler/costs/graph_properties.h" diff --git a/tensorflow/core/grappler/optimizers/constant_folding.cc b/tensorflow/core/grappler/optimizers/constant_folding.cc index f2ac3a44c0..815bd23307 100644 --- a/tensorflow/core/grappler/optimizers/constant_folding.cc +++ b/tensorflow/core/grappler/optimizers/constant_folding.cc @@ -852,7 +852,19 @@ DataType GetDataTypeFromNodeOrProps(const NodeDef& node, } return dtype; } - +bool IsValidConstShapeForNCHW(const TensorShapeProto& shape) { + if (shape.dim_size() != 4) { + return false; + } + int num_dim_larger_than_one = 0; + for (const auto& dim : shape.dim()) { + if (dim.size() > 1) ++num_dim_larger_than_one; + } + return num_dim_larger_than_one <= 1; +} +const string& GetShape(const NodeDef& node) { + return node.attr().at("data_format").s(); +} } // namespace // static @@ -1699,7 +1711,7 @@ Status ConstantFolding::SimplifyNode(bool use_shape_info, NodeDef* node, return Status::OK(); } - if (MulConvPushDown(node, *properties)) { + if (MulConvPushDown(*properties, optimized_graph, node)) { graph_modified_ = true; return Status::OK(); } @@ -2541,8 +2553,9 @@ bool ConstantFolding::ConstantPushDown(NodeDef* node) { return false; } -bool ConstantFolding::MulConvPushDown(NodeDef* node, - const GraphProperties& properties) { +bool ConstantFolding::MulConvPushDown(const GraphProperties& properties, + GraphDef* optimized_graph, + NodeDef* node) { // Push down multiplication on ConvND. // * ConvND // / \ / \ @@ -2618,12 +2631,14 @@ bool ConstantFolding::MulConvPushDown(NodeDef* node, } const auto& const_shape = const_props[0].shape(); - TensorShapeProto new_filter_shape; - if (!ShapeAfterBroadcast(filter_shape, const_shape, &new_filter_shape)) { - return false; - } - if (!ShapesSymbolicallyEqual(filter_shape, new_filter_shape)) { - return false; + if (GetShape(*conv_node) == "NHWC") { + TensorShapeProto new_filter_shape; + if (!ShapeAfterBroadcast(filter_shape, const_shape, &new_filter_shape)) { + return false; + } + if (!ShapesSymbolicallyEqual(filter_shape, new_filter_shape)) { + return false; + } } string mul_new_name = @@ -2657,6 +2672,69 @@ bool ConstantFolding::MulConvPushDown(NodeDef* node, } node_map_->AddNode(mul_new_name, node); + if (GetShape(*conv_node) == "NCHW") { + if (const_node->attr().at("value").tensor().tensor_shape().dim_size() <= + 1) { + // Broadcast should work for scalar or 1D. No need to reshape. + return true; + } + if (!IsValidConstShapeForNCHW( + const_node->attr().at("value").tensor().tensor_shape())) { + return false; + } + // Adds Const node for Reshape. + auto* shape_const_node = optimized_graph->add_node(); + const string shape_const_node_name = + OptimizedNodeName(*const_node, "_new_shape"); + shape_const_node->set_name(shape_const_node_name); + shape_const_node->set_op("Const"); + shape_const_node->set_device(const_node->device()); + (*shape_const_node->mutable_attr())["dtype"].set_type(DT_INT32); + Tensor t(DT_INT32, {4}); + t.flat<int32>()(0) = 1; + t.flat<int32>()(1) = 1; + t.flat<int32>()(2) = 1; + t.flat<int32>()(3) = const_node->attr() + .at("value") + .tensor() + .tensor_shape() + .dim(1) // IsValidConstShapeForNCHW guarantees + // dim 1 is the dim to reshape + .size(); + t.AsProtoTensorContent( + (*shape_const_node->mutable_attr())["value"].mutable_tensor()); + node_map_->AddNode(shape_const_node_name, shape_const_node); + + // Adds Reshape node. + auto* reshape_node = optimized_graph->add_node(); + const string reshape_node_name = + OptimizedNodeName(*const_node, "_reshape"); + reshape_node->set_op("Reshape"); + reshape_node->set_name(reshape_node_name); + reshape_node->set_device(const_node->device()); + (*reshape_node->mutable_attr())["T"].set_type( + const_node->attr().at("dtype").type()); + (*reshape_node->mutable_attr())["Tshape"].set_type(DT_INT32); + node_map_->AddNode(reshape_node_name, reshape_node); + + // const_node -> reshape_node + node_map_->RemoveOutput(const_node->name(), node->name()); + *reshape_node->add_input() = const_node->name(); + node_map_->AddOutput(const_node->name(), reshape_node_name); + + // shape_const_node -> reshape_node + *reshape_node->add_input() = shape_const_node_name; + node_map_->AddOutput(shape_const_node_name, reshape_node_name); + + // reshape_node -> node (Mul) + node_map_->AddOutput(reshape_node_name, node->name()); + if (left_child_is_constant) { + node->set_input(0, reshape_node_name); + } else { + node->set_input(1, reshape_node_name); + } + } + return true; } return false; diff --git a/tensorflow/core/grappler/optimizers/constant_folding.h b/tensorflow/core/grappler/optimizers/constant_folding.h index b42d5f201e..051dfb681e 100644 --- a/tensorflow/core/grappler/optimizers/constant_folding.h +++ b/tensorflow/core/grappler/optimizers/constant_folding.h @@ -125,7 +125,8 @@ class ConstantFolding : public GraphOptimizer { // Aggregate constants present around a conv operator. Returns true if the // transformation was applied successfully. - bool MulConvPushDown(NodeDef* node, const GraphProperties& properties); + bool MulConvPushDown(const GraphProperties& properties, + GraphDef* optimized_graph, NodeDef* node); // Strength reduces floating point division by a constant Div(x, const) to // multiplication by the reciprocal Mul(x, Reciprocal(const)). diff --git a/tensorflow/core/grappler/optimizers/constant_folding_test.cc b/tensorflow/core/grappler/optimizers/constant_folding_test.cc index b9765b9292..0683572dcc 100644 --- a/tensorflow/core/grappler/optimizers/constant_folding_test.cc +++ b/tensorflow/core/grappler/optimizers/constant_folding_test.cc @@ -240,7 +240,7 @@ TEST_F(ConstantFoldingTest, AddTree) { } } -TEST_F(ConstantFoldingTest, ConvPushDownTest) { +TEST_F(ConstantFoldingTest, ConvPushDownTestNHWC) { // Tests if the following rewrite is performed: // // * Conv2D @@ -3047,6 +3047,143 @@ TEST_F(ConstantFoldingTest, TensorArraySize) { test::ExpectTensorEqual<int32>(tensors_expected[1], tensors_actual[1]); } +TEST_F(ConstantFoldingTest, FoldingPreservesDenormalFlushing) { + // Multiplying min() with 0.1 gives a denormal without FTZ and zero with FTZ. + // Make sure constant folding behaves the same way as TensorFlow. + tensorflow::Scope s = tensorflow::Scope::NewRootScope(); + + Output a = + ops::Const(s.WithOpName("a"), std::numeric_limits<float>::min(), {1}); + Output b = ops::Const(s.WithOpName("b"), 0.1f, {1}); + Output c = ops::Mul(s.WithOpName("c"), a, b); + + GrapplerItem item; + item.fetch.push_back("c"); + TF_CHECK_OK(s.ToGraphDef(&item.graph)); + + ConstantFolding optimizer(nullptr /* cpu_device */); + GraphDef output; + Status status = optimizer.Optimize(nullptr, item, &output); + TF_EXPECT_OK(status); + + EXPECT_EQ(1, output.node_size()); + + const NodeDef& node_d = output.node(0); + EXPECT_EQ("c", node_d.name()); + EXPECT_EQ("Const", node_d.op()); + + std::vector<string> fetch = {"c"}; + auto tensors_expected = EvaluateNodes(item.graph, fetch); + auto tensors = EvaluateNodes(output, fetch); + EXPECT_EQ(1, tensors_expected.size()); + EXPECT_EQ(1, tensors.size()); + test::ExpectTensorEqual<float>(tensors_expected[0], tensors[0]); +} + +#if GOOGLE_CUDA +TEST_F(ConstantFoldingTest, ConvPushDownTestNCHW) { + // Tests if the following rewrite is performed: + // + // * Conv2D + // / \ / \ + // c Conv2D --> x (c * filter) + // / \ + // x filter + tensorflow::Scope s = tensorflow::Scope::NewRootScope(); + + int input_channel = 1; + int output_channel = 2; + int filter_size = 1; + + TensorShape filter_shape( + {filter_size, filter_size, input_channel, output_channel}); + + // Filter shape: [1, 1, 1, 2] + // Filter for output channel 0 = {2.f} + // Filter for output channel 1 = {-2.f} + // clang-format off + Output filter = + ops::Const(s.WithOpName("filter"), { + { + {{2.f, -2.f}} + } + }); + // clang-format on + + int batch_size = 1; + int matrix_size = 3; + // input shape: [1,1,3,3] + TensorShape input_shape( + {batch_size, input_channel, matrix_size, matrix_size}); + Output input = ops::Placeholder(s.WithOpName("x"), DT_FLOAT, + ops::Placeholder::Shape(input_shape)); + + Output conv = ops::Conv2D(s.WithOpName("conv"), input, filter, {1, 1, 1, 1}, + "VALID", ops::Conv2D::DataFormat("NCHW")); + Output c = ops::Const(s.WithOpName("c"), 2.0f, /* shape */ {1, 2, 1, 1}); + Output mul = ops::Mul(s.WithOpName("mul"), c, conv); + + GrapplerItem item; + TF_CHECK_OK(s.ToGraphDef(&item.graph)); + + ConstantFolding fold(nullptr); + GraphDef output; + Status status = fold.Optimize(nullptr, item, &output); + TF_EXPECT_OK(status); + + // Here only op/IO are checked. The values are verified by EvaluateNodes + // below. + int found = 0; + for (const auto& node : output.node()) { + if (node.name() == "mul") { + ++found; + EXPECT_EQ("Conv2D", node.op()); + EXPECT_EQ(2, node.input_size()); + EXPECT_EQ("x", node.input(0)); + EXPECT_EQ("conv/merged_input", node.input(1)); + } else if (node.name() == "conv/merged_input") { + ++found; + EXPECT_EQ("Const", node.op()); + EXPECT_EQ(0, node.input_size()); + } + } + EXPECT_EQ(2, found); + + // Check that const folded multiplication node has the expected value. + std::vector<string> fetch = {"mul"}; + // Input shape (NCHW) is [1,1,3,3], filter is [1,1,1,2] output shape should be + // (NCHW) [1,2,3,3] + ::tensorflow::Input::Initializer x{ + { + { + {1.f, 2.f, 3.f}, // H = 0 + {4.f, 5.f, 6.f}, // H = 1 + {7.f, 8.f, 9.f} // H = 2 + } // C = 0 + } // N = 0 + }; + + // |1,2,3| + // conv( |4,5,6|, // input + // |7,8,9| + // [[[2,-2]]]) // filter + // * [1,2,1,1] // mul by const + // = + // [ + // |4, 8, 12| + // |16,20,24| ==> output channel 0 + // |28,32,36| + // + // | -4, -8,-12| + // |-16,-20,-24| ==> output channel 1 + // |-28,-32,-36| + // ] + auto actual = EvaluateNodes(output, fetch, {{"x", x.tensor}}); + auto expected = EvaluateNodes(item.graph, fetch, {{"x", x.tensor}}); + test::ExpectTensorEqual<float>(expected[0], actual[0]); +} +#endif + } // namespace } // namespace grappler } // namespace tensorflow diff --git a/tensorflow/core/grappler/optimizers/data/BUILD b/tensorflow/core/grappler/optimizers/data/BUILD index b8e69787e3..530c957068 100644 --- a/tensorflow/core/grappler/optimizers/data/BUILD +++ b/tensorflow/core/grappler/optimizers/data/BUILD @@ -4,36 +4,41 @@ load("//tensorflow:tensorflow.bzl", "tf_cc_test") load("//tensorflow/core:platform/default/build_config.bzl", "tf_protos_all") cc_library( - name = "function_rename", - srcs = ["function_rename.cc"], + name = "filter_fusion", + srcs = ["filter_fusion.cc"], hdrs = [ - "function_rename.h", + "filter_fusion.h", ], visibility = ["//visibility:public"], deps = [ ":graph_utils", + ":fusion_utils", + "//tensorflow/core/grappler:mutable_graph_view", "//tensorflow/core:lib", - "//tensorflow/core/grappler:graph_view", "//tensorflow/core/grappler:grappler_item", "//tensorflow/core/grappler:op_types", "//tensorflow/core/grappler:utils", "//tensorflow/core/grappler/clusters:cluster", + "//tensorflow/core/kernels:cast_op", + "//tensorflow/core/grappler/utils:topological_sort", "//tensorflow/core/grappler/optimizers:custom_graph_optimizer", "//tensorflow/core/grappler/optimizers:custom_graph_optimizer_registry", ] + tf_protos_all(), ) tf_cc_test( - name = "function_rename_test", - srcs = ["function_rename_test.cc"], + name = "filter_fusion_test", + srcs = ["filter_fusion_test.cc"], visibility = ["//visibility:public"], deps = [ - ":function_rename", + ":filter_fusion", + ":graph_utils", "//tensorflow/core:framework", "//tensorflow/core:test", "//tensorflow/core:test_main", + "//tensorflow/core:testlib", "//tensorflow/core/grappler:grappler_item", - ] + tf_protos_all(), + ], ) cc_library( @@ -46,11 +51,13 @@ cc_library( deps = [ ":graph_utils", "//tensorflow/core/grappler:mutable_graph_view", + "//tensorflow/core:framework", "//tensorflow/core:lib", "//tensorflow/core/grappler:grappler_item", "//tensorflow/core/grappler:op_types", "//tensorflow/core/grappler:utils", "//tensorflow/core/kernels:cast_op", + "//tensorflow/core/kernels:functional_ops", "//tensorflow/core/grappler/optimizers:custom_graph_optimizer_registry", "//tensorflow/core:lib_internal", ] + tf_protos_all(), @@ -125,6 +132,43 @@ cc_library( ) cc_library( + name = "map_vectorization", + srcs = ["map_vectorization.cc"], + hdrs = [ + "map_vectorization.h", + ], + visibility = ["//visibility:public"], + deps = [ + ":graph_utils", + "//tensorflow/core:lib", + "//tensorflow/core/grappler:mutable_graph_view", + "//tensorflow/core/grappler:grappler_item", + "//tensorflow/core/grappler:op_types", + "//tensorflow/core/grappler:utils", + "//tensorflow/core/grappler/clusters:cluster", + "//tensorflow/core/grappler/optimizers:custom_graph_optimizer", + "//tensorflow/core/grappler/optimizers:custom_graph_optimizer_registry", + "//tensorflow/core:lib_internal", + ] + tf_protos_all(), +) + +tf_cc_test( + name = "map_vectorization_test", + srcs = ["map_vectorization_test.cc"], + visibility = ["//visibility:public"], + deps = [ + ":graph_utils", + ":map_vectorization", + "//tensorflow/core:framework", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + "//tensorflow/core:testlib", + "//tensorflow/core/grappler:grappler_item", + "//tensorflow/core/kernels:cast_op", # Must be linked for the testlib functions to work. + ], +) + +cc_library( name = "map_and_batch_fusion", srcs = ["map_and_batch_fusion.cc"], hdrs = [ @@ -306,11 +350,12 @@ cc_library( name = "data", visibility = ["//visibility:public"], deps = [ - ":function_rename", + ":filter_fusion", ":latency_all_edges", ":map_and_batch_fusion", ":map_and_filter_fusion", ":map_fusion", + ":map_vectorization", ":noop_elimination", ":shuffle_and_repeat_fusion", ], diff --git a/tensorflow/core/grappler/optimizers/data/filter_fusion.cc b/tensorflow/core/grappler/optimizers/data/filter_fusion.cc new file mode 100644 index 0000000000..c71aa6e804 --- /dev/null +++ b/tensorflow/core/grappler/optimizers/data/filter_fusion.cc @@ -0,0 +1,141 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/optimizers/data/filter_fusion.h" + +#include "tensorflow/core/framework/attr_value.pb.h" +#include "tensorflow/core/framework/node_def.pb.h" +#include "tensorflow/core/grappler/clusters/cluster.h" +#include "tensorflow/core/grappler/grappler_item.h" +#include "tensorflow/core/grappler/mutable_graph_view.h" +#include "tensorflow/core/grappler/op_types.h" +#include "tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.h" +#include "tensorflow/core/grappler/optimizers/data/fusion_utils.h" +#include "tensorflow/core/grappler/optimizers/data/graph_utils.h" +#include "tensorflow/core/grappler/utils.h" +#include "tensorflow/core/grappler/utils/topological_sort.h" +#include "tensorflow/core/platform/protobuf.h" + +namespace tensorflow { +namespace grappler { +namespace { + +NodeDef MakeFusedFilterNode(const NodeDef& first_filter_node, + const NodeDef& second_filter_node, + const FunctionDef& fused_function, + MutableGraphView* graph) { + NodeDef fused_node; + graph_utils::SetUniqueGraphNodeName("fused_filter", graph->GetGraph(), + &fused_node); + + fused_node.set_op("FilterDataset"); + fused_node.add_input(first_filter_node.input(0)); + + auto copy_attribute = [](const string& attribute_name, const NodeDef& from, + NodeDef* to) { + (*to->mutable_attr())[attribute_name] = from.attr().at(attribute_name); + }; + + auto attr = first_filter_node.attr().at("predicate"); + *attr.mutable_func()->mutable_name() = fused_function.signature().name(); + (*fused_node.mutable_attr())["predicate"] = std::move(attr); + + copy_attribute("Targuments", first_filter_node, &fused_node); + + for (auto key : {"output_shapes", "output_types"}) + copy_attribute(key, second_filter_node, &fused_node); + + return fused_node; +} + +} // namespace + +Status FilterFusion::Optimize(Cluster* cluster, const GrapplerItem& item, + GraphDef* output) { + GraphDef sorted_old_graph = item.graph; + TF_RETURN_IF_ERROR(TopologicalSort(&sorted_old_graph)); + *output = sorted_old_graph; + + MutableGraphView graph(output); + std::set<string> nodes_to_delete; + FunctionLibraryDefinition function_library(OpRegistry::Global(), + output->library()); + + auto get_filter_node = [](const NodeDef& node) -> const NodeDef* { + if (node.op() == "FilterDataset") return &node; + return nullptr; + }; + + auto get_fused_predicate = + [&](const NodeDef* first_filter_node, + const NodeDef* second_filter_node) -> FunctionDef* { + const auto& parent_fun = first_filter_node->attr().at("predicate"); + const FunctionDef* first_func = + function_library.Find(parent_fun.func().name()); + const auto& fun = second_filter_node->attr().at("predicate"); + const FunctionDef* second_func = function_library.Find(fun.func().name()); + + if (!fusion_utils::HasSameSignature(first_func->signature(), + second_func->signature())) { + VLOG(1) << "Can't fuse Filters because they have different signature\n"; + return nullptr; + } + + return fusion_utils::FuseFunctions( + *first_func, *second_func, "fused_predicate", + fusion_utils::SameSignature, fusion_utils::SameInput, + fusion_utils::LazyConjunctionOutput, fusion_utils::LazyConjunctionNodes, + output->mutable_library()); + }; + + for (const NodeDef& node : sorted_old_graph.node()) { + const NodeDef* second_filter_node = get_filter_node(node); + if (!second_filter_node) continue; + + const NodeDef* first_filter_node = + get_filter_node(*graph_utils::GetInputNode(*second_filter_node, graph)); + if (!first_filter_node) continue; + + const auto* fused_predicate = + get_fused_predicate(first_filter_node, second_filter_node); + if (!fused_predicate) continue; + const auto* fused_filter_node = graph.AddNode(MakeFusedFilterNode( + *first_filter_node, *second_filter_node, *fused_predicate, &graph)); + + graph.ReplaceInput(*second_filter_node, *fused_filter_node); + + // TODO(prazek): we should run some optimizations on the fused filter + // functions, or make sure that optimization passes run after filter + // fusion. + TF_RETURN_IF_ERROR(function_library.AddFunctionDef(*fused_predicate)); + // TODO(prazek): we could also remove map functions from library if they + // are not used anymore. + nodes_to_delete.insert(first_filter_node->name()); + nodes_to_delete.insert(second_filter_node->name()); + } + + graph.DeleteNodes(nodes_to_delete); + return Status::OK(); +} + +void FilterFusion::Feedback(Cluster* cluster, const GrapplerItem& item, + const GraphDef& optimize_output, double result) { + // no-op +} + +REGISTER_GRAPH_OPTIMIZER_AS(FilterFusion, "filter_fusion"); + +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/optimizers/data/filter_fusion.h b/tensorflow/core/grappler/optimizers/data/filter_fusion.h new file mode 100644 index 0000000000..91a0364a46 --- /dev/null +++ b/tensorflow/core/grappler/optimizers/data/filter_fusion.h @@ -0,0 +1,47 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_GRAPPLER_OPTIMIZERS_DATA_FILTER_FUSION_H_ +#define TENSORFLOW_CORE_GRAPPLER_OPTIMIZERS_DATA_FILTER_FUSION_H_ + +#include "tensorflow/core/grappler/optimizers/custom_graph_optimizer.h" + +namespace tensorflow { +namespace grappler { + +// This optimization fuses filter transformations. +class FilterFusion : public CustomGraphOptimizer { + public: + FilterFusion() = default; + ~FilterFusion() override = default; + + string name() const override { return "filter_fusion"; }; + + Status Init( + const tensorflow::RewriterConfig_CustomGraphOptimizer* config) override { + return Status::OK(); + } + + Status Optimize(Cluster* cluster, const GrapplerItem& item, + GraphDef* output) override; + + void Feedback(Cluster* cluster, const GrapplerItem& item, + const GraphDef& optimize_output, double result) override; +}; + +} // end namespace grappler +} // end namespace tensorflow + +#endif // TENSORFLOW_CORE_GRAPPLER_OPTIMIZERS_DATA_FILTER_FUSION_H_ diff --git a/tensorflow/core/grappler/optimizers/data/filter_fusion_test.cc b/tensorflow/core/grappler/optimizers/data/filter_fusion_test.cc new file mode 100644 index 0000000000..12b1924efd --- /dev/null +++ b/tensorflow/core/grappler/optimizers/data/filter_fusion_test.cc @@ -0,0 +1,91 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/optimizers/data/filter_fusion.h" + +#include "tensorflow/core/framework/attr_value_util.h" +#include "tensorflow/core/framework/function_testlib.h" +#include "tensorflow/core/framework/tensor_testutil.h" +#include "tensorflow/core/grappler/grappler_item.h" +#include "tensorflow/core/grappler/optimizers/data/graph_utils.h" + +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/platform/test.h" + +namespace tensorflow { +namespace grappler { +namespace { + +NodeDef MakeFilterNode(StringPiece name, StringPiece input_node_name) { + return test::function::NDef( + name, "FilterDataset", {string(input_node_name)}, + {{"predicate", FunctionDefHelper::FunctionRef("IsZero")}, + {"Targuments", {}}, + {"output_shapes", {}}, + {"output_types", {}}}); +} + +TEST(FilterFusionTest, FuseTwoFilterIntoOne) { + using test::function::NDef; + GrapplerItem item; + item.graph = test::function::GDef( + {NDef("start", "Const", {}, {{"value", 0}, {"dtype", DT_INT32}}), + NDef("stop", "Const", {}, {{"value", 10}, {"dtype", DT_INT32}}), + NDef("step", "Const", {}, {{"value", 1}, {"dtype", DT_INT32}}), + NDef("range", "RangeDataset", {"start", "stop", "step"}, {}), + MakeFilterNode("filter1", "range"), + MakeFilterNode("filter2", "filter1")}, + // FunctionLib + { + test::function::IsZero(), + }); + + FilterFusion optimizer; + GraphDef output; + TF_ASSERT_OK(optimizer.Optimize(nullptr, item, &output)); + EXPECT_TRUE(graph_utils::ContainsNodeWithOp("FilterDataset", output)); + EXPECT_FALSE(graph_utils::ContainsGraphNodeWithName("filter1", output)); + EXPECT_FALSE(graph_utils::ContainsGraphNodeWithName("filter2", output)); +} + +TEST(FilterFusionTest, FuseThreeNodesIntoOne) { + using test::function::NDef; + GrapplerItem item; + item.graph = test::function::GDef( + {NDef("start", "Const", {}, {{"value", 0}, {"dtype", DT_INT32}}), + NDef("stop", "Const", {}, {{"value", 10}, {"dtype", DT_INT32}}), + NDef("step", "Const", {}, {{"value", 1}, {"dtype", DT_INT32}}), + NDef("filename", "Const", {}, {{"value", ""}, {"dtype", DT_STRING}}), + NDef("range", "RangeDataset", {"start", "stop", "step"}, {}), + MakeFilterNode("filter1", "range"), MakeFilterNode("filter2", "filter1"), + MakeFilterNode("filter3", "filter2"), + NDef("cache", "CacheDataset", {"filter3", "filename"}, {})}, + // FunctionLib + { + test::function::IsZero(), + }); + + FilterFusion optimizer; + GraphDef output; + TF_ASSERT_OK(optimizer.Optimize(nullptr, item, &output)); + EXPECT_TRUE(graph_utils::ContainsNodeWithOp("FilterDataset", output)); + EXPECT_FALSE(graph_utils::ContainsGraphNodeWithName("filter1", output)); + EXPECT_FALSE(graph_utils::ContainsGraphNodeWithName("filter2", output)); + EXPECT_FALSE(graph_utils::ContainsGraphNodeWithName("filter3", output)); +} + +} // namespace +} // namespace grappler +} // namespace tensorflow diff --git a/tensorflow/core/grappler/optimizers/data/function_rename.cc b/tensorflow/core/grappler/optimizers/data/function_rename.cc deleted file mode 100644 index 8cf044d1bd..0000000000 --- a/tensorflow/core/grappler/optimizers/data/function_rename.cc +++ /dev/null @@ -1,51 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/core/grappler/optimizers/data/function_rename.h" - -#include "tensorflow/core/grappler/clusters/cluster.h" -#include "tensorflow/core/grappler/graph_view.h" -#include "tensorflow/core/grappler/grappler_item.h" -#include "tensorflow/core/grappler/op_types.h" -#include "tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.h" -#include "tensorflow/core/grappler/optimizers/data/graph_utils.h" -#include "tensorflow/core/grappler/utils.h" -#include "tensorflow/core/platform/protobuf.h" - -namespace tensorflow { -namespace grappler { - -Status FunctionRename::Optimize(Cluster* cluster, const GrapplerItem& item, - GraphDef* output) { - *output = item.graph; - GraphView graph(output); - int n = output->mutable_library()->function_size(); - for (int i = 0; i < n; ++i) { - FunctionDef* fn = output->mutable_library()->mutable_function(i); - fn->mutable_signature()->set_name(fn->signature().name() + "world"); - } - - return Status::OK(); -} - -void FunctionRename::Feedback(Cluster* cluster, const GrapplerItem& item, - const GraphDef& optimize_output, double result) { - // no-op -} - -REGISTER_GRAPH_OPTIMIZER_AS(FunctionRename, "_test_only_function_rename"); - -} // end namespace grappler -} // end namespace tensorflow diff --git a/tensorflow/core/grappler/optimizers/data/function_rename_test.cc b/tensorflow/core/grappler/optimizers/data/function_rename_test.cc deleted file mode 100644 index 56b8a960a7..0000000000 --- a/tensorflow/core/grappler/optimizers/data/function_rename_test.cc +++ /dev/null @@ -1,42 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/core/grappler/optimizers/data/function_rename.h" - -#include "tensorflow/core/framework/function.pb.h" -#include "tensorflow/core/framework/op_def.pb.h" -#include "tensorflow/core/grappler/grappler_item.h" -#include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/platform/test.h" - -namespace tensorflow { -namespace grappler { -namespace { - -TEST(FunctionRenameTest, RenameFunction) { - GrapplerItem item; - GraphDef *graph = &item.graph; - FunctionDef *fn = graph->mutable_library()->add_function(); - fn->mutable_signature()->set_name("hello"); - - FunctionRename optimizer; - GraphDef output; - TF_ASSERT_OK(optimizer.Optimize(nullptr, item, &output)); - EXPECT_EQ(output.library().function(0).signature().name(), "helloworld"); -} - -} // namespace -} // namespace grappler -} // namespace tensorflow diff --git a/tensorflow/core/grappler/optimizers/data/fusion_utils.cc b/tensorflow/core/grappler/optimizers/data/fusion_utils.cc index f84f109af6..01a78c04b0 100644 --- a/tensorflow/core/grappler/optimizers/data/fusion_utils.cc +++ b/tensorflow/core/grappler/optimizers/data/fusion_utils.cc @@ -16,8 +16,8 @@ limitations under the License. #include "tensorflow/core/grappler/optimizers/data/fusion_utils.h" #include "tensorflow/core/framework/node_def.pb.h" +#include "tensorflow/core/framework/node_def_builder.h" #include "tensorflow/core/framework/op_def.pb.h" - #include "tensorflow/core/grappler/grappler_item.h" #include "tensorflow/core/grappler/mutable_graph_view.h" #include "tensorflow/core/grappler/op_types.h" @@ -52,6 +52,12 @@ string GetOutputNode(const FunctionDef& function, int output_idx) { return function.ret().at(ret_output_name); } +string& GetMutableOutputNode(FunctionDef* function, int output_idx) { + const auto& ret_output_name = + function->signature().output_arg(output_idx).name(); + return function->mutable_ret()->at(ret_output_name); +} + template <typename Iterable> StringCollection GetNames(const Iterable& iterable, int allocate_size) { StringCollection names; @@ -106,7 +112,6 @@ gtl::FlatMap<string, string> GetUniqueNames(const Iterable& first_iterable, // Nodes that will be added to the function can have the same name as the nodes // from parent function. void RenameFunctionNodes(const FunctionDef& first_function, - FunctionDef* fused_function, protobuf::RepeatedPtrField<NodeDef>* nodes_to_fuse, protobuf::Map<string, string>* rets_to_fuse) { const gtl::FlatMap<string, string> changed_node_names = @@ -149,6 +154,7 @@ OpDef GetUniqueSignature(const OpDef& first_signature, const gtl::FlatMap<string, string> changed_input_names = GetUniqueNames(first_signature.input_arg(), second_signature.input_arg()); OpDef signature; + signature.set_name(second_signature.name()); for (const auto& input_arg : second_signature.input_arg()) { auto& input = *signature.add_input_arg(); @@ -221,12 +227,13 @@ void FuseFunctionNodes(const StringCollection& first_inputs, } // This function looks for direct edges from input to return and rewrites -// them to the coresponding input of the return of `first_function`. +// them to the corresponding input of the return of `first_function`. void FuseReturns(const StringCollection& first_inputs, const StringCollection& second_inputs, const StringCollection& first_outputs, - const SetInputFn& set_input, FunctionDef* fused_function) { - for (auto& ret : *fused_function->mutable_ret()) { + const SetInputFn& set_input, + protobuf::Map<string, string>* fused_ret) { + for (auto& ret : *fused_ret) { auto return_input = ParseNodeConnection(ret.second); auto input_it = std::find(second_inputs.begin(), second_inputs.end(), return_input); @@ -249,6 +256,33 @@ StringCollection GetFunctionOutputs(const FunctionDef& function) { return outputs; } +FunctionDef* CreateFalsePredicate( + const protobuf::RepeatedPtrField<OpDef_ArgDef>& fake_args, + FunctionDefLibrary* library) { + GraphDef graph; + MutableGraphView graph_view(&graph); + auto* node = graph_utils::AddScalarConstNode(false, &graph_view); + auto* false_predicate = library->add_function(); + graph_utils::SetUniqueGraphFunctionName("false_predicate", library, + false_predicate); + + int num = 0; + for (const auto& fake_arg : fake_args) { + auto* arg = false_predicate->mutable_signature()->add_input_arg(); + arg->set_type(fake_arg.type()); + arg->set_name(strings::StrCat("fake_arg", num)); + num++; + } + + auto* output = false_predicate->mutable_signature()->add_output_arg(); + output->set_name("false_out"); + output->set_type(DT_BOOL); + + (*false_predicate->mutable_ret())["false_out"] = node->name() + ":output:0"; + *false_predicate->mutable_node_def() = std::move(*graph.mutable_node()); + return false_predicate; +} + void CheckIfCanCompose(const OpDef& first_signature, const OpDef& second_signature) { CHECK(CanCompose(first_signature, second_signature)) @@ -259,6 +293,15 @@ void CheckIfCanCompose(const OpDef& first_signature, } // namespace +void MergeNodes(const FunctionDef& first_function, + const FunctionDef& second_function, FunctionDef* fused_function, + FunctionDefLibrary* library) { + // Copy all nodes from first_function. + fused_function->mutable_node_def()->CopyFrom(first_function.node_def()); + // Copy transformed nodes from the second function. + fused_function->mutable_node_def()->MergeFrom(second_function.node_def()); +} + bool CanCompose(const OpDef& first_signature, const OpDef& second_signature) { // TODO(prazek): Functions can have additional inputs being placeholders // for a values used in function. We should be able to also fuse these @@ -285,8 +328,8 @@ void ComposeSignature(const OpDef& first_signature, void ComposeOutput(const protobuf::Map<string, string>& first_ret, const protobuf::Map<string, string>& second_ret, - FunctionDef* fused_function) { - *fused_function->mutable_ret() = second_ret; + protobuf::Map<string, string>* fused_ret) { + *fused_ret = second_ret; } void CombineSignature(const OpDef& first_signature, @@ -302,41 +345,110 @@ void CombineSignature(const OpDef& first_signature, void CombineOutput(const protobuf::Map<string, string>& first_ret, const protobuf::Map<string, string>& second_ret, - FunctionDef* fused_function) { - *fused_function->mutable_ret() = first_ret; - fused_function->mutable_ret()->insert(second_ret.begin(), second_ret.end()); + protobuf::Map<string, string>* fused_ret) { + *fused_ret = first_ret; + fused_ret->insert(second_ret.begin(), second_ret.end()); +} + +string SameInput(const StringCollection& first_inputs, + const StringCollection& second_inputs, + const StringCollection& first_outputs, int arg_num) { + return first_inputs.at(arg_num); +} + +bool HasSameSignature(const OpDef& first_signature, + const OpDef& second_signature) { + return first_signature.input_arg_size() == + second_signature.input_arg_size() && + first_signature.output_arg_size() == + second_signature.output_arg_size(); +} + +void SameSignature(const OpDef& first_signature, const OpDef& second_signature, + OpDef* fused_signature) { + CHECK(HasSameSignature(first_signature, second_signature)) + << "Functions do not have the same signature"; + // Copy signature from first function. + *fused_signature = first_signature; +} + +void LazyConjunctionNodes(const FunctionDef& first_function, + const FunctionDef& second_function, + FunctionDef* fused_function, + FunctionDefLibrary* library) { + fused_function->mutable_node_def()->CopyFrom(first_function.node_def()); + + NodeDefBuilder if_builder("", "If"); + if_builder.Input(GetOutputNode(first_function, 0), 0, DT_BOOL); + DataTypeVector in_arg_types; + std::vector<NodeDefBuilder::NodeOut> inputs; + for (const auto& input_arg : first_function.signature().input_arg()) { + inputs.push_back({input_arg.name(), 0, input_arg.type()}); + in_arg_types.push_back(input_arg.type()); + } + if_builder.Attr("Tin", in_arg_types); + + if_builder.Attr("Tcond", DT_BOOL); + if_builder.Attr("Tout", DataTypeVector{DT_BOOL}); + if_builder.Attr("_lower_using_switch_merge", true); + + NameAttrList then_branch; + then_branch.set_name(second_function.signature().name()); + if_builder.Attr("then_branch", then_branch); + + auto* false_predicate = + CreateFalsePredicate(first_function.signature().input_arg(), library); + + NameAttrList else_branch; + else_branch.set_name(false_predicate->signature().name()); + if_builder.Attr("else_branch", else_branch); + if_builder.Input(inputs); + + auto* if_node = fused_function->add_node_def(); + // This is guaranteed to succeed. + TF_CHECK_OK(if_builder.Finalize(if_node)); + graph_utils::SetUniqueFunctionNodeName("cond", fused_function, if_node); + + GetMutableOutputNode(fused_function, 0) = if_node->name() + ":output:0"; +} + +void LazyConjunctionOutput(const protobuf::Map<string, string>& first_ret, + const protobuf::Map<string, string>& second_ret, + protobuf::Map<string, string>* fused_ret) { + CHECK_EQ(first_ret.size(), 1); + CHECK_EQ(second_ret.size(), 1); + // Temporarily copy returns from first_ret. We are going to change the + // output node after creating it. + *fused_ret = first_ret; } -FunctionDef* FuseFunctions(const FunctionDef& first_function, - const FunctionDef& function, - StringPiece fused_name_prefix, - const SetFunctionSignatureFn& set_signature, - const SetInputFn& set_input, - const SetOutputFn& set_output, - FunctionDefLibrary* library) { - if (first_function.attr_size() != 0 || function.attr_size() != 0) +FunctionDef* FuseFunctions( + const FunctionDef& first_function, const FunctionDef& second_function, + StringPiece fused_name_prefix, const SetFunctionSignatureFn& set_signature, + const SetInputFn& set_input, const SetOutputFn& set_output, + const SetNodesFn& set_nodes, FunctionDefLibrary* library) { + if (first_function.attr_size() != 0 || second_function.attr_size() != 0) return nullptr; // Functions with attributes are currently not supported // This function will be used as a clone of second function, having unique // names. - FunctionDef setup_function = function; + FunctionDef setup_function = second_function; *setup_function.mutable_signature() = GetUniqueSignature( first_function.signature(), setup_function.signature(), setup_function.mutable_ret(), setup_function.mutable_node_def()); FunctionDef* fused_function = library->add_function(); - // Copy all nodes from first_function. - fused_function->mutable_node_def()->CopyFrom(first_function.node_def()); + set_signature(first_function.signature(), setup_function.signature(), fused_function->mutable_signature()); graph_utils::SetUniqueGraphFunctionName(fused_name_prefix, library, fused_function); - RenameFunctionNodes(first_function, fused_function, - setup_function.mutable_node_def(), + RenameFunctionNodes(first_function, setup_function.mutable_node_def(), setup_function.mutable_ret()); - set_output(first_function.ret(), setup_function.ret(), fused_function); + set_output(first_function.ret(), setup_function.ret(), + fused_function->mutable_ret()); CHECK(fused_function->signature().output_arg_size() == fused_function->ret_size()) @@ -351,10 +463,10 @@ FunctionDef* FuseFunctions(const FunctionDef& first_function, FuseFunctionNodes(first_inputs, second_inputs, first_outputs, set_input, setup_function.mutable_node_def()); FuseReturns(first_inputs, second_inputs, first_outputs, set_input, - fused_function); + fused_function->mutable_ret()); + + set_nodes(first_function, setup_function, fused_function, library); - // Copy transformed nodes from the second function. - fused_function->mutable_node_def()->MergeFrom(setup_function.node_def()); return fused_function; } diff --git a/tensorflow/core/grappler/optimizers/data/fusion_utils.h b/tensorflow/core/grappler/optimizers/data/fusion_utils.h index 41f13f6cb8..19b7002dcd 100644 --- a/tensorflow/core/grappler/optimizers/data/fusion_utils.h +++ b/tensorflow/core/grappler/optimizers/data/fusion_utils.h @@ -48,14 +48,20 @@ using SetInputFn = const StringCollection& second_function_inputs, const StringCollection& parent_outputs, int arg_num)>; -// This function is invoked with first function ret. It is used to set up -// returns of fused function. If you need to combine outputs -// of first and second function, then this is a right place to create a new -// nodes. +// This function is invoked with first and second function ret. It is used to +// set up returns of fused function. using SetOutputFn = std::function<void(const protobuf::Map<string, string>& parent_ret, const protobuf::Map<string, string>& second_function_ret, - FunctionDef* fused_function)>; + protobuf::Map<string, string>* fused_ret)>; + +using SetNodesFn = std::function<void( + const FunctionDef& first_function, const FunctionDef& second_function, + FunctionDef* fused_function, FunctionDefLibrary* library)>; + +void MergeNodes(const FunctionDef& first_function, + const FunctionDef& second_function, FunctionDef* fused_function, + FunctionDefLibrary* library); // Returns true if functions can be composed. bool CanCompose(const OpDef& first_signature, const OpDef& second_signature); @@ -71,7 +77,7 @@ string ComposeInput(const StringCollection& first_inputs, // second_function(first_function(args...)). void ComposeOutput(const protobuf::Map<string, string>& first_ret, const protobuf::Map<string, string>& second_ret, - FunctionDef* fused_function); + protobuf::Map<string, string>* fused_ret); // Set input signature to `first_function_signature` and output signature // to `first_function_signature` + `second_function_signature` @@ -83,7 +89,32 @@ void CombineSignature(const OpDef& first_signature, // return *first_function(...), *second_function(...) void CombineOutput(const protobuf::Map<string, string>& first_ret, const protobuf::Map<string, string>& second_ret, - FunctionDef* fused_function); + protobuf::Map<string, string>* fused_ret); + +// Returns true if both signatures have the same number of input and output +// args. +bool HasSameSignature(const OpDef& first_signature, + const OpDef& second_signature); + +// Check if both signatures are same and copy it from `first_signature`. +void SameSignature(const OpDef& first_signature, const OpDef& second_signature, + OpDef* fused_signature); + +// Take the same input as first function. +string SameInput(const StringCollection& first_inputs, + const StringCollection& second_inputs, + const StringCollection& first_outputs, int arg_num); + +// Create a fused function that computes the short-circuit logical AND of the +// result of the first function and the result of the second function. +void LazyConjunctionOutput(const protobuf::Map<string, string>& first_ret, + const protobuf::Map<string, string>& second_ret, + protobuf::Map<string, string>* fused_ret); + +void LazyConjunctionNodes(const FunctionDef& first_function, + const FunctionDef& second_function, + FunctionDef* fused_function, + FunctionDefLibrary* library); // Fuse `first_function` with `second_function`, setting `fused_name_prefix` as // a name prefix. The nodes from `first_function` are copied unmodified. All @@ -91,13 +122,11 @@ void CombineOutput(const protobuf::Map<string, string>& first_ret, // that are not conflicting with first function. This means that copied nodes // from second function can end up having different names. For explanation of // set up functions see the documentation of the functions types. -FunctionDef* FuseFunctions(const FunctionDef& first_function, - const FunctionDef& second_function, - StringPiece fused_name_prefix, - const SetFunctionSignatureFn& set_signature, - const SetInputFn& set_input, - const SetOutputFn& set_output, - FunctionDefLibrary* library); +FunctionDef* FuseFunctions( + const FunctionDef& first_function, const FunctionDef& second_function, + StringPiece fused_name_prefix, const SetFunctionSignatureFn& set_signature, + const SetInputFn& set_input, const SetOutputFn& set_output, + const SetNodesFn& set_nodes, FunctionDefLibrary* library); } // namespace fusion_utils } // namespace grappler diff --git a/tensorflow/core/grappler/optimizers/data/fusion_utils_test.cc b/tensorflow/core/grappler/optimizers/data/fusion_utils_test.cc index 7ad5d63bf6..d5c6466080 100644 --- a/tensorflow/core/grappler/optimizers/data/fusion_utils_test.cc +++ b/tensorflow/core/grappler/optimizers/data/fusion_utils_test.cc @@ -57,10 +57,10 @@ TEST(FusionUtilsTest, FuseFunctionsByComposition) { auto *function = graph.mutable_library()->add_function(); *function = test::function::XTimesTwo(); - auto *fused_function = - FuseFunctions(*parent_function, *function, "fused_maps", - fusion_utils::ComposeSignature, fusion_utils::ComposeInput, - fusion_utils::ComposeOutput, graph.mutable_library()); + auto *fused_function = FuseFunctions( + *parent_function, *function, "fused_maps", fusion_utils::ComposeSignature, + fusion_utils::ComposeInput, fusion_utils::ComposeOutput, + fusion_utils::MergeNodes, graph.mutable_library()); EXPECT_EQ(fused_function->signature().name(), "fused_maps"); EXPECT_EQ(fused_function->signature().input_arg_size(), 1); @@ -98,7 +98,8 @@ TEST(FusionUtilsTest, FuseFunctionWithPredicate) { auto *fused_function = FuseFunctions(*xtimes_two, *is_zero, "fused_map_and_filter_function", fusion_utils::CombineSignature, fusion_utils::ComposeInput, - fusion_utils::CombineOutput, graph.mutable_library()); + fusion_utils::CombineOutput, fusion_utils::MergeNodes, + graph.mutable_library()); EXPECT_EQ(fused_function->signature().name(), "fused_map_and_filter_function"); @@ -134,10 +135,10 @@ TEST(FusionUtilsTest, FuseSameFunctionWithExtraOutput) { auto *function = graph.mutable_library()->add_function(); *function = test::function::XTimesTwo(); - auto *fused_function = - FuseFunctions(*parent_function, *function, "fused_maps", - fusion_utils::CombineSignature, fusion_utils::ComposeInput, - fusion_utils::CombineOutput, graph.mutable_library()); + auto *fused_function = FuseFunctions( + *parent_function, *function, "fused_maps", fusion_utils::CombineSignature, + fusion_utils::ComposeInput, fusion_utils::CombineOutput, + fusion_utils::MergeNodes, graph.mutable_library()); EXPECT_EQ(fused_function->signature().input_arg_size(), 1); EXPECT_EQ(fused_function->signature().output_arg_size(), 2); @@ -169,7 +170,8 @@ TEST(FusionUtilsTest, ZipFusion) { auto *fused_function = FuseFunctions(*function, *function, "zip_maps", zip_signature, zip_input, - fusion_utils::CombineOutput, graph.mutable_library()); + fusion_utils::CombineOutput, fusion_utils::MergeNodes, + graph.mutable_library()); EXPECT_EQ(fused_function->signature().input_arg_size(), 2); EXPECT_EQ(fused_function->signature().output_arg_size(), 2); diff --git a/tensorflow/core/grappler/optimizers/data/graph_utils.cc b/tensorflow/core/grappler/optimizers/data/graph_utils.cc index 0eceaf4017..5a7fe19265 100644 --- a/tensorflow/core/grappler/optimizers/data/graph_utils.cc +++ b/tensorflow/core/grappler/optimizers/data/graph_utils.cc @@ -94,11 +94,11 @@ NodeDef* AddNode(StringPiece name, StringPiece op, MutableGraphView* graph) { NodeDef node; if (!name.empty()) { - node.set_name(name.ToString()); + node.set_name(string(name)); } else { SetUniqueGraphNodeName(op, graph->GetGraph(), &node); } - node.set_op(op.ToString()); + node.set_op(string(op)); for (const string& input : inputs) { node.add_input(input); } @@ -108,6 +108,26 @@ NodeDef* AddNode(StringPiece name, StringPiece op, return graph->AddNode(std::move(node)); } +NodeDef* AddNode(StringPiece name, StringPiece op, + const std::vector<string>& inputs, + const std::vector<std::pair<string, AttrValue>>& attributes, + FunctionDef* fd) { + NodeDef* node = fd->add_node_def(); + if (!name.empty()) { + node->set_name(string(name)); + } else { + SetUniqueFunctionNodeName(op, fd, node); + } + node->set_op(string(op)); + for (const string& input : inputs) { + node->add_input(input); + } + for (auto attr : attributes) { + (*node->mutable_attr())[attr.first] = attr.second; + } + return node; +} + template <> NodeDef* AddScalarConstNode(bool v, MutableGraphView* graph) { return AddScalarConstNodeHelper( @@ -181,7 +201,7 @@ bool ContainsGraphNodeWithName(StringPiece name, const GraphDef& graph) { } bool ContainsNodeWithOp(StringPiece op, const GraphDef& graph) { - return FindNodeWithOp(op, graph) != -1; + return FindGraphNodeWithOp(op, graph) != -1; } bool ContainsGraphFunctionWithName(StringPiece name, @@ -205,7 +225,7 @@ int FindGraphNodeWithName(StringPiece name, const GraphDef& graph) { return indices.empty() ? -1 : indices.front(); } -int FindNodeWithOp(StringPiece op, const GraphDef& graph) { +int FindGraphNodeWithOp(StringPiece op, const GraphDef& graph) { std::vector<int> indices = GetElementIndicesWithPredicate( [&op](const NodeDef& node) { return node.op() == op; }, graph.node()); return indices.empty() ? -1 : indices.front(); @@ -242,9 +262,15 @@ int FindFunctionNodeWithOp(StringPiece op, const FunctionDef& function) { return indices.empty() ? -1 : indices.front(); } +NodeDef* GetInputNode(const NodeDef& node, const MutableGraphView& graph) { + if (node.input_size() == 0) return nullptr; + GraphView::InputPort input_port = graph.GetInputPort(node.name(), 0); + return graph.GetRegularFanin(input_port).node; +} + void SetUniqueGraphNodeName(StringPiece prefix, GraphDef* graph, NodeDef* node) { - string name = prefix.ToString(); + string name = string(prefix); int id = graph->node_size(); while (ContainsGraphNodeWithName(name, *graph)) { if (name.rfind("_generated") != std::string::npos && @@ -260,7 +286,7 @@ void SetUniqueGraphNodeName(StringPiece prefix, GraphDef* graph, void SetUniqueFunctionNodeName(StringPiece prefix, FunctionDef* function, NodeDef* node) { - string name = prefix.ToString(); + string name = string(prefix); int id = function->node_def_size(); while (ContainsFunctionNodeWithName(name, *function)) { name = strings::StrCat(prefix, "/_", id); @@ -271,7 +297,7 @@ void SetUniqueFunctionNodeName(StringPiece prefix, FunctionDef* function, void SetUniqueGraphFunctionName(StringPiece prefix, FunctionDefLibrary* library, FunctionDef* function) { - string name = prefix.ToString(); + string name = string(prefix); int id = library->function_size(); while (ContainsGraphFunctionWithName(name, *library)) { name = strings::StrCat(prefix, "/_", id); diff --git a/tensorflow/core/grappler/optimizers/data/graph_utils.h b/tensorflow/core/grappler/optimizers/data/graph_utils.h index 28a1aff877..6f431c232d 100644 --- a/tensorflow/core/grappler/optimizers/data/graph_utils.h +++ b/tensorflow/core/grappler/optimizers/data/graph_utils.h @@ -37,6 +37,12 @@ NodeDef* AddNode(StringPiece name, StringPiece op, const std::vector<std::pair<string, AttrValue>>& attributes, MutableGraphView* graph); +// Adds a node to a FunctionDef. +NodeDef* AddNode(StringPiece name, StringPiece op, + const std::vector<string>& inputs, + const std::vector<std::pair<string, AttrValue>>& attributes, + FunctionDef* fd); + // Adds a Const node with the given value to the graph. template <typename T> NodeDef* AddScalarConstNode(T v, MutableGraphView* graph) { @@ -99,7 +105,10 @@ int FindFunctionNodeWithOp(StringPiece op, const FunctionDef& function); // Returns the index of the first node with the given op or -1 if no such node // exists. -int FindNodeWithOp(StringPiece op, const GraphDef& graph); +int FindGraphNodeWithOp(StringPiece op, const GraphDef& graph); + +// Gets the 0th input to a node in the graph. +NodeDef* GetInputNode(const NodeDef& node, const MutableGraphView& graph); // Returns the list of indices of all nodes with the given op or empty list if // no such node exists. diff --git a/tensorflow/core/grappler/optimizers/data/graph_utils_test.cc b/tensorflow/core/grappler/optimizers/data/graph_utils_test.cc index 0a3af1a914..c19ac7b880 100644 --- a/tensorflow/core/grappler/optimizers/data/graph_utils_test.cc +++ b/tensorflow/core/grappler/optimizers/data/graph_utils_test.cc @@ -176,25 +176,25 @@ TEST(GraphUtilsTest, FindGraphFunctionWithName) { FindGraphFunctionWithName(new_function->signature().name(), library), -1); } -TEST(GraphUtilsTest, FindNodeWithOp) { +TEST(GraphUtilsTest, FindGraphNodeWithOp) { GraphDef graph_def; MutableGraphView graph(&graph_def); - EXPECT_EQ(FindNodeWithOp("OpA", *graph.GetGraph()), -1); + EXPECT_EQ(FindGraphNodeWithOp("OpA", *graph.GetGraph()), -1); AddNode("A", "OpA", {}, {}, &graph); AddNode("B", "OpB", {"A"}, {}, &graph); AddNode("A2", "OpA", {"B"}, {}, &graph); - EXPECT_EQ(FindNodeWithOp("OpA", *graph.GetGraph()), 0); + EXPECT_EQ(FindGraphNodeWithOp("OpA", *graph.GetGraph()), 0); graph.DeleteNodes({"B"}); - EXPECT_EQ(FindNodeWithOp("OpB", *graph.GetGraph()), -1); + EXPECT_EQ(FindGraphNodeWithOp("OpB", *graph.GetGraph()), -1); EXPECT_EQ(FindGraphNodeWithName("A2", *graph.GetGraph()), 1); } TEST(GraphUtilsTest, FindAllGraphNodesWithOp) { GraphDef graph_def; MutableGraphView graph(&graph_def); - EXPECT_EQ(FindNodeWithOp("OpA", *graph.GetGraph()), -1); + EXPECT_EQ(FindGraphNodeWithOp("OpA", *graph.GetGraph()), -1); AddNode("A", "OpA", {}, {}, &graph); AddNode("B", "OpB", {"A"}, {}, &graph); @@ -251,6 +251,54 @@ TEST(GraphUtilsTest, SetUniqueGraphFunctionName) { other_function->signature().name()); } +TEST(GraphUtilsTest, AddNodeToFunctionDef) { + FunctionDef func; + const char* op_name = "xxx"; + AddNode(op_name, op_name, {}, {}, &func); + + const NodeDef& node1 = func.node_def(FindFunctionNodeWithName("xxx", func)); + EXPECT_EQ(node1.op(), op_name); + EXPECT_EQ(node1.input_size(), 0); + EXPECT_EQ(node1.attr_size(), 0); + + const std::vector<string> inputs({"input1", "input2"}); + AddNode("", op_name, inputs, {}, &func); + const NodeDef& node2 = + func.node_def(FindFunctionNodeWithName("xxx/_2", func)); + EXPECT_EQ(node2.op(), op_name); + EXPECT_EQ(node2.attr_size(), 0); + EXPECT_EQ(node2.input_size(), inputs.size()); + for (size_t i = 0; i < inputs.size(); ++i) { + EXPECT_EQ(node2.input(i), inputs[i]); + } + + AttrValue a1, a2; + a1.set_type(DT_INT32); + a2.set_type(DT_INT64); + const std::vector<std::pair<string, AttrValue>> attrs( + {{"attr1", a1}, {"attr2", a2}}); + AddNode("", op_name, {}, attrs, &func); + const NodeDef& node3 = + func.node_def(FindFunctionNodeWithName("xxx/_3", func)); + EXPECT_EQ(node3.op(), op_name); + EXPECT_EQ(node3.input_size(), 0); + EXPECT_EQ(node3.attr_size(), attrs.size()); + for (size_t i = 0; i < attrs.size(); ++i) { + EXPECT_EQ(attrs[i].second.type(), node3.attr().at(attrs[i].first).type()); + } +} + +TEST(GraphUtilsTest, GetInputNode) { + GraphDef graph_def; + MutableGraphView graph(&graph_def); + + NodeDef* node1 = AddNode("", "A", {}, {}, &graph); + NodeDef* node2 = AddNode("", "A", {node1->name()}, {}, &graph); + + EXPECT_EQ(GetInputNode(*node2, graph), node1); + EXPECT_EQ(GetInputNode(*node1, graph), nullptr); +} + } // namespace } // namespace graph_utils } // namespace grappler diff --git a/tensorflow/core/grappler/optimizers/data/latency_all_edges.cc b/tensorflow/core/grappler/optimizers/data/latency_all_edges.cc index 0b25b1ea9d..9e382aeef9 100644 --- a/tensorflow/core/grappler/optimizers/data/latency_all_edges.cc +++ b/tensorflow/core/grappler/optimizers/data/latency_all_edges.cc @@ -33,7 +33,7 @@ namespace { constexpr char kInsertOpName[] = "LatencyStatsDataset"; -NodeDef make_latency_node(const NodeDef& node, MutableGraphView* graph) { +NodeDef MakeLatencyNode(const NodeDef& node, MutableGraphView* graph) { NodeDef new_node; new_node.set_op(kInsertOpName); graph_utils::SetUniqueGraphNodeName( @@ -96,7 +96,7 @@ Status LatencyAllEdges::Optimize(Cluster* cluster, const GrapplerItem& item, } } - graph.InsertNode(node, make_latency_node(node, &graph)); + graph.InsertNode(node, MakeLatencyNode(node, &graph)); } return Status::OK(); } diff --git a/tensorflow/core/grappler/optimizers/data/map_and_batch_fusion.cc b/tensorflow/core/grappler/optimizers/data/map_and_batch_fusion.cc index 3ce238a30a..63945b8b9e 100644 --- a/tensorflow/core/grappler/optimizers/data/map_and_batch_fusion.cc +++ b/tensorflow/core/grappler/optimizers/data/map_and_batch_fusion.cc @@ -32,9 +32,8 @@ namespace { constexpr char kFusedOpName[] = "MapAndBatchDatasetV2"; -NodeDef make_map_and_batch_node(const NodeDef& map_node, - const NodeDef& batch_node, - MutableGraphView* graph) { +NodeDef MakeMapAndBatchNode(const NodeDef& map_node, const NodeDef& batch_node, + MutableGraphView* graph) { NodeDef new_node; new_node.set_op(kFusedOpName); graph_utils::SetUniqueGraphNodeName(kFusedOpName, graph->GetGraph(), @@ -104,8 +103,8 @@ Status MapAndBatchFusion::Optimize(Cluster* cluster, const GrapplerItem& item, // Use a more descriptive variable name now that we know the node type. const NodeDef& batch_node = node; - GraphView::InputPort input_port = graph.GetInputPort(batch_node.name(), 0); - NodeDef* node2 = graph.GetRegularFanin(input_port).node; + NodeDef* node2 = graph_utils::GetInputNode(batch_node, graph); + if (node2->op() != "MapDataset" && node2->op() != "ParallelMapDataset") { continue; } @@ -113,7 +112,7 @@ Status MapAndBatchFusion::Optimize(Cluster* cluster, const GrapplerItem& item, NodeDef* map_node = node2; auto* new_node = - graph.AddNode(make_map_and_batch_node(*map_node, batch_node, &graph)); + graph.AddNode(MakeMapAndBatchNode(*map_node, batch_node, &graph)); graph.ReplaceInput(batch_node, *new_node); // Mark the `Map` and `Batch` nodes for removal. diff --git a/tensorflow/core/grappler/optimizers/data/map_and_batch_fusion_test.cc b/tensorflow/core/grappler/optimizers/data/map_and_batch_fusion_test.cc index a46c504ac4..b676246b31 100644 --- a/tensorflow/core/grappler/optimizers/data/map_and_batch_fusion_test.cc +++ b/tensorflow/core/grappler/optimizers/data/map_and_batch_fusion_test.cc @@ -85,8 +85,8 @@ TEST(MapAndBatchFusionTest, FuseMapAndBatchNodesIntoOne) { EXPECT_FALSE( graph_utils::ContainsGraphNodeWithName(batch_node->name(), output)); EXPECT_TRUE(graph_utils::ContainsNodeWithOp("MapAndBatchDatasetV2", output)); - NodeDef map_and_batch_node = - output.node(graph_utils::FindNodeWithOp("MapAndBatchDatasetV2", output)); + NodeDef map_and_batch_node = output.node( + graph_utils::FindGraphNodeWithOp("MapAndBatchDatasetV2", output)); EXPECT_EQ(map_and_batch_node.input_size(), 5); EXPECT_EQ(map_and_batch_node.input(0), map_node->input(0)); EXPECT_EQ(map_and_batch_node.input(1), map_node->input(1)); @@ -170,8 +170,8 @@ TEST(MapAndBatchFusionTest, FuseMapAndBatchV2NodesIntoOne) { EXPECT_FALSE( graph_utils::ContainsGraphNodeWithName(batch_node->name(), output)); EXPECT_TRUE(graph_utils::ContainsNodeWithOp("MapAndBatchDatasetV2", output)); - NodeDef map_and_batch_node = - output.node(graph_utils::FindNodeWithOp("MapAndBatchDatasetV2", output)); + NodeDef map_and_batch_node = output.node( + graph_utils::FindGraphNodeWithOp("MapAndBatchDatasetV2", output)); EXPECT_EQ(map_and_batch_node.input_size(), 5); EXPECT_EQ(map_and_batch_node.input(0), map_node->input(0)); EXPECT_EQ(map_and_batch_node.input(1), map_node->input(1)); @@ -253,8 +253,8 @@ TEST(MapAndBatchFusionTest, FuseParallelMapAndBatchNodesIntoOne) { EXPECT_FALSE( graph_utils::ContainsGraphNodeWithName(batch_node->name(), output)); EXPECT_TRUE(graph_utils::ContainsNodeWithOp("MapAndBatchDatasetV2", output)); - NodeDef map_and_batch_node = - output.node(graph_utils::FindNodeWithOp("MapAndBatchDatasetV2", output)); + NodeDef map_and_batch_node = output.node( + graph_utils::FindGraphNodeWithOp("MapAndBatchDatasetV2", output)); EXPECT_EQ(map_and_batch_node.input_size(), 5); EXPECT_EQ(map_and_batch_node.input(0), map_node->input(0)); EXPECT_EQ(map_and_batch_node.input(1), map_node->input(1)); diff --git a/tensorflow/core/grappler/optimizers/data/map_and_filter_fusion.cc b/tensorflow/core/grappler/optimizers/data/map_and_filter_fusion.cc index 5e76c9f819..f1844a141c 100644 --- a/tensorflow/core/grappler/optimizers/data/map_and_filter_fusion.cc +++ b/tensorflow/core/grappler/optimizers/data/map_and_filter_fusion.cc @@ -116,22 +116,25 @@ Status MapAndFilterFusion::Optimize(Cluster* cluster, const GrapplerItem& item, const auto& fun = filter_node->attr().at("predicate"); const FunctionDef* filter_func = function_library.Find(fun.func().name()); if (!fusion_utils::CanCompose(map_func->signature(), - filter_func->signature())) + filter_func->signature())) { + VLOG(1) << "Can't fuse map and filter because the output signature of " + "the map function does not match the input signature of the " + "filter function\n"; return nullptr; + } return fusion_utils::FuseFunctions( *map_func, *filter_func, "fused_map_and_filter_function", fusion_utils::CombineSignature, fusion_utils::ComposeInput, - fusion_utils::CombineOutput, output->mutable_library()); + fusion_utils::CombineOutput, fusion_utils::MergeNodes, + output->mutable_library()); }; for (const NodeDef& node : sorted_old_graph.node()) { const NodeDef* filter_node = get_filter_node(node); if (!filter_node) continue; - GraphView::InputPort input_port = - graph.GetInputPort(filter_node->name(), 0); const NodeDef* map_node = - get_map_node(*graph.GetRegularFanin(input_port).node); + get_map_node(*graph_utils::GetInputNode(*filter_node, graph)); if (!map_node) continue; const auto* fused_function = make_fused_function(map_node, filter_node); diff --git a/tensorflow/core/grappler/optimizers/data/map_and_filter_fusion_test.cc b/tensorflow/core/grappler/optimizers/data/map_and_filter_fusion_test.cc index 027e0c1590..f029a093fa 100644 --- a/tensorflow/core/grappler/optimizers/data/map_and_filter_fusion_test.cc +++ b/tensorflow/core/grappler/optimizers/data/map_and_filter_fusion_test.cc @@ -30,7 +30,7 @@ namespace { NodeDef MakeMapNode(StringPiece name, StringPiece input_node_name) { return test::function::NDef( - name, "MapDataset", {input_node_name.ToString()}, + name, "MapDataset", {string(input_node_name)}, {{"f", FunctionDefHelper::FunctionRef("XTimesTwo")}, {"Targuments", {}}, {"output_shapes", {}}, @@ -39,7 +39,7 @@ NodeDef MakeMapNode(StringPiece name, StringPiece input_node_name) { NodeDef MakeFilterNode(StringPiece name, StringPiece input_node_name) { return test::function::NDef( - name, "FilterDataset", {input_node_name.ToString()}, + name, "FilterDataset", {string(input_node_name)}, {{"predicate", FunctionDefHelper::FunctionRef("IsZero")}, {"Targuments", {}}, {"output_shapes", {}}, @@ -101,18 +101,18 @@ TEST(MapAndFilterFusionTest, FuseMapAndFilterWithExtraChild) { graph_utils::ContainsNodeWithOp("FilterByLastComponentDataset", output)); ASSERT_TRUE(graph_utils::ContainsNodeWithOp("CacheDataset", output)); - int map_id = graph_utils::FindNodeWithOp("MapDataset", output); + int map_id = graph_utils::FindGraphNodeWithOp("MapDataset", output); auto& map_node = output.node(map_id); ASSERT_EQ(map_node.input_size(), 1); EXPECT_EQ(map_node.input(0), "range"); int filter_by_component_id = - graph_utils::FindNodeWithOp("FilterByLastComponentDataset", output); + graph_utils::FindGraphNodeWithOp("FilterByLastComponentDataset", output); auto& filter_by_component = output.node(filter_by_component_id); ASSERT_EQ(filter_by_component.input_size(), 1); EXPECT_EQ(filter_by_component.input(0), map_node.name()); - int cache_id = graph_utils::FindNodeWithOp("CacheDataset", output); + int cache_id = graph_utils::FindGraphNodeWithOp("CacheDataset", output); auto& cache_node = output.node(cache_id); ASSERT_EQ(cache_node.input_size(), 2); EXPECT_EQ(cache_node.input(0), filter_by_component.name()); diff --git a/tensorflow/core/grappler/optimizers/data/map_fusion.cc b/tensorflow/core/grappler/optimizers/data/map_fusion.cc index feb370eb9d..a78ecb09f7 100644 --- a/tensorflow/core/grappler/optimizers/data/map_fusion.cc +++ b/tensorflow/core/grappler/optimizers/data/map_fusion.cc @@ -90,21 +90,25 @@ Status MapFusion::Optimize(Cluster* cluster, const GrapplerItem& item, const auto& fun = map_node->attr().at("f"); const FunctionDef* func = function_library.Find(fun.func().name()); - if (!fusion_utils::CanCompose(parent_func->signature(), func->signature())) + if (!fusion_utils::CanCompose(parent_func->signature(), + func->signature())) { + VLOG(1) << "Can't fuse two maps because the output signature of the " + "first map function does not match the input signature of the " + "second function\n"; return nullptr; + } return fusion_utils::FuseFunctions( *parent_func, *func, "fused_map", fusion_utils::ComposeSignature, fusion_utils::ComposeInput, fusion_utils::ComposeOutput, - output->mutable_library()); + fusion_utils::MergeNodes, output->mutable_library()); }; for (const NodeDef& node : sorted_old_graph.node()) { const NodeDef* map_node = get_map_node(node); if (!map_node) continue; - GraphView::InputPort input_port = graph.GetInputPort(map_node->name(), 0); const NodeDef* parent_map_node = - get_map_node(*graph.GetRegularFanin(input_port).node); + get_map_node(*graph_utils::GetInputNode(*map_node, graph)); if (!parent_map_node) continue; const auto* fused_function = get_fused_function(parent_map_node, map_node); diff --git a/tensorflow/core/grappler/optimizers/data/map_fusion_test.cc b/tensorflow/core/grappler/optimizers/data/map_fusion_test.cc index df6c19dc7c..b25dfbd0b8 100644 --- a/tensorflow/core/grappler/optimizers/data/map_fusion_test.cc +++ b/tensorflow/core/grappler/optimizers/data/map_fusion_test.cc @@ -30,7 +30,7 @@ namespace { NodeDef MakeMapNode(StringPiece name, StringPiece input_node_name) { return test::function::NDef( - name, "MapDataset", {input_node_name.ToString()}, + name, "MapDataset", {string(input_node_name)}, {{"f", FunctionDefHelper::FunctionRef("XTimesTwo")}, {"Targuments", {}}, {"output_shapes", {}}, diff --git a/tensorflow/core/grappler/optimizers/data/map_vectorization.cc b/tensorflow/core/grappler/optimizers/data/map_vectorization.cc new file mode 100644 index 0000000000..a019b77eb7 --- /dev/null +++ b/tensorflow/core/grappler/optimizers/data/map_vectorization.cc @@ -0,0 +1,258 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/optimizers/data/map_vectorization.h" + +#include "tensorflow/core/framework/attr_value.pb.h" +#include "tensorflow/core/framework/node_def.pb.h" +#include "tensorflow/core/framework/tensor.pb.h" // NOLINT +#include "tensorflow/core/framework/tensor_shape.pb.h" +#include "tensorflow/core/grappler/clusters/cluster.h" +#include "tensorflow/core/grappler/grappler_item.h" +#include "tensorflow/core/grappler/mutable_graph_view.h" +#include "tensorflow/core/grappler/op_types.h" +#include "tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.h" +#include "tensorflow/core/grappler/optimizers/data/graph_utils.h" +#include "tensorflow/core/grappler/utils.h" +#include "tensorflow/core/lib/gtl/map_util.h" +#include "tensorflow/core/platform/protobuf.h" + +namespace tensorflow { +namespace grappler { +namespace { + +void CopyAttribute(const string& attr_name, const NodeDef& from, NodeDef* to) { + (*to->mutable_attr())[attr_name] = from.attr().at(attr_name); +} + +FunctionDef* AddVectorizedFunction(const NodeDef& map_node, + const FunctionDef& orig_func, + FunctionDefLibrary* library) { + // If we decide to use a different method of vectorization, we can just + // swap out this part. + FunctionDef* vectorized_func = library->add_function(); + // Function inputs and outputs are the same as original, just + // with different shapes. + *vectorized_func->mutable_signature() = orig_func.signature(); + graph_utils::SetUniqueGraphFunctionName("vectorized_function", library, + vectorized_func); + + // Add MapDefun node + NodeDef* map_defun_node = vectorized_func->mutable_node_def()->Add(); + map_defun_node->set_op("MapDefun"); + graph_utils::SetUniqueFunctionNodeName(map_defun_node->op(), vectorized_func, + map_defun_node); + + // Set attrs and inputs + for (const string& k : {"f", "output_types", "output_shapes"}) { + // Function, output types and (unbatched) shapes are the same as the + // original map node. + CopyAttribute(k, map_node, map_defun_node); + } + + // Get types of input arguments from original map function + AttrValue t_args; + for (const auto& input : vectorized_func->signature().input_arg()) { + t_args.mutable_list()->add_type(input.type()); + map_defun_node->add_input(input.name()); + } + (*map_defun_node->mutable_attr())["Targuments"] = t_args; + + // Set return values to match output names + string output_prefix = strings::StrCat(map_defun_node->name(), ":output:"); + for (size_t i = 0; i < vectorized_func->signature().output_arg_size(); ++i) { + const auto& output_arg = vectorized_func->signature().output_arg(i); + (*vectorized_func->mutable_ret())[output_arg.name()] = + strings::StrCat(output_prefix, i); + } + + return vectorized_func; +} + +bool IsOutputShapesFullyDefined(const NodeDef& node) { + auto* shapes_attr = gtl::FindOrNull(node.attr(), "output_shapes"); + if (shapes_attr == nullptr) return false; + const auto& shapes = shapes_attr->list().shape(); + + for (const TensorShapeProto& shape : shapes) { + for (const auto& dim : shape.dim()) { + if (dim.size() == -1) { + return false; + } + } + } + return true; +} + +bool IsStatefulFn(const FunctionLibraryDefinition& library, + const FunctionDef& function_def) { + for (const NodeDef& node_def : function_def.node_def()) { + const OpDef* op_def; + Status s = library.LookUpOpDef(node_def.op(), &op_def); + if (!s.ok() || op_def->is_stateful()) { + return true; + } + } + return false; +} + +bool HasCapturedInputs(const NodeDef& map_node) { + return map_node.attr().at("Targuments").list().type_size() > 0; +} + +NodeDef MakeNewBatchNode(const NodeDef& old_batch_node, + const NodeDef& input_node, + const FunctionDef& vectorized_func, + MutableGraphView* graph) { + NodeDef batch_node; + batch_node.set_op(old_batch_node.op()); + graph_utils::SetUniqueGraphNodeName(batch_node.op(), graph->GetGraph(), + &batch_node); + + // Set the `input_dataset` input argument + batch_node.add_input(input_node.name()); + // Set the `batch_size` input_argument + batch_node.add_input(old_batch_node.input(1)); + if (batch_node.op() == "BatchDatasetV2") { + // Set the `drop_remainder` input argument + batch_node.add_input(old_batch_node.input(2)); + } + + // Set attrs + AttrValue output_types; + for (const auto& input : vectorized_func.signature().input_arg()) { + output_types.mutable_list()->add_type(input.type()); + } + (*batch_node.mutable_attr())["output_types"] = output_types; + + auto& output_shapes_attr = (*batch_node.mutable_attr())["output_shapes"]; + const auto& input_shapes = + input_node.attr().at("output_shapes").list().shape(); + int64 batch_size = + old_batch_node.attr().at("output_shapes").list().shape()[0].dim(0).size(); + for (size_t i = 0; i < input_shapes.size(); ++i) { + TensorShapeProto* shape = output_shapes_attr.mutable_list()->add_shape(); + TensorShapeProto_Dim* dim = shape->add_dim(); + dim->set_size(batch_size); + shape->MergeFrom(input_shapes.Get(i)); + } + return batch_node; +} + +NodeDef MakeNewMapNode(const NodeDef& old_map_node, + const NodeDef& old_batch_node, + const NodeDef& new_batch_node, + const FunctionDef& vectorized_func, + MutableGraphView* graph) { + NodeDef map_node; + map_node.set_op(old_map_node.op()); + graph_utils::SetUniqueGraphNodeName(map_node.op(), graph->GetGraph(), + &map_node); + + // Set the `input_dataset` input argument + map_node.add_input(new_batch_node.name()); + for (int i = 1; i < old_map_node.input_size(); i++) { + // Set the `other_arguments` and `num_parallel_calls` input arguments + map_node.add_input(old_map_node.input(i)); + } + + // Set attrs + CopyAttribute("Targuments", old_map_node, &map_node); + auto& func_attr = (*map_node.mutable_attr())["f"]; + func_attr.mutable_func()->set_name(vectorized_func.signature().name()); + + for (auto key : {"output_shapes", "output_types"}) { + CopyAttribute(key, old_batch_node, &map_node); + } + return map_node; +} + +} // namespace + +Status MapVectorization::Optimize(Cluster* cluster, const GrapplerItem& item, + GraphDef* output) { + *output = item.graph; + MutableGraphView graph(output); + std::set<string> nodes_to_delete; + + for (const NodeDef& node : item.graph.node()) { + // Find Map->Batch nodes. + // TODO(rachelim): Optimize MapAndBatchDataset[V2] as well. + if (node.op() != "BatchDataset" && node.op() != "BatchDatasetV2") { + continue; + } + + const NodeDef& batch_node(node); + NodeDef* node2 = graph_utils::GetInputNode(batch_node, graph); + if (node2->op() != "MapDataset" && node2->op() != "ParallelMapDataset") { + continue; + } + + // Use a more descriptive variable name now that we know the node type. + NodeDef* map_node = node2; + // Input to the map node + NodeDef* input_node = graph_utils::GetInputNode(*map_node, graph); + CHECK_NOTNULL(input_node); + + FunctionDefLibrary* library = output->mutable_library(); + + FunctionLibraryDefinition function_library(OpRegistry::Global(), *library); + const FunctionDef* orig_func = + function_library.Find(map_node->attr().at("f").func().name()); + + // Check that this is a valid optimization. + if (!IsOutputShapesFullyDefined(*input_node) || + !IsOutputShapesFullyDefined(*map_node) || + IsStatefulFn(function_library, *orig_func) || + HasCapturedInputs(*map_node)) { + // 1. If any of the inputs have an unknown shape, don't optimize, since + // inputs might not be batchable. + // 2. If any of the map func outputs have an unknown shape, don't + // optimize, so that batching errors surface as before. + // 3. If the function is stateful, don't vectorize it. + // 4. TODO(rachelim): Make this work for MapDataset with captured inputs + // by tiling inputs or modifying the signature of MapDefun. + continue; + } + + FunctionDef* vectorized_func = + AddVectorizedFunction(*map_node, *orig_func, library); + CHECK_NOTNULL(vectorized_func); + + auto* new_batch_node = graph.AddNode( + MakeNewBatchNode(batch_node, *input_node, *vectorized_func, &graph)); + + auto* new_map_node = graph.AddNode(MakeNewMapNode( + *map_node, batch_node, *new_batch_node, *vectorized_func, &graph)); + graph.ReplaceInput(batch_node, *new_map_node); + + // Mark the `Map` and `Batch` nodes for removal. + nodes_to_delete.insert(map_node->name()); + nodes_to_delete.insert(batch_node.name()); + } + graph.DeleteNodes(nodes_to_delete); + return Status::OK(); +} + +void MapVectorization::Feedback(Cluster* cluster, const GrapplerItem& item, + const GraphDef& optimize_output, + double result) { + // no-op +} + +REGISTER_GRAPH_OPTIMIZER_AS(MapVectorization, "map_vectorization"); + +} // end namespace grappler +} // end namespace tensorflow diff --git a/tensorflow/core/grappler/optimizers/data/function_rename.h b/tensorflow/core/grappler/optimizers/data/map_vectorization.h index 23ad9470ff..cc56a8ee5e 100644 --- a/tensorflow/core/grappler/optimizers/data/function_rename.h +++ b/tensorflow/core/grappler/optimizers/data/map_vectorization.h @@ -13,20 +13,20 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_GRAPPLER_OPTIMIZERS_DATA_FUNCTION_RENAME_H_ -#define TENSORFLOW_CORE_GRAPPLER_OPTIMIZERS_DATA_FUNCTION_RENAME_H_ +#ifndef TENSORFLOW_CORE_GRAPPLER_OPTIMIZERS_DATA_MAP_VECTORIZATION_H_ +#define TENSORFLOW_CORE_GRAPPLER_OPTIMIZERS_DATA_MAP_VECTORIZATION_H_ #include "tensorflow/core/grappler/optimizers/custom_graph_optimizer.h" namespace tensorflow { namespace grappler { -class FunctionRename : public CustomGraphOptimizer { +class MapVectorization : public CustomGraphOptimizer { public: - FunctionRename() = default; - ~FunctionRename() override = default; + MapVectorization() = default; + ~MapVectorization() override = default; - string name() const override { return "_test_only_function_rename"; }; + string name() const override { return "map_vectorization"; }; Status Init( const tensorflow::RewriterConfig_CustomGraphOptimizer* config) override { @@ -43,4 +43,4 @@ class FunctionRename : public CustomGraphOptimizer { } // end namespace grappler } // end namespace tensorflow -#endif // TENSORFLOW_CORE_GRAPPLER_OPTIMIZERS_DATA_FUNCTION_RENAME_H_ +#endif // TENSORFLOW_CORE_GRAPPLER_OPTIMIZERS_DATA_MAP_VECTORIZATION_H_ diff --git a/tensorflow/core/grappler/optimizers/data/map_vectorization_test.cc b/tensorflow/core/grappler/optimizers/data/map_vectorization_test.cc new file mode 100644 index 0000000000..ed1bd6bc97 --- /dev/null +++ b/tensorflow/core/grappler/optimizers/data/map_vectorization_test.cc @@ -0,0 +1,201 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/grappler/optimizers/data/map_vectorization.h" + +#include "tensorflow/core/framework/attr_value_util.h" +#include "tensorflow/core/framework/function_testlib.h" +#include "tensorflow/core/framework/tensor_testutil.h" +#include "tensorflow/core/grappler/grappler_item.h" +#include "tensorflow/core/grappler/optimizers/data/graph_utils.h" +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/platform/test.h" + +namespace tensorflow { +namespace grappler { +namespace { + +using test::function::GDef; +using test::function::NDef; + +void MakeTensorShapeProtoHelper(const gtl::ArraySlice<int> dims, + TensorShapeProto* t) { + for (size_t i = 0; i < dims.size(); ++i) { + auto* d = t->add_dim(); + d->set_size(dims[i]); + } +} + +AttrValue MakeShapeListAttr( + const gtl::ArraySlice<const gtl::ArraySlice<int>>& shapes) { + AttrValue shapes_attr; + for (size_t i = 0; i < shapes.size(); ++i) { + MakeTensorShapeProtoHelper(shapes[i], + shapes_attr.mutable_list()->add_shape()); + } + + return shapes_attr; +} + +NodeDef MakeMapNodeHelper( + StringPiece name, StringPiece input_node_name, StringPiece function_name, + StringPiece map_op_name, + const gtl::ArraySlice<const gtl::ArraySlice<int>>& output_shapes, + const gtl::ArraySlice<DataType>& output_types) { + return test::function::NDef( + name, map_op_name, {string(input_node_name)}, + {{"f", FunctionDefHelper::FunctionRef(string(function_name))}, + {"Targuments", {}}, + {"output_shapes", MakeShapeListAttr(output_shapes)}, + {"output_types", output_types}}); +} + +NodeDef MakeMapNode( + StringPiece name, StringPiece input_node_name, StringPiece function_name, + const gtl::ArraySlice<const gtl::ArraySlice<int>>& output_shapes, + const gtl::ArraySlice<DataType>& output_types) { + return MakeMapNodeHelper(name, input_node_name, function_name, "MapDataset", + output_shapes, output_types); +} + +NodeDef MakeBatchNode( + StringPiece name, StringPiece input_node_name, + StringPiece input_batch_size_name, + const gtl::ArraySlice<const gtl::ArraySlice<int>>& output_shapes, + const gtl::ArraySlice<DataType>& output_types) { + return NDef(name, "BatchDataset", + {string(input_node_name), string(input_batch_size_name)}, + {{"output_types", output_types}, + {"output_shapes", MakeShapeListAttr(output_shapes)}}); +} + +NodeDef MakeBatchV2Node( + StringPiece name, StringPiece input_node_name, + StringPiece input_batch_size_name, StringPiece input_drop_remainder_name, + const gtl::ArraySlice<const gtl::ArraySlice<int>>& output_shapes, + const gtl::ArraySlice<DataType>& output_types) { + return NDef(name, "BatchDatasetV2", + {string(input_node_name), string(input_batch_size_name), + string(input_drop_remainder_name)}, + {{"output_types", output_types}, + {"output_shapes", MakeShapeListAttr(output_shapes)}}); +} + +NodeDef MakeRangeNode(StringPiece name, const gtl::ArraySlice<string>& inputs) { + return NDef(name, "RangeDataset", inputs, + {{"output_shapes", MakeShapeListAttr({{}})}, + {"output_types", gtl::ArraySlice<DataType>({DT_INT64})}}); +} + +TEST(MapVectorizationTest, VectorizeMapWithBatch) { + GrapplerItem item; + item.graph = GDef( + {NDef("start", "Const", {}, {{"value", 0}, {"dtype", DT_INT32}}), + NDef("stop", "Const", {}, {{"value", 10}, {"dtype", DT_INT32}}), + NDef("step", "Const", {}, {{"value", 1}, {"dtype", DT_INT32}}), + NDef("batch_size", "Const", {}, {{"value", 1}, {"dtype", DT_INT32}}), + MakeRangeNode("range", {"start", "stop", "step"}), + MakeMapNode("map", "range", "XTimesTwo", {{}}, {DT_INT32}), + MakeBatchNode("batch", "map", "batch_size", {{-1}}, {DT_INT32})}, + // FunctionLib + { + test::function::XTimesTwo(), + }); + MapVectorization optimizer; + GraphDef output; + TF_ASSERT_OK(optimizer.Optimize(nullptr, item, &output)); + + EXPECT_EQ(graph_utils::FindAllGraphNodesWithOp("MapDataset", output).size(), + 1); + EXPECT_EQ(graph_utils::FindAllGraphNodesWithOp("BatchDataset", output).size(), + 1); + const NodeDef& map_node = + output.node(graph_utils::FindGraphNodeWithOp("MapDataset", output)); + const NodeDef& batch_node = + output.node(graph_utils::FindGraphNodeWithOp("BatchDataset", output)); + EXPECT_EQ(map_node.input(0), batch_node.name()); + EXPECT_EQ(batch_node.input(0), "range"); +} + +TEST(MapVectorizationTest, VectorizeMapWithBatchV2) { + GrapplerItem item; + item.graph = GDef( + {NDef("start", "Const", {}, {{"value", 0}, {"dtype", DT_INT32}}), + NDef("stop", "Const", {}, {{"value", 10}, {"dtype", DT_INT32}}), + NDef("step", "Const", {}, {{"value", 1}, {"dtype", DT_INT32}}), + NDef("batch_size", "Const", {}, {{"value", 1}, {"dtype", DT_INT32}}), + NDef("drop_remainder", "Const", {}, + {{"value", false}, {"dtype", DT_BOOL}}), + MakeRangeNode("range", {"start", "stop", "step"}), + MakeMapNode("map", "range", "XTimesTwo", {{}}, {DT_INT32}), + MakeBatchV2Node("batch", "map", "batch_size", "drop_remainder", {{-1}}, + {DT_INT32})}, + // FunctionLib + { + test::function::XTimesTwo(), + }); + MapVectorization optimizer; + GraphDef output; + TF_ASSERT_OK(optimizer.Optimize(nullptr, item, &output)); + + EXPECT_EQ(graph_utils::FindAllGraphNodesWithOp("MapDataset", output).size(), + 1); + EXPECT_EQ( + graph_utils::FindAllGraphNodesWithOp("BatchDatasetV2", output).size(), 1); + const NodeDef& map_node = + output.node(graph_utils::FindGraphNodeWithOp("MapDataset", output)); + const NodeDef& batch_node = + output.node(graph_utils::FindGraphNodeWithOp("BatchDatasetV2", output)); + EXPECT_EQ(map_node.input(0), batch_node.name()); + EXPECT_EQ(batch_node.input(0), "range"); +} + +TEST(MapVectorizationTest, VectorizeWithUndefinedOutputShape) { + GrapplerItem item; + item.graph = GDef( + {NDef("batch_size", "Const", {}, {{"value", 1}, {"dtype", DT_INT32}}), + NDef("input", "InputDataset", {}, + {{"output_types", gtl::ArraySlice<DataType>({DT_INT32})}}), + MakeMapNode("map", "input", "XTimesTwo", {{}}, {DT_INT32}), + MakeBatchNode("batch", "map", "batch_size", {{-1}}, {DT_INT32})}, + // FunctionLib + { + test::function::XTimesTwo(), + }); + MapVectorization optimizer; + GraphDef output; + TF_ASSERT_OK(optimizer.Optimize(nullptr, item, &output)); +} + +TEST(MapVectorizationTest, VectorizeWithUndefinedOutputTypes) { + GrapplerItem item; + item.graph = GDef( + {NDef("batch_size", "Const", {}, {{"value", 1}, {"dtype", DT_INT32}}), + NDef("input", "InputDataset", {}, + {{"output_shapes", MakeShapeListAttr({{}})}}), + MakeMapNode("map", "input", "XTimesTwo", {{}}, {DT_INT32}), + MakeBatchNode("batch", "map", "batch_size", {{-1}}, {DT_INT32})}, + // FunctionLib + { + test::function::XTimesTwo(), + }); + MapVectorization optimizer; + GraphDef output; + TF_ASSERT_OK(optimizer.Optimize(nullptr, item, &output)); +} + +} // namespace +} // namespace grappler +} // namespace tensorflow diff --git a/tensorflow/core/grappler/optimizers/data/noop_elimination.cc b/tensorflow/core/grappler/optimizers/data/noop_elimination.cc index 55d57b3b97..a26f1000a3 100644 --- a/tensorflow/core/grappler/optimizers/data/noop_elimination.cc +++ b/tensorflow/core/grappler/optimizers/data/noop_elimination.cc @@ -69,8 +69,7 @@ Status NoOpElimination::Optimize(Cluster* cluster, const GrapplerItem& item, for (const NodeDef& node : item.graph.node()) { if (!IsNoOp(node, graph)) continue; - GraphView::InputPort input_port = graph.GetInputPort(node.name(), 0); - NodeDef* const parent = graph.GetRegularFanin(input_port).node; + NodeDef* const parent = graph_utils::GetInputNode(node, graph); graph.ReplaceInput(node, *parent); nodes_to_delete.insert(node.name()); diff --git a/tensorflow/core/grappler/optimizers/data/shuffle_and_repeat_fusion.cc b/tensorflow/core/grappler/optimizers/data/shuffle_and_repeat_fusion.cc index 7c7161c5b2..cb0ff670e8 100644 --- a/tensorflow/core/grappler/optimizers/data/shuffle_and_repeat_fusion.cc +++ b/tensorflow/core/grappler/optimizers/data/shuffle_and_repeat_fusion.cc @@ -76,8 +76,8 @@ Status ShuffleAndRepeatFusion::Optimize(Cluster* cluster, // Use a more descriptive variable name now that we know the node type. const NodeDef& repeat_node = node; - GraphView::InputPort input_port = graph.GetInputPort(repeat_node.name(), 0); - NodeDef* node2 = graph.GetRegularFanin(input_port).node; + NodeDef* node2 = graph_utils::GetInputNode(repeat_node, graph); + if (node2->op() != "ShuffleDataset") { continue; } diff --git a/tensorflow/core/grappler/optimizers/data/shuffle_and_repeat_fusion_test.cc b/tensorflow/core/grappler/optimizers/data/shuffle_and_repeat_fusion_test.cc index a2e470e511..f0696eb76d 100644 --- a/tensorflow/core/grappler/optimizers/data/shuffle_and_repeat_fusion_test.cc +++ b/tensorflow/core/grappler/optimizers/data/shuffle_and_repeat_fusion_test.cc @@ -78,7 +78,7 @@ TEST(ShuffleAndRepeatFusionTest, FuseShuffleAndRepeatNodesIntoOne) { EXPECT_TRUE( graph_utils::ContainsNodeWithOp("ShuffleAndRepeatDataset", output)); NodeDef shuffle_and_repeat_node = output.node( - graph_utils::FindNodeWithOp("ShuffleAndRepeatDataset", output)); + graph_utils::FindGraphNodeWithOp("ShuffleAndRepeatDataset", output)); EXPECT_EQ(shuffle_and_repeat_node.input_size(), 5); EXPECT_EQ(shuffle_and_repeat_node.input(0), shuffle_node->input(0)); EXPECT_EQ(shuffle_and_repeat_node.input(1), shuffle_node->input(1)); diff --git a/tensorflow/core/grappler/optimizers/evaluation_utils.cc b/tensorflow/core/grappler/optimizers/evaluation_utils.cc index 00ad7494f4..79d9ea1608 100644 --- a/tensorflow/core/grappler/optimizers/evaluation_utils.cc +++ b/tensorflow/core/grappler/optimizers/evaluation_utils.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/core/grappler/optimizers/evaluation_utils.h" +#include "tensorflow/core/framework/tensor.pb.h" #include "tensorflow/core/lib/core/threadpool.h" #include "tensorflow/core/platform/cpu_info.h" #include "tensorflow/core/platform/denormal.h" diff --git a/tensorflow/core/grappler/optimizers/evaluation_utils.h b/tensorflow/core/grappler/optimizers/evaluation_utils.h index 8414b5b8ca..c9dfb6dc0b 100644 --- a/tensorflow/core/grappler/optimizers/evaluation_utils.h +++ b/tensorflow/core/grappler/optimizers/evaluation_utils.h @@ -21,6 +21,7 @@ limitations under the License. #include "tensorflow/core/framework/device_base.h" #include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/framework/op_kernel.h" +#include "tensorflow/core/framework/tensor.pb.h" #include "tensorflow/core/lib/gtl/inlined_vector.h" namespace Eigen { diff --git a/tensorflow/core/grappler/optimizers/function_optimizer.cc b/tensorflow/core/grappler/optimizers/function_optimizer.cc index 645e4c2087..56364f0095 100644 --- a/tensorflow/core/grappler/optimizers/function_optimizer.cc +++ b/tensorflow/core/grappler/optimizers/function_optimizer.cc @@ -453,6 +453,7 @@ Status InitializeFunctionSpecializationSignature( } Status SpecializeFunction(const NodeDef& func_node, const FunctionDef& func, + const int graph_def_version, FunctionOptimizerContext* ctx, GraphDef* optimized_graph) { VLOG(2) << "Specialize function instantiation: " @@ -492,7 +493,8 @@ Status SpecializeFunction(const NodeDef& func_node, const FunctionDef& func, // Make a GrapplerFunctionItem and convert it back to FunctionDef after // pushing all constant inputs into the function body. GrapplerFunctionItem item; - TF_RETURN_IF_ERROR(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_RETURN_IF_ERROR(MakeGrapplerFunctionItem(func, func_attr, flib, + graph_def_version, &item)); // Push const inputs into the function body, and keep track of their control // dependencies. @@ -576,15 +578,15 @@ NodeDef InlinedFunctionOutputsNode(const NodeDef& func_node, Status InlineFunction(const NodeDef& func_node, const FunctionDef& func, const FunctionOptimizerContext& ctx, - GraphDef* optimized_graph) { + const int graph_def_version, GraphDef* optimized_graph) { VLOG(2) << "Inline function instantiation: " << SummarizeNodeDef(func_node); const std::unordered_map<string, AttrValue> func_attr( func_node.attr().begin(), func_node.attr().end()); GrapplerFunctionItem item; - Status item_status = - MakeGrapplerFunctionItem(func, func_attr, ctx.function_library(), &item); + Status item_status = MakeGrapplerFunctionItem( + func, func_attr, ctx.function_library(), graph_def_version, &item); if (!item_status.ok()) { return errors::InvalidArgument("Failed to inline function ", func_node.op(), @@ -645,7 +647,8 @@ Status InlineFunction(const NodeDef& func_node, const FunctionDef& func, if (func_body_node_func != nullptr) { // Recursively inline function calls. TF_RETURN_IF_ERROR(InlineFunction(func_body_node, *func_body_node_func, - ctx, optimized_graph)); + ctx, graph_def_version, + optimized_graph)); } else { // Annotate the node with the function attributes. for (const auto& attr : func.attr()) { @@ -824,7 +827,8 @@ Status FunctionOptimizer::Optimize(Cluster* cluster, const GrapplerItem& item, if (inline_func && ctx.IsInlinedFunction(func_name)) { // Inline function body into the optimized graph} TF_SKIP_ERROR_IF_GRAPH_UNMODIFIED( - InlineFunction(node, *func, ctx, optimized_graph)); + InlineFunction(node, *func, ctx, item.graph.versions().producer(), + optimized_graph)); continue; } @@ -837,7 +841,8 @@ Status FunctionOptimizer::Optimize(Cluster* cluster, const GrapplerItem& item, // TODO(ezhulenev): Specialize function call if input has a known shape. // Specialize function body for its instantiation attributes and inputs. TF_SKIP_ERROR_IF_GRAPH_UNMODIFIED( - SpecializeFunction(node, *func, &ctx, optimized_graph)); + SpecializeFunction(node, *func, item.graph.versions().producer(), + &ctx, optimized_graph)); continue; } } diff --git a/tensorflow/core/grappler/optimizers/memory_optimizer.cc b/tensorflow/core/grappler/optimizers/memory_optimizer.cc index 1be5f8dcc2..91794cefe5 100644 --- a/tensorflow/core/grappler/optimizers/memory_optimizer.cc +++ b/tensorflow/core/grappler/optimizers/memory_optimizer.cc @@ -24,6 +24,7 @@ limitations under the License. #include "tensorflow/core/framework/attr_value.pb.h" #include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/framework/op.h" +#include "tensorflow/core/framework/tensor.pb.h" // NOLINT #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/grappler/clusters/virtual_cluster.h" #include "tensorflow/core/grappler/costs/graph_memory.h" diff --git a/tensorflow/core/grappler/optimizers/meta_optimizer.cc b/tensorflow/core/grappler/optimizers/meta_optimizer.cc index e778b7879d..5fd34efeb1 100644 --- a/tensorflow/core/grappler/optimizers/meta_optimizer.cc +++ b/tensorflow/core/grappler/optimizers/meta_optimizer.cc @@ -361,7 +361,8 @@ Status MetaOptimizer::Optimize(Cluster* cluster, const GrapplerItem& item, // Make a GrapplerItem from a FunctionDef. GrapplerFunctionItem func_item; - TF_RETURN_IF_ERROR(MakeGrapplerFunctionItem(func, flib, &func_item)); + TF_RETURN_IF_ERROR(MakeGrapplerFunctionItem( + func, flib, item.graph.versions().producer(), &func_item)); // Optimize function body graph. GraphDef optimized_func_graph; diff --git a/tensorflow/core/grappler/optimizers/scoped_allocator_optimizer.cc b/tensorflow/core/grappler/optimizers/scoped_allocator_optimizer.cc index 275568e464..0d4aaf6462 100644 --- a/tensorflow/core/grappler/optimizers/scoped_allocator_optimizer.cc +++ b/tensorflow/core/grappler/optimizers/scoped_allocator_optimizer.cc @@ -203,7 +203,7 @@ void ScopedAllocatorOptimizer::ExtendNodeAttr(StringPiece name, NodeDef* node_def) { if (HasNodeAttr(*node_def, name)) { VLOG(2) << "extending"; - AttrValue* existing = &(*node_def->mutable_attr())[name.ToString()]; + AttrValue* existing = &(*node_def->mutable_attr())[string(name)]; for (int32 i : values) { existing->mutable_list()->add_i(i); } diff --git a/tensorflow/core/grappler/optimizers/scoped_allocator_optimizer_test.cc b/tensorflow/core/grappler/optimizers/scoped_allocator_optimizer_test.cc index 89847f83d4..b033cff8e6 100644 --- a/tensorflow/core/grappler/optimizers/scoped_allocator_optimizer_test.cc +++ b/tensorflow/core/grappler/optimizers/scoped_allocator_optimizer_test.cc @@ -18,6 +18,7 @@ limitations under the License. #include "tensorflow/cc/ops/standard_ops.h" #include "tensorflow/core/framework/node_def.pb.h" +#include "tensorflow/core/framework/tensor.pb.h" // NOLINT #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/framework/tensor_testutil.h" #include "tensorflow/core/graph/testlib.h" diff --git a/tensorflow/core/grappler/optimizers/shape_optimizer.cc b/tensorflow/core/grappler/optimizers/shape_optimizer.cc index 26c54df56b..caa0b7b0cb 100644 --- a/tensorflow/core/grappler/optimizers/shape_optimizer.cc +++ b/tensorflow/core/grappler/optimizers/shape_optimizer.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/core/grappler/optimizers/shape_optimizer.h" +#include "tensorflow/core/framework/tensor.pb.h" #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/framework/types.h" #include "tensorflow/core/grappler/graph_view.h" diff --git a/tensorflow/core/grappler/utils.h b/tensorflow/core/grappler/utils.h index a9c34b6d08..20dbeea2cf 100644 --- a/tensorflow/core/grappler/utils.h +++ b/tensorflow/core/grappler/utils.h @@ -139,7 +139,7 @@ inline StringPiece ParseNodeNameAsStringPiece(const string& name, // Returns the node name and position in a single call. inline string ParseNodeName(const string& name, int* position) { - return std::string(ParseNodeNameAsStringPiece(name, position)); + return string(ParseNodeNameAsStringPiece(name, position)); } // Add a prefix to a node name with a custom delimiter. diff --git a/tensorflow/core/grappler/utils/functions.cc b/tensorflow/core/grappler/utils/functions.cc index 462b752316..a2c363ea6e 100644 --- a/tensorflow/core/grappler/utils/functions.cc +++ b/tensorflow/core/grappler/utils/functions.cc @@ -24,6 +24,7 @@ limitations under the License. #include "tensorflow/core/framework/op.h" #include "tensorflow/core/framework/tensor_shape.pb.h" #include "tensorflow/core/framework/types.pb.h" +#include "tensorflow/core/framework/versions.pb.h" #include "tensorflow/core/grappler/op_types.h" #include "tensorflow/core/grappler/utils.h" #include "tensorflow/core/lib/gtl/map_util.h" @@ -307,8 +308,8 @@ GrapplerFunctionItem::GrapplerFunctionItem( const AttrValueMap& func_attr, const std::vector<InputArgExpansion>& input_arg_expansions, const std::vector<OutputArgExpansion>& output_arg_expansions, - const std::vector<string>& keep_nodes, bool is_stateful, - GraphDef&& function_body) + const std::vector<string>& keep_nodes, const int graph_def_version, + bool is_stateful, GraphDef&& function_body) : description_(description), func_attr_(func_attr), input_arg_expansions_(input_arg_expansions), @@ -318,6 +319,7 @@ GrapplerFunctionItem::GrapplerFunctionItem( keep_ops = keep_nodes; // Swap the graph body. graph.Swap(&function_body); + graph.mutable_versions()->set_producer(graph_def_version); // Fill the feed nodes with input placeholders. for (const InputArgExpansion& input_arg : input_arg_expansions_) { for (const string& placeholder : input_arg.placeholders) { @@ -472,6 +474,7 @@ Status InstantiationBodyParameters( Status MakeGrapplerFunctionItem(const FunctionDef& func, const AttrValueMap& func_instantiation_attr, const FunctionLibraryDefinition& flib, + const int graph_def_version, GrapplerFunctionItem* item) { const OpDef& signature = func.signature(); @@ -595,14 +598,17 @@ Status MakeGrapplerFunctionItem(const FunctionDef& func, *item = GrapplerFunctionItem( /*func_name=*/signature.name(), /*description=*/signature.description(), /*func_attr=*/AttrValueMap(func.attr().begin(), func.attr().end()), - inputs, outputs, keep_nodes, is_stateful, std::move(function_body)); + inputs, outputs, keep_nodes, graph_def_version, is_stateful, + std::move(function_body)); return Status::OK(); } Status MakeGrapplerFunctionItem(const FunctionDef& func, const FunctionLibraryDefinition& flib, + const int graph_def_version, GrapplerFunctionItem* item) { - return MakeGrapplerFunctionItem(func, AttrValueMap(), flib, item); + return MakeGrapplerFunctionItem(func, AttrValueMap(), flib, graph_def_version, + item); } // Register GrapplerFunctionItem input arg expansion and function body outputs diff --git a/tensorflow/core/grappler/utils/functions.h b/tensorflow/core/grappler/utils/functions.h index 9f607dc2ee..61588ceb83 100644 --- a/tensorflow/core/grappler/utils/functions.h +++ b/tensorflow/core/grappler/utils/functions.h @@ -141,8 +141,8 @@ class GrapplerFunctionItem : public GrapplerItem { const AttrValueMap& func_attr, const std::vector<InputArgExpansion>& input_arg_expansions, const std::vector<OutputArgExpansion>& output_arg_expansions, - const std::vector<string>& keep_nodes, bool is_stateful, - GraphDef&& function_body); + const std::vector<string>& keep_nodes, const int versions, + bool is_stateful, GraphDef&& function_body); const string& description() const; @@ -222,6 +222,7 @@ Status ReplaceInputWithConst(const NodeDef& input_const, int input_position, Status MakeGrapplerFunctionItem(const FunctionDef& func, const AttrValueMap& func_instantiation_attr, const FunctionLibraryDefinition& flib, + const int graph_def_version, GrapplerFunctionItem* item); // Make a GrapplerFunction item from the function definition. Function must be @@ -231,6 +232,7 @@ Status MakeGrapplerFunctionItem(const FunctionDef& func, // without specializing it to it's instantiation attributes (at least types)? Status MakeGrapplerFunctionItem(const FunctionDef& func, const FunctionLibraryDefinition& flib, + const int graph_def_version, GrapplerFunctionItem* item); // Make a FunctionDef from the GrapplerFunctionItem. Use function library diff --git a/tensorflow/core/grappler/utils/functions_test.cc b/tensorflow/core/grappler/utils/functions_test.cc index b2d059e0ac..b51f2781b8 100644 --- a/tensorflow/core/grappler/utils/functions_test.cc +++ b/tensorflow/core/grappler/utils/functions_test.cc @@ -22,6 +22,7 @@ limitations under the License. #include "tensorflow/core/lib/core/status_test_util.h" #include "tensorflow/core/lib/gtl/map_util.h" #include "tensorflow/core/platform/test.h" +#include "tensorflow/core/public/version.h" namespace tensorflow { namespace grappler { @@ -239,7 +240,8 @@ TEST_F(FunctionsTest, FromSimpleFunctionDef) { FunctionLibraryDefinition flib(OpRegistry::Global(), FunctionDefLibrary()); GrapplerFunctionItem item; - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); EXPECT_EQ("XTimesTwo", item.id); EXPECT_EQ(4, item.function_body().node_size()); @@ -314,7 +316,8 @@ TEST_F(FunctionsTest, FromFunctionDefWithMultiOutputNodes) { FunctionLibraryDefinition flib(OpRegistry::Global(), FunctionDefLibrary()); GrapplerFunctionItem item; - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); EXPECT_EQ("SubGrad", item.id); EXPECT_EQ(12, item.function_body().node_size()); @@ -395,7 +398,8 @@ TEST_F(FunctionsTest, FromFunctionDefWithNestedFuncs) { func_attr["T"].set_type(DT_FLOAT); GrapplerFunctionItem item; - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); int count = 0; for (const NodeDef &node : item.function_body().node()) { @@ -456,7 +460,8 @@ TEST_F(FunctionsTest, FromFunctionDefWithOutputMappings) { FunctionLibraryDefinition flib(OpRegistry::Global(), FunctionDefLibrary()); GrapplerFunctionItem item; - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); EXPECT_EQ(1, item.output_size()); EXPECT_EQ("Exp", item.output(0).output_tensors[0]); @@ -499,7 +504,8 @@ TEST_F(FunctionsTest, FromFunctionDefWithInputForwarding) { FunctionLibraryDefinition flib(OpRegistry::Global(), FunctionDefLibrary()); GrapplerFunctionItem item; - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); EXPECT_EQ("ForwardInputs", item.id); EXPECT_EQ(5, item.function_body().node_size()); @@ -545,7 +551,8 @@ TEST_F(FunctionsTest, FromFunctionDefWithoutInput) { FunctionLibraryDefinition flib(OpRegistry::Global(), FunctionDefLibrary()); GrapplerFunctionItem item; - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); EXPECT_EQ(0, item.input_size()); EXPECT_EQ(1, item.output_size()); @@ -584,7 +591,8 @@ TEST_F(FunctionsTest, MakeFunctionDef) { FunctionLibraryDefinition flib(OpRegistry::Global(), FunctionDefLibrary()); GrapplerFunctionItem item; - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); FunctionDef specialized; TF_EXPECT_OK(MakeFunctionDef(item, flib, &specialized)); @@ -622,7 +630,8 @@ TEST_F(FunctionsTest, ReplaceInputWithConst) { FunctionLibraryDefinition flib(OpRegistry::Global(), FunctionDefLibrary()); GrapplerFunctionItem item; - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); EXPECT_EQ(2, item.input_size()); EXPECT_EQ(1, item.output_size()); @@ -713,7 +722,8 @@ TEST_F(FunctionsTest, SwapFunctionBodyAndMakeFunctionDef) { FunctionLibraryDefinition flib(OpRegistry::Global(), lib_def); GrapplerFunctionItem item; - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); // Replace function body with identity function item.SwapFunctionBody(std::move(id_func_body)); @@ -754,7 +764,8 @@ TEST_F(FunctionsTest, FunctionDefGrapplerFunctionItemRoundTrip) { GrapplerFunctionItem item; std::unordered_map<string, AttrValue> func_attr; func_attr["T"].set_type(DT_INT32); - TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, &item)); + TF_EXPECT_OK(MakeGrapplerFunctionItem(func, func_attr, flib, + TF_GRAPH_DEF_VERSION, &item)); FunctionDef func2; TF_EXPECT_OK(MakeFunctionDef(item, flib, &func2)); diff --git a/tensorflow/core/kernels/BUILD b/tensorflow/core/kernels/BUILD index bb17511a09..633fe9ab77 100644 --- a/tensorflow/core/kernels/BUILD +++ b/tensorflow/core/kernels/BUILD @@ -495,16 +495,6 @@ cc_library( ], ) -cc_library( - name = "warn_about_ints", - srcs = ["warn_about_ints.cc"], - hdrs = ["warn_about_ints.h"], - deps = [ - "//tensorflow/core:framework", - "//tensorflow/core:protos_all_cc", - ], -) - # Private support libraries --------------------------------------------------- cc_header_only_library( @@ -1290,6 +1280,7 @@ tf_cuda_cc_test( srcs = ["gather_op_test.cc"], deps = [ ":gather_op", + ":host_constant_op", ":ops_testutil", ":ops_util", "//tensorflow/core:core_cpu", @@ -3534,13 +3525,13 @@ tf_kernel_library( tf_kernel_library( name = "softplus_op", prefix = "softplus_op", - deps = NN_DEPS + [":warn_about_ints"], + deps = NN_DEPS, ) tf_kernel_library( name = "softsign_op", prefix = "softsign_op", - deps = NN_DEPS + [":warn_about_ints"], + deps = NN_DEPS, ) tf_kernel_library( @@ -3775,7 +3766,7 @@ tf_kernel_library( "spacetobatch_functor.h", "spacetobatch_functor_gpu.cu.cc", ], - visibility = ["//visibility:private"], + visibility = [":friends"], deps = [ ":bounds_check", "//tensorflow/core:framework", @@ -4451,12 +4442,48 @@ tf_kernel_library( deps = STRING_DEPS + ["@com_googlesource_code_re2//:re2"], ) +tf_cc_test( + name = "regex_replace_op_test", + size = "small", + srcs = ["regex_replace_op_test.cc"], + deps = [ + ":regex_replace_op", + "//tensorflow/core:core_cpu", + "//tensorflow/core:framework", + "//tensorflow/core:lib", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + "//tensorflow/core:testlib", + "//tensorflow/core/kernels:ops_testutil", + "//tensorflow/core/kernels:ops_util", + ], +) + tf_kernel_library( name = "string_split_op", prefix = "string_split_op", deps = STRING_DEPS, ) +tf_cc_test( + name = "string_split_op_test", + size = "small", + srcs = ["string_split_op_test.cc"], + deps = [ + ":string_split_op", + "//tensorflow/core:core_cpu", + "//tensorflow/core:framework", + "//tensorflow/core:lib", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + "//tensorflow/core:testlib", + "//tensorflow/core/kernels:ops_testutil", + "//tensorflow/core/kernels:ops_util", + ], +) + tf_kernel_library( name = "string_strip_op", prefix = "string_strip_op", @@ -5068,7 +5095,6 @@ filegroup( "training_ops.h", "transpose_functor.h", "transpose_op.h", - "warn_about_ints.h", "where_op.h", "xent_op.h", ], @@ -5245,7 +5271,6 @@ filegroup( "transpose_functor_cpu.cc", "transpose_op.cc", "unique_op.cc", - "warn_about_ints.cc", "where_op.cc", "xent_op.cc", ":android_extended_ops_headers", diff --git a/tensorflow/core/kernels/adjust_contrast_op.h b/tensorflow/core/kernels/adjust_contrast_op.h index 7689c04214..f4a53c2ef9 100644 --- a/tensorflow/core/kernels/adjust_contrast_op.h +++ b/tensorflow/core/kernels/adjust_contrast_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_ADJUST_CONTRAST_OP_H_ -#define TENSORFLOW_KERNELS_ADJUST_CONTRAST_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_ADJUST_CONTRAST_OP_H_ +#define TENSORFLOW_CORE_KERNELS_ADJUST_CONTRAST_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -153,4 +153,4 @@ struct AdjustContrastv2 { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_ADJUST_CONTRAST_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_ADJUST_CONTRAST_OP_H_ diff --git a/tensorflow/core/kernels/adjust_hue_op.h b/tensorflow/core/kernels/adjust_hue_op.h index 03d52a9e77..983a4072bf 100644 --- a/tensorflow/core/kernels/adjust_hue_op.h +++ b/tensorflow/core/kernels/adjust_hue_op.h @@ -11,8 +11,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef _TENSORFLOW_CORE_KERNELS_ADJUST_HUE_OP_H -#define _TENSORFLOW_CORE_KERNELS_ADJUST_HUE_OP_H +#ifndef TENSORFLOW_CORE_KERNELS_ADJUST_HUE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_ADJUST_HUE_OP_H_ #if GOOGLE_CUDA #define EIGEN_USE_GPU @@ -37,4 +37,4 @@ struct AdjustHueGPU { } // namespace tensorflow #endif // GOOGLE_CUDA -#endif // _TENSORFLOW_CORE_KERNELS_ADJUST_HUE_OP_H +#endif // TENSORFLOW_CORE_KERNELS_ADJUST_HUE_OP_H_ diff --git a/tensorflow/core/kernels/adjust_saturation_op.h b/tensorflow/core/kernels/adjust_saturation_op.h index 05c45c07c3..fd28ba536f 100644 --- a/tensorflow/core/kernels/adjust_saturation_op.h +++ b/tensorflow/core/kernels/adjust_saturation_op.h @@ -11,8 +11,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef _TENSORFLOW_CORE_KERNELS_ADJUST_SATURATION_OP_H -#define _TENSORFLOW_CORE_KERNELS_ADJUST_SATURATION_OP_H +#ifndef TENSORFLOW_CORE_KERNELS_ADJUST_SATURATION_OP_H_ +#define TENSORFLOW_CORE_KERNELS_ADJUST_SATURATION_OP_H_ #if GOOGLE_CUDA #define EIGEN_USE_GPU @@ -37,4 +37,4 @@ struct AdjustSaturationGPU { } // namespace tensorflow #endif // GOOGLE_CUDA -#endif // _TENSORFLOW_CORE_KERNELS_ADJUST_SATURATION_OP_H +#endif // TENSORFLOW_CORE_KERNELS_ADJUST_SATURATION_OP_H_ diff --git a/tensorflow/core/kernels/aggregate_ops.h b/tensorflow/core/kernels/aggregate_ops.h index 9ea49fc34b..e074d0c2d9 100644 --- a/tensorflow/core/kernels/aggregate_ops.h +++ b/tensorflow/core/kernels/aggregate_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_AGGREGATE_OPS_H_ -#define TENSORFLOW_KERNELS_AGGREGATE_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_AGGREGATE_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_AGGREGATE_OPS_H_ // Functor definitions for Aggregate ops, must be compilable by nvcc. @@ -223,4 +223,4 @@ struct Add9EigenImpl { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_AGGREGATE_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_AGGREGATE_OPS_H_ diff --git a/tensorflow/core/kernels/aggregate_ops_cpu.h b/tensorflow/core/kernels/aggregate_ops_cpu.h index aa1cead928..3e87917b64 100644 --- a/tensorflow/core/kernels/aggregate_ops_cpu.h +++ b/tensorflow/core/kernels/aggregate_ops_cpu.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_AGGREGATE_OPS_CPU_H_ -#define TENSORFLOW_KERNELS_AGGREGATE_OPS_CPU_H_ +#ifndef TENSORFLOW_CORE_KERNELS_AGGREGATE_OPS_CPU_H_ +#define TENSORFLOW_CORE_KERNELS_AGGREGATE_OPS_CPU_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -250,4 +250,4 @@ struct Add9Functor<SYCLDevice, T> { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_AGGREGATE_OPS_CPU_H_ +#endif // TENSORFLOW_CORE_KERNELS_AGGREGATE_OPS_CPU_H_ diff --git a/tensorflow/core/kernels/argmax_op.h b/tensorflow/core/kernels/argmax_op.h index b8bc41e089..224aa4654d 100644 --- a/tensorflow/core/kernels/argmax_op.h +++ b/tensorflow/core/kernels/argmax_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_ARGMAX_OP_H_ -#define TENSORFLOW_KERNELS_ARGMAX_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_ARGMAX_OP_H_ +#define TENSORFLOW_CORE_KERNELS_ARGMAX_OP_H_ // Generator definition for ArgMaxOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -65,4 +65,4 @@ struct ArgMin { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_ARGMAX_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_ARGMAX_OP_H_ diff --git a/tensorflow/core/kernels/assign_op.h b/tensorflow/core/kernels/assign_op.h index a450b1d1ee..74f926bdc8 100644 --- a/tensorflow/core/kernels/assign_op.h +++ b/tensorflow/core/kernels/assign_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_ASSIGN_OP_H_ -#define TENSORFLOW_KERNELS_ASSIGN_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_ASSIGN_OP_H_ +#define TENSORFLOW_CORE_KERNELS_ASSIGN_OP_H_ #define EIGEN_USE_THREADS @@ -143,4 +143,4 @@ class AssignOp : public OpKernel { } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_ASSIGN_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_ASSIGN_OP_H_ diff --git a/tensorflow/core/kernels/avgpooling_op.h b/tensorflow/core/kernels/avgpooling_op.h index f5e81dbc09..1e49a66af9 100644 --- a/tensorflow/core/kernels/avgpooling_op.h +++ b/tensorflow/core/kernels/avgpooling_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_AVGPOOLING_OP_H_ -#define TENSORFLOW_KERNELS_AVGPOOLING_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_AVGPOOLING_OP_H_ +#define TENSORFLOW_CORE_KERNELS_AVGPOOLING_OP_H_ // Functor definition for AvgPoolingOp, must be compilable by nvcc. #include "tensorflow/core/framework/tensor_types.h" @@ -76,4 +76,4 @@ bool RunAvePoolBackwardNHWC(const T* const top_diff, const int num, } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_AVGPOOLING_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_AVGPOOLING_OP_H_ diff --git a/tensorflow/core/kernels/batch_matmul_op_impl.h b/tensorflow/core/kernels/batch_matmul_op_impl.h index 475bda848d..766713a338 100644 --- a/tensorflow/core/kernels/batch_matmul_op_impl.h +++ b/tensorflow/core/kernels/batch_matmul_op_impl.h @@ -15,6 +15,9 @@ limitations under the License. // See docs in ../ops/math_ops.cc. +#ifndef TENSORFLOW_CORE_KERNELS_BATCH_MATMUL_OP_IMPL_H_ +#define TENSORFLOW_CORE_KERNELS_BATCH_MATMUL_OP_IMPL_H_ + #define EIGEN_USE_THREADS #include <vector> @@ -613,3 +616,5 @@ class BatchMatMul : public OpKernel { BatchMatMul<SYCLDevice, TYPE>) #endif // TENSORFLOW_USE_SYCL } // end namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_BATCH_MATMUL_OP_IMPL_H_ diff --git a/tensorflow/core/kernels/batch_norm_op.h b/tensorflow/core/kernels/batch_norm_op.h index 48e73c8757..76b156f8fd 100644 --- a/tensorflow/core/kernels/batch_norm_op.h +++ b/tensorflow/core/kernels/batch_norm_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_BATCH_NORM_OP_H_ -#define TENSORFLOW_KERNELS_BATCH_NORM_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_BATCH_NORM_OP_H_ +#define TENSORFLOW_CORE_KERNELS_BATCH_NORM_OP_H_ // Functor definition for BatchNormOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -153,4 +153,4 @@ struct BatchNormGrad { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_BATCH_NORM_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_BATCH_NORM_OP_H_ diff --git a/tensorflow/core/kernels/betainc_op.h b/tensorflow/core/kernels/betainc_op.h index c4aa9543ab..b941b27ad3 100644 --- a/tensorflow/core/kernels/betainc_op.h +++ b/tensorflow/core/kernels/betainc_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_BETAINC_OP_H_ -#define TENSORFLOW_KERNELS_BETAINC_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_BETAINC_OP_H_ +#define TENSORFLOW_CORE_KERNELS_BETAINC_OP_H_ // Functor definition for BetaincOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -48,4 +48,4 @@ struct Betainc { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_BETAINC_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_BETAINC_OP_H_ diff --git a/tensorflow/core/kernels/bias_op.h b/tensorflow/core/kernels/bias_op.h index 065934c709..77f683455d 100644 --- a/tensorflow/core/kernels/bias_op.h +++ b/tensorflow/core/kernels/bias_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_BIAS_OP_H_ -#define TENSORFLOW_KERNELS_BIAS_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_BIAS_OP_H_ +#define TENSORFLOW_CORE_KERNELS_BIAS_OP_H_ // Functor definition for BiasOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -52,4 +52,4 @@ struct Bias { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_BIAS_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_BIAS_OP_H_ diff --git a/tensorflow/core/kernels/bincount_op.h b/tensorflow/core/kernels/bincount_op.h index cd3d560cd1..54cfb79de7 100644 --- a/tensorflow/core/kernels/bincount_op.h +++ b/tensorflow/core/kernels/bincount_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_BINCOUNT_OP_H_ -#define TENSORFLOW_BINCOUNT_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_BINCOUNT_OP_H_ +#define TENSORFLOW_CORE_KERNELS_BINCOUNT_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/op_kernel.h" @@ -38,4 +38,4 @@ struct BincountFunctor { } // end namespace tensorflow -#endif // TENSORFLOW_BINCOUNT_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_BINCOUNT_OP_H_ diff --git a/tensorflow/core/kernels/boosted_trees/quantiles/BUILD b/tensorflow/core/kernels/boosted_trees/quantiles/BUILD new file mode 100644 index 0000000000..3163c63949 --- /dev/null +++ b/tensorflow/core/kernels/boosted_trees/quantiles/BUILD @@ -0,0 +1,63 @@ +# Description: +# This directory contains common utilities used in boosted_trees. +package( + default_visibility = ["//tensorflow:internal"], +) + +licenses(["notice"]) # Apache 2.0 + +exports_files(["LICENSE"]) + +load("//tensorflow:tensorflow.bzl", "tf_cc_test") + +# Quantiles + +cc_library( + name = "weighted_quantiles", + srcs = [], + hdrs = [ + "weighted_quantiles_buffer.h", + "weighted_quantiles_stream.h", + "weighted_quantiles_summary.h", + ], + visibility = ["//visibility:public"], + deps = [ + "//tensorflow/core:framework_headers_lib", + ], +) + +tf_cc_test( + name = "weighted_quantiles_buffer_test", + size = "small", + srcs = ["weighted_quantiles_buffer_test.cc"], + deps = [ + ":weighted_quantiles", + "//tensorflow/core:lib", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + ], +) + +tf_cc_test( + name = "weighted_quantiles_summary_test", + size = "small", + srcs = ["weighted_quantiles_summary_test.cc"], + deps = [ + ":weighted_quantiles", + "//tensorflow/core:lib", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + ], +) + +tf_cc_test( + name = "weighted_quantiles_stream_test", + size = "small", + srcs = ["weighted_quantiles_stream_test.cc"], + deps = [ + ":weighted_quantiles", + "//tensorflow/core:lib", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + ], +) diff --git a/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_buffer.h b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_buffer.h new file mode 100644 index 0000000000..07aa9831c4 --- /dev/null +++ b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_buffer.h @@ -0,0 +1,132 @@ +// Copyright 2018 The TensorFlow Authors. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// ============================================================================= +#ifndef TENSORFLOW_CORE_KERNELS_BOOSTED_TREES_QUANTILES_WEIGHTED_QUANTILES_BUFFER_H_ +#define TENSORFLOW_CORE_KERNELS_BOOSTED_TREES_QUANTILES_WEIGHTED_QUANTILES_BUFFER_H_ + +#include <algorithm> +#include <unordered_map> +#include <vector> + +#include "tensorflow/core/platform/logging.h" +#include "tensorflow/core/platform/types.h" + +namespace tensorflow { +namespace boosted_trees { +namespace quantiles { + +// Buffering container ideally suited for scenarios where we need +// to sort and dedupe/compact fixed chunks of a stream of weighted elements. +template <typename ValueType, typename WeightType, + typename CompareFn = std::less<ValueType>> +class WeightedQuantilesBuffer { + public: + struct BufferEntry { + BufferEntry(ValueType v, WeightType w) + : value(std::move(v)), weight(std::move(w)) {} + BufferEntry() : value(), weight(0) {} + + bool operator<(const BufferEntry& other) const { + return kCompFn(value, other.value); + } + bool operator==(const BufferEntry& other) const { + return value == other.value && weight == other.weight; + } + friend std::ostream& operator<<(std::ostream& strm, + const BufferEntry& entry) { + return strm << "{" << entry.value << ", " << entry.weight << "}"; + } + ValueType value; + WeightType weight; + }; + + explicit WeightedQuantilesBuffer(int64 block_size, int64 max_elements) + : max_size_(std::min(block_size << 1, max_elements)) { + QCHECK(max_size_ > 0) << "Invalid buffer specification: (" << block_size + << ", " << max_elements << ")"; + vec_.reserve(max_size_); + } + + // Disallow copying as it's semantically non-sensical in the Squawd algorithm + // but enable move semantics. + WeightedQuantilesBuffer(const WeightedQuantilesBuffer& other) = delete; + WeightedQuantilesBuffer& operator=(const WeightedQuantilesBuffer&) = delete; + WeightedQuantilesBuffer(WeightedQuantilesBuffer&& other) = default; + WeightedQuantilesBuffer& operator=(WeightedQuantilesBuffer&& other) = default; + + // Push entry to buffer and maintain a compact representation within + // pre-defined size limit. + void PushEntry(ValueType value, WeightType weight) { + // Callers are expected to act on a full compacted buffer after the + // PushEntry call returns. + QCHECK(!IsFull()) << "Buffer already full: " << max_size_; + + // Ignore zero and negative weight entries. + if (weight <= 0) { + return; + } + + // Push back the entry to the buffer. + vec_.push_back(BufferEntry(std::move(value), std::move(weight))); + } + + // Returns a sorted vector view of the base buffer and clears the buffer. + // Callers should minimize how often this is called, ideally only right after + // the buffer becomes full. + std::vector<BufferEntry> GenerateEntryList() { + std::vector<BufferEntry> ret; + if (vec_.size() == 0) { + return ret; + } + ret.swap(vec_); + vec_.reserve(max_size_); + std::sort(ret.begin(), ret.end()); + size_t num_entries = 0; + for (size_t i = 1; i < ret.size(); ++i) { + if (ret[i].value != ret[i - 1].value) { + BufferEntry tmp = ret[i]; + ++num_entries; + ret[num_entries] = tmp; + } else { + ret[num_entries].weight += ret[i].weight; + } + } + ret.resize(num_entries + 1); + return ret; + } + + int64 Size() const { return vec_.size(); } + bool IsFull() const { return vec_.size() >= max_size_; } + void Clear() { vec_.clear(); } + + private: + using BufferVector = typename std::vector<BufferEntry>; + + // Comparison function. + static constexpr decltype(CompareFn()) kCompFn = CompareFn(); + + // Base buffer. + size_t max_size_; + BufferVector vec_; +}; + +template <typename ValueType, typename WeightType, typename CompareFn> +constexpr decltype(CompareFn()) + WeightedQuantilesBuffer<ValueType, WeightType, CompareFn>::kCompFn; + +} // namespace quantiles +} // namespace boosted_trees +} // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_BOOSTED_TREES_QUANTILES_WEIGHTED_QUANTILES_BUFFER_H_ diff --git a/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_buffer_test.cc b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_buffer_test.cc new file mode 100644 index 0000000000..75f05d64f3 --- /dev/null +++ b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_buffer_test.cc @@ -0,0 +1,99 @@ +// Copyright 2018 The TensorFlow Authors. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// ============================================================================= +#include "tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_buffer.h" +#include "tensorflow/core/lib/random/philox_random.h" +#include "tensorflow/core/lib/random/simple_philox.h" +#include "tensorflow/core/platform/test.h" +#include "tensorflow/core/platform/test_benchmark.h" + +namespace tensorflow { +namespace { + +using Buffer = + boosted_trees::quantiles::WeightedQuantilesBuffer<double, double>; +using BufferEntry = + boosted_trees::quantiles::WeightedQuantilesBuffer<double, + double>::BufferEntry; + +class WeightedQuantilesBufferTest : public ::testing::Test {}; + +TEST_F(WeightedQuantilesBufferTest, Invalid) { + EXPECT_DEATH( + ({ + boosted_trees::quantiles::WeightedQuantilesBuffer<double, double> + buffer(2, 0); + }), + "Invalid buffer specification"); + EXPECT_DEATH( + ({ + boosted_trees::quantiles::WeightedQuantilesBuffer<double, double> + buffer(0, 2); + }), + "Invalid buffer specification"); +} + +TEST_F(WeightedQuantilesBufferTest, PushEntryNotFull) { + Buffer buffer(20, 100); + buffer.PushEntry(5, 9); + buffer.PushEntry(2, 3); + buffer.PushEntry(-1, 7); + buffer.PushEntry(3, 0); // This entry will be ignored. + + EXPECT_FALSE(buffer.IsFull()); + EXPECT_EQ(buffer.Size(), 3); +} + +TEST_F(WeightedQuantilesBufferTest, PushEntryFull) { + // buffer capacity is 4. + Buffer buffer(2, 100); + buffer.PushEntry(5, 9); + buffer.PushEntry(2, 3); + buffer.PushEntry(-1, 7); + buffer.PushEntry(2, 1); + + std::vector<BufferEntry> expected; + expected.emplace_back(-1, 7); + expected.emplace_back(2, 4); + expected.emplace_back(5, 9); + + // At this point, we have pushed 4 entries and we expect the buffer to be + // full. + EXPECT_TRUE(buffer.IsFull()); + EXPECT_EQ(buffer.GenerateEntryList(), expected); + EXPECT_FALSE(buffer.IsFull()); +} + +TEST_F(WeightedQuantilesBufferTest, PushEntryFullDeath) { + // buffer capacity is 4. + Buffer buffer(2, 100); + buffer.PushEntry(5, 9); + buffer.PushEntry(2, 3); + buffer.PushEntry(-1, 7); + buffer.PushEntry(2, 1); + + std::vector<BufferEntry> expected; + expected.emplace_back(-1, 7); + expected.emplace_back(2, 4); + expected.emplace_back(5, 9); + + // At this point, we have pushed 4 entries and we expect the buffer to be + // full. + EXPECT_TRUE(buffer.IsFull()); + // Can't push any more entries before clearing. + EXPECT_DEATH(({ buffer.PushEntry(6, 6); }), "Buffer already full"); +} + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_stream.h b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_stream.h new file mode 100644 index 0000000000..525e2a6a64 --- /dev/null +++ b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_stream.h @@ -0,0 +1,330 @@ +// Copyright 2018 The TensorFlow Authors. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// ============================================================================= +#ifndef TENSORFLOW_CORE_KERNELS_BOOSTED_TREES_QUANTILES_WEIGHTED_QUANTILES_STREAM_H_ +#define TENSORFLOW_CORE_KERNELS_BOOSTED_TREES_QUANTILES_WEIGHTED_QUANTILES_STREAM_H_ + +#include <cmath> +#include <memory> +#include <vector> + +#include "tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_buffer.h" +#include "tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_summary.h" +#include "tensorflow/core/platform/types.h" + +namespace tensorflow { +namespace boosted_trees { +namespace quantiles { + +// Class to compute approximate quantiles with error bound guarantees for +// weighted data sets. +// This implementation is an adaptation of techniques from the following papers: +// * (2001) Space-efficient online computation of quantile summaries. +// * (2004) Power-conserving computation of order-statistics over +// sensor networks. +// * (2007) A fast algorithm for approximate quantiles in high speed +// data streams. +// * (2016) XGBoost: A Scalable Tree Boosting System. +// +// The key ideas at play are the following: +// - Maintain an in-memory multi-level quantile summary in a way to guarantee +// a maximum approximation error of eps * W per bucket where W is the total +// weight across all points in the input dataset. +// - Two base operations are defined: MERGE and COMPRESS. MERGE combines two +// summaries guaranteeing a epsNew = max(eps1, eps2). COMPRESS compresses +// a summary to b + 1 elements guaranteeing epsNew = epsOld + 1/b. +// - b * sizeof(summary entry) must ideally be small enough to fit in an +// average CPU L2 cache. +// - To distribute this algorithm with maintaining error bounds, we need +// the worker-computed summaries to have no more than eps / h error +// where h is the height of the distributed computation graph which +// is 2 for an MR with no combiner. +// +// We mainly want to max out IO bw by ensuring we're not compute-bound and +// using a reasonable amount of RAM. +// +// Complexity: +// Compute: O(n * log(1/eps * log(eps * n))). +// Memory: O(1/eps * log^2(eps * n)) <- for one worker streaming through the +// entire dataset. +// An epsilon value of zero would make the algorithm extremely inefficent and +// therefore, is disallowed. +template <typename ValueType, typename WeightType, + typename CompareFn = std::less<ValueType>> +class WeightedQuantilesStream { + public: + using Buffer = WeightedQuantilesBuffer<ValueType, WeightType, CompareFn>; + using BufferEntry = typename Buffer::BufferEntry; + using Summary = WeightedQuantilesSummary<ValueType, WeightType, CompareFn>; + using SummaryEntry = typename Summary::SummaryEntry; + + explicit WeightedQuantilesStream(double eps, int64 max_elements) + : eps_(eps), buffer_(1LL, 2LL), finalized_(false) { + // See the class documentation. An epsilon value of zero could cause + // perfoamance issues. + QCHECK(eps > 0) << "An epsilon value of zero is not allowed."; + std::tie(max_levels_, block_size_) = GetQuantileSpecs(eps, max_elements); + buffer_ = Buffer(block_size_, max_elements); + summary_levels_.reserve(max_levels_); + } + + // Disallow copy and assign but enable move semantics for the stream. + WeightedQuantilesStream(const WeightedQuantilesStream& other) = delete; + WeightedQuantilesStream& operator=(const WeightedQuantilesStream&) = delete; + WeightedQuantilesStream(WeightedQuantilesStream&& other) = default; + WeightedQuantilesStream& operator=(WeightedQuantilesStream&& other) = default; + + // Pushes one entry while maintaining approximation error invariants. + void PushEntry(const ValueType& value, const WeightType& weight) { + // Validate state. + QCHECK(!finalized_) << "Finalize() already called."; + + // Push element to base buffer. + buffer_.PushEntry(value, weight); + + // When compacted buffer is full we need to compress + // and push weighted quantile summary up the level chain. + if (buffer_.IsFull()) { + PushBuffer(buffer_); + } + } + + // Pushes full buffer while maintaining approximation error invariants. + void PushBuffer(Buffer& buffer) { + // Validate state. + QCHECK(!finalized_) << "Finalize() already called."; + + // Create local compressed summary and propagate. + local_summary_.BuildFromBufferEntries(buffer.GenerateEntryList()); + local_summary_.Compress(block_size_, eps_); + PropagateLocalSummary(); + } + + // Pushes full summary while maintaining approximation error invariants. + void PushSummary(const std::vector<SummaryEntry>& summary) { + // Validate state. + QCHECK(!finalized_) << "Finalize() already called."; + + // Create local compressed summary and propagate. + local_summary_.BuildFromSummaryEntries(summary); + local_summary_.Compress(block_size_, eps_); + PropagateLocalSummary(); + } + + // Flushes approximator and finalizes state. + void Finalize() { + // Validate state. + QCHECK(!finalized_) << "Finalize() may only be called once."; + + // Flush any remaining buffer elements. + PushBuffer(buffer_); + + // Create final merged summary. + local_summary_.Clear(); + for (auto& summary : summary_levels_) { + local_summary_.Merge(summary); + summary.Clear(); + } + summary_levels_.clear(); + summary_levels_.shrink_to_fit(); + finalized_ = true; + } + + // Generates requested number of quantiles after finalizing stream. + // The returned quantiles can be queried using std::lower_bound to get + // the bucket for a given value. + std::vector<ValueType> GenerateQuantiles(int64 num_quantiles) const { + // Validate state. + QCHECK(finalized_) + << "Finalize() must be called before generating quantiles."; + return local_summary_.GenerateQuantiles(num_quantiles); + } + + // Generates requested number of boundaries after finalizing stream. + // The returned boundaries can be queried using std::lower_bound to get + // the bucket for a given value. + // The boundaries, while still guaranteeing approximation bounds, don't + // necessarily represent the actual quantiles of the distribution. + // Boundaries are preferable over quantiles when the caller is less + // interested in the actual quantiles distribution and more interested in + // getting a representative sample of boundary values. + std::vector<ValueType> GenerateBoundaries(int64 num_boundaries) const { + // Validate state. + QCHECK(finalized_) + << "Finalize() must be called before generating boundaries."; + return local_summary_.GenerateBoundaries(num_boundaries); + } + + // Calculates approximation error for the specified level. + // If the passed level is negative, the approximation error for the entire + // summary is returned. Note that after Finalize is called, only the overall + // error is available. + WeightType ApproximationError(int64 level = -1) const { + if (finalized_) { + QCHECK(level <= 0) << "Only overall error is available after Finalize()"; + return local_summary_.ApproximationError(); + } + + if (summary_levels_.empty()) { + // No error even if base buffer isn't empty. + return 0; + } + + // If level is negative, we get the approximation error + // for the top-most level which is the max approximation error + // in all summaries by construction. + if (level < 0) { + level = summary_levels_.size() - 1; + } + QCHECK(level < summary_levels_.size()) << "Invalid level."; + return summary_levels_[level].ApproximationError(); + } + + size_t MaxDepth() const { return summary_levels_.size(); } + + // Generates requested number of quantiles after finalizing stream. + const Summary& GetFinalSummary() const { + // Validate state. + QCHECK(finalized_) + << "Finalize() must be called before requesting final summary."; + return local_summary_; + } + + // Helper method which, given the desired approximation error + // and an upper bound on the number of elements, computes the optimal + // number of levels and block size and returns them in the tuple. + static std::tuple<int64, int64> GetQuantileSpecs(double eps, + int64 max_elements); + + // Serializes the internal state of the stream. + std::vector<Summary> SerializeInternalSummaries() const { + // The buffer should be empty for serialize to work. + QCHECK_EQ(buffer_.Size(), 0); + std::vector<Summary> result; + result.reserve(summary_levels_.size() + 1); + for (const Summary& summary : summary_levels_) { + result.push_back(summary); + } + result.push_back(local_summary_); + return result; + } + + // Resets the state of the stream with a serialized state. + void DeserializeInternalSummaries(const std::vector<Summary>& summaries) { + // Clear the state before deserializing. + buffer_.Clear(); + summary_levels_.clear(); + local_summary_.Clear(); + QCHECK_GT(max_levels_, summaries.size() - 1); + for (int i = 0; i < summaries.size() - 1; ++i) { + summary_levels_.push_back(summaries[i]); + } + local_summary_ = summaries[summaries.size() - 1]; + } + + private: + // Propagates local summary through summary levels while maintaining + // approximation error invariants. + void PropagateLocalSummary() { + // Validate state. + QCHECK(!finalized_) << "Finalize() already called."; + + // No-op if there's nothing to add. + if (local_summary_.Size() <= 0) { + return; + } + + // Propagate summary through levels. + size_t level = 0; + for (bool settled = false; !settled; ++level) { + // Ensure we have enough depth. + if (summary_levels_.size() <= level) { + summary_levels_.emplace_back(); + } + + // Merge summaries. + Summary& current_summary = summary_levels_[level]; + local_summary_.Merge(current_summary); + + // Check if we need to compress and propagate summary higher. + if (current_summary.Size() == 0 || + local_summary_.Size() <= block_size_ + 1) { + current_summary = std::move(local_summary_); + settled = true; + } else { + // Compress, empty current level and propagate. + local_summary_.Compress(block_size_, eps_); + current_summary.Clear(); + } + } + } + + // Desired approximation precision. + double eps_; + // Maximum number of levels. + int64 max_levels_; + // Max block size per level. + int64 block_size_; + // Base buffer. + Buffer buffer_; + // Local summary used to minimize memory allocation and cache misses. + // After the stream is finalized, this summary holds the final quantile + // estimates. + Summary local_summary_; + // Summary levels; + std::vector<Summary> summary_levels_; + // Flag indicating whether the stream is finalized. + bool finalized_; +}; + +template <typename ValueType, typename WeightType, typename CompareFn> +inline std::tuple<int64, int64> +WeightedQuantilesStream<ValueType, WeightType, CompareFn>::GetQuantileSpecs( + double eps, int64 max_elements) { + int64 max_level = 1LL; + int64 block_size = 2LL; + QCHECK(eps >= 0 && eps < 1); + QCHECK_GT(max_elements, 0); + + if (eps <= std::numeric_limits<double>::epsilon()) { + // Exact quantile computation at the expense of RAM. + max_level = 1; + block_size = std::max(max_elements, int64{2}); + } else { + // The bottom-most level will become full at most + // (max_elements / block_size) times, the level above will become full + // (max_elements / 2 * block_size) times and generally level l becomes + // full (max_elements / 2^l * block_size) times until the last + // level max_level becomes full at most once meaning when the inequality + // (2^max_level * block_size >= max_elements) is satisfied. + // In what follows, we jointly solve for max_level and block_size by + // gradually increasing the level until the inequality above is satisfied. + // We could alternatively set max_level = ceil(log2(eps * max_elements)); + // and block_size = ceil(max_level / eps) + 1 but that tends to give more + // pessimistic bounds and wastes RAM needlessly. + for (max_level = 1, block_size = 2; + (1LL << max_level) * block_size < max_elements; ++max_level) { + // Update upper bound on block size at current level, we always + // increase the estimate by 2 to hold the min/max elements seen so far. + block_size = static_cast<size_t>(ceil(max_level / eps)) + 1; + } + } + return std::make_tuple(max_level, std::max(block_size, int64{2})); +} + +} // namespace quantiles +} // namespace boosted_trees +} // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_BOOSTED_TREES_QUANTILES_WEIGHTED_QUANTILES_STREAM_H_ diff --git a/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_stream_test.cc b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_stream_test.cc new file mode 100644 index 0000000000..6c5b9fd23b --- /dev/null +++ b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_stream_test.cc @@ -0,0 +1,276 @@ +// Copyright 2018 The TensorFlow Authors. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// ============================================================================= +#include "tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_stream.h" +#include "tensorflow/core/lib/random/philox_random.h" +#include "tensorflow/core/lib/random/simple_philox.h" +#include "tensorflow/core/platform/test.h" +#include "tensorflow/core/platform/test_benchmark.h" + +namespace tensorflow { +namespace { +using Tuple = std::tuple<int64, int64>; + +using Summary = + boosted_trees::quantiles::WeightedQuantilesSummary<double, double>; +using SummaryEntry = + boosted_trees::quantiles::WeightedQuantilesSummary<double, + double>::SummaryEntry; +using Stream = + boosted_trees::quantiles::WeightedQuantilesStream<double, double>; + +TEST(GetQuantileSpecs, InvalidEps) { + EXPECT_DEATH({ Stream::GetQuantileSpecs(-0.01, 0L); }, "eps >= 0"); + EXPECT_DEATH({ Stream::GetQuantileSpecs(1.01, 0L); }, "eps < 1"); +} + +TEST(GetQuantileSpecs, ZeroEps) { + EXPECT_DEATH({ Stream::GetQuantileSpecs(0.0, 0L); }, "max_elements > 0"); + EXPECT_EQ(Stream::GetQuantileSpecs(0.0, 1LL), Tuple(1LL, 2LL)); + EXPECT_EQ(Stream::GetQuantileSpecs(0.0, 20LL), Tuple(1LL, 20LL)); +} + +TEST(GetQuantileSpecs, NonZeroEps) { + EXPECT_DEATH({ Stream::GetQuantileSpecs(0.01, 0L); }, "max_elements > 0"); + EXPECT_EQ(Stream::GetQuantileSpecs(0.1, 320LL), Tuple(4LL, 31LL)); + EXPECT_EQ(Stream::GetQuantileSpecs(0.01, 25600LL), Tuple(6LL, 501LL)); + EXPECT_EQ(Stream::GetQuantileSpecs(0.01, 104857600LL), Tuple(17LL, 1601LL)); + EXPECT_EQ(Stream::GetQuantileSpecs(0.1, 104857600LL), Tuple(20LL, 191LL)); + EXPECT_EQ(Stream::GetQuantileSpecs(0.01, 1LL << 40), Tuple(29LL, 2801LL)); + EXPECT_EQ(Stream::GetQuantileSpecs(0.001, 1LL << 40), Tuple(26LL, 25001LL)); +} + +class WeightedQuantilesStreamTest : public ::testing::Test {}; + +// Stream generators. +void GenerateFixedUniformSummary(int32 worker_id, int64 max_elements, + double *total_weight, Stream *stream) { + for (int64 i = 0; i < max_elements; ++i) { + const double x = static_cast<double>(i) / max_elements; + stream->PushEntry(x, 1.0); + ++(*total_weight); + } + stream->Finalize(); +} + +void GenerateFixedNonUniformSummary(int32 worker_id, int64 max_elements, + double *total_weight, Stream *stream) { + for (int64 i = 0; i < max_elements; ++i) { + const double x = static_cast<double>(i) / max_elements; + stream->PushEntry(x, x); + (*total_weight) += x; + } + stream->Finalize(); +} + +void GenerateRandUniformFixedWeightsSummary(int32 worker_id, int64 max_elements, + double *total_weight, + Stream *stream) { + // Simulate uniform distribution stream. + random::PhiloxRandom philox(13 + worker_id); + random::SimplePhilox rand(&philox); + for (int64 i = 0; i < max_elements; ++i) { + const double x = rand.RandDouble(); + stream->PushEntry(x, 1); + ++(*total_weight); + } + stream->Finalize(); +} + +void GenerateRandUniformRandWeightsSummary(int32 worker_id, int64 max_elements, + double *total_weight, + Stream *stream) { + // Simulate uniform distribution stream. + random::PhiloxRandom philox(13 + worker_id); + random::SimplePhilox rand(&philox); + for (int64 i = 0; i < max_elements; ++i) { + const double x = rand.RandDouble(); + const double w = rand.RandDouble(); + stream->PushEntry(x, w); + (*total_weight) += w; + } + stream->Finalize(); +} + +// Single worker tests. +void TestSingleWorkerStreams( + double eps, int64 max_elements, + const std::function<void(int32, int64, double *, Stream *)> + &worker_summary_generator, + std::initializer_list<double> expected_quantiles, + double quantiles_matcher_epsilon) { + // Generate single stream. + double total_weight = 0; + Stream stream(eps, max_elements); + worker_summary_generator(0, max_elements, &total_weight, &stream); + + // Ensure we didn't lose track of any elements and are + // within approximation error bound. + EXPECT_LE(stream.ApproximationError(), eps); + EXPECT_NEAR(stream.GetFinalSummary().TotalWeight(), total_weight, 1e-6); + + // Verify expected quantiles. + int i = 0; + auto actuals = stream.GenerateQuantiles(expected_quantiles.size() - 1); + for (auto expected_quantile : expected_quantiles) { + EXPECT_NEAR(actuals[i], expected_quantile, quantiles_matcher_epsilon); + ++i; + } +} + +// Stream generators. +void GenerateOneValue(int32 worker_id, int64 max_elements, double *total_weight, + Stream *stream) { + stream->PushEntry(10, 1); + ++(*total_weight); + stream->Finalize(); +} + +void GenerateOneZeroWeightedValue(int32 worker_id, int64 max_elements, + double *total_weight, Stream *stream) { + stream->PushEntry(10, 0); + stream->Finalize(); +} + +TEST(WeightedQuantilesStreamTest, OneValue) { + const double eps = 0.01; + const int64 max_elements = 1 << 16; + TestSingleWorkerStreams(eps, max_elements, GenerateOneValue, + {10.0, 10.0, 10.0, 10.0, 10.0}, 1e-2); +} + +TEST(WeightedQuantilesStreamTest, OneZeroWeightValue) { + const double eps = 0.01; + const int64 max_elements = 1 << 16; + TestSingleWorkerStreams(eps, max_elements, GenerateOneZeroWeightedValue, {}, + 1e-2); +} + +TEST(WeightedQuantilesStreamTest, FixedUniform) { + const double eps = 0.01; + const int64 max_elements = 1 << 16; + TestSingleWorkerStreams(eps, max_elements, GenerateFixedUniformSummary, + {0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0}, + 1e-2); +} + +TEST(WeightedQuantilesStreamTest, FixedNonUniform) { + const double eps = 0.01; + const int64 max_elements = 1 << 16; + TestSingleWorkerStreams(eps, max_elements, GenerateFixedNonUniformSummary, + {0, std::sqrt(0.1), std::sqrt(0.2), std::sqrt(0.3), + std::sqrt(0.4), std::sqrt(0.5), std::sqrt(0.6), + std::sqrt(0.7), std::sqrt(0.8), std::sqrt(0.9), 1.0}, + 1e-2); +} + +TEST(WeightedQuantilesStreamTest, RandUniformFixedWeights) { + const double eps = 0.01; + const int64 max_elements = 1 << 16; + TestSingleWorkerStreams( + eps, max_elements, GenerateRandUniformFixedWeightsSummary, + {0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0}, 1e-2); +} + +TEST(WeightedQuantilesStreamTest, RandUniformRandWeights) { + const double eps = 0.01; + const int64 max_elements = 1 << 16; + TestSingleWorkerStreams( + eps, max_elements, GenerateRandUniformRandWeightsSummary, + {0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0}, 1e-2); +} + +// Distributed tests. +void TestDistributedStreams( + int32 num_workers, double eps, int64 max_elements, + const std::function<void(int32, int64, double *, Stream *)> + &worker_summary_generator, + std::initializer_list<double> expected_quantiles, + double quantiles_matcher_epsilon) { + // Simulate streams on each worker running independently + double total_weight = 0; + std::vector<std::vector<SummaryEntry>> worker_summaries; + for (int32 i = 0; i < num_workers; ++i) { + Stream stream(eps / 2, max_elements); + worker_summary_generator(i, max_elements / num_workers, &total_weight, + &stream); + worker_summaries.push_back(stream.GetFinalSummary().GetEntryList()); + } + + // In the accumulation phase, we aggregate the summaries from each worker + // and build an overall summary while maintaining error bounds by ensuring we + // don't increase the error by more than eps / 2. + Stream reducer_stream(eps, max_elements); + for (const auto &summary : worker_summaries) { + reducer_stream.PushSummary(summary); + } + reducer_stream.Finalize(); + + // Ensure we didn't lose track of any elements and are + // within approximation error bound. + EXPECT_LE(reducer_stream.ApproximationError(), eps); + EXPECT_NEAR(reducer_stream.GetFinalSummary().TotalWeight(), total_weight, + total_weight); + + // Verify expected quantiles. + int i = 0; + auto actuals = + reducer_stream.GenerateQuantiles(expected_quantiles.size() - 1); + for (auto expected_quantile : expected_quantiles) { + EXPECT_NEAR(actuals[i], expected_quantile, quantiles_matcher_epsilon); + ++i; + } +} + +TEST(WeightedQuantilesStreamTest, FixedUniformDistributed) { + const int32 num_workers = 10; + const double eps = 0.01; + const int64 max_elements = num_workers * (1 << 16); + TestDistributedStreams( + num_workers, eps, max_elements, GenerateFixedUniformSummary, + {0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0}, 1e-2); +} + +TEST(WeightedQuantilesStreamTest, FixedNonUniformDistributed) { + const int32 num_workers = 10; + const double eps = 0.01; + const int64 max_elements = num_workers * (1 << 16); + TestDistributedStreams(num_workers, eps, max_elements, + GenerateFixedNonUniformSummary, + {0, std::sqrt(0.1), std::sqrt(0.2), std::sqrt(0.3), + std::sqrt(0.4), std::sqrt(0.5), std::sqrt(0.6), + std::sqrt(0.7), std::sqrt(0.8), std::sqrt(0.9), 1.0}, + 1e-2); +} + +TEST(WeightedQuantilesStreamTest, RandUniformFixedWeightsDistributed) { + const int32 num_workers = 10; + const double eps = 0.01; + const int64 max_elements = num_workers * (1 << 16); + TestDistributedStreams( + num_workers, eps, max_elements, GenerateRandUniformFixedWeightsSummary, + {0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0}, 1e-2); +} + +TEST(WeightedQuantilesStreamTest, RandUniformRandWeightsDistributed) { + const int32 num_workers = 10; + const double eps = 0.01; + const int64 max_elements = num_workers * (1 << 16); + TestDistributedStreams( + num_workers, eps, max_elements, GenerateRandUniformRandWeightsSummary, + {0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0}, 1e-2); +} + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_summary.h b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_summary.h new file mode 100644 index 0000000000..31d7fe25a4 --- /dev/null +++ b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_summary.h @@ -0,0 +1,344 @@ +// Copyright 2018 The TensorFlow Authors. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// ============================================================================= +#ifndef TENSORFLOW_CORE_KERNELS_BOOSTED_TREES_QUANTILES_WEIGHTED_QUANTILES_SUMMARY_H_ +#define TENSORFLOW_CORE_KERNELS_BOOSTED_TREES_QUANTILES_WEIGHTED_QUANTILES_SUMMARY_H_ + +#include <cstring> +#include <vector> + +#include "tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_buffer.h" + +namespace tensorflow { +namespace boosted_trees { +namespace quantiles { + +// Summary holding a sorted block of entries with upper bound guarantees +// over the approximation error. +template <typename ValueType, typename WeightType, + typename CompareFn = std::less<ValueType>> +class WeightedQuantilesSummary { + public: + using Buffer = WeightedQuantilesBuffer<ValueType, WeightType, CompareFn>; + using BufferEntry = typename Buffer::BufferEntry; + + struct SummaryEntry { + SummaryEntry(const ValueType& v, const WeightType& w, const WeightType& min, + const WeightType& max) { + // Explicitly initialize all of memory (including padding from memory + // alignment) to allow the struct to be msan-resistant "plain old data". + // + // POD = http://en.cppreference.com/w/cpp/concept/PODType + memset(this, 0, sizeof(*this)); + + value = v; + weight = w; + min_rank = min; + max_rank = max; + } + + SummaryEntry() { + memset(this, 0, sizeof(*this)); + + value = ValueType(); + weight = 0; + min_rank = 0; + max_rank = 0; + } + + bool operator==(const SummaryEntry& other) const { + return value == other.value && weight == other.weight && + min_rank == other.min_rank && max_rank == other.max_rank; + } + friend std::ostream& operator<<(std::ostream& strm, + const SummaryEntry& entry) { + return strm << "{" << entry.value << ", " << entry.weight << ", " + << entry.min_rank << ", " << entry.max_rank << "}"; + } + + // Max rank estimate for previous smaller value. + WeightType PrevMaxRank() const { return max_rank - weight; } + + // Min rank estimate for next larger value. + WeightType NextMinRank() const { return min_rank + weight; } + + ValueType value; + WeightType weight; + WeightType min_rank; + WeightType max_rank; + }; + + // Re-construct summary from the specified buffer. + void BuildFromBufferEntries(const std::vector<BufferEntry>& buffer_entries) { + entries_.clear(); + entries_.reserve(buffer_entries.size()); + WeightType cumulative_weight = 0; + for (const auto& entry : buffer_entries) { + WeightType current_weight = entry.weight; + entries_.emplace_back(entry.value, entry.weight, cumulative_weight, + cumulative_weight + current_weight); + cumulative_weight += current_weight; + } + } + + // Re-construct summary from the specified summary entries. + void BuildFromSummaryEntries( + const std::vector<SummaryEntry>& summary_entries) { + entries_.clear(); + entries_.reserve(summary_entries.size()); + entries_.insert(entries_.begin(), summary_entries.begin(), + summary_entries.end()); + } + + // Merges two summaries through an algorithm that's derived from MergeSort + // for summary entries while guaranteeing that the max approximation error + // of the final merged summary is no greater than the approximation errors + // of each individual summary. + // For example consider summaries where each entry is of the form + // (element, weight, min rank, max rank): + // summary entries 1: (1, 3, 0, 3), (4, 2, 3, 5) + // summary entries 2: (3, 1, 0, 1), (4, 1, 1, 2) + // merged: (1, 3, 0, 3), (3, 1, 3, 4), (4, 3, 4, 7). + void Merge(const WeightedQuantilesSummary& other_summary) { + // Make sure we have something to merge. + const auto& other_entries = other_summary.entries_; + if (other_entries.empty()) { + return; + } + if (entries_.empty()) { + BuildFromSummaryEntries(other_summary.entries_); + return; + } + + // Move current entries to make room for a new buffer. + std::vector<SummaryEntry> base_entries(std::move(entries_)); + entries_.clear(); + entries_.reserve(base_entries.size() + other_entries.size()); + + // Merge entries maintaining ranks. The idea is to stack values + // in order which we can do in linear time as the two summaries are + // already sorted. We keep track of the next lower rank from either + // summary and update it as we pop elements from the summaries. + // We handle the special case when the next two elements from either + // summary are equal, in which case we just merge the two elements + // and simultaneously update both ranks. + auto it1 = base_entries.cbegin(); + auto it2 = other_entries.cbegin(); + WeightType next_min_rank1 = 0; + WeightType next_min_rank2 = 0; + while (it1 != base_entries.cend() && it2 != other_entries.cend()) { + if (kCompFn(it1->value, it2->value)) { // value1 < value2 + // Take value1 and use the last added value2 to compute + // the min rank and the current value2 to compute the max rank. + entries_.emplace_back(it1->value, it1->weight, + it1->min_rank + next_min_rank2, + it1->max_rank + it2->PrevMaxRank()); + // Update next min rank 1. + next_min_rank1 = it1->NextMinRank(); + ++it1; + } else if (kCompFn(it2->value, it1->value)) { // value1 > value2 + // Take value2 and use the last added value1 to compute + // the min rank and the current value1 to compute the max rank. + entries_.emplace_back(it2->value, it2->weight, + it2->min_rank + next_min_rank1, + it2->max_rank + it1->PrevMaxRank()); + // Update next min rank 2. + next_min_rank2 = it2->NextMinRank(); + ++it2; + } else { // value1 == value2 + // Straight additive merger of the two entries into one. + entries_.emplace_back(it1->value, it1->weight + it2->weight, + it1->min_rank + it2->min_rank, + it1->max_rank + it2->max_rank); + // Update next min ranks for both. + next_min_rank1 = it1->NextMinRank(); + next_min_rank2 = it2->NextMinRank(); + ++it1; + ++it2; + } + } + + // Fill in any residual. + while (it1 != base_entries.cend()) { + entries_.emplace_back(it1->value, it1->weight, + it1->min_rank + next_min_rank2, + it1->max_rank + other_entries.back().max_rank); + ++it1; + } + while (it2 != other_entries.cend()) { + entries_.emplace_back(it2->value, it2->weight, + it2->min_rank + next_min_rank1, + it2->max_rank + base_entries.back().max_rank); + ++it2; + } + } + + // Compresses buffer into desired size. The size specification is + // considered a hint as we always keep the first and last elements and + // maintain strict approximation error bounds. + // The approximation error delta is taken as the max of either the requested + // min error or 1 / size_hint. + // After compression, the approximation error is guaranteed to increase + // by no more than that error delta. + // This algorithm is linear in the original size of the summary and is + // designed to be cache-friendly. + void Compress(int64 size_hint, double min_eps = 0) { + // No-op if we're already within the size requirement. + size_hint = std::max(size_hint, int64{2}); + if (entries_.size() <= size_hint) { + return; + } + + // First compute the max error bound delta resulting from this compression. + double eps_delta = TotalWeight() * std::max(1.0 / size_hint, min_eps); + + // Compress elements ensuring approximation bounds and elements diversity + // are both maintained. + int64 add_accumulator = 0, add_step = entries_.size(); + auto write_it = entries_.begin() + 1, last_it = write_it; + for (auto read_it = entries_.begin(); read_it + 1 != entries_.end();) { + auto next_it = read_it + 1; + while (next_it != entries_.end() && add_accumulator < add_step && + next_it->PrevMaxRank() - read_it->NextMinRank() <= eps_delta) { + add_accumulator += size_hint; + ++next_it; + } + if (read_it == next_it - 1) { + ++read_it; + } else { + read_it = next_it - 1; + } + (*write_it++) = (*read_it); + last_it = read_it; + add_accumulator -= add_step; + } + // Write last element and resize. + if (last_it + 1 != entries_.end()) { + (*write_it++) = entries_.back(); + } + entries_.resize(write_it - entries_.begin()); + } + + // To construct the boundaries we first run a soft compress over a copy + // of the summary and retrieve the values. + // The resulting boundaries are guaranteed to both contain at least + // num_boundaries unique elements and maintain approximation bounds. + std::vector<ValueType> GenerateBoundaries(int64 num_boundaries) const { + std::vector<ValueType> output; + if (entries_.empty()) { + return output; + } + + // Generate soft compressed summary. + WeightedQuantilesSummary<ValueType, WeightType, CompareFn> + compressed_summary; + compressed_summary.BuildFromSummaryEntries(entries_); + // Set an epsilon for compression that's at most 1.0 / num_boundaries + // more than epsilon of original our summary since the compression operation + // adds ~1.0/num_boundaries to final approximation error. + float compression_eps = ApproximationError() + (1.0 / num_boundaries); + compressed_summary.Compress(num_boundaries, compression_eps); + + // Return boundaries. + output.reserve(compressed_summary.entries_.size()); + for (const auto& entry : compressed_summary.entries_) { + output.push_back(entry.value); + } + return output; + } + + // To construct the desired n-quantiles we repetitively query n ranks from the + // original summary. The following algorithm is an efficient cache-friendly + // O(n) implementation of that idea which avoids the cost of the repetitive + // full rank queries O(nlogn). + std::vector<ValueType> GenerateQuantiles(int64 num_quantiles) const { + std::vector<ValueType> output; + if (entries_.empty()) { + return output; + } + num_quantiles = std::max(num_quantiles, int64{2}); + output.reserve(num_quantiles + 1); + + // Make successive rank queries to get boundaries. + // We always keep the first (min) and last (max) entries. + for (size_t cur_idx = 0, rank = 0; rank <= num_quantiles; ++rank) { + // This step boils down to finding the next element sub-range defined by + // r = (rmax[i + 1] + rmin[i + 1]) / 2 where the desired rank d < r. + WeightType d_2 = 2 * (rank * entries_.back().max_rank / num_quantiles); + size_t next_idx = cur_idx + 1; + while (next_idx < entries_.size() && + d_2 >= entries_[next_idx].min_rank + entries_[next_idx].max_rank) { + ++next_idx; + } + cur_idx = next_idx - 1; + + // Determine insertion order. + if (next_idx == entries_.size() || + d_2 < entries_[cur_idx].NextMinRank() + + entries_[next_idx].PrevMaxRank()) { + output.push_back(entries_[cur_idx].value); + } else { + output.push_back(entries_[next_idx].value); + } + } + return output; + } + + // Calculates current approximation error which should always be <= eps. + double ApproximationError() const { + if (entries_.empty()) { + return 0; + } + + WeightType max_gap = 0; + for (auto it = entries_.cbegin() + 1; it < entries_.end(); ++it) { + max_gap = std::max(max_gap, + std::max(it->max_rank - it->min_rank - it->weight, + it->PrevMaxRank() - (it - 1)->NextMinRank())); + } + return static_cast<double>(max_gap) / TotalWeight(); + } + + ValueType MinValue() const { + return !entries_.empty() ? entries_.front().value + : std::numeric_limits<ValueType>::max(); + } + ValueType MaxValue() const { + return !entries_.empty() ? entries_.back().value + : std::numeric_limits<ValueType>::max(); + } + WeightType TotalWeight() const { + return !entries_.empty() ? entries_.back().max_rank : 0; + } + int64 Size() const { return entries_.size(); } + void Clear() { entries_.clear(); } + const std::vector<SummaryEntry>& GetEntryList() const { return entries_; } + + private: + // Comparison function. + static constexpr decltype(CompareFn()) kCompFn = CompareFn(); + + // Summary entries. + std::vector<SummaryEntry> entries_; +}; + +template <typename ValueType, typename WeightType, typename CompareFn> +constexpr decltype(CompareFn()) + WeightedQuantilesSummary<ValueType, WeightType, CompareFn>::kCompFn; + +} // namespace quantiles +} // namespace boosted_trees +} // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_BOOSTED_TREES_QUANTILES_WEIGHTED_QUANTILES_SUMMARY_H_ diff --git a/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_summary_test.cc b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_summary_test.cc new file mode 100644 index 0000000000..ccd1215cf4 --- /dev/null +++ b/tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_summary_test.cc @@ -0,0 +1,223 @@ +// Copyright 2018 The TensorFlow Authors. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// ============================================================================= +#include "tensorflow/core/kernels/boosted_trees/quantiles/weighted_quantiles_summary.h" +#include "tensorflow/core/lib/random/philox_random.h" +#include "tensorflow/core/lib/random/simple_philox.h" +#include "tensorflow/core/platform/test.h" +#include "tensorflow/core/platform/test_benchmark.h" + +namespace tensorflow { +namespace { + +using Buffer = boosted_trees::quantiles::WeightedQuantilesBuffer<float, float>; +using BufferEntry = + boosted_trees::quantiles::WeightedQuantilesBuffer<float, + float>::BufferEntry; +using Summary = + boosted_trees::quantiles::WeightedQuantilesSummary<float, float>; +using SummaryEntry = + boosted_trees::quantiles::WeightedQuantilesSummary<float, + float>::SummaryEntry; + +class WeightedQuantilesSummaryTest : public ::testing::Test { + protected: + void SetUp() override { + // Constructs a buffer of 10 weighted unique entries. + buffer1_.reset(new Buffer(10, 1000)); + buffer1_->PushEntry(5, 9); + buffer1_->PushEntry(2, 3); + buffer1_->PushEntry(-1, 7); + buffer1_->PushEntry(-7, 1); + buffer1_->PushEntry(3, 2); + buffer1_->PushEntry(-2, 3); + buffer1_->PushEntry(21, 8); + buffer1_->PushEntry(-13, 4); + buffer1_->PushEntry(8, 2); + buffer1_->PushEntry(-5, 6); + + // Constructs a buffer of 7 weighted unique entries. + buffer2_.reset(new Buffer(7, 1000)); + buffer2_->PushEntry(9, 2); + buffer2_->PushEntry(-7, 3); + buffer2_->PushEntry(2, 1); + buffer2_->PushEntry(4, 13); + buffer2_->PushEntry(0, 5); + buffer2_->PushEntry(-5, 3); + buffer2_->PushEntry(11, 3); + } + + void TearDown() override { buffer1_->Clear(); } + + std::unique_ptr<Buffer> buffer1_; + std::unique_ptr<Buffer> buffer2_; + const double buffer1_min_value_ = -13; + const double buffer1_max_value_ = 21; + const double buffer1_total_weight_ = 45; + const double buffer2_min_value_ = -7; + const double buffer2_max_value_ = 11; + const double buffer2_total_weight_ = 30; +}; + +TEST_F(WeightedQuantilesSummaryTest, BuildFromBuffer) { + Summary summary; + summary.BuildFromBufferEntries(buffer1_->GenerateEntryList()); + + // We expect no approximation error because no compress operation occurred. + EXPECT_EQ(summary.ApproximationError(), 0); + + // Check first and last elements in the summary. + const auto& entries = summary.GetEntryList(); + // First element's rmin should be zero. + EXPECT_EQ(summary.MinValue(), buffer1_min_value_); + EXPECT_EQ(entries.front(), SummaryEntry(-13, 4, 0, 4)); + // Last element's rmax should be cumulative weight. + EXPECT_EQ(summary.MaxValue(), buffer1_max_value_); + EXPECT_EQ(entries.back(), SummaryEntry(21, 8, 37, 45)); + // Check total weight. + EXPECT_EQ(summary.TotalWeight(), buffer1_total_weight_); +} + +TEST_F(WeightedQuantilesSummaryTest, CompressSeparately) { + const auto entry_list = buffer1_->GenerateEntryList(); + for (int new_size = 9; new_size >= 2; --new_size) { + Summary summary; + summary.BuildFromBufferEntries(entry_list); + summary.Compress(new_size); + + // Expect a max approximation error of 1 / n + // ie. eps0 + 1/n but eps0 = 0. + EXPECT_TRUE(summary.Size() >= new_size && summary.Size() <= new_size + 2); + EXPECT_LE(summary.ApproximationError(), 1.0 / new_size); + + // Min/Max elements and total weight should not change. + EXPECT_EQ(summary.MinValue(), buffer1_min_value_); + EXPECT_EQ(summary.MaxValue(), buffer1_max_value_); + EXPECT_EQ(summary.TotalWeight(), buffer1_total_weight_); + } +} + +TEST_F(WeightedQuantilesSummaryTest, CompressSequentially) { + Summary summary; + summary.BuildFromBufferEntries(buffer1_->GenerateEntryList()); + for (int new_size = 9; new_size >= 2; new_size -= 2) { + double prev_eps = summary.ApproximationError(); + summary.Compress(new_size); + + // Expect a max approximation error of prev_eps + 1 / n. + EXPECT_TRUE(summary.Size() >= new_size && summary.Size() <= new_size + 2); + EXPECT_LE(summary.ApproximationError(), prev_eps + 1.0 / new_size); + + // Min/Max elements and total weight should not change. + EXPECT_EQ(summary.MinValue(), buffer1_min_value_); + EXPECT_EQ(summary.MaxValue(), buffer1_max_value_); + EXPECT_EQ(summary.TotalWeight(), buffer1_total_weight_); + } +} + +TEST_F(WeightedQuantilesSummaryTest, CompressRandomized) { + // Check multiple size compressions and ensure approximation bounds + // are always respected. + int prev_size = 1; + int size = 2; + float max_value = 1 << 20; + while (size < (1 << 16)) { + // Create buffer of size from uniform random elements. + Buffer buffer(size, size << 4); + random::PhiloxRandom philox(13); + random::SimplePhilox rand(&philox); + for (int i = 0; i < size; ++i) { + buffer.PushEntry(rand.RandFloat() * max_value, + rand.RandFloat() * max_value); + } + + // Create summary and compress. + Summary summary; + summary.BuildFromBufferEntries(buffer.GenerateEntryList()); + int new_size = std::max(rand.Uniform(size), 2u); + summary.Compress(new_size); + + // Ensure approximation error is acceptable. + EXPECT_TRUE(summary.Size() >= new_size && summary.Size() <= new_size + 2); + EXPECT_LE(summary.ApproximationError(), 1.0 / new_size); + + // Update size to next fib number. + size_t last_size = size; + size += prev_size; + prev_size = last_size; + } +} + +TEST_F(WeightedQuantilesSummaryTest, MergeSymmetry) { + // Create two separate summaries and merge. + const auto list_1 = buffer1_->GenerateEntryList(); + const auto list_2 = buffer2_->GenerateEntryList(); + Summary summary1; + summary1.BuildFromBufferEntries(list_1); + Summary summary2; + summary2.BuildFromBufferEntries(list_2); + + // Merge summary 2 into 1 and verify. + summary1.Merge(summary2); + EXPECT_EQ(summary1.ApproximationError(), 0.0); + EXPECT_EQ(summary1.MinValue(), + std::min(buffer1_min_value_, buffer2_min_value_)); + EXPECT_EQ(summary1.MaxValue(), + std::max(buffer1_max_value_, buffer2_max_value_)); + EXPECT_EQ(summary1.TotalWeight(), + buffer1_total_weight_ + buffer2_total_weight_); + EXPECT_EQ(summary1.Size(), 14); // 14 unique values. + + // Merge summary 1 into 2 and verify same result. + summary1.BuildFromBufferEntries(list_1); + summary2.Merge(summary1); + EXPECT_EQ(summary2.ApproximationError(), 0.0); + EXPECT_EQ(summary2.MinValue(), + std::min(buffer1_min_value_, buffer2_min_value_)); + EXPECT_EQ(summary2.MaxValue(), + std::max(buffer1_max_value_, buffer2_max_value_)); + EXPECT_EQ(summary2.TotalWeight(), + buffer1_total_weight_ + buffer2_total_weight_); + EXPECT_EQ(summary2.Size(), 14); // 14 unique values. +} + +TEST_F(WeightedQuantilesSummaryTest, CompressThenMerge) { + // Create two separate summaries and merge. + Summary summary1; + summary1.BuildFromBufferEntries(buffer1_->GenerateEntryList()); + Summary summary2; + summary2.BuildFromBufferEntries(buffer2_->GenerateEntryList()); + + // Compress summaries. + summary1.Compress(5); // max error is 1/5. + const auto eps1 = 1.0 / 5; + EXPECT_LE(summary1.ApproximationError(), eps1); + summary2.Compress(3); // max error is 1/3. + const auto eps2 = 1.0 / 3; + EXPECT_LE(summary2.ApproximationError(), eps2); + + // Merge guarantees an approximation error of max(eps1, eps2). + // Merge summary 2 into 1 and verify. + summary1.Merge(summary2); + EXPECT_LE(summary1.ApproximationError(), std::max(eps1, eps2)); + EXPECT_EQ(summary1.MinValue(), + std::min(buffer1_min_value_, buffer2_min_value_)); + EXPECT_EQ(summary1.MaxValue(), + std::max(buffer1_max_value_, buffer2_max_value_)); + EXPECT_EQ(summary1.TotalWeight(), + buffer1_total_weight_ + buffer2_total_weight_); +} + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/core/kernels/bounds_check.h b/tensorflow/core/kernels/bounds_check.h index c8c60c5524..18727c0db3 100644 --- a/tensorflow/core/kernels/bounds_check.h +++ b/tensorflow/core/kernels/bounds_check.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_BOUNDS_CHECK_H_ -#define TENSORFLOW_UTIL_BOUNDS_CHECK_H_ +#ifndef TENSORFLOW_CORE_KERNELS_BOUNDS_CHECK_H_ +#define TENSORFLOW_CORE_KERNELS_BOUNDS_CHECK_H_ #include <type_traits> @@ -51,4 +51,4 @@ EIGEN_ALWAYS_INLINE EIGEN_DEVICE_FUNC const T SubtleMustCopy(const T &x) { } // namespace internal } // namespace tensorflow -#endif // TENSORFLOW_UTIL_BOUNDS_CHECK_H_ +#endif // TENSORFLOW_CORE_KERNELS_BOUNDS_CHECK_H_ diff --git a/tensorflow/core/kernels/broadcast_to_op.h b/tensorflow/core/kernels/broadcast_to_op.h index 73fdd5d28e..a2327a7272 100644 --- a/tensorflow/core/kernels/broadcast_to_op.h +++ b/tensorflow/core/kernels/broadcast_to_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_BROADCAST_TO_OP_H_ -#define TENSORFLOW_KERNELS_BROADCAST_TO_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_BROADCAST_TO_OP_H_ +#define TENSORFLOW_CORE_KERNELS_BROADCAST_TO_OP_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/tensor.h" @@ -239,4 +239,4 @@ struct BroadcastTo { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_BROADCAST_TO_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_BROADCAST_TO_OP_H_ diff --git a/tensorflow/core/kernels/bucketize_op.h b/tensorflow/core/kernels/bucketize_op.h index c8e461beb9..32be475f86 100644 --- a/tensorflow/core/kernels/bucketize_op.h +++ b/tensorflow/core/kernels/bucketize_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_BUCKETIZE_OP_H_ -#define TENSORFLOW_BUCKETIZE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_BUCKETIZE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_BUCKETIZE_OP_H_ #include <vector> #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -38,4 +38,4 @@ struct BucketizeFunctor { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_BUCKETIZE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_BUCKETIZE_OP_H_ diff --git a/tensorflow/core/kernels/cast_op.cc b/tensorflow/core/kernels/cast_op.cc index 0478c93280..3a72567655 100644 --- a/tensorflow/core/kernels/cast_op.cc +++ b/tensorflow/core/kernels/cast_op.cc @@ -98,7 +98,13 @@ void CastOpBase::Compute(OpKernelContext* ctx) { ctx->set_output(0, inp); } else { Tensor in; - in.UnsafeCopyFromInternal(inp, src_dtype_, inp.shape()); + if (external_src_dtype_ != src_dtype_) { + // If the type is a quantized type we need to do an UnsafeCopyFromInternal + // since the src_dtype_ is different from external_src_type_. + in.UnsafeCopyFromInternal(inp, src_dtype_, inp.shape()); + } else { + in = inp; + } Tensor* out = nullptr; OP_REQUIRES_OK(ctx, ctx->allocate_output(0, in.shape(), &out)); out->set_dtype(dst_dtype_); diff --git a/tensorflow/core/kernels/cast_op.h b/tensorflow/core/kernels/cast_op.h index 527ab528c9..84c44f6b5e 100644 --- a/tensorflow/core/kernels/cast_op.h +++ b/tensorflow/core/kernels/cast_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CAST_OP_H_ -#define TENSORFLOW_KERNELS_CAST_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CAST_OP_H_ +#define TENSORFLOW_CORE_KERNELS_CAST_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/bfloat16.h" @@ -323,4 +323,4 @@ struct functor_traits<scalar_cast_op<float, ::tensorflow::bfloat16>> { } // namespace internal } // namespace Eigen -#endif // TENSORFLOW_KERNELS_CAST_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_CAST_OP_H_ diff --git a/tensorflow/core/kernels/colorspace_op.h b/tensorflow/core/kernels/colorspace_op.h index 90bfce1419..4de14bc339 100644 --- a/tensorflow/core/kernels/colorspace_op.h +++ b/tensorflow/core/kernels/colorspace_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_COLORSPACE_OP_H_ -#define TENSORFLOW_KERNELS_COLORSPACE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_COLORSPACE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_COLORSPACE_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_shape.h" @@ -91,4 +91,4 @@ struct HSVToRGB { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_COLORSPACE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_COLORSPACE_OP_H_ diff --git a/tensorflow/core/kernels/concat_lib.h b/tensorflow/core/kernels/concat_lib.h index 16784c4770..8b53ecf121 100644 --- a/tensorflow/core/kernels/concat_lib.h +++ b/tensorflow/core/kernels/concat_lib.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CONCAT_LIB_H_ -#define TENSORFLOW_KERNELS_CONCAT_LIB_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CONCAT_LIB_H_ +#define TENSORFLOW_CORE_KERNELS_CONCAT_LIB_H_ #include <vector> @@ -66,4 +66,4 @@ void ConcatSYCL( #endif // TENSORFLOW_USE_SYCL } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_CONCAT_LIB_H_ +#endif // TENSORFLOW_CORE_KERNELS_CONCAT_LIB_H_ diff --git a/tensorflow/core/kernels/concat_lib_cpu.h b/tensorflow/core/kernels/concat_lib_cpu.h index 720b506537..29f3a427fe 100644 --- a/tensorflow/core/kernels/concat_lib_cpu.h +++ b/tensorflow/core/kernels/concat_lib_cpu.h @@ -13,6 +13,9 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#ifndef TENSORFLOW_CORE_KERNELS_CONCAT_LIB_CPU_H_ +#define TENSORFLOW_CORE_KERNELS_CONCAT_LIB_CPU_H_ + #define EIGEN_USE_THREADS #include <vector> @@ -162,3 +165,5 @@ void ConcatSYCLImpl( } #endif // TENSORFLOW_USE_SYCL } // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_CONCAT_LIB_CPU_H_ diff --git a/tensorflow/core/kernels/conditional_accumulator.h b/tensorflow/core/kernels/conditional_accumulator.h index 414891b142..a7836896c7 100644 --- a/tensorflow/core/kernels/conditional_accumulator.h +++ b/tensorflow/core/kernels/conditional_accumulator.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CONDITIONAL_ACCUMULATOR_H_ -#define TENSORFLOW_KERNELS_CONDITIONAL_ACCUMULATOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CONDITIONAL_ACCUMULATOR_H_ +#define TENSORFLOW_CORE_KERNELS_CONDITIONAL_ACCUMULATOR_H_ #include "tensorflow/core/kernels/fill_functor.h" #include "tensorflow/core/kernels/typed_conditional_accumulator_base.h" @@ -133,4 +133,4 @@ class ConditionalAccumulator } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_CONDITIONAL_ACCUMULATOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_CONDITIONAL_ACCUMULATOR_H_ diff --git a/tensorflow/core/kernels/conditional_accumulator_base.h b/tensorflow/core/kernels/conditional_accumulator_base.h index c7c7c98369..b7b7482a00 100644 --- a/tensorflow/core/kernels/conditional_accumulator_base.h +++ b/tensorflow/core/kernels/conditional_accumulator_base.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_H_ -#define TENSORFLOW_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_H_ +#define TENSORFLOW_CORE_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_H_ #include <deque> @@ -199,4 +199,4 @@ class TypeConverter<Eigen::half, U> { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_H_ +#endif // TENSORFLOW_CORE_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_H_ diff --git a/tensorflow/core/kernels/conditional_accumulator_base_op.h b/tensorflow/core/kernels/conditional_accumulator_base_op.h index 33c2d596c8..012a0dcc12 100644 --- a/tensorflow/core/kernels/conditional_accumulator_base_op.h +++ b/tensorflow/core/kernels/conditional_accumulator_base_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_OP_H_ -#define TENSORFLOW_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_OP_H_ #define EIGEN_USE_THREADS @@ -234,4 +234,4 @@ class ConditionalAccumulatorBaseTakeGradientOp } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_CONDITIONAL_ACCUMULATOR_BASE_OP_H_ diff --git a/tensorflow/core/kernels/control_flow_ops.h b/tensorflow/core/kernels/control_flow_ops.h index 8edbcc9077..c607fcf298 100644 --- a/tensorflow/core/kernels/control_flow_ops.h +++ b/tensorflow/core/kernels/control_flow_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CONTROL_FLOW_OPS_H_ -#define TENSORFLOW_KERNELS_CONTROL_FLOW_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CONTROL_FLOW_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_CONTROL_FLOW_OPS_H_ #include "tensorflow/core/framework/op_kernel.h" @@ -115,4 +115,4 @@ class LoopCondOp : public OpKernel { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_CONTROL_FLOW_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_CONTROL_FLOW_OPS_H_ diff --git a/tensorflow/core/kernels/conv_2d.h b/tensorflow/core/kernels/conv_2d.h index 6b7544fd4c..de9b69828e 100644 --- a/tensorflow/core/kernels/conv_2d.h +++ b/tensorflow/core/kernels/conv_2d.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CONV_2D_H_ -#define TENSORFLOW_KERNELS_CONV_2D_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CONV_2D_H_ +#define TENSORFLOW_CORE_KERNELS_CONV_2D_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -298,4 +298,4 @@ template <> class ConvAlgorithmMap<Eigen::ThreadPoolDevice> {}; } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_CONV_2D_H_ +#endif // TENSORFLOW_CORE_KERNELS_CONV_2D_H_ diff --git a/tensorflow/core/kernels/conv_3d.h b/tensorflow/core/kernels/conv_3d.h index 083dec63cc..02e3655ad1 100644 --- a/tensorflow/core/kernels/conv_3d.h +++ b/tensorflow/core/kernels/conv_3d.h @@ -15,8 +15,8 @@ limitations under the License. // Functors for 3d convolution. -#ifndef TENSORFLOW_KERNELS_CONV_3D_H_ -#define TENSORFLOW_KERNELS_CONV_3D_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CONV_3D_H_ +#define TENSORFLOW_CORE_KERNELS_CONV_3D_H_ #include "tensorflow/core/framework/tensor_types.h" #include "tensorflow/core/kernels/eigen_cuboid_convolution.h" @@ -45,4 +45,4 @@ struct CuboidConvolution<CPUDevice, T> { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_CONV_3D_H_ +#endif // TENSORFLOW_CORE_KERNELS_CONV_3D_H_ diff --git a/tensorflow/core/kernels/conv_ops.h b/tensorflow/core/kernels/conv_ops.h index 09a3b78776..adf4601b43 100644 --- a/tensorflow/core/kernels/conv_ops.h +++ b/tensorflow/core/kernels/conv_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CONV_OPS_H_ -#define TENSORFLOW_KERNELS_CONV_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CONV_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_CONV_OPS_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/resource_mgr.h" @@ -68,4 +68,4 @@ struct Im2ColBufferResource : public ResourceBase { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_CONV_OPS_H +#endif // TENSORFLOW_CORE_KERNELS_CONV_OPS_H_ diff --git a/tensorflow/core/kernels/cross_op.h b/tensorflow/core/kernels/cross_op.h index ca6beba52b..45bc46a921 100644 --- a/tensorflow/core/kernels/cross_op.h +++ b/tensorflow/core/kernels/cross_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_COLORSPACE_OP_H_ -#define TENSORFLOW_KERNELS_COLORSPACE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CROSS_OP_H_ +#define TENSORFLOW_CORE_KERNELS_CROSS_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_shape.h" @@ -51,4 +51,4 @@ struct Cross { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_COLORSPACE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_CROSS_OP_H_ diff --git a/tensorflow/core/kernels/cuda_solvers.h b/tensorflow/core/kernels/cuda_solvers.h index b2e8ee23a9..2c30d036df 100644 --- a/tensorflow/core/kernels/cuda_solvers.h +++ b/tensorflow/core/kernels/cuda_solvers.h @@ -14,6 +14,9 @@ limitations under the License. ============================================================================== */ +#ifndef TENSORFLOW_CORE_KERNELS_CUDA_SOLVERS_H_ +#define TENSORFLOW_CORE_KERNELS_CUDA_SOLVERS_H_ + // This header declares the class CudaSolver, which contains wrappers of linear // algebra solvers in the cuBlas and cuSolverDN libraries for use in TensorFlow // kernels. @@ -433,3 +436,5 @@ inline DeviceLapackInfo CudaSolver::GetDeviceLapackInfo( } // namespace tensorflow #endif // GOOGLE_CUDA + +#endif // TENSORFLOW_CORE_KERNELS_CUDA_SOLVERS_H_ diff --git a/tensorflow/core/kernels/cudnn_pooling_gpu.h b/tensorflow/core/kernels/cudnn_pooling_gpu.h index 280d697fc2..738e928246 100644 --- a/tensorflow/core/kernels/cudnn_pooling_gpu.h +++ b/tensorflow/core/kernels/cudnn_pooling_gpu.h @@ -15,8 +15,8 @@ limitations under the License. // Helper functions to run 3d pooling on GPU using CuDNN. -#ifndef TENSORFLOW_KERNELS_CUDNN_POOLING_GPU_H_ -#define TENSORFLOW_KERNELS_CUDNN_POOLING_GPU_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CUDNN_POOLING_GPU_H_ +#define TENSORFLOW_CORE_KERNELS_CUDNN_POOLING_GPU_H_ #include <array> @@ -67,4 +67,4 @@ class DnnPooling3dGradOp { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_CUDNN_POOLING_GPU_H_ +#endif // TENSORFLOW_CORE_KERNELS_CUDNN_POOLING_GPU_H_ diff --git a/tensorflow/core/kernels/cwise_op_div.cc b/tensorflow/core/kernels/cwise_op_div.cc index d6a2403816..313d976e2c 100644 --- a/tensorflow/core/kernels/cwise_op_div.cc +++ b/tensorflow/core/kernels/cwise_op_div.cc @@ -24,8 +24,7 @@ REGISTER5(BinaryOp, CPU, "TruncateDiv", functor::safe_div, uint8, uint16, int16, int32, int64); REGISTER6(BinaryOp, CPU, "RealDiv", functor::div, float, Eigen::half, double, bfloat16, complex64, complex128); -REGISTER5(BinaryOp, CPU, "UnsafeDiv", functor::unsafe_div, float, double, int16, - int32, int64); +REGISTER2(BinaryOp, CPU, "DivNoNan", functor::div_no_nan, float, double); #if GOOGLE_CUDA REGISTER9(BinaryOp, GPU, "Div", functor::div, float, Eigen::half, double, uint8, @@ -34,6 +33,7 @@ REGISTER4(BinaryOp, GPU, "TruncateDiv", functor::div, uint8, uint16, int16, int64); REGISTER5(BinaryOp, GPU, "RealDiv", functor::div, float, Eigen::half, double, complex64, complex128); +REGISTER2(BinaryOp, GPU, "DivNoNan", functor::div_no_nan, float, double); // A special GPU kernel for int32. // TODO(b/25387198): Also enable int32 in device memory. This kernel diff --git a/tensorflow/core/kernels/cwise_op_gpu_div.cu.cc b/tensorflow/core/kernels/cwise_op_gpu_div.cu.cc index 0b05416274..25ccdcfb00 100644 --- a/tensorflow/core/kernels/cwise_op_gpu_div.cu.cc +++ b/tensorflow/core/kernels/cwise_op_gpu_div.cu.cc @@ -21,6 +21,7 @@ namespace tensorflow { namespace functor { DEFINE_BINARY10(div, Eigen::half, float, double, uint8, uint16, int16, int32, int64, complex64, complex128); +DEFINE_BINARY2(div_no_nan, float, double); } // namespace functor } // namespace tensorflow diff --git a/tensorflow/core/kernels/cwise_ops.h b/tensorflow/core/kernels/cwise_ops.h index 1014519059..22eb66e979 100644 --- a/tensorflow/core/kernels/cwise_ops.h +++ b/tensorflow/core/kernels/cwise_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CWISE_OPS_H_ -#define TENSORFLOW_KERNELS_CWISE_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CWISE_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_CWISE_OPS_H_ #include <cmath> #include <functional> @@ -154,8 +154,8 @@ struct functor_traits<safe_div_or_mod_op<T, DivOrMod>> { }; template <typename T> -struct unsafe_div_op { - EIGEN_EMPTY_STRUCT_CTOR(unsafe_div_op) +struct div_no_nan_op { + EIGEN_EMPTY_STRUCT_CTOR(div_no_nan_op) EIGEN_DEVICE_FUNC EIGEN_STRONG_INLINE const T operator()(const T& a, const T& b) const { if (b != 0) { @@ -167,7 +167,7 @@ struct unsafe_div_op { }; template <typename T> -struct functor_traits<unsafe_div_op<T>> { +struct functor_traits<div_no_nan_op<T>> { enum { Cost = functor_traits<scalar_quotient_op<T>>::Cost + NumTraits<T>::AddCost, PacketAccess = false, @@ -742,7 +742,7 @@ struct safe_div : base<T, Eigen::internal::safe_div_or_mod_op< }; template <typename T> -struct unsafe_div : base<T, Eigen::internal::unsafe_div_op<T>> {}; +struct div_no_nan : base<T, Eigen::internal::div_no_nan_op<T>> {}; template <typename T> struct fmod : base<T, Eigen::internal::scalar_fmod_op<T>> {}; @@ -1036,4 +1036,4 @@ struct BatchSelectFunctor { } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_CWISE_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_CWISE_OPS_H_ diff --git a/tensorflow/core/kernels/cwise_ops_common.h b/tensorflow/core/kernels/cwise_ops_common.h index e32eccf547..f77d7238af 100644 --- a/tensorflow/core/kernels/cwise_ops_common.h +++ b/tensorflow/core/kernels/cwise_ops_common.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CWISE_OPS_COMMON_H_ -#define TENSORFLOW_KERNELS_CWISE_OPS_COMMON_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CWISE_OPS_COMMON_H_ +#define TENSORFLOW_CORE_KERNELS_CWISE_OPS_COMMON_H_ // See docs in ../ops/math_ops.cc. @@ -602,4 +602,4 @@ struct ApproximateEqual<CPUDevice, T> { } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_CWISE_OPS_COMMON_H_ +#endif // TENSORFLOW_CORE_KERNELS_CWISE_OPS_COMMON_H_ diff --git a/tensorflow/core/kernels/cwise_ops_gpu_common.cu.h b/tensorflow/core/kernels/cwise_ops_gpu_common.cu.h index 965e42dcce..cfae273bf4 100644 --- a/tensorflow/core/kernels/cwise_ops_gpu_common.cu.h +++ b/tensorflow/core/kernels/cwise_ops_gpu_common.cu.h @@ -17,8 +17,8 @@ limitations under the License. #error This file must only be included when building with Cuda support #endif -#ifndef TENSORFLOW_KERNELS_CWISE_OPS_GPU_COMMON_CU_H_ -#define TENSORFLOW_KERNELS_CWISE_OPS_GPU_COMMON_CU_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CWISE_OPS_GPU_COMMON_CU_H_ +#define TENSORFLOW_CORE_KERNELS_CWISE_OPS_GPU_COMMON_CU_H_ #define EIGEN_USE_GPU @@ -188,4 +188,4 @@ struct ApproximateEqual<GPUDevice, T> { } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_CWISE_OPS_GPU_COMMON_CU_H_ +#endif // TENSORFLOW_CORE_KERNELS_CWISE_OPS_GPU_COMMON_CU_H_ diff --git a/tensorflow/core/kernels/cwise_ops_gpu_gradients.cu.h b/tensorflow/core/kernels/cwise_ops_gpu_gradients.cu.h index e81b840a50..15e5de0f72 100644 --- a/tensorflow/core/kernels/cwise_ops_gpu_gradients.cu.h +++ b/tensorflow/core/kernels/cwise_ops_gpu_gradients.cu.h @@ -17,8 +17,8 @@ limitations under the License. #error This file must only be included when building with Cuda support #endif -#ifndef TENSORFLOW_KERNELS_CWISE_OPS_GPU_GRADIENTS_CU_H_ -#define TENSORFLOW_KERNELS_CWISE_OPS_GPU_GRADIENTS_CU_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CWISE_OPS_GPU_GRADIENTS_CU_H_ +#define TENSORFLOW_CORE_KERNELS_CWISE_OPS_GPU_GRADIENTS_CU_H_ #define EIGEN_USE_GPU @@ -68,4 +68,4 @@ struct SimpleBinaryFunctor<GPUDevice, Functor> { } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_CWISE_OPS_GPU_GRADIENTS_CU_H_ +#endif // TENSORFLOW_CORE_KERNELS_CWISE_OPS_GPU_GRADIENTS_CU_H_ diff --git a/tensorflow/core/kernels/cwise_ops_gradients.h b/tensorflow/core/kernels/cwise_ops_gradients.h index 7a6f14babc..53b53cc277 100644 --- a/tensorflow/core/kernels/cwise_ops_gradients.h +++ b/tensorflow/core/kernels/cwise_ops_gradients.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_CWISE_OPS_GRADIENTS_H_ -#define TENSORFLOW_KERNELS_CWISE_OPS_GRADIENTS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_CWISE_OPS_GRADIENTS_H_ +#define TENSORFLOW_CORE_KERNELS_CWISE_OPS_GRADIENTS_H_ #define EIGEN_USE_THREADS #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -208,4 +208,4 @@ struct igamma_grad_a : base<T, Eigen::internal::scalar_igamma_der_a_op<T>> {}; } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_CWISE_OPS_GRADIENTS_H_ +#endif // TENSORFLOW_CORE_KERNELS_CWISE_OPS_GRADIENTS_H_ diff --git a/tensorflow/core/kernels/data/BUILD b/tensorflow/core/kernels/data/BUILD index 607a694dba..8d867455e7 100644 --- a/tensorflow/core/kernels/data/BUILD +++ b/tensorflow/core/kernels/data/BUILD @@ -233,6 +233,16 @@ cc_library( ) tf_kernel_library( + name = "parse_example_dataset_op", + srcs = ["parse_example_dataset_op.cc"], + deps = [ + ":parallel_map_iterator", + "//tensorflow/core:core_cpu_internal", + "//tensorflow/core:framework", + ], +) + +tf_kernel_library( name = "parallel_map_dataset_op", srcs = ["parallel_map_dataset_op.cc"], deps = [ @@ -668,6 +678,7 @@ tf_kernel_library( ":padded_batch_dataset_op", ":parallel_interleave_dataset_op", ":parallel_map_dataset_op", + ":parse_example_dataset_op", ":prefetch_dataset_op", ":random_dataset_op", ":range_dataset_op", diff --git a/tensorflow/core/kernels/data/captured_function.cc b/tensorflow/core/kernels/data/captured_function.cc index 82da385405..abdf6ee4e8 100644 --- a/tensorflow/core/kernels/data/captured_function.cc +++ b/tensorflow/core/kernels/data/captured_function.cc @@ -172,31 +172,17 @@ class BorrowedArgsCallFrame : public CallFrameBase { } // namespace -Status CapturedFunction::MaybeInstantiate( - IteratorContext* ctx, FunctionLibraryRuntime::Handle* out_handle) { - mutex_lock l(mu_); +Status CapturedFunction::GetHandle(IteratorContext* ctx, + FunctionLibraryRuntime::Handle* out_handle) { + tf_shared_lock l(mu_); if (lib_ == nullptr) { - // The context's runtime will be used for all subsequent calls. - lib_ = ctx->lib(); - DCHECK(f_handle_ == kInvalidHandle); - FunctionLibraryRuntime::InstantiateOptions inst_opts; - inst_opts.overlay_lib = ctx->function_library().get(); - inst_opts.state_handle = std::to_string(random::New64()); - TF_RETURN_IF_ERROR(lib_->Instantiate(func_.name(), AttrSlice(&func_.attr()), - inst_opts, &f_handle_)); - const FunctionBody* fbody = lib_->GetFunctionBody(f_handle_); - if (fbody == nullptr) { - return errors::Internal("Failed to instantiate function body."); - } - ret_types_ = fbody->ret_types; - } else { - // TODO(mrry): Consider moving this under a shared lock, as it is - // the common case. - if (ctx->lib() != lib_) { - return errors::Internal( - "Captured function was called with a different " - "FunctionLibraryRuntime*, which is not permitted."); - } + return errors::Internal("Captured function \"", func_.name(), + "\" was called before it was instantiated."); + } + if (ctx->lib() != lib_) { + return errors::Internal("Captured function \"", func_.name(), + "\" was called with a different " + "FunctionLibraryRuntime*, which is not permitted."); } *out_handle = f_handle_; return Status::OK(); @@ -205,7 +191,7 @@ Status CapturedFunction::MaybeInstantiate( Status CapturedFunction::Run(IteratorContext* ctx, std::vector<Tensor>&& args, std::vector<Tensor>* rets) { FunctionLibraryRuntime::Handle handle; - TF_RETURN_IF_ERROR(MaybeInstantiate(ctx, &handle)); + TF_RETURN_IF_ERROR(GetHandle(ctx, &handle)); FunctionLibraryRuntime::Options f_opts; f_opts.step_id = CapturedFunction::generate_step_id(); @@ -242,7 +228,7 @@ Status CapturedFunction::RunWithBorrowedArgs(IteratorContext* ctx, const std::vector<Tensor>& args, std::vector<Tensor>* rets) { FunctionLibraryRuntime::Handle handle; - TF_RETURN_IF_ERROR(MaybeInstantiate(ctx, &handle)); + TF_RETURN_IF_ERROR(GetHandle(ctx, &handle)); FunctionLibraryRuntime::Options f_opts; f_opts.step_id = CapturedFunction::generate_step_id(); @@ -277,9 +263,30 @@ Status CapturedFunction::RunWithBorrowedArgs(IteratorContext* ctx, } Status CapturedFunction::Instantiate(IteratorContext* ctx) { - FunctionLibraryRuntime::Handle unused_handle; - TF_RETURN_IF_ERROR(MaybeInstantiate(ctx, &unused_handle)); mutex_lock l(mu_); + if (lib_ == nullptr) { + // The context's runtime will be used for all subsequent calls. + lib_ = ctx->lib(); + DCHECK(f_handle_ == kInvalidHandle); + FunctionLibraryRuntime::InstantiateOptions inst_opts; + inst_opts.overlay_lib = ctx->function_library().get(); + inst_opts.state_handle = std::to_string(random::New64()); + inst_opts.create_kernels_eagerly = true; + Status s = (lib_->Instantiate(func_.name(), AttrSlice(&func_.attr()), + inst_opts, &f_handle_)); + TF_RETURN_IF_ERROR(s); + const FunctionBody* fbody = lib_->GetFunctionBody(f_handle_); + if (fbody == nullptr) { + return errors::Internal("Failed to instantiate function body."); + } + ret_types_ = fbody->ret_types; + } else { + if (ctx->lib() != lib_) { + return errors::Internal( + "Captured function was called with a different " + "FunctionLibraryRuntime*, which is not permitted."); + } + } if (captured_runner_ == nullptr) { captured_runner_ = *ctx->runner(); } @@ -343,7 +350,7 @@ void CapturedFunction::RunAsync(IteratorContext* ctx, // be deleted before `done` is called. Take care not to capture `ctx` in any // code that may execute asynchronously in this function. FunctionLibraryRuntime::Handle handle; - Status s = MaybeInstantiate(ctx, &handle); + Status s = GetHandle(ctx, &handle); if (!s.ok()) { done(s); return; diff --git a/tensorflow/core/kernels/data/captured_function.h b/tensorflow/core/kernels/data/captured_function.h index e9ad3e381d..c95f2b1c01 100644 --- a/tensorflow/core/kernels/data/captured_function.h +++ b/tensorflow/core/kernels/data/captured_function.h @@ -116,8 +116,8 @@ class CapturedFunction { CapturedFunction(const NameAttrList& func, std::vector<Tensor> captured_inputs); - Status MaybeInstantiate(IteratorContext* ctx, - FunctionLibraryRuntime::Handle* out_handle); + Status GetHandle(IteratorContext* ctx, + FunctionLibraryRuntime::Handle* out_handle); mutex mu_; const NameAttrList func_; diff --git a/tensorflow/core/kernels/data/filter_dataset_op.cc b/tensorflow/core/kernels/data/filter_dataset_op.cc index a80e102ccf..bbce001eaf 100644 --- a/tensorflow/core/kernels/data/filter_dataset_op.cc +++ b/tensorflow/core/kernels/data/filter_dataset_op.cc @@ -112,7 +112,7 @@ class FilterDatasetOp : public UnaryDatasetOpKernel { Status AsGraphDefInternal(SerializationContext* ctx, DatasetGraphDefBuilder* b, Node** output) const override { - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, func_.name())); Node* input_graph_node; TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_graph_node)); @@ -149,7 +149,9 @@ class FilterDatasetOp : public UnaryDatasetOpKernel { : DatasetIterator<FilterDatasetBase>(params) {} Status Initialize(IteratorContext* ctx) override { - return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); + return dataset()->captured_func_->Instantiate(ctx); } Status GetNextInternal(IteratorContext* ctx, diff --git a/tensorflow/core/kernels/data/flat_map_dataset_op.cc b/tensorflow/core/kernels/data/flat_map_dataset_op.cc index 07bcb9d414..b1eb2fd849 100644 --- a/tensorflow/core/kernels/data/flat_map_dataset_op.cc +++ b/tensorflow/core/kernels/data/flat_map_dataset_op.cc @@ -94,7 +94,7 @@ class FlatMapDatasetOp : public UnaryDatasetOpKernel { Status AsGraphDefInternal(SerializationContext* ctx, DatasetGraphDefBuilder* b, Node** output) const override { - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, func_.name())); Node* input_graph_node = nullptr; TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_graph_node)); @@ -129,7 +129,9 @@ class FlatMapDatasetOp : public UnaryDatasetOpKernel { : DatasetIterator<Dataset>(params) {} Status Initialize(IteratorContext* ctx) override { - return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); + return dataset()->captured_func_->Instantiate(ctx); } Status GetNextInternal(IteratorContext* ctx, diff --git a/tensorflow/core/kernels/data/generator_dataset_op.cc b/tensorflow/core/kernels/data/generator_dataset_op.cc index 3c3d78b724..ccee690d7e 100644 --- a/tensorflow/core/kernels/data/generator_dataset_op.cc +++ b/tensorflow/core/kernels/data/generator_dataset_op.cc @@ -19,6 +19,7 @@ limitations under the License. #include "tensorflow/core/framework/partial_tensor_shape.h" #include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/kernels/data/captured_function.h" #include "tensorflow/core/lib/random/random.h" namespace tensorflow { @@ -80,20 +81,20 @@ class GeneratorDatasetOp::Dataset : public DatasetBase { } } + Status Initialize(IteratorContext* ctx) override { + TF_RETURN_IF_ERROR(dataset()->init_func_->Instantiate(ctx)); + TF_RETURN_IF_ERROR(dataset()->next_func_->Instantiate(ctx)); + TF_RETURN_IF_ERROR(dataset()->finalize_func_->Instantiate(ctx)); + TF_RETURN_IF_ERROR( + dataset()->init_func_->RunWithBorrowedArgs(ctx, {}, &state_)); + return Status::OK(); + } + Status GetNextInternal(IteratorContext* ctx, std::vector<Tensor>* out_tensors, bool* end_of_sequence) override { mutex_lock l(mu_); - if (!initialized_) { - TF_RETURN_IF_ERROR( - dataset()->init_func_->RunWithBorrowedArgs(ctx, {}, &state_)); - // Explicitly instantiate the finalize function here so that - // we can invoke it in the destructor. - TF_RETURN_IF_ERROR(dataset()->finalize_func_->Instantiate(ctx)); - initialized_ = true; - } - if (finalized_) { *end_of_sequence = true; return Status::OK(); @@ -121,7 +122,6 @@ class GeneratorDatasetOp::Dataset : public DatasetBase { private: mutex mu_; - bool initialized_ GUARDED_BY(mu_) = false; bool finalized_ GUARDED_BY(mu_) = false; std::vector<Tensor> state_ GUARDED_BY(mu_); }; diff --git a/tensorflow/core/kernels/data/generator_dataset_op.h b/tensorflow/core/kernels/data/generator_dataset_op.h index 3f84fa9c2e..8407543136 100644 --- a/tensorflow/core/kernels/data/generator_dataset_op.h +++ b/tensorflow/core/kernels/data/generator_dataset_op.h @@ -17,7 +17,6 @@ limitations under the License. #define TENSORFLOW_CORE_KERNELS_DATA_GENERATOR_DATASET_OP_H_ #include "tensorflow/core/framework/dataset.h" -#include "tensorflow/core/kernels/data/captured_function.h" namespace tensorflow { diff --git a/tensorflow/core/kernels/data/group_by_reducer_dataset_op.cc b/tensorflow/core/kernels/data/group_by_reducer_dataset_op.cc index be4132a064..130f04da3e 100644 --- a/tensorflow/core/kernels/data/group_by_reducer_dataset_op.cc +++ b/tensorflow/core/kernels/data/group_by_reducer_dataset_op.cc @@ -109,11 +109,10 @@ class GroupByReducerDatasetOp : public UnaryDatasetOpKernel { Status AsGraphDefInternal(SerializationContext* ctx, DatasetGraphDefBuilder* b, Node** output) const override { - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), key_func().name())); - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), init_func().name())); - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), reduce_func().name())); - TF_RETURN_IF_ERROR( - b->AddFunction(ctx->flib_def(), finalize_func().name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, key_func().name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, init_func().name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, reduce_func().name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, finalize_func().name())); Node* input_graph_node = nullptr; TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_graph_node)); @@ -190,7 +189,14 @@ class GroupByReducerDatasetOp : public UnaryDatasetOpKernel { : DatasetIterator<Dataset>(params) {} Status Initialize(IteratorContext* ctx) override { - return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); + TF_RETURN_IF_ERROR(dataset()->captured_key_func_->Instantiate(ctx)); + TF_RETURN_IF_ERROR(dataset()->captured_init_func_->Instantiate(ctx)); + TF_RETURN_IF_ERROR(dataset()->captured_reduce_func_->Instantiate(ctx)); + TF_RETURN_IF_ERROR( + dataset()->captured_finalize_func_->Instantiate(ctx)); + return Status::OK(); } Status GetNextInternal(IteratorContext* ctx, diff --git a/tensorflow/core/kernels/data/group_by_window_dataset_op.cc b/tensorflow/core/kernels/data/group_by_window_dataset_op.cc index 288695f3cd..46a3185b49 100644 --- a/tensorflow/core/kernels/data/group_by_window_dataset_op.cc +++ b/tensorflow/core/kernels/data/group_by_window_dataset_op.cc @@ -139,10 +139,9 @@ class GroupByWindowDatasetOp : public UnaryDatasetOpKernel { Status AsGraphDefInternal(SerializationContext* ctx, DatasetGraphDefBuilder* b, Node** output) const override { - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), key_func_.name())); - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), reduce_func_.name())); - TF_RETURN_IF_ERROR( - b->AddFunction(ctx->flib_def(), window_size_func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, key_func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, reduce_func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, window_size_func_.name())); Node* input_graph_node = nullptr; TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_graph_node)); @@ -205,7 +204,13 @@ class GroupByWindowDatasetOp : public UnaryDatasetOpKernel { : DatasetIterator<Dataset>(params) {} Status Initialize(IteratorContext* ctx) override { - return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); + TF_RETURN_IF_ERROR(dataset()->captured_key_func_->Instantiate(ctx)); + TF_RETURN_IF_ERROR(dataset()->captured_reduce_func_->Instantiate(ctx)); + TF_RETURN_IF_ERROR( + dataset()->captured_window_size_func_->Instantiate(ctx)); + return Status::OK(); } Status GetNextInternal(IteratorContext* ctx, diff --git a/tensorflow/core/kernels/data/interleave_dataset_op.cc b/tensorflow/core/kernels/data/interleave_dataset_op.cc index 58b79d6026..716e040277 100644 --- a/tensorflow/core/kernels/data/interleave_dataset_op.cc +++ b/tensorflow/core/kernels/data/interleave_dataset_op.cc @@ -1,4 +1,3 @@ - /* Copyright 2017 The TensorFlow Authors. All Rights Reserved. Licensed under the Apache License, Version 2.0 (the "License"); @@ -117,7 +116,7 @@ class InterleaveDatasetOp : public UnaryDatasetOpKernel { Status AsGraphDefInternal(SerializationContext* ctx, DatasetGraphDefBuilder* b, Node** output) const override { - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, func_.name())); Node* input_node; TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_node)); Node* cycle_length_node; @@ -156,7 +155,9 @@ class InterleaveDatasetOp : public UnaryDatasetOpKernel { args_list_(params.dataset->cycle_length_) {} Status Initialize(IteratorContext* ctx) override { - return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); + return dataset()->captured_func_->Instantiate(ctx); } void AdvanceToNextInCycle() EXCLUSIVE_LOCKS_REQUIRED(mu_) { diff --git a/tensorflow/core/kernels/data/iterator_ops.cc b/tensorflow/core/kernels/data/iterator_ops.cc index 61a6c06135..4e9b280968 100644 --- a/tensorflow/core/kernels/data/iterator_ops.cc +++ b/tensorflow/core/kernels/data/iterator_ops.cc @@ -104,9 +104,8 @@ class IteratorResource : public ResourceBase { bool* end_of_sequence) { std::shared_ptr<IteratorBase> captured_iterator(iterator_); if (captured_iterator) { - if (lib_ != nullptr) { - ctx->set_lib(lib_); - } + CHECK_NOTNULL(lib_); + ctx->set_lib(lib_); return captured_iterator->GetNext(ctx, out_tensors, end_of_sequence); } else { return errors::FailedPrecondition( @@ -162,8 +161,10 @@ class IteratorResource : public ResourceBase { TF_RETURN_IF_ERROR(GetDatasetFromVariantTensor(outputs[0], &dataset)); std::unique_ptr<IteratorBase> iterator; + IteratorContext iter_ctx(ctx); + iter_ctx.set_lib(lib); TF_RETURN_IF_ERROR( - dataset->MakeIterator(IteratorContext(ctx), "Iterator", &iterator)); + dataset->MakeIterator(std::move(iter_ctx), "Iterator", &iterator)); TF_RETURN_IF_ERROR(set_iterator(std::move(iterator))); std::shared_ptr<IteratorBase> captured_iterator(iterator_); @@ -198,6 +199,8 @@ class IteratorResource : public ResourceBase { return lib_def_; } + FunctionLibraryRuntime* function_library_runtime() { return lib_; } + // Transfers ownership of iterator to this. This method is thread-safe. Status set_iterator(std::unique_ptr<IteratorBase> iterator) { if (iterator) { @@ -258,7 +261,7 @@ class VariantTensorDataReader : public IteratorStateReader { } bool Contains(StringPiece key) override { - return map_.find(key.ToString()) != map_.end(); + return map_.find(string(key)) != map_.end(); } private: @@ -279,18 +282,18 @@ class VariantTensorDataReader : public IteratorStateReader { template <typename T> Status ReadScalarInternal(StringPiece key, T* val) { - if (map_.find(key.ToString()) == map_.end()) { + if (map_.find(string(key)) == map_.end()) { return errors::NotFound(key); } - *val = data_->tensors(map_[key.ToString()]).scalar<T>()(); + *val = data_->tensors(map_[string(key)]).scalar<T>()(); return Status::OK(); } Status ReadTensorInternal(StringPiece key, Tensor* val) { - if (map_.find(key.ToString()) == map_.end()) { + if (map_.find(string(key)) == map_.end()) { return errors::NotFound(key); } - *val = data_->tensors(map_[key.ToString()]); + *val = data_->tensors(map_[string(key)]); return Status::OK(); } @@ -339,7 +342,7 @@ class VariantTensorDataWriter : public IteratorStateWriter { // Write key to the metadata proto. This gets written to `data_` // when `Flush()` is called. We do this lazily to avoid multiple // serialization calls. - metadata_proto_.add_keys(key.ToString()); + metadata_proto_.add_keys(string(key)); // Update tensors. *(data_->add_tensors()) = val; @@ -612,8 +615,10 @@ void MakeIteratorOp::Compute(OpKernelContext* ctx) { core::ScopedUnref unref(iterator_resource); std::unique_ptr<IteratorBase> iterator; + IteratorContext iter_ctx(ctx); + iter_ctx.set_lib(iterator_resource->function_library_runtime()); OP_REQUIRES_OK( - ctx, dataset->MakeIterator(IteratorContext(ctx), "Iterator", &iterator)); + ctx, dataset->MakeIterator(std::move(iter_ctx), "Iterator", &iterator)); OP_REQUIRES_OK(ctx, iterator_resource->set_iterator(std::move(iterator))); } @@ -837,8 +842,10 @@ class OneShotIteratorOp : public AsyncOpKernel { DatasetBase* dataset; TF_RETURN_IF_ERROR(GetDatasetFromVariantTensor(return_values[0], &dataset)); std::unique_ptr<IteratorBase> iter; + IteratorContext iter_ctx(ctx); + iter_ctx.set_lib(lib); TF_RETURN_IF_ERROR( - dataset->MakeIterator(IteratorContext(ctx), "Iterator", &iter)); + dataset->MakeIterator(std::move(iter_ctx), "Iterator", &iter)); TF_RETURN_IF_ERROR((*iterator)->set_iterator(std::move(iter))); (*iterator)->Ref(); @@ -922,39 +929,33 @@ void IteratorGetNextOp::ComputeAsync(OpKernelContext* ctx, DoneCallback done) { std::move(done))); } -class IteratorGetNextSyncOp : public OpKernel { - public: - explicit IteratorGetNextSyncOp(OpKernelConstruction* ctx) : OpKernel(ctx) {} - - void Compute(OpKernelContext* ctx) override { - IteratorResource* iterator; - OP_REQUIRES_OK(ctx, - LookupResource(ctx, HandleFromInput(ctx, 0), &iterator)); - core::ScopedUnref unref_iterator(iterator); - - std::vector<Tensor> components; - bool end_of_sequence = false; - - IteratorContext::Params params; - params.env = ctx->env(); - params.runner = *(ctx->runner()); - params.function_library = iterator->function_library(); - DeviceBase* device = ctx->function_library()->device(); - params.allocator_getter = [device](AllocatorAttributes attrs) { - return device->GetAllocator(attrs); - }; - IteratorContext iter_ctx(std::move(params)); +void IteratorGetNextSyncOp::Compute(OpKernelContext* ctx) { + IteratorResource* iterator; + OP_REQUIRES_OK(ctx, LookupResource(ctx, HandleFromInput(ctx, 0), &iterator)); + core::ScopedUnref unref_iterator(iterator); + + std::vector<Tensor> components; + bool end_of_sequence = false; + + IteratorContext::Params params; + params.env = ctx->env(); + params.runner = *(ctx->runner()); + params.function_library = iterator->function_library(); + DeviceBase* device = ctx->function_library()->device(); + params.allocator_getter = [device](AllocatorAttributes attrs) { + return device->GetAllocator(attrs); + }; + IteratorContext iter_ctx(std::move(params)); - OP_REQUIRES_OK(ctx, - iterator->GetNext(&iter_ctx, &components, &end_of_sequence)); - OP_REQUIRES(ctx, !end_of_sequence, errors::OutOfRange("End of sequence")); + OP_REQUIRES_OK(ctx, + iterator->GetNext(&iter_ctx, &components, &end_of_sequence)); + OP_REQUIRES(ctx, !end_of_sequence, errors::OutOfRange("End of sequence")); - for (int i = 0; i < components.size(); ++i) { - // TODO(mrry): Check that the shapes match the shape attrs. - ctx->set_output(i, components[i]); - } + for (int i = 0; i < components.size(); ++i) { + // TODO(mrry): Check that the shapes match the shape attrs. + ctx->set_output(i, components[i]); } -}; +} class IteratorGetNextAsOptionalOp : public AsyncOpKernel { public: diff --git a/tensorflow/core/kernels/data/iterator_ops.h b/tensorflow/core/kernels/data/iterator_ops.h index e426febcce..723564286c 100644 --- a/tensorflow/core/kernels/data/iterator_ops.h +++ b/tensorflow/core/kernels/data/iterator_ops.h @@ -116,6 +116,13 @@ class IteratorGetNextOp : public AsyncOpKernel { BackgroundWorker background_worker_; }; +class IteratorGetNextSyncOp : public OpKernel { + public: + explicit IteratorGetNextSyncOp(OpKernelConstruction* ctx) : OpKernel(ctx) {} + + void Compute(OpKernelContext* ctx) override; +}; + class IteratorToStringHandleOp : public OpKernel { public: explicit IteratorToStringHandleOp(OpKernelConstruction* ctx) diff --git a/tensorflow/core/kernels/data/map_and_batch_dataset_op.cc b/tensorflow/core/kernels/data/map_and_batch_dataset_op.cc index 0e17011b05..8b0c9ad6b2 100644 --- a/tensorflow/core/kernels/data/map_and_batch_dataset_op.cc +++ b/tensorflow/core/kernels/data/map_and_batch_dataset_op.cc @@ -147,7 +147,7 @@ class MapAndBatchDatasetOp : public UnaryDatasetOpKernel { Status AsGraphDefInternal(SerializationContext* ctx, DatasetGraphDefBuilder* b, Node** output) const override { - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), map_fn_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, map_fn_.name())); Node* input_graph_node = nullptr; TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_graph_node)); Node* batch_size_node; @@ -204,7 +204,9 @@ class MapAndBatchDatasetOp : public UnaryDatasetOpKernel { } Status Initialize(IteratorContext* ctx) override { - return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); + return dataset()->captured_func_->Instantiate(ctx); } Status GetNextInternal(IteratorContext* ctx, diff --git a/tensorflow/core/kernels/data/map_dataset_op.cc b/tensorflow/core/kernels/data/map_dataset_op.cc index 294fb1c49a..7f8182d917 100644 --- a/tensorflow/core/kernels/data/map_dataset_op.cc +++ b/tensorflow/core/kernels/data/map_dataset_op.cc @@ -92,7 +92,7 @@ class MapDatasetOp : public UnaryDatasetOpKernel { Status AsGraphDefInternal(SerializationContext* ctx, DatasetGraphDefBuilder* b, Node** output) const override { - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, func_.name())); Node* input_graph_node = nullptr; TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_graph_node)); @@ -127,7 +127,9 @@ class MapDatasetOp : public UnaryDatasetOpKernel { : DatasetIterator<Dataset>(params) {} Status Initialize(IteratorContext* ctx) override { - return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); + return dataset()->captured_func_->Instantiate(ctx); } Status GetNextInternal(IteratorContext* ctx, diff --git a/tensorflow/core/kernels/data/map_defun_op.cc b/tensorflow/core/kernels/data/map_defun_op.cc index d66716ef66..607d0ca028 100644 --- a/tensorflow/core/kernels/data/map_defun_op.cc +++ b/tensorflow/core/kernels/data/map_defun_op.cc @@ -74,7 +74,11 @@ class MapDefunOp : public AsyncOpKernel { arg_shapes->at(i).RemoveDim(0); // Remove the first batch dimension OP_REQUIRES_ASYNC( ctx, batch_size == ctx->input(i).dim_size(0), - errors::InvalidArgument("All inputs must have the same dimension 0."), + errors::InvalidArgument( + "All inputs must have the same dimension 0. Input ", i, + " has leading dimension ", ctx->input(i).dim_size(0), + ", while all previous inputs have leading dimension ", batch_size, + "."), done); } diff --git a/tensorflow/core/kernels/data/optimize_dataset_op.cc b/tensorflow/core/kernels/data/optimize_dataset_op.cc index b097598cd9..831e7252da 100644 --- a/tensorflow/core/kernels/data/optimize_dataset_op.cc +++ b/tensorflow/core/kernels/data/optimize_dataset_op.cc @@ -92,24 +92,33 @@ class OptimizeDatasetOp : public UnaryDatasetOpKernel { DatasetGraphDefBuilder db(&b); Node* input_node = nullptr; SerializationContext::Params params; + params.allow_stateful_functions = true; params.flib_def = ctx->function_library()->GetFunctionLibraryDefinition(); SerializationContext serialization_ctx(params); TF_RETURN_IF_ERROR( db.AddInputDataset(&serialization_ctx, input_, &input_node)); string output_node = input_node->name(); + GraphDef graph_def; TF_RETURN_IF_ERROR(b.ToGraphDef(&graph_def)); VLOG(3) << "Before optimization: " << graph_def.DebugString(); + TF_RETURN_IF_ERROR(ApplyOptimizations(ctx, &graph_def, &output_node)); VLOG(3) << "After optimization: " << graph_def.DebugString(); - flib_def_.reset(new FunctionLibraryDefinition(OpRegistry::Global(), - graph_def.library())); + + // Instantiate the optimized input pipeline by running the optimized graph + // using the optimized function library. + TF_RETURN_IF_ERROR( + ctx->function_library()->Clone(&flib_def_, &pflr_, &lib_)); + TF_RETURN_IF_ERROR(flib_def_->AddLibrary(graph_def.library())); + Graph graph(OpRegistry::Global()); TF_RETURN_IF_ERROR(ImportGraphDef({}, graph_def, &graph, nullptr)); std::vector<Tensor> outputs; GraphRunner graph_runner(ctx->function_library()->device()); - TF_RETURN_IF_ERROR(graph_runner.Run(&graph, ctx->function_library(), {}, - {output_node}, &outputs)); + + TF_RETURN_IF_ERROR( + graph_runner.Run(&graph, lib_, {}, {output_node}, &outputs)); TF_RETURN_IF_ERROR( GetDatasetFromVariantTensor(outputs[0], &optimized_input_)); optimized_input_->Ref(); @@ -142,8 +151,14 @@ class OptimizeDatasetOp : public UnaryDatasetOpKernel { : DatasetIterator<Dataset>(params) {} Status Initialize(IteratorContext* ctx) override { - return dataset()->optimized_input_->MakeIterator(ctx, prefix(), - &input_impl_); + IteratorContext::Params params; + params.env = ctx->env(); + params.runner = *(ctx->runner()); + params.stats_aggregator_getter = ctx->stats_aggregator_getter(); + params.lib = dataset()->lib_; + params.allocator_getter = ctx->allocator_getter(); + return dataset()->optimized_input_->MakeIterator( + IteratorContext(params), prefix(), &input_impl_); } Status GetNextInternal(IteratorContext* ctx, @@ -153,8 +168,7 @@ class OptimizeDatasetOp : public UnaryDatasetOpKernel { params.env = ctx->env(); params.runner = *(ctx->runner()); params.stats_aggregator_getter = ctx->stats_aggregator_getter(); - params.lib = ctx->lib(); - params.function_library = dataset()->flib_def_; + params.lib = dataset()->lib_; params.allocator_getter = ctx->allocator_getter(); IteratorContext iter_ctx(params); return input_impl_->GetNext(&iter_ctx, out_tensors, end_of_sequence); @@ -236,7 +250,9 @@ class OptimizeDatasetOp : public UnaryDatasetOpKernel { } DatasetBase* optimized_input_; - std::shared_ptr<FunctionLibraryDefinition> flib_def_; + FunctionLibraryRuntime* lib_ = nullptr; + std::unique_ptr<ProcessFunctionLibraryRuntime> pflr_ = nullptr; + std::unique_ptr<FunctionLibraryDefinition> flib_def_ = nullptr; const DatasetBase* input_; const std::vector<string> optimizations_; const DataTypeVector output_types_; diff --git a/tensorflow/core/kernels/data/parallel_interleave_dataset_op.cc b/tensorflow/core/kernels/data/parallel_interleave_dataset_op.cc index e492a8215a..f6b3fd97e3 100644 --- a/tensorflow/core/kernels/data/parallel_interleave_dataset_op.cc +++ b/tensorflow/core/kernels/data/parallel_interleave_dataset_op.cc @@ -137,8 +137,7 @@ class ParallelInterleaveDatasetOp : public UnaryDatasetOpKernel { Status AsGraphDefInternal(SerializationContext* ctx, DatasetGraphDefBuilder* b, Node** output) const override { - TF_RETURN_IF_ERROR( - b->AddFunction(ctx->flib_def(), interleave_func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, interleave_func_.name())); Node* input_node; TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_node)); Node* cycle_length_node; @@ -251,7 +250,9 @@ class ParallelInterleaveDatasetOp : public UnaryDatasetOpKernel { } Status Initialize(IteratorContext* ctx) override { - return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); + return dataset()->captured_func_->Instantiate(ctx); } // It is implemented so that it matches the deterministic interleave @@ -279,7 +280,12 @@ class ParallelInterleaveDatasetOp : public UnaryDatasetOpKernel { if (!current_worker->outputs.empty()) { // We have an element! next_index_ = index; - if (i == 0) { + const bool element_acquired_sloppily = + dataset()->sloppy_ && i > 1; + if (!element_acquired_sloppily) { + // If the element was acquired in the regular (non-sloppy) + // order, then advance the current block and cycle pointers to + // the next element in the regular order. block_count_++; if (block_count_ == dataset()->block_length_) { next_index_ = (index + 1) % interleave_indices_.size(); diff --git a/tensorflow/core/kernels/data/parallel_map_dataset_op.cc b/tensorflow/core/kernels/data/parallel_map_dataset_op.cc index a407abfce4..bff54813d6 100644 --- a/tensorflow/core/kernels/data/parallel_map_dataset_op.cc +++ b/tensorflow/core/kernels/data/parallel_map_dataset_op.cc @@ -88,6 +88,10 @@ class ParallelMapDatasetOp : public UnaryDatasetOpKernel { std::unique_ptr<IteratorBase> MakeIteratorInternal( const string& prefix) const override { + auto init_func = [this](IteratorContext* ctx) { + return captured_func_->Instantiate(ctx); + }; + auto map_func = [this](IteratorContext* ctx, std::vector<Tensor> input_element, std::vector<Tensor>* result, StatusCallback done) { @@ -97,7 +101,7 @@ class ParallelMapDatasetOp : public UnaryDatasetOpKernel { return NewParallelMapIterator( {this, strings::StrCat(prefix, "::ParallelMap")}, input_, - std::move(map_func), num_parallel_calls_); + std::move(init_func), std::move(map_func), num_parallel_calls_); } const DataTypeVector& output_dtypes() const override { @@ -138,7 +142,7 @@ class ParallelMapDatasetOp : public UnaryDatasetOpKernel { b->AddScalar(num_parallel_calls_, &num_parallel_calls)); // Attr: f - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, func_.name())); AttrValue f; b->BuildAttrValue(func_, &f); diff --git a/tensorflow/core/kernels/data/parallel_map_iterator.cc b/tensorflow/core/kernels/data/parallel_map_iterator.cc index 4d32b719a4..61f8139b9e 100644 --- a/tensorflow/core/kernels/data/parallel_map_iterator.cc +++ b/tensorflow/core/kernels/data/parallel_map_iterator.cc @@ -26,10 +26,12 @@ class ParallelMapIterator : public DatasetBaseIterator { public: explicit ParallelMapIterator( const typename DatasetBaseIterator::BaseParams& params, - const DatasetBase* input_dataset, ParallelMapIteratorFunction map_func, - int32 num_parallel_calls) + const DatasetBase* input_dataset, + std::function<Status(IteratorContext*)> init_func, + ParallelMapIteratorFunction map_func, int32 num_parallel_calls) : DatasetBaseIterator(params), input_dataset_(input_dataset), + init_func_(std::move(init_func)), map_func_(std::move(map_func)), num_parallel_calls_(num_parallel_calls) {} @@ -50,7 +52,12 @@ class ParallelMapIterator : public DatasetBaseIterator { } Status Initialize(IteratorContext* ctx) override { - return input_dataset_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + input_dataset_->MakeIterator(ctx, prefix(), &input_impl_)); + if (init_func_) { + TF_RETURN_IF_ERROR(init_func_(ctx)); + } + return Status::OK(); } Status GetNextInternal(IteratorContext* ctx, std::vector<Tensor>* out_tensors, @@ -285,6 +292,7 @@ class ParallelMapIterator : public DatasetBaseIterator { } const DatasetBase* const input_dataset_; // Not owned. + const std::function<Status(IteratorContext*)> init_func_; const ParallelMapIteratorFunction map_func_; const int32 num_parallel_calls_; // Used for coordination between the main thread and the runner thread. @@ -311,8 +319,18 @@ std::unique_ptr<IteratorBase> NewParallelMapIterator( const DatasetBaseIterator::BaseParams& params, const DatasetBase* input_dataset, ParallelMapIteratorFunction map_func, int32 num_parallel_calls) { - return std::unique_ptr<IteratorBase>(new ParallelMapIterator( - params, input_dataset, std::move(map_func), num_parallel_calls)); + return NewParallelMapIterator(params, input_dataset, nullptr, + std::move(map_func), num_parallel_calls); +} + +std::unique_ptr<IteratorBase> NewParallelMapIterator( + const DatasetBaseIterator::BaseParams& params, + const DatasetBase* input_dataset, + std::function<Status(IteratorContext*)> init_func, + ParallelMapIteratorFunction map_func, int32 num_parallel_calls) { + return std::unique_ptr<IteratorBase>( + new ParallelMapIterator(params, input_dataset, std::move(init_func), + std::move(map_func), num_parallel_calls)); } } // namespace tensorflow diff --git a/tensorflow/core/kernels/data/parallel_map_iterator.h b/tensorflow/core/kernels/data/parallel_map_iterator.h index 2ce36c3869..7e6cc586f3 100644 --- a/tensorflow/core/kernels/data/parallel_map_iterator.h +++ b/tensorflow/core/kernels/data/parallel_map_iterator.h @@ -33,7 +33,15 @@ using ParallelMapIteratorFunction = std::vector<Tensor>*, StatusCallback)>; // Returns a new iterator that applies `map_func` to the elements of -// `input_dataset` using the given degree of parallelism. +// `input_dataset` using the given degree of parallelism. `init_func` (if +// specified) will be executed when the iterator is initialized (see +// `IteratorBase::Initialize()`) and enables the user to specify error checking +// logic that can fail early. +std::unique_ptr<IteratorBase> NewParallelMapIterator( + const DatasetBaseIterator::BaseParams& params, + const DatasetBase* input_dataset, + std::function<Status(IteratorContext*)> init_func, + ParallelMapIteratorFunction map_func, int32 num_parallel_calls); std::unique_ptr<IteratorBase> NewParallelMapIterator( const DatasetBaseIterator::BaseParams& params, const DatasetBase* input_dataset, ParallelMapIteratorFunction map_func, diff --git a/tensorflow/core/kernels/data/parse_example_dataset_op.cc b/tensorflow/core/kernels/data/parse_example_dataset_op.cc new file mode 100644 index 0000000000..9057800d94 --- /dev/null +++ b/tensorflow/core/kernels/data/parse_example_dataset_op.cc @@ -0,0 +1,372 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include <deque> + +#include "tensorflow/core/common_runtime/device.h" +#include "tensorflow/core/framework/stats_aggregator.h" +#include "tensorflow/core/kernels/data/parallel_map_iterator.h" +#include "tensorflow/core/util/example_proto_fast_parsing.h" + +namespace tensorflow { + +namespace { + +// See documentation in ../ops/dataset_ops.cc for a high-level +// description of the following op. + +class ParseExampleDatasetOp : public UnaryDatasetOpKernel { + public: + explicit ParseExampleDatasetOp(OpKernelConstruction* ctx) + : UnaryDatasetOpKernel(ctx), + graph_def_version_(ctx->graph_def_version()) { + OP_REQUIRES_OK(ctx, ctx->GetAttr("sparse_keys", &sparse_keys_)); + OP_REQUIRES_OK(ctx, ctx->GetAttr("dense_keys", &dense_keys_)); + OP_REQUIRES_OK(ctx, ctx->GetAttr("sparse_types", &sparse_types_)); + OP_REQUIRES_OK(ctx, ctx->GetAttr("Tdense", &dense_types_)); + OP_REQUIRES_OK(ctx, ctx->GetAttr("dense_shapes", &dense_shapes_)); + OP_REQUIRES_OK(ctx, ctx->GetAttr("output_types", &output_types_)); + OP_REQUIRES_OK(ctx, ctx->GetAttr("output_shapes", &output_shapes_)); + for (int i = 0; i < dense_shapes_.size(); ++i) { + bool shape_ok = true; + if (dense_shapes_[i].dims() == -1) { + shape_ok = false; + } else { + for (int d = 1; d < dense_shapes_[i].dims(); ++d) { + if (dense_shapes_[i].dim_size(d) == -1) { + shape_ok = false; + } + } + } + OP_REQUIRES(ctx, shape_ok, + errors::InvalidArgument( + "dense_shapes[", i, + "] has unknown rank or unknown inner dimensions: ", + dense_shapes_[i].DebugString())); + TensorShape dense_shape; + if (dense_shapes_[i].dims() > 0 && dense_shapes_[i].dim_size(0) == -1) { + variable_length_.push_back(true); + for (int d = 1; d < dense_shapes_[i].dims(); ++d) { + dense_shape.AddDim(dense_shapes_[i].dim_size(d)); + } + } else { + variable_length_.push_back(false); + dense_shapes_[i].AsTensorShape(&dense_shape); + } + elements_per_stride_.push_back(dense_shape.num_elements()); + } + } + + protected: + void MakeDataset(OpKernelContext* ctx, DatasetBase* input, + DatasetBase** output) override { + int64 num_parallel_calls; + OP_REQUIRES_OK(ctx, ParseScalarArgument(ctx, "num_parallel_calls", + &num_parallel_calls)); + OP_REQUIRES(ctx, num_parallel_calls > 0, + errors::InvalidArgument( + "num_parallel_calls must be greater than zero.")); + + OpInputList dense_default_tensors; + OP_REQUIRES_OK(ctx, + ctx->input_list("dense_defaults", &dense_default_tensors)); + + OP_REQUIRES(ctx, dense_default_tensors.size() == dense_keys_.size(), + errors::InvalidArgument( + "Expected len(dense_defaults) == len(dense_keys) but got: ", + dense_default_tensors.size(), " vs. ", dense_keys_.size())); + + std::vector<Tensor> dense_defaults; + dense_defaults.reserve(dense_default_tensors.size()); + for (const Tensor& dense_default_t : dense_default_tensors) { + dense_defaults.push_back(dense_default_t); + } + + for (int d = 0; d < dense_keys_.size(); ++d) { + const Tensor& def_value = dense_defaults[d]; + if (variable_length_[d]) { + OP_REQUIRES(ctx, def_value.NumElements() == 1, + errors::InvalidArgument( + "dense_shape[", d, "] is a variable length shape: ", + dense_shapes_[d].DebugString(), + ", therefore " + "def_value[", + d, + "] must contain a single element (" + "the padding element). But its shape is: ", + def_value.shape().DebugString())); + } else if (def_value.NumElements() > 0) { + OP_REQUIRES(ctx, dense_shapes_[d].IsCompatibleWith(def_value.shape()), + errors::InvalidArgument( + "def_value[", d, + "].shape() == ", def_value.shape().DebugString(), + " is not compatible with dense_shapes_[", d, + "] == ", dense_shapes_[d].DebugString())); + } + OP_REQUIRES(ctx, def_value.dtype() == dense_types_[d], + errors::InvalidArgument( + "dense_defaults[", d, "].dtype() == ", + DataTypeString(def_value.dtype()), " != dense_types_[", d, + "] == ", DataTypeString(dense_types_[d]))); + } + + example::FastParseExampleConfig config; + std::map<string, int> key_to_output_index; + for (int d = 0; d < dense_keys_.size(); ++d) { + config.dense.push_back({dense_keys_[d], dense_types_[d], dense_shapes_[d], + dense_default_tensors[d], variable_length_[d], + elements_per_stride_[d]}); + auto result = key_to_output_index.insert({dense_keys_[d], 0}); + OP_REQUIRES(ctx, result.second, + errors::InvalidArgument("Duplicate key not allowed: ", + dense_keys_[d])); + } + for (int d = 0; d < sparse_keys_.size(); ++d) { + config.sparse.push_back({sparse_keys_[d], sparse_types_[d]}); + auto result = key_to_output_index.insert({sparse_keys_[d], 0}); + OP_REQUIRES(ctx, result.second, + errors::InvalidArgument("Duplicate key not allowed: ", + sparse_keys_[d])); + } + int i = 0; + for (auto it = key_to_output_index.begin(); it != key_to_output_index.end(); + it++) { + it->second = i++; + } + + *output = new Dataset(ctx, input, std::move(dense_defaults), + std::move(sparse_keys_), std::move(dense_keys_), + std::move(key_to_output_index), std::move(config), + num_parallel_calls, sparse_types_, dense_types_, + dense_shapes_, output_types_, output_shapes_); + } + + private: + class Dataset : public DatasetBase { + public: + Dataset(OpKernelContext* ctx, const DatasetBase* input, + std::vector<Tensor> dense_defaults, std::vector<string> sparse_keys, + std::vector<string> dense_keys, + std::map<string, int> key_to_output_index, + example::FastParseExampleConfig config, int32 num_parallel_calls, + const DataTypeVector& sparse_types, + const DataTypeVector& dense_types, + const std::vector<PartialTensorShape>& dense_shapes, + const DataTypeVector& output_types, + const std::vector<PartialTensorShape>& output_shapes) + : DatasetBase(DatasetContext(ctx)), + input_(input), + dense_defaults_(std::move(dense_defaults)), + sparse_keys_(std::move(sparse_keys)), + dense_keys_(std::move(dense_keys)), + key_to_output_index_(std::move(key_to_output_index)), + config_(std::move(config)), + num_parallel_calls_(num_parallel_calls), + sparse_types_(sparse_types), + dense_types_(dense_types), + dense_shapes_(dense_shapes), + output_types_(output_types), + output_shapes_(output_shapes) { + input_->Ref(); + } + + ~Dataset() override { input_->Unref(); } + + std::unique_ptr<IteratorBase> MakeIteratorInternal( + const string& prefix) const override { + auto map_fn = [this](IteratorContext* ctx, + std::vector<Tensor> input_element, + std::vector<Tensor>* result, StatusCallback done) { + (*ctx->runner())([this, ctx, input_element, result, done]() { + thread::ThreadPool* device_threadpool = + ctx->lib()->device()->tensorflow_cpu_worker_threads()->workers; + std::vector<string> slice_vec; + for (Tensor t : input_element) { + auto serialized_t = t.flat<string>(); + gtl::ArraySlice<string> slice(serialized_t.data(), + serialized_t.size()); + for (auto it = slice.begin(); it != slice.end(); it++) + slice_vec.push_back(*it); + } + example::FastParseExampleConfig config = config_; + // local copy of config_ for modification. + auto stats_aggregator = ctx->stats_aggregator(); + if (stats_aggregator) { + config.collect_feature_stats = true; + } + example::Result example_result; + Status s = FastParseExample(config, slice_vec, {}, device_threadpool, + &example_result); + if (s.ok()) { + (*result).resize(key_to_output_index_.size()); + for (int d = 0; d < dense_keys_.size(); ++d) { + int output_index = key_to_output_index_.at(dense_keys_[d]); + CHECK(example_result.dense_values[d].dtype() == + output_dtypes()[output_index]) + << "Got wrong type for FastParseExample return value " << d + << " (expected " + << DataTypeString(output_dtypes()[output_index]) << ", got " + << DataTypeString(example_result.dense_values[d].dtype()) + << ")."; + CHECK(output_shapes()[output_index].IsCompatibleWith( + example_result.dense_values[d].shape())) + << "Got wrong shape for FastParseExample return value " << d + << " (expected " + << output_shapes()[output_index].DebugString() << ", got " + << example_result.dense_values[d].shape().DebugString() + << ")."; + (*result)[output_index] = example_result.dense_values[d]; + } + for (int d = 0; d < sparse_keys_.size(); ++d) { + Tensor serialized_sparse = Tensor(DT_VARIANT, TensorShape({3})); + auto serialized_sparse_t = serialized_sparse.vec<Variant>(); + serialized_sparse_t(0) = example_result.sparse_indices[d]; + serialized_sparse_t(1) = example_result.sparse_values[d]; + serialized_sparse_t(2) = example_result.sparse_shapes[d]; + int output_index = key_to_output_index_.at(sparse_keys_[d]); + CHECK(serialized_sparse.dtype() == output_dtypes()[output_index]) + << "Got wrong type for FastParseExample return value " << d + << " (expected " + << DataTypeString(output_dtypes()[output_index]) << ", got " + << DataTypeString(serialized_sparse.dtype()) << ")."; + CHECK(output_shapes()[output_index].IsCompatibleWith( + serialized_sparse.shape())) + << "Got wrong shape for FastParseExample return value " << d + << " (expected " + << output_shapes()[output_index].DebugString() << ", got " + << serialized_sparse.shape().DebugString() << ")."; + (*result)[output_index] = serialized_sparse; + } + // TODO(b/111553342): User provided tags instead of fixed tag. + if (stats_aggregator) { + stats_aggregator->IncrementCounter( + "examples_count", "trainer", + example_result.feature_stats.size()); + for (example::PerExampleFeatureStats feature_stats : + example_result.feature_stats) { + stats_aggregator->AddToHistogram( + strings::StrCat("record_stats", ":features"), + {static_cast<double>(feature_stats.features_count)}); + stats_aggregator->IncrementCounter( + "features_count", "trainer", feature_stats.features_count); + stats_aggregator->IncrementCounter( + "feature_values_count", "trainer", + feature_stats.feature_values_count); + stats_aggregator->AddToHistogram( + strings::StrCat("record_stats", ":feature-values"), + {static_cast<double>(feature_stats.feature_values_count)}); + } + } + } + done(s); + }); + }; + + return NewParallelMapIterator( + {this, strings::StrCat(prefix, "::ParseExample")}, input_, + std::move(map_fn), num_parallel_calls_); + } + + const DataTypeVector& output_dtypes() const override { + return output_types_; + } + + const std::vector<PartialTensorShape>& output_shapes() const override { + return output_shapes_; + } + + string DebugString() const override { + return "ParseExampleDatasetOp::Dataset"; + } + + protected: + Status AsGraphDefInternal(SerializationContext* ctx, + DatasetGraphDefBuilder* b, + Node** output) const override { + Node* input_graph_node = nullptr; + TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_graph_node)); + + Node* num_parallle_calls_node; + std::vector<Node*> dense_defaults_nodes; + dense_defaults_nodes.reserve(dense_defaults_.size()); + + TF_RETURN_IF_ERROR( + b->AddScalar(num_parallel_calls_, &num_parallle_calls_node)); + + for (const Tensor& dense_default : dense_defaults_) { + Node* node; + TF_RETURN_IF_ERROR(b->AddTensor(dense_default, &node)); + dense_defaults_nodes.emplace_back(node); + } + + AttrValue sparse_keys_attr; + AttrValue dense_keys_attr; + AttrValue sparse_types_attr; + AttrValue dense_attr; + AttrValue dense_shapes_attr; + + b->BuildAttrValue(sparse_keys_, &sparse_keys_attr); + b->BuildAttrValue(dense_keys_, &dense_keys_attr); + b->BuildAttrValue(sparse_types_, &sparse_types_attr); + b->BuildAttrValue(dense_types_, &dense_attr); + b->BuildAttrValue(dense_shapes_, &dense_shapes_attr); + + TF_RETURN_IF_ERROR(b->AddDataset(this, + { + {0, input_graph_node}, + {1, num_parallle_calls_node}, + }, + {{2, dense_defaults_nodes}}, + {{"sparse_keys", sparse_keys_attr}, + {"dense_keys", dense_keys_attr}, + {"sparse_types", sparse_types_attr}, + {"Tdense", dense_attr}, + {"dense_shapes", dense_shapes_attr}}, + output)); + return Status::OK(); + } + + private: + const DatasetBase* const input_; + const std::vector<Tensor> dense_defaults_; + const std::vector<string> sparse_keys_; + const std::vector<string> dense_keys_; + const std::map<string, int> key_to_output_index_; + const example::FastParseExampleConfig config_; + const int64 num_parallel_calls_; + const DataTypeVector sparse_types_; + const DataTypeVector dense_types_; + const std::vector<PartialTensorShape> dense_shapes_; + const DataTypeVector output_types_; + const std::vector<PartialTensorShape> output_shapes_; + }; + + const int graph_def_version_; + DataTypeVector output_types_; + std::vector<PartialTensorShape> output_shapes_; + std::vector<string> sparse_keys_; + std::vector<string> dense_keys_; + DataTypeVector sparse_types_; + DataTypeVector dense_types_; + std::vector<PartialTensorShape> dense_shapes_; + std::vector<bool> variable_length_; + std::vector<std::size_t> elements_per_stride_; +}; + +REGISTER_KERNEL_BUILDER(Name("ParseExampleDataset").Device(DEVICE_CPU), + ParseExampleDatasetOp); + +} // namespace + +} // namespace tensorflow diff --git a/tensorflow/core/kernels/data/repeat_dataset_op.cc b/tensorflow/core/kernels/data/repeat_dataset_op.cc index 5e9ace3486..299949b99f 100644 --- a/tensorflow/core/kernels/data/repeat_dataset_op.cc +++ b/tensorflow/core/kernels/data/repeat_dataset_op.cc @@ -172,32 +172,39 @@ class RepeatDatasetOp : public UnaryDatasetOpKernel { class ForeverIterator : public DatasetIterator<Dataset> { public: explicit ForeverIterator(const Params& params) - : DatasetIterator<Dataset>(params), input_impl_(nullptr) {} + : DatasetIterator<Dataset>(params), + input_impl_(nullptr), + first_call_(true) {} + + Status Initialize(IteratorContext* ctx) override { + mutex_lock l(mu_); + return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + } Status GetNextInternal(IteratorContext* ctx, std::vector<Tensor>* out_tensors, bool* end_of_sequence) override { mutex_lock l(mu_); // TODO(mrry): Make locking less conservative. do { - bool first_call = false; if (!input_impl_) { - first_call = true; TF_RETURN_IF_ERROR( dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); } - TF_RETURN_IF_ERROR( - input_impl_->GetNext(ctx, out_tensors, end_of_sequence)); - if (!*end_of_sequence) { + Status s = input_impl_->GetNext(ctx, out_tensors, end_of_sequence); + if (first_call_ && *end_of_sequence) { + // If the first call to GetNext() fails because the end + // of sequence has been reached, we terminate the + // iteration immediately. (Otherwise, this iterator + // would loop infinitely and never produce a value.) + input_impl_.reset(); return Status::OK(); + } + first_call_ = false; + if (!*end_of_sequence) { + return s; } else { input_impl_.reset(); - if (first_call) { - // If the first call to GetNext() fails because the end - // of sequence has been reached, we terminate the - // iteration immediately. (Otherwise, this iterator - // would loop infinitely and never produce a value.) - return Status::OK(); - } + first_call_ = true; } } while (true); } @@ -205,7 +212,7 @@ class RepeatDatasetOp : public UnaryDatasetOpKernel { protected: Status SaveInternal(IteratorStateWriter* writer) override { mutex_lock l(mu_); - if (input_impl_) + if (!first_call_) TF_RETURN_IF_ERROR(SaveInput(writer, input_impl_)); else TF_RETURN_IF_ERROR( @@ -218,10 +225,12 @@ class RepeatDatasetOp : public UnaryDatasetOpKernel { mutex_lock l(mu_); if (reader->Contains(full_name("uninitialized"))) { input_impl_.reset(); + first_call_ = true; } else { TF_RETURN_IF_ERROR( dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); TF_RETURN_IF_ERROR(RestoreInput(ctx, reader, input_impl_)); + first_call_ = false; } return Status::OK(); } @@ -229,6 +238,7 @@ class RepeatDatasetOp : public UnaryDatasetOpKernel { private: mutex mu_; std::unique_ptr<IteratorBase> input_impl_ GUARDED_BY(mu_); + bool first_call_ GUARDED_BY(mu_); }; const int64 count_; diff --git a/tensorflow/core/kernels/data/scan_dataset_op.cc b/tensorflow/core/kernels/data/scan_dataset_op.cc index e4cb31e2b2..fccad933d0 100644 --- a/tensorflow/core/kernels/data/scan_dataset_op.cc +++ b/tensorflow/core/kernels/data/scan_dataset_op.cc @@ -109,7 +109,7 @@ class ScanDatasetOp : public UnaryDatasetOpKernel { Status AsGraphDefInternal(SerializationContext* ctx, DatasetGraphDefBuilder* b, Node** output) const override { - TF_RETURN_IF_ERROR(b->AddFunction(ctx->flib_def(), func_.name())); + TF_RETURN_IF_ERROR(b->AddFunction(ctx, func_.name())); Node* input_node; TF_RETURN_IF_ERROR(b->AddInputDataset(ctx, input_, &input_node)); std::vector<Node*> initial_state_nodes; @@ -153,7 +153,9 @@ class ScanDatasetOp : public UnaryDatasetOpKernel { state_(params.dataset->initial_state_) {} Status Initialize(IteratorContext* ctx) override { - return dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_); + TF_RETURN_IF_ERROR( + dataset()->input_->MakeIterator(ctx, prefix(), &input_impl_)); + return dataset()->captured_func_->Instantiate(ctx); } Status GetNextInternal(IteratorContext* ctx, diff --git a/tensorflow/core/kernels/data_format_ops.h b/tensorflow/core/kernels/data_format_ops.h index 1ca144cb40..bc416fa78b 100644 --- a/tensorflow/core/kernels/data_format_ops.h +++ b/tensorflow/core/kernels/data_format_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_DATA_FORMAT_OPS_H_ -#define TENSORFLOW_KERNELS_DATA_FORMAT_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_DATA_FORMAT_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_DATA_FORMAT_OPS_H_ // Functor definition for data format dim mapping ops, must be compilable // by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -83,4 +83,4 @@ struct DataFormatVecPermute { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_DATA_FORMAT_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_DATA_FORMAT_OPS_H_ diff --git a/tensorflow/core/kernels/debug_ops.h b/tensorflow/core/kernels/debug_ops.h index 53a23b1306..33ed5522d0 100644 --- a/tensorflow/core/kernels/debug_ops.h +++ b/tensorflow/core/kernels/debug_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_DEBUG_OP_H_ -#define TENSORFLOW_KERNELS_DEBUG_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_DEBUG_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_DEBUG_OPS_H_ #if GOOGLE_CUDA #include "tensorflow/core/common_runtime/gpu/gpu_util.h" @@ -177,8 +177,10 @@ class BaseDebugOp : public OpKernel { // Publish a tensor to all debug URLs of the debug op. // Log an error if the publishing failed. - void PublishTensor(const Tensor& tensor) { - if (!debug_urls_.empty()) { + Status PublishTensor(const Tensor& tensor) { + if (debug_urls_.empty()) { + return Status::OK(); + } else { Status status = DebugIO::PublishDebugTensor(*debug_watch_key_, tensor, Env::Default()->NowMicros(), debug_urls_, gated_grpc_); @@ -189,6 +191,7 @@ class BaseDebugOp : public OpKernel { << str_util::Join(debug_urls_, ", ") << ", due to: " << status.error_message(); } + return status; } } @@ -213,7 +216,7 @@ class DebugIdentityOp : public BaseDebugOp { return; } - PublishTensor(context->input(0)); + OP_REQUIRES_OK(context, PublishTensor(context->input(0))); context->set_output(0, context->input(0)); } }; @@ -389,4 +392,4 @@ class DebugNumericSummaryOp : public BaseDebugOp { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_DEBUG_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_DEBUG_OPS_H_ diff --git a/tensorflow/core/kernels/dense_update_functor.h b/tensorflow/core/kernels/dense_update_functor.h index 240c13261e..61b5731250 100644 --- a/tensorflow/core/kernels/dense_update_functor.h +++ b/tensorflow/core/kernels/dense_update_functor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_DENSE_UPDATE_FUNCTOR_H_ -#define TENSORFLOW_KERNELS_DENSE_UPDATE_FUNCTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_DENSE_UPDATE_FUNCTOR_H_ +#define TENSORFLOW_CORE_KERNELS_DENSE_UPDATE_FUNCTOR_H_ #define EIGEN_USE_THREADS @@ -105,4 +105,4 @@ Status VariantCopyFn<GPUDevice>(OpKernelContext* context, const Tensor& from, } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_DENSE_UPDATE_FUNCTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_DENSE_UPDATE_FUNCTOR_H_ diff --git a/tensorflow/core/kernels/eigen_backward_spatial_convolutions.h b/tensorflow/core/kernels/eigen_backward_spatial_convolutions.h index 099696105b..cb0a76dac4 100644 --- a/tensorflow/core/kernels/eigen_backward_spatial_convolutions.h +++ b/tensorflow/core/kernels/eigen_backward_spatial_convolutions.h @@ -499,4 +499,4 @@ SpatialConvolutionBackwardKernel( } // end namespace Eigen -#endif // EIGEN_CXX11_NEURAL_NETWORKS_BACKWARD_SPATIAL_CONVOLUTIONS_H +#endif // TENSORFLOW_CORE_KERNELS_EIGEN_BACKWARD_SPATIAL_CONVOLUTIONS_H_ diff --git a/tensorflow/core/kernels/extract_image_patches_op.h b/tensorflow/core/kernels/extract_image_patches_op.h index e430a23d20..64b8c0338b 100644 --- a/tensorflow/core/kernels/extract_image_patches_op.h +++ b/tensorflow/core/kernels/extract_image_patches_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_EXTRACT_IMAGE_PATCHES_OP_H_ -#define TENSORFLOW_KERNELS_EXTRACT_IMAGE_PATCHES_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_EXTRACT_IMAGE_PATCHES_OP_H_ +#define TENSORFLOW_CORE_KERNELS_EXTRACT_IMAGE_PATCHES_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_shape.h" @@ -53,4 +53,4 @@ struct ExtractImagePatchesForward { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_EXTRACT_IMAGE_PATCHES_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_EXTRACT_IMAGE_PATCHES_OP_H_ diff --git a/tensorflow/core/kernels/fake_quant_ops_functor.h b/tensorflow/core/kernels/fake_quant_ops_functor.h index d51acc38ef..045a96ac1e 100644 --- a/tensorflow/core/kernels/fake_quant_ops_functor.h +++ b/tensorflow/core/kernels/fake_quant_ops_functor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_KERNELS_FAKE_QUANT_FUNCTOR_H_ -#define TENSORFLOW_CORE_KERNELS_FAKE_QUANT_FUNCTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_FAKE_QUANT_OPS_FUNCTOR_H_ +#define TENSORFLOW_CORE_KERNELS_FAKE_QUANT_OPS_FUNCTOR_H_ #include <tuple> @@ -277,4 +277,4 @@ struct FakeQuantWithMinMaxVarsPerChannelGradientFunctor { } // namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_FAKE_QUANT_FUNCTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_FAKE_QUANT_OPS_FUNCTOR_H_ diff --git a/tensorflow/core/kernels/fill_functor.h b/tensorflow/core/kernels/fill_functor.h index 4c8b3f01a7..46bffa5173 100644 --- a/tensorflow/core/kernels/fill_functor.h +++ b/tensorflow/core/kernels/fill_functor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_FILL_FUNCTOR_H_ -#define TENSORFLOW_KERNELS_FILL_FUNCTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_FILL_FUNCTOR_H_ +#define TENSORFLOW_CORE_KERNELS_FILL_FUNCTOR_H_ #define EIGEN_USE_THREADS @@ -89,4 +89,4 @@ struct SetOneFunctor<Eigen::ThreadPoolDevice, string> { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_FILL_FUNCTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_FILL_FUNCTOR_H_ diff --git a/tensorflow/core/kernels/fractional_pool_common.h b/tensorflow/core/kernels/fractional_pool_common.h index 2d7a230fc0..55a959f3c3 100644 --- a/tensorflow/core/kernels/fractional_pool_common.h +++ b/tensorflow/core/kernels/fractional_pool_common.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_FRACTIONAL_POOL_COMMON_H_ -#define TENSORFLOW_KERNELS_FRACTIONAL_POOL_COMMON_H_ +#ifndef TENSORFLOW_CORE_KERNELS_FRACTIONAL_POOL_COMMON_H_ +#define TENSORFLOW_CORE_KERNELS_FRACTIONAL_POOL_COMMON_H_ #include <algorithm> #include <vector> @@ -75,4 +75,4 @@ std::vector<int64> GeneratePoolingSequence(int input_length, int output_length, bool pseudo_random); } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_FRACTIONAL_POOL_COMMON_H_ +#endif // TENSORFLOW_CORE_KERNELS_FRACTIONAL_POOL_COMMON_H_ diff --git a/tensorflow/core/kernels/fused_batch_norm_op.h b/tensorflow/core/kernels/fused_batch_norm_op.h index d6c68df986..c45b6f79e3 100644 --- a/tensorflow/core/kernels/fused_batch_norm_op.h +++ b/tensorflow/core/kernels/fused_batch_norm_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_FUSED_BATCH_NORM_OP_H_ -#define TENSORFLOW_KERNELS_FUSED_BATCH_NORM_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_FUSED_BATCH_NORM_OP_H_ +#define TENSORFLOW_CORE_KERNELS_FUSED_BATCH_NORM_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor.h" @@ -128,4 +128,4 @@ struct FusedBatchNormFreezeGrad { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_FUSED_BATCH_NORM_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_FUSED_BATCH_NORM_OP_H_ diff --git a/tensorflow/core/kernels/gather_functor.h b/tensorflow/core/kernels/gather_functor.h index 2c6e8bf3bc..cd2873bdca 100644 --- a/tensorflow/core/kernels/gather_functor.h +++ b/tensorflow/core/kernels/gather_functor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_GATHER_FUNCTOR_H_ -#define TENSORFLOW_KERNELS_GATHER_FUNCTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_GATHER_FUNCTOR_H_ +#define TENSORFLOW_CORE_KERNELS_GATHER_FUNCTOR_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -176,4 +176,4 @@ struct GatherFunctor<GPUDevice, Variant, Index> { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_GATHER_FUNCTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_GATHER_FUNCTOR_H_ diff --git a/tensorflow/core/kernels/gather_nd_op.h b/tensorflow/core/kernels/gather_nd_op.h index 60780fb50c..003badb74d 100644 --- a/tensorflow/core/kernels/gather_nd_op.h +++ b/tensorflow/core/kernels/gather_nd_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_GATHER_ND_OP_H_ -#define TENSORFLOW_KERNELS_GATHER_ND_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_GATHER_ND_OP_H_ +#define TENSORFLOW_CORE_KERNELS_GATHER_ND_OP_H_ // Functor definition for GatherOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -47,4 +47,4 @@ Status DoGatherNd(OpKernelContext* c, const Tensor& params, } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_GATHER_ND_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_GATHER_ND_OP_H_ diff --git a/tensorflow/core/kernels/gather_nd_op_cpu_impl.h b/tensorflow/core/kernels/gather_nd_op_cpu_impl.h index dc028c2f1e..ad0112e6cb 100644 --- a/tensorflow/core/kernels/gather_nd_op_cpu_impl.h +++ b/tensorflow/core/kernels/gather_nd_op_cpu_impl.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_GATHER_ND_OP_CPU_IMPL_H_ -#define TENSORFLOW_KERNELS_GATHER_ND_OP_CPU_IMPL_H_ +#ifndef TENSORFLOW_CORE_KERNELS_GATHER_ND_OP_CPU_IMPL_H_ +#define TENSORFLOW_CORE_KERNELS_GATHER_ND_OP_CPU_IMPL_H_ // Specialization of GatherNdSlice to CPU @@ -142,4 +142,4 @@ TF_CALL_ALL_TYPES(REGISTER_GATHER_ND_CPU); } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_GATHER_ND_OP_CPU_IMPL_H_ +#endif // TENSORFLOW_CORE_KERNELS_GATHER_ND_OP_CPU_IMPL_H_ diff --git a/tensorflow/core/kernels/gemm_functors.h b/tensorflow/core/kernels/gemm_functors.h index 4b30c1f17f..1c80844085 100644 --- a/tensorflow/core/kernels/gemm_functors.h +++ b/tensorflow/core/kernels/gemm_functors.h @@ -24,6 +24,9 @@ limitations under the License. #error "EIGEN_USE_THREADS must be enabled by all .cc files including this." #endif // EIGEN_USE_THREADS +#ifndef TENSORFLOW_CORE_KERNELS_GEMM_FUNCTORS_H_ +#define TENSORFLOW_CORE_KERNELS_GEMM_FUNCTORS_H_ + #include <string.h> #include <map> #include <vector> @@ -116,3 +119,5 @@ class FastGemmFunctor<float, float, float> { } }; #endif // USE_CBLAS_GEMM + +#endif // TENSORFLOW_CORE_KERNELS_GEMM_FUNCTORS_H_ diff --git a/tensorflow/core/kernels/hexagon/graph_transfer_utils.h b/tensorflow/core/kernels/hexagon/graph_transfer_utils.h index ada96ae4ea..d0d5c3e018 100644 --- a/tensorflow/core/kernels/hexagon/graph_transfer_utils.h +++ b/tensorflow/core/kernels/hexagon/graph_transfer_utils.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_HEXAGON_GRAPH_TRANSFER_UTILS_H_ -#define TENSORFLOW_PLATFORM_HEXAGON_GRAPH_TRANSFER_UTILS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_HEXAGON_GRAPH_TRANSFER_UTILS_H_ +#define TENSORFLOW_CORE_KERNELS_HEXAGON_GRAPH_TRANSFER_UTILS_H_ #include <queue> #include <utility> @@ -56,4 +56,4 @@ class GraphTransferUtils { } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_HEXAGON_GRAPH_TRANSFER_UTILS_H_ +#endif // TENSORFLOW_CORE_KERNELS_HEXAGON_GRAPH_TRANSFER_UTILS_H_ diff --git a/tensorflow/core/kernels/hexagon/graph_transferer.cc b/tensorflow/core/kernels/hexagon/graph_transferer.cc index e05de3fe8e..477e729dcb 100644 --- a/tensorflow/core/kernels/hexagon/graph_transferer.cc +++ b/tensorflow/core/kernels/hexagon/graph_transferer.cc @@ -161,7 +161,7 @@ Status GraphTransferer::LoadGraphFromProto( for (const string& output_node_name : output_node_names) { const TensorId tid = ParseTensorName(output_node_name); - const string node_name = std::string(tid.first); + const string node_name(tid.first); const int port = tid.second; const int node_id = node_name_to_id_cache_map_.at(node_name); const Node* node = node_name_cache_list_.at(node_id); diff --git a/tensorflow/core/kernels/hexagon/graph_transferer.h b/tensorflow/core/kernels/hexagon/graph_transferer.h index 86c1c5625f..4328d51916 100644 --- a/tensorflow/core/kernels/hexagon/graph_transferer.h +++ b/tensorflow/core/kernels/hexagon/graph_transferer.h @@ -228,4 +228,4 @@ class GraphTransferer { } // namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_HEXAGON_GRAPH_TRANSFERER_H +#endif // TENSORFLOW_CORE_KERNELS_HEXAGON_GRAPH_TRANSFERER_H_ diff --git a/tensorflow/core/kernels/hexagon/hexagon_control_wrapper.cc b/tensorflow/core/kernels/hexagon/hexagon_control_wrapper.cc index 1580b72605..cc469f6dba 100644 --- a/tensorflow/core/kernels/hexagon/hexagon_control_wrapper.cc +++ b/tensorflow/core/kernels/hexagon/hexagon_control_wrapper.cc @@ -168,7 +168,7 @@ bool HexagonControlWrapper::SetupGraph() { new_output_node_info.set_output_count(0); const TensorId tid = ParseTensorName(graph_output.name()); - const string node_name = std::string(tid.first); + const string node_name(tid.first); const int port = tid.second; // Register node input for the new output node const GraphTransferNodeInfo* node_info = diff --git a/tensorflow/core/kernels/hexagon/hexagon_control_wrapper.h b/tensorflow/core/kernels/hexagon/hexagon_control_wrapper.h index 132cfde2db..1b382996f8 100644 --- a/tensorflow/core/kernels/hexagon/hexagon_control_wrapper.h +++ b/tensorflow/core/kernels/hexagon/hexagon_control_wrapper.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_KERNELS_HEXAGON_CONTROL_WRAPPER_H_ -#define TENSORFLOW_CORE_KERNELS_HEXAGON_CONTROL_WRAPPER_H_ +#ifndef TENSORFLOW_CORE_KERNELS_HEXAGON_HEXAGON_CONTROL_WRAPPER_H_ +#define TENSORFLOW_CORE_KERNELS_HEXAGON_HEXAGON_CONTROL_WRAPPER_H_ #include <unordered_map> #include <vector> @@ -88,4 +88,4 @@ class HexagonControlWrapper final : public IRemoteFusedGraphExecutor { } // namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_HEXAGON_CONTROL_WRAPPER_H_ +#endif // TENSORFLOW_CORE_KERNELS_HEXAGON_HEXAGON_CONTROL_WRAPPER_H_ diff --git a/tensorflow/core/kernels/hexagon/hexagon_ops_definitions.h b/tensorflow/core/kernels/hexagon/hexagon_ops_definitions.h index b9328c8e0e..270d697e96 100644 --- a/tensorflow/core/kernels/hexagon/hexagon_ops_definitions.h +++ b/tensorflow/core/kernels/hexagon/hexagon_ops_definitions.h @@ -55,4 +55,4 @@ class HexagonOpsDefinitions final : public IRemoteFusedGraphOpsDefinitions { } // namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_HEXAGON_HEXAGON_OPS_DEFINITIONS_H +#endif // TENSORFLOW_CORE_KERNELS_HEXAGON_HEXAGON_OPS_DEFINITIONS_H_ diff --git a/tensorflow/core/kernels/hexagon/soc_interface.h b/tensorflow/core/kernels/hexagon/soc_interface.h index 062103ed98..d1a41d47c8 100644 --- a/tensorflow/core/kernels/hexagon/soc_interface.h +++ b/tensorflow/core/kernels/hexagon/soc_interface.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_HEXAGON_SOC_INTERFACE_H_ -#define TENSORFLOW_PLATFORM_HEXAGON_SOC_INTERFACE_H_ +#ifndef TENSORFLOW_CORE_KERNELS_HEXAGON_SOC_INTERFACE_H_ +#define TENSORFLOW_CORE_KERNELS_HEXAGON_SOC_INTERFACE_H_ // Declaration of APIs provided by hexagon shared library. This header is shared // with both hexagon library built with qualcomm SDK and tensorflow. @@ -111,4 +111,4 @@ void soc_interface_SetDebugFlag(uint64_t flag); } #endif // __cplusplus -#endif // TENSORFLOW_PLATFORM_HEXAGON_SOC_INTERFACE_H_ +#endif // TENSORFLOW_CORE_KERNELS_HEXAGON_SOC_INTERFACE_H_ diff --git a/tensorflow/core/kernels/hinge-loss.h b/tensorflow/core/kernels/hinge-loss.h index d303e9c877..b12910d27d 100644 --- a/tensorflow/core/kernels/hinge-loss.h +++ b/tensorflow/core/kernels/hinge-loss.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_HINGE_LOSS_H_ -#define TENSORFLOW_KERNELS_HINGE_LOSS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_HINGE_LOSS_H_ +#define TENSORFLOW_CORE_KERNELS_HINGE_LOSS_H_ #include <algorithm> #include <limits> @@ -123,4 +123,4 @@ class HingeLossUpdater : public DualLossUpdater { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_HINGE_LOSS_H_ +#endif // TENSORFLOW_CORE_KERNELS_HINGE_LOSS_H_ diff --git a/tensorflow/core/kernels/histogram_op.h b/tensorflow/core/kernels/histogram_op.h index 1b253f7fed..b14fc2bee3 100644 --- a/tensorflow/core/kernels/histogram_op.h +++ b/tensorflow/core/kernels/histogram_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_HISTOGRAM_OP_H_ -#define TENSORFLOW_HISTOGRAM_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_HISTOGRAM_OP_H_ +#define TENSORFLOW_CORE_KERNELS_HISTOGRAM_OP_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/tensor_types.h" @@ -35,4 +35,4 @@ struct HistogramFixedWidthFunctor { } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_HISTOGRAM_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_HISTOGRAM_OP_H_ diff --git a/tensorflow/core/kernels/i_remote_fused_graph_executor.h b/tensorflow/core/kernels/i_remote_fused_graph_executor.h index 6072412689..b2329f4b61 100644 --- a/tensorflow/core/kernels/i_remote_fused_graph_executor.h +++ b/tensorflow/core/kernels/i_remote_fused_graph_executor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_KERNELS_I_REMOTE_GRAPH_EXECUTOR_H_ -#define TENSORFLOW_CORE_KERNELS_I_REMOTE_GRAPH_EXECUTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_I_REMOTE_FUSED_GRAPH_EXECUTOR_H_ +#define TENSORFLOW_CORE_KERNELS_I_REMOTE_FUSED_GRAPH_EXECUTOR_H_ #include "tensorflow/core/framework/tensor.h" #include "tensorflow/core/framework/types.h" @@ -74,4 +74,4 @@ class IRemoteFusedGraphExecutor { } // namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_I_REMOTE_GRAPH_EXECUTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_I_REMOTE_FUSED_GRAPH_EXECUTOR_H_ diff --git a/tensorflow/core/kernels/identity_n_op.h b/tensorflow/core/kernels/identity_n_op.h index 490bbf456c..7339cbbe29 100644 --- a/tensorflow/core/kernels/identity_n_op.h +++ b/tensorflow/core/kernels/identity_n_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_IDENTITY_N_OP_H_ -#define TENSORFLOW_KERNELS_IDENTITY_N_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_IDENTITY_N_OP_H_ +#define TENSORFLOW_CORE_KERNELS_IDENTITY_N_OP_H_ #include "tensorflow/core/framework/op_kernel.h" @@ -41,4 +41,4 @@ class IdentityNOp : public OpKernel { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_IDENTITY_N_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_IDENTITY_N_OP_H_ diff --git a/tensorflow/core/kernels/identity_op.h b/tensorflow/core/kernels/identity_op.h index f8856a1b9b..6b74868ad4 100644 --- a/tensorflow/core/kernels/identity_op.h +++ b/tensorflow/core/kernels/identity_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_IDENTITY_OP_H_ -#define TENSORFLOW_KERNELS_IDENTITY_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_IDENTITY_OP_H_ +#define TENSORFLOW_CORE_KERNELS_IDENTITY_OP_H_ #include "tensorflow/core/framework/op_kernel.h" @@ -37,4 +37,4 @@ class IdentityOp : public OpKernel { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_IDENTITY_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_IDENTITY_OP_H_ diff --git a/tensorflow/core/kernels/image_resizer_state.h b/tensorflow/core/kernels/image_resizer_state.h index 8dcb5977c6..1d4fa1a7db 100644 --- a/tensorflow/core/kernels/image_resizer_state.h +++ b/tensorflow/core/kernels/image_resizer_state.h @@ -18,8 +18,8 @@ limitations under the License. // reduce code duplication and ensure consistency across the different // resizers, it performs the input validation. -#ifndef TENSORFLOW_KERNELS_IMAGE_RESIZER_STATE_H_ -#define TENSORFLOW_KERNELS_IMAGE_RESIZER_STATE_H_ +#ifndef TENSORFLOW_CORE_KERNELS_IMAGE_RESIZER_STATE_H_ +#define TENSORFLOW_CORE_KERNELS_IMAGE_RESIZER_STATE_H_ #define EIGEN_USE_THREADS @@ -191,4 +191,4 @@ struct ImageResizerGradientState { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_IMAGE_RESIZER_STATE_H_ +#endif // TENSORFLOW_CORE_KERNELS_IMAGE_RESIZER_STATE_H_ diff --git a/tensorflow/core/kernels/immutable_constant_op.h b/tensorflow/core/kernels/immutable_constant_op.h index 795331b4b2..97af8c7dc5 100644 --- a/tensorflow/core/kernels/immutable_constant_op.h +++ b/tensorflow/core/kernels/immutable_constant_op.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_IMMUTABLE_CONSTANT_OP_H_ -#define TENSORFLOW_KERNELS_IMMUTABLE_CONSTANT_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_IMMUTABLE_CONSTANT_OP_H_ +#define TENSORFLOW_CORE_KERNELS_IMMUTABLE_CONSTANT_OP_H_ #include <memory> @@ -46,4 +46,4 @@ class ImmutableConstantOp : public OpKernel { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_IMMUTABLE_CONSTANT_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_IMMUTABLE_CONSTANT_OP_H_ diff --git a/tensorflow/core/kernels/initializable_lookup_table.cc b/tensorflow/core/kernels/initializable_lookup_table.cc index 06d53eba30..fcf468f5a8 100644 --- a/tensorflow/core/kernels/initializable_lookup_table.cc +++ b/tensorflow/core/kernels/initializable_lookup_table.cc @@ -14,7 +14,6 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/core/kernels/initializable_lookup_table.h" - #include "tensorflow/core/lib/core/errors.h" namespace tensorflow { @@ -32,6 +31,13 @@ Status InitializableLookupTable::Find(OpKernelContext* ctx, const Tensor& keys, return DoFind(keys, values, default_value); } +Status InitializableLookupTable::ImportValues(OpKernelContext* ctx, + const Tensor& keys, + const Tensor& values) { + lookup::KeyValueTensorIterator iter(&keys, &values); + return Initialize(iter); +} + Status InitializableLookupTable::Initialize(InitTableIterator& iter) { if (!iter.Valid()) { return iter.status(); diff --git a/tensorflow/core/kernels/initializable_lookup_table.h b/tensorflow/core/kernels/initializable_lookup_table.h index b4f81d9a70..424fe5df3c 100644 --- a/tensorflow/core/kernels/initializable_lookup_table.h +++ b/tensorflow/core/kernels/initializable_lookup_table.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_INITIALIZABLE_LOOKUP_TABLE_H_ -#define TENSORFLOW_KERNELS_INITIALIZABLE_LOOKUP_TABLE_H_ +#ifndef TENSORFLOW_CORE_KERNELS_INITIALIZABLE_LOOKUP_TABLE_H_ +#define TENSORFLOW_CORE_KERNELS_INITIALIZABLE_LOOKUP_TABLE_H_ #include "tensorflow/core/framework/lookup_interface.h" #include "tensorflow/core/platform/macros.h" @@ -58,11 +58,7 @@ class InitializableLookupTable : public LookupInterface { } Status ImportValues(OpKernelContext* ctx, const Tensor& keys, - const Tensor& values) final { - return errors::Unimplemented( - "ImportValues not supported by InitializableLookupTable " - "implementations"); - } + const Tensor& values) final; TensorShape key_shape() const final { return TensorShape(); } @@ -155,7 +151,58 @@ class InitializableLookupTable : public LookupInterface { bool is_initialized_ = false; }; +// Iterator to initialize tables given 'keys' and 'values' tensors. +// +// The two tensors are returned in the first iteration. It doesn't loop +// over each element of the tensor since insertions in the lookup table can +// process batches. +class KeyValueTensorIterator + : public InitializableLookupTable::InitTableIterator { + public: + // keys and values are not owned by the iterator. + explicit KeyValueTensorIterator(const Tensor* keys, const Tensor* values) + : keys_(keys), values_(values), valid_(true), status_(Status::OK()) { + TensorShape key_shape = keys_->shape(); + if (!key_shape.IsSameSize(values_->shape())) { + valid_ = false; + status_ = errors::InvalidArgument( + "keys and values should have the same dimension.", + key_shape.DebugString(), " vs ", values_->shape().DebugString()); + } + if (key_shape.num_elements() == 0) { + valid_ = false; + status_ = + errors::InvalidArgument("keys and values cannot be empty tensors."); + } + } + + bool Valid() const override { return valid_; } + + void Next() override { + valid_ = false; + status_ = errors::OutOfRange("No more data."); + } + + const Tensor& keys() const override { return *keys_; } + + const Tensor& values() const override { return *values_; } + + Status status() const override { return status_; } + + int64 total_size() const override { + return keys_ == nullptr ? -1 : keys_->NumElements(); + } + + private: + TF_DISALLOW_COPY_AND_ASSIGN(KeyValueTensorIterator); + + const Tensor* keys_; // Doesn't own it. + const Tensor* values_; // Doesn't own it. + bool valid_; // true if the iterator points to an existing range. + Status status_; +}; + } // namespace lookup } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_INITIALIZABLE_LOOKUP_TABLE_H_ +#endif // TENSORFLOW_CORE_KERNELS_INITIALIZABLE_LOOKUP_TABLE_H_ diff --git a/tensorflow/core/kernels/inplace_ops_functor.h b/tensorflow/core/kernels/inplace_ops_functor.h index b806787e91..2023869f49 100644 --- a/tensorflow/core/kernels/inplace_ops_functor.h +++ b/tensorflow/core/kernels/inplace_ops_functor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_INPLACE_FUNCTOR_H_ -#define TENSORFLOW_KERNELS_INPLACE_FUNCTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_INPLACE_OPS_FUNCTOR_H_ +#define TENSORFLOW_CORE_KERNELS_INPLACE_OPS_FUNCTOR_H_ #include "tensorflow/core/framework/tensor.h" #include "tensorflow/core/lib/core/status.h" @@ -46,4 +46,4 @@ Status DoCopy(const Device& device, const Tensor& x, Tensor* y); } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_INPLACE_FUNCTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_INPLACE_OPS_FUNCTOR_H_ diff --git a/tensorflow/core/kernels/l2loss_op.h b/tensorflow/core/kernels/l2loss_op.h index 4953aa237c..465ef96a51 100644 --- a/tensorflow/core/kernels/l2loss_op.h +++ b/tensorflow/core/kernels/l2loss_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_L2LOSS_OP_H_ -#define TENSORFLOW_KERNELS_L2LOSS_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_L2LOSS_OP_H_ +#define TENSORFLOW_CORE_KERNELS_L2LOSS_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/tensor_types.h" @@ -30,4 +30,4 @@ struct L2LossOp : public OpKernel { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_L2LOSS_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_L2LOSS_OP_H_ diff --git a/tensorflow/core/kernels/linalg_ops_common.h b/tensorflow/core/kernels/linalg_ops_common.h index f7c3f1950b..692f916439 100644 --- a/tensorflow/core/kernels/linalg_ops_common.h +++ b/tensorflow/core/kernels/linalg_ops_common.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_LINALG_OPS_COMMON_H_ -#define TENSORFLOW_KERNELS_LINALG_OPS_COMMON_H_ +#ifndef TENSORFLOW_CORE_KERNELS_LINALG_OPS_COMMON_H_ +#define TENSORFLOW_CORE_KERNELS_LINALG_OPS_COMMON_H_ // Classes to support linear algebra functionality, similar to the numpy.linalg // module. Supports batch computation on several matrices at once, sharding the @@ -194,4 +194,4 @@ extern template class LinearAlgebraOp<complex128>; #define REGISTER_LINALG_OP(OpName, OpClass, Scalar) \ REGISTER_LINALG_OP_CPU(OpName, OpClass, Scalar) -#endif // TENSORFLOW_KERNELS_LINALG_OPS_COMMON_H_ +#endif // TENSORFLOW_CORE_KERNELS_LINALG_OPS_COMMON_H_ diff --git a/tensorflow/core/kernels/logistic-loss.h b/tensorflow/core/kernels/logistic-loss.h index 6479e6f5dc..b43902e0b9 100644 --- a/tensorflow/core/kernels/logistic-loss.h +++ b/tensorflow/core/kernels/logistic-loss.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_LOGISTIC_LOSS_H_ -#define TENSORFLOW_KERNELS_LOGISTIC_LOSS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_LOGISTIC_LOSS_H_ +#define TENSORFLOW_CORE_KERNELS_LOGISTIC_LOSS_H_ #include <cmath> @@ -131,4 +131,4 @@ class LogisticLossUpdater : public DualLossUpdater { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_LOGISTIC_LOSS_H_ +#endif // TENSORFLOW_CORE_KERNELS_LOGISTIC_LOSS_H_ diff --git a/tensorflow/core/kernels/lookup_table_init_op.cc b/tensorflow/core/kernels/lookup_table_init_op.cc index b352dd257c..6e77e1ee01 100644 --- a/tensorflow/core/kernels/lookup_table_init_op.cc +++ b/tensorflow/core/kernels/lookup_table_init_op.cc @@ -74,13 +74,11 @@ class InitializeTableOp : public OpKernel { "Keys and values must have the same size ", keys.NumElements(), " vs ", values.NumElements())); - lookup::KeyValueTensorIterator iter(&keys, &values); - int memory_used_before = 0; if (ctx->track_allocations()) { memory_used_before = table->MemoryUsed(); } - OP_REQUIRES_OK(ctx, table->Initialize(iter)); + OP_REQUIRES_OK(ctx, table->ImportValues(ctx, keys, values)); if (ctx->track_allocations()) { ctx->record_persistent_memory_allocation(table->MemoryUsed() - memory_used_before); diff --git a/tensorflow/core/kernels/lookup_table_init_op.h b/tensorflow/core/kernels/lookup_table_init_op.h index 177a26daa8..101e528659 100644 --- a/tensorflow/core/kernels/lookup_table_init_op.h +++ b/tensorflow/core/kernels/lookup_table_init_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_LOOKUP_TABLE_INIT_OP_H_ -#define TENSORFLOW_KERNELS_LOOKUP_TABLE_INIT_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_LOOKUP_TABLE_INIT_OP_H_ +#define TENSORFLOW_CORE_KERNELS_LOOKUP_TABLE_INIT_OP_H_ #include "tensorflow/core/kernels/initializable_lookup_table.h" @@ -30,4 +30,4 @@ Status InitializeTableFromTextFile(const string& filename, int64 vocab_size, } // namespace lookup } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_LOOKUP_TABLE_INIT_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_LOOKUP_TABLE_INIT_OP_H_ diff --git a/tensorflow/core/kernels/lookup_table_op.h b/tensorflow/core/kernels/lookup_table_op.h index 3977f16299..9451247f26 100644 --- a/tensorflow/core/kernels/lookup_table_op.h +++ b/tensorflow/core/kernels/lookup_table_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_LOOKUP_TABLE_OP_H_ -#define TENSORFLOW_KERNELS_LOOKUP_TABLE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_LOOKUP_TABLE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_LOOKUP_TABLE_OP_H_ #include "tensorflow/core/framework/lookup_interface.h" #include "tensorflow/core/framework/op_kernel.h" @@ -102,9 +102,12 @@ class LookupTableOp : public OpKernel { ~LookupTableOp() override { // If the table object was not shared, delete it. if (table_handle_set_ && cinfo_.resource_is_private_to_kernel()) { - TF_CHECK_OK( - cinfo_.resource_manager()->template Delete<lookup::LookupInterface>( - cinfo_.container(), cinfo_.name())); + if (!cinfo_.resource_manager() + ->template Delete<lookup::LookupInterface>(cinfo_.container(), + cinfo_.name()) + .ok()) { + // Do nothing; the resource can have been deleted by session resets. + } } } @@ -272,4 +275,4 @@ class HashTable : public InitializableLookupTable { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_LOOKUP_TABLE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_LOOKUP_TABLE_OP_H_ diff --git a/tensorflow/core/kernels/lookup_util.h b/tensorflow/core/kernels/lookup_util.h index 894769960a..ec28cf9fa7 100644 --- a/tensorflow/core/kernels/lookup_util.h +++ b/tensorflow/core/kernels/lookup_util.h @@ -46,57 +46,6 @@ Status InitializeTableFromTextFile(const string& filename, int64 vocab_size, int32 value_index, Env* env, InitializableLookupTable* table); -// Iterator to initialize tables given 'keys' and 'values' tensors. -// -// The two tensors are returned in the first iteration. It doesn't loop -// over each element of the tensor since insertions in the lookup table can -// process batches. -class KeyValueTensorIterator - : public InitializableLookupTable::InitTableIterator { - public: - // keys and values are not owned by the iterator. - explicit KeyValueTensorIterator(const Tensor* keys, const Tensor* values) - : keys_(keys), values_(values), valid_(true), status_(Status::OK()) { - TensorShape key_shape = keys_->shape(); - if (!key_shape.IsSameSize(values_->shape())) { - valid_ = false; - status_ = errors::InvalidArgument( - "keys and values should have the same dimension.", - key_shape.DebugString(), " vs ", values_->shape().DebugString()); - } - if (key_shape.num_elements() == 0) { - valid_ = false; - status_ = - errors::InvalidArgument("keys and values cannot be empty tensors."); - } - } - - bool Valid() const override { return valid_; } - - void Next() override { - valid_ = false; - status_ = errors::OutOfRange("No more data."); - } - - const Tensor& keys() const override { return *keys_; } - - const Tensor& values() const override { return *values_; } - - Status status() const override { return status_; } - - int64 total_size() const override { - return keys_ == nullptr ? -1 : keys_->NumElements(); - } - - private: - TF_DISALLOW_COPY_AND_ASSIGN(KeyValueTensorIterator); - - const Tensor* keys_; // Doesn't own it. - const Tensor* values_; // Doesn't own it. - bool valid_; // true if the iterator points to an existing range. - Status status_; -}; - } // namespace lookup } // namespace tensorflow diff --git a/tensorflow/core/kernels/loss.h b/tensorflow/core/kernels/loss.h index a77aa7587b..7db348800e 100644 --- a/tensorflow/core/kernels/loss.h +++ b/tensorflow/core/kernels/loss.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_LOSS_H_ -#define TENSORFLOW_KERNELS_LOSS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_LOSS_H_ +#define TENSORFLOW_CORE_KERNELS_LOSS_H_ #include "tensorflow/core/lib/core/status.h" @@ -56,4 +56,4 @@ class DualLossUpdater { }; } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_LOSS_H_ +#endif // TENSORFLOW_CORE_KERNELS_LOSS_H_ diff --git a/tensorflow/core/kernels/matmul_op.h b/tensorflow/core/kernels/matmul_op.h index 628895ca86..4b74a64025 100644 --- a/tensorflow/core/kernels/matmul_op.h +++ b/tensorflow/core/kernels/matmul_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_MATMUL_OP_H_ -#define TENSORFLOW_KERNELS_MATMUL_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_MATMUL_OP_H_ +#define TENSORFLOW_CORE_KERNELS_MATMUL_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor.h" @@ -117,4 +117,4 @@ typedef Eigen::GpuDevice GPUDevice; } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_MATMUL_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_MATMUL_OP_H_ diff --git a/tensorflow/core/kernels/matrix_band_part_op.h b/tensorflow/core/kernels/matrix_band_part_op.h index 97cc950793..b04e36db8e 100644 --- a/tensorflow/core/kernels/matrix_band_part_op.h +++ b/tensorflow/core/kernels/matrix_band_part_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_MATRIX_DIAG_OP_H_ -#define TENSORFLOW_KERNELS_MATRIX_DIAG_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_MATRIX_BAND_PART_OP_H_ +#define TENSORFLOW_CORE_KERNELS_MATRIX_BAND_PART_OP_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/tensor_types.h" @@ -34,4 +34,4 @@ struct MatrixBandPartFunctor { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_MATRIX_DIAG_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_MATRIX_BAND_PART_OP_H_ diff --git a/tensorflow/core/kernels/matrix_diag_op.h b/tensorflow/core/kernels/matrix_diag_op.h index 14095845b8..108ba0f56b 100644 --- a/tensorflow/core/kernels/matrix_diag_op.h +++ b/tensorflow/core/kernels/matrix_diag_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_MATRIX_DIAG_OP_H_ -#define TENSORFLOW_KERNELS_MATRIX_DIAG_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_MATRIX_DIAG_OP_H_ +#define TENSORFLOW_CORE_KERNELS_MATRIX_DIAG_OP_H_ // Generator definition for MatrixDiagOp, must be compilable by nvcc. @@ -91,4 +91,4 @@ struct MatrixDiag { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_MATRIX_DIAG_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_MATRIX_DIAG_OP_H_ diff --git a/tensorflow/core/kernels/matrix_exponential_op.cc b/tensorflow/core/kernels/matrix_exponential_op.cc index 99db898301..01d4894438 100644 --- a/tensorflow/core/kernels/matrix_exponential_op.cc +++ b/tensorflow/core/kernels/matrix_exponential_op.cc @@ -49,6 +49,7 @@ class MatrixExponentialOp : public LinearAlgebraOp<Scalar> { TF_DISALLOW_COPY_AND_ASSIGN(MatrixExponentialOp); }; +// Deprecated kernels (2018/08/21). REGISTER_LINALG_OP("MatrixExponential", (MatrixExponentialOp<float>), float); REGISTER_LINALG_OP("MatrixExponential", (MatrixExponentialOp<double>), double); REGISTER_LINALG_OP("MatrixExponential", (MatrixExponentialOp<complex64>), diff --git a/tensorflow/core/kernels/matrix_set_diag_op.h b/tensorflow/core/kernels/matrix_set_diag_op.h index aeb144559f..341ef12e97 100644 --- a/tensorflow/core/kernels/matrix_set_diag_op.h +++ b/tensorflow/core/kernels/matrix_set_diag_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_MATRIX_SET_DIAG_OP_H_ -#define TENSORFLOW_KERNELS_MATRIX_SET_DIAG_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_MATRIX_SET_DIAG_OP_H_ +#define TENSORFLOW_CORE_KERNELS_MATRIX_SET_DIAG_OP_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/tensor_types.h" @@ -34,4 +34,4 @@ struct MatrixSetDiag { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_MATRIX_SET_DIAG_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_MATRIX_SET_DIAG_OP_H_ diff --git a/tensorflow/core/kernels/matrix_solve_ls_op_impl.h b/tensorflow/core/kernels/matrix_solve_ls_op_impl.h index 0e09078365..00a05a87a3 100644 --- a/tensorflow/core/kernels/matrix_solve_ls_op_impl.h +++ b/tensorflow/core/kernels/matrix_solve_ls_op_impl.h @@ -13,6 +13,9 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#ifndef TENSORFLOW_CORE_KERNELS_MATRIX_SOLVE_LS_OP_IMPL_H_ +#define TENSORFLOW_CORE_KERNELS_MATRIX_SOLVE_LS_OP_IMPL_H_ + // See docs in ../ops/linalg_ops.cc. #include "third_party/eigen3/Eigen/Cholesky" @@ -159,3 +162,5 @@ class MatrixSolveLsOp : public LinearAlgebraOp<Scalar> { }; } // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_MATRIX_SOLVE_LS_OP_IMPL_H_ diff --git a/tensorflow/core/kernels/maxpooling_op.h b/tensorflow/core/kernels/maxpooling_op.h index f82e57d44c..2adb8081ce 100644 --- a/tensorflow/core/kernels/maxpooling_op.h +++ b/tensorflow/core/kernels/maxpooling_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_MAXPOOLING_OP_H_ -#define TENSORFLOW_KERNELS_MAXPOOLING_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_MAXPOOLING_OP_H_ +#define TENSORFLOW_CORE_KERNELS_MAXPOOLING_OP_H_ // Functor definition for MaxPoolingOp, must be compilable by nvcc. #include "tensorflow/core/framework/numeric_types.h" @@ -51,4 +51,4 @@ struct SpatialMaxPooling<Device, qint8> { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_MAXPOOLING_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_MAXPOOLING_OP_H_ diff --git a/tensorflow/core/kernels/mirror_pad_op.h b/tensorflow/core/kernels/mirror_pad_op.h index 81150a9e79..cc4b6941b9 100644 --- a/tensorflow/core/kernels/mirror_pad_op.h +++ b/tensorflow/core/kernels/mirror_pad_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_MIRROR_PAD_OP_H_ -#define TENSORFLOW_KERNELS_MIRROR_PAD_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_MIRROR_PAD_OP_H_ +#define TENSORFLOW_CORE_KERNELS_MIRROR_PAD_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -437,4 +437,4 @@ struct MirrorPadGrad { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_MIRROR_PAD_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_MIRROR_PAD_OP_H_ diff --git a/tensorflow/core/kernels/mirror_pad_op_cpu_impl.h b/tensorflow/core/kernels/mirror_pad_op_cpu_impl.h index f27ca139c9..98e3be082d 100644 --- a/tensorflow/core/kernels/mirror_pad_op_cpu_impl.h +++ b/tensorflow/core/kernels/mirror_pad_op_cpu_impl.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_MIRROR_PAD_OP_CPU_IMPL_H_ -#define TENSORFLOW_CORE_MIRROR_PAD_OP_CPU_IMPL_H_ +#ifndef TENSORFLOW_CORE_KERNELS_MIRROR_PAD_OP_CPU_IMPL_H_ +#define TENSORFLOW_CORE_KERNELS_MIRROR_PAD_OP_CPU_IMPL_H_ #define EIGEN_USE_THREADS @@ -42,4 +42,4 @@ TF_CALL_NUMBER_TYPES(DEFINE_CPU_SPECS); } // namespace tensorflow -#endif // TENSORFLOW_CORE_MIRROR_PAD_OP_CPU_IMPL_H_ +#endif // TENSORFLOW_CORE_KERNELS_MIRROR_PAD_OP_CPU_IMPL_H_ diff --git a/tensorflow/core/kernels/mkl_aggregate_ops.cc b/tensorflow/core/kernels/mkl_aggregate_ops.cc index 28edf51546..20aa1f7ea1 100644 --- a/tensorflow/core/kernels/mkl_aggregate_ops.cc +++ b/tensorflow/core/kernels/mkl_aggregate_ops.cc @@ -392,16 +392,28 @@ class MklAddNOp : public OpKernel { memory::format src1_mkl_data_format = src1_mkl_shape.GetTfDataFormat(); auto src1_tf_data_format = MklDnnDataFormatToTFDataFormat(src1_mkl_data_format); - auto src2_dims = - TFShapeToMklDnnDimsInNCHW(src2_tensor.shape(), src1_tf_data_format); + memory::dims src2_dims; + if (src2_tensor.dims() == 4) { + src2_dims = TFShapeToMklDnnDimsInNCHW(src2_tensor.shape(), + src1_tf_data_format); + } else { + src2_dims = TFShapeToMklDnnDimsInNCDHW(src2_tensor.shape(), + src1_tf_data_format); + } md2 = memory::desc(src2_dims, MklDnnType<T>(), src1_mkl_data_format); } else if (input2_in_mkl_format && !input1_in_mkl_format) { // Same comment as above. memory::format src2_mkl_data_format = src2_mkl_shape.GetTfDataFormat(); auto src2_tf_data_format = MklDnnDataFormatToTFDataFormat(src2_mkl_data_format); - auto src1_dims = - TFShapeToMklDnnDimsInNCHW(src1_tensor.shape(), src2_tf_data_format); + memory::dims src1_dims; + if (src1_tensor.dims() == 4) { + src1_dims = TFShapeToMklDnnDimsInNCHW(src1_tensor.shape(), + src2_tf_data_format); + } else { + src1_dims = TFShapeToMklDnnDimsInNCDHW(src1_tensor.shape(), + src2_tf_data_format); + } md1 = memory::desc(src1_dims, MklDnnType<T>(), src2_mkl_data_format); md2 = src2_mkl_shape.GetMklLayout(); diff --git a/tensorflow/core/kernels/mkl_avgpooling_op.cc b/tensorflow/core/kernels/mkl_avgpooling_op.cc index 969baecc51..2409f7e9dc 100644 --- a/tensorflow/core/kernels/mkl_avgpooling_op.cc +++ b/tensorflow/core/kernels/mkl_avgpooling_op.cc @@ -453,6 +453,8 @@ class MklAvgPoolingOp : public MklPoolingForwardOpBase<T> { // initialize variables for the pooling op MklPoolParameters pool_params; + // check whether pooling is 2D or 3D + bool is_pool2d = (this->ksize_.size() == 4); // Get the input tensor and initialize the pooling parameters TensorShape input_tensor_shape = input_tensor.shape(); this->InitMklPoolParameters(context, &pool_params, dnn_shape_input, @@ -473,23 +475,22 @@ class MklAvgPoolingOp : public MklPoolingForwardOpBase<T> { } memory::dims filter_dims, strides, padding_left, padding_right; + // Get src/filter/stride/padding information this->PoolParamsToDims(&pool_params, &filter_dims, &strides, - &padding_left, &padding_right); + &padding_left, &padding_right, is_pool2d); // Get the input memory descriptor - memory::desc input_md = - dnn_shape_input.IsMklTensor() - ? dnn_shape_input.GetMklLayout() - : memory::desc(TFShapeToMklDnnDimsInNCHW(input_tensor_shape, - this->data_format_tf_), - MklDnnType<T>(), this->data_format_mkldnn_); - - // Get src/filter/stride/padding information memory::dims src_dims = dnn_shape_input.IsMklTensor() ? dnn_shape_input.GetSizesAsMklDnnDims() - : TFShapeToMklDnnDimsInNCHW(input_tensor.shape(), - this->data_format_tf_); + : is_pool2d ? TFShapeToMklDnnDimsInNCHW(input_tensor.shape(), + this->data_format_tf_) + : TFShapeToMklDnnDimsInNCDHW(input_tensor.shape(), + this->data_format_tf_); + memory::desc input_md = dnn_shape_input.IsMklTensor() + ? dnn_shape_input.GetMklLayout() + : memory::desc(src_dims, MklDnnType<T>(), + this->data_format_mkldnn_); // Get an average pooling primitive from the op pool MklPoolingFwdPrimitive<T>* pooling_fwd = nullptr; @@ -562,24 +563,30 @@ class MklAvgPoolingGradOp : public MklPoolingBackwardOpBase<T> { for (int i = 0; i < orig_input_tensor.NumElements(); i++) { orig_input_shape.AddDim(shape_vec(i)); } + + bool is_pool2d = (this->ksize_.size() == 4); this->InitMklPoolParameters(context, &pool_params, orig_input_mkl_shape, orig_input_shape); memory::dims filter_dims, strides, padding_left, padding_right; this->PoolParamsToDims(&pool_params, &filter_dims, &strides, - &padding_left, &padding_right); + &padding_left, &padding_right, is_pool2d); memory::dims orig_input_dims_mkl_order = orig_input_mkl_shape.IsMklTensor() ? orig_input_mkl_shape.GetSizesAsMklDnnDims() - : TFShapeToMklDnnDimsInNCHW(orig_input_shape, - this->data_format_tf_); + : is_pool2d ? TFShapeToMklDnnDimsInNCHW(orig_input_shape, + this->data_format_tf_) + : TFShapeToMklDnnDimsInNCDHW(orig_input_shape, + this->data_format_tf_); memory::dims diff_dst_dims = grad_mkl_shape.IsMklTensor() ? grad_mkl_shape.GetSizesAsMklDnnDims() - : TFShapeToMklDnnDimsInNCHW(grad_tensor.shape(), - this->data_format_tf_); + : is_pool2d ? TFShapeToMklDnnDimsInNCHW(grad_tensor.shape(), + this->data_format_tf_) + : TFShapeToMklDnnDimsInNCDHW(grad_tensor.shape(), + this->data_format_tf_); memory::dims output_dims_mkl_order; this->GetOutputDims(pool_params, &output_dims_mkl_order); @@ -664,6 +671,18 @@ class MklAvgPoolingGradOp : public MklPoolingBackwardOpBase<T> { } }; // MklAvgPoolingGradOp +REGISTER_KERNEL_BUILDER(Name("_MklAvgPool3D") + .Device(DEVICE_CPU) + .TypeConstraint<float>("T") + .Label(mkl_op_registry::kMklOpLabel), + MklAvgPoolingOp<CPUDevice, float>); + +REGISTER_KERNEL_BUILDER(Name("_MklAvgPool3DGrad") + .Device(DEVICE_CPU) + .TypeConstraint<float>("T") + .Label(mkl_op_registry::kMklOpLabel), + MklAvgPoolingGradOp<CPUDevice, float>); + #endif // INTEL_MKL_ML_ONLY REGISTER_KERNEL_BUILDER(Name("_MklAvgPool") diff --git a/tensorflow/core/kernels/mkl_input_conversion_op.cc b/tensorflow/core/kernels/mkl_input_conversion_op.cc index c89b8048ee..84ee241b8e 100644 --- a/tensorflow/core/kernels/mkl_input_conversion_op.cc +++ b/tensorflow/core/kernels/mkl_input_conversion_op.cc @@ -406,8 +406,8 @@ class MklInputConversionOp : public OpKernel { } // Broadcast is needed if the shapes are not the same - if (mkl_shape->GetTfShape().num_elements() - == tf_tensor->shape().num_elements() ) { + if (mkl_shape->GetTfShape().num_elements() == + tf_tensor->shape().num_elements()) { // Both shapes are same, convert the TF input to MKL VLOG(1) << "MklInputConversionOp: No broadcast needed."; VLOG(1) << "MklInputConversionOp: Converting input " << tf_tensor_index diff --git a/tensorflow/core/kernels/mkl_maxpooling_op.cc b/tensorflow/core/kernels/mkl_maxpooling_op.cc index e149f003e5..256d48f4d5 100644 --- a/tensorflow/core/kernels/mkl_maxpooling_op.cc +++ b/tensorflow/core/kernels/mkl_maxpooling_op.cc @@ -524,6 +524,8 @@ class MklMaxPoolingOp : public MklPoolingForwardOpBase<T> { // initialize variables for the pooling op MklPoolParameters pool_params; + // check whether pooling is 2D or 3D + bool is_pool2d = (this->ksize_.size() == 4); // Get the input tensor and initialize the pooling parameters TensorShape input_tensor_shape = input_tensor.shape(); this->InitMklPoolParameters(context, &pool_params, dnn_shape_input, @@ -547,20 +549,26 @@ class MklMaxPoolingOp : public MklPoolingForwardOpBase<T> { memory::desc input_md = dnn_shape_input.IsMklTensor() ? dnn_shape_input.GetMklLayout() - : memory::desc(TFShapeToMklDnnDimsInNCHW(input_tensor_shape, - this->data_format_tf_), - MklDnnType<T>(), this->data_format_mkldnn_); + : is_pool2d ? memory::desc( + TFShapeToMklDnnDimsInNCHW(input_tensor_shape, + this->data_format_tf_), + MklDnnType<T>(), this->data_format_mkldnn_) + : memory::desc( + TFShapeToMklDnnDimsInNCDHW( + input_tensor_shape, this->data_format_tf_), + MklDnnType<T>(), this->data_format_mkldnn_); // Get src/filter/stride/padding information memory::dims src_dims = dnn_shape_input.IsMklTensor() ? dnn_shape_input.GetSizesAsMklDnnDims() - : TFShapeToMklDnnDimsInNCHW(input_tensor.shape(), - this->data_format_tf_); - + : is_pool2d ? TFShapeToMklDnnDimsInNCHW(input_tensor.shape(), + this->data_format_tf_) + : TFShapeToMklDnnDimsInNCDHW(input_tensor.shape(), + this->data_format_tf_); memory::dims filter_dims, strides, padding_left, padding_right; this->PoolParamsToDims(&pool_params, &filter_dims, &strides, - &padding_left, &padding_right); + &padding_left, &padding_right, is_pool2d); // Get a pooling op from the cached pool MklPoolingFwdPrimitive<T>* pooling_fwd = nullptr; @@ -663,23 +671,30 @@ class MklMaxPoolingGradOp : public MklPoolingBackwardOpBase<T> { MklPoolParameters pool_params; TensorShape orig_input_shape = orig_input_tensor.shape(); + + bool is_pool2d = (this->ksize_.size() == 4); this->InitMklPoolParameters(context, &pool_params, orig_input_mkl_shape, orig_input_shape); memory::dims filter_dims, strides, padding_left, padding_right; this->PoolParamsToDims(&pool_params, &filter_dims, &strides, - &padding_left, &padding_right); + &padding_left, &padding_right, is_pool2d); - memory::dims diff_dst_dims = - grad_mkl_shape.IsMklTensor() - ? grad_mkl_shape.GetSizesAsMklDnnDims() - : TFShapeToMklDnnDimsInNCHW(grad_tensor.shape(), - this->data_format_tf_); memory::dims orig_input_dims_mkl_order = orig_input_mkl_shape.IsMklTensor() ? orig_input_mkl_shape.GetSizesAsMklDnnDims() - : TFShapeToMklDnnDimsInNCHW(orig_input_shape, - this->data_format_tf_); + : is_pool2d ? TFShapeToMklDnnDimsInNCHW(orig_input_shape, + this->data_format_tf_) + : TFShapeToMklDnnDimsInNCDHW(orig_input_shape, + this->data_format_tf_); + + memory::dims diff_dst_dims = + grad_mkl_shape.IsMklTensor() + ? grad_mkl_shape.GetSizesAsMklDnnDims() + : is_pool2d ? TFShapeToMklDnnDimsInNCHW(grad_tensor.shape(), + this->data_format_tf_) + : TFShapeToMklDnnDimsInNCDHW(grad_tensor.shape(), + this->data_format_tf_); memory::dims output_dims_mkl_order; this->GetOutputDims(pool_params, &output_dims_mkl_order); @@ -715,7 +730,7 @@ class MklMaxPoolingGradOp : public MklPoolingBackwardOpBase<T> { void* ws_data = static_cast<void*>( const_cast<uint8*>(workspace_tensor.flat<uint8>().data())); - ; + auto ws_md = pooling_bwd->GetPoolingFwdPd()->workspace_primitive_desc().desc(); if (ws_md.data.format != pooling_bwd->GetWorkspaceFormat()) { @@ -817,6 +832,18 @@ class MklMaxPoolingGradOp : public MklPoolingBackwardOpBase<T> { } }; // MklMaxPoolingGradOp +REGISTER_KERNEL_BUILDER(Name("_MklMaxPool3D") + .Device(DEVICE_CPU) + .TypeConstraint<float>("T") + .Label(mkl_op_registry::kMklOpLabel), + MklMaxPoolingOp<CPUDevice, float>); + +REGISTER_KERNEL_BUILDER(Name("_MklMaxPool3DGrad") + .Device(DEVICE_CPU) + .TypeConstraint<float>("T") + .Label(mkl_op_registry::kMklOpLabel), + MklMaxPoolingGradOp<CPUDevice, float>); + #endif // INTEL_MKL_ML_ONLY REGISTER_KERNEL_BUILDER(Name("_MklMaxPool") diff --git a/tensorflow/core/kernels/mkl_pooling_ops_common.cc b/tensorflow/core/kernels/mkl_pooling_ops_common.cc index d7ad3f9dcd..ec6d241e17 100644 --- a/tensorflow/core/kernels/mkl_pooling_ops_common.cc +++ b/tensorflow/core/kernels/mkl_pooling_ops_common.cc @@ -24,7 +24,7 @@ limitations under the License. namespace tensorflow { -#ifndef INTEL_MKL_ML +#ifndef INTEL_MKL_ML_ONLY using mkldnn::pooling_avg; using mkldnn::pooling_avg_exclude_padding; @@ -46,9 +46,10 @@ void MklPoolingFwdPrimitive<T>::Setup(const MklPoolingParams& fwdParams) { // so src format is currently hard-coded. // A utility function is used to do this, // which may be broken with future CPU architectures + bool is_2d = (fwdParams.src_dims.size() == 4); context_.src_md.reset( new memory::desc({fwdParams.src_dims}, MklDnnType<T>(), - get_desired_format(fwdParams.src_dims[1]))); + get_desired_format(fwdParams.src_dims[1], is_2d))); context_.dst_md.reset(new memory::desc({fwdParams.dst_dims}, MklDnnType<T>(), memory::format::any)); @@ -61,7 +62,7 @@ void MklPoolingFwdPrimitive<T>::Setup(const MklPoolingParams& fwdParams) { new pooling_forward::primitive_desc(*context_.fwd_desc, cpu_engine_)); // store expected primitive format - context_.src_fmt = get_desired_format(fwdParams.src_dims[1]); + context_.src_fmt = get_desired_format(fwdParams.src_dims[1], is_2d); context_.dst_fmt = static_cast<mkldnn::memory::format>( context_.fwd_pd.get()->dst_primitive_desc().desc().data.format); @@ -126,12 +127,14 @@ void MklPoolingBwdPrimitive<T>::Setup(const MklPoolingParams& bwdParams) { } context_.alg_kind = bwdParams.alg_kind; + // check whether it is 2d or 3d + bool is_2d = (bwdParams.dst_dims.size() == 4); // Create memory desc context_.diff_src_md.reset(new memory::desc( {bwdParams.src_dims}, MklDnnType<T>(), memory::format::any)); context_.diff_dst_md.reset( new memory::desc({bwdParams.dst_dims}, MklDnnType<T>(), - get_desired_format(bwdParams.dst_dims[1]))); + get_desired_format(bwdParams.dst_dims[1], is_2d))); context_.bwd_desc.reset(new pooling_backward::desc( bwdParams.alg_kind, *context_.diff_src_md, *context_.diff_dst_md, bwdParams.strides, bwdParams.filter_dims, bwdParams.padding_left, @@ -151,7 +154,7 @@ void MklPoolingBwdPrimitive<T>::Setup(const MklPoolingParams& bwdParams) { // store expected primitive format context_.diff_src_fmt = static_cast<mkldnn::memory::format>( context_.bwd_pd.get()->diff_src_primitive_desc().desc().data.format); - context_.diff_dst_fmt = get_desired_format(bwdParams.dst_dims[1]); + context_.diff_dst_fmt = get_desired_format(bwdParams.dst_dims[1], is_2d); // create MKL-DNN internal memory object with dummy data context_.diff_src_mem.reset( @@ -165,7 +168,7 @@ void MklPoolingBwdPrimitive<T>::Setup(const MklPoolingParams& bwdParams) { if (bwdParams.alg_kind == pooling_max) { auto ws_pd = context_.fwd_pd.get()->workspace_primitive_desc().desc().data; context_.ws_dims.assign(ws_pd.dims, ws_pd.dims + ws_pd.ndims); - context_.ws_fmt = get_desired_format(context_.ws_dims[1]); + context_.ws_fmt = get_desired_format(context_.ws_dims[1], is_2d); context_.ws_dt = static_cast<mkldnn::memory::data_type>(ws_pd.data_type); context_.ws_mem.reset(new memory( {{{context_.ws_dims}, context_.ws_dt, context_.ws_fmt}, cpu_engine}, @@ -211,13 +214,22 @@ void MklPoolParameters::Init(OpKernelContext* context, const std::vector<int32>& stride, Padding padding, TensorFormat data_format, const TensorShape& tensor_in_shape) { - // For maxpooling, tensor_in should have 4 dimensions. - OP_REQUIRES(context, tensor_in_shape.dims() == 4, - errors::InvalidArgument("tensor_in must be 4-dimensional")); + // For maxpooling, tensor_in should have 4 or 5 dimensions. + OP_REQUIRES(context, + tensor_in_shape.dims() == 4 || tensor_in_shape.dims() == 5, + errors::InvalidArgument("tensor_in must be 4 or 5-dimensional")); depth = GetTensorDim(tensor_in_shape, data_format, 'C'); - tensor_in_cols = GetTensorDim(tensor_in_shape, data_format, 'W'); - tensor_in_rows = GetTensorDim(tensor_in_shape, data_format, 'H'); + if (tensor_in_shape.dims() == 4) { + // Pool2D + tensor_in_cols = GetTensorDim(tensor_in_shape, data_format, 'W'); + tensor_in_rows = GetTensorDim(tensor_in_shape, data_format, 'H'); + } else { + // Pool3D + tensor_in_planes = GetTensorDim(tensor_in_shape, data_format, '0'); + tensor_in_rows = GetTensorDim(tensor_in_shape, data_format, '1'); + tensor_in_cols = GetTensorDim(tensor_in_shape, data_format, '2'); + } tensor_in_batch = GetTensorDim(tensor_in_shape, data_format, 'N'); Init(context, ksize, stride, padding, data_format); @@ -246,10 +258,20 @@ void MklPoolParameters::Init(OpKernelContext* context, TensorFormat data_format, const MklDnnShape* mklInputShape) { // Get the input sizes - depth = mklInputShape->GetDimension('C'); - tensor_in_cols = mklInputShape->GetDimension('W'); - tensor_in_rows = mklInputShape->GetDimension('H'); - tensor_in_batch = mklInputShape->GetDimension('N'); + if (ksize.size() == 4) { + // Pool2D + depth = mklInputShape->GetDimension('C'); + tensor_in_cols = mklInputShape->GetDimension('W'); + tensor_in_rows = mklInputShape->GetDimension('H'); + tensor_in_batch = mklInputShape->GetDimension('N'); + } else { + // Pool3D + depth = mklInputShape->GetDimension3D('C'); + tensor_in_cols = mklInputShape->GetDimension3D('W'); + tensor_in_rows = mklInputShape->GetDimension3D('H'); + tensor_in_planes = mklInputShape->GetDimension3D('D'); + tensor_in_batch = mklInputShape->GetDimension3D('N'); + } Init(context, ksize, stride, padding, data_format); } @@ -262,25 +284,58 @@ void MklPoolParameters::Init(OpKernelContext* context, // Get the data format this->data_format = data_format; - // Get the output sizes - window_rows = GetTensorDim(ksize, data_format, 'H'); - window_cols = GetTensorDim(ksize, data_format, 'W'); - depth_window = GetTensorDim(ksize, data_format, 'C'); - - // Get the strides - row_stride = GetTensorDim(stride, data_format, 'H'); - col_stride = GetTensorDim(stride, data_format, 'W'); - depth_stride = GetTensorDim(stride, data_format, 'C'); + bool is_pool2d = (ksize.size() == 4); + if (is_pool2d) { + // Pool2D + // Get the output sizes + window_rows = GetTensorDim(ksize, data_format, 'H'); + window_cols = GetTensorDim(ksize, data_format, 'W'); + depth_window = GetTensorDim(ksize, data_format, 'C'); + + // Get the strides + row_stride = GetTensorDim(stride, data_format, 'H'); + col_stride = GetTensorDim(stride, data_format, 'W'); + depth_stride = GetTensorDim(stride, data_format, 'C'); + + // We only support 2D pooling across width/height and depthwise + // pooling, not a combination. + OP_REQUIRES(context, + (depth_window == 1 || (window_rows == 1 && window_cols == 1)), + errors::Unimplemented( + "MaxPooling supports exactly one of pooling across depth " + "or pooling across width/height.")); + } else { + // Pool3D + // Get the output sizes + window_planes = GetTensorDim(ksize, data_format, '0'); + window_rows = GetTensorDim(ksize, data_format, '1'); + window_cols = GetTensorDim(ksize, data_format, '2'); + depth_window = GetTensorDim(ksize, data_format, 'C'); + + // Get the strides + planes_stride = GetTensorDim(stride, data_format, '0'); + row_stride = GetTensorDim(stride, data_format, '1'); + col_stride = GetTensorDim(stride, data_format, '2'); + depth_stride = GetTensorDim(stride, data_format, 'C'); + + // We only support 3D pooling across depth/width/height and depthwise + // pooling, not a combination. + OP_REQUIRES(context, + (depth_window == 1 || + (window_rows == 1 && window_cols == 1 && window_planes == 1)), + errors::Unimplemented( + "AvgPooling3D supports exactly one of pooling across depth " + "or pooling across depth/width/height.")); + } - // We only support 2D pooling across width/height and depthwise - // pooling, not a combination. - OP_REQUIRES(context, - (depth_window == 1 || (window_rows == 1 && window_cols == 1)), - errors::Unimplemented( - "MaxPooling supports exactly one of pooling across depth " - "or pooling across width/height.")); + if (depth_window == 1) { // we are pooling in the D (Pool3D only), H and W + if (!is_pool2d) { + OP_REQUIRES_OK( + context, GetWindowedOutputSizeVerbose(tensor_in_planes, window_planes, + planes_stride, padding, + &out_planes, &pad_P1, &pad_P2)); + } - if (depth_window == 1) { // we are pooling in the H and W OP_REQUIRES_OK(context, GetWindowedOutputSizeVerbose( tensor_in_rows, window_rows, row_stride, padding, &out_height, &pad_top, &pad_bottom)); @@ -290,7 +345,14 @@ void MklPoolParameters::Init(OpKernelContext* context, padding, &out_width, &pad_left, &pad_right)); #ifndef INTEL_MKL_ML_ONLY // TF can work with int64, but mkldnn only supports int32 - // Fail if the height or width are greater than MAX_INT + // Fail if the depth, height or width are greater than MAX_INT + // We check depth only for 3D pooling case + + if (!is_pool2d) { + OP_REQUIRES(context, + FastBoundsCheck(out_planes, std::numeric_limits<int>::max()), + errors::InvalidArgument("output depth/planes is too large")); + } OP_REQUIRES(context, FastBoundsCheck(out_height, std::numeric_limits<int>::max()), @@ -299,7 +361,6 @@ void MklPoolParameters::Init(OpKernelContext* context, OP_REQUIRES(context, FastBoundsCheck(out_width, std::numeric_limits<int>::max()), errors::InvalidArgument("output width is too large")); - #endif out_depth = depth; // output will have the same depth as the input } else { // we are pooling in the depth dimension diff --git a/tensorflow/core/kernels/mkl_pooling_ops_common.h b/tensorflow/core/kernels/mkl_pooling_ops_common.h index ec7af5092d..49f799d7ba 100644 --- a/tensorflow/core/kernels/mkl_pooling_ops_common.h +++ b/tensorflow/core/kernels/mkl_pooling_ops_common.h @@ -19,6 +19,7 @@ limitations under the License. #ifdef INTEL_MKL #include <memory> #include <vector> +#include <string> #include "tensorflow/core/util/mkl_util.h" #include "tensorflow/core/util/padding.h" @@ -32,7 +33,7 @@ using mkldnn::stream; namespace tensorflow { -#ifndef INTEL_MKL_ML +#ifndef INTEL_MKL_ML_ONLY using mkldnn::memory; using mkldnn::pooling_avg; @@ -357,22 +358,28 @@ typedef Eigen::ThreadPoolDevice CPUDevice; struct MklPoolParameters { int depth; + int tensor_in_planes; // Pool3D int tensor_in_cols; int tensor_in_rows; int tensor_in_batch; + int window_planes; // Pool3D int window_rows; int window_cols; int depth_window; + int planes_stride; // Pool3D int row_stride; int col_stride; int depth_stride; + int64 out_planes; // Pool3D int64 out_height; int64 out_width; int out_depth; + int64 pad_P1; // Pool3D + int64 pad_P2; // Pool3D int64 pad_left; int64 pad_right; int64 pad_top; @@ -382,18 +389,24 @@ struct MklPoolParameters { TensorFormat data_format; MklPoolParameters() : depth(0), + tensor_in_planes(0), tensor_in_cols(0), tensor_in_rows(0), tensor_in_batch(0), + window_planes(0), window_rows(0), window_cols(0), depth_window(0), + planes_stride(0), row_stride(0), col_stride(0), depth_stride(0), + out_planes(0), out_height(0), out_width(0), out_depth(0), + pad_P1(0), + pad_P2(0), pad_left(0), pad_right(0), pad_top(0), @@ -433,20 +446,22 @@ class MklPoolingOpBase : public OpKernel { OP_REQUIRES_OK(context, context->GetAttr("data_format", &data_format)); OP_REQUIRES(context, FormatFromString(data_format, &this->data_format_tf_), errors::InvalidArgument("Invalid data format")); - this->data_format_mkldnn_ = - TFDataFormatToMklDnnDataFormat(this->data_format_tf_); OP_REQUIRES_OK(context, context->GetAttr("ksize", &this->ksize_)); - OP_REQUIRES(context, this->ksize_.size() == 4, + OP_REQUIRES(context, this->ksize_.size() == 4 || this->ksize_.size() == 5, errors::InvalidArgument("Sliding window ksize field must " - "specify 4 dimensions")); + "specify 4 or 5 dimensions")); OP_REQUIRES_OK(context, context->GetAttr("strides", &this->stride_)); - OP_REQUIRES(context, this->stride_.size() == 4, + OP_REQUIRES(context, this->stride_.size() == 4 || this->stride_.size() == 5, errors::InvalidArgument("Sliding window strides field must " - "specify 4 dimensions")); + "specify 4 or 5 dimensions")); OP_REQUIRES_OK(context, context->GetAttr("padding", &this->padding_)); OP_REQUIRES(context, this->ksize_[0] == 1 && this->stride_[0] == 1, errors::Unimplemented("Pooling is not yet supported on the " "batch dimension.")); + bool is_pool2d = (this->ksize_.size() == 4); + this->data_format_mkldnn_ = + is_pool2d ? TFDataFormatToMklDnnDataFormat(this->data_format_tf_) + : TFDataFormatToMklDnn3DDataFormat(this->data_format_tf_); // We may not get this attribute for this node if it does not go through // graph rewrite pass. So we do not check for error while retrieving this @@ -457,17 +472,26 @@ class MklPoolingOpBase : public OpKernel { protected: // Calculate output shape of pooling op in MKL-DNN and TensorFlow order. - // MKL-DNN uses NCHW for output order. But TensorFlow output will be in - // NHWC or NCHW format depending on data format. Function expects - // output height and output width to have already been int32 - // bounds-checked + // MKL-DNN uses NCHW(Pool2D) or NCDHW(Pool3D) for output order. + // But TensorFlow output will be in NHWC/NCHW(Pool2D) or + // NDHWC/NCDHW(Pool3D) format depending on data format. Function expects + // output height and width to have already been int32 bounds-checked. void GetOutputDims(const MklPoolParameters& mkl_pool_params, memory::dims* output_dims_mkl_order) { - // MKL-DNN always needs output in NCHW format. - *output_dims_mkl_order = {mkl_pool_params.tensor_in_batch, - mkl_pool_params.out_depth, - static_cast<int>(mkl_pool_params.out_height), - static_cast<int>(mkl_pool_params.out_width)}; + if (this->ksize_.size() == 4) { + // Pooling2D: MKL-DNN always needs output in NCHW format. + *output_dims_mkl_order = {mkl_pool_params.tensor_in_batch, + mkl_pool_params.out_depth, + static_cast<int>(mkl_pool_params.out_height), + static_cast<int>(mkl_pool_params.out_width)}; + } else { + // Pooling3D: MKL-DNN always needs output in NCDHW format. + *output_dims_mkl_order = {mkl_pool_params.tensor_in_batch, + mkl_pool_params.out_depth, + static_cast<int>(mkl_pool_params.out_planes), + static_cast<int>(mkl_pool_params.out_height), + static_cast<int>(mkl_pool_params.out_width)}; + } } void InitMklPoolParameters(OpKernelContext* context, @@ -485,14 +509,34 @@ class MklPoolingOpBase : public OpKernel { void PoolParamsToDims(const MklPoolParameters* pool_params, memory::dims* filter_dims, memory::dims* strides, - memory::dims* padding_left, - memory::dims* padding_right) { - *filter_dims = {pool_params->window_rows, pool_params->window_cols}; - *strides = {pool_params->row_stride, pool_params->col_stride}; - *padding_left = {static_cast<int>(pool_params->pad_top), - static_cast<int>(pool_params->pad_left)}; - *padding_right = {static_cast<int>(pool_params->pad_bottom), - static_cast<int>(pool_params->pad_right)}; + memory::dims* padding_left, memory::dims* padding_right, + bool is_pool2d) { + if (is_pool2d) { + // Pool2D + *filter_dims = + memory::dims({pool_params->window_rows, pool_params->window_cols}); + *strides = + memory::dims({pool_params->row_stride, pool_params->col_stride}); + *padding_left = memory::dims({static_cast<int>(pool_params->pad_top), + static_cast<int>(pool_params->pad_left)}); + *padding_right = memory::dims({static_cast<int>(pool_params->pad_bottom), + static_cast<int>(pool_params->pad_right)}); + } else { + // Pool3D + *filter_dims = + memory::dims({pool_params->window_planes, pool_params->window_rows, + pool_params->window_cols}); + *strides = + memory::dims({pool_params->planes_stride, pool_params->row_stride, + pool_params->col_stride}); + + *padding_left = memory::dims({static_cast<int>(pool_params->pad_P1), + static_cast<int>(pool_params->pad_top), + static_cast<int>(pool_params->pad_left)}); + *padding_right = memory::dims({static_cast<int>(pool_params->pad_P2), + static_cast<int>(pool_params->pad_bottom), + static_cast<int>(pool_params->pad_right)}); + } } void AllocateEmptyOutputTensor(OpKernelContext* context, @@ -556,12 +600,27 @@ class MklPoolingForwardOpBase : public MklPoolingOpBase<T> { TensorShape input_tensor_shape = input_tensor.shape(); if (input_tensor.NumElements() != 0) { memory::desc input_md = - input_mkl_shape.IsMklTensor() - ? input_mkl_shape.GetMklLayout() - : memory::desc(TFShapeToMklDnnDimsInNCHW(input_tensor_shape, + input_mkl_shape.IsMklTensor() + ? input_mkl_shape.GetMklLayout() + : memory::desc( + (this->ksize_.size() == 4) + ? TFShapeToMklDnnDimsInNCHW(input_tensor_shape, + this->data_format_tf_) + : TFShapeToMklDnnDimsInNCDHW(input_tensor_shape, this->data_format_tf_), - MklDnnType<T>(), this->data_format_mkldnn_); + MklDnnType<T>(), this->data_format_mkldnn_); dnn_data_input->SetUsrMem(input_md, &input_tensor); + + if (this->ksize_.size() == 5) { + // Pool3D + std::vector<int> mkldnn_sizes(5, -1); + mkldnn_sizes[MklDnnDims3D::Dim3d_N] = input_md.data.dims[0]; + mkldnn_sizes[MklDnnDims3D::Dim3d_C] = input_md.data.dims[1]; + mkldnn_sizes[MklDnnDims3D::Dim3d_D] = input_md.data.dims[2]; + mkldnn_sizes[MklDnnDims3D::Dim3d_H] = input_md.data.dims[3]; + mkldnn_sizes[MklDnnDims3D::Dim3d_W] = input_md.data.dims[4]; + dnn_data_input->SetOpMemDesc(mkldnn_sizes, this->data_format_mkldnn_); + } } this->InitMklPoolParameters(context, pool_params, input_mkl_shape, input_tensor_shape); @@ -593,12 +652,13 @@ class MklPoolingForwardOpBase : public MklPoolingOpBase<T> { void SanityCheckInput(OpKernelContext* context, const Tensor& input_tensor, const MklDnnShape& input_mkl_shape) { if (!input_mkl_shape.IsMklTensor()) { - OP_REQUIRES(context, input_tensor.dims() == 4, - errors::InvalidArgument("Input must be 4-dimensional")); + OP_REQUIRES(context, input_tensor.dims() == 4 || input_tensor.dims() == 5, + errors::InvalidArgument("Input must be 4 or 5-dimensional")); } else { - OP_REQUIRES(context, input_mkl_shape.GetDimension() == 4, + OP_REQUIRES(context, input_mkl_shape.GetDimension() == 4 || + input_mkl_shape.GetDimension() == 5, errors::InvalidArgument("Input shape must be " - "4-dimensional")); + "4 or 5-dimensional")); } } // .Input("value: T") @@ -649,8 +709,12 @@ class MklPoolingBackwardOpBase : public MklPoolingOpBase<T> { input_gradient_mkl_shape.IsMklTensor() ? input_gradient_mkl_shape.GetMklLayout() : memory::desc( - TFShapeToMklDnnDimsInNCHW(input_gradient_tensor.shape(), - this->data_format_tf_), + (this->ksize_.size() == 4) + ? TFShapeToMklDnnDimsInNCHW(input_gradient_tensor.shape(), + this->data_format_tf_) + : TFShapeToMklDnnDimsInNCDHW( + input_gradient_tensor.shape(), + this->data_format_tf_), MklDnnType<T>(), this->data_format_mkldnn_); input_gradient_dnn_data->SetUsrMem(original_input_grad_md, diff --git a/tensorflow/core/kernels/mkl_relu_op.cc b/tensorflow/core/kernels/mkl_relu_op.cc index bea6fd6d3c..f4cfc48af5 100644 --- a/tensorflow/core/kernels/mkl_relu_op.cc +++ b/tensorflow/core/kernels/mkl_relu_op.cc @@ -30,6 +30,7 @@ using mkldnn::algorithm; using mkldnn::eltwise_elu; using mkldnn::eltwise_relu; using mkldnn::eltwise_tanh; +using mkldnn::memory; using mkldnn::prop_kind; using mkldnn::relu_backward; using mkldnn::relu_forward; @@ -56,25 +57,27 @@ class MklEltwiseFwdParams { T beta; MklEltwiseFwdParams(memory::dims src_dims, memory::desc src_md, - algorithm alg_kind, T alpha, T beta) : - src_dims(src_dims), src_md(src_md), - alg_kind(alg_kind), alpha(alpha), beta(beta) { - } + algorithm alg_kind, T alpha, T beta) + : src_dims(src_dims), + src_md(src_md), + alg_kind(alg_kind), + alpha(alpha), + beta(beta) {} }; template <typename T> class MklEltwiseFwdPrimitive : public MklPrimitive { public: - explicit MklEltwiseFwdPrimitive(const MklEltwiseFwdParams<T>& fwdParams) : - cpu_engine_(engine::cpu, 0) { + explicit MklEltwiseFwdPrimitive(const MklEltwiseFwdParams<T>& fwdParams) + : cpu_engine_(engine::cpu, 0) { // store expected format - context_.src_fmt = static_cast<mkldnn::memory::format>( - fwdParams.src_md.data.format); + context_.src_fmt = + static_cast<mkldnn::memory::format>(fwdParams.src_md.data.format); context_.fwd_stream.reset(new stream(stream::kind::eager)); // create eltwise primitive if (context_.eltwise_fwd == nullptr) { - Setup(fwdParams); + Setup(fwdParams); } } @@ -98,9 +101,7 @@ class MklEltwiseFwdPrimitive : public MklPrimitive { return context_.fwd_pd; } - memory::format GetSrcMemoryFormat() { - return context_.src_fmt; - } + memory::format GetSrcMemoryFormat() { return context_.src_fmt; } private: // Primitive reuse context for eltwise Fwd ops: Relu, Elu, Tanh @@ -129,19 +130,25 @@ class MklEltwiseFwdPrimitive : public MklPrimitive { std::shared_ptr<stream> fwd_stream; std::vector<mkldnn::primitive> fwd_primitives; - EltwiseFwdContext() : - src_fmt(memory::format::any), src_mem(nullptr), dst_mem(nullptr), - fwd_desc(nullptr), fwd_pd(nullptr), src_md(nullptr), dst_md(nullptr), - src_mpd(nullptr), eltwise_fwd(nullptr), fwd_stream(nullptr) { - } + EltwiseFwdContext() + : src_fmt(memory::format::any), + src_mem(nullptr), + dst_mem(nullptr), + fwd_desc(nullptr), + fwd_pd(nullptr), + src_md(nullptr), + dst_md(nullptr), + src_mpd(nullptr), + eltwise_fwd(nullptr), + fwd_stream(nullptr) {} }; // Eltwise forward primitive setup void Setup(const MklEltwiseFwdParams<T>& fwdParams) { // create memory descriptors for eltwise data with specified format context_.src_md.reset(new memory::desc(fwdParams.src_md.data)); - context_.src_mpd.reset(new memory::primitive_desc( - *context_.src_md, cpu_engine_)); + context_.src_mpd.reset( + new memory::primitive_desc(*context_.src_md, cpu_engine_)); // create a eltwise context_.fwd_desc.reset(new mkldnn::eltwise_forward::desc( @@ -152,12 +159,12 @@ class MklEltwiseFwdPrimitive : public MklPrimitive { // create memory primitive based on dummy data context_.src_mem.reset(new memory(*context_.src_mpd, DummyData)); - context_.dst_mem.reset(new memory( - context_.fwd_pd.get()->dst_primitive_desc(), DummyData)); + context_.dst_mem.reset( + new memory(context_.fwd_pd.get()->dst_primitive_desc(), DummyData)); // create eltwise primitive and add it to net - context_.eltwise_fwd.reset(new mkldnn::eltwise_forward(*context_.fwd_pd, - *context_.src_mem, *context_.dst_mem)); + context_.eltwise_fwd.reset(new mkldnn::eltwise_forward( + *context_.fwd_pd, *context_.src_mem, *context_.dst_mem)); context_.fwd_primitives.push_back(*context_.eltwise_fwd); } @@ -173,13 +180,13 @@ class MklEltwiseFwdPrimitiveFactory : public MklPrimitiveFactory<T> { const MklEltwiseFwdParams<T>& fwdParams) { MklEltwiseFwdPrimitive<T>* eltwise_forward = nullptr; - auto src_fmt = static_cast<mkldnn::memory::format>( - fwdParams.src_md.data.format); + auto src_fmt = + static_cast<mkldnn::memory::format>(fwdParams.src_md.data.format); // Get a eltwise fwd primitive from the cached pool eltwise_forward = static_cast<MklEltwiseFwdPrimitive<T>*>( - MklEltwiseFwdPrimitiveFactory<T>::GetInstance().GetEltwiseFwd( - fwdParams, src_fmt)); + MklEltwiseFwdPrimitiveFactory<T>::GetInstance().GetEltwiseFwd(fwdParams, + src_fmt)); if (eltwise_forward == nullptr) { eltwise_forward = new MklEltwiseFwdPrimitive<T>(fwdParams); MklEltwiseFwdPrimitiveFactory<T>::GetInstance().SetEltwiseFwd( @@ -197,9 +204,9 @@ class MklEltwiseFwdPrimitiveFactory : public MklPrimitiveFactory<T> { MklEltwiseFwdPrimitiveFactory() {} ~MklEltwiseFwdPrimitiveFactory() {} - static std::string CreateKey( - const MklEltwiseFwdParams<T>& fwdParams, memory::format src_fmt) { - std::string prefix = "eltwise_fwd"; + static string CreateKey(const MklEltwiseFwdParams<T>& fwdParams, + memory::format src_fmt) { + string prefix = "eltwise_fwd"; FactoryKeyCreator key_creator; key_creator.AddAsKey(prefix); key_creator.AddAsKey(fwdParams.src_dims); @@ -211,14 +218,14 @@ class MklEltwiseFwdPrimitiveFactory : public MklPrimitiveFactory<T> { } MklPrimitive* GetEltwiseFwd(const MklEltwiseFwdParams<T>& fwdParams, - memory::format src_fmt) { - std::string key = CreateKey(fwdParams, src_fmt); + memory::format src_fmt) { + string key = CreateKey(fwdParams, src_fmt); return this->GetOp(key); } void SetEltwiseFwd(const MklEltwiseFwdParams<T>& fwdParams, - memory::format src_fmt, MklPrimitive* op) { - std::string key = CreateKey(fwdParams, src_fmt); + memory::format src_fmt, MklPrimitive* op) { + string key = CreateKey(fwdParams, src_fmt); this->SetOp(key, op); } }; @@ -232,27 +239,29 @@ class MklEltwiseBwdParams { T alpha; T beta; - MklEltwiseBwdParams(const memory::dims &src_dims, - const memory::desc &common_md, - algorithm alg_kind, T alpha, T beta) : - src_dims(src_dims), common_md(common_md), - alg_kind(alg_kind), alpha(alpha), beta(beta) { - } + MklEltwiseBwdParams(const memory::dims& src_dims, + const memory::desc& common_md, algorithm alg_kind, + T alpha, T beta) + : src_dims(src_dims), + common_md(common_md), + alg_kind(alg_kind), + alpha(alpha), + beta(beta) {} }; template <typename T> class MklEltwiseBwdPrimitive : public MklPrimitive { public: - explicit MklEltwiseBwdPrimitive(const MklEltwiseBwdParams<T>& bwdParams) : - cpu_engine_(engine::cpu, 0) { - context_.src_fmt = static_cast<mkldnn::memory::format>( - bwdParams.common_md.data.format); - context_.diff_dst_fmt = static_cast<mkldnn::memory::format>( - bwdParams.common_md.data.format); + explicit MklEltwiseBwdPrimitive(const MklEltwiseBwdParams<T>& bwdParams) + : cpu_engine_(engine::cpu, 0) { + context_.src_fmt = + static_cast<mkldnn::memory::format>(bwdParams.common_md.data.format); + context_.diff_dst_fmt = + static_cast<mkldnn::memory::format>(bwdParams.common_md.data.format); context_.bwd_stream.reset(new stream(stream::kind::eager)); // create eltwise primitive if (context_.eltwise_bwd == nullptr) { - Setup(bwdParams); + Setup(bwdParams); } } @@ -280,13 +289,9 @@ class MklEltwiseBwdPrimitive : public MklPrimitive { return context_.bwd_pd; } - memory::format GetSrcMemoryFormat() { - return context_.src_fmt; - } + memory::format GetSrcMemoryFormat() { return context_.src_fmt; } - memory::format GetDiffDstMemoryFormat() { - return context_.diff_dst_fmt; - } + memory::format GetDiffDstMemoryFormat() { return context_.diff_dst_fmt; } private: // Primitive reuse context for eltwise Bwd ops: Relu, Elu, Tanh @@ -323,14 +328,22 @@ class MklEltwiseBwdPrimitive : public MklPrimitive { std::shared_ptr<stream> bwd_stream; std::vector<mkldnn::primitive> bwd_primitives; - EltwiseBwdContext() : - src_fmt(memory::format::any), diff_dst_fmt(memory::format::any), - src_mem(nullptr), diff_dst_mem(nullptr), diff_src_mem(nullptr), - src_md(nullptr), diff_dst_md(nullptr), common_md(nullptr), - src_mpd(nullptr), diff_dst_mpd(nullptr), - fwd_desc(nullptr), fwd_pd(nullptr), bwd_pd(nullptr), - eltwise_bwd(nullptr), bwd_stream(nullptr) { - } + EltwiseBwdContext() + : src_fmt(memory::format::any), + diff_dst_fmt(memory::format::any), + src_mem(nullptr), + diff_dst_mem(nullptr), + diff_src_mem(nullptr), + src_md(nullptr), + diff_dst_md(nullptr), + common_md(nullptr), + src_mpd(nullptr), + diff_dst_mpd(nullptr), + fwd_desc(nullptr), + fwd_pd(nullptr), + bwd_pd(nullptr), + eltwise_bwd(nullptr), + bwd_stream(nullptr) {} }; // Eltwise backward primitive setup @@ -339,20 +352,20 @@ class MklEltwiseBwdPrimitive : public MklPrimitive { context_.src_md.reset(new memory::desc(bwdParams.common_md.data)); context_.diff_dst_md.reset(new memory::desc(bwdParams.common_md.data)); - context_.src_mpd.reset(new memory::primitive_desc( - *context_.src_md, cpu_engine_)); - context_.diff_dst_mpd.reset(new memory::primitive_desc( - *context_.diff_dst_md, cpu_engine_)); + context_.src_mpd.reset( + new memory::primitive_desc(*context_.src_md, cpu_engine_)); + context_.diff_dst_mpd.reset( + new memory::primitive_desc(*context_.diff_dst_md, cpu_engine_)); // create forward eltwise primitive context_.fwd_desc.reset(new mkldnn::eltwise_forward::desc( - prop_kind::forward_training, bwdParams.alg_kind, - *context_.src_md, bwdParams.alpha, bwdParams.beta)); + prop_kind::forward_training, bwdParams.alg_kind, *context_.src_md, + bwdParams.alpha, bwdParams.beta)); context_.fwd_pd.reset(new mkldnn::eltwise_forward::primitive_desc( *context_.fwd_desc, cpu_engine_)); context_.bwd_desc.reset(new mkldnn::eltwise_backward::desc( - bwdParams.alg_kind, *context_.diff_dst_md, - *context_.src_md, bwdParams.alpha, bwdParams.beta)); + bwdParams.alg_kind, *context_.diff_dst_md, *context_.src_md, + bwdParams.alpha, bwdParams.beta)); context_.bwd_pd.reset(new mkldnn::eltwise_backward::primitive_desc( *context_.bwd_desc, cpu_engine_, *context_.fwd_pd)); @@ -363,8 +376,9 @@ class MklEltwiseBwdPrimitive : public MklPrimitive { context_.bwd_pd.get()->diff_src_primitive_desc(), DummyData)); // create eltwise primitive and add it to net - context_.eltwise_bwd.reset(new mkldnn::eltwise_backward(*context_.bwd_pd, - *context_.src_mem, *context_.diff_dst_mem, *context_.diff_src_mem)); + context_.eltwise_bwd.reset(new mkldnn::eltwise_backward( + *context_.bwd_pd, *context_.src_mem, *context_.diff_dst_mem, + *context_.diff_src_mem)); context_.bwd_primitives.push_back(*context_.eltwise_bwd); } @@ -373,7 +387,6 @@ class MklEltwiseBwdPrimitive : public MklPrimitive { engine cpu_engine_; }; - template <typename T> class MklEltwiseBwdPrimitiveFactory : public MklPrimitiveFactory<T> { private: @@ -385,20 +398,20 @@ class MklEltwiseBwdPrimitiveFactory : public MklPrimitiveFactory<T> { const MklEltwiseBwdParams<T>& bwdParams) { MklEltwiseBwdPrimitive<T>* eltwise_backward = nullptr; - auto src_fmt = static_cast<mkldnn::memory::format>( - bwdParams.common_md.data.format); - auto diff_dst_fmt = static_cast<mkldnn::memory::format>( - bwdParams.common_md.data.format); + auto src_fmt = + static_cast<mkldnn::memory::format>(bwdParams.common_md.data.format); + auto diff_dst_fmt = + static_cast<mkldnn::memory::format>(bwdParams.common_md.data.format); // try to find a suitable one in pool - eltwise_backward = static_cast<MklEltwiseBwdPrimitive<T>*> ( + eltwise_backward = static_cast<MklEltwiseBwdPrimitive<T>*>( MklEltwiseBwdPrimitiveFactory<T>::GetInstance().GetEltwiseBwd( bwdParams, src_fmt, diff_dst_fmt)); if (eltwise_backward == nullptr) { eltwise_backward = new MklEltwiseBwdPrimitive<T>(bwdParams); - MklEltwiseBwdPrimitiveFactory<T>::GetInstance().SetEltwiseBwd( - bwdParams, src_fmt, diff_dst_fmt, eltwise_backward); + MklEltwiseBwdPrimitiveFactory<T>::GetInstance().SetEltwiseBwd( + bwdParams, src_fmt, diff_dst_fmt, eltwise_backward); } return eltwise_backward; } @@ -409,11 +422,10 @@ class MklEltwiseBwdPrimitiveFactory : public MklPrimitiveFactory<T> { } private: - static std::string CreateKey( - const MklEltwiseBwdParams<T>& bwdParams, - const memory::format &src_fmt, - const memory::format &diff_dst_fmt) { - std::string prefix = "eltwise_bwd"; + static string CreateKey(const MklEltwiseBwdParams<T>& bwdParams, + const memory::format& src_fmt, + const memory::format& diff_dst_fmt) { + string prefix = "eltwise_bwd"; FactoryKeyCreator key_creator; key_creator.AddAsKey(prefix); key_creator.AddAsKey(bwdParams.src_dims); @@ -426,15 +438,16 @@ class MklEltwiseBwdPrimitiveFactory : public MklPrimitiveFactory<T> { } MklPrimitive* GetEltwiseBwd(const MklEltwiseBwdParams<T>& bwdParams, - const memory::format &src_fmt, const memory::format &diff_dst_fmt) { - std::string key = CreateKey(bwdParams, src_fmt, diff_dst_fmt); + const memory::format& src_fmt, + const memory::format& diff_dst_fmt) { + string key = CreateKey(bwdParams, src_fmt, diff_dst_fmt); return this->GetOp(key); } void SetEltwiseBwd(const MklEltwiseBwdParams<T>& bwdParams, - const memory::format &src_fmt, - const memory::format &diff_dst_fmt, MklPrimitive *op) { - std::string key = CreateKey(bwdParams, src_fmt, diff_dst_fmt); + const memory::format& src_fmt, + const memory::format& diff_dst_fmt, MklPrimitive* op) { + string key = CreateKey(bwdParams, src_fmt, diff_dst_fmt); this->SetOp(key, op); } }; @@ -806,9 +819,8 @@ class MklReluOpBase : public OpKernel { T alpha = 0, beta = 0; // get a eltwise fwd from primitive pool - MklEltwiseFwdParams<T> fwdParams(src_dims, src_md, - alg_kind, alpha, beta); - MklEltwiseFwdPrimitive<T> *eltwise_fwd = + MklEltwiseFwdParams<T> fwdParams(src_dims, src_md, alg_kind, alpha, beta); + MklEltwiseFwdPrimitive<T>* eltwise_fwd = MklEltwiseFwdPrimitiveFactory<T>::Get(fwdParams); // prepare for execuation @@ -816,16 +828,17 @@ class MklReluOpBase : public OpKernel { // check wehther src need to reorder if (src_md.data.format != eltwise_fwd->GetSrcMemoryFormat()) { src.SetUsrMem(src_md, &src_tensor); - auto src_target_pd = memory::primitive_desc({{src_dims}, - MklDnnType<T>(), eltwise_fwd->GetSrcMemoryFormat()}, cpu_engine); + auto src_target_pd = memory::primitive_desc( + {{src_dims}, MklDnnType<T>(), eltwise_fwd->GetSrcMemoryFormat()}, + cpu_engine); src.CheckReorderToOpMem(src_target_pd); src_data = const_cast<T*>( reinterpret_cast<T*>(src.GetOpMem().get_data_handle())); } // allocate dst tensor, always set it as MKL-DNN layout - std::shared_ptr<mkldnn::eltwise_forward::primitive_desc> - eltwise_fwd_pd = eltwise_fwd->GetEltwiseFwdPd(); + std::shared_ptr<mkldnn::eltwise_forward::primitive_desc> eltwise_fwd_pd = + eltwise_fwd->GetEltwiseFwdPd(); MklDnnShape dnn_shape_dst; TensorShape tf_shape_dst; if (dnn_shape_src.IsMklTensor()) { @@ -853,7 +866,7 @@ class MklReluOpBase : public OpKernel { // execute eltwise eltwise_fwd->Execute(src_data, dst_data); - } catch (mkldnn::error &e) { + } catch (mkldnn::error& e) { string error_msg = "Status: " + std::to_string(e.status) + ", message: " + string(e.message) + ", in file " + string(__FILE__) + ":" + @@ -961,9 +974,9 @@ class MklReluGradOpBase : public OpKernel { common_md = src_md; } - MklEltwiseBwdParams<T> bwdParams(src_dims, common_md, - alg_kind, alpha, beta); - MklEltwiseBwdPrimitive<T> *eltwise_bwd = + MklEltwiseBwdParams<T> bwdParams(src_dims, common_md, alg_kind, alpha, + beta); + MklEltwiseBwdPrimitive<T>* eltwise_bwd = MklEltwiseBwdPrimitiveFactory<T>::Get(bwdParams); auto eltwise_bwd_pd = eltwise_bwd->GetEltwiseBwdPd(); @@ -1010,23 +1023,22 @@ class MklReluGradOpBase : public OpKernel { tf_shape_diff_src = src_tensor.shape(); } - OP_REQUIRES_OK(context, context->forward_input_or_allocate_output( - {diff_dst_index}, diff_src_index, tf_shape_diff_src, - &diff_src_tensor)); - AllocateOutputSetMklShape(context, diff_src_index, dnn_shape_diff_src); + OP_REQUIRES_OK(context, context->forward_input_or_allocate_output( + {diff_dst_index}, diff_src_index, + tf_shape_diff_src, &diff_src_tensor)); + AllocateOutputSetMklShape(context, diff_src_index, dnn_shape_diff_src); - T* diff_src_data = diff_src_tensor->flat<T>().data(); + T* diff_src_data = diff_src_tensor->flat<T>().data(); // execute eltwise bwd eltwise_bwd->Execute(src_data, diff_dst_data, diff_src_data); - } catch (mkldnn::error &e) { - string error_msg = "Status: " + std::to_string(e.status) + - ", message: " + string(e.message) + - ", in file " + string(__FILE__) + ":" + - std::to_string(__LINE__); - OP_REQUIRES_OK(context, - errors::Aborted("Operation received an exception:", - error_msg)); + } catch (mkldnn::error& e) { + string error_msg = "Status: " + std::to_string(e.status) + + ", message: " + string(e.message) + ", in file " + + string(__FILE__) + ":" + std::to_string(__LINE__); + OP_REQUIRES_OK( + context, + errors::Aborted("Operation received an exception:", error_msg)); } } diff --git a/tensorflow/core/kernels/multinomial_op.h b/tensorflow/core/kernels/multinomial_op.h index 6e41060aa4..34e2123613 100644 --- a/tensorflow/core/kernels/multinomial_op.h +++ b/tensorflow/core/kernels/multinomial_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_MULTINOMIAL_OP_H_ -#define TENSORFLOW_KERNELS_MULTINOMIAL_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_MULTINOMIAL_OP_H_ +#define TENSORFLOW_CORE_KERNELS_MULTINOMIAL_OP_H_ namespace tensorflow { @@ -27,4 +27,4 @@ struct MultinomialFunctor; } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_MULTINOMIAL_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_MULTINOMIAL_OP_H_ diff --git a/tensorflow/core/kernels/neon/depthwiseconv_float.h b/tensorflow/core/kernels/neon/depthwiseconv_float.h index 11f5be7c03..0d5a42bf10 100644 --- a/tensorflow/core/kernels/neon/depthwiseconv_float.h +++ b/tensorflow/core/kernels/neon/depthwiseconv_float.h @@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_KERNELS_NEON_DEPTHWISECONV_H_ -#define TENSORFLOW_CORE_KERNELS_NEON_DEPTHWISECONV_H_ +#ifndef TENSORFLOW_CORE_KERNELS_NEON_DEPTHWISECONV_FLOAT_H_ +#define TENSORFLOW_CORE_KERNELS_NEON_DEPTHWISECONV_FLOAT_H_ #include "public/gemmlowp.h" #include "tensorflow/core/kernels/neon/types.h" @@ -722,4 +722,4 @@ void DepthwiseConv(const float* input_data, const Dims<4>& input_dims, } // end namespace neon } // end namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_NEON_DEPTHWISECONV_H_ +#endif // TENSORFLOW_CORE_KERNELS_NEON_DEPTHWISECONV_FLOAT_H_ diff --git a/tensorflow/core/kernels/no_op.h b/tensorflow/core/kernels/no_op.h index 29ea46aed6..9e16d06978 100644 --- a/tensorflow/core/kernels/no_op.h +++ b/tensorflow/core/kernels/no_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_NO_OP_H_ -#define TENSORFLOW_KERNELS_NO_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_NO_OP_H_ +#define TENSORFLOW_CORE_KERNELS_NO_OP_H_ #include "tensorflow/core/framework/op_kernel.h" @@ -29,4 +29,4 @@ class NoOp : public OpKernel { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_NO_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_NO_OP_H_ diff --git a/tensorflow/core/kernels/nth_element_op.h b/tensorflow/core/kernels/nth_element_op.h index e7d25daecc..7a5ec3d0b5 100644 --- a/tensorflow/core/kernels/nth_element_op.h +++ b/tensorflow/core/kernels/nth_element_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_NTH_ELEMENT_OP_H_ -#define TENSORFLOW_NTH_ELEMENT_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_NTH_ELEMENT_OP_H_ +#define TENSORFLOW_CORE_KERNELS_NTH_ELEMENT_OP_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/tensor_types.h" @@ -34,4 +34,4 @@ struct NthElementFunctor { } // namespace tensorflow -#endif // TENSORFLOW_NTH_ELEMENT_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_NTH_ELEMENT_OP_H_ diff --git a/tensorflow/core/kernels/one_hot_op.h b/tensorflow/core/kernels/one_hot_op.h index db59f0f0d4..879df2b59b 100644 --- a/tensorflow/core/kernels/one_hot_op.h +++ b/tensorflow/core/kernels/one_hot_op.h @@ -15,8 +15,8 @@ limitations under the License. // See docs in ../ops/array_ops.cc -#ifndef TENSORFLOW_KERNELS_ONE_HOT_OP_H_ -#define TENSORFLOW_KERNELS_ONE_HOT_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_ONE_HOT_OP_H_ +#define TENSORFLOW_CORE_KERNELS_ONE_HOT_OP_H_ // Generator definition for OneHotOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -69,4 +69,4 @@ struct OneHot { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_ONE_HOT_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_ONE_HOT_OP_H_ diff --git a/tensorflow/core/kernels/ops_testutil.h b/tensorflow/core/kernels/ops_testutil.h index 2c195beb7f..5d607b9044 100644 --- a/tensorflow/core/kernels/ops_testutil.h +++ b/tensorflow/core/kernels/ops_testutil.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_OPS_TESTUTIL_H_ -#define TENSORFLOW_KERNELS_OPS_TESTUTIL_H_ +#ifndef TENSORFLOW_CORE_KERNELS_OPS_TESTUTIL_H_ +#define TENSORFLOW_CORE_KERNELS_OPS_TESTUTIL_H_ #include <memory> #include <vector> @@ -252,4 +252,4 @@ class OpsTestBase : public ::testing::Test { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_OPS_TESTUTIL_H_ +#endif // TENSORFLOW_CORE_KERNELS_OPS_TESTUTIL_H_ diff --git a/tensorflow/core/kernels/ops_util.h b/tensorflow/core/kernels/ops_util.h index 93ef512778..a496487d1b 100644 --- a/tensorflow/core/kernels/ops_util.h +++ b/tensorflow/core/kernels/ops_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_OPS_UTIL_H_ -#define TENSORFLOW_KERNELS_OPS_UTIL_H_ +#ifndef TENSORFLOW_CORE_KERNELS_OPS_UTIL_H_ +#define TENSORFLOW_CORE_KERNELS_OPS_UTIL_H_ // This file contains utilities for various operations. @@ -113,4 +113,4 @@ gtl::InlinedVector<T, 8> ComputeEigenStrides(const EigenDimensions& shape) { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_OPS_UTIL_H_ +#endif // TENSORFLOW_CORE_KERNELS_OPS_UTIL_H_ diff --git a/tensorflow/core/kernels/pad_op.h b/tensorflow/core/kernels/pad_op.h index ee9e0f0330..ae79f515d9 100644 --- a/tensorflow/core/kernels/pad_op.h +++ b/tensorflow/core/kernels/pad_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_PAD_OP_H_ -#define TENSORFLOW_KERNELS_PAD_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_PAD_OP_H_ +#define TENSORFLOW_CORE_KERNELS_PAD_OP_H_ // Functor definition for PadOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -54,4 +54,4 @@ struct Pad<Device, T, Tpadding, 0> { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_PAD_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_PAD_OP_H_ diff --git a/tensorflow/core/kernels/padding_fifo_queue.h b/tensorflow/core/kernels/padding_fifo_queue.h index 9d7c935068..b86b03c8f0 100644 --- a/tensorflow/core/kernels/padding_fifo_queue.h +++ b/tensorflow/core/kernels/padding_fifo_queue.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_PADDING_FIFO_QUEUE_H_ -#define TENSORFLOW_KERNELS_PADDING_FIFO_QUEUE_H_ +#ifndef TENSORFLOW_CORE_KERNELS_PADDING_FIFO_QUEUE_H_ +#define TENSORFLOW_CORE_KERNELS_PADDING_FIFO_QUEUE_H_ #include <deque> #include <vector> @@ -86,4 +86,4 @@ class PaddingFIFOQueue : public FIFOQueue { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_PADDING_FIFO_QUEUE_H_ +#endif // TENSORFLOW_CORE_KERNELS_PADDING_FIFO_QUEUE_H_ diff --git a/tensorflow/core/kernels/parameterized_truncated_normal_op.cc b/tensorflow/core/kernels/parameterized_truncated_normal_op.cc index 0ab9ff9f65..aa70ee06f5 100644 --- a/tensorflow/core/kernels/parameterized_truncated_normal_op.cc +++ b/tensorflow/core/kernels/parameterized_truncated_normal_op.cc @@ -47,7 +47,7 @@ using random::PhiloxRandom; template <typename T> struct TruncatedNormalFunctor<CPUDevice, T> { - static const int kMaxIterations = 100; + static const int kMaxIterations = 1000; void operator()(OpKernelContext* ctx, const CPUDevice& d, int64 num_batches, int64 samples_per_batch, int64 num_elements, @@ -124,6 +124,7 @@ struct TruncatedNormalFunctor<CPUDevice, T> { (normMin * (normMin - sqrtFactor)) / T(4)) / (normMin + sqrtFactor); const T diff = normMax - normMin; + if (diff < cutoff) { // Sample from a uniform distribution on [normMin, normMax]. @@ -143,15 +144,20 @@ struct TruncatedNormalFunctor<CPUDevice, T> { const auto u = dist(&gen_copy); for (int i = 0; i < size; i++) { - if (u[i] <= Eigen::numext::exp(g[i]) || - numIterations + 1 >= kMaxIterations) { + auto accept = u[i] <= Eigen::numext::exp(g[i]); + if (accept || numIterations + 1 >= kMaxIterations) { // Accept the sample z. // If we run out of iterations, just use the current uniform - // sample. Emperically, the probability of accepting each sample - // is at least 50% for typical inputs, so we will always accept - // by 100 iterations. - // This introduces a slight inaccuracy when at least one bound - // is large, minval is negative and maxval is positive. + // sample, but emit a warning. + // TODO(jjhunt) For small entropies (relative to the bounds), + // this sampler is poor and may take many iterations since + // the proposal distribution is the uniform distribution + // U(lower_bound, upper_bound). + if (!accept) { + LOG(WARNING) << "TruncatedNormal uniform rejection sampler " + << "exceeded max iterations. Sample may contain " + << "outliers."; + } output(sample) = z[i] * stddev + mean; sample++; if (sample >= limit_sample) { @@ -181,8 +187,13 @@ struct TruncatedNormalFunctor<CPUDevice, T> { const T g = Eigen::numext::exp(-x * x / T(2.0)); const T u = rand[i]; i++; - if ((u <= g && z < normMax) || - numIterations + 1 >= kMaxIterations) { + auto accept = (u <= g && z < normMax); + if (accept || numIterations + 1 >= kMaxIterations) { + if (!accept) { + LOG(WARNING) << "TruncatedNormal exponential distribution " + << "rejection sampler exceeds max iterations. " + << "Sample may contain outliers."; + } output(sample) = z * stddev + mean; sample++; if (sample >= limit_sample) { diff --git a/tensorflow/core/kernels/parameterized_truncated_normal_op.h b/tensorflow/core/kernels/parameterized_truncated_normal_op.h index cc801eb810..2e54db31fe 100644 --- a/tensorflow/core/kernels/parameterized_truncated_normal_op.h +++ b/tensorflow/core/kernels/parameterized_truncated_normal_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_PARAMETERIZED_TRUNCATED_NORMAL_OP_H_ -#define TENSORFLOW_KERNELS_PARAMETERIZED_TRUNCATED_NORMAL_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_PARAMETERIZED_TRUNCATED_NORMAL_OP_H_ +#define TENSORFLOW_CORE_KERNELS_PARAMETERIZED_TRUNCATED_NORMAL_OP_H_ #include "tensorflow/core/framework/tensor_types.h" #include "tensorflow/core/lib/random/random_distributions.h" @@ -49,4 +49,4 @@ struct TruncatedNormalFunctor { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_PARAMETERIZED_TRUNCATED_NORMAL_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_PARAMETERIZED_TRUNCATED_NORMAL_OP_H_ diff --git a/tensorflow/core/kernels/parameterized_truncated_normal_op_gpu.cu.cc b/tensorflow/core/kernels/parameterized_truncated_normal_op_gpu.cu.cc index 661d47d925..5b80a962bc 100644 --- a/tensorflow/core/kernels/parameterized_truncated_normal_op_gpu.cu.cc +++ b/tensorflow/core/kernels/parameterized_truncated_normal_op_gpu.cu.cc @@ -190,7 +190,7 @@ __global__ void __launch_bounds__(1024) // Partial specialization for GPU template <typename T> struct TruncatedNormalFunctor<GPUDevice, T> { - static const int kMaxIterations = 100; + static const int kMaxIterations = 1000; void operator()(OpKernelContext* ctx, const GPUDevice& d, int64 num_batches, int64 samples_per_batch, int64 num_elements, diff --git a/tensorflow/core/kernels/partitioned_function_ops.cc b/tensorflow/core/kernels/partitioned_function_ops.cc index 8db78f9784..876a1704c7 100644 --- a/tensorflow/core/kernels/partitioned_function_ops.cc +++ b/tensorflow/core/kernels/partitioned_function_ops.cc @@ -98,8 +98,7 @@ class PartitionedCallOp : public AsyncOpKernel { done); auto graph = tensorflow::MakeUnique<Graph>(fbody->graph->flib_def()); CopyGraph(*fbody->graph, graph.get()); - OP_REQUIRES_OK_ASYNC(ctx, PropagateInheritedDevices(graph.get(), args), - done); + OP_REQUIRES_OK_ASYNC(ctx, PinResourceArgs(graph.get(), args), done); DeviceSet device_set; for (auto d : lib->device_mgr()->ListDevices()) { @@ -163,15 +162,10 @@ class PartitionedCallOp : public AsyncOpKernel { std::vector<AllocatorAttributes>> ArgAndRetAllocAttrs; - // Propagates device annotations from the outer graph to the function body. - // // Pins each arg that emits a `DT_RESOURCE` tensor to the device on which the // corresponding resource lives. This ensures that the Placer assigns ops that - // access these resources to the appropriate devices. Additionally, places - // nodes that are unadorned with device annotations onto PartitiondCallOp's - // device. This lets call-site device annotations influence the execution - // of the function. - Status PropagateInheritedDevices(Graph* graph, const OpInputList& args) { + // access these resources to the appropriate devices. + Status PinResourceArgs(Graph* graph, const OpInputList& args) { for (Node* node : graph->op_nodes()) { string node_type = node->type_string(); if (node_type == FunctionLibraryDefinition::kArgOp) { @@ -184,18 +178,6 @@ class PartitionedCallOp : public AsyncOpKernel { ResourceHandle handle = args[index].flat<ResourceHandle>()(0); node->set_assigned_device_name(handle.device()); } - } else if (node_type != FunctionLibraryDefinition::kRetOp) { - // All non-RetVal nodes that weren't explicitly placed by the user - // inherit PartitionedCallOp's device. RetVal placement is inferred by - // the placer, to avoid forcing the function's outputs through a single - // device. - // - // TODO(b/112166045): Plumb the original requested device into this - // OpKernel (this->requested_device() isn't reliable), and merge it - // with node->requested_device() if possible. - if (node->requested_device().empty()) { - node->set_requested_device(local_device_name_); - } } } return Status::OK(); diff --git a/tensorflow/core/kernels/pooling_ops_3d.h b/tensorflow/core/kernels/pooling_ops_3d.h index d1be3ba407..319b17397e 100644 --- a/tensorflow/core/kernels/pooling_ops_3d.h +++ b/tensorflow/core/kernels/pooling_ops_3d.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_POOLING_OPS_3D_H_ -#define TENSORFLOW_KERNELS_POOLING_OPS_3D_H_ +#ifndef TENSORFLOW_CORE_KERNELS_POOLING_OPS_3D_H_ +#define TENSORFLOW_CORE_KERNELS_POOLING_OPS_3D_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/util/padding.h" @@ -77,4 +77,4 @@ struct Pool3dParameters { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_POOLING_OPS_3D_H_ +#endif // TENSORFLOW_CORE_KERNELS_POOLING_OPS_3D_H_ diff --git a/tensorflow/core/kernels/pooling_ops_3d_gpu.h b/tensorflow/core/kernels/pooling_ops_3d_gpu.h index 350b1b6732..2c3681455e 100644 --- a/tensorflow/core/kernels/pooling_ops_3d_gpu.h +++ b/tensorflow/core/kernels/pooling_ops_3d_gpu.h @@ -17,8 +17,8 @@ limitations under the License. #error This file must only be included when building with Cuda support #endif -#ifndef TENSORFLOW_CORE_KERNELS_POOLING_OP_3D_GPU_H_ -#define TENSORFLOW_CORE_KERNELS_POOLING_OP_3D_GPU_H_ +#ifndef TENSORFLOW_CORE_KERNELS_POOLING_OPS_3D_GPU_H_ +#define TENSORFLOW_CORE_KERNELS_POOLING_OPS_3D_GPU_H_ #define EIGEN_USE_GPU @@ -45,4 +45,4 @@ struct MaxPool3dGradBackward { } // namespace tensorflow -#endif // TENSORFLOW_CORE_KERNELS_POOLING_OP_3D_H_ +#endif // TENSORFLOW_CORE_KERNELS_POOLING_OPS_3D_GPU_H_ diff --git a/tensorflow/core/kernels/pooling_ops_common.h b/tensorflow/core/kernels/pooling_ops_common.h index e9265551e3..dda2c80c49 100644 --- a/tensorflow/core/kernels/pooling_ops_common.h +++ b/tensorflow/core/kernels/pooling_ops_common.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_POOLING_OPS_COMMON_H_ -#define TENSORFLOW_KERNELS_POOLING_OPS_COMMON_H_ +#ifndef TENSORFLOW_CORE_KERNELS_POOLING_OPS_COMMON_H_ +#define TENSORFLOW_CORE_KERNELS_POOLING_OPS_COMMON_H_ #include <vector> @@ -605,4 +605,4 @@ void SpatialAvgPool(OpKernelContext* context, Tensor* output, } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_POOLING_OPS_COMMON_H_ +#endif // TENSORFLOW_CORE_KERNELS_POOLING_OPS_COMMON_H_ diff --git a/tensorflow/core/kernels/priority_queue.h b/tensorflow/core/kernels/priority_queue.h index ff168df449..8e69b5b699 100644 --- a/tensorflow/core/kernels/priority_queue.h +++ b/tensorflow/core/kernels/priority_queue.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_PRIORITY_QUEUE_H_ -#define TENSORFLOW_KERNELS_PRIORITY_QUEUE_H_ +#ifndef TENSORFLOW_CORE_KERNELS_PRIORITY_QUEUE_H_ +#define TENSORFLOW_CORE_KERNELS_PRIORITY_QUEUE_H_ #include <deque> #include <queue> @@ -90,4 +90,4 @@ class PriorityQueue } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_PRIORITY_QUEUE_H_ +#endif // TENSORFLOW_CORE_KERNELS_PRIORITY_QUEUE_H_ diff --git a/tensorflow/core/kernels/qr_op_impl.h b/tensorflow/core/kernels/qr_op_impl.h index 0552c034d2..535df9d160 100644 --- a/tensorflow/core/kernels/qr_op_impl.h +++ b/tensorflow/core/kernels/qr_op_impl.h @@ -13,6 +13,9 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#ifndef TENSORFLOW_CORE_KERNELS_QR_OP_IMPL_H_ +#define TENSORFLOW_CORE_KERNELS_QR_OP_IMPL_H_ + // See docs in ../ops/linalg_ops.cc. // // This header file is used by the individual qr_*op*.cc files for registering @@ -292,6 +295,8 @@ class QrOpGpu : public AsyncOpKernel { TF_DISALLOW_COPY_AND_ASSIGN(QrOpGpu); }; -#endif +#endif // GOOGLE_CUDA } // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_QR_OP_IMPL_H_ diff --git a/tensorflow/core/kernels/random_op.h b/tensorflow/core/kernels/random_op.h index 97bcaf1a49..d313a021dd 100644 --- a/tensorflow/core/kernels/random_op.h +++ b/tensorflow/core/kernels/random_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_RANDOM_OP_H_ -#define TENSORFLOW_KERNELS_RANDOM_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_RANDOM_OP_H_ +#define TENSORFLOW_CORE_KERNELS_RANDOM_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/lib/random/random_distributions.h" @@ -69,4 +69,4 @@ struct FillPhiloxRandom<SYCLDevice, Distribution> { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_RANDOM_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_RANDOM_OP_H_ diff --git a/tensorflow/core/kernels/random_poisson_op.h b/tensorflow/core/kernels/random_poisson_op.h index 4e9fd62520..62ae01c16c 100644 --- a/tensorflow/core/kernels/random_poisson_op.h +++ b/tensorflow/core/kernels/random_poisson_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_RANDOM_POISSON_OP_H_ -#define TENSORFLOW_KERNELS_RANDOM_POISSON_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_RANDOM_POISSON_OP_H_ +#define TENSORFLOW_CORE_KERNELS_RANDOM_POISSON_OP_H_ namespace tensorflow { @@ -28,4 +28,4 @@ struct PoissonFunctor; } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_RANDOM_POISSON_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_RANDOM_POISSON_OP_H_ diff --git a/tensorflow/core/kernels/range_sampler.h b/tensorflow/core/kernels/range_sampler.h index 3010666598..ed160adfb4 100644 --- a/tensorflow/core/kernels/range_sampler.h +++ b/tensorflow/core/kernels/range_sampler.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_RANGE_SAMPLER_H_ -#define TENSORFLOW_KERNELS_RANGE_SAMPLER_H_ +#ifndef TENSORFLOW_CORE_KERNELS_RANGE_SAMPLER_H_ +#define TENSORFLOW_CORE_KERNELS_RANGE_SAMPLER_H_ #include <vector> @@ -249,4 +249,4 @@ class FixedUnigramSampler : public RangeSampler { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_RANGE_SAMPLER_H_ +#endif // TENSORFLOW_CORE_KERNELS_RANGE_SAMPLER_H_ diff --git a/tensorflow/core/kernels/record_yielder.h b/tensorflow/core/kernels/record_yielder.h index 34817ad51b..159b43b4cd 100644 --- a/tensorflow/core/kernels/record_yielder.h +++ b/tensorflow/core/kernels/record_yielder.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_RECORD_YIELDER_H_ -#define TENSORFLOW_KERNELS_RECORD_YIELDER_H_ +#ifndef TENSORFLOW_CORE_KERNELS_RECORD_YIELDER_H_ +#define TENSORFLOW_CORE_KERNELS_RECORD_YIELDER_H_ #include <atomic> #include <random> @@ -157,4 +157,4 @@ class RecordYielder { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_RECORD_YIELDER_H_ +#endif // TENSORFLOW_CORE_KERNELS_RECORD_YIELDER_H_ diff --git a/tensorflow/core/kernels/reduction_gpu_kernels.cu.h b/tensorflow/core/kernels/reduction_gpu_kernels.cu.h index 9af4cc23b6..88b3c2ac76 100644 --- a/tensorflow/core/kernels/reduction_gpu_kernels.cu.h +++ b/tensorflow/core/kernels/reduction_gpu_kernels.cu.h @@ -13,6 +13,9 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#ifndef TENSORFLOW_CORE_KERNELS_REDUCTION_GPU_KERNELS_CU_H_ +#define TENSORFLOW_CORE_KERNELS_REDUCTION_GPU_KERNELS_CU_H_ + #if GOOGLE_CUDA #define EIGEN_USE_GPU @@ -1058,4 +1061,6 @@ struct ReduceFunctor<GPUDevice, Eigen::internal::OrReducer> { } // namespace functor } // namespace tensorflow -#endif +#endif // GOOGLE_CUDA + +#endif // TENSORFLOW_CORE_KERNELS_REDUCTION_GPU_KERNELS_CU_H_ diff --git a/tensorflow/core/kernels/reduction_ops.h b/tensorflow/core/kernels/reduction_ops.h index e43d2828f3..eb264e0e5a 100644 --- a/tensorflow/core/kernels/reduction_ops.h +++ b/tensorflow/core/kernels/reduction_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_REDUCTION_OPS_H_ -#define TENSORFLOW_KERNELS_REDUCTION_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_REDUCTION_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_REDUCTION_OPS_H_ // Functor definitions for Reduction ops, must be compilable by nvcc. @@ -79,4 +79,4 @@ struct ReduceFunctor { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_REDUCTION_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_REDUCTION_OPS_H_ diff --git a/tensorflow/core/kernels/reduction_ops_common.h b/tensorflow/core/kernels/reduction_ops_common.h index 03d6e82e01..d83e1c7d15 100644 --- a/tensorflow/core/kernels/reduction_ops_common.h +++ b/tensorflow/core/kernels/reduction_ops_common.h @@ -18,8 +18,8 @@ limitations under the License. // is a header file because we split the various reduction ops into their // own compilation units to get more parallelism in compilation. -#ifndef TENSORFLOW_KERNELS_REDUCTION_OPS_COMMON_H_ -#define TENSORFLOW_KERNELS_REDUCTION_OPS_COMMON_H_ +#ifndef TENSORFLOW_CORE_KERNELS_REDUCTION_OPS_COMMON_H_ +#define TENSORFLOW_CORE_KERNELS_REDUCTION_OPS_COMMON_H_ #define EIGEN_USE_THREADS @@ -277,4 +277,4 @@ struct ReduceFunctor<SYCLDevice, Reducer> } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_REDUCTION_OPS_COMMON_H_ +#endif // TENSORFLOW_CORE_KERNELS_REDUCTION_OPS_COMMON_H_ diff --git a/tensorflow/core/kernels/regex_replace_op.cc b/tensorflow/core/kernels/regex_replace_op.cc index 59ec854a79..a1b948891d 100644 --- a/tensorflow/core/kernels/regex_replace_op.cc +++ b/tensorflow/core/kernels/regex_replace_op.cc @@ -20,8 +20,43 @@ limitations under the License. #include "tensorflow/core/framework/tensor.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" +#include "tensorflow/core/util/ptr_util.h" namespace tensorflow { +namespace { + +// Execute the specified regex using the given context. +// Context requirements: +// - "input" string Tensor at input_index=0 +// - "output" string Tensor at output_index=0 +Status InternalCompute(const RE2& match, const string& rewrite, + const bool replace_global, OpKernelContext* ctx) { + const Tensor* input_tensor; + TF_RETURN_IF_ERROR(ctx->input("input", &input_tensor)); + Tensor* output_tensor; + std::unique_ptr<Tensor> maybe_forwarded = + ctx->forward_input(0 /*input_index*/, 0 /*output_index*/, + tensorflow::DT_STRING, input_tensor->shape(), + ctx->input_memory_type(0), ctx->input_alloc_attr(0)); + if (maybe_forwarded) { + output_tensor = maybe_forwarded.get(); + TF_RETURN_IF_ERROR(ctx->set_output("output", *output_tensor)); + } else { + TF_RETURN_IF_ERROR( + ctx->allocate_output("output", input_tensor->shape(), &output_tensor)); + output_tensor->flat<string>() = input_tensor->flat<string>(); + } + auto output_flat = output_tensor->flat<string>(); + for (size_t i = 0; i < output_flat.size(); ++i) { + if (replace_global) { + RE2::GlobalReplace(&output_flat(i), match, rewrite); + } else { + RE2::Replace(&output_flat(i), match, rewrite); + } + } + return Status::OK(); +} +} // namespace class RegexReplaceOp : public OpKernel { public: @@ -30,10 +65,6 @@ class RegexReplaceOp : public OpKernel { } void Compute(OpKernelContext* ctx) override { - const Tensor* input_tensor; - OP_REQUIRES_OK(ctx, ctx->input("input", &input_tensor)); - const auto& input_flat = input_tensor->flat<string>(); - const Tensor* pattern_tensor; OP_REQUIRES_OK(ctx, ctx->input("pattern", &pattern_tensor)); OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(pattern_tensor->shape()), @@ -51,19 +82,7 @@ class RegexReplaceOp : public OpKernel { errors::InvalidArgument("Rewrite must be scalar, but received ", rewrite_tensor->shape().DebugString())); const string rewrite = rewrite_tensor->flat<string>()(0); - - Tensor* output_tensor = nullptr; - OP_REQUIRES_OK(ctx, ctx->allocate_output("output", input_tensor->shape(), - &output_tensor)); - auto output_flat = output_tensor->flat<string>(); - for (size_t i = 0; i < input_flat.size(); ++i) { - output_flat(i) = input_flat(i); - if (replace_global_) { - RE2::GlobalReplace(&output_flat(i), match, rewrite); - } else { - RE2::Replace(&output_flat(i), match, rewrite); - } - } + OP_REQUIRES_OK(ctx, InternalCompute(match, rewrite, replace_global_, ctx)); } private: @@ -73,4 +92,31 @@ class RegexReplaceOp : public OpKernel { REGISTER_KERNEL_BUILDER(Name("RegexReplace").Device(DEVICE_CPU), RegexReplaceOp); +class StaticRegexReplaceOp : public OpKernel { + public: + explicit StaticRegexReplaceOp(OpKernelConstruction* ctx) : OpKernel(ctx) { + string pattern; + OP_REQUIRES_OK(ctx, ctx->GetAttr("pattern", &pattern)); + OP_REQUIRES_OK(ctx, ctx->GetAttr("rewrite", &rewrite_str_)); + re_ = MakeUnique<RE2>(pattern); + OP_REQUIRES(ctx, re_->ok(), + errors::InvalidArgument("Invalid pattern: ", pattern, + ", error: ", re_->error())); + OP_REQUIRES_OK(ctx, ctx->GetAttr("replace_global", &replace_global_)); + } + + void Compute(OpKernelContext* ctx) override { + OP_REQUIRES_OK(ctx, + InternalCompute(*re_, rewrite_str_, replace_global_, ctx)); + } + + private: + string rewrite_str_; + std::unique_ptr<RE2> re_; + bool replace_global_; +}; + +REGISTER_KERNEL_BUILDER(Name("StaticRegexReplace").Device(DEVICE_CPU), + StaticRegexReplaceOp); + } // namespace tensorflow diff --git a/tensorflow/core/kernels/regex_replace_op_test.cc b/tensorflow/core/kernels/regex_replace_op_test.cc new file mode 100644 index 0000000000..9691d4a89f --- /dev/null +++ b/tensorflow/core/kernels/regex_replace_op_test.cc @@ -0,0 +1,137 @@ +/* Copyright 2016 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/common_runtime/kernel_benchmark_testlib.h" +#include "tensorflow/core/framework/allocator.h" +#include "tensorflow/core/framework/fake_input.h" +#include "tensorflow/core/framework/node_def_builder.h" +#include "tensorflow/core/framework/op_kernel.h" +#include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/framework/tensor_testutil.h" +#include "tensorflow/core/framework/types.h" +#include "tensorflow/core/framework/types.pb.h" +#include "tensorflow/core/graph/node_builder.h" +#include "tensorflow/core/kernels/ops_testutil.h" +#include "tensorflow/core/kernels/ops_util.h" +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/platform/test.h" +#include "tensorflow/core/platform/test_benchmark.h" + +namespace tensorflow { + +// Test data from the TensorFlow README.md. +const char* lines[] = { + "**TensorFlow** is an open source software library for numerical " + "computation using data flow graphs.", + "The graph nodes represent mathematical operations, while the graph edges " + "represent the multidimensional data arrays (tensors) that flow between " + "them.", + "This flexible architecture enables you to deploy computation to one or " + "more CPUs or GPUs in a desktop, server, or mobile device without " + "rewriting code.", + "TensorFlow also includes " + "[TensorBoard](https://www.tensorflow.org/guide/" + "summaries_and_tensorboard), a data visualization toolkit.", + "TensorFlow was originally developed by researchers and engineers working " + "on the Google Brain team within Google's Machine Intelligence Research " + "organization for the purposes of conducting machine learning and deep " + "neural networks research.", + "The system is general enough to be applicable in a wide variety of other " + "domains, as well.", + "TensorFlow provides stable Python API and C APIs as well as without API " + "backwards compatibility guarantee like C++, Go, Java, JavaScript and " + "Swift."}; + +const char kRegExPattern[] = "\\p{P}"; +const char kRewrite[] = " "; + +Tensor GetTestTensor(int batch) { + const int sz = TF_ARRAYSIZE(lines); + Tensor t(DT_STRING, {batch}); + auto s = t.flat<string>(); + for (int i = 0; i < batch; ++i) { + s(i) = lines[i % sz]; + } + return t; +} + +Graph* SetupRegexReplaceGraph(const Tensor& input, const string& input_pattern, + const string& input_rewrite) { + Graph* g = new Graph(OpRegistry::Global()); + Tensor pattern(DT_STRING, TensorShape({})); + pattern.flat<string>().setConstant(input_pattern); + Tensor rewrite(DT_STRING, TensorShape({})); + rewrite.flat<string>().setConstant(input_rewrite); + + TF_CHECK_OK(NodeBuilder("regex_replace_op", "RegexReplace") + .Input(test::graph::Constant(g, input)) + .Input(test::graph::Constant(g, pattern)) + .Input(test::graph::Constant(g, rewrite)) + .Attr("replace_global", true) + .Finalize(g, nullptr /* node */)); + return g; +} + +void BM_RegexReplace(int iters, int batch_size) { + testing::StopTiming(); + testing::ItemsProcessed(static_cast<int64>(iters)); + testing::UseRealTime(); + Tensor input = GetTestTensor(batch_size); + Graph* g = SetupRegexReplaceGraph(input, kRegExPattern, kRewrite); + testing::StartTiming(); + test::Benchmark("cpu", g).Run(iters); +} + +BENCHMARK(BM_RegexReplace) + ->Arg(1) + ->Arg(8) + ->Arg(16) + ->Arg(32) + ->Arg(64) + ->Arg(128) + ->Arg(256); + +Graph* SetupStaticGraph(const Tensor& input, const string& input_pattern, + const string& rewrite) { + Graph* g = new Graph(OpRegistry::Global()); + + TF_CHECK_OK(NodeBuilder("static_regex_replace_op", "StaticRegexReplace") + .Attr("pattern", input_pattern) + .Attr("rewrite", rewrite) + .Input(test::graph::Constant(g, input)) + .Attr("replace_global", true) + .Finalize(g, nullptr /* node */)); + return g; +} +void BM_StaticRegexReplace(int iters, int batch_size) { + testing::StopTiming(); + testing::ItemsProcessed(static_cast<int64>(iters)); + testing::UseRealTime(); + Tensor input = GetTestTensor(batch_size); + Graph* g = SetupStaticGraph(input, kRegExPattern, kRewrite); + testing::StartTiming(); + test::Benchmark("cpu", g).Run(iters); +} + +BENCHMARK(BM_StaticRegexReplace) + ->Arg(1) + ->Arg(8) + ->Arg(16) + ->Arg(32) + ->Arg(64) + ->Arg(128) + ->Arg(256); + +} // end namespace tensorflow diff --git a/tensorflow/core/kernels/relu_op.cc b/tensorflow/core/kernels/relu_op.cc index d52358737f..173fea37ed 100644 --- a/tensorflow/core/kernels/relu_op.cc +++ b/tensorflow/core/kernels/relu_op.cc @@ -124,6 +124,12 @@ namespace functor { typename TTypes<T>::Tensor backprops); \ extern template struct SeluGrad<GPUDevice, T>; +template <> +void Relu<GPUDevice, qint8>::operator()( + const GPUDevice& d, typename TTypes<qint8>::ConstTensor features, + typename TTypes<qint8>::Tensor activations); +extern template struct Relu<GPUDevice, qint8>; + TF_CALL_GPU_NUMBER_TYPES(DECLARE_GPU_SPEC); } // namespace functor @@ -157,6 +163,27 @@ TF_CALL_GPU_NUMBER_TYPES(DECLARE_GPU_SPEC); TF_CALL_GPU_NUMBER_TYPES(REGISTER_GPU_KERNELS); #undef REGISTER_GPU_KERNELS +template <typename Device> +class ReluOp<Device, qint8> + : public UnaryElementWiseOp<qint8, ReluOp<Device, qint8>> { + public: + using UnaryElementWiseOp<qint8, ReluOp<Device, qint8>>::UnaryElementWiseOp; + + void Operate(OpKernelContext* context, const Tensor& input, Tensor* output) { + auto flat_input = input.flat<qint8>(); + OP_REQUIRES(context, (flat_input.size() % 4) == 0, + errors::InvalidArgument( + "Tensor size must be a multiple of 4 for Relu<qint8>. Got ", + flat_input.size())); + functor::Relu<Device, qint8> func; + func(context->eigen_device<Device>(), flat_input, output->flat<qint8>()); + } +}; + +REGISTER_KERNEL_BUILDER( + Name("Relu").Device(DEVICE_GPU).TypeConstraint<qint8>("T"), + ReluOp<GPUDevice, qint8>); + #endif // GOOGLE_CUDA #ifdef TENSORFLOW_USE_SYCL diff --git a/tensorflow/core/kernels/relu_op.h b/tensorflow/core/kernels/relu_op.h index e712b02bd7..4775deeb61 100644 --- a/tensorflow/core/kernels/relu_op.h +++ b/tensorflow/core/kernels/relu_op.h @@ -15,8 +15,8 @@ limitations under the License. // See docs in ../ops/nn_ops.cc. -#ifndef TENSORFLOW_KERNELS_RELU_OP_H_ -#define TENSORFLOW_KERNELS_RELU_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_RELU_OP_H_ +#define TENSORFLOW_CORE_KERNELS_RELU_OP_H_ #define EIGEN_USE_THREADS @@ -219,4 +219,4 @@ void SeluGradOp<Device, T>::OperateNoTemplate(OpKernelContext* context, #undef EIGEN_USE_THREADS -#endif // TENSORFLOW_KERNELS_RELU_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_RELU_OP_H_ diff --git a/tensorflow/core/kernels/relu_op_functor.h b/tensorflow/core/kernels/relu_op_functor.h index 3bc5ba8a50..e564da335a 100644 --- a/tensorflow/core/kernels/relu_op_functor.h +++ b/tensorflow/core/kernels/relu_op_functor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_RELU_OP_FUNCTOR_H_ -#define TENSORFLOW_KERNELS_RELU_OP_FUNCTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_RELU_OP_FUNCTOR_H_ +#define TENSORFLOW_CORE_KERNELS_RELU_OP_FUNCTOR_H_ // Functor definition for ReluOp and ReluGradOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -168,4 +168,4 @@ struct SeluGrad { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_RELU_OP_FUNCTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_RELU_OP_FUNCTOR_H_ diff --git a/tensorflow/core/kernels/relu_op_gpu.cu.cc b/tensorflow/core/kernels/relu_op_gpu.cu.cc index 089ca8ed27..b9391517c1 100644 --- a/tensorflow/core/kernels/relu_op_gpu.cu.cc +++ b/tensorflow/core/kernels/relu_op_gpu.cu.cc @@ -103,7 +103,7 @@ struct ReluGrad<Device, Eigen::half> { int32 count = gradient.size(); if (count == 0) return; int32 half2_count = Eigen::divup(count, 2); - const int32 kThreadInBlock = 512; + constexpr int32 kThreadInBlock = 512; CudaLaunchConfig config = GetCudaLaunchConfigFixedBlockSize( half2_count, d, ReluGradHalfKernel, 0, kThreadInBlock); ReluGradHalfKernel<<<config.block_count, config.thread_per_block, 0, @@ -111,6 +111,37 @@ struct ReluGrad<Device, Eigen::half> { backprop.data(), count); } }; + +__global__ void Relu_int8x4_kernel(int vect_count, const int32* input, + int32* output) { + CUDA_1D_KERNEL_LOOP(index, vect_count) { + output[index] = __vmaxs4(input[index], 0); + } +} + +// Functor used by ReluOp to do the computations. +template <typename Device> +struct Relu<Device, qint8> { + // Computes Relu activation of 'input' containing int8 elements, whose buffer + // size should be a multiple of 4, and aligned to an int32* boundary. + // (Alignment should be guaranteed by the GPU tensor allocator). + // 'output' should have the same size as 'input'. + void operator()(const Device& d, typename TTypes<qint8>::ConstTensor input, + typename TTypes<qint8>::Tensor output) { + int32 count = input.size(); + if (count == 0) return; + + int32 vect_count = Eigen::divup(count, 4); + constexpr int32 kThreadInBlock = 512; + CudaLaunchConfig config = GetCudaLaunchConfigFixedBlockSize( + vect_count, d, Relu_int8x4_kernel, 0, kThreadInBlock); + Relu_int8x4_kernel<<<config.block_count, config.thread_per_block, 0, + d.stream()>>>( + vect_count, reinterpret_cast<const int32*>(input.data()), + reinterpret_cast<int32*>(output.data())); + } +}; + } // namespace functor // Definition of the GPU implementations declared in relu_op.cc. @@ -126,6 +157,8 @@ struct ReluGrad<Device, Eigen::half> { TF_CALL_GPU_NUMBER_TYPES(DEFINE_GPU_KERNELS); +template struct functor::Relu<GPUDevice, qint8>; + } // end namespace tensorflow #endif // GOOGLE_CUDA diff --git a/tensorflow/core/kernels/reshape_op.h b/tensorflow/core/kernels/reshape_op.h index 5db2d148b9..7458ac75ca 100644 --- a/tensorflow/core/kernels/reshape_op.h +++ b/tensorflow/core/kernels/reshape_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_RESHAPE_OP_H_ -#define TENSORFLOW_KERNELS_RESHAPE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_RESHAPE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_RESHAPE_OP_H_ #include <memory> #include "tensorflow/core/framework/op_kernel.h" @@ -121,4 +121,4 @@ class ReshapeOp : public OpKernel { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_RESHAPE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_RESHAPE_OP_H_ diff --git a/tensorflow/core/kernels/resize_bilinear_op.cc b/tensorflow/core/kernels/resize_bilinear_op.cc index dde59e8e74..f10c9a19a7 100644 --- a/tensorflow/core/kernels/resize_bilinear_op.cc +++ b/tensorflow/core/kernels/resize_bilinear_op.cc @@ -277,13 +277,13 @@ struct ResizeBilinearGrad<CPUDevice, T> { typename TTypes<float, 4>::ConstTensor input_grad, const float height_scale, const float width_scale, typename TTypes<T, 4>::Tensor output_grad) { - const int batch = output_grad.dimension(0); - const int64 original_height = output_grad.dimension(1); - const int64 original_width = output_grad.dimension(2); - const int channels = output_grad.dimension(3); + const Eigen::Index batch = output_grad.dimension(0); + const Eigen::Index original_height = output_grad.dimension(1); + const Eigen::Index original_width = output_grad.dimension(2); + const Eigen::Index channels = output_grad.dimension(3); - const int64 resized_height = input_grad.dimension(1); - const int64 resized_width = input_grad.dimension(2); + const Eigen::Index resized_height = input_grad.dimension(1); + const Eigen::Index resized_width = input_grad.dimension(2); output_grad.setZero(); @@ -294,22 +294,24 @@ struct ResizeBilinearGrad<CPUDevice, T> { // + top_right * (1 - y) * x // + bottom_left * y * (1 - x) // + bottom_right * y * x - for (int64 b = 0; b < batch; ++b) { - for (int64 y = 0; y < resized_height; ++y) { + for (Eigen::Index b = 0; b < batch; ++b) { + for (Eigen::Index y = 0; y < resized_height; ++y) { const float in_y = y * height_scale; - const int64 top_y_index = static_cast<int64>(floorf(in_y)); - const int64 bottom_y_index = - std::min(static_cast<int64>(ceilf(in_y)), original_height - 1); + const Eigen::Index top_y_index = + static_cast<Eigen::Index>(floorf(in_y)); + const Eigen::Index bottom_y_index = std::min( + static_cast<Eigen::Index>(ceilf(in_y)), original_height - 1); const float y_lerp = in_y - top_y_index; const float inverse_y_lerp = (1.0f - y_lerp); - for (int64 x = 0; x < resized_width; ++x) { + for (Eigen::Index x = 0; x < resized_width; ++x) { const float in_x = x * width_scale; - const int64 left_x_index = static_cast<int64>(floorf(in_x)); - const int64 right_x_index = - std::min(static_cast<int64>(ceilf(in_x)), original_width - 1); + const Eigen::Index left_x_index = + static_cast<Eigen::Index>(floorf(in_x)); + const Eigen::Index right_x_index = std::min( + static_cast<Eigen::Index>(ceilf(in_x)), original_width - 1); const float x_lerp = in_x - left_x_index; const float inverse_x_lerp = (1.0f - x_lerp); - for (int64 c = 0; c < channels; ++c) { + for (Eigen::Index c = 0; c < channels; ++c) { output_grad(b, top_y_index, left_x_index, c) += T(input_grad(b, y, x, c) * inverse_y_lerp * inverse_x_lerp); output_grad(b, top_y_index, right_x_index, c) += diff --git a/tensorflow/core/kernels/resize_nearest_neighbor_op.cc b/tensorflow/core/kernels/resize_nearest_neighbor_op.cc index 8ec526c2b2..e985d3e5a5 100644 --- a/tensorflow/core/kernels/resize_nearest_neighbor_op.cc +++ b/tensorflow/core/kernels/resize_nearest_neighbor_op.cc @@ -88,25 +88,27 @@ struct ResizeNearestNeighbor<CPUDevice, T, align_corners> { bool operator()(const CPUDevice& d, typename TTypes<T, 4>::ConstTensor input, const float height_scale, const float width_scale, typename TTypes<T, 4>::Tensor output) { - const int batch_size = input.dimension(0); - const int64 in_height = input.dimension(1); - const int64 in_width = input.dimension(2); - const int channels = input.dimension(3); - - const int64 out_height = output.dimension(1); - const int64 out_width = output.dimension(2); - - for (int b = 0; b < batch_size; ++b) { - for (int y = 0; y < out_height; ++y) { - const int64 in_y = std::min( - (align_corners) ? static_cast<int64>(roundf(y * height_scale)) - : static_cast<int64>(floorf(y * height_scale)), - in_height - 1); - for (int x = 0; x < out_width; ++x) { - const int64 in_x = std::min( - (align_corners) ? static_cast<int64>(roundf(x * width_scale)) - : static_cast<int64>(floorf(x * width_scale)), - in_width - 1); + const Eigen::Index batch_size = input.dimension(0); + const Eigen::Index in_height = input.dimension(1); + const Eigen::Index in_width = input.dimension(2); + const Eigen::Index channels = input.dimension(3); + + const Eigen::Index out_height = output.dimension(1); + const Eigen::Index out_width = output.dimension(2); + + for (Eigen::Index b = 0; b < batch_size; ++b) { + for (Eigen::Index y = 0; y < out_height; ++y) { + const Eigen::Index in_y = + std::min((align_corners) + ? static_cast<Eigen::Index>(roundf(y * height_scale)) + : static_cast<Eigen::Index>(floorf(y * height_scale)), + in_height - 1); + for (Eigen::Index x = 0; x < out_width; ++x) { + const Eigen::Index in_x = + std::min((align_corners) + ? static_cast<Eigen::Index>(roundf(x * width_scale)) + : static_cast<Eigen::Index>(floorf(x * width_scale)), + in_width - 1); std::copy_n(&input(b, in_y, in_x, 0), channels, &output(b, y, x, 0)); } } @@ -199,28 +201,29 @@ struct ResizeNearestNeighborGrad<CPUDevice, T, align_corners> { bool operator()(const CPUDevice& d, typename TTypes<T, 4>::ConstTensor input, const float height_scale, const float width_scale, typename TTypes<T, 4>::Tensor output) { - const int batch_size = input.dimension(0); - const int64 in_height = input.dimension(1); - const int64 in_width = input.dimension(2); - const int channels = input.dimension(3); + const Eigen::Index batch_size = input.dimension(0); + const Eigen::Index in_height = input.dimension(1); + const Eigen::Index in_width = input.dimension(2); + const Eigen::Index channels = input.dimension(3); - const int64 out_height = output.dimension(1); - const int64 out_width = output.dimension(2); + const Eigen::Index out_height = output.dimension(1); + const Eigen::Index out_width = output.dimension(2); output.setZero(); - for (int y = 0; y < in_height; ++y) { - const int64 out_y = std::min( - (align_corners) ? static_cast<int64>(roundf(y * height_scale)) - : static_cast<int64>(floorf(y * height_scale)), + for (Eigen::Index y = 0; y < in_height; ++y) { + const Eigen::Index out_y = std::min( + (align_corners) ? static_cast<Eigen::Index>(roundf(y * height_scale)) + : static_cast<Eigen::Index>(floorf(y * height_scale)), out_height - 1); - for (int x = 0; x < in_width; ++x) { - const int64 out_x = std::min( - (align_corners) ? static_cast<int64>(roundf(x * width_scale)) - : static_cast<int64>(floorf(x * width_scale)), - out_width - 1); - for (int b = 0; b < batch_size; ++b) { - for (int c = 0; c < channels; ++c) { + for (Eigen::Index x = 0; x < in_width; ++x) { + const Eigen::Index out_x = + std::min((align_corners) + ? static_cast<Eigen::Index>(roundf(x * width_scale)) + : static_cast<Eigen::Index>(floorf(x * width_scale)), + out_width - 1); + for (Eigen::Index b = 0; b < batch_size; ++b) { + for (Eigen::Index c = 0; c < channels; ++c) { output(b, out_y, out_x, c) += input(b, y, x, c); } } diff --git a/tensorflow/core/kernels/reverse_op.h b/tensorflow/core/kernels/reverse_op.h index 934f0277a9..44e7967c5d 100644 --- a/tensorflow/core/kernels/reverse_op.h +++ b/tensorflow/core/kernels/reverse_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_REVERSE_OP_H_ -#define TENSORFLOW_KERNELS_REVERSE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_REVERSE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_REVERSE_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -45,4 +45,4 @@ struct Reverse<Device, T, 0> { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_MIRROR_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_REVERSE_OP_H_ diff --git a/tensorflow/core/kernels/reverse_sequence_op.h b/tensorflow/core/kernels/reverse_sequence_op.h index 8ccd32ea16..d6ba2781a9 100644 --- a/tensorflow/core/kernels/reverse_sequence_op.h +++ b/tensorflow/core/kernels/reverse_sequence_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_REVERSE_SEQUENCE_OP_H_ -#define TENSORFLOW_KERNELS_REVERSE_SEQUENCE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_REVERSE_SEQUENCE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_REVERSE_SEQUENCE_OP_H_ // Generator definition for ReverseSequenceOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -75,4 +75,4 @@ struct ReverseSequence { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_REVERSE_SEQUENCE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_REVERSE_SEQUENCE_OP_H_ diff --git a/tensorflow/core/kernels/save_restore_tensor.h b/tensorflow/core/kernels/save_restore_tensor.h index 5b74b586e8..be7f4b889e 100644 --- a/tensorflow/core/kernels/save_restore_tensor.h +++ b/tensorflow/core/kernels/save_restore_tensor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SAVE_RESTORE_TENSOR_H_ -#define TENSORFLOW_KERNELS_SAVE_RESTORE_TENSOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SAVE_RESTORE_TENSOR_H_ +#define TENSORFLOW_CORE_KERNELS_SAVE_RESTORE_TENSOR_H_ #include "tensorflow/core/util/tensor_slice_reader.h" #include "tensorflow/core/util/tensor_slice_writer.h" @@ -70,4 +70,4 @@ Status RestoreTensorsV2(OpKernelContext* context, const Tensor& prefix, } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SAVE_RESTORE_TENSOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_SAVE_RESTORE_TENSOR_H_ diff --git a/tensorflow/core/kernels/scan_ops.h b/tensorflow/core/kernels/scan_ops.h index 1a1f71d722..13831bb377 100644 --- a/tensorflow/core/kernels/scan_ops.h +++ b/tensorflow/core/kernels/scan_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SCAN_OPS_H_ -#define TENSORFLOW_KERNELS_SCAN_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SCAN_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_SCAN_OPS_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -43,4 +43,4 @@ struct Scan { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SCAN_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_SCAN_OPS_H_ diff --git a/tensorflow/core/kernels/scatter_functor.h b/tensorflow/core/kernels/scatter_functor.h index ebaa2bd9c6..2d43bde23f 100644 --- a/tensorflow/core/kernels/scatter_functor.h +++ b/tensorflow/core/kernels/scatter_functor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SCATTER_FUNCTOR_H_ -#define TENSORFLOW_KERNELS_SCATTER_FUNCTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SCATTER_FUNCTOR_H_ +#define TENSORFLOW_CORE_KERNELS_SCATTER_FUNCTOR_H_ #include <type_traits> @@ -488,4 +488,4 @@ struct ScatterScalarFunctorSYCL { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SCATTER_FUNCTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_SCATTER_FUNCTOR_H_ diff --git a/tensorflow/core/kernels/scatter_functor_gpu.cu.h b/tensorflow/core/kernels/scatter_functor_gpu.cu.h index 70809e4dcf..057755a05c 100644 --- a/tensorflow/core/kernels/scatter_functor_gpu.cu.h +++ b/tensorflow/core/kernels/scatter_functor_gpu.cu.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SCATTER_FUNCTOR_GPU_CU_H_ -#define TENSORFLOW_KERNELS_SCATTER_FUNCTOR_GPU_CU_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SCATTER_FUNCTOR_GPU_CU_H_ +#define TENSORFLOW_CORE_KERNELS_SCATTER_FUNCTOR_GPU_CU_H_ #if GOOGLE_CUDA @@ -161,4 +161,4 @@ struct ScatterScalarFunctor<GPUDevice, T, Index, op> { #endif // GOOGLE_CUDA -#endif // TENSORFLOW_KERNELS_SCATTER_FUNCTOR_GPU_CU_H_ +#endif // TENSORFLOW_CORE_KERNELS_SCATTER_FUNCTOR_GPU_CU_H_ diff --git a/tensorflow/core/kernels/self_adjoint_eig_v2_op_impl.h b/tensorflow/core/kernels/self_adjoint_eig_v2_op_impl.h index 271dd2c485..b5274f8788 100644 --- a/tensorflow/core/kernels/self_adjoint_eig_v2_op_impl.h +++ b/tensorflow/core/kernels/self_adjoint_eig_v2_op_impl.h @@ -13,6 +13,9 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#ifndef TENSORFLOW_CORE_KERNELS_SELF_ADJOINT_EIG_V2_OP_IMPL_H_ +#define TENSORFLOW_CORE_KERNELS_SELF_ADJOINT_EIG_V2_OP_IMPL_H_ + // See docs in ../ops/linalg_ops.cc. #include "third_party/eigen3/Eigen/Core" @@ -85,3 +88,5 @@ class SelfAdjointEigV2Op : public LinearAlgebraOp<Scalar> { }; } // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_SELF_ADJOINT_EIG_V2_OP_IMPL_H_ diff --git a/tensorflow/core/kernels/sendrecv_ops.h b/tensorflow/core/kernels/sendrecv_ops.h index 1ff8eff13f..223854de13 100644 --- a/tensorflow/core/kernels/sendrecv_ops.h +++ b/tensorflow/core/kernels/sendrecv_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SENDRECV_OPS_H_ -#define TENSORFLOW_KERNELS_SENDRECV_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SENDRECV_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_SENDRECV_OPS_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/platform/macros.h" @@ -49,4 +49,4 @@ class RecvOp : public AsyncOpKernel { } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_SENDRECV_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_SENDRECV_OPS_H_ diff --git a/tensorflow/core/kernels/shape_ops.cc b/tensorflow/core/kernels/shape_ops.cc index 28a39bae3f..ab1ce0f9c8 100644 --- a/tensorflow/core/kernels/shape_ops.cc +++ b/tensorflow/core/kernels/shape_ops.cc @@ -16,6 +16,7 @@ limitations under the License. // See docs in ../ops/array_ops.cc. #include "tensorflow/core/kernels/shape_ops.h" +#include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/framework/register_types.h" namespace tensorflow { @@ -460,4 +461,96 @@ REGISTER_KERNEL_BUILDER(Name("Squeeze") SqueezeOp); #endif // TENSORFLOW_USE_SYCL +class EnsureShapeOp : public OpKernel { + public: + explicit EnsureShapeOp(OpKernelConstruction* ctx) : OpKernel(ctx) { + OP_REQUIRES_OK(ctx, ctx->GetAttr("shape", &expected_shape_)); + } + + void Compute(OpKernelContext* ctx) override { + TensorShape shape; + OP_REQUIRES_OK(ctx, + shape_op_helpers::GetRegularOrVariantShape(ctx, 0, &shape)); + + if (!expected_shape_.IsCompatibleWith(shape)) { + ctx->SetStatus(errors::InvalidArgument( + "Shape of tensor ", this->def().input(0), " ", shape.DebugString(), + " is not compatible with expected shape ", + expected_shape_.DebugString(), ".")); + } + + // If shape matches, outputs the tensor. + if (IsRefType(ctx->input_dtype(0))) { + ctx->forward_ref_input_to_ref_output(0, 0); + } else { + ctx->set_output(0, ctx->input(0)); + } + } + + bool IsExpensive() override { return false; } + + private: + PartialTensorShape expected_shape_; +}; + +// NOTE(rachelim): The kernel registrations for EnsureShapeOp are identical to +// those of the identity op, since the ops have the same device type +// constraints. +REGISTER_KERNEL_BUILDER(Name("EnsureShape").Device(DEVICE_CPU), EnsureShapeOp); + +#if TENSORFLOW_USE_SYCL +#define REGISTER_SYCL_KERNEL(type) \ + REGISTER_KERNEL_BUILDER( \ + Name("EnsureShape").Device(DEVICE_SYCL).TypeConstraint<type>("T"), \ + EnsureShapeOp) + +TF_CALL_NUMBER_TYPES_NO_INT32(REGISTER_SYCL_KERNEL); + +#undef REGISTER_SYCL_KERNEL + +#define REGISTER_SYCL_HOST_KERNEL(type) \ + REGISTER_KERNEL_BUILDER(Name("EnsureShape") \ + .Device(DEVICE_SYCL) \ + .HostMemory("input") \ + .HostMemory("output") \ + .TypeConstraint<type>("T"), \ + EnsureShapeOp) + +REGISTER_SYCL_HOST_KERNEL(int32); +REGISTER_SYCL_HOST_KERNEL(bool); + +#undef REGISTER_SYCL_HOST_KERNEL + +#endif // TENSORFLOW_USE_SYCL + +#define REGISTER_GPU_KERNEL(type) \ + REGISTER_KERNEL_BUILDER( \ + Name("EnsureShape").Device(DEVICE_GPU).TypeConstraint<type>("T"), \ + EnsureShapeOp) + +TF_CALL_NUMBER_TYPES_NO_INT32(REGISTER_GPU_KERNEL); +REGISTER_GPU_KERNEL(Variant); + +#undef REGISTER_GPU_KERNEL + +#if GOOGLE_CUDA +// A special GPU kernel for int32 and bool. +// TODO(b/25387198): Also enable int32 in device memory. This kernel +// registration requires all int32 inputs and outputs to be in host memory. +#define REGISTER_GPU_HOST_KERNEL(type) \ + REGISTER_KERNEL_BUILDER(Name("EnsureShape") \ + .Device(DEVICE_GPU) \ + .HostMemory("input") \ + .HostMemory("output") \ + .TypeConstraint<type>("T"), \ + EnsureShapeOp) + +REGISTER_GPU_HOST_KERNEL(int32); +REGISTER_GPU_HOST_KERNEL(bool); +REGISTER_GPU_HOST_KERNEL(string); +REGISTER_GPU_HOST_KERNEL(ResourceHandle); + +#undef REGISTER_GPU_HOST_KERNEL + +#endif } // namespace tensorflow diff --git a/tensorflow/core/kernels/shape_ops.h b/tensorflow/core/kernels/shape_ops.h index f75723af7d..7a50f158af 100644 --- a/tensorflow/core/kernels/shape_ops.h +++ b/tensorflow/core/kernels/shape_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SHAPE_OPS_H_ -#define TENSORFLOW_KERNELS_SHAPE_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SHAPE_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_SHAPE_OPS_H_ #include <limits> #include <unordered_set> @@ -274,4 +274,4 @@ class SqueezeOp : public OpKernel { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SHAPE_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_SHAPE_OPS_H_ diff --git a/tensorflow/core/kernels/slice_op.h b/tensorflow/core/kernels/slice_op.h index db7eded745..1d662f6362 100644 --- a/tensorflow/core/kernels/slice_op.h +++ b/tensorflow/core/kernels/slice_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SLICE_OP_H_ -#define TENSORFLOW_KERNELS_SLICE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SLICE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_SLICE_OP_H_ // Functor definition for SliceOp, must be compilable by nvcc. @@ -51,4 +51,4 @@ struct Slice { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SLICE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_SLICE_OP_H_ diff --git a/tensorflow/core/kernels/smooth-hinge-loss.h b/tensorflow/core/kernels/smooth-hinge-loss.h index 5074ad0795..d51f5c130e 100644 --- a/tensorflow/core/kernels/smooth-hinge-loss.h +++ b/tensorflow/core/kernels/smooth-hinge-loss.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SMOOTH_HINGE_LOSS_H_ -#define TENSORFLOW_KERNELS_SMOOTH_HINGE_LOSS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SMOOTH_HINGE_LOSS_H_ +#define TENSORFLOW_CORE_KERNELS_SMOOTH_HINGE_LOSS_H_ #include <limits> @@ -110,5 +110,5 @@ class SmoothHingeLossUpdater : public DualLossUpdater { } // namespace tensorflow -#endif +#endif // TENSORFLOW_CORE_KERNELS_SMOOTH_HINGE_LOSS_H_ // TENSORFLOW_KERNELS_SMOOTH_HINGE_LOSS_H_ diff --git a/tensorflow/core/kernels/snapshot_op.h b/tensorflow/core/kernels/snapshot_op.h index a18065d42b..02d492988e 100644 --- a/tensorflow/core/kernels/snapshot_op.h +++ b/tensorflow/core/kernels/snapshot_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SNAPSHOT_OP_H_ -#define TENSORFLOW_KERNELS_SNAPSHOT_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SNAPSHOT_OP_H_ +#define TENSORFLOW_CORE_KERNELS_SNAPSHOT_OP_H_ #if GOOGLE_CUDA #define EIGEN_USE_GPU @@ -41,4 +41,4 @@ struct Snapshot { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SNAPSHOT_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_SNAPSHOT_OP_H_ diff --git a/tensorflow/core/kernels/softmax_op_functor.h b/tensorflow/core/kernels/softmax_op_functor.h index d3a267ed87..c8bc1ad3bb 100644 --- a/tensorflow/core/kernels/softmax_op_functor.h +++ b/tensorflow/core/kernels/softmax_op_functor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SOFTMAX_OP_FUNCTOR_H_ -#define TENSORFLOW_KERNELS_SOFTMAX_OP_FUNCTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SOFTMAX_OP_FUNCTOR_H_ +#define TENSORFLOW_CORE_KERNELS_SOFTMAX_OP_FUNCTOR_H_ // Functor definition for SoftmaxOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -98,4 +98,4 @@ struct SoftmaxEigenImpl { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SOFTMAX_OP_FUNCTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_SOFTMAX_OP_FUNCTOR_H_ diff --git a/tensorflow/core/kernels/softplus_op.cc b/tensorflow/core/kernels/softplus_op.cc index 494a83ed14..d3fc0e1461 100644 --- a/tensorflow/core/kernels/softplus_op.cc +++ b/tensorflow/core/kernels/softplus_op.cc @@ -23,7 +23,6 @@ limitations under the License. #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/register_types.h" #include "tensorflow/core/framework/tensor.h" -#include "tensorflow/core/kernels/warn_about_ints.h" #include "tensorflow/core/lib/core/errors.h" namespace tensorflow { @@ -35,9 +34,7 @@ template <typename Device, typename T> class SoftplusOp : public UnaryElementWiseOp<T, SoftplusOp<Device, T>> { public: explicit SoftplusOp(OpKernelConstruction* context) - : UnaryElementWiseOp<T, SoftplusOp<Device, T>>(context) { - WarnAboutInts(context); - } + : UnaryElementWiseOp<T, SoftplusOp<Device, T>>(context) {} void Operate(OpKernelContext* context, const Tensor& input, Tensor* output) { functor::Softplus<Device, T> functor; @@ -51,9 +48,7 @@ class SoftplusGradOp : public BinaryElementWiseOp<T, SoftplusGradOp<Device, T>> { public: explicit SoftplusGradOp(OpKernelConstruction* context) - : BinaryElementWiseOp<T, SoftplusGradOp<Device, T>>(context) { - WarnAboutInts(context); - } + : BinaryElementWiseOp<T, SoftplusGradOp<Device, T>>(context) {} void OperateNoTemplate(OpKernelContext* context, const Tensor& g, const Tensor& a, Tensor* output); @@ -89,7 +84,7 @@ void SoftplusGradOp<Device, T>::OperateNoTemplate(OpKernelContext* context, Name("SoftplusGrad").Device(DEVICE_CPU).TypeConstraint<type>("T"), \ SoftplusGradOp<CPUDevice, type>); -TF_CALL_REAL_NUMBER_TYPES(REGISTER_KERNELS); +TF_CALL_FLOAT_TYPES(REGISTER_KERNELS); #undef REGISTER_KERNELS #if GOOGLE_CUDA diff --git a/tensorflow/core/kernels/softplus_op.h b/tensorflow/core/kernels/softplus_op.h index e17e175d41..8c083ba158 100644 --- a/tensorflow/core/kernels/softplus_op.h +++ b/tensorflow/core/kernels/softplus_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SOFTPLUS_OP_H_ -#define TENSORFLOW_KERNELS_SOFTPLUS_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SOFTPLUS_OP_H_ +#define TENSORFLOW_CORE_KERNELS_SOFTPLUS_OP_H_ // Functor definition for SoftplusOp and SoftplusGradOp, must be compilable by // nvcc. @@ -73,4 +73,4 @@ struct SoftplusGrad { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SOFTPLUS_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_SOFTPLUS_OP_H_ diff --git a/tensorflow/core/kernels/softsign_op.cc b/tensorflow/core/kernels/softsign_op.cc index 00ee649b17..d691f15651 100644 --- a/tensorflow/core/kernels/softsign_op.cc +++ b/tensorflow/core/kernels/softsign_op.cc @@ -23,7 +23,6 @@ limitations under the License. #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/register_types.h" #include "tensorflow/core/framework/tensor.h" -#include "tensorflow/core/kernels/warn_about_ints.h" #include "tensorflow/core/lib/core/errors.h" namespace tensorflow { @@ -35,9 +34,7 @@ template <typename Device, typename T> class SoftsignOp : public UnaryElementWiseOp<T, SoftsignOp<Device, T>> { public: explicit SoftsignOp(OpKernelConstruction* context) - : UnaryElementWiseOp<T, SoftsignOp<Device, T>>(context) { - WarnAboutInts(context); - } + : UnaryElementWiseOp<T, SoftsignOp<Device, T>>(context) {} void Operate(OpKernelContext* context, const Tensor& input, Tensor* output) { functor::Softsign<Device, T> functor; @@ -51,9 +48,7 @@ class SoftsignGradOp : public BinaryElementWiseOp<T, SoftsignGradOp<Device, T>> { public: explicit SoftsignGradOp(OpKernelConstruction* context) - : BinaryElementWiseOp<T, SoftsignGradOp<Device, T>>(context) { - WarnAboutInts(context); - } + : BinaryElementWiseOp<T, SoftsignGradOp<Device, T>>(context) {} void OperateNoTemplate(OpKernelContext* context, const Tensor& g, const Tensor& a, Tensor* output); @@ -90,7 +85,7 @@ void SoftsignGradOp<Device, T>::OperateNoTemplate(OpKernelContext* context, Name("SoftsignGrad").Device(DEVICE_CPU).TypeConstraint<type>("T"), \ SoftsignGradOp<CPUDevice, type>); -TF_CALL_REAL_NUMBER_TYPES(REGISTER_KERNELS); +TF_CALL_FLOAT_TYPES(REGISTER_KERNELS); #undef REGISTER_KERNELS #if GOOGLE_CUDA diff --git a/tensorflow/core/kernels/softsign_op.h b/tensorflow/core/kernels/softsign_op.h index c2ababf697..61ff6eeede 100644 --- a/tensorflow/core/kernels/softsign_op.h +++ b/tensorflow/core/kernels/softsign_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SOFTSIGN_OP_H_ -#define TENSORFLOW_KERNELS_SOFTSIGN_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SOFTSIGN_OP_H_ +#define TENSORFLOW_CORE_KERNELS_SOFTSIGN_OP_H_ // Functor definition for SoftsignOp and SoftsignGradOp, must be compilable by // nvcc. @@ -57,4 +57,4 @@ struct SoftsignGrad { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SOFTSIGN_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_SOFTSIGN_OP_H_ diff --git a/tensorflow/core/kernels/sparse_conditional_accumulator.h b/tensorflow/core/kernels/sparse_conditional_accumulator.h index 2c1bffbee4..11149c4d16 100644 --- a/tensorflow/core/kernels/sparse_conditional_accumulator.h +++ b/tensorflow/core/kernels/sparse_conditional_accumulator.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SPARSE_CONDITIONAL_ACCUMULATOR_H_ -#define TENSORFLOW_KERNELS_SPARSE_CONDITIONAL_ACCUMULATOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SPARSE_CONDITIONAL_ACCUMULATOR_H_ +#define TENSORFLOW_CORE_KERNELS_SPARSE_CONDITIONAL_ACCUMULATOR_H_ #include "tensorflow/core/kernels/typed_conditional_accumulator_base.h" @@ -459,4 +459,4 @@ class SparseConditionalAccumulator } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SPARSE_CONDITIONAL_ACCUMULATOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_SPARSE_CONDITIONAL_ACCUMULATOR_H_ diff --git a/tensorflow/core/kernels/sparse_matmul_op.h b/tensorflow/core/kernels/sparse_matmul_op.h index e89280724e..6b9db8f471 100644 --- a/tensorflow/core/kernels/sparse_matmul_op.h +++ b/tensorflow/core/kernels/sparse_matmul_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SPARSE_MATMUL_OP_H_ -#define TENSORFLOW_KERNELS_SPARSE_MATMUL_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SPARSE_MATMUL_OP_H_ +#define TENSORFLOW_CORE_KERNELS_SPARSE_MATMUL_OP_H_ #include "third_party/eigen3/Eigen/Core" #include "tensorflow/core/platform/byte_order.h" @@ -465,4 +465,4 @@ EIGEN_DEVICE_FUNC inline Packet16f pexpand_bf16_u(const Packet16f& from) { #endif } // namespace internal } // namespace Eigen -#endif +#endif // TENSORFLOW_CORE_KERNELS_SPARSE_MATMUL_OP_H_ diff --git a/tensorflow/core/kernels/sparse_tensor_dense_add_op.h b/tensorflow/core/kernels/sparse_tensor_dense_add_op.h index 353cf0e519..c26ed5e874 100644 --- a/tensorflow/core/kernels/sparse_tensor_dense_add_op.h +++ b/tensorflow/core/kernels/sparse_tensor_dense_add_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SPARSE_TENSOR_DENSE_ADD_OP_H_ -#define TENSORFLOW_KERNELS_SPARSE_TENSOR_DENSE_ADD_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SPARSE_TENSOR_DENSE_ADD_OP_H_ +#define TENSORFLOW_CORE_KERNELS_SPARSE_TENSOR_DENSE_ADD_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -39,4 +39,4 @@ struct ScatterNdFunctor { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SPARSE_TENSOR_DENSE_ADD_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_SPARSE_TENSOR_DENSE_ADD_OP_H_ diff --git a/tensorflow/core/kernels/sparse_tensor_dense_matmul_op.h b/tensorflow/core/kernels/sparse_tensor_dense_matmul_op.h index da13190494..d6dd2deca5 100644 --- a/tensorflow/core/kernels/sparse_tensor_dense_matmul_op.h +++ b/tensorflow/core/kernels/sparse_tensor_dense_matmul_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SPARSE_TENSOR_DENSE_MATMUL_OP_H_ -#define TENSORFLOW_KERNELS_SPARSE_TENSOR_DENSE_MATMUL_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SPARSE_TENSOR_DENSE_MATMUL_OP_H_ +#define TENSORFLOW_CORE_KERNELS_SPARSE_TENSOR_DENSE_MATMUL_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -71,4 +71,4 @@ class MaybeAdjoint<MATRIX, true> { } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_SPARSE_TENSOR_DENSE_MATMUL_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_SPARSE_TENSOR_DENSE_MATMUL_OP_H_ diff --git a/tensorflow/core/kernels/sparse_xent_op.h b/tensorflow/core/kernels/sparse_xent_op.h index b5587aa9d7..6ba7931ab5 100644 --- a/tensorflow/core/kernels/sparse_xent_op.h +++ b/tensorflow/core/kernels/sparse_xent_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_XENT_OP_H_ -#define TENSORFLOW_KERNELS_XENT_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SPARSE_XENT_OP_H_ +#define TENSORFLOW_CORE_KERNELS_SPARSE_XENT_OP_H_ // Functor definition for SparseXentOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -224,4 +224,4 @@ struct SparseXentEigenImpl { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_XENT_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_SPARSE_XENT_OP_H_ diff --git a/tensorflow/core/kernels/split_lib.h b/tensorflow/core/kernels/split_lib.h index bc1fa28f8f..9d43a00822 100644 --- a/tensorflow/core/kernels/split_lib.h +++ b/tensorflow/core/kernels/split_lib.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SPLIT_LIB_H_ -#define TENSORFLOW_KERNELS_SPLIT_LIB_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SPLIT_LIB_H_ +#define TENSORFLOW_CORE_KERNELS_SPLIT_LIB_H_ // Functor definition for SplitOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -62,4 +62,4 @@ struct Split<Eigen::SyclDevice, T> { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SPLIT_LIB_H_ +#endif // TENSORFLOW_CORE_KERNELS_SPLIT_LIB_H_ diff --git a/tensorflow/core/kernels/squared-loss.h b/tensorflow/core/kernels/squared-loss.h index 49e6db406e..d256a69350 100644 --- a/tensorflow/core/kernels/squared-loss.h +++ b/tensorflow/core/kernels/squared-loss.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_SQUARED_LOSS_H_ -#define TENSORFLOW_KERNELS_SQUARED_LOSS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_SQUARED_LOSS_H_ +#define TENSORFLOW_CORE_KERNELS_SQUARED_LOSS_H_ #include "tensorflow/core/kernels/loss.h" @@ -70,4 +70,4 @@ class SquaredLossUpdater : public DualLossUpdater { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SQUARED_LOSS_H_ +#endif // TENSORFLOW_CORE_KERNELS_SQUARED_LOSS_H_ diff --git a/tensorflow/core/kernels/strided_slice_op.cc b/tensorflow/core/kernels/strided_slice_op.cc index 59fdc2262a..7b537fef5b 100644 --- a/tensorflow/core/kernels/strided_slice_op.cc +++ b/tensorflow/core/kernels/strided_slice_op.cc @@ -300,7 +300,8 @@ class StridedSliceAssignOp : public OpKernel { gtl::InlinedVector<int64, 4> end; gtl::InlinedVector<int64, 4> strides; - Tensor old_lhs; + Tensor* old_lhs = nullptr; + Tensor tmp; if (context->input_dtype(0) == DT_RESOURCE) { Var* v; OP_REQUIRES_OK(context, @@ -308,29 +309,30 @@ class StridedSliceAssignOp : public OpKernel { mutex_lock ml(*v->mu()); OP_REQUIRES_OK(context, PrepareToUpdateVariable<Device, T>(context, v->tensor())); - old_lhs = *v->tensor(); - OP_REQUIRES(context, old_lhs.dtype() == DataTypeToEnum<T>::value, + old_lhs = v->tensor(); + OP_REQUIRES(context, old_lhs->dtype() == DataTypeToEnum<T>::value, errors::InvalidArgument( - "l-value dtype ", DataTypeString(old_lhs.dtype()), + "l-value dtype ", DataTypeString(old_lhs->dtype()), " does not match r-value dtype ", DataTypeString(DataTypeToEnum<T>::value))); } else { context->forward_ref_input_to_ref_output(0, 0); - old_lhs = context->mutable_input(0, true); + tmp = context->mutable_input(0, true); + old_lhs = &tmp; } OP_REQUIRES_OK( - context, - ValidateStridedSliceOp( - &context->input(1), &context->input(2), context->input(3), - old_lhs.shape(), begin_mask, end_mask, ellipsis_mask, new_axis_mask, - shrink_axis_mask, &processing_shape, &final_shape, &is_identity, - &is_simple_slice, &slice_dim0, &begin, &end, &strides)); + context, ValidateStridedSliceOp( + &context->input(1), &context->input(2), context->input(3), + old_lhs->shape(), begin_mask, end_mask, ellipsis_mask, + new_axis_mask, shrink_axis_mask, &processing_shape, + &final_shape, &is_identity, &is_simple_slice, &slice_dim0, + &begin, &end, &strides)); if (processing_shape.num_elements()) { const Tensor& input = context->input(4); TensorShape input_shape = input.shape(); - TensorShape original_shape = old_lhs.shape(); + TensorShape original_shape = old_lhs->shape(); // TODO(aselle): This check is too strong, we only should need // input_shape to be broadcastable to final_shape OP_REQUIRES( @@ -345,12 +347,12 @@ class StridedSliceAssignOp : public OpKernel { // scalar shape // Handle general dimensions -#define HANDLE_DIM(NDIM) \ - if (processing_dims == NDIM) { \ - HandleStridedSliceAssignCase<Device, T, NDIM>()( \ - context, begin, end, strides, processing_shape, is_simple_slice, \ - &old_lhs); \ - return; \ +#define HANDLE_DIM(NDIM) \ + if (processing_dims == NDIM) { \ + HandleStridedSliceAssignCase<Device, T, NDIM>()(context, begin, end, \ + strides, processing_shape, \ + is_simple_slice, old_lhs); \ + return; \ } HANDLE_DIM(0); HANDLE_DIM(1); diff --git a/tensorflow/core/kernels/strided_slice_op.h b/tensorflow/core/kernels/strided_slice_op.h index 2b58632298..86d105391d 100644 --- a/tensorflow/core/kernels/strided_slice_op.h +++ b/tensorflow/core/kernels/strided_slice_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_STRIDED_SLICE_OP_H_ -#define TENSORFLOW_KERNELS_STRIDED_SLICE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_STRIDED_SLICE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_STRIDED_SLICE_OP_H_ // Functor definition for StridedSliceOp, must be compilable by nvcc. @@ -137,4 +137,4 @@ struct StridedSliceAssignScalar { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_SLICE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_STRIDED_SLICE_OP_H_ diff --git a/tensorflow/core/kernels/strided_slice_op_impl.h b/tensorflow/core/kernels/strided_slice_op_impl.h index 1c4472bb1a..099083b2ff 100644 --- a/tensorflow/core/kernels/strided_slice_op_impl.h +++ b/tensorflow/core/kernels/strided_slice_op_impl.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_STRIDED_SLICE_OP_IMPL_H_ -#define TENSORFLOW_KERNELS_STRIDED_SLICE_OP_IMPL_H_ +#ifndef TENSORFLOW_CORE_KERNELS_STRIDED_SLICE_OP_IMPL_H_ +#define TENSORFLOW_CORE_KERNELS_STRIDED_SLICE_OP_IMPL_H_ // Functor definition for StridedSliceOp, must be compilable by nvcc. @@ -313,4 +313,4 @@ DECLARE_FOR_N_SYCL(int64); } // end namespace tensorflow #endif // END STRIDED_SLICE_INSTANTIATE_DIM -#endif // TENSORFLOW_KERNELS_SLICE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_STRIDED_SLICE_OP_IMPL_H_ diff --git a/tensorflow/core/kernels/string_split_op.cc b/tensorflow/core/kernels/string_split_op.cc index 26ab72f12e..3884370a6c 100644 --- a/tensorflow/core/kernels/string_split_op.cc +++ b/tensorflow/core/kernels/string_split_op.cc @@ -26,25 +26,81 @@ limitations under the License. #include "tensorflow/core/lib/strings/str_util.h" namespace tensorflow { - namespace { +// Split input string `str` based on a character delimiter. +// Returns a vector of StringPieces which are valid as long as input `str` +// is valid. +// Note: The single character delimiter is a common case and is implemented as +// a series of finds in the input string, making it much more effcient than +// SplitOnCharSet. +template <typename Predicate> +std::vector<StringPiece> SplitOnChar(const string& str, const char delim, + Predicate p) { + std::vector<StringPiece> result; + StringPiece text(str); + auto f = text.find(delim); + while (f != StringPiece::npos) { + StringPiece token = text.substr(0, f); + if (p(token)) { + result.emplace_back(token); + } + text.remove_prefix(f + 1); + f = text.find(delim); + } + if (p(text)) { + result.push_back(text); + } + return result; +} -std::vector<string> Split(const string& str, const string& delimiter, - const bool skipEmpty) { - if (!delimiter.empty()) { - if (skipEmpty) { - return str_util::Split(str, delimiter, str_util::SkipEmpty()); +// Split input string `str` based on a set of character delimiters. +// Returns a vector of StringPieces which are valid as long as input `str` +// is valid. +// Based on str_util::Split. +template <typename Predicate> +std::vector<StringPiece> SplitOnCharSet(const string& str, + const string& delim_set, Predicate p) { + std::vector<StringPiece> result; + StringPiece text(str); + StringPiece delims(delim_set); + size_t token_start = 0; + for (size_t i = 0; i < text.size() + 1; i++) { + if ((i == text.size()) || (delims.find(text[i]) != StringPiece::npos)) { + StringPiece token(text.data() + token_start, i - token_start); + if (p(token)) { + result.emplace_back(token); + } + token_start = i + 1; } - return str_util::Split(str, delimiter); } - std::vector<string> char_vector(str.size()); - for (size_t i = 0; i < str.size(); ++i) { - char_vector[i] = str[i]; + return result; +} + +// Split input string `str` based on given delimiter. +// Returns a vector of StringPieces which are valid as long as input `str` +// is valid. +template <typename Predicate> +std::vector<StringPiece> Split(const string& str, const string& delimiter, + Predicate predicate) { + if (str.empty()) { + return std::vector<StringPiece>(); + } + if (delimiter.empty()) { + std::vector<StringPiece> result; + result.resize(str.size()); + for (size_t i = 0; i < str.size(); ++i) { + result[i] = StringPiece(str.data() + i, 1); + } + return result; } - return char_vector; + if (delimiter.size() == 1) { + return SplitOnChar(str, delimiter[0], predicate); + } + return SplitOnCharSet(str, delimiter, predicate); } -std::vector<string> SplitV2(const string& str, StringPiece sep, int maxsplit) { +std::vector<StringPiece> SplitV2(const string& str, StringPiece sep, + int maxsplit) { // This SplitV2 method matches the behavior of python's str.split: // If sep is given, consecutive delimiters are not grouped together // and are deemed to delimit empty strings (for example, '1,,2'.split(',') @@ -59,11 +115,11 @@ std::vector<string> SplitV2(const string& str, StringPiece sep, int maxsplit) { // splitting an empty string or a string consisting of just whitespace // with a None separator returns []. - std::vector<string> result; + std::vector<StringPiece> result; StringPiece text(str); if (maxsplit == 0) { - result.emplace_back(std::string(text)); + result.emplace_back(text); return result; } @@ -73,11 +129,11 @@ std::vector<string> SplitV2(const string& str, StringPiece sep, int maxsplit) { str_util::RemoveLeadingWhitespace(&text); int split = 0; while (str_util::ConsumeNonWhitespace(&text, &token)) { - result.emplace_back(std::string(token)); + result.push_back(token); str_util::RemoveLeadingWhitespace(&text); ++split; if (maxsplit > 0 && split == maxsplit) { - result.emplace_back(std::string(text)); + result.push_back(text); return result; } } @@ -87,17 +143,17 @@ std::vector<string> SplitV2(const string& str, StringPiece sep, int maxsplit) { int split = 0; while (p != text.end()) { StringPiece token = text.substr(0, p - text.begin()); - result.emplace_back(std::string(token)); + result.push_back(token); text.remove_prefix(token.size()); text.remove_prefix(sep.size()); ++split; if (maxsplit > 0 && split == maxsplit) { - result.emplace_back(std::string(text)); + result.push_back(StringPiece(text)); return result; } p = std::search(text.begin(), text.end(), sep.begin(), sep.end()); } - result.emplace_back(std::string(text)); + result.push_back(text); return result; } @@ -134,7 +190,7 @@ class StringSplitOp : public OpKernel { const auto delimiter_vec = delimiter_tensor->flat<string>(); const string& delimiter = delimiter_vec(0); // Empty delimiter means split the input character by character. - std::vector<string> tokens; + std::vector<StringPiece> tokens; // Guess that we'll be unpacking a handful of tokens per example. static constexpr int kReserveSize = 4; tokens.reserve(batch_size * kReserveSize); @@ -143,12 +199,15 @@ class StringSplitOp : public OpKernel { int64 max_num_entries = 0; std::vector<int64> num_indices(batch_size); for (int64 i = 0; i < batch_size; ++i) { - std::vector<string> parts = Split(input_vec(i), delimiter, skip_empty_); + std::vector<StringPiece> parts = + skip_empty_ ? Split(input_vec(i), delimiter, str_util::SkipEmpty()) + : Split(input_vec(i), delimiter, str_util::AllowEmpty()); int64 n_entries = parts.size(); num_indices[i] = n_entries; output_size += n_entries; max_num_entries = std::max(max_num_entries, n_entries); - tokens.insert(tokens.end(), parts.begin(), parts.end()); + tokens.insert(tokens.end(), std::make_move_iterator(parts.begin()), + std::make_move_iterator(parts.end())); } Tensor* sp_indices_t; @@ -170,7 +229,7 @@ class StringSplitOp : public OpKernel { for (size_t j = 0; j < num_indices[i]; ++j) { sp_indices(c, 0) = i; sp_indices(c, 1) = j; - sp_tokens(c) = tokens[c]; + sp_tokens(c).assign(tokens[c].data(), tokens[c].size()); ++c; } } @@ -204,7 +263,7 @@ class StringSplitV2Op : public OpKernel { sep_tensor->shape().DebugString())); const auto sep_vec = sep_tensor->flat<string>(); StringPiece sep(sep_vec(0)); - std::vector<string> tokens; + std::vector<StringPiece> tokens; // Guess that we'll be unpacking a handful of tokens per example. static constexpr int kReserveSize = 4; tokens.reserve(batch_size * kReserveSize); @@ -213,7 +272,7 @@ class StringSplitV2Op : public OpKernel { int64 max_num_entries = 0; std::vector<int64> num_indices(batch_size); for (int64 i = 0; i < batch_size; ++i) { - std::vector<string> parts = SplitV2(input_vec(i), sep, maxsplit_); + std::vector<StringPiece> parts = SplitV2(input_vec(i), sep, maxsplit_); int64 n_entries = parts.size(); num_indices[i] = n_entries; output_size += n_entries; @@ -240,7 +299,7 @@ class StringSplitV2Op : public OpKernel { for (size_t j = 0; j < num_indices[i]; ++j) { sp_indices(c, 0) = i; sp_indices(c, 1) = j; - sp_tokens(c) = tokens[c]; + sp_tokens(c).assign(tokens[c].data(), tokens[c].size()); ++c; } } diff --git a/tensorflow/core/kernels/string_split_op_test.cc b/tensorflow/core/kernels/string_split_op_test.cc new file mode 100644 index 0000000000..58ad61adc8 --- /dev/null +++ b/tensorflow/core/kernels/string_split_op_test.cc @@ -0,0 +1,129 @@ +/* Copyright 2016 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/common_runtime/kernel_benchmark_testlib.h" +#include "tensorflow/core/framework/allocator.h" +#include "tensorflow/core/framework/fake_input.h" +#include "tensorflow/core/framework/node_def_builder.h" +#include "tensorflow/core/framework/op_kernel.h" +#include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/framework/tensor_testutil.h" +#include "tensorflow/core/framework/types.h" +#include "tensorflow/core/framework/types.pb.h" +#include "tensorflow/core/graph/node_builder.h" +#include "tensorflow/core/kernels/ops_testutil.h" +#include "tensorflow/core/kernels/ops_util.h" +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/platform/test.h" +#include "tensorflow/core/platform/test_benchmark.h" + +namespace tensorflow { + +// Test data from the TensorFlow README.md. +const char* lines[] = { + "**TensorFlow** is an open source software library for numerical " + "computation using data flow graphs.", + "The graph nodes represent mathematical operations, while the graph edges " + "represent the multidimensional data arrays (tensors) that flow between " + "them.", + "This flexible architecture enables you to deploy computation to one or " + "more CPUs or GPUs in a desktop, server, or mobile device without " + "rewriting code.", + "TensorFlow also includes " + "[TensorBoard](https://www.tensorflow.org/guide/" + "summaries_and_tensorboard), a data visualization toolkit.", + "TensorFlow was originally developed by researchers and engineers working " + "on the Google Brain team within Google's Machine Intelligence Research " + "organization for the purposes of conducting machine learning and deep " + "neural networks research.", + "The system is general enough to be applicable in a wide variety of other " + "domains, as well.", + "TensorFlow provides stable Python API and C APIs as well as without API " + "backwards compatibility guarantee like C++, Go, Java, JavaScript and " + "Swift."}; + +Tensor GetTestTensor(int batch) { + const int sz = TF_ARRAYSIZE(lines); + Tensor t(DT_STRING, {batch}); + auto s = t.flat<string>(); + for (int i = 0; i < batch; ++i) { + s(i) = lines[i % sz]; + } + return t; +} + +Graph* SetupStringSplitGraph(const Tensor& input) { + Graph* g = new Graph(OpRegistry::Global()); + Tensor delim(DT_STRING, TensorShape({})); + delim.flat<string>().setConstant(" "); + + TF_CHECK_OK(NodeBuilder("string_split_op", "StringSplit") + .Input(test::graph::Constant(g, input)) + .Input(test::graph::Constant(g, delim)) + .Finalize(g, nullptr /* node */)); + return g; +} + +void BM_StringSplit(int iters, int batch_size) { + testing::StopTiming(); + testing::ItemsProcessed(static_cast<int64>(iters)); + testing::UseRealTime(); + Tensor input = GetTestTensor(batch_size); + Graph* g = SetupStringSplitGraph(input); + testing::StartTiming(); + test::Benchmark("cpu", g).Run(iters); +} + +BENCHMARK(BM_StringSplit) + ->Arg(1) + ->Arg(8) + ->Arg(16) + ->Arg(32) + ->Arg(64) + ->Arg(128) + ->Arg(256); + +Graph* SetupStringSplitV2Graph(const Tensor& input) { + Graph* g = new Graph(OpRegistry::Global()); + Tensor sep(DT_STRING, TensorShape({})); + sep.flat<string>().setConstant(" "); + + TF_CHECK_OK(NodeBuilder("string_split_op", "StringSplitV2") + .Input(test::graph::Constant(g, input)) + .Input(test::graph::Constant(g, sep)) + .Finalize(g, nullptr /* node */)); + return g; +} + +void BM_StringSplitV2(int iters, int batch_size) { + testing::StopTiming(); + testing::ItemsProcessed(static_cast<int64>(iters)); + testing::UseRealTime(); + Tensor input = GetTestTensor(batch_size); + Graph* g = SetupStringSplitV2Graph(input); + testing::StartTiming(); + test::Benchmark("cpu", g).Run(iters); +} + +BENCHMARK(BM_StringSplitV2) + ->Arg(1) + ->Arg(8) + ->Arg(16) + ->Arg(32) + ->Arg(64) + ->Arg(128) + ->Arg(256); + +} // end namespace tensorflow diff --git a/tensorflow/core/kernels/svd_op_impl.h b/tensorflow/core/kernels/svd_op_impl.h index a996b67c62..2a67700c12 100644 --- a/tensorflow/core/kernels/svd_op_impl.h +++ b/tensorflow/core/kernels/svd_op_impl.h @@ -13,6 +13,9 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#ifndef TENSORFLOW_CORE_KERNELS_SVD_OP_IMPL_H_ +#define TENSORFLOW_CORE_KERNELS_SVD_OP_IMPL_H_ + // See docs in ../ops/linalg_ops.cc. // // This header file is used by the individual svd_*op*.cc files for registering @@ -101,3 +104,5 @@ class SvdOp : public LinearAlgebraOp<Scalar> { }; } // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_SVD_OP_IMPL_H_ diff --git a/tensorflow/core/kernels/tensor_array.h b/tensorflow/core/kernels/tensor_array.h index 68fab85770..e8dc4fad21 100644 --- a/tensorflow/core/kernels/tensor_array.h +++ b/tensorflow/core/kernels/tensor_array.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_TENSOR_ARRAY_H_ -#define TENSORFLOW_KERNELS_TENSOR_ARRAY_H_ +#ifndef TENSORFLOW_CORE_KERNELS_TENSOR_ARRAY_H_ +#define TENSORFLOW_CORE_KERNELS_TENSOR_ARRAY_H_ #include <limits.h> #include <vector> @@ -629,4 +629,4 @@ Status TensorArray::LockedRead(OpKernelContext* ctx, const int32 index, } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_TENSOR_ARRAY_H_ +#endif // TENSORFLOW_CORE_KERNELS_TENSOR_ARRAY_H_ diff --git a/tensorflow/core/kernels/tensor_array_ops.cc b/tensorflow/core/kernels/tensor_array_ops.cc index b368ffc875..632b65e9b6 100644 --- a/tensorflow/core/kernels/tensor_array_ops.cc +++ b/tensorflow/core/kernels/tensor_array_ops.cc @@ -1119,8 +1119,8 @@ class TensorArrayUnpackOrScatterOp : public OpKernel { {1, num_values, element_shape.num_elements()}); Eigen::DSizes<Eigen::DenseIndex, 3> indices{0, 0, 0}; - Eigen::DSizes<Eigen::DenseIndex, 3> sizes{1, 1, - element_shape.num_elements()}; + Eigen::DSizes<Eigen::DenseIndex, 3> sizes{ + 1, 1, static_cast<Eigen::DenseIndex>(element_shape.num_elements())}; std::vector<PersistentTensor> write_values; write_values.reserve(num_values); @@ -1315,9 +1315,11 @@ class TensorArraySplitOp : public OpKernel { PersistentTensor persistent_tensor; int64 previous_length = (i == 0) ? 0 : cumulative_lengths[i - 1]; - Eigen::DSizes<Eigen::DenseIndex, 3> indices{0, previous_length, 0}; - Eigen::DSizes<Eigen::DenseIndex, 3> sizes{1, tensor_lengths_t(i), - elements_per_row}; + Eigen::DSizes<Eigen::DenseIndex, 3> indices{ + 0, static_cast<Eigen::DenseIndex>(previous_length), 0}; + Eigen::DSizes<Eigen::DenseIndex, 3> sizes{ + 1, static_cast<Eigen::DenseIndex>(tensor_lengths_t(i)), + static_cast<Eigen::DenseIndex>(elements_per_row)}; OP_REQUIRES_OK(ctx, ctx->allocate_persistent( tensor_array->ElemType(), element_shapes[i], diff --git a/tensorflow/core/kernels/tile_functor.h b/tensorflow/core/kernels/tile_functor.h index 189be9239b..95986af8b7 100644 --- a/tensorflow/core/kernels/tile_functor.h +++ b/tensorflow/core/kernels/tile_functor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_TILE_FUNCTOR_H_ -#define TENSORFLOW_KERNELS_TILE_FUNCTOR_H_ +#ifndef TENSORFLOW_CORE_KERNELS_TILE_FUNCTOR_H_ +#define TENSORFLOW_CORE_KERNELS_TILE_FUNCTOR_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -106,4 +106,4 @@ struct Tile { } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_TILE_FUNCTOR_H_ +#endif // TENSORFLOW_CORE_KERNELS_TILE_FUNCTOR_H_ diff --git a/tensorflow/core/kernels/tile_ops_impl.h b/tensorflow/core/kernels/tile_ops_impl.h index 9861717a0b..6a9de388c6 100644 --- a/tensorflow/core/kernels/tile_ops_impl.h +++ b/tensorflow/core/kernels/tile_ops_impl.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_TILE_IMPL_OPS_H_ -#define TENSORFLOW_KERNELS_TILE_IMPL_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_TILE_OPS_IMPL_H_ +#define TENSORFLOW_CORE_KERNELS_TILE_OPS_IMPL_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -68,4 +68,4 @@ struct ReduceAndReshape { } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_TILE_OPS_IMPL_H_ +#endif // TENSORFLOW_CORE_KERNELS_TILE_OPS_IMPL_H_ diff --git a/tensorflow/core/kernels/topk_op.h b/tensorflow/core/kernels/topk_op.h index a53e3ec8d4..1fdbc5b15f 100644 --- a/tensorflow/core/kernels/topk_op.h +++ b/tensorflow/core/kernels/topk_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_TOPK_OP_H_ -#define TENSORFLOW_TOPK_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_TOPK_OP_H_ +#define TENSORFLOW_CORE_KERNELS_TOPK_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/op_kernel.h" @@ -39,4 +39,4 @@ struct TopKFunctor { } // end namespace tensorflow -#endif // TENSORFLOW_TOPK_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_TOPK_OP_H_ diff --git a/tensorflow/core/kernels/training_op_helpers.h b/tensorflow/core/kernels/training_op_helpers.h index 765335d3a0..071cb371a7 100644 --- a/tensorflow/core/kernels/training_op_helpers.h +++ b/tensorflow/core/kernels/training_op_helpers.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_TRAINING_OP_HELPERS_H_ -#define TENSORFLOW_KERNELS_TRAINING_OP_HELPERS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_TRAINING_OP_HELPERS_H_ +#define TENSORFLOW_CORE_KERNELS_TRAINING_OP_HELPERS_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/variant_op_registry.h" @@ -90,4 +90,4 @@ Status GetInputTensorFromVariable(OpKernelContext* ctx, int input, } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_TRAINING_OP_HELPERS_H_ +#endif // TENSORFLOW_CORE_KERNELS_TRAINING_OP_HELPERS_H_ diff --git a/tensorflow/core/kernels/training_ops.cc b/tensorflow/core/kernels/training_ops.cc index 271329599f..9a07ded17d 100644 --- a/tensorflow/core/kernels/training_ops.cc +++ b/tensorflow/core/kernels/training_ops.cc @@ -14,7 +14,6 @@ limitations under the License. ==============================================================================*/ #define EIGEN_USE_THREADS - #include "tensorflow/core/lib/bfloat16/bfloat16.h" #include <algorithm> @@ -201,7 +200,7 @@ struct ApplyFtrlV2<CPUDevice, T> { typename TTypes<T>::ConstScalar l2_shrinkage, typename TTypes<T>::ConstScalar lr_power) { auto grad_with_shrinkage = grad + static_cast<T>(2) * l2_shrinkage() * var; - auto new_accum = accum + grad_with_shrinkage.square(); + auto new_accum = accum + grad * grad; // special case for which lr_power=-0.5. if (lr_power() == static_cast<T>(-0.5)) { linear.device(d) += @@ -226,7 +225,7 @@ struct ApplyFtrlV2<CPUDevice, T> { var.device(d) = (linear.abs() > linear.constant(l1())) .select(pre_shrink, var.constant(static_cast<T>(0))); } - accum.device(d) += grad_with_shrinkage.square(); + accum.device(d) += grad * grad; } }; @@ -2167,15 +2166,15 @@ class SparseApplyFtrlOp : public OpKernel { // Use a macro to implement the computation here due to the templating of the // eigen tensor library. -#define COMPUTE_FTRL(grad_to_use) \ - auto new_accum = accum + grad_to_use.square(); \ +#define COMPUTE_FTRL(grad, grad_maybe_with_shrinkage) \ + auto new_accum = accum + grad.square(); \ if (lr_power_scalar == static_cast<T>(-0.5)) { \ - linear += \ - grad_to_use - (new_accum.sqrt() - accum.sqrt()) / lr_scalar * var; \ + linear += grad_maybe_with_shrinkage - \ + (new_accum.sqrt() - accum.sqrt()) / lr_scalar * var; \ } else { \ - linear += grad_to_use - (new_accum.pow(-lr_power_scalar) - \ - accum.pow(-lr_power_scalar)) / \ - lr_scalar * var; \ + linear += grad_maybe_with_shrinkage - (new_accum.pow(-lr_power_scalar) - \ + accum.pow(-lr_power_scalar)) / \ + lr_scalar * var; \ } \ auto l1_reg_adjust = linear.cwiseMin(l1_scalar).cwiseMax(-l1_scalar); \ auto x = l1_reg_adjust - linear; \ @@ -2188,14 +2187,14 @@ class SparseApplyFtrlOp : public OpKernel { linear.constant(static_cast<T>(2) * l2_scalar); \ var = x / y; \ } \ - accum += grad_to_use.square(); + accum += grad.square(); if (has_l2_shrinkage) { auto grad_with_shrinkage = grad + static_cast<T>(2) * l2_shrinkage_scalar * var; - COMPUTE_FTRL(grad_with_shrinkage); + COMPUTE_FTRL(grad, grad_with_shrinkage); } else { - COMPUTE_FTRL(grad); + COMPUTE_FTRL(grad, grad); } } #undef COMPUTE_FTRL @@ -2228,12 +2227,12 @@ class SparseApplyFtrlOp : public OpKernel { T g; if (has_l2_shrinkage) { g = grad_flat(i) + - (static_cast<T>(2) * l2_shrinkage_scalar * var_flat(i)); + (static_cast<T>(2) * l2_shrinkage_scalar * var_flat(index)); } else { g = grad_flat(i); } - T updated_a = a + g * g; + T updated_a = a + grad_flat(i) * grad_flat(i); using Eigen::numext::pow; T sigma = pow(updated_a, -lr_power_scalar) - pow(a, -lr_power_scalar); sigma /= lr_scalar; @@ -2856,9 +2855,8 @@ class ApplyAdaMaxOp : public OpKernel { const Device& device = ctx->template eigen_device<Device>(); functor::ApplyAdaMax<Device, T>()( device, var.flat<T>(), m.flat<T>(), v.flat<T>(), - beta1_power.scalar<T>(), lr.scalar<T>(), - beta1.scalar<T>(), beta2.scalar<T>(), epsilon.scalar<T>(), - grad.flat<T>()); + beta1_power.scalar<T>(), lr.scalar<T>(), beta1.scalar<T>(), + beta2.scalar<T>(), epsilon.scalar<T>(), grad.flat<T>()); MaybeForwardRefInputToRefOutput(ctx, 0, 0); } @@ -2867,16 +2865,16 @@ class ApplyAdaMaxOp : public OpKernel { bool use_exclusive_lock_; }; -#define REGISTER_KERNELS(D, T) \ - REGISTER_KERNEL_BUILDER( \ +#define REGISTER_KERNELS(D, T) \ + REGISTER_KERNEL_BUILDER( \ Name("ApplyAdaMax").Device(DEVICE_##D).TypeConstraint<T>("T"), \ ApplyAdaMaxOp<D##Device, T>); \ REGISTER_KERNEL_BUILDER(Name("ResourceApplyAdaMax") \ - .HostMemory("var") \ - .HostMemory("m") \ - .HostMemory("v") \ - .Device(DEVICE_##D) \ - .TypeConstraint<T>("T"), \ + .HostMemory("var") \ + .HostMemory("m") \ + .HostMemory("v") \ + .Device(DEVICE_##D) \ + .TypeConstraint<T>("T"), \ ApplyAdaMaxOp<D##Device, T>); #define REGISTER_CPU_KERNELS(T) REGISTER_KERNELS(CPU, T); @@ -2889,7 +2887,7 @@ TF_CALL_double(REGISTER_CPU_KERNELS); namespace functor { #define DECLARE_GPU_SPEC(T) \ template <> \ - void ApplyAdaMax<GPUDevice, T>::operator()( \ + void ApplyAdaMax<GPUDevice, T>::operator()( \ const GPUDevice& d, typename TTypes<T>::Flat var, \ typename TTypes<T>::Flat m, typename TTypes<T>::Flat v, \ typename TTypes<T>::ConstScalar beta1_power, \ @@ -2897,7 +2895,7 @@ namespace functor { typename TTypes<T>::ConstScalar beta1, \ typename TTypes<T>::ConstScalar beta2, \ typename TTypes<T>::ConstScalar epsilon, \ - typename TTypes<T>::ConstFlat grad); \ + typename TTypes<T>::ConstFlat grad); \ extern template struct ApplyAdaMax<GPUDevice, T>; DECLARE_GPU_SPEC(Eigen::half); DECLARE_GPU_SPEC(float); diff --git a/tensorflow/core/kernels/training_ops.h b/tensorflow/core/kernels/training_ops.h index 495a94f1a1..e10a4cb125 100644 --- a/tensorflow/core/kernels/training_ops.h +++ b/tensorflow/core/kernels/training_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_TRAINING_OPS_H_ -#define TENSORFLOW_KERNELS_TRAINING_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_TRAINING_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_TRAINING_OPS_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/tensor_types.h" @@ -199,4 +199,4 @@ struct ApplyPowerSign { } // end namespace functor } // end namespace tensorflow -#endif // TENSORFLOW_KERNELS_TRAINING_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_TRAINING_OPS_H_ diff --git a/tensorflow/core/kernels/typed_conditional_accumulator_base.h b/tensorflow/core/kernels/typed_conditional_accumulator_base.h index 1980f758fc..9dedb618f9 100644 --- a/tensorflow/core/kernels/typed_conditional_accumulator_base.h +++ b/tensorflow/core/kernels/typed_conditional_accumulator_base.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_TYPED_CONDITIONAL_ACCUMULATOR_BASE_H_ -#define TENSORFLOW_KERNELS_TYPED_CONDITIONAL_ACCUMULATOR_BASE_H_ +#ifndef TENSORFLOW_CORE_KERNELS_TYPED_CONDITIONAL_ACCUMULATOR_BASE_H_ +#define TENSORFLOW_CORE_KERNELS_TYPED_CONDITIONAL_ACCUMULATOR_BASE_H_ #include "tensorflow/core/kernels/conditional_accumulator_base.h" @@ -91,4 +91,4 @@ class TypedConditionalAccumulatorBase : public ConditionalAccumulatorBase { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_TYPED_CONDITIONAL_ACCUMULATOR_BASE_H_ +#endif // TENSORFLOW_CORE_KERNELS_TYPED_CONDITIONAL_ACCUMULATOR_BASE_H_ diff --git a/tensorflow/core/kernels/variable_ops.h b/tensorflow/core/kernels/variable_ops.h index f27dab4ddd..4742e429ed 100644 --- a/tensorflow/core/kernels/variable_ops.h +++ b/tensorflow/core/kernels/variable_ops.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_VARIABLE_OPS_H_ -#define TENSORFLOW_KERNELS_VARIABLE_OPS_H_ +#ifndef TENSORFLOW_CORE_KERNELS_VARIABLE_OPS_H_ +#define TENSORFLOW_CORE_KERNELS_VARIABLE_OPS_H_ #include "tensorflow/core/framework/allocator.h" #include "tensorflow/core/framework/op_kernel.h" @@ -46,4 +46,4 @@ class VariableOp : public OpKernel { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_VARIABLE_OPS_H_ +#endif // TENSORFLOW_CORE_KERNELS_VARIABLE_OPS_H_ diff --git a/tensorflow/core/kernels/warn_about_ints.cc b/tensorflow/core/kernels/warn_about_ints.cc deleted file mode 100644 index 75ecdf2ae4..0000000000 --- a/tensorflow/core/kernels/warn_about_ints.cc +++ /dev/null @@ -1,33 +0,0 @@ -/* Copyright 2015 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/core/kernels/warn_about_ints.h" -#include "tensorflow/core/framework/node_def.pb.h" - -namespace tensorflow { - -void WarnAboutInts(OpKernelConstruction* context) { - DataType dtype; - OP_REQUIRES_OK(context, context->GetAttr("T", &dtype)); - if (DataTypeIsInteger(dtype)) { - LOG(WARNING) << "Op " << context->def().name() << " of type " - << context->def().op() << " used with integer dtype " - << DataTypeString(dtype) - << ". This op was registered with integer support " - << "accidentally, and you won't like the result."; - } -} - -} // namespace tensorflow diff --git a/tensorflow/core/kernels/where_op.h b/tensorflow/core/kernels/where_op.h index d26849c8bd..e63b3ba8cd 100644 --- a/tensorflow/core/kernels/where_op.h +++ b/tensorflow/core/kernels/where_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_WHERE_OP_H_ -#define TENSORFLOW_KERNELS_WHERE_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_WHERE_OP_H_ +#define TENSORFLOW_CORE_KERNELS_WHERE_OP_H_ #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" #include "tensorflow/core/framework/op_kernel.h" @@ -63,4 +63,4 @@ struct Where { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_WHERE_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_WHERE_OP_H_ diff --git a/tensorflow/core/kernels/where_op_gpu.cu.h b/tensorflow/core/kernels/where_op_gpu.cu.h index 57f51889de..8879d9dd4c 100644 --- a/tensorflow/core/kernels/where_op_gpu.cu.h +++ b/tensorflow/core/kernels/where_op_gpu.cu.h @@ -13,6 +13,9 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#ifndef TENSORFLOW_CORE_KERNELS_WHERE_OP_GPU_CU_H_ +#define TENSORFLOW_CORE_KERNELS_WHERE_OP_GPU_CU_H_ + #if GOOGLE_CUDA #define EIGEN_USE_GPU @@ -346,3 +349,5 @@ TF_CALL_WHERE_GPU_TYPES(DECLARE_GPU_SPEC); } // namespace tensorflow #endif // GOOGLE_CUDA + +#endif // TENSORFLOW_CORE_KERNELS_WHERE_OP_GPU_CU_H_ diff --git a/tensorflow/core/kernels/xent_op.h b/tensorflow/core/kernels/xent_op.h index 87be17fca9..23d3ad39a8 100644 --- a/tensorflow/core/kernels/xent_op.h +++ b/tensorflow/core/kernels/xent_op.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_XENT_OP_H_ -#define TENSORFLOW_KERNELS_XENT_OP_H_ +#ifndef TENSORFLOW_CORE_KERNELS_XENT_OP_H_ +#define TENSORFLOW_CORE_KERNELS_XENT_OP_H_ // Functor definition for XentOp, must be compilable by nvcc. #include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" @@ -125,4 +125,4 @@ struct XentEigenImpl { } // namespace functor } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_XENT_OP_H_ +#endif // TENSORFLOW_CORE_KERNELS_XENT_OP_H_ diff --git a/tensorflow/core/lib/core/arena.h b/tensorflow/core/lib/core/arena.h index 5698303247..624ee77027 100644 --- a/tensorflow/core/lib/core/arena.h +++ b/tensorflow/core/lib/core/arena.h @@ -15,8 +15,8 @@ limitations under the License. // TODO(vrv): Switch this to an open-sourced version of Arena. -#ifndef TENSORFLOW_LIB_CORE_ARENA_H_ -#define TENSORFLOW_LIB_CORE_ARENA_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_ARENA_H_ +#define TENSORFLOW_CORE_LIB_CORE_ARENA_H_ #include <assert.h> @@ -107,4 +107,4 @@ class Arena { } // namespace core } // namespace tensorflow -#endif // TENSORFLOW_LIB_CORE_ARENA_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_ARENA_H_ diff --git a/tensorflow/core/lib/core/bits.h b/tensorflow/core/lib/core/bits.h index 1110ef5c2a..86e539a266 100644 --- a/tensorflow/core/lib/core/bits.h +++ b/tensorflow/core/lib/core/bits.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_CORE_BITS_H_ -#define TENSORFLOW_LIB_CORE_BITS_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_BITS_H_ +#define TENSORFLOW_CORE_LIB_CORE_BITS_H_ #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -106,4 +106,4 @@ inline uint64 NextPowerOfTwo64(uint64 value) { } // namespace tensorflow -#endif // TENSORFLOW_LIB_CORE_BITS_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_BITS_H_ diff --git a/tensorflow/core/lib/core/casts.h b/tensorflow/core/lib/core/casts.h index 0f925c6051..7546d4edc5 100644 --- a/tensorflow/core/lib/core/casts.h +++ b/tensorflow/core/lib/core/casts.h @@ -20,8 +20,8 @@ limitations under the License. // any changes here, make sure that you're not breaking any platforms. // -#ifndef TENSORFLOW_LIB_CORE_CASTS_H_ -#define TENSORFLOW_LIB_CORE_CASTS_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_CASTS_H_ +#define TENSORFLOW_CORE_LIB_CORE_CASTS_H_ #include <string.h> // for memcpy @@ -97,4 +97,4 @@ inline Dest bit_cast(const Source& source) { } // namespace tensorflow -#endif // TENSORFLOW_LIB_CORE_CASTS_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_CASTS_H_ diff --git a/tensorflow/core/lib/core/coding.h b/tensorflow/core/lib/core/coding.h index 8265aec870..4a70ffa619 100644 --- a/tensorflow/core/lib/core/coding.h +++ b/tensorflow/core/lib/core/coding.h @@ -18,8 +18,8 @@ limitations under the License. // * In addition we support variable length "varint" encoding // * Strings are encoded prefixed by their length in varint format -#ifndef TENSORFLOW_LIB_CORE_CODING_H_ -#define TENSORFLOW_LIB_CORE_CODING_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_CODING_H_ +#define TENSORFLOW_CORE_LIB_CORE_CODING_H_ #include "tensorflow/core/lib/core/raw_coding.h" #include "tensorflow/core/lib/core/stringpiece.h" @@ -76,4 +76,4 @@ extern int VarintLength(uint64_t v); } // namespace core } // namespace tensorflow -#endif // TENSORFLOW_LIB_CORE_CODING_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_CODING_H_ diff --git a/tensorflow/core/lib/core/errors.h b/tensorflow/core/lib/core/errors.h index a631d9815a..49a8a4dbd4 100644 --- a/tensorflow/core/lib/core/errors.h +++ b/tensorflow/core/lib/core/errors.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_CORE_ERRORS_H_ -#define TENSORFLOW_LIB_CORE_ERRORS_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_ERRORS_H_ +#define TENSORFLOW_CORE_LIB_CORE_ERRORS_H_ #include <sstream> @@ -144,4 +144,4 @@ using ::tensorflow::error::OK; } // namespace errors } // namespace tensorflow -#endif // TENSORFLOW_LIB_CORE_ERRORS_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_ERRORS_H_ diff --git a/tensorflow/core/lib/core/notification.h b/tensorflow/core/lib/core/notification.h index b3e515e28f..5def958e6b 100644 --- a/tensorflow/core/lib/core/notification.h +++ b/tensorflow/core/lib/core/notification.h @@ -13,11 +13,11 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_NOTIFICATION_H_ -#define TENSORFLOW_UTIL_NOTIFICATION_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_NOTIFICATION_H_ +#define TENSORFLOW_CORE_LIB_CORE_NOTIFICATION_H_ // Notification implementation is platform-dependent, to support // alternative synchronization primitives. #include "tensorflow/core/platform/notification.h" -#endif // TENSORFLOW_UTIL_NOTIFICATION_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_NOTIFICATION_H_ diff --git a/tensorflow/core/lib/core/raw_coding.h b/tensorflow/core/lib/core/raw_coding.h index 37201b755d..f49214939b 100644 --- a/tensorflow/core/lib/core/raw_coding.h +++ b/tensorflow/core/lib/core/raw_coding.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_CORE_RAW_CODING_H_ -#define TENSORFLOW_LIB_CORE_RAW_CODING_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_RAW_CODING_H_ +#define TENSORFLOW_CORE_LIB_CORE_RAW_CODING_H_ #include <string.h> #include "tensorflow/core/platform/byte_order.h" @@ -68,4 +68,4 @@ inline uint64 DecodeFixed64(const char* ptr) { } // namespace core } // namespace tensorflow -#endif // TENSORFLOW_LIB_CORE_RAW_CODING_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_RAW_CODING_H_ diff --git a/tensorflow/core/lib/core/status.cc b/tensorflow/core/lib/core/status.cc index 12dfcd284f..cb2a06e620 100644 --- a/tensorflow/core/lib/core/status.cc +++ b/tensorflow/core/lib/core/status.cc @@ -22,7 +22,7 @@ Status::Status(tensorflow::error::Code code, StringPiece msg) { assert(code != tensorflow::error::OK); state_ = std::unique_ptr<State>(new State); state_->code = code; - state_->msg = msg.ToString(); + state_->msg = string(msg); } void Status::Update(const Status& new_status) { diff --git a/tensorflow/core/lib/core/status_test_util.h b/tensorflow/core/lib/core/status_test_util.h index b35633c9da..c695caa8d1 100644 --- a/tensorflow/core/lib/core/status_test_util.h +++ b/tensorflow/core/lib/core/status_test_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_CORE_STATUS_TEST_UTIL_H_ -#define TENSORFLOW_LIB_CORE_STATUS_TEST_UTIL_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_STATUS_TEST_UTIL_H_ +#define TENSORFLOW_CORE_LIB_CORE_STATUS_TEST_UTIL_H_ #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/platform/test.h" @@ -31,4 +31,4 @@ limitations under the License. // If you want to check for particular errors, a better alternative is: // EXPECT_EQ(..expected tensorflow::error::Code..., status.code()); -#endif // TENSORFLOW_LIB_CORE_STATUS_TEST_UTIL_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_STATUS_TEST_UTIL_H_ diff --git a/tensorflow/core/lib/core/stringpiece.h b/tensorflow/core/lib/core/stringpiece.h index 329f115608..02dded42c1 100644 --- a/tensorflow/core/lib/core/stringpiece.h +++ b/tensorflow/core/lib/core/stringpiece.h @@ -23,8 +23,8 @@ limitations under the License. // non-const method, all threads accessing the same StringPiece must use // external synchronization. -#ifndef TENSORFLOW_LIB_CORE_STRINGPIECE_H_ -#define TENSORFLOW_LIB_CORE_STRINGPIECE_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_STRINGPIECE_H_ +#define TENSORFLOW_CORE_LIB_CORE_STRINGPIECE_H_ #include <assert.h> #include <stddef.h> @@ -92,10 +92,6 @@ class StringPiece { StringPiece substr(size_t pos, size_t n = npos) const; - // Return a string that contains the copy of the referenced data. - // DEPRECATED: use std::string(sv) instead. - std::string ToString() const { return std::string(data_, size_); } - // Three-way comparison. Returns value: // < 0 iff "*this" < "b", // == 0 iff "*this" == "b", @@ -156,4 +152,4 @@ extern std::ostream& operator<<(std::ostream& o, tensorflow::StringPiece piece); } // namespace tensorflow -#endif // TENSORFLOW_LIB_CORE_STRINGPIECE_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_STRINGPIECE_H_ diff --git a/tensorflow/core/lib/core/threadpool.h b/tensorflow/core/lib/core/threadpool.h index b89b74b8de..74df7c84a4 100644 --- a/tensorflow/core/lib/core/threadpool.h +++ b/tensorflow/core/lib/core/threadpool.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_CORE_THREADPOOL_H_ -#define TENSORFLOW_LIB_CORE_THREADPOOL_H_ +#ifndef TENSORFLOW_CORE_LIB_CORE_THREADPOOL_H_ +#define TENSORFLOW_CORE_LIB_CORE_THREADPOOL_H_ #include <functional> #include <memory> @@ -108,4 +108,4 @@ class ThreadPool { } // namespace thread } // namespace tensorflow -#endif // TENSORFLOW_LIB_CORE_THREADPOOL_H_ +#endif // TENSORFLOW_CORE_LIB_CORE_THREADPOOL_H_ diff --git a/tensorflow/core/lib/gtl/array_slice.h b/tensorflow/core/lib/gtl/array_slice.h index 002d166c72..b773a65569 100644 --- a/tensorflow/core/lib/gtl/array_slice.h +++ b/tensorflow/core/lib/gtl/array_slice.h @@ -91,8 +91,8 @@ limitations under the License. // for (int i = 0; i < 10; ++i) { my_proto.add_value(i); } // MyMutatingRoutine(my_proto.mutable_value()); -#ifndef TENSORFLOW_LIB_GTL_ARRAY_SLICE_H_ -#define TENSORFLOW_LIB_GTL_ARRAY_SLICE_H_ +#ifndef TENSORFLOW_CORE_LIB_GTL_ARRAY_SLICE_H_ +#define TENSORFLOW_CORE_LIB_GTL_ARRAY_SLICE_H_ #include <initializer_list> #include <type_traits> @@ -187,8 +187,6 @@ class ArraySlice { void remove_prefix(size_type n) { impl_.remove_prefix(n); } void remove_suffix(size_type n) { impl_.remove_suffix(n); } - void pop_back() { remove_suffix(1); } - void pop_front() { remove_prefix(1); } // These relational operators have the same semantics as the // std::vector<T> relational operators: they do deep (element-wise) @@ -286,8 +284,6 @@ class MutableArraySlice { void remove_prefix(size_type n) { impl_.remove_prefix(n); } void remove_suffix(size_type n) { impl_.remove_suffix(n); } - void pop_back() { remove_suffix(1); } - void pop_front() { remove_prefix(1); } bool operator==(ArraySlice<T> other) const { return ArraySlice<T>(*this) == other; @@ -296,9 +292,6 @@ class MutableArraySlice { return ArraySlice<T>(*this) != other; } - // DEPRECATED(jacobsa): Please use data() instead. - pointer mutable_data() const { return impl_.data(); } - private: Impl impl_; }; @@ -311,4 +304,4 @@ const typename MutableArraySlice<T>::size_type MutableArraySlice<T>::npos; } // namespace gtl } // namespace tensorflow -#endif // TENSORFLOW_LIB_GTL_ARRAY_SLICE_H_ +#endif // TENSORFLOW_CORE_LIB_GTL_ARRAY_SLICE_H_ diff --git a/tensorflow/core/lib/gtl/array_slice_test.cc b/tensorflow/core/lib/gtl/array_slice_test.cc index 4d3da85b88..c798a488cb 100644 --- a/tensorflow/core/lib/gtl/array_slice_test.cc +++ b/tensorflow/core/lib/gtl/array_slice_test.cc @@ -73,13 +73,13 @@ static void TestHelper(const IntSlice& vorig, const IntVec& vec) { if (len > 0) { EXPECT_EQ(0, v.front()); EXPECT_EQ(len - 1, v.back()); - v.pop_back(); + v.remove_suffix(1); EXPECT_EQ(len - 1, v.size()); for (size_t i = 0; i < v.size(); ++i) { EXPECT_EQ(i, v[i]); } if (len > 1) { - v.pop_front(); + v.remove_prefix(1); EXPECT_EQ(len - 2, v.size()); for (size_t i = 0; i < v.size(); ++i) { EXPECT_EQ(i + 1, v[i]); @@ -128,7 +128,7 @@ static void MutableTestHelper(const MutableIntSlice& vorig, int* ptr, MutableIntSlice other; // To test the assignment return value. MutableIntSlice v = other = vorig; - EXPECT_EQ(ptr, v.mutable_data()); + EXPECT_EQ(ptr, v.data()); int counter = 0; for (MutableIntSlice::iterator it = v.begin(); it != v.end(); ++it) { @@ -142,17 +142,17 @@ static void MutableTestHelper(const MutableIntSlice& vorig, int* ptr, v[0] = 1; v.front() = 2; v.back() = 5; - *v.mutable_data() = 4; + *v.data() = 4; std::fill(v.begin(), v.end(), 5); std::fill(v.rbegin(), v.rend(), 6); // Test size-changing methods. - v.pop_back(); + v.remove_suffix(1); EXPECT_EQ(len - 1, v.size()); for (size_t i = 0; i < v.size(); ++i) { EXPECT_EQ(ptr + i, &v[i]); } if (len > 1) { - v.pop_front(); + v.remove_prefix(1); EXPECT_EQ(len - 2, v.size()); for (size_t i = 0; i < v.size(); ++i) { EXPECT_EQ(ptr + i + 1, &v[i]); @@ -605,7 +605,6 @@ TEST(MutableIntSlice, IteratorsAndReferences) { MutableIntSlice s = a; accept_pointer(s.data()); - accept_pointer(s.mutable_data()); accept_iterator(s.begin()); accept_iterator(s.end()); accept_reverse_iterator(s.rbegin()); @@ -627,7 +626,6 @@ TEST(MutableIntSlice, IteratorsAndReferences_Const) { const MutableIntSlice s = a; accept_pointer(s.data()); - accept_pointer(s.mutable_data()); accept_iterator(s.begin()); accept_iterator(s.end()); accept_reverse_iterator(s.rbegin()); diff --git a/tensorflow/core/lib/gtl/cleanup.h b/tensorflow/core/lib/gtl/cleanup.h index 6bd60ca482..8c73dc6aa9 100644 --- a/tensorflow/core/lib/gtl/cleanup.h +++ b/tensorflow/core/lib/gtl/cleanup.h @@ -39,8 +39,8 @@ limitations under the License. // // You can call 'release()' on a Cleanup object to cancel the cleanup. -#ifndef TENSORFLOW_LIB_GTL_CLEANUP_H_ -#define TENSORFLOW_LIB_GTL_CLEANUP_H_ +#ifndef TENSORFLOW_CORE_LIB_GTL_CLEANUP_H_ +#define TENSORFLOW_CORE_LIB_GTL_CLEANUP_H_ #include <type_traits> #include <utility> @@ -110,4 +110,4 @@ TF_MUST_USE_RESULT Cleanup<DecayF> MakeCleanup(F&& f) { } // namespace gtl } // namespace tensorflow -#endif // TENSORFLOW_LIB_GTL_CLEANUP_H_ +#endif // TENSORFLOW_CORE_LIB_GTL_CLEANUP_H_ diff --git a/tensorflow/core/lib/gtl/inlined_vector.h b/tensorflow/core/lib/gtl/inlined_vector.h index 2011f7d4a1..c18dc9ad1a 100644 --- a/tensorflow/core/lib/gtl/inlined_vector.h +++ b/tensorflow/core/lib/gtl/inlined_vector.h @@ -28,8 +28,8 @@ limitations under the License. // // TODO(billydonahue): change size_t to size_type where appropriate. -#ifndef TENSORFLOW_LIB_GTL_INLINED_VECTOR_H_ -#define TENSORFLOW_LIB_GTL_INLINED_VECTOR_H_ +#ifndef TENSORFLOW_CORE_LIB_GTL_INLINED_VECTOR_H_ +#define TENSORFLOW_CORE_LIB_GTL_INLINED_VECTOR_H_ #include <stddef.h> #include <stdlib.h> @@ -685,4 +685,4 @@ inline void InlinedVector<T, N>::AppendRange(Iter first, Iter last) { } // namespace gtl } // namespace tensorflow -#endif // TENSORFLOW_LIB_GTL_INLINED_VECTOR_H_ +#endif // TENSORFLOW_CORE_LIB_GTL_INLINED_VECTOR_H_ diff --git a/tensorflow/core/lib/gtl/optional.h b/tensorflow/core/lib/gtl/optional.h index 4ee3f88d18..7ad916ad3d 100644 --- a/tensorflow/core/lib/gtl/optional.h +++ b/tensorflow/core/lib/gtl/optional.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_GTL_OPTIONAL_H_ -#define TENSORFLOW_LIB_GTL_OPTIONAL_H_ +#ifndef TENSORFLOW_CORE_LIB_GTL_OPTIONAL_H_ +#define TENSORFLOW_CORE_LIB_GTL_OPTIONAL_H_ #include <assert.h> #include <functional> @@ -873,4 +873,4 @@ struct hash<::tensorflow::gtl::optional<T>> { } // namespace std -#endif // TENSORFLOW_LIB_GTL_OPTIONAL_H_ +#endif // TENSORFLOW_CORE_LIB_GTL_OPTIONAL_H_ diff --git a/tensorflow/core/lib/gtl/priority_queue_util.h b/tensorflow/core/lib/gtl/priority_queue_util.h index 07311e3725..93bf3d3037 100644 --- a/tensorflow/core/lib/gtl/priority_queue_util.h +++ b/tensorflow/core/lib/gtl/priority_queue_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_GTL_PRIORITY_QUEUE_UTIL_H_ -#define TENSORFLOW_LIB_GTL_PRIORITY_QUEUE_UTIL_H_ +#ifndef TENSORFLOW_CORE_LIB_GTL_PRIORITY_QUEUE_UTIL_H_ +#define TENSORFLOW_CORE_LIB_GTL_PRIORITY_QUEUE_UTIL_H_ #include <algorithm> #include <queue> @@ -52,4 +52,4 @@ T ConsumeTop(std::priority_queue<T, Container, Comparator>* q) { } // namespace gtl } // namespace tensorflow -#endif // TENSORFLOW_LIB_GTL_PRIORITY_QUEUE_UTIL_H_ +#endif // TENSORFLOW_CORE_LIB_GTL_PRIORITY_QUEUE_UTIL_H_ diff --git a/tensorflow/core/lib/hash/crc32c.h b/tensorflow/core/lib/hash/crc32c.h index ee0bda93b1..2718cd31b3 100644 --- a/tensorflow/core/lib/hash/crc32c.h +++ b/tensorflow/core/lib/hash/crc32c.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_HASH_CRC32C_H_ -#define TENSORFLOW_LIB_HASH_CRC32C_H_ +#ifndef TENSORFLOW_CORE_LIB_HASH_CRC32C_H_ +#define TENSORFLOW_CORE_LIB_HASH_CRC32C_H_ #include <stddef.h> #include "tensorflow/core/platform/types.h" @@ -51,4 +51,4 @@ inline uint32 Unmask(uint32 masked_crc) { } // namespace crc32c } // namespace tensorflow -#endif // TENSORFLOW_LIB_HASH_CRC32C_H_ +#endif // TENSORFLOW_CORE_LIB_HASH_CRC32C_H_ diff --git a/tensorflow/core/lib/hash/hash.h b/tensorflow/core/lib/hash/hash.h index 737d23f699..675bab7191 100644 --- a/tensorflow/core/lib/hash/hash.h +++ b/tensorflow/core/lib/hash/hash.h @@ -15,8 +15,8 @@ limitations under the License. // Simple hash functions used for internal data structures -#ifndef TENSORFLOW_LIB_HASH_HASH_H_ -#define TENSORFLOW_LIB_HASH_HASH_H_ +#ifndef TENSORFLOW_CORE_LIB_HASH_HASH_H_ +#define TENSORFLOW_CORE_LIB_HASH_HASH_H_ #include <stddef.h> #include <stdint.h> @@ -110,4 +110,4 @@ struct hash<std::pair<T, U>> { } // namespace tensorflow -#endif // TENSORFLOW_LIB_HASH_HASH_H_ +#endif // TENSORFLOW_CORE_LIB_HASH_HASH_H_ diff --git a/tensorflow/core/lib/histogram/histogram.h b/tensorflow/core/lib/histogram/histogram.h index 65ce10786d..f882ee9abe 100644 --- a/tensorflow/core/lib/histogram/histogram.h +++ b/tensorflow/core/lib/histogram/histogram.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_HISTOGRAM_HISTOGRAM_H_ -#define TENSORFLOW_LIB_HISTOGRAM_HISTOGRAM_H_ +#ifndef TENSORFLOW_CORE_LIB_HISTOGRAM_HISTOGRAM_H_ +#define TENSORFLOW_CORE_LIB_HISTOGRAM_HISTOGRAM_H_ #include <string> #include <vector> @@ -136,4 +136,4 @@ class ThreadSafeHistogram { } // namespace histogram } // namespace tensorflow -#endif // TENSORFLOW_LIB_HISTOGRAM_HISTOGRAM_H_ +#endif // TENSORFLOW_CORE_LIB_HISTOGRAM_HISTOGRAM_H_ diff --git a/tensorflow/core/lib/io/buffered_inputstream.h b/tensorflow/core/lib/io/buffered_inputstream.h index 924619f40f..96a95b7ed9 100644 --- a/tensorflow/core/lib/io/buffered_inputstream.h +++ b/tensorflow/core/lib/io/buffered_inputstream.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_IO_BUFFERED_INPUTSTREAM_H_ -#define TENSORFLOW_LIB_IO_BUFFERED_INPUTSTREAM_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_BUFFERED_INPUTSTREAM_H_ +#define TENSORFLOW_CORE_LIB_IO_BUFFERED_INPUTSTREAM_H_ #include "tensorflow/core/lib/io/inputstream_interface.h" #include "tensorflow/core/platform/file_system.h" @@ -104,4 +104,4 @@ class BufferedInputStream : public InputStreamInterface { } // namespace io } // namespace tensorflow -#endif // TENSORFLOW_LIB_IO_BUFFERED_INPUTSTREAM_H_ +#endif // TENSORFLOW_CORE_LIB_IO_BUFFERED_INPUTSTREAM_H_ diff --git a/tensorflow/core/lib/io/inputstream_interface.h b/tensorflow/core/lib/io/inputstream_interface.h index 3083d20776..cbfc509d93 100644 --- a/tensorflow/core/lib/io/inputstream_interface.h +++ b/tensorflow/core/lib/io/inputstream_interface.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_IO_INPUTSTREAM_INTERFACE_H_ -#define TENSORFLOW_LIB_IO_INPUTSTREAM_INTERFACE_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_INPUTSTREAM_INTERFACE_H_ +#define TENSORFLOW_CORE_LIB_IO_INPUTSTREAM_INTERFACE_H_ #include <string> #include "tensorflow/core/lib/core/status.h" diff --git a/tensorflow/core/lib/io/path.cc b/tensorflow/core/lib/io/path.cc index b62206012c..b75dcecadf 100644 --- a/tensorflow/core/lib/io/path.cc +++ b/tensorflow/core/lib/io/path.cc @@ -42,7 +42,7 @@ string JoinPathImpl(std::initializer_list<StringPiece> paths) { if (path.empty()) continue; if (result.empty()) { - result = std::string(path); + result = string(path); continue; } @@ -124,7 +124,7 @@ StringPiece Extension(StringPiece path) { } string CleanPath(StringPiece unclean_path) { - string path = std::string(unclean_path); + string path(unclean_path); const char* src = path.c_str(); string::iterator dst = path.begin(); @@ -237,7 +237,7 @@ void ParseURI(StringPiece remaining, StringPiece* scheme, StringPiece* host, string CreateURI(StringPiece scheme, StringPiece host, StringPiece path) { if (scheme.empty()) { - return std::string(path); + return string(path); } return strings::StrCat(scheme, "://", host, path); } diff --git a/tensorflow/core/lib/io/path.h b/tensorflow/core/lib/io/path.h index 818ba99888..e3649fd0c9 100644 --- a/tensorflow/core/lib/io/path.h +++ b/tensorflow/core/lib/io/path.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_IO_PATH_H_ -#define TENSORFLOW_LIB_IO_PATH_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_PATH_H_ +#define TENSORFLOW_CORE_LIB_IO_PATH_H_ #include "tensorflow/core/lib/core/stringpiece.h" @@ -94,4 +94,4 @@ string GetTempFilename(const string& extension); } // namespace io } // namespace tensorflow -#endif // TENSORFLOW_LIB_IO_PATH_H_ +#endif // TENSORFLOW_CORE_LIB_IO_PATH_H_ diff --git a/tensorflow/core/lib/io/path_test.cc b/tensorflow/core/lib/io/path_test.cc index e3275b93b6..0090b9100c 100644 --- a/tensorflow/core/lib/io/path_test.cc +++ b/tensorflow/core/lib/io/path_test.cc @@ -104,9 +104,9 @@ TEST(PathTest, CleanPath) { StringPiece u(uri); \ StringPiece s, h, p; \ ParseURI(u, &s, &h, &p); \ - EXPECT_EQ(scheme, s.ToString()); \ - EXPECT_EQ(host, h.ToString()); \ - EXPECT_EQ(path, p.ToString()); \ + EXPECT_EQ(scheme, s); \ + EXPECT_EQ(host, h); \ + EXPECT_EQ(path, p); \ EXPECT_EQ(uri, CreateURI(scheme, host, path)); \ EXPECT_LE(u.begin(), s.begin()); \ EXPECT_GE(u.end(), s.begin()); \ diff --git a/tensorflow/core/lib/io/proto_encode_helper.h b/tensorflow/core/lib/io/proto_encode_helper.h index f70e1cbaab..34905520f1 100644 --- a/tensorflow/core/lib/io/proto_encode_helper.h +++ b/tensorflow/core/lib/io/proto_encode_helper.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_IO_PROTO_ENCODE_HELPER_H_ -#define TENSORFLOW_LIB_IO_PROTO_ENCODE_HELPER_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_PROTO_ENCODE_HELPER_H_ +#define TENSORFLOW_CORE_LIB_IO_PROTO_ENCODE_HELPER_H_ #include "tensorflow/core/lib/core/coding.h" #include "tensorflow/core/lib/core/stringpiece.h" @@ -95,4 +95,4 @@ class ProtoEncodeHelper { } // namespace io } // namespace tensorflow -#endif // TENSORFLOW_LIB_IO_PROTO_ENCODE_HELPER_H_ +#endif // TENSORFLOW_CORE_LIB_IO_PROTO_ENCODE_HELPER_H_ diff --git a/tensorflow/core/lib/io/random_inputstream.h b/tensorflow/core/lib/io/random_inputstream.h index bdbdbd71ff..c822fe50e9 100644 --- a/tensorflow/core/lib/io/random_inputstream.h +++ b/tensorflow/core/lib/io/random_inputstream.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_IO_RANDOM_INPUTSTREAM_H_ -#define TENSORFLOW_LIB_IO_RANDOM_INPUTSTREAM_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_RANDOM_INPUTSTREAM_H_ +#define TENSORFLOW_CORE_LIB_IO_RANDOM_INPUTSTREAM_H_ #include "tensorflow/core/lib/io/inputstream_interface.h" #include "tensorflow/core/platform/file_system.h" @@ -54,4 +54,4 @@ class RandomAccessInputStream : public InputStreamInterface { } // namespace io } // namespace tensorflow -#endif // TENSORFLOW_LIB_IO_RANDOM_INPUTSTREAM_H_ +#endif // TENSORFLOW_CORE_LIB_IO_RANDOM_INPUTSTREAM_H_ diff --git a/tensorflow/core/lib/io/record_reader.h b/tensorflow/core/lib/io/record_reader.h index f6d587dfa0..c05f9e1b36 100644 --- a/tensorflow/core/lib/io/record_reader.h +++ b/tensorflow/core/lib/io/record_reader.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_IO_RECORD_READER_H_ -#define TENSORFLOW_LIB_IO_RECORD_READER_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_RECORD_READER_H_ +#define TENSORFLOW_CORE_LIB_IO_RECORD_READER_H_ #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/stringpiece.h" @@ -122,4 +122,4 @@ class SequentialRecordReader { } // namespace io } // namespace tensorflow -#endif // TENSORFLOW_LIB_IO_RECORD_READER_H_ +#endif // TENSORFLOW_CORE_LIB_IO_RECORD_READER_H_ diff --git a/tensorflow/core/lib/io/record_writer.h b/tensorflow/core/lib/io/record_writer.h index daed809af3..2f6afa5487 100644 --- a/tensorflow/core/lib/io/record_writer.h +++ b/tensorflow/core/lib/io/record_writer.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_IO_RECORD_WRITER_H_ -#define TENSORFLOW_LIB_IO_RECORD_WRITER_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_RECORD_WRITER_H_ +#define TENSORFLOW_CORE_LIB_IO_RECORD_WRITER_H_ #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/core/stringpiece.h" @@ -82,4 +82,4 @@ class RecordWriter { } // namespace io } // namespace tensorflow -#endif // TENSORFLOW_LIB_IO_RECORD_WRITER_H_ +#endif // TENSORFLOW_CORE_LIB_IO_RECORD_WRITER_H_ diff --git a/tensorflow/core/lib/io/table.h b/tensorflow/core/lib/io/table.h index a1b78eae5b..b9c6b8d9d2 100644 --- a/tensorflow/core/lib/io/table.h +++ b/tensorflow/core/lib/io/table.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_IO_TABLE_H_ -#define TENSORFLOW_LIB_IO_TABLE_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_TABLE_H_ +#define TENSORFLOW_CORE_LIB_IO_TABLE_H_ #include <stdint.h> #include "tensorflow/core/lib/io/iterator.h" @@ -84,4 +84,4 @@ class Table { } // namespace table } // namespace tensorflow -#endif // TENSORFLOW_LIB_IO_TABLE_H_ +#endif // TENSORFLOW_CORE_LIB_IO_TABLE_H_ diff --git a/tensorflow/core/lib/io/table_builder.h b/tensorflow/core/lib/io/table_builder.h index 0202f90446..0e37e0a77f 100644 --- a/tensorflow/core/lib/io/table_builder.h +++ b/tensorflow/core/lib/io/table_builder.h @@ -21,8 +21,8 @@ limitations under the License. // non-const method, all threads accessing the same TableBuilder must use // external synchronization. -#ifndef TENSORFLOW_LIB_IO_TABLE_BUILDER_H_ -#define TENSORFLOW_LIB_IO_TABLE_BUILDER_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_TABLE_BUILDER_H_ +#define TENSORFLOW_CORE_LIB_IO_TABLE_BUILDER_H_ #include <stdint.h> #include "tensorflow/core/lib/core/status.h" @@ -96,4 +96,4 @@ class TableBuilder { } // namespace table } // namespace tensorflow -#endif // TENSORFLOW_LIB_IO_TABLE_BUILDER_H_ +#endif // TENSORFLOW_CORE_LIB_IO_TABLE_BUILDER_H_ diff --git a/tensorflow/core/lib/io/table_options.h b/tensorflow/core/lib/io/table_options.h index fd8a9d4a78..9a36bf1631 100644 --- a/tensorflow/core/lib/io/table_options.h +++ b/tensorflow/core/lib/io/table_options.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_IO_TABLE_OPTIONS_H_ -#define TENSORFLOW_LIB_IO_TABLE_OPTIONS_H_ +#ifndef TENSORFLOW_CORE_LIB_IO_TABLE_OPTIONS_H_ +#define TENSORFLOW_CORE_LIB_IO_TABLE_OPTIONS_H_ #include <stddef.h> @@ -65,4 +65,4 @@ struct Options { } // namespace table } // namespace tensorflow -#endif // TENSORFLOW_LIB_IO_TABLE_OPTIONS_H_ +#endif // TENSORFLOW_CORE_LIB_IO_TABLE_OPTIONS_H_ diff --git a/tensorflow/core/lib/io/table_test.cc b/tensorflow/core/lib/io/table_test.cc index 9e3309f0a7..877ac40f1c 100644 --- a/tensorflow/core/lib/io/table_test.cc +++ b/tensorflow/core/lib/io/table_test.cc @@ -147,7 +147,7 @@ class Constructor { virtual ~Constructor() {} void Add(const string& key, const StringPiece& value) { - data_[key] = std::string(value); + data_[key] = string(value); } // Finish constructing the data structure with all the keys that have @@ -188,7 +188,7 @@ class BlockConstructor : public Constructor { builder.Add(it->first, it->second); } // Open the block - data_ = std::string(builder.Finish()); + data_ = string(builder.Finish()); BlockContents contents; contents.data = data_; contents.cachable = false; @@ -515,7 +515,7 @@ TEST_F(Harness, Randomized) { for (int e = 0; e < num_entries; e++) { string v; Add(test::RandomKey(&rnd, rnd.Skewed(4)), - std::string(test::RandomString(&rnd, rnd.Skewed(5), &v))); + string(test::RandomString(&rnd, rnd.Skewed(5), &v))); } Test(&rnd); } diff --git a/tensorflow/core/lib/jpeg/jpeg_handle.h b/tensorflow/core/lib/jpeg/jpeg_handle.h index 7d86be51da..86fa3ac5c2 100644 --- a/tensorflow/core/lib/jpeg/jpeg_handle.h +++ b/tensorflow/core/lib/jpeg/jpeg_handle.h @@ -16,8 +16,8 @@ limitations under the License. // This file declares the functions and structures for memory I/O with libjpeg // These functions are not meant to be used directly, see jpeg_mem.h instead. -#ifndef TENSORFLOW_LIB_JPEG_JPEG_HANDLE_H_ -#define TENSORFLOW_LIB_JPEG_JPEG_HANDLE_H_ +#ifndef TENSORFLOW_CORE_LIB_JPEG_JPEG_HANDLE_H_ +#define TENSORFLOW_CORE_LIB_JPEG_JPEG_HANDLE_H_ #include "tensorflow/core/platform/jpeg.h" #include "tensorflow/core/platform/types.h" @@ -57,4 +57,4 @@ void SetDest(j_compress_ptr cinfo, void *buffer, int bufsize, } // namespace jpeg } // namespace tensorflow -#endif // TENSORFLOW_LIB_JPEG_JPEG_HANDLE_H_ +#endif // TENSORFLOW_CORE_LIB_JPEG_JPEG_HANDLE_H_ diff --git a/tensorflow/core/lib/jpeg/jpeg_mem.h b/tensorflow/core/lib/jpeg/jpeg_mem.h index 59342d28c0..03437a4e78 100644 --- a/tensorflow/core/lib/jpeg/jpeg_mem.h +++ b/tensorflow/core/lib/jpeg/jpeg_mem.h @@ -18,8 +18,8 @@ limitations under the License. // (data array and size fields). // Direct manipulation of JPEG strings are supplied: Flip, Rotate, Crop.. -#ifndef TENSORFLOW_LIB_JPEG_JPEG_MEM_H_ -#define TENSORFLOW_LIB_JPEG_JPEG_MEM_H_ +#ifndef TENSORFLOW_CORE_LIB_JPEG_JPEG_MEM_H_ +#define TENSORFLOW_CORE_LIB_JPEG_JPEG_MEM_H_ #include <functional> #include <string> @@ -159,4 +159,4 @@ bool Compress(const void* srcdata, int width, int height, } // namespace jpeg } // namespace tensorflow -#endif // TENSORFLOW_LIB_JPEG_JPEG_MEM_H_ +#endif // TENSORFLOW_CORE_LIB_JPEG_JPEG_MEM_H_ diff --git a/tensorflow/core/lib/math/math_util.h b/tensorflow/core/lib/math/math_util.h index 41d486f2bd..502d741512 100644 --- a/tensorflow/core/lib/math/math_util.h +++ b/tensorflow/core/lib/math/math_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_MATH_MATH_UTIL_H_ -#define TENSORFLOW_LIB_MATH_MATH_UTIL_H_ +#ifndef TENSORFLOW_CORE_LIB_MATH_MATH_UTIL_H_ +#define TENSORFLOW_CORE_LIB_MATH_MATH_UTIL_H_ #include <type_traits> @@ -160,4 +160,4 @@ T MathUtil::IPow(T base, int exp) { } // namespace tensorflow -#endif // TENSORFLOW_LIB_MATH_MATH_UTIL_H_ +#endif // TENSORFLOW_CORE_LIB_MATH_MATH_UTIL_H_ diff --git a/tensorflow/core/lib/monitoring/collection_registry.cc b/tensorflow/core/lib/monitoring/collection_registry.cc index 8c28620ff9..fface033cb 100644 --- a/tensorflow/core/lib/monitoring/collection_registry.cc +++ b/tensorflow/core/lib/monitoring/collection_registry.cc @@ -38,15 +38,15 @@ void Collector::CollectMetricDescriptor( mutex_lock l(mu_); return collected_metrics_->metric_descriptor_map .insert(std::make_pair( - std::string(metric_def->name()), + string(metric_def->name()), std::unique_ptr<MetricDescriptor>(new MetricDescriptor()))) .first->second.get(); }(); - metric_descriptor->name = std::string(metric_def->name()); - metric_descriptor->description = std::string(metric_def->description()); + metric_descriptor->name = string(metric_def->name()); + metric_descriptor->description = string(metric_def->description()); for (const StringPiece label_name : metric_def->label_descriptions()) { - metric_descriptor->label_names.push_back(std::string(label_name)); + metric_descriptor->label_names.emplace_back(label_name); } metric_descriptor->metric_kind = metric_def->kind(); diff --git a/tensorflow/core/lib/monitoring/collection_registry.h b/tensorflow/core/lib/monitoring/collection_registry.h index 20f0444f8b..c204d52cfe 100644 --- a/tensorflow/core/lib/monitoring/collection_registry.h +++ b/tensorflow/core/lib/monitoring/collection_registry.h @@ -72,7 +72,7 @@ class MetricCollector { registration_time_millis_(registration_time_millis), collector_(collector), point_set_(point_set) { - point_set_->metric_name = std::string(metric_def->name()); + point_set_->metric_name = string(metric_def->name()); } const MetricDef<metric_kind, Value, NumLabels>* const metric_def_; @@ -261,7 +261,7 @@ class Collector { auto* const point_set = [&]() { mutex_lock l(mu_); return collected_metrics_->point_set_map - .insert(std::make_pair(std::string(metric_def->name()), + .insert(std::make_pair(string(metric_def->name()), std::unique_ptr<PointSet>(new PointSet()))) .first->second.get(); }(); diff --git a/tensorflow/core/lib/monitoring/metric_def.h b/tensorflow/core/lib/monitoring/metric_def.h index 6f94685665..756e5c2af8 100644 --- a/tensorflow/core/lib/monitoring/metric_def.h +++ b/tensorflow/core/lib/monitoring/metric_def.h @@ -98,8 +98,8 @@ class AbstractMetricDef { const std::vector<string>& label_descriptions) : kind_(kind), value_type_(value_type), - name_(std::string(name)), - description_(std::string(description)), + name_(name), + description_(description), label_descriptions_(std::vector<string>(label_descriptions.begin(), label_descriptions.end())) {} diff --git a/tensorflow/core/lib/random/distribution_sampler.h b/tensorflow/core/lib/random/distribution_sampler.h index 25605d8ed4..7aa50ece03 100644 --- a/tensorflow/core/lib/random/distribution_sampler.h +++ b/tensorflow/core/lib/random/distribution_sampler.h @@ -28,8 +28,8 @@ limitations under the License. // // The algorithm used is Walker's Aliasing algorithm, described in Knuth, Vol 2. -#ifndef TENSORFLOW_LIB_RANDOM_DISTRIBUTION_SAMPLER_H_ -#define TENSORFLOW_LIB_RANDOM_DISTRIBUTION_SAMPLER_H_ +#ifndef TENSORFLOW_CORE_LIB_RANDOM_DISTRIBUTION_SAMPLER_H_ +#define TENSORFLOW_CORE_LIB_RANDOM_DISTRIBUTION_SAMPLER_H_ #include <memory> #include <utility> @@ -91,4 +91,4 @@ class DistributionSampler { } // namespace random } // namespace tensorflow -#endif // TENSORFLOW_LIB_RANDOM_DISTRIBUTION_SAMPLER_H_ +#endif // TENSORFLOW_CORE_LIB_RANDOM_DISTRIBUTION_SAMPLER_H_ diff --git a/tensorflow/core/lib/random/philox_random.h b/tensorflow/core/lib/random/philox_random.h index b2adb4462b..058ed95ffb 100644 --- a/tensorflow/core/lib/random/philox_random.h +++ b/tensorflow/core/lib/random/philox_random.h @@ -17,8 +17,8 @@ limitations under the License. // Salmon et al. SC 2011. Parallel random numbers: as easy as 1, 2, 3. // http://www.thesalmons.org/john/random123/papers/random123sc11.pdf -#ifndef TENSORFLOW_LIB_RANDOM_PHILOX_RANDOM_H_ -#define TENSORFLOW_LIB_RANDOM_PHILOX_RANDOM_H_ +#ifndef TENSORFLOW_CORE_LIB_RANDOM_PHILOX_RANDOM_H_ +#define TENSORFLOW_CORE_LIB_RANDOM_PHILOX_RANDOM_H_ #include <stdlib.h> @@ -248,4 +248,4 @@ class PhiloxRandom { } // namespace random } // namespace tensorflow -#endif // TENSORFLOW_LIB_RANDOM_PHILOX_RANDOM_H_ +#endif // TENSORFLOW_CORE_LIB_RANDOM_PHILOX_RANDOM_H_ diff --git a/tensorflow/core/lib/random/random_distributions.h b/tensorflow/core/lib/random/random_distributions.h index e963511f5c..c3801a0412 100644 --- a/tensorflow/core/lib/random/random_distributions.h +++ b/tensorflow/core/lib/random/random_distributions.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_RANDOM_RANDOM_DISTRIBUTIONS_H_ -#define TENSORFLOW_LIB_RANDOM_RANDOM_DISTRIBUTIONS_H_ +#ifndef TENSORFLOW_CORE_LIB_RANDOM_RANDOM_DISTRIBUTIONS_H_ +#define TENSORFLOW_CORE_LIB_RANDOM_RANDOM_DISTRIBUTIONS_H_ #define _USE_MATH_DEFINES #include <math.h> @@ -744,4 +744,4 @@ PHILOX_DEVICE_INLINE double Uint64ToDouble(uint32 x0, uint32 x1) { } // namespace random } // namespace tensorflow -#endif // TENSORFLOW_LIB_RANDOM_RANDOM_DISTRIBUTIONS_H_ +#endif // TENSORFLOW_CORE_LIB_RANDOM_RANDOM_DISTRIBUTIONS_H_ diff --git a/tensorflow/core/lib/random/simple_philox.h b/tensorflow/core/lib/random/simple_philox.h index d529e08913..6464036856 100644 --- a/tensorflow/core/lib/random/simple_philox.h +++ b/tensorflow/core/lib/random/simple_philox.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_RANDOM_SIMPLE_PHILOX_H_ -#define TENSORFLOW_LIB_RANDOM_SIMPLE_PHILOX_H_ +#ifndef TENSORFLOW_CORE_LIB_RANDOM_SIMPLE_PHILOX_H_ +#define TENSORFLOW_CORE_LIB_RANDOM_SIMPLE_PHILOX_H_ #include <math.h> #include <string.h> @@ -73,4 +73,4 @@ class SimplePhilox { } // namespace random } // namespace tensorflow -#endif // TENSORFLOW_LIB_RANDOM_SIMPLE_PHILOX_H_ +#endif // TENSORFLOW_CORE_LIB_RANDOM_SIMPLE_PHILOX_H_ diff --git a/tensorflow/core/lib/strings/numbers.h b/tensorflow/core/lib/strings/numbers.h index 1d5bacac93..959290ba8c 100644 --- a/tensorflow/core/lib/strings/numbers.h +++ b/tensorflow/core/lib/strings/numbers.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_STRINGS_NUMBERS_H_ -#define TENSORFLOW_LIB_STRINGS_NUMBERS_H_ +#ifndef TENSORFLOW_CORE_LIB_STRINGS_NUMBERS_H_ +#define TENSORFLOW_CORE_LIB_STRINGS_NUMBERS_H_ #include <string> @@ -140,11 +140,11 @@ inline bool ProtoParseNumeric(StringPiece s, uint64* value) { } inline bool ProtoParseNumeric(StringPiece s, float* value) { - return safe_strtof(std::string(s).c_str(), value); + return safe_strtof(s, value); } inline bool ProtoParseNumeric(StringPiece s, double* value) { - return safe_strtod(std::string(s).c_str(), value); + return safe_strtod(s, value); } // Convert strings to number of type T. @@ -176,4 +176,4 @@ string HumanReadableElapsedTime(double seconds); } // namespace strings } // namespace tensorflow -#endif // TENSORFLOW_LIB_STRINGS_NUMBERS_H_ +#endif // TENSORFLOW_CORE_LIB_STRINGS_NUMBERS_H_ diff --git a/tensorflow/core/lib/strings/str_util.cc b/tensorflow/core/lib/strings/str_util.cc index cab8f81585..3aba5ec80e 100644 --- a/tensorflow/core/lib/strings/str_util.cc +++ b/tensorflow/core/lib/strings/str_util.cc @@ -332,7 +332,7 @@ string StringReplace(StringPiece s, StringPiece oldsub, StringPiece newsub, bool replace_all) { // TODO(jlebar): We could avoid having to shift data around in the string if // we had a StringPiece::find() overload that searched for a StringPiece. - string res = std::string(s); + string res(s); size_t pos = 0; while ((pos = res.find(oldsub.data(), pos, oldsub.size())) != string::npos) { res.replace(pos, oldsub.size(), newsub.data(), newsub.size()); @@ -448,8 +448,7 @@ bool SplitAndParseAsFloats(StringPiece text, char delim, std::vector<float>* result) { return SplitAndParseAsInts<float>(text, delim, [](StringPiece str, float* value) { - return strings::safe_strtof( - std::string(str).c_str(), value); + return strings::safe_strtof(str, value); }, result); } diff --git a/tensorflow/core/lib/strings/str_util.h b/tensorflow/core/lib/strings/str_util.h index c887db7eff..9f52cf29fc 100644 --- a/tensorflow/core/lib/strings/str_util.h +++ b/tensorflow/core/lib/strings/str_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_LIB_STRINGS_STR_UTIL_H_ -#define TENSORFLOW_LIB_STRINGS_STR_UTIL_H_ +#ifndef TENSORFLOW_CORE_LIB_STRINGS_STR_UTIL_H_ +#define TENSORFLOW_CORE_LIB_STRINGS_STR_UTIL_H_ #include <functional> #include <string> @@ -205,7 +205,7 @@ std::vector<string> Split(StringPiece text, StringPiece delims, Predicate p) { if ((i == text.size()) || (delims.find(text[i]) != StringPiece::npos)) { StringPiece token(text.data() + token_start, i - token_start); if (p(token)) { - result.push_back(std::string(token)); + result.emplace_back(token); } token_start = i + 1; } @@ -231,4 +231,4 @@ size_t Strnlen(const char* str, const size_t string_max_len); } // namespace str_util } // namespace tensorflow -#endif // TENSORFLOW_LIB_STRINGS_STR_UTIL_H_ +#endif // TENSORFLOW_CORE_LIB_STRINGS_STR_UTIL_H_ diff --git a/tensorflow/core/lib/strings/strcat.h b/tensorflow/core/lib/strings/strcat.h index fb2cd5bc7e..5ae3d220e3 100644 --- a/tensorflow/core/lib/strings/strcat.h +++ b/tensorflow/core/lib/strings/strcat.h @@ -17,8 +17,8 @@ limitations under the License. // #category: operations on strings // #summary: Merges strings or numbers with no delimiter. // -#ifndef TENSORFLOW_LIB_STRINGS_STRCAT_H_ -#define TENSORFLOW_LIB_STRINGS_STRCAT_H_ +#ifndef TENSORFLOW_CORE_LIB_STRINGS_STRCAT_H_ +#define TENSORFLOW_CORE_LIB_STRINGS_STRCAT_H_ #include <string> @@ -233,4 +233,4 @@ inline void StrAppend(string *dest, const AlphaNum &a, const AlphaNum &b, } // namespace strings } // namespace tensorflow -#endif // TENSORFLOW_LIB_STRINGS_STRCAT_H_ +#endif // TENSORFLOW_CORE_LIB_STRINGS_STRCAT_H_ diff --git a/tensorflow/core/lib/strings/stringprintf.h b/tensorflow/core/lib/strings/stringprintf.h index f7957252ea..52af410d42 100644 --- a/tensorflow/core/lib/strings/stringprintf.h +++ b/tensorflow/core/lib/strings/stringprintf.h @@ -20,8 +20,8 @@ limitations under the License. // strings::SPrintf(&result, "%d %s\n", 10, "hello"); // strings::Appendf(&result, "%d %s\n", 20, "there"); -#ifndef TENSORFLOW_LIB_STRINGS_STRINGPRINTF_H_ -#define TENSORFLOW_LIB_STRINGS_STRINGPRINTF_H_ +#ifndef TENSORFLOW_CORE_LIB_STRINGS_STRINGPRINTF_H_ +#define TENSORFLOW_CORE_LIB_STRINGS_STRINGPRINTF_H_ #include <stdarg.h> #include <string> @@ -49,4 +49,4 @@ extern void Appendv(string* dst, const char* format, va_list ap); } // namespace strings } // namespace tensorflow -#endif // TENSORFLOW_LIB_STRINGS_STRINGPRINTF_H_ +#endif // TENSORFLOW_CORE_LIB_STRINGS_STRINGPRINTF_H_ diff --git a/tensorflow/core/ops/array_grad.cc b/tensorflow/core/ops/array_grad.cc index 1f2e57e9a9..3d03bc1d5f 100644 --- a/tensorflow/core/ops/array_grad.cc +++ b/tensorflow/core/ops/array_grad.cc @@ -354,6 +354,27 @@ Status TransposeGrad(const AttrSlice& attrs, FunctionDef* g) { } REGISTER_OP_GRADIENT("Transpose", TransposeGrad); +Status GatherNdGrad(const AttrSlice& attrs, FunctionDef* g) { + // clang-format off + *g = FDH::Define( + // Arg defs + {"params: Tparams", "indices: Tindices", "doutput: Tparams"}, + // Ret val defs + {"dparams: Tparams", "dindices: Tindices"}, + // Attr defs + {"Tparams: type", "Tindices: type"}, + // Nodes + { + {{"x_shape"}, "Shape", {"params"}, {{"T", "$Tparams"}}}, + {{"dparams"}, "ScatterNd", {"indices", "doutput", "x_shape"}, + {{"T", "$Tparams"}, {"Tindices", "$Tindices"}}}, + {{"dindices"}, "ZerosLike", {"indices"}, {{"T", "$Tindices"}}}, + }); + // clang-format on + return Status::OK(); +} +REGISTER_OP_GRADIENT("GatherNd", GatherNdGrad); + Status ConjugateTransposeGrad(const AttrSlice& attrs, FunctionDef* g) { *g = FDH::Define( // Arg defs diff --git a/tensorflow/core/ops/array_ops.cc b/tensorflow/core/ops/array_ops.cc index 1d11ec00ce..7dbb18aa5d 100644 --- a/tensorflow/core/ops/array_ops.cc +++ b/tensorflow/core/ops/array_ops.cc @@ -1446,6 +1446,30 @@ REGISTER_OP("ShapeN") .Attr("out_type: {int32, int64} = DT_INT32") .SetShapeFn(ShapeShapeFn); +REGISTER_OP("EnsureShape") + .Input("input: T") + .Output("output: T") + .Attr("shape: shape") + .Attr("T: type") + .SetShapeFn([](InferenceContext* c) { + // Merges desired shape and statically known shape of input + PartialTensorShape desired_shape; + TF_RETURN_IF_ERROR(c->GetAttr("shape", &desired_shape)); + + int rank = desired_shape.dims(); + ShapeHandle input_shape_handle; + ShapeHandle desired_shape_handle; + TF_RETURN_IF_ERROR(c->WithRank(c->input(0), rank, &input_shape_handle)); + TF_RETURN_IF_ERROR(c->MakeShapeFromPartialTensorShape( + desired_shape, &desired_shape_handle)); + + ShapeHandle merged_shape; + TF_RETURN_IF_ERROR( + c->Merge(desired_shape_handle, input_shape_handle, &merged_shape)); + c->set_output(0, merged_shape); + return Status::OK(); + }); + // -------------------------------------------------------------------------- REGISTER_OP("ReverseSequence") .Input("input: T") diff --git a/tensorflow/core/ops/array_ops_test.cc b/tensorflow/core/ops/array_ops_test.cc index c15409a246..03dab390a7 100644 --- a/tensorflow/core/ops/array_ops_test.cc +++ b/tensorflow/core/ops/array_ops_test.cc @@ -1620,6 +1620,24 @@ TEST(ArrayOpsTest, Slice_ShapeFn) { INFER_ERROR("cannot be < -1", op, "[2,3,4,5];[4];[4]"); } +TEST(ArrayOpsTest, StridedSlice_ShapeFn) { + ShapeInferenceTestOp op("StridedSlice"); + TF_ASSERT_OK(NodeDefBuilder("test", "StridedSlice") + .Input("input", 0, DT_FLOAT) + .Input("begin", 1, DT_INT32) + .Input("end", 2, DT_INT32) + .Input("strides", 3, DT_INT32) + .Attr("shrink_axis_mask", 1) + .Finalize(&op.node_def)); + op.input_tensors.resize(4); + Tensor strides = test::AsTensor<int32>({1}); + op.input_tensors[3] = &strides; + // Slicing on the 0-th dimension. + INFER_OK(op, "[2,3,4,5];[1];[1];[1]", "[3,4,5]"); + // Slicing on the 0-th dimension. This time some of the result dimension is 0. + INFER_OK(op, "[2,0,3,4];[1];[1];[1]", "[0,3,4]"); +} + TEST(ArrayOpsTest, StridedSliceGrad_ShapeFn) { ShapeInferenceTestOp op("StridedSliceGrad"); op.input_tensors.resize(5); diff --git a/tensorflow/core/ops/compat/ops_history.v1.pbtxt b/tensorflow/core/ops/compat/ops_history.v1.pbtxt index 72b9477f28..82e4831e00 100644 --- a/tensorflow/core/ops/compat/ops_history.v1.pbtxt +++ b/tensorflow/core/ops/compat/ops_history.v1.pbtxt @@ -20317,6 +20317,31 @@ op { } } op { + name: "DivNoNan" + input_arg { + name: "x" + type_attr: "T" + } + input_arg { + name: "y" + type_attr: "T" + } + output_arg { + name: "z" + type_attr: "T" + } + attr { + name: "T" + type: "type" + allowed_values { + list { + type: DT_FLOAT + type: DT_DOUBLE + } + } + } +} +op { name: "DrawBoundingBoxes" input_arg { name: "images" @@ -20865,6 +20890,25 @@ op { is_stateful: true } op { + name: "EnsureShape" + input_arg { + name: "input" + type_attr: "T" + } + output_arg { + name: "output" + type_attr: "T" + } + attr { + name: "shape" + type: "shape" + } + attr { + name: "T" + type: "type" + } +} +op { name: "Enter" input_arg { name: "data" @@ -29991,6 +30035,32 @@ op { } } op { + name: "MatrixExponential" + input_arg { + name: "input" + type_attr: "T" + } + output_arg { + name: "output" + type_attr: "T" + } + attr { + name: "T" + type: "type" + allowed_values { + list { + type: DT_DOUBLE + type: DT_FLOAT + type: DT_COMPLEX64 + type: DT_COMPLEX128 + } + } + } + deprecation { + version: 27 + } +} +op { name: "MatrixInverse" input_arg { name: "input" @@ -37284,6 +37354,76 @@ op { } } op { + name: "ParseExampleDataset" + input_arg { + name: "input_dataset" + type: DT_VARIANT + } + input_arg { + name: "num_parallel_calls" + type: DT_INT64 + } + input_arg { + name: "dense_defaults" + type_list_attr: "Tdense" + } + output_arg { + name: "handle" + type: DT_VARIANT + } + attr { + name: "sparse_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "dense_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "sparse_types" + type: "list(type)" + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "Tdense" + type: "list(type)" + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "dense_shapes" + type: "list(shape)" + has_minimum: true + } + attr { + name: "output_types" + type: "list(type)" + has_minimum: true + minimum: 1 + } + attr { + name: "output_shapes" + type: "list(shape)" + has_minimum: true + minimum: 1 + } +} +op { name: "ParseSingleExample" input_arg { name: "serialized" @@ -43819,6 +43959,38 @@ op { } } op { + name: "Relu" + input_arg { + name: "features" + type_attr: "T" + } + output_arg { + name: "activations" + type_attr: "T" + } + attr { + name: "T" + type: "type" + allowed_values { + list { + type: DT_FLOAT + type: DT_DOUBLE + type: DT_INT32 + type: DT_UINT8 + type: DT_INT16 + type: DT_INT8 + type: DT_INT64 + type: DT_BFLOAT16 + type: DT_UINT16 + type: DT_HALF + type: DT_UINT32 + type: DT_UINT64 + type: DT_QINT8 + } + } + } +} +op { name: "Relu6" input_arg { name: "features" @@ -68834,6 +69006,32 @@ op { } } op { + name: "StaticRegexReplace" + input_arg { + name: "input" + type: DT_STRING + } + output_arg { + name: "output" + type: DT_STRING + } + attr { + name: "pattern" + type: "string" + } + attr { + name: "rewrite" + type: "string" + } + attr { + name: "replace_global" + type: "bool" + default_value { + b: true + } + } +} +op { name: "StatsAggregatorHandle" output_arg { name: "handle" @@ -73417,41 +73615,6 @@ op { } } op { - name: "UnsafeDiv" - input_arg { - name: "x" - type_attr: "T" - } - input_arg { - name: "y" - type_attr: "T" - } - output_arg { - name: "z" - type_attr: "T" - } - attr { - name: "T" - type: "type" - allowed_values { - list { - type: DT_BFLOAT16 - type: DT_HALF - type: DT_FLOAT - type: DT_DOUBLE - type: DT_UINT8 - type: DT_INT8 - type: DT_UINT16 - type: DT_INT16 - type: DT_INT32 - type: DT_INT64 - type: DT_COMPLEX64 - type: DT_COMPLEX128 - } - } - } -} -op { name: "UnsortedSegmentMax" input_arg { name: "data" diff --git a/tensorflow/core/ops/dataset_ops.cc b/tensorflow/core/ops/dataset_ops.cc index 13733d48f0..41f5f9aebe 100644 --- a/tensorflow/core/ops/dataset_ops.cc +++ b/tensorflow/core/ops/dataset_ops.cc @@ -166,6 +166,22 @@ REGISTER_OP("LatencyStatsDataset") return shape_inference::ScalarShape(c); }); +REGISTER_OP("ParseExampleDataset") + .Input("input_dataset: variant") + .Input("num_parallel_calls: int64") + .Input("dense_defaults: Tdense") + .Output("handle: variant") + .Attr("sparse_keys: list(string) >= 0") + .Attr("dense_keys: list(string) >= 0") + .Attr("sparse_types: list({float,int64,string}) >= 0") + .Attr("Tdense: list({float,int64,string}) >= 0") + .Attr("dense_shapes: list(shape) >= 0") + .Attr("output_types: list(type) >= 1") + .Attr("output_shapes: list(shape) >= 1") // Output components will be + // sorted by key (dense_keys and + // sparse_keys combined) here. + .SetShapeFn(shape_inference::ScalarShape); + REGISTER_OP("FeatureStatsDataset") .Input("input_dataset: variant") .Input("tag: string") diff --git a/tensorflow/core/ops/linalg_ops.cc b/tensorflow/core/ops/linalg_ops.cc index f37f79ddbf..1d4d51a25d 100644 --- a/tensorflow/core/ops/linalg_ops.cc +++ b/tensorflow/core/ops/linalg_ops.cc @@ -235,6 +235,8 @@ REGISTER_OP("MatrixInverse") .SetShapeFn(BatchUnchangedSquareShapeFn); REGISTER_OP("MatrixExponential") + .Deprecated( + 27, "Use Python implementation tf.linalg.matrix_exponential instead.") .Input("input: T") .Output("output: T") .Attr("T: {double, float, complex64, complex128}") diff --git a/tensorflow/core/ops/lookup_ops.cc b/tensorflow/core/ops/lookup_ops.cc index 7c71406c6b..72a77be70d 100644 --- a/tensorflow/core/ops/lookup_ops.cc +++ b/tensorflow/core/ops/lookup_ops.cc @@ -294,7 +294,9 @@ REGISTER_OP("LookupTableImportV2") ShapeHandle handle; TF_RETURN_IF_ERROR(c->WithRank(c->input(0), 0, &handle)); - // TODO: Validate keys and values shape. + ShapeHandle keys; + TF_RETURN_IF_ERROR(c->WithRank(c->input(1), 1, &keys)); + TF_RETURN_IF_ERROR(c->Merge(keys, c->input(2), &keys)); return Status::OK(); }); diff --git a/tensorflow/core/ops/math_grad.cc b/tensorflow/core/ops/math_grad.cc index 57499a6f1d..07f876cb90 100644 --- a/tensorflow/core/ops/math_grad.cc +++ b/tensorflow/core/ops/math_grad.cc @@ -495,18 +495,18 @@ Status RealDivGrad(const AttrSlice& attrs, FunctionDef* g) { } REGISTER_OP_GRADIENT("RealDiv", RealDivGrad); -Status UnsafeDivGrad(const AttrSlice& attrs, FunctionDef* g) { +Status DivNoNanGrad(const AttrSlice& attrs, FunctionDef* g) { // clang-format off return GradForBinaryCwise(g, { - {{"gx"}, "UnsafeDiv", {"dz", "y"}}, + {{"gx"}, "DivNoNan", {"dz", "y"}}, {{"nx"}, "Neg", {"x"}, {}, {"dz"}}, {{"y2"}, "Square", {"y"}, {}, {"dz"}}, - {{"nx_y2"}, "UnsafeDiv", {"nx", "y2"}}, + {{"nx_y2"}, "DivNoNan", {"nx", "y2"}}, {{"gy"}, "Mul", {"dz", "nx_y2"}}, // dz * (- x / y^2) }); // clang-format on } -REGISTER_OP_GRADIENT("UnsafeDiv", UnsafeDivGrad); +REGISTER_OP_GRADIENT("DivNoNan", DivNoNanGrad); Status PowGrad(const AttrSlice& attrs, FunctionDef* g) { // clang-format off diff --git a/tensorflow/core/ops/math_grad_test.cc b/tensorflow/core/ops/math_grad_test.cc index b0d1595c31..5ee79809ac 100644 --- a/tensorflow/core/ops/math_grad_test.cc +++ b/tensorflow/core/ops/math_grad_test.cc @@ -753,14 +753,14 @@ TEST_F(MathGradTest, Div) { } } -TEST_F(MathGradTest, UnsafeDiv) { +TEST_F(MathGradTest, DivNoNan) { auto x = test::AsTensor<float>( {0.f, -3.f, -2.f, -1.f, 0.f, 1.f, 2.f, 3.f, 0.f}, TensorShape({3, 3})); auto y = test::AsTensor<float>({-10.f, 0.f, 10.f}, TensorShape({3, 1})); Tensor dx; Tensor dy; { - SymGrad("UnsafeDiv", x, y, &dx, &dy); + SymGrad("DivNoNan", x, y, &dx, &dy); { auto g = [](float x, float y) { if (y == 0.f) { @@ -792,7 +792,7 @@ TEST_F(MathGradTest, UnsafeDiv) { } } { // Swap x and y. - SymGrad("UnsafeDiv", y, x, &dy, &dx); + SymGrad("DivNoNan", y, x, &dy, &dx); { auto g = [](float x, float y) { if (y == 0.f) { diff --git a/tensorflow/core/ops/math_ops.cc b/tensorflow/core/ops/math_ops.cc index 49646f1f3a..717263a9b0 100644 --- a/tensorflow/core/ops/math_ops.cc +++ b/tensorflow/core/ops/math_ops.cc @@ -392,8 +392,11 @@ Returns x * y element-wise. REGISTER_OP("Div").BINARY_MORE().SetShapeFn( shape_inference::BroadcastBinaryOpShapeFn); -REGISTER_OP("UnsafeDiv") - .BINARY_MORE() +REGISTER_OP("DivNoNan") + .Input("x: T") + .Input("y: T") + .Output("z: T") + .Attr("T: {float, double}") .SetShapeFn(shape_inference::BroadcastBinaryOpShapeFn); REGISTER_OP("FloorDiv") diff --git a/tensorflow/core/ops/math_ops_test.cc b/tensorflow/core/ops/math_ops_test.cc index ebeb048157..be4c3ed2b6 100644 --- a/tensorflow/core/ops/math_ops_test.cc +++ b/tensorflow/core/ops/math_ops_test.cc @@ -121,7 +121,7 @@ TEST(MathOpsTest, BroadcastBinaryOps_ShapeFn) { "Mod", "Mul", "NotEqual", "Pow", "Sub", "SquaredDifference", - "UnsafeDiv"}) { + "DivNoNan"}) { ShapeInferenceTestOp op(op_name); INFER_OK(op, "?;?", "?"); INFER_OK(op, "[1,2];?", "?"); diff --git a/tensorflow/core/ops/nn_ops.cc b/tensorflow/core/ops/nn_ops.cc index 385021b168..2485fa4717 100644 --- a/tensorflow/core/ops/nn_ops.cc +++ b/tensorflow/core/ops/nn_ops.cc @@ -960,7 +960,7 @@ REGISTER_OP("Dilation2DBackpropFilter") REGISTER_OP("Relu") .Input("features: T") .Output("activations: T") - .Attr("T: realnumbertype") + .Attr("T: {realnumbertype, qint8}") .SetShapeFn(shape_inference::UnchangedShape); REGISTER_OP("ReluGrad") @@ -1009,6 +1009,7 @@ REGISTER_OP("SeluGrad") .Attr("T: {half, bfloat16, float, double}") .SetShapeFn(shape_inference::MergeBothInputsShapeFn); +// TODO(b/111515541): change T to {half, bfloat16, float, double} REGISTER_OP("Softplus") .Input("features: T") .Output("activations: T") @@ -1022,6 +1023,7 @@ REGISTER_OP("SoftplusGrad") .Attr("T: realnumbertype") .SetShapeFn(shape_inference::MergeBothInputsShapeFn); +// TODO(b/111515541): change T to {half, bfloat16, float, double} REGISTER_OP("Softsign") .Input("features: T") .Output("activations: T") @@ -2024,6 +2026,104 @@ NOTE Do not invoke this operator directly in Python. Graph rewrite pass is expected to invoke these operators. )doc"); +REGISTER_OP("_MklAvgPool3D") + .Input("value: T") + .Input("mkl_input: uint8") + .Output("output: T") + .Output("mkl_output: uint8") + .Attr("ksize: list(int) >= 5") + .Attr("strides: list(int) >= 5") + .Attr(GetPaddingAttrString()) + .Attr(GetConvnet3dDataFormatAttrString()) + .Attr("T: {float, half, double}") + .SetShapeFn(shape_inference::Pool3DShape) + .Doc(R"doc( +MKL version of AvgPool3D operator. Uses MKL DNN APIs to perform average pooling +on the input. + +NOTE Do not invoke this operator directly in Python. Graph rewrite pass is +expected to invoke these operators. +)doc"); + + +REGISTER_OP("_MklAvgPool3DGrad") + .Input("orig_input_shape: int32") + .Input("grad: T") + .Input("mkl_orig_input: uint8") + .Input("mkl_grad: uint8") + .Output("output: T") + .Output("mkl_output: uint8") + .Attr("ksize: list(int) >= 5") + .Attr("strides: list(int) >= 5") + .Attr(GetPaddingAttrString()) + .Attr(GetConvnet3dDataFormatAttrString()) + .Attr("T: {float, half, double}") + .SetShapeFn([](InferenceContext* c) { + ShapeHandle s; + TF_RETURN_IF_ERROR(c->MakeShapeFromShapeTensor(0, &s)); + TF_RETURN_IF_ERROR(c->WithRank(s, 5, &s)); + c->set_output(0, s); + return Status::OK(); + }) + .Doc(R"doc( +MKL version of AvgPool3DGrad operator. Uses MKL DNN APIs to compute gradients +of AvgPool function. + +NOTE Do not invoke this operator directly in Python. Graph rewrite pass is +expected to invoke these operators. +)doc"); + +REGISTER_OP("_MklMaxPool3D") + .Input("input: T") + .Input("mkl_input: uint8") + .Output("output: T") + .Output("workspace: uint8") + .Output("mkl_output: uint8") + .Output("mkl_workspace: uint8") + .Attr("ksize: list(int) >= 5") + .Attr("strides: list(int) >= 5") + .Attr(GetPaddingAttrString()) + .Attr(GetConvnet3dDataFormatAttrString()) + .Attr("T: {half, bfloat16, float}") + .Attr("workspace_enabled: bool = false") + .SetShapeFn(shape_inference::Pool3DShape) + .Doc(R"doc( +MKL version of MaxPool3D operator. Uses MKL DNN APIs to perform average pooling +on the input. + +NOTE Do not invoke this operator directly in Python. Graph rewrite pass is +expected to invoke these operators. +)doc"); + +REGISTER_OP("_MklMaxPool3DGrad") + .Input("orig_input: TInput") + .Input("orig_output: TInput") + .Input("grad: T") + .Input("workspace: uint8") + .Input("mkl_orig_input: uint8") + .Input("mkl_orig_output: uint8") + .Input("mkl_grad: uint8") + .Input("mkl_workspace: uint8") + .Output("output: T") + .Output("mkl_output: uint8") + .Attr("ksize: list(int) >= 5") + .Attr("strides: list(int) >= 5") + .Attr(GetPaddingAttrString()) + .Attr(GetConvnet3dDataFormatAttrString()) + .Attr("T: {half, bfloat16, float} = DT_FLOAT") + .Attr("TInput: {half, bfloat16, float} = DT_FLOAT") + .Attr("workspace_enabled: bool = false") + .SetShapeFn([](InferenceContext* c) { + return UnchangedShapeWithRank(c, 5); + }) + .Doc(R"doc( +MKL version of MklPool3DGrad operator. Uses MKL DNN APIs to compute gradients +of MklPool function. + +NOTE Do not invoke this operator directly in Python. Graph rewrite pass is +expected to invoke these operators. +)doc"); + REGISTER_OP("_MklLRN") .Input("input: T") .Input("mkl_input: uint8") diff --git a/tensorflow/core/ops/ops.pbtxt b/tensorflow/core/ops/ops.pbtxt index f2595279e0..9429d91cb9 100644 --- a/tensorflow/core/ops/ops.pbtxt +++ b/tensorflow/core/ops/ops.pbtxt @@ -9190,6 +9190,31 @@ op { } } op { + name: "DivNoNan" + input_arg { + name: "x" + type_attr: "T" + } + input_arg { + name: "y" + type_attr: "T" + } + output_arg { + name: "z" + type_attr: "T" + } + attr { + name: "T" + type: "type" + allowed_values { + list { + type: DT_FLOAT + type: DT_DOUBLE + } + } + } +} +op { name: "DrawBoundingBoxes" input_arg { name: "images" @@ -9642,6 +9667,25 @@ op { is_stateful: true } op { + name: "EnsureShape" + input_arg { + name: "input" + type_attr: "T" + } + output_arg { + name: "output" + type_attr: "T" + } + attr { + name: "shape" + type: "shape" + } + attr { + name: "T" + type: "type" + } +} +op { name: "Enter" input_arg { name: "data" @@ -15021,6 +15065,10 @@ op { } } } + deprecation { + version: 27 + explanation: "Use Python implementation tf.linalg.matrix_exponential instead." + } } op { name: "MatrixInverse" @@ -18357,6 +18405,76 @@ op { } } op { + name: "ParseExampleDataset" + input_arg { + name: "input_dataset" + type: DT_VARIANT + } + input_arg { + name: "num_parallel_calls" + type: DT_INT64 + } + input_arg { + name: "dense_defaults" + type_list_attr: "Tdense" + } + output_arg { + name: "handle" + type: DT_VARIANT + } + attr { + name: "sparse_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "dense_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "sparse_types" + type: "list(type)" + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "Tdense" + type: "list(type)" + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "dense_shapes" + type: "list(shape)" + has_minimum: true + } + attr { + name: "output_types" + type: "list(type)" + has_minimum: true + minimum: 1 + } + attr { + name: "output_shapes" + type: "list(shape)" + has_minimum: true + minimum: 1 + } +} +op { name: "ParseSingleExample" input_arg { name: "serialized" @@ -22290,6 +22408,7 @@ op { type: DT_HALF type: DT_UINT32 type: DT_UINT64 + type: DT_QINT8 } } } @@ -31820,6 +31939,32 @@ op { } } op { + name: "StaticRegexReplace" + input_arg { + name: "input" + type: DT_STRING + } + output_arg { + name: "output" + type: DT_STRING + } + attr { + name: "pattern" + type: "string" + } + attr { + name: "rewrite" + type: "string" + } + attr { + name: "replace_global" + type: "bool" + default_value { + b: true + } + } +} +op { name: "StatsAggregatorHandle" output_arg { name: "handle" @@ -34960,41 +35105,6 @@ op { } } op { - name: "UnsafeDiv" - input_arg { - name: "x" - type_attr: "T" - } - input_arg { - name: "y" - type_attr: "T" - } - output_arg { - name: "z" - type_attr: "T" - } - attr { - name: "T" - type: "type" - allowed_values { - list { - type: DT_BFLOAT16 - type: DT_HALF - type: DT_FLOAT - type: DT_DOUBLE - type: DT_UINT8 - type: DT_INT8 - type: DT_UINT16 - type: DT_INT16 - type: DT_INT32 - type: DT_INT64 - type: DT_COMPLEX64 - type: DT_COMPLEX128 - } - } - } -} -op { name: "UnsortedSegmentMax" input_arg { name: "data" diff --git a/tensorflow/core/ops/string_ops.cc b/tensorflow/core/ops/string_ops.cc index d1e38e6d22..7aa1e71809 100644 --- a/tensorflow/core/ops/string_ops.cc +++ b/tensorflow/core/ops/string_ops.cc @@ -37,6 +37,14 @@ REGISTER_OP("RegexReplace") return Status::OK(); }); +REGISTER_OP("StaticRegexReplace") + .Input("input: string") + .Attr("pattern: string") + .Attr("rewrite: string") + .Output("output: string") + .Attr("replace_global: bool = true") + .SetShapeFn(shape_inference::UnchangedShape); + REGISTER_OP("RegexFullMatch") .Input("input: string") .Input("pattern: string") diff --git a/tensorflow/core/platform/abi.h b/tensorflow/core/platform/abi.h index 763d467457..591e83b0c4 100644 --- a/tensorflow/core/platform/abi.h +++ b/tensorflow/core/platform/abi.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_ABI_H_ -#define TENSORFLOW_PLATFORM_ABI_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_ABI_H_ +#define TENSORFLOW_CORE_PLATFORM_ABI_H_ #include <string> @@ -26,4 +26,4 @@ std::string MaybeAbiDemangle(const char* name); } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_ABI_H_ +#endif // TENSORFLOW_CORE_PLATFORM_ABI_H_ diff --git a/tensorflow/core/platform/cloud/auth_provider.h b/tensorflow/core/platform/cloud/auth_provider.h index 465ff248d9..7347bc626d 100644 --- a/tensorflow/core/platform/cloud/auth_provider.h +++ b/tensorflow/core/platform/cloud/auth_provider.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_PLATFORM_AUTH_PROVIDER_H_ -#define TENSORFLOW_CORE_PLATFORM_AUTH_PROVIDER_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_CLOUD_AUTH_PROVIDER_H_ +#define TENSORFLOW_CORE_PLATFORM_CLOUD_AUTH_PROVIDER_H_ #include <string> #include "tensorflow/core/lib/core/errors.h" @@ -51,4 +51,4 @@ class EmptyAuthProvider : public AuthProvider { } // namespace tensorflow -#endif // TENSORFLOW_CORE_PLATFORM_AUTH_PROVIDER_H_ +#endif // TENSORFLOW_CORE_PLATFORM_CLOUD_AUTH_PROVIDER_H_ diff --git a/tensorflow/core/platform/cloud/compute_engine_zone_provider.cc b/tensorflow/core/platform/cloud/compute_engine_zone_provider.cc index dacf56187c..e147d88371 100644 --- a/tensorflow/core/platform/cloud/compute_engine_zone_provider.cc +++ b/tensorflow/core/platform/cloud/compute_engine_zone_provider.cc @@ -43,7 +43,7 @@ Status ComputeEngineZoneProvider::GetZone(string* zone) { *zone = cached_zone; } else { LOG(ERROR) << "Failed to parse the zone name from location: " - << location.ToString(); + << string(location); } return Status::OK(); diff --git a/tensorflow/core/platform/cloud/gcs_dns_cache.h b/tensorflow/core/platform/cloud/gcs_dns_cache.h index 40f16f1044..07d0e59fd5 100644 --- a/tensorflow/core/platform/cloud/gcs_dns_cache.h +++ b/tensorflow/core/platform/cloud/gcs_dns_cache.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATNFORM_CLOUD_DNS_CACHE_H_ -#define TENSORFLOW_PLATNFORM_CLOUD_DNS_CACHE_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_CLOUD_GCS_DNS_CACHE_H_ +#define TENSORFLOW_CORE_PLATFORM_CLOUD_GCS_DNS_CACHE_H_ #include <random> @@ -74,4 +74,4 @@ class GcsDnsCache { } // namespace tensorflow -#endif // TENSORFLOW_PLATNFORM_CLOUD_DNS_CACHE_H_ +#endif // TENSORFLOW_CORE_PLATFORM_CLOUD_GCS_DNS_CACHE_H_ diff --git a/tensorflow/core/platform/cloud/google_auth_provider.h b/tensorflow/core/platform/cloud/google_auth_provider.h index 58a785fd60..3755b124a8 100644 --- a/tensorflow/core/platform/cloud/google_auth_provider.h +++ b/tensorflow/core/platform/cloud/google_auth_provider.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_PLATFORM_GOOGLE_AUTH_PROVIDER_H_ -#define TENSORFLOW_CORE_PLATFORM_GOOGLE_AUTH_PROVIDER_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_CLOUD_GOOGLE_AUTH_PROVIDER_H_ +#define TENSORFLOW_CORE_PLATFORM_CLOUD_GOOGLE_AUTH_PROVIDER_H_ #include <memory> #include "tensorflow/core/platform/cloud/auth_provider.h" @@ -65,4 +65,4 @@ class GoogleAuthProvider : public AuthProvider { } // namespace tensorflow -#endif // TENSORFLOW_CORE_PLATFORM_GOOGLE_AUTH_PROVIDER_H_ +#endif // TENSORFLOW_CORE_PLATFORM_CLOUD_GOOGLE_AUTH_PROVIDER_H_ diff --git a/tensorflow/core/platform/cloud/http_request.h b/tensorflow/core/platform/cloud/http_request.h index 2343bca608..e925eefb1f 100644 --- a/tensorflow/core/platform/cloud/http_request.h +++ b/tensorflow/core/platform/cloud/http_request.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_PLATFORM_HTTP_REQUEST_H_ -#define TENSORFLOW_CORE_PLATFORM_HTTP_REQUEST_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_CLOUD_HTTP_REQUEST_H_ +#define TENSORFLOW_CORE_PLATFORM_CLOUD_HTTP_REQUEST_H_ #include <string> #include <unordered_map> @@ -188,4 +188,4 @@ class HttpRequest { } // namespace tensorflow -#endif // TENSORFLOW_CORE_PLATFORM_HTTP_REQUEST_H_ +#endif // TENSORFLOW_CORE_PLATFORM_CLOUD_HTTP_REQUEST_H_ diff --git a/tensorflow/core/platform/cloud/http_request_fake.h b/tensorflow/core/platform/cloud/http_request_fake.h index 7711eaceb2..0a1164b64a 100644 --- a/tensorflow/core/platform/cloud/http_request_fake.h +++ b/tensorflow/core/platform/cloud/http_request_fake.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_PLATFORM_HTTP_REQUEST_FAKE_H_ -#define TENSORFLOW_CORE_PLATFORM_HTTP_REQUEST_FAKE_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_CLOUD_HTTP_REQUEST_FAKE_H_ +#define TENSORFLOW_CORE_PLATFORM_CLOUD_HTTP_REQUEST_FAKE_H_ #include <algorithm> #include <fstream> @@ -212,4 +212,4 @@ class FakeHttpRequestFactory : public HttpRequest::Factory { } // namespace tensorflow -#endif // TENSORFLOW_CORE_PLATFORM_HTTP_REQUEST_FAKE_H_ +#endif // TENSORFLOW_CORE_PLATFORM_CLOUD_HTTP_REQUEST_FAKE_H_ diff --git a/tensorflow/core/platform/context.h b/tensorflow/core/platform/context.h index 728ef91631..9f7beb7a68 100644 --- a/tensorflow/core/platform/context.h +++ b/tensorflow/core/platform/context.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_CONTEXT_H_ -#define TENSORFLOW_PLATFORM_CONTEXT_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_CONTEXT_H_ +#define TENSORFLOW_CORE_PLATFORM_CONTEXT_H_ namespace tensorflow { @@ -42,4 +42,4 @@ class WithContext; #include "tensorflow/core/platform/default/context.h" #endif -#endif // TENSORFLOW_PLATFORM_CONTEXT_H_ +#endif // TENSORFLOW_CORE_PLATFORM_CONTEXT_H_ diff --git a/tensorflow/core/platform/cpu_feature_guard.h b/tensorflow/core/platform/cpu_feature_guard.h index 586a6be55e..3d7bfe95b1 100644 --- a/tensorflow/core/platform/cpu_feature_guard.h +++ b/tensorflow/core/platform/cpu_feature_guard.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_CPU_FEATURE_GUARD_H_ -#define TENSORFLOW_PLATFORM_CPU_FEATURE_GUARD_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_CPU_FEATURE_GUARD_H_ +#define TENSORFLOW_CORE_PLATFORM_CPU_FEATURE_GUARD_H_ namespace tensorflow { namespace port { @@ -29,4 +29,4 @@ void InfoAboutUnusedCPUFeatures(); } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_CPU_FEATURE_GUARD_H_ +#endif // TENSORFLOW_CORE_PLATFORM_CPU_FEATURE_GUARD_H_ diff --git a/tensorflow/core/platform/cpu_info.h b/tensorflow/core/platform/cpu_info.h index 175c9ae8b1..6eba83224a 100644 --- a/tensorflow/core/platform/cpu_info.h +++ b/tensorflow/core/platform/cpu_info.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_CPU_INFO_H_ -#define TENSORFLOW_PLATFORM_CPU_INFO_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_CPU_INFO_H_ +#define TENSORFLOW_CORE_PLATFORM_CPU_INFO_H_ #include <string> @@ -117,4 +117,4 @@ int CPUIDNumSMT(); } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_CPU_INFO_H_ +#endif // TENSORFLOW_CORE_PLATFORM_CPU_INFO_H_ diff --git a/tensorflow/core/platform/default/build_config.bzl b/tensorflow/core/platform/default/build_config.bzl index 7251c6c725..6a4ff9a1cb 100644 --- a/tensorflow/core/platform/default/build_config.bzl +++ b/tensorflow/core/platform/default/build_config.bzl @@ -13,219 +13,224 @@ load( # Appends a suffix to a list of deps. def tf_deps(deps, suffix): - tf_deps = [] + tf_deps = [] - # If the package name is in shorthand form (ie: does not contain a ':'), - # expand it to the full name. - for dep in deps: - tf_dep = dep + # If the package name is in shorthand form (ie: does not contain a ':'), + # expand it to the full name. + for dep in deps: + tf_dep = dep - if not ":" in dep: - dep_pieces = dep.split("/") - tf_dep += ":" + dep_pieces[len(dep_pieces) - 1] + if not ":" in dep: + dep_pieces = dep.split("/") + tf_dep += ":" + dep_pieces[len(dep_pieces) - 1] - tf_deps += [tf_dep + suffix] + tf_deps += [tf_dep + suffix] - return tf_deps + return tf_deps # Modified from @cython//:Tools/rules.bzl def pyx_library( - name, - deps=[], - py_deps=[], - srcs=[], - **kwargs): - """Compiles a group of .pyx / .pxd / .py files. - - First runs Cython to create .cpp files for each input .pyx or .py + .pxd - pair. Then builds a shared object for each, passing "deps" to each cc_binary - rule (includes Python headers by default). Finally, creates a py_library rule - with the shared objects and any pure Python "srcs", with py_deps as its - dependencies; the shared objects can be imported like normal Python files. - - Args: - name: Name for the rule. - deps: C/C++ dependencies of the Cython (e.g. Numpy headers). - py_deps: Pure Python dependencies of the final library. - srcs: .py, .pyx, or .pxd files to either compile or pass through. - **kwargs: Extra keyword arguments passed to the py_library. - """ - # First filter out files that should be run compiled vs. passed through. - py_srcs = [] - pyx_srcs = [] - pxd_srcs = [] - for src in srcs: - if src.endswith(".pyx") or (src.endswith(".py") - and src[:-3] + ".pxd" in srcs): - pyx_srcs.append(src) - elif src.endswith(".py"): - py_srcs.append(src) - else: - pxd_srcs.append(src) - if src.endswith("__init__.py"): - pxd_srcs.append(src) - - # Invoke cython to produce the shared object libraries. - for filename in pyx_srcs: - native.genrule( - name = filename + "_cython_translation", - srcs = [filename], - outs = [filename.split(".")[0] + ".cpp"], - # Optionally use PYTHON_BIN_PATH on Linux platforms so that python 3 - # works. Windows has issues with cython_binary so skip PYTHON_BIN_PATH. - cmd = "PYTHONHASHSEED=0 $(location @cython//:cython_binary) --cplus $(SRCS) --output-file $(OUTS)", - tools = ["@cython//:cython_binary"] + pxd_srcs, + name, + deps = [], + py_deps = [], + srcs = [], + **kwargs): + """Compiles a group of .pyx / .pxd / .py files. + + First runs Cython to create .cpp files for each input .pyx or .py + .pxd + pair. Then builds a shared object for each, passing "deps" to each cc_binary + rule (includes Python headers by default). Finally, creates a py_library rule + with the shared objects and any pure Python "srcs", with py_deps as its + dependencies; the shared objects can be imported like normal Python files. + + Args: + name: Name for the rule. + deps: C/C++ dependencies of the Cython (e.g. Numpy headers). + py_deps: Pure Python dependencies of the final library. + srcs: .py, .pyx, or .pxd files to either compile or pass through. + **kwargs: Extra keyword arguments passed to the py_library. + """ + + # First filter out files that should be run compiled vs. passed through. + py_srcs = [] + pyx_srcs = [] + pxd_srcs = [] + for src in srcs: + if src.endswith(".pyx") or (src.endswith(".py") and + src[:-3] + ".pxd" in srcs): + pyx_srcs.append(src) + elif src.endswith(".py"): + py_srcs.append(src) + else: + pxd_srcs.append(src) + if src.endswith("__init__.py"): + pxd_srcs.append(src) + + # Invoke cython to produce the shared object libraries. + for filename in pyx_srcs: + native.genrule( + name = filename + "_cython_translation", + srcs = [filename], + outs = [filename.split(".")[0] + ".cpp"], + # Optionally use PYTHON_BIN_PATH on Linux platforms so that python 3 + # works. Windows has issues with cython_binary so skip PYTHON_BIN_PATH. + cmd = "PYTHONHASHSEED=0 $(location @cython//:cython_binary) --cplus $(SRCS) --output-file $(OUTS)", + tools = ["@cython//:cython_binary"] + pxd_srcs, + ) + + shared_objects = [] + for src in pyx_srcs: + stem = src.split(".")[0] + shared_object_name = stem + ".so" + native.cc_binary( + name = shared_object_name, + srcs = [stem + ".cpp"], + deps = deps + ["//third_party/python_runtime:headers"], + linkshared = 1, + ) + shared_objects.append(shared_object_name) + + # Now create a py_library with these shared objects as data. + native.py_library( + name = name, + srcs = py_srcs, + deps = py_deps, + srcs_version = "PY2AND3", + data = shared_objects, + **kwargs ) - shared_objects = [] - for src in pyx_srcs: - stem = src.split(".")[0] - shared_object_name = stem + ".so" - native.cc_binary( - name=shared_object_name, - srcs=[stem + ".cpp"], - deps=deps + ["//third_party/python_runtime:headers"], - linkshared = 1, - ) - shared_objects.append(shared_object_name) - - # Now create a py_library with these shared objects as data. - native.py_library( - name=name, - srcs=py_srcs, - deps=py_deps, - srcs_version = "PY2AND3", - data=shared_objects, - **kwargs - ) - -def _proto_cc_hdrs(srcs, use_grpc_plugin=False): - ret = [s[:-len(".proto")] + ".pb.h" for s in srcs] - if use_grpc_plugin: - ret += [s[:-len(".proto")] + ".grpc.pb.h" for s in srcs] - return ret - -def _proto_cc_srcs(srcs, use_grpc_plugin=False): - ret = [s[:-len(".proto")] + ".pb.cc" for s in srcs] - if use_grpc_plugin: - ret += [s[:-len(".proto")] + ".grpc.pb.cc" for s in srcs] - return ret - -def _proto_py_outs(srcs, use_grpc_plugin=False): - ret = [s[:-len(".proto")] + "_pb2.py" for s in srcs] - if use_grpc_plugin: - ret += [s[:-len(".proto")] + "_pb2_grpc.py" for s in srcs] - return ret +def _proto_cc_hdrs(srcs, use_grpc_plugin = False): + ret = [s[:-len(".proto")] + ".pb.h" for s in srcs] + if use_grpc_plugin: + ret += [s[:-len(".proto")] + ".grpc.pb.h" for s in srcs] + return ret + +def _proto_cc_srcs(srcs, use_grpc_plugin = False): + ret = [s[:-len(".proto")] + ".pb.cc" for s in srcs] + if use_grpc_plugin: + ret += [s[:-len(".proto")] + ".grpc.pb.cc" for s in srcs] + return ret + +def _proto_py_outs(srcs, use_grpc_plugin = False): + ret = [s[:-len(".proto")] + "_pb2.py" for s in srcs] + if use_grpc_plugin: + ret += [s[:-len(".proto")] + "_pb2_grpc.py" for s in srcs] + return ret # Re-defined protocol buffer rule to allow building "header only" protocol # buffers, to avoid duplicate registrations. Also allows non-iterable cc_libs # containing select() statements. def cc_proto_library( - name, - srcs=[], - deps=[], - cc_libs=[], - include=None, - protoc="@protobuf_archive//:protoc", - internal_bootstrap_hack=False, - use_grpc_plugin=False, - use_grpc_namespace=False, - default_header=False, - **kargs): - """Bazel rule to create a C++ protobuf library from proto source files. - - Args: - name: the name of the cc_proto_library. - srcs: the .proto files of the cc_proto_library. - deps: a list of dependency labels; must be cc_proto_library. - cc_libs: a list of other cc_library targets depended by the generated - cc_library. - include: a string indicating the include path of the .proto files. - protoc: the label of the protocol compiler to generate the sources. - internal_bootstrap_hack: a flag indicate the cc_proto_library is used only - for bootstraping. When it is set to True, no files will be generated. - The rule will simply be a provider for .proto files, so that other - cc_proto_library can depend on it. - use_grpc_plugin: a flag to indicate whether to call the grpc C++ plugin - when processing the proto files. - default_header: Controls the naming of generated rules. If True, the `name` - rule will be header-only, and an _impl rule will contain the - implementation. Otherwise the header-only rule (name + "_headers_only") - must be referred to explicitly. - **kargs: other keyword arguments that are passed to cc_library. - """ - - includes = [] - if include != None: - includes = [include] - - if internal_bootstrap_hack: - # For pre-checked-in generated files, we add the internal_bootstrap_hack - # which will skip the codegen action. + name, + srcs = [], + deps = [], + cc_libs = [], + include = None, + protoc = "@protobuf_archive//:protoc", + internal_bootstrap_hack = False, + use_grpc_plugin = False, + use_grpc_namespace = False, + default_header = False, + **kargs): + """Bazel rule to create a C++ protobuf library from proto source files. + + Args: + name: the name of the cc_proto_library. + srcs: the .proto files of the cc_proto_library. + deps: a list of dependency labels; must be cc_proto_library. + cc_libs: a list of other cc_library targets depended by the generated + cc_library. + include: a string indicating the include path of the .proto files. + protoc: the label of the protocol compiler to generate the sources. + internal_bootstrap_hack: a flag indicate the cc_proto_library is used only + for bootstraping. When it is set to True, no files will be generated. + The rule will simply be a provider for .proto files, so that other + cc_proto_library can depend on it. + use_grpc_plugin: a flag to indicate whether to call the grpc C++ plugin + when processing the proto files. + default_header: Controls the naming of generated rules. If True, the `name` + rule will be header-only, and an _impl rule will contain the + implementation. Otherwise the header-only rule (name + "_headers_only") + must be referred to explicitly. + **kargs: other keyword arguments that are passed to cc_library. + """ + + includes = [] + if include != None: + includes = [include] + + if internal_bootstrap_hack: + # For pre-checked-in generated files, we add the internal_bootstrap_hack + # which will skip the codegen action. + proto_gen( + name = name + "_genproto", + srcs = srcs, + deps = [s + "_genproto" for s in deps], + includes = includes, + protoc = protoc, + visibility = ["//visibility:public"], + ) + + # An empty cc_library to make rule dependency consistent. + native.cc_library( + name = name, + **kargs + ) + return + + grpc_cpp_plugin = None + plugin_options = [] + if use_grpc_plugin: + grpc_cpp_plugin = "//external:grpc_cpp_plugin" + if use_grpc_namespace: + plugin_options = ["services_namespace=grpc"] + + gen_srcs = _proto_cc_srcs(srcs, use_grpc_plugin) + gen_hdrs = _proto_cc_hdrs(srcs, use_grpc_plugin) + outs = gen_srcs + gen_hdrs + proto_gen( - name=name + "_genproto", - srcs=srcs, - deps=[s + "_genproto" for s in deps], - includes=includes, - protoc=protoc, - visibility=["//visibility:public"], + name = name + "_genproto", + srcs = srcs, + deps = [s + "_genproto" for s in deps], + includes = includes, + protoc = protoc, + plugin = grpc_cpp_plugin, + plugin_language = "grpc", + plugin_options = plugin_options, + gen_cc = 1, + outs = outs, + visibility = ["//visibility:public"], ) - # An empty cc_library to make rule dependency consistent. - native.cc_library( - name=name, - **kargs) - return - - grpc_cpp_plugin = None - plugin_options = [] - if use_grpc_plugin: - grpc_cpp_plugin = "//external:grpc_cpp_plugin" - if use_grpc_namespace: - plugin_options = ["services_namespace=grpc"] - - gen_srcs = _proto_cc_srcs(srcs, use_grpc_plugin) - gen_hdrs = _proto_cc_hdrs(srcs, use_grpc_plugin) - outs = gen_srcs + gen_hdrs - - proto_gen( - name=name + "_genproto", - srcs=srcs, - deps=[s + "_genproto" for s in deps], - includes=includes, - protoc=protoc, - plugin=grpc_cpp_plugin, - plugin_language="grpc", - plugin_options=plugin_options, - gen_cc=1, - outs=outs, - visibility=["//visibility:public"], - ) - - if use_grpc_plugin: - cc_libs += select({ - "//tensorflow:linux_s390x": ["//external:grpc_lib_unsecure"], - "//conditions:default": ["//external:grpc_lib"], - }) - if default_header: - header_only_name = name - impl_name = name + "_impl" - else: - header_only_name = name + "_headers_only" - impl_name = name - - native.cc_library( - name=impl_name, - srcs=gen_srcs, - hdrs=gen_hdrs, - deps=cc_libs + deps, - includes=includes, - **kargs) - native.cc_library( - name=header_only_name, - deps=["@protobuf_archive//:protobuf_headers"] + if_static([impl_name]), - hdrs=gen_hdrs, - **kargs) + if use_grpc_plugin: + cc_libs += select({ + "//tensorflow:linux_s390x": ["//external:grpc_lib_unsecure"], + "//conditions:default": ["//external:grpc_lib"], + }) + + if default_header: + header_only_name = name + impl_name = name + "_impl" + else: + header_only_name = name + "_headers_only" + impl_name = name + + native.cc_library( + name = impl_name, + srcs = gen_srcs, + hdrs = gen_hdrs, + deps = cc_libs + deps, + includes = includes, + **kargs + ) + native.cc_library( + name = header_only_name, + deps = ["@protobuf_archive//:protobuf_headers"] + if_static([impl_name]), + hdrs = gen_hdrs, + **kargs + ) # Re-defined protocol buffer rule to bring in the change introduced in commit # https://github.com/google/protobuf/commit/294b5758c373cbab4b72f35f4cb62dc1d8332b68 @@ -234,484 +239,512 @@ def cc_proto_library( # to include the above commit. def py_proto_library( name, - srcs=[], - deps=[], - py_libs=[], - py_extra_srcs=[], - include=None, - default_runtime="@protobuf_archive//:protobuf_python", - protoc="@protobuf_archive//:protoc", - use_grpc_plugin=False, + srcs = [], + deps = [], + py_libs = [], + py_extra_srcs = [], + include = None, + default_runtime = "@protobuf_archive//:protobuf_python", + protoc = "@protobuf_archive//:protoc", + use_grpc_plugin = False, **kargs): - """Bazel rule to create a Python protobuf library from proto source files - - NOTE: the rule is only an internal workaround to generate protos. The - interface may change and the rule may be removed when bazel has introduced - the native rule. - - Args: - name: the name of the py_proto_library. - srcs: the .proto files of the py_proto_library. - deps: a list of dependency labels; must be py_proto_library. - py_libs: a list of other py_library targets depended by the generated - py_library. - py_extra_srcs: extra source files that will be added to the output - py_library. This attribute is used for internal bootstrapping. - include: a string indicating the include path of the .proto files. - default_runtime: the implicitly default runtime which will be depended on by - the generated py_library target. - protoc: the label of the protocol compiler to generate the sources. - use_grpc_plugin: a flag to indicate whether to call the Python C++ plugin - when processing the proto files. - **kargs: other keyword arguments that are passed to cc_library. - """ - outs = _proto_py_outs(srcs, use_grpc_plugin) - - includes = [] - if include != None: - includes = [include] - - grpc_python_plugin = None - if use_grpc_plugin: - grpc_python_plugin = "//external:grpc_python_plugin" - # Note: Generated grpc code depends on Python grpc module. This dependency - # is not explicitly listed in py_libs. Instead, host system is assumed to - # have grpc installed. - - proto_gen( - name=name + "_genproto", - srcs=srcs, - deps=[s + "_genproto" for s in deps], - includes=includes, - protoc=protoc, - gen_py=1, - outs=outs, - visibility=["//visibility:public"], - plugin=grpc_python_plugin, - plugin_language="grpc" - ) - - if default_runtime and not default_runtime in py_libs + deps: - py_libs = py_libs + [default_runtime] - - native.py_library( - name=name, - srcs=outs+py_extra_srcs, - deps=py_libs+deps, - imports=includes, - **kargs) - -def tf_proto_library_cc(name, srcs = [], has_services = None, - protodeps = [], - visibility = [], testonly = 0, - cc_libs = [], - cc_stubby_versions = None, - cc_grpc_version = None, - j2objc_api_version = 1, - cc_api_version = 2, - dart_api_version = 2, - java_api_version = 2, py_api_version = 2, - js_api_version = 2, js_codegen = "jspb", - default_header = False): - js_codegen = js_codegen # unused argument - js_api_version = js_api_version # unused argument - native.filegroup( - name = name + "_proto_srcs", - srcs = srcs + tf_deps(protodeps, "_proto_srcs"), - testonly = testonly, - visibility = visibility, - ) - - use_grpc_plugin = None - if cc_grpc_version: - use_grpc_plugin = True - - cc_deps = tf_deps(protodeps, "_cc") - cc_name = name + "_cc" - if not srcs: - # This is a collection of sub-libraries. Build header-only and impl - # libraries containing all the sources. + """Bazel rule to create a Python protobuf library from proto source files + + NOTE: the rule is only an internal workaround to generate protos. The + interface may change and the rule may be removed when bazel has introduced + the native rule. + + Args: + name: the name of the py_proto_library. + srcs: the .proto files of the py_proto_library. + deps: a list of dependency labels; must be py_proto_library. + py_libs: a list of other py_library targets depended by the generated + py_library. + py_extra_srcs: extra source files that will be added to the output + py_library. This attribute is used for internal bootstrapping. + include: a string indicating the include path of the .proto files. + default_runtime: the implicitly default runtime which will be depended on by + the generated py_library target. + protoc: the label of the protocol compiler to generate the sources. + use_grpc_plugin: a flag to indicate whether to call the Python C++ plugin + when processing the proto files. + **kargs: other keyword arguments that are passed to cc_library. + """ + outs = _proto_py_outs(srcs, use_grpc_plugin) + + includes = [] + if include != None: + includes = [include] + + grpc_python_plugin = None + if use_grpc_plugin: + grpc_python_plugin = "//external:grpc_python_plugin" + # Note: Generated grpc code depends on Python grpc module. This dependency + # is not explicitly listed in py_libs. Instead, host system is assumed to + # have grpc installed. + proto_gen( - name = cc_name + "_genproto", - deps = [s + "_genproto" for s in cc_deps], - protoc = "@protobuf_archive//:protoc", - visibility=["//visibility:public"], + name = name + "_genproto", + srcs = srcs, + deps = [s + "_genproto" for s in deps], + includes = includes, + protoc = protoc, + gen_py = 1, + outs = outs, + visibility = ["//visibility:public"], + plugin = grpc_python_plugin, + plugin_language = "grpc", ) - native.cc_library( - name = cc_name, - deps = cc_deps + ["@protobuf_archive//:protobuf_headers"] + - if_static([name + "_cc_impl"]), + + if default_runtime and not default_runtime in py_libs + deps: + py_libs = py_libs + [default_runtime] + + native.py_library( + name = name, + srcs = outs + py_extra_srcs, + deps = py_libs + deps, + imports = includes, + **kargs + ) + +def tf_proto_library_cc( + name, + srcs = [], + has_services = None, + protodeps = [], + visibility = [], + testonly = 0, + cc_libs = [], + cc_stubby_versions = None, + cc_grpc_version = None, + j2objc_api_version = 1, + cc_api_version = 2, + dart_api_version = 2, + java_api_version = 2, + py_api_version = 2, + js_api_version = 2, + js_codegen = "jspb", + default_header = False): + js_codegen = js_codegen # unused argument + js_api_version = js_api_version # unused argument + native.filegroup( + name = name + "_proto_srcs", + srcs = srcs + tf_deps(protodeps, "_proto_srcs"), testonly = testonly, visibility = visibility, ) - native.cc_library( - name = cc_name + "_impl", - deps = [s + "_impl" for s in cc_deps] + ["@protobuf_archive//:cc_wkt_protos"], - ) - return - - cc_proto_library( - name = cc_name, - srcs = srcs, - deps = cc_deps + ["@protobuf_archive//:cc_wkt_protos"], - cc_libs = cc_libs + if_static( - ["@protobuf_archive//:protobuf"], - ["@protobuf_archive//:protobuf_headers"] - ), - copts = if_not_windows([ - "-Wno-unknown-warning-option", - "-Wno-unused-but-set-variable", - "-Wno-sign-compare", - ]), - protoc = "@protobuf_archive//:protoc", - use_grpc_plugin = use_grpc_plugin, - testonly = testonly, - visibility = visibility, - default_header = default_header, - ) - -def tf_proto_library_py(name, srcs=[], protodeps=[], deps=[], visibility=[], - testonly=0, srcs_version="PY2AND3", use_grpc_plugin=False): - py_deps = tf_deps(protodeps, "_py") - py_name = name + "_py" - if not srcs: - # This is a collection of sub-libraries. Build header-only and impl - # libraries containing all the sources. - proto_gen( - name = py_name + "_genproto", - deps = [s + "_genproto" for s in py_deps], + use_grpc_plugin = None + if cc_grpc_version: + use_grpc_plugin = True + + cc_deps = tf_deps(protodeps, "_cc") + cc_name = name + "_cc" + if not srcs: + # This is a collection of sub-libraries. Build header-only and impl + # libraries containing all the sources. + proto_gen( + name = cc_name + "_genproto", + deps = [s + "_genproto" for s in cc_deps], + protoc = "@protobuf_archive//:protoc", + visibility = ["//visibility:public"], + ) + native.cc_library( + name = cc_name, + deps = cc_deps + ["@protobuf_archive//:protobuf_headers"] + + if_static([name + "_cc_impl"]), + testonly = testonly, + visibility = visibility, + ) + native.cc_library( + name = cc_name + "_impl", + deps = [s + "_impl" for s in cc_deps] + ["@protobuf_archive//:cc_wkt_protos"], + ) + + return + + cc_proto_library( + name = cc_name, + srcs = srcs, + deps = cc_deps + ["@protobuf_archive//:cc_wkt_protos"], + cc_libs = cc_libs + if_static( + ["@protobuf_archive//:protobuf"], + ["@protobuf_archive//:protobuf_headers"], + ), + copts = if_not_windows([ + "-Wno-unknown-warning-option", + "-Wno-unused-but-set-variable", + "-Wno-sign-compare", + ]), protoc = "@protobuf_archive//:protoc", - visibility=["//visibility:public"], + use_grpc_plugin = use_grpc_plugin, + testonly = testonly, + visibility = visibility, + default_header = default_header, ) - native.py_library( + +def tf_proto_library_py( + name, + srcs = [], + protodeps = [], + deps = [], + visibility = [], + testonly = 0, + srcs_version = "PY2AND3", + use_grpc_plugin = False): + py_deps = tf_deps(protodeps, "_py") + py_name = name + "_py" + if not srcs: + # This is a collection of sub-libraries. Build header-only and impl + # libraries containing all the sources. + proto_gen( + name = py_name + "_genproto", + deps = [s + "_genproto" for s in py_deps], + protoc = "@protobuf_archive//:protoc", + visibility = ["//visibility:public"], + ) + native.py_library( + name = py_name, + deps = py_deps + ["@protobuf_archive//:protobuf_python"], + testonly = testonly, + visibility = visibility, + ) + return + + py_proto_library( name = py_name, - deps = py_deps + ["@protobuf_archive//:protobuf_python"], - testonly = testonly, + srcs = srcs, + srcs_version = srcs_version, + deps = deps + py_deps + ["@protobuf_archive//:protobuf_python"], + protoc = "@protobuf_archive//:protoc", + default_runtime = "@protobuf_archive//:protobuf_python", visibility = visibility, + testonly = testonly, + use_grpc_plugin = use_grpc_plugin, ) - return - - py_proto_library( - name = py_name, - srcs = srcs, - srcs_version = srcs_version, - deps = deps + py_deps + ["@protobuf_archive//:protobuf_python"], - protoc = "@protobuf_archive//:protoc", - default_runtime = "@protobuf_archive//:protobuf_python", - visibility = visibility, - testonly = testonly, - use_grpc_plugin = use_grpc_plugin, - ) def tf_jspb_proto_library(**kwargs): - pass + pass def tf_nano_proto_library(**kwargs): - pass - -def tf_proto_library(name, srcs = [], has_services = None, - protodeps = [], - visibility = [], testonly = 0, - cc_libs = [], - cc_api_version = 2, cc_grpc_version = None, - dart_api_version = 2, j2objc_api_version = 1, - java_api_version = 2, py_api_version = 2, - js_api_version = 2, js_codegen = "jspb", - provide_cc_alias = False, - default_header = False): - """Make a proto library, possibly depending on other proto libraries.""" - _ignore = (js_api_version, js_codegen, provide_cc_alias) - - tf_proto_library_cc( - name = name, - srcs = srcs, - protodeps = protodeps, - cc_grpc_version = cc_grpc_version, - cc_libs = cc_libs, - testonly = testonly, - visibility = visibility, - default_header = default_header, - ) - - tf_proto_library_py( - name = name, - srcs = srcs, - protodeps = protodeps, - srcs_version = "PY2AND3", - testonly = testonly, - visibility = visibility, - use_grpc_plugin = has_services, - ) + pass + +def tf_proto_library( + name, + srcs = [], + has_services = None, + protodeps = [], + visibility = [], + testonly = 0, + cc_libs = [], + cc_api_version = 2, + cc_grpc_version = None, + dart_api_version = 2, + j2objc_api_version = 1, + java_api_version = 2, + py_api_version = 2, + js_api_version = 2, + js_codegen = "jspb", + provide_cc_alias = False, + default_header = False): + """Make a proto library, possibly depending on other proto libraries.""" + _ignore = (js_api_version, js_codegen, provide_cc_alias) + + tf_proto_library_cc( + name = name, + srcs = srcs, + protodeps = protodeps, + cc_grpc_version = cc_grpc_version, + cc_libs = cc_libs, + testonly = testonly, + visibility = visibility, + default_header = default_header, + ) + + tf_proto_library_py( + name = name, + srcs = srcs, + protodeps = protodeps, + srcs_version = "PY2AND3", + testonly = testonly, + visibility = visibility, + use_grpc_plugin = has_services, + ) # A list of all files under platform matching the pattern in 'files'. In # contrast with 'tf_platform_srcs' below, which seletive collects files that # must be compiled in the 'default' platform, this is a list of all headers # mentioned in the platform/* files. def tf_platform_hdrs(files): - return native.glob(["platform/*/" + f for f in files]) + return native.glob(["platform/*/" + f for f in files]) def tf_platform_srcs(files): - base_set = ["platform/default/" + f for f in files] - windows_set = base_set + ["platform/windows/" + f for f in files] - posix_set = base_set + ["platform/posix/" + f for f in files] - - # Handle cases where we must also bring the posix file in. Usually, the list - # of files to build on windows builds is just all the stuff in the - # windows_set. However, in some cases the implementations in 'posix/' are - # just what is necessary and historically we choose to simply use the posix - # file instead of making a copy in 'windows'. - for f in files: - if f == "error.cc": - windows_set.append("platform/posix/" + f) - - return select({ - "//tensorflow:windows" : native.glob(windows_set), - "//conditions:default" : native.glob(posix_set), - }) + base_set = ["platform/default/" + f for f in files] + windows_set = base_set + ["platform/windows/" + f for f in files] + posix_set = base_set + ["platform/posix/" + f for f in files] + + # Handle cases where we must also bring the posix file in. Usually, the list + # of files to build on windows builds is just all the stuff in the + # windows_set. However, in some cases the implementations in 'posix/' are + # just what is necessary and historically we choose to simply use the posix + # file instead of making a copy in 'windows'. + for f in files: + if f == "error.cc": + windows_set.append("platform/posix/" + f) + + return select({ + "//tensorflow:windows": native.glob(windows_set), + "//conditions:default": native.glob(posix_set), + }) def tf_additional_lib_hdrs(exclude = []): - windows_hdrs = native.glob([ - "platform/default/*.h", - "platform/windows/*.h", - "platform/posix/error.h", - ], exclude = exclude) - return select({ - "//tensorflow:windows" : windows_hdrs, - "//conditions:default" : native.glob([ + windows_hdrs = native.glob([ "platform/default/*.h", - "platform/posix/*.h", - ], exclude = exclude), - }) + "platform/windows/*.h", + "platform/posix/error.h", + ], exclude = exclude) + return select({ + "//tensorflow:windows": windows_hdrs, + "//conditions:default": native.glob([ + "platform/default/*.h", + "platform/posix/*.h", + ], exclude = exclude), + }) def tf_additional_lib_srcs(exclude = []): - windows_srcs = native.glob([ - "platform/default/*.cc", - "platform/windows/*.cc", - "platform/posix/error.cc", - ], exclude = exclude) - return select({ - "//tensorflow:windows" : windows_srcs, - "//conditions:default" : native.glob([ + windows_srcs = native.glob([ "platform/default/*.cc", - "platform/posix/*.cc", - ], exclude = exclude), - }) + "platform/windows/*.cc", + "platform/posix/error.cc", + ], exclude = exclude) + return select({ + "//tensorflow:windows": windows_srcs, + "//conditions:default": native.glob([ + "platform/default/*.cc", + "platform/posix/*.cc", + ], exclude = exclude), + }) def tf_additional_minimal_lib_srcs(): - return [ - "platform/default/integral_types.h", - "platform/default/mutex.h", - ] + return [ + "platform/default/integral_types.h", + "platform/default/mutex.h", + ] def tf_additional_proto_hdrs(): - return [ - "platform/default/integral_types.h", - "platform/default/logging.h", - "platform/default/protobuf.h" - ] + if_windows([ - "platform/windows/integral_types.h", - ]) + return [ + "platform/default/integral_types.h", + "platform/default/logging.h", + "platform/default/protobuf.h", + ] + if_windows([ + "platform/windows/integral_types.h", + ]) def tf_additional_proto_compiler_hdrs(): - return [ - "platform/default/protobuf_compiler.h" - ] + return [ + "platform/default/protobuf_compiler.h", + ] def tf_additional_proto_srcs(): - return [ - "platform/default/protobuf.cc", - ] + return [ + "platform/default/protobuf.cc", + ] def tf_additional_human_readable_json_deps(): - return [] + return [] def tf_additional_all_protos(): - return ["//tensorflow/core:protos_all"] + return ["//tensorflow/core:protos_all"] def tf_protos_all_impl(): - return ["//tensorflow/core:protos_all_cc_impl"] + return ["//tensorflow/core:protos_all_cc_impl"] def tf_protos_all(): - return if_static( - extra_deps=tf_protos_all_impl(), - otherwise=["//tensorflow/core:protos_all_cc"]) + return if_static( + extra_deps = tf_protos_all_impl(), + otherwise = ["//tensorflow/core:protos_all_cc"], + ) def tf_protos_grappler_impl(): - return ["//tensorflow/core/grappler/costs:op_performance_data_cc_impl"] + return ["//tensorflow/core/grappler/costs:op_performance_data_cc_impl"] def tf_protos_grappler(): - return if_static( - extra_deps=tf_protos_grappler_impl(), - otherwise=["//tensorflow/core/grappler/costs:op_performance_data_cc"]) + return if_static( + extra_deps = tf_protos_grappler_impl(), + otherwise = ["//tensorflow/core/grappler/costs:op_performance_data_cc"], + ) def tf_additional_cupti_wrapper_deps(): - return ["//tensorflow/core/platform/default/gpu:cupti_wrapper"] + return ["//tensorflow/core/platform/default/gpu:cupti_wrapper"] def tf_additional_device_tracer_srcs(): - return ["platform/default/device_tracer.cc"] + return ["platform/default/device_tracer.cc"] def tf_additional_device_tracer_cuda_deps(): - return [] + return [] def tf_additional_device_tracer_deps(): - return [] + return [] def tf_additional_libdevice_data(): - return [] + return [] def tf_additional_libdevice_deps(): - return ["@local_config_cuda//cuda:cuda_headers"] + return ["@local_config_cuda//cuda:cuda_headers"] def tf_additional_libdevice_srcs(): - return ["platform/default/cuda_libdevice_path.cc"] + return ["platform/default/cuda_libdevice_path.cc"] def tf_additional_test_deps(): - return [] + return [] def tf_additional_test_srcs(): - return [ - "platform/default/test_benchmark.cc", - ] + select({ - "//tensorflow:windows" : [ - "platform/windows/test.cc" + return [ + "platform/default/test_benchmark.cc", + ] + select({ + "//tensorflow:windows": [ + "platform/windows/test.cc", ], - "//conditions:default" : [ - "platform/posix/test.cc", + "//conditions:default": [ + "platform/posix/test.cc", ], }) def tf_kernel_tests_linkstatic(): - return 0 + return 0 def tf_additional_lib_defines(): - """Additional defines needed to build TF libraries.""" - return select({ - "//tensorflow:with_jemalloc_linux_x86_64": ["TENSORFLOW_USE_JEMALLOC"], - "//tensorflow:with_jemalloc_linux_ppc64le":["TENSORFLOW_USE_JEMALLOC"], - "//conditions:default": [], - }) + if_not_mobile(["TENSORFLOW_USE_ABSL"]) + """Additional defines needed to build TF libraries.""" + return select({ + "//tensorflow:with_jemalloc_linux_x86_64": ["TENSORFLOW_USE_JEMALLOC"], + "//tensorflow:with_jemalloc_linux_ppc64le": ["TENSORFLOW_USE_JEMALLOC"], + "//conditions:default": [], + }) def tf_additional_lib_deps(): - """Additional dependencies needed to build TF libraries.""" - return if_not_mobile(["@com_google_absl//absl/base:base"]) + if_static( - ["@nsync//:nsync_cpp"], - ["@nsync//:nsync_headers"] - ) + select({ - "//tensorflow:with_jemalloc_linux_x86_64_dynamic": ["@jemalloc//:jemalloc_headers"], - "//tensorflow:with_jemalloc_linux_ppc64le_dynamic": ["@jemalloc//:jemalloc_headers"], - "//tensorflow:with_jemalloc_linux_x86_64": ["@jemalloc//:jemalloc_impl"], - "//tensorflow:with_jemalloc_linux_ppc64le": ["@jemalloc//:jemalloc_impl"], - "//conditions:default": [], - }) + """Additional dependencies needed to build TF libraries.""" + return ["@com_google_absl//absl/base:base"] + if_static( + ["@nsync//:nsync_cpp"], + ["@nsync//:nsync_headers"], + ) + select({ + "//tensorflow:with_jemalloc_linux_x86_64_dynamic": ["@jemalloc//:jemalloc_headers"], + "//tensorflow:with_jemalloc_linux_ppc64le_dynamic": ["@jemalloc//:jemalloc_headers"], + "//tensorflow:with_jemalloc_linux_x86_64": ["@jemalloc//:jemalloc_impl"], + "//tensorflow:with_jemalloc_linux_ppc64le": ["@jemalloc//:jemalloc_impl"], + "//conditions:default": [], + }) def tf_additional_core_deps(): - return select({ - "//tensorflow:with_gcp_support_android_override": [], - "//tensorflow:with_gcp_support_ios_override": [], - "//tensorflow:with_gcp_support": [ - "//tensorflow/core/platform/cloud:gcs_file_system", - ], - "//conditions:default": [], - }) + select({ - "//tensorflow:with_hdfs_support_windows_override": [], - "//tensorflow:with_hdfs_support_android_override": [], - "//tensorflow:with_hdfs_support_ios_override": [], - "//tensorflow:with_hdfs_support": [ - "//tensorflow/core/platform/hadoop:hadoop_file_system", - ], - "//conditions:default": [], - }) + select({ - "//tensorflow:with_aws_support_windows_override": [], - "//tensorflow:with_aws_support_android_override": [], - "//tensorflow:with_aws_support_ios_override": [], - "//tensorflow:with_aws_support": [ - "//tensorflow/core/platform/s3:s3_file_system", - ], - "//conditions:default": [], - }) + return select({ + "//tensorflow:with_gcp_support_android_override": [], + "//tensorflow:with_gcp_support_ios_override": [], + "//tensorflow:with_gcp_support": [ + "//tensorflow/core/platform/cloud:gcs_file_system", + ], + "//conditions:default": [], + }) + select({ + "//tensorflow:with_hdfs_support_windows_override": [], + "//tensorflow:with_hdfs_support_android_override": [], + "//tensorflow:with_hdfs_support_ios_override": [], + "//tensorflow:with_hdfs_support": [ + "//tensorflow/core/platform/hadoop:hadoop_file_system", + ], + "//conditions:default": [], + }) + select({ + "//tensorflow:with_aws_support_windows_override": [], + "//tensorflow:with_aws_support_android_override": [], + "//tensorflow:with_aws_support_ios_override": [], + "//tensorflow:with_aws_support": [ + "//tensorflow/core/platform/s3:s3_file_system", + ], + "//conditions:default": [], + }) # TODO(jart, jhseu): Delete when GCP is default on. def tf_additional_cloud_op_deps(): - return select({ - "//tensorflow:with_gcp_support_windows_override": [], - "//tensorflow:with_gcp_support_android_override": [], - "//tensorflow:with_gcp_support_ios_override": [], - "//tensorflow:with_gcp_support": [ - "//tensorflow/contrib/cloud:bigquery_reader_ops_op_lib", - "//tensorflow/contrib/cloud:gcs_config_ops_op_lib", - ], - "//conditions:default": [], - }) + return select({ + "//tensorflow:with_gcp_support_windows_override": [], + "//tensorflow:with_gcp_support_android_override": [], + "//tensorflow:with_gcp_support_ios_override": [], + "//tensorflow:with_gcp_support": [ + "//tensorflow/contrib/cloud:bigquery_reader_ops_op_lib", + "//tensorflow/contrib/cloud:gcs_config_ops_op_lib", + ], + "//conditions:default": [], + }) # TODO(jart, jhseu): Delete when GCP is default on. def tf_additional_cloud_kernel_deps(): - return select({ - "//tensorflow:with_gcp_support_windows_override": [], - "//tensorflow:with_gcp_support_android_override": [], - "//tensorflow:with_gcp_support_ios_override": [], - "//tensorflow:with_gcp_support": [ - "//tensorflow/contrib/cloud/kernels:bigquery_reader_ops", - "//tensorflow/contrib/cloud/kernels:gcs_config_ops", - ], - "//conditions:default": [], - }) + return select({ + "//tensorflow:with_gcp_support_windows_override": [], + "//tensorflow:with_gcp_support_android_override": [], + "//tensorflow:with_gcp_support_ios_override": [], + "//tensorflow:with_gcp_support": [ + "//tensorflow/contrib/cloud/kernels:bigquery_reader_ops", + "//tensorflow/contrib/cloud/kernels:gcs_config_ops", + ], + "//conditions:default": [], + }) def tf_lib_proto_parsing_deps(): - return [ - ":protos_all_cc", - "//third_party/eigen3", - "//tensorflow/core/platform/default/build_config:proto_parsing", - ] + return [ + ":protos_all_cc", + "//third_party/eigen3", + "//tensorflow/core/platform/default/build_config:proto_parsing", + ] def tf_lib_proto_compiler_deps(): - return [ - "@protobuf_archive//:protoc_lib", - ] + return [ + "@protobuf_archive//:protoc_lib", + ] def tf_additional_verbs_lib_defines(): - return select({ - "//tensorflow:with_verbs_support": ["TENSORFLOW_USE_VERBS"], - "//conditions:default": [], - }) + return select({ + "//tensorflow:with_verbs_support": ["TENSORFLOW_USE_VERBS"], + "//conditions:default": [], + }) def tf_additional_mpi_lib_defines(): - return select({ - "//tensorflow:with_mpi_support": ["TENSORFLOW_USE_MPI"], - "//conditions:default": [], - }) + return select({ + "//tensorflow:with_mpi_support": ["TENSORFLOW_USE_MPI"], + "//conditions:default": [], + }) def tf_additional_gdr_lib_defines(): - return select({ - "//tensorflow:with_gdr_support": ["TENSORFLOW_USE_GDR"], - "//conditions:default": [], - }) + return select({ + "//tensorflow:with_gdr_support": ["TENSORFLOW_USE_GDR"], + "//conditions:default": [], + }) -def tf_py_clif_cc(name, visibility=None, **kwargs): - pass +def tf_py_clif_cc(name, visibility = None, **kwargs): + pass -def tf_pyclif_proto_library(name, proto_lib, proto_srcfile="", visibility=None, - **kwargs): - pass +def tf_pyclif_proto_library( + name, + proto_lib, + proto_srcfile = "", + visibility = None, + **kwargs): + pass def tf_additional_binary_deps(): - return ["@nsync//:nsync_cpp"] + if_cuda( - [ - "//tensorflow/stream_executor:cuda_platform", - "//tensorflow/core/platform/default/build_config:cuda", - ], - ) + select({ - "//tensorflow:with_jemalloc_linux_x86_64": ["@jemalloc//:jemalloc_impl"], - "//tensorflow:with_jemalloc_linux_ppc64le": ["@jemalloc//:jemalloc_impl"], - "//conditions:default": [], - }) + [ - # TODO(allenl): Split these out into their own shared objects (they are - # here because they are shared between contrib/ op shared objects and - # core). - "//tensorflow/core/kernels:lookup_util", - "//tensorflow/core/util/tensor_bundle", - ] + if_mkl_ml( - [ - "//third_party/intel_mkl_ml", - ], - ) + return ["@nsync//:nsync_cpp"] + if_cuda( + [ + "//tensorflow/stream_executor:cuda_platform", + "//tensorflow/core/platform/default/build_config:cuda", + ], + ) + select({ + "//tensorflow:with_jemalloc_linux_x86_64": ["@jemalloc//:jemalloc_impl"], + "//tensorflow:with_jemalloc_linux_ppc64le": ["@jemalloc//:jemalloc_impl"], + "//conditions:default": [], + }) + [ + # TODO(allenl): Split these out into their own shared objects (they are + # here because they are shared between contrib/ op shared objects and + # core). + "//tensorflow/core/kernels:lookup_util", + "//tensorflow/core/util/tensor_bundle", + ] + if_mkl_ml( + [ + "//third_party/mkl:intel_binary_blob", + ], + ) diff --git a/tensorflow/core/platform/default/integral_types.h b/tensorflow/core/platform/default/integral_types.h index 7cbe7d62f7..92186bc912 100644 --- a/tensorflow/core/platform/default/integral_types.h +++ b/tensorflow/core/platform/default/integral_types.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_DEFAULT_INTEGRAL_TYPES_H_ -#define TENSORFLOW_PLATFORM_DEFAULT_INTEGRAL_TYPES_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_DEFAULT_INTEGRAL_TYPES_H_ +#define TENSORFLOW_CORE_PLATFORM_DEFAULT_INTEGRAL_TYPES_H_ // IWYU pragma: private, include "third_party/tensorflow/core/platform/types.h" // IWYU pragma: friend third_party/tensorflow/core/platform/types.h @@ -33,4 +33,4 @@ typedef unsigned long long uint64; } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_DEFAULT_INTEGRAL_TYPES_H_ +#endif // TENSORFLOW_CORE_PLATFORM_DEFAULT_INTEGRAL_TYPES_H_ diff --git a/tensorflow/core/platform/default/logging.h b/tensorflow/core/platform/default/logging.h index 2c134f1be9..08a692fff7 100644 --- a/tensorflow/core/platform/default/logging.h +++ b/tensorflow/core/platform/default/logging.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_DEFAULT_LOGGING_H_ -#define TENSORFLOW_PLATFORM_DEFAULT_LOGGING_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_DEFAULT_LOGGING_H_ +#define TENSORFLOW_CORE_PLATFORM_DEFAULT_LOGGING_H_ // IWYU pragma: private, include "third_party/tensorflow/core/platform/logging.h" // IWYU pragma: friend third_party/tensorflow/core/platform/logging.h @@ -314,4 +314,4 @@ int64 MinVLogLevelFromEnv(); } // namespace internal } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_DEFAULT_LOGGING_H_ +#endif // TENSORFLOW_CORE_PLATFORM_DEFAULT_LOGGING_H_ diff --git a/tensorflow/core/platform/default/mutex.h b/tensorflow/core/platform/default/mutex.h index 48d90779e1..bef7801037 100644 --- a/tensorflow/core/platform/default/mutex.h +++ b/tensorflow/core/platform/default/mutex.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_DEFAULT_MUTEX_H_ -#define TENSORFLOW_PLATFORM_DEFAULT_MUTEX_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_DEFAULT_MUTEX_H_ +#define TENSORFLOW_CORE_PLATFORM_DEFAULT_MUTEX_H_ // IWYU pragma: private, include "third_party/tensorflow/core/platform/mutex.h" // IWYU pragma: friend third_party/tensorflow/core/platform/mutex.h @@ -173,4 +173,4 @@ inline ConditionResult WaitForMilliseconds(mutex_lock* mu, } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_DEFAULT_MUTEX_H_ +#endif // TENSORFLOW_CORE_PLATFORM_DEFAULT_MUTEX_H_ diff --git a/tensorflow/core/platform/default/thread_annotations.h b/tensorflow/core/platform/default/thread_annotations.h index a6aa5b1b5e..d21d60ab0b 100644 --- a/tensorflow/core/platform/default/thread_annotations.h +++ b/tensorflow/core/platform/default/thread_annotations.h @@ -32,8 +32,8 @@ limitations under the License. // (e.g. &MyClass::mutex_) to refer to a mutex in some (unknown) object. // -#ifndef TENSORFLOW_PLATFORM_DEFAULT_THREAD_ANNOTATIONS_H_ -#define TENSORFLOW_PLATFORM_DEFAULT_THREAD_ANNOTATIONS_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_DEFAULT_THREAD_ANNOTATIONS_H_ +#define TENSORFLOW_CORE_PLATFORM_DEFAULT_THREAD_ANNOTATIONS_H_ // IWYU pragma: private, include "third_party/tensorflow/core/platform/thread_annotations.h" // IWYU pragma: friend third_party/tensorflow/core/platform/thread_annotations.h @@ -174,4 +174,4 @@ inline T& ts_unchecked_read(T& v) NO_THREAD_SAFETY_ANALYSIS { } // namespace thread_safety_analysis } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_DEFAULT_THREAD_ANNOTATIONS_H_ +#endif // TENSORFLOW_CORE_PLATFORM_DEFAULT_THREAD_ANNOTATIONS_H_ diff --git a/tensorflow/core/platform/default/tracing_impl.h b/tensorflow/core/platform/default/tracing_impl.h index b161378405..b7a5f1386c 100644 --- a/tensorflow/core/platform/default/tracing_impl.h +++ b/tensorflow/core/platform/default/tracing_impl.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_DEFAULT_TRACING_IMPL_H_ -#define TENSORFLOW_PLATFORM_DEFAULT_TRACING_IMPL_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_DEFAULT_TRACING_IMPL_H_ +#define TENSORFLOW_CORE_PLATFORM_DEFAULT_TRACING_IMPL_H_ // Stub implementations of tracing functionality. @@ -43,4 +43,4 @@ inline bool EventCollector::IsEnabled() { return false; } } // namespace tracing } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_DEFAULT_TRACING_IMPL_H_ +#endif // TENSORFLOW_CORE_PLATFORM_DEFAULT_TRACING_IMPL_H_ diff --git a/tensorflow/core/platform/denormal.h b/tensorflow/core/platform/denormal.h index 09bb0352a2..555ac023db 100644 --- a/tensorflow/core/platform/denormal.h +++ b/tensorflow/core/platform/denormal.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_DENORMAL_H_ -#define TENSORFLOW_PLATFORM_DENORMAL_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_DENORMAL_H_ +#define TENSORFLOW_CORE_PLATFORM_DENORMAL_H_ #include "tensorflow/core/platform/macros.h" @@ -59,4 +59,4 @@ class ScopedDontFlushDenormal { } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_DENORMAL_H_ +#endif // TENSORFLOW_CORE_PLATFORM_DENORMAL_H_ diff --git a/tensorflow/core/platform/dynamic_annotations.h b/tensorflow/core/platform/dynamic_annotations.h index f51f3f33a3..dad0d0f4e4 100644 --- a/tensorflow/core/platform/dynamic_annotations.h +++ b/tensorflow/core/platform/dynamic_annotations.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_DYNAMIC_ANNOTATIONS_H_ -#define TENSORFLOW_PLATFORM_DYNAMIC_ANNOTATIONS_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_DYNAMIC_ANNOTATIONS_H_ +#define TENSORFLOW_CORE_PLATFORM_DYNAMIC_ANNOTATIONS_H_ #include "tensorflow/core/platform/platform.h" @@ -28,4 +28,4 @@ limitations under the License. #error Define the appropriate PLATFORM_<foo> macro for this platform #endif -#endif // TENSORFLOW_PLATFORM_DYNAMIC_ANNOTATIONS_H_ +#endif // TENSORFLOW_CORE_PLATFORM_DYNAMIC_ANNOTATIONS_H_ diff --git a/tensorflow/core/platform/env.cc b/tensorflow/core/platform/env.cc index 47c59d435b..afc4201e53 100644 --- a/tensorflow/core/platform/env.cc +++ b/tensorflow/core/platform/env.cc @@ -92,7 +92,7 @@ Env::Env() : file_system_registry_(new FileSystemRegistryImpl) {} Status Env::GetFileSystemForFile(const string& fname, FileSystem** result) { StringPiece scheme, host, path; io::ParseURI(fname, &scheme, &host, &path); - FileSystem* file_system = file_system_registry_->Lookup(std::string(scheme)); + FileSystem* file_system = file_system_registry_->Lookup(string(scheme)); if (!file_system) { if (scheme.empty()) { scheme = "[local]"; @@ -166,7 +166,7 @@ bool Env::FilesExist(const std::vector<string>& files, for (const auto& file : files) { StringPiece scheme, host, path; io::ParseURI(file, &scheme, &host, &path); - files_per_fs[std::string(scheme)].push_back(file); + files_per_fs[string(scheme)].push_back(file); } std::unordered_map<string, Status> per_file_status; diff --git a/tensorflow/core/platform/file_system.cc b/tensorflow/core/platform/file_system.cc index 922773684b..3ab542a5d8 100644 --- a/tensorflow/core/platform/file_system.cc +++ b/tensorflow/core/platform/file_system.cc @@ -158,7 +158,7 @@ Status FileSystem::RecursivelyCreateDir(const string& dirname) { std::reverse(sub_dirs.begin(), sub_dirs.end()); // Now create the directories. - string built_path = std::string(remaining_dir); + string built_path(remaining_dir); for (const StringPiece sub_dir : sub_dirs) { built_path = io::JoinPath(built_path, sub_dir); Status status = CreateDir(io::CreateURI(scheme, host, built_path)); diff --git a/tensorflow/core/platform/file_system_helper.cc b/tensorflow/core/platform/file_system_helper.cc index 0ba0e6304f..342cf28e38 100644 --- a/tensorflow/core/platform/file_system_helper.cc +++ b/tensorflow/core/platform/file_system_helper.cc @@ -59,7 +59,7 @@ Status GetMatchingPaths(FileSystem* fs, Env* env, const string& pattern, string fixed_prefix = pattern.substr(0, pattern.find_first_of("*?[\\")); string eval_pattern = pattern; std::vector<string> all_files; - string dir = std::string(io::Dirname(fixed_prefix)); + string dir(io::Dirname(fixed_prefix)); // If dir is empty then we need to fix up fixed_prefix and eval_pattern to // include . as the top level directory. if (dir.empty()) { diff --git a/tensorflow/core/platform/file_system_test.cc b/tensorflow/core/platform/file_system_test.cc index c0a16c95f9..a637d42a92 100644 --- a/tensorflow/core/platform/file_system_test.cc +++ b/tensorflow/core/platform/file_system_test.cc @@ -125,7 +125,7 @@ class InterPlanetaryFileSystem : public NullFileSystem { ASSERT_EQ(scheme, "ipfs"); ASSERT_EQ(host, "solarsystem"); str_util::ConsumePrefix(&path, "/"); - *parsed_path = std::string(path); + *parsed_path = string(path); } std::map<string, std::set<string>> celestial_bodies_ = { diff --git a/tensorflow/core/platform/hadoop/hadoop_file_system.cc b/tensorflow/core/platform/hadoop/hadoop_file_system.cc index ff4b4436bb..8cdb08f51b 100644 --- a/tensorflow/core/platform/hadoop/hadoop_file_system.cc +++ b/tensorflow/core/platform/hadoop/hadoop_file_system.cc @@ -144,7 +144,7 @@ Status HadoopFileSystem::Connect(StringPiece fname, hdfsFS* fs) { StringPiece scheme, namenode, path; io::ParseURI(fname, &scheme, &namenode, &path); - const string nn = namenode.ToString(); + const string nn(namenode); hdfsBuilder* builder = hdfs_->hdfsNewBuilder(); if (scheme == "file") { @@ -183,7 +183,7 @@ Status HadoopFileSystem::Connect(StringPiece fname, hdfsFS* fs) { string HadoopFileSystem::TranslateName(const string& name) const { StringPiece scheme, namenode, path; io::ParseURI(name, &scheme, &namenode, &path); - return path.ToString(); + return string(path); } class HDFSRandomAccessFile : public RandomAccessFile { @@ -392,7 +392,7 @@ Status HadoopFileSystem::GetChildren(const string& dir, return IOError(dir, errno); } for (int i = 0; i < entries; i++) { - result->push_back(io::Basename(info[i].mName).ToString()); + result->push_back(string(io::Basename(info[i].mName))); } hdfs_->hdfsFreeFileInfo(info, entries); return Status::OK(); diff --git a/tensorflow/core/platform/host_info.h b/tensorflow/core/platform/host_info.h index 6124c95923..e76b83adf3 100644 --- a/tensorflow/core/platform/host_info.h +++ b/tensorflow/core/platform/host_info.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_HOST_INFO_H_ -#define TENSORFLOW_PLATFORM_HOST_INFO_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_HOST_INFO_H_ +#define TENSORFLOW_CORE_PLATFORM_HOST_INFO_H_ #include "tensorflow/core/platform/types.h" @@ -27,4 +27,4 @@ string Hostname(); } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_HOST_INFO_H_ +#endif // TENSORFLOW_CORE_PLATFORM_HOST_INFO_H_ diff --git a/tensorflow/core/platform/init_main.h b/tensorflow/core/platform/init_main.h index 20cbc615b1..834c529816 100644 --- a/tensorflow/core/platform/init_main.h +++ b/tensorflow/core/platform/init_main.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_INIT_MAIN_H_ -#define TENSORFLOW_PLATFORM_INIT_MAIN_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_INIT_MAIN_H_ +#define TENSORFLOW_CORE_PLATFORM_INIT_MAIN_H_ namespace tensorflow { namespace port { @@ -28,4 +28,4 @@ void InitMain(const char* usage, int* argc, char*** argv); } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_INIT_MAIN_H_ +#endif // TENSORFLOW_CORE_PLATFORM_INIT_MAIN_H_ diff --git a/tensorflow/core/platform/load_library.h b/tensorflow/core/platform/load_library.h index 9038de25f3..c7eeb2918c 100644 --- a/tensorflow/core/platform/load_library.h +++ b/tensorflow/core/platform/load_library.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_LOAD_LIBRARY_H_ -#define TENSORFLOW_PLATFORM_LOAD_LIBRARY_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_LOAD_LIBRARY_H_ +#define TENSORFLOW_CORE_PLATFORM_LOAD_LIBRARY_H_ #include "tensorflow/core/lib/core/status.h" @@ -31,4 +31,4 @@ string FormatLibraryFileName(const string& name, const string& version); } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_LOAD_LIBRARY_H_ +#endif // TENSORFLOW_CORE_PLATFORM_LOAD_LIBRARY_H_ diff --git a/tensorflow/core/platform/logging.h b/tensorflow/core/platform/logging.h index 985c061676..17a5d5fb5b 100644 --- a/tensorflow/core/platform/logging.h +++ b/tensorflow/core/platform/logging.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_LOGGING_H_ -#define TENSORFLOW_PLATFORM_LOGGING_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_LOGGING_H_ +#define TENSORFLOW_CORE_PLATFORM_LOGGING_H_ #include "tensorflow/core/platform/platform.h" // To pick up PLATFORM_define @@ -36,4 +36,4 @@ void LogString(const char* fname, int line, int severity, } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_LOGGING_H_ +#endif // TENSORFLOW_CORE_PLATFORM_LOGGING_H_ diff --git a/tensorflow/core/platform/macros.h b/tensorflow/core/platform/macros.h index b65eb43146..e1d83e18ac 100644 --- a/tensorflow/core/platform/macros.h +++ b/tensorflow/core/platform/macros.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_MACROS_H_ -#define TENSORFLOW_PLATFORM_MACROS_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_MACROS_H_ +#define TENSORFLOW_CORE_PLATFORM_MACROS_H_ // Compiler attributes #if (defined(__GNUC__) || defined(__APPLE__)) && !defined(SWIG) @@ -125,4 +125,4 @@ limitations under the License. } while (0) #endif -#endif // TENSORFLOW_PLATFORM_MACROS_H_ +#endif // TENSORFLOW_CORE_PLATFORM_MACROS_H_ diff --git a/tensorflow/core/platform/mem.h b/tensorflow/core/platform/mem.h index fca3a2332d..e8150f7322 100644 --- a/tensorflow/core/platform/mem.h +++ b/tensorflow/core/platform/mem.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_MEM_H_ -#define TENSORFLOW_PLATFORM_MEM_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_MEM_H_ +#define TENSORFLOW_CORE_PLATFORM_MEM_H_ // TODO(cwhipkey): remove this when callers use annotations directly. #include "tensorflow/core/platform/dynamic_annotations.h" @@ -65,4 +65,4 @@ int64 AvailableRam(); } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_MEM_H_ +#endif // TENSORFLOW_CORE_PLATFORM_MEM_H_ diff --git a/tensorflow/core/platform/mutex.h b/tensorflow/core/platform/mutex.h index 42d46ceb5b..66b20da95a 100644 --- a/tensorflow/core/platform/mutex.h +++ b/tensorflow/core/platform/mutex.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_MUTEX_H_ -#define TENSORFLOW_PLATFORM_MUTEX_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_MUTEX_H_ +#define TENSORFLOW_CORE_PLATFORM_MUTEX_H_ #include "tensorflow/core/platform/platform.h" #include "tensorflow/core/platform/types.h" @@ -50,4 +50,4 @@ ConditionResult WaitForMilliseconds(mutex_lock* mu, condition_variable* cv, int64 ms); } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_MUTEX_H_ +#endif // TENSORFLOW_CORE_PLATFORM_MUTEX_H_ diff --git a/tensorflow/core/platform/net.h b/tensorflow/core/platform/net.h index 9e7851728d..7dbc92f058 100644 --- a/tensorflow/core/platform/net.h +++ b/tensorflow/core/platform/net.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_NET_H_ -#define TENSORFLOW_PLATFORM_NET_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_NET_H_ +#define TENSORFLOW_CORE_PLATFORM_NET_H_ namespace tensorflow { namespace internal { @@ -24,4 +24,4 @@ int PickUnusedPortOrDie(); } // namespace internal } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_NET_H_ +#endif // TENSORFLOW_CORE_PLATFORM_NET_H_ diff --git a/tensorflow/core/platform/png.h b/tensorflow/core/platform/png.h index b110d63aba..93b1425f7a 100644 --- a/tensorflow/core/platform/png.h +++ b/tensorflow/core/platform/png.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_PNG_H_ -#define TENSORFLOW_PLATFORM_PNG_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_PNG_H_ +#define TENSORFLOW_CORE_PLATFORM_PNG_H_ #include "tensorflow/core/platform/platform.h" @@ -27,4 +27,4 @@ limitations under the License. #error Define the appropriate PLATFORM_<foo> macro for this platform #endif -#endif // TENSORFLOW_PLATFORM_PNG_H_ +#endif // TENSORFLOW_CORE_PLATFORM_PNG_H_ diff --git a/tensorflow/core/platform/posix/error.h b/tensorflow/core/platform/posix/error.h index 9b614d0f70..9df5f2daa1 100644 --- a/tensorflow/core/platform/posix/error.h +++ b/tensorflow/core/platform/posix/error.h @@ -24,4 +24,4 @@ Status IOError(const string& context, int err_number); } // namespace tensorflow -#endif // TENSORFLOW_CORE_PLATFORM_POSIX_POSIX_FILE_SYSTEM_H_ +#endif // TENSORFLOW_CORE_PLATFORM_POSIX_ERROR_H_ diff --git a/tensorflow/core/platform/posix/port.cc b/tensorflow/core/platform/posix/port.cc index 1939cf72fb..b46b9927cd 100644 --- a/tensorflow/core/platform/posix/port.cc +++ b/tensorflow/core/platform/posix/port.cc @@ -17,9 +17,7 @@ limitations under the License. #include "jemalloc/jemalloc.h" #endif -#ifdef TENSORFLOW_USE_ABSL #include "absl/base/internal/sysinfo.h" -#endif #include "tensorflow/core/platform/cpu_info.h" #include "tensorflow/core/platform/logging.h" @@ -194,11 +192,7 @@ bool Snappy_Uncompress(const char* input, size_t length, char* output) { string Demangle(const char* mangled) { return mangled; } double NominalCPUFrequency() { -#ifdef TENSORFLOW_USE_ABSL return absl::base_internal::NominalCPUFrequency(); -#else - return 1.0; -#endif } int64 AvailableRam() { diff --git a/tensorflow/core/platform/posix/posix_file_system.h b/tensorflow/core/platform/posix/posix_file_system.h index e8898d0a97..752eccea66 100644 --- a/tensorflow/core/platform/posix/posix_file_system.h +++ b/tensorflow/core/platform/posix/posix_file_system.h @@ -70,7 +70,7 @@ class LocalPosixFileSystem : public PosixFileSystem { string TranslateName(const string& name) const override { StringPiece scheme, host, path; io::ParseURI(name, &scheme, &host, &path); - return path.ToString(); + return string(path); } }; diff --git a/tensorflow/core/platform/posix/subprocess.h b/tensorflow/core/platform/posix/subprocess.h index 53f95f3c14..9740d75595 100644 --- a/tensorflow/core/platform/posix/subprocess.h +++ b/tensorflow/core/platform/posix/subprocess.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_DEFAULT_SUBPROCESS_H_ -#define TENSORFLOW_PLATFORM_DEFAULT_SUBPROCESS_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_POSIX_SUBPROCESS_H_ +#define TENSORFLOW_CORE_PLATFORM_POSIX_SUBPROCESS_H_ #include <errno.h> #include <unistd.h> @@ -128,4 +128,4 @@ class SubProcess { } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_DEFAULT_SUBPROCESS_H_ +#endif // TENSORFLOW_CORE_PLATFORM_POSIX_SUBPROCESS_H_ diff --git a/tensorflow/core/platform/prefetch.h b/tensorflow/core/platform/prefetch.h index 81e1a5210a..9cefab3c1b 100644 --- a/tensorflow/core/platform/prefetch.h +++ b/tensorflow/core/platform/prefetch.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_PREFETCH_H_ -#define TENSORFLOW_PLATFORM_PREFETCH_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_PREFETCH_H_ +#define TENSORFLOW_CORE_PLATFORM_PREFETCH_H_ #include "tensorflow/core/platform/platform.h" @@ -56,4 +56,4 @@ inline void prefetch(const void* x) { } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_PREFETCH_H_ +#endif // TENSORFLOW_CORE_PLATFORM_PREFETCH_H_ diff --git a/tensorflow/core/platform/profile_utils/android_armv7a_cpu_utils_helper.h b/tensorflow/core/platform/profile_utils/android_armv7a_cpu_utils_helper.h index ce2069b004..2d94736c97 100644 --- a/tensorflow/core/platform/profile_utils/android_armv7a_cpu_utils_helper.h +++ b/tensorflow/core/platform/profile_utils/android_armv7a_cpu_utils_helper.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_PROFILEUTILS_ANDROID_ARMV7A_CPU_UTILS_HELPER_H__ -#define TENSORFLOW_PLATFORM_PROFILEUTILS_ANDROID_ARMV7A_CPU_UTILS_HELPER_H__ +#ifndef TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_ANDROID_ARMV7A_CPU_UTILS_HELPER_H_ +#define TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_ANDROID_ARMV7A_CPU_UTILS_HELPER_H_ #include <sys/types.h> @@ -64,4 +64,4 @@ class AndroidArmV7ACpuUtilsHelper : public ICpuUtilsHelper { #endif // defined(__ANDROID__) && (__ANDROID_API__ >= 21) && // (defined(__ARM_ARCH_7A__) || defined(__aarch64__)) -#endif // TENSORFLOW_PLATFORM_PROFILEUTILS_ANDROID_ARMV7A_CPU_UTILS_HELPER_H__ +#endif // TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_ANDROID_ARMV7A_CPU_UTILS_HELPER_H_ diff --git a/tensorflow/core/platform/profile_utils/clock_cycle_profiler.h b/tensorflow/core/platform/profile_utils/clock_cycle_profiler.h index de4eec28e3..e25456374c 100644 --- a/tensorflow/core/platform/profile_utils/clock_cycle_profiler.h +++ b/tensorflow/core/platform/profile_utils/clock_cycle_profiler.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_PROFILE_UTILS_CLOCK_CYCLE_PROFILER_H_ -#define TENSORFLOW_PLATFORM_PROFILE_UTILS_CLOCK_CYCLE_PROFILER_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_CLOCK_CYCLE_PROFILER_H_ +#define TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_CLOCK_CYCLE_PROFILER_H_ #include <algorithm> @@ -103,4 +103,4 @@ class ClockCycleProfiler { } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_PROFILE_UTILS_CLOCK_CYCLE_PROFILER_H_ +#endif // TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_CLOCK_CYCLE_PROFILER_H_ diff --git a/tensorflow/core/platform/profile_utils/cpu_utils.h b/tensorflow/core/platform/profile_utils/cpu_utils.h index 8f06290303..b0b1ef0363 100644 --- a/tensorflow/core/platform/profile_utils/cpu_utils.h +++ b/tensorflow/core/platform/profile_utils/cpu_utils.h @@ -14,8 +14,8 @@ limitations under the License. ==============================================================================*/ // This class is designed to get accurate profile for programs. -#ifndef TENSORFLOW_PLATFORM_PROFILEUTILS_CPU_UTILS_H__ -#define TENSORFLOW_PLATFORM_PROFILEUTILS_CPU_UTILS_H__ +#ifndef TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_CPU_UTILS_H_ +#define TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_CPU_UTILS_H_ #include <chrono> #include <memory> @@ -164,4 +164,4 @@ class CpuUtils { } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_PROFILEUTILS_CPU_UTILS_H__ +#endif // TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_CPU_UTILS_H_ diff --git a/tensorflow/core/platform/profile_utils/i_cpu_utils_helper.h b/tensorflow/core/platform/profile_utils/i_cpu_utils_helper.h index 11b739c009..cab7618a70 100644 --- a/tensorflow/core/platform/profile_utils/i_cpu_utils_helper.h +++ b/tensorflow/core/platform/profile_utils/i_cpu_utils_helper.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_PROFILEUTILS_I_CPU_UTILS_HELPER_H__ -#define TENSORFLOW_PLATFORM_PROFILEUTILS_I_CPU_UTILS_HELPER_H__ +#ifndef TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_I_CPU_UTILS_HELPER_H_ +#define TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_I_CPU_UTILS_HELPER_H_ #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/types.h" @@ -50,4 +50,4 @@ class ICpuUtilsHelper { } // namespace profile_utils } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_PROFILEUTILS_I_CPU_UTILS_HELPER_H__ +#endif // TENSORFLOW_CORE_PLATFORM_PROFILE_UTILS_I_CPU_UTILS_HELPER_H_ diff --git a/tensorflow/core/platform/protobuf.h b/tensorflow/core/platform/protobuf.h index 288d091624..fcbf1fc8c5 100644 --- a/tensorflow/core/platform/protobuf.h +++ b/tensorflow/core/platform/protobuf.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_PROTOBUF_H_ -#define TENSORFLOW_PLATFORM_PROTOBUF_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_PROTOBUF_H_ +#define TENSORFLOW_CORE_PLATFORM_PROTOBUF_H_ #include "tensorflow/core/platform/platform.h" #include "tensorflow/core/platform/types.h" @@ -52,4 +52,4 @@ inline void SetProtobufStringSwapAllowed(string* src, string* dest) { } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_PROTOBUF_H_ +#endif // TENSORFLOW_CORE_PLATFORM_PROTOBUF_H_ diff --git a/tensorflow/core/platform/protobuf_internal.h b/tensorflow/core/platform/protobuf_internal.h index 2f151a5aee..d0cfde09bc 100644 --- a/tensorflow/core/platform/protobuf_internal.h +++ b/tensorflow/core/platform/protobuf_internal.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_PROTOBUF_INTERNAL_H_ -#define TENSORFLOW_PLATFORM_PROTOBUF_INTERNAL_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_PROTOBUF_INTERNAL_H_ +#define TENSORFLOW_CORE_PLATFORM_PROTOBUF_INTERNAL_H_ #include "google/protobuf/any.pb.h" #include "tensorflow/core/lib/core/errors.h" @@ -69,4 +69,4 @@ Status ParseAny(const google::protobuf::Any& any, T* message, } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_PROTOBUF_INTERNAL_H_ +#endif // TENSORFLOW_CORE_PLATFORM_PROTOBUF_INTERNAL_H_ diff --git a/tensorflow/core/platform/s3/s3_file_system.cc b/tensorflow/core/platform/s3/s3_file_system.cc index 462113f9bb..ce0f6cd741 100644 --- a/tensorflow/core/platform/s3/s3_file_system.cc +++ b/tensorflow/core/platform/s3/s3_file_system.cc @@ -150,13 +150,13 @@ Status ParseS3Path(const string& fname, bool empty_object_ok, string* bucket, return errors::InvalidArgument("S3 path doesn't start with 's3://': ", fname); } - *bucket = bucketp.ToString(); + *bucket = string(bucketp); if (bucket->empty() || *bucket == ".") { return errors::InvalidArgument("S3 path doesn't contain a bucket name: ", fname); } str_util::ConsumePrefix(&objectp, "/"); - *object = objectp.ToString(); + *object = string(objectp); if (!empty_object_ok && object->empty()) { return errors::InvalidArgument("S3 path doesn't contain an object name: ", fname); diff --git a/tensorflow/core/platform/setround.h b/tensorflow/core/platform/setround.h index d076e7acc6..ded00b23b1 100644 --- a/tensorflow/core/platform/setround.h +++ b/tensorflow/core/platform/setround.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_SETROUND_H_ -#define TENSORFLOW_PLATFORM_SETROUND_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_SETROUND_H_ +#define TENSORFLOW_CORE_PLATFORM_SETROUND_H_ #include <cfenv> @@ -42,4 +42,4 @@ class ScopedSetRound { } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_SETROUND_H_ +#endif // TENSORFLOW_CORE_PLATFORM_SETROUND_H_ diff --git a/tensorflow/core/platform/snappy.h b/tensorflow/core/platform/snappy.h index 62c208ffb4..5477b097ef 100644 --- a/tensorflow/core/platform/snappy.h +++ b/tensorflow/core/platform/snappy.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_SNAPPY_H_ -#define TENSORFLOW_PLATFORM_SNAPPY_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_SNAPPY_H_ +#define TENSORFLOW_CORE_PLATFORM_SNAPPY_H_ #include "tensorflow/core/platform/types.h" @@ -31,4 +31,4 @@ bool Snappy_Uncompress(const char* input, size_t length, char* output); } // namespace port } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_SNAPPY_H_ +#endif // TENSORFLOW_CORE_PLATFORM_SNAPPY_H_ diff --git a/tensorflow/core/platform/stacktrace_handler.h b/tensorflow/core/platform/stacktrace_handler.h index a52970fdaa..9f118b91b8 100644 --- a/tensorflow/core/platform/stacktrace_handler.h +++ b/tensorflow/core/platform/stacktrace_handler.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_PLATFORM_BACKTRACE_H_ -#define TENSORFLOW_CORE_PLATFORM_BACKTRACE_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_STACKTRACE_HANDLER_H_ +#define TENSORFLOW_CORE_PLATFORM_STACKTRACE_HANDLER_H_ namespace tensorflow { namespace testing { @@ -25,4 +25,4 @@ void InstallStacktraceHandler(); } // namespace testing } // namespace tensorflow -#endif // TENSORFLOW_CORE_PLATFORM_BACKTRACE_H_ +#endif // TENSORFLOW_CORE_PLATFORM_STACKTRACE_HANDLER_H_ diff --git a/tensorflow/core/platform/subprocess.h b/tensorflow/core/platform/subprocess.h index dcc0c1a4ee..7c11e6232f 100644 --- a/tensorflow/core/platform/subprocess.h +++ b/tensorflow/core/platform/subprocess.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_SUBPROCESS_H_ -#define TENSORFLOW_PLATFORM_SUBPROCESS_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_SUBPROCESS_H_ +#define TENSORFLOW_CORE_PLATFORM_SUBPROCESS_H_ #include <memory> #include <vector> @@ -67,4 +67,4 @@ std::unique_ptr<SubProcess> CreateSubProcess(const std::vector<string>& argv); #error Define the appropriate PLATFORM_<foo> macro for this platform #endif -#endif // TENSORFLOW_PLATFORM_SUBPROCESS_H_ +#endif // TENSORFLOW_CORE_PLATFORM_SUBPROCESS_H_ diff --git a/tensorflow/core/platform/test.h b/tensorflow/core/platform/test.h index 99bae63edf..f5d3282f57 100644 --- a/tensorflow/core/platform/test.h +++ b/tensorflow/core/platform/test.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_TEST_H_ -#define TENSORFLOW_PLATFORM_TEST_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_TEST_H_ +#define TENSORFLOW_CORE_PLATFORM_TEST_H_ #include <memory> #include <vector> @@ -55,4 +55,4 @@ int PickUnusedPortOrDie(); } // namespace testing } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_TEST_H_ +#endif // TENSORFLOW_CORE_PLATFORM_TEST_H_ diff --git a/tensorflow/core/platform/test_benchmark.h b/tensorflow/core/platform/test_benchmark.h index 9b8726d98f..61fcd0d372 100644 --- a/tensorflow/core/platform/test_benchmark.h +++ b/tensorflow/core/platform/test_benchmark.h @@ -14,8 +14,8 @@ limitations under the License. ==============================================================================*/ // Simple benchmarking facility. -#ifndef TENSORFLOW_PLATFORM_TEST_BENCHMARK_H_ -#define TENSORFLOW_PLATFORM_TEST_BENCHMARK_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_TEST_BENCHMARK_H_ +#define TENSORFLOW_CORE_PLATFORM_TEST_BENCHMARK_H_ #include <utility> #include <vector> @@ -115,4 +115,4 @@ void UseRealTime(); } // namespace testing } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_TEST_BENCHMARK_H_ +#endif // TENSORFLOW_CORE_PLATFORM_TEST_BENCHMARK_H_ diff --git a/tensorflow/core/platform/thread_annotations.h b/tensorflow/core/platform/thread_annotations.h index 50195cbbc7..aec34df8a1 100644 --- a/tensorflow/core/platform/thread_annotations.h +++ b/tensorflow/core/platform/thread_annotations.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_THREAD_ANNOTATIONS_H_ -#define TENSORFLOW_PLATFORM_THREAD_ANNOTATIONS_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_THREAD_ANNOTATIONS_H_ +#define TENSORFLOW_CORE_PLATFORM_THREAD_ANNOTATIONS_H_ #include "tensorflow/core/platform/types.h" @@ -27,4 +27,4 @@ limitations under the License. #error Define the appropriate PLATFORM_<foo> macro for this platform #endif -#endif // TENSORFLOW_PLATFORM_THREAD_ANNOTATIONS_H_ +#endif // TENSORFLOW_CORE_PLATFORM_THREAD_ANNOTATIONS_H_ diff --git a/tensorflow/core/platform/tracing.h b/tensorflow/core/platform/tracing.h index c322777705..e5851f1dfe 100644 --- a/tensorflow/core/platform/tracing.h +++ b/tensorflow/core/platform/tracing.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_TRACING_H_ -#define TENSORFLOW_PLATFORM_TRACING_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_TRACING_H_ +#define TENSORFLOW_CORE_PLATFORM_TRACING_H_ // Tracing interface @@ -238,4 +238,4 @@ const char* GetLogDir(); #include "tensorflow/core/platform/default/tracing_impl.h" #endif -#endif // TENSORFLOW_PLATFORM_TRACING_H_ +#endif // TENSORFLOW_CORE_PLATFORM_TRACING_H_ diff --git a/tensorflow/core/platform/types.h b/tensorflow/core/platform/types.h index 68897ac423..a4fa790317 100644 --- a/tensorflow/core/platform/types.h +++ b/tensorflow/core/platform/types.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_TYPES_H_ -#define TENSORFLOW_PLATFORM_TYPES_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_TYPES_H_ +#define TENSORFLOW_CORE_PLATFORM_TYPES_H_ #include <string> #include "tensorflow/core/platform/platform.h" @@ -66,4 +66,4 @@ namespace tensorflow { namespace se = ::stream_executor; } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_TYPES_H_ +#endif // TENSORFLOW_CORE_PLATFORM_TYPES_H_ diff --git a/tensorflow/core/platform/windows/cpu_info.h b/tensorflow/core/platform/windows/cpu_info.h index ba2126abcf..8b42cbec7a 100644 --- a/tensorflow/core/platform/windows/cpu_info.h +++ b/tensorflow/core/platform/windows/cpu_info.h @@ -13,10 +13,10 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_WINDOWS_CPU_INFO_H_ -#define TENSORFLOW_PLATFORM_WINDOWS_CPU_INFO_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_WINDOWS_CPU_INFO_H_ +#define TENSORFLOW_CORE_PLATFORM_WINDOWS_CPU_INFO_H_ // included so __cpuidex function is available for GETCPUID on Windows #include <intrin.h> -#endif // TENSORFLOW_PLATFORM_WINDOWS_CPU_INFO_H_ +#endif // TENSORFLOW_CORE_PLATFORM_WINDOWS_CPU_INFO_H_ diff --git a/tensorflow/core/platform/windows/integral_types.h b/tensorflow/core/platform/windows/integral_types.h index 46338a536d..283af49f20 100644 --- a/tensorflow/core/platform/windows/integral_types.h +++ b/tensorflow/core/platform/windows/integral_types.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_WINDOWS_INTEGRAL_TYPES_H_ -#define TENSORFLOW_PLATFORM_WINDOWS_INTEGRAL_TYPES_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_WINDOWS_INTEGRAL_TYPES_H_ +#define TENSORFLOW_CORE_PLATFORM_WINDOWS_INTEGRAL_TYPES_H_ #include "tensorflow/core/platform/default/integral_types.h" @@ -22,4 +22,4 @@ limitations under the License. typedef std::ptrdiff_t ssize_t; -#endif // TENSORFLOW_PLATFORM_WINDOWS_INTEGRAL_TYPES_H_ +#endif // TENSORFLOW_CORE_PLATFORM_WINDOWS_INTEGRAL_TYPES_H_ diff --git a/tensorflow/core/platform/windows/subprocess.h b/tensorflow/core/platform/windows/subprocess.h index f00471d484..9084ff5a92 100644 --- a/tensorflow/core/platform/windows/subprocess.h +++ b/tensorflow/core/platform/windows/subprocess.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PLATFORM_WINDOWS_SUBPROCESS_H_ -#define TENSORFLOW_PLATFORM_WINDOWS_SUBPROCESS_H_ +#ifndef TENSORFLOW_CORE_PLATFORM_WINDOWS_SUBPROCESS_H_ +#define TENSORFLOW_CORE_PLATFORM_WINDOWS_SUBPROCESS_H_ #include <memory> #include <vector> @@ -33,4 +33,4 @@ std::unique_ptr<SubProcess> CreateSubProcess(const std::vector<string>& argv) { } // namespace tensorflow -#endif // TENSORFLOW_PLATFORM_WINDOWS_SUBPROCESS_H_ +#endif // TENSORFLOW_CORE_PLATFORM_WINDOWS_SUBPROCESS_H_ diff --git a/tensorflow/core/platform/windows/windows_file_system.h b/tensorflow/core/platform/windows/windows_file_system.h index 6b04720c68..1f4c535f24 100644 --- a/tensorflow/core/platform/windows/windows_file_system.h +++ b/tensorflow/core/platform/windows/windows_file_system.h @@ -71,7 +71,7 @@ class LocalWinFileSystem : public WindowsFileSystem { string TranslateName(const string& name) const override { StringPiece scheme, host, path; io::ParseURI(name, &scheme, &host, &path); - return path.ToString(); + return string(path); } }; diff --git a/tensorflow/core/profiler/internal/advisor/expensive_operation_checker.h b/tensorflow/core/profiler/internal/advisor/expensive_operation_checker.h index f5ac5c9c5a..0d1c92eb08 100644 --- a/tensorflow/core/profiler/internal/advisor/expensive_operation_checker.h +++ b/tensorflow/core/profiler/internal/advisor/expensive_operation_checker.h @@ -137,4 +137,4 @@ class ExpensiveOperationChecker : public Checker { } // namespace tfprof } // namespace tensorflow -#endif // TENSORFLOW_CORE_PROFILER_INTERNAL_ADVISOR_EXPENSIVE_OP_CHECKER_H_ +#endif // TENSORFLOW_CORE_PROFILER_INTERNAL_ADVISOR_EXPENSIVE_OPERATION_CHECKER_H_ diff --git a/tensorflow/core/profiler/internal/advisor/tfprof_advisor.h b/tensorflow/core/profiler/internal/advisor/tfprof_advisor.h index 270662bd4a..e1533f882f 100644 --- a/tensorflow/core/profiler/internal/advisor/tfprof_advisor.h +++ b/tensorflow/core/profiler/internal/advisor/tfprof_advisor.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_PROFILER_INTERNAL_ADVISOR_TFPROF_ADVICE_H_ -#define TENSORFLOW_CORE_PROFILER_INTERNAL_ADVISOR_TFPROF_ADVICE_H_ +#ifndef TENSORFLOW_CORE_PROFILER_INTERNAL_ADVISOR_TFPROF_ADVISOR_H_ +#define TENSORFLOW_CORE_PROFILER_INTERNAL_ADVISOR_TFPROF_ADVISOR_H_ #include "tensorflow/core/profiler/internal/advisor/accelerator_utilization_checker.h" #include "tensorflow/core/profiler/internal/advisor/checker.h" @@ -78,4 +78,4 @@ class Advisor { } // namespace tfprof } // namespace tensorflow -#endif // TENSORFLOW_CORE_PROFILER_INTERNAL_ADVISOR_TFPROF_ADVICE_H_ +#endif // TENSORFLOW_CORE_PROFILER_INTERNAL_ADVISOR_TFPROF_ADVISOR_H_ diff --git a/tensorflow/core/profiler/internal/tfprof_code.cc b/tensorflow/core/profiler/internal/tfprof_code.cc index 2c4f52e3ad..744e1e95de 100644 --- a/tensorflow/core/profiler/internal/tfprof_code.cc +++ b/tensorflow/core/profiler/internal/tfprof_code.cc @@ -37,7 +37,7 @@ const char* const kGradientSuffix = " (gradient)"; // Convert to Trace proto into a short readable string. string GetTraceString(const CallStack::Trace& trace) { - string ntrace = io::Basename(trace.file()).ToString(); + string ntrace(io::Basename(trace.file())); ntrace += strings::StrCat(":", trace.lineno()); if (trace.function().length() < 20) { ntrace += ":" + trace.function(); @@ -113,7 +113,7 @@ class FunctionTable { // function index should start from 1. func_pb->set_id(function_table_.size()); - string file_base = io::Basename(file_path).ToString(); + string file_base(io::Basename(file_path)); file_base = file_base.substr(0, file_base.find_last_of(".")); func_pb->set_name( string_table_->GetIndex(strings::StrCat(file_base, ":", func_name))); diff --git a/tensorflow/core/profiler/tfprof_options.h b/tensorflow/core/profiler/tfprof_options.h index d61deb72ac..57c7e11fa2 100644 --- a/tensorflow/core/profiler/tfprof_options.h +++ b/tensorflow/core/profiler/tfprof_options.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_PROFILER_INTERNAL_TFPROF_OPTIONS_H_ -#define TENSORFLOW_CORE_PROFILER_INTERNAL_TFPROF_OPTIONS_H_ +#ifndef TENSORFLOW_CORE_PROFILER_TFPROF_OPTIONS_H_ +#define TENSORFLOW_CORE_PROFILER_TFPROF_OPTIONS_H_ #include <set> #include <string> @@ -183,4 +183,4 @@ tensorflow::Status ParseOutput(const string& output_opt, string* output_type, } // namespace tfprof } // namespace tensorflow -#endif // TENSORFLOW_CORE_PROFILER_INTERNAL_TFPROF_OPTIONS_H_ +#endif // TENSORFLOW_CORE_PROFILER_TFPROF_OPTIONS_H_ diff --git a/tensorflow/core/protobuf/debug.proto b/tensorflow/core/protobuf/debug.proto index 811cf406b9..8ca76c44c0 100644 --- a/tensorflow/core/protobuf/debug.proto +++ b/tensorflow/core/protobuf/debug.proto @@ -60,6 +60,12 @@ message DebugOptions { // Note that this is distinct from the session run count and the executor // step count. int64 global_step = 10; + + // Whether the total disk usage of tfdbg is to be reset to zero + // in this Session.run call. This is used by wrappers and hooks + // such as the local CLI ones to indicate that the dumped tensors + // are cleaned up from the disk after each Session.run. + bool reset_disk_byte_usage = 11; } message DebuggedSourceFile { diff --git a/tensorflow/core/public/session.h b/tensorflow/core/public/session.h index cc8596ef3d..536a07c413 100644 --- a/tensorflow/core/public/session.h +++ b/tensorflow/core/public/session.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PUBLIC_SESSION_H_ -#define TENSORFLOW_PUBLIC_SESSION_H_ +#ifndef TENSORFLOW_CORE_PUBLIC_SESSION_H_ +#define TENSORFLOW_CORE_PUBLIC_SESSION_H_ #include <string> #include <vector> @@ -279,4 +279,4 @@ Session* NewSession(const SessionOptions& options); } // end namespace tensorflow -#endif // TENSORFLOW_PUBLIC_SESSION_H_ +#endif // TENSORFLOW_CORE_PUBLIC_SESSION_H_ diff --git a/tensorflow/core/public/version.h b/tensorflow/core/public/version.h index 563564119f..4129c93af5 100644 --- a/tensorflow/core/public/version.h +++ b/tensorflow/core/public/version.h @@ -96,10 +96,12 @@ limitations under the License. // GraphDef. (7dec2017) // 27. Deprecate TensorArray ops v2 in favor of v3 and deprecated io_ops // deprecated in favor of V2 ops. (2018/01/23) +// 28. Deprecate MatrixExponential op in favor of Python implementation. +// (2018/08/21). #define TF_GRAPH_DEF_VERSION_MIN_PRODUCER 0 #define TF_GRAPH_DEF_VERSION_MIN_CONSUMER 0 -#define TF_GRAPH_DEF_VERSION 26 +#define TF_GRAPH_DEF_VERSION 27 // Checkpoint compatibility versions (the versions field in SavedSliceMeta). // diff --git a/tensorflow/core/util/activation_mode.h b/tensorflow/core/util/activation_mode.h index 2e03ccd5c8..2f7820fb47 100644 --- a/tensorflow/core/util/activation_mode.h +++ b/tensorflow/core/util/activation_mode.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_ACTIVATION_MODE_H_ -#define TENSORFLOW_UTIL_ACTIVATION_MODE_H_ +#ifndef TENSORFLOW_CORE_UTIL_ACTIVATION_MODE_H_ +#define TENSORFLOW_CORE_UTIL_ACTIVATION_MODE_H_ // This file contains helper routines to deal with activation mode in various // ops and kernels. @@ -43,4 +43,4 @@ Status GetActivationModeFromString(const string& str_value, } // end namespace tensorflow -#endif // TENSORFLOW_UTIL_ACTIVATION_MODE_H_ +#endif // TENSORFLOW_CORE_UTIL_ACTIVATION_MODE_H_ diff --git a/tensorflow/core/util/bcast.h b/tensorflow/core/util/bcast.h index 81d64e5676..6d73c38e3c 100644 --- a/tensorflow/core/util/bcast.h +++ b/tensorflow/core/util/bcast.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_BCAST_H_ -#define TENSORFLOW_UTIL_BCAST_H_ +#ifndef TENSORFLOW_CORE_UTIL_BCAST_H_ +#define TENSORFLOW_CORE_UTIL_BCAST_H_ #include <algorithm> @@ -132,4 +132,4 @@ class BCast { } // end namespace tensorflow -#endif // TENSORFLOW_UTIL_BCAST_H_ +#endif // TENSORFLOW_CORE_UTIL_BCAST_H_ diff --git a/tensorflow/core/util/command_line_flags.cc b/tensorflow/core/util/command_line_flags.cc index b281acb2b0..55f1e30880 100644 --- a/tensorflow/core/util/command_line_flags.cc +++ b/tensorflow/core/util/command_line_flags.cc @@ -32,7 +32,7 @@ bool ParseStringFlag(tensorflow::StringPiece arg, tensorflow::StringPiece flag, if (str_util::ConsumePrefix(&arg, "--") && str_util::ConsumePrefix(&arg, flag) && str_util::ConsumePrefix(&arg, "=")) { - *value_parsing_ok = hook(std::string(arg)); + *value_parsing_ok = hook(string(arg)); return true; } diff --git a/tensorflow/core/util/ctc/ctc_beam_search.h b/tensorflow/core/util/ctc/ctc_beam_search.h index aee647a1b3..5e2aeb7830 100644 --- a/tensorflow/core/util/ctc/ctc_beam_search.h +++ b/tensorflow/core/util/ctc/ctc_beam_search.h @@ -259,6 +259,16 @@ void CTCBeamSearchDecoder<CTCBeamState, CTCBeamComparer>::Step( } else { max_coeff = raw_input.maxCoeff(); } + + // Get normalization term of softmax: log(sum(exp(logit[j]-max_coeff))). + float logsumexp = 0.0; + for (int j = 0; j < raw_input.size(); ++j) { + logsumexp += Eigen::numext::exp(raw_input(j) - max_coeff); + } + logsumexp = Eigen::numext::log(logsumexp); + // Final normalization offset to get correct log probabilities. + float norm_offset = max_coeff + logsumexp; + const float label_selection_input_min = (label_selection_margin_ >= 0) ? (max_coeff - label_selection_margin_) : -std::numeric_limits<float>::infinity(); @@ -290,10 +300,10 @@ void CTCBeamSearchDecoder<CTCBeamState, CTCBeamComparer>::Step( beam_scorer_->GetStateExpansionScore(b->state, previous)); } // Plabel(l=abc @ t=6) *= P(c @ 6) - b->newp.label += raw_input(b->label) - max_coeff; + b->newp.label += raw_input(b->label) - norm_offset; } // Pblank(l=abc @ t=6) = P(l=abc @ t=5) * P(- @ 6) - b->newp.blank = b->oldp.total + raw_input(blank_index_) - max_coeff; + b->newp.blank = b->oldp.total + raw_input(blank_index_) - norm_offset; // P(l=abc @ t=6) = Plabel(l=abc @ t=6) + Pblank(l=abc @ t=6) b->newp.total = LogSumExp(b->newp.blank, b->newp.label); @@ -328,6 +338,8 @@ void CTCBeamSearchDecoder<CTCBeamState, CTCBeamComparer>::Step( const float logit = top_k ? top_k_logits[ind] : raw_input(ind); // Perform label selection: if input for this label looks very // unpromising, never evaluate it with a scorer. + // We may compare logits instead of log probabilities, + // since the difference is the same in both cases. if (logit < label_selection_input_min) { continue; } @@ -341,7 +353,7 @@ void CTCBeamSearchDecoder<CTCBeamState, CTCBeamComparer>::Step( // Plabel(l=abcd @ t=6) = P(l=abc @ t=5) * P(d @ 6) beam_scorer_->ExpandState(b->state, b->label, &c.state, c.label); float previous = (c.label == b->label) ? b->oldp.blank : b->oldp.total; - c.newp.label = logit - max_coeff + + c.newp.label = logit - norm_offset + beam_scorer_->GetStateExpansionScore(c.state, previous); // P(l=abcd @ t=6) = Plabel(l=abcd @ t=6) c.newp.total = c.newp.label; diff --git a/tensorflow/core/util/device_name_utils.h b/tensorflow/core/util/device_name_utils.h index 4071a70836..3f0bc60562 100644 --- a/tensorflow/core/util/device_name_utils.h +++ b/tensorflow/core/util/device_name_utils.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_DEVICE_NAME_UTILS_H_ -#define TENSORFLOW_UTIL_DEVICE_NAME_UTILS_H_ +#ifndef TENSORFLOW_CORE_UTIL_DEVICE_NAME_UTILS_H_ +#define TENSORFLOW_CORE_UTIL_DEVICE_NAME_UTILS_H_ #include <string> @@ -173,4 +173,4 @@ class DeviceNameUtils { } // namespace tensorflow -#endif // TENSORFLOW_UTIL_DEVICE_NAME_UTILS_H_ +#endif // TENSORFLOW_CORE_UTIL_DEVICE_NAME_UTILS_H_ diff --git a/tensorflow/core/util/env_var.cc b/tensorflow/core/util/env_var.cc index 8d43bcc927..2604a5d66a 100644 --- a/tensorflow/core/util/env_var.cc +++ b/tensorflow/core/util/env_var.cc @@ -28,7 +28,7 @@ namespace tensorflow { Status ReadBoolFromEnvVar(StringPiece env_var_name, bool default_val, bool* value) { *value = default_val; - const char* tf_env_var_val = getenv(std::string(env_var_name).c_str()); + const char* tf_env_var_val = getenv(string(env_var_name).c_str()); if (tf_env_var_val == nullptr) { return Status::OK(); } @@ -48,7 +48,7 @@ Status ReadBoolFromEnvVar(StringPiece env_var_name, bool default_val, Status ReadInt64FromEnvVar(StringPiece env_var_name, int64 default_val, int64* value) { *value = default_val; - const char* tf_env_var_val = getenv(std::string(env_var_name).c_str()); + const char* tf_env_var_val = getenv(string(env_var_name).c_str()); if (tf_env_var_val == nullptr) { return Status::OK(); } @@ -62,11 +62,11 @@ Status ReadInt64FromEnvVar(StringPiece env_var_name, int64 default_val, Status ReadStringFromEnvVar(StringPiece env_var_name, StringPiece default_val, string* value) { - const char* tf_env_var_val = getenv(std::string(env_var_name).c_str()); + const char* tf_env_var_val = getenv(string(env_var_name).c_str()); if (tf_env_var_val != nullptr) { *value = tf_env_var_val; } else { - *value = std::string(default_val); + *value = string(default_val); } return Status::OK(); } diff --git a/tensorflow/core/util/env_var.h b/tensorflow/core/util/env_var.h index 47f9ff3a3b..724ca35729 100644 --- a/tensorflow/core/util/env_var.h +++ b/tensorflow/core/util/env_var.h @@ -13,7 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_ENV_VAR_H_ +#ifndef TENSORFLOW_CORE_UTIL_ENV_VAR_H_ +#define TENSORFLOW_CORE_UTIL_ENV_VAR_H_ #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/core/stringpiece.h" @@ -42,4 +43,4 @@ Status ReadStringFromEnvVar(StringPiece env_var_name, StringPiece default_val, } // namespace tensorflow -#endif // TENSORFLOW_UTIL_ENV_VAR_H_ +#endif // TENSORFLOW_CORE_UTIL_ENV_VAR_H_ diff --git a/tensorflow/core/util/events_writer.h b/tensorflow/core/util/events_writer.h index 5dbaf97af4..d5952c3cbd 100644 --- a/tensorflow/core/util/events_writer.h +++ b/tensorflow/core/util/events_writer.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_EVENTS_WRITER_H_ -#define TENSORFLOW_UTIL_EVENTS_WRITER_H_ +#ifndef TENSORFLOW_CORE_UTIL_EVENTS_WRITER_H_ +#define TENSORFLOW_CORE_UTIL_EVENTS_WRITER_H_ #include <memory> #include <string> @@ -95,4 +95,4 @@ class EventsWriter { } // namespace tensorflow -#endif // TENSORFLOW_UTIL_EVENTS_WRITER_H_ +#endif // TENSORFLOW_CORE_UTIL_EVENTS_WRITER_H_ diff --git a/tensorflow/core/util/example_proto_fast_parsing.cc b/tensorflow/core/util/example_proto_fast_parsing.cc index 1fec0010a1..a38cd1d09f 100644 --- a/tensorflow/core/util/example_proto_fast_parsing.cc +++ b/tensorflow/core/util/example_proto_fast_parsing.cc @@ -353,7 +353,7 @@ bool TestFastParse(const string& serialized, Example* example) { // I.e. last entry in the map overwrites all the previous ones. parsed::FeatureMapEntry& name_and_feature = parsed_example[parsed_example_size - i - 1]; - string name = std::string(name_and_feature.first); + string name(name_and_feature.first); if ((*features.mutable_feature()).count(name) > 0) continue; auto& value = (*features.mutable_feature())[name]; diff --git a/tensorflow/core/util/guarded_philox_random.h b/tensorflow/core/util/guarded_philox_random.h index 44970eb949..8be7a374f0 100644 --- a/tensorflow/core/util/guarded_philox_random.h +++ b/tensorflow/core/util/guarded_philox_random.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_GUARDED_PHILOX_RANDOM_H_ -#define TENSORFLOW_KERNELS_GUARDED_PHILOX_RANDOM_H_ +#ifndef TENSORFLOW_CORE_UTIL_GUARDED_PHILOX_RANDOM_H_ +#define TENSORFLOW_CORE_UTIL_GUARDED_PHILOX_RANDOM_H_ #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/lib/random/philox_random.h" @@ -79,4 +79,4 @@ class GuardedPhiloxRandom { } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_GUARDED_PHILOX_RANDOM_H_ +#endif // TENSORFLOW_CORE_UTIL_GUARDED_PHILOX_RANDOM_H_ diff --git a/tensorflow/core/util/mirror_pad_mode.h b/tensorflow/core/util/mirror_pad_mode.h index f703d47ab1..ceee9b06b0 100644 --- a/tensorflow/core/util/mirror_pad_mode.h +++ b/tensorflow/core/util/mirror_pad_mode.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_MIRROR_PAD_MODE_H_ -#define TENSORFLOW_UTIL_MIRROR_PAD_MODE_H_ +#ifndef TENSORFLOW_CORE_UTIL_MIRROR_PAD_MODE_H_ +#define TENSORFLOW_CORE_UTIL_MIRROR_PAD_MODE_H_ // This file contains helper routines to deal with padding in various ops and // kernels. @@ -49,4 +49,4 @@ Status GetNodeAttr(const NodeDef& node_def, StringPiece attr_name, } // end namespace tensorflow -#endif // TENSORFLOW_UTIL_MIRROR_PAD_MODE_H_ +#endif // TENSORFLOW_CORE_UTIL_MIRROR_PAD_MODE_H_ diff --git a/tensorflow/core/util/mkl_util.h b/tensorflow/core/util/mkl_util.h index 422be9356d..0a96a603d0 100644 --- a/tensorflow/core/util/mkl_util.h +++ b/tensorflow/core/util/mkl_util.h @@ -66,7 +66,6 @@ using mkldnn::reorder; typedef unsigned int uint; #endif - namespace tensorflow { // The file contains a number of utility classes and functions used by MKL @@ -645,6 +644,7 @@ class MklDnnShape { } } + inline void SetTfDimOrder(const size_t dimension, memory::format format) { TensorFormat data_format = MklDnnDataFormatToTFDataFormat(format); SetTfDimOrder(dimension, data_format); @@ -2059,16 +2059,20 @@ class FactoryKeyCreator { } }; -static inline memory::format get_desired_format(int channel) { + +static inline memory::format get_desired_format(int channel, + bool is_2d = true) { memory::format fmt_desired = memory::format::any; - if (port::TestCPUFeature(port::CPUFeature::AVX512F) && (channel % 16) == 0) { - fmt_desired = memory::format::nChw16c; + if (port::TestCPUFeature(port::CPUFeature::AVX512F)) { + fmt_desired = is_2d ? memory::format::nChw16c : memory::format::nCdhw16c; } else if (port::TestCPUFeature(port::CPUFeature::AVX2) && (channel % 8) == 0) { - fmt_desired = memory::format::nChw8c; + fmt_desired = is_2d + ? memory::format::nChw8c + : memory::format::ncdhw; //not support avx2 for 3d yet. } else { - fmt_desired = memory::format::nchw; + fmt_desired = is_2d ? memory::format::nchw : memory::format::ncdhw; } return fmt_desired; } diff --git a/tensorflow/core/util/padding.h b/tensorflow/core/util/padding.h index a4278ff2b4..76f9b4dd9a 100644 --- a/tensorflow/core/util/padding.h +++ b/tensorflow/core/util/padding.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_PADDING_H_ -#define TENSORFLOW_UTIL_PADDING_H_ +#ifndef TENSORFLOW_CORE_UTIL_PADDING_H_ +#define TENSORFLOW_CORE_UTIL_PADDING_H_ // This file contains helper routines to deal with padding in various ops and // kernels. @@ -50,4 +50,4 @@ Status GetNodeAttr(const NodeDef& node_def, StringPiece attr_name, } // end namespace tensorflow -#endif // TENSORFLOW_UTIL_PADDING_H_ +#endif // TENSORFLOW_CORE_UTIL_PADDING_H_ diff --git a/tensorflow/core/util/port.h b/tensorflow/core/util/port.h index 981def9d22..e9b9cb1cd2 100644 --- a/tensorflow/core/util/port.h +++ b/tensorflow/core/util/port.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_PORT_H_ -#define TENSORFLOW_UTIL_PORT_H_ +#ifndef TENSORFLOW_CORE_UTIL_PORT_H_ +#define TENSORFLOW_CORE_UTIL_PORT_H_ namespace tensorflow { @@ -30,4 +30,4 @@ bool IsMklEnabled(); } // end namespace tensorflow -#endif // TENSORFLOW_UTIL_PORT_H_ +#endif // TENSORFLOW_CORE_UTIL_PORT_H_ diff --git a/tensorflow/core/util/saved_tensor_slice_util.h b/tensorflow/core/util/saved_tensor_slice_util.h index 90672a10a8..7c9cfa35f7 100644 --- a/tensorflow/core/util/saved_tensor_slice_util.h +++ b/tensorflow/core/util/saved_tensor_slice_util.h @@ -15,8 +15,8 @@ limitations under the License. // Utilities for saving/restoring tensor slice checkpoints. -#ifndef TENSORFLOW_UTIL_SAVED_TENSOR_SLICE_UTIL_H_ -#define TENSORFLOW_UTIL_SAVED_TENSOR_SLICE_UTIL_H_ +#ifndef TENSORFLOW_CORE_UTIL_SAVED_TENSOR_SLICE_UTIL_H_ +#define TENSORFLOW_CORE_UTIL_SAVED_TENSOR_SLICE_UTIL_H_ #include <string> // for string #include "tensorflow/core/framework/tensor.pb.h" @@ -210,4 +210,4 @@ inline void Fill(const string* data, size_t n, TensorProto* t) { } // namespace tensorflow -#endif // TENSORFLOW_UTIL_SAVED_TENSOR_SLICE_UTIL_H_ +#endif // TENSORFLOW_CORE_UTIL_SAVED_TENSOR_SLICE_UTIL_H_ diff --git a/tensorflow/core/util/strided_slice_op.cc b/tensorflow/core/util/strided_slice_op.cc index aca60b942d..ad8a44a518 100644 --- a/tensorflow/core/util/strided_slice_op.cc +++ b/tensorflow/core/util/strided_slice_op.cc @@ -326,7 +326,7 @@ Status ValidateStridedSliceOp( // Even if we don't have values for begin or end, we do know that this // dimension covers the whole interval. If we have shape information for // this dimension, that tells us the interval length. - if (dim_i > 0) { + if (dim_i >= 0) { if (stride_i < 0) { interval_length = -dim_i; } else { diff --git a/tensorflow/core/util/tensor_bundle/naming.h b/tensorflow/core/util/tensor_bundle/naming.h index 3d21570c74..6539d565e2 100644 --- a/tensorflow/core/util/tensor_bundle/naming.h +++ b/tensorflow/core/util/tensor_bundle/naming.h @@ -31,8 +31,8 @@ limitations under the License. // // Regexp can also be used: e.g. R"<prefix>.data-\d{5}-of-\d{5}" for data files. -#ifndef TENSORFLOW_UTIL_TENSOR_BUNDLE_NAMING_H_ -#define TENSORFLOW_UTIL_TENSOR_BUNDLE_NAMING_H_ +#ifndef TENSORFLOW_CORE_UTIL_TENSOR_BUNDLE_NAMING_H_ +#define TENSORFLOW_CORE_UTIL_TENSOR_BUNDLE_NAMING_H_ #include "tensorflow/core/lib/core/stringpiece.h" @@ -43,4 +43,4 @@ string DataFilename(StringPiece prefix, int32 shard_id, int32 num_shards); } // namespace tensorflow -#endif // TENSORFLOW_UTIL_TENSOR_BUNDLE_NAMING_H_ +#endif // TENSORFLOW_CORE_UTIL_TENSOR_BUNDLE_NAMING_H_ diff --git a/tensorflow/core/util/tensor_bundle/tensor_bundle.cc b/tensorflow/core/util/tensor_bundle/tensor_bundle.cc index 7190614706..ea8a259d1a 100644 --- a/tensorflow/core/util/tensor_bundle/tensor_bundle.cc +++ b/tensorflow/core/util/tensor_bundle/tensor_bundle.cc @@ -370,14 +370,14 @@ Status PadAlignment(FileOutputBuffer* out, int alignment, int64* size) { BundleWriter::BundleWriter(Env* env, StringPiece prefix, const Options& options) : env_(env), options_(options), - prefix_(std::string(prefix)), + prefix_(prefix), tmp_metadata_path_(strings::StrCat(MetaFilename(prefix_), ".tempstate", random::New64())), tmp_data_path_(strings::StrCat(DataFilename(prefix_, 0, 1), ".tempstate", random::New64())), out_(nullptr), size_(0) { - status_ = env_->CreateDir(std::string(io::Dirname(prefix_))); + status_ = env_->CreateDir(string(io::Dirname(prefix_))); if (!status_.ok() && !errors::IsAlreadyExists(status_)) { return; } @@ -394,7 +394,7 @@ BundleWriter::BundleWriter(Env* env, StringPiece prefix, const Options& options) Status BundleWriter::Add(StringPiece key, const Tensor& val) { if (!status_.ok()) return status_; CHECK_NE(key, kHeaderEntryKey); - const string key_string = std::string(key); + const string key_string(key); if (entries_.find(key_string) != entries_.end()) { status_ = errors::InvalidArgument("Adding duplicate key: ", key); return status_; @@ -445,7 +445,7 @@ Status BundleWriter::AddSlice(StringPiece full_tensor_key, // In the case of a sharded save, MergeBundles() is responsible for merging // the "slices" field of multiple metadata entries corresponding to the same // full tensor. - const string full_tensor_key_string = std::string(full_tensor_key); + const string full_tensor_key_string(full_tensor_key); BundleEntryProto* full_entry = &entries_[full_tensor_key_string]; if (full_entry->dtype() != DT_INVALID) { CHECK_EQ(full_entry->dtype(), slice_tensor.dtype()); @@ -600,7 +600,7 @@ static Status MergeOneBundle(Env* env, StringPiece prefix, // Loops through the non-header to-merge entries. BundleEntryProto to_merge_entry; for (; iter->Valid(); iter->Next()) { - const string key = std::string(iter->key()); + const string key(iter->key()); const auto entry_iter = merge_state->entries.find(key); // Illegal: the duplicated entry is a non-slice tensor. @@ -649,7 +649,7 @@ Status MergeBundles(Env* env, gtl::ArraySlice<string> prefixes, // Merges all metadata tables. // TODO(zhifengc): KeyValue sorter if it becomes too big. MergeState merge; - Status status = env->CreateDir(std::string(io::Dirname(merged_prefix))); + Status status = env->CreateDir(string(io::Dirname(merged_prefix))); if (!status.ok() && !errors::IsAlreadyExists(status)) return status; for (int i = 0; i < prefixes.size(); ++i) { TF_RETURN_IF_ERROR(MergeOneBundle(env, prefixes[i], &merge)); @@ -697,7 +697,7 @@ Status MergeBundles(Env* env, gtl::ArraySlice<string> prefixes, BundleReader::BundleReader(Env* env, StringPiece prefix) : env_(env), - prefix_(std::string(prefix)), + prefix_(prefix), metadata_(nullptr), table_(nullptr), iter_(nullptr) { @@ -919,7 +919,7 @@ Status BundleReader::GetSliceValue(StringPiece full_tensor_key, const TensorShape full_shape(TensorShape(full_tensor_entry.shape())); std::vector<std::pair<TensorSlice, string>> details; - const string full_tensor_key_string = std::string(full_tensor_key); + const string full_tensor_key_string(full_tensor_key); const TensorSliceSet* tss = gtl::FindPtrOrNull(tensor_slices_, full_tensor_key_string); diff --git a/tensorflow/core/util/tensor_bundle/tensor_bundle.h b/tensorflow/core/util/tensor_bundle/tensor_bundle.h index d30ce3f0cf..3a2ffbb495 100644 --- a/tensorflow/core/util/tensor_bundle/tensor_bundle.h +++ b/tensorflow/core/util/tensor_bundle/tensor_bundle.h @@ -58,8 +58,8 @@ limitations under the License. // "/fs/model/train/ckpt-step/ckpt" /* merged prefix */); // -#ifndef TENSORFLOW_UTIL_TENSOR_BUNDLE_TENSOR_BUNDLE_H_ -#define TENSORFLOW_UTIL_TENSOR_BUNDLE_TENSOR_BUNDLE_H_ +#ifndef TENSORFLOW_CORE_UTIL_TENSOR_BUNDLE_TENSOR_BUNDLE_H_ +#define TENSORFLOW_CORE_UTIL_TENSOR_BUNDLE_TENSOR_BUNDLE_H_ #include "tensorflow/core/protobuf/tensor_bundle.pb.h" @@ -346,4 +346,4 @@ class FileOutputBuffer { } // namespace tensorflow -#endif // TENSORFLOW_UTIL_TENSOR_BUNDLE_TENSOR_BUNDLE_H_ +#endif // TENSORFLOW_CORE_UTIL_TENSOR_BUNDLE_TENSOR_BUNDLE_H_ diff --git a/tensorflow/core/util/tensor_bundle/tensor_bundle_test.cc b/tensorflow/core/util/tensor_bundle/tensor_bundle_test.cc index 92ce8ae00e..59c42baa06 100644 --- a/tensorflow/core/util/tensor_bundle/tensor_bundle_test.cc +++ b/tensorflow/core/util/tensor_bundle/tensor_bundle_test.cc @@ -107,7 +107,7 @@ std::vector<string> AllTensorKeys(BundleReader* reader) { reader->Seek(kHeaderEntryKey); reader->Next(); for (; reader->Valid(); reader->Next()) { - ret.push_back(std::string(reader->key())); + ret.emplace_back(reader->key()); } return ret; } diff --git a/tensorflow/core/util/tensor_slice_reader.h b/tensorflow/core/util/tensor_slice_reader.h index 263f56c7fc..4aa9a4708e 100644 --- a/tensorflow/core/util/tensor_slice_reader.h +++ b/tensorflow/core/util/tensor_slice_reader.h @@ -16,8 +16,8 @@ limitations under the License. // The utility to read checkpoints for google brain tensor ops and v3 // checkpoints for dist_belief. -#ifndef TENSORFLOW_UTIL_TENSOR_SLICE_READER_H_ -#define TENSORFLOW_UTIL_TENSOR_SLICE_READER_H_ +#ifndef TENSORFLOW_CORE_UTIL_TENSOR_SLICE_READER_H_ +#define TENSORFLOW_CORE_UTIL_TENSOR_SLICE_READER_H_ #include <unordered_map> @@ -192,4 +192,4 @@ bool TensorSliceReader::CopySliceData(const string& name, } // namespace tensorflow -#endif // TENSORFLOW_UTIL_TENSOR_SLICE_READER_H_ +#endif // TENSORFLOW_CORE_UTIL_TENSOR_SLICE_READER_H_ diff --git a/tensorflow/core/util/tensor_slice_reader_cache.h b/tensorflow/core/util/tensor_slice_reader_cache.h index 63a8d0b068..9f1919df4e 100644 --- a/tensorflow/core/util/tensor_slice_reader_cache.h +++ b/tensorflow/core/util/tensor_slice_reader_cache.h @@ -16,8 +16,8 @@ limitations under the License. // The utility to read checkpoints for google brain tensor ops and v3 // checkpoints for dist_belief. -#ifndef TENSORFLOW_UTIL_TENSOR_SLICE_READER_CACHE_H_ -#define TENSORFLOW_UTIL_TENSOR_SLICE_READER_CACHE_H_ +#ifndef TENSORFLOW_CORE_UTIL_TENSOR_SLICE_READER_CACHE_H_ +#define TENSORFLOW_CORE_UTIL_TENSOR_SLICE_READER_CACHE_H_ #include <unordered_map> @@ -85,4 +85,4 @@ class TensorSliceReaderCache { } // namespace tensorflow -#endif // TENSORFLOW_UTIL_TENSOR_SLICE_READER_CACHE_H_ +#endif // TENSORFLOW_CORE_UTIL_TENSOR_SLICE_READER_CACHE_H_ diff --git a/tensorflow/core/util/tensor_slice_writer.h b/tensorflow/core/util/tensor_slice_writer.h index 2888c66d10..0db2fb4804 100644 --- a/tensorflow/core/util/tensor_slice_writer.h +++ b/tensorflow/core/util/tensor_slice_writer.h @@ -16,8 +16,8 @@ limitations under the License. // The utility to write checkpoints for google brain tensor ops and v3 // checkpoints for dist_belief. -#ifndef TENSORFLOW_UTIL_TENSOR_SLICE_WRITER_H_ -#define TENSORFLOW_UTIL_TENSOR_SLICE_WRITER_H_ +#ifndef TENSORFLOW_CORE_UTIL_TENSOR_SLICE_WRITER_H_ +#define TENSORFLOW_CORE_UTIL_TENSOR_SLICE_WRITER_H_ #include <unordered_map> @@ -192,4 +192,4 @@ Status CreateTableTensorSliceBuilder(const string& filename, } // namespace tensorflow -#endif // TENSORFLOW_UTIL_TENSOR_SLICE_WRITER_H_ +#endif // TENSORFLOW_CORE_UTIL_TENSOR_SLICE_WRITER_H_ diff --git a/tensorflow/core/util/util.h b/tensorflow/core/util/util.h index 4adf2f14dc..93dfd51ab5 100644 --- a/tensorflow/core/util/util.h +++ b/tensorflow/core/util/util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_UTIL_H_ -#define TENSORFLOW_UTIL_UTIL_H_ +#ifndef TENSORFLOW_CORE_UTIL_UTIL_H_ +#define TENSORFLOW_CORE_UTIL_UTIL_H_ #include "tensorflow/core/framework/tensor_shape.h" #include "tensorflow/core/lib/core/stringpiece.h" @@ -58,4 +58,4 @@ string SliceDebugString(const TensorShape& shape, const int64 flat); } // namespace tensorflow -#endif // TENSORFLOW_UTIL_UTIL_H_ +#endif // TENSORFLOW_CORE_UTIL_UTIL_H_ diff --git a/tensorflow/core/util/work_sharder.h b/tensorflow/core/util/work_sharder.h index 72ce493c1b..b12c31c1ae 100644 --- a/tensorflow/core/util/work_sharder.h +++ b/tensorflow/core/util/work_sharder.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_UTIL_WORK_SHARDER_H_ -#define TENSORFLOW_UTIL_WORK_SHARDER_H_ +#ifndef TENSORFLOW_CORE_UTIL_WORK_SHARDER_H_ +#define TENSORFLOW_CORE_UTIL_WORK_SHARDER_H_ #include <functional> @@ -95,4 +95,4 @@ class Sharder { } // end namespace tensorflow -#endif // TENSORFLOW_UTIL_WORK_SHARDER_H_ +#endif // TENSORFLOW_CORE_UTIL_WORK_SHARDER_H_ diff --git a/tensorflow/docs_src/README.md b/tensorflow/docs_src/README.md new file mode 100644 index 0000000000..5b824f1150 --- /dev/null +++ b/tensorflow/docs_src/README.md @@ -0,0 +1,3 @@ +# This directory has moved + +The new location is: https://github.com/tensorflow/docs/ diff --git a/tensorflow/docs_src/about/attribution.md b/tensorflow/docs_src/about/attribution.md deleted file mode 100644 index a4858b400a..0000000000 --- a/tensorflow/docs_src/about/attribution.md +++ /dev/null @@ -1,9 +0,0 @@ -# Attribution - -Please only use the TensorFlow name and marks when accurately referencing this -software distribution, and do not use our marks in a way that suggests you are -endorsed by or otherwise affiliated with Google. When referring to our marks, -please include the following attribution statement: "TensorFlow, the TensorFlow -logo and any related marks are trademarks of Google Inc." - - diff --git a/tensorflow/docs_src/about/bib.md b/tensorflow/docs_src/about/bib.md deleted file mode 100644 index 5593a3d95c..0000000000 --- a/tensorflow/docs_src/about/bib.md +++ /dev/null @@ -1,131 +0,0 @@ -# TensorFlow White Papers - -This document identifies white papers about TensorFlow. - -## Large-Scale Machine Learning on Heterogeneous Distributed Systems - -[Access this white paper.](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf) - -**Abstract:** TensorFlow is an interface for expressing machine learning -algorithms, and an implementation for executing such algorithms. -A computation expressed using TensorFlow can be -executed with little or no change on a wide variety of heterogeneous -systems, ranging from mobile devices such as phones -and tablets up to large-scale distributed systems of hundreds -of machines and thousands of computational devices such as -GPU cards. The system is flexible and can be used to express -a wide variety of algorithms, including training and inference -algorithms for deep neural network models, and it has been -used for conducting research and for deploying machine learning -systems into production across more than a dozen areas of -computer science and other fields, including speech recognition, -computer vision, robotics, information retrieval, natural -language processing, geographic information extraction, and -computational drug discovery. This paper describes the TensorFlow -interface and an implementation of that interface that -we have built at Google. The TensorFlow API and a reference -implementation were released as an open-source package under -the Apache 2.0 license in November, 2015 and are available at -www.tensorflow.org. - - -### In BibTeX format - -If you use TensorFlow in your research and would like to cite the TensorFlow -system, we suggest you cite this whitepaper. - -<pre> -@misc{tensorflow2015-whitepaper, -title={ {TensorFlow}: Large-Scale Machine Learning on Heterogeneous Systems}, -url={https://www.tensorflow.org/}, -note={Software available from tensorflow.org}, -author={ - Mart\'{\i}n~Abadi and - Ashish~Agarwal and - Paul~Barham and - Eugene~Brevdo and - Zhifeng~Chen and - Craig~Citro and - Greg~S.~Corrado and - Andy~Davis and - Jeffrey~Dean and - Matthieu~Devin and - Sanjay~Ghemawat and - Ian~Goodfellow and - Andrew~Harp and - Geoffrey~Irving and - Michael~Isard and - Yangqing Jia and - Rafal~Jozefowicz and - Lukasz~Kaiser and - Manjunath~Kudlur and - Josh~Levenberg and - Dandelion~Man\'{e} and - Rajat~Monga and - Sherry~Moore and - Derek~Murray and - Chris~Olah and - Mike~Schuster and - Jonathon~Shlens and - Benoit~Steiner and - Ilya~Sutskever and - Kunal~Talwar and - Paul~Tucker and - Vincent~Vanhoucke and - Vijay~Vasudevan and - Fernanda~Vi\'{e}gas and - Oriol~Vinyals and - Pete~Warden and - Martin~Wattenberg and - Martin~Wicke and - Yuan~Yu and - Xiaoqiang~Zheng}, - year={2015}, -} -</pre> - -Or in textual form: - -<pre> -Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, -Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, -Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, -Andrew Harp, Geoffrey Irving, Michael Isard, Rafal Jozefowicz, Yangqing Jia, -Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Mike Schuster, -Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Jonathon Shlens, -Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, -Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, -Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, -Yuan Yu, and Xiaoqiang Zheng. -TensorFlow: Large-scale machine learning on heterogeneous systems, -2015. Software available from tensorflow.org. -</pre> - - - -## TensorFlow: A System for Large-Scale Machine Learning - -[Access this white paper.](https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf) - -**Abstract:** TensorFlow is a machine learning system that operates at -large scale and in heterogeneous environments. TensorFlow -uses dataflow graphs to represent computation, -shared state, and the operations that mutate that state. It -maps the nodes of a dataflow graph across many machines -in a cluster, and within a machine across multiple computational -devices, including multicore CPUs, generalpurpose -GPUs, and custom-designed ASICs known as -Tensor Processing Units (TPUs). This architecture gives -flexibility to the application developer: whereas in previous -“parameter server” designs the management of shared -state is built into the system, TensorFlow enables developers -to experiment with novel optimizations and training algorithms. -TensorFlow supports a variety of applications, -with a focus on training and inference on deep neural networks. -Several Google services use TensorFlow in production, -we have released it as an open-source project, and -it has become widely used for machine learning research. -In this paper, we describe the TensorFlow dataflow model -and demonstrate the compelling performance that TensorFlow -achieves for several real-world applications. - diff --git a/tensorflow/docs_src/about/index.md b/tensorflow/docs_src/about/index.md deleted file mode 100644 index c3c13ff329..0000000000 --- a/tensorflow/docs_src/about/index.md +++ /dev/null @@ -1,11 +0,0 @@ -# About TensorFlow - -This section provides a few documents about TensorFlow itself, -including the following: - - * [TensorFlow in Use](../about/uses.md), which provides a link to our model zoo and - lists some popular ways that TensorFlow is being used. - * [TensorFlow White Papers](../about/bib.md), which provides abstracts of white papers - about TensorFlow. - * [Attribution](../about/attribution.md), which specifies how to attribute and refer - to TensorFlow. diff --git a/tensorflow/docs_src/about/leftnav_files b/tensorflow/docs_src/about/leftnav_files deleted file mode 100644 index 63763b9d9c..0000000000 --- a/tensorflow/docs_src/about/leftnav_files +++ /dev/null @@ -1,4 +0,0 @@ -index.md -uses.md -bib.md -attribution.md diff --git a/tensorflow/docs_src/about/uses.md b/tensorflow/docs_src/about/uses.md deleted file mode 100644 index d3db98203e..0000000000 --- a/tensorflow/docs_src/about/uses.md +++ /dev/null @@ -1,68 +0,0 @@ -# TensorFlow In Use - -This page highlights TensorFlow models in real world use. - - -## Model zoo - -Please visit our collection of TensorFlow models in the -[TensorFlow Zoo](https://github.com/tensorflow/models). - -If you have built a model with TensorFlow, please consider publishing it in -the Zoo. - - -## Current uses - -This section describes some of the current uses of the TensorFlow system. - -> If you are using TensorFlow for research, for education, or for production -> usage in some product, we would love to add something about your usage here. -> Please feel free to [email us](mailto:usecases@tensorflow.org) a brief -> description of how you're using TensorFlow, or even better, send us a -> pull request to add an entry to this file. - -* **Deep Speech** -<ul> - <li>**Organization**: Mozilla</li> - <li> **Domain**: Speech Recognition</li> - <li> **Description**: A TensorFlow implementation motivated by Baidu's Deep Speech architecture.</li> - <li> **More info**: [GitHub Repo](https://github.com/mozilla/deepspeech)</li> -</ul> - -* **RankBrain** -<ul> - <li>**Organization**: Google</li> - <li> **Domain**: Information Retrieval</li> - <li> **Description**: A large-scale deployment of deep neural nets for search ranking on www.google.com.</li> - <li> **More info**: ["Google Turning Over Its Lucrative Search to AI Machines"](http://www.bloomberg.com/news/articles/2015-10-26/google-turning-its-lucrative-web-search-over-to-ai-machines)</li> -</ul> - -* **Inception Image Classification Model** -<ul> - <li> **Organization**: Google</li> - <li> **Description**: Baseline model and follow on research into highly accurate computer vision models, starting with the model that won the 2014 Imagenet image classification challenge</li> - <li> **More Info**: Baseline model described in [Arxiv paper](http://arxiv.org/abs/1409.4842)</li> -</ul> - -* **SmartReply** -<ul> - <li> **Organization**: Google</li> - <li> **Description**: Deep LSTM model to automatically generate email responses</li> - <li> **More Info**: [Google research blog post](http://googleresearch.blogspot.com/2015/11/computer-respond-to-this-email.html)</li> -</ul> - -* **Massively Multitask Networks for Drug Discovery** -<ul> - <li> **Organization**: Google and Stanford University</li> - <li> **Domain**: Drug discovery</li> - <li> **Description**: A deep neural network model for identifying promising drug candidates.</li> - <li> **More info**: [Arxiv paper](http://arxiv.org/abs/1502.02072)</li> -</ul> - -* **On-Device Computer Vision for OCR** -<ul> - <li> **Organization**: Google</li> - <li> **Description**: On-device computer vision model to do optical character recognition to enable real-time translation.</li> - <li> **More info**: [Google Research blog post](http://googleresearch.blogspot.com/2015/07/how-google-translate-squeezes-deep.html)</li> -</ul> diff --git a/tensorflow/docs_src/api_guides/cc/guide.md b/tensorflow/docs_src/api_guides/cc/guide.md deleted file mode 100644 index 2cd645afa7..0000000000 --- a/tensorflow/docs_src/api_guides/cc/guide.md +++ /dev/null @@ -1,301 +0,0 @@ -# C++ API - -Note: By default [tensorflow.org](https://www.tensorflow.org) shows docs for the -most recent stable version. The instructions in this doc require building from -source. You will probably want to build from the `master` version of tensorflow. -You should, as a result, be sure you are following the -[`master` version of this doc](https://www.tensorflow.org/versions/master/api_guides/cc/guide), -in case there have been any changes. - -Note: The C++ API is only designed to work with TensorFlow `bazel build`. -If you need a stand-alone option use the [C-api](../../install/install_c.md). -See [these instructions](https://docs.bazel.build/versions/master/external.html) -for details on how to include TensorFlow as a subproject (instead of building -your project from inside TensorFlow, as in this example). - -[TOC] - -TensorFlow's C++ API provides mechanisms for constructing and executing a data -flow graph. The API is designed to be simple and concise: graph operations are -clearly expressed using a "functional" construction style, including easy -specification of names, device placement, etc., and the resulting graph can be -efficiently run and the desired outputs fetched in a few lines of code. This -guide explains the basic concepts and data structures needed to get started with -TensorFlow graph construction and execution in C++. - -## The Basics - -Let's start with a simple example that illustrates graph construction and -execution using the C++ API. - -```c++ -// tensorflow/cc/example/example.cc - -#include "tensorflow/cc/client/client_session.h" -#include "tensorflow/cc/ops/standard_ops.h" -#include "tensorflow/core/framework/tensor.h" - -int main() { - using namespace tensorflow; - using namespace tensorflow::ops; - Scope root = Scope::NewRootScope(); - // Matrix A = [3 2; -1 0] - auto A = Const(root, { {3.f, 2.f}, {-1.f, 0.f} }); - // Vector b = [3 5] - auto b = Const(root, { {3.f, 5.f} }); - // v = Ab^T - auto v = MatMul(root.WithOpName("v"), A, b, MatMul::TransposeB(true)); - std::vector<Tensor> outputs; - ClientSession session(root); - // Run and fetch v - TF_CHECK_OK(session.Run({v}, &outputs)); - // Expect outputs[0] == [19; -3] - LOG(INFO) << outputs[0].matrix<float>(); - return 0; -} -``` - -Place this example code in the file `tensorflow/cc/example/example.cc` inside a -clone of the -TensorFlow -[github repository](http://www.github.com/tensorflow/tensorflow). Also place a -`BUILD` file in the same directory with the following contents: - -```python -load("//tensorflow:tensorflow.bzl", "tf_cc_binary") - -tf_cc_binary( - name = "example", - srcs = ["example.cc"], - deps = [ - "//tensorflow/cc:cc_ops", - "//tensorflow/cc:client_session", - "//tensorflow/core:tensorflow", - ], -) -``` - -Use `tf_cc_binary` rather than Bazel's native `cc_binary` to link in necessary -symbols from `libtensorflow_framework.so`. You should be able to build and run -the example using the following command (be sure to run `./configure` in your -build sandbox first): - -```shell -bazel run -c opt //tensorflow/cc/example:example -``` - -This example shows some of the important features of the C++ API such as the -following: - -* Constructing tensor constants from C++ nested initializer lists -* Constructing and naming of TensorFlow operations -* Specifying optional attributes to operation constructors -* Executing and fetching the tensor values from the TensorFlow session. - -We will delve into the details of each below. - -## Graph Construction - -### Scope - -`tensorflow::Scope` is the main data structure that holds the current state -of graph construction. A `Scope` acts as a handle to the graph being -constructed, as well as storing TensorFlow operation properties. The `Scope` -object is the first argument to operation constructors, and operations that use -a given `Scope` as their first argument inherit that `Scope`'s properties, such -as a common name prefix. Multiple `Scope`s can refer to the same graph, as -explained further below. - -Create a new `Scope` object by calling `Scope::NewRootScope`. This creates -some resources such as a graph to which operations are added. It also creates a -`tensorflow::Status` object which will be used to indicate errors encountered -when constructing operations. The `Scope` class has value semantics, thus, a -`Scope` object can be freely copied and passed around. - -The `Scope` object returned by `Scope::NewRootScope` is referred -to as the root scope. "Child" scopes can be constructed from the root scope by -calling various member functions of the `Scope` class, thus forming a hierarchy -of scopes. A child scope inherits all of the properties of the parent scope and -typically has one property added or changed. For instance, `NewSubScope(name)` -appends `name` to the prefix of names for operations created using the returned -`Scope` object. - -Here are some of the properties controlled by a `Scope` object: - -* Operation names -* Set of control dependencies for an operation -* Device placement for an operation -* Kernel attribute for an operation - -Please refer to `tensorflow::Scope` for the complete list of member functions -that let you create child scopes with new properties. - -### Operation Constructors - -You can create graph operations with operation constructors, one C++ class per -TensorFlow operation. Unlike the Python API which uses snake-case to name the -operation constructors, the C++ API uses camel-case to conform to C++ coding -style. For instance, the `MatMul` operation has a C++ class with the same name. - -Using this class-per-operation method, it is possible, though not recommended, -to construct an operation as follows: - -```c++ -// Not recommended -MatMul m(scope, a, b); -``` - -Instead, we recommend the following "functional" style for constructing -operations: - -```c++ -// Recommended -auto m = MatMul(scope, a, b); -``` - -The first parameter for all operation constructors is always a `Scope` object. -Tensor inputs and mandatory attributes form the rest of the arguments. - -For optional arguments, constructors have an optional parameter that allows -optional attributes. For operations with optional arguments, the constructor's -last optional parameter is a `struct` type called `[operation]:Attrs` that -contains data members for each optional attribute. You can construct such -`Attrs` in multiple ways: - -* You can specify a single optional attribute by constructing an `Attrs` object -using the `static` functions provided in the C++ class for the operation. For -example: - -```c++ -auto m = MatMul(scope, a, b, MatMul::TransposeA(true)); -``` - -* You can specify multiple optional attributes by chaining together functions - available in the `Attrs` struct. For example: - -```c++ -auto m = MatMul(scope, a, b, MatMul::TransposeA(true).TransposeB(true)); - -// Or, alternatively -auto m = MatMul(scope, a, b, MatMul::Attrs().TransposeA(true).TransposeB(true)); -``` - -The arguments and return values of operations are handled in different ways -depending on their type: - -* For operations that return single tensors, the object returned by - the operation object can be passed directly to other operation - constructors. For example: - -```c++ -auto m = MatMul(scope, x, W); -auto sum = Add(scope, m, bias); -``` - -* For operations producing multiple outputs, the object returned by the - operation constructor has a member for each of the outputs. The names of those - members are identical to the names present in the `OpDef` for the - operation. For example: - -```c++ -auto u = Unique(scope, a); -// u.y has the unique values and u.idx has the unique indices -auto m = Add(scope, u.y, b); -``` - -* Operations producing a list-typed output return an object that can - be indexed using the `[]` operator. That object can also be directly passed to - other constructors that expect list-typed inputs. For example: - -```c++ -auto s = Split(scope, 0, a, 2); -// Access elements of the returned list. -auto b = Add(scope, s[0], s[1]); -// Pass the list as a whole to other constructors. -auto c = Concat(scope, s, 0); -``` - -### Constants - -You may pass many different types of C++ values directly to tensor -constants. You may explicitly create a tensor constant by calling the -`tensorflow::ops::Const` function from various kinds of C++ values. For -example: - -* Scalars - -```c++ -auto f = Const(scope, 42.0f); -auto s = Const(scope, "hello world!"); -``` - -* Nested initializer lists - -```c++ -// 2x2 matrix -auto c1 = Const(scope, { {1, 2}, {2, 4} }); -// 1x3x1 tensor -auto c2 = Const(scope, { { {1}, {2}, {3} } }); -// 1x2x0 tensor -auto c3 = ops::Const(scope, { { {}, {} } }); -``` - -* Shapes explicitly specified - -```c++ -// 2x2 matrix with all elements = 10 -auto c1 = Const(scope, 10, /* shape */ {2, 2}); -// 1x3x2x1 tensor -auto c2 = Const(scope, {1, 2, 3, 4, 5, 6}, /* shape */ {1, 3, 2, 1}); -``` - -You may directly pass constants to other operation constructors, either by -explicitly constructing one using the `Const` function, or implicitly as any of -the above types of C++ values. For example: - -```c++ -// [1 1] * [41; 1] -auto x = MatMul(scope, { {1, 1} }, { {41}, {1} }); -// [1 2 3 4] + 10 -auto y = Add(scope, {1, 2, 3, 4}, 10); -``` - -## Graph Execution - -When executing a graph, you will need a session. The C++ API provides a -`tensorflow::ClientSession` class that will execute ops created by the -operation constructors. TensorFlow will automatically determine which parts of -the graph need to be executed, and what values need feeding. For example: - -```c++ -Scope root = Scope::NewRootScope(); -auto c = Const(root, { {1, 1} }); -auto m = MatMul(root, c, { {42}, {1} }); - -ClientSession session(root); -std::vector<Tensor> outputs; -session.Run({m}, &outputs); -// outputs[0] == {42} -``` - -Similarly, the object returned by the operation constructor can be used as the -argument to specify a value being fed when executing the graph. Furthermore, the -value to feed can be specified with the different kinds of C++ values used to -specify tensor constants. For example: - -```c++ -Scope root = Scope::NewRootScope(); -auto a = Placeholder(root, DT_INT32); -// [3 3; 3 3] -auto b = Const(root, 3, {2, 2}); -auto c = Add(root, a, b); -ClientSession session(root); -std::vector<Tensor> outputs; - -// Feed a <- [1 2; 3 4] -session.Run({ {a, { {1, 2}, {3, 4} } } }, {c}, &outputs); -// outputs[0] == [4 5; 6 7] -``` - -Please see the `tensorflow::Tensor` documentation for more information on how -to use the execution output. diff --git a/tensorflow/docs_src/api_guides/python/array_ops.md b/tensorflow/docs_src/api_guides/python/array_ops.md deleted file mode 100644 index ddeea80c56..0000000000 --- a/tensorflow/docs_src/api_guides/python/array_ops.md +++ /dev/null @@ -1,87 +0,0 @@ -# Tensor Transformations - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Casting - -TensorFlow provides several operations that you can use to cast tensor data -types in your graph. - -* `tf.string_to_number` -* `tf.to_double` -* `tf.to_float` -* `tf.to_bfloat16` -* `tf.to_int32` -* `tf.to_int64` -* `tf.cast` -* `tf.bitcast` -* `tf.saturate_cast` - -## Shapes and Shaping - -TensorFlow provides several operations that you can use to determine the shape -of a tensor and change the shape of a tensor. - -* `tf.broadcast_dynamic_shape` -* `tf.broadcast_static_shape` -* `tf.shape` -* `tf.shape_n` -* `tf.size` -* `tf.rank` -* `tf.reshape` -* `tf.squeeze` -* `tf.expand_dims` -* `tf.meshgrid` - -## Slicing and Joining - -TensorFlow provides several operations to slice or extract parts of a tensor, -or join multiple tensors together. - -* `tf.slice` -* `tf.strided_slice` -* `tf.split` -* `tf.tile` -* `tf.pad` -* `tf.concat` -* `tf.stack` -* `tf.parallel_stack` -* `tf.unstack` -* `tf.reverse_sequence` -* `tf.reverse` -* `tf.reverse_v2` -* `tf.transpose` -* `tf.extract_image_patches` -* `tf.space_to_batch_nd` -* `tf.space_to_batch` -* `tf.required_space_to_batch_paddings` -* `tf.batch_to_space_nd` -* `tf.batch_to_space` -* `tf.space_to_depth` -* `tf.depth_to_space` -* `tf.gather` -* `tf.gather_nd` -* `tf.unique_with_counts` -* `tf.scatter_nd` -* `tf.dynamic_partition` -* `tf.dynamic_stitch` -* `tf.boolean_mask` -* `tf.one_hot` -* `tf.sequence_mask` -* `tf.dequantize` -* `tf.quantize_v2` -* `tf.quantized_concat` -* `tf.setdiff1d` - -## Fake quantization -Operations used to help train for better quantization accuracy. - -* `tf.fake_quant_with_min_max_args` -* `tf.fake_quant_with_min_max_args_gradient` -* `tf.fake_quant_with_min_max_vars` -* `tf.fake_quant_with_min_max_vars_gradient` -* `tf.fake_quant_with_min_max_vars_per_channel` -* `tf.fake_quant_with_min_max_vars_per_channel_gradient` diff --git a/tensorflow/docs_src/api_guides/python/check_ops.md b/tensorflow/docs_src/api_guides/python/check_ops.md deleted file mode 100644 index b52fdaa3ab..0000000000 --- a/tensorflow/docs_src/api_guides/python/check_ops.md +++ /dev/null @@ -1,19 +0,0 @@ -# Asserts and boolean checks - -* `tf.assert_negative` -* `tf.assert_positive` -* `tf.assert_proper_iterable` -* `tf.assert_non_negative` -* `tf.assert_non_positive` -* `tf.assert_equal` -* `tf.assert_integer` -* `tf.assert_less` -* `tf.assert_less_equal` -* `tf.assert_greater` -* `tf.assert_greater_equal` -* `tf.assert_rank` -* `tf.assert_rank_at_least` -* `tf.assert_type` -* `tf.is_non_decreasing` -* `tf.is_numeric_tensor` -* `tf.is_strictly_increasing` diff --git a/tensorflow/docs_src/api_guides/python/client.md b/tensorflow/docs_src/api_guides/python/client.md deleted file mode 100644 index fdd48e66dc..0000000000 --- a/tensorflow/docs_src/api_guides/python/client.md +++ /dev/null @@ -1,36 +0,0 @@ -# Running Graphs -[TOC] - -This library contains classes for launching graphs and executing operations. - -[This guide](../../guide/low_level_intro.md) has examples of how a graph -is launched in a `tf.Session`. - -## Session management - -* `tf.Session` -* `tf.InteractiveSession` -* `tf.get_default_session` - -## Error classes and convenience functions - -* `tf.OpError` -* `tf.errors.CancelledError` -* `tf.errors.UnknownError` -* `tf.errors.InvalidArgumentError` -* `tf.errors.DeadlineExceededError` -* `tf.errors.NotFoundError` -* `tf.errors.AlreadyExistsError` -* `tf.errors.PermissionDeniedError` -* `tf.errors.UnauthenticatedError` -* `tf.errors.ResourceExhaustedError` -* `tf.errors.FailedPreconditionError` -* `tf.errors.AbortedError` -* `tf.errors.OutOfRangeError` -* `tf.errors.UnimplementedError` -* `tf.errors.InternalError` -* `tf.errors.UnavailableError` -* `tf.errors.DataLossError` -* `tf.errors.exception_type_from_error_code` -* `tf.errors.error_code_from_exception_type` -* `tf.errors.raise_exception_on_not_ok_status` diff --git a/tensorflow/docs_src/api_guides/python/constant_op.md b/tensorflow/docs_src/api_guides/python/constant_op.md deleted file mode 100644 index 9ba95b0f55..0000000000 --- a/tensorflow/docs_src/api_guides/python/constant_op.md +++ /dev/null @@ -1,87 +0,0 @@ -# Constants, Sequences, and Random Values - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Constant Value Tensors - -TensorFlow provides several operations that you can use to generate constants. - -* `tf.zeros` -* `tf.zeros_like` -* `tf.ones` -* `tf.ones_like` -* `tf.fill` -* `tf.constant` - -## Sequences - -* `tf.linspace` -* `tf.range` - -## Random Tensors - -TensorFlow has several ops that create random tensors with different -distributions. The random ops are stateful, and create new random values each -time they are evaluated. - -The `seed` keyword argument in these functions acts in conjunction with -the graph-level random seed. Changing either the graph-level seed using -`tf.set_random_seed` or the -op-level seed will change the underlying seed of these operations. Setting -neither graph-level nor op-level seed, results in a random seed for all -operations. -See `tf.set_random_seed` -for details on the interaction between operation-level and graph-level random -seeds. - -### Examples: - -```python -# Create a tensor of shape [2, 3] consisting of random normal values, with mean -# -1 and standard deviation 4. -norm = tf.random_normal([2, 3], mean=-1, stddev=4) - -# Shuffle the first dimension of a tensor -c = tf.constant([[1, 2], [3, 4], [5, 6]]) -shuff = tf.random_shuffle(c) - -# Each time we run these ops, different results are generated -sess = tf.Session() -print(sess.run(norm)) -print(sess.run(norm)) - -# Set an op-level seed to generate repeatable sequences across sessions. -norm = tf.random_normal([2, 3], seed=1234) -sess = tf.Session() -print(sess.run(norm)) -print(sess.run(norm)) -sess = tf.Session() -print(sess.run(norm)) -print(sess.run(norm)) -``` - -Another common use of random values is the initialization of variables. Also see -the [Variables How To](../../guide/variables.md). - -```python -# Use random uniform values in [0, 1) as the initializer for a variable of shape -# [2, 3]. The default type is float32. -var = tf.Variable(tf.random_uniform([2, 3]), name="var") -init = tf.global_variables_initializer() - -sess = tf.Session() -sess.run(init) -print(sess.run(var)) -``` - -* `tf.random_normal` -* `tf.truncated_normal` -* `tf.random_uniform` -* `tf.random_shuffle` -* `tf.random_crop` -* `tf.multinomial` -* `tf.random_gamma` -* `tf.set_random_seed` diff --git a/tensorflow/docs_src/api_guides/python/contrib.crf.md b/tensorflow/docs_src/api_guides/python/contrib.crf.md deleted file mode 100644 index a544f136b3..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.crf.md +++ /dev/null @@ -1,11 +0,0 @@ -# CRF (contrib) - -Linear-chain CRF layer. - -* `tf.contrib.crf.crf_sequence_score` -* `tf.contrib.crf.crf_log_norm` -* `tf.contrib.crf.crf_log_likelihood` -* `tf.contrib.crf.crf_unary_score` -* `tf.contrib.crf.crf_binary_score` -* `tf.contrib.crf.CrfForwardRnnCell` -* `tf.contrib.crf.viterbi_decode` diff --git a/tensorflow/docs_src/api_guides/python/contrib.ffmpeg.md b/tensorflow/docs_src/api_guides/python/contrib.ffmpeg.md deleted file mode 100644 index 7df7547131..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.ffmpeg.md +++ /dev/null @@ -1,23 +0,0 @@ -# FFmpeg (contrib) -[TOC] - -## Encoding and decoding audio using FFmpeg - -TensorFlow provides Ops to decode and encode audio files using the -[FFmpeg](https://www.ffmpeg.org/) library. FFmpeg must be -locally [installed](https://ffmpeg.org/download.html) for these Ops to succeed. - -Example: - -```python -from tensorflow.contrib import ffmpeg - -audio_binary = tf.read_file('song.mp3') -waveform = ffmpeg.decode_audio( - audio_binary, file_format='mp3', samples_per_second=44100, channel_count=2) -uncompressed_binary = ffmpeg.encode_audio( - waveform, file_format='wav', samples_per_second=44100) -``` - -* `tf.contrib.ffmpeg.decode_audio` -* `tf.contrib.ffmpeg.encode_audio` diff --git a/tensorflow/docs_src/api_guides/python/contrib.framework.md b/tensorflow/docs_src/api_guides/python/contrib.framework.md deleted file mode 100644 index 00fb8b0ac3..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.framework.md +++ /dev/null @@ -1,64 +0,0 @@ -# Framework (contrib) -[TOC] - -Framework utilities. - -* `tf.contrib.framework.assert_same_float_dtype` -* `tf.contrib.framework.assert_scalar` -* `tf.contrib.framework.assert_scalar_int` -* `tf.convert_to_tensor_or_sparse_tensor` -* `tf.contrib.framework.get_graph_from_inputs` -* `tf.is_numeric_tensor` -* `tf.is_non_decreasing` -* `tf.is_strictly_increasing` -* `tf.contrib.framework.is_tensor` -* `tf.contrib.framework.reduce_sum_n` -* `tf.contrib.framework.remove_squeezable_dimensions` -* `tf.contrib.framework.with_shape` -* `tf.contrib.framework.with_same_shape` - -## Deprecation - -* `tf.contrib.framework.deprecated` -* `tf.contrib.framework.deprecated_args` -* `tf.contrib.framework.deprecated_arg_values` - -## Arg_Scope - -* `tf.contrib.framework.arg_scope` -* `tf.contrib.framework.add_arg_scope` -* `tf.contrib.framework.has_arg_scope` -* `tf.contrib.framework.arg_scoped_arguments` - -## Variables - -* `tf.contrib.framework.add_model_variable` -* `tf.train.assert_global_step` -* `tf.contrib.framework.assert_or_get_global_step` -* `tf.contrib.framework.assign_from_checkpoint` -* `tf.contrib.framework.assign_from_checkpoint_fn` -* `tf.contrib.framework.assign_from_values` -* `tf.contrib.framework.assign_from_values_fn` -* `tf.contrib.framework.create_global_step` -* `tf.contrib.framework.filter_variables` -* `tf.train.get_global_step` -* `tf.contrib.framework.get_or_create_global_step` -* `tf.contrib.framework.get_local_variables` -* `tf.contrib.framework.get_model_variables` -* `tf.contrib.framework.get_unique_variable` -* `tf.contrib.framework.get_variables_by_name` -* `tf.contrib.framework.get_variables_by_suffix` -* `tf.contrib.framework.get_variables_to_restore` -* `tf.contrib.framework.get_variables` -* `tf.contrib.framework.local_variable` -* `tf.contrib.framework.model_variable` -* `tf.contrib.framework.variable` -* `tf.contrib.framework.VariableDeviceChooser` -* `tf.contrib.framework.zero_initializer` - -## Checkpoint utilities - -* `tf.contrib.framework.load_checkpoint` -* `tf.contrib.framework.list_variables` -* `tf.contrib.framework.load_variable` -* `tf.contrib.framework.init_from_checkpoint` diff --git a/tensorflow/docs_src/api_guides/python/contrib.graph_editor.md b/tensorflow/docs_src/api_guides/python/contrib.graph_editor.md deleted file mode 100644 index 8ce49b952b..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.graph_editor.md +++ /dev/null @@ -1,177 +0,0 @@ -# Graph Editor (contrib) -[TOC] - -TensorFlow Graph Editor. - -The TensorFlow Graph Editor library allows for modification of an existing -`tf.Graph` instance in-place. - -The author's github username is [purpledog](https://github.com/purpledog). - -## Library overview - -Appending new nodes is the only graph editing operation allowed by the -TensorFlow core library. The Graph Editor library is an attempt to allow for -other kinds of editing operations, namely, *rerouting* and *transforming*. - -* *rerouting* is a local operation consisting in re-plugging existing tensors - (the edges of the graph). Operations (the nodes) are not modified by this - operation. For example, rerouting can be used to insert an operation adding - noise in place of an existing tensor. -* *transforming* is a global operation consisting in transforming a graph into - another. By default, a transformation is a simple copy but it can be - customized to achieved other goals. For instance, a graph can be transformed - into another one in which noise is added after all the operations of a - specific type. - -**Important: modifying a graph in-place with the Graph Editor must be done -`offline`, that is, without any active sessions.** - -Of course new operations can be appended online but Graph Editor specific -operations like rerouting and transforming can currently only be done offline. - -Here is an example of what you **cannot** do: - -* Build a graph. -* Create a session and run the graph. -* Modify the graph with the Graph Editor. -* Re-run the graph with the `same` previously created session. - -To edit an already running graph, follow these steps: - -* Build a graph. -* Create a session and run the graph. -* Save the graph state and terminate the session -* Modify the graph with the Graph Editor. -* create a new session and restore the graph state -* Re-run the graph with the newly created session. - -Note that this procedure is very costly because a new session must be created -after any modifications. Among other things, it takes time because the entire -graph state must be saved and restored again. - -## Sub-graph - -Most of the functions in the Graph Editor library operate on *sub-graph*. -More precisely, they take as input arguments instances of the SubGraphView class -(or anything which can be converted to it). Doing so allows the same function -to transparently operate on single operations as well as sub-graph of any size. - -A subgraph can be created in several ways: - -* using a list of ops: - - ```python - my_sgv = ge.sgv(ops) - ``` - -* from a name scope: - - ```python - my_sgv = ge.sgv_scope("foo/bar", graph=tf.get_default_graph()) - ``` - -* using regular expression: - - ```python - my_sgv = ge.sgv("foo/.*/.*read$", graph=tf.get_default_graph()) - ``` - -Note that the Graph Editor is meant to manipulate several graphs at the same -time, typically during transform or copy operation. For that reason, -to avoid any confusion, the default graph is never used and the graph on -which to operate must always be given explicitly. This is the reason why -*`graph=tf.get_default_graph()`* is used in the code snippets above. - -## Modules overview - -* util: utility functions. -* select: various selection methods of TensorFlow tensors and operations. -* match: TensorFlow graph matching. Think of this as regular expressions for - graphs (but not quite yet). -* reroute: various ways of rerouting tensors to different consuming ops like - *swap* or *reroute_a2b*. -* subgraph: the SubGraphView class, which enables subgraph manipulations in a - TensorFlow `tf.Graph`. -* edit: various editing functions operating on subgraphs like *detach*, - *connect* or *bypass*. -* transform: the Transformer class, which enables transforming - (or simply copying) a subgraph into another one. - -## Module: util - -* `tf.contrib.graph_editor.make_list_of_op` -* `tf.contrib.graph_editor.get_tensors` -* `tf.contrib.graph_editor.make_list_of_t` -* `tf.contrib.graph_editor.get_generating_ops` -* `tf.contrib.graph_editor.get_consuming_ops` -* `tf.contrib.graph_editor.ControlOutputs` -* `tf.contrib.graph_editor.placeholder_name` -* `tf.contrib.graph_editor.make_placeholder_from_tensor` -* `tf.contrib.graph_editor.make_placeholder_from_dtype_and_shape` - -## Module: select - -* `tf.contrib.graph_editor.filter_ts` -* `tf.contrib.graph_editor.filter_ts_from_regex` -* `tf.contrib.graph_editor.filter_ops` -* `tf.contrib.graph_editor.filter_ops_from_regex` -* `tf.contrib.graph_editor.get_name_scope_ops` -* `tf.contrib.graph_editor.check_cios` -* `tf.contrib.graph_editor.get_ops_ios` -* `tf.contrib.graph_editor.compute_boundary_ts` -* `tf.contrib.graph_editor.get_within_boundary_ops` -* `tf.contrib.graph_editor.get_forward_walk_ops` -* `tf.contrib.graph_editor.get_backward_walk_ops` -* `tf.contrib.graph_editor.get_walks_intersection_ops` -* `tf.contrib.graph_editor.get_walks_union_ops` -* `tf.contrib.graph_editor.select_ops` -* `tf.contrib.graph_editor.select_ts` -* `tf.contrib.graph_editor.select_ops_and_ts` - -## Module: subgraph - -* `tf.contrib.graph_editor.SubGraphView` -* `tf.contrib.graph_editor.make_view` -* `tf.contrib.graph_editor.make_view_from_scope` - -## Module: reroute - -* `tf.contrib.graph_editor.swap_ts` -* `tf.contrib.graph_editor.reroute_ts` -* `tf.contrib.graph_editor.swap_inputs` -* `tf.contrib.graph_editor.reroute_inputs` -* `tf.contrib.graph_editor.swap_outputs` -* `tf.contrib.graph_editor.reroute_outputs` -* `tf.contrib.graph_editor.swap_ios` -* `tf.contrib.graph_editor.reroute_ios` -* `tf.contrib.graph_editor.remove_control_inputs` -* `tf.contrib.graph_editor.add_control_inputs` - -## Module: edit - -* `tf.contrib.graph_editor.detach_control_inputs` -* `tf.contrib.graph_editor.detach_control_outputs` -* `tf.contrib.graph_editor.detach_inputs` -* `tf.contrib.graph_editor.detach_outputs` -* `tf.contrib.graph_editor.detach` -* `tf.contrib.graph_editor.connect` -* `tf.contrib.graph_editor.bypass` - -## Module: transform - -* `tf.contrib.graph_editor.replace_t_with_placeholder_handler` -* `tf.contrib.graph_editor.keep_t_if_possible_handler` -* `tf.contrib.graph_editor.assign_renamed_collections_handler` -* `tf.contrib.graph_editor.transform_op_if_inside_handler` -* `tf.contrib.graph_editor.copy_op_handler` -* `tf.contrib.graph_editor.Transformer` -* `tf.contrib.graph_editor.copy` -* `tf.contrib.graph_editor.copy_with_input_replacements` -* `tf.contrib.graph_editor.graph_replace` - -## Useful aliases - -* `tf.contrib.graph_editor.ph` -* `tf.contrib.graph_editor.sgv` -* `tf.contrib.graph_editor.sgv_scope` diff --git a/tensorflow/docs_src/api_guides/python/contrib.integrate.md b/tensorflow/docs_src/api_guides/python/contrib.integrate.md deleted file mode 100644 index a70d202ab5..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.integrate.md +++ /dev/null @@ -1,41 +0,0 @@ -# Integrate (contrib) -[TOC] - -Integration and ODE solvers for TensorFlow. - -## Example: Lorenz attractor - -We can use `odeint` to solve the -[Lorentz system](https://en.wikipedia.org/wiki/Lorenz_system) of ordinary -differential equations, a prototypical example of chaotic dynamics: - -```python -rho = 28.0 -sigma = 10.0 -beta = 8.0/3.0 - -def lorenz_equation(state, t): - x, y, z = tf.unstack(state) - dx = sigma * (y - x) - dy = x * (rho - z) - y - dz = x * y - beta * z - return tf.stack([dx, dy, dz]) - -init_state = tf.constant([0, 2, 20], dtype=tf.float64) -t = np.linspace(0, 50, num=5000) -tensor_state, tensor_info = tf.contrib.integrate.odeint( - lorenz_equation, init_state, t, full_output=True) - -sess = tf.Session() -state, info = sess.run([tensor_state, tensor_info]) -x, y, z = state.T -plt.plot(x, z) -``` - -<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://www.tensorflow.org/images/lorenz_attractor.png" alt> -</div> - -## Ops - -* `tf.contrib.integrate.odeint` diff --git a/tensorflow/docs_src/api_guides/python/contrib.layers.md b/tensorflow/docs_src/api_guides/python/contrib.layers.md deleted file mode 100644 index 4c176a129c..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.layers.md +++ /dev/null @@ -1,109 +0,0 @@ -# Layers (contrib) -[TOC] - -Ops for building neural network layers, regularizers, summaries, etc. - -## Higher level ops for building neural network layers - -This package provides several ops that take care of creating variables that are -used internally in a consistent way and provide the building blocks for many -common machine learning algorithms. - -* `tf.contrib.layers.avg_pool2d` -* `tf.contrib.layers.batch_norm` -* `tf.contrib.layers.convolution2d` -* `tf.contrib.layers.conv2d_in_plane` -* `tf.contrib.layers.convolution2d_in_plane` -* `tf.nn.conv2d_transpose` -* `tf.contrib.layers.convolution2d_transpose` -* `tf.nn.dropout` -* `tf.contrib.layers.flatten` -* `tf.contrib.layers.fully_connected` -* `tf.contrib.layers.layer_norm` -* `tf.contrib.layers.max_pool2d` -* `tf.contrib.layers.one_hot_encoding` -* `tf.nn.relu` -* `tf.nn.relu6` -* `tf.contrib.layers.repeat` -* `tf.contrib.layers.safe_embedding_lookup_sparse` -* `tf.nn.separable_conv2d` -* `tf.contrib.layers.separable_convolution2d` -* `tf.nn.softmax` -* `tf.stack` -* `tf.contrib.layers.unit_norm` -* `tf.contrib.layers.embed_sequence` - -Aliases for fully_connected which set a default activation function are -available: `relu`, `relu6` and `linear`. - -`stack` operation is also available. It builds a stack of layers by applying -a layer repeatedly. - -## Regularizers - -Regularization can help prevent overfitting. These have the signature -`fn(weights)`. The loss is typically added to -`tf.GraphKeys.REGULARIZATION_LOSSES`. - -* `tf.contrib.layers.apply_regularization` -* `tf.contrib.layers.l1_regularizer` -* `tf.contrib.layers.l2_regularizer` -* `tf.contrib.layers.sum_regularizer` - -## Initializers - -Initializers are used to initialize variables with sensible values given their -size, data type, and purpose. - -* `tf.contrib.layers.xavier_initializer` -* `tf.contrib.layers.xavier_initializer_conv2d` -* `tf.contrib.layers.variance_scaling_initializer` - -## Optimization - -Optimize weights given a loss. - -* `tf.contrib.layers.optimize_loss` - -## Summaries - -Helper functions to summarize specific variables or ops. - -* `tf.contrib.layers.summarize_activation` -* `tf.contrib.layers.summarize_tensor` -* `tf.contrib.layers.summarize_tensors` -* `tf.contrib.layers.summarize_collection` - -The layers module defines convenience functions `summarize_variables`, -`summarize_weights` and `summarize_biases`, which set the `collection` argument -of `summarize_collection` to `VARIABLES`, `WEIGHTS` and `BIASES`, respectively. - -* `tf.contrib.layers.summarize_activations` - -## Feature columns - -Feature columns provide a mechanism to map data to a model. - -* `tf.contrib.layers.bucketized_column` -* `tf.contrib.layers.check_feature_columns` -* `tf.contrib.layers.create_feature_spec_for_parsing` -* `tf.contrib.layers.crossed_column` -* `tf.contrib.layers.embedding_column` -* `tf.contrib.layers.scattered_embedding_column` -* `tf.contrib.layers.input_from_feature_columns` -* `tf.contrib.layers.joint_weighted_sum_from_feature_columns` -* `tf.contrib.layers.make_place_holder_tensors_for_base_features` -* `tf.contrib.layers.multi_class_target` -* `tf.contrib.layers.one_hot_column` -* `tf.contrib.layers.parse_feature_columns_from_examples` -* `tf.contrib.layers.parse_feature_columns_from_sequence_examples` -* `tf.contrib.layers.real_valued_column` -* `tf.contrib.layers.shared_embedding_columns` -* `tf.contrib.layers.sparse_column_with_hash_bucket` -* `tf.contrib.layers.sparse_column_with_integerized_feature` -* `tf.contrib.layers.sparse_column_with_keys` -* `tf.contrib.layers.sparse_column_with_vocabulary_file` -* `tf.contrib.layers.weighted_sparse_column` -* `tf.contrib.layers.weighted_sum_from_feature_columns` -* `tf.contrib.layers.infer_real_valued_columns` -* `tf.contrib.layers.sequence_input_from_feature_columns` diff --git a/tensorflow/docs_src/api_guides/python/contrib.learn.md b/tensorflow/docs_src/api_guides/python/contrib.learn.md deleted file mode 100644 index 635849ead5..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.learn.md +++ /dev/null @@ -1,63 +0,0 @@ -# Learn (contrib) -[TOC] - -High level API for learning with TensorFlow. - -## Estimators - -Train and evaluate TensorFlow models. - -* `tf.contrib.learn.BaseEstimator` -* `tf.contrib.learn.Estimator` -* `tf.contrib.learn.Trainable` -* `tf.contrib.learn.Evaluable` -* `tf.contrib.learn.KMeansClustering` -* `tf.contrib.learn.ModeKeys` -* `tf.contrib.learn.ModelFnOps` -* `tf.contrib.learn.MetricSpec` -* `tf.contrib.learn.PredictionKey` -* `tf.contrib.learn.DNNClassifier` -* `tf.contrib.learn.DNNRegressor` -* `tf.contrib.learn.DNNLinearCombinedRegressor` -* `tf.contrib.learn.DNNLinearCombinedClassifier` -* `tf.contrib.learn.LinearClassifier` -* `tf.contrib.learn.LinearRegressor` -* `tf.contrib.learn.LogisticRegressor` - -## Distributed training utilities - -* `tf.contrib.learn.Experiment` -* `tf.contrib.learn.ExportStrategy` -* `tf.contrib.learn.TaskType` - -## Graph actions - -Perform various training, evaluation, and inference actions on a graph. - -* `tf.train.NanLossDuringTrainingError` -* `tf.contrib.learn.RunConfig` -* `tf.contrib.learn.evaluate` -* `tf.contrib.learn.infer` -* `tf.contrib.learn.run_feeds` -* `tf.contrib.learn.run_n` -* `tf.contrib.learn.train` - -## Input processing - -Queue and read batched input data. - -* `tf.contrib.learn.extract_dask_data` -* `tf.contrib.learn.extract_dask_labels` -* `tf.contrib.learn.extract_pandas_data` -* `tf.contrib.learn.extract_pandas_labels` -* `tf.contrib.learn.extract_pandas_matrix` -* `tf.contrib.learn.infer_real_valued_columns_from_input` -* `tf.contrib.learn.infer_real_valued_columns_from_input_fn` -* `tf.contrib.learn.read_batch_examples` -* `tf.contrib.learn.read_batch_features` -* `tf.contrib.learn.read_batch_record_features` - -Export utilities - -* `tf.contrib.learn.build_parsing_serving_input_fn` -* `tf.contrib.learn.ProblemType` diff --git a/tensorflow/docs_src/api_guides/python/contrib.linalg.md b/tensorflow/docs_src/api_guides/python/contrib.linalg.md deleted file mode 100644 index 3055449dc2..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.linalg.md +++ /dev/null @@ -1,30 +0,0 @@ -# Linear Algebra (contrib) -[TOC] - -Linear algebra libraries for TensorFlow. - -## `LinearOperator` - -Subclasses of `LinearOperator` provide a access to common methods on a -(batch) matrix, without the need to materialize the matrix. This allows: - -* Matrix free computations -* Different operators to take advantage of special structure, while providing a - consistent API to users. - -### Base class - -* `tf.contrib.linalg.LinearOperator` - -### Individual operators - -* `tf.contrib.linalg.LinearOperatorDiag` -* `tf.contrib.linalg.LinearOperatorIdentity` -* `tf.contrib.linalg.LinearOperatorScaledIdentity` -* `tf.contrib.linalg.LinearOperatorFullMatrix` -* `tf.contrib.linalg.LinearOperatorLowerTriangular` -* `tf.contrib.linalg.LinearOperatorLowRankUpdate` - -### Transformations and Combinations of operators - -* `tf.contrib.linalg.LinearOperatorComposition` diff --git a/tensorflow/docs_src/api_guides/python/contrib.losses.md b/tensorflow/docs_src/api_guides/python/contrib.losses.md deleted file mode 100644 index 8787454af6..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.losses.md +++ /dev/null @@ -1,125 +0,0 @@ -# Losses (contrib) - -## Deprecated - -This module is deprecated. Instructions for updating: Use `tf.losses` instead. - -## Loss operations for use in neural networks. - -Note: By default, all the losses are collected into the `GraphKeys.LOSSES` -collection. - -All of the loss functions take a pair of predictions and ground truth labels, -from which the loss is computed. It is assumed that the shape of both these -tensors is of the form [batch_size, d1, ... dN] where `batch_size` is the number -of samples in the batch and `d1` ... `dN` are the remaining dimensions. - -It is common, when training with multiple loss functions, to adjust the relative -strengths of individual losses. This is performed by rescaling the losses via -a `weight` parameter passed to the loss functions. For example, if we were -training with both log_loss and mean_squared_error, and we wished that the -log_loss penalty be twice as severe as the mean_squared_error, we would -implement this as: - -```python - # Explicitly set the weight. - tf.contrib.losses.log(predictions, labels, weight=2.0) - - # Uses default weight of 1.0 - tf.contrib.losses.mean_squared_error(predictions, labels) - - # All the losses are collected into the `GraphKeys.LOSSES` collection. - losses = tf.get_collection(tf.GraphKeys.LOSSES) -``` - -While specifying a scalar loss rescales the loss over the entire batch, -we sometimes want to rescale the loss per batch sample. For example, if we have -certain examples that matter more to us to get correctly, we might want to have -a higher loss that other samples whose mistakes matter less. In this case, we -can provide a weight vector of length `batch_size` which results in the loss -for each sample in the batch being scaled by the corresponding weight element. -For example, consider the case of a classification problem where we want to -maximize our accuracy but we especially interested in obtaining high accuracy -for a specific class: - -```python - inputs, labels = LoadData(batch_size=3) - logits = MyModelPredictions(inputs) - - # Ensures that the loss for examples whose ground truth class is `3` is 5x - # higher than the loss for all other examples. - weight = tf.multiply(4, tf.cast(tf.equal(labels, 3), tf.float32)) + 1 - - onehot_labels = tf.one_hot(labels, num_classes=5) - tf.contrib.losses.softmax_cross_entropy(logits, onehot_labels, weight=weight) -``` - -Finally, in certain cases, we may want to specify a different loss for every -single measurable value. For example, if we are performing per-pixel depth -prediction, or per-pixel denoising, a single batch sample has P values where P -is the number of pixels in the image. For many losses, the number of measurable -values matches the number of elements in the predictions and labels tensors. -For others, such as softmax_cross_entropy and cosine_distance, the -loss functions reduces the dimensions of the inputs to produces a tensor of -losses for each measurable value. For example, softmax_cross_entropy takes as -input predictions and labels of dimension [batch_size, num_classes] but the -number of measurable values is [batch_size]. Consequently, when passing a weight -tensor to specify a different loss for every measurable value, the dimension of -the tensor will depend on the loss being used. - -For a concrete example, consider the case of per-pixel depth prediction where -certain ground truth depth values are missing (due to sensor noise in the -capture process). In this case, we want to assign zero weight to losses for -these predictions. - -```python - # 'depths' that are missing have a value of 0: - images, depths = LoadData(...) - predictions = MyModelPredictions(images) - - weight = tf.cast(tf.greater(depths, 0), tf.float32) - loss = tf.contrib.losses.mean_squared_error(predictions, depths, weight) -``` - -Note that when using weights for the losses, the final average is computed -by rescaling the losses by the weights and then dividing by the total number of -non-zero samples. For an arbitrary set of weights, this may not necessarily -produce a weighted average. Instead, it simply and transparently rescales the -per-element losses before averaging over the number of observations. For example -if the losses computed by the loss function is an array [4, 1, 2, 3] and the -weights are an array [1, 0.5, 3, 9], then the average loss is: - -```python - (4*1 + 1*0.5 + 2*3 + 3*9) / 4 -``` - -However, with a single loss function and an arbitrary set of weights, one can -still easily create a loss function such that the resulting loss is a -weighted average over the individual prediction errors: - - -```python - images, labels = LoadData(...) - predictions = MyModelPredictions(images) - - weight = MyComplicatedWeightingFunction(labels) - weight = tf.div(weight, tf.size(weight)) - loss = tf.contrib.losses.mean_squared_error(predictions, depths, weight) -``` - -* `tf.contrib.losses.absolute_difference` -* `tf.contrib.losses.add_loss` -* `tf.contrib.losses.hinge_loss` -* `tf.contrib.losses.compute_weighted_loss` -* `tf.contrib.losses.cosine_distance` -* `tf.contrib.losses.get_losses` -* `tf.contrib.losses.get_regularization_losses` -* `tf.contrib.losses.get_total_loss` -* `tf.contrib.losses.log_loss` -* `tf.contrib.losses.mean_pairwise_squared_error` -* `tf.contrib.losses.mean_squared_error` -* `tf.contrib.losses.sigmoid_cross_entropy` -* `tf.contrib.losses.softmax_cross_entropy` -* `tf.contrib.losses.sparse_softmax_cross_entropy` - - diff --git a/tensorflow/docs_src/api_guides/python/contrib.metrics.md b/tensorflow/docs_src/api_guides/python/contrib.metrics.md deleted file mode 100644 index de6346ca80..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.metrics.md +++ /dev/null @@ -1,133 +0,0 @@ -# Metrics (contrib) -[TOC] - -##Ops for evaluation metrics and summary statistics. - -### API - -This module provides functions for computing streaming metrics: metrics computed -on dynamically valued `Tensors`. Each metric declaration returns a -"value_tensor", an idempotent operation that returns the current value of the -metric, and an "update_op", an operation that accumulates the information -from the current value of the `Tensors` being measured as well as returns the -value of the "value_tensor". - -To use any of these metrics, one need only declare the metric, call `update_op` -repeatedly to accumulate data over the desired number of `Tensor` values (often -each one is a single batch) and finally evaluate the value_tensor. For example, -to use the `streaming_mean`: - -```python -value = ... -mean_value, update_op = tf.contrib.metrics.streaming_mean(values) -sess.run(tf.local_variables_initializer()) - -for i in range(number_of_batches): - print('Mean after batch %d: %f' % (i, update_op.eval()) -print('Final Mean: %f' % mean_value.eval()) -``` - -Each metric function adds nodes to the graph that hold the state necessary to -compute the value of the metric as well as a set of operations that actually -perform the computation. Every metric evaluation is composed of three steps - -* Initialization: initializing the metric state. -* Aggregation: updating the values of the metric state. -* Finalization: computing the final metric value. - -In the above example, calling streaming_mean creates a pair of state variables -that will contain (1) the running sum and (2) the count of the number of samples -in the sum. Because the streaming metrics use local variables, -the Initialization stage is performed by running the op returned -by `tf.local_variables_initializer()`. It sets the sum and count variables to -zero. - -Next, Aggregation is performed by examining the current state of `values` -and incrementing the state variables appropriately. This step is executed by -running the `update_op` returned by the metric. - -Finally, finalization is performed by evaluating the "value_tensor" - -In practice, we commonly want to evaluate across many batches and multiple -metrics. To do so, we need only run the metric computation operations multiple -times: - -```python -labels = ... -predictions = ... -accuracy, update_op_acc = tf.contrib.metrics.streaming_accuracy( - labels, predictions) -error, update_op_error = tf.contrib.metrics.streaming_mean_absolute_error( - labels, predictions) - -sess.run(tf.local_variables_initializer()) -for batch in range(num_batches): - sess.run([update_op_acc, update_op_error]) - -accuracy, error = sess.run([accuracy, error]) -``` - -Note that when evaluating the same metric multiple times on different inputs, -one must specify the scope of each metric to avoid accumulating the results -together: - -```python -labels = ... -predictions0 = ... -predictions1 = ... - -accuracy0 = tf.contrib.metrics.accuracy(labels, predictions0, name='preds0') -accuracy1 = tf.contrib.metrics.accuracy(labels, predictions1, name='preds1') -``` - -Certain metrics, such as streaming_mean or streaming_accuracy, can be weighted -via a `weights` argument. The `weights` tensor must be the same size as the -labels and predictions tensors and results in a weighted average of the metric. - -## Metric `Ops` - -* `tf.contrib.metrics.streaming_accuracy` -* `tf.contrib.metrics.streaming_mean` -* `tf.contrib.metrics.streaming_recall` -* `tf.contrib.metrics.streaming_recall_at_thresholds` -* `tf.contrib.metrics.streaming_precision` -* `tf.contrib.metrics.streaming_precision_at_thresholds` -* `tf.contrib.metrics.streaming_auc` -* `tf.contrib.metrics.streaming_recall_at_k` -* `tf.contrib.metrics.streaming_mean_absolute_error` -* `tf.contrib.metrics.streaming_mean_iou` -* `tf.contrib.metrics.streaming_mean_relative_error` -* `tf.contrib.metrics.streaming_mean_squared_error` -* `tf.contrib.metrics.streaming_mean_tensor` -* `tf.contrib.metrics.streaming_root_mean_squared_error` -* `tf.contrib.metrics.streaming_covariance` -* `tf.contrib.metrics.streaming_pearson_correlation` -* `tf.contrib.metrics.streaming_mean_cosine_distance` -* `tf.contrib.metrics.streaming_percentage_less` -* `tf.contrib.metrics.streaming_sensitivity_at_specificity` -* `tf.contrib.metrics.streaming_sparse_average_precision_at_k` -* `tf.contrib.metrics.streaming_sparse_precision_at_k` -* `tf.contrib.metrics.streaming_sparse_precision_at_top_k` -* `tf.contrib.metrics.streaming_sparse_recall_at_k` -* `tf.contrib.metrics.streaming_specificity_at_sensitivity` -* `tf.contrib.metrics.streaming_concat` -* `tf.contrib.metrics.streaming_false_negatives` -* `tf.contrib.metrics.streaming_false_negatives_at_thresholds` -* `tf.contrib.metrics.streaming_false_positives` -* `tf.contrib.metrics.streaming_false_positives_at_thresholds` -* `tf.contrib.metrics.streaming_true_negatives` -* `tf.contrib.metrics.streaming_true_negatives_at_thresholds` -* `tf.contrib.metrics.streaming_true_positives` -* `tf.contrib.metrics.streaming_true_positives_at_thresholds` -* `tf.contrib.metrics.auc_using_histogram` -* `tf.contrib.metrics.accuracy` -* `tf.contrib.metrics.aggregate_metrics` -* `tf.contrib.metrics.aggregate_metric_map` -* `tf.contrib.metrics.confusion_matrix` - -## Set `Ops` - -* `tf.contrib.metrics.set_difference` -* `tf.contrib.metrics.set_intersection` -* `tf.contrib.metrics.set_size` -* `tf.contrib.metrics.set_union` diff --git a/tensorflow/docs_src/api_guides/python/contrib.rnn.md b/tensorflow/docs_src/api_guides/python/contrib.rnn.md deleted file mode 100644 index d265ab6925..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.rnn.md +++ /dev/null @@ -1,61 +0,0 @@ -# RNN and Cells (contrib) -[TOC] - -Module for constructing RNN Cells and additional RNN operations. - -## Base interface for all RNN Cells - -* `tf.contrib.rnn.RNNCell` - -## Core RNN Cells for use with TensorFlow's core RNN methods - -* `tf.contrib.rnn.BasicRNNCell` -* `tf.contrib.rnn.BasicLSTMCell` -* `tf.contrib.rnn.GRUCell` -* `tf.contrib.rnn.LSTMCell` -* `tf.contrib.rnn.LayerNormBasicLSTMCell` - -## Classes storing split `RNNCell` state - -* `tf.contrib.rnn.LSTMStateTuple` - -## Core RNN Cell wrappers (RNNCells that wrap other RNNCells) - -* `tf.contrib.rnn.MultiRNNCell` -* `tf.contrib.rnn.LSTMBlockWrapper` -* `tf.contrib.rnn.DropoutWrapper` -* `tf.contrib.rnn.EmbeddingWrapper` -* `tf.contrib.rnn.InputProjectionWrapper` -* `tf.contrib.rnn.OutputProjectionWrapper` -* `tf.contrib.rnn.DeviceWrapper` -* `tf.contrib.rnn.ResidualWrapper` - -### Block RNNCells -* `tf.contrib.rnn.LSTMBlockCell` -* `tf.contrib.rnn.GRUBlockCell` - -### Fused RNNCells -* `tf.contrib.rnn.FusedRNNCell` -* `tf.contrib.rnn.FusedRNNCellAdaptor` -* `tf.contrib.rnn.TimeReversedFusedRNN` -* `tf.contrib.rnn.LSTMBlockFusedCell` - -### LSTM-like cells -* `tf.contrib.rnn.CoupledInputForgetGateLSTMCell` -* `tf.contrib.rnn.TimeFreqLSTMCell` -* `tf.contrib.rnn.GridLSTMCell` - -### RNNCell wrappers -* `tf.contrib.rnn.AttentionCellWrapper` -* `tf.contrib.rnn.CompiledWrapper` - - -## Recurrent Neural Networks - -TensorFlow provides a number of methods for constructing Recurrent Neural -Networks. - -* `tf.contrib.rnn.static_rnn` -* `tf.contrib.rnn.static_state_saving_rnn` -* `tf.contrib.rnn.static_bidirectional_rnn` -* `tf.contrib.rnn.stack_bidirectional_dynamic_rnn` diff --git a/tensorflow/docs_src/api_guides/python/contrib.seq2seq.md b/tensorflow/docs_src/api_guides/python/contrib.seq2seq.md deleted file mode 100644 index 54f2fafc71..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.seq2seq.md +++ /dev/null @@ -1,138 +0,0 @@ -# Seq2seq Library (contrib) -[TOC] - -Module for constructing seq2seq models and dynamic decoding. Builds on top of -libraries in `tf.contrib.rnn`. - -This library is composed of two primary components: - -* New attention wrappers for `tf.contrib.rnn.RNNCell` objects. -* A new object-oriented dynamic decoding framework. - -## Attention - -Attention wrappers are `RNNCell` objects that wrap other `RNNCell` objects and -implement attention. The form of attention is determined by a subclass of -`tf.contrib.seq2seq.AttentionMechanism`. These subclasses describe the form -of attention (e.g. additive vs. multiplicative) to use when creating the -wrapper. An instance of an `AttentionMechanism` is constructed with a -`memory` tensor, from which lookup keys and values tensors are created. - -### Attention Mechanisms - -The two basic attention mechanisms are: - -* `tf.contrib.seq2seq.BahdanauAttention` (additive attention, - [ref.](https://arxiv.org/abs/1409.0473)) -* `tf.contrib.seq2seq.LuongAttention` (multiplicative attention, - [ref.](https://arxiv.org/abs/1508.04025)) - -The `memory` tensor passed the attention mechanism's constructor is expected to -be shaped `[batch_size, memory_max_time, memory_depth]`; and often an additional -`memory_sequence_length` vector is accepted. If provided, the `memory` -tensors' rows are masked with zeros past their true sequence lengths. - -Attention mechanisms also have a concept of depth, usually determined as a -construction parameter `num_units`. For some kinds of attention (like -`BahdanauAttention`), both queries and memory are projected to tensors of depth -`num_units`. For other kinds (like `LuongAttention`), `num_units` should match -the depth of the queries; and the `memory` tensor will be projected to this -depth. - -### Attention Wrappers - -The basic attention wrapper is `tf.contrib.seq2seq.AttentionWrapper`. -This wrapper accepts an `RNNCell` instance, an instance of `AttentionMechanism`, -and an attention depth parameter (`attention_size`); as well as several -optional arguments that allow one to customize intermediate calculations. - -At each time step, the basic calculation performed by this wrapper is: - -```python -cell_inputs = concat([inputs, prev_state.attention], -1) -cell_output, next_cell_state = cell(cell_inputs, prev_state.cell_state) -score = attention_mechanism(cell_output) -alignments = softmax(score) -context = matmul(alignments, attention_mechanism.values) -attention = tf.layers.Dense(attention_size)(concat([cell_output, context], 1)) -next_state = AttentionWrapperState( - cell_state=next_cell_state, - attention=attention) -output = attention -return output, next_state -``` - -In practice, a number of the intermediate calculations are configurable. -For example, the initial concatenation of `inputs` and `prev_state.attention` -can be replaced with another mixing function. The function `softmax` can -be replaced with alternative options when calculating `alignments` from the -`score`. Finally, the outputs returned by the wrapper can be configured to -be the value `cell_output` instead of `attention`. - -The benefit of using a `AttentionWrapper` is that it plays nicely with -other wrappers and the dynamic decoder described below. For example, one can -write: - -```python -cell = tf.contrib.rnn.DeviceWrapper(LSTMCell(512), "/device:GPU:0") -attention_mechanism = tf.contrib.seq2seq.LuongAttention(512, encoder_outputs) -attn_cell = tf.contrib.seq2seq.AttentionWrapper( - cell, attention_mechanism, attention_size=256) -attn_cell = tf.contrib.rnn.DeviceWrapper(attn_cell, "/device:GPU:1") -top_cell = tf.contrib.rnn.DeviceWrapper(LSTMCell(512), "/device:GPU:1") -multi_cell = MultiRNNCell([attn_cell, top_cell]) -``` - -The `multi_rnn` cell will perform the bottom layer calculations on GPU 0; -attention calculations will be performed on GPU 1 and immediately passed -up to the top layer which is also calculated on GPU 1. The attention is -also passed forward in time to the next time step and copied to GPU 0 for the -next time step of `cell`. (*Note*: This is just an example of use, -not a suggested device partitioning strategy.) - -## Dynamic Decoding - -Example usage: - -``` python -cell = # instance of RNNCell - -if mode == "train": - helper = tf.contrib.seq2seq.TrainingHelper( - input=input_vectors, - sequence_length=input_lengths) -elif mode == "infer": - helper = tf.contrib.seq2seq.GreedyEmbeddingHelper( - embedding=embedding, - start_tokens=tf.tile([GO_SYMBOL], [batch_size]), - end_token=END_SYMBOL) - -decoder = tf.contrib.seq2seq.BasicDecoder( - cell=cell, - helper=helper, - initial_state=cell.zero_state(batch_size, tf.float32)) -outputs, _ = tf.contrib.seq2seq.dynamic_decode( - decoder=decoder, - output_time_major=False, - impute_finished=True, - maximum_iterations=20) -``` - -### Decoder base class and functions - -* `tf.contrib.seq2seq.Decoder` -* `tf.contrib.seq2seq.dynamic_decode` - -### Basic Decoder - -* `tf.contrib.seq2seq.BasicDecoderOutput` -* `tf.contrib.seq2seq.BasicDecoder` - -### Decoder Helpers - -* `tf.contrib.seq2seq.Helper` -* `tf.contrib.seq2seq.CustomHelper` -* `tf.contrib.seq2seq.GreedyEmbeddingHelper` -* `tf.contrib.seq2seq.ScheduledEmbeddingTrainingHelper` -* `tf.contrib.seq2seq.ScheduledOutputTrainingHelper` -* `tf.contrib.seq2seq.TrainingHelper` diff --git a/tensorflow/docs_src/api_guides/python/contrib.signal.md b/tensorflow/docs_src/api_guides/python/contrib.signal.md deleted file mode 100644 index 66df561084..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.signal.md +++ /dev/null @@ -1,172 +0,0 @@ -# Signal Processing (contrib) -[TOC] - -`tf.contrib.signal` is a module for signal processing primitives. All -operations have GPU support and are differentiable. This module is especially -helpful for building TensorFlow models that process or generate audio, though -the techniques are useful in many domains. - -## Framing variable length sequences - -When dealing with variable length signals (e.g. audio) it is common to "frame" -them into multiple fixed length windows. These windows can overlap if the 'step' -of the frame is less than the frame length. `tf.contrib.signal.frame` does -exactly this. For example: - -```python -# A batch of float32 time-domain signals in the range [-1, 1] with shape -# [batch_size, signal_length]. Both batch_size and signal_length may be unknown. -signals = tf.placeholder(tf.float32, [None, None]) - -# Compute a [batch_size, ?, 128] tensor of fixed length, overlapping windows -# where each window overlaps the previous by 75% (frame_length - frame_step -# samples of overlap). -frames = tf.contrib.signal.frame(signals, frame_length=128, frame_step=32) -``` - -The `axis` parameter to `tf.contrib.signal.frame` allows you to frame tensors -with inner structure (e.g. a spectrogram): - -```python -# `magnitude_spectrograms` is a [batch_size, ?, 129] tensor of spectrograms. We -# would like to produce overlapping fixed-size spectrogram patches; for example, -# for use in a situation where a fixed size input is needed. -magnitude_spectrograms = tf.abs(tf.contrib.signal.stft( - signals, frame_length=256, frame_step=64, fft_length=256)) - -# `spectrogram_patches` is a [batch_size, ?, 64, 129] tensor containing a -# variable number of [64, 129] spectrogram patches per batch item. -spectrogram_patches = tf.contrib.signal.frame( - magnitude_spectrograms, frame_length=64, frame_step=16, axis=1) -``` - -## Reconstructing framed sequences and applying a tapering window - -`tf.contrib.signal.overlap_and_add` can be used to reconstruct a signal from a -framed representation. For example, the following code reconstructs the signal -produced in the preceding example: - -```python -# Reconstructs `signals` from `frames` produced in the above example. However, -# the magnitude of `reconstructed_signals` will be greater than `signals`. -reconstructed_signals = tf.contrib.signal.overlap_and_add(frames, frame_step=32) -``` - -Note that because `frame_step` is 25% of `frame_length` in the above example, -the resulting reconstruction will have a greater magnitude than the original -`signals`. To compensate for this, we can use a tapering window function. If the -window function satisfies the Constant Overlap-Add (COLA) property for the given -frame step, then it will recover the original `signals`. - -`tf.contrib.signal.hamming_window` and `tf.contrib.signal.hann_window` both -satisfy the COLA property for a 75% overlap. - -```python -frame_length = 128 -frame_step = 32 -windowed_frames = frames * tf.contrib.signal.hann_window(frame_length) -reconstructed_signals = tf.contrib.signal.overlap_and_add( - windowed_frames, frame_step) -``` - -## Computing spectrograms - -A spectrogram is a time-frequency decomposition of a signal that indicates its -frequency content over time. The most common approach to computing spectrograms -is to take the magnitude of the [Short-time Fourier Transform][stft] (STFT), -which `tf.contrib.signal.stft` can compute as follows: - -```python -# A batch of float32 time-domain signals in the range [-1, 1] with shape -# [batch_size, signal_length]. Both batch_size and signal_length may be unknown. -signals = tf.placeholder(tf.float32, [None, None]) - -# `stfts` is a complex64 Tensor representing the Short-time Fourier Transform of -# each signal in `signals`. Its shape is [batch_size, ?, fft_unique_bins] -# where fft_unique_bins = fft_length // 2 + 1 = 513. -stfts = tf.contrib.signal.stft(signals, frame_length=1024, frame_step=512, - fft_length=1024) - -# A power spectrogram is the squared magnitude of the complex-valued STFT. -# A float32 Tensor of shape [batch_size, ?, 513]. -power_spectrograms = tf.real(stfts * tf.conj(stfts)) - -# An energy spectrogram is the magnitude of the complex-valued STFT. -# A float32 Tensor of shape [batch_size, ?, 513]. -magnitude_spectrograms = tf.abs(stfts) -``` - -You may use a power spectrogram or a magnitude spectrogram; each has its -advantages. Note that if you apply logarithmic compression, the power -spectrogram and magnitude spectrogram will differ by a factor of 2. - -## Logarithmic compression - -It is common practice to apply a compressive nonlinearity such as a logarithm or -power-law compression to spectrograms. This helps to balance the importance of -detail in low and high energy regions of the spectrum, which more closely -matches human auditory sensitivity. - -When compressing with a logarithm, it's a good idea to use a stabilizing offset -to avoid high dynamic ranges caused by the singularity at zero. - -```python -log_offset = 1e-6 -log_magnitude_spectrograms = tf.log(magnitude_spectrograms + log_offset) -``` - -## Computing log-mel spectrograms - -When working with spectral representations of audio, the [mel scale][mel] is a -common reweighting of the frequency dimension, which results in a -lower-dimensional and more perceptually-relevant representation of the audio. - -`tf.contrib.signal.linear_to_mel_weight_matrix` produces a matrix you can use -to convert a spectrogram to the mel scale. - -```python -# Warp the linear-scale, magnitude spectrograms into the mel-scale. -num_spectrogram_bins = magnitude_spectrograms.shape[-1].value -lower_edge_hertz, upper_edge_hertz, num_mel_bins = 80.0, 7600.0, 64 -linear_to_mel_weight_matrix = tf.contrib.signal.linear_to_mel_weight_matrix( - num_mel_bins, num_spectrogram_bins, sample_rate, lower_edge_hertz, - upper_edge_hertz) -mel_spectrograms = tf.tensordot( - magnitude_spectrograms, linear_to_mel_weight_matrix, 1) -# Note: Shape inference for `tf.tensordot` does not currently handle this case. -mel_spectrograms.set_shape(magnitude_spectrograms.shape[:-1].concatenate( - linear_to_mel_weight_matrix.shape[-1:])) -``` - -If desired, compress the mel spectrogram magnitudes. For example, you may use -logarithmic compression (as discussed in the previous section). - -Order matters! Compressing the spectrogram magnitudes after -reweighting the frequencies is different from reweighting the compressed -spectrogram magnitudes. According to the perceptual justification of the mel -scale, conversion from linear scale entails summing intensity or energy among -adjacent bands, i.e. it should be applied before logarithmic compression. Taking -the weighted sum of log-compressed values amounts to multiplying the -pre-logarithm values, which rarely, if ever, makes sense. - -```python -log_offset = 1e-6 -log_mel_spectrograms = tf.log(mel_spectrograms + log_offset) -``` - -## Computing Mel-Frequency Cepstral Coefficients (MFCCs) - -Call `tf.contrib.signal.mfccs_from_log_mel_spectrograms` to compute -[MFCCs][mfcc] from log-magnitude, mel-scale spectrograms (as computed in the -preceding example): - -```python -num_mfccs = 13 -# Keep the first `num_mfccs` MFCCs. -mfccs = tf.contrib.signal.mfccs_from_log_mel_spectrograms( - log_mel_spectrograms)[..., :num_mfccs] -``` - -[stft]: https://en.wikipedia.org/wiki/Short-time_Fourier_transform -[mel]: https://en.wikipedia.org/wiki/Mel_scale -[mfcc]: https://en.wikipedia.org/wiki/Mel-frequency_cepstrum diff --git a/tensorflow/docs_src/api_guides/python/contrib.staging.md b/tensorflow/docs_src/api_guides/python/contrib.staging.md deleted file mode 100644 index de143a7bd3..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.staging.md +++ /dev/null @@ -1,6 +0,0 @@ -# Staging (contrib) -[TOC] - -This library contains utilities for adding pipelining to a model. - -* `tf.contrib.staging.StagingArea` diff --git a/tensorflow/docs_src/api_guides/python/contrib.training.md b/tensorflow/docs_src/api_guides/python/contrib.training.md deleted file mode 100644 index 068efdc829..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.training.md +++ /dev/null @@ -1,50 +0,0 @@ -# Training (contrib) -[TOC] - -Training and input utilities. - -## Splitting sequence inputs into minibatches with state saving - -Use `tf.contrib.training.SequenceQueueingStateSaver` or -its wrapper `tf.contrib.training.batch_sequences_with_states` if -you have input data with a dynamic primary time / frame count axis which -you'd like to convert into fixed size segments during minibatching, and would -like to store state in the forward direction across segments of an example. - -* `tf.contrib.training.batch_sequences_with_states` -* `tf.contrib.training.NextQueuedSequenceBatch` -* `tf.contrib.training.SequenceQueueingStateSaver` - - -## Online data resampling - -To resample data with replacement on a per-example basis, use -`tf.contrib.training.rejection_sample` or -`tf.contrib.training.resample_at_rate`. For `rejection_sample`, provide -a boolean Tensor describing whether to accept or reject. Resulting batch sizes -are always the same. For `resample_at_rate`, provide the desired rate for each -example. Resulting batch sizes may vary. If you wish to specify relative -rates, rather than absolute ones, use `tf.contrib.training.weighted_resample` -(which also returns the actual resampling rate used for each output example). - -Use `tf.contrib.training.stratified_sample` to resample without replacement -from the data to achieve a desired mix of class proportions that the Tensorflow -graph sees. For instance, if you have a binary classification dataset that is -99.9% class 1, a common approach is to resample from the data so that the data -is more balanced. - -* `tf.contrib.training.rejection_sample` -* `tf.contrib.training.resample_at_rate` -* `tf.contrib.training.stratified_sample` -* `tf.contrib.training.weighted_resample` - -## Bucketing - -Use `tf.contrib.training.bucket` or -`tf.contrib.training.bucket_by_sequence_length` to stratify -minibatches into groups ("buckets"). Use `bucket_by_sequence_length` -with the argument `dynamic_pad=True` to receive minibatches of similarly -sized sequences for efficient training via `dynamic_rnn`. - -* `tf.contrib.training.bucket` -* `tf.contrib.training.bucket_by_sequence_length` diff --git a/tensorflow/docs_src/api_guides/python/contrib.util.md b/tensorflow/docs_src/api_guides/python/contrib.util.md deleted file mode 100644 index e5fd97e9f2..0000000000 --- a/tensorflow/docs_src/api_guides/python/contrib.util.md +++ /dev/null @@ -1,12 +0,0 @@ -# Utilities (contrib) -[TOC] - -Utilities for dealing with Tensors. - -## Miscellaneous Utility Functions - -* `tf.contrib.util.constant_value` -* `tf.contrib.util.make_tensor_proto` -* `tf.contrib.util.make_ndarray` -* `tf.contrib.util.ops_used_by_graph_def` -* `tf.contrib.util.stripped_op_list_for_graph` diff --git a/tensorflow/docs_src/api_guides/python/control_flow_ops.md b/tensorflow/docs_src/api_guides/python/control_flow_ops.md deleted file mode 100644 index 42c86d9978..0000000000 --- a/tensorflow/docs_src/api_guides/python/control_flow_ops.md +++ /dev/null @@ -1,57 +0,0 @@ -# Control Flow - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Control Flow Operations - -TensorFlow provides several operations and classes that you can use to control -the execution of operations and add conditional dependencies to your graph. - -* `tf.identity` -* `tf.tuple` -* `tf.group` -* `tf.no_op` -* `tf.count_up_to` -* `tf.cond` -* `tf.case` -* `tf.while_loop` - -## Logical Operators - -TensorFlow provides several operations that you can use to add logical operators -to your graph. - -* `tf.logical_and` -* `tf.logical_not` -* `tf.logical_or` -* `tf.logical_xor` - -## Comparison Operators - -TensorFlow provides several operations that you can use to add comparison -operators to your graph. - -* `tf.equal` -* `tf.not_equal` -* `tf.less` -* `tf.less_equal` -* `tf.greater` -* `tf.greater_equal` -* `tf.where` - -## Debugging Operations - -TensorFlow provides several operations that you can use to validate values and -debug your graph. - -* `tf.is_finite` -* `tf.is_inf` -* `tf.is_nan` -* `tf.verify_tensor_all_finite` -* `tf.check_numerics` -* `tf.add_check_numerics_ops` -* `tf.Assert` -* `tf.Print` diff --git a/tensorflow/docs_src/api_guides/python/framework.md b/tensorflow/docs_src/api_guides/python/framework.md deleted file mode 100644 index 40a6c0783a..0000000000 --- a/tensorflow/docs_src/api_guides/python/framework.md +++ /dev/null @@ -1,51 +0,0 @@ -# Building Graphs -[TOC] - -Classes and functions for building TensorFlow graphs. - -## Core graph data structures - -* `tf.Graph` -* `tf.Operation` -* `tf.Tensor` - -## Tensor types - -* `tf.DType` -* `tf.as_dtype` - -## Utility functions - -* `tf.device` -* `tf.container` -* `tf.name_scope` -* `tf.control_dependencies` -* `tf.convert_to_tensor` -* `tf.convert_to_tensor_or_indexed_slices` -* `tf.convert_to_tensor_or_sparse_tensor` -* `tf.get_default_graph` -* `tf.reset_default_graph` -* `tf.import_graph_def` -* `tf.load_file_system_library` -* `tf.load_op_library` - -## Graph collections - -* `tf.add_to_collection` -* `tf.get_collection` -* `tf.get_collection_ref` -* `tf.GraphKeys` - -## Defining new operations - -* `tf.RegisterGradient` -* `tf.NotDifferentiable` -* `tf.NoGradient` -* `tf.TensorShape` -* `tf.Dimension` -* `tf.op_scope` -* `tf.get_seed` - -## For libraries building on TensorFlow - -* `tf.register_tensor_conversion_function` diff --git a/tensorflow/docs_src/api_guides/python/functional_ops.md b/tensorflow/docs_src/api_guides/python/functional_ops.md deleted file mode 100644 index 0a9fe02ad5..0000000000 --- a/tensorflow/docs_src/api_guides/python/functional_ops.md +++ /dev/null @@ -1,18 +0,0 @@ -# Higher Order Functions - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -Functional operations. - -## Higher Order Operators - -TensorFlow provides several higher order operators to simplify the common -map-reduce programming patterns. - -* `tf.map_fn` -* `tf.foldl` -* `tf.foldr` -* `tf.scan` diff --git a/tensorflow/docs_src/api_guides/python/image.md b/tensorflow/docs_src/api_guides/python/image.md deleted file mode 100644 index c51b92db05..0000000000 --- a/tensorflow/docs_src/api_guides/python/image.md +++ /dev/null @@ -1,144 +0,0 @@ -# Images - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Encoding and Decoding - -TensorFlow provides Ops to decode and encode JPEG and PNG formats. Encoded -images are represented by scalar string Tensors, decoded images by 3-D uint8 -tensors of shape `[height, width, channels]`. (PNG also supports uint16.) - -The encode and decode Ops apply to one image at a time. Their input and output -are all of variable size. If you need fixed size images, pass the output of -the decode Ops to one of the cropping and resizing Ops. - -Note: The PNG encode and decode Ops support RGBA, but the conversions Ops -presently only support RGB, HSV, and GrayScale. Presently, the alpha channel has -to be stripped from the image and re-attached using slicing ops. - -* `tf.image.decode_bmp` -* `tf.image.decode_gif` -* `tf.image.decode_jpeg` -* `tf.image.encode_jpeg` -* `tf.image.decode_png` -* `tf.image.encode_png` -* `tf.image.decode_image` - -## Resizing - -The resizing Ops accept input images as tensors of several types. They always -output resized images as float32 tensors. - -The convenience function `tf.image.resize_images` supports both 4-D -and 3-D tensors as input and output. 4-D tensors are for batches of images, -3-D tensors for individual images. - -Other resizing Ops only support 4-D batches of images as input: -`tf.image.resize_area`, `tf.image.resize_bicubic`, -`tf.image.resize_bilinear`, -`tf.image.resize_nearest_neighbor`. - -Example: - -```python -# Decode a JPG image and resize it to 299 by 299 using default method. -image = tf.image.decode_jpeg(...) -resized_image = tf.image.resize_images(image, [299, 299]) -``` - -* `tf.image.resize_images` -* `tf.image.resize_area` -* `tf.image.resize_bicubic` -* `tf.image.resize_bilinear` -* `tf.image.resize_nearest_neighbor` - -## Cropping - -* `tf.image.resize_image_with_crop_or_pad` -* `tf.image.central_crop` -* `tf.image.pad_to_bounding_box` -* `tf.image.crop_to_bounding_box` -* `tf.image.extract_glimpse` -* `tf.image.crop_and_resize` - -## Flipping, Rotating and Transposing - -* `tf.image.flip_up_down` -* `tf.image.random_flip_up_down` -* `tf.image.flip_left_right` -* `tf.image.random_flip_left_right` -* `tf.image.transpose_image` -* `tf.image.rot90` - -## Converting Between Colorspaces - -Image ops work either on individual images or on batches of images, depending on -the shape of their input Tensor. - -If 3-D, the shape is `[height, width, channels]`, and the Tensor represents one -image. If 4-D, the shape is `[batch_size, height, width, channels]`, and the -Tensor represents `batch_size` images. - -Currently, `channels` can usefully be 1, 2, 3, or 4. Single-channel images are -grayscale, images with 3 channels are encoded as either RGB or HSV. Images -with 2 or 4 channels include an alpha channel, which has to be stripped from the -image before passing the image to most image processing functions (and can be -re-attached later). - -Internally, images are either stored in as one `float32` per channel per pixel -(implicitly, values are assumed to lie in `[0,1)`) or one `uint8` per channel -per pixel (values are assumed to lie in `[0,255]`). - -TensorFlow can convert between images in RGB or HSV. The conversion functions -work only on float images, so you need to convert images in other formats using -`tf.image.convert_image_dtype`. - -Example: - -```python -# Decode an image and convert it to HSV. -rgb_image = tf.image.decode_png(..., channels=3) -rgb_image_float = tf.image.convert_image_dtype(rgb_image, tf.float32) -hsv_image = tf.image.rgb_to_hsv(rgb_image) -``` - -* `tf.image.rgb_to_grayscale` -* `tf.image.grayscale_to_rgb` -* `tf.image.hsv_to_rgb` -* `tf.image.rgb_to_hsv` -* `tf.image.convert_image_dtype` - -## Image Adjustments - -TensorFlow provides functions to adjust images in various ways: brightness, -contrast, hue, and saturation. Each adjustment can be done with predefined -parameters or with random parameters picked from predefined intervals. Random -adjustments are often useful to expand a training set and reduce overfitting. - -If several adjustments are chained it is advisable to minimize the number of -redundant conversions by first converting the images to the most natural data -type and representation (RGB or HSV). - -* `tf.image.adjust_brightness` -* `tf.image.random_brightness` -* `tf.image.adjust_contrast` -* `tf.image.random_contrast` -* `tf.image.adjust_hue` -* `tf.image.random_hue` -* `tf.image.adjust_gamma` -* `tf.image.adjust_saturation` -* `tf.image.random_saturation` -* `tf.image.per_image_standardization` - -## Working with Bounding Boxes - -* `tf.image.draw_bounding_boxes` -* `tf.image.non_max_suppression` -* `tf.image.sample_distorted_bounding_box` - -## Denoising - -* `tf.image.total_variation` diff --git a/tensorflow/docs_src/api_guides/python/index.md b/tensorflow/docs_src/api_guides/python/index.md deleted file mode 100644 index a791a1432a..0000000000 --- a/tensorflow/docs_src/api_guides/python/index.md +++ /dev/null @@ -1,52 +0,0 @@ -# Python API Guides - -* [Asserts and boolean checks](check_ops.md) -* [Building Graphs](framework.md) -* [Constants, Sequences, and Random Values](constant_op.md) -* [Control Flow](control_flow_ops.md) -* [Data IO (Python functions)](python_io.md) -* [Exporting and Importing a MetaGraph](meta_graph.md) -* [Higher Order Functions](functional_ops.md) -* [Histograms](histogram_ops.md) -* [Images](image.md) -* [Inputs and Readers](io_ops.md) -* [Math](math_ops.md) -* [Neural Network](nn.md) -* [Reading data](reading_data.md) -* [Running Graphs](client.md) -* [Sparse Tensors](sparse_ops.md) -* [Spectral Functions](spectral_ops.md) -* [Strings](string_ops.md) -* [Summary Operations](summary.md) -* [TensorFlow Debugger](tfdbg.md) -* [Tensor Handle Operations](session_ops.md) -* [Tensor Transformations](array_ops.md) -* [Testing](test.md) -* [Training](train.md) -* [Variables](state_ops.md) -* [Wraps python functions](script_ops.md) -* [BayesFlow Entropy (contrib)](contrib.bayesflow.entropy.md) -* [BayesFlow Monte Carlo (contrib)](contrib.bayesflow.monte_carlo.md) -* [BayesFlow Stochastic Graph (contrib)](contrib.bayesflow.stochastic_graph.md) -* [BayesFlow Stochastic Tensors (contrib)](contrib.bayesflow.stochastic_tensor.md) -* [BayesFlow Variational Inference (contrib)](contrib.bayesflow.variational_inference.md) -* [Copying Graph Elements (contrib)](contrib.copy_graph.md) -* [CRF (contrib)](contrib.crf.md) -* [FFmpeg (contrib)](contrib.ffmpeg.md) -* [Framework (contrib)](contrib.framework.md) -* [Graph Editor (contrib)](contrib.graph_editor.md) -* [Integrate (contrib)](contrib.integrate.md) -* [Layers (contrib)](contrib.layers.md) -* [Learn (contrib)](contrib.learn.md) -* [Linear Algebra (contrib)](contrib.linalg.md) -* [Losses (contrib)](contrib.losses.md) -* [Metrics (contrib)](contrib.metrics.md) -* [Optimization (contrib)](contrib.opt.md) -* [Random variable transformations (contrib)](contrib.distributions.bijectors.md) -* [RNN and Cells (contrib)](contrib.rnn.md) -* [Seq2seq Library (contrib)](contrib.seq2seq.md) -* [Signal Processing (contrib)](contrib.signal.md) -* [Staging (contrib)](contrib.staging.md) -* [Statistical Distributions (contrib)](contrib.distributions.md) -* [Training (contrib)](contrib.training.md) -* [Utilities (contrib)](contrib.util.md) diff --git a/tensorflow/docs_src/api_guides/python/input_dataset.md b/tensorflow/docs_src/api_guides/python/input_dataset.md deleted file mode 100644 index 911a76c2df..0000000000 --- a/tensorflow/docs_src/api_guides/python/input_dataset.md +++ /dev/null @@ -1,85 +0,0 @@ -# Dataset Input Pipeline -[TOC] - -`tf.data.Dataset` allows you to build complex input pipelines. See the -[Importing Data](../../guide/datasets.md) for an in-depth explanation of how to use this API. - -## Reader classes - -Classes that create a dataset from input files. - -* `tf.data.FixedLengthRecordDataset` -* `tf.data.TextLineDataset` -* `tf.data.TFRecordDataset` - -## Creating new datasets - -Static methods in `Dataset` that create new datasets. - -* `tf.data.Dataset.from_generator` -* `tf.data.Dataset.from_tensor_slices` -* `tf.data.Dataset.from_tensors` -* `tf.data.Dataset.list_files` -* `tf.data.Dataset.range` -* `tf.data.Dataset.zip` - -## Transformations on existing datasets - -These functions transform an existing dataset, and return a new dataset. Calls -can be chained together, as shown in the example below: - -``` -train_data = train_data.batch(100).shuffle().repeat() -``` - -* `tf.data.Dataset.apply` -* `tf.data.Dataset.batch` -* `tf.data.Dataset.cache` -* `tf.data.Dataset.concatenate` -* `tf.data.Dataset.filter` -* `tf.data.Dataset.flat_map` -* `tf.data.Dataset.interleave` -* `tf.data.Dataset.map` -* `tf.data.Dataset.padded_batch` -* `tf.data.Dataset.prefetch` -* `tf.data.Dataset.repeat` -* `tf.data.Dataset.shard` -* `tf.data.Dataset.shuffle` -* `tf.data.Dataset.skip` -* `tf.data.Dataset.take` - -### Custom transformation functions - -Custom transformation functions can be applied to a `Dataset` using `tf.data.Dataset.apply`. Below are custom transformation functions from `tf.contrib.data`: - -* `tf.contrib.data.batch_and_drop_remainder` -* `tf.contrib.data.dense_to_sparse_batch` -* `tf.contrib.data.enumerate_dataset` -* `tf.contrib.data.group_by_window` -* `tf.contrib.data.ignore_errors` -* `tf.contrib.data.map_and_batch` -* `tf.contrib.data.padded_batch_and_drop_remainder` -* `tf.contrib.data.parallel_interleave` -* `tf.contrib.data.rejection_resample` -* `tf.contrib.data.scan` -* `tf.contrib.data.shuffle_and_repeat` -* `tf.contrib.data.unbatch` - -## Iterating over datasets - -These functions make a `tf.data.Iterator` from a `Dataset`. - -* `tf.data.Dataset.make_initializable_iterator` -* `tf.data.Dataset.make_one_shot_iterator` - -The `Iterator` class also contains static methods that create a `tf.data.Iterator` that can be used with multiple `Dataset` objects. - -* `tf.data.Iterator.from_structure` -* `tf.data.Iterator.from_string_handle` - -## Extra functions from `tf.contrib.data` - -* `tf.contrib.data.get_single_element` -* `tf.contrib.data.make_saveable_from_iterator` -* `tf.contrib.data.read_batch_features` - diff --git a/tensorflow/docs_src/api_guides/python/io_ops.md b/tensorflow/docs_src/api_guides/python/io_ops.md deleted file mode 100644 index d7ce6fdfde..0000000000 --- a/tensorflow/docs_src/api_guides/python/io_ops.md +++ /dev/null @@ -1,130 +0,0 @@ -# Inputs and Readers - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Placeholders - -TensorFlow provides a placeholder operation that must be fed with data -on execution. For more info, see the section on [Feeding data](../../api_guides/python/reading_data.md#Feeding). - -* `tf.placeholder` -* `tf.placeholder_with_default` - -For feeding `SparseTensor`s which are composite type, -there is a convenience function: - -* `tf.sparse_placeholder` - -## Readers - -TensorFlow provides a set of Reader classes for reading data formats. -For more information on inputs and readers, see [Reading data](../../api_guides/python/reading_data.md). - -* `tf.ReaderBase` -* `tf.TextLineReader` -* `tf.WholeFileReader` -* `tf.IdentityReader` -* `tf.TFRecordReader` -* `tf.FixedLengthRecordReader` - -## Converting - -TensorFlow provides several operations that you can use to convert various data -formats into tensors. - -* `tf.decode_csv` -* `tf.decode_raw` - -- - - - -### Example protocol buffer - -TensorFlow's [recommended format for training examples](../../api_guides/python/reading_data.md#standard_tensorflow_format) -is serialized `Example` protocol buffers, [described -here](https://www.tensorflow.org/code/tensorflow/core/example/example.proto). -They contain `Features`, [described -here](https://www.tensorflow.org/code/tensorflow/core/example/feature.proto). - -* `tf.VarLenFeature` -* `tf.FixedLenFeature` -* `tf.FixedLenSequenceFeature` -* `tf.SparseFeature` -* `tf.parse_example` -* `tf.parse_single_example` -* `tf.parse_tensor` -* `tf.decode_json_example` - -## Queues - -TensorFlow provides several implementations of 'Queues', which are -structures within the TensorFlow computation graph to stage pipelines -of tensors together. The following describe the basic Queue interface -and some implementations. To see an example use, see [Threading and Queues](../../api_guides/python/threading_and_queues.md). - -* `tf.QueueBase` -* `tf.FIFOQueue` -* `tf.PaddingFIFOQueue` -* `tf.RandomShuffleQueue` -* `tf.PriorityQueue` - -## Conditional Accumulators - -* `tf.ConditionalAccumulatorBase` -* `tf.ConditionalAccumulator` -* `tf.SparseConditionalAccumulator` - -## Dealing with the filesystem - -* `tf.matching_files` -* `tf.read_file` -* `tf.write_file` - -## Input pipeline - -TensorFlow functions for setting up an input-prefetching pipeline. -Please see the [reading data how-to](../../api_guides/python/reading_data.md) -for context. - -### Beginning of an input pipeline - -The "producer" functions add a queue to the graph and a corresponding -`QueueRunner` for running the subgraph that fills that queue. - -* `tf.train.match_filenames_once` -* `tf.train.limit_epochs` -* `tf.train.input_producer` -* `tf.train.range_input_producer` -* `tf.train.slice_input_producer` -* `tf.train.string_input_producer` - -### Batching at the end of an input pipeline - -These functions add a queue to the graph to assemble a batch of -examples, with possible shuffling. They also add a `QueueRunner` for -running the subgraph that fills that queue. - -Use `tf.train.batch` or `tf.train.batch_join` for batching -examples that have already been well shuffled. Use -`tf.train.shuffle_batch` or -`tf.train.shuffle_batch_join` for examples that would -benefit from additional shuffling. - -Use `tf.train.batch` or `tf.train.shuffle_batch` if you want a -single thread producing examples to batch, or if you have a -single subgraph producing examples but you want to run it in *N* threads -(where you increase *N* until it can keep the queue full). Use -`tf.train.batch_join` or `tf.train.shuffle_batch_join` -if you have *N* different subgraphs producing examples to batch and you -want them run by *N* threads. Use `maybe_*` to enqueue conditionally. - -* `tf.train.batch` -* `tf.train.maybe_batch` -* `tf.train.batch_join` -* `tf.train.maybe_batch_join` -* `tf.train.shuffle_batch` -* `tf.train.maybe_shuffle_batch` -* `tf.train.shuffle_batch_join` -* `tf.train.maybe_shuffle_batch_join` diff --git a/tensorflow/docs_src/api_guides/python/math_ops.md b/tensorflow/docs_src/api_guides/python/math_ops.md deleted file mode 100644 index e738161e49..0000000000 --- a/tensorflow/docs_src/api_guides/python/math_ops.md +++ /dev/null @@ -1,199 +0,0 @@ -# Math - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -Note: Elementwise binary operations in TensorFlow follow [numpy-style -broadcasting](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html). - -## Arithmetic Operators - -TensorFlow provides several operations that you can use to add basic arithmetic -operators to your graph. - -* `tf.add` -* `tf.subtract` -* `tf.multiply` -* `tf.scalar_mul` -* `tf.div` -* `tf.divide` -* `tf.truediv` -* `tf.floordiv` -* `tf.realdiv` -* `tf.truncatediv` -* `tf.floor_div` -* `tf.truncatemod` -* `tf.floormod` -* `tf.mod` -* `tf.cross` - -## Basic Math Functions - -TensorFlow provides several operations that you can use to add basic -mathematical functions to your graph. - -* `tf.add_n` -* `tf.abs` -* `tf.negative` -* `tf.sign` -* `tf.reciprocal` -* `tf.square` -* `tf.round` -* `tf.sqrt` -* `tf.rsqrt` -* `tf.pow` -* `tf.exp` -* `tf.expm1` -* `tf.log` -* `tf.log1p` -* `tf.ceil` -* `tf.floor` -* `tf.maximum` -* `tf.minimum` -* `tf.cos` -* `tf.sin` -* `tf.lbeta` -* `tf.tan` -* `tf.acos` -* `tf.asin` -* `tf.atan` -* `tf.cosh` -* `tf.sinh` -* `tf.asinh` -* `tf.acosh` -* `tf.atanh` -* `tf.lgamma` -* `tf.digamma` -* `tf.erf` -* `tf.erfc` -* `tf.squared_difference` -* `tf.igamma` -* `tf.igammac` -* `tf.zeta` -* `tf.polygamma` -* `tf.betainc` -* `tf.rint` - -## Matrix Math Functions - -TensorFlow provides several operations that you can use to add linear algebra -functions on matrices to your graph. - -* `tf.diag` -* `tf.diag_part` -* `tf.trace` -* `tf.transpose` -* `tf.eye` -* `tf.matrix_diag` -* `tf.matrix_diag_part` -* `tf.matrix_band_part` -* `tf.matrix_set_diag` -* `tf.matrix_transpose` -* `tf.matmul` -* `tf.norm` -* `tf.matrix_determinant` -* `tf.matrix_inverse` -* `tf.cholesky` -* `tf.cholesky_solve` -* `tf.matrix_solve` -* `tf.matrix_triangular_solve` -* `tf.matrix_solve_ls` -* `tf.qr` -* `tf.self_adjoint_eig` -* `tf.self_adjoint_eigvals` -* `tf.svd` - - -## Tensor Math Function - -TensorFlow provides operations that you can use to add tensor functions to your -graph. - -* `tf.tensordot` - - -## Complex Number Functions - -TensorFlow provides several operations that you can use to add complex number -functions to your graph. - -* `tf.complex` -* `tf.conj` -* `tf.imag` -* `tf.angle` -* `tf.real` - - -## Reduction - -TensorFlow provides several operations that you can use to perform -common math computations that reduce various dimensions of a tensor. - -* `tf.reduce_sum` -* `tf.reduce_prod` -* `tf.reduce_min` -* `tf.reduce_max` -* `tf.reduce_mean` -* `tf.reduce_all` -* `tf.reduce_any` -* `tf.reduce_logsumexp` -* `tf.count_nonzero` -* `tf.accumulate_n` -* `tf.einsum` - -## Scan - -TensorFlow provides several operations that you can use to perform scans -(running totals) across one axis of a tensor. - -* `tf.cumsum` -* `tf.cumprod` - -## Segmentation - -TensorFlow provides several operations that you can use to perform common -math computations on tensor segments. -Here a segmentation is a partitioning of a tensor along -the first dimension, i.e. it defines a mapping from the first dimension onto -`segment_ids`. The `segment_ids` tensor should be the size of -the first dimension, `d0`, with consecutive IDs in the range `0` to `k`, -where `k<d0`. -In particular, a segmentation of a matrix tensor is a mapping of rows to -segments. - -For example: - -```python -c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]]) -tf.segment_sum(c, tf.constant([0, 0, 1])) - ==> [[0 0 0 0] - [5 6 7 8]] -``` - -* `tf.segment_sum` -* `tf.segment_prod` -* `tf.segment_min` -* `tf.segment_max` -* `tf.segment_mean` -* `tf.unsorted_segment_sum` -* `tf.sparse_segment_sum` -* `tf.sparse_segment_mean` -* `tf.sparse_segment_sqrt_n` - - -## Sequence Comparison and Indexing - -TensorFlow provides several operations that you can use to add sequence -comparison and index extraction to your graph. You can use these operations to -determine sequence differences and determine the indexes of specific values in -a tensor. - -* `tf.argmin` -* `tf.argmax` -* `tf.setdiff1d` -* `tf.where` -* `tf.unique` -* `tf.edit_distance` -* `tf.invert_permutation` diff --git a/tensorflow/docs_src/api_guides/python/meta_graph.md b/tensorflow/docs_src/api_guides/python/meta_graph.md deleted file mode 100644 index 5e8a8b4d0f..0000000000 --- a/tensorflow/docs_src/api_guides/python/meta_graph.md +++ /dev/null @@ -1,277 +0,0 @@ -# Exporting and Importing a MetaGraph - -A [`MetaGraph`](https://www.tensorflow.org/code/tensorflow/core/protobuf/meta_graph.proto) contains both a TensorFlow GraphDef -as well as associated metadata necessary for running computation in a -graph when crossing a process boundary. It can also be used for long -term storage of graphs. The MetaGraph contains the information required -to continue training, perform evaluation, or run inference on a previously trained graph. - -The APIs for exporting and importing the complete model are in -the `tf.train.Saver` class: -`tf.train.export_meta_graph` -and -`tf.train.import_meta_graph`. - -## What's in a MetaGraph - -The information contained in a MetaGraph is expressed as a -[`MetaGraphDef`](https://www.tensorflow.org/code/tensorflow/core/protobuf/meta_graph.proto) -protocol buffer. It contains the following fields: - -* [`MetaInfoDef`](https://www.tensorflow.org/code/tensorflow/core/protobuf/meta_graph.proto) for meta information, such as version and other user information. -* [`GraphDef`](https://www.tensorflow.org/code/tensorflow/core/framework/graph.proto) for describing the graph. -* [`SaverDef`](https://www.tensorflow.org/code/tensorflow/core/protobuf/saver.proto) for the saver. -* [`CollectionDef`](https://www.tensorflow.org/code/tensorflow/core/protobuf/meta_graph.proto) -map that further describes additional components of the model such as -[`Variables`](../../api_guides/python/state_ops.md), -`tf.train.QueueRunner`, etc. - -In order for a Python object to be serialized -to and from `MetaGraphDef`, the Python class must implement `to_proto()` and -`from_proto()` methods, and register them with the system using -`register_proto_function`. For example: - - ```Python - def to_proto(self, export_scope=None): - - """Converts a `Variable` to a `VariableDef` protocol buffer. - - Args: - export_scope: Optional `string`. Name scope to remove. - - Returns: - A `VariableDef` protocol buffer, or `None` if the `Variable` is not - in the specified name scope. - """ - if (export_scope is None or - self._variable.name.startswith(export_scope)): - var_def = variable_pb2.VariableDef() - var_def.variable_name = ops.strip_name_scope( - self._variable.name, export_scope) - var_def.initializer_name = ops.strip_name_scope( - self.initializer.name, export_scope) - var_def.snapshot_name = ops.strip_name_scope( - self._snapshot.name, export_scope) - if self._save_slice_info: - var_def.save_slice_info_def.MergeFrom(self._save_slice_info.to_proto( - export_scope=export_scope)) - return var_def - else: - return None - - @staticmethod - def from_proto(variable_def, import_scope=None): - """Returns a `Variable` object created from `variable_def`.""" - return Variable(variable_def=variable_def, import_scope=import_scope) - - ops.register_proto_function(ops.GraphKeys.GLOBAL_VARIABLES, - proto_type=variable_pb2.VariableDef, - to_proto=Variable.to_proto, - from_proto=Variable.from_proto) - ``` - -## Exporting a Complete Model to MetaGraph - -The API for exporting a running model as a MetaGraph is `export_meta_graph()`. - - ```Python - def export_meta_graph(filename=None, collection_list=None, as_text=False): - """Writes `MetaGraphDef` to save_path/filename. - - Args: - filename: Optional meta_graph filename including the path. - collection_list: List of string keys to collect. - as_text: If `True`, writes the meta_graph as an ASCII proto. - - Returns: - A `MetaGraphDef` proto. - """ - ``` - - A `collection` can contain any Python objects that users would like to - be able to uniquely identify and easily retrieve. These objects can be - special operations in the graph, such as `train_op`, or hyper parameters, - such as "learning rate". Users can specify the list of collections - they would like to export. If no `collection_list` is specified, - all collections in the model will be exported. - - The API returns a serialized protocol buffer. If `filename` is - specified, the protocol buffer will also be written to a file. - - Here are some of the typical usage models: - - * Export the default running graph: - - ```Python - # Build the model - ... - with tf.Session() as sess: - # Use the model - ... - # Export the model to /tmp/my-model.meta. - meta_graph_def = tf.train.export_meta_graph(filename='/tmp/my-model.meta') - ``` - - * Export the default running graph and only a subset of the collections. - - ```Python - meta_graph_def = tf.train.export_meta_graph( - filename='/tmp/my-model.meta', - collection_list=["input_tensor", "output_tensor"]) - ``` - - -The MetaGraph is also automatically exported via the `save()` API in -`tf.train.Saver`. - - -## Import a MetaGraph - -The API for importing a MetaGraph file into a graph is `import_meta_graph()`. - -Here are some of the typical usage models: - -* Import and continue training without building the model from scratch. - - ```Python - ... - # Create a saver. - saver = tf.train.Saver(...variables...) - # Remember the training_op we want to run by adding it to a collection. - tf.add_to_collection('train_op', train_op) - sess = tf.Session() - for step in xrange(1000000): - sess.run(train_op) - if step % 1000 == 0: - # Saves checkpoint, which by default also exports a meta_graph - # named 'my-model-global_step.meta'. - saver.save(sess, 'my-model', global_step=step) - ``` - - Later we can continue training from this saved `meta_graph` without building - the model from scratch. - - ```Python - with tf.Session() as sess: - new_saver = tf.train.import_meta_graph('my-save-dir/my-model-10000.meta') - new_saver.restore(sess, 'my-save-dir/my-model-10000') - # tf.get_collection() returns a list. In this example we only want the - # first one. - train_op = tf.get_collection('train_op')[0] - for step in xrange(1000000): - sess.run(train_op) - ``` - -* Import and extend the graph. - - For example, we can first build an inference graph, export it as a meta graph: - - ```Python - # Creates an inference graph. - # Hidden 1 - images = tf.constant(1.2, tf.float32, shape=[100, 28]) - with tf.name_scope("hidden1"): - weights = tf.Variable( - tf.truncated_normal([28, 128], - stddev=1.0 / math.sqrt(float(28))), - name="weights") - biases = tf.Variable(tf.zeros([128]), - name="biases") - hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases) - # Hidden 2 - with tf.name_scope("hidden2"): - weights = tf.Variable( - tf.truncated_normal([128, 32], - stddev=1.0 / math.sqrt(float(128))), - name="weights") - biases = tf.Variable(tf.zeros([32]), - name="biases") - hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases) - # Linear - with tf.name_scope("softmax_linear"): - weights = tf.Variable( - tf.truncated_normal([32, 10], - stddev=1.0 / math.sqrt(float(32))), - name="weights") - biases = tf.Variable(tf.zeros([10]), - name="biases") - logits = tf.matmul(hidden2, weights) + biases - tf.add_to_collection("logits", logits) - - init_all_op = tf.global_variables_initializer() - - with tf.Session() as sess: - # Initializes all the variables. - sess.run(init_all_op) - # Runs to logit. - sess.run(logits) - # Creates a saver. - saver0 = tf.train.Saver() - saver0.save(sess, 'my-save-dir/my-model-10000') - # Generates MetaGraphDef. - saver0.export_meta_graph('my-save-dir/my-model-10000.meta') - ``` - - Then later import it and extend it to a training graph. - - ```Python - with tf.Session() as sess: - new_saver = tf.train.import_meta_graph('my-save-dir/my-model-10000.meta') - new_saver.restore(sess, 'my-save-dir/my-model-10000') - # Addes loss and train. - labels = tf.constant(0, tf.int32, shape=[100], name="labels") - batch_size = tf.size(labels) - logits = tf.get_collection("logits")[0] - loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, - logits=logits) - - tf.summary.scalar('loss', loss) - # Creates the gradient descent optimizer with the given learning rate. - optimizer = tf.train.GradientDescentOptimizer(0.01) - - # Runs train_op. - train_op = optimizer.minimize(loss) - sess.run(train_op) - ``` - -* Import a graph with preset devices. - - Sometimes an exported meta graph is from a training environment that the - importer doesn't have. For example, the model might have been trained - on GPUs, or in a distributed environment with replicas. When importing - such models, it's useful to be able to clear the device settings in - the graph so that we can run it on locally available devices. This can - be achieved by calling `import_meta_graph` with the `clear_devices` - option set to `True`. - - ```Python - with tf.Session() as sess: - new_saver = tf.train.import_meta_graph('my-save-dir/my-model-10000.meta', - clear_devices=True) - new_saver.restore(sess, 'my-save-dir/my-model-10000') - ... - ``` - -* Import within the default graph. - - Sometimes you might want to run `export_meta_graph` and `import_meta_graph` - in codelab using the default graph. In that case, you need to reset - the default graph by calling `tf.reset_default_graph()` first before - running import. - - ```Python - meta_graph_def = tf.train.export_meta_graph() - ... - tf.reset_default_graph() - ... - tf.train.import_meta_graph(meta_graph_def) - ... - ``` - -* Retrieve Hyper Parameters - - ```Python - filename = ".".join([tf.train.latest_checkpoint(train_dir), "meta"]) - tf.train.import_meta_graph(filename) - hparams = tf.get_collection("hparams") - ``` diff --git a/tensorflow/docs_src/api_guides/python/nn.md b/tensorflow/docs_src/api_guides/python/nn.md deleted file mode 100644 index 40dda3941d..0000000000 --- a/tensorflow/docs_src/api_guides/python/nn.md +++ /dev/null @@ -1,418 +0,0 @@ -# Neural Network - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Activation Functions - -The activation ops provide different types of nonlinearities for use in neural -networks. These include smooth nonlinearities (`sigmoid`, `tanh`, `elu`, `selu`, -`softplus`, and `softsign`), continuous but not everywhere differentiable -functions (`relu`, `relu6`, `crelu` and `relu_x`), and random regularization -(`dropout`). - -All activation ops apply componentwise, and produce a tensor of the same -shape as the input tensor. - -* `tf.nn.relu` -* `tf.nn.relu6` -* `tf.nn.crelu` -* `tf.nn.elu` -* `tf.nn.selu` -* `tf.nn.softplus` -* `tf.nn.softsign` -* `tf.nn.dropout` -* `tf.nn.bias_add` -* `tf.sigmoid` -* `tf.tanh` - -## Convolution - -The convolution ops sweep a 2-D filter over a batch of images, applying the -filter to each window of each image of the appropriate size. The different -ops trade off between generic vs. specific filters: - -* `conv2d`: Arbitrary filters that can mix channels together. -* `depthwise_conv2d`: Filters that operate on each channel independently. -* `separable_conv2d`: A depthwise spatial filter followed by a pointwise filter. - -Note that although these ops are called "convolution", they are strictly -speaking "cross-correlation" since the filter is combined with an input window -without reversing the filter. For details, see [the properties of -cross-correlation](https://en.wikipedia.org/wiki/Cross-correlation#Properties). - -The filter is applied to image patches of the same size as the filter and -strided according to the `strides` argument. `strides = [1, 1, 1, 1]` applies -the filter to a patch at every offset, `strides = [1, 2, 2, 1]` applies the -filter to every other image patch in each dimension, etc. - -Ignoring channels for the moment, assume that the 4-D `input` has shape -`[batch, in_height, in_width, ...]` and the 4-D `filter` has shape -`[filter_height, filter_width, ...]`. The spatial semantics of the -convolution ops depend on the padding scheme chosen: `'SAME'` or `'VALID'`. -Note that the padding values are always zero. - -First, consider the `'SAME'` padding scheme. A detailed explanation of the -reasoning behind it is given in -[these notes](#Notes_on_SAME_Convolution_Padding). Here, we summarize the -mechanics of this padding scheme. When using `'SAME'`, the output height and -width are computed as: - - out_height = ceil(float(in_height) / float(strides[1])) - out_width = ceil(float(in_width) / float(strides[2])) - -The total padding applied along the height and width is computed as: - - if (in_height % strides[1] == 0): - pad_along_height = max(filter_height - strides[1], 0) - else: - pad_along_height = max(filter_height - (in_height % strides[1]), 0) - if (in_width % strides[2] == 0): - pad_along_width = max(filter_width - strides[2], 0) - else: - pad_along_width = max(filter_width - (in_width % strides[2]), 0) - -Finally, the padding on the top, bottom, left and right are: - - pad_top = pad_along_height // 2 - pad_bottom = pad_along_height - pad_top - pad_left = pad_along_width // 2 - pad_right = pad_along_width - pad_left - -Note that the division by 2 means that there might be cases when the padding on -both sides (top vs bottom, right vs left) are off by one. In this case, the -bottom and right sides always get the one additional padded pixel. For example, -when `pad_along_height` is 5, we pad 2 pixels at the top and 3 pixels at the -bottom. Note that this is different from existing libraries such as cuDNN and -Caffe, which explicitly specify the number of padded pixels and always pad the -same number of pixels on both sides. - -For the `'VALID'` scheme, the output height and width are computed as: - - out_height = ceil(float(in_height - filter_height + 1) / float(strides[1])) - out_width = ceil(float(in_width - filter_width + 1) / float(strides[2])) - -and no padding is used. - -Given the output size and the padding, the output can be computed as - -$$ output[b, i, j, :] = - sum_{d_i, d_j} input[b, strides[1] * i + d_i - pad_{top},\ - strides[2] * j + d_j - pad_{left}, ...] * - filter[d_i, d_j,\ ...]$$ - -where any value outside the original input image region are considered zero ( -i.e. we pad zero values around the border of the image). - -Since `input` is 4-D, each `input[b, i, j, :]` is a vector. For `conv2d`, these -vectors are multiplied by the `filter[di, dj, :, :]` matrices to produce new -vectors. For `depthwise_conv_2d`, each scalar component `input[b, i, j, k]` -is multiplied by a vector `filter[di, dj, k]`, and all the vectors are -concatenated. - -* `tf.nn.convolution` -* `tf.nn.conv2d` -* `tf.nn.depthwise_conv2d` -* `tf.nn.depthwise_conv2d_native` -* `tf.nn.separable_conv2d` -* `tf.nn.atrous_conv2d` -* `tf.nn.atrous_conv2d_transpose` -* `tf.nn.conv2d_transpose` -* `tf.nn.conv1d` -* `tf.nn.conv3d` -* `tf.nn.conv3d_transpose` -* `tf.nn.conv2d_backprop_filter` -* `tf.nn.conv2d_backprop_input` -* `tf.nn.conv3d_backprop_filter_v2` -* `tf.nn.depthwise_conv2d_native_backprop_filter` -* `tf.nn.depthwise_conv2d_native_backprop_input` - -## Pooling - -The pooling ops sweep a rectangular window over the input tensor, computing a -reduction operation for each window (average, max, or max with argmax). Each -pooling op uses rectangular windows of size `ksize` separated by offset -`strides`. For example, if `strides` is all ones every window is used, if -`strides` is all twos every other window is used in each dimension, etc. - -In detail, the output is - - output[i] = reduce(value[strides * i:strides * i + ksize]) - -where the indices also take into consideration the padding values. Please refer -to the `Convolution` section for details about the padding calculation. - -* `tf.nn.avg_pool` -* `tf.nn.max_pool` -* `tf.nn.max_pool_with_argmax` -* `tf.nn.avg_pool3d` -* `tf.nn.max_pool3d` -* `tf.nn.fractional_avg_pool` -* `tf.nn.fractional_max_pool` -* `tf.nn.pool` - -## Morphological filtering - -Morphological operators are non-linear filters used in image processing. - -[Greyscale morphological dilation -](https://en.wikipedia.org/wiki/Dilation_(morphology)) -is the max-sum counterpart of standard sum-product convolution: - -$$ output[b, y, x, c] = - max_{dy, dx} input[b, - strides[1] * y + rates[1] * dy, - strides[2] * x + rates[2] * dx, - c] + - filter[dy, dx, c]$$ - -The `filter` is usually called structuring function. Max-pooling is a special -case of greyscale morphological dilation when the filter assumes all-zero -values (a.k.a. flat structuring function). - -[Greyscale morphological erosion -](https://en.wikipedia.org/wiki/Erosion_(morphology)) -is the min-sum counterpart of standard sum-product convolution: - -$$ output[b, y, x, c] = - min_{dy, dx} input[b, - strides[1] * y - rates[1] * dy, - strides[2] * x - rates[2] * dx, - c] - - filter[dy, dx, c]$$ - -Dilation and erosion are dual to each other. The dilation of the input signal -`f` by the structuring signal `g` is equal to the negation of the erosion of -`-f` by the reflected `g`, and vice versa. - -Striding and padding is carried out in exactly the same way as in standard -convolution. Please refer to the `Convolution` section for details. - -* `tf.nn.dilation2d` -* `tf.nn.erosion2d` -* `tf.nn.with_space_to_batch` - -## Normalization - -Normalization is useful to prevent neurons from saturating when inputs may -have varying scale, and to aid generalization. - -* `tf.nn.l2_normalize` -* `tf.nn.local_response_normalization` -* `tf.nn.sufficient_statistics` -* `tf.nn.normalize_moments` -* `tf.nn.moments` -* `tf.nn.weighted_moments` -* `tf.nn.fused_batch_norm` -* `tf.nn.batch_normalization` -* `tf.nn.batch_norm_with_global_normalization` - -## Losses - -The loss ops measure error between two tensors, or between a tensor and zero. -These can be used for measuring accuracy of a network in a regression task -or for regularization purposes (weight decay). - -* `tf.nn.l2_loss` -* `tf.nn.log_poisson_loss` - -## Classification - -TensorFlow provides several operations that help you perform classification. - -* `tf.nn.sigmoid_cross_entropy_with_logits` -* `tf.nn.softmax` -* `tf.nn.log_softmax` -* `tf.nn.softmax_cross_entropy_with_logits` -* `tf.nn.softmax_cross_entropy_with_logits_v2` - identical to the base - version, except it allows gradient propagation into the labels. -* `tf.nn.sparse_softmax_cross_entropy_with_logits` -* `tf.nn.weighted_cross_entropy_with_logits` - -## Embeddings - -TensorFlow provides library support for looking up values in embedding -tensors. - -* `tf.nn.embedding_lookup` -* `tf.nn.embedding_lookup_sparse` - -## Recurrent Neural Networks - -TensorFlow provides a number of methods for constructing Recurrent -Neural Networks. Most accept an `RNNCell`-subclassed object -(see the documentation for `tf.contrib.rnn`). - -* `tf.nn.dynamic_rnn` -* `tf.nn.bidirectional_dynamic_rnn` -* `tf.nn.raw_rnn` - -## Connectionist Temporal Classification (CTC) - -* `tf.nn.ctc_loss` -* `tf.nn.ctc_greedy_decoder` -* `tf.nn.ctc_beam_search_decoder` - -## Evaluation - -The evaluation ops are useful for measuring the performance of a network. -They are typically used at evaluation time. - -* `tf.nn.top_k` -* `tf.nn.in_top_k` - -## Candidate Sampling - -Do you want to train a multiclass or multilabel model with thousands -or millions of output classes (for example, a language model with a -large vocabulary)? Training with a full Softmax is slow in this case, -since all of the classes are evaluated for every training example. -Candidate Sampling training algorithms can speed up your step times by -only considering a small randomly-chosen subset of contrastive classes -(called candidates) for each batch of training examples. - -See our -[Candidate Sampling Algorithms -Reference](https://www.tensorflow.org/extras/candidate_sampling.pdf) - -### Sampled Loss Functions - -TensorFlow provides the following sampled loss functions for faster training. - -* `tf.nn.nce_loss` -* `tf.nn.sampled_softmax_loss` - -### Candidate Samplers - -TensorFlow provides the following samplers for randomly sampling candidate -classes when using one of the sampled loss functions above. - -* `tf.nn.uniform_candidate_sampler` -* `tf.nn.log_uniform_candidate_sampler` -* `tf.nn.learned_unigram_candidate_sampler` -* `tf.nn.fixed_unigram_candidate_sampler` - -### Miscellaneous candidate sampling utilities - -* `tf.nn.compute_accidental_hits` - -### Quantization ops - -* `tf.nn.quantized_conv2d` -* `tf.nn.quantized_relu_x` -* `tf.nn.quantized_max_pool` -* `tf.nn.quantized_avg_pool` - -## Notes on SAME Convolution Padding - -In these notes, we provide more background on the use of the `'SAME'` padding -scheme for convolution operations. - -Tensorflow uses the smallest possible padding to achieve the desired output -size. To understand what is done, consider the \\(1\\)-dimensional case. Denote -\\(n_i\\) and \\(n_o\\) the input and output sizes, respectively, and denote the -kernel size \\(k\\) and stride \\(s\\). As discussed in the -[Convolution section](#Convolution), for `'SAME'`, -\\(n_o = \left \lceil{\frac{n_i}{s}}\right \rceil\\). - -To achieve a desired output size \\(n_o\\), we need to pad the input such that the -output size after a `'VALID'` convolution is \\(n_o\\). In other words, we need to -have padding \\(p_i\\) such that: - -\begin{equation} -\left \lceil{\frac{n_i + p_i - k + 1}{s}}\right \rceil = n_o -\label{eq:tf_pad_1} -\end{equation} - -What is the smallest \\(p_i\\) that we could possibly use? In general, \\(\left -\lceil{\frac{x}{a}}\right \rceil = b\\) (with \\(a > 0\\)) means that \\(b-1 < -\frac{x}{a} \leq b\\), and the smallest integer \\(x\\) we can choose to satisfy -this is \\(x = a\cdot (b-1) + 1\\). The same applies to our problem; we need -\\(p_i\\) such that: - -\begin{equation} -n_i + p_i - k + 1 = s\cdot (n_o - 1) + 1 -\label{eq:tf_pad_2} -\end{equation} - -which leads to: - -\begin{equation} -p_i = s\cdot (n_o - 1) + k - n_i -\label{eq:tf_pad_3} -\end{equation} - -Note that this might lead to negative \\(p_i\\), since in some cases we might -already have more input samples than we actually need. Thus, - -\begin{equation} -p_i = max(s\cdot (n_o - 1) + k - n_i, 0) -\label{eq:tf_pad_4} -\end{equation} - -Remember that, for `'SAME'` padding, -\\(n_o = \left \lceil{\frac{n_i}{s}}\right \rceil\\), as mentioned above. -We need to analyze in detail two cases: - -- \\(n_i \text{ mod } s = 0\\) - -In this simple case, \\(n_o = \frac{n_i}{s}\\), and the expression for \\(p_i\\) -becomes: - -\begin{equation} -p_i = max(k - s, 0) -\label{eq:tf_pad_5} -\end{equation} - -- \\(n_i \text{ mod } s \neq 0\\) - -This case is more involved to parse. First, we write: - -\begin{equation} -n_i = s\cdot\left \lceil{\frac{n_i}{s}}\right \rceil -- s \left(\left \lceil{\frac{n_i}{s}}\right \rceil - - \left \lfloor{\frac{n_i}{s}}\right \rfloor\right) -+ (n_i \text{ mod } s) -\label{eq:tf_pad_6} -\end{equation} - -For the case where \\((n_i \text{ mod } s) \neq 0\\), we have \\(\left -\lceil{\frac{n_i}{s}}\right \rceil -\left \lfloor{\frac{n_i}{s}}\right \rfloor = -1\\), leading to: - -\begin{equation} -n_i = s\cdot\left \lceil{\frac{n_i}{s}}\right \rceil -- s -+ (n_i \text{ mod } s) -\label{eq:tf_pad_7} -\end{equation} - -We can use this expression to substitute \\(n_o = \left -\lceil{\frac{n_i}{s}}\right \rceil\\) and get: - -$$\begin{align} -p_i &= max\left(s\cdot \left(\frac{n_i + s - (n_i \text{ mod } s)}{s} - - 1\right) + k - n_i, 0\right) \nonumber\\ -&= max(n_i + s - (n_i \text{ mod } s) - s + k - n_i,0) \nonumber \\ -&= max(k - (n_i \text{ mod } s),0) -\label{eq:tf_pad_8} -\end{align}$$ - -### Final expression - -Putting all together, the total padding used by tensorflow's convolution with -`'SAME'` mode is: - -$$\begin{align} -p_i = - \begin{cases} - max(k - s, 0), & \text{if $(n_i \text{ mod } s) = 0$} \\ - max(k - (n_i \text{ mod } s),0), & \text{if $(n_i \text{ mod } s) \neq 0$} - \end{cases} - \label{eq:tf_pad_9} -\end{align}$$ - -This expression is exactly equal to the ones presented for `pad_along_height` -and `pad_along_width` in the [Convolution section](#Convolution). diff --git a/tensorflow/docs_src/api_guides/python/python_io.md b/tensorflow/docs_src/api_guides/python/python_io.md deleted file mode 100644 index e7e82a8701..0000000000 --- a/tensorflow/docs_src/api_guides/python/python_io.md +++ /dev/null @@ -1,29 +0,0 @@ -# Data IO (Python functions) -[TOC] - -A TFRecords file represents a sequence of (binary) strings. The format is not -random access, so it is suitable for streaming large amounts of data but not -suitable if fast sharding or other non-sequential access is desired. - -* `tf.python_io.TFRecordWriter` -* `tf.python_io.tf_record_iterator` -* `tf.python_io.TFRecordCompressionType` -* `tf.python_io.TFRecordOptions` - -- - - - -## TFRecords Format Details - -A TFRecords file contains a sequence of strings with CRC32C (32-bit CRC using -the Castagnoli polynomial) hashes. Each record has the format - - uint64 length - uint32 masked_crc32_of_length - byte data[length] - uint32 masked_crc32_of_data - -and the records are concatenated together to produce the file. CRCs are -[described here](https://en.wikipedia.org/wiki/Cyclic_redundancy_check), and -the mask of a CRC is - - masked_crc = ((crc >> 15) | (crc << 17)) + 0xa282ead8ul diff --git a/tensorflow/docs_src/api_guides/python/reading_data.md b/tensorflow/docs_src/api_guides/python/reading_data.md deleted file mode 100644 index 9f555ee85d..0000000000 --- a/tensorflow/docs_src/api_guides/python/reading_data.md +++ /dev/null @@ -1,522 +0,0 @@ -# Reading data - -Note: The preferred way to feed data into a tensorflow program is using the -[`tf.data` API](../../guide/datasets.md). - -There are four methods of getting data into a TensorFlow program: - -* `tf.data` API: Easily construct a complex input pipeline. (preferred method) -* Feeding: Python code provides the data when running each step. -* `QueueRunner`: a queue-based input pipeline reads the data from files - at the beginning of a TensorFlow graph. -* Preloaded data: a constant or variable in the TensorFlow graph holds - all the data (for small data sets). - -[TOC] - -## `tf.data` API - -See the [Importing Data](../../guide/datasets.md) for an in-depth explanation of `tf.data.Dataset`. -The `tf.data` API enables you to extract and preprocess data -from different input/file formats, and apply transformations such as batching, -shuffling, and mapping functions over the dataset. This is an improved version -of the old input methods---feeding and `QueueRunner`---which are described -below for historical purposes. - -## Feeding - -Warning: "Feeding" is the least efficient way to feed data into a TensorFlow -program and should only be used for small experiments and debugging. - -TensorFlow's feed mechanism lets you inject data into any Tensor in a -computation graph. A Python computation can thus feed data directly into the -graph. - -Supply feed data through the `feed_dict` argument to a run() or eval() call -that initiates computation. - -```python -with tf.Session(): - input = tf.placeholder(tf.float32) - classifier = ... - print(classifier.eval(feed_dict={input: my_python_preprocessing_fn()})) -``` - -While you can replace any Tensor with feed data, including variables and -constants, the best practice is to use a -`tf.placeholder` node. A -`placeholder` exists solely to serve as the target of feeds. It is not -initialized and contains no data. A placeholder generates an error if -it is executed without a feed, so you won't forget to feed it. - -An example using `placeholder` and feeding to train on MNIST data can be found -in -[`tensorflow/examples/tutorials/mnist/fully_connected_feed.py`](https://www.tensorflow.org/code/tensorflow/examples/tutorials/mnist/fully_connected_feed.py). - -## `QueueRunner` - -Warning: This section discusses implementing input pipelines using the -queue-based APIs which can be cleanly replaced by the [`tf.data` -API](../../guide/datasets.md). - -A typical queue-based pipeline for reading records from files has the following stages: - -1. The list of filenames -2. *Optional* filename shuffling -3. *Optional* epoch limit -4. Filename queue -5. A Reader for the file format -6. A decoder for a record read by the reader -7. *Optional* preprocessing -8. Example queue - -### Filenames, shuffling, and epoch limits - -For the list of filenames, use either a constant string Tensor (like -`["file0", "file1"]` or `[("file%d" % i) for i in range(2)]`) or the -`tf.train.match_filenames_once` function. - -Pass the list of filenames to the `tf.train.string_input_producer` function. -`string_input_producer` creates a FIFO queue for holding the filenames until -the reader needs them. - -`string_input_producer` has options for shuffling and setting a maximum number -of epochs. A queue runner adds the whole list of filenames to the queue once -for each epoch, shuffling the filenames within an epoch if `shuffle=True`. -This procedure provides a uniform sampling of files, so that examples are not -under- or over- sampled relative to each other. - -The queue runner works in a thread separate from the reader that pulls -filenames from the queue, so the shuffling and enqueuing process does not -block the reader. - -### File formats - -Select the reader that matches your input file format and pass the filename -queue to the reader's read method. The read method outputs a key identifying -the file and record (useful for debugging if you have some weird records), and -a scalar string value. Use one (or more) of the decoder and conversion ops to -decode this string into the tensors that make up an example. - -#### CSV files - -To read text files in [comma-separated value (CSV) -format](https://tools.ietf.org/html/rfc4180), use a -`tf.TextLineReader` with the -`tf.decode_csv` operation. For example: - -```python -filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"]) - -reader = tf.TextLineReader() -key, value = reader.read(filename_queue) - -# Default values, in case of empty columns. Also specifies the type of the -# decoded result. -record_defaults = [[1], [1], [1], [1], [1]] -col1, col2, col3, col4, col5 = tf.decode_csv( - value, record_defaults=record_defaults) -features = tf.stack([col1, col2, col3, col4]) - -with tf.Session() as sess: - # Start populating the filename queue. - coord = tf.train.Coordinator() - threads = tf.train.start_queue_runners(coord=coord) - - for i in range(1200): - # Retrieve a single instance: - example, label = sess.run([features, col5]) - - coord.request_stop() - coord.join(threads) -``` - -Each execution of `read` reads a single line from the file. The -`decode_csv` op then parses the result into a list of tensors. The -`record_defaults` argument determines the type of the resulting tensors and -sets the default value to use if a value is missing in the input string. - -You must call `tf.train.start_queue_runners` to populate the queue before -you call `run` or `eval` to execute the `read`. Otherwise `read` will -block while it waits for filenames from the queue. - -#### Fixed length records - -To read binary files in which each record is a fixed number of bytes, use -`tf.FixedLengthRecordReader` -with the `tf.decode_raw` operation. -The `decode_raw` op converts from a string to a uint8 tensor. - -For example, [the CIFAR-10 dataset](http://www.cs.toronto.edu/~kriz/cifar.html) -uses a file format where each record is represented using a fixed number of -bytes: 1 byte for the label followed by 3072 bytes of image data. Once you have -a uint8 tensor, standard operations can slice out each piece and reformat as -needed. For CIFAR-10, you can see how to do the reading and decoding in -[`tensorflow_models/tutorials/image/cifar10/cifar10_input.py`](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/cifar10_input.py) -and described in -[this tutorial](../../tutorials/images/deep_cnn.md#prepare-the-data). - -#### Standard TensorFlow format - -Another approach is to convert whatever data you have into a supported format. -This approach makes it easier to mix and match data sets and network -architectures. The recommended format for TensorFlow is a -[TFRecords file](../../api_guides/python/python_io.md#tfrecords_format_details) -containing -[`tf.train.Example` protocol buffers](https://www.tensorflow.org/code/tensorflow/core/example/example.proto) -(which contain -[`Features`](https://www.tensorflow.org/code/tensorflow/core/example/feature.proto) -as a field). You write a little program that gets your data, stuffs it in an -`Example` protocol buffer, serializes the protocol buffer to a string, and then -writes the string to a TFRecords file using the -`tf.python_io.TFRecordWriter`. -For example, -[`tensorflow/examples/how_tos/reading_data/convert_to_records.py`](https://www.tensorflow.org/code/tensorflow/examples/how_tos/reading_data/convert_to_records.py) -converts MNIST data to this format. - -The recommended way to read a TFRecord file is with a `tf.data.TFRecordDataset`, [as in this example](https://www.tensorflow.org/code/tensorflow/examples/how_tos/reading_data/fully_connected_reader.py): - -``` python - dataset = tf.data.TFRecordDataset(filename) - dataset = dataset.repeat(num_epochs) - - # map takes a python function and applies it to every sample - dataset = dataset.map(decode) -``` - -To accomplish the same task with a queue based input pipeline requires the following code -(using the same `decode` function from the above example): - -``` python - filename_queue = tf.train.string_input_producer([filename], num_epochs=num_epochs) - reader = tf.TFRecordReader() - _, serialized_example = reader.read(filename_queue) - image,label = decode(serialized_example) -``` - -### Preprocessing - -You can then do any preprocessing of these examples you want. This would be any -processing that doesn't depend on trainable parameters. Examples include -normalization of your data, picking a random slice, adding noise or distortions, -etc. See -[`tensorflow_models/tutorials/image/cifar10/cifar10_input.py`](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/cifar10_input.py) -for an example. - -### Batching - -At the end of the pipeline we use another queue to batch together examples for -training, evaluation, or inference. For this we use a queue that randomizes the -order of examples, using the -`tf.train.shuffle_batch`. - -Example: - -``` -def read_my_file_format(filename_queue): - reader = tf.SomeReader() - key, record_string = reader.read(filename_queue) - example, label = tf.some_decoder(record_string) - processed_example = some_processing(example) - return processed_example, label - -def input_pipeline(filenames, batch_size, num_epochs=None): - filename_queue = tf.train.string_input_producer( - filenames, num_epochs=num_epochs, shuffle=True) - example, label = read_my_file_format(filename_queue) - # min_after_dequeue defines how big a buffer we will randomly sample - # from -- bigger means better shuffling but slower start up and more - # memory used. - # capacity must be larger than min_after_dequeue and the amount larger - # determines the maximum we will prefetch. Recommendation: - # min_after_dequeue + (num_threads + a small safety margin) * batch_size - min_after_dequeue = 10000 - capacity = min_after_dequeue + 3 * batch_size - example_batch, label_batch = tf.train.shuffle_batch( - [example, label], batch_size=batch_size, capacity=capacity, - min_after_dequeue=min_after_dequeue) - return example_batch, label_batch -``` - -If you need more parallelism or shuffling of examples between files, use -multiple reader instances using the -`tf.train.shuffle_batch_join`. -For example: - -``` -def read_my_file_format(filename_queue): - # Same as above - -def input_pipeline(filenames, batch_size, read_threads, num_epochs=None): - filename_queue = tf.train.string_input_producer( - filenames, num_epochs=num_epochs, shuffle=True) - example_list = [read_my_file_format(filename_queue) - for _ in range(read_threads)] - min_after_dequeue = 10000 - capacity = min_after_dequeue + 3 * batch_size - example_batch, label_batch = tf.train.shuffle_batch_join( - example_list, batch_size=batch_size, capacity=capacity, - min_after_dequeue=min_after_dequeue) - return example_batch, label_batch -``` - -You still only use a single filename queue that is shared by all the readers. -That way we ensure that the different readers use different files from the same -epoch until all the files from the epoch have been started. (It is also usually -sufficient to have a single thread filling the filename queue.) - -An alternative is to use a single reader via the -`tf.train.shuffle_batch` -with `num_threads` bigger than 1. This will make it read from a single file at -the same time (but faster than with 1 thread), instead of N files at once. -This can be important: - -* If you have more reading threads than input files, to avoid the risk that - you will have two threads reading the same example from the same file near - each other. -* Or if reading N files in parallel causes too many disk seeks. - -How many threads do you need? the `tf.train.shuffle_batch*` functions add a -summary to the graph that indicates how full the example queue is. If you have -enough reading threads, that summary will stay above zero. You can -[view your summaries as training progresses using TensorBoard](../../guide/summaries_and_tensorboard.md). - -### Creating threads to prefetch using `QueueRunner` objects - -The short version: many of the `tf.train` functions listed above add -`tf.train.QueueRunner` objects to your -graph. These require that you call -`tf.train.start_queue_runners` -before running any training or inference steps, or it will hang forever. This -will start threads that run the input pipeline, filling the example queue so -that the dequeue to get the examples will succeed. This is best combined with a -`tf.train.Coordinator` to cleanly -shut down these threads when there are errors. If you set a limit on the number -of epochs, that will use an epoch counter that will need to be initialized. The -recommended code pattern combining these is: - -```python -# Create the graph, etc. -init_op = tf.global_variables_initializer() - -# Create a session for running operations in the Graph. -sess = tf.Session() - -# Initialize the variables (like the epoch counter). -sess.run(init_op) - -# Start input enqueue threads. -coord = tf.train.Coordinator() -threads = tf.train.start_queue_runners(sess=sess, coord=coord) - -try: - while not coord.should_stop(): - # Run training steps or whatever - sess.run(train_op) - -except tf.errors.OutOfRangeError: - print('Done training -- epoch limit reached') -finally: - # When done, ask the threads to stop. - coord.request_stop() - -# Wait for threads to finish. -coord.join(threads) -sess.close() -``` - -#### Aside: What is happening here? - -First we create the graph. It will have a few pipeline stages that are -connected by queues. The first stage will generate filenames to read and enqueue -them in the filename queue. The second stage consumes filenames (using a -`Reader`), produces examples, and enqueues them in an example queue. Depending -on how you have set things up, you may actually have a few independent copies of -the second stage, so that you can read from multiple files in parallel. At the -end of these stages is an enqueue operation, which enqueues into a queue that -the next stage dequeues from. We want to start threads running these enqueuing -operations, so that our training loop can dequeue examples from the example -queue. - -<div style="width:70%; margin-left:12%; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://www.tensorflow.org/images/AnimatedFileQueues.gif"> -</div> - -The helpers in `tf.train` that create these queues and enqueuing operations add -a `tf.train.QueueRunner` to the -graph using the -`tf.train.add_queue_runner` -function. Each `QueueRunner` is responsible for one stage, and holds the list of -enqueue operations that need to be run in threads. Once the graph is -constructed, the -`tf.train.start_queue_runners` -function asks each QueueRunner in the graph to start its threads running the -enqueuing operations. - -If all goes well, you can now run your training steps and the queues will be -filled by the background threads. If you have set an epoch limit, at some point -an attempt to dequeue examples will get an -`tf.errors.OutOfRangeError`. This -is the TensorFlow equivalent of "end of file" (EOF) -- this means the epoch -limit has been reached and no more examples are available. - -The last ingredient is the -`tf.train.Coordinator`. This is responsible -for letting all the threads know if anything has signaled a shut down. Most -commonly this would be because an exception was raised, for example one of the -threads got an error when running some operation (or an ordinary Python -exception). - -For more about threading, queues, QueueRunners, and Coordinators -[see here](../../api_guides/python/threading_and_queues.md). - -#### Aside: How clean shut-down when limiting epochs works - -Imagine you have a model that has set a limit on the number of epochs to train -on. That means that the thread generating filenames will only run that many -times before generating an `OutOfRange` error. The QueueRunner will catch that -error, close the filename queue, and exit the thread. Closing the queue does two -things: - -* Any future attempt to enqueue in the filename queue will generate an error. - At this point there shouldn't be any threads trying to do that, but this - is helpful when queues are closed due to other errors. -* Any current or future dequeue will either succeed (if there are enough - elements left) or fail (with an `OutOfRange` error) immediately. They won't - block waiting for more elements to be enqueued, since by the previous point - that can't happen. - -The point is that when the filename queue is closed, there will likely still be -many filenames in that queue, so the next stage of the pipeline (with the reader -and other preprocessing) may continue running for some time. Once the filename -queue is exhausted, though, the next attempt to dequeue a filename (e.g. from a -reader that has finished with the file it was working on) will trigger an -`OutOfRange` error. In this case, though, you might have multiple threads -associated with a single QueueRunner. If this isn't the last thread in the -QueueRunner, the `OutOfRange` error just causes the one thread to exit. This -allows the other threads, which are still finishing up their last file, to -proceed until they finish as well. (Assuming you are using a -`tf.train.Coordinator`, -other types of errors will cause all the threads to stop.) Once all the reader -threads hit the `OutOfRange` error, only then does the next queue, the example -queue, gets closed. - -Again, the example queue will have some elements queued, so training will -continue until those are exhausted. If the example queue is a -`tf.RandomShuffleQueue`, say -because you are using `shuffle_batch` or `shuffle_batch_join`, it normally will -avoid ever having fewer than its `min_after_dequeue` attr elements buffered. -However, once the queue is closed that restriction will be lifted and the queue -will eventually empty. At that point the actual training threads, when they -try and dequeue from example queue, will start getting `OutOfRange` errors and -exiting. Once all the training threads are done, -`tf.train.Coordinator.join` -will return and you can exit cleanly. - -### Filtering records or producing multiple examples per record - -Instead of examples with shapes `[x, y, z]`, you will produce a batch of -examples with shape `[batch, x, y, z]`. The batch size can be 0 if you want to -filter this record out (maybe it is in a hold-out set?), or bigger than 1 if you -are producing multiple examples per record. Then simply set `enqueue_many=True` -when calling one of the batching functions (such as `shuffle_batch` or -`shuffle_batch_join`). - -### Sparse input data - -SparseTensors don't play well with queues. If you use SparseTensors you have -to decode the string records using -`tf.parse_example` **after** -batching (instead of using `tf.parse_single_example` before batching). - -## Preloaded data - -This is only used for small data sets that can be loaded entirely in memory. -There are two approaches: - -* Store the data in a constant. -* Store the data in a variable, that you initialize (or assign to) and then - never change. - -Using a constant is a bit simpler, but uses more memory (since the constant is -stored inline in the graph data structure, which may be duplicated a few times). - -```python -training_data = ... -training_labels = ... -with tf.Session(): - input_data = tf.constant(training_data) - input_labels = tf.constant(training_labels) - ... -``` - -To instead use a variable, you need to also initialize it after the graph has been built. - -```python -training_data = ... -training_labels = ... -with tf.Session() as sess: - data_initializer = tf.placeholder(dtype=training_data.dtype, - shape=training_data.shape) - label_initializer = tf.placeholder(dtype=training_labels.dtype, - shape=training_labels.shape) - input_data = tf.Variable(data_initializer, trainable=False, collections=[]) - input_labels = tf.Variable(label_initializer, trainable=False, collections=[]) - ... - sess.run(input_data.initializer, - feed_dict={data_initializer: training_data}) - sess.run(input_labels.initializer, - feed_dict={label_initializer: training_labels}) -``` - -Setting `trainable=False` keeps the variable out of the -`GraphKeys.TRAINABLE_VARIABLES` collection in the graph, so we won't try and -update it when training. Setting `collections=[]` keeps the variable out of the -`GraphKeys.GLOBAL_VARIABLES` collection used for saving and restoring checkpoints. - -Either way, -`tf.train.slice_input_producer` -can be used to produce a slice at a time. This shuffles the examples across an -entire epoch, so further shuffling when batching is undesirable. So instead of -using the `shuffle_batch` functions, we use the plain -`tf.train.batch` function. To use -multiple preprocessing threads, set the `num_threads` parameter to a number -bigger than 1. - -An MNIST example that preloads the data using constants can be found in -[`tensorflow/examples/how_tos/reading_data/fully_connected_preloaded.py`](https://www.tensorflow.org/code/tensorflow/examples/how_tos/reading_data/fully_connected_preloaded.py), and one that preloads the data using variables can be found in -[`tensorflow/examples/how_tos/reading_data/fully_connected_preloaded_var.py`](https://www.tensorflow.org/code/tensorflow/examples/how_tos/reading_data/fully_connected_preloaded_var.py), -You can compare these with the `fully_connected_feed` and -`fully_connected_reader` versions above. - -## Multiple input pipelines - -Commonly you will want to train on one dataset and evaluate (or "eval") on -another. One way to do this is to actually have two separate graphs and -sessions, maybe in separate processes: - -* The training process reads training input data and periodically writes - checkpoint files with all the trained variables. -* The evaluation process restores the checkpoint files into an inference - model that reads validation input data. - -This is what is done `tf.estimator` and manually in -[the example CIFAR-10 model](../../tutorials/images/deep_cnn.md#save-and-restore-checkpoints). -This has a couple of benefits: - -* The eval is performed on a single snapshot of the trained variables. -* You can perform the eval even after training has completed and exited. - -You can have the train and eval in the same graph in the same process, and share -their trained variables or layers. See [the shared variables tutorial](../../guide/variables.md). - -To support the single-graph approach -[`tf.data`](../../guide/datasets.md) also supplies -[advanced iterator types](../../guide/datasets.md#creating_an_iterator) that -that allow the user to change the input pipeline without rebuilding the graph or -session. - -Note: Regardless of the implementation, many -operations (like `tf.layers.batch_normalization`, and `tf.layers.dropout`) -need to know if they are in training or evaluation mode, and you must be -careful to set this appropriately if you change the data source. diff --git a/tensorflow/docs_src/api_guides/python/regression_examples.md b/tensorflow/docs_src/api_guides/python/regression_examples.md deleted file mode 100644 index d67f38f57a..0000000000 --- a/tensorflow/docs_src/api_guides/python/regression_examples.md +++ /dev/null @@ -1,232 +0,0 @@ -# Regression Examples - -This unit provides the following short examples demonstrating how -to implement regression in Estimators: - -<table> - <tr> <th>Example</th> <th>Demonstrates How To...</th></tr> - - <tr> - <td><a href="https://www.tensorflow.org/code/tensorflow/examples/get_started/regression/linear_regression.py">linear_regression.py</a></td> - <td>Use the `tf.estimator.LinearRegressor` Estimator to train a - regression model on numeric data.</td> - </tr> - - <tr> - <td><a href="https://www.tensorflow.org/code/tensorflow/examples/get_started/regression/linear_regression_categorical.py">linear_regression_categorical.py</a></td> - <td>Use the `tf.estimator.LinearRegressor` Estimator to train a - regression model on categorical data.</td> - </tr> - - <tr> - <td><a href="https://www.tensorflow.org/code/tensorflow/examples/get_started/regression/dnn_regression.py">dnn_regression.py</a></td> - <td>Use the `tf.estimator.DNNRegressor` Estimator to train a - regression model on discrete data with a deep neural network.</td> - </tr> - - <tr> - <td><a href="https://www.tensorflow.org/code/tensorflow/examples/get_started/regression/custom_regression.py">custom_regression.py</a></td> - <td>Use `tf.estimator.Estimator` to train a customized dnn - regression model.</td> - </tr> - -</table> - -The preceding examples rely on the following data set utility: - -<table> - <tr> <th>Utility</th> <th>Description</th></tr> - - <tr> - <td><a href="https://www.tensorflow.org/code/tensorflow/examples/get_started/regression/imports85.py">imports85.py</a></td> - <td>This program provides utility functions that load the - <tt>imports85</tt> data set into formats that other TensorFlow - programs (for example, <tt>linear_regression.py</tt> and - <tt>dnn_regression.py</tt>) can use.</td> - </tr> - - -</table> - - -<!-- -## Linear regression concepts - -If you are new to machine learning and want to learn about regression, -watch the following video: - -(todo:jbgordon) Video introduction goes here. ---> - -<!-- -[When MLCC becomes available externally, add links to the relevant MLCC units.] ---> - - -<a name="running"></a> -## Running the examples - -You must [install TensorFlow](../../install/index.md) prior to running these examples. -Depending on the way you've installed TensorFlow, you might also -need to activate your TensorFlow environment. Then, do the following: - -1. Clone the TensorFlow repository from github. -2. `cd` to the top of the downloaded tree. -3. Check out the branch for you current tensorflow version: `git checkout rX.X` -4. `cd tensorflow/examples/get_started/regression`. - -You can now run any of the example TensorFlow programs in the -`tensorflow/examples/get_started/regression` directory as you -would run any Python program: - -```bsh -python linear_regressor.py -``` - -During training, all three programs output the following information: - -* The name of the checkpoint directory, which is important for TensorBoard. -* The training loss after every 100 iterations, which helps you - determine whether the model is converging. - -For example, here's some possible output for the `linear_regressor.py` -program: - -``` None -INFO:tensorflow:Saving checkpoints for 1 into /tmp/tmpAObiz9/model.ckpt. -INFO:tensorflow:loss = 161.308, step = 1 -INFO:tensorflow:global_step/sec: 1557.24 -INFO:tensorflow:loss = 15.7937, step = 101 (0.065 sec) -INFO:tensorflow:global_step/sec: 1529.17 -INFO:tensorflow:loss = 12.1988, step = 201 (0.065 sec) -INFO:tensorflow:global_step/sec: 1663.86 -... -INFO:tensorflow:loss = 6.99378, step = 901 (0.058 sec) -INFO:tensorflow:Saving checkpoints for 1000 into /tmp/tmpAObiz9/model.ckpt. -INFO:tensorflow:Loss for final step: 5.12413. -``` - - -<a name="basic"></a> -## linear_regressor.py - -`linear_regressor.py` trains a model that predicts the price of a car from -two numerical features. - -<table> - <tr> - <td>Estimator</td> - <td><tt>LinearRegressor</tt>, which is a pre-made Estimator for linear - regression.</td> - </tr> - - <tr> - <td>Features</td> - <td>Numerical: <tt>body-style</tt> and <tt>make</tt>.</td> - </tr> - - <tr> - <td>Label</td> - <td>Numerical: <tt>price</tt> - </tr> - - <tr> - <td>Algorithm</td> - <td>Linear regression.</td> - </tr> -</table> - -After training the model, the program concludes by outputting predicted -car prices for two car models. - - - -<a name="categorical"></a> -## linear_regression_categorical.py - -This program illustrates ways to represent categorical features. It -also demonstrates how to train a linear model based on a mix of -categorical and numerical features. - -<table> - <tr> - <td>Estimator</td> - <td><tt>LinearRegressor</tt>, which is a pre-made Estimator for linear - regression. </td> - </tr> - - <tr> - <td>Features</td> - <td>Categorical: <tt>curb-weight</tt> and <tt>highway-mpg</tt>.<br/> - Numerical: <tt>body-style</tt> and <tt>make</tt>.</td> - </tr> - - <tr> - <td>Label</td> - <td>Numerical: <tt>price</tt>.</td> - </tr> - - <tr> - <td>Algorithm</td> - <td>Linear regression.</td> - </tr> -</table> - - -<a name="dnn"></a> -## dnn_regression.py - -Like `linear_regression_categorical.py`, the `dnn_regression.py` example -trains a model that predicts the price of a car from two features. -Unlike `linear_regression_categorical.py`, the `dnn_regression.py` example uses -a deep neural network to train the model. Both examples rely on the same -features; `dnn_regression.py` demonstrates how to treat categorical features -in a deep neural network. - -<table> - <tr> - <td>Estimator</td> - <td><tt>DNNRegressor</tt>, which is a pre-made Estimator for - regression that relies on a deep neural network. The - `hidden_units` parameter defines the topography of the network.</td> - </tr> - - <tr> - <td>Features</td> - <td>Categorical: <tt>curb-weight</tt> and <tt>highway-mpg</tt>.<br/> - Numerical: <tt>body-style</tt> and <tt>make</tt>.</td> - </tr> - - <tr> - <td>Label</td> - <td>Numerical: <tt>price</tt>.</td> - </tr> - - <tr> - <td>Algorithm</td> - <td>Regression through a deep neural network.</td> - </tr> -</table> - -After printing loss values, the program outputs the Mean Square Error -on a test set. - - -<a name="dnn"></a> -## custom_regression.py - -The `custom_regression.py` example also trains a model that predicts the price -of a car based on mixed real-valued and categorical input features, described by -feature_columns. Unlike `linear_regression_categorical.py`, and -`dnn_regression.py` this example does not use a pre-made estimator, but defines -a custom model using the base `tf.estimator.Estimator` class. The -custom model is quite similar to the model defined by `dnn_regression.py`. - -The custom model is defined by the `model_fn` argument to the constructor. The -customization is made more reusable through `params` dictionary, which is later -passed through to the `model_fn` when the `model_fn` is called. - -The `model_fn` returns an -`tf.estimator.EstimatorSpec` which is a simple structure -indicating to the `Estimator` which operations should be run to accomplish -various tasks. diff --git a/tensorflow/docs_src/api_guides/python/session_ops.md b/tensorflow/docs_src/api_guides/python/session_ops.md deleted file mode 100644 index 5f41bcf209..0000000000 --- a/tensorflow/docs_src/api_guides/python/session_ops.md +++ /dev/null @@ -1,15 +0,0 @@ -# Tensor Handle Operations - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Tensor Handle Operations - -TensorFlow provides several operators that allows the user to keep tensors -"in-place" across run calls. - -* `tf.get_session_handle` -* `tf.get_session_tensor` -* `tf.delete_session_tensor` diff --git a/tensorflow/docs_src/api_guides/python/sparse_ops.md b/tensorflow/docs_src/api_guides/python/sparse_ops.md deleted file mode 100644 index b360055ed0..0000000000 --- a/tensorflow/docs_src/api_guides/python/sparse_ops.md +++ /dev/null @@ -1,45 +0,0 @@ -# Sparse Tensors - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Sparse Tensor Representation - -TensorFlow supports a `SparseTensor` representation for data that is sparse -in multiple dimensions. Contrast this representation with `IndexedSlices`, -which is efficient for representing tensors that are sparse in their first -dimension, and dense along all other dimensions. - -* `tf.SparseTensor` -* `tf.SparseTensorValue` - -## Conversion - -* `tf.sparse_to_dense` -* `tf.sparse_tensor_to_dense` -* `tf.sparse_to_indicator` -* `tf.sparse_merge` - -## Manipulation - -* `tf.sparse_concat` -* `tf.sparse_reorder` -* `tf.sparse_reshape` -* `tf.sparse_split` -* `tf.sparse_retain` -* `tf.sparse_reset_shape` -* `tf.sparse_fill_empty_rows` -* `tf.sparse_transpose` - -## Reduction -* `tf.sparse_reduce_sum` -* `tf.sparse_reduce_sum_sparse` - -## Math Operations -* `tf.sparse_add` -* `tf.sparse_softmax` -* `tf.sparse_tensor_dense_matmul` -* `tf.sparse_maximum` -* `tf.sparse_minimum` diff --git a/tensorflow/docs_src/api_guides/python/spectral_ops.md b/tensorflow/docs_src/api_guides/python/spectral_ops.md deleted file mode 100644 index f6d109a3a0..0000000000 --- a/tensorflow/docs_src/api_guides/python/spectral_ops.md +++ /dev/null @@ -1,26 +0,0 @@ -# Spectral Functions - -[TOC] - -The `tf.spectral` module supports several spectral decomposition operations -that you can use to transform Tensors of real and complex signals. - -## Discrete Fourier Transforms - -* `tf.spectral.fft` -* `tf.spectral.ifft` -* `tf.spectral.fft2d` -* `tf.spectral.ifft2d` -* `tf.spectral.fft3d` -* `tf.spectral.ifft3d` -* `tf.spectral.rfft` -* `tf.spectral.irfft` -* `tf.spectral.rfft2d` -* `tf.spectral.irfft2d` -* `tf.spectral.rfft3d` -* `tf.spectral.irfft3d` - -## Discrete Cosine Transforms - -* `tf.spectral.dct` -* `tf.spectral.idct` diff --git a/tensorflow/docs_src/api_guides/python/state_ops.md b/tensorflow/docs_src/api_guides/python/state_ops.md deleted file mode 100644 index fc55ea1481..0000000000 --- a/tensorflow/docs_src/api_guides/python/state_ops.md +++ /dev/null @@ -1,110 +0,0 @@ -# Variables - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Variables - -* `tf.Variable` - -## Variable helper functions - -TensorFlow provides a set of functions to help manage the set of variables -collected in the graph. - -* `tf.global_variables` -* `tf.local_variables` -* `tf.model_variables` -* `tf.trainable_variables` -* `tf.moving_average_variables` -* `tf.global_variables_initializer` -* `tf.local_variables_initializer` -* `tf.variables_initializer` -* `tf.is_variable_initialized` -* `tf.report_uninitialized_variables` -* `tf.assert_variables_initialized` -* `tf.assign` -* `tf.assign_add` -* `tf.assign_sub` - -## Saving and Restoring Variables - -* `tf.train.Saver` -* `tf.train.latest_checkpoint` -* `tf.train.get_checkpoint_state` -* `tf.train.update_checkpoint_state` - -## Sharing Variables - -TensorFlow provides several classes and operations that you can use to -create variables contingent on certain conditions. - -* `tf.get_variable` -* `tf.get_local_variable` -* `tf.VariableScope` -* `tf.variable_scope` -* `tf.variable_op_scope` -* `tf.get_variable_scope` -* `tf.make_template` -* `tf.no_regularizer` -* `tf.constant_initializer` -* `tf.random_normal_initializer` -* `tf.truncated_normal_initializer` -* `tf.random_uniform_initializer` -* `tf.uniform_unit_scaling_initializer` -* `tf.zeros_initializer` -* `tf.ones_initializer` -* `tf.orthogonal_initializer` - -## Variable Partitioners for Sharding - -* `tf.fixed_size_partitioner` -* `tf.variable_axis_size_partitioner` -* `tf.min_max_variable_partitioner` - -## Sparse Variable Updates - -The sparse update ops modify a subset of the entries in a dense `Variable`, -either overwriting the entries or adding / subtracting a delta. These are -useful for training embedding models and similar lookup-based networks, since -only a small subset of embedding vectors change in any given step. - -Since a sparse update of a large tensor may be generated automatically during -gradient computation (as in the gradient of -`tf.gather`), -an `tf.IndexedSlices` class is provided that encapsulates a set -of sparse indices and values. `IndexedSlices` objects are detected and handled -automatically by the optimizers in most cases. - -* `tf.scatter_update` -* `tf.scatter_add` -* `tf.scatter_sub` -* `tf.scatter_mul` -* `tf.scatter_div` -* `tf.scatter_min` -* `tf.scatter_max` -* `tf.scatter_nd_update` -* `tf.scatter_nd_add` -* `tf.scatter_nd_sub` -* `tf.sparse_mask` -* `tf.IndexedSlices` - -### Read-only Lookup Tables - -* `tf.initialize_all_tables` -* `tf.tables_initializer` - - -## Exporting and Importing Meta Graphs - -* `tf.train.export_meta_graph` -* `tf.train.import_meta_graph` - -# Deprecated functions (removed after 2017-03-02). Please don't use them. - -* `tf.all_variables` -* `tf.initialize_all_variables` -* `tf.initialize_local_variables` -* `tf.initialize_variables` diff --git a/tensorflow/docs_src/api_guides/python/string_ops.md b/tensorflow/docs_src/api_guides/python/string_ops.md deleted file mode 100644 index 24a3aad642..0000000000 --- a/tensorflow/docs_src/api_guides/python/string_ops.md +++ /dev/null @@ -1,39 +0,0 @@ -# Strings - -Note: Functions taking `Tensor` arguments can also take anything accepted by -`tf.convert_to_tensor`. - -[TOC] - -## Hashing - -String hashing ops take a string input tensor and map each element to an -integer. - -* `tf.string_to_hash_bucket_fast` -* `tf.string_to_hash_bucket_strong` -* `tf.string_to_hash_bucket` - -## Joining - -String joining ops concatenate elements of input string tensors to produce a new -string tensor. - -* `tf.reduce_join` -* `tf.string_join` - -## Splitting - -* `tf.string_split` -* `tf.substr` - -## Conversion - -* `tf.as_string` -* `tf.string_to_number` - -* `tf.decode_raw` -* `tf.decode_csv` - -* `tf.encode_base64` -* `tf.decode_base64` diff --git a/tensorflow/docs_src/api_guides/python/summary.md b/tensorflow/docs_src/api_guides/python/summary.md deleted file mode 100644 index fc45e7b4c3..0000000000 --- a/tensorflow/docs_src/api_guides/python/summary.md +++ /dev/null @@ -1,23 +0,0 @@ -# Summary Operations -[TOC] - -Summaries provide a way to export condensed information about a model, which is -then accessible in tools such as [TensorBoard](../../guide/summaries_and_tensorboard.md). - -## Generation of Summaries - -### Class for writing Summaries -* `tf.summary.FileWriter` -* `tf.summary.FileWriterCache` - -### Summary Ops -* `tf.summary.tensor_summary` -* `tf.summary.scalar` -* `tf.summary.histogram` -* `tf.summary.audio` -* `tf.summary.image` -* `tf.summary.merge` -* `tf.summary.merge_all` - -## Utilities -* `tf.summary.get_summary_description` diff --git a/tensorflow/docs_src/api_guides/python/test.md b/tensorflow/docs_src/api_guides/python/test.md deleted file mode 100644 index b6e0a332b9..0000000000 --- a/tensorflow/docs_src/api_guides/python/test.md +++ /dev/null @@ -1,47 +0,0 @@ -# Testing -[TOC] - -## Unit tests - -TensorFlow provides a convenience class inheriting from `unittest.TestCase` -which adds methods relevant to TensorFlow tests. Here is an example: - -```python - import tensorflow as tf - - - class SquareTest(tf.test.TestCase): - - def testSquare(self): - with self.test_session(): - x = tf.square([2, 3]) - self.assertAllEqual(x.eval(), [4, 9]) - - - if __name__ == '__main__': - tf.test.main() -``` - -`tf.test.TestCase` inherits from `unittest.TestCase` but adds a few additional -methods. See `tf.test.TestCase` for details. - -* `tf.test.main` -* `tf.test.TestCase` -* `tf.test.test_src_dir_path` - -## Utilities - -Note: `tf.test.mock` is an alias to the python `mock` or `unittest.mock` -depending on the python version. - -* `tf.test.assert_equal_graph_def` -* `tf.test.get_temp_dir` -* `tf.test.is_built_with_cuda` -* `tf.test.is_gpu_available` -* `tf.test.gpu_device_name` - -## Gradient checking - -`tf.test.compute_gradient` and `tf.test.compute_gradient_error` perform -numerical differentiation of graphs for comparison against registered analytic -gradients. diff --git a/tensorflow/docs_src/api_guides/python/tfdbg.md b/tensorflow/docs_src/api_guides/python/tfdbg.md deleted file mode 100644 index 9778cdc0b0..0000000000 --- a/tensorflow/docs_src/api_guides/python/tfdbg.md +++ /dev/null @@ -1,50 +0,0 @@ -# TensorFlow Debugger -[TOC] - -Public Python API of TensorFlow Debugger (tfdbg). - -## Functions for adding debug watches - -These functions help you modify `RunOptions` to specify which `Tensor`s are to -be watched when the TensorFlow graph is executed at runtime. - -* `tfdbg.add_debug_tensor_watch` -* `tfdbg.watch_graph` -* `tfdbg.watch_graph_with_blacklists` - - -## Classes for debug-dump data and directories - -These classes allow you to load and inspect tensor values dumped from -TensorFlow graphs during runtime. - -* `tfdbg.DebugTensorDatum` -* `tfdbg.DebugDumpDir` - - -## Functions for loading debug-dump data - -* `tfdbg.load_tensor_from_event_file` - - -## Tensor-value predicates - -Built-in tensor-filter predicates to support conditional breakpoint between -runs. See `DebugDumpDir.find()` for more details. - -* `tfdbg.has_inf_or_nan` - - -## Session wrapper class and `SessionRunHook` implementations - -These classes allow you to - -* wrap aroundTensorFlow `Session` objects to debug plain TensorFlow models - (see `DumpingDebugWrapperSession` and `LocalCLIDebugWrapperSession`), or -* generate `SessionRunHook` objects to debug `tf.contrib.learn` models (see - `DumpingDebugHook` and `LocalCLIDebugHook`). - -* `tfdbg.DumpingDebugHook` -* `tfdbg.DumpingDebugWrapperSession` -* `tfdbg.LocalCLIDebugHook` -* `tfdbg.LocalCLIDebugWrapperSession` diff --git a/tensorflow/docs_src/api_guides/python/threading_and_queues.md b/tensorflow/docs_src/api_guides/python/threading_and_queues.md deleted file mode 100644 index e00f17f955..0000000000 --- a/tensorflow/docs_src/api_guides/python/threading_and_queues.md +++ /dev/null @@ -1,270 +0,0 @@ -# Threading and Queues - -Note: In versions of TensorFlow before 1.2, we recommended using multi-threaded, -queue-based input pipelines for performance. Beginning with TensorFlow 1.4, -however, we recommend using the `tf.data` module instead. (See -[Datasets](../../guide/datasets.md) for details. In TensorFlow 1.2 and 1.3, the module was -called `tf.contrib.data`.) The `tf.data` module offers an easier-to-use -interface for constructing efficient input pipelines. Furthermore, we've stopped -developing the old multi-threaded, queue-based input pipelines. We've retained -the documentation in this file to help developers who are still maintaining -older code. - -Multithreaded queues are a powerful and widely used mechanism supporting -asynchronous computation. - -Following the [dataflow programming model](graphs.md), TensorFlow's queues are -implemented using nodes in the computation graph. A queue is a stateful node, -like a variable: other nodes can modify its content. In particular, nodes can -enqueue new items in to the queue, or dequeue existing items from the -queue. TensorFlow's queues provide a way to coordinate multiple steps of a -computation: a queue will **block** any step that attempts to dequeue from it -when it is empty, or enqueue to it when it is full. When that condition no -longer holds, the queue will unblock the step and allow execution to proceed. - -TensorFlow implements several classes of queue. The principal difference between -these classes is the order that items are removed from the queue. To get a feel -for queues, let's consider a simple example. We will create a "first in, first -out" queue (`tf.FIFOQueue`) and fill it with zeros. Then we'll construct a -graph that takes an item off the queue, adds one to that item, and puts it back -on the end of the queue. Slowly, the numbers on the queue increase. - -<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://www.tensorflow.org/images/IncremeterFifoQueue.gif"> -</div> - -`Enqueue`, `EnqueueMany`, and `Dequeue` are special nodes. They take a pointer -to the queue instead of a normal value, allowing them to mutate its state. We -recommend that you think of these operations as being like methods of the queue -in an object-oriented sense. In fact, in the Python API, these operations are -created by calling methods on a queue object (e.g. `q.enqueue(...)`). - -Note: Queue methods (such as `q.enqueue(...)`) *must* run on the same device -as the queue. Incompatible device placement directives will be ignored when -creating these operations. - -Now that you have a bit of a feel for queues, let's dive into the details... - -## Queue usage overview - -Queues, such as `tf.FIFOQueue` -and `tf.RandomShuffleQueue`, -are important TensorFlow objects that aid in computing tensors asynchronously -in a graph. - -For example, a typical queue-based input pipeline uses a `RandomShuffleQueue` to -prepare inputs for training a model as follows: - -* Multiple threads prepare training examples and enqueue them. -* A training thread executes a training op that dequeues mini-batches from the - queue - -We recommend using the `tf.data.Dataset.shuffle` -and `tf.data.Dataset.batch` methods of a -`tf.data.Dataset` to accomplish this. However, if you'd prefer -to use a queue-based version instead, you can find a full implementation in the -`tf.train.shuffle_batch` function. - -For demonstration purposes a simplified implementation is given below. - -This function takes a source tensor, a capacity, and a batch size as arguments -and returns a tensor that dequeues a shuffled batch when executed. - -``` python -def simple_shuffle_batch(source, capacity, batch_size=10): - # Create a random shuffle queue. - queue = tf.RandomShuffleQueue(capacity=capacity, - min_after_dequeue=int(0.9*capacity), - shapes=source.shape, dtypes=source.dtype) - - # Create an op to enqueue one item. - enqueue = queue.enqueue(source) - - # Create a queue runner that, when started, will launch 4 threads applying - # that enqueue op. - num_threads = 4 - qr = tf.train.QueueRunner(queue, [enqueue] * num_threads) - - # Register the queue runner so it can be found and started by - # `tf.train.start_queue_runners` later (the threads are not launched yet). - tf.train.add_queue_runner(qr) - - # Create an op to dequeue a batch - return queue.dequeue_many(batch_size) -``` - -Once started by `tf.train.start_queue_runners`, or indirectly through -`tf.train.MonitoredSession`, the `QueueRunner` will launch the -threads in the background to fill the queue. Meanwhile the main thread will -execute the `dequeue_many` op to pull data from it. Note how these ops do not -depend on each other, except indirectly through the internal state of the queue. - -The simplest possible use of this function might be something like this: - -``` python -# create a dataset that counts from 0 to 99 -input = tf.constant(list(range(100))) -input = tf.data.Dataset.from_tensor_slices(input) -input = input.make_one_shot_iterator().get_next() - -# Create a slightly shuffled batch from the sorted elements -get_batch = simple_shuffle_batch(input, capacity=20) - -# `MonitoredSession` will start and manage the `QueueRunner` threads. -with tf.train.MonitoredSession() as sess: - # Since the `QueueRunners` have been started, data is available in the - # queue, so the `sess.run(get_batch)` call will not hang. - while not sess.should_stop(): - print(sess.run(get_batch)) -``` - -``` -[ 8 10 7 5 4 13 15 14 25 0] -[23 29 28 31 33 18 19 11 34 27] -[12 21 37 39 35 22 44 36 20 46] -... -``` - -For most use cases, the automatic thread startup and management provided -by `tf.train.MonitoredSession` is sufficient. In the rare case that it is not, -TensorFlow provides tools for manually managing your threads and queues. - -## Manual Thread Management - -As we have seen, the TensorFlow `Session` object is multithreaded and -thread-safe, so multiple threads can -easily use the same session and run ops in parallel. However, it is not always -easy to implement a Python program that drives threads as required. All -threads must be able to stop together, exceptions must be caught and -reported, and queues must be properly closed when stopping. - -TensorFlow provides two classes to help: -`tf.train.Coordinator` and -`tf.train.QueueRunner`. These two classes -are designed to be used together. The `Coordinator` class helps multiple threads -stop together and report exceptions to a program that waits for them to stop. -The `QueueRunner` class is used to create a number of threads cooperating to -enqueue tensors in the same queue. - -### Coordinator - -The `tf.train.Coordinator` class manages background threads in a TensorFlow -program and helps multiple threads stop together. - -Its key methods are: - -* `tf.train.Coordinator.should_stop`: returns `True` if the threads should stop. -* `tf.train.Coordinator.request_stop`: requests that threads should stop. -* `tf.train.Coordinator.join`: waits until the specified threads have stopped. - -You first create a `Coordinator` object, and then create a number of threads -that use the coordinator. The threads typically run loops that stop when -`should_stop()` returns `True`. - -Any thread can decide that the computation should stop. It only has to call -`request_stop()` and the other threads will stop as `should_stop()` will then -return `True`. - -```python -# Using Python's threading library. -import threading - -# Thread body: loop until the coordinator indicates a stop was requested. -# If some condition becomes true, ask the coordinator to stop. -def MyLoop(coord): - while not coord.should_stop(): - ...do something... - if ...some condition...: - coord.request_stop() - -# Main thread: create a coordinator. -coord = tf.train.Coordinator() - -# Create 10 threads that run 'MyLoop()' -threads = [threading.Thread(target=MyLoop, args=(coord,)) for i in xrange(10)] - -# Start the threads and wait for all of them to stop. -for t in threads: - t.start() -coord.join(threads) -``` - -Obviously, the coordinator can manage threads doing very different things. -They don't have to be all the same as in the example above. The coordinator -also has support to capture and report exceptions. See the `tf.train.Coordinator` documentation for more details. - -### QueueRunner - -The `tf.train.QueueRunner` class creates a number of threads that repeatedly -run an enqueue op. These threads can use a coordinator to stop together. In -addition, a queue runner will run a *closer operation* that closes the queue if -an exception is reported to the coordinator. - -You can use a queue runner to implement the architecture described above. - -First build a graph that uses a TensorFlow queue (e.g. a `tf.RandomShuffleQueue`) for input examples. Add ops that -process examples and enqueue them in the queue. Add training ops that start by -dequeueing from the queue. - -```python -example = ...ops to create one example... -# Create a queue, and an op that enqueues examples one at a time in the queue. -queue = tf.RandomShuffleQueue(...) -enqueue_op = queue.enqueue(example) -# Create a training graph that starts by dequeueing a batch of examples. -inputs = queue.dequeue_many(batch_size) -train_op = ...use 'inputs' to build the training part of the graph... -``` - -In the Python training program, create a `QueueRunner` that will run a few -threads to process and enqueue examples. Create a `Coordinator` and ask the -queue runner to start its threads with the coordinator. Write a training loop -that also uses the coordinator. - -```python -# Create a queue runner that will run 4 threads in parallel to enqueue -# examples. -qr = tf.train.QueueRunner(queue, [enqueue_op] * 4) - -# Launch the graph. -sess = tf.Session() -# Create a coordinator, launch the queue runner threads. -coord = tf.train.Coordinator() -enqueue_threads = qr.create_threads(sess, coord=coord, start=True) -# Run the training loop, controlling termination with the coordinator. -for step in xrange(1000000): - if coord.should_stop(): - break - sess.run(train_op) -# When done, ask the threads to stop. -coord.request_stop() -# And wait for them to actually do it. -coord.join(enqueue_threads) -``` - -### Handling exceptions - -Threads started by queue runners do more than just run the enqueue ops. They -also catch and handle exceptions generated by queues, including the -`tf.errors.OutOfRangeError` exception, which is used to report that a queue was -closed. - -A training program that uses a coordinator must similarly catch and report -exceptions in its main loop. - -Here is an improved version of the training loop above. - -```python -try: - for step in xrange(1000000): - if coord.should_stop(): - break - sess.run(train_op) -except Exception, e: - # Report exceptions to the coordinator. - coord.request_stop(e) -finally: - # Terminate as usual. It is safe to call `coord.request_stop()` twice. - coord.request_stop() - coord.join(threads) -``` diff --git a/tensorflow/docs_src/api_guides/python/train.md b/tensorflow/docs_src/api_guides/python/train.md deleted file mode 100644 index 4b4c6a4fe3..0000000000 --- a/tensorflow/docs_src/api_guides/python/train.md +++ /dev/null @@ -1,139 +0,0 @@ -# Training -[TOC] - -`tf.train` provides a set of classes and functions that help train models. - -## Optimizers - -The Optimizer base class provides methods to compute gradients for a loss and -apply gradients to variables. A collection of subclasses implement classic -optimization algorithms such as GradientDescent and Adagrad. - -You never instantiate the Optimizer class itself, but instead instantiate one -of the subclasses. - -* `tf.train.Optimizer` -* `tf.train.GradientDescentOptimizer` -* `tf.train.AdadeltaOptimizer` -* `tf.train.AdagradOptimizer` -* `tf.train.AdagradDAOptimizer` -* `tf.train.MomentumOptimizer` -* `tf.train.AdamOptimizer` -* `tf.train.FtrlOptimizer` -* `tf.train.ProximalGradientDescentOptimizer` -* `tf.train.ProximalAdagradOptimizer` -* `tf.train.RMSPropOptimizer` - -See `tf.contrib.opt` for more optimizers. - -## Gradient Computation - -TensorFlow provides functions to compute the derivatives for a given -TensorFlow computation graph, adding operations to the graph. The -optimizer classes automatically compute derivatives on your graph, but -creators of new Optimizers or expert users can call the lower-level -functions below. - -* `tf.gradients` -* `tf.AggregationMethod` -* `tf.stop_gradient` -* `tf.hessians` - - -## Gradient Clipping - -TensorFlow provides several operations that you can use to add clipping -functions to your graph. You can use these functions to perform general data -clipping, but they're particularly useful for handling exploding or vanishing -gradients. - -* `tf.clip_by_value` -* `tf.clip_by_norm` -* `tf.clip_by_average_norm` -* `tf.clip_by_global_norm` -* `tf.global_norm` - -## Decaying the learning rate - -* `tf.train.exponential_decay` -* `tf.train.inverse_time_decay` -* `tf.train.natural_exp_decay` -* `tf.train.piecewise_constant` -* `tf.train.polynomial_decay` -* `tf.train.cosine_decay` -* `tf.train.linear_cosine_decay` -* `tf.train.noisy_linear_cosine_decay` - -## Moving Averages - -Some training algorithms, such as GradientDescent and Momentum often benefit -from maintaining a moving average of variables during optimization. Using the -moving averages for evaluations often improve results significantly. - -* `tf.train.ExponentialMovingAverage` - -## Coordinator and QueueRunner - -See [Threading and Queues](../../api_guides/python/threading_and_queues.md) -for how to use threads and queues. For documentation on the Queue API, -see [Queues](../../api_guides/python/io_ops.md#queues). - - -* `tf.train.Coordinator` -* `tf.train.QueueRunner` -* `tf.train.LooperThread` -* `tf.train.add_queue_runner` -* `tf.train.start_queue_runners` - -## Distributed execution - -See [Distributed TensorFlow](../../deploy/distributed.md) for -more information about how to configure a distributed TensorFlow program. - -* `tf.train.Server` -* `tf.train.Supervisor` -* `tf.train.SessionManager` -* `tf.train.ClusterSpec` -* `tf.train.replica_device_setter` -* `tf.train.MonitoredTrainingSession` -* `tf.train.MonitoredSession` -* `tf.train.SingularMonitoredSession` -* `tf.train.Scaffold` -* `tf.train.SessionCreator` -* `tf.train.ChiefSessionCreator` -* `tf.train.WorkerSessionCreator` - -## Reading Summaries from Event Files - -See [Summaries and TensorBoard](../../guide/summaries_and_tensorboard.md) for an -overview of summaries, event files, and visualization in TensorBoard. - -* `tf.train.summary_iterator` - -## Training Hooks - -Hooks are tools that run in the process of training/evaluation of the model. - -* `tf.train.SessionRunHook` -* `tf.train.SessionRunArgs` -* `tf.train.SessionRunContext` -* `tf.train.SessionRunValues` -* `tf.train.LoggingTensorHook` -* `tf.train.StopAtStepHook` -* `tf.train.CheckpointSaverHook` -* `tf.train.NewCheckpointReader` -* `tf.train.StepCounterHook` -* `tf.train.NanLossDuringTrainingError` -* `tf.train.NanTensorHook` -* `tf.train.SummarySaverHook` -* `tf.train.GlobalStepWaiterHook` -* `tf.train.FinalOpsHook` -* `tf.train.FeedFnHook` - -## Training Utilities - -* `tf.train.global_step` -* `tf.train.basic_train_loop` -* `tf.train.get_global_step` -* `tf.train.assert_global_step` -* `tf.train.write_graph` diff --git a/tensorflow/docs_src/community/benchmarks.md b/tensorflow/docs_src/community/benchmarks.md deleted file mode 100644 index 153ef4a015..0000000000 --- a/tensorflow/docs_src/community/benchmarks.md +++ /dev/null @@ -1,108 +0,0 @@ -# Defining and Running Benchmarks - -This guide contains instructions for defining and running a TensorFlow benchmark. These benchmarks store output in [TestResults](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/util/test_log.proto) format. If these benchmarks are added to the TensorFlow github repo, we will run them daily with our continuous build and display a graph on our dashboard: https://benchmarks-dot-tensorflow-testing.appspot.com/. - -[TOC] - - -## Defining a Benchmark - -Defining a TensorFlow benchmark requires extending the `tf.test.Benchmark` -class and calling the `self.report_benchmark` method. Below, you'll find an example of benchmark code: - -```python -import time - -import tensorflow as tf - - -# Define a class that extends from tf.test.Benchmark. -class SampleBenchmark(tf.test.Benchmark): - - # Note: benchmark method name must start with `benchmark`. - def benchmarkSum(self): - with tf.Session() as sess: - x = tf.constant(10) - y = tf.constant(5) - result = tf.add(x, y) - - iters = 100 - start_time = time.time() - for _ in range(iters): - sess.run(result) - total_wall_time = time.time() - start_time - - # Call report_benchmark to report a metric value. - self.report_benchmark( - name="sum_wall_time", - # This value should always be per iteration. - wall_time=total_wall_time/iters, - iters=iters) - -if __name__ == "__main__": - tf.test.main() -``` -See the full example for [SampleBenchmark](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/benchmark/). - - -Key points to note in the example above: - -* Benchmark class extends from `tf.test.Benchmark`. -* Each benchmark method should start with `benchmark` prefix. -* Benchmark method calls `report_benchmark` to report the metric value. - - -## Running with Python - -Use the `--benchmarks` flag to run the benchmark with Python. A [BenchmarkEntries](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/core/util/test_log.proto) proto will be printed. - -``` -python sample_benchmark.py --benchmarks=SampleBenchmark -``` - -Setting the flag as `--benchmarks=.` or `--benchmarks=all` works as well. - -(Please ensure that Tensorflow is installed to successfully import the package in the line `import tensorflow as tf`. For installation instructions, see [Installing TensorFlow](https://www.tensorflow.org/install/). This step is not necessary when running with Bazel.) - - -## Adding a `bazel` Target - -We have a special target called `tf_py_logged_benchmark` for benchmarks defined under the TensorFlow github repo. `tf_py_logged_benchmark` should wrap around a regular `py_test` target. Running a `tf_py_logged_benchmark` would print a [TestResults](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/util/test_log.proto) proto. Defining a `tf_py_logged_benchmark` also lets us run it with TensorFlow continuous build. - -First, define a regular `py_test` target. See example below: - -```build -py_test( - name = "sample_benchmark", - srcs = ["sample_benchmark.py"], - srcs_version = "PY2AND3", - deps = [ - "//tensorflow:tensorflow_py", - ], -) -``` - -You can run benchmarks in a `py_test` target by passing the `--benchmarks` flag. The benchmark should just print out a [BenchmarkEntries](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/core/util/test_log.proto) proto. - -```shell -bazel test :sample_benchmark --test_arg=--benchmarks=all -``` - - -Now, add the `tf_py_logged_benchmark` target (if available). This target would -pass in `--benchmarks=all` to the wrapped `py_test` target and provide a way to store output for our TensorFlow continuous build. The target `tf_py_logged_benchmark` should be available in TensorFlow repository. - -```build -load("//tensorflow/tools/test:performance.bzl", "tf_py_logged_benchmark") - -tf_py_logged_benchmark( - name = "sample_logged_benchmark", - target = "//tensorflow/examples/benchmark:sample_benchmark", -) -``` - -Use the following command to run the benchmark target: - -```shell -bazel test :sample_logged_benchmark -``` diff --git a/tensorflow/docs_src/community/contributing.md b/tensorflow/docs_src/community/contributing.md deleted file mode 100644 index ece4a7c70b..0000000000 --- a/tensorflow/docs_src/community/contributing.md +++ /dev/null @@ -1,49 +0,0 @@ -# Contributing to TensorFlow - -TensorFlow is an open-source project, and we welcome your participation -and contribution. This page describes how to get involved. - -## Repositories - -The code for TensorFlow is hosted in the [TensorFlow GitHub -organization](https://github.com/tensorflow). Multiple projects are located -inside the organization, including: - -* [TensorFlow](https://github.com/tensorflow/tensorflow) -* [Models](https://github.com/tensorflow/models) -* [TensorBoard](https://github.com/tensorflow/tensorboard) -* [TensorFlow.js](https://github.com/tensorflow/tfjs) -* [TensorFlow Serving](https://github.com/tensorflow/serving) -* [TensorFlow Documentation](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/docs_src) - -## Contributor checklist - -* Before contributing to TensorFlow source code, please review the [contribution -guidelines](https://github.com/tensorflow/tensorflow/blob/master/CONTRIBUTING.md). - -* Join the -[developers@tensorflow.org](https://groups.google.com/a/tensorflow.org/d/forum/developers) -mailing list, to coordinate and discuss with others contributing to TensorFlow. - -* For coding style conventions, read the [TensorFlow Style Guide](../community/style_guide.md). - -* Finally, review [Writing TensorFlow Documentation](../community/documentation.md), which - explains documentation conventions. - -You may also wish to review our guide to [defining and running benchmarks](../community/benchmarks.md). - -## Special Interest Groups - -To enable focused collaboration on particular areas of TensorFlow, we host -Special Interest Groups (SIGs). SIGs do their work in public: if you want to -join and contribute, review the work of the group, and get in touch with the -relevant SIG leader. Membership policies vary on a per-SIG basis. - -* **SIG Build** focuses on issues surrounding building, packaging, and - distribution of TensorFlow. [Mailing list](https://groups.google.com/a/tensorflow.org/d/forum/build). - -* **SIG TensorBoard** furthers the development and direction of TensorBoard and its plugins. - [Mailing list](https://groups.google.com/a/tensorflow.org/d/forum/sig-tensorboard). - -* **SIG Rust** collaborates on the development of TensorFlow's Rust bindings. - [Mailing list](https://groups.google.com/a/tensorflow.org/d/forum/rust). diff --git a/tensorflow/docs_src/community/documentation.md b/tensorflow/docs_src/community/documentation.md deleted file mode 100644 index 8639656d07..0000000000 --- a/tensorflow/docs_src/community/documentation.md +++ /dev/null @@ -1,673 +0,0 @@ -# Writing TensorFlow Documentation - -We welcome contributions to the TensorFlow documentation from the community. -This document explains how you can contribute to that documentation. In -particular, this document explains the following: - -* Where the documentation is located. -* How to make conformant edits. -* How to build and test your documentation changes before you submit them. - -You can view TensorFlow documentation on https://www.tensorflow.org, and you -can view and edit the raw files on -[GitHub](https://www.tensorflow.org/code/tensorflow/docs_src/). -We're publishing our docs on GitHub so everybody can contribute. Whatever gets -checked in to `tensorflow/docs_src` will be published soon after on -https://www.tensorflow.org. - -Republishing TensorFlow documentation in different forms is absolutely allowed, -but we are unlikely to accept other documentation formats (or the tooling to -generate them) into our repository. If you do choose to republish our -documentation in another form, please be sure to include: - -* The version of the API this represents (for example, r1.0, master, etc.) -* The commit or version from which the documentation was generated -* Where to get the latest documentation (that is, https://www.tensorflow.org) -* The Apache 2.0 license. - -## A note on versions - -tensorflow.org, at root, shows documentation for the latest stable binary. This -is the documentation you should be reading if you are using `pip` to install -TensorFlow. - -However, most developers will contribute documentation into the master GitHub -branch, which is published, occasionally, -at [tensorflow.org/versions/master](https://www.tensorflow.org/versions/master). - -If you want documentation changes to appear at root, you will need to also -contribute that change to the current stable binary branch (and/or -[cherrypick](https://stackoverflow.com/questions/9339429/what-does-cherry-picking-a-commit-with-git-mean)). - -## Reference vs. non-reference documentation - -The following reference documentation is automatically generated from comments -in the code: - -- C++ API reference docs -- Java API reference docs -- Python API reference docs - -To modify the reference documentation, you edit the appropriate code comments. - -Non-reference documentation (for example, the TensorFlow installation guides) is -authored by humans. This documentation is located in the -[`tensorflow/docs_src`](https://www.tensorflow.org/code/tensorflow/docs_src/) -directory. Each subdirectory of `docs_src` contains a set of related TensorFlow -documentation. For example, the TensorFlow installation guides are all in the -`docs_src/install` directory. - -The C++ documentation is generated from XML files generated via doxygen; -however, those tools are not available in open source at this time. - -## Markdown - -Editable TensorFlow documentation is written in Markdown. With a few exceptions, -TensorFlow uses -the [standard Markdown rules](https://daringfireball.net/projects/markdown/). - -This section explains the primary differences between standard Markdown rules -and the Markdown rules that editable TensorFlow documentation uses. - -### Math in Markdown - -You may use MathJax within TensorFlow when editing Markdown files, but note the -following: - -- MathJax renders properly on [tensorflow.org](https://www.tensorflow.org) -- MathJax does not render properly on [github](https://github.com/tensorflow/tensorflow). - -When writing MathJax, you can use <code>$$</code> and `\\(` and `\\)` to -surround your math. <code>$$</code> guards will cause line breaks, so -within text, use `\\(` `\\)` instead. - -### Links in Markdown - -Links fall into a few categories: - -- Links to a different part of the same file -- Links to a URL outside of tensorflow.org -- Links from a Markdown file (or code comments) to another file within tensorflow.org - -For the first two link categories, you may use standard Markdown links, but put -the link entirely on one line, rather than splitting it across lines. For -example: - -- `[text](link) # Good link` -- `[text]\n(link) # Bad link` -- `[text](\nlink) # Bad link` - -For the final link category (links to another file within tensorflow.org), -please use a special link parameterization mechanism. This mechanism enables -authors to move and reorganize files without breaking links. - -The parameterization scheme is as follows. Use: - -<!-- Note: the use of @ is a hack so we don't translate these as symbols --> -- <code>@{tf.symbol}</code> to make a link to the reference page for a - Python symbol. Note that class members don't get their own page, but the - syntax still works, since <code>@{tf.MyClass.method}</code> links to the - proper part of the tf.MyClass page. - -- <code>@{tensorflow::symbol}</code> to make a link to the reference page - for a C++ symbol. - -- <code>@{$doc_page}</code> to make a link to another (not an API reference) - doc page. To link to - - - `red/green/blue/index.md` use <code>@{$blue}</code> or - <code>@{$green/blue}</code>, - - - `foo/bar/baz.md` use <code>@{$baz}</code> or - <code>@{$bar/baz}</code>. - - The shorter one is preferred, so we can move pages around without breaking - these references. The main exception is that the Python API guides should - probably be referred to using <code>@{$python/<guide-name>}</code> to - avoid ambiguity. - -- <code>@{$doc_page#anchor-tag$link-text}</code> to link to an anchor in - that doc and use different link text (by default, the link text is the title - of the target page). - - To override the link text only, omit the `#anchor-tag`. - -To link to source code, use a link starting with: -`https://www.tensorflow.org/code/`, followed by -the file name starting at the github root. For instance, a link to the file you -are currently reading should be written as -`https://www.tensorflow.org/code/tensorflow/docs_src/community/documentation.md`. - -This URL naming scheme ensures -that [tensorflow.org](https://www.tensorflow.org/) can forward the link to the -branch of the code corresponding to the version of the documentation you're -viewing. Do not include url parameters in the source code URL. - -## Generating docs and previewing links - -Before building the documentation, you must first set up your environment by -doing the following: - -1. If bazel is not installed on your machine, install it now. If you are on - Linux, install bazel by issuing the following command: - - $ sudo apt-get install bazel # Linux - - If you are on Mac OS, find bazel installation instructions on - [this page](https://bazel.build/versions/master/docs/install.html#mac-os-x). - -2. Change directory to the top-level `tensorflow` directory of the TensorFlow - source code. - -3. Run the `configure` script and answer its prompts appropriately for your - system. - - $ ./configure - -Then, change to the `tensorflow` directory which contains `docs_src` (`cd -tensorflow`). Run the following command to compile TensorFlow and generate the -documentation in the `/tmp/tfdocs` dir: - - bazel run tools/docs:generate -- \ - --src_dir="$(pwd)/docs_src/" \ - --output_dir=/tmp/tfdocs/ - -Note: You must set `src_dir` and `output_dir` to absolute file paths. - -## Generating Python API documentation - -Ops, classes, and utility functions are defined in Python modules, such as -`image_ops.py`. Python modules contain a module docstring. For example: - -```python -"""Image processing and decoding ops.""" -``` - -The documentation generator places this module docstring at the beginning of the -Markdown file generated for the module, in this -case, [tf.image](https://www.tensorflow.org/api_docs/python/tf/image). - -It used to be a requirement to list every member of a module inside the module -file at the beginning, putting a `@@` before each member. The `@@member_name` -syntax is deprecated and no longer generates any docs. But depending on how a -module is [sealed](#sealing_modules) it may still be necessary to mark the -elements of the module’s contents as public. The called-out op, function, or -class does not have to be defined in the same file. The next few sections of -this document discuss sealing and how to add elements to the public -documentation. - -The new documentation system automatically documents public symbols, except for -the following: - -- Private symbols whose names start with an underscore. -- Symbols originally defined in `object` or protobuf’s `Message`. -- Some class members, such as `__base__`, `__class__`, which are dynamically - created but generally have no useful documentation. - -Only top level modules (currently just `tf` and `tfdbg`) need to be manually -added to the generate script. - -### Sealing modules - -Because the doc generator walks all visible symbols, and descends into anything -it finds, it will document any accidentally exposed symbols. If a module only -exposes symbols that are meant to be part of the public API, we call it -**sealed**. Because of Python’s loose import and visibility conventions, naively -written Python code will inadvertently expose a lot of modules which are -implementation details. Improperly sealed modules may expose other unsealed -modules, which will typically lead the doc generator to fail. **This failure is -the intended behavior.** It ensures that our API is well defined, and allows us -to change implementation details (including which modules are imported where) -without fear of accidentally breaking users. - -If a module is accidentally imported, it typically breaks the doc generator -(`generate_test`). This is a clear sign you need to seal your modules. However, -even if the doc generator succeeds, unwanted symbols may show up in the -docs. Check the generated docs to make sure that all symbols that are documented -are expected. If there are symbols that shouldn’t be there, you have the -following options for dealing with them: - -- Private symbols and imports -- The `remove_undocumented` filter -- A traversal blacklist. - -We'll discuss these options in detail below. - -#### Private symbols and imports - -The easiest way to conform to the API sealing expectations is to make non-public -symbols private (by prepending an underscore _). The doc generator respects -private symbols. This also applies to modules. If the only problem is that there -is a small number of imported modules that show up in the docs (or break the -generator), you can simply rename them on import, e.g.: `import sys as _sys`. - -Because Python considers all files to be modules, this applies to files as -well. If you have a directory containing the following two files/modules: - - module/__init__.py - module/private_impl.py - -Then, after `module` is imported, it will be possible to access -`module.private_impl`. Renaming `private_impl.py` to `_private_impl.py` solves -the problem. If renaming modules is awkward, read on. - -#### Use the `remove_undocumented` filter - -Another way to seal a module is to split your implementation from the API. To do -so, consider using `remove_undocumented`, which takes a list of allowed symbols, -and deletes everything else from the module. For example, the following snippet -demonstrates how to put `remove_undocumented` in the `__init__.py` file for a -module: - -__init__.py: - - # Use * imports only if __all__ defined in some_file - from tensorflow.some_module.some_file import * - - # Otherwise import symbols directly - from tensorflow.some_module.some_other_file import some_symbol - - from tensorflow.python.util.all_util import remove_undocumented - - _allowed_symbols = [‘some_symbol’, ‘some_other_symbol’] - - remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) - -The `@@member_name` syntax is deprecated, but it still exists in some places in -the documentation as an indicator to `remove_undocumented` that those symbols -are public. All `@@`s will eventually be removed. If you see them, however, -please do not randomly delete them as they are still in use by some of our -systems. - -#### Traversal blacklist - -If all else fails, you may add entries to the traversal blacklist in -`generate_lib.py.` **Almost all entries in this list are an abuse of its -purpose; avoid adding to it if you can!** - -The traversal blacklist maps qualified module names (without the leading `tf.`) -to local names that are not to be descended into. For instance, the following -entry will exclude `some_module` from traversal. - - { ... - ‘contrib.my_module’: [‘some_module’] - ... - } - -That means that the doc generator will show that `some_module` exists, but it -will not enumerate its content. - -This blacklist was originally intended to make sure that system modules (mock, -flags, ...) included for platform abstraction can be documented without -documenting their interior. Its use beyond this purpose is a shortcut that may -be acceptable for contrib, but not for core tensorflow. - -## Op documentation style guide - -Long, descriptive module-level documentation for modules should go in the API -Guides in `docs_src/api_guides/python`. - -For classes and ops, ideally, you should provide the following information, in -order of presentation: - -* A short sentence that describes what the op does. -* A short description of what happens when you pass arguments to the op. -* An example showing how the op works (pseudocode is best). -* Requirements, caveats, important notes (if there are any). -* Descriptions of inputs, outputs, and Attrs or other parameters of the op - constructor. - -Each of these is described in more -detail [below](#description-of-the-docstring-sections). - -Write your text in Markdown format. A basic syntax reference -is [here](https://daringfireball.net/projects/markdown/). You are allowed to -use [MathJax](https://www.mathjax.org) notation for equations (see above for -restrictions). - -### Writing about code - -Put backticks around these things when they're used in text: - -* Argument names (for example, `input`, `x`, `tensor`) -* Returned tensor names (for example, `output`, `idx`, `out`) -* Data types (for example, `int32`, `float`, `uint8`) -* Other op names referenced in text (for example, `list_diff()`, `shuffle()`) -* Class names (for example, `Tensor` when you actually mean a `Tensor` object; - don't capitalize or use backticks if you're just explaining what an op does to - a tensor, or a graph, or an operation in general) -* File names (for example, `image_ops.py`, or - `/path-to-your-data/xml/example-name`) -* Math expressions or conditions (for example, `-1-input.dims() <= dim <= - input.dims()`) - -Put three backticks around sample code and pseudocode examples. And use `==>` -instead of a single equal sign when you want to show what an op returns. For -example: - - ``` - # 'input' is a tensor of shape [2, 3, 5] - (tf.expand_dims(input, 0)) ==> [1, 2, 3, 5] - ``` - -If you're providing a Python code sample, add the python style label to ensure -proper syntax highlighting: - - ```python - # some Python code - ``` - -Two notes about backticks for code samples in Markdown: - -1. You can use backticks for pretty printing languages other than Python, if - necessary. A full list of languages is available - [here](https://github.com/google/code-prettify#how-do-i-specify-the-language-of-my-code). -2. Markdown also allows you to indent four spaces to specify a code sample. - However, do NOT indent four spaces and use backticks simultaneously. Use one - or the other. - -### Tensor dimensions - -When you're talking about a tensor in general, don't capitalize the word tensor. -When you're talking about the specific object that's provided to an op as an -argument or returned by an op, then you should capitalize the word Tensor and -add backticks around it because you're talking about a `Tensor` object. - -Don't use the word `Tensors` to describe multiple Tensor objects unless you -really are talking about a `Tensors` object. Better to say "a list of `Tensor` -objects." - -Use the term "dimension" to refer to the size of a tensor. If you need to be -specific about the size, use these conventions: - -- Refer to a scalar as a "0-D tensor" -- Refer to a vector as a "1-D tensor" -- Refer to a matrix as a "2-D tensor" -- Refer to tensors with 3 or more dimensions as 3-D tensors or n-D tensors. Use - the word "rank" only if it makes sense, but try to use "dimension" instead. - Never use the word "order" to describe the size of a tensor. - -Use the word "shape" to detail the dimensions of a tensor, and show the shape in -square brackets with backticks. For example: - - If `input` is a 3-D tensor with shape `[3, 4, 3]`, this operation - returns a 3-D tensor with shape `[6, 8, 6]`. - -### Ops defined in C++ - -All Ops defined in C++ (and accessible from other languages) must be documented -with a `REGISTER_OP` declaration. The docstring in the C++ file is processed to -automatically add some information for the input types, output types, and Attr -types and default values. - -For example: - -```c++ -REGISTER_OP("PngDecode") - .Input("contents: string") - .Attr("channels: int = 0") - .Output("image: uint8") - .Doc(R"doc( -Decodes the contents of a PNG file into a uint8 tensor. - -contents: PNG file contents. -channels: Number of color channels, or 0 to autodetect based on the input. - Must be 0 for autodetect, 1 for grayscale, 3 for RGB, or 4 for RGBA. - If the input has a different number of channels, it will be transformed - accordingly. -image:= A 3-D uint8 tensor of shape `[height, width, channels]`. - If `channels` is 0, the last dimension is determined - from the png contents. -)doc"); -``` - -Results in this piece of Markdown: - - ### tf.image.png_decode(contents, channels=None, name=None) {#png_decode} - - Decodes the contents of a PNG file into a uint8 tensor. - - #### Args: - - * **contents**: A string Tensor. PNG file contents. - * **channels**: An optional int. Defaults to 0. - Number of color channels, or 0 to autodetect based on the input. - Must be 0 for autodetect, 1 for grayscale, 3 for RGB, or 4 for RGBA. If the - input has a different number of channels, it will be transformed accordingly. - * **name**: A name for the operation (optional). - - #### Returns: - A 3-D uint8 tensor of shape `[height, width, channels]`. If `channels` is - 0, the last dimension is determined from the png contents. - -Much of the argument description is added automatically. In particular, the doc -generator automatically adds the name and type of all inputs, attrs, and -outputs. In the above example, `contents: A string Tensor.` was added -automatically. You should write your additional text to flow naturally after -that description. - -For inputs and output, you can prefix your additional text with an equal sign to -prevent the automatically added name and type. In the above example, the -description for the output named `image` starts with `=` to prevent the addition -of `A uint8 Tensor.` before our text `A 3-D uint8 Tensor...`. You cannot prevent -the addition of the name, type, and default value of attrs this way, so write -your text carefully. - -### Ops defined in Python - -If your op is defined in a `python/ops/*.py` file, then you need to provide text -for all of the arguments and output (returned) tensors. The doc generator does -not auto-generate any text for ops that are defined in Python, so what you write -is what you get. - -You should conform to the usual Python docstring conventions, except that you -should use Markdown in the docstring. - -Here's a simple example: - - def foo(x, y, name="bar"): - """Computes foo. - - Given two 1-D tensors `x` and `y`, this operation computes the foo. - - Example: - - ``` - # x is [1, 1] - # y is [2, 2] - tf.foo(x, y) ==> [3, 3] - ``` - Args: - x: A `Tensor` of type `int32`. - y: A `Tensor` of type `int32`. - name: A name for the operation (optional). - - Returns: - A `Tensor` of type `int32` that is the foo of `x` and `y`. - - Raises: - ValueError: If `x` or `y` are not of type `int32`. - """ - -## Description of the docstring sections - -This section details each of the elements in docstrings. - -### Short sentence describing what the op does - -Examples: - -``` -Concatenates tensors. -``` - -``` -Flips an image horizontally from left to right. -``` - -``` -Computes the Levenshtein distance between two sequences. -``` - -``` -Saves a list of tensors to a file. -``` - -``` -Extracts a slice from a tensor. -``` - -### Short description of what happens when you pass arguments to the op - -Examples: - - Given a tensor input of numerical type, this operation returns a tensor of - the same type and size with values reversed along dimension `seq_dim`. A - vector `seq_lengths` determines which elements are reversed for each index - within dimension 0 (usually the batch dimension). - - - This operation returns a tensor of type `dtype` and dimensions `shape`, with - all elements set to zero. - -### Example demonstrating the op - -Good code samples are short and easy to understand, typically containing a brief -snippet of code to clarify what the example is demonstrating. When an op -manipulates the shape of a Tensor it is often useful to include an example of -the before and after, as well. - -The `squeeze()` op has a nice pseudocode example: - - # 't' is a tensor of shape [1, 2, 1, 3, 1, 1] - shape(squeeze(t)) ==> [2, 3] - -The `tile()` op provides a good example in descriptive text: - - For example, tiling `[a, b, c, d]` by `[2]` produces `[a b c d a b c d]`. - -It is often helpful to show code samples in Python. Never put them in the C++ -Ops file, and avoid putting them in the Python Ops doc. We recommend, if -possible, putting code samples in the -[API guides](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/docs_src/api_guides). -Otherwise, add them to the module or class docstring where the Ops constructors -are called out. - -Here's an example from the module docstring in `api_guides/python/math_ops.md`: - - ## Segmentation - - TensorFlow provides several operations that you can use to perform common - math computations on tensor segments. - ... - In particular, a segmentation of a matrix tensor is a mapping of rows to - segments. - - For example: - - ```python - c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]]) - tf.segment_sum(c, tf.constant([0, 0, 1])) - ==> [[0 0 0 0] - [5 6 7 8]] - ``` - -### Requirements, caveats, important notes - -Examples: - -``` -This operation requires that: `-1-input.dims() <= dim <= input.dims()` -``` - -``` -Note: This tensor will produce an error if evaluated. Its value must -be fed using the `feed_dict` optional argument to `Session.run()`, -`Tensor.eval()`, or `Operation.run()`. -``` - -### Descriptions of arguments and output (returned) tensors. - -Keep the descriptions brief and to the point. You should not have to explain how -the operation works in the argument sections. - -Mention if the Op has strong constraints on the dimensions of the input or -output tensors. Remember that for C++ Ops, the type of the tensor is -automatically added as either as "A ..type.. Tensor" or "A Tensor with type in -{...list of types...}". In such cases, if the Op has a constraint on the -dimensions either add text such as "Must be 4-D" or start the description with -`=` (to prevent the tensor type to be added) and write something like "A 4-D -float tensor". - -For example, here are two ways to document an image argument of a C++ op (note -the "=" sign): - -``` -image: Must be 4-D. The image to resize. -``` - -``` -image:= A 4-D `float` tensor. The image to resize. -``` - -In the documentation, these will be rendered to markdown as - -``` -image: A `float` Tensor. Must be 4-D. The image to resize. -``` - -``` -image: A 4-D `float` Tensor. The image to resize. -``` - -### Optional arguments descriptions ("attrs") - -The doc generator always describes the type for each attr and their default -value, if any. You cannot override that with an equal sign because the -description is very different in the C++ and Python generated docs. - -Phrase any additional attr description so that it flows well after the type -and default value. The type and defaults are displayed first, and additional -descriptions follow afterwards. Therefore, complete sentences are best. - -Here's an example from `image_ops.cc`: - - REGISTER_OP("DecodePng") - .Input("contents: string") - .Attr("channels: int = 0") - .Attr("dtype: {uint8, uint16} = DT_UINT8") - .Output("image: dtype") - .SetShapeFn(DecodeImageShapeFn) - .Doc(R"doc( - Decode a PNG-encoded image to a uint8 or uint16 tensor. - - The attr `channels` indicates the desired number of color channels for the - decoded image. - - Accepted values are: - - * 0: Use the number of channels in the PNG-encoded image. - * 1: output a grayscale image. - * 3: output an RGB image. - * 4: output an RGBA image. - - If needed, the PNG-encoded image is transformed to match the requested - number of color channels. - - contents: 0-D. The PNG-encoded image. - channels: Number of color channels for the decoded image. - image: 3-D with shape `[height, width, channels]`. - )doc"); - -This generates the following Args section in -`api_docs/python/tf/image/decode_png.md`: - - #### Args: - - * **`contents`**: A `Tensor` of type `string`. 0-D. The PNG-encoded - image. - * **`channels`**: An optional `int`. Defaults to `0`. Number of color - channels for the decoded image. - * **`dtype`**: An optional `tf.DType` from: `tf.uint8, - tf.uint16`. Defaults to `tf.uint 8`. - * **`name`**: A name for the operation (optional). diff --git a/tensorflow/docs_src/community/groups.md b/tensorflow/docs_src/community/groups.md deleted file mode 100644 index 0b07d413da..0000000000 --- a/tensorflow/docs_src/community/groups.md +++ /dev/null @@ -1,38 +0,0 @@ -# User Groups - -TensorFlow has communities around the world. [Submit your community!](https://docs.google.com/forms/d/e/1FAIpQLSc_RQIUYtVgLLihzATaO_WUXkEyBDE_OoRoOXYDPmBEvHuEBA/viewform) - -## Asia - -* [TensorFlow China community](https://www.tensorflowers.cn) -* [TensorFlow Korea (TF-KR) User Group](https://www.facebook.com/groups/TensorFlowKR/) -* [TensorFlow User Group Tokyo](https://tfug-tokyo.connpass.com/) -* [Soleil Data Dojo](https://soleildatadojo.connpass.com/) -* [TensorFlow User Group Utsunomiya](https://tfug-utsunomiya.connpass.com/) -* [TensorFlow Philippines Community](https://www.facebook.com/groups/TensorFlowPH/) -* [TensorFlow and Deep Learning Singapore](https://www.meetup.com/TensorFlow-and-Deep-Learning-Singapore/) -* [TensorFlow India](https://www.facebook.com/tensorflowindia) - - -## Europe - -* [TensorFlow Barcelona](https://www.meetup.com/Barcelona-Machine-Learning-Meetup/) -* [TensorFlow Madrid](https://www.meetup.com/TensorFlow-Madrid/) -* [Tensorflow Belgium](https://www.meetup.com/TensorFlow-Belgium) -* [TensorFlow x Rome Meetup](https://www.meetup.com/it-IT/TensorFlow-x-Rome-Meetup) -* [TensorFlow London](https://www.meetup.com/TensorFlow-London/) -* [TensorFlow Edinburgh](https://www.meetup.com/tensorflow-edinburgh/) - - -## America - -* [TensorFlow Buenos Aires](https://www.meetup.com/TensorFlow-Buenos-Aires/) - - -## Oceania -* [Melbourne TensorFlow Meetup](https://www.meetup.com/Melbourne-TensorFlow-Meetup) - - -## Africa - -* [TensorFlow Tunis Meetup](https://www.meetup.com/fr-FR/TensorFlow-Tunis-Meetup/) diff --git a/tensorflow/docs_src/community/index.md b/tensorflow/docs_src/community/index.md deleted file mode 100644 index 1a30be32a5..0000000000 --- a/tensorflow/docs_src/community/index.md +++ /dev/null @@ -1,85 +0,0 @@ -# Community - -Welcome to the TensorFlow community! This page explains where to get help, and -different ways to be part of the community. We are committed to fostering an -open and welcoming environment, and request that you review our [code of -conduct](https://github.com/tensorflow/tensorflow/blob/master/CODE_OF_CONDUCT.md). - -## Get Help - -### Technical Questions - -To ask or answer technical questions about TensorFlow, use [Stack -Overflow](https://stackoverflow.com/questions/tagged/tensorflow). For example, -ask or search about a particular error message you encountered during -installation. - -### Bugs and Feature Requests - -To report bugs or make feature requests, file an issue on GitHub. Please choose -the appropriate repository for the project. Major repositories include: - - * [TensorFlow](https://github.com/tensorflow/tensorflow/issues) - * [TensorBoard](https://github.com/tensorflow/tensorboard/issues) - * [TensorFlow models](https://github.com/tensorflow/models/issues) - -### Security - -Before using TensorFlow, please take a look at our [security model](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md#tensorflow-models-are-programs), -[list of recent security advisories and announcements](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/security/index.md), -and [ways you can report security issues](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md#reporting-vulnerabilities) -to the TensorFlow team at the [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md) page on GitHub. - -## Stay Informed - -### Announcements Mailing List - -All major releases and important announcements are sent to -[announce@tensorflow.org](https://groups.google.com/a/tensorflow.org/forum/#!forum/announce). -We recommend that you join this list if you depend on TensorFlow in any way. - -### Development Roadmap - -The [Roadmap](../community/roadmap.md) summarizes plans for upcoming additions to TensorFlow. - -### Social Media - -For news and updates from around the universe of TensorFlow projects, follow -[@tensorflow](https://twitter.com/tensorflow) on Twitter. - -### Blog - -We post regularly to the [TensorFlow Blog](http://blog.tensorflow.org/), -with content from the TensorFlow team and the best articles from the community. - -### YouTube - -Our [YouTube Channel](http://youtube.com/tensorflow/) focuses on machine learning -and AI with TensorFlow. On it we have a number of new shows, including: - -- TensorFlow Meets: meet with community contributors to learn and share what they're doing -- Ask TensorFlow: the team answers the best questions tagged #AskTensorFlow from social media -- Coding TensorFlow: short bites with tips for success with TensorFlow - -## Community Support - -### Mailing Lists - -For general discussion about TensorFlow development and direction, please join -the [TensorFlow discuss mailing -list](https://groups.google.com/a/tensorflow.org/d/forum/discuss). - -A number of other mailing lists exist, focused on different project areas, which -can be found at [TensorFlow Mailing Lists](../community/lists.md). - -### User Groups - -To meet with like-minded people local to you, check out the many -[TensorFlow user groups](../community/groups.md) around the world. - - -## Contributing To TensorFlow - -We welcome contributions and collaboration on TensorFlow. For more information, -please read [Contributing to TensorFlow](contributing.md). - diff --git a/tensorflow/docs_src/community/leftnav_files b/tensorflow/docs_src/community/leftnav_files deleted file mode 100644 index 0bd1f14de9..0000000000 --- a/tensorflow/docs_src/community/leftnav_files +++ /dev/null @@ -1,8 +0,0 @@ -index.md -roadmap.md -contributing.md -lists.md -groups.md -documentation.md -style_guide.md -benchmarks.md diff --git a/tensorflow/docs_src/community/lists.md b/tensorflow/docs_src/community/lists.md deleted file mode 100644 index bc2f573c29..0000000000 --- a/tensorflow/docs_src/community/lists.md +++ /dev/null @@ -1,53 +0,0 @@ -# Mailing Lists - -As a community, we do much of our collaboration on public mailing lists. -Please note that if you're looking for help using TensorFlow, [Stack -Overflow](https://stackoverflow.com/questions/tagged/tensorflow) and -[GitHub issues](https://github.com/tensorflow/tensorflow/issues) -are the best initial places to look. For more information, -see [how to get help](/community/#get_help). - -## General TensorFlow lists - -* [announce](https://groups.google.com/a/tensorflow.org/d/forum/announce) - Low-volume announcements of new releases. -* [discuss](https://groups.google.com/a/tensorflow.org/d/forum/discuss) - General community discussion around TensorFlow. -* [developers](https://groups.google.com/a/tensorflow.org/d/forum/developers) - Discussion for developers contributing to TensorFlow. - -## Project-specific lists - -These projects inside the TensorFlow GitHub organization have lists dedicated to their communities: - -* [hub](https://groups.google.com/a/tensorflow.org/d/forum/hub) - - Discussion and collaboration around [TensorFlow Hub](https://github.com/tensorflow/hub). -* [magenta-discuss](https://groups.google.com/a/tensorflow.org/d/forum/magenta-discuss) - - General discussion about [Magenta](https://magenta.tensorflow.org/) - development and directions. -* [swift](https://groups.google.com/a/tensorflow.org/d/forum/swift) - - Community and collaboration around Swift for TensorFlow. -* [tensor2tensor](https://groups.google.com/d/forum/tensor2tensor) - Discussion - and peer support for Tensor2Tensor. -* [tfjs-announce](https://groups.google.com/a/tensorflow.org/d/forum/tfjs-announce) - - Announcements of new TensorFlow.js releases. -* [tfjs](https://groups.google.com/a/tensorflow.org/d/forum/tfjs) - Discussion - and peer support for TensorFlow.js. -* [tflite](https://groups.google.com/a/tensorflow.org/d/forum/tflite) - Discussion and - peer support for TensorFlow Lite. -* [tfprobability](https://groups.google.com/a/tensorflow.org/d/forum/tfprobability) - Discussion and - peer support for TensorFlow Probability. -* [tpu-users](https://groups.google.com/a/tensorflow.org/d/forum/tpu-users) - Community discussion - and support for TPU users. - -## Special Interest Groups - -TensorFlow's [Special Interest -Groups](/community/contributing#special_interest_groups) (SIGs) support -community collaboration on particular project focuses. Members of these groups -work together to build and support TensorFlow related projects. While their -archives are public, different SIGs have their own membership policies. - -* [build](https://groups.google.com/a/tensorflow.org/d/forum/build) - - Supporting SIG Build, for build, distribution and packaging of TensorFlow. -* [sig-tensorboard](https://groups.google.com/a/tensorflow.org/d/forum/sig-tensorboard) - - Supporting SIG TensorBoard, for plugin development and other contribution. -* [rust](https://groups.google.com/a/tensorflow.org/d/forum/rust) - - Supporting SIG Rust, for the Rust language bindings. diff --git a/tensorflow/docs_src/community/roadmap.md b/tensorflow/docs_src/community/roadmap.md deleted file mode 100644 index 0463ca05fe..0000000000 --- a/tensorflow/docs_src/community/roadmap.md +++ /dev/null @@ -1,121 +0,0 @@ -# Roadmap -**Last updated: Apr 27, 2018** - -TensorFlow is a rapidly moving, community supported project. This document is intended -to provide guidance about priorities and focus areas of the core set of TensorFlow -developers and about functionality that can be expected in the upcoming releases of -TensorFlow. Many of these areas are driven by community use cases, and we welcome -further -[contributions](https://github.com/tensorflow/tensorflow/blob/master/CONTRIBUTING.md) -to TensorFlow. - -The features below do not have concrete release dates. However, the majority can be -expected in the next one to two releases. - -### APIs -#### High Level APIs: -* Easy multi-GPU and TPU utilization with Estimators -* Easy-to-use high-level pre-made estimators for Gradient Boosted Trees, Time Series, and other models - -#### Eager Execution: -* Efficient utilization of multiple GPUs -* Distributed training support (multi-machine) -* Performance improvements -* Simpler export to a GraphDef/SavedModel - -#### Keras API: -* Better integration with tf.data (ability to call `model.fit` with data tensors) -* Full support for Eager Execution (both Eager support for the regular Keras API, and ability -to create Keras models Eager- style via Model subclassing) -* Better distribution/multi-GPU support and TPU support (including a smoother model-to-estimator workflow) - -#### Official Models: -* A set of -[models](https://github.com/tensorflow/models/tree/master/official) -across image recognition, speech, object detection, and - translation that demonstrate best practices and serve as a starting point for - high-performance model development. - -#### Contrib: -* Deprecate parts of tf.contrib where preferred implementations exist outside of tf.contrib. -* As much as possible, move large projects inside tf.contrib to separate repositories. -* The tf.contrib module will eventually be discontinued in its current form, experimental development will in future happen in other repositories. - - -#### Probabilistic Reasoning and Statistical Analysis: -* Rich set of tools for probabilistic and statistical analysis in tf.distributions - and tf.probability. These include new samplers, layers, optimizers, losses, and structured models -* Statistical tools for hypothesis testing, convergence diagnostics, and sample statistics -* Edward 2.0: High-level API for probabilistic programming - -### Platforms -#### TensorFlow Lite: -* Increase coverage of supported ops in TensorFlow Lite -* Easier conversion of a trained TensorFlow graph for use on TensorFlow Lite -* Support for GPU acceleration in TensorFlow Lite (iOS and Android) -* Support for hardware accelerators via Android NeuralNets API -* Improve CPU performance by quantization and other network optimizations (eg. pruning, distillation) -* Increase support for devices beyond Android and iOS (eg. RPi, Cortex-M) - -#### TensorFlow.js: -* Release package for Node.js bindings to the TensorFlow C API through the TensorFlow.js backend interface -* Expand support for importing TensorFlow SavedModels and Keras models into browser with unified APIs supporting retraining in browser -* Improve Layers API and allow model exporting/saving -* Release tfjs-data API for efficient data input pipelines - -#### TensorFlow with Swift: -* Establish open source project including documentation, open design, and code availability. -* Continue implementing and refining implementation and design through 2018. -* Aim for implementation to be solid enough for general use later in 2018. - -### Performance -#### Distributed TensorFlow: -* Optimize Multi-GPU support for a variety of GPU topologies -* Improve mechanisms for distributing computations on several machines - -#### GPU Optimizations: -* Simplify mixed precision API with initial example model and guide. -* Finalize TensorRT API and move to core. -* CUDA 9.2 and NCCL 2.x default in TensorFlow builds. -* Optimizations for DGX-2. -* Remove support for CUDA less than 8.x and cuDNN less than 6.x. - - -#### CPU Optimizations -* Int8 support for SkyLake via MKL -* Dynamic loading of SIMD-optimized kernels -* MKL for Linux and Windows - -### End-to-end ML systems: -#### TensorFlow Hub: -* Expand support for module-types in TF Hub with TF Eager integration, Keras layers integration, and TensorFlow.js integration -* Accept variable-sized image input -* Improve multi-GPU estimator support -* Document and improve TPU integration - -#### TensorFlow Extended: -* Open source more of the TensorFlow Extended platform to facilitate adoption of TensorFlow in production settings. -* Release TFX libraries for Data Validation - -### Documentation and Resources: -* Update documentation, tutorials and Getting Started guides on all features and APIs -* Update [Youtube Tensorflow channel](https://youtube.com/tensorflow) weekly with new content: -Coding TensorFlow - where we teach folks coding with tensorflow -TensorFlow Meets - where we highlight community contributions -Ask TensorFlow - where we answer community questions -Guest and Showcase videos -* Update [Official TensorFlow blog](https://blog.tensorflow.org) with regular articles from Google team and the Community - - -### Community and Partner Engagement -#### Special Interest Groups: -* Mobilize the community to work together in focused domains -* [tf-distribute](https://groups.google.com/a/tensorflow.org/forum/#!forum/tf-distribute): build and packaging of TensorFlow -* SIG TensorBoard, SIG Rust, and more to be identified and launched - -#### Community: -* Incorporate public feedback on significant design decisions via a Request-for-Comment (RFC) process -* Formalize process for external contributions to land in TensorFlow and associated projects -* Grow global TensorFlow communities and user groups -* Collaborate with partners to co-develop and publish research papers -* Process to enable external contributions to tutorials, documentation, and blogs showcasing best practice use-cases of TensorFlow and high-impact applications diff --git a/tensorflow/docs_src/community/style_guide.md b/tensorflow/docs_src/community/style_guide.md deleted file mode 100644 index c78da20edd..0000000000 --- a/tensorflow/docs_src/community/style_guide.md +++ /dev/null @@ -1,136 +0,0 @@ -# TensorFlow Style Guide - -This page contains style decisions that both developers and users of TensorFlow -should follow to increase the readability of their code, reduce the number of -errors, and promote consistency. - -[TOC] - -## Python style - -Generally follow -[PEP8 Python style guide](https://www.python.org/dev/peps/pep-0008/), -except for using 2 spaces. - - -## Python 2 and 3 compatible - -* All code needs to be compatible with Python 2 and 3. - -* Next lines should be present in all Python files: - -``` -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -``` - -* Use `six` to write compatible code (for example `six.moves.range`). - - -## Bazel BUILD rules - -TensorFlow uses Bazel build system and enforces next requirements: - -* Every BUILD file should contain next header: - -``` -# Description: -# <...> - -package( - default_visibility = ["//visibility:private"], -) - -licenses(["notice"]) # Apache 2.0 - -exports_files(["LICENSE"]) -``` - - - -* For all Python BUILD targets (libraries and tests) add next line: - -``` -srcs_version = "PY2AND3", -``` - - -## Tensor - -* Operations that deal with batches may assume that the first dimension of a Tensor is the batch dimension. - -* In most models the *last dimension* is the number of channels. - -* Dimensions excluding the first and last usually make up the "space" dimensions: Sequence-length or Image-size. - -## Python operations - -A *Python operation* is a function that, given input tensors and parameters, -creates a part of the graph and returns output tensors. - -* The first arguments should be tensors, followed by basic python parameters. - The last argument is `name` with a default value of `None`. - If operation needs to save some `Tensor`s to Graph collections, - put the arguments with names of the collections right before `name` argument. - -* Tensor arguments should be either a single tensor or an iterable of tensors. - E.g. a "Tensor or list of Tensors" is too broad. See `assert_proper_iterable`. - -* Operations that take tensors as arguments should call `convert_to_tensor` - to convert non-tensor inputs into tensors if they are using C++ operations. - Note that the arguments are still described as a `Tensor` object - of a specific dtype in the documentation. - -* Each Python operation should have a `name_scope` like below. Pass as - arguments `name`, a default name of the op, and a list of the input tensors. - -* Operations should contain an extensive Python comment with Args and Returns - declarations that explain both the type and meaning of each value. Possible - shapes, dtypes, or ranks should be specified in the description. - [See documentation details](../community/documentation.md) - -* For increased usability include an example of usage with inputs / outputs - of the op in Example section. - -Example: - - def my_op(tensor_in, other_tensor_in, my_param, other_param=0.5, - output_collections=(), name=None): - """My operation that adds two tensors with given coefficients. - - Args: - tensor_in: `Tensor`, input tensor. - other_tensor_in: `Tensor`, same shape as `tensor_in`, other input tensor. - my_param: `float`, coefficient for `tensor_in`. - other_param: `float`, coefficient for `other_tensor_in`. - output_collections: `tuple` of `string`s, name of the collection to - collect result of this op. - name: `string`, name of the operation. - - Returns: - `Tensor` of same shape as `tensor_in`, sum of input values with coefficients. - - Example: - >>> my_op([1., 2.], [3., 4.], my_param=0.5, other_param=0.6, - output_collections=['MY_OPS'], name='add_t1t2') - [2.3, 3.4] - """ - with tf.name_scope(name, "my_op", [tensor_in, other_tensor_in]): - tensor_in = tf.convert_to_tensor(tensor_in) - other_tensor_in = tf.convert_to_tensor(other_tensor_in) - result = my_param * tensor_in + other_param * other_tensor_in - tf.add_to_collection(output_collections, result) - return result - -Usage: - - output = my_op(t1, t2, my_param=0.5, other_param=0.6, - output_collections=['MY_OPS'], name='add_t1t2') - - -## Layers - -Use `tf.keras.layers`, not `tf.layers`. - -See `tf.keras.layers` and [the Keras guide](../guide/keras.md#custom_layers) for details on how to sub-class layers. diff --git a/tensorflow/docs_src/deploy/deploy_to_js.md b/tensorflow/docs_src/deploy/deploy_to_js.md deleted file mode 100644 index d7ce3ea90b..0000000000 --- a/tensorflow/docs_src/deploy/deploy_to_js.md +++ /dev/null @@ -1,4 +0,0 @@ -# Deploy to JavaScript - -You can find details about deploying JavaScript TensorFlow programs -in the separate [js.tensorflow.org site](https://js.tensorflow.org). diff --git a/tensorflow/docs_src/deploy/distributed.md b/tensorflow/docs_src/deploy/distributed.md deleted file mode 100644 index 2fba36cfa7..0000000000 --- a/tensorflow/docs_src/deploy/distributed.md +++ /dev/null @@ -1,354 +0,0 @@ -# Distributed TensorFlow - -This document shows how to create a cluster of TensorFlow servers, and how to -distribute a computation graph across that cluster. We assume that you are -familiar with the [basic concepts](../guide/low_level_intro.md) of -writing low level TensorFlow programs. - -## Hello distributed TensorFlow! - -To see a simple TensorFlow cluster in action, execute the following: - -```shell -# Start a TensorFlow server as a single-process "cluster". -$ python ->>> import tensorflow as tf ->>> c = tf.constant("Hello, distributed TensorFlow!") ->>> server = tf.train.Server.create_local_server() ->>> sess = tf.Session(server.target) # Create a session on the server. ->>> sess.run(c) -'Hello, distributed TensorFlow!' -``` - -The -`tf.train.Server.create_local_server` -method creates a single-process cluster, with an in-process server. - -## Create a cluster - -<div class="video-wrapper"> - <iframe class="devsite-embedded-youtube-video" data-video-id="la_M6bCV91M" - data-autohide="1" data-showinfo="0" frameborder="0" allowfullscreen> - </iframe> -</div> - -A TensorFlow "cluster" is a set of "tasks" that participate in the distributed -execution of a TensorFlow graph. Each task is associated with a TensorFlow -"server", which contains a "master" that can be used to create sessions, and a -"worker" that executes operations in the graph. A cluster can also be divided -into one or more "jobs", where each job contains one or more tasks. - -To create a cluster, you start one TensorFlow server per task in the cluster. -Each task typically runs on a different machine, but you can run multiple tasks -on the same machine (e.g. to control different GPU devices). In each task, do -the following: - -1. **Create a `tf.train.ClusterSpec`** that describes all of the tasks - in the cluster. This should be the same for each task. - -2. **Create a `tf.train.Server`**, passing the `tf.train.ClusterSpec` to - the constructor, and identifying the local task with a job name - and task index. - - -### Create a `tf.train.ClusterSpec` to describe the cluster - -The cluster specification dictionary maps job names to lists of network -addresses. Pass this dictionary to -the `tf.train.ClusterSpec` -constructor. For example: - -<table> - <tr><th><code>tf.train.ClusterSpec</code> construction</th><th>Available tasks</th> - <tr> - <td><pre> -tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]}) -</pre></td> -<td><code>/job:local/task:0<br/>/job:local/task:1</code></td> - </tr> - <tr> - <td><pre> -tf.train.ClusterSpec({ - "worker": [ - "worker0.example.com:2222", - "worker1.example.com:2222", - "worker2.example.com:2222" - ], - "ps": [ - "ps0.example.com:2222", - "ps1.example.com:2222" - ]}) -</pre></td><td><code>/job:worker/task:0</code><br/><code>/job:worker/task:1</code><br/><code>/job:worker/task:2</code><br/><code>/job:ps/task:0</code><br/><code>/job:ps/task:1</code></td> - </tr> -</table> - -### Create a `tf.train.Server` instance in each task - -A `tf.train.Server` object contains a -set of local devices, a set of connections to other tasks in its -`tf.train.ClusterSpec`, and a -`tf.Session` that can use these -to perform a distributed computation. Each server is a member of a specific -named job and has a task index within that job. A server can communicate with -any other server in the cluster. - -For example, to launch a cluster with two servers running on `localhost:2222` -and `localhost:2223`, run the following snippets in two different processes on -the local machine: - -```python -# In task 0: -cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]}) -server = tf.train.Server(cluster, job_name="local", task_index=0) -``` -```python -# In task 1: -cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]}) -server = tf.train.Server(cluster, job_name="local", task_index=1) -``` - -**Note:** Manually specifying these cluster specifications can be tedious, -especially for large clusters. We are working on tools for launching tasks -programmatically, e.g. using a cluster manager like -[Kubernetes](http://kubernetes.io). If there are particular cluster managers for -which you'd like to see support, please raise a -[GitHub issue](https://github.com/tensorflow/tensorflow/issues). - -## Specifying distributed devices in your model - -To place operations on a particular process, you can use the same -`tf.device` -function that is used to specify whether ops run on the CPU or GPU. For example: - -```python -with tf.device("/job:ps/task:0"): - weights_1 = tf.Variable(...) - biases_1 = tf.Variable(...) - -with tf.device("/job:ps/task:1"): - weights_2 = tf.Variable(...) - biases_2 = tf.Variable(...) - -with tf.device("/job:worker/task:7"): - input, labels = ... - layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1) - logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2) - # ... - train_op = ... - -with tf.Session("grpc://worker7.example.com:2222") as sess: - for _ in range(10000): - sess.run(train_op) -``` - -In the above example, the variables are created on two tasks in the `ps` job, -and the compute-intensive part of the model is created in the `worker` -job. TensorFlow will insert the appropriate data transfers between the jobs -(from `ps` to `worker` for the forward pass, and from `worker` to `ps` for -applying gradients). - -## Replicated training - -A common training configuration, called "data parallelism," involves multiple -tasks in a `worker` job training the same model on different mini-batches of -data, updating shared parameters hosted in one or more tasks in a `ps` -job. All tasks typically run on different machines. There are many ways to -specify this structure in TensorFlow, and we are building libraries that will -simplify the work of specifying a replicated model. Possible approaches include: - -* **In-graph replication.** In this approach, the client builds a single - `tf.Graph` that contains one set of parameters (in `tf.Variable` nodes pinned - to `/job:ps`); and multiple copies of the compute-intensive part of the model, - each pinned to a different task in `/job:worker`. - -* **Between-graph replication.** In this approach, there is a separate client - for each `/job:worker` task, typically in the same process as the worker - task. Each client builds a similar graph containing the parameters (pinned to - `/job:ps` as before using - `tf.train.replica_device_setter` - to map them deterministically to the same tasks); and a single copy of the - compute-intensive part of the model, pinned to the local task in - `/job:worker`. - -* **Asynchronous training.** In this approach, each replica of the graph has an - independent training loop that executes without coordination. It is compatible - with both forms of replication above. - -* **Synchronous training.** In this approach, all of the replicas read the same - values for the current parameters, compute gradients in parallel, and then - apply them together. It is compatible with in-graph replication (e.g. using - gradient averaging as in the - [CIFAR-10 multi-GPU trainer](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/cifar10_multi_gpu_train.py)), - and between-graph replication (e.g. using the - `tf.train.SyncReplicasOptimizer`). - -### Putting it all together: example trainer program - -The following code shows the skeleton of a distributed trainer program, -implementing **between-graph replication** and **asynchronous training**. It -includes the code for the parameter server and worker tasks. - -```python -import argparse -import sys - -import tensorflow as tf - -FLAGS = None - - -def main(_): - ps_hosts = FLAGS.ps_hosts.split(",") - worker_hosts = FLAGS.worker_hosts.split(",") - - # Create a cluster from the parameter server and worker hosts. - cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts}) - - # Create and start a server for the local task. - server = tf.train.Server(cluster, - job_name=FLAGS.job_name, - task_index=FLAGS.task_index) - - if FLAGS.job_name == "ps": - server.join() - elif FLAGS.job_name == "worker": - - # Assigns ops to the local worker by default. - with tf.device(tf.train.replica_device_setter( - worker_device="/job:worker/task:%d" % FLAGS.task_index, - cluster=cluster)): - - # Build model... - loss = ... - global_step = tf.contrib.framework.get_or_create_global_step() - - train_op = tf.train.AdagradOptimizer(0.01).minimize( - loss, global_step=global_step) - - # The StopAtStepHook handles stopping after running given steps. - hooks=[tf.train.StopAtStepHook(last_step=1000000)] - - # The MonitoredTrainingSession takes care of session initialization, - # restoring from a checkpoint, saving to a checkpoint, and closing when done - # or an error occurs. - with tf.train.MonitoredTrainingSession(master=server.target, - is_chief=(FLAGS.task_index == 0), - checkpoint_dir="/tmp/train_logs", - hooks=hooks) as mon_sess: - while not mon_sess.should_stop(): - # Run a training step asynchronously. - # See `tf.train.SyncReplicasOptimizer` for additional details on how to - # perform *synchronous* training. - # mon_sess.run handles AbortedError in case of preempted PS. - mon_sess.run(train_op) - - -if __name__ == "__main__": - parser = argparse.ArgumentParser() - parser.register("type", "bool", lambda v: v.lower() == "true") - # Flags for defining the tf.train.ClusterSpec - parser.add_argument( - "--ps_hosts", - type=str, - default="", - help="Comma-separated list of hostname:port pairs" - ) - parser.add_argument( - "--worker_hosts", - type=str, - default="", - help="Comma-separated list of hostname:port pairs" - ) - parser.add_argument( - "--job_name", - type=str, - default="", - help="One of 'ps', 'worker'" - ) - # Flags for defining the tf.train.Server - parser.add_argument( - "--task_index", - type=int, - default=0, - help="Index of task within the job" - ) - FLAGS, unparsed = parser.parse_known_args() - tf.app.run(main=main, argv=[sys.argv[0]] + unparsed) -``` - -To start the trainer with two parameter servers and two workers, use the -following command line (assuming the script is called `trainer.py`): - -```shell -# On ps0.example.com: -$ python trainer.py \ - --ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \ - --worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \ - --job_name=ps --task_index=0 -# On ps1.example.com: -$ python trainer.py \ - --ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \ - --worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \ - --job_name=ps --task_index=1 -# On worker0.example.com: -$ python trainer.py \ - --ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \ - --worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \ - --job_name=worker --task_index=0 -# On worker1.example.com: -$ python trainer.py \ - --ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \ - --worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \ - --job_name=worker --task_index=1 -``` - -## Glossary - -**Client** - -A client is typically a program that builds a TensorFlow graph and constructs a -`tensorflow::Session` to interact with a cluster. Clients are typically written -in Python or C++. A single client process can directly interact with multiple -TensorFlow servers (see "Replicated training" above), and a single server can -serve multiple clients. - -**Cluster** - -A TensorFlow cluster comprises one or more "jobs", each divided into lists of -one or more "tasks". A cluster is typically dedicated to a particular high-level -objective, such as training a neural network, using many machines in parallel. A -cluster is defined by -a `tf.train.ClusterSpec` object. - -**Job** - -A job comprises a list of "tasks", which typically serve a common purpose. -For example, a job named `ps` (for "parameter server") typically hosts nodes -that store and update variables; while a job named `worker` typically hosts -stateless nodes that perform compute-intensive tasks. The tasks in a job -typically run on different machines. The set of job roles is flexible: -for example, a `worker` may maintain some state. - -**Master service** - -An RPC service that provides remote access to a set of distributed devices, -and acts as a session target. The master service implements the -`tensorflow::Session` interface, and is responsible for coordinating work across -one or more "worker services". All TensorFlow servers implement the master -service. - -**Task** - -A task corresponds to a specific TensorFlow server, and typically corresponds -to a single process. A task belongs to a particular "job" and is identified by -its index within that job's list of tasks. - -**TensorFlow server** A process running -a `tf.train.Server` instance, which is -a member of a cluster, and exports a "master service" and "worker service". - -**Worker service** - -An RPC service that executes parts of a TensorFlow graph using its local devices. -A worker service implements [worker_service.proto](https://www.tensorflow.org/code/tensorflow/core/protobuf/worker_service.proto). -All TensorFlow servers implement the worker service. diff --git a/tensorflow/docs_src/deploy/hadoop.md b/tensorflow/docs_src/deploy/hadoop.md deleted file mode 100644 index b0d416df2e..0000000000 --- a/tensorflow/docs_src/deploy/hadoop.md +++ /dev/null @@ -1,65 +0,0 @@ -# How to run TensorFlow on Hadoop - -This document describes how to run TensorFlow on Hadoop. It will be expanded to -describe running on various cluster managers, but only describes running on HDFS -at the moment. - -## HDFS - -We assume that you are familiar with [reading data](../api_guides/python/reading_data.md). - -To use HDFS with TensorFlow, change the file paths you use to read and write -data to an HDFS path. For example: - -```python -filename_queue = tf.train.string_input_producer([ - "hdfs://namenode:8020/path/to/file1.csv", - "hdfs://namenode:8020/path/to/file2.csv", -]) -``` - -If you want to use the namenode specified in your HDFS configuration files, then -change the file prefix to `hdfs://default/`. - -When launching your TensorFlow program, the following environment variables must -be set: - -* **JAVA_HOME**: The location of your Java installation. -* **HADOOP_HDFS_HOME**: The location of your HDFS installation. You can also - set this environment variable by running: - - ```shell - source ${HADOOP_HOME}/libexec/hadoop-config.sh - ``` - -* **LD_LIBRARY_PATH**: To include the path to libjvm.so, and optionally the path - to libhdfs.so if your Hadoop distribution does not install libhdfs.so in - `$HADOOP_HDFS_HOME/lib/native`. On Linux: - - ```shell - export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${JAVA_HOME}/jre/lib/amd64/server - ``` - -* **CLASSPATH**: The Hadoop jars must be added prior to running your - TensorFlow program. The CLASSPATH set by - `${HADOOP_HOME}/libexec/hadoop-config.sh` is insufficient. Globs must be - expanded as described in the libhdfs documentation: - - ```shell - CLASSPATH=$(${HADOOP_HDFS_HOME}/bin/hadoop classpath --glob) python your_script.py - ``` - For older version of Hadoop/libhdfs (older than 2.6.0), you have to expand the - classpath wildcard manually. For more details, see - [HADOOP-10903](https://issues.apache.org/jira/browse/HADOOP-10903). - -If the Hadoop cluster is in secure mode, the following environment variable must -be set: - -* **KRB5CCNAME**: The path of Kerberos ticket cache file. For example: - - ```shell - export KRB5CCNAME=/tmp/krb5cc_10002 - ``` - -If you are running [Distributed TensorFlow](../deploy/distributed.md), then all -workers must have the environment variables set and Hadoop installed. diff --git a/tensorflow/docs_src/deploy/index.md b/tensorflow/docs_src/deploy/index.md deleted file mode 100644 index 08b28de639..0000000000 --- a/tensorflow/docs_src/deploy/index.md +++ /dev/null @@ -1,21 +0,0 @@ -# Deploy - -This section focuses on deploying real-world models. It contains -the following documents: - - * [Distributed TensorFlow](../deploy/distributed.md), which explains how to create - a cluster of TensorFlow servers. - * [How to run TensorFlow on Hadoop](../deploy/hadoop.md), which has a highly - self-explanatory title. - * [How to run TensorFlow with the S3 filesystem](../deploy/s3.md), which explains how - to run TensorFlow with the S3 file system. - * The entire document set for [TensorFlow serving](/serving), an open-source, - flexible, high-performance serving system for machine-learned models - designed for production environments. TensorFlow Serving provides - out-of-the-box integration with TensorFlow models. - [Source code for TensorFlow Serving](https://github.com/tensorflow/serving) - is available on GitHub. - -[TensorFlow Extended (TFX)](/tfx) is an end-to-end machine learning platform for -TensorFlow. Implemented at Google, we've open sourced some TFX libraries with the -rest of the system to come. diff --git a/tensorflow/docs_src/deploy/leftnav_files b/tensorflow/docs_src/deploy/leftnav_files deleted file mode 100644 index 93f5bd1ed2..0000000000 --- a/tensorflow/docs_src/deploy/leftnav_files +++ /dev/null @@ -1,5 +0,0 @@ -index.md -distributed.md -hadoop.md -s3.md -deploy_to_js.md diff --git a/tensorflow/docs_src/deploy/s3.md b/tensorflow/docs_src/deploy/s3.md deleted file mode 100644 index b4a759d687..0000000000 --- a/tensorflow/docs_src/deploy/s3.md +++ /dev/null @@ -1,93 +0,0 @@ -# How to run TensorFlow on S3 - -Tensorflow supports reading and writing data to S3. S3 is an object storage API which is nearly ubiquitous, and can help in situations where data must accessed by multiple actors, such as in distributed training. - -This document guides you through the required setup, and provides examples on usage. - -## Configuration - -When reading or writing data on S3 with your TensorFlow program, the behavior -can be controlled by various environmental variables: - -* **AWS_REGION**: By default, regional endpoint is used for S3, with region - controlled by `AWS_REGION`. If `AWS_REGION` is not specified, then - `us-east-1` is used. -* **S3_ENDPOINT**: The endpoint could be overridden explicitly with - `S3_ENDPOINT` specified. -* **S3_USE_HTTPS**: HTTPS is used to access S3 by default, unless - `S3_USE_HTTPS=0`. -* **S3_VERIFY_SSL**: If HTTPS is used, SSL verification could be disabled - with `S3_VERIFY_SSL=0`. - -To read or write objects in a bucket that is not publicly accessible, -AWS credentials must be provided through one of the following methods: - -* Set credentials in the AWS credentials profile file on the local system, - located at: `~/.aws/credentials` on Linux, macOS, or Unix, or - `C:\Users\USERNAME\.aws\credentials` on Windows. -* Set the `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` environment - variables. -* If TensorFlow is deployed on an EC2 instance, specify an IAM role and then - give the EC2 instance access to that role. - -## Example Setup - -Using the above information, we can configure Tensorflow to communicate to an S3 endpoint by setting the following environment variables: - -```bash -AWS_ACCESS_KEY_ID=XXXXX # Credentials only needed if connecting to a private endpoint -AWS_SECRET_ACCESS_KEY=XXXXX -AWS_REGION=us-east-1 # Region for the S3 bucket, this is not always needed. Default is us-east-1. -S3_ENDPOINT=s3.us-east-1.amazonaws.com # The S3 API Endpoint to connect to. This is specified in a HOST:PORT format. -S3_USE_HTTPS=1 # Whether or not to use HTTPS. Disable with 0. -S3_VERIFY_SSL=1 # If HTTPS is used, controls if SSL should be enabled. Disable with 0. -``` - -## Usage - -Once setup is completed, Tensorflow can interact with S3 in a variety of ways. Anywhere there is a Tensorflow IO function, an S3 URL can be used. - -### Smoke Test - -To test your setup, stat a file: - -```python -from tensorflow.python.lib.io import file_io -print file_io.stat('s3://bucketname/path/') -``` - -You should see output similar to this: - -```console -<tensorflow.python.pywrap_tensorflow_internal.FileStatistics; proxy of <Swig Object of type 'tensorflow::FileStatistics *' at 0x10c2171b0> > -``` - -### Reading Data - -When [reading data](../api_guides/python/reading_data.md), change the file paths you use to read and write -data to an S3 path. For example: - -```python -filenames = ["s3://bucketname/path/to/file1.tfrecord", - "s3://bucketname/path/to/file2.tfrecord"] -dataset = tf.data.TFRecordDataset(filenames) -``` - -### Tensorflow Tools - -Many Tensorflow tools, such as Tensorboard or model serving, can also take S3 URLS as arguments: - -```bash -tensorboard --logdir s3://bucketname/path/to/model/ -tensorflow_model_server --port=9000 --model_name=model --model_base_path=s3://bucketname/path/to/model/export/ -``` - -This enables an end to end workflow using S3 for all data needs. - -## S3 Endpoint Implementations - -S3 was invented by Amazon, but the S3 API has spread in popularity and has several implementations. The following implementations have passed basic compatibility tests: - -* [Amazon S3](https://aws.amazon.com/s3/) -* [Google Storage](https://cloud.google.com/storage/docs/interoperability) -* [Minio](https://www.minio.io/kubernetes.html) diff --git a/tensorflow/docs_src/extend/add_filesys.md b/tensorflow/docs_src/extend/add_filesys.md deleted file mode 100644 index 5f8ac64d25..0000000000 --- a/tensorflow/docs_src/extend/add_filesys.md +++ /dev/null @@ -1,260 +0,0 @@ -# Adding a Custom Filesystem Plugin - -## Background - -The TensorFlow framework is often used in multi-process and -multi-machine environments, such as Google data centers, Google Cloud -Machine Learning, Amazon Web Services (AWS), and on-site distributed clusters. -In order to both share and save certain types of state produced by TensorFlow, -the framework assumes the existence of a reliable, shared filesystem. This -shared filesystem has numerous uses, for example: - -* Checkpoints of state are often saved to a distributed filesystem for - reliability and fault-tolerance. -* Training processes communicate with TensorBoard by writing event files - to a directory, which TensorBoard watches. A shared filesystem allows this - communication to work even when TensorBoard runs in a different process or - machine. - -There are many different implementations of shared or distributed filesystems in -the real world, so TensorFlow provides an ability for users to implement a -custom FileSystem plugin that can be registered with the TensorFlow runtime. -When the TensorFlow runtime attempts to write to a file through the `FileSystem` -interface, it uses a portion of the pathname to dynamically select the -implementation that should be used for filesystem operations. Thus, adding -support for your custom filesystem requires implementing a `FileSystem` -interface, building a shared object containing that implementation, and loading -that object at runtime in whichever process needs to write to that filesystem. - -Note that TensorFlow already includes many filesystem implementations, such as: - -* A standard POSIX filesystem - - Note: NFS filesystems often mount as a POSIX interface, and so standard - TensorFlow can work on top of NFS-mounted remote filesystems. - -* HDFS - the Hadoop File System -* GCS - Google Cloud Storage filesystem -* S3 - Amazon Simple Storage Service filesystem -* A "memory-mapped-file" filesystem - -The rest of this guide describes how to implement a custom filesystem. - -## Implementing a custom filesystem plugin - -To implement a custom filesystem plugin, you must do the following: - -* Implement subclasses of `RandomAccessFile`, `WriteableFile`, - `AppendableFile`, and `ReadOnlyMemoryRegion`. -* Implement the `FileSystem` interface as a subclass. -* Register the `FileSystem` implementation with an appropriate prefix pattern. -* Load the filesystem plugin in a process that wants to write to that - filesystem. - -### The FileSystem interface - -The `FileSystem` interface is an abstract C++ interface defined in -[file_system.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h). -An implementation of the `FileSystem` interface should implement all relevant -the methods defined by the interface. Implementing the interface requires -defining operations such as creating `RandomAccessFile`, `WritableFile`, and -implementing standard filesystem operations such as `FileExists`, `IsDirectory`, -`GetMatchingPaths`, `DeleteFile`, and so on. An implementation of these -interfaces will often involve translating the function's input arguments to -delegate to an already-existing library function implementing the equivalent -functionality in your custom filesystem. - -For example, the `PosixFileSystem` implementation implements `DeleteFile` using -the POSIX `unlink()` function; `CreateDir` simply calls `mkdir()`; `GetFileSize` -involves calling `stat()` on the file and then returns the filesize as reported -by the return of the stat object. Similarly, for the `HDFSFileSystem` -implementation, these calls simply delegate to the `libHDFS` implementation of -similar functionality, such as `hdfsDelete` for -[DeleteFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.cc#L386). - -We suggest looking through these code examples to get an idea of how different -filesystem implementations call their existing libraries. Examples include: - -* [POSIX - plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/posix/posix_file_system.h) -* [HDFS - plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.h) -* [GCS - plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/cloud/gcs_file_system.h) -* [S3 - plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/s3/s3_file_system.h) - -#### The File interfaces - -Beyond operations that allow you to query and manipulate files and directories -in a filesystem, the `FileSystem` interface requires you to implement factories -that return implementations of abstract objects such as the -[RandomAccessFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h#L223), -the `WritableFile`, so that TensorFlow code and read and write to files in that -`FileSystem` implementation. - -To implement a `RandomAccessFile`, you must implement a single interface called -`Read()`, in which the implementation must provide a way to read from an offset -within a named file. - -For example, below is the implementation of RandomAccessFile for the POSIX -filesystem, which uses the `pread()` random-access POSIX function to implement -read. Notice that the particular implementation must know how to retry or -propagate errors from the underlying filesystem. - -```C++ - class PosixRandomAccessFile : public RandomAccessFile { - public: - PosixRandomAccessFile(const string& fname, int fd) - : filename_(fname), fd_(fd) {} - ~PosixRandomAccessFile() override { close(fd_); } - - Status Read(uint64 offset, size_t n, StringPiece* result, - char* scratch) const override { - Status s; - char* dst = scratch; - while (n > 0 && s.ok()) { - ssize_t r = pread(fd_, dst, n, static_cast<off_t>(offset)); - if (r > 0) { - dst += r; - n -= r; - offset += r; - } else if (r == 0) { - s = Status(error::OUT_OF_RANGE, "Read less bytes than requested"); - } else if (errno == EINTR || errno == EAGAIN) { - // Retry - } else { - s = IOError(filename_, errno); - } - } - *result = StringPiece(scratch, dst - scratch); - return s; - } - - private: - string filename_; - int fd_; - }; -``` - -To implement the WritableFile sequential-writing abstraction, one must implement -a few interfaces, such as `Append()`, `Flush()`, `Sync()`, and `Close()`. - -For example, below is the implementation of WritableFile for the POSIX -filesystem, which takes a `FILE` object in its constructor and uses standard -posix functions on that object to implement the interface. - -```C++ - class PosixWritableFile : public WritableFile { - public: - PosixWritableFile(const string& fname, FILE* f) - : filename_(fname), file_(f) {} - - ~PosixWritableFile() override { - if (file_ != NULL) { - fclose(file_); - } - } - - Status Append(const StringPiece& data) override { - size_t r = fwrite(data.data(), 1, data.size(), file_); - if (r != data.size()) { - return IOError(filename_, errno); - } - return Status::OK(); - } - - Status Close() override { - Status result; - if (fclose(file_) != 0) { - result = IOError(filename_, errno); - } - file_ = NULL; - return result; - } - - Status Flush() override { - if (fflush(file_) != 0) { - return IOError(filename_, errno); - } - return Status::OK(); - } - - Status Sync() override { - Status s; - if (fflush(file_) != 0) { - s = IOError(filename_, errno); - } - return s; - } - - private: - string filename_; - FILE* file_; - }; - -``` - -For more details, please see the documentations of those interfaces, and look at -example implementations for inspiration. - -### Registering and loading the filesystem - -Once you have implemented the `FileSystem` implementation for your custom -filesystem, you need to register it under a "scheme" so that paths prefixed with -that scheme are directed to your implementation. To do this, you call -`REGISTER_FILE_SYSTEM`:: - -``` - REGISTER_FILE_SYSTEM("foobar", FooBarFileSystem); -``` - -When TensorFlow tries to operate on a file whose path starts with `foobar://`, -it will use the `FooBarFileSystem` implementation. - -```C++ - string filename = "foobar://path/to/file.txt"; - std::unique_ptr<WritableFile> file; - - // Calls FooBarFileSystem::NewWritableFile to return - // a WritableFile class, which happens to be the FooBarFileSystem's - // WritableFile implementation. - TF_RETURN_IF_ERROR(env->NewWritableFile(filename, &file)); -``` - -Next, you must build a shared object containing this implementation. An example -of doing so using bazel's `cc_binary` rule can be found -[here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/BUILD#L244), -but you may use any build system to do so. See the section on [building the op library](../extend/adding_an_op.md#build_the_op_library) for similar -instructions. - -The result of building this target is a `.so` shared object file. - -Lastly, you must dynamically load this implementation in the process. In Python, -you can call the `tf.load_file_system_library(file_system_library)` function, -passing the path to the shared object. Calling this in your client program loads -the shared object in the process, thus registering your implementation as -available for any file operations going through the `FileSystem` interface. You -can see -[test_file_system.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/framework/file_system_test.py) -for an example. - -## What goes through this interface? - -Almost all core C++ file operations within TensorFlow use the `FileSystem` -interface, such as the `CheckpointWriter`, the `EventsWriter`, and many other -utilities. This means implementing a `FileSystem` implementation allows most of -your TensorFlow programs to write to your shared filesystem. - -In Python, the `gfile` and `file_io` classes bind underneath to the `FileSystem -implementation via SWIG, which means that once you have loaded this filesystem -library, you can do: - -``` -with gfile.Open("foobar://path/to/file.txt") as w: - - w.write("hi") -``` - -When you do this, a file containing "hi" will appear in the "/path/to/file.txt" -of your shared filesystem. diff --git a/tensorflow/docs_src/extend/adding_an_op.md b/tensorflow/docs_src/extend/adding_an_op.md deleted file mode 100644 index cc25ab9b45..0000000000 --- a/tensorflow/docs_src/extend/adding_an_op.md +++ /dev/null @@ -1,1460 +0,0 @@ -# Adding a New Op - -Note: By default [www.tensorflow.org](https://www.tensorflow.org) shows docs for the -most recent stable version. The instructions in this doc require building from -source. You will probably want to build from the `master` version of tensorflow. -You should, as a result, be sure you are following the -[`master` version of this doc](https://www.tensorflow.org/versions/master/extend/adding_an_op), -in case there have been any changes. - -If you'd like to create an op that isn't covered by the existing TensorFlow -library, we recommend that you first try writing the op in Python as -a composition of existing Python ops or functions. If that isn't possible, you -can create a custom C++ op. There are several reasons why you might want to -create a custom C++ op: - -* It's not easy or possible to express your operation as a composition of - existing ops. -* It's not efficient to express your operation as a composition of existing - primitives. -* You want to hand-fuse a composition of primitives that a future compiler - would find difficult fusing. - -For example, imagine you want to implement something like "median pooling", -similar to the "MaxPool" operator, but computing medians over sliding windows -instead of maximum values. Doing this using a composition of operations may be -possible (e.g., using ExtractImagePatches and TopK), but may not be as -performance- or memory-efficient as a native operation where you can do -something more clever in a single, fused operation. As always, it is typically -first worth trying to express what you want using operator composition, only -choosing to add a new operation if that proves to be difficult or inefficient. - -To incorporate your custom op you'll need to: - -1. Register the new op in a C++ file. Op registration defines an interface - (specification) for the op's functionality, which is independent of the - op's implementation. For example, op registration defines the op's name and - the op's inputs and outputs. It also defines the shape function - that is used for tensor shape inference. -2. Implement the op in C++. The implementation of an op is known - as a kernel, and it is the concrete implementation of the specification you - registered in Step 1. There can be multiple kernels for different input / - output types or architectures (for example, CPUs, GPUs). -3. Create a Python wrapper (optional). This wrapper is the public API that's - used to create the op in Python. A default wrapper is generated from the - op registration, which can be used directly or added to. -4. Write a function to compute gradients for the op (optional). -5. Test the op. We usually do this in Python for convenience, but you can also - test the op in C++. If you define gradients, you can verify them with the - Python `tf.test.compute_gradient_error`. - See - [`relu_op_test.py`](https://www.tensorflow.org/code/tensorflow/python/kernel_tests/relu_op_test.py) as - an example that tests the forward functions of Relu-like operators and - their gradients. - -PREREQUISITES: - -* Some familiarity with C++. -* Must have installed the - [TensorFlow binary](../install/index.md), or must have - [downloaded TensorFlow source](../install/install_sources.md), - and be able to build it. - -[TOC] - -## Define the op's interface - -You define the interface of an op by registering it with the TensorFlow system. -In the registration, you specify the name of your op, its inputs (types and -names) and outputs (types and names), as well as docstrings and -any [attrs](#attrs) the op might require. - -To see how this works, suppose you'd like to create an op that takes a tensor of -`int32`s and outputs a copy of the tensor, with all but the first element set to -zero. To do this, create a file named `zero_out.cc`. Then add a call to the -`REGISTER_OP` macro that defines the interface for your op: - -```c++ -#include "tensorflow/core/framework/op.h" -#include "tensorflow/core/framework/shape_inference.h" - -using namespace tensorflow; - -REGISTER_OP("ZeroOut") - .Input("to_zero: int32") - .Output("zeroed: int32") - .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { - c->set_output(0, c->input(0)); - return Status::OK(); - }); -``` - -This `ZeroOut` op takes one tensor `to_zero` of 32-bit integers as input, and -outputs a tensor `zeroed` of 32-bit integers. The op also uses a shape function -to ensure that the output tensor is the same shape as the input tensor. For -example, if the input is a tensor of shape [10, 20], then this shape function -specifies that the output shape is also [10, 20]. - - -> A note on naming: The op name must be in CamelCase and it must be unique -> among all other ops that are registered in the binary. - -## Implement the kernel for the op - -After you define the interface, provide one or more implementations of the op. -To create one of these kernels, create a class that extends `OpKernel` and -overrides the `Compute` method. The `Compute` method provides one `context` -argument of type `OpKernelContext*`, from which you can access useful things -like the input and output tensors. - -Add your kernel to the file you created above. The kernel might look something -like this: - -```c++ -#include "tensorflow/core/framework/op_kernel.h" - -using namespace tensorflow; - -class ZeroOutOp : public OpKernel { - public: - explicit ZeroOutOp(OpKernelConstruction* context) : OpKernel(context) {} - - void Compute(OpKernelContext* context) override { - // Grab the input tensor - const Tensor& input_tensor = context->input(0); - auto input = input_tensor.flat<int32>(); - - // Create an output tensor - Tensor* output_tensor = NULL; - OP_REQUIRES_OK(context, context->allocate_output(0, input_tensor.shape(), - &output_tensor)); - auto output_flat = output_tensor->flat<int32>(); - - // Set all but the first element of the output tensor to 0. - const int N = input.size(); - for (int i = 1; i < N; i++) { - output_flat(i) = 0; - } - - // Preserve the first input value if possible. - if (N > 0) output_flat(0) = input(0); - } -}; -``` - -After implementing your kernel, you register it with the TensorFlow system. In -the registration, you specify different constraints under which this kernel -will run. For example, you might have one kernel made for CPUs, and a separate -one for GPUs. - -To do this for the `ZeroOut` op, add the following to `zero_out.cc`: - -```c++ -REGISTER_KERNEL_BUILDER(Name("ZeroOut").Device(DEVICE_CPU), ZeroOutOp); -``` - -> Important: Instances of your OpKernel may be accessed concurrently. -> Your `Compute` method must be thread-safe. Guard any access to class -> members with a mutex. Or better yet, don't share state via class members! -> Consider using a [`ResourceMgr`](https://www.tensorflow.org/code/tensorflow/core/framework/resource_mgr.h) -> to keep track of op state. - -### Multi-threaded CPU kernels - -To write a multi-threaded CPU kernel, the Shard function in -[`work_sharder.h`](https://www.tensorflow.org/code/tensorflow/core/util/work_sharder.h) -can be used. This function shards a computation function across the -threads configured to be used for intra-op threading (see -intra_op_parallelism_threads in -[`config.proto`](https://www.tensorflow.org/code/tensorflow/core/protobuf/config.proto)). - -### GPU kernels - -A GPU kernel is implemented in two parts: the OpKernel and the CUDA kernel and -its launch code. - -Sometimes the OpKernel implementation is common between a CPU and GPU kernel, -such as around inspecting inputs and allocating outputs. In that case, a -suggested implementation is to: - -1. Define the OpKernel templated on the Device and the primitive type of the - tensor. -2. To do the actual computation of the output, the Compute function calls a - templated functor struct. -3. The specialization of that functor for the CPUDevice is defined in the same - file, but the specialization for the GPUDevice is defined in a .cu.cc file, - since it will be compiled with the CUDA compiler. - -Here is an example implementation. - -```c++ -// kernel_example.h -#ifndef KERNEL_EXAMPLE_H_ -#define KERNEL_EXAMPLE_H_ - -template <typename Device, typename T> -struct ExampleFunctor { - void operator()(const Device& d, int size, const T* in, T* out); -}; - -#if GOOGLE_CUDA -// Partially specialize functor for GpuDevice. -template <typename Eigen::GpuDevice, typename T> -struct ExampleFunctor { - void operator()(const Eigen::GpuDevice& d, int size, const T* in, T* out); -}; -#endif - -#endif KERNEL_EXAMPLE_H_ -``` - -```c++ -// kernel_example.cc -#include "example.h" -#include "tensorflow/core/framework/op_kernel.h" - -using namespace tensorflow; - -using CPUDevice = Eigen::ThreadPoolDevice; -using GPUDevice = Eigen::GpuDevice; - -// CPU specialization of actual computation. -template <typename T> -struct ExampleFunctor<CPUDevice, T> { - void operator()(const CPUDevice& d, int size, const T* in, T* out) { - for (int i = 0; i < size; ++i) { - out[i] = 2 * in[i]; - } - } -}; - -// OpKernel definition. -// template parameter <T> is the datatype of the tensors. -template <typename Device, typename T> -class ExampleOp : public OpKernel { - public: - explicit ExampleOp(OpKernelConstruction* context) : OpKernel(context) {} - - void Compute(OpKernelContext* context) override { - // Grab the input tensor - const Tensor& input_tensor = context->input(0); - - // Create an output tensor - Tensor* output_tensor = NULL; - OP_REQUIRES_OK(context, context->allocate_output(0, input_tensor.shape(), - &output_tensor)); - - // Do the computation. - OP_REQUIRES(context, input_tensor.NumElements() <= tensorflow::kint32max, - errors::InvalidArgument("Too many elements in tensor")); - ExampleFunctor<Device, T>()( - context->eigen_device<Device>(), - static_cast<int>(input_tensor.NumElements()), - input_tensor.flat<T>().data(), - output_tensor->flat<T>().data()); - } -}; - -// Register the CPU kernels. -#define REGISTER_CPU(T) \ - REGISTER_KERNEL_BUILDER( \ - Name("Example").Device(DEVICE_CPU).TypeConstraint<T>("T"), \ - ExampleOp<CPUDevice, T>); -REGISTER_CPU(float); -REGISTER_CPU(int32); - -// Register the GPU kernels. -#ifdef GOOGLE_CUDA -#define REGISTER_GPU(T) \ - /* Declare explicit instantiations in kernel_example.cu.cc. */ \ - extern template ExampleFunctor<GPUDevice, T>; \ - REGISTER_KERNEL_BUILDER( \ - Name("Example").Device(DEVICE_GPU).TypeConstraint<T>("T"), \ - ExampleOp<GPUDevice, T>); -REGISTER_GPU(float); -REGISTER_GPU(int32); -#endif // GOOGLE_CUDA -``` - -```c++ -// kernel_example.cu.cc -#ifdef GOOGLE_CUDA -#define EIGEN_USE_GPU -#include "example.h" -#include "tensorflow/core/util/cuda_kernel_helper.h" - -using namespace tensorflow; - -using GPUDevice = Eigen::GpuDevice; - -// Define the CUDA kernel. -template <typename T> -__global__ void ExampleCudaKernel(const int size, const T* in, T* out) { - for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < size; - i += blockDim.x * gridDim.x) { - out[i] = 2 * ldg(in + i); - } -} - -// Define the GPU implementation that launches the CUDA kernel. -template <typename T> -void ExampleFunctor<GPUDevice, T>::operator()( - const GPUDevice& d, int size, const T* in, T* out) { - // Launch the cuda kernel. - // - // See core/util/cuda_kernel_helper.h for example of computing - // block count and thread_per_block count. - int block_count = 1024; - int thread_per_block = 20; - ExampleCudaKernel<T> - <<<block_count, thread_per_block, 0, d.stream()>>>(size, in, out); -} - -// Explicitly instantiate functors for the types of OpKernels registered. -template struct ExampleFunctor<GPUDevice, float>; -template struct ExampleFunctor<GPUDevice, int32>; - -#endif // GOOGLE_CUDA -``` - -## Build the op library -### Compile the op using your system compiler (TensorFlow binary installation) - -You should be able to compile `zero_out.cc` with a `C++` compiler such as `g++` -or `clang` available on your system. The binary PIP package installs the header -files and the library that you need to compile your op in locations that are -system specific. However, the TensorFlow python library provides the -`get_include` function to get the header directory, and the `get_lib` directory -has a shared object to link against. -Here are the outputs of these functions on an Ubuntu machine. - -```bash -$ python ->>> import tensorflow as tf ->>> tf.sysconfig.get_include() -'/usr/local/lib/python2.7/site-packages/tensorflow/include' ->>> tf.sysconfig.get_lib() -'/usr/local/lib/python2.7/site-packages/tensorflow' -``` - -Assuming you have `g++` installed, here is the sequence of commands you can use -to compile your op into a dynamic library. - -```bash -TF_CFLAGS=( $(python -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_compile_flags()))') ) -TF_LFLAGS=( $(python -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_link_flags()))') ) -g++ -std=c++11 -shared zero_out.cc -o zero_out.so -fPIC ${TF_CFLAGS[@]} ${TF_LFLAGS[@]} -O2 -``` - -On Mac OS X, the additional flag "-undefined dynamic_lookup" is required when -building the `.so` file. - -> Note on `gcc` version `>=5`: gcc uses the new C++ -> [ABI](https://gcc.gnu.org/gcc-5/changes.html#libstdcxx) since version `5`. The binary pip -> packages available on the TensorFlow website are built with `gcc4` that uses -> the older ABI. If you compile your op library with `gcc>=5`, add -> `-D_GLIBCXX_USE_CXX11_ABI=0` to the command line to make the library -> compatible with the older abi. -> Furthermore if you are using TensorFlow package created from source remember to add `--cxxopt="-D_GLIBCXX_USE_CXX11_ABI=0"` -> as bazel command to compile the Python package. - -### Compile the op using bazel (TensorFlow source installation) - -If you have TensorFlow sources installed, you can make use of TensorFlow's build -system to compile your op. Place a BUILD file with following Bazel build rule in -the [`tensorflow/core/user_ops`][user_ops] directory. - -```python -load("//tensorflow:tensorflow.bzl", "tf_custom_op_library") - -tf_custom_op_library( - name = "zero_out.so", - srcs = ["zero_out.cc"], -) -``` - -Run the following command to build `zero_out.so`. - -```bash -$ bazel build --config opt //tensorflow/core/user_ops:zero_out.so -``` - -> Note: Although you can create a shared library (a `.so` file) with the -> standard `cc_library` rule, we strongly recommend that you use the -> `tf_custom_op_library` macro. It adds some required dependencies, and -> performs checks to ensure that the shared library is compatible with -> TensorFlow's plugin loading mechanism. - -## Use the op in Python - -TensorFlow Python API provides the -`tf.load_op_library` function to -load the dynamic library and register the op with the TensorFlow -framework. `load_op_library` returns a Python module that contains the Python -wrappers for the op and the kernel. Thus, once you have built the op, you can -do the following to run it from Python: - -```python -import tensorflow as tf -zero_out_module = tf.load_op_library('./zero_out.so') -with tf.Session(''): - zero_out_module.zero_out([[1, 2], [3, 4]]).eval() - -# Prints -array([[1, 0], [0, 0]], dtype=int32) -``` - -Keep in mind, the generated function will be given a snake\_case name (to comply -with [PEP8](https://www.python.org/dev/peps/pep-0008/)). So, if your op is -named `ZeroOut` in the C++ files, the python function will be called `zero_out`. - -To make the op available as a regular function `import`-able from a Python -module, it maybe useful to have the `load_op_library` call in a Python source -file as follows: - -```python -import tensorflow as tf - -zero_out_module = tf.load_op_library('./zero_out.so') -zero_out = zero_out_module.zero_out -``` - -## Verify that the op works - -A good way to verify that you've successfully implemented your op is to write a -test for it. Create the file -`zero_out_op_test.py` with the contents: - -```python -import tensorflow as tf - -class ZeroOutTest(tf.test.TestCase): - def testZeroOut(self): - zero_out_module = tf.load_op_library('./zero_out.so') - with self.test_session(): - result = zero_out_module.zero_out([5, 4, 3, 2, 1]) - self.assertAllEqual(result.eval(), [5, 0, 0, 0, 0]) - -if __name__ == "__main__": - tf.test.main() -``` - -Then run your test (assuming you have tensorflow installed): - -```sh -$ python zero_out_op_test.py -``` - -## Building advanced features into your op - -Now that you know how to build a basic (and somewhat restricted) op and -implementation, we'll look at some of the more complicated things you will -typically need to build into your op. This includes: - -* [Conditional checks and validation](#conditional-checks-and-validation) -* [Op registration](#op-registration) - * [Attrs](#attrs) - * [Attr types](#attr-types) - * [Polymorphism](#polymorphism) - * [Inputs and outputs](#inputs-and-outputs) - * [Backwards compatibility](#backwards-compatibility) -* [GPU support](#gpu-support) - * [Compiling the kernel for the GPU device](#compiling-the-kernel-for-the-gpu-device) -* [Implement the gradient in Python](#implement-the-gradient-in-python) -* [Shape functions in C++](#shape-functions-in-c) - -### Conditional checks and validation - -The example above assumed that the op applied to a tensor of any shape. What -if it only applied to vectors? That means adding a check to the above OpKernel -implementation. - -```c++ - void Compute(OpKernelContext* context) override { - // Grab the input tensor - const Tensor& input_tensor = context->input(0); - - OP_REQUIRES(context, TensorShapeUtils::IsVector(input_tensor.shape()), - errors::InvalidArgument("ZeroOut expects a 1-D vector.")); - // ... - } -``` - -This asserts that the input is a vector, and returns having set the -`InvalidArgument` status if it isn't. The -[`OP_REQUIRES` macro][validation-macros] takes three arguments: - -* The `context`, which can either be an `OpKernelContext` or - `OpKernelConstruction` pointer (see - [`tensorflow/core/framework/op_kernel.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)), - for its `SetStatus()` method. -* The condition. For example, there are functions for validating the shape - of a tensor in - [`tensorflow/core/framework/tensor_shape.h`](https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.h) -* The error itself, which is represented by a `Status` object, see - [`tensorflow/core/lib/core/status.h`](https://www.tensorflow.org/code/tensorflow/core/lib/core/status.h). A - `Status` has both a type (frequently `InvalidArgument`, but see the list of - types) and a message. Functions for constructing an error may be found in - [`tensorflow/core/lib/core/errors.h`][validation-macros]. - -Alternatively, if you want to test whether a `Status` object returned from some -function is an error, and if so return it, use -[`OP_REQUIRES_OK`][validation-macros]. Both of these macros return from the -function on error. - -### Op registration - -#### Attrs - -Ops can have attrs, whose values are set when the op is added to a graph. These -are used to configure the op, and their values can be accessed both within the -kernel implementation and in the types of inputs and outputs in the op -registration. Prefer using an input instead of an attr when possible, since -inputs are more flexible. This is because attrs are constants and must be -defined at graph construction time. In contrast, inputs are Tensors whose -values can be dynamic; that is, inputs can change every step, be set using a -feed, etc. Attrs are used for things that can't be done with inputs: any -configuration that affects the signature (number or type of inputs or outputs) -or that can't change from step-to-step. - -You define an attr when you register the op, by specifying its name and type -using the `Attr` method, which expects a spec of the form: - -``` -<name>: <attr-type-expr> -``` - -where `<name>` begins with a letter and can be composed of alphanumeric -characters and underscores, and `<attr-type-expr>` is a type expression of the -form [described below](#attr_types). - -For example, if you'd like the `ZeroOut` op to preserve a user-specified index, -instead of only the 0th element, you can register the op like so: -```c++ -REGISTER_OP("ZeroOut") - .Attr("preserve_index: int") - .Input("to_zero: int32") - .Output("zeroed: int32"); -``` - -(Note that the set of [attribute types](#attr_types) is different from the -`tf.DType` used for inputs and outputs.) - -Your kernel can then access this attr in its constructor via the `context` -parameter: -```c++ -class ZeroOutOp : public OpKernel { - public: - explicit ZeroOutOp(OpKernelConstruction* context) : OpKernel(context) { - // Get the index of the value to preserve - OP_REQUIRES_OK(context, - context->GetAttr("preserve_index", &preserve_index_)); - // Check that preserve_index is positive - OP_REQUIRES(context, preserve_index_ >= 0, - errors::InvalidArgument("Need preserve_index >= 0, got ", - preserve_index_)); - } - void Compute(OpKernelContext* context) override { - // ... - } - private: - int preserve_index_; -}; -``` - -which can then be used in the `Compute` method: -```c++ - void Compute(OpKernelContext* context) override { - // ... - - // We're using saved attr to validate potentially dynamic input - // So we check that preserve_index is in range - OP_REQUIRES(context, preserve_index_ < input.dimension(0), - errors::InvalidArgument("preserve_index out of range")); - - // Set all the elements of the output tensor to 0 - const int N = input.size(); - for (int i = 0; i < N; i++) { - output\_flat(i) = 0; - } - - // Preserve the requested input value - output_flat(preserve_index_) = input(preserve_index_); - } -``` - -#### Attr types - -The following types are supported in an attr: - -* `string`: Any sequence of bytes (not required to be UTF8). -* `int`: A signed integer. -* `float`: A floating point number. -* `bool`: True or false. -* `type`: One of the (non-ref) values of [`DataType`][DataTypeString]. -* `shape`: A [`TensorShapeProto`][TensorShapeProto]. -* `tensor`: A [`TensorProto`][TensorProto]. -* `list(<type>)`: A list of `<type>`, where `<type>` is one of the above types. - Note that `list(list(<type>))` is invalid. - -See also: [`op_def_builder.cc:FinalizeAttr`][FinalizeAttr] for a definitive list. - -##### Default values & constraints - -Attrs may have default values, and some types of attrs can have constraints. To -define an attr with constraints, you can use the following `<attr-type-expr>`s: - -* `{'<string1>', '<string2>'}`: The value must be a string that has either the - value `<string1>` or `<string2>`. The name of the type, `string`, is implied - when you use this syntax. This emulates an enum: - - ```c++ - REGISTER_OP("EnumExample") - .Attr("e: {'apple', 'orange'}"); - ``` - -* `{<type1>, <type2>}`: The value is of type `type`, and must be one of - `<type1>` or `<type2>`, where `<type1>` and `<type2>` are supported - `tf.DType`. You don't specify - that the type of the attr is `type`. This is implied when you have a list of - types in `{...}`. For example, in this case the attr `t` is a type that must - be an `int32`, a `float`, or a `bool`: - - ```c++ - REGISTER_OP("RestrictedTypeExample") - .Attr("t: {int32, float, bool}"); - ``` - -* There are shortcuts for common type constraints: - * `numbertype`: Type `type` restricted to the numeric (non-string and - non-bool) types. - * `realnumbertype`: Like `numbertype` without complex types. - * `quantizedtype`: Like `numbertype` but just the quantized number types. - - The specific lists of types allowed by these are defined by the functions - (like `NumberTypes()`) in - [`tensorflow/core/framework/types.h`](https://www.tensorflow.org/code/tensorflow/core/framework/types.h). - In this example the attr `t` must be one of the numeric types: - - ```c++ - REGISTER_OP("NumberType") - .Attr("t: numbertype"); - ``` - - For this op: - - ```python - tf.number_type(t=tf.int32) # Valid - tf.number_type(t=tf.bool) # Invalid - ``` - - Lists can be combined with other lists and single types. The following - op allows attr `t` to be any of the numeric types, or the bool type: - - ```c++ - REGISTER_OP("NumberOrBooleanType") - .Attr("t: {numbertype, bool}"); - ``` - - For this op: - - ```python - tf.number_or_boolean_type(t=tf.int32) # Valid - tf.number_or_boolean_type(t=tf.bool) # Valid - tf.number_or_boolean_type(t=tf.string) # Invalid - ``` - -* `int >= <n>`: The value must be an int whose value is greater than or equal to - `<n>`, where `<n>` is a natural number. - - For example, the following op registration specifies that the attr `a` must - have a value that is at least `2`: - - ```c++ - REGISTER_OP("MinIntExample") - .Attr("a: int >= 2"); - ``` - -* `list(<type>) >= <n>`: A list of type `<type>` whose length is greater than - or equal to `<n>`. - - For example, the following op registration specifies that the attr `a` is a - list of types (either `int32` or `float`), and that there must be at least 3 - of them: - - ```c++ - REGISTER_OP("TypeListExample") - .Attr("a: list({int32, float}) >= 3"); - ``` - -To set a default value for an attr (making it optional in the generated code), -add `= <default>` to the end, as in: - -```c++ -REGISTER_OP("AttrDefaultExample") - .Attr("i: int = 0"); -``` - -The supported syntax of the default value is what would be used in the proto -representation of the resulting GraphDef definition. - -Here are examples for how to specify a default for all types: - -```c++ -REGISTER_OP("AttrDefaultExampleForAllTypes") - .Attr("s: string = 'foo'") - .Attr("i: int = 0") - .Attr("f: float = 1.0") - .Attr("b: bool = true") - .Attr("ty: type = DT_INT32") - .Attr("sh: shape = { dim { size: 1 } dim { size: 2 } }") - .Attr("te: tensor = { dtype: DT_INT32 int_val: 5 }") - .Attr("l_empty: list(int) = []") - .Attr("l_int: list(int) = [2, 3, 5, 7]"); -``` - -Note in particular that the values of type `type` -use `tf.DType`. - -#### Polymorphism - -##### Type Polymorphism - -For ops that can take different types as input or produce different output -types, you can specify [an attr](#attrs) in -[an input or output type](#inputs-and-outputs) in the op registration. Typically -you would then register an `OpKernel` for each supported type. - -For instance, if you'd like the `ZeroOut` op to work on `float`s -in addition to `int32`s, your op registration might look like: -```c++ -REGISTER_OP("ZeroOut") - .Attr("T: {float, int32}") - .Input("to_zero: T") - .Output("zeroed: T"); -``` - -Your op registration now specifies that the input's type must be `float`, or -`int32`, and that its output will be the same type, since both have type `T`. - -> <a id="naming"></a>A note on naming: Inputs, outputs, and attrs generally should be -> given snake\_case names. The one exception is attrs that are used as the type -> of an input or in the type of an input. Those attrs can be inferred when the -> op is added to the graph and so don't appear in the op's function. For -> example, this last definition of ZeroOut will generate a Python function that -> looks like: -> -> ```python -> def zero_out(to_zero, name=None): -> """... -> Args: -> to_zero: A `Tensor`. Must be one of the following types: -> `float32`, `int32`. -> name: A name for the operation (optional). -> -> Returns: -> A `Tensor`. Has the same type as `to_zero`. -> """ -> ``` -> -> If `to_zero` is passed an `int32` tensor, then `T` is automatically set to -> `int32` (well, actually `DT_INT32`). Those inferred attrs are given -> Capitalized or CamelCase names. -> -> Compare this with an op that has a type attr that determines the output -> type: -> -> ```c++ -> REGISTER_OP("StringToNumber") -> .Input("string_tensor: string") -> .Output("output: out_type") -> .Attr("out_type: {float, int32} = DT_FLOAT"); -> .Doc(R"doc( -> Converts each string in the input Tensor to the specified numeric type. -> )doc"); -> ``` -> -> In this case, the user has to specify the output type, as in the generated -> Python: -> -> ```python -> def string_to_number(string_tensor, out_type=None, name=None): -> """Converts each string in the input Tensor to the specified numeric type. -> -> Args: -> string_tensor: A `Tensor` of type `string`. -> out_type: An optional `tf.DType` from: `tf.float32, tf.int32`. -> Defaults to `tf.float32`. -> name: A name for the operation (optional). -> -> Returns: -> A `Tensor` of type `out_type`. -> """ -> ``` - -```c++ -#include "tensorflow/core/framework/op_kernel.h" - -class ZeroOutInt32Op : public OpKernel { - // as before -}; - -class ZeroOutFloatOp : public OpKernel { - public: - explicit ZeroOutFloatOp(OpKernelConstruction* context) - : OpKernel(context) {} - - void Compute(OpKernelContext* context) override { - // Grab the input tensor - const Tensor& input_tensor = context->input(0); - auto input = input_tensor.flat<float>(); - - // Create an output tensor - Tensor* output = NULL; - OP_REQUIRES_OK(context, - context->allocate_output(0, input_tensor.shape(), &output)); - auto output_flat = output->template flat<float>(); - - // Set all the elements of the output tensor to 0 - const int N = input.size(); - for (int i = 0; i < N; i++) { - output_flat(i) = 0; - } - - // Preserve the first input value - if (N > 0) output_flat(0) = input(0); - } -}; - -// Note that TypeConstraint<int32>("T") means that attr "T" (defined -// in the op registration above) must be "int32" to use this template -// instantiation. -REGISTER_KERNEL_BUILDER( - Name("ZeroOut") - .Device(DEVICE_CPU) - .TypeConstraint<int32>("T"), - ZeroOutOpInt32); -REGISTER_KERNEL_BUILDER( - Name("ZeroOut") - .Device(DEVICE_CPU) - .TypeConstraint<float>("T"), - ZeroOutFloatOp); -``` - -> To preserve [backwards compatibility](#backwards-compatibility), you should -> specify a [default value](#default-values-constraints) when adding an attr to -> an existing op: -> -> ```c++ -> REGISTER_OP("ZeroOut") -> .Attr("T: {float, int32} = DT_INT32") -> .Input("to_zero: T") -> .Output("zeroed: T") -> ``` - -Let's say you wanted to add more types, say `double`: -```c++ -REGISTER_OP("ZeroOut") - .Attr("T: {float, double, int32}") - .Input("to_zero: T") - .Output("zeroed: T"); -``` - -Instead of writing another `OpKernel` with redundant code as above, often you -will be able to use a C++ template instead. You will still have one kernel -registration (`REGISTER_KERNEL_BUILDER` call) per overload. -```c++ -template <typename T> -class ZeroOutOp : public OpKernel { - public: - explicit ZeroOutOp(OpKernelConstruction* context) : OpKernel(context) {} - - void Compute(OpKernelContext* context) override { - // Grab the input tensor - const Tensor& input_tensor = context->input(0); - auto input = input_tensor.flat<T>(); - - // Create an output tensor - Tensor* output = NULL; - OP_REQUIRES_OK(context, - context->allocate_output(0, input_tensor.shape(), &output)); - auto output_flat = output->template flat<T>(); - - // Set all the elements of the output tensor to 0 - const int N = input.size(); - for (int i = 0; i < N; i++) { - output_flat(i) = 0; - } - - // Preserve the first input value - if (N > 0) output_flat(0) = input(0); - } -}; - -// Note that TypeConstraint<int32>("T") means that attr "T" (defined -// in the op registration above) must be "int32" to use this template -// instantiation. -REGISTER_KERNEL_BUILDER( - Name("ZeroOut") - .Device(DEVICE_CPU) - .TypeConstraint<int32>("T"), - ZeroOutOp<int32>); -REGISTER_KERNEL_BUILDER( - Name("ZeroOut") - .Device(DEVICE_CPU) - .TypeConstraint<float>("T"), - ZeroOutOp<float>); -REGISTER_KERNEL_BUILDER( - Name("ZeroOut") - .Device(DEVICE_CPU) - .TypeConstraint<double>("T"), - ZeroOutOp<double>); -``` - -If you have more than a couple overloads, you can put the registration in a -macro. - -```c++ -#include "tensorflow/core/framework/op_kernel.h" - -#define REGISTER_KERNEL(type) \ - REGISTER_KERNEL_BUILDER( \ - Name("ZeroOut").Device(DEVICE_CPU).TypeConstraint<type>("T"), \ - ZeroOutOp<type>) - -REGISTER_KERNEL(int32); -REGISTER_KERNEL(float); -REGISTER_KERNEL(double); - -#undef REGISTER_KERNEL -``` - -Depending on the list of types you are registering the kernel for, you may be -able to use a macro provided by -[`tensorflow/core/framework/register_types.h`][register_types]: - -```c++ -#include "tensorflow/core/framework/op_kernel.h" -#include "tensorflow/core/framework/register_types.h" - -REGISTER_OP("ZeroOut") - .Attr("T: realnumbertype") - .Input("to_zero: T") - .Output("zeroed: T"); - -template <typename T> -class ZeroOutOp : public OpKernel { ... }; - -#define REGISTER_KERNEL(type) \ - REGISTER_KERNEL_BUILDER( \ - Name("ZeroOut").Device(DEVICE_CPU).TypeConstraint<type>("T"), \ - ZeroOutOp<type>) - -TF_CALL_REAL_NUMBER_TYPES(REGISTER_KERNEL); - -#undef REGISTER_KERNEL -``` - -##### List Inputs and Outputs - -In addition to being able to accept or produce different types, ops can consume -or produce a variable number of tensors. - -In the next example, the attr `T` holds a *list* of types, and is used as the -type of both the input `in` and the output `out`. The input and output are -lists of tensors of that type (and the number and types of tensors in the output -are the same as the input, since both have type `T`). - -```c++ -REGISTER_OP("PolymorphicListExample") - .Attr("T: list(type)") - .Input("in: T") - .Output("out: T"); -``` - -You can also place restrictions on what types can be specified in the list. In -this next case, the input is a list of `float` and `double` tensors. The op -accepts, for example, input types `(float, double, float)` and in that case the -output type would also be `(float, double, float)`. - -```c++ -REGISTER_OP("ListTypeRestrictionExample") - .Attr("T: list({float, double})") - .Input("in: T") - .Output("out: T"); -``` - -If you want all the tensors in a list to be of the same type, you might do -something like: - -```c++ -REGISTER_OP("IntListInputExample") - .Attr("N: int") - .Input("in: N * int32") - .Output("out: int32"); -``` - -This accepts a list of `int32` tensors, and uses an `int` attr `N` to -specify the length of the list. - -This can be made [type polymorphic](#type-polymorphism) as well. In the next -example, the input is a list of tensors (with length `"N"`) of the same (but -unspecified) type (`"T"`), and the output is a single tensor of matching type: - -```c++ -REGISTER_OP("SameListInputExample") - .Attr("N: int") - .Attr("T: type") - .Input("in: N * T") - .Output("out: T"); -``` - -By default, tensor lists have a minimum length of 1. You can change that default -using -[a `">="` constraint on the corresponding attr](#default-values-constraints). -In this next example, the input is a list of at least 2 `int32` tensors: - -```c++ -REGISTER_OP("MinLengthIntListExample") - .Attr("N: int >= 2") - .Input("in: N * int32") - .Output("out: int32"); -``` - -The same syntax works with `"list(type)"` attrs: - -```c++ -REGISTER_OP("MinimumLengthPolymorphicListExample") - .Attr("T: list(type) >= 3") - .Input("in: T") - .Output("out: T"); -``` - -#### Inputs and Outputs - -To summarize the above, an op registration can have multiple inputs and outputs: - -```c++ -REGISTER_OP("MultipleInsAndOuts") - .Input("y: int32") - .Input("z: float") - .Output("a: string") - .Output("b: int32"); -``` - -Each input or output spec is of the form: - -``` -<name>: <io-type-expr> -``` - -where `<name>` begins with a letter and can be composed of alphanumeric -characters and underscores. `<io-type-expr>` is one of the following type -expressions: - -* `<type>`, where `<type>` is a supported input type (e.g. `float`, `int32`, - `string`). This specifies a single tensor of the given type. - - See - `tf.DType`. - - ```c++ - REGISTER_OP("BuiltInTypesExample") - .Input("integers: int32") - .Input("complex_numbers: complex64"); - ``` - -* `<attr-type>`, where `<attr-type>` is the name of an [Attr](#attrs) with type - `type` or `list(type)` (with a possible type restriction). This syntax allows - for [polymorphic ops](#polymorphism). - - ```c++ - REGISTER_OP("PolymorphicSingleInput") - .Attr("T: type") - .Input("in: T"); - - REGISTER_OP("RestrictedPolymorphicSingleInput") - .Attr("T: {int32, int64}") - .Input("in: T"); - ``` - - Referencing an attr of type `list(type)` allows you to accept a sequence of - tensors. - - ```c++ - REGISTER_OP("ArbitraryTensorSequenceExample") - .Attr("T: list(type)") - .Input("in: T") - .Output("out: T"); - - REGISTER_OP("RestrictedTensorSequenceExample") - .Attr("T: list({int32, int64})") - .Input("in: T") - .Output("out: T"); - ``` - - Note that the number and types of tensors in the output `out` is the same as - in the input `in`, since both are of type `T`. - -* For a sequence of tensors with the same type: `<number> * <type>`, where - `<number>` is the name of an [Attr](#attrs) with type `int`. The `<type>` can - either be a `tf.DType`, - or the name of an attr with type `type`. As an example of the first, this - op accepts a list of `int32` tensors: - - ```c++ - REGISTER_OP("Int32SequenceExample") - .Attr("NumTensors: int") - .Input("in: NumTensors * int32") - ``` - - Whereas this op accepts a list of tensors of any type, as long as they are all - the same: - - ```c++ - REGISTER_OP("SameTypeSequenceExample") - .Attr("NumTensors: int") - .Attr("T: type") - .Input("in: NumTensors * T") - ``` - -* For a reference to a tensor: `Ref(<type>)`, where `<type>` is one of the - previous types. - -> A note on naming: Any attr used in the type of an input will be inferred. By -> convention those inferred attrs use capital names (like `T` or `N`). -> Otherwise inputs, outputs, and attrs have names like function parameters -> (e.g. `num_outputs`). For more details, see the -> [earlier note on naming](#naming). - -For more details, see -[`tensorflow/core/framework/op_def_builder.h`][op_def_builder]. - -#### Backwards compatibility - -Let's assume you have written a nice, custom op and shared it with others, so -you have happy customers using your operation. However, you'd like to make -changes to the op in some way. - -In general, changes to existing, checked-in specifications must be -backwards-compatible: changing the specification of an op must not break prior -serialized `GraphDef` protocol buffers constructed from older specifications. -The details of `GraphDef` compatibility are -[described here](../guide/version_compat.md#compatibility_of_graphs_and_checkpoints). - -There are several ways to preserve backwards-compatibility. - -1. Any new attrs added to an operation must have default values defined, and - with that default value the op must have the original behavior. To change an - operation from not polymorphic to polymorphic, you *must* give a default - value to the new type attr to preserve the original signature by default. For - example, if your operation was: - - REGISTER_OP("MyGeneralUnaryOp") - .Input("in: float") - .Output("out: float"); - - you can make it polymorphic in a backwards-compatible way using: - - REGISTER_OP("MyGeneralUnaryOp") - .Input("in: T") - .Output("out: T") - .Attr("T: numerictype = DT_FLOAT"); - -2. You can safely make a constraint on an attr less restrictive. For example, - you can change from `{int32, int64}` to `{int32, int64, float}` or `type`. - Or you may change from `{"apple", "orange"}` to `{"apple", "banana", - "orange"}` or `string`. - -3. You can change single inputs / outputs into list inputs / outputs, as long as - the default for the list type matches the old signature. - -4. You can add a new list input / output, if it defaults to empty. - -5. Namespace any new ops you create, by prefixing the op names with something - unique to your project. This avoids having your op colliding with any ops - that might be included in future versions of TensorFlow. - -6. Plan ahead! Try to anticipate future uses for the op. Some signature changes - can't be done in a compatible way (for example, making a list of the same - type into a list of varying types). - -The full list of safe and unsafe changes can be found in -[`tensorflow/core/framework/op_compatibility_test.cc`](https://www.tensorflow.org/code/tensorflow/core/framework/op_compatibility_test.cc). -If you cannot make your change to an operation backwards compatible, then create -a new operation with a new name with the new semantics. - -Also note that while these changes can maintain `GraphDef` compatibility, the -generated Python code may change in a way that isn't compatible with old -callers. The Python API may be kept compatible by careful changes in a -hand-written Python wrapper, by keeping the old signature except possibly adding -new optional arguments to the end. Generally incompatible changes may only be -made when TensorFlow's changes major versions, and must conform to the -[`GraphDef` version semantics](../guide/version_compat.md#compatibility_of_graphs_and_checkpoints). - -### GPU Support - -You can implement different OpKernels and register one for CPU and another for -GPU, just like you can [register kernels for different types](#polymorphism). -There are several examples of kernels with GPU support in -[`tensorflow/core/kernels/`](https://www.tensorflow.org/code/tensorflow/core/kernels/). -Notice some kernels have a CPU version in a `.cc` file, a GPU version in a file -ending in `_gpu.cu.cc`, and some code shared in common in a `.h` file. - -For example, the `tf.pad` has -everything but the GPU kernel in [`tensorflow/core/kernels/pad_op.cc`][pad_op]. -The GPU kernel is in -[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op_gpu.cu.cc), -and the shared code is a templated class defined in -[`tensorflow/core/kernels/pad_op.h`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.h). -We organize the code this way for two reasons: it allows you to share common -code among the CPU and GPU implementations, and it puts the GPU implementation -into a separate file so that it can be compiled only by the GPU compiler. - -One thing to note, even when the GPU kernel version of `pad` is used, it still -needs its `"paddings"` input in CPU memory. To mark that inputs or outputs are -kept on the CPU, add a `HostMemory()` call to the kernel registration, e.g.: - -```c++ -#define REGISTER_GPU_KERNEL(T) \ - REGISTER_KERNEL_BUILDER(Name("Pad") \ - .Device(DEVICE_GPU) \ - .TypeConstraint<T>("T") \ - .HostMemory("paddings"), \ - PadOp<GPUDevice, T>) -``` - -#### Compiling the kernel for the GPU device - -Look at -[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc) -for an example that uses a CUDA kernel to implement an op. The -`tf_custom_op_library` accepts a `gpu_srcs` argument in which the list of source -files containing the CUDA kernels (`*.cu.cc` files) can be specified. For use -with a binary installation of TensorFlow, the CUDA kernels have to be compiled -with NVIDIA's `nvcc` compiler. Here is the sequence of commands you can use to -compile the -[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc) -and -[cuda_op_kernel.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cc) -into a single dynamically loadable library: - -```bash -nvcc -std=c++11 -c -o cuda_op_kernel.cu.o cuda_op_kernel.cu.cc \ - ${TF_CFLAGS[@]} -D GOOGLE_CUDA=1 -x cu -Xcompiler -fPIC - -g++ -std=c++11 -shared -o cuda_op_kernel.so cuda_op_kernel.cc \ - cuda_op_kernel.cu.o ${TF_CFLAGS[@]} -fPIC -lcudart ${TF_LFLAGS[@]} -``` - -`cuda_op_kernel.so` produced above can be loaded as usual in Python, using the -`tf.load_op_library` function. - -Note that if your CUDA libraries are not installed in `/usr/local/lib64`, -you'll need to specify the path explicitly in the second (g++) command above. -For example, add `-L /usr/local/cuda-8.0/lib64/` if your CUDA is installed in -`/usr/local/cuda-8.0`. - -> Note in some linux settings, additional options to `nvcc` compiling step are needed. Add `-D_MWAITXINTRIN_H_INCLUDED` to the `nvcc` command line to avoid errors from `mwaitxintrin.h`. - -### Implement the gradient in Python - -Given a graph of ops, TensorFlow uses automatic differentiation -(backpropagation) to add new ops representing gradients with respect to the -existing ops (see -[Gradient Computation](../api_guides/python/train.md#gradient_computation)). -To make automatic differentiation work for new ops, you must register a gradient -function which computes gradients with respect to the ops' inputs given -gradients with respect to the ops' outputs. - -Mathematically, if an op computes \\(y = f(x)\\) the registered gradient op -converts gradients \\(\partial L/ \partial y\\) of loss \\(L\\) with respect to -\\(y\\) into gradients \\(\partial L/ \partial x\\) with respect to \\(x\\) via -the chain rule: - -$$\frac{\partial L}{\partial x} - = \frac{\partial L}{\partial y} \frac{\partial y}{\partial x} - = \frac{\partial L}{\partial y} \frac{\partial f}{\partial x}.$$ - -In the case of `ZeroOut`, only one entry in the input affects the output, so the -gradient with respect to the input is a sparse "one hot" tensor. This is -expressed as follows: - -```python -from tensorflow.python.framework import ops -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import sparse_ops - -@ops.RegisterGradient("ZeroOut") -def _zero_out_grad(op, grad): - """The gradients for `zero_out`. - - Args: - op: The `zero_out` `Operation` that we are differentiating, which we can use - to find the inputs and outputs of the original op. - grad: Gradient with respect to the output of the `zero_out` op. - - Returns: - Gradients with respect to the input of `zero_out`. - """ - to_zero = op.inputs[0] - shape = array_ops.shape(to_zero) - index = array_ops.zeros_like(shape) - first_grad = array_ops.reshape(grad, [-1])[0] - to_zero_grad = sparse_ops.sparse_to_dense([index], shape, first_grad, 0) - return [to_zero_grad] # List of one Tensor, since we have one input -``` - -Details about registering gradient functions with -`tf.RegisterGradient`: - -* For an op with one output, the gradient function will take an - `tf.Operation` `op` and a - `tf.Tensor` `grad` and build new ops - out of the tensors - [`op.inputs[i]`](../../api_docs/python/framework.md#Operation.inputs), - [`op.outputs[i]`](../../api_docs/python/framework.md#Operation.outputs), and `grad`. Information - about any attrs can be found via - `tf.Operation.get_attr`. - -* If the op has multiple outputs, the gradient function will take `op` and - `grads`, where `grads` is a list of gradients with respect to each output. - The result of the gradient function must be a list of `Tensor` objects - representing the gradients with respect to each input. - -* If there is no well-defined gradient for some input, such as for integer - inputs used as indices, the corresponding returned gradient should be - `None`. For example, for an op taking a floating point tensor `x` and an - integer index `i`, the gradient function would `return [x_grad, None]`. - -* If there is no meaningful gradient for the op at all, you often will not have - to register any gradient, and as long as the op's gradient is never needed, - you will be fine. In some cases, an op has no well-defined gradient but can - be involved in the computation of the gradient. Here you can use - `ops.NotDifferentiable` to automatically propagate zeros backwards. - -Note that at the time the gradient function is called, only the data flow graph -of ops is available, not the tensor data itself. Thus, all computation must be -performed using other tensorflow ops, to be run at graph execution time. - -### Shape functions in C++ - -The TensorFlow API has a feature called "shape inference" that provides -information about the shapes of tensors without having to execute the -graph. Shape inference is supported by "shape functions" that are registered for -each op type in the C++ `REGISTER_OP` declaration, and perform two roles: -asserting that the shapes of the inputs are compatible during graph -construction, and specifying the shapes for the outputs. - -Shape functions are defined as operations on the -`shape_inference::InferenceContext` class. For example, in the shape function -for ZeroOut: - -```c++ - .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { - c->set_output(0, c->input(0)); - return Status::OK(); - }); -``` - -`c->set_output(0, c->input(0));` declares that the first output's shape should -be set to the first input's shape. If the output is selected by its index as in the above example, the second parameter of `set_output` should be a `ShapeHandle` object. You can create an empty `ShapeHandle` object by its default constructor. The `ShapeHandle` object for an input with index `idx` can be obtained by `c->input(idx)`. - -There are a number of common shape functions -that apply to many ops, such as `shape_inference::UnchangedShape` which can be -found in [common_shape_fns.h](https://www.tensorflow.org/code/tensorflow/core/framework/common_shape_fns.h) and used as follows: - -```c++ -REGISTER_OP("ZeroOut") - .Input("to_zero: int32") - .Output("zeroed: int32") - .SetShapeFn(::tensorflow::shape_inference::UnchangedShape); -``` - -A shape function can also constrain the shape of an input. For the version of -[`ZeroOut` with a vector shape constraint](#validation), the shape function -would be as follows: - -```c++ - .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { - ::tensorflow::shape_inference::ShapeHandle input; - TF_RETURN_IF_ERROR(c->WithRank(c->input(0), 1, &input)); - c->set_output(0, input); - return Status::OK(); - }); -``` - -The `WithRank` call validates that the input shape `c->input(0)` has -a shape with exactly one dimension (or if the input shape is unknown, -the output shape will be a vector with one unknown dimension). - -If your op is [polymorphic with multiple inputs](#polymorphism), you can use -members of `InferenceContext` to determine the number of shapes to check, and -`Merge` to validate that the shapes are all compatible (alternatively, access -attributes that indicate the lengths, with `InferenceContext::GetAttr`, which -provides access to the attributes of the op). - -```c++ - .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { - ::tensorflow::shape_inference::ShapeHandle input; - ::tensorflow::shape_inference::ShapeHandle output; - for (size_t i = 0; i < c->num_inputs(); ++i) { - TF_RETURN_IF_ERROR(c->WithRank(c->input(i), 2, &input)); - TF_RETURN_IF_ERROR(c->Merge(output, input, &output)); - } - c->set_output(0, output); - return Status::OK(); - }); -``` - -Since shape inference is an optional feature, and the shapes of tensors may vary -dynamically, shape functions must be robust to incomplete shape information for -any of the inputs. The `Merge` method in [`InferenceContext`](https://www.tensorflow.org/code/tensorflow/core/framework/shape_inference.h) -allows the caller to assert that two shapes are the same, even if either -or both of them do not have complete information. Shape functions are defined -for all of the core TensorFlow ops and provide many different usage examples. - -The `InferenceContext` class has a number of functions that can be used to -define shape function manipulations. For example, you can validate that a -particular dimension has a very specific value using `InferenceContext::Dim` and -`InferenceContext::WithValue`; you can specify that an output dimension is the -sum / product of two input dimensions using `InferenceContext::Add` and -`InferenceContext::Multiply`. See the `InferenceContext` class for -all of the various shape manipulations you can specify. The following example sets -shape of the first output to (n, 3), where first input has shape (n, ...) - -```c++ -.SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { - c->set_output(0, c->Matrix(c->Dim(c->input(0), 0), 3)); - return Status::OK(); -}); -``` - -If you have a complicated shape function, you should consider adding a test for -validating that various input shape combinations produce the expected output -shape combinations. You can see examples of how to write these tests in some -our -[core ops tests](https://www.tensorflow.org/code/tensorflow/core/ops/array_ops_test.cc). -(The syntax of `INFER_OK` and `INFER_ERROR` are a little cryptic, but try to be -compact in representing input and output shape specifications in tests. For -now, see the surrounding comments in those tests to get a sense of the shape -string specification). - - -[core-array_ops]:https://www.tensorflow.org/code/tensorflow/core/ops/array_ops.cc -[python-user_ops]:https://www.tensorflow.org/code/tensorflow/python/user_ops/user_ops.py -[tf-kernels]:https://www.tensorflow.org/code/tensorflow/core/kernels/ -[user_ops]:https://www.tensorflow.org/code/tensorflow/core/user_ops/ -[pad_op]:https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.cc -[standard_ops-py]:https://www.tensorflow.org/code/tensorflow/python/ops/standard_ops.py -[standard_ops-cc]:https://www.tensorflow.org/code/tensorflow/cc/ops/standard_ops.h -[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD -[validation-macros]:https://www.tensorflow.org/code/tensorflow/core/lib/core/errors.h -[op_def_builder]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.h -[register_types]:https://www.tensorflow.org/code/tensorflow/core/framework/register_types.h -[FinalizeAttr]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.cc -[DataTypeString]:https://www.tensorflow.org/code/tensorflow/core/framework/types.cc -[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD -[types-proto]:https://www.tensorflow.org/code/tensorflow/core/framework/types.proto -[TensorShapeProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.proto -[TensorProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor.proto diff --git a/tensorflow/docs_src/extend/architecture.md b/tensorflow/docs_src/extend/architecture.md deleted file mode 100644 index eb33336bee..0000000000 --- a/tensorflow/docs_src/extend/architecture.md +++ /dev/null @@ -1,217 +0,0 @@ -# TensorFlow Architecture - -We designed TensorFlow for large-scale distributed training and inference, but -it is also flexible enough to support experimentation with new machine -learning models and system-level optimizations. - -This document describes the system architecture that makes this -combination of scale and flexibility possible. It assumes that you have basic familiarity -with TensorFlow programming concepts such as the computation graph, operations, -and sessions. See [this document](../guide/low_level_intro.md) for an introduction to -these topics. Some familiarity with [distributed TensorFlow](../deploy/distributed.md) -will also be helpful. - -This document is for developers who want to extend TensorFlow in some way not -supported by current APIs, hardware engineers who want to optimize for -TensorFlow, implementers of machine learning systems working on scaling and -distribution, or anyone who wants to look under Tensorflow's hood. By the end of this document -you should understand the TensorFlow architecture well enough to read -and modify the core TensorFlow code. - -## Overview - -The TensorFlow runtime is a cross-platform library. Figure 1 illustrates its -general architecture. A C API separates user level code in different languages -from the core runtime. - -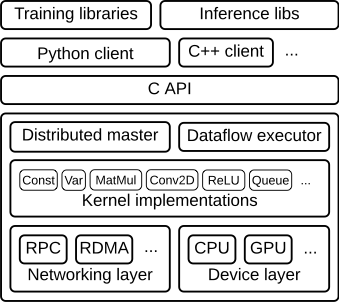{: width="300"} - -**Figure 1** - - -This document focuses on the following layers: - -* **Client**: - * Defines the computation as a dataflow graph. - * Initiates graph execution using a [**session**]( - https://www.tensorflow.org/code/tensorflow/python/client/session.py). -* **Distributed Master** - * Prunes a specific subgraph from the graph, as defined by the arguments - to Session.run(). - * Partitions the subgraph into multiple pieces that run in different - processes and devices. - * Distributes the graph pieces to worker services. - * Initiates graph piece execution by worker services. -* **Worker Services** (one for each task) - * Schedule the execution of graph operations using kernel implementations - appropriate to the available hardware (CPUs, GPUs, etc). - * Send and receive operation results to and from other worker services. -* **Kernel Implementations** - * Perform the computation for individual graph operations. - -Figure 2 illustrates the interaction of these components. "/job:worker/task:0" and -"/job:ps/task:0" are both tasks with worker services. "PS" stands for "parameter -server": a task responsible for storing and updating the model's parameters. -Other tasks send updates to these parameters as they work on optimizing the -parameters. This particular division of labor between tasks is not required, but - is common for distributed training. - -{: width="500"} - -**Figure 2** - -Note that the Distributed Master and Worker Service only exist in -distributed TensorFlow. The single-process version of TensorFlow includes a -special Session implementation that does everything the distributed master does -but only communicates with devices in the local process. - -The following sections describe the core TensorFlow layers in greater detail and -step through the processing of an example graph. - -## Client - -Users write the client TensorFlow program that builds the computation graph. -This program can either directly compose individual operations or use a -convenience library like the Estimators API to compose neural network layers and -other higher-level abstractions. TensorFlow supports multiple client -languages, and we have prioritized Python and C++, because our internal users -are most familiar with these languages. As features become more established, -we typically port them to C++, so that users can access an optimized -implementation from all client languages. Most of the training libraries are -still Python-only, but C++ does have support for efficient inference. - -The client creates a session, which sends the graph definition to the -distributed master as a `tf.GraphDef` -protocol buffer. When the client evaluates a node or nodes in the -graph, the evaluation triggers a call to the distributed master to initiate -computation. - -In Figure 3, the client has built a graph that applies weights (w) to a -feature vector (x), adds a bias term (b) and saves the result in a variable -(s). - -{: width="700"} - -**Figure 3** - -### Code - -* `tf.Session` - -## Distributed master - -The distributed master: - -* prunes the graph to obtain the subgraph required to evaluate the nodes - requested by the client, -* partitions the graph to obtain graph pieces for - each participating device, and -* caches these pieces so that they may be re-used in subsequent steps. - -Since the master sees the overall computation for -a step, it applies standard optimizations such as common subexpression -elimination and constant folding. It then coordinates execution of the -optimized subgraphs across a set of tasks. - -{: width="700"} - -**Figure 4** - - -Figure 5 shows a possible partition of our example graph. The distributed -master has grouped the model parameters in order to place them together on the -parameter server. - -{: width="700"} - -**Figure 5** - - -Where graph edges are cut by the partition, the distributed master inserts -send and receive nodes to pass information between the distributed tasks -(Figure 6). - -{: width="700"} - -**Figure 6** - - -The distributed master then ships the graph pieces to the distributed tasks. - -{: width="700"} - -**Figure 7** - -### Code - -* [MasterService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/master_service.proto) -* [Master interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/master_interface.h) - -## Worker Service - -The worker service in each task: - -* handles requests from the master, -* schedules the execution of the kernels for the operations that comprise a - local subgraph, and -* mediates direct communication between tasks. - -We optimize the worker service for running large graphs with low overhead. Our -current implementation can execute tens of thousands of subgraphs per second, -which enables a large number of replicas to make rapid, fine-grained training -steps. The worker service dispatches kernels to local devices and runs kernels -in parallel when possible, for example by using multiple CPU cores or GPU -streams. - -We specialize Send and Recv operations for each pair of source and destination -device types: - -* Transfers between local CPU and GPU devices use the - `cudaMemcpyAsync()` API to overlap computation and data transfer. -* Transfers between two local GPUs use peer-to-peer DMA, to avoid an expensive - copy via the host CPU. - -For transfers between tasks, TensorFlow uses multiple protocols, including: - -* gRPC over TCP. -* RDMA over Converged Ethernet. - -We also have preliminary support for NVIDIA's NCCL library for multi-GPU -communication (see [`tf.contrib.nccl`]( -https://www.tensorflow.org/code/tensorflow/contrib/nccl/python/ops/nccl_ops.py)). - -{: width="700"} - -**Figure 8** - -### Code - -* [WorkerService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/worker_service.proto) -* [Worker interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/worker_interface.h) -* [Remote rendezvous (for Send and Recv implementations)](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h) - -## Kernel Implementations - -The runtime contains over 200 standard operations including mathematical, array -manipulation, control flow, and state management operations. Each of these -operations can have kernel implementations optimized for a variety of devices. -Many of the operation kernels are implemented using Eigen::Tensor, which uses -C++ templates to generate efficient parallel code for multicore CPUs and GPUs; -however, we liberally use libraries like cuDNN where a more efficient kernel -implementation is possible. We have also implemented -[quantization](../performance/quantization.md), which enables -faster inference in environments such as mobile devices and high-throughput -datacenter applications, and use the -[gemmlowp](https://github.com/google/gemmlowp) low-precision matrix library to -accelerate quantized computation. - -If it is difficult or inefficient to represent a subcomputation as a composition -of operations, users can register additional kernels that provide an efficient -implementation written in C++. For example, we recommend registering your own -fused kernels for some performance critical operations, such as the ReLU and -Sigmoid activation functions and their corresponding gradients. The [XLA Compiler](../performance/xla/index.md) has an -experimental implementation of automatic kernel fusion. - -### Code - -* [`OpKernel` interface](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h) diff --git a/tensorflow/docs_src/extend/index.md b/tensorflow/docs_src/extend/index.md deleted file mode 100644 index bbf4a8139b..0000000000 --- a/tensorflow/docs_src/extend/index.md +++ /dev/null @@ -1,34 +0,0 @@ -# Extend - -This section explains how developers can add functionality to TensorFlow's -capabilities. Begin by reading the following architectural overview: - - * [TensorFlow Architecture](../extend/architecture.md) - -The following guides explain how to extend particular aspects of -TensorFlow: - - * [Adding a New Op](../extend/adding_an_op.md), which explains how to create your own - operations. - * [Adding a Custom Filesystem Plugin](../extend/add_filesys.md), which explains how to - add support for your own shared or distributed filesystem. - * [Custom Data Readers](../extend/new_data_formats.md), which details how to add support - for your own file and record formats. - -Python is currently the only language supported by TensorFlow's API stability -promises. However, TensorFlow also provides functionality in C++, Go, Java and -[JavaScript](https://js.tensorflow.org) (including -[Node.js](https://github.com/tensorflow/tfjs-node)), -plus community support for [Haskell](https://github.com/tensorflow/haskell) and -[Rust](https://github.com/tensorflow/rust). If you'd like to create or -develop TensorFlow features in a language other than these languages, read the -following guide: - - * [TensorFlow in Other Languages](../extend/language_bindings.md) - -To create tools compatible with TensorFlow's model format, read the following -guide: - - * [A Tool Developer's Guide to TensorFlow Model Files](../extend/tool_developers/index.md) - - diff --git a/tensorflow/docs_src/extend/language_bindings.md b/tensorflow/docs_src/extend/language_bindings.md deleted file mode 100644 index 4727eabdc1..0000000000 --- a/tensorflow/docs_src/extend/language_bindings.md +++ /dev/null @@ -1,231 +0,0 @@ -# TensorFlow in other languages - -## Background - -This document is intended as a guide for those interested in the creation or -development of TensorFlow functionality in other programming languages. It -describes the features of TensorFlow and recommended steps for making the same -available in other programming languages. - -Python was the first client language supported by TensorFlow and currently -supports the most features. More and more of that functionality is being moved -into the core of TensorFlow (implemented in C++) and exposed via a [C API]. -Client languages should use the language's [foreign function interface -(FFI)](https://en.wikipedia.org/wiki/Foreign_function_interface) to call into -this [C API] to provide TensorFlow functionality. - -## Overview - -Providing TensorFlow functionality in a programming language can be broken down -into broad categories: - -- *Run a predefined graph*: Given a `GraphDef` (or - `MetaGraphDef`) protocol message, be able to create a session, run queries, - and get tensor results. This is sufficient for a mobile app or server that - wants to run inference on a pre-trained model. -- *Graph construction*: At least one function per defined - TensorFlow op that adds an operation to the graph. Ideally these functions - would be automatically generated so they stay in sync as the op definitions - are modified. -- *Gradients (AKA automatic differentiation)*: Given a graph and a list of - input and output operations, add operations to the graph that compute the - partial derivatives (gradients) of the inputs with respect to the outputs. - Allows for customization of the gradient function for a particular operation - in the graph. -- *Functions*: Define a subgraph that may be called in multiple places in the - main `GraphDef`. Defines a `FunctionDef` in the `FunctionDefLibrary` - included in a `GraphDef`. -- *Control Flow*: Construct "If" and "While" with user-specified subgraphs. - Ideally these work with gradients (see above). -- *Neural Network library*: A number of components that together support the - creation of neural network models and training them (possibly in a - distributed setting). While it would be convenient to have this available in - other languages, there are currently no plans to support this in languages - other than Python. These libraries are typically wrappers over the features - described above. - -At a minimum, a language binding should support running a predefined graph, but -most should also support graph construction. The TensorFlow Python API provides -all these features. - -## Current Status - -New language support should be built on top of the [C API]. However, as you can -see in the table below, not all functionality is available in C yet. Providing -more functionality in the [C API] is an ongoing project. - -Feature | Python | C -:--------------------------------------------- | :---------------------------------------------------------- | :-- -Run a predefined Graph | `tf.import_graph_def`, `tf.Session` | `TF_GraphImportGraphDef`, `TF_NewSession` -Graph construction with generated op functions | Yes | Yes (The C API supports client languages that do this) -Gradients | `tf.gradients` | -Functions | `tf.python.framework.function.Defun` | -Control Flow | `tf.cond`, `tf.while_loop` | -Neural Network library | `tf.train`, `tf.nn`, `tf.contrib.layers`, `tf.contrib.slim` | - -## Recommended Approach - -### Run a predefined graph - -A language binding is expected to define the following classes: - -- `Graph`: A graph representing a TensorFlow computation. Consists of - operations (represented in the client language by `Operation`s) and - corresponds to a `TF_Graph` in the C API. Mainly used as an argument when - creating new `Operation` objects and when starting a `Session`. Also - supports iterating through the operations in the graph - (`TF_GraphNextOperation`), looking up operations by name - (`TF_GraphOperationByName`), and converting to and from a `GraphDef` - protocol message (`TF_GraphToGraphDef` and `TF_GraphImportGraphDef` in the C - API). -- `Operation`: Represents a computation node in the graph. Corresponds to a - `TF_Operation` in the C API. -- `Output`: Represents one of the outputs of an operation in the graph. Has a - `DataType` (and eventually a shape). May be passed as an input argument to a - function for adding operations to a graph, or to a `Session`'s `Run()` - method to fetch that output as a tensor. Corresponds to a `TF_Output` in the - C API. -- `Session`: Represents a client to a particular instance of the TensorFlow - runtime. Its main job is to be constructed with a `Graph` and some options - and then field calls to `Run()` the graph. Corresponds to a `TF_Session` in - the C API. -- `Tensor`: Represents an N-dimensional (rectangular) array with elements all - the same `DataType`. Gets data into and out of a `Session`'s `Run()` call. - Corresponds to a `TF_Tensor` in the C API. -- `DataType`: An enumerant with all the possible tensor types supported by - TensorFlow. Corresponds to `TF_DataType` in the C API and often referred to - as `dtype` in the Python API. - -### Graph construction - -TensorFlow has many ops, and the list is not static, so we recommend generating -the functions for adding ops to a graph instead of writing them by individually -by hand (though writing a few by hand is a good way to figure out what the -generator should generate). The information needed to generate a function is -contained in an `OpDef` protocol message. - -There are a few ways to get a list of the `OpDef`s for the registered ops: - -- `TF_GetAllOpList` in the C API retrieves all registered `OpDef` protocol - messages. This can be used to write the generator in the client language. - This requires that the client language have protocol buffer support in order - to interpret the `OpDef` messages. -- The C++ function `OpRegistry::Global()->GetRegisteredOps()` returns the same - list of all registered `OpDef`s (defined in - [`tensorflow/core/framework/op.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op.h)). This can be used to write the generator - in C++ (particularly useful for languages that do not have protocol buffer - support). -- The ASCII-serialized version of that list is periodically checked in to - [`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt) by an automated process. - -The `OpDef` specifies the following: - -- Name of the op in CamelCase. For generated functions follow the conventions - of the language. For example, if the language uses snake_case, use that - instead of CamelCase for the op's function name. -- A list of inputs and outputs. The types for these may be polymorphic by - referencing attributes, as described in the inputs and outputs section of - [Adding an op](../extend/adding_an_op.md). -- A list of attributes, along with their default values (if any). Note that - some of these will be inferred (if they are determined by an input), some - will be optional (if they have a default), and some will be required (no - default). -- Documentation for the op in general and the inputs, outputs, and - non-inferred attributes. -- Some other fields that are used by the runtime and can be ignored by the - code generators. - -An `OpDef` can be converted into the text of a function that adds that op to the -graph using the `TF_OperationDescription` C API (wrapped in the language's FFI): - -- Start with `TF_NewOperation()` to create the `TF_OperationDescription*`. -- Call `TF_AddInput()` or `TF_AddInputList()` once per input (depending on - whether the input has a list type). -- Call `TF_SetAttr*()` functions to set non-inferred attributes. May skip - attributes with defaults if you don't want to override the default value. -- Set optional fields if necessary: - - `TF_SetDevice()`: force the operation onto a specific device. - - `TF_AddControlInput()`: add requirements that another operation finish - before this operation starts running - - `TF_SetAttrString("_kernel")` to set the kernel label (rarely used) - - `TF_ColocateWith()` to colocate one op with another -- Call `TF_FinishOperation()` when done. This adds the operation to the graph, - after which it can't be modified. - -The existing examples run the code generator as part of the build process (using -a Bazel genrule). Alternatively, the code generator can be run by an automated -cron process, possibly checking in the result. This creates a risk of divergence -between the generated code and the `OpDef`s checked into the repository, but is -useful for languages where code is expected to be generated ahead of time like -`go get` for Go and `cargo ops` for Rust. At the other end of the spectrum, for -some languages the code could be generated dynamically from -[`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt). - -#### Handling Constants - -Calling code will be much more concise if users can provide constants to input -arguments. The generated code should convert those constants to operations that -are added to the graph and used as input to the op being instantiated. - -#### Optional parameters - -If the language allows for optional parameters to a function (like keyword -arguments with defaults in Python), use them for optional attributes, operation -names, devices, control inputs etc. In some languages, these optional parameters -can be set using dynamic scopes (like "with" blocks in Python). Without these -features, the library may resort to the "builder pattern", as is done in the C++ -version of the TensorFlow API. - -#### Name scopes - -It is a good idea to have support for naming graph operations using some sort of -scoping hierarchy, especially considering the fact that TensorBoard relies on it -to display large graphs in a reasonable way. The existing Python and C++ APIs -take different approaches: In Python, the "directory" part of the name -(everything up to the last "/") comes from `with` blocks. In effect, there is a -thread-local stack with the scopes defining the name hierarchy. The last -component of the name is either supplied explicitly by the user (using the -optional `name` keyword argument) or defaults to the name of the type of the op -being added. In C++ the "directory" part of the name is stored in an explicit -`Scope` object. The `NewSubScope()` method appends to that part of the name and -returns a new `Scope`. The last component of the name is set using the -`WithOpName()` method, and like Python defaults to the name of the type of op -being added. `Scope` objects are explicitly passed around to specify the name of -the context. - -#### Wrappers - -It may make sense to keep the generated functions private for some ops so that -wrapper functions that do a little bit of additional work can be used instead. -This also gives an escape hatch for supporting features outside the scope of -generated code. - -One use of a wrapper is for supporting `SparseTensor` input and output. A -`SparseTensor` is a tuple of 3 dense tensors: indices, values, and shape. values -is a vector size [n], shape is a vector size [rank], and indices is a matrix -size [n, rank]. There are some sparse ops that use this triple to represent a -single sparse tensor. - -Another reason to use wrappers is for ops that hold state. There are a few such -ops (e.g. a variable) that have several companion ops for operating on that -state. The Python API has classes for these ops where the constructor creates -the op, and methods on that class add operations to the graph that operate on -the state. - -#### Other Considerations - -- It is good to have a list of keywords used to rename op functions and - arguments that collide with language keywords (or other symbols that will - cause trouble, like the names of library functions or variables referenced - in the generated code). -- The function for adding a `Const` operation to a graph typically is a - wrapper since the generated function will typically have redundant - `DataType` inputs. - -### Gradients, functions and control flow - -At this time, support for gradients, functions and control flow operations ("if" -and "while") is not available in languages other than Python. This will be -updated when the [C API] provides necessary support. - -[C API]: https://www.tensorflow.org/code/tensorflow/c/c_api.h diff --git a/tensorflow/docs_src/extend/leftnav_files b/tensorflow/docs_src/extend/leftnav_files deleted file mode 100644 index 12315b711b..0000000000 --- a/tensorflow/docs_src/extend/leftnav_files +++ /dev/null @@ -1,7 +0,0 @@ -index.md -architecture.md -adding_an_op.md -add_filesys.md -new_data_formats.md -language_bindings.md -tool_developers/index.md diff --git a/tensorflow/docs_src/extend/new_data_formats.md b/tensorflow/docs_src/extend/new_data_formats.md deleted file mode 100644 index 7ca50c9c76..0000000000 --- a/tensorflow/docs_src/extend/new_data_formats.md +++ /dev/null @@ -1,305 +0,0 @@ -# Reading custom file and record formats - -PREREQUISITES: - -* Some familiarity with C++. -* Must have - [downloaded TensorFlow source](../install/install_sources.md), and be - able to build it. - -We divide the task of supporting a file format into two pieces: - -* File formats: We use a reader `tf.data.Dataset` to read raw *records* (which - are typically represented by scalar string tensors, but can have more - structure) from a file. -* Record formats: We use decoder or parsing ops to turn a string record - into tensors usable by TensorFlow. - -For example, to re-implement `tf.contrib.data.make_csv_dataset` function, we -could use `tf.data.TextLineDataset` to extract the records, and then -use `tf.data.Dataset.map` and `tf.decode_csv` to parses the CSV records from -each line of text in the dataset. - -[TOC] - -## Writing a `Dataset` for a file format - -A `tf.data.Dataset` represents a sequence of *elements*, which can be the -individual records in a file. There are several examples of "reader" datasets -that are already built into TensorFlow: - -* `tf.data.TFRecordDataset` - ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc)) -* `tf.data.FixedLengthRecordDataset` - ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc)) -* `tf.data.TextLineDataset` - ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc)) - -Each of these implementations comprises three related classes: - -* A `tensorflow::DatasetOpKernel` subclass (e.g. `TextLineDatasetOp`), which - tells TensorFlow how to construct a dataset object from the inputs to and - attrs of an op, in its `MakeDataset()` method. - -* A `tensorflow::GraphDatasetBase` subclass (e.g. `TextLineDatasetOp::Dataset`), - which represents the *immutable* definition of the dataset itself, and tells - TensorFlow how to construct an iterator object over that dataset, in its - `MakeIteratorInternal()` method. - -* A `tensorflow::DatasetIterator<Dataset>` subclass (e.g. - `TextLineDatasetOp::Dataset::Iterator`), which represents the *mutable* state - of an iterator over a particular dataset, and tells TensorFlow how to get the - next element from the iterator, in its `GetNextInternal()` method. - -The most important method is the `GetNextInternal()` method, since it defines -how to actually read records from the file and represent them as one or more -`Tensor` objects. - -To create a new reader dataset called (for example) `MyReaderDataset`, you will -need to: - -1. In C++, define subclasses of `tensorflow::DatasetOpKernel`, - `tensorflow::GraphDatasetBase`, and `tensorflow::DatasetIterator<Dataset>` - that implement the reading logic. -2. In C++, register a new reader op and kernel with the name - `"MyReaderDataset"`. -3. In Python, define a subclass of `tf.data.Dataset` called `MyReaderDataset`. - -You can put all the C++ code in a single file, such as -`my_reader_dataset_op.cc`. It will help if you are -familiar with [the adding an op how-to](../extend/adding_an_op.md). The following skeleton -can be used as a starting point for your implementation: - -```c++ -#include "tensorflow/core/framework/common_shape_fns.h" -#include "tensorflow/core/framework/dataset.h" -#include "tensorflow/core/framework/op.h" -#include "tensorflow/core/framework/shape_inference.h" - -namespace myproject { -namespace { - -using ::tensorflow::DT_STRING; -using ::tensorflow::PartialTensorShape; -using ::tensorflow::Status; - -class MyReaderDatasetOp : public tensorflow::DatasetOpKernel { - public: - - MyReaderDatasetOp(tensorflow::OpKernelConstruction* ctx) - : DatasetOpKernel(ctx) { - // Parse and validate any attrs that define the dataset using - // `ctx->GetAttr()`, and store them in member variables. - } - - void MakeDataset(tensorflow::OpKernelContext* ctx, - tensorflow::DatasetBase** output) override { - // Parse and validate any input tensors 0that define the dataset using - // `ctx->input()` or the utility function - // `ParseScalarArgument<T>(ctx, &arg)`. - - // Create the dataset object, passing any (already-validated) arguments from - // attrs or input tensors. - *output = new Dataset(ctx); - } - - private: - class Dataset : public tensorflow::GraphDatasetBase { - public: - Dataset(tensorflow::OpKernelContext* ctx) : GraphDatasetBase(ctx) {} - - std::unique_ptr<tensorflow::IteratorBase> MakeIteratorInternal( - const string& prefix) const override { - return std::unique_ptr<tensorflow::IteratorBase>(new Iterator( - {this, tensorflow::strings::StrCat(prefix, "::MyReader")})); - } - - // Record structure: Each record is represented by a scalar string tensor. - // - // Dataset elements can have a fixed number of components of different - // types and shapes; replace the following two methods to customize this - // aspect of the dataset. - const tensorflow::DataTypeVector& output_dtypes() const override { - static auto* const dtypes = new tensorflow::DataTypeVector({DT_STRING}); - return *dtypes; - } - const std::vector<PartialTensorShape>& output_shapes() const override { - static std::vector<PartialTensorShape>* shapes = - new std::vector<PartialTensorShape>({{}}); - return *shapes; - } - - string DebugString() const override { return "MyReaderDatasetOp::Dataset"; } - - protected: - // Optional: Implementation of `GraphDef` serialization for this dataset. - // - // Implement this method if you want to be able to save and restore - // instances of this dataset (and any iterators over it). - Status AsGraphDefInternal(DatasetGraphDefBuilder* b, - tensorflow::Node** output) const override { - // Construct nodes to represent any of the input tensors from this - // object's member variables using `b->AddScalar()` and `b->AddVector()`. - std::vector<tensorflow::Node*> input_tensors; - TF_RETURN_IF_ERROR(b->AddDataset(this, input_tensors, output)); - return Status::OK(); - } - - private: - class Iterator : public tensorflow::DatasetIterator<Dataset> { - public: - explicit Iterator(const Params& params) - : DatasetIterator<Dataset>(params), i_(0) {} - - // Implementation of the reading logic. - // - // The example implementation in this file yields the string "MyReader!" - // ten times. In general there are three cases: - // - // 1. If an element is successfully read, store it as one or more tensors - // in `*out_tensors`, set `*end_of_sequence = false` and return - // `Status::OK()`. - // 2. If the end of input is reached, set `*end_of_sequence = true` and - // return `Status::OK()`. - // 3. If an error occurs, return an error status using one of the helper - // functions from "tensorflow/core/lib/core/errors.h". - Status GetNextInternal(tensorflow::IteratorContext* ctx, - std::vector<tensorflow::Tensor>* out_tensors, - bool* end_of_sequence) override { - // NOTE: `GetNextInternal()` may be called concurrently, so it is - // recommended that you protect the iterator state with a mutex. - tensorflow::mutex_lock l(mu_); - if (i_ < 10) { - // Create a scalar string tensor and add it to the output. - tensorflow::Tensor record_tensor(ctx->allocator({}), DT_STRING, {}); - record_tensor.scalar<string>()() = "MyReader!"; - out_tensors->emplace_back(std::move(record_tensor)); - ++i_; - *end_of_sequence = false; - } else { - *end_of_sequence = true; - } - return Status::OK(); - } - - protected: - // Optional: Implementation of iterator state serialization for this - // iterator. - // - // Implement these two methods if you want to be able to save and restore - // instances of this iterator. - Status SaveInternal(tensorflow::IteratorStateWriter* writer) override { - tensorflow::mutex_lock l(mu_); - TF_RETURN_IF_ERROR(writer->WriteScalar(full_name("i"), i_)); - return Status::OK(); - } - Status RestoreInternal(tensorflow::IteratorContext* ctx, - tensorflow::IteratorStateReader* reader) override { - tensorflow::mutex_lock l(mu_); - TF_RETURN_IF_ERROR(reader->ReadScalar(full_name("i"), &i_)); - return Status::OK(); - } - - private: - tensorflow::mutex mu_; - int64 i_ GUARDED_BY(mu_); - }; - }; -}; - -// Register the op definition for MyReaderDataset. -// -// Dataset ops always have a single output, of type `variant`, which represents -// the constructed `Dataset` object. -// -// Add any attrs and input tensors that define the dataset here. -REGISTER_OP("MyReaderDataset") - .Output("handle: variant") - .SetIsStateful() - .SetShapeFn(tensorflow::shape_inference::ScalarShape); - -// Register the kernel implementation for MyReaderDataset. -REGISTER_KERNEL_BUILDER(Name("MyReaderDataset").Device(tensorflow::DEVICE_CPU), - MyReaderDatasetOp); - -} // namespace -} // namespace myproject -``` - -The last step is to build the C++ code and add a Python wrapper. The easiest way -to do this is by [compiling a dynamic -library](../extend/adding_an_op.md#build_the_op_library) (e.g. called `"my_reader_dataset_op.so"`), and adding a Python class -that subclasses `tf.data.Dataset` to wrap it. An example Python program is -given here: - -```python -import tensorflow as tf - -# Assumes the file is in the current working directory. -my_reader_dataset_module = tf.load_op_library("./my_reader_dataset_op.so") - -class MyReaderDataset(tf.data.Dataset): - - def __init__(self): - super(MyReaderDataset, self).__init__() - # Create any input attrs or tensors as members of this class. - - def _as_variant_tensor(self): - # Actually construct the graph node for the dataset op. - # - # This method will be invoked when you create an iterator on this dataset - # or a dataset derived from it. - return my_reader_dataset_module.my_reader_dataset() - - # The following properties define the structure of each element: a scalar - # `tf.string` tensor. Change these properties to match the `output_dtypes()` - # and `output_shapes()` methods of `MyReaderDataset::Dataset` if you modify - # the structure of each element. - @property - def output_types(self): - return tf.string - - @property - def output_shapes(self): - return tf.TensorShape([]) - - @property - def output_classes(self): - return tf.Tensor - -if __name__ == "__main__": - # Create a MyReaderDataset and print its elements. - with tf.Session() as sess: - iterator = MyReaderDataset().make_one_shot_iterator() - next_element = iterator.get_next() - try: - while True: - print(sess.run(next_element)) # Prints "MyReader!" ten times. - except tf.errors.OutOfRangeError: - pass -``` - -You can see some examples of `Dataset` wrapper classes in -[`tensorflow/python/data/ops/dataset_ops.py`](https://www.tensorflow.org/code/tensorflow/python/data/ops/dataset_ops.py). - -## Writing an Op for a record format - -Generally this is an ordinary op that takes a scalar string record as input, and -so follow [the instructions to add an Op](../extend/adding_an_op.md). -You may optionally take a scalar string key as input, and include that in error -messages reporting improperly formatted data. That way users can more easily -track down where the bad data came from. - -Examples of Ops useful for decoding records: - -* `tf.parse_single_example` (and `tf.parse_example`) -* `tf.decode_csv` -* `tf.decode_raw` - -Note that it can be useful to use multiple Ops to decode a particular record -format. For example, you may have an image saved as a string in -[a `tf.train.Example` protocol buffer](https://www.tensorflow.org/code/tensorflow/core/example/example.proto). -Depending on the format of that image, you might take the corresponding output -from a `tf.parse_single_example` op and call `tf.image.decode_jpeg`, -`tf.image.decode_png`, or `tf.decode_raw`. It is common to take the output -of `tf.decode_raw` and use `tf.slice` and `tf.reshape` to extract pieces. diff --git a/tensorflow/docs_src/extend/tool_developers/index.md b/tensorflow/docs_src/extend/tool_developers/index.md deleted file mode 100644 index f02cd23be8..0000000000 --- a/tensorflow/docs_src/extend/tool_developers/index.md +++ /dev/null @@ -1,186 +0,0 @@ -# A Tool Developer's Guide to TensorFlow Model Files - -Most users shouldn't need to care about the internal details of how TensorFlow -stores data on disk, but you might if you're a tool developer. For example, you -may want to analyze models, or convert back and forth between TensorFlow and -other formats. This guide tries to explain some of the details of how you can -work with the main files that hold model data, to make it easier to develop -those kind of tools. - -[TOC] - -## Protocol Buffers - -All of TensorFlow's file formats are based on -[Protocol Buffers](https://developers.google.com/protocol-buffers/?hl=en), so to -start it's worth getting familiar with how they work. The summary is that you -define data structures in text files, and the protobuf tools generate classes in -C, Python, and other languages that can load, save, and access the data in a -friendly way. We often refer to Protocol Buffers as protobufs, and I'll use -that convention in this guide. - -## GraphDef - -The foundation of computation in TensorFlow is the `Graph` object. This holds a -network of nodes, each representing one operation, connected to each other as -inputs and outputs. After you've created a `Graph` object, you can save it out -by calling `as_graph_def()`, which returns a `GraphDef` object. - -The GraphDef class is an object created by the ProtoBuf library from the -definition in -[tensorflow/core/framework/graph.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto). The protobuf tools parse -this text file, and generate the code to load, store, and manipulate graph -definitions. If you see a standalone TensorFlow file representing a model, it's -likely to contain a serialized version of one of these `GraphDef` objects -saved out by the protobuf code. - -This generated code is used to save and load the GraphDef files from disk. The code that actually loads the model looks like this: - -```python -graph_def = graph_pb2.GraphDef() -``` - -This line creates an empty `GraphDef` object, the class that's been created -from the textual definition in graph.proto. This is the object we're going to -populate with the data from our file. - -```python -with open(FLAGS.graph, "rb") as f: -``` - -Here we get a file handle for the path we've passed in to the script - -```python - if FLAGS.input_binary: - graph_def.ParseFromString(f.read()) - else: - text_format.Merge(f.read(), graph_def) -``` - -## Text or Binary? - -There are actually two different formats that a ProtoBuf can be saved in. -TextFormat is a human-readable form, which makes it nice for debugging and -editing, but can get large when there's numerical data like weights stored in -it. You can see a small example of that in -[graph_run_run2.pbtxt](https://github.com/tensorflow/tensorboard/blob/master/tensorboard/demo/data/graph_run_run2.pbtxt). - -Binary format files are a lot smaller than their text equivalents, even though -they're not as readable for us. In this script, we ask the user to supply a -flag indicating whether the input file is binary or text, so we know the right -function to call. You can find an example of a large binary file inside the -[inception_v3 archive](https://storage.googleapis.com/download.tensorflow.org/models/inception_v3_2016_08_28_frozen.pb.tar.gz), -as `inception_v3_2016_08_28_frozen.pb`. - -The API itself can be a bit confusing - the binary call is actually -`ParseFromString()`, whereas you use a utility function from the `text_format` -module to load textual files. - -## Nodes - -Once you've loaded a file into the `graph_def` variable, you can now access the -data inside it. For most practical purposes, the important section is the list -of nodes stored in the node member. Here's the code that loops through those: - -```python -for node in graph_def.node -``` - -Each node is a `NodeDef` object, defined in -[tensorflow/core/framework/node_def.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/node_def.proto). These -are the fundamental building blocks of TensorFlow graphs, with each one defining -a single operation along with its input connections. Here are the members of a -`NodeDef`, and what they mean. - -### `name` - -Every node should have a unique identifier that's not used by any other nodes -in the graph. If you don't specify one as you're building a graph using the -Python API, one reflecting the name of operation, such as "MatMul", -concatenated with a monotonically increasing number, such as "5", will be -picked for you. The name is used when defining the connections between nodes, -and when setting inputs and outputs for the whole graph when it's run. - -### `op` - -This defines what operation to run, for example `"Add"`, `"MatMul"`, or -`"Conv2D"`. When a graph is run, this op name is looked up in a registry to -find an implementation. The registry is populated by calls to the -`REGISTER_OP()` macro, like those in -[tensorflow/core/ops/nn_ops.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/ops/nn_ops.cc). - -### `input` - -A list of strings, each one of which is the name of another node, optionally -followed by a colon and an output port number. For example, a node with two -inputs might have a list like `["some_node_name", "another_node_name"]`, which -is equivalent to `["some_node_name:0", "another_node_name:0"]`, and defines the -node's first input as the first output from the node with the name -`"some_node_name"`, and a second input from the first output of -`"another_node_name"` - -### `device` - -In most cases you can ignore this, since it defines where to run a node in a -distributed environment, or when you want to force the operation onto CPU or -GPU. - -### `attr` - -This is a key/value store holding all the attributes of a node. These are the -permanent properties of nodes, things that don't change at runtime such as the -size of filters for convolutions, or the values of constant ops. Because there -can be so many different types of attribute values, from strings, to ints, to -arrays of tensor values, there's a separate protobuf file defining the data -structure that holds them, in -[tensorflow/core/framework/attr_value.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto). - -Each attribute has a unique name string, and the expected attributes are listed -when the operation is defined. If an attribute isn't present in a node, but it -has a default listed in the operation definition, that default is used when the -graph is created. - -You can access all of these members by calling `node.name`, `node.op`, etc. in -Python. The list of nodes stored in the `GraphDef` is a full definition of the -model architecture. - -## Freezing - -One confusing part about this is that the weights usually aren't stored inside -the file format during training. Instead, they're held in separate checkpoint -files, and there are `Variable` ops in the graph that load the latest values -when they're initialized. It's often not very convenient to have separate files -when you're deploying to production, so there's the -[freeze_graph.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py) script that takes a graph definition and a set -of checkpoints and freezes them together into a single file. - -What this does is load the `GraphDef`, pull in the values for all the variables -from the latest checkpoint file, and then replace each `Variable` op with a -`Const` that has the numerical data for the weights stored in its attributes -It then strips away all the extraneous nodes that aren't used for forward -inference, and saves out the resulting `GraphDef` into an output file. - -## Weight Formats - -If you're dealing with TensorFlow models that represent neural networks, one of -the most common problems is extracting and interpreting the weight values. A -common way to store them, for example in graphs created by the freeze_graph -script, is as `Const` ops containing the weights as `Tensors`. These are -defined in -[tensorflow/core/framework/tensor.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto), and contain information -about the size and type of the data, as well as the values themselves. In -Python, you get a `TensorProto` object from a `NodeDef` representing a `Const` -op by calling something like `some_node_def.attr['value'].tensor`. - -This will give you an object representing the weights data. The data itself -will be stored in one of the lists with the suffix _val as indicated by the -type of the object, for example `float_val` for 32-bit float data types. - -The ordering of convolution weight values is often tricky to deal with when -converting between different frameworks. In TensorFlow, the filter weights for -the `Conv2D` operation are stored on the second input, and are expected to be -in the order `[filter_height, filter_width, input_depth, output_depth]`, where -filter_count increasing by one means moving to an adjacent value in memory. - -Hopefully this rundown gives you a better idea of what's going on inside -TensorFlow model files, and will help you if you ever need to manipulate them. diff --git a/tensorflow/docs_src/extras/README.txt b/tensorflow/docs_src/extras/README.txt deleted file mode 100644 index 765809a762..0000000000 --- a/tensorflow/docs_src/extras/README.txt +++ /dev/null @@ -1,3 +0,0 @@ -This directory holds extra files we'd like to be able -to link to and serve from within tensorflow.org. -They are excluded from versioning.
\ No newline at end of file diff --git a/tensorflow/docs_src/guide/autograph.md b/tensorflow/docs_src/guide/autograph.md deleted file mode 100644 index 823e1c6d6b..0000000000 --- a/tensorflow/docs_src/guide/autograph.md +++ /dev/null @@ -1,3 +0,0 @@ -# AutoGraph: Easy control flow for graphs - -[Colab notebook](https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/guide/autograph.ipynb) diff --git a/tensorflow/docs_src/guide/checkpoints.md b/tensorflow/docs_src/guide/checkpoints.md deleted file mode 100644 index 3c92cbbd40..0000000000 --- a/tensorflow/docs_src/guide/checkpoints.md +++ /dev/null @@ -1,238 +0,0 @@ -# Checkpoints - -This document examines how to save and restore TensorFlow models built with -Estimators. TensorFlow provides two model formats: - -* checkpoints, which is a format dependent on the code that created - the model. -* SavedModel, which is a format independent of the code that created - the model. - -This document focuses on checkpoints. For details on `SavedModel`, see the -[Saving and Restoring](../guide/saved_model.md) guide. - - -## Sample code - -This document relies on the same -[Iris classification example](https://github.com/tensorflow/models/blob/master/samples/core/get_started/premade_estimator.py) detailed in [Getting Started with TensorFlow](../guide/premade_estimators.md). -To download and access the example, invoke the following two commands: - -```shell -git clone https://github.com/tensorflow/models/ -cd models/samples/core/get_started -``` - -Most of the code snippets in this document are minor variations -on `premade_estimator.py`. - - -## Saving partially-trained models - -Estimators automatically write the following to disk: - -* **checkpoints**, which are versions of the model created during training. -* **event files**, which contain information that - [TensorBoard](https://developers.google.com/machine-learning/glossary/#TensorBoard) - uses to create visualizations. - -To specify the top-level directory in which the Estimator stores its -information, assign a value to the optional `model_dir` argument of *any* -`Estimator`'s constructor. -Taking `DNNClassifier` as an example, -the following code sets the `model_dir` -argument to the `models/iris` directory: - -```python -classifier = tf.estimator.DNNClassifier( - feature_columns=my_feature_columns, - hidden_units=[10, 10], - n_classes=3, - model_dir='models/iris') -``` - -Suppose you call the Estimator's `train` method. For example: - - -```python -classifier.train( - input_fn=lambda:train_input_fn(train_x, train_y, batch_size=100), - steps=200) -``` - -As suggested by the following diagrams, the first call to `train` -adds checkpoints and other files to the `model_dir` directory: - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/first_train_calls.png"> -</div> -<div style="text-align: center"> -The first call to train(). -</div> - - -To see the objects in the created `model_dir` directory on a -UNIX-based system, just call `ls` as follows: - -```none -$ ls -1 models/iris -checkpoint -events.out.tfevents.timestamp.hostname -graph.pbtxt -model.ckpt-1.data-00000-of-00001 -model.ckpt-1.index -model.ckpt-1.meta -model.ckpt-200.data-00000-of-00001 -model.ckpt-200.index -model.ckpt-200.meta -``` - -The preceding `ls` command shows that the Estimator created checkpoints -at steps 1 (the start of training) and 200 (the end of training). - - -### Default checkpoint directory - -If you don't specify `model_dir` in an Estimator's constructor, the Estimator -writes checkpoint files to a temporary directory chosen by Python's -[tempfile.mkdtemp](https://docs.python.org/3/library/tempfile.html#tempfile.mkdtemp) -function. For example, the following Estimator constructor does *not* specify -the `model_dir` argument: - -```python -classifier = tf.estimator.DNNClassifier( - feature_columns=my_feature_columns, - hidden_units=[10, 10], - n_classes=3) - -print(classifier.model_dir) -``` - -The `tempfile.mkdtemp` function picks a secure, temporary directory -appropriate for your operating system. For example, a typical temporary -directory on macOS might be something like the following: - -```None -/var/folders/0s/5q9kfzfj3gx2knj0vj8p68yc00dhcr/T/tmpYm1Rwa -``` - -### Checkpointing Frequency - -By default, the Estimator saves -[checkpoints](https://developers.google.com/machine-learning/glossary/#checkpoint) -in the `model_dir` according to the following schedule: - -* Writes a checkpoint every 10 minutes (600 seconds). -* Writes a checkpoint when the `train` method starts (first iteration) - and completes (final iteration). -* Retains only the 5 most recent checkpoints in the directory. - -You may alter the default schedule by taking the following steps: - -1. Create a `tf.estimator.RunConfig` object that defines the - desired schedule. -2. When instantiating the Estimator, pass that `RunConfig` object to the - Estimator's `config` argument. - -For example, the following code changes the checkpointing schedule to every -20 minutes and retains the 10 most recent checkpoints: - -```python -my_checkpointing_config = tf.estimator.RunConfig( - save_checkpoints_secs = 20*60, # Save checkpoints every 20 minutes. - keep_checkpoint_max = 10, # Retain the 10 most recent checkpoints. -) - -classifier = tf.estimator.DNNClassifier( - feature_columns=my_feature_columns, - hidden_units=[10, 10], - n_classes=3, - model_dir='models/iris', - config=my_checkpointing_config) -``` - -## Restoring your model - -The first time you call an Estimator's `train` method, TensorFlow saves a -checkpoint to the `model_dir`. Each subsequent call to the Estimator's -`train`, `evaluate`, or `predict` method causes the following: - -1. The Estimator builds the model's - [graph](https://developers.google.com/machine-learning/glossary/#graph) - by running the `model_fn()`. (For details on the `model_fn()`, see - [Creating Custom Estimators.](../guide/custom_estimators.md)) -2. The Estimator initializes the weights of the new model from the data - stored in the most recent checkpoint. - -In other words, as the following illustration suggests, once checkpoints -exist, TensorFlow rebuilds the model each time you call `train()`, -`evaluate()`, or `predict()`. - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/subsequent_calls.png"> -</div> -<div style="text-align: center"> -Subsequent calls to train(), evaluate(), or predict() -</div> - - -### Avoiding a bad restoration - -Restoring a model's state from a checkpoint only works if the model -and checkpoint are compatible. For example, suppose you trained a -`DNNClassifier` Estimator containing two hidden layers, -each having 10 nodes: - -```python -classifier = tf.estimator.DNNClassifier( - feature_columns=feature_columns, - hidden_units=[10, 10], - n_classes=3, - model_dir='models/iris') - -classifier.train( - input_fn=lambda:train_input_fn(train_x, train_y, batch_size=100), - steps=200) -``` - -After training (and, therefore, after creating checkpoints in `models/iris`), -imagine that you changed the number of neurons in each hidden layer from 10 to -20 and then attempted to retrain the model: - -``` python -classifier2 = tf.estimator.DNNClassifier( - feature_columns=my_feature_columns, - hidden_units=[20, 20], # Change the number of neurons in the model. - n_classes=3, - model_dir='models/iris') - -classifier.train( - input_fn=lambda:train_input_fn(train_x, train_y, batch_size=100), - steps=200) -``` - -Since the state in the checkpoint is incompatible with the model described -in `classifier2`, retraining fails with the following error: - -```None -... -InvalidArgumentError (see above for traceback): tensor_name = -dnn/hiddenlayer_1/bias/t_0/Adagrad; shape in shape_and_slice spec [10] -does not match the shape stored in checkpoint: [20] -``` - -To run experiments in which you train and compare slightly different -versions of a model, save a copy of the code that created each -`model_dir`, possibly by creating a separate git branch for each version. -This separation will keep your checkpoints recoverable. - -## Summary - -Checkpoints provide an easy automatic mechanism for saving and restoring -models created by Estimators. - -See the [Saving and Restoring](../guide/saved_model.md) guide for details about: - -* Saving and restoring models using low-level TensorFlow APIs. -* Exporting and importing models in the SavedModel format, which is a - language-neutral, recoverable, serialization format. diff --git a/tensorflow/docs_src/guide/custom_estimators.md b/tensorflow/docs_src/guide/custom_estimators.md deleted file mode 100644 index 913a35920f..0000000000 --- a/tensorflow/docs_src/guide/custom_estimators.md +++ /dev/null @@ -1,602 +0,0 @@ - -# Creating Custom Estimators - -This document introduces custom Estimators. In particular, this document -demonstrates how to create a custom `tf.estimator.Estimator` that -mimics the behavior of the pre-made Estimator -`tf.estimator.DNNClassifier` in solving the Iris problem. See -the [Pre-Made Estimators chapter](../guide/premade_estimators.md) for details -on the Iris problem. - -To download and access the example code invoke the following two commands: - -```shell -git clone https://github.com/tensorflow/models/ -cd models/samples/core/get_started -``` - -In this document we will be looking at -[`custom_estimator.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/custom_estimator.py). -You can run it with the following command: - -```bsh -python custom_estimator.py -``` - -If you are feeling impatient, feel free to compare and contrast -[`custom_estimator.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/custom_estimator.py) -with -[`premade_estimator.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/premade_estimator.py). -(which is in the same directory). - - - -## Pre-made vs. custom - -As the following figure shows, pre-made Estimators are subclasses of the -`tf.estimator.Estimator` base class, while custom Estimators are an instance -of tf.estimator.Estimator: - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="display:block; margin: 0 auto" - alt="Premade estimators are sub-classes of `Estimator`. Custom Estimators are usually (direct) instances of `Estimator`" - src="../images/custom_estimators/estimator_types.png"> -</div> -<div style="text-align: center"> -Pre-made and custom Estimators are all Estimators. -</div> - -Pre-made Estimators are fully baked. Sometimes though, you need more control -over an Estimator's behavior. That's where custom Estimators come in. You can -create a custom Estimator to do just about anything. If you want hidden layers -connected in some unusual fashion, write a custom Estimator. If you want to -calculate a unique -[metric](https://developers.google.com/machine-learning/glossary/#metric) -for your model, write a custom Estimator. Basically, if you want an Estimator -optimized for your specific problem, write a custom Estimator. - -A model function (or `model_fn`) implements the ML algorithm. The -only difference between working with pre-made Estimators and custom Estimators -is: - -* With pre-made Estimators, someone already wrote the model function for you. -* With custom Estimators, you must write the model function. - -Your model function could implement a wide range of algorithms, defining all -sorts of hidden layers and metrics. Like input functions, all model functions -must accept a standard group of input parameters and return a standard group of -output values. Just as input functions can leverage the Dataset API, model -functions can leverage the Layers API and the Metrics API. - -Let's see how to solve the Iris problem with a custom Estimator. A quick -reminder--here's the organization of the Iris model that we're trying to mimic: - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="display:block; margin: 0 auto" - alt="A diagram of the network architecture: Inputs, 2 hidden layers, and outputs" - src="../images/custom_estimators/full_network.png"> -</div> -<div style="text-align: center"> -Our implementation of Iris contains four features, two hidden layers, -and a logits output layer. -</div> - -## Write an Input function - -Our custom Estimator implementation uses the same input function as our -[pre-made Estimator implementation](../guide/premade_estimators.md), from -[`iris_data.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/iris_data.py). -Namely: - -```python -def train_input_fn(features, labels, batch_size): - """An input function for training""" - # Convert the inputs to a Dataset. - dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels)) - - # Shuffle, repeat, and batch the examples. - dataset = dataset.shuffle(1000).repeat().batch(batch_size) - - # Return the read end of the pipeline. - return dataset.make_one_shot_iterator().get_next() -``` - -This input function builds an input pipeline that yields batches of -`(features, labels)` pairs, where `features` is a dictionary features. - -## Create feature columns - -As detailed in the [Premade Estimators](../guide/premade_estimators.md) and -[Feature Columns](../guide/feature_columns.md) chapters, you must define -your model's feature columns to specify how the model should use each feature. -Whether working with pre-made Estimators or custom Estimators, you define -feature columns in the same fashion. - -The following code creates a simple `numeric_column` for each input feature, -indicating that the value of the input feature should be used directly as an -input to the model: - -```python -# Feature columns describe how to use the input. -my_feature_columns = [] -for key in train_x.keys(): - my_feature_columns.append(tf.feature_column.numeric_column(key=key)) -``` - -## Write a model function - -The model function we'll use has the following call signature: - -```python -def my_model_fn( - features, # This is batch_features from input_fn - labels, # This is batch_labels from input_fn - mode, # An instance of tf.estimator.ModeKeys - params): # Additional configuration -``` - -The first two arguments are the batches of features and labels returned from -the input function; that is, `features` and `labels` are the handles to the -data your model will use. The `mode` argument indicates whether the caller is -requesting training, predicting, or evaluation. - -The caller may pass `params` to an Estimator's constructor. Any `params` passed -to the constructor are in turn passed on to the `model_fn`. In -[`custom_estimator.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/custom_estimator.py) -the following lines create the estimator and set the params to configure the -model. This configuration step is similar to how we configured the `tf.estimator.DNNClassifier` in -[Premade Estimators](../guide/premade_estimators.md). - -```python -classifier = tf.estimator.Estimator( - model_fn=my_model_fn, - params={ - 'feature_columns': my_feature_columns, - # Two hidden layers of 10 nodes each. - 'hidden_units': [10, 10], - # The model must choose between 3 classes. - 'n_classes': 3, - }) -``` - -To implement a typical model function, you must do the following: - -* [Define the model](#define_the_model). -* Specify additional calculations for each of - the [three different modes](#modes): - * [Predict](#predict) - * [Evaluate](#evaluate) - * [Train](#train) - -## Define the model - -The basic deep neural network model must define the following three sections: - -* An [input layer](https://developers.google.com/machine-learning/glossary/#input_layer) -* One or more [hidden layers](https://developers.google.com/machine-learning/glossary/#hidden_layer) -* An [output layer](https://developers.google.com/machine-learning/glossary/#output_layer) - -### Define the input layer - -The first line of the `model_fn` calls `tf.feature_column.input_layer` to -convert the feature dictionary and `feature_columns` into input for your model, -as follows: - -```python - # Use `input_layer` to apply the feature columns. - net = tf.feature_column.input_layer(features, params['feature_columns']) -``` - -The preceding line applies the transformations defined by your feature columns, -creating the model's input layer. - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="display:block; margin: 0 auto" - alt="A diagram of the input layer, in this case a 1:1 mapping from raw-inputs to features." - src="../images/custom_estimators/input_layer.png"> -</div> - - -### Hidden Layers - -If you are creating a deep neural network, you must define one or more hidden -layers. The Layers API provides a rich set of functions to define all types of -hidden layers, including convolutional, pooling, and dropout layers. For Iris, -we're simply going to call `tf.layers.dense` to create hidden layers, with -dimensions defined by `params['hidden_layers']`. In a `dense` layer each node -is connected to every node in the preceding layer. Here's the relevant code: - -``` python - # Build the hidden layers, sized according to the 'hidden_units' param. - for units in params['hidden_units']: - net = tf.layers.dense(net, units=units, activation=tf.nn.relu) -``` - -* The `units` parameter defines the number of output neurons in a given layer. -* The `activation` parameter defines the [activation function](https://developers.google.com/machine-learning/glossary/#activation_function) — - [Relu](https://developers.google.com/machine-learning/glossary/#ReLU) in this - case. - -The variable `net` here signifies the current top layer of the network. During -the first iteration, `net` signifies the input layer. On each loop iteration -`tf.layers.dense` creates a new layer, which takes the previous layer's output -as its input, using the variable `net`. - -After creating two hidden layers, our network looks as follows. For -simplicity, the figure does not show all the units in each layer. - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="display:block; margin: 0 auto" - alt="The input layer with two hidden layers added." - src="../images/custom_estimators/add_hidden_layer.png"> -</div> - -Note that `tf.layers.dense` provides many additional capabilities, including -the ability to set a multitude of regularization parameters. For the sake of -simplicity, though, we're going to simply accept the default values of the -other parameters. - -### Output Layer - -We'll define the output layer by calling `tf.layers.dense` yet again, this -time without an activation function: - -```python - # Compute logits (1 per class). - logits = tf.layers.dense(net, params['n_classes'], activation=None) -``` - -Here, `net` signifies the final hidden layer. Therefore, the full set of layers -is now connected as follows: - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="display:block; margin: 0 auto" - alt="A logit output layer connected to the top hidden layer" - src="../images/custom_estimators/add_logits.png"> -</div> -<div style="text-align: center"> -The final hidden layer feeds into the output layer. -</div> - -When defining an output layer, the `units` parameter specifies the number of -outputs. So, by setting `units` to `params['n_classes']`, the model produces -one output value per class. Each element of the output vector will contain the -score, or "logit", calculated for the associated class of Iris: Setosa, -Versicolor, or Virginica, respectively. - -Later on, these logits will be transformed into probabilities by the -`tf.nn.softmax` function. - -## Implement training, evaluation, and prediction {#modes} - -The final step in creating a model function is to write branching code that -implements prediction, evaluation, and training. - -The model function gets invoked whenever someone calls the Estimator's `train`, -`evaluate`, or `predict` methods. Recall that the signature for the model -function looks like this: - -``` python -def my_model_fn( - features, # This is batch_features from input_fn - labels, # This is batch_labels from input_fn - mode, # An instance of tf.estimator.ModeKeys, see below - params): # Additional configuration -``` - -Focus on that third argument, mode. As the following table shows, when someone -calls `train`, `evaluate`, or `predict`, the Estimator framework invokes your model -function with the mode parameter set as follows: - -| Estimator method | Estimator Mode | -|:---------------------------------|:------------------| -|`tf.estimator.Estimator.train` |`tf.estimator.ModeKeys.TRAIN` | -|`tf.estimator.Estimator.evaluate` |`tf.estimator.ModeKeys.EVAL` | -|`tf.estimator.Estimator.predict`|`tf.estimator.ModeKeys.PREDICT` | - -For example, suppose you instantiate a custom Estimator to generate an object -named `classifier`. Then, you make the following call: - -``` python -classifier = tf.estimator.Estimator(...) -classifier.train(input_fn=lambda: my_input_fn(FILE_TRAIN, True, 500)) -``` -The Estimator framework then calls your model function with mode set to -`ModeKeys.TRAIN`. - -Your model function must provide code to handle all three of the mode values. -For each mode value, your code must return an instance of -`tf.estimator.EstimatorSpec`, which contains the information the caller -requires. Let's examine each mode. - -### Predict - -When the Estimator's `predict` method is called, the `model_fn` receives -`mode = ModeKeys.PREDICT`. In this case, the model function must return a -`tf.estimator.EstimatorSpec` containing the prediction. - -The model must have been trained prior to making a prediction. The trained model -is stored on disk in the `model_dir` directory established when you -instantiated the Estimator. - -The code to generate the prediction for this model looks as follows: - -```python -# Compute predictions. -predicted_classes = tf.argmax(logits, 1) -if mode == tf.estimator.ModeKeys.PREDICT: - predictions = { - 'class_ids': predicted_classes[:, tf.newaxis], - 'probabilities': tf.nn.softmax(logits), - 'logits': logits, - } - return tf.estimator.EstimatorSpec(mode, predictions=predictions) -``` -The prediction dictionary contains everything that your model returns when run -in prediction mode. - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="display:block; margin: 0 auto" - alt="Additional outputs added to the output layer." - src="../images/custom_estimators/add_predictions.png"> -</div> - -The `predictions` holds the following three key/value pairs: - -* `class_ids` holds the class id (0, 1, or 2) representing the model's - prediction of the most likely species for this example. -* `probabilities` holds the three probabilities (in this example, 0.02, 0.95, - and 0.03) -* `logit` holds the raw logit values (in this example, -1.3, 2.6, and -0.9) - -We return that dictionary to the caller via the `predictions` parameter of the -`tf.estimator.EstimatorSpec`. The Estimator's -`tf.estimator.Estimator.predict` method will yield these -dictionaries. - -### Calculate the loss - -For both [training](#train) and [evaluation](#evaluate) we need to calculate the -model's loss. This is the -[objective](https://developers.google.com/machine-learning/glossary/#objective) -that will be optimized. - -We can calculate the loss by calling `tf.losses.sparse_softmax_cross_entropy`. -The value returned by this function will be approximately 0 at lowest, -when the probability of the correct class (at index `label`) is near 1.0. -The loss value returned is progressively larger as the probability of the -correct class decreases. - -This function returns the average over the whole batch. - -```python -# Compute loss. -loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits) -``` - -### Evaluate - -When the Estimator's `evaluate` method is called, the `model_fn` receives -`mode = ModeKeys.EVAL`. In this case, the model function must return a -`tf.estimator.EstimatorSpec` containing the model's loss and optionally one -or more metrics. - -Although returning metrics is optional, most custom Estimators do return at -least one metric. TensorFlow provides a Metrics module `tf.metrics` to -calculate common metrics. For brevity's sake, we'll only return accuracy. The -`tf.metrics.accuracy` function compares our predictions against the -true values, that is, against the labels provided by the input function. The -`tf.metrics.accuracy` function requires the labels and predictions to have the -same shape. Here's the call to `tf.metrics.accuracy`: - -``` python -# Compute evaluation metrics. -accuracy = tf.metrics.accuracy(labels=labels, - predictions=predicted_classes, - name='acc_op') -``` - -The `tf.estimator.EstimatorSpec` returned for evaluation -typically contains the following information: - -* `loss`, which is the model's loss -* `eval_metric_ops`, which is an optional dictionary of metrics. - -So, we'll create a dictionary containing our sole metric. If we had calculated -other metrics, we would have added them as additional key/value pairs to that -same dictionary. Then, we'll pass that dictionary in the `eval_metric_ops` -argument of `tf.estimator.EstimatorSpec`. Here's the code: - -```python -metrics = {'accuracy': accuracy} -tf.summary.scalar('accuracy', accuracy[1]) - -if mode == tf.estimator.ModeKeys.EVAL: - return tf.estimator.EstimatorSpec( - mode, loss=loss, eval_metric_ops=metrics) -``` - -The `tf.summary.scalar` will make accuracy available to TensorBoard -in both `TRAIN` and `EVAL` modes. (More on this later). - -### Train - -When the Estimator's `train` method is called, the `model_fn` is called -with `mode = ModeKeys.TRAIN`. In this case, the model function must return an -`EstimatorSpec` that contains the loss and a training operation. - -Building the training operation will require an optimizer. We will use -`tf.train.AdagradOptimizer` because we're mimicking the `DNNClassifier`, which -also uses `Adagrad` by default. The `tf.train` package provides many other -optimizers—feel free to experiment with them. - -Here is the code that builds the optimizer: - -``` python -optimizer = tf.train.AdagradOptimizer(learning_rate=0.1) -``` - -Next, we build the training operation using the optimizer's -`tf.train.Optimizer.minimize` method on the loss we calculated -earlier. - -The `minimize` method also takes a `global_step` parameter. TensorFlow uses this -parameter to count the number of training steps that have been processed -(to know when to end a training run). Furthermore, the `global_step` is -essential for TensorBoard graphs to work correctly. Simply call -`tf.train.get_global_step` and pass the result to the `global_step` -argument of `minimize`. - -Here's the code to train the model: - -``` python -train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step()) -``` - -The `tf.estimator.EstimatorSpec` returned for training -must have the following fields set: - -* `loss`, which contains the value of the loss function. -* `train_op`, which executes a training step. - -Here's our code to call `EstimatorSpec`: - -```python -return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op) -``` - -The model function is now complete. - -## The custom Estimator - -Instantiate the custom Estimator through the Estimator base class as follows: - -```python - # Build 2 hidden layer DNN with 10, 10 units respectively. - classifier = tf.estimator.Estimator( - model_fn=my_model_fn, - params={ - 'feature_columns': my_feature_columns, - # Two hidden layers of 10 nodes each. - 'hidden_units': [10, 10], - # The model must choose between 3 classes. - 'n_classes': 3, - }) -``` -Here the `params` dictionary serves the same purpose as the key-word -arguments of `DNNClassifier`; that is, the `params` dictionary lets you -configure your Estimator without modifying the code in the `model_fn`. - -The rest of the code to train, evaluate, and generate predictions using our -Estimator is the same as in the -[Premade Estimators](../guide/premade_estimators.md) chapter. For -example, the following line will train the model: - -```python -# Train the Model. -classifier.train( - input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size), - steps=args.train_steps) -``` - -## TensorBoard - -You can view training results for your custom Estimator in TensorBoard. To see -this reporting, start TensorBoard from your command line as follows: - -```bsh -# Replace PATH with the actual path passed as model_dir -tensorboard --logdir=PATH -``` - -Then, open TensorBoard by browsing to: [http://localhost:6006](http://localhost:6006) - -All the pre-made Estimators automatically log a lot of information to -TensorBoard. With custom Estimators, however, TensorBoard only provides one -default log (a graph of the loss) plus the information you explicitly tell -TensorBoard to log. For the custom Estimator you just created, TensorBoard -generates the following: - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> - -<img style="display:block; margin: 0 auto" - alt="Accuracy, 'scalar' graph from tensorboard" - src="../images/custom_estimators/accuracy.png"> - -<img style="display:block; margin: 0 auto" - alt="loss 'scalar' graph from tensorboard" - src="../images/custom_estimators/loss.png"> - -<img style="display:block; margin: 0 auto" - alt="steps/second 'scalar' graph from tensorboard" - src="../images/custom_estimators/steps_per_second.png"> -</div> - -<div style="text-align: center"> -TensorBoard displays three graphs. -</div> - - -In brief, here's what the three graphs tell you: - -* global_step/sec: A performance indicator showing how many batches (gradient - updates) we processed per second as the model trains. - -* loss: The loss reported. - -* accuracy: The accuracy is recorded by the following two lines: - - * `eval_metric_ops={'my_accuracy': accuracy}`, during evaluation. - * `tf.summary.scalar('accuracy', accuracy[1])`, during training. - -These tensorboard graphs are one of the main reasons it's important to pass a -`global_step` to your optimizer's `minimize` method. The model can't record -the x-coordinate for these graphs without it. - -Note the following in the `my_accuracy` and `loss` graphs: - -* The orange line represents training. -* The blue dot represents evaluation. - -During training, summaries (the orange line) are recorded periodically as -batches are processed, which is why it becomes a graph spanning x-axis range. - -By contrast, evaluation produces only a single point on the graph for each call -to `evaluate`. This point contains the average over the entire evaluation call. -This has no width on the graph as it is evaluated entirely from the model state -at a particular training step (from a single checkpoint). - -As suggested in the following figure, you may see and also selectively -disable/enable the reporting using the controls on the left side. - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="display:block; margin: 0 auto" - alt="Check-boxes allowing the user to select which runs are shown." - src="../images/custom_estimators/select_run.jpg"> -</div> -<div style="text-align: center"> -Enable or disable reporting. -</div> - - -## Summary - -Although pre-made Estimators can be an effective way to quickly create new -models, you will often need the additional flexibility that custom Estimators -provide. Fortunately, pre-made and custom Estimators follow the same -programming model. The only practical difference is that you must write a model -function for custom Estimators; everything else is the same. - -For more details, be sure to check out: - -* The - [official TensorFlow implementation of MNIST](https://github.com/tensorflow/models/tree/master/official/mnist), - which uses a custom estimator. -* The TensorFlow - [official models repository](https://github.com/tensorflow/models/tree/master/official), - which contains more curated examples using custom estimators. -* This [TensorBoard video](https://youtu.be/eBbEDRsCmv4), which introduces - TensorBoard. -* The [Low Level Introduction](../guide/low_level_intro.md), which demonstrates - how to experiment directly with TensorFlow's low level APIs, making debugging - easier. diff --git a/tensorflow/docs_src/guide/datasets.md b/tensorflow/docs_src/guide/datasets.md deleted file mode 100644 index bf77550f6a..0000000000 --- a/tensorflow/docs_src/guide/datasets.md +++ /dev/null @@ -1,823 +0,0 @@ -# Importing Data - -The `tf.data` API enables you to build complex input pipelines from -simple, reusable pieces. For example, the pipeline for an image model might -aggregate data from files in a distributed file system, apply random -perturbations to each image, and merge randomly selected images into a batch -for training. The pipeline for a text model might involve extracting symbols -from raw text data, converting them to embedding identifiers with a lookup -table, and batching together sequences of different lengths. The `tf.data` API -makes it easy to deal with large amounts of data, different data formats, and -complicated transformations. - -The `tf.data` API introduces two new abstractions to TensorFlow: - -* A `tf.data.Dataset` represents a sequence of elements, in which - each element contains one or more `Tensor` objects. For example, in an image - pipeline, an element might be a single training example, with a pair of - tensors representing the image data and a label. There are two distinct - ways to create a dataset: - - * Creating a **source** (e.g. `Dataset.from_tensor_slices()`) constructs a - dataset from - one or more `tf.Tensor` objects. - - * Applying a **transformation** (e.g. `Dataset.batch()`) constructs a dataset - from one or more `tf.data.Dataset` objects. - -* A `tf.data.Iterator` provides the main way to extract elements from a - dataset. The operation returned by `Iterator.get_next()` yields the next - element of a `Dataset` when executed, and typically acts as the interface - between input pipeline code and your model. The simplest iterator is a - "one-shot iterator", which is associated with a particular `Dataset` and - iterates through it once. For more sophisticated uses, the - `Iterator.initializer` operation enables you to reinitialize and parameterize - an iterator with different datasets, so that you can, for example, iterate - over training and validation data multiple times in the same program. - -## Basic mechanics - -This section of the guide describes the fundamentals of creating different kinds -of `Dataset` and `Iterator` objects, and how to extract data from them. - -To start an input pipeline, you must define a *source*. For example, to -construct a `Dataset` from some tensors in memory, you can use -`tf.data.Dataset.from_tensors()` or -`tf.data.Dataset.from_tensor_slices()`. Alternatively, if your input -data are on disk in the recommended TFRecord format, you can construct a -`tf.data.TFRecordDataset`. - -Once you have a `Dataset` object, you can *transform* it into a new `Dataset` by -chaining method calls on the `tf.data.Dataset` object. For example, you -can apply per-element transformations such as `Dataset.map()` (to apply a -function to each element), and multi-element transformations such as -`Dataset.batch()`. See the documentation for `tf.data.Dataset` -for a complete list of transformations. - -The most common way to consume values from a `Dataset` is to make an -**iterator** object that provides access to one element of the dataset at a time -(for example, by calling `Dataset.make_one_shot_iterator()`). A -`tf.data.Iterator` provides two operations: `Iterator.initializer`, -which enables you to (re)initialize the iterator's state; and -`Iterator.get_next()`, which returns `tf.Tensor` objects that correspond to the -symbolic next element. Depending on your use case, you might choose a different -type of iterator, and the options are outlined below. - -### Dataset structure - -A dataset comprises elements that each have the same structure. An element -contains one or more `tf.Tensor` objects, called *components*. Each component -has a `tf.DType` representing the type of elements in the tensor, and a -`tf.TensorShape` representing the (possibly partially specified) static shape of -each element. The `Dataset.output_types` and `Dataset.output_shapes` properties -allow you to inspect the inferred types and shapes of each component of a -dataset element. The *nested structure* of these properties map to the structure -of an element, which may be a single tensor, a tuple of tensors, or a nested -tuple of tensors. For example: - -```python -dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10])) -print(dataset1.output_types) # ==> "tf.float32" -print(dataset1.output_shapes) # ==> "(10,)" - -dataset2 = tf.data.Dataset.from_tensor_slices( - (tf.random_uniform([4]), - tf.random_uniform([4, 100], maxval=100, dtype=tf.int32))) -print(dataset2.output_types) # ==> "(tf.float32, tf.int32)" -print(dataset2.output_shapes) # ==> "((), (100,))" - -dataset3 = tf.data.Dataset.zip((dataset1, dataset2)) -print(dataset3.output_types) # ==> (tf.float32, (tf.float32, tf.int32)) -print(dataset3.output_shapes) # ==> "(10, ((), (100,)))" -``` - -It is often convenient to give names to each component of an element, for -example if they represent different features of a training example. In addition -to tuples, you can use `collections.namedtuple` or a dictionary mapping strings -to tensors to represent a single element of a `Dataset`. - -```python -dataset = tf.data.Dataset.from_tensor_slices( - {"a": tf.random_uniform([4]), - "b": tf.random_uniform([4, 100], maxval=100, dtype=tf.int32)}) -print(dataset.output_types) # ==> "{'a': tf.float32, 'b': tf.int32}" -print(dataset.output_shapes) # ==> "{'a': (), 'b': (100,)}" -``` - -The `Dataset` transformations support datasets of any structure. When using the -`Dataset.map()`, `Dataset.flat_map()`, and `Dataset.filter()` transformations, -which apply a function to each element, the element structure determines the -arguments of the function: - -```python -dataset1 = dataset1.map(lambda x: ...) - -dataset2 = dataset2.flat_map(lambda x, y: ...) - -# Note: Argument destructuring is not available in Python 3. -dataset3 = dataset3.filter(lambda x, (y, z): ...) -``` - -### Creating an iterator - -Once you have built a `Dataset` to represent your input data, the next step is to -create an `Iterator` to access elements from that dataset. The `tf.data` API -currently supports the following iterators, in increasing level of -sophistication: - -* **one-shot**, -* **initializable**, -* **reinitializable**, and -* **feedable**. - -A **one-shot** iterator is the simplest form of iterator, which only supports -iterating once through a dataset, with no need for explicit initialization. -One-shot iterators handle almost all of the cases that the existing queue-based -input pipelines support, but they do not support parameterization. Using the -example of `Dataset.range()`: - -```python -dataset = tf.data.Dataset.range(100) -iterator = dataset.make_one_shot_iterator() -next_element = iterator.get_next() - -for i in range(100): - value = sess.run(next_element) - assert i == value -``` - -Note: Currently, one-shot iterators are the only type that is easily usable -with an `Estimator`. - -An **initializable** iterator requires you to run an explicit -`iterator.initializer` operation before using it. In exchange for this -inconvenience, it enables you to *parameterize* the definition of the dataset, -using one or more `tf.placeholder()` tensors that can be fed when you -initialize the iterator. Continuing the `Dataset.range()` example: - -```python -max_value = tf.placeholder(tf.int64, shape=[]) -dataset = tf.data.Dataset.range(max_value) -iterator = dataset.make_initializable_iterator() -next_element = iterator.get_next() - -# Initialize an iterator over a dataset with 10 elements. -sess.run(iterator.initializer, feed_dict={max_value: 10}) -for i in range(10): - value = sess.run(next_element) - assert i == value - -# Initialize the same iterator over a dataset with 100 elements. -sess.run(iterator.initializer, feed_dict={max_value: 100}) -for i in range(100): - value = sess.run(next_element) - assert i == value -``` - -A **reinitializable** iterator can be initialized from multiple different -`Dataset` objects. For example, you might have a training input pipeline that -uses random perturbations to the input images to improve generalization, and -a validation input pipeline that evaluates predictions on unmodified data. These -pipelines will typically use different `Dataset` objects that have the same -structure (i.e. the same types and compatible shapes for each component). - -```python -# Define training and validation datasets with the same structure. -training_dataset = tf.data.Dataset.range(100).map( - lambda x: x + tf.random_uniform([], -10, 10, tf.int64)) -validation_dataset = tf.data.Dataset.range(50) - -# A reinitializable iterator is defined by its structure. We could use the -# `output_types` and `output_shapes` properties of either `training_dataset` -# or `validation_dataset` here, because they are compatible. -iterator = tf.data.Iterator.from_structure(training_dataset.output_types, - training_dataset.output_shapes) -next_element = iterator.get_next() - -training_init_op = iterator.make_initializer(training_dataset) -validation_init_op = iterator.make_initializer(validation_dataset) - -# Run 20 epochs in which the training dataset is traversed, followed by the -# validation dataset. -for _ in range(20): - # Initialize an iterator over the training dataset. - sess.run(training_init_op) - for _ in range(100): - sess.run(next_element) - - # Initialize an iterator over the validation dataset. - sess.run(validation_init_op) - for _ in range(50): - sess.run(next_element) -``` - -A **feedable** iterator can be used together with `tf.placeholder` to select -what `Iterator` to use in each call to `tf.Session.run`, via the familiar -`feed_dict` mechanism. It offers the same functionality as a reinitializable -iterator, but it does not require you to initialize the iterator from the start -of a dataset when you switch between iterators. For example, using the same -training and validation example from above, you can use -`tf.data.Iterator.from_string_handle` to define a feedable iterator -that allows you to switch between the two datasets: - -```python -# Define training and validation datasets with the same structure. -training_dataset = tf.data.Dataset.range(100).map( - lambda x: x + tf.random_uniform([], -10, 10, tf.int64)).repeat() -validation_dataset = tf.data.Dataset.range(50) - -# A feedable iterator is defined by a handle placeholder and its structure. We -# could use the `output_types` and `output_shapes` properties of either -# `training_dataset` or `validation_dataset` here, because they have -# identical structure. -handle = tf.placeholder(tf.string, shape=[]) -iterator = tf.data.Iterator.from_string_handle( - handle, training_dataset.output_types, training_dataset.output_shapes) -next_element = iterator.get_next() - -# You can use feedable iterators with a variety of different kinds of iterator -# (such as one-shot and initializable iterators). -training_iterator = training_dataset.make_one_shot_iterator() -validation_iterator = validation_dataset.make_initializable_iterator() - -# The `Iterator.string_handle()` method returns a tensor that can be evaluated -# and used to feed the `handle` placeholder. -training_handle = sess.run(training_iterator.string_handle()) -validation_handle = sess.run(validation_iterator.string_handle()) - -# Loop forever, alternating between training and validation. -while True: - # Run 200 steps using the training dataset. Note that the training dataset is - # infinite, and we resume from where we left off in the previous `while` loop - # iteration. - for _ in range(200): - sess.run(next_element, feed_dict={handle: training_handle}) - - # Run one pass over the validation dataset. - sess.run(validation_iterator.initializer) - for _ in range(50): - sess.run(next_element, feed_dict={handle: validation_handle}) -``` - -### Consuming values from an iterator - -The `Iterator.get_next()` method returns one or more `tf.Tensor` objects that -correspond to the symbolic next element of an iterator. Each time these tensors -are evaluated, they take the value of the next element in the underlying -dataset. (Note that, like other stateful objects in TensorFlow, calling -`Iterator.get_next()` does not immediately advance the iterator. Instead you -must use the returned `tf.Tensor` objects in a TensorFlow expression, and pass -the result of that expression to `tf.Session.run()` to get the next elements and -advance the iterator.) - -If the iterator reaches the end of the dataset, executing -the `Iterator.get_next()` operation will raise a `tf.errors.OutOfRangeError`. -After this point the iterator will be in an unusable state, and you must -initialize it again if you want to use it further. - -```python -dataset = tf.data.Dataset.range(5) -iterator = dataset.make_initializable_iterator() -next_element = iterator.get_next() - -# Typically `result` will be the output of a model, or an optimizer's -# training operation. -result = tf.add(next_element, next_element) - -sess.run(iterator.initializer) -print(sess.run(result)) # ==> "0" -print(sess.run(result)) # ==> "2" -print(sess.run(result)) # ==> "4" -print(sess.run(result)) # ==> "6" -print(sess.run(result)) # ==> "8" -try: - sess.run(result) -except tf.errors.OutOfRangeError: - print("End of dataset") # ==> "End of dataset" -``` - -A common pattern is to wrap the "training loop" in a `try`-`except` block: - -```python -sess.run(iterator.initializer) -while True: - try: - sess.run(result) - except tf.errors.OutOfRangeError: - break -``` - -If each element of the dataset has a nested structure, the return value of -`Iterator.get_next()` will be one or more `tf.Tensor` objects in the same -nested structure: - -```python -dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10])) -dataset2 = tf.data.Dataset.from_tensor_slices((tf.random_uniform([4]), tf.random_uniform([4, 100]))) -dataset3 = tf.data.Dataset.zip((dataset1, dataset2)) - -iterator = dataset3.make_initializable_iterator() - -sess.run(iterator.initializer) -next1, (next2, next3) = iterator.get_next() -``` - -Note that `next1`, `next2`, and `next3` are tensors produced by the -same op/node (created by `Iterator.get_next()`). Therefore, evaluating *any* of -these tensors will advance the iterator for all components. A typical consumer -of an iterator will include all components in a single expression. - -### Saving iterator state - -The `tf.contrib.data.make_saveable_from_iterator` function creates a -`SaveableObject` from an iterator, which can be used to save and -restore the current state of the iterator (and, effectively, the whole input -pipeline). A saveable object thus created can be added to `tf.train.Saver` -variables list or the `tf.GraphKeys.SAVEABLE_OBJECTS` collection for saving and -restoring in the same manner as a `tf.Variable`. Refer to -[Saving and Restoring](../guide/saved_model.md) for details on how to save and restore -variables. - -```python -# Create saveable object from iterator. -saveable = tf.contrib.data.make_saveable_from_iterator(iterator) - -# Save the iterator state by adding it to the saveable objects collection. -tf.add_to_collection(tf.GraphKeys.SAVEABLE_OBJECTS, saveable) -saver = tf.train.Saver() - -with tf.Session() as sess: - - if should_checkpoint: - saver.save(path_to_checkpoint) - -# Restore the iterator state. -with tf.Session() as sess: - saver.restore(sess, path_to_checkpoint) -``` - -## Reading input data - -### Consuming NumPy arrays - -If all of your input data fit in memory, the simplest way to create a `Dataset` -from them is to convert them to `tf.Tensor` objects and use -`Dataset.from_tensor_slices()`. - -```python -# Load the training data into two NumPy arrays, for example using `np.load()`. -with np.load("/var/data/training_data.npy") as data: - features = data["features"] - labels = data["labels"] - -# Assume that each row of `features` corresponds to the same row as `labels`. -assert features.shape[0] == labels.shape[0] - -dataset = tf.data.Dataset.from_tensor_slices((features, labels)) -``` - -Note that the above code snippet will embed the `features` and `labels` arrays -in your TensorFlow graph as `tf.constant()` operations. This works well for a -small dataset, but wastes memory---because the contents of the array will be -copied multiple times---and can run into the 2GB limit for the `tf.GraphDef` -protocol buffer. - -As an alternative, you can define the `Dataset` in terms of `tf.placeholder()` -tensors, and *feed* the NumPy arrays when you initialize an `Iterator` over the -dataset. - -```python -# Load the training data into two NumPy arrays, for example using `np.load()`. -with np.load("/var/data/training_data.npy") as data: - features = data["features"] - labels = data["labels"] - -# Assume that each row of `features` corresponds to the same row as `labels`. -assert features.shape[0] == labels.shape[0] - -features_placeholder = tf.placeholder(features.dtype, features.shape) -labels_placeholder = tf.placeholder(labels.dtype, labels.shape) - -dataset = tf.data.Dataset.from_tensor_slices((features_placeholder, labels_placeholder)) -# [Other transformations on `dataset`...] -dataset = ... -iterator = dataset.make_initializable_iterator() - -sess.run(iterator.initializer, feed_dict={features_placeholder: features, - labels_placeholder: labels}) -``` - -### Consuming TFRecord data - -The `tf.data` API supports a variety of file formats so that you can process -large datasets that do not fit in memory. For example, the TFRecord file format -is a simple record-oriented binary format that many TensorFlow applications use -for training data. The `tf.data.TFRecordDataset` class enables you to -stream over the contents of one or more TFRecord files as part of an input -pipeline. - -```python -# Creates a dataset that reads all of the examples from two files. -filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] -dataset = tf.data.TFRecordDataset(filenames) -``` - -The `filenames` argument to the `TFRecordDataset` initializer can either be a -string, a list of strings, or a `tf.Tensor` of strings. Therefore if you have -two sets of files for training and validation purposes, you can use a -`tf.placeholder(tf.string)` to represent the filenames, and initialize an -iterator from the appropriate filenames: - -```python -filenames = tf.placeholder(tf.string, shape=[None]) -dataset = tf.data.TFRecordDataset(filenames) -dataset = dataset.map(...) # Parse the record into tensors. -dataset = dataset.repeat() # Repeat the input indefinitely. -dataset = dataset.batch(32) -iterator = dataset.make_initializable_iterator() - -# You can feed the initializer with the appropriate filenames for the current -# phase of execution, e.g. training vs. validation. - -# Initialize `iterator` with training data. -training_filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] -sess.run(iterator.initializer, feed_dict={filenames: training_filenames}) - -# Initialize `iterator` with validation data. -validation_filenames = ["/var/data/validation1.tfrecord", ...] -sess.run(iterator.initializer, feed_dict={filenames: validation_filenames}) -``` - -### Consuming text data - -Many datasets are distributed as one or more text files. The -`tf.data.TextLineDataset` provides an easy way to extract lines from -one or more text files. Given one or more filenames, a `TextLineDataset` will -produce one string-valued element per line of those files. Like a -`TFRecordDataset`, `TextLineDataset` accepts `filenames` as a `tf.Tensor`, so -you can parameterize it by passing a `tf.placeholder(tf.string)`. - -```python -filenames = ["/var/data/file1.txt", "/var/data/file2.txt"] -dataset = tf.data.TextLineDataset(filenames) -``` - -By default, a `TextLineDataset` yields *every* line of each file, which may -not be desirable, for example if the file starts with a header line, or contains -comments. These lines can be removed using the `Dataset.skip()` and -`Dataset.filter()` transformations. To apply these transformations to each -file separately, we use `Dataset.flat_map()` to create a nested `Dataset` for -each file. - -```python -filenames = ["/var/data/file1.txt", "/var/data/file2.txt"] - -dataset = tf.data.Dataset.from_tensor_slices(filenames) - -# Use `Dataset.flat_map()` to transform each file as a separate nested dataset, -# and then concatenate their contents sequentially into a single "flat" dataset. -# * Skip the first line (header row). -# * Filter out lines beginning with "#" (comments). -dataset = dataset.flat_map( - lambda filename: ( - tf.data.TextLineDataset(filename) - .skip(1) - .filter(lambda line: tf.not_equal(tf.substr(line, 0, 1), "#")))) -``` - -### Consuming CSV data - -The CSV file format is a popular format for storing tabular data in plain text. -The `tf.contrib.data.CsvDataset` class provides a way to extract records from -one or more CSV files that comply with [RFC 4180](https://tools.ietf.org/html/rfc4180). -Given one or more filenames and a list of defaults, a `CsvDataset` will produce -a tuple of elements whose types correspond to the types of the defaults -provided, per CSV record. Like `TFRecordDataset` and `TextLineDataset`, -`CsvDataset` accepts `filenames` as a `tf.Tensor`, so you can parameterize it -by passing a `tf.placeholder(tf.string)`. - -``` -# Creates a dataset that reads all of the records from two CSV files, each with -# eight float columns -filenames = ["/var/data/file1.csv", "/var/data/file2.csv"] -record_defaults = [tf.float32] * 8 # Eight required float columns -dataset = tf.contrib.data.CsvDataset(filenames, record_defaults) -``` - -If some columns are empty, you can provide defaults instead of types. - -``` -# Creates a dataset that reads all of the records from two CSV files, each with -# four float columns which may have missing values -record_defaults = [[0.0]] * 8 -dataset = tf.contrib.data.CsvDataset(filenames, record_defaults) -``` - -By default, a `CsvDataset` yields *every* column of *every* line of the file, -which may not be desirable, for example if the file starts with a header line -that should be ignored, or if some columns are not required in the input. -These lines and fields can be removed with the `header` and `select_cols` -arguments respectively. - -``` -# Creates a dataset that reads all of the records from two CSV files with -# headers, extracting float data from columns 2 and 4. -record_defaults = [[0.0]] * 2 # Only provide defaults for the selected columns -dataset = tf.contrib.data.CsvDataset(filenames, record_defaults, header=True, select_cols=[2,4]) -``` -<!-- -TODO(mrry): Add these sections. - -### Consuming from a Python generator ---> - -## Preprocessing data with `Dataset.map()` - -The `Dataset.map(f)` transformation produces a new dataset by applying a given -function `f` to each element of the input dataset. It is based on -the -[`map()` function](https://en.wikipedia.org/wiki/Map_(higher-order_function)) -that is commonly applied to lists (and other structures) in functional -programming languages. The function `f` takes the `tf.Tensor` objects that -represent a single element in the input, and returns the `tf.Tensor` objects -that will represent a single element in the new dataset. Its implementation uses -standard TensorFlow operations to transform one element into another. - -This section covers common examples of how to use `Dataset.map()`. - -### Parsing `tf.Example` protocol buffer messages - -Many input pipelines extract `tf.train.Example` protocol buffer messages from a -TFRecord-format file (written, for example, using -`tf.python_io.TFRecordWriter`). Each `tf.train.Example` record contains one or -more "features", and the input pipeline typically converts these features into -tensors. - -```python -# Transforms a scalar string `example_proto` into a pair of a scalar string and -# a scalar integer, representing an image and its label, respectively. -def _parse_function(example_proto): - features = {"image": tf.FixedLenFeature((), tf.string, default_value=""), - "label": tf.FixedLenFeature((), tf.int32, default_value=0)} - parsed_features = tf.parse_single_example(example_proto, features) - return parsed_features["image"], parsed_features["label"] - -# Creates a dataset that reads all of the examples from two files, and extracts -# the image and label features. -filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] -dataset = tf.data.TFRecordDataset(filenames) -dataset = dataset.map(_parse_function) -``` - -### Decoding image data and resizing it - -When training a neural network on real-world image data, it is often necessary -to convert images of different sizes to a common size, so that they may be -batched into a fixed size. - -```python -# Reads an image from a file, decodes it into a dense tensor, and resizes it -# to a fixed shape. -def _parse_function(filename, label): - image_string = tf.read_file(filename) - image_decoded = tf.image.decode_jpeg(image_string) - image_resized = tf.image.resize_images(image_decoded, [28, 28]) - return image_resized, label - -# A vector of filenames. -filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg", ...]) - -# `labels[i]` is the label for the image in `filenames[i]. -labels = tf.constant([0, 37, ...]) - -dataset = tf.data.Dataset.from_tensor_slices((filenames, labels)) -dataset = dataset.map(_parse_function) -``` - -### Applying arbitrary Python logic with `tf.py_func()` - -For performance reasons, we encourage you to use TensorFlow operations for -preprocessing your data whenever possible. However, it is sometimes useful to -call upon external Python libraries when parsing your input data. To do so, -invoke, the `tf.py_func()` operation in a `Dataset.map()` transformation. - -```python -import cv2 - -# Use a custom OpenCV function to read the image, instead of the standard -# TensorFlow `tf.read_file()` operation. -def _read_py_function(filename, label): - image_decoded = cv2.imread(filename.decode(), cv2.IMREAD_GRAYSCALE) - return image_decoded, label - -# Use standard TensorFlow operations to resize the image to a fixed shape. -def _resize_function(image_decoded, label): - image_decoded.set_shape([None, None, None]) - image_resized = tf.image.resize_images(image_decoded, [28, 28]) - return image_resized, label - -filenames = ["/var/data/image1.jpg", "/var/data/image2.jpg", ...] -labels = [0, 37, 29, 1, ...] - -dataset = tf.data.Dataset.from_tensor_slices((filenames, labels)) -dataset = dataset.map( - lambda filename, label: tuple(tf.py_func( - _read_py_function, [filename, label], [tf.uint8, label.dtype]))) -dataset = dataset.map(_resize_function) -``` - -<!-- -TODO(mrry): Add this section. - -### Handling text data with unusual sizes ---> - -## Batching dataset elements - -### Simple batching - -The simplest form of batching stacks `n` consecutive elements of a dataset into -a single element. The `Dataset.batch()` transformation does exactly this, with -the same constraints as the `tf.stack()` operator, applied to each component -of the elements: i.e. for each component *i*, all elements must have a tensor -of the exact same shape. - -```python -inc_dataset = tf.data.Dataset.range(100) -dec_dataset = tf.data.Dataset.range(0, -100, -1) -dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset)) -batched_dataset = dataset.batch(4) - -iterator = batched_dataset.make_one_shot_iterator() -next_element = iterator.get_next() - -print(sess.run(next_element)) # ==> ([0, 1, 2, 3], [ 0, -1, -2, -3]) -print(sess.run(next_element)) # ==> ([4, 5, 6, 7], [-4, -5, -6, -7]) -print(sess.run(next_element)) # ==> ([8, 9, 10, 11], [-8, -9, -10, -11]) -``` - -### Batching tensors with padding - -The above recipe works for tensors that all have the same size. However, many -models (e.g. sequence models) work with input data that can have varying size -(e.g. sequences of different lengths). To handle this case, the -`Dataset.padded_batch()` transformation enables you to batch tensors of -different shape by specifying one or more dimensions in which they may be -padded. - -```python -dataset = tf.data.Dataset.range(100) -dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x)) -dataset = dataset.padded_batch(4, padded_shapes=[None]) - -iterator = dataset.make_one_shot_iterator() -next_element = iterator.get_next() - -print(sess.run(next_element)) # ==> [[0, 0, 0], [1, 0, 0], [2, 2, 0], [3, 3, 3]] -print(sess.run(next_element)) # ==> [[4, 4, 4, 4, 0, 0, 0], - # [5, 5, 5, 5, 5, 0, 0], - # [6, 6, 6, 6, 6, 6, 0], - # [7, 7, 7, 7, 7, 7, 7]] -``` - -The `Dataset.padded_batch()` transformation allows you to set different padding -for each dimension of each component, and it may be variable-length (signified -by `None` in the example above) or constant-length. It is also possible to -override the padding value, which defaults to 0. - -<!-- -TODO(mrry): Add this section. - -### Dense ragged -> tf.SparseTensor ---> - -## Training workflows - -### Processing multiple epochs - -The `tf.data` API offers two main ways to process multiple epochs of the same -data. - -The simplest way to iterate over a dataset in multiple epochs is to use the -`Dataset.repeat()` transformation. For example, to create a dataset that repeats -its input for 10 epochs: - -```python -filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] -dataset = tf.data.TFRecordDataset(filenames) -dataset = dataset.map(...) -dataset = dataset.repeat(10) -dataset = dataset.batch(32) -``` - -Applying the `Dataset.repeat()` transformation with no arguments will repeat -the input indefinitely. The `Dataset.repeat()` transformation concatenates its -arguments without signaling the end of one epoch and the beginning of the next -epoch. - -If you want to receive a signal at the end of each epoch, you can write a -training loop that catches the `tf.errors.OutOfRangeError` at the end of a -dataset. At that point you might collect some statistics (e.g. the validation -error) for the epoch. - -```python -filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] -dataset = tf.data.TFRecordDataset(filenames) -dataset = dataset.map(...) -dataset = dataset.batch(32) -iterator = dataset.make_initializable_iterator() -next_element = iterator.get_next() - -# Compute for 100 epochs. -for _ in range(100): - sess.run(iterator.initializer) - while True: - try: - sess.run(next_element) - except tf.errors.OutOfRangeError: - break - - # [Perform end-of-epoch calculations here.] -``` - -### Randomly shuffling input data - -The `Dataset.shuffle()` transformation randomly shuffles the input dataset -using a similar algorithm to `tf.RandomShuffleQueue`: it maintains a fixed-size -buffer and chooses the next element uniformly at random from that buffer. - -```python -filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] -dataset = tf.data.TFRecordDataset(filenames) -dataset = dataset.map(...) -dataset = dataset.shuffle(buffer_size=10000) -dataset = dataset.batch(32) -dataset = dataset.repeat() -``` - -### Using high-level APIs - -The `tf.train.MonitoredTrainingSession` API simplifies many aspects of running -TensorFlow in a distributed setting. `MonitoredTrainingSession` uses the -`tf.errors.OutOfRangeError` to signal that training has completed, so to use it -with the `tf.data` API, we recommend using -`Dataset.make_one_shot_iterator()`. For example: - -```python -filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] -dataset = tf.data.TFRecordDataset(filenames) -dataset = dataset.map(...) -dataset = dataset.shuffle(buffer_size=10000) -dataset = dataset.batch(32) -dataset = dataset.repeat(num_epochs) -iterator = dataset.make_one_shot_iterator() - -next_example, next_label = iterator.get_next() -loss = model_function(next_example, next_label) - -training_op = tf.train.AdagradOptimizer(...).minimize(loss) - -with tf.train.MonitoredTrainingSession(...) as sess: - while not sess.should_stop(): - sess.run(training_op) -``` - -To use a `Dataset` in the `input_fn` of a `tf.estimator.Estimator`, we also -recommend using `Dataset.make_one_shot_iterator()`. For example: - -```python -def dataset_input_fn(): - filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] - dataset = tf.data.TFRecordDataset(filenames) - - # Use `tf.parse_single_example()` to extract data from a `tf.Example` - # protocol buffer, and perform any additional per-record preprocessing. - def parser(record): - keys_to_features = { - "image_data": tf.FixedLenFeature((), tf.string, default_value=""), - "date_time": tf.FixedLenFeature((), tf.int64, default_value=""), - "label": tf.FixedLenFeature((), tf.int64, - default_value=tf.zeros([], dtype=tf.int64)), - } - parsed = tf.parse_single_example(record, keys_to_features) - - # Perform additional preprocessing on the parsed data. - image = tf.image.decode_jpeg(parsed["image_data"]) - image = tf.reshape(image, [299, 299, 1]) - label = tf.cast(parsed["label"], tf.int32) - - return {"image_data": image, "date_time": parsed["date_time"]}, label - - # Use `Dataset.map()` to build a pair of a feature dictionary and a label - # tensor for each example. - dataset = dataset.map(parser) - dataset = dataset.shuffle(buffer_size=10000) - dataset = dataset.batch(32) - dataset = dataset.repeat(num_epochs) - iterator = dataset.make_one_shot_iterator() - - # `features` is a dictionary in which each value is a batch of values for - # that feature; `labels` is a batch of labels. - features, labels = iterator.get_next() - return features, labels -``` diff --git a/tensorflow/docs_src/guide/datasets_for_estimators.md b/tensorflow/docs_src/guide/datasets_for_estimators.md deleted file mode 100644 index 09a3830ca9..0000000000 --- a/tensorflow/docs_src/guide/datasets_for_estimators.md +++ /dev/null @@ -1,387 +0,0 @@ -# Datasets for Estimators - -The `tf.data` module contains a collection of classes that allows you to -easily load data, manipulate it, and pipe it into your model. This document -introduces the API by walking through two simple examples: - -* Reading in-memory data from numpy arrays. -* Reading lines from a csv file. - -<!-- TODO(markdaoust): Add links to an example reading from multiple-files -(image_retraining), and a from_generator example. --> - -## Basic input - -Taking slices from an array is the simplest way to get started with `tf.data`. - -The [Premade Estimators](../guide/premade_estimators.md) chapter describes -the following `train_input_fn`, from -[`iris_data.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/iris_data.py), -to pipe the data into the Estimator: - -``` python -def train_input_fn(features, labels, batch_size): - """An input function for training""" - # Convert the inputs to a Dataset. - dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels)) - - # Shuffle, repeat, and batch the examples. - dataset = dataset.shuffle(1000).repeat().batch(batch_size) - - # Return the dataset. - return dataset -``` - -Let's look at this more closely. - -### Arguments - -This function expects three arguments. Arguments expecting an "array" can -accept nearly anything that can be converted to an array with `numpy.array`. -One exception is -[`tuple`](https://docs.python.org/3/tutorial/datastructures.html#tuples-and-sequences) -which, as we will see, has special meaning for `Datasets`. - -* `features`: A `{'feature_name':array}` dictionary (or - [`DataFrame`](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html)) - containing the raw input features. -* `labels` : An array containing the - [label](https://developers.google.com/machine-learning/glossary/#label) - for each example. -* `batch_size` : An integer indicating the desired batch size. - -In [`premade_estimator.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/premade_estimator.py) -we retrieved the Iris data using the `iris_data.load_data()` function. -You can run it, and unpack the results as follows: - -``` python -import iris_data - -# Fetch the data -train, test = iris_data.load_data() -features, labels = train -``` - -Then we passed this data to the input function, with a line similar to this: - -``` python -batch_size=100 -iris_data.train_input_fn(features, labels, batch_size) -``` - -Let's walk through the `train_input_fn()`. - -### Slices - -The function starts by using the `tf.data.Dataset.from_tensor_slices` function -to create a `tf.data.Dataset` representing slices of the array. The array is -sliced across the first dimension. For example, an array containing the -MNIST training data has a shape of `(60000, 28, 28)`. Passing this to -`from_tensor_slices` returns a `Dataset` object containing 60000 slices, each one -a 28x28 image. - -The code that returns this `Dataset` is as follows: - -``` python -train, test = tf.keras.datasets.mnist.load_data() -mnist_x, mnist_y = train - -mnist_ds = tf.data.Dataset.from_tensor_slices(mnist_x) -print(mnist_ds) -``` - -This will print the following line, showing the -[shapes](../guide/tensors.md#shapes) and -[types](../guide/tensors.md#data_types) of the items in -the dataset. Note that a `Dataset` does not know how many items it contains. - -``` None -<TensorSliceDataset shapes: (28,28), types: tf.uint8> -``` - -The `Dataset` above represents a simple collection of arrays, but datasets are -much more powerful than this. A `Dataset` can transparently handle any nested -combination of dictionaries or tuples (or -[`namedtuple`](https://docs.python.org/2/library/collections.html#collections.namedtuple) -). - -For example after converting the iris `features` -to a standard python dictionary, you can then convert the dictionary of arrays -to a `Dataset` of dictionaries as follows: - -``` python -dataset = tf.data.Dataset.from_tensor_slices(dict(features)) -print(dataset) -``` -``` None -<TensorSliceDataset - - shapes: { - SepalLength: (), PetalWidth: (), - PetalLength: (), SepalWidth: ()}, - - types: { - SepalLength: tf.float64, PetalWidth: tf.float64, - PetalLength: tf.float64, SepalWidth: tf.float64} -> -``` - -Here we see that when a `Dataset` contains structured elements, the `shapes` -and `types` of the `Dataset` take on the same structure. This dataset contains -dictionaries of [scalars](../guide/tensors.md#rank), all of type -`tf.float64`. - -The first line of the iris `train_input_fn` uses the same functionality, but -adds another level of structure. It creates a dataset containing -`(features_dict, label)` pairs. - -The following code shows that the label is a scalar with type `int64`: - -``` python -# Convert the inputs to a Dataset. -dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels)) -print(dataset) -``` -``` -<TensorSliceDataset - shapes: ( - { - SepalLength: (), PetalWidth: (), - PetalLength: (), SepalWidth: ()}, - ()), - - types: ( - { - SepalLength: tf.float64, PetalWidth: tf.float64, - PetalLength: tf.float64, SepalWidth: tf.float64}, - tf.int64)> -``` - -### Manipulation - -Currently the `Dataset` would iterate over the data once, in a fixed order, and -only produce a single element at a time. It needs further processing before it -can be used for training. Fortunately, the `tf.data.Dataset` class provides -methods to better prepare the data for training. The next line of the input -function takes advantage of several of these methods: - -``` python -# Shuffle, repeat, and batch the examples. -dataset = dataset.shuffle(1000).repeat().batch(batch_size) -``` - -The `tf.data.Dataset.shuffle` method uses a fixed-size buffer to -shuffle the items as they pass through. In this case the `buffer_size` is -greater than the number of examples in the `Dataset`, ensuring that the data is -completely shuffled (The Iris data set only contains 150 examples). - -The `tf.data.Dataset.repeat` method restarts the `Dataset` when -it reaches the end. To limit the number of epochs, set the `count` argument. - -The `tf.data.Dataset.batch` method collects a number of examples and -stacks them, to create batches. This adds a dimension to their shape. The new -dimension is added as the first dimension. The following code uses -the `batch` method on the MNIST `Dataset`, from earlier. This results in a -`Dataset` containing 3D arrays representing stacks of `(28,28)` images: - -``` python -print(mnist_ds.batch(100)) -``` - -``` none -<BatchDataset - shapes: (?, 28, 28), - types: tf.uint8> -``` -Note that the dataset has an unknown batch size because the last batch will -have fewer elements. - -In `train_input_fn`, after batching the `Dataset` contains 1D vectors of -elements where each scalar was previously: - -```python -print(dataset) -``` -``` -<TensorSliceDataset - shapes: ( - { - SepalLength: (?,), PetalWidth: (?,), - PetalLength: (?,), SepalWidth: (?,)}, - (?,)), - - types: ( - { - SepalLength: tf.float64, PetalWidth: tf.float64, - PetalLength: tf.float64, SepalWidth: tf.float64}, - tf.int64)> -``` - - -### Return - -At this point the `Dataset` contains `(features_dict, labels)` pairs. -This is the format expected by the `train` and `evaluate` methods, so the -`input_fn` returns the dataset. - -The `labels` can/should be omitted when using the `predict` method. - -<!-- - TODO(markdaoust): link to `input_fn` doc when it exists ---> - - -## Reading a CSV File - -The most common real-world use case for the `Dataset` class is to stream data -from files on disk. The `tf.data` module includes a variety of -file readers. Let's see how parsing the Iris dataset from the csv file looks -using a `Dataset`. - -The following call to the `iris_data.maybe_download` function downloads the -data if necessary, and returns the pathnames of the resulting files: - -``` python -import iris_data -train_path, test_path = iris_data.maybe_download() -``` - -The [`iris_data.csv_input_fn`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/iris_data.py) -function contains an alternative implementation that parses the csv files using -a `Dataset`. - -Let's look at how to build an Estimator-compatible input function that reads -from the local files. - -### Build the `Dataset` - -We start by building a `tf.data.TextLineDataset` object to -read the file one line at a time. Then, we call the -`tf.data.Dataset.skip` method to skip over the first line of the file, which contains a header, not an example: - -``` python -ds = tf.data.TextLineDataset(train_path).skip(1) -``` - -### Build a csv line parser - -We will start by building a function to parse a single line. - -The following `iris_data.parse_line` function accomplishes this task using the -`tf.decode_csv` function, and some simple python code: - -We must parse each of the lines in the dataset in order to generate the -necessary `(features, label)` pairs. The following `_parse_line` function -calls `tf.decode_csv` to parse a single line into its features -and the label. Since Estimators require that features be represented as a -dictionary, we rely on Python's built-in `dict` and `zip` functions to build -that dictionary. The feature names are the keys of that dictionary. -We then call the dictionary's `pop` method to remove the label field from -the features dictionary: - -``` python -# Metadata describing the text columns -COLUMNS = ['SepalLength', 'SepalWidth', - 'PetalLength', 'PetalWidth', - 'label'] -FIELD_DEFAULTS = [[0.0], [0.0], [0.0], [0.0], [0]] -def _parse_line(line): - # Decode the line into its fields - fields = tf.decode_csv(line, FIELD_DEFAULTS) - - # Pack the result into a dictionary - features = dict(zip(COLUMNS,fields)) - - # Separate the label from the features - label = features.pop('label') - - return features, label -``` - -### Parse the lines - -Datasets have many methods for manipulating the data while it is being piped -to a model. The most heavily-used method is `tf.data.Dataset.map`, which -applies a transformation to each element of the `Dataset`. - -The `map` method takes a `map_func` argument that describes how each item in the -`Dataset` should be transformed. - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/datasets/map.png"> -</div> -<div style="text-align: center"> -The `tf.data.Dataset.map` method applies the `map_func` to -transform each item in the <code>Dataset</code>. -</div> - -So to parse the lines as they are streamed out of the csv file, we pass our -`_parse_line` function to the `map` method: - -``` python -ds = ds.map(_parse_line) -print(ds) -``` -``` None -<MapDataset -shapes: ( - {SepalLength: (), PetalWidth: (), ...}, - ()), -types: ( - {SepalLength: tf.float32, PetalWidth: tf.float32, ...}, - tf.int32)> -``` - -Now instead of simple scalar strings, the dataset contains `(features, label)` -pairs. - -the remainder of the `iris_data.csv_input_fn` function is identical -to `iris_data.train_input_fn` which was covered in the in the -[Basic input](#basic_input) section. - -### Try it out - -This function can be used as a replacement for -`iris_data.train_input_fn`. It can be used to feed an estimator as follows: - -``` python -train_path, test_path = iris_data.maybe_download() - -# All the inputs are numeric -feature_columns = [ - tf.feature_column.numeric_column(name) - for name in iris_data.CSV_COLUMN_NAMES[:-1]] - -# Build the estimator -est = tf.estimator.LinearClassifier(feature_columns, - n_classes=3) -# Train the estimator -batch_size = 100 -est.train( - steps=1000, - input_fn=lambda : iris_data.csv_input_fn(train_path, batch_size)) -``` - -Estimators expect an `input_fn` to take no arguments. To work around this -restriction, we use `lambda` to capture the arguments and provide the expected -interface. - -## Summary - -The `tf.data` module provides a collection of classes and functions for easily -reading data from a variety of sources. Furthermore, `tf.data` has simple -powerful methods for applying a wide variety of standard and custom -transformations. - -Now you have the basic idea of how to efficiently load data into an -Estimator. Consider the following documents next: - - -* [Creating Custom Estimators](../guide/custom_estimators.md), which demonstrates how to build your own - custom `Estimator` model. -* The [Low Level Introduction](../guide/low_level_intro.md#datasets), which demonstrates - how to experiment directly with `tf.data.Datasets` using TensorFlow's low - level APIs. -* [Importing Data](../guide/datasets.md) which goes into great detail about additional - functionality of `Datasets`. - diff --git a/tensorflow/docs_src/guide/debugger.md b/tensorflow/docs_src/guide/debugger.md deleted file mode 100644 index 5af27471a2..0000000000 --- a/tensorflow/docs_src/guide/debugger.md +++ /dev/null @@ -1,814 +0,0 @@ -# TensorFlow Debugger - -<!-- [comment]: TODO(barryr): Links to and from sections on "Graphs" & "Monitoring Learning". --> - -[TOC] - -`tfdbg` is a specialized debugger for TensorFlow. It lets you view the internal -structure and states of running TensorFlow graphs during training and inference, -which is difficult to debug with general-purpose debuggers such as Python's `pdb` -due to TensorFlow's computation-graph paradigm. - -This guide focuses on the command-line interface (CLI) of `tfdbg`. For guide on -how to use the graphical user interface (GUI) of tfdbg, i.e., the -**TensorBoard Debugger Plugin**, please visit -[its README](https://github.com/tensorflow/tensorboard/blob/master/tensorboard/plugins/debugger/README.md). - -Note: The TensorFlow debugger uses a -[curses](https://en.wikipedia.org/wiki/Curses_\(programming_library\))-based text -user interface. On Mac OS X, the `ncurses` library is required and can be -installed with `brew install ncurses`. On Windows, curses isn't as -well supported, so a [readline](https://en.wikipedia.org/wiki/GNU_Readline)-based -interface can be used with tfdbg by installing `pyreadline` with `pip`. If you -use Anaconda3, you can install it with a command such as -`"C:\Program Files\Anaconda3\Scripts\pip.exe" install pyreadline`. Unofficial -Windows curses packages can be downloaded -[here](https://www.lfd.uci.edu/~gohlke/pythonlibs/#curses), then subsequently -installed using `pip install <your_version>.whl`, however curses on Windows may -not work as reliably as curses on Linux or Mac. - -This tutorial demonstrates how to use the **tfdbg** CLI to debug the appearance -of [`nan`s](https://en.wikipedia.org/wiki/NaN) -and [`inf`s](https://en.wikipedia.org/wiki/Infinity), a frequently-encountered -type of bug in TensorFlow model development. -The following example is for users who use the low-level -[`Session`](https://www.tensorflow.org/api_docs/python/tf/Session) API of -TensorFlow. Later sections of this document describe how to use **tfdbg** -with higher-level APIs of TensorFlow, including `tf.estimator`, -`tf.keras` / `keras` and `tf.contrib.slim`. -To *observe* such an issue, run the following command without the debugger (the -source code can be found -[here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/debug/examples/debug_mnist.py)): - -```none -python -m tensorflow.python.debug.examples.debug_mnist -``` - -This code trains a simple neural network for MNIST digit image recognition. -Notice that the accuracy increases slightly after the first training step, but -then gets stuck at a low (near-chance) level: - -```none -Accuracy at step 0: 0.1113 -Accuracy at step 1: 0.3183 -Accuracy at step 2: 0.098 -Accuracy at step 3: 0.098 -Accuracy at step 4: 0.098 -``` - -Wondering what might have gone wrong, you suspect that certain nodes in the -training graph generated bad numeric values such as `inf`s and `nan`s, because -this is a common cause of this type of training failure. -Let's use tfdbg to debug this issue and pinpoint the exact graph node where this -numeric problem first surfaced. - -## Wrapping TensorFlow Sessions with tfdbg - -To add support for tfdbg in our example, all that is needed is to add the -following lines of code and wrap the Session object with a debugger wrapper. -This code is already added in -[debug_mnist.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/debug/examples/debug_mnist.py), -so you can activate tfdbg CLI with the `--debug` flag at the command line. - -```python -# Let your BUILD target depend on "//tensorflow/python/debug:debug_py" -# (You don't need to worry about the BUILD dependency if you are using a pip -# install of open-source TensorFlow.) -from tensorflow.python import debug as tf_debug - -sess = tf_debug.LocalCLIDebugWrapperSession(sess) -``` - -This wrapper has the same interface as Session, so enabling debugging requires -no other changes to the code. The wrapper provides additional features, -including: - -* Bringing up a CLI before and after `Session.run()` calls, to let you -control the execution and inspect the graph's internal state. -* Allowing you to register special `filters` for tensor values, to facilitate -the diagnosis of issues. - -In this example, we have already registered a tensor filter called -`tfdbg.has_inf_or_nan`, -which simply determines if there are any `nan` or `inf` values in any -intermediate tensors (tensors that are neither inputs or outputs of the -`Session.run()` call, but are in the path leading from the inputs to the -outputs). This filter is for `nan`s and `inf`s is a common enough use case that -we ship it with the -[`debug_data`](../api_guides/python/tfdbg.md#Classes_for_debug_dump_data_and_directories) -module. - -Note: You can also write your own custom filters. See `tfdbg.DebugDumpDir.find` -for additional information. - -## Debugging Model Training with tfdbg - -Let's try training the model again, but with the `--debug` flag added this time: - -```none -python -m tensorflow.python.debug.examples.debug_mnist --debug -``` - -The debug wrapper session will prompt you when it is about to execute the first -`Session.run()` call, with information regarding the fetched tensor and feed -dictionaries displayed on the screen. - -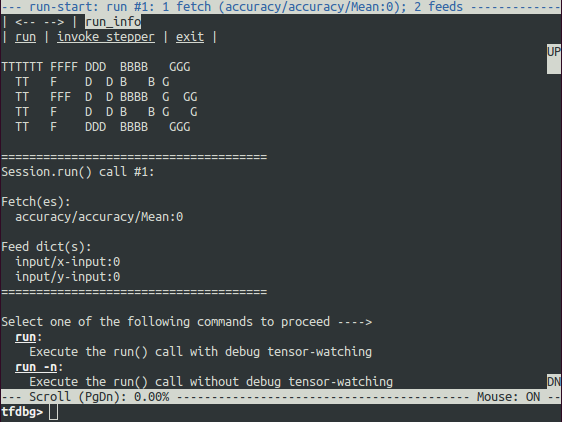 - -This is what we refer to as the *run-start CLI*. It lists the feeds and fetches -to the current `Session.run` call, before executing anything. - -If the screen size is too small to display the content of the message in its -entirety, you can resize it. - -Use the **PageUp** / **PageDown** / **Home** / **End** keys to navigate the -screen output. On most keyboards lacking those keys **Fn + Up** / -**Fn + Down** / **Fn + Right** / **Fn + Left** will work. - -Enter the `run` command (or just `r`) at the command prompt: - -``` -tfdbg> run -``` - -The `run` command causes tfdbg to execute until the end of the next -`Session.run()` call, which calculates the model's accuracy using a test data -set. tfdbg augments the runtime Graph to dump all intermediate tensors. -After the run ends, tfdbg displays all the dumped tensors values in the -*run-end CLI*. For example: - -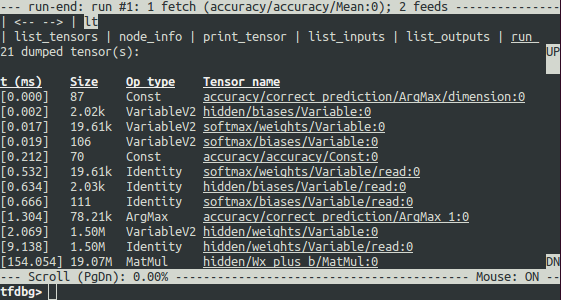 - -This list of tensors can also be obtained by running the command `lt` after you -executed `run`. - -### tfdbg CLI Frequently-Used Commands - -Try the following commands at the `tfdbg>` prompt (referencing the code at -`tensorflow/python/debug/examples/debug_mnist.py`): - -| Command | Syntax or Option | Explanation | Example | -|:-------------------|:---------------- |:------------ |:------------------------- | -| **`lt`** | | **List dumped tensors.** | `lt` | -| | `-n <name_pattern>` | List dumped tensors with names matching given regular-expression pattern. | `lt -n Softmax.*` | -| | `-t <op_pattern>` | List dumped tensors with op types matching given regular-expression pattern. | `lt -t MatMul` | -| | `-f <filter_name>` | List only the tensors that pass a registered tensor filter. | `lt -f has_inf_or_nan` | -| | `-f <filter_name> -fenn <regex>` | List only the tensors that pass a registered tensor filter, excluding nodes with names matching the regular expression. | `lt -f has_inf_or_nan` `-fenn .*Sqrt.*` | -| | `-s <sort_key>` | Sort the output by given `sort_key`, whose possible values are `timestamp` (default), `dump_size`, `op_type` and `tensor_name`. | `lt -s dump_size` | -| | `-r` | Sort in reverse order. | `lt -r -s dump_size` | -| **`pt`** | | **Print value of a dumped tensor.** | | -| | `pt <tensor>` | Print tensor value. | `pt hidden/Relu:0` | -| | `pt <tensor>[slicing]` | Print a subarray of tensor, using [numpy](http://www.numpy.org/)-style array slicing. | `pt hidden/Relu:0[0:50,:]` | -| | `-a` | Print the entirety of a large tensor, without using ellipses. (May take a long time for large tensors.) | `pt -a hidden/Relu:0[0:50,:]` | -| | `-r <range>` | Highlight elements falling into specified numerical range. Multiple ranges can be used in conjunction. | `pt hidden/Relu:0 -a -r [[-inf,-1],[1,inf]]` | -| | `-n <number>` | Print dump corresponding to specified 0-based dump number. Required for tensors with multiple dumps. | `pt -n 0 hidden/Relu:0` | -| | `-s` | Include a summary of the numeric values of the tensor (applicable only to non-empty tensors with Boolean and numeric types such as `int*` and `float*`.) | `pt -s hidden/Relu:0[0:50,:]` | -| | `-w` | Write the value of the tensor (possibly sliced) to a Numpy file using [`numpy.save()`](https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.save.html) | `pt -s hidden/Relu:0 -w /tmp/relu.npy` | -| **`@[coordinates]`** | | Navigate to specified element in `pt` output. | `@[10,0]` or `@10,0` | -| **`/regex`** | | [less](https://linux.die.net/man/1/less)-style search for given regular expression. | `/inf` | -| **`/`** | | Scroll to the next line with matches to the searched regex (if any). | `/` | -| **`pf`** | | **Print a value in the feed_dict to `Session.run`.** | | -| | `pf <feed_tensor_name>` | Print the value of the feed. Also note that the `pf` command has the `-a`, `-r` and `-s` flags (not listed below), which have the same syntax and semantics as the identically-named flags of `pt`. | `pf input_xs:0` | -| **eval** | | **Evaluate arbitrary Python and numpy expression.** | | -| | `eval <expression>` | Evaluate a Python / numpy expression, with numpy available as `np` and debug tensor names enclosed in backticks. | ``eval "np.matmul((`output/Identity:0` / `Softmax:0`).T, `Softmax:0`)"`` | -| | `-a` | Print a large-sized evaluation result in its entirety, i.e., without using ellipses. | ``eval -a 'np.sum(`Softmax:0`, axis=1)'`` | -| | `-w` | Write the result of the evaluation to a Numpy file using [`numpy.save()`](https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.save.html) | ``eval -a 'np.sum(`Softmax:0`, axis=1)' -w /tmp/softmax_sum.npy`` | -| **`ni`** | | **Display node information.** | | -| | `-a` | Include node attributes in the output. | `ni -a hidden/Relu` | -| | `-d` | List the debug dumps available from the node. | `ni -d hidden/Relu` | -| | `-t` | Display the Python stack trace of the node's creation. | `ni -t hidden/Relu` | -| **`li`** | | **List inputs to node** | | -| | `-r` | List the inputs to node, recursively (the input tree.) | `li -r hidden/Relu:0` | -| | `-d <max_depth>` | Limit recursion depth under the `-r` mode. | `li -r -d 3 hidden/Relu:0` | -| | `-c` | Include control inputs. | `li -c -r hidden/Relu:0` | -| | `-t` | Show op types of input nodes. | `li -t -r hidden/Relu:0` | -| **`lo`** | | **List output recipients of node** | | -| | `-r` | List the output recipients of node, recursively (the output tree.) | `lo -r hidden/Relu:0` | -| | `-d <max_depth>` | Limit recursion depth under the `-r` mode. | `lo -r -d 3 hidden/Relu:0` | -| | `-c` | Include recipients via control edges. | `lo -c -r hidden/Relu:0` | -| | `-t` | Show op types of recipient nodes. | `lo -t -r hidden/Relu:0` | -| **`ls`** | | **List Python source files involved in node creation.** | | -| | `-p <path_pattern>` | Limit output to source files matching given regular-expression path pattern. | `ls -p .*debug_mnist.*` | -| | `-n` | Limit output to node names matching given regular-expression pattern. | `ls -n Softmax.*` | -| **`ps`** | | **Print Python source file.** | | -| | `ps <file_path>` | Print given Python source file source.py, with the lines annotated with the nodes created at each of them (if any). | `ps /path/to/source.py` | -| | `-t` | Perform annotation with respect to Tensors, instead of the default, nodes. | `ps -t /path/to/source.py` | -| | `-b <line_number>` | Annotate source.py beginning at given line. | `ps -b 30 /path/to/source.py` | -| | `-m <max_elements>` | Limit the number of elements in the annotation for each line. | `ps -m 100 /path/to/source.py` | -| **`run`** | | **Proceed to the next Session.run()** | `run` | -| | `-n` | Execute through the next `Session.run` without debugging, and drop to CLI right before the run after that. | `run -n` | -| | `-t <T>` | Execute `Session.run` `T - 1` times without debugging, followed by a run with debugging. Then drop to CLI right after the debugged run. | `run -t 10` | -| | `-f <filter_name>` | Continue executing `Session.run` until any intermediate tensor triggers the specified Tensor filter (causes the filter to return `True`). | `run -f has_inf_or_nan` | -| | `-f <filter_name> -fenn <regex>` | Continue executing `Session.run` until any intermediate tensor whose node names doesn't match the regular expression triggers the specified Tensor filter (causes the filter to return `True`). | `run -f has_inf_or_nan -fenn .*Sqrt.*` | -| | `--node_name_filter <pattern>` | Execute the next `Session.run`, watching only nodes with names matching the given regular-expression pattern. | `run --node_name_filter Softmax.*` | -| | `--op_type_filter <pattern>` | Execute the next `Session.run`, watching only nodes with op types matching the given regular-expression pattern. | `run --op_type_filter Variable.*` | -| | `--tensor_dtype_filter <pattern>` | Execute the next `Session.run`, dumping only Tensors with data types (`dtype`s) matching the given regular-expression pattern. | `run --tensor_dtype_filter int.*` | -| | `-p` | Execute the next `Session.run` call in profiling mode. | `run -p` | -| **`ri`** | | **Display information about the run the current run, including fetches and feeds.** | `ri` | -| **`config`** | | **Set or show persistent TFDBG UI configuration.** | | -| | `set` | Set the value of a config item: {`graph_recursion_depth`, `mouse_mode`}. | `config set graph_recursion_depth 3` | -| | `show` | Show current persistent UI configuration. | `config show` | -| **`version`** | | **Print the version of TensorFlow and its key dependencies.** | `version` | -| **`help`** | | **Print general help information** | `help` | -| | `help <command>` | Print help for given command. | `help lt` | - -Note that each time you enter a command, a new screen output -will appear. This is somewhat analogous to web pages in a browser. You can -navigate between these screens by clicking the `<--` and -`-->` text arrows near the top-left corner of the CLI. - -### Other Features of the tfdbg CLI - -In addition to the commands listed above, the tfdbg CLI provides the following -additional features: - -* To navigate through previous tfdbg commands, type in a few characters - followed by the Up or Down arrow keys. tfdbg will show you the history of - commands that started with those characters. -* To navigate through the history of screen outputs, do either of the - following: - * Use the `prev` and `next` commands. - * Click underlined `<--` and `-->` links near the top left corner of the - screen. -* Tab completion of commands and some command arguments. -* To redirect the screen output to a file instead of the screen, end the - command with bash-style redirection. For example, the following command - redirects the output of the pt command to the `/tmp/xent_value_slices.txt` - file: - - ```none - tfdbg> pt cross_entropy/Log:0[:, 0:10] > /tmp/xent_value_slices.txt - ``` - -### Finding `nan`s and `inf`s - -In this first `Session.run()` call, there happen to be no problematic numerical -values. You can move on to the next run by using the command `run` or its -shorthand `r`. - -> TIP: If you enter `run` or `r` repeatedly, you will be able to move through -> the `Session.run()` calls in a sequential manner. -> -> You can also use the `-t` flag to move ahead a number of `Session.run()` calls -> at a time, for example: -> -> ``` -> tfdbg> run -t 10 -> ``` - -Instead of entering `run` repeatedly and manually searching for `nan`s and -`inf`s in the run-end UI after every `Session.run()` call (for example, by using -the `pt` command shown in the table above) , you can use the following -command to let the debugger repeatedly execute `Session.run()` calls without -stopping at the run-start or run-end prompt, until the first `nan` or `inf` -value shows up in the graph. This is analogous to *conditional breakpoints* in -some procedural-language debuggers: - -```none -tfdbg> run -f has_inf_or_nan -``` - -> NOTE: The preceding command works properly because a tensor filter called -> `has_inf_or_nan` has been registered for you when the wrapped session is -> created. This filter detects `nan`s and `inf`s (as explained previously). -> If you have registered any other filters, you can -> use "run -f" to have tfdbg run until any tensor triggers that filter (cause -> the filter to return True). -> -> ``` python -> def my_filter_callable(datum, tensor): -> # A filter that detects zero-valued scalars. -> return len(tensor.shape) == 0 and tensor == 0.0 -> -> sess.add_tensor_filter('my_filter', my_filter_callable) -> ``` -> -> Then at the tfdbg run-start prompt run until your filter is triggered: -> -> ``` -> tfdbg> run -f my_filter -> ``` - -See [this API document](https://www.tensorflow.org/api_docs/python/tfdbg/DebugDumpDir#find) -for more information on the expected signature and return value of the predicate -`Callable` used with `add_tensor_filter()`. - -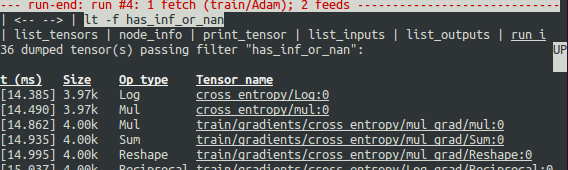 - -As the screen display indicates on the first line, the `has_inf_or_nan` filter is first triggered -during the fourth `Session.run()` call: an -[Adam optimizer](https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer) -forward-backward training pass on the graph. In this run, 36 (out of the total -95) intermediate tensors contain `nan` or `inf` values. These tensors are listed -in chronological order, with their timestamps displayed on the left. At the top -of the list, you can see the first tensor in which the bad numerical values -first surfaced: `cross_entropy/Log:0`. - -To view the value of the tensor, click the underlined tensor name -`cross_entropy/Log:0` or enter the equivalent command: - -```none -tfdbg> pt cross_entropy/Log:0 -``` - -Scroll down a little and you will notice some scattered `inf` values. If the -instances of `inf` and `nan` are difficult to spot by eye, you can use the -following command to perform a regex search and highlight the output: - -```none -tfdbg> /inf -``` - -Or, alternatively: - -```none -tfdbg> /(inf|nan) -``` - -You can also use the `-s` or `--numeric_summary` command to get a quick summary -of the types of numeric values in the tensor: - -``` none -tfdbg> pt -s cross_entropy/Log:0 -``` - -From the summary, you can see that several of the 1000 elements of the -`cross_entropy/Log:0` tensor are `-inf`s (negative infinities). - -Why did these infinities appear? To further debug, display more information -about the node `cross_entropy/Log` by clicking the underlined `node_info` menu -item on the top or entering the equivalent node_info (`ni`) command: - -```none -tfdbg> ni cross_entropy/Log -``` - - - -You can see that this node has the op type `Log` -and that its input is the node `Softmax`. Run the following command to -take a closer look at the input tensor: - -```none -tfdbg> pt Softmax:0 -``` - -Examine the values in the input tensor, searching for zeros: - -```none -tfdbg> /0\.000 -``` - -Indeed, there are zeros. Now it is clear that the origin of the bad numerical -values is the node `cross_entropy/Log` taking logs of zeros. To find out the -culprit line in the Python source code, use the `-t` flag of the `ni` command -to show the traceback of the node's construction: - -```none -tfdbg> ni -t cross_entropy/Log -``` - -If you click "node_info" at the top of the screen, tfdbg automatically shows the -traceback of the node's construction. - -From the traceback, you can see that the op is constructed at the following -line: -[`debug_mnist.py`](https://www.tensorflow.org/code/tensorflow/python/debug/examples/debug_mnist.py): - -```python -diff = y_ * tf.log(y) -``` - -**tfdbg** has a feature that makes it easy to trace Tensors and ops back to -lines in Python source files. It can annotate lines of a Python file with -the ops or Tensors created by them. To use this feature, -simply click the underlined line numbers in the stack trace output of the -`ni -t <op_name>` commands, or use the `ps` (or `print_source`) command such as: -`ps /path/to/source.py`. For example, the following screenshot shows the output -of a `ps` command. - - - -### Fixing the problem - -To fix the problem, edit `debug_mnist.py`, changing the original line: - -```python -diff = -(y_ * tf.log(y)) -``` - -to the built-in, numerically-stable implementation of softmax cross-entropy: - -```python -diff = tf.losses.softmax_cross_entropy(labels=y_, logits=logits) -``` - -Rerun with the `--debug` flag as follows: - -```none -python -m tensorflow.python.debug.examples.debug_mnist --debug -``` - -At the `tfdbg>` prompt, enter the following command: - -```none -run -f has_inf_or_nan` -``` - -Confirm that no tensors are flagged as containing `nan` or `inf` values, and -accuracy now continues to rise rather than getting stuck. Success! - -## Debugging TensorFlow Estimators - -This section explains how to debug TensorFlow programs that use the `Estimator` -APIs. Part of the convenience provided by these APIs is that -they manage `Session`s internally. This makes the `LocalCLIDebugWrapperSession` -described in the preceding sections inapplicable. Fortunately, you can still -debug them by using special `hook`s provided by `tfdbg`. - -`tfdbg` can debug the -`tf.estimator.Estimator.train`, -`tf.estimator.Estimator.evaluate` and -`tf.estimator.Estimator.predict` -methods of tf-learn `Estimator`s. To debug `Estimator.train()`, -create a `LocalCLIDebugHook` and supply it in the `hooks` argument. For example: - -```python -# First, let your BUILD target depend on "//tensorflow/python/debug:debug_py" -# (You don't need to worry about the BUILD dependency if you are using a pip -# install of open-source TensorFlow.) -from tensorflow.python import debug as tf_debug - -# Create a LocalCLIDebugHook and use it as a monitor when calling fit(). -hooks = [tf_debug.LocalCLIDebugHook()] - -# To debug `train`: -classifier.train(input_fn, - steps=1000, - hooks=hooks) -``` - -Similarly, to debug `Estimator.evaluate()` and `Estimator.predict()`, assign -hooks to the `hooks` parameter, as in the following example: - -```python -# To debug `evaluate`: -accuracy_score = classifier.evaluate(eval_input_fn, - hooks=hooks)["accuracy"] - -# To debug `predict`: -predict_results = classifier.predict(predict_input_fn, hooks=hooks) -``` - -[debug_tflearn_iris.py](https://www.tensorflow.org/code/tensorflow/python/debug/examples/debug_tflearn_iris.py), -contains a full example of how to use the tfdbg with `Estimator`s. -To run this example, do: - -```none -python -m tensorflow.python.debug.examples.debug_tflearn_iris --debug -``` - -The `LocalCLIDebugHook` also allows you to configure a `watch_fn` that can be -used to flexibly specify what `Tensor`s to watch on different `Session.run()` -calls, as a function of the `fetches` and `feed_dict` and other states. See -`tfdbg.DumpingDebugWrapperSession.__init__` -for more details. - -## Debugging Keras Models with TFDBG - -To use TFDBG with -[tf.keras](https://www.tensorflow.org/api_docs/python/tf/keras), -let the Keras backend use a TFDBG-wrapped Session object. For example, to use -the CLI wrapper: - -``` python -import tensorflow as tf -from tensorflow.python import debug as tf_debug - -tf.keras.backend.set_session(tf_debug.LocalCLIDebugWrapperSession(tf.Session())) - -# Define your keras model, called "model". - -# Calls to `fit()`, 'evaluate()` and `predict()` methods will break into the -# TFDBG CLI. -model.fit(...) -model.evaluate(...) -model.predict(...) -``` - -With minor modification, the preceding code example also works for the -[non-TensorFlow version of Keras](https://keras.io/) running against a -TensorFlow backend. You just need to replace `tf.keras.backend` with -`keras.backend`. - -## Debugging tf-slim with TFDBG - -TFDBG supports debugging of training and evaluation with -[tf-slim](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/slim). -As detailed below, training and evaluation require slightly different debugging -workflows. - -### Debugging training in tf-slim -To debug the training process, provide `LocalCLIDebugWrapperSession` to the -`session_wrapper` argument of `slim.learning.train()`. For example: - -``` python -import tensorflow as tf -from tensorflow.python import debug as tf_debug - -# ... Code that creates the graph and the train_op ... -tf.contrib.slim.learning.train( - train_op, - logdir, - number_of_steps=10, - session_wrapper=tf_debug.LocalCLIDebugWrapperSession) -``` - -### Debugging evaluation in tf-slim -To debug the evaluation process, provide `LocalCLIDebugHook` to the -`hooks` argument of `slim.evaluation.evaluate_once()`. For example: - -``` python -import tensorflow as tf -from tensorflow.python import debug as tf_debug - -# ... Code that creates the graph and the eval and final ops ... -tf.contrib.slim.evaluation.evaluate_once( - '', - checkpoint_path, - logdir, - eval_op=my_eval_op, - final_op=my_value_op, - hooks=[tf_debug.LocalCLIDebugHook()]) -``` - -## Offline Debugging of Remotely-Running Sessions - -Often, your model is running on a remote machine or a process that you don't -have terminal access to. To perform model debugging in such cases, you can use -the `offline_analyzer` binary of `tfdbg` (described below). It operates on -dumped data directories. This can be done to both the lower-level `Session` API -and the higher-level `Estimator` API. - -### Debugging Remote tf.Sessions - -If you interact directly with the `tf.Session` API in `python`, you can -configure the `RunOptions` proto that you call your `Session.run()` method -with, by using the method `tfdbg.watch_graph`. -This will cause the intermediate tensors and runtime graphs to be dumped to a -shared storage location of your choice when the `Session.run()` call occurs -(at the cost of slower performance). For example: - -```python -from tensorflow.python import debug as tf_debug - -# ... Code where your session and graph are set up... - -run_options = tf.RunOptions() -tf_debug.watch_graph( - run_options, - session.graph, - debug_urls=["file:///shared/storage/location/tfdbg_dumps_1"]) -# Be sure to specify different directories for different run() calls. - -session.run(fetches, feed_dict=feeds, options=run_options) -``` - -Later, in an environment that you have terminal access to (for example, a local -computer that can access the shared storage location specified in the code -above), you can load and inspect the data in the dump directory on the shared -storage by using the `offline_analyzer` binary of `tfdbg`. For example: - -```none -python -m tensorflow.python.debug.cli.offline_analyzer \ - --dump_dir=/shared/storage/location/tfdbg_dumps_1 -``` - -The `Session` wrapper `DumpingDebugWrapperSession` offers an easier and more -flexible way to generate file-system dumps that can be analyzed offline. -To use it, simply wrap your session in a `tf_debug.DumpingDebugWrapperSession`. -For example: - -```python -# Let your BUILD target depend on "//tensorflow/python/debug:debug_py -# (You don't need to worry about the BUILD dependency if you are using a pip -# install of open-source TensorFlow.) -from tensorflow.python import debug as tf_debug - -sess = tf_debug.DumpingDebugWrapperSession( - sess, "/shared/storage/location/tfdbg_dumps_1/", watch_fn=my_watch_fn) -``` - -The `watch_fn` argument accepts a `Callable` that allows you to configure what -`tensor`s to watch on different `Session.run()` calls, as a function of the -`fetches` and `feed_dict` to the `run()` call and other states. - -### C++ and other languages - -If your model code is written in C++ or other languages, you can also -modify the `debug_options` field of `RunOptions` to generate debug dumps that -can be inspected offline. See -[the proto definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/debug.proto) -for more details. - -### Debugging Remotely-Running Estimators - -If your remote TensorFlow server runs `Estimator`s, -you can use the non-interactive `DumpingDebugHook`. For example: - -```python -# Let your BUILD target depend on "//tensorflow/python/debug:debug_py -# (You don't need to worry about the BUILD dependency if you are using a pip -# install of open-source TensorFlow.) -from tensorflow.python import debug as tf_debug - -hooks = [tf_debug.DumpingDebugHook("/shared/storage/location/tfdbg_dumps_1")] -``` - -Then this `hook` can be used in the same way as the `LocalCLIDebugHook` examples -described earlier in this document. -As the training, evaluation or prediction happens with `Estimator`, -tfdbg creates directories having the following name pattern: -`/shared/storage/location/tfdbg_dumps_1/run_<epoch_timestamp_microsec>_<uuid>`. -Each directory corresponds to a `Session.run()` call that underlies -the `fit()` or `evaluate()` call. You can load these directories and inspect -them in a command-line interface in an offline manner using the -`offline_analyzer` offered by tfdbg. For example: - -```bash -python -m tensorflow.python.debug.cli.offline_analyzer \ - --dump_dir="/shared/storage/location/tfdbg_dumps_1/run_<epoch_timestamp_microsec>_<uuid>" -``` - -## Frequently Asked Questions - -**Q**: _Do the timestamps on the left side of the `lt` output reflect actual - performance in a non-debugging session?_ - -**A**: No. The debugger inserts additional special-purpose debug nodes to the - graph to record the values of intermediate tensors. These nodes - slow down the graph execution. If you are interested in profiling your - model, check out - - 1. The profiling mode of tfdbg: `tfdbg> run -p`. - 2. [tfprof](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/core/profiler) - and other profiling tools for TensorFlow. - -**Q**: _How do I link tfdbg against my `Session` in Bazel? Why do I see an - error such as "ImportError: cannot import name debug"?_ - -**A**: In your BUILD rule, declare dependencies: - `"//tensorflow:tensorflow_py"` and `"//tensorflow/python/debug:debug_py"`. - The first is the dependency that you include to use TensorFlow even - without debugger support; the second enables the debugger. - Then, In your Python file, add: - -```python -from tensorflow.python import debug as tf_debug - -# Then wrap your TensorFlow Session with the local-CLI wrapper. -sess = tf_debug.LocalCLIDebugWrapperSession(sess) -``` - -**Q**: _Does tfdbg help debug runtime errors such as shape mismatches?_ - -**A**: Yes. tfdbg intercepts errors generated by ops during runtime and presents - the errors with some debug instructions to the user in the CLI. - See examples: - -```none -# Debugging shape mismatch during matrix multiplication. -python -m tensorflow.python.debug.examples.debug_errors \ - --error shape_mismatch --debug - -# Debugging uninitialized variable. -python -m tensorflow.python.debug.examples.debug_errors \ - --error uninitialized_variable --debug -``` - -**Q**: _How can I let my tfdbg-wrapped Sessions or Hooks run the debug mode -only from the main thread?_ - -**A**: -This is a common use case, in which the `Session` object is used from multiple -threads concurrently. Typically, the child threads take care of background tasks -such as running enqueue operations. Often, you want to debug only the main -thread (or less frequently, only one of the child threads). You can use the -`thread_name_filter` keyword argument of `LocalCLIDebugWrapperSession` to -achieve this type of thread-selective debugging. For example, to debug from the -main thread only, construct a wrapped `Session` as follows: - -```python -sess = tf_debug.LocalCLIDebugWrapperSession(sess, thread_name_filter="MainThread$") -``` - -The above example relies on the fact that main threads in Python have the -default name `MainThread`. - -**Q**: _The model I am debugging is very large. The data dumped by tfdbg -fills up the free space of my disk. What can I do?_ - -**A**: -You might encounter this problem in any of the following situations: - -* models with many intermediate tensors -* very large intermediate tensors -* many `tf.while_loop` iterations - -There are three possible workarounds or solutions: - -* The constructors of `LocalCLIDebugWrapperSession` and `LocalCLIDebugHook` - provide a keyword argument, `dump_root`, to specify the path - to which tfdbg dumps the debug data. You can use it to let tfdbg dump the - debug data on a disk with larger free space. For example: - -```python -# For LocalCLIDebugWrapperSession -sess = tf_debug.LocalCLIDebugWrapperSession(dump_root="/with/lots/of/space") - -# For LocalCLIDebugHook -hooks = [tf_debug.LocalCLIDebugHook(dump_root="/with/lots/of/space")] -``` - Make sure that the directory pointed to by dump_root is empty or nonexistent. - `tfdbg` cleans up the dump directories before exiting. - -* Reduce the batch size used during the runs. -* Use the filtering options of tfdbg's `run` command to watch only specific - nodes in the graph. For example: - - ``` - tfdbg> run --node_name_filter .*hidden.* - tfdbg> run --op_type_filter Variable.* - tfdbg> run --tensor_dtype_filter int.* - ``` - - The first command above watches only nodes whose name match the - regular-expression pattern `.*hidden.*`. The second command watches only - operations whose name match the pattern `Variable.*`. The third one watches - only the tensors whose dtype match the pattern `int.*` (e.g., `int32`). - - -**Q**: _Why can't I select text in the tfdbg CLI?_ - -**A**: This is because the tfdbg CLI enables mouse events in the terminal by - default. This [mouse-mask](https://linux.die.net/man/3/mousemask) mode - overrides default terminal interactions, including text selection. You - can re-enable text selection by using the command `mouse off` or - `m off`. - -**Q**: _Why does the tfdbg CLI show no dumped tensors when I debug code like the following?_ - -``` python -a = tf.ones([10], name="a") -b = tf.add(a, a, name="b") -sess = tf.Session() -sess = tf_debug.LocalCLIDebugWrapperSession(sess) -sess.run(b) -``` - -**A**: The reason why you see no data dumped is because every node in the - executed TensorFlow graph is constant-folded by the TensorFlow runtime. - In this example, `a` is a constant tensor; therefore, the fetched - tensor `b` is effectively also a constant tensor. TensorFlow's graph - optimization folds the graph that contains `a` and `b` into a single - node to speed up future runs of the graph, which is why `tfdbg` does - not generate any intermediate tensor dumps. However, if `a` were a - `tf.Variable`, as in the following example: - -``` python -import numpy as np - -a = tf.Variable(np.ones(10), name="a") -b = tf.add(a, a, name="b") -sess = tf.Session() -sess.run(tf.global_variables_initializer()) -sess = tf_debug.LocalCLIDebugWrapperSession(sess) -sess.run(b) -``` - -the constant-folding would not occur and `tfdbg` should show the intermediate -tensor dumps. - - -**Q**: I am debugging a model that generates unwanted infinities or NaNs. But - there are some nodes in my model that are known to generate infinities - or NaNs in their output tensors even under completely normal conditions. - How can I skip those nodes during my `run -f has_inf_or_nan` actions? - -**A**: Use the `--filter_exclude_node_names` (`-fenn` for short) flag. For - example, if you known you have a node with name matching the regular - expression `.*Sqrt.*` that generates infinities or NaNs regardless - of whether the model is behaving correctly, you can exclude the nodes - from the infinity/NaN-finding runs with the command - `run -f has_inf_or_nan -fenn .*Sqrt.*`. - - -**Q**: Is there a GUI for tfdbg? - -**A**: Yes, the **TensorBoard Debugger Plugin** is the GUI of tfdbg. - It offers features such as inspection of the computation graph, - real-time visualization of tensor values, continuation to tensor - and conditional breakpoints, and tying tensors to their - graph-construction source code, all in the browser environment. - To get started, please visit - [its README](https://github.com/tensorflow/tensorboard/blob/master/tensorboard/plugins/debugger/README.md). diff --git a/tensorflow/docs_src/guide/eager.md b/tensorflow/docs_src/guide/eager.md deleted file mode 100644 index 3b5797a638..0000000000 --- a/tensorflow/docs_src/guide/eager.md +++ /dev/null @@ -1,854 +0,0 @@ -# Eager Execution - -TensorFlow's eager execution is an imperative programming environment that -evaluates operations immediately, without building graphs: operations return -concrete values instead of constructing a computational graph to run later. This -makes it easy to get started with TensorFlow and debug models, and it -reduces boilerplate as well. To follow along with this guide, run the code -samples below in an interactive `python` interpreter. - -Eager execution is a flexible machine learning platform for research and -experimentation, providing: - -* *An intuitive interface*—Structure your code naturally and use Python data - structures. Quickly iterate on small models and small data. -* *Easier debugging*—Call ops directly to inspect running models and test - changes. Use standard Python debugging tools for immediate error reporting. -* *Natural control flow*—Use Python control flow instead of graph control - flow, simplifying the specification of dynamic models. - -Eager execution supports most TensorFlow operations and GPU acceleration. For a -collection of examples running in eager execution, see: -[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples). - -Note: Some models may experience increased overhead with eager execution -enabled. Performance improvements are ongoing, but please -[file a bug](https://github.com/tensorflow/tensorflow/issues) if you find a -problem and share your benchmarks. - -## Setup and basic usage - -Upgrade to the latest version of TensorFlow: - -``` -$ pip install --upgrade tensorflow -``` - -To start eager execution, add `tf.enable_eager_execution()` to the beginning of -the program or console session. Do not add this operation to other modules that -the program calls. - -```py -from __future__ import absolute_import, division, print_function - -import tensorflow as tf - -tf.enable_eager_execution() -``` - -Now you can run TensorFlow operations and the results will return immediately: - -```py -tf.executing_eagerly() # => True - -x = [[2.]] -m = tf.matmul(x, x) -print("hello, {}".format(m)) # => "hello, [[4.]]" -``` - -Enabling eager execution changes how TensorFlow operations behave—now they -immediately evaluate and return their values to Python. `tf.Tensor` objects -reference concrete values instead of symbolic handles to nodes in a computational -graph. Since there isn't a computational graph to build and run later in a -session, it's easy to inspect results using `print()` or a debugger. Evaluating, -printing, and checking tensor values does not break the flow for computing -gradients. - -Eager execution works nicely with [NumPy](http://www.numpy.org/). NumPy -operations accept `tf.Tensor` arguments. TensorFlow -[math operations](https://www.tensorflow.org/api_guides/python/math_ops) convert -Python objects and NumPy arrays to `tf.Tensor` objects. The -`tf.Tensor.numpy` method returns the object's value as a NumPy `ndarray`. - -```py -a = tf.constant([[1, 2], - [3, 4]]) -print(a) -# => tf.Tensor([[1 2] -# [3 4]], shape=(2, 2), dtype=int32) - -# Broadcasting support -b = tf.add(a, 1) -print(b) -# => tf.Tensor([[2 3] -# [4 5]], shape=(2, 2), dtype=int32) - -# Operator overloading is supported -print(a * b) -# => tf.Tensor([[ 2 6] -# [12 20]], shape=(2, 2), dtype=int32) - -# Use NumPy values -import numpy as np - -c = np.multiply(a, b) -print(c) -# => [[ 2 6] -# [12 20]] - -# Obtain numpy value from a tensor: -print(a.numpy()) -# => [[1 2] -# [3 4]] -``` - -The `tf.contrib.eager` module contains symbols available to both eager and graph execution -environments and is useful for writing code to [work with graphs](#work_with_graphs): - -```py -tfe = tf.contrib.eager -``` - -## Dynamic control flow - -A major benefit of eager execution is that all the functionality of the host -language is available while your model is executing. So, for example, -it is easy to write [fizzbuzz](https://en.wikipedia.org/wiki/Fizz_buzz): - -```py -def fizzbuzz(max_num): - counter = tf.constant(0) - max_num = tf.convert_to_tensor(max_num) - for num in range(max_num.numpy()): - num = tf.constant(num) - if int(num % 3) == 0 and int(num % 5) == 0: - print('FizzBuzz') - elif int(num % 3) == 0: - print('Fizz') - elif int(num % 5) == 0: - print('Buzz') - else: - print(num) - counter += 1 - return counter -``` - -This has conditionals that depend on tensor values and it prints these values -at runtime. - -## Build a model - -Many machine learning models are represented by composing layers. When -using TensorFlow with eager execution you can either write your own layers or -use a layer provided in the `tf.keras.layers` package. - -While you can use any Python object to represent a layer, -TensorFlow has `tf.keras.layers.Layer` as a convenient base class. Inherit from -it to implement your own layer: - -```py -class MySimpleLayer(tf.keras.layers.Layer): - def __init__(self, output_units): - super(MySimpleLayer, self).__init__() - self.output_units = output_units - - def build(self, input_shape): - # The build method gets called the first time your layer is used. - # Creating variables on build() allows you to make their shape depend - # on the input shape and hence removes the need for the user to specify - # full shapes. It is possible to create variables during __init__() if - # you already know their full shapes. - self.kernel = self.add_variable( - "kernel", [input_shape[-1], self.output_units]) - - def call(self, input): - # Override call() instead of __call__ so we can perform some bookkeeping. - return tf.matmul(input, self.kernel) -``` - -Use `tf.keras.layers.Dense` layer instead of `MySimpleLayer` above as it has -a superset of its functionality (it can also add a bias). - -When composing layers into models you can use `tf.keras.Sequential` to represent -models which are a linear stack of layers. It is easy to use for basic models: - -```py -model = tf.keras.Sequential([ - tf.keras.layers.Dense(10, input_shape=(784,)), # must declare input shape - tf.keras.layers.Dense(10) -]) -``` - -Alternatively, organize models in classes by inheriting from `tf.keras.Model`. -This is a container for layers that is a layer itself, allowing `tf.keras.Model` -objects to contain other `tf.keras.Model` objects. - -```py -class MNISTModel(tf.keras.Model): - def __init__(self): - super(MNISTModel, self).__init__() - self.dense1 = tf.keras.layers.Dense(units=10) - self.dense2 = tf.keras.layers.Dense(units=10) - - def call(self, input): - """Run the model.""" - result = self.dense1(input) - result = self.dense2(result) - result = self.dense2(result) # reuse variables from dense2 layer - return result - -model = MNISTModel() -``` - -It's not required to set an input shape for the `tf.keras.Model` class since -the parameters are set the first time input is passed to the layer. - -`tf.keras.layers` classes create and contain their own model variables that -are tied to the lifetime of their layer objects. To share layer variables, share -their objects. - - -## Eager training - -### Computing gradients - -[Automatic differentiation](https://en.wikipedia.org/wiki/Automatic_differentiation) -is useful for implementing machine learning algorithms such as -[backpropagation](https://en.wikipedia.org/wiki/Backpropagation) for training -neural networks. During eager execution, use `tf.GradientTape` to trace -operations for computing gradients later. - -`tf.GradientTape` is an opt-in feature to provide maximal performance when -not tracing. Since different operations can occur during each call, all -forward-pass operations get recorded to a "tape". To compute the gradient, play -the tape backwards and then discard. A particular `tf.GradientTape` can only -compute one gradient; subsequent calls throw a runtime error. - -```py -w = tf.Variable([[1.0]]) -with tf.GradientTape() as tape: - loss = w * w - -grad = tape.gradient(loss, w) -print(grad) # => tf.Tensor([[ 2.]], shape=(1, 1), dtype=float32) -``` - -Here's an example of `tf.GradientTape` that records forward-pass operations -to train a simple model: - -```py -# A toy dataset of points around 3 * x + 2 -NUM_EXAMPLES = 1000 -training_inputs = tf.random_normal([NUM_EXAMPLES]) -noise = tf.random_normal([NUM_EXAMPLES]) -training_outputs = training_inputs * 3 + 2 + noise - -def prediction(input, weight, bias): - return input * weight + bias - -# A loss function using mean-squared error -def loss(weights, biases): - error = prediction(training_inputs, weights, biases) - training_outputs - return tf.reduce_mean(tf.square(error)) - -# Return the derivative of loss with respect to weight and bias -def grad(weights, biases): - with tf.GradientTape() as tape: - loss_value = loss(weights, biases) - return tape.gradient(loss_value, [weights, biases]) - -train_steps = 200 -learning_rate = 0.01 -# Start with arbitrary values for W and B on the same batch of data -W = tf.Variable(5.) -B = tf.Variable(10.) - -print("Initial loss: {:.3f}".format(loss(W, B))) - -for i in range(train_steps): - dW, dB = grad(W, B) - W.assign_sub(dW * learning_rate) - B.assign_sub(dB * learning_rate) - if i % 20 == 0: - print("Loss at step {:03d}: {:.3f}".format(i, loss(W, B))) - -print("Final loss: {:.3f}".format(loss(W, B))) -print("W = {}, B = {}".format(W.numpy(), B.numpy())) -``` - -Output (exact numbers may vary): - -``` -Initial loss: 71.204 -Loss at step 000: 68.333 -Loss at step 020: 30.222 -Loss at step 040: 13.691 -Loss at step 060: 6.508 -Loss at step 080: 3.382 -Loss at step 100: 2.018 -Loss at step 120: 1.422 -Loss at step 140: 1.161 -Loss at step 160: 1.046 -Loss at step 180: 0.996 -Final loss: 0.974 -W = 3.01582956314, B = 2.1191945076 -``` - -Replay the `tf.GradientTape` to compute the gradients and apply them in a -training loop. This is demonstrated in an excerpt from the -[mnist_eager.py](https://github.com/tensorflow/models/blob/master/official/mnist/mnist_eager.py) -example: - -```py -dataset = tf.data.Dataset.from_tensor_slices((data.train.images, - data.train.labels)) -... -for (batch, (images, labels)) in enumerate(dataset): - ... - with tf.GradientTape() as tape: - logits = model(images, training=True) - loss_value = loss(logits, labels) - ... - grads = tape.gradient(loss_value, model.variables) - optimizer.apply_gradients(zip(grads, model.variables), - global_step=tf.train.get_or_create_global_step()) -``` - - -The following example creates a multi-layer model that classifies the standard -MNIST handwritten digits. It demonstrates the optimizer and layer APIs to build -trainable graphs in an eager execution environment. - -### Train a model - -Even without training, call the model and inspect the output in eager execution: - -```py -# Create a tensor representing a blank image -batch = tf.zeros([1, 1, 784]) -print(batch.shape) # => (1, 1, 784) - -result = model(batch) -# => tf.Tensor([[[ 0. 0., ..., 0.]]], shape=(1, 1, 10), dtype=float32) -``` - -This example uses the -[dataset.py module](https://github.com/tensorflow/models/blob/master/official/mnist/dataset.py) -from the -[TensorFlow MNIST example](https://github.com/tensorflow/models/tree/master/official/mnist); -download this file to your local directory. Run the following to download the -MNIST data files to your working directory and prepare a `tf.data.Dataset` -for training: - -```py -import dataset # download dataset.py file -dataset_train = dataset.train('./datasets').shuffle(60000).repeat(4).batch(32) -``` - -To train a model, define a loss function to optimize and then calculate -gradients. Use an optimizer to update the variables: - -```py -def loss(model, x, y): - prediction = model(x) - return tf.losses.sparse_softmax_cross_entropy(labels=y, logits=prediction) - -def grad(model, inputs, targets): - with tf.GradientTape() as tape: - loss_value = loss(model, inputs, targets) - return tape.gradient(loss_value, model.variables) - -optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001) - -x, y = iter(dataset_train).next() -print("Initial loss: {:.3f}".format(loss(model, x, y))) - -# Training loop -for (i, (x, y)) in enumerate(dataset_train): - # Calculate derivatives of the input function with respect to its parameters. - grads = grad(model, x, y) - # Apply the gradient to the model - optimizer.apply_gradients(zip(grads, model.variables), - global_step=tf.train.get_or_create_global_step()) - if i % 200 == 0: - print("Loss at step {:04d}: {:.3f}".format(i, loss(model, x, y))) - -print("Final loss: {:.3f}".format(loss(model, x, y))) -``` - -Output (exact numbers may vary): - -``` -Initial loss: 2.674 -Loss at step 0000: 2.593 -Loss at step 0200: 2.143 -Loss at step 0400: 2.009 -Loss at step 0600: 2.103 -Loss at step 0800: 1.621 -Loss at step 1000: 1.695 -... -Loss at step 6600: 0.602 -Loss at step 6800: 0.557 -Loss at step 7000: 0.499 -Loss at step 7200: 0.744 -Loss at step 7400: 0.681 -Final loss: 0.670 -``` - -And for faster training, move the computation to a GPU: - -```py -with tf.device("/gpu:0"): - for (i, (x, y)) in enumerate(dataset_train): - # minimize() is equivalent to the grad() and apply_gradients() calls. - optimizer.minimize(lambda: loss(model, x, y), - global_step=tf.train.get_or_create_global_step()) -``` - -### Variables and optimizers - -`tf.Variable` objects store mutable `tf.Tensor` values accessed during -training to make automatic differentiation easier. The parameters of a model can -be encapsulated in classes as variables. - -Better encapsulate model parameters by using `tf.Variable` with -`tf.GradientTape`. For example, the automatic differentiation example above -can be rewritten: - -```py -class Model(tf.keras.Model): - def __init__(self): - super(Model, self).__init__() - self.W = tf.Variable(5., name='weight') - self.B = tf.Variable(10., name='bias') - def call(self, inputs): - return inputs * self.W + self.B - -# A toy dataset of points around 3 * x + 2 -NUM_EXAMPLES = 2000 -training_inputs = tf.random_normal([NUM_EXAMPLES]) -noise = tf.random_normal([NUM_EXAMPLES]) -training_outputs = training_inputs * 3 + 2 + noise - -# The loss function to be optimized -def loss(model, inputs, targets): - error = model(inputs) - targets - return tf.reduce_mean(tf.square(error)) - -def grad(model, inputs, targets): - with tf.GradientTape() as tape: - loss_value = loss(model, inputs, targets) - return tape.gradient(loss_value, [model.W, model.B]) - -# Define: -# 1. A model. -# 2. Derivatives of a loss function with respect to model parameters. -# 3. A strategy for updating the variables based on the derivatives. -model = Model() -optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01) - -print("Initial loss: {:.3f}".format(loss(model, training_inputs, training_outputs))) - -# Training loop -for i in range(300): - grads = grad(model, training_inputs, training_outputs) - optimizer.apply_gradients(zip(grads, [model.W, model.B]), - global_step=tf.train.get_or_create_global_step()) - if i % 20 == 0: - print("Loss at step {:03d}: {:.3f}".format(i, loss(model, training_inputs, training_outputs))) - -print("Final loss: {:.3f}".format(loss(model, training_inputs, training_outputs))) -print("W = {}, B = {}".format(model.W.numpy(), model.B.numpy())) -``` - -Output (exact numbers may vary): - -``` -Initial loss: 69.066 -Loss at step 000: 66.368 -Loss at step 020: 30.107 -Loss at step 040: 13.959 -Loss at step 060: 6.769 -Loss at step 080: 3.567 -Loss at step 100: 2.141 -Loss at step 120: 1.506 -Loss at step 140: 1.223 -Loss at step 160: 1.097 -Loss at step 180: 1.041 -Loss at step 200: 1.016 -Loss at step 220: 1.005 -Loss at step 240: 1.000 -Loss at step 260: 0.998 -Loss at step 280: 0.997 -Final loss: 0.996 -W = 2.99431324005, B = 2.02129220963 -``` - -## Use objects for state during eager execution - -With graph execution, program state (such as the variables) is stored in global -collections and their lifetime is managed by the `tf.Session` object. In -contrast, during eager execution the lifetime of state objects is determined by -the lifetime of their corresponding Python object. - -### Variables are objects - -During eager execution, variables persist until the last reference to the object -is removed, and is then deleted. - -```py -with tf.device("gpu:0"): - v = tf.Variable(tf.random_normal([1000, 1000])) - v = None # v no longer takes up GPU memory -``` - -### Object-based saving - -`tf.train.Checkpoint` can save and restore `tf.Variable`s to and from -checkpoints: - -```py -x = tf.Variable(10.) - -checkpoint = tf.train.Checkpoint(x=x) # save as "x" - -x.assign(2.) # Assign a new value to the variables and save. -save_path = checkpoint.save('./ckpt/') - -x.assign(11.) # Change the variable after saving. - -# Restore values from the checkpoint -checkpoint.restore(save_path) - -print(x) # => 2.0 -``` - -To save and load models, `tf.train.Checkpoint` stores the internal state of objects, -without requiring hidden variables. To record the state of a `model`, -an `optimizer`, and a global step, pass them to a `tf.train.Checkpoint`: - -```py -model = MyModel() -optimizer = tf.train.AdamOptimizer(learning_rate=0.001) -checkpoint_dir = ‘/path/to/model_dir’ -checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt") -root = tf.train.Checkpoint(optimizer=optimizer, - model=model, - optimizer_step=tf.train.get_or_create_global_step()) - -root.save(file_prefix=checkpoint_prefix) -# or -root.restore(tf.train.latest_checkpoint(checkpoint_dir)) -``` - -### Object-oriented metrics - -`tfe.metrics` are stored as objects. Update a metric by passing the new data to -the callable, and retrieve the result using the `tfe.metrics.result` method, -for example: - -```py -m = tfe.metrics.Mean("loss") -m(0) -m(5) -m.result() # => 2.5 -m([8, 9]) -m.result() # => 5.5 -``` - -#### Summaries and TensorBoard - -[TensorBoard](../guide/summaries_and_tensorboard.md) is a visualization tool for -understanding, debugging and optimizing the model training process. It uses -summary events that are written while executing the program. - -`tf.contrib.summary` is compatible with both eager and graph execution -environments. Summary operations, such as `tf.contrib.summary.scalar`, are -inserted during model construction. For example, to record summaries once every -100 global steps: - -```py -global_step = tf.train.get_or_create_global_step() -writer = tf.contrib.summary.create_file_writer(logdir) -writer.set_as_default() - -for _ in range(iterations): - global_step.assign_add(1) - # Must include a record_summaries method - with tf.contrib.summary.record_summaries_every_n_global_steps(100): - # your model code goes here - tf.contrib.summary.scalar('loss', loss) - ... -``` - -## Advanced automatic differentiation topics - -### Dynamic models - -`tf.GradientTape` can also be used in dynamic models. This example for a -[backtracking line search](https://wikipedia.org/wiki/Backtracking_line_search) -algorithm looks like normal NumPy code, except there are gradients and is -differentiable, despite the complex control flow: - -```py -def line_search_step(fn, init_x, rate=1.0): - with tf.GradientTape() as tape: - # Variables are automatically recorded, but manually watch a tensor - tape.watch(init_x) - value = fn(init_x) - grad = tape.gradient(value, init_x) - grad_norm = tf.reduce_sum(grad * grad) - init_value = value - while value > init_value - rate * grad_norm: - x = init_x - rate * grad - value = fn(x) - rate /= 2.0 - return x, value -``` - -### Additional functions to compute gradients - -`tf.GradientTape` is a powerful interface for computing gradients, but there -is another [Autograd](https://github.com/HIPS/autograd)-style API available for -automatic differentiation. These functions are useful if writing math code with -only tensors and gradient functions, and without `tf.Variables`: - -* `tfe.gradients_function` —Returns a function that computes the derivatives - of its input function parameter with respect to its arguments. The input - function parameter must return a scalar value. When the returned function is - invoked, it returns a list of `tf.Tensor` objects: one element for each - argument of the input function. Since anything of interest must be passed as a - function parameter, this becomes unwieldy if there's a dependency on many - trainable parameters. -* `tfe.value_and_gradients_function` —Similar to - `tfe.gradients_function`, but when the returned function is invoked, it - returns the value from the input function in addition to the list of - derivatives of the input function with respect to its arguments. - -In the following example, `tfe.gradients_function` takes the `square` -function as an argument and returns a function that computes the partial -derivatives of `square` with respect to its inputs. To calculate the derivative -of `square` at `3`, `grad(3.0)` returns `6`. - -```py -def square(x): - return tf.multiply(x, x) - -grad = tfe.gradients_function(square) - -square(3.) # => 9.0 -grad(3.) # => [6.0] - -# The second-order derivative of square: -gradgrad = tfe.gradients_function(lambda x: grad(x)[0]) -gradgrad(3.) # => [2.0] - -# The third-order derivative is None: -gradgradgrad = tfe.gradients_function(lambda x: gradgrad(x)[0]) -gradgradgrad(3.) # => [None] - - -# With flow control: -def abs(x): - return x if x > 0. else -x - -grad = tfe.gradients_function(abs) - -grad(3.) # => [1.0] -grad(-3.) # => [-1.0] -``` - -### Custom gradients - -Custom gradients are an easy way to override gradients in eager and graph -execution. Within the forward function, define the gradient with respect to the -inputs, outputs, or intermediate results. For example, here's an easy way to clip -the norm of the gradients in the backward pass: - -```py -@tf.custom_gradient -def clip_gradient_by_norm(x, norm): - y = tf.identity(x) - def grad_fn(dresult): - return [tf.clip_by_norm(dresult, norm), None] - return y, grad_fn -``` - -Custom gradients are commonly used to provide a numerically stable gradient for a -sequence of operations: - -```py -def log1pexp(x): - return tf.log(1 + tf.exp(x)) -grad_log1pexp = tfe.gradients_function(log1pexp) - -# The gradient computation works fine at x = 0. -grad_log1pexp(0.) # => [0.5] - -# However, x = 100 fails because of numerical instability. -grad_log1pexp(100.) # => [nan] -``` - -Here, the `log1pexp` function can be analytically simplified with a custom -gradient. The implementation below reuses the value for `tf.exp(x)` that is -computed during the forward pass—making it more efficient by eliminating -redundant calculations: - -```py -@tf.custom_gradient -def log1pexp(x): - e = tf.exp(x) - def grad(dy): - return dy * (1 - 1 / (1 + e)) - return tf.log(1 + e), grad - -grad_log1pexp = tfe.gradients_function(log1pexp) - -# As before, the gradient computation works fine at x = 0. -grad_log1pexp(0.) # => [0.5] - -# And the gradient computation also works at x = 100. -grad_log1pexp(100.) # => [1.0] -``` - -## Performance - -Computation is automatically offloaded to GPUs during eager execution. If you -want control over where a computation runs you can enclose it in a -`tf.device('/gpu:0')` block (or the CPU equivalent): - -```py -import time - -def measure(x, steps): - # TensorFlow initializes a GPU the first time it's used, exclude from timing. - tf.matmul(x, x) - start = time.time() - for i in range(steps): - x = tf.matmul(x, x) - # tf.matmul can return before completing the matrix multiplication - # (e.g., can return after enqueing the operation on a CUDA stream). - # The x.numpy() call below will ensure that all enqueued operations - # have completed (and will also copy the result to host memory, - # so we're including a little more than just the matmul operation - # time). - _ = x.numpy() - end = time.time() - return end - start - -shape = (1000, 1000) -steps = 200 -print("Time to multiply a {} matrix by itself {} times:".format(shape, steps)) - -# Run on CPU: -with tf.device("/cpu:0"): - print("CPU: {} secs".format(measure(tf.random_normal(shape), steps))) - -# Run on GPU, if available: -if tfe.num_gpus() > 0: - with tf.device("/gpu:0"): - print("GPU: {} secs".format(measure(tf.random_normal(shape), steps))) -else: - print("GPU: not found") -``` - -Output (exact numbers depend on hardware): - -``` -Time to multiply a (1000, 1000) matrix by itself 200 times: -CPU: 1.46628093719 secs -GPU: 0.0593810081482 secs -``` - -A `tf.Tensor` object can be copied to a different device to execute its -operations: - -```py -x = tf.random_normal([10, 10]) - -x_gpu0 = x.gpu() -x_cpu = x.cpu() - -_ = tf.matmul(x_cpu, x_cpu) # Runs on CPU -_ = tf.matmul(x_gpu0, x_gpu0) # Runs on GPU:0 - -if tfe.num_gpus() > 1: - x_gpu1 = x.gpu(1) - _ = tf.matmul(x_gpu1, x_gpu1) # Runs on GPU:1 -``` - -### Benchmarks - -For compute-heavy models, such as -[ResNet50](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples/resnet50) -training on a GPU, eager execution performance is comparable to graph execution. -But this gap grows larger for models with less computation and there is work to -be done for optimizing hot code paths for models with lots of small operations. - - -## Work with graphs - -While eager execution makes development and debugging more interactive, -TensorFlow graph execution has advantages for distributed training, performance -optimizations, and production deployment. However, writing graph code can feel -different than writing regular Python code and more difficult to debug. - -For building and training graph-constructed models, the Python program first -builds a graph representing the computation, then invokes `Session.run` to send -the graph for execution on the C++-based runtime. This provides: - -* Automatic differentiation using static autodiff. -* Simple deployment to a platform independent server. -* Graph-based optimizations (common subexpression elimination, constant-folding, etc.). -* Compilation and kernel fusion. -* Automatic distribution and replication (placing nodes on the distributed system). - -Deploying code written for eager execution is more difficult: either generate a -graph from the model, or run the Python runtime and code directly on the server. - -### Write compatible code - -The same code written for eager execution will also build a graph during graph -execution. Do this by simply running the same code in a new Python session where -eager execution is not enabled. - -Most TensorFlow operations work during eager execution, but there are some things -to keep in mind: - -* Use `tf.data` for input processing instead of queues. It's faster and easier. -* Use object-oriented layer APIs—like `tf.keras.layers` and - `tf.keras.Model`—since they have explicit storage for variables. -* Most model code works the same during eager and graph execution, but there are - exceptions. (For example, dynamic models using Python control flow to change the - computation based on inputs.) -* Once eager execution is enabled with `tf.enable_eager_execution`, it - cannot be turned off. Start a new Python session to return to graph execution. - -It's best to write code for both eager execution *and* graph execution. This -gives you eager's interactive experimentation and debuggability with the -distributed performance benefits of graph execution. - -Write, debug, and iterate in eager execution, then import the model graph for -production deployment. Use `tf.train.Checkpoint` to save and restore model -variables, this allows movement between eager and graph execution environments. -See the examples in: -[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples). - -### Use eager execution in a graph environment - -Selectively enable eager execution in a TensorFlow graph environment using -`tfe.py_func`. This is used when `tf.enable_eager_execution()` has *not* -been called. - -```py -def my_py_func(x): - x = tf.matmul(x, x) # You can use tf ops - print(x) # but it's eager! - return x - -with tf.Session() as sess: - x = tf.placeholder(dtype=tf.float32) - # Call eager function in graph! - pf = tfe.py_func(my_py_func, [x], tf.float32) - sess.run(pf, feed_dict={x: [[2.0]]}) # [[4.0]] -``` diff --git a/tensorflow/docs_src/guide/embedding.md b/tensorflow/docs_src/guide/embedding.md deleted file mode 100644 index 6007e6847b..0000000000 --- a/tensorflow/docs_src/guide/embedding.md +++ /dev/null @@ -1,262 +0,0 @@ -# Embeddings - -This document introduces the concept of embeddings, gives a simple example of -how to train an embedding in TensorFlow, and explains how to view embeddings -with the TensorBoard Embedding Projector -([live example](http://projector.tensorflow.org)). The first two parts target -newcomers to machine learning or TensorFlow, and the Embedding Projector how-to -is for users at all levels. - -An alternative tutorial on these concepts is available in the -[Embeddings section of Machine Learning Crash Course](https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture). - -[TOC] - -An **embedding** is a mapping from discrete objects, such as words, to vectors -of real numbers. For example, a 300-dimensional embedding for English words -could include: - -``` -blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259) -blues: (0.01396, 0.11887, -0.48963, ..., 0.033483, -0.10007, 0.1158) -orange: (-0.24776, -0.12359, 0.20986, ..., 0.079717, 0.23865, -0.014213) -oranges: (-0.35609, 0.21854, 0.080944, ..., -0.35413, 0.38511, -0.070976) -``` - -The individual dimensions in these vectors typically have no inherent meaning. -Instead, it's the overall patterns of location and distance between vectors -that machine learning takes advantage of. - -Embeddings are important for input to machine learning. Classifiers, and neural -networks more generally, work on vectors of real numbers. They train best on -dense vectors, where all values contribute to define an object. However, many -important inputs to machine learning, such as words of text, do not have a -natural vector representation. Embedding functions are the standard and -effective way to transform such discrete input objects into useful -continuous vectors. - -Embeddings are also valuable as outputs of machine learning. Because embeddings -map objects to vectors, applications can use similarity in vector space (for -instance, Euclidean distance or the angle between vectors) as a robust and -flexible measure of object similarity. One common use is to find nearest -neighbors. Using the same word embeddings as above, for instance, here are the -three nearest neighbors for each word and the corresponding angles: - -``` -blue: (red, 47.6°), (yellow, 51.9°), (purple, 52.4°) -blues: (jazz, 53.3°), (folk, 59.1°), (bluegrass, 60.6°) -orange: (yellow, 53.5°), (colored, 58.0°), (bright, 59.9°) -oranges: (apples, 45.3°), (lemons, 48.3°), (mangoes, 50.4°) -``` - -This would tell an application that apples and oranges are in some way more -similar (45.3° apart) than lemons and oranges (48.3° apart). - -## Embeddings in TensorFlow - -To create word embeddings in TensorFlow, we first split the text into words -and then assign an integer to every word in the vocabulary. Let us assume that -this has already been done, and that `word_ids` is a vector of these integers. -For example, the sentence “I have a cat.” could be split into -`[“I”, “have”, “a”, “cat”, “.”]` and then the corresponding `word_ids` tensor -would have shape `[5]` and consist of 5 integers. To map these word ids -to vectors, we need to create the embedding variable and use the -`tf.nn.embedding_lookup` function as follows: - -``` -word_embeddings = tf.get_variable(“word_embeddings”, - [vocabulary_size, embedding_size]) -embedded_word_ids = tf.nn.embedding_lookup(word_embeddings, word_ids) -``` - -After this, the tensor `embedded_word_ids` will have shape `[5, embedding_size]` -in our example and contain the embeddings (dense vectors) for each of the 5 -words. At the end of training, `word_embeddings` will contain the embeddings -for all words in the vocabulary. - -Embeddings can be trained in many network types, and with various loss -functions and data sets. For example, one could use a recurrent neural network -to predict the next word from the previous one given a large corpus of -sentences, or one could train two networks to do multi-lingual translation. -These methods are described in the [Vector Representations of Words](../tutorials/representation/word2vec.md) -tutorial. - -## Visualizing Embeddings - -TensorBoard includes the **Embedding Projector**, a tool that lets you -interactively visualize embeddings. This tool can read embeddings from your -model and render them in two or three dimensions. - -The Embedding Projector has three panels: - -- *Data panel* on the top left, where you can choose the run, the embedding - variable and data columns to color and label points by. -- *Projections panel* on the bottom left, where you can choose the type of - projection. -- *Inspector panel* on the right side, where you can search for particular - points and see a list of nearest neighbors. - -### Projections -The Embedding Projector provides three ways to reduce the dimensionality of a -data set. - -- *[t-SNE](https://en.wikipedia.org/wiki/T-distributed_stochastic_neighbor_embedding)*: - a nonlinear nondeterministic algorithm (T-distributed stochastic neighbor - embedding) that tries to preserve local neighborhoods in the data, often at - the expense of distorting global structure. You can choose whether to compute - two- or three-dimensional projections. - -- *[PCA](https://en.wikipedia.org/wiki/Principal_component_analysis)*: - a linear deterministic algorithm (principal component analysis) that tries to - capture as much of the data variability in as few dimensions as possible. PCA - tends to highlight large-scale structure in the data, but can distort local - neighborhoods. The Embedding Projector computes the top 10 principal - components, from which you can choose two or three to view. - -- *Custom*: a linear projection onto horizontal and vertical axes that you - specify using labels in the data. You define the horizontal axis, for - instance, by giving text patterns for "Left" and "Right". The Embedding - Projector finds all points whose label matches the "Left" pattern and - computes the centroid of that set; similarly for "Right". The line passing - through these two centroids defines the horizontal axis. The vertical axis is - likewise computed from the centroids for points matching the "Up" and "Down" - text patterns. - -Further useful articles are -[How to Use t-SNE Effectively](https://distill.pub/2016/misread-tsne/) and -[Principal Component Analysis Explained Visually](http://setosa.io/ev/principal-component-analysis/). - -### Exploration - -You can explore visually by zooming, rotating, and panning using natural -click-and-drag gestures. Hovering your mouse over a point will show any -[metadata](#metadata) for that point. You can also inspect nearest-neighbor -subsets. Clicking on a point causes the right pane to list the nearest -neighbors, along with distances to the current point. The nearest-neighbor -points are also highlighted in the projection. - -It is sometimes useful to restrict the view to a subset of points and perform -projections only on those points. To do so, you can select points in multiple -ways: - -- After clicking on a point, its nearest neighbors are also selected. -- After a search, the points matching the query are selected. -- Enabling selection, clicking on a point and dragging defines a selection - sphere. - -Then click the "Isolate *nnn* points" button at the top of the Inspector pane -on the right hand side. The following image shows 101 points selected and ready -for the user to click "Isolate 101 points": - - - -*Selection of the nearest neighbors of “important” in a word embedding dataset.* - -Advanced tip: filtering with custom projection can be powerful. Below, we -filtered the 100 nearest neighbors of “politics” and projected them onto the -“worst” - “best” vector as an x axis. The y axis is random. As a result, one -finds on the right side “ideas”, “science”, “perspective”, “journalism” but on -the left “crisis”, “violence” and “conflict”. - -<table width="100%;"> - <tr> - <td style="width: 30%;"> - <img src="https://www.tensorflow.org/images/embedding-custom-controls.png" alt="Custom controls panel" title="Custom controls panel" /> - </td> - <td style="width: 70%;"> - <img src="https://www.tensorflow.org/images/embedding-custom-projection.png" alt="Custom projection" title="Custom projection" /> - </td> - </tr> - <tr> - <td style="width: 30%;"> - Custom projection controls. - </td> - <td style="width: 70%;"> - Custom projection of neighbors of "politics" onto "best" - "worst" vector. - </td> - </tr> -</table> - -To share your findings, you can use the bookmark panel in the bottom right -corner and save the current state (including computed coordinates of any -projection) as a small file. The Projector can then be pointed to a set of one -or more of these files, producing the panel below. Other users can then walk -through a sequence of bookmarks. - -<img src="https://www.tensorflow.org/images/embedding-bookmark.png" alt="Bookmark panel" style="width:300px;"> - -### Metadata - -If you are working with an embedding, you'll probably want to attach -labels/images to the data points. You can do this by generating a metadata file -containing the labels for each point and clicking "Load data" in the data panel -of the Embedding Projector. - -The metadata can be either labels or images, which are -stored in a separate file. For labels, the format should -be a [TSV file](https://en.wikipedia.org/wiki/Tab-separated_values) -(tab characters shown in red) whose first line contains column headers -(shown in bold) and subsequent lines contain the metadata values. For example: - -<code> -<b>Word<span style="color:#800;">\t</span>Frequency</b><br/> - Airplane<span style="color:#800;">\t</span>345<br/> - Car<span style="color:#800;">\t</span>241<br/> - ... -</code> - -The order of lines in the metadata file is assumed to match the order of -vectors in the embedding variable, except for the header. Consequently, the -(i+1)-th line in the metadata file corresponds to the i-th row of the embedding -variable. If the TSV metadata file has only a single column, then we don’t -expect a header row, and assume each row is the label of the embedding. We -include this exception because it matches the commonly-used "vocab file" -format. - -To use images as metadata, you must produce a single -[sprite image](https://www.google.com/webhp#q=what+is+a+sprite+image), -consisting of small thumbnails, one for each vector in the embedding. The -sprite should store thumbnails in row-first order: the first data point placed -in the top left and the last data point in the bottom right, though the last -row doesn't have to be filled, as shown below. - -<table style="border: none;"> -<tr style="background-color: transparent;"> - <td style="border: 1px solid black">0</td> - <td style="border: 1px solid black">1</td> - <td style="border: 1px solid black">2</td> -</tr> -<tr style="background-color: transparent;"> - <td style="border: 1px solid black">3</td> - <td style="border: 1px solid black">4</td> - <td style="border: 1px solid black">5</td> -</tr> -<tr style="background-color: transparent;"> - <td style="border: 1px solid black">6</td> - <td style="border: 1px solid black">7</td> - <td style="border: 1px solid black"></td> -</tr> -</table> - -Follow [this link](https://www.tensorflow.org/images/embedding-mnist.mp4) -to see a fun example of thumbnail images in the Embedding Projector. - - -## Mini-FAQ - -**Is "embedding" an action or a thing?** -Both. People talk about embedding words in a vector space (action) and about -producing word embeddings (things). Common to both is the notion of embedding -as a mapping from discrete objects to vectors. Creating or applying that -mapping is an action, but the mapping itself is a thing. - -**Are embeddings high-dimensional or low-dimensional?** -It depends. A 300-dimensional vector space of words and phrases, for instance, -is often called low-dimensional (and dense) when compared to the millions of -words and phrases it can contain. But mathematically it is high-dimensional, -displaying many properties that are dramatically different from what our human -intuition has learned about 2- and 3-dimensional spaces. - -**Is an embedding the same as an embedding layer?** -No. An *embedding layer* is a part of neural network, but an *embedding* is a more -general concept. diff --git a/tensorflow/docs_src/guide/estimators.md b/tensorflow/docs_src/guide/estimators.md deleted file mode 100644 index 3903bfd126..0000000000 --- a/tensorflow/docs_src/guide/estimators.md +++ /dev/null @@ -1,196 +0,0 @@ -# Estimators - -This document introduces `tf.estimator`--a high-level TensorFlow -API that greatly simplifies machine learning programming. Estimators encapsulate -the following actions: - -* training -* evaluation -* prediction -* export for serving - -You may either use the pre-made Estimators we provide or write your -own custom Estimators. All Estimators--whether pre-made or custom--are -classes based on the `tf.estimator.Estimator` class. - -For a quick example try [Estimator tutorials]](../tutorials/estimators/linear). -To see each sub-topic in depth, see the [Estimator guides](premade_estimators). - -Note: TensorFlow also includes a deprecated `Estimator` class at -`tf.contrib.learn.Estimator`, which you should not use. - - -## Advantages of Estimators - -Estimators provide the following benefits: - -* You can run Estimator-based models on a local host or on a - distributed multi-server environment without changing your model. - Furthermore, you can run Estimator-based models on CPUs, GPUs, - or TPUs without recoding your model. -* Estimators simplify sharing implementations between model developers. -* You can develop a state of the art model with high-level intuitive code. - In short, it is generally much easier to create models with Estimators - than with the low-level TensorFlow APIs. -* Estimators are themselves built on `tf.keras.layers`, which - simplifies customization. -* Estimators build the graph for you. -* Estimators provide a safe distributed training loop that controls how and - when to: - * build the graph - * initialize variables - * load data - * handle exceptions - * create checkpoint files and recover from failures - * save summaries for TensorBoard - -When writing an application with Estimators, you must separate the data input -pipeline from the model. This separation simplifies experiments with -different data sets. - - -## Pre-made Estimators - -Pre-made Estimators enable you to work at a much higher conceptual level -than the base TensorFlow APIs. You no longer have to worry about creating -the computational graph or sessions since Estimators handle all -the "plumbing" for you. That is, pre-made Estimators create and manage -`tf.Graph` and `tf.Session` objects for you. Furthermore, -pre-made Estimators let you experiment with different model architectures by -making only minimal code changes. `tf.estimator.DNNClassifier`, -for example, is a pre-made Estimator class that trains classification models -based on dense, feed-forward neural networks. - - -### Structure of a pre-made Estimators program - -A TensorFlow program relying on a pre-made Estimator typically consists -of the following four steps: - -1. **Write one or more dataset importing functions.** For example, you might - create one function to import the training set and another function to - import the test set. Each dataset importing function must return two - objects: - - * a dictionary in which the keys are feature names and the - values are Tensors (or SparseTensors) containing the corresponding - feature data - * a Tensor containing one or more labels - - For example, the following code illustrates the basic skeleton for - an input function: - - def input_fn(dataset): - ... # manipulate dataset, extracting the feature dict and the label - return feature_dict, label - - (See [Importing Data](../guide/datasets.md) for full details.) - -2. **Define the feature columns.** Each `tf.feature_column` - identifies a feature name, its type, and any input pre-processing. - For example, the following snippet creates three feature - columns that hold integer or floating-point data. The first two - feature columns simply identify the feature's name and type. The - third feature column also specifies a lambda the program will invoke - to scale the raw data: - - # Define three numeric feature columns. - population = tf.feature_column.numeric_column('population') - crime_rate = tf.feature_column.numeric_column('crime_rate') - median_education = tf.feature_column.numeric_column('median_education', - normalizer_fn=lambda x: x - global_education_mean) - -3. **Instantiate the relevant pre-made Estimator.** For example, here's - a sample instantiation of a pre-made Estimator named `LinearClassifier`: - - # Instantiate an estimator, passing the feature columns. - estimator = tf.estimator.LinearClassifier( - feature_columns=[population, crime_rate, median_education], - ) - -4. **Call a training, evaluation, or inference method.** - For example, all Estimators provide a `train` method, which trains a model. - - # my_training_set is the function created in Step 1 - estimator.train(input_fn=my_training_set, steps=2000) - - -### Benefits of pre-made Estimators - -Pre-made Estimators encode best practices, providing the following benefits: - -* Best practices for determining where different parts of the computational - graph should run, implementing strategies on a single machine or on a - cluster. -* Best practices for event (summary) writing and universally useful - summaries. - -If you don't use pre-made Estimators, you must implement the preceding -features yourself. - - -## Custom Estimators - -The heart of every Estimator--whether pre-made or custom--is its -**model function**, which is a method that builds graphs for training, -evaluation, and prediction. When you are using a pre-made Estimator, -someone else has already implemented the model function. When relying -on a custom Estimator, you must write the model function yourself. A -[companion document](../guide/custom_estimators.md) -explains how to write the model function. - - -## Recommended workflow - -We recommend the following workflow: - -1. Assuming a suitable pre-made Estimator exists, use it to build your - first model and use its results to establish a baseline. -2. Build and test your overall pipeline, including the integrity and - reliability of your data with this pre-made Estimator. -3. If suitable alternative pre-made Estimators are available, run - experiments to determine which pre-made Estimator produces the - best results. -4. Possibly, further improve your model by building your own custom Estimator. - - -## Creating Estimators from Keras models - -You can convert existing Keras models to Estimators. Doing so enables your Keras -model to access Estimator's strengths, such as distributed training. Call -`tf.keras.estimator.model_to_estimator` as in the -following sample: - -```python -# Instantiate a Keras inception v3 model. -keras_inception_v3 = tf.keras.applications.inception_v3.InceptionV3(weights=None) -# Compile model with the optimizer, loss, and metrics you'd like to train with. -keras_inception_v3.compile(optimizer=tf.keras.optimizers.SGD(lr=0.0001, momentum=0.9), - loss='categorical_crossentropy', - metric='accuracy') -# Create an Estimator from the compiled Keras model. Note the initial model -# state of the keras model is preserved in the created Estimator. -est_inception_v3 = tf.keras.estimator.model_to_estimator(keras_model=keras_inception_v3) - -# Treat the derived Estimator as you would with any other Estimator. -# First, recover the input name(s) of Keras model, so we can use them as the -# feature column name(s) of the Estimator input function: -keras_inception_v3.input_names # print out: ['input_1'] -# Once we have the input name(s), we can create the input function, for example, -# for input(s) in the format of numpy ndarray: -train_input_fn = tf.estimator.inputs.numpy_input_fn( - x={"input_1": train_data}, - y=train_labels, - num_epochs=1, - shuffle=False) -# To train, we call Estimator's train function: -est_inception_v3.train(input_fn=train_input_fn, steps=2000) -``` -Note that the names of feature columns and labels of a keras estimator come from -the corresponding compiled keras model. For example, the input key names for -`train_input_fn` above can be obtained from `keras_inception_v3.input_names`, -and similarly, the predicted output names can be obtained from -`keras_inception_v3.output_names`. - -For more details, please refer to the documentation for -`tf.keras.estimator.model_to_estimator`. diff --git a/tensorflow/docs_src/guide/faq.md b/tensorflow/docs_src/guide/faq.md deleted file mode 100644 index a02635ebba..0000000000 --- a/tensorflow/docs_src/guide/faq.md +++ /dev/null @@ -1,296 +0,0 @@ -# Frequently Asked Questions - -This document provides answers to some of the frequently asked questions about -TensorFlow. If you have a question that is not covered here, you might find an -answer on one of the TensorFlow [community resources](../about/index.md). - -[TOC] - -## Features and Compatibility - -#### Can I run distributed training on multiple computers? - -Yes! TensorFlow gained -[support for distributed computation](../deploy/distributed.md) in -version 0.8. TensorFlow now supports multiple devices (CPUs and GPUs) in one or -more computers. - -#### Does TensorFlow work with Python 3? - -As of the 0.6.0 release timeframe (Early December 2015), we do support Python -3.3+. - -## Building a TensorFlow graph - -See also the -[API documentation on building graphs](../api_guides/python/framework.md). - -#### Why does `c = tf.matmul(a, b)` not execute the matrix multiplication immediately? - -In the TensorFlow Python API, `a`, `b`, and `c` are -`tf.Tensor` objects. A `Tensor` object is -a symbolic handle to the result of an operation, but does not actually hold the -values of the operation's output. Instead, TensorFlow encourages users to build -up complicated expressions (such as entire neural networks and its gradients) as -a dataflow graph. You then offload the computation of the entire dataflow graph -(or a subgraph of it) to a TensorFlow -`tf.Session`, which is able to execute the -whole computation much more efficiently than executing the operations -one-by-one. - -#### How are devices named? - -The supported device names are `"/device:CPU:0"` (or `"/cpu:0"`) for the CPU -device, and `"/device:GPU:i"` (or `"/gpu:i"`) for the *i*th GPU device. - -#### How do I place operations on a particular device? - -To place a group of operations on a device, create them within a -`tf.device` context. See -the how-to documentation on -[using GPUs with TensorFlow](../guide/using_gpu.md) for details of how -TensorFlow assigns operations to devices, and the -[CIFAR-10 tutorial](../tutorials/images/deep_cnn.md) for an example model that -uses multiple GPUs. - - -## Running a TensorFlow computation - -See also the -[API documentation on running graphs](../api_guides/python/client.md). - -#### What's the deal with feeding and placeholders? - -Feeding is a mechanism in the TensorFlow Session API that allows you to -substitute different values for one or more tensors at run time. The `feed_dict` -argument to `tf.Session.run` is a -dictionary that maps `tf.Tensor` objects to -numpy arrays (and some other types), which will be used as the values of those -tensors in the execution of a step. - -#### What is the difference between `Session.run()` and `Tensor.eval()`? - -If `t` is a `tf.Tensor` object, -`tf.Tensor.eval` is shorthand for -`tf.Session.run`, where `sess` is the -current `tf.get_default_session`. The -two following snippets of code are equivalent: - -```python -# Using `Session.run()`. -sess = tf.Session() -c = tf.constant(5.0) -print(sess.run(c)) - -# Using `Tensor.eval()`. -c = tf.constant(5.0) -with tf.Session(): - print(c.eval()) -``` - -In the second example, the session acts as a -[context manager](https://docs.python.org/2.7/reference/compound_stmts.html#with), -which has the effect of installing it as the default session for the lifetime of -the `with` block. The context manager approach can lead to more concise code for -simple use cases (like unit tests); if your code deals with multiple graphs and -sessions, it may be more straightforward to make explicit calls to -`Session.run()`. - -#### Do Sessions have a lifetime? What about intermediate tensors? - -Sessions can own resources, such as -`tf.Variable`, -`tf.QueueBase`, and -`tf.ReaderBase`. These resources can sometimes use -a significant amount of memory, and can be released when the session is closed by calling -`tf.Session.close`. - -The intermediate tensors that are created as part of a call to -[`Session.run()`](../api_guides/python/client.md) will be freed at or before the -end of the call. - -#### Does the runtime parallelize parts of graph execution? - -The TensorFlow runtime parallelizes graph execution across many different -dimensions: - -* The individual ops have parallel implementations, using multiple cores in a - CPU, or multiple threads in a GPU. -* Independent nodes in a TensorFlow graph can run in parallel on multiple - devices, which makes it possible to speed up - [CIFAR-10 training using multiple GPUs](../tutorials/images/deep_cnn.md). -* The Session API allows multiple concurrent steps (i.e. calls to - `tf.Session.run` in parallel). This - enables the runtime to get higher throughput, if a single step does not use - all of the resources in your computer. - -#### Which client languages are supported in TensorFlow? - -TensorFlow is designed to support multiple client languages. -Currently, the best-supported client language is [Python](../api_docs/python/index.md). Experimental interfaces for -executing and constructing graphs are also available for -[C++](../api_docs/cc/index.md), [Java](../api_docs/java/reference/org/tensorflow/package-summary.html) and [Go](https://godoc.org/github.com/tensorflow/tensorflow/tensorflow/go). - -TensorFlow also has a -[C-based client API](https://www.tensorflow.org/code/tensorflow/c/c_api.h) -to help build support for more client languages. We invite contributions of new -language bindings. - -Bindings for various other languages (such as [C#](https://github.com/migueldeicaza/TensorFlowSharp), [Julia](https://github.com/malmaud/TensorFlow.jl), [Ruby](https://github.com/somaticio/tensorflow.rb) and [Scala](https://github.com/eaplatanios/tensorflow_scala)) created and supported by the open source community build on top of the C API supported by the TensorFlow maintainers. - -#### Does TensorFlow make use of all the devices (GPUs and CPUs) available on my machine? - -TensorFlow supports multiple GPUs and CPUs. See the how-to documentation on -[using GPUs with TensorFlow](../guide/using_gpu.md) for details of how -TensorFlow assigns operations to devices, and the -[CIFAR-10 tutorial](../tutorials/images/deep_cnn.md) for an example model that -uses multiple GPUs. - -Note that TensorFlow only uses GPU devices with a compute capability greater -than 3.5. - -#### Why does `Session.run()` hang when using a reader or a queue? - -The `tf.ReaderBase` and -`tf.QueueBase` classes provide special operations that -can *block* until input (or free space in a bounded queue) becomes -available. These operations allow you to build sophisticated -[input pipelines](../api_guides/python/reading_data.md), at the cost of making the -TensorFlow computation somewhat more complicated. See the how-to documentation -for -[using `QueueRunner` objects to drive queues and readers](../api_guides/python/reading_data.md#creating_threads_to_prefetch_using_queuerunner_objects) -for more information on how to use them. - -## Variables - -See also the how-to documentation on [variables](../guide/variables.md) and -[the API documentation for variables](../api_guides/python/state_ops.md). - -#### What is the lifetime of a variable? - -A variable is created when you first run the -`tf.Variable.initializer` -operation for that variable in a session. It is destroyed when that -`tf.Session.close`. - -#### How do variables behave when they are concurrently accessed? - -Variables allow concurrent read and write operations. The value read from a -variable may change if it is concurrently updated. By default, concurrent -assignment operations to a variable are allowed to run with no mutual exclusion. -To acquire a lock when assigning to a variable, pass `use_locking=True` to -`tf.Variable.assign`. - -## Tensor shapes - -See also the -`tf.TensorShape`. - -#### How can I determine the shape of a tensor in Python? - -In TensorFlow, a tensor has both a static (inferred) shape and a dynamic (true) -shape. The static shape can be read using the -`tf.Tensor.get_shape` -method: this shape is inferred from the operations that were used to create the -tensor, and may be partially complete (the static-shape may contain `None`). If -the static shape is not fully defined, the dynamic shape of a `tf.Tensor`, `t` -can be determined using `tf.shape(t)`. - -#### What is the difference between `x.set_shape()` and `x = tf.reshape(x)`? - -The `tf.Tensor.set_shape` method updates -the static shape of a `Tensor` object, and it is typically used to provide -additional shape information when this cannot be inferred directly. It does not -change the dynamic shape of the tensor. - -The `tf.reshape` operation creates -a new tensor with a different dynamic shape. - -#### How do I build a graph that works with variable batch sizes? - -It is often useful to build a graph that works with variable batch sizes -so that the same code can be used for (mini-)batch training, and -single-instance inference. The resulting graph can be -`tf.Graph.as_graph_def` -and -`tf.import_graph_def`. - -When building a variable-size graph, the most important thing to remember is not -to encode the batch size as a Python constant, but instead to use a symbolic -`Tensor` to represent it. The following tips may be useful: - -* Use [`batch_size = tf.shape(input)[0]`](../api_docs/python/array_ops.md#shape) - to extract the batch dimension from a `Tensor` called `input`, and store it in - a `Tensor` called `batch_size`. - -* Use `tf.reduce_mean` instead - of `tf.reduce_sum(...) / batch_size`. - - -## TensorBoard - -#### How can I visualize a TensorFlow graph? - -See the [graph visualization tutorial](../guide/graph_viz.md). - -#### What is the simplest way to send data to TensorBoard? - -Add summary ops to your TensorFlow graph, and write -these summaries to a log directory. Then, start TensorBoard using - - python tensorflow/tensorboard/tensorboard.py --logdir=path/to/log-directory - -For more details, see the -[Summaries and TensorBoard tutorial](../guide/summaries_and_tensorboard.md). - -#### Every time I launch TensorBoard, I get a network security popup! - -You can change TensorBoard to serve on localhost rather than '0.0.0.0' by -the flag --host=localhost. This should quiet any security warnings. - -## Extending TensorFlow - -See the how-to documentation for -[adding a new operation to TensorFlow](../extend/adding_an_op.md). - -#### My data is in a custom format. How do I read it using TensorFlow? - -There are three main options for dealing with data in a custom format. - -The easiest option is to write parsing code in Python that transforms the data -into a numpy array. Then, use `tf.data.Dataset.from_tensor_slices` to -create an input pipeline from the in-memory data. - -If your data doesn't fit in memory, try doing the parsing in the Dataset -pipeline. Start with an appropriate file reader, like -`tf.data.TextLineDataset`. Then convert the dataset by mapping -`tf.data.Dataset.map` appropriate operations over it. -Prefer predefined TensorFlow operations such as `tf.decode_raw`, -`tf.decode_csv`, `tf.parse_example`, or `tf.image.decode_png`. - -If your data is not easily parsable with the built-in TensorFlow operations, -consider converting it, offline, to a format that is easily parsable, such -as `tf.python_io.TFRecordWriter` format. - -The most efficient method to customize the parsing behavior is to -[add a new op written in C++](../extend/adding_an_op.md) that parses your -data format. The [guide to handling new data formats](../extend/new_data_formats.md) has -more information about the steps for doing this. - - -## Miscellaneous - -#### What is TensorFlow's coding style convention? - -The TensorFlow Python API adheres to the -[PEP8](https://www.python.org/dev/peps/pep-0008/) conventions.<sup>*</sup> In -particular, we use `CamelCase` names for classes, and `snake_case` names for -functions, methods, and properties. We also adhere to the -[Google Python style guide](https://google.github.io/styleguide/pyguide.html). - -The TensorFlow C++ code base adheres to the -[Google C++ style guide](https://google.github.io/styleguide/cppguide.html). - -(<sup>*</sup> With one exception: we use 2-space indentation instead of 4-space -indentation.) - diff --git a/tensorflow/docs_src/guide/feature_columns.md b/tensorflow/docs_src/guide/feature_columns.md deleted file mode 100644 index 3ad41855e4..0000000000 --- a/tensorflow/docs_src/guide/feature_columns.md +++ /dev/null @@ -1,572 +0,0 @@ -# Feature Columns - -This document details feature columns. Think of **feature columns** as the -intermediaries between raw data and Estimators. Feature columns are very rich, -enabling you to transform a diverse range of raw data into formats that -Estimators can use, allowing easy experimentation. - -In [Premade Estimators](../guide/premade_estimators.md), we used the premade -Estimator, `tf.estimator.DNNClassifier` to train a model to -predict different types of Iris flowers from four input features. That example -created only numerical feature columns (of type -`tf.feature_column.numeric_column`). Although numerical feature columns model -the lengths of petals and sepals effectively, real world data sets contain all -kinds of features, many of which are non-numerical. - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/feature_cloud.jpg"> -</div> -<div style="text-align: center"> -Some real-world features (such as, longitude) are numerical, but many are not. -</div> - -## Input to a Deep Neural Network - -What kind of data can a deep neural network operate on? The answer -is, of course, numbers (for example, `tf.float32`). After all, every neuron in -a neural network performs multiplication and addition operations on weights and -input data. Real-life input data, however, often contains non-numerical -(categorical) data. For example, consider a `product_class` feature that can -contain the following three non-numerical values: - -* `kitchenware` -* `electronics` -* `sports` - -ML models generally represent categorical values as simple vectors in which a -1 represents the presence of a value and a 0 represents the absence of a value. -For example, when `product_class` is set to `sports`, an ML model would usually -represent `product_class` as `[0, 0, 1]`, meaning: - -* `0`: `kitchenware` is absent -* `0`: `electronics` is absent -* `1`: `sports` is present - -So, although raw data can be numerical or categorical, an ML model represents -all features as numbers. - -## Feature Columns - -As the following figure suggests, you specify the input to a model through the -`feature_columns` argument of an Estimator (`DNNClassifier` for Iris). -Feature Columns bridge input data (as returned by `input_fn`) with your model. - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/inputs_to_model_bridge.jpg"> -</div> -<div style="text-align: center"> -Feature columns bridge raw data with the data your model needs. -</div> - -To create feature columns, call functions from the -`tf.feature_column` module. This document explains nine of the functions in -that module. As the following figure shows, all nine functions return either a -Categorical-Column or a Dense-Column object, except `bucketized_column`, which -inherits from both classes: - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/some_constructors.jpg"> -</div> -<div style="text-align: center"> -Feature column methods fall into two main categories and one hybrid category. -</div> - -Let's look at these functions in more detail. - -### Numeric column - -The Iris classifier calls the `tf.feature_column.numeric_column` function for -all input features: - - * `SepalLength` - * `SepalWidth` - * `PetalLength` - * `PetalWidth` - -Although `tf.numeric_column` provides optional arguments, calling -`tf.numeric_column` without any arguments, as follows, is a fine way to specify -a numerical value with the default data type (`tf.float32`) as input to your -model: - -```python -# Defaults to a tf.float32 scalar. -numeric_feature_column = tf.feature_column.numeric_column(key="SepalLength") -``` - -To specify a non-default numerical data type, use the `dtype` argument. For -example: - -``` python -# Represent a tf.float64 scalar. -numeric_feature_column = tf.feature_column.numeric_column(key="SepalLength", - dtype=tf.float64) -``` - -By default, a numeric column creates a single value (scalar). Use the shape -argument to specify another shape. For example: - -<!--TODO(markdaoust) link to full example--> -```python -# Represent a 10-element vector in which each cell contains a tf.float32. -vector_feature_column = tf.feature_column.numeric_column(key="Bowling", - shape=10) - -# Represent a 10x5 matrix in which each cell contains a tf.float32. -matrix_feature_column = tf.feature_column.numeric_column(key="MyMatrix", - shape=[10,5]) -``` -### Bucketized column - -Often, you don't want to feed a number directly into the model, but instead -split its value into different categories based on numerical ranges. To do so, -create a `tf.feature_column.bucketized_column`. For -example, consider raw data that represents the year a house was built. Instead -of representing that year as a scalar numeric column, we could split the year -into the following four buckets: - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/bucketized_column.jpg"> -</div> -<div style="text-align: center"> -Dividing year data into four buckets. -</div> - -The model will represent the buckets as follows: - -|Date Range |Represented as... | -|:----------|:-----------------| -|< 1960 | [1, 0, 0, 0] | -|>= 1960 but < 1980 | [0, 1, 0, 0] | -|>= 1980 but < 2000 | [0, 0, 1, 0] | -|>= 2000 | [0, 0, 0, 1] | - -Why would you want to split a number—a perfectly valid input to your -model—into a categorical value? Well, notice that the categorization splits a -single input number into a four-element vector. Therefore, the model now can -learn _four individual weights_ rather than just one; four weights creates a -richer model than one weight. More importantly, bucketizing enables the model -to clearly distinguish between different year categories since only one of the -elements is set (1) and the other three elements are cleared (0). For example, -when we just use a single number (a year) as input, a linear model can only -learn a linear relationship. So, bucketing provides the model with additional -flexibility that the model can use to learn. - -The following code demonstrates how to create a bucketized feature: - -<!--TODO(markdaoust) link to full example - housing price grid?--> -```python -# First, convert the raw input to a numeric column. -numeric_feature_column = tf.feature_column.numeric_column("Year") - -# Then, bucketize the numeric column on the years 1960, 1980, and 2000. -bucketized_feature_column = tf.feature_column.bucketized_column( - source_column = numeric_feature_column, - boundaries = [1960, 1980, 2000]) -``` -Note that specifying a _three_-element boundaries vector creates a -_four_-element bucketized vector. - - -### Categorical identity column - -**Categorical identity columns** can be seen as a special case of bucketized -columns. In traditional bucketized columns, each bucket represents a range of -values (for example, from 1960 to 1979). In a categorical identity column, each -bucket represents a single, unique integer. For example, let's say you want to -represent the integer range `[0, 4)`. That is, you want to represent the -integers 0, 1, 2, or 3. In this case, the categorical identity mapping looks -like this: - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/categorical_column_with_identity.jpg"> -</div> -<div style="text-align: center"> -A categorical identity column mapping. Note that this is a one-hot -encoding, not a binary numerical encoding. -</div> - -As with bucketized columns, a model can learn a separate weight for each class -in a categorical identity column. For example, instead of using a string to -represent the `product_class`, let's represent each class with a unique integer -value. That is: - -* `0="kitchenware"` -* `1="electronics"` -* `2="sport"` - -Call `tf.feature_column.categorical_column_with_identity` to implement a -categorical identity column. For example: - -``` python -# Create categorical output for an integer feature named "my_feature_b", -# The values of my_feature_b must be >= 0 and < num_buckets -identity_feature_column = tf.feature_column.categorical_column_with_identity( - key='my_feature_b', - num_buckets=4) # Values [0, 4) - -# In order for the preceding call to work, the input_fn() must return -# a dictionary containing 'my_feature_b' as a key. Furthermore, the values -# assigned to 'my_feature_b' must belong to the set [0, 4). -def input_fn(): - ... - return ({ 'my_feature_a':[7, 9, 5, 2], 'my_feature_b':[3, 1, 2, 2] }, - [Label_values]) -``` - -### Categorical vocabulary column - -We cannot input strings directly to a model. Instead, we must first map strings -to numeric or categorical values. Categorical vocabulary columns provide a good -way to represent strings as a one-hot vector. For example: - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/categorical_column_with_vocabulary.jpg"> -</div> -<div style="text-align: center"> -Mapping string values to vocabulary columns. -</div> - -As you can see, categorical vocabulary columns are kind of an enum version of -categorical identity columns. TensorFlow provides two different functions to -create categorical vocabulary columns: - -* `tf.feature_column.categorical_column_with_vocabulary_list` -* `tf.feature_column.categorical_column_with_vocabulary_file` - -`categorical_column_with_vocabulary_list` maps each string to an integer based -on an explicit vocabulary list. For example: - -```python -# Given input "feature_name_from_input_fn" which is a string, -# create a categorical feature by mapping the input to one of -# the elements in the vocabulary list. -vocabulary_feature_column = - tf.feature_column.categorical_column_with_vocabulary_list( - key=feature_name_from_input_fn, - vocabulary_list=["kitchenware", "electronics", "sports"]) -``` - -The preceding function is pretty straightforward, but it has a significant -drawback. Namely, there's way too much typing when the vocabulary list is long. -For these cases, call -`tf.feature_column.categorical_column_with_vocabulary_file` instead, which lets -you place the vocabulary words in a separate file. For example: - -```python - -# Given input "feature_name_from_input_fn" which is a string, -# create a categorical feature to our model by mapping the input to one of -# the elements in the vocabulary file -vocabulary_feature_column = - tf.feature_column.categorical_column_with_vocabulary_file( - key=feature_name_from_input_fn, - vocabulary_file="product_class.txt", - vocabulary_size=3) -``` - -`product_class.txt` should contain one line for each vocabulary element. In our -case: - -```None -kitchenware -electronics -sports -``` - -### Hashed Column - -So far, we've worked with a naively small number of categories. For example, -our product_class example has only 3 categories. Often though, the number of -categories can be so big that it's not possible to have individual categories -for each vocabulary word or integer because that would consume too much memory. -For these cases, we can instead turn the question around and ask, "How many -categories am I willing to have for my input?" In fact, the -`tf.feature_column.categorical_column_with_hash_bucket` function enables you -to specify the number of categories. For this type of feature column the model -calculates a hash value of the input, then puts it into one of -the `hash_bucket_size` categories using the modulo operator, as in the following -pseudocode: - -```python -# pseudocode -feature_id = hash(raw_feature) % hash_bucket_size -``` - -The code to create the `feature_column` might look something like this: - -``` python -hashed_feature_column = - tf.feature_column.categorical_column_with_hash_bucket( - key = "some_feature", - hash_bucket_size = 100) # The number of categories -``` -At this point, you might rightfully think: "This is crazy!" After all, we are -forcing the different input values to a smaller set of categories. This means -that two probably unrelated inputs will be mapped to the same -category, and consequently mean the same thing to the neural network. The -following figure illustrates this dilemma, showing that kitchenware and sports -both get assigned to category (hash bucket) 12: - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/hashed_column.jpg"> -</div> -<div style="text-align: center"> -Representing data with hash buckets. -</div> - -As with many counterintuitive phenomena in machine learning, it turns out that -hashing often works well in practice. That's because hash categories provide -the model with some separation. The model can use additional features to further -separate kitchenware from sports. - -### Crossed column - -Combining features into a single feature, better known as -[feature crosses](https://developers.google.com/machine-learning/glossary/#feature_cross), -enables the model to learn separate weights for each combination of -features. - -More concretely, suppose we want our model to calculate real estate prices in -Atlanta, GA. Real-estate prices within this city vary greatly depending on -location. Representing latitude and longitude as separate features isn't very -useful in identifying real-estate location dependencies; however, crossing -latitude and longitude into a single feature can pinpoint locations. Suppose we -represent Atlanta as a grid of 100x100 rectangular sections, identifying each -of the 10,000 sections by a feature cross of latitude and longitude. This -feature cross enables the model to train on pricing conditions related to each -individual section, which is a much stronger signal than latitude and longitude -alone. - -The following figure shows our plan, with the latitude & longitude values for -the corners of the city in red text: - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/Atlanta.jpg"> -</div> -<div style="text-align: center"> -Map of Atlanta. Imagine this map divided into 10,000 sections of -equal size. -</div> - -For the solution, we used a combination of the `bucketized_column` we looked at -earlier, with the `tf.feature_column.crossed_column` function. - -<!--TODO(markdaoust) link to full example--> - -``` python -def make_dataset(latitude, longitude, labels): - assert latitude.shape == longitude.shape == labels.shape - - features = {'latitude': latitude.flatten(), - 'longitude': longitude.flatten()} - labels=labels.flatten() - - return tf.data.Dataset.from_tensor_slices((features, labels)) - - -# Bucketize the latitude and longitude using the `edges` -latitude_bucket_fc = tf.feature_column.bucketized_column( - tf.feature_column.numeric_column('latitude'), - list(atlanta.latitude.edges)) - -longitude_bucket_fc = tf.feature_column.bucketized_column( - tf.feature_column.numeric_column('longitude'), - list(atlanta.longitude.edges)) - -# Cross the bucketized columns, using 5000 hash bins. -crossed_lat_lon_fc = tf.feature_column.crossed_column( - [latitude_bucket_fc, longitude_bucket_fc], 5000) - -fc = [ - latitude_bucket_fc, - longitude_bucket_fc, - crossed_lat_lon_fc] - -# Build and train the Estimator. -est = tf.estimator.LinearRegressor(fc, ...) -``` - -You may create a feature cross from either of the following: - -* Feature names; that is, names from the `dict` returned from `input_fn`. -* Any categorical column, except `categorical_column_with_hash_bucket` - (since `crossed_column` hashes the input). - -When the feature columns `latitude_bucket_fc` and `longitude_bucket_fc` are -crossed, TensorFlow will create `(latitude_fc, longitude_fc)` pairs for each -example. This would produce a full grid of possibilities as follows: - -``` None - (0,0), (0,1)... (0,99) - (1,0), (1,1)... (1,99) - ... ... ... -(99,0), (99,1)...(99, 99) -``` - -Except that a full grid would only be tractable for inputs with limited -vocabularies. Instead of building this, potentially huge, table of inputs, -the `crossed_column` only builds the number requested by the `hash_bucket_size` -argument. The feature column assigns an example to a index by running a hash -function on the tuple of inputs, followed by a modulo operation with -`hash_bucket_size`. - -As discussed earlier, performing the -hash and modulo function limits the number of categories, but can cause category -collisions; that is, multiple (latitude, longitude) feature crosses will end -up in the same hash bucket. In practice though, performing feature crosses -still adds significant value to the learning capability of your models. - -Somewhat counterintuitively, when creating feature crosses, you typically still -should include the original (uncrossed) features in your model (as in the -preceding code snippet). The independent latitude and longitude features help the -model distinguish between examples where a hash collision has occurred in the -crossed feature. - -## Indicator and embedding columns - -Indicator columns and embedding columns never work on features directly, but -instead take categorical columns as input. - -When using an indicator column, we're telling TensorFlow to do exactly what -we've seen in our categorical product_class example. That is, an -**indicator column** treats each category as an element in a one-hot vector, -where the matching category has value 1 and the rest have 0s: - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/categorical_column_with_identity.jpg"> -</div> -<div style="text-align: center"> -Representing data in indicator columns. -</div> - -Here's how you create an indicator column by calling -`tf.feature_column.indicator_column`: - -``` python -categorical_column = ... # Create any type of categorical column. - -# Represent the categorical column as an indicator column. -indicator_column = tf.feature_column.indicator_column(categorical_column) -``` - -Now, suppose instead of having just three possible classes, we have a million. -Or maybe a billion. For a number of reasons, as the number of categories grow -large, it becomes infeasible to train a neural network using indicator columns. - -We can use an embedding column to overcome this limitation. Instead of -representing the data as a one-hot vector of many dimensions, an -**embedding column** represents that data as a lower-dimensional, ordinary -vector in which each cell can contain any number, not just 0 or 1. By -permitting a richer palette of numbers for every cell, an embedding column -contains far fewer cells than an indicator column. - -Let's look at an example comparing indicator and embedding columns. Suppose our -input examples consist of different words from a limited palette of only 81 -words. Further suppose that the data set provides the following input -words in 4 separate examples: - -* `"dog"` -* `"spoon"` -* `"scissors"` -* `"guitar"` - -In that case, the following figure illustrates the processing path for -embedding columns or indicator columns. - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/feature_columns/embedding_vs_indicator.jpg"> -</div> -<div style="text-align: center"> -An embedding column stores categorical data in a lower-dimensional -vector than an indicator column. (We just placed random numbers into the -embedding vectors; training determines the actual numbers.) -</div> - -When an example is processed, one of the `categorical_column_with...` functions -maps the example string to a numerical categorical value. For example, a -function maps "spoon" to `[32]`. (The 32 comes from our imagination—the actual -values depend on the mapping function.) You may then represent these numerical -categorical values in either of the following two ways: - -* As an indicator column. A function converts each numeric categorical value - into an 81-element vector (because our palette consists of 81 words), placing - a 1 in the index of the categorical value (0, 32, 79, 80) and a 0 in all the - other positions. - -* As an embedding column. A function uses the numerical categorical values - `(0, 32, 79, 80)` as indices to a lookup table. Each slot in that lookup table - contains a 3-element vector. - -How do the values in the embeddings vectors magically get assigned? Actually, -the assignments happen during training. That is, the model learns the best way -to map your input numeric categorical values to the embeddings vector value in -order to solve your problem. Embedding columns increase your model's -capabilities, since an embeddings vector learns new relationships between -categories from the training data. - -Why is the embedding vector size 3 in our example? Well, the following "formula" -provides a general rule of thumb about the number of embedding dimensions: - -```python -embedding_dimensions = number_of_categories**0.25 -``` - -That is, the embedding vector dimension should be the 4th root of the number of -categories. Since our vocabulary size in this example is 81, the recommended -number of dimensions is 3: - -``` python -3 = 81**0.25 -``` -Note that this is just a general guideline; you can set the number of embedding -dimensions as you please. - -Call `tf.feature_column.embedding_column` to create an `embedding_column` as -suggested by the following snippet: - -``` python -categorical_column = ... # Create any categorical column - -# Represent the categorical column as an embedding column. -# This means creating an embedding vector lookup table with one element for each category. -embedding_column = tf.feature_column.embedding_column( - categorical_column=categorical_column, - dimension=embedding_dimensions) -``` - -[Embeddings](../guide/embedding.md) is a significant topic within machine -learning. This information was just to get you started using them as feature -columns. - -## Passing feature columns to Estimators - -As the following list indicates, not all Estimators permit all types of -`feature_columns` argument(s): - -* `tf.estimator.LinearClassifier` and - `tf.estimator.LinearRegressor`: Accept all types of - feature column. -* `tf.estimator.DNNClassifier` and - `tf.estimator.DNNRegressor`: Only accept dense columns. Other - column types must be wrapped in either an `indicator_column` or - `embedding_column`. -* `tf.estimator.DNNLinearCombinedClassifier` and - `tf.estimator.DNNLinearCombinedRegressor`: - * The `linear_feature_columns` argument accepts any feature column type. - * The `dnn_feature_columns` argument only accepts dense columns. - -## Other Sources - -For more examples on feature columns, view the following: - -* The [Low Level Introduction](../guide/low_level_intro.md#feature_columns) demonstrates how - experiment directly with `feature_columns` using TensorFlow's low level APIs. -* The [Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/wide_deep) - solves a binary classification problem using `feature_columns` on a variety of - input data types. - -To learn more about embeddings, see the following: - -* [Deep Learning, NLP, and representations](http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/) - (Chris Olah's blog) -* The TensorFlow [Embedding Projector](http://projector.tensorflow.org) diff --git a/tensorflow/docs_src/guide/graph_viz.md b/tensorflow/docs_src/guide/graph_viz.md deleted file mode 100644 index 23f722bbe7..0000000000 --- a/tensorflow/docs_src/guide/graph_viz.md +++ /dev/null @@ -1,317 +0,0 @@ -# TensorBoard: Graph Visualization - -TensorFlow computation graphs are powerful but complicated. The graph visualization can help you understand and debug them. Here's an example of the visualization at work. - - -*Visualization of a TensorFlow graph.* - -To see your own graph, run TensorBoard pointing it to the log directory of the job, click on the graph tab on the top pane and select the appropriate run using the menu at the upper left corner. For in depth information on how to run TensorBoard and make sure you are logging all the necessary information, see [TensorBoard: Visualizing Learning](../guide/summaries_and_tensorboard.md). - -## Name scoping and nodes - -Typical TensorFlow graphs can have many thousands of nodes--far too many to see -easily all at once, or even to lay out using standard graph tools. To simplify, -variable names can be scoped and the visualization uses this information to -define a hierarchy on the nodes in the graph. By default, only the top of this -hierarchy is shown. Here is an example that defines three operations under the -`hidden` name scope using -`tf.name_scope`: - -```python -import tensorflow as tf - -with tf.name_scope('hidden') as scope: - a = tf.constant(5, name='alpha') - W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0), name='weights') - b = tf.Variable(tf.zeros([1]), name='biases') -``` - -This results in the following three op names: - -* `hidden/alpha` -* `hidden/weights` -* `hidden/biases` - -By default, the visualization will collapse all three into a node labeled `hidden`. -The extra detail isn't lost. You can double-click, or click -on the orange `+` sign in the top right to expand the node, and then you'll see -three subnodes for `alpha`, `weights` and `biases`. - -Here's a real-life example of a more complicated node in its initial and -expanded states. - -<table width="100%;"> - <tr> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/pool1_collapsed.png" alt="Unexpanded name scope" title="Unexpanded name scope" /> - </td> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/pool1_expanded.png" alt="Expanded name scope" title="Expanded name scope" /> - </td> - </tr> - <tr> - <td style="width: 50%;"> - Initial view of top-level name scope <code>pool_1</code>. Clicking on the orange <code>+</code> button on the top right or double-clicking on the node itself will expand it. - </td> - <td style="width: 50%;"> - Expanded view of <code>pool_1</code> name scope. Clicking on the orange <code>-</code> button on the top right or double-clicking on the node itself will collapse the name scope. - </td> - </tr> -</table> - -Grouping nodes by name scopes is critical to making a legible graph. If you're -building a model, name scopes give you control over the resulting visualization. -**The better your name scopes, the better your visualization.** - -The figure above illustrates a second aspect of the visualization. TensorFlow -graphs have two kinds of connections: data dependencies and control -dependencies. Data dependencies show the flow of tensors between two ops and -are shown as solid arrows, while control dependencies use dotted lines. In the -expanded view (right side of the figure above) all the connections are data -dependencies with the exception of the dotted line connecting `CheckNumerics` -and `control_dependency`. - -There's a second trick to simplifying the layout. Most TensorFlow graphs have a -few nodes with many connections to other nodes. For example, many nodes might -have a control dependency on an initialization step. Drawing all edges between -the `init` node and its dependencies would create a very cluttered view. - -To reduce clutter, the visualization separates out all high-degree nodes to an -*auxiliary* area on the right and doesn't draw lines to represent their edges. -Instead of lines, we draw small *node icons* to indicate the connections. -Separating out the auxiliary nodes typically doesn't remove critical -information since these nodes are usually related to bookkeeping functions. -See [Interaction](#interaction) for how to move nodes between the main graph -and the auxiliary area. - -<table width="100%;"> - <tr> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/conv_1.png" alt="conv_1 is part of the main graph" title="conv_1 is part of the main graph" /> - </td> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/save.png" alt="save is extracted as auxiliary node" title="save is extracted as auxiliary node" /> - </td> - </tr> - <tr> - <td style="width: 50%;"> - Node <code>conv_1</code> is connected to <code>save</code>. Note the little <code>save</code> node icon on its right. - </td> - <td style="width: 50%;"> - <code>save</code> has a high degree, and will appear as an auxiliary node. The connection with <code>conv_1</code> is shown as a node icon on its left. To further reduce clutter, since <code>save</code> has a lot of connections, we show the first 5 and abbreviate the others as <code>... 12 more</code>. - </td> - </tr> -</table> - -One last structural simplification is *series collapsing*. Sequential -motifs--that is, nodes whose names differ by a number at the end and have -isomorphic structures--are collapsed into a single *stack* of nodes, as shown -below. For networks with long sequences, this greatly simplifies the view. As -with hierarchical nodes, double-clicking expands the series. See -[Interaction](#interaction) for how to disable/enable series collapsing for a -specific set of nodes. - -<table width="100%;"> - <tr> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/series.png" alt="Sequence of nodes" title="Sequence of nodes" /> - </td> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/series_expanded.png" alt="Expanded sequence of nodes" title="Expanded sequence of nodes" /> - </td> - </tr> - <tr> - <td style="width: 50%;"> - A collapsed view of a node sequence. - </td> - <td style="width: 50%;"> - A small piece of the expanded view, after double-click. - </td> - </tr> -</table> - -Finally, as one last aid to legibility, the visualization uses special icons -for constants and summary nodes. To summarize, here's a table of node symbols: - -Symbol | Meaning ---- | --- - | *High-level* node representing a name scope. Double-click to expand a high-level node. - | Sequence of numbered nodes that are not connected to each other. - | Sequence of numbered nodes that are connected to each other. - | An individual operation node. - | A constant. - | A summary node. - | Edge showing the data flow between operations. - | Edge showing the control dependency between operations. - | A reference edge showing that the outgoing operation node can mutate the incoming tensor. - -## Interaction {#interaction} - -Navigate the graph by panning and zooming. Click and drag to pan, and use a -scroll gesture to zoom. Double-click on a node, or click on its `+` button, to -expand a name scope that represents a group of operations. To easily keep -track of the current viewpoint when zooming and panning, there is a minimap in -the bottom right corner. - -To close an open node, double-click it again or click its `-` button. You can -also click once to select a node. It will turn a darker color, and details -about it and the nodes it connects to will appear in the info card at upper -right corner of the visualization. - -<table width="100%;"> - <tr> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/infocard.png" alt="Info card of a name scope" title="Info card of a name scope" /> - </td> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/infocard_op.png" alt="Info card of operation node" title="Info card of operation node" /> - </td> - </tr> - <tr> - <td style="width: 50%;"> - Info card showing detailed information for the <code>conv2</code> name scope. The inputs and outputs are combined from the inputs and outputs of the operation nodes inside the name scope. For name scopes no attributes are shown. - </td> - <td style="width: 50%;"> - Info card showing detailed information for the <code>DecodeRaw</code> operation node. In addition to inputs and outputs, the card shows the device and the attributes associated with the current operation. - </td> - </tr> -</table> - -TensorBoard provides several ways to change the visual layout of the graph. This -doesn't change the graph's computational semantics, but it can bring some -clarity to the network's structure. By right clicking on a node or pressing -buttons on the bottom of that node's info card, you can make the following -changes to its layout: - -* Nodes can be moved between the main graph and the auxiliary area. -* A series of nodes can be ungrouped so that the nodes in the series do not -appear grouped together. Ungrouped series can likewise be regrouped. - -Selection can also be helpful in understanding high-degree nodes. Select any -high-degree node, and the corresponding node icons for its other connections -will be selected as well. This makes it easy, for example, to see which nodes -are being saved--and which aren't. - -Clicking on a node name in the info card will select it. If necessary, the -viewpoint will automatically pan so that the node is visible. - -Finally, you can choose two color schemes for your graph, using the color menu -above the legend. The default *Structure View* shows structure: when two -high-level nodes have the same structure, they appear in the same color of the -rainbow. Uniquely structured nodes are gray. There's a second view, which shows -what device the different operations run on. Name scopes are colored -proportionally to the fraction of devices for the operations inside them. - -The images below give an illustration for a piece of a real-life graph. - -<table width="100%;"> - <tr> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/colorby_structure.png" alt="Color by structure" title="Color by structure" /> - </td> - <td style="width: 50%;"> - <img src="https://www.tensorflow.org/images/colorby_device.png" alt="Color by device" title="Color by device" /> - </td> - </tr> - <tr> - <td style="width: 50%;"> - Structure view: The gray nodes have unique structure. The orange <code>conv1</code> and <code>conv2</code> nodes have the same structure, and analogously for nodes with other colors. - </td> - <td style="width: 50%;"> - Device view: Name scopes are colored proportionally to the fraction of devices of the operation nodes inside them. Here, purple means GPU and the green is CPU. - </td> - </tr> -</table> - -## Tensor shape information - -When the serialized `GraphDef` includes tensor shapes, the graph visualizer -labels edges with tensor dimensions, and edge thickness reflects total tensor -size. To include tensor shapes in the `GraphDef` pass the actual graph object -(as in `sess.graph`) to the `FileWriter` when serializing the graph. -The images below show the CIFAR-10 model with tensor shape information: -<table width="100%;"> - <tr> - <td style="width: 100%;"> - <img src="https://www.tensorflow.org/images/tensor_shapes.png" alt="CIFAR-10 model with tensor shape information" title="CIFAR-10 model with tensor shape information" /> - </td> - </tr> - <tr> - <td style="width: 100%;"> - CIFAR-10 model with tensor shape information. - </td> - </tr> -</table> - -## Runtime statistics - -Often it is useful to collect runtime metadata for a run, such as total memory -usage, total compute time, and tensor shapes for nodes. The code example below -is a snippet from the train and test section of a modification of the -[Estimators MNIST tutorial](../tutorials/estimators/cnn.md), in which we have -recorded summaries and -runtime statistics. See the -[Summaries Tutorial](../guide/summaries_and_tensorboard.md#serializing-the-data) -for details on how to record summaries. -Full source is [here](https://www.tensorflow.org/code/tensorflow/examples/tutorials/mnist/mnist_with_summaries.py). - -```python - # Train the model, and also write summaries. - # Every 10th step, measure test-set accuracy, and write test summaries - # All other steps, run train_step on training data, & add training summaries - - def feed_dict(train): - """Make a TensorFlow feed_dict: maps data onto Tensor placeholders.""" - if train or FLAGS.fake_data: - xs, ys = mnist.train.next_batch(100, fake_data=FLAGS.fake_data) - k = FLAGS.dropout - else: - xs, ys = mnist.test.images, mnist.test.labels - k = 1.0 - return {x: xs, y_: ys, keep_prob: k} - - for i in range(FLAGS.max_steps): - if i % 10 == 0: # Record summaries and test-set accuracy - summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False)) - test_writer.add_summary(summary, i) - print('Accuracy at step %s: %s' % (i, acc)) - else: # Record train set summaries, and train - if i % 100 == 99: # Record execution stats - run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE) - run_metadata = tf.RunMetadata() - summary, _ = sess.run([merged, train_step], - feed_dict=feed_dict(True), - options=run_options, - run_metadata=run_metadata) - train_writer.add_run_metadata(run_metadata, 'step%d' % i) - train_writer.add_summary(summary, i) - print('Adding run metadata for', i) - else: # Record a summary - summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True)) - train_writer.add_summary(summary, i) -``` - -This code will emit runtime statistics for every 100th step starting at step99. - -When you launch tensorboard and go to the Graph tab, you will now see options -under "Session runs" which correspond to the steps where run metadata was added. -Selecting one of these runs will show you the snapshot of the network at that -step, fading out unused nodes. In the controls on the left hand side, you will -be able to color the nodes by total memory or total compute time. Additionally, -clicking on a node will display the exact total memory, compute time, and -tensor output sizes. - - -<table width="100%;"> - <tr style="height: 380px"> - <td> - <img src="https://www.tensorflow.org/images/colorby_compute_time.png" alt="Color by compute time" title="Color by compute time"/> - </td> - <td> - <img src="https://www.tensorflow.org/images/run_metadata_graph.png" alt="Run metadata graph" title="Run metadata graph" /> - </td> - <td> - <img src="https://www.tensorflow.org/images/run_metadata_infocard.png" alt="Run metadata info card" title="Run metadata info card" /> - </td> - </tr> -</table> diff --git a/tensorflow/docs_src/guide/graphs.md b/tensorflow/docs_src/guide/graphs.md deleted file mode 100644 index c70479dba2..0000000000 --- a/tensorflow/docs_src/guide/graphs.md +++ /dev/null @@ -1,558 +0,0 @@ -# Graphs and Sessions - -TensorFlow uses a **dataflow graph** to represent your computation in terms of -the dependencies between individual operations. This leads to a low-level -programming model in which you first define the dataflow graph, then create a -TensorFlow **session** to run parts of the graph across a set of local and -remote devices. - -This guide will be most useful if you intend to use the low-level programming -model directly. Higher-level APIs such as `tf.estimator.Estimator` and Keras -hide the details of graphs and sessions from the end user, but this guide may -also be useful if you want to understand how these APIs are implemented. - -## Why dataflow graphs? - - - -[Dataflow](https://en.wikipedia.org/wiki/Dataflow_programming) is a common -programming model for parallel computing. In a dataflow graph, the nodes -represent units of computation, and the edges represent the data consumed or -produced by a computation. For example, in a TensorFlow graph, the `tf.matmul` -operation would correspond to a single node with two incoming edges (the -matrices to be multiplied) and one outgoing edge (the result of the -multiplication). - -<!-- TODO(barryr): Add a diagram to illustrate the `tf.matmul` graph. --> - -Dataflow has several advantages that TensorFlow leverages when executing your -programs: - -* **Parallelism.** By using explicit edges to represent dependencies between - operations, it is easy for the system to identify operations that can execute - in parallel. - -* **Distributed execution.** By using explicit edges to represent the values - that flow between operations, it is possible for TensorFlow to partition your - program across multiple devices (CPUs, GPUs, and TPUs) attached to different - machines. TensorFlow inserts the necessary communication and coordination - between devices. - -* **Compilation.** TensorFlow's [XLA compiler](../performance/xla/index.md) can - use the information in your dataflow graph to generate faster code, for - example, by fusing together adjacent operations. - -* **Portability.** The dataflow graph is a language-independent representation - of the code in your model. You can build a dataflow graph in Python, store it - in a [SavedModel](../guide/saved_model.md), and restore it in a C++ program for - low-latency inference. - - -## What is a `tf.Graph`? - -A `tf.Graph` contains two relevant kinds of information: - -* **Graph structure.** The nodes and edges of the graph, indicating how - individual operations are composed together, but not prescribing how they - should be used. The graph structure is like assembly code: inspecting it can - convey some useful information, but it does not contain all of the useful - context that source code conveys. - -* **Graph collections.** TensorFlow provides a general mechanism for storing - collections of metadata in a `tf.Graph`. The `tf.add_to_collection` function - enables you to associate a list of objects with a key (where `tf.GraphKeys` - defines some of the standard keys), and `tf.get_collection` enables you to - look up all objects associated with a key. Many parts of the TensorFlow - library use this facility: for example, when you create a `tf.Variable`, it - is added by default to collections representing "global variables" and - "trainable variables". When you later come to create a `tf.train.Saver` or - `tf.train.Optimizer`, the variables in these collections are used as the - default arguments. - - -## Building a `tf.Graph` - -Most TensorFlow programs start with a dataflow graph construction phase. In this -phase, you invoke TensorFlow API functions that construct new `tf.Operation` -(node) and `tf.Tensor` (edge) objects and add them to a `tf.Graph` -instance. TensorFlow provides a **default graph** that is an implicit argument -to all API functions in the same context. For example: - -* Calling `tf.constant(42.0)` creates a single `tf.Operation` that produces the - value `42.0`, adds it to the default graph, and returns a `tf.Tensor` that - represents the value of the constant. - -* Calling `tf.matmul(x, y)` creates a single `tf.Operation` that multiplies - the values of `tf.Tensor` objects `x` and `y`, adds it to the default graph, - and returns a `tf.Tensor` that represents the result of the multiplication. - -* Executing `v = tf.Variable(0)` adds to the graph a `tf.Operation` that will - store a writeable tensor value that persists between `tf.Session.run` calls. - The `tf.Variable` object wraps this operation, and can be used [like a - tensor](#tensor-like_objects), which will read the current value of the - stored value. The `tf.Variable` object also has methods such as - `tf.Variable.assign` and `tf.Variable.assign_add` that - create `tf.Operation` objects that, when executed, update the stored value. - (See [Variables](../guide/variables.md) for more information about variables.) - -* Calling `tf.train.Optimizer.minimize` will add operations and tensors to the - default graph that calculates gradients, and return a `tf.Operation` that, - when run, will apply those gradients to a set of variables. - -Most programs rely solely on the default graph. However, -see [Dealing with multiple graphs](#programming_with_multiple_graphs) for more -advanced use cases. High-level APIs such as the `tf.estimator.Estimator` API -manage the default graph on your behalf, and--for example--may create different -graphs for training and evaluation. - -Note: Calling most functions in the TensorFlow API merely adds operations -and tensors to the default graph, but **does not** perform the actual -computation. Instead, you compose these functions until you have a `tf.Tensor` -or `tf.Operation` that represents the overall computation--such as performing -one step of gradient descent--and then pass that object to a `tf.Session` to -perform the computation. See the section "Executing a graph in a `tf.Session`" -for more details. - -## Naming operations - -A `tf.Graph` object defines a **namespace** for the `tf.Operation` objects it -contains. TensorFlow automatically chooses a unique name for each operation in -your graph, but giving operations descriptive names can make your program easier -to read and debug. The TensorFlow API provides two ways to override the name of -an operation: - -* Each API function that creates a new `tf.Operation` or returns a new - `tf.Tensor` accepts an optional `name` argument. For example, - `tf.constant(42.0, name="answer")` creates a new `tf.Operation` named - `"answer"` and returns a `tf.Tensor` named `"answer:0"`. If the default graph - already contains an operation named `"answer"`, then TensorFlow would append - `"_1"`, `"_2"`, and so on to the name, in order to make it unique. - -* The `tf.name_scope` function makes it possible to add a **name scope** prefix - to all operations created in a particular context. The current name scope - prefix is a `"/"`-delimited list of the names of all active `tf.name_scope` - context managers. If a name scope has already been used in the current - context, TensorFlow appends `"_1"`, `"_2"`, and so on. For example: - - ```python - c_0 = tf.constant(0, name="c") # => operation named "c" - - # Already-used names will be "uniquified". - c_1 = tf.constant(2, name="c") # => operation named "c_1" - - # Name scopes add a prefix to all operations created in the same context. - with tf.name_scope("outer"): - c_2 = tf.constant(2, name="c") # => operation named "outer/c" - - # Name scopes nest like paths in a hierarchical file system. - with tf.name_scope("inner"): - c_3 = tf.constant(3, name="c") # => operation named "outer/inner/c" - - # Exiting a name scope context will return to the previous prefix. - c_4 = tf.constant(4, name="c") # => operation named "outer/c_1" - - # Already-used name scopes will be "uniquified". - with tf.name_scope("inner"): - c_5 = tf.constant(5, name="c") # => operation named "outer/inner_1/c" - ``` - -The graph visualizer uses name scopes to group operations and reduce the visual -complexity of a graph. See [Visualizing your graph](#visualizing-your-graph) for -more information. - -Note that `tf.Tensor` objects are implicitly named after the `tf.Operation` -that produces the tensor as output. A tensor name has the form `"<OP_NAME>:<i>"` -where: - -* `"<OP_NAME>"` is the name of the operation that produces it. -* `"<i>"` is an integer representing the index of that tensor among the - operation's outputs. - -## Placing operations on different devices - -If you want your TensorFlow program to use multiple different devices, the -`tf.device` function provides a convenient way to request that all operations -created in a particular context are placed on the same device (or type of -device). - -A **device specification** has the following form: - -``` -/job:<JOB_NAME>/task:<TASK_INDEX>/device:<DEVICE_TYPE>:<DEVICE_INDEX> -``` - -where: - -* `<JOB_NAME>` is an alpha-numeric string that does not start with a number. -* `<DEVICE_TYPE>` is a registered device type (such as `GPU` or `CPU`). -* `<TASK_INDEX>` is a non-negative integer representing the index of the task - in the job named `<JOB_NAME>`. See `tf.train.ClusterSpec` for an explanation - of jobs and tasks. -* `<DEVICE_INDEX>` is a non-negative integer representing the index of the - device, for example, to distinguish between different GPU devices used in the - same process. - -You do not need to specify every part of a device specification. For example, -if you are running in a single-machine configuration with a single GPU, you -might use `tf.device` to pin some operations to the CPU and GPU: - -```python -# Operations created outside either context will run on the "best possible" -# device. For example, if you have a GPU and a CPU available, and the operation -# has a GPU implementation, TensorFlow will choose the GPU. -weights = tf.random_normal(...) - -with tf.device("/device:CPU:0"): - # Operations created in this context will be pinned to the CPU. - img = tf.decode_jpeg(tf.read_file("img.jpg")) - -with tf.device("/device:GPU:0"): - # Operations created in this context will be pinned to the GPU. - result = tf.matmul(weights, img) -``` -If you are deploying TensorFlow in a [typical distributed configuration](../deploy/distributed.md), -you might specify the job name and task ID to place variables on -a task in the parameter server job (`"/job:ps"`), and the other operations on -task in the worker job (`"/job:worker"`): - -```python -with tf.device("/job:ps/task:0"): - weights_1 = tf.Variable(tf.truncated_normal([784, 100])) - biases_1 = tf.Variable(tf.zeroes([100])) - -with tf.device("/job:ps/task:1"): - weights_2 = tf.Variable(tf.truncated_normal([100, 10])) - biases_2 = tf.Variable(tf.zeroes([10])) - -with tf.device("/job:worker"): - layer_1 = tf.matmul(train_batch, weights_1) + biases_1 - layer_2 = tf.matmul(train_batch, weights_2) + biases_2 -``` - -`tf.device` gives you a lot of flexibility to choose placements for individual -operations or broad regions of a TensorFlow graph. In many cases, there are -simple heuristics that work well. For example, the -`tf.train.replica_device_setter` API can be used with `tf.device` to place -operations for **data-parallel distributed training**. For example, the -following code fragment shows how `tf.train.replica_device_setter` applies -different placement policies to `tf.Variable` objects and other operations: - -```python -with tf.device(tf.train.replica_device_setter(ps_tasks=3)): - # tf.Variable objects are, by default, placed on tasks in "/job:ps" in a - # round-robin fashion. - w_0 = tf.Variable(...) # placed on "/job:ps/task:0" - b_0 = tf.Variable(...) # placed on "/job:ps/task:1" - w_1 = tf.Variable(...) # placed on "/job:ps/task:2" - b_1 = tf.Variable(...) # placed on "/job:ps/task:0" - - input_data = tf.placeholder(tf.float32) # placed on "/job:worker" - layer_0 = tf.matmul(input_data, w_0) + b_0 # placed on "/job:worker" - layer_1 = tf.matmul(layer_0, w_1) + b_1 # placed on "/job:worker" -``` - -## Tensor-like objects - -Many TensorFlow operations take one or more `tf.Tensor` objects as arguments. -For example, `tf.matmul` takes two `tf.Tensor` objects, and `tf.add_n` takes -a list of `n` `tf.Tensor` objects. For convenience, these functions will accept -a **tensor-like object** in place of a `tf.Tensor`, and implicitly convert it -to a `tf.Tensor` using the `tf.convert_to_tensor` method. Tensor-like objects -include elements of the following types: - -* `tf.Tensor` -* `tf.Variable` -* [`numpy.ndarray`](https://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.html) -* `list` (and lists of tensor-like objects) -* Scalar Python types: `bool`, `float`, `int`, `str` - -You can register additional tensor-like types using -`tf.register_tensor_conversion_function`. - -Note: By default, TensorFlow will create a new `tf.Tensor` each time you use -the same tensor-like object. If the tensor-like object is large (e.g. a -`numpy.ndarray` containing a set of training examples) and you use it multiple -times, you may run out of memory. To avoid this, manually call -`tf.convert_to_tensor` on the tensor-like object once and use the returned -`tf.Tensor` instead. - -## Executing a graph in a `tf.Session` - -TensorFlow uses the `tf.Session` class to represent a connection between the -client program---typically a Python program, although a similar interface is -available in other languages---and the C++ runtime. A `tf.Session` object -provides access to devices in the local machine, and remote devices using the -distributed TensorFlow runtime. It also caches information about your -`tf.Graph` so that you can efficiently run the same computation multiple times. - -### Creating a `tf.Session` - -If you are using the low-level TensorFlow API, you can create a `tf.Session` -for the current default graph as follows: - -```python -# Create a default in-process session. -with tf.Session() as sess: - # ... - -# Create a remote session. -with tf.Session("grpc://example.org:2222"): - # ... -``` - -Since a `tf.Session` owns physical resources (such as GPUs and -network connections), it is typically used as a context manager (in a `with` -block) that automatically closes the session when you exit the block. It is -also possible to create a session without using a `with` block, but you should -explicitly call `tf.Session.close` when you are finished with it to free the -resources. - -Note: Higher-level APIs such as `tf.train.MonitoredTrainingSession` or -`tf.estimator.Estimator` will create and manage a `tf.Session` for you. These -APIs accept optional `target` and `config` arguments (either directly, or as -part of a `tf.estimator.RunConfig` object), with the same meaning as -described below. - -`tf.Session.__init__` accepts three optional arguments: - -* **`target`.** If this argument is left empty (the default), the session will - only use devices in the local machine. However, you may also specify a - `grpc://` URL to specify the address of a TensorFlow server, which gives the - session access to all devices on machines that this server controls. See - `tf.train.Server` for details of how to create a TensorFlow - server. For example, in the common **between-graph replication** - configuration, the `tf.Session` connects to a `tf.train.Server` in the same - process as the client. The [distributed TensorFlow](../deploy/distributed.md) - deployment guide describes other common scenarios. - -* **`graph`.** By default, a new `tf.Session` will be bound to---and only able - to run operations in---the current default graph. If you are using multiple - graphs in your program (see [Programming with multiple - graphs](#programming_with_multiple_graphs) for more details), you can specify - an explicit `tf.Graph` when you construct the session. - -* **`config`.** This argument allows you to specify a `tf.ConfigProto` that - controls the behavior of the session. For example, some of the configuration - options include: - - * `allow_soft_placement`. Set this to `True` to enable a "soft" device - placement algorithm, which ignores `tf.device` annotations that attempt - to place CPU-only operations on a GPU device, and places them on the CPU - instead. - - * `cluster_def`. When using distributed TensorFlow, this option allows you - to specify what machines to use in the computation, and provide a mapping - between job names, task indices, and network addresses. See - `tf.train.ClusterSpec.as_cluster_def` for details. - - * `graph_options.optimizer_options`. Provides control over the optimizations - that TensorFlow performs on your graph before executing it. - - * `gpu_options.allow_growth`. Set this to `True` to change the GPU memory - allocator so that it gradually increases the amount of memory allocated, - rather than allocating most of the memory at startup. - - -### Using `tf.Session.run` to execute operations - -The `tf.Session.run` method is the main mechanism for running a `tf.Operation` -or evaluating a `tf.Tensor`. You can pass one or more `tf.Operation` or -`tf.Tensor` objects to `tf.Session.run`, and TensorFlow will execute the -operations that are needed to compute the result. - -`tf.Session.run` requires you to specify a list of **fetches**, which determine -the return values, and may be a `tf.Operation`, a `tf.Tensor`, or -a [tensor-like type](#tensor-like_objects) such as `tf.Variable`. These fetches -determine what **subgraph** of the overall `tf.Graph` must be executed to -produce the result: this is the subgraph that contains all operations named in -the fetch list, plus all operations whose outputs are used to compute the value -of the fetches. For example, the following code fragment shows how different -arguments to `tf.Session.run` cause different subgraphs to be executed: - -```python -x = tf.constant([[37.0, -23.0], [1.0, 4.0]]) -w = tf.Variable(tf.random_uniform([2, 2])) -y = tf.matmul(x, w) -output = tf.nn.softmax(y) -init_op = w.initializer - -with tf.Session() as sess: - # Run the initializer on `w`. - sess.run(init_op) - - # Evaluate `output`. `sess.run(output)` will return a NumPy array containing - # the result of the computation. - print(sess.run(output)) - - # Evaluate `y` and `output`. Note that `y` will only be computed once, and its - # result used both to return `y_val` and as an input to the `tf.nn.softmax()` - # op. Both `y_val` and `output_val` will be NumPy arrays. - y_val, output_val = sess.run([y, output]) -``` - -`tf.Session.run` also optionally takes a dictionary of **feeds**, which is a -mapping from `tf.Tensor` objects (typically `tf.placeholder` tensors) to -values (typically Python scalars, lists, or NumPy arrays) that will be -substituted for those tensors in the execution. For example: - -```python -# Define a placeholder that expects a vector of three floating-point values, -# and a computation that depends on it. -x = tf.placeholder(tf.float32, shape=[3]) -y = tf.square(x) - -with tf.Session() as sess: - # Feeding a value changes the result that is returned when you evaluate `y`. - print(sess.run(y, {x: [1.0, 2.0, 3.0]})) # => "[1.0, 4.0, 9.0]" - print(sess.run(y, {x: [0.0, 0.0, 5.0]})) # => "[0.0, 0.0, 25.0]" - - # Raises `tf.errors.InvalidArgumentError`, because you must feed a value for - # a `tf.placeholder()` when evaluating a tensor that depends on it. - sess.run(y) - - # Raises `ValueError`, because the shape of `37.0` does not match the shape - # of placeholder `x`. - sess.run(y, {x: 37.0}) -``` - -`tf.Session.run` also accepts an optional `options` argument that enables you -to specify options about the call, and an optional `run_metadata` argument that -enables you to collect metadata about the execution. For example, you can use -these options together to collect tracing information about the execution: - -``` -y = tf.matmul([[37.0, -23.0], [1.0, 4.0]], tf.random_uniform([2, 2])) - -with tf.Session() as sess: - # Define options for the `sess.run()` call. - options = tf.RunOptions() - options.output_partition_graphs = True - options.trace_level = tf.RunOptions.FULL_TRACE - - # Define a container for the returned metadata. - metadata = tf.RunMetadata() - - sess.run(y, options=options, run_metadata=metadata) - - # Print the subgraphs that executed on each device. - print(metadata.partition_graphs) - - # Print the timings of each operation that executed. - print(metadata.step_stats) -``` - - -## Visualizing your graph - -TensorFlow includes tools that can help you to understand the code in a graph. -The **graph visualizer** is a component of TensorBoard that renders the -structure of your graph visually in a browser. The easiest way to create a -visualization is to pass a `tf.Graph` when creating the -`tf.summary.FileWriter`: - -```python -# Build your graph. -x = tf.constant([[37.0, -23.0], [1.0, 4.0]]) -w = tf.Variable(tf.random_uniform([2, 2])) -y = tf.matmul(x, w) -# ... -loss = ... -train_op = tf.train.AdagradOptimizer(0.01).minimize(loss) - -with tf.Session() as sess: - # `sess.graph` provides access to the graph used in a `tf.Session`. - writer = tf.summary.FileWriter("/tmp/log/...", sess.graph) - - # Perform your computation... - for i in range(1000): - sess.run(train_op) - # ... - - writer.close() -``` - -Note: If you are using a `tf.estimator.Estimator`, the graph (and any -summaries) will be logged automatically to the `model_dir` that you specified -when creating the estimator. - -You can then open the log in `tensorboard`, navigate to the "Graph" tab, and -see a high-level visualization of your graph's structure. Note that a typical -TensorFlow graph---especially training graphs with automatically computed -gradients---has too many nodes to visualize at once. The graph visualizer makes -use of name scopes to group related operations into "super" nodes. You can -click on the orange "+" button on any of these super nodes to expand the -subgraph inside. - - - -For more information about visualizing your TensorFlow application with -TensorBoard, see the [TensorBoard guide](./summaries_and_tensorboard.md). - -## Programming with multiple graphs - -Note: When training a model, a common way of organizing your code is to use one -graph for training your model, and a separate graph for evaluating or performing -inference with a trained model. In many cases, the inference graph will be -different from the training graph: for example, techniques like dropout and -batch normalization use different operations in each case. Furthermore, by -default utilities like `tf.train.Saver` use the names of `tf.Variable` objects -(which have names based on an underlying `tf.Operation`) to identify each -variable in a saved checkpoint. When programming this way, you can either use -completely separate Python processes to build and execute the graphs, or you can -use multiple graphs in the same process. This section describes how to use -multiple graphs in the same process. - -As noted above, TensorFlow provides a "default graph" that is implicitly passed -to all API functions in the same context. For many applications, a single graph -is sufficient. However, TensorFlow also provides methods for manipulating -the default graph, which can be useful in more advanced use cases. For example: - -* A `tf.Graph` defines the namespace for `tf.Operation` objects: each - operation in a single graph must have a unique name. TensorFlow will - "uniquify" the names of operations by appending `"_1"`, `"_2"`, and so on to - their names if the requested name is already taken. Using multiple explicitly - created graphs gives you more control over what name is given to each - operation. - -* The default graph stores information about every `tf.Operation` and - `tf.Tensor` that was ever added to it. If your program creates a large number - of unconnected subgraphs, it may be more efficient to use a different - `tf.Graph` to build each subgraph, so that unrelated state can be garbage - collected. - -You can install a different `tf.Graph` as the default graph, using the -`tf.Graph.as_default` context manager: - -```python -g_1 = tf.Graph() -with g_1.as_default(): - # Operations created in this scope will be added to `g_1`. - c = tf.constant("Node in g_1") - - # Sessions created in this scope will run operations from `g_1`. - sess_1 = tf.Session() - -g_2 = tf.Graph() -with g_2.as_default(): - # Operations created in this scope will be added to `g_2`. - d = tf.constant("Node in g_2") - -# Alternatively, you can pass a graph when constructing a `tf.Session`: -# `sess_2` will run operations from `g_2`. -sess_2 = tf.Session(graph=g_2) - -assert c.graph is g_1 -assert sess_1.graph is g_1 - -assert d.graph is g_2 -assert sess_2.graph is g_2 -``` - -To inspect the current default graph, call `tf.get_default_graph`, which -returns a `tf.Graph` object: - -```python -# Print all of the operations in the default graph. -g = tf.get_default_graph() -print(g.get_operations()) -``` diff --git a/tensorflow/docs_src/guide/index.md b/tensorflow/docs_src/guide/index.md deleted file mode 100644 index 50499582cc..0000000000 --- a/tensorflow/docs_src/guide/index.md +++ /dev/null @@ -1,82 +0,0 @@ -# TensorFlow Guide - -The documents in this unit dive into the details of how TensorFlow -works. The units are as follows: - -## High Level APIs - - * [Keras](../guide/keras.md), TensorFlow's high-level API for building and - training deep learning models. - * [Eager Execution](../guide/eager.md), an API for writing TensorFlow code - imperatively, like you would use Numpy. - * [Importing Data](../guide/datasets.md), easy input pipelines to bring your data into - your TensorFlow program. - * [Estimators](../guide/estimators.md), a high-level API that provides - fully-packaged models ready for large-scale training and production. - -## Estimators - -* [Premade Estimators](../guide/premade_estimators.md), the basics of premade Estimators. -* [Checkpoints](../guide/checkpoints.md), save training progress and resume where you left off. -* [Feature Columns](../guide/feature_columns.md), handle a variety of input data types without changes to the model. -* [Datasets for Estimators](../guide/datasets_for_estimators.md), use `tf.data` to input data. -* [Creating Custom Estimators](../guide/custom_estimators.md), write your own Estimator. - -## Accelerators - - * [Using GPUs](../guide/using_gpu.md) explains how TensorFlow assigns operations to - devices and how you can change the arrangement manually. - * [Using TPUs](../guide/using_tpu.md) explains how to modify `Estimator` programs to run on a TPU. - -## Low Level APIs - - * [Introduction](../guide/low_level_intro.md), which introduces the - basics of how you can use TensorFlow outside of the high Level APIs. - * [Tensors](../guide/tensors.md), which explains how to create, - manipulate, and access Tensors--the fundamental object in TensorFlow. - * [Variables](../guide/variables.md), which details how - to represent shared, persistent state in your program. - * [Graphs and Sessions](../guide/graphs.md), which explains: - * dataflow graphs, which are TensorFlow's representation of computations - as dependencies between operations. - * sessions, which are TensorFlow's mechanism for running dataflow graphs - across one or more local or remote devices. - If you are programming with the low-level TensorFlow API, this unit - is essential. If you are programming with a high-level TensorFlow API - such as Estimators or Keras, the high-level API creates and manages - graphs and sessions for you, but understanding graphs and sessions - can still be helpful. - * [Save and Restore](../guide/saved_model.md), which - explains how to save and restore variables and models. - -## ML Concepts - - * [Embeddings](../guide/embedding.md), which introduces the concept - of embeddings, provides a simple example of training an embedding in - TensorFlow, and explains how to view embeddings with the TensorBoard - Embedding Projector. - -## Debugging - - * [TensorFlow Debugger](../guide/debugger.md), which - explains how to use the TensorFlow debugger (tfdbg). - -## TensorBoard - -TensorBoard is a utility to visualize different aspects of machine learning. -The following guides explain how to use TensorBoard: - - * [TensorBoard: Visualizing Learning](../guide/summaries_and_tensorboard.md), - which introduces TensorBoard. - * [TensorBoard: Graph Visualization](../guide/graph_viz.md), which - explains how to visualize the computational graph. - * [TensorBoard Histogram Dashboard](../guide/tensorboard_histograms.md) which demonstrates the how to - use TensorBoard's histogram dashboard. - - -## Misc - - * [TensorFlow Version Compatibility](../guide/version_compat.md), - which explains backward compatibility guarantees and non-guarantees. - * [Frequently Asked Questions](../guide/faq.md), which contains frequently asked - questions about TensorFlow. diff --git a/tensorflow/docs_src/guide/keras.md b/tensorflow/docs_src/guide/keras.md deleted file mode 100644 index 2330fa03c7..0000000000 --- a/tensorflow/docs_src/guide/keras.md +++ /dev/null @@ -1,623 +0,0 @@ -# Keras - -Keras is a high-level API to build and train deep learning models. It's used for -fast prototyping, advanced research, and production, with three key advantages: - -- *User friendly*<br> - Keras has a simple, consistent interface optimized for common use cases. It - provides clear and actionable feedback for user errors. -- *Modular and composable*<br> - Keras models are made by connecting configurable building blocks together, - with few restrictions. -- *Easy to extend*<br> Write custom building blocks to express new ideas for - research. Create new layers, loss functions, and develop state-of-the-art - models. - -## Import tf.keras - -`tf.keras` is TensorFlow's implementation of the -[Keras API specification](https://keras.io){:.external}. This is a high-level -API to build and train models that includes first-class support for -TensorFlow-specific functionality, such as [eager execution](#eager_execution), -`tf.data` pipelines, and [Estimators](./estimators.md). -`tf.keras` makes TensorFlow easier to use without sacrificing flexibility and -performance. - -To get started, import `tf.keras` as part of your TensorFlow program setup: - -```python -import tensorflow as tf -from tensorflow import keras -``` - -`tf.keras` can run any Keras-compatible code, but keep in mind: - -* The `tf.keras` version in the latest TensorFlow release might not be the same - as the latest `keras` version from PyPI. Check `tf.keras.__version__`. -* When [saving a model's weights](#weights_only), `tf.keras` defaults to the - [checkpoint format](./checkpoints.md). Pass `save_format='h5'` to - use HDF5. - -## Build a simple model - -### Sequential model - -In Keras, you assemble *layers* to build *models*. A model is (usually) a graph -of layers. The most common type of model is a stack of layers: the -`tf.keras.Sequential` model. - -To build a simple, fully-connected network (i.e. multi-layer perceptron): - -```python -model = keras.Sequential() -# Adds a densely-connected layer with 64 units to the model: -model.add(keras.layers.Dense(64, activation='relu')) -# Add another: -model.add(keras.layers.Dense(64, activation='relu')) -# Add a softmax layer with 10 output units: -model.add(keras.layers.Dense(10, activation='softmax')) -``` - -### Configure the layers - -There are many `tf.keras.layers` available with some common constructor -parameters: - -* `activation`: Set the activation function for the layer. This parameter is - specified by the name of a built-in function or as a callable object. By - default, no activation is applied. -* `kernel_initializer` and `bias_initializer`: The initialization schemes - that create the layer's weights (kernel and bias). This parameter is a name or - a callable object. This defaults to the `"Glorot uniform"` initializer. -* `kernel_regularizer` and `bias_regularizer`: The regularization schemes - that apply the layer's weights (kernel and bias), such as L1 or L2 - regularization. By default, no regularization is applied. - -The following instantiates `tf.keras.layers.Dense` layers using constructor -arguments: - -```python -# Create a sigmoid layer: -layers.Dense(64, activation='sigmoid') -# Or: -layers.Dense(64, activation=tf.sigmoid) - -# A linear layer with L1 regularization of factor 0.01 applied to the kernel matrix: -layers.Dense(64, kernel_regularizer=keras.regularizers.l1(0.01)) -# A linear layer with L2 regularization of factor 0.01 applied to the bias vector: -layers.Dense(64, bias_regularizer=keras.regularizers.l2(0.01)) - -# A linear layer with a kernel initialized to a random orthogonal matrix: -layers.Dense(64, kernel_initializer='orthogonal') -# A linear layer with a bias vector initialized to 2.0s: -layers.Dense(64, bias_initializer=keras.initializers.constant(2.0)) -``` - -## Train and evaluate - -### Set up training - -After the model is constructed, configure its learning process by calling the -`compile` method: - -```python -model.compile(optimizer=tf.train.AdamOptimizer(0.001), - loss='categorical_crossentropy', - metrics=['accuracy']) -``` - -`tf.keras.Model.compile` takes three important arguments: - -* `optimizer`: This object specifies the training procedure. Pass it optimizer - instances from the `tf.train` module, such as - [`AdamOptimizer`](/api_docs/python/tf/train/AdamOptimizer), - [`RMSPropOptimizer`](/api_docs/python/tf/train/RMSPropOptimizer), or - [`GradientDescentOptimizer`](/api_docs/python/tf/train/GradientDescentOptimizer). -* `loss`: The function to minimize during optimization. Common choices include - mean square error (`mse`), `categorical_crossentropy`, and - `binary_crossentropy`. Loss functions are specified by name or by - passing a callable object from the `tf.keras.losses` module. -* `metrics`: Used to monitor training. These are string names or callables from - the `tf.keras.metrics` module. - -The following shows a few examples of configuring a model for training: - -```python -# Configure a model for mean-squared error regression. -model.compile(optimizer=tf.train.AdamOptimizer(0.01), - loss='mse', # mean squared error - metrics=['mae']) # mean absolute error - -# Configure a model for categorical classification. -model.compile(optimizer=tf.train.RMSPropOptimizer(0.01), - loss=keras.losses.categorical_crossentropy, - metrics=[keras.metrics.categorical_accuracy]) -``` - -### Input NumPy data - -For small datasets, use in-memory [NumPy](https://www.numpy.org/){:.external} -arrays to train and evaluate a model. The model is "fit" to the training data -using the `fit` method: - -```python -import numpy as np - -data = np.random.random((1000, 32)) -labels = np.random.random((1000, 10)) - -model.fit(data, labels, epochs=10, batch_size=32) -``` - -`tf.keras.Model.fit` takes three important arguments: - -* `epochs`: Training is structured into *epochs*. An epoch is one iteration over - the entire input data (this is done in smaller batches). -* `batch_size`: When passed NumPy data, the model slices the data into smaller - batches and iterates over these batches during training. This integer - specifies the size of each batch. Be aware that the last batch may be smaller - if the total number of samples is not divisible by the batch size. -* `validation_data`: When prototyping a model, you want to easily monitor its - performance on some validation data. Passing this argument—a tuple of inputs - and labels—allows the model to display the loss and metrics in inference mode - for the passed data, at the end of each epoch. - -Here's an example using `validation_data`: - -```python -import numpy as np - -data = np.random.random((1000, 32)) -labels = np.random.random((1000, 10)) - -val_data = np.random.random((100, 32)) -val_labels = np.random.random((100, 10)) - -model.fit(data, labels, epochs=10, batch_size=32, - validation_data=(val_data, val_labels)) -``` - -### Input tf.data datasets - -Use the [Datasets API](./datasets.md) to scale to large datasets -or multi-device training. Pass a `tf.data.Dataset` instance to the `fit` -method: - -```python -# Instantiates a toy dataset instance: -dataset = tf.data.Dataset.from_tensor_slices((data, labels)) -dataset = dataset.batch(32) -dataset = dataset.repeat() - -# Don't forget to specify `steps_per_epoch` when calling `fit` on a dataset. -model.fit(dataset, epochs=10, steps_per_epoch=30) -``` - -Here, the `fit` method uses the `steps_per_epoch` argument—this is the number of -training steps the model runs before it moves to the next epoch. Since the -`Dataset` yields batches of data, this snippet does not require a `batch_size`. - -Datasets can also be used for validation: - -```python -dataset = tf.data.Dataset.from_tensor_slices((data, labels)) -dataset = dataset.batch(32).repeat() - -val_dataset = tf.data.Dataset.from_tensor_slices((val_data, val_labels)) -val_dataset = val_dataset.batch(32).repeat() - -model.fit(dataset, epochs=10, steps_per_epoch=30, - validation_data=val_dataset, - validation_steps=3) -``` - -### Evaluate and predict - -The `tf.keras.Model.evaluate` and `tf.keras.Model.predict` methods can use NumPy -data and a `tf.data.Dataset`. - -To *evaluate* the inference-mode loss and metrics for the data provided: - -```python -model.evaluate(x, y, batch_size=32) - -model.evaluate(dataset, steps=30) -``` - -And to *predict* the output of the last layer in inference for the data provided, -as a NumPy array: - -``` -model.predict(x, batch_size=32) - -model.predict(dataset, steps=30) -``` - - -## Build advanced models - -### Functional API - -The `tf.keras.Sequential` model is a simple stack of layers that cannot -represent arbitrary models. Use the -[Keras functional API](https://keras.io/getting-started/functional-api-guide/){:.external} -to build complex model topologies such as: - -* Multi-input models, -* Multi-output models, -* Models with shared layers (the same layer called several times), -* Models with non-sequential data flows (e.g. residual connections). - -Building a model with the functional API works like this: - -1. A layer instance is callable and returns a tensor. -2. Input tensors and output tensors are used to define a `tf.keras.Model` - instance. -3. This model is trained just like the `Sequential` model. - -The following example uses the functional API to build a simple, fully-connected -network: - -```python -inputs = keras.Input(shape=(32,)) # Returns a placeholder tensor - -# A layer instance is callable on a tensor, and returns a tensor. -x = keras.layers.Dense(64, activation='relu')(inputs) -x = keras.layers.Dense(64, activation='relu')(x) -predictions = keras.layers.Dense(10, activation='softmax')(x) - -# Instantiate the model given inputs and outputs. -model = keras.Model(inputs=inputs, outputs=predictions) - -# The compile step specifies the training configuration. -model.compile(optimizer=tf.train.RMSPropOptimizer(0.001), - loss='categorical_crossentropy', - metrics=['accuracy']) - -# Trains for 5 epochs -model.fit(data, labels, batch_size=32, epochs=5) -``` - -### Model subclassing - -Build a fully-customizable model by subclassing `tf.keras.Model` and defining -your own forward pass. Create layers in the `__init__` method and set them as -attributes of the class instance. Define the forward pass in the `call` method. - -Model subclassing is particularly useful when -[eager execution](./eager.md) is enabled since the forward pass -can be written imperatively. - -Key Point: Use the right API for the job. While model subclassing offers -flexibility, it comes at a cost of greater complexity and more opportunities for -user errors. If possible, prefer the functional API. - -The following example shows a subclassed `tf.keras.Model` using a custom forward -pass: - -```python -class MyModel(keras.Model): - - def __init__(self, num_classes=10): - super(MyModel, self).__init__(name='my_model') - self.num_classes = num_classes - # Define your layers here. - self.dense_1 = keras.layers.Dense(32, activation='relu') - self.dense_2 = keras.layers.Dense(num_classes, activation='sigmoid') - - def call(self, inputs): - # Define your forward pass here, - # using layers you previously defined (in `__init__`). - x = self.dense_1(inputs) - return self.dense_2(x) - - def compute_output_shape(self, input_shape): - # You need to override this function if you want to use the subclassed model - # as part of a functional-style model. - # Otherwise, this method is optional. - shape = tf.TensorShape(input_shape).as_list() - shape[-1] = self.num_classes - return tf.TensorShape(shape) - - -# Instantiates the subclassed model. -model = MyModel(num_classes=10) - -# The compile step specifies the training configuration. -model.compile(optimizer=tf.train.RMSPropOptimizer(0.001), - loss='categorical_crossentropy', - metrics=['accuracy']) - -# Trains for 5 epochs. -model.fit(data, labels, batch_size=32, epochs=5) -``` - - -### Custom layers - -Create a custom layer by subclassing `tf.keras.layers.Layer` and implementing -the following methods: - -* `build`: Create the weights of the layer. Add weights with the `add_weight` - method. -* `call`: Define the forward pass. -* `compute_output_shape`: Specify how to compute the output shape of the layer - given the input shape. -* Optionally, a layer can be serialized by implementing the `get_config` method - and the `from_config` class method. - -Here's an example of a custom layer that implements a `matmul` of an input with -a kernel matrix: - -```python -class MyLayer(keras.layers.Layer): - - def __init__(self, output_dim, **kwargs): - self.output_dim = output_dim - super(MyLayer, self).__init__(**kwargs) - - def build(self, input_shape): - shape = tf.TensorShape((input_shape[1], self.output_dim)) - # Create a trainable weight variable for this layer. - self.kernel = self.add_weight(name='kernel', - shape=shape, - initializer='uniform', - trainable=True) - # Be sure to call this at the end - super(MyLayer, self).build(input_shape) - - def call(self, inputs): - return tf.matmul(inputs, self.kernel) - - def compute_output_shape(self, input_shape): - shape = tf.TensorShape(input_shape).as_list() - shape[-1] = self.output_dim - return tf.TensorShape(shape) - - def get_config(self): - base_config = super(MyLayer, self).get_config() - base_config['output_dim'] = self.output_dim - - @classmethod - def from_config(cls, config): - return cls(**config) - - -# Create a model using the custom layer -model = keras.Sequential([MyLayer(10), - keras.layers.Activation('softmax')]) - -# The compile step specifies the training configuration -model.compile(optimizer=tf.train.RMSPropOptimizer(0.001), - loss='categorical_crossentropy', - metrics=['accuracy']) - -# Trains for 5 epochs. -model.fit(data, targets, batch_size=32, epochs=5) -``` - - -## Callbacks - -A callback is an object passed to a model to customize and extend its behavior -during training. You can write your own custom callback, or use the built-in -`tf.keras.callbacks` that include: - -* `tf.keras.callbacks.ModelCheckpoint`: Save checkpoints of your model at - regular intervals. -* `tf.keras.callbacks.LearningRateScheduler`: Dynamically change the learning - rate. -* `tf.keras.callbacks.EarlyStopping`: Interrupt training when validation - performance has stopped improving. -* `tf.keras.callbacks.TensorBoard`: Monitor the model's behavior using - [TensorBoard](./summaries_and_tensorboard.md). - -To use a `tf.keras.callbacks.Callback`, pass it to the model's `fit` method: - -```python -callbacks = [ - # Interrupt training if `val_loss` stops improving for over 2 epochs - keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'), - # Write TensorBoard logs to `./logs` directory - keras.callbacks.TensorBoard(log_dir='./logs') -] -model.fit(data, labels, batch_size=32, epochs=5, callbacks=callbacks, - validation_data=(val_data, val_targets)) -``` - - -## Save and restore - -### Weights only - -Save and load the weights of a model using `tf.keras.Model.save_weights`: - -```python -# Save weights to a TensorFlow Checkpoint file -model.save_weights('./my_model') - -# Restore the model's state, -# this requires a model with the same architecture. -model.load_weights('my_model') -``` - -By default, this saves the model's weights in the -[TensorFlow checkpoint](./checkpoints.md) file format. Weights can -also be saved to the Keras HDF5 format (the default for the multi-backend -implementation of Keras): - -```python -# Save weights to a HDF5 file -model.save_weights('my_model.h5', save_format='h5') - -# Restore the model's state -model.load_weights('my_model.h5') -``` - - -### Configuration only - -A model's configuration can be saved—this serializes the model architecture -without any weights. A saved configuration can recreate and initialize the same -model, even without the code that defined the original model. Keras supports -JSON and YAML serialization formats: - -```python -# Serialize a model to JSON format -json_string = model.to_json() - -# Recreate the model (freshly initialized) -fresh_model = keras.models.model_from_json(json_string) - -# Serializes a model to YAML format -yaml_string = model.to_yaml() - -# Recreate the model -fresh_model = keras.models.model_from_yaml(yaml_string) -``` - -Caution: Subclassed models are not serializable because their architecture is -defined by the Python code in the body of the `call` method. - - -### Entire model - -The entire model can be saved to a file that contains the weight values, the -model's configuration, and even the optimizer's configuration. This allows you -to checkpoint a model and resume training later—from the exact same -state—without access to the original code. - -```python -# Create a trivial model -model = keras.Sequential([ - keras.layers.Dense(10, activation='softmax', input_shape=(32,)), - keras.layers.Dense(10, activation='softmax') -]) -model.compile(optimizer='rmsprop', - loss='categorical_crossentropy', - metrics=['accuracy']) -model.fit(data, targets, batch_size=32, epochs=5) - - -# Save entire model to a HDF5 file -model.save('my_model.h5') - -# Recreate the exact same model, including weights and optimizer. -model = keras.models.load_model('my_model.h5') -``` - - -## Eager execution - -[Eager execution](./eager.md) is an imperative programming -environment that evaluates operations immediately. This is not required for -Keras, but is supported by `tf.keras` and useful for inspecting your program and -debugging. - -All of the `tf.keras` model-building APIs are compatible with eager execution. -And while the `Sequential` and functional APIs can be used, eager execution -especially benefits *model subclassing* and building *custom layers*—the APIs -that require you to write the forward pass as code (instead of the APIs that -create models by assembling existing layers). - -See the [eager execution guide](./eager.md#build_a_model) for -examples of using Keras models with custom training loops and `tf.GradientTape`. - - -## Distribution - -### Estimators - -The [Estimators](./estimators.md) API is used for training models -for distributed environments. This targets industry use cases such as -distributed training on large datasets that can export a model for production. - -A `tf.keras.Model` can be trained with the `tf.estimator` API by converting the -model to an `tf.estimator.Estimator` object with -`tf.keras.estimator.model_to_estimator`. See -[Creating Estimators from Keras models](./estimators.md#creating_estimators_from_keras_models). - -```python -model = keras.Sequential([layers.Dense(10,activation='softmax'), - layers.Dense(10,activation='softmax')]) - -model.compile(optimizer=tf.train.RMSPropOptimizer(0.001), - loss='categorical_crossentropy', - metrics=['accuracy']) - -estimator = keras.estimator.model_to_estimator(model) -``` - -Note: Enable [eager execution](./eager.md) for debugging -[Estimator input functions](./premade_estimators.md#create_input_functions) -and inspecting data. - -### Multiple GPUs - -`tf.keras` models can run on multiple GPUs using -`tf.contrib.distribute.DistributionStrategy`. This API provides distributed -training on multiple GPUs with almost no changes to existing code. - -Currently, `tf.contrib.distribute.MirroredStrategy` is the only supported -distribution strategy. `MirroredStrategy` does in-graph replication with -synchronous training using all-reduce on a single machine. To use -`DistributionStrategy` with Keras, convert the `tf.keras.Model` to a -`tf.estimator.Estimator` with `tf.keras.estimator.model_to_estimator`, then -train the estimator - -The following example distributes a `tf.keras.Model` across multiple GPUs on a -single machine. - -First, define a simple model: - -```python -model = keras.Sequential() -model.add(keras.layers.Dense(16, activation='relu', input_shape=(10,))) -model.add(keras.layers.Dense(1, activation='sigmoid')) - -optimizer = tf.train.GradientDescentOptimizer(0.2) - -model.compile(loss='binary_crossentropy', optimizer=optimizer) -model.summary() -``` - -Define an *input pipeline*. The `input_fn` returns a `tf.data.Dataset` object -used to distribute the data across multiple devices—with each device processing -a slice of the input batch. - -```python -def input_fn(): - x = np.random.random((1024, 10)) - y = np.random.randint(2, size=(1024, 1)) - x = tf.cast(x, tf.float32) - dataset = tf.data.Dataset.from_tensor_slices((x, y)) - dataset = dataset.repeat(10) - dataset = dataset.batch(32) - return dataset -``` - -Next, create a `tf.estimator.RunConfig` and set the `train_distribute` argument -to the `tf.contrib.distribute.MirroredStrategy` instance. When creating -`MirroredStrategy`, you can specify a list of devices or set the `num_gpus` -argument. The default uses all available GPUs, like the following: - -```python -strategy = tf.contrib.distribute.MirroredStrategy() -config = tf.estimator.RunConfig(train_distribute=strategy) -``` - -Convert the Keras model to a `tf.estimator.Estimator` instance: - -```python -keras_estimator = keras.estimator.model_to_estimator( - keras_model=model, - config=config, - model_dir='/tmp/model_dir') -``` - -Finally, train the `Estimator` instance by providing the `input_fn` and `steps` -arguments: - -```python -keras_estimator.train(input_fn=input_fn, steps=10) -``` diff --git a/tensorflow/docs_src/guide/leftnav_files b/tensorflow/docs_src/guide/leftnav_files deleted file mode 100644 index 8e227e0c8f..0000000000 --- a/tensorflow/docs_src/guide/leftnav_files +++ /dev/null @@ -1,41 +0,0 @@ -index.md - -### High Level APIs -keras.md -eager.md -datasets.md -estimators.md: Introduction to Estimators - -### Estimators -premade_estimators.md -checkpoints.md -feature_columns.md -datasets_for_estimators.md -custom_estimators.md - -### Accelerators -using_gpu.md -using_tpu.md - -### Low Level APIs -low_level_intro.md -tensors.md -variables.md -graphs.md -saved_model.md -autograph.md : Control flow - -### ML Concepts -embedding.md - -### Debugging -debugger.md - -### TensorBoard -summaries_and_tensorboard.md: Visualizing Learning -graph_viz.md: Graphs -tensorboard_histograms.md: Histograms - -### Misc -version_compat.md -faq.md diff --git a/tensorflow/docs_src/guide/low_level_intro.md b/tensorflow/docs_src/guide/low_level_intro.md deleted file mode 100644 index d002f8af0b..0000000000 --- a/tensorflow/docs_src/guide/low_level_intro.md +++ /dev/null @@ -1,604 +0,0 @@ -# Introduction - -This guide gets you started programming in the low-level TensorFlow APIs -(TensorFlow Core), showing you how to: - - * Manage your own TensorFlow program (a `tf.Graph`) and TensorFlow - runtime (a `tf.Session`), instead of relying on Estimators to manage them. - * Run TensorFlow operations, using a `tf.Session`. - * Use high level components ([datasets](#datasets), [layers](#layers), and - [feature_columns](#feature_columns)) in this low level environment. - * Build your own training loop, instead of using the one - [provided by Estimators](../guide/premade_estimators.md). - -We recommend using the higher level APIs to build models when possible. -Knowing TensorFlow Core is valuable for the following reasons: - - * Experimentation and debugging are both more straight forward - when you can use low level TensorFlow operations directly. - * It gives you a mental model of how things work internally when - using the higher level APIs. - -## Setup - -Before using this guide, [install TensorFlow](../install/index.md). - -To get the most out of this guide, you should know the following: - -* How to program in Python. -* At least a little bit about arrays. -* Ideally, something about machine learning. - -Feel free to launch `python` and follow along with this walkthrough. -Run the following lines to set up your Python environment: - -```python -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf -``` - -## Tensor Values - -The central unit of data in TensorFlow is the **tensor**. A tensor consists of a -set of primitive values shaped into an array of any number of dimensions. A -tensor's **rank** is its number of dimensions, while its **shape** is a tuple -of integers specifying the array's length along each dimension. Here are some -examples of tensor values: - -```python -3. # a rank 0 tensor; a scalar with shape [], -[1., 2., 3.] # a rank 1 tensor; a vector with shape [3] -[[1., 2., 3.], [4., 5., 6.]] # a rank 2 tensor; a matrix with shape [2, 3] -[[[1., 2., 3.]], [[7., 8., 9.]]] # a rank 3 tensor with shape [2, 1, 3] -``` - -TensorFlow uses numpy arrays to represent tensor **values**. - -## TensorFlow Core Walkthrough - -You might think of TensorFlow Core programs as consisting of two discrete -sections: - -1. Building the computational graph (a `tf.Graph`). -2. Running the computational graph (using a `tf.Session`). - -### Graph - -A **computational graph** is a series of TensorFlow operations arranged into a -graph. The graph is composed of two types of objects. - - * `tf.Operation` (or "ops"): The nodes of the graph. - Operations describe calculations that consume and produce tensors. - * `tf.Tensor`: The edges in the graph. These represent the values - that will flow through the graph. Most TensorFlow functions return - `tf.Tensors`. - -Important: `tf.Tensors` do not have values, they are just handles to elements -in the computation graph. - -Let's build a simple computational graph. The most basic operation is a -constant. The Python function that builds the operation takes a tensor value as -input. The resulting operation takes no inputs. When run, it outputs the -value that was passed to the constructor. We can create two floating point -constants `a` and `b` as follows: - -```python -a = tf.constant(3.0, dtype=tf.float32) -b = tf.constant(4.0) # also tf.float32 implicitly -total = a + b -print(a) -print(b) -print(total) -``` - -The print statements produce: - -``` -Tensor("Const:0", shape=(), dtype=float32) -Tensor("Const_1:0", shape=(), dtype=float32) -Tensor("add:0", shape=(), dtype=float32) -``` - -Notice that printing the tensors does not output the values `3.0`, `4.0`, and -`7.0` as you might expect. The above statements only build the computation -graph. These `tf.Tensor` objects just represent the results of the operations -that will be run. - -Each operation in a graph is given a unique name. This name is independent of -the names the objects are assigned to in Python. Tensors are named after the -operation that produces them followed by an output index, as in -`"add:0"` above. - -### TensorBoard - -TensorFlow provides a utility called TensorBoard. One of TensorBoard's many -capabilities is visualizing a computation graph. You can easily do this with -a few simple commands. - -First you save the computation graph to a TensorBoard summary file as -follows: - -``` -writer = tf.summary.FileWriter('.') -writer.add_graph(tf.get_default_graph()) -``` - -This will produce an `event` file in the current directory with a name in the -following format: - -``` -events.out.tfevents.{timestamp}.{hostname} -``` - -Now, in a new terminal, launch TensorBoard with the following shell command: - -```bsh -tensorboard --logdir . -``` - -Then open TensorBoard's [graphs page](http://localhost:6006/#graphs) in your -browser, and you should see a graph similar to the following: - - - -For more about TensorBoard's graph visualization tools see [TensorBoard: Graph Visualization](../guide/graph_viz.md). - -### Session - -To evaluate tensors, instantiate a `tf.Session` object, informally known as a -**session**. A session encapsulates the state of the TensorFlow runtime, and -runs TensorFlow operations. If a `tf.Graph` is like a `.py` file, a `tf.Session` -is like the `python` executable. - -The following code creates a `tf.Session` object and then invokes its `run` -method to evaluate the `total` tensor we created above: - -```python -sess = tf.Session() -print(sess.run(total)) -``` - -When you request the output of a node with `Session.run` TensorFlow backtracks -through the graph and runs all the nodes that provide input to the requested -output node. So this prints the expected value of 7.0: - -``` -7.0 -``` - -You can pass multiple tensors to `tf.Session.run`. The `run` method -transparently handles any combination of tuples or dictionaries, as in the -following example: - -```python -print(sess.run({'ab':(a, b), 'total':total})) -``` - -which returns the results in a structure of the same layout: - -``` None -{'total': 7.0, 'ab': (3.0, 4.0)} -``` - -During a call to `tf.Session.run` any `tf.Tensor` only has a single value. -For example, the following code calls `tf.random_uniform` to produce a -`tf.Tensor` that generates a random 3-element vector (with values in `[0,1)`): - -```python -vec = tf.random_uniform(shape=(3,)) -out1 = vec + 1 -out2 = vec + 2 -print(sess.run(vec)) -print(sess.run(vec)) -print(sess.run((out1, out2))) -``` - -The result shows a different random value on each call to `run`, but -a consistent value during a single `run` (`out1` and `out2` receive the same -random input): - -``` -[ 0.52917576 0.64076328 0.68353939] -[ 0.66192627 0.89126778 0.06254101] -( - array([ 1.88408756, 1.87149239, 1.84057522], dtype=float32), - array([ 2.88408756, 2.87149239, 2.84057522], dtype=float32) -) -``` - -Some TensorFlow functions return `tf.Operations` instead of `tf.Tensors`. -The result of calling `run` on an Operation is `None`. You run an operation -to cause a side-effect, not to retrieve a value. Examples of this include the -[initialization](#Initializing Layers), and [training](#Training) ops -demonstrated later. - -### Feeding - -As it stands, this graph is not especially interesting because it always -produces a constant result. A graph can be parameterized to accept external -inputs, known as **placeholders**. A **placeholder** is a promise to provide a -value later, like a function argument. - -```python -x = tf.placeholder(tf.float32) -y = tf.placeholder(tf.float32) -z = x + y -``` - -The preceding three lines are a bit like a function in which we -define two input parameters (`x` and `y`) and then an operation on them. We can -evaluate this graph with multiple inputs by using the `feed_dict` argument of -the `tf.Session.run` method to feed concrete values to the placeholders: - -```python -print(sess.run(z, feed_dict={x: 3, y: 4.5})) -print(sess.run(z, feed_dict={x: [1, 3], y: [2, 4]})) -``` -This results in the following output: - -``` -7.5 -[ 3. 7.] -``` - -Also note that the `feed_dict` argument can be used to overwrite any tensor in -the graph. The only difference between placeholders and other `tf.Tensors` is -that placeholders throw an error if no value is fed to them. - -## Datasets - -Placeholders work for simple experiments, but `tf.data` are the -preferred method of streaming data into a model. - -To get a runnable `tf.Tensor` from a Dataset you must first convert it to a -`tf.data.Iterator`, and then call the Iterator's -`tf.data.Iterator.get_next` method. - -The simplest way to create an Iterator is with the -`tf.data.Dataset.make_one_shot_iterator` method. -For example, in the following code the `next_item` tensor will return a row from -the `my_data` array on each `run` call: - -``` python -my_data = [ - [0, 1,], - [2, 3,], - [4, 5,], - [6, 7,], -] -slices = tf.data.Dataset.from_tensor_slices(my_data) -next_item = slices.make_one_shot_iterator().get_next() -``` - -Reaching the end of the data stream causes `Dataset` to throw an -`tf.errors.OutOfRangeError`. For example, the following code -reads the `next_item` until there is no more data to read: - -``` python -while True: - try: - print(sess.run(next_item)) - except tf.errors.OutOfRangeError: - break -``` - -If the `Dataset` depends on stateful operations you may need to -initialize the iterator before using it, as shown below: - -``` python -r = tf.random_normal([10,3]) -dataset = tf.data.Dataset.from_tensor_slices(r) -iterator = dataset.make_initializable_iterator() -next_row = iterator.get_next() - -sess.run(iterator.initializer) -while True: - try: - print(sess.run(next_row)) - except tf.errors.OutOfRangeError: - break -``` - -For more details on Datasets and Iterators see: [Importing Data](../guide/datasets.md). - -## Layers - -A trainable model must modify the values in the graph to get new outputs with -the same input. `tf.layers` are the preferred way to add trainable -parameters to a graph. - -Layers package together both the variables and the operations that act -on them. For example a -[densely-connected layer](https://developers.google.com/machine-learning/glossary/#fully_connected_layer) -performs a weighted sum across all inputs -for each output and applies an optional -[activation function](https://developers.google.com/machine-learning/glossary/#activation_function). -The connection weights and biases are managed by the layer object. - -### Creating Layers - -The following code creates a `tf.layers.Dense` layer that takes a -batch of input vectors, and produces a single output value for each. To apply a -layer to an input, call the layer as if it were a function. For example: - -```python -x = tf.placeholder(tf.float32, shape=[None, 3]) -linear_model = tf.layers.Dense(units=1) -y = linear_model(x) -``` - -The layer inspects its input to determine sizes for its internal variables. So -here we must set the shape of the `x` placeholder so that the layer can -build a weight matrix of the correct size. - -Now that we have defined the calculation of the output, `y`, there is one more -detail we need to take care of before we run the calculation. - -### Initializing Layers - -The layer contains variables that must be **initialized** before they can be -used. While it is possible to initialize variables individually, you can easily -initialize all the variables in a TensorFlow graph as follows: - -```python -init = tf.global_variables_initializer() -sess.run(init) -``` - -Important: Calling `tf.global_variables_initializer` only -creates and returns a handle to a TensorFlow operation. That op -will initialize all the global variables when we run it with `tf.Session.run`. - -Also note that this `global_variables_initializer` only initializes variables -that existed in the graph when the initializer was created. So the initializer -should be one of the last things added during graph construction. - -### Executing Layers - -Now that the layer is initialized, we can evaluate the `linear_model`'s output -tensor as we would any other tensor. For example, the following code: - -```python -print(sess.run(y, {x: [[1, 2, 3],[4, 5, 6]]})) -``` - -will generate a two-element output vector such as the following: - -``` -[[-3.41378999] - [-9.14999008]] -``` - -### Layer Function shortcuts - -For each layer class (like `tf.layers.Dense`) TensorFlow also supplies a -shortcut function (like `tf.layers.dense`). The only difference is that the -shortcut function versions create and run the layer in a single call. For -example, the following code is equivalent to the earlier version: - -```python -x = tf.placeholder(tf.float32, shape=[None, 3]) -y = tf.layers.dense(x, units=1) - -init = tf.global_variables_initializer() -sess.run(init) - -print(sess.run(y, {x: [[1, 2, 3], [4, 5, 6]]})) -``` - -While convenient, this approach allows no access to the `tf.layers.Layer` -object. This makes introspection and debugging more difficult, -and layer reuse impossible. - -## Feature columns - -The easiest way to experiment with feature columns is using the -`tf.feature_column.input_layer` function. This function only accepts -[dense columns](../guide/feature_columns.md) as inputs, so to view the result -of a categorical column you must wrap it in an -`tf.feature_column.indicator_column`. For example: - -``` python -features = { - 'sales' : [[5], [10], [8], [9]], - 'department': ['sports', 'sports', 'gardening', 'gardening']} - -department_column = tf.feature_column.categorical_column_with_vocabulary_list( - 'department', ['sports', 'gardening']) -department_column = tf.feature_column.indicator_column(department_column) - -columns = [ - tf.feature_column.numeric_column('sales'), - department_column -] - -inputs = tf.feature_column.input_layer(features, columns) -``` - -Running the `inputs` tensor will parse the `features` into a batch of vectors. - -Feature columns can have internal state, like layers, so they often need to be -initialized. Categorical columns use `tf.contrib.lookup` -internally and these require a separate initialization op, -`tf.tables_initializer`. - -``` python -var_init = tf.global_variables_initializer() -table_init = tf.tables_initializer() -sess = tf.Session() -sess.run((var_init, table_init)) -``` - -Once the internal state has been initialized you can run `inputs` like any -other `tf.Tensor`: - -```python -print(sess.run(inputs)) -``` - -This shows how the feature columns have packed the input vectors, with the -one-hot "department" as the first two indices and "sales" as the third. - -```None -[[ 1. 0. 5.] - [ 1. 0. 10.] - [ 0. 1. 8.] - [ 0. 1. 9.]] -``` - -## Training - -Now that you're familiar with the basics of core TensorFlow, let's train a -small regression model manually. - -### Define the data - -First let's define some inputs, `x`, and the expected output for each input, -`y_true`: - -```python -x = tf.constant([[1], [2], [3], [4]], dtype=tf.float32) -y_true = tf.constant([[0], [-1], [-2], [-3]], dtype=tf.float32) -``` - -### Define the model - -Next, build a simple linear model, with 1 output: - -``` python -linear_model = tf.layers.Dense(units=1) - -y_pred = linear_model(x) -``` - -You can evaluate the predictions as follows: - -``` python -sess = tf.Session() -init = tf.global_variables_initializer() -sess.run(init) - -print(sess.run(y_pred)) -``` - -The model hasn't yet been trained, so the four "predicted" values aren't very -good. Here's what we got; your own output will almost certainly differ: - -``` None -[[ 0.02631879] - [ 0.05263758] - [ 0.07895637] - [ 0.10527515]] -``` - -### Loss - -To optimize a model, you first need to define the loss. We'll use the mean -square error, a standard loss for regression problems. - -While you could do this manually with lower level math operations, -the `tf.losses` module provides a set of common loss functions. You can use it -to calculate the mean square error as follows: - -``` python -loss = tf.losses.mean_squared_error(labels=y_true, predictions=y_pred) - -print(sess.run(loss)) -``` -This will produce a loss value, something like: - -``` None -2.23962 -``` - -### Training - -TensorFlow provides -[**optimizers**](https://developers.google.com/machine-learning/glossary/#optimizer) -implementing standard optimization algorithms. These are implemented as -sub-classes of `tf.train.Optimizer`. They incrementally change each -variable in order to minimize the loss. The simplest optimization algorithm is -[**gradient descent**](https://developers.google.com/machine-learning/glossary/#gradient_descent), -implemented by `tf.train.GradientDescentOptimizer`. It modifies each -variable according to the magnitude of the derivative of loss with respect to -that variable. For example: - -```python -optimizer = tf.train.GradientDescentOptimizer(0.01) -train = optimizer.minimize(loss) -``` - -This code builds all the graph components necessary for the optimization, and -returns a training operation. When run, the training op will update variables -in the graph. You might run it as follows: - -```python -for i in range(100): - _, loss_value = sess.run((train, loss)) - print(loss_value) -``` - -Since `train` is an op, not a tensor, it doesn't return a value when run. -To see the progression of the loss during training, we run the loss tensor at -the same time, producing output like the following: - -``` None -1.35659 -1.00412 -0.759167 -0.588829 -0.470264 -0.387626 -0.329918 -0.289511 -0.261112 -0.241046 -... -``` - -### Complete program - -```python -x = tf.constant([[1], [2], [3], [4]], dtype=tf.float32) -y_true = tf.constant([[0], [-1], [-2], [-3]], dtype=tf.float32) - -linear_model = tf.layers.Dense(units=1) - -y_pred = linear_model(x) -loss = tf.losses.mean_squared_error(labels=y_true, predictions=y_pred) - -optimizer = tf.train.GradientDescentOptimizer(0.01) -train = optimizer.minimize(loss) - -init = tf.global_variables_initializer() - -sess = tf.Session() -sess.run(init) -for i in range(100): - _, loss_value = sess.run((train, loss)) - print(loss_value) - -print(sess.run(y_pred)) -``` - -## Next steps - -To learn more about building models with TensorFlow consider the following: - -* [Custom Estimators](../guide/custom_estimators.md), to learn how to build - customized models with TensorFlow. Your knowledge of TensorFlow Core will - help you understand and debug your own models. - -If you want to learn more about the inner workings of TensorFlow consider the -following documents, which go into more depth on many of the topics discussed -here: - -* [Graphs and Sessions](../guide/graphs.md) -* [Tensors](../guide/tensors.md) -* [Variables](../guide/variables.md) - - diff --git a/tensorflow/docs_src/guide/premade_estimators.md b/tensorflow/docs_src/guide/premade_estimators.md deleted file mode 100644 index a1703058c3..0000000000 --- a/tensorflow/docs_src/guide/premade_estimators.md +++ /dev/null @@ -1,430 +0,0 @@ -# Premade Estimators - -This document introduces the TensorFlow programming environment and shows you -how to solve the Iris classification problem in TensorFlow. - -## Prerequisites - -Prior to using the sample code in this document, you'll need to do the -following: - -* [Install TensorFlow](../install/index.md). -* If you installed TensorFlow with virtualenv or Anaconda, activate your - TensorFlow environment. -* Install or upgrade pandas by issuing the following command: - - pip install pandas - -## Getting the sample code - -Take the following steps to get the sample code we'll be going through: - -1. Clone the TensorFlow Models repository from GitHub by entering the following - command: - - git clone https://github.com/tensorflow/models - -1. Change directory within that branch to the location containing the examples - used in this document: - - cd models/samples/core/get_started/ - -The program described in this document is -[`premade_estimator.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/premade_estimator.py). -This program uses -[`iris_data.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/iris_data.py) -to fetch its training data. - -### Running the program - -You run TensorFlow programs as you would run any Python program. For example: - -``` bsh -python premade_estimator.py -``` - -The program should output training logs followed by some predictions against -the test set. For example, the first line in the following output shows that -the model thinks there is a 99.6% chance that the first example in the test -set is a Setosa. Since the test set expected Setosa, this appears to be -a good prediction. - -``` None -... -Prediction is "Setosa" (99.6%), expected "Setosa" - -Prediction is "Versicolor" (99.8%), expected "Versicolor" - -Prediction is "Virginica" (97.9%), expected "Virginica" -``` - -If the program generates errors instead of answers, ask yourself the following -questions: - -* Did you install TensorFlow properly? -* Are you using the correct version of TensorFlow? -* Did you activate the environment you installed TensorFlow in? (This is - only relevant in certain installation mechanisms.) - -## The programming stack - -Before getting into the details of the program itself, let's investigate the -programming environment. As the following illustration shows, TensorFlow -provides a programming stack consisting of multiple API layers: - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="../images/tensorflow_programming_environment.png"> -</div> - -We strongly recommend writing TensorFlow programs with the following APIs: - -* [Estimators](../guide/estimators.md), which represent a complete model. - The Estimator API provides methods to train the model, to judge the model's - accuracy, and to generate predictions. -* [Datasets for Estimators](../guide/datasets_for_estimators.md), which build a data input - pipeline. The Dataset API has methods to load and manipulate data, and feed - it into your model. The Dataset API meshes well with the Estimators API. - -## Classifying irises: an overview - -The sample program in this document builds and tests a model that -classifies Iris flowers into three different species based on the size of their -[sepals](https://en.wikipedia.org/wiki/Sepal) and -[petals](https://en.wikipedia.org/wiki/Petal). - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" - alt="Petal geometry compared for three iris species: Iris setosa, Iris virginica, and Iris versicolor" - src="../images/iris_three_species.jpg"> -</div> - -**From left to right, -[*Iris setosa*](https://commons.wikimedia.org/w/index.php?curid=170298) (by -[Radomil](https://commons.wikimedia.org/wiki/User:Radomil), CC BY-SA 3.0), -[*Iris versicolor*](https://commons.wikimedia.org/w/index.php?curid=248095) (by -[Dlanglois](https://commons.wikimedia.org/wiki/User:Dlanglois), CC BY-SA 3.0), -and [*Iris virginica*](https://www.flickr.com/photos/33397993@N05/3352169862) -(by [Frank Mayfield](https://www.flickr.com/photos/33397993@N05), CC BY-SA -2.0).** - -### The data set - -The Iris data set contains four features and one -[label](https://developers.google.com/machine-learning/glossary/#label). -The four features identify the following botanical characteristics of -individual Iris flowers: - -* sepal length -* sepal width -* petal length -* petal width - -Our model will represent these features as `float32` numerical data. - -The label identifies the Iris species, which must be one of the following: - -* Iris setosa (0) -* Iris versicolor (1) -* Iris virginica (2) - -Our model will represent the label as `int32` categorical data. - -The following table shows three examples in the data set: - -|sepal length | sepal width | petal length | petal width| species (label) | -|------------:|------------:|-------------:|-----------:|:---------------:| -| 5.1 | 3.3 | 1.7 | 0.5 | 0 (Setosa) | -| 5.0 | 2.3 | 3.3 | 1.0 | 1 (versicolor)| -| 6.4 | 2.8 | 5.6 | 2.2 | 2 (virginica) | - -### The algorithm - -The program trains a Deep Neural Network classifier model having the following -topology: - -* 2 hidden layers. -* Each hidden layer contains 10 nodes. - -The following figure illustrates the features, hidden layers, and predictions -(not all of the nodes in the hidden layers are shown): - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" - alt="A diagram of the network architecture: Inputs, 2 hidden layers, and outputs" - src="../images/custom_estimators/full_network.png"> -</div> - -### Inference - -Running the trained model on an unlabeled example yields three predictions, -namely, the likelihood that this flower is the given Iris species. The sum of -those output predictions will be 1.0. For example, the prediction on an -unlabeled example might be something like the following: - -* 0.03 for Iris Setosa -* 0.95 for Iris Versicolor -* 0.02 for Iris Virginica - -The preceding prediction indicates a 95% probability that the given unlabeled -example is an Iris Versicolor. - -## Overview of programming with Estimators - -An Estimator is TensorFlow's high-level representation of a complete model. It -handles the details of initialization, logging, saving and restoring, and many -other features so you can concentrate on your model. For more details see -[Estimators](../guide/estimators.md). - -An Estimator is any class derived from `tf.estimator.Estimator`. TensorFlow -provides a collection of -`tf.estimator` -(for example, `LinearRegressor`) to implement common ML algorithms. Beyond -those, you may write your own -[custom Estimators](../guide/custom_estimators.md). -We recommend using pre-made Estimators when just getting started. - -To write a TensorFlow program based on pre-made Estimators, you must perform the -following tasks: - -* Create one or more input functions. -* Define the model's feature columns. -* Instantiate an Estimator, specifying the feature columns and various - hyperparameters. -* Call one or more methods on the Estimator object, passing the appropriate - input function as the source of the data. - -Let's see how those tasks are implemented for Iris classification. - -## Create input functions - -You must create input functions to supply data for training, -evaluating, and prediction. - -An **input function** is a function that returns a `tf.data.Dataset` object -which outputs the following two-element tuple: - -* [`features`](https://developers.google.com/machine-learning/glossary/#feature) - A Python dictionary in which: - * Each key is the name of a feature. - * Each value is an array containing all of that feature's values. -* `label` - An array containing the values of the - [label](https://developers.google.com/machine-learning/glossary/#label) for - every example. - -Just to demonstrate the format of the input function, here's a simple -implementation: - -```python -def input_evaluation_set(): - features = {'SepalLength': np.array([6.4, 5.0]), - 'SepalWidth': np.array([2.8, 2.3]), - 'PetalLength': np.array([5.6, 3.3]), - 'PetalWidth': np.array([2.2, 1.0])} - labels = np.array([2, 1]) - return features, labels -``` - -Your input function may generate the `features` dictionary and `label` list any -way you like. However, we recommend using TensorFlow's Dataset API, which can -parse all sorts of data. At a high level, the Dataset API consists of the -following classes: - -<div style="width:80%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" - alt="A diagram showing subclasses of the Dataset class" - src="../images/dataset_classes.png"> -</div> - -Where the individual members are: - -* `Dataset` - Base class containing methods to create and transform - datasets. Also allows you to initialize a dataset from data in memory, or from - a Python generator. -* `TextLineDataset` - Reads lines from text files. -* `TFRecordDataset` - Reads records from TFRecord files. -* `FixedLengthRecordDataset` - Reads fixed size records from binary files. -* `Iterator` - Provides a way to access one data set element at a time. - -The Dataset API can handle a lot of common cases for you. For example, -using the Dataset API, you can easily read in records from a large collection -of files in parallel and join them into a single stream. - -To keep things simple in this example we are going to load the data with -[pandas](https://pandas.pydata.org/), and build our input pipeline from this -in-memory data. - -Here is the input function used for training in this program, which is available -in [`iris_data.py`](https://github.com/tensorflow/models/blob/master/samples/core/get_started/iris_data.py): - -``` python -def train_input_fn(features, labels, batch_size): - """An input function for training""" - # Convert the inputs to a Dataset. - dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels)) - - # Shuffle, repeat, and batch the examples. - return dataset.shuffle(1000).repeat().batch(batch_size) -``` - -## Define the feature columns - -A [**feature column**](https://developers.google.com/machine-learning/glossary/#feature_columns) -is an object describing how the model should use raw input data from the -features dictionary. When you build an Estimator model, you pass it a list of -feature columns that describes each of the features you want the model to use. -The `tf.feature_column` module provides many options for representing data -to the model. - -For Iris, the 4 raw features are numeric values, so we'll build a list of -feature columns to tell the Estimator model to represent each of the four -features as 32-bit floating-point values. Therefore, the code to create the -feature column is: - -```python -# Feature columns describe how to use the input. -my_feature_columns = [] -for key in train_x.keys(): - my_feature_columns.append(tf.feature_column.numeric_column(key=key)) -``` - -Feature columns can be far more sophisticated than those we're showing here. We -detail feature columns [later on](../guide/feature_columns.md) in our Getting -Started guide. - -Now that we have the description of how we want the model to represent the raw -features, we can build the estimator. - - -## Instantiate an estimator - -The Iris problem is a classic classification problem. Fortunately, TensorFlow -provides several pre-made classifier Estimators, including: - -* `tf.estimator.DNNClassifier` for deep models that perform multi-class - classification. -* `tf.estimator.DNNLinearCombinedClassifier` for wide & deep models. -* `tf.estimator.LinearClassifier` for classifiers based on linear models. - -For the Iris problem, `tf.estimator.DNNClassifier` seems like the best choice. -Here's how we instantiated this Estimator: - -```python -# Build a DNN with 2 hidden layers and 10 nodes in each hidden layer. -classifier = tf.estimator.DNNClassifier( - feature_columns=my_feature_columns, - # Two hidden layers of 10 nodes each. - hidden_units=[10, 10], - # The model must choose between 3 classes. - n_classes=3) -``` - -## Train, Evaluate, and Predict - -Now that we have an Estimator object, we can call methods to do the following: - -* Train the model. -* Evaluate the trained model. -* Use the trained model to make predictions. - -### Train the model - -Train the model by calling the Estimator's `train` method as follows: - -```python -# Train the Model. -classifier.train( - input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size), - steps=args.train_steps) -``` - -Here we wrap up our `input_fn` call in a -[`lambda`](https://docs.python.org/3/tutorial/controlflow.html) -to capture the arguments while providing an input function that takes no -arguments, as expected by the Estimator. The `steps` argument tells the method -to stop training after a number of training steps. - -### Evaluate the trained model - -Now that the model has been trained, we can get some statistics on its -performance. The following code block evaluates the accuracy of the trained -model on the test data: - -```python -# Evaluate the model. -eval_result = classifier.evaluate( - input_fn=lambda:iris_data.eval_input_fn(test_x, test_y, args.batch_size)) - -print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result)) -``` - -Unlike our call to the `train` method, we did not pass the `steps` -argument to evaluate. Our `eval_input_fn` only yields a single -[epoch](https://developers.google.com/machine-learning/glossary/#epoch) of data. - -Running this code yields the following output (or something similar): - -```none -Test set accuracy: 0.967 -``` - -### Making predictions (inferring) from the trained model - -We now have a trained model that produces good evaluation results. -We can now use the trained model to predict the species of an Iris flower -based on some unlabeled measurements. As with training and evaluation, we make -predictions using a single function call: - -```python -# Generate predictions from the model -expected = ['Setosa', 'Versicolor', 'Virginica'] -predict_x = { - 'SepalLength': [5.1, 5.9, 6.9], - 'SepalWidth': [3.3, 3.0, 3.1], - 'PetalLength': [1.7, 4.2, 5.4], - 'PetalWidth': [0.5, 1.5, 2.1], -} - -predictions = classifier.predict( - input_fn=lambda:iris_data.eval_input_fn(predict_x, - batch_size=args.batch_size)) -``` - -The `predict` method returns a Python iterable, yielding a dictionary of -prediction results for each example. The following code prints a few -predictions and their probabilities: - - -``` python -template = ('\nPrediction is "{}" ({:.1f}%), expected "{}"') - -for pred_dict, expec in zip(predictions, expected): - class_id = pred_dict['class_ids'][0] - probability = pred_dict['probabilities'][class_id] - - print(template.format(iris_data.SPECIES[class_id], - 100 * probability, expec)) -``` - -Running the preceding code yields the following output: - -``` None -... -Prediction is "Setosa" (99.6%), expected "Setosa" - -Prediction is "Versicolor" (99.8%), expected "Versicolor" - -Prediction is "Virginica" (97.9%), expected "Virginica" -``` - - -## Summary - -Pre-made Estimators are an effective way to quickly create standard models. - -Now that you've gotten started writing TensorFlow programs, consider the -following material: - -* [Checkpoints](../guide/checkpoints.md) to learn how to save and restore models. -* [Datasets for Estimators](../guide/datasets_for_estimators.md) to learn more about importing - data into your model. -* [Creating Custom Estimators](../guide/custom_estimators.md) to learn how to - write your own Estimator, customized for a particular problem. diff --git a/tensorflow/docs_src/guide/saved_model.md b/tensorflow/docs_src/guide/saved_model.md deleted file mode 100644 index 6c967fd882..0000000000 --- a/tensorflow/docs_src/guide/saved_model.md +++ /dev/null @@ -1,999 +0,0 @@ -# Save and Restore - -The `tf.train.Saver` class provides methods to save and restore models. The -`tf.saved_model.simple_save` function is an easy way to build a -`tf.saved_model` suitable for serving. [Estimators](./estimators) -automatically save and restore variables in the `model_dir`. - -## Save and restore variables - -TensorFlow [Variables](../guide/variables.md) are the best way to represent shared, persistent state -manipulated by your program. The `tf.train.Saver` constructor adds `save` and -`restore` ops to the graph for all, or a specified list, of the variables in the -graph. The `Saver` object provides methods to run these ops, specifying paths -for the checkpoint files to write to or read from. - -`Saver` restores all variables already defined in your model. If you're -loading a model without knowing how to build its graph (for example, if you're -writing a generic program to load models), then read the -[Overview of saving and restoring models](#models) section -later in this document. - -TensorFlow saves variables in binary *checkpoint files* that map variable -names to tensor values. - -Caution: TensorFlow model files are code. Be careful with untrusted code. -See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md) -for details. - -### Save variables - -Create a `Saver` with `tf.train.Saver()` to manage all variables in the -model. For example, the following snippet demonstrates how to call the -`tf.train.Saver.save` method to save variables to checkpoint files: - -```python -# Create some variables. -v1 = tf.get_variable("v1", shape=[3], initializer = tf.zeros_initializer) -v2 = tf.get_variable("v2", shape=[5], initializer = tf.zeros_initializer) - -inc_v1 = v1.assign(v1+1) -dec_v2 = v2.assign(v2-1) - -# Add an op to initialize the variables. -init_op = tf.global_variables_initializer() - -# Add ops to save and restore all the variables. -saver = tf.train.Saver() - -# Later, launch the model, initialize the variables, do some work, and save the -# variables to disk. -with tf.Session() as sess: - sess.run(init_op) - # Do some work with the model. - inc_v1.op.run() - dec_v2.op.run() - # Save the variables to disk. - save_path = saver.save(sess, "/tmp/model.ckpt") - print("Model saved in path: %s" % save_path) -``` - -### Restore variables - -The `tf.train.Saver` object not only saves variables to checkpoint files, it -also restores variables. Note that when you restore variables you do not have -to initialize them beforehand. For example, the following snippet demonstrates -how to call the `tf.train.Saver.restore` method to restore variables from the -checkpoint files: - -```python -tf.reset_default_graph() - -# Create some variables. -v1 = tf.get_variable("v1", shape=[3]) -v2 = tf.get_variable("v2", shape=[5]) - -# Add ops to save and restore all the variables. -saver = tf.train.Saver() - -# Later, launch the model, use the saver to restore variables from disk, and -# do some work with the model. -with tf.Session() as sess: - # Restore variables from disk. - saver.restore(sess, "/tmp/model.ckpt") - print("Model restored.") - # Check the values of the variables - print("v1 : %s" % v1.eval()) - print("v2 : %s" % v2.eval()) -``` - -Note: There is not a physical file called `/tmp/model.ckpt`. It is the *prefix* of -filenames created for the checkpoint. Users only interact with the prefix -instead of physical checkpoint files. - -### Choose variables to save and restore - -If you do not pass any arguments to `tf.train.Saver()`, the saver handles all -variables in the graph. Each variable is saved under the name that was passed -when the variable was created. - -It is sometimes useful to explicitly specify names for variables in the -checkpoint files. For example, you may have trained a model with a variable -named `"weights"` whose value you want to restore into a variable named -`"params"`. - -It is also sometimes useful to only save or restore a subset of the variables -used by a model. For example, you may have trained a neural net with five -layers, and you now want to train a new model with six layers that reuses the -existing weights of the five trained layers. You can use the saver to restore -the weights of just the first five layers. - -You can easily specify the names and variables to save or load by passing to the -`tf.train.Saver()` constructor either of the following: - -* A list of variables (which will be stored under their own names). -* A Python dictionary in which keys are the names to use and the values are the -variables to manage. - -Continuing from the save/restore examples shown earlier: - -```python -tf.reset_default_graph() -# Create some variables. -v1 = tf.get_variable("v1", [3], initializer = tf.zeros_initializer) -v2 = tf.get_variable("v2", [5], initializer = tf.zeros_initializer) - -# Add ops to save and restore only `v2` using the name "v2" -saver = tf.train.Saver({"v2": v2}) - -# Use the saver object normally after that. -with tf.Session() as sess: - # Initialize v1 since the saver will not. - v1.initializer.run() - saver.restore(sess, "/tmp/model.ckpt") - - print("v1 : %s" % v1.eval()) - print("v2 : %s" % v2.eval()) -``` - -Notes: - -* You can create as many `Saver` objects as you want if you need to save and - restore different subsets of the model variables. The same variable can be - listed in multiple saver objects; its value is only changed when the - `Saver.restore()` method is run. - -* If you only restore a subset of the model variables at the start of a - session, you have to run an initialize op for the other variables. See - `tf.variables_initializer` for more information. - -* To inspect the variables in a checkpoint, you can use the - [`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py) - library, particularly the `print_tensors_in_checkpoint_file` function. - -* By default, `Saver` uses the value of the `tf.Variable.name` property - for each variable. However, when you create a `Saver` object, you may - optionally choose names for the variables in the checkpoint files. - - -### Inspect variables in a checkpoint - -We can quickly inspect variables in a checkpoint with the -[`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py) library. - -Continuing from the save/restore examples shown earlier: - -```python -# import the inspect_checkpoint library -from tensorflow.python.tools import inspect_checkpoint as chkp - -# print all tensors in checkpoint file -chkp.print_tensors_in_checkpoint_file("/tmp/model.ckpt", tensor_name='', all_tensors=True) - -# tensor_name: v1 -# [ 1. 1. 1.] -# tensor_name: v2 -# [-1. -1. -1. -1. -1.] - -# print only tensor v1 in checkpoint file -chkp.print_tensors_in_checkpoint_file("/tmp/model.ckpt", tensor_name='v1', all_tensors=False) - -# tensor_name: v1 -# [ 1. 1. 1.] - -# print only tensor v2 in checkpoint file -chkp.print_tensors_in_checkpoint_file("/tmp/model.ckpt", tensor_name='v2', all_tensors=False) - -# tensor_name: v2 -# [-1. -1. -1. -1. -1.] -``` - - -<a name="models"></a> -## Save and restore models - -Use `SavedModel` to save and load your model—variables, the graph, and the -graph's metadata. This is a language-neutral, recoverable, hermetic -serialization format that enables higher-level systems and tools to produce, -consume, and transform TensorFlow models. TensorFlow provides several ways to -interact with `SavedModel`, including the `tf.saved_model` APIs, -`tf.estimator.Estimator`, and a command-line interface. - - -## Build and load a SavedModel - -### Simple save - -The easiest way to create a `SavedModel` is to use the `tf.saved_model.simple_save` -function: - -```python -simple_save(session, - export_dir, - inputs={"x": x, "y": y}, - outputs={"z": z}) -``` - -This configures the `SavedModel` so it can be loaded by -[TensorFlow serving](/serving/serving_basic) and supports the -[Predict API](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/predict.proto). -To access the classify, regress, or multi-inference APIs, use the manual -`SavedModel` builder APIs or an `tf.estimator.Estimator`. - -### Manually build a SavedModel - -If your use case isn't covered by `tf.saved_model.simple_save`, use the manual -`tf.saved_model.builder` to create a `SavedModel`. - -The `tf.saved_model.builder.SavedModelBuilder` class provides functionality to -save multiple `MetaGraphDef`s. A **MetaGraph** is a dataflow graph, plus -its associated variables, assets, and signatures. A **`MetaGraphDef`** -is the protocol buffer representation of a MetaGraph. A **signature** is -the set of inputs to and outputs from a graph. - -If assets need to be saved and written or copied to disk, they can be provided -when the first `MetaGraphDef` is added. If multiple `MetaGraphDef`s are -associated with an asset of the same name, only the first version is retained. - -Each `MetaGraphDef` added to the SavedModel must be annotated with -user-specified tags. The tags provide a means to identify the specific -`MetaGraphDef` to load and restore, along with the shared set of variables -and assets. These tags -typically annotate a `MetaGraphDef` with its functionality (for example, -serving or training), and optionally with hardware-specific aspects (for -example, GPU). - -For example, the following code suggests a typical way to use -`SavedModelBuilder` to build a SavedModel: - -```python -export_dir = ... -... -builder = tf.saved_model.builder.SavedModelBuilder(export_dir) -with tf.Session(graph=tf.Graph()) as sess: - ... - builder.add_meta_graph_and_variables(sess, - [tag_constants.TRAINING], - signature_def_map=foo_signatures, - assets_collection=foo_assets, - strip_default_attrs=True) -... -# Add a second MetaGraphDef for inference. -with tf.Session(graph=tf.Graph()) as sess: - ... - builder.add_meta_graph([tag_constants.SERVING], strip_default_attrs=True) -... -builder.save() -``` - -<a name="forward_compatibility"></a> -#### Forward compatibility via `strip_default_attrs=True` - -Following the guidance below gives you forward compatibility only if the set of -Ops has not changed. - -The `tf.saved_model.builder.SavedModelBuilder` class allows -users to control whether default-valued attributes must be stripped from the -[`NodeDefs`](../extend/tool_developers/index.md#nodes) -while adding a meta graph to the SavedModel bundle. Both -`tf.saved_model.builder.SavedModelBuilder.add_meta_graph_and_variables` -and `tf.saved_model.builder.SavedModelBuilder.add_meta_graph` -methods accept a Boolean flag `strip_default_attrs` that controls this behavior. - -If `strip_default_attrs` is `False`, the exported `tf.MetaGraphDef` will have -the default valued attributes in all its `tf.NodeDef` instances. -This can break forward compatibility with a sequence of events such as the -following: - -* An existing Op (`Foo`) is updated to include a new attribute (`T`) with a - default (`bool`) at version 101. -* A model producer such as a "trainer binary" picks up this change (version 101) - to the `OpDef` and re-exports an existing model that uses Op `Foo`. -* A model consumer (such as [Tensorflow Serving](/serving)) running an older - binary (version 100) doesn't have attribute `T` for Op `Foo`, but tries to - import this model. The model consumer doesn't recognize attribute `T` in a - `NodeDef` that uses Op `Foo` and therefore fails to load the model. -* By setting `strip_default_attrs` to True, the model producers can strip away - any default valued attributes in the `NodeDefs`. This helps ensure that newly - added attributes with defaults don't cause older model consumers to fail - loading models regenerated with newer training binaries. - -See [compatibility guidance](./version_compat.md) -for more information. - -### Loading a SavedModel in Python - -The Python version of the SavedModel -`tf.saved_model.loader` -provides load and restore capability for a SavedModel. The `load` operation -requires the following information: - -* The session in which to restore the graph definition and variables. -* The tags used to identify the MetaGraphDef to load. -* The location (directory) of the SavedModel. - -Upon a load, the subset of variables, assets, and signatures supplied as part of -the specific MetaGraphDef will be restored into the supplied session. - - -```python -export_dir = ... -... -with tf.Session(graph=tf.Graph()) as sess: - tf.saved_model.loader.load(sess, [tag_constants.TRAINING], export_dir) - ... -``` - - -### Load a SavedModel in C++ - -The C++ version of the SavedModel -[loader](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/loader.h) -provides an API to load a SavedModel from a path, while allowing -`SessionOptions` and `RunOptions`. -You have to specify the tags associated with the graph to be loaded. -The loaded version of SavedModel is referred to as `SavedModelBundle` -and contains the MetaGraphDef and the session within which it is loaded. - -```c++ -const string export_dir = ... -SavedModelBundle bundle; -... -LoadSavedModel(session_options, run_options, export_dir, {kSavedModelTagTrain}, - &bundle); -``` - -### Load and serve a SavedModel in TensorFlow serving - -You can easily load and serve a SavedModel with the TensorFlow Serving Model -Server binary. See [instructions](https://www.tensorflow.org/serving/setup#installing_using_apt-get) -on how to install the server, or build it if you wish. - -Once you have the Model Server, run it with: -``` -tensorflow_model_server --port=port-numbers --model_name=your-model-name --model_base_path=your_model_base_path -``` -Set the port and model_name flags to values of your choosing. The -model_base_path flag expects to be to a base directory, with each version of -your model residing in a numerically named subdirectory. If you only have a -single version of your model, simply place it in a subdirectory like so: -* Place the model in /tmp/model/0001 -* Set model_base_path to /tmp/model - -Store different versions of your model in numerically named subdirectories of a -common base directory. For example, suppose the base directory is `/tmp/model`. -If you have only one version of your model, store it in `/tmp/model/0001`. If -you have two versions of your model, store the second version in -`/tmp/model/0002`, and so on. Set the `--model-base_path` flag to the base -directory (`/tmp/model`, in this example). TensorFlow Model Server will serve -the model in the highest numbered subdirectory of that base directory. - -### Standard constants - -SavedModel offers the flexibility to build and load TensorFlow graphs for a -variety of use-cases. For the most common use-cases, SavedModel's APIs -provide a set of constants in Python and C++ that are easy to -reuse and share across tools consistently. - -#### Standard MetaGraphDef tags - -You may use sets of tags to uniquely identify a `MetaGraphDef` saved in a -SavedModel. A subset of commonly used tags is specified in: - -* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/tag_constants.py) -* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/tag_constants.h) - - -#### Standard SignatureDef constants - -A [**SignatureDef**](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/meta_graph.proto) -is a protocol buffer that defines the signature of a computation -supported by a graph. -Commonly used input keys, output keys, and method names are -defined in: - -* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/signature_constants.py) -* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/signature_constants.h) - -## Using SavedModel with Estimators - -After training an `Estimator` model, you may want to create a service -from that model that takes requests and returns a result. You can run such a -service locally on your machine or deploy it in the cloud. - -To prepare a trained Estimator for serving, you must export it in the standard -SavedModel format. This section explains how to: - -* Specify the output nodes and the corresponding - [APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto) - that can be served (Classify, Regress, or Predict). -* Export your model to the SavedModel format. -* Serve the model from a local server and request predictions. - - -### Prepare serving inputs - -During training, an [`input_fn()`](../guide/premade_estimators.md#input_fn) ingests data -and prepares it for use by the model. At serving time, similarly, a -`serving_input_receiver_fn()` accepts inference requests and prepares them for -the model. This function has the following purposes: - -* To add placeholders to the graph that the serving system will feed - with inference requests. -* To add any additional ops needed to convert data from the input format - into the feature `Tensor`s expected by the model. - -The function returns a `tf.estimator.export.ServingInputReceiver` object, -which packages the placeholders and the resulting feature `Tensor`s together. - -A typical pattern is that inference requests arrive in the form of serialized -`tf.Example`s, so the `serving_input_receiver_fn()` creates a single string -placeholder to receive them. The `serving_input_receiver_fn()` is then also -responsible for parsing the `tf.Example`s by adding a `tf.parse_example` op to -the graph. - -When writing such a `serving_input_receiver_fn()`, you must pass a parsing -specification to `tf.parse_example` to tell the parser what feature names to -expect and how to map them to `Tensor`s. A parsing specification takes the -form of a dict from feature names to `tf.FixedLenFeature`, `tf.VarLenFeature`, -and `tf.SparseFeature`. Note this parsing specification should not include -any label or weight columns, since those will not be available at serving -time—in contrast to a parsing specification used in the `input_fn()` at -training time. - -In combination, then: - -```py -feature_spec = {'foo': tf.FixedLenFeature(...), - 'bar': tf.VarLenFeature(...)} - -def serving_input_receiver_fn(): - """An input receiver that expects a serialized tf.Example.""" - serialized_tf_example = tf.placeholder(dtype=tf.string, - shape=[default_batch_size], - name='input_example_tensor') - receiver_tensors = {'examples': serialized_tf_example} - features = tf.parse_example(serialized_tf_example, feature_spec) - return tf.estimator.export.ServingInputReceiver(features, receiver_tensors) -``` - -The `tf.estimator.export.build_parsing_serving_input_receiver_fn` utility -function provides that input receiver for the common case. - -> Note: when training a model to be served using the Predict API with a local -> server, the parsing step is not needed because the model will receive raw -> feature data. - -Even if you require no parsing or other input processing—that is, if the -serving system will feed feature `Tensor`s directly—you must still provide -a `serving_input_receiver_fn()` that creates placeholders for the feature -`Tensor`s and passes them through. The -`tf.estimator.export.build_raw_serving_input_receiver_fn` utility provides for -this. - -If these utilities do not meet your needs, you are free to write your own -`serving_input_receiver_fn()`. One case where this may be needed is if your -training `input_fn()` incorporates some preprocessing logic that must be -recapitulated at serving time. To reduce the risk of training-serving skew, we -recommend encapsulating such processing in a function which is then called -from both `input_fn()` and `serving_input_receiver_fn()`. - -Note that the `serving_input_receiver_fn()` also determines the *input* -portion of the signature. That is, when writing a -`serving_input_receiver_fn()`, you must tell the parser what signatures -to expect and how to map them to your model's expected inputs. -By contrast, the *output* portion of the signature is determined by the model. - -<a name="specify_outputs"></a> -### Specify the outputs of a custom model - -When writing a custom `model_fn`, you must populate the `export_outputs` element -of the `tf.estimator.EstimatorSpec` return value. This is a dict of -`{name: output}` describing the output signatures to be exported and used during -serving. - -In the usual case of making a single prediction, this dict contains -one element, and the `name` is immaterial. In a multi-headed model, each head -is represented by an entry in this dict. In this case the `name` is a string -of your choice that can be used to request a specific head at serving time. - -Each `output` value must be an `ExportOutput` object such as -`tf.estimator.export.ClassificationOutput`, -`tf.estimator.export.RegressionOutput`, or -`tf.estimator.export.PredictOutput`. - -These output types map straightforwardly to the -[TensorFlow Serving APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto), -and so determine which request types will be honored. - -Note: In the multi-headed case, a `SignatureDef` will be generated for each -element of the `export_outputs` dict returned from the model_fn, named using -the same keys. These `SignatureDef`s differ only in their outputs, as -provided by the corresponding `ExportOutput` entry. The inputs are always -those provided by the `serving_input_receiver_fn`. -An inference request may specify the head by name. One head must be named -using [`signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY`](https://www.tensorflow.org/code/tensorflow/python/saved_model/signature_constants.py) -indicating which `SignatureDef` will be served when an inference request -does not specify one. - -<a name="perform_export"></a> -### Perform the export - -To export your trained Estimator, call -`tf.estimator.Estimator.export_savedmodel` with the export base path and -the `serving_input_receiver_fn`. - -```py -estimator.export_savedmodel(export_dir_base, serving_input_receiver_fn, - strip_default_attrs=True) -``` - -This method builds a new graph by first calling the -`serving_input_receiver_fn()` to obtain feature `Tensor`s, and then calling -this `Estimator`'s `model_fn()` to generate the model graph based on those -features. It starts a fresh `Session`, and, by default, restores the most recent -checkpoint into it. (A different checkpoint may be passed, if needed.) -Finally it creates a time-stamped export directory below the given -`export_dir_base` (i.e., `export_dir_base/<timestamp>`), and writes a -SavedModel into it containing a single `MetaGraphDef` saved from this -Session. - -> Note: It is your responsibility to garbage-collect old exports. -> Otherwise, successive exports will accumulate under `export_dir_base`. - -### Serve the exported model locally - -For local deployment, you can serve your model using -[TensorFlow Serving](https://github.com/tensorflow/serving), an open-source project that loads a -SavedModel and exposes it as a [gRPC](https://www.grpc.io/) service. - -First, [install TensorFlow Serving](https://github.com/tensorflow/serving). - -Then build and run the local model server, substituting `$export_dir_base` with -the path to the SavedModel you exported above: - -```sh -bazel build //tensorflow_serving/model_servers:tensorflow_model_server -bazel-bin/tensorflow_serving/model_servers/tensorflow_model_server --port=9000 --model_base_path=$export_dir_base -``` - -Now you have a server listening for inference requests via gRPC on port 9000! - - -### Request predictions from a local server - -The server responds to gRPC requests according to the -[PredictionService](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto#L15) -gRPC API service definition. (The nested protocol buffers are defined in -various [neighboring files](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis)). - -From the API service definition, the gRPC framework generates client libraries -in various languages providing remote access to the API. In a project using the -Bazel build tool, these libraries are built automatically and provided via -dependencies like these (using Python for example): - -```build - deps = [ - "//tensorflow_serving/apis:classification_proto_py_pb2", - "//tensorflow_serving/apis:regression_proto_py_pb2", - "//tensorflow_serving/apis:predict_proto_py_pb2", - "//tensorflow_serving/apis:prediction_service_proto_py_pb2" - ] -``` - -Python client code can then import the libraries thus: - -```py -from tensorflow_serving.apis import classification_pb2 -from tensorflow_serving.apis import regression_pb2 -from tensorflow_serving.apis import predict_pb2 -from tensorflow_serving.apis import prediction_service_pb2 -``` - -> Note: `prediction_service_pb2` defines the service as a whole and so -> is always required. However a typical client will need only one of -> `classification_pb2`, `regression_pb2`, and `predict_pb2`, depending on the -> type of requests being made. - -Sending a gRPC request is then accomplished by assembling a protocol buffer -containing the request data and passing it to the service stub. Note how the -request protocol buffer is created empty and then populated via the -[generated protocol buffer API](https://developers.google.com/protocol-buffers/docs/reference/python-generated). - -```py -from grpc.beta import implementations - -channel = implementations.insecure_channel(host, int(port)) -stub = prediction_service_pb2.beta_create_PredictionService_stub(channel) - -request = classification_pb2.ClassificationRequest() -example = request.input.example_list.examples.add() -example.features.feature['x'].float_list.value.extend(image[0].astype(float)) - -result = stub.Classify(request, 10.0) # 10 secs timeout -``` - -The returned result in this example is a `ClassificationResponse` protocol -buffer. - -This is a skeletal example; please see the [Tensorflow Serving](../deploy/index.md) -documentation and [examples](https://github.com/tensorflow/serving/tree/master/tensorflow_serving/example) -for more details. - -> Note: `ClassificationRequest` and `RegressionRequest` contain a -> `tensorflow.serving.Input` protocol buffer, which in turn contains a list of -> `tensorflow.Example` protocol buffers. `PredictRequest`, by contrast, -> contains a mapping from feature names to values encoded via `TensorProto`. -> Correspondingly: When using the `Classify` and `Regress` APIs, TensorFlow -> Serving feeds serialized `tf.Example`s to the graph, so your -> `serving_input_receiver_fn()` should include a `tf.parse_example()` Op. -> When using the generic `Predict` API, however, TensorFlow Serving feeds raw -> feature data to the graph, so a pass through `serving_input_receiver_fn()` -> should be used. - - -<!-- TODO(soergel): give examples of making requests against this server, using -the different Tensorflow Serving APIs, selecting the signature by key, etc. --> - -<!-- TODO(soergel): document ExportStrategy here once Experiment moves -from contrib to core. --> - - - - -## CLI to inspect and execute SavedModel - -You can use the SavedModel Command Line Interface (CLI) to inspect and -execute a SavedModel. -For example, you can use the CLI to inspect the model's `SignatureDef`s. -The CLI enables you to quickly confirm that the input -[Tensor dtype and shape](../guide/tensors.md) match the model. Moreover, if you -want to test your model, you can use the CLI to do a sanity check by -passing in sample inputs in various formats (for example, Python -expressions) and then fetching the output. - - -### Install the SavedModel CLI - -Broadly speaking, you can install TensorFlow in either of the following -two ways: - -* By installing a pre-built TensorFlow binary. -* By building TensorFlow from source code. - -If you installed TensorFlow through a pre-built TensorFlow binary, -then the SavedModel CLI is already installed on your system -at pathname `bin\saved_model_cli`. - -If you built TensorFlow from source code, you must run the following -additional command to build `saved_model_cli`: - -``` -$ bazel build tensorflow/python/tools:saved_model_cli -``` - -### Overview of commands - -The SavedModel CLI supports the following two commands on a -`MetaGraphDef` in a SavedModel: - -* `show`, which shows a computation on a `MetaGraphDef` in a SavedModel. -* `run`, which runs a computation on a `MetaGraphDef`. - - -### `show` command - -A SavedModel contains one or more `MetaGraphDef`s, identified by their tag-sets. -To serve a model, you -might wonder what kind of `SignatureDef`s are in each model, and what are their -inputs and outputs. The `show` command let you examine the contents of the -SavedModel in hierarchical order. Here's the syntax: - -``` -usage: saved_model_cli show [-h] --dir DIR [--all] -[--tag_set TAG_SET] [--signature_def SIGNATURE_DEF_KEY] -``` - -For example, the following command shows all available -MetaGraphDef tag-sets in the SavedModel: - -``` -$ saved_model_cli show --dir /tmp/saved_model_dir -The given SavedModel contains the following tag-sets: -serve -serve, gpu -``` - -The following command shows all available `SignatureDef` keys in -a `MetaGraphDef`: - -``` -$ saved_model_cli show --dir /tmp/saved_model_dir --tag_set serve -The given SavedModel `MetaGraphDef` contains `SignatureDefs` with the -following keys: -SignatureDef key: "classify_x2_to_y3" -SignatureDef key: "classify_x_to_y" -SignatureDef key: "regress_x2_to_y3" -SignatureDef key: "regress_x_to_y" -SignatureDef key: "regress_x_to_y2" -SignatureDef key: "serving_default" -``` - -If a `MetaGraphDef` has *multiple* tags in the tag-set, you must specify -all tags, each tag separated by a comma. For example: - -```none -$ saved_model_cli show --dir /tmp/saved_model_dir --tag_set serve,gpu -``` - -To show all inputs and outputs TensorInfo for a specific `SignatureDef`, pass in -the `SignatureDef` key to `signature_def` option. This is very useful when you -want to know the tensor key value, dtype and shape of the input tensors for -executing the computation graph later. For example: - -``` -$ saved_model_cli show --dir \ -/tmp/saved_model_dir --tag_set serve --signature_def serving_default -The given SavedModel SignatureDef contains the following input(s): - inputs['x'] tensor_info: - dtype: DT_FLOAT - shape: (-1, 1) - name: x:0 -The given SavedModel SignatureDef contains the following output(s): - outputs['y'] tensor_info: - dtype: DT_FLOAT - shape: (-1, 1) - name: y:0 -Method name is: tensorflow/serving/predict -``` - -To show all available information in the SavedModel, use the `--all` option. -For example: - -```none -$ saved_model_cli show --dir /tmp/saved_model_dir --all -MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs: - -signature_def['classify_x2_to_y3']: - The given SavedModel SignatureDef contains the following input(s): - inputs['inputs'] tensor_info: - dtype: DT_FLOAT - shape: (-1, 1) - name: x2:0 - The given SavedModel SignatureDef contains the following output(s): - outputs['scores'] tensor_info: - dtype: DT_FLOAT - shape: (-1, 1) - name: y3:0 - Method name is: tensorflow/serving/classify - -... - -signature_def['serving_default']: - The given SavedModel SignatureDef contains the following input(s): - inputs['x'] tensor_info: - dtype: DT_FLOAT - shape: (-1, 1) - name: x:0 - The given SavedModel SignatureDef contains the following output(s): - outputs['y'] tensor_info: - dtype: DT_FLOAT - shape: (-1, 1) - name: y:0 - Method name is: tensorflow/serving/predict -``` - - -### `run` command - -Invoke the `run` command to run a graph computation, passing -inputs and then displaying (and optionally saving) the outputs. -Here's the syntax: - -``` -usage: saved_model_cli run [-h] --dir DIR --tag_set TAG_SET --signature_def - SIGNATURE_DEF_KEY [--inputs INPUTS] - [--input_exprs INPUT_EXPRS] - [--input_examples INPUT_EXAMPLES] [--outdir OUTDIR] - [--overwrite] [--tf_debug] -``` - -The `run` command provides the following three ways to pass inputs to the model: - -* `--inputs` option enables you to pass numpy ndarray in files. -* `--input_exprs` option enables you to pass Python expressions. -* `--input_examples` option enables you to pass `tf.train.Example`. - - -#### `--inputs` - -To pass input data in files, specify the `--inputs` option, which takes the -following general format: - -```bsh ---inputs <INPUTS> -``` - -where *INPUTS* is either of the following formats: - -* `<input_key>=<filename>` -* `<input_key>=<filename>[<variable_name>]` - -You may pass multiple *INPUTS*. If you do pass multiple inputs, use a semicolon -to separate each of the *INPUTS*. - -`saved_model_cli` uses `numpy.load` to load the *filename*. -The *filename* may be in any of the following formats: - -* `.npy` -* `.npz` -* pickle format - -A `.npy` file always contains a numpy ndarray. Therefore, when loading from -a `.npy` file, the content will be directly assigned to the specified input -tensor. If you specify a *variable_name* with that `.npy` file, the -*variable_name* will be ignored and a warning will be issued. - -When loading from a `.npz` (zip) file, you may optionally specify a -*variable_name* to identify the variable within the zip file to load for -the input tensor key. If you don't specify a *variable_name*, the SavedModel -CLI will check that only one file is included in the zip file and load it -for the specified input tensor key. - -When loading from a pickle file, if no `variable_name` is specified in the -square brackets, whatever that is inside the pickle file will be passed to the -specified input tensor key. Otherwise, the SavedModel CLI will assume a -dictionary is stored in the pickle file and the value corresponding to -the *variable_name* will be used. - - -#### `--input_exprs` - -To pass inputs through Python expressions, specify the `--input_exprs` option. -This can be useful for when you don't have data -files lying around, but still want to sanity check the model with some simple -inputs that match the dtype and shape of the model's `SignatureDef`s. -For example: - -```bsh -`<input_key>=[[1],[2],[3]]` -``` - -In addition to Python expressions, you may also pass numpy functions. For -example: - -```bsh -`<input_key>=np.ones((32,32,3))` -``` - -(Note that the `numpy` module is already available to you as `np`.) - - -#### `--input_examples` - -To pass `tf.train.Example` as inputs, specify the `--input_examples` option. -For each input key, it takes a list of dictionary, where each dictionary is an -instance of `tf.train.Example`. The dictionary keys are the features and the -values are the value lists for each feature. -For example: - -```bsh -`<input_key>=[{"age":[22,24],"education":["BS","MS"]}]` -``` - -#### Save output - -By default, the SavedModel CLI writes output to stdout. If a directory is -passed to `--outdir` option, the outputs will be saved as npy files named after -output tensor keys under the given directory. - -Use `--overwrite` to overwrite existing output files. - - -#### TensorFlow debugger (tfdbg) integration - -If `--tf_debug` option is set, the SavedModel CLI will use the -TensorFlow Debugger (tfdbg) to watch the intermediate Tensors and runtime -graphs or subgraphs while running the SavedModel. - - -#### Full examples of `run` - -Given: - -* Your model simply adds `x1` and `x2` to get output `y`. -* All tensors in the model have shape `(-1, 1)`. -* You have two `npy` files: - * `/tmp/my_data1.npy`, which contains a numpy ndarray `[[1], [2], [3]]`. - * `/tmp/my_data2.npy`, which contains another numpy - ndarray `[[0.5], [0.5], [0.5]]`. - -To run these two `npy` files through the model to get output `y`, issue -the following command: - -``` -$ saved_model_cli run --dir /tmp/saved_model_dir --tag_set serve \ ---signature_def x1_x2_to_y --inputs x1=/tmp/my_data1.npy;x2=/tmp/my_data2.npy \ ---outdir /tmp/out -Result for output key y: -[[ 1.5] - [ 2.5] - [ 3.5]] -``` - -Let's change the preceding example slightly. This time, instead of two -`.npy` files, you now have an `.npz` file and a pickle file. Furthermore, -you want to overwrite any existing output file. Here's the command: - -``` -$ saved_model_cli run --dir /tmp/saved_model_dir --tag_set serve \ ---signature_def x1_x2_to_y \ ---inputs x1=/tmp/my_data1.npz[x];x2=/tmp/my_data2.pkl --outdir /tmp/out \ ---overwrite -Result for output key y: -[[ 1.5] - [ 2.5] - [ 3.5]] -``` - -You may specify python expression instead of an input file. For example, -the following command replaces input `x2` with a Python expression: - -``` -$ saved_model_cli run --dir /tmp/saved_model_dir --tag_set serve \ ---signature_def x1_x2_to_y --inputs x1=/tmp/my_data1.npz[x] \ ---input_exprs 'x2=np.ones((3,1))' -Result for output key y: -[[ 2] - [ 3] - [ 4]] -``` - -To run the model with the TensorFlow Debugger on, issue the -following command: - -``` -$ saved_model_cli run --dir /tmp/saved_model_dir --tag_set serve \ ---signature_def serving_default --inputs x=/tmp/data.npz[x] --tf_debug -``` - - -<a name="structure"></a> -## Structure of a SavedModel directory - -When you save a model in SavedModel format, TensorFlow creates -a SavedModel directory consisting of the following subdirectories -and files: - -```bsh -assets/ -assets.extra/ -variables/ - variables.data-?????-of-????? - variables.index -saved_model.pb|saved_model.pbtxt -``` - -where: - -* `assets` is a subfolder containing auxiliary (external) files, - such as vocabularies. Assets are copied to the SavedModel location - and can be read when loading a specific `MetaGraphDef`. -* `assets.extra` is a subfolder where higher-level libraries and users can - add their own assets that co-exist with the model, but are not loaded by - the graph. This subfolder is not managed by the SavedModel libraries. -* `variables` is a subfolder that includes output from - `tf.train.Saver`. -* `saved_model.pb` or `saved_model.pbtxt` is the SavedModel protocol buffer. - It includes the graph definitions as `MetaGraphDef` protocol buffers. - -A single SavedModel can represent multiple graphs. In this case, all the -graphs in the SavedModel share a *single* set of checkpoints (variables) -and assets. For example, the following diagram shows one SavedModel -containing three `MetaGraphDef`s, all three of which share the same set -of checkpoints and assets: - - - -Each graph is associated with a specific set of tags, which enables -identification during a load or restore operation. diff --git a/tensorflow/docs_src/guide/summaries_and_tensorboard.md b/tensorflow/docs_src/guide/summaries_and_tensorboard.md deleted file mode 100644 index 788c556b9d..0000000000 --- a/tensorflow/docs_src/guide/summaries_and_tensorboard.md +++ /dev/null @@ -1,225 +0,0 @@ -# TensorBoard: Visualizing Learning - -The computations you'll use TensorFlow for - like training a massive -deep neural network - can be complex and confusing. To make it easier to -understand, debug, and optimize TensorFlow programs, we've included a suite of -visualization tools called TensorBoard. You can use TensorBoard to visualize -your TensorFlow graph, plot quantitative metrics about the execution of your -graph, and show additional data like images that pass through it. When -TensorBoard is fully configured, it looks like this: - - - -<div class="video-wrapper"> - <iframe class="devsite-embedded-youtube-video" data-video-id="eBbEDRsCmv4" - data-autohide="1" data-showinfo="0" frameborder="0" allowfullscreen> - </iframe> -</div> - -This 30-minute tutorial is intended to get you started with simple TensorBoard -usage. It assumes a basic understanding of TensorFlow. - -There are other resources available as well! The [TensorBoard GitHub](https://github.com/tensorflow/tensorboard) -has a lot more information on using individual dashboards within TensorBoard -including tips & tricks and debugging information. - -## Setup - -[Install TensorFlow](https://www.tensorflow.org/install/). Installing TensorFlow -via pip should also automatically install TensorBoard. - -## Serializing the data - -TensorBoard operates by reading TensorFlow events files, which contain summary -data that you can generate when running TensorFlow. Here's the general -lifecycle for summary data within TensorBoard. - -First, create the TensorFlow graph that you'd like to collect summary -data from, and decide which nodes you would like to annotate with -[summary operations](../api_guides/python/summary.md). - -For example, suppose you are training a convolutional neural network for -recognizing MNIST digits. You'd like to record how the learning rate -varies over time, and how the objective function is changing. Collect these by -attaching `tf.summary.scalar` ops -to the nodes that output the learning rate and loss respectively. Then, give -each `scalar_summary` a meaningful `tag`, like `'learning rate'` or `'loss -function'`. - -Perhaps you'd also like to visualize the distributions of activations coming -off a particular layer, or the distribution of gradients or weights. Collect -this data by attaching -`tf.summary.histogram` ops to -the gradient outputs and to the variable that holds your weights, respectively. - -For details on all of the summary operations available, check out the docs on -[summary operations](../api_guides/python/summary.md). - -Operations in TensorFlow don't do anything until you run them, or an op that -depends on their output. And the summary nodes that we've just created are -peripheral to your graph: none of the ops you are currently running depend on -them. So, to generate summaries, we need to run all of these summary nodes. -Managing them by hand would be tedious, so use -`tf.summary.merge_all` -to combine them into a single op that generates all the summary data. - -Then, you can just run the merged summary op, which will generate a serialized -`Summary` protobuf object with all of your summary data at a given step. -Finally, to write this summary data to disk, pass the summary protobuf to a -`tf.summary.FileWriter`. - -The `FileWriter` takes a logdir in its constructor - this logdir is quite -important, it's the directory where all of the events will be written out. -Also, the `FileWriter` can optionally take a `Graph` in its constructor. -If it receives a `Graph` object, then TensorBoard will visualize your graph -along with tensor shape information. This will give you a much better sense of -what flows through the graph: see -[Tensor shape information](../guide/graph_viz.md#tensor-shape-information). - -Now that you've modified your graph and have a `FileWriter`, you're ready to -start running your network! If you want, you could run the merged summary op -every single step, and record a ton of training data. That's likely to be more -data than you need, though. Instead, consider running the merged summary op -every `n` steps. - -The code example below is a modification of the -[simple MNIST tutorial](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/tutorials/mnist/mnist.py), -in which we have added some summary ops, and run them every ten steps. If you -run this and then launch `tensorboard --logdir=/tmp/tensorflow/mnist`, you'll be able -to visualize statistics, such as how the weights or accuracy varied during -training. The code below is an excerpt; full source is -[here](https://www.tensorflow.org/code/tensorflow/examples/tutorials/mnist/mnist_with_summaries.py). - -```python -def variable_summaries(var): - """Attach a lot of summaries to a Tensor (for TensorBoard visualization).""" - with tf.name_scope('summaries'): - mean = tf.reduce_mean(var) - tf.summary.scalar('mean', mean) - with tf.name_scope('stddev'): - stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean))) - tf.summary.scalar('stddev', stddev) - tf.summary.scalar('max', tf.reduce_max(var)) - tf.summary.scalar('min', tf.reduce_min(var)) - tf.summary.histogram('histogram', var) - -def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu): - """Reusable code for making a simple neural net layer. - - It does a matrix multiply, bias add, and then uses relu to nonlinearize. - It also sets up name scoping so that the resultant graph is easy to read, - and adds a number of summary ops. - """ - # Adding a name scope ensures logical grouping of the layers in the graph. - with tf.name_scope(layer_name): - # This Variable will hold the state of the weights for the layer - with tf.name_scope('weights'): - weights = weight_variable([input_dim, output_dim]) - variable_summaries(weights) - with tf.name_scope('biases'): - biases = bias_variable([output_dim]) - variable_summaries(biases) - with tf.name_scope('Wx_plus_b'): - preactivate = tf.matmul(input_tensor, weights) + biases - tf.summary.histogram('pre_activations', preactivate) - activations = act(preactivate, name='activation') - tf.summary.histogram('activations', activations) - return activations - -hidden1 = nn_layer(x, 784, 500, 'layer1') - -with tf.name_scope('dropout'): - keep_prob = tf.placeholder(tf.float32) - tf.summary.scalar('dropout_keep_probability', keep_prob) - dropped = tf.nn.dropout(hidden1, keep_prob) - -# Do not apply softmax activation yet, see below. -y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity) - -with tf.name_scope('cross_entropy'): - # The raw formulation of cross-entropy, - # - # tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.softmax(y)), - # reduction_indices=[1])) - # - # can be numerically unstable. - # - # So here we use tf.losses.sparse_softmax_cross_entropy on the - # raw logit outputs of the nn_layer above. - with tf.name_scope('total'): - cross_entropy = tf.losses.sparse_softmax_cross_entropy(labels=y_, logits=y) -tf.summary.scalar('cross_entropy', cross_entropy) - -with tf.name_scope('train'): - train_step = tf.train.AdamOptimizer(FLAGS.learning_rate).minimize( - cross_entropy) - -with tf.name_scope('accuracy'): - with tf.name_scope('correct_prediction'): - correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) - with tf.name_scope('accuracy'): - accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) -tf.summary.scalar('accuracy', accuracy) - -# Merge all the summaries and write them out to /tmp/mnist_logs (by default) -merged = tf.summary.merge_all() -train_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/train', - sess.graph) -test_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/test') -tf.global_variables_initializer().run() -``` - -After we've initialized the `FileWriters`, we have to add summaries to the -`FileWriters` as we train and test the model. - -```python -# Train the model, and also write summaries. -# Every 10th step, measure test-set accuracy, and write test summaries -# All other steps, run train_step on training data, & add training summaries - -def feed_dict(train): - """Make a TensorFlow feed_dict: maps data onto Tensor placeholders.""" - if train or FLAGS.fake_data: - xs, ys = mnist.train.next_batch(100, fake_data=FLAGS.fake_data) - k = FLAGS.dropout - else: - xs, ys = mnist.test.images, mnist.test.labels - k = 1.0 - return {x: xs, y_: ys, keep_prob: k} - -for i in range(FLAGS.max_steps): - if i % 10 == 0: # Record summaries and test-set accuracy - summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False)) - test_writer.add_summary(summary, i) - print('Accuracy at step %s: %s' % (i, acc)) - else: # Record train set summaries, and train - summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True)) - train_writer.add_summary(summary, i) -``` - -You're now all set to visualize this data using TensorBoard. - - -## Launching TensorBoard - -To run TensorBoard, use the following command (alternatively `python -m -tensorboard.main`) - -```bash -tensorboard --logdir=path/to/log-directory -``` - -where `logdir` points to the directory where the `FileWriter` serialized its -data. If this `logdir` directory contains subdirectories which contain -serialized data from separate runs, then TensorBoard will visualize the data -from all of those runs. Once TensorBoard is running, navigate your web browser -to `localhost:6006` to view the TensorBoard. - -When looking at TensorBoard, you will see the navigation tabs in the top right -corner. Each tab represents a set of serialized data that can be visualized. - -For in depth information on how to use the *graph* tab to visualize your graph, -see [TensorBoard: Graph Visualization](../guide/graph_viz.md). - -For more usage information on TensorBoard in general, see the -[TensorBoard GitHub](https://github.com/tensorflow/tensorboard). diff --git a/tensorflow/docs_src/guide/tensorboard_histograms.md b/tensorflow/docs_src/guide/tensorboard_histograms.md deleted file mode 100644 index af8f2cadd1..0000000000 --- a/tensorflow/docs_src/guide/tensorboard_histograms.md +++ /dev/null @@ -1,245 +0,0 @@ -# TensorBoard Histogram Dashboard - -The TensorBoard Histogram Dashboard displays how the distribution of some -`Tensor` in your TensorFlow graph has changed over time. It does this by showing -many histograms visualizations of your tensor at different points in time. - -## A Basic Example - -Let's start with a simple case: a normally-distributed variable, where the mean -shifts over time. -TensorFlow has an op -[`tf.random_normal`](https://www.tensorflow.org/api_docs/python/tf/random_normal) -which is perfect for this purpose. As is usually the case with TensorBoard, we -will ingest data using a summary op; in this case, -['tf.summary.histogram'](https://www.tensorflow.org/api_docs/python/tf/summary/histogram). -For a primer on how summaries work, please see the -[TensorBoard guide](./summaries_and_tensorboard.md). - -Here is a code snippet that will generate some histogram summaries containing -normally distributed data, where the mean of the distribution increases over -time. - -```python -import tensorflow as tf - -k = tf.placeholder(tf.float32) - -# Make a normal distribution, with a shifting mean -mean_moving_normal = tf.random_normal(shape=[1000], mean=(5*k), stddev=1) -# Record that distribution into a histogram summary -tf.summary.histogram("normal/moving_mean", mean_moving_normal) - -# Setup a session and summary writer -sess = tf.Session() -writer = tf.summary.FileWriter("/tmp/histogram_example") - -summaries = tf.summary.merge_all() - -# Setup a loop and write the summaries to disk -N = 400 -for step in range(N): - k_val = step/float(N) - summ = sess.run(summaries, feed_dict={k: k_val}) - writer.add_summary(summ, global_step=step) -``` - -Once that code runs, we can load the data into TensorBoard via the command line: - - -```sh -tensorboard --logdir=/tmp/histogram_example -``` - -Once TensorBoard is running, load it in Chrome or Firefox and navigate to the -Histogram Dashboard. Then we can see a histogram visualization for our normally -distributed data. - - - -`tf.summary.histogram` takes an arbitrarily sized and shaped Tensor, and -compresses it into a histogram data structure consisting of many bins with -widths and counts. For example, let's say we want to organize the numbers -`[0.5, 1.1, 1.3, 2.2, 2.9, 2.99]` into bins. We could make three bins: -* a bin -containing everything from 0 to 1 (it would contain one element, 0.5), -* a bin -containing everything from 1-2 (it would contain two elements, 1.1 and 1.3), -* a bin containing everything from 2-3 (it would contain three elements: 2.2, -2.9 and 2.99). - -TensorFlow uses a similar approach to create bins, but unlike in our example, it -doesn't create integer bins. For large, sparse datasets, that might result in -many thousands of bins. -Instead, [the bins are exponentially distributed, with many bins close to 0 and -comparatively few bins for very large numbers.](https://github.com/tensorflow/tensorflow/blob/c8b59c046895fa5b6d79f73e0b5817330fcfbfc1/tensorflow/core/lib/histogram/histogram.cc#L28) -However, visualizing exponentially-distributed bins is tricky; if height is used -to encode count, then wider bins take more space, even if they have the same -number of elements. Conversely, encoding count in the area makes height -comparisons impossible. Instead, the histograms [resample the data](https://github.com/tensorflow/tensorflow/blob/17c47804b86e340203d451125a721310033710f1/tensorflow/tensorboard/components/tf_backend/backend.ts#L400) -into uniform bins. This can lead to unfortunate artifacts in some cases. - -Each slice in the histogram visualizer displays a single histogram. -The slices are organized by step; -older slices (e.g. step 0) are further "back" and darker, while newer slices -(e.g. step 400) are close to the foreground, and lighter in color. -The y-axis on the right shows the step number. - -You can mouse over the histogram to see tooltips with some more detailed -information. For example, in the following image we can see that the histogram -at timestep 176 has a bin centered at 2.25 with 177 elements in that bin. - - - -Also, you may note that the histogram slices are not always evenly spaced in -step count or time. This is because TensorBoard uses -[reservoir sampling](https://en.wikipedia.org/wiki/Reservoir_sampling) to keep a -subset of all the histograms, to save on memory. Reservoir sampling guarantees -that every sample has an equal likelihood of being included, but because it is -a randomized algorithm, the samples chosen don't occur at even steps. - -## Overlay Mode - -There is a control on the left of the dashboard that allows you to toggle the -histogram mode from "offset" to "overlay": - - - -In "offset" mode, the visualization rotates 45 degrees, so that the individual -histogram slices are no longer spread out in time, but instead are all plotted -on the same y-axis. - - -Now, each slice is a separate line on the chart, and the y-axis shows the item -count within each bucket. Darker lines are older, earlier steps, and lighter -lines are more recent, later steps. Once again, you can mouse over the chart to -see some additional information. - - - -In general, the overlay visualization is useful if you want to directly compare -the counts of different histograms. - -## Multimodal Distributions - -The Histogram Dashboard is great for visualizing multimodal -distributions. Let's construct a simple bimodal distribution by concatenating -the outputs from two different normal distributions. The code will look like -this: - -```python -import tensorflow as tf - -k = tf.placeholder(tf.float32) - -# Make a normal distribution, with a shifting mean -mean_moving_normal = tf.random_normal(shape=[1000], mean=(5*k), stddev=1) -# Record that distribution into a histogram summary -tf.summary.histogram("normal/moving_mean", mean_moving_normal) - -# Make a normal distribution with shrinking variance -variance_shrinking_normal = tf.random_normal(shape=[1000], mean=0, stddev=1-(k)) -# Record that distribution too -tf.summary.histogram("normal/shrinking_variance", variance_shrinking_normal) - -# Let's combine both of those distributions into one dataset -normal_combined = tf.concat([mean_moving_normal, variance_shrinking_normal], 0) -# We add another histogram summary to record the combined distribution -tf.summary.histogram("normal/bimodal", normal_combined) - -summaries = tf.summary.merge_all() - -# Setup a session and summary writer -sess = tf.Session() -writer = tf.summary.FileWriter("/tmp/histogram_example") - -# Setup a loop and write the summaries to disk -N = 400 -for step in range(N): - k_val = step/float(N) - summ = sess.run(summaries, feed_dict={k: k_val}) - writer.add_summary(summ, global_step=step) -``` - -You already remember our "moving mean" normal distribution from the example -above. Now we also have a "shrinking variance" distribution. Side-by-side, they -look like this: - - -When we concatenate them, we get a chart that clearly reveals the divergent, -bimodal structure: - - -## Some more distributions - -Just for fun, let's generate and visualize a few more distributions, and then -combine them all into one chart. Here's the code we'll use: - -```python -import tensorflow as tf - -k = tf.placeholder(tf.float32) - -# Make a normal distribution, with a shifting mean -mean_moving_normal = tf.random_normal(shape=[1000], mean=(5*k), stddev=1) -# Record that distribution into a histogram summary -tf.summary.histogram("normal/moving_mean", mean_moving_normal) - -# Make a normal distribution with shrinking variance -variance_shrinking_normal = tf.random_normal(shape=[1000], mean=0, stddev=1-(k)) -# Record that distribution too -tf.summary.histogram("normal/shrinking_variance", variance_shrinking_normal) - -# Let's combine both of those distributions into one dataset -normal_combined = tf.concat([mean_moving_normal, variance_shrinking_normal], 0) -# We add another histogram summary to record the combined distribution -tf.summary.histogram("normal/bimodal", normal_combined) - -# Add a gamma distribution -gamma = tf.random_gamma(shape=[1000], alpha=k) -tf.summary.histogram("gamma", gamma) - -# And a poisson distribution -poisson = tf.random_poisson(shape=[1000], lam=k) -tf.summary.histogram("poisson", poisson) - -# And a uniform distribution -uniform = tf.random_uniform(shape=[1000], maxval=k*10) -tf.summary.histogram("uniform", uniform) - -# Finally, combine everything together! -all_distributions = [mean_moving_normal, variance_shrinking_normal, - gamma, poisson, uniform] -all_combined = tf.concat(all_distributions, 0) -tf.summary.histogram("all_combined", all_combined) - -summaries = tf.summary.merge_all() - -# Setup a session and summary writer -sess = tf.Session() -writer = tf.summary.FileWriter("/tmp/histogram_example") - -# Setup a loop and write the summaries to disk -N = 400 -for step in range(N): - k_val = step/float(N) - summ = sess.run(summaries, feed_dict={k: k_val}) - writer.add_summary(summ, global_step=step) -``` -### Gamma Distribution - - -### Uniform Distribution - - -### Poisson Distribution - -The poisson distribution is defined over the integers. So, all of the values -being generated are perfect integers. The histogram compression moves the data -into floating-point bins, causing the visualization to show little -bumps over the integer values rather than perfect spikes. - -### All Together Now -Finally, we can concatenate all of the data into one funny-looking curve. - - diff --git a/tensorflow/docs_src/guide/tensors.md b/tensorflow/docs_src/guide/tensors.md deleted file mode 100644 index 4f0ddb21b5..0000000000 --- a/tensorflow/docs_src/guide/tensors.md +++ /dev/null @@ -1,330 +0,0 @@ -# Tensors - -TensorFlow, as the name indicates, is a framework to define and run computations -involving tensors. A **tensor** is a generalization of vectors and matrices to -potentially higher dimensions. Internally, TensorFlow represents tensors as -n-dimensional arrays of base datatypes. - -When writing a TensorFlow program, the main object you manipulate and pass -around is the `tf.Tensor`. A `tf.Tensor` object represents a partially defined -computation that will eventually produce a value. TensorFlow programs work by -first building a graph of `tf.Tensor` objects, detailing how each tensor is -computed based on the other available tensors and then by running parts of this -graph to achieve the desired results. - -A `tf.Tensor` has the following properties: - - * a data type (`float32`, `int32`, or `string`, for example) - * a shape - - -Each element in the Tensor has the same data type, and the data type is always -known. The shape (that is, the number of dimensions it has and the size of each -dimension) might be only partially known. Most operations produce tensors of -fully-known shapes if the shapes of their inputs are also fully known, but in -some cases it's only possible to find the shape of a tensor at graph execution -time. - -Some types of tensors are special, and these will be covered in other -units of the TensorFlow guide. The main ones are: - - * `tf.Variable` - * `tf.constant` - * `tf.placeholder` - * `tf.SparseTensor` - -With the exception of `tf.Variable`, the value of a tensor is immutable, which -means that in the context of a single execution tensors only have a single -value. However, evaluating the same tensor twice can return different values; -for example that tensor can be the result of reading data from disk, or -generating a random number. - -## Rank - -The **rank** of a `tf.Tensor` object is its number of dimensions. Synonyms for -rank include **order** or **degree** or **n-dimension**. -Note that rank in TensorFlow is not the same as matrix rank in mathematics. -As the following table shows, each rank in TensorFlow corresponds to a -different mathematical entity: - -Rank | Math entity ---- | --- -0 | Scalar (magnitude only) -1 | Vector (magnitude and direction) -2 | Matrix (table of numbers) -3 | 3-Tensor (cube of numbers) -n | n-Tensor (you get the idea) - - -### Rank 0 - -The following snippet demonstrates creating a few rank 0 variables: - -```python -mammal = tf.Variable("Elephant", tf.string) -ignition = tf.Variable(451, tf.int16) -floating = tf.Variable(3.14159265359, tf.float64) -its_complicated = tf.Variable(12.3 - 4.85j, tf.complex64) -``` - -Note: A string is treated as a single item in TensorFlow, not as a sequence of -characters. It is possible to have scalar strings, vectors of strings, etc. - -### Rank 1 - -To create a rank 1 `tf.Tensor` object, you can pass a list of items as the -initial value. For example: - -```python -mystr = tf.Variable(["Hello"], tf.string) -cool_numbers = tf.Variable([3.14159, 2.71828], tf.float32) -first_primes = tf.Variable([2, 3, 5, 7, 11], tf.int32) -its_very_complicated = tf.Variable([12.3 - 4.85j, 7.5 - 6.23j], tf.complex64) -``` - - -### Higher ranks - -A rank 2 `tf.Tensor` object consists of at least one row and at least -one column: - -```python -mymat = tf.Variable([[7],[11]], tf.int16) -myxor = tf.Variable([[False, True],[True, False]], tf.bool) -linear_squares = tf.Variable([[4], [9], [16], [25]], tf.int32) -squarish_squares = tf.Variable([ [4, 9], [16, 25] ], tf.int32) -rank_of_squares = tf.rank(squarish_squares) -mymatC = tf.Variable([[7],[11]], tf.int32) -``` - -Higher-rank Tensors, similarly, consist of an n-dimensional array. For example, -during image processing, many tensors of rank 4 are used, with dimensions -corresponding to example-in-batch, image width, image height, and color channel. - -``` python -my_image = tf.zeros([10, 299, 299, 3]) # batch x height x width x color -``` - -### Getting a `tf.Tensor` object's rank - -To determine the rank of a `tf.Tensor` object, call the `tf.rank` method. -For example, the following method programmatically determines the rank -of the `tf.Tensor` defined in the previous section: - -```python -r = tf.rank(my_image) -# After the graph runs, r will hold the value 4. -``` - -### Referring to `tf.Tensor` slices - -Since a `tf.Tensor` is an n-dimensional array of cells, to access a single cell -in a `tf.Tensor` you need to specify n indices. - -For a rank 0 tensor (a scalar), no indices are necessary, since it is already a -single number. - -For a rank 1 tensor (a vector), passing a single index allows you to access a -number: - -```python -my_scalar = my_vector[2] -``` - -Note that the index passed inside the `[]` can itself be a scalar `tf.Tensor`, if -you want to dynamically choose an element from the vector. - -For tensors of rank 2 or higher, the situation is more interesting. For a -`tf.Tensor` of rank 2, passing two numbers returns a scalar, as expected: - - -```python -my_scalar = my_matrix[1, 2] -``` - - -Passing a single number, however, returns a subvector of a matrix, as follows: - - -```python -my_row_vector = my_matrix[2] -my_column_vector = my_matrix[:, 3] -``` - -The `:` notation is python slicing syntax for "leave this dimension alone". This -is useful in higher-rank Tensors, as it allows you to access its subvectors, -submatrices, and even other subtensors. - - -## Shape - -The **shape** of a tensor is the number of elements in each dimension. -TensorFlow automatically infers shapes during graph construction. These inferred -shapes might have known or unknown rank. If the rank is known, the sizes of each -dimension might be known or unknown. - -The TensorFlow documentation uses three notational conventions to describe -tensor dimensionality: rank, shape, and dimension number. The following table -shows how these relate to one another: - -Rank | Shape | Dimension number | Example ---- | --- | --- | --- -0 | [] | 0-D | A 0-D tensor. A scalar. -1 | [D0] | 1-D | A 1-D tensor with shape [5]. -2 | [D0, D1] | 2-D | A 2-D tensor with shape [3, 4]. -3 | [D0, D1, D2] | 3-D | A 3-D tensor with shape [1, 4, 3]. -n | [D0, D1, ... Dn-1] | n-D | A tensor with shape [D0, D1, ... Dn-1]. - -Shapes can be represented via Python lists / tuples of ints, or with the -`tf.TensorShape`. - -### Getting a `tf.Tensor` object's shape - -There are two ways of accessing the shape of a `tf.Tensor`. While building the -graph, it is often useful to ask what is already known about a tensor's -shape. This can be done by reading the `shape` property of a `tf.Tensor` object. -This method returns a `TensorShape` object, which is a convenient way of -representing partially-specified shapes (since, when building the graph, not all -shapes will be fully known). - -It is also possible to get a `tf.Tensor` that will represent the fully-defined -shape of another `tf.Tensor` at runtime. This is done by calling the `tf.shape` -operation. This way, you can build a graph that manipulates the shapes of -tensors by building other tensors that depend on the dynamic shape of the input -`tf.Tensor`. - -For example, here is how to make a vector of zeros with the same size as the -number of columns in a given matrix: - -``` python -zeros = tf.zeros(my_matrix.shape[1]) -``` - -### Changing the shape of a `tf.Tensor` - -The **number of elements** of a tensor is the product of the sizes of all its -shapes. The number of elements of a scalar is always `1`. Since there are often -many different shapes that have the same number of elements, it's often -convenient to be able to change the shape of a `tf.Tensor`, keeping its elements -fixed. This can be done with `tf.reshape`. - -The following examples demonstrate how to reshape tensors: - -```python -rank_three_tensor = tf.ones([3, 4, 5]) -matrix = tf.reshape(rank_three_tensor, [6, 10]) # Reshape existing content into - # a 6x10 matrix -matrixB = tf.reshape(matrix, [3, -1]) # Reshape existing content into a 3x20 - # matrix. -1 tells reshape to calculate - # the size of this dimension. -matrixAlt = tf.reshape(matrixB, [4, 3, -1]) # Reshape existing content into a - #4x3x5 tensor - -# Note that the number of elements of the reshaped Tensors has to match the -# original number of elements. Therefore, the following example generates an -# error because no possible value for the last dimension will match the number -# of elements. -yet_another = tf.reshape(matrixAlt, [13, 2, -1]) # ERROR! -``` - -## Data types - -In addition to dimensionality, Tensors have a data type. Refer to the -`tf.DType` page for a complete list of the data types. - -It is not possible to have a `tf.Tensor` with more than one data type. It is -possible, however, to serialize arbitrary data structures as `string`s and store -those in `tf.Tensor`s. - -It is possible to cast `tf.Tensor`s from one datatype to another using -`tf.cast`: - -``` python -# Cast a constant integer tensor into floating point. -float_tensor = tf.cast(tf.constant([1, 2, 3]), dtype=tf.float32) -``` - -To inspect a `tf.Tensor`'s data type use the `Tensor.dtype` property. - -When creating a `tf.Tensor` from a python object you may optionally specify the -datatype. If you don't, TensorFlow chooses a datatype that can represent your -data. TensorFlow converts Python integers to `tf.int32` and python floating -point numbers to `tf.float32`. Otherwise TensorFlow uses the same rules numpy -uses when converting to arrays. - -## Evaluating Tensors - -Once the computation graph has been built, you can run the computation that -produces a particular `tf.Tensor` and fetch the value assigned to it. This is -often useful for debugging as well as being required for much of TensorFlow to -work. - -The simplest way to evaluate a Tensor is using the `Tensor.eval` method. For -example: - -```python -constant = tf.constant([1, 2, 3]) -tensor = constant * constant -print(tensor.eval()) -``` - -The `eval` method only works when a default `tf.Session` is active (see -Graphs and Sessions for more information). - -`Tensor.eval` returns a numpy array with the same contents as the tensor. - -Sometimes it is not possible to evaluate a `tf.Tensor` with no context because -its value might depend on dynamic information that is not available. For -example, tensors that depend on `placeholder`s can't be evaluated without -providing a value for the `placeholder`. - -``` python -p = tf.placeholder(tf.float32) -t = p + 1.0 -t.eval() # This will fail, since the placeholder did not get a value. -t.eval(feed_dict={p:2.0}) # This will succeed because we're feeding a value - # to the placeholder. -``` - -Note that it is possible to feed any `tf.Tensor`, not just placeholders. - -Other model constructs might make evaluating a `tf.Tensor` -complicated. TensorFlow can't directly evaluate `tf.Tensor`s defined inside -functions or inside control flow constructs. If a `tf.Tensor` depends on a value -from a queue, evaluating the `tf.Tensor` will only work once something has been -enqueued; otherwise, evaluating it will hang. When working with queues, remember -to call `tf.train.start_queue_runners` before evaluating any `tf.Tensor`s. - -## Printing Tensors - -For debugging purposes you might want to print the value of a `tf.Tensor`. While - [tfdbg](../guide/debugger.md) provides advanced debugging support, TensorFlow also has an - operation to directly print the value of a `tf.Tensor`. - -Note that you rarely want to use the following pattern when printing a -`tf.Tensor`: - -``` python -t = <<some tensorflow operation>> -print(t) # This will print the symbolic tensor when the graph is being built. - # This tensor does not have a value in this context. -``` - -This code prints the `tf.Tensor` object (which represents deferred computation) -and not its value. Instead, TensorFlow provides the `tf.Print` operation, which -returns its first tensor argument unchanged while printing the set of -`tf.Tensor`s it is passed as the second argument. - -To correctly use `tf.Print` its return value must be used. See the example below - -``` python -t = <<some tensorflow operation>> -tf.Print(t, [t]) # This does nothing -t = tf.Print(t, [t]) # Here we are using the value returned by tf.Print -result = t + 1 # Now when result is evaluated the value of `t` will be printed. -``` - -When you evaluate `result` you will evaluate everything `result` depends -upon. Since `result` depends upon `t`, and evaluating `t` has the side effect of -printing its input (the old value of `t`), `t` gets printed. - diff --git a/tensorflow/docs_src/guide/using_gpu.md b/tensorflow/docs_src/guide/using_gpu.md deleted file mode 100644 index 8cb9b354c7..0000000000 --- a/tensorflow/docs_src/guide/using_gpu.md +++ /dev/null @@ -1,215 +0,0 @@ -# Using GPUs - -## Supported devices - -On a typical system, there are multiple computing devices. In TensorFlow, the -supported device types are `CPU` and `GPU`. They are represented as `strings`. -For example: - -* `"/cpu:0"`: The CPU of your machine. -* `"/device:GPU:0"`: The GPU of your machine, if you have one. -* `"/device:GPU:1"`: The second GPU of your machine, etc. - -If a TensorFlow operation has both CPU and GPU implementations, the GPU devices -will be given priority when the operation is assigned to a device. For example, -`matmul` has both CPU and GPU kernels. On a system with devices `cpu:0` and -`gpu:0`, `gpu:0` will be selected to run `matmul`. - -## Logging Device placement - -To find out which devices your operations and tensors are assigned to, create -the session with `log_device_placement` configuration option set to `True`. - -```python -# Creates a graph. -a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') -b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b') -c = tf.matmul(a, b) -# Creates a session with log_device_placement set to True. -sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) -# Runs the op. -print(sess.run(c)) -``` - -You should see the following output: - -``` -Device mapping: -/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: Tesla K40c, pci bus -id: 0000:05:00.0 -b: /job:localhost/replica:0/task:0/device:GPU:0 -a: /job:localhost/replica:0/task:0/device:GPU:0 -MatMul: /job:localhost/replica:0/task:0/device:GPU:0 -[[ 22. 28.] - [ 49. 64.]] - -``` - -## Manual device placement - -If you would like a particular operation to run on a device of your choice -instead of what's automatically selected for you, you can use `with tf.device` -to create a device context such that all the operations within that context will -have the same device assignment. - -```python -# Creates a graph. -with tf.device('/cpu:0'): - a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') - b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b') -c = tf.matmul(a, b) -# Creates a session with log_device_placement set to True. -sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) -# Runs the op. -print(sess.run(c)) -``` - -You will see that now `a` and `b` are assigned to `cpu:0`. Since a device was -not explicitly specified for the `MatMul` operation, the TensorFlow runtime will -choose one based on the operation and available devices (`gpu:0` in this -example) and automatically copy tensors between devices if required. - -``` -Device mapping: -/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: Tesla K40c, pci bus -id: 0000:05:00.0 -b: /job:localhost/replica:0/task:0/cpu:0 -a: /job:localhost/replica:0/task:0/cpu:0 -MatMul: /job:localhost/replica:0/task:0/device:GPU:0 -[[ 22. 28.] - [ 49. 64.]] -``` - -## Allowing GPU memory growth - -By default, TensorFlow maps nearly all of the GPU memory of all GPUs (subject to -[`CUDA_VISIBLE_DEVICES`](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#env-vars)) -visible to the process. This is done to more efficiently use the relatively -precious GPU memory resources on the devices by reducing [memory -fragmentation](https://en.wikipedia.org/wiki/Fragmentation_\(computing\)). - -In some cases it is desirable for the process to only allocate a subset of the -available memory, or to only grow the memory usage as is needed by the process. -TensorFlow provides two Config options on the Session to control this. - -The first is the `allow_growth` option, which attempts to allocate only as much -GPU memory based on runtime allocations: it starts out allocating very little -memory, and as Sessions get run and more GPU memory is needed, we extend the GPU -memory region needed by the TensorFlow process. Note that we do not release -memory, since that can lead to even worse memory fragmentation. To turn this -option on, set the option in the ConfigProto by: - -```python -config = tf.ConfigProto() -config.gpu_options.allow_growth = True -session = tf.Session(config=config, ...) -``` - -The second method is the `per_process_gpu_memory_fraction` option, which -determines the fraction of the overall amount of memory that each visible GPU -should be allocated. For example, you can tell TensorFlow to only allocate 40% -of the total memory of each GPU by: - -```python -config = tf.ConfigProto() -config.gpu_options.per_process_gpu_memory_fraction = 0.4 -session = tf.Session(config=config, ...) -``` - -This is useful if you want to truly bound the amount of GPU memory available to -the TensorFlow process. - -## Using a single GPU on a multi-GPU system - -If you have more than one GPU in your system, the GPU with the lowest ID will be -selected by default. If you would like to run on a different GPU, you will need -to specify the preference explicitly: - -```python -# Creates a graph. -with tf.device('/device:GPU:2'): - a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') - b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b') - c = tf.matmul(a, b) -# Creates a session with log_device_placement set to True. -sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) -# Runs the op. -print(sess.run(c)) -``` - -If the device you have specified does not exist, you will get -`InvalidArgumentError`: - -``` -InvalidArgumentError: Invalid argument: Cannot assign a device to node 'b': -Could not satisfy explicit device specification '/device:GPU:2' - [[{{node b}} = Const[dtype=DT_FLOAT, value=Tensor<type: float shape: [3,2] - values: 1 2 3...>, _device="/device:GPU:2"]()]] -``` - -If you would like TensorFlow to automatically choose an existing and supported -device to run the operations in case the specified one doesn't exist, you can -set `allow_soft_placement` to `True` in the configuration option when creating -the session. - -```python -# Creates a graph. -with tf.device('/device:GPU:2'): - a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') - b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b') - c = tf.matmul(a, b) -# Creates a session with allow_soft_placement and log_device_placement set -# to True. -sess = tf.Session(config=tf.ConfigProto( - allow_soft_placement=True, log_device_placement=True)) -# Runs the op. -print(sess.run(c)) -``` - -## Using multiple GPUs - -If you would like to run TensorFlow on multiple GPUs, you can construct your -model in a multi-tower fashion where each tower is assigned to a different GPU. -For example: - -``` python -# Creates a graph. -c = [] -for d in ['/device:GPU:2', '/device:GPU:3']: - with tf.device(d): - a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3]) - b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2]) - c.append(tf.matmul(a, b)) -with tf.device('/cpu:0'): - sum = tf.add_n(c) -# Creates a session with log_device_placement set to True. -sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) -# Runs the op. -print(sess.run(sum)) -``` - -You will see the following output. - -``` -Device mapping: -/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: Tesla K20m, pci bus -id: 0000:02:00.0 -/job:localhost/replica:0/task:0/device:GPU:1 -> device: 1, name: Tesla K20m, pci bus -id: 0000:03:00.0 -/job:localhost/replica:0/task:0/device:GPU:2 -> device: 2, name: Tesla K20m, pci bus -id: 0000:83:00.0 -/job:localhost/replica:0/task:0/device:GPU:3 -> device: 3, name: Tesla K20m, pci bus -id: 0000:84:00.0 -Const_3: /job:localhost/replica:0/task:0/device:GPU:3 -Const_2: /job:localhost/replica:0/task:0/device:GPU:3 -MatMul_1: /job:localhost/replica:0/task:0/device:GPU:3 -Const_1: /job:localhost/replica:0/task:0/device:GPU:2 -Const: /job:localhost/replica:0/task:0/device:GPU:2 -MatMul: /job:localhost/replica:0/task:0/device:GPU:2 -AddN: /job:localhost/replica:0/task:0/cpu:0 -[[ 44. 56.] - [ 98. 128.]] -``` - -The [cifar10 tutorial](../tutorials/images/deep_cnn.md) is a good example -demonstrating how to do training with multiple GPUs. diff --git a/tensorflow/docs_src/guide/using_tpu.md b/tensorflow/docs_src/guide/using_tpu.md deleted file mode 100644 index 59b34e19e0..0000000000 --- a/tensorflow/docs_src/guide/using_tpu.md +++ /dev/null @@ -1,395 +0,0 @@ -# Using TPUs - -This document walks through the principal TensorFlow APIs necessary to make -effective use of a [Cloud TPU](https://cloud.google.com/tpu/), and highlights -the differences between regular TensorFlow usage, and usage on a TPU. - -This doc is aimed at users who: - -* Are familiar with TensorFlow's `Estimator` and `Dataset` APIs -* Have maybe [tried out a Cloud TPU](https://cloud.google.com/tpu/docs/quickstart) - using an existing model. -* Have, perhaps, skimmed the code of an example TPU model - [[1]](https://github.com/tensorflow/models/blob/master/official/mnist/mnist_tpu.py) - [[2]](https://github.com/tensorflow/tpu/tree/master/models). -* Are interested in porting an existing `Estimator` model to - run on Cloud TPUs - -## TPUEstimator - -`tf.estimator.Estimator` are TensorFlow's model-level abstraction. -Standard `Estimators` can drive models on CPU and GPUs. You must use -`tf.contrib.tpu.TPUEstimator` to drive a model on TPUs. - -Refer to TensorFlow's Getting Started section for an introduction to the basics -of using a [pre-made `Estimator`](../guide/premade_estimators.md), and -[custom `Estimator`s](../guide/custom_estimators.md). - -The `TPUEstimator` class differs somewhat from the `Estimator` class. - -The simplest way to maintain a model that can be run both on CPU/GPU or on a -Cloud TPU is to define the model's inference phase (from inputs to predictions) -outside of the `model_fn`. Then maintain separate implementations of the -`Estimator` setup and `model_fn`, both wrapping this inference step. For an -example of this pattern compare the `mnist.py` and `mnist_tpu.py` implementation in -[tensorflow/models](https://github.com/tensorflow/models/tree/master/official/mnist). - -### Running a `TPUEstimator` locally - -To create a standard `Estimator` you call the constructor, and pass it a -`model_fn`, for example: - -``` -my_estimator = tf.estimator.Estimator( - model_fn=my_model_fn) -``` - -The changes required to use a `tf.contrib.tpu.TPUEstimator` on your local -machine are relatively minor. The constructor requires two additional arguments. -You should set the `use_tpu` argument to `False`, and pass a -`tf.contrib.tpu.RunConfig` as the `config` argument, as shown below: - -``` python -my_tpu_estimator = tf.contrib.tpu.TPUEstimator( - model_fn=my_model_fn, - config=tf.contrib.tpu.RunConfig() - use_tpu=False) -``` - -Just this simple change will allow you to run a `TPUEstimator` locally. -The majority of example TPU models can be run in this local mode, -by setting the command line flags as follows: - - -``` -$> python mnist_tpu.py --use_tpu=false --master='' -``` - -Note: This `use_tpu=False` argument is useful for trying out the `TPUEstimator` -API. It is not meant to be a complete TPU compatibility test. Successfully -running a model locally in a `TPUEstimator` does not guarantee that it will -work on a TPU. - - -### Building a `tpu.RunConfig` - -While the default `RunConfig` is sufficient for local training, these settings -cannot be ignored in real usage. - -A more typical setup for a `RunConfig`, that can be switched to use a Cloud -TPU, might be as follows: - -``` python -import tempfile -import subprocess - -class FLAGS(object): - use_tpu=False - tpu_name=None - # Use a local temporary path for the `model_dir` - model_dir = tempfile.mkdtemp() - # Number of training steps to run on the Cloud TPU before returning control. - iterations = 50 - # A single Cloud TPU has 8 shards. - num_shards = 8 - -if FLAGS.use_tpu: - my_project_name = subprocess.check_output([ - 'gcloud','config','get-value','project']) - my_zone = subprocess.check_output([ - 'gcloud','config','get-value','compute/zone']) - cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver( - tpu_names=[FLAGS.tpu_name], - zone=my_zone, - project=my_project) - master = tpu_cluster_resolver.get_master() -else: - master = '' - -my_tpu_run_config = tf.contrib.tpu.RunConfig( - master=master, - evaluation_master=master, - model_dir=FLAGS.model_dir, - session_config=tf.ConfigProto( - allow_soft_placement=True, log_device_placement=True), - tpu_config=tf.contrib.tpu.TPUConfig(FLAGS.iterations, - FLAGS.num_shards), -) -``` - -Then you must pass the `tf.contrib.tpu.RunConfig` to the constructor: - -``` python -my_tpu_estimator = tf.contrib.tpu.TPUEstimator( - model_fn=my_model_fn, - config = my_tpu_run_config, - use_tpu=FLAGS.use_tpu) -``` - -Typically the `FLAGS` would be set by command line arguments. To switch from -training locally to training on a cloud TPU you would need to: - -* Set `FLAGS.use_tpu` to `True` -* Set `FLAGS.tpu_name` so the `tf.contrib.cluster_resolver.TPUClusterResolver` can find it -* Set `FLAGS.model_dir` to a Google Cloud Storage bucket url (`gs://`). - - -## Optimizer - -When training on a cloud TPU you **must** wrap the optimizer in a -`tf.contrib.tpu.CrossShardOptimizer`, which uses an `allreduce` to aggregate -gradients and broadcast the result to each shard (each TPU core). - -The `CrossShardOptimizer` is not compatible with local training. So, to have -the same code run both locally and on a Cloud TPU, add lines like the following: - -``` python -optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate) -if FLAGS.use_tpu: - optimizer = tf.contrib.tpu.CrossShardOptimizer(optimizer) -``` - -If you prefer to avoid a global `FLAGS` variable in your model code, one -approach is to set the optimizer as one of the `Estimator`'s params, -as follows: - -``` python -my_tpu_estimator = tf.contrib.tpu.TPUEstimator( - model_fn=my_model_fn, - config = my_tpu_run_config, - use_tpu=FLAGS.use_tpu, - params={'optimizer':optimizer}) -``` - -## Model Function - -This section details the changes you must make to the model function -(`model_fn()`) to make it `TPUEstimator` compatible. - -### Static shapes - -During regular usage TensorFlow attempts to determine the shapes of each -`tf.Tensor` during graph construction. During execution any unknown shape -dimensions are determined dynamically, -see [Tensor Shapes](../guide/tensors.md#shape) for more details. - -To run on Cloud TPUs TensorFlow models are compiled using [XLA](../performance/xla/index.md). -XLA uses a similar system for determining shapes at compile time. XLA requires -that all tensor dimensions be statically defined at compile time. All shapes -must evaluate to a constant, and not depend on external data, or stateful -operations like variables or a random number generator. - - -### Summaries - -Remove any use of `tf.summary` from your model. - -[TensorBoard summaries](../guide/summaries_and_tensorboard.md) are a great way see inside -your model. A minimal set of basic summaries are automatically recorded by the -`TPUEstimator`, to `event` files in the `model_dir`. Custom summaries, however, -are currently unsupported when training on a Cloud TPU. So while the -`TPUEstimator` will still run locally with summaries, it will fail if used on a -TPU. - -### Metrics - -Build your evaluation metrics dictionary in a stand-alone `metric_fn`. - -<!-- TODO(markdaoust) link to guide/metrics when it exists --> - -Evaluation metrics are an essential part of training a model. These are fully -supported on Cloud TPUs, but with a slightly different syntax. - -A standard `tf.metrics` returns two tensors. The first returns the running -average of the metric value, while the second updates the running average and -returns the value for this batch: - -``` -running_average, current_batch = tf.metrics.accuracy(labels, predictions) -``` - -In a standard `Estimator` you create a dictionary of these pairs, and return it -as part of the `EstimatorSpec`. - -```python -my_metrics = {'accuracy': tf.metrics.accuracy(labels, predictions)} - -return tf.estimator.EstimatorSpec( - ... - eval_metric_ops=my_metrics -) -``` - -In a `TPUEstimator` you instead pass a function (which returns a metrics -dictionary) and a list of argument tensors, as shown below: - -```python -def my_metric_fn(labels, predictions): - return {'accuracy': tf.metrics.accuracy(labels, predictions)} - -return tf.contrib.tpu.TPUEstimatorSpec( - ... - eval_metrics=(my_metric_fn, [labels, predictions]) -) -``` - -### Use `TPUEstimatorSpec` - -`TPUEstimatorSpec` do not support hooks, and require function wrappers for -some fields. - -An `Estimator`'s `model_fn` must return an `EstimatorSpec`. An `EstimatorSpec` -is a simple structure of named fields containing all the `tf.Tensors` of the -model that the `Estimator` may need to interact with. - -`TPUEstimators` use a `tf.contrib.tpu.TPUEstimatorSpec`. There are a few -differences between it and a standard `tf.estimator.EstimatorSpec`: - - -* The `eval_metric_ops` must be wrapped into a `metrics_fn`, this field is - renamed `eval_metrics` ([see above](#metrics)). -* The `tf.train.SessionRunHook` are unsupported, so these fields are - omitted. -* The `tf.train.Scaffold`, if used, must also be wrapped in a - function. This field is renamed to `scaffold_fn`. - -`Scaffold` and `Hooks` are for advanced usage, and can typically be omitted. - -## Input functions - -Input functions work mainly unchanged as they run on the host computer, not the -Cloud TPU itself. This section explains the two necessary adjustments. - -### Params argument - -<!-- TODO(markdaoust) link to input_fn doc when it exists --> - -The `input_fn` for a standard `Estimator` _can_ include a -`params` argument; the `input_fn` for a `TPUEstimator` *must* include a -`params` argument. This is necessary to allow the estimator to set the batch -size for each replica of the input stream. So the minimum signature for an -`input_fn` for a `TPUEstimator` is: - -``` -def my_input_fn(params): - pass -``` - -Where `params['batch-size']` will contain the batch size. - -### Static shapes and batch size - -The input pipeline generated by your `input_fn` is run on CPU. So it is mostly -free from the strict static shape requirements imposed by the XLA/TPU environment. -The one requirement is that the batches of data fed from your input pipeline to -the TPU have a static shape, as determined by the standard TensorFlow shape -inference algorithm. Intermediate tensors are free to have a dynamic shapes. -If shape inference has failed, but the shape is known it is possible to -impose the correct shape using `tf.set_shape()`. - -In the example below the shape -inference algorithm fails, but it is correctly using `set_shape`: - -``` ->>> x = tf.zeros(tf.constant([1,2,3])+1) ->>> x.shape - -TensorShape([Dimension(None), Dimension(None), Dimension(None)]) - ->>> x.set_shape([2,3,4]) -``` - -In many cases the batch size is the only unknown dimension. - -A typical input pipeline, using `tf.data`, will usually produce batches of a -fixed size. The last batch of a finite `Dataset`, however, is typically smaller, -containing just the remaining elements. Since a `Dataset` does not know its own -length or finiteness, the standard `tf.data.Dataset.batch` method -cannot determine if all batches will have a fixed size batch on its own: - -``` ->>> params = {'batch_size':32} ->>> ds = tf.data.Dataset.from_tensors([0, 1, 2]) ->>> ds = ds.repeat().batch(params['batch-size']) ->>> ds - -<BatchDataset shapes: (?, 3), types: tf.int32> -``` - -The most straightforward fix is to -`tf.data.Dataset.apply` `tf.contrib.data.batch_and_drop_remainder` -as follows: - -``` ->>> params = {'batch_size':32} ->>> ds = tf.data.Dataset.from_tensors([0, 1, 2]) ->>> ds = ds.repeat().apply( -... tf.contrib.data.batch_and_drop_remainder(params['batch-size'])) ->>> ds - - <_RestructuredDataset shapes: (32, 3), types: tf.int32> -``` - -The one downside to this approach is that, as the name implies, this batching -method throws out any fractional batch at the end of the dataset. This is fine -for an infinitely repeating dataset being used for training, but could be a -problem if you want to train for an exact number of epochs. - -To do an exact 1-epoch of _evaluation_ you can work around this by manually -padding the length of the batches, and setting the padding entries to have zero -weight when creating your `tf.metrics`. - -## Datasets - -Efficient use of the `tf.data.Dataset` API is critical when using a Cloud -TPU, as it is impossible to use the Cloud TPU's unless you can feed it data -quickly enough. See [Input Pipeline Performance Guide](../performance/datasets_performance.md) for details on dataset performance. - -For all but the simplest experimentation (using -`tf.data.Dataset.from_tensor_slices` or other in-graph data) you will need to -store all data files read by the `TPUEstimator`'s `Dataset` in Google Cloud -Storage Buckets. - -<!--TODO(markdaoust): link to the `TFRecord` doc when it exists.--> - -For most use-cases, we recommend converting your data into `TFRecord` -format and using a `tf.data.TFRecordDataset` to read it. This, however, is not -a hard requirement and you can use other dataset readers -(`FixedLengthRecordDataset` or `TextLineDataset`) if you prefer. - -Small datasets can be loaded entirely into memory using -`tf.data.Dataset.cache`. - -Regardless of the data format used, it is strongly recommended that you -[use large files](../performance/performance_guide.md#use_large_files), on the order of -100MB. This is especially important in this networked setting as the overhead -of opening a file is significantly higher. - -It is also important, regardless of the type of reader used, to enable buffering -using the `buffer_size` argument to the constructor. This argument is specified -in bytes. A minimum of a few MB (`buffer_size=8*1024*1024`) is recommended so -that data is available when needed. - -The TPU-demos repo includes -[a script](https://github.com/tensorflow/tpu/blob/master/tools/datasets/imagenet_to_gcs.py) -for downloading the imagenet dataset and converting it to an appropriate format. -This together with the imagenet -[models](https://github.com/tensorflow/tpu/tree/master/models) -included in the repo demonstrate all of these best-practices. - - -## What Next - -For details on how to actually set up and run a Cloud TPU see: - - * [Google Cloud TPU Documentation](https://cloud.google.com/tpu/docs/) - -This document is by no means exhaustive. The best source of more detail on how -to make a Cloud TPU compatible model are the example models published in: - - * The [TPU Demos Repository.](https://github.com/tensorflow/tpu) - -For more information about tuning TensorFlow code for performance see: - - * The [Performance Section.](../performance/index.md) - diff --git a/tensorflow/docs_src/guide/variables.md b/tensorflow/docs_src/guide/variables.md deleted file mode 100644 index 5d5d73394c..0000000000 --- a/tensorflow/docs_src/guide/variables.md +++ /dev/null @@ -1,319 +0,0 @@ -# Variables - -A TensorFlow **variable** is the best way to represent shared, persistent state -manipulated by your program. - -Variables are manipulated via the `tf.Variable` class. A `tf.Variable` -represents a tensor whose value can be changed by running ops on it. Unlike -`tf.Tensor` objects, a `tf.Variable` exists outside the context of a single -`session.run` call. - -Internally, a `tf.Variable` stores a persistent tensor. Specific ops allow you -to read and modify the values of this tensor. These modifications are visible -across multiple `tf.Session`s, so multiple workers can see the same values for a -`tf.Variable`. - -## Creating a Variable - -The best way to create a variable is to call the `tf.get_variable` -function. This function requires you to specify the Variable's name. This name -will be used by other replicas to access the same variable, as well as to name -this variable's value when checkpointing and exporting models. `tf.get_variable` -also allows you to reuse a previously created variable of the same name, making it -easy to define models which reuse layers. - -To create a variable with `tf.get_variable`, simply provide the name and shape - -``` python -my_variable = tf.get_variable("my_variable", [1, 2, 3]) -``` - -This creates a variable named "my_variable" which is a three-dimensional tensor -with shape `[1, 2, 3]`. This variable will, by default, have the `dtype` -`tf.float32` and its initial value will be randomized via -`tf.glorot_uniform_initializer`. - -You may optionally specify the `dtype` and initializer to `tf.get_variable`. For -example: - -``` python -my_int_variable = tf.get_variable("my_int_variable", [1, 2, 3], dtype=tf.int32, - initializer=tf.zeros_initializer) -``` - -TensorFlow provides many convenient initializers. Alternatively, you may -initialize a `tf.Variable` to have the value of a `tf.Tensor`. For example: - -``` python -other_variable = tf.get_variable("other_variable", dtype=tf.int32, - initializer=tf.constant([23, 42])) -``` - -Note that when the initializer is a `tf.Tensor` you should not specify the -variable's shape, as the shape of the initializer tensor will be used. - - -<a name="collections"></a> -### Variable collections - -Because disconnected parts of a TensorFlow program might want to create -variables, it is sometimes useful to have a single way to access all of -them. For this reason TensorFlow provides **collections**, which are named lists -of tensors or other objects, such as `tf.Variable` instances. - -By default every `tf.Variable` gets placed in the following two collections: - - * `tf.GraphKeys.GLOBAL_VARIABLES` --- variables that can be shared across - multiple devices, - * `tf.GraphKeys.TRAINABLE_VARIABLES` --- variables for which TensorFlow will - calculate gradients. - -If you don't want a variable to be trainable, add it to the -`tf.GraphKeys.LOCAL_VARIABLES` collection instead. For example, the following -snippet demonstrates how to add a variable named `my_local` to this collection: - -``` python -my_local = tf.get_variable("my_local", shape=(), -collections=[tf.GraphKeys.LOCAL_VARIABLES]) -``` - -Alternatively, you can specify `trainable=False` as an argument to -`tf.get_variable`: - -``` python -my_non_trainable = tf.get_variable("my_non_trainable", - shape=(), - trainable=False) -``` - - -You can also use your own collections. Any string is a valid collection name, -and there is no need to explicitly create a collection. To add a variable (or -any other object) to a collection after creating the variable, call -`tf.add_to_collection`. For example, the following code adds an existing -variable named `my_local` to a collection named `my_collection_name`: - -``` python -tf.add_to_collection("my_collection_name", my_local) -``` - -And to retrieve a list of all the variables (or other objects) you've placed in -a collection you can use: - -``` python -tf.get_collection("my_collection_name") -``` - -### Device placement - -Just like any other TensorFlow operation, you can place variables on particular -devices. For example, the following snippet creates a variable named `v` and -places it on the second GPU device: - -``` python -with tf.device("/device:GPU:1"): - v = tf.get_variable("v", [1]) -``` - -It is particularly important for variables to be in the correct device in -distributed settings. Accidentally putting variables on workers instead of -parameter servers, for example, can severely slow down training or, in the worst -case, let each worker blithely forge ahead with its own independent copy of each -variable. For this reason we provide `tf.train.replica_device_setter`, which -can automatically place variables in parameter servers. For example: - -``` python -cluster_spec = { - "ps": ["ps0:2222", "ps1:2222"], - "worker": ["worker0:2222", "worker1:2222", "worker2:2222"]} -with tf.device(tf.train.replica_device_setter(cluster=cluster_spec)): - v = tf.get_variable("v", shape=[20, 20]) # this variable is placed - # in the parameter server - # by the replica_device_setter -``` - -## Initializing variables - -Before you can use a variable, it must be initialized. If you are programming in -the low-level TensorFlow API (that is, you are explicitly creating your own -graphs and sessions), you must explicitly initialize the variables. Most -high-level frameworks such as `tf.contrib.slim`, `tf.estimator.Estimator` and -`Keras` automatically initialize variables for you before training a model. - -Explicit initialization is otherwise useful because it allows you not to rerun -potentially expensive initializers when reloading a model from a checkpoint as -well as allowing determinism when randomly-initialized variables are shared in a -distributed setting. - -To initialize all trainable variables in one go, before training starts, call -`tf.global_variables_initializer()`. This function returns a single operation -responsible for initializing all variables in the -`tf.GraphKeys.GLOBAL_VARIABLES` collection. Running this operation initializes -all variables. For example: - -``` python -session.run(tf.global_variables_initializer()) -# Now all variables are initialized. -``` - -If you do need to initialize variables yourself, you can run the variable's -initializer operation. For example: - -``` python -session.run(my_variable.initializer) -``` - - -You can also ask which variables have still not been initialized. For example, -the following code prints the names of all variables which have not yet been -initialized: - -``` python -print(session.run(tf.report_uninitialized_variables())) -``` - - -Note that by default `tf.global_variables_initializer` does not specify the -order in which variables are initialized. Therefore, if the initial value of a -variable depends on another variable's value, it's likely that you'll get an -error. Any time you use the value of a variable in a context in which not all -variables are initialized (say, if you use a variable's value while initializing -another variable), it is best to use `variable.initialized_value()` instead of -`variable`: - -``` python -v = tf.get_variable("v", shape=(), initializer=tf.zeros_initializer()) -w = tf.get_variable("w", initializer=v.initialized_value() + 1) -``` - -## Using variables - -To use the value of a `tf.Variable` in a TensorFlow graph, simply treat it like -a normal `tf.Tensor`: - -``` python -v = tf.get_variable("v", shape=(), initializer=tf.zeros_initializer()) -w = v + 1 # w is a tf.Tensor which is computed based on the value of v. - # Any time a variable is used in an expression it gets automatically - # converted to a tf.Tensor representing its value. -``` - -To assign a value to a variable, use the methods `assign`, `assign_add`, and -friends in the `tf.Variable` class. For example, here is how you can call these -methods: - -``` python -v = tf.get_variable("v", shape=(), initializer=tf.zeros_initializer()) -assignment = v.assign_add(1) -tf.global_variables_initializer().run() -sess.run(assignment) # or assignment.op.run(), or assignment.eval() -``` - -Most TensorFlow optimizers have specialized ops that efficiently update the -values of variables according to some gradient descent-like algorithm. See -`tf.train.Optimizer` for an explanation of how to use optimizers. - -Because variables are mutable it's sometimes useful to know what version of a -variable's value is being used at any point in time. To force a re-read of the -value of a variable after something has happened, you can use -`tf.Variable.read_value`. For example: - -``` python -v = tf.get_variable("v", shape=(), initializer=tf.zeros_initializer()) -assignment = v.assign_add(1) -with tf.control_dependencies([assignment]): - w = v.read_value() # w is guaranteed to reflect v's value after the - # assign_add operation. -``` - - -## Sharing variables - -TensorFlow supports two ways of sharing variables: - - * Explicitly passing `tf.Variable` objects around. - * Implicitly wrapping `tf.Variable` objects within `tf.variable_scope` objects. - -While code which explicitly passes variables around is very clear, it is -sometimes convenient to write TensorFlow functions that implicitly use -variables in their implementations. Most of the functional layers from -`tf.layers` use this approach, as well as all `tf.metrics`, and a few other -library utilities. - -Variable scopes allow you to control variable reuse when calling functions which -implicitly create and use variables. They also allow you to name your variables -in a hierarchical and understandable way. - -For example, let's say we write a function to create a convolutional / relu -layer: - -```python -def conv_relu(input, kernel_shape, bias_shape): - # Create variable named "weights". - weights = tf.get_variable("weights", kernel_shape, - initializer=tf.random_normal_initializer()) - # Create variable named "biases". - biases = tf.get_variable("biases", bias_shape, - initializer=tf.constant_initializer(0.0)) - conv = tf.nn.conv2d(input, weights, - strides=[1, 1, 1, 1], padding='SAME') - return tf.nn.relu(conv + biases) -``` - -This function uses short names `weights` and `biases`, which is good for -clarity. In a real model, however, we want many such convolutional layers, and -calling this function repeatedly would not work: - -``` python -input1 = tf.random_normal([1,10,10,32]) -input2 = tf.random_normal([1,20,20,32]) -x = conv_relu(input1, kernel_shape=[5, 5, 32, 32], bias_shape=[32]) -x = conv_relu(x, kernel_shape=[5, 5, 32, 32], bias_shape = [32]) # This fails. -``` - -Since the desired behavior is unclear (create new variables or reuse the -existing ones?) TensorFlow will fail. Calling `conv_relu` in different scopes, -however, clarifies that we want to create new variables: - -```python -def my_image_filter(input_images): - with tf.variable_scope("conv1"): - # Variables created here will be named "conv1/weights", "conv1/biases". - relu1 = conv_relu(input_images, [5, 5, 32, 32], [32]) - with tf.variable_scope("conv2"): - # Variables created here will be named "conv2/weights", "conv2/biases". - return conv_relu(relu1, [5, 5, 32, 32], [32]) -``` - -If you do want the variables to be shared, you have two options. First, you can -create a scope with the same name using `reuse=True`: - -``` python -with tf.variable_scope("model"): - output1 = my_image_filter(input1) -with tf.variable_scope("model", reuse=True): - output2 = my_image_filter(input2) - -``` - -You can also call `scope.reuse_variables()` to trigger a reuse: - -``` python -with tf.variable_scope("model") as scope: - output1 = my_image_filter(input1) - scope.reuse_variables() - output2 = my_image_filter(input2) - -``` - -Since depending on exact string names of scopes can feel dangerous, it's also -possible to initialize a variable scope based on another one: - -``` python -with tf.variable_scope("model") as scope: - output1 = my_image_filter(input1) -with tf.variable_scope(scope, reuse=True): - output2 = my_image_filter(input2) - -``` - diff --git a/tensorflow/docs_src/guide/version_compat.md b/tensorflow/docs_src/guide/version_compat.md deleted file mode 100644 index 882f2a3806..0000000000 --- a/tensorflow/docs_src/guide/version_compat.md +++ /dev/null @@ -1,324 +0,0 @@ -# TensorFlow Version Compatibility - -This document is for users who need backwards compatibility across different -versions of TensorFlow (either for code or data), and for developers who want -to modify TensorFlow while preserving compatibility. - -## Semantic Versioning 2.0 - -TensorFlow follows Semantic Versioning 2.0 ([semver](http://semver.org)) for its -public API. Each release version of TensorFlow has the form `MAJOR.MINOR.PATCH`. -For example, TensorFlow version 1.2.3 has `MAJOR` version 1, `MINOR` version 2, -and `PATCH` version 3. Changes to each number have the following meaning: - -* **MAJOR**: Potentially backwards incompatible changes. Code and data that - worked with a previous major release will not necessarily work with the new - release. However, in some cases existing TensorFlow graphs and checkpoints - may be migratable to the newer release; see - [Compatibility of graphs and checkpoints](#compatibility_of_graphs_and_checkpoints) - for details on data compatibility. - -* **MINOR**: Backwards compatible features, speed improvements, etc. Code and - data that worked with a previous minor release *and* which depends only on the - public API will continue to work unchanged. For details on what is and is - not the public API, see [What is covered](#what_is_covered). - -* **PATCH**: Backwards compatible bug fixes. - -For example, release 1.0.0 introduced backwards *incompatible* changes from -release 0.12.1. However, release 1.1.1 was backwards *compatible* with release -1.0.0. - -## What is covered - -Only the public APIs of TensorFlow are backwards compatible across minor and -patch versions. The public APIs consist of - -* All the documented [Python](../api_docs/python) functions and classes in the - `tensorflow` module and its submodules, except for - * functions and classes in `tf.contrib` - * functions and classes whose names start with `_` (as these are private) - Note that the code in the `examples/` and `tools/` directories is not - reachable through the `tensorflow` Python module and is thus not covered by - the compatibility guarantee. - - If a symbol is available through the `tensorflow` Python module or its - submodules, but is not documented, then it is **not** considered part of the - public API. - -* The [C API](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/c_api.h). - -* The following protocol buffer files: - * [`attr_value`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto) - * [`config`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/config.proto) - * [`event`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/util/event.proto) - * [`graph`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto) - * [`op_def`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_def.proto) - * [`reader_base`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/reader_base.proto) - * [`summary`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/summary.proto) - * [`tensor`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto) - * [`tensor_shape`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor_shape.proto) - * [`types`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/types.proto) - -<a name="not_covered"></a> -## What is *not* covered - -Some API functions are explicitly marked as "experimental" and can change in -backward incompatible ways between minor releases. These include: - -* **Experimental APIs**: The `tf.contrib` module and its submodules in Python - and any functions in the C API or fields in protocol buffers that are - explicitly commented as being experimental. In particular, any field in a - protocol buffer which is called "experimental" and all its fields and - submessages can change at any time. - -* **Other languages**: TensorFlow APIs in languages other than Python and C, - such as: - - - [C++](../api_guides/cc/guide.md) (exposed through header files in - [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/cc)). - - [Java](../api_docs/java/reference/org/tensorflow/package-summary), - - [Go](https://godoc.org/github.com/tensorflow/tensorflow/tensorflow/go) - - [JavaScript](https://js.tensorflow.org) - -* **Details of composite ops:** Many public functions in Python expand to - several primitive ops in the graph, and these details will be part of any - graphs saved to disk as `GraphDef`s. These details may change for - minor releases. In particular, regressions tests that check for exact - matching between graphs are likely to break across minor releases, even - though the behavior of the graph should be unchanged and existing - checkpoints will still work. - -* **Floating point numerical details:** The specific floating point values - computed by ops may change at any time. Users should rely only on - approximate accuracy and numerical stability, not on the specific bits - computed. Changes to numerical formulas in minor and patch releases should - result in comparable or improved accuracy, with the caveat that in machine - learning improved accuracy of specific formulas may result in decreased - accuracy for the overall system. - -* **Random numbers:** The specific random numbers computed by the - [random ops](../api_guides/python/constant_op.md#Random_Tensors) may change at any time. - Users should rely only on approximately correct distributions and - statistical strength, not the specific bits computed. However, we will make - changes to random bits rarely (or perhaps never) for patch releases. We - will, of course, document all such changes. - -* **Version skew in distributed Tensorflow:** Running two different versions - of TensorFlow in a single cluster is unsupported. There are no guarantees - about backwards compatibility of the wire protocol. - -* **Bugs:** We reserve the right to make backwards incompatible behavior - (though not API) changes if the current implementation is clearly broken, - that is, if it contradicts the documentation or if a well-known and - well-defined intended behavior is not properly implemented due to a bug. - For example, if an optimizer claims to implement a well-known optimization - algorithm but does not match that algorithm due to a bug, then we will fix - the optimizer. Our fix may break code relying on the wrong behavior for - convergence. We will note such changes in the release notes. - -* **Error messages:** We reserve the right to change the text of error - messages. In addition, the type of an error may change unless the type is - specified in the documentation. For example, a function documented to - raise an `InvalidArgument` exception will continue to - raise `InvalidArgument`, but the human-readable message contents can change. - -## Compatibility of graphs and checkpoints - -You'll sometimes need to preserve graphs and checkpoints. -Graphs describe the data flow of ops to be run during training and -inference, and checkpoints contain the saved tensor values of variables in a -graph. - -Many TensorFlow users save graphs and trained models to disk for -later evaluation or additional training, but end up running their saved graphs -or models on a later release. In compliance with semver, any graph or checkpoint -written out with one version of TensorFlow can be loaded and evaluated with a -later version of TensorFlow with the same major release. However, we will -endeavor to preserve backwards compatibility even across major releases when -possible, so that the serialized files are usable over long periods of time. - - -Graphs are serialized via the `GraphDef` protocol buffer. To facilitate (rare) -backwards incompatible changes to graphs, each `GraphDef` has a version number -separate from the TensorFlow version. For example, `GraphDef` version 17 -deprecated the `inv` op in favor of `reciprocal`. The semantics are: - -* Each version of TensorFlow supports an interval of `GraphDef` versions. This - interval will be constant across patch releases, and will only grow across - minor releases. Dropping support for a `GraphDef` version will only occur - for a major release of TensorFlow. - -* Newly created graphs are assigned the latest `GraphDef` version number. - -* If a given version of TensorFlow supports the `GraphDef` version of a graph, - it will load and evaluate with the same behavior as the TensorFlow version - used to generate it (except for floating point numerical details and random - numbers), regardless of the major version of TensorFlow. In particular, all - checkpoint files will be compatible. - -* If the `GraphDef` *upper* bound is increased to X in a (minor) release, there - will be at least six months before the *lower* bound is increased to X. For - example (we're using hypothetical version numbers here): - * TensorFlow 1.2 might support `GraphDef` versions 4 to 7. - * TensorFlow 1.3 could add `GraphDef` version 8 and support versions 4 to 8. - * At least six months later, TensorFlow 2.0.0 could drop support for - versions 4 to 7, leaving version 8 only. - -Finally, when support for a `GraphDef` version is dropped, we will attempt to -provide tools for automatically converting graphs to a newer supported -`GraphDef` version. - -## Graph and checkpoint compatibility when extending TensorFlow - -This section is relevant only when making incompatible changes to the `GraphDef` -format, such as when adding ops, removing ops, or changing the functionality -of existing ops. The previous section should suffice for most users. - -<a id="backward_forward"/> - -### Backward and partial forward compatibility - -Our versioning scheme has three requirements: - -* **Backward compatibility** to support loading graphs and checkpoints - created with older versions of TensorFlow. -* **Forward compatibility** to support scenarios where the producer of a - graph or checkpoint is upgraded to a newer version of TensorFlow before - the consumer. -* Enable evolving TensorFlow in incompatible ways. For example, removing ops, - adding attributes, and removing attributes. - -Note that while the `GraphDef` version mechanism is separate from the TensorFlow -version, backwards incompatible changes to the `GraphDef` format are still -restricted by Semantic Versioning. This means functionality can only be removed -or changed between `MAJOR` versions of TensorFlow (such as `1.7` to `2.0`). -Additionally, forward compatibility is enforced within Patch releases (`1.x.1` -to `1.x.2` for example). - -To achieve backward and forward compatibility and to know when to enforce changes -in formats, graphs and checkpoints have metadata that describes when they -were produced. The sections below detail the TensorFlow implementation and -guidelines for evolving `GraphDef` versions. - -### Independent data version schemes - -There are different data versions for graphs and checkpoints. The two data -formats evolve at different rates from each other and also at different rates -from TensorFlow. Both versioning systems are defined in -[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h). -Whenever a new version is added, a note is added to the header detailing what -changed and the date. - -### Data, producers, and consumers - -We distinguish between the following kinds of data version information: -* **producers**: binaries that produce data. Producers have a version - (`producer`) and a minimum consumer version that they are compatible with - (`min_consumer`). -* **consumers**: binaries that consume data. Consumers have a version - (`consumer`) and a minimum producer version that they are compatible with - (`min_producer`). - -Each piece of versioned data has a [`VersionDef -versions`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/versions.proto) -field which records the `producer` that made the data, the `min_consumer` -that it is compatible with, and a list of `bad_consumers` versions that are -disallowed. - -By default, when a producer makes some data, the data inherits the producer's -`producer` and `min_consumer` versions. `bad_consumers` can be set if specific -consumer versions are known to contain bugs and must be avoided. A consumer can -accept a piece of data if the following are all true: - -* `consumer` >= data's `min_consumer` -* data's `producer` >= consumer's `min_producer` -* `consumer` not in data's `bad_consumers` - -Since both producers and consumers come from the same TensorFlow code base, -[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h) -contains a main data version which is treated as either `producer` or -`consumer` depending on context and both `min_consumer` and `min_producer` -(needed by producers and consumers, respectively). Specifically, - -* For `GraphDef` versions, we have `TF_GRAPH_DEF_VERSION`, - `TF_GRAPH_DEF_VERSION_MIN_CONSUMER`, and - `TF_GRAPH_DEF_VERSION_MIN_PRODUCER`. -* For checkpoint versions, we have `TF_CHECKPOINT_VERSION`, - `TF_CHECKPOINT_VERSION_MIN_CONSUMER`, and - `TF_CHECKPOINT_VERSION_MIN_PRODUCER`. - -### Add a new attribute with default to an existing op - -Following the guidance below gives you forward compatibility only if the set of -ops has not changed: - -1. If forward compatibility is desired, set `strip_default_attrs` to `True` - while exporting the model using either the - `tf.saved_model.builder.SavedModelBuilder.add_meta_graph_and_variables` - and `tf.saved_model.builder.SavedModelBuilder.add_meta_graph` - methods of the `SavedModelBuilder` class, or - `tf.estimator.Estimator.export_savedmodel` -2. This strips off the default valued attributes at the time of - producing/exporting the models. This makes sure that the exported - `tf.MetaGraphDef` does not contain the new op-attribute when the default - value is used. -3. Having this control could allow out-of-date consumers (for example, serving - binaries that lag behind training binaries) to continue loading the models - and prevent interruptions in model serving. - -### Evolving GraphDef versions - -This section explains how to use this versioning mechanism to make different -types of changes to the `GraphDef` format. - -#### Add an op - -Add the new op to both consumers and producers at the same time, and do not -change any `GraphDef` versions. This type of change is automatically -backward compatible, and does not impact forward compatibility plan since -existing producer scripts will not suddenly use the new functionality. - -#### Add an op and switch existing Python wrappers to use it - -1. Implement new consumer functionality and increment the `GraphDef` version. -2. If it is possible to make the wrappers use the new functionality only in - cases that did not work before, the wrappers can be updated now. -3. Change Python wrappers to use the new functionality. Do not increment - `min_consumer`, since models that do not use this op should not break. - -#### Remove or restrict an op's functionality - -1. Fix all producer scripts (not TensorFlow itself) to not use the banned op or - functionality. -2. Increment the `GraphDef` version and implement new consumer functionality - that bans the removed op or functionality for GraphDefs at the new version - and above. If possible, make TensorFlow stop producing `GraphDefs` with the - banned functionality. To do so, add the - [`REGISTER_OP(...).Deprecated(deprecated_at_version, - message)`](https://github.com/tensorflow/tensorflow/blob/b289bc7a50fc0254970c60aaeba01c33de61a728/tensorflow/core/ops/array_ops.cc#L1009). -3. Wait for a major release for backward compatibility purposes. -4. Increase `min_producer` to the GraphDef version from (2) and remove the - functionality entirely. - -#### Change an op's functionality - -1. Add a new similar op named `SomethingV2` or similar and go through the - process of adding it and switching existing Python wrappers to use it. - To ensure forward compatibility use the checks suggested in - [compat.py](https://www.tensorflow.org/code/tensorflow/python/compat/compat.py) - when changing the Python wrappers. -2. Remove the old op (Can only take place with a major version change due to - backward compatibility). -3. Increase `min_consumer` to rule out consumers with the old op, add back the - old op as an alias for `SomethingV2`, and go through the process to switch - existing Python wrappers to use it. -4. Go through the process to remove `SomethingV2`. - -#### Ban a single unsafe consumer version - -1. Bump the `GraphDef` version and add the bad version to `bad_consumers` for - all new GraphDefs. If possible, add to `bad_consumers` only for GraphDefs - which contain a certain op or similar. -2. If existing consumers have the bad version, push them out as soon as - possible. diff --git a/tensorflow/docs_src/install/index.md b/tensorflow/docs_src/install/index.md deleted file mode 100644 index 76e590e1e1..0000000000 --- a/tensorflow/docs_src/install/index.md +++ /dev/null @@ -1,39 +0,0 @@ -# Install TensorFlow - -Note: Run the [TensorFlow tutorials](../tutorials) in a pre-configured -[Colab notebook environment](https://colab.research.google.com/notebooks/welcome.ipynb){: .external}, -without installation. - -TensorFlow is built and tested on the following 64-bit operating systems: - - * macOS 10.12.6 (Sierra) or later. - * Ubuntu 16.04 or later - * Windows 7 or later. - * Raspbian 9.0 or later. - -While TensorFlow may work on other systems, we only support—and fix issues in—the -systems listed above. - -The following guides explain how to install a version of TensorFlow -that enables you to write applications in Python: - - * [Install TensorFlow on Ubuntu](../install/install_linux.md) - * [Install TensorFlow on macOS](../install/install_mac.md) - * [Install TensorFlow on Windows](../install/install_windows.md) - * [Install TensorFlow on a Raspberry Pi](../install/install_raspbian.md) - * [Install TensorFlow from source code](../install/install_sources.md) - -Many aspects of the Python TensorFlow API changed from version 0.n to 1.0. -The following guide explains how to migrate older TensorFlow applications -to Version 1.0: - - * [Transition to TensorFlow 1.0](../install/migration.md) - -The following guides explain how to install TensorFlow libraries for use in -other programming languages. These APIs are aimed at deploying TensorFlow -models in applications and are not as extensive as the Python APIs. - - * [Install TensorFlow for Java](../install/install_java.md) - * [Install TensorFlow for C](../install/install_c.md) - * [Install TensorFlow for Go](../install/install_go.md) - diff --git a/tensorflow/docs_src/install/install_c.md b/tensorflow/docs_src/install/install_c.md deleted file mode 100644 index 084634bc9c..0000000000 --- a/tensorflow/docs_src/install/install_c.md +++ /dev/null @@ -1,118 +0,0 @@ -# Install TensorFlow for C - -TensorFlow provides a C API defined in -[`c_api.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/c_api.h), -which is suitable for -[building bindings for other languages](https://www.tensorflow.org/extend/language_bindings). -The API leans towards simplicity and uniformity rather than convenience. - - -## Supported Platforms - -This guide explains how to install TensorFlow for C. Although these -instructions might also work on other variants, we have only tested -(and we only support) these instructions on machines meeting the -following requirements: - - * Linux, 64-bit, x86 - * macOS X, Version 10.12.6 (Sierra) or higher - - -## Installation - -Take the following steps to install the TensorFlow for C library and -enable TensorFlow for C: - - 1. Decide whether you will run TensorFlow for C on CPU(s) only or - with the help of GPU(s). To help you decide, read the section - entitled "Determine which TensorFlow to install" in one of the - following guides: - - * [Installing TensorFlow on Linux](../install/install_linux.md#determine_which_tensorflow_to_install) - * [Installing TensorFlow on macOS](../install/install_mac.md#determine_which_tensorflow_to_install) - - 2. Download and extract the TensorFlow C library into `/usr/local/lib` by - invoking the following shell commands: - - TF_TYPE="cpu" # Change to "gpu" for GPU support - OS="linux" # Change to "darwin" for macOS - TARGET_DIRECTORY="/usr/local" - curl -L \ - "https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-${TF_TYPE}-${OS}-x86_64-1.10.0.tar.gz" | - sudo tar -C $TARGET_DIRECTORY -xz - - The `tar` command extracts the TensorFlow C library into the `lib` - subdirectory of `TARGET_DIRECTORY`. For example, specifying `/usr/local` - as `TARGET_DIRECTORY` causes `tar` to extract the TensorFlow C library - into `/usr/local/lib`. - - If you'd prefer to extract the library into a different directory, - adjust `TARGET_DIRECTORY` accordingly. - - 3. In Step 2, if you specified a system directory (for example, `/usr/local`) - as the `TARGET_DIRECTORY`, then run `ldconfig` to configure the linker. - For example: - - <pre><b>sudo ldconfig</b></pre> - - If you assigned a `TARGET_DIRECTORY` other than a system - directory (for example, `~/mydir`), then you must append the extraction - directory (for example, `~/mydir/lib`) to two environment variables. - For example: - - <pre> <b>export LIBRARY_PATH=$LIBRARY_PATH:~/mydir/lib</b> # For both Linux and macOS X - <b>export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/mydir/lib</b> # For Linux only - <b>export DYLD_LIBRARY_PATH=$DYLD_LIBRARY_PATH:~/mydir/lib</b> # For macOS X only</pre> - - - -## Validate your installation - -After installing TensorFlow for C, enter the following code into a file named -`hello_tf.c`: - -```c -#include <stdio.h> -#include <tensorflow/c/c_api.h> - -int main() { - printf("Hello from TensorFlow C library version %s\n", TF_Version()); - return 0; -} -``` - -### Build and Run - -Build `hello_tf.c` by invoking the following command: - - -<pre><b>gcc hello_tf.c</b></pre> - - -Running the resulting executable should output the following message: - - -<pre><b>a.out</b> -Hello from TensorFlow C library version <i>number</i></pre> - - -### Troubleshooting - -If building the program fails, the most likely culprit is that `gcc` cannot -find the TensorFlow C library. One way to fix this problem is to specify -the `-I` and `-L` options to `gcc`. For example, if the `TARGET_LIBRARY` -was `/usr/local`, you would invoke `gcc` as follows: - -<pre><b>gcc -I/usr/local/include -L/usr/local/lib hello_tf.c -ltensorflow</b></pre> - -If executing `a.out` fails, ask yourself the following questions: - - * Did the program build without error? - * Have you assigned the correct directory to the environment variables - noted in Step 3 of [Installation](#installation)? - * Did you export those environment variables? - -If you are still seeing build or execution error messages, search (or post to) -[StackOverflow](https://stackoverflow.com/questions/tagged/tensorflow) for -possible solutions. - diff --git a/tensorflow/docs_src/install/install_go.md b/tensorflow/docs_src/install/install_go.md deleted file mode 100644 index 0c604d7713..0000000000 --- a/tensorflow/docs_src/install/install_go.md +++ /dev/null @@ -1,142 +0,0 @@ -# Install TensorFlow for Go - -TensorFlow provides APIs for use in Go programs. These APIs are particularly -well-suited to loading models created in Python and executing them within -a Go application. This guide explains how to install and set up the -[TensorFlow Go package](https://godoc.org/github.com/tensorflow/tensorflow/tensorflow/go). - -Warning: The TensorFlow Go API is *not* covered by the TensorFlow -[API stability guarantees](../guide/version_compat.md). - - -## Supported Platforms - -This guide explains how to install TensorFlow for Go. Although these -instructions might also work on other variants, we have only tested -(and we only support) these instructions on machines meeting the -following requirements: - - * Linux, 64-bit, x86 - * macOS X, 10.12.6 (Sierra) or higher - - -## Installation - -TensorFlow for Go depends on the TensorFlow C library. Take the following -steps to install this library and enable TensorFlow for Go: - - 1. Decide whether you will run TensorFlow for Go on CPU(s) only or with - the help of GPU(s). To help you decide, read the section entitled - "Determine which TensorFlow to install" in one of the following guides: - - * [Installing TensorFlow on Linux](../install/install_linux.md#determine_which_tensorflow_to_install) - * [Installing TensorFlow on macOS](../install/install_mac.md#determine_which_tensorflow_to_install) - - 2. Download and extract the TensorFlow C library into `/usr/local/lib` by - invoking the following shell commands: - - TF_TYPE="cpu" # Change to "gpu" for GPU support - TARGET_DIRECTORY='/usr/local' - curl -L \ - "https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-${TF_TYPE}-$(go env GOOS)-x86_64-1.10.0.tar.gz" | - sudo tar -C $TARGET_DIRECTORY -xz - - The `tar` command extracts the TensorFlow C library into the `lib` - subdirectory of `TARGET_DIRECTORY`. For example, specifying `/usr/local` - as `TARGET_DIRECTORY` causes `tar` to extract the TensorFlow C library - into `/usr/local/lib`. - - If you'd prefer to extract the library into a different directory, - adjust `TARGET_DIRECTORY` accordingly. - - 3. In Step 2, if you specified a system directory (for example, `/usr/local`) - as the `TARGET_DIRECTORY`, then run `ldconfig` to configure the linker. - For example: - - <pre><b>sudo ldconfig</b></pre> - - If you assigned a `TARGET_DIRECTORY` other than a system - directory (for example, `~/mydir`), then you must append the extraction - directory (for example, `~/mydir/lib`) to two environment variables - as follows: - - <pre> <b>export LIBRARY_PATH=$LIBRARY_PATH:~/mydir/lib</b> # For both Linux and macOS X - <b>export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/mydir/lib</b> # For Linux only - <b>export DYLD_LIBRARY_PATH=$DYLD_LIBRARY_PATH:~/mydir/lib</b> # For macOS X only</pre> - - 4. Now that the TensorFlow C library is installed, invoke `go get` as follows - to download the appropriate packages and their dependencies: - - <pre><b>go get github.com/tensorflow/tensorflow/tensorflow/go</b></pre> - - 5. Invoke `go test` as follows to validate the TensorFlow for Go - installation: - - <pre><b>go test github.com/tensorflow/tensorflow/tensorflow/go</b></pre> - -If `go get` or `go test` generate error messages, search (or post to) -[StackOverflow](http://www.stackoverflow.com/questions/tagged/tensorflow) -for possible solutions. - - -## Hello World - -After installing TensorFlow for Go, enter the following code into a -file named `hello_tf.go`: - -```go -package main - -import ( - tf "github.com/tensorflow/tensorflow/tensorflow/go" - "github.com/tensorflow/tensorflow/tensorflow/go/op" - "fmt" -) - -func main() { - // Construct a graph with an operation that produces a string constant. - s := op.NewScope() - c := op.Const(s, "Hello from TensorFlow version " + tf.Version()) - graph, err := s.Finalize() - if err != nil { - panic(err) - } - - // Execute the graph in a session. - sess, err := tf.NewSession(graph, nil) - if err != nil { - panic(err) - } - output, err := sess.Run(nil, []tf.Output{c}, nil) - if err != nil { - panic(err) - } - fmt.Println(output[0].Value()) -} -``` - -For a more advanced example of TensorFlow in Go, look at the -[example in the API documentation](https://godoc.org/github.com/tensorflow/tensorflow/tensorflow/go#ex-package), -which uses a pre-trained TensorFlow model to label contents of an image. - - -### Running - -Run `hello_tf.go` by invoking the following command: - -<pre><b>go run hello_tf.go</b> -Hello from TensorFlow version <i>number</i></pre> - -The program might also generate multiple warning messages of the -following form, which you can ignore: - -<pre>W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library -wasn't compiled to use *Type* instructions, but these are available on your -machine and could speed up CPU computations.</pre> - - -## Building from source code - -TensorFlow is open-source. You may build TensorFlow for Go from the -TensorFlow source code by following the instructions in a -[separate document](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/go/README.md). diff --git a/tensorflow/docs_src/install/install_java.md b/tensorflow/docs_src/install/install_java.md deleted file mode 100644 index c411cb78fe..0000000000 --- a/tensorflow/docs_src/install/install_java.md +++ /dev/null @@ -1,268 +0,0 @@ -# Install TensorFlow for Java - -TensorFlow provides APIs for use in Java programs. These APIs are particularly -well-suited to loading models created in Python and executing them within a -Java application. This guide explains how to install -[TensorFlow for Java](https://www.tensorflow.org/api_docs/java/reference/org/tensorflow/package-summary) -and use it in a Java application. - -Warning: The TensorFlow Java API is *not* covered by the TensorFlow -[API stability guarantees](../guide/version_semantics.md). - - -## Supported Platforms - -This guide explains how to install TensorFlow for Java. Although these -instructions might also work on other variants, we have only tested -(and we only support) these instructions on machines meeting the -following requirements: - - * Ubuntu 16.04 or higher; 64-bit, x86 - * macOS 10.12.6 (Sierra) or higher - * Windows 7 or higher; 64-bit, x86 - -The installation instructions for Android are in a separate -[Android TensorFlow Support page](https://www.tensorflow.org/code/tensorflow/contrib/android). -After installation, please see this -[complete example](https://www.tensorflow.org/code/tensorflow/examples/android) -of TensorFlow on Android. - -## Using TensorFlow with a Maven project - -If your project uses [Apache Maven](https://maven.apache.org), then add the -following to the project's `pom.xml` to use the TensorFlow Java APIs: - -```xml -<dependency> - <groupId>org.tensorflow</groupId> - <artifactId>tensorflow</artifactId> - <version>1.10.0</version> -</dependency> -``` - -That's all. - -### Example - -As an example, these steps will create a Maven project that uses TensorFlow: - - 1. Create the project's `pom.xml`: - - - <project> - <modelVersion>4.0.0</modelVersion> - <groupId>org.myorg</groupId> - <artifactId>hellotf</artifactId> - <version>1.0-SNAPSHOT</version> - <properties> - <exec.mainClass>HelloTF</exec.mainClass> - <!-- The sample code requires at least JDK 1.7. --> - <!-- The maven compiler plugin defaults to a lower version --> - <maven.compiler.source>1.7</maven.compiler.source> - <maven.compiler.target>1.7</maven.compiler.target> - </properties> - <dependencies> - <dependency> - <groupId>org.tensorflow</groupId> - <artifactId>tensorflow</artifactId> - <version>1.10.0</version> - </dependency> - </dependencies> - </project> - - - 2. Create the source file (`src/main/java/HelloTF.java`): - - - import org.tensorflow.Graph; - import org.tensorflow.Session; - import org.tensorflow.Tensor; - import org.tensorflow.TensorFlow; - - public class HelloTF { - public static void main(String[] args) throws Exception { - try (Graph g = new Graph()) { - final String value = "Hello from " + TensorFlow.version(); - - // Construct the computation graph with a single operation, a constant - // named "MyConst" with a value "value". - try (Tensor t = Tensor.create(value.getBytes("UTF-8"))) { - // The Java API doesn't yet include convenience functions for adding operations. - g.opBuilder("Const", "MyConst").setAttr("dtype", t.dataType()).setAttr("value", t).build(); - } - - // Execute the "MyConst" operation in a Session. - try (Session s = new Session(g); - // Generally, there may be multiple output tensors, all of them must be closed to prevent resource leaks. - Tensor output = s.runner().fetch("MyConst").run().get(0)) { - System.out.println(new String(output.bytesValue(), "UTF-8")); - } - } - } - } - - - 3. Compile and execute: - - <pre> # Use -q to hide logging from the mvn tool - <b>mvn -q compile exec:java</b></pre> - - -The preceding command should output <tt>Hello from <i>version</i></tt>. If it -does, you've successfully set up TensorFlow for Java and are ready to use it in -Maven projects. If not, check -[Stack Overflow](http://stackoverflow.com/questions/tagged/tensorflow) -for possible solutions. You can skip reading the rest of this document. - -### GPU support - -If your Linux system has an NVIDIA® GPU and your TensorFlow Java program -requires GPU acceleration, then add the following to the project's `pom.xml` -instead: - -```xml -<dependency> - <groupId>org.tensorflow</groupId> - <artifactId>libtensorflow</artifactId> - <version>1.10.0</version> -</dependency> -<dependency> - <groupId>org.tensorflow</groupId> - <artifactId>libtensorflow_jni_gpu</artifactId> - <version>1.10.0</version> -</dependency> -``` - -GPU acceleration is available via Maven only for Linux and only if your system -meets the -[requirements for GPU](../install/install_linux.md#determine_which_tensorflow_to_install). - -## Using TensorFlow with JDK - -This section describes how to use TensorFlow using the `java` and `javac` -commands from a JDK installation. If your project uses Apache Maven, then -refer to the simpler instructions above instead. - -### Install on Linux or macOS - -Take the following steps to install TensorFlow for Java on Linux or macOS: - - 1. Download - [libtensorflow.jar](https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-1.10.0.jar), - which is the TensorFlow Java Archive (JAR). - - 2. Decide whether you will run TensorFlow for Java on CPU(s) only or with - the help of GPU(s). To help you decide, read the section entitled - "Determine which TensorFlow to install" in one of the following guides: - - * [Installing TensorFlow on Linux](../install/install_linux.md#determine_which_tensorflow_to_install) - * [Installing TensorFlow on macOS](../install/install_mac.md#determine_which_tensorflow_to_install) - - 3. Download and extract the appropriate Java Native Interface (JNI) - file for your operating system and processor support by running the - following shell commands: - - - TF_TYPE="cpu" # Default processor is CPU. If you want GPU, set to "gpu" - OS=$(uname -s | tr '[:upper:]' '[:lower:]') - mkdir -p ./jni - curl -L \ - "https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow_jni-${TF_TYPE}-${OS}-x86_64-1.10.0.tar.gz" | - tar -xz -C ./jni - -### Install on Windows - -Take the following steps to install TensorFlow for Java on Windows: - - 1. Download - [libtensorflow.jar](https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-1.10.0.jar), - which is the TensorFlow Java Archive (JAR). - 2. Download the following Java Native Interface (JNI) file appropriate for - [TensorFlow for Java on Windows](https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow_jni-cpu-windows-x86_64-1.10.0.zip). - 3. Extract this .zip file. - -__Note__: The native library (`tensorflow_jni.dll`) requires `msvcp140.dll` at runtime, which is included in the [Visual C++ 2015 Redistributable](https://www.microsoft.com/en-us/download/details.aspx?id=48145) package. - -### Validate the installation - -After installing TensorFlow for Java, validate your installation by entering -the following code into a file named `HelloTF.java`: - -```java -import org.tensorflow.Graph; -import org.tensorflow.Session; -import org.tensorflow.Tensor; -import org.tensorflow.TensorFlow; - -public class HelloTF { - public static void main(String[] args) throws Exception { - try (Graph g = new Graph()) { - final String value = "Hello from " + TensorFlow.version(); - - // Construct the computation graph with a single operation, a constant - // named "MyConst" with a value "value". - try (Tensor t = Tensor.create(value.getBytes("UTF-8"))) { - // The Java API doesn't yet include convenience functions for adding operations. - g.opBuilder("Const", "MyConst").setAttr("dtype", t.dataType()).setAttr("value", t).build(); - } - - // Execute the "MyConst" operation in a Session. - try (Session s = new Session(g); - // Generally, there may be multiple output tensors, all of them must be closed to prevent resource leaks. - Tensor output = s.runner().fetch("MyConst").run().get(0)) { - System.out.println(new String(output.bytesValue(), "UTF-8")); - } - } - } -} -``` - -And use the instructions below to compile and run `HelloTF.java`. - - -### Compiling - -When compiling a Java program that uses TensorFlow, the downloaded `.jar` -must be part of your `classpath`. For example, you can include the -downloaded `.jar` in your `classpath` by using the `-cp` compilation flag -as follows: - -<pre><b>javac -cp libtensorflow-1.10.0.jar HelloTF.java</b></pre> - - -### Running - -To execute a Java program that depends on TensorFlow, ensure that the following -two files are available to the JVM: - - * the downloaded `.jar` file - * the extracted JNI library - -For example, the following command line executes the `HelloTF` program on Linux -and macOS X: - -<pre><b>java -cp libtensorflow-1.10.0.jar:. -Djava.library.path=./jni HelloTF</b></pre> - -And the following command line executes the `HelloTF` program on Windows: - -<pre><b>java -cp libtensorflow-1.10.0.jar;. -Djava.library.path=jni HelloTF</b></pre> - -If the program prints <tt>Hello from <i>version</i></tt>, you've successfully -installed TensorFlow for Java and are ready to use the API. If the program -outputs something else, check -[Stack Overflow](http://stackoverflow.com/questions/tagged/tensorflow) for -possible solutions. - - -### Advanced Example - -For a more sophisticated example, see -[LabelImage.java](https://www.tensorflow.org/code/tensorflow/java/src/main/java/org/tensorflow/examples/LabelImage.java), -which recognizes objects in an image. - - -## Building from source code - -TensorFlow is open-source. You may build TensorFlow for Java from the -TensorFlow source code by following the instructions in a -[separate document](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/java/README.md). diff --git a/tensorflow/docs_src/install/install_linux.md b/tensorflow/docs_src/install/install_linux.md deleted file mode 100644 index 5fcfa4b988..0000000000 --- a/tensorflow/docs_src/install/install_linux.md +++ /dev/null @@ -1,714 +0,0 @@ -# Install TensorFlow on Ubuntu - -This guide explains how to install TensorFlow on Ubuntu Linux. While these -instructions may work on other Linux variants, they are tested and supported -with the following system requirements: - -* 64-bit desktops or laptops -* Ubuntu 16.04 or higher - -## Choose which TensorFlow to install - -The following TensorFlow variants are available for installation: - -* __TensorFlow with CPU support only__. If your system does not have a - NVIDIA® GPU, you must install this version. This version of TensorFlow - is usually easier to install, so even if you have an NVIDIA GPU, we - recommend installing this version first. -* __TensorFlow with GPU support__. TensorFlow programs usually run much faster - on a GPU instead of a CPU. If you run performance-critical applications and - your system has an NVIDIA® GPU that meets the prerequisites, you should - install this version. See [TensorFlow GPU support](#NVIDIARequirements) for - details. - -## How to install TensorFlow - -There are a few options to install TensorFlow on your machine: - -* [Use pip in a virtual environment](#InstallingVirtualenv) *(recommended)* -* [Use pip in your system environment](#InstallingNativePip) -* [Configure a Docker container](#InstallingDocker) -* [Use pip in Anaconda](#InstallingAnaconda) -* [Install TensorFlow from source](/install/install_sources) - -<a name="InstallingVirtualenv"></a> - -### Use `pip` in a virtual environment - -Key Point: Using a virtual environment is the recommended install method. - -The [Virtualenv](https://virtualenv.pypa.io/en/stable/) tool creates virtual -Python environments that are isolated from other Python development on the same -machine. In this scenario, you install TensorFlow and its dependencies within a -virtual environment that is available when *activated*. Virtualenv provides a -reliable way to install and run TensorFlow while avoiding conflicts with the -rest of the system. - -##### 1. Install Python, `pip`, and `virtualenv`. - -On Ubuntu, Python is automatically installed and `pip` is *usually* installed. -Confirm the `python` and `pip` versions: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">python -V # or: python3 -V</code> - <code class="devsite-terminal">pip -V # or: pip3 -V</code> -</pre> - -To install these packages on Ubuntu: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">sudo apt-get install python-pip python-dev python-virtualenv # for Python 2.7</code> - <code class="devsite-terminal">sudo apt-get install python3-pip python3-dev python-virtualenv # for Python 3.n</code> -</pre> - -We *recommend* using `pip` version 8.1 or higher. If using a release before -version 8.1, upgrade `pip`: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">pip install --upgrade pip</code> -</pre> - -If not using Ubuntu and [setuptools](https://pypi.org/project/setuptools/) is -installed, use `easy_install` to install `pip`: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">easy_install -U pip</code> -</pre> - -##### 2. Create a directory for the virtual environment and choose a Python interpreter. - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">mkdir ~/tensorflow # somewhere to work out of</code> - <code class="devsite-terminal">cd ~/tensorflow</code> - <code># Choose one of the following Python environments for the ./venv directory:</code> - <code class="devsite-terminal">virtualenv --system-site-packages <var>venv</var> # Use python default (Python 2.7)</code> - <code class="devsite-terminal">virtualenv --system-site-packages -p python3 <var>venv</var> # Use Python 3.n</code> -</pre> - -##### 3. Activate the Virtualenv environment. - -Use one of these shell-specific commands to activate the virtual environment: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">source ~/tensorflow/<var>venv</var>/bin/activate # bash, sh, ksh, or zsh</code> - <code class="devsite-terminal">source ~/tensorflow/<var>venv</var>/bin/activate.csh # csh or tcsh</code> - <code class="devsite-terminal">. ~/tensorflow/<var>venv</var>/bin/activate.fish # fish</code> -</pre> - -When the Virtualenv is activated, the shell prompt displays as `(venv) $`. - -##### 4. Upgrade `pip` in the virtual environment. - -Within the active virtual environment, upgrade `pip`: - -<pre class="prettyprint lang-bsh"> -(venv)$ pip install --upgrade pip -</pre> - -You can install other Python packages within the virtual environment without -affecting packages outside the `virtualenv`. - -##### 5. Install TensorFlow in the virtual environment. - -Choose one of the available TensorFlow packages for installation: - -* `tensorflow` —Current release for CPU -* `tensorflow-gpu` —Current release with GPU support -* `tf-nightly` —Nightly build for CPU -* `tf-nightly-gpu` —Nightly build with GPU support - -Within an active Virtualenv environment, use `pip` to install the package: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">pip install --upgrade tensorflow</code> -</pre> - -Use `pip list` to show the packages installed in the virtual environment. -[Validate the install](#ValidateYourInstallation) and test the version: - -<pre class="prettyprint lang-bsh"> -(venv)$ python -c "import tensorflow as tf; print(tf.__version__)" -</pre> - -Success: TensorFlow is now installed. - -Use the `deactivate` command to stop the Python virtual environment. - -#### Problems - -If the above steps failed, try installing the TensorFlow binary using the remote -URL of the `pip` package: - -<pre class="prettyprint lang-bsh"> -(venv)$ pip install --upgrade <var>remote-pkg-URL</var> # Python 2.7 -(venv)$ pip3 install --upgrade <var>remote-pkg-URL</var> # Python 3.n -</pre> - -The <var>remote-pkg-URL</var> depends on the operating system, Python version, -and GPU support. See [here](#the_url_of_the_tensorflow_python_package) for the -URL naming scheme and location. - -See [Common Installation Problems](#common_installation_problems) if you -encounter problems. - -#### Uninstall TensorFlow - -To uninstall TensorFlow, remove the Virtualenv directory you created in step 2: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">deactivate # stop the virtualenv</code> - <code class="devsite-terminal">rm -r ~/tensorflow/<var>venv</var></code> -</pre> - -<a name="InstallingNativePip"></a> - -### Use `pip` in your system environment - -Use `pip` to install the TensorFlow package directly on your system without -using a container or virtual environment for isolation. This method is -recommended for system administrators that want a TensorFlow installation that -is available to everyone on a multi-user system. - -Since a system install is not isolated, it could interfere with other -Python-based installations. But if you understand `pip` and your Python -environment, a system `pip` install is straightforward. - -See the -[REQUIRED_PACKAGES section of setup.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/pip_package/setup.py) -for a list of packages that TensorFlow installs. - -##### 1. Install Python, `pip`, and `virtualenv`. - -On Ubuntu, Python is automatically installed and `pip` is *usually* installed. -Confirm the `python` and `pip` versions: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">python -V # or: python3 -V</code> - <code class="devsite-terminal">pip -V # or: pip3 -V</code> -</pre> - -To install these packages on Ubuntu: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">sudo apt-get install python-pip python-dev # for Python 2.7</code> - <code class="devsite-terminal">sudo apt-get install python3-pip python3-dev # for Python 3.n</code> -</pre> - -We *recommend* using `pip` version 8.1 or higher. If using a release before -version 8.1, upgrade `pip`: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">pip install --upgrade pip</code> -</pre> - -If not using Ubuntu and [setuptools](https://pypi.org/project/setuptools/) is -installed, use `easy_install` to install `pip`: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">easy_install -U pip</code> -</pre> - -##### 2. Install TensorFlow on system. - -Choose one of the available TensorFlow packages for installation: - -* `tensorflow` —Current release for CPU -* `tensorflow-gpu` —Current release with GPU support -* `tf-nightly` —Nightly build for CPU -* `tf-nightly-gpu` —Nightly build with GPU support - -And use `pip` to install the package for Python 2 or 3: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">pip install --upgrade --user tensorflow # Python 2.7</code> - <code class="devsite-terminal">pip3 install --upgrade --user tensorflow # Python 3.n</code> -</pre> - -Use `pip list` to show the packages installed on the system. -[Validate the install](#ValidateYourInstallation) and test the version: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">python -c "import tensorflow as tf; print(tf.__version__)"</code> -</pre> - -Success: TensorFlow is now installed. - -#### Problems - -If the above steps failed, try installing the TensorFlow binary using the remote -URL of the `pip` package: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">pip install --user --upgrade <var>remote-pkg-URL</var> # Python 2.7</code> - <code class="devsite-terminal">pip3 install --user --upgrade <var>remote-pkg-URL</var> # Python 3.n</code> -</pre> - -The <var>remote-pkg-URL</var> depends on the operating system, Python version, -and GPU support. See [here](#the_url_of_the_tensorflow_python_package) for the -URL naming scheme and location. - -See [Common Installation Problems](#common_installation_problems) if you -encounter problems. - -#### Uninstall TensorFlow - -To uninstall TensorFlow on your system, use one of following commands: - -<pre class="prettyprint lang-bsh"> - <code class="devsite-terminal">pip uninstall tensorflow # for Python 2.7</code> - <code class="devsite-terminal">pip3 uninstall tensorflow # for Python 3.n</code> -</pre> - -<a name="InstallingDocker"></a> - -### Configure a Docker container - -Docker completely isolates the TensorFlow installation from pre-existing -packages on your machine. The Docker container contains TensorFlow and all its -dependencies. Note that the Docker image can be quite large (hundreds of MBs). -You might choose the Docker installation if you are incorporating TensorFlow -into a larger application architecture that already uses Docker. - -Take the following steps to install TensorFlow through Docker: - -1. Install Docker on your machine as described in the - [Docker documentation](http://docs.docker.com/engine/installation/). -2. Optionally, create a Linux group called <code>docker</code> to allow - launching containers without sudo as described in the - [Docker documentation](https://docs.docker.com/engine/installation/linux/linux-postinstall/). - (If you don't do this step, you'll have to use sudo each time you invoke - Docker.) -3. To install a version of TensorFlow that supports GPUs, you must first - install [nvidia-docker](https://github.com/NVIDIA/nvidia-docker), which is - stored in github. -4. Launch a Docker container that contains one of the - [TensorFlow binary images](https://hub.docker.com/r/tensorflow/tensorflow/tags/). - -The remainder of this section explains how to launch a Docker container. - -#### CPU-only - -To launch a Docker container with CPU-only support (that is, without GPU -support), enter a command of the following format: - -<pre> -$ docker run -it <i>-p hostPort:containerPort TensorFlowCPUImage</i> -</pre> - -where: - -* <tt><i>-p hostPort:containerPort</i></tt> is optional. If you plan to run - TensorFlow programs from the shell, omit this option. If you plan to run - TensorFlow programs as Jupyter notebooks, set both <tt><i>hostPort</i></tt> - and <tt><i>containerPort</i></tt> to <tt>8888</tt>. If you'd like to run - TensorBoard inside the container, add a second `-p` flag, setting both - <i>hostPort</i> and <i>containerPort</i> to 6006. -* <tt><i>TensorFlowCPUImage</i></tt> is required. It identifies the Docker - container. Specify one of the following values: - - * <tt>tensorflow/tensorflow</tt>, which is the TensorFlow CPU binary - image. - * <tt>tensorflow/tensorflow:latest-devel</tt>, which is the latest - TensorFlow CPU Binary image plus source code. - * <tt>tensorflow/tensorflow:<i>version</i></tt>, which is the specified - version (for example, 1.1.0rc1) of TensorFlow CPU binary image. - * <tt>tensorflow/tensorflow:<i>version</i>-devel</tt>, which is the - specified version (for example, 1.1.0rc1) of the TensorFlow GPU binary - image plus source code. - - TensorFlow images are available at - [dockerhub](https://hub.docker.com/r/tensorflow/tensorflow/). - -For example, the following command launches the latest TensorFlow CPU binary -image in a Docker container from which you can run TensorFlow programs in a -shell: - -<pre> -$ <b>docker run -it tensorflow/tensorflow bash</b> -</pre> - -The following command also launches the latest TensorFlow CPU binary image in a -Docker container. However, in this Docker container, you can run TensorFlow -programs in a Jupyter notebook: - -<pre> -$ <b>docker run -it -p 8888:8888 tensorflow/tensorflow</b> -</pre> - -Docker will download the TensorFlow binary image the first time you launch it. - -#### GPU support - -To launch a Docker container with NVidia GPU support, enter a command of the -following format (this -[does not require any local CUDA installation](https://github.com/nvidia/nvidia-docker/wiki/CUDA#requirements)): - -<pre> -$ <b>nvidia-docker run -it</b> <i>-p hostPort:containerPort TensorFlowGPUImage</i> -</pre> - -where: - -* <tt><i>-p hostPort:containerPort</i></tt> is optional. If you plan to run - TensorFlow programs from the shell, omit this option. If you plan to run - TensorFlow programs as Jupyter notebooks, set both <tt><i>hostPort</i></tt> - and <code><em>containerPort</em></code> to `8888`. -* <i>TensorFlowGPUImage</i> specifies the Docker container. You must specify - one of the following values: - * <tt>tensorflow/tensorflow:latest-gpu</tt>, which is the latest - TensorFlow GPU binary image. - * <tt>tensorflow/tensorflow:latest-devel-gpu</tt>, which is the latest - TensorFlow GPU Binary image plus source code. - * <tt>tensorflow/tensorflow:<i>version</i>-gpu</tt>, which is the - specified version (for example, 0.12.1) of the TensorFlow GPU binary - image. - * <tt>tensorflow/tensorflow:<i>version</i>-devel-gpu</tt>, which is the - specified version (for example, 0.12.1) of the TensorFlow GPU binary - image plus source code. - -We recommend installing one of the `latest` versions. For example, the following -command launches the latest TensorFlow GPU binary image in a Docker container -from which you can run TensorFlow programs in a shell: - -<pre> -$ <b>nvidia-docker run -it tensorflow/tensorflow:latest-gpu bash</b> -</pre> - -The following command also launches the latest TensorFlow GPU binary image in a -Docker container. In this Docker container, you can run TensorFlow programs in a -Jupyter notebook: - -<pre> -$ <b>nvidia-docker run -it -p 8888:8888 tensorflow/tensorflow:latest-gpu</b> -</pre> - -The following command installs an older TensorFlow version (0.12.1): - -<pre> -$ <b>nvidia-docker run -it -p 8888:8888 tensorflow/tensorflow:0.12.1-gpu</b> -</pre> - -Docker will download the TensorFlow binary image the first time you launch it. -For more details see the -[TensorFlow docker readme](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/docker). - -#### Next Steps - -You should now [validate your installation](#ValidateYourInstallation). - -<a name="InstallingAnaconda"></a> - -### Use `pip` in Anaconda - -Anaconda provides the `conda` utility to create a virtual environment. However, -within Anaconda, we recommend installing TensorFlow using the `pip install` -command and *not* with the `conda install` command. - -Caution: `conda` is a community supported package this is not officially -maintained by the TensorFlow team. Use this package at your own risk since it is -not tested on new TensorFlow releases. - -Take the following steps to install TensorFlow in an Anaconda environment: - -1. Follow the instructions on the - [Anaconda download site](https://www.continuum.io/downloads) to download and - install Anaconda. - -2. Create a conda environment named <tt>tensorflow</tt> to run a version of - Python by invoking the following command: - - <pre>$ <b>conda create -n tensorflow pip python=2.7 # or python=3.3, etc.</b></pre> - -3. Activate the conda environment by issuing the following command: - - <pre>$ <b>source activate tensorflow</b> - (tensorflow)$ # Your prompt should change </pre> - -4. Issue a command of the following format to install TensorFlow inside your - conda environment: - - <pre>(tensorflow)$ <b>pip install --ignore-installed --upgrade</b> <i>tfBinaryURL</i></pre> - - where <code><em>tfBinaryURL</em></code> is the - [URL of the TensorFlow Python package](#the_url_of_the_tensorflow_python_package). - For example, the following command installs the CPU-only version of - TensorFlow for Python 3.4: - - <pre> - (tensorflow)$ <b>pip install --ignore-installed --upgrade \ - https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.10.0-cp34-cp34m-linux_x86_64.whl</b></pre> - -<a name="ValidateYourInstallation"></a> - -## Validate your installation - -To validate your TensorFlow installation, do the following: - -1. Ensure that your environment is prepared to run TensorFlow programs. -2. Run a short TensorFlow program. - -### Prepare your environment - -If you installed on native pip, Virtualenv, or Anaconda, then do the following: - -1. Start a terminal. -2. If you installed with Virtualenv or Anaconda, activate your container. -3. If you installed TensorFlow source code, navigate to any directory *except* - one containing TensorFlow source code. - -If you installed through Docker, start a Docker container from which you can run -bash. For example: - -<pre> -$ <b>docker run -it tensorflow/tensorflow bash</b> -</pre> - -### Run a short TensorFlow program - -Invoke python from your shell as follows: - -<pre>$ <b>python</b></pre> - -Enter the following short program inside the python interactive shell: - -```python -# Python -import tensorflow as tf -hello = tf.constant('Hello, TensorFlow!') -sess = tf.Session() -print(sess.run(hello)) -``` - -If the system outputs the following, then you are ready to begin writing -TensorFlow programs: - -<pre>Hello, TensorFlow!</pre> - -If the system outputs an error message instead of a greeting, see -[Common installation problems](#common_installation_problems). - -To learn more, see the [TensorFlow tutorials](../tutorials/). - -<a name="NVIDIARequirements"></a> - -## TensorFlow GPU support - -Note: Due to the number of libraries required, using [Docker](#InstallingDocker) -is recommended over installing directly on the host system. - -The following NVIDIA® <i>hardware</i> must be installed on your system: - -* GPU card with CUDA Compute Capability 3.5 or higher. See - [NVIDIA documentation](https://developer.nvidia.com/cuda-gpus) for a list of - supported GPU cards. - -The following NVIDIA® <i>software</i> must be installed on your system: - -* [GPU drivers](http://nvidia.com/driver). CUDA 9.0 requires 384.x or higher. -* [CUDA Toolkit 9.0](http://nvidia.com/cuda). -* [cuDNN SDK](http://developer.nvidia.com/cudnn) (>= 7.0). Version 7.1 is - recommended. -* [CUPTI](http://docs.nvidia.com/cuda/cupti/) ships with the CUDA Toolkit, but - you also need to append its path to the `LD_LIBRARY_PATH` environment - variable: `export - LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/extras/CUPTI/lib64` -* *OPTIONAL*: [NCCL 2.2](https://developer.nvidia.com/nccl) to use TensorFlow - with multiple GPUs. -* *OPTIONAL*: - [TensorRT](http://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html) - which can improve latency and throughput for inference for some models. - -To use a GPU with CUDA Compute Capability 3.0, or different versions of the -preceding NVIDIA libraries see -[installing TensorFlow from Sources](../install/install_sources.md). If using Ubuntu 16.04 -and possibly other Debian based linux distros, `apt-get` can be used with the -NVIDIA repository to simplify installation. - -```bash -# Adds NVIDIA package repository. -sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub -wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.1.85-1_amd64.deb -wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1604/x86_64/nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb -sudo dpkg -i cuda-repo-ubuntu1604_9.1.85-1_amd64.deb -sudo dpkg -i nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb -sudo apt-get update -# Includes optional NCCL 2.x. -sudo apt-get install cuda9.0 cuda-cublas-9-0 cuda-cufft-9-0 cuda-curand-9-0 \ - cuda-cusolver-9-0 cuda-cusparse-9-0 libcudnn7=7.1.4.18-1+cuda9.0 \ - libnccl2=2.2.13-1+cuda9.0 cuda-command-line-tools-9-0 -# Optionally install TensorRT runtime, must be done after above cuda install. -sudo apt-get update -sudo apt-get install libnvinfer4=4.1.2-1+cuda9.0 -``` - -## Common installation problems - -We are relying on Stack Overflow to document TensorFlow installation problems -and their remedies. The following table contains links to Stack Overflow answers -for some common installation problems. If you encounter an error message or -other installation problem not listed in the following table, search for it on -Stack Overflow. If Stack Overflow doesn't show the error message, ask a new -question about it on Stack Overflow and specify the `tensorflow` tag. - -<table> -<tr> <th>Link to GitHub or Stack Overflow</th> <th>Error Message</th> </tr> - -<tr> - <td><a href="https://stackoverflow.com/q/36159194">36159194</a></td> - <td><pre>ImportError: libcudart.so.<i>Version</i>: cannot open shared object file: - No such file or directory</pre></td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/41991101">41991101</a></td> - <td><pre>ImportError: libcudnn.<i>Version</i>: cannot open shared object file: - No such file or directory</pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/36371137">36371137</a> and - <a href="#Protobuf31">here</a></td> - <td><pre>libprotobuf ERROR google/protobuf/src/google/protobuf/io/coded_stream.cc:207] A - protocol message was rejected because it was too big (more than 67108864 bytes). - To increase the limit (or to disable these warnings), see - CodedInputStream::SetTotalBytesLimit() in google/protobuf/io/coded_stream.h.</pre></td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/35252888">35252888</a></td> - <td><pre>Error importing tensorflow. Unless you are using bazel, you should - not try to import tensorflow from its source directory; please exit the - tensorflow source tree, and relaunch your python interpreter from - there.</pre></td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/33623453">33623453</a></td> - <td><pre>IOError: [Errno 2] No such file or directory: - '/tmp/pip-o6Tpui-build/setup.py'</tt></pre> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/42006320">42006320</a></td> - <td><pre>ImportError: Traceback (most recent call last): - File ".../tensorflow/core/framework/graph_pb2.py", line 6, in <module> - from google.protobuf import descriptor as _descriptor - ImportError: cannot import name 'descriptor'</pre> - </td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/questions/35190574">35190574</a> </td> - <td><pre>SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify - failed</pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/42009190">42009190</a></td> - <td><pre> - Installing collected packages: setuptools, protobuf, wheel, numpy, tensorflow - Found existing installation: setuptools 1.1.6 - Uninstalling setuptools-1.1.6: - Exception: - ... - [Errno 1] Operation not permitted: - '/tmp/pip-a1DXRT-uninstall/.../lib/python/_markerlib' </pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/questions/36933958">36933958</a></td> - <td><pre> - ... - Installing collected packages: setuptools, protobuf, wheel, numpy, tensorflow - Found existing installation: setuptools 1.1.6 - Uninstalling setuptools-1.1.6: - Exception: - ... - [Errno 1] Operation not permitted: - '/tmp/pip-a1DXRT-uninstall/System/Library/Frameworks/Python.framework/ - Versions/2.7/Extras/lib/python/_markerlib'</pre> - </td> -</tr> - -</table> - -<a name="TF_PYTHON_URL"></a> - -## The URL of the TensorFlow Python package - -A few installation mechanisms require the URL of the TensorFlow Python package. -The value you specify depends on three factors: - -* operating system -* Python version -* CPU only vs. GPU support - -This section documents the relevant values for Linux installations. - -### Python 2.7 - -CPU only: - -<pre> -https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.10.0-cp27-none-linux_x86_64.whl -</pre> - -GPU support: - -<pre> -https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.10.0-cp27-none-linux_x86_64.whl -</pre> - -Note that GPU support requires the NVIDIA hardware and software described in -[NVIDIA requirements to run TensorFlow with GPU support](#NVIDIARequirements). - -### Python 3.4 - -CPU only: - -<pre> -https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.10.0-cp34-cp34m-linux_x86_64.whl -</pre> - -GPU support: - -<pre> -https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.10.0-cp34-cp34m-linux_x86_64.whl -</pre> - -Note that GPU support requires the NVIDIA hardware and software described in -[NVIDIA requirements to run TensorFlow with GPU support](#NVIDIARequirements). - -### Python 3.5 - -CPU only: - -<pre> -https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.10.0-cp35-cp35m-linux_x86_64.whl -</pre> - -GPU support: - -<pre> -https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.10.0-cp35-cp35m-linux_x86_64.whl -</pre> - -Note that GPU support requires the NVIDIA hardware and software described in -[NVIDIA requirements to run TensorFlow with GPU support](#NVIDIARequirements). - -### Python 3.6 - -CPU only: - -<pre> -https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.10.0-cp36-cp36m-linux_x86_64.whl -</pre> - -GPU support: - -<pre> -https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.10.0-cp36-cp36m-linux_x86_64.whl -</pre> - -Note that GPU support requires the NVIDIA hardware and software described in -[NVIDIA requirements to run TensorFlow with GPU support](#NVIDIARequirements). diff --git a/tensorflow/docs_src/install/install_mac.md b/tensorflow/docs_src/install/install_mac.md deleted file mode 100644 index c4d63cc107..0000000000 --- a/tensorflow/docs_src/install/install_mac.md +++ /dev/null @@ -1,529 +0,0 @@ -# Install TensorFlow on macOS - -This guide explains how to install TensorFlow on macOS. Although these -instructions might also work on other macOS variants, we have only -tested (and we only support) these instructions on machines meeting the -following requirements: - - * macOS 10.12.6 (Sierra) or higher - -Note: There are known, accuracy-affecting numerical issues before macOS 10.12.6 -(Sierra) that are described in -[GitHub#15933](https://github.com/tensorflow/tensorflow/issues/15933#issuecomment-366331383). - -Note: As of version 1.2, TensorFlow no longer provides GPU support on macOS. - -## Determine how to install TensorFlow - -You must pick the mechanism by which you install TensorFlow. The supported choices are as follows: - - * Virtualenv - * "native" pip - * Docker - * installing from sources, which is documented in - [a separate guide](https://www.tensorflow.org/install/install_sources). - -**We recommend the Virtualenv installation.** -[Virtualenv](https://virtualenv.pypa.io/en/stable) -is a virtual Python environment isolated from other Python development, -incapable of interfering with or being affected by other Python programs -on the same machine. During the Virtualenv installation process, -you will install not only TensorFlow but also all the packages that -TensorFlow requires. (This is actually pretty easy.) -To start working with TensorFlow, you simply need to "activate" the -virtual environment. All in all, Virtualenv provides a safe and -reliable mechanism for installing and running TensorFlow. - -Native pip installs TensorFlow directly on your system without going through -any container or virtual environment system. Since a native pip installation -is not walled-off, the pip installation might interfere with or be influenced -by other Python-based installations on your system. Furthermore, you might need -to disable System Integrity Protection (SIP) in order to install through native -pip. However, if you understand SIP, pip, and your Python environment, a -native pip installation is relatively easy to perform. - -[Docker](http://docker.com) completely isolates the TensorFlow installation -from pre-existing packages on your machine. The Docker container contains -TensorFlow and all its dependencies. Note that the Docker image can be quite -large (hundreds of MBs). You might choose the Docker installation if you are -incorporating TensorFlow into a larger application architecture that -already uses Docker. - -In Anaconda, you may use conda to create a virtual environment. -However, within Anaconda, we recommend installing TensorFlow with the -`pip install` command, not with the `conda install` command. - -**NOTE:** The conda package is community supported, not officially supported. -That is, the TensorFlow team neither tests nor maintains the conda package. -Use that package at your own risk. - -## Installing with Virtualenv - -Take the following steps to install TensorFlow with Virtualenv: - - 1. Start a terminal (a shell). You'll perform all subsequent steps - in this shell. - - 2. Install pip and Virtualenv by issuing the following commands: - - <pre> $ <b>sudo easy_install pip</b> - $ <b>pip install --upgrade virtualenv</b> </pre> - - 3. Create a Virtualenv environment by issuing a command of one - of the following formats: - - <pre> $ <b>virtualenv --system-site-packages</b> <i>targetDirectory</i> # for Python 2.7 - $ <b>virtualenv --system-site-packages -p python3</b> <i>targetDirectory</i> # for Python 3.n - </pre> - - where <i>targetDirectory</i> identifies the top of the Virtualenv tree. - Our instructions assume that <i>targetDirectory</i> - is `~/tensorflow`, but you may choose any directory. - - 4. Activate the Virtualenv environment by issuing one of the - following commands: - - <pre>$ <b>cd <i>targetDirectory</i></b> - $ <b>source ./bin/activate</b> # If using bash, sh, ksh, or zsh - $ <b>source ./bin/activate.csh</b> # If using csh or tcsh </pre> - - The preceding `source` command should change your prompt to the following: - - <pre> (<i>targetDirectory</i>)$ </pre> - - 5. Ensure pip ≥8.1 is installed: - - <pre> (<i>targetDirectory</i>)$ <b>easy_install -U pip</b></pre> - - 6. Issue one of the following commands to install TensorFlow and all the - packages that TensorFlow requires into the active Virtualenv environment: - - <pre> (<i>targetDirectory</i>)$ <b>pip install --upgrade tensorflow</b> # for Python 2.7 - (<i>targetDirectory</i>)$ <b>pip3 install --upgrade tensorflow</b> # for Python 3.n - - 7. Optional. If Step 6 failed (typically because you invoked a pip version - lower than 8.1), install TensorFlow in the active - Virtualenv environment by issuing a command of the following format: - - <pre> $ <b>pip install --upgrade</b> <i>tfBinaryURL</i> # Python 2.7 - $ <b>pip3 install --upgrade</b> <i>tfBinaryURL</i> # Python 3.n </pre> - - where <i>tfBinaryURL</i> identifies the URL - of the TensorFlow Python package. The appropriate value of - <i>tfBinaryURL</i> depends on the operating system and - Python version. Find the appropriate value for - <i>tfBinaryURL</i> for your system - [here](#the_url_of_the_tensorflow_python_package). - For example, if you are installing TensorFlow for macOS, - Python 2.7, the command to install - TensorFlow in the active Virtualenv is as follows: - - <pre> $ <b>pip3 install --upgrade \ - https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.10.0-py3-none-any.whl</b></pre> - -If you encounter installation problems, see -[Common Installation Problems](#common-installation-problems). - - -### Next Steps - -After installing TensorFlow, -[validate your installation](#ValidateYourInstallation) -to confirm that the installation worked properly. - -Note that you must activate the Virtualenv environment each time you -use TensorFlow in a new shell. If the Virtualenv environment is not -currently active (that is, the prompt is not `(<i>targetDirectory</i>)`, invoke -one of the following commands: - -<pre>$ <b>cd <i>targetDirectory</i></b> -$ <b>source ./bin/activate</b> # If using bash, sh, ksh, or zsh -$ <b>source ./bin/activate.csh</b> # If using csh or tcsh </pre> - - -Your prompt will transform to the following to indicate that your -tensorflow environment is active: - -<pre> (<i>targetDirectory</i>)$ </pre> - -When the Virtualenv environment is active, you may run -TensorFlow programs from this shell. - -When you are done using TensorFlow, you may deactivate the -environment by issuing the following command: - -<pre> (<i>targetDirectory</i>)$ <b>deactivate</b> </pre> - -The prompt will revert back to your default prompt (as defined by `PS1`). - - -### Uninstalling TensorFlow - -If you want to uninstall TensorFlow, simply remove the tree you created. For example: - -<pre> $ <b>rm -r ~/tensorflow</b> </pre> - - -## Installing with native pip - -We have uploaded the TensorFlow binaries to PyPI. -Therefore, you can install TensorFlow through pip. - -The -[REQUIRED_PACKAGES section of setup.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/pip_package/setup.py) -lists the packages that pip will install or upgrade. - - -### Prerequisite: Python - -In order to install TensorFlow, your system must contain one of the following Python versions: - - * Python 2.7 - * Python 3.3+ - -If your system does not already have one of the preceding Python versions, -[install](https://wiki.python.org/moin/BeginnersGuide/Download) it now. - -When installing Python, you might need to disable -System Integrity Protection (SIP) to permit any entity other than -Mac App Store to install software. - - -### Prerequisite: pip - -[Pip](https://en.wikipedia.org/wiki/Pip_(package_manager)) installs -and manages software packages written in Python. If you intend to install -with native pip, then one of the following flavors of pip must be -installed on your system: - - * `pip`, for Python 2.7 - * `pip3`, for Python 3.n. - -`pip` or `pip3` was probably installed on your system when you -installed Python. To determine whether pip or pip3 is actually -installed on your system, issue one of the following commands: - -<pre>$ <b>pip -V</b> # for Python 2.7 -$ <b>pip3 -V</b> # for Python 3.n </pre> - -We strongly recommend pip or pip3 version 8.1 or higher in order -to install TensorFlow. If pip or pip3 8.1 or later is not -installed, issue the following commands to install or upgrade: - -<pre>$ <b>sudo easy_install --upgrade pip</b> -$ <b>sudo easy_install --upgrade six</b> </pre> - - -### Install TensorFlow - -Assuming the prerequisite software is installed on your Mac, -take the following steps: - - 1. Install TensorFlow by invoking **one** of the following commands: - - <pre> $ <b>pip install tensorflow</b> # Python 2.7; CPU support - $ <b>pip3 install tensorflow</b> # Python 3.n; CPU support - - If the preceding command runs to completion, you should now - [validate your installation](#ValidateYourInstallation). - - 2. (Optional.) If Step 1 failed, install the latest version of TensorFlow - by issuing a command of the following format: - - <pre> $ <b>sudo pip install --upgrade</b> <i>tfBinaryURL</i> # Python 2.7 - $ <b>sudo pip3 install --upgrade</b> <i>tfBinaryURL</i> # Python 3.n </pre> - - where <i>tfBinaryURL</i> identifies the URL of the TensorFlow Python - package. The appropriate value of <i>tfBinaryURL</i> depends on the - operating system and Python version. Find the appropriate - value for <i>tfBinaryURL</i> - [here](#the_url_of_the_tensorflow_python_package). For example, if - you are installing TensorFlow for macOS and Python 2.7 - issue the following command: - - <pre> $ <b>sudo pip3 install --upgrade \ - https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.10.0-py3-none-any.whl</b> </pre> - - If the preceding command fails, see - [installation problems](#common-installation-problems). - - - -### Next Steps - -After installing TensorFlow, -[validate your installation](#ValidateYourInstallation) -to confirm that the installation worked properly. - - -### Uninstalling TensorFlow - -To uninstall TensorFlow, issue one of following commands: - -<pre>$ <b>pip uninstall tensorflow</b> -$ <b>pip3 uninstall tensorflow</b> </pre> - - -## Installing with Docker - -Follow these steps to install TensorFlow through Docker. - - 1. Install Docker on your machine as described in the - [Docker documentation](https://docs.docker.com/engine/installation/#/on-macos-and-windows). - - 2. Launch a Docker container that contains one of the TensorFlow - binary images. - -The remainder of this section explains how to launch a Docker container. - -To launch a Docker container that holds the TensorFlow binary image, -enter a command of the following format: - -<pre> $ <b>docker run -it <i>-p hostPort:containerPort</i> TensorFlowImage</b> </pre> - -where: - - * <i>-p hostPort:containerPort</i> is optional. If you'd like to run - TensorFlow programs from the shell, omit this option. If you'd like - to run TensorFlow programs from Jupyter notebook, set both - <i>hostPort</i> and <i>containerPort</i> to <code>8888</code>. - If you'd like to run TensorBoard inside the container, add - a second `-p` flag, setting both <i>hostPort</i> and <i>containerPort</i> - to 6006. - * <i>TensorFlowImage</i> is required. It identifies the Docker container. - You must specify one of the following values: - * <code>tensorflow/tensorflow</code>: TensorFlow binary image. - * <code>tensorflow/tensorflow:latest-devel</code>: TensorFlow - Binary image plus source code. - -The TensorFlow images are available at -[dockerhub](https://hub.docker.com/r/tensorflow/tensorflow/). - -For example, the following command launches a TensorFlow CPU binary image -in a Docker container from which you can run TensorFlow programs in a shell: - -<pre>$ <b>docker run -it tensorflow/tensorflow bash</b></pre> - -The following command also launches a TensorFlow CPU binary image in a -Docker container. However, in this Docker container, you can run -TensorFlow programs in a Jupyter notebook: - -<pre>$ <b>docker run -it -p 8888:8888 tensorflow/tensorflow</b></pre> - -Docker will download the TensorFlow binary image the first time you launch it. - - -### Next Steps - -You should now -[validate your installation](#ValidateYourInstallation). - - -## Installing with Anaconda - -**The Anaconda installation is community supported, not officially supported.** - -Take the following steps to install TensorFlow in an Anaconda environment: - - 1. Follow the instructions on the - [Anaconda download site](https://www.continuum.io/downloads) - to download and install Anaconda. - - 2. Create a conda environment named `tensorflow` - by invoking the following command: - - <pre>$ <b>conda create -n tensorflow pip python=2.7 # or python=3.3, etc.</b></pre> - - 3. Activate the conda environment by issuing the following command: - - <pre>$ <b>source activate tensorflow</b> - (<i>targetDirectory</i>)$ # Your prompt should change</pre> - - 4. Issue a command of the following format to install - TensorFlow inside your conda environment: - - <pre>(<i>targetDirectory</i>)<b>$ pip install --ignore-installed --upgrade</b> <i>TF_PYTHON_URL</i></pre> - - where <i>TF_PYTHON_URL</i> is the - [URL of the TensorFlow Python package](#the_url_of_the_tensorflow_python_package). - For example, the following command installs the CPU-only version of - TensorFlow for Python 2.7: - - <pre> (<i>targetDirectory</i>)$ <b>pip install --ignore-installed --upgrade \ - https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.10.0-py2-none-any.whl</b></pre> - - -<a name="ValidateYourInstallation"></a> -## Validate your installation - -To validate your TensorFlow installation, do the following: - - 1. Ensure that your environment is prepared to run TensorFlow programs. - 2. Run a short TensorFlow program. - - -### Prepare your environment - -If you installed on native pip, Virtualenv, or Anaconda, then -do the following: - - 1. Start a terminal. - 2. If you installed with Virtualenv or Anaconda, activate your container. - 3. If you installed TensorFlow source code, navigate to any - directory *except* one containing TensorFlow source code. - -If you installed through Docker, start a Docker container that runs bash. -For example: - -<pre>$ <b>docker run -it tensorflow/tensorflow bash</b></pre> - - - -### Run a short TensorFlow program - -Invoke python from your shell as follows: - -<pre>$ <b>python</b></pre> - -Enter the following short program inside the python interactive shell: - -```python -# Python -import tensorflow as tf -hello = tf.constant('Hello, TensorFlow!') -sess = tf.Session() -print(sess.run(hello)) -``` - -If the system outputs the following, then you are ready to begin -writing TensorFlow programs: - -<pre>Hello, TensorFlow!</pre> - -If the system outputs an error message instead of a greeting, see -[Common installation problems](#common_installation_problems). - -To learn more, see the [TensorFlow tutorials](../tutorials/). - -## Common installation problems - -We are relying on Stack Overflow to document TensorFlow installation problems -and their remedies. The following table contains links to Stack Overflow -answers for some common installation problems. -If you encounter an error message or other -installation problem not listed in the following table, search for it -on Stack Overflow. If Stack Overflow doesn't show the error message, -ask a new question about it on Stack Overflow and specify -the `tensorflow` tag. - -<table> -<tr> <th>Stack Overflow Link</th> <th>Error Message</th> </tr> - - -<tr> - <td><a href="http://stackoverflow.com/q/42006320">42006320</a></td> - <td><pre>ImportError: Traceback (most recent call last): -File ".../tensorflow/core/framework/graph_pb2.py", line 6, in <module> -from google.protobuf import descriptor as _descriptor -ImportError: cannot import name 'descriptor'</pre> - </td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/33623453">33623453</a></td> - <td><pre>IOError: [Errno 2] No such file or directory: - '/tmp/pip-o6Tpui-build/setup.py'</tt></pre> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/questions/35190574">35190574</a> </td> - <td><pre>SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify - failed</pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/42009190">42009190</a></td> - <td><pre> - Installing collected packages: setuptools, protobuf, wheel, numpy, tensorflow - Found existing installation: setuptools 1.1.6 - Uninstalling setuptools-1.1.6: - Exception: - ... - [Errno 1] Operation not permitted: - '/tmp/pip-a1DXRT-uninstall/.../lib/python/_markerlib' </pre></td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/33622019">33622019</a></td> - <td><pre>ImportError: No module named copyreg</pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/37810228">37810228</a></td> - <td>During a <tt>pip install</tt> operation, the system returns: - <pre>OSError: [Errno 1] Operation not permitted</pre> - </td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/33622842">33622842</a></td> - <td>An <tt>import tensorflow</tt> statement triggers an error such as the - following:<pre>Traceback (most recent call last): - File "<stdin>", line 1, in <module> - File "/usr/local/lib/python2.7/site-packages/tensorflow/__init__.py", - line 4, in <module> - from tensorflow.python import * - ... - File "/usr/local/lib/python2.7/site-packages/tensorflow/core/framework/tensor_shape_pb2.py", - line 22, in <module> - serialized_pb=_b('\n,tensorflow/core/framework/tensor_shape.proto\x12\ntensorflow\"d\n\x10TensorShapeProto\x12-\n\x03\x64im\x18\x02 - \x03(\x0b\x32 - .tensorflow.TensorShapeProto.Dim\x1a!\n\x03\x44im\x12\x0c\n\x04size\x18\x01 - \x01(\x03\x12\x0c\n\x04name\x18\x02 \x01(\tb\x06proto3') - TypeError: __init__() got an unexpected keyword argument 'syntax'</pre> - </td> -</tr> - - -<tr> - <td><a href="http://stackoverflow.com/q/42075397">42075397</a></td> - <td>A <tt>pip install</tt> command triggers the following error: -<pre>...<lots of warnings and errors> -You have not agreed to the Xcode license agreements, please run -'xcodebuild -license' (for user-level acceptance) or -'sudo xcodebuild -license' (for system-wide acceptance) from within a -Terminal window to review and agree to the Xcode license agreements. -...<more stack trace output> - File "numpy/core/setup.py", line 653, in get_mathlib_info - - raise RuntimeError("Broken toolchain: cannot link a simple C program") - -RuntimeError: Broken toolchain: cannot link a simple C program</pre> -</td> - - -</table> - - - - -<a name="TF_PYTHON_URL"></a> -## The URL of the TensorFlow Python package - -A few installation mechanisms require the URL of the TensorFlow Python package. -The value you specify depends on your Python version. - -### Python 2.7 - - -<pre> -https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.10.0-py2-none-any.whl -</pre> - - -### Python 3.4, 3.5, or 3.6 - - -<pre> -https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.10.0-py3-none-any.whl -</pre> diff --git a/tensorflow/docs_src/install/install_raspbian.md b/tensorflow/docs_src/install/install_raspbian.md deleted file mode 100644 index cf6b6b4f79..0000000000 --- a/tensorflow/docs_src/install/install_raspbian.md +++ /dev/null @@ -1,313 +0,0 @@ -# Install TensorFlow on Raspbian - -This guide explains how to install TensorFlow on a Raspberry Pi running -Raspbian. Although these instructions might also work on other Pi variants, we -have only tested (and we only support) these instructions on machines meeting -the following requirements: - -* Raspberry Pi devices running Raspbian 9.0 or higher - -## Determine how to install TensorFlow - -You must pick the mechanism by which you install TensorFlow. The supported -choices are as follows: - -* "Native" pip. -* Cross-compiling from sources. - -**We recommend pip installation.** - -## Installing with native pip - -We have uploaded the TensorFlow binaries to piwheels.org. Therefore, you can -install TensorFlow through pip. - -The [REQUIRED_PACKAGES section of -setup.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/pip_package/setup.py) -lists the packages that pip will install or upgrade. - -### Prerequisite: Python - -In order to install TensorFlow, your system must contain one of the following -Python versions: - -* Python 2.7 -* Python 3.4+ - -If your system does not already have one of the preceding Python versions, -[install](https://wiki.python.org/moin/BeginnersGuide/Download) it now. It -should already be included when Raspbian was installed though, so no extra steps -should be needed. - -### Prerequisite: pip - -[Pip](https://en.wikipedia.org/wiki/Pip_\(package_manager\)) installs and -manages software packages written in Python. If you intend to install with -native pip, then one of the following flavors of pip must be installed on your -system: - -* `pip3`, for Python 3.n (preferred). -* `pip`, for Python 2.7. - -`pip` or `pip3` was probably installed on your system when you installed Python. -To determine whether pip or pip3 is actually installed on your system, issue one -of the following commands: - -<pre>$ <b>pip3 -V</b> # for Python 3.n -$ <b>pip -V</b> # for Python 2.7</pre> - -If it gives the error "Command not found", then the package has not been -installed yet. To install if for the first time, run: - -<pre>$ sudo apt-get install python3-pip # for Python 3.n -$ sudo apt-get install python-pip # for Python 2.7</pre> - -You can find more help on installing and upgrading pip in -[the Raspberry Pi documentation](https://www.raspberrypi.org/documentation/linux/software/python.md). - -### Prerequisite: Atlas - -[Atlas](http://math-atlas.sourceforge.net/) is a linear algebra library that -numpy depends on, and so needs to be installed before TensorFlow. To add it to -your system, run the following command: - -<pre>$ sudo apt install libatlas-base-dev</pre> - -### Install TensorFlow - -Assuming the prerequisite software is installed on your Pi, install TensorFlow -by invoking **one** of the following commands: - -<pre>$ <b>pip3 install tensorflow</b> # Python 3.n -$ <b>pip install tensorflow</b> # Python 2.7</pre> - -This can take some time on certain platforms like the Pi Zero, where some Python -packages like scipy that TensorFlow depends on need to be compiled before the -installation can complete. The Python 3 version will typically be faster to -install because piwheels.org has pre-built versions of the dependencies -available, so this is our recommended option. - -### Next Steps - -After installing TensorFlow, [validate your -installation](#ValidateYourInstallation) to confirm that the installation worked -properly. - -### Uninstalling TensorFlow - -To uninstall TensorFlow, issue one of following commands: - -<pre>$ <b>pip uninstall tensorflow</b> -$ <b>pip3 uninstall tensorflow</b> </pre> - -## Cross-compiling from sources - -Cross-compilation means building on a different machine than than you'll be -deploying on. Since Raspberry Pi's only have limited RAM and comparatively slow -processors, and TensorFlow has a large amount of source code to compile, it's -easier to use a MacOS or Linux desktop or laptop to handle the build process. -Because it can take over 24 hours to build on a Pi, and requires external swap -space to cope with the memory shortage, we recommend using cross-compilation if -you do need to compile TensorFlow from source. To make the dependency management -process easier, we also recommend using Docker to help simplify building. - -Note that we provide well-tested, pre-built TensorFlow binaries for Raspbian -systems. So, don't build a TensorFlow binary yourself unless you are very -comfortable building complex packages from source and dealing with the -inevitable aftermath should things not go exactly as documented - -### Prerequisite: Docker - -Install Docker on your machine as described in the [Docker -documentation](https://docs.docker.com/engine/installation/#/on-macos-and-windows). - -### Clone the TensorFlow repository - -Start the process of building TensorFlow by cloning a TensorFlow repository. - -To clone **the latest** TensorFlow repository, issue the following command: - -<pre>$ <b>git clone https://github.com/tensorflow/tensorflow</b> </pre> - -The preceding <code>git clone</code> command creates a subdirectory named -`tensorflow`. After cloning, you may optionally build a **specific branch** -(such as a release branch) by invoking the following commands: - -<pre> -$ <b>cd tensorflow</b> -$ <b>git checkout</b> <i>Branch</i> # where <i>Branch</i> is the desired branch -</pre> - -For example, to work with the `r1.0` release instead of the master release, -issue the following command: - -<pre>$ <b>git checkout r1.0</b></pre> - -### Build from source - -To compile TensorFlow and produce a binary pip can install, do the following: - -1. Start a terminal. -2. Navigate to the directory containing the tensorflow source code. -3. Run a command to cross-compile the library, for example: - -<pre>$ CI_DOCKER_EXTRA_PARAMS="-e CI_BUILD_PYTHON=python3 -e CROSSTOOL_PYTHON_INCLUDE_PATH=/usr/include/python3.4" \ -tensorflow/tools/ci_build/ci_build.sh PI-PYTHON3 tensorflow/tools/ci_build/pi/build_raspberry_pi.sh - </pre> - -This will build a pip .whl file for Python 3.4, with Arm v7 instructions that -will only work on the Pi models 2 or 3. These NEON instructions are required for -the fastest operation on those devices, but you can build a library that will -run across all Pi devices by passing `PI_ONE` at the end of the command line. -You can also target Python 2.7 by omitting the initial docker parameters. Here's -an example of building for Python 2.7 and Raspberry Pi model Zero or One -devices: - -<pre>$ tensorflow/tools/ci_build/ci_build.sh PI tensorflow/tools/ci_build/pi/build_raspberry_pi.sh PI_ONE</pre> - -This will take some time to complete, typically twenty or thirty minutes, and -should produce a .whl file in an output-artifacts sub-folder inside your source -tree at the end. This wheel file can be installed through pip or pip3 (depending -on your Python version) by copying it to a Raspberry Pi and running a terminal -command like this (with the name of your actual file substituted): - -<pre>$ pip3 install tensorflow-1.9.0-cp34-none-linux_armv7l.whl</pre> - -### Troubleshooting the build - -The build script uses Docker internally to create a Linux virtual machine to -handle the compilation. If you do have problems running the script, first check -that you're able to run Docker tests like `docker run hello-world` on your -system. - -If you're building from the latest development branch, try syncing to an older -version that's known to work, for example release 1.9, with a command like this: - -<pre>$ <b>git checkout r1.0</b></pre> - -<a name="ValidateYourInstallation"></a> - -## Validate your installation - -To validate your TensorFlow installation, do the following: - -1. Ensure that your environment is prepared to run TensorFlow programs. -2. Run a short TensorFlow program. - -### Prepare your environment - -If you installed on native pip, Virtualenv, or Anaconda, then do the following: - -1. Start a terminal. -2. If you installed TensorFlow source code, navigate to any directory *except* - one containing TensorFlow source code. - -### Run a short TensorFlow program - -Invoke python from your shell as follows: - -<pre>$ <b>python</b></pre> - -Enter the following short program inside the python interactive shell: - -```python -# Python -import tensorflow as tf -hello = tf.constant('Hello, TensorFlow!') -sess = tf.Session() -print(sess.run(hello)) -``` - -If the system outputs the following, then you are ready to begin writing -TensorFlow programs: - -<pre>Hello, TensorFlow!</pre> - -If you're running with Python 3.5, you may see a warning when you first import -TensorFlow. This is not an error, and TensorFlow should continue to run with no -problems, despite the log message. - -If the system outputs an error message instead of a greeting, see [Common -installation problems](#common_installation_problems). - -To learn more, see the [TensorFlow tutorials](../tutorials/). - -## Common installation problems - -We are relying on Stack Overflow to document TensorFlow installation problems -and their remedies. The following table contains links to Stack Overflow answers -for some common installation problems. If you encounter an error message or -other installation problem not listed in the following table, search for it on -Stack Overflow. If Stack Overflow doesn't show the error message, ask a new -question about it on Stack Overflow and specify the `tensorflow` tag. - -<table> -<tr> <th>Stack Overflow Link</th> <th>Error Message</th> </tr> - - -<tr> - <td><a href="http://stackoverflow.com/q/42006320">42006320</a></td> - <td><pre>ImportError: Traceback (most recent call last): -File ".../tensorflow/core/framework/graph_pb2.py", line 6, in <module> -from google.protobuf import descriptor as _descriptor -ImportError: cannot import name 'descriptor'</pre> - </td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/33623453">33623453</a></td> - <td><pre>IOError: [Errno 2] No such file or directory: - '/tmp/pip-o6Tpui-build/setup.py'</tt></pre> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/questions/35190574">35190574</a> </td> - <td><pre>SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify - failed</pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/42009190">42009190</a></td> - <td><pre> - Installing collected packages: setuptools, protobuf, wheel, numpy, tensorflow - Found existing installation: setuptools 1.1.6 - Uninstalling setuptools-1.1.6: - Exception: - ... - [Errno 1] Operation not permitted: - '/tmp/pip-a1DXRT-uninstall/.../lib/python/_markerlib' </pre></td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/33622019">33622019</a></td> - <td><pre>ImportError: No module named copyreg</pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/37810228">37810228</a></td> - <td>During a <tt>pip install</tt> operation, the system returns: - <pre>OSError: [Errno 1] Operation not permitted</pre> - </td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/33622842">33622842</a></td> - <td>An <tt>import tensorflow</tt> statement triggers an error such as the - following:<pre>Traceback (most recent call last): - File "<stdin>", line 1, in <module> - File "/usr/local/lib/python2.7/site-packages/tensorflow/__init__.py", - line 4, in <module> - from tensorflow.python import * - ... - File "/usr/local/lib/python2.7/site-packages/tensorflow/core/framework/tensor_shape_pb2.py", - line 22, in <module> - serialized_pb=_b('\n,tensorflow/core/framework/tensor_shape.proto\x12\ntensorflow\"d\n\x10TensorShapeProto\x12-\n\x03\x64im\x18\x02 - \x03(\x0b\x32 - .tensorflow.TensorShapeProto.Dim\x1a!\n\x03\x44im\x12\x0c\n\x04size\x18\x01 - \x01(\x03\x12\x0c\n\x04name\x18\x02 \x01(\tb\x06proto3') - TypeError: __init__() got an unexpected keyword argument 'syntax'</pre> - </td> -</tr> - - -</table> diff --git a/tensorflow/docs_src/install/install_sources.md b/tensorflow/docs_src/install/install_sources.md deleted file mode 100644 index dfd9fbce4b..0000000000 --- a/tensorflow/docs_src/install/install_sources.md +++ /dev/null @@ -1,577 +0,0 @@ -# Install TensorFlow from Sources - -This guide explains how to build TensorFlow sources into a TensorFlow binary and -how to install that TensorFlow binary. Note that we provide well-tested, -pre-built TensorFlow binaries for Ubuntu, macOS, and Windows systems. In -addition, there are pre-built TensorFlow -[docker images](https://hub.docker.com/r/tensorflow/tensorflow/). So, don't -build a TensorFlow binary yourself unless you are very comfortable building -complex packages from source and dealing with the inevitable aftermath should -things not go exactly as documented. - -If the last paragraph didn't scare you off, welcome. This guide explains how to -build TensorFlow on 64-bit desktops and laptops running either of the following -operating systems: - -* Ubuntu -* macOS X - -Note: Some users have successfully built and installed TensorFlow from sources -on non-supported systems. Please remember that we do not fix issues stemming -from these attempts. - -We **do not support** building TensorFlow on Windows. That said, if you'd like -to try to build TensorFlow on Windows anyway, use either of the following: - -* [Bazel on Windows](https://bazel.build/versions/master/docs/windows.html) -* [TensorFlow CMake build](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/cmake) - -Note: Starting from 1.6 release, our prebuilt binaries will use AVX -instructions. Older CPUs may not be able to execute these binaries. - -## Determine which TensorFlow to install - -You must choose one of the following types of TensorFlow to build and install: - -* **TensorFlow with CPU support only**. If your system does not have a NVIDIA® - GPU, build and install this version. Note that this version of TensorFlow is - typically easier to build and install, so even if you have an NVIDIA GPU, we - recommend building and installing this version first. -* **TensorFlow with GPU support**. TensorFlow programs typically run - significantly faster on a GPU than on a CPU. Therefore, if your system has a - NVIDIA GPU and you need to run performance-critical applications, you should - ultimately build and install this version. Beyond the NVIDIA GPU itself, - your system must also fulfill the NVIDIA software requirements described in - one of the following documents: - - * @ {$install_linux#NVIDIARequirements$Installing TensorFlow on Ubuntu} - * @ {$install_mac#NVIDIARequirements$Installing TensorFlow on macOS} - -## Clone the TensorFlow repository - -Start the process of building TensorFlow by cloning a TensorFlow repository. - -To clone **the latest** TensorFlow repository, issue the following command: - -<pre>$ <b>git clone https://github.com/tensorflow/tensorflow</b> </pre> - -The preceding <code>git clone</code> command creates a subdirectory named -`tensorflow`. After cloning, you may optionally build a **specific branch** -(such as a release branch) by invoking the following commands: - -<pre> -$ <b>cd tensorflow</b> -$ <b>git checkout</b> <i>Branch</i> # where <i>Branch</i> is the desired branch -</pre> - -For example, to work with the `r1.0` release instead of the master release, -issue the following command: - -<pre>$ <b>git checkout r1.0</b></pre> - -Next, you must prepare your environment for [Linux](#PrepareLinux) or -[macOS](#PrepareMac) - -<a name="PrepareLinux"></a> - -## Prepare environment for Linux - -Before building TensorFlow on Linux, install the following build tools on your -system: - -* bazel -* TensorFlow Python dependencies -* optionally, NVIDIA packages to support TensorFlow for GPU. - -### Install Bazel - -If bazel is not installed on your system, install it now by following -[these directions](https://bazel.build/versions/master/docs/install.html). - -### Install TensorFlow Python dependencies - -To install TensorFlow, you must install the following packages: - -* `numpy`, which is a numerical processing package that TensorFlow requires. -* `dev`, which enables adding extensions to Python. -* `pip`, which enables you to install and manage certain Python packages. -* `wheel`, which enables you to manage Python compressed packages in the wheel - (.whl) format. - -To install these packages for Python 2.7, issue the following command: - -<pre> -$ <b>sudo apt-get install python-numpy python-dev python-pip python-wheel</b> -</pre> - -To install these packages for Python 3.n, issue the following command: - -<pre> -$ <b>sudo apt-get install python3-numpy python3-dev python3-pip python3-wheel</b> -</pre> - -### Optional: install TensorFlow for GPU prerequisites - -If you are building TensorFlow without GPU support, skip this section. - -The following NVIDIA® <i>hardware</i> must be installed on your system: - -* GPU card with CUDA Compute Capability 3.5 or higher. See - [NVIDIA documentation](https://developer.nvidia.com/cuda-gpus) for a list of - supported GPU cards. - -The following NVIDIA® <i>software</i> must be installed on your system: - -* [GPU drivers](http://nvidia.com/driver). CUDA 9.0 requires 384.x or higher. -* [CUDA Toolkit](http://nvidia.com/cuda) (>= 8.0). We recommend version 9.0. -* [cuDNN SDK](http://developer.nvidia.com/cudnn) (>= 6.0). We recommend - version 7.1.x. -* [CUPTI](http://docs.nvidia.com/cuda/cupti/) ships with the CUDA Toolkit, but - you also need to append its path to the `LD_LIBRARY_PATH` environment - variable: `export - LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/extras/CUPTI/lib64` -* *OPTIONAL*: [NCCL 2.2](https://developer.nvidia.com/nccl) to use TensorFlow - with multiple GPUs. -* *OPTIONAL*: - [TensorRT](http://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html) - which can improve latency and throughput for inference for some models. - -While it is possible to install the NVIDIA libraries via `apt-get` from the -NVIDIA repository, the libraries and headers are installed in locations that -make it difficult to configure and debug build issues. Downloading and -installing the libraries manually or using docker -([latest-devel-gpu](https://hub.docker.com/r/tensorflow/tensorflow/tags/)) is -recommended. - -### Next - -After preparing the environment, you must now -[configure the installation](#ConfigureInstallation). - -<a name="PrepareMac"></a> - -## Prepare environment for macOS - -Before building TensorFlow, you must install the following on your system: - -* bazel -* TensorFlow Python dependencies. -* optionally, NVIDIA packages to support TensorFlow for GPU. - -### Install bazel - -If bazel is not installed on your system, install it now by following -[these directions](https://bazel.build/versions/master/docs/install.html#mac-os-x). - -### Install python dependencies - -To build TensorFlow, you must install the following packages: - -* six -* mock -* numpy, which is a numerical processing package that TensorFlow requires. -* wheel, which enables you to manage Python compressed packages in the wheel - (.whl) format. - -You may install the python dependencies using pip. If you don't have pip on your -machine, we recommend using homebrew to install Python and pip as -[documented here](http://docs.python-guide.org/en/latest/starting/install/osx/). -If you follow these instructions, you will not need to disable SIP. - -After installing pip, invoke the following commands: - -<pre> $ <b>sudo pip install six numpy wheel mock h5py</b> - $ <b>sudo pip install keras_applications==1.0.4 --no-deps</b> - $ <b>sudo pip install keras_preprocessing==1.0.2 --no-deps</b> -</pre> - -Note: These are just the minimum requirements to _build_ tensorflow. Installing -the pip package will download additional packages required to _run_ it. If you -plan on executing tasks directly with `bazel` , without the pip installation, -you may need to install additional python packages. For example, you should `pip -install mock enum34` before running TensorFlow's tests with bazel. - -<a name="ConfigureInstallation"></a> - -## Configure the installation - -The root of the source tree contains a bash script named <code>configure</code>. -This script asks you to identify the pathname of all relevant TensorFlow -dependencies and specify other build configuration options such as compiler -flags. You must run this script *prior* to creating the pip package and -installing TensorFlow. - -If you wish to build TensorFlow with GPU, `configure` will ask you to specify -the version numbers of CUDA and cuDNN. If several versions of CUDA or cuDNN are -installed on your system, explicitly select the desired version instead of -relying on the default. - -One of the questions that `configure` will ask is as follows: - -<pre> -Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native] -</pre> - -This question refers to a later phase in which you'll use bazel to -[build the pip package](#build-the-pip-package) or the -[C/Java libraries](#BuildCorJava). We recommend accepting the default -(`-march=native`), which will optimize the generated code for your local -machine's CPU type. However, if you are building TensorFlow on one CPU type but -will run TensorFlow on a different CPU type, then consider specifying a more -specific optimization flag as described in -[the gcc documentation](https://gcc.gnu.org/onlinedocs/gcc-4.5.3/gcc/i386-and-x86_002d64-Options.html). - -Here is an example execution of the `configure` script. Note that your own input -will likely differ from our sample input: - -<pre> -$ <b>cd tensorflow</b> # cd to the top-level directory created -$ <b>./configure</b> -You have bazel 0.15.0 installed. -Please specify the location of python. [Default is /usr/bin/python]: <b>/usr/bin/python2.7</b> - - -Found possible Python library paths: - /usr/local/lib/python2.7/dist-packages - /usr/lib/python2.7/dist-packages -Please input the desired Python library path to use. Default is [/usr/lib/python2.7/dist-packages] - -Do you wish to build TensorFlow with jemalloc as malloc support? [Y/n]: -jemalloc as malloc support will be enabled for TensorFlow. - -Do you wish to build TensorFlow with Google Cloud Platform support? [Y/n]: -Google Cloud Platform support will be enabled for TensorFlow. - -Do you wish to build TensorFlow with Hadoop File System support? [Y/n]: -Hadoop File System support will be enabled for TensorFlow. - -Do you wish to build TensorFlow with Amazon AWS Platform support? [Y/n]: -Amazon AWS Platform support will be enabled for TensorFlow. - -Do you wish to build TensorFlow with Apache Kafka Platform support? [Y/n]: -Apache Kafka Platform support will be enabled for TensorFlow. - -Do you wish to build TensorFlow with XLA JIT support? [y/N]: -No XLA JIT support will be enabled for TensorFlow. - -Do you wish to build TensorFlow with GDR support? [y/N]: -No GDR support will be enabled for TensorFlow. - -Do you wish to build TensorFlow with VERBS support? [y/N]: -No VERBS support will be enabled for TensorFlow. - -Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: -No OpenCL SYCL support will be enabled for TensorFlow. - -Do you wish to build TensorFlow with CUDA support? [y/N]: <b>Y</b> -CUDA support will be enabled for TensorFlow. - -Please specify the CUDA SDK version you want to use. [Leave empty to default to CUDA 9.0]: <b>9.0</b> - - -Please specify the location where CUDA 9.0 toolkit is installed. Refer to README.md for more details. [Default is /usr/local/cuda]: - - -Please specify the cuDNN version you want to use. [Leave empty to default to cuDNN 7.0]: <b>7.0</b> - - -Please specify the location where cuDNN 7 library is installed. Refer to README.md for more details. [Default is /usr/local/cuda]: - - -Do you wish to build TensorFlow with TensorRT support? [y/N]: -No TensorRT support will be enabled for TensorFlow. - -Please specify the NCCL version you want to use. If NCLL 2.2 is not installed, then you can use version 1.3 that can be fetched automatically but it may have worse performance with multiple GPUs. [Default is 2.2]: 1.3 - - -Please specify a list of comma-separated Cuda compute capabilities you want to build with. -You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus. -Please note that each additional compute capability significantly increases your -build time and binary size. [Default is: 3.5,7.0] <b>6.1</b> - - -Do you want to use clang as CUDA compiler? [y/N]: -nvcc will be used as CUDA compiler. - -Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]: - - -Do you wish to build TensorFlow with MPI support? [y/N]: -No MPI support will be enabled for TensorFlow. - -Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]: - - -Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: -Not configuring the WORKSPACE for Android builds. - -Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See tools/bazel.rc for more details. - --config=mkl # Build with MKL support. - --config=monolithic # Config for mostly static monolithic build. -Configuration finished -</pre> - -If you told `configure` to build for GPU support, then `configure` will create a -canonical set of symbolic links to the CUDA libraries on your system. Therefore, -every time you change the CUDA library paths, you must rerun the `configure` -script before re-invoking the <code>bazel build</code> command. - -Note the following: - -* Although it is possible to build both CUDA and non-CUDA configs under the - same source tree, we recommend running `bazel clean` when switching between - these two configurations in the same source tree. -* If you don't run the `configure` script *before* running the `bazel build` - command, the `bazel build` command will fail. - -## Build the pip package - -Note: If you're only interested in building the libraries for the TensorFlow C -or Java APIs, see [Build the C or Java libraries](#BuildCorJava), you do not -need to build the pip package in that case. - -### CPU-only support - -To build a pip package for TensorFlow with CPU-only support: - -<pre> -$ bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package -</pre> - -To build a pip package for TensorFlow with CPU-only support for the Intel® -MKL-DNN: - -<pre> -$ bazel build --config=mkl --config=opt //tensorflow/tools/pip_package:build_pip_package -</pre> - -### GPU support - -To build a pip package for TensorFlow with GPU support: - -<pre> -$ bazel build --config=opt --config=cuda //tensorflow/tools/pip_package:build_pip_package -</pre> - -**NOTE on gcc 5 or later:** the binary pip packages available on the TensorFlow -website are built with gcc 4, which uses the older ABI. To make your build -compatible with the older ABI, you need to add -`--cxxopt="-D_GLIBCXX_USE_CXX11_ABI=0"` to your `bazel build` command. ABI -compatibility allows custom ops built against the TensorFlow pip package to -continue to work against your built package. - -<b>Tip:</b> By default, building TensorFlow from sources consumes a lot of RAM. -If RAM is an issue on your system, you may limit RAM usage by specifying -<code>--local_resources 2048,.5,1.0</code> while invoking `bazel`. - -The <code>bazel build</code> command builds a script named `build_pip_package`. -Running this script as follows will build a `.whl` file within the -`/tmp/tensorflow_pkg` directory: - -<pre> -$ <b>bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg</b> -</pre> - -## Install the pip package - -Invoke `pip install` to install that pip package. The filename of the `.whl` -file depends on your platform. For example, the following command will install -the pip package - -for TensorFlow 1.10.0 on Linux: - -<pre> -$ <b>sudo pip install /tmp/tensorflow_pkg/tensorflow-1.10.0-py2-none-any.whl</b> -</pre> - -## Validate your installation - -Validate your TensorFlow installation by doing the following: - -Start a terminal. - -Change directory (`cd`) to any directory on your system other than the -`tensorflow` subdirectory from which you invoked the `configure` command. - -Invoke python: - -<pre>$ <b>python</b></pre> - -Enter the following short program inside the python interactive shell: - -```python -# Python -import tensorflow as tf -hello = tf.constant('Hello, TensorFlow!') -sess = tf.Session() -print(sess.run(hello)) -``` - -If the system outputs the following, then you are ready to begin writing -TensorFlow programs: - -<pre>Hello, TensorFlow!</pre> - -To learn more, see the [TensorFlow tutorials](../tutorials/). - -If the system outputs an error message instead of a greeting, see -[Common installation problems](#common_installation_problems). - -## Common build and installation problems - -The build and installation problems you encounter typically depend on the -operating system. See the "Common installation problems" section of one of the -following guides: - -* @ - {$install_linux#common_installation_problems$Installing TensorFlow on Linux} -* @ - {$install_mac#common_installation_problems$Installing TensorFlow on Mac OS} -* @ - {$install_windows#common_installation_problems$Installing TensorFlow on Windows} - -Beyond the errors documented in those two guides, the following table notes -additional errors specific to building TensorFlow. Note that we are relying on -Stack Overflow as the repository for build and installation problems. If you -encounter an error message not listed in the preceding two guides or in the -following table, search for it on Stack Overflow. If Stack Overflow doesn't show -the error message, ask a new question on Stack Overflow and specify the -`tensorflow` tag. - -<table> -<tr> <th>Stack Overflow Link</th> <th>Error Message</th> </tr> - -<tr> - <td><a - href="https://stackoverflow.com/questions/41293077/how-to-compile-tensorflow-with-sse4-2-and-avx-instructions">41293077</a></td> - <td><pre>W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow - library wasn't compiled to use SSE4.1 instructions, but these are available on - your machine and could speed up CPU computations.</pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/42013316">42013316</a></td> - <td><pre>ImportError: libcudart.so.8.0: cannot open shared object file: - No such file or directory</pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/42013316">42013316</a></td> - <td><pre>ImportError: libcudnn.5: cannot open shared object file: - No such file or directory</pre></td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/35953210">35953210</a></td> - <td>Invoking `python` or `ipython` generates the following error: - <pre>ImportError: cannot import name pywrap_tensorflow</pre></td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/questions/45276830">45276830</a></td> - <td><pre>external/local_config_cc/BUILD:50:5: in apple_cc_toolchain rule - @local_config_cc//:cc-compiler-darwin_x86_64: Xcode version must be specified - to use an Apple CROSSTOOL.</pre> - </td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/47080760">47080760</a></td> - <td><pre>undefined reference to `cublasGemmEx@libcublas.so.9.0'</pre></td> -</tr> - -</table> - -## Tested source configurations - -**Linux** -<table> -<tr><th>Version:</th><th>CPU/GPU:</th><th>Python Version:</th><th>Compiler:</th><th>Build Tools:</th><th>cuDNN:</th><th>CUDA:</th></tr> -<tr><td>tensorflow-1.10.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.15.0</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.10.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.15.0</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.9.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.11.0</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.9.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.11.0</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.8.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.10.0</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.8.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.9.0</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.7.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.10.0</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.7.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.9.0</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.6.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.9.0</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.6.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.9.0</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.5.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.8.0</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.5.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.8.0</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.4.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.5.4</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.4.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.5.4</td><td>6</td><td>8</td></tr> -<tr><td>tensorflow-1.3.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.4.5</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.3.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.4.5</td><td>6</td><td>8</td></tr> -<tr><td>tensorflow-1.2.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.4.5</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.2.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.4.5</td><td>5.1</td><td>8</td></tr> -<tr><td>tensorflow-1.1.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.4.2</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.1.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.4.2</td><td>5.1</td><td>8</td></tr> -<tr><td>tensorflow-1.0.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.4.2</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.0.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>GCC 4.8</td><td>Bazel 0.4.2</td><td>5.1</td><td>8</td></tr> -</table> - -**Mac** -<table> -<tr><th>Version:</th><th>CPU/GPU:</th><th>Python Version:</th><th>Compiler:</th><th>Build Tools:</th><th>cuDNN:</th><th>CUDA:</th></tr> -<tr><td>tensorflow-1.10.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.15.0</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow-1.9.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.11.0</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow-1.8.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.10.1</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow-1.7.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.10.1</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow-1.6.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.8.1</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow-1.5.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.8.1</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow-1.4.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.5.4</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow-1.3.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.4.5</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow-1.2.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.4.5</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow-1.1.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.4.2</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.1.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.4.2</td><td>5.1</td><td>8</td></tr> -<tr><td>tensorflow-1.0.0</td><td>CPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.4.2</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.0.0</td><td>GPU</td><td>2.7, 3.3-3.6</td><td>Clang from xcode</td><td>Bazel 0.4.2</td><td>5.1</td><td>8</td></tr> -</table> - -**Windows** -<table> -<tr><th>Version:</th><th>CPU/GPU:</th><th>Python Version:</th><th>Compiler:</th><th>Build Tools:</th><th>cuDNN:</th><th>CUDA:</th></tr> -<tr><td>tensorflow-1.10.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.10.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.9.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.9.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.8.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.8.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.7.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.7.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.6.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.6.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.5.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.5.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>7</td><td>9</td></tr> -<tr><td>tensorflow-1.4.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.4.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>6</td><td>8</td></tr> -<tr><td>tensorflow-1.3.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.3.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>6</td><td>8</td></tr> -<tr><td>tensorflow-1.2.0</td><td>CPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.2.0</td><td>GPU</td><td>3.5-3.6</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>5.1</td><td>8</td></tr> -<tr><td>tensorflow-1.1.0</td><td>CPU</td><td>3.5</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.1.0</td><td>GPU</td><td>3.5</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>5.1</td><td>8</td></tr> -<tr><td>tensorflow-1.0.0</td><td>CPU</td><td>3.5</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>N/A</td><td>N/A</td></tr> -<tr><td>tensorflow_gpu-1.0.0</td><td>GPU</td><td>3.5</td><td>MSVC 2015 update 3</td><td>Cmake v3.6.3</td><td>5.1</td><td>8</td></tr> -</table> - -<a name="BuildCorJava"></a> - -## Build the C or Java libraries - -The instructions above are tailored to building the TensorFlow Python packages. - -If you're interested in building the libraries for the TensorFlow C API, do the -following: - -1. Follow the steps up to [Configure the installation](#ConfigureInstallation) -2. Build the C libraries following instructions in the - [README](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/lib_package/README.md). - -If you're interested inv building the libraries for the TensorFlow Java API, do -the following: - -1. Follow the steps up to [Configure the installation](#ConfigureInstallation) -2. Build the Java library following instructions in the - [README](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/lib_package/README.md). diff --git a/tensorflow/docs_src/install/install_sources_windows.md b/tensorflow/docs_src/install/install_sources_windows.md deleted file mode 100644 index a1da122317..0000000000 --- a/tensorflow/docs_src/install/install_sources_windows.md +++ /dev/null @@ -1,320 +0,0 @@ -# Install TensorFlow from Sources on Windows - -This guide explains how to build TensorFlow sources into a TensorFlow binary and -how to install that TensorFlow binary on Windows. - -## Determine which TensorFlow to install - -You must choose one of the following types of TensorFlow to build and install: - -* **TensorFlow with CPU support only**. If your system does not have a NVIDIA® - GPU, build and install this version. Note that this version of TensorFlow is - typically easier to build and install, so even if you have an NVIDIA GPU, we - recommend building and installing this version first. -* **TensorFlow with GPU support**. TensorFlow programs typically run - significantly faster on a GPU than on a CPU. Therefore, if your system has a - NVIDIA GPU and you need to run performance-critical applications, you should - ultimately build and install this version. Beyond the NVIDIA GPU itself, - your system must also fulfill the NVIDIA software requirements described in - the following document: - - * [Installing TensorFlow on Windows](install_windows.md#NVIDIARequirements) - -## Prepare environment for Windows - -Before building TensorFlow on Windows, install the following build tools on your -system: - -* [MSYS2](#InstallMSYS2) -* [Visual C++ build tools](#InstallVCBuildTools) -* [Bazel for Windows](#InstallBazel) -* [TensorFlow Python dependencies](#InstallPython) -* [optionally, NVIDIA packages to support TensorFlow for GPU](#InstallCUDA) - -<a name="InstallMSYS2"></a> - -### Install MSYS2 - -Bash bin tools are used in TensorFlow Bazel build, you can install them through [MSYS2](https://www.msys2.org/). - -Assume you installed MSYS2 at `C:\msys64`, add `C:\msys64\usr\bin` to your `%PATH%` environment variable. - -To install necessary bash bin tools, issue the following command under `cmd.exe`: - -<pre> -C:\> <b>pacman -S git patch unzip</b> -</pre> - -<a name="InstallVCBuildTools"></a> - -### Install Visual C++ Build Tools 2015 - -To build TensorFlow, you need to install Visual C++ build tools 2015. It is a part of Visual Studio 2015. -But you can install it separately by the following way: - - * Open the [official downloand page](https://visualstudio.microsoft.com/vs/older-downloads/). - * Go to <b>Redistributables and Build Tools</b> section. - * Find <b>Microsoft Build Tools 2015 Update 3</b> and click download. - * Run the installer. - -It's possible to build TensorFlow with newer version of Visual C++ build tools, -but we only test against Visual Studio 2015 Update 3. - -<a name="InstallBazel"></a> - -### Install Bazel - -If bazel is not installed on your system, install it now by following -[these instructions](https://docs.bazel.build/versions/master/install-windows.html). -It is recommended to use a Bazel version >= `0.15.0`. - -Add the directory where you installed Bazel to your `%PATH%` environment variable. - -<a name="InstallPython"></a> - -### Install TensorFlow Python dependencies - -If you don't have Python 3.5 or Python 3.6 installed, install it now: - - * [Python 3.5.x 64-bit from python.org](https://www.python.org/downloads/release/python-352/) - * [Python 3.6.x 64-bit from python.org](https://www.python.org/downloads/release/python-362/) - -To build and install TensorFlow, you must install the following python packages: - -* `six`, which provides simple utilities for wrapping over differences between - Python 2 and Python 3. -* `numpy`, which is a numerical processing package that TensorFlow requires. -* `wheel`, which enables you to manage Python compressed packages in the wheel - (.whl) format. -* `keras_applications`, the applications module of the Keras deep learning library. -* `keras_preprocessing`, the data preprocessing and data augmentation module - of the Keras deep learning library. - -Assume you already have `pip3` in `%PATH%`, issue the following command: - -<pre> -C:\> <b>pip3 install six numpy wheel</b> -C:\> <b>pip3 install keras_applications==1.0.4 --no-deps</b> -C:\> <b>pip3 install keras_preprocessing==1.0.2 --no-deps</b> -</pre> - -<a name="InstallCUDA"></a> - -### Optional: install TensorFlow for GPU prerequisites - -If you are building TensorFlow without GPU support, skip this section. - -The following NVIDIA® _hardware_ must be installed on your system: - -* GPU card with CUDA Compute Capability 3.5 or higher. See - [NVIDIA documentation](https://developer.nvidia.com/cuda-gpus) for a list of - supported GPU cards. - -The following NVIDIA® _software_ must be installed on your system: - -* [GPU drivers](http://nvidia.com/driver). CUDA 9.0 requires 384.x or higher. -* [CUDA Toolkit](http://nvidia.com/cuda) (>= 8.0). We recommend version 9.0. -* [cuDNN SDK](http://developer.nvidia.com/cudnn) (>= 6.0). We recommend - version 7.1.x. -* [CUPTI](http://docs.nvidia.com/cuda/cupti/) ships with the CUDA Toolkit, but - you also need to append its path to `%PATH%` environment - variable. - -Assume you have CUDA Toolkit installed at `C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0` -and cuDNN at `C:\tools\cuda`, issue the following commands. - -<pre> -C:\> SET PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\bin;%PATH% -C:\> SET PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\extras\CUPTI\libx64;%PATH% -C:\> SET PATH=C:\tools\cuda\bin;%PATH% -</pre> - -## Clone the TensorFlow repository - -Now you need to clone **the latest** TensorFlow repository, -thanks to MSYS2 we already have `git` avaiable, issue the following command: - -<pre>C:\> <b>git clone https://github.com/tensorflow/tensorflow.git</b> </pre> - -The preceding <code>git clone</code> command creates a subdirectory named -`tensorflow`. After cloning, you may optionally build a **specific branch** -(such as a release branch) by invoking the following commands: - -<pre> -C:\> <b>cd tensorflow</b> -C:\> <b>git checkout</b> <i>Branch</i> # where <i>Branch</i> is the desired branch -</pre> - -For example, to work with the `r1.11` release instead of the master release, -issue the following command: - -<pre>C:\> <b>git checkout r1.11</b></pre> - -Next, you must now configure the installation. - -## Configure the installation - -The root of the source tree contains a python script named <code>configure.py</code>. -This script asks you to identify the pathname of all relevant TensorFlow -dependencies and specify other build configuration options such as compiler -flags. You must run this script *prior* to creating the pip package and -installing TensorFlow. - -If you wish to build TensorFlow with GPU, `configure.py` will ask you to specify -the version numbers of CUDA and cuDNN. If several versions of CUDA or cuDNN are -installed on your system, explicitly select the desired version instead of -relying on the default. - -One of the questions that `configure.py` will ask is as follows: - -<pre> -Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is /arch:AVX]: -</pre> - -Here is an example execution of the `configure.py` script. Note that your own input -will likely differ from our sample input: - -<pre> -C:\> <b>cd tensorflow</b> # cd to the top-level directory created -C:\tensorflow> <b>python ./configure.py</b> -Starting local Bazel server and connecting to it... -................ -You have bazel 0.15.0 installed. -Please specify the location of python. [Default is C:\python36\python.exe]: - -Found possible Python library paths: - C:\python36\lib\site-packages -Please input the desired Python library path to use. Default is [C:\python36\lib\site-packages] - -Do you wish to build TensorFlow with CUDA support? [y/N]: <b>Y</b> -CUDA support will be enabled for TensorFlow. - -Please specify the CUDA SDK version you want to use. [Leave empty to default to CUDA 9.0]: - -Please specify the location where CUDA 9.0 toolkit is installed. Refer to README.md for more details. [Default is C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v9.0]: - -Please specify the cuDNN version you want to use. [Leave empty to default to cuDNN 7.0]: <b>7.0</b> - -Please specify the location where cuDNN 7 library is installed. Refer to README.md for more details. [Default is C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v9.0]: <b>C:\tools\cuda</b> - -Please specify a list of comma-separated Cuda compute capabilities you want to build with. -You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus. -Please note that each additional compute capability significantly increases your build time and binary size. [Default is: 3.5,7.0]: <b>3.7</b> - -Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is /arch:AVX]: - -Would you like to override eigen strong inline for some C++ compilation to reduce the compilation time? [Y/n]: -Eigen strong inline overridden. - -Configuration finished -</pre> - -## Build the pip package - -### CPU-only support - -To build a pip package for TensorFlow with CPU-only support: - -<pre> -C:\tensorflow> <b>bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package</b> -</pre> - -### GPU support - -To build a pip package for TensorFlow with GPU support: - -<pre> -C:\tensorflow> <b>bazel build --config=opt --config=cuda //tensorflow/tools/pip_package:build_pip_package</b> -</pre> - -**NOTE :** When building with GPU support, you might want to add `--copt=-nvcc_options=disable-warnings` -to suppress nvcc warning messages. - -The `bazel build` command builds a binary named `build_pip_package` -(an executable binary to launch bash and run a bash script to create the pip package). -Running this binary as follows will build a `.whl` file within the `C:/tmp/tensorflow_pkg` directory: - -<pre> -C:\tensorflow> <b>bazel-bin\tensorflow\tools\pip_package\build_pip_package C:/tmp/tensorflow_pkg</b> -</pre> - -## Install the pip package - -Invoke `pip3 install` to install that pip package. The filename of the `.whl` -file depends on the TensorFlow version and your platform. For example, the -following command will install the pip package for TensorFlow 1.11.0rc0: - -<pre> -C:\tensorflow> <b>pip3 install C:/tmp/tensorflow_pkg/tensorflow-1.11.0rc0-cp36-cp36m-win_amd64.whl</b> -</pre> - -## Validate your installation - -Validate your TensorFlow installation by doing the following: - -Start a terminal. - -Change directory (`cd`) to any directory on your system other than the -`tensorflow` subdirectory from which you invoked the `configure` command. - -Invoke python: - -<pre>$ <b>python</b></pre> - -Enter the following short program inside the python interactive shell: - -```python -# Python -import tensorflow as tf -hello = tf.constant('Hello, TensorFlow!') -sess = tf.Session() -print(sess.run(hello)) -``` - -If the system outputs the following, then you are ready to begin writing -TensorFlow programs: - -<pre>Hello, TensorFlow!</pre> - -To learn more, see the [TensorFlow tutorials](../tutorials/). - -## Build under MSYS shell -The above instruction assumes you are building under the Windows native command line (`cmd.exe`), but you can also -build TensorFlow from MSYS shell. There are a few things to notice: - -* Disable the path conversion heuristic in MSYS. MSYS automatically converts arguments that look - like a Unix path to Windows path when running a program, this will confuse Bazel. - (eg. A Bazel label `//foo/bar:bin` is considered a Unix absolute path, only because it starts with a slash) - - ```sh -$ export MSYS_NO_PATHCONV=1 -$ export MSYS2_ARG_CONV_EXCL="*" -``` - -* Add the directory where you install Bazel in `$PATH`. Assume you have Bazel - installed at `C:\tools\bazel.exe`, issue the following command: - - ```sh -# `:` is used as path separator, so we have to convert the path to Unix style. -$ export PATH="/c/tools:$PATH" -``` - -* Add the directory where you install Python in `$PATH`. Assume you have - Python installed at `C:\Python36\python.exe`, issue the following command: - - ```sh -$ export PATH="/c/Python36:$PATH" -``` - -* If you have Python in `$PATH`, you can run configure script just by - `./configure`, a shell script will help you invoke python. - -* (For GPU build only) Add Cuda and cuDNN bin directories in `$PATH` in the following way: - - ```sh -$ export PATH="/c/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v9.0/bin:$PATH" -$ export PATH="/c/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v9.0/extras/CUPTI/libx64:$PATH" -$ export PATH="/c/tools/cuda/bin:$PATH" -``` - -The rest steps should be the same as building under `cmd.exe`. diff --git a/tensorflow/docs_src/install/install_windows.md b/tensorflow/docs_src/install/install_windows.md deleted file mode 100644 index 0bb0e5aeb9..0000000000 --- a/tensorflow/docs_src/install/install_windows.md +++ /dev/null @@ -1,227 +0,0 @@ -# Install TensorFlow on Windows - -This guide explains how to install TensorFlow on Windows. Although these -instructions might also work on other Windows variants, we have only -tested (and we only support) these instructions on machines meeting the -following requirements: - - * 64-bit, x86 desktops or laptops - * Windows 7 or later - - -## Determine which TensorFlow to install - -You must choose one of the following types of TensorFlow to install: - - * **TensorFlow with CPU support only**. If your system does not have a - NVIDIA® GPU, you must install this version. Note that this version of - TensorFlow is typically much easier to install (typically, - in 5 or 10 minutes), so even if you have an NVIDIA GPU, we recommend - installing this version first. Prebuilt binaries will use AVX instructions. - * **TensorFlow with GPU support**. TensorFlow programs typically run - significantly faster on a GPU than on a CPU. Therefore, if your - system has a NVIDIA® GPU meeting the prerequisites shown below - and you need to run performance-critical applications, you should - ultimately install this version. - -<a name="NVIDIARequirements"></a> - -### Requirements to run TensorFlow with GPU support - -If you are installing TensorFlow with GPU support using one of the mechanisms -described in this guide, then the following NVIDIA software must be -installed on your system: - - * CUDA® Toolkit 9.0. For details, see - [NVIDIA's - documentation](http://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/) - Ensure that you append the relevant Cuda pathnames to the `%PATH%` - environment variable as described in the NVIDIA documentation. - * The NVIDIA drivers associated with CUDA Toolkit 9.0. - * cuDNN v7.0. For details, see - [NVIDIA's documentation](https://developer.nvidia.com/cudnn). - Note that cuDNN is typically installed in a different location from the - other CUDA DLLs. Ensure that you add the directory where you installed - the cuDNN DLL to your `%PATH%` environment variable. - * GPU card with CUDA Compute Capability 3.0 or higher for building - from source and 3.5 or higher for our binaries. See - [NVIDIA documentation](https://developer.nvidia.com/cuda-gpus) for a - list of supported GPU cards. - -If you have a different version of one of the preceding packages, please -change to the specified versions. In particular, the cuDNN version -must match exactly: TensorFlow will not load if it cannot find `cuDNN64_7.dll`. -To use a different version of cuDNN, you must build from source. - -## Determine how to install TensorFlow - -You must pick the mechanism by which you install TensorFlow. The -supported choices are as follows: - - * "native" pip - * Anaconda - -Native pip installs TensorFlow directly on your system without going -through a virtual environment. Since a native pip installation is not -walled-off in a separate container, the pip installation might interfere -with other Python-based installations on your system. However, if you -understand pip and your Python environment, a native pip installation -often entails only a single command! Furthermore, if you install with -native pip, users can run TensorFlow programs from any directory on -the system. - -In Anaconda, you may use conda to create a virtual environment. -However, within Anaconda, we recommend installing TensorFlow with the -`pip install` command, not with the `conda install` command. - -**NOTE:** The conda package is community supported, not officially supported. -That is, the TensorFlow team neither tests nor maintains this conda package. -Use that package at your own risk. - - -## Installing with native pip - -If one of the following versions of Python is not installed on your machine, -install it now: - - * [Python 3.5.x 64-bit from python.org](https://www.python.org/downloads/release/python-352/) - * [Python 3.6.x 64-bit from python.org](https://www.python.org/downloads/release/python-362/) - -TensorFlow supports Python 3.5.x and 3.6.x on Windows. -Note that Python 3 comes with the pip3 package manager, which is the -program you'll use to install TensorFlow. - -To install TensorFlow, start a terminal. Then issue the appropriate -<tt>pip3 install</tt> command in that terminal. To install the CPU-only -version of TensorFlow, enter the following command: - -<pre>C:\> <b>pip3 install --upgrade tensorflow</b></pre> - -To install the GPU version of TensorFlow, enter the following command: - -<pre>C:\> <b>pip3 install --upgrade tensorflow-gpu</b></pre> - -## Installing with Anaconda - -**The Anaconda installation is community supported, not officially supported.** - -Take the following steps to install TensorFlow in an Anaconda environment: - - 1. Follow the instructions on the - [Anaconda download site](https://www.continuum.io/downloads) - to download and install Anaconda. - - 2. Create a conda environment named <tt>tensorflow</tt> - by invoking the following command: - - <pre>C:\> <b>conda create -n tensorflow pip python=3.5</b> </pre> - - 3. Activate the conda environment by issuing the following command: - - <pre>C:\> <b>activate tensorflow</b> - (tensorflow)C:\> # Your prompt should change </pre> - - 4. Issue the appropriate command to install TensorFlow inside your conda - environment. To install the CPU-only version of TensorFlow, enter the - following command: - - <pre>(tensorflow)C:\> <b>pip install --ignore-installed --upgrade tensorflow</b> </pre> - - To install the GPU version of TensorFlow, enter the following command - (on a single line): - - <pre>(tensorflow)C:\> <b>pip install --ignore-installed --upgrade tensorflow-gpu</b> </pre> - -## Validate your installation - -Start a terminal. - -If you installed through Anaconda, activate your Anaconda environment. - -Invoke python from your shell as follows: - -<pre>$ <b>python</b></pre> - -Enter the following short program inside the python interactive shell: - -```python ->>> import tensorflow as tf ->>> hello = tf.constant('Hello, TensorFlow!') ->>> sess = tf.Session() ->>> print(sess.run(hello)) -``` - -If the system outputs the following, then you are ready to begin writing -TensorFlow programs: - -<pre>Hello, TensorFlow!</pre> - -If the system outputs an error message instead of a greeting, see [Common -installation problems](#common_installation_problems). - -To learn more, see the [TensorFlow tutorials](../tutorials/). - -## Common installation problems - -We are relying on Stack Overflow to document TensorFlow installation problems -and their remedies. The following table contains links to Stack Overflow -answers for some common installation problems. -If you encounter an error message or other -installation problem not listed in the following table, search for it -on Stack Overflow. If Stack Overflow doesn't show the error message, -ask a new question about it on Stack Overflow and specify -the `tensorflow` tag. - -<table> -<tr> <th>Stack Overflow Link</th> <th>Error Message</th> </tr> - -<tr> - <td><a href="https://stackoverflow.com/q/41007279">41007279</a></td> - <td> - <pre>[...\stream_executor\dso_loader.cc] Couldn't open CUDA library nvcuda.dll</pre> - </td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/41007279">41007279</a></td> - <td> - <pre>[...\stream_executor\cuda\cuda_dnn.cc] Unable to load cuDNN DSO</pre> - </td> -</tr> - -<tr> - <td><a href="http://stackoverflow.com/q/42006320">42006320</a></td> - <td><pre>ImportError: Traceback (most recent call last): -File "...\tensorflow\core\framework\graph_pb2.py", line 6, in <module> -from google.protobuf import descriptor as _descriptor -ImportError: cannot import name 'descriptor'</pre> - </td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/42011070">42011070</a></td> - <td><pre>No module named "pywrap_tensorflow"</pre></td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/42217532">42217532</a></td> - <td> - <pre>OpKernel ('op: "BestSplits" device_type: "CPU"') for unknown op: BestSplits</pre> - </td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/43134753">43134753</a></td> - <td> - <pre>The TensorFlow library wasn't compiled to use SSE instructions</pre> - </td> -</tr> - -<tr> - <td><a href="https://stackoverflow.com/q/38896424">38896424</a></td> - <td> - <pre>Could not find a version that satisfies the requirement tensorflow</pre> - </td> -</tr> - -</table> diff --git a/tensorflow/docs_src/install/leftnav_files b/tensorflow/docs_src/install/leftnav_files deleted file mode 100644 index 59292f7121..0000000000 --- a/tensorflow/docs_src/install/leftnav_files +++ /dev/null @@ -1,18 +0,0 @@ -index.md - -### Python -install_linux.md: Ubuntu -install_mac.md: MacOS -install_windows.md: Windows -install_raspbian.md: Raspbian -install_sources.md: From source -install_sources_windows.md: From source on Windows ->>> -migration.md - -### Other Languages -install_java.md: Java -install_go.md: Go -install_c.md: C - - diff --git a/tensorflow/docs_src/install/migration.md b/tensorflow/docs_src/install/migration.md deleted file mode 100644 index 19315ace2d..0000000000 --- a/tensorflow/docs_src/install/migration.md +++ /dev/null @@ -1,336 +0,0 @@ -# Transition to TensorFlow 1.0 - - -The APIs in TensorFlow 1.0 have changed in ways that are not all backwards -compatible. That is, TensorFlow programs that worked on TensorFlow 0.n won't -necessarily work on TensorFlow 1.0. We have made this API changes to ensure an -internally-consistent API, and do not plan to make backwards-breaking changes -throughout the 1.N lifecycle. - -This guide walks you through the major changes in the API and how to -automatically upgrade your programs for TensorFlow 1.0. This guide not -only steps you through the changes but also explains why we've made them. - -## How to upgrade - -If you would like to automatically port your code to 1.0, you can try our -`tf_upgrade.py` script. While this script handles many cases, manual changes -are sometimes necessary. - Get this script from our -[GitHub tree](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/compatibility). - -To convert a single 0.n TensorFlow source file to 1.0, enter a -command of the following format: - -<pre> -$ <b>python tf_upgrade.py --infile</b> <i>InputFile</i> <b>--outfile</b> <i>OutputFile</i> -</pre> - -For example, the following command converts a 0.n TensorFlow -program named `test.py` to a 1.0 TensorFlow program named `test_1.0.py`: - -<pre> -$ <b>python tf_upgrade.py --infile test.py --outfile test_1.0.py</b> -</pre> - -The `tf_upgrade.py` script also generates a file named `report.txt`, which -details all the changes it performed and makes additional suggestions about -changes you might need to make manually. - -To upgrade a whole directory of 0.n TensorFlow programs to 1.0, -enter a command having the following format: - -<pre> -$ <b>python tf_upgrade.py --intree</b> <i>InputDir</i> <b>--outtree</b> <i>OutputDir</i> -</pre> - -For example, the following command converts all the 0.n TensorFlow programs -in the `/home/user/cool` directory, creating their 1.0 equivalents in -the `/home/user/cool_1.0` directory: - -<pre> -$ <b>python tf_upgrade.py --intree /home/user/cool --outtree /home/user/cool_1.0</b> -</pre> - -### Limitations - -There are a few things to watch out for. Specifically: - - * You must manually fix any instances of `tf.reverse()`. - The `tf_upgrade.py` script will warn you about `tf.reverse()` in - stdout and in the `report.txt` file. - * On reordered arguments, `tf_upgrade.py` tries to minimally reformat - your code, so it cannot automatically change the actual argument order. - Instead, `tf_upgrade.py` makes your function invocations order-independent - by introducing keyword arguments. - * Constructions like `tf.get_variable_scope().reuse_variables()` - will likely not work. We recommend deleting those lines and replacing - them with lines such as the following: - - <pre class="prettyprint"> - with tf.variable_scope(tf.get_variable_scope(), reuse=True): - ... - </pre> - - * Analogously to `tf.pack` and `tf.unpack`, we're renamed - `TensorArray.pack` and `TensorArray.unpack` to - `TensorArray.stack` and `TensorArray.unstack`. However, `TensorArray.pack` - and `TensorArray.unpack` cannot be detected lexically since they are - indirectly related to the `tf` namespace e.g. - `foo = tf.TensorArray(); foo.unpack()` - -## Upgrading your code manually - -Instead of running `tf_upgrade.py`, you may manually upgrade your code. -The remainder of this document provides a comprehensive list of -all backward incompatible changes made in TensorFlow 1.0. - - -### Variables - -Variable functions have been made more consistent and less confusing. - -* `tf.VARIABLES` - * should be renamed to `tf.GLOBAL_VARIABLES` -* `tf.all_variables` - * should be renamed to `tf.global_variables` -* `tf.initialize_all_variables` - * should be renamed to `tf.global_variables_initializer` -* `tf.initialize_local_variables` - * should be renamed to `tf.local_variables_initializer` -* `tf.initialize_variables` - * should be renamed to `tf.variables_initializer` - -### Summary functions - -Summary functions have been consolidated under the `tf.summary` namespace. - -* `tf.audio_summary` - * should be renamed to `tf.summary.audio` -* `tf.contrib.deprecated.histogram_summary` - * should be renamed to `tf.summary.histogram` -* `tf.contrib.deprecated.scalar_summary` - * should be renamed to `tf.summary.scalar` -* `tf.histogram_summary` - * should be renamed to `tf.summary.histogram` -* `tf.image_summary` - * should be renamed to `tf.summary.image` -* `tf.merge_all_summaries` - * should be renamed to `tf.summary.merge_all` -* `tf.merge_summary` - * should be renamed to `tf.summary.merge` -* `tf.scalar_summary` - * should be renamed to `tf.summary.scalar` -* `tf.train.SummaryWriter` - * should be renamed to `tf.summary.FileWriter` - -### Numeric differences - - -Integer division and `tf.floordiv` now uses flooring semantics. This is to -make the results of `np.divide` and `np.mod` consistent with `tf.divide` and -`tf.mod`, respectively. In addition we have changed the rounding algorithm -used by `tf.round` to match NumPy. - - -* `tf.div` - - * The semantics of `tf.divide` division have been changed to match Python -semantics completely. That is, `/` in Python 3 and future division mode in -Python 2 will produce floating point numbers always, `//` will produce floored -division. However, even `tf.div` will produce floored integer division. -To force C-style truncation semantics, you must use `tf.truncatediv`. - - * Consider changing your code to use `tf.divide`, which follows Python semantics for promotion. - -* `tf.mod` - - * The semantics of `tf.mod` have been changed to match Python semantics. In -particular, flooring semantics are used for integers. If you wish to have -C-style truncation mod (remainders), you can use `tf.truncatemod` - - -The old and new behavior of division can be summarized with this table: - -| Expr | TF 0.11 (py2) | TF 0.11 (py3) | TF 1.0 (py2) | TF 1.0 (py3) | -|---------------------|---------------|---------------|--------------|--------------| -| tf.div(3,4) | 0 | 0 | 0 | 0 | -| tf.div(-3,4) | 0 | 0 | -1 | -1 | -| tf.mod(-3,4) | -3 | -3 | 1 | 1 | -| -3/4 | 0 | -0.75 | -1 | -0.75 | -| -3/4tf.divide(-3,4) | N/A | N/A | -0.75 | -1 | - -The old and new behavior of rounding can be summarized with this table: - -| Input | Python | NumPy | C++ round() | TensorFlow 0.11(floor(x+.5)) | TensorFlow 1.0 | -|-------|--------|-------|-------------|------------------------------|----------------| -| -3.5 | -4 | -4 | -4 | -3 | -4 | -| -2.5 | -2 | -2 | -3 | -2 | -2 | -| -1.5 | -2 | -2 | -2 | -1 | -2 | -| -0.5 | 0 | 0 | -1 | 0 | 0 | -| 0.5 | 0 | 0 | 1 | 1 | 0 | -| 1.5 | 2 | 2 | 2 | 2 | 2 | -| 2.5 | 2 | 2 | 3 | 3 | 2 | -| 3.5 | 4 | 4 | 4 | 4 | 4 | - - - -### NumPy matching names - - -Many functions have been renamed to match NumPy. This was done to make the -transition between NumPy and TensorFlow as easy as possible. There are still -numerous cases where functions do not match, so this is far from a hard and -fast rule, but we have removed several commonly noticed inconsistencies. - -* `tf.inv` - * should be renamed to `tf.reciprocal` - * This was done to avoid confusion with NumPy's matrix inverse `np.inv` -* `tf.list_diff` - * should be renamed to `tf.setdiff1d` -* `tf.listdiff` - * should be renamed to `tf.setdiff1d` -* `tf.mul` - * should be renamed to `tf.multiply` -* `tf.neg` - * should be renamed to `tf.negative` -* `tf.select` - * should be renamed to `tf.where` - * `tf.where` now takes 3 arguments or 1 argument, just like `np.where` -* `tf.sub` - * should be renamed to `tf.subtract` - -### NumPy matching arguments - -Arguments for certain TensorFlow 1.0 methods now match arguments in certain -NumPy methods. To achieve this, TensorFlow 1.0 has changed keyword arguments -and reordered some arguments. Notably, TensorFlow 1.0 now uses `axis` rather -than `dimension`. TensorFlow 1.0 aims to keep the tensor argument first on -operations that modify Tensors. (see the `tf.concat` change). - - -* `tf.argmax` - * keyword argument `dimension` should be renamed to `axis` -* `tf.argmin` - * keyword argument `dimension` should be renamed to `axis` -* `tf.concat` - * keyword argument `concat_dim` should be renamed to `axis` - * arguments have been reordered to `tf.concat(values, axis, name='concat')`. -* `tf.count_nonzero` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.expand_dims` - * keyword argument `dim` should be renamed to `axis` -* `tf.reduce_all` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.reduce_any` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.reduce_join` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.reduce_logsumexp` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.reduce_max` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.reduce_mean` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.reduce_min` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.reduce_prod` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.reduce_sum` - * keyword argument `reduction_indices` should be renamed to `axis` -* `tf.reverse` - * `tf.reverse` used to take a 1D `bool` tensor to control which dimensions were reversed. Now we use a Tensor of axis indices. - * For example `tf.reverse(a, [True, False, True])` now must be `tf.reverse(a, [0, 2])` -* `tf.reverse_sequence` - * keyword argument `batch_dim` should be renamed to `batch_axis` - * keyword argument `seq_dim` should be renamed to `seq_axis` -* `tf.sparse_concat` - * keyword argument `concat_dim` should be renamed to `axis` -* `tf.sparse_reduce_sum` - * keyword argument `reduction_axes` should be renamed to `axis` -* `tf.sparse_reduce_sum_sparse` - * keyword argument `reduction_axes` should be renamed to `axis` -* `tf.sparse_split` - * keyword argument `split_dim` should be renamed to `axis` - * arguments have been reordered to `tf.sparse_split(keyword_required=KeywordRequired(), sp_input=None, num_split=None, axis=None, name=None, split_dim=None)`. -* `tf.split` - * keyword argument `split_dim` should be renamed to `axis` - * keyword argument `num_split` should be renamed to `num_or_size_splits` - * arguments have been reordered to `tf.split(value, num_or_size_splits, axis=0, num=None, name='split')`. -* `tf.squeeze` - * keyword argument `squeeze_dims` should be renamed to `axis` -* `tf.svd` - * arguments have been reordered to `tf.svd(tensor, full_matrices=False, compute_uv=True, name=None)`. - -### Simplified math variants - -Batched versions of math operations have been removed. Now the functionality is -contained in the non-batched versions. Similarly,`tf.complex_abs` has had its -functionality moved to `tf.abs` - -* `tf.batch_band_part` - * should be renamed to `tf.band_part` -* `tf.batch_cholesky` - * should be renamed to `tf.cholesky` -* `tf.batch_cholesky_solve` - * should be renamed to `tf.cholesky_solve` -* `tf.batch_fft` - * should be renamed to `tf.fft` -* `tf.batch_fft3d` - * should be renamed to `tf.fft3d` -* `tf.batch_ifft` - * should be renamed to `tf.ifft` -* `tf.batch_ifft2d` - * should be renamed to `tf.ifft2d` -* `tf.batch_ifft3d` - * should be renamed to `tf.ifft3d` -* `tf.batch_matmul` - * should be renamed to `tf.matmul` -* `tf.batch_matrix_determinant` - * should be renamed to `tf.matrix_determinant` -* `tf.batch_matrix_diag` - * should be renamed to `tf.matrix_diag` -* `tf.batch_matrix_inverse` - * should be renamed to `tf.matrix_inverse` -* `tf.batch_matrix_solve` - * should be renamed to `tf.matrix_solve` -* `tf.batch_matrix_solve_ls` - * should be renamed to `tf.matrix_solve_ls` -* `tf.batch_matrix_transpose` - * should be renamed to `tf.matrix_transpose` -* `tf.batch_matrix_triangular_solve` - * should be renamed to `tf.matrix_triangular_solve` -* `tf.batch_self_adjoint_eig` - * should be renamed to `tf.self_adjoint_eig` -* `tf.batch_self_adjoint_eigvals` - * should be renamed to `tf.self_adjoint_eigvals` -* `tf.batch_set_diag` - * should be renamed to `tf.set_diag` -* `tf.batch_svd` - * should be renamed to `tf.svd` -* `tf.complex_abs` - * should be renamed to `tf.abs` - -### Misc Changes - -Several other changes have been made, including the following: - -* `tf.image.per_image_whitening` - * should be renamed to `tf.image.per_image_standardization` -* `tf.nn.sigmoid_cross_entropy_with_logits` - * arguments have been reordered to `tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)`. -* `tf.nn.softmax_cross_entropy_with_logits` - * arguments have been reordered to `tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)`. -* `tf.nn.sparse_softmax_cross_entropy_with_logits` - * arguments have been reordered to `tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)`. -* `tf.ones_initializer` - * should be changed to a function call i.e. `tf.ones_initializer()` -* `tf.pack` - * should be renamed to `tf.stack` -* `tf.round` - * The semantics of `tf.round` now match Banker's rounding. -* `tf.unpack` - * should be renamed to `tf.unstack` -* `tf.zeros_initializer` - * should be changed to a function call i.e. `tf.zeros_initializer()` - diff --git a/tensorflow/docs_src/mobile/README.md b/tensorflow/docs_src/mobile/README.md deleted file mode 100644 index ecf4267265..0000000000 --- a/tensorflow/docs_src/mobile/README.md +++ /dev/null @@ -1,3 +0,0 @@ -# TF Lite subsite - -This subsite directory lives in [tensorflow/contrib/lite/g3doc](../../contrib/lite/g3doc/). diff --git a/tensorflow/docs_src/performance/benchmarks.md b/tensorflow/docs_src/performance/benchmarks.md deleted file mode 100644 index a5fa551dd4..0000000000 --- a/tensorflow/docs_src/performance/benchmarks.md +++ /dev/null @@ -1,412 +0,0 @@ -# Benchmarks - -## Overview - -A selection of image classification models were tested across multiple platforms -to create a point of reference for the TensorFlow community. The -[Methodology](#methodology) section details how the tests were executed and has -links to the scripts used. - -## Results for image classification models - -InceptionV3 ([arXiv:1512.00567](https://arxiv.org/abs/1512.00567)), ResNet-50 -([arXiv:1512.03385](https://arxiv.org/abs/1512.03385)), ResNet-152 -([arXiv:1512.03385](https://arxiv.org/abs/1512.03385)), VGG16 -([arXiv:1409.1556](https://arxiv.org/abs/1409.1556)), and -[AlexNet](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf) -were tested using the [ImageNet](http://www.image-net.org/) data set. Tests were -run on Google Compute Engine, Amazon Elastic Compute Cloud (Amazon EC2), and an -NVIDIA® DGX-1™. Most of the tests were run with both synthetic and real data. -Testing with synthetic data was done by using a `tf.Variable` set to the same -shape as the data expected by each model for ImageNet. We believe it is -important to include real data measurements when benchmarking a platform. This -load tests both the underlying hardware and the framework at preparing data for -actual training. We start with synthetic data to remove disk I/O as a variable -and to set a baseline. Real data is then used to verify that the TensorFlow -input pipeline and the underlying disk I/O are saturating the compute units. - -### Training with NVIDIA® DGX-1™ (NVIDIA® Tesla® P100) - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:80%" src="../images/perf_summary_p100_single_server.png"> -</div> - -Details and additional results are in the [Details for NVIDIA® DGX-1™ (NVIDIA® -Tesla® P100)](#details_for_nvidia_dgx-1tm_nvidia_tesla_p100) section. - -### Training with NVIDIA® Tesla® K80 - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:80%" src="../images/perf_summary_k80_single_server.png"> -</div> - -Details and additional results are in the [Details for Google Compute Engine -(NVIDIA® Tesla® K80)](#details_for_google_compute_engine_nvidia_tesla_k80) and -[Details for Amazon EC2 (NVIDIA® Tesla® -K80)](#details_for_amazon_ec2_nvidia_tesla_k80) sections. - -### Distributed training with NVIDIA® Tesla® K80 - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:80%" src="../images/perf_summary_k80_aws_distributed.png"> -</div> - -Details and additional results are in the [Details for Amazon EC2 Distributed -(NVIDIA® Tesla® K80)](#details_for_amazon_ec2_distributed_nvidia_tesla_k80) -section. - -### Compare synthetic with real data training - -**NVIDIA® Tesla® P100** - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:35%" src="../images/perf_summary_p100_data_compare_inceptionv3.png"> - <img style="width:35%" src="../images/perf_summary_p100_data_compare_resnet50.png"> -</div> - -**NVIDIA® Tesla® K80** - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:35%" src="../images/perf_summary_k80_data_compare_inceptionv3.png"> - <img style="width:35%" src="../images/perf_summary_k80_data_compare_resnet50.png"> -</div> - -## Details for NVIDIA® DGX-1™ (NVIDIA® Tesla® P100) - -### Environment - -* **Instance type**: NVIDIA® DGX-1™ -* **GPU:** 8x NVIDIA® Tesla® P100 -* **OS:** Ubuntu 16.04 LTS with tests run via Docker -* **CUDA / cuDNN:** 8.0 / 5.1 -* **TensorFlow GitHub hash:** b1e174e -* **Benchmark GitHub hash:** 9165a70 -* **Build Command:** `bazel build -c opt --copt=-march="haswell" --config=cuda - //tensorflow/tools/pip_package:build_pip_package` -* **Disk:** Local SSD -* **DataSet:** ImageNet -* **Test Date:** May 2017 - -Batch size and optimizer used for each model are listed in the table below. In -addition to the batch sizes listed in the table, InceptionV3, ResNet-50, -ResNet-152, and VGG16 were tested with a batch size of 32. Those results are in -the *other results* section. - -Options | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 ------------------- | ----------- | --------- | ---------- | ------- | ----- -Batch size per GPU | 64 | 64 | 64 | 512 | 64 -Optimizer | sgd | sgd | sgd | sgd | sgd - -Configuration used for each model. - -Model | variable_update | local_parameter_device ------------ | ---------------------- | ---------------------- -InceptionV3 | parameter_server | cpu -ResNet50 | parameter_server | cpu -ResNet152 | parameter_server | cpu -AlexNet | replicated (with NCCL) | n/a -VGG16 | replicated (with NCCL) | n/a - -### Results - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:80%" src="../images/perf_summary_p100_single_server.png"> -</div> - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:35%" src="../images/perf_dgx1_synth_p100_single_server_scaling.png"> - <img style="width:35%" src="../images/perf_dgx1_real_p100_single_server_scaling.png"> -</div> - -**Training synthetic data** - -GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 ----- | ----------- | --------- | ---------- | ------- | ----- -1 | 142 | 219 | 91.8 | 2987 | 154 -2 | 284 | 422 | 181 | 5658 | 295 -4 | 569 | 852 | 356 | 10509 | 584 -8 | 1131 | 1734 | 716 | 17822 | 1081 - -**Training real data** - -GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 ----- | ----------- | --------- | ---------- | ------- | ----- -1 | 142 | 218 | 91.4 | 2890 | 154 -2 | 278 | 425 | 179 | 4448 | 284 -4 | 551 | 853 | 359 | 7105 | 534 -8 | 1079 | 1630 | 708 | N/A | 898 - -Training AlexNet with real data on 8 GPUs was excluded from the graph and table -above due to it maxing out the input pipeline. - -### Other Results - -The results below are all with a batch size of 32. - -**Training synthetic data** - -GPUs | InceptionV3 | ResNet-50 | ResNet-152 | VGG16 ----- | ----------- | --------- | ---------- | ----- -1 | 128 | 195 | 82.7 | 144 -2 | 259 | 368 | 160 | 281 -4 | 520 | 768 | 317 | 549 -8 | 995 | 1485 | 632 | 820 - -**Training real data** - -GPUs | InceptionV3 | ResNet-50 | ResNet-152 | VGG16 ----- | ----------- | --------- | ---------- | ----- -1 | 130 | 193 | 82.4 | 144 -2 | 257 | 369 | 159 | 253 -4 | 507 | 760 | 317 | 457 -8 | 966 | 1410 | 609 | 690 - -## Details for Google Compute Engine (NVIDIA® Tesla® K80) - -### Environment - -* **Instance type**: n1-standard-32-k80x8 -* **GPU:** 8x NVIDIA® Tesla® K80 -* **OS:** Ubuntu 16.04 LTS -* **CUDA / cuDNN:** 8.0 / 5.1 -* **TensorFlow GitHub hash:** b1e174e -* **Benchmark GitHub hash:** 9165a70 -* **Build Command:** `bazel build -c opt --copt=-march="haswell" --config=cuda - //tensorflow/tools/pip_package:build_pip_package` -* **Disk:** 1.7 TB Shared SSD persistent disk (800 MB/s) -* **DataSet:** ImageNet -* **Test Date:** May 2017 - -Batch size and optimizer used for each model are listed in the table below. In -addition to the batch sizes listed in the table, InceptionV3 and ResNet-50 were -tested with a batch size of 32. Those results are in the *other results* -section. - -Options | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 ------------------- | ----------- | --------- | ---------- | ------- | ----- -Batch size per GPU | 64 | 64 | 32 | 512 | 32 -Optimizer | sgd | sgd | sgd | sgd | sgd - -The configuration used for each model was `variable_update` equal to -`parameter_server` and `local_parameter_device` equal to `cpu`. - -### Results - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:35%" src="../images/perf_gce_synth_k80_single_server_scaling.png"> - <img style="width:35%" src="../images/perf_gce_real_k80_single_server_scaling.png"> -</div> - -**Training synthetic data** - -GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 ----- | ----------- | --------- | ---------- | ------- | ----- -1 | 30.5 | 51.9 | 20.0 | 656 | 35.4 -2 | 57.8 | 99.0 | 38.2 | 1209 | 64.8 -4 | 116 | 195 | 75.8 | 2328 | 120 -8 | 227 | 387 | 148 | 4640 | 234 - -**Training real data** - -GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 ----- | ----------- | --------- | ---------- | ------- | ----- -1 | 30.6 | 51.2 | 20.0 | 639 | 34.2 -2 | 58.4 | 98.8 | 38.3 | 1136 | 62.9 -4 | 115 | 194 | 75.4 | 2067 | 118 -8 | 225 | 381 | 148 | 4056 | 230 - -### Other Results - -**Training synthetic data** - -GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) ----- | --------------------------- | ------------------------- -1 | 29.3 | 49.5 -2 | 55.0 | 95.4 -4 | 109 | 183 -8 | 216 | 362 - -**Training real data** - -GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) ----- | --------------------------- | ------------------------- -1 | 29.5 | 49.3 -2 | 55.4 | 95.3 -4 | 110 | 186 -8 | 216 | 359 - -## Details for Amazon EC2 (NVIDIA® Tesla® K80) - -### Environment - -* **Instance type**: p2.8xlarge -* **GPU:** 8x NVIDIA® Tesla® K80 -* **OS:** Ubuntu 16.04 LTS -* **CUDA / cuDNN:** 8.0 / 5.1 -* **TensorFlow GitHub hash:** b1e174e -* **Benchmark GitHub hash:** 9165a70 -* **Build Command:** `bazel build -c opt --copt=-march="haswell" --config=cuda - //tensorflow/tools/pip_package:build_pip_package` -* **Disk:** 1TB Amazon EFS (burst 100 MiB/sec for 12 hours, continuous 50 - MiB/sec) -* **DataSet:** ImageNet -* **Test Date:** May 2017 - -Batch size and optimizer used for each model are listed in the table below. In -addition to the batch sizes listed in the table, InceptionV3 and ResNet-50 were -tested with a batch size of 32. Those results are in the *other results* -section. - -Options | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 ------------------- | ----------- | --------- | ---------- | ------- | ----- -Batch size per GPU | 64 | 64 | 32 | 512 | 32 -Optimizer | sgd | sgd | sgd | sgd | sgd - -Configuration used for each model. - -Model | variable_update | local_parameter_device ------------ | ------------------------- | ---------------------- -InceptionV3 | parameter_server | cpu -ResNet-50 | replicated (without NCCL) | gpu -ResNet-152 | replicated (without NCCL) | gpu -AlexNet | parameter_server | gpu -VGG16 | parameter_server | gpu - -### Results - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:35%" src="../images/perf_aws_synth_k80_single_server_scaling.png"> - <img style="width:35%" src="../images/perf_aws_real_k80_single_server_scaling.png"> -</div> - -**Training synthetic data** - -GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 ----- | ----------- | --------- | ---------- | ------- | ----- -1 | 30.8 | 51.5 | 19.7 | 684 | 36.3 -2 | 58.7 | 98.0 | 37.6 | 1244 | 69.4 -4 | 117 | 195 | 74.9 | 2479 | 141 -8 | 230 | 384 | 149 | 4853 | 260 - -**Training real data** - -GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 ----- | ----------- | --------- | ---------- | ------- | ----- -1 | 30.5 | 51.3 | 19.7 | 674 | 36.3 -2 | 59.0 | 94.9 | 38.2 | 1227 | 67.5 -4 | 118 | 188 | 75.2 | 2201 | 136 -8 | 228 | 373 | 149 | N/A | 242 - -Training AlexNet with real data on 8 GPUs was excluded from the graph and table -above due to our EFS setup not providing enough throughput. - -### Other Results - -**Training synthetic data** - -GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) ----- | --------------------------- | ------------------------- -1 | 29.9 | 49.0 -2 | 57.5 | 94.1 -4 | 114 | 184 -8 | 216 | 355 - -**Training real data** - -GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) ----- | --------------------------- | ------------------------- -1 | 30.0 | 49.1 -2 | 57.5 | 95.1 -4 | 113 | 185 -8 | 212 | 353 - -## Details for Amazon EC2 Distributed (NVIDIA® Tesla® K80) - -### Environment - -* **Instance type**: p2.8xlarge -* **GPU:** 8x NVIDIA® Tesla® K80 -* **OS:** Ubuntu 16.04 LTS -* **CUDA / cuDNN:** 8.0 / 5.1 -* **TensorFlow GitHub hash:** b1e174e -* **Benchmark GitHub hash:** 9165a70 -* **Build Command:** `bazel build -c opt --copt=-march="haswell" --config=cuda - //tensorflow/tools/pip_package:build_pip_package` -* **Disk:** 1.0 TB EFS (burst 100 MB/sec for 12 hours, continuous 50 MB/sec) -* **DataSet:** ImageNet -* **Test Date:** May 2017 - -The batch size and optimizer used for the tests are listed in the table. In -addition to the batch sizes listed in the table, InceptionV3 and ResNet-50 were -tested with a batch size of 32. Those results are in the *other results* -section. - -Options | InceptionV3 | ResNet-50 | ResNet-152 ------------------- | ----------- | --------- | ---------- -Batch size per GPU | 64 | 64 | 32 -Optimizer | sgd | sgd | sgd - -Configuration used for each model. - -Model | variable_update | local_parameter_device | cross_replica_sync ------------ | ---------------------- | ---------------------- | ------------------ -InceptionV3 | distributed_replicated | n/a | True -ResNet-50 | distributed_replicated | n/a | True -ResNet-152 | distributed_replicated | n/a | True - -To simplify server setup, EC2 instances (p2.8xlarge) running worker servers also -ran parameter servers. Equal numbers of parameter servers and worker servers were -used with the following exceptions: - -* InceptionV3: 8 instances / 6 parameter servers -* ResNet-50: (batch size 32) 8 instances / 4 parameter servers -* ResNet-152: 8 instances / 4 parameter servers - -### Results - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:80%" src="../images/perf_summary_k80_aws_distributed.png"> -</div> - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:70%" src="../images/perf_aws_synth_k80_distributed_scaling.png"> -</div> - -**Training synthetic data** - -GPUs | InceptionV3 | ResNet-50 | ResNet-152 ----- | ----------- | --------- | ---------- -1 | 29.7 | 52.4 | 19.4 -8 | 229 | 378 | 146 -16 | 459 | 751 | 291 -32 | 902 | 1388 | 565 -64 | 1783 | 2744 | 981 - -### Other Results - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:50%" src="../images/perf_aws_synth_k80_multi_server_batch32.png"> -</div> - -**Training synthetic data** - -GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) ----- | --------------------------- | ------------------------- -1 | 29.2 | 48.4 -8 | 219 | 333 -16 | 427 | 667 -32 | 820 | 1180 -64 | 1608 | 2315 - -## Methodology - -This -[script](https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks) -was run on the various platforms to generate the above results. - -In order to create results that are as repeatable as possible, each test was run -5 times and then the times were averaged together. GPUs are run in their default -state on the given platform. For NVIDIA® Tesla® K80 this means leaving on [GPU -Boost](https://devblogs.nvidia.com/parallelforall/increase-performance-gpu-boost-k80-autoboost/). -For each test, 10 warmup steps are done and then the next 100 steps are -averaged. diff --git a/tensorflow/docs_src/performance/datasets_performance.md b/tensorflow/docs_src/performance/datasets_performance.md deleted file mode 100644 index 5d9e4ba392..0000000000 --- a/tensorflow/docs_src/performance/datasets_performance.md +++ /dev/null @@ -1,331 +0,0 @@ -# Input Pipeline Performance Guide - -GPUs and TPUs can radically reduce the time required to execute a single -training step. Achieving peak performance requires an efficient input pipeline -that delivers data for the next step before the current step has finished. The -`tf.data` API helps to build flexible and efficient input pipelines. This -document explains the `tf.data` API's features and best practices for building -high performance TensorFlow input pipelines across a variety of models and -accelerators. - -This guide does the following: - -* Illustrates that TensorFlow input pipelines are essentially an - [ETL](https://en.wikipedia.org/wiki/Extract,_transform,_load) process. -* Describes common performance optimizations in the context of the `tf.data` - API. -* Discusses the performance implications of the order in which you apply - transformations. -* Summarizes the best practices for designing performant TensorFlow input - pipelines. - - -## Input Pipeline Structure - -A typical TensorFlow training input pipeline can be framed as an ETL process: - -1. **Extract**: Read data from persistent storage -- either local (e.g. HDD or - SSD) or remote (e.g. [GCS](https://cloud.google.com/storage/) or - [HDFS](https://en.wikipedia.org/wiki/Apache_Hadoop#Hadoop_distributed_file_system)). -2. **Transform**: Use CPU cores to parse and perform preprocessing operations - on the data such as image decompression, data augmentation transformations - (such as random crop, flips, and color distortions), shuffling, and batching. -3. **Load**: Load the transformed data onto the accelerator device(s) (for - example, GPU(s) or TPU(s)) that execute the machine learning model. - -This pattern effectively utilizes the CPU, while reserving the accelerator for -the heavy lifting of training your model. In addition, viewing input pipelines -as an ETL process provides structure that facilitates the application of -performance optimizations. - -When using the `tf.estimator.Estimator` API, the first two phases (Extract and -Transform) are captured in the `input_fn` passed to -`tf.estimator.Estimator.train`. In code, this might look like the following -(naive, sequential) implementation: - -``` -def parse_fn(example): - "Parse TFExample records and perform simple data augmentation." - example_fmt = { - "image": tf.FixedLengthFeature((), tf.string, ""), - "label": tf.FixedLengthFeature((), tf.int64, -1) - } - parsed = tf.parse_single_example(example, example_fmt) - image = tf.image.decode_image(parsed["image"]) - image = _augment_helper(image) # augments image using slice, reshape, resize_bilinear - return image, parsed["label"] - -def input_fn(): - files = tf.data.Dataset.list_files("/path/to/dataset/train-*.tfrecord") - dataset = files.interleave(tf.data.TFRecordDataset) - dataset = dataset.shuffle(buffer_size=FLAGS.shuffle_buffer_size) - dataset = dataset.map(map_func=parse_fn) - dataset = dataset.batch(batch_size=FLAGS.batch_size) - return dataset -``` - -The next section builds on this input pipeline, adding performance -optimizations. - -## Optimizing Performance - -As new computing devices (such as GPUs and TPUs) make it possible to train -neural networks at an increasingly fast rate, the CPU processing is prone to -becoming the bottleneck. The `tf.data` API provides users with building blocks -to design input pipelines that effectively utilize the CPU, optimizing each step -of the ETL process. - -### Pipelining - -To perform a training step, you must first extract and transform the training -data and then feed it to a model running on an accelerator. However, in a naive -synchronous implementation, while the CPU is preparing the data, the accelerator -is sitting idle. Conversely, while the accelerator is training the model, the -CPU is sitting idle. The training step time is thus the sum of both CPU -pre-processing time and the accelerator training time. - -**Pipelining** overlaps the preprocessing and model execution of a training -step. While the accelerator is performing training step `N`, the CPU is -preparing the data for step `N+1`. Doing so reduces the step time to the maximum -(as opposed to the sum) of the training and the time it takes to extract and -transform the data. - -Without pipelining, the CPU and the GPU/TPU sit idle much of the time: - - - -With pipelining, idle time diminishes significantly: - - - -The `tf.data` API provides a software pipelining mechanism through the -`tf.data.Dataset.prefetch` transformation, which can be used to decouple the -time data is produced from the time it is consumed. In particular, the -transformation uses a background thread and an internal buffer to prefetch -elements from the input dataset ahead of the time they are requested. Thus, to -achieve the pipelining effect illustrated above, you can add `prefetch(1)` as -the final transformation to your dataset pipeline (or `prefetch(n)` if a single -training step consumes n elements). - -To apply this change to our running example, change: - -``` -dataset = dataset.batch(batch_size=FLAGS.batch_size) -return dataset -``` - -to: - - -``` -dataset = dataset.batch(batch_size=FLAGS.batch_size) -dataset = dataset.prefetch(buffer_size=FLAGS.prefetch_buffer_size) -return dataset -``` - -Note that the prefetch transformation will yield benefits any time there is an -opportunity to overlap the work of a "producer" with the work of a "consumer." -The preceding recommendation is simply the most common application. - -### Parallelize Data Transformation - -When preparing a batch, input elements may need to be pre-processed. To this -end, the `tf.data` API offers the `tf.data.Dataset.map` transformation, which -applies a user-defined function (for example, `parse_fn` from the running -example) to each element of the input dataset. Because input elements are -independent of one another, the pre-processing can be parallelized across -multiple CPU cores. To make this possible, the `map` transformation provides the -`num_parallel_calls` argument to specify the level of parallelism. For example, -the following diagram illustrates the effect of setting `num_parallel_calls=2` -to the `map` transformation: - - - -Choosing the best value for the `num_parallel_calls` argument depends on your -hardware, characteristics of your training data (such as its size and shape), -the cost of your map function, and what other processing is happening on the -CPU at the same time; a simple heuristic is to use the number of available CPU -cores. For instance, if the machine executing the example above had 4 cores, it -would have been more efficient to set `num_parallel_calls=4`. On the other hand, -setting `num_parallel_calls` to a value much greater than the number of -available CPUs can lead to inefficient scheduling, resulting in a slowdown. - -To apply this change to our running example, change: - -``` -dataset = dataset.map(map_func=parse_fn) -``` - -to: - -``` -dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls) -``` - -Furthermore, if your batch size is in the hundreds or thousands, your pipeline -will likely additionally benefit from parallelizing the batch creation. To this -end, the `tf.data` API provides the `tf.contrib.data.map_and_batch` -transformation, which effectively "fuses" the map and batch transformations. - -To apply this change to our running example, change: - -``` -dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls) -dataset = dataset.batch(batch_size=FLAGS.batch_size) -``` - -to: - -``` -dataset = dataset.apply(tf.contrib.data.map_and_batch( - map_func=parse_fn, batch_size=FLAGS.batch_size)) -``` - -### Parallelize Data Extraction - -In a real-world setting, the input data may be stored remotely (for example, -GCS or HDFS), either because the input data would not fit locally or because the -training is distributed and it would not make sense to replicate the input data -on every machine. A dataset pipeline that works well when reading data locally -might become bottlenecked on I/O when reading data remotely because of the -following differences between local and remote storage: - - -* **Time-to-first-byte:** Reading the first byte of a file from remote storage - can take orders of magnitude longer than from local storage. -* **Read throughput:** While remote storage typically offers large aggregate - bandwidth, reading a single file might only be able to utilize a small - fraction of this bandwidth. - -In addition, once the raw bytes are read into memory, it may also be necessary -to deserialize or decrypt the data -(e.g. [protobuf](https://developers.google.com/protocol-buffers/)), which adds -additional overhead. This overhead is present irrespective of whether the data -is stored locally or remotely, but can be worse in the remote case if data is -not prefetched effectively. - -To mitigate the impact of the various data extraction overheads, the `tf.data` -API offers the `tf.contrib.data.parallel_interleave` transformation. Use this -transformation to parallelize the execution of and interleave the contents of -other datasets (such as data file readers). The -number of datasets to overlap can be specified by the `cycle_length` argument. - -The following diagram illustrates the effect of supplying `cycle_length=2` to -the `parallel_interleave` transformation: - - - -To apply this change to our running example, change: - -``` -dataset = files.interleave(tf.data.TFRecordDataset) -``` - -to: - -``` -dataset = files.apply(tf.contrib.data.parallel_interleave( - tf.data.TFRecordDataset, cycle_length=FLAGS.num_parallel_readers)) -``` - - -The throughput of remote storage systems can vary over time due to load or -network events. To account for this variance, the `parallel_interleave` -transformation can optionally use prefetching. (See -`tf.contrib.data.parallel_interleave` for details). - -By default, the `parallel_interleave` transformation provides a deterministic -ordering of elements to aid reproducibility. As an alternative to prefetching -(which may be ineffective in some cases), the `parallel_interleave` -transformation also provides an option that can boost performance at the expense -of ordering guarantees. In particular, if the `sloppy` argument is set to true, -the transformation may depart from its otherwise deterministic ordering, by -temporarily skipping over files whose elements are not available when the next -element is requested. - -## Performance Considerations - -The `tf.data` API is designed around composable transformations to provide its -users with flexibility. Although many of these transformations are commutative, -the ordering of certain transformations has performance implications. - -### Map and Batch - -Invoking the user-defined function passed into the `map` transformation has -overhead related to scheduling and executing the user-defined function. -Normally, this overhead is small compared to the amount of computation performed -by the function. However, if `map` does little work, this overhead can dominate -the total cost. In such cases, we recommend vectorizing the user-defined -function (that is, have it operate over a batch of inputs at once) and apply the -`batch` transformation _before_ the `map` transformation. - -### Map and Cache - -The `tf.data.Dataset.cache` transformation can cache a dataset, either in -memory or on local storage. If the user-defined function passed into the `map` -transformation is expensive, apply the cache transformation after the map -transformation as long as the resulting dataset can still fit into memory or -local storage. If the user-defined function increases the space required to -store the dataset beyond the cache capacity, consider pre-processing your data -before your training job to reduce resource usage. - -### Map and Interleave / Prefetch / Shuffle - -A number of transformations, including `interleave`, `prefetch`, and `shuffle`, -maintain an internal buffer of elements. If the user-defined function passed -into the `map` transformation changes the size of the elements, then the -ordering of the map transformation and the transformations that buffer elements -affects the memory usage. In general, we recommend choosing the order that -results in lower memory footprint, unless different ordering is desirable for -performance (for example, to enable fusing of the map and batch transformations). - -### Repeat and Shuffle - -The `tf.data.Dataset.repeat` transformation repeats the input data a finite (or -infinite) number of times; each repetition of the data is typically referred to -as an _epoch_. The `tf.data.Dataset.shuffle` transformation randomizes the -order of the dataset's examples. - -If the `repeat` transformation is applied before the `shuffle` transformation, -then the epoch boundaries are blurred. That is, certain elements can be repeated -before other elements appear even once. On the other hand, if the `shuffle` -transformation is applied before the repeat transformation, then performance -might slow down at the beginning of each epoch related to initialization of the -internal state of the `shuffle` transformation. In other words, the former -(`repeat` before `shuffle`) provides better performance, while the latter -(`shuffle` before `repeat`) provides stronger ordering guarantees. - -When possible, we recommend using the fused -`tf.contrib.data.shuffle_and_repeat` transformation, which combines the best of -both worlds (good performance and strong ordering guarantees). Otherwise, we -recommend shuffling before repeating. - -## Summary of Best Practices - -Here is a summary of the best practices for designing input pipelines: - -* Use the `prefetch` transformation to overlap the work of a producer and - consumer. In particular, we recommend adding prefetch(n) (where n is the - number of elements / batches consumed by a training step) to the end of your - input pipeline to overlap the transformations performed on the CPU with the - training done on the accelerator. -* Parallelize the `map` transformation by setting the `num_parallel_calls` - argument. We recommend using the number of available CPU cores for its value. -* If you are combining pre-processed elements into a batch using the `batch` - transformation, we recommend using the fused `map_and_batch` transformation; - especially if you are using large batch sizes. -* If you are working with data stored remotely and / or requiring - deserialization, we recommend using the `parallel_interleave` - transformation to overlap the reading (and deserialization) of data from - different files. -* Vectorize cheap user-defined functions passed in to the `map` transformation - to amortize the overhead associated with scheduling and executing the - function. -* If your data can fit into memory, use the `cache` transformation to cache it - in memory during the first epoch, so that subsequent epochs can avoid the - overhead associated with reading, parsing, and transforming it. -* If your pre-processing increases the size of your data, we recommend - applying the `interleave`, `prefetch`, and `shuffle` first (if possible) to - reduce memory usage. -* We recommend applying the `shuffle` transformation _before_ the `repeat` - transformation, ideally using the fused `shuffle_and_repeat` transformation. diff --git a/tensorflow/docs_src/performance/index.md b/tensorflow/docs_src/performance/index.md deleted file mode 100644 index a0f26a8c3a..0000000000 --- a/tensorflow/docs_src/performance/index.md +++ /dev/null @@ -1,52 +0,0 @@ -# Performance - -Performance is an important consideration when training machine learning -models. Performance speeds up and scales research while -also providing end users with near instant predictions. This section provides -details on the high level APIs to use along with best practices to build -and train high performance models, and quantize models for the least latency -and highest throughput for inference. - - * [Performance Guide](../performance/performance_guide.md) contains a collection of best - practices for optimizing your TensorFlow code. - - * [Data input pipeline guide](../performance/datasets_performance.md) describes the tf.data - API for building efficient data input pipelines for TensorFlow. - - * [Benchmarks](../performance/benchmarks.md) contains a collection of - benchmark results for a variety of hardware configurations. - - * For improving inference efficiency on mobile and - embedded hardware, see - [How to Quantize Neural Networks with TensorFlow](../performance/quantization.md), which - explains how to use quantization to reduce model size, both in storage - and at runtime. - - * For optimizing inference on GPUs, refer to [NVIDIA TensorRT™ - integration with TensorFlow.]( - https://medium.com/tensorflow/speed-up-tensorflow-inference-on-gpus-with-tensorrt-13b49f3db3fa) - - -XLA (Accelerated Linear Algebra) is an experimental compiler for linear -algebra that optimizes TensorFlow computations. The following guides explore -XLA: - - * [XLA Overview](../performance/xla/index.md), which introduces XLA. - * [Broadcasting Semantics](../performance/xla/broadcasting.md), which describes XLA's - broadcasting semantics. - * [Developing a new back end for XLA](../performance/xla/developing_new_backend.md), which - explains how to re-target TensorFlow in order to optimize the performance - of the computational graph for particular hardware. - * [Using JIT Compilation](../performance/xla/jit.md), which describes the XLA JIT compiler that - compiles and runs parts of TensorFlow graphs via XLA in order to optimize - performance. - * [Operation Semantics](../performance/xla/operation_semantics.md), which is a reference manual - describing the semantics of operations in the `ComputationBuilder` - interface. - * [Shapes and Layout](../performance/xla/shapes.md), which details the `Shape` protocol buffer. - * [Using AOT compilation](../performance/xla/tfcompile.md), which explains `tfcompile`, a - standalone tool that compiles TensorFlow graphs into executable code in - order to optimize performance. - - - diff --git a/tensorflow/docs_src/performance/leftnav_files b/tensorflow/docs_src/performance/leftnav_files deleted file mode 100644 index 12e0dbd48a..0000000000 --- a/tensorflow/docs_src/performance/leftnav_files +++ /dev/null @@ -1,14 +0,0 @@ -index.md -performance_guide.md -datasets_performance.md -benchmarks.md -quantization.md - -### XLA -xla/index.md -xla/broadcasting.md -xla/developing_new_backend.md -xla/jit.md -xla/operation_semantics.md -xla/shapes.md -xla/tfcompile.md diff --git a/tensorflow/docs_src/performance/performance_guide.md b/tensorflow/docs_src/performance/performance_guide.md deleted file mode 100644 index 9ea1d6a705..0000000000 --- a/tensorflow/docs_src/performance/performance_guide.md +++ /dev/null @@ -1,733 +0,0 @@ -# Performance Guide - -This guide contains a collection of best practices for optimizing TensorFlow -code. The guide is divided into a few sections: - -* [General best practices](#general_best_practices) covers topics that are - common across a variety of model types and hardware. -* [Optimizing for GPU](#optimizing_for_gpu) details tips specifically relevant - to GPUs. -* [Optimizing for CPU](#optimizing_for_cpu) details CPU specific information. - -## General best practices - -The sections below cover best practices that are relevant to a variety of -hardware and models. The best practices section is broken down into the -following sections: - -* [Input pipeline optimizations](#input-pipeline-optimization) -* [Data formats](#data-formats) -* [Common fused Ops](#common-fused-ops) -* [RNN Performance](#rnn-performance) -* [Building and installing from source](#building-and-installing-from-source) - -### Input pipeline optimization - -Typical models retrieve data from disk and preprocess it before sending the data -through the network. For example, models that process JPEG images will follow -this flow: load image from disk, decode JPEG into a tensor, crop and pad, -possibly flip and distort, and then batch. This flow is referred to as the input -pipeline. As GPUs and other hardware accelerators get faster, preprocessing of -data can be a bottleneck. - -Determining if the input pipeline is the bottleneck can be complicated. One of -the most straightforward methods is to reduce the model to a single operation -(trivial model) after the input pipeline and measure the examples per second. If -the difference in examples per second for the full model and the trivial model -is minimal then the input pipeline is likely a bottleneck. Below are some other -approaches to identifying issues: - -* Check if a GPU is underutilized by running `nvidia-smi -l 2`. If GPU - utilization is not approaching 80-100%, then the input pipeline may be the - bottleneck. -* Generate a timeline and look for large blocks of white space (waiting). An - example of generating a timeline exists as part of the [XLA JIT](../performance/xla/jit.md) - tutorial. -* Check CPU usage. It is possible to have an optimized input pipeline and lack - the CPU cycles to process the pipeline. -* Estimate the throughput needed and verify the disk used is capable of that - level of throughput. Some cloud solutions have network attached disks that - start as low as 50 MB/sec, which is slower than spinning disks (150 MB/sec), - SATA SSDs (500 MB/sec), and PCIe SSDs (2,000+ MB/sec). - -#### Preprocessing on the CPU - -Placing input pipeline operations on the CPU can significantly improve -performance. Utilizing the CPU for the input pipeline frees the GPU to focus on -training. To ensure preprocessing is on the CPU, wrap the preprocessing -operations as shown below: - -```python -with tf.device('/cpu:0'): - # function to get and process images or data. - distorted_inputs = load_and_distort_images() -``` - -If using `tf.estimator.Estimator` the input function is automatically placed on -the CPU. - -#### Using the tf.data API - -The [tf.data API](../guide/datasets.md) is replacing `queue_runner` as the recommended API -for building input pipelines. This -[ResNet example](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10_estimator/cifar10_main.py) -([arXiv:1512.03385](https://arxiv.org/abs/1512.03385)) -training CIFAR-10 illustrates the use of the `tf.data` API along with -`tf.estimator.Estimator`. - -The `tf.data` API utilizes C++ multi-threading and has a much lower overhead -than the Python-based `queue_runner` that is limited by Python's multi-threading -performance. A detailed performance guide for the `tf.data` API can be found -[here](../performance/datasets_performance.md). - -While feeding data using a `feed_dict` offers a high level of flexibility, in -general `feed_dict` does not provide a scalable solution. If only a single GPU -is used, the difference between the `tf.data` API and `feed_dict` performance -may be negligible. Our recommendation is to avoid using `feed_dict` for all but -trivial examples. In particular, avoid using `feed_dict` with large inputs: - -```python -# feed_dict often results in suboptimal performance when using large inputs. -sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) -``` - -#### Fused decode and crop - -If inputs are JPEG images that also require cropping, use fused -`tf.image.decode_and_crop_jpeg` to speed up preprocessing. -`tf.image.decode_and_crop_jpeg` only decodes the part of -the image within the crop window. This significantly speeds up the process if -the crop window is much smaller than the full image. For imagenet data, this -approach could speed up the input pipeline by up to 30%. - -Example Usage: - -```python -def _image_preprocess_fn(image_buffer): - # image_buffer 1-D string Tensor representing the raw JPEG image buffer. - - # Extract image shape from raw JPEG image buffer. - image_shape = tf.image.extract_jpeg_shape(image_buffer) - - # Get a crop window with distorted bounding box. - sample_distorted_bounding_box = tf.image.sample_distorted_bounding_box( - image_shape, ...) - bbox_begin, bbox_size, distort_bbox = sample_distorted_bounding_box - - # Decode and crop image. - offset_y, offset_x, _ = tf.unstack(bbox_begin) - target_height, target_width, _ = tf.unstack(bbox_size) - crop_window = tf.stack([offset_y, offset_x, target_height, target_width]) - cropped_image = tf.image.decode_and_crop_jpeg(image, crop_window) -``` - -`tf.image.decode_and_crop_jpeg` is available on all platforms. There is no speed -up on Windows due to the use of `libjpeg` vs. `libjpeg-turbo` on other -platforms. - -#### Use large files - -Reading large numbers of small files significantly impacts I/O performance. -One approach to get maximum I/O throughput is to preprocess input data into -larger (~100MB) `TFRecord` files. For smaller data sets (200MB-1GB), the best -approach is often to load the entire data set into memory. The document -[Downloading and converting to TFRecord format](https://github.com/tensorflow/models/tree/master/research/slim#downloading-and-converting-to-tfrecord-format) -includes information and scripts for creating `TFRecords` and this -[script](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10_estimator/generate_cifar10_tfrecords.py) -converts the CIFAR-10 data set into `TFRecords`. - -### Data formats - -Data formats refers to the structure of the Tensor passed to a given Op. The -discussion below is specifically about 4D Tensors representing images. In -TensorFlow the parts of the 4D tensor are often referred to by the following -letters: - -* N refers to the number of images in a batch. -* H refers to the number of pixels in the vertical (height) dimension. -* W refers to the number of pixels in the horizontal (width) dimension. -* C refers to the channels. For example, 1 for black and white or grayscale - and 3 for RGB. - -Within TensorFlow there are two naming conventions representing the two most -common data formats: - -* `NCHW` or `channels_first` -* `NHWC` or `channels_last` - -`NHWC` is the TensorFlow default and `NCHW` is the optimal format to use when -training on NVIDIA GPUs using [cuDNN](https://developer.nvidia.com/cudnn). - -The best practice is to build models that work with both data formats. This -simplifies training on GPUs and then running inference on CPUs. If TensorFlow is -compiled with the [Intel MKL](#tensorflow_with_intel_mkl-dnn) optimizations, -many operations, especially those related to CNN based models, will be optimized -and support `NCHW`. If not using the MKL, some operations are not supported on -CPU when using `NCHW`. - -The brief history of these two formats is that TensorFlow started by using -`NHWC` because it was a little faster on CPUs. In the long term, we are working -on tools to auto rewrite graphs to make switching between the formats -transparent and take advantages of micro optimizations where a GPU Op may be -faster using `NHWC` than the normally most efficient `NCHW`. - -### Common fused Ops - -Fused Ops combine multiple operations into a single kernel for improved -performance. There are many fused Ops within TensorFlow and [XLA](../performance/xla/index.md) will -create fused Ops when possible to automatically improve performance. Collected -below are select fused Ops that can greatly improve performance and may be -overlooked. - -#### Fused batch norm - -Fused batch norm combines the multiple operations needed to do batch -normalization into a single kernel. Batch norm is an expensive process that for -some models makes up a large percentage of the operation time. Using fused batch -norm can result in a 12%-30% speedup. - -There are two commonly used batch norms and both support fusing. The core -`tf.layers.batch_normalization` added fused starting in TensorFlow 1.3. - -```python -bn = tf.layers.batch_normalization( - input_layer, fused=True, data_format='NCHW') -``` - -The contrib `tf.contrib.layers.batch_norm` method has had fused as an option -since before TensorFlow 1.0. - -```python -bn = tf.contrib.layers.batch_norm(input_layer, fused=True, data_format='NCHW') -``` - -### RNN Performance - -There are many ways to specify an RNN computation in TensorFlow and they have -trade-offs with respect to model flexibility and performance. The -`tf.nn.rnn_cell.BasicLSTMCell` should be considered a reference implementation -and used only as a last resort when no other options will work. - -When using one of the cells, rather than the fully fused RNN layers, you have a -choice of whether to use `tf.nn.static_rnn` or `tf.nn.dynamic_rnn`. There -shouldn't generally be a performance difference at runtime, but large unroll -amounts can increase the graph size of the `tf.nn.static_rnn` and cause long -compile times. An additional advantage of `tf.nn.dynamic_rnn` is that it can -optionally swap memory from the GPU to the CPU to enable training of very long -sequences. Depending on the model and hardware configuration, this can come at -a performance cost. It is also possible to run multiple iterations of -`tf.nn.dynamic_rnn` and the underlying `tf.while_loop` construct in parallel, -although this is rarely useful with RNN models as they are inherently -sequential. - -On NVIDIA GPUs, the use of `tf.contrib.cudnn_rnn` should always be preferred -unless you want layer normalization, which it doesn't support. It is often at -least an order of magnitude faster than `tf.contrib.rnn.BasicLSTMCell` and -`tf.contrib.rnn.LSTMBlockCell` and uses 3-4x less memory than -`tf.contrib.rnn.BasicLSTMCell`. - -If you need to run one step of the RNN at a time, as might be the case in -reinforcement learning with a recurrent policy, then you should use the -`tf.contrib.rnn.LSTMBlockCell` with your own environment interaction loop -inside a `tf.while_loop` construct. Running one step of the RNN at a time and -returning to Python is possible, but it will be slower. - -On CPUs, mobile devices, and if `tf.contrib.cudnn_rnn` is not available on -your GPU, the fastest and most memory efficient option is -`tf.contrib.rnn.LSTMBlockFusedCell`. - -For all of the less common cell types like `tf.contrib.rnn.NASCell`, -`tf.contrib.rnn.PhasedLSTMCell`, `tf.contrib.rnn.UGRNNCell`, -`tf.contrib.rnn.GLSTMCell`, `tf.contrib.rnn.Conv1DLSTMCell`, -`tf.contrib.rnn.Conv2DLSTMCell`, `tf.contrib.rnn.LayerNormBasicLSTMCell`, -etc., one should be aware that they are implemented in the graph like -`tf.contrib.rnn.BasicLSTMCell` and as such will suffer from the same poor -performance and high memory usage. One should consider whether or not those -trade-offs are worth it before using these cells. For example, while layer -normalization can speed up convergence, because cuDNN is 20x faster the fastest -wall clock time to convergence is usually obtained without it. - - -### Building and installing from source - -The default TensorFlow binaries target the broadest range of hardware to make -TensorFlow accessible to everyone. If using CPUs for training or inference, it -is recommended to compile TensorFlow with all of the optimizations available for -the CPU in use. Speedups for training and inference on CPU are documented below -in [Comparing compiler optimizations](#comparing-compiler-optimizations). - -To install the most optimized version of TensorFlow, -[build and install](../install/install_sources.md) from source. If there is a need to build -TensorFlow on a platform that has different hardware than the target, then -cross-compile with the highest optimizations for the target platform. The -following command is an example of using `bazel` to compile for a specific -platform: - -```python -# This command optimizes for Intel’s Broadwell processor -bazel build -c opt --copt=-march="broadwell" --config=cuda //tensorflow/tools/pip_package:build_pip_package - -``` - -#### Environment, build, and install tips - -* `./configure` asks which compute capability to include in the build. This - does not impact overall performance but does impact initial startup. After - running TensorFlow once, the compiled kernels are cached by CUDA. If using - a docker container, the data is not cached and the penalty is paid each time - TensorFlow starts. The best practice is to include the - [compute capabilities](http://developer.nvidia.com/cuda-gpus) - of the GPUs that will be used, e.g. P100: 6.0, Titan X (Pascal): 6.1, Titan - X (Maxwell): 5.2, and K80: 3.7. -* Use a version of gcc that supports all of the optimizations of the target - CPU. The recommended minimum gcc version is 4.8.3. On OS X, upgrade to the - latest Xcode version and use the version of clang that comes with Xcode. -* Install the latest stable CUDA platform and cuDNN libraries supported by - TensorFlow. - -## Optimizing for GPU - -This section contains GPU-specific tips that are not covered in the -[General best practices](#general-best-practices). Obtaining optimal performance -on multi-GPUs is a challenge. A common approach is to use data parallelism. -Scaling through the use of data parallelism involves making multiple copies of -the model, which are referred to as "towers", and then placing one tower on each -of the GPUs. Each tower operates on a different mini-batch of data and then -updates variables, also known as parameters, that need to be shared between -each of the towers. How each tower gets the updated variables and how the -gradients are applied has an impact on the performance, scaling, and convergence -of the model. The rest of this section provides an overview of variable -placement and the towering of a model on multiple GPUs. -[High-Performance Models](../performance/performance_models.md) gets into more details regarding -more complex methods that can be used to share and update variables between -towers. - -The best approach to handling variable updates depends on the model, hardware, -and even how the hardware has been configured. An example of this, is that two -systems can be built with NVIDIA Tesla P100s but one may be using PCIe and the -other [NVLink](http://www.nvidia.com/object/nvlink.html). In that scenario, the -optimal solution for each system may be different. For real world examples, read -the [benchmark](../performance/benchmarks.md) page which details the settings that -were optimal for a variety of platforms. Below is a summary of what was learned -from benchmarking various platforms and configurations: - -* **Tesla K80**: If the GPUs are on the same PCI Express root complex and are - able to use [NVIDIA GPUDirect](https://developer.nvidia.com/gpudirect) Peer - to Peer, then placing the variables equally across the GPUs used for - training is the best approach. If the GPUs cannot use GPUDirect, then - placing the variables on the CPU is the best option. - -* **Titan X (Maxwell and Pascal), M40, P100, and similar**: For models like - ResNet and InceptionV3, placing variables on the CPU is the optimal setting, - but for models with a lot of variables like AlexNet and VGG, using GPUs with - `NCCL` is better. - -A common approach to managing where variables are placed, is to create a method -to determine where each Op is to be placed and use that method in place of a -specific device name when calling `with tf.device():`. Consider a scenario where -a model is being trained on 2 GPUs and the variables are to be placed on the -CPU. There would be a loop for creating and placing the "towers" on each of the -2 GPUs. A custom device placement method would be created that watches for Ops -of type `Variable`, `VariableV2`, and `VarHandleOp` and indicates that they are -to be placed on the CPU. All other Ops would be placed on the target GPU. -The building of the graph would proceed as follows: - -* On the first loop a "tower" of the model would be created for `gpu:0`. - During the placement of the Ops, the custom device placement method would - indicate that variables are to be placed on `cpu:0` and all other Ops on - `gpu:0`. - -* On the second loop, `reuse` is set to `True` to indicate that variables are - to be reused and then the "tower" is created on `gpu:1`. During the - placement of the Ops associated with the "tower", the variables that were - placed on `cpu:0` are reused and all other Ops are created and placed on - `gpu:1`. - -The final result is all of the variables are placed on the CPU with each GPU -having a copy of all of the computational Ops associated with the model. - -The code snippet below illustrates two different approaches for variable -placement: one is placing variables on the CPU; the other is placing variables -equally across the GPUs. - -```python - -class GpuParamServerDeviceSetter(object): - """Used with tf.device() to place variables on the least loaded GPU. - - A common use for this class is to pass a list of GPU devices, e.g. ['gpu:0', - 'gpu:1','gpu:2'], as ps_devices. When each variable is placed, it will be - placed on the least loaded gpu. All other Ops, which will be the computation - Ops, will be placed on the worker_device. - """ - - def __init__(self, worker_device, ps_devices): - """Initializer for GpuParamServerDeviceSetter. - Args: - worker_device: the device to use for computation Ops. - ps_devices: a list of devices to use for Variable Ops. Each variable is - assigned to the least loaded device. - """ - self.ps_devices = ps_devices - self.worker_device = worker_device - self.ps_sizes = [0] * len(self.ps_devices) - - def __call__(self, op): - if op.device: - return op.device - if op.type not in ['Variable', 'VariableV2', 'VarHandleOp']: - return self.worker_device - - # Gets the least loaded ps_device - device_index, _ = min(enumerate(self.ps_sizes), key=operator.itemgetter(1)) - device_name = self.ps_devices[device_index] - var_size = op.outputs[0].get_shape().num_elements() - self.ps_sizes[device_index] += var_size - - return device_name - -def _create_device_setter(is_cpu_ps, worker, num_gpus): - """Create device setter object.""" - if is_cpu_ps: - # tf.train.replica_device_setter supports placing variables on the CPU, all - # on one GPU, or on ps_servers defined in a cluster_spec. - return tf.train.replica_device_setter( - worker_device=worker, ps_device='/cpu:0', ps_tasks=1) - else: - gpus = ['/gpu:%d' % i for i in range(num_gpus)] - return ParamServerDeviceSetter(worker, gpus) - -# The method below is a modified snippet from the full example. -def _resnet_model_fn(): - # When set to False, variables are placed on the least loaded GPU. If set - # to True, the variables will be placed on the CPU. - is_cpu_ps = False - - # Loops over the number of GPUs and creates a copy ("tower") of the model on - # each GPU. - for i in range(num_gpus): - worker = '/gpu:%d' % i - # Creates a device setter used to determine where Ops are to be placed. - device_setter = _create_device_setter(is_cpu_ps, worker, FLAGS.num_gpus) - # Creates variables on the first loop. On subsequent loops reuse is set - # to True, which results in the "towers" sharing variables. - with tf.variable_scope('resnet', reuse=bool(i != 0)): - with tf.name_scope('tower_%d' % i) as name_scope: - # tf.device calls the device_setter for each Op that is created. - # device_setter returns the device the Op is to be placed on. - with tf.device(device_setter): - # Creates the "tower". - _tower_fn(is_training, weight_decay, tower_features[i], - tower_labels[i], tower_losses, tower_gradvars, - tower_preds, False) - -``` - -In the near future the above code will be for illustration purposes only as -there will be easy to use high level methods to support a wide range of popular -approaches. This -[example](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10_estimator) -will continue to get updated as the API expands and evolves to address multi-GPU -scenarios. - -## Optimizing for CPU - -CPUs, which includes Intel® Xeon Phi™, achieve optimal performance when -TensorFlow is [built from source](../install/install_sources.md) with all of the instructions -supported by the target CPU. - -Beyond using the latest instruction sets, Intel® has added support for the -Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN) to -TensorFlow. While the name is not completely accurate, these optimizations are -often simply referred to as 'MKL' or 'TensorFlow with MKL'. [TensorFlow -with Intel® MKL-DNN](#tensorflow_with_intel_mkl_dnn) contains details on the -MKL optimizations. - -The two configurations listed below are used to optimize CPU performance by -adjusting the thread pools. - -* `intra_op_parallelism_threads`: Nodes that can use multiple threads to - parallelize their execution will schedule the individual pieces into this - pool. -* `inter_op_parallelism_threads`: All ready nodes are scheduled in this pool. - -These configurations are set via the `tf.ConfigProto` and passed to `tf.Session` -in the `config` attribute as shown in the snippet below. For both configuration -options, if they are unset or set to 0, will default to the number of logical -CPU cores. Testing has shown that the default is effective for systems ranging -from one CPU with 4 cores to multiple CPUs with 70+ combined logical cores. -A common alternative optimization is to set the number of threads in both pools -equal to the number of physical cores rather than logical cores. - -```python - - config = tf.ConfigProto() - config.intra_op_parallelism_threads = 44 - config.inter_op_parallelism_threads = 44 - tf.Session(config=config) - -``` - -The [Comparing compiler optimizations](#comparing-compiler-optimizations) -section contains the results of tests that used different compiler -optimizations. - -### TensorFlow with Intel® MKL DNN - -Intel® has added optimizations to TensorFlow for Intel® Xeon® and Intel® Xeon -Phi™ through the use of the Intel® Math Kernel Library for Deep Neural Networks -(Intel® MKL-DNN) optimized primitives. The optimizations also provide speedups -for the consumer line of processors, e.g. i5 and i7 Intel processors. The Intel -published paper -[TensorFlow* Optimizations on Modern Intel® Architecture](https://software.intel.com/en-us/articles/tensorflow-optimizations-on-modern-intel-architecture) -contains additional details on the implementation. - -> Note: MKL was added as of TensorFlow 1.2 and currently only works on Linux. It -> also does not work when also using `--config=cuda`. - -In addition to providing significant performance improvements for training CNN -based models, compiling with the MKL creates a binary that is optimized for AVX -and AVX2. The result is a single binary that is optimized and compatible with -most modern (post-2011) processors. - -TensorFlow can be compiled with the MKL optimizations using the following -commands that depending on the version of the TensorFlow source used. - -For TensorFlow source versions after 1.3.0: - -```bash -./configure -# Pick the desired options -bazel build --config=mkl --config=opt //tensorflow/tools/pip_package:build_pip_package - -``` - -For TensorFlow versions 1.2.0 through 1.3.0: - -```bash -./configure -Do you wish to build TensorFlow with MKL support? [y/N] Y -Do you wish to download MKL LIB from the web? [Y/n] Y -# Select the defaults for the rest of the options. - -bazel build --config=mkl --copt="-DEIGEN_USE_VML" -c opt //tensorflow/tools/pip_package:build_pip_package - -``` - -#### Tuning MKL for the best performance - -This section details the different configurations and environment variables that -can be used to tune the MKL to get optimal performance. Before tweaking various -environment variables make sure the model is using the `NCHW` (`channels_first`) -[data format](#data-formats). The MKL is optimized for `NCHW` and Intel is -working to get near performance parity when using `NHWC`. - -MKL uses the following environment variables to tune performance: - -* KMP_BLOCKTIME - Sets the time, in milliseconds, that a thread should wait, - after completing the execution of a parallel region, before sleeping. -* KMP_AFFINITY - Enables the run-time library to bind threads to physical - processing units. -* KMP_SETTINGS - Enables (true) or disables (false) the printing of OpenMP* - run-time library environment variables during program execution. -* OMP_NUM_THREADS - Specifies the number of threads to use. - -More details on the KMP variables are on -[Intel's](https://software.intel.com/en-us/node/522775) site and the OMP -variables on -[gnu.org](https://gcc.gnu.org/onlinedocs/libgomp/Environment-Variables.html) - -While there can be substantial gains from adjusting the environment variables, -which is discussed below, the simplified advice is to set the -`inter_op_parallelism_threads` equal to the number of physical CPUs and to set -the following environment variables: - -* KMP_BLOCKTIME=0 -* KMP_AFFINITY=granularity=fine,verbose,compact,1,0 - -Example setting MKL variables with command-line arguments: - -```bash -KMP_BLOCKTIME=0 KMP_AFFINITY=granularity=fine,verbose,compact,1,0 \ -KMP_SETTINGS=1 python your_python_script.py -``` - -Example setting MKL variables with python `os.environ`: - -```python -os.environ["KMP_BLOCKTIME"] = str(FLAGS.kmp_blocktime) -os.environ["KMP_SETTINGS"] = str(FLAGS.kmp_settings) -os.environ["KMP_AFFINITY"]= FLAGS.kmp_affinity -if FLAGS.num_intra_threads > 0: - os.environ["OMP_NUM_THREADS"]= str(FLAGS.num_intra_threads) - -``` - -There are models and hardware platforms that benefit from different settings. -Each variable that impacts performance is discussed below. - -* **KMP_BLOCKTIME**: The MKL default is 200ms, which was not optimal in our - testing. 0 (0ms) was a good default for CNN based models that were tested. - The best performance for AlexNex was achieved at 30ms and both GoogleNet and - VGG11 performed best set at 1ms. - -* **KMP_AFFINITY**: The recommended setting is - `granularity=fine,verbose,compact,1,0`. - -* **OMP_NUM_THREADS**: This defaults to the number of physical cores. - Adjusting this parameter beyond matching the number of cores can have an - impact when using Intel® Xeon Phi™ (Knights Landing) for some models. See - [TensorFlow* Optimizations on Modern Intel® Architecture](https://software.intel.com/en-us/articles/tensorflow-optimizations-on-modern-intel-architecture) - for optimal settings. - -* **intra_op_parallelism_threads**: Setting this equal to the number of - physical cores is recommended. Setting the value to 0, which is the default, - results in the value being set to the number of logical cores - this is an - alternate option to try for some architectures. This value and `OMP_NUM_THREADS` - should be equal. - -* **inter_op_parallelism_threads**: Setting this equal to the number of - sockets is recommended. Setting the value to 0, which is the default, - results in the value being set to the number of logical cores. - -### Comparing compiler optimizations - -Collected below are performance results running training and inference on -different types of CPUs on different platforms with various compiler -optimizations. The models used were ResNet-50 -([arXiv:1512.03385](https://arxiv.org/abs/1512.03385)) and -InceptionV3 ([arXiv:1512.00567](https://arxiv.org/abs/1512.00567)). - -For each test, when the MKL optimization was used the environment variable -KMP_BLOCKTIME was set to 0 (0ms) and KMP_AFFINITY to -`granularity=fine,verbose,compact,1,0`. - -#### Inference InceptionV3 - -**Environment** - -* Instance Type: AWS EC2 m4.xlarge -* CPU: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (Broadwell) -* Dataset: ImageNet -* TensorFlow Version: 1.2.0 RC2 -* Test Script: [tf_cnn_benchmarks.py](https://github.com/tensorflow/benchmarks/blob/mkl_experiment/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py) - -**Batch Size: 1** - -Command executed for the MKL test: - -```bash -python tf_cnn_benchmarks.py --forward_only=True --device=cpu --mkl=True \ ---kmp_blocktime=0 --nodistortions --model=inception3 --data_format=NCHW \ ---batch_size=1 --num_inter_threads=1 --num_intra_threads=4 \ ---data_dir=<path to ImageNet TFRecords> -``` - -| Optimization | Data Format | Images/Sec | Intra threads | Inter Threads | -: : : (step time) : : : -| ------------ | ----------- | ------------ | ------------- | ------------- | -| AVX2 | NHWC | 7.0 (142ms) | 4 | 0 | -| MKL | NCHW | 6.6 (152ms) | 4 | 1 | -| AVX | NHWC | 5.0 (202ms) | 4 | 0 | -| SSE3 | NHWC | 2.8 (361ms) | 4 | 0 | - -**Batch Size: 32** - -Command executed for the MKL test: - -```bash -python tf_cnn_benchmarks.py --forward_only=True --device=cpu --mkl=True \ ---kmp_blocktime=0 --nodistortions --model=inception3 --data_format=NCHW \ ---batch_size=32 --num_inter_threads=1 --num_intra_threads=4 \ ---data_dir=<path to ImageNet TFRecords> -``` - -| Optimization | Data Format | Images/Sec | Intra threads | Inter Threads | -: : : (step time) : : : -| ------------ | ----------- | ------------- | ------------- | ------------- | -| MKL | NCHW | 10.3 | 4 | 1 | -: : : (3,104ms) : : : -| AVX2 | NHWC | 7.5 (4,255ms) | 4 | 0 | -| AVX | NHWC | 5.1 (6,275ms) | 4 | 0 | -| SSE3 | NHWC | 2.8 (11,428ms)| 4 | 0 | - -#### Inference ResNet-50 - -**Environment** - -* Instance Type: AWS EC2 m4.xlarge -* CPU: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (Broadwell) -* Dataset: ImageNet -* TensorFlow Version: 1.2.0 RC2 -* Test Script: [tf_cnn_benchmarks.py](https://github.com/tensorflow/benchmarks/blob/mkl_experiment/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py) - -**Batch Size: 1** - -Command executed for the MKL test: - -```bash -python tf_cnn_benchmarks.py --forward_only=True --device=cpu --mkl=True \ ---kmp_blocktime=0 --nodistortions --model=resnet50 --data_format=NCHW \ ---batch_size=1 --num_inter_threads=1 --num_intra_threads=4 \ ---data_dir=<path to ImageNet TFRecords> -``` - -| Optimization | Data Format | Images/Sec | Intra threads | Inter Threads | -: : : (step time) : : : -| ------------ | ----------- | ------------ | ------------- | ------------- | -| AVX2 | NHWC | 8.8 (113ms) | 4 | 0 | -| MKL | NCHW | 8.5 (120ms) | 4 | 1 | -| AVX | NHWC | 6.4 (157ms) | 4 | 0 | -| SSE3 | NHWC | 3.7 (270ms) | 4 | 0 | - -**Batch Size: 32** - -Command executed for the MKL test: - -```bash -python tf_cnn_benchmarks.py --forward_only=True --device=cpu --mkl=True \ ---kmp_blocktime=0 --nodistortions --model=resnet50 --data_format=NCHW \ ---batch_size=32 --num_inter_threads=1 --num_intra_threads=4 \ ---data_dir=<path to ImageNet TFRecords> -``` - -| Optimization | Data Format | Images/Sec | Intra threads | Inter Threads | -: : : (step time) : : : -| ------------ | ----------- | ------------- | ------------- | ------------- | -| MKL | NCHW | 12.4 | 4 | 1 | -: : : (2,590ms) : : : -| AVX2 | NHWC | 10.4 (3,079ms)| 4 | 0 | -| AVX | NHWC | 7.3 (4,4416ms)| 4 | 0 | -| SSE3 | NHWC | 4.0 (8,054ms) | 4 | 0 | - -#### Training InceptionV3 - -**Environment** - -* Instance Type: Dedicated AWS EC2 r4.16xlarge (Broadwell) -* CPU: Intel Xeon E5-2686 v4 (Broadwell) Processors -* Dataset: ImageNet -* TensorFlow Version: 1.2.0 RC2 -* Test Script: [tf_cnn_benchmarks.py](https://github.com/tensorflow/benchmarks/blob/mkl_experiment/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py) - -Command executed for MKL test: - -```bash -python tf_cnn_benchmarks.py --device=cpu --mkl=True --kmp_blocktime=0 \ ---nodistortions --model=resnet50 --data_format=NCHW --batch_size=32 \ ---num_inter_threads=2 --num_intra_threads=36 \ ---data_dir=<path to ImageNet TFRecords> -``` - -Optimization | Data Format | Images/Sec | Intra threads | Inter Threads ------------- | ----------- | ---------- | ------------- | ------------- -MKL | NCHW | 20.8 | 36 | 2 -AVX2 | NHWC | 6.2 | 36 | 0 -AVX | NHWC | 5.7 | 36 | 0 -SSE3 | NHWC | 4.3 | 36 | 0 - -ResNet and [AlexNet](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf) -were also run on this configuration but in an ad hoc manner. There were not -enough runs executed to publish a coherent table of results. The incomplete -results strongly indicated the final result would be similar to the table above -with MKL providing significant 3x+ gains over AVX2. diff --git a/tensorflow/docs_src/performance/performance_models.md b/tensorflow/docs_src/performance/performance_models.md deleted file mode 100644 index 151c0b2946..0000000000 --- a/tensorflow/docs_src/performance/performance_models.md +++ /dev/null @@ -1,422 +0,0 @@ -# High-Performance Models - -This document and accompanying -[scripts](https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks) -detail how to build highly scalable models that target a variety of system types -and network topologies. The techniques in this document utilize some low-level -TensorFlow Python primitives. In the future, many of these techniques will be -incorporated into high-level APIs. - -## Input Pipeline - -The [Performance Guide](../performance/performance_guide.md) explains how to identify possible -input pipeline issues and best practices. We found that using `tf.FIFOQueue` -and `tf.train.queue_runner` could not saturate multiple current generation GPUs -when using large inputs and processing with higher samples per second, such -as training ImageNet with [AlexNet](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf). -This is due to the use of Python threads as its underlying implementation. The -overhead of Python threads is too large. - -Another approach, which we have implemented in the -[scripts](https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks), -is to build an input pipeline using the native parallelism in TensorFlow. Our -implementation is made up of 3 stages: - -* I/O reads: Choose and read image files from disk. -* Image Processing: Decode image records into images, preprocess, and organize - into mini-batches. -* CPU-to-GPU Data Transfer: Transfer images from CPU to GPU. - -The dominant part of each stage is executed in parallel with the other stages -using `data_flow_ops.StagingArea`. `StagingArea` is a queue-like operator -similar to `tf.FIFOQueue`. The difference is that `StagingArea` does not -guarantee FIFO ordering, but offers simpler functionality and can be executed -on both CPU and GPU in parallel with other stages. Breaking the input pipeline -into 3 stages that operate independently in parallel is scalable and takes full -advantage of large multi-core environments. The rest of this section details -the stages followed by details about using `data_flow_ops.StagingArea`. - -### Parallelize I/O Reads - -`data_flow_ops.RecordInput` is used to parallelize reading from disk. Given a -list of input files representing TFRecords, `RecordInput` continuously reads -records using background threads. The records are placed into its own large -internal pool and when it has loaded at least half of its capacity, it produces -output tensors. - -This op has its own internal threads that are dominated by I/O time that consume -minimal CPU, which allows it to run smoothly in parallel with the rest of the -model. - -### Parallelize Image Processing - -After images are read from `RecordInput` they are passed as tensors to the image -processing pipeline. To make the image processing pipeline easier to explain, -assume that the input pipeline is targeting 8 GPUs with a batch size of 256 (32 -per GPU). - -256 records are read and processed individually in parallel. This starts with -256 independent `RecordInput` read ops in the graph. Each read op is followed by -an identical set of ops for image preprocessing that are considered independent -and executed in parallel. The image preprocessing ops include operations such as -image decoding, distortion, and resizing. - -Once the images are through preprocessing, they are concatenated together into 8 -tensors each with a batch-size of 32. Rather than using `tf.concat` for this -purpose, which is implemented as a single op that waits for all the inputs to be -ready before concatenating them together, `tf.parallel_stack` is used. -`tf.parallel_stack` allocates an uninitialized tensor as an output, and each -input tensor is written to its designated portion of the output tensor as soon -as the input is available. - -When all the input tensors are finished, the output tensor is passed along in -the graph. This effectively hides all the memory latency with the long tail of -producing all the input tensors. - -### Parallelize CPU-to-GPU Data Transfer - -Continuing with the assumption that the target is 8 GPUs with a batch size of -256 (32 per GPU). Once the input images are processed and concatenated together -by the CPU, we have 8 tensors each with a batch-size of 32. - -TensorFlow enables tensors from one device to be used on any other device -directly. TensorFlow inserts implicit copies to make the tensors available on -any devices where they are used. The runtime schedules the copy between devices -to run before the tensors are actually used. However, if the copy cannot finish -in time, the computation that needs those tensors will stall and result in -decreased performance. - -In this implementation, `data_flow_ops.StagingArea` is used to explicitly -schedule the copy in parallel. The end result is that when computation starts on -the GPU, all the tensors are already available. - -### Software Pipelining - -With all the stages capable of being driven by different processors, -`data_flow_ops.StagingArea` is used between them so they run in parallel. -`StagingArea` is a queue-like operator similar to `tf.FIFOQueue` that offers -simpler functionalities that can be executed on both CPU and GPU. - -Before the model starts running all the stages, the input pipeline stages are -warmed up to prime the staging buffers in between with one set of data. -During each run step, one set of data is read from the staging buffers at -the beginning of each stage, and one set is pushed at the end. - -For example: if there are three stages: A, B and C. There are two staging areas -in between: S1 and S2. During the warm up, we run: - -``` -Warm up: -Step 1: A0 -Step 2: A1 B0 - -Actual execution: -Step 3: A2 B1 C0 -Step 4: A3 B2 C1 -Step 5: A4 B3 C2 -``` - -After the warm up, S1 and S2 each have one set of data in them. For each step of -the actual execution, one set of data is consumed from each staging area, and -one set is added to each. - -Benefits of using this scheme: - -* All stages are non-blocking, since the staging areas always have one set of - data after the warm up. -* Each stage can run in parallel since they can all start immediately. -* The staging buffers have a fixed memory overhead. They will have at most one - extra set of data. -* Only a single`session.run()` call is needed to run all stages of the step, - which makes profiling and debugging much easier. - -## Best Practices in Building High-Performance Models - -Collected below are a couple of additional best practices that can improve -performance and increase the flexibility of models. - -### Build the model with both NHWC and NCHW - -Most TensorFlow operations used by a CNN support both NHWC and NCHW data format. -On GPU, NCHW is faster. But on CPU, NHWC is sometimes faster. - -Building a model to support both data formats keeps the model flexible and -capable of operating optimally regardless of platform. Most TensorFlow -operations used by a CNN support both NHWC and NCHW data formats. The benchmark -script was written to support both NCHW and NHWC. NCHW should always be used -when training with GPUs. NHWC is sometimes faster on CPU. A flexible model can -be trained on GPUs using NCHW with inference done on CPU using NHWC with the -weights obtained from training. - -### Use Fused Batch-Normalization - -The default batch-normalization in TensorFlow is implemented as composite -operations. This is very general, but often leads to suboptimal performance. An -alternative is to use fused batch-normalization which often has much better -performance on GPU. Below is an example of using `tf.contrib.layers.batch_norm` -to implement fused batch-normalization. - -```python -bn = tf.contrib.layers.batch_norm( - input_layer, fused=True, data_format='NCHW' - scope=scope) -``` - -## Variable Distribution and Gradient Aggregation - -During training, training variable values are updated using aggregated gradients -and deltas. In the benchmark script, we demonstrate that with the flexible and -general-purpose TensorFlow primitives, a diverse range of high-performance -distribution and aggregation schemes can be built. - -Three examples of variable distribution and aggregation were included in the -script: - -* `parameter_server` where each replica of the training model reads the - variables from a parameter server and updates the variable independently. - When each model needs the variables, they are copied over through the - standard implicit copies added by the TensorFlow runtime. The example - [script](https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks) - illustrates using this method for local training, distributed synchronous - training, and distributed asynchronous training. -* `replicated` places an identical copy of each training variable on each - GPU. The forward and backward computation can start immediately as the - variable data is immediately available. Gradients are accumulated across all - GPUs, and the aggregated total is applied to each GPU's copy of the - variables to keep them in sync. -* `distributed_replicated` places an identical copy of the training parameters - on each GPU along with a master copy on the parameter servers. The forward - and backward computation can start immediately as the variable data is - immediately available. Gradients are accumulated across all GPUs on each - server and then the per-server aggregated gradients are applied to the - master copy. After all workers do this, each worker updates its copy of the - variable from the master copy. - -Below are additional details about each approach. - -### Parameter Server Variables - -The most common way trainable variables are managed in TensorFlow models is -parameter server mode. - -In a distributed system, each worker process runs the same model, and parameter -server processes own the master copies of the variables. When a worker needs a -variable from a parameter server, it refers to it directly. The TensorFlow -runtime adds implicit copies to the graph to make the variable value available -on the computation device that needs it. When a gradient is computed on a -worker, it is sent to the parameter server that owns the particular variable, -and the corresponding optimizer is used to update the variable. - -There are some techniques to improve throughput: - -* The variables are spread among parameter servers based on their size, for - load balancing. -* When each worker has multiple GPUs, gradients are accumulated across the - GPUs and a single aggregated gradient is sent to the parameter server. This - reduces the network bandwidth and the amount of work done by the parameter - servers. - -For coordinating between workers, a very common mode is async updates, where -each worker updates the master copy of the variables without synchronizing with -other workers. In our model, we demonstrate that it is fairly easy to introduce -synchronization across workers so updates for all workers are finished in one -step before the next step can start. - -The parameter server method can also be used for local training, In this case, -instead of spreading the master copies of variables across parameters servers, -they are either on the CPU or spread across the available GPUs. - -Due to the simple nature of this setup, this architecture has gained a lot of -popularity within the community. - -This mode can be used in the script by passing -`--variable_update=parameter_server`. - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" alt="parameter_server mode in distributed training" - src="../images/perf_parameter_server_mode_doc.png"> -</div> - -### Replicated Variables - -In this design, each GPU on the server has its own copy of each variable. The -values are kept in sync across GPUs by applying the fully aggregated gradient to -each GPU's copy of the variable. - -The variables and data are available at the start of training, so the forward -pass of training can start immediately. Gradients are aggregated across the -devices and the fully aggregated gradient is then applied to each local copy. - -Gradient aggregation across the server can be done in different ways: - -* Using standard TensorFlow operations to accumulate the total on a single - device (CPU or GPU) and then copy it back to all GPUs. -* Using NVIDIA® NCCL, described below in the NCCL section. - -This mode can be used in the script by passing `--variable_update=replicated`. - -### Replicated Variables in Distributed Training - -The replicated method for variables can be extended to distributed training. One -way to do this like the replicated mode: aggregate the gradients fully across -the cluster and apply them to each local copy of the variable. This may be shown -in a future version of this scripts; the scripts do present a different -variation, described here. - -In this mode, in addition to each GPU's copy of the variables, a master copy is -stored on the parameter servers. As with the replicated mode, training can start -immediately using the local copies of the variables. - -As the gradients of the weights become available, they are sent back to the -parameter servers and all local copies are updated: - -1. All the gradients from the GPU on the same worker are aggregated together. -2. Aggregated gradients from each worker are sent to the parameter server that - owns the variable, where the specified optimizer is used to update the - master copy of the variable. -3. Each worker updates its local copy of the variable from the master. In the - example model, this is done with a cross-replica barrier that waits for all - the workers to finish updating the variables, and fetches the new variable - only after the barrier has been released by all replicas. Once the copy - finishes for all variables, this marks the end of a training step, and a new - step can start. - -Although this sounds similar to the standard use of parameter servers, the -performance is often better in many cases. This is largely due to the fact the -computation can happen without any delay, and much of the copy latency of early -gradients can be hidden by later computation layers. - -This mode can be used in the script by passing -`--variable_update=distributed_replicated`. - - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" alt="distributed_replicated mode" - src="../images/perf_distributed_replicated_mode_doc.png"> -</div> - -#### NCCL - -In order to broadcast variables and aggregate gradients across different GPUs -within the same host machine, we can use the default TensorFlow implicit copy -mechanism. - -However, we can instead use the optional NCCL (`tf.contrib.nccl`) support. NCCL -is an NVIDIA® library that can efficiently broadcast and aggregate data across -different GPUs. It schedules a cooperating kernel on each GPU that knows how to -best utilize the underlying hardware topology; this kernel uses a single SM of -the GPU. - -In our experiment, we demonstrate that although NCCL often leads to much faster -data aggregation by itself, it doesn't necessarily lead to faster training. Our -hypothesis is that the implicit copies are essentially free since they go to the -copy engine on GPU, as long as its latency can be hidden by the main computation -itself. Although NCCL can transfer data faster, it takes one SM away, and adds -more pressure to the underlying L2 cache. Our results show that for 8-GPUs, NCCL -often leads to better performance. However, for fewer GPUs, the implicit copies -often perform better. - -#### Staged Variables - -We further introduce a staged-variable mode where we use staging areas for both -the variable reads, and their updates. Similar to software pipelining of the -input pipeline, this can hide the data copy latency. If the computation time -takes longer than the copy and aggregation, the copy itself becomes essentially -free. - -The downside is that all the weights read are from the previous training step. -So it is a different algorithm from SGD. But it is possible to improve its -convergence by adjusting learning rate and other hyperparameters. - -## Executing the script - -This section lists the core command line arguments and a few basic examples for -executing the main script -([tf_cnn_benchmarks.py](https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py)). - -> Note: `tf_cnn_benchmarks.py` uses the config `force_gpu_compatible`, -> which was introduced after TensorFlow 1.1. Until TensorFlow 1.2 is released -> building from source is advised. - -#### Base command line arguments - -* **`model`**: Model to use, e.g. `resnet50`, `inception3`, `vgg16`, and - `alexnet`. -* **`num_gpus`**: Number of GPUs to use. -* **`data_dir`**: Path to data to process. If not set, synthetic data is used. - To use ImageNet data use these - [instructions](https://github.com/tensorflow/models/tree/master/research/inception#getting-started) - as a starting point. -* **`batch_size`**: Batch size for each GPU. -* **`variable_update`**: The method for managing variables: `parameter_server` - ,`replicated`, `distributed_replicated`, `independent` -* **`local_parameter_device`**: Device to use as parameter server: `cpu` or - `gpu`. - -#### Single instance examples - -```bash -# VGG16 training ImageNet with 8 GPUs using arguments that optimize for -# Google Compute Engine. -python tf_cnn_benchmarks.py --local_parameter_device=cpu --num_gpus=8 \ ---batch_size=32 --model=vgg16 --data_dir=/home/ubuntu/imagenet/train \ ---variable_update=parameter_server --nodistortions - -# VGG16 training synthetic ImageNet data with 8 GPUs using arguments that -# optimize for the NVIDIA DGX-1. -python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \ ---batch_size=64 --model=vgg16 --variable_update=replicated --use_nccl=True - -# VGG16 training ImageNet data with 8 GPUs using arguments that optimize for -# Amazon EC2. -python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \ ---batch_size=64 --model=vgg16 --variable_update=parameter_server - -# ResNet-50 training ImageNet data with 8 GPUs using arguments that optimize for -# Amazon EC2. -python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \ ---batch_size=64 --model=resnet50 --variable_update=replicated --use_nccl=False - -``` - -#### Distributed command line arguments - -* **`ps_hosts`**: Comma separated list of hosts to use as parameter servers - in the format of ```<host>:port```, e.g. ```10.0.0.2:50000```. -* **`worker_hosts`**: Comma separated list of hosts to use as workers in the - format of ```<host>:port```, e.g. ```10.0.0.2:50001```. -* **`task_index`**: Index of the host in the list of `ps_hosts` or - `worker_hosts` being started. -* **`job_name`**: Type of job, e.g `ps` or `worker` - -#### Distributed examples - -Below is an example of training ResNet-50 on 2 hosts: host_0 (10.0.0.1) and -host_1 (10.0.0.2). The example uses synthetic data. To use real data pass the -`--data_dir` argument. - -```bash -# Run the following commands on host_0 (10.0.0.1): -python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \ ---batch_size=64 --model=resnet50 --variable_update=distributed_replicated \ ---job_name=worker --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \ ---worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=0 - -python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \ ---batch_size=64 --model=resnet50 --variable_update=distributed_replicated \ ---job_name=ps --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \ ---worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=0 - - -# Run the following commands on host_1 (10.0.0.2): -python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \ ---batch_size=64 --model=resnet50 --variable_update=distributed_replicated \ ---job_name=worker --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \ ---worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=1 - -python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \ ---batch_size=64 --model=resnet50 --variable_update=distributed_replicated \ ---job_name=ps --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \ ---worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=1 - -``` diff --git a/tensorflow/docs_src/performance/quantization.md b/tensorflow/docs_src/performance/quantization.md deleted file mode 100644 index 3326d82964..0000000000 --- a/tensorflow/docs_src/performance/quantization.md +++ /dev/null @@ -1,253 +0,0 @@ -# Fixed Point Quantization - -Quantization techniques store and calculate numbers in more compact formats. -[TensorFlow Lite](/mobile/tflite/) adds quantization that uses an 8-bit fixed -point representation. - -Since a challenge for modern neural networks is optimizing for high accuracy, the -priority has been improving accuracy and speed during training. Using floating -point arithmetic is an easy way to preserve accuracy and GPUs are designed to -accelerate these calculations. - -However, as more machine learning models are deployed to mobile devices, -inference efficiency has become a critical issue. Where the computational demand -for *training* grows with the amount of models trained on different -architectures, the computational demand for *inference* grows in proportion to -the amount of users. - -## Quantization benefits - - -Using 8-bit calculations help your models run faster and use less power. This is -especially important for mobile devices and embedded applications that can't run -floating point code efficiently, for example, Internet of Things (IoT) and -robotics devices. There are additional opportunities to extend this support to -more backends and research lower precision networks. - -### Smaller file sizes {: .hide-from-toc} - -Neural network models require a lot of space on disk. For example, the original -AlexNet requires over 200 MB for the float format—almost all of that for the -model's millions of weights. Because the weights are slightly different -floating point numbers, simple compression formats perform poorly (like zip). - -Weights fall in large layers of numerical values. For each layer, weights tend to -be normally distributed within a range. Quantization can shrink file sizes by -storing the minimum and maximum weight for each layer, then compress each -weight's float value to an 8-bit integer representing the closest real number in -a linear set of 256 within the range. - -### Faster inference {: .hide-from-toc} - -Since calculations are run entirely on 8-bit inputs and outputs, quantization -reduces the computational resources needed for inference calculations. This is -more involved, requiring changes to all floating point calculations, but results -in a large speed-up for inference time. - -### Memory efficiency {: .hide-from-toc} - -Since fetching 8-bit values only requires 25% of the memory bandwidth of floats, -more efficient caches avoid bottlenecks for RAM access. In many cases, the power -consumption for running a neural network is dominated by memory access. The -savings from using fixed-point 8-bit weights and activations are significant. - -Typically, SIMD operations are available that run more operations per clock -cycle. In some cases, a DSP chip is available that accelerates 8-bit calculations -resulting in a massive speedup. - -## Fixed point quantization techniques - -The goal is to use the same precision for weights and activations during both -training and inference. But an important difference is that training consists of -a forward pass and a backward pass, while inference only uses a forward pass. -When we train the model with quantization in the loop, we ensure that the forward -pass matches precision for both training and inference. - -To minimize the loss in accuracy for fully fixed point models (weights and -activations), train the model with quantization in the loop. This simulates -quantization in the forward pass of a model so weights tend towards values that -perform better during quantized inference. The backward pass uses quantized -weights and activations and models quantization as a straight through estimator. -(See Bengio et al., [2013](https://arxiv.org/abs/1308.3432)) - -Additionally, the minimum and maximum values for activations are determined -during training. This allows a model trained with quantization in the loop to be -converted to a fixed point inference model with little effort, eliminating the -need for a separate calibration step. - -## Quantization training with TensorFlow - -TensorFlow can train models with quantization in the loop. Because training -requires small gradient adjustments, floating point values are still used. To -keep models as floating point while adding the quantization error in the training -loop, [fake quantization](../api_guides/python/array_ops.md#Fake_quantization) nodes simulate the -effect of quantization in the forward and backward passes. - -Since it's difficult to add these fake quantization operations to all the -required locations in the model, there's a function available that rewrites the -training graph. To create a fake quantized training graph: - -``` -# Build forward pass of model. -loss = tf.losses.get_total_loss() - -# Call the training rewrite which rewrites the graph in-place with -# FakeQuantization nodes and folds batchnorm for training. It is -# often needed to fine tune a floating point model for quantization -# with this training tool. When training from scratch, quant_delay -# can be used to activate quantization after training to converge -# with the float graph, effectively fine-tuning the model. -tf.contrib.quantize.create_training_graph(quant_delay=2000000) - -# Call backward pass optimizer as usual. -optimizer = tf.train.GradientDescentOptimizer(learning_rate) -optimizer.minimize(loss) -``` - -The rewritten *eval graph* is non-trivially different from the *training graph* -since the quantization ops affect the batch normalization step. Because of this, -we've added a separate rewrite for the *eval graph*: - -``` -# Build eval model -logits = tf.nn.softmax_cross_entropy_with_logits_v2(...) - -# Call the eval rewrite which rewrites the graph in-place with -# FakeQuantization nodes and fold batchnorm for eval. -tf.contrib.quantize.create_eval_graph() - -# Save the checkpoint and eval graph proto to disk for freezing -# and providing to TFLite. -with open(eval_graph_file, ‘w’) as f: - f.write(str(g.as_graph_def())) -saver = tf.train.Saver() -saver.save(sess, checkpoint_name) -``` - -Methods to rewrite the training and eval graphs are an active area of research -and experimentation. Although rewrites and quantized training might not work or -improve performance for all models, we are working to generalize these -techniques. - -## Generating fully quantized models - -The previously demonstrated after-rewrite eval graph only *simulates* -quantization. To generate real fixed point computations from a trained -quantization model, convert it to a fixed point kernel. Tensorflow Lite supports -this conversion from the graph resulting from `create_eval_graph`. - -First, create a frozen graph that will be the input for the TensorFlow Lite -toolchain: - -``` -bazel build tensorflow/python/tools:freeze_graph && \ - bazel-bin/tensorflow/python/tools/freeze_graph \ - --input_graph=eval_graph_def.pb \ - --input_checkpoint=checkpoint \ - --output_graph=frozen_eval_graph.pb --output_node_names=outputs -``` - -Provide this to the TensorFlow Lite Optimizing Converter (TOCO) to get a fully -quantized TensorFLow Lite model: - -``` -bazel build tensorflow/contrib/lite/toco:toco && \ - ./bazel-bin/third_party/tensorflow/contrib/lite/toco/toco \ - --input_file=frozen_eval_graph.pb \ - --output_file=tflite_model.tflite \ - --input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE \ - --inference_type=QUANTIZED_UINT8 \ - --input_shape="1,224, 224,3" \ - --input_array=input \ - --output_array=outputs \ - --std_value=127.5 --mean_value=127.5 -``` - -See the documentation for `tf.contrib.quantize` and -[TensorFlow Lite](/mobile/tflite/). - -## Quantized accuracy - -Fixed point [MobileNet](https://arxiv.org/abs/1704.0486) models are released with -8-bit weights and activations. Using the rewriters, these models achieve the -Top-1 accuracies listed in Table 1. For comparison, the floating point accuracies -are listed for the same models. The code used to generate these models -[is available](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md) -along with links to all of the pretrained mobilenet_v1 models. - -<figure> - <table> - <tr> - <th>Image Size</th> - <th>Depth</th> - <th>Top-1 Accuracy:<br>Floating point</th> - <th>Top-1 Accuracy:<br>Fixed point: 8 bit weights and activations</th> - </tr> - <tr><td>128</td><td>0.25</td><td>0.415</td><td>0.399</td></tr> - <tr><td>128</td><td>0.5</td><td>0.563</td><td>0.549</td></tr> - <tr><td>128</td><td>0.75</td><td>0.621</td><td>0.598</td></tr> - <tr><td>128</td><td>1</td><td>0.652</td><td>0.64</td></tr> - <tr><td>160</td><td>0.25</td><td>0.455</td><td>0.435</td></tr> - <tr><td>160</td><td>0.5</td><td>0.591</td><td>0.577</td></tr> - <tr><td>160</td><td>0.75</td><td>0.653</td><td>0.639</td></tr> - <tr><td>160</td><td>1</td><td>0.68</td><td>0.673</td></tr> - <tr><td>192</td><td>0.25</td><td>0.477</td><td>0.458</td></tr> - <tr><td>192</td><td>0.5</td><td>0.617</td><td>0.604</td></tr> - <tr><td>192</td><td>0.75</td><td>0.672</td><td>0.662</td></tr> - <tr><td>192</td><td>1</td><td>0.7</td><td>0.69</td></tr> - <tr><td>224</td><td>0.25</td><td>0.498</td><td>0.482</td></tr> - <tr><td>224</td><td>0.5</td><td>0.633</td><td>0.622</td></tr> - <tr><td>224</td><td>0.75</td><td>0.684</td><td>0.679</td></tr> - <tr><td>224</td><td>1</td><td>0.709</td><td>0.697</td></tr> - </table> - <figcaption> - <b>Table 1</b>: MobileNet Top-1 accuracy on Imagenet Validation dataset. - </figcaption> -</figure> - -## Representation for quantized tensors - -TensorFlow approaches the conversion of floating-point arrays of numbers into -8-bit representations as a compression problem. Since the weights and activation -tensors in trained neural network models tend to have values that are distributed -across comparatively small ranges (for example, -15 to +15 for weights or -500 to -1000 for image model activations). And since neural nets tend to be robust -handling noise, the error introduced by quantizing to a small set of values -maintains the precision of the overall results within an acceptable threshold. A -chosen representation must perform fast calculations, especially the large matrix -multiplications that comprise the bulk of the computations while running a model. - -This is represented with two floats that store the overall minimum and maximum -values corresponding to the lowest and highest quantized value. Each entry in the -quantized array represents a float value in that range, distributed linearly -between the minimum and maximum. For example, with a minimum of -10.0 and maximum -of 30.0f, and an 8-bit array, the quantized values represent the following: - -<figure> - <table> - <tr><th>Quantized</th><th>Float</th></tr> - <tr><td>0</td><td>-10.0</td></tr> - <tr><td>128</td><td>10.0</td></tr> - <tr><td>255</td><td>30.0</td></tr> - </table> - <figcaption> - <b>Table 2</b>: Example quantized value range - </figcaption> -</figure> - -The advantages of this representation format are: - -* It efficiently represents an arbitrary magnitude of ranges. -* The values don't have to be symmetrical. -* The format represents both signed and unsigned values. -* The linear spread makes multiplications straightforward. - -Alternative techniques use lower bit depths by non-linearly distributing the -float values across the representation, but currently are more expensive in terms -of computation time. (See Han et al., -[2016](https://arxiv.org/abs/1510.00149).) - -The advantage of having a clear definition of the quantized format is that it's -always possible to convert back and forth from fixed-point to floating-point for -operations that aren't quantization-ready, or to inspect the tensors for -debugging. diff --git a/tensorflow/docs_src/performance/xla/broadcasting.md b/tensorflow/docs_src/performance/xla/broadcasting.md deleted file mode 100644 index 7018ded53f..0000000000 --- a/tensorflow/docs_src/performance/xla/broadcasting.md +++ /dev/null @@ -1,204 +0,0 @@ -# Broadcasting semantics - -This document describes how the broadcasting semantics in XLA work. - -## What is broadcasting? - -Broadcasting is the process of making arrays with different shapes have -compatible shapes for arithmetic operations. The terminology is borrowed from -Numpy -[(broadcasting)](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html). - -Broadcasting may be required for operations between multi-dimensional arrays of -different ranks, or between multi-dimensional arrays with different but -compatible shapes. Consider the addition `X+v` where `X` is a matrix (an array -of rank 2) and `v` is a vector (an array of rank 1). To perform element-wise -addition, XLA needs to "broadcast" the vector `v` to the same rank as the -matrix `X`, by replicating `v` a certain number of times. The vector's length -has to match at least one of the dimensions of the matrix. - -For example: - - |1 2 3| + |7 8 9| - |4 5 6| - -The matrix's dimensions are (2,3), the vector's are (3). The vector is broadcast -by replicating it over rows to get: - - |1 2 3| + |7 8 9| = |8 10 12| - |4 5 6| |7 8 9| |11 13 15| - -In Numpy, this is called [broadcasting] -(http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html). - -## Principles - -The XLA language is as strict and explicit as possible, avoiding implicit and -"magical" features. Such features may make some computations slightly easier to -define, at the cost of more assumptions baked into user code that will be -difficult to change in the long term. If necessary, implicit and magical -features can be added in client-level wrappers. - -In regards to broadcasting, explicit broadcasting specifications on operations -between arrays of different ranks is required. This is different from Numpy, -which infers the specification when possible. - -## Broadcasting a lower-rank array onto a higher-rank array - -*Scalars* can always be broadcast over arrays without an explicit specification -of broadcasting dimensions. An element-wise binary operation between a scalar -and an array means applying the operation with the scalar for each element in -the array. For example, adding a scalar to a matrix means producing a matrix -each element of which is a sum of the scalar with the corresponding input -matrix's element. - - |1 2 3| + 7 = |8 9 10| - |4 5 6| |11 12 13| - -Most broadcasting needs can be captured by using a tuple of dimensions on a -binary operation. When the inputs to the operation have different ranks, this -broadcasting tuple specifies which dimension(s) in the **higher-rank** array to -match with the **lower-rank** array. - -Consider the previous example, instead of adding a scalar to a (2,3) matrix, add -a vector of dimension (3) to a matrix of dimensions (2,3). *Without specifying -broadcasting, this operation is invalid.* To correctly request matrix-vector -addition, specify the broadcasting dimension to be (1), meaning the vector's -dimension is matched to dimension 1 of the matrix. In 2D, if dimension 0 is -considered as rows and dimension 1 as columns, this means that each element of -the vector becomes a column of a size matching the number of rows in the matrix: - - |7 8 9| ==> |7 8 9| - |7 8 9| - -As a more complex example, consider adding a 3-element vector (dimension (3)) to -a 3x3 matrix (dimensions (3,3)). There are two ways broadcasting can happen for -this example: - -(1) A broadcasting dimension of 1 can be used. Each vector element becomes a -column and the vector is duplicated for each row in the matrix. - - |7 8 9| ==> |7 8 9| - |7 8 9| - |7 8 9| - -(2) A broadcasting dimension of 0 can be used. Each vector element becomes a row -and the vector is duplicated for each column in the matrix. - - |7| ==> |7 7 7| - |8| |8 8 8| - |9| |9 9 9| - -> Note: when adding a 2x3 matrix to a 3-element vector, a broadcasting dimension -> of 0 is invalid. - -The broadcasting dimensions can be a tuple that describes how a smaller rank -shape is broadcast into a larger rank shape. For example, given a 2x3x4 cuboid -and a 3x4 matrix, a broadcasting tuple (1,2) means matching the matrix to -dimensions 1 and 2 of the cuboid. - -This type of broadcast is used in the binary ops in `XlaBuilder`, if the -`broadcast_dimensions` argument is given. For example, see -[XlaBuilder::Add](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.cc). -In the XLA source code, this type of broadcasting is sometimes called "InDim" -broadcasting. - -### Formal definition - -The broadcasting attribute allows matching a lower-rank array to a higher-rank -array, by specifying which dimensions of the higher-rank array to match. For -example, for an array with dimensions MxNxPxQ, a vector with dimension T can be -matched as follows: - - MxNxPxQ - - dim 3: T - dim 2: T - dim 1: T - dim 0: T - -In each case, T has to be equal to the matching dimension of the higher-rank -array. The vector's values are then broadcast from the matched dimension to all -the other dimensions. - -To match a TxV matrix onto the MxNxPxQ array, a pair of broadcasting dimensions -are used: - - MxNxPxQ - dim 2,3: T V - dim 1,2: T V - dim 0,3: T V - etc... - -The order of dimensions in the broadcasting tuple has to be the order in which -the lower-rank array's dimensions are expected to match the higher-rank array's -dimensions. The first element in the tuple says which dimension in the -higher-rank array has to match dimension 0 in the lower-rank array. The second -element for dimension 1, and so on. The order of broadcast dimensions has to be -strictly increasing. For example, in the previous example it is illegal to match -V to N and T to P; it is also illegal to match V to both P and N. - -## Broadcasting similar-rank arrays with degenerate dimensions - -A related broadcasting problem is broadcasting two arrays that have the same -rank but different dimension sizes. Similarly to Numpy's rules, this is only -possible when the arrays are *compatible*. Two arrays are compatible when all -their dimensions are compatible. Two dimensions are compatible if: - -* They are equal, or -* One of them is 1 (a "degenerate" dimension) - -When two compatible arrays are encountered, the result shape has the maximum -among the two inputs at every dimension index. - -Examples: - -1. (2,1) and (2,3) broadcast to (2,3). -2. (1,2,5) and (7,2,5) broadcast to (7,2,5) -3. (7,2,5) and (7,1,5) broadcast to (7,2,5) -4. (7,2,5) and (7,2,6) are incompatible and cannot be broadcast. - -A special case arises, and is also supported, where each of the input arrays has -a degenerate dimension at a different index. In this case, the result is an -"outer operation": (2,1) and (1,3) broadcast to (2,3). For more examples, -consult the [Numpy documentation on -broadcasting](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html). - -## Broadcast composition - -Broadcasting of a lower-rank array to a higher-rank array **and** broadcasting -using degenerate dimensions can both be performed in the same binary operation. -For example, a vector of size 4 and an matrix of size 1x2 can be added together -using broadcast dimensions value of (0): - - |1 2 3 4| + [5 6] // [5 6] is a 1x2 matrix, not a vector. - -First the vector is broadcast up to rank 2 (matrix) using the broadcast -dimensions. The single value (0) in the broadcast dimensions indicates that -dimension zero of the vector matches to dimension zero of the matrix. This -produces an matrix of size 4xM where the value M is chosen to match the -corresponding dimension size in the 1x2 array. Therefore, a 4x2 matrix is -produced: - - |1 1| + [5 6] - |2 2| - |3 3| - |4 4| - -Then "degenerate dimension broadcasting" broadcasts dimension zero of the 1x2 -matrix to match the corresponding dimension size of the right hand side: - - |1 1| + |5 6| |6 7| - |2 2| + |5 6| = |7 8| - |3 3| + |5 6| |8 9| - |4 4| + |5 6| |9 10| - -A more complicated example is a matrix of size 1x2 added to an array of size -4x3x1 using broadcast dimensions of (1, 2). First the 1x2 matrix is broadcast up -to rank 3 using the broadcast dimensions to produces an intermediate Mx1x2 array -where the dimension size M is determined by the size of the larger operand (the -4x3x1 array) producing a 4x1x2 intermediate array. The M is at dimension 0 -(left-most dimension) because the dimensions 1 and 2 are mapped to the -dimensions of the original 1x2 matrix as the broadcast dimension are (1, 2). -This intermediate array can be added to the 4x3x1 matrix using broadcasting of -degenerate dimensions to produce a 4x3x2 array result. diff --git a/tensorflow/docs_src/performance/xla/developing_new_backend.md b/tensorflow/docs_src/performance/xla/developing_new_backend.md deleted file mode 100644 index 840f6983c2..0000000000 --- a/tensorflow/docs_src/performance/xla/developing_new_backend.md +++ /dev/null @@ -1,77 +0,0 @@ -# Developing a new backend for XLA - -This preliminary guide is for early adopters that want to easily retarget -TensorFlow to their hardware in an efficient manner. The guide is not -step-by-step and assumes knowledge of [LLVM](http://llvm.org), -[Bazel](https://bazel.build/), and TensorFlow. - -XLA provides an abstract interface that a new architecture or accelerator can -implement to create a backend to run TensorFlow graphs. Retargeting XLA should -be significantly simpler and scalable than implementing every existing -TensorFlow Op for new hardware. - -Most implementations will fall into one of the following scenarios: - -1. Existing CPU architecture not yet officially supported by XLA, with or - without an existing [LLVM](http://llvm.org) backend. -2. Non-CPU-like hardware with an existing LLVM backend. -3. Non-CPU-like hardware without an existing LLVM backend. - -> Note: An LLVM backend can mean either one of the officially released LLVM -> backends or a custom LLVM backend developed in-house. - -## Scenario 1: Existing CPU architecture not yet officially supported by XLA - -In this scenario, start by looking at the existing [XLA CPU backend] -(https://www.tensorflow.org/code/tensorflow/compiler/xla/service/cpu/). -XLA makes it easy to retarget TensorFlow to different CPUs by using LLVM, since -the main difference between XLA backends for CPUs is the code generated by LLVM. -Google tests XLA for x64 and ARM64 architectures. - -If the hardware vendor has an LLVM backend for their hardware, it is simple to -link the backend with the LLVM built with XLA. In JIT mode, the XLA CPU backend -emits code for the host CPU. For ahead-of-time compilation, -[`xla::AotCompilationOptions`](https://www.tensorflow.org/code/tensorflow/compiler/xla/service/compiler.h) -can provide an LLVM triple to configure the target architecture. - -If there is no existing LLVM backend but another kind of code generator exists, -it should be possible to reuse most of the existing CPU backend. - -## Scenario 2: Non-CPU-like hardware with an existing LLVM backend - -It is possible to model a new -[`xla::Compiler`](https://www.tensorflow.org/code/tensorflow/compiler/xla/service/compiler.h) -implementation on the existing [`xla::CPUCompiler`] -(https://www.tensorflow.org/code/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc) -and [`xla::GPUCompiler`] -(https://www.tensorflow.org/code/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc) -classes, since these already emit LLVM IR. Depending on the nature of the -hardware, it is possible that many of the LLVM IR generation aspects will have -to be changed, but a lot of code can be shared with the existing backends. - -A good example to follow is the [GPU backend] -(https://www.tensorflow.org/code/tensorflow/compiler/xla/service/gpu/) -of XLA. The GPU backend targets a non-CPU-like ISA, and therefore some aspects -of its code generation are unique to the GPU domain. Other kinds of hardware, -e.g. DSPs like Hexagon (which has an upstream LLVM backend), can reuse parts of -the LLVM IR emission logic, but other parts will be unique. - -## Scenario 3: Non-CPU-like hardware without an existing LLVM backend - -If it is not possible to utilize LLVM, then the best option is to implement a -new backend for XLA for the desired hardware. This option requires the most -effort. The classes that need to be implemented are as follows: - -* [`StreamExecutor`](https://www.tensorflow.org/code/tensorflow/stream_executor/stream_executor.h): - For many devices not all methods of `StreamExecutor` are needed. See - existing `StreamExecutor` implementations for details. -* [`xla::Compiler`](https://www.tensorflow.org/code/tensorflow/compiler/xla/service/compiler.h): - This class encapsulates the compilation of an HLO computation into an - `xla::Executable`. -* [`xla::Executable`](https://www.tensorflow.org/code/tensorflow/compiler/xla/service/executable.h): - This class is used to launch a compiled computation on the platform. -* [`xla::TransferManager`](https://www.tensorflow.org/code/tensorflow/compiler/xla/service/transfer_manager.h): - This class enables backends to provide platform-specific mechanisms for - constructing XLA literal data from given device memory handles. In other - words, it helps encapsulate the transfer of data from the host to the device - and back. diff --git a/tensorflow/docs_src/performance/xla/index.md b/tensorflow/docs_src/performance/xla/index.md deleted file mode 100644 index 770737c34c..0000000000 --- a/tensorflow/docs_src/performance/xla/index.md +++ /dev/null @@ -1,98 +0,0 @@ -# XLA Overview - -<div style="width:50%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:50%" src="/images/xlalogo.png"> -</div> - -> Note: XLA is experimental and considered alpha. Most use cases will not -> see improvements in performance (speed or decreased memory usage). We have -> released XLA early so the Open Source Community can contribute to its -> development, as well as create a path for integration with hardware -> accelerators. - -XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear -algebra that optimizes TensorFlow computations. The results are improvements in -speed, memory usage, and portability on server and mobile platforms. Initially, -most users will not see large benefits from XLA, but are welcome to experiment -by using XLA via [just-in-time (JIT) compilation](../../performance/xla/jit.md) or [ahead-of-time (AOT) compilation](../../performance/xla/tfcompile.md). Developers targeting new hardware accelerators are -especially encouraged to try out XLA. - -The XLA framework is experimental and in active development. In particular, -while it is unlikely that the semantics of existing operations will change, it -is expected that more operations will be added to cover important use cases. The -team welcomes feedback from the community about missing functionality and -community contributions via GitHub. - -## Why did we build XLA? - -We had several objectives for XLA to work with TensorFlow: - -* *Improve execution speed.* Compile subgraphs to reduce the execution time of - short-lived Ops to eliminate overhead from the TensorFlow runtime, fuse - pipelined operations to reduce memory overhead, and specialize to known - tensor shapes to allow for more aggressive constant propagation. - -* *Improve memory usage.* Analyze and schedule memory usage, in principle - eliminating many intermediate storage buffers. - -* *Reduce reliance on custom Ops.* Remove the need for many custom Ops by - improving the performance of automatically fused low-level Ops to match the - performance of custom Ops that were fused by hand. - -* *Reduce mobile footprint.* Eliminate the TensorFlow runtime by ahead-of-time - compiling the subgraph and emitting an object/header file pair that can be - linked directly into another application. The results can reduce the - footprint for mobile inference by several orders of magnitude. - -* *Improve portability.* Make it relatively easy to write a new backend for - novel hardware, at which point a large fraction of TensorFlow programs will - run unmodified on that hardware. This is in contrast with the approach of - specializing individual monolithic Ops for new hardware, which requires - TensorFlow programs to be rewritten to make use of those Ops. - -## How does XLA work? - -The input language to XLA is called "HLO IR", or just HLO (High Level -Optimizer). The semantics of HLO are described on the -[Operation Semantics](../../performance/xla/operation_semantics.md) page. It -is most convenient to think of HLO as a [compiler -IR](https://en.wikipedia.org/wiki/Intermediate_representation). - -XLA takes graphs ("computations") defined in HLO and compiles them into machine -instructions for various architectures. XLA is modular in the sense that it is -easy to slot in an alternative backend to [target some novel HW architecture](../../performance/xla/developing_new_backend.md). The CPU backend for x64 and ARM64 as -well as the NVIDIA GPU backend are in the TensorFlow source tree. - -The following diagram shows the compilation process in XLA: - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img src="https://www.tensorflow.org/images/how-does-xla-work.png"> -</div> - -XLA comes with several optimizations and analysis passes that are -target-independent, such as -[CSE](https://en.wikipedia.org/wiki/Common_subexpression_elimination), -target-independent operation fusion, and buffer analysis for allocating runtime -memory for the computation. - -After the target-independent step, XLA sends the HLO computation to a backend. -The backend can perform further HLO-level optimizations, this time with target -specific information and needs in mind. For example, the XLA GPU backend may -perform operation fusion beneficial specifically for the GPU programming model -and determine how to partition the computation into streams. At this stage, -backends may also pattern-match certain operations or combinations thereof to -optimized library calls. - -The next step is target-specific code generation. The CPU and GPU backends -included with XLA use [LLVM](http://llvm.org) for low-level IR, optimization, -and code-generation. These backends emit the LLVM IR necessary to represent the -XLA HLO computation in an efficient manner, and then invoke LLVM to emit native -code from this LLVM IR. - -The GPU backend currently supports NVIDIA GPUs via the LLVM NVPTX backend; the -CPU backend supports multiple CPU ISAs. - -## Supported Platforms - -XLA currently supports [JIT compilation](../../performance/xla/jit.md) on x86-64 and NVIDIA GPUs; and -[AOT compilation](../../performance/xla/tfcompile.md) for x86-64 and ARM. diff --git a/tensorflow/docs_src/performance/xla/jit.md b/tensorflow/docs_src/performance/xla/jit.md deleted file mode 100644 index 7202ef47f7..0000000000 --- a/tensorflow/docs_src/performance/xla/jit.md +++ /dev/null @@ -1,169 +0,0 @@ -# Using JIT Compilation - -> Note: TensorFlow must be compiled from source to include XLA. - -## Why use just-in-time (JIT) compilation? - -The TensorFlow/XLA JIT compiler compiles and runs parts of TensorFlow graphs via -XLA. The benefit of this over the standard TensorFlow implementation is that XLA -can fuse multiple operators (kernel fusion) into a small number of compiled -kernels. Fusing operators can reduce memory bandwidth requirements and improve -performance compared to executing operators one-at-a-time, as the TensorFlow -executor does. - -## Running TensorFlow graphs via XLA - -There are two ways to run TensorFlow computations via XLA, either by -JIT-compiling operators placed on a CPU or GPU device, or by placing operators -on the `XLA_CPU` or `XLA_GPU` TensorFlow devices. Placing operators directly on -a TensorFlow XLA device forces the operator to run on that device and is mainly -used for testing. - -> Note: The XLA CPU backend supports intra-op parallelism (i.e. it can shard a -> single operation across multiple cores) but it does not support inter-op -> parallelism (i.e. it cannot execute independent operations concurrently across -> multiple cores). The XLA GPU backend is competitive with the standard -> TensorFlow implementation, sometimes faster, sometimes slower. - -### Turning on JIT compilation - -JIT compilation can be turned on at the session level or manually for select -operations. Both of these approaches are zero-copy --- data does not need to be -copied when passing data between a compiled XLA kernel and a TensorFlow operator -placed on the same device. - -#### Session - -Turning on JIT compilation at the session level will result in all possible -operators being greedily compiled into XLA computations. Each XLA computation -will be compiled into one or more kernels for the underlying device. - -Subject to a few constraints, if there are two adjacent operators in the graph -that both have XLA implementations, then they will be compiled into a single XLA -computation. - -JIT compilation is turned on at the session level by setting the -`global_jit_level` config to `tf.OptimizerOptions.ON_1` and passing the config -during session initialization. - -```python -# Config to turn on JIT compilation -config = tf.ConfigProto() -config.graph_options.optimizer_options.global_jit_level = tf.OptimizerOptions.ON_1 - -sess = tf.Session(config=config) -``` - -> Note: Turning on JIT at the session level will not result in operations being -> compiled for the CPU. JIT compilation for CPU operations must be done via -> the manual method documented below. - -#### Manual - -JIT compilation can also be turned on manually for one or more operators. This -is done by tagging the operators to compile with the attribute -`_XlaCompile=true`. The simplest way to do this is via the -`tf.contrib.compiler.jit.experimental_jit_scope()` scope defined in -[`tensorflow/contrib/compiler/jit.py`](https://www.tensorflow.org/code/tensorflow/contrib/compiler/jit.py). -Example usage: - -```python - jit_scope = tf.contrib.compiler.jit.experimental_jit_scope - - x = tf.placeholder(np.float32) - with jit_scope(): - y = tf.add(x, x) # The "add" will be compiled with XLA. -``` - -The `_XlaCompile` attribute is currently supported on a best-effort basis. If an -operator cannot be compiled, TensorFlow will silently fall back to the normal -implementation. - -### Placing operators on XLA devices - -Another way to run computations via XLA is to place an operator on a specific -XLA device. This method is normally only used for testing. Valid targets are -`XLA_CPU` or `XLA_GPU`. - -```python -with tf.device("/job:localhost/replica:0/task:0/device:XLA_GPU:0"): - output = tf.add(input1, input2) -``` - -Unlike JIT compilation on the standard CPU and GPU devices, these devices make a -copy of data when it is transferred on and off the device. The extra copy makes -it expensive to mix XLA and TensorFlow operators in the same graph. - -## Tutorial - -This tutorial covers training a simple version of MNIST softmax with JIT turned -on. Currently JIT at the session level, which is what is used for the tutorial, -only supports GPU. - -Before starting the tutorial verify that the LD_LIBRARY environment variable or -ldconfig contains `$CUDA_ROOT/extras/CUPTI/lib64`, which contains libraries for -the CUDA Profiling Tools Interface [(CUPTI)](http://docs.nvidia.com/cuda/cupti/index.html). -TensorFlow uses CUPTI to pull tracing information from the GPU. - -### Step #1: Prepare sample script - -Download or move -[mnist_softmax_xla.py](https://www.tensorflow.org/code/tensorflow/examples/tutorials/mnist/mnist_softmax_xla.py) -into a folder outside of the TensorFlow source tree. - -### Step #2: Run without XLA - -Execute the python script to train the model without XLA. - -```shell -python mnist_softmax_xla.py --xla='' -``` - -Using the Chrome Trace Event Profiler (browse to chrome://tracing), -open the timeline file created when the script finishes: `timeline.ctf.json`. -The rendered timeline should look similar to the picture below with multiple -green boxes labeled `MatMul`, possibly across multiple CPUs. -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/jit_timeline_gpu.png"> -</div> - -### Step #3 Run with XLA - -Execute the python script to train the model with XLA and turn on a debugging -feature of XLA via an environmental variable that outputs the XLA graph. - -```shell -TF_XLA_FLAGS=--xla_generate_hlo_graph=.* python mnist_softmax_xla.py -``` - -Open the timeline file created (`timeline.ctf.json`). The rendered timeline -should look similar to the picture below with one long bar labeled `XlaLaunch`. -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/jit_timeline_gpu_xla.png"> -</div> - -To understand what is happening in `XlaLaunch`, look at the console output for -statements similar to the following: - -```shell -computation cluster_0[_XlaCompiledKernel=true,_XlaNumConstantArgs=1].v82 [CPU: -pipeline start, before inline]: /tmp/hlo_graph_0.dot - -``` - -The console statements point to the location of `hlo_graph_xx.dot` files that -contain information about the graph created by XLA. The process that XLA takes -to fuse Ops is visible by starting at `hlo_graph_0.dot` and viewing each diagram -in succession. - -To Render the .dot file into a png, install -[GraphViz](https://www.graphviz.org/download/) and run: - -```shell -dot -Tpng hlo_graph_80.dot -o hlo_graph_80.png -``` - -The result will look like the following: -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/jit_gpu_xla_graph.png"> -</div> diff --git a/tensorflow/docs_src/performance/xla/operation_semantics.md b/tensorflow/docs_src/performance/xla/operation_semantics.md deleted file mode 100644 index 2de30d1b3d..0000000000 --- a/tensorflow/docs_src/performance/xla/operation_semantics.md +++ /dev/null @@ -1,2422 +0,0 @@ -# Operation Semantics - -The following describes the semantics of operations defined in the -[`XlaBuilder`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h) -interface. Typically, these operations map one-to-one to operations defined in -the RPC interface in -[`xla_data.proto`](https://www.tensorflow.org/code/tensorflow/compiler/xla/xla_data.proto). - -A note on nomenclature: the generalized data type XLA deals with is an -N-dimensional array holding elements of some uniform type (such as 32-bit -float). Throughout the documentation, *array* is used to denote an -arbitrary-dimensional array. For convenience, special cases have more specific -and familiar names; for example a *vector* is a 1-dimensional array and a -*matrix* is a 2-dimensional array. - -## AllToAll - -See also -[`XlaBuilder::AllToAll`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Alltoall is a collective operation that sends data from all cores to all cores. -It has two phases: - -1. the scatter phase. On each core, the operand is split into `split_count` - number of blocks along the `split_dimensions`, and the blocks are scattered - to all cores, e.g., the ith block is send to the ith core. -2. the gather phase. Each core concatenates the received blocks along the - `concat_dimension`. - -The participating cores can be configured by: - -- `replica_groups`: each ReplicaGroup contains a list of replica id. If empty, - all replicas belong to one group in the order of 0 - (n-1). Alltoall will be - applied within subgroups in the specified order. For example, replica - groups = {{1,2,3},{4,5,0}} means, an Alltoall will be applied within replica - 1, 2, 3, and in the gather phase, the received blocks will be concatenated - in the order of 1, 2, 3; another Alltoall will be applied within replica 4, - 5, 0, and the concatenation order is 4, 5, 0. - -Prerequisites: - -- The dimension size of the operand on the split_dimension is divisible by - split_count. -- The operand's shape is not tuple. - -<b> `AllToAll(operand, split_dimension, concat_dimension, split_count, -replica_groups)` </b> - - -| Arguments | Type | Semantics | -| ------------------ | --------------------- | ------------------------------- | -| `operand` | `XlaOp` | n dimensional input array | -| `split_dimension` | `int64` | A value in the interval `[0, | -: : : n)` that names the dimension : -: : : along which the operand is : -: : : split : -| `concat_dimension` | `int64` | a value in the interval `[0, | -: : : n)` that names the dimension : -: : : along which the split blocks : -: : : are concatenated : -| `split_count` | `int64` | the number of cores that | -: : : participate this operation. If : -: : : `replica_groups` is empty, this : -: : : should be the number of : -: : : replicas; otherwise, this : -: : : should be equal to the number : -: : : of replicas in each group. : -| `replica_groups` | `ReplicaGroup` vector | each group contains a list of | -: : : replica id. : - -Below shows an example of Alltoall. - -``` -XlaBuilder b("alltoall"); -auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x"); -AllToAll(x, /*split_dimension=*/1, /*concat_dimension=*/0, /*split_count=*/4); -``` - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="../../images/xla/ops_alltoall.png"> -</div> - -In this example, there are 4 cores participating the Alltoall. On each core, the -operand is split into 4 parts along dimension 0, so each part has shape -f32[4,4]. The 4 parts are scattered to all cores. Then each core concatenates -the received parts along dimension 1, in the order or core 0-4. So the output on -each core has shape f32[16,4]. - -## BatchNormGrad - -See also -[`XlaBuilder::BatchNormGrad`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h) -and [the original batch normalization paper](https://arxiv.org/abs/1502.03167) -for a detailed description of the algorithm. - -Calculates gradients of batch norm. - -<b> `BatchNormGrad(operand, scale, mean, variance, grad_output, epsilon, feature_index)` </b> - -| Arguments | Type | Semantics | -| --------------- | ----------------------- | -------------------------------- | -| `operand` | `XlaOp` | n dimensional array to be | -: : : normalized (x) : -| `scale` | `XlaOp` | 1 dimensional array | -: : : (\\(\gamma\\)) : -| `mean` | `XlaOp` | 1 dimensional array (\\(\mu\\)) | -| `variance` | `XlaOp` | 1 dimensional array | -: : : (\\(\sigma^2\\)) : -| `grad_output` | `XlaOp` | Gradients passed to | -: : : `BatchNormTraining` : -: : : (\\( \nabla y\\)) : -| `epsilon` | `float` | Epsilon value (\\(\epsilon\\)) | -| `feature_index` | `int64` | Index to feature dimension in | -: : : `operand` : - -For each feature in the feature dimension (`feature_index` is the index for the -feature dimension in `operand`), the operation calculates the gradients with -respect to `operand`, `offset` and `scale` across all the other dimensions. The -`feature_index` must be a valid index for the feature dimension in `operand`. - -The three gradients are defined by the following formulas (assuming a -4-dimensional tensor as `operand` and with feature dimension index \\(l\\), -batch size `m` and spatial sizes `w` and `h`): - -\\[ \begin{split} c_l&= -\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h -\left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sigma^2_l+\epsilon} \right) -\\\\ -\nabla x_{ijkl} &= \frac{\gamma_{l}}{\sqrt{\sigma^2_{l}+\epsilon}} -\left( \nabla y_{ijkl} - \mathrm{mean}(\nabla y) - c_l (x_{ijkl} - \mu_{l}) -\right) -\\\\ -\nabla \gamma_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} -\frac{x_{ijkl} - \mu_l}{\sqrt{\sigma^2_{l}+\epsilon}} \right) -\\\\\ -\nabla \beta_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} -\end{split} \\] - -The inputs `mean` and `variance` represent moments value -across batch and spatial dimensions. - -The output type is a tuple of three handles: - -| Outputs | Type | Semantics | -| ------------- | ----------------------- | --------------------------------- | -| `grad_operand` | `XlaOp` | gradient with respect to input | -: : : `operand` (\\( \nabla x\\)) : -| `grad_scale` | `XlaOp` | gradient with respect to input | -: : : `scale` (\\( \nabla \gamma\\)) : -| `grad_offset` | `XlaOp` | gradient with respect to input | -: : : `offset`(\\( \nabla \beta\\)) : - -## BatchNormInference - -See also -[`XlaBuilder::BatchNormInference`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h) -and [the original batch normalization paper](https://arxiv.org/abs/1502.03167) -for a detailed description of the algorithm. - -Normalizes an array across batch and spatial dimensions. - -<b> `BatchNormInference(operand, scale, offset, mean, variance, epsilon, feature_index)` </b> - -Arguments | Type | Semantics ---------------- | ------- | --------------------------------------- -`operand` | `XlaOp` | n dimensional array to be normalized -`scale` | `XlaOp` | 1 dimensional array -`offset` | `XlaOp` | 1 dimensional array -`mean` | `XlaOp` | 1 dimensional array -`variance` | `XlaOp` | 1 dimensional array -`epsilon` | `float` | Epsilon value -`feature_index` | `int64` | Index to feature dimension in `operand` - -For each feature in the feature dimension (`feature_index` is the index for the -feature dimension in `operand`), the operation calculates the mean and variance -across all the other dimensions and uses the mean and variance to normalize each -element in `operand`. The `feature_index` must be a valid index for the feature -dimension in `operand`. - -`BatchNormInference` is equivalent to calling `BatchNormTraining` without -computing `mean` and `variance` for each batch. It uses the input `mean` and -`variance` instead as estimated values. The purpose of this op is to reduce -latency in inference, hence the name `BatchNormInference`. - -The output is an n-dimensional, normalized array with the same shape as input -`operand`. - -## BatchNormTraining - -See also -[`XlaBuilder::BatchNormTraining`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h) -and [`the original batch normalization paper`](https://arxiv.org/abs/1502.03167) -for a detailed description of the algorithm. - -Normalizes an array across batch and spatial dimensions. - -<b> `BatchNormTraining(operand, scale, offset, epsilon, feature_index)` </b> - -Arguments | Type | Semantics ---------------- | ------- | ---------------------------------------- -`operand` | `XlaOp` | n dimensional array to be normalized (x) -`scale` | `XlaOp` | 1 dimensional array (\\(\gamma\\)) -`offset` | `XlaOp` | 1 dimensional array (\\(\beta\\)) -`epsilon` | `float` | Epsilon value (\\(\epsilon\\)) -`feature_index` | `int64` | Index to feature dimension in `operand` - -For each feature in the feature dimension (`feature_index` is the index for the -feature dimension in `operand`), the operation calculates the mean and variance -across all the other dimensions and uses the mean and variance to normalize each -element in `operand`. The `feature_index` must be a valid index for the feature -dimension in `operand`. - -The algorithm goes as follows for each batch in `operand` \\(x\\) that -contains `m` elements with `w` and `h` as the size of spatial dimensions -(assuming `operand` is an 4 dimensional array): - -- Calculates batch mean \\(\mu_l\\) for each feature `l` in feature dimension: -\\(\mu_l=\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h x_{ijkl}\\) - -- Calculates batch variance \\(\sigma^2_l\\): -\\(\sigma^2_l=\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h (x_{ijkl} - \mu_l)^2\\) - -- Normalizes, scales and shifts: -\\(y_{ijkl}=\frac{\gamma_l(x_{ijkl}-\mu_l)}{\sqrt[2]{\sigma^2_l+\epsilon}}+\beta_l\\) - -The epsilon value, usually a small number, is added to avoid divide-by-zero errors. - -The output type is a tuple of three `XlaOp`s: - -| Outputs | Type | Semantics | -| ------------ | ----------------------- | -------------------------------------| -| `output` | `XlaOp` | n dimensional array with the same | -: : : shape as input `operand` (y) : -| `batch_mean` | `XlaOp` | 1 dimensional array (\\(\mu\\)) | -| `batch_var` | `XlaOp` | 1 dimensional array (\\(\sigma^2\\)) | - -The `batch_mean` and `batch_var` are moments calculated across the batch and -spatial dimensions using the formulas above. - -## BitcastConvertType - -See also -[`XlaBuilder::BitcastConvertType`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Similar to a `tf.bitcast` in TensorFlow, performs an element-wise bitcast -operation from a data shape to a target shape. The dimensions must match, and -the conversion is an element-wise one; e.g. `s32` elements become `f32` elements -via bitcast routine. Bitcast is implemented as a low-level cast, so machines -with different floating-point representations will give different results. - -<b> `BitcastConvertType(operand, new_element_type)` </b> - -Arguments | Type | Semantics ------------------- | --------------- | --------------------------- -`operand` | `XlaOp` | array of type T with dims D -`new_element_type` | `PrimitiveType` | type U - -The dimensions of the operand and the target shape must match. The bit-width of -the source and destination element types must be equal. The source -and destination element types must not be tuples. - -## Broadcast - -See also -[`XlaBuilder::Broadcast`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Adds dimensions to an array by duplicating the data in the array. - -<b> `Broadcast(operand, broadcast_sizes)` </b> - -Arguments | Type | Semantics ------------------ | ------------------- | ------------------------------- -`operand` | `XlaOp` | The array to duplicate -`broadcast_sizes` | `ArraySlice<int64>` | The sizes of the new dimensions - -The new dimensions are inserted on the left, i.e. if `broadcast_sizes` has -values `{a0, ..., aN}` and the operand shape has dimensions `{b0, ..., bM}` then -the shape of the output has dimensions `{a0, ..., aN, b0, ..., bM}`. - -The new dimensions index into copies of the operand, i.e. - -``` -output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM] -``` - -For example, if `operand` is a scalar `f32` with value `2.0f`, and -`broadcast_sizes` is `{2, 3}`, then the result will be an array with shape -`f32[2, 3]` and all the values in the result will be `2.0f`. - -## Call - -See also -[`XlaBuilder::Call`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Invokes a computation with the given arguments. - -<b> `Call(computation, args...)` </b> - -| Arguments | Type | Semantics | -| ------------- | ---------------------- | ----------------------------------- | -| `computation` | `XlaComputation` | computation of type `T_0, T_1, ..., | -: : : T_N -> S` with N parameters of : -: : : arbitrary type : -| `args` | sequence of N `XlaOp`s | N arguments of arbitrary type | - -The arity and types of the `args` must match the parameters of the -`computation`. It is allowed to have no `args`. - -## Clamp - -See also -[`XlaBuilder::Clamp`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Clamps an operand to within the range between a minimum and maximum value. - -<b> `Clamp(min, operand, max)` </b> - -Arguments | Type | Semantics ---------- | ------- | --------------- -`min` | `XlaOp` | array of type T -`operand` | `XlaOp` | array of type T -`max` | `XlaOp` | array of type T - -Given an operand and minimum and maximum values, returns the operand if it is in -the range between the minimum and maximum, else returns the minimum value if the -operand is below this range or the maximum value if the operand is above this -range. That is, `clamp(a, x, b) = min(max(a, x), b)`. - -All three arrays must be the same shape. Alternatively, as a restricted form of -[broadcasting](broadcasting.md), `min` and/or `max` can be a scalar of type `T`. - -Example with scalar `min` and `max`: - -``` -let operand: s32[3] = {-1, 5, 9}; -let min: s32 = 0; -let max: s32 = 6; -==> -Clamp(min, operand, max) = s32[3]{0, 5, 6}; -``` - -## Collapse - -See also -[`XlaBuilder::Collapse`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h) -and the `tf.reshape` operation. - -Collapses dimensions of an array into one dimension. - -<b> `Collapse(operand, dimensions)` </b> - -Arguments | Type | Semantics ------------- | -------------- | ----------------------------------------------- -`operand` | `XlaOp` | array of type T -`dimensions` | `int64` vector | in-order, consecutive subset of T's dimensions. - -Collapse replaces the given subset of the operand's dimensions by a single -dimension. The input arguments are an arbitrary array of type T and a -compile-time-constant vector of dimension indices. The dimension indices must be -an in-order (low to high dimension numbers), consecutive subset of T's -dimensions. Thus, {0, 1, 2}, {0, 1}, or {1, 2} are all valid dimension sets, but -{1, 0} or {0, 2} are not. They are replaced by a single new dimension, in the -same position in the dimension sequence as those they replace, with the new -dimension size equal to the product of original dimension sizes. The lowest -dimension number in `dimensions` is the slowest varying dimension (most major) -in the loop nest which collapses these dimension, and the highest dimension -number is fastest varying (most minor). See the `tf.reshape` operator -if more general collapse ordering is needed. - -For example, let v be an array of 24 elements: - -``` -let v = f32[4x2x3] {{{10, 11, 12}, {15, 16, 17}}, - {{20, 21, 22}, {25, 26, 27}}, - {{30, 31, 32}, {35, 36, 37}}, - {{40, 41, 42}, {45, 46, 47}}}; - -// Collapse to a single dimension, leaving one dimension. -let v012 = Collapse(v, {0,1,2}); -then v012 == f32[24] {10, 11, 12, 15, 16, 17, - 20, 21, 22, 25, 26, 27, - 30, 31, 32, 35, 36, 37, - 40, 41, 42, 45, 46, 47}; - -// Collapse the two lower dimensions, leaving two dimensions. -let v01 = Collapse(v, {0,1}); -then v01 == f32[4x6] {{10, 11, 12, 15, 16, 17}, - {20, 21, 22, 25, 26, 27}, - {30, 31, 32, 35, 36, 37}, - {40, 41, 42, 45, 46, 47}}; - -// Collapse the two higher dimensions, leaving two dimensions. -let v12 = Collapse(v, {1,2}); -then v12 == f32[8x3] {{10, 11, 12}, - {15, 16, 17}, - {20, 21, 22}, - {25, 26, 27}, - {30, 31, 32}, - {35, 36, 37}, - {40, 41, 42}, - {45, 46, 47}}; - -``` - -## Concatenate - -See also -[`XlaBuilder::ConcatInDim`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Concatenate composes an array from multiple array operands. The array is of the -same rank as each of the input array operands (which must be of the same rank as -each other) and contains the arguments in the order that they were specified. - -<b> `Concatenate(operands..., dimension)` </b> - -| Arguments | Type | Semantics | -| ----------- | --------------------- | -------------------------------------- | -| `operands` | sequence of N `XlaOp` | N arrays of type T with dimensions | -: : : [L0, L1, ...]. Requires N >= 1. : -| `dimension` | `int64` | A value in the interval `[0, N)` that | -: : : names the dimension to be concatenated : -: : : between the `operands`. : - -With the exception of `dimension` all dimensions must be the same. This is -because XLA does not support "ragged" arrays. Also note that rank-0 values -cannot be concatenated (as it's impossible to name the dimension along which the -concatenation occurs). - -1-dimensional example: - -``` -Concat({{2, 3}, {4, 5}, {6, 7}}, 0) ->>> {2, 3, 4, 5, 6, 7} -``` - -2-dimensional example: - -``` -let a = { - {1, 2}, - {3, 4}, - {5, 6}, -}; -let b = { - {7, 8}, -}; -Concat({a, b}, 0) ->>> { - {1, 2}, - {3, 4}, - {5, 6}, - {7, 8}, -} -``` - -Diagram: -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/ops_concatenate.png"> -</div> - -## Conditional - -See also -[`XlaBuilder::Conditional`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `Conditional(pred, true_operand, true_computation, false_operand, -false_computation)` </b> - -Arguments | Type | Semantics -------------------- | ---------------- | --------------------------------- -`pred` | `XlaOp` | Scalar of type `PRED` -`true_operand` | `XlaOp` | Argument of type `T_0` -`true_computation` | `XlaComputation` | XlaComputation of type `T_0 -> S` -`false_operand` | `XlaOp` | Argument of type `T_1` -`false_computation` | `XlaComputation` | XlaComputation of type `T_1 -> S` - -Executes `true_computation` if `pred` is `true`, `false_computation` if `pred` -is `false`, and returns the result. - -The `true_computation` must take in a single argument of type `T_0` and will be -invoked with `true_operand` which must be of the same type. The -`false_computation` must take in a single argument of type `T_1` and will be -invoked with `false_operand` which must be of the same type. The type of the -returned value of `true_computation` and `false_computation` must be the same. - -Note that only one of `true_computation` and `false_computation` will be -executed depending on the value of `pred`. - -## Conv (convolution) - -See also -[`XlaBuilder::Conv`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -As ConvWithGeneralPadding, but the padding is specified in a short-hand way as -either SAME or VALID. SAME padding pads the input (`lhs`) with zeroes so that -the output has the same shape as the input when not taking striding into -account. VALID padding simply means no padding. - -## ConvWithGeneralPadding (convolution) - -See also -[`XlaBuilder::ConvWithGeneralPadding`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Computes a convolution of the kind used in neural networks. Here, a convolution -can be thought of as a n-dimensional window moving across a n-dimensional base -area and a computation is performed for each possible position of the window. - -| Arguments | Type | Semantics | -| --------------------- | -------------------- | ----------------------------- | -| `lhs` | `XlaOp` | rank n+2 array of inputs | -| `rhs` | `XlaOp` | rank n+2 array of kernel | -: : : weights : -| `window_strides` | `ArraySlice<int64>` | n-d array of kernel strides | -| `padding` | `ArraySlice< | n-d array of (low, high) | -: : pair<int64, int64>>` : padding : -| `lhs_dilation` | `ArraySlice<int64>` | n-d lhs dilation factor array | -| `rhs_dilation` | `ArraySlice<int64>` | n-d rhs dilation factor array | -| `feature_group_count` | int64 | the number of feature groups | - -Let n be the number of spatial dimensions. The `lhs` argument is a rank n+2 -array describing the base area. This is called the input, even though of course -the rhs is also an input. In a neural network, these are the input activations. -The n+2 dimensions are, in this order: - -* `batch`: Each coordinate in this dimension represents an independent input - for which convolution is carried out. -* `z/depth/features`: Each (y,x) position in the base area has a vector - associated to it, which goes into this dimension. -* `spatial_dims`: Describes the `n` spatial dimensions that define the base - area that the window moves across. - -The `rhs` argument is a rank n+2 array describing the convolutional -filter/kernel/window. The dimensions are, in this order: - -* `output-z`: The `z` dimension of the output. -* `input-z`: The size of this dimension times `feature_group_count` should - equal the size of the `z` dimension in lhs. -* `spatial_dims`: Describes the `n` spatial dimensions that define the n-d - window that moves across the base area. - -The `window_strides` argument specifies the stride of the convolutional window -in the spatial dimensions. For example, if the stride in the first spatial -dimension is 3, then the window can only be placed at coordinates where the -first spatial index is divisible by 3. - -The `padding` argument specifies the amount of zero padding to be applied to the -base area. The amount of padding can be negative -- the absolute value of -negative padding indicates the number of elements to remove from the specified -dimension before doing the convolution. `padding[0]` specifies the padding for -dimension `y` and `padding[1]` specifies the padding for dimension `x`. Each -pair has the low padding as the first element and the high padding as the second -element. The low padding is applied in the direction of lower indices while the -high padding is applied in the direction of higher indices. For example, if -`padding[1]` is `(2,3)` then there will be a padding by 2 zeroes on the left and -by 3 zeroes on the right in the second spatial dimension. Using padding is -equivalent to inserting those same zero values into the input (`lhs`) before -doing the convolution. - -The `lhs_dilation` and `rhs_dilation` arguments specify the dilation factor to -be applied to the lhs and rhs, respectively, in each spatial dimension. If the -dilation factor in a spatial dimension is d, then d-1 holes are implicitly -placed between each of the entries in that dimension, increasing the size of the -array. The holes are filled with a no-op value, which for convolution means -zeroes. - -Dilation of the rhs is also called atrous convolution. For more details, see -`tf.nn.atrous_conv2d`. Dilation of the lhs is also called transposed -convolution. For more details, see `tf.nn.conv2d_transpose`. - -The `feature_group_count` argument (default value 1) can be used for grouped -convolutions. `feature_group_count` needs to be a divisor of both the input and -the output feature dimension. If `feature_group_count` is greater than 1, it -means that conceptually the input and output feature dimension and the `rhs` -output feature dimension are split evenly into `feature_group_count` many -groups, each group consisting of a consecutive subsequence of features. The -input feature dimension of `rhs` needs to be equal to the `lhs` input feature -dimension divided by `feature_group_count` (so it already has the size of a -group of input features). The i-th groups are used together to compute -`feature_group_count` many separate convolutions. The results of these -convolutions are concatenated together in the output feature dimension. - -For depthwise convolution the `feature_group_count` argument would be set to the -input feature dimension, and the filter would be reshaped from -`[filter_height, filter_width, in_channels, channel_multiplier]` to -`[filter_height, filter_width, 1, in_channels * channel_multiplier]`. For more -details, see `tf.nn.depthwise_conv2d`. - -The output shape has these dimensions, in this order: - -* `batch`: Same size as `batch` on the input (`lhs`). -* `z`: Same size as `output-z` on the kernel (`rhs`). -* `spatial_dims`: One value for each valid placement of the convolutional - window. - -The valid placements of the convolutional window are determined by the strides -and the size of the base area after padding. - -To describe what a convolution does, consider a 2d convolution, and pick some -fixed `batch`, `z`, `y`, `x` coordinates in the output. Then `(y,x)` is a -position of a corner of the window within the base area (e.g. the upper left -corner, depending on how you interpret the spatial dimensions). We now have a 2d -window, taken from the base area, where each 2d point is associated to a 1d -vector, so we get a 3d box. From the convolutional kernel, since we fixed the -output coordinate `z`, we also have a 3d box. The two boxes have the same -dimensions, so we can take the sum of the element-wise products between the two -boxes (similar to a dot product). That is the output value. - -Note that if `output-z` is e.g., 5, then each position of the window produces 5 -values in the output into the `z` dimension of the output. These values differ -in what part of the convolutional kernel is used - there is a separate 3d box of -values used for each `output-z` coordinate. So you could think of it as 5 -separate convolutions with a different filter for each of them. - -Here is pseudo-code for a 2d convolution with padding and striding: - -``` -for (b, oz, oy, ox) { // output coordinates - value = 0; - for (iz, ky, kx) { // kernel coordinates and input z - iy = oy*stride_y + ky - pad_low_y; - ix = ox*stride_x + kx - pad_low_x; - if ((iy, ix) inside the base area considered without padding) { - value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx); - } - } - output(b, oz, oy, ox) = value; -} -``` - -## ConvertElementType - -See also -[`XlaBuilder::ConvertElementType`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Similar to an element-wise `static_cast` in C++, performs an element-wise -conversion operation from a data shape to a target shape. The dimensions must -match, and the conversion is an element-wise one; e.g. `s32` elements become -`f32` elements via an `s32`-to-`f32` conversion routine. - -<b> `ConvertElementType(operand, new_element_type)` </b> - -Arguments | Type | Semantics ------------------- | --------------- | --------------------------- -`operand` | `XlaOp` | array of type T with dims D -`new_element_type` | `PrimitiveType` | type U - -The dimensions of the operand and the target shape must match. The source and -destination element types must not be tuples. - -A conversion such as `T=s32` to `U=f32` will perform a normalizing int-to-float -conversion routine such as round-to-nearest-even. - -> Note: The precise float-to-int and visa-versa conversions are currently -> unspecified, but may become additional arguments to the convert operation in -> the future. Not all possible conversions have been implemented for all ->targets. - -``` -let a: s32[3] = {0, 1, 2}; -let b: f32[3] = convert(a, f32); -then b == f32[3]{0.0, 1.0, 2.0} -``` - -## CrossReplicaSum - -See also -[`XlaBuilder::CrossReplicaSum`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Computes a sum across replicas. - -<b> `CrossReplicaSum(operand)` </b> - -Arguments | Type | Semantics ---------- | ------- | ----------------------------- -`operand` | `XlaOp` | Array to sum across replicas. -| `replica_group_ids` | `int64` vector | Group ID for each replica. | - -The output shape is the same as the input shape. For example, if there are two -replicas and the operand has the value `(1.0, 2.5)` and `(3.0, 5.25)` -respectively on the two replicas, then the output value from this op will be -`(4.0, 7.75)` on both replicas. - -`replica_group_ids` identifies the group ID of each replica. The group ID must -either be empty (all replicas belong to a single group), or contain the same -number of elements as the number of replicas. For example, if -`replica_group_ids` = {0, 1, 2, 3, 0, 1, 2, 3} has eight replicas, there are -four subgroups of replica IDs: {0, 4}, {1, 5}, {2, 6}, and {3, 7}. The size of -each subgroup *must* be identical, so, for example, using: -`replica_group_ids` = {0, 1, 2, 0} for four replicas is invalid. - -Computing the result of CrossReplicaSum requires having one input from each -replica, so if one replica executes a CrossReplicaSum node more times than -another, then the former replica will wait forever. Since the replicas are all -running the same program, there are not a lot of ways for that to happen, but it -is possible when a while loop's condition depends on data from infeed and the -data that is infed causes the while loop to iterate more times on one replica -than another. - -## CustomCall - -See also -[`XlaBuilder::CustomCall`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Call a user-provided function within a computation. - -<b> `CustomCall(target_name, args..., shape)` </b> - -| Arguments | Type | Semantics | -| ------------- | ---------------------- | --------------------------------- | -| `target_name` | `string` | Name of the function. A call | -: : : instruction will be emitted which : -: : : targets this symbol name. : -| `args` | sequence of N `XlaOp`s | N arguments of arbitrary type, | -: : : which will be passed to the : -: : : function. : -| `shape` | `Shape` | Output shape of the function | - -The function signature is the same, regardless of the arity or type of args: - -``` -extern "C" void target_name(void* out, void** in); -``` - -For example, if CustomCall is used as follows: - -``` -let x = f32[2] {1,2}; -let y = f32[2x3] {{10, 20, 30}, {40, 50, 60}}; - -CustomCall("myfunc", {x, y}, f32[3x3]) -``` - -Here is an example of an implementation of `myfunc`: - -``` -extern "C" void myfunc(void* out, void** in) { - float (&x)[2] = *static_cast<float(*)[2]>(in[0]); - float (&y)[2][3] = *static_cast<float(*)[2][3]>(in[1]); - EXPECT_EQ(1, x[0]); - EXPECT_EQ(2, x[1]); - EXPECT_EQ(10, y[0][0]); - EXPECT_EQ(20, y[0][1]); - EXPECT_EQ(30, y[0][2]); - EXPECT_EQ(40, y[1][0]); - EXPECT_EQ(50, y[1][1]); - EXPECT_EQ(60, y[1][2]); - float (&z)[3][3] = *static_cast<float(*)[3][3]>(out); - z[0][0] = x[1] + y[1][0]; - // ... -} -``` - -The user-provided function must not have side-effects and its execution must be -idempotent. - -> Note: The opaque nature of the user-provided function restricts optimization -> opportunities for the compiler. Try to express your computation in terms of -> native XLA ops whenever possible; only use CustomCall as a last resort. - -## Dot - -See also -[`XlaBuilder::Dot`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `Dot(lhs, rhs)` </b> - -Arguments | Type | Semantics ---------- | ------- | --------------- -`lhs` | `XlaOp` | array of type T -`rhs` | `XlaOp` | array of type T - -The exact semantics of this operation depend on the ranks of the operands: - -| Input | Output | Semantics | -| ----------------------- | --------------------- | ----------------------- | -| vector [n] `dot` vector | scalar | vector dot product | -: [n] : : : -| matrix [m x k] `dot` | vector [m] | matrix-vector | -: vector [k] : : multiplication : -| matrix [m x k] `dot` | matrix [m x n] | matrix-matrix | -: matrix [k x n] : : multiplication : - -The operation performs sum of products over the last dimension of `lhs` and the -one-before-last dimension of `rhs`. These are the "contracted" dimensions. The -contracted dimensions of `lhs` and `rhs` must be of the same size. In practice, -it can be used to perform dot products between vectors, vector/matrix -multiplications or matrix/matrix multiplications. - -## DotGeneral - -See also -[`XlaBuilder::DotGeneral`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `DotGeneral(lhs, rhs, dimension_numbers)` </b> - -Arguments | Type | Semantics -------------------- | --------------------- | --------------- -`lhs` | `XlaOp` | array of type T -`rhs` | `XlaOp` | array of type T -`dimension_numbers` | `DotDimensionNumbers` | array of type T - -As Dot, but allows contracting and batch dimension numbers to be specified for -both the 'lhs' and 'rhs'. - -| DotDimensionNumbers Fields | Type | Semantics -| --------- | ----------------------- | --------------- -| 'lhs_contracting_dimensions' | repeated int64 | 'lhs' contracting dimension numbers | -| 'rhs_contracting_dimensions' | repeated int64 | 'rhs' contracting dimension numbers | -| 'lhs_batch_dimensions' | repeated int64 | 'lhs' batch dimension numbers | -| 'rhs_batch_dimensions' | repeated int64 | 'rhs' batch dimension numbers | - -DotGeneral performs the sum of products over contracting dimensions specified -in 'dimension_numbers'. - -Associated contracting dimension numbers from the 'lhs' and 'rhs' do not need -to be the same, but must be listed in the same order in both -'lhs/rhs_contracting_dimensions' arrays and have the same dimension sizes. -There must be exactly one contracting dimension on both 'lhs' and 'rhs'. - -Example with contracting dimension numbers: - -``` -lhs = { {1.0, 2.0, 3.0}, - {4.0, 5.0, 6.0} } - -rhs = { {1.0, 1.0, 1.0}, - {2.0, 2.0, 2.0} } - -DotDimensionNumbers dnums; -dnums.add_lhs_contracting_dimensions(1); -dnums.add_rhs_contracting_dimensions(1); - -DotGeneral(lhs, rhs, dnums) -> { {6.0, 12.0}, - {15.0, 30.0} } -``` - -Associated batch dimension numbers from the 'lhs' and 'rhs' must have the same -dimension number, must be listed in the same order in both arrays, must -have the same dimension sizes, and must be ordered before contracting and -non-contracting/non-batch dimension numbers. - -Example with batch dimension numbers (batch size 2, 2x2 matrices): - -``` -lhs = { { {1.0, 2.0}, - {3.0, 4.0} }, - { {5.0, 6.0}, - {7.0, 8.0} } } - -rhs = { { {1.0, 0.0}, - {0.0, 1.0} }, - { {1.0, 0.0}, - {0.0, 1.0} } } - -DotDimensionNumbers dnums; -dnums.add_lhs_contracting_dimensions(2); -dnums.add_rhs_contracting_dimensions(1); -dnums.add_lhs_batch_dimensions(0); -dnums.add_rhs_batch_dimensions(0); - -DotGeneral(lhs, rhs, dnums) -> { { {1.0, 2.0}, - {3.0, 4.0} }, - { {5.0, 6.0}, - {7.0, 8.0} } } -``` - -| Input | Output | Semantics | -| ----------------------------------- | ----------------- | ---------------- | -| [b0, m, k] `dot` [b0, k, n] | [b0, m, n] | batch matmul | -| [b0, b1, m, k] `dot` [b0, b1, k, n] | [b0, b1, m, n] | batch matmul | - -It follows that the resulting dimension number starts with the batch dimension, -then the 'lhs' non-contracting/non-batch dimension, and finally the 'rhs' -non-contracting/non-batch dimension. - -## DynamicSlice - -See also -[`XlaBuilder::DynamicSlice`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -DynamicSlice extracts a sub-array from the input array at dynamic -`start_indices`. The size of the slice in each dimension is passed in -`size_indices`, which specify the end point of exclusive slice intervals in each -dimension: [start, start + size). The shape of `start_indices` must be rank == -1, with dimension size equal to the rank of `operand`. - -<b> `DynamicSlice(operand, start_indices, size_indices)` </b> - -| Arguments | Type | Semantics | -| --------------- | ------------------- | ----------------------------------- | -| `operand` | `XlaOp` | N dimensional array of type T | -| `start_indices` | `XlaOp` | Rank 1 array of N integers | -: : : containing the starting indices of : -: : : the slice for each dimension. Value : -: : : must be greater than or equal to : -: : : zero. : -| `size_indices` | `ArraySlice<int64>` | List of N integers containing the | -: : : slice size for each dimension. Each : -: : : value must be strictly greater than : -: : : zero, and start + size must be less : -: : : than or equal to the size of the : -: : : dimension to avoid wrapping modulo : -: : : dimension size. : - -The effective slice indices are computed by applying the following -transformation for each index `i` in `[1, N)` before performing the slice: - -``` -start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - size_indices[i]) -``` - -This ensures that the extracted slice is always in-bounds with respect to the -operand array. If the slice is in-bounds before the transformation is applied, -the transformation has no effect. - -1-dimensional example: - -``` -let a = {0.0, 1.0, 2.0, 3.0, 4.0} -let s = {2} - -DynamicSlice(a, s, {2}) produces: - {2.0, 3.0} -``` - -2-dimensional example: - -``` -let b = - { {0.0, 1.0, 2.0}, - {3.0, 4.0, 5.0}, - {6.0, 7.0, 8.0}, - {9.0, 10.0, 11.0} } -let s = {2, 1} - -DynamicSlice(b, s, {2, 2}) produces: - { { 7.0, 8.0}, - {10.0, 11.0} } -``` -## DynamicUpdateSlice - -See also -[`XlaBuilder::DynamicUpdateSlice`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -DynamicUpdateSlice generates a result which is the value of the input array -`operand`, with a slice `update` overwritten at `start_indices`. -The shape of `update` determines the shape of the sub-array of the result which -is updated. -The shape of `start_indices` must be rank == 1, with dimension size equal to -the rank of `operand`. - -<b> `DynamicUpdateSlice(operand, update, start_indices)` </b> - -| Arguments | Type | Semantics | -| --------------- | ------- | ------------------------------------------------ | -| `operand` | `XlaOp` | N dimensional array of type T | -| `update` | `XlaOp` | N dimensional array of type T containing the | -: : : slice update. Each dimension of update shape : -: : : must be strictly greater than zero, and start + : -: : : update must be less than or equal to the operand : -: : : size for each dimension to avoid generating : -: : : out-of-bounds update indices. : -| `start_indices` | `XlaOp` | Rank 1 array of N integers containing the | -: : : starting indices of the slice for each : -: : : dimension. Value must be greater than or equal : -: : : to zero. : - -The effective slice indices are computed by applying the following -transformation for each index `i` in `[1, N)` before performing the slice: - -``` -start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i]) -``` - -This ensures that the updated slice is always in-bounds with respect to the -operand array. If the slice is in-bounds before the transformation is applied, -the transformation has no effect. - -1-dimensional example: - -``` -let a = {0.0, 1.0, 2.0, 3.0, 4.0} -let u = {5.0, 6.0} -let s = {2} - -DynamicUpdateSlice(a, u, s) produces: - {0.0, 1.0, 5.0, 6.0, 4.0} -``` - -2-dimensional example: - -``` -let b = - { {0.0, 1.0, 2.0}, - {3.0, 4.0, 5.0}, - {6.0, 7.0, 8.0}, - {9.0, 10.0, 11.0} } -let u = - { {12.0, 13.0}, - {14.0, 15.0}, - {16.0, 17.0} } - -let s = {1, 1} - -DynamicUpdateSlice(b, u, s) produces: - { {0.0, 1.0, 2.0}, - {3.0, 12.0, 13.0}, - {6.0, 14.0, 15.0}, - {9.0, 16.0, 17.0} } -``` - -## Element-wise binary arithmetic operations - -See also -[`XlaBuilder::Add`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -A set of element-wise binary arithmetic operations is supported. - -<b> `Op(lhs, rhs)` </b> - -Where `Op` is one of `Add` (addition), `Sub` (subtraction), `Mul` -(multiplication), `Div` (division), `Rem` (remainder), `Max` (maximum), `Min` -(minimum), `LogicalAnd` (logical AND), or `LogicalOr` (logical OR). - -Arguments | Type | Semantics ---------- | ------- | ---------------------------------------- -`lhs` | `XlaOp` | left-hand-side operand: array of type T -`rhs` | `XlaOp` | right-hand-side operand: array of type T - -The arguments' shapes have to be either similar or compatible. See the -[broadcasting](../../performance/xla/broadcasting.md) documentation about what it means for shapes to -be compatible. The result of an operation has a shape which is the result of -broadcasting the two input arrays. In this variant, operations between arrays of -different ranks are *not* supported, unless one of the operands is a scalar. - -When `Op` is `Rem`, the sign of the result is taken from the dividend, and the -absolute value of the result is always less than the divisor's absolute value. - -An alternative variant with different-rank broadcasting support exists for these -operations: - -<b> `Op(lhs, rhs, broadcast_dimensions)` </b> - -Where `Op` is the same as above. This variant of the operation should be used -for arithmetic operations between arrays of different ranks (such as adding a -matrix to a vector). - -The additional `broadcast_dimensions` operand is a slice of integers used to -expand the rank of the lower-rank operand up to the rank of the higher-rank -operand. `broadcast_dimensions` maps the dimensions of the lower-rank shape to -the dimensions of the higher-rank shape. The unmapped dimensions of the expanded -shape are filled with dimensions of size one. Degenerate-dimension broadcasting -then broadcasts the shapes along these degenerate dimensions to equalize the -shapes of both operands. The semantics are described in detail on the -[broadcasting page](../../performance/xla/broadcasting.md). - -## Element-wise comparison operations - -See also -[`XlaBuilder::Eq`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -A set of standard element-wise binary comparison operations is supported. Note -that standard IEEE 754 floating-point comparison semantics apply when comparing -floating-point types. - -<b> `Op(lhs, rhs)` </b> - -Where `Op` is one of `Eq` (equal-to), `Ne` (not equal-to), `Ge` -(greater-or-equal-than), `Gt` (greater-than), `Le` (less-or-equal-than), `Lt` -(less-than). - -Arguments | Type | Semantics ---------- | ------- | ---------------------------------------- -`lhs` | `XlaOp` | left-hand-side operand: array of type T -`rhs` | `XlaOp` | right-hand-side operand: array of type T - -The arguments' shapes have to be either similar or compatible. See the -[broadcasting](../../performance/xla/broadcasting.md) documentation about what it means for shapes to -be compatible. The result of an operation has a shape which is the result of -broadcasting the two input arrays with the element type `PRED`. In this variant, -operations between arrays of different ranks are *not* supported, unless one of -the operands is a scalar. - -An alternative variant with different-rank broadcasting support exists for these -operations: - -<b> `Op(lhs, rhs, broadcast_dimensions)` </b> - -Where `Op` is the same as above. This variant of the operation should be used -for comparison operations between arrays of different ranks (such as adding a -matrix to a vector). - -The additional `broadcast_dimensions` operand is a slice of integers specifying -the dimensions to use for broadcasting the operands. The semantics are described -in detail on the [broadcasting page](../../performance/xla/broadcasting.md). - -## Element-wise unary functions - -XlaBuilder supports these element-wise unary functions: - -<b>`Abs(operand)`</b> Element-wise abs `x -> |x|`. - -<b>`Ceil(operand)`</b> Element-wise ceil `x -> ⌈x⌉`. - -<b>`Cos(operand)`</b> Element-wise cosine `x -> cos(x)`. - -<b>`Exp(operand)`</b> Element-wise natural exponential `x -> e^x`. - -<b>`Floor(operand)`</b> Element-wise floor `x -> ⌊x⌋`. - -<b>`IsFinite(operand)`</b> Tests whether each element of `operand` is finite, -i.e., is not positive or negative infinity, and is not `NaN`. Returns an array -of `PRED` values with the same shape as the input, where each element is `true` -if and only if the corresponding input element is finite. - -<b>`Log(operand)`</b> Element-wise natural logarithm `x -> ln(x)`. - -<b>`LogicalNot(operand)`</b> Element-wise logical not `x -> !(x)`. - -<b>`Neg(operand)`</b> Element-wise negation `x -> -x`. - -<b>`Sign(operand)`</b> Element-wise sign operation `x -> sgn(x)` where - -$$\text{sgn}(x) = \begin{cases} -1 & x < 0\\ 0 & x = 0\\ 1 & x > 0 \end{cases}$$ - -using the comparison operator of the element type of `operand`. - -<b>`Tanh(operand)`</b> Element-wise hyperbolic tangent `x -> tanh(x)`. - - -Arguments | Type | Semantics ---------- | ------- | --------------------------- -`operand` | `XlaOp` | The operand to the function - -The function is applied to each element in the `operand` array, resulting in an -array with the same shape. It is allowed for `operand` to be a scalar (rank 0). - -## Gather - -The XLA gather operation stitches together several slices (each slice at a -potentially different runtime offset) of an input array. - -### General Semantics - -See also -[`XlaBuilder::Gather`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). -For a more intuitive description, see the "Informal Description" section below. - -<b> `gather(operand, start_indices, offset_dims, collapsed_slice_dims, slice_sizes, start_index_map)` </b> - -|Arguments | Type | Semantics | -|----------------- | ----------------------- | --------------------------------| -|`operand` | `XlaOp` | The array we’re gathering | -: : : from. : -|`start_indices` | `XlaOp` | Array containing the starting | -: : : indices of the slices we gather.: -|`index_vector_dim` | `int64` | The dimension in | -: : : `start_indices` that "contains" : -: : : the starting indices. See : -: : : below for a detailed : -: : : description. : -|`offset_dims` | `ArraySlice<int64>` | The set of dimensions in the : -: : : output shape that offset into a : -: : : array sliced from operand. : -|`slice_sizes` | `ArraySlice<int64>` | `slice_sizes[i]` is the bounds | -: : : for the slice on dimension `i`.: -|`collapsed_slice_dims` | `ArraySlice<int64>` | The set of dimensions in each : -| : | slice that are collapsed away. : -| : | These dimensions must have size: -| : | 1. | -|`start_index_map` | `ArraySlice<int64>` | A map that describes how to map| -: : : indices in `start_indices` to : -: : : to legal indices into operand. : - -For convenience, we label dimensions in the output array not in `offset_dims` -as `batch_dims`. - -The output is an array of rank `batch_dims.size` + `operand.rank` - -`collapsed_slice_dims`.size. - -If `index_vector_dim` is equal to `start_indices.rank` we implicitly consider -`start_indices` to have a trailing `1` dimension (i.e. if `start_indices` was of -shape `[6,7]` and `index_vector_dim` is `2` then we implicitly consider the -shape of `start_indices` to be `[6,7,1]`). - -The bounds for the output array along dimension `i` is computed as follows: - - 1. If `i` is present in `batch_dims` (i.e. is equal to `batch_dims[k]` for - some `k`) then we pick the corresponding dimension bounds out of - `start_indices.shape`, skipping `index_vector_dim` (i.e. pick - `start_indices.shape.dims`[`k`] if `k` < `index_vector_dim` and - `start_indices.shape.dims`[`k`+`1`] otherwise). - - 2. If `i` is present in `offset_dims` (i.e. equal to `offset_dims`[`k`] for - some `k`) then we pick the corresponding bound out of `slice_sizes` after - accounting for `collapsed_slice_dims` (i.e. we pick - `adjusted_slice_sizes`[`k`] where `adjusted_slice_sizes` is `slice_sizes` - with the bounds at indices `collapsed_slice_dims` removed). - -Formally, the operand index `In` corresponding to an output index `Out` is -computed as follows: - - 1. Let `G` = { `Out`[`k`] for `k` in `batch_dims` }. Use `G` to slice out - vector `S` such that `S`[`i`] = `start_indices`[Combine(`G`, `i`)] where - Combine(A, b) inserts b at position `index_vector_dim` into A. Note that - this is well defined even if `G` is empty -- if `G` is empty then `S` = - `start_indices`. - - 2. Create a starting index, `S`<sub>`in`</sub>, into `operand` using `S` by - scattering `S` using `start_index_map`. More precisely: - 1. `S`<sub>`in`</sub>[`start_index_map`[`k`]] = `S`[`k`] if `k` < - `start_index_map.size`. - 2. `S`<sub>`in`</sub>[`_`] = `0` otherwise. - - 3. Create an index `O`<sub>`in`</sub> into `operand` by scattering the indices - at the offset dimensions in `Out` according to the `collapsed_slice_dims` - set. More precisely: - 1. `O`<sub>`in`</sub>[`expand_offset_dims`(`k`)] = - `Out`[`offset_dims`[`k`]] if `k` < `offset_dims.size` - (`expand_offset_dims` is defined below). - 2. `O`<sub>`in`</sub>[`_`] = `0` otherwise. - 4. `In` is `O`<sub>`in`</sub> + `S`<sub>`in`</sub> where + is element-wise - addition. - -`expand_offset_dims` is the monotonic function with domain [`0`, `offset.size`) -and range [`0`, `operand.rank`) \ `collapsed_slice_dims`. So if, e.g., -`offset.size` is `4`, `operand.rank` is `6` and `collapsed_slice_dims` is {`0`, -`2`} then `expand_offset_dims` is {`0`→`1`, `1`→`3`, `2`→`4`, `3`→`5`}. - -### Informal Description and Examples - -Informally, every index `Out` in the output array corresponds to an element `E` -in the operand array, computed as follows: - - - We use the batch dimensions in `Out` to look up a starting index from - `start_indices`. - - - We use `start_index_map` to map the starting index (which may have size less - than operand.rank) to a "full" starting index into operand. - - - We dynamic-slice out a slice with size `slice_sizes` using the full starting - index. - - - We reshape the slice by collapsing the `collapsed_slice_dims` dimensions. - Since all collapsed slice dimensions have to have bound 1 this reshape is - always legal. - - - We use the offset dimensions in `Out` to index into this slice to get the - input element, `E`, corresponding to output index `Out`. - -`index_vector_dim` is set to `start_indices.rank` - `1` in all of the -examples that follow. More interesting values for `index_vector_dim` does not -change the operation fundamentally, but makes the visual representation more -cumbersome. - -To get an intuition on how all of the above fits together, let's look at an -example that gathers 5 slices of shape `[8,6]` from a `[16,11]` array. The -position of a slice into the `[16,11]` array can be represented as an index -vector of shape `S64[2]`, so the set of 5 positions can be represented as a -`S64[5,2]` array. - -The behavior of the gather operation can then be depicted as an index -transformation that takes [`G`,`O`<sub>`0`</sub>,`O`<sub>`1`</sub>], an index in -the output shape, and maps it to an element in the input array in the following -way: - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="../../images/ops_xla_gather_0.svg"> -</div> - -We first select an (`X`,`Y`) vector from the gather indices array using `G`. -The element in the output array at index -[`G`,`O`<sub>`0`</sub>,`O`<sub>`1`</sub>] is then the element in the input -array at index [`X`+`O`<sub>`0`</sub>,`Y`+`O`<sub>`1`</sub>]. - -`slice_sizes` is `[8,6]`, which decides the range of W<sub>`0`</sub> and -W<sub>`1`</sub>, and this in turn decides the bounds of the slice. - -This gather operation acts as a batch dynamic slice with `G` as the batch -dimension. - -The gather indices may be multidimensional. For instance, a more general -version of the example above using a "gather indices" array of shape `[4,5,2]` -would translate indices like this: - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="../../images/ops_xla_gather_1.svg"> -</div> - -Again, this acts as a batch dynamic slice `G`<sub>`0`</sub> and -`G`<sub>`1`</sub> as the batch dimensions. The slice size is still `[8,6]`. - -The gather operation in XLA generalizes the informal semantics outlined above in -the following ways: - - 1. We can configure which dimensions in the output shape are the offset - dimensions (dimensions containing `O`<sub>`0`</sub>, `O`<sub>`1`</sub> in - the last example). The output batch dimensions (dimensions containing - `G`<sub>`0`</sub>, `G`<sub>`1`</sub> in the last example) are defined to be - the output dimensions that are not offset dimensions. - - 2. The number of output offset dimensions explicitly present in the output - shape may be smaller than the input rank. These "missing" dimensions, which - are listed explicitly as `collapsed_slice_dims`, must have a slice size of - `1`. Since they have a slice size of `1` the only valid index for them is - `0` and eliding them does not introduce ambiguity. - - 3. The slice extracted from the "Gather Indices" array ((`X`, `Y`) in the last - example) may have fewer elements than the input array rank, and an explicit - mapping dictates how the index should be expanded to have the same rank as - the input. - -As a final example, we use (2) and (3) to implement `tf.gather_nd`: - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="../../images/ops_xla_gather_2.svg"> -</div> - -`G`<sub>`0`</sub> and `G`<sub>`1`</sub> are used to slice out a starting index -from the gather indices array as usual, except the starting index has only one -element, `X`. Similarly, there is only one output offset index with the value -`O`<sub>`0`</sub>. However, before being used as indices into the input array, -these are expanded in accordance to "Gather Index Mapping" (`start_index_map` in -the formal description) and "Offset Mapping" (`expand_offset_dims` in the formal -description) into [`0`,`O`<sub>`0`</sub>] and [`X`,`0`] respectively, adding up -to [`X`,`O`<sub>`0`</sub>]. In other words, the output index -[`G`<sub>`0`</sub>,`G`<sub>`1`</sub>,`O`<sub>`0`</sub>] maps to the input index -[`GatherIndices`[`G`<sub>`0`</sub>,`G`<sub>`1`</sub>,`0`],`X`] which gives us -the semantics for `tf.gather_nd`. - -`slice_sizes` for this case is `[1,11]`. Intuitively this means that every -index `X` in the gather indices array picks an entire row and the result is the -concatenation of all these rows. - -## GetTupleElement - -See also -[`XlaBuilder::GetTupleElement`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Indexes into a tuple with a compile-time-constant value. - -The value must be a compile-time-constant so that shape inference can determine -the type of the resulting value. - -This is analogous to `std::get<int N>(t)` in C++. Conceptually: - -``` -let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; -let s: s32 = 5; -let t: (f32[10], s32) = tuple(v, s); -let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32. -``` - -See also `tf.tuple`. - -## Infeed - -See also -[`XlaBuilder::Infeed`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `Infeed(shape)` </b> - -| Argument | Type | Semantics | -| -------- | ------- | ----------------------------------------------------- | -| `shape` | `Shape` | Shape of the data read from the Infeed interface. The | -: : : layout field of the shape must be set to match the : -: : : layout of the data sent to the device; otherwise its : -: : : behavior is undefined. : - -Reads a single data item from the implicit Infeed streaming interface of the -device, interpreting the data as the given shape and its layout, and returns a -`XlaOp` of the data. Multiple Infeed operations are allowed in a -computation, but there must be a total order among the Infeed operations. For -example, two Infeeds in the code below have a total order since there is a -dependency between the while loops. - -``` -result1 = while (condition, init = init_value) { - Infeed(shape) -} - -result2 = while (condition, init = result1) { - Infeed(shape) -} -``` - -Nested tuple shapes are not supported. For an empty tuple shape, the Infeed -operation is effectively a no-op and proceeds without reading any data from the -Infeed of the device. - -> Note: We plan to allow multiple Infeed operations without a total order, in -> which case the compiler will provide information about how the Infeed -> operations are serialized in the compiled program. - -## Iota - -<b> `Iota()` </b> - -Builds a constant literal on device rather than a potentially large host -transfer. Creates a rank 1 tensor of values starting at zero and incrementing -by one. - -Arguments | Type | Semantics ------------------- | --------------- | --------------------------- -`type` | `PrimitiveType` | type U -`size` | `int64` | The number of elements in the tensor. - -## Map - -See also -[`XlaBuilder::Map`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `Map(operands..., computation)` </b> - -| Arguments | Type | Semantics | -| ----------------- | ---------------------- | ------------------------------ | -| `operands` | sequence of N `XlaOp`s | N arrays of types T_0..T_{N-1} | -| `computation` | `XlaComputation` | computation of type `T_0, T_1, | -: : : ..., T_{N + M -1} -> S` with N : -: : : parameters of type T and M of : -: : : arbitrary type : -| `dimensions` | `int64` array | array of map dimensions | - -Applies a scalar function over the given `operands` arrays, producing an array -of the same dimensions where each element is the result of the mapped function -applied to the corresponding elements in the input arrays. - -The mapped function is an arbitrary computation with the restriction that it has -N inputs of scalar type `T` and a single output with type `S`. The output has -the same dimensions as the operands except that the element type T is replaced -with S. - -For example: `Map(op1, op2, op3, computation, par1)` maps `elem_out <- -computation(elem1, elem2, elem3, par1)` at each (multi-dimensional) index in the -input arrays to produce the output array. - -## Pad - -See also -[`XlaBuilder::Pad`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `Pad(operand, padding_value, padding_config)` </b> - -| Arguments | Type | Semantics | -| ---------------- | --------------- | --------------------------------------- | -| `operand` | `XlaOp` | array of type `T` | -| `padding_value` | `XlaOp` | scalar of type `T` to fill in the added | -: : : padding : -| `padding_config` | `PaddingConfig` | padding amount on both edges (low, | -: : : high) and between the elements of each : -: : : dimension : - -Expands the given `operand` array by padding around the array as well as between -the elements of the array with the given `padding_value`. `padding_config` -specifies the amount of edge padding and the interior padding for each -dimension. - -`PaddingConfig` is a repeated field of `PaddingConfigDimension`, which contains -three fields for each dimension: `edge_padding_low`, `edge_padding_high`, and -`interior_padding`. `edge_padding_low` and `edge_padding_high` specify the -amount of padding added at the low-end (next to index 0) and the high-end (next -to the highest index) of each dimension respectively. The amount of edge padding -can be negative -- the absolute value of negative padding indicates the number -of elements to remove from the specified dimension. `interior_padding` specifies -the amount of padding added between any two elements in each dimension. Interior -padding occurs logically before edge padding, so in the case of negative edge -padding elements are removed from the interior-padded operand. This operation is -a no-op if the edge padding pairs are all (0, 0) and the interior padding values -are all 0. The figure below shows examples of different `edge_padding` and -`interior_padding` values for a two-dimensional array. - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/ops_pad.png"> -</div> - -## Recv - -See also -[`XlaBuilder::Recv`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `Recv(shape, channel_handle)` </b> - -| Arguments | Type | Semantics | -| ---------------- | --------------- | ------------------------------------ | -| `shape` | `Shape` | shape of the data to receive | -| `channel_handle` | `ChannelHandle` | unique identifier for each send/recv pair | - -Receives data of the given shape from a `Send` instruction in another -computation that shares the same channel handle. Returns a -XlaOp for the received data. - -The client API of `Recv` operation represents synchronous communication. -However, the instruction is internally decomposed into 2 HLO instructions -(`Recv` and `RecvDone`) to enable asynchronous data transfers. See also -[`HloInstruction::CreateRecv` and `HloInstruction::CreateRecvDone`](https://www.tensorflow.org/code/tensorflow/compiler/xla/service/hlo_instruction.h). - -<b>`Recv(const Shape& shape, int64 channel_id)`</b> - -Allocates resources required to receive data from a `Send` instruction with the -same channel_id. Returns a context for the allocated resources, which is used -by a following `RecvDone` instruction to wait for the completion of the data -transfer. The context is a tuple of {receive buffer (shape), request identifier -(U32)} and it can only be used by a `RecvDone` instruction. - -<b> `RecvDone(HloInstruction context)` </b> - -Given a context created by a `Recv` instruction, waits for the data transfer to -complete and returns the received data. - -## Reduce - -See also -[`XlaBuilder::Reduce`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Applies a reduction function to one or more arrays in parallel. - -<b> `Reduce(operands..., init_values..., computation, dimensions)` </b> - -Arguments | Type | Semantics -------------- | --------------------- | --------------------------------------- -`operands` | Sequence of N `XlaOp` | N arrays of types `T_0, ..., T_N`. -`init_values` | Sequence of N `XlaOp` | N scalars of types `T_0, ..., T_N`. -`computation` | `XlaComputation` | computation of type - : : `T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N)` -`dimensions` | `int64` array | unordered array of dimensions to reduce - -Where: -* N is required to be greater or equal to 1. -* All input arrays must have the same dimensions. -* If `N = 1`, `Collate(T)` is `T`. -* If `N > 1`, `Collate(T_0, ..., T_N)` is a tuple of `N` elements of type `T`. - -The output of the op is `Collate(Q_0, ..., Q_N)` where `Q_i` is an array of type -`T_i`, the dimensions of which are described below. - -This operation reduces one or more dimensions of each input array into scalars. -The rank of each returned array is `rank(operand) - len(dimensions)`. -`init_value` is the initial value used for every reduction and may be inserted -anywhere during computation by the back-end. In most cases, `init_value` is an -identity of the reduction function (for example, 0 for addition). The applied -`computation` is always passed the `init_value` on the left-hand side. - -The evaluation order of the reduction function is arbitrary and may be -non-deterministic. Therefore, the reduction function should not be overly -sensitive to reassociation. - -Some reduction functions like addition are not strictly associative for floats. -However, if the range of the data is limited, floating-point addition is close -enough to being associative for most practical uses. It is possible to conceive -of some completely non-associative reductions, however, and these will produce -incorrect or unpredictable results in XLA reductions. - -As an example, when reducing across one dimension in a single 1D array with -values [10, 11, 12, 13], with reduction function `f` (this is `computation`) -then that could be computed as - -`f(10, f(11, f(12, f(init_value, 13)))` - -but there are also many other possibilities, e.g. - -`f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))` - -The following is a rough pseudo-code example of how reduction could be -implemented, using summation as the reduction computation with an initial value -of 0. - -```python -result_shape <- remove all dims in dimensions from operand_shape - -# Iterate over all elements in result_shape. The number of r's here is equal -# to the rank of the result -for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...: - # Initialize this result element - result[r0, r1...] <- 0 - - # Iterate over all the reduction dimensions - for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...: - # Increment the result element with the value of the operand's element. - # The index of the operand's element is constructed from all ri's and di's - # in the right order (by construction ri's and di's together index over the - # whole operand shape). - result[r0, r1...] += operand[ri... di] -``` - -Here's an example of reducing a 2D array (matrix). The shape has rank 2, -dimension 0 of size 2 and dimension 1 of size 3: - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:35%" src="https://www.tensorflow.org/images/ops_2d_matrix.png"> -</div> - -Results of reducing dimensions 0 or 1 with an "add" function: - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:35%" src="https://www.tensorflow.org/images/ops_reduce_from_2d_matrix.png"> -</div> - -Note that both reduction results are 1D arrays. The diagram shows one as column -and another as row just for visual convenience. - -For a more complex example, here is a 3D array. Its rank is 3, dimension 0 of -size 4, dimension 1 of size 2 and dimension 2 of size 3. For simplicity, the -values 1 to 6 are replicated across dimension 0. - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:35%" src="https://www.tensorflow.org/images/ops_reduce_from_3d_matrix.png"> -</div> - -Similarly to the 2D example, we can reduce just one dimension. If we reduce -dimension 0, for example, we get a rank-2 array where all values across -dimension 0 were folded into a scalar: - -```text -| 4 8 12 | -| 16 20 24 | -``` - -If we reduce dimension 2, we also get a rank-2 array where all values across -dimension 2 were folded into a scalar: - -```text -| 6 15 | -| 6 15 | -| 6 15 | -| 6 15 | -``` - -Note that the relative order between the remaining dimensions in the input is -preserved in the output, but some dimensions may get assigned new numbers (since -the rank changes). - -We can also reduce multiple dimensions. Add-reducing dimensions 0 and 1 produces -the 1D array `| 20 28 36 |`. - -Reducing the 3D array over all its dimensions produces the scalar `84`. - -When `N > 1`, reduce function application is slightly more complex, as it is -applied simultaneously to all inputs. For example, consider the following -reduction function, which can be used to compute the max and the argmax of a -a 1-D tensor in parallel: - -``` -f: (Float, Int, Float, Int) -> Float, Int -f(max, argmax, value, index): - if value >= argmax: - return (value, index) - else: - return (max, argmax) -``` - -For 1-D Input arrays `V = Float[N], K = Int[N]`, and init values -`I_V = Float, I_K = Int`, the result `f_(N-1)` of reducing across the only -input dimension is equivalent to the following recursive application: -``` -f_0 = f(I_V, I_K, V_0, K_0) -f_1 = f(f_0.first, f_0.second, V_1, K_1) -... -f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1)) -``` - -Applying this reduction to an array of values, and an array of sequential -indices (i.e. iota), will co-iterate over the arrays, and return a tuple -containing the maximal value and the matching index. - -## ReducePrecision - -See also -[`XlaBuilder::ReducePrecision`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Models the effect of converting floating-point values to a lower-precision -format (such as IEEE-FP16) and back to the original format. The number of -exponent and mantissa bits in the lower-precision format can be specified -arbitrarily, although all bit sizes may not be supported on all hardware -implementations. - -<b> `ReducePrecision(operand, mantissa_bits, exponent_bits)` </b> - -Arguments | Type | Semantics ---------------- | ------- | ------------------------------------------------- -`operand` | `XlaOp` | array of floating-point type `T`. -`exponent_bits` | `int32` | number of exponent bits in lower-precision format -`mantissa_bits` | `int32` | number of mantissa bits in lower-precision format - -The result is an array of type `T`. The input values are rounded to the nearest -value representable with the given number of mantissa bits (using "ties to even" -semantics), and any values that exceed the range specified by the number of -exponent bits are clamped to positive or negative infinity. `NaN` values are -retained, although they may be converted to canonical `NaN` values. - -The lower-precision format must have at least one exponent bit (in order to -distinguish a zero value from an infinity, since both have a zero mantissa), and -must have a non-negative number of mantissa bits. The number of exponent or -mantissa bits may exceed the corresponding value for type `T`; the corresponding -portion of the conversion is then simply a no-op. - -## ReduceWindow - -See also -[`XlaBuilder::ReduceWindow`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Applies a reduction function to all elements in each window of the input -multi-dimensional array, producing an output multi-dimensional array with the -same number of elements as the number of valid positions of the window. A -pooling layer can be expressed as a `ReduceWindow`. Similar to -[`Reduce`](#reduce), the applied `computation` is always passed the `init_value` -on the left-hand side. - -<b> `ReduceWindow(operand, init_value, computation, window_dimensions, -window_strides, padding)` </b> - -| Arguments | Type | Semantics | -| ------------------- | ------------------- | -------------------------------- | -| `operand` | `XlaOp` | N dimensional array containing | -: : : elements of type T. This is the : -: : : base area on which the window is : -: : : placed. : -| `init_value` | `XlaOp` | Starting value for the | -: : : reduction. See [Reduce](#reduce) : -: : : for details. : -| `computation` | `XlaComputation` | Reduction function of type `T, T | -: : : -> T`, to apply to all elements : -: : : in each window : -| `window_dimensions` | `ArraySlice<int64>` | array of integers for window | -: : : dimension values : -| `window_strides` | `ArraySlice<int64>` | array of integers for window | -: : : stride values : -| `padding` | `Padding` | padding type for window | -: : : (Padding\:\:kSame or : -: : : Padding\:\:kValid) : - -Below code and figure shows an example of using `ReduceWindow`. Input is a -matrix of size [4x6] and both window_dimensions and window_stride_dimensions are -[2x3]. - -``` -// Create a computation for the reduction (maximum). -XlaComputation max; -{ - XlaBuilder builder(client_, "max"); - auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y"); - auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x"); - builder.Max(y, x); - max = builder.Build().ConsumeValueOrDie(); -} - -// Create a ReduceWindow computation with the max reduction computation. -XlaBuilder builder(client_, "reduce_window_2x3"); -auto shape = ShapeUtil::MakeShape(F32, {4, 6}); -auto input = builder.Parameter(0, shape, "input"); -builder.ReduceWindow( - input, *max, - /*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)), - /*window_dimensions=*/{2, 3}, - /*window_stride_dimensions=*/{2, 3}, - Padding::kValid); -``` - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:35%" src="https://www.tensorflow.org/images/ops_reduce_window.png"> -</div> - -Stride of 1 in a dimension specifies that the position of a window in the -dimension is 1 element away from its adjacent window. In order to specify that -no windows overlap with each other, window_stride_dimensions should be equal to -window_dimensions. The figure below illustrates the use of two different stride -values. Padding is applied to each dimension of the input and the calculations -are the same as though the input came in with the dimensions it has after -padding. - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:75%" src="https://www.tensorflow.org/images/ops_reduce_window_stride.png"> -</div> - -The evaluation order of the reduction function is arbitrary and may be -non-deterministic. Therefore, the reduction function should not be overly -sensitive to reassociation. See the discussion about associativity in the -context of [`Reduce`](#reduce) for more details. - -## Reshape - -See also -[`XlaBuilder::Reshape`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h) -and the [`Collapse`](#collapse) operation. - -Reshapes the dimensions of an array into a new configuration. - -<b> `Reshape(operand, new_sizes)` </b> -<b> `Reshape(operand, dimensions, new_sizes)` </b> - -Arguments | Type | Semantics ------------- | -------------- | --------------------------------------- -`operand` | `XlaOp` | array of type T -`dimensions` | `int64` vector | order in which dimensions are collapsed -`new_sizes` | `int64` vector | vector of sizes of new dimensions - -Conceptually, reshape first flattens an array into a one-dimensional vector of -data values, and then refines this vector into a new shape. The input arguments -are an arbitrary array of type T, a compile-time-constant vector of dimension -indices, and a compile-time-constant vector of dimension sizes for the result. -The values in the `dimension` vector, if given, must be a permutation of all of -T's dimensions; the default if not given is `{0, ..., rank - 1}`. The order of -the dimensions in `dimensions` is from slowest-varying dimension (most major) to -fastest-varying dimension (most minor) in the loop nest which collapses the -input array into a single dimension. The `new_sizes` vector determines the size -of the output array. The value at index 0 in `new_sizes` is the size of -dimension 0, the value at index 1 is the size of dimension 1, and so on. The -product of the `new_size` dimensions must equal the product of the operand's -dimension sizes. When refining the collapsed array into the multidimensional -array defined by `new_sizes`, the dimensions in `new_sizes` are ordered from -slowest varying (most major) and to fastest varying (most minor). - -For example, let v be an array of 24 elements: - -``` -let v = f32[4x2x3] {{{10, 11, 12}, {15, 16, 17}}, - {{20, 21, 22}, {25, 26, 27}}, - {{30, 31, 32}, {35, 36, 37}}, - {{40, 41, 42}, {45, 46, 47}}}; - -In-order collapse: -let v012_24 = Reshape(v, {0,1,2}, {24}); -then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27, - 30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47}; - -let v012_83 = Reshape(v, {0,1,2}, {8,3}); -then v012_83 == f32[8x3] {{10, 11, 12}, {15, 16, 17}, - {20, 21, 22}, {25, 26, 27}, - {30, 31, 32}, {35, 36, 37}, - {40, 41, 42}, {45, 46, 47}}; - -Out-of-order collapse: -let v021_24 = Reshape(v, {1,2,0}, {24}); -then v012_24 == f32[24] {10, 20, 30, 40, 11, 21, 31, 41, 12, 22, 32, 42, - 15, 25, 35, 45, 16, 26, 36, 46, 17, 27, 37, 47}; - -let v021_83 = Reshape(v, {1,2,0}, {8,3}); -then v021_83 == f32[8x3] {{10, 20, 30}, {40, 11, 21}, - {31, 41, 12}, {22, 32, 42}, - {15, 25, 35}, {45, 16, 26}, - {36, 46, 17}, {27, 37, 47}}; - - -let v021_262 = Reshape(v, {1,2,0}, {2,6,2}); -then v021_262 == f32[2x6x2] {{{10, 20}, {30, 40}, - {11, 21}, {31, 41}, - {12, 22}, {32, 42}}, - {{15, 25}, {35, 45}, - {16, 26}, {36, 46}, - {17, 27}, {37, 47}}}; -``` - -As a special case, reshape can transform a single-element array to a scalar and -vice versa. For example, - -``` -Reshape(f32[1x1] {{5}}, {0,1}, {}) == 5; -Reshape(5, {}, {1,1}) == f32[1x1] {{5}}; -``` - -## Rev (reverse) - -See also -[`XlaBuilder::Rev`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b>`Rev(operand, dimensions)`</b> - -Arguments | Type | Semantics ------------- | ------------------- | --------------------- -`operand` | `XlaOp` | array of type T -`dimensions` | `ArraySlice<int64>` | dimensions to reverse - -Reverses the order of elements in the `operand` array along the specified -`dimensions`, generating an output array of the same shape. Each element of the -operand array at a multidimensional index is stored into the output array at a -transformed index. The multidimensional index is transformed by reversing the -index in each dimension to be reversed (i.e., if a dimension of size N is one of -the reversing dimensions, its index i is transformed into N - 1 - i). - -One use for the `Rev` operation is to reverse the convolution weight array along -the two window dimensions during the gradient computation in neural networks. - -## RngNormal - -See also -[`XlaBuilder::RngNormal`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Constructs an output of a given shape with random numbers generated following -the $$N(\mu, \sigma)$$ normal distribution. The parameters $$\mu$$ and -$$\sigma$$, and output shape have to have a floating point elemental type. The -parameters furthermore have to be scalar valued. - -<b>`RngNormal(mu, sigma, shape)`</b> - -| Arguments | Type | Semantics | -| --------- | ------- | --------------------------------------------------- | -| `mu` | `XlaOp` | Scalar of type T specifying mean of generated | -: : : numbers : -| `sigma` | `XlaOp` | Scalar of type T specifying standard deviation of | -: : : generated numbers : -| `shape` | `Shape` | Output shape of type T | - -## RngUniform - -See also -[`XlaBuilder::RngUniform`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Constructs an output of a given shape with random numbers generated following -the uniform distribution over the interval $$[a,b)$$. The parameters and output -element type have to be a boolean type, an integral type or a floating point -types, and the types have to be consistent. The CPU and GPU backends currently -only support F64, F32, F16, BF16, S64, U64, S32 and U32. Furthermore, the -parameters need to be scalar valued. If $$b <= a$$ the result is -implementation-defined. - -<b>`RngUniform(a, b, shape)`</b> - -| Arguments | Type | Semantics | -| --------- | ----------------------- | --------------------------------- | -| `a` | `XlaOp` | Scalar of type T specifying lower | -: : : limit of interval : -| `b` | `XlaOp` | Scalar of type T specifying upper | -: : : limit of interval : -| `shape` | `Shape` | Output shape of type T | - -## Scatter - -The XLA scatter operation generates a result which is the value of the input -tensor `operand`, with several slices (at indices specified by -`scatter_indices`) updated with the values in `updates` using -`update_computation`. - -See also -[`XlaBuilder::Scatter`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `scatter(operand, scatter_indices, updates, update_computation, index_vector_dim, update_window_dims, inserted_window_dims, scatter_dims_to_operand_dims)` </b> - -|Arguments | Type | Semantics | -|------------------|------------------------|----------------------------------| -|`operand` | `XlaOp` | Tensor to be scattered into. | -|`scatter_indices` | `XlaOp` | Tensor containing the starting | -: : : indices of the slices that must : -: : : be scattered to. : -|`updates` | `XlaOp` | Tensor containing the values that| -: : : must be used for scattering. : -|`update_computation`| `XlaComputation` | Computation to be used for | -: : : combining the existing values in : -: : : the input tensor and the updates : -: : : during scatter. This computation : -: : : should be of type `T, T -> T`. : -|`index_vector_dim`| `int64` | The dimension in | -: : : `scatter_indices` that contains : -: : : the starting indices. : -|`update_window_dims`| `ArraySlice<int64>` | The set of dimensions in | -: : : `updates` shape that are _window : -: : : dimensions_. : -|`inserted_window_dims`| `ArraySlice<int64>`| The set of _window dimensions_ | -: : : that must be inserted into : -: : : `updates` shape. : -|`scatter_dims_to_operand_dims`| `ArraySlice<int64>` | A dimensions map from | -: : : the scatter indices to the : -: : : operand index space. This array : -: : : is interpreted as mapping `i` to : -: : : `scatter_dims_to_operand_dims[i]`: -: : : . It has to be one-to-one and : -: : : total. : - -If `index_vector_dim` is equal to `scatter_indices.rank` we implicitly consider -`scatter_indices` to have a trailing `1` dimension. - -We define `update_scatter_dims` of type `ArraySlice<int64>` as the set of -dimensions in `updates` shape that are not in `update_window_dims`, in ascending -order. - -The arguments of scatter should follow these constraints: - - - `updates` tensor must be of rank `update_window_dims.size + - scatter_indices.rank - 1`. - - - Bounds of dimension `i` in `updates` must conform to the following: - - If `i` is present in `update_window_dims` (i.e. equal to - `update_window_dims`[`k`] for some `k`), then the bound of dimension - `i` in `updates` must not exceed the corresponding bound of `operand` - after accounting for the `inserted_window_dims` (i.e. - `adjusted_window_bounds`[`k`], where `adjusted_window_bounds` contains - the bounds of `operand` with the bounds at indices - `inserted_window_dims` removed). - - If `i` is present in `update_scatter_dims` (i.e. equal to - `update_scatter_dims`[`k`] for some `k`), then the bound of dimension - `i` in `updates` must be equal to the corresponding bound of - `scatter_indices`, skipping `index_vector_dim` (i.e. - `scatter_indices.shape.dims`[`k`], if `k` < `index_vector_dim` and - `scatter_indices.shape.dims`[`k+1`] otherwise). - - - `update_window_dims` must be in ascending order, not have any repeating - dimension numbers, and be in the range `[0, updates.rank)`. - - - `inserted_window_dims` must be in ascending order, not have any - repeating dimension numbers, and be in the range `[0, operand.rank)`. - - - `scatter_dims_to_operand_dims.size` must be equal to - `scatter_indices`[`index_vector_dim`], and its values must be in the range - `[0, operand.rank)`. - -For a given index `U` in the `updates` tensor, the corresponding index `I` in -the `operand` tensor into which this update has to be applied is computed as -follows: - - 1. Let `G` = { `U`[`k`] for `k` in `update_scatter_dims` }. Use `G` to look up - an index vector `S` in the `scatter_indices` tensor such that `S`[`i`] = - `scatter_indices`[Combine(`G`, `i`)] where Combine(A, b) inserts b at - positions `index_vector_dim` into A. - 2. Create an index `S`<sub>`in`</sub> into `operand` using `S` by scattering - `S` using the `scatter_dims_to_operand_dims` map. More formally: - 1. `S`<sub>`in`</sub>[`scatter_dims_to_operand_dims`[`k`]] = `S`[`k`] if - `k` < `scatter_dims_to_operand_dims.size`. - 2. `S`<sub>`in`</sub>[`_`] = `0` otherwise. - 3. Create an index `W`<sub>`in`</sub> into `operand` by scattering the indices - at `update_window_dims` in `U` according to `inserted_window_dims`. - More formally: - 1. `W`<sub>`in`</sub>[`window_dims_to_operand_dims`(`k`)] = `U`[`k`] if - `k` < `update_window_dims.size`, where `window_dims_to_operand_dims` - is the monotonic function with domain [`0`, `update_window_dims.size`) - and range [`0`, `operand.rank`) \\ `inserted_window_dims`. (For - example, if `update_window_dims.size` is `4`, `operand.rank` is `6`, - and `inserted_window_dims` is {`0`, `2`} then - `window_dims_to_operand_dims` is {`0`→`1`, `1`→`3`, `2`→`4`, - `3`→`5`}). - 2. `W`<sub>`in`</sub>[`_`] = `0` otherwise. - 4. `I` is `W`<sub>`in`</sub> + `S`<sub>`in`</sub> where + is element-wise - addition. - -In summary, the scatter operation can be defined as follows. - - - Initialize `output` with `operand`, i.e. for all indices `O` in the - `operand` tensor:\ - `output`[`O`] = `operand`[`O`] - - For every index `U` in the `updates` tensor and the corresponding index `O` - in the `operand` tensor:\ - `output`[`O`] = `update_computation`(`output`[`O`], `updates`[`U`]) - -The order in which updates are applied is non-deterministic. So, when multiple -indices in `updates` refer to the same index in `operand`, the corresponding -value in `output` will be non-deterministic. - -Note that the first parameter that is passed into the `update_computation` will -always be the current value from the `output` tensor and the second parameter -will always be the value from the `updates` tensor. This is important -specifically for cases when the `update_computation` is _not commutative_. - -Informally, the scatter op can be viewed as an _inverse_ of the gather op, i.e. -the scatter op updates the elements in the input that are extracted by the -corresponding gather op. - -For a detailed informal description and examples, refer to the -"Informal Description" section under `Gather`. - -## Select - -See also -[`XlaBuilder::Select`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Constructs an output array from elements of two input arrays, based on the -values of a predicate array. - -<b> `Select(pred, on_true, on_false)` </b> - -Arguments | Type | Semantics ----------- | ------- | ------------------ -`pred` | `XlaOp` | array of type PRED -`on_true` | `XlaOp` | array of type T -`on_false` | `XlaOp` | array of type T - -The arrays `on_true` and `on_false` must have the same shape. This is also the -shape of the output array. The array `pred` must have the same dimensionality as -`on_true` and `on_false`, with the `PRED` element type. - -For each element `P` of `pred`, the corresponding element of the output array is -taken from `on_true` if the value of `P` is `true`, and from `on_false` if the -value of `P` is `false`. As a restricted form of [broadcasting] -(broadcasting.md), `pred` can be a scalar of type `PRED`. In this case, the -output array is taken wholly from `on_true` if `pred` is `true`, and from -`on_false` if `pred` is `false`. - -Example with non-scalar `pred`: - -``` -let pred: PRED[4] = {true, false, false, true}; -let v1: s32[4] = {1, 2, 3, 4}; -let v2: s32[4] = {100, 200, 300, 400}; -==> -Select(pred, v1, v2) = s32[4]{1, 200, 300, 4}; -``` - -Example with scalar `pred`: - -``` -let pred: PRED = true; -let v1: s32[4] = {1, 2, 3, 4}; -let v2: s32[4] = {100, 200, 300, 400}; -==> -Select(pred, v1, v2) = s32[4]{1, 2, 3, 4}; -``` - -Selections between tuples are supported. Tuples are considered to be scalar -types for this purpose. If `on_true` and `on_false` are tuples (which must have -the same shape!) then `pred` has to be a scalar of type `PRED`. - -## SelectAndScatter - -See also -[`XlaBuilder::SelectAndScatter`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -This operation can be considered as a composite operation that first computes -`ReduceWindow` on the `operand` array to select an element from each window, and -then scatters the `source` array to the indices of the selected elements to -construct an output array with the same shape as the operand array. The binary -`select` function is used to select an element from each window by applying it -across each window, and it is called with the property that the first -parameter's index vector is lexicographically less than the second parameter's -index vector. The `select` function returns `true` if the first parameter is -selected and returns `false` if the second parameter is selected, and the -function must hold transitivity (i.e., if `select(a, b)` and `select(b, c)` are -`true`, then `select(a, c)` is also `true`) so that the selected element does -not depend on the order of the elements traversed for a given window. - -The function `scatter` is applied at each selected index in the output array. It -takes two scalar parameters: - -1. Current value at the selected index in the output array -2. The scatter value from `source` that applies to the selected index - -It combines the two parameters and returns a scalar value that's used to update -the value at the selected index in the output array. Initially, all indices of -the output array are set to `init_value`. - -The output array has the same shape as the `operand` array and the `source` -array must have the same shape as the result of applying a `ReduceWindow` -operation on the `operand` array. `SelectAndScatter` can be used to -backpropagate the gradient values for a pooling layer in a neural network. - -<b>`SelectAndScatter(operand, select, window_dimensions, window_strides, -padding, source, init_value, scatter)`</b> - -| Arguments | Type | Semantics | -| ------------------- | ------------------- | -------------------------------- | -| `operand` | `XlaOp` | array of type T over which the | -: : : windows slide : -| `select` | `XlaComputation` | binary computation of type `T, T | -: : : -> PRED`, to apply to all : -: : : elements in each window; returns : -: : : `true` if the first parameter is : -: : : selected and returns `false` if : -: : : the second parameter is selected : -| `window_dimensions` | `ArraySlice<int64>` | array of integers for window | -: : : dimension values : -| `window_strides` | `ArraySlice<int64>` | array of integers for window | -: : : stride values : -| `padding` | `Padding` | padding type for window | -: : : (Padding\:\:kSame or : -: : : Padding\:\:kValid) : -| `source` | `XlaOp` | array of type T with the values | -: : : to scatter : -| `init_value` | `XlaOp` | scalar value of type T for the | -: : : initial value of the output : -: : : array : -| `scatter` | `XlaComputation` | binary computation of type `T, T | -: : : -> T`, to apply each scatter : -: : : source element with its : -: : : destination element : - -The figure below shows examples of using `SelectAndScatter`, with the `select` -function computing the maximal value among its parameters. Note that when the -windows overlap, as in the figure (2) below, an index of the `operand` array may -be selected multiple times by different windows. In the figure, the element of -value 9 is selected by both of the top windows (blue and red) and the binary -addition `scatter` function produces the output element of value 8 (2 + 6). - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" - src="https://www.tensorflow.org/images/ops_scatter_to_selected_window_element.png"> -</div> - -The evaluation order of the `scatter` function is arbitrary and may be -non-deterministic. Therefore, the `scatter` function should not be overly -sensitive to reassociation. See the discussion about associativity in the -context of [`Reduce`](#reduce) for more details. - -## Send - -See also -[`XlaBuilder::Send`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `Send(operand, channel_handle)` </b> - -Arguments | Type | Semantics ----------------- | --------------- | ----------------------------------------- -`operand` | `XlaOp` | data to send (array of type T) -`channel_handle` | `ChannelHandle` | unique identifier for each send/recv pair - -Sends the given operand data to a `Recv` instruction in another computation -that shares the same channel handle. Does not return any data. - -Similar to the `Recv` operation, the client API of `Send` operation represents -synchronous communication, and is internally decomposed into 2 HLO instructions -(`Send` and `SendDone`) to enable asynchronous data transfers. See also -[`HloInstruction::CreateSend` and `HloInstruction::CreateSendDone`](https://www.tensorflow.org/code/tensorflow/compiler/xla/service/hlo_instruction.h). - -<b>`Send(HloInstruction operand, int64 channel_id)`</b> - -Initiates an asynchronous transfer of the operand to the resources allocated by -the `Recv` instruction with the same channel id. Returns a context, which is -used by a following `SendDone` instruction to wait for the completion of the -data transfer. The context is a tuple of {operand (shape), request identifier -(U32)} and it can only be used by a `SendDone` instruction. - -<b> `SendDone(HloInstruction context)` </b> - -Given a context created by a `Send` instruction, waits for the data transfer to -complete. The instruction does not return any data. - -<b> Scheduling of channel instructions </b> - -The execution order of the 4 instructions for each channel (`Recv`, `RecvDone`, -`Send`, `SendDone`) is as below. - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:70%" src="../../images/send_recv_order.png"> -</div> - -* `Recv` happens before `Send` -* `Send` happens before `RecvDone` -* `Recv` happens before `RecvDone` -* `Send` happens before `SendDone` - -When the backend compilers generate a linear schedule for each computation that -communicates via channel instructions, there must not be cycles across the -computations. For example, below schedules lead to deadlocks. - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="../../images/send_recv_schedule.png"> -</div> - -## Slice - -See also -[`XlaBuilder::Slice`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -Slicing extracts a sub-array from the input array. The sub-array is of the same -rank as the input and contains the values inside a bounding box within the input -array where the dimensions and indices of the bounding box are given as -arguments to the slice operation. - -<b> `Slice(operand, start_indices, limit_indices)` </b> - -| Arguments | Type | Semantics | -| --------------- | ------------------- | ------------------------------------ | -| `operand` | `XlaOp` | N dimensional array of type T | -| `start_indices` | `ArraySlice<int64>` | List of N integers containing the | -: : : starting indices of the slice for : -: : : each dimension. Values must be : -: : : greater than or equal to zero. : -| `limit_indices` | `ArraySlice<int64>` | List of N integers containing the | -: : : ending indices (exclusive) for the : -: : : slice for each dimension. Each value : -: : : must be strictly greater than the : -: : : respective `start_indices` value for : -: : : the dimension and less than or equal : -: : : to the size of the dimension. : - -1-dimensional example: - -``` -let a = {0.0, 1.0, 2.0, 3.0, 4.0} -Slice(a, {2}, {4}) produces: - {2.0, 3.0} -``` - -2-dimensional example: - -``` -let b = - { {0.0, 1.0, 2.0}, - {3.0, 4.0, 5.0}, - {6.0, 7.0, 8.0}, - {9.0, 10.0, 11.0} } - -Slice(b, {2, 1}, {4, 3}) produces: - { { 7.0, 8.0}, - {10.0, 11.0} } -``` - -## Sort - -See also -[`XlaBuilder::Sort`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -There are two versions of the Sort instruction: a single-operand and a -two-operand version. - -<b>`Sort(operand)`</b> - -Arguments | Type | Semantics ------------ | ------- | -------------------- -`operand` | `XlaOp` | The operand to sort. -`dimension` | `int64` | The dimension along which to sort. - -Sorts the elements in the operand in ascending order along the provided -dimension. For example, for a rank-2 (matrix) operand, a `dimension` value of 0 -will sort each column independently, and a `dimension` value of 1 will sort each -row independently. If the operand's elements have floating point type, and the -operand contains NaN elements, the order of elements in the output is -implementation-defined. - -<b>`Sort(key, value)`</b> - -Sorts both the key and the value operands. The keys are sorted as in the -single-operand version. The values are sorted according to the order of their -corresponding keys. For example, if the inputs are `keys = [3, 1]` and -`values = [42, 50]`, then the output of the sort is the tuple -`{[1, 3], [50, 42]}`. - -The sort is not guaranteed to be stable, that is, if the keys array contains -duplicates, the order of their corresponding values may not be preserved. - -Arguments | Type | Semantics ------------ | ------- | ------------------- -`keys` | `XlaOp` | The sort keys. -`values` | `XlaOp` | The values to sort. -`dimension` | `int64` | The dimension along which to sort. - -The `keys` and `values` must have the same dimensions, but may have different -element types. - -## Transpose - -See also the `tf.reshape` operation. - -<b>`Transpose(operand)`</b> - -Arguments | Type | Semantics -------------- | ------------------- | ------------------------------ -`operand` | `XlaOp` | The operand to transpose. -`permutation` | `ArraySlice<int64>` | How to permute the dimensions. - - -Permutes the operand dimensions with the given permutation, so -`∀ i . 0 ≤ i < rank ⇒ input_dimensions[permutation[i]] = output_dimensions[i]`. - -This is the same as Reshape(operand, permutation, - Permute(permutation, operand.shape.dimensions)). - -## Tuple - -See also -[`XlaBuilder::Tuple`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -A tuple containing a variable number of data handles, each of which has its own -shape. - -This is analogous to `std::tuple` in C++. Conceptually: - -``` -let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; -let s: s32 = 5; -let t: (f32[10], s32) = tuple(v, s); -``` - -Tuples can be deconstructed (accessed) via the [`GetTupleElement`] -(#gettupleelement) operation. - -## While - -See also -[`XlaBuilder::While`](https://www.tensorflow.org/code/tensorflow/compiler/xla/client/xla_builder.h). - -<b> `While(condition, body, init)` </b> - -| Arguments | Type | Semantics | -| ----------- | ---------------- | ---------------------------------------- | -| `condition` | `XlaComputation` | XlaComputation of type `T -> PRED` which | -: : : defines the termination condition of the : -: : : loop. : -| `body` | `XlaComputation` | XlaComputation of type `T -> T` which | -: : : defines the body of the loop. : -| `init` | `T` | Initial value for the parameter of | -: : : `condition` and `body`. : - -Sequentially executes the `body` until the `condition` fails. This is similar to -a typical while loop in many other languages except for the differences and -restrictions listed below. - -* A `While` node returns a value of type `T`, which is the result from the - last execution of the `body`. -* The shape of the type `T` is statically determined and must be the same - across all iterations. - -The T parameters of the computations are initialized with the `init` value in -the first iteration and are automatically updated to the new result from `body` -in each subsequent iteration. - -One main use case of the `While` node is to implement the repeated execution of -training in neural networks. Simplified pseudocode is shown below with a graph -that represents the computation. The code can be found in -[`while_test.cc`](https://www.tensorflow.org/code/tensorflow/compiler/xla/tests/while_test.cc). -The type `T` in this example is a `Tuple` consisting of an `int32` for the -iteration count and a `vector[10]` for the accumulator. For 1000 iterations, the -loop keeps adding a constant vector to the accumulator. - -``` -// Pseudocode for the computation. -init = {0, zero_vector[10]} // Tuple of int32 and float[10]. -result = init; -while (result(0) < 1000) { - iteration = result(0) + 1; - new_vector = result(1) + constant_vector[10]; - result = {iteration, new_vector}; -} -``` - -<div style="width:95%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/ops_while.png"> -</div> diff --git a/tensorflow/docs_src/performance/xla/shapes.md b/tensorflow/docs_src/performance/xla/shapes.md deleted file mode 100644 index 39e74ff307..0000000000 --- a/tensorflow/docs_src/performance/xla/shapes.md +++ /dev/null @@ -1,150 +0,0 @@ -# Shapes and Layout - -The XLA `Shape` proto -([xla_data.proto](https://www.tensorflow.org/code/tensorflow/compiler/xla/xla_data.proto)) -describes the rank, size, and data type of an N-dimensional array (*array* in -short). - -## Terminology, Notation, and Conventions - -* The rank of an array is equal to the number of dimensions. The *true rank* - of an array is the number of dimensions which have a size greater than 1. - -* Dimensions are numbered from `0` up to `N-1` for an `N` dimensional array. - The dimension numbers are arbitrary labels for convenience. The order of - these dimension numbers does not imply a particular minor/major ordering in - the layout of the shape. The layout is determined by the `Layout` proto. - -* By convention, dimensions are listed in increasing order of dimension - number. For example, for a 3-dimensional array of size `[A x B x C]`, - dimension 0 has size `A`, dimension 1 has size `B` and dimension 2 has size - `C`. - - Some utilities in XLA also support negative indexing, similarly to Python; - dimension -1 is the last dimension (equivalent to `N-1` for an `N` - dimensional array). For example, for the 3-dimensional array described - above, dimension -1 has size `C`, dimension -2 has size `B` and so on. - -* Two, three, and four dimensional arrays often have specific letters - associated with dimensions. For example, for a 2D array: - - * dimension 0: `y` - * dimension 1: `x` - - For a 3D array: - - * dimension 0: `z` - * dimension 1: `y` - * dimension 2: `x` - - For a 4D array: - - * dimension 0: `p` - * dimension 1: `z` - * dimension 2: `y` - * dimension 3: `x` - -* Functions in the XLA API which take dimensions do so in increasing order of - dimension number. This matches the ordering used when passing dimensions as - an `initializer_list`; e.g. - - `ShapeUtil::MakeShape(F32, {A, B, C, D})` - - Will create a shape whose dimension size array consists of the sequence - `[A, B, C, D]`. - -## Layout - -The `Layout` proto describes how an array is represented in memory. The `Layout` -proto includes the following fields: - -``` -message Layout { - repeated int64 minor_to_major = 1; - repeated int64 padded_dimensions = 2; - optional PaddingValue padding_value = 3; -} -``` - -### Minor-to-major dimension ordering - -The only required field is `minor_to_major`. This field describes the -minor-to-major ordering of the dimensions within a shape. Values in -`minor_to_major` are an ordering of the dimensions of the array (`0` to `N-1` -for an `N` dimensional array) with the first value being the most-minor -dimension up to the last value which is the most-major dimension. The most-minor -dimension is the dimension which changes most rapidly when stepping through the -elements of the array laid out in linear memory. - -For example, consider the following 2D array of size `[2 x 3]`: - -``` -a b c -d e f -``` - -Here dimension `0` is size 2, and dimension `1` is size 3. If the -`minor_to_major` field in the layout is `[0, 1]` then dimension `0` is the -most-minor dimension and dimension `1` is the most-major dimension. This -corresponds to the following layout in linear memory: - -``` -a d b e c f -``` - -This minor-to-major dimension order of `0` up to `N-1` is akin to *column-major* -(at rank 2). Assuming a monotonic ordering of dimensions, another name we may -use to refer to this layout in the code is simply "dim 0 is minor". - -On the other hand, if the `minor_to_major` field in the layout is `[1, 0]` then -the layout in linear memory is: - -``` -a b c d e f -``` - -A minor-to-major dimension order of `N-1` down to `0` for an `N` dimensional -array is akin to *row-major* (at rank 2). Assuming a monotonic ordering of -dimensions, another name we may use to refer to this layout in the code is -simply "dim 0 is major". - -#### Default minor-to-major ordering - -The default layout for newly created Shapes is "dimension order is -major-to-minor" (akin to row-major at rank 2). - -### Padding - -Padding is defined in the optional `padded_dimensions` and `padding_value` -fields. The field `padded_dimensions` describes the sizes (widths) to which each -dimension is padded. If present, the number of elements in `padded_dimensions` -must equal the rank of the shape. - -For example, given the `[2 x 3]` array defined above, if `padded_dimension` is -`[3, 5]` then dimension 0 is padded to a width of 3 and dimension 1 is padded to -a width of 5. The layout in linear memory (assuming a padding value of 0 and -column-major layout) is: - -``` -a d 0 b e 0 c f 0 0 0 0 0 0 0 -``` - -This is equivalent to the layout of the following array with the same -minor-to-major dimension order: - -``` -a b c 0 0 -d e f 0 0 -0 0 0 0 0 -``` - -### Indexing into arrays - -The class `IndexUtil` in -[index_util.h](https://www.tensorflow.org/code/tensorflow/compiler/xla/index_util.h) -provides utilities for converting between multidimensional indices and linear -indices given a shape and layout. Multidimensional indices include a `int64` -index for each dimension. Linear indices are a single `int64` value which -indexes into the buffer holding the array. See `shape_util.h` and -`layout_util.h` in the same directory for utilities that simplify creation and -manipulation of shapes and layouts. diff --git a/tensorflow/docs_src/performance/xla/tfcompile.md b/tensorflow/docs_src/performance/xla/tfcompile.md deleted file mode 100644 index 2e0f3774c4..0000000000 --- a/tensorflow/docs_src/performance/xla/tfcompile.md +++ /dev/null @@ -1,281 +0,0 @@ -# Using AOT compilation - -## What is tfcompile? - -`tfcompile` is a standalone tool that ahead-of-time (AOT) compiles TensorFlow -graphs into executable code. It can reduce total binary size, and also avoid -some runtime overheads. A typical use-case of `tfcompile` is to compile an -inference graph into executable code for mobile devices. - -The TensorFlow graph is normally executed by the TensorFlow runtime. This incurs -some runtime overhead for execution of each node in the graph. This also leads -to a larger total binary size, since the code for the TensorFlow runtime needs -to be available, in addition to the graph itself. The executable code produced -by `tfcompile` does not use the TensorFlow runtime, and only has dependencies on -kernels that are actually used in the computation. - -The compiler is built on top of the XLA framework. The code bridging TensorFlow -to the XLA framework resides under -[tensorflow/compiler](https://www.tensorflow.org/code/tensorflow/compiler/), -which also includes support for [just-in-time (JIT) compilation](../../performance/xla/jit.md) of -TensorFlow graphs. - -## What does tfcompile do? - -`tfcompile` takes a subgraph, identified by the TensorFlow concepts of -feeds and fetches, and generates a function that implements that subgraph. -The `feeds` are the input arguments for the function, and the `fetches` are the -output arguments for the function. All inputs must be fully specified by the -feeds; the resulting pruned subgraph cannot contain Placeholder or Variable -nodes. It is common to specify all Placeholders and Variables as feeds, which -ensures the resulting subgraph no longer contains these nodes. The generated -function is packaged as a `cc_library`, with a header file exporting the -function signature, and an object file containing the implementation. The user -writes code to invoke the generated function as appropriate. - -## Using tfcompile - -This section details high level steps for generating an executable binary with -`tfcompile` from a TensorFlow subgraph. The steps are: - -* Step 1: Configure the subgraph to compile -* Step 2: Use the `tf_library` build macro to compile the subgraph -* Step 3: Write code to invoke the subgraph -* Step 4: Create the final binary - -### Step 1: Configure the subgraph to compile - -Identify the feeds and fetches that correspond to the input and output -arguments for the generated function. Then configure the `feeds` and `fetches` -in a [`tensorflow.tf2xla.Config`](https://www.tensorflow.org/code/tensorflow/compiler/tf2xla/tf2xla.proto) -proto. - -```textproto -# Each feed is a positional input argument for the generated function. The order -# of each entry matches the order of each input argument. Here “x_hold” and “y_hold” -# refer to the names of placeholder nodes defined in the graph. -feed { - id { node_name: "x_hold" } - shape { - dim { size: 2 } - dim { size: 3 } - } -} -feed { - id { node_name: "y_hold" } - shape { - dim { size: 3 } - dim { size: 2 } - } -} - -# Each fetch is a positional output argument for the generated function. The order -# of each entry matches the order of each output argument. Here “x_y_prod” -# refers to the name of a matmul node defined in the graph. -fetch { - id { node_name: "x_y_prod" } -} -``` - -### Step 2: Use tf_library build macro to compile the subgraph - -This step converts the graph into a `cc_library` using the `tf_library` build -macro. The `cc_library` consists of an object file containing the code generated -from the graph, along with a header file that gives access to the generated -code. `tf_library` utilizes `tfcompile` to compile the TensorFlow graph into -executable code. - -```build -load("//tensorflow/compiler/aot:tfcompile.bzl", "tf_library") - -# Use the tf_library macro to compile your graph into executable code. -tf_library( - # name is used to generate the following underlying build rules: - # <name> : cc_library packaging the generated header and object files - # <name>_test : cc_test containing a simple test and benchmark - # <name>_benchmark : cc_binary containing a stand-alone benchmark with minimal deps; - # can be run on a mobile device - name = "test_graph_tfmatmul", - # cpp_class specifies the name of the generated C++ class, with namespaces allowed. - # The class will be generated in the given namespace(s), or if no namespaces are - # given, within the global namespace. - cpp_class = "foo::bar::MatMulComp", - # graph is the input GraphDef proto, by default expected in binary format. To - # use the text format instead, just use the ‘.pbtxt’ suffix. A subgraph will be - # created from this input graph, with feeds as inputs and fetches as outputs. - # No Placeholder or Variable ops may exist in this subgraph. - graph = "test_graph_tfmatmul.pb", - # config is the input Config proto, by default expected in binary format. To - # use the text format instead, use the ‘.pbtxt’ suffix. This is where the - # feeds and fetches were specified above, in the previous step. - config = "test_graph_tfmatmul.config.pbtxt", -) -``` - -> To generate the GraphDef proto (test_graph_tfmatmul.pb) for this example, run -> [make_test_graphs.py]("https://www.tensorflow.org/code/tensorflow/compiler/aot/tests/make_test_graphs.py") -> and specify the output location with the --out_dir flag. - -Typical graphs contain [`Variables`](../../api_guides/python/state_ops.md) -representing the weights that are learned via training, but `tfcompile` cannot -compile a subgraph that contain `Variables`. The -[freeze_graph.py](https://www.tensorflow.org/code/tensorflow/python/tools/freeze_graph.py) -tool converts variables into constants, using values stored in a checkpoint -file. As a convenience, the `tf_library` macro supports the `freeze_checkpoint` -argument, which runs the tool. For more examples see -[tensorflow/compiler/aot/tests/BUILD](https://www.tensorflow.org/code/tensorflow/compiler/aot/tests/BUILD). - -> Constants that show up in the compiled subgraph are compiled directly into the -> generated code. To pass the constants into the generated function, rather than -> having them compiled-in, simply pass them in as feeds. - -For details on the `tf_library` build macro, see -[tfcompile.bzl](https://www.tensorflow.org/code/tensorflow/compiler/aot/tfcompile.bzl). - -For details on the underlying `tfcompile` tool, see -[tfcompile_main.cc](https://www.tensorflow.org/code/tensorflow/compiler/aot/tfcompile_main.cc). - -### Step 3: Write code to invoke the subgraph - -This step uses the header file (`test_graph_tfmatmul.h`) generated by the -`tf_library` build macro in the previous step to invoke the generated code. The -header file is located in the `bazel-genfiles` directory corresponding to the -build package, and is named based on the name attribute set on the `tf_library` -build macro. For example, the header generated for `test_graph_tfmatmul` would -be `test_graph_tfmatmul.h`. Below is an abbreviated version of what is -generated. The generated file, in `bazel-genfiles`, contains additional useful -comments. - -```c++ -namespace foo { -namespace bar { - -// MatMulComp represents a computation previously specified in a -// TensorFlow graph, now compiled into executable code. -class MatMulComp { - public: - // AllocMode controls the buffer allocation mode. - enum class AllocMode { - ARGS_RESULTS_AND_TEMPS, // Allocate arg, result and temp buffers - RESULTS_AND_TEMPS_ONLY, // Only allocate result and temp buffers - }; - - MatMulComp(AllocMode mode = AllocMode::ARGS_RESULTS_AND_TEMPS); - ~MatMulComp(); - - // Runs the computation, with inputs read from arg buffers, and outputs - // written to result buffers. Returns true on success and false on failure. - bool Run(); - - // Arg methods for managing input buffers. Buffers are in row-major order. - // There is a set of methods for each positional argument. - void** args(); - - void set_arg0_data(float* data); - float* arg0_data(); - float& arg0(size_t dim0, size_t dim1); - - void set_arg1_data(float* data); - float* arg1_data(); - float& arg1(size_t dim0, size_t dim1); - - // Result methods for managing output buffers. Buffers are in row-major order. - // Must only be called after a successful Run call. There is a set of methods - // for each positional result. - void** results(); - - - float* result0_data(); - float& result0(size_t dim0, size_t dim1); -}; - -} // end namespace bar -} // end namespace foo -``` - -The generated C++ class is called `MatMulComp` in the `foo::bar` namespace, -because that was the `cpp_class` specified in the `tf_library` macro. All -generated classes have a similar API, with the only difference being the methods -to handle arg and result buffers. Those methods differ based on the number and -types of the buffers, which were specified by the `feed` and `fetch` arguments -to the `tf_library` macro. - -There are three types of buffers managed within the generated class: `args` -representing the inputs, `results` representing the outputs, and `temps` -representing temporary buffers used internally to perform the computation. By -default, each instance of the generated class allocates and manages all of these -buffers for you. The `AllocMode` constructor argument may be used to change this -behavior. All buffers are aligned to 64-byte boundaries. - -The generated C++ class is just a wrapper around the low-level code generated by -XLA. - -Example of invoking the generated function based on -[`tfcompile_test.cc`](https://www.tensorflow.org/code/tensorflow/compiler/aot/tests/tfcompile_test.cc): - -```c++ -#define EIGEN_USE_THREADS -#define EIGEN_USE_CUSTOM_THREAD_POOL - -#include <iostream> -#include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" -#include "tensorflow/compiler/aot/tests/test_graph_tfmatmul.h" // generated - -int main(int argc, char** argv) { - Eigen::ThreadPool tp(2); // Size the thread pool as appropriate. - Eigen::ThreadPoolDevice device(&tp, tp.NumThreads()); - - - foo::bar::MatMulComp matmul; - matmul.set_thread_pool(&device); - - // Set up args and run the computation. - const float args[12] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}; - std::copy(args + 0, args + 6, matmul.arg0_data()); - std::copy(args + 6, args + 12, matmul.arg1_data()); - matmul.Run(); - - // Check result - if (matmul.result0(0, 0) == 58) { - std::cout << "Success" << std::endl; - } else { - std::cout << "Failed. Expected value 58 at 0,0. Got:" - << matmul.result0(0, 0) << std::endl; - } - - return 0; -} -``` - -### Step 4: Create the final binary - -This step combines the library generated by `tf_library` in step 2 and the code -written in step 3 to create a final binary. Below is an example `bazel` BUILD -file. - -```build -# Example of linking your binary -# Also see //tensorflow/compiler/aot/tests/BUILD -load("//tensorflow/compiler/aot:tfcompile.bzl", "tf_library") - -# The same tf_library call from step 2 above. -tf_library( - name = "test_graph_tfmatmul", - ... -) - -# The executable code generated by tf_library can then be linked into your code. -cc_binary( - name = "my_binary", - srcs = [ - "my_code.cc", # include test_graph_tfmatmul.h to access the generated header - ], - deps = [ - ":test_graph_tfmatmul", # link in the generated object file - "//third_party/eigen3", - ], - linkopts = [ - "-lpthread", - ] -) -``` diff --git a/tensorflow/docs_src/tutorials/_index.yaml b/tensorflow/docs_src/tutorials/_index.yaml deleted file mode 100644 index 9534114689..0000000000 --- a/tensorflow/docs_src/tutorials/_index.yaml +++ /dev/null @@ -1,202 +0,0 @@ -project_path: /_project.yaml -book_path: /_book.yaml -description: <!--no description--> -landing_page: - custom_css_path: /site-assets/css/style.css - show_side_navs: True - rows: - - description: > - <h1 class="hide-from-toc">Get Started with TensorFlow</h1> - <p> - TensorFlow is an open-source machine learning library for research and - production. TensorFlow offers APIs for beginners and experts to develop - for desktop, mobile, web, and cloud. See the sections below to get - started. - </p> - items: - - custom_html: > - <div class="devsite-landing-row-item-description"> - <h3 class="hide-from-toc">Learn and use ML</h3> - <div class="devsite-landing-row-item-description-content"> - <p> - The high-level Keras API provides building blocks to create and - train deep learning models. Start with these beginner-friendly - notebook examples, then read the - <a href="/guide/keras">TensorFlow Keras guide</a>. - </p> - <ol style="padding-left:20px;"> - <li><a href="./keras/basic_classification">Basic classification</a></li> - <li><a href="./keras/basic_text_classification">Text classification</a></li> - <li><a href="./keras/basic_regression">Regression</a></li> - <li><a href="./keras/overfit_and_underfit">Overfitting and underfitting</a></li> - <li><a href="./keras/save_and_restore_models">Save and load</a></li> - </ol> - </div> - <div class="devsite-landing-row-item-buttons" style="margin-top:0;"> - <a class="button button-primary tfo-button-primary" href="/guide/keras">Read the Keras guide</a> - </div> - </div> - - classname: tfo-landing-row-item-code-block - code_block: | - <pre class="prettyprint"> - import tensorflow as tf - mnist = tf.keras.datasets.mnist - - (x_train, y_train),(x_test, y_test) = mnist.load_data() - x_train, x_test = x_train / 255.0, x_test / 255.0 - - model = tf.keras.models.Sequential([ - tf.keras.layers.Flatten(), - tf.keras.layers.Dense(512, activation=tf.nn.relu), - tf.keras.layers.Dropout(0.2), - tf.keras.layers.Dense(10, activation=tf.nn.softmax) - ]) - model.compile(optimizer='adam', - loss='sparse_categorical_crossentropy', - metrics=['accuracy']) - - model.fit(x_train, y_train, epochs=5) - model.evaluate(x_test, y_test) - </pre> - {% dynamic if request.tld != 'cn' %} - <a class="colab-button" target="_blank" href="https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/get_started/_index.ipynb">Run in a <span>Notebook</span></a> - {% dynamic endif %} - - - items: - - custom_html: > - <div class="devsite-landing-row-item-description" style="border-right: 2px solid #eee;"> - <h3 class="hide-from-toc">Research and experimentation</h3> - <div class="devsite-landing-row-item-description-content"> - <p> - Eager execution provides an imperative, define-by-run interface for advanced operations. Write custom layers, forward passes, and training loops with auto‑differentiation. Start with - these notebooks, then read the <a href="/guide/eager">eager execution guide</a>. - </p> - <ol style="padding-left:20px;"> - <li> - {% dynamic if request.tld == 'cn' %} - <a href="https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb" class="external">Eager execution basics</a> - {% dynamic else %} - <a href="https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb" class="external">Eager execution basics</a> - {% dynamic endif %} - </li> - <li> - {% dynamic if request.tld == 'cn' %} - <a href="https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb" class="external">Automatic differentiation and gradient tape</a> - {% dynamic else %} - <a href="https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb" class="external">Automatic differentiation and gradient tape</a> - {% dynamic endif %} - </li> - <li> - {% dynamic if request.tld == 'cn' %} - <a href="https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb" class="external">Custom training: basics</a> - {% dynamic else %} - <a href="https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb" class="external">Custom training: basics</a> - {% dynamic endif %} - </li> - <li> - {% dynamic if request.tld == 'cn' %} - <a href="https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb" class="external">Custom layers</a> - {% dynamic else %} - <a href="https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb" class="external">Custom layers</a> - {% dynamic endif %} - </li> - <li><a href="./eager/custom_training_walkthrough">Custom training: walkthrough</a></li> - <li> - {% dynamic if request.tld == 'cn' %} - <a href="https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb" class="external">Example: Neural machine translation w/ attention</a> - {% dynamic else %} - <a href="https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb" class="external">Example: Neural machine translation w/ attention</a> - {% dynamic endif %} - </li> - </ol> - </div> - <div class="devsite-landing-row-item-buttons"> - <a class="button button-primary tfo-button-primary" href="/guide/eager">Read the eager execution guide</a> - </div> - </div> - - custom_html: > - <div class="devsite-landing-row-item-description"> - <h3 class="hide-from-toc">ML at production scale</h3> - <div class="devsite-landing-row-item-description-content"> - <p> - Estimators can train large models on multiple machines in a - production environment. TensorFlow provides a collection of - pre-made Estimators to implement common ML algorithms. See the - <a href="/guide/estimators">Estimators guide</a>. - </p> - <ol style="padding-left: 20px;"> - <li><a href="/tutorials/estimators/linear">Build a linear model with Estimators</a></li> - <li><a href="https://github.com/tensorflow/models/tree/master/official/wide_deep" class="external">Wide and deep learning with Estimators</a></li> - <li><a href="https://github.com/tensorflow/models/tree/master/official/boosted_trees" class="external">Boosted trees</a></li> - <li><a href="/hub/tutorials/text_classification_with_tf_hub">How to build a simple text classifier with TF-Hub</a></li> - <li><a href="/tutorials/estimators/cnn">Build a Convolutional Neural Network using Estimators</a></li> - </ol> - </div> - <div class="devsite-landing-row-item-buttons"> - <a class="button button-primary tfo-button-primary" href="/guide/estimators">Read the Estimators guide</a> - </div> - </div> - - - description: > - <h2 class="hide-from-toc">Google Colab: An easy way to learn and use TensorFlow</h2> - <p> - <a href="https://colab.research.google.com/notebooks/welcome.ipynb" class="external">Colaboratory</a> - is a Google research project created to help disseminate machine learning - education and research. It's a Jupyter notebook environment that requires - no setup to use and runs entirely in the cloud. - <a href="https://medium.com/tensorflow/colab-an-easy-way-to-learn-and-use-tensorflow-d74d1686e309" class="external">Read the blog post</a>. - </p> - - - description: > - <h2 class="hide-from-toc">Build your first ML app</h2> - <p>Create and deploy TensorFlow models on web and mobile.</p> - background: grey - items: - - custom_html: > - <div class="devsite-landing-row-item-description" style="background: #fff; padding:32px;"> - <a href="https://js.tensorflow.org"> - <h3 class="hide-from-toc">Web developers</h3> - </a> - <div class="devsite-landing-row-item-description-content"> - TensorFlow.js is a WebGL accelerated, JavaScript library to train and - deploy ML models in the browser and for Node.js. - </div> - </div> - - custom_html: > - <div class="devsite-landing-row-item-description" style="background: #fff; padding:32px;"> - <a href="/mobile/tflite/"> - <h3 class="hide-from-toc">Mobile developers</h3> - </a> - <div class="devsite-landing-row-item-description-content"> - TensorFlow Lite is lightweight solution for mobile and embedded devices. - </div> - </div> - - - description: > - <h2 class="hide-from-toc">Videos and updates</h2> - <p> - Subscribe to the TensorFlow - <a href="https://www.youtube.com/tensorflow" class="external">YouTube channel</a> - and <a href="https://blog.tensorflow.org" class="external">blog</a> for - the latest videos and updates. - </p> - items: - - description: > - <h3 class="hide-from-toc">Get started with TensorFlow's High-Level APIs</h3> - youtube_id: tjsHSIG8I08 - buttons: - - label: Watch the video - path: https://www.youtube.com/watch?v=tjsHSIG8I08 - - description: > - <h3 class="hide-from-toc">Eager execution</h3> - youtube_id: T8AW0fKP0Hs - background: grey - buttons: - - label: Watch the video - path: https://www.youtube.com/watch?v=T8AW0fKP0Hs - - description: > - <h3 class="hide-from-toc">tf.data: Fast, flexible, and easy-to-use input pipelines</h3> - youtube_id: uIcqeP7MFH0 - buttons: - - label: Watch the video - path: https://www.youtube.com/watch?v=uIcqeP7MFH0 diff --git a/tensorflow/docs_src/tutorials/_toc.yaml b/tensorflow/docs_src/tutorials/_toc.yaml deleted file mode 100644 index 0e25208a00..0000000000 --- a/tensorflow/docs_src/tutorials/_toc.yaml +++ /dev/null @@ -1,124 +0,0 @@ -toc: -- title: Get started with TensorFlow - path: /tutorials/ - -- title: Learn and use ML - style: accordion - section: - - title: Overview - path: /tutorials/keras/ - - title: Basic classification - path: /tutorials/keras/basic_classification - - title: Text classification - path: /tutorials/keras/basic_text_classification - - title: Regression - path: /tutorials/keras/basic_regression - - title: Overfitting and underfitting - path: /tutorials/keras/overfit_and_underfit - - title: Save and restore models - path: /tutorials/keras/save_and_restore_models - -- title: Research and experimentation - style: accordion - section: - - title: Overview - path: /tutorials/eager/ - - title: Eager execution - path: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb - status: external - - title: Automatic differentiation - path: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb - status: external - - title: "Custom training: basics" - path: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb - status: external - - title: Custom layers - path: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb - status: external - - title: "Custom training: walkthrough" - path: /tutorials/eager/custom_training_walkthrough - - title: Text generation - path: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb - status: external - - title: Translation with attention - path: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb - status: external - - title: Image captioning - path: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb - status: external - - title: Neural Style Transfer - path: https://github.com/tensorflow/models/blob/master/research/nst_blogpost/4_Neural_Style_Transfer_with_Eager_Execution.ipynb - status: external - - title: DCGAN - path: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/generative_examples/dcgan.ipynb - status: external - - title: VAE - path: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples/generative_examples/cvae.ipynb - status: external - - title: Pix2Pix - path: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb - status: external - - title: Image Segmentation - path: https://github.com/tensorflow/models/blob/master/samples/outreach/blogs/segmentation_blogpost/image_segmentation.ipynb - status: external - -- title: ML at production scale - style: accordion - section: - - title: Linear model with Estimators - path: /tutorials/estimators/linear - - title: Wide and deep learning - path: https://github.com/tensorflow/models/tree/master/official/wide_deep - status: external - - title: Boosted trees - path: https://github.com/tensorflow/models/tree/master/official/boosted_trees - status: external - - title: Text classifier with TF-Hub - path: /hub/tutorials/text_classification_with_tf_hub - - title: Build a CNN using Estimators - path: /tutorials/estimators/cnn - -- title: Images - style: accordion - section: - - title: Image recognition - path: /tutorials/images/image_recognition - - title: Image retraining - path: /hub/tutorials/image_retraining - - title: Advanced CNN - path: /tutorials/images/deep_cnn - -- title: Sequences - style: accordion - section: - - title: Recurrent neural network - path: /tutorials/sequences/recurrent - - title: Drawing classification - path: /tutorials/sequences/recurrent_quickdraw - - title: Simple audio recognition - path: /tutorials/sequences/audio_recognition - - title: Neural machine translation - path: https://github.com/tensorflow/nmt - status: external - -- title: Data representation - style: accordion - section: - - title: Vector representations of words - path: /tutorials/representation/word2vec - - title: Kernel methods - path: /tutorials/representation/kernel_methods - - title: Large-scale linear models - path: /tutorials/representation/linear - -- title: Non-ML - style: accordion - section: - - title: Mandelbrot set - path: /tutorials/non-ml/mandelbrot - - title: Partial differential equations - path: /tutorials/non-ml/pdes - -- break: True -- title: Next steps - path: /tutorials/next_steps diff --git a/tensorflow/docs_src/tutorials/eager/custom_training_walkthrough.md b/tensorflow/docs_src/tutorials/eager/custom_training_walkthrough.md deleted file mode 100644 index b564a27ecf..0000000000 --- a/tensorflow/docs_src/tutorials/eager/custom_training_walkthrough.md +++ /dev/null @@ -1,3 +0,0 @@ -# Custom training: walkthrough - -[Colab notebook](https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/tutorials/eager/custom_training_walkthrough.ipynb) diff --git a/tensorflow/docs_src/tutorials/eager/index.md b/tensorflow/docs_src/tutorials/eager/index.md deleted file mode 100644 index a13b396094..0000000000 --- a/tensorflow/docs_src/tutorials/eager/index.md +++ /dev/null @@ -1,13 +0,0 @@ -# Research and experimentation - -Eager execution provides an imperative, define-by-run interface for advanced -operations. Write custom layers, forward passes, and training loops with -auto differentiation. Start with these notebooks, then read the -[eager execution guide](../../guide/eager). - -1. <span>[Eager execution](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/eager_basics.ipynb){:.external}</span> -2. <span>[Automatic differentiation and gradient tape](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/automatic_differentiation.ipynb){:.external}</span> -3. <span>[Custom training: basics](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_training.ipynb){:.external}</span> -4. <span>[Custom layers](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/notebooks/custom_layers.ipynb){:.external}</span> -5. [Custom training: walkthrough](/tutorials/eager/custom_training_walkthrough) -6. <span>[Advanced example: Neural machine translation with attention](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb){:.external}</span> diff --git a/tensorflow/docs_src/tutorials/estimators/cnn.md b/tensorflow/docs_src/tutorials/estimators/cnn.md deleted file mode 100644 index 2fd69f50a0..0000000000 --- a/tensorflow/docs_src/tutorials/estimators/cnn.md +++ /dev/null @@ -1,694 +0,0 @@ -# Build a Convolutional Neural Network using Estimators - -The `tf.layers` module provides a high-level API that makes -it easy to construct a neural network. It provides methods that facilitate the -creation of dense (fully connected) layers and convolutional layers, adding -activation functions, and applying dropout regularization. In this tutorial, -you'll learn how to use `layers` to build a convolutional neural network model -to recognize the handwritten digits in the MNIST data set. - - - -**The [MNIST dataset](http://yann.lecun.com/exdb/mnist/) comprises 60,000 -training examples and 10,000 test examples of the handwritten digits 0–9, -formatted as 28x28-pixel monochrome images.** - -## Getting Started - -Let's set up the skeleton for our TensorFlow program. Create a file called -`cnn_mnist.py`, and add the following code: - -```python -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# Imports -import numpy as np -import tensorflow as tf - -tf.logging.set_verbosity(tf.logging.INFO) - -# Our application logic will be added here - -if __name__ == "__main__": - tf.app.run() -``` - -As you work through the tutorial, you'll add code to construct, train, and -evaluate the convolutional neural network. The complete, final code can be -[found here](https://www.tensorflow.org/code/tensorflow/examples/tutorials/layers/cnn_mnist.py). - -## Intro to Convolutional Neural Networks - -Convolutional neural networks (CNNs) are the current state-of-the-art model -architecture for image classification tasks. CNNs apply a series of filters to -the raw pixel data of an image to extract and learn higher-level features, which -the model can then use for classification. CNNs contains three components: - -* **Convolutional layers**, which apply a specified number of convolution - filters to the image. For each subregion, the layer performs a set of - mathematical operations to produce a single value in the output feature map. - Convolutional layers then typically apply a - [ReLU activation function](https://en.wikipedia.org/wiki/Rectifier_\(neural_networks\)) to - the output to introduce nonlinearities into the model. - -* **Pooling layers**, which - [downsample the image data](https://en.wikipedia.org/wiki/Convolutional_neural_network#Pooling_layer) - extracted by the convolutional layers to reduce the dimensionality of the - feature map in order to decrease processing time. A commonly used pooling - algorithm is max pooling, which extracts subregions of the feature map - (e.g., 2x2-pixel tiles), keeps their maximum value, and discards all other - values. - -* **Dense (fully connected) layers**, which perform classification on the - features extracted by the convolutional layers and downsampled by the - pooling layers. In a dense layer, every node in the layer is connected to - every node in the preceding layer. - -Typically, a CNN is composed of a stack of convolutional modules that perform -feature extraction. Each module consists of a convolutional layer followed by a -pooling layer. The last convolutional module is followed by one or more dense -layers that perform classification. The final dense layer in a CNN contains a -single node for each target class in the model (all the possible classes the -model may predict), with a -[softmax](https://en.wikipedia.org/wiki/Softmax_function) activation function to -generate a value between 0–1 for each node (the sum of all these softmax values -is equal to 1). We can interpret the softmax values for a given image as -relative measurements of how likely it is that the image falls into each target -class. - -> Note: For a more comprehensive walkthrough of CNN architecture, see Stanford -> University's <a href="https://cs231n.github.io/convolutional-networks/"> -> Convolutional Neural Networks for Visual Recognition course materials</a>.</p> - -## Building the CNN MNIST Classifier {#building_the_cnn_mnist_classifier} - -Let's build a model to classify the images in the MNIST dataset using the -following CNN architecture: - -1. **Convolutional Layer #1**: Applies 32 5x5 filters (extracting 5x5-pixel - subregions), with ReLU activation function -2. **Pooling Layer #1**: Performs max pooling with a 2x2 filter and stride of 2 - (which specifies that pooled regions do not overlap) -3. **Convolutional Layer #2**: Applies 64 5x5 filters, with ReLU activation - function -4. **Pooling Layer #2**: Again, performs max pooling with a 2x2 filter and - stride of 2 -5. **Dense Layer #1**: 1,024 neurons, with dropout regularization rate of 0.4 - (probability of 0.4 that any given element will be dropped during training) -6. **Dense Layer #2 (Logits Layer)**: 10 neurons, one for each digit target - class (0–9). - -The `tf.layers` module contains methods to create each of the three layer types -above: - -* `conv2d()`. Constructs a two-dimensional convolutional layer. Takes number - of filters, filter kernel size, padding, and activation function as - arguments. -* `max_pooling2d()`. Constructs a two-dimensional pooling layer using the - max-pooling algorithm. Takes pooling filter size and stride as arguments. -* `dense()`. Constructs a dense layer. Takes number of neurons and activation - function as arguments. - -Each of these methods accepts a tensor as input and returns a transformed tensor -as output. This makes it easy to connect one layer to another: just take the -output from one layer-creation method and supply it as input to another. - -Open `cnn_mnist.py` and add the following `cnn_model_fn` function, which -conforms to the interface expected by TensorFlow's Estimator API (more on this -later in [Create the Estimator](#create-the-estimator)). `cnn_mnist.py` takes -MNIST feature data, labels, and mode (from -`tf.estimator.ModeKeys`: `TRAIN`, `EVAL`, `PREDICT`) as arguments; -configures the CNN; and returns predictions, loss, and a training operation: - -```python -def cnn_model_fn(features, labels, mode): - """Model function for CNN.""" - # Input Layer - input_layer = tf.reshape(features["x"], [-1, 28, 28, 1]) - - # Convolutional Layer #1 - conv1 = tf.layers.conv2d( - inputs=input_layer, - filters=32, - kernel_size=[5, 5], - padding="same", - activation=tf.nn.relu) - - # Pooling Layer #1 - pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2) - - # Convolutional Layer #2 and Pooling Layer #2 - conv2 = tf.layers.conv2d( - inputs=pool1, - filters=64, - kernel_size=[5, 5], - padding="same", - activation=tf.nn.relu) - pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2) - - # Dense Layer - pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64]) - dense = tf.layers.dense(inputs=pool2_flat, units=1024, activation=tf.nn.relu) - dropout = tf.layers.dropout( - inputs=dense, rate=0.4, training=mode == tf.estimator.ModeKeys.TRAIN) - - # Logits Layer - logits = tf.layers.dense(inputs=dropout, units=10) - - predictions = { - # Generate predictions (for PREDICT and EVAL mode) - "classes": tf.argmax(input=logits, axis=1), - # Add `softmax_tensor` to the graph. It is used for PREDICT and by the - # `logging_hook`. - "probabilities": tf.nn.softmax(logits, name="softmax_tensor") - } - - if mode == tf.estimator.ModeKeys.PREDICT: - return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions) - - # Calculate Loss (for both TRAIN and EVAL modes) - loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits) - - # Configure the Training Op (for TRAIN mode) - if mode == tf.estimator.ModeKeys.TRAIN: - optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001) - train_op = optimizer.minimize( - loss=loss, - global_step=tf.train.get_global_step()) - return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op) - - # Add evaluation metrics (for EVAL mode) - eval_metric_ops = { - "accuracy": tf.metrics.accuracy( - labels=labels, predictions=predictions["classes"])} - return tf.estimator.EstimatorSpec( - mode=mode, loss=loss, eval_metric_ops=eval_metric_ops) -``` - -The following sections (with headings corresponding to each code block above) -dive deeper into the `tf.layers` code used to create each layer, as well as how -to calculate loss, configure the training op, and generate predictions. If -you're already experienced with CNNs and [TensorFlow `Estimator`s](../../guide/custom_estimators.md), -and find the above code intuitive, you may want to skim these sections or just -skip ahead to ["Training and Evaluating the CNN MNIST Classifier"](#train_eval_mnist). - -### Input Layer - -The methods in the `layers` module for creating convolutional and pooling layers -for two-dimensional image data expect input tensors to have a shape of -<code>[<em>batch_size</em>, <em>image_height</em>, <em>image_width</em>, -<em>channels</em>]</code> by default. This behavior can be changed using the <code><em>data_format</em></code> parameter; defined as follows: - - -* _`batch_size`_. Size of the subset of examples to use when performing - gradient descent during training. -* _`image_height`_. Height of the example images. -* _`image_width`_. Width of the example images. -* _`channels`_. Number of color channels in the example images. For color - images, the number of channels is 3 (red, green, blue). For monochrome - images, there is just 1 channel (black). -* _`data_format`_. A string, one of `channels_last` (default) or `channels_first`. - `channels_last` corresponds to inputs with shape - `(batch, ..., channels)` while `channels_first` corresponds to - inputs with shape `(batch, channels, ...)`. - -Here, our MNIST dataset is composed of monochrome 28x28 pixel images, so the -desired shape for our input layer is <code>[<em>batch_size</em>, 28, 28, -1]</code>. - -To convert our input feature map (`features`) to this shape, we can perform the -following `reshape` operation: - -```python -input_layer = tf.reshape(features["x"], [-1, 28, 28, 1]) -``` - -Note that we've indicated `-1` for batch size, which specifies that this -dimension should be dynamically computed based on the number of input values in -`features["x"]`, holding the size of all other dimensions constant. This allows -us to treat `batch_size` as a hyperparameter that we can tune. For example, if -we feed examples into our model in batches of 5, `features["x"]` will contain -3,920 values (one value for each pixel in each image), and `input_layer` will -have a shape of `[5, 28, 28, 1]`. Similarly, if we feed examples in batches of -100, `features["x"]` will contain 78,400 values, and `input_layer` will have a -shape of `[100, 28, 28, 1]`. - -### Convolutional Layer #1 - -In our first convolutional layer, we want to apply 32 5x5 filters to the input -layer, with a ReLU activation function. We can use the `conv2d()` method in the -`layers` module to create this layer as follows: - -```python -conv1 = tf.layers.conv2d( - inputs=input_layer, - filters=32, - kernel_size=[5, 5], - padding="same", - activation=tf.nn.relu) -``` - -The `inputs` argument specifies our input tensor, which must have the shape -<code>[<em>batch_size</em>, <em>image_height</em>, <em>image_width</em>, -<em>channels</em>]</code>. Here, we're connecting our first convolutional layer -to `input_layer`, which has the shape <code>[<em>batch_size</em>, 28, 28, -1]</code>. - -> Note: <code>conv2d()</code> will instead accept a shape of -> <code>[<em>batch_size</em>, <em>channels</em>, <em>image_height</em>, <em>image_width</em>]</code> when passed the argument -> <code>data_format=channels_first</code>. - -The `filters` argument specifies the number of filters to apply (here, 32), and -`kernel_size` specifies the dimensions of the filters as <code>[<em>height</em>, -<em>width</em>]</code> (here, <code>[5, 5]</code>). - -<p class="tip"><b>TIP:</b> If filter height and width have the same value, you can instead specify a -single integer for <code>kernel_size</code>—e.g., <code>kernel_size=5</code>.</p> - -The `padding` argument specifies one of two enumerated values -(case-insensitive): `valid` (default value) or `same`. To specify that the -output tensor should have the same height and width values as the input tensor, -we set `padding=same` here, which instructs TensorFlow to add 0 values to the -edges of the input tensor to preserve height and width of 28. (Without padding, -a 5x5 convolution over a 28x28 tensor will produce a 24x24 tensor, as there are -24x24 locations to extract a 5x5 tile from a 28x28 grid.) - -The `activation` argument specifies the activation function to apply to the -output of the convolution. Here, we specify ReLU activation with -`tf.nn.relu`. - -Our output tensor produced by `conv2d()` has a shape of -<code>[<em>batch_size</em>, 28, 28, 32]</code>: the same height and width -dimensions as the input, but now with 32 channels holding the output from each -of the filters. - -### Pooling Layer #1 - -Next, we connect our first pooling layer to the convolutional layer we just -created. We can use the `max_pooling2d()` method in `layers` to construct a -layer that performs max pooling with a 2x2 filter and stride of 2: - -```python -pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2) -``` - -Again, `inputs` specifies the input tensor, with a shape of -<code>[<em>batch_size</em>, <em>image_height</em>, <em>image_width</em>, -<em>channels</em>]</code>. Here, our input tensor is `conv1`, the output from -the first convolutional layer, which has a shape of <code>[<em>batch_size</em>, -28, 28, 32]</code>. - -> Note: As with <code>conv2d()</code>, <code>max_pooling2d()</code> will instead -> accept a shape of <code>[<em>batch_size</em>, <em>channels</em>, -> <em>image_height</em>, <em>image_width</em>]</code> when passed the argument -> <code>data_format=channels_first</code>. - -The `pool_size` argument specifies the size of the max pooling filter as -<code>[<em>height</em>, <em>width</em>]</code> (here, `[2, 2]`). If both -dimensions have the same value, you can instead specify a single integer (e.g., -`pool_size=2`). - -The `strides` argument specifies the size of the stride. Here, we set a stride -of 2, which indicates that the subregions extracted by the filter should be -separated by 2 pixels in both the height and width dimensions (for a 2x2 filter, -this means that none of the regions extracted will overlap). If you want to set -different stride values for height and width, you can instead specify a tuple or -list (e.g., `stride=[3, 6]`). - -Our output tensor produced by `max_pooling2d()` (`pool1`) has a shape of -<code>[<em>batch_size</em>, 14, 14, 32]</code>: the 2x2 filter reduces height and width by 50% each. - -### Convolutional Layer #2 and Pooling Layer #2 - -We can connect a second convolutional and pooling layer to our CNN using -`conv2d()` and `max_pooling2d()` as before. For convolutional layer #2, we -configure 64 5x5 filters with ReLU activation, and for pooling layer #2, we use -the same specs as pooling layer #1 (a 2x2 max pooling filter with stride of 2): - -```python -conv2 = tf.layers.conv2d( - inputs=pool1, - filters=64, - kernel_size=[5, 5], - padding="same", - activation=tf.nn.relu) - -pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2) -``` - -Note that convolutional layer #2 takes the output tensor of our first pooling -layer (`pool1`) as input, and produces the tensor `conv2` as output. `conv2` -has a shape of <code>[<em>batch_size</em>, 14, 14, 64]</code>, the same height and width as `pool1` (due to `padding="same"`), and 64 channels for the 64 -filters applied. - -Pooling layer #2 takes `conv2` as input, producing `pool2` as output. `pool2` -has shape <code>[<em>batch_size</em>, 7, 7, 64]</code> (50% reduction of height and width from `conv2`). - -### Dense Layer - -Next, we want to add a dense layer (with 1,024 neurons and ReLU activation) to -our CNN to perform classification on the features extracted by the -convolution/pooling layers. Before we connect the layer, however, we'll flatten -our feature map (`pool2`) to shape <code>[<em>batch_size</em>, -<em>features</em>]</code>, so that our tensor has only two dimensions: - -```python -pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64]) -``` - -In the `reshape()` operation above, the `-1` signifies that the *`batch_size`* -dimension will be dynamically calculated based on the number of examples in our -input data. Each example has 7 (`pool2` height) * 7 (`pool2` width) * 64 -(`pool2` channels) features, so we want the `features` dimension to have a value -of 7 * 7 * 64 (3136 in total). The output tensor, `pool2_flat`, has shape -<code>[<em>batch_size</em>, 3136]</code>. - -Now, we can use the `dense()` method in `layers` to connect our dense layer as -follows: - -```python -dense = tf.layers.dense(inputs=pool2_flat, units=1024, activation=tf.nn.relu) -``` - -The `inputs` argument specifies the input tensor: our flattened feature map, -`pool2_flat`. The `units` argument specifies the number of neurons in the dense -layer (1,024). The `activation` argument takes the activation function; again, -we'll use `tf.nn.relu` to add ReLU activation. - -To help improve the results of our model, we also apply dropout regularization -to our dense layer, using the `dropout` method in `layers`: - -```python -dropout = tf.layers.dropout( - inputs=dense, rate=0.4, training=mode == tf.estimator.ModeKeys.TRAIN) -``` - -Again, `inputs` specifies the input tensor, which is the output tensor from our -dense layer (`dense`). - -The `rate` argument specifies the dropout rate; here, we use `0.4`, which means -40% of the elements will be randomly dropped out during training. - -The `training` argument takes a boolean specifying whether or not the model is -currently being run in training mode; dropout will only be performed if -`training` is `True`. Here, we check if the `mode` passed to our model function -`cnn_model_fn` is `TRAIN` mode. - -Our output tensor `dropout` has shape <code>[<em>batch_size</em>, 1024]</code>. - -### Logits Layer - -The final layer in our neural network is the logits layer, which will return the -raw values for our predictions. We create a dense layer with 10 neurons (one for -each target class 0–9), with linear activation (the default): - -```python -logits = tf.layers.dense(inputs=dropout, units=10) -``` - -Our final output tensor of the CNN, `logits`, has shape -<code>[<em>batch_size</em>, 10]</code>. - -### Generate Predictions {#generate_predictions} - -The logits layer of our model returns our predictions as raw values in a -<code>[<em>batch_size</em>, 10]</code>-dimensional tensor. Let's convert these -raw values into two different formats that our model function can return: - -* The **predicted class** for each example: a digit from 0–9. -* The **probabilities** for each possible target class for each example: the - probability that the example is a 0, is a 1, is a 2, etc. - -For a given example, our predicted class is the element in the corresponding row -of the logits tensor with the highest raw value. We can find the index of this -element using the `tf.argmax` -function: - -```python -tf.argmax(input=logits, axis=1) -``` - -The `input` argument specifies the tensor from which to extract maximum -values—here `logits`. The `axis` argument specifies the axis of the `input` -tensor along which to find the greatest value. Here, we want to find the largest -value along the dimension with index of 1, which corresponds to our predictions -(recall that our logits tensor has shape <code>[<em>batch_size</em>, -10]</code>). - -We can derive probabilities from our logits layer by applying softmax activation -using `tf.nn.softmax`: - -```python -tf.nn.softmax(logits, name="softmax_tensor") -``` - -> Note: We use the `name` argument to explicitly name this operation -> `softmax_tensor`, so we can reference it later. (We'll set up logging for the -> softmax values in ["Set Up a Logging Hook"](#set-up-a-logging-hook)). - -We compile our predictions in a dict, and return an `EstimatorSpec` object: - -```python -predictions = { - "classes": tf.argmax(input=logits, axis=1), - "probabilities": tf.nn.softmax(logits, name="softmax_tensor") -} -if mode == tf.estimator.ModeKeys.PREDICT: - return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions) -``` - -### Calculate Loss {#calculating-loss} - -For both training and evaluation, we need to define a -[loss function](https://en.wikipedia.org/wiki/Loss_function) -that measures how closely the model's predictions match the target classes. For -multiclass classification problems like MNIST, -[cross entropy](https://en.wikipedia.org/wiki/Cross_entropy) is typically used -as the loss metric. The following code calculates cross entropy when the model -runs in either `TRAIN` or `EVAL` mode: - -```python -loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits) -``` - -Let's take a closer look at what's happening above. - -Our `labels` tensor contains a list of prediction indices for our examples, e.g. `[1, -9, ...]`. `logits` contains the linear outputs of our last layer. - -`tf.losses.sparse_softmax_cross_entropy`, calculates the softmax crossentropy -(aka: categorical crossentropy, negative log-likelihood) from these two inputs -in an efficient, numerically stable way. - - -### Configure the Training Op - -In the previous section, we defined loss for our CNN as the softmax -cross-entropy of the logits layer and our labels. Let's configure our model to -optimize this loss value during training. We'll use a learning rate of 0.001 and -[stochastic gradient descent](https://en.wikipedia.org/wiki/Stochastic_gradient_descent) -as the optimization algorithm: - -```python -if mode == tf.estimator.ModeKeys.TRAIN: - optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001) - train_op = optimizer.minimize( - loss=loss, - global_step=tf.train.get_global_step()) - return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op) -``` - -> Note: For a more in-depth look at configuring training ops for Estimator model -> functions, see ["Defining the training op for the model"](../../guide/custom_estimators.md#defining-the-training-op-for-the-model) -> in the ["Creating Estimations in tf.estimator"](../../guide/custom_estimators.md) tutorial. - - -### Add evaluation metrics - -To add accuracy metric in our model, we define `eval_metric_ops` dict in EVAL -mode as follows: - -```python -eval_metric_ops = { - "accuracy": tf.metrics.accuracy( - labels=labels, predictions=predictions["classes"])} -return tf.estimator.EstimatorSpec( - mode=mode, loss=loss, eval_metric_ops=eval_metric_ops) -``` - -<a id="train_eval_mnist"></a> -## Training and Evaluating the CNN MNIST Classifier - -We've coded our MNIST CNN model function; now we're ready to train and evaluate -it. - -### Load Training and Test Data - -First, let's load our training and test data. Add a `main()` function to -`cnn_mnist.py` with the following code: - -```python -def main(unused_argv): - # Load training and eval data - mnist = tf.contrib.learn.datasets.load_dataset("mnist") - train_data = mnist.train.images # Returns np.array - train_labels = np.asarray(mnist.train.labels, dtype=np.int32) - eval_data = mnist.test.images # Returns np.array - eval_labels = np.asarray(mnist.test.labels, dtype=np.int32) -``` - -We store the training feature data (the raw pixel values for 55,000 images of -hand-drawn digits) and training labels (the corresponding value from 0–9 for -each image) as [numpy -arrays](https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html) -in `train_data` and `train_labels`, respectively. Similarly, we store the -evaluation feature data (10,000 images) and evaluation labels in `eval_data` -and `eval_labels`, respectively. - -### Create the Estimator {#create-the-estimator} - -Next, let's create an `Estimator` (a TensorFlow class for performing high-level -model training, evaluation, and inference) for our model. Add the following code -to `main()`: - -```python -# Create the Estimator -mnist_classifier = tf.estimator.Estimator( - model_fn=cnn_model_fn, model_dir="/tmp/mnist_convnet_model") -``` - -The `model_fn` argument specifies the model function to use for training, -evaluation, and prediction; we pass it the `cnn_model_fn` we created in -["Building the CNN MNIST Classifier."](#building-the-cnn-mnist-classifier) The -`model_dir` argument specifies the directory where model data (checkpoints) will -be saved (here, we specify the temp directory `/tmp/mnist_convnet_model`, but -feel free to change to another directory of your choice). - -> Note: For an in-depth walkthrough of the TensorFlow `Estimator` API, see the -> tutorial ["Creating Estimators in tf.estimator."](../../guide/custom_estimators.md) - -### Set Up a Logging Hook {#set_up_a_logging_hook} - -Since CNNs can take a while to train, let's set up some logging so we can track -progress during training. We can use TensorFlow's `tf.train.SessionRunHook` to create a -`tf.train.LoggingTensorHook` -that will log the probability values from the softmax layer of our CNN. Add the -following to `main()`: - -```python -# Set up logging for predictions -tensors_to_log = {"probabilities": "softmax_tensor"} -logging_hook = tf.train.LoggingTensorHook( - tensors=tensors_to_log, every_n_iter=50) -``` - -We store a dict of the tensors we want to log in `tensors_to_log`. Each key is a -label of our choice that will be printed in the log output, and the -corresponding label is the name of a `Tensor` in the TensorFlow graph. Here, our -`probabilities` can be found in `softmax_tensor`, the name we gave our softmax -operation earlier when we generated the probabilities in `cnn_model_fn`. - -> Note: If you don't explicitly assign a name to an operation via the `name` -> argument, TensorFlow will assign a default name. A couple easy ways to -> discover the names applied to operations are to visualize your graph on -> [TensorBoard](../../guide/graph_viz.md)) or to enable the -> [TensorFlow Debugger (tfdbg)](../../guide/debugger.md). - -Next, we create the `LoggingTensorHook`, passing `tensors_to_log` to the -`tensors` argument. We set `every_n_iter=50`, which specifies that probabilities -should be logged after every 50 steps of training. - -### Train the Model - -Now we're ready to train our model, which we can do by creating `train_input_fn` -and calling `train()` on `mnist_classifier`. Add the following to `main()`: - -```python -# Train the model -train_input_fn = tf.estimator.inputs.numpy_input_fn( - x={"x": train_data}, - y=train_labels, - batch_size=100, - num_epochs=None, - shuffle=True) -mnist_classifier.train( - input_fn=train_input_fn, - steps=20000, - hooks=[logging_hook]) -``` - -In the `numpy_input_fn` call, we pass the training feature data and labels to -`x` (as a dict) and `y`, respectively. We set a `batch_size` of `100` (which -means that the model will train on minibatches of 100 examples at each step). -`num_epochs=None` means that the model will train until the specified number of -steps is reached. We also set `shuffle=True` to shuffle the training data. -In the `train` call, we set `steps=20000` -(which means the model will train for 20,000 steps total). We pass our -`logging_hook` to the `hooks` argument, so that it will be triggered during -training. - -### Evaluate the Model - -Once training is complete, we want to evaluate our model to determine its -accuracy on the MNIST test set. We call the `evaluate` method, which evaluates -the metrics we specified in `eval_metric_ops` argument in the `model_fn`. -Add the following to `main()`: - -```python -# Evaluate the model and print results -eval_input_fn = tf.estimator.inputs.numpy_input_fn( - x={"x": eval_data}, - y=eval_labels, - num_epochs=1, - shuffle=False) -eval_results = mnist_classifier.evaluate(input_fn=eval_input_fn) -print(eval_results) -``` - -To create `eval_input_fn`, we set `num_epochs=1`, so that the model evaluates -the metrics over one epoch of data and returns the result. We also set -`shuffle=False` to iterate through the data sequentially. - -### Run the Model - -We've coded the CNN model function, `Estimator`, and the training/evaluation -logic; now let's see the results. Run `cnn_mnist.py`. - -> Note: Training CNNs is quite computationally intensive. Estimated completion -> time of `cnn_mnist.py` will vary depending on your processor, but will likely -> be upwards of 1 hour on CPU. To train more quickly, you can decrease the -> number of `steps` passed to `train()`, but note that this will affect accuracy. - -As the model trains, you'll see log output like the following: - -```python -INFO:tensorflow:loss = 2.36026, step = 1 -INFO:tensorflow:probabilities = [[ 0.07722801 0.08618255 0.09256398, ...]] -... -INFO:tensorflow:loss = 2.13119, step = 101 -INFO:tensorflow:global_step/sec: 5.44132 -... -INFO:tensorflow:Loss for final step: 0.553216. - -INFO:tensorflow:Restored model from /tmp/mnist_convnet_model -INFO:tensorflow:Eval steps [0,inf) for training step 20000. -INFO:tensorflow:Input iterator is exhausted. -INFO:tensorflow:Saving evaluation summary for step 20000: accuracy = 0.9733, loss = 0.0902271 -{'loss': 0.090227105, 'global_step': 20000, 'accuracy': 0.97329998} -``` - -Here, we've achieved an accuracy of 97.3% on our test data set. - -## Additional Resources - -To learn more about TensorFlow Estimators and CNNs in TensorFlow, see the -following resources: - -* [Creating Estimators in tf.estimator](../../guide/custom_estimators.md) - provides an introduction to the TensorFlow Estimator API. It walks through - configuring an Estimator, writing a model function, calculating loss, and - defining a training op. -* [Advanced Convolutional Neural Networks](../../tutorials/images/deep_cnn.md) walks through how to build a MNIST CNN classification model - *without estimators* using lower-level TensorFlow operations. diff --git a/tensorflow/docs_src/tutorials/estimators/linear.md b/tensorflow/docs_src/tutorials/estimators/linear.md deleted file mode 100644 index 067a33ac03..0000000000 --- a/tensorflow/docs_src/tutorials/estimators/linear.md +++ /dev/null @@ -1,3 +0,0 @@ -# Build a linear model with Estimators - -[Colab notebook](https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/tutorials/estimators/linear.ipynb) diff --git a/tensorflow/docs_src/tutorials/images/deep_cnn.md b/tensorflow/docs_src/tutorials/images/deep_cnn.md deleted file mode 100644 index 00996b82e6..0000000000 --- a/tensorflow/docs_src/tutorials/images/deep_cnn.md +++ /dev/null @@ -1,446 +0,0 @@ -# Advanced Convolutional Neural Networks - -## Overview - -CIFAR-10 classification is a common benchmark problem in machine learning. The -problem is to classify RGB 32x32 pixel images across 10 categories: -``` -airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck. -``` - -For more details refer to the [CIFAR-10 page](https://www.cs.toronto.edu/~kriz/cifar.html) -and a [Tech Report](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf) -by Alex Krizhevsky. - -### Goals - -The goal of this tutorial is to build a relatively small [convolutional neural -network](https://en.wikipedia.org/wiki/Convolutional_neural_network) (CNN) for -recognizing images. In the process, this tutorial: - -1. Highlights a canonical organization for network architecture, -training and evaluation. -2. Provides a template for constructing larger and more sophisticated models. - -The reason CIFAR-10 was selected was that it is complex enough to exercise -much of TensorFlow's ability to scale to large models. At the same time, -the model is small enough to train fast, which is ideal for trying out -new ideas and experimenting with new techniques. - -### Highlights of the Tutorial -The CIFAR-10 tutorial demonstrates several important constructs for -designing larger and more sophisticated models in TensorFlow: - -* Core mathematical components including `tf.nn.conv2d` -([wiki](https://en.wikipedia.org/wiki/Convolution)), -`tf.nn.relu` -([wiki](https://en.wikipedia.org/wiki/Rectifier_(neural_networks))), -`tf.nn.max_pool` -([wiki](https://en.wikipedia.org/wiki/Convolutional_neural_network#Pooling_layer)) -and `tf.nn.local_response_normalization` -(Chapter 3.3 in -[AlexNet paper](https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)). -* [Visualization](../../guide/summaries_and_tensorboard.md) -of network activities during training, including input images, -losses and distributions of activations and gradients. -* Routines for calculating the -`tf.train.ExponentialMovingAverage` -of learned parameters and using these averages -during evaluation to boost predictive performance. -* Implementation of a -`tf.train.exponential_decay` -that systematically decrements over time. -* Prefetching `tf.train.shuffle_batch` -for input -data to isolate the model from disk latency and expensive image pre-processing. - -We also provide a [multi-GPU version](#training-a-model-using-multiple-gpu-cards) -of the model which demonstrates: - -* Configuring a model to train across multiple GPU cards in parallel. -* Sharing and updating variables among multiple GPUs. - -We hope that this tutorial provides a launch point for building larger CNNs for -vision tasks on TensorFlow. - -### Model Architecture - -The model in this CIFAR-10 tutorial is a multi-layer architecture consisting of -alternating convolutions and nonlinearities. These layers are followed by fully -connected layers leading into a softmax classifier. The model follows the -architecture described by -[Alex Krizhevsky](https://code.google.com/p/cuda-convnet/), with a few -differences in the top few layers. - -This model achieves a peak performance of about 86% accuracy within a few hours -of training time on a GPU. Please see [below](#evaluating-a-model) and the code -for details. It consists of 1,068,298 learnable parameters and requires about -19.5M multiply-add operations to compute inference on a single image. - -## Code Organization - -The code for this tutorial resides in -[`models/tutorials/image/cifar10/`](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/). - -File | Purpose ---- | --- -[`cifar10_input.py`](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/cifar10_input.py) | Reads the native CIFAR-10 binary file format. -[`cifar10.py`](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/cifar10.py) | Builds the CIFAR-10 model. -[`cifar10_train.py`](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/cifar10_train.py) | Trains a CIFAR-10 model on a CPU or GPU. -[`cifar10_multi_gpu_train.py`](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/cifar10_multi_gpu_train.py) | Trains a CIFAR-10 model on multiple GPUs. -[`cifar10_eval.py`](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/cifar10_eval.py) | Evaluates the predictive performance of a CIFAR-10 model. - - -## CIFAR-10 Model - -The CIFAR-10 network is largely contained in -[`cifar10.py`](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10/cifar10.py). -The complete training -graph contains roughly 765 operations. We find that we can make the code most -reusable by constructing the graph with the following modules: - -1. [**Model inputs:**](#model-inputs) `inputs()` and `distorted_inputs()` add -operations that read and preprocess CIFAR images for evaluation and training, -respectively. -1. [**Model prediction:**](#model-prediction) `inference()` -adds operations that perform inference, i.e. classification, on supplied images. -1. [**Model training:**](#model-training) `loss()` and `train()` -add operations that compute the loss, -gradients, variable updates and visualization summaries. - -### Model Inputs - -The input part of the model is built by the functions `inputs()` and -`distorted_inputs()` which read images from the CIFAR-10 binary data files. -These files contain fixed byte length records, so we use -`tf.FixedLengthRecordReader`. -See [Reading Data](../../api_guides/python/reading_data.md#reading-from-files) to -learn more about how the `Reader` class works. - -The images are processed as follows: - -* They are cropped to 24 x 24 pixels, centrally for evaluation or - `tf.random_crop` for training. -* They are `tf.image.per_image_standardization` - to make the model insensitive to dynamic range. - -For training, we additionally apply a series of random distortions to -artificially increase the data set size: - -* `tf.image.random_flip_left_right` the image from left to right. -* Randomly distort the `tf.image.random_brightness`. -* Randomly distort the `tf.image.random_contrast`. - -Please see the [Images](../../api_guides/python/image.md) page for the list of -available distortions. We also attach an -`tf.summary.image` to the images -so that we may visualize them in [TensorBoard](../../guide/summaries_and_tensorboard.md). -This is a good practice to verify that inputs are built correctly. - -<div style="width:50%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:70%" src="https://www.tensorflow.org/images/cifar_image_summary.png"> -</div> - -Reading images from disk and distorting them can use a non-trivial amount of -processing time. To prevent these operations from slowing down training, we run -them inside 16 separate threads which continuously fill a TensorFlow -`tf.train.shuffle_batch`. - -### Model Prediction - -The prediction part of the model is constructed by the `inference()` function -which adds operations to compute the *logits* of the predictions. That part of -the model is organized as follows: - -Layer Name | Description ---- | --- -`conv1` | `tf.nn.conv2d` and `tf.nn.relu` activation. -`pool1` | `tf.nn.max_pool`. -`norm1` | `tf.nn.local_response_normalization`. -`conv2` | `tf.nn.conv2d` and `tf.nn.relu` activation. -`norm2` | `tf.nn.local_response_normalization`. -`pool2` | `tf.nn.max_pool`. -`local3` | [fully connected layer with rectified linear activation](../../api_guides/python/nn.md). -`local4` | [fully connected layer with rectified linear activation](../../api_guides/python/nn.md). -`softmax_linear` | linear transformation to produce logits. - -Here is a graph generated from TensorBoard describing the inference operation: - -<div style="width:15%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/cifar_graph.png"> -</div> - -> **EXERCISE**: The output of `inference` are un-normalized logits. Try editing -the network architecture to return normalized predictions using -`tf.nn.softmax`. - -The `inputs()` and `inference()` functions provide all the components -necessary to perform an evaluation of a model. We now shift our focus towards -building operations for training a model. - -> **EXERCISE:** The model architecture in `inference()` differs slightly from -the CIFAR-10 model specified in -[cuda-convnet](https://code.google.com/p/cuda-convnet/). In particular, the top -layers of Alex's original model are locally connected and not fully connected. -Try editing the architecture to exactly reproduce the locally connected -architecture in the top layer. - -### Model Training - -The usual method for training a network to perform N-way classification is -[multinomial logistic regression](https://en.wikipedia.org/wiki/Multinomial_logistic_regression), -aka. *softmax regression*. Softmax regression applies a -`tf.nn.softmax` nonlinearity to the -output of the network and calculates the -`tf.nn.sparse_softmax_cross_entropy_with_logits` -between the normalized predictions and the label index. -For regularization, we also apply the usual -`tf.nn.l2_loss` losses to all learned -variables. The objective function for the model is the sum of the cross entropy -loss and all these weight decay terms, as returned by the `loss()` function. - -We visualize it in TensorBoard with a `tf.summary.scalar`: - - - -We train the model using standard -[gradient descent](https://en.wikipedia.org/wiki/Gradient_descent) -algorithm (see [Training](../../api_guides/python/train.md) for other methods) -with a learning rate that -`tf.train.exponential_decay` -over time. - - - -The `train()` function adds the operations needed to minimize the objective by -calculating the gradient and updating the learned variables (see -`tf.train.GradientDescentOptimizer` -for details). It returns an operation that executes all the calculations -needed to train and update the model for one batch of images. - -## Launching and Training the Model - -We have built the model, let's now launch it and run the training operation with -the script `cifar10_train.py`. - -```shell -python cifar10_train.py -``` - -> **NOTE:** The first time you run any target in the CIFAR-10 tutorial, -the CIFAR-10 dataset is automatically downloaded. The data set is ~160MB -so you may want to grab a quick cup of coffee for your first run. - -You should see the output: - -```shell -Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes. -2015-11-04 11:45:45.927302: step 0, loss = 4.68 (2.0 examples/sec; 64.221 sec/batch) -2015-11-04 11:45:49.133065: step 10, loss = 4.66 (533.8 examples/sec; 0.240 sec/batch) -2015-11-04 11:45:51.397710: step 20, loss = 4.64 (597.4 examples/sec; 0.214 sec/batch) -2015-11-04 11:45:54.446850: step 30, loss = 4.62 (391.0 examples/sec; 0.327 sec/batch) -2015-11-04 11:45:57.152676: step 40, loss = 4.61 (430.2 examples/sec; 0.298 sec/batch) -2015-11-04 11:46:00.437717: step 50, loss = 4.59 (406.4 examples/sec; 0.315 sec/batch) -... -``` - -The script reports the total loss every 10 steps as well as the speed at which -the last batch of data was processed. A few comments: - -* The first batch of data can be inordinately slow (e.g. several minutes) as the -preprocessing threads fill up the shuffling queue with 20,000 processed CIFAR -images. - -* The reported loss is the average loss of the most recent batch. Remember that -this loss is the sum of the cross entropy and all weight decay terms. - -* Keep an eye on the processing speed of a batch. The numbers shown above were -obtained on a Tesla K40c. If you are running on a CPU, expect slower performance. - - -> **EXERCISE:** When experimenting, it is sometimes annoying that the first -training step can take so long. Try decreasing the number of images that -initially fill up the queue. Search for `min_fraction_of_examples_in_queue` -in `cifar10_input.py`. - -`cifar10_train.py` periodically uses a `tf.train.Saver` to save -all model parameters in -[checkpoint files](../../guide/saved_model.md) -but it does *not* evaluate the model. The checkpoint file -will be used by `cifar10_eval.py` to measure the predictive -performance (see [Evaluating a Model](#evaluating-a-model) below). - - -If you followed the previous steps, then you have now started training -a CIFAR-10 model. [Congratulations!](https://www.youtube.com/watch?v=9bZkp7q19f0) - -The terminal text returned from `cifar10_train.py` provides minimal insight into -how the model is training. We want more insight into the model during training: - -* Is the loss *really* decreasing or is that just noise? -* Is the model being provided appropriate images? -* Are the gradients, activations and weights reasonable? -* What is the learning rate currently at? - -[TensorBoard](../../guide/summaries_and_tensorboard.md) provides this -functionality, displaying data exported periodically from `cifar10_train.py` via -a -`tf.summary.FileWriter`. - -For instance, we can watch how the distribution of activations and degree of -sparsity in `local3` features evolve during training: - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px; display: flex; flex-direction: row"> - <img style="flex-grow:1; flex-shrink:1;" src="https://www.tensorflow.org/images/cifar_sparsity.png"> - <img style="flex-grow:1; flex-shrink:1;" src="https://www.tensorflow.org/images/cifar_activations.png"> -</div> - -Individual loss functions, as well as the total loss, are particularly -interesting to track over time. However, the loss exhibits a considerable amount -of noise due to the small batch size employed by training. In practice we find -it extremely useful to visualize their moving averages in addition to their raw -values. See how the scripts use -`tf.train.ExponentialMovingAverage` -for this purpose. - -## Evaluating a Model - -Let us now evaluate how well the trained model performs on a hold-out data set. -The model is evaluated by the script `cifar10_eval.py`. It constructs the model -with the `inference()` function and uses all 10,000 images in the evaluation set -of CIFAR-10. It calculates the *precision at 1:* how often the top prediction -matches the true label of the image. - -To monitor how the model improves during training, the evaluation script runs -periodically on the latest checkpoint files created by the `cifar10_train.py`. - -```shell -python cifar10_eval.py -``` - -> Be careful not to run the evaluation and training binary on the same GPU or -else you might run out of memory. Consider running the evaluation on -a separate GPU if available or suspending the training binary while running -the evaluation on the same GPU. - -You should see the output: - -```shell -2015-11-06 08:30:44.391206: precision @ 1 = 0.860 -... -``` - -The script merely returns the precision @ 1 periodically -- in this case -it returned 86% accuracy. `cifar10_eval.py` also -exports summaries that may be visualized in TensorBoard. These summaries -provide additional insight into the model during evaluation. - -The training script calculates the -`tf.train.ExponentialMovingAverage` of all learned variables. -The evaluation script substitutes -all learned model parameters with the moving average version. This -substitution boosts model performance at evaluation time. - -> **EXERCISE:** Employing averaged parameters may boost predictive performance -by about 3% as measured by precision @ 1. Edit `cifar10_eval.py` to not employ -the averaged parameters for the model and verify that the predictive performance -drops. - - -## Training a Model Using Multiple GPU Cards - -Modern workstations may contain multiple GPUs for scientific computation. -TensorFlow can leverage this environment to run the training operation -concurrently across multiple cards. - -Training a model in a parallel, distributed fashion requires -coordinating training processes. For what follows we term *model replica* -to be one copy of a model training on a subset of data. - -Naively employing asynchronous updates of model parameters -leads to sub-optimal training performance -because an individual model replica might be trained on a stale -copy of the model parameters. Conversely, employing fully synchronous -updates will be as slow as the slowest model replica. - -In a workstation with multiple GPU cards, each GPU will have similar speed -and contain enough memory to run an entire CIFAR-10 model. Thus, we opt to -design our training system in the following manner: - -* Place an individual model replica on each GPU. -* Update model parameters synchronously by waiting for all GPUs to finish -processing a batch of data. - -Here is a diagram of this model: - -<div style="width:40%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/Parallelism.png"> -</div> - -Note that each GPU computes inference as well as the gradients for a unique -batch of data. This setup effectively permits dividing up a larger batch -of data across the GPUs. - -This setup requires that all GPUs share the model parameters. A well-known -fact is that transferring data to and from GPUs is quite slow. For this -reason, we decide to store and update all model parameters on the CPU (see -green box). A fresh set of model parameters is transferred to the GPU -when a new batch of data is processed by all GPUs. - -The GPUs are synchronized in operation. All gradients are accumulated from -the GPUs and averaged (see green box). The model parameters are updated with -the gradients averaged across all model replicas. - -### Placing Variables and Operations on Devices - -Placing operations and variables on devices requires some special -abstractions. - -The first abstraction we require is a function for computing inference and -gradients for a single model replica. In the code we term this abstraction -a "tower". We must set two attributes for each tower: - -* A unique name for all operations within a tower. -`tf.name_scope` provides -this unique name by prepending a scope. For instance, all operations in -the first tower are prepended with `tower_0`, e.g. `tower_0/conv1/Conv2D`. - -* A preferred hardware device to run the operation within a tower. -`tf.device` specifies this. For -instance, all operations in the first tower reside within `device('/device:GPU:0')` -scope indicating that they should be run on the first GPU. - -All variables are pinned to the CPU and accessed via -`tf.get_variable` -in order to share them in a multi-GPU version. -See how-to on [Sharing Variables](../../guide/variables.md). - -### Launching and Training the Model on Multiple GPU cards - -If you have several GPU cards installed on your machine you can use them to -train the model faster with the `cifar10_multi_gpu_train.py` script. This -version of the training script parallelizes the model across multiple GPU cards. - -```shell -python cifar10_multi_gpu_train.py --num_gpus=2 -``` - -Note that the number of GPU cards used defaults to 1. Additionally, if only 1 -GPU is available on your machine, all computations will be placed on it, even if -you ask for more. - -> **EXERCISE:** The default settings for `cifar10_train.py` is to -run on a batch size of 128. Try running `cifar10_multi_gpu_train.py` on 2 GPUs -with a batch size of 64 and compare the training speed. - -## Next Steps - -If you are now interested in developing and training your own image -classification system, we recommend forking this tutorial and replacing -components to address your image classification problem. - - -> **EXERCISE:** Download the -[Street View House Numbers (SVHN)](http://ufldl.stanford.edu/housenumbers/) data set. -Fork the CIFAR-10 tutorial and swap in the SVHN as the input data. Try adapting -the network architecture to improve predictive performance. diff --git a/tensorflow/docs_src/tutorials/images/image_recognition.md b/tensorflow/docs_src/tutorials/images/image_recognition.md deleted file mode 100644 index 52913b2082..0000000000 --- a/tensorflow/docs_src/tutorials/images/image_recognition.md +++ /dev/null @@ -1,455 +0,0 @@ -# Image Recognition - -Our brains make vision seem easy. It doesn't take any effort for humans to -tell apart a lion and a jaguar, read a sign, or recognize a human's face. -But these are actually hard problems to solve with a computer: they only -seem easy because our brains are incredibly good at understanding images. - -In the last few years, the field of machine learning has made tremendous -progress on addressing these difficult problems. In particular, we've -found that a kind of model called a deep -[convolutional neural network](https://colah.github.io/posts/2014-07-Conv-Nets-Modular/) -can achieve reasonable performance on hard visual recognition tasks -- -matching or exceeding human performance in some domains. - -Researchers have demonstrated steady progress -in computer vision by validating their work against -[ImageNet](http://www.image-net.org) -- an academic benchmark for computer vision. -Successive models continue to show improvements, each time achieving -a new state-of-the-art result: -[QuocNet], [AlexNet], [Inception (GoogLeNet)], [BN-Inception-v2]. -Researchers both internal and external to Google have published papers describing all -these models but the results are still hard to reproduce. -We're now taking the next step by releasing code for running image recognition -on our latest model, [Inception-v3]. - -[QuocNet]: https://static.googleusercontent.com/media/research.google.com/en//archive/unsupervised_icml2012.pdf -[AlexNet]: https://www.cs.toronto.edu/~fritz/absps/imagenet.pdf -[Inception (GoogLeNet)]: https://arxiv.org/abs/1409.4842 -[BN-Inception-v2]: https://arxiv.org/abs/1502.03167 -[Inception-v3]: https://arxiv.org/abs/1512.00567 - -Inception-v3 is trained for the [ImageNet] Large Visual Recognition Challenge -using the data from 2012. This is a standard task in computer vision, -where models try to classify entire -images into [1000 classes], like "Zebra", "Dalmatian", and "Dishwasher". -For example, here are the results from [AlexNet] classifying some images: - -<div style="width:50%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://www.tensorflow.org/images/AlexClassification.png"> -</div> - -To compare models, we examine how often the model fails to predict the -correct answer as one of their top 5 guesses -- termed "top-5 error rate". -[AlexNet] achieved by setting a top-5 error rate of 15.3% on the 2012 -validation data set; [Inception (GoogLeNet)] achieved 6.67%; -[BN-Inception-v2] achieved 4.9%; [Inception-v3] reaches 3.46%. - -> How well do humans do on ImageNet Challenge? There's a [blog post] by -Andrej Karpathy who attempted to measure his own performance. He reached -5.1% top-5 error rate. - -[ImageNet]: http://image-net.org/ -[1000 classes]: http://image-net.org/challenges/LSVRC/2014/browse-synsets -[blog post]: https://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/ - -This tutorial will teach you how to use [Inception-v3]. You'll learn how to -classify images into [1000 classes] in Python or C++. We'll also discuss how to -extract higher level features from this model which may be reused for other -vision tasks. - -We're excited to see what the community will do with this model. - - -##Usage with Python API - -`classify_image.py` downloads the trained model from `tensorflow.org` -when the program is run for the first time. You'll need about 200M of free space -available on your hard disk. - -Start by cloning the [TensorFlow models repo](https://github.com/tensorflow/models) from GitHub. Run the following commands: - - cd models/tutorials/image/imagenet - python classify_image.py - -The above command will classify a supplied image of a panda bear. - -<div style="width:15%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/cropped_panda.jpg"> -</div> - -If the model runs correctly, the script will produce the following output: - - giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.88493) - indri, indris, Indri indri, Indri brevicaudatus (score = 0.00878) - lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens (score = 0.00317) - custard apple (score = 0.00149) - earthstar (score = 0.00127) - -If you wish to supply other JPEG images, you may do so by editing -the `--image_file` argument. - -> If you download the model data to a different directory, you -will need to point `--model_dir` to the directory used. - -## Usage with the C++ API - -You can run the same [Inception-v3] model in C++ for use in production -environments. You can download the archive containing the GraphDef that defines -the model like this (running from the root directory of the TensorFlow -repository): - -```bash -curl -L "https://storage.googleapis.com/download.tensorflow.org/models/inception_v3_2016_08_28_frozen.pb.tar.gz" | - tar -C tensorflow/examples/label_image/data -xz -``` - -Next, we need to compile the C++ binary that includes the code to load and run the graph. -If you've followed -[the instructions to download the source installation of TensorFlow](../../install/install_sources.md) -for your platform, you should be able to build the example by -running this command from your shell terminal: - -```bash -bazel build tensorflow/examples/label_image/... -``` - -That should create a binary executable that you can then run like this: - -```bash -bazel-bin/tensorflow/examples/label_image/label_image -``` - -This uses the default example image that ships with the framework, and should -output something similar to this: - -``` -I tensorflow/examples/label_image/main.cc:206] military uniform (653): 0.834306 -I tensorflow/examples/label_image/main.cc:206] mortarboard (668): 0.0218692 -I tensorflow/examples/label_image/main.cc:206] academic gown (401): 0.0103579 -I tensorflow/examples/label_image/main.cc:206] pickelhaube (716): 0.00800814 -I tensorflow/examples/label_image/main.cc:206] bulletproof vest (466): 0.00535088 -``` -In this case, we're using the default image of -[Admiral Grace Hopper](https://en.wikipedia.org/wiki/Grace_Hopper), and you can -see the network correctly identifies she's wearing a military uniform, with a high -score of 0.8. - - -<div style="width:45%; margin:auto; margin-bottom:10px; margin-top:20px;"> - <img style="width:100%" src="https://www.tensorflow.org/images/grace_hopper.jpg"> -</div> - -Next, try it out on your own images by supplying the --image= argument, e.g. - -```bash -bazel-bin/tensorflow/examples/label_image/label_image --image=my_image.png -``` - -If you look inside the [`tensorflow/examples/label_image/main.cc`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc) -file, you can find out -how it works. We hope this code will help you integrate TensorFlow into -your own applications, so we will walk step by step through the main functions: - -The command line flags control where the files are loaded from, and properties of the input images. -The model expects to get square 299x299 RGB images, so those are the `input_width` -and `input_height` flags. We also need to scale the pixel values from integers that -are between 0 and 255 to the floating point values that the graph operates on. -We control the scaling with the `input_mean` and `input_std` flags: we first subtract -`input_mean` from each pixel value, then divide it by `input_std`. - -These values probably look somewhat magical, but they are just defined by the -original model author based on what he/she wanted to use as input images for -training. If you have a graph that you've trained yourself, you'll just need -to adjust the values to match whatever you used during your training process. - -You can see how they're applied to an image in the -[`ReadTensorFromImageFile()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L88) -function. - -```C++ -// Given an image file name, read in the data, try to decode it as an image, -// resize it to the requested size, and then scale the values as desired. -Status ReadTensorFromImageFile(string file_name, const int input_height, - const int input_width, const float input_mean, - const float input_std, - std::vector<Tensor>* out_tensors) { - tensorflow::GraphDefBuilder b; -``` -We start by creating a `GraphDefBuilder`, which is an object we can use to -specify a model to run or load. - -```C++ - string input_name = "file_reader"; - string output_name = "normalized"; - tensorflow::Node* file_reader = - tensorflow::ops::ReadFile(tensorflow::ops::Const(file_name, b.opts()), - b.opts().WithName(input_name)); -``` -We then start creating nodes for the small model we want to run -to load, resize, and scale the pixel values to get the result the main model -expects as its input. The first node we create is just a `Const` op that holds a -tensor with the file name of the image we want to load. That's then passed as the -first input to the `ReadFile` op. You might notice we're passing `b.opts()` as the last -argument to all the op creation functions. The argument ensures that the node is added to -the model definition held in the `GraphDefBuilder`. We also name the `ReadFile` -operator by making the `WithName()` call to `b.opts()`. This gives a name to the node, -which isn't strictly necessary since an automatic name will be assigned if you don't -do this, but it does make debugging a bit easier. - -```C++ - // Now try to figure out what kind of file it is and decode it. - const int wanted_channels = 3; - tensorflow::Node* image_reader; - if (tensorflow::StringPiece(file_name).ends_with(".png")) { - image_reader = tensorflow::ops::DecodePng( - file_reader, - b.opts().WithAttr("channels", wanted_channels).WithName("png_reader")); - } else { - // Assume if it's not a PNG then it must be a JPEG. - image_reader = tensorflow::ops::DecodeJpeg( - file_reader, - b.opts().WithAttr("channels", wanted_channels).WithName("jpeg_reader")); - } - // Now cast the image data to float so we can do normal math on it. - tensorflow::Node* float_caster = tensorflow::ops::Cast( - image_reader, tensorflow::DT_FLOAT, b.opts().WithName("float_caster")); - // The convention for image ops in TensorFlow is that all images are expected - // to be in batches, so that they're four-dimensional arrays with indices of - // [batch, height, width, channel]. Because we only have a single image, we - // have to add a batch dimension of 1 to the start with ExpandDims(). - tensorflow::Node* dims_expander = tensorflow::ops::ExpandDims( - float_caster, tensorflow::ops::Const(0, b.opts()), b.opts()); - // Bilinearly resize the image to fit the required dimensions. - tensorflow::Node* resized = tensorflow::ops::ResizeBilinear( - dims_expander, tensorflow::ops::Const({input_height, input_width}, - b.opts().WithName("size")), - b.opts()); - // Subtract the mean and divide by the scale. - tensorflow::ops::Div( - tensorflow::ops::Sub( - resized, tensorflow::ops::Const({input_mean}, b.opts()), b.opts()), - tensorflow::ops::Const({input_std}, b.opts()), - b.opts().WithName(output_name)); -``` -We then keep adding more nodes, to decode the file data as an image, to cast the -integers into floating point values, to resize it, and then finally to run the -subtraction and division operations on the pixel values. - -```C++ - // This runs the GraphDef network definition that we've just constructed, and - // returns the results in the output tensor. - tensorflow::GraphDef graph; - TF_RETURN_IF_ERROR(b.ToGraphDef(&graph)); -``` -At the end of this we have -a model definition stored in the b variable, which we turn into a full graph -definition with the `ToGraphDef()` function. - -```C++ - std::unique_ptr<tensorflow::Session> session( - tensorflow::NewSession(tensorflow::SessionOptions())); - TF_RETURN_IF_ERROR(session->Create(graph)); - TF_RETURN_IF_ERROR(session->Run({}, {output_name}, {}, out_tensors)); - return Status::OK(); -``` -Then we create a `tf.Session` -object, which is the interface to actually running the graph, and run it, -specifying which node we want to get the output from, and where to put the -output data. - -This gives us a vector of `Tensor` objects, which in this case we know will only be a -single object long. You can think of a `Tensor` as a multi-dimensional array in this -context, and it holds a 299 pixel high, 299 pixel wide, 3 channel image as float -values. If you have your own image-processing framework in your product already, you -should be able to use that instead, as long as you apply the same transformations -before you feed images into the main graph. - -This is a simple example of creating a small TensorFlow graph dynamically in C++, -but for the pre-trained Inception model we want to load a much larger definition from -a file. You can see how we do that in the `LoadGraph()` function. - -```C++ -// Reads a model graph definition from disk, and creates a session object you -// can use to run it. -Status LoadGraph(string graph_file_name, - std::unique_ptr<tensorflow::Session>* session) { - tensorflow::GraphDef graph_def; - Status load_graph_status = - ReadBinaryProto(tensorflow::Env::Default(), graph_file_name, &graph_def); - if (!load_graph_status.ok()) { - return tensorflow::errors::NotFound("Failed to load compute graph at '", - graph_file_name, "'"); - } -``` -If you've looked through the image loading code, a lot of the terms should seem familiar. Rather than -using a `GraphDefBuilder` to produce a `GraphDef` object, we load a protobuf file that -directly contains the `GraphDef`. - -```C++ - session->reset(tensorflow::NewSession(tensorflow::SessionOptions())); - Status session_create_status = (*session)->Create(graph_def); - if (!session_create_status.ok()) { - return session_create_status; - } - return Status::OK(); -} -``` -Then we create a Session object from that `GraphDef` and -pass it back to the caller so that they can run it at a later time. - -The `GetTopLabels()` function is a lot like the image loading, except that in this case -we want to take the results of running the main graph, and turn it into a sorted list -of the highest-scoring labels. Just like the image loader, it creates a -`GraphDefBuilder`, adds a couple of nodes to it, and then runs the short graph to get a -pair of output tensors. In this case they represent the sorted scores and index -positions of the highest results. - -```C++ -// Analyzes the output of the Inception graph to retrieve the highest scores and -// their positions in the tensor, which correspond to categories. -Status GetTopLabels(const std::vector<Tensor>& outputs, int how_many_labels, - Tensor* indices, Tensor* scores) { - tensorflow::GraphDefBuilder b; - string output_name = "top_k"; - tensorflow::ops::TopK(tensorflow::ops::Const(outputs[0], b.opts()), - how_many_labels, b.opts().WithName(output_name)); - // This runs the GraphDef network definition that we've just constructed, and - // returns the results in the output tensors. - tensorflow::GraphDef graph; - TF_RETURN_IF_ERROR(b.ToGraphDef(&graph)); - std::unique_ptr<tensorflow::Session> session( - tensorflow::NewSession(tensorflow::SessionOptions())); - TF_RETURN_IF_ERROR(session->Create(graph)); - // The TopK node returns two outputs, the scores and their original indices, - // so we have to append :0 and :1 to specify them both. - std::vector<Tensor> out_tensors; - TF_RETURN_IF_ERROR(session->Run({}, {output_name + ":0", output_name + ":1"}, - {}, &out_tensors)); - *scores = out_tensors[0]; - *indices = out_tensors[1]; - return Status::OK(); -``` -The `PrintTopLabels()` function takes those sorted results, and prints them out in a -friendly way. The `CheckTopLabel()` function is very similar, but just makes sure that -the top label is the one we expect, for debugging purposes. - -At the end, [`main()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L252) -ties together all of these calls. - -```C++ -int main(int argc, char* argv[]) { - // We need to call this to set up global state for TensorFlow. - tensorflow::port::InitMain(argv[0], &argc, &argv); - Status s = tensorflow::ParseCommandLineFlags(&argc, argv); - if (!s.ok()) { - LOG(ERROR) << "Error parsing command line flags: " << s.ToString(); - return -1; - } - - // First we load and initialize the model. - std::unique_ptr<tensorflow::Session> session; - string graph_path = tensorflow::io::JoinPath(FLAGS_root_dir, FLAGS_graph); - Status load_graph_status = LoadGraph(graph_path, &session); - if (!load_graph_status.ok()) { - LOG(ERROR) << load_graph_status; - return -1; - } -``` -We load the main graph. - -```C++ - // Get the image from disk as a float array of numbers, resized and normalized - // to the specifications the main graph expects. - std::vector<Tensor> resized_tensors; - string image_path = tensorflow::io::JoinPath(FLAGS_root_dir, FLAGS_image); - Status read_tensor_status = ReadTensorFromImageFile( - image_path, FLAGS_input_height, FLAGS_input_width, FLAGS_input_mean, - FLAGS_input_std, &resized_tensors); - if (!read_tensor_status.ok()) { - LOG(ERROR) << read_tensor_status; - return -1; - } - const Tensor& resized_tensor = resized_tensors[0]; -``` -Load, resize, and process the input image. - -```C++ - // Actually run the image through the model. - std::vector<Tensor> outputs; - Status run_status = session->Run({{FLAGS_input_layer, resized_tensor}}, - {FLAGS_output_layer}, {}, &outputs); - if (!run_status.ok()) { - LOG(ERROR) << "Running model failed: " << run_status; - return -1; - } -``` -Here we run the loaded graph with the image as an input. - -```C++ - // This is for automated testing to make sure we get the expected result with - // the default settings. We know that label 866 (military uniform) should be - // the top label for the Admiral Hopper image. - if (FLAGS_self_test) { - bool expected_matches; - Status check_status = CheckTopLabel(outputs, 866, &expected_matches); - if (!check_status.ok()) { - LOG(ERROR) << "Running check failed: " << check_status; - return -1; - } - if (!expected_matches) { - LOG(ERROR) << "Self-test failed!"; - return -1; - } - } -``` -For testing purposes we can check to make sure we get the output we expect here. - -```C++ - // Do something interesting with the results we've generated. - Status print_status = PrintTopLabels(outputs, FLAGS_labels); -``` -Finally we print the labels we found. - -```C++ - if (!print_status.ok()) { - LOG(ERROR) << "Running print failed: " << print_status; - return -1; - } -``` - -The error handling here is using TensorFlow's `Status` -object, which is very convenient because it lets you know whether any error has -occurred with the `ok()` checker, and then can be printed out to give a readable error -message. - -In this case we are demonstrating object recognition, but you should be able to -use very similar code on other models you've found or trained yourself, across -all -sorts of domains. We hope this small example gives you some ideas on how to use -TensorFlow within your own products. - -> **EXERCISE**: Transfer learning is the idea that, if you know how to solve a task well, you -should be able to transfer some of that understanding to solving related -problems. One way to perform transfer learning is to remove the final -classification layer of the network and extract -the [next-to-last layer of the CNN](https://arxiv.org/abs/1310.1531), in this case a 2048 dimensional vector. - - -## Resources for Learning More - -To learn about neural networks in general, Michael Nielsen's -[free online book](http://neuralnetworksanddeeplearning.com/chap1.html) -is an excellent resource. For convolutional neural networks in particular, -Chris Olah has some -[nice blog posts](https://colah.github.io/posts/2014-07-Conv-Nets-Modular/), -and Michael Nielsen's book has a -[great chapter](http://neuralnetworksanddeeplearning.com/chap6.html) -covering them. - -To find out more about implementing convolutional neural networks, you can jump -to the TensorFlow [deep convolutional networks tutorial](../../tutorials/images/deep_cnn.md), -or start a bit more gently with our [Estimator MNIST tutorial](../estimators/cnn.md). -Finally, if you want to get up to speed on research in this area, you can -read the recent work of all the papers referenced in this tutorial. - diff --git a/tensorflow/docs_src/tutorials/keras/basic_classification.md b/tensorflow/docs_src/tutorials/keras/basic_classification.md deleted file mode 100644 index e028af99b9..0000000000 --- a/tensorflow/docs_src/tutorials/keras/basic_classification.md +++ /dev/null @@ -1,3 +0,0 @@ -# Basic Classification - -[Colab notebook](https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/tutorials/keras/basic_classification.ipynb) diff --git a/tensorflow/docs_src/tutorials/keras/basic_regression.md b/tensorflow/docs_src/tutorials/keras/basic_regression.md deleted file mode 100644 index 8721b7aca1..0000000000 --- a/tensorflow/docs_src/tutorials/keras/basic_regression.md +++ /dev/null @@ -1,3 +0,0 @@ -# Basic Regression - -[Colab notebook](https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/tutorials/keras/basic_regression.ipynb) diff --git a/tensorflow/docs_src/tutorials/keras/basic_text_classification.md b/tensorflow/docs_src/tutorials/keras/basic_text_classification.md deleted file mode 100644 index c2a16bdd20..0000000000 --- a/tensorflow/docs_src/tutorials/keras/basic_text_classification.md +++ /dev/null @@ -1,3 +0,0 @@ -# Basic Text Classification - -[Colab notebook](https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/tutorials/keras/basic_text_classification.ipynb) diff --git a/tensorflow/docs_src/tutorials/keras/index.md b/tensorflow/docs_src/tutorials/keras/index.md deleted file mode 100644 index 9d42281c8f..0000000000 --- a/tensorflow/docs_src/tutorials/keras/index.md +++ /dev/null @@ -1,22 +0,0 @@ -# Learn and use machine learning - -This notebook collection is inspired by the book -*[Deep Learning with Python](https://books.google.com/books?id=Yo3CAQAACAAJ)*. -These tutorials use `tf.keras`, TensorFlow's high-level Python API for building -and training deep learning models. To learn more about using Keras with -TensorFlow, see the [TensorFlow Keras Guide](../../guide/keras). - -Publisher's note: *Deep Learning with Python* introduces the field of deep -learning using the Python language and the powerful Keras library. Written by -Keras creator and Google AI researcher François Chollet, this book builds your -understanding through intuitive explanations and practical examples. - -To learn about machine learning fundamentals and concepts, consider taking the -[Machine Learning Crash Course](https://developers.google.com/machine-learning/crash-course/). -Additional TensorFlow and machine learning resources are listed in [next steps](../next_steps). - -1. [Basic classification](./basic_classification) -2. [Text classification](./basic_text_classification) -3. [Regression](./basic_regression) -4. [Overfitting and underfitting](./overfit_and_underfit) -5. [Save and restore models](./save_and_restore_models) diff --git a/tensorflow/docs_src/tutorials/keras/overfit_and_underfit.md b/tensorflow/docs_src/tutorials/keras/overfit_and_underfit.md deleted file mode 100644 index f07f3addd8..0000000000 --- a/tensorflow/docs_src/tutorials/keras/overfit_and_underfit.md +++ /dev/null @@ -1,3 +0,0 @@ -# Overfitting and Underfitting - -[Colab notebook](https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/tutorials/keras/overfit_and_underfit.ipynb) diff --git a/tensorflow/docs_src/tutorials/keras/save_and_restore_models.md b/tensorflow/docs_src/tutorials/keras/save_and_restore_models.md deleted file mode 100644 index a799b379a0..0000000000 --- a/tensorflow/docs_src/tutorials/keras/save_and_restore_models.md +++ /dev/null @@ -1,3 +0,0 @@ -# Save and restore Models - -[Colab notebook](https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/tutorials/keras/save_and_restore_models.ipynb) diff --git a/tensorflow/docs_src/tutorials/next_steps.md b/tensorflow/docs_src/tutorials/next_steps.md deleted file mode 100644 index 01c9f7204a..0000000000 --- a/tensorflow/docs_src/tutorials/next_steps.md +++ /dev/null @@ -1,36 +0,0 @@ -# Next steps - -## Learn more about TensorFlow - -* The [TensorFlow Guide](/guide) includes usage guides for the - high-level APIs, as well as advanced TensorFlow operations. -* [Premade Estimators](/guide/premade_estimators) are designed to - get results out of the box. Use TensorFlow without building your own models. -* [TensorFlow.js](https://js.tensorflow.org/) allows web developers to train and - deploy ML models in the browser and using Node.js. -* [TFLite](/mobile/tflite) allows mobile developers to do inference efficiently - on mobile devices. -* [TensorFlow Serving](/serving) is an open-source project that can put - TensorFlow models in production quickly. -* The [ecosystem](/ecosystem) contains more projects, including - [Magenta](https://magenta.tensorflow.org/), [TFX](/tfx), - [Swift for TensorFlow](https://github.com/tensorflow/swift), and more. - -## Learn more about machine learning - -Recommended resources include: - -* [Machine Learning Crash Course](https://developers.google.com/machine-learning/crash-course/), - a course from Google that introduces machine learning concepts. -* [CS 20: Tensorflow for Deep Learning Research](http://web.stanford.edu/class/cs20si/), - notes from an intro course from Stanford. -* [CS231n: Convolutional Neural Networks for Visual Recognition](http://cs231n.stanford.edu/), - a course that teaches how convolutional networks work. -* [Machine Learning Recipes](https://www.youtube.com/watch?v=cKxRvEZd3Mw&list=PLOU2XLYxmsIIuiBfYad6rFYQU_jL2ryal), - a video series that introduces basic machine learning concepts with few prerequisites. -* [Deep Learning with Python](https://www.manning.com/books/deep-learning-with-python), - a book by Francois Chollet about the Keras API, as well as an excellent hands on intro to Deep Learning. -* [Hands-on Machine Learning with Scikit-Learn and TensorFlow](https://github.com/ageron/handson-ml), - a book by Aurélien Geron's that is a clear getting-started guide to data science and deep learning. -* [Deep Learning](https://www.deeplearningbook.org/), a book by Ian Goodfellow et al. - that provides a technical dive into learning machine learning. diff --git a/tensorflow/docs_src/tutorials/non-ml/mandelbrot.md b/tensorflow/docs_src/tutorials/non-ml/mandelbrot.md deleted file mode 100644 index 1c0a548129..0000000000 --- a/tensorflow/docs_src/tutorials/non-ml/mandelbrot.md +++ /dev/null @@ -1,116 +0,0 @@ -# Mandelbrot Set - -Visualizing the [Mandelbrot set](https://en.wikipedia.org/wiki/Mandelbrot_set) -doesn't have anything to do with machine learning, but it makes for a fun -example of how one can use TensorFlow for general mathematics. This is -actually a pretty naive implementation of the visualization, but it makes the -point. (We may end up providing a more elaborate implementation down the line -to produce more truly beautiful images.) - - -## Basic Setup - -We'll need a few imports to get started. - -```python -# Import libraries for simulation -import tensorflow as tf -import numpy as np - -# Imports for visualization -import PIL.Image -from io import BytesIO -from IPython.display import Image, display -``` - -Now we'll define a function to actually display the image once we have -iteration counts. - -```python -def DisplayFractal(a, fmt='jpeg'): - """Display an array of iteration counts as a - colorful picture of a fractal.""" - a_cyclic = (6.28*a/20.0).reshape(list(a.shape)+[1]) - img = np.concatenate([10+20*np.cos(a_cyclic), - 30+50*np.sin(a_cyclic), - 155-80*np.cos(a_cyclic)], 2) - img[a==a.max()] = 0 - a = img - a = np.uint8(np.clip(a, 0, 255)) - f = BytesIO() - PIL.Image.fromarray(a).save(f, fmt) - display(Image(data=f.getvalue())) -``` - -## Session and Variable Initialization - -For playing around like this, we often use an interactive session, but a regular -session would work as well. - -```python -sess = tf.InteractiveSession() -``` - -It's handy that we can freely mix NumPy and TensorFlow. - -```python -# Use NumPy to create a 2D array of complex numbers - -Y, X = np.mgrid[-1.3:1.3:0.005, -2:1:0.005] -Z = X+1j*Y -``` - -Now we define and initialize TensorFlow tensors. - -```python -xs = tf.constant(Z.astype(np.complex64)) -zs = tf.Variable(xs) -ns = tf.Variable(tf.zeros_like(xs, tf.float32)) -``` - -TensorFlow requires that you explicitly initialize variables before using them. - -```python -tf.global_variables_initializer().run() -``` - -## Defining and Running the Computation - -Now we specify more of the computation... - -```python -# Compute the new values of z: z^2 + x -zs_ = zs*zs + xs - -# Have we diverged with this new value? -not_diverged = tf.abs(zs_) < 4 - -# Operation to update the zs and the iteration count. -# -# Note: We keep computing zs after they diverge! This -# is very wasteful! There are better, if a little -# less simple, ways to do this. -# -step = tf.group( - zs.assign(zs_), - ns.assign_add(tf.cast(not_diverged, tf.float32)) - ) -``` - -... and run it for a couple hundred steps - -```python -for i in range(200): step.run() -``` - -Let's see what we've got. - -```python -DisplayFractal(ns.eval()) -``` - - - -Not bad! - - diff --git a/tensorflow/docs_src/tutorials/non-ml/pdes.md b/tensorflow/docs_src/tutorials/non-ml/pdes.md deleted file mode 100644 index b5a0fa834a..0000000000 --- a/tensorflow/docs_src/tutorials/non-ml/pdes.md +++ /dev/null @@ -1,140 +0,0 @@ -# Partial Differential Equations - -TensorFlow isn't just for machine learning. Here we give a (somewhat -pedestrian) example of using TensorFlow for simulating the behavior of a -[partial differential equation]( -https://en.wikipedia.org/wiki/Partial_differential_equation). -We'll simulate the surface of square pond as a few raindrops land on it. - - -## Basic Setup - -A few imports we'll need. - -```python -#Import libraries for simulation -import tensorflow as tf -import numpy as np - -#Imports for visualization -import PIL.Image -from io import BytesIO -from IPython.display import clear_output, Image, display -``` - -A function for displaying the state of the pond's surface as an image. - -```python -def DisplayArray(a, fmt='jpeg', rng=[0,1]): - """Display an array as a picture.""" - a = (a - rng[0])/float(rng[1] - rng[0])*255 - a = np.uint8(np.clip(a, 0, 255)) - f = BytesIO() - PIL.Image.fromarray(a).save(f, fmt) - clear_output(wait = True) - display(Image(data=f.getvalue())) -``` - -Here we start an interactive TensorFlow session for convenience in playing -around. A regular session would work as well if we were doing this in an -executable .py file. - -```python -sess = tf.InteractiveSession() -``` - -## Computational Convenience Functions - - -```python -def make_kernel(a): - """Transform a 2D array into a convolution kernel""" - a = np.asarray(a) - a = a.reshape(list(a.shape) + [1,1]) - return tf.constant(a, dtype=1) - -def simple_conv(x, k): - """A simplified 2D convolution operation""" - x = tf.expand_dims(tf.expand_dims(x, 0), -1) - y = tf.nn.depthwise_conv2d(x, k, [1, 1, 1, 1], padding='SAME') - return y[0, :, :, 0] - -def laplace(x): - """Compute the 2D laplacian of an array""" - laplace_k = make_kernel([[0.5, 1.0, 0.5], - [1.0, -6., 1.0], - [0.5, 1.0, 0.5]]) - return simple_conv(x, laplace_k) -``` - -## Define the PDE - -Our pond is a perfect 500 x 500 square, as is the case for most ponds found in -nature. - -```python -N = 500 -``` - -Here we create our pond and hit it with some rain drops. - -```python -# Initial Conditions -- some rain drops hit a pond - -# Set everything to zero -u_init = np.zeros([N, N], dtype=np.float32) -ut_init = np.zeros([N, N], dtype=np.float32) - -# Some rain drops hit a pond at random points -for n in range(40): - a,b = np.random.randint(0, N, 2) - u_init[a,b] = np.random.uniform() - -DisplayArray(u_init, rng=[-0.1, 0.1]) -``` - - - - -Now let's specify the details of the differential equation. - - -```python -# Parameters: -# eps -- time resolution -# damping -- wave damping -eps = tf.placeholder(tf.float32, shape=()) -damping = tf.placeholder(tf.float32, shape=()) - -# Create variables for simulation state -U = tf.Variable(u_init) -Ut = tf.Variable(ut_init) - -# Discretized PDE update rules -U_ = U + eps * Ut -Ut_ = Ut + eps * (laplace(U) - damping * Ut) - -# Operation to update the state -step = tf.group( - U.assign(U_), - Ut.assign(Ut_)) -``` - -## Run The Simulation - -This is where it gets fun -- running time forward with a simple for loop. - -```python -# Initialize state to initial conditions -tf.global_variables_initializer().run() - -# Run 1000 steps of PDE -for i in range(1000): - # Step simulation - step.run({eps: 0.03, damping: 0.04}) - DisplayArray(U.eval(), rng=[-0.1, 0.1]) -``` - - - -Look! Ripples! diff --git a/tensorflow/docs_src/tutorials/representation/kernel_methods.md b/tensorflow/docs_src/tutorials/representation/kernel_methods.md deleted file mode 100644 index 67adc4951c..0000000000 --- a/tensorflow/docs_src/tutorials/representation/kernel_methods.md +++ /dev/null @@ -1,303 +0,0 @@ -# Improving Linear Models Using Explicit Kernel Methods - -Note: This document uses a deprecated version of `tf.estimator`, -`tf.contrib.learn.Estimator`, which has a different interface. It also uses -other `contrib` methods whose [API may not be stable](../../guide/version_compat.md#not_covered). - -In this tutorial, we demonstrate how combining (explicit) kernel methods with -linear models can drastically increase the latters' quality of predictions -without significantly increasing training and inference times. Unlike dual -kernel methods, explicit (primal) kernel methods scale well with the size of the -training dataset both in terms of training/inference times and in terms of -memory requirements. - -**Intended audience:** Even though we provide a high-level overview of concepts -related to explicit kernel methods, this tutorial primarily targets readers who -already have at least basic knowledge of kernel methods and Support Vector -Machines (SVMs). If you are new to kernel methods, refer to either of the -following sources for an introduction: - -* If you have a strong mathematical background: -[Kernel Methods in Machine Learning](https://arxiv.org/pdf/math/0701907.pdf) -* [Kernel method wikipedia page](https://en.wikipedia.org/wiki/Kernel_method) - -Currently, TensorFlow supports explicit kernel mappings for dense features only; -TensorFlow will provide support for sparse features at a later release. - -This tutorial uses [tf.contrib.learn](https://www.tensorflow.org/code/tensorflow/contrib/learn/python/learn) -(TensorFlow's high-level Machine Learning API) Estimators for our ML models. -If you are not familiar with this API, The [Estimator guide](../../guide/estimators.md) -is a good place to start. We will use the MNIST dataset. The tutorial consists -of the following steps: - -* Load and prepare MNIST data for classification. -* Construct a simple linear model, train it, and evaluate it on the eval data. -* Replace the linear model with a kernelized linear model, re-train, and -re-evaluate. - -## Load and prepare MNIST data for classification -Run the following utility command to load the MNIST dataset: - -```python -data = tf.contrib.learn.datasets.mnist.load_mnist() -``` -The preceding method loads the entire MNIST dataset (containing 70K samples) and -splits it into train, validation, and test data with 55K, 5K, and 10K samples -respectively. Each split contains one numpy array for images (with shape -[sample_size, 784]) and one for labels (with shape [sample_size, 1]). In this -tutorial, we only use the train and validation splits to train and evaluate our -models respectively. - -In order to feed data to a `tf.contrib.learn Estimator`, it is helpful to convert -it to Tensors. For this, we will use an `input function` which adds Ops to the -TensorFlow graph that, when executed, create mini-batches of Tensors to be used -downstream. For more background on input functions, check -[this section on input functions](../../guide/premade_estimators.md#create_input_functions). -In this example, we will use the `tf.train.shuffle_batch` Op which, besides -converting numpy arrays to Tensors, allows us to specify the batch_size and -whether to randomize the input every time the input_fn Ops are executed -(randomization typically expedites convergence during training). The full code -for loading and preparing the data is shown in the snippet below. In this -example, we use mini-batches of size 256 for training and the entire sample -(5K entries) for evaluation. Feel free to experiment with different batch sizes. - -```python -import numpy as np -import tensorflow as tf - -def get_input_fn(dataset_split, batch_size, capacity=10000, min_after_dequeue=3000): - - def _input_fn(): - images_batch, labels_batch = tf.train.shuffle_batch( - tensors=[dataset_split.images, dataset_split.labels.astype(np.int32)], - batch_size=batch_size, - capacity=capacity, - min_after_dequeue=min_after_dequeue, - enqueue_many=True, - num_threads=4) - features_map = {'images': images_batch} - return features_map, labels_batch - - return _input_fn - -data = tf.contrib.learn.datasets.mnist.load_mnist() - -train_input_fn = get_input_fn(data.train, batch_size=256) -eval_input_fn = get_input_fn(data.validation, batch_size=5000) - -``` - -## Training a simple linear model -We can now train a linear model over the MNIST dataset. We will use the -`tf.contrib.learn.LinearClassifier` estimator with 10 classes representing the -10 digits. The input features form a 784-dimensional dense vector which can -be specified as follows: - -```python -image_column = tf.contrib.layers.real_valued_column('images', dimension=784) -``` - -The full code for constructing, training and evaluating a LinearClassifier -estimator is as follows: - -```python -import time - -# Specify the feature(s) to be used by the estimator. -image_column = tf.contrib.layers.real_valued_column('images', dimension=784) -estimator = tf.contrib.learn.LinearClassifier(feature_columns=[image_column], n_classes=10) - -# Train. -start = time.time() -estimator.fit(input_fn=train_input_fn, steps=2000) -end = time.time() -print('Elapsed time: {} seconds'.format(end - start)) - -# Evaluate and report metrics. -eval_metrics = estimator.evaluate(input_fn=eval_input_fn, steps=1) -print(eval_metrics) -``` -The following table summarizes the results on the eval data. - -metric | value -:------------ | :------------ -loss | 0.25 to 0.30 -accuracy | 92.5% -training time | ~25 seconds on my machine - -Note: Metrics will vary depending on various factors. - -In addition to experimenting with the (training) batch size and the number of -training steps, there are a couple other parameters that can be tuned as well. -For instance, you can change the optimization method used to minimize the loss -by explicitly selecting another optimizer from the collection of -[available optimizers](https://www.tensorflow.org/code/tensorflow/python/training). -As an example, the following code constructs a LinearClassifier estimator that -uses the Follow-The-Regularized-Leader (FTRL) optimization strategy with a -specific learning rate and L2-regularization. - - -```python -optimizer = tf.train.FtrlOptimizer(learning_rate=5.0, l2_regularization_strength=1.0) -estimator = tf.contrib.learn.LinearClassifier( - feature_columns=[image_column], n_classes=10, optimizer=optimizer) -``` - -Regardless of the values of the parameters, the maximum accuracy a linear model -can achieve on this dataset caps at around **93%**. - -## Using explicit kernel mappings with the linear model. -The relatively high error (~7%) of the linear model over MNIST indicates that -the input data is not linearly separable. We will use explicit kernel mappings -to reduce the classification error. - -**Intuition:** The high-level idea is to use a non-linear map to transform the -input space to another feature space (of possibly higher dimension) where the -(transformed) features are (almost) linearly separable and then apply a linear -model on the mapped features. This is shown in the following figure: - -<div style="text-align:center"> -<img src="https://www.tensorflow.org/versions/master/images/kernel_mapping.png" /> -</div> - - -### Technical details -In this example we will use **Random Fourier Features**, introduced in the -["Random Features for Large-Scale Kernel Machines"](https://people.eecs.berkeley.edu/~brecht/papers/07.rah.rec.nips.pdf) -paper by Rahimi and Recht, to map the input data. Random Fourier Features map a -vector \\(\mathbf{x} \in \mathbb{R}^d\\) to \\(\mathbf{x'} \in \mathbb{R}^D\\) -via the following mapping: - -$$ -RFFM(\cdot): \mathbb{R}^d \to \mathbb{R}^D, \quad -RFFM(\mathbf{x}) = \cos(\mathbf{\Omega} \cdot \mathbf{x}+ \mathbf{b}) -$$ - -where \\(\mathbf{\Omega} \in \mathbb{R}^{D \times d}\\), -\\(\mathbf{x} \in \mathbb{R}^d,\\) \\(\mathbf{b} \in \mathbb{R}^D\\) and the -cosine is applied element-wise. - -In this example, the entries of \\(\mathbf{\Omega}\\) and \\(\mathbf{b}\\) are -sampled from distributions such that the mapping satisfies the following -property: - -$$ -RFFM(\mathbf{x})^T \cdot RFFM(\mathbf{y}) \approx -e^{-\frac{\|\mathbf{x} - \mathbf{y}\|^2}{2 \sigma^2}} -$$ - -The right-hand-side quantity of the expression above is known as the RBF (or -Gaussian) kernel function. This function is one of the most-widely used kernel -functions in Machine Learning and implicitly measures similarity in a different, -much higher dimensional space than the original one. See -[Radial basis function kernel](https://en.wikipedia.org/wiki/Radial_basis_function_kernel) -for more details. - -### Kernel classifier -`tf.contrib.kernel_methods.KernelLinearClassifier` is a pre-packaged -`tf.contrib.learn` estimator that combines the power of explicit kernel mappings -with linear models. Its constructor is almost identical to that of the -LinearClassifier estimator with the additional option to specify a list of -explicit kernel mappings to be applied to each feature the classifier uses. The -following code snippet demonstrates how to replace LinearClassifier with -KernelLinearClassifier. - - -```python -# Specify the feature(s) to be used by the estimator. This is identical to the -# code used for the LinearClassifier. -image_column = tf.contrib.layers.real_valued_column('images', dimension=784) -optimizer = tf.train.FtrlOptimizer( - learning_rate=50.0, l2_regularization_strength=0.001) - - -kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper( - input_dim=784, output_dim=2000, stddev=5.0, name='rffm') -kernel_mappers = {image_column: [kernel_mapper]} -estimator = tf.contrib.kernel_methods.KernelLinearClassifier( - n_classes=10, optimizer=optimizer, kernel_mappers=kernel_mappers) - -# Train. -start = time.time() -estimator.fit(input_fn=train_input_fn, steps=2000) -end = time.time() -print('Elapsed time: {} seconds'.format(end - start)) - -# Evaluate and report metrics. -eval_metrics = estimator.evaluate(input_fn=eval_input_fn, steps=1) -print(eval_metrics) -``` -The only additional parameter passed to `KernelLinearClassifier` is a dictionary -from feature_columns to a list of kernel mappings to be applied to the -corresponding feature column. The following lines instruct the classifier to -first map the initial 784-dimensional images to 2000-dimensional vectors using -random Fourier features and then learn a linear model on the transformed -vectors: - -```python -kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper( - input_dim=784, output_dim=2000, stddev=5.0, name='rffm') -kernel_mappers = {image_column: [kernel_mapper]} -estimator = tf.contrib.kernel_methods.KernelLinearClassifier( - n_classes=10, optimizer=optimizer, kernel_mappers=kernel_mappers) -``` -Notice the `stddev` parameter. This is the standard deviation (\\(\sigma\\)) of -the approximated RBF kernel and controls the similarity measure used in -classification. `stddev` is typically determined via hyperparameter tuning. - -The results of running the preceding code are summarized in the following table. -We can further increase the accuracy by increasing the output dimension of the -mapping and tuning the standard deviation. - -metric | value -:------------ | :------------ -loss | 0.10 -accuracy | 97% -training time | ~35 seconds on my machine - - -### stddev -The classification quality is very sensitive to the value of stddev. The -following table shows the accuracy of the classifier on the eval data for -different values of stddev. The optimal value is stddev=5.0. Notice how too -small or too high stddev values can dramatically decrease the accuracy of the -classification. - -stddev | eval accuracy -:----- | :------------ -1.0 | 0.1362 -2.0 | 0.4764 -4.0 | 0.9654 -5.0 | 0.9766 -8.0 | 0.9714 -16.0 | 0.8878 - -### Output dimension -Intuitively, the larger the output dimension of the mapping, the closer the -inner product of two mapped vectors approximates the kernel, which typically -translates to better classification accuracy. Another way to think about this is -that the output dimension equals the number of weights of the linear model; the -larger this dimension, the larger the "degrees of freedom" of the model. -However, after a certain threshold, higher output dimensions increase the -accuracy by very little, while making training take more time. This is shown in -the following two Figures which depict the eval accuracy as a function of the -output dimension and the training time, respectively. - - - - - -## Summary -Explicit kernel mappings combine the predictive power of nonlinear models with -the scalability of linear models. Unlike traditional dual kernel methods, -explicit kernel methods can scale to millions or hundreds of millions of -samples. When using explicit kernel mappings, consider the following tips: - -* Random Fourier Features can be particularly effective for datasets with dense -features. -* The parameters of the kernel mapping are often data-dependent. Model quality -can be very sensitive to these parameters. Use hyperparameter tuning to find the -optimal values. -* If you have multiple numerical features, concatenate them into a single -multi-dimensional feature and apply the kernel mapping to the concatenated -vector. diff --git a/tensorflow/docs_src/tutorials/representation/linear.md b/tensorflow/docs_src/tutorials/representation/linear.md deleted file mode 100644 index 4f0e67f08e..0000000000 --- a/tensorflow/docs_src/tutorials/representation/linear.md +++ /dev/null @@ -1,239 +0,0 @@ -# Large-scale Linear Models with TensorFlow - -`tf.estimator` provides (among other things) a rich set of tools for -working with linear models in TensorFlow. This document provides an overview of -those tools. It explains: - - * What a linear model is. - * Why you might want to use a linear model. - * How Estimators make it easy to build linear models in TensorFlow. - * How you can use Estimators to combine linear models with. - deep learning to get the advantages of both. - -Read this overview to decide whether the Estimator's linear model tools might -be useful to you. Then work through the -[Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/wide_deep) -to give it a try. This overview uses code samples from the tutorial, but the -tutorial walks through the code in greater detail. - -To understand this overview it will help to have some familiarity -with basic machine learning concepts, and also with -[Estimators](../../guide/premade_estimators.md). - -[TOC] - -## What is a linear model? - -A **linear model** uses a single weighted sum of features to make a prediction. -For example, if you have [data](https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.names) -on age, years of education, and weekly hours of -work for a population, a model can learn weights for each of those numbers so that -their weighted sum estimates a person's salary. You can also use linear models -for classification. - -Some linear models transform the weighted sum into a more convenient form. For -example, [**logistic regression**](https://developers.google.com/machine-learning/glossary/#logistic_regression) plugs the weighted sum into the logistic -function to turn the output into a value between 0 and 1. But you still just -have one weight for each input feature. - -## Why would you want to use a linear model? - -Why would you want to use so simple a model when recent research has -demonstrated the power of more complex neural networks with many layers? - -Linear models: - - * train quickly, compared to deep neural nets. - * can work well on very large feature sets. - * can be trained with algorithms that don't require a lot of fiddling - with learning rates, etc. - * can be interpreted and debugged more easily than neural nets. - You can examine the weights assigned to each feature to figure out what's - having the biggest impact on a prediction. - * provide an excellent starting point for learning about machine learning. - * are widely used in industry. - -## How do Estimators help you build linear models? - -You can build a linear model from scratch in TensorFlow without the help of a -special API. But Estimators provides some tools that make it easier to build -effective large-scale linear models. - -### Feature columns and transformations - -Much of the work of designing a linear model consists of transforming raw data -into suitable input features. Tensorflow uses the `FeatureColumn` abstraction to -enable these transformations. - -A `FeatureColumn` represents a single feature in your data. A `FeatureColumn` -may represent a quantity like 'height', or it may represent a category like -'eye_color' where the value is drawn from a set of discrete possibilities like -{'blue', 'brown', 'green'}. - -In the case of both *continuous features* like 'height' and *categorical -features* like 'eye_color', a single value in the data might get transformed -into a sequence of numbers before it is input into the model. The -`FeatureColumn` abstraction lets you manipulate the feature as a single -semantic unit in spite of this fact. You can specify transformations and -select features to include without dealing with specific indices in the -tensors you feed into the model. - -#### Sparse columns - -Categorical features in linear models are typically translated into a sparse -vector in which each possible value has a corresponding index or id. For -example, if there are only three possible eye colors you can represent -'eye_color' as a length 3 vector: 'brown' would become [1, 0, 0], 'blue' would -become [0, 1, 0] and 'green' would become [0, 0, 1]. These vectors are called -"sparse" because they may be very long, with many zeros, when the set of -possible values is very large (such as all English words). - -While you don't need to use categorical columns to use the linear model tools -provided by Estimators, one of the strengths of linear models is their ability -to deal with large sparse vectors. Sparse features are a primary use case for -the linear model tools provided by Estimators. - -##### Encoding sparse columns - -`FeatureColumn` handles the conversion of categorical values into vectors -automatically, with code like this: - -```python -eye_color = tf.feature_column.categorical_column_with_vocabulary_list( - "eye_color", vocabulary_list=["blue", "brown", "green"]) -``` - -where `eye_color` is the name of a column in your source data. - -You can also generate `FeatureColumn`s for categorical features for which you -don't know all possible values. For this case you would use -`categorical_column_with_hash_bucket()`, which uses a hash function to assign -indices to feature values. - -```python -education = tf.feature_column.categorical_column_with_hash_bucket( - "education", hash_bucket_size=1000) -``` - -##### Feature Crosses - -Because linear models assign independent weights to separate features, they -can't learn the relative importance of specific combinations of feature -values. If you have a feature 'favorite_sport' and a feature 'home_city' and -you're trying to predict whether a person likes to wear red, your linear model -won't be able to learn that baseball fans from St. Louis especially like to -wear red. - -You can get around this limitation by creating a new feature -'favorite_sport_x_home_city'. The value of this feature for a given person is -just the concatenation of the values of the two source features: -'baseball_x_stlouis', for example. This sort of combination feature is called -a *feature cross*. - -The `crossed_column()` method makes it easy to set up feature crosses: - -```python -sport_x_city = tf.feature_column.crossed_column( - ["sport", "city"], hash_bucket_size=int(1e4)) -``` - -#### Continuous columns - -You can specify a continuous feature like so: - -```python -age = tf.feature_column.numeric_column("age") -``` - -Although, as a single real number, a continuous feature can often be input -directly into the model, Tensorflow offers useful transformations for this sort -of column as well. - -##### Bucketization - -*Bucketization* turns a continuous column into a categorical column. This -transformation lets you use continuous features in feature crosses, or learn -cases where specific value ranges have particular importance. - -Bucketization divides the range of possible values into subranges called -buckets: - -```python -age_buckets = tf.feature_column.bucketized_column( - age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65]) -``` - -The bucket into which a value falls becomes the categorical label for -that value. - -#### Input function - -`FeatureColumn`s provide a specification for the input data for your model, -indicating how to represent and transform the data. But they do not provide -the data itself. You provide the data through an input function. - -The input function must return a dictionary of tensors. Each key corresponds to -the name of a `FeatureColumn`. Each key's value is a tensor containing the -values of that feature for all data instances. See -[Premade Estimators](../../guide/premade_estimators.md#input_fn) for a -more comprehensive look at input functions, and `input_fn` in the -[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/wide_deep) -for an example implementation of an input function. - -The input function is passed to the `train()` and `evaluate()` calls that -initiate training and testing, as described in the next section. - -### Linear estimators - -Tensorflow estimator classes provide a unified training and evaluation harness -for regression and classification models. They take care of the details of the -training and evaluation loops and allow the user to focus on model inputs and -architecture. - -To build a linear estimator, you can use either the -`tf.estimator.LinearClassifier` estimator or the -`tf.estimator.LinearRegressor` estimator, for classification and -regression respectively. - -As with all tensorflow estimators, to run the estimator you just: - - 1. Instantiate the estimator class. For the two linear estimator classes, - you pass a list of `FeatureColumn`s to the constructor. - 2. Call the estimator's `train()` method to train it. - 3. Call the estimator's `evaluate()` method to see how it does. - -For example: - -```python -e = tf.estimator.LinearClassifier( - feature_columns=[ - native_country, education, occupation, workclass, marital_status, - race, age_buckets, education_x_occupation, - age_buckets_x_race_x_occupation], - model_dir=YOUR_MODEL_DIRECTORY) -e.train(input_fn=input_fn_train, steps=200) -# Evaluate for one step (one pass through the test data). -results = e.evaluate(input_fn=input_fn_test) - -# Print the stats for the evaluation. -for key in sorted(results): - print("%s: %s" % (key, results[key])) -``` - -### Wide and deep learning - -The `tf.estimator` module also provides an estimator class that lets you jointly -train a linear model and a deep neural network. This novel approach combines the -ability of linear models to "memorize" key features with the generalization -ability of neural nets. Use `tf.estimator.DNNLinearCombinedClassifier` to -create this sort of "wide and deep" model: - -```python -e = tf.estimator.DNNLinearCombinedClassifier( - model_dir=YOUR_MODEL_DIR, - linear_feature_columns=wide_columns, - dnn_feature_columns=deep_columns, - dnn_hidden_units=[100, 50]) -``` -For more information, see the -[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/wide_deep). diff --git a/tensorflow/docs_src/tutorials/representation/word2vec.md b/tensorflow/docs_src/tutorials/representation/word2vec.md deleted file mode 100644 index df0d3176b6..0000000000 --- a/tensorflow/docs_src/tutorials/representation/word2vec.md +++ /dev/null @@ -1,405 +0,0 @@ -# Vector Representations of Words - -In this tutorial we look at the word2vec model by -[Mikolov et al.](https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf) -This model is used for learning vector representations of words, called "word -embeddings". - -## Highlights - -This tutorial is meant to highlight the interesting, substantive parts of -building a word2vec model in TensorFlow. - -* We start by giving the motivation for why we would want to -represent words as vectors. -* We look at the intuition behind the model and how it is trained -(with a splash of math for good measure). -* We also show a simple implementation of the model in TensorFlow. -* Finally, we look at ways to make the naive version scale better. - -We walk through the code later during the tutorial, but if you'd prefer to dive -straight in, feel free to look at the minimalistic implementation in -[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://www.tensorflow.org/code/tensorflow/examples/tutorials/word2vec/word2vec_basic.py) -This basic example contains the code needed to download some data, train on it a -bit and visualize the result. Once you get comfortable with reading and running -the basic version, you can graduate to -[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/tutorials/embedding/word2vec.py) -which is a more serious implementation that showcases some more advanced -TensorFlow principles about how to efficiently use threads to move data into a -text model, how to checkpoint during training, etc. - -But first, let's look at why we would want to learn word embeddings in the first -place. Feel free to skip this section if you're an Embedding Pro and you'd just -like to get your hands dirty with the details. - -## Motivation: Why Learn Word Embeddings? - -Image and audio processing systems work with rich, high-dimensional datasets -encoded as vectors of the individual raw pixel-intensities for image data, or -e.g. power spectral density coefficients for audio data. For tasks like object -or speech recognition we know that all the information required to successfully -perform the task is encoded in the data (because humans can perform these tasks -from the raw data). However, natural language processing systems traditionally -treat words as discrete atomic symbols, and therefore 'cat' may be represented -as `Id537` and 'dog' as `Id143`. These encodings are arbitrary, and provide -no useful information to the system regarding the relationships that may exist -between the individual symbols. This means that the model can leverage -very little of what it has learned about 'cats' when it is processing data about -'dogs' (such that they are both animals, four-legged, pets, etc.). Representing -words as unique, discrete ids furthermore leads to data sparsity, and usually -means that we may need more data in order to successfully train statistical -models. Using vector representations can overcome some of these obstacles. - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://www.tensorflow.org/images/audio-image-text.png" alt> -</div> - -[Vector space models](https://en.wikipedia.org/wiki/Vector_space_model) (VSMs) -represent (embed) words in a continuous vector space where semantically -similar words are mapped to nearby points ('are embedded nearby each other'). -VSMs have a long, rich history in NLP, but all methods depend in some way or -another on the -[Distributional Hypothesis](https://en.wikipedia.org/wiki/Distributional_semantics#Distributional_Hypothesis), -which states that words that appear in the same contexts share -semantic meaning. The different approaches that leverage this principle can be -divided into two categories: *count-based methods* (e.g. -[Latent Semantic Analysis](https://en.wikipedia.org/wiki/Latent_semantic_analysis)), -and *predictive methods* (e.g. -[neural probabilistic language models](http://www.scholarpedia.org/article/Neural_net_language_models)). - -This distinction is elaborated in much more detail by -[Baroni et al.](http://clic.cimec.unitn.it/marco/publications/acl2014/baroni-etal-countpredict-acl2014.pdf), -but in a nutshell: Count-based methods compute the statistics of -how often some word co-occurs with its neighbor words in a large text corpus, -and then map these count-statistics down to a small, dense vector for each word. -Predictive models directly try to predict a word from its neighbors in terms of -learned small, dense *embedding vectors* (considered parameters of the -model). - -Word2vec is a particularly computationally-efficient predictive model for -learning word embeddings from raw text. It comes in two flavors, the Continuous -Bag-of-Words model (CBOW) and the Skip-Gram model (Section 3.1 and 3.2 in [Mikolov et al.](https://arxiv.org/pdf/1301.3781.pdf)). Algorithmically, these -models are similar, except that CBOW predicts target words (e.g. 'mat') from -source context words ('the cat sits on the'), while the skip-gram does the -inverse and predicts source context-words from the target words. This inversion -might seem like an arbitrary choice, but statistically it has the effect that -CBOW smoothes over a lot of the distributional information (by treating an -entire context as one observation). For the most part, this turns out to be a -useful thing for smaller datasets. However, skip-gram treats each context-target -pair as a new observation, and this tends to do better when we have larger -datasets. We will focus on the skip-gram model in the rest of this tutorial. - - -## Scaling up with Noise-Contrastive Training - -Neural probabilistic language models are traditionally trained using the -[maximum likelihood](https://en.wikipedia.org/wiki/Maximum_likelihood) (ML) -principle to maximize the probability of the next word \\(w_t\\) (for "target") -given the previous words \\(h\\) (for "history") in terms of a -[*softmax* function](https://en.wikipedia.org/wiki/Softmax_function), - -$$ -\begin{align} -P(w_t | h) &= \text{softmax}(\text{score}(w_t, h)) \\ - &= \frac{\exp \{ \text{score}(w_t, h) \} } - {\sum_\text{Word w' in Vocab} \exp \{ \text{score}(w', h) \} } -\end{align} -$$ - -where \\(\text{score}(w_t, h)\\) computes the compatibility of word \\(w_t\\) -with the context \\(h\\) (a dot product is commonly used). We train this model -by maximizing its [log-likelihood](https://en.wikipedia.org/wiki/Likelihood_function) -on the training set, i.e. by maximizing - -$$ -\begin{align} - J_\text{ML} &= \log P(w_t | h) \\ - &= \text{score}(w_t, h) - - \log \left( \sum_\text{Word w' in Vocab} \exp \{ \text{score}(w', h) \} \right). -\end{align} -$$ - -This yields a properly normalized probabilistic model for language modeling. -However this is very expensive, because we need to compute and normalize each -probability using the score for all other \\(V\\) words \\(w'\\) in the current -context \\(h\\), *at every training step*. - -<div style="width:60%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://www.tensorflow.org/images/softmax-nplm.png" alt> -</div> - -On the other hand, for feature learning in word2vec we do not need a full -probabilistic model. The CBOW and skip-gram models are instead trained using a -binary classification objective ([logistic regression](https://en.wikipedia.org/wiki/Logistic_regression)) -to discriminate the real target words \\(w_t\\) from \\(k\\) imaginary (noise) words \\(\tilde w\\), in the -same context. We illustrate this below for a CBOW model. For skip-gram the -direction is simply inverted. - -<div style="width:60%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://www.tensorflow.org/images/nce-nplm.png" alt> -</div> - -Mathematically, the objective (for each example) is to maximize - -$$J_\text{NEG} = \log Q_\theta(D=1 |w_t, h) + - k \mathop{\mathbb{E}}_{\tilde w \sim P_\text{noise}} - \left[ \log Q_\theta(D = 0 |\tilde w, h) \right]$$ - -where \\(Q_\theta(D=1 | w, h)\\) is the binary logistic regression probability -under the model of seeing the word \\(w\\) in the context \\(h\\) in the dataset -\\(D\\), calculated in terms of the learned embedding vectors \\(\theta\\). In -practice we approximate the expectation by drawing \\(k\\) contrastive words -from the noise distribution (i.e. we compute a -[Monte Carlo average](https://en.wikipedia.org/wiki/Monte_Carlo_integration)). - -This objective is maximized when the model assigns high probabilities -to the real words, and low probabilities to noise words. Technically, this is -called -[Negative Sampling](https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf), -and there is good mathematical motivation for using this loss function: -The updates it proposes approximate the updates of the softmax function in the -limit. But computationally it is especially appealing because computing the -loss function now scales only with the number of *noise words* that we -select (\\(k\\)), and not *all words* in the vocabulary (\\(V\\)). This makes it -much faster to train. We will actually make use of the very similar -[noise-contrastive estimation (NCE)](https://papers.nips.cc/paper/5165-learning-word-embeddings-efficiently-with-noise-contrastive-estimation.pdf) -loss, for which TensorFlow has a handy helper function `tf.nn.nce_loss()`. - -Let's get an intuitive feel for how this would work in practice! - -## The Skip-gram Model - -As an example, let's consider the dataset - -`the quick brown fox jumped over the lazy dog` - -We first form a dataset of words and the contexts in which they appear. We -could define 'context' in any way that makes sense, and in fact people have -looked at syntactic contexts (i.e. the syntactic dependents of the current -target word, see e.g. -[Levy et al.](https://levyomer.files.wordpress.com/2014/04/dependency-based-word-embeddings-acl-2014.pdf)), -words-to-the-left of the target, words-to-the-right of the target, etc. For now, -let's stick to the vanilla definition and define 'context' as the window -of words to the left and to the right of a target word. Using a window -size of 1, we then have the dataset - -`([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox), ...` - -of `(context, target)` pairs. Recall that skip-gram inverts contexts and -targets, and tries to predict each context word from its target word, so the -task becomes to predict 'the' and 'brown' from 'quick', 'quick' and 'fox' from -'brown', etc. Therefore our dataset becomes - -`(quick, the), (quick, brown), (brown, quick), (brown, fox), ...` - -of `(input, output)` pairs. The objective function is defined over the entire -dataset, but we typically optimize this with -[stochastic gradient descent](https://en.wikipedia.org/wiki/Stochastic_gradient_descent) -(SGD) using one example at a time (or a 'minibatch' of `batch_size` examples, -where typically `16 <= batch_size <= 512`). So let's look at one step of -this process. - -Let's imagine at training step \\(t\\) we observe the first training case above, -where the goal is to predict `the` from `quick`. We select `num_noise` number -of noisy (contrastive) examples by drawing from some noise distribution, -typically the unigram distribution, \\(P(w)\\). For simplicity let's say -`num_noise=1` and we select `sheep` as a noisy example. Next we compute the -loss for this pair of observed and noisy examples, i.e. the objective at time -step \\(t\\) becomes - -$$J^{(t)}_\text{NEG} = \log Q_\theta(D=1 | \text{the, quick}) + - \log(Q_\theta(D=0 | \text{sheep, quick}))$$ - -The goal is to make an update to the embedding parameters \\(\theta\\) to improve -(in this case, maximize) this objective function. We do this by deriving the -gradient of the loss with respect to the embedding parameters \\(\theta\\), i.e. -\\(\frac{\partial}{\partial \theta} J_\text{NEG}\\) (luckily TensorFlow provides -easy helper functions for doing this!). We then perform an update to the -embeddings by taking a small step in the direction of the gradient. When this -process is repeated over the entire training set, this has the effect of -'moving' the embedding vectors around for each word until the model is -successful at discriminating real words from noise words. - -We can visualize the learned vectors by projecting them down to 2 dimensions -using for instance something like the -[t-SNE dimensionality reduction technique](https://lvdmaaten.github.io/tsne/). -When we inspect these visualizations it becomes apparent that the vectors -capture some general, and in fact quite useful, semantic information about -words and their relationships to one another. It was very interesting when we -first discovered that certain directions in the induced vector space specialize -towards certain semantic relationships, e.g. *male-female*, *verb tense* and -even *country-capital* relationships between words, as illustrated in the figure -below (see also for example -[Mikolov et al., 2013](https://www.aclweb.org/anthology/N13-1090)). - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://www.tensorflow.org/images/linear-relationships.png" alt> -</div> - -This explains why these vectors are also useful as features for many canonical -NLP prediction tasks, such as part-of-speech tagging or named entity recognition -(see for example the original work by -[Collobert et al., 2011](https://arxiv.org/abs/1103.0398) -([pdf](https://arxiv.org/pdf/1103.0398.pdf)), or follow-up work by -[Turian et al., 2010](https://www.aclweb.org/anthology/P10-1040)). - -But for now, let's just use them to draw pretty pictures! - -## Building the Graph - -This is all about embeddings, so let's define our embedding matrix. -This is just a big random matrix to start. We'll initialize the values to be -uniform in the unit cube. - -```python -embeddings = tf.Variable( - tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0)) -``` - -The noise-contrastive estimation loss is defined in terms of a logistic regression -model. For this, we need to define the weights and biases for each word in the -vocabulary (also called the `output weights` as opposed to the `input -embeddings`). So let's define that. - -```python -nce_weights = tf.Variable( - tf.truncated_normal([vocabulary_size, embedding_size], - stddev=1.0 / math.sqrt(embedding_size))) -nce_biases = tf.Variable(tf.zeros([vocabulary_size])) -``` - -Now that we have the parameters in place, we can define our skip-gram model -graph. For simplicity, let's suppose we've already integerized our text corpus -with a vocabulary so that each word is represented as an integer (see -[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://www.tensorflow.org/code/tensorflow/examples/tutorials/word2vec/word2vec_basic.py) -for the details). The skip-gram model takes two inputs. One is a batch full of -integers representing the source context words, the other is for the target -words. Let's create placeholder nodes for these inputs, so that we can feed in -data later. - -```python -# Placeholders for inputs -train_inputs = tf.placeholder(tf.int32, shape=[batch_size]) -train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1]) -``` - -Now what we need to do is look up the vector for each of the source words in -the batch. TensorFlow has handy helpers that make this easy. - -```python -embed = tf.nn.embedding_lookup(embeddings, train_inputs) -``` - -Ok, now that we have the embeddings for each word, we'd like to try to predict -the target word using the noise-contrastive training objective. - -```python -# Compute the NCE loss, using a sample of the negative labels each time. -loss = tf.reduce_mean( - tf.nn.nce_loss(weights=nce_weights, - biases=nce_biases, - labels=train_labels, - inputs=embed, - num_sampled=num_sampled, - num_classes=vocabulary_size)) -``` - -Now that we have a loss node, we need to add the nodes required to compute -gradients and update the parameters, etc. For this we will use stochastic -gradient descent, and TensorFlow has handy helpers to make this easy as well. - -```python -# We use the SGD optimizer. -optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0).minimize(loss) -``` - -## Training the Model - -Training the model is then as simple as using a `feed_dict` to push data into -the placeholders and calling -`tf.Session.run` with this new data -in a loop. - -```python -for inputs, labels in generate_batch(...): - feed_dict = {train_inputs: inputs, train_labels: labels} - _, cur_loss = session.run([optimizer, loss], feed_dict=feed_dict) -``` - -See the full example code in -[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://www.tensorflow.org/code/tensorflow/examples/tutorials/word2vec/word2vec_basic.py). - -## Visualizing the Learned Embeddings - -After training has finished we can visualize the learned embeddings using -t-SNE. - -<div style="width:100%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://www.tensorflow.org/images/tsne.png" alt> -</div> - -Et voila! As expected, words that are similar end up clustering nearby each -other. For a more heavyweight implementation of word2vec that showcases more of -the advanced features of TensorFlow, see the implementation in -[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/tutorials/embedding/word2vec.py). - -## Evaluating Embeddings: Analogical Reasoning - -Embeddings are useful for a wide variety of prediction tasks in NLP. Short of -training a full-blown part-of-speech model or named-entity model, one simple way -to evaluate embeddings is to directly use them to predict syntactic and semantic -relationships like `king is to queen as father is to ?`. This is called -*analogical reasoning* and the task was introduced by -[Mikolov and colleagues -](https://www.aclweb.org/anthology/N13-1090). -Download the dataset for this task from -[download.tensorflow.org](http://download.tensorflow.org/data/questions-words.txt). - -To see how we do this evaluation, have a look at the `build_eval_graph()` and -`eval()` functions in -[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/tutorials/embedding/word2vec.py). - -The choice of hyperparameters can strongly influence the accuracy on this task. -To achieve state-of-the-art performance on this task requires training over a -very large dataset, carefully tuning the hyperparameters and making use of -tricks like subsampling the data, which is out of the scope of this tutorial. - - -## Optimizing the Implementation - -Our vanilla implementation showcases the flexibility of TensorFlow. For -example, changing the training objective is as simple as swapping out the call -to `tf.nn.nce_loss()` for an off-the-shelf alternative such as -`tf.nn.sampled_softmax_loss()`. If you have a new idea for a loss function, you -can manually write an expression for the new objective in TensorFlow and let -the optimizer compute its derivatives. This flexibility is invaluable in the -exploratory phase of machine learning model development, where we are trying -out several different ideas and iterating quickly. - -Once you have a model structure you're satisfied with, it may be worth -optimizing your implementation to run more efficiently (and cover more data in -less time). For example, the naive code we used in this tutorial would suffer -compromised speed because we use Python for reading and feeding data items -- -each of which require very little work on the TensorFlow back-end. If you find -your model is seriously bottlenecked on input data, you may want to implement a -custom data reader for your problem, as described in -[New Data Formats](../../extend/new_data_formats.md). For the case of Skip-Gram -modeling, we've actually already done this for you as an example in -[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/tutorials/embedding/word2vec.py). - -If your model is no longer I/O bound but you want still more performance, you -can take things further by writing your own TensorFlow Ops, as described in -[Adding a New Op](../../extend/adding_an_op.md). Again we've provided an -example of this for the Skip-Gram case -[models/tutorials/embedding/word2vec_optimized.py](https://github.com/tensorflow/models/tree/master/tutorials/embedding/word2vec_optimized.py). -Feel free to benchmark these against each other to measure performance -improvements at each stage. - -## Conclusion - -In this tutorial we covered the word2vec model, a computationally efficient -model for learning word embeddings. We motivated why embeddings are useful, -discussed efficient training techniques and showed how to implement all of this -in TensorFlow. Overall, we hope that this has show-cased how TensorFlow affords -you the flexibility you need for early experimentation, and the control you -later need for bespoke optimized implementation. diff --git a/tensorflow/docs_src/tutorials/sequences/audio_recognition.md b/tensorflow/docs_src/tutorials/sequences/audio_recognition.md deleted file mode 100644 index d7a8da6f96..0000000000 --- a/tensorflow/docs_src/tutorials/sequences/audio_recognition.md +++ /dev/null @@ -1,631 +0,0 @@ -# Simple Audio Recognition - -This tutorial will show you how to build a basic speech recognition network that -recognizes ten different words. It's important to know that real speech and -audio recognition systems are much more complex, but like MNIST for images, it -should give you a basic understanding of the techniques involved. Once you've -completed this tutorial, you'll have a model that tries to classify a one second -audio clip as either silence, an unknown word, "yes", "no", "up", "down", -"left", "right", "on", "off", "stop", or "go". You'll also be able to take this -model and run it in an Android application. - -## Preparation - -You should make sure you have TensorFlow installed, and since the script -downloads over 1GB of training data, you'll need a good internet connection and -enough free space on your machine. The training process itself can take several -hours, so make sure you have a machine available for that long. - -## Training - -To begin the training process, go to the TensorFlow source tree and run: - -```bash -python tensorflow/examples/speech_commands/train.py -``` - -The script will start off by downloading the [Speech Commands -dataset](https://storage.cloud.google.com/download.tensorflow.org/data/speech_commands_v0.02.tar.gz), -which consists of over 105,000 WAVE audio files of people saying thirty -different words. This data was collected by Google and released under a CC BY -license, and you can help improve it by [contributing five minutes of your own -voice](https://aiyprojects.withgoogle.com/open_speech_recording). The archive is -over 2GB, so this part may take a while, but you should see progress logs, and -once it's been downloaded once you won't need to do this step again. You can -find more information about this dataset in this -[Speech Commands paper](https://arxiv.org/abs/1804.03209). - -Once the downloading has completed, you'll see logging information that looks -like this: - -``` -I0730 16:53:44.766740 55030 train.py:176] Training from step: 1 -I0730 16:53:47.289078 55030 train.py:217] Step #1: rate 0.001000, accuracy 7.0%, cross entropy 2.611571 -``` - -This shows that the initialization process is done and the training loop has -begun. You'll see that it outputs information for every training step. Here's a -break down of what it means: - -`Step #1` shows that we're on the first step of the training loop. In this case -there are going to be 18,000 steps in total, so you can look at the step number -to get an idea of how close it is to finishing. - -`rate 0.001000` is the learning rate that's controlling the speed of the -network's weight updates. Early on this is a comparatively high number (0.001), -but for later training cycles it will be reduced 10x, to 0.0001. - -`accuracy 7.0%` is the how many classes were correctly predicted on this -training step. This value will often fluctuate a lot, but should increase on -average as training progresses. The model outputs an array of numbers, one for -each label, and each number is the predicted likelihood of the input being that -class. The predicted label is picked by choosing the entry with the highest -score. The scores are always between zero and one, with higher values -representing more confidence in the result. - -`cross entropy 2.611571` is the result of the loss function that we're using to -guide the training process. This is a score that's obtained by comparing the -vector of scores from the current training run to the correct labels, and this -should trend downwards during training. - -After a hundred steps, you should see a line like this: - -`I0730 16:54:41.813438 55030 train.py:252] Saving to -"/tmp/speech_commands_train/conv.ckpt-100"` - -This is saving out the current trained weights to a checkpoint file. If your -training script gets interrupted, you can look for the last saved checkpoint and -then restart the script with -`--start_checkpoint=/tmp/speech_commands_train/conv.ckpt-100` as a command line -argument to start from that point. - -## Confusion Matrix - -After four hundred steps, this information will be logged: - -``` -I0730 16:57:38.073667 55030 train.py:243] Confusion Matrix: - [[258 0 0 0 0 0 0 0 0 0 0 0] - [ 7 6 26 94 7 49 1 15 40 2 0 11] - [ 10 1 107 80 13 22 0 13 10 1 0 4] - [ 1 3 16 163 6 48 0 5 10 1 0 17] - [ 15 1 17 114 55 13 0 9 22 5 0 9] - [ 1 1 6 97 3 87 1 12 46 0 0 10] - [ 8 6 86 84 13 24 1 9 9 1 0 6] - [ 9 3 32 112 9 26 1 36 19 0 0 9] - [ 8 2 12 94 9 52 0 6 72 0 0 2] - [ 16 1 39 74 29 42 0 6 37 9 0 3] - [ 15 6 17 71 50 37 0 6 32 2 1 9] - [ 11 1 6 151 5 42 0 8 16 0 0 20]] -``` - -The first section is a [confusion -matrix](https://www.tensorflow.org/api_docs/python/tf/confusion_matrix). To -understand what it means, you first need to know the labels being used, which in -this case are "_silence_", "_unknown_", "yes", "no", "up", "down", "left", -"right", "on", "off", "stop", and "go". Each column represents a set of samples -that were predicted to be each label, so the first column represents all the -clips that were predicted to be silence, the second all those that were -predicted to be unknown words, the third "yes", and so on. - -Each row represents clips by their correct, ground truth labels. The first row -is all the clips that were silence, the second clips that were unknown words, -the third "yes", etc. - -This matrix can be more useful than just a single accuracy score because it -gives a good summary of what mistakes the network is making. In this example you -can see that all of the entries in the first row are zero, apart from the -initial one. Because the first row is all the clips that are actually silence, -this means that none of them were mistakenly labeled as words, so we have no -false negatives for silence. This shows the network is already getting pretty -good at distinguishing silence from words. - -If we look down the first column though, we see a lot of non-zero values. The -column represents all the clips that were predicted to be silence, so positive -numbers outside of the first cell are errors. This means that some clips of real -spoken words are actually being predicted to be silence, so we do have quite a -few false positives. - -A perfect model would produce a confusion matrix where all of the entries were -zero apart from a diagonal line through the center. Spotting deviations from -that pattern can help you figure out how the model is most easily confused, and -once you've identified the problems you can address them by adding more data or -cleaning up categories. - -## Validation - -After the confusion matrix, you should see a line like this: - -`I0730 16:57:38.073777 55030 train.py:245] Step 400: Validation accuracy = 26.3% -(N=3093)` - -It's good practice to separate your data set into three categories. The largest -(in this case roughly 80% of the data) is used for training the network, a -smaller set (10% here, known as "validation") is reserved for evaluation of the -accuracy during training, and another set (the last 10%, "testing") is used to -evaluate the accuracy once after the training is complete. - -The reason for this split is that there's always a danger that networks will -start memorizing their inputs during training. By keeping the validation set -separate, you can ensure that the model works with data it's never seen before. -The testing set is an additional safeguard to make sure that you haven't just -been tweaking your model in a way that happens to work for both the training and -validation sets, but not a broader range of inputs. - -The training script automatically separates the data set into these three -categories, and the logging line above shows the accuracy of model when run on -the validation set. Ideally, this should stick fairly close to the training -accuracy. If the training accuracy increases but the validation doesn't, that's -a sign that overfitting is occurring, and your model is only learning things -about the training clips, not broader patterns that generalize. - -## Tensorboard - -A good way to visualize how the training is progressing is using Tensorboard. By -default, the script saves out events to /tmp/retrain_logs, and you can load -these by running: - -`tensorboard --logdir /tmp/retrain_logs` - -Then navigate to [http://localhost:6006](http://localhost:6006) in your browser, -and you'll see charts and graphs showing your models progress. - -<div style="width:50%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://storage.googleapis.com/download.tensorflow.org/example_images/speech_commands_tensorflow.png"/> -</div> - -## Training Finished - -After a few hours of training (depending on your machine's speed), the script -should have completed all 18,000 steps. It will print out a final confusion -matrix, along with an accuracy score, all run on the testing set. With the -default settings, you should see an accuracy of between 85% and 90%. - -Because audio recognition is particularly useful on mobile devices, next we'll -export it to a compact format that's easy to work with on those platforms. To do -that, run this command line: - -``` -python tensorflow/examples/speech_commands/freeze.py \ ---start_checkpoint=/tmp/speech_commands_train/conv.ckpt-18000 \ ---output_file=/tmp/my_frozen_graph.pb -``` - -Once the frozen model has been created, you can test it with the `label_wav.py` -script, like this: - -``` -python tensorflow/examples/speech_commands/label_wav.py \ ---graph=/tmp/my_frozen_graph.pb \ ---labels=/tmp/speech_commands_train/conv_labels.txt \ ---wav=/tmp/speech_dataset/left/a5d485dc_nohash_0.wav -``` - -This should print out three labels: - -``` -left (score = 0.81477) -right (score = 0.14139) -_unknown_ (score = 0.03808) -``` - -Hopefully "left" is the top score since that's the correct label, but since the -training is random it may not for the first file you try. Experiment with some -of the other .wav files in that same folder to see how well it does. - -The scores are between zero and one, and higher values mean the model is more -confident in its prediction. - -## Running the Model in an Android App - -The easiest way to see how this model works in a real application is to download -[the prebuilt Android demo -applications](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/android#prebuilt-components) -and install them on your phone. You'll see 'TF Speech' appear in your app list, -and opening it will show you the same list of action words we've just trained -our model on, starting with "Yes" and "No". Once you've given the app permission -to use the microphone, you should be able to try saying those words and see them -highlighted in the UI when the model recognizes one of them. - -You can also build this application yourself, since it's open source and -[available as part of the TensorFlow repository on -github](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/android#building-in-android-studio-using-the-tensorflow-aar-from-jcenter). -By default it downloads [a pretrained model from -tensorflow.org](http://download.tensorflow.org/models/speech_commands_v0.02.zip), -but you can easily [replace it with a model you've trained -yourself](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/android#install-model-files-optional). -If you do this, you'll need to make sure that the constants in [the main -SpeechActivity Java source -file](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/android/src/org/tensorflow/demo/SpeechActivity.java) -like `SAMPLE_RATE` and `SAMPLE_DURATION` match any changes you've made to the -defaults while training. You'll also see that there's a [Java version of the -RecognizeCommands -module](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/android/src/org/tensorflow/demo/RecognizeCommands.java) -that's very similar to the C++ version in this tutorial. If you've tweaked -parameters for that, you can also update them in SpeechActivity to get the same -results as in your server testing. - -The demo app updates its UI list of results automatically based on the labels -text file you copy into assets alongside your frozen graph, which means you can -easily try out different models without needing to make any code changes. You -will need to update `LABEL_FILENAME` and `MODEL_FILENAME` to point to the files -you've added if you change the paths though. - -## How does this Model Work? - -The architecture used in this tutorial is based on some described in the paper -[Convolutional Neural Networks for Small-footprint Keyword -Spotting](http://www.isca-speech.org/archive/interspeech_2015/papers/i15_1478.pdf). -It was chosen because it's comparatively simple, quick to train, and easy to -understand, rather than being state of the art. There are lots of different -approaches to building neural network models to work with audio, including -[recurrent networks](https://svds.com/tensorflow-rnn-tutorial/) or [dilated -(atrous) -convolutions](https://deepmind.com/blog/wavenet-generative-model-raw-audio/). -This tutorial is based on the kind of convolutional network that will feel very -familiar to anyone who's worked with image recognition. That may seem surprising -at first though, since audio is inherently a one-dimensional continuous signal -across time, not a 2D spatial problem. - -We solve that issue by defining a window of time we believe our spoken words -should fit into, and converting the audio signal in that window into an image. -This is done by grouping the incoming audio samples into short segments, just a -few milliseconds long, and calculating the strength of the frequencies across a -set of bands. Each set of frequency strengths from a segment is treated as a -vector of numbers, and those vectors are arranged in time order to form a -two-dimensional array. This array of values can then be treated like a -single-channel image, and is known as a -[spectrogram](https://en.wikipedia.org/wiki/Spectrogram). If you want to view -what kind of image an audio sample produces, you can run the `wav_to_spectrogram -tool: - -``` -bazel run tensorflow/examples/wav_to_spectrogram:wav_to_spectrogram -- \ ---input_wav=/tmp/speech_dataset/happy/ab00c4b2_nohash_0.wav \ ---output_image=/tmp/spectrogram.png -``` - -If you open up `/tmp/spectrogram.png` you should see something like this: - -<div style="width:50%; margin:auto; margin-bottom:10px; margin-top:20px;"> -<img style="width:100%" src="https://storage.googleapis.com/download.tensorflow.org/example_images/spectrogram.png"/> -</div> - -Because of TensorFlow's memory order, time in this image is increasing from top -to bottom, with frequencies going from left to right, unlike the usual -convention for spectrograms where time is left to right. You should be able to -see a couple of distinct parts, with the first syllable "Ha" distinct from -"ppy". - -Because the human ear is more sensitive to some frequencies than others, it's -been traditional in speech recognition to do further processing to this -representation to turn it into a set of [Mel-Frequency Cepstral -Coefficients](https://en.wikipedia.org/wiki/Mel-frequency_cepstrum), or MFCCs -for short. This is also a two-dimensional, one-channel representation so it can -be treated like an image too. If you're targeting general sounds rather than -speech you may find you can skip this step and operate directly on the -spectrograms. - -The image that's produced by these processing steps is then fed into a -multi-layer convolutional neural network, with a fully-connected layer followed -by a softmax at the end. You can see the definition of this portion in -[tensorflow/examples/speech_commands/models.py](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/speech_commands/models.py). - -## Streaming Accuracy - -Most audio recognition applications need to run on a continuous stream of audio, -rather than on individual clips. A typical way to use a model in this -environment is to apply it repeatedly at different offsets in time and average -the results over a short window to produce a smoothed prediction. If you think -of the input as an image, it's continuously scrolling along the time axis. The -words we want to recognize can start at any time, so we need to take a series of -snapshots to have a chance of having an alignment that captures most of the -utterance in the time window we feed into the model. If we sample at a high -enough rate, then we have a good chance of capturing the word in multiple -windows, so averaging the results improves the overall confidence of the -prediction. - -For an example of how you can use your model on streaming data, you can look at -[test_streaming_accuracy.cc](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/speech_commands/). -This uses the -[RecognizeCommands](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/speech_commands/recognize_commands.h) -class to run through a long-form input audio, try to spot words, and compare -those predictions against a ground truth list of labels and times. This makes it -a good example of applying a model to a stream of audio signals over time. - -You'll need a long audio file to test it against, along with labels showing -where each word was spoken. If you don't want to record one yourself, you can -generate some synthetic test data using the `generate_streaming_test_wav` -utility. By default this will create a ten minute .wav file with words roughly -every three seconds, and a text file containing the ground truth of when each -word was spoken. These words are pulled from the test portion of your current -dataset, mixed in with background noise. To run it, use: - -``` -bazel run tensorflow/examples/speech_commands:generate_streaming_test_wav -``` - -This will save a .wav file to `/tmp/speech_commands_train/streaming_test.wav`, -and a text file listing the labels to -`/tmp/speech_commands_train/streaming_test_labels.txt`. You can then run -accuracy testing with: - -``` -bazel run tensorflow/examples/speech_commands:test_streaming_accuracy -- \ ---graph=/tmp/my_frozen_graph.pb \ ---labels=/tmp/speech_commands_train/conv_labels.txt \ ---wav=/tmp/speech_commands_train/streaming_test.wav \ ---ground_truth=/tmp/speech_commands_train/streaming_test_labels.txt \ ---verbose -``` - -This will output information about the number of words correctly matched, how -many were given the wrong labels, and how many times the model triggered when -there was no real word spoken. There are various parameters that control how the -signal averaging works, including `--average_window_ms` which sets the length of -time to average results over, `--clip_stride_ms` which is the time between -applications of the model, `--suppression_ms` which stops subsequent word -detections from triggering for a certain time after an initial one is found, and -`--detection_threshold`, which controls how high the average score must be -before it's considered a solid result. - -You'll see that the streaming accuracy outputs three numbers, rather than just -the one metric used in training. This is because different applications have -varying requirements, with some being able to tolerate frequent incorrect -results as long as real words are found (high recall), while others very focused -on ensuring the predicted labels are highly likely to be correct even if some -aren't detected (high precision). The numbers from the tool give you an idea of -how your model will perform in an application, and you can try tweaking the -signal averaging parameters to tune it to give the kind of performance you want. -To understand what the right parameters are for your application, you can look -at generating an [ROC -curve](https://en.wikipedia.org/wiki/Receiver_operating_characteristic) to help -you understand the tradeoffs. - -## RecognizeCommands - -The streaming accuracy tool uses a simple decoder contained in a small C++ class -called -[RecognizeCommands](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/speech_commands/recognize_commands.h). -This class is fed the output of running the TensorFlow model over time, it -averages the signals, and returns information about a label when it has enough -evidence to think that a recognized word has been found. The implementation is -fairly small, just keeping track of the last few predictions and averaging them, -so it's easy to port to other platforms and languages as needed. For example, -it's convenient to do something similar at the Java level on Android, or Python -on the Raspberry Pi. As long as these implementations share the same logic, you -can tune the parameters that control the averaging using the streaming test -tool, and then transfer them over to your application to get similar results. - -## Advanced Training - -The defaults for the training script are designed to produce good end to end -results in a comparatively small file, but there are a lot of options you can -change to customize the results for your own requirements. - -### Custom Training Data - -By default the script will download the [Speech Commands -dataset](https://download.tensorflow.org/data/speech_commands_v0.01.tgz), but -you can also supply your own training data. To train on your own data, you -should make sure that you have at least several hundred recordings of each sound -you would like to recognize, and arrange them into folders by class. For -example, if you were trying to recognize dog barks from cat miaows, you would -create a root folder called `animal_sounds`, and then within that two -sub-folders called `bark` and `miaow`. You would then organize your audio files -into the appropriate folders. - -To point the script to your new audio files, you'll need to set `--data_url=` to -disable downloading of the Speech Commands dataset, and -`--data_dir=/your/data/folder/` to find the files you've just created. - -The files themselves should be 16-bit little-endian PCM-encoded WAVE format. The -sample rate defaults to 16,000, but as long as all your audio is consistently -the same rate (the script doesn't support resampling) you can change this with -the `--sample_rate` argument. The clips should also all be roughly the same -duration. The default expected duration is one second, but you can set this with -the `--clip_duration_ms` flag. If you have clips with variable amounts of -silence at the start, you can look at word alignment tools to standardize them -([here's a quick and dirty approach you can use -too](https://petewarden.com/2017/07/17/a-quick-hack-to-align-single-word-audio-recordings/)). - -One issue to watch out for is that you may have very similar repetitions of the -same sounds in your dataset, and these can give misleading metrics if they're -spread across your training, validation, and test sets. For example, the Speech -Commands set has people repeating the same word multiple times. Each one of -those repetitions is likely to be pretty close to the others, so if training was -overfitting and memorizing one, it could perform unrealistically well when it -saw a very similar copy in the test set. To avoid this danger, Speech Commands -trys to ensure that all clips featuring the same word spoken by a single person -are put into the same partition. Clips are assigned to training, test, or -validation sets based on a hash of their filename, to ensure that the -assignments remain steady even as new clips are added and avoid any training -samples migrating into the other sets. To make sure that all a given speaker's -words are in the same bucket, [the hashing -function](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/speech_commands/input_data.py) -ignores anything in a filename after '_nohash_' when calculating the -assignments. This means that if you have file names like `pete_nohash_0.wav` and -`pete_nohash_1.wav`, they're guaranteed to be in the same set. - -### Unknown Class - -It's likely that your application will hear sounds that aren't in your training -set, and you'll want the model to indicate that it doesn't recognize the noise -in those cases. To help the network learn what sounds to ignore, you need to -provide some clips of audio that are neither of your classes. To do this, you'd -create `quack`, `oink`, and `moo` subfolders and populate them with noises from -other animals your users might encounter. The `--wanted_words` argument to the -script defines which classes you care about, all the others mentioned in -subfolder names will be used to populate an `_unknown_` class during training. -The Speech Commands dataset has twenty words in its unknown classes, including -the digits zero through nine and random names like "Sheila". - -By default 10% of the training examples are picked from the unknown classes, but -you can control this with the `--unknown_percentage` flag. Increasing this will -make the model less likely to mistake unknown words for wanted ones, but making -it too large can backfire as the model might decide it's safest to categorize -all words as unknown! - -### Background Noise - -Real applications have to recognize audio even when there are other irrelevant -sounds happening in the environment. To build a model that's robust to this kind -of interference, we need to train against recorded audio with similar -properties. The files in the Speech Commands dataset were captured on a variety -of devices by users in many different environments, not in a studio, so that -helps add some realism to the training. To add even more, you can mix in random -segments of environmental audio to the training inputs. In the Speech Commands -set there's a special folder called `_background_noise_` which contains -minute-long WAVE files with white noise and recordings of machinery and everyday -household activity. - -Small snippets of these files are chosen at random and mixed at a low volume -into clips during training. The loudness is also chosen randomly, and controlled -by the `--background_volume` argument as a proportion where 0 is silence, and 1 -is full volume. Not all clips have background added, so the -`--background_frequency` flag controls what proportion have them mixed in. - -Your own application might operate in its own environment with different -background noise patterns than these defaults, so you can supply your own audio -clips in the `_background_noise_` folder. These should be the same sample rate -as your main dataset, but much longer in duration so that a good set of random -segments can be selected from them. - -### Silence - -In most cases the sounds you care about will be intermittent and so it's -important to know when there's no matching audio. To support this, there's a -special `_silence_` label that indicates when the model detects nothing -interesting. Because there's never complete silence in real environments, we -actually have to supply examples with quiet and irrelevant audio. For this, we -reuse the `_background_noise_` folder that's also mixed in to real clips, -pulling short sections of the audio data and feeding those in with the ground -truth class of `_silence_`. By default 10% of the training data is supplied like -this, but the `--silence_percentage` can be used to control the proportion. As -with unknown words, setting this higher can weight the model results in favor of -true positives for silence, at the expense of false negatives for words, but too -large a proportion can cause it to fall into the trap of always guessing -silence. - -### Time Shifting - -Adding in background noise is one way of distorting the training data in a -realistic way to effectively increase the size of the dataset, and so increase -overall accuracy, and time shifting is another. This involves a random offset in -time of the training sample data, so that a small part of the start or end is -cut off and the opposite section is padded with zeroes. This mimics the natural -variations in starting time in the training data, and is controlled with the -`--time_shift_ms` flag, which defaults to 100ms. Increasing this value will -provide more variation, but at the risk of cutting off important parts of the -audio. A related way of augmenting the data with realistic distortions is by -using [time stretching and pitch -scaling](https://en.wikipedia.org/wiki/Audio_time_stretching_and_pitch_scaling), -but that's outside the scope of this tutorial. - -## Customizing the Model - -The default model used for this script is pretty large, taking over 800 million -FLOPs for each inference and using 940,000 weight parameters. This runs at -usable speeds on desktop machines or modern phones, but it involves too many -calculations to run at interactive speeds on devices with more limited -resources. To support these use cases, there's a couple of alternatives -available: - - -**low_latency_conv** -Based on the 'cnn-one-fstride4' topology described in the [Convolutional -Neural Networks for Small-footprint Keyword Spotting -paper](http://www.isca-speech.org/archive/interspeech_2015/papers/i15_1478.pdf). -The accuracy is slightly lower than 'conv' but the number of weight parameters -is about the same, and it only needs 11 million FLOPs to run one prediction, -making it much faster. - -To use this model, you specify `--model_architecture=low_latency_conv` on -the command line. You'll also need to update the training rates and the number -of steps, so the full command will look like: - -``` -python tensorflow/examples/speech_commands/train \ ---model_architecture=low_latency_conv \ ---how_many_training_steps=20000,6000 \ ---learning_rate=0.01,0.001 -``` - -This asks the script to train with a learning rate of 0.01 for 20,000 steps, and -then do a fine-tuning pass of 6,000 steps with a 10x smaller rate. - -**low_latency_svdf** -Based on the topology presented in the [Compressing Deep Neural Networks using a -Rank-Constrained Topology paper](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/43813.pdf). -The accuracy is also lower than 'conv' but it only uses about 750 thousand -parameters, and most significantly, it allows for an optimized execution at -test time (i.e. when you will actually use it in your application), resulting -in 750 thousand FLOPs. - -To use this model, you specify `--model_architecture=low_latency_svdf` on -the command line, and update the training rates and the number -of steps, so the full command will look like: - -``` -python tensorflow/examples/speech_commands/train \ ---model_architecture=low_latency_svdf \ ---how_many_training_steps=100000,35000 \ ---learning_rate=0.01,0.005 -``` - -Note that despite requiring a larger number of steps than the previous two -topologies, the reduced number of computations means that training should take -about the same time, and at the end reach an accuracy of around 85%. -You can also further tune the topology fairly easily for computation and -accuracy by changing these parameters in the SVDF layer: - -* rank - The rank of the approximation (higher typically better, but results in - more computation). -* num_units - Similar to other layer types, specifies the number of nodes in - the layer (more nodes better quality, and more computation). - -Regarding runtime, since the layer allows optimizations by caching some of the -internal neural network activations, you need to make sure to use a consistent -stride (e.g. 'clip_stride_ms' flag) both when you freeze the graph, and when -executing the model in streaming mode (e.g. test_streaming_accuracy.cc). - -**Other parameters to customize** -If you want to experiment with customizing models, a good place to start is by -tweaking the spectrogram creation parameters. This has the effect of altering -the size of the input image to the model, and the creation code in -[models.py](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/speech_commands/models.py) -will adjust the number of computations and weights automatically to fit with -different dimensions. If you make the input smaller, the model will need fewer -computations to process it, so it can be a great way to trade off some accuracy -for improved latency. The `--window_stride_ms` controls how far apart each -frequency analysis sample is from the previous. If you increase this value, then -fewer samples will be taken for a given duration, and the time axis of the input -will shrink. The `--dct_coefficient_count` flag controls how many buckets are -used for the frequency counting, so reducing this will shrink the input in the -other dimension. The `--window_size_ms` argument doesn't affect the size, but -does control how wide the area used to calculate the frequencies is for each -sample. Reducing the duration of the training samples, controlled by -`--clip_duration_ms`, can also help if the sounds you're looking for are short, -since that also reduces the time dimension of the input. You'll need to make -sure that all your training data contains the right audio in the initial portion -of the clip though. - -If you have an entirely different model in mind for your problem, you may find -that you can plug it into -[models.py](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/speech_commands/models.py) -and have the rest of the script handle all of the preprocessing and training -mechanics. You would add a new clause to `create_model`, looking for the name of -your architecture and then calling a model creation function. This function is -given the size of the spectrogram input, along with other model information, and -is expected to create TensorFlow ops to read that in and produce an output -prediction vector, and a placeholder to control the dropout rate. The rest of -the script will handle integrating this model into a larger graph doing the -input calculations and applying softmax and a loss function to train it. - -One common problem when you're adjusting models and training hyper-parameters is -that not-a-number values can creep in, thanks to numerical precision issues. In -general you can solve these by reducing the magnitude of things like learning -rates and weight initialization functions, but if they're persistent you can -enable the `--check_nans` flag to track down the source of the errors. This will -insert check ops between most regular operations in TensorFlow, and abort the -training process with a useful error message when they're encountered. diff --git a/tensorflow/docs_src/tutorials/sequences/recurrent.md b/tensorflow/docs_src/tutorials/sequences/recurrent.md deleted file mode 100644 index 39ad441381..0000000000 --- a/tensorflow/docs_src/tutorials/sequences/recurrent.md +++ /dev/null @@ -1,230 +0,0 @@ -# Recurrent Neural Networks - -## Introduction - -See [Understanding LSTM Networks](https://colah.github.io/posts/2015-08-Understanding-LSTMs/){:.external} -for an introduction to recurrent neural networks and LSTMs. - -## Language Modeling - -In this tutorial we will show how to train a recurrent neural network on -a challenging task of language modeling. The goal of the problem is to fit a -probabilistic model which assigns probabilities to sentences. It does so by -predicting next words in a text given a history of previous words. For this -purpose we will use the [Penn Tree Bank](https://catalog.ldc.upenn.edu/ldc99t42) -(PTB) dataset, which is a popular benchmark for measuring the quality of these -models, whilst being small and relatively fast to train. - -Language modeling is key to many interesting problems such as speech -recognition, machine translation, or image captioning. It is also fun -- -take a look [here](https://karpathy.github.io/2015/05/21/rnn-effectiveness/). - -For the purpose of this tutorial, we will reproduce the results from -[Zaremba et al., 2014](https://arxiv.org/abs/1409.2329) -([pdf](https://arxiv.org/pdf/1409.2329.pdf)), which achieves very good quality -on the PTB dataset. - -## Tutorial Files - -This tutorial references the following files from `models/tutorials/rnn/ptb` in the [TensorFlow models repo](https://github.com/tensorflow/models): - -File | Purpose ---- | --- -`ptb_word_lm.py` | The code to train a language model on the PTB dataset. -`reader.py` | The code to read the dataset. - -## Download and Prepare the Data - -The data required for this tutorial is in the `data/` directory of the -[PTB dataset from Tomas Mikolov's webpage](http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz). - -The dataset is already preprocessed and contains overall 10000 different words, -including the end-of-sentence marker and a special symbol (\<unk\>) for rare -words. In `reader.py`, we convert each word to a unique integer identifier, -in order to make it easy for the neural network to process the data. - -## The Model - -### LSTM - -The core of the model consists of an LSTM cell that processes one word at a -time and computes probabilities of the possible values for the next word in the -sentence. The memory state of the network is initialized with a vector of zeros -and gets updated after reading each word. For computational reasons, we will -process data in mini-batches of size `batch_size`. In this example, it is -important to note that `current_batch_of_words` does not correspond to a -"sentence" of words. Every word in a batch should correspond to a time t. -TensorFlow will automatically sum the gradients of each batch for you. - -For example: - -``` - t=0 t=1 t=2 t=3 t=4 -[The, brown, fox, is, quick] -[The, red, fox, jumped, high] - -words_in_dataset[0] = [The, The] -words_in_dataset[1] = [brown, red] -words_in_dataset[2] = [fox, fox] -words_in_dataset[3] = [is, jumped] -words_in_dataset[4] = [quick, high] -batch_size = 2, time_steps = 5 -``` - -The basic pseudocode is as follows: - -```python -words_in_dataset = tf.placeholder(tf.float32, [time_steps, batch_size, num_features]) -lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size) -# Initial state of the LSTM memory. -state = lstm.zero_state(batch_size, dtype=tf.float32) -probabilities = [] -loss = 0.0 -for current_batch_of_words in words_in_dataset: - # The value of state is updated after processing each batch of words. - output, state = lstm(current_batch_of_words, state) - - # The LSTM output can be used to make next word predictions - logits = tf.matmul(output, softmax_w) + softmax_b - probabilities.append(tf.nn.softmax(logits)) - loss += loss_function(probabilities, target_words) -``` - -### Truncated Backpropagation - -By design, the output of a recurrent neural network (RNN) depends on arbitrarily -distant inputs. Unfortunately, this makes backpropagation computation difficult. -In order to make the learning process tractable, it is common practice to create -an "unrolled" version of the network, which contains a fixed number -(`num_steps`) of LSTM inputs and outputs. The model is then trained on this -finite approximation of the RNN. This can be implemented by feeding inputs of -length `num_steps` at a time and performing a backward pass after each -such input block. - -Here is a simplified block of code for creating a graph which performs -truncated backpropagation: - -```python -# Placeholder for the inputs in a given iteration. -words = tf.placeholder(tf.int32, [batch_size, num_steps]) - -lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size) -# Initial state of the LSTM memory. -initial_state = state = lstm.zero_state(batch_size, dtype=tf.float32) - -for i in range(num_steps): - # The value of state is updated after processing each batch of words. - output, state = lstm(words[:, i], state) - - # The rest of the code. - # ... - -final_state = state -``` - -And this is how to implement an iteration over the whole dataset: - -```python -# A numpy array holding the state of LSTM after each batch of words. -numpy_state = initial_state.eval() -total_loss = 0.0 -for current_batch_of_words in words_in_dataset: - numpy_state, current_loss = session.run([final_state, loss], - # Initialize the LSTM state from the previous iteration. - feed_dict={initial_state: numpy_state, words: current_batch_of_words}) - total_loss += current_loss -``` - -### Inputs - -The word IDs will be embedded into a dense representation (see the -[Vector Representations Tutorial](../../tutorials/representation/word2vec.md)) before feeding to -the LSTM. This allows the model to efficiently represent the knowledge about -particular words. It is also easy to write: - -```python -# embedding_matrix is a tensor of shape [vocabulary_size, embedding size] -word_embeddings = tf.nn.embedding_lookup(embedding_matrix, word_ids) -``` - -The embedding matrix will be initialized randomly and the model will learn to -differentiate the meaning of words just by looking at the data. - -### Loss Function - -We want to minimize the average negative log probability of the target words: - -$$ \text{loss} = -\frac{1}{N}\sum_{i=1}^{N} \ln p_{\text{target}_i} $$ - -It is not very difficult to implement but the function -`sequence_loss_by_example` is already available, so we can just use it here. - -The typical measure reported in the papers is average per-word perplexity (often -just called perplexity), which is equal to - -$$e^{-\frac{1}{N}\sum_{i=1}^{N} \ln p_{\text{target}_i}} = e^{\text{loss}} $$ - -and we will monitor its value throughout the training process. - -### Stacking multiple LSTMs - -To give the model more expressive power, we can add multiple layers of LSTMs -to process the data. The output of the first layer will become the input of -the second and so on. - -We have a class called `MultiRNNCell` that makes the implementation seamless: - -```python -def lstm_cell(): - return tf.contrib.rnn.BasicLSTMCell(lstm_size) -stacked_lstm = tf.contrib.rnn.MultiRNNCell( - [lstm_cell() for _ in range(number_of_layers)]) - -initial_state = state = stacked_lstm.zero_state(batch_size, tf.float32) -for i in range(num_steps): - # The value of state is updated after processing each batch of words. - output, state = stacked_lstm(words[:, i], state) - - # The rest of the code. - # ... - -final_state = state -``` - -## Run the Code - -Before running the code, download the PTB dataset, as discussed at the beginning -of this tutorial. Then, extract the PTB dataset underneath your home directory -as follows: - -```bsh -tar xvfz simple-examples.tgz -C $HOME -``` -_(Note: On Windows, you may need to use -[other tools](https://wiki.haskell.org/How_to_unpack_a_tar_file_in_Windows).)_ - -Now, clone the [TensorFlow models repo](https://github.com/tensorflow/models) -from GitHub. Run the following commands: - -```bsh -cd models/tutorials/rnn/ptb -python ptb_word_lm.py --data_path=$HOME/simple-examples/data/ --model=small -``` - -There are 3 supported model configurations in the tutorial code: "small", -"medium" and "large". The difference between them is in size of the LSTMs and -the set of hyperparameters used for training. - -The larger the model, the better results it should get. The `small` model should -be able to reach perplexity below 120 on the test set and the `large` one below -80, though it might take several hours to train. - -## What Next? - -There are several tricks that we haven't mentioned that make the model better, -including: - -* decreasing learning rate schedule, -* dropout between the LSTM layers. - -Study the code and modify it to improve the model even further. diff --git a/tensorflow/docs_src/tutorials/sequences/recurrent_quickdraw.md b/tensorflow/docs_src/tutorials/sequences/recurrent_quickdraw.md deleted file mode 100644 index 2c537c60a1..0000000000 --- a/tensorflow/docs_src/tutorials/sequences/recurrent_quickdraw.md +++ /dev/null @@ -1,411 +0,0 @@ -# Recurrent Neural Networks for Drawing Classification - -[Quick, Draw!]: http://quickdraw.withgoogle.com - -[Quick, Draw!] is a game where a player is challenged to draw a number of -objects and see if a computer can recognize the drawing. - -The recognition in [Quick, Draw!] is performed by a classifier that takes the -user input, given as a sequence of strokes of points in x and y, and recognizes -the object category that the user tried to draw. - -In this tutorial we'll show how to build an RNN-based recognizer for this -problem. The model will use a combination of convolutional layers, LSTM layers, -and a softmax output layer to classify the drawings: - -<center>  </center> - -The figure above shows the structure of the model that we will build in this -tutorial. The input is a drawing that is encoded as a sequence of strokes of -points in x, y, and n, where n indicates whether a the point is the first point -in a new stroke. - -Then, a series of 1-dimensional convolutions is applied. Then LSTM layers are -applied and the sum of the outputs of all LSTM steps is fed into a softmax layer -to make a classification decision among the classes of drawings that we know. - -This tutorial uses the data from actual [Quick, Draw!] games [that is publicly -available](https://quickdraw.withgoogle.com/data). This dataset contains of 50M -drawings in 345 categories. - -## Run the tutorial code - -To try the code for this tutorial: - -1. [Install TensorFlow](../../install/index.md) if you haven't already. -1. Download the [tutorial code] -(https://github.com/tensorflow/models/tree/master/tutorials/rnn/quickdraw/train_model.py). -1. [Download the data](#download-the-data) in `TFRecord` format from - [here](http://download.tensorflow.org/data/quickdraw_tutorial_dataset_v1.tar.gz) and unzip it. More details about [how to - obtain the original Quick, Draw! - data](#optional_download_the_full_quick_draw_data) and [how to convert that - to `TFRecord` files](#optional_converting_the_data) is available below. - -1. Execute the tutorial code with the following command to train the RNN-based - model described in this tutorial. Make sure to adjust the paths to point to - the unzipped data from the download in step 3. - -```shell - python train_model.py \ - --training_data=rnn_tutorial_data/training.tfrecord-?????-of-????? \ - --eval_data=rnn_tutorial_data/eval.tfrecord-?????-of-????? \ - --classes_file=rnn_tutorial_data/training.tfrecord.classes -``` - -## Tutorial details - -### Download the data - -We make the data that we use in this tutorial available as `TFRecord` files -containing `TFExamples`. You can download the data from here: - -http://download.tensorflow.org/data/quickdraw_tutorial_dataset_v1.tar.gz - -Alternatively you can download the original data in `ndjson` format from the -Google cloud and convert it to the `TFRecord` files containing `TFExamples` -yourself as described in the next section. - -### Optional: Download the full Quick Draw Data - -The full [Quick, Draw!](https://quickdraw.withgoogle.com) -[dataset](https://quickdraw.withgoogle.com/data) is available on Google Cloud -Storage as [ndjson](http://ndjson.org/) files separated by category. You can -[browse the list of files in Cloud -Console](https://console.cloud.google.com/storage/quickdraw_dataset). - -To download the data we recommend using -[gsutil](https://cloud.google.com/storage/docs/gsutil_install#install) to -download the entire dataset. Note that the original .ndjson files require -downloading ~22GB. - -Then use the following command to check that your gsutil installation works and -that you can access the data bucket: - -```shell -gsutil ls -r "gs://quickdraw_dataset/full/simplified/*" -``` - -which will output a long list of files like the following: - -```shell -gs://quickdraw_dataset/full/simplified/The Eiffel Tower.ndjson -gs://quickdraw_dataset/full/simplified/The Great Wall of China.ndjson -gs://quickdraw_dataset/full/simplified/The Mona Lisa.ndjson -gs://quickdraw_dataset/full/simplified/aircraft carrier.ndjson -... -``` - -Then create a folder and download the dataset there. - -```shell -mkdir rnn_tutorial_data -cd rnn_tutorial_data -gsutil -m cp "gs://quickdraw_dataset/full/simplified/*" . -``` - -This download will take a while and download a bit more than 23GB of data. - -### Optional: Converting the data - -To convert the `ndjson` files to -[TFRecord](../../api_guides/python/python_io.md#TFRecords_Format_Details) files containing -[`tf.train.Example`](https://www.tensorflow.org/code/tensorflow/core/example/example.proto) -protos run the following command. - -```shell - python create_dataset.py --ndjson_path rnn_tutorial_data \ - --output_path rnn_tutorial_data -``` - -This will store the data in 10 shards of -[TFRecord](../../api_guides/python/python_io.md#TFRecords_Format_Details) files with 10000 items -per class for the training data and 1000 items per class as eval data. - -This conversion process is described in more detail in the following. - -The original QuickDraw data is formatted as `ndjson` files where each line -contains a JSON object like the following: - -```json -{"word":"cat", - "countrycode":"VE", - "timestamp":"2017-03-02 23:25:10.07453 UTC", - "recognized":true, - "key_id":"5201136883597312", - "drawing":[ - [ - [130,113,99,109,76,64,55,48,48,51,59,86,133,154,170,203,214,217,215,208,186,176,162,157,132], - [72,40,27,79,82,88,100,120,134,152,165,184,189,186,179,152,131,114,100,89,76,0,31,65,70] - ],[ - [76,28,7], - [136,128,128] - ],[ - [76,23,0], - [160,164,175] - ],[ - [87,52,37], - [175,191,204] - ],[ - [174,220,246,251], - [134,132,136,139] - ],[ - [175,255], - [147,168] - ],[ - [171,208,215], - [164,198,210] - ],[ - [130,110,108,111,130,139,139,119], - [129,134,137,144,148,144,136,130] - ],[ - [107,106], - [96,113] - ] - ] -} -``` - -For our purpose of building a classifier we only care about the fields "`word`" -and "`drawing`". While parsing the ndjson files, we process them line by line -using a function that converts the strokes from the `drawing` field into a -tensor of size `[number of points, 3]` containing the differences of consecutive -points. This function also returns the class name as a string. - -```python -def parse_line(ndjson_line): - """Parse an ndjson line and return ink (as np array) and classname.""" - sample = json.loads(ndjson_line) - class_name = sample["word"] - inkarray = sample["drawing"] - stroke_lengths = [len(stroke[0]) for stroke in inkarray] - total_points = sum(stroke_lengths) - np_ink = np.zeros((total_points, 3), dtype=np.float32) - current_t = 0 - for stroke in inkarray: - for i in [0, 1]: - np_ink[current_t:(current_t + len(stroke[0])), i] = stroke[i] - current_t += len(stroke[0]) - np_ink[current_t - 1, 2] = 1 # stroke_end - # Preprocessing. - # 1. Size normalization. - lower = np.min(np_ink[:, 0:2], axis=0) - upper = np.max(np_ink[:, 0:2], axis=0) - scale = upper - lower - scale[scale == 0] = 1 - np_ink[:, 0:2] = (np_ink[:, 0:2] - lower) / scale - # 2. Compute deltas. - np_ink = np_ink[1:, 0:2] - np_ink[0:-1, 0:2] - return np_ink, class_name -``` - -Since we want the data to be shuffled for writing we read from each of the -category files in random order and write to a random shard. - -For the training data we read the first 10000 items for each class and for the -eval data we read the next 1000 items for each class. - -This data is then reformatted into a tensor of shape `[num_training_samples, -max_length, 3]`. Then we determine the bounding box of the original drawing in -screen coordinates and normalize the size such that the drawing has unit height. - -<center>  </center> - -Finally, we compute the differences between consecutive points and store these -as a `VarLenFeature` in a -[tensorflow.Example](https://www.tensorflow.org/code/tensorflow/core/example/example.proto) -under the key `ink`. In addition we store the `class_index` as a single entry -`FixedLengthFeature` and the `shape` of the `ink` as a `FixedLengthFeature` of -length 2. - -### Defining the model - -To define the model we create a new `Estimator`. If you want to read more about -estimators, we recommend [this tutorial](../../guide/custom_estimators.md). - -To build the model, we: - -1. reshape the input back into the original shape - where the mini batch is - padded to the maximal length of its contents. In addition to the ink data we - also have the lengths for each example and the target class. This happens in - the function [`_get_input_tensors`](#-get-input-tensors). - -1. pass the input through to a series of convolution layers in - [`_add_conv_layers`](#-add-conv-layers). - -1. pass the output of the convolutions into a series of bidirectional LSTM - layers in [`_add_rnn_layers`](#-add-rnn-layers). At the end of that, the - outputs for each time step are summed up to have a compact, fixed length - embedding of the input. - -1. classify this embedding using a softmax layer in - [`_add_fc_layers`](#-add-fc-layers). - -In code this looks like: - -```python -inks, lengths, targets = _get_input_tensors(features, targets) -convolved = _add_conv_layers(inks) -final_state = _add_rnn_layers(convolved, lengths) -logits =_add_fc_layers(final_state) -``` - -### _get_input_tensors - -To obtain the input features we first obtain the shape from the features dict -and then create a 1D tensor of size `[batch_size]` containing the lengths of the -input sequences. The ink is stored as a SparseTensor in the features dict which -we convert into a dense tensor and then reshape to be `[batch_size, ?, 3]`. And -finally, if targets were passed in we make sure they are stored as a 1D tensor -of size `[batch_size]` - -In code this looks like this: - -```python -shapes = features["shape"] -lengths = tf.squeeze( - tf.slice(shapes, begin=[0, 0], size=[params["batch_size"], 1])) -inks = tf.reshape( - tf.sparse_tensor_to_dense(features["ink"]), - [params["batch_size"], -1, 3]) -if targets is not None: - targets = tf.squeeze(targets) -``` - -### _add_conv_layers - -The desired number of convolution layers and the lengths of the filters is -configured through the parameters `num_conv` and `conv_len` in the `params` -dict. - -The input is a sequence where each point has dimensionality 3. We are going to -use 1D convolutions where we treat the 3 input features as channels. That means -that the input is a `[batch_size, length, 3]` tensor and the output will be a -`[batch_size, length, number_of_filters]` tensor. - -```python -convolved = inks -for i in range(len(params.num_conv)): - convolved_input = convolved - if params.batch_norm: - convolved_input = tf.layers.batch_normalization( - convolved_input, - training=(mode == tf.estimator.ModeKeys.TRAIN)) - # Add dropout layer if enabled and not first convolution layer. - if i > 0 and params.dropout: - convolved_input = tf.layers.dropout( - convolved_input, - rate=params.dropout, - training=(mode == tf.estimator.ModeKeys.TRAIN)) - convolved = tf.layers.conv1d( - convolved_input, - filters=params.num_conv[i], - kernel_size=params.conv_len[i], - activation=None, - strides=1, - padding="same", - name="conv1d_%d" % i) -return convolved, lengths -``` - -### _add_rnn_layers - -We pass the output from the convolutions into bidirectional LSTM layers for -which we use a helper function from contrib. - -```python -outputs, _, _ = contrib_rnn.stack_bidirectional_dynamic_rnn( - cells_fw=[cell(params.num_nodes) for _ in range(params.num_layers)], - cells_bw=[cell(params.num_nodes) for _ in range(params.num_layers)], - inputs=convolved, - sequence_length=lengths, - dtype=tf.float32, - scope="rnn_classification") -``` - -see the code for more details and how to use `CUDA` accelerated implementations. - -To create a compact, fixed-length embedding, we sum up the output of the LSTMs. -We first zero out the regions of the batch where the sequences have no data. - -```python -mask = tf.tile( - tf.expand_dims(tf.sequence_mask(lengths, tf.shape(outputs)[1]), 2), - [1, 1, tf.shape(outputs)[2]]) -zero_outside = tf.where(mask, outputs, tf.zeros_like(outputs)) -outputs = tf.reduce_sum(zero_outside, axis=1) -``` - -### _add_fc_layers - -The embedding of the input is passed into a fully connected layer which we then -use as a softmax layer. - -```python -tf.layers.dense(final_state, params.num_classes) -``` - -### Loss, predictions, and optimizer - -Finally, we need to add a loss, a training op, and predictions to create the -`ModelFn`: - -```python -cross_entropy = tf.reduce_mean( - tf.nn.sparse_softmax_cross_entropy_with_logits( - labels=targets, logits=logits)) -# Add the optimizer. -train_op = tf.contrib.layers.optimize_loss( - loss=cross_entropy, - global_step=tf.train.get_global_step(), - learning_rate=params.learning_rate, - optimizer="Adam", - # some gradient clipping stabilizes training in the beginning. - clip_gradients=params.gradient_clipping_norm, - summaries=["learning_rate", "loss", "gradients", "gradient_norm"]) -predictions = tf.argmax(logits, axis=1) -return model_fn_lib.ModelFnOps( - mode=mode, - predictions={"logits": logits, - "predictions": predictions}, - loss=cross_entropy, - train_op=train_op, - eval_metric_ops={"accuracy": tf.metrics.accuracy(targets, predictions)}) -``` - -### Training and evaluating the model - -To train and evaluate the model we can rely on the functionalities of the -`Estimator` APIs and easily run training and evaluation with the `Experiment` -APIs: - -```python - estimator = tf.estimator.Estimator( - model_fn=model_fn, - model_dir=output_dir, - config=config, - params=model_params) - # Train the model. - tf.contrib.learn.Experiment( - estimator=estimator, - train_input_fn=get_input_fn( - mode=tf.contrib.learn.ModeKeys.TRAIN, - tfrecord_pattern=FLAGS.training_data, - batch_size=FLAGS.batch_size), - train_steps=FLAGS.steps, - eval_input_fn=get_input_fn( - mode=tf.contrib.learn.ModeKeys.EVAL, - tfrecord_pattern=FLAGS.eval_data, - batch_size=FLAGS.batch_size), - min_eval_frequency=1000) -``` - -Note that this tutorial is just a quick example on a relatively small dataset to -get you familiar with the APIs of recurrent neural networks and estimators. Such -models can be even more powerful if you try them on a large dataset. - -When training the model for 1M steps you can expect to get an accuracy of -approximately of approximately 70% on the top-1 candidate. Note that this -accuracy is sufficient to build the quickdraw game because of the game dynamics -the user will be able to adjust their drawing until it is ready. Also, the game -does not use the top-1 candidate only but accepts a drawing as correct if the -target category shows up with a score better than a fixed threshold. diff --git a/tensorflow/examples/adding_an_op/cuda_op_test.py b/tensorflow/examples/adding_an_op/cuda_op_test.py index 07390bc3bf..a9aaa81e3f 100644 --- a/tensorflow/examples/adding_an_op/cuda_op_test.py +++ b/tensorflow/examples/adding_an_op/cuda_op_test.py @@ -26,7 +26,7 @@ class AddOneTest(tf.test.TestCase): def test(self): if tf.test.is_built_with_cuda(): - with self.test_session(): + with self.cached_session(): result = cuda_op.add_one([5, 4, 3, 2, 1]) self.assertAllEqual(result.eval(), [6, 5, 4, 3, 2]) diff --git a/tensorflow/examples/adding_an_op/fact_test.py b/tensorflow/examples/adding_an_op/fact_test.py index f7f17e5180..11163e7ba5 100644 --- a/tensorflow/examples/adding_an_op/fact_test.py +++ b/tensorflow/examples/adding_an_op/fact_test.py @@ -24,7 +24,7 @@ import tensorflow as tf class FactTest(tf.test.TestCase): def test(self): - with self.test_session(): + with self.cached_session(): print(tf.user_ops.my_fact().eval()) diff --git a/tensorflow/examples/adding_an_op/zero_out_1_test.py b/tensorflow/examples/adding_an_op/zero_out_1_test.py index fac486100d..342d3a020c 100644 --- a/tensorflow/examples/adding_an_op/zero_out_1_test.py +++ b/tensorflow/examples/adding_an_op/zero_out_1_test.py @@ -28,7 +28,7 @@ from tensorflow.examples.adding_an_op import zero_out_op_1 class ZeroOut1Test(tf.test.TestCase): def test(self): - with self.test_session(): + with self.cached_session(): result = zero_out_op_1.zero_out([5, 4, 3, 2, 1]) self.assertAllEqual(result.eval(), [5, 0, 0, 0, 0]) diff --git a/tensorflow/examples/adding_an_op/zero_out_2_test.py b/tensorflow/examples/adding_an_op/zero_out_2_test.py index 217bbbcffa..4504597817 100644 --- a/tensorflow/examples/adding_an_op/zero_out_2_test.py +++ b/tensorflow/examples/adding_an_op/zero_out_2_test.py @@ -29,17 +29,17 @@ from tensorflow.examples.adding_an_op import zero_out_op_2 class ZeroOut2Test(tf.test.TestCase): def test(self): - with self.test_session(): + with self.cached_session(): result = zero_out_op_2.zero_out([5, 4, 3, 2, 1]) self.assertAllEqual(result.eval(), [5, 0, 0, 0, 0]) def test_2d(self): - with self.test_session(): + with self.cached_session(): result = zero_out_op_2.zero_out([[6, 5, 4], [3, 2, 1]]) self.assertAllEqual(result.eval(), [[6, 0, 0], [0, 0, 0]]) def test_grad(self): - with self.test_session(): + with self.cached_session(): shape = (5,) x = tf.constant([5, 4, 3, 2, 1], dtype=tf.float32) y = zero_out_op_2.zero_out(x) @@ -47,7 +47,7 @@ class ZeroOut2Test(tf.test.TestCase): self.assertLess(err, 1e-4) def test_grad_2d(self): - with self.test_session(): + with self.cached_session(): shape = (2, 3) x = tf.constant([[6, 5, 4], [3, 2, 1]], dtype=tf.float32) y = zero_out_op_2.zero_out(x) diff --git a/tensorflow/examples/adding_an_op/zero_out_3_test.py b/tensorflow/examples/adding_an_op/zero_out_3_test.py index 01280caf49..15d62495aa 100644 --- a/tensorflow/examples/adding_an_op/zero_out_3_test.py +++ b/tensorflow/examples/adding_an_op/zero_out_3_test.py @@ -26,23 +26,23 @@ from tensorflow.examples.adding_an_op import zero_out_op_3 class ZeroOut3Test(tf.test.TestCase): def test(self): - with self.test_session(): + with self.cached_session(): result = zero_out_op_3.zero_out([5, 4, 3, 2, 1]) self.assertAllEqual(result.eval(), [5, 0, 0, 0, 0]) def testAttr(self): - with self.test_session(): + with self.cached_session(): result = zero_out_op_3.zero_out([5, 4, 3, 2, 1], preserve_index=3) self.assertAllEqual(result.eval(), [0, 0, 0, 2, 0]) def testNegative(self): - with self.test_session(): + with self.cached_session(): result = zero_out_op_3.zero_out([5, 4, 3, 2, 1], preserve_index=-1) with self.assertRaisesOpError("Need preserve_index >= 0, got -1"): result.eval() def testLarge(self): - with self.test_session(): + with self.cached_session(): result = zero_out_op_3.zero_out([5, 4, 3, 2, 1], preserve_index=17) with self.assertRaisesOpError("preserve_index out of range"): result.eval() diff --git a/tensorflow/examples/android/jni/object_tracking/jni_utils.h b/tensorflow/examples/android/jni/object_tracking/jni_utils.h index b81d9e0c12..06048ecfd3 100644 --- a/tensorflow/examples/android/jni/object_tracking/jni_utils.h +++ b/tensorflow/examples/android/jni/object_tracking/jni_utils.h @@ -60,4 +60,4 @@ class JniLongField { jfieldID field_ID_; }; -#endif +#endif // TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_JNI_UTILS_H_ diff --git a/tensorflow/examples/android/jni/object_tracking/logging.h b/tensorflow/examples/android/jni/object_tracking/logging.h index 852a749399..24d05e3398 100644 --- a/tensorflow/examples/android/jni/object_tracking/logging.h +++ b/tensorflow/examples/android/jni/object_tracking/logging.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_LOG_STREAMING_H_ -#define TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_LOG_STREAMING_H_ +#ifndef TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_LOGGING_H_ +#define TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_LOGGING_H_ #include <android/log.h> #include <string.h> @@ -118,4 +118,4 @@ void LogPrintF(const int severity, const char* format, ...); #endif -#endif // TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_LOG_STREAMING_H_ +#endif // TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_LOGGING_H_ diff --git a/tensorflow/examples/android/jni/object_tracking/object_model.h b/tensorflow/examples/android/jni/object_tracking/object_model.h index 5e81c49080..4bc4d5bc9e 100644 --- a/tensorflow/examples/android/jni/object_tracking/object_model.h +++ b/tensorflow/examples/android/jni/object_tracking/object_model.h @@ -19,8 +19,8 @@ limitations under the License. // Contains ObjectModelBase declaration. -#ifndef TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_DETECTION_OBJECT_MODEL_H_ -#define TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_DETECTION_OBJECT_MODEL_H_ +#ifndef TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_OBJECT_MODEL_H_ +#define TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_OBJECT_MODEL_H_ #ifdef __RENDER_OPENGL__ #include <GLES/gl.h> @@ -99,4 +99,4 @@ class ObjectModel : public ObjectModelBase { } // namespace tf_tracking -#endif // TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_DETECTION_OBJECT_MODEL_H_ +#endif // TENSORFLOW_EXAMPLES_ANDROID_JNI_OBJECT_TRACKING_OBJECT_MODEL_H_ diff --git a/tensorflow/examples/android/jni/rgb2yuv.h b/tensorflow/examples/android/jni/rgb2yuv.h index 13ac4148f3..ff720fda7d 100755 --- a/tensorflow/examples/android/jni/rgb2yuv.h +++ b/tensorflow/examples/android/jni/rgb2yuv.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef ORG_TENSORFLOW_JNI_IMAGEUTILS_RGB2YUV_H_ -#define ORG_TENSORFLOW_JNI_IMAGEUTILS_RGB2YUV_H_ +#ifndef TENSORFLOW_EXAMPLES_ANDROID_JNI_RGB2YUV_H_ +#define TENSORFLOW_EXAMPLES_ANDROID_JNI_RGB2YUV_H_ #include <stdint.h> @@ -32,4 +32,4 @@ void ConvertRGB565ToYUV420SP(const uint16_t* const input, uint8_t* const output, } #endif -#endif // ORG_TENSORFLOW_JNI_IMAGEUTILS_RGB2YUV_H_ +#endif // TENSORFLOW_EXAMPLES_ANDROID_JNI_RGB2YUV_H_ diff --git a/tensorflow/examples/android/jni/yuv2rgb.h b/tensorflow/examples/android/jni/yuv2rgb.h index 7d2b8ab7f4..fab462f0e1 100644 --- a/tensorflow/examples/android/jni/yuv2rgb.h +++ b/tensorflow/examples/android/jni/yuv2rgb.h @@ -16,8 +16,8 @@ limitations under the License. // This is a collection of routines which converts various YUV image formats // to (A)RGB. -#ifndef ORG_TENSORFLOW_JNI_IMAGEUTILS_YUV2RGB_H_ -#define ORG_TENSORFLOW_JNI_IMAGEUTILS_YUV2RGB_H_ +#ifndef TENSORFLOW_EXAMPLES_ANDROID_JNI_YUV2RGB_H_ +#define TENSORFLOW_EXAMPLES_ANDROID_JNI_YUV2RGB_H_ #include <stdint.h> @@ -54,4 +54,4 @@ void ConvertYUV420SPToRGB565(const uint8_t* const input, uint16_t* const output, } #endif -#endif // ORG_TENSORFLOW_JNI_IMAGEUTILS_YUV2RGB_H_ +#endif // TENSORFLOW_EXAMPLES_ANDROID_JNI_YUV2RGB_H_ diff --git a/tensorflow/examples/ios/benchmark/ios_image_load.h b/tensorflow/examples/ios/benchmark/ios_image_load.h index 78eaded8d7..3f94984692 100644 --- a/tensorflow/examples/ios/benchmark/ios_image_load.h +++ b/tensorflow/examples/ios/benchmark/ios_image_load.h @@ -12,8 +12,8 @@ // See the License for the specific language governing permissions and // limitations under the License. -#ifndef TENSORFLOW_EXAMPLES_IOS_IOS_IMAGE_LOAD_H_ -#define TENSORFLOW_EXAMPLES_IOS_IOS_IMAGE_LOAD_H_ +#ifndef TENSORFLOW_EXAMPLES_IOS_BENCHMARK_IOS_IMAGE_LOAD_H_ +#define TENSORFLOW_EXAMPLES_IOS_BENCHMARK_IOS_IMAGE_LOAD_H_ #include <vector> @@ -24,4 +24,4 @@ std::vector<tensorflow::uint8> LoadImageFromFile(const char* file_name, int* out_height, int* out_channels); -#endif // TENSORFLOW_EXAMPLES_IOS_IOS_IMAGE_LOAD_H_ +#endif // TENSORFLOW_EXAMPLES_IOS_BENCHMARK_IOS_IMAGE_LOAD_H_ diff --git a/tensorflow/examples/ios/camera/ios_image_load.h b/tensorflow/examples/ios/camera/ios_image_load.h index 87a847e145..f10b0b983a 100644 --- a/tensorflow/examples/ios/camera/ios_image_load.h +++ b/tensorflow/examples/ios/camera/ios_image_load.h @@ -12,8 +12,8 @@ // See the License for the specific language governing permissions and // limitations under the License. -#ifndef TENSORFLOW_CONTRIB_IOS_EXAMPLES_CAMERA_IMAGE_LOAD_H_ -#define TENSORFLOW_CONTRIB_IOS_EXAMPLES_CAMERA_IMAGE_LOAD_H_ +#ifndef TENSORFLOW_EXAMPLES_IOS_CAMERA_IOS_IMAGE_LOAD_H_ +#define TENSORFLOW_EXAMPLES_IOS_CAMERA_IOS_IMAGE_LOAD_H_ #include <vector> @@ -24,4 +24,4 @@ std::vector<tensorflow::uint8> LoadImageFromFile(const char* file_name, int* out_height, int* out_channels); -#endif // TENSORFLOW_CONTRIB_IOS_EXAMPLES_CAMERA_IMAGE_LOAD_H_ +#endif // TENSORFLOW_EXAMPLES_IOS_CAMERA_IOS_IMAGE_LOAD_H_ diff --git a/tensorflow/examples/label_image/main.cc b/tensorflow/examples/label_image/main.cc index baa65d3243..ee2927d0a5 100644 --- a/tensorflow/examples/label_image/main.cc +++ b/tensorflow/examples/label_image/main.cc @@ -106,7 +106,7 @@ static Status ReadEntireFile(tensorflow::Env* env, const string& filename, "' expected ", file_size, " got ", data.size()); } - output->scalar<string>()() = data.ToString(); + output->scalar<string>()() = string(data); return Status::OK(); } diff --git a/tensorflow/go/op/wrappers.go b/tensorflow/go/op/wrappers.go index 3775af4c77..0aba0393af 100644 --- a/tensorflow/go/op/wrappers.go +++ b/tensorflow/go/op/wrappers.go @@ -3355,6 +3355,28 @@ func BitwiseXor(scope *Scope, x tf.Output, y tf.Output) (z tf.Output) { return op.Output(0) } +// Computes element-wise population count (a.k.a. popcount, bitsum, bitcount). +// +// For each entry in `x`, calculates the number of `1` (on) bits in the binary +// representation of that entry. +// +// **NOTE**: It is more efficient to first `tf.bitcast` your tensors into +// `int32` or `int64` and perform the bitcount on the result, than to feed in +// 8- or 16-bit inputs and then aggregate the resulting counts. +func PopulationCount(scope *Scope, x tf.Output) (y tf.Output) { + if scope.Err() != nil { + return + } + opspec := tf.OpSpec{ + Type: "PopulationCount", + Input: []tf.Input{ + x, + }, + } + op := scope.AddOperation(opspec) + return op.Output(0) +} + // Computes the mean along sparse segments of a tensor. // // Read @{$math_ops#Segmentation$the section on segmentation} for an explanation of @@ -4037,78 +4059,6 @@ func SlideDataset(scope *Scope, input_dataset tf.Output, window_size tf.Output, return op.Output(0) } -// FusedBatchNormAttr is an optional argument to FusedBatchNorm. -type FusedBatchNormAttr func(optionalAttr) - -// FusedBatchNormEpsilon sets the optional epsilon attribute to value. -// -// value: A small float number added to the variance of x. -// If not specified, defaults to 0.0001 -func FusedBatchNormEpsilon(value float32) FusedBatchNormAttr { - return func(m optionalAttr) { - m["epsilon"] = value - } -} - -// FusedBatchNormDataFormat sets the optional data_format attribute to value. -// -// value: The data format for x and y. Either "NHWC" (default) or "NCHW". -// If not specified, defaults to "NHWC" -func FusedBatchNormDataFormat(value string) FusedBatchNormAttr { - return func(m optionalAttr) { - m["data_format"] = value - } -} - -// FusedBatchNormIsTraining sets the optional is_training attribute to value. -// -// value: A bool value to indicate the operation is for training (default) -// or inference. -// If not specified, defaults to true -func FusedBatchNormIsTraining(value bool) FusedBatchNormAttr { - return func(m optionalAttr) { - m["is_training"] = value - } -} - -// Batch normalization. -// -// Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". -// The size of 1D Tensors matches the dimension C of the 4D Tensors. -// -// Arguments: -// x: A 4D Tensor for input data. -// scale: A 1D Tensor for scaling factor, to scale the normalized x. -// offset: A 1D Tensor for offset, to shift to the normalized x. -// mean: A 1D Tensor for population mean. Used for inference only; -// must be empty for training. -// variance: A 1D Tensor for population variance. Used for inference only; -// must be empty for training. -// -// Returns A 4D Tensor for output data.A 1D Tensor for the computed batch mean, to be used by TensorFlow -// to compute the running mean.A 1D Tensor for the computed batch variance, to be used by -// TensorFlow to compute the running variance.A 1D Tensor for the computed batch mean, to be reused -// in the gradient computation.A 1D Tensor for the computed batch variance (inverted variance -// in the cuDNN case), to be reused in the gradient computation. -func FusedBatchNorm(scope *Scope, x tf.Output, scale tf.Output, offset tf.Output, mean tf.Output, variance tf.Output, optional ...FusedBatchNormAttr) (y tf.Output, batch_mean tf.Output, batch_variance tf.Output, reserve_space_1 tf.Output, reserve_space_2 tf.Output) { - if scope.Err() != nil { - return - } - attrs := map[string]interface{}{} - for _, a := range optional { - a(attrs) - } - opspec := tf.OpSpec{ - Type: "FusedBatchNorm", - Input: []tf.Input{ - x, scale, offset, mean, variance, - }, - Attrs: attrs, - } - op := scope.AddOperation(opspec) - return op.Output(0), op.Output(1), op.Output(2), op.Output(3), op.Output(4) -} - // ApproximateEqualAttr is an optional argument to ApproximateEqual. type ApproximateEqualAttr func(optionalAttr) @@ -8661,28 +8611,6 @@ func Assert(scope *Scope, condition tf.Output, data []tf.Output, optional ...Ass return scope.AddOperation(opspec) } -// Computes element-wise population count (a.k.a. popcount, bitsum, bitcount). -// -// For each entry in `x`, calculates the number of `1` (on) bits in the binary -// representation of that entry. -// -// **NOTE**: It is more efficient to first `tf.bitcast` your tensors into -// `int32` or `int64` and perform the bitcount on the result, than to feed in -// 8- or 16-bit inputs and then aggregate the resulting counts. -func PopulationCount(scope *Scope, x tf.Output) (y tf.Output) { - if scope.Err() != nil { - return - } - opspec := tf.OpSpec{ - Type: "PopulationCount", - Input: []tf.Input{ - x, - }, - } - op := scope.AddOperation(opspec) - return op.Output(0) -} - // Broadcasts a tensor value to one or more other devices. func CollectiveBcastSend(scope *Scope, input tf.Output, group_size int64, group_key int64, instance_key int64, shape tf.Shape) (data tf.Output) { if scope.Err() != nil { @@ -11427,6 +11355,85 @@ func FakeQuantWithMinMaxVars(scope *Scope, inputs tf.Output, min tf.Output, max return op.Output(0) } +// ResourceScatterNdUpdateAttr is an optional argument to ResourceScatterNdUpdate. +type ResourceScatterNdUpdateAttr func(optionalAttr) + +// ResourceScatterNdUpdateUseLocking sets the optional use_locking attribute to value. +// +// value: An optional bool. Defaults to True. If True, the assignment will +// be protected by a lock; otherwise the behavior is undefined, +// but may exhibit less contention. +// If not specified, defaults to true +func ResourceScatterNdUpdateUseLocking(value bool) ResourceScatterNdUpdateAttr { + return func(m optionalAttr) { + m["use_locking"] = value + } +} + +// Applies sparse `updates` to individual values or slices within a given +// +// variable according to `indices`. +// +// `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. +// +// `indices` must be integer tensor, containing indices into `ref`. +// It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. +// +// The innermost dimension of `indices` (with length `K`) corresponds to +// indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th +// dimension of `ref`. +// +// `updates` is `Tensor` of rank `Q-1+P-K` with shape: +// +// ``` +// [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. +// ``` +// +// For example, say we want to update 4 scattered elements to a rank-1 tensor to +// 8 elements. In Python, that update would look like this: +// +// ```python +// ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) +// indices = tf.constant([[4], [3], [1] ,[7]]) +// updates = tf.constant([9, 10, 11, 12]) +// update = tf.scatter_nd_update(ref, indices, updates) +// with tf.Session() as sess: +// print sess.run(update) +// ``` +// +// The resulting update to ref would look like this: +// +// [1, 11, 3, 10, 9, 6, 7, 12] +// +// See @{tf.scatter_nd} for more details about how to make updates to +// slices. +// +// Arguments: +// ref: A resource handle. Must be from a VarHandleOp. +// indices: A Tensor. Must be one of the following types: int32, int64. +// A tensor of indices into ref. +// updates: A Tensor. Must have the same type as ref. A tensor of updated +// values to add to ref. +// +// Returns the created operation. +func ResourceScatterNdUpdate(scope *Scope, ref tf.Output, indices tf.Output, updates tf.Output, optional ...ResourceScatterNdUpdateAttr) (o *tf.Operation) { + if scope.Err() != nil { + return + } + attrs := map[string]interface{}{} + for _, a := range optional { + a(attrs) + } + opspec := tf.OpSpec{ + Type: "ResourceScatterNdUpdate", + Input: []tf.Input{ + ref, indices, updates, + }, + Attrs: attrs, + } + return scope.AddOperation(opspec) +} + // Applies softmax to a batched N-D `SparseTensor`. // // The inputs represent an N-D SparseTensor with logical shape `[..., B, C]` @@ -12371,34 +12378,6 @@ func OrderedMapPeek(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf. return values } -// Inverse fast Fourier transform. -// -// Computes the inverse 1-dimensional discrete Fourier transform over the -// inner-most dimension of `input`. -// -// Arguments: -// input: A complex64 tensor. -// -// Returns A complex64 tensor of the same shape as `input`. The inner-most -// dimension of `input` is replaced with its inverse 1D Fourier transform. -// -// @compatibility(numpy) -// Equivalent to np.fft.ifft -// @end_compatibility -func IFFT(scope *Scope, input tf.Output) (output tf.Output) { - if scope.Err() != nil { - return - } - opspec := tf.OpSpec{ - Type: "IFFT", - Input: []tf.Input{ - input, - }, - } - op := scope.AddOperation(opspec) - return op.Output(0) -} - // ResourceSparseApplyRMSPropAttr is an optional argument to ResourceSparseApplyRMSProp. type ResourceSparseApplyRMSPropAttr func(optionalAttr) @@ -12977,85 +12956,6 @@ func DeserializeSparse(scope *Scope, serialized_sparse tf.Output, dtype tf.DataT return op.Output(0), op.Output(1), op.Output(2) } -// ResourceScatterNdUpdateAttr is an optional argument to ResourceScatterNdUpdate. -type ResourceScatterNdUpdateAttr func(optionalAttr) - -// ResourceScatterNdUpdateUseLocking sets the optional use_locking attribute to value. -// -// value: An optional bool. Defaults to True. If True, the assignment will -// be protected by a lock; otherwise the behavior is undefined, -// but may exhibit less contention. -// If not specified, defaults to true -func ResourceScatterNdUpdateUseLocking(value bool) ResourceScatterNdUpdateAttr { - return func(m optionalAttr) { - m["use_locking"] = value - } -} - -// Applies sparse `updates` to individual values or slices within a given -// -// variable according to `indices`. -// -// `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. -// -// `indices` must be integer tensor, containing indices into `ref`. -// It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. -// -// The innermost dimension of `indices` (with length `K`) corresponds to -// indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th -// dimension of `ref`. -// -// `updates` is `Tensor` of rank `Q-1+P-K` with shape: -// -// ``` -// [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. -// ``` -// -// For example, say we want to update 4 scattered elements to a rank-1 tensor to -// 8 elements. In Python, that update would look like this: -// -// ```python -// ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) -// indices = tf.constant([[4], [3], [1] ,[7]]) -// updates = tf.constant([9, 10, 11, 12]) -// update = tf.scatter_nd_update(ref, indices, updates) -// with tf.Session() as sess: -// print sess.run(update) -// ``` -// -// The resulting update to ref would look like this: -// -// [1, 11, 3, 10, 9, 6, 7, 12] -// -// See @{tf.scatter_nd} for more details about how to make updates to -// slices. -// -// Arguments: -// ref: A resource handle. Must be from a VarHandleOp. -// indices: A Tensor. Must be one of the following types: int32, int64. -// A tensor of indices into ref. -// updates: A Tensor. Must have the same type as ref. A tensor of updated -// values to add to ref. -// -// Returns the created operation. -func ResourceScatterNdUpdate(scope *Scope, ref tf.Output, indices tf.Output, updates tf.Output, optional ...ResourceScatterNdUpdateAttr) (o *tf.Operation) { - if scope.Err() != nil { - return - } - attrs := map[string]interface{}{} - for _, a := range optional { - a(attrs) - } - opspec := tf.OpSpec{ - Type: "ResourceScatterNdUpdate", - Input: []tf.Input{ - ref, indices, updates, - }, - Attrs: attrs, - } - return scope.AddOperation(opspec) -} - // SqueezeAttr is an optional argument to Squeeze. type SqueezeAttr func(optionalAttr) @@ -16274,6 +16174,78 @@ func Sigmoid(scope *Scope, x tf.Output) (y tf.Output) { return op.Output(0) } +// FusedBatchNormAttr is an optional argument to FusedBatchNorm. +type FusedBatchNormAttr func(optionalAttr) + +// FusedBatchNormEpsilon sets the optional epsilon attribute to value. +// +// value: A small float number added to the variance of x. +// If not specified, defaults to 0.0001 +func FusedBatchNormEpsilon(value float32) FusedBatchNormAttr { + return func(m optionalAttr) { + m["epsilon"] = value + } +} + +// FusedBatchNormDataFormat sets the optional data_format attribute to value. +// +// value: The data format for x and y. Either "NHWC" (default) or "NCHW". +// If not specified, defaults to "NHWC" +func FusedBatchNormDataFormat(value string) FusedBatchNormAttr { + return func(m optionalAttr) { + m["data_format"] = value + } +} + +// FusedBatchNormIsTraining sets the optional is_training attribute to value. +// +// value: A bool value to indicate the operation is for training (default) +// or inference. +// If not specified, defaults to true +func FusedBatchNormIsTraining(value bool) FusedBatchNormAttr { + return func(m optionalAttr) { + m["is_training"] = value + } +} + +// Batch normalization. +// +// Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". +// The size of 1D Tensors matches the dimension C of the 4D Tensors. +// +// Arguments: +// x: A 4D Tensor for input data. +// scale: A 1D Tensor for scaling factor, to scale the normalized x. +// offset: A 1D Tensor for offset, to shift to the normalized x. +// mean: A 1D Tensor for population mean. Used for inference only; +// must be empty for training. +// variance: A 1D Tensor for population variance. Used for inference only; +// must be empty for training. +// +// Returns A 4D Tensor for output data.A 1D Tensor for the computed batch mean, to be used by TensorFlow +// to compute the running mean.A 1D Tensor for the computed batch variance, to be used by +// TensorFlow to compute the running variance.A 1D Tensor for the computed batch mean, to be reused +// in the gradient computation.A 1D Tensor for the computed batch variance (inverted variance +// in the cuDNN case), to be reused in the gradient computation. +func FusedBatchNorm(scope *Scope, x tf.Output, scale tf.Output, offset tf.Output, mean tf.Output, variance tf.Output, optional ...FusedBatchNormAttr) (y tf.Output, batch_mean tf.Output, batch_variance tf.Output, reserve_space_1 tf.Output, reserve_space_2 tf.Output) { + if scope.Err() != nil { + return + } + attrs := map[string]interface{}{} + for _, a := range optional { + a(attrs) + } + opspec := tf.OpSpec{ + Type: "FusedBatchNorm", + Input: []tf.Input{ + x, scale, offset, mean, variance, + }, + Attrs: attrs, + } + op := scope.AddOperation(opspec) + return op.Output(0), op.Output(1), op.Output(2), op.Output(3), op.Output(4) +} + // RandomStandardNormalAttr is an optional argument to RandomStandardNormal. type RandomStandardNormalAttr func(optionalAttr) @@ -17181,6 +17153,34 @@ func MutableDenseHashTableV2(scope *Scope, empty_key tf.Output, value_dtype tf.D return op.Output(0) } +// Inverse fast Fourier transform. +// +// Computes the inverse 1-dimensional discrete Fourier transform over the +// inner-most dimension of `input`. +// +// Arguments: +// input: A complex64 tensor. +// +// Returns A complex64 tensor of the same shape as `input`. The inner-most +// dimension of `input` is replaced with its inverse 1D Fourier transform. +// +// @compatibility(numpy) +// Equivalent to np.fft.ifft +// @end_compatibility +func IFFT(scope *Scope, input tf.Output) (output tf.Output) { + if scope.Err() != nil { + return + } + opspec := tf.OpSpec{ + Type: "IFFT", + Input: []tf.Input{ + input, + }, + } + op := scope.AddOperation(opspec) + return op.Output(0) +} + // 2D fast Fourier transform. // // Computes the 2-dimensional discrete Fourier transform over the inner-most @@ -17689,123 +17689,6 @@ func TextLineDataset(scope *Scope, filenames tf.Output, compression_type tf.Outp return op.Output(0) } -// CudnnRNNParamsSizeAttr is an optional argument to CudnnRNNParamsSize. -type CudnnRNNParamsSizeAttr func(optionalAttr) - -// CudnnRNNParamsSizeRnnMode sets the optional rnn_mode attribute to value. -// If not specified, defaults to "lstm" -func CudnnRNNParamsSizeRnnMode(value string) CudnnRNNParamsSizeAttr { - return func(m optionalAttr) { - m["rnn_mode"] = value - } -} - -// CudnnRNNParamsSizeInputMode sets the optional input_mode attribute to value. -// If not specified, defaults to "linear_input" -func CudnnRNNParamsSizeInputMode(value string) CudnnRNNParamsSizeAttr { - return func(m optionalAttr) { - m["input_mode"] = value - } -} - -// CudnnRNNParamsSizeDirection sets the optional direction attribute to value. -// If not specified, defaults to "unidirectional" -func CudnnRNNParamsSizeDirection(value string) CudnnRNNParamsSizeAttr { - return func(m optionalAttr) { - m["direction"] = value - } -} - -// CudnnRNNParamsSizeDropout sets the optional dropout attribute to value. -// If not specified, defaults to 0 -func CudnnRNNParamsSizeDropout(value float32) CudnnRNNParamsSizeAttr { - return func(m optionalAttr) { - m["dropout"] = value - } -} - -// CudnnRNNParamsSizeSeed sets the optional seed attribute to value. -// If not specified, defaults to 0 -func CudnnRNNParamsSizeSeed(value int64) CudnnRNNParamsSizeAttr { - return func(m optionalAttr) { - m["seed"] = value - } -} - -// CudnnRNNParamsSizeSeed2 sets the optional seed2 attribute to value. -// If not specified, defaults to 0 -func CudnnRNNParamsSizeSeed2(value int64) CudnnRNNParamsSizeAttr { - return func(m optionalAttr) { - m["seed2"] = value - } -} - -// Computes size of weights that can be used by a Cudnn RNN model. -// -// Return the params size that can be used by the Cudnn RNN model. Subsequent -// weight allocation and initialization should use this size. -// -// num_layers: Specifies the number of layers in the RNN model. -// num_units: Specifies the size of the hidden state. -// input_size: Specifies the size of the input state. -// rnn_mode: Indicates the type of the RNN model. -// input_mode: Indicate whether there is a linear projection between the input and -// The actual computation before the first layer. 'skip_input' is only allowed -// when input_size == num_units; 'auto_select' implies 'skip_input' when -// input_size == num_units; otherwise, it implies 'linear_input'. -// direction: Indicates whether a bidirectional model will be used. -// dir = (direction == bidirectional) ? 2 : 1 -// dropout: dropout probability. When set to 0., dropout is disabled. -// seed: the 1st part of a seed to initialize dropout. -// seed2: the 2nd part of a seed to initialize dropout. -// params_size: The size of the params buffer that should be allocated and -// initialized for this RNN model. Note that this params buffer may not be -// compatible across GPUs. Please use CudnnRNNParamsWeights and -// CudnnRNNParamsBiases to save and restore them in a way that is compatible -// across different runs. -func CudnnRNNParamsSize(scope *Scope, num_layers tf.Output, num_units tf.Output, input_size tf.Output, T tf.DataType, S tf.DataType, optional ...CudnnRNNParamsSizeAttr) (params_size tf.Output) { - if scope.Err() != nil { - return - } - attrs := map[string]interface{}{"T": T, "S": S} - for _, a := range optional { - a(attrs) - } - opspec := tf.OpSpec{ - Type: "CudnnRNNParamsSize", - Input: []tf.Input{ - num_layers, num_units, input_size, - }, - Attrs: attrs, - } - op := scope.AddOperation(opspec) - return op.Output(0) -} - -// Computes gradients for SparseSegmentMean. -// -// Returns tensor "output" with same shape as grad, except for dimension 0 whose -// value is output_dim0. -// -// Arguments: -// grad: gradient propagated to the SparseSegmentMean op. -// indices: indices passed to the corresponding SparseSegmentMean op. -// segment_ids: segment_ids passed to the corresponding SparseSegmentMean op. -// output_dim0: dimension 0 of "data" passed to SparseSegmentMean op. -func SparseSegmentMeanGrad(scope *Scope, grad tf.Output, indices tf.Output, segment_ids tf.Output, output_dim0 tf.Output) (output tf.Output) { - if scope.Err() != nil { - return - } - opspec := tf.OpSpec{ - Type: "SparseSegmentMeanGrad", - Input: []tf.Input{ - grad, indices, segment_ids, output_dim0, - }, - } - op := scope.AddOperation(opspec) - return op.Output(0) -} - // Returns the set of files matching one or more glob patterns. // // Note that this routine only supports wildcard characters in the @@ -20538,6 +20421,123 @@ func RandomUniformInt(scope *Scope, shape tf.Output, minval tf.Output, maxval tf return op.Output(0) } +// CudnnRNNParamsSizeAttr is an optional argument to CudnnRNNParamsSize. +type CudnnRNNParamsSizeAttr func(optionalAttr) + +// CudnnRNNParamsSizeRnnMode sets the optional rnn_mode attribute to value. +// If not specified, defaults to "lstm" +func CudnnRNNParamsSizeRnnMode(value string) CudnnRNNParamsSizeAttr { + return func(m optionalAttr) { + m["rnn_mode"] = value + } +} + +// CudnnRNNParamsSizeInputMode sets the optional input_mode attribute to value. +// If not specified, defaults to "linear_input" +func CudnnRNNParamsSizeInputMode(value string) CudnnRNNParamsSizeAttr { + return func(m optionalAttr) { + m["input_mode"] = value + } +} + +// CudnnRNNParamsSizeDirection sets the optional direction attribute to value. +// If not specified, defaults to "unidirectional" +func CudnnRNNParamsSizeDirection(value string) CudnnRNNParamsSizeAttr { + return func(m optionalAttr) { + m["direction"] = value + } +} + +// CudnnRNNParamsSizeDropout sets the optional dropout attribute to value. +// If not specified, defaults to 0 +func CudnnRNNParamsSizeDropout(value float32) CudnnRNNParamsSizeAttr { + return func(m optionalAttr) { + m["dropout"] = value + } +} + +// CudnnRNNParamsSizeSeed sets the optional seed attribute to value. +// If not specified, defaults to 0 +func CudnnRNNParamsSizeSeed(value int64) CudnnRNNParamsSizeAttr { + return func(m optionalAttr) { + m["seed"] = value + } +} + +// CudnnRNNParamsSizeSeed2 sets the optional seed2 attribute to value. +// If not specified, defaults to 0 +func CudnnRNNParamsSizeSeed2(value int64) CudnnRNNParamsSizeAttr { + return func(m optionalAttr) { + m["seed2"] = value + } +} + +// Computes size of weights that can be used by a Cudnn RNN model. +// +// Return the params size that can be used by the Cudnn RNN model. Subsequent +// weight allocation and initialization should use this size. +// +// num_layers: Specifies the number of layers in the RNN model. +// num_units: Specifies the size of the hidden state. +// input_size: Specifies the size of the input state. +// rnn_mode: Indicates the type of the RNN model. +// input_mode: Indicate whether there is a linear projection between the input and +// The actual computation before the first layer. 'skip_input' is only allowed +// when input_size == num_units; 'auto_select' implies 'skip_input' when +// input_size == num_units; otherwise, it implies 'linear_input'. +// direction: Indicates whether a bidirectional model will be used. +// dir = (direction == bidirectional) ? 2 : 1 +// dropout: dropout probability. When set to 0., dropout is disabled. +// seed: the 1st part of a seed to initialize dropout. +// seed2: the 2nd part of a seed to initialize dropout. +// params_size: The size of the params buffer that should be allocated and +// initialized for this RNN model. Note that this params buffer may not be +// compatible across GPUs. Please use CudnnRNNParamsWeights and +// CudnnRNNParamsBiases to save and restore them in a way that is compatible +// across different runs. +func CudnnRNNParamsSize(scope *Scope, num_layers tf.Output, num_units tf.Output, input_size tf.Output, T tf.DataType, S tf.DataType, optional ...CudnnRNNParamsSizeAttr) (params_size tf.Output) { + if scope.Err() != nil { + return + } + attrs := map[string]interface{}{"T": T, "S": S} + for _, a := range optional { + a(attrs) + } + opspec := tf.OpSpec{ + Type: "CudnnRNNParamsSize", + Input: []tf.Input{ + num_layers, num_units, input_size, + }, + Attrs: attrs, + } + op := scope.AddOperation(opspec) + return op.Output(0) +} + +// Computes gradients for SparseSegmentMean. +// +// Returns tensor "output" with same shape as grad, except for dimension 0 whose +// value is output_dim0. +// +// Arguments: +// grad: gradient propagated to the SparseSegmentMean op. +// indices: indices passed to the corresponding SparseSegmentMean op. +// segment_ids: segment_ids passed to the corresponding SparseSegmentMean op. +// output_dim0: dimension 0 of "data" passed to SparseSegmentMean op. +func SparseSegmentMeanGrad(scope *Scope, grad tf.Output, indices tf.Output, segment_ids tf.Output, output_dim0 tf.Output) (output tf.Output) { + if scope.Err() != nil { + return + } + opspec := tf.OpSpec{ + Type: "SparseSegmentMeanGrad", + Input: []tf.Input{ + grad, indices, segment_ids, output_dim0, + }, + } + op := scope.AddOperation(opspec) + return op.Output(0) +} + // Computes the sum along sparse segments of a tensor divided by the sqrt of N. // // N is the size of the segment being reduced. @@ -23396,6 +23396,8 @@ func TensorListSetItem(scope *Scope, input_handle tf.Output, index tf.Output, it // Computes the matrix exponential of one or more square matrices: // +// DEPRECATED at GraphDef version 27: Use Python implementation tf.linalg.matrix_exponential instead. +// // \\(exp(A) = \sum_{n=0}^\infty A^n/n!\\) // // The exponential is computed using a combination of the scaling and squaring diff --git a/tensorflow/java/maven/pom.xml b/tensorflow/java/maven/pom.xml index 035077e1e0..e1bf2c7dba 100644 --- a/tensorflow/java/maven/pom.xml +++ b/tensorflow/java/maven/pom.xml @@ -32,8 +32,8 @@ <module>libtensorflow_jni_gpu</module> <module>tensorflow</module> <module>proto</module> - <module>hadoop</module> - <module>spark-connector</module> + <module>tensorflow-hadoop</module> + <module>spark-tensorflow-connector</module> </modules> <!-- Two profiles are used: diff --git a/tensorflow/java/maven/run_inside_container.sh b/tensorflow/java/maven/run_inside_container.sh index 8c4c9d498c..75c6cff529 100644 --- a/tensorflow/java/maven/run_inside_container.sh +++ b/tensorflow/java/maven/run_inside_container.sh @@ -41,7 +41,7 @@ clean() { mvn -q clean rm -rf libtensorflow_jni/src libtensorflow_jni/target libtensorflow_jni_gpu/src libtensorflow_jni_gpu/target \ libtensorflow/src libtensorflow/target tensorflow-android/target proto/src proto/target \ - hadoop/src hadoop/target spark-connector/src spark-connector/target + tensorflow-hadoop/src tensorflow-hadoop/target spark-tensorflow-connector/src spark-tensorflow-connector/target } update_version_in_pom() { @@ -170,8 +170,8 @@ generate_java_protos() { # is updated for each module. download_tf_ecosystem() { ECOSYSTEM_DIR="/tmp/tensorflow-ecosystem" - HADOOP_DIR="${DIR}/hadoop" - SPARK_DIR="${DIR}/spark-connector" + HADOOP_DIR="${DIR}/tensorflow-hadoop" + SPARK_DIR="${DIR}/spark-tensorflow-connector" # Clean any previous attempts rm -rf "${ECOSYSTEM_DIR}" diff --git a/tensorflow/java/maven/spark-connector/pom.xml b/tensorflow/java/maven/spark-tensorflow-connector/pom.xml index 31e39c588a..1b7995be2c 100644 --- a/tensorflow/java/maven/spark-connector/pom.xml +++ b/tensorflow/java/maven/spark-tensorflow-connector/pom.xml @@ -4,7 +4,7 @@ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.tensorflow</groupId> - <artifactId>spark-connector_2.11</artifactId> + <artifactId>spark-tensorflow-connector_2.11</artifactId> <packaging>jar</packaging> <version>1.10.0</version> <name>spark-tensorflow-connector</name> @@ -120,7 +120,7 @@ <artifactSet> <includes> <include>com.google.protobuf:protobuf-java</include> - <include>org.tensorflow:hadoop</include> + <include>org.tensorflow:tensorflow-hadoop</include> <include>org.tensorflow:proto</include> </includes> </artifactSet> @@ -305,7 +305,7 @@ <dependencies> <dependency> <groupId>org.tensorflow</groupId> - <artifactId>hadoop</artifactId> + <artifactId>tensorflow-hadoop</artifactId> <version>${project.version}</version> </dependency> <dependency> diff --git a/tensorflow/java/maven/hadoop/pom.xml b/tensorflow/java/maven/tensorflow-hadoop/pom.xml index e0409fa41b..0fe6f4dce4 100644 --- a/tensorflow/java/maven/hadoop/pom.xml +++ b/tensorflow/java/maven/tensorflow-hadoop/pom.xml @@ -3,7 +3,7 @@ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.tensorflow</groupId> - <artifactId>hadoop</artifactId> + <artifactId>tensorflow-hadoop</artifactId> <packaging>jar</packaging> <version>1.10.0</version> <name>tensorflow-hadoop</name> @@ -15,7 +15,7 @@ <maven.compiler.source>1.6</maven.compiler.source> <maven.compiler.target>1.6</maven.compiler.target> <hadoop.version>2.6.0</hadoop.version> - <protobuf.version>3.3.1</protobuf.version> + <protobuf.version>3.5.1</protobuf.version> <junit.version>4.11</junit.version> </properties> diff --git a/tensorflow/java/src/gen/cc/java_defs.h b/tensorflow/java/src/gen/cc/java_defs.h index d9d6f8adc8..d39653ef41 100644 --- a/tensorflow/java/src/gen/cc/java_defs.h +++ b/tensorflow/java/src/gen/cc/java_defs.h @@ -21,6 +21,8 @@ limitations under the License. #include <string> #include <utility> +#include "tensorflow/core/framework/types.h" + namespace tensorflow { namespace java { @@ -95,6 +97,34 @@ class Type { static Type IterableOf(const Type& type) { return Interface("Iterable").add_parameter(type); } + static Type ForDataType(DataType data_type) { + switch (data_type) { + case DataType::DT_BOOL: + return Class("Boolean"); + case DataType::DT_STRING: + return Class("String"); + case DataType::DT_FLOAT: + return Class("Float"); + case DataType::DT_DOUBLE: + return Class("Double"); + case DataType::DT_UINT8: + return Class("UInt8", "org.tensorflow.types"); + case DataType::DT_INT32: + return Class("Integer"); + case DataType::DT_INT64: + return Class("Long"); + case DataType::DT_RESOURCE: + // TODO(karllessard) create a Resource utility class that could be + // used to store a resource and its type (passed in a second argument). + // For now, we need to force a wildcard and we will unfortunately lose + // track of the resource type. + // Falling through... + default: + // Any other datatypes does not have a equivalent in Java and must + // remain a wildcard (e.g. DT_COMPLEX64, DT_QINT8, ...) + return Wildcard(); + } + } const Kind& kind() const { return kind_; } const string& name() const { return name_; } const string& package() const { return package_; } diff --git a/tensorflow/java/src/gen/cc/op_generator.cc b/tensorflow/java/src/gen/cc/op_generator.cc index d5bd99bdd9..5d6387e88e 100644 --- a/tensorflow/java/src/gen/cc/op_generator.cc +++ b/tensorflow/java/src/gen/cc/op_generator.cc @@ -18,6 +18,7 @@ limitations under the License. #include <memory> #include <set> #include <string> +#include <utility> #include <vector> #include "tensorflow/core/framework/op_gen_lib.h" @@ -100,6 +101,10 @@ void CollectOpDependencies(const OpSpec& op, RenderMode mode, for (const AttributeSpec& attribute : op.attributes()) { out->push_back(attribute.var().type()); out->push_back(attribute.jni_type()); + if (attribute.has_default_value() && + attribute.type().kind() == Type::GENERIC) { + out->push_back(Type::ForDataType(attribute.default_value()->type())); + } } for (const AttributeSpec& optional_attribute : op.optional_attributes()) { out->push_back(optional_attribute.var().type()); @@ -139,6 +144,60 @@ void WriteSetAttrDirective(const AttributeSpec& attr, bool optional, } } +void RenderSecondaryFactoryMethod(const OpSpec& op, const Type& op_class, + std::map<string, Type> default_types, + SourceWriter* writer) { + // Build the return type for the secondary factory, replacing generic + // parameters with their default value if any + Type return_type = Type::Class(op_class.name(), op_class.package()); + for (const Type& parameter : op_class.parameters()) { + if (parameter.kind() == Type::GENERIC && + default_types.find(parameter.name()) != default_types.end()) { + return_type.add_parameter(default_types.at(parameter.name())); + } else { + return_type.add_parameter(parameter); + } + } + Method factory = Method::Create("create", return_type); + Javadoc factory_doc = Javadoc::Create( + "Factory method to create a class to wrap a new " + op_class.name() + + " operation to the graph, using " + "default output types."); + Variable scope = + Variable::Create("scope", Type::Class("Scope", "org.tensorflow.op")); + AddArgument(scope, "current graph scope", &factory, &factory_doc); + std::stringstream factory_statement; + factory_statement << "return create(scope"; + for (const ArgumentSpec& input : op.inputs()) { + AddArgument(input.var(), input.description(), &factory, &factory_doc); + factory_statement << ", " << input.var().name(); + } + for (const AttributeSpec& attr : op.attributes()) { + // Only add attributes that are not types or have no default value to the + // signature of the secondary factory + factory_statement << ", "; + if (attr.type().kind() == Type::GENERIC && + default_types.find(attr.type().name()) != default_types.end()) { + factory_statement << default_types.at(attr.type().name()).name() + << ".class"; + } else { + AddArgument(attr.var(), attr.description(), &factory, &factory_doc); + factory_statement << attr.var().name(); + } + } + if (!op.optional_attributes().empty()) { + Variable options_var = Variable::Varargs("options", Type::Class("Options")); + AddArgument(options_var, "carries optional attributes values", &factory, + &factory_doc); + factory_statement << ", " << options_var.name(); + } + factory_doc.add_tag("return", "a new instance of " + op_class.name()); + + writer->BeginMethod(factory, PUBLIC | STATIC, &factory_doc); + writer->Append(factory_statement.str().c_str()).Append(");").EndLine(); + writer->EndMethod(); +} + void RenderFactoryMethods(const OpSpec& op, const Type& op_class, SourceWriter* writer) { Method factory = Method::Create("create", op_class); @@ -151,8 +210,17 @@ void RenderFactoryMethods(const OpSpec& op, const Type& op_class, for (const ArgumentSpec& input : op.inputs()) { AddArgument(input.var(), input.description(), &factory, &factory_doc); } + std::map<string, Type> default_types; for (const AttributeSpec& attr : op.attributes()) { AddArgument(attr.var(), attr.description(), &factory, &factory_doc); + // If this attribute is a type with a default value, save its value + // for passing it implicitly in a secondary factory method + if (attr.has_default_value() && attr.type().kind() == Type::GENERIC) { + Type default_type = Type::ForDataType(attr.default_value()->type()); + if (!default_type.wildcard()) { + default_types.insert(std::make_pair(attr.type().name(), default_type)); + } + } } if (!op.optional_attributes().empty()) { AddArgument(Variable::Varargs("options", Type::Class("Options")), @@ -194,6 +262,12 @@ void RenderFactoryMethods(const OpSpec& op, const Type& op_class, .Append("(opBuilder.build());") .EndLine(); writer->EndMethod(); + + // If this operation has type attributes with a default value, create a + // second factory method that infers those values implicitly + if (!default_types.empty()) { + RenderSecondaryFactoryMethod(op, op_class, default_types, writer); + } } void RenderConstructor(const OpSpec& op, const Type& op_class, diff --git a/tensorflow/java/src/gen/cc/op_specs.cc b/tensorflow/java/src/gen/cc/op_specs.cc index 941ab2699c..4f5a491d25 100644 --- a/tensorflow/java/src/gen/cc/op_specs.cc +++ b/tensorflow/java/src/gen/cc/op_specs.cc @@ -96,43 +96,10 @@ Type TypeResolver::TypeOf(const OpDef_ArgDef& arg_def, bool* iterable_out) { *iterable_out = true; visited_attrs_.insert(std::make_pair(arg_def.number_attr(), Type::Int())); } - Type type = Type::Wildcard(); if (arg_def.type() != DataType::DT_INVALID) { - // resolve type from DataType - switch (arg_def.type()) { - case DataType::DT_BOOL: - type = Type::Class("Boolean"); - break; - case DataType::DT_STRING: - type = Type::Class("String"); - break; - case DataType::DT_FLOAT: - type = Type::Class("Float"); - break; - case DataType::DT_DOUBLE: - type = Type::Class("Double"); - break; - case DataType::DT_UINT8: - type = Type::Class("UInt8", "org.tensorflow.types"); - break; - case DataType::DT_INT32: - type = Type::Class("Integer"); - break; - case DataType::DT_INT64: - type = Type::Class("Long"); - break; - case DataType::DT_RESOURCE: - // TODO(karllessard) create a Resource utility class that could be - // used to store a resource and its type (passed in a second argument). - // For now, we need to force a wildcard and we will unfortunately lose - // track of the resource type. - break; - default: - // Any other datatypes does not have a equivalent in Java and must - // remain a wildcard (e.g. DT_COMPLEX64, DT_QINT8, ...) - break; - } + type = Type::ForDataType(arg_def.type()); + } else if (!arg_def.type_attr().empty()) { // resolve type from attribute (if already visited, retrieve its type) if (IsAttributeVisited(arg_def.type_attr())) { @@ -337,7 +304,7 @@ AttributeSpec CreateAttribute(const OpDef_AttrDef& attr_def, bool iterable = false; std::pair<Type, Type> types = type_resolver->TypesOf(attr_def, &iterable); Type var_type = types.first.kind() == Type::GENERIC - ? Type::Class("Class").add_parameter(types.first) + ? Type::ClassOf(types.first) : types.first; if (iterable) { var_type = Type::ListOf(var_type); @@ -346,7 +313,8 @@ AttributeSpec CreateAttribute(const OpDef_AttrDef& attr_def, attr_api_def.name(), Variable::Create(SnakeToCamelCase(attr_api_def.rename_to()), var_type), types.first, types.second, ParseDocumentation(attr_api_def.description()), - iterable, attr_api_def.has_default_value()); + iterable, + attr_def.has_default_value() ? &attr_def.default_value() : nullptr); } ArgumentSpec CreateOutput(const OpDef_ArgDef& output_def, diff --git a/tensorflow/java/src/gen/cc/op_specs.h b/tensorflow/java/src/gen/cc/op_specs.h index 30ecb8ce53..4adcfca96a 100644 --- a/tensorflow/java/src/gen/cc/op_specs.h +++ b/tensorflow/java/src/gen/cc/op_specs.h @@ -94,18 +94,21 @@ class AttributeSpec { // jni_type: the type of this attribute in JNI layer (see OperationBuilder) // description: a description of this attribute, in javadoc // iterable: true if this attribute is a list - // has_default_value: true if this attribute has a default value if not set + // default_value: default value for this attribute or nullptr if none. Any + // value referenced by this pointer must outlive the lifetime + // of the AttributeSpec. This is guaranteed if the value is + // issued by an OpDef of the global OpRegistry. AttributeSpec(const string& op_def_name, const Variable& var, const Type& type, const Type& jni_type, const string& description, bool iterable, - bool has_default_value) + const AttrValue* default_value) : op_def_name_(op_def_name), var_(var), type_(type), description_(description), iterable_(iterable), jni_type_(jni_type), - has_default_value_(has_default_value) {} + default_value_(default_value) {} const string& op_def_name() const { return op_def_name_; } const Variable& var() const { return var_; } @@ -113,7 +116,8 @@ class AttributeSpec { const string& description() const { return description_; } bool iterable() const { return iterable_; } const Type& jni_type() const { return jni_type_; } - bool has_default_value() const { return has_default_value_; } + bool has_default_value() const { return default_value_ != nullptr; } + const AttrValue* default_value() const { return default_value_; } private: const string op_def_name_; @@ -122,7 +126,7 @@ class AttributeSpec { const string description_; const bool iterable_; const Type jni_type_; - const bool has_default_value_; + const AttrValue* default_value_; }; class OpSpec { diff --git a/tensorflow/java/src/gen/cc/source_writer.cc b/tensorflow/java/src/gen/cc/source_writer.cc index 8e5fba7e32..a71b367691 100644 --- a/tensorflow/java/src/gen/cc/source_writer.cc +++ b/tensorflow/java/src/gen/cc/source_writer.cc @@ -16,7 +16,6 @@ limitations under the License. #include <string> #include <algorithm> #include <list> -#include <string> #include "tensorflow/java/src/gen/cc/source_writer.h" diff --git a/tensorflow/java/src/main/native/exception_jni.h b/tensorflow/java/src/main/native/exception_jni.h index 28f26d7ebf..465281f804 100644 --- a/tensorflow/java/src/main/native/exception_jni.h +++ b/tensorflow/java/src/main/native/exception_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_JAVA_EXCEPTION_JNI_H_ -#define TENSORFLOW_JAVA_EXCEPTION_JNI_H_ +#ifndef TENSORFLOW_JAVA_SRC_MAIN_NATIVE_EXCEPTION_JNI_H_ +#define TENSORFLOW_JAVA_SRC_MAIN_NATIVE_EXCEPTION_JNI_H_ #include <jni.h> @@ -39,4 +39,4 @@ bool throwExceptionIfNotOK(JNIEnv* env, const TF_Status* status); #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_JAVA_EXCEPTION_JNI_H_ +#endif // TENSORFLOW_JAVA_SRC_MAIN_NATIVE_EXCEPTION_JNI_H_ diff --git a/tensorflow/java/src/main/native/graph_jni.h b/tensorflow/java/src/main/native/graph_jni.h index 215695cdfd..efed23f83b 100644 --- a/tensorflow/java/src/main/native/graph_jni.h +++ b/tensorflow/java/src/main/native/graph_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_JAVA_GRAPH_JNI_H_ -#define TENSORFLOW_JAVA_GRAPH_JNI_H_ +#ifndef TENSORFLOW_JAVA_SRC_MAIN_NATIVE_GRAPH_JNI_H_ +#define TENSORFLOW_JAVA_SRC_MAIN_NATIVE_GRAPH_JNI_H_ #include <jni.h> @@ -85,4 +85,4 @@ JNIEXPORT jlongArray JNICALL Java_org_tensorflow_Graph_addGradients( #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_JAVA_GRAPH_JNI_H_ +#endif // TENSORFLOW_JAVA_SRC_MAIN_NATIVE_GRAPH_JNI_H_ diff --git a/tensorflow/java/src/main/native/operation_builder_jni.h b/tensorflow/java/src/main/native/operation_builder_jni.h index cf0abe4829..1cda7acea8 100644 --- a/tensorflow/java/src/main/native/operation_builder_jni.h +++ b/tensorflow/java/src/main/native/operation_builder_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_JAVA_OPERATION_BUILDER_JNI_H_ -#define TENSORFLOW_JAVA_OPERATION_BUILDER_JNI_H_ +#ifndef TENSORFLOW_JAVA_SRC_MAIN_NATIVE_OPERATION_BUILDER_JNI_H_ +#define TENSORFLOW_JAVA_SRC_MAIN_NATIVE_OPERATION_BUILDER_JNI_H_ #include <jni.h> @@ -188,4 +188,4 @@ JNIEXPORT void JNICALL Java_org_tensorflow_OperationBuilder_setAttrStringList( #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_JAVA_OPERATION_BUILDER_JNI_H_ +#endif // TENSORFLOW_JAVA_SRC_MAIN_NATIVE_OPERATION_BUILDER_JNI_H_ diff --git a/tensorflow/java/src/main/native/operation_jni.h b/tensorflow/java/src/main/native/operation_jni.h index 6f379256d2..56da2ebaee 100644 --- a/tensorflow/java/src/main/native/operation_jni.h +++ b/tensorflow/java/src/main/native/operation_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_JAVA_OPERATION_JNI_H_ -#define TENSORFLOW_JAVA_OPERATION_JNI_H_ +#ifndef TENSORFLOW_JAVA_SRC_MAIN_NATIVE_OPERATION_JNI_H_ +#define TENSORFLOW_JAVA_SRC_MAIN_NATIVE_OPERATION_JNI_H_ #include <jni.h> @@ -87,4 +87,4 @@ JNIEXPORT jint JNICALL Java_org_tensorflow_Operation_inputListLength(JNIEnv *, #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_JAVA_OPERATION_JNI_H_ +#endif // TENSORFLOW_JAVA_SRC_MAIN_NATIVE_OPERATION_JNI_H_ diff --git a/tensorflow/java/src/main/native/saved_model_bundle_jni.h b/tensorflow/java/src/main/native/saved_model_bundle_jni.h index a4b05d0409..e8f28dd670 100644 --- a/tensorflow/java/src/main/native/saved_model_bundle_jni.h +++ b/tensorflow/java/src/main/native/saved_model_bundle_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_JAVA_SAVEDMODELBUNDLE_JNI_H_ -#define TENSORFLOW_JAVA_SAVEDMODELBUNDLE_JNI_H_ +#ifndef TENSORFLOW_JAVA_SRC_MAIN_NATIVE_SAVED_MODEL_BUNDLE_JNI_H_ +#define TENSORFLOW_JAVA_SRC_MAIN_NATIVE_SAVED_MODEL_BUNDLE_JNI_H_ #include <jni.h> @@ -34,4 +34,4 @@ JNIEXPORT jobject JNICALL Java_org_tensorflow_SavedModelBundle_load( #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_JAVA_SAVEDMODELBUNDLE_JNI_H_ +#endif // TENSORFLOW_JAVA_SRC_MAIN_NATIVE_SAVED_MODEL_BUNDLE_JNI_H_ diff --git a/tensorflow/java/src/main/native/session_jni.h b/tensorflow/java/src/main/native/session_jni.h index 54c9c0aa4d..1cc196bdc8 100644 --- a/tensorflow/java/src/main/native/session_jni.h +++ b/tensorflow/java/src/main/native/session_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_JAVA_SESSION_JNI_H_ -#define TENSORFLOW_JAVA_SESSION_JNI_H_ +#ifndef TENSORFLOW_JAVA_SRC_MAIN_NATIVE_SESSION_JNI_H_ +#define TENSORFLOW_JAVA_SRC_MAIN_NATIVE_SESSION_JNI_H_ #include <jni.h> @@ -59,4 +59,4 @@ JNIEXPORT jbyteArray JNICALL Java_org_tensorflow_Session_run( #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_JAVA_SESSION_JNI_H_ +#endif // TENSORFLOW_JAVA_SRC_MAIN_NATIVE_SESSION_JNI_H_ diff --git a/tensorflow/java/src/main/native/tensor_jni.h b/tensorflow/java/src/main/native/tensor_jni.h index a300936884..4cf682548e 100644 --- a/tensorflow/java/src/main/native/tensor_jni.h +++ b/tensorflow/java/src/main/native/tensor_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_JAVA_TENSOR_JNI_H_ -#define TENSORFLOW_JAVA_TENSOR_JNI_H_ +#ifndef TENSORFLOW_JAVA_SRC_MAIN_NATIVE_TENSOR_JNI_H_ +#define TENSORFLOW_JAVA_SRC_MAIN_NATIVE_TENSOR_JNI_H_ #include <jni.h> @@ -153,4 +153,4 @@ JNIEXPORT void JNICALL Java_org_tensorflow_Tensor_readNDArray(JNIEnv *, jclass, #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_JAVA_TENSOR_JNI_H_ +#endif // TENSORFLOW_JAVA_SRC_MAIN_NATIVE_TENSOR_JNI_H_ diff --git a/tensorflow/java/src/main/native/tensorflow_jni.h b/tensorflow/java/src/main/native/tensorflow_jni.h index c0c9322020..d7c44fb0e2 100644 --- a/tensorflow/java/src/main/native/tensorflow_jni.h +++ b/tensorflow/java/src/main/native/tensorflow_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_JAVA_TENSORFLOW_JNI_H_ -#define TENSORFLOW_JAVA_TENSORFLOW_JNI_H_ +#ifndef TENSORFLOW_JAVA_SRC_MAIN_NATIVE_TENSORFLOW_JNI_H_ +#define TENSORFLOW_JAVA_SRC_MAIN_NATIVE_TENSORFLOW_JNI_H_ #include <jni.h> @@ -67,4 +67,4 @@ Java_org_tensorflow_TensorFlow_libraryOpList(JNIEnv *, jclass, jlong); #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif // TENSORFLOW_JAVA_TENSORFLOW_JNI_H_ +#endif // TENSORFLOW_JAVA_SRC_MAIN_NATIVE_TENSORFLOW_JNI_H_ diff --git a/tensorflow/java/src/main/native/utils_jni.h b/tensorflow/java/src/main/native/utils_jni.h index 352298e7de..d1e1b93878 100644 --- a/tensorflow/java/src/main/native/utils_jni.h +++ b/tensorflow/java/src/main/native/utils_jni.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_JAVA_UTILS_JNI_H_ -#define TENSORFLOW_JAVA_UTILS_JNI_H_ +#ifndef TENSORFLOW_JAVA_SRC_MAIN_NATIVE_UTILS_JNI_H_ +#define TENSORFLOW_JAVA_SRC_MAIN_NATIVE_UTILS_JNI_H_ #include <jni.h> @@ -30,4 +30,4 @@ void resolveOutputs(JNIEnv* env, const char* type, jlongArray src_op, #ifdef __cplusplus } // extern "C" #endif // __cplusplus -#endif /* TENSORFLOW_JAVA_UTILS_JNI_H_ */ +#endif // TENSORFLOW_JAVA_SRC_MAIN_NATIVE_UTILS_JNI_H_ diff --git a/tensorflow/js/BUILD b/tensorflow/js/BUILD new file mode 100644 index 0000000000..ad0dc44f54 --- /dev/null +++ b/tensorflow/js/BUILD @@ -0,0 +1,52 @@ +# Description: +# JavaScript/TypeScript code generation for TensorFlow.js + +visibility = [ + "//tensorflow:internal", +] + +package(default_visibility = visibility) + +licenses(["notice"]) # Apache 2.0 + +load( + "//tensorflow:tensorflow.bzl", + "tf_cc_test", +) + +cc_library( + name = "ts_op_gen", + srcs = [ + "ops/ts_op_gen.cc", + ], + hdrs = [ + "ops/ts_op_gen.h", + ], + visibility = ["//visibility:public"], + deps = [ + "//tensorflow/core:framework", + "//tensorflow/core:lib", + "//tensorflow/core:lib_internal", + "//tensorflow/core:op_gen_lib", + "//tensorflow/core:protos_all_cc", + ], +) + +tf_cc_test( + name = "ts_op_gen_test", + srcs = [ + "ops/ts_op_gen.cc", + "ops/ts_op_gen.h", + "ops/ts_op_gen_test.cc", + ], + deps = [ + "//tensorflow/core:framework", + "//tensorflow/core:lib", + "//tensorflow/core:lib_internal", + "//tensorflow/core:op_gen_lib", + "//tensorflow/core:proto_text", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + ], +) diff --git a/tensorflow/js/ops/ts_op_gen.cc b/tensorflow/js/ops/ts_op_gen.cc new file mode 100644 index 0000000000..fb93bb6d8e --- /dev/null +++ b/tensorflow/js/ops/ts_op_gen.cc @@ -0,0 +1,290 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/js/ops/ts_op_gen.h" +#include <unordered_map> + +#include "tensorflow/core/framework/api_def.pb.h" +#include "tensorflow/core/framework/op_def_util.h" +#include "tensorflow/core/lib/gtl/map_util.h" +#include "tensorflow/core/lib/strings/strcat.h" +#include "tensorflow/core/public/version.h" + +namespace tensorflow { +namespace { + +static bool IsListAttr(const OpDef_ArgDef& arg) { + return !arg.type_list_attr().empty() || !arg.number_attr().empty(); +} + +// Struct to hold a combo OpDef and ArgDef for a given Op argument: +struct ArgDefs { + ArgDefs(const OpDef::ArgDef& op_def_arg, const ApiDef::Arg& api_def_arg) + : op_def_arg(op_def_arg), api_def_arg(api_def_arg) {} + + const OpDef::ArgDef& op_def_arg; + const ApiDef::Arg& api_def_arg; +}; + +// Struct to hold a combo OpDef::AttrDef and ApiDef::Attr for an Op. +struct OpAttrs { + OpAttrs(const OpDef::AttrDef& op_def_attr, const ApiDef::Attr& api_def_attr) + : op_def_attr(op_def_attr), api_def_attr(api_def_attr) {} + + const OpDef::AttrDef& op_def_attr; + const ApiDef::Attr& api_def_attr; +}; + +// Helper class to generate TypeScript code for a given OpDef: +class GenTypeScriptOp { + public: + GenTypeScriptOp(const OpDef& op_def, const ApiDef& api_def); + ~GenTypeScriptOp(); + + // Returns the generated code as a string: + string Code(); + + private: + void ProcessArgs(); + void ProcessAttrs(); + void AddAttrForArg(const string& attr, int arg_index); + string InputForAttr(const OpDef::AttrDef& op_def_attr); + + void AddMethodSignature(); + void AddOpAttrs(); + void AddMethodReturnAndClose(); + + const OpDef& op_def_; + const ApiDef& api_def_; + + // Placeholder string for all generated code: + string result_; + + // Holds in-order vector of Op inputs: + std::vector<ArgDefs> input_op_args_; + + // Holds in-order vector of Op attributes: + std::vector<OpAttrs> op_attrs_; + + // Stores attributes-to-arguments by name: + typedef std::unordered_map<string, std::vector<int>> AttrArgIdxMap; + AttrArgIdxMap attr_arg_idx_map_; + + // Holds number of outputs: + int num_outputs_; +}; + +GenTypeScriptOp::GenTypeScriptOp(const OpDef& op_def, const ApiDef& api_def) + : op_def_(op_def), api_def_(api_def), num_outputs_(0) {} + +GenTypeScriptOp::~GenTypeScriptOp() {} + +string GenTypeScriptOp::Code() { + ProcessArgs(); + ProcessAttrs(); + + // Generate exported function for Op: + AddMethodSignature(); + AddOpAttrs(); + AddMethodReturnAndClose(); + + strings::StrAppend(&result_, "\n"); + return result_; +} + +void GenTypeScriptOp::ProcessArgs() { + for (int i = 0; i < api_def_.arg_order_size(); i++) { + auto op_def_arg = FindInputArg(api_def_.arg_order(i), op_def_); + if (op_def_arg == nullptr) { + LOG(WARNING) << "Could not find OpDef::ArgDef for " + << api_def_.arg_order(i); + continue; + } + auto api_def_arg = FindInputArg(api_def_.arg_order(i), api_def_); + if (api_def_arg == nullptr) { + LOG(WARNING) << "Could not find ApiDef::Arg for " + << api_def_.arg_order(i); + continue; + } + + // Map attr names to arg indexes: + if (!op_def_arg->type_attr().empty()) { + AddAttrForArg(op_def_arg->type_attr(), i); + } else if (!op_def_arg->type_list_attr().empty()) { + AddAttrForArg(op_def_arg->type_list_attr(), i); + } + if (!op_def_arg->number_attr().empty()) { + AddAttrForArg(op_def_arg->number_attr(), i); + } + + input_op_args_.push_back(ArgDefs(*op_def_arg, *api_def_arg)); + } + + num_outputs_ = api_def_.out_arg_size(); +} + +void GenTypeScriptOp::ProcessAttrs() { + for (int i = 0; i < op_def_.attr_size(); i++) { + op_attrs_.push_back(OpAttrs(op_def_.attr(i), api_def_.attr(i))); + } +} + +void GenTypeScriptOp::AddAttrForArg(const string& attr, int arg_index) { + // Keep track of attributes-to-arguments by name. These will be used for + // construction Op attributes that require information about the inputs. + auto iter = attr_arg_idx_map_.find(attr); + if (iter == attr_arg_idx_map_.end()) { + attr_arg_idx_map_.insert(AttrArgIdxMap::value_type(attr, {arg_index})); + } else { + iter->second.push_back(arg_index); + } +} + +string GenTypeScriptOp::InputForAttr(const OpDef::AttrDef& op_def_attr) { + string inputs; + auto arg_list = attr_arg_idx_map_.find(op_def_attr.name()); + if (arg_list != attr_arg_idx_map_.end()) { + for (auto iter = arg_list->second.begin(); iter != arg_list->second.end(); + ++iter) { + strings::StrAppend(&inputs, input_op_args_[*iter].op_def_arg.name()); + } + } + return inputs; +} + +void GenTypeScriptOp::AddMethodSignature() { + strings::StrAppend(&result_, "export function ", api_def_.endpoint(0).name(), + "("); + + bool is_first = true; + for (auto& in_arg : input_op_args_) { + if (is_first) { + is_first = false; + } else { + strings::StrAppend(&result_, ", "); + } + + auto op_def_arg = in_arg.op_def_arg; + + strings::StrAppend(&result_, op_def_arg.name(), ": "); + if (IsListAttr(op_def_arg)) { + strings::StrAppend(&result_, "tfc.Tensor[]"); + } else { + strings::StrAppend(&result_, "tfc.Tensor"); + } + } + + if (num_outputs_ == 1) { + strings::StrAppend(&result_, "): tfc.Tensor {\n"); + } else { + strings::StrAppend(&result_, "): tfc.Tensor[] {\n"); + } +} + +void GenTypeScriptOp::AddOpAttrs() { + strings::StrAppend(&result_, " const opAttrs = [\n"); + + bool is_first = true; + for (auto& attr : op_attrs_) { + if (is_first) { + is_first = false; + } else { + strings::StrAppend(&result_, ",\n"); + } + + // Append 4 spaces to start: + strings::StrAppend(&result_, " "); + + if (attr.op_def_attr.type() == "type") { + // Type OpAttributes can be generated from a helper function: + strings::StrAppend(&result_, "createTensorsTypeOpAttr('", + attr.op_def_attr.name(), "', ", + InputForAttr(attr.op_def_attr), ")"); + } else if (attr.op_def_attr.type() == "int") { + strings::StrAppend(&result_, "{name: '", attr.op_def_attr.name(), "', "); + strings::StrAppend(&result_, "type: nodeBackend().binding.TF_ATTR_INT, "); + strings::StrAppend(&result_, "value: ", InputForAttr(attr.op_def_attr), + ".length}"); + } + } + strings::StrAppend(&result_, "\n ];\n"); +} + +void GenTypeScriptOp::AddMethodReturnAndClose() { + strings::StrAppend(&result_, " return null;\n}\n"); +} + +void WriteTSOp(const OpDef& op_def, const ApiDef& api_def, WritableFile* ts) { + GenTypeScriptOp ts_op(op_def, api_def); + TF_CHECK_OK(ts->Append(GenTypeScriptOp(op_def, api_def).Code())); +} + +void StartFile(WritableFile* ts_file) { + const string header = + R"header(/** + * @license + * Copyright 2018 Google Inc. All Rights Reserved. + * Licensed under the Apache License, Version 2.0 (the "License"); + * you may not use this file except in compliance with the License. + * You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + * ============================================================================= + */ + +// This file is MACHINE GENERATED! Do not edit + +import * as tfc from '@tensorflow/tfjs-core'; +import {createTensorsTypeOpAttr, nodeBackend} from './op_utils'; + +)header"; + + TF_CHECK_OK(ts_file->Append(header)); +} + +} // namespace + +void WriteTSOps(const OpList& ops, const ApiDefMap& api_def_map, + const string& ts_filename) { + Env* env = Env::Default(); + + std::unique_ptr<WritableFile> ts_file = nullptr; + TF_CHECK_OK(env->NewWritableFile(ts_filename, &ts_file)); + + StartFile(ts_file.get()); + + for (const auto& op_def : ops.op()) { + // Skip deprecated ops + if (op_def.has_deprecation() && + op_def.deprecation().version() <= TF_GRAPH_DEF_VERSION) { + continue; + } + + const auto* api_def = api_def_map.GetApiDef(op_def.name()); + if (api_def->visibility() == ApiDef::VISIBLE) { + WriteTSOp(op_def, *api_def, ts_file.get()); + } + } + + TF_CHECK_OK(ts_file->Close()); +} + +} // namespace tensorflow diff --git a/tensorflow/core/kernels/warn_about_ints.h b/tensorflow/js/ops/ts_op_gen.h index 20666b230e..fcd46a17a7 100644 --- a/tensorflow/core/kernels/warn_about_ints.h +++ b/tensorflow/js/ops/ts_op_gen.h @@ -1,4 +1,4 @@ -/* Copyright 2015 The TensorFlow Authors. All Rights Reserved. +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. @@ -13,17 +13,19 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_KERNELS_WARN_ABOUT_INTS_H_ -#define TENSORFLOW_KERNELS_WARN_ABOUT_INTS_H_ +#ifndef TENSORFLOW_JS_OPS_TS_OP_GEN_H_ +#define TENSORFLOW_JS_OPS_TS_OP_GEN_H_ -#include "tensorflow/core/framework/op_kernel.h" +#include "tensorflow/core/framework/op_def.pb.h" +#include "tensorflow/core/framework/op_gen_lib.h" +#include "tensorflow/core/platform/types.h" namespace tensorflow { -// Warn if a kernel is being created using ints -// TODO(irving): Remove in TF 2.0 along with the bad op registrations. -void WarnAboutInts(OpKernelConstruction* context); +// Generated code is written to the file ts_filename: +void WriteTSOps(const OpList& ops, const ApiDefMap& api_def_map, + const string& ts_filename); } // namespace tensorflow -#endif // TENSORFLOW_KERNELS_WARN_ABOUT_INTS_H_ +#endif // TENSORFLOW_JS_OPS_TS_OP_GEN_H_ diff --git a/tensorflow/js/ops/ts_op_gen_test.cc b/tensorflow/js/ops/ts_op_gen_test.cc new file mode 100644 index 0000000000..03241689b5 --- /dev/null +++ b/tensorflow/js/ops/ts_op_gen_test.cc @@ -0,0 +1,246 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/js/ops/ts_op_gen.h" + +#include "tensorflow/core/framework/op_def.pb.h" +#include "tensorflow/core/framework/op_gen_lib.h" +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/lib/io/path.h" +#include "tensorflow/core/lib/strings/str_util.h" +#include "tensorflow/core/platform/env.h" +#include "tensorflow/core/platform/test.h" + +namespace tensorflow { +namespace { + +void ExpectContainsStr(StringPiece s, StringPiece expected) { + EXPECT_TRUE(str_util::StrContains(s, expected)) + << "'" << s << "' does not contain '" << expected << "'"; +} + +void ExpectDoesNotContainStr(StringPiece s, StringPiece expected) { + EXPECT_FALSE(str_util::StrContains(s, expected)) + << "'" << s << "' does not contain '" << expected << "'"; +} + +constexpr char kBaseOpDef[] = R"( +op { + name: "Foo" + input_arg { + name: "images" + type_attr: "T" + number_attr: "N" + description: "Images to process." + } + input_arg { + name: "dim" + description: "Description for dim." + type: DT_FLOAT + } + output_arg { + name: "output" + description: "Description for output." + type: DT_FLOAT + } + attr { + name: "T" + type: "type" + description: "Type for images" + allowed_values { + list { + type: DT_UINT8 + type: DT_INT8 + } + } + default_value { + i: 1 + } + } + attr { + name: "N" + type: "int" + has_minimum: true + minimum: 1 + } + summary: "Summary for op Foo." + description: "Description for op Foo." +} +)"; + +// Generate TypeScript code +void GenerateTsOpFileText(const string& op_def_str, const string& api_def_str, + string* ts_file_text) { + Env* env = Env::Default(); + OpList op_defs; + protobuf::TextFormat::ParseFromString( + op_def_str.empty() ? kBaseOpDef : op_def_str, &op_defs); + ApiDefMap api_def_map(op_defs); + + if (!api_def_str.empty()) { + TF_ASSERT_OK(api_def_map.LoadApiDef(api_def_str)); + } + + const string& tmpdir = testing::TmpDir(); + const auto ts_file_path = io::JoinPath(tmpdir, "test.ts"); + + WriteTSOps(op_defs, api_def_map, ts_file_path); + TF_ASSERT_OK(ReadFileToString(env, ts_file_path, ts_file_text)); +} + +TEST(TsOpGenTest, TestImports) { + string ts_file_text; + GenerateTsOpFileText("", "", &ts_file_text); + + const string expected = R"( +import * as tfc from '@tensorflow/tfjs-core'; +import {createTensorsTypeOpAttr, nodeBackend} from './op_utils'; +)"; + ExpectContainsStr(ts_file_text, expected); +} + +TEST(TsOpGenTest, InputSingleAndList) { + const string api_def = R"( +op { + name: "Foo" + input_arg { + name: "images" + type_attr: "T" + number_attr: "N" + } +} +)"; + + string ts_file_text; + GenerateTsOpFileText("", api_def, &ts_file_text); + + const string expected = R"( +export function Foo(images: tfc.Tensor[], dim: tfc.Tensor): tfc.Tensor { +)"; + ExpectContainsStr(ts_file_text, expected); +} + +TEST(TsOpGenTest, TestVisibility) { + const string api_def = R"( +op { + graph_op_name: "Foo" + visibility: HIDDEN +} +)"; + + string ts_file_text; + GenerateTsOpFileText("", api_def, &ts_file_text); + + const string expected = R"( +export function Foo(images: tfc.Tensor[], dim: tfc.Tensor): tfc.Tensor { +)"; + ExpectDoesNotContainStr(ts_file_text, expected); +} + +TEST(TsOpGenTest, SkipDeprecated) { + const string op_def = R"( +op { + name: "DeprecatedFoo" + input_arg { + name: "input" + type_attr: "T" + description: "Description for input." + } + output_arg { + name: "output" + description: "Description for output." + type: DT_FLOAT + } + attr { + name: "T" + type: "type" + description: "Type for input" + allowed_values { + list { + type: DT_FLOAT + } + } + } + deprecation { + explanation: "Deprecated." + } +} +)"; + + string ts_file_text; + GenerateTsOpFileText(op_def, "", &ts_file_text); + + ExpectDoesNotContainStr(ts_file_text, "DeprecatedFoo"); +} + +TEST(TsOpGenTest, MultiOutput) { + const string op_def = R"( +op { + name: "MultiOutputFoo" + input_arg { + name: "input" + description: "Description for input." + type_attr: "T" + } + output_arg { + name: "output1" + description: "Description for output 1." + type: DT_FLOAT + } + output_arg { + name: "output2" + description: "Description for output 2." + type: DT_FLOAT + } + attr { + name: "T" + type: "type" + description: "Type for input" + allowed_values { + list { + type: DT_FLOAT + } + } + } + summary: "Summary for op MultiOutputFoo." + description: "Description for op MultiOutputFoo." +} +)"; + + string ts_file_text; + GenerateTsOpFileText(op_def, "", &ts_file_text); + + const string expected = R"( +export function MultiOutputFoo(input: tfc.Tensor): tfc.Tensor[] { +)"; + ExpectContainsStr(ts_file_text, expected); +} + +TEST(TsOpGenTest, OpAttrs) { + string ts_file_text; + GenerateTsOpFileText("", "", &ts_file_text); + + const string expectedFooAttrs = R"( + const opAttrs = [ + createTensorsTypeOpAttr('T', images), + {name: 'N', type: nodeBackend().binding.TF_ATTR_INT, value: images.length} + ]; +)"; + + ExpectContainsStr(ts_file_text, expectedFooAttrs); +} + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/python/BUILD b/tensorflow/python/BUILD index 91c7fd16c5..5af6437c56 100644 --- a/tensorflow/python/BUILD +++ b/tensorflow/python/BUILD @@ -44,6 +44,10 @@ load("//tensorflow/core:platform/default/build_config_root.bzl", "tf_additional_ load("//tensorflow/core:platform/default/build_config_root.bzl", "tf_additional_mpi_deps") load("//tensorflow/core:platform/default/build_config_root.bzl", "tf_additional_gdr_deps") load("//tensorflow/core:platform/default/build_config_root.bzl", "if_static") +load( + "//third_party/ngraph:build_defs.bzl", + "if_ngraph", +) py_library( name = "python", @@ -130,6 +134,7 @@ py_library( "//tensorflow/core:protos_all_py", "//tensorflow/python/compat", "//tensorflow/python/data", + "//tensorflow/python/distribute:estimator_training", "//tensorflow/python/feature_column:feature_column_py", "//tensorflow/python/keras", "//tensorflow/python/ops/distributions", @@ -138,6 +143,8 @@ py_library( "//tensorflow/python/ops/parallel_for", "//tensorflow/python/profiler", "//tensorflow/python/saved_model", + "//tensorflow/python/tools:component_api_helper", + "//tensorflow/python/tools/api/generator:create_python_api", "//third_party/py/numpy", ], ) @@ -717,7 +724,6 @@ py_library( srcs_version = "PY2AND3", deps = [ ":array_ops", - ":cond_v2_impl", ":dtypes", ":framework_ops", ":graph_to_function_def", @@ -1342,6 +1348,19 @@ py_test( ) py_test( + name = "framework_ops_enable_eager_test", + size = "small", + srcs = ["framework/ops_enable_eager_test.py"], + main = "framework/ops_enable_eager_test.py", + srcs_version = "PY2AND3", + deps = [ + ":framework", + ":platform_test", + "//tensorflow/python/eager:context", + ], +) + +py_test( name = "framework_tensor_shape_test", size = "small", srcs = ["framework/tensor_shape_test.py"], @@ -2608,6 +2627,19 @@ py_library( ], ) +py_test( + name = "sparse_ops_test", + srcs = ["ops/sparse_ops_test.py"], + srcs_version = "PY2AND3", + deps = [ + ":constant_op", + ":dtypes", + ":framework_test_lib", + ":sparse_ops", + ":sparse_tensor", + ], +) + py_library( name = "spectral_grad", srcs = ["ops/spectral_grad.py"], @@ -2779,11 +2811,13 @@ py_library( srcs = ["ops/state_ops.py"], srcs_version = "PY2AND3", deps = [ + ":array_ops", ":framework_ops", + ":math_ops_gen", ":resource_variable_ops_gen", ":state_ops_gen", ":tensor_shape", - "//tensorflow/python/eager:context", + ":util", ], ) @@ -3226,7 +3260,6 @@ py_library( ), srcs_version = "PY2AND3", deps = [ - "saver", ":array_ops", ":array_ops_gen", ":checkpoint_management", @@ -3250,6 +3283,7 @@ py_library( ":random_ops", ":resource_variable_ops", ":resources", + ":saver", ":sdca_ops", ":session", ":sparse_ops", @@ -3743,6 +3777,7 @@ tf_py_wrap_cc( "framework/python_op_gen.i", "grappler/cluster.i", "grappler/cost_analyzer.i", + "grappler/graph_analyzer.i", "grappler/item.i", "grappler/model_analyzer.i", "grappler/tf_optimizer.i", @@ -3801,6 +3836,7 @@ tf_py_wrap_cc( "//tensorflow/core/grappler/clusters:single_machine", "//tensorflow/core/grappler/clusters:virtual_cluster", "//tensorflow/core/grappler/costs:graph_memory", + "//tensorflow/core/grappler/graph_analyzer:graph_analyzer_tool", "//tensorflow/core/grappler/optimizers:meta_optimizer", "//tensorflow/core:lib", "//tensorflow/core:reader_base", @@ -3813,7 +3849,9 @@ tf_py_wrap_cc( tf_additional_plugin_deps() + tf_additional_verbs_deps() + tf_additional_mpi_deps() + - tf_additional_gdr_deps()), + tf_additional_gdr_deps()) + if_ngraph([ + "@ngraph_tf//:ngraph_tf", + ]), ) # ** Targets for Windows build (start) ** @@ -5500,6 +5538,18 @@ py_test( ], ) +py_binary( + name = "graph_analyzer", + srcs = [ + "grappler/graph_analyzer.py", + ], + srcs_version = "PY2AND3", + deps = [ + ":framework_for_generated_wrappers", + ":pywrap_tensorflow_internal", + ], +) + pyx_library( name = "framework_fast_tensor_util", srcs = ["framework/fast_tensor_util.pyx"], diff --git a/tensorflow/python/compat/compat.py b/tensorflow/python/compat/compat.py index 6ab8cab7cb..74b001a572 100644 --- a/tensorflow/python/compat/compat.py +++ b/tensorflow/python/compat/compat.py @@ -26,7 +26,7 @@ import datetime from tensorflow.python.util import tf_contextlib from tensorflow.python.util.tf_export import tf_export -_FORWARD_COMPATIBILITY_HORIZON = datetime.date(2018, 8, 16) +_FORWARD_COMPATIBILITY_HORIZON = datetime.date(2018, 8, 28) @tf_export("compat.forward_compatible") diff --git a/tensorflow/python/data/kernel_tests/concatenate_dataset_op_test.py b/tensorflow/python/data/kernel_tests/concatenate_dataset_op_test.py index e16aa82d4d..159218c99b 100644 --- a/tensorflow/python/data/kernel_tests/concatenate_dataset_op_test.py +++ b/tensorflow/python/data/kernel_tests/concatenate_dataset_op_test.py @@ -110,8 +110,24 @@ class ConcatenateDatasetTest(test.TestCase): dataset_to_concatenate = dataset_ops.Dataset.from_tensor_slices( to_concatenate_components) - with self.assertRaisesRegexp(ValueError, - "don't have the same number of elements"): + with self.assertRaisesRegexp(TypeError, "have different types"): + input_dataset.concatenate(dataset_to_concatenate) + + def testConcatenateDatasetDifferentKeys(self): + input_components = { + "foo": np.array([[1], [2], [3], [4]]), + "bar": np.array([[12], [13], [14], [15]]) + } + to_concatenate_components = { + "foo": np.array([[1], [2], [3], [4]]), + "baz": np.array([[5], [6], [7], [8]]) + } + + input_dataset = dataset_ops.Dataset.from_tensor_slices(input_components) + dataset_to_concatenate = dataset_ops.Dataset.from_tensor_slices( + to_concatenate_components) + + with self.assertRaisesRegexp(TypeError, "have different types"): input_dataset.concatenate(dataset_to_concatenate) def testConcatenateDatasetDifferentType(self): diff --git a/tensorflow/python/data/kernel_tests/iterator_ops_test.py b/tensorflow/python/data/kernel_tests/iterator_ops_test.py index 352424514e..b0414ad655 100644 --- a/tensorflow/python/data/kernel_tests/iterator_ops_test.py +++ b/tensorflow/python/data/kernel_tests/iterator_ops_test.py @@ -756,7 +756,7 @@ class IteratorTest(test.TestCase): # Saving iterator for RangeDataset graph. with ops.Graph().as_default() as g: init_op, _, save_op, _ = _build_range_dataset_graph() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) sess.run(save_op) @@ -767,7 +767,7 @@ class IteratorTest(test.TestCase): # IteratorResource::set_iterator. with ops.Graph().as_default() as g: _, _, _, restore_op = _build_reader_dataset_graph() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: with self.assertRaises(errors.InvalidArgumentError): sess.run(restore_op) diff --git a/tensorflow/python/data/kernel_tests/map_dataset_op_test.py b/tensorflow/python/data/kernel_tests/map_dataset_op_test.py index 637bde9ae4..52b4320bf1 100644 --- a/tensorflow/python/data/kernel_tests/map_dataset_op_test.py +++ b/tensorflow/python/data/kernel_tests/map_dataset_op_test.py @@ -24,6 +24,7 @@ import warnings import numpy as np +from tensorflow.core.framework import attr_value_pb2 from tensorflow.python.client import session from tensorflow.python.data.ops import dataset_ops from tensorflow.python.framework import constant_op @@ -31,6 +32,7 @@ from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors from tensorflow.python.framework import ops from tensorflow.python.framework import sparse_tensor +from tensorflow.python.framework import tensor_util from tensorflow.python.ops import array_ops from tensorflow.python.ops import data_flow_ops from tensorflow.python.ops import functional_ops @@ -673,6 +675,36 @@ class MapDatasetTest(test.TestCase): r"Dataset.map\(\): None."): _ = dataset.map(lambda x: None) + def testBrokenFunctionErrorOnInitialization(self): + dataset = dataset_ops.Dataset.from_tensor_slices([1.0, 2.0, 3.0]) + + def broken_function(_): + """A function deliberately designed to fail on instantiation.""" + value = [] + tensor_value = attr_value_pb2.AttrValue() + tensor_value.tensor.CopyFrom( + tensor_util.make_tensor_proto( + value, dtype=dtypes.float32, shape=[0], verify_shape=False)) + dtype_value = attr_value_pb2.AttrValue(type=dtypes.int32.as_datatype_enum) + + # Create a "Const" op with a `tf.float32` value and a `tf.int32` type + # attr. + const_tensor = ops.get_default_graph().create_op( + "Const", [], [dtypes.int32], + attrs={ + "value": tensor_value, + "dtype": dtype_value + }, + name="BrokenConst").outputs[0] + return const_tensor + + dataset = dataset.map(broken_function) + iterator = dataset.make_initializable_iterator() + + with self.test_session() as sess: + with self.assertRaisesRegexp(errors.InvalidArgumentError, "BrokenConst"): + sess.run(iterator.initializer) + class MapDatasetBenchmark(test.Benchmark): diff --git a/tensorflow/python/data/kernel_tests/range_dataset_op_test.py b/tensorflow/python/data/kernel_tests/range_dataset_op_test.py index 0c530522b8..ad87f31b01 100644 --- a/tensorflow/python/data/kernel_tests/range_dataset_op_test.py +++ b/tensorflow/python/data/kernel_tests/range_dataset_op_test.py @@ -203,7 +203,7 @@ class RangeDatasetTest(test.TestCase): break_point = 5 with ops.Graph().as_default() as g: init_op, get_next, save_op, _ = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) for i in range(start, break_point): @@ -212,7 +212,7 @@ class RangeDatasetTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next, _, restore_op = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) sess.run(restore_op) for i in range(break_point, stop): @@ -223,7 +223,7 @@ class RangeDatasetTest(test.TestCase): # Saving and restoring in same session. with ops.Graph().as_default() as g: init_op, get_next, save_op, restore_op = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) for i in range(start, break_point): @@ -254,7 +254,7 @@ class RangeDatasetTest(test.TestCase): break_epoch = 3 with ops.Graph().as_default() as g: init_op, get_next, save_op, _ = _build_graph(start, stop, num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) for _ in range(break_epoch): @@ -272,7 +272,7 @@ class RangeDatasetTest(test.TestCase): output_shapes) restore_op = self._restore_op(iterator._iterator_resource) get_next = iterator.get_next() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) for i in range(break_point, stop): self.assertEqual(i, sess.run(get_next)) @@ -300,7 +300,7 @@ class RangeDatasetTest(test.TestCase): break_point = 5 with ops.Graph().as_default() as g: init_op, get_next, save_op, _ = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) for i in range(start, break_point): @@ -311,7 +311,7 @@ class RangeDatasetTest(test.TestCase): # Intentionally build a graph with a different value for stop to make sure # the original dataset graph is actually getting loaded. init_op, get_next, _, restore_op = _build_graph(start, stop_1) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) for i in range(break_point, stop): self.assertEqual(i, sess.run(get_next)) @@ -338,7 +338,7 @@ class RangeDatasetTest(test.TestCase): break_point = 5 with ops.Graph().as_default() as g: init_op, get_next, save_op, _ = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) for i in range(start, break_point): @@ -347,7 +347,7 @@ class RangeDatasetTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next, _, restore_op = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) sess.run(restore_op) for i in range(break_point, stop): @@ -373,7 +373,7 @@ class RangeDatasetTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next, save_op, _ = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) for i in range(start, break_point1): @@ -382,7 +382,7 @@ class RangeDatasetTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next, save_op, restore_op = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) for i in range(break_point1, break_point2): self.assertEqual(i, sess.run(get_next)) @@ -391,7 +391,7 @@ class RangeDatasetTest(test.TestCase): break_point2 = 7 with ops.Graph().as_default() as g: init_op, get_next, save_op, restore_op = _build_graph(start, stop) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) for i in range(break_point2, stop): self.assertEqual(i, sess.run(get_next)) @@ -417,7 +417,7 @@ class RangeDatasetTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next, save_op, restore_op = _build_graph( start, stop, num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) # Note: There is no checkpoint saved currently so a NotFoundError is @@ -433,7 +433,7 @@ class RangeDatasetTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next, _, restore_op = _build_graph(start, stop, num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) for i in range(break_range, stop): self.assertEqual(i, sess.run(get_next)) @@ -460,7 +460,7 @@ class RangeDatasetTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next, save_op, restore_op = _build_graph( start, stop, num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) sess.run(init_op) # Note: There is no checkpoint saved currently so a NotFoundError is @@ -476,7 +476,7 @@ class RangeDatasetTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next, _, restore_op = _build_graph(start, stop, num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) with self.assertRaises(errors.OutOfRangeError): sess.run(get_next) diff --git a/tensorflow/python/data/kernel_tests/reader_dataset_ops_test.py b/tensorflow/python/data/kernel_tests/reader_dataset_ops_test.py index e99f0a203b..431362aa9a 100644 --- a/tensorflow/python/data/kernel_tests/reader_dataset_ops_test.py +++ b/tensorflow/python/data/kernel_tests/reader_dataset_ops_test.py @@ -374,7 +374,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) # Note: There is no checkpoint saved currently so a NotFoundError is # raised. @@ -401,7 +401,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) for epoch in range(num_epochs): for f in range(self._num_files): @@ -427,7 +427,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) # Note: There is no checkpoint saved currently so a NotFoundError is # raised. @@ -454,7 +454,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) sess.run(restore_op) for epoch in range(num_epochs): @@ -479,7 +479,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) # Note: There is no checkpoint saved currently so a NotFoundError is # raised. @@ -506,7 +506,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs_1) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) for epoch in range(num_epochs): for f in range(self._num_files): @@ -529,7 +529,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) # Note: There is no checkpoint saved currently so a NotFoundError is # raised. @@ -555,7 +555,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: restore_op, get_next_op = self._restore_iterator() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) for epoch in range(num_epochs): for f in range(self._num_files): @@ -574,7 +574,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) # Note: There is no checkpoint saved currently so a NotFoundError is # raised. @@ -585,7 +585,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) for _ in range(num_epochs * self._num_files * self._num_records): sess.run(get_next_op) @@ -598,7 +598,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(init_op) # Note: There is no checkpoint saved currently so a NotFoundError is # raised. @@ -615,7 +615,7 @@ class FixedLengthRecordReaderTest(test.TestCase): with ops.Graph().as_default() as g: init_op, get_next_op, save_op, restore_op = self._build_iterator_graph( num_epochs=num_epochs) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(restore_op) with self.assertRaises(errors.OutOfRangeError): sess.run(get_next_op) diff --git a/tensorflow/python/data/ops/BUILD b/tensorflow/python/data/ops/BUILD index 50ba5f403e..57517afae8 100644 --- a/tensorflow/python/data/ops/BUILD +++ b/tensorflow/python/data/ops/BUILD @@ -27,6 +27,7 @@ py_library( "//tensorflow/python/data/util:nest", "//tensorflow/python/data/util:random_seed", "//tensorflow/python/data/util:sparse", + "//tensorflow/python/data/util:structure", "//third_party/py/numpy", ], ) diff --git a/tensorflow/python/data/ops/dataset_ops.py b/tensorflow/python/data/ops/dataset_ops.py index fdab8abfae..8c37b1871b 100644 --- a/tensorflow/python/data/ops/dataset_ops.py +++ b/tensorflow/python/data/ops/dataset_ops.py @@ -1684,15 +1684,14 @@ class ConcatenateDataset(Dataset): super(ConcatenateDataset, self).__init__() self._input_dataset = input_dataset self._dataset_to_concatenate = dataset_to_concatenate - nest.assert_same_structure(input_dataset.output_types, - dataset_to_concatenate.output_types) - for a, b in zip( - nest.flatten(input_dataset.output_types), - nest.flatten(dataset_to_concatenate.output_types)): - if a != b: - raise TypeError( - "Two datasets to concatenate have different types %s and %s" % - (input_dataset.output_types, dataset_to_concatenate.output_types)) + if input_dataset.output_types != dataset_to_concatenate.output_types: + raise TypeError( + "Two datasets to concatenate have different types %s and %s" % + (input_dataset.output_types, dataset_to_concatenate.output_types)) + if input_dataset.output_classes != dataset_to_concatenate.output_classes: + raise TypeError( + "Two datasets to concatenate have different classes %s and %s" % + (input_dataset.output_classes, dataset_to_concatenate.output_classes)) def _as_variant_tensor(self): # pylint: disable=protected-access diff --git a/tensorflow/python/data/util/BUILD b/tensorflow/python/data/util/BUILD index 5fcc62b60b..39082ce370 100644 --- a/tensorflow/python/data/util/BUILD +++ b/tensorflow/python/data/util/BUILD @@ -63,6 +63,41 @@ py_test( ) py_library( + name = "structure", + srcs = ["structure.py"], + srcs_version = "PY2AND3", + deps = [ + ":nest", + "//tensorflow/python:dtypes", + "//tensorflow/python:framework_ops", + "//tensorflow/python:ops", + "//tensorflow/python:sparse_ops", + "//tensorflow/python:sparse_tensor", + "//tensorflow/python:tensor_shape", + "//tensorflow/python:tensor_util", + "//tensorflow/python:util", + ], +) + +py_test( + name = "structure_test", + size = "small", + srcs = ["structure_test.py"], + srcs_version = "PY2AND3", + deps = [ + ":nest", + ":structure", + "//tensorflow/python:array_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:dtypes", + "//tensorflow/python:sparse_tensor", + "//tensorflow/python:tensor_shape", + "//tensorflow/python:variables", + "@absl_py//absl/testing:parameterized", + ], +) + +py_library( name = "convert", srcs = ["convert.py"], srcs_version = "PY2AND3", diff --git a/tensorflow/python/data/util/nest.py b/tensorflow/python/data/util/nest.py index 1b596bdfc0..9d621fcd30 100644 --- a/tensorflow/python/data/util/nest.py +++ b/tensorflow/python/data/util/nest.py @@ -129,35 +129,18 @@ def flatten(nest): return _pywrap_tensorflow.FlattenForData(nest) -def _recursive_assert_same_structure(nest1, nest2, check_types): - is_sequence_nest1 = is_sequence(nest1) - if is_sequence_nest1 != is_sequence(nest2): - raise ValueError( - "The two structures don't have the same nested structure. " - "First structure: %s, second structure: %s." % (nest1, nest2)) - - if is_sequence_nest1: - type_nest1 = type(nest1) - type_nest2 = type(nest2) - if check_types and type_nest1 != type_nest2: - raise TypeError( - "The two structures don't have the same sequence type. First " - "structure has type %s, while second structure has type %s." - % (type_nest1, type_nest2)) - - for n1, n2 in zip(_yield_value(nest1), _yield_value(nest2)): - _recursive_assert_same_structure(n1, n2, check_types) - - def assert_same_structure(nest1, nest2, check_types=True): """Asserts that two structures are nested in the same way. Args: nest1: an arbitrarily nested structure. nest2: an arbitrarily nested structure. - check_types: if `True` (default) types of sequences are checked as - well. If set to `False`, for example a list and a tuple of objects will - look same if they have the same size. + check_types: if `True` (default) types of sequences should be same as + well. For dictionary, "type" of dictionary is considered to include its + keys. In other words, two dictionaries with different keys are considered + to have a different "type". If set to `False`, two iterables are + considered same as long as they yield the elements that have same + structures. Raises: ValueError: If the two structures do not have the same number of elements or @@ -165,13 +148,7 @@ def assert_same_structure(nest1, nest2, check_types=True): TypeError: If the two structures differ in the type of sequence in any of their substructures. Only possible if `check_types` is `True`. """ - len_nest1 = len(flatten(nest1)) if is_sequence(nest1) else 1 - len_nest2 = len(flatten(nest2)) if is_sequence(nest2) else 1 - if len_nest1 != len_nest2: - raise ValueError("The two structures don't have the same number of " - "elements. First structure: %s, second structure: %s." - % (nest1, nest2)) - _recursive_assert_same_structure(nest1, nest2, check_types) + _pywrap_tensorflow.AssertSameStructureForData(nest1, nest2, check_types) def _packed_nest_with_indices(structure, flat, index): diff --git a/tensorflow/python/data/util/nest_test.py b/tensorflow/python/data/util/nest_test.py index ff380815a4..616aa9f551 100644 --- a/tensorflow/python/data/util/nest_test.py +++ b/tensorflow/python/data/util/nest_test.py @@ -163,21 +163,30 @@ class NestTest(test.TestCase): structure2 = ((("foo1", "foo2"), "foo3"), "foo4", ("foo5", "foo6")) structure_different_num_elements = ("spam", "eggs") structure_different_nesting = (((1, 2), 3), 4, 5, (6,)) + structure_dictionary = {"foo": 2, "bar": 4, "baz": {"foo": 5, "bar": 6}} + structure_dictionary_diff_nested = { + "foo": 2, + "bar": 4, + "baz": { + "foo": 5, + "baz": 6 + } + } nest.assert_same_structure(structure1, structure2) nest.assert_same_structure("abc", 1.0) nest.assert_same_structure("abc", np.array([0, 1])) nest.assert_same_structure("abc", constant_op.constant([0, 1])) with self.assertRaisesRegexp(ValueError, - "don't have the same number of elements"): + "don't have the same nested structure"): nest.assert_same_structure(structure1, structure_different_num_elements) with self.assertRaisesRegexp(ValueError, - "don't have the same number of elements"): + "don't have the same nested structure"): nest.assert_same_structure((0, 1), np.array([0, 1])) with self.assertRaisesRegexp(ValueError, - "don't have the same number of elements"): + "don't have the same nested structure"): nest.assert_same_structure(0, (0, 1)) with self.assertRaisesRegexp(ValueError, @@ -203,11 +212,23 @@ class NestTest(test.TestCase): nest.assert_same_structure(((3,), 4), (3, (4,))) structure1_list = {"a": ((1, 2), 3), "b": 4, "c": (5, 6)} + structure2_list = {"a": ((1, 2), 3), "b": 4, "d": (5, 6)} with self.assertRaisesRegexp(TypeError, "don't have the same sequence type"): nest.assert_same_structure(structure1, structure1_list) nest.assert_same_structure(structure1, structure2, check_types=False) nest.assert_same_structure(structure1, structure1_list, check_types=False) + with self.assertRaisesRegexp(ValueError, "don't have the same set of keys"): + nest.assert_same_structure(structure1_list, structure2_list) + with self.assertRaisesRegexp(ValueError, "don't have the same set of keys"): + nest.assert_same_structure(structure_dictionary, + structure_dictionary_diff_nested) + nest.assert_same_structure( + structure_dictionary, + structure_dictionary_diff_nested, + check_types=False) + nest.assert_same_structure( + structure1_list, structure2_list, check_types=False) def testMapStructure(self): structure1 = (((1, 2), 3), 4, (5, 6)) diff --git a/tensorflow/python/data/util/structure.py b/tensorflow/python/data/util/structure.py new file mode 100644 index 0000000000..c5764b8dfe --- /dev/null +++ b/tensorflow/python/data/util/structure.py @@ -0,0 +1,315 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Utilities for describing the structure of a `tf.data` type.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import abc + +from tensorflow.python.data.util import nest +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops +from tensorflow.python.framework import sparse_tensor as sparse_tensor_lib +from tensorflow.python.framework import tensor_shape +from tensorflow.python.framework import tensor_util +from tensorflow.python.ops import sparse_ops + + +class Structure(object): + """Represents structural information, such as type and shape, about a value. + + A `Structure` generalizes the `tf.Tensor.dtype` and `tf.Tensor.shape` + properties, so that we can define generic containers of objects including: + + * `tf.Tensor` + * `tf.SparseTensor` + * Nested structures of the above. + + TODO(b/110122868): In the future, a single `Structure` will replace the + `tf.data.Dataset.output_types`, `tf.data.Dataset.output_shapes`, + and `tf.data.Dataset.output_classes`, and similar properties and arguments in + the `tf.data.Iterator` and `Optional` classes. + """ + __metaclass__ = abc.ABCMeta + + @abc.abstractproperty + def _flat_shapes(self): + """A list of shapes matching the shapes of `self._to_tensor_list()`. + + Returns: + A list of `tf.TensorShape` objects. + """ + raise NotImplementedError("Structure._flat_shapes") + + @abc.abstractproperty + def _flat_types(self): + """A list of types matching the types of `self._to_tensor_list()`. + + Returns: + A list of `tf.DType` objects. + """ + raise NotImplementedError("Structure._flat_shapes") + + @abc.abstractmethod + def is_compatible_with(self, value): + """Returns `True` if `value` is compatible with this structure. + + A value `value` is compatible with a structure `s` if + `Structure.from_value(value)` would return a structure `t` that is a + "subtype" of `s`. A structure `t` is a "subtype" of `s` if: + + * `s` and `t` are instances of the same `Structure` subclass. + * The nested structures (if any) of `s` and `t` are the same, according to + `tf.contrib.framework.nest.assert_same_structure`, and each nested + structure of `t` is a "subtype" of the corresponding nested structure of + `s`. + * Any `tf.DType` components of `t` are the same as the corresponding + components in `s`. + * Any `tf.TensorShape` components of `t` are compatible with the + corresponding components in `s`, according to + `tf.TensorShape.is_compatible_with`. + + Args: + value: A potentially structured value. + + Returns: + `True` if `value` matches this structure, otherwise `False`. + """ + raise NotImplementedError("Structure.is_compatible_with()") + + @abc.abstractmethod + def _to_tensor_list(self, value): + """Returns a flat list of `tf.Tensor` representing `value`. + + This method can be used, along with `self._flat_shapes` and + `self._flat_types` to represent structured values in lower level APIs + (such as plain TensorFlow operations) that do not understand structure. + + Requires: `self.is_compatible_with(value)`. + + Args: + value: A value with compatible structure. + + Returns: + A flat list of `tf.Tensor` representing `value`. + """ + raise NotImplementedError("Structure._to_tensor_list()") + + @abc.abstractmethod + def _from_tensor_list(self, flat_value): + """Builds a flat list of `tf.Tensor` into a value matching this structure. + + Requires: The shapes and types of the tensors in `flat_value` must be + compatible with `self._flat_shapes` and `self._flat_types` respectively. + + Args: + flat_value: A list of `tf.Tensor` with compatible flat structure. + + Returns: + A structured object matching this structure. + """ + raise NotImplementedError("Structure._from_tensor_list()") + + @staticmethod + def from_value(value): + """Returns a `Structure` that represents the given `value`. + + Args: + value: A potentially structured value. + + Returns: + A `Structure` that is compatible with `value`. + + Raises: + TypeError: If a structure cannot be built for `value`, because its type + or one of its component types is not supported. + """ + + # TODO(b/110122868): Add support for custom types, Dataset, and Optional + # to this method. + if isinstance( + value, + (sparse_tensor_lib.SparseTensor, sparse_tensor_lib.SparseTensorValue)): + return SparseTensorStructure.from_value(value) + elif isinstance(value, (tuple, dict)): + return NestedStructure.from_value(value) + else: + try: + tensor = ops.convert_to_tensor(value) + except (ValueError, TypeError): + raise TypeError("Could not build a structure for %r" % value) + return TensorStructure.from_value(tensor) + + +# NOTE(mrry): The following classes make extensive use of non-public methods of +# their base class, so we disable the protected-access lint warning once here. +# pylint: disable=protected-access +class NestedStructure(Structure): + """Represents a nested structure in which each leaf is a `Structure`.""" + + def __init__(self, nested_structure): + self._nested_structure = nested_structure + self._flat_shapes_list = [] + self._flat_types_list = [] + for s in nest.flatten(nested_structure): + if not isinstance(s, Structure): + raise TypeError("nested_structure must be a (potentially nested) tuple " + "or dictionary of Structure objects.") + self._flat_shapes_list.extend(s._flat_shapes) + self._flat_types_list.extend(s._flat_types) + + @property + def _flat_shapes(self): + return self._flat_shapes_list + + @property + def _flat_types(self): + return self._flat_types_list + + def is_compatible_with(self, value): + try: + nest.assert_shallow_structure(self._nested_structure, value) + except (ValueError, TypeError): + return False + + return all( + s.is_compatible_with(v) for s, v in zip( + nest.flatten(self._nested_structure), + nest.flatten_up_to(self._nested_structure, value))) + + def _to_tensor_list(self, value): + ret = [] + + try: + flat_value = nest.flatten_up_to(self._nested_structure, value) + except (ValueError, TypeError): + raise ValueError("The value %r is not compatible with the nested " + "structure %r." % (value, self._nested_structure)) + + for sub_value, structure in zip(flat_value, + nest.flatten(self._nested_structure)): + if not structure.is_compatible_with(sub_value): + raise ValueError("Component value %r is not compatible with the nested " + "structure %r." % (sub_value, structure)) + ret.extend(structure._to_tensor_list(sub_value)) + return ret + + def _from_tensor_list(self, flat_value): + if len(flat_value) != len(self._flat_types): + raise ValueError("Expected %d flat values in NestedStructure but got %d." + % (len(self._flat_types), len(flat_value))) + + flat_ret = [] + for sub_value, structure in zip(flat_value, + nest.flatten(self._nested_structure)): + flat_ret.append(structure._from_tensor_list([sub_value])) + + return nest.pack_sequence_as(self._nested_structure, flat_ret) + + @staticmethod + def from_value(value): + flat_nested_structure = [ + Structure.from_value(sub_value) for sub_value in nest.flatten(value) + ] + return NestedStructure(nest.pack_sequence_as(value, flat_nested_structure)) + + +class TensorStructure(Structure): + """Represents structural information about a `tf.Tensor`.""" + + def __init__(self, dtype, shape): + self._dtype = dtypes.as_dtype(dtype) + self._shape = tensor_shape.as_shape(shape) + + @property + def _flat_shapes(self): + return [self._shape] + + @property + def _flat_types(self): + return [self._dtype] + + def is_compatible_with(self, value): + try: + value = ops.convert_to_tensor(value, dtype=self._dtype) + except (ValueError, TypeError): + return False + + return (self._dtype.is_compatible_with(value.dtype) and + self._shape.is_compatible_with(value.shape)) + + def _to_tensor_list(self, value): + if not self.is_compatible_with(value): + raise ValueError("Value %r is not convertible to a tensor with dtype %s " + "and shape %s." % (value, self._dtype, self._shape)) + return [value] + + def _from_tensor_list(self, flat_value): + if len(flat_value) != 1: + raise ValueError("TensorStructure corresponds to a single tf.Tensor.") + if not self.is_compatible_with(flat_value[0]): + raise ValueError("Cannot convert %r to a tensor with dtype %s and shape " + "%s." % (flat_value[0], self._dtype, self._shape)) + return flat_value[0] + + @staticmethod + def from_value(value): + return TensorStructure(value.dtype, value.shape) + + +class SparseTensorStructure(Structure): + """Represents structural information about a `tf.SparseTensor`.""" + + def __init__(self, dtype, dense_shape): + self._dtype = dtypes.as_dtype(dtype) + self._dense_shape = tensor_shape.as_shape(dense_shape) + + @property + def _flat_shapes(self): + return [tensor_shape.vector(3)] + + @property + def _flat_types(self): + return [dtypes.variant] + + def is_compatible_with(self, value): + try: + value = sparse_tensor_lib.SparseTensor.from_value(value) + except TypeError: + return False + return (isinstance(value, (sparse_tensor_lib.SparseTensor, + sparse_tensor_lib.SparseTensorValue)) and + self._dtype.is_compatible_with(value.dtype) and + self._dense_shape.is_compatible_with( + tensor_util.constant_value_as_shape(value.dense_shape))) + + def _to_tensor_list(self, value): + return [sparse_ops.serialize_sparse(value, out_type=dtypes.variant)] + + def _from_tensor_list(self, flat_value): + if (len(flat_value) != 1 or flat_value[0].dtype != dtypes.variant or + not flat_value[0].shape.is_compatible_with(tensor_shape.vector(3))): + raise ValueError("SparseTensorStructure corresponds to a single " + "tf.variant vector of length 3.") + return sparse_ops.deserialize_sparse( + flat_value[0], dtype=self._dtype, rank=self._dense_shape.ndims) + + @staticmethod + def from_value(value): + sparse_tensor = sparse_tensor_lib.SparseTensor.from_value(value) + return SparseTensorStructure( + sparse_tensor.dtype, + tensor_util.constant_value_as_shape(sparse_tensor.dense_shape)) diff --git a/tensorflow/python/data/util/structure_test.py b/tensorflow/python/data/util/structure_test.py new file mode 100644 index 0000000000..d0c7df67ae --- /dev/null +++ b/tensorflow/python/data/util/structure_test.py @@ -0,0 +1,327 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for utilities working with arbitrarily nested structures.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from absl.testing import parameterized +import numpy as np + +from tensorflow.python.data.util import nest +from tensorflow.python.data.util import structure +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import sparse_tensor +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import variables +from tensorflow.python.platform import test + + +class StructureTest(test.TestCase, parameterized.TestCase): + # pylint disable=protected-access + + @parameterized.parameters( + (constant_op.constant(37.0), structure.TensorStructure, [dtypes.float32], + [[]]), (sparse_tensor.SparseTensor( + indices=[[3, 4]], values=[-1], dense_shape=[4, 5]), + structure.SparseTensorStructure, [dtypes.variant], [[3]]), + ((constant_op.constant(37.0), constant_op.constant([1, 2, 3])), + structure.NestedStructure, [dtypes.float32, dtypes.int32], [[], [3]]), ({ + "a": constant_op.constant(37.0), + "b": constant_op.constant([1, 2, 3]) + }, structure.NestedStructure, [dtypes.float32, dtypes.int32], [[], [3]]), + ({ + "a": + constant_op.constant(37.0), + "b": (sparse_tensor.SparseTensor( + indices=[[0, 0]], values=[1], dense_shape=[1, 1]), + sparse_tensor.SparseTensor( + indices=[[3, 4]], values=[-1], dense_shape=[4, 5])) + }, structure.NestedStructure, + [dtypes.float32, dtypes.variant, dtypes.variant], [[], [3], [3]])) + def testFlatStructure(self, value, expected_structure, expected_types, + expected_shapes): + s = structure.Structure.from_value(value) + self.assertIsInstance(s, expected_structure) + self.assertEqual(expected_types, s._flat_types) + self.assertEqual(expected_shapes, s._flat_shapes) + + @parameterized.parameters( + (constant_op.constant(37.0), [ + constant_op.constant(38.0), + array_ops.placeholder(dtypes.float32), + variables.Variable(100.0), 42.0, + np.array(42.0, dtype=np.float32) + ], [constant_op.constant([1.0, 2.0]), + constant_op.constant(37)]), + (sparse_tensor.SparseTensor( + indices=[[3, 4]], values=[-1], dense_shape=[4, 5]), + [ + sparse_tensor.SparseTensor( + indices=[[1, 1], [3, 4]], values=[10, -1], dense_shape=[4, 5]), + sparse_tensor.SparseTensorValue( + indices=[[1, 1], [3, 4]], values=[10, -1], dense_shape=[4, 5]), + array_ops.sparse_placeholder(dtype=dtypes.int32), + array_ops.sparse_placeholder(dtype=dtypes.int32, shape=[None, None]) + ], [ + constant_op.constant(37, shape=[4, 5]), + sparse_tensor.SparseTensor( + indices=[[3, 4]], values=[-1], dense_shape=[5, 6]), + array_ops.sparse_placeholder( + dtype=dtypes.int32, shape=[None, None, None]), + sparse_tensor.SparseTensor( + indices=[[3, 4]], values=[-1.0], dense_shape=[4, 5]) + ]), + ({ + "a": constant_op.constant(37.0), + "b": constant_op.constant([1, 2, 3]) + }, [{ + "a": constant_op.constant(15.0), + "b": constant_op.constant([4, 5, 6]) + }], [{ + "a": constant_op.constant(15.0), + "b": constant_op.constant([4, 5, 6, 7]) + }, { + "a": constant_op.constant(15), + "b": constant_op.constant([4, 5, 6]) + }, { + "a": + constant_op.constant(15), + "b": + sparse_tensor.SparseTensor( + indices=[[0], [1], [2]], values=[4, 5, 6], dense_shape=[3]) + }, (constant_op.constant(15.0), constant_op.constant([4, 5, 6]))]), + ) + def testIsCompatibleWith(self, original_value, compatible_values, + incompatible_values): + s = structure.Structure.from_value(original_value) + for compatible_value in compatible_values: + self.assertTrue(s.is_compatible_with(compatible_value)) + for incompatible_value in incompatible_values: + self.assertFalse(s.is_compatible_with(incompatible_value)) + + # NOTE(mrry): The arguments must be lifted into lambdas because otherwise they + # will be executed before the (eager- or graph-mode) test environment has been + # set up. + # pylint: disable=g-long-lambda + @parameterized.parameters( + (lambda: constant_op.constant(37.0),), + (lambda: sparse_tensor.SparseTensor( + indices=[[3, 4]], values=[-1], dense_shape=[4, 5]),), + (lambda: {"a": constant_op.constant(37.0), + "b": constant_op.constant([1, 2, 3])},), + (lambda: {"a": constant_op.constant(37.0), + "b": (sparse_tensor.SparseTensor( + indices=[[0, 0]], values=[1], dense_shape=[1, 1]), + sparse_tensor.SparseTensor( + indices=[[3, 4]], values=[-1], dense_shape=[4, 5])) + },), + ) + def testRoundTripConversion(self, value_fn): + value = value_fn() + s = structure.Structure.from_value(value) + before = self.evaluate(value) + after = self.evaluate(s._from_tensor_list(s._to_tensor_list(value))) + + flat_before = nest.flatten(before) + flat_after = nest.flatten(after) + for b, a in zip(flat_before, flat_after): + if isinstance(b, sparse_tensor.SparseTensorValue): + self.assertAllEqual(b.indices, a.indices) + self.assertAllEqual(b.values, a.values) + self.assertAllEqual(b.dense_shape, a.dense_shape) + else: + self.assertAllEqual(b, a) + # pylint: enable=g-long-lambda + + def testIncompatibleStructure(self): + # Define three mutually incompatible values/structures, and assert that: + # 1. Using one structure to flatten a value with an incompatible structure + # fails. + # 2. Using one structure to restructre a flattened value with an + # incompatible structure fails. + value_tensor = constant_op.constant(42.0) + s_tensor = structure.Structure.from_value(value_tensor) + flat_tensor = s_tensor._to_tensor_list(value_tensor) + + value_sparse_tensor = sparse_tensor.SparseTensor( + indices=[[0, 0]], values=[1], dense_shape=[1, 1]) + s_sparse_tensor = structure.Structure.from_value(value_sparse_tensor) + flat_sparse_tensor = s_sparse_tensor._to_tensor_list(value_sparse_tensor) + + value_nest = { + "a": constant_op.constant(37.0), + "b": constant_op.constant([1, 2, 3]) + } + s_nest = structure.Structure.from_value(value_nest) + flat_nest = s_nest._to_tensor_list(value_nest) + + with self.assertRaisesRegexp( + ValueError, r"SparseTensor.* is not convertible to a tensor with " + r"dtype.*float32.* and shape \(\)"): + s_tensor._to_tensor_list(value_sparse_tensor) + with self.assertRaisesRegexp( + ValueError, r"Value \{.*\} is not convertible to a tensor with " + r"dtype.*float32.* and shape \(\)"): + s_tensor._to_tensor_list(value_nest) + + with self.assertRaisesRegexp(TypeError, "Input must be a SparseTensor"): + s_sparse_tensor._to_tensor_list(value_tensor) + + with self.assertRaisesRegexp(TypeError, "Input must be a SparseTensor"): + s_sparse_tensor._to_tensor_list(value_nest) + + with self.assertRaisesRegexp( + ValueError, "Tensor.* not compatible with the nested structure " + ".*TensorStructure.*TensorStructure"): + s_nest._to_tensor_list(value_tensor) + + with self.assertRaisesRegexp( + ValueError, "SparseTensor.* not compatible with the nested structure " + ".*TensorStructure.*TensorStructure"): + s_nest._to_tensor_list(value_sparse_tensor) + + with self.assertRaisesRegexp( + ValueError, r"Cannot convert.*with dtype.*float32.* and shape \(\)"): + s_tensor._from_tensor_list(flat_sparse_tensor) + + with self.assertRaisesRegexp( + ValueError, "TensorStructure corresponds to a single tf.Tensor."): + s_tensor._from_tensor_list(flat_nest) + + with self.assertRaisesRegexp( + ValueError, "SparseTensorStructure corresponds to a single tf.variant " + "vector of length 3."): + s_sparse_tensor._from_tensor_list(flat_tensor) + + with self.assertRaisesRegexp( + ValueError, "SparseTensorStructure corresponds to a single tf.variant " + "vector of length 3."): + s_sparse_tensor._from_tensor_list(flat_nest) + + with self.assertRaisesRegexp( + ValueError, "Expected 2 flat values in NestedStructure but got 1."): + s_nest._from_tensor_list(flat_tensor) + + with self.assertRaisesRegexp( + ValueError, "Expected 2 flat values in NestedStructure but got 1."): + s_nest._from_tensor_list(flat_sparse_tensor) + + def testIncompatibleNestedStructure(self): + # Define three mutually incompatible nested values/structures, and assert + # that: + # 1. Using one structure to flatten a value with an incompatible structure + # fails. + # 2. Using one structure to restructre a flattened value with an + # incompatible structure fails. + + value_0 = { + "a": constant_op.constant(37.0), + "b": constant_op.constant([1, 2, 3]) + } + s_0 = structure.Structure.from_value(value_0) + flat_s_0 = s_0._to_tensor_list(value_0) + + # `value_1` has compatible nested structure with `value_0`, but different + # classes. + value_1 = { + "a": + constant_op.constant(37.0), + "b": + sparse_tensor.SparseTensor( + indices=[[0, 0]], values=[1], dense_shape=[1, 1]) + } + s_1 = structure.Structure.from_value(value_1) + flat_s_1 = s_1._to_tensor_list(value_1) + + # `value_2` has incompatible nested structure with `value_0` and `value_1`. + value_2 = { + "a": + constant_op.constant(37.0), + "b": (sparse_tensor.SparseTensor( + indices=[[0, 0]], values=[1], dense_shape=[1, 1]), + sparse_tensor.SparseTensor( + indices=[[3, 4]], values=[-1], dense_shape=[4, 5])) + } + s_2 = structure.Structure.from_value(value_2) + flat_s_2 = s_2._to_tensor_list(value_2) + + with self.assertRaisesRegexp( + ValueError, "SparseTensor.* not compatible with the nested structure " + ".*TensorStructure"): + s_0._to_tensor_list(value_1) + + with self.assertRaisesRegexp( + ValueError, "SparseTensor.*SparseTensor.* not compatible with the " + "nested structure .*TensorStructure"): + s_0._to_tensor_list(value_2) + + with self.assertRaisesRegexp( + ValueError, "Tensor.* not compatible with the nested structure " + ".*SparseTensorStructure"): + s_1._to_tensor_list(value_0) + + with self.assertRaisesRegexp( + ValueError, "SparseTensor.*SparseTensor.* not compatible with the " + "nested structure .*TensorStructure"): + s_0._to_tensor_list(value_2) + + # NOTE(mrry): The repr of the dictionaries is not sorted, so the regexp + # needs to account for "a" coming before or after "b". It might be worth + # adding a deterministic repr for these error messages (among other + # improvements). + with self.assertRaisesRegexp( + ValueError, "Tensor.*Tensor.* not compatible with the nested structure " + ".*(TensorStructure.*SparseTensorStructure.*SparseTensorStructure|" + "SparseTensorStructure.*SparseTensorStructure.*TensorStructure)"): + s_2._to_tensor_list(value_0) + + with self.assertRaisesRegexp( + ValueError, "(Tensor.*SparseTensor|SparseTensor.*Tensor).* " + "not compatible with the nested structure .*" + "(TensorStructure.*SparseTensorStructure.*SparseTensorStructure|" + "SparseTensorStructure.*SparseTensorStructure.*TensorStructure)"): + s_2._to_tensor_list(value_1) + + with self.assertRaisesRegexp( + ValueError, r"Cannot convert.*with dtype.*int32.* and shape \(3,\)"): + s_0._from_tensor_list(flat_s_1) + + with self.assertRaisesRegexp( + ValueError, "Expected 2 flat values in NestedStructure but got 3."): + s_0._from_tensor_list(flat_s_2) + + with self.assertRaisesRegexp( + ValueError, "SparseTensorStructure corresponds to a single tf.variant " + "vector of length 3."): + s_1._from_tensor_list(flat_s_0) + + with self.assertRaisesRegexp( + ValueError, "Expected 2 flat values in NestedStructure but got 3."): + s_1._from_tensor_list(flat_s_2) + + with self.assertRaisesRegexp( + ValueError, "Expected 3 flat values in NestedStructure but got 2."): + s_2._from_tensor_list(flat_s_0) + + with self.assertRaisesRegexp( + ValueError, "Expected 3 flat values in NestedStructure but got 2."): + s_2._from_tensor_list(flat_s_1) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/python/debug/BUILD b/tensorflow/python/debug/BUILD index 8a4ac6aaef..849d165bfa 100644 --- a/tensorflow/python/debug/BUILD +++ b/tensorflow/python/debug/BUILD @@ -576,7 +576,6 @@ py_test( srcs_version = "PY2AND3", tags = [ "no_windows", - "nomac", "oss_serial", ], deps = [ @@ -1047,7 +1046,6 @@ cuda_py_test( tags = [ "no_oss", # Incompatible with bazel_pip. "no_windows", - "nomac", # TODO(cais): Install of futures and grpcio on all macs. "notsan", ], ) @@ -1102,6 +1100,23 @@ py_test( ], ) +py_test( + name = "disk_usage_test", + size = "small", + srcs = ["wrappers/disk_usage_test.py"], + srcs_version = "PY2AND3", + deps = [ + ":dumping_wrapper", + ":hooks", + "//tensorflow/python:client", + "//tensorflow/python:errors", + "//tensorflow/python:framework_test_lib", + "//tensorflow/python:platform_test", + "//tensorflow/python:training", + "//tensorflow/python:variables", + ], +) + sh_test( name = "examples_test", size = "medium", diff --git a/tensorflow/python/debug/lib/debug_utils.py b/tensorflow/python/debug/lib/debug_utils.py index f1e972940b..f2a43a6152 100644 --- a/tensorflow/python/debug/lib/debug_utils.py +++ b/tensorflow/python/debug/lib/debug_utils.py @@ -87,7 +87,8 @@ def watch_graph(run_options, op_type_regex_whitelist=None, tensor_dtype_regex_whitelist=None, tolerate_debug_op_creation_failures=False, - global_step=-1): + global_step=-1, + reset_disk_byte_usage=False): """Add debug watches to `RunOptions` for a TensorFlow graph. To watch all `Tensor`s on the graph, let both `node_name_regex_whitelist` @@ -130,6 +131,8 @@ def watch_graph(run_options, throwing exceptions. global_step: (`int`) Optional global_step count for this debug tensor watch. + reset_disk_byte_usage: (`bool`) whether to reset the tracked disk byte + usage to zero (default: `False`). """ if isinstance(debug_ops, str): @@ -170,6 +173,7 @@ def watch_graph(run_options, tolerate_debug_op_creation_failures=( tolerate_debug_op_creation_failures), global_step=global_step) + run_options.debug_options.reset_disk_byte_usage = reset_disk_byte_usage def watch_graph_with_blacklists(run_options, @@ -180,7 +184,8 @@ def watch_graph_with_blacklists(run_options, op_type_regex_blacklist=None, tensor_dtype_regex_blacklist=None, tolerate_debug_op_creation_failures=False, - global_step=-1): + global_step=-1, + reset_disk_byte_usage=False): """Add debug tensor watches, blacklisting nodes and op types. This is similar to `watch_graph()`, but the node names and op types are @@ -219,6 +224,8 @@ def watch_graph_with_blacklists(run_options, throwing exceptions. global_step: (`int`) Optional global_step count for this debug tensor watch. + reset_disk_byte_usage: (`bool`) whether to reset the tracked disk byte + usage to zero (default: `False`). """ if isinstance(debug_ops, str): @@ -259,3 +266,4 @@ def watch_graph_with_blacklists(run_options, tolerate_debug_op_creation_failures=( tolerate_debug_op_creation_failures), global_step=global_step) + run_options.debug_options.reset_disk_byte_usage = reset_disk_byte_usage diff --git a/tensorflow/python/debug/wrappers/disk_usage_test.py b/tensorflow/python/debug/wrappers/disk_usage_test.py new file mode 100644 index 0000000000..0874525966 --- /dev/null +++ b/tensorflow/python/debug/wrappers/disk_usage_test.py @@ -0,0 +1,109 @@ +# Copyright 2016 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Debugger Wrapper Session Consisting of a Local Curses-based CLI.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os +import tempfile + +from tensorflow.python.client import session +from tensorflow.python.debug.wrappers import dumping_wrapper +from tensorflow.python.debug.wrappers import hooks +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import test_util +from tensorflow.python.ops import state_ops +from tensorflow.python.ops import variables +from tensorflow.python.platform import googletest +from tensorflow.python.training import monitored_session + + +class DumpingDebugWrapperDiskUsageLimitTest(test_util.TensorFlowTestCase): + + @classmethod + def setUpClass(cls): + # For efficient testing, set the disk usage bytes limit to a small + # number (10). + os.environ["TFDBG_DISK_BYTES_LIMIT"] = "10" + + def setUp(self): + self.session_root = tempfile.mkdtemp() + + self.v = variables.Variable(10.0, dtype=dtypes.float32, name="v") + self.delta = constant_op.constant(1.0, dtype=dtypes.float32, name="delta") + self.eta = constant_op.constant(-1.4, dtype=dtypes.float32, name="eta") + self.inc_v = state_ops.assign_add(self.v, self.delta, name="inc_v") + self.dec_v = state_ops.assign_add(self.v, self.eta, name="dec_v") + + self.sess = session.Session() + self.sess.run(self.v.initializer) + + def testWrapperSessionNotExceedingLimit(self): + def _watch_fn(fetches, feeds): + del fetches, feeds + return "DebugIdentity", r"(.*delta.*|.*inc_v.*)", r".*" + sess = dumping_wrapper.DumpingDebugWrapperSession( + self.sess, session_root=self.session_root, + watch_fn=_watch_fn, log_usage=False) + sess.run(self.inc_v) + + def testWrapperSessionExceedingLimit(self): + def _watch_fn(fetches, feeds): + del fetches, feeds + return "DebugIdentity", r".*delta.*", r".*" + sess = dumping_wrapper.DumpingDebugWrapperSession( + self.sess, session_root=self.session_root, + watch_fn=_watch_fn, log_usage=False) + # Due to the watch function, each run should dump only 1 tensor, + # which has a size of 4 bytes, which corresponds to the dumped 'delta:0' + # tensor of scalar shape and float32 dtype. + # 1st run should pass, after which the disk usage is at 4 bytes. + sess.run(self.inc_v) + # 2nd run should also pass, after which 8 bytes are used. + sess.run(self.inc_v) + # 3rd run should fail, because the total byte count (12) exceeds the + # limit (10) + with self.assertRaises(ValueError): + sess.run(self.inc_v) + + def testHookNotExceedingLimit(self): + def _watch_fn(fetches, feeds): + del fetches, feeds + return "DebugIdentity", r".*delta.*", r".*" + dumping_hook = hooks.DumpingDebugHook( + self.session_root, watch_fn=_watch_fn, log_usage=False) + mon_sess = monitored_session._HookedSession(self.sess, [dumping_hook]) + mon_sess.run(self.inc_v) + + def testHookExceedingLimit(self): + def _watch_fn(fetches, feeds): + del fetches, feeds + return "DebugIdentity", r".*delta.*", r".*" + dumping_hook = hooks.DumpingDebugHook( + self.session_root, watch_fn=_watch_fn, log_usage=False) + mon_sess = monitored_session._HookedSession(self.sess, [dumping_hook]) + # Like in `testWrapperSessionExceedingLimit`, the first two calls + # should be within the byte limit, but the third one should error + # out due to exceeding the limit. + mon_sess.run(self.inc_v) + mon_sess.run(self.inc_v) + with self.assertRaises(ValueError): + mon_sess.run(self.inc_v) + + +if __name__ == "__main__": + googletest.main() diff --git a/tensorflow/python/debug/wrappers/framework.py b/tensorflow/python/debug/wrappers/framework.py index b9524ce649..afda1fdc0d 100644 --- a/tensorflow/python/debug/wrappers/framework.py +++ b/tensorflow/python/debug/wrappers/framework.py @@ -447,13 +447,16 @@ class BaseDebugWrapperSession(session.SessionInterface): "callable_runner and callable_options are mutually exclusive, but " "are both specified in this call to BaseDebugWrapperSession.run().") - if not (callable_runner or callable_options): - self.increment_run_call_count() - elif callable_runner and (fetches or feed_dict): + if callable_runner and (fetches or feed_dict): raise ValueError( "callable_runner and fetches/feed_dict are mutually exclusive, " "but are used simultaneously.") + elif callable_options and (fetches or feed_dict): + raise ValueError( + "callable_options and fetches/feed_dict are mutually exclusive, " + "but are used simultaneously.") + self.increment_run_call_count() empty_fetches = not nest.flatten(fetches) if empty_fetches: tf_logging.info( @@ -649,6 +652,18 @@ class BaseDebugWrapperSession(session.SessionInterface): def increment_run_call_count(self): self._run_call_count += 1 + def _is_disk_usage_reset_each_run(self): + """Indicates whether disk usage is reset after each Session.run. + + Subclasses that clean up the disk usage after every run should + override this protected method. + + Returns: + (`bool`) Whether the disk usage amount is reset to zero after + each Session.run. + """ + return False + def _decorate_run_options_for_debug( self, run_options, @@ -686,7 +701,9 @@ class BaseDebugWrapperSession(session.SessionInterface): node_name_regex_whitelist=node_name_regex_whitelist, op_type_regex_whitelist=op_type_regex_whitelist, tensor_dtype_regex_whitelist=tensor_dtype_regex_whitelist, - tolerate_debug_op_creation_failures=tolerate_debug_op_creation_failures) + tolerate_debug_op_creation_failures=tolerate_debug_op_creation_failures, + reset_disk_byte_usage=(self._run_call_count == 1 or + self._is_disk_usage_reset_each_run())) def _decorate_run_options_for_profile(self, run_options): """Modify a RunOptions object for profiling TensorFlow graph execution. diff --git a/tensorflow/python/debug/wrappers/hooks.py b/tensorflow/python/debug/wrappers/hooks.py index 5e4604fda4..872b675506 100644 --- a/tensorflow/python/debug/wrappers/hooks.py +++ b/tensorflow/python/debug/wrappers/hooks.py @@ -188,6 +188,7 @@ class DumpingDebugHook(session_run_hook.SessionRunHook): pass def before_run(self, run_context): + reset_disk_byte_usage = False if not self._session_wrapper: self._session_wrapper = dumping_wrapper.DumpingDebugWrapperSession( run_context.session, @@ -195,6 +196,7 @@ class DumpingDebugHook(session_run_hook.SessionRunHook): watch_fn=self._watch_fn, thread_name_filter=self._thread_name_filter, log_usage=self._log_usage) + reset_disk_byte_usage = True self._session_wrapper.increment_run_call_count() @@ -212,7 +214,8 @@ class DumpingDebugHook(session_run_hook.SessionRunHook): op_type_regex_whitelist=watch_options.op_type_regex_whitelist, tensor_dtype_regex_whitelist=watch_options.tensor_dtype_regex_whitelist, tolerate_debug_op_creation_failures=( - watch_options.tolerate_debug_op_creation_failures)) + watch_options.tolerate_debug_op_creation_failures), + reset_disk_byte_usage=reset_disk_byte_usage) run_args = session_run_hook.SessionRunArgs( None, feed_dict=None, options=run_options) diff --git a/tensorflow/python/debug/wrappers/local_cli_wrapper.py b/tensorflow/python/debug/wrappers/local_cli_wrapper.py index 668ffb57f1..a3ce4d388b 100644 --- a/tensorflow/python/debug/wrappers/local_cli_wrapper.py +++ b/tensorflow/python/debug/wrappers/local_cli_wrapper.py @@ -124,6 +124,11 @@ class LocalCLIDebugWrapperSession(framework.BaseDebugWrapperSession): self._ui_type = ui_type + def _is_disk_usage_reset_each_run(self): + # The dumped tensors are all cleaned up after every Session.run + # in a command-line wrapper. + return True + def _initialize_argparsers(self): self._argparsers = {} ap = argparse.ArgumentParser( diff --git a/tensorflow/python/distribute/BUILD b/tensorflow/python/distribute/BUILD index 98ef9bf492..a081c30781 100644 --- a/tensorflow/python/distribute/BUILD +++ b/tensorflow/python/distribute/BUILD @@ -9,6 +9,25 @@ exports_files(["LICENSE"]) load("//tensorflow:tensorflow.bzl", "py_test") py_library( + name = "distribute", + srcs_version = "PY2AND3", + visibility = ["//visibility:public"], + deps = [ + ":distribute_config", + ":distribute_coordinator", + ":distribute_coordinator_context", + ], +) + +py_library( + name = "distribute_config", + srcs = [ + "distribute_config.py", + ], + deps = [], +) + +py_library( name = "distribute_coordinator", srcs = [ "distribute_coordinator.py", @@ -25,7 +44,11 @@ py_test( size = "large", srcs = ["distribute_coordinator_test.py"], srcs_version = "PY2AND3", - tags = ["no_pip"], + tags = [ + "manual", + "no_pip", + "notap", + ], deps = [ ":distribute_coordinator", "//tensorflow/core:protos_all_py", @@ -81,3 +104,17 @@ py_test( "@absl_py//absl/testing:parameterized", ], ) + +# Used only by estimator. +py_library( + name = "estimator_training", + srcs = [ + "estimator_training.py", + ], + srcs_version = "PY2AND3", + deps = [ + ":distribute_coordinator", + ":distribute_coordinator_context", + "//tensorflow/python:training", + ], +) diff --git a/tensorflow/python/distribute/distribute_config.py b/tensorflow/python/distribute/distribute_config.py new file mode 100644 index 0000000000..fac35742fe --- /dev/null +++ b/tensorflow/python/distribute/distribute_config.py @@ -0,0 +1,45 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""A configure tuple for high-level APIs for running distribution strategies.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import collections + + +class DistributeConfig( + collections.namedtuple( + 'DistributeConfig', + ['train_distribute', 'eval_distribute', 'remote_cluster'])): + """A config tuple for distribution strategies. + + Attributes: + train_distribute: a `DistributionStrategy` object for training. + eval_distribute: an optional `DistributionStrategy` object for + evaluation. + remote_cluster: a dict, `ClusterDef` or `ClusterSpec` object specifying + the cluster configurations. If this is given, the `train_and_evaluate` + method will be running as a standalone client which connects to the + cluster for training. + """ + + def __new__(cls, + train_distribute=None, + eval_distribute=None, + remote_cluster=None): + return super(DistributeConfig, cls).__new__(cls, train_distribute, + eval_distribute, remote_cluster) diff --git a/tensorflow/python/distribute/distribute_coordinator.py b/tensorflow/python/distribute/distribute_coordinator.py index eb081b65fc..46cdd64a6e 100644 --- a/tensorflow/python/distribute/distribute_coordinator.py +++ b/tensorflow/python/distribute/distribute_coordinator.py @@ -22,9 +22,12 @@ import copy import json import os import threading +import time from tensorflow.core.protobuf import cluster_pb2 +from tensorflow.python.client import session from tensorflow.python.distribute import distribute_coordinator_context +from tensorflow.python.platform import tf_logging as logging from tensorflow.python.training import monitored_session from tensorflow.python.training import server_lib @@ -311,7 +314,11 @@ def _run_single_worker(worker_fn, worker_barrier=None): """Runs a single worker by calling `worker_fn` under context.""" strategy = copy.deepcopy(strategy) - strategy.configure(session_config, cluster_spec, task_type, task_id) + # If there is an EVALUATOR task, we run single-machine eval on that task. + if task_type == _TaskType.EVALUATOR: + strategy.configure(session_config) + else: + strategy.configure(session_config, cluster_spec, task_type, task_id) context = _WorkerContext( strategy, cluster_spec, @@ -328,26 +335,48 @@ def _run_std_server(cluster_spec=None, task_type=None, task_id=None, session_config=None, - rpc_layer=None): + rpc_layer=None, + environment=None): """Runs a standard server.""" - server = server_lib.Server( - cluster_spec, - job_name=task_type, - task_index=task_id, - config=session_config, - protocol=rpc_layer) - server.start() - return server - -def _run_between_graph_client(worker_fn, strategy, cluster_spec, session_config, - rpc_layer): + class _FakeServer(object): + """A fake server that runs a master session.""" + + def start(self): + assert cluster_spec + target = cluster_spec.task_address(task_type, task_id) + if rpc_layer: + target = rpc_layer + "://" + target + # A tensorflow server starts when a remote session is created. + session.Session(target=target, config=session_config) + + def join(self): + while True: + time.sleep(5) + + if environment == "google": + server = _FakeServer() + server.start() + return server + else: + server = server_lib.Server( + cluster_spec, + job_name=task_type, + task_index=task_id, + config=session_config, + protocol=rpc_layer) + server.start() + return server + + +def _run_between_graph_client(worker_fn, strategy, eval_fn, eval_strategy, + cluster_spec, session_config, rpc_layer): """Runs a standalone client for between-graph replication.""" eval_thread = None if _TaskType.EVALUATOR in cluster_spec.jobs: eval_thread = threading.Thread( target=_run_single_worker, - args=(worker_fn, strategy, cluster_spec, _TaskType.EVALUATOR, 0, + args=(eval_fn, eval_strategy, None, _TaskType.EVALUATOR, 0, session_config), kwargs={ "rpc_layer": rpc_layer, @@ -378,14 +407,14 @@ def _run_between_graph_client(worker_fn, strategy, cluster_spec, session_config, eval_thread.join() -def _run_in_graph_client(worker_fn, strategy, cluster_spec, session_config, - rpc_layer): +def _run_in_graph_client(worker_fn, strategy, eval_fn, eval_strategy, + cluster_spec, session_config, rpc_layer): """Runs a standalone client for in-graph replication.""" eval_thread = None if _TaskType.EVALUATOR in cluster_spec.jobs: eval_thread = threading.Thread( target=_run_single_worker, - args=(worker_fn, strategy, cluster_spec, _TaskType.EVALUATOR, 0, + args=(eval_fn, eval_strategy, cluster_spec, _TaskType.EVALUATOR, 0, session_config), kwargs={ "rpc_layer": rpc_layer, @@ -408,6 +437,8 @@ def _run_in_graph_client(worker_fn, strategy, cluster_spec, session_config, # is the special task when we support cluster_spec propagation. def run_distribute_coordinator(worker_fn, strategy, + eval_fn=None, + eval_strategy=None, mode=CoordinatorMode.STANDALONE_CLIENT, cluster_spec=None, task_type=None, @@ -488,10 +519,12 @@ def run_distribute_coordinator(worker_fn, If `cluster_spec` is not given in any format, it becomes local training and this coordinator will connect to a local session. - For evaluation, if "evaluator" exist in the cluster_spec, a separate thread - will be created with its `task_type` set to "evaluator". If "evaluator" is not - set in the cluster_spec, it entirely depends on the `worker_fn` for how to do - evaluation. + For evaluation, if "evaluator" exists in the cluster_spec, a separate thread + will be created to call `eval_fn` with its `task_type` set to "evaluator". If + `eval_fn` is not defined, fall back to `worker_fn`. This implies that + evaluation will be done on a single machine if there is an "evaluator" task. + If "evaluator" doesn't exit in the cluster_spec, it entirely depends on the + `worker_fn` for how to do evaluation. Args: worker_fn: the function to be called. The function should accept a @@ -501,6 +534,8 @@ def run_distribute_coordinator(worker_fn, run between-graph replicated training or not, whether to run init ops, etc. This object will also be configured given `session_config`, `cluster_spc`, `task_type` and `task_id`. + eval_fn: optional function for "evaluator" task. + eval_strategy: optional DistributionStrategy object for "evaluator" task. mode: in which mode this distribute coordinator runs. cluster_spec: a dict, ClusterDef or ClusterSpec specifying servers and roles in a cluster. If not set or empty, fall back to local training. @@ -531,32 +566,59 @@ def run_distribute_coordinator(worker_fn, "`tf.train.ClusterDef` object") # TODO(yuefengz): validate cluster_spec. + rpc_layer = tf_config.get("rpc_layer", rpc_layer) + environment = tf_config.get("environment", None) + + if cluster_spec: + logging.info( + "Running Distribute Coordinator with mode = %r, cluster_spec = %r, " + "task_type = %r, task_id = %r, environment = %r, rpc_layer = %r", mode, + cluster_spec.as_dict(), task_type, task_id, environment, rpc_layer) + if not cluster_spec: # `mode` is ignored in the local case. + logging.info("Running local Distribute Coordinator.") _run_single_worker(worker_fn, strategy, None, None, None, session_config, rpc_layer) + if eval_fn: + _run_single_worker(eval_fn, eval_strategy or strategy, None, None, None, + session_config, rpc_layer) elif mode == CoordinatorMode.STANDALONE_CLIENT: + eval_fn = eval_fn or worker_fn + eval_strategy = eval_strategy or strategy + # The client must know the cluster but servers in the cluster don't have to # know the client. if task_type in [_TaskType.CLIENT, None]: if strategy.between_graph: - _run_between_graph_client(worker_fn, strategy, cluster_spec, - session_config, rpc_layer) + _run_between_graph_client(worker_fn, strategy, eval_fn, eval_strategy, + cluster_spec, session_config, rpc_layer) else: - _run_in_graph_client(worker_fn, strategy, cluster_spec, session_config, - rpc_layer) + _run_in_graph_client(worker_fn, strategy, eval_fn, eval_strategy, + cluster_spec, session_config, rpc_layer) else: # If not a client job, run the standard server. server = _run_std_server( - cluster_spec=cluster_spec, task_type=task_type, task_id=task_id) + cluster_spec=cluster_spec, + task_type=task_type, + task_id=task_id, + rpc_layer=rpc_layer, + environment=environment) server.join() else: if mode != CoordinatorMode.INDEPENDENT_WORKER: raise ValueError("Unexpected coordinator mode: %r" % mode) + eval_fn = eval_fn or worker_fn + eval_strategy = eval_strategy or strategy + # Every one starts a standard server. server = _run_std_server( - cluster_spec=cluster_spec, task_type=task_type, task_id=task_id) + cluster_spec=cluster_spec, + task_type=task_type, + task_id=task_id, + rpc_layer=rpc_layer, + environment=environment) if task_type in [_TaskType.CHIEF, _TaskType.WORKER]: if strategy.between_graph: @@ -572,8 +634,8 @@ def run_distribute_coordinator(worker_fn, else: server.join() elif task_type == _TaskType.EVALUATOR: - _run_single_worker(worker_fn, strategy, cluster_spec, task_type, task_id, - session_config, rpc_layer) + _run_single_worker(eval_fn, eval_strategy, cluster_spec, task_type, + task_id, session_config, rpc_layer) else: if task_type != _TaskType.PS: raise ValueError("Unexpected task_type: %r" % task_type) diff --git a/tensorflow/python/distribute/distribute_coordinator_test.py b/tensorflow/python/distribute/distribute_coordinator_test.py index 97c6bdd15a..5dd57fa134 100644 --- a/tensorflow/python/distribute/distribute_coordinator_test.py +++ b/tensorflow/python/distribute/distribute_coordinator_test.py @@ -20,8 +20,10 @@ from __future__ import print_function import contextlib import copy +import json import os import sys +import time import threading import six @@ -59,6 +61,8 @@ INDEPENDENT_WORKER = distribute_coordinator.CoordinatorMode.INDEPENDENT_WORKER NUM_WORKERS = 3 NUM_PS = 2 +original_sys_exit = sys.exit + def _bytes_to_str(maybe_bytes): if isinstance(maybe_bytes, six.string_types): @@ -369,7 +373,8 @@ class DistributeCoordinatorTestBase(test.TestCase): cluster_spec=None, task_type=None, task_id=None, - rpc_layer=None): + rpc_layer=None, + environment=None): task_type = str(task_type) task_id = task_id or 0 with self._lock: @@ -730,6 +735,63 @@ class DistributeCoordinatorTestInpendentWorkerMode( self.assertTrue(self._std_servers[WORKER][2].joined) self.assertFalse(self._std_servers[EVALUATOR][0].joined) + def testRunStdServerInGoogleEnvironment(self): + cluster_spec = {"worker": ["fake_worker"], "ps": ["localhost:0"]} + tf_config = {"cluster": cluster_spec, "environment": "google"} + + joined = [False] + + def _fake_sleep(_): + joined[0] = True + original_sys_exit(0) + + def _thread_fn(cluster_spec): + distribute_coordinator.run_distribute_coordinator( + None, + None, + mode=INDEPENDENT_WORKER, + cluster_spec=cluster_spec, + task_type="ps", + task_id=0) + + with test.mock.patch.dict( + "os.environ", + {"TF_CONFIG": json.dumps(tf_config)}), test.mock.patch.object( + time, "sleep", _fake_sleep): + t = threading.Thread(target=_thread_fn, args=(cluster_spec,)) + t.start() + t.join() + self.assertTrue(joined[0]) + + def testRpcLayerEnvironmentVariable(self): + cluster_spec = {"worker": ["fake_worker"], "ps": ["fake_ps"]} + tf_config = {"cluster": cluster_spec, "rpc_layer": "cake"} + + rpc_layer_from_coordinator = [None] + + def _run_mock_server(cluster_spec=None, + task_type=None, + task_id=None, + session_config=None, + rpc_layer=None, + environment=None): + del cluster_spec, task_type, task_id, session_config, environment + rpc_layer_from_coordinator[0] = rpc_layer + return MockServer() + + with test.mock.patch.dict( + "os.environ", + {"TF_CONFIG": json.dumps(tf_config)}), test.mock.patch.object( + distribute_coordinator, "_run_std_server", _run_mock_server): + distribute_coordinator.run_distribute_coordinator( + None, + None, + mode=INDEPENDENT_WORKER, + cluster_spec=cluster_spec, + task_type="ps", + task_id=0) + self.assertEqual(rpc_layer_from_coordinator[0], "cake") + if __name__ == "__main__": # TODO(yuefengz): find a smart way to terminite std server threads. diff --git a/tensorflow/python/distribute/estimator_training.py b/tensorflow/python/distribute/estimator_training.py new file mode 100644 index 0000000000..202e19c420 --- /dev/null +++ b/tensorflow/python/distribute/estimator_training.py @@ -0,0 +1,264 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Training utilities for Estimator to use Distribute Coordinator.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import copy + +import six + +from tensorflow.python.distribute import distribute_coordinator as dc +from tensorflow.python.distribute import distribute_coordinator_context as dc_context +from tensorflow.python.platform import tf_logging as logging +from tensorflow.python.training import server_lib + +# pylint: disable=protected-access +CHIEF = dc._TaskType.CHIEF +EVALUATOR = dc._TaskType.EVALUATOR +PS = dc._TaskType.PS +WORKER = dc._TaskType.WORKER + +# pylint: enable=protected-access + + +def _count_ps(cluster_spec): + """Counts the number of parameter servers in cluster_spec.""" + if not cluster_spec: + raise RuntimeError( + 'Internal error: `_count_ps` does not expect empty cluster_spec.') + + return len(cluster_spec.as_dict().get(PS, [])) + + +def _count_worker(cluster_spec, chief_task_type): + """Counts the number of workers (including chief) in cluster_spec.""" + if not cluster_spec: + raise RuntimeError( + 'Internal error: `_count_worker` does not expect empty cluster_spec.') + + return (len(cluster_spec.as_dict().get(WORKER, [])) + len( + cluster_spec.as_dict().get(chief_task_type, []))) + + +def _get_global_id(cluster_spec, task_type, task_id, chief_task_type): + """Returns the global id of the given task type in a cluster.""" + if not task_type: + return 0 + + # Sort task names in cluster by "chief"/"master", "evaluator", "worker" + # and "ps". More details can be found at the documentation of + # @{tf.estimator.RunConfig.global_id_in_cluster}. + task_type_ordered_list = [] + if chief_task_type in cluster_spec.jobs: + task_type_ordered_list = [chief_task_type] + task_type_ordered_list.extend([ + t for t in sorted(cluster_spec.jobs) if t != chief_task_type and t != PS + ]) + if PS in cluster_spec.jobs: + task_type_ordered_list.append(PS) + + # Find the right gloabl_id for current task. + next_global_id = 0 + for t in task_type_ordered_list: + if t == task_type: + return next_global_id + task_id + # `cluster_spec.job_tasks` returns all task addresses of type `t`. + next_global_id += len(cluster_spec.job_tasks(t)) + + # It is unexpected that it passes through all task_types in + # `task_type_ordered_list`. + raise RuntimeError('Internal Error: `task_type` ({}) is not in ' + 'cluster_spec ({}).'.format(task_type, cluster_spec)) + + +def _init_run_config_from_worker_context(config, worker_context): + """Initializes run config from distribute coordinator's worker context.""" + + # pylint: disable=protected-access + config._service = None + config._cluster_spec = worker_context.cluster_spec + config._task_type = worker_context.task_type + config._task_id = worker_context.task_id + config._evaluation_master = worker_context.master_target + config._master = worker_context.master_target + config._is_chief = worker_context.is_chief + + if config._cluster_spec: + # Distributed mode. + if config._task_type != EVALUATOR: + + config._num_ps_replicas = _count_ps(config._cluster_spec) + config._num_worker_replicas = _count_worker( + config._cluster_spec, chief_task_type=CHIEF) + config._global_id_in_cluster = _get_global_id( + config._cluster_spec, + config._task_type, + config._task_id, + chief_task_type=CHIEF) + else: + # Evaluator task should not be aware of the other tasks. + config._cluster_spec = server_lib.ClusterSpec({}) + config._num_ps_replicas = 0 + config._num_worker_replicas = 0 + config._global_id_in_cluster = None # undefined + else: + # Local mode. + config._global_id_in_cluster = 0 + config._num_ps_replicas = 0 + config._num_worker_replicas = 1 + + +def init_run_config(config, tf_config): + """Initializes RunConfig for distribution strategies.""" + # pylint: disable=protected-access + if (config._experimental_distribute and + config._experimental_distribute.train_distribute): + if config._train_distribute: + raise ValueError('Either `train_distribute` or' + '`experimental_distribute.train_distribute` can be set.') + config._train_distribute = config._experimental_distribute.train_distribute + + if (config._experimental_distribute and + config._experimental_distribute.eval_distribute): + if config._eval_distribute: + raise ValueError('Either `eval_distribute` or' + '`experimental_distribute.eval_distribute` can be set.') + config._eval_distribute = config._experimental_distribute.eval_distribute + + cluster_spec = server_lib.ClusterSpec(tf_config.get('cluster', {})) + config._init_distributed_setting_from_environment_var({}) + + # Use distribute coordinator with STANDALONE_CLIENT mode if + # `experimental_distribute.remote_cluster` is set. + if (config._train_distribute and config._experimental_distribute and + config._experimental_distribute.remote_cluster): + if tf_config: + raise ValueError('Cannot set both TF_CONFIG environment variable and ' + '`experimental_distribute.remote_cluster`') + config._distribute_coordinator_mode = dc.CoordinatorMode.STANDALONE_CLIENT + config._cluster_spec = config._experimental_distribute.remote_cluster + logging.info('RunConfig initialized for Distribute Coordinator with ' + 'STANDALONE_CLIENT mode') + return + + # Don't use distribute coordinator if it is local training or cluster has a + # MASTER job or `train_distribute` is not specifed. + if (not tf_config or 'master' in cluster_spec.jobs or + not config._train_distribute): + config._distribute_coordinator_mode = None + config._init_distributed_setting_from_environment_var(tf_config) + config._maybe_overwrite_session_config_for_distributed_training() + logging.info('Not using Distribute Coordinator.') + return + + # Use distribute coordinator with INDEPENDENT_WORKER mode otherwise. + assert tf_config + + # Set the cluster_spec only since the distributed setting will come from + # distribute coordinator. + config._cluster_spec = cluster_spec + config._distribute_coordinator_mode = dc.CoordinatorMode.INDEPENDENT_WORKER + logging.info('RunConfig initialized for Distribute Coordinator with ' + 'INDEPENDENT_WORKER mode') + + +def should_run_distribute_coordinator(config): + """Checks the config to see whether to run distribute coordinator.""" + # pylint: disable=protected-access + if (not hasattr(config, '_distribute_coordinator_mode') or + config._distribute_coordinator_mode is None): + return False + if (not isinstance(config._distribute_coordinator_mode, six.string_types) or + config._distribute_coordinator_mode not in [ + dc.CoordinatorMode.STANDALONE_CLIENT, + dc.CoordinatorMode.INDEPENDENT_WORKER + ]): + logging.warning('Unexpected distribute_coordinator_mode: %r', + config._distribute_coordinator_mode) + return False + if not config.cluster_spec: + logging.warning('Running `train_and_evaluate` locally, ignoring ' + '`experimental_distribute_coordinator_mode`.') + return False + return True + + +def train_and_evaluate(estimator, train_spec, eval_spec, executor_cls): + """Run distribute coordinator for Estimator's `train_and_evaluate`. + + Args: + estimator: An `Estimator` instance to train and evaluate. + train_spec: A `TrainSpec` instance to specify the training specification. + eval_spec: A `EvalSpec` instance to specify the evaluation and export + specification. + executor_cls: the evaluation executor class of Estimator. + + Raises: + ValueError: if `distribute_coordinator_mode` is None in RunConfig. + """ + run_config = estimator.config + if not run_config._distribute_coordinator_mode: # pylint: disable=protected-access + raise ValueError( + 'Distribute coordinator mode is not specified in `RunConfig`.') + + def _worker_fn(strategy): + """Function for worker task.""" + local_estimator = copy.deepcopy(estimator) + # pylint: disable=protected-access + local_estimator._config._train_distribute = strategy + _init_run_config_from_worker_context( + local_estimator._config, dc_context.get_current_worker_context()) + local_estimator._train_distribution = strategy + # pylint: enable=protected-access + + local_estimator.train( + input_fn=train_spec.input_fn, + max_steps=train_spec.max_steps, + hooks=list(train_spec.hooks)) + + def _eval_fn(strategy): + """Function for evaluator task.""" + local_estimator = copy.deepcopy(estimator) + # pylint: disable=protected-access + local_estimator._config._eval_distribute = strategy + _init_run_config_from_worker_context( + local_estimator._config, dc_context.get_current_worker_context()) + local_estimator._eval_distribution = strategy + + executor = executor_cls(local_estimator, train_spec, eval_spec) + executor._start_continuous_evaluation() + # pylint: enable=protected-access + + # pylint: disable=protected-access + if (run_config._distribute_coordinator_mode == + dc.CoordinatorMode.STANDALONE_CLIENT): + cluster_spec = run_config.cluster_spec + assert cluster_spec + else: + # The cluster_spec comes from TF_CONFIG environment variable if it is + # INDEPENDENT_WORKER mode. + cluster_spec = None + + dc.run_distribute_coordinator( + _worker_fn, + run_config.train_distribute, + _eval_fn, + run_config.eval_distribute, + mode=run_config._distribute_coordinator_mode, + cluster_spec=cluster_spec, + session_config=run_config.session_config) diff --git a/tensorflow/python/eager/BUILD b/tensorflow/python/eager/BUILD index de93b1e2e1..6f48d38b58 100644 --- a/tensorflow/python/eager/BUILD +++ b/tensorflow/python/eager/BUILD @@ -47,7 +47,6 @@ py_library( ":core", ":execute", ":function", - ":graph_callable", ":graph_only_ops", ":tape", ":test", @@ -238,6 +237,7 @@ py_library( visibility = ["//tensorflow:internal"], deps = [ ":graph_only_ops", + "//tensorflow/python:cond_v2_impl", "//tensorflow/python:dtypes", "//tensorflow/python:errors", "//tensorflow/python:framework_ops", @@ -254,41 +254,6 @@ py_library( ) py_library( - name = "graph_callable", - srcs = ["graph_callable.py"], - srcs_version = "PY2AND3", - visibility = ["//tensorflow:internal"], - deps = [ - "//tensorflow/python:array_ops", - "//tensorflow/python:dtypes", - "//tensorflow/python:errors", - "//tensorflow/python:framework_ops", - "//tensorflow/python:resource_variable_ops", - "//tensorflow/python:util", - "//tensorflow/python:variable_scope", - "//tensorflow/python/eager:context", - "//tensorflow/python/eager:function", - "//tensorflow/python/eager:tape", - ], -) - -py_test( - name = "graph_callable_test", - srcs = ["graph_callable_test.py"], - srcs_version = "PY2AND3", - deps = [ - ":backprop", - ":graph_callable", - "//tensorflow/python:dtypes", - "//tensorflow/python:function", - "//tensorflow/python:init_ops", - "//tensorflow/python:math_ops", - "//tensorflow/python:variable_scope", - "//tensorflow/python/eager:test", - ], -) - -py_library( name = "backprop", srcs = ["backprop.py"], srcs_version = "PY2AND3", diff --git a/tensorflow/python/eager/backprop.py b/tensorflow/python/eager/backprop.py index 553f761a14..7978383e55 100644 --- a/tensorflow/python/eager/backprop.py +++ b/tensorflow/python/eager/backprop.py @@ -34,6 +34,7 @@ from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_shape from tensorflow.python.ops import array_ops from tensorflow.python.ops import gen_array_ops +from tensorflow.python.ops import gen_math_ops from tensorflow.python.ops import math_ops from tensorflow.python.ops import resource_variable_ops from tensorflow.python.platform import tf_logging as logging @@ -180,10 +181,10 @@ def implicit_val_and_grad(f): ``` Args: - f: function to be differentiated. If `f` returns a scalar, this scalar will - be differentiated. If `f` returns a tensor or list of tensors, by default - a scalar will be computed by adding all their values to produce a single - scalar. + f: function to be differentiated. If `f` returns a scalar, this scalar will + be differentiated. If `f` returns a tensor or list of tensors, by default + a scalar will be computed by adding all their values to produce a single + scalar. Returns: A function which, when called, returns a tuple pair. @@ -255,10 +256,10 @@ def implicit_grad(f): ``` Args: - f: function to be differentiated. If `f` returns a scalar, this scalar will - be differentiated. If `f` returns a tensor or list of tensors, by default - a scalar will be computed by adding all their values to produce a single - scalar. + f: function to be differentiated. If `f` returns a scalar, this scalar will + be differentiated. If `f` returns a tensor or list of tensors, by default + a scalar will be computed by adding all their values to produce a single + scalar. Returns: A function which, when called, returns a list of (gradient, variable) pairs. @@ -343,24 +344,24 @@ def gradients_function(f, params=None): Note that only tensors with real or complex dtypes are differentiable. Args: - f: function to be differentiated. If `f` returns a scalar, this scalar will - be differentiated. If `f` returns a tensor or list of tensors, by default - a scalar will be computed by adding all their values to produce a single - scalar. If desired, the tensors can be elementwise multiplied by the - tensors passed as the `dy` keyword argument to the returned gradient - function. - params: list of parameter names of f or list of integers indexing the - parameters with respect to which we'll differentiate. Passing None - differentiates with respect to all parameters. + f: function to be differentiated. If `f` returns a scalar, this scalar will + be differentiated. If `f` returns a tensor or list of tensors, by default + a scalar will be computed by adding all their values to produce a single + scalar. If desired, the tensors can be elementwise multiplied by the + tensors passed as the `dy` keyword argument to the returned gradient + function. + params: list of parameter names of f or list of integers indexing the + parameters with respect to which we'll differentiate. Passing None + differentiates with respect to all parameters. Returns: function which, when called, returns the value of f and the gradient - of f with respect to all of `params`. The function takes an extra optional - keyword argument "dy". Setting it allows computation of vector jacobian + of `f` with respect to all of `params`. The function takes an extra optional + keyword argument `dy`. Setting it allows computation of vector jacobian products for vectors other than the vector of ones. Raises: - ValueError: if the params are not all strings or all integers. + ValueError: if the params are not all strings or all integers. """ def decorated(*args, **kwds): @@ -440,23 +441,24 @@ def val_and_grad_function(f, params=None): ``` Args: - f: function to be differentiated. If `f` returns a scalar, this scalar will - be differentiated. If `f` returns a tensor or list of tensors, by default - a scalar will be computed by adding all their values to produce a single - scalar. If desired, the tensors can be elementwise multiplied by the - tensors passed as the `dy` keyword argument to the returned gradient - function. - params: list of parameter names of f or list of integers indexing the - parameters with respect to which we'll differentiate. Passing `None` - differentiates with respect to all parameters. - - Returns: function which, when called, returns the value of f and the gradient - of f with respect to all of `params`. The function takes an extra optional - keyword argument "dy". Setting it allows computation of vector jacobian - products for vectors other than the vector of ones. + f: function to be differentiated. If `f` returns a scalar, this scalar will + be differentiated. If `f` returns a tensor or list of tensors, by default + a scalar will be computed by adding all their values to produce a single + scalar. If desired, the tensors can be elementwise multiplied by the + tensors passed as the `dy` keyword argument to the returned gradient + function. + params: list of parameter names of f or list of integers indexing the + parameters with respect to which we'll differentiate. Passing `None` + differentiates with respect to all parameters. + + Returns: + function which, when called, returns the value of f and the gradient + of f with respect to all of `params`. The function takes an extra optional + keyword argument "dy". Setting it allows computation of vector jacobian + products for vectors other than the vector of ones. Raises: - ValueError: if the params are not all strings or all integers. + ValueError: if the params are not all strings or all integers. """ def decorated(*args, **kwds): @@ -557,7 +559,7 @@ def _aggregate_grads(gradients): if len(gradients) == 1: return gradients[0] if all([isinstance(g, ops.Tensor) for g in gradients]): - return math_ops.add_n(gradients) + return gen_math_ops.add_n(gradients) else: assert all([isinstance(g, (ops.Tensor, ops.IndexedSlices)) for g in gradients]) @@ -592,7 +594,9 @@ def _num_elements(grad): def _fast_fill(value, shape, dtype): - return array_ops.fill(shape, constant_op.constant(value, dtype=dtype)) + return array_ops.fill( + constant_op.constant(shape, dtype=dtypes.int32), + constant_op.constant(value, dtype=dtype)) def _zeros(shape, dtype): diff --git a/tensorflow/python/eager/benchmarks_test.py b/tensorflow/python/eager/benchmarks_test.py index e2b1890c2f..a2e8422671 100644 --- a/tensorflow/python/eager/benchmarks_test.py +++ b/tensorflow/python/eager/benchmarks_test.py @@ -350,6 +350,21 @@ class MicroBenchmarks(test.Benchmark): func = lambda: f(m, m, transpose_b) self._run(func, num_iters, execution_mode=execution_mode) + def _benchmark_defun_matmul_forward_backward(self, + m, + transpose_b, + num_iters, + execution_mode=None): + f = function.defun(math_ops.matmul) + + def func(): + with backprop.GradientTape() as gt: + gt.watch(m) + y = f(m, m, transpose_b) + _ = gt.gradient(y, m) + + self._run(func, num_iters, execution_mode=execution_mode) + def _benchmark_read_variable(self, m, num_iters): self._run(m.value, num_iters) @@ -421,6 +436,21 @@ class MicroBenchmarks(test.Benchmark): num_iters=self._num_iters_2_by_2, execution_mode=context.ASYNC) + def benchmark_defun_matmul_forward_backward_2_by_2_CPU(self): + with context.device(CPU): + m = self._m_2_by_2.cpu() + self._benchmark_defun_matmul_forward_backward( + m, transpose_b=False, num_iters=self._num_iters_2_by_2) + + def benchmark_defun_matmul_forward_backward_2_by_2_CPU_async(self): + with context.device(CPU): + m = self._m_2_by_2.cpu() + self._benchmark_defun_matmul_forward_backward( + m, + transpose_b=False, + num_iters=self._num_iters_2_by_2, + execution_mode=context.ASYNC) + def benchmark_tf_matmul_2_by_2_GPU(self): if not context.num_gpus(): return diff --git a/tensorflow/python/eager/context.py b/tensorflow/python/eager/context.py index 6a327bd010..13fb0e88a6 100644 --- a/tensorflow/python/eager/context.py +++ b/tensorflow/python/eager/context.py @@ -504,9 +504,7 @@ class Context(object): Args: fn: A wrapped TF_Function (returned from TF_GraphToFunction_wrapper). """ - pywrap_tensorflow.TFE_ContextAddFunction( - self._handle, # pylint: disable=protected-access - fn) + pywrap_tensorflow.TFE_ContextAddFunction(self._handle, fn) def add_function_def(self, fdef): """Add a function definition to the context. @@ -519,9 +517,7 @@ class Context(object): """ fdef_string = fdef.SerializeToString() pywrap_tensorflow.TFE_ContextAddFunctionDef( - self._handle, # pylint: disable=protected-access - fdef_string, - len(fdef_string)) + self._handle, fdef_string, len(fdef_string)) def add_post_execution_callback(self, callback): """Add a post-execution callback to the context. @@ -633,14 +629,7 @@ def context(): def context_safe(): - return _context - - -# TODO(agarwal): remove this. -def get_default_context(): - """Same as context.""" - if _context is None: - _initialize_context() + """Returns current context (or None if one hasn't been initialized).""" return _context diff --git a/tensorflow/python/eager/core_test.py b/tensorflow/python/eager/core_test.py index cc765725a4..cbd6f4cb75 100644 --- a/tensorflow/python/eager/core_test.py +++ b/tensorflow/python/eager/core_test.py @@ -18,6 +18,8 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import os +import pickle import threading import numpy as np @@ -185,6 +187,17 @@ class TFETest(test_util.TensorFlowTestCase): device_count={'GPU': 0})) self.assertEquals(0, ctx.num_gpus()) + def testPickle(self): + tmp_dir = self.get_temp_dir() + fname = os.path.join(tmp_dir, 't.pickle') + with open(fname, 'wb') as f: + t = constant_op.constant(10.0) + pickle.dump(t, f) + + with open(fname, 'rb') as f: + t = pickle.load(f) + self.assertAllEqual(t.numpy(), 10.0) + def testTensorPlacement(self): if not context.context().num_gpus(): self.skipTest('No GPUs found') diff --git a/tensorflow/python/eager/execution_callbacks.py b/tensorflow/python/eager/execution_callbacks.py index 9a08259653..80ff4459d6 100644 --- a/tensorflow/python/eager/execution_callbacks.py +++ b/tensorflow/python/eager/execution_callbacks.py @@ -146,7 +146,7 @@ def inf_nan_callback(op_type, """ del attrs, inputs # Not used. - ctx = context.get_default_context() + ctx = context.context() for index, output in enumerate(outputs): if not output.dtype.is_numpy_compatible: @@ -263,12 +263,12 @@ def add_execution_callback(callback): Return value(s) from the callback are ignored. """ execute.execute = execute.execute_with_callbacks - context.get_default_context().add_post_execution_callback(callback) + context.context().add_post_execution_callback(callback) def clear_execution_callbacks(): """Clear all execution callbacks from the default eager context.""" - context.get_default_context().clear_post_execution_callbacks() + context.context().clear_post_execution_callbacks() def seterr(inf_or_nan=None): @@ -309,7 +309,7 @@ def seterr(inf_or_nan=None): "Valid actions are %s." % (inf_or_nan, _VALID_CALLBACK_ACTIONS)) old_settings = {"inf_or_nan": "ignore"} - default_context = context.get_default_context() + default_context = context.context() carryover_callbacks = [] for callback in default_context.post_execution_callbacks: diff --git a/tensorflow/python/eager/function.py b/tensorflow/python/eager/function.py index 5afba466bc..6c87dccaf1 100644 --- a/tensorflow/python/eager/function.py +++ b/tensorflow/python/eager/function.py @@ -21,12 +21,12 @@ from __future__ import print_function import collections import functools +import sys import threading import numpy as np import six -from tensorflow.core.framework import attr_value_pb2 from tensorflow.core.framework import function_pb2 from tensorflow.python import pywrap_tensorflow from tensorflow.python.eager import context @@ -34,10 +34,12 @@ from tensorflow.python.eager import execute from tensorflow.python.eager import tape from tensorflow.python.eager.graph_only_ops import graph_placeholder from tensorflow.python.framework import c_api_util +from tensorflow.python.framework import device as pydev from tensorflow.python.framework import dtypes as dtypes_module from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_spec from tensorflow.python.ops import array_ops +from tensorflow.python.ops import cond_v2_impl from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import functional_ops from tensorflow.python.ops import gradients_impl @@ -49,6 +51,10 @@ from tensorflow.python.util import nest from tensorflow.python.util import tf_decorator from tensorflow.python.util import tf_inspect +# This is to avoid a circular dependency with cond_v2_impl +# (function -> gradients_impl -> control_flow_ops -> cond_v2_impl). +cond_v2_impl._function = sys.modules[__name__] # pylint: disable=protected-access + def create_substitute_placeholder(value, name, dtype=None): """Creates a placeholder for `value` and propagates shape info to it.""" @@ -113,10 +119,6 @@ class CapturingGraph(ops.Graph): # for resource tensors. self._last_op_using_resource_tensor = {} - # TODO(apassos) remove once the C API is used by default. - def _use_c_api_hack(self): - return True - def clear_resource_control_flow_state(self): self._last_op_using_resource_tensor = {} @@ -180,12 +182,19 @@ class CapturingGraph(ops.Graph): compute_device=compute_device) +def _get_device_functions(ctx, graph): + """Returns a tuple of device functions representing the device stack.""" + if ctx.executing_eagerly(): + return (pydev.merge_device(ctx.device_name),) + else: + return tuple(graph._device_functions_outer_to_inner) # pylint: disable=protected-access + + class FuncGraph(CapturingGraph): """Graph representing a function body. Attributes: name: The name of the function. - inputs: Placeholder tensors representing the inputs to this function. The tensors are in this FuncGraph. This represents "regular" inputs as well as captured inputs (i.e. the values of self.captures), with the regular @@ -196,16 +205,19 @@ class FuncGraph(CapturingGraph): by this function. The Tensors in this structure are the same as those of self.outputs. Note that this structure might contain Python `None`s. variables: Variables that should be watched during function execution. + outer_graph: The graph this function is defined in. May be another FuncGraph + or the global default Graph. seed: The graph-level random seed. """ - def __init__(self, name, graph=None): + def __init__(self, name): """Construct a new FuncGraph. + The graph will inherit its graph key, collections, seed, device stack, and + distribution strategy stack from the current context or graph. + Args: name: the name of the function. - graph: if specified, this FuncGraph will inherit its graph key, - collections, and seed from `graph`. """ super(FuncGraph, self).__init__() @@ -214,27 +226,34 @@ class FuncGraph(CapturingGraph): self.outputs = [] self.structured_outputs = None self.variables = [] + self.outer_graph = ops.get_default_graph() - if graph is not None: - # Inherit the graph key, since this is used for matching variables in - # optimizers. - self._graph_key = graph._graph_key # pylint: disable=protected-access - - # Copy the graph collections to ensure summaries and other things work. - # This lets the function access (but not mutate) collections of the - # containing graph, such as the global step and the summary writer - # collections. - for collection in graph.collections: - self.get_collection_ref(collection)[:] = graph.get_collection( - collection) - - # Copy distribution strategy scope from the containing graph as well. - self._distribution_strategy_stack = graph._distribution_strategy_stack # pylint: disable=protected-access + graph = self.outer_graph - if context.executing_eagerly(): - self.seed = context.global_seed() - else: - self.seed = graph.seed + if context.executing_eagerly(): + self.seed = context.global_seed() + self._xla_compile = (context.context().device_spec.device_type == "TPU") + self._add_device_to_stack(context.context().device_name) + else: + self.seed = graph.seed + self._xla_compile = getattr(graph, "_xla_compile", False) + self._device_function_stack = graph._device_function_stack.copy() # pylint: disable=protected-access + self._colocation_stack = graph._colocation_stack.copy() # pylint: disable=protected-access + + # TODO(b/112165328, b/112906995): summaries depend on inheriting collections + # from the default graph even in eager mode. It'd be nice to not have a + # default graph with eager execution, so hopefully this will go away when we + # remove collections. + # pylint: disable=protected-access + self._collections = graph._collections + # TODO(b/112906995): distribution strategy depends on inheriting this stack + # from the default graph even in eager mode. Maybe it should be part of the + # eager context? + self._distribution_strategy_stack = graph._distribution_strategy_stack + # Inherit the graph key, since this is used for matching variables in + # optimizers. + self._graph_key = graph._graph_key + # pylint: enable=protected-access def capture(self, tensor, name=None): """Calls CapturingGraph.capture and updates self.inputs if necessary.""" @@ -246,6 +265,16 @@ class FuncGraph(CapturingGraph): return internal_tensor + @property + def external_captures(self): + """External tensors captured by this function.""" + return list(self.captures.keys()) + + @property + def internal_captures(self): + """Placeholders in this function corresponding captured tensors.""" + return list(self.captures.values()) + def _forward_name(n): """The name of a generated forward defun named n.""" @@ -267,9 +296,6 @@ def _register(fn): context.context().add_function(fn) -_xla_compile_attr = "_XlaCompile" - - # TODO(apassos) get rid of this by splitting framework.function._DefinedFunction # so it doesn't have the definition-generating logic and is just a container for # an already-defined function. @@ -282,18 +308,20 @@ class _EagerDefinedFunction(object): class may be provided as the value of these `func` attributes. """ - def __init__(self, name, graph, operations, inputs, outputs, attrs): + def __init__(self, name, graph, inputs, outputs, attrs): """Initializes an eager defined function. Args: name: str, the name for the created function. graph: Graph, the graph containing the operations in the function - operations: list of Operation; the subset of operations in the graph - which will be in the function inputs: the tensors in the graph to be used as inputs to the function outputs: the tensors in the graph which will be outputs to the function attrs: dict mapping names of attributes to their AttrValue values """ + operations = [ + op for op in graph.get_operations() + if op not in set(arg.op for arg in inputs) + ] fn = pywrap_tensorflow.TF_GraphToFunction_wrapper( graph._c_graph, # pylint: disable=protected-access compat.as_str(name), @@ -311,7 +339,6 @@ class _EagerDefinedFunction(object): # It might be worth creating a convenient way to re-use status. pywrap_tensorflow.TF_FunctionSetAttrValueProto( fn, compat.as_str(name), serialized) - self._xla_compile = _xla_compile_attr in attrs # TODO(apassos) avoid creating a FunctionDef (specially to grab the # signature, but also in general it's nice not to depend on it. @@ -327,6 +354,7 @@ class _EagerDefinedFunction(object): self.signature = function_def.signature self._num_outputs = len(self.signature.output_arg) self._output_types = [o.type for o in self.signature.output_arg] + self._output_shapes = [o.shape for o in outputs] self.grad_func_name = None self.python_grad_func = None self._c_func = c_api_util.ScopedTFFunction(fn) @@ -347,7 +375,7 @@ class _EagerDefinedFunction(object): def stateful_ops(self): return self._stateful_ops - def call(self, ctx, args, output_shapes): + def call(self, ctx, args): """Calls this function with `args` as inputs. Function execution respects device annotations only if the function won't @@ -356,8 +384,6 @@ class _EagerDefinedFunction(object): Args: ctx: a Context object args: a list of arguments to supply this function with. - output_shapes: shapes to which outputs should be set; ignored when - executing eagerly. Returns: The outputs of the function call. @@ -365,10 +391,7 @@ class _EagerDefinedFunction(object): executing_eagerly = ctx.executing_eagerly() - xla_compile = self._xla_compile or (executing_eagerly and - ctx.device_spec.device_type == "TPU") - - if xla_compile: + if self._graph._xla_compile: # pylint: disable=protected-access # XLA compilation relies upon a custom kernel creator to run functions. signature = self.signature if executing_eagerly: @@ -406,7 +429,7 @@ class _EagerDefinedFunction(object): if executing_eagerly: return outputs else: - for i, shape in enumerate(output_shapes): + for i, shape in enumerate(self._output_shapes): outputs[i].set_shape(shape) return outputs @@ -427,179 +450,117 @@ def _flatten(sequence): return outputs -# TODO(akshayka): Perhaps rename to something more appropriate. -class GraphModeFunction(object): +class Function(object): """Callable object encapsulating a function definition and its gradient. - `GraphModeFunction` is a callable that encapsulates a function definition and + `Function` is a callable that encapsulates a function definition and is differentiable under `tf.GradientTape` objects. """ - def __init__(self, - name, - input_placeholders, - extra_inputs, - graph, - operations, - outputs, - python_func_outputs, - output_shapes, - variables=None, - attrs=None): - """Initialize a GraphModeFunction. + def __init__(self, func_graph, attrs=None): + """Initialize a Function. Args: - name: str the name of the created function - input_placeholders: list of placeholder values (tensors) to feed when - calling the wrapped function. - extra_inputs: Tensor inputs this function definition closed over which - are passed as arguments. Need to track so gradients are supported - correctly. - graph: the Graph from which the operations will be pulled. Used as - a context when computing gradients. - operations: the subset of Operations in the graph used in the function - definition. - outputs: a flat list of the Tensors in the graph used as outputs to the - function - python_func_outputs: a possibly nested python object which will be - returned by this function. The Tensors in this structure will be - replaced by their corresponding values in outputs. Note that this - structure might contain Python `None`s. - output_shapes: List of shapes of all tensors in outputs - variables: (optional) List of variables to watch during function - execution. + func_graph: An instance of FuncGraph: the function body to wrap. attrs: (optional) dict mapping names of attributes to their AttrValue values. Attributes in `attrs` will be included in this function's definition. + + Raises: + ValueError: If number of input_placeholders is not equal to the number + of function inputs. """ + self._func_graph = func_graph + self._captured_inputs = list(self._func_graph.captures.keys()) + self._num_outputs = len(self._func_graph.outputs) + self._output_shapes = tuple( + output.shape for output in self._func_graph.outputs) self._attrs = attrs or {} - defined_function = _EagerDefinedFunction( - name, graph, operations, input_placeholders, outputs, self._attrs) - if len(input_placeholders) != len(defined_function.signature.input_arg): - raise ValueError("Internal error: invalid lengths. %s %s" % ( - len(input_placeholders), len(defined_function.signature.input_arg))) - self._input_placeholders = input_placeholders - self._extra_inputs = list(extra_inputs) - self._graph = graph - self._backward_function = None - self._func_name = name - self._function_def = defined_function - self._num_outputs = len(defined_function.signature.output_arg) - self._python_func_outputs = python_func_outputs - self._python_returns = [python_func_outputs] if isinstance( - python_func_outputs, - (ops.Tensor, type(None))) else _flatten(python_func_outputs) - self._output_shapes = output_shapes - self._variables = variables if variables is not None else [] - - # Find the variables that are components of something distributed and - # put them into a {handle_tensor -> distributed variable object} map. + self._device_functions = tuple( + self._func_graph._device_functions_outer_to_inner) # pylint: disable=protected-access + + self._inference_function = _EagerDefinedFunction( + _inference_name(self._func_graph.name), self._func_graph, + self._func_graph.inputs, self._func_graph.outputs, self._attrs) + self._backward_graph_function = None + + # Map holding distributed variables, keyed by resource handle tensors. self._distributed_variables = {} strategy = distribution_strategy_context.get_distribution_strategy() - for variable in self._variables: + for variable in self._func_graph.variables: # If variable is not distributed, unwrap returns [variable]. component_variables = strategy.unwrap(variable) - # Only add to the dictionary when the variable is actually distributed, - # i.e. more than one component or the component is different from the - # variable itself. component_variables cannot be empty. + # Only update the dictionary when the variable is actually distributed. if (len(component_variables) > 1 or component_variables[0] != variable): for component_variable in component_variables: self._distributed_variables[component_variable.handle] = variable - @property - def variables(self): - return self._variables + def __call__(self, *args): + """Executes the wrapped function.""" + ctx = context.context() + device_functions = _get_device_functions(ctx, ops.get_default_graph()) + if device_functions != self._device_functions: + raise ValueError( + "The current device stack does not match the device stack under " + "which the TensorFlow function '%s' was created.\n" + "Current device stack: %s\n%s device stack: %s" % + (self._inference_function.name, device_functions, + self._inference_function.name, self._device_functions)) + + for v in self._func_graph.variables: + if v.trainable: + tape.watch_variable(v) - def _construct_backprop_function(self): - """Constructs the backprop function object for this function.""" - filtered_outputs = [x for x in self._python_returns if x is not None] - # TODO(skyewm): use FuncGraph - backwards_graph = CapturingGraph() - backwards_graph._graph_key = self._graph._graph_key # pylint: disable=protected-access - for collection in self._graph.collections: - backwards_graph.get_collection_ref( - collection)[:] = self._graph.get_collection(collection) - backwards_graph.seed = self._graph.seed - with backwards_graph.as_default(): - self._out_grad_placeholders = [ - graph_placeholder(x.dtype, x.shape) for x in filtered_outputs] - in_gradients = gradients_impl._GradientsHelper( # pylint: disable=protected-access - filtered_outputs, - self._input_placeholders, - grad_ys=self._out_grad_placeholders, - src_graph=self._graph) - - backward_outputs = tuple( - grad for grad in _flatten(in_gradients) if grad is not None) - output_shapes = tuple(grad.shape for grad in backward_outputs) - - extra_inputs = backwards_graph.captures.keys() - extra_placeholders = backwards_graph.captures.values() - - forward_name = _forward_name(self._func_name) - # Note: we cannot have placeholder ops in the graph or the TPU compilation - # pass fails. - placeholder_ops = set([y.op for y in self._input_placeholders]) - function_ops = [x for x in self._graph.get_operations() - if x not in placeholder_ops] - self._forward_fdef = _EagerDefinedFunction( - forward_name, self._graph, function_ops, - self._input_placeholders, filtered_outputs + list(extra_inputs), - self._attrs) - all_inputs = self._out_grad_placeholders + list(extra_placeholders) - # Excluding input ops from the body as we do not intend to execute these - # operations when the function is executed. - all_ignored_ops = frozenset(x.op for x in all_inputs) - # Enforce a deterministic order of operations in the generated graph. This - # means rerunning the function-defining code will always define the same - # function, which is useful if we serialize this etc. - function_def_ops = tuple(x - for x in sorted(backwards_graph.get_operations(), - key=lambda x: x.name) - if x not in all_ignored_ops) - bname = _backward_name(self._func_name) - self._backward_function = GraphModeFunction( - bname, all_inputs, [], backwards_graph, function_def_ops, - backward_outputs, in_gradients, output_shapes, attrs=self._attrs) + captures = self._resolve_captured_inputs() + tensor_inputs = [x for x in nest.flatten(args) if isinstance(x, ops.Tensor)] + args = tensor_inputs + captures - def _backprop_call(self, args): - """Calls the wrapped function and records the result on a tape. + if tape.should_record(tensor_inputs) or tape.should_record(captures): + return self._backprop_call(args) - (Only records results on a tape if the function has outputs) + outputs = self._inference_function.call(ctx, args) + return self._build_call_outputs(outputs) - Args: - args: All inputs to the function, including resolved extra inputs - Returns: - The call output. - """ - ctx = context.context() - outputs = self._forward_fdef.call(ctx, args, self._output_shapes) - if isinstance(outputs, ops.Operation) or outputs is None: - return outputs + @property + def graph(self): + """Returns the graph from which this function was constructed.""" + return self._func_graph - # `real_outputs` are the actual outputs of the inference graph function; - # `side_outputs` are the intermediate Tensors that were added as outputs to - # the forward graph function so that we can compute its gradient. - real_outputs = outputs[:self._num_outputs] - side_outputs = outputs[self._num_outputs:] + @property + def variables(self): + """Returns all variables touched by this function.""" + return self._func_graph.variables - def backward_function(*args): - return self._backward_function(*(list(args) + side_outputs)) # pylint: disable=not-callable + @property + def inputs(self): + """Returns tensors in `self.graph` corresponding to arguments.""" + return self._func_graph.inputs - tape.record_operation( - self._forward_fdef.signature.name, - real_outputs, - args, - backward_function) + @property + def outputs(self): + """Returns tensors in `self.graph` corresponding to return values.""" + return self._func_graph.outputs - return self._build_call_outputs(real_outputs) + @property + def captured_inputs(self): + """Returns external Tensors captured by this function. + + self.__call__(*args) passes `args + self.captured_inputs` to the function. + """ + return self._captured_inputs + + @property + def function_def(self): + """Returns a `FunctionDef` object representing this function.""" + return self._inference_function.definition @property def output_shapes(self): """The function's output shapes.""" # TODO(ebrevdo): Should we only keep the output shapes associated # with len(self._python_returns) outputs? - outputs_list = nest.flatten(self._python_func_outputs) + # TODO(akshayka): Consider removing this. + outputs_list = nest.flatten(self._func_graph.structured_outputs) j = 0 for i, o in enumerate(outputs_list): if o is not None: @@ -613,23 +574,80 @@ class GraphModeFunction(object): else: outputs_list[i] = self._output_shapes[j] j += 1 - return nest.pack_sequence_as(self._python_func_outputs, outputs_list) + return nest.pack_sequence_as(self._func_graph.structured_outputs, + outputs_list) @property def output_dtypes(self): - return nest.map_structure( - lambda x: x.dtype if x is not None else None, self._python_func_outputs) + # TODO(akshayka): Consider removing this. + return nest.map_structure(lambda x: x.dtype if x is not None else None, + self._func_graph.structured_outputs) - @property - def captured_inputs(self): - return self._extra_inputs + def _construct_backprop_function(self): + """Constructs the backprop function object for this function.""" + backwards_graph = FuncGraph(_backward_name(self._func_graph.name)) + with backwards_graph.as_default(): + gradients_wrt_outputs = [ + graph_placeholder(x.dtype, x.shape) for x in self._func_graph.outputs + ] + gradients_wrt_inputs = gradients_impl._GradientsHelper( # pylint: disable=protected-access + self._func_graph.outputs, + self._func_graph.inputs, + grad_ys=gradients_wrt_outputs, + src_graph=self._func_graph) + + self._forward_function = _EagerDefinedFunction( + _forward_name( + self._func_graph.name), self._func_graph, self._func_graph.inputs, + self._func_graph.outputs + list(backwards_graph.captures.keys()), + self._attrs) - @property - def name(self): - """Returns the name of the function in Eager-compatible format.""" - return self._function_def.name.encode("utf-8") + # The ordering of `backwards_graph.inputs` is important: inputs of + # `self._backward_graph_function` correspond to outputs of + # `self._forward_function`. + backwards_graph.inputs = gradients_wrt_outputs + list( + backwards_graph.captures.values()) + # Clear captures, since we pass them in as inputs. + backwards_graph.captures = {} + backwards_graph.outputs.extend( + grad for grad in _flatten(gradients_wrt_inputs) if grad is not None) + backwards_graph.structured_outputs = gradients_wrt_inputs + self._backward_graph_function = Function( + backwards_graph, attrs=self._attrs) + + def _backprop_call(self, args): + """Calls the forward function and records the result on a tape. + + (Only records results on a tape if the function has outputs) + + Args: + args: All inputs to the function, including resolved captured inputs + + Returns: + The call output. + """ + if self._backward_graph_function is None: + self._construct_backprop_function() + + ctx = context.context() + outputs = self._forward_function.call(ctx, args) + if isinstance(outputs, ops.Operation) or outputs is None: + return outputs + + # `real_outputs` are the actual outputs of the inference graph function; + # `side_outputs` are the intermediate Tensors that were added as outputs to + # the forward graph function so that we can compute its gradient. + real_outputs = outputs[:self._num_outputs] + side_outputs = outputs[self._num_outputs:] + + def backward_function(*args): + return self._backward_graph_function(*(list(args) + side_outputs)) # pylint: disable=not-callable - def _resolve_extra_inputs(self): + tape.record_operation(self._forward_function.signature.name, real_outputs, + args, backward_function) + return self._build_call_outputs(real_outputs) + + def _resolve_captured_inputs(self): """Resolve captured distributed variables to their current values. Some inputs can be distributed variables. Such variables yield a different @@ -637,44 +655,23 @@ class GraphModeFunction(object): execution. Returns: - a list of resolved extra input tensors. + a list of resolved captured input tensors. """ if self._distributed_variables: - # Loop over each extra_inputs and check if it corresponds to something + # Loop over each captured input and check if it corresponds to something # distributed. If so, get its _distributed_container and fetch the # component appropriate for the current execution context. - resolved_extra_inputs = self._extra_inputs[:] - for i, extra_input in enumerate(self._extra_inputs): - distributed_var = self._distributed_variables.get(extra_input, None) + resolved_captured_inputs = self._captured_inputs[:] + for i, captured_input in enumerate(self._captured_inputs): + distributed_var = self._distributed_variables.get(captured_input, None) if distributed_var is not None: # distributed variables override __getattr__ and substitute the # right component variable. In here, `distributed_var.handle` # actually does the equivalent of # distributed_var.get_current_component_var().handle. - resolved_extra_inputs[i] = distributed_var.handle - return resolved_extra_inputs - - return self._extra_inputs - - def __call__(self, *args): - """Executes the passed function in eager mode.""" - for v in self._variables: - if v.trainable: - tape.watch_variable(v) - - resolved_extra_inputs = self._resolve_extra_inputs() - - tensor_inputs = [x for x in nest.flatten(args) if isinstance(x, ops.Tensor)] - args = tensor_inputs + resolved_extra_inputs - if tape.should_record(tensor_inputs) or tape.should_record( - resolved_extra_inputs): - if self._backward_function is None: - self._construct_backprop_function() - return self._backprop_call(args) - - ctx = context.context() - outputs = self._function_def.call(ctx, args, self._output_shapes) - return self._build_call_outputs(outputs) + resolved_captured_inputs[i] = distributed_var.handle + return resolved_captured_inputs + return self._captured_inputs def _build_call_outputs(self, result): """Maps the fdef output list to actual output structure. @@ -684,12 +681,12 @@ class GraphModeFunction(object): Returns: The actual call output. """ - if self._python_func_outputs is None: + if self._func_graph.structured_outputs is None: return result # Use `nest.flatten` instead of `_flatten` in order to preserve any - # IndexedSlices in `self._python_func_outputs`. - outputs_list = nest.flatten(self._python_func_outputs) + # IndexedSlices in `self._func_graph.structured_outputs`. + outputs_list = nest.flatten(self._func_graph.structured_outputs) j = 0 for i, o in enumerate(outputs_list): if o is not None: @@ -703,13 +700,13 @@ class GraphModeFunction(object): j += 3 else: outputs_list[i] = ops.IndexedSlices( - values=result[j], - indices=result[j + 1]) + values=result[j], indices=result[j + 1]) j += 2 else: outputs_list[i] = result[j] j += 1 - ret = nest.pack_sequence_as(self._python_func_outputs, outputs_list) + ret = nest.pack_sequence_as(self._func_graph.structured_outputs, + outputs_list) return ret @@ -725,20 +722,18 @@ def _get_defun_inputs_from_signature(signature): def _get_defun_inputs_from_args(args): """Maps python function args to graph-construction inputs.""" function_inputs = [ - graph_placeholder(arg.dtype, arg.shape) if isinstance(arg, ops.Tensor) - else arg for arg in nest.flatten(args) + graph_placeholder(arg.dtype, arg.shape) + if isinstance(arg, ops.Tensor) else arg for arg in nest.flatten(args) ] return nest.pack_sequence_as(args, function_inputs) -def _trace_and_define_function(name, python_func, compiled, args, kwds, - signature=None): - """Defines and returns graph-mode version of `python_func`. +def func_graph_from_py_func(name, python_func, args, kwds, signature=None): + """Returns a `FuncGraph` generated from `python_func`. Args: name: an identifier for the function. python_func: the Python function to trace. - compiled: whether the graph function should be compiled through XLA. args: the positional args with which the Python function should be called; ignored if a signature is provided. kwds: the keyword args with which the Python function should be called; @@ -750,14 +745,13 @@ def _trace_and_define_function(name, python_func, compiled, args, kwds, inputs. Returns: - A GraphModeFunction. + A FuncGraph. Raises: TypeError: If any of `python_func`'s return values is neither `None` nor a `Tensor`. """ - func_graph = FuncGraph(_inference_name(name), graph=ops.get_default_graph()) - + func_graph = FuncGraph(name) with func_graph.as_default(), AutomaticControlDependencies() as a: variable_scope.get_variable_scope().set_use_resource(True) @@ -771,8 +765,7 @@ def _trace_and_define_function(name, python_func, compiled, args, kwds, # Note: `nest.flatten` sorts by keys, as does `_deterministic_dict_values`. func_graph.inputs.extend( x for x in nest.flatten(func_args) + nest.flatten(func_kwds) - if isinstance(x, ops.Tensor) - ) + if isinstance(x, ops.Tensor)) # Variables to help check whether mutation happens in calling the function # Copy the recursive list, tuple and map structure, but not base objects @@ -797,6 +790,7 @@ def _trace_and_define_function(name, python_func, compiled, args, kwds, this_tape = tape.push_new_tape() try: func_outputs = python_func(*func_args, **func_kwds) + # invariant: `func_outputs` contains only Tensors and `None`s. func_outputs = nest.map_structure(convert, func_outputs) def check_mutation(n1, n2): @@ -816,53 +810,34 @@ def _trace_and_define_function(name, python_func, compiled, args, kwds, check_mutation(func_args_before, func_args) check_mutation(func_kwds_before, func_kwds) - finally: tape.pop_tape(this_tape) + func_graph.structured_outputs = func_outputs + # Returning a closed-over tensor does not trigger convert_to_tensor. + func_graph.outputs.extend( + func_graph.capture(x) + for x in _flatten(func_graph.structured_outputs) + if x is not None) + + # Some captured variables might be components of DistributedValues. + # Instead of storing non-distributed component variables, we + # store their distributed containers so we can retrieve the correct + # component variables at call-time. variables = list(this_tape.watched_variables()) - - # Some variables captured by the tape can come from a DistributedValue. - # At call time, DistributedValue can return another variable (e.g. if - # the function is run on a different device). Thus, instead of storing - # the specific captured variable, we replace it with its distributed - # container. strategy = distribution_strategy_context.get_distribution_strategy() for i, variable in enumerate(variables): # If variable is not distributed value_container returns itself. variables[i] = strategy.value_container(variable) - func_graph.variables = variables - # Returning a closed-over tensor as an output does not trigger a - # call to convert_to_tensor, so we manually capture all such tensors. - func_graph.outputs.extend( - func_graph.capture(x) for x in _flatten(func_graph.structured_outputs) - if x is not None - ) - - output_shapes = tuple( - x.shape if isinstance(x, ops.Tensor) else None - for x in func_graph.outputs) - - all_ignored_ops = frozenset(x.op for x in func_graph.inputs) - operations = tuple(x for x in func_graph.get_operations() - if x not in all_ignored_ops) - # Register any other functions defined in the graph - # TODO(ashankar): Oh lord, forgive me for this lint travesty. + # Register any other functions defined in the graph. if context.executing_eagerly(): for f in func_graph._functions.values(): # pylint: disable=protected-access # TODO(ashankar): What about the gradient registry? _register(f._c_func.func) # pylint: disable=protected-access - attrs = {} - if compiled: - attrs[_xla_compile_attr] = attr_value_pb2.AttrValue(b=True) - - return GraphModeFunction( - func_graph.name, func_graph.inputs, func_graph.captures.keys(), - func_graph, operations, func_graph.outputs, func_graph.structured_outputs, - output_shapes, func_graph.variables, attrs) + return func_graph _TensorType = collections.namedtuple("_TensorType", ["dtype", "shape"]) @@ -911,13 +886,13 @@ def _deterministic_dict_values(dictionary): return tuple(dictionary[key] for key in sorted(dictionary)) -class _PolymorphicFunction(object): +class PolymorphicFunction(object): """Wrapper class for the graph functions defined for a Python function. See the documentation for `defun` for more information on the semantics of defined functions. - _PolymorphicFunction class is thread-compatible meaning that minimal + PolymorphicFunction class is thread-compatible meaning that minimal usage of defuns (defining and calling) is thread-safe, but if users call other methods or invoke the base `python_function` themselves, external synchronization is necessary. @@ -926,8 +901,7 @@ class _PolymorphicFunction(object): def __init__(self, python_function, name, - input_signature=None, - compiled=False): + input_signature=None): """Initializes a polymorphic function. Args: @@ -936,14 +910,10 @@ class _PolymorphicFunction(object): input_signature: a possibly nested sequence of `TensorSpec` objects specifying the input signature of this function. If `None`, a separate function is instantiated for each inferred input signature. - compiled: if True, the framework will attempt to compile func with XLA. Raises: ValueError: if `input_signature` is not None and the `python_function`'s argspec has keyword arguments. - TypeError: if `input_signature` contains anything other than - `TensorSpec` objects, or (if not None) is anything other than a tuple or - list. """ if isinstance(python_function, functools.partial): @@ -955,8 +925,7 @@ class _PolymorphicFunction(object): self._args_to_prepend = tuple() self._kwds_to_include = {} self._name = name - self._compiled = compiled - self._arguments_to_functions = {} + self._function_cache = collections.OrderedDict() self._variables = [] self._lock = threading.Lock() @@ -991,15 +960,40 @@ class _PolymorphicFunction(object): self._input_signature = tuple(input_signature) self._flat_input_signature = tuple(nest.flatten(input_signature)) - if any(not isinstance(arg, tensor_spec.TensorSpec) - for arg in self._flat_input_signature): - raise TypeError("Invalid input_signature %s; input_signature must be " - "a possibly nested sequence of TensorSpec objects.") + + def __call__(self, *args, **kwds): + """Calls a graph function specialized to the inputs.""" + graph_function, inputs = self._maybe_define_function(*args, **kwds) + return graph_function(*inputs) + + @property + def python_function(self): + """Returns the wrapped Python function.""" + return self._python_function + + # TODO(akshayka): Remove this property. + @property + def variables(self): + """Returns the union of all variables referenced by cached `Function`s`.""" + return self._variables + + def get_concrete_function(self, *args, **kwargs): + """Returns a `Function` object specialized to inputs and execution context. + + `args` and `kwargs` are ignored if this `PolymorphicFunction` was created + with an `input_signature`. + + Args: + *args: inputs to specialize on. + **kwargs: inputs to specialize on. + """ + graph_function, _ = self._maybe_define_function(*args, **kwargs) + return graph_function def __get__(self, instance, owner): """Makes it possible to defun instance methods.""" del owner - # `instance` here is the instance that this `_PolymorphicFunction` was + # `instance` here is the instance that this `PolymorphicFunction` was # accessed through; e.g., for # # class Foo(object): @@ -1009,29 +1003,42 @@ class _PolymorphicFunction(object): # ... # # foo = Foo() - # foo.bar() # `foo.bar` is a `_PolymorphicFunction` instance + # foo.bar() # `foo.bar` is a `PolymorphicFunction` instance # # then `instance` will be `foo` (and `owner` will be `Foo`). return functools.partial(self.__call__, instance) - def _cache_key(self, args, kwds): - """Computes the cache key given inputs.""" + def _cache_key(self, args, kwds, ctx, graph): + """Computes the cache key given inputs and execution context.""" if self._input_signature is None: inputs = (args, kwds) if kwds else args cache_key = tuple(_encode_arg(arg) for arg in inputs) else: del args, kwds cache_key = self._flat_input_signature + # The graph, or whether we're executing eagerly, should be a part of the # cache key so we don't improperly capture tensors such as variables. - return cache_key + (context.executing_eagerly() or ops.get_default_graph(),) + executing_eagerly = ctx.executing_eagerly() + execution_context = executing_eagerly or graph + + # Putting the device in the cache key ensures that call-site device + # annotations are respected. + device_functions = _get_device_functions(ctx, graph) + + # `ops.colocate_with` directives translate into `ops.device` directives when + # eager execution is enabled. + colocation_stack = (None if executing_eagerly else + tuple(graph._colocation_stack.peek_objs())) # pylint: disable=protected-access + + return cache_key + (execution_context, device_functions, colocation_stack) def _canonicalize_function_inputs(self, *args, **kwds): """Canonicalizes `args` and `kwds`. Canonicalize the inputs to the Python function using its fullargspec. In particular, we parse the varags and kwargs that this - `_PolymorphicFunction` was called with into a tuple corresponding to the + `PolymorphicFunction` was called with into a tuple corresponding to the Python function's positional (named) arguments and a dictionary corresponding to its kwargs. @@ -1085,8 +1092,9 @@ class _PolymorphicFunction(object): if any(not isinstance(arg, ops.Tensor) for arg in flat_inputs): raise ValueError("When input_signature is provided, all inputs to " "the Python function must be Tensors.") - tensor_specs = [tensor_spec.TensorSpec.from_tensor(tensor) - for tensor in flat_inputs] + tensor_specs = [ + tensor_spec.TensorSpec.from_tensor(tensor) for tensor in flat_inputs + ] if any(not spec.is_compatible_with(other) for spec, other in zip(self._flat_input_signature, tensor_specs)): raise ValueError("Python inputs incompatible with input_signature: " @@ -1111,42 +1119,33 @@ class _PolymorphicFunction(object): """ args, kwds = self._canonicalize_function_inputs(*args, **kwds) - cache_key = self._cache_key(args, kwds) + cache_key = self._cache_key(args, kwds, context.context(), + ops.get_default_graph()) with self._lock: try: - graph_function = self._arguments_to_functions.get(cache_key, None) + graph_function = self._function_cache.get(cache_key, None) except TypeError: raise TypeError("Arguments supplied to `defun`-generated functions " "must be hashable.") if graph_function is None: - graph_function = _trace_and_define_function( - self._name, self._python_function, self._compiled, args, kwds, - self._input_signature) + graph_function = Function( + func_graph_from_py_func(self._name, self._python_function, args, + kwds, self._input_signature)) self._variables.extend( [v for v in graph_function.variables if v not in self._variables]) - self._arguments_to_functions[cache_key] = graph_function + self._function_cache[cache_key] = graph_function return graph_function, (args, kwds) - def __call__(self, *args, **kwds): - """Calls a graph function specialized for this input signature.""" - graph_function, inputs = self._maybe_define_function(*args, **kwds) - return graph_function(*inputs) - - def call_python_function(self, *args, **kwargs): - """Directly calls the wrapped python function.""" - return self._python_function(*args, **kwargs) - @property - def variables(self): - """Returns a list of variables used in any of the defined functions.""" - return self._variables +def _validate_signature(signature): + if any(not isinstance(arg, tensor_spec.TensorSpec) + for arg in nest.flatten(signature)): + raise TypeError("Invalid input_signature %s; input_signature must be " + "a possibly nested sequence of TensorSpec objects.") -# TODO(akshayka): Remove the `compiled` flag and create a separate -# API for xla compilation (`defun` is already complicated enough -# as it is, and the keyword argument makes 'compiled' an overloaded concept) -def defun(func=None, input_signature=None, compiled=False): +def defun(func=None, input_signature=None): """Compiles a Python function into a callable TensorFlow graph. `defun` (short for "define function") trace-compiles a Python function @@ -1221,6 +1220,7 @@ def defun(func=None, input_signature=None, compiled=False): self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax) self.keep_probability = keep_probability + @tf.contrib.eager.defun def call(self, inputs, training=True): x = self.dense2(self.dense1(inputs)) if training: @@ -1229,7 +1229,6 @@ def defun(func=None, input_signature=None, compiled=False): return x model = MyModel() - model.call = tf.contrib.eager.defun(model.call) model(x, training=True) # executes a graph, with dropout model(x, training=False) # executes a graph, without dropout @@ -1437,9 +1436,10 @@ def defun(func=None, input_signature=None, compiled=False): func: function to be compiled. If `func` is None, returns a decorator that can be invoked with a single argument - `func`. The end result is equivalent to providing all the arguments up front. - In other words, defun(compiled=True)(func) is equivalent to - defun(func, compiled=True). The former allows the following use case: - @tf.contrib.eager.defun(compiled=True) + In other words, defun(input_signature=...)(func) is equivalent to + defun(func, input_signature=...). The former allows + the following use case: + @tf.contrib.eager.defun(input_signature=...) def foo(...): ... @@ -1450,17 +1450,20 @@ def defun(func=None, input_signature=None, compiled=False): signature is specified, every input to `func` must be a `Tensor`, and `func` cannot accept `**kwargs`. - compiled: If True, an attempt to compile `func` with XLA will be made. - If it fails, function will be run normally. Experimental. Currently - supported only for execution on TPUs. For the vast majority of users, - this argument should be False. - Returns: If `func` is not None, returns a callable that will execute the compiled function (and return zero or more `tf.Tensor` objects). If `func` is None, returns a decorator that, when invoked with a single `func` argument, returns a callable equivalent to the case above. + + Raises: + TypeError: If `input_signature` is neither `None` nor a sequence of + `tf.contrib.eager.TensorSpec` objects. """ + + if input_signature is not None: + _validate_signature(input_signature) + # TODO(apassos): deal with captured global state. Deal with control flow. def decorated(function): try: @@ -1469,8 +1472,7 @@ def defun(func=None, input_signature=None, compiled=False): name = "function" return tf_decorator.make_decorator( function, - _PolymorphicFunction( - function, name, input_signature=input_signature, compiled=compiled)) + PolymorphicFunction(function, name, input_signature=input_signature)) # This code path is for the `foo = tfe.defun(foo, ...)` use case if func is not None: @@ -1486,51 +1488,6 @@ def defun(func=None, input_signature=None, compiled=False): return decorated -def make_defun_op(func, *args, **kwds): - """Compile func into graph_mode, assuming func arguments are *args, **kwargs. - - `make_defun_op` converts a function that constructs a TensorFlow graph into - a function object and attaches it to the graph. The resulting function - object can be queried for its properties, and called directly with different - inputs to execute. - - More details on use cases and limitations are available in the - documentation for `defun`. - - Example: - ```python - def f(x, y): - return tf.reduce_mean(tf.multiply(x ** 2, 3) + y) - - def g(x, y): - return tf.reduce_mean(tf.multiply(x ** 2, 3) + y) - - z = tf.constant([[0.0, 0.0]]) - g_op = make_defun_op(g, z, z) - - assert g_op.output_shapes == tf.TensorShape([]) - assert g_op.output_types == tf.float32 - - x = tf.constant([[2.0, 3.0]]) - y = tf.constant([[3.0, -2.0]]) - - # The plain function and defun-compiled function should return the same value. - assert f(x, y).numpy() == g_op(x, y).numpy() - ``` - - Args: - func: function to be compiled. - *args: List arguments to pass to `func` when attaching to the graph. - **kwds: Keyword arguments to pass to `func` when attaching to the graph. - - Returns: - A wrapper object which can be queried for its output properties, - and which can be called directly the way a `@defun` wrapped function - can. - """ - return _trace_and_define_function(func.__name__, func, False, args, kwds) - - class AutomaticControlDependencies(object): """Context manager to automatically add control dependencies. diff --git a/tensorflow/python/eager/function_test.py b/tensorflow/python/eager/function_test.py index 380bcf763f..3c79099d87 100644 --- a/tensorflow/python/eager/function_test.py +++ b/tensorflow/python/eager/function_test.py @@ -130,16 +130,16 @@ class FunctionTest(test.TestCase): with ops.Graph().as_default(): self.assertEqual(f().shape, ()) - def testBasicDefunOpGraphMode(self): + def testBasicGraphFunction(self): matmul = function.defun(math_ops.matmul) + @function.defun def sq(a): return matmul(a, a) t = constant_op.constant([[1.0, 2.0], [3.0, 4.0]]) - sq_op = function.make_defun_op(sq, t) - + sq_op = sq.get_concrete_function(t) self.assertEqual(sq_op.output_shapes, tensor_shape.TensorShape([2, 2])) out = sq_op(t) self.assertAllEqual(out, math_ops.matmul(t, t).numpy()) @@ -211,33 +211,44 @@ class FunctionTest(test.TestCase): random_seed.set_random_seed(1) self.assertAllEqual(f(), x) - def testNestedInputsDefunOpGraphMode(self): + def testSymGradGatherNd(self): + with ops.Graph().as_default(), self.test_session() as sess: + + @function.defun + def f(x): + return array_ops.gather_nd(x, [[0]]) + + c = constant_op.constant([[2.]]) + f_c = f(c) + g, = gradients_impl.gradients(f_c, c) + self.assertAllEqual(sess.run(g), [[1.0]]) + + def testNestedInputsGraphFunction(self): matmul = function.defun(math_ops.matmul) pair = collections.namedtuple('pair', ['a', 'b']) + @function.defun def a_times_b(inputs): return matmul(inputs.a['a'], inputs.b['b']) t = constant_op.constant([[1.0, 2.0], [3.0, 4.0]]) - inputs = pair({'a': t}, {'b': t}) - sq_op = function.make_defun_op(a_times_b, inputs) - + sq_op = a_times_b.get_concrete_function(inputs) self.assertEqual(sq_op.output_shapes, tensor_shape.TensorShape([2, 2])) out = sq_op(inputs) self.assertAllEqual(out, math_ops.matmul(t, t).numpy()) - def testNestedOutputDefunOpGraphMode(self): + def testNestedOutputGraphFunction(self): matmul = function.defun(math_ops.matmul) + @function.defun def sq(a): return (matmul(a, a), {'b': constant_op.constant(1.0)}) t = constant_op.constant([[1.0, 2.0], [3.0, 4.0]]) - sq_op = function.make_defun_op(sq, t) - + sq_op = sq.get_concrete_function(t) self.assertEqual(sq_op.output_shapes, (tensor_shape.TensorShape([2, 2]), {'b': tensor_shape.TensorShape([])})) @@ -247,28 +258,28 @@ class FunctionTest(test.TestCase): self.assertAllEqual(a, math_ops.matmul(t, t).numpy()) self.assertAllEqual(b['b'].numpy(), 1.0) - def testDefunOpGraphModeWithGradients(self): + def testGraphFunctionWithGradients(self): v = resource_variable_ops.ResourceVariable(1.0, name='v') + @function.defun def step(): def inner(): return v * v return backprop.implicit_grad(inner)()[0][0] - step_op = function.make_defun_op(step) - + step_op = step.get_concrete_function() self.assertEqual(step_op.output_dtypes, dtypes.float32) self.assertEqual(step_op.output_shapes, tensor_shape.TensorShape([])) self.assertAllEqual(step_op(), 2.0) - def testDefunOpGraphModeNoneOutput(self): + def testGraphFunctionNoneOutput(self): + @function.defun def fn(unused_a, unused_b): return None x = constant_op.constant(1) - fn_op = function.make_defun_op(fn, x, x) - + fn_op = fn.get_concrete_function(x, x) self.assertEqual(fn_op.output_dtypes, None) self.assertEqual(fn_op.output_shapes, None) self.assertAllEqual(fn_op(x, x), None) @@ -309,13 +320,13 @@ class FunctionTest(test.TestCase): x = random_ops.random_uniform([2, 2]).numpy() defined = function.defun(f) defined(x) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) x = random_ops.random_uniform([2, 2]).numpy() defined(x) # A NumPy array with different values but the same shape and dtype # shouldn't trigger another function definition. - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) def testDefunCapturedInt32(self): x = constant_op.constant(1, dtype=dtypes.int32) @@ -346,6 +357,47 @@ class FunctionTest(test.TestCase): self.assertEqual(3.0, float(test_assign_add())) + @test_util.run_in_graph_and_eager_modes + def testTensorInitializationInFunctionRaisesError(self): + error_msg = ('Tensor-typed variable initializers must either be ' + 'wrapped in an init_scope or callable.*') + + @function.defun + def tensor_init(): + with self.assertRaisesRegexp(ValueError, error_msg): + resource_variable_ops.ResourceVariable(constant_op.constant(2.0)) + + tensor_init() + + @test_util.run_in_graph_and_eager_modes + def testCallableTensorInitializationInFunction(self): + + @function.defun + def tensor_init(): + v = resource_variable_ops.ResourceVariable( + lambda: constant_op.constant(2.0)) + return v.read_value() + + value = tensor_init() + if not context.executing_eagerly(): + self.evaluate(variables.global_variables_initializer()) + self.assertEqual(self.evaluate(value), 2.0) + + @test_util.run_in_graph_and_eager_modes + def testInitScopeTensorInitializationInFunction(self): + + @function.defun + def tensor_init(): + with ops.init_scope(): + const = constant_op.constant(2.0) + v = resource_variable_ops.ResourceVariable(const) + return v.read_value() + + value = tensor_init() + if not context.executing_eagerly(): + self.evaluate(variables.global_variables_initializer()) + self.assertEqual(self.evaluate(value), 2.0) + def testDefunShapeInferenceWithCapturedResourceVariable(self): v = resource_variable_ops.ResourceVariable([[1, 2], [3, 4]]) @@ -633,17 +685,19 @@ class FunctionTest(test.TestCase): def testReturningIndexedSlicesWithDefun(self): def validate(indexed_slice): + @function.defun def f(): return indexed_slice - output = function.defun(f)() + output = f() self.assertTrue(isinstance(output, ops.IndexedSlices)) self.assertAllEqual(indexed_slice.values, output.values) self.assertAllEqual(indexed_slice.indices, output.indices) self.assertAllEqual(indexed_slice.dense_shape, output.dense_shape) self.assertEqual( - function.make_defun_op(f).output_shapes, indexed_slice.values.shape) + f.get_concrete_function().output_shapes, + indexed_slice.values.shape) arg = ops.IndexedSlices( values=constant_op.constant([1, 2]), @@ -966,39 +1020,109 @@ class FunctionTest(test.TestCase): config=config_pb2.ConfigProto(device_count={'CPU': 4})) def testDeviceAnnotationsRespected(self): - @function.defun def multi_device_fn(): with ops.device('/cpu:0'): - s1 = iterator_ops.Iterator.from_structure( + s0 = iterator_ops.Iterator.from_structure( (dtypes.float32,)).string_handle() with ops.device('/cpu:1'): - s2 = iterator_ops.Iterator.from_structure( + s1 = iterator_ops.Iterator.from_structure( (dtypes.float32,)).string_handle() with ops.device('/cpu:2'): - s3 = iterator_ops.Iterator.from_structure( - (dtypes.float32,)).string_handle() - with ops.device(''): - # TODO(akshayka): This is unfortunate and brittle. It prevents - # `Iterator.from_structure` from assigning the iterator op to 'cpu:0'. - # Remove this hack once we have a way of obtaining metadata about - # function execution. - s4 = iterator_ops.Iterator.from_structure( + s2 = iterator_ops.Iterator.from_structure( (dtypes.float32,)).string_handle() - return s1, s2, s3, s4 + s3 = iterator_ops.Iterator.from_structure( + (dtypes.float32,)).string_handle() + return s0, s1, s2, s3 - with ops.device('/cpu:3'): - outputs = self.evaluate(multi_device_fn()) + defined = function.defun(multi_device_fn) + outputs = self.evaluate(defined()) + self.assertEqual(len(defined._function_cache), 1) self.assertIn(compat.as_bytes('CPU:0'), outputs[0]) self.assertIn(compat.as_bytes('CPU:1'), outputs[1]) self.assertIn(compat.as_bytes('CPU:2'), outputs[2]) - self.assertIn(compat.as_bytes('CPU:3'), outputs[3]) - with ops.device('/cpu:0'): - outputs = self.evaluate(multi_device_fn()) + with ops.device('/cpu:3'): + outputs = self.evaluate(defined()) + self.assertEqual(len(defined._function_cache), 2) self.assertIn(compat.as_bytes('CPU:0'), outputs[0]) self.assertIn(compat.as_bytes('CPU:1'), outputs[1]) self.assertIn(compat.as_bytes('CPU:2'), outputs[2]) - self.assertIn(compat.as_bytes('CPU:0'), outputs[3]) + self.assertIn(compat.as_bytes('CPU:3'), outputs[3]) + + # This should retrieve the call-site-device agnostic function + defined() + self.assertEqual(len(defined._function_cache), 2) + + # And this should retrieve the function created for '/cpu:3' + with ops.device('/cpu:3'): + defined() + self.assertEqual(len(defined._function_cache), 2) + + @test_util.run_in_graph_and_eager_modes( + config=config_pb2.ConfigProto(device_count={'CPU': 2})) + def testCallingGraphFunctionOnIncompatibleDeviceRaisesError(self): + + def func(): + return constant_op.constant(0) + + defined = function.defun(func) + with ops.device('cpu:0'): + cpu_graph_function = defined.get_concrete_function() + + with ops.device('cpu:0'): + self.assertEqual( + self.evaluate(cpu_graph_function()), self.evaluate(func())) + + with self.assertRaisesRegexp( + ValueError, + 'The current device stack does not match the device stack under ' + 'which the TensorFlow function \'.*func.*\' was created.\n' + 'Current device stack: .*\n.*func.* device stack.*'): + with ops.device('cpu:1'): + cpu_graph_function() + + with self.assertRaisesRegexp( + ValueError, + 'The current device stack does not match the device stack under ' + 'which the TensorFlow function \'.*func.*\' was created.\n' + 'Current device stack: .*\n.*func.* device stack.*'): + with ops.device(None): + cpu_graph_function() + + default_graph_function = defined.get_concrete_function() + self.assertEqual( + self.evaluate(default_graph_function()), self.evaluate(func())) + + with self.assertRaisesRegexp( + ValueError, + 'The current device stack does not match the device stack under ' + 'which the TensorFlow function \'.*func.*\' was created.\n' + 'Current device stack: .*\n.*func.* device stack.*'): + with ops.device('cpu:1'): + default_graph_function() + + @test_util.run_in_graph_and_eager_modes + def testColocateWithRespected(self): + # TODO(b/113291792): Use multiple CPUs instead of a GPU. + if not context.context().num_gpus(): + self.skipTest('No GPUs found.') + + with ops.device('cpu:0'): + x = constant_op.constant(1.0) + + with ops.device('gpu:0'): + y = constant_op.constant(1.0) + + @function.defun + def foo(): + return iterator_ops.Iterator.from_structure( + (dtypes.float32,)).string_handle() + + with ops.colocate_with(x): + self.assertIn(compat.as_bytes('CPU:0'), self.evaluate(foo())) + + with ops.colocate_with(y): + self.assertIn(compat.as_bytes('GPU:0'), self.evaluate(foo())) def testVariablesAreTracked(self): v = resource_variable_ops.ResourceVariable(1.0) @@ -1027,26 +1151,31 @@ class FunctionTest(test.TestCase): defined = function.defun(func) defined(0, baz=20) + + def cache_keys(): + """Sanitizes cache keys of non-input metadata.""" + return tuple(key[:3] for key in defined._function_cache) + # `True` corresponds to the fact that we're executing eagerly - self.assertIn((0, 1, 20, True), defined._arguments_to_functions) + self.assertIn((0, 1, 20), cache_keys()) defined(1) # bar=1, baz=2 - self.assertIn((1, 1, 2, True), defined._arguments_to_functions) + self.assertIn((1, 1, 2), cache_keys()) # This matches the previous call. defined(foo=1) - self.assertEqual(len(defined._arguments_to_functions), 2) + self.assertEqual(len(defined._function_cache), 2) defined(1, 2, 3) - self.assertIn((1, 2, 3, True), defined._arguments_to_functions) + self.assertIn((1, 2, 3), cache_keys()) # This matches the previous call. defined(1, bar=2, baz=3) - self.assertEqual(len(defined._arguments_to_functions), 3) + self.assertEqual(len(defined._function_cache), 3) # This matches the previous call. defined(1, baz=3, bar=2) - self.assertEqual(len(defined._arguments_to_functions), 3) + self.assertEqual(len(defined._function_cache), 3) def testFunctoolsPartialUnwrappedCorrectly(self): @@ -1072,7 +1201,7 @@ class FunctionTest(test.TestCase): defined = function.defun(foo, input_signature=signature) a = array_ops.ones([2]) out = defined(a) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) self.assertAllEqual(out, a) def bar(a): @@ -1083,13 +1212,13 @@ class FunctionTest(test.TestCase): defined = function.defun(bar, input_signature=signature) a = array_ops.ones([2, 1]) out = defined(a) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) self.assertAllEqual(out, a) # Changing the second dimension shouldn't create a new function. b = array_ops.ones([2, 3]) out = defined(b) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) self.assertAllEqual(out, b) def testNestedInputSignatures(self): @@ -1106,7 +1235,7 @@ class FunctionTest(test.TestCase): a = array_ops.ones([2, 1]) b = array_ops.ones([1]) out = defined([a, a], b) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) nest.assert_same_structure(out, [[a, a], b]) self.assertAllEqual(out[0][0], a) self.assertAllEqual(out[0][1], a) @@ -1117,7 +1246,7 @@ class FunctionTest(test.TestCase): b = array_ops.ones([2, 5]) c = array_ops.ones([1]) out = defined([a, b], c) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) nest.assert_same_structure(out, [[a, b], c]) self.assertAllEqual(out[0][0], a) self.assertAllEqual(out[0][1], b) @@ -1153,13 +1282,13 @@ class FunctionTest(test.TestCase): # Signatures must consist exclusively of `TensorSpec` objects. signature = [(2, 3), tensor_spec.TensorSpec([2, 3], dtypes.float32)] with self.assertRaisesRegexp(TypeError, 'Invalid input_signature.*'): - function.defun(foo, input_signature=signature)(1, 2) + function.defun(foo, input_signature=signature) # Signatures must be either lists or tuples on their outermost levels. signature = {'t1': tensor_spec.TensorSpec([], dtypes.float32)} with self.assertRaisesRegexp(TypeError, 'input_signature must be either a ' 'tuple or a list.*'): - function.defun(foo, input_signature=signature)(1, 2) + function.defun(foo, input_signature=signature) def testInputsIncompatibleWithSignatureRaisesError(self): @@ -1213,22 +1342,22 @@ class FunctionTest(test.TestCase): integer = constant_op.constant(2, dtypes.int64) out1, out2 = foo(flt, integer) - self.assertEqual(len(foo._arguments_to_functions), 1) + self.assertEqual(len(foo._function_cache), 1) self.assertEqual(out1.numpy(), 1.0) self.assertEqual(out2.numpy(), 2) out1, out2 = foo(flt=flt, integer=integer) - self.assertEqual(len(foo._arguments_to_functions), 1) + self.assertEqual(len(foo._function_cache), 1) self.assertEqual(out1.numpy(), 1.0) self.assertEqual(out2.numpy(), 2) out1, out2 = foo(integer=integer, flt=flt) - self.assertEqual(len(foo._arguments_to_functions), 1) + self.assertEqual(len(foo._function_cache), 1) self.assertEqual(out1.numpy(), 1.0) self.assertEqual(out2.numpy(), 2) out1, out2 = foo(flt, integer=integer) - self.assertEqual(len(foo._arguments_to_functions), 1) + self.assertEqual(len(foo._function_cache), 1) self.assertEqual(out1.numpy(), 1.0) self.assertEqual(out2.numpy(), 2) @@ -1258,27 +1387,27 @@ class FunctionTest(test.TestCase): a = constant_op.constant(2.0) b = constant_op.constant([1.0, 2.0]) one = defined(a, b) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) two = defined(a=a, b=b) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) three = defined(b=b, a=a) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) four = defined(a, b=b) - self.assertEqual(len(defined._arguments_to_functions), 1) + self.assertEqual(len(defined._function_cache), 1) # The next call corresponds to a new input signature, hence # we expect another function to be defined. five = defined(b, a) - self.assertEqual(len(defined._arguments_to_functions), 2) + self.assertEqual(len(defined._function_cache), 2) six = defined(a=b, b=a) - self.assertEqual(len(defined._arguments_to_functions), 2) + self.assertEqual(len(defined._function_cache), 2) seven = defined(b=a, a=b) - self.assertEqual(len(defined._arguments_to_functions), 2) + self.assertEqual(len(defined._function_cache), 2) self.assertAllEqual(one, [1.0, 2.0]) self.assertAllEqual(two, [1.0, 2.0]) @@ -1363,7 +1492,7 @@ class FunctionTest(test.TestCase): self.assertAllEqual(state, [0]) # Whereas calling the python function directly should create a side-effect. - side_effecting_function.call_python_function() + side_effecting_function.python_function() self.assertAllEqual(state, [0, 0]) diff --git a/tensorflow/python/eager/graph_callable.py b/tensorflow/python/eager/graph_callable.py deleted file mode 100644 index 7105d2e399..0000000000 --- a/tensorflow/python/eager/graph_callable.py +++ /dev/null @@ -1,435 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Decorator that produces a callable object that executes a TensorFlow graph. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import contextlib - -from tensorflow.python.eager import context -from tensorflow.python.eager import function -from tensorflow.python.eager import tape -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import errors -from tensorflow.python.framework import ops as tf_ops -from tensorflow.python.framework import tensor_shape -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import resource_variable_ops -from tensorflow.python.ops import variable_scope -from tensorflow.python.util import nest -from tensorflow.python.util import tf_decorator -from tensorflow.python.util import tf_inspect - - -def _default_initializer(name, shape, dtype): - """The default initializer for variables.""" - # pylint: disable=protected-access - store = variable_scope._get_default_variable_store() - initializer = store._get_default_initializer(name, shape=shape, dtype=dtype) - # pylint: enable=protected-access - return initializer[0] - - -class _CapturedVariable(object): - """Variable captured by graph_callable. - - Internal to the implementation of graph_callable. Created only by - _VariableCapturingScope and used only to read the variable values when calling - the function after the variables are initialized. - """ - - def __init__(self, name, initializer, shape, dtype, trainable): - self.name = name - if initializer is None: - initializer = _default_initializer(name, shape, dtype) - initial_value = lambda: initializer(shape, dtype=dtype) - - with context.eager_mode(): - self.variable = resource_variable_ops.ResourceVariable( - initial_value=initial_value, name=name, dtype=dtype, - trainable=trainable) - self.shape = shape - self.dtype = dtype - self.placeholder = None - self.trainable = trainable - - def read(self, want_gradients=True): - if want_gradients and self.trainable: - v = tape.watch_variable(self.variable) - else: - v = self.variable - return v.read_value() - - -class _VariableCapturingScope(object): - """Variable-scope-like object which captures tf.get_variable calls. - - This is responsible for the main difference between the initialization version - of a function object and the calling version of a function object. - - capturing_scope replaces calls to tf.get_variable with placeholder tensors to - be fed the variable's current value. TODO(apassos): these placeholders should - instead be objects implementing a similar API to tf.Variable, for full - compatibility. - - initializing_scope replaces calls to tf.get_variable with creation of - variables and initialization of their values. This allows eventual support of - initialized_value and friends. - - TODO(apassos): once the eager mode layers API is implemented support eager - func-to-object as well. - """ - - def __init__(self): - self.variables = {} - self.tf_variables = {} - - @contextlib.contextmanager - def capturing_scope(self): - """Context manager to capture variable creations. - - Replaces variable accesses with placeholders. - - Yields: - nothing - """ - # TODO(apassos) ignoring the regularizer and partitioner here; figure out - # how to deal with these. - def _custom_getter( # pylint: disable=missing-docstring - getter=None, - name=None, - shape=None, - dtype=dtypes.float32, - initializer=None, - regularizer=None, - reuse=None, - trainable=None, - collections=None, - caching_device=None, # pylint: disable=redefined-outer-name - partitioner=None, - validate_shape=True, - use_resource=None, - aggregation=variable_scope.VariableAggregation.NONE, - synchronization=variable_scope.VariableSynchronization.AUTO): - del getter, regularizer, partitioner, validate_shape, use_resource, dtype - del collections, initializer, trainable, reuse, caching_device, shape - del aggregation, synchronization - assert name in self.variables - v = self.variables[name] - return v.variable - - scope = variable_scope.get_variable_scope() - with variable_scope.variable_scope(scope, custom_getter=_custom_getter): - yield - - @contextlib.contextmanager - def initializing_scope(self): - """Context manager to capture variable creations. - - Forcibly initializes all created variables. - - Yields: - nothing - """ - # TODO(apassos) ignoring the regularizer and partitioner here; figure out - # how to deal with these. - def _custom_getter( # pylint: disable=missing-docstring - getter=None, - name=None, - shape=None, - dtype=dtypes.float32, - initializer=None, - regularizer=None, - reuse=None, - trainable=None, - collections=None, - caching_device=None, # pylint: disable=redefined-outer-name - partitioner=None, - validate_shape=True, - use_resource=None, - aggregation=variable_scope.VariableAggregation.NONE, - synchronization=variable_scope.VariableSynchronization.AUTO): - del getter, regularizer, collections, caching_device, partitioner - del use_resource, validate_shape, aggregation, synchronization - if name in self.tf_variables: - if reuse: - return self.tf_variables[name].initialized_value() - else: - raise ValueError("Specified reuse=%s but tried to reuse variables." - % reuse) - # TODO(apassos): ensure this is on the same device as above - v = _CapturedVariable(name, initializer, shape, dtype, trainable) - self.variables[name] = v - - graph_mode_resource = v.variable.handle - if initializer is None: - initializer = _default_initializer(name, shape, dtype) - resource_variable_ops.shape_safe_assign_variable_handle( - graph_mode_resource, v.variable.shape, initializer(shape, dtype)) - return v.variable - - scope = variable_scope.get_variable_scope() - with variable_scope.variable_scope(scope, custom_getter=_custom_getter): - yield - - -class _InitializingFunctionObject(object): - """Responsible for deciding which version of func-to-object to call. - - call_fn is the version which calls the function with the current values of the - variables and init_fn is the version which calls the function to initialize - all variables. - - TODO(apassos): figure out a way to support initializing only _some_ - variables. This requires a way to pull out a variable's initialization code - from the graph, which might not be possible in general. - """ - - def __init__(self, call_fn, init_fn, shape_and_dtypes): - self._init_fn = init_fn - self._call_fn = call_fn - self.shape_and_dtypes = shape_and_dtypes - self.flattened_shapes = [tensor_shape.as_shape(sd.shape) for sd in - nest.flatten(self.shape_and_dtypes)] - - @property - def variables(self): - return self._call_fn.variables - - def __call__(self, *args): - nest.assert_same_structure(self.shape_and_dtypes, args, check_types=False) - if not all([ - shape.is_compatible_with(arg.shape) - for shape, arg in zip(self.flattened_shapes, nest.flatten(args)) - ]): - raise ValueError( - "Declared shapes do not match argument shapes: Expected %s, found %s." - % (self.flattened_shapes, [arg.shape for arg in nest.flatten(args)])) - - initialized = [resource_variable_ops.var_is_initialized_op( - v.handle).numpy() for v in self._call_fn.variables] - if all(x for x in initialized): - for v in self._call_fn.variables: - if v.trainable: - tape.watch_variable(v) - return self._call_fn(*args) - elif all(not x for x in initialized): - return self._init_fn(*args) - else: - raise ValueError("Some, but not all, variables are initialized.") - - -def _get_graph_callable_inputs(shape_and_dtypes): - """Maps specified shape_and_dtypes to graph inputs.""" - ret = [] - for x in shape_and_dtypes: - if isinstance(x, ShapeAndDtype): - ret.append(array_ops.placeholder(x.dtype, x.shape)) - elif isinstance(x, (tuple, list)): - ret.append(_get_graph_callable_inputs(x)) - else: - raise errors.InvalidArgumentError( - None, None, "Expected the argument to @graph_callable to be a " - "(possibly nested) list or tuple of ShapeAndDtype objects, " - "but got an object of type: %s" % type(x)) - - return tuple(ret) if isinstance(shape_and_dtypes, tuple) else ret - - -def _graph_callable_internal(func, shape_and_dtypes): - """Defines and returns a template version of func. - - Under the hood we make two function objects, each wrapping a different version - of the graph-mode code. One version immediately runs variable initialization - before making the variable's Tensors available for use, while the other - version replaces the Variables with placeholders which become function - arguments and get the current variable's value. - - Limitations in (2) and (4) are because this does not implement a graph-mode - Variable class which has a convert_to_tensor(as_ref=True) method and a - initialized_value method. This is fixable. - - Args: - func: The tfe Python function to compile. - shape_and_dtypes: A possibly nested list or tuple of ShapeAndDtype objects. - - Raises: - ValueError: If any one of func's outputs is not a Tensor. - - Returns: - Callable graph object. - """ - container = tf_ops.get_default_graph()._container # pylint: disable=protected-access - graph_key = tf_ops.get_default_graph()._graph_key # pylint: disable=protected-access - with context.graph_mode(): - # This graph will store both the initialization and the call version of the - # wrapped function. It will later be used by the backprop code to build the - # backprop graph, if necessary. - tmp_graph = function.CapturingGraph() - # Inherit the graph key from the original graph to ensure optimizers don't - # misbehave. - tmp_graph._container = container # pylint: disable=protected-access - tmp_graph._graph_key = graph_key # pylint: disable=protected-access - with tmp_graph.as_default(): - # Placeholders for the non-variable inputs. - func_inputs = _get_graph_callable_inputs(shape_and_dtypes) - func_num_args = len(tf_inspect.getfullargspec(func).args) - if len(func_inputs) != func_num_args: - raise TypeError("The number of arguments accepted by the decorated " - "function `%s` (%d) must match the number of " - "ShapeAndDtype objects passed to the graph_callable() " - "decorator (%d)." % - (func.__name__, func_num_args, len(func_inputs))) - - # First call the function to generate a graph which can initialize all - # variables. As a side-effect this will populate the variable capturing - # scope's view of which variables exist. - variable_captures = _VariableCapturingScope() - with variable_captures.initializing_scope( - ), function.AutomaticControlDependencies() as a: - func_outputs = func(*func_inputs) - outputs_list = nest.flatten(func_outputs) - for i, x in enumerate(outputs_list): - if x is not None: - outputs_list[i] = a.mark_as_return(x) - if len(outputs_list) == 1 and outputs_list[0] is None: - outputs_list = [] - output_shapes = [x.shape for x in outputs_list] - if not all(isinstance(x, tf_ops.Tensor) for x in outputs_list): - raise ValueError("Found non-tensor output in %s" % str(outputs_list)) - initializing_operations = tmp_graph.get_operations() - - # Call the function again, now replacing usages of variables with - # placeholders. This assumes the variable capturing scope created above - # knows about all variables. - tmp_graph.clear_resource_control_flow_state() - with variable_captures.capturing_scope( - ), function.AutomaticControlDependencies() as a: - captured_outputs = func(*func_inputs) - captured_outlist = nest.flatten(captured_outputs) - for i, x in enumerate(captured_outlist): - if x is not None: - captured_outlist[i] = a.mark_as_return(x) - capturing_operations = tmp_graph.get_operations()[ - len(initializing_operations):] - - sorted_variables = sorted(variable_captures.variables.values(), - key=lambda x: x.name) - - extra_inputs = tmp_graph.captures.keys() - extra_placeholders = tmp_graph.captures.values() - - flat_inputs = [x for x in nest.flatten(func_inputs) - if isinstance(x, tf_ops.Tensor)] - placeholder_inputs = flat_inputs+ list(extra_placeholders) - - func_def_outputs = [x for x in outputs_list if isinstance(x, tf_ops.Tensor)] - initialization_name = function._inference_name(func.__name__) # pylint: disable=protected-access - # TODO(ashankar): Oh lord, forgive me for this lint travesty. - # Also, what about the gradient registry of these functions? Those need to be - # addressed as well. - for f in tmp_graph._functions.values(): # pylint: disable=protected-access - function._register(f._c_func.func) # pylint: disable=protected-access - initializer_function = function.GraphModeFunction( - initialization_name, - placeholder_inputs, - extra_inputs, - tmp_graph, - initializing_operations, - func_def_outputs, - func_outputs, - output_shapes) - - capture_func_def_outputs = [ - x for x in captured_outlist if isinstance(x, tf_ops.Tensor)] - captured_function_name = function._inference_name(func.__name__) # pylint: disable=protected-access - captured_function = function.GraphModeFunction( - captured_function_name, - placeholder_inputs, - extra_inputs, - tmp_graph, - capturing_operations, - capture_func_def_outputs, - captured_outputs, - output_shapes, - variables=[x.variable for x in sorted_variables]) - - return _InitializingFunctionObject(captured_function, initializer_function, - shape_and_dtypes) - - -class ShapeAndDtype(object): - """Data type that packages together shape and type information. - - Used for arguments to graph callables. See graph_callable() for an example. - """ - - def __init__(self, shape, dtype): - self.shape = shape - self.dtype = dtype - - -def graph_callable(shape_and_dtypes): - """Decorator that produces a callable that executes a TensorFlow graph. - - When applied on a function that constructs a TensorFlow graph, this decorator - produces a callable object that: - - 1. Executes the graph when invoked. The first call will initialize any - variables defined in the graph. - - 2. Provides a .variables() method to return the list of TensorFlow variables - defined in the graph. - - Note that the wrapped function is not allowed to change the values of the - variables, just use them. - - The return value of the wrapped function must be one of the following: - (1) None, (2) a Tensor, or (3) a possibly nested sequence of Tensors. - - Example: - - ```python - @tfe.graph_callable([tfe.ShapeAndDtype(shape(), dtype=dtypes.float32)]) - def foo(x): - v = tf.get_variable('v', initializer=tf.ones_initializer(), shape=()) - return v + x - - ret = foo(tfe.Tensor(2.0)) # `ret` here is a Tensor with value 3.0. - - foo.variables[0].assign(7.0) # Modify the value of variable `v`. - ret = foo(tfe.Tensor(2.0)) # `ret` here now is a Tensor with value 9.0. - ``` - Args: - shape_and_dtypes: A possibly nested list or tuple of ShapeAndDtype objects - that specifies shape and type information for each of the callable's - arguments. The length of this list must be equal to the number of - arguments accepted by the wrapped function. - - Returns: - A callable graph object. - """ - # TODO(alive,apassos): support initialized_value and friends from tf.Variable. - assert context.executing_eagerly(), ( - "graph_callable can only be used when Eager execution is enabled.") - def decorator(func): - return tf_decorator.make_decorator(func, - _graph_callable_internal( - func, shape_and_dtypes)) - - return decorator diff --git a/tensorflow/python/eager/graph_callable_test.py b/tensorflow/python/eager/graph_callable_test.py deleted file mode 100644 index b9e6ca2a93..0000000000 --- a/tensorflow/python/eager/graph_callable_test.py +++ /dev/null @@ -1,249 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from tensorflow.python.eager import backprop -from tensorflow.python.eager import graph_callable -from tensorflow.python.eager import test -from tensorflow.python.framework import constant_op -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import function -from tensorflow.python.framework import tensor_shape -from tensorflow.python.ops import init_ops -from tensorflow.python.ops import math_ops -from tensorflow.python.ops import variable_scope - - -class GraphCallableTest(test.TestCase): - - def testBasic(self): - - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.float32)]) - def my_function(x): - v = variable_scope.get_variable( - "v", initializer=init_ops.zeros_initializer(), shape=()) - return v + x - - self.assertEqual( - 2, my_function(constant_op.constant(2, dtype=dtypes.float32)).numpy()) - - my_function.variables[0].assign(1.) - self.assertEqual( - 3, my_function(constant_op.constant(2, dtype=dtypes.float32)).numpy()) - - def testFunctionWithoutReturnValue(self): - - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.float32)]) - def my_function(x): - v = variable_scope.get_variable( - "v", initializer=init_ops.zeros_initializer(), shape=()) - v.assign(x) - - my_function(constant_op.constant(4, dtype=dtypes.float32)) - self.assertAllEqual(4, my_function.variables[0].read_value()) - - def testFunctionWithoutReturnValueAndArgs(self): - - @graph_callable.graph_callable([]) - def my_function(): - v = variable_scope.get_variable( - "v", initializer=init_ops.zeros_initializer(), shape=()) - v.assign(4) - - my_function() - self.assertAllEqual(4, my_function.variables[0].read_value()) - - def testVariableAPI(self): - - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.float32)]) - def my_function(x): - v = variable_scope.get_variable( - "v", initializer=init_ops.zeros_initializer(), shape=()) - return v.read_value() + x - - self.assertEqual( - 2, my_function(constant_op.constant(2, dtype=dtypes.float32)).numpy()) - - my_function.variables[0].assign(1.) - self.assertEqual( - 3, my_function(constant_op.constant(2, dtype=dtypes.float32)).numpy()) - - def testTensorShape(self): - - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(1), dtype=dtypes.float32)]) - def my_function(x): - _ = x.get_shape() - v = variable_scope.get_variable( - "v", initializer=init_ops.zeros_initializer(), shape=[x.shape[0]]) - self.assertEqual(v.shape[0], x.shape[0]) - return v + x - - self.assertEqual([2.], - my_function( - constant_op.constant([2.], - dtype=dtypes.float32)).numpy()) - - def testUpdatesAreOrdered(self): - - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.float32)]) - def my_function(x): - v = variable_scope.get_variable( - "v", initializer=init_ops.zeros_initializer(), shape=()) - v.assign(x + 1) - v.assign(v * x) - return v.read_value() - - self.assertAllEqual(my_function(constant_op.constant(2.0)), 6.0) - - def testEmptyInitializer(self): - - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(1), dtype=dtypes.float32)]) - def my_function(x): - v = variable_scope.get_variable("v", shape=[1]) - return x + 0 * v - - self.assertEqual([2.], - my_function( - constant_op.constant([2.], - dtype=dtypes.float32)).numpy()) - - def testMismatchingNumArgs(self): - # pylint: disable=anomalous-backslash-in-string - with self.assertRaisesRegexp(TypeError, - "The number of arguments accepted by the " - "decorated function `my_function` \(2\) must " - "match the number of ShapeAndDtype objects " - "passed to the graph_callable\(\) decorator " - "\(1\)."): - @graph_callable.graph_callable([ - graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.float32)]) - def my_function(x, y): # pylint: disable=unused-variable - return x + y - # pylint: enable=anomalous-backslash-in-string - - def testPureFunction(self): - - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.int32)]) - def f(x): - return math_ops.add(x, constant_op.constant(3)) - - self.assertAllEqual(5, f(constant_op.constant(2))) - - def testNestedFunction(self): - # TensorFlow function (which is what would be used in TensorFlow graph - # construction). - @function.Defun(dtypes.int32, dtypes.int32) - def add(a, b): - return math_ops.add(a, b) - - # A graph_callable that will invoke the TensorFlow function. - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.int32)]) - def add_one(x): - return add(x, 1) - - self.assertAllEqual(3, add_one(constant_op.constant(2))) - - # TODO(ashankar): Make this work. - # The problem is that the two graph_callables (for add_one and add_two) - # are both trying to register the FunctionDef corresponding to "add". - def DISABLED_testRepeatedUseOfSubFunction(self): - - @function.Defun(dtypes.int32, dtypes.int32) - def add(a, b): - return math_ops.add(a, b) - - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.int32)]) - def add_one(x): - return add(x, 1) - - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.int32)]) - def add_two(x): - return add(x, 2) - - two = constant_op.constant(2) - self.assertAllEqual(3, add_one(two)) - self.assertAllEqual(4, add_two(two)) - - def testNestedSequenceInputs(self): - sd = graph_callable.ShapeAndDtype(shape=(), dtype=dtypes.float32) - @graph_callable.graph_callable([[sd, tuple([sd, sd]), sd]]) - def my_op(inputs): - a, b, c = inputs - e, f = b - v = variable_scope.get_variable( - "my_v", initializer=init_ops.zeros_initializer(), shape=()) - return [a + a + v, tuple([e + e, f + f]), c + c], a + e + f + c + v - - inputs = [constant_op.constant(1.), - [constant_op.constant(2.), constant_op.constant(3.)], - constant_op.constant(4.)] - ret = my_op(inputs) - self.assertEqual(len(ret), 2.) - self.assertAllEqual(ret[1], 10.) - - my_op.variables[0].assign(1.) - ret = my_op(inputs) - self.assertAllEqual(ret[1], 11.) - - def testVariableShapeIsTensorShape(self): - @graph_callable.graph_callable([]) - def my_function(): - v = variable_scope.get_variable( - "v", initializer=init_ops.zeros_initializer(), shape=()) - self.assertIsInstance(v.get_shape(), tensor_shape.TensorShape) - - my_function() - - def testIncorrectlyShapedInputs(self): - @graph_callable.graph_callable( - [graph_callable.ShapeAndDtype(shape=(3), dtype=dtypes.float32)]) - def my_function(x): - v = variable_scope.get_variable( - "v", initializer=init_ops.zeros_initializer(), shape=()) - return v + x - - with self.assertRaises(ValueError): - my_function([1, 2]) - - self.assertTrue(([1, 2, 3] == my_function( - constant_op.constant([1, 2, 3], dtype=dtypes.float32)).numpy()).all()) - - def testGradients(self): - @graph_callable.graph_callable([]) - def my_function(): - v = variable_scope.get_variable( - "v", initializer=init_ops.constant_initializer(3.), shape=()) - return v * v - - grad_fn = backprop.implicit_grad(my_function) - grads_and_vars = list(zip(*grad_fn())) - self.assertAllEqual(6., grads_and_vars[0][0]) - - -if __name__ == "__main__": - test.main() diff --git a/tensorflow/python/eager/pywrap_tensor.cc b/tensorflow/python/eager/pywrap_tensor.cc index 15d2ccf9d2..c12bf89f8f 100644 --- a/tensorflow/python/eager/pywrap_tensor.cc +++ b/tensorflow/python/eager/pywrap_tensor.cc @@ -800,9 +800,6 @@ PyObject* TFE_Py_InitEagerTensor(PyObject* base_class) { EagerTensorType = &_EagerTensorType; Py_INCREF(EagerTensorType); #endif - // We disable instance based attribute lookup. Its not clear if these - // dictionaries are correctly initialized in the first place. - EagerTensorType->tp_dictoffset = 0; return reinterpret_cast<PyObject*>(EagerTensorType); } diff --git a/tensorflow/python/eager/pywrap_tfe.h b/tensorflow/python/eager/pywrap_tfe.h index a916a75f00..823c4078b8 100644..100755 --- a/tensorflow/python/eager/pywrap_tfe.h +++ b/tensorflow/python/eager/pywrap_tfe.h @@ -89,7 +89,7 @@ int MaybeRaiseExceptionFromStatus(const tensorflow::Status& status, PyObject* exception); // Returns the string associated with the passed-in python object. -char* TFE_GetPythonString(PyObject* o); +const char* TFE_GetPythonString(PyObject* o); // Returns a unique id on each call. int64_t get_uid(); diff --git a/tensorflow/python/eager/pywrap_tfe_src.cc b/tensorflow/python/eager/pywrap_tfe_src.cc index 2d54555cd3..64cf36d079 100644 --- a/tensorflow/python/eager/pywrap_tfe_src.cc +++ b/tensorflow/python/eager/pywrap_tfe_src.cc @@ -216,7 +216,7 @@ bool ParseStringValue(const string& key, PyObject* py_value, TF_Status* status, #if PY_MAJOR_VERSION >= 3 if (PyUnicode_Check(py_value)) { Py_ssize_t size = 0; - char* buf = PyUnicode_AsUTF8AndSize(py_value, &size); + const char* buf = PyUnicode_AsUTF8AndSize(py_value, &size); if (buf == nullptr) return false; *value = tensorflow::StringPiece(buf, size); return true; @@ -825,7 +825,7 @@ int MaybeRaiseExceptionFromStatus(const tensorflow::Status& status, return -1; } -char* TFE_GetPythonString(PyObject* o) { +const char* TFE_GetPythonString(PyObject* o) { if (PyBytes_Check(o)) { return PyBytes_AsString(o); } diff --git a/tensorflow/python/estimator/BUILD b/tensorflow/python/estimator/BUILD index 817c8e6848..9fce172bee 100644 --- a/tensorflow/python/estimator/BUILD +++ b/tensorflow/python/estimator/BUILD @@ -211,6 +211,9 @@ py_test( shard_count = 2, srcs_version = "PY2AND3", tags = [ + "manual", + "no_oss", + "notap", "optonly", ], deps = [ diff --git a/tensorflow/python/estimator/canned/boosted_trees.py b/tensorflow/python/estimator/canned/boosted_trees.py index 16928ca4b7..ef7c217190 100644 --- a/tensorflow/python/estimator/canned/boosted_trees.py +++ b/tensorflow/python/estimator/canned/boosted_trees.py @@ -404,18 +404,21 @@ class _EnsembleGrower(object): training_ops.append(grow_op) """ - def __init__(self, tree_ensemble, tree_hparams): + def __init__(self, tree_ensemble, tree_hparams, feature_ids_list): """Initializes a grower object. Args: tree_ensemble: A TreeEnsemble variable. tree_hparams: TODO. collections.namedtuple for hyper parameters. + feature_ids_list: a list of lists of feature ids for each bucket size. + Raises: ValueError: when pruning mode is invalid or pruning is used and no tree complexity is set. """ self._tree_ensemble = tree_ensemble self._tree_hparams = tree_hparams + self._feature_ids_list = feature_ids_list # pylint: disable=protected-access self._pruning_mode_parsed = boosted_trees_ops.PruningMode.from_str( tree_hparams.pruning_mode) @@ -440,14 +443,12 @@ class _EnsembleGrower(object): """ @abc.abstractmethod - def grow_tree(self, stats_summaries_list, feature_ids_list, - last_layer_nodes_range): + def grow_tree(self, stats_summaries_list, last_layer_nodes_range): """Grows a tree, if ready, based on provided statistics. Args: stats_summaries_list: List of stats summary tensors, representing sums of gradients and hessians for each feature bucket. - feature_ids_list: a list of lists of feature ids for each bucket size. last_layer_nodes_range: A tensor representing ids of the nodes in the current layer, to be split. @@ -455,6 +456,10 @@ class _EnsembleGrower(object): An op for growing a tree. """ + def chief_init_op(self): + """Ops that chief needs to run to initialize the state.""" + return control_flow_ops.no_op() + # ============= Helper methods =========== def _center_bias_fn(self, center_bias_var, mean_gradients, mean_hessians): @@ -468,7 +473,7 @@ class _EnsembleGrower(object): return center_bias_var.assign(continue_centering) def _grow_tree_from_stats_summaries(self, stats_summaries_list, - feature_ids_list, last_layer_nodes_range): + last_layer_nodes_range): """Updates ensemble based on the best gains from stats summaries.""" node_ids_per_feature = [] gains_list = [] @@ -476,11 +481,11 @@ class _EnsembleGrower(object): left_node_contribs_list = [] right_node_contribs_list = [] all_feature_ids = [] - assert len(stats_summaries_list) == len(feature_ids_list) + assert len(stats_summaries_list) == len(self._feature_ids_list) max_splits = _get_max_splits(self._tree_hparams) - for i, feature_ids in enumerate(feature_ids_list): + for i, feature_ids in enumerate(self._feature_ids_list): (numeric_node_ids_per_feature, numeric_gains_list, numeric_thresholds_list, numeric_left_node_contribs_list, numeric_right_node_contribs_list) = ( @@ -516,12 +521,13 @@ class _EnsembleGrower(object): class _InMemoryEnsembleGrower(_EnsembleGrower): - """A base class for ensemble growers.""" + """An in-memory ensemble grower.""" - def __init__(self, tree_ensemble, tree_hparams): + def __init__(self, tree_ensemble, tree_hparams, feature_ids_list): super(_InMemoryEnsembleGrower, self).__init__( - tree_ensemble=tree_ensemble, tree_hparams=tree_hparams) + tree_ensemble=tree_ensemble, tree_hparams=tree_hparams, + feature_ids_list=feature_ids_list) def center_bias(self, center_bias_var, gradients, hessians): # For in memory, we already have a full batch of gradients and hessians, @@ -531,83 +537,98 @@ class _InMemoryEnsembleGrower(_EnsembleGrower): mean_heassians = array_ops.expand_dims(math_ops.reduce_mean(hessians, 0), 0) return self._center_bias_fn(center_bias_var, mean_gradients, mean_heassians) - def grow_tree(self, stats_summaries_list, feature_ids_list, - last_layer_nodes_range): + def grow_tree(self, stats_summaries_list, last_layer_nodes_range): # For in memory, we already have full data in one batch, so we can grow the # tree immediately. return self._grow_tree_from_stats_summaries( - stats_summaries_list, feature_ids_list, last_layer_nodes_range) + stats_summaries_list, last_layer_nodes_range) class _AccumulatorEnsembleGrower(_EnsembleGrower): - """A base class for ensemble growers.""" + """An accumulator based ensemble grower.""" def __init__(self, tree_ensemble, tree_hparams, stamp_token, - n_batches_per_layer, bucket_size_list, is_chief): + n_batches_per_layer, bucket_size_list, is_chief, center_bias, + feature_ids_list): super(_AccumulatorEnsembleGrower, self).__init__( - tree_ensemble=tree_ensemble, tree_hparams=tree_hparams) + tree_ensemble=tree_ensemble, tree_hparams=tree_hparams, + feature_ids_list=feature_ids_list) self._stamp_token = stamp_token self._n_batches_per_layer = n_batches_per_layer self._bucket_size_list = bucket_size_list self._is_chief = is_chief + self._growing_accumulators = [] + self._chief_init_ops = [] + max_splits = _get_max_splits(self._tree_hparams) + for i, feature_ids in enumerate(self._feature_ids_list): + accumulator = data_flow_ops.ConditionalAccumulator( + dtype=dtypes.float32, + # The stats consist of grads and hessians (the last dimension). + shape=[len(feature_ids), max_splits, self._bucket_size_list[i], 2], + shared_name='numeric_stats_summary_accumulator_' + str(i)) + self._chief_init_ops.append( + accumulator.set_global_step(self._stamp_token)) + self._growing_accumulators.append(accumulator) + self._center_bias = center_bias + if center_bias: + self._bias_accumulator = data_flow_ops.ConditionalAccumulator( + dtype=dtypes.float32, + # The stats consist of grads and hessians means only. + # TODO(nponomareva): this will change for a multiclass + shape=[2, 1], + shared_name='bias_accumulator') + self._chief_init_ops.append( + self._bias_accumulator.set_global_step(self._stamp_token)) def center_bias(self, center_bias_var, gradients, hessians): # For not in memory situation, we need to accumulate enough of batches first # before proceeding with centering bias. # Create an accumulator. + if not self._center_bias: + raise RuntimeError('center_bias called but bias centering is disabled.') bias_dependencies = [] - bias_accumulator = data_flow_ops.ConditionalAccumulator( - dtype=dtypes.float32, - # The stats consist of grads and hessians means only. - # TODO(nponomareva): this will change for a multiclass - shape=[2, 1], - shared_name='bias_accumulator') - grads_and_hess = array_ops.stack([gradients, hessians], axis=0) grads_and_hess = math_ops.reduce_mean(grads_and_hess, axis=1) - apply_grad = bias_accumulator.apply_grad(grads_and_hess, self._stamp_token) + apply_grad = self._bias_accumulator.apply_grad( + grads_and_hess, self._stamp_token) bias_dependencies.append(apply_grad) # Center bias if enough batches were processed. with ops.control_dependencies(bias_dependencies): if not self._is_chief: return control_flow_ops.no_op() + def _set_accumulators_stamp(): + return control_flow_ops.group( + [acc.set_global_step(self._stamp_token + 1) for acc in + self._growing_accumulators]) def center_bias_from_accumulator(): - accumulated = array_ops.unstack(bias_accumulator.take_grad(1), axis=0) - return self._center_bias_fn(center_bias_var, - array_ops.expand_dims(accumulated[0], 0), - array_ops.expand_dims(accumulated[1], 0)) + accumulated = array_ops.unstack(self._bias_accumulator.take_grad(1), + axis=0) + center_bias_op = self._center_bias_fn( + center_bias_var, + array_ops.expand_dims(accumulated[0], 0), + array_ops.expand_dims(accumulated[1], 0)) + with ops.control_dependencies([center_bias_op]): + return control_flow_ops.cond(center_bias_var, + control_flow_ops.no_op, + _set_accumulators_stamp) center_bias_op = control_flow_ops.cond( - math_ops.greater_equal(bias_accumulator.num_accumulated(), + math_ops.greater_equal(self._bias_accumulator.num_accumulated(), self._n_batches_per_layer), center_bias_from_accumulator, control_flow_ops.no_op, name='wait_until_n_batches_for_bias_accumulated') return center_bias_op - def grow_tree(self, stats_summaries_list, feature_ids_list, - last_layer_nodes_range): - # For not in memory situation, we need to accumulate enough of batches first - # before proceeding with building a tree layer. - max_splits = _get_max_splits(self._tree_hparams) - - # Prepare accumulators. - accumulators = [] + def grow_tree(self, stats_summaries_list, last_layer_nodes_range): dependencies = [] - for i, feature_ids in enumerate(feature_ids_list): + for i in range(len(self._feature_ids_list)): stats_summaries = stats_summaries_list[i] - accumulator = data_flow_ops.ConditionalAccumulator( - dtype=dtypes.float32, - # The stats consist of grads and hessians (the last dimension). - shape=[len(feature_ids), max_splits, self._bucket_size_list[i], 2], - shared_name='numeric_stats_summary_accumulator_' + str(i)) - accumulators.append(accumulator) - - apply_grad = accumulator.apply_grad( + apply_grad = self._growing_accumulators[i].apply_grad( array_ops.stack(stats_summaries, axis=0), self._stamp_token) dependencies.append(apply_grad) @@ -617,7 +638,8 @@ class _AccumulatorEnsembleGrower(_EnsembleGrower): return control_flow_ops.no_op() min_accumulated = math_ops.reduce_min( - array_ops.stack([acc.num_accumulated() for acc in accumulators])) + array_ops.stack([acc.num_accumulated() for acc in + self._growing_accumulators])) def grow_tree_from_accumulated_summaries_fn(): """Updates tree with the best layer from accumulated summaries.""" @@ -625,10 +647,11 @@ class _AccumulatorEnsembleGrower(_EnsembleGrower): stats_summaries_list = [] stats_summaries_list = [ array_ops.unstack(accumulator.take_grad(1), axis=0) - for accumulator in accumulators + for accumulator in self._growing_accumulators ] grow_op = self._grow_tree_from_stats_summaries( - stats_summaries_list, feature_ids_list, last_layer_nodes_range) + stats_summaries_list, last_layer_nodes_range + ) return grow_op grow_model = control_flow_ops.cond( @@ -638,6 +661,10 @@ class _AccumulatorEnsembleGrower(_EnsembleGrower): name='wait_until_n_batches_accumulated') return grow_model + def chief_init_op(self): + """Ops that chief needs to run to initialize the state.""" + return control_flow_ops.group(self._chief_init_ops) + def _bt_model_fn( features, @@ -683,21 +710,7 @@ def _bt_model_fn( Raises: ValueError: mode or params are invalid, or features has the wrong type. """ - is_single_machine = (config.num_worker_replicas <= 1) sorted_feature_columns = sorted(feature_columns, key=lambda tc: tc.name) - center_bias = tree_hparams.center_bias - - if train_in_memory: - assert n_batches_per_layer == 1, ( - 'When train_in_memory is enabled, input_fn should return the entire ' - 'dataset as a single batch, and n_batches_per_layer should be set as ' - '1.') - if (not config.is_chief or config.num_worker_replicas > 1 or - config.num_ps_replicas > 0): - raise ValueError('train_in_memory is supported only for ' - 'non-distributed training.') - worker_device = control_flow_ops.no_op().device - train_op = [] with ops.name_scope(name) as name: # Prepare. global_step = training_util.get_or_create_global_step() @@ -724,6 +737,20 @@ def _bt_model_fn( logits=logits) # ============== Training graph ============== + center_bias = tree_hparams.center_bias + is_single_machine = (config.num_worker_replicas <= 1) + + if train_in_memory: + assert n_batches_per_layer == 1, ( + 'When train_in_memory is enabled, input_fn should return the entire ' + 'dataset as a single batch, and n_batches_per_layer should be set as ' + '1.') + if (not config.is_chief or config.num_worker_replicas > 1 or + config.num_ps_replicas > 0): + raise ValueError('train_in_memory is supported only for ' + 'non-distributed training.') + worker_device = control_flow_ops.no_op().device + train_op = [] # Extract input features and set up cache for training. training_state_cache = None if train_in_memory: @@ -742,22 +769,6 @@ def _bt_model_fn( example_ids = features[example_id_column_name] training_state_cache = _CacheTrainingStatesUsingHashTable( example_ids, head.logits_dimension) - - # Variable that determines whether bias centering is needed. - center_bias_var = variable_scope.variable( - initial_value=center_bias, name='center_bias_needed', trainable=False) - if is_single_machine: - local_tree_ensemble = tree_ensemble - ensemble_reload = control_flow_ops.no_op() - else: - # Have a local copy of ensemble for the distributed setting. - with ops.device(worker_device): - local_tree_ensemble = boosted_trees_ops.TreeEnsemble( - name=name + '_local', is_local=True) - # TODO(soroush): Do partial updates if this becomes a bottleneck. - ensemble_reload = local_tree_ensemble.deserialize( - *tree_ensemble.serialize()) - if training_state_cache: cached_tree_ids, cached_node_ids, cached_logits = ( training_state_cache.lookup()) @@ -770,21 +781,46 @@ def _bt_model_fn( array_ops.zeros( [batch_size, head.logits_dimension], dtype=dtypes.float32)) + if is_single_machine: + local_tree_ensemble = tree_ensemble + ensemble_reload = control_flow_ops.no_op() + else: + # Have a local copy of ensemble for the distributed setting. + with ops.device(worker_device): + local_tree_ensemble = boosted_trees_ops.TreeEnsemble( + name=name + '_local', is_local=True) + # TODO(soroush): Do partial updates if this becomes a bottleneck. + ensemble_reload = local_tree_ensemble.deserialize( + *tree_ensemble.serialize()) with ops.control_dependencies([ensemble_reload]): (stamp_token, num_trees, num_finalized_trees, num_attempted_layers, last_layer_nodes_range) = local_tree_ensemble.get_states() - summary.scalar('ensemble/num_trees', num_trees) - summary.scalar('ensemble/num_finalized_trees', num_finalized_trees) - summary.scalar('ensemble/num_attempted_layers', num_attempted_layers) - partial_logits, tree_ids, node_ids = boosted_trees_ops.training_predict( tree_ensemble_handle=local_tree_ensemble.resource_handle, cached_tree_ids=cached_tree_ids, cached_node_ids=cached_node_ids, bucketized_features=input_feature_list, logits_dimension=head.logits_dimension) - logits = cached_logits + partial_logits + logits = cached_logits + partial_logits + + if train_in_memory: + grower = _InMemoryEnsembleGrower(tree_ensemble, tree_hparams, + feature_ids_list=feature_ids_list) + else: + grower = _AccumulatorEnsembleGrower(tree_ensemble, tree_hparams, + stamp_token, n_batches_per_layer, + bucket_size_list, config.is_chief, + center_bias=center_bias, + feature_ids_list=feature_ids_list) + + summary.scalar('ensemble/num_trees', num_trees) + summary.scalar('ensemble/num_finalized_trees', num_finalized_trees) + summary.scalar('ensemble/num_attempted_layers', num_attempted_layers) + # Variable that determines whether bias centering is needed. + center_bias_var = variable_scope.variable( + initial_value=center_bias, name='center_bias_needed', trainable=False, + use_resource=True) # Create training graph. def _train_op_fn(loss): """Run one training iteration.""" @@ -823,24 +859,20 @@ def _bt_model_fn( axis=0) for f in feature_ids ] stats_summaries_list.append(summaries) - - if train_in_memory and is_single_machine: - grower = _InMemoryEnsembleGrower(tree_ensemble, tree_hparams) + if center_bias: + update_model = control_flow_ops.cond( + center_bias_var, + functools.partial( + grower.center_bias, + center_bias_var, + gradients, + hessians, + ), + functools.partial(grower.grow_tree, stats_summaries_list, + last_layer_nodes_range)) else: - grower = _AccumulatorEnsembleGrower(tree_ensemble, tree_hparams, - stamp_token, n_batches_per_layer, - bucket_size_list, config.is_chief) - - update_model = control_flow_ops.cond( - center_bias_var, - functools.partial( - grower.center_bias, - center_bias_var, - gradients, - hessians, - ), - functools.partial(grower.grow_tree, stats_summaries_list, - feature_ids_list, last_layer_nodes_range)) + update_model = grower.grow_tree(stats_summaries_list, + last_layer_nodes_range) train_op.append(update_model) with ops.control_dependencies([update_model]): @@ -859,10 +891,22 @@ def _bt_model_fn( estimator_spec = estimator_spec._replace( training_hooks=estimator_spec.training_hooks + (_StopAtAttemptsHook(num_finalized_trees, num_attempted_layers, - tree_hparams.n_trees, tree_hparams.max_depth),)) + tree_hparams.n_trees, tree_hparams.max_depth),), + training_chief_hooks=[GrowerInitializationHook(grower.chief_init_op())] + + list(estimator_spec.training_chief_hooks)) return estimator_spec +class GrowerInitializationHook(session_run_hook.SessionRunHook): + """A SessionRunHook handles initialization of `_EnsembleGrower`.""" + + def __init__(self, init_op): + self._init_op = init_op + + def after_create_session(self, session, coord): + session.run(self._init_op) + + def _create_classification_head(n_classes, weight_column=None, label_vocabulary=None): diff --git a/tensorflow/python/estimator/canned/boosted_trees_test.py b/tensorflow/python/estimator/canned/boosted_trees_test.py index ec597e4686..08026a93c5 100644 --- a/tensorflow/python/estimator/canned/boosted_trees_test.py +++ b/tensorflow/python/estimator/canned/boosted_trees_test.py @@ -173,6 +173,26 @@ class BoostedTreesEstimatorTest(test_util.TensorFlowTestCase): eval_res = est.evaluate(input_fn=input_fn, steps=1) self.assertAllClose(eval_res['accuracy'], 1.0) + def testTrainTwiceAndEvaluateBinaryClassifier(self): + input_fn = _make_train_input_fn(is_classification=True) + + est = boosted_trees.BoostedTreesClassifier( + feature_columns=self._feature_columns, + n_batches_per_layer=1, + n_trees=5, + max_depth=10) + + num_steps = 2 + # Train for a few steps, and validate final checkpoint. + est.train(input_fn, steps=num_steps) + est.train(input_fn, steps=num_steps) + + self._assert_checkpoint( + est.model_dir, global_step=num_steps * 2, + finalized_trees=0, attempted_layers=4) + eval_res = est.evaluate(input_fn=input_fn, steps=1) + self.assertAllClose(eval_res['accuracy'], 1.0) + def testInferBinaryClassifier(self): train_input_fn = _make_train_input_fn(is_classification=True) predict_input_fn = numpy_io.numpy_input_fn( diff --git a/tensorflow/python/estimator/canned/head.py b/tensorflow/python/estimator/canned/head.py index da9a64c2bc..06593f9520 100644 --- a/tensorflow/python/estimator/canned/head.py +++ b/tensorflow/python/estimator/canned/head.py @@ -335,8 +335,8 @@ def _check_dense_labels_match_logits_and_reshape( 'Expected labels dimension=%s. Received %s. ' 'Suggested Fix:' 'If your classifier expects one-hot encoding label,' - 'check your n_classes argument to the estimator' - 'and/or the shape of your label.' + 'check your n_classes argument to the estimator ' + 'and/or the shape of your label. ' 'Otherwise, check the shape of your label.' % (expected_labels_dimension, dim1)) expected_labels_shape = array_ops.concat( diff --git a/tensorflow/python/estimator/estimator.py b/tensorflow/python/estimator/estimator.py index 2d0675d26a..97a02bd1e8 100644 --- a/tensorflow/python/estimator/estimator.py +++ b/tensorflow/python/estimator/estimator.py @@ -120,7 +120,9 @@ class Estimator(object): warm_start_from=None): """Constructs an `Estimator` instance. - See [estimators](https://tensorflow.org/guide/estimators) for more information. + See [estimators](https://tensorflow.org/guide/estimators) for more + information. + To warm-start an `Estimator`: ```python @@ -153,9 +155,9 @@ class Estimator(object): * `params`: Optional `dict` of hyperparameters. Will receive what is passed to Estimator in `params` parameter. This allows to configure Estimators from hyper parameter tuning. - * `config`: Optional configuration object. Will receive what is passed - to Estimator in `config` parameter, or the default `config`. - Allows updating things in your `model_fn` based on + * `config`: Optional `estimator.RunConfig` object. Will receive what + is passed to Estimator as its `config` parameter, or a default + value. Allows setting up things in your `model_fn` based on configuration such as `num_ps_replicas`, or `model_dir`. * Returns: @@ -167,7 +169,7 @@ class Estimator(object): path will be resolved. If `None`, the model_dir in `config` will be used if set. If both are set, they must be same. If both are `None`, a temporary directory will be used. - config: Configuration object. + config: `estimator.RunConfig` configuration object. params: `dict` of hyper parameters that will be passed into `model_fn`. Keys are names of parameters, values are basic python types. warm_start_from: Optional string filepath to a checkpoint or SavedModel to @@ -185,8 +187,8 @@ class Estimator(object): """ Estimator._assert_members_are_not_overridden(self) - config = maybe_overwrite_model_dir_and_session_config(config, model_dir) - self._config = config + self._config = maybe_overwrite_model_dir_and_session_config(config, + model_dir) # The distribute field contains an instance of DistributionStrategy. self._train_distribution = self._config.train_distribute @@ -286,8 +288,8 @@ class Estimator(object): Args: input_fn: A function that provides input data for training as minibatches. - See [Premade - Estimators](https://tensorflow.org/guide/premade_estimators#create_input_functions) + See [Premade Estimators]( + https://tensorflow.org/guide/premade_estimators#create_input_functions) for more information. The function should construct and return one of the following: * A `tf.data.Dataset` object: Outputs of `Dataset` object must be a tuple @@ -405,7 +407,8 @@ class Estimator(object): Args: input_fn: A function that constructs the input data for evaluation. See - [Premade Estimators](https://tensorflow.org/guide/premade#create_input_functions} + [Premade Estimators]( + https://tensorflow.org/guide/premade#create_input_functions) for more information. The function should construct and return one of the following: * A `tf.data.Dataset` object: Outputs of `Dataset` object must be a tuple @@ -431,7 +434,11 @@ class Estimator(object): Returns: A dict containing the evaluation metrics specified in `model_fn` keyed by name, as well as an entry `global_step` which contains the value of the - global step for which this evaluation was performed. + global step for which this evaluation was performed. For canned + estimators, the dict contains the `loss` (mean loss per mini-batch) and + the `average_loss` (mean loss per sample). Canned classifiers also return + the `accuracy`. Canned regressors also return the `label/mean` and the + `prediction/mean`. Raises: ValueError: If `steps <= 0`. @@ -462,9 +469,7 @@ class Estimator(object): output_dir=self.eval_dir(name)) with ops.Graph().as_default(): - # TODO(priyag): Support distributed eval on TPUs. - if (self._eval_distribution - and self._eval_distribution.__class__.__name__ != 'TPUStrategy'): + if self._eval_distribution: with self._eval_distribution.scope(): return _evaluate() else: @@ -490,8 +495,8 @@ class Estimator(object): input_fn: A function that constructs the features. Prediction continues until `input_fn` raises an end-of-input exception (`tf.errors.OutOfRangeError` or `StopIteration`). - See [Premade - Estimators](https://tensorflow.org/guide/premade_estimators#create_input_functions) + See [Premade Estimators]( + https://tensorflow.org/guide/premade_estimators#create_input_functions) for more information. The function should construct and return one of the following: @@ -604,6 +609,38 @@ class Estimator(object): as_text=False, checkpoint_path=None, strip_default_attrs=False): + # pylint: disable=line-too-long,g-doc-args,g-doc-return-or-yield + """Exports inference graph as a `SavedModel` into the given dir. + + Note that `export_to_savedmodel` will be renamed to `export_to_saved_model` + in TensorFlow 2.0. At that time, `export_to_savedmodel` without the + additional underscore will be available only through tf.compat.v1. + + Please see `tf.estimator.Estimator.export_saved_model` for more information. + + There is one additional arg versus the new method: + strip_default_attrs: This parameter is going away in TF 2.0, and + the new behavior will automatically strip all default attributes. + Boolean. If `True`, default-valued attributes will be + removed from the `NodeDef`s. For a detailed guide, see [Stripping + Default-Valued Attributes]( + https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/README.md#stripping-default-valued-attributes). + """ + # pylint: enable=line-too-long,g-doc-args,g-doc-return-or-yield + return self._export_saved_model_for_mode( + export_dir_base, + serving_input_receiver_fn, + assets_extra=assets_extra, + as_text=as_text, + checkpoint_path=checkpoint_path, + strip_default_attrs=strip_default_attrs, + mode=model_fn_lib.ModeKeys.PREDICT) + + def export_saved_model( + self, export_dir_base, serving_input_receiver_fn, + assets_extra=None, + as_text=False, + checkpoint_path=None): # pylint: disable=line-too-long """Exports inference graph as a `SavedModel` into the given dir. @@ -650,28 +687,25 @@ class Estimator(object): as_text: whether to write the `SavedModel` proto in text format. checkpoint_path: The checkpoint path to export. If `None` (the default), the most recent checkpoint found within the model directory is chosen. - strip_default_attrs: Boolean. If `True`, default-valued attributes will be - removed from the `NodeDef`s. For a detailed guide, see [Stripping - Default-Valued - Attributes](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/README.md#stripping-default-valued-attributes). Returns: The string path to the exported directory. Raises: ValueError: if no `serving_input_receiver_fn` is provided, no - `export_outputs` - are provided, or no checkpoint can be found. + `export_outputs` are provided, or no checkpoint can be found. """ # pylint: enable=line-too-long - return self._export_saved_model_for_mode( + # TODO(b/111442174): `export_to_savedmodel` will be renamed to + # `export_to_saved_model` in TensorFlow 2.0. This function is a wrapper + # while staging the new version; do not add any logic here. + return self.export_savedmodel( export_dir_base, serving_input_receiver_fn, assets_extra=assets_extra, as_text=as_text, checkpoint_path=checkpoint_path, - strip_default_attrs=strip_default_attrs, - mode=model_fn_lib.ModeKeys.PREDICT) + strip_default_attrs=True) def _export_saved_model_for_mode( self, export_dir_base, input_receiver_fn, @@ -1032,16 +1066,21 @@ class Estimator(object): 'QueueRunner. That means predict yields forever. ' 'This is probably a mistake.') - def _get_features_and_labels_from_input_fn(self, input_fn, mode, - distribution=None): - """Extracts the `features` and labels from return values of `input_fn`.""" + def _get_iterator_from_input_fn(self, input_fn, mode, distribution=None): if distribution is not None: result = distribution.distribute_dataset( lambda: self._call_input_fn(input_fn, mode)) else: result = self._call_input_fn(input_fn, mode) - return estimator_util.parse_input_fn_result(result) + iterator = result.make_initializable_iterator() + input_hooks = [estimator_util._DatasetInitializerHook(iterator)] # pylint: disable=protected-access + return iterator, input_hooks + + def _get_features_and_labels_from_input_fn(self, input_fn, mode): + """Extracts the `features` and labels from return values of `input_fn`.""" + return estimator_util.parse_input_fn_result( + self._call_input_fn(input_fn, mode)) def _extract_batch_length(self, preds_evaluated): """Extracts batch length of predictions.""" @@ -1234,30 +1273,23 @@ class Estimator(object): # We want to create the iterations variable outside the distribution scope # as that is just stored on the host and mainly used to drive the loop # and doesn't need to be a Mirrored/Device variable. - steps_per_run_variable = training.get_or_create_steps_per_run_variable() + if is_tpu_strategy: + steps_per_run_variable = training.get_or_create_steps_per_run_variable() with self._train_distribution.scope(): random_seed.set_random_seed(self._config.tf_random_seed) + iterator, input_hooks = self._get_iterator_from_input_fn( + input_fn, model_fn_lib.ModeKeys.TRAIN, self._train_distribution) + worker_hooks.extend(input_hooks) + global_step_tensor = self._create_and_assert_global_step(g) + # we want to add to the global collection in the main thread not the + # tower threads. + ops.add_to_collection( + training_util.GLOBAL_STEP_READ_KEY, + self._train_distribution.read_var(global_step_tensor)) if is_tpu_strategy: - # Create the iterator for run_on_dataset function - # TODO(sourabhbajaj): refactor this out to call a function on the - # strategy - dataset = self._train_distribution.distribute_dataset( - lambda: self._call_input_fn(input_fn, # pylint: disable=g-long-lambda - model_fn_lib.ModeKeys.TRAIN)) - iterator = dataset.make_initializable_iterator() - worker_hooks.append( - estimator_util._DatasetInitializerHook(iterator)) # pylint: disable=protected-access - - global_step_tensor = self._create_and_assert_global_step(g) - # we want to add to the global collection in the main thread not the - # tower threads. - ops.add_to_collection( - training_util.GLOBAL_STEP_READ_KEY, - self._train_distribution.read_var(global_step_tensor)) - # Create a step_fn from the train_op of grouped_estimator_spec - def step_fn(ctx, features, labels): + def step_fn(ctx, features, labels=None): """A single step that is passed to run_on_dataset.""" estimator_spec = self._train_distribution.call_for_each_tower( self._call_model_fn, @@ -1279,26 +1311,23 @@ class Estimator(object): step_fn, iterator, iterations=steps_per_run_variable, initial_loop_values={'loss': initial_training_loss}) distributed_train_op = ctx.run_op - tpu_result = ctx.last_step_outputs + loss = ctx.last_step_outputs['loss'] grouped_estimator_spec = ctx.non_tensor_outputs['estimator_spec'] else: - features, labels, input_hooks = ( - self._get_features_and_labels_from_input_fn( - input_fn, model_fn_lib.ModeKeys.TRAIN, - self._train_distribution)) - worker_hooks.extend(input_hooks) - global_step_tensor = self._create_and_assert_global_step(g) - # we want to add to the global collection in the main thread not the - # tower threads. - ops.add_to_collection( - training_util.GLOBAL_STEP_READ_KEY, - self._train_distribution.read_var(global_step_tensor)) + features, labels = estimator_util.parse_iterator_result( + iterator.get_next()) grouped_estimator_spec = self._train_distribution.call_for_each_tower( self._call_model_fn, features, labels, # although this will be None it seems model_fn_lib.ModeKeys.TRAIN, self.config) + loss = self._train_distribution.unwrap( + self._train_distribution.reduce( + distribute_lib.get_loss_reduction(), + grouped_estimator_spec.loss, + destinations='/device:CPU:0'))[0] + distributed_train_op = grouped_estimator_spec.train_op scaffold = _combine_distributed_scaffold( grouped_estimator_spec.scaffold, self._train_distribution) @@ -1312,21 +1341,10 @@ class Estimator(object): grouped_estimator_spec.training_hooks) training_chief_hooks = get_hooks_from_the_first_device( grouped_estimator_spec.training_chief_hooks) - - # TODO(sourabhbajaj): Merge the two code paths and clean up the code - if is_tpu_strategy: - loss = tpu_result['loss'] - worker_hooks.append( - estimator_util.StrategyInitFinalizeHook( - self._train_distribution.initialize, - self._train_distribution.finalize)) - else: - loss = self._train_distribution.unwrap( - self._train_distribution.reduce( - distribute_lib.get_loss_reduction(), - grouped_estimator_spec.loss, - destinations='/device:CPU:0'))[0] - distributed_train_op = grouped_estimator_spec.train_op + worker_hooks.append( + estimator_util.StrategyInitFinalizeHook( + self._train_distribution.initialize, + self._train_distribution.finalize)) estimator_spec = model_fn_lib.EstimatorSpec( mode=grouped_estimator_spec.mode, @@ -1427,31 +1445,18 @@ class Estimator(object): """Builds the graph and related hooks to run evaluation.""" random_seed.set_random_seed(self._config.tf_random_seed) self._create_and_assert_global_step(ops.get_default_graph()) - features, labels, input_hooks = ( - self._get_features_and_labels_from_input_fn( - input_fn, model_fn_lib.ModeKeys.EVAL, self._eval_distribution)) if self._eval_distribution: - (loss_metric, scaffold, evaluation_hooks, eval_metric_ops) = ( - self._call_model_fn_eval_distributed(features, labels, self.config)) + (scaffold, evaluation_hooks, input_hooks, update_op, eval_dict) = ( + self._call_model_fn_eval_distributed(input_fn, self.config)) else: - (loss_metric, scaffold, evaluation_hooks, eval_metric_ops) = ( - self._call_model_fn_eval(features, labels, self.config)) + (scaffold, evaluation_hooks, input_hooks, update_op, eval_dict) = ( + self._call_model_fn_eval(input_fn, self.config)) global_step_tensor = training_util.get_global_step(ops.get_default_graph()) # Call to warm_start has to be after model_fn is called. self._maybe_warm_start(checkpoint_path) - if model_fn_lib.LOSS_METRIC_KEY in eval_metric_ops: - raise ValueError( - 'Metric with name "%s" is not allowed, because Estimator ' % - (model_fn_lib.LOSS_METRIC_KEY) + - 'already defines a default metric with the same name.') - eval_metric_ops[model_fn_lib.LOSS_METRIC_KEY] = loss_metric - - update_op, eval_dict = _extract_metric_update_ops(eval_metric_ops, - self._eval_distribution) - if ops.GraphKeys.GLOBAL_STEP in eval_dict: raise ValueError( 'Metric with name `global_step` is not allowed, because Estimator ' @@ -1476,26 +1481,71 @@ class Estimator(object): return scaffold, update_op, eval_dict, all_hooks - def _call_model_fn_eval(self, features, labels, config): + def _call_model_fn_eval(self, input_fn, config): + """Call model_fn for evaluation and handle return values.""" + features, labels, input_hooks = self._get_features_and_labels_from_input_fn( + input_fn, model_fn_lib.ModeKeys.EVAL) + estimator_spec = self._call_model_fn( features, labels, model_fn_lib.ModeKeys.EVAL, config) - loss_metric = metrics_lib.mean(estimator_spec.loss) - return (loss_metric, estimator_spec.scaffold, - estimator_spec.evaluation_hooks, estimator_spec.eval_metric_ops) + eval_metric_ops = _verify_and_create_loss_metric( + estimator_spec.eval_metric_ops, estimator_spec.loss) + update_op, eval_dict = _extract_metric_update_ops(eval_metric_ops) + return (estimator_spec.scaffold, estimator_spec.evaluation_hooks, + input_hooks, update_op, eval_dict) - def _call_model_fn_eval_distributed(self, features, labels, config): + def _call_model_fn_eval_distributed(self, input_fn, config): """Call model_fn in distribution mode and handle return values.""" - grouped_estimator_spec = self._eval_distribution.call_for_each_tower( - self._call_model_fn, features, labels, - model_fn_lib.ModeKeys.EVAL, config) + + iterator, input_hooks = self._get_iterator_from_input_fn( + input_fn, model_fn_lib.ModeKeys.EVAL, self._eval_distribution) + + is_tpu_strategy = ( + self._eval_distribution.__class__.__name__ == 'TPUStrategy') + + if is_tpu_strategy: + def step_fn(ctx, features, labels=None): + """Runs one step of the eval computation and captures outputs.""" + estimator_spec = self._eval_distribution.call_for_each_tower( + self._call_model_fn, features, labels, model_fn_lib.ModeKeys.EVAL, + config) + eval_metric_ops = _verify_and_create_loss_metric( + estimator_spec.eval_metric_ops, estimator_spec.loss, + self._eval_distribution) + update_op, eval_dict = _extract_metric_update_ops( + eval_metric_ops, self._eval_distribution) + ctx.set_non_tensor_output(name='estimator_spec', output=estimator_spec) + ctx.set_non_tensor_output(name='eval_dict', output=eval_dict) + return update_op + + # TODO(priyag): Fix eval step hook to account for steps_per_run. + ctx = self._eval_distribution.run_steps_on_dataset( + step_fn, iterator, iterations=self._eval_distribution.steps_per_run) + update_op = ctx.run_op + eval_dict = ctx.non_tensor_outputs['eval_dict'] + grouped_estimator_spec = ctx.non_tensor_outputs['estimator_spec'] + else: + features, labels = estimator_util.parse_iterator_result( + iterator.get_next()) + grouped_estimator_spec = self._eval_distribution.call_for_each_tower( + self._call_model_fn, features, labels, + model_fn_lib.ModeKeys.EVAL, config) + eval_metric_ops = _verify_and_create_loss_metric( + grouped_estimator_spec.eval_metric_ops, grouped_estimator_spec.loss, + self._eval_distribution) + update_op, eval_dict = _extract_metric_update_ops( + eval_metric_ops, self._eval_distribution) + scaffold = _combine_distributed_scaffold( grouped_estimator_spec.scaffold, self._eval_distribution) evaluation_hooks = self._eval_distribution.unwrap( grouped_estimator_spec.evaluation_hooks)[0] - loss_metric = self._eval_distribution.call_for_each_tower( - metrics_lib.mean, grouped_estimator_spec.loss) - return (loss_metric, scaffold, - evaluation_hooks, grouped_estimator_spec.eval_metric_ops) + evaluation_hooks = evaluation_hooks + ( + estimator_util.StrategyInitFinalizeHook( + self._eval_distribution.initialize, + self._eval_distribution.finalize),) + + return (scaffold, evaluation_hooks, input_hooks, update_op, eval_dict) def _evaluate_run(self, checkpoint_path, scaffold, update_op, eval_dict, all_hooks, output_dir): @@ -1531,6 +1581,23 @@ class Estimator(object): warm_starting_util.warm_start(*self._warm_start_settings) +def _verify_and_create_loss_metric(eval_metric_ops, loss, distribution=None): + """Creates a metric for loss and throws an error if one already exists.""" + if model_fn_lib.LOSS_METRIC_KEY in eval_metric_ops: + raise ValueError( + 'Metric with name "%s" is not allowed, because Estimator ' % + (model_fn_lib.LOSS_METRIC_KEY) + + 'already defines a default metric with the same name.') + + if distribution is None: + loss_metric = metrics_lib.mean(loss) + else: + loss_metric = distribution.call_for_each_tower( + metrics_lib.mean, loss) + eval_metric_ops[model_fn_lib.LOSS_METRIC_KEY] = loss_metric + return eval_metric_ops + + def maybe_overwrite_model_dir_and_session_config(config, model_dir): """Overwrite estimator config by `model_dir` and `session_config` if needed. diff --git a/tensorflow/python/estimator/export/export.py b/tensorflow/python/estimator/export/export.py index 3d171f7811..55aace5fa9 100644 --- a/tensorflow/python/estimator/export/export.py +++ b/tensorflow/python/estimator/export/export.py @@ -217,6 +217,29 @@ class TensorServingInputReceiver( receiver_tensors_alternatives=receiver.receiver_tensors_alternatives) +class UnsupervisedInputReceiver(ServingInputReceiver): + """A return type for a training_input_receiver_fn or eval_input_receiver_fn. + + This differs from SupervisedInputReceiver in that it does not require a set + of labels. + + The expected return values are: + features: A `Tensor`, `SparseTensor`, or dict of string to `Tensor` or + `SparseTensor`, specifying the features to be passed to the model. + receiver_tensors: A `Tensor`, `SparseTensor`, or dict of string to `Tensor` + or `SparseTensor`, specifying input nodes where this receiver expects to + be fed by default. Typically, this is a single placeholder expecting + serialized `tf.Example` protos. + """ + + def __new__(cls, features, receiver_tensors): + return super(UnsupervisedInputReceiver, cls).__new__( + cls, + features=features, + receiver_tensors=receiver_tensors, + receiver_tensors_alternatives=None) + + class SupervisedInputReceiver( collections.namedtuple('SupervisedInputReceiver', ['features', 'labels', 'receiver_tensors'])): @@ -288,13 +311,33 @@ def build_parsing_serving_input_receiver_fn(feature_spec, def _placeholder_from_tensor(t, default_batch_size=None): + """Creates a placeholder that matches the dtype and shape of passed tensor. + + Args: + t: Tensor or EagerTensor + default_batch_size: the number of query examples expected per batch. + Leave unset for variable batch size (recommended). + + Returns: + Placeholder that matches the passed tensor. + """ batch_shape = tensor_shape.TensorShape([default_batch_size]) shape = batch_shape.concatenate(t.get_shape()[1:]) # Reuse the feature tensor's op name (t.op.name) for the placeholder, # excluding the index from the tensor's name (t.name): # t.name = "%s:%d" % (t.op.name, t._value_index) - return array_ops.placeholder(dtype=t.dtype, shape=shape, name=t.op.name) + try: + name = t.op.name + except AttributeError: + # In Eager mode, tensors don't have ops or names, and while they do have + # IDs, those are not maintained across runs. The name here is used + # primarily for debugging, and is not critical to the placeholder. + # So, in order to make this Eager-compatible, continue with an empty + # name if none is available. + name = None + + return array_ops.placeholder(dtype=t.dtype, shape=shape, name=name) def _placeholders_from_receiver_tensors_dict(input_vals, diff --git a/tensorflow/python/estimator/export/export_test.py b/tensorflow/python/estimator/export/export_test.py index 1d475adb43..3eed1ab163 100644 --- a/tensorflow/python/estimator/export/export_test.py +++ b/tensorflow/python/estimator/export/export_test.py @@ -163,6 +163,29 @@ class ServingInputReceiverTest(test_util.TensorFlowTestCase): _ = export.ServingInputReceiver(feature, receiver_tensor) +class UnsupervisedInputReceiverTest(test_util.TensorFlowTestCase): + + # Since this is basically a wrapper around ServingInputReceiver, we only + # have a simple sanity check to ensure that it works. + + def test_unsupervised_input_receiver_constructor(self): + """Tests that no errors are raised when input is expected.""" + features = { + "feature0": + constant_op.constant([0]), + u"feature1": + constant_op.constant([1]), + "feature2": + sparse_tensor.SparseTensor( + indices=[[0, 0]], values=[1], dense_shape=[1, 1]), + } + receiver_tensors = { + "example0": array_ops.placeholder(dtypes.string, name="example0"), + u"example1": array_ops.placeholder(dtypes.string, name="example1"), + } + export.UnsupervisedInputReceiver(features, receiver_tensors) + + class SupervisedInputReceiverTest(test_util.TensorFlowTestCase): def test_input_receiver_constructor(self): @@ -393,6 +416,7 @@ class ExportTest(test_util.TensorFlowTestCase): tensor_shape.unknown_shape(), v.receiver_tensors["feature_2"].shape) + @test_util.run_in_graph_and_eager_modes def test_build_raw_serving_input_receiver_fn(self): features = {"feature_1": constant_op.constant(["hello"]), "feature_2": constant_op.constant([42])} @@ -411,6 +435,7 @@ class ExportTest(test_util.TensorFlowTestCase): dtypes.int32, serving_input_receiver.receiver_tensors["feature_2"].dtype) + @test_util.run_in_graph_and_eager_modes def test_build_raw_supervised_input_receiver_fn(self): features = {"feature_1": constant_op.constant(["hello"]), "feature_2": constant_op.constant([42])} @@ -431,6 +456,7 @@ class ExportTest(test_util.TensorFlowTestCase): self.assertEqual( dtypes.int32, input_receiver.receiver_tensors["feature_2"].dtype) + @test_util.run_in_graph_and_eager_modes def test_build_raw_supervised_input_receiver_fn_raw_tensors(self): features = {"feature_1": constant_op.constant(["hello"]), "feature_2": constant_op.constant([42])} @@ -454,6 +480,7 @@ class ExportTest(test_util.TensorFlowTestCase): self.assertEqual(set(["input", "label"]), set(input_receiver.receiver_tensors.keys())) + @test_util.run_in_graph_and_eager_modes def test_build_raw_supervised_input_receiver_fn_batch_size(self): features = {"feature_1": constant_op.constant(["hello"]), "feature_2": constant_op.constant([42])} @@ -466,6 +493,7 @@ class ExportTest(test_util.TensorFlowTestCase): self.assertEqual([10], input_receiver.receiver_tensors["feature_1"].shape) self.assertEqual([10], input_receiver.features["feature_1"].shape) + @test_util.run_in_graph_and_eager_modes def test_build_raw_supervised_input_receiver_fn_overlapping_keys(self): features = {"feature_1": constant_op.constant(["hello"]), "feature_2": constant_op.constant([42])} @@ -474,6 +502,7 @@ class ExportTest(test_util.TensorFlowTestCase): with self.assertRaises(ValueError): export.build_raw_supervised_input_receiver_fn(features, labels) + @test_util.run_in_graph_and_eager_modes def test_build_supervised_input_receiver_fn_from_input_fn(self): def dummy_input_fn(): return ({"x": constant_op.constant([[1], [1]]), @@ -491,6 +520,7 @@ class ExportTest(test_util.TensorFlowTestCase): self.assertEqual(set(["x", "y", "label"]), set(input_receiver.receiver_tensors.keys())) + @test_util.run_in_graph_and_eager_modes def test_build_supervised_input_receiver_fn_from_input_fn_args(self): def dummy_input_fn(feature_key="x"): return ({feature_key: constant_op.constant([[1], [1]]), diff --git a/tensorflow/python/estimator/keras.py b/tensorflow/python/estimator/keras.py index e2b8bfaa8e..6361c6acc1 100644 --- a/tensorflow/python/estimator/keras.py +++ b/tensorflow/python/estimator/keras.py @@ -33,9 +33,6 @@ from tensorflow.python.framework import tensor_util from tensorflow.python.keras import backend as K from tensorflow.python.keras import models from tensorflow.python.keras import optimizers -from tensorflow.python.keras.engine.base_layer import Layer -from tensorflow.python.keras.engine.network import Network -from tensorflow.python.keras.utils.generic_utils import CustomObjectScope from tensorflow.python.ops import check_ops from tensorflow.python.ops import math_ops from tensorflow.python.ops import metrics as metrics_module @@ -47,8 +44,6 @@ from tensorflow.python.training import distribution_strategy_context from tensorflow.python.training import optimizer as tf_optimizer_module from tensorflow.python.training import saver as saver_lib from tensorflow.python.training import training_util -from tensorflow.python.training.checkpointable import base as checkpointable -from tensorflow.python.training.checkpointable import data_structures _DEFAULT_SERVING_KEY = signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY @@ -92,184 +87,78 @@ def _any_weight_initialized(keras_model): return False -def _create_ordered_io(keras_model, estimator_io, is_input=True): - """Create a list of tensors from IO dictionary based on Keras IO order. +def _convert_estimator_io_to_keras(keras_model, features, labels): + """Converts estimator features and labels to keras input and target tensors. Args: - keras_model: An instance of compiled keras model. - estimator_io: The features or labels (dict or plain array) from model_fn. - is_input: True if dictionary is for inputs. + keras_model: a compiled `tf.keras.Model` instance, used to determine the + order of the returned lists. + features: Dict of tensors or `None`. + labels: Dict of tensors, a single tensor, or `None`. Returns: - A list of tensors based on Keras IO order. - - Raises: - ValueError: if dictionary keys cannot be found in Keras model input_names - or output_names. - """ - if isinstance(estimator_io, (list, tuple)): - # Case currently not supported by most built-in input_fn, - # but it's good to have for sanity - return [_convert_tensor(x) for x in estimator_io] - elif isinstance(estimator_io, dict): - if is_input: - if keras_model._is_graph_network: - keras_io_names = keras_model.input_names - else: - keras_io_names = [ - 'input_%d' % i for i in range(1, len(estimator_io) + 1)] - else: - if keras_model._is_graph_network: - keras_io_names = keras_model.output_names - else: - keras_io_names = [ - 'output_%d' % i for i in range(1, len(estimator_io) + 1)] - - for key in estimator_io: - if key not in keras_io_names: - raise ValueError( - 'Cannot find %s with name "%s" in Keras Model. ' - 'It needs to match one ' - 'of the following: %s' % ('input' if is_input else 'output', key, - ', '.join(keras_io_names))) - tensors = [_convert_tensor(estimator_io[io_name]) - for io_name in keras_io_names] - return tensors - else: - # Plain array. - return _convert_tensor(estimator_io) - - -def _in_place_subclassed_model_reset(model): - """Substitute for model cloning that works for subclassed models. - - Subclassed models cannot be cloned because their topology is not serializable. - To "instantiate" an identical model in a new TF graph, we reuse the original - model object, but we clear its state. - - After calling this function on a model instance, you can use the model - instance as if it were a model clone (in particular you can use it in a new - graph). - - This method clears the state of the input model. It is thus destructive. - However the original state can be restored fully by calling - `_in_place_subclassed_model_state_restoration`. - - Args: - model: Instance of a Keras model created via subclassing. - - Raises: - ValueError: In case the model uses a subclassed model as inner layer. + Tuple of ( + list of input tensors or `None`, + list of target tensors or `None`) + The order of tensors is determined by the order set in the keras model. """ - assert not model._is_graph_network # Only makes sense for subclassed networks - # Retrieve all layers tracked by the model as well as their attribute names - attributes_cache = {} - for name in dir(model): - try: - value = getattr(model, name) - except (AttributeError, ValueError, TypeError): - continue - if isinstance(value, Layer): - attributes_cache[name] = value - assert value in model._layers - elif isinstance(value, (list, tuple)) and name not in ('layers', '_layers'): - # Handle case: list/tuple of layers (also tracked by the Network API). - if value and all(isinstance(val, Layer) for val in value): - raise ValueError('We do not support the use of list-of-layers ' - 'attributes in subclassed models used with ' - '`model_to_estimator` at this time. Found list ' - 'model: %s' % name) - - # Replace layers on the model with fresh layers - layers_to_names = {value: key for key, value in attributes_cache.items()} - original_layers = model._layers[:] - model._layers = data_structures.NoDependency([]) - for layer in original_layers: # We preserve layer order. - config = layer.get_config() - # This will not work for nested subclassed models used as layers. - # This would be theoretically possible to support, but would add complexity. - # Only do it if users complain. - if isinstance(layer, Network) and not layer._is_graph_network: - raise ValueError('We do not support the use of nested subclassed models ' - 'in `model_to_estimator` at this time. Found nested ' - 'model: %s' % layer) - fresh_layer = layer.__class__.from_config(config) - name = layers_to_names[layer] - setattr(model, name, fresh_layer) - - # Cache original model build attributes (in addition to layers) - if (not hasattr(model, '_original_attributes_cache') or - model._original_attributes_cache is None): - if model.built: - attributes_to_cache = [ - 'inputs', - 'outputs', - '_feed_outputs', - '_feed_output_names', - '_feed_output_shapes', - '_feed_loss_fns', - 'loss_weights_list', - 'targets', - '_feed_targets', - 'sample_weight_modes', - 'weighted_metrics', - 'metrics_names', - 'metrics_tensors', - 'metrics_updates', - 'stateful_metric_names', - 'total_loss', - 'sample_weights', - '_feed_sample_weights', - 'train_function', - 'test_function', - 'predict_function', - '_collected_trainable_weights', - '_feed_inputs', - '_feed_input_names', - '_feed_input_shapes', - 'optimizer', - ] - for name in attributes_to_cache: - attributes_cache[name] = getattr(model, name) - model._original_attributes_cache = data_structures.NoDependency( - attributes_cache) - # Reset built state - model.built = False - model.inputs = None - model.outputs = None - - -def _in_place_subclassed_model_state_restoration(model): - """Restores the original state of a model after it was "reset". - - This undoes this action of `_in_place_subclassed_model_reset`. - Args: - model: Instance of a Keras model created via subclassing, on which - `_in_place_subclassed_model_reset` was previously called. - """ - assert not model._is_graph_network - # Restore layers and build attributes - if (hasattr(model, '_original_attributes_cache') and - model._original_attributes_cache is not None): - # Models have sticky attribute assignment, so we want to be careful to add - # back the previous attributes and track Layers by their original names - # without adding dependencies on "utility" attributes which Models exempt - # when they're constructed. - model._layers = data_structures.NoDependency([]) - for name, value in model._original_attributes_cache.items(): - if not isinstance(value, checkpointable.CheckpointableBase): - # If this value is not already checkpointable, it's probably that way - # for a reason; we don't want to start tracking data structures that the - # original Model didn't. - value = data_structures.NoDependency(value) - setattr(model, name, value) - model._original_attributes_cache = None - else: - # Restore to the state of a never-called model. - model.built = False - model.inputs = None - model.outputs = None + def _to_ordered_tensor_list(obj, key_order, obj_name, order_name): + """Convert obj to an ordered list of tensors. + + Args: + obj: List, dict, or single tensor. May be `None`. + key_order: List of strings with the order to return (used if obj is a + dict). + obj_name: String name of object (e.g. "features" or "labels") + order_name: String name of the key order (e.g. "inputs" or "outputs") + + Returns: + List of tensors, or `None` + + Raises: + KeyError: If obj has invalid keys. + """ + if obj is None: + return None + elif isinstance(obj, (list, tuple)): + return [_convert_tensor(x) for x in obj] + elif isinstance(obj, dict): + # Ensure that the obj keys and keys in key_order are exactly the same. + different_keys = set(obj.keys()) ^ set(key_order) + + if different_keys: + raise KeyError( + 'The dictionary passed into {obj_name} does not have the expected ' + '{order_name} keys defined in the keras model.' + '\n\tExpected keys: {order_keys}' + '\n\t{obj_name} keys: {obj_keys}' + '\n\tDifference: {different_keys}'.format( + order_name=order_name, order_keys=set(key_order), + obj_name=obj_name, obj_keys=set(obj.keys()), + different_keys=different_keys)) + + return [_convert_tensor(obj[key]) for key in key_order] + else: # Assume obj is a tensor. + return [_convert_tensor(obj)] + + input_names = None + output_names = None + if isinstance(features, dict): + input_names = ( + keras_model.input_names if keras_model._is_graph_network else + ['input_%d' % i for i in range(1, len(features) + 1)]) + if isinstance(labels, dict): + output_names = ( + keras_model.output_names if keras_model._is_graph_network else + ['output_%d' % i for i in range(1, len(labels) + 1)]) + + input_tensors = _to_ordered_tensor_list( + features, input_names, 'features', 'inputs') + target_tensors = _to_ordered_tensor_list( + labels, output_names, 'labels', 'outputs') + + return input_tensors, target_tensors def _clone_and_build_model(mode, @@ -289,61 +178,14 @@ def _clone_and_build_model(mode, Returns: The newly built model. """ - # Set to True during training, False for inference. + # Set to True during training, False for inference or testing. K.set_learning_phase(mode == model_fn_lib.ModeKeys.TRAIN) - - # Get list of inputs. - if features is None: - input_tensors = None - else: - input_tensors = _create_ordered_io(keras_model, - estimator_io=features, - is_input=True) - # Get list of outputs. - if labels is None: - target_tensors = None - elif isinstance(labels, dict): - target_tensors = _create_ordered_io(keras_model, - estimator_io=labels, - is_input=False) - else: - target_tensors = [ - _convert_tensor(labels) - ] - - if keras_model._is_graph_network: - if custom_objects: - with CustomObjectScope(custom_objects): - model = models.clone_model(keras_model, input_tensors=input_tensors) - else: - model = models.clone_model(keras_model, input_tensors=input_tensors) - else: - model = keras_model - _in_place_subclassed_model_reset(model) - if input_tensors is not None: - model._set_inputs(input_tensors) - - # Compile/Build model - if mode is model_fn_lib.ModeKeys.PREDICT: - if isinstance(model, models.Sequential): - model.build() - else: - if isinstance(keras_model.optimizer, optimizers.TFOptimizer): - optimizer = keras_model.optimizer - else: - optimizer_config = keras_model.optimizer.get_config() - optimizer = keras_model.optimizer.__class__.from_config(optimizer_config) - optimizer.iterations = training_util.get_or_create_global_step() - - model.compile( - optimizer, - keras_model.loss, - metrics=keras_model.metrics, - loss_weights=keras_model.loss_weights, - sample_weight_mode=keras_model.sample_weight_mode, - weighted_metrics=keras_model.weighted_metrics, - target_tensors=target_tensors) - return model + input_tensors, target_tensors = _convert_estimator_io_to_keras( + keras_model, features, labels) + return models.clone_and_build_model( + keras_model, input_tensors, target_tensors, custom_objects, + compile_clone=(mode != model_fn_lib.ModeKeys.PREDICT), + in_place_reset=(not keras_model._is_graph_network)) def _create_keras_model_fn(keras_model, custom_objects=None): @@ -423,7 +265,7 @@ def _create_keras_model_fn(keras_model, custom_objects=None): if not model._is_graph_network: # Reset model state to original state, # to avoid `model_fn` being destructive for the initial model argument. - _in_place_subclassed_model_state_restoration(keras_model) + models.in_place_subclassed_model_state_restoration(keras_model) return model_fn_lib.EstimatorSpec( mode=mode, predictions=predictions, diff --git a/tensorflow/python/estimator/keras_test.py b/tensorflow/python/estimator/keras_test.py index 332e385726..290c4604ce 100644 --- a/tensorflow/python/estimator/keras_test.py +++ b/tensorflow/python/estimator/keras_test.py @@ -184,12 +184,14 @@ class TestKerasEstimator(test_util.TensorFlowTestCase): gfile.MakeDirs(self._base_dir) self._config = run_config_lib.RunConfig( tf_random_seed=_RANDOM_SEED, model_dir=self._base_dir) + super(TestKerasEstimator, self).setUp() def tearDown(self): # Make sure nothing is stuck in limbo. writer_cache.FileWriterCache.clear() if os.path.isdir(self._base_dir): gfile.DeleteRecursively(self._base_dir) + super(TestKerasEstimator, self).tearDown() def test_train(self): for model_type in ['sequential', 'functional']: @@ -511,19 +513,19 @@ class TestKerasEstimator(test_util.TensorFlowTestCase): input_dict = {'input_1': x_train} output_dict = {'invalid_output_name': y_train} return input_dict, output_dict - model = simple_functional_model() model.compile( loss='categorical_crossentropy', optimizer='adam', metrics=['acc']) with self.test_session(): est_keras = keras_lib.model_to_estimator( keras_model=model, config=self._config) - with self.test_session(): - with self.assertRaises(ValueError): + with self.assertRaisesRegexp(KeyError, + 'Difference: .*invalid_input_name'): est_keras.train(input_fn=invald_input_name_input_fn, steps=100) - with self.assertRaises(ValueError): + with self.assertRaisesRegexp(KeyError, + 'Difference: .*invalid_output_name'): est_keras.train(input_fn=invald_output_name_input_fn, steps=100) def test_custom_objects(self): diff --git a/tensorflow/python/estimator/model_fn.py b/tensorflow/python/estimator/model_fn.py index 9db9ccd01d..007970bef7 100644 --- a/tensorflow/python/estimator/model_fn.py +++ b/tensorflow/python/estimator/model_fn.py @@ -141,7 +141,7 @@ class EstimatorSpec( prediction. predictions: Predictions `Tensor` or dict of `Tensor`. loss: Training loss `Tensor`. Must be either scalar, or with shape `[1]`. - train_op: Op for the training step. + train_op: Op to run one training step. eval_metric_ops: Dict of metric results keyed by name. The values of the dict are the results of calling a metric function, namely a `(metric_tensor, update_op)` tuple. `metric_tensor` should be evaluated diff --git a/tensorflow/python/estimator/model_fn_test.py b/tensorflow/python/estimator/model_fn_test.py index 08e41fd414..b6f1b16a22 100644 --- a/tensorflow/python/estimator/model_fn_test.py +++ b/tensorflow/python/estimator/model_fn_test.py @@ -48,7 +48,7 @@ class EstimatorSpecTrainTest(test.TestCase): def testRequiredArgumentsSet(self): """Tests that no errors are raised when all required arguments are set.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.TRAIN, loss=constant_op.constant(1.), @@ -56,7 +56,7 @@ class EstimatorSpecTrainTest(test.TestCase): def testAllArgumentsSet(self): """Tests that no errors are raised when all arguments are set.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) predictions = {'loss': loss} classes = constant_op.constant('hello') @@ -77,7 +77,7 @@ class EstimatorSpecTrainTest(test.TestCase): def testLossNumber(self): """Tests that error is raised when loss is a number (not Tensor).""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp(TypeError, 'loss must be Tensor'): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.TRAIN, @@ -86,20 +86,20 @@ class EstimatorSpecTrainTest(test.TestCase): def testLoss1DTensor(self): """Tests that no errors are raised when loss is 1D tensor.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.TRAIN, loss=constant_op.constant([1.]), train_op=control_flow_ops.no_op()) def testLossMissing(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp(ValueError, 'Missing loss'): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.TRAIN, train_op=control_flow_ops.no_op()) def testLossNotScalar(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp(ValueError, 'Loss must be scalar'): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.TRAIN, @@ -107,7 +107,7 @@ class EstimatorSpecTrainTest(test.TestCase): train_op=control_flow_ops.no_op()) def testLossSparseTensor(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = sparse_tensor.SparseTensor( indices=[[0]], values=[0.], @@ -121,7 +121,7 @@ class EstimatorSpecTrainTest(test.TestCase): def testLossFromDifferentGraph(self): with ops.Graph().as_default(): loss = constant_op.constant(1.) - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( ValueError, 'must be from the default graph'): model_fn.EstimatorSpec( @@ -130,13 +130,13 @@ class EstimatorSpecTrainTest(test.TestCase): train_op=control_flow_ops.no_op()) def testTrainOpMissing(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp(ValueError, 'Missing train_op'): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.TRAIN, loss=constant_op.constant(1.)) def testTrainOpNotOperationAndTensor(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp(TypeError, 'train_op must be Operation or Tensor'): model_fn.EstimatorSpec( @@ -147,7 +147,7 @@ class EstimatorSpecTrainTest(test.TestCase): def testTrainOpFromDifferentGraph(self): with ops.Graph().as_default(): train_op = control_flow_ops.no_op() - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( ValueError, 'must be from the default graph'): model_fn.EstimatorSpec( @@ -156,7 +156,7 @@ class EstimatorSpecTrainTest(test.TestCase): train_op=train_op) def testTrainingChiefHookInvalid(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( TypeError, 'All hooks must be SessionRunHook instances'): model_fn.EstimatorSpec( @@ -166,7 +166,7 @@ class EstimatorSpecTrainTest(test.TestCase): training_chief_hooks=[_InvalidHook()]) def testTrainingHookInvalid(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( TypeError, 'All hooks must be SessionRunHook instances'): model_fn.EstimatorSpec( @@ -176,7 +176,7 @@ class EstimatorSpecTrainTest(test.TestCase): training_hooks=[_InvalidHook()]) def testScaffoldInvalid(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( TypeError, r'scaffold must be tf\.train\.Scaffold'): model_fn.EstimatorSpec( @@ -186,7 +186,7 @@ class EstimatorSpecTrainTest(test.TestCase): scaffold=_InvalidScaffold()) def testReturnDefaultScaffold(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): estimator_spec = model_fn.EstimatorSpec( mode=model_fn.ModeKeys.TRAIN, loss=constant_op.constant(1.), @@ -199,7 +199,7 @@ class EstimatorSpecEvalTest(test.TestCase): def testRequiredArgumentsSet(self): """Tests that no errors are raised when all required arguments are set.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, @@ -208,7 +208,7 @@ class EstimatorSpecEvalTest(test.TestCase): def testAllArgumentsSet(self): """Tests that no errors are raised when all arguments are set.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) predictions = {'loss': loss} classes = constant_op.constant('hello') @@ -227,7 +227,7 @@ class EstimatorSpecEvalTest(test.TestCase): evaluation_hooks=[_FakeHook()]) def testEvaluationHookInvalid(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( TypeError, 'All hooks must be SessionRunHook instances'): model_fn.EstimatorSpec( @@ -237,7 +237,7 @@ class EstimatorSpecEvalTest(test.TestCase): def testTupleMetric(self): """Tests that no errors are raised when a metric is tuple-valued.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, @@ -248,7 +248,7 @@ class EstimatorSpecEvalTest(test.TestCase): def testLoss1DTensor(self): """Tests that no errors are raised when loss is 1D tensor.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant([1.]) model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, @@ -257,7 +257,7 @@ class EstimatorSpecEvalTest(test.TestCase): def testLossNumber(self): """Tests that error is raised when loss is a number (not Tensor).""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp(TypeError, 'loss must be Tensor'): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, @@ -265,14 +265,14 @@ class EstimatorSpecEvalTest(test.TestCase): loss=1.) def testLossMissing(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp(ValueError, 'Missing loss'): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, predictions={'loss': constant_op.constant(1.)}) def testLossNotScalar(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant([1., 2.]) with self.assertRaisesRegexp(ValueError, 'Loss must be scalar'): model_fn.EstimatorSpec( @@ -281,7 +281,7 @@ class EstimatorSpecEvalTest(test.TestCase): loss=loss) def testLossSparseTensor(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = sparse_tensor.SparseTensor( indices=[[0]], values=[0.], @@ -296,7 +296,7 @@ class EstimatorSpecEvalTest(test.TestCase): def testLossFromDifferentGraph(self): with ops.Graph().as_default(): loss = constant_op.constant(1.) - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( ValueError, 'must be from the default graph'): model_fn.EstimatorSpec( @@ -305,7 +305,7 @@ class EstimatorSpecEvalTest(test.TestCase): loss=loss) def testReplaceRaisesConstructorChecks(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) spec = model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, predictions={'loss': loss}, loss=loss) @@ -313,7 +313,7 @@ class EstimatorSpecEvalTest(test.TestCase): spec._replace(loss=constant_op.constant([1., 2.])) def testReplaceDoesReplace(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) spec = model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, predictions={'loss': loss}, loss=loss) @@ -321,7 +321,7 @@ class EstimatorSpecEvalTest(test.TestCase): self.assertEqual(['m'], list(new_spec.predictions.keys())) def testReplaceNotAllowModeChange(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) spec = model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, predictions={'loss': loss}, loss=loss) @@ -331,13 +331,13 @@ class EstimatorSpecEvalTest(test.TestCase): spec._replace(mode=model_fn.ModeKeys.TRAIN) def testPredictionsMissingIsOkay(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, loss=constant_op.constant(1.)) def testPredictionsTensor(self): """Tests that no error is raised when predictions is Tensor (not dict).""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) model_fn.EstimatorSpec( mode=model_fn.ModeKeys.EVAL, @@ -345,7 +345,7 @@ class EstimatorSpecEvalTest(test.TestCase): loss=loss) def testPredictionsNumber(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( TypeError, r'predictions\[number\] must be Tensor'): model_fn.EstimatorSpec( @@ -354,7 +354,7 @@ class EstimatorSpecEvalTest(test.TestCase): loss=constant_op.constant(1.)) def testPredictionsSparseTensor(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): predictions = { 'sparse': sparse_tensor.SparseTensor( indices=[[0]], @@ -370,7 +370,7 @@ class EstimatorSpecEvalTest(test.TestCase): def testPredictionsFromDifferentGraph(self): with ops.Graph().as_default(): predictions = {'loss': constant_op.constant(1.)} - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( ValueError, 'must be from the default graph'): model_fn.EstimatorSpec( @@ -379,7 +379,7 @@ class EstimatorSpecEvalTest(test.TestCase): loss=constant_op.constant(1.)) def testEvalMetricOpsNoDict(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) with self.assertRaisesRegexp( TypeError, 'eval_metric_ops must be a dict'): @@ -390,7 +390,7 @@ class EstimatorSpecEvalTest(test.TestCase): eval_metric_ops=loss) def testEvalMetricOpsNoTuple(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) with self.assertRaisesRegexp( TypeError, @@ -403,7 +403,7 @@ class EstimatorSpecEvalTest(test.TestCase): eval_metric_ops={'loss': loss}) def testEvalMetricOpsNoTensorOrOperation(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) with self.assertRaisesRegexp(TypeError, 'must be Operation or Tensor'): model_fn.EstimatorSpec( @@ -413,7 +413,7 @@ class EstimatorSpecEvalTest(test.TestCase): eval_metric_ops={'loss': ('NonTensor', loss)}) def testEvalMetricNestedNoTensorOrOperation(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) with self.assertRaisesRegexp(TypeError, 'must be Operation or Tensor'): model_fn.EstimatorSpec( @@ -427,7 +427,7 @@ class EstimatorSpecEvalTest(test.TestCase): with ops.Graph().as_default(): eval_metric_ops = { 'loss': (control_flow_ops.no_op(), constant_op.constant(1.))} - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) with self.assertRaisesRegexp( ValueError, 'must be from the default graph'): @@ -443,14 +443,14 @@ class EstimatorSpecInferTest(test.TestCase): def testRequiredArgumentsSet(self): """Tests that no errors are raised when all required arguments are set.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.PREDICT, predictions={'loss': constant_op.constant(1.)}) def testAllArgumentsSet(self): """Tests that no errors are raised when all arguments are set.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): loss = constant_op.constant(1.) predictions = {'loss': loss} classes = constant_op.constant('hello') @@ -470,7 +470,7 @@ class EstimatorSpecInferTest(test.TestCase): prediction_hooks=[_FakeHook()]) def testPredictionHookInvalid(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( TypeError, 'All hooks must be SessionRunHook instances'): model_fn.EstimatorSpec( @@ -479,25 +479,25 @@ class EstimatorSpecInferTest(test.TestCase): prediction_hooks=[_InvalidHook()]) def testPredictionsMissing(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp(ValueError, 'Missing predictions'): model_fn.EstimatorSpec(mode=model_fn.ModeKeys.PREDICT) def testPredictionsTensor(self): """Tests that no error is raised when predictions is Tensor (not dict).""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.PREDICT, predictions=constant_op.constant(1.)) def testPredictionsNumber(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): with self.assertRaisesRegexp( TypeError, r'predictions\[number\] must be Tensor'): model_fn.EstimatorSpec( mode=model_fn.ModeKeys.PREDICT, predictions={'number': 1.}) def testPredictionsSparseTensor(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): predictions = { 'sparse': sparse_tensor.SparseTensor( indices=[[0]], @@ -509,7 +509,7 @@ class EstimatorSpecInferTest(test.TestCase): mode=model_fn.ModeKeys.PREDICT, predictions=predictions) def testExportOutputsNoDict(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): predictions = {'loss': constant_op.constant(1.)} classes = constant_op.constant('hello') with self.assertRaisesRegexp( @@ -520,7 +520,7 @@ class EstimatorSpecInferTest(test.TestCase): export_outputs=export_output.ClassificationOutput(classes=classes)) def testExportOutputsValueNotExportOutput(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): predictions = {'loss': constant_op.constant(1.)} with self.assertRaisesRegexp( TypeError, @@ -533,7 +533,7 @@ class EstimatorSpecInferTest(test.TestCase): export_outputs={'head_name': predictions}) def testExportOutputsSingleheadMissingDefault(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): predictions = {'loss': constant_op.constant(1.)} output_1 = constant_op.constant([1.]) regression_output = export_output.RegressionOutput(value=output_1) @@ -552,7 +552,7 @@ class EstimatorSpecInferTest(test.TestCase): self.assertEqual(expected_export_outputs, estimator_spec.export_outputs) def testExportOutputsMultiheadWithDefault(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): predictions = {'loss': constant_op.constant(1.)} output_1 = constant_op.constant([1.]) output_2 = constant_op.constant(['2']) @@ -571,7 +571,7 @@ class EstimatorSpecInferTest(test.TestCase): self.assertEqual(export_outputs, estimator_spec.export_outputs) def testExportOutputsMultiheadMissingDefault(self): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): predictions = {'loss': constant_op.constant(1.)} output_1 = constant_op.constant([1.]) output_2 = constant_op.constant(['2']) @@ -594,13 +594,13 @@ class EstimatorSpecInferTest(test.TestCase): def testDefaultExportOutputCreated(self): """Ensure that a default PredictOutput is created for export.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): predictions = constant_op.constant(1.) self._assertDefaultExportOutputForPredictions(predictions) def testDefaultExportOutputCreatedDict(self): """Ensure that a default PredictOutput is created for export for dicts.""" - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): predictions = {'loss': constant_op.constant(1.), 'score': constant_op.constant(10.)} self._assertDefaultExportOutputForPredictions(predictions) diff --git a/tensorflow/python/estimator/run_config.py b/tensorflow/python/estimator/run_config.py index 220c3e58ca..b1ca207b62 100644 --- a/tensorflow/python/estimator/run_config.py +++ b/tensorflow/python/estimator/run_config.py @@ -26,6 +26,7 @@ import six from tensorflow.core.protobuf import config_pb2 from tensorflow.core.protobuf import rewriter_config_pb2 +from tensorflow.python.distribute import estimator_training as distribute_coordinator_training from tensorflow.python.platform import tf_logging as logging from tensorflow.python.training import server_lib from tensorflow.python.util import compat_internal @@ -51,6 +52,7 @@ _DEFAULT_REPLACEABLE_LIST = [ 'device_fn', 'protocol', 'eval_distribute', + 'experimental_distribute', ] _SAVE_CKPT_ERR = ( @@ -331,7 +333,8 @@ class RunConfig(object): train_distribute=None, device_fn=None, protocol=None, - eval_distribute=None): + eval_distribute=None, + experimental_distribute=None): """Constructs a RunConfig. All distributed training related properties `cluster_spec`, `is_chief`, @@ -458,7 +461,8 @@ class RunConfig(object): train_distribute: An optional instance of `tf.contrib.distribute.DistributionStrategy`. If specified, then Estimator will distribute the user's model during training, - according to the policy specified by that strategy. + according to the policy specified by that strategy. Setting + `experimental_distribute.train_distribute` is preferred. device_fn: A callable invoked for every `Operation` that takes the `Operation` and returns the device string. If `None`, defaults to the device function returned by `tf.train.replica_device_setter` @@ -468,7 +472,13 @@ class RunConfig(object): eval_distribute: An optional instance of `tf.contrib.distribute.DistributionStrategy`. If specified, then Estimator will distribute the user's model during evaluation, - according to the policy specified by that strategy. + according to the policy specified by that strategy. Setting + `experimental_distribute.eval_distribute` is preferred. + experimental_distribute: an optional + `tf.contrib.distribute.DistributeConfig` object specifying + DistributionStrategy-related configuration. The `train_distribute` and + `eval_distribute` can be passed as parameters to `RunConfig` or set in + `experimental_distribute` but not both. Raises: ValueError: If both `save_checkpoints_steps` and `save_checkpoints_secs` @@ -508,11 +518,15 @@ class RunConfig(object): train_distribute=train_distribute, device_fn=device_fn, protocol=protocol, - eval_distribute=eval_distribute) + eval_distribute=eval_distribute, + experimental_distribute=experimental_distribute) - self._init_distributed_setting_from_environment_var(tf_config) - - self._maybe_overwrite_session_config_for_distributed_training() + if train_distribute or eval_distribute or experimental_distribute: + logging.info('Initializing RunConfig with distribution strategies.') + distribute_coordinator_training.init_run_config(self, tf_config) + else: + self._init_distributed_setting_from_environment_var(tf_config) + self._maybe_overwrite_session_config_for_distributed_training() def _maybe_overwrite_session_config_for_distributed_training(self): """Overwrites the session_config for distributed training. @@ -810,6 +824,7 @@ class RunConfig(object): - `device_fn`, - `protocol`. - `eval_distribute`, + - `experimental_distribute`, In addition, either `save_checkpoints_steps` or `save_checkpoints_secs` can be set (should not be both). diff --git a/tensorflow/python/estimator/training.py b/tensorflow/python/estimator/training.py index 5c04387b65..240be5dabe 100644 --- a/tensorflow/python/estimator/training.py +++ b/tensorflow/python/estimator/training.py @@ -26,6 +26,7 @@ import time import six from tensorflow.core.protobuf import config_pb2 +from tensorflow.python.distribute import estimator_training as distribute_coordinator_training from tensorflow.python.estimator import estimator as estimator_lib from tensorflow.python.estimator import exporter as exporter_lib from tensorflow.python.estimator import run_config as run_config_lib @@ -274,8 +275,10 @@ def train_and_evaluate(estimator, train_spec, eval_spec): evaluation `input_fn`, steps, etc. This utility function provides consistent behavior for both local - (non-distributed) and distributed configurations. Currently, the only - supported distributed training configuration is between-graph replication. + (non-distributed) and distributed configurations. The default distribution + configuration is parameter server-based between-graph replication. For other + types of distribution configurations such as all-reduce training, please use + [DistributionStrategies](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/distribute). # pylint: disable=line-too-long Overfitting: In order to avoid overfitting, it is recommended to set up the training `input_fn` to shuffle the training data properly. @@ -426,6 +429,11 @@ def train_and_evaluate(estimator, train_spec, eval_spec): }' ``` + When `distribute` or `experimental_distribute.train_distribute` and + `experimental_distribute.remote_cluster` is set, this method will start a + client running on the current host which connects to the `remote_cluster` for + training and evaluation. + Args: estimator: An `Estimator` instance to train and evaluate. train_spec: A `TrainSpec` instance to specify the training specification. @@ -444,8 +452,16 @@ def train_and_evaluate(estimator, train_spec, eval_spec): executor = _TrainingExecutor( estimator=estimator, train_spec=train_spec, eval_spec=eval_spec) - config = estimator.config + + # If `distribute_coordinator_mode` is set and running in distributed + # environment, we run `train_and_evaluate` via distribute coordinator. + if distribute_coordinator_training.should_run_distribute_coordinator(config): + logging.info('Running `train_and_evaluate` with Distribute Coordinator.') + distribute_coordinator_training.train_and_evaluate( + estimator, train_spec, eval_spec, _TrainingExecutor) + return + if (config.task_type == run_config_lib.TaskType.EVALUATOR and config.task_id > 0): raise ValueError( @@ -837,6 +853,13 @@ class _TrainingExecutor(object): if difference > 0: logging.info('Waiting %f secs before starting next eval run.', difference) time.sleep(difference) + elif (throttle_secs == 0 and + eval_result.status != _EvalStatus.EVALUATED): + # Prints a user-actionable warning to avoid unnecessary load on evaluator. + logging.warning( + 'EvalSpec.throttle_secs is set as 0. This might overload the job ' + 'before finding (next) new checkpoint. Please consider to increase ' + 'it.') return (eval_result, should_early_stop) diff --git a/tensorflow/python/estimator/training_test.py b/tensorflow/python/estimator/training_test.py index dc106c7d3b..7d46917a6f 100644 --- a/tensorflow/python/estimator/training_test.py +++ b/tensorflow/python/estimator/training_test.py @@ -83,6 +83,9 @@ _INVALID_EVAL_LISTENER_MSG = 'must have type `_ContinuousEvalListener`' _INVALID_CONFIG_FOR_STD_SERVER_MSG = 'Could not start server; .*TF_CONFIG' _INVALID_LOCAL_TASK_WITH_CLUSTER = '`task.type` in TF_CONFIG cannot be `local`' _INVALID_TASK_TYPE = '`estimator.config` must have task_type set.' +_INPROPER_THROTTL_SECS = ( + 'EvalSpec.throttle_secs is set as 0.*Please consider to increase') + # The message should NOT have 'local' word as part of it. As (?!word) is looking # ahead, so, the $ (ending) check is required; otherwise, it will match # partially and return successuful. @@ -1281,7 +1284,7 @@ class TrainingExecutorRunEvaluatorTest(test.TestCase): ] eval_spec = training.EvalSpec( - input_fn=lambda: 1, start_delay_secs=0, throttle_secs=0) + input_fn=lambda: 1, start_delay_secs=0, throttle_secs=2) executor = training._TrainingExecutor(mock_est, mock_train_spec, eval_spec) with test.mock.patch.object(logging, 'warning') as mock_log: @@ -1295,6 +1298,34 @@ class TrainingExecutorRunEvaluatorTest(test.TestCase): # successuful evaluation) self.assertEqual(2, mock_log.call_count) + def test_warning_if_throttle_secs_is_zero(self): + training_max_step = 200 + mock_est = test.mock.Mock(spec=estimator_lib.Estimator) + mock_est.evaluate.side_effect = [ + {_GLOBAL_STEP_KEY: training_max_step} + ] + mock_train_spec = test.mock.Mock(spec=training.TrainSpec) + mock_train_spec.max_steps = training_max_step + + self._set_up_mock_est_to_train_and_evaluate_once(mock_est, mock_train_spec) + + # We need to make the first one invalid, so it will check the + # throttle_secs=0. + mock_est.latest_checkpoint.side_effect = [None, 'path'] + + eval_spec = training.EvalSpec( + input_fn=lambda: 1, start_delay_secs=0, throttle_secs=0) + + executor = training._TrainingExecutor(mock_est, mock_train_spec, eval_spec) + with test.mock.patch.object(logging, 'warning') as mock_log: + executor.run_evaluator() + + # First ckpt is invalid. + self.assertEqual(2, mock_est.latest_checkpoint.call_count) + self.assertEqual(1, mock_est.evaluate.call_count) + + self.assertRegexpMatches(str(mock_log.call_args), _INPROPER_THROTTL_SECS) + def test_continuous_eval_listener_eval_result(self): training_max_step = 200 mock_est = test.mock.Mock(spec=estimator_lib.Estimator) diff --git a/tensorflow/python/estimator/util.py b/tensorflow/python/estimator/util.py index d4a75478d5..31e4778e72 100644 --- a/tensorflow/python/estimator/util.py +++ b/tensorflow/python/estimator/util.py @@ -109,13 +109,17 @@ def parse_input_fn_result(result): else: input_hooks.append(_DatasetInitializerHook(iterator)) result = iterator.get_next() + return parse_iterator_result(result) + (input_hooks,) + +def parse_iterator_result(result): + """Gets features, labels from result.""" if isinstance(result, (list, tuple)): if len(result) != 2: raise ValueError( 'input_fn should return (features, labels) as a len 2 tuple.') - return result[0], result[1], input_hooks - return result, None, input_hooks + return result[0], result[1] + return result, None class _DatasetInitializerHook(training.SessionRunHook): diff --git a/tensorflow/python/estimator/util_test.py b/tensorflow/python/estimator/util_test.py index d7e0610779..d440c454dc 100644 --- a/tensorflow/python/estimator/util_test.py +++ b/tensorflow/python/estimator/util_test.py @@ -39,7 +39,7 @@ class UtilTest(test.TestCase): features, labels, hooks = util.parse_input_fn_result(_input_fn()) - with self.test_session() as sess: + with self.cached_session() as sess: vals = sess.run([features, labels]) self.assertAllEqual(vals[0], np.arange(100)) @@ -67,7 +67,7 @@ class UtilTest(test.TestCase): features, labels, hooks = util.parse_input_fn_result(_input_fn()) - with self.test_session() as sess: + with self.cached_session() as sess: vals = sess.run([features]) self.assertAllEqual(vals[0], np.arange(100)) diff --git a/tensorflow/python/feature_column/feature_column_test.py b/tensorflow/python/feature_column/feature_column_test.py index 6be930be87..9b482237ab 100644 --- a/tensorflow/python/feature_column/feature_column_test.py +++ b/tensorflow/python/feature_column/feature_column_test.py @@ -262,7 +262,7 @@ class NumericColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([price])) self.assertIn('price', features) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[20., 110.]], features['price'].eval()) def test_parse_example_with_default_value(self): @@ -284,7 +284,7 @@ class NumericColumnTest(test.TestCase): no_data.SerializeToString()], features=fc.make_parse_example_spec([price])) self.assertIn('price', features) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[20., 110.], [11., 11.]], features['price'].eval()) def test_normalizer_fn_must_be_callable(self): @@ -298,7 +298,7 @@ class NumericColumnTest(test.TestCase): price = fc.numeric_column('price', shape=[2], normalizer_fn=_increment_two) output = _transform_features({'price': [[1., 2.], [5., 6.]]}, [price]) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[3., 4.], [7., 8.]], output[price].eval()) def test_get_dense_tensor(self): @@ -433,7 +433,7 @@ class BucketizedColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([bucketized_price])) self.assertIn('price', features) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[20., 110.]], features['price'].eval()) def test_transform_feature(self): @@ -700,7 +700,7 @@ class HashedCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -719,7 +719,7 @@ class HashedCategoricalColumnTest(test.TestCase): output = outputs[hashed_sparse] # Check exact hashed output. If hashing changes this test will break. expected_values = [6, 4, 1] - with self.test_session(): + with self.cached_session(): self.assertEqual(dtypes.int64, output.values.dtype) self.assertAllEqual(expected_values, output.values.eval()) self.assertAllEqual(wire_tensor.indices.eval(), output.indices.eval()) @@ -775,7 +775,7 @@ class HashedCategoricalColumnTest(test.TestCase): output = builder.get(hashed_sparse) # Check exact hashed output. If hashing changes this test will break. expected_values = [3, 7, 5] - with self.test_session(): + with self.cached_session(): self.assertAllEqual(expected_values, output.values.eval()) def test_int32_64_is_compatible(self): @@ -789,7 +789,7 @@ class HashedCategoricalColumnTest(test.TestCase): output = builder.get(hashed_sparse) # Check exact hashed output. If hashing changes this test will break. expected_values = [3, 7, 5] - with self.test_session(): + with self.cached_session(): self.assertAllEqual(expected_values, output.values.eval()) def test_get_sparse_tensors(self): @@ -984,7 +984,7 @@ class CrossedColumnTest(test.TestCase): features=fc.make_parse_example_spec([price_cross_wire])) self.assertIn('price', features) self.assertIn('wire', features) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[20., 110.]], features['price'].eval()) wire_sparse = features['wire'] self.assertAllEqual([[0, 0], [0, 1]], wire_sparse.indices.eval()) @@ -1007,7 +1007,7 @@ class CrossedColumnTest(test.TestCase): } outputs = _transform_features(features, [price_cross_wire]) output = outputs[price_cross_wire] - with self.test_session() as sess: + with self.cached_session() as sess: output_val = sess.run(output) self.assertAllEqual( [[0, 0], [0, 1], [1, 0], [1, 1], [1, 2], [1, 3]], output_val.indices) @@ -2747,6 +2747,62 @@ class FunctionalInputLayerTest(test.TestCase): variables_lib.Variable) self.assertAllEqual(cols_to_vars[some_embedding_column][0].shape, [5, 10]) + def test_fills_cols_to_vars_shared_embedding(self): + # Provide 5 DenseColumn's to input_layer: a NumericColumn, a + # BucketizedColumn, an EmbeddingColumn, two SharedEmbeddingColumns. The + # EmbeddingColumn creates a Variable and the two SharedEmbeddingColumns + # shared one variable. + price1 = fc.numeric_column('price1') + dense_feature = fc.numeric_column('dense_feature') + dense_feature_bucketized = fc.bucketized_column( + dense_feature, boundaries=[0.]) + some_sparse_column = fc.categorical_column_with_hash_bucket( + 'sparse_feature', hash_bucket_size=5) + some_embedding_column = fc.embedding_column( + some_sparse_column, dimension=10) + categorical_column_a = fc.categorical_column_with_identity( + key='aaa', num_buckets=3) + categorical_column_b = fc.categorical_column_with_identity( + key='bbb', num_buckets=3) + shared_embedding_a, shared_embedding_b = fc.shared_embedding_columns( + [categorical_column_a, categorical_column_b], dimension=2) + with ops.Graph().as_default(): + features = { + 'price1': [[3.], [4.]], + 'dense_feature': [[-1.], [4.]], + 'sparse_feature': [['a'], ['x']], + 'aaa': + sparse_tensor.SparseTensor( + indices=((0, 0), (1, 0), (1, 1)), + values=(0, 1, 0), + dense_shape=(2, 2)), + 'bbb': + sparse_tensor.SparseTensor( + indices=((0, 0), (1, 0), (1, 1)), + values=(1, 2, 1), + dense_shape=(2, 2)), + } + cols_to_vars = {} + all_cols = [ + price1, dense_feature_bucketized, some_embedding_column, + shared_embedding_a, shared_embedding_b + ] + fc.input_layer(features, all_cols, cols_to_vars=cols_to_vars) + self.assertItemsEqual(list(cols_to_vars.keys()), all_cols) + self.assertEqual(0, len(cols_to_vars[price1])) + self.assertEqual(0, len(cols_to_vars[dense_feature_bucketized])) + self.assertEqual(1, len(cols_to_vars[some_embedding_column])) + self.assertEqual(1, len(cols_to_vars[shared_embedding_a])) + # This is a bug in the current implementation and should be fixed in the + # new one. + self.assertEqual(0, len(cols_to_vars[shared_embedding_b])) + self.assertIsInstance(cols_to_vars[some_embedding_column][0], + variables_lib.Variable) + self.assertAllEqual(cols_to_vars[some_embedding_column][0].shape, [5, 10]) + self.assertIsInstance(cols_to_vars[shared_embedding_a][0], + variables_lib.Variable) + self.assertAllEqual(cols_to_vars[shared_embedding_a][0].shape, [3, 2]) + def test_fills_cols_to_vars_partitioned_variables(self): price1 = fc.numeric_column('price1') dense_feature = fc.numeric_column('dense_feature') @@ -2772,6 +2828,10 @@ class FunctionalInputLayerTest(test.TestCase): self.assertEqual(0, len(cols_to_vars[price1])) self.assertEqual(0, len(cols_to_vars[dense_feature_bucketized])) self.assertEqual(3, len(cols_to_vars[some_embedding_column])) + self.assertEqual( + 'input_from_feature_columns/input_layer/sparse_feature_embedding/' + 'embedding_weights/part_0:0', + cols_to_vars[some_embedding_column][0].name) self.assertAllEqual(cols_to_vars[some_embedding_column][0].shape, [2, 10]) self.assertAllEqual(cols_to_vars[some_embedding_column][1].shape, [2, 10]) self.assertAllEqual(cols_to_vars[some_embedding_column][2].shape, [1, 10]) @@ -3262,7 +3322,7 @@ class VocabularyFileCategoricalColumnTest(test.TestCase): dense_shape=(2, 2)) column._get_sparse_tensors(_LazyBuilder({'aaa': inputs})) with self.assertRaisesRegexp(errors.OpError, 'file_does_not_exist'): - with self.test_session(): + with self.cached_session(): lookup_ops.tables_initializer().run() def test_invalid_vocabulary_size(self): @@ -3286,7 +3346,7 @@ class VocabularyFileCategoricalColumnTest(test.TestCase): dense_shape=(2, 2)) column._get_sparse_tensors(_LazyBuilder({'aaa': inputs})) with self.assertRaisesRegexp(errors.OpError, 'Invalid vocab_size'): - with self.test_session(): + with self.cached_session(): lookup_ops.tables_initializer().run() def test_invalid_num_oov_buckets(self): @@ -3350,7 +3410,7 @@ class VocabularyFileCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -3775,7 +3835,7 @@ class VocabularyListCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -3797,7 +3857,7 @@ class VocabularyListCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -4096,7 +4156,7 @@ class IdentityCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -4365,7 +4425,7 @@ class IndicatorColumnTest(test.TestCase): fc.categorical_column_with_hash_bucket('animal', 4)) builder = _LazyBuilder({'animal': ['fox', 'fox']}) output = builder.get(animal) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[0., 0., 1., 0.], [0., 0., 1., 0.]], output.eval()) def test_2D_shape_succeeds(self): @@ -4380,7 +4440,7 @@ class IndicatorColumnTest(test.TestCase): dense_shape=[2, 1]) }) output = builder.get(animal) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[0., 0., 1., 0.], [0., 0., 1., 0.]], output.eval()) def test_multi_hot(self): @@ -4393,7 +4453,7 @@ class IndicatorColumnTest(test.TestCase): indices=[[0, 0], [0, 1]], values=[1, 1], dense_shape=[1, 2]) }) output = builder.get(animal) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[0., 2., 0., 0.]], output.eval()) def test_multi_hot2(self): @@ -4405,7 +4465,7 @@ class IndicatorColumnTest(test.TestCase): indices=[[0, 0], [0, 1]], values=[1, 2], dense_shape=[1, 2]) }) output = builder.get(animal) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[0., 1., 1., 0.]], output.eval()) def test_deep_copy(self): @@ -4430,7 +4490,7 @@ class IndicatorColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a_indicator])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -4641,7 +4701,7 @@ class EmbeddingColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a_embedded])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -5407,7 +5467,7 @@ class SharedEmbeddingColumnTest(test.TestCase): features=fc.make_parse_example_spec([a_embedded, b_embedded])) self.assertIn('aaa', features) self.assertIn('bbb', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -5544,20 +5604,6 @@ class SharedEmbeddingColumnTest(test.TestCase): self.assertIsNone(partition_info) return embedding_values - # Expected lookup result, using combiner='mean'. - expected_lookups_a = ( - # example 0: - (7., 11.), # ids [2], embedding = [7, 11] - # example 1: - (2., 3.5), # ids [0, 1], embedding = mean([1, 2] + [3, 5]) = [2, 3.5] - ) - expected_lookups_b = ( - # example 0: - (1., 2.), # ids [0], embedding = [1, 2] - # example 1: - (0., 0.), # ids [], embedding = [0, 0] - ) - # Build columns. categorical_column_a = fc.categorical_column_with_identity( key='aaa', num_buckets=vocabulary_size) @@ -5990,7 +6036,7 @@ class WeightedCategoricalColumnTest(test.TestCase): features=fc.make_parse_example_spec([a_weighted])) self.assertIn('aaa', features) self.assertIn('weights', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( diff --git a/tensorflow/python/feature_column/feature_column_v2.py b/tensorflow/python/feature_column/feature_column_v2.py index b6bf516286..aa66ed77e9 100644 --- a/tensorflow/python/feature_column/feature_column_v2.py +++ b/tensorflow/python/feature_column/feature_column_v2.py @@ -142,6 +142,7 @@ from tensorflow.python.framework import ops from tensorflow.python.framework import sparse_tensor as sparse_tensor_lib from tensorflow.python.framework import tensor_shape from tensorflow.python.keras.engine import training +from tensorflow.python.keras.engine.base_layer import Layer from tensorflow.python.layers import base from tensorflow.python.ops import array_ops from tensorflow.python.ops import check_ops @@ -155,7 +156,6 @@ from tensorflow.python.ops import parsing_ops from tensorflow.python.ops import resource_variable_ops from tensorflow.python.ops import sparse_ops from tensorflow.python.ops import string_ops -from tensorflow.python.ops import template from tensorflow.python.ops import variable_scope from tensorflow.python.ops import variables from tensorflow.python.platform import gfile @@ -164,67 +164,148 @@ from tensorflow.python.training import checkpoint_utils from tensorflow.python.util import nest -def _internal_input_layer(features, - feature_columns, - weight_collections=None, - trainable=True, - cols_to_vars=None, - scope=None): - """See input_layer. `scope` is a name or variable scope to use.""" +class StateManager(object): + """Manages the state associated with FeatureColumns. - feature_columns = fc_old._normalize_feature_columns(feature_columns) # pylint: disable=protected-access - for column in feature_columns: - if not isinstance(column, fc_old._DenseColumn): # pylint: disable=protected-access - raise ValueError( - 'Items of feature_columns must be a _DenseColumn. ' - 'You can wrap a categorical column with an ' - 'embedding_column or indicator_column. Given: {}'.format(column)) - weight_collections = list(weight_collections or []) - if ops.GraphKeys.GLOBAL_VARIABLES not in weight_collections: - weight_collections.append(ops.GraphKeys.GLOBAL_VARIABLES) - if ops.GraphKeys.MODEL_VARIABLES not in weight_collections: - weight_collections.append(ops.GraphKeys.MODEL_VARIABLES) - - # a non-None `scope` can allow for variable reuse, when, e.g., this function - # is wrapped by a `make_template`. - with variable_scope.variable_scope( - scope, default_name='input_layer', values=features.values()): - builder = fc_old._LazyBuilder(features) # pylint: disable=protected-access - output_tensors = [] - ordered_columns = [] - for column in sorted(feature_columns, key=lambda x: x.name): - ordered_columns.append(column) - with variable_scope.variable_scope( - None, default_name=column._var_scope_name): # pylint: disable=protected-access - tensor = column._get_dense_tensor( # pylint: disable=protected-access - builder, - weight_collections=weight_collections, - trainable=trainable) - num_elements = column._variable_shape.num_elements() # pylint: disable=protected-access - batch_size = array_ops.shape(tensor)[0] - output_tensors.append( - array_ops.reshape(tensor, shape=(batch_size, num_elements))) - if cols_to_vars is not None: - # Retrieve any variables created (some _DenseColumn's don't create - # variables, in which case an empty list is returned). - cols_to_vars[column] = ops.get_collection( - ops.GraphKeys.GLOBAL_VARIABLES, - scope=variable_scope.get_variable_scope().name) - _verify_static_batch_size_equality(output_tensors, ordered_columns) - return array_ops.concat(output_tensors, 1) + Some `FeatureColumn`s create variables or resources to assist their + computation. The `StateManager` is responsible for creating and storing these + objects since `FeatureColumn`s are supposed to be stateless configuration + only. + """ + + def create_variable(self, + feature_column, + name, + shape, + dtype=None, + trainable=True, + initializer=None): + """Creates a new variable. + + Args: + feature_column: A `FeatureColumn` object this variable corresponds to. + name: variable name. + shape: variable shape. + dtype: The type of the variable. Defaults to `self.dtype` or `float32`. + trainable: Whether this variable is trainable or not. + initializer: initializer instance (callable). + + Returns: + The created variable. + """ + del feature_column, name, shape, dtype, trainable, initializer + raise NotImplementedError('StateManager.create_variable') + + def add_variable(self, feature_column, var): + """Adds an existing variable to the state. + + Args: + feature_column: A `FeatureColumn` object to associate this variable with. + var: The variable. + """ + del feature_column, var + raise NotImplementedError('StateManager.add_variable') + + def get_variable(self, feature_column, name): + """Returns an existing variable. + + Args: + feature_column: A `FeatureColumn` object this variable corresponds to. + name: variable name. + """ + del feature_column, name + raise NotImplementedError('StateManager.get_var') + + def add_resource(self, feature_column, name, resource): + """Creates a new resource. + + Resources can be things such as tables etc. + + Args: + feature_column: A `FeatureColumn` object this resource corresponds to. + name: Name of the resource. + resource: The resource. + + Returns: + The created resource. + """ + del feature_column, name, resource + raise NotImplementedError('StateManager.add_resource') + def get_resource(self, feature_column, name): + """Returns an already created resource. -def input_layer(features, - feature_columns, - weight_collections=None, - trainable=True, - cols_to_vars=None): - """Returns a dense `Tensor` as input layer based on given `feature_columns`. + Resources can be things such as tables etc. + + Args: + feature_column: A `FeatureColumn` object this variable corresponds to. + name: Name of the resource. + """ + del feature_column, name + raise NotImplementedError('StateManager.get_resource') + + +class _InputLayerStateManager(StateManager): + """Manages the state of InputLayer.""" + + def __init__(self, layer, feature_columns, trainable): + """Creates an _InputLayerStateManager object. + + Args: + layer: The input layer this state manager is associated with. + feature_columns: List of feature columns for the input layer + trainable: Whether by default, variables created are trainable or not. + """ + self._trainable = trainable + self._layer = layer + self._cols_to_vars_map = {} + self._cols_to_names_map = {} + for column in sorted(feature_columns, key=lambda x: x.name): + self._cols_to_vars_map[column] = {} + base_name = column.name + if isinstance(column, SharedEmbeddingColumn): + base_name = column.shared_collection_name + with variable_scope.variable_scope(base_name) as vs: + self._cols_to_names_map[column] = _strip_leading_slashes(vs.name) + + def create_variable(self, + feature_column, + name, + shape, + dtype=None, + trainable=True, + initializer=None): + if name in self._cols_to_vars_map[feature_column]: + raise ValueError('Variable already exists.') + with variable_scope.variable_scope(self._cols_to_names_map[feature_column]): + var = self._layer.add_variable( + name=name, + shape=shape, + dtype=dtype, + initializer=initializer, + trainable=self._trainable and trainable, + # TODO(rohanj): Get rid of this hack once we have a mechanism for + # specifying a default partitioner for an entire layer. In that case, + # the default getter for Layers should work. + getter=variable_scope.get_variable) + self._cols_to_vars_map[feature_column][name] = var + return var + + def get_variable(self, feature_column, name): + if name in self._cols_to_vars_map[feature_column]: + return self._cols_to_vars_map[feature_column][name] + raise ValueError('Variable does not exist.') + + +class FeatureLayer(Layer): + """A layer that produces a dense `Tensor` based on given `feature_columns`. Generally a single example in training data is described with FeatureColumns. At the first layer of the model, this column oriented data should be converted to a single `Tensor`. + This layer can be called multiple times with different features. + Example: ```python @@ -233,105 +314,122 @@ def input_layer(features, categorical_column_with_hash_bucket("keywords", 10K), dimensions=16) columns = [price, keywords_embedded, ...] features = tf.parse_example(..., features=make_parse_example_spec(columns)) - dense_tensor = input_layer(features, columns) + feature_layer = FeatureLayer(columns) + dense_tensor = feature_layer(features) for units in [128, 64, 32]: dense_tensor = tf.layers.dense(dense_tensor, units, tf.nn.relu) - prediction = tf.layers.dense(dense_tensor, 1) - ``` - - Args: - features: A mapping from key to tensors. `_FeatureColumn`s look up via these - keys. For example `numeric_column('price')` will look at 'price' key in - this dict. Values can be a `SparseTensor` or a `Tensor` depends on - corresponding `_FeatureColumn`. - feature_columns: An iterable containing the FeatureColumns to use as inputs - to your model. All items should be instances of classes derived from - `_DenseColumn` such as `numeric_column`, `embedding_column`, - `bucketized_column`, `indicator_column`. If you have categorical features, - you can wrap them with an `embedding_column` or `indicator_column`. - weight_collections: A list of collection names to which the Variable will be - added. Note that variables will also be added to collections - `tf.GraphKeys.GLOBAL_VARIABLES` and `ops.GraphKeys.MODEL_VARIABLES`. - trainable: If `True` also add the variable to the graph collection - `GraphKeys.TRAINABLE_VARIABLES` (see `tf.Variable`). - cols_to_vars: If not `None`, must be a dictionary that will be filled with a - mapping from `_FeatureColumn` to list of `Variable`s. For example, after - the call, we might have cols_to_vars = - {_EmbeddingColumn( - categorical_column=_HashedCategoricalColumn( - key='sparse_feature', hash_bucket_size=5, dtype=tf.string), - dimension=10): [<tf.Variable 'some_variable:0' shape=(5, 10), - <tf.Variable 'some_variable:1' shape=(5, 10)]} - If a column creates no variables, its value will be an empty list. - - Returns: - A `Tensor` which represents input layer of a model. Its shape - is (batch_size, first_layer_dimension) and its dtype is `float32`. - first_layer_dimension is determined based on given `feature_columns`. - - Raises: - ValueError: if an item in `feature_columns` is not a `_DenseColumn`. - """ - return _internal_input_layer(features, feature_columns, weight_collections, - trainable, cols_to_vars) - - -# TODO(akshayka): InputLayer should be a subclass of Layer, and it -# should implement the logic in input_layer using Layer's build-and-call -# paradigm; input_layer should create an instance of InputLayer and -# return the result of invoking its apply method, just as functional layers do. -class InputLayer(object): - """An object-oriented version of `input_layer` that reuses variables.""" + prediction = tf.layers.dense(dense_tensor, 1).""" def __init__(self, feature_columns, - weight_collections=None, trainable=True, - cols_to_vars=None): - """See `input_layer`.""" + name=None, + shared_state_manager=None, + **kwargs): + """Constructs a FeatureLayer. - self._feature_columns = feature_columns - self._weight_collections = weight_collections - self._trainable = trainable - self._cols_to_vars = cols_to_vars - self._input_layer_template = template.make_template( - 'feature_column_input_layer', - _internal_input_layer, - create_scope_now_=True) - self._scope = self._input_layer_template.variable_scope - - def __call__(self, features): - return self._input_layer_template( - features=features, - feature_columns=self._feature_columns, - weight_collections=self._weight_collections, - trainable=self._trainable, - cols_to_vars=None, - scope=self._scope) + Args: + feature_columns: An iterable containing the FeatureColumns to use as + inputs to your model. All items should be instances of classes derived + from `DenseColumn` such as `numeric_column`, `embedding_column`, + `bucketized_column`, `indicator_column`. If you have categorical + features, you can wrap them with an `embedding_column` or + `indicator_column`. + trainable: If `True` also add the variable to the graph collection + `GraphKeys.TRAINABLE_VARIABLES` (see `tf.Variable`). + name: Name to give to the FeatureLayer. + shared_state_manager: SharedEmbeddingStateManager that manages the state + of SharedEmbeddingColumns. The state of SharedEmbeddingColumns, unlike + regular embedding columns cannot be owned by the InputLayer itself since + SharedEmbeddingColumns can be shared across different InputLayers. As a + result users are expected to create a SharedEmbeddingStateManager object + which would be responsible for managing the shared state and can be + passed into different InputLayer objects to share state. For example, + + ```python + sc_1, sc_2 = shared_embedding_column_v2(...) + sc_3, sc_4 = shared_embedding_column_v2(...) + ssm = SharedEmbeddingStateManager() + feature_layer1 = FeatureLayer([sc_1, sc_3], ..., + shared_state_manager=ssm) + feature_layer2 = FeatureLayer([sc_2, sc_4], ..., + shared_state_manager=ssm) + ``` + now input_layer1 and input_layer2 will share variables across. If + sharing is not desired, one can create 2 separate + SharedEmbeddingStateManager objects + + ```python + ssm1 = SharedEmbeddingStateManager() + ssm2 = SharedEmbeddingStateManager() + feature_layer1 = FeatureLayer([sc_1, sc_3], ..., + shared_state_manager=ssm1) + feature_layer2 = FeatureLayer([sc_2, sc_4], ..., + shared_state_manager=ssm2) + ``` + **kwargs: Keyword arguments to construct a layer. - @property - def non_trainable_variables(self): - return self._input_layer_template.non_trainable_variables + Raises: + ValueError: if an item in `feature_columns` is not a `DenseColumn`. + """ + super(FeatureLayer, self).__init__(name=name, trainable=trainable, **kwargs) - @property - def non_trainable_weights(self): - return self._input_layer_template.non_trainable_weights + self._feature_columns = _normalize_feature_columns(feature_columns) + self._state_manager = _InputLayerStateManager(self, self._feature_columns, + self.trainable) + self._shared_state_manager = shared_state_manager + for column in sorted(self._feature_columns, key=lambda x: x.name): + if not isinstance(column, DenseColumn): + raise ValueError( + 'Items of feature_columns must be a DenseColumn. ' + 'You can wrap a categorical column with an ' + 'embedding_column or indicator_column. Given: {}'.format(column)) - @property - def trainable_variables(self): - return self._input_layer_template.trainable_variables + def build(self, _): + for column in sorted(self._feature_columns, key=lambda x: x.name): + if isinstance(column, SharedEmbeddingColumn): + column.create_state(self._shared_state_manager) + else: + with variable_scope.variable_scope(None, default_name=self.name): + column.create_state(self._state_manager) + super(FeatureLayer, self).build(None) - @property - def trainable_weights(self): - return self._input_layer_template.trainable_weights + def call(self, features, cols_to_output_tensors=None): + """Returns a dense tensor corresponding to the `feature_columns`. - @property - def variables(self): - return self._input_layer_template.variables + Args: + features: A mapping from key to tensors. `FeatureColumn`s look up via + these keys. For example `numeric_column('price')` will look at 'price' + key in this dict. Values can be a `SparseTensor` or a `Tensor` depends + on corresponding `FeatureColumn`. + cols_to_output_tensors: If not `None`, this will be filled with a dict + mapping feature columns to output tensors created. - @property - def weights(self): - return self._input_layer_template.weights + Returns: + A `Tensor` which represents input layer of a model. Its shape + is (batch_size, first_layer_dimension) and its dtype is `float32`. + first_layer_dimension is determined based on given `feature_columns`. + """ + transformation_cache = FeatureTransformationCache(features) + output_tensors = [] + ordered_columns = [] + for column in sorted(self._feature_columns, key=lambda x: x.name): + ordered_columns.append(column) + if isinstance(column, SharedEmbeddingColumn): + tensor = column.get_dense_tensor(transformation_cache, + self._shared_state_manager) + else: + tensor = column.get_dense_tensor(transformation_cache, + self._state_manager) + num_elements = column.variable_shape.num_elements() + batch_size = array_ops.shape(tensor)[0] + tensor = array_ops.reshape(tensor, shape=(batch_size, num_elements)) + output_tensors.append(tensor) + if cols_to_output_tensors is not None: + cols_to_output_tensors[column] = tensor + + _verify_static_batch_size_equality(output_tensors, ordered_columns) + return array_ops.concat(output_tensors, 1) def linear_model(features, @@ -565,12 +663,15 @@ class _BiasLayer(base.Layer): return self._bias_variable -def _get_expanded_variable_list(variable): - if (isinstance(variable, variables.Variable) or - resource_variable_ops.is_resource_variable(variable)): - return [variable] # Single variable case. - else: # Must be a PartitionedVariable, so convert into a list. - return list(variable) +def _get_expanded_variable_list(var_list): + returned_list = [] + for variable in var_list: + if (isinstance(variable, variables.Variable) or + resource_variable_ops.is_resource_variable(variable)): + returned_list.append(variable) # Single variable case. + else: # Must be a PartitionedVariable, so convert into a list. + returned_list.extend(list(variable)) + return returned_list def _strip_leading_slashes(name): @@ -661,7 +762,7 @@ class _LinearModel(training.Model): scope=variable_scope.get_variable_scope()), # pylint: disable=not-callable name='weighted_sum') bias = self._bias_layer.variables[0] - self._cols_to_vars['bias'] = _get_expanded_variable_list(bias) + self._cols_to_vars['bias'] = _get_expanded_variable_list([bias]) return predictions def _add_layers(self, layers): @@ -877,10 +978,15 @@ def embedding_column( trainable=trainable) -def shared_embedding_columns( - categorical_columns, dimension, combiner='mean', initializer=None, - shared_embedding_collection_name=None, ckpt_to_load_from=None, - tensor_name_in_ckpt=None, max_norm=None, trainable=True): +def shared_embedding_columns_v2(categorical_columns, + dimension, + combiner='mean', + initializer=None, + shared_embedding_collection_name=None, + ckpt_to_load_from=None, + tensor_name_in_ckpt=None, + max_norm=None, + trainable=True): """List of dense columns that convert from sparse, categorical input. This is similar to `embedding_column`, except that it produces a list of @@ -1803,51 +1909,6 @@ def crossed_column(keys, hash_bucket_size, hash_key=None): keys=tuple(keys), hash_bucket_size=hash_bucket_size, hash_key=hash_key) -class StateManager(object): - """Manages the state associated with FeatureColumns. - - Some `FeatureColumn`s create variables or resources to assist their - computation. The `StateManager` is responsible for creating and storing these - objects since `FeatureColumn`s are supposed to be stateless configuration - only. - """ - - def get_variable(self, - feature_column, - name, - shape, - dtype=None, - initializer=None): - """Creates a new variable or returns an existing one. - - Args: - feature_column: A `FeatureColumn` object this variable corresponds to. - name: variable name. - shape: variable shape. - dtype: The type of the variable. Defaults to `self.dtype` or `float32`. - initializer: initializer instance (callable). - - Returns: - The variable. - """ - raise NotImplementedError('StateManager.get_variable') - - def get_resource(self, feature_column, name, resource_creator): - """Creates a new resource or returns an existing one. - - Resources can be things such as tables etc. - - Args: - feature_column: A `FeatureColumn` object this variable corresponds to. - name: Name of the resource. - resource_creator: A callable that can create the resource. - - Returns: - The resource. - """ - raise NotImplementedError('StateManager.get_resource') - - class FeatureColumn(object): """Represents a feature column abstraction. @@ -2550,6 +2611,17 @@ class EmbeddingColumn( """See `DenseColumn` base class.""" return tensor_shape.vector(self.dimension) + def create_state(self, state_manager): + """Creates the embedding lookup variable.""" + embedding_shape = (self.categorical_column.num_buckets, self.dimension) + state_manager.create_variable( + self, + name='embedding_weights', + shape=embedding_shape, + dtype=dtypes.float32, + trainable=self.trainable, + initializer=self.initializer) + def _get_dense_tensor_internal(self, transformation_cache, state_manager): """Private method that follows the signature of _get_dense_tensor.""" # Get sparse IDs and weights. @@ -2558,13 +2630,8 @@ class EmbeddingColumn( sparse_ids = sparse_tensors.id_tensor sparse_weights = sparse_tensors.weight_tensor - embedding_shape = (self.categorical_column.num_buckets, self.dimension) embedding_weights = state_manager.get_variable( - self, - name='embedding_weights', - shape=embedding_shape, - dtype=dtypes.float32, - initializer=self.initializer) + self, name='embedding_weights') if self.ckpt_to_load_from is not None: to_restore = embedding_weights @@ -2637,6 +2704,68 @@ def _get_graph_for_variable(var): return var.graph +class SharedEmbeddingStateManager(Layer): + """A state manager that handle the state of shared embedding columns. + + This can handle multiple sets of columns that share variables.""" + + def __init__(self, trainable=True, name=None, **kwargs): + """Constructs a `SharedEmbeddingStateManager`. + + Args: + trainable: If true, variables created are trainable. + name: Name of the State Manager. + **kwargs: Keyword arguments. + """ + super(SharedEmbeddingStateManager, self).__init__( + name=name, trainable=trainable, **kwargs) + self._var_dict = {} + + def create_variable(self, + name, + shape, + dtype=None, + trainable=True, + initializer=None): + """Creates a variable. + + Makes sure only one var is created per `shared_collection_name`. `name` is + ignored here as the variable is named `shared_collection_name` instead. + + Args: + name: Name of the variable. Not used. + shape: Variable shape. + dtype: Variable type. + trainable: If variable created should be trainable or not. + initializer: Variable initializer. + + Returns: + A variable or partitioned variable. + """ + if name in self._var_dict: + var = self._var_dict[name] + return var + with variable_scope.variable_scope( + self.name, reuse=variable_scope.AUTO_REUSE): + var = self.add_variable( + name=name, + shape=shape, + dtype=dtype, + trainable=self.trainable and trainable, + initializer=initializer, + # TODO(rohanj): Get rid of this hack once we have a mechanism for + # specifying a default partitioner for an entire layer. In that case, + # the default getter for Layers should work. + getter=variable_scope.get_variable) + self._var_dict[name] = var + return var + + def get_variable(self, feature_column, name): + if name not in self._var_dict: + raise ValueError('Variable name: {} not recognized.'.format(name)) + return self._var_dict[name] + + class SharedEmbeddingColumn( DenseColumn, SequenceDenseColumn, collections.namedtuple( @@ -2675,6 +2804,16 @@ class SharedEmbeddingColumn( """See `DenseColumn` base class.""" return tensor_shape.vector(self.dimension) + def create_state(self, state_manager): + """Creates the shared embedding lookup variable.""" + embedding_shape = (self.categorical_column.num_buckets, self.dimension) + state_manager.create_variable( + name=self.shared_collection_name, + shape=embedding_shape, + dtype=dtypes.float32, + trainable=self.trainable, + initializer=self.initializer) + def _get_dense_tensor_internal(self, transformation_cache, state_manager): """Private method that follows the signature of _get_dense_tensor.""" # This method is called from a variable_scope with name _var_scope_name, @@ -2687,13 +2826,8 @@ class SharedEmbeddingColumn( sparse_ids = sparse_tensors.id_tensor sparse_weights = sparse_tensors.weight_tensor - embedding_shape = (self.categorical_column.num_buckets, self.dimension) embedding_weights = state_manager.get_variable( - self, - name='embedding_weights', - shape=embedding_shape, - dtype=dtypes.float32, - initializer=self.initializer) + self, name=self.shared_collection_name) if self.ckpt_to_load_from is not None: to_restore = embedding_weights diff --git a/tensorflow/python/feature_column/feature_column_v2_test.py b/tensorflow/python/feature_column/feature_column_v2_test.py index 80a9d5d40e..6b343ecf3e 100644 --- a/tensorflow/python/feature_column/feature_column_v2_test.py +++ b/tensorflow/python/feature_column/feature_column_v2_test.py @@ -33,12 +33,12 @@ from tensorflow.python.eager import context from tensorflow.python.estimator.inputs import numpy_io from tensorflow.python.feature_column import feature_column as fc_old from tensorflow.python.feature_column import feature_column_v2 as fc +from tensorflow.python.feature_column.feature_column_v2 import _LinearModel +from tensorflow.python.feature_column.feature_column_v2 import _transform_features from tensorflow.python.feature_column.feature_column_v2 import FeatureColumn +from tensorflow.python.feature_column.feature_column_v2 import FeatureLayer from tensorflow.python.feature_column.feature_column_v2 import FeatureTransformationCache -from tensorflow.python.feature_column.feature_column_v2 import InputLayer from tensorflow.python.feature_column.feature_column_v2 import StateManager -from tensorflow.python.feature_column.feature_column_v2 import _LinearModel -from tensorflow.python.feature_column.feature_column_v2 import _transform_features from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors @@ -269,7 +269,7 @@ class NumericColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([price])) self.assertIn('price', features) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[20., 110.]], features['price'].eval()) def test_parse_example_with_default_value(self): @@ -291,7 +291,7 @@ class NumericColumnTest(test.TestCase): no_data.SerializeToString()], features=fc.make_parse_example_spec([price])) self.assertIn('price', features) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[20., 110.], [11., 11.]], features['price'].eval()) def test_normalizer_fn_must_be_callable(self): @@ -305,7 +305,7 @@ class NumericColumnTest(test.TestCase): price = fc.numeric_column('price', shape=[2], normalizer_fn=_increment_two) output = _transform_features({'price': [[1., 2.], [5., 6.]]}, [price], None) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[3., 4.], [7., 8.]], output[price].eval()) def test_get_dense_tensor(self): @@ -439,7 +439,7 @@ class BucketizedColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([bucketized_price])) self.assertIn('price', features) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[20., 110.]], features['price'].eval()) def test_transform_feature(self): @@ -717,7 +717,7 @@ class HashedCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -736,7 +736,7 @@ class HashedCategoricalColumnTest(test.TestCase): output = outputs[hashed_sparse] # Check exact hashed output. If hashing changes this test will break. expected_values = [6, 4, 1] - with self.test_session(): + with self.cached_session(): self.assertEqual(dtypes.int64, output.values.dtype) self.assertAllEqual(expected_values, output.values.eval()) self.assertAllEqual(wire_tensor.indices.eval(), output.indices.eval()) @@ -792,7 +792,7 @@ class HashedCategoricalColumnTest(test.TestCase): output = transformation_cache.get(hashed_sparse, None) # Check exact hashed output. If hashing changes this test will break. expected_values = [3, 7, 5] - with self.test_session(): + with self.cached_session(): self.assertAllEqual(expected_values, output.values.eval()) def test_int32_64_is_compatible(self): @@ -806,7 +806,7 @@ class HashedCategoricalColumnTest(test.TestCase): output = transformation_cache.get(hashed_sparse, None) # Check exact hashed output. If hashing changes this test will break. expected_values = [3, 7, 5] - with self.test_session(): + with self.cached_session(): self.assertAllEqual(expected_values, output.values.eval()) def test_get_sparse_tensors(self): @@ -824,22 +824,6 @@ class HashedCategoricalColumnTest(test.TestCase): self.assertEqual( transformation_cache.get(hashed_sparse, None), id_weight_pair.id_tensor) - def DISABLED_test_get_sparse_tensors_weight_collections(self): - column = fc.categorical_column_with_hash_bucket('aaa', 10) - inputs = sparse_tensor.SparseTensor( - values=['omar', 'stringer', 'marlo'], - indices=[[0, 0], [1, 0], [1, 1]], - dense_shape=[2, 2]) - column._get_sparse_tensors( - FeatureTransformationCache({ - 'aaa': inputs - }), - weight_collections=('my_weights',)) - - self.assertItemsEqual( - [], ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)) - self.assertItemsEqual([], ops.get_collection('my_weights')) - def test_get_sparse_tensors_dense_input(self): hashed_sparse = fc.categorical_column_with_hash_bucket('wire', 10) transformation_cache = FeatureTransformationCache({ @@ -1000,7 +984,7 @@ class CrossedColumnTest(test.TestCase): features=fc.make_parse_example_spec([price_cross_wire])) self.assertIn('price', features) self.assertIn('wire', features) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[20., 110.]], features['price'].eval()) wire_sparse = features['wire'] self.assertAllEqual([[0, 0], [0, 1]], wire_sparse.indices.eval()) @@ -1023,7 +1007,7 @@ class CrossedColumnTest(test.TestCase): } outputs = _transform_features(features, [price_cross_wire], None) output = outputs[price_cross_wire] - with self.test_session() as sess: + with self.cached_session() as sess: output_val = sess.run(output) self.assertAllEqual( [[0, 0], [0, 1], [1, 0], [1, 1], [1, 2], [1, 3]], output_val.indices) @@ -2640,13 +2624,13 @@ class _LinearModelTest(test.TestCase): sess.run(net, feed_dict={features['price']: np.array(1)}) -class InputLayerTest(test.TestCase): +class FeatureLayerTest(test.TestCase): @test_util.run_in_graph_and_eager_modes() def test_retrieving_input(self): features = {'a': [0.]} - input_layer = InputLayer(fc_old.numeric_column('a')) - inputs = self.evaluate(input_layer(features)) + feature_layer = FeatureLayer(fc.numeric_column('a')) + inputs = self.evaluate(feature_layer(features)) self.assertAllClose([[0.]], inputs) def test_reuses_variables(self): @@ -2657,7 +2641,7 @@ class InputLayerTest(test.TestCase): dense_shape=(3, 3)) # Create feature columns (categorical and embedding). - categorical_column = fc_old.categorical_column_with_identity( + categorical_column = fc.categorical_column_with_identity( key='a', num_buckets=3) embedding_dimension = 2 def _embedding_column_initializer(shape, dtype, partition_info): @@ -2670,16 +2654,16 @@ class InputLayerTest(test.TestCase): (1, 1)) # id 2 return embedding_values - embedding_column = fc_old.embedding_column( + embedding_column = fc.embedding_column( categorical_column, dimension=embedding_dimension, initializer=_embedding_column_initializer) - input_layer = InputLayer([embedding_column]) + feature_layer = FeatureLayer([embedding_column]) features = {'a': sparse_input} - inputs = input_layer(features) - variables = input_layer.variables + inputs = feature_layer(features) + variables = feature_layer.variables # Sanity check: test that the inputs are correct. self.assertAllEqual([[1, 0], [0, 1], [1, 1]], inputs) @@ -2687,13 +2671,13 @@ class InputLayerTest(test.TestCase): # Check that only one variable was created. self.assertEqual(1, len(variables)) - # Check that invoking input_layer on the same features does not create + # Check that invoking feature_layer on the same features does not create # additional variables - _ = input_layer(features) + _ = feature_layer(features) self.assertEqual(1, len(variables)) - self.assertEqual(variables[0], input_layer.variables[0]) + self.assertEqual(variables[0], feature_layer.variables[0]) - def test_feature_column_input_layer_gradient(self): + def test_feature_column_feature_layer_gradient(self): with context.eager_mode(): sparse_input = sparse_tensor.SparseTensor( indices=((0, 0), (1, 0), (2, 0)), @@ -2701,7 +2685,7 @@ class InputLayerTest(test.TestCase): dense_shape=(3, 3)) # Create feature columns (categorical and embedding). - categorical_column = fc_old.categorical_column_with_identity( + categorical_column = fc.categorical_column_with_identity( key='a', num_buckets=3) embedding_dimension = 2 @@ -2715,16 +2699,16 @@ class InputLayerTest(test.TestCase): (1, 1)) # id 2 return embedding_values - embedding_column = fc_old.embedding_column( + embedding_column = fc.embedding_column( categorical_column, dimension=embedding_dimension, initializer=_embedding_column_initializer) - input_layer = InputLayer([embedding_column]) + feature_layer = FeatureLayer([embedding_column]) features = {'a': sparse_input} def scale_matrix(): - matrix = input_layer(features) + matrix = feature_layer(features) return 2 * matrix # Sanity check: Verify that scale_matrix returns the correct output. @@ -2739,185 +2723,139 @@ class InputLayerTest(test.TestCase): self.assertAllEqual([0, 1, 2], indexed_slice.indices) self.assertAllEqual([[2, 2], [2, 2], [2, 2]], gradient) - -class FunctionalInputLayerTest(test.TestCase): - def test_raises_if_empty_feature_columns(self): with self.assertRaisesRegexp(ValueError, 'feature_columns must not be empty'): - fc.input_layer(features={}, feature_columns=[]) + FeatureLayer(feature_columns=[])(features={}) def test_should_be_dense_column(self): - with self.assertRaisesRegexp(ValueError, 'must be a _DenseColumn'): - fc.input_layer( - features={'a': [[0]]}, - feature_columns=[ - fc_old.categorical_column_with_hash_bucket('wire_cast', 4) - ]) + with self.assertRaisesRegexp(ValueError, 'must be a DenseColumn'): + FeatureLayer(feature_columns=[ + fc.categorical_column_with_hash_bucket('wire_cast', 4) + ])( + features={ + 'a': [[0]] + }) def test_does_not_support_dict_columns(self): with self.assertRaisesRegexp( ValueError, 'Expected feature_columns to be iterable, found dict.'): - fc.input_layer( - features={'a': [[0]]}, - feature_columns={'a': fc_old.numeric_column('a')}) + FeatureLayer(feature_columns={'a': fc.numeric_column('a')})( + features={ + 'a': [[0]] + }) def test_bare_column(self): with ops.Graph().as_default(): features = features = {'a': [0.]} - net = fc.input_layer(features, fc_old.numeric_column('a')) + net = FeatureLayer(fc.numeric_column('a'))(features) with _initialized_session(): self.assertAllClose([[0.]], net.eval()) def test_column_generator(self): with ops.Graph().as_default(): features = features = {'a': [0.], 'b': [1.]} - columns = (fc_old.numeric_column(key) for key in features) - net = fc.input_layer(features, columns) + columns = (fc.numeric_column(key) for key in features) + net = FeatureLayer(columns)(features) with _initialized_session(): self.assertAllClose([[0., 1.]], net.eval()) def test_raises_if_duplicate_name(self): with self.assertRaisesRegexp( ValueError, 'Duplicate feature column name found for columns'): - fc.input_layer( - features={'a': [[0]]}, - feature_columns=[ - fc_old.numeric_column('a'), - fc_old.numeric_column('a') - ]) + FeatureLayer( + feature_columns=[fc.numeric_column('a'), + fc.numeric_column('a')])( + features={ + 'a': [[0]] + }) def test_one_column(self): - price = fc_old.numeric_column('price') + price = fc.numeric_column('price') with ops.Graph().as_default(): features = {'price': [[1.], [5.]]} - net = fc.input_layer(features, [price]) + net = FeatureLayer([price])(features) with _initialized_session(): self.assertAllClose([[1.], [5.]], net.eval()) def test_multi_dimension(self): - price = fc_old.numeric_column('price', shape=2) + price = fc.numeric_column('price', shape=2) with ops.Graph().as_default(): features = {'price': [[1., 2.], [5., 6.]]} - net = fc.input_layer(features, [price]) + net = FeatureLayer([price])(features) with _initialized_session(): self.assertAllClose([[1., 2.], [5., 6.]], net.eval()) def test_raises_if_shape_mismatch(self): - price = fc_old.numeric_column('price', shape=2) + price = fc.numeric_column('price', shape=2) with ops.Graph().as_default(): features = {'price': [[1.], [5.]]} with self.assertRaisesRegexp( Exception, r'Cannot reshape a tensor with 2 elements to shape \[2,2\]'): - fc.input_layer(features, [price]) + FeatureLayer([price])(features) def test_reshaping(self): - price = fc_old.numeric_column('price', shape=[1, 2]) + price = fc.numeric_column('price', shape=[1, 2]) with ops.Graph().as_default(): features = {'price': [[[1., 2.]], [[5., 6.]]]} - net = fc.input_layer(features, [price]) + net = FeatureLayer([price])(features) with _initialized_session(): self.assertAllClose([[1., 2.], [5., 6.]], net.eval()) def test_multi_column(self): - price1 = fc_old.numeric_column('price1', shape=2) - price2 = fc_old.numeric_column('price2') + price1 = fc.numeric_column('price1', shape=2) + price2 = fc.numeric_column('price2') with ops.Graph().as_default(): features = { 'price1': [[1., 2.], [5., 6.]], 'price2': [[3.], [4.]] } - net = fc.input_layer(features, [price1, price2]) + net = FeatureLayer([price1, price2])(features) with _initialized_session(): self.assertAllClose([[1., 2., 3.], [5., 6., 4.]], net.eval()) - def test_fills_cols_to_vars(self): - # Provide three _DenseColumn's to input_layer: a _NumericColumn, a - # _BucketizedColumn, and an _EmbeddingColumn. Only the _EmbeddingColumn - # creates a Variable. - price1 = fc_old.numeric_column('price1') - dense_feature = fc_old.numeric_column('dense_feature') - dense_feature_bucketized = fc_old.bucketized_column( - dense_feature, boundaries=[0.]) - some_sparse_column = fc_old.categorical_column_with_hash_bucket( - 'sparse_feature', hash_bucket_size=5) - some_embedding_column = fc_old.embedding_column( - some_sparse_column, dimension=10) - with ops.Graph().as_default(): - features = { - 'price1': [[3.], [4.]], - 'dense_feature': [[-1.], [4.]], - 'sparse_feature': [['a'], ['x']], - } - cols_to_vars = {} - all_cols = [price1, dense_feature_bucketized, some_embedding_column] - fc.input_layer(features, all_cols, cols_to_vars=cols_to_vars) - self.assertItemsEqual(list(cols_to_vars.keys()), all_cols) - self.assertEqual(0, len(cols_to_vars[price1])) - self.assertEqual(0, len(cols_to_vars[dense_feature_bucketized])) - self.assertEqual(1, len(cols_to_vars[some_embedding_column])) - self.assertIsInstance(cols_to_vars[some_embedding_column][0], - variables_lib.Variable) - self.assertAllEqual(cols_to_vars[some_embedding_column][0].shape, [5, 10]) - - def test_fills_cols_to_vars_partitioned_variables(self): - price1 = fc_old.numeric_column('price1') - dense_feature = fc_old.numeric_column('dense_feature') - dense_feature_bucketized = fc_old.bucketized_column( - dense_feature, boundaries=[0.]) - some_sparse_column = fc_old.categorical_column_with_hash_bucket( - 'sparse_feature', hash_bucket_size=5) - some_embedding_column = fc_old.embedding_column( - some_sparse_column, dimension=10) + def test_cols_to_output_tensors(self): + price1 = fc.numeric_column('price1', shape=2) + price2 = fc.numeric_column('price2') with ops.Graph().as_default(): - features = { - 'price1': [[3.], [4.]], - 'dense_feature': [[-1.], [4.]], - 'sparse_feature': [['a'], ['x']], - } - cols_to_vars = {} - all_cols = [price1, dense_feature_bucketized, some_embedding_column] - with variable_scope.variable_scope( - 'input_from_feature_columns', - partitioner=partitioned_variables.fixed_size_partitioner(3, axis=0)): - fc.input_layer(features, all_cols, cols_to_vars=cols_to_vars) - self.assertItemsEqual(list(cols_to_vars.keys()), all_cols) - self.assertEqual(0, len(cols_to_vars[price1])) - self.assertEqual(0, len(cols_to_vars[dense_feature_bucketized])) - self.assertEqual(3, len(cols_to_vars[some_embedding_column])) - self.assertAllEqual(cols_to_vars[some_embedding_column][0].shape, [2, 10]) - self.assertAllEqual(cols_to_vars[some_embedding_column][1].shape, [2, 10]) - self.assertAllEqual(cols_to_vars[some_embedding_column][2].shape, [1, 10]) + cols_dict = {} + features = {'price1': [[1., 2.], [5., 6.]], 'price2': [[3.], [4.]]} + feature_layer = FeatureLayer([price1, price2]) + net = feature_layer(features, cols_dict) + with _initialized_session(): + self.assertAllClose([[1., 2.], [5., 6.]], cols_dict[price1].eval()) + self.assertAllClose([[3.], [4.]], cols_dict[price2].eval()) + self.assertAllClose([[1., 2., 3.], [5., 6., 4.]], net.eval()) def test_column_order(self): - price_a = fc_old.numeric_column('price_a') - price_b = fc_old.numeric_column('price_b') + price_a = fc.numeric_column('price_a') + price_b = fc.numeric_column('price_b') with ops.Graph().as_default(): features = { 'price_a': [[1.]], 'price_b': [[3.]], } - net1 = fc.input_layer(features, [price_a, price_b]) - net2 = fc.input_layer(features, [price_b, price_a]) + net1 = FeatureLayer([price_a, price_b])(features) + net2 = FeatureLayer([price_b, price_a])(features) with _initialized_session(): self.assertAllClose([[1., 3.]], net1.eval()) self.assertAllClose([[1., 3.]], net2.eval()) def test_fails_for_categorical_column(self): - animal = fc_old.categorical_column_with_identity('animal', num_buckets=4) + animal = fc.categorical_column_with_identity('animal', num_buckets=4) with ops.Graph().as_default(): features = { 'animal': sparse_tensor.SparseTensor( indices=[[0, 0], [0, 1]], values=[1, 2], dense_shape=[1, 2]) } - with self.assertRaisesRegexp(Exception, 'must be a _DenseColumn'): - fc.input_layer(features, [animal]) + with self.assertRaisesRegexp(Exception, 'must be a DenseColumn'): + FeatureLayer([animal])(features) def test_static_batch_size_mismatch(self): - price1 = fc_old.numeric_column('price1') - price2 = fc_old.numeric_column('price2') + price1 = fc.numeric_column('price1') + price2 = fc.numeric_column('price2') with ops.Graph().as_default(): features = { 'price1': [[1.], [5.], [7.]], # batchsize = 3 @@ -2926,12 +2864,12 @@ class FunctionalInputLayerTest(test.TestCase): with self.assertRaisesRegexp( ValueError, 'Batch size \(first dimension\) of each feature must be same.'): # pylint: disable=anomalous-backslash-in-string - fc.input_layer(features, [price1, price2]) + FeatureLayer([price1, price2])(features) def test_subset_of_static_batch_size_mismatch(self): - price1 = fc_old.numeric_column('price1') - price2 = fc_old.numeric_column('price2') - price3 = fc_old.numeric_column('price3') + price1 = fc.numeric_column('price1') + price2 = fc.numeric_column('price2') + price3 = fc.numeric_column('price3') with ops.Graph().as_default(): features = { 'price1': array_ops.placeholder(dtype=dtypes.int64), # batchsize = 3 @@ -2941,31 +2879,31 @@ class FunctionalInputLayerTest(test.TestCase): with self.assertRaisesRegexp( ValueError, 'Batch size \(first dimension\) of each feature must be same.'): # pylint: disable=anomalous-backslash-in-string - fc.input_layer(features, [price1, price2, price3]) + FeatureLayer([price1, price2, price3])(features) def test_runtime_batch_size_mismatch(self): - price1 = fc_old.numeric_column('price1') - price2 = fc_old.numeric_column('price2') + price1 = fc.numeric_column('price1') + price2 = fc.numeric_column('price2') with ops.Graph().as_default(): features = { 'price1': array_ops.placeholder(dtype=dtypes.int64), # batchsize = 3 'price2': [[3.], [4.]] # batchsize = 2 } - net = fc.input_layer(features, [price1, price2]) + net = FeatureLayer([price1, price2])(features) with _initialized_session() as sess: with self.assertRaisesRegexp(errors.OpError, 'Dimensions of inputs should match'): sess.run(net, feed_dict={features['price1']: [[1.], [5.], [7.]]}) def test_runtime_batch_size_matches(self): - price1 = fc_old.numeric_column('price1') - price2 = fc_old.numeric_column('price2') + price1 = fc.numeric_column('price1') + price2 = fc.numeric_column('price2') with ops.Graph().as_default(): features = { 'price1': array_ops.placeholder(dtype=dtypes.int64), # batchsize = 2 'price2': array_ops.placeholder(dtype=dtypes.int64), # batchsize = 2 } - net = fc.input_layer(features, [price1, price2]) + net = FeatureLayer([price1, price2])(features) with _initialized_session() as sess: sess.run( net, @@ -2975,9 +2913,9 @@ class FunctionalInputLayerTest(test.TestCase): }) def test_multiple_layers_with_same_embedding_column(self): - some_sparse_column = fc_old.categorical_column_with_hash_bucket( + some_sparse_column = fc.categorical_column_with_hash_bucket( 'sparse_feature', hash_bucket_size=5) - some_embedding_column = fc_old.embedding_column( + some_embedding_column = fc.embedding_column( some_sparse_column, dimension=10) with ops.Graph().as_default(): @@ -2985,28 +2923,30 @@ class FunctionalInputLayerTest(test.TestCase): 'sparse_feature': [['a'], ['x']], } all_cols = [some_embedding_column] - fc.input_layer(features, all_cols) - fc.input_layer(features, all_cols) + FeatureLayer(all_cols)(features) + FeatureLayer(all_cols)(features) # Make sure that 2 variables get created in this case. self.assertEqual(2, len( ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES))) expected_var_names = [ - 'input_layer/sparse_feature_embedding/embedding_weights:0', - 'input_layer_1/sparse_feature_embedding/embedding_weights:0' + 'feature_layer/sparse_feature_embedding/embedding_weights:0', + 'feature_layer_1/sparse_feature_embedding/embedding_weights:0' ] self.assertItemsEqual( expected_var_names, [v.name for v in ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)]) def test_multiple_layers_with_same_shared_embedding_column(self): - categorical_column_a = fc_old.categorical_column_with_identity( + categorical_column_a = fc.categorical_column_with_identity( key='aaa', num_buckets=3) - categorical_column_b = fc_old.categorical_column_with_identity( + categorical_column_b = fc.categorical_column_with_identity( key='bbb', num_buckets=3) embedding_dimension = 2 - embedding_column_b, embedding_column_a = fc_old.shared_embedding_columns( + embedding_column_b, embedding_column_a = fc.shared_embedding_columns_v2( [categorical_column_b, categorical_column_a], dimension=embedding_dimension) + shared_state_manager = fc.SharedEmbeddingStateManager( + name='shared_feature_layer') with ops.Graph().as_default(): features = { @@ -3022,27 +2962,33 @@ class FunctionalInputLayerTest(test.TestCase): dense_shape=(2, 2)), } all_cols = [embedding_column_a, embedding_column_b] - fc.input_layer(features, all_cols) - fc.input_layer(features, all_cols) + FeatureLayer( + all_cols, shared_state_manager=shared_state_manager)( + features) + FeatureLayer( + all_cols, shared_state_manager=shared_state_manager)( + features) # Make sure that only 1 variable gets created in this case. self.assertEqual(1, len( ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES))) self.assertItemsEqual( - ['input_layer/aaa_bbb_shared_embedding/embedding_weights:0'], + ['shared_feature_layer/aaa_bbb_shared_embedding:0'], [v.name for v in ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)]) def test_multiple_layers_with_same_shared_embedding_column_diff_graphs(self): - categorical_column_a = fc_old.categorical_column_with_identity( + categorical_column_a = fc.categorical_column_with_identity( key='aaa', num_buckets=3) - categorical_column_b = fc_old.categorical_column_with_identity( + categorical_column_b = fc.categorical_column_with_identity( key='bbb', num_buckets=3) embedding_dimension = 2 - embedding_column_b, embedding_column_a = fc_old.shared_embedding_columns( + embedding_column_b, embedding_column_a = fc.shared_embedding_columns_v2( [categorical_column_b, categorical_column_a], dimension=embedding_dimension) all_cols = [embedding_column_a, embedding_column_b] with ops.Graph().as_default(): + shared_state_manager1 = fc.SharedEmbeddingStateManager( + name='shared_feature_layer') features = { 'aaa': sparse_tensor.SparseTensor( @@ -3055,12 +3001,16 @@ class FunctionalInputLayerTest(test.TestCase): values=(1, 2, 1), dense_shape=(2, 2)), } - fc.input_layer(features, all_cols) + FeatureLayer( + all_cols, shared_state_manager=shared_state_manager1)( + features) # Make sure that only 1 variable gets created in this case. self.assertEqual(1, len( ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES))) with ops.Graph().as_default(): + shared_state_manager2 = fc.SharedEmbeddingStateManager( + name='shared_feature_layer') features1 = { 'aaa': sparse_tensor.SparseTensor( @@ -3074,12 +3024,14 @@ class FunctionalInputLayerTest(test.TestCase): dense_shape=(2, 2)), } - fc.input_layer(features1, all_cols) + FeatureLayer( + all_cols, shared_state_manager=shared_state_manager2)( + features1) # Make sure that only 1 variable gets created in this case. self.assertEqual(1, len( ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES))) self.assertItemsEqual( - ['input_layer/aaa_bbb_shared_embedding/embedding_weights:0'], + ['shared_feature_layer/aaa_bbb_shared_embedding:0'], [v.name for v in ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)]) def test_with_numpy_input_fn(self): @@ -3092,14 +3044,14 @@ class FunctionalInputLayerTest(test.TestCase): del shape, dtype, partition_info return embedding_values - # price has 1 dimension in input_layer - price = fc_old.numeric_column('price') - body_style = fc_old.categorical_column_with_vocabulary_list( + # price has 1 dimension in feature_layer + price = fc.numeric_column('price') + body_style = fc.categorical_column_with_vocabulary_list( 'body-style', vocabulary_list=['hardtop', 'wagon', 'sedan']) - # one_hot_body_style has 3 dims in input_layer. - one_hot_body_style = fc_old.indicator_column(body_style) - # embedded_body_style has 5 dims in input_layer. - embedded_body_style = fc_old.embedding_column( + # one_hot_body_style has 3 dims in feature_layer. + one_hot_body_style = fc.indicator_column(body_style) + # embedded_body_style has 5 dims in feature_layer. + embedded_body_style = fc.embedding_column( body_style, dimension=5, initializer=_initializer) input_fn = numpy_io.numpy_input_fn( @@ -3110,8 +3062,8 @@ class FunctionalInputLayerTest(test.TestCase): batch_size=2, shuffle=False) features = input_fn() - net = fc.input_layer(features, - [price, one_hot_body_style, embedded_body_style]) + net = FeatureLayer([price, one_hot_body_style, embedded_body_style])( + features) self.assertEqual(1 + 3 + 5, net.shape[1]) with _initialized_session() as sess: coord = coordinator.Coordinator() @@ -3137,18 +3089,18 @@ class FunctionalInputLayerTest(test.TestCase): del shape, dtype, partition_info return embedding_values - # price has 1 dimension in input_layer - price = fc_old.numeric_column('price') + # price has 1 dimension in feature_layer + price = fc.numeric_column('price') - # one_hot_body_style has 3 dims in input_layer. - body_style = fc_old.categorical_column_with_vocabulary_list( + # one_hot_body_style has 3 dims in feature_layer. + body_style = fc.categorical_column_with_vocabulary_list( 'body-style', vocabulary_list=['hardtop', 'wagon', 'sedan']) - one_hot_body_style = fc_old.indicator_column(body_style) + one_hot_body_style = fc.indicator_column(body_style) - # embedded_body_style has 5 dims in input_layer. - country = fc_old.categorical_column_with_vocabulary_list( + # embedded_body_style has 5 dims in feature_layer. + country = fc.categorical_column_with_vocabulary_list( 'country', vocabulary_list=['US', 'JP', 'CA']) - embedded_country = fc_old.embedding_column( + embedded_country = fc.embedding_column( country, dimension=5, initializer=_initializer) # Provides 1-dim tensor and dense tensor. @@ -3165,8 +3117,7 @@ class FunctionalInputLayerTest(test.TestCase): self.assertEqual(1, features['body-style'].dense_shape.get_shape()[0]) self.assertEqual(1, features['country'].shape.ndims) - net = fc.input_layer(features, - [price, one_hot_body_style, embedded_country]) + net = FeatureLayer([price, one_hot_body_style, embedded_country])(features) self.assertEqual(1 + 3 + 5, net.shape[1]) with _initialized_session() as sess: @@ -3187,18 +3138,18 @@ class FunctionalInputLayerTest(test.TestCase): del shape, dtype, partition_info return embedding_values - # price has 1 dimension in input_layer - price = fc_old.numeric_column('price') + # price has 1 dimension in feature_layer + price = fc.numeric_column('price') - # one_hot_body_style has 3 dims in input_layer. - body_style = fc_old.categorical_column_with_vocabulary_list( + # one_hot_body_style has 3 dims in feature_layer. + body_style = fc.categorical_column_with_vocabulary_list( 'body-style', vocabulary_list=['hardtop', 'wagon', 'sedan']) - one_hot_body_style = fc_old.indicator_column(body_style) + one_hot_body_style = fc.indicator_column(body_style) - # embedded_body_style has 5 dims in input_layer. - country = fc_old.categorical_column_with_vocabulary_list( + # embedded_body_style has 5 dims in feature_layer. + country = fc.categorical_column_with_vocabulary_list( 'country', vocabulary_list=['US', 'JP', 'CA']) - embedded_country = fc_old.embedding_column( + embedded_country = fc.embedding_column( country, dimension=2, initializer=_initializer) # Provides 1-dim tensor and dense tensor. @@ -3219,8 +3170,7 @@ class FunctionalInputLayerTest(test.TestCase): dense_shape=(2,)) country_data = np.array([['US'], ['CA']]) - net = fc.input_layer(features, - [price, one_hot_body_style, embedded_country]) + net = FeatureLayer([price, one_hot_body_style, embedded_country])(features) self.assertEqual(1 + 3 + 2, net.shape[1]) with _initialized_session() as sess: @@ -3237,8 +3187,8 @@ class FunctionalInputLayerTest(test.TestCase): })) def test_with_rank_0_feature(self): - # price has 1 dimension in input_layer - price = fc_old.numeric_column('price') + # price has 1 dimension in feature_layer + price = fc.numeric_column('price') features = { 'price': constant_op.constant(0), } @@ -3246,13 +3196,13 @@ class FunctionalInputLayerTest(test.TestCase): # Static rank 0 should fail with self.assertRaisesRegexp(ValueError, 'Feature .* cannot have rank 0'): - fc.input_layer(features, [price]) + FeatureLayer([price])(features) # Dynamic rank 0 should fail features = { 'price': array_ops.placeholder(dtypes.float32), } - net = fc.input_layer(features, [price]) + net = FeatureLayer([price])(features) self.assertEqual(1, net.shape[1]) with _initialized_session() as sess: with self.assertRaisesOpError('Feature .* cannot have rank 0'): @@ -3267,7 +3217,7 @@ class MakeParseExampleSpecTest(test.TestCase): @property def name(self): - return "_TestFeatureColumn" + return '_TestFeatureColumn' def transform_feature(self, transformation_cache, state_manager): pass @@ -3427,7 +3377,7 @@ class VocabularyFileCategoricalColumnTest(test.TestCase): dense_shape=(2, 2)) column.get_sparse_tensors(FeatureTransformationCache({'aaa': inputs}), None) with self.assertRaisesRegexp(errors.OpError, 'file_does_not_exist'): - with self.test_session(): + with self.cached_session(): lookup_ops.tables_initializer().run() def test_invalid_vocabulary_size(self): @@ -3451,7 +3401,7 @@ class VocabularyFileCategoricalColumnTest(test.TestCase): dense_shape=(2, 2)) column.get_sparse_tensors(FeatureTransformationCache({'aaa': inputs}), None) with self.assertRaisesRegexp(errors.OpError, 'Invalid vocab_size'): - with self.test_session(): + with self.cached_session(): lookup_ops.tables_initializer().run() def test_invalid_num_oov_buckets(self): @@ -3521,7 +3471,7 @@ class VocabularyFileCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -3593,25 +3543,6 @@ class VocabularyFileCategoricalColumnTest(test.TestCase): dense_shape=inputs.dense_shape), id_tensor.eval()) - def DISABLED_test_get_sparse_tensors_weight_collections(self): - column = fc.categorical_column_with_vocabulary_file( - key='aaa', - vocabulary_file=self._wire_vocabulary_file_name, - vocabulary_size=self._wire_vocabulary_size) - inputs = sparse_tensor.SparseTensor( - values=['omar', 'stringer', 'marlo'], - indices=[[0, 0], [1, 0], [1, 1]], - dense_shape=[2, 2]) - column.get_sparse_tensors( - FeatureTransformationCache({ - 'aaa': inputs - }), - weight_collections=('my_weights',)) - - self.assertItemsEqual( - [], ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)) - self.assertItemsEqual([], ops.get_collection('my_weights')) - def test_get_sparse_tensors_dense_input(self): column = fc.categorical_column_with_vocabulary_file( key='aaa', @@ -3972,7 +3903,7 @@ class VocabularyListCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -3994,7 +3925,7 @@ class VocabularyListCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -4043,24 +3974,6 @@ class VocabularyListCategoricalColumnTest(test.TestCase): dense_shape=inputs.dense_shape), id_tensor.eval()) - def DISABLED_test_get_sparse_tensors_weight_collections(self): - column = fc.categorical_column_with_vocabulary_list( - key='aaa', - vocabulary_list=('omar', 'stringer', 'marlo')) - inputs = sparse_tensor.SparseTensor( - values=['omar', 'stringer', 'marlo'], - indices=[[0, 0], [1, 0], [1, 1]], - dense_shape=[2, 2]) - column.get_sparse_tensors( - FeatureTransformationCache({ - 'aaa': inputs - }), - weight_collections=('my_weights',)) - - self.assertItemsEqual( - [], ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)) - self.assertItemsEqual([], ops.get_collection('my_weights')) - def test_get_sparse_tensors_dense_input(self): column = fc.categorical_column_with_vocabulary_list( key='aaa', @@ -4311,7 +4224,7 @@ class IdentityCategoricalColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -4356,22 +4269,6 @@ class IdentityCategoricalColumnTest(test.TestCase): dense_shape=inputs.dense_shape), id_tensor.eval()) - def DISABLED_test_get_sparse_tensors_weight_collections(self): - column = fc.categorical_column_with_identity(key='aaa', num_buckets=3) - inputs = sparse_tensor.SparseTensorValue( - indices=((0, 0), (1, 0), (1, 1)), - values=(0, 1, 0), - dense_shape=(2, 2)) - column.get_sparse_tensors( - FeatureTransformationCache({ - 'aaa': inputs - }), - weight_collections=('my_weights',)) - - self.assertItemsEqual( - [], ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)) - self.assertItemsEqual([], ops.get_collection('my_weights')) - def test_get_sparse_tensors_dense_input(self): column = fc.categorical_column_with_identity(key='aaa', num_buckets=3) id_weight_pair = column.get_sparse_tensors( @@ -4595,7 +4492,7 @@ class IndicatorColumnTest(test.TestCase): 'animal': ['fox', 'fox'] }) output = transformation_cache.get(animal, None) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[0., 0., 1., 0.], [0., 0., 1., 0.]], output.eval()) def test_2D_shape_succeeds(self): @@ -4610,7 +4507,7 @@ class IndicatorColumnTest(test.TestCase): dense_shape=[2, 1]) }) output = transformation_cache.get(animal, None) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[0., 0., 1., 0.], [0., 0., 1., 0.]], output.eval()) def test_multi_hot(self): @@ -4623,7 +4520,7 @@ class IndicatorColumnTest(test.TestCase): indices=[[0, 0], [0, 1]], values=[1, 1], dense_shape=[1, 2]) }) output = transformation_cache.get(animal, None) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[0., 2., 0., 0.]], output.eval()) def test_multi_hot2(self): @@ -4635,7 +4532,7 @@ class IndicatorColumnTest(test.TestCase): indices=[[0, 0], [0, 1]], values=[1, 2], dense_shape=[1, 2]) }) output = transformation_cache.get(animal, None) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([[0., 1., 1., 0.]], output.eval()) def test_deep_copy(self): @@ -4660,7 +4557,7 @@ class IndicatorColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a_indicator])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -4765,16 +4662,16 @@ class IndicatorColumnTest(test.TestCase): weight_var.assign([[1.], [2.], [3.], [4.]]).eval() self.assertAllClose([[2. + 3.]], predictions.eval()) - def test_input_layer(self): - animal = fc_old.indicator_column( - fc_old.categorical_column_with_identity('animal', num_buckets=4)) + def test_feature_layer(self): + animal = fc.indicator_column( + fc.categorical_column_with_identity('animal', num_buckets=4)) with ops.Graph().as_default(): features = { 'animal': sparse_tensor.SparseTensor( indices=[[0, 0], [0, 1]], values=[1, 2], dense_shape=[1, 2]) } - net = fc.input_layer(features, [animal]) + net = FeatureLayer([animal])(features) with _initialized_session(): self.assertAllClose([[0., 1., 1., 0.]], net.eval()) @@ -4786,12 +4683,13 @@ class _TestStateManager(StateManager): self._all_variables = {} self._trainable = trainable - def get_variable(self, - feature_column, - name, - shape, - dtype=None, - initializer=None): + def create_variable(self, + feature_column, + name, + shape, + dtype=None, + trainable=True, + initializer=None): if feature_column not in self._all_variables: self._all_variables[feature_column] = {} var_dict = self._all_variables[feature_column] @@ -4801,11 +4699,19 @@ class _TestStateManager(StateManager): var = variable_scope.get_variable( name=name, shape=shape, - initializer=initializer, - trainable=self._trainable) + dtype=dtype, + trainable=self._trainable and trainable, + initializer=initializer) var_dict[name] = var return var + def get_variable(self, feature_column, name): + if feature_column not in self._all_variables: + raise ValueError('Do not recognize FeatureColumn.') + if name in self._all_variables[feature_column]: + return self._all_variables[feature_column][name] + raise ValueError('Could not find variable.') + class EmbeddingColumnTest(test.TestCase): @@ -4898,7 +4804,7 @@ class EmbeddingColumnTest(test.TestCase): serialized=[data.SerializeToString()], features=fc.make_parse_example_spec([a_embedded])) self.assertIn('aaa', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -4967,6 +4873,7 @@ class EmbeddingColumnTest(test.TestCase): categorical_column, dimension=embedding_dimension, initializer=_initializer) state_manager = _TestStateManager() + embedding_column.create_state(state_manager) # Provide sparse input and get dense result. embedding_lookup = embedding_column.get_dense_tensor( @@ -5028,6 +4935,7 @@ class EmbeddingColumnTest(test.TestCase): categorical_column, dimension=embedding_dimension, initializer=_initializer) state_manager = _TestStateManager() + embedding_column.create_state(state_manager) # Provide sparse input and get dense result. embedding_lookup = embedding_column.get_dense_tensor( @@ -5043,36 +4951,6 @@ class EmbeddingColumnTest(test.TestCase): self.assertAllEqual(embedding_values, global_vars[0].eval()) self.assertAllEqual(expected_lookups, embedding_lookup.eval()) - def DISABLED_test_get_dense_tensor_weight_collections(self): - sparse_input = sparse_tensor.SparseTensorValue( - # example 0, ids [2] - # example 1, ids [0, 1] - # example 2, ids [] - # example 3, ids [1] - indices=((0, 0), (1, 0), (1, 4), (3, 0)), - values=(2, 0, 1, 1), - dense_shape=(4, 5)) - - # Build columns. - categorical_column = fc.categorical_column_with_identity( - key='aaa', num_buckets=3) - embedding_column = fc.embedding_column(categorical_column, dimension=2) - - # Provide sparse input and get dense result. - embedding_column.get_dense_tensor( - FeatureTransformationCache({ - 'aaa': sparse_input - }), - weight_collections=('my_vars',)) - - # Assert expected embedding variable and lookups. - global_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - self.assertItemsEqual(('embedding_weights:0',), - tuple([v.name for v in global_vars])) - my_vars = ops.get_collection('my_vars') - self.assertItemsEqual( - ('embedding_weights:0',), tuple([v.name for v in my_vars])) - def test_get_dense_tensor_placeholder_inputs(self): # Inputs. vocabulary_size = 3 @@ -5117,6 +4995,7 @@ class EmbeddingColumnTest(test.TestCase): categorical_column, dimension=embedding_dimension, initializer=_initializer) state_manager = _TestStateManager() + embedding_column.create_state(state_manager) # Provide sparse input and get dense result. input_indices = array_ops.placeholder(dtype=dtypes.int64) @@ -5187,6 +5066,7 @@ class EmbeddingColumnTest(test.TestCase): ckpt_to_load_from=ckpt_path, tensor_name_in_ckpt=ckpt_tensor) state_manager = _TestStateManager() + embedding_column.create_state(state_manager) # Provide sparse input and get dense result. embedding_lookup = embedding_column.get_dense_tensor( @@ -5354,7 +5234,7 @@ class EmbeddingColumnTest(test.TestCase): # = [4*7 + 6*11, 4*2 + 6*3.5, 4*0 + 6*0, 4*3 + 6*5] = [94, 29, 0, 42] self.assertAllClose(((94.,), (29.,), (0.,), (42.,)), predictions.eval()) - def test_input_layer(self): + def test_feature_layer(self): # Inputs. vocabulary_size = 3 sparse_input = sparse_tensor.SparseTensorValue( @@ -5392,30 +5272,29 @@ class EmbeddingColumnTest(test.TestCase): ) # Build columns. - categorical_column = fc_old.categorical_column_with_identity( + categorical_column = fc.categorical_column_with_identity( key='aaa', num_buckets=vocabulary_size) - embedding_column = fc_old.embedding_column( + embedding_column = fc.embedding_column( categorical_column, dimension=embedding_dimension, initializer=_initializer) # Provide sparse input and get dense result. - input_layer = fc.input_layer({'aaa': sparse_input}, (embedding_column,)) + l = FeatureLayer((embedding_column,)) + feature_layer = l({'aaa': sparse_input}) # Assert expected embedding variable and lookups. global_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - self.assertItemsEqual( - ('input_layer/aaa_embedding/embedding_weights:0',), - tuple([v.name for v in global_vars])) + self.assertItemsEqual(('feature_layer/aaa_embedding/embedding_weights:0',), + tuple([v.name for v in global_vars])) trainable_vars = ops.get_collection(ops.GraphKeys.TRAINABLE_VARIABLES) - self.assertItemsEqual( - ('input_layer/aaa_embedding/embedding_weights:0',), - tuple([v.name for v in trainable_vars])) + self.assertItemsEqual(('feature_layer/aaa_embedding/embedding_weights:0',), + tuple([v.name for v in trainable_vars])) with _initialized_session(): self.assertAllEqual(embedding_values, trainable_vars[0].eval()) - self.assertAllEqual(expected_lookups, input_layer.eval()) + self.assertAllEqual(expected_lookups, feature_layer.eval()) - def test_input_layer_not_trainable(self): + def test_feature_layer_not_trainable(self): # Inputs. vocabulary_size = 3 sparse_input = sparse_tensor.SparseTensorValue( @@ -5453,65 +5332,26 @@ class EmbeddingColumnTest(test.TestCase): ) # Build columns. - categorical_column = fc_old.categorical_column_with_identity( + categorical_column = fc.categorical_column_with_identity( key='aaa', num_buckets=vocabulary_size) - embedding_column = fc_old.embedding_column( + embedding_column = fc.embedding_column( categorical_column, dimension=embedding_dimension, initializer=_initializer, trainable=False) # Provide sparse input and get dense result. - input_layer = fc.input_layer({'aaa': sparse_input}, (embedding_column,)) + feature_layer = FeatureLayer((embedding_column,))({'aaa': sparse_input}) # Assert expected embedding variable and lookups. global_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - self.assertItemsEqual( - ('input_layer/aaa_embedding/embedding_weights:0',), - tuple([v.name for v in global_vars])) + self.assertItemsEqual(('feature_layer/aaa_embedding/embedding_weights:0',), + tuple([v.name for v in global_vars])) self.assertItemsEqual( [], ops.get_collection(ops.GraphKeys.TRAINABLE_VARIABLES)) with _initialized_session(): self.assertAllEqual(embedding_values, global_vars[0].eval()) - self.assertAllEqual(expected_lookups, input_layer.eval()) - - -class _TestSharedEmbeddingStateManager(StateManager): - """Manages the state for shared embedding columns. - - This can handle multiple groups of shared embedding columns. - """ - - def __init__(self, trainable=True): - # Dict of shared_embedding_collection_name to a dict of variables. - self._all_variables = {} - self._trainable = trainable - - def get_variable(self, - feature_column, - name, - shape, - dtype=None, - initializer=None): - if not isinstance(feature_column, fc.SharedEmbeddingColumn): - raise ValueError( - 'SharedEmbeddingStateManager can only handle SharedEmbeddingColumns. ' - 'Given type: {} '.format(type(feature_column))) - - collection_name = feature_column.shared_collection_name - if collection_name not in self._all_variables: - self._all_variables[collection_name] = {} - var_dict = self._all_variables[collection_name] - if name in var_dict: - return var_dict[name] - else: - var = variable_scope.get_variable( - name=name, - shape=shape, - initializer=initializer, - trainable=self._trainable) - var_dict[name] = var - return var + self.assertAllEqual(expected_lookups, feature_layer.eval()) class SharedEmbeddingColumnTest(test.TestCase): @@ -5522,7 +5362,7 @@ class SharedEmbeddingColumnTest(test.TestCase): categorical_column_b = fc.categorical_column_with_identity( key='bbb', num_buckets=3) embedding_dimension = 2 - embedding_column_b, embedding_column_a = fc.shared_embedding_columns( + embedding_column_b, embedding_column_a = fc.shared_embedding_columns_v2( [categorical_column_b, categorical_column_a], dimension=embedding_dimension) self.assertIs(categorical_column_a, embedding_column_a.categorical_column) @@ -5560,7 +5400,7 @@ class SharedEmbeddingColumnTest(test.TestCase): categorical_column_b = fc.categorical_column_with_identity( key='bbb', num_buckets=3) embedding_dimension = 2 - embedding_column_a, embedding_column_b = fc.shared_embedding_columns( + embedding_column_a, embedding_column_b = fc.shared_embedding_columns_v2( [categorical_column_a, categorical_column_b], dimension=embedding_dimension, combiner='my_combiner', @@ -5605,7 +5445,7 @@ class SharedEmbeddingColumnTest(test.TestCase): categorical_column_b = fc.categorical_column_with_identity( key='bbb', num_buckets=3) embedding_dimension = 2 - original_a, _ = fc.shared_embedding_columns( + original_a, _ = fc.shared_embedding_columns_v2( [categorical_column_a, categorical_column_b], dimension=embedding_dimension, combiner='my_combiner', @@ -5613,7 +5453,8 @@ class SharedEmbeddingColumnTest(test.TestCase): shared_embedding_collection_name='shared_embedding_collection_name', ckpt_to_load_from='my_ckpt', tensor_name_in_ckpt='my_ckpt_tensor', - max_norm=42., trainable=False) + max_norm=42., + trainable=False) for embedding_column_a in (original_a, copy.deepcopy(original_a)): self.assertEqual('aaa', embedding_column_a.categorical_column.name) self.assertEqual(3, embedding_column_a.categorical_column.num_buckets) @@ -5642,8 +5483,9 @@ class SharedEmbeddingColumnTest(test.TestCase): categorical_column_b = fc.categorical_column_with_identity( key='bbb', num_buckets=3) with self.assertRaisesRegexp(ValueError, 'initializer must be callable'): - fc.shared_embedding_columns( - [categorical_column_a, categorical_column_b], dimension=2, + fc.shared_embedding_columns_v2( + [categorical_column_a, categorical_column_b], + dimension=2, initializer='not_fn') def test_incompatible_column_type(self): @@ -5656,7 +5498,7 @@ class SharedEmbeddingColumnTest(test.TestCase): with self.assertRaisesRegexp( ValueError, 'all categorical_columns must have the same type.*' 'IdentityCategoricalColumn.*HashedCategoricalColumn'): - fc.shared_embedding_columns( + fc.shared_embedding_columns_v2( [categorical_column_a, categorical_column_b, categorical_column_c], dimension=2) @@ -5669,11 +5511,11 @@ class SharedEmbeddingColumnTest(test.TestCase): key='bbb', num_buckets=3) weighted_categorical_column_b = fc.weighted_categorical_column( categorical_column_b, weight_feature_key='bbb_weights') - fc.shared_embedding_columns( + fc.shared_embedding_columns_v2( [weighted_categorical_column_a, categorical_column_b], dimension=2) - fc.shared_embedding_columns( + fc.shared_embedding_columns_v2( [categorical_column_a, weighted_categorical_column_b], dimension=2) - fc.shared_embedding_columns( + fc.shared_embedding_columns_v2( [weighted_categorical_column_a, weighted_categorical_column_b], dimension=2) @@ -5682,8 +5524,7 @@ class SharedEmbeddingColumnTest(test.TestCase): key='aaa', vocabulary_list=('omar', 'stringer', 'marlo')) b = fc.categorical_column_with_vocabulary_list( key='bbb', vocabulary_list=('omar', 'stringer', 'marlo')) - a_embedded, b_embedded = fc.shared_embedding_columns( - [a, b], dimension=2) + a_embedded, b_embedded = fc.shared_embedding_columns_v2([a, b], dimension=2) data = example_pb2.Example(features=feature_pb2.Features( feature={ 'aaa': @@ -5698,7 +5539,7 @@ class SharedEmbeddingColumnTest(test.TestCase): features=fc.make_parse_example_spec([a_embedded, b_embedded])) self.assertIn('aaa', features) self.assertIn('bbb', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( @@ -5717,8 +5558,7 @@ class SharedEmbeddingColumnTest(test.TestCase): def test_transform_feature(self): a = fc.categorical_column_with_identity(key='aaa', num_buckets=3) b = fc.categorical_column_with_identity(key='bbb', num_buckets=3) - a_embedded, b_embedded = fc.shared_embedding_columns( - [a, b], dimension=2) + a_embedded, b_embedded = fc.shared_embedding_columns_v2([a, b], dimension=2) features = { 'aaa': sparse_tensor.SparseTensor( indices=((0, 0), (1, 0), (1, 1)), @@ -5788,10 +5628,13 @@ class SharedEmbeddingColumnTest(test.TestCase): key='aaa', num_buckets=vocabulary_size) categorical_column_b = fc.categorical_column_with_identity( key='bbb', num_buckets=vocabulary_size) - embedding_column_a, embedding_column_b = fc.shared_embedding_columns( + embedding_column_a, embedding_column_b = fc.shared_embedding_columns_v2( [categorical_column_a, categorical_column_b], - dimension=embedding_dimension, initializer=_initializer) - state_manager = _TestSharedEmbeddingStateManager() + dimension=embedding_dimension, + initializer=_initializer) + state_manager = fc.SharedEmbeddingStateManager(name='shared_feature_layer') + embedding_column_a.create_state(state_manager) + embedding_column_b.create_state(state_manager) # Provide sparse input and get dense result. embedding_lookup_a = embedding_column_a.get_dense_tensor( @@ -5801,7 +5644,7 @@ class SharedEmbeddingColumnTest(test.TestCase): # Assert expected embedding variable and lookups. global_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - self.assertItemsEqual(('embedding_weights:0',), + self.assertItemsEqual(('shared_feature_layer/aaa_bbb_shared_embedding:0',), tuple([v.name for v in global_vars])) embedding_var = global_vars[0] with _initialized_session(): @@ -5809,58 +5652,6 @@ class SharedEmbeddingColumnTest(test.TestCase): self.assertAllEqual(expected_lookups_a, embedding_lookup_a.eval()) self.assertAllEqual(expected_lookups_b, embedding_lookup_b.eval()) - def DISABLED_test_get_dense_tensor_weight_collections(self): - # Inputs. - vocabulary_size = 3 - # -1 values are ignored. - input_a = np.array([ - [2, -1, -1], # example 0, ids [2] - [0, 1, -1] - ]) # example 1, ids [0, 1] - input_b = np.array([ - [0, -1, -1], # example 0, ids [0] - [-1, -1, -1] - ]) # example 1, ids [] - input_features = {'aaa': input_a, 'bbb': input_b} - - # Embedding variable. - embedding_dimension = 2 - embedding_values = ( - (1., 2.), # id 0 - (3., 5.), # id 1 - (7., 11.) # id 2 - ) - - def _initializer(shape, dtype, partition_info): - self.assertAllEqual((vocabulary_size, embedding_dimension), shape) - self.assertEqual(dtypes.float32, dtype) - self.assertIsNone(partition_info) - return embedding_values - - # Build columns. - categorical_column_a = fc.categorical_column_with_identity( - key='aaa', num_buckets=vocabulary_size) - categorical_column_b = fc.categorical_column_with_identity( - key='bbb', num_buckets=vocabulary_size) - embedding_column_a, embedding_column_b = fc.shared_embedding_columns( - [categorical_column_a, categorical_column_b], - dimension=embedding_dimension, - initializer=_initializer) - - fc.input_layer( - input_features, [embedding_column_a, embedding_column_b], - weight_collections=('my_vars',)) - - # Assert expected embedding variable and lookups. - global_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - self.assertItemsEqual( - ('input_layer/aaa_bbb_shared_embedding/embedding_weights:0',), - tuple(v.name for v in global_vars)) - my_vars = ops.get_collection('my_vars') - self.assertItemsEqual( - ('input_layer/aaa_bbb_shared_embedding/embedding_weights:0',), - tuple(v.name for v in my_vars)) - def test_get_dense_tensor_placeholder_inputs(self): # Inputs. vocabulary_size = 3 @@ -5903,10 +5694,13 @@ class SharedEmbeddingColumnTest(test.TestCase): key='aaa', num_buckets=vocabulary_size) categorical_column_b = fc.categorical_column_with_identity( key='bbb', num_buckets=vocabulary_size) - embedding_column_a, embedding_column_b = fc.shared_embedding_columns( + embedding_column_a, embedding_column_b = fc.shared_embedding_columns_v2( [categorical_column_a, categorical_column_b], - dimension=embedding_dimension, initializer=_initializer) - state_manager = _TestSharedEmbeddingStateManager() + dimension=embedding_dimension, + initializer=_initializer) + state_manager = fc.SharedEmbeddingStateManager() + embedding_column_a.create_state(state_manager) + embedding_column_b.create_state(state_manager) # Provide sparse input and get dense result. embedding_lookup_a = embedding_column_a.get_dense_tensor( @@ -6096,7 +5890,7 @@ class SharedEmbeddingColumnTest(test.TestCase): # = [3*1 + 5*2, 3*0 +5*0] = [13, 0] self.assertAllClose([[94. + 13.], [29.]], predictions.eval()) - def _test_input_layer(self, trainable=True): + def _test_feature_layer(self, trainable=True): # Inputs. vocabulary_size = 3 sparse_input_a = sparse_tensor.SparseTensorValue( @@ -6111,6 +5905,18 @@ class SharedEmbeddingColumnTest(test.TestCase): indices=((0, 0),), values=(0,), dense_shape=(2, 5)) + sparse_input_c = sparse_tensor.SparseTensorValue( + # example 0, ids [2] + # example 1, ids [0, 1] + indices=((0, 1), (1, 1), (1, 3)), + values=(2, 0, 1), + dense_shape=(2, 5)) + sparse_input_d = sparse_tensor.SparseTensorValue( + # example 0, ids [2] + # example 1, ids [] + indices=((0, 1),), + values=(2,), + dense_shape=(2, 5)) # Embedding variable. embedding_dimension = 2 @@ -6130,51 +5936,127 @@ class SharedEmbeddingColumnTest(test.TestCase): # example 0: # A ids [2], embedding = [7, 11] # B ids [0], embedding = [1, 2] - (7., 11., 1., 2.), + # C ids [2], embedding = [7, 11] + # D ids [2], embedding = [7, 11] + (7., 11., 1., 2., 7., 11., 7., 11.), # example 1: # A ids [0, 1], embedding = mean([1, 2] + [3, 5]) = [2, 3.5] # B ids [], embedding = [0, 0] - (2., 3.5, 0., 0.), + # C ids [0, 1], embedding = mean([1, 2] + [3, 5]) = [2, 3.5] + # D ids [], embedding = [0, 0] + (2., 3.5, 0., 0., 2., 3.5, 0., 0.), ) # Build columns. - categorical_column_a = fc_old.categorical_column_with_identity( + categorical_column_a = fc.categorical_column_with_identity( key='aaa', num_buckets=vocabulary_size) - categorical_column_b = fc_old.categorical_column_with_identity( + categorical_column_b = fc.categorical_column_with_identity( key='bbb', num_buckets=vocabulary_size) - embedding_column_a, embedding_column_b = fc_old.shared_embedding_columns( + categorical_column_c = fc.categorical_column_with_identity( + key='ccc', num_buckets=vocabulary_size) + categorical_column_d = fc.categorical_column_with_identity( + key='ddd', num_buckets=vocabulary_size) + + embedding_column_a, embedding_column_b = fc.shared_embedding_columns_v2( [categorical_column_a, categorical_column_b], dimension=embedding_dimension, initializer=_initializer, trainable=trainable) + embedding_column_c, embedding_column_d = fc.shared_embedding_columns_v2( + [categorical_column_c, categorical_column_d], + dimension=embedding_dimension, + initializer=_initializer, + trainable=trainable) + shared_state_manager = fc.SharedEmbeddingStateManager( + name='shared_feature_layer') + + features = { + 'aaa': sparse_input_a, + 'bbb': sparse_input_b, + 'ccc': sparse_input_c, + 'ddd': sparse_input_d + } # Provide sparse input and get dense result. - input_layer = fc.input_layer( - features={'aaa': sparse_input_a, 'bbb': sparse_input_b}, - feature_columns=(embedding_column_b, embedding_column_a)) + feature_layer = FeatureLayer( + feature_columns=(embedding_column_b, embedding_column_a, + embedding_column_c, embedding_column_d), + shared_state_manager=shared_state_manager)( + features) # Assert expected embedding variable and lookups. global_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) - self.assertItemsEqual( - ['input_layer/aaa_bbb_shared_embedding/embedding_weights:0'], - tuple([v.name for v in global_vars])) + self.assertItemsEqual([ + 'shared_feature_layer/aaa_bbb_shared_embedding:0', + 'shared_feature_layer/ccc_ddd_shared_embedding:0' + ], tuple([v.name for v in global_vars])) trainable_vars = ops.get_collection(ops.GraphKeys.TRAINABLE_VARIABLES) if trainable: - self.assertItemsEqual( - ['input_layer/aaa_bbb_shared_embedding/embedding_weights:0'], - tuple([v.name for v in trainable_vars])) + self.assertItemsEqual([ + 'shared_feature_layer/aaa_bbb_shared_embedding:0', + 'shared_feature_layer/ccc_ddd_shared_embedding:0' + ], tuple([v.name for v in trainable_vars])) else: self.assertItemsEqual([], tuple([v.name for v in trainable_vars])) shared_embedding_vars = global_vars with _initialized_session(): self.assertAllEqual(embedding_values, shared_embedding_vars[0].eval()) - self.assertAllEqual(expected_lookups, input_layer.eval()) + self.assertAllEqual(expected_lookups, feature_layer.eval()) + + def test_feature_layer(self): + self._test_feature_layer() + + def test_feature_layer_no_trainable(self): + self._test_feature_layer(trainable=False) + - def test_input_layer(self): - self._test_input_layer() +class SharedEmbeddingStateManagerTest(test.TestCase): - def test_input_layer_no_trainable(self): - self._test_input_layer(trainable=False) + def test_basic(self): + categorical_column_a = fc.categorical_column_with_identity( + key='aaa', num_buckets=3) + categorical_column_b = fc.categorical_column_with_identity( + key='bbb', num_buckets=3) + fc.shared_embedding_columns_v2( + [categorical_column_a, categorical_column_b], dimension=2) + shared_state_manager = fc.SharedEmbeddingStateManager( + name='shared_feature_layer') + var_a = shared_state_manager.create_variable('aaa_bbb_shared_embedding', + [5, 10]) + var_b = shared_state_manager.create_variable('aaa_bbb_shared_embedding', + [5, 10]) + self.assertEqual(var_a, var_b) + self.assertEqual('shared_feature_layer/aaa_bbb_shared_embedding:0', + var_a.name) + self.assertIsInstance(var_a, variables_lib.Variable) + + def test_multiple_sets(self): + categorical_column_a = fc.categorical_column_with_identity( + key='aaa', num_buckets=3) + categorical_column_b = fc.categorical_column_with_identity( + key='bbb', num_buckets=3) + categorical_column_c = fc.categorical_column_with_identity( + key='ccc', num_buckets=3) + categorical_column_d = fc.categorical_column_with_identity( + key='ddd', num_buckets=3) + + fc.shared_embedding_columns_v2( + [categorical_column_a, categorical_column_b], dimension=2) + fc.shared_embedding_columns_v2( + [categorical_column_c, categorical_column_d], dimension=2) + shared_state_manager = fc.SharedEmbeddingStateManager( + name='shared_feature_layer') + var_a = shared_state_manager.create_variable('aaa_bbb_shared_embedding', + [5, 10]) + var_c = shared_state_manager.create_variable('ccc_ddd_shared_embedding', + [5, 10]) + self.assertIsInstance(var_a, variables_lib.Variable) + self.assertIsInstance(var_c, variables_lib.Variable) + self.assertNotEquals(var_a, var_c) + self.assertEqual('shared_feature_layer/aaa_bbb_shared_embedding:0', + var_a.name) + self.assertEqual('shared_feature_layer/ccc_ddd_shared_embedding:0', + var_c.name) class WeightedCategoricalColumnTest(test.TestCase): @@ -6271,7 +6153,7 @@ class WeightedCategoricalColumnTest(test.TestCase): features=fc.make_parse_example_spec([a_weighted])) self.assertIn('aaa', features) self.assertIn('weights', features) - with self.test_session(): + with self.cached_session(): _assert_sparse_tensor_value( self, sparse_tensor.SparseTensorValue( diff --git a/tensorflow/python/framework/device.py b/tensorflow/python/framework/device.py index ab06a2babf..06c653097a 100644 --- a/tensorflow/python/framework/device.py +++ b/tensorflow/python/framework/device.py @@ -19,6 +19,7 @@ from __future__ import division from __future__ import print_function import copy +import threading from tensorflow.python.util.tf_export import tf_export @@ -229,6 +230,12 @@ class DeviceSpec(object): """ return DeviceSpec().parse_from_string(spec) + def __eq__(self, other): + return self.to_string() == other.to_string() + + def __hash__(self): + return hash(self.to_string()) + def check_valid(spec): """Check that a device spec is valid. @@ -254,6 +261,14 @@ def canonical_name(device): return device.to_string() +# Cache from DeviceSpec objects to their corresponding device functions. +# This cache is maintained for correctness, not performance: it makes it +# possible to compare the device function stacks belonging to different +# graphs in a meaningful way. +_cached_device_functions = {} +_cache_lock = threading.Lock() + + def merge_device(spec): """Returns a device function that merges devices specifications. @@ -280,11 +295,18 @@ def merge_device(spec): Raises: ValueError: if the spec was not valid. """ - if not isinstance(spec, DeviceSpec): - spec = DeviceSpec.from_string(spec or "") - def _device_function(node_def): - current_device = DeviceSpec.from_string(node_def.device or "") - copy_spec = copy.copy(spec) - copy_spec.merge_from(current_device) # current_device takes precedence. - return copy_spec - return _device_function + with _cache_lock: + if not isinstance(spec, DeviceSpec): + spec = DeviceSpec.from_string(spec or "") + cached_function = _cached_device_functions.get(spec, None) + if cached_function is not None: + return cached_function + + def _device_function(node_def): + current_device = DeviceSpec.from_string(node_def.device or "") + copy_spec = copy.copy(spec) + copy_spec.merge_from(current_device) # current_device takes precedence. + return copy_spec + + _cached_device_functions[spec] = _device_function + return _device_function diff --git a/tensorflow/python/framework/function.py b/tensorflow/python/framework/function.py index f47c0d8a5e..a8aef3a009 100644 --- a/tensorflow/python/framework/function.py +++ b/tensorflow/python/framework/function.py @@ -23,7 +23,6 @@ from __future__ import print_function import collections import hashlib -import sys from tensorflow.core.framework import attr_value_pb2 from tensorflow.core.framework import function_pb2 @@ -34,7 +33,6 @@ from tensorflow.python.framework import dtypes from tensorflow.python.framework import graph_to_function_def from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops -from tensorflow.python.ops import cond_v2_impl from tensorflow.python.ops import resource_variable_ops from tensorflow.python.ops import variable_scope as vs from tensorflow.python.util import compat @@ -42,9 +40,6 @@ from tensorflow.python.util import function_utils from tensorflow.python.util import tf_contextlib from tensorflow.python.util import tf_inspect -# This is to avoid a circular dependency with cond_v2_impl. -cond_v2_impl._function = sys.modules[__name__] # pylint: disable=protected-access - class Defun(object): """Decorator used to define TensorFlow functions. @@ -1029,20 +1024,10 @@ def _from_definition(fdef, grad_func=None): result = _DefinedFunction(func, argnames, input_types, func_name, grad_func, python_grad_func, out_names) # pylint: disable=protected-access - if ops._USE_C_API: - serialized = fdef.SerializeToString() - c_func = c_api.TF_FunctionImportFunctionDef(serialized) - result._c_func = c_api_util.ScopedTFFunction(c_func) - result._extra_inputs = [] - else: - result._definition = fdef - # Captured inputs are added as regular inputs to a function when it's - # serialized, i.e. any extra inputs from the original function are now - # included in `result`._args - result._extra_inputs = [] - result._hash_str = result._create_hash_str( - result._definition.signature.input_arg, - result._definition.signature.output_arg, result._definition.node_def) + serialized = fdef.SerializeToString() + c_func = c_api.TF_FunctionImportFunctionDef(serialized) + result._c_func = c_api_util.ScopedTFFunction(c_func) + result._extra_inputs = [] # pylint: enable=protected-access return result diff --git a/tensorflow/python/framework/function_def_to_graph.py b/tensorflow/python/framework/function_def_to_graph.py index 1b09506662..a04fa369ae 100644 --- a/tensorflow/python/framework/function_def_to_graph.py +++ b/tensorflow/python/framework/function_def_to_graph.py @@ -23,7 +23,7 @@ import sys from tensorflow.core.framework import graph_pb2 from tensorflow.core.framework import types_pb2 from tensorflow.core.framework import versions_pb2 -from tensorflow.python.framework import function +from tensorflow.python.eager import function from tensorflow.python.framework import importer from tensorflow.python.framework import ops from tensorflow.python.framework import versions @@ -34,13 +34,13 @@ cond_v2_impl._function_def_to_graph = sys.modules[__name__] # pylint: disable=p def function_def_to_graph(fdef, input_shapes=None): - """Converts a FunctionDef to a function._FuncGraph (sub-class Graph). + """Converts a FunctionDef to a function.FuncGraph (sub-class Graph). - The returned _FuncGraph's `name`, `inputs` and `outputs` fields will be set. + The returned FuncGraph's `name`, `inputs` and `outputs` fields will be set. The input tensors are represented as placeholders. - Note: `_FuncGraph.inputs` and `_FuncGraph._captured` are not set and may be - set by the caller. + Note: `FuncGraph.inputs` and `FuncGraph.captures` are not set and may be set + by the caller. Args: fdef: FunctionDef. @@ -50,9 +50,9 @@ def function_def_to_graph(fdef, input_shapes=None): placeholder will have unknown shape. Returns: - A _FuncGraph. + A FuncGraph. """ - func_graph = function._FuncGraph(fdef.signature.name, capture_by_value=False) # pylint: disable=protected-access + func_graph = function.FuncGraph(fdef.signature.name) graph_def, nested_to_flat_tensor_name = function_def_to_graph_def( fdef, input_shapes) @@ -60,7 +60,7 @@ def function_def_to_graph(fdef, input_shapes=None): # Add all function nodes to the graph. importer.import_graph_def(graph_def, name="") - # Initialize fields specific to _FuncGraph. + # Initialize fields specific to FuncGraph. # inputs input_tensor_names = [ @@ -144,6 +144,8 @@ def function_def_to_graph_def(fdef, input_shapes=None): for arg_def in fdef.signature.input_arg: nested_to_flat_tensor_name[arg_def.name] = "{}:0".format(arg_def.name) + control_name = "^" + arg_def.name + nested_to_flat_tensor_name[control_name] = control_name for node_def in fdef.node_def: op_def = ops.get_default_graph()._get_op_def(node_def.op) # pylint: disable=protected-access @@ -172,6 +174,8 @@ def function_def_to_graph_def(fdef, input_shapes=None): flat_name = "{}:{}".format(node_def.name, flattened_index) nested_to_flat_tensor_name[nested_name] = flat_name flattened_index += 1 + control_name = "^" + node_def.name + nested_to_flat_tensor_name[control_name] = control_name # Update inputs of all nodes in graph. for node_def in graph_def.node: diff --git a/tensorflow/python/framework/function_def_to_graph_test.py b/tensorflow/python/framework/function_def_to_graph_test.py index cd2a16ed5a..e013fb6e4d 100644 --- a/tensorflow/python/framework/function_def_to_graph_test.py +++ b/tensorflow/python/framework/function_def_to_graph_test.py @@ -18,9 +18,9 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from tensorflow.python.eager import function from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes -from tensorflow.python.framework import function from tensorflow.python.framework import function_def_to_graph from tensorflow.python.framework import graph_to_function_def from tensorflow.python.framework import ops @@ -56,7 +56,7 @@ class FunctionDefToGraphTest(test.TestCase): fdef = self._build_function_def() g = function_def_to_graph.function_def_to_graph(fdef) self.assertEqual(g.name, "_whats_in_a_name") - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: inputs = sess.run(g.inputs, feed_dict={"x:0": 2, "y:0": 3}) self.assertSequenceEqual(inputs, [2.0, 3.0]) outputs = sess.run(g.outputs, feed_dict={"x:0": 2, "y:0": 3}) @@ -154,14 +154,20 @@ class FunctionDefToGraphDefTest(test.TestCase): self.assertDictEqual( tensor_name_map, { "x": "x:0", + "^x": "^x", "y": "y:0", + "^y": "^y", "z": "z:0", + "^z": "^z", "foo_1:d:0": "foo_1:0", "foo_1:e:0": "foo_1:1", + "^foo_1": "^foo_1", "list_output:a:0": "list_output:0", "list_output:a:1": "list_output:1", + "^list_output": "^list_output", "foo_2:d:0": "foo_2:0", "foo_2:e:0": "foo_2:1", + "^foo_2": "^foo_2", }) def testShapes(self): @@ -184,33 +190,56 @@ class FunctionDefToGraphDefTest(test.TestCase): x = constant_op.constant(5.0) y = constant_op.constant(10.0) - @function.Defun() + @function.defun def fn(): - @function.Defun() + @function.defun def inner_fn(): return x + y return inner_fn() - # Instantiate the function in this graph so that - # `function_def_to_graph` can find it. - fn() - + @function.defun def fn2(): return 2 * fn() - fdef = function._DefinedFunction(fn2, [], []).definition + fn2_defun = fn2.get_concrete_function() + + # Call `fn2` to make sure `fn` is correctly instantiated so + # `function_def_to_graph` can find it. + fn2_defun() + + fdef = fn2_defun._inference_function.definition func_graph = function_def_to_graph.function_def_to_graph(fdef) with func_graph.as_default(): x_ph, y_ph = func_graph.inputs - with self.test_session(graph=func_graph) as sess: + with self.session(graph=func_graph) as sess: self.assertEqual( sess.run(func_graph.outputs[0], feed_dict={ x_ph: 5.0, y_ph: 10.0 }), 30.0) + def testControlDependencies(self): + + @function.defun + def fn(inp): + x = constant_op.constant(2.0, name="x") + # TODO(b/79881896): Test external control dependency once that's + # supported. + with ops.control_dependencies([x, inp]): + constant_op.constant(3.0, name="y") + return 4.0 + + inp = constant_op.constant(1.0) + fdef = fn.get_concrete_function(inp).function_def + func_graph = function_def_to_graph.function_def_to_graph(fdef) + + op = func_graph.get_operation_by_name("y") + self.assertEqual(len(op.control_inputs), 2) + self.assertEqual(op.control_inputs[0].name, "x") + self.assertEqual(op.control_inputs[1].name, "placeholder") + if __name__ == "__main__": test.main() diff --git a/tensorflow/python/framework/function_test.py b/tensorflow/python/framework/function_test.py index 1707f929b8..ee723bacaf 100644 --- a/tensorflow/python/framework/function_test.py +++ b/tensorflow/python/framework/function_test.py @@ -347,7 +347,7 @@ class FunctionTest(test.TestCase): do_function_inlining=True, do_constant_folding=True))) - with self.test_session(graph=g, config=cfg): + with self.session(graph=g, config=cfg): self.assertAllClose(y.eval(), 6.) self.assertAllClose(dx.eval(), 2.) @@ -530,7 +530,7 @@ class FunctionTest(test.TestCase): v = variables.Variable(constant_op.constant(10.0)) z = Foo(v) - with self.test_session(graph=g): + with self.session(graph=g): variables.global_variables_initializer().run() self.assertAllEqual(z.eval(), 101.) @@ -552,7 +552,7 @@ class FunctionTest(test.TestCase): expected_val = v.value() actual_val, actual_shape = Foo() - with self.test_session(graph=g): + with self.session(graph=g): v.initializer.run() self.assertAllEqual(expected_val.eval(), actual_val.eval()) self.assertAllEqual(expected_shape, actual_shape.eval()) @@ -732,7 +732,7 @@ class FunctionTest(test.TestCase): dx1, = gradients_impl.gradients([y1], [x]) # Both should produce the same result and gradient. - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: vals = sess.run([y0, y1, dx0, dx1], {x: np.random.uniform(size=(3, 7))}) self.assertAllClose(vals[0], vals[1]) self.assertAllClose(vals[2], vals[3]) @@ -762,7 +762,7 @@ class FunctionTest(test.TestCase): z = Bar() - with self.test_session(graph=g): + with self.session(graph=g): variables.global_variables_initializer().run() self.assertAllEqual(y.eval(), [[12.0]]) self.assertAllEqual(z.eval(), [[1.0]]) @@ -795,7 +795,7 @@ class FunctionTest(test.TestCase): y = Foo() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: self.assertEqual(sess.run(y), 10) def testCaptureInCond(self): @@ -810,7 +810,7 @@ class FunctionTest(test.TestCase): y = Foo(True) z = Foo(False) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: self.assertEqual(sess.run(y), 1) self.assertEqual(sess.run(z), 2) @@ -855,7 +855,7 @@ class FunctionTest(test.TestCase): y = Foo(x) z = Bar(x) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: v0, v1 = sess.run([y, z]) self.assertAllEqual(v0, 20.) self.assertAllEqual(v1, 20.) @@ -1128,7 +1128,7 @@ class FunctionTest(test.TestCase): y2 = PartThree(x2) dx2, = gradients_impl.gradients(ys=[y2], xs=[x2]) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: v0, v1, v2 = sess.run([dx0, dx1, dx2]) self.assertAllEqual(v0, 2.) @@ -1353,7 +1353,7 @@ class FunctionOverloadTest(test.TestCase): x = Sinh(constant_op.constant(0.25, dtypes.float32)) y = Sinh(constant_op.constant(0.25, dtypes.float64)) - with self.test_session(graph=g): + with self.session(graph=g): self.assertAllClose(x.eval(), np.sinh(0.25)) self.assertAllClose(y.eval(), np.sinh(0.25)) @@ -1374,7 +1374,7 @@ class FunctionOverloadTest(test.TestCase): y = F(x) dx, = gradients_impl.gradients(y, x) - with self.test_session(graph=g): + with self.session(graph=g): self.assertAllClose(dx.eval(), 0.25) def testDocString(self): @@ -1418,7 +1418,7 @@ class FunctionCaptureByValueTest(test.TestCase): self.assertEqual(0, len(Foo.captured_inputs)) - with self.test_session(graph=g): + with self.session(graph=g): self.assertAllEqual(y.eval(), [[12.0]]) @@ -1701,7 +1701,7 @@ class VariableHoistingTest(test.TestCase): self.assertEqual("Foo/w", w.op.name) self.assertEqual("Foo/b", b.op.name) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(variables.global_variables_initializer()) w, b, x, y0, loss, dw, db = sess.run([w, b, x, y0, loss, dw, db]) diff --git a/tensorflow/python/framework/importer_test.py b/tensorflow/python/framework/importer_test.py index 7182c28666..18e7d8aa14 100644 --- a/tensorflow/python/framework/importer_test.py +++ b/tensorflow/python/framework/importer_test.py @@ -1205,7 +1205,7 @@ class ImportGraphDefTest(test.TestCase): gdef, return_elements=["p1:0", "p2:0", "f:0", "f:1"], name="") grad = gradients_impl.gradients([a], [p1, p2]) - with self.test_session(graph=g2) as sess: + with self.session(graph=g2) as sess: feed_dict = {p1: 1, p2: 2} a_val, b_val, grad_val = sess.run([a, b, grad], feed_dict=feed_dict) self.assertEqual(a_val, 3.0) @@ -1225,7 +1225,7 @@ class ImportGraphDefTest(test.TestCase): # functions created in g2). grad = gradients_impl.gradients([a], [p1, p2]) - with self.test_session(graph=g3) as sess: + with self.session(graph=g3) as sess: feed_dict = {p1: 1, p2: 2} a_val, b_val, grad_val = sess.run([a, b, grad], feed_dict=feed_dict) self.assertEqual(a_val, 3.0) diff --git a/tensorflow/python/framework/meta_graph_test.py b/tensorflow/python/framework/meta_graph_test.py index 5cf8697210..6e5f7aafac 100644 --- a/tensorflow/python/framework/meta_graph_test.py +++ b/tensorflow/python/framework/meta_graph_test.py @@ -70,7 +70,7 @@ class SimpleMetaGraphTest(test.TestCase): input_feed_value = -10 # Arbitrary input value for feed_dict. orig_graph = ops.Graph() - with self.test_session(graph=orig_graph) as sess: + with self.session(graph=orig_graph) as sess: # Create a minimal graph with zero variables. input_tensor = array_ops.placeholder( dtypes.float32, shape=[], name="input") @@ -98,7 +98,7 @@ class SimpleMetaGraphTest(test.TestCase): # Create a clean graph and import the MetaGraphDef nodes. new_graph = ops.Graph() - with self.test_session(graph=new_graph) as sess: + with self.session(graph=new_graph) as sess: # Import the previously export meta graph. meta_graph.import_scoped_meta_graph(filename) @@ -197,7 +197,7 @@ class SimpleMetaGraphTest(test.TestCase): # When inputs to the Complex Op are float64 instances, "T" maps to float64 # and "Tout" maps to complex128. Since these attr values don't map to their # defaults, they must not be stripped. - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): real_num = constant_op.constant(1.0, dtype=dtypes.float64, name="real") imag_num = constant_op.constant(2.0, dtype=dtypes.float64, name="imag") math_ops.complex(real_num, imag_num, name="complex") @@ -855,7 +855,7 @@ class MetaGraphWithVariableScopeTest(test.TestCase): _TestDir("metrics_export"), "meta_graph.pb") graph = ops.Graph() - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: values_queue = data_flow_ops.FIFOQueue( 4, dtypes.float32, shapes=(1, 2)) _enqueue_vector(sess, values_queue, [0, 1]) @@ -876,7 +876,7 @@ class MetaGraphWithVariableScopeTest(test.TestCase): # Verifies that importing a meta_graph with LOCAL_VARIABLES collection # works correctly. graph = ops.Graph() - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: meta_graph.import_scoped_meta_graph(meta_graph_filename) initializer = variables.local_variables_initializer() sess.run(initializer) @@ -885,7 +885,7 @@ class MetaGraphWithVariableScopeTest(test.TestCase): # collection is of node_list type works, but cannot build initializer # with the collection. graph = ops.Graph() - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: meta_graph.import_scoped_meta_graph( test.test_src_dir_path( "python/framework/testdata/metrics_export_meta_graph.pb")) diff --git a/tensorflow/python/framework/ops.py b/tensorflow/python/framework/ops.py index 21eb306865..8d72eb39c0 100644 --- a/tensorflow/python/framework/ops.py +++ b/tensorflow/python/framework/ops.py @@ -20,7 +20,6 @@ from __future__ import print_function import collections import copy -import os import re import sys import threading @@ -67,7 +66,7 @@ from tensorflow.python.util.tf_export import tf_export # Temporary global switches determining if we should enable the work-in-progress # calls to the C API. These will be removed once all functionality is supported. _USE_C_API = True -_USE_C_SHAPES = os.getenv("TF_C_API_GRAPH_CONSTRUCTION_SHAPES", "1") != "0" +_USE_C_SHAPES = True def tensor_id(tensor): @@ -516,6 +515,11 @@ class Tensor(_TensorLike): ==> TensorShape([Dimension(28), Dimension(28), Dimension(3)]) ``` + NOTE: This shape is not enforced at runtime. Setting incorrect shapes can + result in inconsistencies between the statically-known graph and the runtime + value of tensors. For runtime validation of the shape, use `tf.ensure_shape` + instead. + Args: shape: A `TensorShape` representing the shape of this tensor, a `TensorShapeProto`, a list, a tuple, or None. @@ -753,6 +757,9 @@ class _EagerTensorBase(Tensor): def __format__(self, format_spec): return self.numpy().__format__(format_spec) + def __reduce__(self): + return (convert_to_tensor, (self.numpy(),)) + def _numpy(self): raise NotImplementedError() @@ -2856,19 +2863,11 @@ class Graph(object): # TODO(skyewm): fold as much of the above as possible into the C # implementation - if self._use_c_api_hack(): - self._scoped_c_graph = c_api_util.ScopedTFGraph() - # The C API requires all ops to have shape functions. Disable this - # requirement (many custom ops do not have shape functions, and we don't - # want to break these existing cases). - c_api.SetRequireShapeInferenceFns(self._c_graph, False) - else: - self._scoped_c_graph = None - - # TODO(apassos) remove once the C API is used by default. - def _use_c_api_hack(self): - """Temporary hack; can be overridden to force C API usage.""" - return _USE_C_API + self._scoped_c_graph = c_api_util.ScopedTFGraph() + # The C API requires all ops to have shape functions. Disable this + # requirement (many custom ops do not have shape functions, and we don't + # want to break these existing cases). + c_api.SetRequireShapeInferenceFns(self._c_graph, False) # Note: this method is private because the API of tf.Graph() is public and # frozen, and this functionality is still not ready for public visibility. @@ -3118,7 +3117,7 @@ class Graph(object): Returns: bool indicating whether or not 'name' is registered in function library. """ - return name in self._functions + return compat.as_str(name) in self._functions def _get_function(self, name): """Returns the function definition for 'name'. @@ -3128,7 +3127,7 @@ class Graph(object): Returns: The function def proto. """ - return self._functions.get(name, None) + return self._functions.get(compat.as_str(name), None) def _add_function(self, function): """Adds a function to the graph. @@ -3164,7 +3163,7 @@ class Graph(object): c_api.TF_GraphCopyFunction(self._c_graph, function._c_func.func, gradient) # pylint: enable=protected-access - self._functions[name] = function + self._functions[compat.as_str(name)] = function # Need a new-enough consumer to support the functions we add to the graph. if self._graph_def_versions.min_consumer < 12: @@ -5223,6 +5222,7 @@ _default_graph_stack = _DefaultGraphStack() # pylint: disable=g-doc-return-or-yield,line-too-long +@tf_export("init_scope") @tf_contextlib.contextmanager def init_scope(): """A context manager that lifts ops out of control-flow scopes and function-building graphs. @@ -5252,6 +5252,23 @@ def init_scope(): (3) The gradient tape is paused while the scope is active. + When eager execution is enabled, code inside an init_scope block runs with + eager execution enabled even when defining graph functions via + tf.contrib.eager.defun. For example: + + ```python + tf.enable_eager_execution() + + @tf.contrib.eager.defun + def func(): + # A defun-decorated function constructs TensorFlow graphs, + # it does not execute eagerly. + assert not tf.executing_eagerly() + with tf.init_scope(): + # Initialization runs with eager execution enabled + assert tf.executing_eagerly() + ``` + Raises: RuntimeError: if graph state is incompatible with this initialization. """ @@ -5382,11 +5399,12 @@ def enable_eager_execution(config=None, TensorFlow graph, or if options provided conflict with a previous call to this function. """ - return enable_eager_execution_internal( - config=config, - device_policy=device_policy, - execution_mode=execution_mode, - server_def=None) + if context._default_mode != context.EAGER_MODE: # pylint: disable=protected-access + return enable_eager_execution_internal( + config=config, + device_policy=device_policy, + execution_mode=execution_mode, + server_def=None) def enable_eager_execution_internal(config=None, diff --git a/tensorflow/contrib/kfac/examples/convnet_mnist_single_main.py b/tensorflow/python/framework/ops_enable_eager_test.py index 2c1f099360..99d06f1c2d 100644 --- a/tensorflow/contrib/kfac/examples/convnet_mnist_single_main.py +++ b/tensorflow/python/framework/ops_enable_eager_test.py @@ -1,4 +1,4 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. @@ -12,28 +12,27 @@ # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================== -r"""Train a ConvNet on MNIST using K-FAC. - -Train on single machine. See `convnet.train_mnist_single_machine` for details. -""" +"""Tests enabling eager execution at process level.""" from __future__ import absolute_import from __future__ import division from __future__ import print_function +from tensorflow.python.eager import context +from tensorflow.python.framework import ops +from tensorflow.python.platform import googletest -from absl import flags -import tensorflow as tf - -from tensorflow.contrib.kfac.examples import convnet -FLAGS = flags.FLAGS -flags.DEFINE_string("data_dir", "/tmp/mnist", "local mnist dir") +class OpsEnableEagerTest(googletest.TestCase): + def test_enable_eager_execution_multiple_times(self): + ops.enable_eager_execution() + self.assertTrue(context.executing_eagerly()) -def main(unused_argv): - convnet.train_mnist_single_machine(FLAGS.data_dir, num_epochs=200) + # Calling enable eager execution a second time should not cause an error. + ops.enable_eager_execution() + self.assertTrue(context.executing_eagerly()) -if __name__ == "__main__": - tf.app.run(main=main) +if __name__ == '__main__': + googletest.main() diff --git a/tensorflow/python/framework/ops_test.py b/tensorflow/python/framework/ops_test.py index 318387c61b..ced0581402 100644 --- a/tensorflow/python/framework/ops_test.py +++ b/tensorflow/python/framework/ops_test.py @@ -493,7 +493,7 @@ class OperationTest(test_util.TensorFlowTestCase): y.op._add_control_input(z.op) # pylint: disable=protected-access y.op._add_control_input(x.op) # pylint: disable=protected-access x.op._add_control_input(y.op) # pylint: disable=protected-access - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: with self.assertRaisesRegexp( errors.InvalidArgumentError, "Graph is invalid, contains a cycle with 2 nodes"): @@ -1614,6 +1614,33 @@ class CollectionTest(test_util.TensorFlowTestCase): # Collections are ordered. self.assertEqual([90, 100], ops.get_collection("key")) + def test_defun(self): + with context.eager_mode(): + + @eager_function.defun + def defun(): + ops.add_to_collection("int", 1) + ops.add_to_collection("tensor", constant_op.constant(2)) + + @eager_function.defun + def inner_defun(): + self.assertEqual(ops.get_collection("int"), [1]) + three = ops.get_collection("tensor")[0] + ops.get_collection("int")[0] + ops.add_to_collection("int", 2) + self.assertEqual(ops.get_collection("int"), [1, 2]) + ops.add_to_collection("foo", "bar") + self.assertEqual(ops.get_collection("foo"), ["bar"]) + return three + + self.assertEqual(ops.get_collection("int"), [1]) + three = inner_defun() + self.assertEqual(ops.get_collection("int"), [1, 2]) + self.assertEqual(ops.get_collection("foo"), ["bar"]) + return three + + three = defun() + self.assertEqual(three.numpy(), 3) + ops.NotDifferentiable("FloatOutput") @@ -2459,7 +2486,7 @@ class AsGraphDefTest(test_util.TensorFlowTestCase): """Test that the graphdef version is plumbed through to kernels.""" with ops.Graph().as_default() as g: version = g.graph_def_versions.producer - with self.test_session(graph=g): + with self.session(graph=g): v = test_ops.graph_def_version().eval() self.assertEqual(version, v) @@ -2757,7 +2784,7 @@ class DeprecatedTest(test_util.TensorFlowTestCase): with ops.Graph().as_default() as g: test_util.set_producer_version(g, 7) old = test_ops.old() - with self.test_session(graph=g): + with self.session(graph=g): old.run() def _error(self): diff --git a/tensorflow/python/framework/python_op_gen.cc b/tensorflow/python/framework/python_op_gen.cc index 76d4c2017c..2022fbcbaa 100644 --- a/tensorflow/python/framework/python_op_gen.cc +++ b/tensorflow/python/framework/python_op_gen.cc @@ -102,15 +102,6 @@ string TensorPBString(const TensorProto& pb) { return strings::StrCat("\"\"\"", ProtoShortDebugString(pb), "\"\"\""); } -const ApiDef::Arg* FindInputArg(StringPiece name, const ApiDef& api_def) { - for (int i = 0; i < api_def.in_arg_size(); ++i) { - if (api_def.in_arg(i).name() == name) { - return &api_def.in_arg(i); - } - } - return nullptr; -} - class GenEagerPythonOp : public python_op_gen_internal::GenPythonOp { public: GenEagerPythonOp(const OpDef& op_def, const ApiDef& api_def, diff --git a/tensorflow/python/framework/python_op_gen_internal.cc b/tensorflow/python/framework/python_op_gen_internal.cc index 031b4a384e..f2270342b0 100644 --- a/tensorflow/python/framework/python_op_gen_internal.cc +++ b/tensorflow/python/framework/python_op_gen_internal.cc @@ -483,15 +483,6 @@ const ApiDef::Attr* FindAttr(StringPiece name, const ApiDef& api_def) { return nullptr; } -const ApiDef::Arg* FindInputArg(StringPiece name, const ApiDef& api_def) { - for (int i = 0; i < api_def.in_arg_size(); ++i) { - if (api_def.in_arg(i).name() == name) { - return &api_def.in_arg(i); - } - } - return nullptr; -} - GenPythonOp::GenPythonOp(const OpDef& op_def, const ApiDef& api_def, const string& function_name) : op_def_(op_def), diff --git a/tensorflow/python/framework/python_op_gen_main.cc b/tensorflow/python/framework/python_op_gen_main.cc index 8eb943b960..e20ad5fd33 100644 --- a/tensorflow/python/framework/python_op_gen_main.cc +++ b/tensorflow/python/framework/python_op_gen_main.cc @@ -52,7 +52,7 @@ Status ReadOpListFromFile(const string& filename, if (scanner.One(strings::Scanner::LETTER_DIGIT_DOT) .Any(strings::Scanner::LETTER_DIGIT_DASH_DOT_SLASH_UNDERSCORE) .GetResult(nullptr, &op_name)) { - op_list->emplace_back(op_name.ToString()); + op_list->emplace_back(op_name); } s = input_buffer->ReadLine(&line_contents); } diff --git a/tensorflow/python/framework/smart_cond.py b/tensorflow/python/framework/smart_cond.py index 48a834392b..7ee2b5b347 100644 --- a/tensorflow/python/framework/smart_cond.py +++ b/tensorflow/python/framework/smart_cond.py @@ -77,11 +77,9 @@ def smart_constant_value(pred): pred_value = pred elif isinstance(pred, ops.Tensor): pred_value = tensor_util.constant_value(pred) - # TODO(skyewm): consider folding this into tensor_util.constant_value when - # _USE_C_API is removed (there may be performance and correctness bugs, so I - # wanted to limit the change hidden behind _USE_C_API). + # TODO(skyewm): consider folding this into tensor_util.constant_value. # pylint: disable=protected-access - if pred_value is None and ops._USE_C_API: + if pred_value is None: pred_value = c_api.TF_TryEvaluateConstant_wrapper(pred.graph._c_graph, pred._as_tf_output()) # pylint: enable=protected-access diff --git a/tensorflow/python/framework/sparse_tensor.py b/tensorflow/python/framework/sparse_tensor.py index a45581190f..d1bdd9b80a 100644 --- a/tensorflow/python/framework/sparse_tensor.py +++ b/tensorflow/python/framework/sparse_tensor.py @@ -112,8 +112,6 @@ class SparseTensor(_TensorLike): values: A 1-D tensor of any type and shape `[N]`. dense_shape: A 1-D int64 tensor of shape `[ndims]`. - Returns: - A `SparseTensor`. """ with ops.name_scope(None, "SparseTensor", [indices, values, dense_shape]): @@ -184,10 +182,31 @@ class SparseTensor(_TensorLike): return self._dense_shape @property + def shape(self): + """Get the `TensorShape` representing the shape of the dense tensor. + + Returns: + A `TensorShape` object. + """ + return tensor_util.constant_value_as_shape(self._dense_shape) + + @property def graph(self): """The `Graph` that contains the index, value, and dense_shape tensors.""" return self._indices.graph + def consumers(self): + """Returns a list of `Operation`s that consume this `SparseTensor`. + + Returns: + A list of `Operation`s. + """ + values_consumers = set(self._values.consumers()) + indices_consumers = set(self._indices.consumers()) + dense_shape_consumers = set(self._dense_shape.consumers()) + return list(values_consumers \ + .union(indices_consumers, dense_shape_consumers)) + def __str__(self): return "SparseTensor(indices=%s, values=%s, dense_shape=%s)" % ( self._indices, self._values, self._dense_shape) diff --git a/tensorflow/python/framework/sparse_tensor_test.py b/tensorflow/python/framework/sparse_tensor_test.py index c001fed3b0..2bcfbc17df 100644 --- a/tensorflow/python/framework/sparse_tensor_test.py +++ b/tensorflow/python/framework/sparse_tensor_test.py @@ -21,8 +21,10 @@ from __future__ import print_function import numpy as np from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops from tensorflow.python.framework import sparse_tensor from tensorflow.python.framework import test_util +from tensorflow.python.ops import sparse_ops from tensorflow.python.platform import googletest @@ -63,6 +65,18 @@ class SparseTensorTest(test_util.TensorFlowTestCase): sparse_tensor.is_sparse( sparse_tensor.SparseTensorValue([[0]], [0], [1]))) + def testConsumers(self): + sp = sparse_tensor.SparseTensor([[0, 0], [1, 2]], [1.0, 3.0], [3, 4]) + w = ops.convert_to_tensor(np.ones([4, 1], np.float32)) + out = sparse_ops.sparse_tensor_dense_matmul(sp, w) + self.assertEqual(len(sp.consumers()), 1) + self.assertEqual(sp.consumers()[0], out.op) + + dense = sparse_ops.sparse_tensor_to_dense(sp) + self.assertEqual(len(sp.consumers()), 2) + self.assertTrue(dense.op in sp.consumers()) + self.assertTrue(out.op in sp.consumers()) + class ConvertToTensorOrSparseTensorTest(test_util.TensorFlowTestCase): diff --git a/tensorflow/python/framework/subscribe.py b/tensorflow/python/framework/subscribe.py index cee7398974..00759eb611 100644 --- a/tensorflow/python/framework/subscribe.py +++ b/tensorflow/python/framework/subscribe.py @@ -137,12 +137,7 @@ def _subscribe_new(tensor, side_effects, control_cache): # are subscribed at the same time, we remove the control dependency from # the original op only once and we add the dependencies to all the # new identities. - if ops._USE_C_API: # pylint: disable=protected-access - new_control_inputs = consumer_op.control_inputs - else: - # Make a copy so we don't modify the actual control inputs (this is fixed - # in the C API). - new_control_inputs = list(consumer_op.control_inputs) + new_control_inputs = consumer_op.control_inputs if tensor.op in new_control_inputs: new_control_inputs.remove(tensor.op) new_control_inputs.append(out.op) diff --git a/tensorflow/python/framework/test_util.py b/tensorflow/python/framework/test_util.py index d2d18222ba..7cddd861c8 100644 --- a/tensorflow/python/framework/test_util.py +++ b/tensorflow/python/framework/test_util.py @@ -63,6 +63,7 @@ from tensorflow.python.framework import random_seed from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import versions from tensorflow.python.ops import array_ops +from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import variables from tensorflow.python.platform import googletest from tensorflow.python.platform import tf_logging as logging @@ -369,6 +370,7 @@ def enable_c_shapes(fn): fn(*args, **kwargs) finally: ops._USE_C_SHAPES = prev_value + # pylint: enable=protected-access return wrapper @@ -398,6 +400,53 @@ def with_c_shapes(cls): return cls +def enable_cond_v2(fn): + """Decorator for enabling CondV2 on a test. + + Note this enables using CondV2 after running the test class's setup/teardown + methods. + + Args: + fn: the function to be wrapped + + Returns: + The wrapped function + """ + + # pylint: disable=protected-access + def wrapper(*args, **kwargs): + prev_value = control_flow_ops._ENABLE_COND_V2 + control_flow_ops._ENABLE_COND_V2 = True + try: + fn(*args, **kwargs) + finally: + control_flow_ops._ENABLE_COND_V2 = prev_value + # pylint: enable=protected-access + + return wrapper + + +def with_cond_v2(cls): + """Adds methods that call original methods but with CondV2 enabled. + + Note this enables CondV2 in new methods after running the test class's + setup method. + + Args: + cls: class to decorate + + Returns: + cls with new test methods added + """ + if control_flow_ops._ENABLE_COND_V2: + return cls + + for name, value in cls.__dict__.copy().items(): + if callable(value) and name.startswith("test"): + setattr(cls, name + "WithCondV2", enable_cond_v2(value)) + return cls + + def assert_no_new_pyobjects_executing_eagerly(f): """Decorator for asserting that no new Python objects persist after a test. @@ -418,7 +467,8 @@ def assert_no_new_pyobjects_executing_eagerly(f): previous_count = len(gc.get_objects()) collection_sizes_before = { collection: len(ops.get_collection(collection)) - for collection in ops.get_default_graph().collections} + for collection in ops.get_default_graph().collections + } for _ in range(3): f(self, **kwargs) # Note that gc.get_objects misses anything that isn't subject to garbage @@ -430,8 +480,8 @@ def assert_no_new_pyobjects_executing_eagerly(f): if len(collection) > size_before: raise AssertionError( ("Collection %s increased in size from " - "%d to %d (current items %s).") - % (collection_key, size_before, len(collection), collection)) + "%d to %d (current items %s).") % (collection_key, size_before, + len(collection), collection)) # Make sure our collection checks don't show up as leaked memory by # removing references to temporary variables. del collection @@ -446,8 +496,8 @@ def assert_no_new_pyobjects_executing_eagerly(f): # Using plain assert because not all classes using this decorator # have assertLessEqual assert new_count <= previous_count, ( - "new_count(%d) is not less than or equal to previous_count(%d)" % ( - new_count, previous_count)) + "new_count(%d) is not less than or equal to previous_count(%d)" % + (new_count, previous_count)) gc.enable() return decorator @@ -497,7 +547,7 @@ def assert_no_new_tensors(f): f(self, **kwargs) # Make an effort to clear caches, which would otherwise look like leaked # Tensors. - context.get_default_context()._clear_caches() # pylint: disable=protected-access + context.context()._clear_caches() # pylint: disable=protected-access gc.collect() tensors_after = [ obj for obj in gc.get_objects() @@ -547,10 +597,12 @@ def assert_no_garbage_created(f): return "<%s %d>" % (obj.__class__.__name__, id(obj)) logging.error(" Object type: %s", _safe_object_str(obj)) - logging.error(" Referrer types: %s", ", ".join( - [_safe_object_str(ref) for ref in gc.get_referrers(obj)])) - logging.error(" Referent types: %s", ", ".join( - [_safe_object_str(ref) for ref in gc.get_referents(obj)])) + logging.error( + " Referrer types: %s", ", ".join( + [_safe_object_str(ref) for ref in gc.get_referrers(obj)])) + logging.error( + " Referent types: %s", ", ".join( + [_safe_object_str(ref) for ref in gc.get_referents(obj)])) logging.error(" Object attribute names: %s", dir(obj)) logging.error(" Object __str__:") logging.error(obj) @@ -629,9 +681,8 @@ def generate_combinations_with_testcase_name(**kwargs): for combination in combinations: assert isinstance(combination, OrderedDict) name = "".join([ - "_{}_{}".format( - "".join(filter(str.isalnum, key)), - "".join(filter(str.isalnum, str(value)))) + "_{}_{}".format("".join(filter(str.isalnum, key)), "".join( + filter(str.isalnum, str(value)))) for key, value in combination.items() ]) named_combinations.append( @@ -971,21 +1022,64 @@ class TensorFlowTestCase(googletest.TestCase): # pylint: disable=g-doc-return-or-yield @contextlib.contextmanager - def test_session(self, - graph=None, - config=None, - use_gpu=False, - force_gpu=False): + def session(self, graph=None, config=None, use_gpu=False, force_gpu=False): """Returns a TensorFlow Session for use in executing tests. - This method should be used for all functional tests. + Note that this will set this session and the graph as global defaults. - This method behaves different than session.Session: for performance reasons - `test_session` will by default (if `graph` is None) reuse the same session - across tests. This means you may want to either call the function - `reset_default_graph()` before tests, or if creating an explicit new graph, - pass it here (simply setting it with `as_default()` won't do it), which will - trigger the creation of a new session. + Use the `use_gpu` and `force_gpu` options to control where ops are run. If + `force_gpu` is True, all ops are pinned to `/device:GPU:0`. Otherwise, if + `use_gpu` is True, TensorFlow tries to run as many ops on the GPU as + possible. If both `force_gpu and `use_gpu` are False, all ops are pinned to + the CPU. + + Example: + ```python + class MyOperatorTest(test_util.TensorFlowTestCase): + def testMyOperator(self): + with self.session(use_gpu=True): + valid_input = [1.0, 2.0, 3.0, 4.0, 5.0] + result = MyOperator(valid_input).eval() + self.assertEqual(result, [1.0, 2.0, 3.0, 5.0, 8.0] + invalid_input = [-1.0, 2.0, 7.0] + with self.assertRaisesOpError("negative input not supported"): + MyOperator(invalid_input).eval() + ``` + + Args: + graph: Optional graph to use during the returned session. + config: An optional config_pb2.ConfigProto to use to configure the + session. + use_gpu: If True, attempt to run as many ops as possible on GPU. + force_gpu: If True, pin all ops to `/device:GPU:0`. + + Yields: + A Session object that should be used as a context manager to surround + the graph building and execution code in a test case. + """ + if context.executing_eagerly(): + yield None + else: + sess = self._create_session(graph, config, use_gpu, force_gpu) + with self._constrain_devices_and_set_default( + sess, use_gpu, force_gpu) as constrained_sess: + # We need to do this to make sure the session closes, otherwise, even + # if the user does with self.session():, it will not close the session. + with constrained_sess: + yield constrained_sess + + @contextlib.contextmanager + def cached_session(self, + graph=None, + config=None, + use_gpu=False, + force_gpu=False): + """Returns a TensorFlow Session for use in executing tests. + + This method behaves differently than self.session(): for performance reasons + `cached_session` will by default reuse the same session within the same + test. The session returned by this function will only be closed at the end + of the test (in the TearDown function). Use the `use_gpu` and `force_gpu` options to control where ops are run. If `force_gpu` is True, all ops are pinned to `/device:GPU:0`. Otherwise, if @@ -997,7 +1091,7 @@ class TensorFlowTestCase(googletest.TestCase): ```python class MyOperatorTest(test_util.TensorFlowTestCase): def testMyOperator(self): - with self.test_session(use_gpu=True): + with self.cached_session(use_gpu=True) as sess: valid_input = [1.0, 2.0, 3.0, 4.0, 5.0] result = MyOperator(valid_input).eval() self.assertEqual(result, [1.0, 2.0, 3.0, 5.0, 8.0] @@ -1013,74 +1107,39 @@ class TensorFlowTestCase(googletest.TestCase): use_gpu: If True, attempt to run as many ops as possible on GPU. force_gpu: If True, pin all ops to `/device:GPU:0`. - Returns: + Yields: A Session object that should be used as a context manager to surround the graph building and execution code in a test case. """ + if context.executing_eagerly(): + yield None + else: + with self._get_cached_session( + graph, config, use_gpu, force_gpu, + crash_if_inconsistent_args=True) as sess: + yield sess + + @contextlib.contextmanager + def test_session(self, + graph=None, + config=None, + use_gpu=False, + force_gpu=False): + """Use cached_session instead.""" if self.id().endswith(".test_session"): self.skipTest("Not a test.") - def prepare_config(config): - """Returns a config for sessions. - - Args: - config: An optional config_pb2.ConfigProto to use to configure the - session. - Returns: - A config_pb2.ConfigProto object. - """ - if config is None: - config = config_pb2.ConfigProto() - config.allow_soft_placement = not force_gpu - config.gpu_options.per_process_gpu_memory_fraction = 0.3 - elif force_gpu and config.allow_soft_placement: - config = config_pb2.ConfigProto().CopyFrom(config) - config.allow_soft_placement = False - # Don't perform optimizations for tests so we don't inadvertently run - # gpu ops on cpu - config.graph_options.optimizer_options.opt_level = -1 - config.graph_options.rewrite_options.constant_folding = ( - rewriter_config_pb2.RewriterConfig.OFF) - config.graph_options.rewrite_options.arithmetic_optimization = ( - rewriter_config_pb2.RewriterConfig.OFF) - return config - if context.executing_eagerly(): yield None - elif graph is None: - if self._cached_session is None: - self._cached_session = session.Session( - graph=None, config=prepare_config(config)) - sess = self._cached_session - with sess.graph.as_default(), sess.as_default(): - if force_gpu: - # Use the name of an actual device if one is detected, or '/device:GPU:0' - # otherwise - gpu_name = gpu_device_name() - if not gpu_name: - gpu_name = "/device:GPU:0" - with sess.graph.device(gpu_name): - yield sess - elif use_gpu: - yield sess - else: - with sess.graph.device("/cpu:0"): - yield sess else: - with session.Session(graph=graph, config=prepare_config(config)) as sess: - if force_gpu: - # Use the name of an actual device if one is detected, or '/device:GPU:0' - # otherwise - gpu_name = gpu_device_name() - if not gpu_name: - gpu_name = "/device:GPU:0" - with sess.graph.device(gpu_name): - yield sess - elif use_gpu: + if graph is None: + with self._get_cached_session( + graph, config, use_gpu, force_gpu, + crash_if_inconsistent_args=False) as sess: + yield sess + else: + with self.session(graph, config, use_gpu, force_gpu) as sess: yield sess - else: - with sess.graph.device("/cpu:0"): - yield sess # pylint: enable=g-doc-return-or-yield @@ -1206,9 +1265,10 @@ class TensorFlowTestCase(googletest.TestCase): msg: An optional string message to append to the failure message. """ # f1 == f2 is needed here as we might have: f1, f2 = inf, inf - self.assertTrue(f1 == f2 or math.fabs(f1 - f2) <= err, - "%f != %f +/- %f%s" % (f1, f2, err, " (%s)" % msg - if msg is not None else "")) + self.assertTrue( + f1 == f2 or math.fabs(f1 - f2) <= err, + "%f != %f +/- %f%s" % (f1, f2, err, " (%s)" % msg + if msg is not None else "")) def assertArrayNear(self, farray1, farray2, err, msg=None): """Asserts that two float arrays are near each other. @@ -1254,8 +1314,9 @@ class TensorFlowTestCase(googletest.TestCase): def _assertArrayLikeAllClose(self, a, b, rtol=1e-6, atol=1e-6, msg=None): a = self._GetNdArray(a) b = self._GetNdArray(b) - self.assertEqual(a.shape, b.shape, "Shape mismatch: expected %s, got %s." % - (a.shape, b.shape)) + self.assertEqual( + a.shape, b.shape, + "Shape mismatch: expected %s, got %s." % (a.shape, b.shape)) if not np.allclose(a, b, rtol=rtol, atol=atol): # Prints more details than np.testing.assert_allclose. # @@ -1457,8 +1518,9 @@ class TensorFlowTestCase(googletest.TestCase): msg = msg if msg else "" a = self._GetNdArray(a) b = self._GetNdArray(b) - self.assertEqual(a.shape, b.shape, "Shape mismatch: expected %s, got %s." - " %s" % (a.shape, b.shape, msg)) + self.assertEqual( + a.shape, b.shape, "Shape mismatch: expected %s, got %s." + " %s" % (a.shape, b.shape, msg)) same = (a == b) if (a.dtype in [ @@ -1686,8 +1748,8 @@ class TensorFlowTestCase(googletest.TestCase): self.fail(exception_type.__name__ + " not raised") except Exception as e: # pylint: disable=broad-except if not isinstance(e, exception_type) or not predicate(e): - raise AssertionError("Exception of type %s: %s" % (str(type(e)), - str(e))) + raise AssertionError( + "Exception of type %s: %s" % (str(type(e)), str(e))) # pylint: enable=g-doc-return-or-yield @@ -1723,8 +1785,9 @@ class TensorFlowTestCase(googletest.TestCase): """ device1 = pydev.canonical_name(device1) device2 = pydev.canonical_name(device2) - self.assertEqual(device1, device2, "Devices %s and %s are not equal. %s" % - (device1, device2, msg)) + self.assertEqual( + device1, device2, + "Devices %s and %s are not equal. %s" % (device1, device2, msg)) # Fix Python 3 compatibility issues if six.PY3: @@ -1738,6 +1801,113 @@ class TensorFlowTestCase(googletest.TestCase): # pylint: enable=invalid-name + @contextlib.contextmanager + def _constrain_devices_and_set_default(self, sess, use_gpu, force_gpu): + """Set the session and its graph to global default and constrain devices.""" + if context.executing_eagerly(): + yield None + else: + with sess.graph.as_default(), sess.as_default(): + if force_gpu: + # Use the name of an actual device if one is detected, or + # '/device:GPU:0' otherwise + gpu_name = gpu_device_name() + if not gpu_name: + gpu_name = "/device:GPU:0" + with sess.graph.device(gpu_name): + yield sess + elif use_gpu: + yield sess + else: + with sess.graph.device("/cpu:0"): + yield sess + + def _create_session(self, graph, config, use_gpu, force_gpu): + """See session() for details.""" + if context.executing_eagerly(): + return None + else: + + def prepare_config(config): + """Returns a config for sessions. + + Args: + config: An optional config_pb2.ConfigProto to use to configure the + session. + Returns: + A config_pb2.ConfigProto object. + """ + if config is None: + config = config_pb2.ConfigProto() + config.allow_soft_placement = not force_gpu + config.gpu_options.per_process_gpu_memory_fraction = 0.3 + elif force_gpu and config.allow_soft_placement: + config = config_pb2.ConfigProto().CopyFrom(config) + config.allow_soft_placement = False + # Don't perform optimizations for tests so we don't inadvertently run + # gpu ops on cpu + config.graph_options.optimizer_options.opt_level = -1 + config.graph_options.rewrite_options.constant_folding = ( + rewriter_config_pb2.RewriterConfig.OFF) + config.graph_options.rewrite_options.arithmetic_optimization = ( + rewriter_config_pb2.RewriterConfig.OFF) + return config + + return session.Session(graph=graph, config=prepare_config(config)) + + @contextlib.contextmanager + def _get_cached_session(self, + graph=None, + config=None, + use_gpu=False, + force_gpu=False, + crash_if_inconsistent_args=True): + """See cached_session() for documentation.""" + if context.executing_eagerly(): + yield None + else: + if self._cached_session is None: + sess = self._create_session( + graph=graph, config=config, use_gpu=use_gpu, force_gpu=force_gpu) + self._cached_session = sess + self._cached_graph = graph + self._cached_config = config + self._cached_use_gpu = use_gpu + self._cached_force_gpu = force_gpu + with self._constrain_devices_and_set_default( + sess, use_gpu, force_gpu) as constrained_sess: + yield constrained_sess + else: + if crash_if_inconsistent_args and self._cached_graph is not graph: + raise ValueError("The graph used to get the cached session is " + "different than the one that was used to create the " + "session. Maybe create a new session with " + "self.session()") + if crash_if_inconsistent_args and self._cached_config is not config: + raise ValueError("The config used to get the cached session is " + "different than the one that was used to create the " + "session. Maybe create a new session with " + "self.session()") + if crash_if_inconsistent_args and self._cached_use_gpu is not use_gpu: + raise ValueError( + "The use_gpu value used to get the cached session is " + "different than the one that was used to create the " + "session. Maybe create a new session with " + "self.session()") + if crash_if_inconsistent_args and (self._cached_force_gpu is + not force_gpu): + raise ValueError( + "The force_gpu value used to get the cached session is " + "different than the one that was used to create the " + "session. Maybe create a new session with " + "self.session()") + # If you modify this logic, make sure to modify it in _create_session + # as well. + sess = self._cached_session + with self._constrain_devices_and_set_default( + sess, use_gpu, force_gpu) as constrained_sess: + yield constrained_sess + @tf_export("test.create_local_cluster") def create_local_cluster(num_workers, diff --git a/tensorflow/python/framework/test_util_test.py b/tensorflow/python/framework/test_util_test.py index 3a34dd9505..a0939f98b2 100644 --- a/tensorflow/python/framework/test_util_test.py +++ b/tensorflow/python/framework/test_util_test.py @@ -22,6 +22,7 @@ import collections import copy import random import threading +import weakref import numpy as np @@ -58,6 +59,33 @@ class TestUtilTest(test_util.TensorFlowTestCase): self.assertRaises(ValueError, test_util.assert_ops_in_graph, {"hello": "Variable"}, ops.get_default_graph()) + def test_session_functions(self): + with self.test_session() as sess: + sess_ref = weakref.ref(sess) + with self.cached_session(graph=None, config=None) as sess2: + # We make sure that sess2 is sess. + assert sess2 is sess + # We make sure we raise an exception if we use cached_session with + # different values. + with self.assertRaises(ValueError): + with self.cached_session(graph=ops.Graph()) as sess2: + pass + with self.assertRaises(ValueError): + with self.cached_session(use_gpu=True) as sess2: + pass + with self.assertRaises(ValueError): + with self.cached_session(force_gpu=True) as sess2: + pass + # We make sure that test_session will cache the session even after the + # with scope. + assert not sess_ref()._closed + with self.session() as unique_sess: + unique_sess_ref = weakref.ref(unique_sess) + with self.session() as sess2: + assert sess2 is not unique_sess + # We make sure the session is closed when we leave the with statement. + assert unique_sess_ref()._closed + def test_assert_equal_graph_def(self): with ops.Graph().as_default() as g: def_empty = g.as_graph_def() @@ -93,6 +121,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): else: print("MKL is disabled") + @test_util.run_in_graph_and_eager_modes def testAssertProtoEqualsStr(self): graph_str = "node { name: 'w1' op: 'params' }" @@ -105,6 +134,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): # test original comparison self.assertProtoEquals(graph_def, graph_def) + @test_util.run_in_graph_and_eager_modes def testAssertProtoEqualsAny(self): # Test assertProtoEquals with a protobuf.Any field. meta_graph_def_str = """ @@ -133,6 +163,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): r'meta_graph_version: "inner"'): self.assertProtoEquals("", meta_graph_def_outer) + @test_util.run_in_graph_and_eager_modes def testNDArrayNear(self): a1 = np.array([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]) a2 = np.array([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]) @@ -140,6 +171,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): self.assertTrue(self._NDArrayNear(a1, a2, 1e-5)) self.assertFalse(self._NDArrayNear(a1, a3, 1e-5)) + @test_util.run_in_graph_and_eager_modes def testCheckedThreadSucceeds(self): def noop(ev): @@ -153,6 +185,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): t.join() self.assertTrue(event_arg.is_set()) + @test_util.run_in_graph_and_eager_modes def testCheckedThreadFails(self): def err_func(): @@ -164,6 +197,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): t.join() self.assertTrue("integer division or modulo by zero" in str(fe.exception)) + @test_util.run_in_graph_and_eager_modes def testCheckedThreadWithWrongAssertionFails(self): x = 37 @@ -176,6 +210,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): t.join() self.assertTrue("False is not true" in str(fe.exception)) + @test_util.run_in_graph_and_eager_modes def testMultipleThreadsWithOneFailure(self): def err_func(i): @@ -204,6 +239,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): original_op=op_orig) raise errors.UnauthenticatedError(node_def, op, "true_err") + @test_util.run_in_graph_and_eager_modes def testAssertRaisesOpErrorDoesNotPassMessageDueToLeakedStack(self): with self.assertRaises(AssertionError): self._WeMustGoDeeper("this_is_not_the_error_you_are_looking_for") @@ -212,6 +248,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): self._WeMustGoDeeper("name") self._WeMustGoDeeper("orig") + @test_util.run_in_graph_and_eager_modes def testAllCloseTensors(self): a_raw_data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] a = constant_op.constant(a_raw_data) @@ -227,17 +264,20 @@ class TestUtilTest(test_util.TensorFlowTestCase): y_list = [a_raw_data, b] self.assertAllClose(x_list, y_list) + @test_util.run_in_graph_and_eager_modes def testAllCloseScalars(self): self.assertAllClose(7, 7 + 1e-8) with self.assertRaisesRegexp(AssertionError, r"Not equal to tolerance"): self.assertAllClose(7, 7 + 1e-5) + @test_util.run_in_graph_and_eager_modes def testAllCloseDictToNonDict(self): with self.assertRaisesRegexp(ValueError, r"Can't compare dict to non-dict"): self.assertAllClose(1, {"a": 1}) with self.assertRaisesRegexp(ValueError, r"Can't compare dict to non-dict"): self.assertAllClose({"a": 1}, 1) + @test_util.run_in_graph_and_eager_modes def testAllCloseNamedtuples(self): a = 7 b = (2., 3.) @@ -250,6 +290,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): self.assertAllClose( my_named_tuple(a=a, b=b, c=c), my_named_tuple(a=a, b=b, c=c)) + @test_util.run_in_graph_and_eager_modes def testAllCloseDicts(self): a = 7 b = (2., 3.) @@ -277,6 +318,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): with self.assertRaisesRegexp(AssertionError, r"Not equal to tolerance"): self.assertAllClose(expected, {"a": a, "b": b, "c": c_copy}) + @test_util.run_in_graph_and_eager_modes def testAllCloseListOfNamedtuples(self): my_named_tuple = collections.namedtuple("MyNamedTuple", ["x", "y"]) l1 = [ @@ -289,6 +331,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): ] self.assertAllClose(l1, l2) + @test_util.run_in_graph_and_eager_modes def testAllCloseNestedStructure(self): a = {"x": np.ones((3, 2, 4)) * 7, "y": (2, [{"nested": {"m": 3, "n": 4}}])} self.assertAllClose(a, a) @@ -302,6 +345,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): r"\[y\]\[1\]\[0\]\[nested\]\[n\]"): self.assertAllClose(a, b) + @test_util.run_in_graph_and_eager_modes def testArrayNear(self): a = [1, 2] b = [1, 2, 5] @@ -324,6 +368,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): y = [15] control_flow_ops.Assert(x, y).run() + @test_util.run_in_graph_and_eager_modes def testAssertAllCloseAccordingToType(self): # test plain int self.assertAllCloseAccordingToType(1, 1, rtol=1e-8, atol=1e-8) @@ -400,6 +445,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): half_rtol=1e-4, half_atol=1e-4 ) + @test_util.run_in_graph_and_eager_modes def testAssertAllEqual(self): i = variables.Variable([100] * 3, dtype=dtypes.int32, name="i") j = constant_op.constant([20] * 3, dtype=dtypes.int32, name="j") @@ -409,6 +455,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): self.assertAllEqual([120] * 3, k) self.assertAllEqual([20] * 3, j) + @test_util.run_in_graph_and_eager_modes def testAssertNotAllClose(self): # Test with arrays self.assertNotAllClose([0.1], [0.2]) @@ -425,6 +472,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): with self.assertRaises(AssertionError): self.assertNotAllClose([1.0, 1.0], x) + @test_util.run_in_graph_and_eager_modes def testAssertNotAllCloseRTol(self): # Test with arrays with self.assertRaises(AssertionError): @@ -439,6 +487,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): with self.assertRaises(AssertionError): self.assertNotAllClose([0.9, 1.0], x, rtol=0.2) + @test_util.run_in_graph_and_eager_modes def testAssertNotAllCloseATol(self): # Test with arrays with self.assertRaises(AssertionError): @@ -453,6 +502,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): with self.assertRaises(AssertionError): self.assertNotAllClose([0.9, 1.0], x, atol=0.2) + @test_util.run_in_graph_and_eager_modes def testAssertAllGreaterLess(self): x = constant_op.constant([100.0, 110.0, 120.0], dtype=dtypes.float32) y = constant_op.constant([10.0] * 3, dtype=dtypes.float32) @@ -473,6 +523,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): with self.assertRaises(AssertionError): self.assertAllLess(x, 95.0) + @test_util.run_in_graph_and_eager_modes def testAssertAllGreaterLessEqual(self): x = constant_op.constant([100.0, 110.0, 120.0], dtype=dtypes.float32) y = constant_op.constant([10.0] * 3, dtype=dtypes.float32) @@ -505,6 +556,7 @@ class TestUtilTest(test_util.TensorFlowTestCase): with self.assertRaises(AssertionError): self.assertAllInRange(b, 0, 1) + @test_util.run_in_graph_and_eager_modes def testAssertAllInRange(self): x = constant_op.constant([10.0, 15.0], name="x") self.assertAllInRange(x, 10, 15) @@ -517,24 +569,28 @@ class TestUtilTest(test_util.TensorFlowTestCase): self.assertAllInRange( x, 10, 15, open_lower_bound=True, open_upper_bound=True) + @test_util.run_in_graph_and_eager_modes def testAssertAllInRangeErrorMessageEllipses(self): x_init = np.array([[10.0, 15.0]] * 12) x = constant_op.constant(x_init, name="x") with self.assertRaises(AssertionError): self.assertAllInRange(x, 5, 10) + @test_util.run_in_graph_and_eager_modes def testAssertAllInRangeDetectsNaNs(self): x = constant_op.constant( [[np.nan, 0.0], [np.nan, np.inf], [np.inf, np.nan]], name="x") with self.assertRaises(AssertionError): self.assertAllInRange(x, 0.0, 2.0) + @test_util.run_in_graph_and_eager_modes def testAssertAllInRangeWithInfinities(self): x = constant_op.constant([10.0, np.inf], name="x") self.assertAllInRange(x, 10, np.inf) with self.assertRaises(AssertionError): self.assertAllInRange(x, 10, np.inf, open_upper_bound=True) + @test_util.run_in_graph_and_eager_modes def testAssertAllInSet(self): b = constant_op.constant([True, False], name="b") x = constant_op.constant([13, 37], name="x") diff --git a/tensorflow/python/grappler/cost_analyzer.h b/tensorflow/python/grappler/cost_analyzer.h index b5364aa37a..d15858c1ee 100644 --- a/tensorflow/python/grappler/cost_analyzer.h +++ b/tensorflow/python/grappler/cost_analyzer.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_GRAPPLER_COSTS_COST_ANALYZER_H_ -#define TENSORFLOW_CORE_GRAPPLER_COSTS_COST_ANALYZER_H_ +#ifndef TENSORFLOW_PYTHON_GRAPPLER_COST_ANALYZER_H_ +#define TENSORFLOW_PYTHON_GRAPPLER_COST_ANALYZER_H_ #include <iostream> #include "tensorflow/core/framework/cost_graph.pb.h" @@ -80,4 +80,4 @@ class CostAnalyzer { } // end namespace grappler } // end namespace tensorflow -#endif // TENSORFLOW_CORE_GRAPPLER_COSTS_COST_ANALYZER_H_ +#endif // TENSORFLOW_PYTHON_GRAPPLER_COST_ANALYZER_H_ diff --git a/tensorflow/compiler/jit/ops/parallel_check_op.cc b/tensorflow/python/grappler/graph_analyzer.i index db5c195578..cc7b5358eb 100644 --- a/tensorflow/compiler/jit/ops/parallel_check_op.cc +++ b/tensorflow/python/grappler/graph_analyzer.i @@ -1,4 +1,4 @@ -/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. @@ -13,18 +13,14 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#include "tensorflow/core/framework/op.h" +%{ +#include "tensorflow/core/grappler/graph_analyzer/graph_analyzer_tool.h" +%} -namespace tensorflow { +%{ +void GraphAnalyzer(const string& file_path, int n) { + tensorflow::grappler::graph_analyzer::GraphAnalyzerTool(file_path, n); +} +%} -REGISTER_OP("ParallelCheck") - .Attr("T: list(type) >= 0") - .Input("expected: T") - .Input("actual: T") - .Output("result: T") - .Doc(R"doc( -Op that compares two sets of inputs for near-identity, and propagates the first. -Inequality is logged to ERROR log. -)doc"); - -} // namespace tensorflow +void GraphAnalyzer(const string& file_path, int n); diff --git a/tensorflow/python/grappler/graph_analyzer.py b/tensorflow/python/grappler/graph_analyzer.py new file mode 100644 index 0000000000..ec5544e38e --- /dev/null +++ b/tensorflow/python/grappler/graph_analyzer.py @@ -0,0 +1,46 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================= +"""A tool that finds all subgraphs of a given size in a TF graph. + +The subgraph patterns are sorted by occurrence, and only the transitive fanin +part of the graph with regard to the fetch nodes is considered. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import argparse +import sys + +from tensorflow.python import pywrap_tensorflow as tf_wrap +from tensorflow.python.platform import app + + +def main(_): + tf_wrap.GraphAnalyzer(FLAGS.input, FLAGS.n) + + +if __name__ == "__main__": + parser = argparse.ArgumentParser() + parser.add_argument( + "--input", + type=str, + default=None, + help="Input file path for a TensorFlow MetaGraphDef.") + parser.add_argument( + "--n", type=int, default=None, help="The size of the subgraphs.") + FLAGS, unparsed = parser.parse_known_args() + app.run(main=main, argv=[sys.argv[0]] + unparsed) diff --git a/tensorflow/python/grappler/model_analyzer.h b/tensorflow/python/grappler/model_analyzer.h index 97ffafabe1..9764a75b29 100644 --- a/tensorflow/python/grappler/model_analyzer.h +++ b/tensorflow/python/grappler/model_analyzer.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_GRAPPLER_COSTS_MODEL_ANALYZER_H_ -#define TENSORFLOW_CORE_GRAPPLER_COSTS_MODEL_ANALYZER_H_ +#ifndef TENSORFLOW_PYTHON_GRAPPLER_MODEL_ANALYZER_H_ +#define TENSORFLOW_PYTHON_GRAPPLER_MODEL_ANALYZER_H_ #include <iostream> #include "tensorflow/core/framework/node_def.pb.h" @@ -43,4 +43,4 @@ class ModelAnalyzer { } // end namespace grappler } // end namespace tensorflow -#endif // TENSORFLOW_CORE_GRAPPLER_COSTS_MODEL_ANALYZER_H_ +#endif // TENSORFLOW_PYTHON_GRAPPLER_MODEL_ANALYZER_H_ diff --git a/tensorflow/python/keras/BUILD b/tensorflow/python/keras/BUILD index fa1ec51aa7..7246341519 100755 --- a/tensorflow/python/keras/BUILD +++ b/tensorflow/python/keras/BUILD @@ -102,7 +102,6 @@ py_library( "//tensorflow/python:tensor_array_ops", "//tensorflow/python:tensor_shape", "//tensorflow/python:util", - "//tensorflow/python:variable_scope", "//tensorflow/python:variables", ], ) @@ -140,6 +139,7 @@ py_library( ":backend", "//tensorflow/python/data", "//tensorflow/python/training/checkpointable:data_structures", + "//tensorflow/tools/docs:doc_controls", "@six_archive//:six", ], ) @@ -388,7 +388,7 @@ py_test( py_test( name = "embeddings_test", - size = "small", + size = "medium", srcs = ["layers/embeddings_test.py"], srcs_version = "PY2AND3", deps = [ @@ -688,7 +688,7 @@ py_test( py_test( name = "training_test", - size = "large", + size = "enormous", srcs = ["engine/training_test.py"], srcs_version = "PY2AND3", tags = ["notsan"], diff --git a/tensorflow/python/keras/activations_test.py b/tensorflow/python/keras/activations_test.py index 5cff1f8f9c..dd0bbcff39 100644 --- a/tensorflow/python/keras/activations_test.py +++ b/tensorflow/python/keras/activations_test.py @@ -45,7 +45,7 @@ class KerasActivationsTest(test.TestCase): assert fn == ref_fn def test_softmax(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.placeholder(ndim=2) f = keras.backend.function([x], [keras.activations.softmax(x)]) test_values = np.random.random((2, 5)) @@ -59,7 +59,7 @@ class KerasActivationsTest(test.TestCase): keras.activations.softmax(x) def test_temporal_softmax(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.placeholder(shape=(2, 2, 3)) f = keras.backend.function([x], [keras.activations.softmax(x)]) test_values = np.random.random((2, 2, 3)) * 10 @@ -73,7 +73,7 @@ class KerasActivationsTest(test.TestCase): alpha = 1.6732632423543772848170429916717 scale = 1.0507009873554804934193349852946 - with self.test_session(): + with self.cached_session(): positive_values = np.array([[1, 2]], dtype=keras.backend.floatx()) result = f([positive_values])[0] self.assertAllClose(result, positive_values * scale, rtol=1e-05) @@ -87,7 +87,7 @@ class KerasActivationsTest(test.TestCase): def softplus(x): return np.log(np.ones_like(x) + np.exp(x)) - with self.test_session(): + with self.cached_session(): x = keras.backend.placeholder(ndim=2) f = keras.backend.function([x], [keras.activations.softplus(x)]) test_values = np.random.random((2, 5)) @@ -99,7 +99,7 @@ class KerasActivationsTest(test.TestCase): def softsign(x): return np.divide(x, np.ones_like(x) + np.absolute(x)) - with self.test_session(): + with self.cached_session(): x = keras.backend.placeholder(ndim=2) f = keras.backend.function([x], [keras.activations.softsign(x)]) test_values = np.random.random((2, 5)) @@ -116,7 +116,7 @@ class KerasActivationsTest(test.TestCase): return z / (1 + z) sigmoid = np.vectorize(ref_sigmoid) - with self.test_session(): + with self.cached_session(): x = keras.backend.placeholder(ndim=2) f = keras.backend.function([x], [keras.activations.sigmoid(x)]) test_values = np.random.random((2, 5)) @@ -130,7 +130,7 @@ class KerasActivationsTest(test.TestCase): z = 0.0 if x <= 0 else (1.0 if x >= 1 else x) return z hard_sigmoid = np.vectorize(ref_hard_sigmoid) - with self.test_session(): + with self.cached_session(): x = keras.backend.placeholder(ndim=2) f = keras.backend.function([x], [keras.activations.hard_sigmoid(x)]) test_values = np.random.random((2, 5)) @@ -139,7 +139,7 @@ class KerasActivationsTest(test.TestCase): self.assertAllClose(result, expected, rtol=1e-05) def test_relu(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.placeholder(ndim=2) f = keras.backend.function([x], [keras.activations.relu(x)]) test_values = np.random.random((2, 5)) @@ -148,7 +148,7 @@ class KerasActivationsTest(test.TestCase): self.assertAllClose(result, test_values, rtol=1e-05) def test_elu(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.placeholder(ndim=2) f = keras.backend.function([x], [keras.activations.elu(x, 0.5)]) test_values = np.random.random((2, 5)) @@ -160,7 +160,7 @@ class KerasActivationsTest(test.TestCase): self.assertAllClose(result, true_result) def test_tanh(self): - with self.test_session(): + with self.cached_session(): test_values = np.random.random((2, 5)) x = keras.backend.placeholder(ndim=2) exp = keras.activations.tanh(x) diff --git a/tensorflow/python/keras/applications/__init__.py b/tensorflow/python/keras/applications/__init__.py index cd9462d6b5..a8b6d55e41 100644 --- a/tensorflow/python/keras/applications/__init__.py +++ b/tensorflow/python/keras/applications/__init__.py @@ -14,6 +14,7 @@ # ============================================================================== """Keras Applications are canned architectures with pre-trained weights.""" # pylint: disable=g-import-not-at-top +# pylint: disable=g-bad-import-order from __future__ import absolute_import from __future__ import division from __future__ import print_function @@ -25,13 +26,49 @@ from tensorflow.python.keras import engine from tensorflow.python.keras import layers from tensorflow.python.keras import models from tensorflow.python.keras import utils +from tensorflow.python.util import tf_inspect + +# `get_submodules_from_kwargs` has been introduced in 1.0.5, but we would +# like to be able to handle prior versions. Note that prior to 1.0.5, +# `keras_applications` did not expose a `__version__` attribute. +if not hasattr(keras_applications, 'get_submodules_from_kwargs'): + + if 'engine' in tf_inspect.getfullargspec( + keras_applications.set_keras_submodules)[0]: + keras_applications.set_keras_submodules( + backend=backend, + layers=layers, + models=models, + utils=utils, + engine=engine) + else: + keras_applications.set_keras_submodules( + backend=backend, + layers=layers, + models=models, + utils=utils) + + +def keras_modules_injection(base_fun): + """Decorator injecting tf.keras replacements for Keras modules. + + Arguments: + base_fun: Application function to decorate (e.g. `MobileNet`). + + Returns: + Decorated function that injects keyword argument for the tf.keras + modules required by the Applications. + """ + + def wrapper(*args, **kwargs): + if hasattr(keras_applications, 'get_submodules_from_kwargs'): + kwargs['backend'] = backend + kwargs['layers'] = layers + kwargs['models'] = models + kwargs['utils'] = utils + return base_fun(*args, **kwargs) + return wrapper -keras_applications.set_keras_submodules( - backend=backend, - engine=engine, - layers=layers, - models=models, - utils=utils) from tensorflow.python.keras.applications.densenet import DenseNet121 from tensorflow.python.keras.applications.densenet import DenseNet169 @@ -39,7 +76,7 @@ from tensorflow.python.keras.applications.densenet import DenseNet201 from tensorflow.python.keras.applications.inception_resnet_v2 import InceptionResNetV2 from tensorflow.python.keras.applications.inception_v3 import InceptionV3 from tensorflow.python.keras.applications.mobilenet import MobileNet -# TODO(fchollet): enable MobileNetV2 in next version. +from tensorflow.python.keras.applications.mobilenet_v2 import MobileNetV2 from tensorflow.python.keras.applications.nasnet import NASNetLarge from tensorflow.python.keras.applications.nasnet import NASNetMobile from tensorflow.python.keras.applications.resnet50 import ResNet50 diff --git a/tensorflow/python/keras/applications/applications_test.py b/tensorflow/python/keras/applications/applications_test.py index ef3198a937..b15ca5990a 100644 --- a/tensorflow/python/keras/applications/applications_test.py +++ b/tensorflow/python/keras/applications/applications_test.py @@ -32,7 +32,8 @@ MODEL_LIST = [ (applications.InceptionV3, 2048), (applications.InceptionResNetV2, 1536), (applications.MobileNet, 1024), - # TODO(fchollet): enable MobileNetV2 in next version. + # TODO(fchollet): enable MobileNetV2 tests when a new TensorFlow test image + # is released with keras_applications upgraded to 1.0.5 or above. (applications.DenseNet121, 1024), (applications.DenseNet169, 1664), (applications.DenseNet201, 1920), @@ -44,11 +45,6 @@ MODEL_LIST = [ class ApplicationsTest(test.TestCase, parameterized.TestCase): @parameterized.parameters(*MODEL_LIST) - def test_classification_model(self, model_fn, _): - model = model_fn(classes=1000, weights=None) - self.assertEqual(model.output_shape[-1], 1000) - - @parameterized.parameters(*MODEL_LIST) def test_feature_extration_model(self, model_fn, output_dim): model = model_fn(include_top=False, weights=None) self.assertEqual(model.output_shape, (None, None, None, output_dim)) diff --git a/tensorflow/python/keras/applications/densenet.py b/tensorflow/python/keras/applications/densenet.py index fbdcc66d2d..172848bbdb 100644 --- a/tensorflow/python/keras/applications/densenet.py +++ b/tensorflow/python/keras/applications/densenet.py @@ -20,18 +20,39 @@ from __future__ import division from __future__ import print_function from keras_applications import densenet + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -DenseNet121 = densenet.DenseNet121 -DenseNet169 = densenet.DenseNet169 -DenseNet201 = densenet.DenseNet201 -decode_predictions = densenet.decode_predictions -preprocess_input = densenet.preprocess_input - -tf_export('keras.applications.densenet.DenseNet121', - 'keras.applications.DenseNet121')(DenseNet121) -tf_export('keras.applications.densenet.DenseNet169', - 'keras.applications.DenseNet169')(DenseNet169) -tf_export('keras.applications.densenet.DenseNet201', - 'keras.applications.DenseNet201')(DenseNet201) -tf_export('keras.applications.densenet.preprocess_input')(preprocess_input) + +@tf_export('keras.applications.densenet.DenseNet121', + 'keras.applications.DenseNet121') +@keras_modules_injection +def DenseNet121(*args, **kwargs): + return densenet.DenseNet121(*args, **kwargs) + + +@tf_export('keras.applications.densenet.DenseNet169', + 'keras.applications.DenseNet169') +@keras_modules_injection +def DenseNet169(*args, **kwargs): + return densenet.DenseNet169(*args, **kwargs) + + +@tf_export('keras.applications.densenet.DenseNet201', + 'keras.applications.DenseNet201') +@keras_modules_injection +def DenseNet201(*args, **kwargs): + return densenet.DenseNet201(*args, **kwargs) + + +@tf_export('keras.applications.densenet.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return densenet.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.densenet.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return densenet.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/imagenet_utils.py b/tensorflow/python/keras/applications/imagenet_utils.py index 70f8f6fb32..c25b5c2bdd 100644 --- a/tensorflow/python/keras/applications/imagenet_utils.py +++ b/tensorflow/python/keras/applications/imagenet_utils.py @@ -19,27 +19,18 @@ from __future__ import division from __future__ import print_function from keras_applications import imagenet_utils + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -decode_predictions = imagenet_utils.decode_predictions -preprocess_input = imagenet_utils.preprocess_input -tf_export( - 'keras.applications.imagenet_utils.decode_predictions', - 'keras.applications.densenet.decode_predictions', - 'keras.applications.inception_resnet_v2.decode_predictions', - 'keras.applications.inception_v3.decode_predictions', - 'keras.applications.mobilenet.decode_predictions', - 'keras.applications.mobilenet_v2.decode_predictions', - 'keras.applications.nasnet.decode_predictions', - 'keras.applications.resnet50.decode_predictions', - 'keras.applications.vgg16.decode_predictions', - 'keras.applications.vgg19.decode_predictions', - 'keras.applications.xception.decode_predictions', -)(decode_predictions) -tf_export( - 'keras.applications.imagenet_utils.preprocess_input', - 'keras.applications.resnet50.preprocess_input', - 'keras.applications.vgg16.preprocess_input', - 'keras.applications.vgg19.preprocess_input', -)(preprocess_input) +@tf_export('keras.applications.imagenet_utils.preprocess_input') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return imagenet_utils.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.imagenet_utils.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return imagenet_utils.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/inception_resnet_v2.py b/tensorflow/python/keras/applications/inception_resnet_v2.py index 63debb4e0d..0b9ef371fa 100644 --- a/tensorflow/python/keras/applications/inception_resnet_v2.py +++ b/tensorflow/python/keras/applications/inception_resnet_v2.py @@ -20,13 +20,25 @@ from __future__ import division from __future__ import print_function from keras_applications import inception_resnet_v2 + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -InceptionResNetV2 = inception_resnet_v2.InceptionResNetV2 -decode_predictions = inception_resnet_v2.decode_predictions -preprocess_input = inception_resnet_v2.preprocess_input -tf_export('keras.applications.inception_resnet_v2.InceptionResNetV2', - 'keras.applications.InceptionResNetV2')(InceptionResNetV2) -tf_export( - 'keras.applications.inception_resnet_v2.preprocess_input')(preprocess_input) +@tf_export('keras.applications.inception_resnet_v2.InceptionResNetV2', + 'keras.applications.InceptionResNetV2') +@keras_modules_injection +def InceptionResNetV2(*args, **kwargs): + return inception_resnet_v2.InceptionResNetV2(*args, **kwargs) + + +@tf_export('keras.applications.inception_resnet_v2.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return inception_resnet_v2.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.inception_resnet_v2.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return inception_resnet_v2.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/inception_v3.py b/tensorflow/python/keras/applications/inception_v3.py index 87534086c8..ab76826e17 100644 --- a/tensorflow/python/keras/applications/inception_v3.py +++ b/tensorflow/python/keras/applications/inception_v3.py @@ -20,12 +20,25 @@ from __future__ import division from __future__ import print_function from keras_applications import inception_v3 + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -InceptionV3 = inception_v3.InceptionV3 -decode_predictions = inception_v3.decode_predictions -preprocess_input = inception_v3.preprocess_input -tf_export('keras.applications.inception_v3.InceptionV3', - 'keras.applications.InceptionV3')(InceptionV3) -tf_export('keras.applications.inception_v3.preprocess_input')(preprocess_input) +@tf_export('keras.applications.inception_v3.InceptionV3', + 'keras.applications.InceptionV3') +@keras_modules_injection +def InceptionV3(*args, **kwargs): + return inception_v3.InceptionV3(*args, **kwargs) + + +@tf_export('keras.applications.inception_v3.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return inception_v3.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.inception_v3.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return inception_v3.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/mobilenet.py b/tensorflow/python/keras/applications/mobilenet.py index 3528f027b3..1f71a5ae99 100644 --- a/tensorflow/python/keras/applications/mobilenet.py +++ b/tensorflow/python/keras/applications/mobilenet.py @@ -20,12 +20,25 @@ from __future__ import division from __future__ import print_function from keras_applications import mobilenet + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -MobileNet = mobilenet.MobileNet -decode_predictions = mobilenet.decode_predictions -preprocess_input = mobilenet.preprocess_input -tf_export('keras.applications.mobilenet.MobileNet', - 'keras.applications.MobileNet')(MobileNet) -tf_export('keras.applications.mobilenet.preprocess_input')(preprocess_input) +@tf_export('keras.applications.mobilenet.MobileNet', + 'keras.applications.MobileNet') +@keras_modules_injection +def MobileNet(*args, **kwargs): + return mobilenet.MobileNet(*args, **kwargs) + + +@tf_export('keras.applications.mobilenet.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return mobilenet.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.mobilenet.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return mobilenet.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/mobilenet_v2.py b/tensorflow/python/keras/applications/mobilenet_v2.py index 9194c3ee14..52ac5959ad 100644 --- a/tensorflow/python/keras/applications/mobilenet_v2.py +++ b/tensorflow/python/keras/applications/mobilenet_v2.py @@ -19,4 +19,26 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function -# TODO(fchollet): export MobileNetV2 as part of the public API in next version. +from keras_applications import mobilenet_v2 + +from tensorflow.python.keras.applications import keras_modules_injection +from tensorflow.python.util.tf_export import tf_export + + +@tf_export('keras.applications.mobilenet_v2.MobileNetV2', + 'keras.applications.MobileNetV2') +@keras_modules_injection +def MobileNetV2(*args, **kwargs): + return mobilenet_v2.MobileNetV2(*args, **kwargs) + + +@tf_export('keras.applications.mobilenet_v2.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return mobilenet_v2.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.mobilenet_v2.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return mobilenet_v2.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/nasnet.py b/tensorflow/python/keras/applications/nasnet.py index 26ff5db53f..44fc329d57 100644 --- a/tensorflow/python/keras/applications/nasnet.py +++ b/tensorflow/python/keras/applications/nasnet.py @@ -20,15 +20,32 @@ from __future__ import division from __future__ import print_function from keras_applications import nasnet + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -NASNetMobile = nasnet.NASNetMobile -NASNetLarge = nasnet.NASNetLarge -decode_predictions = nasnet.decode_predictions -preprocess_input = nasnet.preprocess_input -tf_export('keras.applications.nasnet.NASNetMobile', - 'keras.applications.NASNetMobile')(NASNetMobile) -tf_export('keras.applications.nasnet.NASNetLarge', - 'keras.applications.NASNetLarge')(NASNetLarge) -tf_export('keras.applications.nasnet.preprocess_input')(preprocess_input) +@tf_export('keras.applications.nasnet.NASNetMobile', + 'keras.applications.NASNetMobile') +@keras_modules_injection +def NASNetMobile(*args, **kwargs): + return nasnet.NASNetMobile(*args, **kwargs) + + +@tf_export('keras.applications.nasnet.NASNetLarge', + 'keras.applications.NASNetLarge') +@keras_modules_injection +def NASNetLarge(*args, **kwargs): + return nasnet.NASNetLarge(*args, **kwargs) + + +@tf_export('keras.applications.nasnet.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return nasnet.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.nasnet.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return nasnet.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/resnet50.py b/tensorflow/python/keras/applications/resnet50.py index 4d804a3c44..80d3f9044f 100644 --- a/tensorflow/python/keras/applications/resnet50.py +++ b/tensorflow/python/keras/applications/resnet50.py @@ -20,11 +20,25 @@ from __future__ import division from __future__ import print_function from keras_applications import resnet50 + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -ResNet50 = resnet50.ResNet50 -decode_predictions = resnet50.decode_predictions -preprocess_input = resnet50.preprocess_input -tf_export('keras.applications.resnet50.ResNet50', - 'keras.applications.ResNet50')(ResNet50) +@tf_export('keras.applications.resnet50.ResNet50', + 'keras.applications.ResNet50') +@keras_modules_injection +def ResNet50(*args, **kwargs): + return resnet50.ResNet50(*args, **kwargs) + + +@tf_export('keras.applications.resnet50.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return resnet50.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.resnet50.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return resnet50.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/vgg16.py b/tensorflow/python/keras/applications/vgg16.py index c420d9b81e..8557d26931 100644 --- a/tensorflow/python/keras/applications/vgg16.py +++ b/tensorflow/python/keras/applications/vgg16.py @@ -20,11 +20,25 @@ from __future__ import division from __future__ import print_function from keras_applications import vgg16 + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -VGG16 = vgg16.VGG16 -decode_predictions = vgg16.decode_predictions -preprocess_input = vgg16.preprocess_input -tf_export('keras.applications.vgg16.VGG16', - 'keras.applications.VGG16')(VGG16) +@tf_export('keras.applications.vgg16.VGG16', + 'keras.applications.VGG16') +@keras_modules_injection +def VGG16(*args, **kwargs): + return vgg16.VGG16(*args, **kwargs) + + +@tf_export('keras.applications.vgg16.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return vgg16.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.vgg16.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return vgg16.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/vgg19.py b/tensorflow/python/keras/applications/vgg19.py index 73d3d1d1c3..8fc04413a0 100644 --- a/tensorflow/python/keras/applications/vgg19.py +++ b/tensorflow/python/keras/applications/vgg19.py @@ -20,11 +20,25 @@ from __future__ import division from __future__ import print_function from keras_applications import vgg19 + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -VGG19 = vgg19.VGG19 -decode_predictions = vgg19.decode_predictions -preprocess_input = vgg19.preprocess_input -tf_export('keras.applications.vgg19.VGG19', - 'keras.applications.VGG19')(VGG19) +@tf_export('keras.applications.vgg19.VGG19', + 'keras.applications.VGG19') +@keras_modules_injection +def VGG19(*args, **kwargs): + return vgg19.VGG19(*args, **kwargs) + + +@tf_export('keras.applications.vgg19.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return vgg19.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.vgg19.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return vgg19.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/applications/xception.py b/tensorflow/python/keras/applications/xception.py index 5b221ac8e0..960e6dec69 100644 --- a/tensorflow/python/keras/applications/xception.py +++ b/tensorflow/python/keras/applications/xception.py @@ -20,12 +20,25 @@ from __future__ import division from __future__ import print_function from keras_applications import xception + +from tensorflow.python.keras.applications import keras_modules_injection from tensorflow.python.util.tf_export import tf_export -Xception = xception.Xception -decode_predictions = xception.decode_predictions -preprocess_input = xception.preprocess_input -tf_export('keras.applications.xception.Xception', - 'keras.applications.Xception')(Xception) -tf_export('keras.applications.xception.preprocess_input')(preprocess_input) +@tf_export('keras.applications.xception.Xception', + 'keras.applications.Xception') +@keras_modules_injection +def Xception(*args, **kwargs): + return xception.Xception(*args, **kwargs) + + +@tf_export('keras.applications.xception.decode_predictions') +@keras_modules_injection +def decode_predictions(*args, **kwargs): + return xception.decode_predictions(*args, **kwargs) + + +@tf_export('keras.applications.xception.preprocess_input') +@keras_modules_injection +def preprocess_input(*args, **kwargs): + return xception.preprocess_input(*args, **kwargs) diff --git a/tensorflow/python/keras/backend.py b/tensorflow/python/keras/backend.py index 418586b85f..b52ab7f05c 100644 --- a/tensorflow/python/keras/backend.py +++ b/tensorflow/python/keras/backend.py @@ -94,6 +94,14 @@ _IMAGE_DATA_FORMAT = 'channels_last' # We assume our devices don't change henceforth. _LOCAL_DEVICES = None +# This dictionary holds a mapping between a graph and variables to initialize +# in the graph. +_GRAPH_VARIABLES = {} + +# This dictionary holds a mapping between a graph and TF optimizers created in +# the graph. +_GRAPH_TF_OPTIMIZERS = {} + @tf_export('keras.backend.backend') def backend(): @@ -309,6 +317,8 @@ def clear_session(): """ global _SESSION global _GRAPH_LEARNING_PHASES # pylint: disable=global-variable-not-assigned + global _GRAPH_VARIABLES # pylint: disable=global-variable-not-assigned + global _GRAPH_TF_OPTIMIZERS # pylint: disable=global-variable-not-assigned ops.reset_default_graph() reset_uids() _SESSION = None @@ -316,6 +326,8 @@ def clear_session(): False, shape=(), name='keras_learning_phase') _GRAPH_LEARNING_PHASES = {} _GRAPH_LEARNING_PHASES[ops.get_default_graph()] = phase + _GRAPH_VARIABLES.pop(ops.get_default_graph(), None) + _GRAPH_TF_OPTIMIZERS.pop(ops.get_default_graph(), None) @tf_export('keras.backend.manual_variable_initialization') @@ -651,12 +663,42 @@ def variable(value, dtype=None, name=None, constraint=None): elif hasattr(value, 'shape'): v._keras_shape = int_shape(value) v._uses_learning_phase = False + track_variable(v) return v +def track_tf_optimizer(tf_optimizer): + """Tracks the given TF optimizer for initialization of its variables.""" + if context.executing_eagerly(): + return + graph = ops.get_default_graph() + if graph not in _GRAPH_TF_OPTIMIZERS: + _GRAPH_TF_OPTIMIZERS[graph] = set() + _GRAPH_TF_OPTIMIZERS[graph].add(tf_optimizer) + + +def track_variable(v): + """Tracks the given variable for initialization.""" + if context.executing_eagerly(): + return + graph = v.graph if hasattr(v, 'graph') else ops.get_default_graph() + if graph not in _GRAPH_VARIABLES: + _GRAPH_VARIABLES[graph] = set() + _GRAPH_VARIABLES[graph].add(v) + + +def _get_variables(graph=None): + """Returns variables corresponding to the given graph for initialization.""" + assert not context.executing_eagerly() + variables = _GRAPH_VARIABLES.get(graph, set()) + for opt in _GRAPH_TF_OPTIMIZERS.get(graph, set()): + variables.update(opt.optimizer.variables()) + return variables + + def _initialize_variables(session): """Utility to initialize uninitialized variables on the fly.""" - variables = variables_module.global_variables() + variables = _get_variables(ops.get_default_graph()) candidate_vars = [] for v in variables: if not getattr(v, '_keras_initialized', False): @@ -974,6 +1016,7 @@ def zeros(shape, dtype=None, name=None): v = array_ops.zeros(shape=shape, dtype=tf_dtype, name=name) if py_all(v.shape.as_list()): return variable(v, dtype=dtype, name=name) + track_variable(v) return v @@ -1008,6 +1051,7 @@ def ones(shape, dtype=None, name=None): v = array_ops.ones(shape=shape, dtype=tf_dtype, name=name) if py_all(v.shape.as_list()): return variable(v, dtype=dtype, name=name) + track_variable(v) return v @@ -2766,7 +2810,8 @@ class Function(object): outputs: Output tensors to fetch. updates: Additional update ops to be run at function call. name: A name to help users identify what this function does. - session_kwargs: Arguments to `tf.Session.run()`: `fetches`, `feed_dict`. + session_kwargs: Arguments to `tf.Session.run()`: + `fetches`, `feed_dict`, `options`, `run_metadata`. """ def __init__(self, inputs, outputs, updates=None, name=None, @@ -2800,6 +2845,8 @@ class Function(object): self.fetches = session_kwargs.pop('fetches', []) if not isinstance(self.fetches, list): self.fetches = [self.fetches] + self.run_options = session_kwargs.pop('options', None) + self.run_metadata = session_kwargs.pop('run_metadata', None) # The main use case of `fetches` being passed to a model is the ability # to run custom updates # This requires us to wrap fetches in `identity` ops. @@ -2857,6 +2904,9 @@ class Function(object): callable_opts.fetch.append(x.name) # Handle updates. callable_opts.target.append(self.updates_op.name) + # Handle run_options. + if self.run_options: + callable_opts.run_options.CopyFrom(self.run_options) # Create callable. callable_fn = session._make_callable_from_options(callable_opts) # Cache parameters corresponding to the generated callable, so that @@ -2915,7 +2965,8 @@ class Function(object): session != self._session): self._make_callable(feed_arrays, feed_symbols, symbol_vals, session) - fetched = self._callable_fn(*array_vals) + fetched = self._callable_fn(*array_vals, + run_metadata=self.run_metadata) self._call_fetch_callbacks(fetched[-len(self._fetches):]) return fetched[:len(self.outputs)] diff --git a/tensorflow/python/keras/backend_test.py b/tensorflow/python/keras/backend_test.py index 40e7910061..266af56611 100644 --- a/tensorflow/python/keras/backend_test.py +++ b/tensorflow/python/keras/backend_test.py @@ -21,6 +21,7 @@ from absl.testing import parameterized import numpy as np import scipy.sparse +from tensorflow.core.protobuf import config_pb2 from tensorflow.python import keras from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops @@ -118,7 +119,7 @@ class BackendUtilsTest(test.TestCase): self.assertEqual(keras.backend.get_uid('foo'), 1) def test_learning_phase(self): - with self.test_session() as sess: + with self.cached_session() as sess: keras.backend.set_learning_phase(1) self.assertEqual(keras.backend.learning_phase(), 1) with self.assertRaises(ValueError): @@ -132,7 +133,7 @@ class BackendUtilsTest(test.TestCase): sess.run(y, feed_dict={x: np.random.random((2, 3))}) def test_learning_phase_scope(self): - with self.test_session(): + with self.cached_session(): initial_learning_phase = keras.backend.learning_phase() with keras.backend.learning_phase_scope(1) as lp: self.assertEqual(lp, 1) @@ -155,7 +156,7 @@ class BackendUtilsTest(test.TestCase): self.assertEqual(keras.backend.int_shape(x), (None, 4)) def test_in_train_phase(self): - with self.test_session(): + with self.cached_session(): y1 = keras.backend.variable(1) y2 = keras.backend.variable(2) y = keras.backend.in_train_phase(y1, y2) @@ -193,7 +194,7 @@ class BackendUtilsTest(test.TestCase): self.assertEqual(y.op.name[:12], 'StopGradient') def test_function_tf_feed_symbols(self): - with self.test_session(): + with self.cached_session(): # Test feeding a resource variable to `function`. x1 = keras.backend.placeholder(shape=()) x2 = keras.backend.placeholder(shape=()) @@ -231,7 +232,7 @@ class BackendUtilsTest(test.TestCase): # keras.backend.function() these do not have control dependency on `outputs` # so they can run in parallel. Also they should not contribute to output of # keras.backend.function(). - with self.test_session(): + with self.cached_session(): x = keras.backend.variable(0.) y = keras.backend.variable(0.) x_placeholder = keras.backend.placeholder(shape=()) @@ -252,7 +253,7 @@ class BackendUtilsTest(test.TestCase): # constructor but we can modify the values in the dictionary. Through # this feed_dict we can provide additional substitutions besides Keras # inputs. - with self.test_session(): + with self.cached_session(): x = keras.backend.variable(0.) y = keras.backend.variable(0.) x_placeholder = keras.backend.placeholder(shape=()) @@ -277,6 +278,29 @@ class BackendUtilsTest(test.TestCase): self.assertEqual( keras.backend.get_session().run(fetches=[x, y]), [30., 40.]) + def test_function_tf_run_options_with_run_metadata(self): + with self.test_session(): + x_placeholder = keras.backend.placeholder(shape=()) + y_placeholder = keras.backend.placeholder(shape=()) + + run_options = config_pb2.RunOptions(output_partition_graphs=True) + run_metadata = config_pb2.RunMetadata() + # enable run_options. + f = keras.backend.function(inputs=[x_placeholder, y_placeholder], + outputs=[x_placeholder + y_placeholder], + options=run_options, + run_metadata=run_metadata) + output = f([10., 20.]) + self.assertEqual(output, [30.]) + self.assertGreater(len(run_metadata.partition_graphs), 0) + # disable run_options. + f1 = keras.backend.function(inputs=[x_placeholder, y_placeholder], + outputs=[x_placeholder + y_placeholder], + run_metadata=run_metadata) + output1 = f1([10., 20.]) + self.assertEqual(output1, [30.]) + self.assertEqual(len(run_metadata.partition_graphs), 0) + def test_function_fetch_callbacks(self): class CallbackStub(object): @@ -289,7 +313,7 @@ class BackendUtilsTest(test.TestCase): self.times_called += 1 self.callback_result = result - with self.test_session(): + with self.cached_session(): callback = CallbackStub() x_placeholder = keras.backend.placeholder(shape=()) y_placeholder = keras.backend.placeholder(shape=()) @@ -311,39 +335,39 @@ class BackendUtilsTest(test.TestCase): class BackendVariableTest(test.TestCase): def test_zeros(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.zeros((3, 4)) val = keras.backend.eval(x) self.assertAllClose(val, np.zeros((3, 4))) def test_ones(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.ones((3, 4)) val = keras.backend.eval(x) self.assertAllClose(val, np.ones((3, 4))) def test_eye(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.eye(4) val = keras.backend.eval(x) self.assertAllClose(val, np.eye(4)) def test_zeros_like(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.zeros((3, 4)) y = keras.backend.zeros_like(x) val = keras.backend.eval(y) self.assertAllClose(val, np.zeros((3, 4))) def test_ones_like(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.zeros((3, 4)) y = keras.backend.ones_like(x) val = keras.backend.eval(y) self.assertAllClose(val, np.ones((3, 4))) def test_random_uniform_variable(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.random_uniform_variable((30, 20), low=1, high=2, seed=0) val = keras.backend.eval(x) self.assertAllClose(val.mean(), 1.5, atol=1e-1) @@ -351,7 +375,7 @@ class BackendVariableTest(test.TestCase): self.assertAllClose(val.min(), 1., atol=1e-1) def test_random_normal_variable(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.random_normal_variable((30, 20), 1., 0.5, seed=0) val = keras.backend.eval(x) @@ -359,20 +383,20 @@ class BackendVariableTest(test.TestCase): self.assertAllClose(val.std(), 0.5, atol=1e-1) def test_count_params(self): - with self.test_session(): + with self.cached_session(): x = keras.backend.zeros((4, 5)) val = keras.backend.count_params(x) self.assertAllClose(val, 20) def test_constant(self): - with self.test_session(): + with self.cached_session(): ref_val = np.random.random((3, 4)).astype('float32') x = keras.backend.constant(ref_val) val = keras.backend.eval(x) self.assertAllClose(val, ref_val) def test_sparse_variable(self): - with self.test_session(): + with self.cached_session(): val = scipy.sparse.eye(10) x = keras.backend.variable(val) self.assertTrue(isinstance(x, sparse_tensor.SparseTensor)) @@ -421,7 +445,7 @@ class BackendLinearAlgebraTest(test.TestCase): (keras.backend.argmax, np.argmax), ] for keras_op, np_op in ops_to_test: - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy(keras_op, np_op, input_shape=(4, 7, 5), keras_kwargs={'axis': 1}, np_kwargs={'axis': 1}) @@ -447,7 +471,7 @@ class BackendLinearAlgebraTest(test.TestCase): (keras.backend.exp, np.exp), ] for keras_op, np_op in ops_to_test: - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy(keras_op, np_op, input_shape=(4, 7)) ops_to_test = [ @@ -455,19 +479,19 @@ class BackendLinearAlgebraTest(test.TestCase): (keras.backend.log, np.log), ] for keras_op, np_op in ops_to_test: - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy(keras_op, np_op, input_shape=(4, 7), negative_values=False) - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy( keras.backend.clip, np.clip, input_shape=(6, 4), keras_kwargs={'min_value': 0.1, 'max_value': 2.4}, np_kwargs={'a_min': 0.1, 'a_max': 1.4}) - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy( keras.backend.pow, np.power, input_shape=(6, 4), @@ -486,14 +510,14 @@ class BackendLinearAlgebraTest(test.TestCase): (keras.backend.minimum, np.minimum), ] for keras_op, np_op in ops_to_test: - with self.test_session(): + with self.cached_session(): compare_two_inputs_op_to_numpy(keras_op, np_op, input_shape_a=(4, 7), input_shape_b=(4, 7)) def test_relu(self): x = ops.convert_to_tensor([[-4, 0], [2, 7]], 'float32') - with self.test_session(): + with self.cached_session(): # standard relu relu_op = keras.backend.relu(x) self.assertAllClose(keras.backend.eval(relu_op), [[0, 0], [2, 7]]) @@ -555,7 +579,7 @@ class BackendLinearAlgebraTest(test.TestCase): class BackendShapeOpsTest(test.TestCase): def test_reshape(self): - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy(keras.backend.reshape, np.reshape, input_shape=(4, 7), keras_args=[(2, 14)], @@ -568,7 +592,7 @@ class BackendShapeOpsTest(test.TestCase): self.assertEqual(y.get_shape().as_list(), [1, 2, 5]) def test_permute_dimensions(self): - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy(keras.backend.permute_dimensions, np.transpose, input_shape=(4, 7), @@ -647,14 +671,14 @@ class BackendShapeOpsTest(test.TestCase): self.assertEqual(y.get_shape().as_list(), [1, 2, 3]) def test_flatten(self): - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy(keras.backend.flatten, np.reshape, input_shape=(4, 7, 6), np_args=[(4 * 7 * 6,)]) def test_batch_flatten(self): - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy(keras.backend.batch_flatten, np.reshape, input_shape=(4, 7, 6), @@ -669,7 +693,7 @@ class BackendShapeOpsTest(test.TestCase): y[:, padding[0]:-padding[1], :] = x return y - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy(keras.backend.temporal_padding, ref_op, input_shape=(4, 7, 6), @@ -692,7 +716,7 @@ class BackendShapeOpsTest(test.TestCase): y[:, :, padding[0][0]:-padding[0][1], padding[1][0]:-padding[1][1]] = x return y - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy( keras.backend.spatial_2d_padding, ref_op, @@ -735,7 +759,7 @@ class BackendShapeOpsTest(test.TestCase): padding[2][0]:-padding[2][1]] = x return y - with self.test_session(): + with self.cached_session(): compare_single_input_op_to_numpy( keras.backend.spatial_3d_padding, ref_op, @@ -757,7 +781,7 @@ class BackendShapeOpsTest(test.TestCase): class BackendNNOpsTest(test.TestCase, parameterized.TestCase): def test_bias_add(self): - with self.test_session(): + with self.cached_session(): keras_op = keras.backend.bias_add np_op = np.add compare_two_inputs_op_to_numpy(keras_op, np_op, @@ -783,7 +807,8 @@ class BackendNNOpsTest(test.TestCase, parameterized.TestCase): keras.backend.bias_add(x, b, data_format='unknown') def test_bias_add_channels_first(self): - with self.test_session(): + with self.cached_session(): + def keras_op(x, b): return keras.backend.bias_add(x, b, data_format='channels_first') @@ -959,7 +984,7 @@ class BackendNNOpsTest(test.TestCase, parameterized.TestCase): strides, output_shape, 'channels_last') - with self.test_session(): + with self.cached_session(): conv_cf = keras.backend.eval(conv_cf) conv_cl = keras.backend.eval(conv_cl) @@ -1009,7 +1034,7 @@ class BackendNNOpsTest(test.TestCase, parameterized.TestCase): output_shape, 'channels_last') - with self.test_session(): + with self.cached_session(): local_conv = keras.backend.eval(local_conv) local_conv_dim = keras.backend.eval(local_conv_dim) @@ -1167,7 +1192,7 @@ class BackendNNOpsTest(test.TestCase, parameterized.TestCase): {'go_backwards': False, 'mask': mask}, {'go_backwards': False, 'mask': mask, 'unroll': True}, ] - with self.test_session(): + with self.cached_session(): for i, kwargs in enumerate(kwargs_list): last_output, outputs, new_states = keras.backend.rnn(rnn_fn, inputs, initial_states, @@ -1263,7 +1288,7 @@ class BackendNNOpsTest(test.TestCase, parameterized.TestCase): {'go_backwards': False, 'mask': mask}, {'go_backwards': False, 'mask': mask, 'unroll': True}, ] - with self.test_session(): + with self.cached_session(): for i, kwargs in enumerate(kwargs_list): last_output, outputs, new_states = keras.backend.rnn(rnn_fn, inputs, initial_states, @@ -1359,7 +1384,7 @@ class BackendNNOpsTest(test.TestCase, parameterized.TestCase): class TestCTC(test.TestCase): def test_ctc_decode(self): - with self.test_session(): + with self.cached_session(): depth = 6 seq_len_0 = 5 input_prob_matrix_0 = np.asarray( @@ -1384,8 +1409,8 @@ class TestCTC(test.TestCase): np.array([seq_len_0], dtype=np.int32)) # batch_size length vector of negative log probabilities log_prob_truth = np.array([ - 0.584855, # output beam 0 - 0.389139 # output beam 1 + -3.5821197, # output beam 0 + -3.777835 # output beam 1 ], np.float32)[np.newaxis, :] decode_truth = [np.array([1, 0]), np.array([0, 1, 0])] @@ -1408,7 +1433,7 @@ class TestCTC(test.TestCase): self.assertAllClose(log_prob_truth, log_prob_pred) def test_ctc_batch_cost(self): - with self.test_session(): + with self.cached_session(): label_lens = np.expand_dims(np.asarray([5, 4]), 1) input_lens = np.expand_dims(np.asarray([5, 5]), 1) # number of timesteps loss_log_probs = [3.34211, 5.42262] @@ -1464,13 +1489,13 @@ class TestCTC(test.TestCase): class TestRandomOps(test.TestCase): def test_random_binomial(self): - with self.test_session(): + with self.cached_session(): np.random.seed(123) x = keras.backend.random_binomial((1000, 1000), p=0.5) self.assertAllClose(np.mean(keras.backend.eval(x)), 0.5, atol=0.1) def test_truncated_normal(self): - with self.test_session(): + with self.cached_session(): np.random.seed(123) x = keras.backend.truncated_normal((1000, 1000), mean=0.0, stddev=1.0) y = keras.backend.eval(x) diff --git a/tensorflow/python/keras/callbacks_test.py b/tensorflow/python/keras/callbacks_test.py index e84e023384..7675a6586f 100644 --- a/tensorflow/python/keras/callbacks_test.py +++ b/tensorflow/python/keras/callbacks_test.py @@ -235,11 +235,8 @@ class KerasCallbacksTest(test.TestCase): num_classes=NUM_CLASSES) y_test = keras.utils.to_categorical(y_test) y_train = keras.utils.to_categorical(y_train) - model = keras.models.Sequential() - model.add( - keras.layers.Dense( - NUM_HIDDEN, input_dim=INPUT_DIM, activation='relu')) - model.add(keras.layers.Dense(NUM_CLASSES, activation='softmax')) + model = testing_utils.get_small_sequential_mlp( + num_hidden=NUM_HIDDEN, num_classes=NUM_CLASSES, input_dim=INPUT_DIM) model.compile( loss='categorical_crossentropy', optimizer='rmsprop', @@ -298,9 +295,8 @@ class KerasCallbacksTest(test.TestCase): test_samples=50, input_shape=(1,), num_classes=NUM_CLASSES) - model = keras.models.Sequential((keras.layers.Dense( - 1, input_dim=1, activation='relu'), keras.layers.Dense( - 1, activation='sigmoid'),)) + model = testing_utils.get_small_sequential_mlp( + num_hidden=1, num_classes=1, input_dim=1) model.compile( optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy']) @@ -334,11 +330,8 @@ class KerasCallbacksTest(test.TestCase): num_classes=NUM_CLASSES) y_test = keras.utils.to_categorical(y_test) y_train = keras.utils.to_categorical(y_train) - model = keras.models.Sequential() - model.add( - keras.layers.Dense( - NUM_HIDDEN, input_dim=INPUT_DIM, activation='relu')) - model.add(keras.layers.Dense(NUM_CLASSES, activation='softmax')) + model = testing_utils.get_small_sequential_mlp( + num_hidden=NUM_HIDDEN, num_classes=NUM_CLASSES, input_dim=INPUT_DIM) model.compile( loss='categorical_crossentropy', optimizer='sgd', @@ -388,12 +381,8 @@ class KerasCallbacksTest(test.TestCase): def make_model(): random_seed.set_random_seed(1234) np.random.seed(1337) - model = keras.models.Sequential() - model.add( - keras.layers.Dense( - NUM_HIDDEN, input_dim=INPUT_DIM, activation='relu')) - model.add(keras.layers.Dense(NUM_CLASSES, activation='softmax')) - + model = testing_utils.get_small_sequential_mlp( + num_hidden=NUM_HIDDEN, num_classes=NUM_CLASSES, input_dim=INPUT_DIM) model.compile( loss='categorical_crossentropy', optimizer=keras.optimizers.SGD(lr=0.1), @@ -498,12 +487,8 @@ class KerasCallbacksTest(test.TestCase): def make_model(): np.random.seed(1337) - model = keras.models.Sequential() - model.add( - keras.layers.Dense( - NUM_HIDDEN, input_dim=INPUT_DIM, activation='relu')) - model.add(keras.layers.Dense(NUM_CLASSES, activation='softmax')) - + model = testing_utils.get_small_sequential_mlp( + num_hidden=NUM_HIDDEN, num_classes=NUM_CLASSES, input_dim=INPUT_DIM) model.compile( loss='categorical_crossentropy', optimizer=keras.optimizers.SGD(lr=0.1), @@ -985,9 +970,8 @@ class KerasCallbacksTest(test.TestCase): yield x, y with self.test_session(): - model = keras.models.Sequential() - model.add(keras.layers.Dense(10, input_dim=100, activation='relu')) - model.add(keras.layers.Dense(10, activation='softmax')) + model = testing_utils.get_small_sequential_mlp( + num_hidden=10, num_classes=10, input_dim=100) model.compile( loss='categorical_crossentropy', optimizer='sgd', @@ -1083,11 +1067,8 @@ class KerasCallbacksTest(test.TestCase): y_test = keras.utils.to_categorical(y_test) y_train = keras.utils.to_categorical(y_train) - model = keras.models.Sequential() - model.add( - keras.layers.Dense( - NUM_HIDDEN, input_dim=INPUT_DIM, activation='relu')) - model.add(keras.layers.Dense(NUM_CLASSES, activation='softmax')) + model = testing_utils.get_small_sequential_mlp( + num_hidden=NUM_HIDDEN, num_classes=NUM_CLASSES, input_dim=INPUT_DIM) model.compile( loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy']) @@ -1179,40 +1160,36 @@ class KerasCallbacksTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def test_Tensorboard_eager(self): - with self.test_session(): - temp_dir = tempfile.mkdtemp(dir=self.get_temp_dir()) - self.addCleanup(shutil.rmtree, temp_dir, ignore_errors=True) - - (x_train, y_train), (x_test, y_test) = testing_utils.get_test_data( - train_samples=TRAIN_SAMPLES, - test_samples=TEST_SAMPLES, - input_shape=(INPUT_DIM,), - num_classes=NUM_CLASSES) - y_test = keras.utils.to_categorical(y_test) - y_train = keras.utils.to_categorical(y_train) - - model = keras.models.Sequential() - model.add( - keras.layers.Dense( - NUM_HIDDEN, input_dim=INPUT_DIM, activation='relu')) - model.add(keras.layers.Dense(NUM_CLASSES, activation='softmax')) - model.compile( - loss='binary_crossentropy', - optimizer=adam.AdamOptimizer(0.01), - metrics=['accuracy']) - - cbks = [keras.callbacks.TensorBoard(log_dir=temp_dir)] + temp_dir = tempfile.mkdtemp(dir=self.get_temp_dir()) + self.addCleanup(shutil.rmtree, temp_dir, ignore_errors=True) - model.fit( - x_train, - y_train, - batch_size=BATCH_SIZE, - validation_data=(x_test, y_test), - callbacks=cbks, - epochs=2, - verbose=0) + (x_train, y_train), (x_test, y_test) = testing_utils.get_test_data( + train_samples=TRAIN_SAMPLES, + test_samples=TEST_SAMPLES, + input_shape=(INPUT_DIM,), + num_classes=NUM_CLASSES) + y_test = keras.utils.to_categorical(y_test) + y_train = keras.utils.to_categorical(y_train) - self.assertTrue(os.path.exists(temp_dir)) + model = testing_utils.get_small_sequential_mlp( + num_hidden=NUM_HIDDEN, num_classes=NUM_CLASSES, input_dim=INPUT_DIM) + model.compile( + loss='binary_crossentropy', + optimizer=adam.AdamOptimizer(0.01), + metrics=['accuracy']) + + cbks = [keras.callbacks.TensorBoard(log_dir=temp_dir)] + + model.fit( + x_train, + y_train, + batch_size=BATCH_SIZE, + validation_data=(x_test, y_test), + callbacks=cbks, + epochs=2, + verbose=0) + + self.assertTrue(os.path.exists(temp_dir)) def test_RemoteMonitorWithJsonPayload(self): if requests is None: diff --git a/tensorflow/python/keras/constraints_test.py b/tensorflow/python/keras/constraints_test.py index 84e2db1033..4f674ea7c5 100644 --- a/tensorflow/python/keras/constraints_test.py +++ b/tensorflow/python/keras/constraints_test.py @@ -49,7 +49,7 @@ class KerasConstraintsTest(test.TestCase): assert fn.__class__ == ref_fn.__class__ def test_max_norm(self): - with self.test_session(): + with self.cached_session(): array = get_example_array() for m in get_test_values(): norm_instance = keras.constraints.max_norm(m) @@ -69,13 +69,13 @@ class KerasConstraintsTest(test.TestCase): self.assertAllClose(x_normed_actual, x_normed_target, rtol=1e-05) def test_non_neg(self): - with self.test_session(): + with self.cached_session(): non_neg_instance = keras.constraints.non_neg() normed = non_neg_instance(keras.backend.variable(get_example_array())) assert np.all(np.min(keras.backend.eval(normed), axis=1) == 0.) def test_unit_norm(self): - with self.test_session(): + with self.cached_session(): unit_norm_instance = keras.constraints.unit_norm() normalized = unit_norm_instance( keras.backend.variable(get_example_array())) @@ -87,7 +87,7 @@ class KerasConstraintsTest(test.TestCase): assert np.abs(largest_difference) < 10e-5 def test_min_max_norm(self): - with self.test_session(): + with self.cached_session(): array = get_example_array() for m in get_test_values(): norm_instance = keras.constraints.min_max_norm(min_value=m, diff --git a/tensorflow/python/keras/engine/base_layer.py b/tensorflow/python/keras/engine/base_layer.py index d6d3db21fb..b6b05c0311 100644 --- a/tensorflow/python/keras/engine/base_layer.py +++ b/tensorflow/python/keras/engine/base_layer.py @@ -18,7 +18,7 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function -import collections +import collections as collections_lib import enum # pylint: disable=g-bad-import-order import inspect # Necessary supplement to tf_inspect to deal with variadic args. @@ -42,7 +42,6 @@ from tensorflow.python.keras.utils.generic_utils import to_snake_case # pylint: from tensorflow.python.keras.utils.tf_utils import is_tensor_or_tensor_list # pylint: disable=unused-import from tensorflow.python.ops import array_ops from tensorflow.python.ops import init_ops -from tensorflow.python.ops import variable_scope as vs from tensorflow.python.ops import variables as tf_variables from tensorflow.python.training.checkpointable import base as checkpointable from tensorflow.python.util import function_utils @@ -50,6 +49,7 @@ from tensorflow.python.util import nest from tensorflow.python.util import tf_decorator from tensorflow.python.util import tf_inspect from tensorflow.python.util.tf_export import tf_export +from tensorflow.tools.docs import doc_controls class CallConvention(enum.Enum): @@ -79,6 +79,7 @@ class Layer(checkpointable.CheckpointableBase): Users will just instantiate a layer and then treat it as a callable. We recommend that descendants of `Layer` implement the following methods: + * `__init__()`: Save configuration in member variables * `build()`: Called once from `__call__`, when we know the shapes of inputs and `dtype`. Should have the calls to `add_weight()`, and then @@ -272,6 +273,7 @@ class Layer(checkpointable.CheckpointableBase): return [] return self._updates + @doc_controls.for_subclass_implementers def add_update(self, updates, inputs=None): """Add update op(s), potentially dependent on layer inputs. @@ -372,6 +374,7 @@ class Layer(checkpointable.CheckpointableBase): else: return self._losses + @doc_controls.for_subclass_implementers def add_loss(self, losses, inputs=None): """Add loss tensor(s), potentially dependent on layer inputs. @@ -463,10 +466,12 @@ class Layer(checkpointable.CheckpointableBase): """Creates the variables of the layer.""" self.built = True + @doc_controls.for_subclass_implementers def add_variable(self, *args, **kwargs): """Alias for `add_weight`.""" return self.add_weight(*args, **kwargs) + @doc_controls.for_subclass_implementers def add_weight(self, name, shape, @@ -477,9 +482,9 @@ class Layer(checkpointable.CheckpointableBase): constraint=None, partitioner=None, use_resource=None, - synchronization=vs.VariableSynchronization.AUTO, - aggregation=vs.VariableAggregation.NONE, - getter=None): + synchronization=tf_variables.VariableSynchronization.AUTO, + aggregation=tf_variables.VariableAggregation.NONE, + **kwargs): """Adds a new variable to the layer, or gets an existing one; returns it. Arguments: @@ -507,7 +512,8 @@ class Layer(checkpointable.CheckpointableBase): aggregation: Indicates how a distributed variable will be aggregated. Accepted values are constants defined in the class `tf.VariableAggregation`. - getter: Variable getter argument to be passed to the `Checkpointable` API. + **kwargs: Additional keyword arguments. Accepted values are `getter` and + `collections`. Returns: The created variable. Usually either a `Variable` or `ResourceVariable` @@ -520,6 +526,13 @@ class Layer(checkpointable.CheckpointableBase): ValueError: When giving unsupported dtype and no initializer or when trainable has been set to True with synchronization set as `ON_READ`. """ + # Validate optional keyword arguments. + for kwarg in kwargs: + if kwarg not in ['getter', 'collections']: + raise TypeError('Unknown keyword argument:', kwarg) + getter = kwargs.pop('getter', None) + collections = kwargs.pop('collections', None) + if dtype is None: dtype = self.dtype or backend.floatx() dtype = dtypes.as_dtype(dtype) @@ -527,7 +540,7 @@ class Layer(checkpointable.CheckpointableBase): regularizer = regularizers.get(regularizer) constraint = constraints.get(constraint) - if synchronization == vs.VariableSynchronization.ON_READ: + if synchronization == tf_variables.VariableSynchronization.ON_READ: if trainable: raise ValueError( 'Synchronization value can be set to ' @@ -568,8 +581,10 @@ class Layer(checkpointable.CheckpointableBase): trainable=trainable and self.trainable, partitioner=partitioner, use_resource=use_resource, + collections=collections, synchronization=synchronization, aggregation=aggregation) + backend.track_variable(variable) if regularizer is not None: # TODO(fchollet): in the future, this should be handled at the @@ -646,6 +661,7 @@ class Layer(checkpointable.CheckpointableBase): activity_regularization = self._activity_regularizer(output) self.add_loss(activity_regularization, inputs=inputs) + @doc_controls.for_subclass_implementers def call(self, inputs, **kwargs): # pylint: disable=unused-argument """This is where the layer's logic lives. @@ -1412,11 +1428,13 @@ class Layer(checkpointable.CheckpointableBase): 'instead.' % self.name) @property + @doc_controls.do_not_doc_inheritable def inbound_nodes(self): """Deprecated, do NOT use! Only for compatibility with external Keras.""" return self._inbound_nodes @property + @doc_controls.do_not_doc_inheritable def outbound_nodes(self): """Deprecated, do NOT use! Only for compatibility with external Keras.""" return self._outbound_nodes @@ -1871,7 +1889,7 @@ def get_default_graph_uid_map(): graph = ops.get_default_graph() name_uid_map = backend.PER_GRAPH_LAYER_NAME_UIDS.get(graph, None) if name_uid_map is None: - name_uid_map = collections.defaultdict(int) + name_uid_map = collections_lib.defaultdict(int) backend.PER_GRAPH_LAYER_NAME_UIDS[graph] = name_uid_map return name_uid_map @@ -1886,8 +1904,9 @@ def make_variable(name, validate_shape=True, constraint=None, use_resource=None, - synchronization=vs.VariableSynchronization.AUTO, - aggregation=vs.VariableAggregation.NONE, + collections=None, + synchronization=tf_variables.VariableSynchronization.AUTO, + aggregation=tf_variables.VariableAggregation.NONE, partitioner=None): # pylint: disable=unused-argument """Temporary util to create a variable (relies on `variable_scope.variable`). @@ -1915,10 +1934,12 @@ def make_variable(name, then this parameter is ignored and any added variables are also marked as non-trainable. `trainable` defaults to `True` unless `synchronization` is set to `ON_READ`. - caching_device: Passed to `vs.variable`. - validate_shape: Passed to `vs.variable`. + caching_device: Passed to `tf.Variable`. + validate_shape: Passed to `tf.Variable`. constraint: Constraint instance (callable). use_resource: Whether to use a `ResourceVariable`. + collections: List of graph collections keys. The new variable is added to + these collections. Defaults to `[GraphKeys.GLOBAL_VARIABLES]`. synchronization: Indicates when a distributed a variable will be aggregated. Accepted values are constants defined in the class `tf.VariableSynchronization`. By default the synchronization is set to @@ -1951,7 +1972,7 @@ def make_variable(name, if use_resource is None: use_resource = True - v = vs.variable( + v = tf_variables.Variable( initial_value=init_val, name=name, trainable=trainable, @@ -1960,6 +1981,7 @@ def make_variable(name, validate_shape=validate_shape, constraint=constraint, use_resource=use_resource, + collections=collections, synchronization=synchronization, aggregation=aggregation) return v diff --git a/tensorflow/python/keras/engine/network.py b/tensorflow/python/keras/engine/network.py index 708fa1c807..cd74e36e68 100644 --- a/tensorflow/python/keras/engine/network.py +++ b/tensorflow/python/keras/engine/network.py @@ -394,10 +394,10 @@ class Network(base_layer.Layer): no_dependency = isinstance(value, data_structures.NoDependency) value = data_structures.sticky_attribute_assignment( checkpointable=self, value=value, name=name) - if isinstance(value, ( - base_layer.Layer, - Network, - data_structures.CheckpointableDataStructure)): + if (isinstance(value, (base_layer.Layer, + Network, + data_structures.CheckpointableDataStructure)) + or checkpointable_layer_utils.has_weights(value)): try: is_graph_network = self._is_graph_network except AttributeError: @@ -689,14 +689,14 @@ class Network(base_layer.Layer): def trainable_weights(self): return checkpointable_layer_utils.gather_trainable_weights( trainable=self.trainable, - sub_layers=self.layers, + sub_layers=self._layers, extra_variables=self._extra_variables) @property def non_trainable_weights(self): return checkpointable_layer_utils.gather_non_trainable_weights( trainable=self.trainable, - sub_layers=self.layers, + sub_layers=self._layers, extra_variables=self._extra_variables) @property diff --git a/tensorflow/python/keras/engine/saving_test.py b/tensorflow/python/keras/engine/saving_test.py index b7c2e9cb53..441f3f4948 100644 --- a/tensorflow/python/keras/engine/saving_test.py +++ b/tensorflow/python/keras/engine/saving_test.py @@ -687,7 +687,7 @@ class TestWeightSavingAndLoadingTFFormat(test.TestCase): def test_keras_optimizer_warning(self): graph = ops.Graph() - with graph.as_default(), self.test_session(graph): + with graph.as_default(), self.session(graph): model = keras.models.Sequential() model.add(keras.layers.Dense(2, input_shape=(3,))) model.add(keras.layers.Dense(3)) @@ -741,7 +741,7 @@ class TestWeightSavingAndLoadingTFFormat(test.TestCase): def test_no_graph_pollution(self): with context.graph_mode(): graph = ops.Graph() - with graph.as_default(), self.test_session(graph) as session: + with graph.as_default(), self.session(graph) as session: model = SubclassedModel() temp_dir = self.get_temp_dir() prefix = os.path.join(temp_dir, 'ckpt') diff --git a/tensorflow/python/keras/engine/sequential.py b/tensorflow/python/keras/engine/sequential.py index 415b15fde1..9f4019e29c 100644 --- a/tensorflow/python/keras/engine/sequential.py +++ b/tensorflow/python/keras/engine/sequential.py @@ -239,9 +239,9 @@ class Sequential(Model): x = inputs for layer in self.layers: kwargs = {} - if 'mask' in tf_inspect.getargspec(layer.call).args: + if 'mask' in tf_inspect.getfullargspec(layer.call).args: kwargs['mask'] = mask - if 'training' in tf_inspect.getargspec(layer.call).args: + if 'training' in tf_inspect.getfullargspec(layer.call).args: kwargs['training'] = training if isinstance(layer, Network) and layer._compute_output_and_mask_jointly: @@ -332,6 +332,7 @@ class Sequential(Model): else: name = None build_input_shape = None + layer_configs = config model = cls(name=name) for layer_config in layer_configs: layer = layer_module.deserialize(layer_config, diff --git a/tensorflow/python/keras/engine/sequential_test.py b/tensorflow/python/keras/engine/sequential_test.py index 3f8e120df0..28af8d61bc 100644 --- a/tensorflow/python/keras/engine/sequential_test.py +++ b/tensorflow/python/keras/engine/sequential_test.py @@ -25,22 +25,12 @@ from tensorflow.python import keras from tensorflow.python.data.ops import dataset_ops from tensorflow.python.eager import function from tensorflow.python.framework import test_util as tf_test_util +from tensorflow.python.keras import testing_utils from tensorflow.python.ops import array_ops from tensorflow.python.platform import test from tensorflow.python.training import rmsprop -def _get_small_mlp(num_hidden, num_classes, input_dim=None): - model = keras.models.Sequential() - if input_dim: - model.add(keras.layers.Dense(num_hidden, activation='relu', - input_dim=input_dim)) - else: - model.add(keras.layers.Dense(num_hidden, activation='relu')) - model.add(keras.layers.Dense(num_classes, activation='softmax')) - return model - - class TestSequential(test.TestCase, parameterized.TestCase): """Most Sequential model API tests are covered in `training_test.py`. """ @@ -63,7 +53,8 @@ class TestSequential(test.TestCase, parameterized.TestCase): batch_size = 5 num_classes = 2 - model = _get_small_mlp(num_hidden, num_classes, input_dim) + model = testing_utils.get_small_sequential_mlp( + num_hidden, num_classes, input_dim) model.compile(loss='mse', optimizer=rmsprop.RMSPropOptimizer(1e-3)) x = np.random.random((batch_size, input_dim)) y = np.random.random((batch_size, num_classes)) @@ -94,7 +85,7 @@ class TestSequential(test.TestCase, parameterized.TestCase): batch_size = 5 num_classes = 2 - model = _get_small_mlp(num_hidden, num_classes) + model = testing_utils.get_small_sequential_mlp(num_hidden, num_classes) model.compile( loss='mse', optimizer=rmsprop.RMSPropOptimizer(1e-3), @@ -118,7 +109,7 @@ class TestSequential(test.TestCase, parameterized.TestCase): num_samples = 50 steps_per_epoch = 10 - model = _get_small_mlp(num_hidden, num_classes) + model = testing_utils.get_small_sequential_mlp(num_hidden, num_classes) model.compile( loss='mse', optimizer=rmsprop.RMSPropOptimizer(1e-3), @@ -145,9 +136,9 @@ class TestSequential(test.TestCase, parameterized.TestCase): def get_model(): if deferred: - model = _get_small_mlp(10, 4) + model = testing_utils.get_small_sequential_mlp(10, 4) else: - model = _get_small_mlp(10, 4, input_dim=3) + model = testing_utils.get_small_sequential_mlp(10, 4, input_dim=3) model.compile( optimizer=rmsprop.RMSPropOptimizer(1e-3), loss='categorical_crossentropy', @@ -262,7 +253,7 @@ class TestSequential(test.TestCase, parameterized.TestCase): batch_size = 5 num_classes = 2 - model = _get_small_mlp(num_hidden, num_classes) + model = testing_utils.get_small_sequential_mlp(num_hidden, num_classes) model.compile( loss='mse', optimizer=rmsprop.RMSPropOptimizer(1e-3), @@ -284,21 +275,21 @@ class TestSequential(test.TestCase, parameterized.TestCase): @tf_test_util.run_in_graph_and_eager_modes def test_sequential_shape_inference_deferred(self): - model = _get_small_mlp(4, 5) + model = testing_utils.get_small_sequential_mlp(4, 5) output_shape = model.compute_output_shape((None, 7)) self.assertEqual(tuple(output_shape.as_list()), (None, 5)) @tf_test_util.run_in_graph_and_eager_modes def test_sequential_build_deferred(self): - model = _get_small_mlp(4, 5) + model = testing_utils.get_small_sequential_mlp(4, 5) model.build((None, 10)) self.assertTrue(model.built) self.assertEqual(len(model.weights), 4) # Test with nested model - model = _get_small_mlp(4, 3) - inner_model = _get_small_mlp(4, 5) + model = testing_utils.get_small_sequential_mlp(4, 3) + inner_model = testing_utils.get_small_sequential_mlp(4, 5) model.add(inner_model) model.build((None, 10)) @@ -308,8 +299,8 @@ class TestSequential(test.TestCase, parameterized.TestCase): @tf_test_util.run_in_graph_and_eager_modes def test_sequential_nesting(self): - model = _get_small_mlp(4, 3) - inner_model = _get_small_mlp(4, 5) + model = testing_utils.get_small_sequential_mlp(4, 3) + inner_model = testing_utils.get_small_sequential_mlp(4, 5) model.add(inner_model) model.compile(loss='mse', optimizer=rmsprop.RMSPropOptimizer(1e-3)) @@ -353,7 +344,7 @@ class TestSequentialEagerIntegration(test.TestCase): @tf_test_util.run_in_graph_and_eager_modes def test_build_before_fit(self): # Fix for b/112433577 - model = _get_small_mlp(4, 5) + model = testing_utils.get_small_sequential_mlp(4, 5) model.compile(loss='mse', optimizer=rmsprop.RMSPropOptimizer(1e-3)) model.build((None, 6)) diff --git a/tensorflow/python/keras/engine/training.py b/tensorflow/python/keras/engine/training.py index f71388cadb..85d25411b4 100644 --- a/tensorflow/python/keras/engine/training.py +++ b/tensorflow/python/keras/engine/training.py @@ -800,18 +800,18 @@ class Model(Network): RuntimeError: If the model was never compiled. """ if sample_weight is not None and sample_weight.all(): - raise NotImplementedError('sample_weight is currently not supported when ' - 'using DistributionStrategy.') + raise NotImplementedError('`sample_weight` is currently not supported ' + 'when using DistributionStrategy.') if class_weight: - raise NotImplementedError('class_weight is currently not supported when ' - 'using DistributionStrategy.') + raise NotImplementedError('`class_weight` is currently not supported ' + 'when using DistributionStrategy.') # TODO(anjalisridhar): Can we use the iterator and getnext op cache? # We require users to pass Datasets since we distribute the dataset across # multiple devices. if not isinstance(x, dataset_ops.Dataset): - raise ValueError('When using DistributionStrategy you must specify a ' - 'Dataset object instead of a %s.' % type(x)) + raise ValueError('When using DistributionStrategy, model inputs should be' + ' Dataset instances; found instead %s.' % type(x)) # TODO(anjalisridhar): We want distribute_dataset() to accept a Dataset or a # function which returns a Dataset. Currently distribute_dataset() only # accepts a function that returns a Dataset. Once we add support for being @@ -834,8 +834,9 @@ class Model(Network): next_element = iterator.get_next() if not isinstance(next_element, (list, tuple)) or len(next_element) != 2: - raise ValueError('Please provide data as a list or tuple of 2 elements ' - ' - input and target pair. Received %s' % next_element) + raise ValueError('Please provide model inputs as a list or tuple of 2 ' + 'elements: input and target pair. ' + 'Received %s' % next_element) x, y = next_element # Validate that all the elements in x and y are of the same type and shape. # We can then pass the first element of x and y to `_standardize_weights` @@ -971,8 +972,9 @@ class Model(Network): 'required number of samples.') if not isinstance(next_element, (list, tuple)) or len(next_element) != 2: - raise ValueError('Please provide data as a list or tuple of 2 elements ' - ' - input and target pair. Received %s' % next_element) + raise ValueError('Please provide model inputs as a list or tuple of 2 ' + 'elements: input and target pair. ' + 'Received %s' % next_element) x, y = next_element x, y, sample_weights = self._standardize_weights(x, y, sample_weight, class_weight, batch_size) @@ -980,6 +982,10 @@ class Model(Network): def _standardize_weights(self, x, y, sample_weight=None, class_weight=None, batch_size=None,): + if sample_weight is not None and class_weight is not None: + logging.warning( + 'Received both a `sample_weight` and `class_weight` argument. ' + 'The `class_weight` argument will be ignored.') # First, we build/compile the model on the fly if necessary. all_inputs = [] is_build_called = False @@ -1721,6 +1727,13 @@ class Model(Network): if batch_size is None and steps is None: batch_size = 32 + # Turn off prefetching since this is currently not deterministic. Once + # b/112498930 is fixed we can turn it back on. + # `_prefetch_on_device` is currently a property of only `MirroredStrategy`. + if (self._distribution_strategy and + hasattr(self._distribution_strategy, '_prefetch_on_device')): + self._distribution_strategy._prefetch_on_device = False # pylint: disable=protected-access + # Validate and standardize user data. x, _, _ = self._standardize_user_data( x, check_steps=True, steps_name='steps', steps=steps) @@ -1729,8 +1742,12 @@ class Model(Network): return training_eager.predict_loop( self, x, batch_size=batch_size, verbose=verbose, steps=steps) elif self._distribution_strategy: - return training_distributed.predict_loop( + results = training_distributed.predict_loop( self, x, verbose=verbose, steps=steps) + # Turn prefetching back on since we turned it off previously. + if hasattr(self._distribution_strategy, '_prefetch_on_device'): + self._distribution_strategy._prefetch_on_device = True # pylint: disable=protected-access + return results else: return training_arrays.predict_loop( self, x, batch_size=batch_size, verbose=verbose, steps=steps) diff --git a/tensorflow/python/keras/engine/training_test.py b/tensorflow/python/keras/engine/training_test.py index 15e7d725de..bf5c7fd7f8 100644 --- a/tensorflow/python/keras/engine/training_test.py +++ b/tensorflow/python/keras/engine/training_test.py @@ -35,6 +35,8 @@ from tensorflow.python.keras import testing_utils from tensorflow.python.keras.engine.training_utils import weighted_masked_objective from tensorflow.python.keras.utils.generic_utils import slice_arrays from tensorflow.python.ops import array_ops +from tensorflow.python.ops import sparse_ops +from tensorflow.python.ops import variables as variables_lib from tensorflow.python.platform import test from tensorflow.python.platform import tf_logging as logging from tensorflow.python.training.rmsprop import RMSPropOptimizer @@ -49,289 +51,287 @@ class TrainingTest(test.TestCase): @tf_test_util.run_in_graph_and_eager_modes def test_fit_on_arrays(self): - with self.test_session(): - a = keras.layers.Input(shape=(3,), name='input_a') - b = keras.layers.Input(shape=(3,), name='input_b') - - dense = keras.layers.Dense(4, name='dense') - c = dense(a) - d = dense(b) - e = keras.layers.Dropout(0.5, name='dropout')(c) - - model = keras.models.Model([a, b], [d, e]) - - optimizer = RMSPropOptimizer(learning_rate=0.001) - loss = 'mse' - loss_weights = [1., 0.5] - model.compile( - optimizer, - loss, - metrics=[metrics_module.CategoricalAccuracy(), 'mae'], - loss_weights=loss_weights) - - input_a_np = np.random.random((10, 3)) - input_b_np = np.random.random((10, 3)) - - output_d_np = np.random.random((10, 4)) - output_e_np = np.random.random((10, 4)) - - # Test fit at different verbosity - model.fit( - [input_a_np, input_b_np], [output_d_np, output_e_np], - epochs=1, - batch_size=5, - verbose=0) - model.fit( - [input_a_np, input_b_np], [output_d_np, output_e_np], - epochs=1, - batch_size=5, - verbose=1) - model.fit( - [input_a_np, input_b_np], [output_d_np, output_e_np], - epochs=2, - batch_size=5, - verbose=2) - model.train_on_batch([input_a_np, input_b_np], [output_d_np, output_e_np]) - - # Test model with input data as a list of lists - model.fit( - [np.ndarray.tolist(input_a_np), np.ndarray.tolist(input_b_np)], - [output_d_np, output_e_np], - epochs=2, - batch_size=5, - verbose=2) + a = keras.layers.Input(shape=(3,), name='input_a') + b = keras.layers.Input(shape=(3,), name='input_b') - # Test with validation data - model.fit( - [input_a_np, input_b_np], [output_d_np, output_e_np], - validation_data=([input_a_np, input_b_np], [output_d_np, - output_e_np]), - epochs=1, - batch_size=5, - verbose=0) - model.fit( - [input_a_np, input_b_np], [output_d_np, output_e_np], - validation_data=([input_a_np, input_b_np], [output_d_np, - output_e_np]), - epochs=2, - batch_size=5, - verbose=1) - model.fit( - [input_a_np, input_b_np], [output_d_np, output_e_np], - validation_data=([input_a_np, input_b_np], [output_d_np, - output_e_np]), - epochs=2, - batch_size=5, - verbose=2) - # Test with validation split - model.fit( - [input_a_np, input_b_np], [output_d_np, output_e_np], - epochs=2, - batch_size=5, - verbose=0, - validation_split=0.2) + dense = keras.layers.Dense(4, name='dense') + c = dense(a) + d = dense(b) + e = keras.layers.Dropout(0.5, name='dropout')(c) - # Test with dictionary inputs - model.fit( - { - 'input_a': input_a_np, - 'input_b': input_b_np - }, { - 'dense': output_d_np, - 'dropout': output_e_np - }, - epochs=1, - batch_size=5, - verbose=0) - model.fit( - { - 'input_a': input_a_np, - 'input_b': input_b_np - }, { - 'dense': output_d_np, - 'dropout': output_e_np - }, - epochs=1, - batch_size=5, - verbose=1) - model.fit( - { - 'input_a': input_a_np, - 'input_b': input_b_np - }, { - 'dense': output_d_np, - 'dropout': output_e_np - }, - validation_data=({ - 'input_a': input_a_np, - 'input_b': input_b_np - }, { - 'dense': output_d_np, - 'dropout': output_e_np - }), - epochs=1, - batch_size=5, - verbose=0) - model.train_on_batch({ - 'input_a': input_a_np, - 'input_b': input_b_np - }, { - 'dense': output_d_np, - 'dropout': output_e_np - }) - - # Test with lists for loss, metrics - loss = ['mae', 'mse'] - model.compile( - optimizer, - loss, - metrics=[metrics_module.CategoricalAccuracy(), 'mae']) - model.fit( - [input_a_np, input_b_np], [output_d_np, output_e_np], - epochs=1, - batch_size=5, - verbose=0) + model = keras.models.Model([a, b], [d, e]) - # Test with dictionaries for loss, metrics, loss weights - loss = {'dense': 'mse', 'dropout': 'mae'} - loss_weights = {'dense': 1., 'dropout': 0.5} - metrics = { - 'dense': 'mse', - 'dropout': metrics_module.CategoricalAccuracy() - } - model.compile(optimizer, loss, metrics=metrics, loss_weights=loss_weights) + optimizer = RMSPropOptimizer(learning_rate=0.001) + loss = 'mse' + loss_weights = [1., 0.5] + model.compile( + optimizer, + loss, + metrics=[metrics_module.CategoricalAccuracy(), 'mae'], + loss_weights=loss_weights) + + input_a_np = np.random.random((10, 3)) + input_b_np = np.random.random((10, 3)) + + output_d_np = np.random.random((10, 4)) + output_e_np = np.random.random((10, 4)) + + # Test fit at different verbosity + model.fit( + [input_a_np, input_b_np], [output_d_np, output_e_np], + epochs=1, + batch_size=5, + verbose=0) + model.fit( + [input_a_np, input_b_np], [output_d_np, output_e_np], + epochs=1, + batch_size=5, + verbose=1) + model.fit( + [input_a_np, input_b_np], [output_d_np, output_e_np], + epochs=2, + batch_size=5, + verbose=2) + model.train_on_batch([input_a_np, input_b_np], [output_d_np, output_e_np]) + + # Test model with input data as a list of lists + model.fit( + [np.ndarray.tolist(input_a_np), np.ndarray.tolist(input_b_np)], + [output_d_np, output_e_np], + epochs=2, + batch_size=5, + verbose=2) + + # Test with validation data + model.fit( + [input_a_np, input_b_np], [output_d_np, output_e_np], + validation_data=([input_a_np, input_b_np], [output_d_np, + output_e_np]), + epochs=1, + batch_size=5, + verbose=0) + model.fit( + [input_a_np, input_b_np], [output_d_np, output_e_np], + validation_data=([input_a_np, input_b_np], [output_d_np, + output_e_np]), + epochs=2, + batch_size=5, + verbose=1) + model.fit( + [input_a_np, input_b_np], [output_d_np, output_e_np], + validation_data=([input_a_np, input_b_np], [output_d_np, + output_e_np]), + epochs=2, + batch_size=5, + verbose=2) + # Test with validation split + model.fit( + [input_a_np, input_b_np], [output_d_np, output_e_np], + epochs=2, + batch_size=5, + verbose=0, + validation_split=0.2) + + # Test with dictionary inputs + model.fit( + { + 'input_a': input_a_np, + 'input_b': input_b_np + }, { + 'dense': output_d_np, + 'dropout': output_e_np + }, + epochs=1, + batch_size=5, + verbose=0) + model.fit( + { + 'input_a': input_a_np, + 'input_b': input_b_np + }, { + 'dense': output_d_np, + 'dropout': output_e_np + }, + epochs=1, + batch_size=5, + verbose=1) + model.fit( + { + 'input_a': input_a_np, + 'input_b': input_b_np + }, { + 'dense': output_d_np, + 'dropout': output_e_np + }, + validation_data=({ + 'input_a': input_a_np, + 'input_b': input_b_np + }, { + 'dense': output_d_np, + 'dropout': output_e_np + }), + epochs=1, + batch_size=5, + verbose=0) + model.train_on_batch({ + 'input_a': input_a_np, + 'input_b': input_b_np + }, { + 'dense': output_d_np, + 'dropout': output_e_np + }) + + # Test with lists for loss, metrics + loss = ['mae', 'mse'] + model.compile( + optimizer, + loss, + metrics=[metrics_module.CategoricalAccuracy(), 'mae']) + model.fit( + [input_a_np, input_b_np], [output_d_np, output_e_np], + epochs=1, + batch_size=5, + verbose=0) + + # Test with dictionaries for loss, metrics, loss weights + loss = {'dense': 'mse', 'dropout': 'mae'} + loss_weights = {'dense': 1., 'dropout': 0.5} + metrics = { + 'dense': 'mse', + 'dropout': metrics_module.CategoricalAccuracy() + } + model.compile(optimizer, loss, metrics=metrics, loss_weights=loss_weights) + model.fit( + [input_a_np, input_b_np], [output_d_np, output_e_np], + epochs=1, + batch_size=5, + verbose=0) + + # Invalid use cases + with self.assertRaises(ValueError): + model.train_on_batch({'input_a': input_a_np}, + [output_d_np, output_e_np]) + with self.assertRaises(AttributeError): model.fit( [input_a_np, input_b_np], [output_d_np, output_e_np], epochs=1, - batch_size=5, + validation_data=([input_a_np, input_b_np], 0, 0), verbose=0) + with self.assertRaises(ValueError): + model.train_on_batch([input_a_np], [output_d_np, output_e_np]) + with self.assertRaises(AttributeError): + model.train_on_batch(1, [output_d_np, output_e_np]) + with self.assertRaises(ValueError): + model.train_on_batch(input_a_np, [output_d_np, output_e_np]) + with self.assertRaises(ValueError): + bad_input = np.random.random((11, 3)) + model.train_on_batch([bad_input, input_b_np], + [output_d_np, output_e_np]) + with self.assertRaises(ValueError): + bad_target = np.random.random((11, 4)) + model.train_on_batch([input_a_np, input_b_np], + [bad_target, output_e_np]) + + # Build single-input model + x = keras.layers.Input(shape=(3,), name='input_a') + y = keras.layers.Dense(4)(x) + model = keras.models.Model(x, y) + model.compile(optimizer, loss='mse') + # This will work + model.fit([input_a_np], output_d_np, epochs=1) + with self.assertRaises(ValueError): + model.fit([input_a_np, input_a_np], output_d_np, epochs=1) - # Invalid use cases - with self.assertRaises(ValueError): - model.train_on_batch({'input_a': input_a_np}, - [output_d_np, output_e_np]) - with self.assertRaises(AttributeError): - model.fit( - [input_a_np, input_b_np], [output_d_np, output_e_np], - epochs=1, - validation_data=([input_a_np, input_b_np], 0, 0), - verbose=0) - with self.assertRaises(ValueError): - model.train_on_batch([input_a_np], [output_d_np, output_e_np]) - with self.assertRaises(AttributeError): - model.train_on_batch(1, [output_d_np, output_e_np]) - with self.assertRaises(ValueError): - model.train_on_batch(input_a_np, [output_d_np, output_e_np]) - with self.assertRaises(ValueError): - bad_input = np.random.random((11, 3)) - model.train_on_batch([bad_input, input_b_np], - [output_d_np, output_e_np]) - with self.assertRaises(ValueError): - bad_target = np.random.random((11, 4)) - model.train_on_batch([input_a_np, input_b_np], - [bad_target, output_e_np]) - - # Build single-input model - x = keras.layers.Input(shape=(3,), name='input_a') - y = keras.layers.Dense(4)(x) - model = keras.models.Model(x, y) - model.compile(optimizer, loss='mse') - # This will work - model.fit([input_a_np], output_d_np, epochs=1) - with self.assertRaises(ValueError): - model.fit([input_a_np, input_a_np], output_d_np, epochs=1) - - # Test model on a list of floats - input_a_np = np.random.random((10, 3)) - input_b_np = np.random.random((10, 4)) + # Test model on a list of floats + input_a_np = np.random.random((10, 3)) + input_b_np = np.random.random((10, 4)) - model.fit([np.ndarray.tolist(input_a_np)], - [np.ndarray.tolist(input_b_np)], - epochs=2, - batch_size=5, - verbose=2) + model.fit([np.ndarray.tolist(input_a_np)], + [np.ndarray.tolist(input_b_np)], + epochs=2, + batch_size=5, + verbose=2) @tf_test_util.run_in_graph_and_eager_modes def test_evaluate_predict_on_arrays(self): - with self.test_session(): - a = keras.layers.Input(shape=(3,), name='input_a') - b = keras.layers.Input(shape=(3,), name='input_b') - - dense = keras.layers.Dense(4, name='dense') - c = dense(a) - d = dense(b) - e = keras.layers.Dropout(0.5, name='dropout')(c) - - model = keras.models.Model([a, b], [d, e]) - - optimizer = RMSPropOptimizer(learning_rate=0.001) - loss = 'mse' - loss_weights = [1., 0.5] - model.compile( - optimizer, - loss, - metrics=['mae', metrics_module.CategoricalAccuracy()], - loss_weights=loss_weights, - sample_weight_mode=None) + a = keras.layers.Input(shape=(3,), name='input_a') + b = keras.layers.Input(shape=(3,), name='input_b') - input_a_np = np.random.random((10, 3)) - input_b_np = np.random.random((10, 3)) + dense = keras.layers.Dense(4, name='dense') + c = dense(a) + d = dense(b) + e = keras.layers.Dropout(0.5, name='dropout')(c) - output_d_np = np.random.random((10, 4)) - output_e_np = np.random.random((10, 4)) + model = keras.models.Model([a, b], [d, e]) - # Test evaluate at different verbosity - out = model.evaluate( - [input_a_np, input_b_np], [output_d_np, output_e_np], - batch_size=5, - verbose=0) - self.assertEqual(len(out), 7) - out = model.evaluate( - [input_a_np, input_b_np], [output_d_np, output_e_np], - batch_size=5, - verbose=1) - self.assertEqual(len(out), 7) - out = model.evaluate( - [input_a_np, input_b_np], [output_d_np, output_e_np], - batch_size=5, - verbose=2) - self.assertEqual(len(out), 7) - out = model.test_on_batch([input_a_np, input_b_np], - [output_d_np, output_e_np]) - self.assertEqual(len(out), 7) - - # Test evaluate with dictionary inputs - model.evaluate( - { - 'input_a': input_a_np, - 'input_b': input_b_np - }, { - 'dense': output_d_np, - 'dropout': output_e_np - }, - batch_size=5, - verbose=0) - model.evaluate( - { - 'input_a': input_a_np, - 'input_b': input_b_np - }, { - 'dense': output_d_np, - 'dropout': output_e_np - }, - batch_size=5, - verbose=1) - - # Test predict - out = model.predict([input_a_np, input_b_np], batch_size=5) - self.assertEqual(len(out), 2) - out = model.predict({'input_a': input_a_np, 'input_b': input_b_np}) - self.assertEqual(len(out), 2) - out = model.predict_on_batch({ - 'input_a': input_a_np, - 'input_b': input_b_np - }) - self.assertEqual(len(out), 2) + optimizer = RMSPropOptimizer(learning_rate=0.001) + loss = 'mse' + loss_weights = [1., 0.5] + model.compile( + optimizer, + loss, + metrics=['mae', metrics_module.CategoricalAccuracy()], + loss_weights=loss_weights, + sample_weight_mode=None) + + input_a_np = np.random.random((10, 3)) + input_b_np = np.random.random((10, 3)) + + output_d_np = np.random.random((10, 4)) + output_e_np = np.random.random((10, 4)) + + # Test evaluate at different verbosity + out = model.evaluate( + [input_a_np, input_b_np], [output_d_np, output_e_np], + batch_size=5, + verbose=0) + self.assertEqual(len(out), 7) + out = model.evaluate( + [input_a_np, input_b_np], [output_d_np, output_e_np], + batch_size=5, + verbose=1) + self.assertEqual(len(out), 7) + out = model.evaluate( + [input_a_np, input_b_np], [output_d_np, output_e_np], + batch_size=5, + verbose=2) + self.assertEqual(len(out), 7) + out = model.test_on_batch([input_a_np, input_b_np], + [output_d_np, output_e_np]) + self.assertEqual(len(out), 7) + + # Test evaluate with dictionary inputs + model.evaluate( + { + 'input_a': input_a_np, + 'input_b': input_b_np + }, { + 'dense': output_d_np, + 'dropout': output_e_np + }, + batch_size=5, + verbose=0) + model.evaluate( + { + 'input_a': input_a_np, + 'input_b': input_b_np + }, { + 'dense': output_d_np, + 'dropout': output_e_np + }, + batch_size=5, + verbose=1) + + # Test predict + out = model.predict([input_a_np, input_b_np], batch_size=5) + self.assertEqual(len(out), 2) + out = model.predict({'input_a': input_a_np, 'input_b': input_b_np}) + self.assertEqual(len(out), 2) + out = model.predict_on_batch({ + 'input_a': input_a_np, + 'input_b': input_b_np + }) + self.assertEqual(len(out), 2) @tf_test_util.run_in_graph_and_eager_modes def test_invalid_loss(self): @@ -340,31 +340,27 @@ class TrainingTest(test.TestCase): test_samples = 1000 input_dim = 5 - with self.test_session(): - model = keras.models.Sequential() - model.add(keras.layers.Dense(10, input_shape=(input_dim,))) - model.add(keras.layers.Activation('relu')) - model.add(keras.layers.Dense(num_classes)) - model.add(keras.layers.Activation('softmax')) - optimizer = RMSPropOptimizer(learning_rate=0.001) - model.compile(optimizer, loss='categorical_crossentropy') - np.random.seed(1337) - (x_train, y_train), (_, _) = testing_utils.get_test_data( - train_samples=train_samples, - test_samples=test_samples, - input_shape=(input_dim,), - num_classes=num_classes) + model = testing_utils.get_small_sequential_mlp( + num_hidden=10, num_classes=num_classes, input_dim=input_dim) + optimizer = RMSPropOptimizer(learning_rate=0.001) + model.compile(optimizer, loss='categorical_crossentropy') + np.random.seed(1337) + (x_train, y_train), (_, _) = testing_utils.get_test_data( + train_samples=train_samples, + test_samples=test_samples, + input_shape=(input_dim,), + num_classes=num_classes) - with self.assertRaises(ValueError): - model.fit(x_train, np.concatenate([y_train, y_train], axis=-1)) + with self.assertRaises(ValueError): + model.fit(x_train, np.concatenate([y_train, y_train], axis=-1)) - if not context.executing_eagerly(): - # TODO(psv): Investigate these use cases in eager mode. - with self.assertRaises(ValueError): - model.fit(x_train, y_train) + if not context.executing_eagerly(): + # TODO(psv): Investigate these use cases in eager mode. + with self.assertRaises(ValueError): + model.fit(x_train, y_train) - with self.assertRaises(ValueError): - model.compile(optimizer, loss=None) + with self.assertRaises(ValueError): + model.compile(optimizer, loss=None) def test_training_on_sparse_data_with_dense_placeholders(self): if scipy_sparse is None: @@ -392,6 +388,19 @@ class TrainingTest(test.TestCase): epochs=1, batch_size=2, validation_split=0.5) model.evaluate(test_inputs, test_outputs, batch_size=2) + def test_compile_with_sparse_placeholders(self): + with self.test_session(): + input_layer = keras.layers.Input(shape=(10,), sparse=True) + weights = variables_lib.Variable( + np.ones((10, 1)).astype(np.float32), name='weights') + weights_mult = lambda x: sparse_ops.sparse_tensor_dense_matmul(x, weights) + output_layer = keras.layers.Lambda(weights_mult)(input_layer) + model = keras.Model([input_layer], output_layer) + model.compile( + loss='binary_crossentropy', + optimizer=keras.optimizers.Adam(lr=0.0001), + metrics=['accuracy']) + def test_that_trainable_disables_updates(self): val_a = np.random.random((10, 4)) val_out = np.random.random((10, 4)) @@ -468,67 +477,63 @@ class LossWeightingTest(test.TestCase): input_dim = 5 learning_rate = 0.001 - with self.test_session(): - model = keras.models.Sequential() - model.add(keras.layers.Dense(10, input_shape=(input_dim,))) - model.add(keras.layers.Activation('relu')) - model.add(keras.layers.Dense(num_classes)) - model.add(keras.layers.Activation('softmax')) - model.compile( - loss='categorical_crossentropy', - metrics=['acc'], - weighted_metrics=['mae'], - optimizer=RMSPropOptimizer(learning_rate=learning_rate)) - - np.random.seed(1337) - (x_train, y_train), (x_test, y_test) = testing_utils.get_test_data( - train_samples=train_samples, - test_samples=test_samples, - input_shape=(input_dim,), - num_classes=num_classes) - int_y_test = y_test.copy() - int_y_train = y_train.copy() - # convert class vectors to binary class matrices - y_train = keras.utils.to_categorical(y_train, num_classes) - y_test = keras.utils.to_categorical(y_test, num_classes) - test_ids = np.where(int_y_test == np.array(weighted_class))[0] - - class_weight = dict([(i, 1.) for i in range(num_classes)]) - class_weight[weighted_class] = 2. - - sample_weight = np.ones((y_train.shape[0])) - sample_weight[int_y_train == weighted_class] = 2. - - model.fit( - x_train, - y_train, - batch_size=batch_size, - epochs=epochs // 3, - verbose=0, - class_weight=class_weight, - validation_data=(x_train, y_train, sample_weight)) - model.fit( - x_train, - y_train, - batch_size=batch_size, - epochs=epochs // 2, - verbose=0, - class_weight=class_weight) - model.fit( - x_train, - y_train, - batch_size=batch_size, - epochs=epochs // 2, - verbose=0, - class_weight=class_weight, - validation_split=0.1) - - model.train_on_batch( - x_train[:batch_size], y_train[:batch_size], class_weight=class_weight) - ref_score = model.evaluate(x_test, y_test, verbose=0) - score = model.evaluate( - x_test[test_ids, :], y_test[test_ids, :], verbose=0) - self.assertLess(score[0], ref_score[0]) + model = testing_utils.get_small_sequential_mlp( + num_hidden=10, num_classes=num_classes, input_dim=input_dim) + model.compile( + loss='categorical_crossentropy', + metrics=['acc'], + weighted_metrics=['mae'], + optimizer=RMSPropOptimizer(learning_rate=learning_rate)) + + np.random.seed(1337) + (x_train, y_train), (x_test, y_test) = testing_utils.get_test_data( + train_samples=train_samples, + test_samples=test_samples, + input_shape=(input_dim,), + num_classes=num_classes) + int_y_test = y_test.copy() + int_y_train = y_train.copy() + # convert class vectors to binary class matrices + y_train = keras.utils.to_categorical(y_train, num_classes) + y_test = keras.utils.to_categorical(y_test, num_classes) + test_ids = np.where(int_y_test == np.array(weighted_class))[0] + + class_weight = dict([(i, 1.) for i in range(num_classes)]) + class_weight[weighted_class] = 2. + + sample_weight = np.ones((y_train.shape[0])) + sample_weight[int_y_train == weighted_class] = 2. + + model.fit( + x_train, + y_train, + batch_size=batch_size, + epochs=epochs // 3, + verbose=0, + class_weight=class_weight, + validation_data=(x_train, y_train, sample_weight)) + model.fit( + x_train, + y_train, + batch_size=batch_size, + epochs=epochs // 2, + verbose=0, + class_weight=class_weight) + model.fit( + x_train, + y_train, + batch_size=batch_size, + epochs=epochs // 2, + verbose=0, + class_weight=class_weight, + validation_split=0.1) + + model.train_on_batch( + x_train[:batch_size], y_train[:batch_size], class_weight=class_weight) + ref_score = model.evaluate(x_test, y_test, verbose=0) + score = model.evaluate( + x_test[test_ids, :], y_test[test_ids, :], verbose=0) + self.assertLess(score[0], ref_score[0]) @tf_test_util.run_in_graph_and_eager_modes def test_sample_weights(self): @@ -541,63 +546,82 @@ class LossWeightingTest(test.TestCase): input_dim = 5 learning_rate = 0.001 - with self.test_session(): - model = keras.models.Sequential() - model.add(keras.layers.Dense(10, input_shape=(input_dim,))) - model.add(keras.layers.Activation('relu')) - model.add(keras.layers.Dense(num_classes)) - model.add(keras.layers.Activation('softmax')) - model.compile( - RMSPropOptimizer(learning_rate=learning_rate), - metrics=['acc'], - weighted_metrics=['mae'], - loss='categorical_crossentropy') - - np.random.seed(43) - (x_train, y_train), (x_test, y_test) = testing_utils.get_test_data( - train_samples=train_samples, - test_samples=test_samples, - input_shape=(input_dim,), - num_classes=num_classes) - int_y_test = y_test.copy() - int_y_train = y_train.copy() - # convert class vectors to binary class matrices - y_train = keras.utils.to_categorical(y_train, num_classes) - y_test = keras.utils.to_categorical(y_test, num_classes) - test_ids = np.where(int_y_test == np.array(weighted_class))[0] - - sample_weight = np.ones((y_train.shape[0])) - sample_weight[int_y_train == weighted_class] = 2. + model = testing_utils.get_small_sequential_mlp( + num_hidden=10, num_classes=num_classes, input_dim=input_dim) + model.compile( + RMSPropOptimizer(learning_rate=learning_rate), + metrics=['acc'], + weighted_metrics=['mae'], + loss='categorical_crossentropy') + + np.random.seed(43) + (x_train, y_train), (x_test, y_test) = testing_utils.get_test_data( + train_samples=train_samples, + test_samples=test_samples, + input_shape=(input_dim,), + num_classes=num_classes) + int_y_test = y_test.copy() + int_y_train = y_train.copy() + # convert class vectors to binary class matrices + y_train = keras.utils.to_categorical(y_train, num_classes) + y_test = keras.utils.to_categorical(y_test, num_classes) + test_ids = np.where(int_y_test == np.array(weighted_class))[0] + + sample_weight = np.ones((y_train.shape[0])) + sample_weight[int_y_train == weighted_class] = 2. + + model.fit( + x_train, + y_train, + batch_size=batch_size, + epochs=epochs // 3, + verbose=0, + sample_weight=sample_weight) + model.fit( + x_train, + y_train, + batch_size=batch_size, + epochs=epochs // 3, + verbose=0, + sample_weight=sample_weight, + validation_split=0.1) + + model.train_on_batch( + x_train[:batch_size], + y_train[:batch_size], + sample_weight=sample_weight[:batch_size]) + model.test_on_batch( + x_train[:batch_size], + y_train[:batch_size], + sample_weight=sample_weight[:batch_size]) + ref_score = model.evaluate(x_test, y_test, verbose=0) + if not context.executing_eagerly(): + score = model.evaluate( + x_test[test_ids, :], y_test[test_ids, :], verbose=0) + self.assertLess(score[0], ref_score[0]) + @tf_test_util.run_in_graph_and_eager_modes + def test_warning_for_concurrent_sample_and_class_weights(self): + model = keras.models.Sequential() + model.add(keras.layers.Dense(10, input_shape=(3,))) + model.compile( + loss='mse', + optimizer=RMSPropOptimizer(learning_rate=0.01)) + x_train = np.random.random((10, 3)) + y_train = np.random.random((10, 10)) + sample_weight = np.ones((y_train.shape[0])) + class_weight = {0: 1., 1: 1.} + + with test.mock.patch.object(logging, 'warning') as mock_log: model.fit( x_train, y_train, - batch_size=batch_size, - epochs=epochs // 3, - verbose=0, - sample_weight=sample_weight) - model.fit( - x_train, - y_train, - batch_size=batch_size, - epochs=epochs // 3, + epochs=1, verbose=0, sample_weight=sample_weight, - validation_split=0.1) - - model.train_on_batch( - x_train[:batch_size], - y_train[:batch_size], - sample_weight=sample_weight[:batch_size]) - model.test_on_batch( - x_train[:batch_size], - y_train[:batch_size], - sample_weight=sample_weight[:batch_size]) - ref_score = model.evaluate(x_test, y_test, verbose=0) - if not context.executing_eagerly(): - score = model.evaluate( - x_test[test_ids, :], y_test[test_ids, :], verbose=0) - self.assertLess(score[0], ref_score[0]) + class_weight=class_weight) + msg = ('The `class_weight` argument will be ignored.') + self.assertRegexpMatches(str(mock_log.call_args), msg) @tf_test_util.run_in_graph_and_eager_modes def test_temporal_sample_weights(self): @@ -1465,9 +1489,10 @@ class TestTrainingWithDataTensors(test.TestCase): output_a_np = np.random.random((10, 4)) output_b_np = np.random.random((10, 3)) - a = keras.Input( - tensor=keras.backend.variables_module.Variable(input_a_np, - dtype='float32')) + input_v = keras.backend.variables_module.Variable( + input_a_np, dtype='float32') + self.evaluate(variables_lib.variables_initializer([input_v])) + a = keras.Input(tensor=input_v) b = keras.Input(shape=(3,), name='input_b') a_2 = keras.layers.Dense(4, name='dense_1')(a) @@ -1512,9 +1537,8 @@ class TestTrainingWithDataTensors(test.TestCase): # Now test a model with a single input # i.e. we don't pass any data to fit the model. - a = keras.Input( - tensor=keras.backend.variables_module.Variable(input_a_np, - dtype='float32')) + self.evaluate(variables_lib.variables_initializer([input_v])) + a = keras.Input(tensor=input_v) a_2 = keras.layers.Dense(4, name='dense_1')(a) a_2 = keras.layers.Dropout(0.5, name='dropout')(a_2) model = keras.models.Model(a, a_2) @@ -1552,9 +1576,8 @@ class TestTrainingWithDataTensors(test.TestCase): # Same, without learning phase # i.e. we don't pass any data to fit the model. - a = keras.Input( - tensor=keras.backend.variables_module.Variable(input_a_np, - dtype='float32')) + self.evaluate(variables_lib.variables_initializer([input_v])) + a = keras.Input(tensor=input_v) a_2 = keras.layers.Dense(4, name='dense_1')(a) model = keras.models.Model(a, a_2) model.summary() @@ -1677,9 +1700,10 @@ class TestTrainingWithDataTensors(test.TestCase): out = model.evaluate(input_a_np, None) # Test model with no external data at all. - a = keras.Input( - tensor=keras.backend.variables_module.Variable(input_a_np, - dtype='float32')) + input_v = keras.backend.variables_module.Variable( + input_a_np, dtype='float32') + self.evaluate(variables_lib.variables_initializer([input_v])) + a = keras.Input(tensor=input_v) a_2 = keras.layers.Dense(4, name='dense_1')(a) a_2 = keras.layers.Dropout(0.5, name='dropout')(a_2) model = keras.models.Model(a, a_2) @@ -1720,9 +1744,8 @@ class TestTrainingWithDataTensors(test.TestCase): self.assertEqual(out.shape, (10 * 3, 4)) # Test multi-output model with no external data at all. - a = keras.Input( - tensor=keras.backend.variables_module.Variable(input_a_np, - dtype='float32')) + self.evaluate(variables_lib.variables_initializer([input_v])) + a = keras.Input(tensor=input_v) a_1 = keras.layers.Dense(4, name='dense_1')(a) a_2 = keras.layers.Dropout(0.5, name='dropout')(a_1) model = keras.models.Model(a, [a_1, a_2]) @@ -1886,223 +1909,198 @@ class TestTrainingWithDatasetIterators(test.TestCase): @tf_test_util.run_in_graph_and_eager_modes def test_training_and_eval_methods_on_iterators_single_io(self): - with self.test_session(): - x = keras.layers.Input(shape=(3,), name='input') - y = keras.layers.Dense(4, name='dense')(x) - model = keras.Model(x, y) - - optimizer = RMSPropOptimizer(learning_rate=0.001) - loss = 'mse' - metrics = ['mae', metrics_module.CategoricalAccuracy()] - model.compile(optimizer, loss, metrics=metrics) - - inputs = np.zeros((10, 3)) - targets = np.zeros((10, 4)) - dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) - dataset = dataset.repeat(100) - dataset = dataset.batch(10) - iterator = dataset.make_one_shot_iterator() - - model.fit(iterator, epochs=1, steps_per_epoch=2, verbose=1) - model.evaluate(iterator, steps=2, verbose=1) - model.predict(iterator, steps=2) - model.train_on_batch(iterator) - model.test_on_batch(iterator) - model.predict_on_batch(iterator) - - # Test with validation data + model = testing_utils.get_small_functional_mlp(1, 4, input_dim=3) + optimizer = RMSPropOptimizer(learning_rate=0.001) + loss = 'mse' + metrics = ['mae', metrics_module.CategoricalAccuracy()] + model.compile(optimizer, loss, metrics=metrics) + + inputs = np.zeros((10, 3)) + targets = np.zeros((10, 4)) + dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) + dataset = dataset.repeat(100) + dataset = dataset.batch(10) + iterator = dataset.make_one_shot_iterator() + + model.fit(iterator, epochs=1, steps_per_epoch=2, verbose=1) + model.evaluate(iterator, steps=2, verbose=1) + model.predict(iterator, steps=2) + model.train_on_batch(iterator) + model.test_on_batch(iterator) + model.predict_on_batch(iterator) + + # Test with validation data + model.fit(iterator, + epochs=1, steps_per_epoch=2, verbose=0, + validation_data=iterator, validation_steps=2) + # Test with validation split + with self.assertRaisesRegexp( + ValueError, '`validation_split` argument is not supported ' + 'when input `x` is a dataset or a dataset iterator'): model.fit(iterator, epochs=1, steps_per_epoch=2, verbose=0, - validation_data=iterator, validation_steps=2) - # Test with validation split - with self.assertRaisesRegexp( - ValueError, '`validation_split` argument is not supported ' - 'when input `x` is a dataset or a dataset iterator'): - model.fit(iterator, - epochs=1, steps_per_epoch=2, verbose=0, - validation_split=0.5, validation_steps=2) - - # Test with sample weight. - sample_weight = np.random.random((10,)) - with self.assertRaisesRegexp( - ValueError, '`sample_weight` argument is not supported ' - 'when input `x` is a dataset or a dataset iterator'): - model.fit( - iterator, - epochs=1, - steps_per_epoch=2, - verbose=0, - sample_weight=sample_weight) + validation_split=0.5, validation_steps=2) - # Test invalid usage - with self.assertRaisesRegexp(ValueError, - 'you should not specify a target'): - model.fit(iterator, iterator, - epochs=1, steps_per_epoch=2, verbose=0) + # Test with sample weight. + sample_weight = np.random.random((10,)) + with self.assertRaisesRegexp( + ValueError, '`sample_weight` argument is not supported ' + 'when input `x` is a dataset or a dataset iterator'): + model.fit( + iterator, + epochs=1, + steps_per_epoch=2, + verbose=0, + sample_weight=sample_weight) - with self.assertRaisesRegexp( - ValueError, 'you should specify the `steps_per_epoch` argument'): - model.fit(iterator, epochs=1, verbose=0) - with self.assertRaisesRegexp(ValueError, - 'you should specify the `steps` argument'): - model.evaluate(iterator, verbose=0) - with self.assertRaisesRegexp(ValueError, - 'you should specify the `steps` argument'): - model.predict(iterator, verbose=0) + # Test invalid usage + with self.assertRaisesRegexp(ValueError, + 'you should not specify a target'): + model.fit(iterator, iterator, + epochs=1, steps_per_epoch=2, verbose=0) + + with self.assertRaisesRegexp( + ValueError, 'you should specify the `steps_per_epoch` argument'): + model.fit(iterator, epochs=1, verbose=0) + with self.assertRaisesRegexp(ValueError, + 'you should specify the `steps` argument'): + model.evaluate(iterator, verbose=0) + with self.assertRaisesRegexp(ValueError, + 'you should specify the `steps` argument'): + model.predict(iterator, verbose=0) @tf_test_util.run_in_graph_and_eager_modes def test_get_next_op_created_once(self): - with self.test_session(): - x = keras.layers.Input(shape=(3,), name='input') - y = keras.layers.Dense(4, name='dense')(x) - model = keras.Model(x, y) - - optimizer = RMSPropOptimizer(learning_rate=0.001) - loss = 'mse' - metrics = ['mae'] - model.compile(optimizer, loss, metrics=metrics) - - inputs = np.zeros((10, 3)) - targets = np.zeros((10, 4)) - dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) - dataset = dataset.repeat(100) - dataset = dataset.batch(10) - iterator = dataset.make_one_shot_iterator() - - model.fit(iterator, epochs=1, steps_per_epoch=2, verbose=1) - # Finalize graph to make sure we are not appending another iterator - # get_next op in the graph. - ops.get_default_graph().finalize() - model.fit(iterator, epochs=1, steps_per_epoch=2, verbose=1) + model = testing_utils.get_small_functional_mlp(1, 4, input_dim=3) + optimizer = RMSPropOptimizer(learning_rate=0.001) + loss = 'mse' + metrics = ['mae'] + model.compile(optimizer, loss, metrics=metrics) + + inputs = np.zeros((10, 3)) + targets = np.zeros((10, 4)) + dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) + dataset = dataset.repeat(100) + dataset = dataset.batch(10) + iterator = dataset.make_one_shot_iterator() + + model.fit(iterator, epochs=1, steps_per_epoch=2, verbose=1) + # Finalize graph to make sure we are not appending another iterator + # get_next op in the graph. + ops.get_default_graph().finalize() + model.fit(iterator, epochs=1, steps_per_epoch=2, verbose=1) @tf_test_util.run_in_graph_and_eager_modes def test_iterators_running_out_of_data(self): - with self.test_session(): - x = keras.layers.Input(shape=(3,), name='input') - y = keras.layers.Dense(4, name='dense')(x) - model = keras.Model(x, y) - - optimizer = RMSPropOptimizer(learning_rate=0.001) - loss = 'mse' - metrics = ['mae'] - model.compile(optimizer, loss, metrics=metrics) + model = testing_utils.get_small_functional_mlp(1, 4, input_dim=3) + optimizer = RMSPropOptimizer(learning_rate=0.001) + loss = 'mse' + metrics = ['mae'] + model.compile(optimizer, loss, metrics=metrics) - inputs = np.zeros((10, 3)) - targets = np.zeros((10, 4)) - dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) - dataset = dataset.repeat(2) - dataset = dataset.batch(10) - iterator = dataset.make_one_shot_iterator() + inputs = np.zeros((10, 3)) + targets = np.zeros((10, 4)) + dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) + dataset = dataset.repeat(2) + dataset = dataset.batch(10) + iterator = dataset.make_one_shot_iterator() - with test.mock.patch.object(logging, 'warning') as mock_log: - model.fit(iterator, epochs=1, steps_per_epoch=3, verbose=0) - self.assertRegexpMatches( - str(mock_log.call_args), - 'dataset iterator ran out of data') + with test.mock.patch.object(logging, 'warning') as mock_log: + model.fit(iterator, epochs=1, steps_per_epoch=3, verbose=0) + self.assertRegexpMatches( + str(mock_log.call_args), + 'dataset iterator ran out of data') class TestTrainingWithDataset(test.TestCase): @tf_test_util.run_in_graph_and_eager_modes def test_calling_model_on_same_dataset(self): - with self.test_session(): - x = keras.layers.Input(shape=(3,), name='input') - y = keras.layers.Dense(4, name='dense')(x) - model = keras.Model(x, y) - - optimizer = RMSPropOptimizer(learning_rate=0.001) - loss = 'mse' - metrics = ['mae'] - model.compile(optimizer, loss, metrics=metrics) - - inputs = np.zeros((10, 3)) - targets = np.zeros((10, 4)) - dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) - dataset = dataset.repeat(100) - dataset = dataset.batch(10) - - # Call fit with validation data - model.fit(dataset, epochs=1, steps_per_epoch=2, verbose=0, - validation_data=dataset, validation_steps=2) - # Finalize the graph to make sure new ops aren't added when calling on the - # same dataset - ops.get_default_graph().finalize() - model.fit(dataset, epochs=1, steps_per_epoch=2, verbose=0, - validation_data=dataset, validation_steps=2) + model = testing_utils.get_small_functional_mlp(1, 4, input_dim=3) + optimizer = RMSPropOptimizer(learning_rate=0.001) + loss = 'mse' + metrics = ['mae'] + model.compile(optimizer, loss, metrics=metrics) + + inputs = np.zeros((10, 3)) + targets = np.zeros((10, 4)) + dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) + dataset = dataset.repeat(100) + dataset = dataset.batch(10) + + # Call fit with validation data + model.fit(dataset, epochs=1, steps_per_epoch=2, verbose=0, + validation_data=dataset, validation_steps=2) + # Finalize the graph to make sure new ops aren't added when calling on the + # same dataset + ops.get_default_graph().finalize() + model.fit(dataset, epochs=1, steps_per_epoch=2, verbose=0, + validation_data=dataset, validation_steps=2) @tf_test_util.run_in_graph_and_eager_modes def test_training_and_eval_methods_on_dataset(self): - with self.test_session(): - x = keras.layers.Input(shape=(3,), name='input') - y = keras.layers.Dense(4, name='dense')(x) - model = keras.Model(x, y) - - optimizer = RMSPropOptimizer(learning_rate=0.001) - loss = 'mse' - metrics = ['mae', metrics_module.CategoricalAccuracy()] - model.compile(optimizer, loss, metrics=metrics) - - inputs = np.zeros((10, 3)) - targets = np.zeros((10, 4)) - dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) - dataset = dataset.repeat(100) - dataset = dataset.batch(10) - - model.fit(dataset, epochs=1, steps_per_epoch=2, verbose=1) - model.evaluate(dataset, steps=2, verbose=1) - model.predict(dataset, steps=2) - model.train_on_batch(dataset) - model.predict_on_batch(dataset) - - # Test with validation data - model.fit(dataset, epochs=1, steps_per_epoch=2, verbose=0, - validation_data=dataset, validation_steps=2) - - # Test with validation split - with self.assertRaisesRegexp( - ValueError, '`validation_split` argument is not supported ' - 'when input `x` is a dataset or a dataset iterator'): - model.fit(dataset, - epochs=1, steps_per_epoch=2, verbose=0, - validation_split=0.5, validation_steps=2) - - # Test with sample weight. - sample_weight = np.random.random((10,)) - with self.assertRaisesRegexp( - ValueError, '`sample_weight` argument is not supported ' - 'when input `x` is a dataset or a dataset iterator'): - model.fit( - dataset, - epochs=1, - steps_per_epoch=2, - verbose=0, - sample_weight=sample_weight) + model = testing_utils.get_small_functional_mlp(1, 4, input_dim=3) + optimizer = RMSPropOptimizer(learning_rate=0.001) + loss = 'mse' + metrics = ['mae', metrics_module.CategoricalAccuracy()] + model.compile(optimizer, loss, metrics=metrics) + + inputs = np.zeros((10, 3)) + targets = np.zeros((10, 4)) + dataset = dataset_ops.Dataset.from_tensor_slices((inputs, targets)) + dataset = dataset.repeat(100) + dataset = dataset.batch(10) + + model.fit(dataset, epochs=1, steps_per_epoch=2, verbose=1) + model.evaluate(dataset, steps=2, verbose=1) + model.predict(dataset, steps=2) + model.train_on_batch(dataset) + model.predict_on_batch(dataset) + + # Test with validation data + model.fit(dataset, epochs=1, steps_per_epoch=2, verbose=0, + validation_data=dataset, validation_steps=2) + + # Test with validation split + with self.assertRaisesRegexp( + ValueError, '`validation_split` argument is not supported ' + 'when input `x` is a dataset or a dataset iterator'): + model.fit(dataset, + epochs=1, steps_per_epoch=2, verbose=0, + validation_split=0.5, validation_steps=2) - # Test invalid usage - with self.assertRaisesRegexp(ValueError, - 'you should not specify a target'): - model.fit(dataset, dataset, - epochs=1, steps_per_epoch=2, verbose=0) + # Test with sample weight. + sample_weight = np.random.random((10,)) + with self.assertRaisesRegexp( + ValueError, '`sample_weight` argument is not supported ' + 'when input `x` is a dataset or a dataset iterator'): + model.fit( + dataset, + epochs=1, + steps_per_epoch=2, + verbose=0, + sample_weight=sample_weight) - with self.assertRaisesRegexp( - ValueError, 'you should specify the `steps_per_epoch` argument'): - model.fit(dataset, epochs=1, verbose=0) - with self.assertRaisesRegexp(ValueError, - 'you should specify the `steps` argument'): - model.evaluate(dataset, verbose=0) - with self.assertRaisesRegexp(ValueError, - 'you should specify the `steps` argument'): - model.predict(dataset, verbose=0) + # Test invalid usage + with self.assertRaisesRegexp(ValueError, + 'you should not specify a target'): + model.fit(dataset, dataset, + epochs=1, steps_per_epoch=2, verbose=0) + + with self.assertRaisesRegexp( + ValueError, 'you should specify the `steps_per_epoch` argument'): + model.fit(dataset, epochs=1, verbose=0) + with self.assertRaisesRegexp(ValueError, + 'you should specify the `steps` argument'): + model.evaluate(dataset, verbose=0) + with self.assertRaisesRegexp(ValueError, + 'you should specify the `steps` argument'): + model.predict(dataset, verbose=0) def test_dataset_input_shape_validation(self): with self.test_session(): - x = keras.layers.Input(shape=(3,), name='input') - y = keras.layers.Dense(4, name='dense')(x) - model = keras.Model(x, y) - - optimizer = RMSPropOptimizer(learning_rate=0.001) - loss = 'mse' - model.compile(optimizer, loss) + model = testing_utils.get_small_functional_mlp(1, 4, input_dim=3) + model.compile(optimizer=RMSPropOptimizer(learning_rate=0.001), loss='mse') # User forgets to batch the dataset inputs = np.zeros((10, 3)) @@ -2111,7 +2109,7 @@ class TestTrainingWithDataset(test.TestCase): dataset = dataset.repeat(100) with self.assertRaisesRegexp(ValueError, - 'expected input to have 2 dimensions'): + r'expected (.*?) to have 2 dimensions'): model.train_on_batch(dataset) # Wrong input shape @@ -2122,7 +2120,7 @@ class TestTrainingWithDataset(test.TestCase): dataset = dataset.batch(10) with self.assertRaisesRegexp(ValueError, - 'expected input to have shape'): + r'expected (.*?) to have shape \(3,\)'): model.train_on_batch(dataset) @@ -2153,134 +2151,127 @@ class TestTrainingWithMetrics(test.TestCase): @tf_test_util.run_in_graph_and_eager_modes def test_metrics_correctness(self): - with self.test_session(): - model = keras.Sequential() - model.add( - keras.layers.Dense( - 3, activation='relu', input_dim=4, kernel_initializer='ones')) - model.add( - keras.layers.Dense( - 1, activation='sigmoid', kernel_initializer='ones')) - model.compile( - loss='mae', - metrics=['accuracy', metrics_module.BinaryAccuracy()], - optimizer=RMSPropOptimizer(learning_rate=0.001)) - - # verify correctness of stateful and stateless metrics. - x = np.ones((100, 4)) - y = np.ones((100, 1)) - outs = model.evaluate(x, y) - self.assertEqual(outs[1], 1.) - self.assertEqual(outs[2], 1.) - - y = np.zeros((100, 1)) - outs = model.evaluate(x, y) - self.assertEqual(outs[1], 0.) - self.assertEqual(outs[2], 0.) + model = keras.Sequential() + model.add( + keras.layers.Dense( + 3, activation='relu', input_dim=4, kernel_initializer='ones')) + model.add( + keras.layers.Dense( + 1, activation='sigmoid', kernel_initializer='ones')) + model.compile( + loss='mae', + metrics=['accuracy', metrics_module.BinaryAccuracy()], + optimizer=RMSPropOptimizer(learning_rate=0.001)) + + # verify correctness of stateful and stateless metrics. + x = np.ones((100, 4)) + y = np.ones((100, 1)) + outs = model.evaluate(x, y) + self.assertEqual(outs[1], 1.) + self.assertEqual(outs[2], 1.) + + y = np.zeros((100, 1)) + outs = model.evaluate(x, y) + self.assertEqual(outs[1], 0.) + self.assertEqual(outs[2], 0.) @tf_test_util.run_in_graph_and_eager_modes def test_metrics_correctness_with_iterator(self): - with self.test_session(): - model = keras.Sequential() - model.add( - keras.layers.Dense( - 8, activation='relu', input_dim=4, kernel_initializer='ones')) - model.add( - keras.layers.Dense( - 1, activation='sigmoid', kernel_initializer='ones')) - model.compile( - loss='binary_crossentropy', - metrics=['accuracy', metrics_module.BinaryAccuracy()], - optimizer=RMSPropOptimizer(learning_rate=0.001)) - - np.random.seed(123) - x = np.random.randint(10, size=(100, 4)).astype(np.float32) - y = np.random.randint(2, size=(100, 1)).astype(np.float32) - dataset = dataset_ops.Dataset.from_tensor_slices((x, y)) - dataset = dataset.batch(10) - iterator = dataset.make_one_shot_iterator() - outs = model.evaluate(iterator, steps=10) - self.assertEqual(np.around(outs[1], decimals=1), 0.5) - self.assertEqual(np.around(outs[2], decimals=1), 0.5) - - y = np.zeros((100, 1), dtype=np.float32) - dataset = dataset_ops.Dataset.from_tensor_slices((x, y)) - dataset = dataset.repeat(100) - dataset = dataset.batch(10) - iterator = dataset.make_one_shot_iterator() - outs = model.evaluate(iterator, steps=10) - self.assertEqual(outs[1], 0.) - self.assertEqual(outs[2], 0.) + model = keras.Sequential() + model.add( + keras.layers.Dense( + 8, activation='relu', input_dim=4, kernel_initializer='ones')) + model.add( + keras.layers.Dense( + 1, activation='sigmoid', kernel_initializer='ones')) + model.compile( + loss='binary_crossentropy', + metrics=['accuracy', metrics_module.BinaryAccuracy()], + optimizer=RMSPropOptimizer(learning_rate=0.001)) + + np.random.seed(123) + x = np.random.randint(10, size=(100, 4)).astype(np.float32) + y = np.random.randint(2, size=(100, 1)).astype(np.float32) + dataset = dataset_ops.Dataset.from_tensor_slices((x, y)) + dataset = dataset.batch(10) + iterator = dataset.make_one_shot_iterator() + outs = model.evaluate(iterator, steps=10) + self.assertEqual(np.around(outs[1], decimals=1), 0.5) + self.assertEqual(np.around(outs[2], decimals=1), 0.5) + + y = np.zeros((100, 1), dtype=np.float32) + dataset = dataset_ops.Dataset.from_tensor_slices((x, y)) + dataset = dataset.repeat(100) + dataset = dataset.batch(10) + iterator = dataset.make_one_shot_iterator() + outs = model.evaluate(iterator, steps=10) + self.assertEqual(outs[1], 0.) + self.assertEqual(outs[2], 0.) @tf_test_util.run_in_graph_and_eager_modes def test_metrics_correctness_with_weighted_metrics(self): - with self.test_session(): - np.random.seed(1337) - x = np.array([[[1.], [1.]], [[0.], [0.]]]) - model = keras.models.Sequential() - model.add( - keras.layers.TimeDistributed( - keras.layers.Dense(1, kernel_initializer='ones'), - input_shape=(2, 1))) - model.compile( - RMSPropOptimizer(learning_rate=0.001), - loss='mse', - sample_weight_mode='temporal', - weighted_metrics=['accuracy', - metrics_module.BinaryAccuracy()]) - y = np.array([[[1.], [1.]], [[1.], [1.]]]) - - outs = model.evaluate(x, y) - self.assertEqual(outs, [0.5, 0.5, 0.5]) - - w = np.array([[0., 0.], [0., 0.]]) - outs = model.evaluate(x, y, sample_weight=w) - self.assertEqual(outs, [0., 0., 0.]) - - w = np.array([[3., 4.], [1., 2.]]) - outs = model.evaluate(x, y, sample_weight=w) - self.assertArrayNear(outs, [0.3, 0.7, 0.7], .001) + np.random.seed(1337) + x = np.array([[[1.], [1.]], [[0.], [0.]]]) + model = keras.models.Sequential() + model.add( + keras.layers.TimeDistributed( + keras.layers.Dense(1, kernel_initializer='ones'), + input_shape=(2, 1))) + model.compile( + RMSPropOptimizer(learning_rate=0.001), + loss='mse', + sample_weight_mode='temporal', + weighted_metrics=['accuracy', + metrics_module.BinaryAccuracy()]) + y = np.array([[[1.], [1.]], [[1.], [1.]]]) + + outs = model.evaluate(x, y) + self.assertEqual(outs, [0.5, 0.5, 0.5]) + + w = np.array([[0., 0.], [0., 0.]]) + outs = model.evaluate(x, y, sample_weight=w) + self.assertEqual(outs, [0., 0., 0.]) + + w = np.array([[3., 4.], [1., 2.]]) + outs = model.evaluate(x, y, sample_weight=w) + self.assertArrayNear(outs, [0.3, 0.7, 0.7], .001) @tf_test_util.run_in_graph_and_eager_modes def test_metric_state_reset_between_fit_and_evaluate(self): - with self.test_session(): - model = keras.Sequential() - model.add(keras.layers.Dense(3, activation='relu', input_dim=4)) - model.add(keras.layers.Dense(1, activation='sigmoid')) - acc_obj = metrics_module.BinaryAccuracy() - model.compile( - loss='mae', - metrics=[acc_obj], - optimizer=RMSPropOptimizer(learning_rate=0.001)) - - x_train = np.random.random((100, 4)) - y_train = np.random.random((100, 1)) - model.fit(x_train, y_train, batch_size=5, epochs=2) - self.assertEqual(self.evaluate(acc_obj.count), 100) - - x_test = np.random.random((10, 4)) - y_test = np.random.random((10, 1)) - model.evaluate(x_test, y_test, batch_size=5) - self.assertEqual(self.evaluate(acc_obj.count), 10) + model = keras.Sequential() + model.add(keras.layers.Dense(3, activation='relu', input_dim=4)) + model.add(keras.layers.Dense(1, activation='sigmoid')) + acc_obj = metrics_module.BinaryAccuracy() + model.compile( + loss='mae', + metrics=[acc_obj], + optimizer=RMSPropOptimizer(learning_rate=0.001)) + + x_train = np.random.random((100, 4)) + y_train = np.random.random((100, 1)) + model.fit(x_train, y_train, batch_size=5, epochs=2) + self.assertEqual(self.evaluate(acc_obj.count), 100) + + x_test = np.random.random((10, 4)) + y_test = np.random.random((10, 1)) + model.evaluate(x_test, y_test, batch_size=5) + self.assertEqual(self.evaluate(acc_obj.count), 10) @tf_test_util.run_in_graph_and_eager_modes def test_invalid_metrics(self): num_classes = 5 input_dim = 5 - with self.test_session(): - model = keras.models.Sequential() - model.add( - keras.layers.Dense(10, activation='relu', input_shape=(input_dim,))) - model.add(keras.layers.Dense(num_classes, activation='softmax')) + model = testing_utils.get_small_sequential_mlp( + num_hidden=10, num_classes=num_classes, input_dim=input_dim) - with self.assertRaisesRegexp( - TypeError, 'Type of `metrics` argument not understood. ' - 'Expected a list or dictionary, found: '): - model.compile( - RMSPropOptimizer(learning_rate=0.001), - loss='categorical_crossentropy', - metrics=metrics_module.CategoricalAccuracy()) + with self.assertRaisesRegexp( + TypeError, 'Type of `metrics` argument not understood. ' + 'Expected a list or dictionary, found: '): + model.compile( + RMSPropOptimizer(learning_rate=0.001), + loss='categorical_crossentropy', + metrics=metrics_module.CategoricalAccuracy()) @tf_test_util.run_in_graph_and_eager_modes def test_metrics_masking(self): diff --git a/tensorflow/python/keras/initializers_test.py b/tensorflow/python/keras/initializers_test.py index 51725e03f2..8ddc9a17bf 100644 --- a/tensorflow/python/keras/initializers_test.py +++ b/tensorflow/python/keras/initializers_test.py @@ -40,7 +40,7 @@ class KerasInitializersTest(test.TestCase): def test_uniform(self): tensor_shape = (9, 6, 7) - with self.test_session(): + with self.cached_session(): self._runner(keras.initializers.RandomUniform(minval=-1, maxval=1, seed=124), @@ -49,14 +49,14 @@ class KerasInitializersTest(test.TestCase): def test_normal(self): tensor_shape = (8, 12, 99) - with self.test_session(): + with self.cached_session(): self._runner(keras.initializers.RandomNormal(mean=0, stddev=1, seed=153), tensor_shape, target_mean=0., target_std=1) def test_truncated_normal(self): tensor_shape = (12, 99, 7) - with self.test_session(): + with self.cached_session(): self._runner(keras.initializers.TruncatedNormal(mean=0, stddev=1, seed=126), @@ -65,13 +65,13 @@ class KerasInitializersTest(test.TestCase): def test_constant(self): tensor_shape = (5, 6, 4) - with self.test_session(): + with self.cached_session(): self._runner(keras.initializers.Constant(2), tensor_shape, target_mean=2, target_max=2, target_min=2) def test_lecun_uniform(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, _ = init_ops._compute_fans(tensor_shape) std = np.sqrt(1. / fan_in) self._runner(keras.initializers.lecun_uniform(seed=123), tensor_shape, @@ -79,7 +79,7 @@ class KerasInitializersTest(test.TestCase): def test_glorot_uniform(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, fan_out = init_ops._compute_fans(tensor_shape) std = np.sqrt(2. / (fan_in + fan_out)) self._runner(keras.initializers.glorot_uniform(seed=123), tensor_shape, @@ -87,7 +87,7 @@ class KerasInitializersTest(test.TestCase): def test_he_uniform(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, _ = init_ops._compute_fans(tensor_shape) std = np.sqrt(2. / fan_in) self._runner(keras.initializers.he_uniform(seed=123), tensor_shape, @@ -95,7 +95,7 @@ class KerasInitializersTest(test.TestCase): def test_lecun_normal(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, _ = init_ops._compute_fans(tensor_shape) std = np.sqrt(1. / fan_in) self._runner(keras.initializers.lecun_normal(seed=123), tensor_shape, @@ -103,7 +103,7 @@ class KerasInitializersTest(test.TestCase): def test_glorot_normal(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, fan_out = init_ops._compute_fans(tensor_shape) std = np.sqrt(2. / (fan_in + fan_out)) self._runner(keras.initializers.glorot_normal(seed=123), tensor_shape, @@ -111,7 +111,7 @@ class KerasInitializersTest(test.TestCase): def test_he_normal(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, _ = init_ops._compute_fans(tensor_shape) std = np.sqrt(2. / fan_in) self._runner(keras.initializers.he_normal(seed=123), tensor_shape, @@ -119,12 +119,12 @@ class KerasInitializersTest(test.TestCase): def test_orthogonal(self): tensor_shape = (20, 20) - with self.test_session(): + with self.cached_session(): self._runner(keras.initializers.orthogonal(seed=123), tensor_shape, target_mean=0.) def test_identity(self): - with self.test_session(): + with self.cached_session(): tensor_shape = (3, 4, 5) with self.assertRaises(ValueError): self._runner(keras.initializers.identity(), tensor_shape, @@ -136,13 +136,13 @@ class KerasInitializersTest(test.TestCase): def test_zero(self): tensor_shape = (4, 5) - with self.test_session(): + with self.cached_session(): self._runner(keras.initializers.zeros(), tensor_shape, target_mean=0., target_max=0.) def test_one(self): tensor_shape = (4, 5) - with self.test_session(): + with self.cached_session(): self._runner(keras.initializers.ones(), tensor_shape, target_mean=1., target_max=1.) diff --git a/tensorflow/python/keras/integration_test.py b/tensorflow/python/keras/integration_test.py index a103b9fbf2..3c0f73b1c3 100644 --- a/tensorflow/python/keras/integration_test.py +++ b/tensorflow/python/keras/integration_test.py @@ -35,7 +35,7 @@ class KerasIntegrationTest(test.TestCase): self.assertTrue(keras.__version__.endswith('-tf')) def test_vector_classification_sequential(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, @@ -60,7 +60,7 @@ class KerasIntegrationTest(test.TestCase): self.assertGreater(history.history['val_acc'][-1], 0.7) def test_vector_classification_functional(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, @@ -84,7 +84,7 @@ class KerasIntegrationTest(test.TestCase): self.assertGreater(history.history['val_acc'][-1], 0.7) def test_temporal_classification_sequential(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, @@ -106,7 +106,7 @@ class KerasIntegrationTest(test.TestCase): self.assertGreater(history.history['val_acc'][-1], 0.7) def test_temporal_classification_sequential_tf_rnn(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, @@ -130,7 +130,7 @@ class KerasIntegrationTest(test.TestCase): self.assertGreater(history.history['val_acc'][-1], 0.7) def test_image_classification_sequential(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, @@ -164,7 +164,7 @@ class KerasIntegrationTest(test.TestCase): self.assertGreater(history.history['val_acc'][-1], 0.7) def test_video_classification_functional(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, @@ -194,7 +194,7 @@ class KerasIntegrationTest(test.TestCase): def test_vector_classification_shared_sequential(self): # Test that Sequential models that feature internal updates # and internal losses can be shared. - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, @@ -228,7 +228,7 @@ class KerasIntegrationTest(test.TestCase): def test_vector_classification_shared_model(self): # Test that functional models that feature internal updates # and internal losses can be shared. - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, @@ -259,14 +259,14 @@ class KerasIntegrationTest(test.TestCase): self.assertGreater(history.history['val_acc'][-1], 0.7) def test_embedding_with_clipnorm(self): - with self.test_session(): + with self.cached_session(): model = keras.models.Sequential() model.add(keras.layers.Embedding(input_dim=1, output_dim=1)) model.compile(optimizer=keras.optimizers.SGD(clipnorm=0.1), loss='mse') model.fit(np.array([[0]]), np.array([[[0.5]]]), epochs=1) def test_using_tf_layers_in_keras_sequential_model(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, @@ -289,7 +289,7 @@ class KerasIntegrationTest(test.TestCase): self.assertGreater(history.history['val_acc'][-1], 0.7) def test_using_tf_layers_in_keras_functional_model(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1337) (x_train, y_train), _ = testing_utils.get_test_data( train_samples=100, diff --git a/tensorflow/python/keras/layers/advanced_activations_test.py b/tensorflow/python/keras/layers/advanced_activations_test.py index 53c1baa2bb..b020b6e730 100644 --- a/tensorflow/python/keras/layers/advanced_activations_test.py +++ b/tensorflow/python/keras/layers/advanced_activations_test.py @@ -26,44 +26,44 @@ from tensorflow.python.platform import test class AdvancedActivationsTest(test.TestCase): def test_leaky_relu(self): - with self.test_session(): + with self.cached_session(): for alpha in [0., .5, -1.]: testing_utils.layer_test(keras.layers.LeakyReLU, kwargs={'alpha': alpha}, input_shape=(2, 3, 4)) def test_prelu(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test(keras.layers.PReLU, kwargs={}, input_shape=(2, 3, 4)) def test_prelu_share(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test(keras.layers.PReLU, kwargs={'shared_axes': 1}, input_shape=(2, 3, 4)) def test_elu(self): - with self.test_session(): + with self.cached_session(): for alpha in [0., .5, -1.]: testing_utils.layer_test(keras.layers.ELU, kwargs={'alpha': alpha}, input_shape=(2, 3, 4)) def test_thresholded_relu(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test(keras.layers.ThresholdedReLU, kwargs={'theta': 0.5}, input_shape=(2, 3, 4)) def test_softmax(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test(keras.layers.Softmax, kwargs={'axis': 1}, input_shape=(2, 3, 4)) def test_relu(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test(keras.layers.ReLU, kwargs={'max_value': 10}, input_shape=(2, 3, 4)) @@ -71,14 +71,14 @@ class AdvancedActivationsTest(test.TestCase): def test_relu_with_invalid_arg(self): with self.assertRaisesRegexp( ValueError, 'max_value of Relu layer cannot be negative value: -10'): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test(keras.layers.ReLU, kwargs={'max_value': -10}, input_shape=(2, 3, 4)) with self.assertRaisesRegexp( ValueError, 'negative_slope of Relu layer cannot be negative value: -2'): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test( keras.layers.ReLU, kwargs={'negative_slope': -2}, diff --git a/tensorflow/python/keras/layers/convolutional_recurrent_test.py b/tensorflow/python/keras/layers/convolutional_recurrent_test.py index 4b8f6f2a14..4a75793884 100644 --- a/tensorflow/python/keras/layers/convolutional_recurrent_test.py +++ b/tensorflow/python/keras/layers/convolutional_recurrent_test.py @@ -47,7 +47,7 @@ class ConvLSTMTest(test.TestCase): input_channel) for return_sequences in [True, False]: - with self.test_session(): + with self.cached_session(): # test for return state: x = keras.Input(batch_shape=inputs.shape) kwargs = {'data_format': data_format, @@ -92,7 +92,7 @@ class ConvLSTMTest(test.TestCase): input_num_row, input_num_col, input_channel) - with self.test_session(): + with self.cached_session(): model = keras.models.Sequential() kwargs = {'data_format': 'channels_last', 'return_sequences': False, @@ -144,7 +144,7 @@ class ConvLSTMTest(test.TestCase): input_num_row, input_num_col, input_channel) - with self.test_session(): + with self.cached_session(): kwargs = {'data_format': 'channels_last', 'return_sequences': False, 'kernel_size': (num_row, num_col), @@ -168,7 +168,7 @@ class ConvLSTMTest(test.TestCase): def test_conv_lstm_dropout(self): # check dropout - with self.test_session(): + with self.cached_session(): testing_utils.layer_test( keras.layers.ConvLSTM2D, kwargs={'data_format': 'channels_last', @@ -181,7 +181,7 @@ class ConvLSTMTest(test.TestCase): input_shape=(1, 2, 5, 5, 2)) def test_conv_lstm_cloning(self): - with self.test_session(): + with self.cached_session(): model = keras.models.Sequential() model.add(keras.layers.ConvLSTM2D(5, 3, input_shape=(None, 5, 5, 3))) @@ -190,7 +190,7 @@ class ConvLSTMTest(test.TestCase): weights = model.get_weights() # Use a new graph to clone the model - with self.test_session(): + with self.cached_session(): clone = keras.models.clone_model(model) clone.set_weights(weights) diff --git a/tensorflow/python/keras/layers/core_test.py b/tensorflow/python/keras/layers/core_test.py index 49ca68ee9e..1df1d575b1 100644 --- a/tensorflow/python/keras/layers/core_test.py +++ b/tensorflow/python/keras/layers/core_test.py @@ -30,16 +30,16 @@ from tensorflow.python.platform import test class CoreLayersTest(test.TestCase): def test_masking(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test( keras.layers.Masking, kwargs={}, input_shape=(3, 2, 3)) def test_dropout(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test( keras.layers.Dropout, kwargs={'rate': 0.5}, input_shape=(3, 2)) - with self.test_session(): + with self.cached_session(): testing_utils.layer_test( keras.layers.Dropout, kwargs={'rate': 0.5, @@ -47,7 +47,7 @@ class CoreLayersTest(test.TestCase): input_shape=(3, 2)) # https://github.com/tensorflow/tensorflow/issues/14819 - with self.test_session(): + with self.cached_session(): dropout = keras.layers.Dropout(0.5) self.assertEqual(True, dropout.supports_masking) @@ -210,7 +210,7 @@ class CoreLayersTest(test.TestCase): keras.layers.Dense, kwargs={'units': 3}, input_shape=(3, 4, 5, 2)) def test_dense_regularization(self): - with self.test_session(): + with self.cached_session(): layer = keras.layers.Dense( 3, kernel_regularizer=keras.regularizers.l1(0.01), @@ -221,7 +221,7 @@ class CoreLayersTest(test.TestCase): self.assertEqual(3, len(layer.losses)) def test_dense_constraints(self): - with self.test_session(): + with self.cached_session(): k_constraint = keras.constraints.max_norm(0.01) b_constraint = keras.constraints.max_norm(0.01) layer = keras.layers.Dense( @@ -231,14 +231,14 @@ class CoreLayersTest(test.TestCase): self.assertEqual(layer.bias.constraint, b_constraint) def test_activity_regularization(self): - with self.test_session(): + with self.cached_session(): layer = keras.layers.ActivityRegularization(l1=0.1) layer(keras.backend.variable(np.ones((2, 4)))) self.assertEqual(1, len(layer.losses)) _ = layer.get_config() def test_lambda_output_shape(self): - with self.test_session(): + with self.cached_session(): l = keras.layers.Lambda(lambda x: x + 1, output_shape=(1, 1)) l(keras.backend.variable(np.ones((1, 1)))) self.assertEqual((1, 1), l.get_config()['output_shape']) @@ -247,13 +247,13 @@ class CoreLayersTest(test.TestCase): def get_output_shape(input_shape): return 1 * input_shape - with self.test_session(): + with self.cached_session(): l = keras.layers.Lambda(lambda x: x + 1, output_shape=get_output_shape) l(keras.backend.variable(np.ones((1, 1)))) self.assertEqual('lambda', l.get_config()['output_shape_type']) def test_lambda_config_serialization(self): - with self.test_session(): + with self.cached_session(): # test serialization with output_shape and output_shape_type layer = keras.layers.Lambda(lambda x: x + 1, output_shape=(1, 1)) layer(keras.backend.variable(np.ones((1, 1)))) diff --git a/tensorflow/python/keras/layers/embeddings_test.py b/tensorflow/python/keras/layers/embeddings_test.py index fff1c5ef98..cab176ee34 100644 --- a/tensorflow/python/keras/layers/embeddings_test.py +++ b/tensorflow/python/keras/layers/embeddings_test.py @@ -68,7 +68,7 @@ class EmbeddingTest(test.TestCase): expected_output_dtype='float32') def test_embedding_correctness(self): - with self.test_session(): + with self.cached_session(): layer = keras.layers.Embedding(output_dim=2, input_dim=2) layer.build((None, 2)) matrix = np.array([[1, 1], [2, 2]]) diff --git a/tensorflow/python/keras/layers/local_test.py b/tensorflow/python/keras/layers/local_test.py index 4781bcae07..8589b32b3c 100644 --- a/tensorflow/python/keras/layers/local_test.py +++ b/tensorflow/python/keras/layers/local_test.py @@ -87,7 +87,7 @@ class LocallyConnectedLayersTest(test.TestCase): keras.layers.LocallyConnected1D, **kwargs) else: - with self.test_session(): + with self.cached_session(): layer = keras.layers.LocallyConnected1D(**kwargs) layer.build((num_samples, num_steps, input_dim)) self.assertEqual(len(layer.losses), 2) @@ -105,7 +105,7 @@ class LocallyConnectedLayersTest(test.TestCase): 'kernel_constraint': k_constraint, 'bias_constraint': b_constraint, } - with self.test_session(): + with self.cached_session(): layer = keras.layers.LocallyConnected1D(**kwargs) layer.build((num_samples, num_steps, input_dim)) self.assertEqual(layer.kernel.constraint, k_constraint) @@ -197,7 +197,7 @@ class LocallyConnectedLayersTest(test.TestCase): keras.layers.LocallyConnected2D, **kwargs) else: - with self.test_session(): + with self.cached_session(): layer = keras.layers.LocallyConnected2D(**kwargs) layer.build((num_samples, num_row, num_col, stack_size)) self.assertEqual(len(layer.losses), 2) @@ -214,7 +214,7 @@ class LocallyConnectedLayersTest(test.TestCase): 'kernel_constraint': k_constraint, 'bias_constraint': b_constraint, } - with self.test_session(): + with self.cached_session(): layer = keras.layers.LocallyConnected2D(**kwargs) layer.build((num_samples, num_row, num_col, stack_size)) self.assertEqual(layer.kernel.constraint, k_constraint) diff --git a/tensorflow/python/keras/layers/merge_test.py b/tensorflow/python/keras/layers/merge_test.py index 39bc98d039..7bcfcaeddb 100644 --- a/tensorflow/python/keras/layers/merge_test.py +++ b/tensorflow/python/keras/layers/merge_test.py @@ -46,7 +46,7 @@ class MergeLayersTest(test.TestCase): self.assertAllClose(out, x1 + x2 + x3, atol=1e-4) def test_merge_add_masking(self): - with self.test_session(): + with self.cached_session(): i1 = keras.layers.Input(shape=(4, 5)) i2 = keras.layers.Input(shape=(4, 5)) m1 = keras.layers.Masking()(i1) @@ -57,7 +57,7 @@ class MergeLayersTest(test.TestCase): self.assertListEqual(mask.get_shape().as_list(), [None, 4]) def test_merge_add_dynamic_shape(self): - with self.test_session(): + with self.cached_session(): i1 = array_ops.placeholder(shape=(4, None), dtype='float32') i2 = array_ops.placeholder(shape=(4, 5), dtype='float32') layer = keras.layers.Add() @@ -149,7 +149,7 @@ class MergeLayersTest(test.TestCase): self.assertAllClose(out, np.concatenate([x1, x2], axis=1), atol=1e-4) def test_merge_concatenate_masking(self): - with self.test_session(): + with self.cached_session(): i1 = keras.layers.Input(shape=(4, 5)) i2 = keras.layers.Input(shape=(4, 5)) m1 = keras.layers.Masking()(i1) diff --git a/tensorflow/python/keras/layers/noise_test.py b/tensorflow/python/keras/layers/noise_test.py index aa2be62390..cea304680b 100644 --- a/tensorflow/python/keras/layers/noise_test.py +++ b/tensorflow/python/keras/layers/noise_test.py @@ -27,14 +27,14 @@ from tensorflow.python.platform import test class NoiseLayersTest(test.TestCase): def test_GaussianNoise(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test( keras.layers.GaussianNoise, kwargs={'stddev': 1.}, input_shape=(3, 2, 3)) def test_GaussianDropout(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test( keras.layers.GaussianDropout, kwargs={'rate': 0.5}, diff --git a/tensorflow/python/keras/layers/normalization.py b/tensorflow/python/keras/layers/normalization.py index cd26e04c39..013d572088 100644 --- a/tensorflow/python/keras/layers/normalization.py +++ b/tensorflow/python/keras/layers/normalization.py @@ -34,7 +34,7 @@ from tensorflow.python.ops import init_ops from tensorflow.python.ops import math_ops from tensorflow.python.ops import nn from tensorflow.python.ops import state_ops -from tensorflow.python.ops import variable_scope +from tensorflow.python.ops import variables as tf_variables from tensorflow.python.platform import tf_logging as logging from tensorflow.python.training import distribution_strategy_context from tensorflow.python.util.tf_export import tf_export @@ -313,18 +313,18 @@ class BatchNormalization(Layer): shape=param_shape, dtype=param_dtype, initializer=self.moving_mean_initializer, - synchronization=variable_scope.VariableSynchronization.ON_READ, + synchronization=tf_variables.VariableSynchronization.ON_READ, trainable=False, - aggregation=variable_scope.VariableAggregation.MEAN) + aggregation=tf_variables.VariableAggregation.MEAN) self.moving_variance = self.add_weight( name='moving_variance', shape=param_shape, dtype=param_dtype, initializer=self.moving_variance_initializer, - synchronization=variable_scope.VariableSynchronization.ON_READ, + synchronization=tf_variables.VariableSynchronization.ON_READ, trainable=False, - aggregation=variable_scope.VariableAggregation.MEAN) + aggregation=tf_variables.VariableAggregation.MEAN) if self.renorm: # Create variables to maintain the moving mean and standard deviation. @@ -340,9 +340,9 @@ class BatchNormalization(Layer): shape=shape, dtype=param_dtype, initializer=init_ops.zeros_initializer(), - synchronization=variable_scope.VariableSynchronization.ON_READ, + synchronization=tf_variables.VariableSynchronization.ON_READ, trainable=False, - aggregation=variable_scope.VariableAggregation.MEAN) + aggregation=tf_variables.VariableAggregation.MEAN) return var with distribution_strategy_context.get_distribution_strategy( diff --git a/tensorflow/python/keras/layers/normalization_test.py b/tensorflow/python/keras/layers/normalization_test.py index a97b4cac46..2844b84799 100644 --- a/tensorflow/python/keras/layers/normalization_test.py +++ b/tensorflow/python/keras/layers/normalization_test.py @@ -28,7 +28,7 @@ from tensorflow.python.platform import test class NormalizationLayersTest(test.TestCase): def test_basic_batchnorm(self): - with self.test_session(): + with self.cached_session(): testing_utils.layer_test( keras.layers.BatchNormalization, kwargs={ @@ -54,7 +54,7 @@ class NormalizationLayersTest(test.TestCase): input_shape=(3, 3)) def test_batchnorm_weights(self): - with self.test_session(): + with self.cached_session(): layer = keras.layers.BatchNormalization(scale=False, center=False) layer.build((None, 3, 4)) self.assertEqual(len(layer.trainable_weights), 0) @@ -66,7 +66,7 @@ class NormalizationLayersTest(test.TestCase): self.assertEqual(len(layer.weights), 4) def test_batchnorm_regularization(self): - with self.test_session(): + with self.cached_session(): layer = keras.layers.BatchNormalization( gamma_regularizer='l1', beta_regularizer='l1') layer.build((None, 3, 4)) @@ -79,7 +79,7 @@ class NormalizationLayersTest(test.TestCase): self.assertEqual(layer.beta.constraint, max_norm) def test_batchnorm_correctness(self): - with self.test_session(): + with self.cached_session(): model = keras.models.Sequential() norm = keras.layers.BatchNormalization(input_shape=(10,), momentum=0.8) model.add(norm) @@ -96,7 +96,7 @@ class NormalizationLayersTest(test.TestCase): np.testing.assert_allclose(out.std(), 1.0, atol=1e-1) def test_batchnorm_mixed_precision(self): - with self.test_session(): + with self.cached_session(): model = keras.models.Sequential() norm = keras.layers.BatchNormalization(input_shape=(10,), momentum=0.8) model.add(norm) @@ -133,7 +133,7 @@ class NormalizationLayersTest(test.TestCase): np.testing.assert_allclose(np.std(out, axis=(0, 2, 3)), 1.0, atol=1e-1) def test_batchnorm_convnet_channel_last(self): - with self.test_session(): + with self.cached_session(): # keras.backend.set_learning_phase(True) model = keras.models.Sequential() @@ -155,7 +155,7 @@ class NormalizationLayersTest(test.TestCase): def test_shared_batchnorm(self): """Test that a BN layer can be shared across different data streams. """ - with self.test_session(): + with self.cached_session(): # Test single layer reuse bn = keras.layers.BatchNormalization() x1 = keras.layers.Input(shape=(10,)) @@ -187,7 +187,7 @@ class NormalizationLayersTest(test.TestCase): new_model.train_on_batch(x, x) def test_that_trainable_disables_updates(self): - with self.test_session(): + with self.cached_session(): val_a = np.random.random((10, 4)) val_out = np.random.random((10, 4)) @@ -230,7 +230,7 @@ class NormalizationLayersTest(test.TestCase): Computes mean and std for current inputs then applies batch normalization using them. """ - with self.test_session(): + with self.cached_session(): bn_mean = 0.5 bn_std = 10. val_a = np.expand_dims(np.arange(10.), axis=1) diff --git a/tensorflow/python/keras/layers/recurrent.py b/tensorflow/python/keras/layers/recurrent.py index 12c82a53f6..04b3aecff8 100644 --- a/tensorflow/python/keras/layers/recurrent.py +++ b/tensorflow/python/keras/layers/recurrent.py @@ -33,7 +33,6 @@ from tensorflow.python.keras.engine.base_layer import Layer from tensorflow.python.keras.utils import generic_utils from tensorflow.python.keras.utils import tf_utils from tensorflow.python.ops import array_ops -from tensorflow.python.ops import math_ops from tensorflow.python.ops import state_ops from tensorflow.python.platform import tf_logging as logging from tensorflow.python.training.checkpointable import base as checkpointable @@ -74,19 +73,27 @@ class StackedRNNCells(Layer): '`state_size` attribute. ' 'received cells:', cells) self.cells = cells + # reverse_state_order determines whether the state size will be in a reverse + # order of the cells' state. User might want to set this to True to keep the + # existing behavior. This is only useful when use RNN(return_state=True) + # since the state will be returned as the same order of state_size. + self.reverse_state_order = kwargs.pop('reverse_state_order', False) + if self.reverse_state_order: + logging.warning('reverse_state_order=True in StackedRNNCells will soon ' + 'be deprecated. Please update the code to work with the ' + 'natural order of states if you reply on the RNN states, ' + 'eg RNN(return_state=True).') super(StackedRNNCells, self).__init__(**kwargs) @property def state_size(self): - # States are a flat list - # in reverse order of the cell stack. - # This allows to preserve the requirement - # `stack.state_size[0] == output_dim`. - # e.g. states of a 2-layer LSTM would be - # `[h2, c2, h1, c1]` + # States are a flat list of the individual cell state size. + # e.g. states of a 2-layer LSTM would be `[h1, c1, h2, c2]`. # (assuming one LSTM has states [h, c]) + # In the case of reverse_state_order=True, the state_size will be + # [h2, c2, h1, c1]. state_size = [] - for cell in self.cells[::-1]: + for cell in self.cells[::-1] if self.reverse_state_order else self.cells: if _is_multiple_state(cell.state_size): state_size += list(cell.state_size) else: @@ -95,22 +102,40 @@ class StackedRNNCells(Layer): @property def output_size(self): - if hasattr(self.cells[-1], 'output_size'): + if getattr(self.cells[-1], 'output_size', None) is not None: return self.cells[-1].output_size + elif _is_multiple_state(self.cells[-1].state_size): + return self.cells[-1].state_size[0] else: - return self.state_size[0] + return self.cells[-1].state_size + + def get_initial_state(self, inputs=None, batch_size=None, dtype=None): + # The init state is flattened into a list because state_size is a flattened + # list. + initial_states = [] + for cell in self.cells[::-1] if self.reverse_state_order else self.cells: + get_initial_state_fn = getattr(cell, 'get_initial_state', None) + if get_initial_state_fn: + initial_states.append(get_initial_state_fn( + inputs=inputs, batch_size=batch_size, dtype=dtype)) + else: + initial_states.append(_generate_zero_filled_state_for_cell( + cell, inputs, batch_size, dtype)) + + return nest.flatten(initial_states) def call(self, inputs, states, constants=None, **kwargs): # Recover per-cell states. nested_states = [] - for cell in self.cells[::-1]: + for cell in self.cells[::-1] if self.reverse_state_order else self.cells: if _is_multiple_state(cell.state_size): nested_states.append(states[:len(cell.state_size)]) states = states[len(cell.state_size):] else: nested_states.append([states[0]]) states = states[1:] - nested_states = nested_states[::-1] + if self.reverse_state_order: + nested_states = nested_states[::-1] # Call the cells in order and store the returned states. new_nested_states = [] @@ -124,11 +149,12 @@ class StackedRNNCells(Layer): new_nested_states.append(states) # Format the new states as a flat list - # in reverse cell order. - states = [] - for cell_states in new_nested_states[::-1]: - states += cell_states - return inputs, states + new_states = [] + if self.reverse_state_order: + new_nested_states = new_nested_states[::-1] + for cell_states in new_nested_states: + new_states += cell_states + return inputs, new_states @tf_utils.shape_type_conversion def build(self, input_shape): @@ -141,7 +167,9 @@ class StackedRNNCells(Layer): cell.build([input_shape] + constants_shape) else: cell.build(input_shape) - if _is_multiple_state(cell.state_size): + if getattr(cell, 'output_size', None) is not None: + output_dim = cell.output_size + elif _is_multiple_state(cell.state_size): output_dim = cell.state_size[0] else: output_dim = cell.state_size @@ -261,6 +289,22 @@ class RNN(Layer): compatible reason, if this attribute is not available for the cell, the value will be inferred by the first element of the `state_size`. + - a `get_initial_state(inputs=None, batch_size=None, dtype=None)` + method that creates a tensor meant to be fed to `call()` as the + initial state, if user didn't specify any initial state via other + means. The returned initial state should be in shape of + [batch, cell.state_size]. Cell might choose to create zero filled + tensor, or with other values based on the cell implementations. + `inputs` is the input tensor to the RNN layer, which should + contain the batch size as its shape[0], and also dtype. Note that + the shape[0] might be None during the graph construction. Either + the `inputs` or the pair of `batch` and `dtype `are provided. + `batch` is a scalar tensor that represent the batch size + of the input. `dtype` is `tf.dtype` that represent the dtype of + the input. + For backward compatible reason, if this method is not implemented + by the cell, RNN layer will create a zero filled tensors with the + size of [batch, cell.state_size]. In the case that `cell` is a list of RNN cell instances, the cells will be stacked on after the other in the RNN, implementing an efficient stacked RNN. @@ -453,7 +497,7 @@ class RNN(Layer): else: state_size = [self.cell.state_size] - if hasattr(self.cell, 'output_size'): + if getattr(self.cell, 'output_size', None) is not None: output_dim = tensor_shape.as_shape(self.cell.output_size).as_list() else: # Note that state_size[0] could be a tensor_shape or int. @@ -553,26 +597,18 @@ class RNN(Layer): raise validation_error def get_initial_state(self, inputs): - # build an all-zero tensor of shape (batch, cell.state_size) - initial_state = array_ops.zeros_like(inputs) - # shape of initial_state = (batch, timesteps, ...) - initial_state = math_ops.reduce_sum( - initial_state, axis=list(range(1, len(inputs.shape)))) - # shape of initial_state = (batch,) - if _is_multiple_state(self.cell.state_size): - states = [] - for dims in self.cell.state_size: - state = initial_state - flat_dims = tensor_shape.as_shape(dims).as_list() - # reshape the state to (batch, 1, 1, ....) and then expand each state. - state = array_ops.reshape(state, [-1,] + [1] * len(flat_dims)) - states.append(K.tile(state, [1] + flat_dims)) - return states + get_initial_state_fn = getattr(self.cell, 'get_initial_state', None) + if get_initial_state_fn: + init_state = get_initial_state_fn( + inputs=inputs, batch_size=None, dtype=None) else: - flat_dims = tensor_shape.as_shape(self.cell.state_size).as_list() - initial_state = array_ops.reshape( - initial_state, [-1] + [1] * len(flat_dims)) - return [K.tile(initial_state, [1] + flat_dims)] + init_state = _generate_zero_filled_state( + array_ops.shape(inputs)[0], self.cell.state_size, inputs.dtype) + # Keras RNN expect the states in a list, even if it's a single state tensor. + if not nest.is_sequence(init_state): + init_state = [init_state] + # Force the state to be a list in case it is a namedtuple eg LSTMStateTuple. + return list(init_state) def __call__(self, inputs, initial_state=None, constants=None, **kwargs): inputs, initial_state, constants = _standardize_args(inputs, @@ -636,6 +672,14 @@ class RNN(Layer): # note that the .build() method of subclasses MUST define # self.input_spec and self.state_spec with complete input shapes. if isinstance(inputs, list): + # get initial_state from full input spec + # as they could be copied to multiple GPU. + if self._num_constants is None: + initial_state = inputs[1:] + else: + initial_state = inputs[1:-self._num_constants] + if len(initial_state) == 0: + initial_state = None inputs = inputs[0] if initial_state is not None: pass @@ -986,6 +1030,9 @@ class SimpleRNNCell(Layer): output._uses_learning_phase = True return output, [output] + def get_initial_state(self, inputs=None, batch_size=None, dtype=None): + return _generate_zero_filled_state_for_cell(self, inputs, batch_size, dtype) + def get_config(self): config = { 'units': @@ -1517,6 +1564,9 @@ class GRUCell(Layer): base_config = super(GRUCell, self).get_config() return dict(list(base_config.items()) + list(config.items())) + def get_initial_state(self, inputs=None, batch_size=None, dtype=None): + return _generate_zero_filled_state_for_cell(self, inputs, batch_size, dtype) + @tf_export('keras.layers.GRU') class GRU(RNN): @@ -2042,6 +2092,9 @@ class LSTMCell(Layer): base_config = super(LSTMCell, self).get_config() return dict(list(base_config.items()) + list(config.items())) + def get_initial_state(self, inputs=None, batch_size=None, dtype=None): + return _generate_zero_filled_state_for_cell(self, inputs, batch_size, dtype) + @tf_export('keras.layers.LSTM') class LSTM(RNN): @@ -2354,3 +2407,30 @@ def _is_multiple_state(state_size): """Check whether the state_size contains multiple states.""" return (hasattr(state_size, '__len__') and not isinstance(state_size, tensor_shape.TensorShape)) + + +def _generate_zero_filled_state_for_cell(cell, inputs, batch_size, dtype): + if inputs is not None: + batch_size = array_ops.shape(inputs)[0] + dtype = inputs.dtype + return _generate_zero_filled_state(batch_size, cell.state_size, dtype) + + +def _generate_zero_filled_state(batch_size_tensor, state_size, dtype): + """Generate a zero filled tensor with shape [batch_size, state_size].""" + if None in [batch_size_tensor, dtype]: + raise ValueError( + 'batch_size and dtype cannot be None while constructing initial state: ' + 'batch_size={}, dtype={}'.format(batch_size_tensor, dtype)) + if _is_multiple_state(state_size): + states = [] + for dims in state_size: + flat_dims = tensor_shape.as_shape(dims).as_list() + init_state_size = [batch_size_tensor] + flat_dims + init_state = array_ops.zeros(init_state_size, dtype=dtype) + states.append(init_state) + return states + else: + flat_dims = tensor_shape.as_shape(state_size).as_list() + init_state_size = [batch_size_tensor] + flat_dims + return array_ops.zeros(init_state_size, dtype=dtype) diff --git a/tensorflow/python/keras/layers/recurrent_test.py b/tensorflow/python/keras/layers/recurrent_test.py index 13bd070528..a3861e44d5 100644 --- a/tensorflow/python/keras/layers/recurrent_test.py +++ b/tensorflow/python/keras/layers/recurrent_test.py @@ -50,7 +50,7 @@ class RNNTest(test.TestCase): output = keras.backend.dot(inputs, self.kernel) + prev_output return output, [output] - with self.test_session(): + with self.cached_session(): # Basic test case. cell = MinimalRNNCell(32, 5) x = keras.Input((None, 5)) @@ -88,7 +88,7 @@ class RNNTest(test.TestCase): output -= prev_output_2 return output, [output * 2, output * 3] - with self.test_session(): + with self.cached_session(): # Basic test case. cell = MinimalRNNCell(32, 5) x = keras.Input((None, 5)) @@ -103,7 +103,8 @@ class RNNTest(test.TestCase): MinimalRNNCell(16, 8), MinimalRNNCell(32, 16)] layer = keras.layers.RNN(cells) - assert layer.cell.state_size == (32, 32, 16, 16, 8, 8) + self.assertEqual(layer.cell.state_size, (8, 8, 16, 16, 32, 32)) + self.assertEqual(layer.cell.output_size, 32) y = layer(x) model = keras.models.Model(x, y) model.compile(optimizer='rmsprop', loss='mse') @@ -139,7 +140,7 @@ class RNNTest(test.TestCase): base_config = super(MinimalRNNCell, self).get_config() return dict(list(base_config.items()) + list(config.items())) - with self.test_session(): + with self.cached_session(): # Test basic case. x = keras.Input((None, 5)) cell = MinimalRNNCell(32) @@ -228,7 +229,7 @@ class RNNTest(test.TestCase): base_config = super(RNNCellWithConstants, self).get_config() return dict(list(base_config.items()) + list(config.items())) - with self.test_session(): + with self.cached_session(): # Test basic case. x = keras.Input((None, 5)) c = keras.Input((3,)) @@ -243,7 +244,7 @@ class RNNTest(test.TestCase): np.zeros((6, 32)) ) - with self.test_session(): + with self.cached_session(): # Test basic case serialization. x_np = np.random.random((6, 5, 5)) c_np = np.random.random((6, 3)) @@ -259,7 +260,7 @@ class RNNTest(test.TestCase): y_np_2 = model.predict([x_np, c_np]) self.assertAllClose(y_np, y_np_2, atol=1e-4) - with self.test_session(): + with self.cached_session(): # test flat list inputs. with keras.utils.CustomObjectScope(custom_objects): layer = keras.layers.RNN.from_config(config.copy()) @@ -269,7 +270,7 @@ class RNNTest(test.TestCase): y_np_3 = model.predict([x_np, c_np]) self.assertAllClose(y_np, y_np_3, atol=1e-4) - with self.test_session(): + with self.cached_session(): # Test stacking. cells = [keras.layers.recurrent.GRUCell(8), RNNCellWithConstants(12), @@ -283,7 +284,7 @@ class RNNTest(test.TestCase): np.zeros((6, 32)) ) - with self.test_session(): + with self.cached_session(): # Test GRUCell reset_after property. x = keras.Input((None, 5)) c = keras.Input((3,)) @@ -297,7 +298,7 @@ class RNNTest(test.TestCase): np.zeros((6, 32)) ) - with self.test_session(): + with self.cached_session(): # Test stacked RNN serialization x_np = np.random.random((6, 5, 5)) c_np = np.random.random((6, 3)) @@ -355,7 +356,7 @@ class RNNTest(test.TestCase): base_config = super(RNNCellWithConstants, self).get_config() return dict(list(base_config.items()) + list(config.items())) - with self.test_session(): + with self.cached_session(): # Test basic case. x = keras.Input((None, 5)) c = keras.Input((3,)) @@ -370,7 +371,7 @@ class RNNTest(test.TestCase): np.zeros((6, 32)) ) - with self.test_session(): + with self.cached_session(): # Test basic case serialization. x_np = np.random.random((6, 5, 5)) s_np = np.random.random((6, 32)) @@ -392,7 +393,7 @@ class RNNTest(test.TestCase): with self.assertRaises(AssertionError): self.assertAllClose(y_np, y_np_2_different_s, atol=1e-4) - with self.test_session(): + with self.cached_session(): # test flat list inputs with keras.utils.CustomObjectScope(custom_objects): layer = keras.layers.RNN.from_config(config.copy()) @@ -467,7 +468,7 @@ class RNNTest(test.TestCase): timesteps = 2 num_samples = 2 - with self.test_session(): + with self.cached_session(): input1 = keras.Input(batch_shape=(num_samples, timesteps, embedding_dim)) layer = layer_class(units, return_state=True, @@ -487,7 +488,7 @@ class RNNTest(test.TestCase): for cell_class in [keras.layers.SimpleRNNCell, keras.layers.GRUCell, keras.layers.LSTMCell]: - with self.test_session(): + with self.cached_session(): # Test basic case. x = keras.Input((None, 5)) cell = cell_class(32) @@ -534,7 +535,7 @@ class RNNTest(test.TestCase): keras.layers.LSTMCell(3, dropout=0.1, recurrent_dropout=0.1)] layer = keras.layers.RNN(cells) - with self.test_session(): + with self.cached_session(): x = keras.Input((None, 5)) y = layer(x) model = keras.models.Model(x, y) @@ -551,6 +552,21 @@ class RNNTest(test.TestCase): layer = keras.layers.RNN(cells, return_state=True, return_sequences=True) output_shape = layer.compute_output_shape((None, timesteps, embedding_dim)) expected_output_shape = [(None, timesteps, 6), + (None, 3), + (None, 3), + (None, 6), + (None, 6)] + self.assertEqual( + [tuple(o.as_list()) for o in output_shape], + expected_output_shape) + + # Test reverse_state_order = True for stacked cell. + stacked_cell = keras.layers.StackedRNNCells( + cells, reverse_state_order=True) + layer = keras.layers.RNN( + stacked_cell, return_state=True, return_sequences=True) + output_shape = layer.compute_output_shape((None, timesteps, embedding_dim)) + expected_output_shape = [(None, timesteps, 6), (None, 6), (None, 6), (None, 3), @@ -561,7 +577,7 @@ class RNNTest(test.TestCase): def test_checkpointable_dependencies(self): rnn = keras.layers.SimpleRNN - with self.test_session(): + with self.cached_session(): x = np.random.random((2, 2, 2)) y = np.random.random((2, 2)) model = keras.models.Sequential() @@ -576,7 +592,7 @@ class RNNTest(test.TestCase): self.assertIn(v, checkpointed_objects) def test_high_dimension_RNN(self): - with self.test_session(): + with self.cached_session(): # Basic test case. unit_a = 10 unit_b = 20 @@ -626,7 +642,7 @@ class RNNTest(test.TestCase): batch = 32 time_step = 4 - with self.test_session(): + with self.cached_session(): # Basic test case. cell = Minimal2DRNNCell(unit_a, unit_b) x = keras.Input((None, input_a, input_b)) @@ -642,7 +658,7 @@ class RNNTest(test.TestCase): ], np.zeros((batch, unit_a, unit_b))) self.assertEqual(model.output_shape, (None, unit_a, unit_b)) - with self.test_session(): + with self.cached_session(): # Bad init state shape. bad_shape_a = unit_a * 2 bad_shape_b = unit_b * 2 @@ -655,7 +671,7 @@ class RNNTest(test.TestCase): layer(x, initial_state=s) def test_inconsistent_output_state_size(self): - with self.test_session(): + with self.cached_session(): batch = 32 time_step = 4 state_size = 5 @@ -678,6 +694,23 @@ class RNNTest(test.TestCase): np.zeros((batch, input_size))) self.assertEqual(model.output_shape, (None, input_size)) + def test_get_initial_state(self): + cell = keras.layers.SimpleRNNCell(5) + with self.assertRaisesRegexp(ValueError, + 'batch_size and dtype cannot be None'): + cell.get_initial_state(None, None, None) + + inputs = keras.Input((None, 2, 10)) + initial_state = cell.get_initial_state(inputs, None, None) + self.assertEqual(initial_state.shape.as_list(), [None, 5]) + self.assertEqual(initial_state.dtype, inputs.dtype) + + batch = array_ops.shape(inputs)[0] + dtype = inputs.dtype + initial_state = cell.get_initial_state(None, batch, dtype) + self.assertEqual(initial_state.shape.as_list(), [None, 5]) + self.assertEqual(initial_state.dtype, inputs.dtype) + class Minimal2DRNNCell(keras.layers.Layer): """The minimal 2D RNN cell is a simple combination of 2 1-D RNN cell. diff --git a/tensorflow/python/keras/layers/wrappers.py b/tensorflow/python/keras/layers/wrappers.py index 9b8d5fc5cc..a1933c11b0 100644 --- a/tensorflow/python/keras/layers/wrappers.py +++ b/tensorflow/python/keras/layers/wrappers.py @@ -545,11 +545,27 @@ class Bidirectional(Wrapper): if initial_state is not None and generic_utils.has_arg( self.layer.call, 'initial_state'): - forward_state = initial_state[:len(initial_state) // 2] - backward_state = initial_state[len(initial_state) // 2:] - y = self.forward_layer.call(inputs, initial_state=forward_state, **kwargs) - y_rev = self.backward_layer.call( - inputs, initial_state=backward_state, **kwargs) + forward_inputs = [inputs[0]] + backward_inputs = [inputs[0]] + pivot = len(initial_state) // 2 + 1 + # add forward initial state + forward_state = inputs[1:pivot] + forward_inputs += forward_state + if self._num_constants is None: + # add backward initial state + backward_state = inputs[pivot:] + backward_inputs += backward_state + else: + # add backward initial state + backward_state = inputs[pivot:-self._num_constants] + backward_inputs += backward_state + # add constants for forward and backward layers + forward_inputs += inputs[-self._num_constants:] + backward_inputs += inputs[-self._num_constants:] + y = self.forward_layer.call(forward_inputs, + initial_state=forward_state, **kwargs) + y_rev = self.backward_layer.call(backward_inputs, + initial_state=backward_state, **kwargs) else: y = self.forward_layer.call(inputs, **kwargs) y_rev = self.backward_layer.call(inputs, **kwargs) diff --git a/tensorflow/python/keras/layers/wrappers_test.py b/tensorflow/python/keras/layers/wrappers_test.py index 0cd774ef0f..965960917c 100644 --- a/tensorflow/python/keras/layers/wrappers_test.py +++ b/tensorflow/python/keras/layers/wrappers_test.py @@ -113,7 +113,7 @@ class TimeDistributedTest(test.TestCase): keras.layers.TimeDistributed(x) def test_timedistributed_conv2d(self): - with self.test_session(): + with self.cached_session(): model = keras.models.Sequential() model.add( keras.layers.TimeDistributed( @@ -128,7 +128,7 @@ class TimeDistributedTest(test.TestCase): model.summary() def test_timedistributed_stacked(self): - with self.test_session(): + with self.cached_session(): model = keras.models.Sequential() model.add( keras.layers.TimeDistributed( @@ -144,7 +144,7 @@ class TimeDistributedTest(test.TestCase): batch_size=10) def test_regularizers(self): - with self.test_session(): + with self.cached_session(): model = keras.models.Sequential() model.add( keras.layers.TimeDistributed( @@ -155,7 +155,7 @@ class TimeDistributedTest(test.TestCase): self.assertEqual(len(model.losses), 1) def test_TimeDistributed_learning_phase(self): - with self.test_session(): + with self.cached_session(): # test layers that need learning_phase to be set np.random.seed(1234) x = keras.layers.Input(shape=(3, 2)) @@ -166,7 +166,7 @@ class TimeDistributedTest(test.TestCase): self.assertAllClose(np.mean(y), 0., atol=1e-1, rtol=1e-1) def test_TimeDistributed_batchnorm(self): - with self.test_session(): + with self.cached_session(): # test that wrapped BN updates still work. model = keras.models.Sequential() model.add(keras.layers.TimeDistributed( @@ -202,7 +202,7 @@ class TimeDistributedTest(test.TestCase): assert len(layer.trainable_weights) == 2 def test_TimeDistributed_with_masked_embedding_and_unspecified_shape(self): - with self.test_session(): + with self.cached_session(): # test with unspecified shape and Embeddings with mask_zero model = keras.models.Sequential() model.add(keras.layers.TimeDistributed( @@ -234,7 +234,7 @@ class TimeDistributedTest(test.TestCase): self.assertIs(mask_outputs[-1], None) # final layer def test_TimeDistributed_with_masking_layer(self): - with self.test_session(): + with self.cached_session(): # test with Masking layer model = keras.models.Sequential() model.add(keras.layers.TimeDistributed(keras.layers.Masking( @@ -266,7 +266,7 @@ class BidirectionalTest(test.TestCase): dim = 2 timesteps = 2 output_dim = 2 - with self.test_session(): + with self.cached_session(): for mode in ['sum', 'concat', 'ave', 'mul']: x = np.random.random((samples, timesteps, dim)) target_dim = 2 * output_dim if mode == 'concat' else output_dim @@ -310,7 +310,7 @@ class BidirectionalTest(test.TestCase): dim = 2 timesteps = 2 output_dim = 2 - with self.test_session(): + with self.cached_session(): x = np.random.random((samples, timesteps, dim)) model = keras.models.Sequential() model.add( @@ -331,7 +331,7 @@ class BidirectionalTest(test.TestCase): output_dim = 2 mode = 'sum' - with self.test_session(): + with self.cached_session(): x = np.random.random((samples, timesteps, dim)) target_dim = 2 * output_dim if mode == 'concat' else output_dim y = np.random.random((samples, target_dim)) @@ -363,7 +363,7 @@ class BidirectionalTest(test.TestCase): output_dim = 2 mode = 'sum' - with self.test_session(): + with self.cached_session(): x = np.random.random((samples, timesteps, dim)) target_dim = 2 * output_dim if mode == 'concat' else output_dim y = np.random.random((samples, target_dim)) @@ -383,7 +383,7 @@ class BidirectionalTest(test.TestCase): units = 3 x = [np.random.rand(samples, timesteps, dim)] - with self.test_session(): + with self.cached_session(): for merge_mode in ['sum', 'mul', 'ave', 'concat', None]: if merge_mode == 'sum': merge_func = lambda y, y_rev: y + y_rev @@ -447,7 +447,7 @@ class BidirectionalTest(test.TestCase): merge_mode = 'sum' x = [np.random.rand(samples, timesteps, dim)] - with self.test_session(): + with self.cached_session(): inputs = keras.Input((timesteps, dim)) wrapped = keras.layers.Bidirectional( rnn(units, dropout=0.2, recurrent_dropout=0.2), merge_mode=merge_mode) @@ -474,7 +474,7 @@ class BidirectionalTest(test.TestCase): timesteps = 3 units = 3 - with self.test_session(): + with self.cached_session(): input1 = keras.layers.Input((timesteps, dim)) layer = keras.layers.Bidirectional( rnn(units, return_state=True, return_sequences=True)) @@ -498,7 +498,7 @@ class BidirectionalTest(test.TestCase): def test_Bidirectional_trainable(self): # test layers that need learning_phase to be set - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(3, 2)) layer = keras.layers.Bidirectional(keras.layers.SimpleRNN(3)) _ = layer(x) @@ -509,7 +509,7 @@ class BidirectionalTest(test.TestCase): assert len(layer.trainable_weights) == 6 def test_Bidirectional_updates(self): - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(3, 2)) x_reachable_update = x * x layer = keras.layers.Bidirectional(keras.layers.SimpleRNN(3)) @@ -526,7 +526,7 @@ class BidirectionalTest(test.TestCase): assert len(layer.get_updates_for(x)) == 2 def test_Bidirectional_losses(self): - with self.test_session(): + with self.cached_session(): x = keras.layers.Input(shape=(3, 2)) x_reachable_loss = x * x layer = keras.layers.Bidirectional( @@ -545,7 +545,7 @@ class BidirectionalTest(test.TestCase): assert len(layer.get_losses_for(x)) == 2 def test_Bidirectional_with_constants(self): - with self.test_session(): + with self.cached_session(): # Test basic case. x = keras.Input((5, 5)) c = keras.Input((3,)) @@ -586,7 +586,7 @@ class BidirectionalTest(test.TestCase): self.assertAllClose(y_np, y_np_3, atol=1e-4) def test_Bidirectional_with_constants_layer_passing_initial_state(self): - with self.test_session(): + with self.cached_session(): # Test basic case. x = keras.Input((5, 5)) c = keras.Input((3,)) diff --git a/tensorflow/python/keras/losses_test.py b/tensorflow/python/keras/losses_test.py index 3098a6d071..c7015270ac 100644 --- a/tensorflow/python/keras/losses_test.py +++ b/tensorflow/python/keras/losses_test.py @@ -63,7 +63,7 @@ class _MSEMAELoss(object): class KerasLossesTest(test.TestCase): def test_objective_shapes_3d(self): - with self.test_session(): + with self.cached_session(): y_a = keras.backend.variable(np.random.random((5, 6, 7))) y_b = keras.backend.variable(np.random.random((5, 6, 7))) for obj in ALL_LOSSES: @@ -71,7 +71,7 @@ class KerasLossesTest(test.TestCase): self.assertListEqual(objective_output.get_shape().as_list(), [5, 6]) def test_objective_shapes_2d(self): - with self.test_session(): + with self.cached_session(): y_a = keras.backend.variable(np.random.random((6, 7))) y_b = keras.backend.variable(np.random.random((6, 7))) for obj in ALL_LOSSES: @@ -79,7 +79,7 @@ class KerasLossesTest(test.TestCase): self.assertListEqual(objective_output.get_shape().as_list(), [6,]) def test_cce_one_hot(self): - with self.test_session(): + with self.cached_session(): y_a = keras.backend.variable(np.random.randint(0, 7, (5, 6))) y_b = keras.backend.variable(np.random.random((5, 6, 7))) objective_output = keras.losses.sparse_categorical_crossentropy(y_a, y_b) @@ -119,7 +119,7 @@ class KerasLossesTest(test.TestCase): self.addCleanup(shutil.rmtree, tmpdir) model_filename = os.path.join(tmpdir, 'custom_loss.h5') - with self.test_session(): + with self.cached_session(): with keras.utils.custom_object_scope({'_MSEMAELoss': _MSEMAELoss}): loss = _MSEMAELoss(0.3) inputs = keras.layers.Input((2,)) diff --git a/tensorflow/python/keras/metrics.py b/tensorflow/python/keras/metrics.py index 9b87170ebe..14cf1ce2af 100644 --- a/tensorflow/python/keras/metrics.py +++ b/tensorflow/python/keras/metrics.py @@ -53,11 +53,12 @@ from tensorflow.python.ops import init_ops from tensorflow.python.ops import math_ops from tensorflow.python.ops import nn from tensorflow.python.ops import state_ops -from tensorflow.python.ops import variable_scope as vs +from tensorflow.python.ops import variables as tf_variables from tensorflow.python.ops import weights_broadcast_ops from tensorflow.python.training import distribution_strategy_context from tensorflow.python.util import tf_decorator from tensorflow.python.util.tf_export import tf_export +from tensorflow.tools.docs import doc_controls def check_is_tensor_or_operation(x, name): @@ -241,7 +242,7 @@ class Metric(Layer): ```python m = SomeMetric(...) - init_op = tf.global_variables_initializer() # Initialize variables + init_op = tf.variables_initializer(m.variables) # Initialize variables with tf.Session() as sess: sess.run(init_op) for input in ...: @@ -388,11 +389,12 @@ class Metric(Layer): return cls(**config) ### For use by subclasses ### + @doc_controls.for_subclass_implementers def add_weight(self, name, shape=(), - aggregation=vs.VariableAggregation.SUM, - synchronization=vs.VariableSynchronization.ON_READ, + aggregation=tf_variables.VariableAggregation.SUM, + synchronization=tf_variables.VariableSynchronization.ON_READ, initializer=None): """Adds state variable. Only for use by subclasses.""" return super(Metric, self).add_weight( @@ -401,6 +403,7 @@ class Metric(Layer): dtype=self._dtype, trainable=False, initializer=initializer, + collections=[], synchronization=synchronization, aggregation=aggregation) diff --git a/tensorflow/python/keras/metrics_test.py b/tensorflow/python/keras/metrics_test.py index 2ac74219d4..0bc95a3952 100644 --- a/tensorflow/python/keras/metrics_test.py +++ b/tensorflow/python/keras/metrics_test.py @@ -40,7 +40,7 @@ from tensorflow.python.training.checkpointable import util as checkpointable_uti class KerasMetricsTest(test.TestCase): def test_metrics(self): - with self.test_session(): + with self.cached_session(): y_a = K.variable(np.random.random((6, 7))) y_b = K.variable(np.random.random((6, 7))) for metric in [metrics.binary_accuracy, metrics.categorical_accuracy]: @@ -48,14 +48,14 @@ class KerasMetricsTest(test.TestCase): self.assertEqual(K.eval(output).shape, (6,)) def test_sparse_categorical_accuracy(self): - with self.test_session(): + with self.cached_session(): metric = metrics.sparse_categorical_accuracy y_a = K.variable(np.random.randint(0, 7, (6,))) y_b = K.variable(np.random.random((6, 7))) self.assertEqual(K.eval(metric(y_a, y_b)).shape, (6,)) def test_sparse_top_k_categorical_accuracy(self): - with self.test_session(): + with self.cached_session(): y_pred = K.variable(np.array([[0.3, 0.2, 0.1], [0.1, 0.2, 0.7]])) y_true = K.variable(np.array([[1], [0]])) result = K.eval( @@ -69,7 +69,7 @@ class KerasMetricsTest(test.TestCase): self.assertEqual(result, 0.) def test_top_k_categorical_accuracy(self): - with self.test_session(): + with self.cached_session(): y_pred = K.variable(np.array([[0.3, 0.2, 0.1], [0.1, 0.2, 0.7]])) y_true = K.variable(np.array([[0, 1, 0], [1, 0, 0]])) result = K.eval(metrics.top_k_categorical_accuracy(y_true, y_pred, k=3)) @@ -80,7 +80,7 @@ class KerasMetricsTest(test.TestCase): self.assertEqual(result, 0.) def test_stateful_metrics(self): - with self.test_session(): + with self.cached_session(): np.random.seed(1334) class BinaryTruePositives(layers.Layer): @@ -198,7 +198,7 @@ class KerasMetricsTest(test.TestCase): self.assertTrue(m.stateful) self.assertEqual(m.dtype, dtypes.float32) self.assertEqual(len(m.variables), 2) - self.evaluate(variables.global_variables_initializer()) + self.evaluate(variables.variables_initializer(m.variables)) # check initial state self.assertEqual(self.evaluate(m.total), 0) @@ -225,7 +225,7 @@ class KerasMetricsTest(test.TestCase): def test_mean_with_sample_weight(self): m = metrics.Mean(dtype=dtypes.float64) self.assertEqual(m.dtype, dtypes.float64) - self.evaluate(variables.global_variables_initializer()) + self.evaluate(variables.variables_initializer(m.variables)) # check scalar weight result_t = m(100, sample_weight=0.5) @@ -266,11 +266,11 @@ class KerasMetricsTest(test.TestCase): self.assertEqual(np.round(self.evaluate(m.count), decimals=2), 5.6) def test_mean_graph_with_placeholder(self): - with context.graph_mode(), self.test_session() as sess: + with context.graph_mode(), self.cached_session() as sess: m = metrics.Mean() v = array_ops.placeholder(dtypes.float32) w = array_ops.placeholder(dtypes.float32) - sess.run(variables.global_variables_initializer()) + sess.run(variables.variables_initializer(m.variables)) # check __call__() result_t = m(v, sample_weight=w) @@ -291,7 +291,7 @@ class KerasMetricsTest(test.TestCase): checkpoint_prefix = os.path.join(checkpoint_directory, 'ckpt') m = metrics.Mean() checkpoint = checkpointable_utils.Checkpoint(mean=m) - self.evaluate(variables.global_variables_initializer()) + self.evaluate(variables.variables_initializer(m.variables)) # update state self.evaluate(m(100.)) @@ -325,7 +325,7 @@ class KerasMetricsTest(test.TestCase): self.assertTrue(acc_obj.stateful) self.assertEqual(len(acc_obj.variables), 2) self.assertEqual(acc_obj.dtype, dtypes.float32) - self.evaluate(variables.global_variables_initializer()) + self.evaluate(variables.variables_initializer(acc_obj.variables)) # verify that correct value is returned update_op = acc_obj.update_state([[1], [0]], [[1], [0]]) @@ -357,7 +357,7 @@ class KerasMetricsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def test_binary_accuracy_threshold(self): acc_obj = metrics.BinaryAccuracy(threshold=0.7) - self.evaluate(variables.global_variables_initializer()) + self.evaluate(variables.variables_initializer(acc_obj.variables)) result_t = acc_obj([[1], [1], [0], [0]], [[0.9], [0.6], [0.4], [0.8]]) result = self.evaluate(result_t) self.assertAlmostEqual(result, 0.5, 2) diff --git a/tensorflow/python/keras/models.py b/tensorflow/python/keras/models.py index 0bd6620220..39b6042597 100644 --- a/tensorflow/python/keras/models.py +++ b/tensorflow/python/keras/models.py @@ -20,13 +20,20 @@ from __future__ import division from __future__ import print_function from tensorflow.python.keras import backend as K +from tensorflow.python.keras import optimizers from tensorflow.python.keras.engine import saving from tensorflow.python.keras.engine import sequential from tensorflow.python.keras.engine import training +from tensorflow.python.keras.engine.base_layer import Layer from tensorflow.python.keras.engine.input_layer import Input from tensorflow.python.keras.engine.input_layer import InputLayer +from tensorflow.python.keras.engine.network import Network from tensorflow.python.keras.utils import generic_utils - +from tensorflow.python.keras.utils.generic_utils import CustomObjectScope +from tensorflow.python.training import training_util +from tensorflow.python.training.checkpointable import base as checkpointable +from tensorflow.python.training.checkpointable import data_structures +from tensorflow.python.util.tf_export import tf_export # API entries importable from `keras.models`: Model = training.Model # pylint: disable=invalid-name @@ -220,6 +227,7 @@ def _clone_sequential_model(model, input_tensors=None): return Sequential(layers=[input_layer] + layers, name=model.name) +@tf_export('keras.models.clone_model') def clone_model(model, input_tensors=None): """Clone any `Model` instance. @@ -246,3 +254,216 @@ def clone_model(model, input_tensors=None): return _clone_sequential_model(model, input_tensors=input_tensors) else: return _clone_functional_model(model, input_tensors=input_tensors) + + +# "Clone" a subclassed model by reseting all of the attributes. + + +def _in_place_subclassed_model_reset(model): + """Substitute for model cloning that works for subclassed models. + + Subclassed models cannot be cloned because their topology is not serializable. + To "instantiate" an identical model in a new TF graph, we reuse the original + model object, but we clear its state. + + After calling this function on a model instance, you can use the model + instance as if it were a model clone (in particular you can use it in a new + graph). + + This method clears the state of the input model. It is thus destructive. + However the original state can be restored fully by calling + `_in_place_subclassed_model_state_restoration`. + + Args: + model: Instance of a Keras model created via subclassing. + + Raises: + ValueError: In case the model uses a subclassed model as inner layer. + """ + assert not model._is_graph_network # Only makes sense for subclassed networks + # Retrieve all layers tracked by the model as well as their attribute names + attributes_cache = {} + for name in dir(model): + try: + value = getattr(model, name) + except (AttributeError, ValueError, TypeError): + continue + if isinstance(value, Layer): + attributes_cache[name] = value + assert value in model._layers + elif isinstance(value, (list, tuple)) and name not in ('layers', '_layers'): + # Handle case: list/tuple of layers (also tracked by the Network API). + if value and all(isinstance(val, Layer) for val in value): + raise ValueError('We do not support the use of list-of-layers ' + 'attributes in subclassed models used with ' + '`model_to_estimator` at this time. Found list ' + 'model: %s' % name) + + # Replace layers on the model with fresh layers + layers_to_names = {value: key for key, value in attributes_cache.items()} + original_layers = model._layers[:] + model._layers = data_structures.NoDependency([]) + for layer in original_layers: # We preserve layer order. + config = layer.get_config() + # This will not work for nested subclassed models used as layers. + # This would be theoretically possible to support, but would add complexity. + # Only do it if users complain. + if isinstance(layer, Network) and not layer._is_graph_network: + raise ValueError('We do not support the use of nested subclassed models ' + 'in `model_to_estimator` at this time. Found nested ' + 'model: %s' % layer) + fresh_layer = layer.__class__.from_config(config) + name = layers_to_names[layer] + setattr(model, name, fresh_layer) + + # Cache original model build attributes (in addition to layers) + if (not hasattr(model, '_original_attributes_cache') or + model._original_attributes_cache is None): + if model.built: + attributes_to_cache = [ + 'inputs', + 'outputs', + '_feed_outputs', + '_feed_output_names', + '_feed_output_shapes', + '_feed_loss_fns', + 'loss_weights_list', + 'targets', + '_feed_targets', + 'sample_weight_modes', + 'weighted_metrics', + 'metrics_names', + 'metrics_tensors', + 'metrics_updates', + 'stateful_metric_names', + 'total_loss', + 'sample_weights', + '_feed_sample_weights', + 'train_function', + 'test_function', + 'predict_function', + '_collected_trainable_weights', + '_feed_inputs', + '_feed_input_names', + '_feed_input_shapes', + 'optimizer', + ] + for name in attributes_to_cache: + attributes_cache[name] = getattr(model, name) + model._original_attributes_cache = data_structures.NoDependency( + attributes_cache) + # Reset built state + model.built = False + model.inputs = None + model.outputs = None + + +def in_place_subclassed_model_state_restoration(model): + """Restores the original state of a model after it was "reset". + + This undoes this action of `_in_place_subclassed_model_reset`, which is called + in `clone_and_build_model` if `in_place_reset` is set to True. + + Args: + model: Instance of a Keras model created via subclassing, on which + `_in_place_subclassed_model_reset` was previously called. + """ + assert not model._is_graph_network + # Restore layers and build attributes + if (hasattr(model, '_original_attributes_cache') and + model._original_attributes_cache is not None): + # Models have sticky attribute assignment, so we want to be careful to add + # back the previous attributes and track Layers by their original names + # without adding dependencies on "utility" attributes which Models exempt + # when they're constructed. + model._layers = data_structures.NoDependency([]) + for name, value in model._original_attributes_cache.items(): + if not isinstance(value, checkpointable.CheckpointableBase): + # If this value is not already checkpointable, it's probably that way + # for a reason; we don't want to start tracking data structures that the + # original Model didn't. + value = data_structures.NoDependency(value) + setattr(model, name, value) + model._original_attributes_cache = None + else: + # Restore to the state of a never-called model. + model.built = False + model.inputs = None + model.outputs = None + + +def clone_and_build_model( + model, input_tensors=None, target_tensors=None, custom_objects=None, + compile_clone=True, in_place_reset=False): + """Clone a `Model` and build/compile it with the same settings used before. + + This function should be run in the same graph as the model. + + Args: + model: `tf.keras.Model` object. Can be Functional, Sequential, or + sub-classed. + input_tensors: Optional list of input tensors to build the model upon. If + not provided, placeholders will be created. + target_tensors: Optional list of target tensors for compiling the model. If + not provided, placeholders will be created. + custom_objects: Optional dictionary mapping string names to custom classes + or functions. + compile_clone: Boolean, whether to compile model clone (default `True`). + in_place_reset: Boolean, whether to reset the model in place. Only used if + the model is not a graph network. If the model is a subclassed model, then + this argument must be set to `True` (default `False`). To restore the + original model, use the function + `in_place_subclassed_model_state_restoration(model)`. + + Returns: + Clone of the model. + + Raises: + ValueError: if trying to clone a subclassed model, and `in_place_reset` is + set to False. + """ + if model._is_graph_network: + if custom_objects: + with CustomObjectScope(custom_objects): + clone = clone_model(model, input_tensors=input_tensors) + else: + clone = clone_model(model, input_tensors=input_tensors) + else: + if not in_place_reset: + raise ValueError( + 'Model is not a graph network (usually means that it is a subclassed ' + 'model). The model cannot be cloned, but there is a workaround where ' + 'the model is reset in-place. To use this, please set the argument ' + '`in_place_reset` to `True`. This will reset the attributes in the ' + 'original model. To restore the attributes, call ' + '`in_place_subclassed_model_state_restoration(model)`.') + clone = model + _in_place_subclassed_model_reset(clone) + if input_tensors is not None: + clone._set_inputs(input_tensors) + + # Compile/Build model + if not compile_clone: + if isinstance(clone, Sequential): + clone.build() + elif model.optimizer: + if isinstance(model.optimizer, optimizers.TFOptimizer): + optimizer = model.optimizer + K.track_tf_optimizer(optimizer) + else: + optimizer_config = model.optimizer.get_config() + optimizer = model.optimizer.__class__.from_config(optimizer_config) + global_step = training_util.get_or_create_global_step() + K.track_variable(global_step) + optimizer.iterations = global_step + + clone.compile( + optimizer, + model.loss, + metrics=model.metrics, + loss_weights=model.loss_weights, + sample_weight_mode=model.sample_weight_mode, + weighted_metrics=model.weighted_metrics, + target_tensors=target_tensors) + + return clone diff --git a/tensorflow/python/keras/models_test.py b/tensorflow/python/keras/models_test.py index 1385ad5390..1d0f56f3c8 100644 --- a/tensorflow/python/keras/models_test.py +++ b/tensorflow/python/keras/models_test.py @@ -18,16 +18,36 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import copy import os import numpy as np from tensorflow.python import keras +from tensorflow.python.eager import context from tensorflow.python.framework import test_util +from tensorflow.python.keras import metrics +from tensorflow.python.keras import models +from tensorflow.python.ops import random_ops +from tensorflow.python.ops import resource_variable_ops from tensorflow.python.platform import test from tensorflow.python.training import adam +class TestModel(keras.Model): + """A model subclass.""" + + def __init__(self, n_outputs=4, trainable=True): + """A test class with one dense layer and number of outputs as a variable.""" + super(TestModel, self).__init__() + self.layer1 = keras.layers.Dense(n_outputs) + self.n_outputs = resource_variable_ops.ResourceVariable( + n_outputs, trainable=trainable) + + def call(self, x): + return self.layer1(x) + + class TestModelCloning(test.TestCase): def test_clone_sequential_model(self): @@ -169,6 +189,7 @@ class CheckpointingTests(test.TestCase): model.load_weights(save_prefix) self.assertEqual(12., self.evaluate(beta1_power)) + class TestModelBackend(test.TestCase): def test_model_backend_float64_use_cases(self): @@ -183,5 +204,166 @@ class TestModelBackend(test.TestCase): keras.backend.set_floatx(floatx) + +class TestModelDeepCopy(test.TestCase): + + def test_deep_copy_eager_mode_trainable(self): + with context.eager_mode(): + x = random_ops.random_normal((32, 4)) + model = TestModel(trainable=True) + model(x) # Initialize Variables. + model_copy = copy.deepcopy(model) + self.assertEqual(len(model_copy.trainable_variables), 3) + model_copy.n_outputs.assign(1200) + self.assertFalse( + np.allclose(model_copy.n_outputs.numpy(), + model.n_outputs.numpy())) + + def test_deep_copy_eager_mode_not_trainable(self): + with context.eager_mode(): + x = random_ops.random_normal((32, 4)) + model = TestModel(trainable=False) + model(x) + model_copy = copy.deepcopy(model) + self.assertEqual(len(model_copy.trainable_variables), 2) + + weights = model_copy.get_weights() + weights = [w * 4 for w in weights] + model_copy.set_weights(weights) + self.assertFalse( + np.allclose(model.get_weights()[0], + model_copy.get_weights()[0])) + + +class TestCloneAndBuildModel(test.TestCase): + + def test_clone_and_build_non_compiled_model(self): + with self.test_session(): + inp = np.random.random((10, 4)) + out = np.random.random((10, 4)) + + model = keras.models.Sequential() + model.add(keras.layers.Dense(4, input_shape=(4,))) + model.add(keras.layers.BatchNormalization()) + model.add(keras.layers.Dropout(0.5)) + model.add(keras.layers.Dense(4)) + + # Everything should work in a new session. + keras.backend.clear_session() + + with self.test_session(): + # With placeholder creation + new_model = models.clone_and_build_model(model, compile_clone=True) + with self.assertRaisesRegexp(RuntimeError, 'must compile'): + new_model.evaluate(inp, out) + with self.assertRaisesRegexp(RuntimeError, 'must compile'): + new_model.train_on_batch(inp, out) + new_model.compile('rmsprop', 'mse') + new_model.train_on_batch(inp, out) + + # Create new tensors for inputs and targets + input_a = keras.Input(shape=(4,)) + target_a = keras.Input(shape=(4,)) + new_model = models.clone_and_build_model(model, input_tensors=input_a, + target_tensors=[target_a], + compile_clone=True) + with self.assertRaisesRegexp(RuntimeError, 'must compile'): + new_model.evaluate(inp, out) + with self.assertRaisesRegexp(RuntimeError, 'must compile'): + new_model.train_on_batch(inp, out) + new_model.compile('rmsprop', 'mse') + new_model.train_on_batch(inp, out) + + def _assert_same_compile_params(self, model): + """Assert that two models have the same compile parameters.""" + + self.assertEqual('mse', model.loss) + self.assertTrue( + isinstance(model.optimizer, keras.optimizers.RMSprop)) + self.assertEqual(['acc', metrics.categorical_accuracy], model.metrics) + + def _clone_and_build_test_helper(self, model, is_subclassed=False): + inp = np.random.random((10, 4)) + out = np.random.random((10, 4)) + + # Everything should work in a new session. + keras.backend.clear_session() + + with self.test_session(): + # With placeholder creation + new_model = models.clone_and_build_model( + model, compile_clone=True, in_place_reset=is_subclassed) + + self._assert_same_compile_params(new_model) + new_model.train_on_batch(inp, out) + new_model.evaluate(inp, out) + + # Create new tensors for inputs and targets + input_a = keras.Input(shape=(4,), name='a') + new_model = models.clone_and_build_model( + model, input_tensors=input_a, compile_clone=True, + in_place_reset=is_subclassed) + self._assert_same_compile_params(new_model) + new_model.train_on_batch(inp, out) + new_model.evaluate(inp, out) + + target_a = keras.Input(shape=(4,), name='b') + new_model = models.clone_and_build_model( + model, input_tensors=input_a, target_tensors=[target_a], + compile_clone=True, in_place_reset=is_subclassed) + self._assert_same_compile_params(new_model) + new_model.train_on_batch(inp, out) + new_model.evaluate(inp, out) + + def test_clone_and_build_compiled_sequential_model(self): + with self.test_session(): + model = keras.models.Sequential() + model.add(keras.layers.Dense(4, input_shape=(4,))) + model.add(keras.layers.BatchNormalization()) + model.add(keras.layers.Dropout(0.5)) + model.add(keras.layers.Dense(4)) + model.compile('rmsprop', 'mse', + metrics=['acc', metrics.categorical_accuracy]) + + self._clone_and_build_test_helper(model) + + def test_clone_and_build_functional_model(self): + with self.test_session(): + input_a = keras.Input(shape=(4,)) + dense_1 = keras.layers.Dense(4,) + dense_2 = keras.layers.Dense(4,) + + x_a = dense_1(input_a) + x_a = keras.layers.Dropout(0.5)(x_a) + x_a = keras.layers.BatchNormalization()(x_a) + x_a = dense_2(x_a) + model = keras.models.Model(input_a, x_a) + model.compile('rmsprop', 'mse', + metrics=['acc', metrics.categorical_accuracy]) + + self._clone_and_build_test_helper(model) + + def test_clone_and_build_subclassed_model(self): + class SubclassedModel(keras.Model): + + def __init__(self): + super(SubclassedModel, self).__init__() + self.layer1 = keras.layers.Dense(4) + self.layer2 = keras.layers.Dense(4) + + def call(self, inp): + out = self.layer1(inp) + out = keras.layers.BatchNormalization()(out) + out = keras.layers.Dropout(0.5)(out) + out = self.layer2(out) + return out + + with self.test_session(): + model = SubclassedModel() + model.compile('rmsprop', 'mse', + metrics=['acc', metrics.categorical_accuracy]) + self._clone_and_build_test_helper(model, True) + + if __name__ == '__main__': test.main() diff --git a/tensorflow/python/keras/optimizers.py b/tensorflow/python/keras/optimizers.py index f339a7e047..2ce79285db 100644 --- a/tensorflow/python/keras/optimizers.py +++ b/tensorflow/python/keras/optimizers.py @@ -699,7 +699,7 @@ class TFOptimizer(Optimizer, checkpointable.CheckpointableBase): self.iterations = K.variable(0, dtype='int64', name='iterations') def apply_gradients(self, grads): - self.optimizer.apply_gradients(grads) + self.optimizer.apply_gradients(grads, global_step=self.iterations) def get_grads(self, loss, params): return self.optimizer.compute_gradients(loss, params) @@ -813,7 +813,9 @@ def get(identifier): """ # Wrap TF optimizer instances if isinstance(identifier, tf_optimizer_module.Optimizer): - return TFOptimizer(identifier) + opt = TFOptimizer(identifier) + K.track_tf_optimizer(opt) + return opt if isinstance(identifier, dict): return deserialize(identifier) elif isinstance(identifier, six.string_types): diff --git a/tensorflow/python/keras/optimizers_test.py b/tensorflow/python/keras/optimizers_test.py index 4d295351f5..9a68fc0e35 100644 --- a/tensorflow/python/keras/optimizers_test.py +++ b/tensorflow/python/keras/optimizers_test.py @@ -21,6 +21,8 @@ from __future__ import print_function import numpy as np from tensorflow.python import keras +from tensorflow.python.eager import context +from tensorflow.python.framework import test_util from tensorflow.python.keras import testing_utils from tensorflow.python.platform import test from tensorflow.python.training.adam import AdamOptimizer @@ -140,6 +142,7 @@ class KerasOptimizersTest(test.TestCase): 2, input_shape=(3,), kernel_constraint=keras.constraints.MaxNorm(1))) # This is possible model.compile(loss='mean_squared_error', optimizer=optimizer) + keras.backend.track_tf_optimizer(optimizer) model.fit(np.random.random((5, 3)), np.random.random((5, 2)), epochs=1, @@ -153,6 +156,7 @@ class KerasOptimizersTest(test.TestCase): with self.assertRaises(NotImplementedError): optimizer.from_config(None) + @test_util.run_in_graph_and_eager_modes def test_tfoptimizer_iterations(self): with self.test_session(): optimizer = keras.optimizers.TFOptimizer(AdamOptimizer(0.01)) @@ -160,6 +164,7 @@ class KerasOptimizersTest(test.TestCase): model.add(keras.layers.Dense( 2, input_shape=(3,), kernel_constraint=keras.constraints.MaxNorm(1))) model.compile(loss='mean_squared_error', optimizer=optimizer) + keras.backend.track_tf_optimizer(optimizer) self.assertEqual(keras.backend.get_value(model.optimizer.iterations), 0) model.fit(np.random.random((55, 3)), @@ -169,11 +174,15 @@ class KerasOptimizersTest(test.TestCase): verbose=0) self.assertEqual(keras.backend.get_value(model.optimizer.iterations), 11) - model.fit(np.random.random((20, 3)), - np.random.random((20, 2)), - steps_per_epoch=8, - verbose=0) - self.assertEqual(keras.backend.get_value(model.optimizer.iterations), 19) + if not context.executing_eagerly(): + # TODO(kathywu): investigate why training with an array input and + # setting the argument steps_per_epoch does not work in eager mode. + model.fit(np.random.random((20, 3)), + np.random.random((20, 2)), + steps_per_epoch=8, + verbose=0) + self.assertEqual( + keras.backend.get_value(model.optimizer.iterations), 19) def test_negative_clipvalue_or_clipnorm(self): with self.assertRaises(ValueError): diff --git a/tensorflow/python/keras/preprocessing/__init__.py b/tensorflow/python/keras/preprocessing/__init__.py index 2f08f88600..0860eed3cf 100644 --- a/tensorflow/python/keras/preprocessing/__init__.py +++ b/tensorflow/python/keras/preprocessing/__init__.py @@ -23,6 +23,8 @@ import keras_preprocessing from tensorflow.python.keras import backend from tensorflow.python.keras import utils +# This exists for compatibility with prior version of keras_preprocessing. +# TODO(fchollet): remove in the future. keras_preprocessing.set_keras_submodules(backend=backend, utils=utils) from tensorflow.python.keras.preprocessing import image diff --git a/tensorflow/python/keras/preprocessing/image.py b/tensorflow/python/keras/preprocessing/image.py index ba227385ef..e33993950d 100644 --- a/tensorflow/python/keras/preprocessing/image.py +++ b/tensorflow/python/keras/preprocessing/image.py @@ -27,6 +27,9 @@ try: except ImportError: pass +from tensorflow.python.keras import backend +from tensorflow.python.keras import utils +from tensorflow.python.util import tf_inspect from tensorflow.python.util.tf_export import tf_export random_rotation = image.random_rotation @@ -38,14 +41,482 @@ random_channel_shift = image.random_channel_shift apply_brightness_shift = image.apply_brightness_shift random_brightness = image.random_brightness apply_affine_transform = image.apply_affine_transform -array_to_img = image.array_to_img -img_to_array = image.img_to_array -save_img = image.save_img load_img = image.load_img -ImageDataGenerator = image.ImageDataGenerator -Iterator = image.Iterator -NumpyArrayIterator = image.NumpyArrayIterator -DirectoryIterator = image.DirectoryIterator + + +@tf_export('keras.preprocessing.image.array_to_img') +def array_to_img(x, data_format=None, scale=True, dtype=None): + """Converts a 3D Numpy array to a PIL Image instance. + + Arguments: + x: Input Numpy array. + data_format: Image data format. + either "channels_first" or "channels_last". + scale: Whether to rescale image values + to be within `[0, 255]`. + dtype: Dtype to use. + + Returns: + A PIL Image instance. + + Raises: + ImportError: if PIL is not available. + ValueError: if invalid `x` or `data_format` is passed. + """ + + if data_format is None: + data_format = backend.image_data_format() + kwargs = {} + if 'dtype' in tf_inspect.getfullargspec(image.array_to_img)[0]: + if dtype is None: + dtype = backend.floatx() + kwargs['dtype'] = dtype + return image.array_to_img(x, data_format=data_format, scale=scale, **kwargs) + + +@tf_export('keras.preprocessing.image.img_to_array') +def img_to_array(img, data_format=None, dtype=None): + """Converts a PIL Image instance to a Numpy array. + + Arguments: + img: PIL Image instance. + data_format: Image data format, + either "channels_first" or "channels_last". + dtype: Dtype to use for the returned array. + + Returns: + A 3D Numpy array. + + Raises: + ValueError: if invalid `img` or `data_format` is passed. + """ + + if data_format is None: + data_format = backend.image_data_format() + kwargs = {} + if 'dtype' in tf_inspect.getfullargspec(image.img_to_array)[0]: + if dtype is None: + dtype = backend.floatx() + kwargs['dtype'] = dtype + return image.img_to_array(img, data_format=data_format, **kwargs) + + +@tf_export('keras.preprocessing.image.save_img') +def save_img(path, + x, + data_format=None, + file_format=None, + scale=True, + **kwargs): + """Saves an image stored as a Numpy array to a path or file object. + + Arguments: + path: Path or file object. + x: Numpy array. + data_format: Image data format, + either "channels_first" or "channels_last". + file_format: Optional file format override. If omitted, the + format to use is determined from the filename extension. + If a file object was used instead of a filename, this + parameter should always be used. + scale: Whether to rescale image values to be within `[0, 255]`. + **kwargs: Additional keyword arguments passed to `PIL.Image.save()`. + """ + if data_format is None: + data_format = backend.image_data_format() + image.save_img(path, + x, + data_format=data_format, + file_format=file_format, + scale=scale, **kwargs) + + +@tf_export('keras.preprocessing.image.Iterator') +class Iterator(image.Iterator, utils.Sequence): + pass + + +@tf_export('keras.preprocessing.image.DirectoryIterator') +class DirectoryIterator(image.DirectoryIterator, Iterator): + """Iterator capable of reading images from a directory on disk. + + Arguments: + directory: Path to the directory to read images from. + Each subdirectory in this directory will be + considered to contain images from one class, + or alternatively you could specify class subdirectories + via the `classes` argument. + image_data_generator: Instance of `ImageDataGenerator` + to use for random transformations and normalization. + target_size: tuple of integers, dimensions to resize input images to. + color_mode: One of `"rgb"`, `"rgba"`, `"grayscale"`. + Color mode to read images. + classes: Optional list of strings, names of subdirectories + containing images from each class (e.g. `["dogs", "cats"]`). + It will be computed automatically if not set. + class_mode: Mode for yielding the targets: + `"binary"`: binary targets (if there are only two classes), + `"categorical"`: categorical targets, + `"sparse"`: integer targets, + `"input"`: targets are images identical to input images (mainly + used to work with autoencoders), + `None`: no targets get yielded (only input images are yielded). + batch_size: Integer, size of a batch. + shuffle: Boolean, whether to shuffle the data between epochs. + seed: Random seed for data shuffling. + data_format: String, one of `channels_first`, `channels_last`. + save_to_dir: Optional directory where to save the pictures + being yielded, in a viewable format. This is useful + for visualizing the random transformations being + applied, for debugging purposes. + save_prefix: String prefix to use for saving sample + images (if `save_to_dir` is set). + save_format: Format to use for saving sample images + (if `save_to_dir` is set). + subset: Subset of data (`"training"` or `"validation"`) if + validation_split is set in ImageDataGenerator. + interpolation: Interpolation method used to resample the image if the + target size is different from that of the loaded image. + Supported methods are "nearest", "bilinear", and "bicubic". + If PIL version 1.1.3 or newer is installed, "lanczos" is also + supported. If PIL version 3.4.0 or newer is installed, "box" and + "hamming" are also supported. By default, "nearest" is used. + dtype: Dtype to use for generated arrays. + """ + + def __init__(self, directory, image_data_generator, + target_size=(256, 256), + color_mode='rgb', + classes=None, + class_mode='categorical', + batch_size=32, + shuffle=True, + seed=None, + data_format=None, + save_to_dir=None, + save_prefix='', + save_format='png', + follow_links=False, + subset=None, + interpolation='nearest', + dtype=None): + if data_format is None: + data_format = backend.image_data_format() + kwargs = {} + if 'dtype' in tf_inspect.getfullargspec( + image.ImageDataGenerator.__init__)[0]: + if dtype is None: + dtype = backend.floatx() + kwargs['dtype'] = dtype + super(DirectoryIterator, self).__init__( + directory, image_data_generator, + target_size=target_size, + color_mode=color_mode, + classes=classes, + class_mode=class_mode, + batch_size=batch_size, + shuffle=shuffle, + seed=seed, + data_format=data_format, + save_to_dir=save_to_dir, + save_prefix=save_prefix, + save_format=save_format, + follow_links=follow_links, + subset=subset, + interpolation=interpolation, + **kwargs) + + +@tf_export('keras.preprocessing.image.NumpyArrayIterator') +class NumpyArrayIterator(image.NumpyArrayIterator, Iterator): + """Iterator yielding data from a Numpy array. + + Arguments: + x: Numpy array of input data or tuple. + If tuple, the second elements is either + another numpy array or a list of numpy arrays, + each of which gets passed + through as an output without any modifications. + y: Numpy array of targets data. + image_data_generator: Instance of `ImageDataGenerator` + to use for random transformations and normalization. + batch_size: Integer, size of a batch. + shuffle: Boolean, whether to shuffle the data between epochs. + sample_weight: Numpy array of sample weights. + seed: Random seed for data shuffling. + data_format: String, one of `channels_first`, `channels_last`. + save_to_dir: Optional directory where to save the pictures + being yielded, in a viewable format. This is useful + for visualizing the random transformations being + applied, for debugging purposes. + save_prefix: String prefix to use for saving sample + images (if `save_to_dir` is set). + save_format: Format to use for saving sample images + (if `save_to_dir` is set). + subset: Subset of data (`"training"` or `"validation"`) if + validation_split is set in ImageDataGenerator. + dtype: Dtype to use for the generated arrays. + """ + + def __init__(self, x, y, image_data_generator, + batch_size=32, + shuffle=False, + sample_weight=None, + seed=None, + data_format=None, + save_to_dir=None, + save_prefix='', + save_format='png', + subset=None, + dtype=None): + if data_format is None: + data_format = backend.image_data_format() + kwargs = {} + if 'dtype' in tf_inspect.getfullargspec( + image.NumpyArrayIterator.__init__)[0]: + if dtype is None: + dtype = backend.floatx() + kwargs['dtype'] = dtype + super(NumpyArrayIterator, self).__init__( + x, y, image_data_generator, + batch_size=batch_size, + shuffle=shuffle, + sample_weight=sample_weight, + seed=seed, + data_format=data_format, + save_to_dir=save_to_dir, + save_prefix=save_prefix, + save_format=save_format, + subset=subset, + **kwargs) + + +@tf_export('keras.preprocessing.image.ImageDataGenerator') +class ImageDataGenerator(image.ImageDataGenerator): + """Generate batches of tensor image data with real-time data augmentation. + + The data will be looped over (in batches). + + Arguments: + featurewise_center: Boolean. + Set input mean to 0 over the dataset, feature-wise. + samplewise_center: Boolean. Set each sample mean to 0. + featurewise_std_normalization: Boolean. + Divide inputs by std of the dataset, feature-wise. + samplewise_std_normalization: Boolean. Divide each input by its std. + zca_epsilon: epsilon for ZCA whitening. Default is 1e-6. + zca_whitening: Boolean. Apply ZCA whitening. + rotation_range: Int. Degree range for random rotations. + width_shift_range: Float, 1-D array-like or int + - float: fraction of total width, if < 1, or pixels if >= 1. + - 1-D array-like: random elements from the array. + - int: integer number of pixels from interval + `(-width_shift_range, +width_shift_range)` + - With `width_shift_range=2` possible values + are integers `[-1, 0, +1]`, + same as with `width_shift_range=[-1, 0, +1]`, + while with `width_shift_range=1.0` possible values are floats + in the interval [-1.0, +1.0). + height_shift_range: Float, 1-D array-like or int + - float: fraction of total height, if < 1, or pixels if >= 1. + - 1-D array-like: random elements from the array. + - int: integer number of pixels from interval + `(-height_shift_range, +height_shift_range)` + - With `height_shift_range=2` possible values + are integers `[-1, 0, +1]`, + same as with `height_shift_range=[-1, 0, +1]`, + while with `height_shift_range=1.0` possible values are floats + in the interval [-1.0, +1.0). + brightness_range: Tuple or list of two floats. Range for picking + a brightness shift value from. + shear_range: Float. Shear Intensity + (Shear angle in counter-clockwise direction in degrees) + zoom_range: Float or [lower, upper]. Range for random zoom. + If a float, `[lower, upper] = [1-zoom_range, 1+zoom_range]`. + channel_shift_range: Float. Range for random channel shifts. + fill_mode: One of {"constant", "nearest", "reflect" or "wrap"}. + Default is 'nearest'. + Points outside the boundaries of the input are filled + according to the given mode: + - 'constant': kkkkkkkk|abcd|kkkkkkkk (cval=k) + - 'nearest': aaaaaaaa|abcd|dddddddd + - 'reflect': abcddcba|abcd|dcbaabcd + - 'wrap': abcdabcd|abcd|abcdabcd + cval: Float or Int. + Value used for points outside the boundaries + when `fill_mode = "constant"`. + horizontal_flip: Boolean. Randomly flip inputs horizontally. + vertical_flip: Boolean. Randomly flip inputs vertically. + rescale: rescaling factor. Defaults to None. + If None or 0, no rescaling is applied, + otherwise we multiply the data by the value provided + (after applying all other transformations). + preprocessing_function: function that will be implied on each input. + The function will run after the image is resized and augmented. + The function should take one argument: + one image (Numpy tensor with rank 3), + and should output a Numpy tensor with the same shape. + data_format: Image data format, + either "channels_first" or "channels_last". + "channels_last" mode means that the images should have shape + `(samples, height, width, channels)`, + "channels_first" mode means that the images should have shape + `(samples, channels, height, width)`. + It defaults to the `image_data_format` value found in your + Keras config file at `~/.keras/keras.json`. + If you never set it, then it will be "channels_last". + validation_split: Float. Fraction of images reserved for validation + (strictly between 0 and 1). + dtype: Dtype to use for the generated arrays. + + Examples: + + Example of using `.flow(x, y)`: + + ```python + (x_train, y_train), (x_test, y_test) = cifar10.load_data() + y_train = np_utils.to_categorical(y_train, num_classes) + y_test = np_utils.to_categorical(y_test, num_classes) + datagen = ImageDataGenerator( + featurewise_center=True, + featurewise_std_normalization=True, + rotation_range=20, + width_shift_range=0.2, + height_shift_range=0.2, + horizontal_flip=True) + # compute quantities required for featurewise normalization + # (std, mean, and principal components if ZCA whitening is applied) + datagen.fit(x_train) + # fits the model on batches with real-time data augmentation: + model.fit_generator(datagen.flow(x_train, y_train, batch_size=32), + steps_per_epoch=len(x_train) / 32, epochs=epochs) + # here's a more "manual" example + for e in range(epochs): + print('Epoch', e) + batches = 0 + for x_batch, y_batch in datagen.flow(x_train, y_train, batch_size=32): + model.fit(x_batch, y_batch) + batches += 1 + if batches >= len(x_train) / 32: + # we need to break the loop by hand because + # the generator loops indefinitely + break + ``` + + Example of using `.flow_from_directory(directory)`: + + ```python + train_datagen = ImageDataGenerator( + rescale=1./255, + shear_range=0.2, + zoom_range=0.2, + horizontal_flip=True) + test_datagen = ImageDataGenerator(rescale=1./255) + train_generator = train_datagen.flow_from_directory( + 'data/train', + target_size=(150, 150), + batch_size=32, + class_mode='binary') + validation_generator = test_datagen.flow_from_directory( + 'data/validation', + target_size=(150, 150), + batch_size=32, + class_mode='binary') + model.fit_generator( + train_generator, + steps_per_epoch=2000, + epochs=50, + validation_data=validation_generator, + validation_steps=800) + ``` + + Example of transforming images and masks together. + + ```python + # we create two instances with the same arguments + data_gen_args = dict(featurewise_center=True, + featurewise_std_normalization=True, + rotation_range=90, + width_shift_range=0.1, + height_shift_range=0.1, + zoom_range=0.2) + image_datagen = ImageDataGenerator(**data_gen_args) + mask_datagen = ImageDataGenerator(**data_gen_args) + # Provide the same seed and keyword arguments to the fit and flow methods + seed = 1 + image_datagen.fit(images, augment=True, seed=seed) + mask_datagen.fit(masks, augment=True, seed=seed) + image_generator = image_datagen.flow_from_directory( + 'data/images', + class_mode=None, + seed=seed) + mask_generator = mask_datagen.flow_from_directory( + 'data/masks', + class_mode=None, + seed=seed) + # combine generators into one which yields image and masks + train_generator = zip(image_generator, mask_generator) + model.fit_generator( + train_generator, + steps_per_epoch=2000, + epochs=50) + ``` + """ + + def __init__(self, + featurewise_center=False, + samplewise_center=False, + featurewise_std_normalization=False, + samplewise_std_normalization=False, + zca_whitening=False, + zca_epsilon=1e-6, + rotation_range=0, + width_shift_range=0., + height_shift_range=0., + brightness_range=None, + shear_range=0., + zoom_range=0., + channel_shift_range=0., + fill_mode='nearest', + cval=0., + horizontal_flip=False, + vertical_flip=False, + rescale=None, + preprocessing_function=None, + data_format=None, + validation_split=0.0, + dtype=None): + if data_format is None: + data_format = backend.image_data_format() + kwargs = {} + if 'dtype' in tf_inspect.getfullargspec( + image.ImageDataGenerator.__init__)[0]: + if dtype is None: + dtype = backend.floatx() + kwargs['dtype'] = dtype + super(ImageDataGenerator, self).__init__( + featurewise_center=featurewise_center, + samplewise_center=samplewise_center, + featurewise_std_normalization=featurewise_std_normalization, + samplewise_std_normalization=samplewise_std_normalization, + zca_whitening=zca_whitening, + zca_epsilon=zca_epsilon, + rotation_range=rotation_range, + width_shift_range=width_shift_range, + height_shift_range=height_shift_range, + brightness_range=brightness_range, + shear_range=shear_range, + zoom_range=zoom_range, + channel_shift_range=channel_shift_range, + fill_mode=fill_mode, + cval=cval, + horizontal_flip=horizontal_flip, + vertical_flip=vertical_flip, + rescale=rescale, + preprocessing_function=preprocessing_function, + data_format=data_format, + validation_split=validation_split, + **kwargs) tf_export('keras.preprocessing.image.random_rotation')(random_rotation) tf_export('keras.preprocessing.image.random_shift')(random_shift) @@ -59,11 +530,4 @@ tf_export( tf_export('keras.preprocessing.image.random_brightness')(random_brightness) tf_export( 'keras.preprocessing.image.apply_affine_transform')(apply_affine_transform) -tf_export('keras.preprocessing.image.array_to_img')(array_to_img) -tf_export('keras.preprocessing.image.img_to_array')(img_to_array) -tf_export('keras.preprocessing.image.save_img')(save_img) tf_export('keras.preprocessing.image.load_img')(load_img) -tf_export('keras.preprocessing.image.ImageDataGenerator')(ImageDataGenerator) -tf_export('keras.preprocessing.image.Iterator')(Iterator) -tf_export('keras.preprocessing.image.NumpyArrayIterator')(NumpyArrayIterator) -tf_export('keras.preprocessing.image.DirectoryIterator')(DirectoryIterator) diff --git a/tensorflow/python/keras/preprocessing/sequence.py b/tensorflow/python/keras/preprocessing/sequence.py index 116d3108d9..f014668909 100644 --- a/tensorflow/python/keras/preprocessing/sequence.py +++ b/tensorflow/python/keras/preprocessing/sequence.py @@ -21,6 +21,7 @@ from __future__ import print_function from keras_preprocessing import sequence +from tensorflow.python.keras import utils from tensorflow.python.util.tf_export import tf_export pad_sequences = sequence.pad_sequences @@ -28,11 +29,67 @@ make_sampling_table = sequence.make_sampling_table skipgrams = sequence.skipgrams # TODO(fchollet): consider making `_remove_long_seq` public. _remove_long_seq = sequence._remove_long_seq # pylint: disable=protected-access -TimeseriesGenerator = sequence.TimeseriesGenerator + + +@tf_export('keras.preprocessing.sequence.TimeseriesGenerator') +class TimeseriesGenerator(sequence.TimeseriesGenerator, utils.Sequence): + """Utility class for generating batches of temporal data. + This class takes in a sequence of data-points gathered at + equal intervals, along with time series parameters such as + stride, length of history, etc., to produce batches for + training/validation. + # Arguments + data: Indexable generator (such as list or Numpy array) + containing consecutive data points (timesteps). + The data should be at 2D, and axis 0 is expected + to be the time dimension. + targets: Targets corresponding to timesteps in `data`. + It should have same length as `data`. + length: Length of the output sequences (in number of timesteps). + sampling_rate: Period between successive individual timesteps + within sequences. For rate `r`, timesteps + `data[i]`, `data[i-r]`, ... `data[i - length]` + are used for create a sample sequence. + stride: Period between successive output sequences. + For stride `s`, consecutive output samples would + be centered around `data[i]`, `data[i+s]`, `data[i+2*s]`, etc. + start_index: Data points earlier than `start_index` will not be used + in the output sequences. This is useful to reserve part of the + data for test or validation. + end_index: Data points later than `end_index` will not be used + in the output sequences. This is useful to reserve part of the + data for test or validation. + shuffle: Whether to shuffle output samples, + or instead draw them in chronological order. + reverse: Boolean: if `true`, timesteps in each output sample will be + in reverse chronological order. + batch_size: Number of timeseries samples in each batch + (except maybe the last one). + # Returns + A [Sequence](/utils/#sequence) instance. + # Examples + ```python + from keras.preprocessing.sequence import TimeseriesGenerator + import numpy as np + data = np.array([[i] for i in range(50)]) + targets = np.array([[i] for i in range(50)]) + data_gen = TimeseriesGenerator(data, targets, + length=10, sampling_rate=2, + batch_size=2) + assert len(data_gen) == 20 + batch_0 = data_gen[0] + x, y = batch_0 + assert np.array_equal(x, + np.array([[[0], [2], [4], [6], [8]], + [[1], [3], [5], [7], [9]]])) + assert np.array_equal(y, + np.array([[10], [11]])) + ``` + """ + pass + tf_export('keras.preprocessing.sequence.pad_sequences')(pad_sequences) tf_export( 'keras.preprocessing.sequence.make_sampling_table')(make_sampling_table) tf_export('keras.preprocessing.sequence.skipgrams')(skipgrams) -tf_export( - 'keras.preprocessing.sequence.TimeseriesGenerator')(TimeseriesGenerator) diff --git a/tensorflow/python/keras/regularizers_test.py b/tensorflow/python/keras/regularizers_test.py index e2075785d8..bba4ebb287 100644 --- a/tensorflow/python/keras/regularizers_test.py +++ b/tensorflow/python/keras/regularizers_test.py @@ -50,7 +50,7 @@ def create_model(kernel_regularizer=None, activity_regularizer=None): class KerasRegularizersTest(test.TestCase): def test_kernel_regularization(self): - with self.test_session(): + with self.cached_session(): (x_train, y_train), _ = get_data() for reg in [keras.regularizers.l1(), keras.regularizers.l2(), @@ -62,7 +62,7 @@ class KerasRegularizersTest(test.TestCase): epochs=1, verbose=0) def test_activity_regularization(self): - with self.test_session(): + with self.cached_session(): (x_train, y_train), _ = get_data() for reg in [keras.regularizers.l1(), keras.regularizers.l2()]: model = create_model(activity_regularizer=reg) diff --git a/tensorflow/python/keras/testing_utils.py b/tensorflow/python/keras/testing_utils.py index 6e8ee06ff5..58405c550b 100644 --- a/tensorflow/python/keras/testing_utils.py +++ b/tensorflow/python/keras/testing_utils.py @@ -184,3 +184,22 @@ def layer_test(layer_cls, kwargs=None, input_shape=None, input_dtype=None, # for further checks in the caller function return actual_output + +def get_small_sequential_mlp(num_hidden, num_classes, input_dim=None): + model = keras.models.Sequential() + if input_dim: + model.add(keras.layers.Dense(num_hidden, activation='relu', + input_dim=input_dim)) + else: + model.add(keras.layers.Dense(num_hidden, activation='relu')) + activation = 'sigmoid' if num_classes == 1 else 'softmax' + model.add(keras.layers.Dense(num_classes, activation=activation)) + return model + + +def get_small_functional_mlp(num_hidden, num_classes, input_dim): + inputs = keras.Input(shape=(input_dim,)) + outputs = keras.layers.Dense(num_hidden, activation='relu')(inputs) + activation = 'sigmoid' if num_classes == 1 else 'softmax' + outputs = keras.layers.Dense(num_classes, activation=activation)(outputs) + return keras.Model(inputs, outputs) diff --git a/tensorflow/python/keras/utils/multi_gpu_utils_test.py b/tensorflow/python/keras/utils/multi_gpu_utils_test.py index 77792d14f5..c7e94998b4 100644 --- a/tensorflow/python/keras/utils/multi_gpu_utils_test.py +++ b/tensorflow/python/keras/utils/multi_gpu_utils_test.py @@ -180,6 +180,23 @@ class TestMultiGPUModel(test.TestCase): target_tensors=[targets]) parallel_model.fit(epochs=1, steps_per_epoch=3) + def test_multi_gpu_with_multi_input_layers(self): + gpus = 2 + + if not check_if_compatible_devices(gpus=gpus): + return + + with self.test_session(): + inputs = keras.Input((4, 3)) + init_state = keras.Input((3,)) + outputs = keras.layers.SimpleRNN( + 3, return_sequences=True)(inputs, initial_state=init_state) + x = [np.random.randn(2, 4, 3), np.random.randn(2, 3)] + y = np.random.randn(2, 4, 3) + model = keras.Model([inputs, init_state], outputs) + parallel_model = keras.utils.multi_gpu_model(model, gpus=gpus) + parallel_model.compile(loss='mean_squared_error', optimizer='adam') + parallel_model.train_on_batch(x, y) if __name__ == '__main__': test.main() diff --git a/tensorflow/python/keras/utils/tf_utils.py b/tensorflow/python/keras/utils/tf_utils.py index 162e5b2cd6..cfdb3de2aa 100644 --- a/tensorflow/python/keras/utils/tf_utils.py +++ b/tensorflow/python/keras/utils/tf_utils.py @@ -20,6 +20,7 @@ from __future__ import print_function from tensorflow.python.framework import ops from tensorflow.python.framework import smart_cond as smart_module from tensorflow.python.framework import tensor_shape +from tensorflow.python.framework import tensor_util from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import variables from tensorflow.python.util import nest @@ -109,10 +110,10 @@ def get_reachable_from_inputs(inputs, targets=None): if isinstance(x, ops.Operation): outputs = x.outputs[:] or [] outputs += x._control_outputs # pylint: disable=protected-access - elif isinstance(x, ops.Tensor): - outputs = x.consumers() elif isinstance(x, variables.Variable): outputs = [x.op] + elif tensor_util.is_tensor(x): + outputs = x.consumers() else: raise TypeError('Expected Operation, Variable, or Tensor, got ' + str(x)) diff --git a/tensorflow/python/kernel_tests/BUILD b/tensorflow/python/kernel_tests/BUILD index c84ed9d485..7671da11ab 100644 --- a/tensorflow/python/kernel_tests/BUILD +++ b/tensorflow/python/kernel_tests/BUILD @@ -84,6 +84,25 @@ tf_py_test( ) tf_py_test( + name = "batch_scatter_ops_test", + srcs = ["batch_scatter_ops_test.py"], + additional_deps = [ + "//tensorflow/python/eager:context", + "//tensorflow/python:array_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:constant_op", + "//tensorflow/python:dtypes", + "//tensorflow/python:errors", + "//tensorflow/python:framework_test_lib", + "//tensorflow/python:gradients", + "//tensorflow/python:resource_variable_ops", + "//tensorflow/python:session", + "//tensorflow/python:state_ops", + "//tensorflow/python:variables", + ], +) + +tf_py_test( name = "bcast_ops_test", size = "small", srcs = ["bcast_ops_test.py"], @@ -582,7 +601,7 @@ tf_py_test( tf_py_test( name = "matrix_logarithm_op_test", - size = "small", + size = "medium", srcs = ["matrix_logarithm_op_test.py"], additional_deps = [ "//third_party/py/numpy", @@ -645,7 +664,7 @@ cuda_py_test( cuda_py_test( name = "parameterized_truncated_normal_op_test", - size = "small", + size = "medium", srcs = ["parameterized_truncated_normal_op_test.py"], additional_deps = [ "//third_party/py/numpy", @@ -747,6 +766,7 @@ tf_py_test( size = "small", srcs = ["regex_replace_op_test.py"], additional_deps = [ + "@absl_py//absl/testing:parameterized", "//tensorflow/python:client_testlib", "//tensorflow/python:constant_op", "//tensorflow/python:dtypes", @@ -1368,6 +1388,8 @@ cuda_py_test( "//tensorflow/python/eager:context", "//tensorflow/python:array_ops", "//tensorflow/python:check_ops", + "//tensorflow/python:math_ops", + "//tensorflow/python:random_ops", "//tensorflow/python:client_testlib", "//tensorflow/python:framework", "//tensorflow/python:framework_for_generated_wrappers", @@ -1420,6 +1442,7 @@ cuda_py_test( "//tensorflow/python:array_ops_gen", "//tensorflow/python:client", "//tensorflow/python:client_testlib", + "//tensorflow/python:cond_v2", "//tensorflow/python:control_flow_ops", "//tensorflow/python:data_flow_ops", "//tensorflow/python:data_flow_ops_gen", diff --git a/tensorflow/python/kernel_tests/array_ops_test.py b/tensorflow/python/kernel_tests/array_ops_test.py index 81442d12e9..b0e24e969c 100644 --- a/tensorflow/python/kernel_tests/array_ops_test.py +++ b/tensorflow/python/kernel_tests/array_ops_test.py @@ -559,6 +559,14 @@ class StridedSliceTest(test_util.TensorFlowTestCase): s = array_ops.strided_slice(x, begin, end, strides) self.assertAllEqual([3.], self.evaluate(s)) + @test_util.assert_no_new_pyobjects_executing_eagerly + def testEagerMemory(self): + with context.eager_mode(): + inputs = constant_op.constant( + [[[1], [2], [3], [4]]], dtype=dtypes.float32) + # Tests that slicing an EagerTensor doesn't leak memory + inputs[0] # pylint: disable=pointless-statement + def testDegenerateSlices(self): with self.test_session(use_gpu=True): checker = StridedSliceChecker(self, StridedSliceChecker.REF_TENSOR) @@ -1145,7 +1153,7 @@ class IdentityTest(test_util.TensorFlowTestCase): def testEagerIdentity(self): with context.eager_mode(): - ctx = context.get_default_context() + ctx = context.context() if not ctx.num_gpus(): self.skipTest("No GPUs found") diff --git a/tensorflow/python/kernel_tests/batch_scatter_ops_test.py b/tensorflow/python/kernel_tests/batch_scatter_ops_test.py new file mode 100644 index 0000000000..0d41a7e3b3 --- /dev/null +++ b/tensorflow/python/kernel_tests/batch_scatter_ops_test.py @@ -0,0 +1,129 @@ +# Copyright 2015 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for tensorflow.ops.tf.scatter.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np + +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.ops import state_ops +from tensorflow.python.ops import variables +from tensorflow.python.platform import test + + +def _AsType(v, vtype): + return v.astype(vtype) if isinstance(v, np.ndarray) else vtype(v) + + +def _NumpyUpdate(ref, indices, updates): + for i, indx in np.ndenumerate(indices): + indx = i[:-1] + (indx,) + ref[indx] = updates[i] + + +_TF_OPS_TO_NUMPY = { + state_ops.batch_scatter_update: _NumpyUpdate, +} + + +class ScatterTest(test.TestCase): + + def _VariableRankTest(self, + tf_scatter, + vtype, + itype, + repeat_indices=False, + updates_are_scalar=False): + np.random.seed(8) + with self.test_session(use_gpu=False): + for indices_shape in (2,), (3, 7), (3, 4, 7): + for extra_shape in (), (5,), (5, 9): + # Generate random indices with no duplicates for easy numpy comparison + sparse_dim = len(indices_shape) - 1 + indices = np.random.randint( + indices_shape[sparse_dim], size=indices_shape, dtype=itype) + updates = _AsType( + np.random.randn(*(indices_shape + extra_shape)), vtype) + + old = _AsType(np.random.randn(*(indices_shape + extra_shape)), vtype) + + # Scatter via numpy + new = old.copy() + np_scatter = _TF_OPS_TO_NUMPY[tf_scatter] + np_scatter(new, indices, updates) + # Scatter via tensorflow + ref = variables.Variable(old) + ref.initializer.run() + tf_scatter(ref, indices, updates).eval() + self.assertAllClose(ref.eval(), new) + + def _VariableRankTests(self, + tf_scatter): + vtypes = [np.float32, np.float64] + if tf_scatter != state_ops.scatter_div: + vtypes.append(np.int32) + + for vtype in vtypes: + for itype in (np.int32, np.int64): + self._VariableRankTest(tf_scatter, vtype, itype) + + def testVariableRankUpdate(self): + vtypes = [np.float32, np.float64] + for vtype in vtypes: + for itype in (np.int32, np.int64): + self._VariableRankTest( + state_ops.batch_scatter_update, vtype, itype) + + def testBooleanScatterUpdate(self): + with self.test_session(use_gpu=False) as session: + var = variables.Variable([True, False]) + update0 = state_ops.batch_scatter_update(var, [1], [True]) + update1 = state_ops.batch_scatter_update( + var, constant_op.constant( + [0], dtype=dtypes.int64), [False]) + var.initializer.run() + + session.run([update0, update1]) + + self.assertAllEqual([False, True], var.eval()) + + def testScatterOutOfRange(self): + params = np.array([1, 2, 3, 4, 5, 6]).astype(np.float32) + updates = np.array([-3, -4, -5]).astype(np.float32) + with self.test_session(use_gpu=False): + ref = variables.Variable(params) + ref.initializer.run() + + # Indices all in range, no problem. + indices = np.array([2, 0, 5]) + state_ops.batch_scatter_update(ref, indices, updates).eval() + + # Test some out of range errors. + indices = np.array([-1, 0, 5]) + with self.assertRaisesOpError( + r'indices\[0\] = \[-1\] does not index into shape \[6\]'): + state_ops.batch_scatter_update(ref, indices, updates).eval() + + indices = np.array([2, 0, 6]) + with self.assertRaisesOpError(r'indices\[2\] = \[6\] does not index into ' + r'shape \[6\]'): + state_ops.batch_scatter_update(ref, indices, updates).eval() + +if __name__ == '__main__': + test.main() diff --git a/tensorflow/python/kernel_tests/check_ops_test.py b/tensorflow/python/kernel_tests/check_ops_test.py index bda6ca5ca9..05f998d0d2 100644 --- a/tensorflow/python/kernel_tests/check_ops_test.py +++ b/tensorflow/python/kernel_tests/check_ops_test.py @@ -18,8 +18,12 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import time import numpy as np +from tensorflow.core.protobuf import config_pb2 +from tensorflow.core.protobuf import rewriter_config_pb2 +from tensorflow.python.client import session from tensorflow.python.eager import context from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes @@ -29,6 +33,8 @@ from tensorflow.python.framework import sparse_tensor from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops from tensorflow.python.ops import check_ops +from tensorflow.python.ops import math_ops +from tensorflow.python.ops import random_ops from tensorflow.python.platform import test @@ -745,6 +751,146 @@ class AssertPositiveTest(test.TestCase): self.evaluate(out) +class EnsureShapeTest(test.TestCase): + + # Static shape inference + def testStaticShape(self): + placeholder = array_ops.placeholder(dtypes.int32) + ensure_shape_op = check_ops.ensure_shape(placeholder, (3, 3, 3)) + self.assertEqual(ensure_shape_op.get_shape(), (3, 3, 3)) + + def testStaticShape_MergesShapes(self): + placeholder = array_ops.placeholder(dtypes.int32, shape=(None, None, 3)) + ensure_shape_op = check_ops.ensure_shape(placeholder, (5, 4, None)) + self.assertEqual(ensure_shape_op.get_shape(), (5, 4, 3)) + + def testStaticShape_RaisesErrorWhenRankIncompatible(self): + placeholder = array_ops.placeholder(dtypes.int32, shape=(None, None, 3)) + with self.assertRaises(ValueError): + check_ops.ensure_shape(placeholder, (2, 3)) + + def testStaticShape_RaisesErrorWhenDimIncompatible(self): + placeholder = array_ops.placeholder(dtypes.int32, shape=(None, None, 3)) + with self.assertRaises(ValueError): + check_ops.ensure_shape(placeholder, (2, 2, 4)) + + def testStaticShape_CanSetUnknownShape(self): + placeholder = array_ops.placeholder(dtypes.int32) + derived = placeholder / 3 + ensure_shape_op = check_ops.ensure_shape(derived, None) + self.assertEqual(ensure_shape_op.get_shape(), None) + + # Dynamic shape check + def testEnsuresDynamicShape_RaisesError(self): + placeholder = array_ops.placeholder(dtypes.int32) + derived = math_ops.divide(placeholder, 3, name="MyDivide") + derived = check_ops.ensure_shape(derived, (3, 3, 3)) + feed_val = [[1], [2]] + with self.test_session() as sess: + with self.assertRaisesWithPredicateMatch( + errors.InvalidArgumentError, + r"Shape of tensor MyDivide \[2,1\] is not compatible with " + r"expected shape \[3,3,3\]."): + sess.run(derived, feed_dict={placeholder: feed_val}) + + def testEnsuresDynamicShape_RaisesErrorDimUnknown(self): + placeholder = array_ops.placeholder(dtypes.int32) + derived = placeholder / 3 + derived = check_ops.ensure_shape(derived, (None, None, 3)) + feed_val = [[1], [2]] + with self.test_session() as sess: + with self.assertRaisesWithPredicateMatch( + errors.InvalidArgumentError, + r"Shape of tensor [A-Za-z_]* \[2,1\] is not compatible with " + r"expected shape \[\?,\?,3\]."): + sess.run(derived, feed_dict={placeholder: feed_val}) + + def testEnsuresDynamicShape(self): + placeholder = array_ops.placeholder(dtypes.int32) + derived = placeholder / 3 + derived = check_ops.ensure_shape(derived, (2, 1)) + feed_val = [[1], [2]] + with self.test_session() as sess: + sess.run(derived, feed_dict={placeholder: feed_val}) + + def testEnsuresDynamicShape_WithUnknownDims(self): + placeholder = array_ops.placeholder(dtypes.int32) + derived = placeholder / 3 + derived = check_ops.ensure_shape(derived, (None, None)) + feed_val = [[1], [2]] + with self.test_session() as sess: + sess.run(derived, feed_dict={placeholder: feed_val}) + + +class EnsureShapeBenchmark(test.Benchmark): + + def _grappler_all_off_config(self): + config = config_pb2.ConfigProto() + off = rewriter_config_pb2.RewriterConfig.OFF + config.graph_options.optimizer_options.opt_level = -1 + config.graph_options.rewrite_options.disable_model_pruning = 1 + config.graph_options.rewrite_options.constant_folding = off + config.graph_options.rewrite_options.layout_optimizer = off + config.graph_options.rewrite_options.arithmetic_optimization = off + config.graph_options.rewrite_options.dependency_optimization = off + return config + + def _run(self, op, feed_dict=None, num_iters=5000, name=None, **kwargs): + config = self._grappler_all_off_config() + with session.Session(config=config) as sess: + deltas = [] + # Warm up the session + for _ in range(5): + sess.run(op, feed_dict=feed_dict) + for _ in range(num_iters): + start = time.time() + sess.run(op, feed_dict=feed_dict) + end = time.time() + deltas.append(end - start) + mean_time = np.median(deltas) + mean_us = mean_time * 1e6 + # mean_us = (end - start) * 1e6 / num_iters + self.report_benchmark( + name=name, + wall_time=mean_us, + extras=kwargs, + ) + + def benchmark_const_op(self): + # In this case, we expect that the overhead of a `session.run` call + # far outweighs the time taken to execute the op... + shape = (3, 3, 100) + input_op = random_ops.random_normal(shape) + self._run(array_ops.identity(input_op), name="SingleConstOp") + + def benchmark_single_ensure_op(self): + # In this case, we expect that the overhead of a `session.run` call + # far outweighs the time taken to execute the op... + shape = (3, 3, 100) + input_op = random_ops.random_normal(shape) + ensure_shape_op = check_ops.ensure_shape(input_op, shape) + self._run(ensure_shape_op, name="SingleEnsureShapeOp") + + def _apply_n_times(self, op, target, n=1000): + for _ in range(n): + target = op(target) + return target + + def benchmark_n_ops(self): + shape = (1000,) + input_op = random_ops.random_normal(shape) + n_ops = self._apply_n_times(array_ops.identity, input_op) + self._run(n_ops, name="NIdentityOps_1000") + + def benchmark_n_ensure_ops(self): + shape = (1000,) + input_op = random_ops.random_normal(shape) + n_ensure_ops = self._apply_n_times( + lambda x: check_ops.ensure_shape(array_ops.identity(x), shape), + input_op) + self._run(n_ensure_ops, name="NEnsureShapeAndIdentityOps_1000") + + class AssertRankTest(test.TestCase): @test_util.run_in_graph_and_eager_modes diff --git a/tensorflow/python/kernel_tests/cond_v2_test.py b/tensorflow/python/kernel_tests/cond_v2_test.py index b9910133d8..0dc3c53bc0 100644 --- a/tensorflow/python/kernel_tests/cond_v2_test.py +++ b/tensorflow/python/kernel_tests/cond_v2_test.py @@ -20,9 +20,9 @@ from __future__ import division from __future__ import print_function from tensorflow.core.protobuf import config_pb2 +from tensorflow.python.eager import function from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes -from tensorflow.python.framework import function from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops from tensorflow.python.ops import cond_v2 @@ -158,7 +158,7 @@ class CondV2Test(test.TestCase): def true_fn(): - @function.Defun() + @function.defun def fn(): return x * y * 2.0 @@ -172,6 +172,8 @@ class CondV2Test(test.TestCase): self._testCond(true_fn, false_fn, [y]) def testNestedDefunInCond(self): + self.skipTest("b/110550782") + x = constant_op.constant(1.0, name="x") y = constant_op.constant(2.0, name="y") @@ -180,10 +182,10 @@ class CondV2Test(test.TestCase): def false_fn(): - @function.Defun() + @function.defun def fn(): - @function.Defun() + @function.defun def nested_fn(): return x * y * 2.0 @@ -196,18 +198,20 @@ class CondV2Test(test.TestCase): self._testCond(true_fn, false_fn, [y]) def testDoubleNestedDefunInCond(self): + self.skipTest("b/110550782") + x = constant_op.constant(1.0, name="x") y = constant_op.constant(2.0, name="y") def true_fn(): - @function.Defun() + @function.defun def fn(): - @function.Defun() + @function.defun def nested_fn(): - @function.Defun() + @function.defun def nested_nested_fn(): return x * y * 2.0 @@ -368,7 +372,7 @@ class CondV2Test(test.TestCase): pred_outer, true_fn, false_fn, name="outer_cond") # Compute grads inside a Defun. - @function.Defun() + @function.defun def nesting_fn(): return gradients_impl.gradients(cond_outer, [x, y]) @@ -426,10 +430,10 @@ class CondV2Test(test.TestCase): pred_outer, true_fn, false_fn, name="outer_cond") # Compute grads inside a Defun. - @function.Defun() + @function.defun def nesting_fn(): - @function.Defun() + @function.defun def inner_nesting_fn(): return gradients_impl.gradients(cond_outer, [x, y]) @@ -464,6 +468,7 @@ class CondV2Test(test.TestCase): }), [5., 0.]) def testBuildCondAndGradientInsideDefun(self): + self.skipTest("b/110550782") def build_graph(): pred_outer = array_ops.placeholder(dtypes.bool, name="pred_outer") @@ -472,7 +477,7 @@ class CondV2Test(test.TestCase): y = constant_op.constant(2.0, name="y") # Build cond and its gradient inside a Defun. - @function.Defun() + @function.defun def fn(): def true_fn(): @@ -718,6 +723,7 @@ class CondV2ContainerTest(test.TestCase): Make sure the containers are set correctly for both variable creation (tested by variables.Variable) and for stateful ops (tested by FIFOQueue) """ + self.skipTest("b/113048653") with ops.Graph().as_default() as g: with self.test_session(graph=g): @@ -795,6 +801,7 @@ class CondV2ContainerTest(test.TestCase): class CondV2ColocationGroupAndDeviceTest(test.TestCase): def testColocateWithBeforeCond(self): + self.skipTest("b/112414483") with ops.Graph().as_default() as g: with self.test_session(graph=g): @@ -819,6 +826,7 @@ class CondV2ColocationGroupAndDeviceTest(test.TestCase): self.assertEquals(cond_v2.cond_v2(True, fn2, fn2)[0].eval(), 3) def testColocateWithInAndOutOfCond(self): + self.skipTest("b/112414483") with ops.Graph().as_default() as g: with self.test_session(graph=g): @@ -866,6 +874,7 @@ class CondV2ColocationGroupAndDeviceTest(test.TestCase): self.assertTrue(len(run_metadata.partition_graphs) >= 2) def testDeviceBeforeCond(self): + self.skipTest("b/112166045") with ops.Graph().as_default() as g: with self.test_session(graph=g): def fn(): diff --git a/tensorflow/python/kernel_tests/constant_op_eager_test.py b/tensorflow/python/kernel_tests/constant_op_eager_test.py index a0d5557b92..cc788219ef 100644 --- a/tensorflow/python/kernel_tests/constant_op_eager_test.py +++ b/tensorflow/python/kernel_tests/constant_op_eager_test.py @@ -523,7 +523,7 @@ class OnesLikeTest(test.TestCase): class FillTest(test.TestCase): def _compare(self, dims, val, np_ans, use_gpu): - ctx = context.get_default_context() + ctx = context.context() device = "GPU:0" if (use_gpu and ctx.num_gpus()) else "CPU:0" with ops.device(device): tf_ans = array_ops.fill(dims, val, name="fill") diff --git a/tensorflow/python/kernel_tests/control_flow_ops_py_test.py b/tensorflow/python/kernel_tests/control_flow_ops_py_test.py index 1a29d0816d..eac97af4ed 100644 --- a/tensorflow/python/kernel_tests/control_flow_ops_py_test.py +++ b/tensorflow/python/kernel_tests/control_flow_ops_py_test.py @@ -23,6 +23,7 @@ from __future__ import print_function import collections import math import time +import unittest import numpy as np from six.moves import xrange # pylint: disable=redefined-builtin @@ -38,7 +39,9 @@ from tensorflow.python.framework import function from tensorflow.python.framework import ops from tensorflow.python.framework import sparse_tensor from tensorflow.python.framework import tensor_shape +from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops +from tensorflow.python.ops import cond_v2 # pylint: disable=unused-import from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import data_flow_ops from tensorflow.python.ops import functional_ops @@ -122,6 +125,7 @@ def isum(s, maximum_iterations=None): return r_s +@test_util.with_cond_v2 class ControlFlowTest(test.TestCase): def testRefIdentity(self): @@ -329,6 +333,9 @@ class ControlFlowTest(test.TestCase): res.eval(feed_dict={data: 1.0}) def testCondBool(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113296297") + values = constant_op.constant(10) fn1 = lambda: math_ops.add(values, 1) fn2 = lambda: math_ops.subtract(values, 1) @@ -377,6 +384,9 @@ class ControlFlowTest(test.TestCase): sess.run(r, feed_dict={t: 3}) def testCondIndexedSlices(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113296180") + with self.test_session(): values = constant_op.constant(10) indices = constant_op.constant(0) @@ -392,6 +402,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(0, ind) def testCondSparseTensor(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113296161 (SparseTensors)") + with self.test_session(): values = constant_op.constant([2.0, 4.0], name="values") indices = constant_op.constant( @@ -409,6 +422,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(r.values.get_shape(), (2,)) def testCondResource(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + with self.test_session(): rv = resource_variable_ops.ResourceVariable(True) variables.global_variables_initializer().run() @@ -422,6 +438,9 @@ class ControlFlowTest(test.TestCase): self.assertEqual(1.0, control_flow_ops.cond(rv, case, lambda: t).eval()) def testCondIndexedSlicesDifferentTypes(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113293074") + with self.test_session(): values = constant_op.constant(10) i_32 = ops.convert_to_tensor(0, name="one", dtype=dtypes.int32) @@ -465,10 +484,16 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(11, result) def testCond_1(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + self._testCond_1(use_gpu=False) self._testCond_1(use_gpu=True) def testCond_2(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + with self.test_session(): x = constant_op.constant(10) r = control_flow_ops.cond( @@ -478,6 +503,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(9, result) def testCond_3(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + with self.test_session(): x = constant_op.constant(10) pred = math_ops.less(1, 2) @@ -490,6 +518,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(12, result) def testCond_4(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113324949 (ref vars)") + with self.test_session(): v1 = variables.Variable(7) v2 = variables.Variable(7) @@ -525,6 +556,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(4, count.eval()) def testCond_6(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + with self.test_session(): v1 = variables.Variable([7]) @@ -549,6 +583,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual([11, 12], sess.run(r)) def testCondRef(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + with self.test_session(): x = gen_state_ops.variable( shape=[1], @@ -562,6 +599,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual([2.0], r.eval()) def testCondWithControl(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/79881896") + with self.test_session() as sess: control_holder = array_ops.placeholder(dtypes.float32, shape=()) a = constant_op.constant(3) @@ -601,6 +641,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual([1.0], sess.run(merged_op.output)) def testCondSwitchIdentity(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/112477618 (Operation returned from cond)") + # Make sure the recv identity is not removed by optimization. with session.Session(config=opt_cfg()) as sess: pred = constant_op.constant(True) @@ -615,6 +658,9 @@ class ControlFlowTest(test.TestCase): sess.run(r) def testCondRecvIdentity(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/112477618 (Operation returned from cond)") + # Make sure the switch identity is not removed by optimization. with session.Session(config=opt_cfg()) as sess: with ops.device(test.gpu_device_name()): @@ -631,6 +677,9 @@ class ControlFlowTest(test.TestCase): sess.run(r) def testCondGrad_1(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113346829 (gpu failure)") + graph = ops.Graph() with graph.as_default(): x = constant_op.constant(10.0, name="x") @@ -642,13 +691,6 @@ class ControlFlowTest(test.TestCase): grad = gradients_impl.gradients(r, [x])[0] with self.test_session(): self.assertAllEqual(1.0, grad.eval()) - # The gradients computation creates a tensor with zeros by broadcasting a - # zeros constant to the required shape. Verify that the zero constant - # feeding into the fill is dominated by a Switch. - zero = graph.get_operation_by_name("gradients/zeros/Const") - self.assertEqual(len(zero.control_inputs), 1) - self.assertEqual(zero.control_inputs[0].type, "Identity") - self.assertEqual(zero.control_inputs[0].inputs[0].op.type, "Switch") def testCondGrad_2(self): with self.test_session(): @@ -664,6 +706,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(3.0, grad.eval(feed_dict={c: 3})) def testCondGrad_3(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/110550782 (gradient w.r.t external variable)") + with self.test_session(): c = array_ops.placeholder(dtypes.int32, shape=[]) ox = constant_op.constant(10.0) @@ -696,6 +741,9 @@ class ControlFlowTest(test.TestCase): self.assertEqual(1.0, result.eval()) def testCondGrad_Gather(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113327884") + with self.test_session() as sess: v1 = variables.Variable([1.0, 42.0]) c = array_ops.placeholder(dtypes.int32, shape=[]) @@ -868,6 +916,9 @@ class ControlFlowTest(test.TestCase): _ = gradients_impl.gradients(loop_with_maxiter, v) def testInvalidMaximumIterationsFromSiblingContextWhileLoopInXLAContext(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113294340 (enable while_v2)") + v = constant_op.constant(1.0) def create_while_loop(): @@ -1324,6 +1375,9 @@ class ControlFlowTest(test.TestCase): self.assertEqual(10, sess.run(r, {b: True})) def testWhileCondWithControl(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113294377 (unknown shape)") + # Ensure that no control edges by an outer control dependency context are # added to nodes inside cond/while contexts. with self.test_session() as sess: @@ -1338,6 +1392,9 @@ class ControlFlowTest(test.TestCase): self.assertEqual(0, sess.run(loop)) def testWhileCondWithControl_1(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113324949 (ref vars)") + with self.test_session(): v = variable_scope.get_variable( "v", [], initializer=init_ops.constant_initializer(2)) @@ -1360,6 +1417,9 @@ class ControlFlowTest(test.TestCase): self.assertAllClose(65536.0, v.eval()) def testWhileCondExitControl(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113294340 (enable while_v2)") + with self.test_session(): v = variables.Variable(1) @@ -1383,6 +1443,9 @@ class ControlFlowTest(test.TestCase): self.assertEqual(99, v.eval()) def testCondWhile_1(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + with self.test_session(): n = ops.convert_to_tensor(0, name="n") c = lambda x: math_ops.less(x, 10) @@ -1393,6 +1456,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(10, r.eval()) def testCondWhile_2(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + with self.test_session(): n = ops.convert_to_tensor(0) c = lambda x: math_ops.less(x, 10) @@ -1403,6 +1469,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(10, r.eval()) def _testCondWhile_3(self, use_gpu): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113294340 (enable while_v2)") + with self.test_session(use_gpu=use_gpu) as sess: p = array_ops.placeholder(dtypes.bool) n = constant_op.constant(0.0) @@ -1429,6 +1498,9 @@ class ControlFlowTest(test.TestCase): self._testCondWhile_3(use_gpu=True) def testWhileCond_1(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113294377 (unknown shape)") + with self.test_session(): i = ops.convert_to_tensor(0, name="i") n = ops.convert_to_tensor(10, name="n") @@ -1444,6 +1516,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(10, r.eval()) def testWhileCond_2(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113294377 (unknown shape)") + with self.test_session(): n = ops.convert_to_tensor(0, name="n") c = lambda x: math_ops.less(x, 10) @@ -1452,6 +1527,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(10, r.eval()) def testWhileCond_3(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113294377 (unknown shape)") + with self.test_session(): n = ops.convert_to_tensor(0) c = lambda x: math_ops.less(x, 10) @@ -1794,6 +1872,9 @@ class ControlFlowTest(test.TestCase): self._testWhileGrad_Mul(use_gpu=True, p_iters=10) def _testNestedWhileCondWhileGrad(self, use_gpu): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113294377 (unknown shape)") + with self.test_session(use_gpu=use_gpu): v = constant_op.constant(1.0) @@ -1832,6 +1913,9 @@ class ControlFlowTest(test.TestCase): self.assertAllClose(216.0, r[0].eval()) def testWhileGradInCond(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/110550782 (gradient w.r.t external variable)") + with self.test_session(): n = ops.convert_to_tensor(1.0, name="n") x = array_ops.placeholder(dtypes.float32, shape=None) @@ -1880,6 +1964,9 @@ class ControlFlowTest(test.TestCase): self.assertAllClose(9.0, r.eval(feed_dict={x: 1.0})) def testCondGradInNestedWhiles(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113346829 (gpu failure)") + def outer_body(i, x): _, x = control_flow_ops.while_loop( lambda j, x: j < 3, inner_body, [0, 0.0]) @@ -2193,6 +2280,9 @@ class ControlFlowTest(test.TestCase): self.assertAllClose(1024.0, r.eval()) def testWhileCondGrad_Simple(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113294377 (unknown shape)") + self._testWhileCondGrad_Simple(use_gpu=False) self._testWhileCondGrad_Simple(use_gpu=True) @@ -2543,6 +2633,9 @@ class ControlFlowTest(test.TestCase): self.assertEqual(5.0, result.eval()) def testOneValueCond(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + with self.test_session(): c = array_ops.placeholder(dtypes.int32, shape=[]) one = ops.convert_to_tensor(1, name="one") @@ -2558,6 +2651,9 @@ class ControlFlowTest(test.TestCase): self.assertEqual([2], i.eval(feed_dict={c: 0})) def testExampleCond(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/111124878 (don't return tuple)") + with self.test_session(): x = ops.convert_to_tensor([-2.0, 2.0], name="x") d = array_ops.placeholder(dtypes.int32, shape=[]) @@ -2573,6 +2669,9 @@ class ControlFlowTest(test.TestCase): self.assertAllClose(2.0 * math.sqrt(2), i.eval(feed_dict={d: 2})) def testCase(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/112477618 (Operation returned from cond)") + with self.test_session(): x = constant_op.constant(1) y = constant_op.constant(2) @@ -2625,6 +2724,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(r6.eval(), 0) def testCaseSideEffects(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/112477618 (Operation returned from cond)") + with self.test_session() as sess: v0 = variables.Variable(-1) v1 = variables.Variable(-1) @@ -2660,6 +2762,9 @@ class ControlFlowTest(test.TestCase): self.assertAllEqual(sess.run([v0, v1, v2]), [0, -1, -1]) def testOneOpCond(self): + if control_flow_ops._ENABLE_COND_V2: + return unittest.skip("b/113324949 (ref vars)") + with self.test_session(): v = variables.Variable(0) c = ops.convert_to_tensor(0) diff --git a/tensorflow/python/kernel_tests/ctc_decoder_ops_test.py b/tensorflow/python/kernel_tests/ctc_decoder_ops_test.py index e1920eb568..41ae0b456f 100644 --- a/tensorflow/python/kernel_tests/ctc_decoder_ops_test.py +++ b/tensorflow/python/kernel_tests/ctc_decoder_ops_test.py @@ -188,11 +188,11 @@ class CTCGreedyDecoderTest(test.TestCase): ], dtype=np.float32) # Add arbitrary offset - this is fine - input_log_prob_matrix_0 = np.log(input_prob_matrix_0) + 2.0 + input_prob_matrix_0 = input_prob_matrix_0 + 2.0 # len max_time_steps array of batch_size x depth matrices inputs = ([ - input_log_prob_matrix_0[t, :][np.newaxis, :] for t in range(seq_len_0) + input_prob_matrix_0[t, :][np.newaxis, :] for t in range(seq_len_0) ] # Pad to max_time_steps = 8 + 2 * [np.zeros( (1, depth), dtype=np.float32)]) @@ -200,11 +200,11 @@ class CTCGreedyDecoderTest(test.TestCase): # batch_size length vector of sequence_lengths seq_lens = np.array([seq_len_0], dtype=np.int32) - # batch_size length vector of negative log probabilities + # batch_size length vector of log probabilities log_prob_truth = np.array( [ - 0.584855, # output beam 0 - 0.389139 # output beam 1 + -5.811451, # output beam 0 + -6.63339 # output beam 1 ], np.float32)[np.newaxis, :] @@ -215,11 +215,11 @@ class CTCGreedyDecoderTest(test.TestCase): [[0, 0], [0, 1]], dtype=np.int64), np.array( [1, 0], dtype=np.int64), np.array( [1, 2], dtype=np.int64)), - # beam 1, batch 0, three outputs decoded + # beam 1, batch 0, one output decoded (np.array( - [[0, 0], [0, 1], [0, 2]], dtype=np.int64), np.array( - [0, 1, 0], dtype=np.int64), np.array( - [1, 3], dtype=np.int64)), + [[0, 0]], dtype=np.int64), np.array( + [1], dtype=np.int64), np.array( + [1, 1], dtype=np.int64)), ] # Test correct decoding. diff --git a/tensorflow/python/kernel_tests/distributions/categorical_test.py b/tensorflow/python/kernel_tests/distributions/categorical_test.py index d8939433ce..c6bb06eab3 100644 --- a/tensorflow/python/kernel_tests/distributions/categorical_test.py +++ b/tensorflow/python/kernel_tests/distributions/categorical_test.py @@ -47,7 +47,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): def testP(self): p = [0.2, 0.8] dist = categorical.Categorical(probs=p) - with self.test_session(): + with self.cached_session(): self.assertAllClose(p, dist.probs.eval()) self.assertAllEqual([2], dist.logits.get_shape()) @@ -55,14 +55,14 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): p = np.array([0.2, 0.8], dtype=np.float32) logits = np.log(p) - 50. dist = categorical.Categorical(logits=logits) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([2], dist.probs.get_shape()) self.assertAllEqual([2], dist.logits.get_shape()) self.assertAllClose(dist.probs.eval(), p) self.assertAllClose(dist.logits.eval(), logits) def testShapes(self): - with self.test_session(): + with self.cached_session(): for batch_shape in ([], [1], [2, 3, 4]): dist = make_categorical(batch_shape, 10) self.assertAllEqual(batch_shape, dist.batch_shape) @@ -108,7 +108,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): self.assertEqual(dist.dtype, dist.sample(5).dtype) def testUnknownShape(self): - with self.test_session(): + with self.cached_session(): logits = array_ops.placeholder(dtype=dtypes.float32) dist = categorical.Categorical(logits) sample = dist.sample() @@ -124,13 +124,13 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): def testPMFWithBatch(self): histograms = [[0.2, 0.8], [0.6, 0.4]] dist = categorical.Categorical(math_ops.log(histograms) - 50.) - with self.test_session(): + with self.cached_session(): self.assertAllClose(dist.prob([0, 1]).eval(), [0.2, 0.4]) def testPMFNoBatch(self): histograms = [0.2, 0.8] dist = categorical.Categorical(math_ops.log(histograms) - 50.) - with self.test_session(): + with self.cached_session(): self.assertAllClose(dist.prob(0).eval(), 0.2) def testCDFWithDynamicEventShapeKnownNdims(self): @@ -162,7 +162,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): event: event_feed_two } - with self.test_session() as sess: + with self.cached_session() as sess: actual_cdf_one = sess.run(cdf_op, feed_dict=feed_dict_one) actual_cdf_two = sess.run(cdf_op, feed_dict=feed_dict_two) @@ -192,7 +192,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): dist = categorical.Categorical(probs=histograms) cdf_op = dist.cdf(event) - with self.test_session(): + with self.cached_session(): self.assertAllClose(cdf_op.eval(), expected_cdf) def testCDFNoBatch(self): @@ -202,7 +202,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): dist = categorical.Categorical(probs=histogram) cdf_op = dist.cdf(event) - with self.test_session(): + with self.cached_session(): self.assertAlmostEqual(cdf_op.eval(), expected_cdf) def testCDFBroadcasting(self): @@ -228,7 +228,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): expected_cdf_result[2, 0] = 0.3 expected_cdf_result[2, 1] = 0.75 - with self.test_session(): + with self.cached_session(): self.assertAllClose(dist.cdf(devent).eval(), expected_cdf_result) def testBroadcastWithBatchParamsAndBiggerEvent(self): @@ -286,7 +286,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): "norm_log_cdf": norm.log_cdf(real_event_tf), } - with self.test_session() as sess: + with self.cached_session() as sess: run_result = sess.run(to_run) self.assertAllEqual(run_result["cat_prob"].shape, @@ -301,28 +301,28 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): def testLogPMF(self): logits = np.log([[0.2, 0.8], [0.6, 0.4]]) - 50. dist = categorical.Categorical(logits) - with self.test_session(): + with self.cached_session(): self.assertAllClose(dist.log_prob([0, 1]).eval(), np.log([0.2, 0.4])) self.assertAllClose(dist.log_prob([0.0, 1.0]).eval(), np.log([0.2, 0.4])) def testEntropyNoBatch(self): logits = np.log([0.2, 0.8]) - 50. dist = categorical.Categorical(logits) - with self.test_session(): + with self.cached_session(): self.assertAllClose(dist.entropy().eval(), -(0.2 * np.log(0.2) + 0.8 * np.log(0.8))) def testEntropyWithBatch(self): logits = np.log([[0.2, 0.8], [0.6, 0.4]]) - 50. dist = categorical.Categorical(logits) - with self.test_session(): + with self.cached_session(): self.assertAllClose(dist.entropy().eval(), [ -(0.2 * np.log(0.2) + 0.8 * np.log(0.8)), -(0.6 * np.log(0.6) + 0.4 * np.log(0.4)) ]) def testEntropyGradient(self): - with self.test_session() as sess: + with self.cached_session() as sess: logits = constant_op.constant([[1., 2., 3.], [2., 5., 1.]]) probabilities = nn_ops.softmax(logits) @@ -348,7 +348,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): res["categorical_entropy_g"]) def testSample(self): - with self.test_session(): + with self.cached_session(): histograms = [[[0.2, 0.8], [0.4, 0.6]]] dist = categorical.Categorical(math_ops.log(histograms) - 50.) n = 10000 @@ -366,7 +366,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): sample_values == 1, axis=0), atol=1e-2) def testSampleWithSampleShape(self): - with self.test_session(): + with self.cached_session(): histograms = [[[0.2, 0.8], [0.4, 0.6]]] dist = categorical.Categorical(math_ops.log(histograms) - 50.) samples = dist.sample((100, 100), seed=123) @@ -387,7 +387,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): self.assertIsNone(grad_p) def testLogPMFBroadcasting(self): - with self.test_session(): + with self.cached_session(): # 1 x 2 x 2 histograms = [[[0.2, 0.8], [0.4, 0.6]]] dist = categorical.Categorical(math_ops.log(histograms) - 50.) @@ -415,7 +415,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): prob.eval()) def testLogPMFShape(self): - with self.test_session(): + with self.cached_session(): # shape [1, 2, 2] histograms = [[[0.2, 0.8], [0.4, 0.6]]] dist = categorical.Categorical(math_ops.log(histograms)) @@ -441,7 +441,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): self.assertAllEqual([2, 2, 2], log_prob.get_shape()) def testMode(self): - with self.test_session(): + with self.cached_session(): histograms = [[[0.2, 0.8], [0.6, 0.4]]] dist = categorical.Categorical(math_ops.log(histograms) - 50.) self.assertAllEqual(dist.mode().eval(), [[1, 0]]) @@ -452,7 +452,7 @@ class CategoricalTest(test.TestCase, parameterized.TestCase): exp_logits = np.exp(logits) return exp_logits / exp_logits.sum(axis=-1, keepdims=True) - with self.test_session() as sess: + with self.cached_session() as sess: for categories in [2, 4]: for batch_size in [1, 10]: a_logits = np.random.randn(batch_size, categories) diff --git a/tensorflow/python/kernel_tests/distributions/dirichlet_multinomial_test.py b/tensorflow/python/kernel_tests/distributions/dirichlet_multinomial_test.py index 1b9edcc85a..d558ca09cc 100644 --- a/tensorflow/python/kernel_tests/distributions/dirichlet_multinomial_test.py +++ b/tensorflow/python/kernel_tests/distributions/dirichlet_multinomial_test.py @@ -37,7 +37,7 @@ class DirichletMultinomialTest(test.TestCase): self._rng = np.random.RandomState(42) def testSimpleShapes(self): - with self.test_session(): + with self.cached_session(): alpha = np.random.rand(3) dist = ds.DirichletMultinomial(1., alpha) self.assertEqual(3, dist.event_shape_tensor().eval()) @@ -46,7 +46,7 @@ class DirichletMultinomialTest(test.TestCase): self.assertEqual(tensor_shape.TensorShape([]), dist.batch_shape) def testComplexShapes(self): - with self.test_session(): + with self.cached_session(): alpha = np.random.rand(3, 2, 2) n = [[3., 2], [4, 5], [6, 7]] dist = ds.DirichletMultinomial(n, alpha) @@ -58,14 +58,14 @@ class DirichletMultinomialTest(test.TestCase): def testNproperty(self): alpha = [[1., 2, 3]] n = [[5.]] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(n, alpha) self.assertEqual([1, 1], dist.total_count.get_shape()) self.assertAllClose(n, dist.total_count.eval()) def testAlphaProperty(self): alpha = [[1., 2, 3]] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(1, alpha) self.assertEqual([1, 3], dist.concentration.get_shape()) self.assertAllClose(alpha, dist.concentration.eval()) @@ -73,7 +73,7 @@ class DirichletMultinomialTest(test.TestCase): def testPmfNandCountsAgree(self): alpha = [[1., 2, 3]] n = [[5.]] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(n, alpha, validate_args=True) dist.prob([2., 3, 0]).eval() dist.prob([3., 0, 2]).eval() @@ -86,7 +86,7 @@ class DirichletMultinomialTest(test.TestCase): def testPmfNonIntegerCounts(self): alpha = [[1., 2, 3]] n = [[5.]] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(n, alpha, validate_args=True) dist.prob([2., 3, 0]).eval() dist.prob([3., 0, 2]).eval() @@ -104,7 +104,7 @@ class DirichletMultinomialTest(test.TestCase): def testPmfBothZeroBatches(self): # The probabilities of one vote falling into class k is the mean for class # k. - with self.test_session(): + with self.cached_session(): # Both zero-batches. No broadcast alpha = [1., 2] counts = [1., 0] @@ -116,7 +116,7 @@ class DirichletMultinomialTest(test.TestCase): def testPmfBothZeroBatchesNontrivialN(self): # The probabilities of one vote falling into class k is the mean for class # k. - with self.test_session(): + with self.cached_session(): # Both zero-batches. No broadcast alpha = [1., 2] counts = [3., 2] @@ -128,7 +128,7 @@ class DirichletMultinomialTest(test.TestCase): def testPmfBothZeroBatchesMultidimensionalN(self): # The probabilities of one vote falling into class k is the mean for class # k. - with self.test_session(): + with self.cached_session(): alpha = [1., 2] counts = [3., 2] n = np.full([4, 3], 5., dtype=np.float32) @@ -140,7 +140,7 @@ class DirichletMultinomialTest(test.TestCase): def testPmfAlphaStretchedInBroadcastWhenSameRank(self): # The probabilities of one vote falling into class k is the mean for class # k. - with self.test_session(): + with self.cached_session(): alpha = [[1., 2]] counts = [[1., 0], [0., 1]] dist = ds.DirichletMultinomial([1.], alpha) @@ -151,7 +151,7 @@ class DirichletMultinomialTest(test.TestCase): def testPmfAlphaStretchedInBroadcastWhenLowerRank(self): # The probabilities of one vote falling into class k is the mean for class # k. - with self.test_session(): + with self.cached_session(): alpha = [1., 2] counts = [[1., 0], [0., 1]] pmf = ds.DirichletMultinomial(1., alpha).prob(counts) @@ -161,7 +161,7 @@ class DirichletMultinomialTest(test.TestCase): def testPmfCountsStretchedInBroadcastWhenSameRank(self): # The probabilities of one vote falling into class k is the mean for class # k. - with self.test_session(): + with self.cached_session(): alpha = [[1., 2], [2., 3]] counts = [[1., 0]] pmf = ds.DirichletMultinomial([1., 1.], alpha).prob(counts) @@ -171,7 +171,7 @@ class DirichletMultinomialTest(test.TestCase): def testPmfCountsStretchedInBroadcastWhenLowerRank(self): # The probabilities of one vote falling into class k is the mean for class # k. - with self.test_session(): + with self.cached_session(): alpha = [[1., 2], [2., 3]] counts = [1., 0] pmf = ds.DirichletMultinomial(1., alpha).prob(counts) @@ -182,7 +182,7 @@ class DirichletMultinomialTest(test.TestCase): # The probabilities of one vote falling into class k is the mean for class # k. alpha = [1., 2, 3] - with self.test_session(): + with self.cached_session(): for class_num in range(3): counts = np.zeros([3], dtype=np.float32) counts[class_num] = 1 @@ -199,7 +199,7 @@ class DirichletMultinomialTest(test.TestCase): # DirichletMultinomial(2, alpha) is twice as much as the probability of one # vote falling into class k for DirichletMultinomial(1, alpha) alpha = [1., 2, 3] - with self.test_session(): + with self.cached_session(): for class_num in range(3): counts_one = np.zeros([3], dtype=np.float32) counts_one[class_num] = 1. @@ -223,7 +223,7 @@ class DirichletMultinomialTest(test.TestCase): # Ideally we'd be able to test broadcasting but, the multinomial sampler # doesn't support different total counts. n = np.float32(5) - with self.test_session() as sess: + with self.cached_session() as sess: # batch_shape=[2], event_shape=[3] dist = ds.DirichletMultinomial(n, alpha) x = dist.sample(int(250e3), seed=1) @@ -281,7 +281,7 @@ class DirichletMultinomialTest(test.TestCase): variance_entry(alpha[1], alpha_0) ]]) - with self.test_session(): + with self.cached_session(): for n in ns: # n is shape [] and alpha is shape [2]. dist = ds.DirichletMultinomial(n, alpha) @@ -319,7 +319,7 @@ class DirichletMultinomialTest(test.TestCase): ]]], dtype=np.float32) - with self.test_session(): + with self.cached_session(): # ns is shape [4, 1], and alpha is shape [4, 3]. dist = ds.DirichletMultinomial(ns, alpha) covariance = dist.covariance() @@ -336,7 +336,7 @@ class DirichletMultinomialTest(test.TestCase): ns = np.random.randint(low=1, high=11, size=[3, 5, 1]).astype(np.float32) ns2 = np.random.randint(low=1, high=11, size=[6, 1, 1]).astype(np.float32) - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(ns, alpha) dist2 = ds.DirichletMultinomial(ns2, alpha2) @@ -350,7 +350,7 @@ class DirichletMultinomialTest(test.TestCase): # probability 1. alpha = [5, 0.5] counts = [0., 0] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(0., alpha) pmf = dist.prob(counts) self.assertAllClose(1.0, pmf.eval()) @@ -365,7 +365,7 @@ class DirichletMultinomialTest(test.TestCase): # One (three sided) coin flip. Prob[coin 3] = 0.8. # Note that since it was one flip, value of tau didn't matter. counts = [0., 0, 1] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(1., alpha) pmf = dist.prob(counts) self.assertAllClose(0.8, pmf.eval(), atol=1e-4) @@ -373,7 +373,7 @@ class DirichletMultinomialTest(test.TestCase): # Two (three sided) coin flips. Prob[coin 3] = 0.8. counts = [0., 0, 2] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(2., alpha) pmf = dist.prob(counts) self.assertAllClose(0.8**2, pmf.eval(), atol=1e-2) @@ -381,7 +381,7 @@ class DirichletMultinomialTest(test.TestCase): # Three (three sided) coin flips. counts = [1., 0, 2] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(3., alpha) pmf = dist.prob(counts) self.assertAllClose(3 * 0.1 * 0.8 * 0.8, pmf.eval(), atol=1e-2) @@ -396,7 +396,7 @@ class DirichletMultinomialTest(test.TestCase): # If there is only one draw, it is still a coin flip, even with small tau. counts = [1., 0] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(1., alpha) pmf = dist.prob(counts) self.assertAllClose(0.5, pmf.eval()) @@ -405,7 +405,7 @@ class DirichletMultinomialTest(test.TestCase): # If there are two draws, it is much more likely that they are the same. counts_same = [2., 0] counts_different = [1, 1.] - with self.test_session(): + with self.cached_session(): dist = ds.DirichletMultinomial(2., alpha) pmf_same = dist.prob(counts_same) pmf_different = dist.prob(counts_different) @@ -414,7 +414,7 @@ class DirichletMultinomialTest(test.TestCase): def testNonStrictTurnsOffAllChecks(self): # Make totally invalid input. - with self.test_session(): + with self.cached_session(): alpha = [[-1., 2]] # alpha should be positive. counts = [[1., 0], [0., -1]] # counts should be non-negative. n = [-5.3] # n should be a non negative integer equal to counts.sum. @@ -422,7 +422,7 @@ class DirichletMultinomialTest(test.TestCase): dist.prob(counts).eval() # Should not raise. def testSampleUnbiasedNonScalarBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: dist = ds.DirichletMultinomial( total_count=5., concentration=1. + 2. * self._rng.rand(4, 3, 2).astype(np.float32)) @@ -451,7 +451,7 @@ class DirichletMultinomialTest(test.TestCase): actual_covariance_, sample_covariance_, atol=0., rtol=0.20) def testSampleUnbiasedScalarBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: dist = ds.DirichletMultinomial( total_count=5., concentration=1. + 2. * self._rng.rand(4).astype(np.float32)) diff --git a/tensorflow/python/kernel_tests/distributions/identity_bijector_test.py b/tensorflow/python/kernel_tests/distributions/identity_bijector_test.py index b347c20db2..e35a8e1cdd 100644 --- a/tensorflow/python/kernel_tests/distributions/identity_bijector_test.py +++ b/tensorflow/python/kernel_tests/distributions/identity_bijector_test.py @@ -42,7 +42,7 @@ class IdentityBijectorTest(test.TestCase): bijector.forward_log_det_jacobian(x, event_ndims=3))) def testScalarCongruency(self): - with self.test_session(): + with self.cached_session(): bijector = identity_bijector.Identity() bijector_test_util.assert_scalar_congruency( bijector, lower_x=-2., upper_x=2.) diff --git a/tensorflow/python/kernel_tests/distributions/kullback_leibler_test.py b/tensorflow/python/kernel_tests/distributions/kullback_leibler_test.py index d0fa1fe989..e77e1117d4 100644 --- a/tensorflow/python/kernel_tests/distributions/kullback_leibler_test.py +++ b/tensorflow/python/kernel_tests/distributions/kullback_leibler_test.py @@ -58,7 +58,7 @@ class KLTest(test.TestCase): # pylint: disable=unused-argument,unused-variable - with self.test_session(): + with self.cached_session(): a = MyDistException(loc=0.0, scale=1.0, allow_nan_stats=False) kl = kullback_leibler.kl_divergence(a, a, allow_nan_stats=False) with self.assertRaisesOpError( diff --git a/tensorflow/python/kernel_tests/distributions/multinomial_test.py b/tensorflow/python/kernel_tests/distributions/multinomial_test.py index bfd40ba2b7..3840d7331c 100644 --- a/tensorflow/python/kernel_tests/distributions/multinomial_test.py +++ b/tensorflow/python/kernel_tests/distributions/multinomial_test.py @@ -34,7 +34,7 @@ class MultinomialTest(test.TestCase): self._rng = np.random.RandomState(42) def testSimpleShapes(self): - with self.test_session(): + with self.cached_session(): p = [.1, .3, .6] dist = multinomial.Multinomial(total_count=1., probs=p) self.assertEqual(3, dist.event_shape_tensor().eval()) @@ -43,7 +43,7 @@ class MultinomialTest(test.TestCase): self.assertEqual(tensor_shape.TensorShape([]), dist.batch_shape) def testComplexShapes(self): - with self.test_session(): + with self.cached_session(): p = 0.5 * np.ones([3, 2, 2], dtype=np.float32) n = [[3., 2], [4, 5], [6, 7]] dist = multinomial.Multinomial(total_count=n, probs=p) @@ -55,14 +55,14 @@ class MultinomialTest(test.TestCase): def testN(self): p = [[0.1, 0.2, 0.7], [0.2, 0.3, 0.5]] n = [[3.], [4]] - with self.test_session(): + with self.cached_session(): dist = multinomial.Multinomial(total_count=n, probs=p) self.assertEqual((2, 1), dist.total_count.get_shape()) self.assertAllClose(n, dist.total_count.eval()) def testP(self): p = [[0.1, 0.2, 0.7]] - with self.test_session(): + with self.cached_session(): dist = multinomial.Multinomial(total_count=3., probs=p) self.assertEqual((1, 3), dist.probs.get_shape()) self.assertEqual((1, 3), dist.logits.get_shape()) @@ -71,7 +71,7 @@ class MultinomialTest(test.TestCase): def testLogits(self): p = np.array([[0.1, 0.2, 0.7]], dtype=np.float32) logits = np.log(p) - 50. - with self.test_session(): + with self.cached_session(): multinom = multinomial.Multinomial(total_count=3., logits=logits) self.assertEqual((1, 3), multinom.probs.get_shape()) self.assertEqual((1, 3), multinom.logits.get_shape()) @@ -80,7 +80,7 @@ class MultinomialTest(test.TestCase): def testPmfUnderflow(self): logits = np.array([[-200, 0]], dtype=np.float32) - with self.test_session(): + with self.cached_session(): dist = multinomial.Multinomial(total_count=1., logits=logits) lp = dist.log_prob([1., 0.]).eval()[0] self.assertAllClose(-200, lp, atol=0, rtol=1e-6) @@ -88,7 +88,7 @@ class MultinomialTest(test.TestCase): def testPmfandCountsAgree(self): p = [[0.1, 0.2, 0.7]] n = [[5.]] - with self.test_session(): + with self.cached_session(): dist = multinomial.Multinomial(total_count=n, probs=p, validate_args=True) dist.prob([2., 3, 0]).eval() dist.prob([3., 0, 2]).eval() @@ -100,7 +100,7 @@ class MultinomialTest(test.TestCase): def testPmfNonIntegerCounts(self): p = [[0.1, 0.2, 0.7]] n = [[5.]] - with self.test_session(): + with self.cached_session(): # No errors with integer n. multinom = multinomial.Multinomial( total_count=n, probs=p, validate_args=True) @@ -122,7 +122,7 @@ class MultinomialTest(test.TestCase): multinom.prob([1.0, 2.5, 1.5]).eval() def testPmfBothZeroBatches(self): - with self.test_session(): + with self.cached_session(): # Both zero-batches. No broadcast p = [0.5, 0.5] counts = [1., 0] @@ -131,7 +131,7 @@ class MultinomialTest(test.TestCase): self.assertEqual((), pmf.get_shape()) def testPmfBothZeroBatchesNontrivialN(self): - with self.test_session(): + with self.cached_session(): # Both zero-batches. No broadcast p = [0.1, 0.9] counts = [3., 2] @@ -142,7 +142,7 @@ class MultinomialTest(test.TestCase): self.assertEqual((), pmf.get_shape()) def testPmfPStretchedInBroadcastWhenSameRank(self): - with self.test_session(): + with self.cached_session(): p = [[0.1, 0.9]] counts = [[1., 0], [0, 1]] pmf = multinomial.Multinomial(total_count=1., probs=p).prob(counts) @@ -150,7 +150,7 @@ class MultinomialTest(test.TestCase): self.assertEqual((2), pmf.get_shape()) def testPmfPStretchedInBroadcastWhenLowerRank(self): - with self.test_session(): + with self.cached_session(): p = [0.1, 0.9] counts = [[1., 0], [0, 1]] pmf = multinomial.Multinomial(total_count=1., probs=p).prob(counts) @@ -158,7 +158,7 @@ class MultinomialTest(test.TestCase): self.assertEqual((2), pmf.get_shape()) def testPmfCountsStretchedInBroadcastWhenSameRank(self): - with self.test_session(): + with self.cached_session(): p = [[0.1, 0.9], [0.7, 0.3]] counts = [[1., 0]] pmf = multinomial.Multinomial(total_count=1., probs=p).prob(counts) @@ -166,7 +166,7 @@ class MultinomialTest(test.TestCase): self.assertEqual((2), pmf.get_shape()) def testPmfCountsStretchedInBroadcastWhenLowerRank(self): - with self.test_session(): + with self.cached_session(): p = [[0.1, 0.9], [0.7, 0.3]] counts = [1., 0] pmf = multinomial.Multinomial(total_count=1., probs=p).prob(counts) @@ -174,7 +174,7 @@ class MultinomialTest(test.TestCase): self.assertEqual(pmf.get_shape(), (2)) def testPmfShapeCountsStretchedN(self): - with self.test_session(): + with self.cached_session(): # [2, 2, 2] p = [[[0.1, 0.9], [0.1, 0.9]], [[0.7, 0.3], [0.7, 0.3]]] # [2, 2] @@ -186,7 +186,7 @@ class MultinomialTest(test.TestCase): self.assertEqual(pmf.get_shape(), (2, 2)) def testPmfShapeCountsPStretchedN(self): - with self.test_session(): + with self.cached_session(): p = [0.1, 0.9] counts = [3., 2] n = np.full([4, 3], 5., dtype=np.float32) @@ -195,7 +195,7 @@ class MultinomialTest(test.TestCase): self.assertEqual((4, 3), pmf.get_shape()) def testMultinomialMean(self): - with self.test_session(): + with self.cached_session(): n = 5. p = [0.1, 0.2, 0.7] dist = multinomial.Multinomial(total_count=n, probs=p) @@ -204,7 +204,7 @@ class MultinomialTest(test.TestCase): self.assertAllClose(expected_means, dist.mean().eval()) def testMultinomialCovariance(self): - with self.test_session(): + with self.cached_session(): n = 5. p = [0.1, 0.2, 0.7] dist = multinomial.Multinomial(total_count=n, probs=p) @@ -215,7 +215,7 @@ class MultinomialTest(test.TestCase): self.assertAllClose(expected_covariances, dist.covariance().eval()) def testMultinomialCovarianceBatch(self): - with self.test_session(): + with self.cached_session(): # Shape [2] n = [5.] * 2 # Shape [4, 1, 2] @@ -237,7 +237,7 @@ class MultinomialTest(test.TestCase): ns = np.random.randint(low=1, high=11, size=[3, 5]).astype(np.float32) ns2 = np.random.randint(low=1, high=11, size=[6, 1]).astype(np.float32) - with self.test_session(): + with self.cached_session(): dist = multinomial.Multinomial(ns, p) dist2 = multinomial.Multinomial(ns2, p2) @@ -253,7 +253,7 @@ class MultinomialTest(test.TestCase): [2.5, 4, 0.01]], dtype=np.float32) theta /= np.sum(theta, 1)[..., array_ops.newaxis] n = np.array([[10., 9.], [8., 7.], [6., 5.]], dtype=np.float32) - with self.test_session() as sess: + with self.cached_session() as sess: # batch_shape=[3, 2], event_shape=[3] dist = multinomial.Multinomial(n, theta) x = dist.sample(int(1000e3), seed=1) @@ -289,7 +289,7 @@ class MultinomialTest(test.TestCase): self.assertAllClose(sample_stddev_, analytic_stddev, atol=0.01, rtol=0.01) def testSampleUnbiasedNonScalarBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: dist = multinomial.Multinomial( total_count=[7., 6., 5.], logits=math_ops.log(2. * self._rng.rand(4, 3, 2).astype(np.float32))) @@ -318,7 +318,7 @@ class MultinomialTest(test.TestCase): actual_covariance_, sample_covariance_, atol=0., rtol=0.20) def testSampleUnbiasedScalarBatch(self): - with self.test_session() as sess: + with self.cached_session() as sess: dist = multinomial.Multinomial( total_count=5., logits=math_ops.log(2. * self._rng.rand(4).astype(np.float32))) diff --git a/tensorflow/python/kernel_tests/embedding_ops_test.py b/tensorflow/python/kernel_tests/embedding_ops_test.py index 55d75cb474..dcd435e1ff 100644 --- a/tensorflow/python/kernel_tests/embedding_ops_test.py +++ b/tensorflow/python/kernel_tests/embedding_ops_test.py @@ -480,7 +480,7 @@ class EmbeddingLookupTest(test.TestCase): id_vals, shape=ids_shape, dtype=dtypes.int32) x, params, _ = _EmbeddingParams(num_shards, vocab_size, shape=[2]) y = embedding_ops.embedding_lookup(x, ids) - y_shape = [num_ids] + list(params[_PName(0) + ":0"].shape[1:]) + y_shape = ids_shape + tuple(params[_PName(0) + ":0"].shape[1:]) x_name = [_PName(i) for i in range(num_shards)] x_init_value = [params[x_n + ":0"] for x_n in x_name] x_shape = [i.shape for i in x_init_value] @@ -663,8 +663,9 @@ class EmbeddingLookupSparseTest(test.TestCase): np.ones(np.sum(vals_per_batch_entry)), vals_per_batch_entry) for num_shards, combiner, dtype, ignore_weights in itertools.product( - [1, 5], ["sum", "mean", "sqrtn"], [dtypes.float32, - dtypes.float64], [True, False]): + [1, 5], ["sum", "mean", "sqrtn"], + [dtypes.float16, dtypes.bfloat16, dtypes.float32, dtypes.float64], + [True, False]): with self.test_session(): p, params, feed_dict = _EmbeddingParams( @@ -677,6 +678,10 @@ class EmbeddingLookupSparseTest(test.TestCase): self.assertEqual(embedding_sum.get_shape().as_list(), expected_lookup_result_shape) + if dtype in (dtypes.float16, dtypes.bfloat16): + self.assertEqual(embedding_sum.dtype, dtypes.float32) + else: + self.assertEqual(embedding_sum.dtype, dtype) tf_embedding_sum = embedding_sum.eval(feed_dict=feed_dict) @@ -692,7 +697,14 @@ class EmbeddingLookupSparseTest(test.TestCase): if combiner == "sqrtn": np_embedding_sum /= np.reshape( np.sqrt(np_weight_sq_sum), (batch_size, 1, 1)) - self.assertAllClose(np_embedding_sum, tf_embedding_sum) + + rtol = 1e-6 + if dtype == dtypes.bfloat16: + rtol = 1e-2 + elif dtype == dtypes.float16: + rtol = 1e-3 + atol = rtol + self.assertAllClose(np_embedding_sum, tf_embedding_sum, rtol, atol) def testGradientsEmbeddingLookupSparse(self): vocab_size = 12 diff --git a/tensorflow/python/kernel_tests/extract_image_patches_grad_test.py b/tensorflow/python/kernel_tests/extract_image_patches_grad_test.py index 60090a1510..e1f5a6b620 100644 --- a/tensorflow/python/kernel_tests/extract_image_patches_grad_test.py +++ b/tensorflow/python/kernel_tests/extract_image_patches_grad_test.py @@ -25,6 +25,8 @@ from tensorflow.python.framework import dtypes from tensorflow.python.framework import random_seed as random_seed_lib from tensorflow.python.ops import array_ops from tensorflow.python.ops import gradient_checker +from tensorflow.python.ops import gradients_impl +from tensorflow.python.ops import variable_scope from tensorflow.python.platform import test @@ -100,6 +102,24 @@ class ExtractImagePatchesGradTest(test.TestCase): print('extract_image_patches gradient err: %.4e' % err) self.assertLess(err, 1e-4) + def testConstructGradientWithLargeImages(self): + batch_size = 4 + height = 1024 + width = 1024 + ksize = 5 + images = variable_scope.get_variable('inputs', + (batch_size, height, width, 1)) + patches = array_ops.extract_image_patches(images, + ksizes=[1, ksize, ksize, 1], + strides=[1, 1, 1, 1], + rates=[1, 1, 1, 1], + padding='SAME') + # Github issue: #20146 + # tf.extract_image_patches() gradient very slow at graph construction time + gradients = gradients_impl.gradients(patches, images) + # Won't time out. + self.assertIsNotNone(gradients) + if __name__ == '__main__': test.main() diff --git a/tensorflow/python/kernel_tests/functional_ops_test.py b/tensorflow/python/kernel_tests/functional_ops_test.py index 5db2e9821d..1e76ad7476 100644 --- a/tensorflow/python/kernel_tests/functional_ops_test.py +++ b/tensorflow/python/kernel_tests/functional_ops_test.py @@ -1075,30 +1075,13 @@ class PartitionedCallTest(test.TestCase): with ops.device("/cpu:2"): s3 = iterator_ops.Iterator.from_structure( (dtypes.float32,)).string_handle() - with ops.device(""): - # TODO(akshayka): This is unfortunate and brittle. It prevents - # `Iterator.from_structure` from assigning the iterator op to 'cpu:0'. - # Remove this hack once we have a way of obtaining metadata about - # function execution. - s4 = iterator_ops.Iterator.from_structure( - (dtypes.float32,)).string_handle() - return s1, s2, s3, s4 + return s1, s2, s3 with self.test_session(config=config, use_gpu=True) as sess: - with ops.device("/cpu:3"): - outputs = sess.run(functional_ops.partitioned_call(args=[], f=Body)) - self.assertIn(compat.as_bytes("CPU:0"), outputs[0]) - self.assertIn(compat.as_bytes("CPU:1"), outputs[1]) - self.assertIn(compat.as_bytes("CPU:2"), outputs[2]) - self.assertIn(compat.as_bytes("CPU:3"), outputs[3]) - - with self.test_session(config=config, use_gpu=True): - with ops.device("/cpu:0"): - outputs = sess.run(functional_ops.partitioned_call(args=[], f=Body)) + outputs = sess.run(functional_ops.partitioned_call(args=[], f=Body)) self.assertIn(compat.as_bytes("CPU:0"), outputs[0]) self.assertIn(compat.as_bytes("CPU:1"), outputs[1]) self.assertIn(compat.as_bytes("CPU:2"), outputs[2]) - self.assertIn(compat.as_bytes("CPU:0"), outputs[3]) def testAssignAddResourceVariable(self): diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_composition_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_composition_test.py index 612a50bcec..99497914f2 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_composition_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_composition_test.py @@ -191,7 +191,7 @@ class NonSquareLinearOperatorCompositionTest( linalg.LinearOperatorFullMatrix(rng.rand(2, 4, 5)) ] operator = linalg.LinearOperatorComposition(operators) - with self.test_session(): + with self.cached_session(): self.assertAllEqual((2, 3, 5), operator.shape_tensor().eval()) def test_shape_tensors_when_only_dynamically_available(self): @@ -206,7 +206,7 @@ class NonSquareLinearOperatorCompositionTest( linalg.LinearOperatorFullMatrix(mat_ph_2) ] operator = linalg.LinearOperatorComposition(operators) - with self.test_session(): + with self.cached_session(): self.assertAllEqual( (1, 2, 3, 5), operator.shape_tensor().eval(feed_dict=feed_dict)) diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_diag_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_diag_test.py index 83cc8c483f..52861ae84a 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_diag_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_diag_test.py @@ -52,7 +52,7 @@ class LinearOperatorDiagTest( def test_assert_positive_definite_raises_for_zero_eigenvalue(self): # Matrix with one positive eigenvalue and one zero eigenvalue. - with self.test_session(): + with self.cached_session(): diag = [1.0, 0.0] operator = linalg.LinearOperatorDiag(diag) @@ -62,7 +62,7 @@ class LinearOperatorDiagTest( operator.assert_positive_definite().run() def test_assert_positive_definite_raises_for_negative_real_eigvalues(self): - with self.test_session(): + with self.cached_session(): diag_x = [1.0, -2.0] diag_y = [0., 0.] # Imaginary eigenvalues should not matter. diag = math_ops.complex(diag_x, diag_y) @@ -74,7 +74,7 @@ class LinearOperatorDiagTest( operator.assert_positive_definite().run() def test_assert_positive_definite_does_not_raise_if_pd_and_complex(self): - with self.test_session(): + with self.cached_session(): x = [1., 2.] y = [1., 0.] diag = math_ops.complex(x, y) # Re[diag] > 0. @@ -83,14 +83,14 @@ class LinearOperatorDiagTest( def test_assert_non_singular_raises_if_zero_eigenvalue(self): # Singlular matrix with one positive eigenvalue and one zero eigenvalue. - with self.test_session(): + with self.cached_session(): diag = [1.0, 0.0] operator = linalg.LinearOperatorDiag(diag, is_self_adjoint=True) with self.assertRaisesOpError("Singular operator"): operator.assert_non_singular().run() def test_assert_non_singular_does_not_raise_for_complex_nonsingular(self): - with self.test_session(): + with self.cached_session(): x = [1., 0.] y = [0., 1.] diag = math_ops.complex(x, y) @@ -98,7 +98,7 @@ class LinearOperatorDiagTest( linalg.LinearOperatorDiag(diag).assert_non_singular().run() def test_assert_self_adjoint_raises_if_diag_has_complex_part(self): - with self.test_session(): + with self.cached_session(): x = [1., 0.] y = [0., 1.] diag = math_ops.complex(x, y) @@ -107,7 +107,7 @@ class LinearOperatorDiagTest( operator.assert_self_adjoint().run() def test_assert_self_adjoint_does_not_raise_for_diag_with_zero_imag(self): - with self.test_session(): + with self.cached_session(): x = [1., 0.] y = [0., 0.] diag = math_ops.complex(x, y) @@ -123,7 +123,7 @@ class LinearOperatorDiagTest( # These cannot be done in the automated (base test class) tests since they # test shapes that tf.matmul cannot handle. # In particular, tf.matmul does not broadcast. - with self.test_session() as sess: + with self.cached_session() as sess: x = random_ops.random_normal(shape=(2, 2, 3, 4)) # This LinearOperatorDiag will be broadcast to (2, 2, 3, 3) during solve diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_full_matrix_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_full_matrix_test.py index 1a40a29ec6..8373b5263f 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_full_matrix_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_full_matrix_test.py @@ -65,7 +65,7 @@ class SquareLinearOperatorFullMatrixTest( self.assertTrue(operator.is_square) def test_assert_non_singular_raises_if_cond_too_big_but_finite(self): - with self.test_session(): + with self.cached_session(): tril = linear_operator_test_util.random_tril_matrix( shape=(50, 50), dtype=np.float32) diag = np.logspace(-2, 2, 50).astype(np.float32) @@ -80,7 +80,7 @@ class SquareLinearOperatorFullMatrixTest( operator.assert_non_singular().run() def test_assert_non_singular_raises_if_cond_infinite(self): - with self.test_session(): + with self.cached_session(): matrix = [[1., 1.], [1., 1.]] # We don't pass the is_self_adjoint hint here, which means we take the # generic code path. @@ -91,14 +91,14 @@ class SquareLinearOperatorFullMatrixTest( def test_assert_self_adjoint(self): matrix = [[0., 1.], [0., 1.]] operator = linalg.LinearOperatorFullMatrix(matrix) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("not equal to its adjoint"): operator.assert_self_adjoint().run() def test_assert_positive_definite(self): matrix = [[1., 1.], [1., 1.]] operator = linalg.LinearOperatorFullMatrix(matrix, is_self_adjoint=True) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Cholesky decomposition was not success"): operator.assert_positive_definite().run() @@ -158,7 +158,7 @@ class SquareLinearOperatorFullMatrixSymmetricPositiveDefiniteTest( matrix = [[1., 1.], [1., 1.]] operator = linalg.LinearOperatorFullMatrix( matrix, is_self_adjoint=True, is_positive_definite=True) - with self.test_session(): + with self.cached_session(): # Cholesky decomposition may fail, so the error is not specific to # non-singular. with self.assertRaisesOpError(""): @@ -168,7 +168,7 @@ class SquareLinearOperatorFullMatrixSymmetricPositiveDefiniteTest( matrix = [[0., 1.], [0., 1.]] operator = linalg.LinearOperatorFullMatrix( matrix, is_self_adjoint=True, is_positive_definite=True) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("not equal to its adjoint"): operator.assert_self_adjoint().run() @@ -176,7 +176,7 @@ class SquareLinearOperatorFullMatrixSymmetricPositiveDefiniteTest( matrix = [[1., 1.], [1., 1.]] operator = linalg.LinearOperatorFullMatrix( matrix, is_self_adjoint=True, is_positive_definite=True) - with self.test_session(): + with self.cached_session(): # Cholesky decomposition may fail, so the error is not specific to # non-singular. with self.assertRaisesOpError(""): diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_identity_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_identity_test.py index 35dcf4417c..0c3c6b390f 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_identity_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_identity_test.py @@ -57,24 +57,24 @@ class LinearOperatorIdentityTest( return operator, mat def test_assert_positive_definite(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorIdentity(num_rows=2) operator.assert_positive_definite().run() # Should not fail def test_assert_non_singular(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorIdentity(num_rows=2) operator.assert_non_singular().run() # Should not fail def test_assert_self_adjoint(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorIdentity(num_rows=2) operator.assert_self_adjoint().run() # Should not fail def test_float16_matmul(self): # float16 cannot be tested by base test class because tf.matrix_solve does # not work with float16. - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorIdentity( num_rows=2, dtype=dtypes.float16) x = rng.randn(2, 3).astype(np.float16) @@ -106,7 +106,7 @@ class LinearOperatorIdentityTest( linalg_lib.LinearOperatorIdentity(num_rows=2, batch_shape=[-2]) def test_non_scalar_num_rows_raises_dynamic(self): - with self.test_session(): + with self.cached_session(): num_rows = array_ops.placeholder(dtypes.int32) operator = linalg_lib.LinearOperatorIdentity( num_rows, assert_proper_shapes=True) @@ -114,7 +114,7 @@ class LinearOperatorIdentityTest( operator.to_dense().eval(feed_dict={num_rows: [2]}) def test_negative_num_rows_raises_dynamic(self): - with self.test_session(): + with self.cached_session(): num_rows = array_ops.placeholder(dtypes.int32) operator = linalg_lib.LinearOperatorIdentity( num_rows, assert_proper_shapes=True) @@ -122,7 +122,7 @@ class LinearOperatorIdentityTest( operator.to_dense().eval(feed_dict={num_rows: -2}) def test_non_1d_batch_shape_raises_dynamic(self): - with self.test_session(): + with self.cached_session(): batch_shape = array_ops.placeholder(dtypes.int32) operator = linalg_lib.LinearOperatorIdentity( num_rows=2, batch_shape=batch_shape, assert_proper_shapes=True) @@ -130,7 +130,7 @@ class LinearOperatorIdentityTest( operator.to_dense().eval(feed_dict={batch_shape: 2}) def test_negative_batch_shape_raises_dynamic(self): - with self.test_session(): + with self.cached_session(): batch_shape = array_ops.placeholder(dtypes.int32) operator = linalg_lib.LinearOperatorIdentity( num_rows=2, batch_shape=batch_shape, assert_proper_shapes=True) @@ -147,7 +147,7 @@ class LinearOperatorIdentityTest( num_rows = array_ops.placeholder(dtypes.int32) x = array_ops.placeholder(dtypes.float32) - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorIdentity( num_rows, assert_proper_shapes=True) y = operator.matmul(x) @@ -158,7 +158,7 @@ class LinearOperatorIdentityTest( # These cannot be done in the automated (base test class) tests since they # test shapes that tf.batch_matmul cannot handle. # In particular, tf.batch_matmul does not broadcast. - with self.test_session() as sess: + with self.cached_session() as sess: x = random_ops.random_normal(shape=(1, 2, 3, 4)) operator = linalg_lib.LinearOperatorIdentity(num_rows=3, dtype=x.dtype) @@ -172,7 +172,7 @@ class LinearOperatorIdentityTest( # These cannot be done in the automated (base test class) tests since they # test shapes that tf.batch_matmul cannot handle. # In particular, tf.batch_matmul does not broadcast. - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(dtypes.float32) operator = linalg_lib.LinearOperatorIdentity(num_rows=3, dtype=x.dtype) @@ -188,7 +188,7 @@ class LinearOperatorIdentityTest( # These cannot be done in the automated (base test class) tests since they # test shapes that tf.batch_matmul cannot handle. # In particular, tf.batch_matmul does not broadcast. - with self.test_session() as sess: + with self.cached_session() as sess: # Given this x and LinearOperatorIdentity shape of (2, 1, 3, 3), the # broadcast shape of operator and 'x' is (2, 2, 3, 4) x = random_ops.random_normal(shape=(1, 2, 3, 4)) @@ -209,7 +209,7 @@ class LinearOperatorIdentityTest( # These cannot be done in the automated (base test class) tests since they # test shapes that tf.batch_matmul cannot handle. # In particular, tf.batch_matmul does not broadcast. - with self.test_session() as sess: + with self.cached_session() as sess: # Given this x and LinearOperatorIdentity shape of (2, 1, 3, 3), the # broadcast shape of operator and 'x' is (2, 2, 3, 4) x = array_ops.placeholder(dtypes.float32) @@ -287,39 +287,39 @@ class LinearOperatorScaledIdentityTest( return operator, matrix def test_assert_positive_definite_does_not_raise_when_positive(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorScaledIdentity( num_rows=2, multiplier=1.) operator.assert_positive_definite().run() # Should not fail def test_assert_positive_definite_raises_when_negative(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorScaledIdentity( num_rows=2, multiplier=-1.) with self.assertRaisesOpError("not positive definite"): operator.assert_positive_definite().run() def test_assert_non_singular_does_not_raise_when_non_singular(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorScaledIdentity( num_rows=2, multiplier=[1., 2., 3.]) operator.assert_non_singular().run() # Should not fail def test_assert_non_singular_raises_when_singular(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorScaledIdentity( num_rows=2, multiplier=[1., 2., 0.]) with self.assertRaisesOpError("was singular"): operator.assert_non_singular().run() def test_assert_self_adjoint_does_not_raise_when_self_adjoint(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorScaledIdentity( num_rows=2, multiplier=[1. + 0J]) operator.assert_self_adjoint().run() # Should not fail def test_assert_self_adjoint_raises_when_not_self_adjoint(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorScaledIdentity( num_rows=2, multiplier=[1. + 1J]) with self.assertRaisesOpError("not self-adjoint"): @@ -328,7 +328,7 @@ class LinearOperatorScaledIdentityTest( def test_float16_matmul(self): # float16 cannot be tested by base test class because tf.matrix_solve does # not work with float16. - with self.test_session(): + with self.cached_session(): multiplier = rng.rand(3).astype(np.float16) operator = linalg_lib.LinearOperatorScaledIdentity( num_rows=2, multiplier=multiplier) @@ -353,7 +353,7 @@ class LinearOperatorScaledIdentityTest( num_rows = array_ops.placeholder(dtypes.int32) x = array_ops.placeholder(dtypes.float32) - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorScaledIdentity( num_rows, multiplier=[1., 2], assert_proper_shapes=True) y = operator.matmul(x) @@ -364,7 +364,7 @@ class LinearOperatorScaledIdentityTest( # These cannot be done in the automated (base test class) tests since they # test shapes that tf.batch_matmul cannot handle. # In particular, tf.batch_matmul does not broadcast. - with self.test_session() as sess: + with self.cached_session() as sess: # Given this x and LinearOperatorScaledIdentity shape of (2, 1, 3, 3), the # broadcast shape of operator and 'x' is (2, 2, 3, 4) x = random_ops.random_normal(shape=(1, 2, 3, 4)) @@ -392,7 +392,7 @@ class LinearOperatorScaledIdentityTest( # These cannot be done in the automated (base test class) tests since they # test shapes that tf.batch_matmul cannot handle. # In particular, tf.batch_matmul does not broadcast. - with self.test_session() as sess: + with self.cached_session() as sess: # Given this x and LinearOperatorScaledIdentity shape of (3, 3), the # broadcast shape of operator and 'x' is (1, 2, 3, 4), which is the same # shape as x. diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_kronecker_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_kronecker_test.py index e26b946151..7e81c9c6c4 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_kronecker_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_kronecker_test.py @@ -70,7 +70,7 @@ class KroneckerDenseTest(test.TestCase): [10., 15., -2., -3.], [5., 10., -1., -2.]], dtype=dtypes.float32) - with self.test_session(): + with self.cached_session(): self.assertAllClose(_kronecker_dense([x, y]).eval(), z.eval()) self.assertAllClose(_kronecker_dense([y, x]).eval(), w.eval()) diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_low_rank_update_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_low_rank_update_test.py index 0e38dbd48d..61268607a4 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_low_rank_update_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_low_rank_update_test.py @@ -256,7 +256,7 @@ class LinearOpearatorLowRankUpdateBroadcastsShape(test.TestCase): # domain_dimension is 3 self.assertAllEqual([2, 3, 3], operator.shape) - with self.test_session(): + with self.cached_session(): self.assertAllEqual([2, 3, 3], operator.to_dense().eval().shape) def test_dynamic_shape_broadcasts_up_from_operator_to_other_args(self): @@ -274,7 +274,7 @@ class LinearOpearatorLowRankUpdateBroadcastsShape(test.TestCase): u_shape_ph: [2, 3, 2], # batch_shape = [2] } - with self.test_session(): + with self.cached_session(): shape_tensor = operator.shape_tensor().eval(feed_dict=feed_dict) self.assertAllEqual([2, 3, 3], shape_tensor) dense = operator.to_dense().eval(feed_dict=feed_dict) diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_lower_triangular_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_lower_triangular_test.py index b389e0cbdf..eb4bff915b 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_lower_triangular_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_lower_triangular_test.py @@ -51,7 +51,7 @@ class LinearOperatorLowerTriangularTest( def test_assert_non_singular(self): # Singlular matrix with one positive eigenvalue and one zero eigenvalue. - with self.test_session(): + with self.cached_session(): tril = [[1., 0.], [1., 0.]] operator = linalg.LinearOperatorLowerTriangular(tril) with self.assertRaisesOpError("Singular operator"): diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_test.py index 8e9f0150a2..819347343b 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_test.py @@ -108,7 +108,7 @@ class LinearOperatorTest(test.TestCase): self.assertAllEqual(3, operator.range_dimension) def test_all_shape_methods_defined_by_the_one_method_shape(self): - with self.test_session(): + with self.cached_session(): shape = (1, 2, 3, 4) operator = LinearOperatorShape(shape) @@ -131,7 +131,7 @@ class LinearOperatorTest(test.TestCase): def test_generic_to_dense_method_non_square_matrix_static(self): matrix = rng.randn(2, 3, 4) operator = LinearOperatorMatmulSolve(matrix) - with self.test_session(): + with self.cached_session(): operator_dense = operator.to_dense() self.assertAllEqual((2, 3, 4), operator_dense.get_shape()) self.assertAllClose(matrix, operator_dense.eval()) @@ -140,7 +140,7 @@ class LinearOperatorTest(test.TestCase): matrix = rng.randn(2, 3, 4) matrix_ph = array_ops.placeholder(dtypes.float64) operator = LinearOperatorMatmulSolve(matrix_ph) - with self.test_session(): + with self.cached_session(): operator_dense = operator.to_dense() self.assertAllClose( matrix, operator_dense.eval(feed_dict={matrix_ph: matrix})) @@ -149,7 +149,7 @@ class LinearOperatorTest(test.TestCase): matrix = [[1., 0], [0., 2.]] operator = LinearOperatorMatmulSolve(matrix) x = [1., 1.] - with self.test_session(): + with self.cached_session(): y = operator.matvec(x) self.assertAllEqual((2,), y.get_shape()) self.assertAllClose([1., 2.], y.eval()) @@ -158,7 +158,7 @@ class LinearOperatorTest(test.TestCase): matrix = [[1., 0], [0., 2.]] operator = LinearOperatorMatmulSolve(matrix) y = [1., 1.] - with self.test_session(): + with self.cached_session(): x = operator.solvevec(y) self.assertAllEqual((2,), x.get_shape()) self.assertAllClose([1., 1 / 2.], x.eval()) diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_util_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_util_test.py index 7b291e29de..86847d38c2 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_util_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_util_test.py @@ -36,7 +36,7 @@ class AssertZeroImagPartTest(test.TestCase): def test_real_tensor_doesnt_raise(self): x = ops.convert_to_tensor([0., 2, 3]) - with self.test_session(): + with self.cached_session(): # Should not raise. linear_operator_util.assert_zero_imag_part(x, message="ABC123").run() @@ -44,7 +44,7 @@ class AssertZeroImagPartTest(test.TestCase): x = ops.convert_to_tensor([1., 0, 3]) y = ops.convert_to_tensor([0., 0, 0]) z = math_ops.complex(x, y) - with self.test_session(): + with self.cached_session(): # Should not raise. linear_operator_util.assert_zero_imag_part(z, message="ABC123").run() @@ -52,7 +52,7 @@ class AssertZeroImagPartTest(test.TestCase): x = ops.convert_to_tensor([1., 2, 0]) y = ops.convert_to_tensor([1., 2, 0]) z = math_ops.complex(x, y) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("ABC123"): linear_operator_util.assert_zero_imag_part(z, message="ABC123").run() @@ -61,7 +61,7 @@ class AssertNoEntriesWithModulusZeroTest(test.TestCase): def test_nonzero_real_tensor_doesnt_raise(self): x = ops.convert_to_tensor([1., 2, 3]) - with self.test_session(): + with self.cached_session(): # Should not raise. linear_operator_util.assert_no_entries_with_modulus_zero( x, message="ABC123").run() @@ -70,14 +70,14 @@ class AssertNoEntriesWithModulusZeroTest(test.TestCase): x = ops.convert_to_tensor([1., 0, 3]) y = ops.convert_to_tensor([1., 2, 0]) z = math_ops.complex(x, y) - with self.test_session(): + with self.cached_session(): # Should not raise. linear_operator_util.assert_no_entries_with_modulus_zero( z, message="ABC123").run() def test_zero_real_tensor_raises(self): x = ops.convert_to_tensor([1., 0, 3]) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("ABC123"): linear_operator_util.assert_no_entries_with_modulus_zero( x, message="ABC123").run() @@ -86,7 +86,7 @@ class AssertNoEntriesWithModulusZeroTest(test.TestCase): x = ops.convert_to_tensor([1., 2, 0]) y = ops.convert_to_tensor([1., 2, 0]) z = math_ops.complex(x, y) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("ABC123"): linear_operator_util.assert_no_entries_with_modulus_zero( z, message="ABC123").run() @@ -103,7 +103,7 @@ class BroadcastMatrixBatchDimsTest(test.TestCase): tensor, = linear_operator_util.broadcast_matrix_batch_dims([arr]) self.assertTrue(isinstance(tensor, ops.Tensor)) - with self.test_session(): + with self.cached_session(): self.assertAllClose(arr, tensor.eval()) def test_static_dims_broadcast(self): @@ -118,7 +118,7 @@ class BroadcastMatrixBatchDimsTest(test.TestCase): x_bc, y_bc = linear_operator_util.broadcast_matrix_batch_dims([x, y]) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual(x_bc_expected.shape, x_bc.get_shape()) self.assertAllEqual(y_bc_expected.shape, y_bc.get_shape()) x_bc_, y_bc_ = sess.run([x_bc, y_bc]) @@ -137,7 +137,7 @@ class BroadcastMatrixBatchDimsTest(test.TestCase): x_bc, y_bc = linear_operator_util.broadcast_matrix_batch_dims([x, y]) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual(x_bc_expected.shape, x_bc.get_shape()) self.assertAllEqual(y_bc_expected.shape, y_bc.get_shape()) x_bc_, y_bc_ = sess.run([x_bc, y_bc]) @@ -159,7 +159,7 @@ class BroadcastMatrixBatchDimsTest(test.TestCase): x_bc, y_bc = linear_operator_util.broadcast_matrix_batch_dims([x_ph, y_ph]) - with self.test_session() as sess: + with self.cached_session() as sess: x_bc_, y_bc_ = sess.run([x_bc, y_bc], feed_dict={x_ph: x, y_ph: y}) self.assertAllClose(x_bc_expected, x_bc_) self.assertAllClose(y_bc_expected, y_bc_) @@ -179,7 +179,7 @@ class BroadcastMatrixBatchDimsTest(test.TestCase): x_bc, y_bc = linear_operator_util.broadcast_matrix_batch_dims([x_ph, y_ph]) - with self.test_session() as sess: + with self.cached_session() as sess: x_bc_, y_bc_ = sess.run([x_bc, y_bc], feed_dict={x_ph: x, y_ph: y}) self.assertAllClose(x_bc_expected, x_bc_) self.assertAllClose(y_bc_expected, y_bc_) @@ -203,7 +203,7 @@ class CholeskySolveWithBroadcastTest(test.TestCase): rhs = rng.rand(2, 3, 7) chol_broadcast = chol + np.zeros((2, 1, 1)) - with self.test_session(): + with self.cached_session(): result = linear_operator_util.cholesky_solve_with_broadcast(chol, rhs) self.assertAllEqual((2, 3, 7), result.get_shape()) expected = linalg_ops.cholesky_solve(chol_broadcast, rhs) @@ -219,7 +219,7 @@ class CholeskySolveWithBroadcastTest(test.TestCase): chol_ph = array_ops.placeholder(dtypes.float64) rhs_ph = array_ops.placeholder(dtypes.float64) - with self.test_session() as sess: + with self.cached_session() as sess: result, expected = sess.run( [ linear_operator_util.cholesky_solve_with_broadcast( @@ -242,7 +242,7 @@ class MatmulWithBroadcastTest(test.TestCase): y = rng.rand(3, 7) y_broadcast = y + np.zeros((2, 1, 1)) - with self.test_session(): + with self.cached_session(): result = linear_operator_util.matmul_with_broadcast(x, y) self.assertAllEqual((2, 1, 7), result.get_shape()) expected = math_ops.matmul(x, y_broadcast) @@ -258,7 +258,7 @@ class MatmulWithBroadcastTest(test.TestCase): x_ph = array_ops.placeholder(dtypes.float64) y_ph = array_ops.placeholder(dtypes.float64) - with self.test_session() as sess: + with self.cached_session() as sess: result, expected = sess.run( [ linear_operator_util.matmul_with_broadcast(x_ph, y_ph), @@ -279,7 +279,7 @@ class MatrixSolveWithBroadcastTest(test.TestCase): rhs = rng.rand(2, 3, 7) matrix_broadcast = matrix + np.zeros((2, 1, 1)) - with self.test_session(): + with self.cached_session(): result = linear_operator_util.matrix_solve_with_broadcast(matrix, rhs) self.assertAllEqual((2, 3, 7), result.get_shape()) expected = linalg_ops.matrix_solve(matrix_broadcast, rhs) @@ -295,7 +295,7 @@ class MatrixSolveWithBroadcastTest(test.TestCase): matrix_ph = array_ops.placeholder(dtypes.float64) rhs_ph = array_ops.placeholder(dtypes.float64) - with self.test_session() as sess: + with self.cached_session() as sess: result, expected = sess.run( [ linear_operator_util.matrix_solve_with_broadcast( @@ -317,7 +317,7 @@ class MatrixTriangularSolveWithBroadcastTest(test.TestCase): rhs = rng.rand(3, 7) rhs_broadcast = rhs + np.zeros((2, 1, 1)) - with self.test_session(): + with self.cached_session(): result = linear_operator_util.matrix_triangular_solve_with_broadcast( matrix, rhs) self.assertAllEqual((2, 3, 7), result.get_shape()) @@ -333,7 +333,7 @@ class MatrixTriangularSolveWithBroadcastTest(test.TestCase): matrix_ph = array_ops.placeholder(dtypes.float64) rhs_ph = array_ops.placeholder(dtypes.float64) - with self.test_session() as sess: + with self.cached_session() as sess: result, expected = sess.run( [ linear_operator_util.matrix_triangular_solve_with_broadcast( @@ -359,7 +359,7 @@ class DomainDimensionStubOperator(object): class AssertCompatibleMatrixDimensionsTest(test.TestCase): def test_compatible_dimensions_do_not_raise(self): - with self.test_session(): + with self.cached_session(): x = ops.convert_to_tensor(rng.rand(2, 3, 4)) operator = DomainDimensionStubOperator(3) # Should not raise @@ -367,7 +367,7 @@ class AssertCompatibleMatrixDimensionsTest(test.TestCase): operator, x).run() # pyformat: disable def test_incompatible_dimensions_raise(self): - with self.test_session(): + with self.cached_session(): x = ops.convert_to_tensor(rng.rand(2, 4, 4)) operator = DomainDimensionStubOperator(3) with self.assertRaisesOpError("Incompatible matrix dimensions"): diff --git a/tensorflow/python/kernel_tests/linalg/linear_operator_zeros_test.py b/tensorflow/python/kernel_tests/linalg/linear_operator_zeros_test.py index 8f60b55e0a..f0556304ad 100644 --- a/tensorflow/python/kernel_tests/linalg/linear_operator_zeros_test.py +++ b/tensorflow/python/kernel_tests/linalg/linear_operator_zeros_test.py @@ -73,7 +73,7 @@ class LinearOperatorZerosTest( operator.assert_non_singular() def test_assert_self_adjoint(self): - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorZeros(num_rows=2) operator.assert_self_adjoint().run() # Should not fail @@ -108,7 +108,7 @@ class LinearOperatorZerosTest( linalg_lib.LinearOperatorZeros(num_rows=2, batch_shape=[-2]) def test_non_scalar_num_rows_raises_dynamic(self): - with self.test_session(): + with self.cached_session(): num_rows = array_ops.placeholder(dtypes.int32) operator = linalg_lib.LinearOperatorZeros( num_rows, assert_proper_shapes=True) @@ -116,7 +116,7 @@ class LinearOperatorZerosTest( operator.to_dense().eval(feed_dict={num_rows: [2]}) def test_negative_num_rows_raises_dynamic(self): - with self.test_session(): + with self.cached_session(): n = array_ops.placeholder(dtypes.int32) operator = linalg_lib.LinearOperatorZeros( num_rows=n, assert_proper_shapes=True) @@ -129,7 +129,7 @@ class LinearOperatorZerosTest( operator.to_dense().eval(feed_dict={n: -2}) def test_non_1d_batch_shape_raises_dynamic(self): - with self.test_session(): + with self.cached_session(): batch_shape = array_ops.placeholder(dtypes.int32) operator = linalg_lib.LinearOperatorZeros( num_rows=2, batch_shape=batch_shape, assert_proper_shapes=True) @@ -137,7 +137,7 @@ class LinearOperatorZerosTest( operator.to_dense().eval(feed_dict={batch_shape: 2}) def test_negative_batch_shape_raises_dynamic(self): - with self.test_session(): + with self.cached_session(): batch_shape = array_ops.placeholder(dtypes.int32) operator = linalg_lib.LinearOperatorZeros( num_rows=2, batch_shape=batch_shape, assert_proper_shapes=True) @@ -154,7 +154,7 @@ class LinearOperatorZerosTest( num_rows = array_ops.placeholder(dtypes.int32) x = array_ops.placeholder(dtypes.float32) - with self.test_session(): + with self.cached_session(): operator = linalg_lib.LinearOperatorZeros( num_rows, assert_proper_shapes=True) y = operator.matmul(x) diff --git a/tensorflow/python/kernel_tests/matrix_logarithm_op_test.py b/tensorflow/python/kernel_tests/matrix_logarithm_op_test.py index 24edc4f59f..723a15fbd1 100644 --- a/tensorflow/python/kernel_tests/matrix_logarithm_op_test.py +++ b/tensorflow/python/kernel_tests/matrix_logarithm_op_test.py @@ -30,6 +30,7 @@ from tensorflow.python.ops import gen_linalg_ops from tensorflow.python.ops import math_ops from tensorflow.python.ops import random_ops from tensorflow.python.ops import variables +from tensorflow.python.ops.linalg import linalg_impl from tensorflow.python.platform import test @@ -39,7 +40,7 @@ class LogarithmOpTest(test.TestCase): inp = x.astype(np_type) with self.test_session(use_gpu=True): # Verify that expm(logm(A)) == A. - tf_ans = gen_linalg_ops.matrix_exponential( + tf_ans = linalg_impl.matrix_exponential( gen_linalg_ops.matrix_logarithm(inp)) out = tf_ans.eval() self.assertAllClose(inp, out, rtol=1e-4, atol=1e-3) @@ -98,16 +99,25 @@ class LogarithmOpTest(test.TestCase): self._verifyLogarithmComplex(np.empty([0, 2, 2], dtype=np.complex64)) self._verifyLogarithmComplex(np.empty([2, 0, 0], dtype=np.complex64)) - def testRandomSmallAndLarge(self): + def testRandomSmallAndLargeComplex64(self): np.random.seed(42) - for dtype in np.complex64, np.complex128: - for batch_dims in [(), (1,), (3,), (2, 2)]: - for size in 8, 31, 32: - shape = batch_dims + (size, size) - matrix = np.random.uniform( - low=-1.0, high=1.0, - size=np.prod(shape)).reshape(shape).astype(dtype) - self._verifyLogarithmComplex(matrix) + for batch_dims in [(), (1,), (3,), (2, 2)]: + for size in 8, 31, 32: + shape = batch_dims + (size, size) + matrix = np.random.uniform( + low=-1.0, high=1.0, + size=np.prod(shape)).reshape(shape).astype(np.complex64) + self._verifyLogarithmComplex(matrix) + + def testRandomSmallAndLargeComplex128(self): + np.random.seed(42) + for batch_dims in [(), (1,), (3,), (2, 2)]: + for size in 8, 31, 32: + shape = batch_dims + (size, size) + matrix = np.random.uniform( + low=-1.0, high=1.0, + size=np.prod(shape)).reshape(shape).astype(np.complex128) + self._verifyLogarithmComplex(matrix) def testConcurrentExecutesWithoutError(self): with self.test_session(use_gpu=True) as sess: diff --git a/tensorflow/python/kernel_tests/parameterized_truncated_normal_op_test.py b/tensorflow/python/kernel_tests/parameterized_truncated_normal_op_test.py index dd67919f69..e14894cf56 100644 --- a/tensorflow/python/kernel_tests/parameterized_truncated_normal_op_test.py +++ b/tensorflow/python/kernel_tests/parameterized_truncated_normal_op_test.py @@ -182,6 +182,19 @@ class ParameterizedTruncatedNormalTest(test.TestCase): def testSmallStddev(self): self.validateKolmogorovSmirnov([10**5], 0.0, 0.1, 0.05, 0.10) + def testSamplingWithSmallStdDevFarFromBound(self): + sample_op = random_ops.parameterized_truncated_normal( + shape=(int(1e5),), means=0.8, stddevs=0.05, minvals=-1., maxvals=1.) + + with self.test_session(use_gpu=True) as sess: + samples = sess.run(sample_op) + # 0. is more than 16 standard deviations from the mean, and + # should have a likelihood < 1e-57. + # TODO(jjhunt) Sampler is still numerically unstable in this case, + # numbers less than 0 should never observed. + no_neg_samples = np.sum(samples < 0.) + self.assertLess(no_neg_samples, 2.) + # Benchmarking code def parameterized_vs_naive(shape, num_iters, use_gpu=False): diff --git a/tensorflow/python/kernel_tests/partitioned_variables_test.py b/tensorflow/python/kernel_tests/partitioned_variables_test.py index ba9359d923..15d5702252 100644 --- a/tensorflow/python/kernel_tests/partitioned_variables_test.py +++ b/tensorflow/python/kernel_tests/partitioned_variables_test.py @@ -18,6 +18,8 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import os + import numpy as np from six.moves import xrange # pylint: disable=redefined-builtin @@ -25,15 +27,13 @@ from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops -from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import init_ops -from tensorflow.python.ops import math_ops from tensorflow.python.ops import partitioned_variables from tensorflow.python.ops import random_ops from tensorflow.python.ops import variable_scope from tensorflow.python.ops import variables from tensorflow.python.platform import test -from tensorflow.python.training import gradient_descent +from tensorflow.python.training import saver as saver_lib class PartitionerCreatorsTest(test.TestCase): @@ -546,6 +546,32 @@ class PartitionedVariablesTestCase(test.TestCase): partitioned_variables.create_partitioned_variables( [10, 43], [1, 50], rnd.initialized_value()) + def testControlDepsNone(self): + with self.test_session() as session: + c = constant_op.constant(1.0) + with ops.control_dependencies([c]): + # d get the control dependency. + d = constant_op.constant(2.0) + # Partitioned variables do not. + var_x = variable_scope.get_variable( + "x", + shape=[2], + initializer=init_ops.ones_initializer(), + partitioner=partitioned_variables.variable_axis_size_partitioner(4)) + + ops_before_read = session.graph.get_operations() + var_x.as_tensor() # Caches the ops for subsequent reads. + reading_ops = [ + op for op in session.graph.get_operations() + if op not in ops_before_read + ] + + self.assertEqual([c.op], d.op.control_inputs) + # Tests that no control dependencies are added to reading a partitioned + # variable which is similar to reading a variable. + for op in reading_ops: + self.assertEqual([], op.control_inputs) + def testConcat(self): with self.test_session() as session: var_x = variable_scope.get_variable( @@ -571,57 +597,38 @@ class PartitionedVariablesTestCase(test.TestCase): variables.global_variables_initializer().run() self.assertAllClose(value.eval(), var_x.as_tensor().eval()) - def testVariableCreationInALoop(self): - """Tests the variable created inside a loop can be used outside the loop.""" - with self.test_session(): - with variable_scope.variable_scope("ascope") as scope: - def Body(i, _): - var_x = variable_scope.get_variable( - "x", - shape=[2], - initializer=init_ops.ones_initializer(), - partitioner=partitioned_variables.variable_axis_size_partitioner( - 4)) - return (i + 1, var_x.as_tensor()) - - cond = lambda i, _: i < 2 - _, x = control_flow_ops.while_loop( - cond, Body, (0, constant_op.constant([7, 8], dtypes.float32))) + def testMetaGraphSaveLoad(self): + save_prefix = os.path.join(self.get_temp_dir(), "ckpt") + save_graph = ops.Graph() + with save_graph.as_default(), self.test_session( + graph=save_graph) as session: + partitioner = partitioned_variables.fixed_size_partitioner(5, axis=0) + with variable_scope.variable_scope("root", partitioner=partitioner): + v0 = variable_scope.get_variable( + "v0", dtype=dtypes.float32, shape=(10, 10)) + v0_list = v0._get_variable_list() + v0_part = v0._get_partitions() + self.assertEqual(len(v0_list), 5) + self.assertAllEqual(v0_part, (5, 1)) variables.global_variables_initializer().run() - self.assertAllClose([1.0, 1.0], x.eval()) - - scope.reuse_variables() - var_x = variable_scope.get_variable( - "x", - shape=[2], - initializer=init_ops.ones_initializer(), - partitioner=partitioned_variables.variable_axis_size_partitioner(4)) - - self.assertAllClose([1.0, 1.0], var_x.as_tensor().eval()) - - def testReadInWhileLoop(self): - """Tests the value is current (not cached) when read within a loop.""" - with self.test_session(): - var_x = variable_scope.get_variable( - "x", - shape=[2], - initializer=init_ops.ones_initializer(), - partitioner=partitioned_variables.variable_axis_size_partitioner(4)) - - def Body(i, _): - # Use a SGD step to update the variable's value. - loss = math_ops.reduce_sum(var_x) - optimizer = gradient_descent.GradientDescentOptimizer(1.0) - minimize = optimizer.minimize(loss * 0.7) - with ops.control_dependencies([minimize]): - return (i + 1, var_x.as_tensor()) - - cond = lambda i, _: i < 2 - _, x = control_flow_ops.while_loop( - cond, Body, (0, constant_op.constant([7, 8], dtypes.float32))) - variables.global_variables_initializer().run() - self.assertAllClose([-0.4, -0.4], x.eval()) + save_graph.get_collection_ref("partvar").append(v0) + saver = saver_lib.Saver() + save_graph.finalize() + save_path = saver.save(sess=session, save_path=save_prefix) + previous_value = session.run( + save_graph.get_tensor_by_name(v0.name + ":0")) + + restore_graph = ops.Graph() + with restore_graph.as_default(), self.test_session( + graph=restore_graph) as session: + saver = saver_lib.import_meta_graph(save_path + ".meta") + saver.restore(sess=session, save_path=save_path) + v0, = save_graph.get_collection_ref("partvar") + self.assertIsInstance(v0, variables.PartitionedVariable) + self.assertAllEqual( + previous_value, + session.run(restore_graph.get_tensor_by_name(v0.name + ":0"))) if __name__ == "__main__": test.main() diff --git a/tensorflow/python/kernel_tests/random/random_crop_test.py b/tensorflow/python/kernel_tests/random/random_crop_test.py index 6028be1228..8ded522320 100644 --- a/tensorflow/python/kernel_tests/random/random_crop_test.py +++ b/tensorflow/python/kernel_tests/random/random_crop_test.py @@ -30,12 +30,12 @@ class RandomCropTest(test.TestCase): # No random cropping is performed since the size is value.shape. for shape in (2, 1, 1), (2, 1, 3), (4, 5, 3): value = np.arange(0, np.prod(shape), dtype=np.int32).reshape(shape) - with self.test_session(): + with self.cached_session(): crop = random_ops.random_crop(value, shape).eval() self.assertAllEqual(crop, value) def testContains(self): - with self.test_session(): + with self.cached_session(): shape = (3, 5, 7) target = (2, 3, 4) value = np.random.randint(1000000, size=shape) @@ -57,7 +57,7 @@ class RandomCropTest(test.TestCase): single = [1, 1, 1] value = np.arange(size).reshape(shape) - with self.test_session(): + with self.cached_session(): crop = random_ops.random_crop(value, single, seed=7) counts = np.zeros(size, dtype=np.int32) for _ in range(num_samples): diff --git a/tensorflow/python/kernel_tests/random/random_gamma_test.py b/tensorflow/python/kernel_tests/random/random_gamma_test.py index aa40228dc1..d969944493 100644 --- a/tensorflow/python/kernel_tests/random/random_gamma_test.py +++ b/tensorflow/python/kernel_tests/random/random_gamma_test.py @@ -256,7 +256,7 @@ class RandomGammaTest(test.TestCase): def testPositive(self): n = int(10e3) for dt in [dtypes.float16, dtypes.float32, dtypes.float64]: - with self.test_session(): + with self.cached_session(): x = random_ops.random_gamma(shape=[n], alpha=0.001, dtype=dt, seed=0) self.assertEqual(0, math_ops.reduce_sum(math_ops.cast( math_ops.less_equal(x, 0.), dtype=dtypes.int64)).eval()) diff --git a/tensorflow/python/kernel_tests/random/random_grad_test.py b/tensorflow/python/kernel_tests/random/random_grad_test.py index c1d455b785..d89056c485 100644 --- a/tensorflow/python/kernel_tests/random/random_grad_test.py +++ b/tensorflow/python/kernel_tests/random/random_grad_test.py @@ -49,7 +49,7 @@ class AddLeadingUnitDimensionsTest(test.TestCase): x = array_ops.placeholder(dtypes.float32) num_dimensions = array_ops.placeholder(dtypes.int32) ret = random_grad.add_leading_unit_dimensions(x, num_dimensions) - with self.test_session() as sess: + with self.cached_session() as sess: ret_val = sess.run(ret, {x: np.ones([2, 2]), num_dimensions: 2}) self.assertAllEqual(ret_val.shape, [1, 1, 2, 2]) @@ -99,7 +99,7 @@ class RandomGammaGradTest(test.TestCase): alpha_val = np.ones([1, 2]) beta_val = np.ones([2, 1]) - with self.test_session() as sess: + with self.cached_session() as sess: grads_alpha_val, grads_beta_val = sess.run( [grads_alpha, grads_beta], {alpha: alpha_val, beta: beta_val, shape: [2, 1]}) diff --git a/tensorflow/python/kernel_tests/random/random_poisson_test.py b/tensorflow/python/kernel_tests/random/random_poisson_test.py index afdf71e652..15ab95cdb7 100644 --- a/tensorflow/python/kernel_tests/random/random_poisson_test.py +++ b/tensorflow/python/kernel_tests/random/random_poisson_test.py @@ -137,7 +137,7 @@ class RandomPoissonTest(test.TestCase): self.assertGreaterEqual(np.linalg.norm(diff.eval()), 1) def testZeroShape(self): - with self.test_session(): + with self.cached_session(): rnd = random_ops.random_poisson([], [], seed=12345) self.assertEqual([0], rnd.get_shape().as_list()) self.assertAllClose(np.array([], dtype=np.float32), rnd.eval()) @@ -186,7 +186,7 @@ class RandomPoissonTest(test.TestCase): def testDTypeCombinationsV2(self): """Tests random_poisson_v2() for all supported dtype combinations.""" - with self.test_session(): + with self.cached_session(): for lam_dt in _SUPPORTED_DTYPES: for out_dt in _SUPPORTED_DTYPES: random_ops.random_poisson( diff --git a/tensorflow/python/kernel_tests/random/random_shuffle_queue_test.py b/tensorflow/python/kernel_tests/random/random_shuffle_queue_test.py index b7a79f239c..0d85a072d4 100644 --- a/tensorflow/python/kernel_tests/random/random_shuffle_queue_test.py +++ b/tensorflow/python/kernel_tests/random/random_shuffle_queue_test.py @@ -46,7 +46,7 @@ class RandomShuffleQueueTest(test.TestCase): tf_logging.error("Finished: %s", self._testMethodName) def testEnqueue(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 5, dtypes_lib.float32) enqueue_op = q.enqueue((10.0,)) self.assertAllEqual(0, q.size().eval()) @@ -54,7 +54,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertAllEqual(1, q.size().eval()) def testEnqueueWithShape(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue( 10, 5, dtypes_lib.float32, shapes=tensor_shape.TensorShape([3, 2])) enqueue_correct_op = q.enqueue(([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]],)) @@ -64,7 +64,7 @@ class RandomShuffleQueueTest(test.TestCase): q.enqueue(([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]],)) def testEnqueueManyWithShape(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue( 10, 5, [dtypes_lib.int32, dtypes_lib.int32], shapes=[(), (2,)]) q.enqueue_many([[1, 2, 3, 4], [[1, 1], [2, 2], [3, 3], [4, 4]]]).run() @@ -76,7 +76,7 @@ class RandomShuffleQueueTest(test.TestCase): q2.enqueue_many(([[1, 2, 3]],)) def testScalarShapes(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue( 10, 0, [dtypes_lib.int32, dtypes_lib.int32], shapes=[(), (1,)]) q.enqueue_many([[1, 2, 3, 4], [[5], [6], [7], [8]]]).run() @@ -93,7 +93,7 @@ class RandomShuffleQueueTest(test.TestCase): results) def testParallelEnqueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32) elems = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] enqueue_ops = [q.enqueue((x,)) for x in elems] @@ -119,7 +119,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, results) def testParallelDequeue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32) elems = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] enqueue_ops = [q.enqueue((x,)) for x in elems] @@ -143,7 +143,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, results) def testDequeue(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32) elems = [10.0, 20.0, 30.0] enqueue_ops = [q.enqueue((x,)) for x in elems] @@ -156,7 +156,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, vals) def testEnqueueAndBlockingDequeue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(3, 0, dtypes_lib.float32) elems = [10.0, 20.0, 30.0] enqueue_ops = [q.enqueue((x,)) for x in elems] @@ -185,7 +185,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, results) def testMultiEnqueueAndDequeue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue( 10, 0, (dtypes_lib.int32, dtypes_lib.float32)) elems = [(5, 10.0), (10, 20.0), (15, 30.0)] @@ -202,12 +202,12 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, results) def testQueueSizeEmpty(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 5, dtypes_lib.float32) self.assertEqual(0, q.size().eval()) def testQueueSizeAfterEnqueueAndDequeue(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32) enqueue_op = q.enqueue((10.0,)) dequeued_t = q.dequeue() @@ -220,7 +220,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual([0], size.eval()) def testEnqueueMany(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -234,7 +234,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems + elems, results) def testEmptyEnqueueMany(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 5, dtypes_lib.float32) empty_t = constant_op.constant( [], dtype=dtypes_lib.float32, shape=[0, 2, 3]) @@ -246,7 +246,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual(0, size_t.eval()) def testEmptyDequeueMany(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32, shapes=()) enqueue_op = q.enqueue((10.0,)) dequeued_t = q.dequeue_many(0) @@ -256,7 +256,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual([], dequeued_t.eval().tolist()) def testEmptyDequeueUpTo(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32, shapes=()) enqueue_op = q.enqueue((10.0,)) dequeued_t = q.dequeue_up_to(0) @@ -266,7 +266,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual([], dequeued_t.eval().tolist()) def testEmptyDequeueManyWithNoShape(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32) enqueue_op = q.enqueue((constant_op.constant( [10.0, 20.0], shape=(1, 2)),)) @@ -287,7 +287,7 @@ class RandomShuffleQueueTest(test.TestCase): dequeued_t.eval() def testEmptyDequeueUpToWithNoShape(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32) enqueue_op = q.enqueue((constant_op.constant( [10.0, 20.0], shape=(1, 2)),)) @@ -308,7 +308,7 @@ class RandomShuffleQueueTest(test.TestCase): dequeued_t.eval() def testMultiEnqueueMany(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue( 10, 0, (dtypes_lib.float32, dtypes_lib.int32)) float_elems = [10.0, 20.0, 30.0, 40.0] @@ -327,7 +327,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(expected, results) def testDequeueMany(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] enqueue_op = q.enqueue_many((elems,)) @@ -340,7 +340,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, results) def testDequeueUpToNoBlocking(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] enqueue_op = q.enqueue_many((elems,)) @@ -353,7 +353,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, results) def testMultiDequeueMany(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue( 10, 0, (dtypes_lib.float32, dtypes_lib.int32), shapes=((), (2,))) float_elems = [ @@ -387,7 +387,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(zip(float_elems, int_elems), results) def testMultiDequeueUpToNoBlocking(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue( 10, 0, (dtypes_lib.float32, dtypes_lib.int32), shapes=((), (2,))) float_elems = [ @@ -422,7 +422,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(zip(float_elems, int_elems), results) def testHighDimension(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.int32, ( (4, 4, 4, 4))) elems = np.array([[[[[x] * 4] * 4] * 4] * 4 for x in range(10)], np.int32) @@ -433,7 +433,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(dequeued_t.eval().tolist(), elems.tolist()) def testParallelEnqueueMany(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue( 1000, 0, dtypes_lib.float32, shapes=()) elems = [10.0 * x for x in range(100)] @@ -453,7 +453,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(dequeued_t.eval(), elems * 10) def testParallelDequeueMany(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue( 1000, 0, dtypes_lib.float32, shapes=()) elems = [10.0 * x for x in range(1000)] @@ -476,7 +476,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, dequeued_elems) def testParallelDequeueUpTo(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue( 1000, 0, dtypes_lib.float32, shapes=()) elems = [10.0 * x for x in range(1000)] @@ -499,7 +499,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, dequeued_elems) def testParallelDequeueUpToRandomPartition(self): - with self.test_session() as sess: + with self.cached_session() as sess: dequeue_sizes = [random.randint(50, 150) for _ in xrange(10)] total_elements = sum(dequeue_sizes) q = data_flow_ops.RandomShuffleQueue( @@ -527,7 +527,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, dequeued_elems) def testBlockingDequeueMany(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -554,7 +554,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, dequeued_elems) def testBlockingDequeueUpTo(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -581,7 +581,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, dequeued_elems) def testDequeueManyWithTensorParameter(self): - with self.test_session(): + with self.cached_session(): # Define a first queue that contains integer counts. dequeue_counts = [random.randint(1, 10) for _ in range(100)] count_q = data_flow_ops.RandomShuffleQueue(100, 0, dtypes_lib.int32) @@ -607,7 +607,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, dequeued_elems) def testDequeueUpToWithTensorParameter(self): - with self.test_session(): + with self.cached_session(): # Define a first queue that contains integer counts. dequeue_counts = [random.randint(1, 10) for _ in range(100)] count_q = data_flow_ops.RandomShuffleQueue(100, 0, dtypes_lib.int32) @@ -633,7 +633,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elems, dequeued_elems) def testDequeueFromClosedQueue(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 2, dtypes_lib.float32) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -652,7 +652,7 @@ class RandomShuffleQueueTest(test.TestCase): dequeued_t.eval() def testBlockingDequeueFromClosedQueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: min_size = 2 q = data_flow_ops.RandomShuffleQueue(10, min_size, dtypes_lib.float32) elems = [10.0, 20.0, 30.0, 40.0] @@ -690,7 +690,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual(len(results), 4) def testBlockingDequeueFromClosedEmptyQueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32) close_op = q.close() dequeued_t = q.dequeue() @@ -715,7 +715,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual(len(finished), 1) def testBlockingDequeueManyFromClosedQueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -751,7 +751,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual(len(progress), 2) def testBlockingDequeueUpToFromClosedQueueReturnsRemainder(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -778,7 +778,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(results, elems) def testBlockingDequeueUpToSmallerThanMinAfterDequeue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue( capacity=10, min_after_dequeue=2, @@ -811,7 +811,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(results, elems) def testBlockingDequeueManyFromClosedQueueWithElementsRemaining(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -845,7 +845,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual(len(results), 4) def testBlockingDequeueManyFromClosedEmptyQueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 5, dtypes_lib.float32, ((),)) close_op = q.close() dequeued_t = q.dequeue_many(4) @@ -865,7 +865,7 @@ class RandomShuffleQueueTest(test.TestCase): dequeue_thread.join() def testBlockingDequeueUpToFromClosedEmptyQueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(10, 5, dtypes_lib.float32, ((),)) close_op = q.close() dequeued_t = q.dequeue_up_to(4) @@ -885,7 +885,7 @@ class RandomShuffleQueueTest(test.TestCase): dequeue_thread.join() def testEnqueueToClosedQueue(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 4, dtypes_lib.float32) enqueue_op = q.enqueue((10.0,)) close_op = q.close() @@ -898,7 +898,7 @@ class RandomShuffleQueueTest(test.TestCase): enqueue_op.run() def testEnqueueManyToClosedQueue(self): - with self.test_session(): + with self.cached_session(): q = data_flow_ops.RandomShuffleQueue(10, 5, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -912,7 +912,7 @@ class RandomShuffleQueueTest(test.TestCase): enqueue_op.run() def testBlockingEnqueueToFullQueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(4, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -940,7 +940,7 @@ class RandomShuffleQueueTest(test.TestCase): thread.join() def testBlockingEnqueueManyToFullQueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(4, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -974,7 +974,7 @@ class RandomShuffleQueueTest(test.TestCase): thread.join() def testBlockingEnqueueToClosedQueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(4, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0, 40.0] enqueue_op = q.enqueue_many((elems,)) @@ -1019,7 +1019,7 @@ class RandomShuffleQueueTest(test.TestCase): thread1.join() def testBlockingEnqueueManyToClosedQueue(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(4, 0, dtypes_lib.float32, ((),)) elems = [10.0, 20.0, 30.0] enqueue_op = q.enqueue_many((elems,)) @@ -1067,7 +1067,7 @@ class RandomShuffleQueueTest(test.TestCase): sess.run(blocking_enqueue_op) def testSharedQueueSameSession(self): - with self.test_session(): + with self.cached_session(): q1 = data_flow_ops.RandomShuffleQueue( 1, 0, dtypes_lib.float32, ((),), shared_name="shared_queue") q1.enqueue((10.0,)).run() @@ -1104,7 +1104,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual(q2_size_t.eval(), 0) def testSharedQueueSameSessionGraphSeedNone(self): - with self.test_session(): + with self.cached_session(): q1 = data_flow_ops.RandomShuffleQueue( 1, 0, @@ -1127,7 +1127,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual(q2_size_t.eval(), 1) def testIncompatibleSharedQueueErrors(self): - with self.test_session(): + with self.cached_session(): q_a_1 = data_flow_ops.RandomShuffleQueue( 10, 5, dtypes_lib.float32, shared_name="q_a") q_a_2 = data_flow_ops.RandomShuffleQueue( @@ -1193,7 +1193,7 @@ class RandomShuffleQueueTest(test.TestCase): q_h_2.queue_ref.op.run() def testSelectQueue(self): - with self.test_session(): + with self.cached_session(): num_queues = 10 qlist = list() for _ in xrange(num_queues): @@ -1207,7 +1207,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertEqual(q.dequeue().eval(), 10.0) def testSelectQueueOutOfRange(self): - with self.test_session(): + with self.cached_session(): q1 = data_flow_ops.RandomShuffleQueue(10, 0, dtypes_lib.float32) q2 = data_flow_ops.RandomShuffleQueue(15, 0, dtypes_lib.float32) enq_q = data_flow_ops.RandomShuffleQueue.from_list(3, [q1, q2]) @@ -1235,7 +1235,7 @@ class RandomShuffleQueueTest(test.TestCase): sess.run(enqueue_many_op) def testResetOfBlockingOperation(self): - with self.test_session() as sess: + with self.cached_session() as sess: q_empty = data_flow_ops.RandomShuffleQueue(5, 0, dtypes_lib.float32, ( (),)) dequeue_op = q_empty.dequeue() @@ -1267,7 +1267,7 @@ class RandomShuffleQueueTest(test.TestCase): t.join() def testDequeueManyInDifferentOrders(self): - with self.test_session(): + with self.cached_session(): # Specify seeds to make the test deterministic # (https://en.wikipedia.org/wiki/Taxicab_number). q1 = data_flow_ops.RandomShuffleQueue( @@ -1301,7 +1301,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertNotEqual(results[i], results[j]) def testDequeueUpToInDifferentOrders(self): - with self.test_session(): + with self.cached_session(): # Specify seeds to make the test deterministic # (https://en.wikipedia.org/wiki/Taxicab_number). q1 = data_flow_ops.RandomShuffleQueue( @@ -1335,7 +1335,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertNotEqual(results[i], results[j]) def testDequeueInDifferentOrders(self): - with self.test_session(): + with self.cached_session(): # Specify seeds to make the test deterministic # (https://en.wikipedia.org/wiki/Taxicab_number). q1 = data_flow_ops.RandomShuffleQueue( @@ -1371,7 +1371,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertNotEqual(results[i], results[j]) def testBigEnqueueMany(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(5, 0, dtypes_lib.int32, ((),)) elem = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] enq = q.enqueue_many((elem,)) @@ -1416,7 +1416,7 @@ class RandomShuffleQueueTest(test.TestCase): self.assertItemsEqual(elem, results) def testBigDequeueMany(self): - with self.test_session() as sess: + with self.cached_session() as sess: q = data_flow_ops.RandomShuffleQueue(2, 0, dtypes_lib.int32, ((),)) elem = np.arange(4, dtype=np.int32) enq_list = [q.enqueue((e,)) for e in elem] diff --git a/tensorflow/python/kernel_tests/regex_replace_op_test.py b/tensorflow/python/kernel_tests/regex_replace_op_test.py index 6739ac3224..f0e84b8fca 100644 --- a/tensorflow/python/kernel_tests/regex_replace_op_test.py +++ b/tensorflow/python/kernel_tests/regex_replace_op_test.py @@ -18,54 +18,104 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from absl.testing import parameterized + +from tensorflow.python.compat import compat from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes +from tensorflow.python.ops import gen_string_ops from tensorflow.python.ops import string_ops from tensorflow.python.platform import test -class RegexReplaceOpTest(test.TestCase): +@parameterized.parameters( + (gen_string_ops.regex_replace), + (gen_string_ops.static_regex_replace)) +class RegexReplaceOpVariantsTest(test.TestCase, parameterized.TestCase): + + def testForwarding(self, op): + with self.test_session(): + # Generate an input that is uniquely consumed by the regex op. + # This exercises code paths which are optimized for this case + # (e.g., using forwarding). + inp = string_ops.substr( + constant_op.constant(["AbCdEfG", + "HiJkLmN"], dtypes.string), + pos=0, + len=5) + stripped = op(inp, "\\p{Ll}", ".").eval() + self.assertAllEqual([b"A.C.E", b"H.J.L"], stripped) - def testRemovePrefix(self): + def testRemovePrefix(self, op): values = ["a:foo", "a:bar", "a:foo", "b:baz", "b:qux", "ca:b"] with self.test_session(): input_vector = constant_op.constant(values, dtypes.string) - stripped = string_ops.regex_replace( - input_vector, "^(a:|b:)", "", replace_global=False).eval() + stripped = op(input_vector, "^(a:|b:)", "", replace_global=False).eval() self.assertAllEqual([b"foo", b"bar", b"foo", b"baz", b"qux", b"ca:b"], stripped) - def testRegexReplace(self): + def testRegexReplace(self, op): values = ["aba\naba", "abcdabcde"] with self.test_session(): input_vector = constant_op.constant(values, dtypes.string) - stripped = string_ops.regex_replace(input_vector, "a.*a", "(\\0)").eval() + stripped = op(input_vector, "a.*a", "(\\0)").eval() self.assertAllEqual([b"(aba)\n(aba)", b"(abcda)bcde"], stripped) - def testEmptyMatch(self): + def testEmptyMatch(self, op): values = ["abc", "1"] with self.test_session(): input_vector = constant_op.constant(values, dtypes.string) - stripped = string_ops.regex_replace(input_vector, "", "x").eval() + stripped = op(input_vector, "", "x").eval() self.assertAllEqual([b"xaxbxcx", b"x1x"], stripped) - def testInvalidPattern(self): + def testInvalidPattern(self, op): values = ["abc", "1"] with self.test_session(): input_vector = constant_op.constant(values, dtypes.string) invalid_pattern = "A[" - replace = string_ops.regex_replace(input_vector, invalid_pattern, "x") + replace = op(input_vector, invalid_pattern, "x") with self.assertRaisesOpError("Invalid pattern"): replace.eval() - def testGlobal(self): + def testGlobal(self, op): values = ["ababababab", "abcabcabc", ""] with self.test_session(): input_vector = constant_op.constant(values, dtypes.string) - stripped = string_ops.regex_replace(input_vector, "ab", "abc", - True).eval() + stripped = op(input_vector, "ab", "abc", True).eval() self.assertAllEqual([b"abcabcabcabcabc", b"abccabccabcc", b""], stripped) +def as_string(s): + return s + + +def as_tensor(s): + return constant_op.constant(s, dtypes.string) + + +class RegexReplaceTest(test.TestCase, parameterized.TestCase): + + @parameterized.parameters( + (as_string, as_tensor), + (as_tensor, as_string), + (as_tensor, as_tensor)) + def testRegexReplaceDelegation(self, pattern_fn, rewrite_fn): + with compat.forward_compatibility_horizon(2018, 10, 11): + with self.test_session(): + input_vector = constant_op.constant("foo", dtypes.string) + pattern = pattern_fn("[a-z]") + replace = rewrite_fn(".") + op = string_ops.regex_replace(input_vector, pattern, replace) + self.assertTrue(op.name.startswith("RegexReplace")) + + def testStaticRegexReplaceDelegation(self): + with compat.forward_compatibility_horizon(2018, 10, 11): + with self.test_session(): + input_vector = constant_op.constant("foo", dtypes.string) + pattern = "[a-z]" + replace = "." + op = string_ops.regex_replace(input_vector, pattern, replace) + self.assertTrue(op.name.startswith("StaticRegexReplace")) + if __name__ == "__main__": test.main() diff --git a/tensorflow/python/kernel_tests/relu_op_test.py b/tensorflow/python/kernel_tests/relu_op_test.py index 25e947f09e..657d92fa23 100644 --- a/tensorflow/python/kernel_tests/relu_op_test.py +++ b/tensorflow/python/kernel_tests/relu_op_test.py @@ -23,6 +23,7 @@ from six.moves import xrange # pylint: disable=redefined-builtin from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes +from tensorflow.python.framework import errors from tensorflow.python.ops import array_ops from tensorflow.python.ops import gradient_checker from tensorflow.python.ops import gradients_impl @@ -71,6 +72,35 @@ class ReluTest(test.TestCase): np.array([[-9, 7, -5, 3, -1], [1, -3, 5, -7, 9]]).astype(t), use_gpu=True) + def _testReluInt8x4(self, np_inputs): + if not test.is_gpu_available(cuda_only=True): + return + np_relu = self._npRelu(np_inputs) + with self.test_session(use_gpu=True): + relu = nn_ops.relu(constant_op.constant(np_inputs, dtypes.qint8)) + if np_inputs.size % 4 == 0: + tf_relu = relu.eval() + self.assertAllClose(np_relu, tf_relu) + self.assertShapeEqual(np_relu, relu) + else: + with self.assertRaisesRegexp( + errors.InvalidArgumentError, + "Tensor size must be a multiple of 4 for Relu<qint8>. Got %d" % + np_inputs.size): + tf_relu = relu.eval() + + def testReluInt8x4GoodShape(self): + self._testReluInt8x4(np.array([[-50, 7, 23, 0], [-1, -5, 6, 11]])) + + def testReluInt8x4BadShape(self): + np_inputs = np.array([[-50, 7, 23], [0, 1, -5], [6, -2, 11]]) + self.assertEqual(np_inputs.size, 9) + self._testReluInt8x4(np_inputs) + np_inputs = np.array( + [1, -2, 3, -4, 5, -6, 7, -8, 9, -8, 7, -6, 5, -4, 3, -2, 1]) + self.assertEqual(np_inputs.size, 17) + self._testReluInt8x4(np_inputs) + # The gradient test for ReLU is a bit tricky as the derivative is not well # defined at around zero and we want to avoid that in terms of input values. def testGradientFloat32(self): diff --git a/tensorflow/python/kernel_tests/resource_variable_ops_test.py b/tensorflow/python/kernel_tests/resource_variable_ops_test.py index b1ef46f2a1..d0ed08933d 100644 --- a/tensorflow/python/kernel_tests/resource_variable_ops_test.py +++ b/tensorflow/python/kernel_tests/resource_variable_ops_test.py @@ -17,7 +17,10 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import copy import gc +import os +import pickle import numpy as np @@ -106,6 +109,34 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): v = resource_variable_ops.ResourceVariable(False, name="bool_test") self.assertAllEqual(bool(v), False) + def testEagerDeepCopy(self): + with context.eager_mode(): + init_value = np.ones((4, 4, 4)) + variable = resource_variable_ops.ResourceVariable(init_value, + name="init") + + copied_variable = copy.deepcopy(variable) + copied_variable.assign(4 * np.ones((4, 4, 4))) + + # Copying the variable should create a new underlying tensor with distinct + # values. + self.assertFalse(np.allclose(variable.numpy(), copied_variable.numpy())) + + def testGraphDeepCopy(self): + with self.test_session(): + init_value = np.ones((4, 4, 4)) + variable = resource_variable_ops.ResourceVariable(init_value, + name="init") + with self.assertRaises(NotImplementedError): + copy.deepcopy(variable) + + @test_util.run_in_graph_and_eager_modes + def testStridedSliceAssign(self): + v = resource_variable_ops.ResourceVariable([1.0, 2.0]) + self.evaluate(variables.global_variables_initializer()) + self.evaluate(v[0].assign(2.0)) + self.assertAllEqual(self.evaluate(v), [2.0, 2.0]) + def testDifferentAssignGraph(self): with ops.Graph().as_default(): v = resource_variable_ops.ResourceVariable(1.0) @@ -233,6 +264,18 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): read = resource_variable_ops.read_variable_op(handle, dtype=dtypes.int32) self.assertEqual(self.evaluate(read), [[5]]) + def testEagerPickle(self): + with context.eager_mode(): + tmp_dir = self.get_temp_dir() + fname = os.path.join(tmp_dir, "var.pickle") + with open(fname, "wb") as f: + v = resource_variable_ops.ResourceVariable(10.0) + pickle.dump(v, f) + + with open(fname, "rb") as f: + v = pickle.load(f) + self.assertAllEqual(v.numpy(), 10.0) + @test_util.run_in_graph_and_eager_modes def testScatterDiv(self): handle = resource_variable_ops.var_handle_op( diff --git a/tensorflow/python/kernel_tests/rnn_test.py b/tensorflow/python/kernel_tests/rnn_test.py index c72ada11da..562d11f0b0 100644 --- a/tensorflow/python/kernel_tests/rnn_test.py +++ b/tensorflow/python/kernel_tests/rnn_test.py @@ -35,6 +35,7 @@ from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops as ops_lib from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import test_util +from tensorflow.python.keras import testing_utils from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import gradients_impl @@ -44,11 +45,13 @@ from tensorflow.python.ops import rnn_cell_impl from tensorflow.python.ops import tensor_array_ops from tensorflow.python.ops import variables as variables_lib import tensorflow.python.ops.data_flow_grad # pylint: disable=unused-import +from tensorflow.python.ops.losses import losses import tensorflow.python.ops.nn_grad # pylint: disable=unused-import import tensorflow.python.ops.sparse_grad # pylint: disable=unused-import import tensorflow.python.ops.tensor_array_grad # pylint: disable=unused-import from tensorflow.python.platform import test from tensorflow.python.training import saver +from tensorflow.python.training import training class Plus1RNNCell(rnn_cell_impl.RNNCell): @@ -226,6 +229,13 @@ class RNNTest(test.TestCase): self.assertAllEqual([[[1, 1], [2, 2], [3, 3], [4, 4]]], outputs[1]) self.assertAllEqual(4, state) + @test_util.assert_no_new_pyobjects_executing_eagerly + def testEagerMemory(self): + with context.eager_mode(): + cell = TensorArrayStateRNNCell() + inputs = np.array([[[1], [2], [3], [4]]], dtype=np.float32) + rnn.dynamic_rnn(cell, inputs, dtype=dtypes.float32, sequence_length=[4]) + @test_util.run_in_graph_and_eager_modes def testTensorArrayStateIsAccepted(self): cell = TensorArrayStateRNNCell() @@ -250,12 +260,44 @@ class RNNTest(test.TestCase): self.assertAllEqual(4, state[0]) self.assertAllEqual([[[1]], [[2]], [[3]], [[4]]], state[1]) + def testCellGetInitialState(self): + cell = rnn_cell_impl.BasicRNNCell(5) + with self.assertRaisesRegexp( + ValueError, "batch_size and dtype cannot be None"): + cell.get_initial_state(None, None, None) + + inputs = array_ops.placeholder(dtypes.float32, shape=(None, 4, 1)) + with self.assertRaisesRegexp( + ValueError, "batch size from input tensor is different from"): + cell.get_initial_state(inputs=inputs, batch_size=50, dtype=None) + + with self.assertRaisesRegexp( + ValueError, "batch size from input tensor is different from"): + cell.get_initial_state( + inputs=inputs, batch_size=constant_op.constant(50), dtype=None) + + with self.assertRaisesRegexp( + ValueError, "dtype from input tensor is different from"): + cell.get_initial_state(inputs=inputs, batch_size=None, dtype=dtypes.int16) + + initial_state = cell.get_initial_state( + inputs=inputs, batch_size=None, dtype=None) + self.assertEqual(initial_state.shape.as_list(), [None, 5]) + self.assertEqual(initial_state.dtype, inputs.dtype) + + batch = array_ops.shape(inputs)[0] + dtype = inputs.dtype + initial_state = cell.get_initial_state(None, batch, dtype) + self.assertEqual(initial_state.shape.as_list(), [None, 5]) + self.assertEqual(initial_state.dtype, inputs.dtype) + def _assert_cell_builds(self, cell_class, dtype, batch_size, in_size, out_size): cell = cell_class(out_size, dtype=dtype) in_shape = tensor_shape.TensorShape((batch_size, in_size)) cell.build(in_shape) - state_output = cell.zero_state(batch_size, dtype) + state_output = cell.get_initial_state( + inputs=None, batch_size=batch_size, dtype=dtype) cell_output, _ = cell(array_ops.zeros(in_shape, dtype), state_output) self.assertAllEqual([batch_size, out_size], cell_output.shape.as_list()) @@ -278,12 +320,228 @@ class RNNTest(test.TestCase): self._assert_cell_builds(contrib_rnn.IndyLSTMCell, f32, 5, 7, 3) self._assert_cell_builds(contrib_rnn.IndyLSTMCell, f64, 5, 7, 3) + def testRNNWithKerasSimpleRNNCell(self): + with self.test_session() as sess: + input_shape = 10 + output_shape = 5 + timestep = 4 + batch = 100 + (x_train, y_train), _ = testing_utils.get_test_data( + train_samples=batch, + test_samples=0, + input_shape=(timestep, input_shape), + num_classes=output_shape) + y_train = keras.utils.to_categorical(y_train) + cell = keras.layers.SimpleRNNCell(output_shape) + + inputs = array_ops.placeholder( + dtypes.float32, shape=(None, timestep, input_shape)) + predict = array_ops.placeholder( + dtypes.float32, shape=(None, output_shape)) + + outputs, state = rnn.dynamic_rnn( + cell, inputs, dtype=dtypes.float32) + self.assertEqual(outputs.shape.as_list(), [None, timestep, output_shape]) + self.assertEqual(state.shape.as_list(), [None, output_shape]) + loss = losses.softmax_cross_entropy(predict, state) + train_op = training.GradientDescentOptimizer(0.001).minimize(loss) + + sess.run([variables_lib.global_variables_initializer()]) + _, outputs, state = sess.run( + [train_op, outputs, state], {inputs: x_train, predict: y_train}) + + self.assertEqual(len(outputs), batch) + self.assertEqual(len(state), batch) + + def testRNNWithKerasGRUCell(self): + with self.test_session() as sess: + input_shape = 10 + output_shape = 5 + timestep = 4 + batch = 100 + (x_train, y_train), _ = testing_utils.get_test_data( + train_samples=batch, + test_samples=0, + input_shape=(timestep, input_shape), + num_classes=output_shape) + y_train = keras.utils.to_categorical(y_train) + cell = keras.layers.GRUCell(output_shape) + + inputs = array_ops.placeholder( + dtypes.float32, shape=(None, timestep, input_shape)) + predict = array_ops.placeholder( + dtypes.float32, shape=(None, output_shape)) + + outputs, state = rnn.dynamic_rnn( + cell, inputs, dtype=dtypes.float32) + self.assertEqual(outputs.shape.as_list(), [None, timestep, output_shape]) + self.assertEqual(state.shape.as_list(), [None, output_shape]) + loss = losses.softmax_cross_entropy(predict, state) + train_op = training.GradientDescentOptimizer(0.001).minimize(loss) + + sess.run([variables_lib.global_variables_initializer()]) + _, outputs, state = sess.run( + [train_op, outputs, state], {inputs: x_train, predict: y_train}) + + self.assertEqual(len(outputs), batch) + self.assertEqual(len(state), batch) + + def testRNNWithKerasLSTMCell(self): + with self.test_session() as sess: + input_shape = 10 + output_shape = 5 + timestep = 4 + batch = 100 + (x_train, y_train), _ = testing_utils.get_test_data( + train_samples=batch, + test_samples=0, + input_shape=(timestep, input_shape), + num_classes=output_shape) + y_train = keras.utils.to_categorical(y_train) + cell = keras.layers.LSTMCell(output_shape) + + inputs = array_ops.placeholder( + dtypes.float32, shape=(None, timestep, input_shape)) + predict = array_ops.placeholder( + dtypes.float32, shape=(None, output_shape)) + + outputs, state = rnn.dynamic_rnn( + cell, inputs, dtype=dtypes.float32) + self.assertEqual(outputs.shape.as_list(), [None, timestep, output_shape]) + self.assertEqual(len(state), 2) + self.assertEqual(state[0].shape.as_list(), [None, output_shape]) + self.assertEqual(state[1].shape.as_list(), [None, output_shape]) + loss = losses.softmax_cross_entropy(predict, state[0]) + train_op = training.GradientDescentOptimizer(0.001).minimize(loss) + + sess.run([variables_lib.global_variables_initializer()]) + _, outputs, state = sess.run( + [train_op, outputs, state], {inputs: x_train, predict: y_train}) + + self.assertEqual(len(outputs), batch) + self.assertEqual(len(state), 2) + self.assertEqual(len(state[0]), batch) + self.assertEqual(len(state[1]), batch) + + def testRNNWithStackKerasCell(self): + with self.test_session() as sess: + input_shape = 10 + output_shape = 5 + timestep = 4 + batch = 100 + (x_train, y_train), _ = testing_utils.get_test_data( + train_samples=batch, + test_samples=0, + input_shape=(timestep, input_shape), + num_classes=output_shape) + y_train = keras.utils.to_categorical(y_train) + cell = keras.layers.StackedRNNCells( + [keras.layers.LSTMCell(2 * output_shape), + keras.layers.LSTMCell(output_shape)]) + + inputs = array_ops.placeholder( + dtypes.float32, shape=(None, timestep, input_shape)) + predict = array_ops.placeholder( + dtypes.float32, shape=(None, output_shape)) + + outputs, state = rnn.dynamic_rnn( + cell, inputs, dtype=dtypes.float32) + self.assertEqual(outputs.shape.as_list(), [None, timestep, output_shape]) + self.assertEqual(len(state), 4) + self.assertEqual(state[0].shape.as_list(), [None, 2 * output_shape]) + self.assertEqual(state[1].shape.as_list(), [None, 2 * output_shape]) + self.assertEqual(state[2].shape.as_list(), [None, output_shape]) + self.assertEqual(state[3].shape.as_list(), [None, output_shape]) + loss = losses.softmax_cross_entropy(predict, state[2]) + train_op = training.GradientDescentOptimizer(0.001).minimize(loss) + + sess.run([variables_lib.global_variables_initializer()]) + _, outputs, state = sess.run( + [train_op, outputs, state], {inputs: x_train, predict: y_train}) + + self.assertEqual(len(outputs), batch) + self.assertEqual(len(state), 4) + for s in state: + self.assertEqual(len(s), batch) + + def testStaticRNNWithKerasSimpleRNNCell(self): + with self.test_session() as sess: + input_shape = 10 + output_shape = 5 + timestep = 4 + batch = 100 + (x_train, y_train), _ = testing_utils.get_test_data( + train_samples=batch, + test_samples=0, + input_shape=(timestep, input_shape), + num_classes=output_shape) + x_train = np.transpose(x_train, (1, 0, 2)) + y_train = keras.utils.to_categorical(y_train) + cell = keras.layers.SimpleRNNCell(output_shape) + + inputs = [array_ops.placeholder( + dtypes.float32, shape=(None, input_shape))] * timestep + predict = array_ops.placeholder( + dtypes.float32, shape=(None, output_shape)) + + outputs, state = rnn.static_rnn( + cell, inputs, dtype=dtypes.float32) + self.assertEqual(len(outputs), timestep) + self.assertEqual(outputs[0].shape.as_list(), [None, output_shape]) + self.assertEqual(state.shape.as_list(), [None, output_shape]) + loss = losses.softmax_cross_entropy(predict, state) + train_op = training.GradientDescentOptimizer(0.001).minimize(loss) + + sess.run([variables_lib.global_variables_initializer()]) + feed_dict = {i: d for i, d in zip(inputs, x_train)} + feed_dict[predict] = y_train + _, outputs, state = sess.run( + [train_op, outputs, state], feed_dict) + + self.assertEqual(len(outputs), timestep) + self.assertEqual(len(outputs[0]), batch) + self.assertEqual(len(state), batch) + + def testKerasAndTFRNNLayerOutputComparison(self): + input_shape = 10 + output_shape = 5 + timestep = 4 + batch = 20 + (x_train, _), _ = testing_utils.get_test_data( + train_samples=batch, + test_samples=0, + input_shape=(timestep, input_shape), + num_classes=output_shape) + fix_weights_generator = keras.layers.SimpleRNNCell(output_shape) + fix_weights_generator.build((None, input_shape)) + weights = fix_weights_generator.get_weights() + + with self.test_session(graph=ops_lib.Graph()) as sess: + inputs = array_ops.placeholder( + dtypes.float32, shape=(None, timestep, input_shape)) + cell = keras.layers.SimpleRNNCell(output_shape) + tf_out, tf_state = rnn.dynamic_rnn( + cell, inputs, dtype=dtypes.float32) + cell.set_weights(weights) + [tf_out, tf_state] = sess.run([tf_out, tf_state], {inputs: x_train}) + with self.test_session(graph=ops_lib.Graph()) as sess: + k_input = keras.Input(shape=(timestep, input_shape), + dtype=dtypes.float32) + cell = keras.layers.SimpleRNNCell(output_shape) + layer = keras.layers.RNN(cell, return_sequences=True, return_state=True) + keras_out = layer(k_input) + cell.set_weights(weights) + k_out, k_state = sess.run(keras_out, {k_input: x_train}) + self.assertAllClose(tf_out, k_out) + self.assertAllClose(tf_state, k_state) + def testBasicLSTMCellInterchangeWithLSTMCell(self): with self.test_session(graph=ops_lib.Graph()) as sess: basic_cell = rnn_cell_impl.BasicLSTMCell(1) basic_cell(array_ops.ones([1, 1]), - state=basic_cell.zero_state(batch_size=1, - dtype=dtypes.float32)) + state=basic_cell.get_initial_state(inputs=None, + batch_size=1, + dtype=dtypes.float32)) self.evaluate([v.initializer for v in basic_cell.variables]) self.evaluate(basic_cell._bias.assign([10.] * 4)) save = saver.Saver() @@ -293,8 +551,9 @@ class RNNTest(test.TestCase): with self.test_session(graph=ops_lib.Graph()) as sess: lstm_cell = rnn_cell_impl.LSTMCell(1, name="basic_lstm_cell") lstm_cell(array_ops.ones([1, 1]), - state=lstm_cell.zero_state(batch_size=1, - dtype=dtypes.float32)) + state=lstm_cell.get_initial_state(inputs=None, + batch_size=1, + dtype=dtypes.float32)) self.evaluate([v.initializer for v in lstm_cell.variables]) save = saver.Saver() save.restore(sess, save_path) diff --git a/tensorflow/python/kernel_tests/softplus_op_test.py b/tensorflow/python/kernel_tests/softplus_op_test.py index b8e7c50a37..c0269db9ae 100644 --- a/tensorflow/python/kernel_tests/softplus_op_test.py +++ b/tensorflow/python/kernel_tests/softplus_op_test.py @@ -21,6 +21,7 @@ from __future__ import print_function import numpy as np from tensorflow.python.framework import constant_op +from tensorflow.python.framework import errors from tensorflow.python.ops import gradient_checker from tensorflow.python.ops import gradients_impl from tensorflow.python.ops import nn_ops @@ -121,9 +122,12 @@ class SoftplusTest(test.TestCase): print("softplus (float) third-order gradient err = ", err) self.assertLess(err, 5e-5) - def testWarnInts(self): - # Running the op triggers address sanitizer errors, so we just make it - nn_ops.softplus(constant_op.constant(7)) + def testNoInts(self): + with self.test_session(): + with self.assertRaisesRegexp( + errors.InvalidArgumentError, + "No OpKernel was registered to support Op 'Softplus'"): + nn_ops.softplus(constant_op.constant(7)).eval() if __name__ == "__main__": diff --git a/tensorflow/python/kernel_tests/softsign_op_test.py b/tensorflow/python/kernel_tests/softsign_op_test.py index 371f86ff15..a5247ce08d 100644 --- a/tensorflow/python/kernel_tests/softsign_op_test.py +++ b/tensorflow/python/kernel_tests/softsign_op_test.py @@ -21,6 +21,7 @@ from __future__ import print_function import numpy as np from tensorflow.python.framework import constant_op +from tensorflow.python.framework import errors from tensorflow.python.ops import gradient_checker from tensorflow.python.ops import nn_ops import tensorflow.python.ops.nn_grad # pylint: disable=unused-import @@ -65,11 +66,12 @@ class SoftsignTest(test.TestCase): print("softsign (float) gradient err = ", err) self.assertLess(err, 1e-4) - def testWarnInts(self): - # NOTE(irving): Actually I don't know how to intercept the warning, but - # let's make sure it runs. I promised I've looked, and there was a warning. + def testNoInts(self): with self.test_session(): - nn_ops.softsign(constant_op.constant(7)).eval() + with self.assertRaisesRegexp( + errors.InvalidArgumentError, + "No OpKernel was registered to support Op 'Softsign'"): + nn_ops.softsign(constant_op.constant(7)).eval() if __name__ == "__main__": diff --git a/tensorflow/python/kernel_tests/stack_op_test.py b/tensorflow/python/kernel_tests/stack_op_test.py index 2f27d1839b..2a33c594a4 100644 --- a/tensorflow/python/kernel_tests/stack_op_test.py +++ b/tensorflow/python/kernel_tests/stack_op_test.py @@ -277,6 +277,18 @@ class AutomaticStackingTest(test.TestCase): [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], dtype=dtypes.float64) self.assertEqual(dtypes.float64, t_2.dtype) + t_3 = ops.convert_to_tensor( + [[0., 0., 0.], + constant_op.constant([0., 0., 0.], dtype=dtypes.float64), [0., 0., 0.] + ], + dtype=dtypes.float32) + self.assertEqual(dtypes.float32, t_3.dtype) + + t_4 = ops.convert_to_tensor( + [constant_op.constant([0., 0., 0.], dtype=dtypes.float64)], + dtype=dtypes.float32) + self.assertEqual(dtypes.float32, t_4.dtype) + with self.assertRaises(TypeError): ops.convert_to_tensor([ constant_op.constant( @@ -284,17 +296,15 @@ class AutomaticStackingTest(test.TestCase): [0., 0., 0.], dtype=dtypes.float64), [0., 0., 0.] ]) - with self.assertRaises(TypeError): - ops.convert_to_tensor( - [[0., 0., 0.], constant_op.constant( - [0., 0., 0.], dtype=dtypes.float64), [0., 0., 0.]], - dtype=dtypes.float32) + def testDtypeConversionWhenTensorDtypeMismatch(self): + t_0 = ops.convert_to_tensor([0., 0., 0.]) + self.assertEqual(dtypes.float32, t_0.dtype) - with self.assertRaises(TypeError): - ops.convert_to_tensor( - [constant_op.constant( - [0., 0., 0.], dtype=dtypes.float64)], - dtype=dtypes.float32) + t_1 = ops.convert_to_tensor([0, 0, 0]) + self.assertEqual(dtypes.int32, t_1.dtype) + + t_2 = ops.convert_to_tensor([t_0, t_0, t_1], dtype=dtypes.float64) + self.assertEqual(dtypes.float64, t_2.dtype) def testPlaceholder(self): with self.test_session(use_gpu=True): diff --git a/tensorflow/python/kernel_tests/string_split_op_test.py b/tensorflow/python/kernel_tests/string_split_op_test.py index e20daccb28..b6a0f45adc 100644 --- a/tensorflow/python/kernel_tests/string_split_op_test.py +++ b/tensorflow/python/kernel_tests/string_split_op_test.py @@ -58,14 +58,28 @@ class StringSplitOpTest(test.TestCase): self.assertAllEqual(shape, [3, 5]) def testStringSplitEmptyToken(self): - strings = [" hello ", "", "world "] + strings = ["", " a", "b ", " c", " ", " d ", " e", "f ", " g ", " "] with self.test_session() as sess: tokens = string_ops.string_split(strings) indices, values, shape = sess.run(tokens) - self.assertAllEqual(indices, [[0, 0], [2, 0]]) - self.assertAllEqual(values, [b"hello", b"world"]) - self.assertAllEqual(shape, [3, 1]) + self.assertAllEqual( + indices, + [[1, 0], [2, 0], [3, 0], [5, 0], [6, 0], [7, 0], [8, 0]]) + self.assertAllEqual(values, [b"a", b"b", b"c", b"d", b"e", b"f", b"g"]) + self.assertAllEqual(shape, [10, 1]) + + def testStringSplitOnSetEmptyToken(self): + strings = ["", " a", "b ", " c", " ", " d ", ". e", "f .", " .g. ", " ."] + + with self.test_session() as sess: + tokens = string_ops.string_split(strings, delimiter=" .") + indices, values, shape = sess.run(tokens) + self.assertAllEqual( + indices, + [[1, 0], [2, 0], [3, 0], [5, 0], [6, 0], [7, 0], [8, 0]]) + self.assertAllEqual(values, [b"a", b"b", b"c", b"d", b"e", b"f", b"g"]) + self.assertAllEqual(shape, [10, 1]) def testStringSplitWithDelimiter(self): strings = ["hello|world", "hello world"] diff --git a/tensorflow/python/kernel_tests/template_test.py b/tensorflow/python/kernel_tests/template_test.py index 0b3a396d6b..9dcdaa61ed 100644 --- a/tensorflow/python/kernel_tests/template_test.py +++ b/tensorflow/python/kernel_tests/template_test.py @@ -25,6 +25,7 @@ from tensorflow.python.eager import context from tensorflow.python.framework import ops from tensorflow.python.framework import random_seed from tensorflow.python.framework import test_util +from tensorflow.python.keras.engine import training from tensorflow.python.ops import array_ops from tensorflow.python.ops import init_ops from tensorflow.python.ops import math_ops @@ -359,6 +360,23 @@ class TemplateTest(test.TestCase): self.assertEqual(2, len(tmpl1._checkpoint_dependencies)) self.assertEqual("nested", tmpl1._checkpoint_dependencies[0].name) self.assertEqual("nested_1", tmpl1._checkpoint_dependencies[1].name) + model = training.Model() + model.template = tmpl1 + self.assertEqual(model.variables, [v1, v2]) + self.assertEqual(model.trainable_variables, [v1, v2]) + self.assertEqual(len(model.non_trainable_variables), 0) + model.templates = [tmpl2] + self.assertEqual(model.variables, [v1, v2, v5, v6]) + self.assertEqual(model.trainable_variables, [v1, v2, v5, v6]) + self.assertEqual(len(model.non_trainable_variables), 0) + # Make sure losses, layers, and updates aren't broken by having a Template + # in the mix, which does not expose any updates or losses. + self.assertEqual([], model.layers) + self.assertEqual([], model.updates) + self.assertEqual([], model.losses) + self.assertEqual([], model.templates.layers) + self.assertEqual([], model.templates.updates) + self.assertEqual([], model.templates.losses) @test_util.run_in_graph_and_eager_modes def test_nested_templates_with_defun(self): diff --git a/tensorflow/python/kernel_tests/topk_op_test.py b/tensorflow/python/kernel_tests/topk_op_test.py index fa7c6a0f8a..d5f0726106 100644 --- a/tensorflow/python/kernel_tests/topk_op_test.py +++ b/tensorflow/python/kernel_tests/topk_op_test.py @@ -76,7 +76,7 @@ class TopKTest(test.TestCase): for result_index, src_index in np.ndenumerate(indices): value = values[result_index] expected_value = np_inputs[result_index[0], src_index] - np.testing.utils.assert_almost_equal(value, expected_value) + np.testing.assert_almost_equal(value, expected_value) # Check that if two elements are equal, the lower-index element appears # first. diff --git a/tensorflow/python/kernel_tests/variable_scope_test.py b/tensorflow/python/kernel_tests/variable_scope_test.py index ae2a0ab29a..b736b12416 100644 --- a/tensorflow/python/kernel_tests/variable_scope_test.py +++ b/tensorflow/python/kernel_tests/variable_scope_test.py @@ -335,7 +335,7 @@ class VariableScopeTest(test.TestCase): # reuse=True is for now only supported when eager execution is disabled. if not context.executing_eagerly(): v = variable_scope.get_variable("v", - []) # "v" is alredy there, reused + []) # "v" is already there, reused losses = ops.get_collection(ops.GraphKeys.REGULARIZATION_LOSSES) self.assertEqual(3, len(losses)) # No new loss added. @@ -389,6 +389,18 @@ class VariableScopeTest(test.TestCase): sess.run(v0.initializer) sess.run(add) + def testEnableResourceVariables(self): + old = variable_scope._DEFAULT_USE_RESOURCE + try: + variable_scope.enable_resource_variables() + self.assertTrue(isinstance(variables_lib.Variable(1.0), + resource_variable_ops.ResourceVariable)) + variable_scope.disable_resource_variables() + self.assertFalse(isinstance(variables_lib.Variable(1.0), + resource_variable_ops.ResourceVariable)) + finally: + variable_scope._DEFAULT_USE_RESOURCE = old + def testControlFlow(self): with self.test_session() as sess: v0 = variable_scope.get_variable( diff --git a/tensorflow/python/layers/base.py b/tensorflow/python/layers/base.py index ab08865532..3ba880d7a1 100644 --- a/tensorflow/python/layers/base.py +++ b/tensorflow/python/layers/base.py @@ -262,11 +262,13 @@ class Layer(base_layer.Layer): use_resource = (use_resource or self._use_resource_variables or scope.use_resource) + if initializer is None: + initializer = scope.initializer variable = super(Layer, self).add_weight( name, shape, dtype=dtypes.as_dtype(dtype), - initializer=initializer or scope.initializer, + initializer=initializer, trainable=trainable, constraint=constraint, partitioner=partitioner, diff --git a/tensorflow/python/layers/convolutional_test.py b/tensorflow/python/layers/convolutional_test.py index 625320b48b..d61d3b6dba 100644 --- a/tensorflow/python/layers/convolutional_test.py +++ b/tensorflow/python/layers/convolutional_test.py @@ -264,7 +264,7 @@ class ConvTest(test.TestCase): self.assertEqual(len(variables.trainable_variables()), 2) def testFunctionalConv2DInitializerFromScope(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( 'scope', initializer=init_ops.ones_initializer()): height, width = 7, 9 @@ -647,7 +647,7 @@ class SeparableConv2DTest(test.TestCase): self.assertEqual(len(variables.trainable_variables()), 3) def testFunctionalConv2DInitializerFromScope(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( 'scope', initializer=init_ops.ones_initializer()): height, width = 7, 9 @@ -882,7 +882,7 @@ class Conv2DTransposeTest(test.TestCase): self.assertEqual(len(variables.trainable_variables()), 2) def testFunctionalConv2DTransposeInitializerFromScope(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( 'scope', initializer=init_ops.ones_initializer()): height, width = 7, 9 @@ -1061,7 +1061,7 @@ class Conv3DTransposeTest(test.TestCase): self.assertEqual(len(variables.trainable_variables()), 2) def testFunctionalConv3DTransposeInitializerFromScope(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( 'scope', initializer=init_ops.ones_initializer()): depth, height, width = 5, 7, 9 diff --git a/tensorflow/python/layers/core_test.py b/tensorflow/python/layers/core_test.py index 040c1cddc0..46009a30ac 100644 --- a/tensorflow/python/layers/core_test.py +++ b/tensorflow/python/layers/core_test.py @@ -60,7 +60,7 @@ class DenseTest(test.TestCase): self.assertEqual(dense.name, 'dense_2') def testVariableInput(self): - with self.test_session(): + with self.cached_session(): v = variable_scope.get_variable( 'X', initializer=init_ops.zeros_initializer(), shape=(1, 1)) x = core_layers.Dense(1)(v) @@ -221,7 +221,7 @@ class DenseTest(test.TestCase): self.assertListEqual(dense.losses, loss_keys) def testFunctionalDense(self): - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((5, 3), seed=1) outputs = core_layers.dense( inputs, 2, activation=nn_ops.relu, name='my_dense') @@ -240,7 +240,7 @@ class DenseTest(test.TestCase): # TODO(alive): get this to work in eager mode. def testFunctionalDenseTwiceReuse(self): - with self.test_session(): + with self.cached_session(): inputs = random_ops.random_uniform((5, 3), seed=1) core_layers.dense(inputs, 2, name='my_dense') vars1 = variables.trainable_variables() @@ -250,7 +250,7 @@ class DenseTest(test.TestCase): # TODO(alive): get this to work in eager mode. def testFunctionalDenseTwiceReuseFromScope(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('scope'): inputs = random_ops.random_uniform((5, 3), seed=1) core_layers.dense(inputs, 2, name='my_dense') @@ -262,7 +262,8 @@ class DenseTest(test.TestCase): def testFunctionalDenseInitializerFromScope(self): with variable_scope.variable_scope( - 'scope', initializer=init_ops.ones_initializer()), self.test_session(): + 'scope', + initializer=init_ops.ones_initializer()), self.cached_session(): inputs = random_ops.random_uniform((5, 3), seed=1) core_layers.dense(inputs, 2) variables.global_variables_initializer().run() @@ -305,7 +306,7 @@ class DenseTest(test.TestCase): self.assertEqual(called[0], 2) def testFunctionalDenseInScope(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope('test'): inputs = random_ops.random_uniform((5, 3), seed=1) core_layers.dense(inputs, 2, name='my_dense') @@ -391,7 +392,7 @@ class DropoutTest(test.TestCase): self.assertAllClose(np.ones((5, 3)), np_output) def testDynamicLearningPhase(self): - with self.test_session() as sess: + with self.cached_session() as sess: dp = core_layers.Dropout(0.5, seed=1) inputs = array_ops.ones((5, 5)) training = array_ops.placeholder(dtype='bool') @@ -424,7 +425,7 @@ class DropoutTest(test.TestCase): self.assertAllClose(np_output[:, 0, :], np_output[:, 1, :]) def testFunctionalDropout(self): - with self.test_session(): + with self.cached_session(): inputs = array_ops.ones((5, 5)) dropped = core_layers.dropout(inputs, 0.5, training=True, seed=1) variables.global_variables_initializer().run() @@ -435,7 +436,7 @@ class DropoutTest(test.TestCase): self.assertAllClose(np.ones((5, 5)), np_output) def testDynamicRate(self): - with self.test_session() as sess: + with self.cached_session() as sess: rate = array_ops.placeholder(dtype='float32', name='rate') dp = core_layers.Dropout(rate, name='dropout') inputs = array_ops.ones((5, 5)) @@ -450,7 +451,7 @@ class DropoutTest(test.TestCase): class FlattenTest(test.TestCase): def testCreateFlatten(self): - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(shape=(None, 2, 3), dtype='float32') y = core_layers.Flatten()(x) np_output = sess.run(y, feed_dict={x: np.zeros((3, 2, 3))}) @@ -484,7 +485,7 @@ class FlattenTest(test.TestCase): core_layers.Flatten()(x) def testFlattenUnknownAxes(self): - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(shape=(5, None, None), dtype='float32') y = core_layers.Flatten()(x) np_output = sess.run(y, feed_dict={x: np.zeros((5, 2, 3))}) diff --git a/tensorflow/python/layers/normalization_test.py b/tensorflow/python/layers/normalization_test.py index e147f348b0..a72d147a0b 100644 --- a/tensorflow/python/layers/normalization_test.py +++ b/tensorflow/python/layers/normalization_test.py @@ -72,7 +72,7 @@ class BNTest(test.TestCase): dtype=dtypes.float32): ops.reset_default_graph() graph = ops.get_default_graph() - with self.test_session(graph=graph, use_gpu=use_gpu) as sess: + with self.session(graph=graph, use_gpu=use_gpu) as sess: image = array_ops.placeholder(dtype=dtype, shape=shape) loss, train_op, saver = self._simple_model(image, is_fused, freeze_mode) if restore: @@ -94,7 +94,7 @@ class BNTest(test.TestCase): dtype = image_val.dtype ops.reset_default_graph() graph = ops.get_default_graph() - with self.test_session(graph=graph, use_gpu=use_gpu) as sess: + with self.session(graph=graph, use_gpu=use_gpu) as sess: image = array_ops.placeholder(dtype=dtype, shape=shape) loss, _, saver = self._simple_model(image, is_fused, True) saver.restore(sess, checkpoint_path) @@ -319,7 +319,7 @@ class BNTest(test.TestCase): training = array_ops.placeholder(dtype='bool') outputs = bn.apply(inputs, training=training) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) @@ -361,7 +361,7 @@ class BNTest(test.TestCase): training = array_ops.placeholder(dtype='bool') outputs = bn.apply(inputs, training=training) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) np_gamma, np_beta = sess.run([bn.gamma, bn.beta]) @@ -442,7 +442,7 @@ class BNTest(test.TestCase): training = array_ops.placeholder(dtype='bool') outputs = bn.apply(inputs, training=training) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) np_gamma, np_beta = sess.run([bn.gamma, bn.beta]) @@ -482,7 +482,7 @@ class BNTest(test.TestCase): training = array_ops.placeholder(dtype='bool') outputs = bn.apply(inputs, training=training) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) np_gamma, np_beta = sess.run([bn.gamma, bn.beta]) @@ -522,7 +522,7 @@ class BNTest(test.TestCase): training = array_ops.placeholder(dtype='bool') outputs = bn.apply(inputs, training=training) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) np_gamma, np_beta = sess.run([bn.gamma, bn.beta]) @@ -563,7 +563,7 @@ class BNTest(test.TestCase): training = array_ops.placeholder(dtype='bool') outputs = bn.apply(inputs, training=training) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) np_gamma, np_beta = sess.run([bn.gamma, bn.beta]) @@ -603,7 +603,7 @@ class BNTest(test.TestCase): training = array_ops.placeholder(dtype='bool') outputs = bn.apply(inputs, training=training) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) np_gamma, np_beta = sess.run([bn.gamma, bn.beta]) @@ -644,7 +644,7 @@ class BNTest(test.TestCase): outputs_training = bn.apply(inputs, training=True) outputs_infer = bn.apply(inputs, training=False) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) np_gamma, np_beta = sess.run([bn.gamma, bn.beta]) @@ -694,7 +694,7 @@ class BNTest(test.TestCase): beta = all_vars['bn/beta:0'] gamma = all_vars['bn/gamma:0'] - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) np_gamma, np_beta = sess.run([gamma, beta]) @@ -756,7 +756,7 @@ class BNTest(test.TestCase): beta = all_vars['bn/beta:0'] gamma = all_vars['bn/gamma:0'] - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) for _ in range(100): @@ -1254,7 +1254,7 @@ class BNTest(test.TestCase): training = array_ops.placeholder(dtype='bool') outputs = bn.apply(inputs, training=training) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) @@ -1294,7 +1294,7 @@ class BNTest(test.TestCase): training = array_ops.placeholder(dtype='bool') outputs = bn.apply(inputs, training=training) - with self.test_session() as sess: + with self.cached_session() as sess: # Test training with placeholder learning phase. sess.run(variables.global_variables_initializer()) diff --git a/tensorflow/python/lib/core/py_func.cc b/tensorflow/python/lib/core/py_func.cc index fc02d6de0e..6189503d8f 100644 --- a/tensorflow/python/lib/core/py_func.cc +++ b/tensorflow/python/lib/core/py_func.cc @@ -398,7 +398,7 @@ Status ConvertNdarrayToTensor(PyObject* obj, Tensor* ret) { TF_RETURN_IF_ERROR(NumericNpDTypeToTfDType(PyArray_TYPE(input), &dtype)); CHECK(DataTypeCanUseMemcpy(dtype)); if (reinterpret_cast<intptr_t>(PyArray_DATA(input)) % - EIGEN_MAX_ALIGN_BYTES != + std::max(1, EIGEN_MAX_ALIGN_BYTES) != 0) { Tensor t(dtype, shape); StringPiece p = t.tensor_data(); diff --git a/tensorflow/python/lib/core/py_util.h b/tensorflow/python/lib/core/py_util.h index 44dfe7ba21..a9f39d3946 100644 --- a/tensorflow/python/lib/core/py_util.h +++ b/tensorflow/python/lib/core/py_util.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_PYTHON_LIB_CORE_UTIL_H_ -#define TENSORFLOW_PYTHON_LIB_CORE_UTIL_H_ +#ifndef TENSORFLOW_PYTHON_LIB_CORE_PY_UTIL_H_ +#define TENSORFLOW_PYTHON_LIB_CORE_PY_UTIL_H_ #include "tensorflow/core/platform/types.h" @@ -24,4 +24,4 @@ namespace tensorflow { string PyExceptionFetch(); } // end namespace tensorflow -#endif // TENSORFLOW_PYTHON_LIB_CORE_UTIL_H_ +#endif // TENSORFLOW_PYTHON_LIB_CORE_PY_UTIL_H_ diff --git a/tensorflow/python/lib/io/file_io.i b/tensorflow/python/lib/io/file_io.i index 891a7b0fd0..0aa08ea3d1 100644 --- a/tensorflow/python/lib/io/file_io.i +++ b/tensorflow/python/lib/io/file_io.i @@ -42,7 +42,7 @@ inline void FileExists(const string& filename, TF_Status* out_status) { inline void FileExists(const tensorflow::StringPiece& filename, TF_Status* out_status) { tensorflow::Status status = - tensorflow::Env::Default()->FileExists(filename.ToString()); + tensorflow::Env::Default()->FileExists(string(filename)); if (!status.ok()) { Set_TF_Status_from_Status(out_status, status); } diff --git a/tensorflow/python/ops/array_grad.py b/tensorflow/python/ops/array_grad.py index a2b5f77f91..6ae869b89e 100644 --- a/tensorflow/python/ops/array_grad.py +++ b/tensorflow/python/ops/array_grad.py @@ -18,8 +18,6 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function -from math import ceil - from tensorflow.python import pywrap_tensorflow from tensorflow.python.eager import context from tensorflow.python.framework import constant_op @@ -734,7 +732,6 @@ def _QuantizeAndDequantizeV3Grad(_, grad): @ops.RegisterGradient("ExtractImagePatches") def _ExtractImagePatchesGrad(op, grad): - batch_size, rows_in, cols_in, channels = [ dim.value for dim in op.inputs[0].get_shape() ] @@ -742,28 +739,45 @@ def _ExtractImagePatchesGrad(op, grad): batch_size = input_bhwc[0] channels = input_bhwc[3] + # Create indices matrix for input tensor. + # Note that 0 is preserved for padding location, + # so indices for input start from 1 to 1 + rows_in * cols_in. + input_indices_num = 1 + rows_in * cols_in + input_idx = array_ops.reshape(math_ops.range(1, input_indices_num, + dtype=ops.dtypes.int64), + (1, rows_in, cols_in, 1)) + input_idx_patched = gen_array_ops.extract_image_patches( + input_idx, + op.get_attr("ksizes"), + op.get_attr("strides"), + op.get_attr("rates"), + op.get_attr("padding")) + + # Create indices matrix for output tensor. _, rows_out, cols_out, _ = [dim.value for dim in op.outputs[0].get_shape()] _, ksize_r, ksize_c, _ = op.get_attr("ksizes") - _, stride_r, stride_h, _ = op.get_attr("strides") - _, rate_r, rate_c, _ = op.get_attr("rates") - padding = op.get_attr("padding") - - ksize_r_eff = ksize_r + (ksize_r - 1) * (rate_r - 1) - ksize_c_eff = ksize_c + (ksize_c - 1) * (rate_c - 1) - - if padding == b"SAME": - rows_out = int(ceil(rows_in / stride_r)) - cols_out = int(ceil(cols_in / stride_h)) - pad_rows = ((rows_out - 1) * stride_r + ksize_r_eff - rows_in) // 2 - pad_cols = ((cols_out - 1) * stride_h + ksize_c_eff - cols_in) // 2 - - elif padding == b"VALID": - rows_out = int(ceil((rows_in - ksize_r_eff + 1) / stride_r)) - cols_out = int(ceil((cols_in - ksize_c_eff + 1) / stride_h)) - pad_rows = (rows_out - 1) * stride_r + ksize_r_eff - rows_in - pad_cols = (cols_out - 1) * stride_h + ksize_c_eff - cols_in - - pad_rows, pad_cols = max(0, pad_rows), max(0, pad_cols) + # Indices for output start from 0. + output_indices_num = rows_out * cols_out * ksize_r * ksize_c + output_idx = array_ops.reshape(math_ops.range(output_indices_num, + dtype=ops.dtypes.int64), + (1, rows_out, cols_out, ksize_r * ksize_c)) + + # Construct mapping table for indices: (input -> output). + idx_matrix = array_ops.concat( + [array_ops.expand_dims(input_idx_patched, axis=-1), + array_ops.expand_dims(output_idx, axis=-1)], + axis=-1) + idx_map = array_ops.reshape(idx_matrix, (-1, 2)) + + sp_shape = (input_indices_num, output_indices_num) + sp_mat_full = sparse_tensor.SparseTensor( + idx_map, + array_ops.ones([output_indices_num], dtype=grad.dtype), + sp_shape) + # Remove all padding locations [0, :]. + sp_mat = sparse_ops.sparse_slice(sp_mat_full, + (1, 0), + (input_indices_num - 1, output_indices_num)) grad_expanded = array_ops.transpose( array_ops.reshape( @@ -771,27 +785,6 @@ def _ExtractImagePatchesGrad(op, grad): (1, 2, 3, 4, 0, 5)) grad_flat = array_ops.reshape(grad_expanded, (-1, batch_size * channels)) - row_steps = range(0, rows_out * stride_r, stride_r) - col_steps = range(0, cols_out * stride_h, stride_h) - - idx = [] - for i in range(rows_out): - for j in range(cols_out): - r_low, c_low = row_steps[i] - pad_rows, col_steps[j] - pad_cols - r_high, c_high = r_low + ksize_r_eff, c_low + ksize_c_eff - - idx.extend([(r * (cols_in) + c, i * (cols_out * ksize_r * ksize_c) + j * - (ksize_r * ksize_c) + ri * (ksize_c) + ci) - for (ri, r) in enumerate(range(r_low, r_high, rate_r)) - for (ci, c) in enumerate(range(c_low, c_high, rate_c)) - if 0 <= r and r < rows_in and 0 <= c and c < cols_in]) - - sp_shape = (rows_in * cols_in, rows_out * cols_out * ksize_r * ksize_c) - - sp_mat = sparse_tensor.SparseTensor( - array_ops.constant(idx, dtype=ops.dtypes.int64), - array_ops.ones((len(idx),), dtype=grad.dtype), sp_shape) - jac = sparse_ops.sparse_tensor_dense_matmul(sp_mat, grad_flat) grad_out = array_ops.reshape(jac, (rows_in, cols_in, batch_size, channels)) diff --git a/tensorflow/python/ops/array_ops.py b/tensorflow/python/ops/array_ops.py index 1e23fff4e3..7bf3869ddf 100644 --- a/tensorflow/python/ops/array_ops.py +++ b/tensorflow/python/ops/array_ops.py @@ -43,6 +43,7 @@ from tensorflow.python.ops import gen_math_ops from tensorflow.python.ops.gen_array_ops import * from tensorflow.python.ops.gen_array_ops import reverse_v2 as reverse # pylint: disable=unused-import from tensorflow.python.util import deprecation +from tensorflow.python.util import nest from tensorflow.python.util.tf_export import tf_export # pylint: enable=wildcard-import @@ -691,30 +692,31 @@ def strided_slice(input_, parent_name = name - def assign(val, name=None): - """Closure that holds all the arguments to create an assignment.""" + if not (var is None and isinstance(op, ops.EagerTensor)): + # TODO(b/113297051): Assigning a function to an EagerTensor seems to leak + # memory. Slicing variables still leaks, although ".assign" is removed for + # EagerTensors which are not variable slices to mitigate the issue. + def assign(val, name=None): + """Closure that holds all the arguments to create an assignment.""" + + if var is None: + raise ValueError("Sliced assignment is only supported for variables") + + if name is None: + name = parent_name + "_assign" + + return var._strided_slice_assign( + begin=begin, + end=end, + strides=strides, + value=val, + name=name, + begin_mask=begin_mask, + end_mask=end_mask, + ellipsis_mask=ellipsis_mask, + new_axis_mask=new_axis_mask, + shrink_axis_mask=shrink_axis_mask) - if var is None: - raise ValueError("Sliced assignment is only supported for variables") - - if name is None: - name = parent_name + "_assign" - - return var._strided_slice_assign( - begin=begin, - end=end, - strides=strides, - value=val, - name=name, - begin_mask=begin_mask, - end_mask=end_mask, - ellipsis_mask=ellipsis_mask, - new_axis_mask=new_axis_mask, - shrink_axis_mask=shrink_axis_mask) - - if not context.executing_eagerly(): - # TODO(apassos) In eager mode assignment will be done by overriding - # __setitem__ instead. op.assign = assign return op @@ -947,6 +949,15 @@ def _get_dtype_from_nested_lists(list_or_tuple): return None +def _cast_nested_seqs_to_dtype(dtype): + def _maybe_cast(elem): + if ops.is_dense_tensor_like(elem): + if dtype != elem.dtype.base_dtype: + elem = gen_math_ops.cast(elem, dtype) + return elem + return _maybe_cast + + def _autopacking_conversion_function(v, dtype=None, name=None, as_ref=False): """Tensor conversion function that automatically packs arguments.""" if as_ref: @@ -956,9 +967,11 @@ def _autopacking_conversion_function(v, dtype=None, name=None, as_ref=False): # We did not find any tensor-like objects in the nested lists, so defer to # other conversion functions. return NotImplemented - if dtype is not None and dtype != inferred_dtype: - return NotImplemented - return _autopacking_helper(v, inferred_dtype, name or "packed") + if dtype is None: + dtype = inferred_dtype + elif dtype != inferred_dtype: + v = nest.map_structure(_cast_nested_seqs_to_dtype(dtype), v) + return _autopacking_helper(v, dtype, name or "packed") # pylint: enable=invalid-name @@ -1714,7 +1727,7 @@ def placeholder(dtype, shape=None, name=None): @compatibility(eager) Placeholders are not compatible with eager execution. @end_compatibility - + Args: dtype: The type of elements in the tensor to be fed. shape: The shape of the tensor to be fed (optional). If the shape is not diff --git a/tensorflow/python/ops/check_ops.py b/tensorflow/python/ops/check_ops.py index c5a0f2949e..6528062f3c 100644 --- a/tensorflow/python/ops/check_ops.py +++ b/tensorflow/python/ops/check_ops.py @@ -30,6 +30,7 @@ from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors from tensorflow.python.framework import ops from tensorflow.python.framework import sparse_tensor +from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import tensor_util from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops @@ -1243,3 +1244,51 @@ def assert_scalar(tensor, name=None): raise ValueError('Expected scalar shape for %s, saw shape: %s.' % (tensor.name, shape)) return tensor + + +@tf_export('ensure_shape') +def ensure_shape(x, shape, name=None): + """Updates the shape of a tensor and checks at runtime that the shape holds. + + For example: + ```python + x = tf.placeholder(tf.int32) + print(x.shape) + ==> TensorShape(None) + y = x * 2 + print(y.shape) + ==> TensorShape(None) + + y = tf.ensure_shape(y, (None, 3, 3)) + print(y.shape) + ==> TensorShape([Dimension(None), Dimension(3), Dimension(3)]) + + with tf.Session() as sess: + # Raises tf.errors.InvalidArgumentError, because the shape (3,) is not + # compatible with the shape (None, 3, 3) + sess.run(y, feed_dict={x: [1, 2, 3]}) + + ``` + + NOTE: This differs from `Tensor.set_shape` in that it sets the static shape + of the resulting tensor and enforces it at runtime, raising an error if the + tensor's runtime shape is incompatible with the specified shape. + `Tensor.set_shape` sets the static shape of the tensor without enforcing it + at runtime, which may result in inconsistencies between the statically-known + shape of tensors and the runtime value of tensors. + + Args: + x: A `Tensor`. + shape: A `TensorShape` representing the shape of this tensor, a + `TensorShapeProto`, a list, a tuple, or None. + name: A name for this operation (optional). Defaults to "EnsureShape". + + Returns: + A `Tensor`. Has the same type and contents as `x`. At runtime, raises a + `tf.errors.InvalidArgumentError` if `shape` is incompatible with the shape + of `x`. + """ + if not isinstance(shape, tensor_shape.TensorShape): + shape = tensor_shape.TensorShape(shape) + + return array_ops.ensure_shape(x, shape, name=name) diff --git a/tensorflow/python/ops/clip_ops_test.py b/tensorflow/python/ops/clip_ops_test.py index 7d8dc90491..444cd0f62c 100644 --- a/tensorflow/python/ops/clip_ops_test.py +++ b/tensorflow/python/ops/clip_ops_test.py @@ -30,7 +30,7 @@ class ClipOpsTest(test.TestCase): super(ClipOpsTest, self).__init__(method_name) def _testClipByNorm(self, inputs, max_norm, expected): - with self.test_session() as sess: + with self.cached_session() as sess: input_op = constant_op.constant(inputs) clipped = clip_ops.clip_by_norm(input_op, max_norm) check_op = numerics.add_check_numerics_ops() diff --git a/tensorflow/python/ops/collective_ops_test.py b/tensorflow/python/ops/collective_ops_test.py index 9cc64ef9f6..6f3cd74406 100644 --- a/tensorflow/python/ops/collective_ops_test.py +++ b/tensorflow/python/ops/collective_ops_test.py @@ -53,6 +53,9 @@ class CollectiveOpTest(test.TestCase): [0.3, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3], [0.2, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2]) + def testCollectiveReduceScalar(self): + self._testCollectiveReduce(0.1, 0.3, 0.2) + def _testCollectiveBroadcast(self, t0): group_key = 1 instance_key = 1 diff --git a/tensorflow/python/ops/cond_v2.py b/tensorflow/python/ops/cond_v2.py index 76173e0f30..75a1a53eb7 100644 --- a/tensorflow/python/ops/cond_v2.py +++ b/tensorflow/python/ops/cond_v2.py @@ -24,7 +24,7 @@ from __future__ import division from __future__ import print_function # pylint: disable=unused-import -from tensorflow.python.framework import function +from tensorflow.python.eager import function from tensorflow.python.framework import function_def_to_graph from tensorflow.python.ops import gradients_impl diff --git a/tensorflow/python/ops/cond_v2_impl.py b/tensorflow/python/ops/cond_v2_impl.py index b3dacff6d6..c4e9c982b5 100644 --- a/tensorflow/python/ops/cond_v2_impl.py +++ b/tensorflow/python/ops/cond_v2_impl.py @@ -27,14 +27,13 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import collections + from tensorflow.core.framework import attr_value_pb2 -from tensorflow.python import pywrap_tensorflow as c_api -from tensorflow.python.framework import c_api_util from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_util from tensorflow.python.ops import gen_functional_ops -from tensorflow.python.util import compat # The following modules cannot be imported directly because they cause circular @@ -57,46 +56,27 @@ def cond_v2(pred, true_fn, false_fn, name="cond"): name = "cond" with ops.name_scope(name) as scope: - # Identify if there is a caller device, & get the innermost if possible. - # pylint: disable=protected-access - device_funcs = ops.get_default_graph()._device_functions_outer_to_inner - caller_device = device_funcs[-1] if device_funcs else None - - caller_colocation_stack = ops.get_default_graph()._colocation_stack - caller_container = ops.get_default_graph()._container - caller_collection_ref = ops.get_default_graph()._collections - with ops.name_scope(None): # Find the outer most graph for uniquing function names. # TODO(jpienaar): Make this work in eager mode. graph = ops.get_default_graph() - while isinstance(graph, _function._FuncGraph): - graph = graph._outer_graph + while isinstance(graph, _function.FuncGraph): + graph = graph.outer_graph true_name = graph.unique_name(("%strue" % scope).replace("/", "_")) false_name = graph.unique_name(("%sfalse" % scope).replace("/", "_")) - # pylint: enable=protected-access + true_graph = _function.func_graph_from_py_func( - true_fn, [], [], - name=true_name, - device=caller_device, - colocation_stack=caller_colocation_stack, - collections_ref=caller_collection_ref, - container=caller_container) + true_name, true_fn, [], {}) false_graph = _function.func_graph_from_py_func( - false_fn, [], [], - name=false_name, - device=caller_device, - colocation_stack=caller_colocation_stack, - collections_ref=caller_collection_ref, - container=caller_container) + false_name, false_fn, [], {}) _check_same_outputs(true_graph, false_graph) # Add inputs to true_graph and false_graph to make them match. Note that # this modifies true_graph and false_graph. cond_inputs = _make_inputs_match(true_graph, false_graph, - true_graph.extra_inputs, - false_graph.extra_inputs) + true_graph.external_captures, + false_graph.external_captures) # Add all intermediate tensors as function outputs so they're available for # the gradient computation. @@ -148,8 +128,8 @@ def _IfGrad(op, *grads): # pylint: disable=invalid-name true_graph, false_graph = _get_func_graphs(op) # Note: op.graph != ops.get_default_graph() when we are computing the gradient # of a nested cond. - assert true_graph._outer_graph == op.graph - assert false_graph._outer_graph == op.graph + assert true_graph.outer_graph == op.graph + assert false_graph.outer_graph == op.graph # Create grad functions that compute the gradient of the true/false forward # graphs. These functions will capture tensors from the forward pass @@ -164,14 +144,13 @@ def _IfGrad(op, *grads): # pylint: disable=invalid-name # Resolve references to forward graph tensors in grad graphs and ensure # they are in-scope, i.e., belong to one of outer graphs of the grad graph. - true_grad_extra_inputs = _resolve_grad_inputs(true_graph, true_grad_graph) - false_grad_extra_inputs = _resolve_grad_inputs(false_graph, false_grad_graph) + true_grad_inputs = _resolve_grad_inputs(true_graph, true_grad_graph) + false_grad_inputs = _resolve_grad_inputs(false_graph, false_grad_graph) # Make the inputs to true_grad_graph and false_grad_graph match. Note that # this modifies true_grad_graph and false_grad_graph. grad_inputs = _make_inputs_match(true_grad_graph, false_grad_graph, - true_grad_extra_inputs, - false_grad_extra_inputs) + true_grad_inputs, false_grad_inputs) # Add all intermediate tensors as function outputs so they're available for # higher-order gradient computations. @@ -211,8 +190,8 @@ def _get_func_graphs(if_op): """ def _get_func_graph_for_branch(branch_name): """Generates and returns a _FuncGraph for the given branch.""" - extra_inputs = if_op.inputs[1:] # First input is pred. - input_shapes = [t.shape for t in extra_inputs] + inputs = if_op.inputs[1:] # First input is pred. + input_shapes = [t.shape for t in inputs] func_name = if_op.get_attr(branch_name).name fdef = if_op.graph._get_function(func_name).definition # `if_op.graph` may not be the same as `ops.get_default_graph()` e.g. @@ -224,9 +203,8 @@ def _get_func_graphs(if_op): with if_op.graph.as_default(): func_graph = _function_def_to_graph.function_def_to_graph( fdef, input_shapes) - func_graph.extra_inputs = extra_inputs - func_graph.extra_args = func_graph.inputs - func_graph._captured = dict(zip(extra_inputs, func_graph.inputs)) + func_graph.captures = collections.OrderedDict(zip(inputs, + func_graph.inputs)) # Set the if op so that the gradient code can use it. func_graph._if = if_op return func_graph @@ -282,12 +260,12 @@ def _grad_fn(func_graph, grads): def _create_grad_func(func_graph, grads, name): """Returns the _FuncGraph representation of _grad_fn.""" - return _function.func_graph_from_py_func(lambda: _grad_fn(func_graph, grads), - [], [], name) + return _function.func_graph_from_py_func( + name, lambda: _grad_fn(func_graph, grads), [], {}) def _resolve_grad_inputs(cond_graph, grad_graph): - """Returns the tensors to pass as `extra_inputs` to `grad_graph`. + """Returns the tensors to pass as inputs to `grad_graph`. The `grad_graph` may have external references to 1. Its outer graph containing the input gradients. These references are kept @@ -305,10 +283,10 @@ def _resolve_grad_inputs(cond_graph, grad_graph): Returns: A list of inputs tensors to be passed to grad_graph. """ - new_extra_inputs = [] + new_inputs = [] - for t in grad_graph.extra_inputs: - if t.graph != grad_graph._outer_graph: + for t in grad_graph.external_captures: + if t.graph != grad_graph.outer_graph: # `t` is a tensor in `cond_graph` or one of its ancestors. We bubble this # tensor to the least common ancestor of the `cond_graph` and # `grad_graph` so that it is "in-scope" for `grad_graph`. @@ -316,19 +294,19 @@ def _resolve_grad_inputs(cond_graph, grad_graph): # common ancestor once and re-use. assert _is_ancestor(cond_graph, t.graph) while not _is_ancestor(grad_graph, t.graph): - assert isinstance(t.graph, _function._FuncGraph) - if t in t.graph.extra_args: - # TODO(srbs): Consider building a map of extra_args -> extra_inputs. - # instead of searching for `t` twice. - t = t.graph.extra_inputs[t.graph.extra_args.index(t)] + assert isinstance(t.graph, _function.FuncGraph) + if t in t.graph.internal_captures: + # TODO(srbs): Consider building a map of internal_captures -> + # external_captures instead of searching for `t` twice. + t = t.graph.external_captures[t.graph.internal_captures.index(t)] else: # Note: All intermediate tensors are output by the If op. # TODO(srbs): .index() calls may be expensive. Optimize. t = t.graph._if.outputs[t.graph.outputs.index(t)] assert _is_ancestor(grad_graph, t.graph) - new_extra_inputs.append(t) + new_inputs.append(t) - return new_extra_inputs + return new_inputs def _create_new_tf_function(func_graph): @@ -340,26 +318,9 @@ def _create_new_tf_function(func_graph): Returns: The name of the new TF_Function. """ - c_func = c_api.TF_GraphToFunction_wrapper( - func_graph._c_graph, - compat.as_str(func_graph.name), - False, # append_hash_to_fn_name - None, # opers - [t._as_tf_output() for t in func_graph.inputs], - [t._as_tf_output() for t in func_graph.outputs], - [], - None, # opts - None) # description - _ = c_api_util.ScopedTFFunction(c_func) - - # TODO(b/109833212): this sucks, we're serializing the TF_Function*, - # deserializing it into a Python FunctionDef, then reserializing it to create - # a new TF_Function that we add to the graph. - fdef = _function.function_def_from_tf_function(c_func) - defined_func = _function._from_definition(fdef) - defined_func._sub_functions = func_graph._functions - defined_func.add_to_graph(func_graph._outer_graph) - + func = _function._EagerDefinedFunction( + func_graph.name, func_graph, func_graph.inputs, func_graph.outputs, {}) + func.add_to_graph(func_graph.outer_graph) return func_graph.name @@ -421,21 +382,20 @@ def _pad_params(true_graph, false_graph, true_params, false_params): return new_true_params, new_false_inputs -def _make_inputs_match(true_graph, false_graph, true_extra_inputs, - false_extra_inputs): +def _make_inputs_match(true_graph, false_graph, true_inputs, false_inputs): """Modifies true_graph and false_graph so they have the same input signature. This method reorders and/or adds parameters to true_graph and false_graph so - they have the same input signature, and updates the 'inputs', 'extra_inputs', - and '_captured' fields of both graphs accordingly. It uses the input tensors - from the outer graph to avoid duplicating shared arguments. + they have the same input signature, and updates the 'inputs' and 'captured' + fields of both graphs accordingly. It uses the input tensors from the outer + graph to avoid duplicating shared arguments. Args: true_graph: function._FuncGraph false_graph: function._FuncGraph - true_extra_inputs: a list of Tensors in the outer graph. The inputs for + true_inputs: a list of Tensors in the outer graph. The inputs for true_graph. - false_extra_inputs: a list of Tensors in the outer graph. The inputs for + false_inputs: a list of Tensors in the outer graph. The inputs for false_graph. Returns: @@ -444,12 +404,12 @@ def _make_inputs_match(true_graph, false_graph, true_extra_inputs, false_inputs. """ shared_inputs, true_only_inputs, false_only_inputs = _separate_unique_inputs( - true_extra_inputs, false_extra_inputs) + true_inputs, false_inputs) new_inputs = shared_inputs + true_only_inputs + false_only_inputs - true_input_to_param = dict(zip(true_extra_inputs, true_graph.inputs)) - false_input_to_param = dict(zip(false_extra_inputs, false_graph.inputs)) + true_input_to_param = dict(zip(true_inputs, true_graph.inputs)) + false_input_to_param = dict(zip(false_inputs, false_graph.inputs)) true_graph.inputs = ( [true_input_to_param[t] for t in shared_inputs] + @@ -462,14 +422,10 @@ def _make_inputs_match(true_graph, false_graph, true_extra_inputs, [false_input_to_param[t] for t in false_only_inputs]) # Rewrite the _FuncGraphs' state to reflect the new inputs. - true_graph.extra_inputs = new_inputs - false_graph.extra_inputs = new_inputs - - true_graph.extra_args = true_graph.inputs - false_graph.extra_args = false_graph.inputs - - true_graph._captured = dict(zip(new_inputs, true_graph.inputs)) - false_graph._captured = dict(zip(new_inputs, false_graph.inputs)) + true_graph.captures = collections.OrderedDict(zip(new_inputs, + true_graph.inputs)) + false_graph.captures = collections.OrderedDict(zip(new_inputs, + false_graph.inputs)) return new_inputs @@ -506,10 +462,10 @@ def _get_grad_fn_name(func_graph): counter = 1 has_conflict = True while has_conflict: - curr_graph = func_graph._outer_graph + curr_graph = func_graph.outer_graph has_conflict = curr_graph._is_function(name) - while not has_conflict and isinstance(curr_graph, _function._FuncGraph): - curr_graph = curr_graph._outer_graph + while not has_conflict and isinstance(curr_graph, _function.FuncGraph): + curr_graph = curr_graph.outer_graph has_conflict = curr_graph._is_function(name) if has_conflict: name = "%s_%s" % (base_name, counter) @@ -534,6 +490,6 @@ def _check_same_outputs(true_graph, false_graph): def _is_ancestor(graph, maybe_ancestor): if maybe_ancestor == graph: return True - if isinstance(graph, _function._FuncGraph): - return _is_ancestor(graph._outer_graph, maybe_ancestor) + if isinstance(graph, _function.FuncGraph): + return _is_ancestor(graph.outer_graph, maybe_ancestor) return False diff --git a/tensorflow/python/ops/control_flow_ops.py b/tensorflow/python/ops/control_flow_ops.py index d1095c8954..e3c1aa3d5a 100644 --- a/tensorflow/python/ops/control_flow_ops.py +++ b/tensorflow/python/ops/control_flow_ops.py @@ -1966,8 +1966,12 @@ def cond(pred, `true_fn` and `false_fn` both return lists of output tensors. `true_fn` and `false_fn` must have the same non-zero number and type of outputs. - Note that the conditional execution applies only to the operations defined in - `true_fn` and `false_fn`. Consider the following simple program: + **WARNING**: Any Tensors or Operations created outside of `true_fn` and + `false_fn` will be executed regardless of which branch is selected at runtime. + + Although this behavior is consistent with the dataflow model of TensorFlow, + it has frequently surprised users who expected a lazier semantics. + Consider the following simple program: ```python z = tf.multiply(a, b) @@ -1978,8 +1982,6 @@ def cond(pred, operation will not be executed. Since `z` is needed for at least one branch of the `cond`, the `tf.multiply` operation is always executed, unconditionally. - Although this behavior is consistent with the dataflow model of TensorFlow, - it has occasionally surprised some users who expected a lazier semantics. Note that `cond` calls `true_fn` and `false_fn` *exactly once* (inside the call to `cond`, and not at all during `Session.run()`). `cond` diff --git a/tensorflow/python/ops/control_flow_ops_test.py b/tensorflow/python/ops/control_flow_ops_test.py index 153548ae92..2c42176158 100644 --- a/tensorflow/python/ops/control_flow_ops_test.py +++ b/tensorflow/python/ops/control_flow_ops_test.py @@ -153,7 +153,7 @@ class WithDependenciesTestCase(test_util.TensorFlowTestCase): const_with_dep = control_flow_ops.with_dependencies( (increment_counter, constant_op.constant(42)), constant_op.constant(7)) - with self.test_session(): + with self.cached_session(): variables.global_variables_initializer().run() self.assertEquals(0, counter.eval()) self.assertEquals(7, const_with_dep.eval()) @@ -167,7 +167,7 @@ class WithDependenciesTestCase(test_util.TensorFlowTestCase): const_with_dep = control_flow_ops.with_dependencies( [increment_counter, constant_op.constant(42)], constant_op.constant(7)) - with self.test_session(): + with self.cached_session(): variables.global_variables_initializer().run() self.assertEquals(0, counter.eval()) self.assertEquals(7, const_with_dep.eval()) @@ -177,7 +177,7 @@ class WithDependenciesTestCase(test_util.TensorFlowTestCase): class SwitchTestCase(test_util.TensorFlowTestCase): def testIndexedSlicesWithDenseShape(self): - with self.test_session(): + with self.cached_session(): data = ops.IndexedSlices( constant_op.constant([1, 2, 3]), constant_op.constant([0, 1]), @@ -208,7 +208,7 @@ class SwitchTestCase(test_util.TensorFlowTestCase): constant_op.constant(0.0)]) optimizer = momentum.MomentumOptimizer(0.1, 0.9) train_op = optimizer.minimize(cost) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) for _ in range(10): sess.run([train_op]) @@ -231,7 +231,7 @@ class SwitchTestCase(test_util.TensorFlowTestCase): _, cost = control_flow_ops.while_loop( cond, body, [constant_op.constant(0), constant_op.constant(0.0)]) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) self.assertAllEqual(10.0, cost.eval()) @@ -268,7 +268,7 @@ class SwitchTestCase(test_util.TensorFlowTestCase): static_grads = math_ops.segment_sum(static_grads.values, static_grads.indices) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) self.assertAllEqual(*sess.run([static_grads, dynamic_grads])) @@ -280,7 +280,7 @@ class SwitchTestCase(test_util.TensorFlowTestCase): def testIndexedSlicesWithShapeGradientInWhileLoop(self): for dtype in [dtypes.float32, dtypes.float64]: - with self.test_session() as sess: + with self.cached_session() as sess: num_steps = 9 inputs = array_ops.placeholder(dtype=dtype, shape=[num_steps]) @@ -309,7 +309,7 @@ class SwitchTestCase(test_util.TensorFlowTestCase): def testIndexedSlicesWithDynamicShapeGradientInWhileLoop(self): for dtype in [dtypes.float32, dtypes.float64]: - with self.test_session() as sess: + with self.cached_session() as sess: inputs = array_ops.placeholder(dtype=dtype) initial_outputs = tensor_array_ops.TensorArray( dtype=dtype, dynamic_size=True, size=1) @@ -335,7 +335,7 @@ class SwitchTestCase(test_util.TensorFlowTestCase): self.assertAllEqual(grad, [1] * 3) def testGradientThroughSingleBranchOutsideOfContext(self): - with self.test_session(): + with self.cached_session(): x = constant_op.constant(2.) s = constant_op.constant(True) x_false, x_true = control_flow_ops.switch(x, s) @@ -434,7 +434,7 @@ class CondTest(test_util.TensorFlowTestCase): class ContextTest(test_util.TensorFlowTestCase): def testCondContext(self): - with self.test_session() as sess: + with self.cached_session() as sess: x = constant_op.constant(2) y = constant_op.constant(5) control_flow_ops.cond( @@ -448,7 +448,7 @@ class ContextTest(test_util.TensorFlowTestCase): control_flow_ops.CondContext.from_proto(c.to_proto()).to_proto()) def _testWhileContextHelper(self, maximum_iterations=None): - with self.test_session() as sess: + with self.cached_session() as sess: i = constant_op.constant(0) c = lambda i: math_ops.less(i, 10) b = lambda i: math_ops.add(i, 1) @@ -469,7 +469,7 @@ class ContextTest(test_util.TensorFlowTestCase): self._testWhileContextHelper(maximum_iterations=10) def testControlContextImportScope(self): - with self.test_session(): + with self.cached_session(): constant_op.constant(0, name="a") constant_op.constant(2, name="test_scope/a") b1 = constant_op.constant(1, name="b") @@ -562,7 +562,7 @@ class DataTypesTest(test_util.TensorFlowTestCase): output_case = control_flow_ops.case([(condition, fn_true)], fn_false, strict=strict) - with self.test_session() as sess: + with self.cached_session() as sess: variables.global_variables_initializer().run() true_feed_dict = {condition: True} true_feed_dict.update(feed_dict) @@ -884,7 +884,7 @@ class CaseTest(test_util.TensorFlowTestCase): (math_ops.equal(x, 2), lambda: constant_op.constant(4))] default = lambda: constant_op.constant(6) output = control_flow_ops.case(conditions, default, exclusive=True) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(output, feed_dict={x: 1}), 2) self.assertEqual(sess.run(output, feed_dict={x: 2}), 4) self.assertEqual(sess.run(output, feed_dict={x: 3}), 6) @@ -896,7 +896,7 @@ class CaseTest(test_util.TensorFlowTestCase): (math_ops.equal(x, 2), lambda: constant_op.constant(6))] default = lambda: constant_op.constant(8) output = control_flow_ops.case(conditions, default, exclusive=True) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(output, feed_dict={x: 1}), 2) self.assertEqual(sess.run(output, feed_dict={x: 3}), 8) with self.assertRaisesRegexp(errors.InvalidArgumentError, "Input error:"): @@ -909,7 +909,7 @@ class CaseTest(test_util.TensorFlowTestCase): (math_ops.equal(x, 2), lambda: constant_op.constant(6))] default = lambda: constant_op.constant(8) output = control_flow_ops.case(conditions, default, exclusive=False) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(output, feed_dict={x: 1}), 2) self.assertEqual(sess.run(output, feed_dict={x: 2}), 4) self.assertEqual(sess.run(output, feed_dict={x: 3}), 8) @@ -920,7 +920,7 @@ class CaseTest(test_util.TensorFlowTestCase): (math_ops.equal(x, 2), lambda: constant_op.constant(4)), (math_ops.equal(x, 3), lambda: constant_op.constant(6))] output = control_flow_ops.case(conditions, exclusive=True) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(output, feed_dict={x: 1}), 2) self.assertEqual(sess.run(output, feed_dict={x: 2}), 4) self.assertEqual(sess.run(output, feed_dict={x: 3}), 6) @@ -931,7 +931,7 @@ class CaseTest(test_util.TensorFlowTestCase): x = array_ops.placeholder(dtype=dtypes.int32, shape=[]) conditions = [(math_ops.equal(x, 1), lambda: constant_op.constant(2))] output = control_flow_ops.case(conditions, exclusive=True) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(output, feed_dict={x: 1}), 2) with self.assertRaisesRegexp(errors.InvalidArgumentError, "Input error:"): sess.run(output, feed_dict={x: 4}) diff --git a/tensorflow/python/ops/dequantize_op_test.py b/tensorflow/python/ops/dequantize_op_test.py index 31338db0dd..13e50273d8 100644 --- a/tensorflow/python/ops/dequantize_op_test.py +++ b/tensorflow/python/ops/dequantize_op_test.py @@ -32,7 +32,7 @@ class DequantizeOpTest(test.TestCase): super(DequantizeOpTest, self).__init__(method_name) def _testDequantizeOp(self, inputs, min_range, max_range, dtype): - with self.test_session(): + with self.cached_session(): input_op = constant_op.constant(inputs, shape=[len(inputs)], dtype=dtype) dequantized = array_ops.dequantize(input_op, min_range, max_range) tf_ans = dequantized.eval() diff --git a/tensorflow/python/ops/embedding_ops.py b/tensorflow/python/ops/embedding_ops.py index 7b9e7de145..6263041b8d 100644 --- a/tensorflow/python/ops/embedding_ops.py +++ b/tensorflow/python/ops/embedding_ops.py @@ -134,7 +134,10 @@ def _embedding_lookup_and_transform(params, ids, max_norm) if transform_fn: result = transform_fn(result) - return result + # Make sure the final result does not have colocation contraints on the + # params. Similar to the case np > 1 where parallel_dynamic_stitch is + # outside the scioe of all with ops.colocate_with(params[p]). + return array_ops.identity(result) else: # Flatten the ids. There are two cases where we need to do this. # - There is more than one params tensor. @@ -427,6 +430,8 @@ def embedding_lookup_sparse(params, embeddings = embedding_lookup( params, ids, partition_strategy=partition_strategy, max_norm=max_norm) + if embeddings.dtype in (dtypes.float16, dtypes.bfloat16): + embeddings = math_ops.to_float(embeddings) if not ignore_weights: weights = sp_weights.values if weights.dtype != embeddings.dtype: diff --git a/tensorflow/python/ops/gradient_checker_test.py b/tensorflow/python/ops/gradient_checker_test.py index b0ecdc6a50..fbb84b9018 100644 --- a/tensorflow/python/ops/gradient_checker_test.py +++ b/tensorflow/python/ops/gradient_checker_test.py @@ -76,7 +76,7 @@ class GradientCheckerTest(test.TestCase): def testAddCustomized(self): np.random.seed(3) # Fix seed to avoid flakiness - with self.test_session(): + with self.cached_session(): # a test case for Add operation size = (2, 3) x1 = constant_op.constant( @@ -94,7 +94,7 @@ class GradientCheckerTest(test.TestCase): def testGather(self): np.random.seed(4) # Fix seed to avoid flakiness - with self.test_session(): + with self.cached_session(): p_shape = (4, 2) p_size = 8 index_values = [1, 3] @@ -111,7 +111,7 @@ class GradientCheckerTest(test.TestCase): def testNestedGather(self): np.random.seed(5) # Fix seed to avoid flakiness - with self.test_session(): + with self.cached_session(): p_shape = (8, 2) p_size = 16 index_values = [1, 3, 5, 6] @@ -131,7 +131,7 @@ class GradientCheckerTest(test.TestCase): assert error < 1e-4 def testComplexMul(self): - with self.test_session(): + with self.cached_session(): size = () c = constant_op.constant(5 + 7j, dtype=dtypes.complex64) x = constant_op.constant(11 - 13j, dtype=dtypes.complex64) @@ -145,7 +145,7 @@ class GradientCheckerTest(test.TestCase): gradient_checker.compute_gradient_error(x, size, y, size), 2e-4) def testComplexConj(self): - with self.test_session(): + with self.cached_session(): size = () x = constant_op.constant(11 - 13j, dtype=dtypes.complex64) y = math_ops.conj(x) @@ -158,7 +158,7 @@ class GradientCheckerTest(test.TestCase): gradient_checker.compute_gradient_error(x, size, y, size), 2e-5) def testEmptySucceeds(self): - with self.test_session(): + with self.cached_session(): x = array_ops.placeholder(dtypes.float32) y = array_ops.identity(x) for grad in gradient_checker.compute_gradient(x, (0, 3), y, (0, 3)): @@ -168,7 +168,7 @@ class GradientCheckerTest(test.TestCase): def testEmptyFails(self): with ops.Graph().as_default() as g: - with self.test_session(graph=g): + with self.session(graph=g): x = array_ops.placeholder(dtypes.float32) with g.gradient_override_map({"Identity": "BadGrad"}): y = array_ops.identity(x) @@ -180,7 +180,7 @@ class GradientCheckerTest(test.TestCase): def testNaNGradFails(self): with ops.Graph().as_default() as g: - with self.test_session(graph=g): + with self.session(graph=g): x = array_ops.placeholder(dtypes.float32) with g.gradient_override_map({"Identity": "NaNGrad"}): y = array_ops.identity(x) diff --git a/tensorflow/python/ops/gradients_test.py b/tensorflow/python/ops/gradients_test.py index d02fcf4ee2..fa9910b351 100644 --- a/tensorflow/python/ops/gradients_test.py +++ b/tensorflow/python/ops/gradients_test.py @@ -159,7 +159,7 @@ class GradientsTest(test_util.TensorFlowTestCase): def testBoundaryContinue(self): # Test that we differentiate both 'x' and 'y' correctly when x is a # predecessor of y. - with self.test_session(): + with self.cached_session(): x = constant(1.0) y = x * 2.0 z = y * 3.0 @@ -168,7 +168,7 @@ class GradientsTest(test_util.TensorFlowTestCase): self.assertEqual(6.0, grads[0].eval()) def testAggregationMethodAccumulateN(self): - with self.test_session(): + with self.cached_session(): x = constant(1.0) y = x * 2.0 z = y + y + y + y + y + y + y + y + y + y @@ -181,7 +181,7 @@ class GradientsTest(test_util.TensorFlowTestCase): self.assertEqual(10.0, grads[1].eval()) def testAggregationMethodAddN(self): - with self.test_session(): + with self.cached_session(): x = constant(1.0) y = x * 2.0 z = y + y + y + y + y + y + y + y + y + y @@ -192,7 +192,7 @@ class GradientsTest(test_util.TensorFlowTestCase): self.assertEqual(10.0, grads[1].eval()) def testAggregationMethodTree(self): - with self.test_session(): + with self.cached_session(): x = constant(1.0) y = x * 2.0 z = y + y + y + y + y + y + y + y + y + y @@ -232,7 +232,7 @@ class GradientsTest(test_util.TensorFlowTestCase): array_ops.placeholder(dtypes.int32)) dx, = gradients.gradients(y, x, grad_ys=dy) # The IndexedSlices gradient of tf.identity is the identity map. - with self.test_session() as sess: + with self.cached_session() as sess: vdx, vdy = sess.run( [dx, dy], feed_dict={x: [1.0], dy.indices: [0], dy.values: [2.0]}) self.assertEqual(vdx, vdy) @@ -276,7 +276,7 @@ class GradientsTest(test_util.TensorFlowTestCase): self.assertIsNotNone(gradient) def testDependentYs(self): - with self.test_session(): + with self.cached_session(): x = constant_op.constant(3.0) y = math_ops.square(x) y1 = math_ops.square(y) @@ -291,7 +291,7 @@ class GradientsTest(test_util.TensorFlowTestCase): self.assertAllClose(17502.0, g[0].eval()) def testPartialDerivatives(self): - with self.test_session(): + with self.cached_session(): x = constant_op.constant(1.) y = 2 * x z = x + y @@ -341,7 +341,7 @@ class GradientsTest(test_util.TensorFlowTestCase): constants=constants, variables=variables_)) # evaluate all tensors in one call to session.run for speed - with self.test_session() as sess: + with self.cached_session() as sess: results = sess.run([(case["grad1"], case["grad2"]) for case in cases]) for (npgrad1, npgrad2), case in zip(results, cases): @@ -378,7 +378,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): y = f(x, b) grads = gradients.gradients(y, [x, b]) - with self.test_session() as sess: + with self.cached_session() as sess: return sess.run(grads) def testFunctionGradientsBasic(self): @@ -401,7 +401,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): # Build gradient graph (should add SymbolicGradient node for function). grads = gradients.gradients(y, [x, b1]) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertAllEqual([40.0], sess.run(grads)[0]) self.assertAllEqual([10.0], sess.run(grads)[1]) @@ -448,7 +448,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): return g[0] f = Foo() - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(f), 2.0) def testGradientOfCaptured(self): @@ -462,7 +462,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): return g[0] f = Foo() - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(f), 2.0) def testCapturedResourceVariable(self): @@ -476,7 +476,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): return g[0] f = Foo() - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) self.assertEqual(sess.run(f), 2.0) @@ -501,7 +501,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): return Inner() x1_grad, x2_grad = Outer() - with self.test_session() as sess: + with self.cached_session() as sess: # 1.0 + None + 2.0 + 1.0 = 4.0 self.assertEqual(sess.run(x1_grad), 4.0) # None + 1.0 + 1.0 + None = 2.0 @@ -524,7 +524,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): return Inner() z_grad = Outer() - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(z_grad), 3.0) @@ -667,7 +667,7 @@ class HessianTest(test_util.TensorFlowTestCase): class IndexedSlicesToTensorTest(test_util.TensorFlowTestCase): def testIndexedSlicesToTensor(self): - with self.test_session(): + with self.cached_session(): np_val = np.random.rand(4, 4, 4, 4).astype(np.float32) c = constant_op.constant(np_val) c_sparse = math_ops._as_indexed_slices(c) @@ -676,7 +676,7 @@ class IndexedSlicesToTensorTest(test_util.TensorFlowTestCase): self.assertAllClose(np_val, c_dense.eval()) def testIndexedSlicesToTensorList(self): - with self.test_session(): + with self.cached_session(): numpy_list = [] dense_list = [] sparse_list = [] @@ -692,7 +692,7 @@ class IndexedSlicesToTensorTest(test_util.TensorFlowTestCase): self.assertAllClose(packed_dense.eval(), packed_sparse.eval()) def testInt64Indices(self): - with self.test_session(): + with self.cached_session(): np_val = np.random.rand(4, 4, 4, 4).astype(np.float32) c = constant_op.constant(np_val) c_sparse = math_ops._as_indexed_slices(c) @@ -938,7 +938,7 @@ class CustomGradientTest(test_util.TensorFlowTestCase): F(x) def testRVGradientsDynamicCond(self): - with self.test_session(): + with self.cached_session(): alpha = resource_variable_ops.ResourceVariable( np.random.random((1,)), dtype="float32") diff --git a/tensorflow/python/ops/histogram_ops_test.py b/tensorflow/python/ops/histogram_ops_test.py index 2e57ae8a2d..1ba805dbb4 100644 --- a/tensorflow/python/ops/histogram_ops_test.py +++ b/tensorflow/python/ops/histogram_ops_test.py @@ -35,7 +35,7 @@ class BinValuesFixedWidth(test.TestCase): value_range = [0.0, 5.0] values = [] expected_bins = [] - with self.test_session(): + with self.cached_session(): bins = histogram_ops.histogram_fixed_width_bins( values, value_range, nbins=5) self.assertEqual(dtypes.int32, bins.dtype) @@ -47,7 +47,7 @@ class BinValuesFixedWidth(test.TestCase): value_range = [0.0, 5.0] values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15] expected_bins = [0, 0, 1, 2, 4, 4] - with self.test_session(): + with self.cached_session(): bins = histogram_ops.histogram_fixed_width_bins( values, value_range, nbins=5, dtype=dtypes.int64) self.assertEqual(dtypes.int32, bins.dtype) @@ -59,7 +59,7 @@ class BinValuesFixedWidth(test.TestCase): value_range = np.float64([0.0, 5.0]) values = np.float64([-1.0, 0.0, 1.5, 2.0, 5.0, 15]) expected_bins = [0, 0, 1, 2, 4, 4] - with self.test_session(): + with self.cached_session(): bins = histogram_ops.histogram_fixed_width_bins( values, value_range, nbins=5) self.assertEqual(dtypes.int32, bins.dtype) @@ -72,7 +72,7 @@ class BinValuesFixedWidth(test.TestCase): values = constant_op.constant( [[-1.0, 0.0, 1.5], [2.0, 5.0, 15]], shape=(2, 3)) expected_bins = [[0, 0, 1], [2, 4, 4]] - with self.test_session(): + with self.cached_session(): bins = histogram_ops.histogram_fixed_width_bins( values, value_range, nbins=5) self.assertEqual(dtypes.int32, bins.dtype) diff --git a/tensorflow/python/ops/image_grad_test.py b/tensorflow/python/ops/image_grad_test.py index 75d00c8ed1..fddde75f6b 100644 --- a/tensorflow/python/ops/image_grad_test.py +++ b/tensorflow/python/ops/image_grad_test.py @@ -108,7 +108,7 @@ class ResizeBilinearOpTest(test.TestCase): x = np.arange(0, 4).reshape(in_shape).astype(np.float32) - with self.test_session() as sess: + with self.cached_session() as sess: input_tensor = constant_op.constant(x, shape=in_shape) resize_out = image_ops.resize_bilinear(input_tensor, out_shape[1:3]) self.assertEqual(out_shape, list(resize_out.get_shape())) @@ -122,7 +122,7 @@ class ResizeBilinearOpTest(test.TestCase): x = np.arange(0, 6).reshape(in_shape).astype(np.float32) - with self.test_session(): + with self.cached_session(): input_tensor = constant_op.constant(x, shape=in_shape) resize_out = image_ops.resize_bilinear(input_tensor, out_shape[1:3]) err = gradient_checker.compute_gradient_error( @@ -135,7 +135,7 @@ class ResizeBilinearOpTest(test.TestCase): x = np.arange(0, 24).reshape(in_shape).astype(np.float32) - with self.test_session(): + with self.cached_session(): input_tensor = constant_op.constant(x, shape=in_shape) resize_out = image_ops.resize_bilinear(input_tensor, out_shape[1:3]) err = gradient_checker.compute_gradient_error( @@ -165,7 +165,7 @@ class ResizeBilinearOpTest(test.TestCase): out_shape = [1, 2, 3, 1] x = np.arange(0, 24).reshape(in_shape) - with self.test_session() as sess: + with self.cached_session() as sess: for dtype in [np.float16, np.float32, np.float64]: input_tensor = constant_op.constant(x.astype(dtype), shape=in_shape) resize_out = image_ops.resize_bilinear(input_tensor, out_shape[1:3]) @@ -190,7 +190,7 @@ class ResizeBicubicOpTest(test.TestCase): x = np.arange(0, 4).reshape(in_shape).astype(np.float32) for align_corners in [True, False]: - with self.test_session() as sess: + with self.cached_session() as sess: input_tensor = constant_op.constant(x, shape=in_shape) resize_out = image_ops.resize_bicubic(input_tensor, out_shape[1:3], align_corners=align_corners) @@ -206,7 +206,7 @@ class ResizeBicubicOpTest(test.TestCase): x = np.arange(0, 6).reshape(in_shape).astype(np.float32) for align_corners in [True, False]: - with self.test_session(): + with self.cached_session(): input_tensor = constant_op.constant(x, shape=in_shape) resize_out = image_ops.resize_bicubic(input_tensor, out_shape[1:3], align_corners=align_corners) @@ -221,7 +221,7 @@ class ResizeBicubicOpTest(test.TestCase): x = np.arange(0, 24).reshape(in_shape).astype(np.float32) for align_corners in [True, False]: - with self.test_session(): + with self.cached_session(): input_tensor = constant_op.constant(x, shape=in_shape) resize_out = image_ops.resize_bicubic(input_tensor, out_shape[1:3], align_corners=align_corners) @@ -235,7 +235,7 @@ class ResizeBicubicOpTest(test.TestCase): x = np.arange(0, 24).reshape(in_shape).astype(np.uint8) - with self.test_session(): + with self.cached_session(): input_tensor = constant_op.constant(x, shape=in_shape) resize_out = image_ops.resize_bicubic(input_tensor, out_shape[1:3]) grad = gradients_impl.gradients(input_tensor, [resize_out]) diff --git a/tensorflow/python/ops/image_ops_test.py b/tensorflow/python/ops/image_ops_test.py index 2c61bb232a..f7502c4018 100644 --- a/tensorflow/python/ops/image_ops_test.py +++ b/tensorflow/python/ops/image_ops_test.py @@ -238,7 +238,7 @@ class AdjustGamma(test_util.TensorFlowTestCase): def test_adjust_gamma_one(self): """Same image should be returned for gamma equal to one""" - with self.test_session(): + with self.cached_session(): x_data = np.random.uniform(0, 255, (8, 8)) x_np = np.array(x_data, dtype=np.float32) @@ -252,7 +252,7 @@ class AdjustGamma(test_util.TensorFlowTestCase): def test_adjust_gamma_less_zero(self): """White image should be returned for gamma equal to zero""" - with self.test_session(): + with self.cached_session(): x_data = np.random.uniform(0, 255, (8, 8)) x_np = np.array(x_data, dtype=np.float32) @@ -270,7 +270,7 @@ class AdjustGamma(test_util.TensorFlowTestCase): def test_adjust_gamma_less_zero_tensor(self): """White image should be returned for gamma equal to zero""" - with self.test_session(): + with self.cached_session(): x_data = np.random.uniform(0, 255, (8, 8)) x_np = np.array(x_data, dtype=np.float32) @@ -290,7 +290,7 @@ class AdjustGamma(test_util.TensorFlowTestCase): def test_adjust_gamma_zero(self): """White image should be returned for gamma equal to zero""" - with self.test_session(): + with self.cached_session(): x_data = np.random.uniform(0, 255, (8, 8)) x_np = np.array(x_data, dtype=np.float32) @@ -308,7 +308,7 @@ class AdjustGamma(test_util.TensorFlowTestCase): def test_adjust_gamma_less_one(self): """Verifying the output with expected results for gamma correction with gamma equal to half""" - with self.test_session(): + with self.cached_session(): x_np = np.arange(0, 255, 4, np.uint8).reshape(8, 8) y = image_ops.adjust_gamma(x_np, gamma=0.5) y_tf = np.trunc(y.eval()) @@ -329,7 +329,7 @@ class AdjustGamma(test_util.TensorFlowTestCase): def test_adjust_gamma_greater_one(self): """Verifying the output with expected results for gamma correction with gamma equal to two""" - with self.test_session(): + with self.cached_session(): x_np = np.arange(0, 255, 4, np.uint8).reshape(8, 8) y = image_ops.adjust_gamma(x_np, gamma=2) y_tf = np.trunc(y.eval()) @@ -2367,7 +2367,7 @@ class ResizeImagesTest(test_util.TensorFlowTestCase): img_np = np.array(data, dtype=np.uint8).reshape(img_shape) for opt in self.OPTIONS: - with self.test_session() as sess: + with self.cached_session() as sess: image = constant_op.constant(img_np, shape=img_shape) y = image_ops.resize_images(image, [height, width], opt) yshape = array_ops.shape(y) @@ -3076,7 +3076,7 @@ class JpegTest(test_util.TensorFlowTestCase): self.assertLess(error, 4) def testCropAndDecodeJpeg(self): - with self.test_session() as sess: + with self.cached_session() as sess: # Encode it, then decode it, then encode it base = "tensorflow/core/lib/jpeg/testdata" jpeg0 = io_ops.read_file(os.path.join(base, "jpeg_merge_test1.jpg")) @@ -3102,7 +3102,7 @@ class JpegTest(test_util.TensorFlowTestCase): self.assertAllEqual(image1_crop, image2) def testCropAndDecodeJpegWithInvalidCropWindow(self): - with self.test_session() as sess: + with self.cached_session() as sess: # Encode it, then decode it, then encode it base = "tensorflow/core/lib/jpeg/testdata" jpeg0 = io_ops.read_file(os.path.join(base, "jpeg_merge_test1.jpg")) @@ -3577,7 +3577,7 @@ class FormatTest(test_util.TensorFlowTestCase): "png": functools.partial(image_ops.decode_png, channels=3), "gif": lambda s: array_ops.squeeze(image_ops.decode_gif(s), axis=0), } - with self.test_session(): + with self.cached_session(): for path in paths: contents = io_ops.read_file(os.path.join(prefix, path)).eval() images = {} @@ -3592,7 +3592,7 @@ class FormatTest(test_util.TensorFlowTestCase): def testError(self): path = "tensorflow/core/lib/gif/testdata/scan.gif" - with self.test_session(): + with self.cached_session(): for decode in image_ops.decode_jpeg, image_ops.decode_png: with self.assertRaisesOpError(r"Got 12 frames"): decode(io_ops.read_file(path)).eval() @@ -3606,7 +3606,7 @@ class NonMaxSuppressionTest(test_util.TensorFlowTestCase): scores_np = [0.9, 0.75, 0.6, 0.95, 0.5, 0.3] max_output_size_np = 3 iou_threshold_np = 0.5 - with self.test_session(): + with self.cached_session(): boxes = constant_op.constant(boxes_np) scores = constant_op.constant(scores_np) max_output_size = constant_op.constant(max_output_size_np) @@ -3686,7 +3686,7 @@ class NonMaxSuppressionPaddedTest(test_util.TensorFlowTestCase): # The output shape of the padded operation must be fully defined. self.assertEqual(selected_indices_padded.shape.is_fully_defined(), True) self.assertEqual(selected_indices.shape.is_fully_defined(), False) - with self.test_session(): + with self.cached_session(): self.assertAllClose(selected_indices_padded.eval(), [3, 0, 5, 0, 0]) self.assertEqual(num_valid_padded.eval(), 3) self.assertAllClose(selected_indices.eval(), [3, 0, 5]) @@ -4035,7 +4035,7 @@ class ImageGradientsTest(test_util.TensorFlowTestCase): expected_dx = np.reshape([[2, 1, -2, 0], [-1, -2, 1, 0]], shape) dy, dx = image_ops.image_gradients(img) - with self.test_session(): + with self.cached_session(): actual_dy = dy.eval() actual_dx = dx.eval() self.assertAllClose(expected_dy, actual_dy) diff --git a/tensorflow/python/ops/init_ops_test.py b/tensorflow/python/ops/init_ops_test.py index f6fffa9079..6a1fe17119 100644 --- a/tensorflow/python/ops/init_ops_test.py +++ b/tensorflow/python/ops/init_ops_test.py @@ -55,7 +55,7 @@ class InitializersTest(test.TestCase): def test_uniform(self): tensor_shape = (9, 6, 7) - with self.test_session(): + with self.cached_session(): self._runner( init_ops.RandomUniform(minval=-1, maxval=1, seed=124), tensor_shape, @@ -65,7 +65,7 @@ class InitializersTest(test.TestCase): def test_normal(self): tensor_shape = (8, 12, 99) - with self.test_session(): + with self.cached_session(): self._runner( init_ops.RandomNormal(mean=0, stddev=1, seed=153), tensor_shape, @@ -74,7 +74,7 @@ class InitializersTest(test.TestCase): def test_truncated_normal(self): tensor_shape = (12, 99, 7) - with self.test_session(): + with self.cached_session(): self._runner( init_ops.TruncatedNormal(mean=0, stddev=1, seed=126), tensor_shape, @@ -84,7 +84,7 @@ class InitializersTest(test.TestCase): def test_constant(self): tensor_shape = (5, 6, 4) - with self.test_session(): + with self.cached_session(): self._runner( init_ops.Constant(2), tensor_shape, @@ -94,7 +94,7 @@ class InitializersTest(test.TestCase): def test_lecun_uniform(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, _ = init_ops._compute_fans(tensor_shape) std = np.sqrt(1. / fan_in) self._runner( @@ -105,7 +105,7 @@ class InitializersTest(test.TestCase): def test_glorot_uniform_initializer(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, fan_out = init_ops._compute_fans(tensor_shape) std = np.sqrt(2. / (fan_in + fan_out)) self._runner( @@ -116,7 +116,7 @@ class InitializersTest(test.TestCase): def test_he_uniform(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, _ = init_ops._compute_fans(tensor_shape) std = np.sqrt(2. / fan_in) self._runner( @@ -127,7 +127,7 @@ class InitializersTest(test.TestCase): def test_lecun_normal(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, _ = init_ops._compute_fans(tensor_shape) std = np.sqrt(1. / fan_in) self._runner( @@ -138,7 +138,7 @@ class InitializersTest(test.TestCase): def test_glorot_normal_initializer(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, fan_out = init_ops._compute_fans(tensor_shape) std = np.sqrt(2. / (fan_in + fan_out)) self._runner( @@ -149,7 +149,7 @@ class InitializersTest(test.TestCase): def test_he_normal(self): tensor_shape = (5, 6, 4, 2) - with self.test_session(): + with self.cached_session(): fan_in, _ = init_ops._compute_fans(tensor_shape) std = np.sqrt(2. / fan_in) self._runner( @@ -160,11 +160,11 @@ class InitializersTest(test.TestCase): def test_Orthogonal(self): tensor_shape = (20, 20) - with self.test_session(): + with self.cached_session(): self._runner(init_ops.Orthogonal(seed=123), tensor_shape, target_mean=0.) def test_Identity(self): - with self.test_session(): + with self.cached_session(): tensor_shape = (3, 4, 5) with self.assertRaises(ValueError): self._runner( @@ -182,13 +182,13 @@ class InitializersTest(test.TestCase): def test_Zeros(self): tensor_shape = (4, 5) - with self.test_session(): + with self.cached_session(): self._runner( init_ops.Zeros(), tensor_shape, target_mean=0., target_max=0.) def test_Ones(self): tensor_shape = (4, 5) - with self.test_session(): + with self.cached_session(): self._runner(init_ops.Ones(), tensor_shape, target_mean=1., target_max=1.) diff --git a/tensorflow/python/ops/lookup_ops.py b/tensorflow/python/ops/lookup_ops.py index fb51fbc626..561a341cf3 100644 --- a/tensorflow/python/ops/lookup_ops.py +++ b/tensorflow/python/ops/lookup_ops.py @@ -22,6 +22,7 @@ import collections import functools import six +from tensorflow.python.compat import compat as fwd_compat from tensorflow.python.eager import context from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes @@ -299,6 +300,7 @@ class HashTable(InitializableLookupTableBase): self._value_shape)) return exported_keys, exported_values + class TableInitializerBase(object): """Base class for lookup table initializers.""" @@ -370,8 +372,13 @@ class KeyValueTensorInitializer(TableInitializerBase): # Ensure a unique name when eager execution is enabled to avoid spurious # sharing issues. scope += str(ops.uid()) - init_op = gen_lookup_ops.initialize_table_v2( - table.table_ref, self._keys, self._values, name=scope) + if fwd_compat.forward_compatible(2018, 9, 19): + init_op = gen_lookup_ops.lookup_table_import_v2( + table.table_ref, self._keys, self._values, name=scope) + else: + # To maintain forward compatibiltiy, use the old implementation. + init_op = gen_lookup_ops.initialize_table_v2( + table.table_ref, self._keys, self._values, name=scope) ops.add_to_collection(ops.GraphKeys.TABLE_INITIALIZERS, init_op) return init_op diff --git a/tensorflow/python/ops/math_grad.py b/tensorflow/python/ops/math_grad.py index 2a7a2fd51f..8e11c4bce1 100644 --- a/tensorflow/python/ops/math_grad.py +++ b/tensorflow/python/ops/math_grad.py @@ -972,9 +972,9 @@ def _RealDivGrad(op, grad): grad * math_ops.realdiv(math_ops.realdiv(-x, y), y), ry), sy)) -@ops.RegisterGradient("UnsafeDiv") -def _UnsafeDivGrad(op, grad): - """UnsafeDiv op gradient.""" +@ops.RegisterGradient("DivNoNan") +def _DivNoNanGrad(op, grad): + """DivNoNan op gradient.""" x = op.inputs[0] y = op.inputs[1] sx = array_ops.shape(x) @@ -983,10 +983,10 @@ def _UnsafeDivGrad(op, grad): x = math_ops.conj(x) y = math_ops.conj(y) return (array_ops.reshape( - math_ops.reduce_sum(math_ops.unsafe_div(grad, y), rx), sx), + math_ops.reduce_sum(math_ops.div_no_nan(grad, y), rx), sx), array_ops.reshape( math_ops.reduce_sum( - grad * math_ops.unsafe_div(math_ops.unsafe_div(-x, y), y), + grad * math_ops.div_no_nan(math_ops.div_no_nan(-x, y), y), ry), sy)) diff --git a/tensorflow/python/ops/math_grad_test.py b/tensorflow/python/ops/math_grad_test.py index f9bb60e7fe..7110e0958c 100644 --- a/tensorflow/python/ops/math_grad_test.py +++ b/tensorflow/python/ops/math_grad_test.py @@ -102,14 +102,14 @@ class MinOrMaxGradientTest(test.TestCase): def testMinGradient(self): inputs = constant_op.constant([1.0], dtype=dtypes.float32) outputs = math_ops.reduce_min(array_ops.concat([inputs, inputs], 0)) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error(inputs, [1], outputs, []) self.assertLess(error, 1e-4) def testMaxGradient(self): inputs = constant_op.constant([1.0], dtype=dtypes.float32) outputs = math_ops.reduce_max(array_ops.concat([inputs, inputs], 0)) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error(inputs, [1], outputs, []) self.assertLess(error, 1e-4) @@ -119,14 +119,14 @@ class MaximumOrMinimumGradientTest(test.TestCase): def testMaximumGradient(self): inputs = constant_op.constant([1.0, 2.0, 3.0, 4.0], dtype=dtypes.float32) outputs = math_ops.maximum(inputs, 3.0) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error(inputs, [4], outputs, [4]) self.assertLess(error, 1e-4) def testMinimumGradient(self): inputs = constant_op.constant([1.0, 2.0, 3.0, 4.0], dtype=dtypes.float32) outputs = math_ops.minimum(inputs, 2.0) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error(inputs, [4], outputs, [4]) self.assertLess(error, 1e-4) @@ -137,7 +137,7 @@ class ProdGradientTest(test.TestCase): inputs = constant_op.constant([[1., 2.], [3., 4.]], dtype=dtypes.float32) outputs = math_ops.reduce_prod(inputs) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error( inputs, inputs.get_shape().as_list(), outputs, outputs.get_shape().as_list()) @@ -147,7 +147,7 @@ class ProdGradientTest(test.TestCase): inputs = constant_op.constant([[1., 2.], [3., 4.]], dtype=dtypes.float32) outputs = math_ops.reduce_prod(inputs, -1) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error( inputs, inputs.get_shape().as_list(), outputs, outputs.get_shape().as_list()) @@ -158,7 +158,7 @@ class ProdGradientTest(test.TestCase): inputs = constant_op.constant([[1 + 3j, 2 - 1j], [3j, 4]], dtype=dtype) outputs = math_ops.reduce_prod(inputs) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error( inputs, inputs.get_shape().as_list(), outputs, outputs.get_shape().as_list()) @@ -169,7 +169,7 @@ class ProdGradientTest(test.TestCase): inputs = constant_op.constant([[1 + 3j, 2 - 1j], [3j, 4]], dtype=dtype) outputs = math_ops.reduce_prod(inputs, -1) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error( inputs, inputs.get_shape().as_list(), outputs, outputs.get_shape().as_list()) @@ -182,7 +182,7 @@ class SegmentMinOrMaxGradientTest(test.TestCase): data = constant_op.constant([1.0, 2.0, 3.0], dtype=dtypes.float32) segment_ids = constant_op.constant([0, 0, 1], dtype=dtypes.int64) segment_min = math_ops.segment_min(data, segment_ids) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error(data, [3], segment_min, [2]) self.assertLess(error, 1e-4) @@ -191,7 +191,7 @@ class SegmentMinOrMaxGradientTest(test.TestCase): data = constant_op.constant([1.0, 2.0, 3.0], dtype=dtypes.float32) segment_ids = constant_op.constant([0, 0, 1], dtype=dtypes.int64) segment_max = math_ops.segment_max(data, segment_ids) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error(data, [3], segment_max, [2]) self.assertLess(error, 1e-4) @@ -201,7 +201,7 @@ class SegmentMinOrMaxGradientTest(test.TestCase): data = array_ops.concat([inputs, inputs], 0) segment_ids = constant_op.constant([0, 0], dtype=dtypes.int64) segment_min = math_ops.segment_min(data, segment_ids) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error(inputs, [1], segment_min, [1]) self.assertLess(error, 1e-4) @@ -211,7 +211,7 @@ class SegmentMinOrMaxGradientTest(test.TestCase): data = array_ops.concat([inputs, inputs], 0) segment_ids = constant_op.constant([0, 0], dtype=dtypes.int64) segment_max = math_ops.segment_max(data, segment_ids) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error(inputs, [1], segment_max, [1]) self.assertLess(error, 1e-4) @@ -225,18 +225,19 @@ class FloorModGradientTest(test.TestCase): ns = constant_op.constant([17.], dtype=dtypes.float32) inputs = constant_op.constant([131.], dtype=dtypes.float32) floor_mod = math_ops.floormod(inputs, ns) - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error(inputs, [1], floor_mod, [1]) self.assertLess(error, 1e-4) -class UnsafeDivGradientTest(test.TestCase): +class DivNoNanGradientTest(test.TestCase): def testBasicGradient(self): - inputs = constant_op.constant(np.arange(-3, 3), dtype=dtypes.float32) - outputs = math_ops.unsafe_div(inputs, 1 + math_ops.abs(inputs)) - with self.test_session(): + inputs = constant_op.constant(np.arange(-3, 3), + dtype=dtypes.float32) + outputs = math_ops.div_no_nan(inputs, 1 + math_ops.abs(inputs)) + with self.cached_session(): error = gradient_checker.compute_gradient_error( inputs, inputs.get_shape().as_list(), outputs, @@ -244,10 +245,12 @@ class UnsafeDivGradientTest(test.TestCase): self.assertLess(error, 1e-4) def testGradientWithDenominatorIsZero(self): - x = constant_op.constant(np.arange(-3, 3), dtype=dtypes.float32) - y = array_ops.zeros_like(x, dtype=dtypes.float32) - outputs = math_ops.unsafe_div(x, y) - with self.test_session(): + x = constant_op.constant(np.arange(-3, 3), + dtype=dtypes.float32) + y = array_ops.zeros_like(x, + dtype=dtypes.float32) + outputs = math_ops.div_no_nan(x, y) + with self.cached_session(): dx, dy = gradients.gradients(outputs, [x, y]) self.assertAllClose(dx.eval(), np.zeros(x.shape.as_list())) self.assertAllClose(dy.eval(), np.zeros(y.shape.as_list())) diff --git a/tensorflow/python/ops/math_ops.py b/tensorflow/python/ops/math_ops.py index 4033d5f079..9b0ab00c7a 100644 --- a/tensorflow/python/ops/math_ops.py +++ b/tensorflow/python/ops/math_ops.py @@ -618,7 +618,7 @@ def cast(x, dtype, name=None): """Casts a tensor to a new type. The operation casts `x` (in case of `Tensor`) or `x.values` - (in case of `SparseTensor`) to `dtype`. + (in case of `SparseTensor` or `IndexedSlices`) to `dtype`. For example: @@ -637,15 +637,16 @@ def cast(x, dtype, name=None): behavior of numpy. Args: - x: A `Tensor` or `SparseTensor` of numeric type. It could be - `uint8`, `uint16`, `uint32`, `uint64`, `int8`, `int16`, `int32`, `int64`, - `float16`, `float32`, `float64`, `complex64`, `complex128`, `bfloat16`. - dtype: The destination type. The list of supported dtypes is the same - as `x`. + x: A `Tensor` or `SparseTensor` or `IndexedSlices` of numeric type. It could + be `uint8`, `uint16`, `uint32`, `uint64`, `int8`, `int16`, `int32`, + `int64`, `float16`, `float32`, `float64`, `complex64`, `complex128`, + `bfloat16`. + dtype: The destination type. The list of supported dtypes is the same as + `x`. name: A name for the operation (optional). Returns: - A `Tensor` or `SparseTensor` with same shape as `x` and + A `Tensor` or `SparseTensor` or `IndexedSlices` with same shape as `x` and same type as `dtype`. Raises: @@ -659,6 +660,9 @@ def cast(x, dtype, name=None): if isinstance(x, sparse_tensor.SparseTensor): values_cast = cast(x.values, base_type, name=name) x = sparse_tensor.SparseTensor(x.indices, values_cast, x.dense_shape) + elif isinstance(x, ops.IndexedSlices): + values_cast = cast(x.values, base_type, name=name) + x = ops.IndexedSlices(values_cast, x.indices, x.dense_shape) else: # TODO(josh11b): If x is not already a Tensor, we could return # ops.convert_to_tensor(x, dtype=dtype, ...) here, but that @@ -711,11 +715,12 @@ def to_float(x, name="ToFloat"): """Casts a tensor to type `float32`. Args: - x: A `Tensor` or `SparseTensor`. + x: A `Tensor` or `SparseTensor` or `IndexedSlices`. name: A name for the operation (optional). Returns: - A `Tensor` or `SparseTensor` with same shape as `x` with type `float32`. + A `Tensor` or `SparseTensor` or `IndexedSlices` with same shape as `x` with + type `float32`. Raises: TypeError: If `x` cannot be cast to the `float32`. @@ -728,11 +733,12 @@ def to_double(x, name="ToDouble"): """Casts a tensor to type `float64`. Args: - x: A `Tensor` or `SparseTensor`. + x: A `Tensor` or `SparseTensor` or `IndexedSlices`. name: A name for the operation (optional). Returns: - A `Tensor` or `SparseTensor` with same shape as `x` with type `float64`. + A `Tensor` or `SparseTensor` or `IndexedSlices` with same shape as `x` with + type `float64`. Raises: TypeError: If `x` cannot be cast to the `float64`. @@ -745,11 +751,12 @@ def to_int32(x, name="ToInt32"): """Casts a tensor to type `int32`. Args: - x: A `Tensor` or `SparseTensor`. + x: A `Tensor` or `SparseTensor` or `IndexedSlices`. name: A name for the operation (optional). Returns: - A `Tensor` or `SparseTensor` with same shape as `x` with type `int32`. + A `Tensor` or `SparseTensor` or `IndexedSlices` with same shape as `x` with + type `int32`. Raises: TypeError: If `x` cannot be cast to the `int32`. @@ -762,11 +769,12 @@ def to_int64(x, name="ToInt64"): """Casts a tensor to type `int64`. Args: - x: A `Tensor` or `SparseTensor`. + x: A `Tensor` or `SparseTensor` or `IndexedSlices`. name: A name for the operation (optional). Returns: - A `Tensor` or `SparseTensor` with same shape as `x` with type `int64`. + A `Tensor` or `SparseTensor` or `IndexedSlices` with same shape as `x` with + type `int64`. Raises: TypeError: If `x` cannot be cast to the `int64`. @@ -779,11 +787,12 @@ def to_bfloat16(x, name="ToBFloat16"): """Casts a tensor to type `bfloat16`. Args: - x: A `Tensor` or `SparseTensor`. + x: A `Tensor` or `SparseTensor` or `IndexedSlices`. name: A name for the operation (optional). Returns: - A `Tensor` or `SparseTensor` with same shape as `x` with type `bfloat16`. + A `Tensor` or `SparseTensor` or `IndexedSlices` with same shape as `x` with + type `bfloat16`. Raises: TypeError: If `x` cannot be cast to the `bfloat16`. @@ -796,11 +805,12 @@ def to_complex64(x, name="ToComplex64"): """Casts a tensor to type `complex64`. Args: - x: A `Tensor` or `SparseTensor`. + x: A `Tensor` or `SparseTensor` or `IndexedSlices`. name: A name for the operation (optional). Returns: - A `Tensor` or `SparseTensor` with same shape as `x` with type `complex64`. + A `Tensor` or `SparseTensor` or `IndexedSlices` with same shape as `x` with + type `complex64`. Raises: TypeError: If `x` cannot be cast to the `complex64`. @@ -813,11 +823,12 @@ def to_complex128(x, name="ToComplex128"): """Casts a tensor to type `complex128`. Args: - x: A `Tensor` or `SparseTensor`. + x: A `Tensor` or `SparseTensor` or `IndexedSlices`. name: A name for the operation (optional). Returns: - A `Tensor` or `SparseTensor` with same shape as `x` with type `complex128`. + A `Tensor` or `SparseTensor` or `IndexedSlices` with same shape as `x` with + type `complex128`. Raises: TypeError: If `x` cannot be cast to the `complex128`. @@ -1038,29 +1049,27 @@ def div(x, y, name=None): return _div_python2(x, y, name) -def unsafe_div(x, y, name=None): +@tf_export("div_no_nan") +def div_no_nan(x, y, name=None): """Computes an unsafe divide which returns 0 if the y is zero. - Note that the function uses Python 3 division operator semantics. - Args: - x: A `Tensor`. Must be one of the following types: - `float32`, `float64`, `int16`, `int32`, `int64`. + x: A `Tensor`. Must be one of the following types: `float32`, `float64`. y: A `Tensor` whose dtype is compatible with `x`. name: A name for the operation (optional). Returns: The element-wise value of the x divided by y. """ - with ops.name_scope(name, "unsafe_div", [x, y]) as name: + with ops.name_scope(name, "div_no_nan", [x, y]) as name: x = ops.convert_to_tensor(x, name="x") y = ops.convert_to_tensor(y, name="y", dtype=x.dtype.base_dtype) x_dtype = x.dtype.base_dtype y_dtype = y.dtype.base_dtype if x_dtype != y_dtype: - raise TypeError( - "x and y must have the same dtype, got %r != %r" % (x_dtype, y_dtype)) - return gen_math_ops.unsafe_div(x, y, name=name) + raise TypeError("x and y must have the same dtype, got %r != %r" % + (x_dtype, y_dtype)) + return gen_math_ops.div_no_nan(x, y, name=name) # TODO(aselle): This should be removed diff --git a/tensorflow/python/ops/math_ops_test.py b/tensorflow/python/ops/math_ops_test.py index 5fe7bbca11..1b01d1d37f 100644 --- a/tensorflow/python/ops/math_ops_test.py +++ b/tensorflow/python/ops/math_ops_test.py @@ -373,7 +373,7 @@ class DivAndModTest(test_util.TensorFlowTestCase): def testFloorModInt(self): nums, divs = self.intTestData() - with self.test_session(): + with self.cached_session(): # TODO(aselle): Change test to use % after switch # tf_result = math_ops.floor_mod(nums, divs).eval() tf_result = math_ops.floormod(nums, divs).eval() @@ -382,7 +382,7 @@ class DivAndModTest(test_util.TensorFlowTestCase): def testFloorModFloat(self): nums, divs = self.floatTestData() - with self.test_session(): + with self.cached_session(): tf_result = math_ops.floormod(nums, divs).eval() np_result = nums % divs self.assertAllEqual(tf_result, np_result) @@ -393,21 +393,21 @@ class DivAndModTest(test_util.TensorFlowTestCase): def testTruncateModInt(self): nums, divs = self.intTestData() - with self.test_session(): + with self.cached_session(): tf_result = math_ops.truncatemod(nums, divs).eval() np_result = np.fmod(nums, divs) self.assertAllEqual(tf_result, np_result) def testTruncateModFloat(self): nums, divs = self.floatTestData() - with self.test_session(): + with self.cached_session(): tf_result = math_ops.truncatemod(nums, divs).eval() np_result = np.fmod(nums, divs) self.assertAllEqual(tf_result, np_result) def testDivideInt(self): nums, divs = self.intTestData() - with self.test_session(): + with self.cached_session(): tf_result = math_ops.floor_div(nums, divs).eval() np_result = nums // divs self.assertAllEqual(tf_result, np_result) @@ -417,29 +417,29 @@ class DivAndModTest(test_util.TensorFlowTestCase): # self.assertAllEqual(tf2_result, tf_result) def testDivideName(self): - with self.test_session(): + with self.cached_session(): op = math_ops.divide( array_ops.constant(3), array_ops.constant(4), name="my_cool_divide") self.assertEqual(op.name, "my_cool_divide:0") def testRealDiv(self): nums, divs = self.floatTestData() - with self.test_session(): + with self.cached_session(): tf_result = math_ops.realdiv(nums, divs).eval() np_result = np.divide(nums, divs) self.assertAllEqual(tf_result, np_result) def testComplexDiv(self): foo = array_ops.constant([1. + 3.j]) - with self.test_session(): + with self.cached_session(): _ = math_ops.divide(foo, 1.).eval() _ = math_ops.div(foo, 2.).eval() def testFloorDivGrad(self): - with self.test_session(): + with self.cached_session(): a = variables.Variable(2.) b = variables.Variable(4.) - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) c_grad = gradients.gradients(math_ops.divide(a, b), [a, b]) self.assertAllEqual([x.eval() for x in c_grad], [.25, -.125]) @@ -451,7 +451,7 @@ class DivAndModTest(test_util.TensorFlowTestCase): def testConsistent(self): nums, divs = self.intTestData() - with self.test_session(): + with self.cached_session(): tf_result = (math_ops.floor_div(nums, divs) * divs + math_ops.floormod( nums, divs)).eval() tf_nums = array_ops.constant(nums) @@ -473,18 +473,19 @@ class DivAndModTest(test_util.TensorFlowTestCase): self.assertAllEqual(tf_result, expanded_nums) -class UnsafeDivTest(test_util.TensorFlowTestCase): +class DivNoNanTest(test_util.TensorFlowTestCase): def testBasic(self): - nums = np.arange(-10, 10, .25).reshape(80, 1) - divs = np.arange(-3, 3, .25).reshape(1, 24) + for dtype in [np.float32, np.float64]: + nums = np.arange(-10, 10, .25, dtype=dtype).reshape(80, 1) + divs = np.arange(-3, 3, .25, dtype=dtype).reshape(1, 24) - np_result = np.true_divide(nums, divs) - np_result[:, divs[0] == 0] = 0 + np_result = np.true_divide(nums, divs) + np_result[:, divs[0] == 0] = 0 - with self.test_session(): - tf_result = math_ops.unsafe_div(nums, divs).eval() - self.assertAllEqual(tf_result, np_result) + with self.cached_session(use_gpu=True): + tf_result = math_ops.div_no_nan(nums, divs).eval() + self.assertAllEqual(tf_result, np_result) if __name__ == "__main__": diff --git a/tensorflow/python/ops/nn_batchnorm_test.py b/tensorflow/python/ops/nn_batchnorm_test.py index 7d6dd3fb02..a7467aa943 100644 --- a/tensorflow/python/ops/nn_batchnorm_test.py +++ b/tensorflow/python/ops/nn_batchnorm_test.py @@ -129,7 +129,7 @@ class BatchNormalizationTest(test.TestCase): v_val = np.random.random_sample(param_shape).astype(np.float64) beta_val = np.random.random_sample(param_shape).astype(np.float64) gamma_val = np.random.random_sample(param_shape).astype(np.float64) - with self.test_session(): + with self.cached_session(): x = constant_op.constant(x_val, name="x") m = constant_op.constant(m_val, name="m") v = constant_op.constant(v_val, name="v") @@ -455,7 +455,7 @@ class MomentsTest(test.TestCase): return nn_impl.moments(x, axes, keep_dims=keep_dims) def RunMomentTestWithDynamicShape(self, shape, axes, keep_dims, dtype): - with self.test_session(): + with self.cached_session(): # shape = [batch, width, height, depth] assert len(shape) == 4 @@ -482,7 +482,7 @@ class MomentsTest(test.TestCase): expected_variance, var.eval(feed_dict={x: x_numpy})) def RunMomentTest(self, shape, axes, keep_dims, dtype): - with self.test_session(): + with self.cached_session(): # shape = [batch, width, height, depth] assert len(shape) == 4 @@ -547,7 +547,7 @@ class MomentsTest(test.TestCase): dtype=dtype) def _testGlobalGradient(self, from_y="mean"): - with self.test_session(): + with self.cached_session(): x_shape = [3, 5, 4, 2] x_val = np.random.random_sample(x_shape).astype(np.float64) x = constant_op.constant(x_val) @@ -644,7 +644,7 @@ class WeightedMomentsTest(MomentsTest): keep_dims, dtype, dynshapes=False): - with self.test_session() as s: + with self.cached_session() as s: x_numpy = np.random.normal(size=shape).astype(np.float32) weights_numpy = np.absolute( # weights must be positive np.random.normal( diff --git a/tensorflow/python/ops/nn_grad.py b/tensorflow/python/ops/nn_grad.py index df23ac55ce..e1a01ab4c3 100644 --- a/tensorflow/python/ops/nn_grad.py +++ b/tensorflow/python/ops/nn_grad.py @@ -27,7 +27,6 @@ from tensorflow.python.ops import gen_nn_ops from tensorflow.python.ops import gradients_impl from tensorflow.python.ops import math_ops from tensorflow.python.ops import nn_ops -from tensorflow.python.ops import sparse_ops @ops.RegisterGradient("Conv2DBackpropInput") @@ -471,7 +470,9 @@ def _SoftmaxCrossEntropyWithLogitsGrad(op, grad_loss, grad_grad): softmax = nn_ops.softmax(logits) grad += ((grad_grad - array_ops.squeeze( - math_ops.matmul(grad_grad[:, None, :], softmax[:, :, None]), axis=1)) * + math_ops.matmul(array_ops.expand_dims(grad_grad, 1), + array_ops.expand_dims(softmax, 2)), + axis=1)) * softmax) return grad, _BroadcastMul(grad_loss, -nn_ops.log_softmax(logits)) @@ -975,25 +976,30 @@ def _TopKGrad(op, grad, _): in_shape = array_ops.shape(op.inputs[0]) ind_shape = array_ops.shape(op.outputs[1]) - ind_lastdim = array_ops.gather(ind_shape, array_ops.size(ind_shape) - 1) + # int32 is not supported on GPU hence up-casting + ind_lastdim = array_ops.gather(math_ops.cast( + ind_shape, dtypes.int64), array_ops.size(ind_shape) - 1) # Flatten indices to 2D. ind_2d = array_ops.reshape(op.outputs[1], array_ops.stack([-1, ind_lastdim])) - in_lastdim = array_ops.gather(in_shape, array_ops.size(in_shape) - 1) + in_lastdim = array_ops.gather(math_ops.cast( + in_shape, dtypes.int64), array_ops.size(in_shape) - 1) outerdim = array_ops.shape(ind_2d)[0] # Compute linear indices (flattened to 1D). - ind = array_ops.reshape(ind_2d + array_ops.expand_dims( - math_ops.range(0, outerdim * in_lastdim, in_lastdim), -1), [-1]) + ind = array_ops.reshape(ind_2d + math_ops.cast(array_ops.expand_dims( + math_ops.range(0, math_ops.cast(outerdim, dtypes.int64) + * in_lastdim, in_lastdim), -1), dtypes.int32), [-1]) # Substitute grad to appropriate locations and fill the rest with zeros, # finally reshaping it to the original input shape. return [ array_ops.reshape( - sparse_ops.sparse_to_dense( - ind, - array_ops.reshape(math_ops.reduce_prod(in_shape), [1]), + array_ops.scatter_nd( + array_ops.expand_dims(ind, -1), array_ops.reshape(grad, [-1]), - validate_indices=False), in_shape), + [math_ops.reduce_prod(in_shape)] + ), + in_shape), array_ops.zeros([], dtype=dtypes.int32) ] diff --git a/tensorflow/python/ops/nn_grad_test.py b/tensorflow/python/ops/nn_grad_test.py index 49d54beb20..8065df4b16 100644 --- a/tensorflow/python/ops/nn_grad_test.py +++ b/tensorflow/python/ops/nn_grad_test.py @@ -37,7 +37,7 @@ class Relu6OpTest(test.TestCase): x_init_value = np.array([[-3.5, -1.5, 2, 4], [4.5, 7.5, 8.5, 11]]) r = nn_ops.relu6(inputs) r_g = gradients_impl.gradients(r, inputs)[0] - with self.test_session(): + with self.cached_session(): error = gradient_checker.compute_gradient_error( inputs, inputs.get_shape().as_list(), diff --git a/tensorflow/python/ops/nn_impl.py b/tensorflow/python/ops/nn_impl.py index 51f812b395..2a1919e66f 100644 --- a/tensorflow/python/ops/nn_impl.py +++ b/tensorflow/python/ops/nn_impl.py @@ -1210,7 +1210,9 @@ def nce_loss(weights, num_true]`. The target classes. inputs: A `Tensor` of shape `[batch_size, dim]`. The forward activations of the input network. - num_sampled: An `int`. The number of classes to randomly sample per batch. + num_sampled: An `int`. The number of negative classes to randomly sample + per batch. This single sample of negative classes is evaluated for each + element in the batch. num_classes: An `int`. The number of possible classes. num_true: An `int`. The number of target classes per training example. sampled_values: a tuple of (`sampled_candidates`, `true_expected_count`, diff --git a/tensorflow/python/ops/nn_ops.py b/tensorflow/python/ops/nn_ops.py index edc6e04b48..474e0bb295 100644 --- a/tensorflow/python/ops/nn_ops.py +++ b/tensorflow/python/ops/nn_ops.py @@ -1586,7 +1586,7 @@ def leaky_relu(features, alpha=0.2, name=None): "Rectifier Nonlinearities Improve Neural Network Acoustic Models" AL Maas, AY Hannun, AY Ng - Proc. ICML, 2013 - http://web.stanford.edu/~awni/papers/relu_hybrid_icml2013_final.pdf + https://ai.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf Args: features: A `Tensor` representing preactivation values. Must be one of diff --git a/tensorflow/python/ops/nn_test.py b/tensorflow/python/ops/nn_test.py index ce0db6b264..2fabb2e966 100644 --- a/tensorflow/python/ops/nn_test.py +++ b/tensorflow/python/ops/nn_test.py @@ -53,7 +53,7 @@ class ZeroFractionTest(test_lib.TestCase): x_shape = [5, 17] x_np = np.random.randint(0, 2, size=x_shape).astype(np.float32) y_np = self._ZeroFraction(x_np) - with self.test_session(): + with self.cached_session(): x_tf = constant_op.constant(x_np) x_tf.set_shape(x_shape) y_tf = nn_impl.zero_fraction(x_tf) @@ -62,7 +62,7 @@ class ZeroFractionTest(test_lib.TestCase): self.assertAllClose(y_tf_np, y_np, eps) def testZeroFractionEmpty(self): - with self.test_session(): + with self.cached_session(): x = np.zeros(0) y = nn_impl.zero_fraction(x).eval() self.assertTrue(np.isnan(y)) @@ -106,7 +106,7 @@ class SoftmaxTest(test_lib.TestCase, parameterized.TestCase): @parameterized.parameters(((5, 10),), ((2, 3, 4),)) def testGradient(self, x_shape): x_np = np.random.randn(*x_shape).astype(np.float64) - with self.test_session(): + with self.cached_session(): x_tf = constant_op.constant(x_np) y_tf = nn_ops.softmax(x_tf) err = gradient_checker.compute_gradient_error(x_tf, x_shape, y_tf, @@ -143,7 +143,7 @@ class LogPoissonLossTest(test_lib.TestCase): x_shape = [5, 10] x_np = np.random.randn(*x_shape).astype(np.float64) z_np = np.random.randint(0, 5, size=x_shape).astype(np.float64) - with self.test_session(): + with self.cached_session(): x_tf = constant_op.constant(x_np) y_tf = nn_impl.log_poisson_loss(z_np, x_tf, compute_full_loss=False) y_tf_stirling = nn_impl.log_poisson_loss( @@ -191,7 +191,7 @@ class LogSoftmaxTest(test_lib.TestCase, parameterized.TestCase): @parameterized.parameters(((5, 10),), ((2, 3, 4),)) def testGradient(self, x_shape): x_np = np.random.randn(*x_shape).astype(np.float64) - with self.test_session(): + with self.cached_session(): x_tf = constant_op.constant(x_np) y_tf = nn_ops.log_softmax(x_tf) err = gradient_checker.compute_gradient_error(x_tf, x_shape, y_tf, @@ -215,7 +215,7 @@ class L2LossTest(test_lib.TestCase): x_shape = [20, 7, 3] np.random.seed(1) # Make it reproducible. x_val = np.random.random_sample(x_shape).astype(np.float64) - with self.test_session(): + with self.cached_session(): x = constant_op.constant(x_val, name="x") output = nn_ops.l2_loss(x) err = gradient_checker.compute_gradient_error(x, x_shape, output, [1]) @@ -263,7 +263,7 @@ class L2NormalizeTest(test_lib.TestCase): np.random.seed(1) x_np = np.random.random_sample(x_shape).astype(np.float64) for dim in range(len(x_shape)): - with self.test_session(): + with self.cached_session(): x_tf = constant_op.constant(x_np, name="x") y_tf = nn_impl.l2_normalize(x_tf, dim) err = gradient_checker.compute_gradient_error(x_tf, x_shape, y_tf, @@ -282,7 +282,7 @@ class DropoutTest(test_lib.TestCase): y_dim = 30 num_iter = 10 for keep_prob in [0.1, 0.5, 0.8]: - with self.test_session(): + with self.cached_session(): t = constant_op.constant( 1.0, shape=[x_dim, y_dim], dtype=dtypes.float32) dropout = nn_ops.dropout(t, keep_prob) @@ -310,7 +310,7 @@ class DropoutTest(test_lib.TestCase): y_dim = 3 num_iter = 10 for keep_prob in [0.1, 0.5, 0.8]: - with self.test_session(): + with self.cached_session(): t = constant_op.constant( 1.0, shape=[x_dim, y_dim], dtype=dtypes.float32) dropout = nn_ops.dropout(t, keep_prob, noise_shape=[x_dim, 1]) @@ -335,7 +335,7 @@ class DropoutTest(test_lib.TestCase): y_dim = 30 num_iter = 10 for keep_prob in [0.1, 0.5, 0.8]: - with self.test_session(): + with self.cached_session(): t = constant_op.constant( 1.0, shape=[x_dim, y_dim], dtype=dtypes.float32) dropout = nn_ops.dropout(t, keep_prob, noise_shape=[x_dim, 1]) @@ -355,7 +355,7 @@ class DropoutTest(test_lib.TestCase): y_dim = 30 num_iter = 10 for keep_prob in [0.1, 0.5, 0.8]: - with self.test_session(): + with self.cached_session(): t = constant_op.constant( 1.0, shape=[x_dim, y_dim], dtype=dtypes.float32) keep_prob_placeholder = array_ops.placeholder(dtypes.float32) @@ -389,7 +389,7 @@ class DropoutTest(test_lib.TestCase): y_dim = 3 num_iter = 10 for keep_prob in [0.1, 0.5, 0.8]: - with self.test_session(): + with self.cached_session(): t = constant_op.constant( 1.0, shape=[x_dim, y_dim], dtype=dtypes.float32) # Set noise_shape=[None, 1] which means [x_dim, 1]. @@ -541,7 +541,7 @@ class ComputeSampledLogitsTest(test_lib.TestCase): "b", partitioner=partitioned_variables.fixed_size_partitioner(num_shards), initializer=constant_op.constant(biases)) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: variables.global_variables_initializer().run() return sess.run([list(sharded_weights), list(sharded_biases)]) @@ -549,7 +549,7 @@ class ComputeSampledLogitsTest(test_lib.TestCase): np.random.seed(0) num_classes = 5 batch_size = 3 - with self.test_session() as sess: + with self.cached_session() as sess: for num_true in range(1, 5): labels = np.random.randint( low=0, high=num_classes, size=batch_size * num_true) @@ -585,7 +585,7 @@ class ComputeSampledLogitsTest(test_lib.TestCase): np.random.seed(0) num_classes = 5 batch_size = 3 - with self.test_session() as sess: + with self.cached_session() as sess: for num_true in range(1, 5): labels = np.random.randint( low=0, high=num_classes, size=batch_size * num_true) @@ -622,7 +622,7 @@ class ComputeSampledLogitsTest(test_lib.TestCase): num_classes = 5 batch_size = 3 sampled = [1, 0, 2, 3] - with self.test_session(): + with self.cached_session(): for num_true in range(1, 5): labels = np.random.randint( low=0, high=num_classes, size=batch_size * num_true) @@ -666,7 +666,7 @@ class ComputeSampledLogitsTest(test_lib.TestCase): np.random.seed(0) num_classes = 5 batch_size = 3 - with self.test_session() as sess: + with self.cached_session() as sess: for num_true in range(1, 5): labels = np.random.randint( low=0, high=num_classes, size=batch_size * num_true) @@ -702,7 +702,7 @@ class ComputeSampledLogitsTest(test_lib.TestCase): np.random.seed(0) num_classes = 5 batch_size = 3 - with self.test_session() as sess: + with self.cached_session() as sess: for num_true in range(1, 5): labels = np.random.randint( low=0, high=num_classes, size=batch_size * num_true) @@ -762,7 +762,7 @@ class ComputeSampledLogitsTest(test_lib.TestCase): exp_nce_loss = np.sum( _SigmoidCrossEntropyWithLogits(exp_logits, exp_labels), 1) - with self.test_session(): + with self.cached_session(): got_nce_loss = nn_impl.nce_loss( weights=constant_op.constant(weights), biases=constant_op.constant(biases), @@ -819,7 +819,7 @@ class ComputeSampledLogitsTest(test_lib.TestCase): exp_sampled_softmax_loss = _SoftmaxCrossEntropyWithLogits( exp_logits, exp_labels) - with self.test_session(): + with self.cached_session(): got_sampled_softmax_loss = nn_impl.sampled_softmax_loss( weights=constant_op.constant(weights), biases=constant_op.constant(biases), @@ -880,7 +880,7 @@ class ComputeSampledLogitsTest(test_lib.TestCase): exp_sampled_softmax_loss = _SoftmaxCrossEntropyWithLogits( exp_logits, exp_labels) - with self.test_session(): + with self.cached_session(): true_exp_bf16 = np.full( [batch_size, 1], fill_value=0.5, dtype=dtypes.bfloat16.as_numpy_dtype) sampled_exp_bf16 = np.full( @@ -911,7 +911,7 @@ class CReluTest(test_lib.TestCase): np.random.seed(1) # Make it reproducible. x = np.random.randn(3, 4).astype(np.float32) y = np.concatenate([x * (x > 0), -x * (x < 0)], axis=1) - with self.test_session(): + with self.cached_session(): z = nn_ops.crelu(constant_op.constant(x)).eval() self.assertAllClose(y, z, 1e-4) @@ -922,7 +922,7 @@ class ReluTest(test_lib.TestCase): np.random.seed(1) # Make it reproducible. x = np.random.randn(3, 4).astype(np.float32) y = np.maximum(x, 0.0) - with self.test_session(): + with self.cached_session(): z = nn_ops.relu(constant_op.constant(x)).eval() self.assertAllEqual(y, z) @@ -930,7 +930,7 @@ class ReluTest(test_lib.TestCase): # Test that relu(nan) = nan for various sizes. for i in range(18): x = np.zeros(i) + np.nan - with self.test_session(): + with self.cached_session(): z = nn_ops.relu(constant_op.constant(x)).eval() self.assertTrue(np.isnan(z).all()) @@ -947,7 +947,7 @@ class LeakyReluTest(test_lib.TestCase): outputs = nn_ops.leaky_relu(inputs) self.assertEquals(inputs.shape, outputs.shape) - with self.test_session() as sess: + with self.cached_session() as sess: inputs, outputs = sess.run([inputs, outputs]) self.assertGreaterEqual(outputs.min(), 0.0) self.assertLessEqual(outputs.max(), 1.0) @@ -957,7 +957,7 @@ class LeakyReluTest(test_lib.TestCase): for dtype in [np.int32, np.int64, np.float16, np.float32, np.float64]: np_values = np.array([-2, -1, 0, 1, 2], dtype=dtype) outputs = nn_ops.leaky_relu(constant_op.constant(np_values)) - with self.test_session() as sess: + with self.cached_session() as sess: outputs = sess.run(outputs) tol = 2e-3 if dtype == np.float16 else 1e-6 self.assertAllClose( @@ -984,7 +984,7 @@ class SwishTest(test_lib.TestCase): tf_values = constant_op.constant(np_values) actual_tf_outputs = nn_impl.swish(tf_values) expected_tf_outputs = tf_values * math_ops.sigmoid(tf_values) - with self.test_session() as sess: + with self.cached_session() as sess: actual_outputs, expected_outputs = sess.run( [actual_tf_outputs, expected_tf_outputs]) self.assertAllClose(actual_outputs, expected_outputs) @@ -995,7 +995,7 @@ class SwishTest(test_lib.TestCase): input_values = np.random.randn(*shape) * sigma x_tf = constant_op.constant(input_values) y_tf = nn_impl.swish(x_tf) - with self.test_session(): + with self.cached_session(): err = gradient_checker.compute_gradient_error(x_tf, shape, y_tf, shape) self.assertLess(err, 1e-4) @@ -1016,7 +1016,7 @@ class MomentsTest(test_lib.TestCase): expected_var = np.var( input_values, axis=moments_axes, keepdims=keep_dims) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: inputs = constant_op.constant( input_values, shape=input_shape, dtype=dtypes.float32) mean, variance = nn_impl.moments( diff --git a/tensorflow/python/ops/nn_xent_test.py b/tensorflow/python/ops/nn_xent_test.py index 90f4b40770..54a0e26bfb 100644 --- a/tensorflow/python/ops/nn_xent_test.py +++ b/tensorflow/python/ops/nn_xent_test.py @@ -54,7 +54,7 @@ class SigmoidCrossEntropyWithLogitsTest(test.TestCase): return logits, targets, losses def testConstructionNamed(self): - with self.test_session(): + with self.cached_session(): logits, targets, _ = self._Inputs() loss = nn_impl.sigmoid_cross_entropy_with_logits( labels=targets, logits=logits, name="mylogistic") @@ -84,7 +84,7 @@ class SigmoidCrossEntropyWithLogitsTest(test.TestCase): def testGradient(self): sizes = [4, 2] - with self.test_session(): + with self.cached_session(): logits, targets, _ = self._Inputs(sizes=sizes) loss = nn_impl.sigmoid_cross_entropy_with_logits( labels=targets, logits=logits) @@ -93,7 +93,7 @@ class SigmoidCrossEntropyWithLogitsTest(test.TestCase): self.assertLess(err, 1e-7) def testGradientAtZero(self): - with self.test_session(): + with self.cached_session(): logits = constant_op.constant([0.0, 0.0], dtype=dtypes.float64) targets = constant_op.constant([0.0, 1.0], dtype=dtypes.float64) loss = nn_impl.sigmoid_cross_entropy_with_logits( @@ -130,7 +130,7 @@ class WeightedCrossEntropyTest(test.TestCase): return logits, targets, q, losses def testConstructionNamed(self): - with self.test_session(): + with self.cached_session(): logits, targets, pos_weight, _ = self._Inputs() loss = nn_impl.weighted_cross_entropy_with_logits( targets=targets, logits=logits, pos_weight=pos_weight, name="mybce") @@ -159,7 +159,7 @@ class WeightedCrossEntropyTest(test.TestCase): def testGradient(self): sizes = [4, 2] - with self.test_session(): + with self.cached_session(): logits, targets, pos_weight, _ = self._Inputs(sizes=sizes) loss = nn_impl.weighted_cross_entropy_with_logits( targets=targets, logits=logits, pos_weight=pos_weight) diff --git a/tensorflow/python/ops/parallel_for/control_flow_ops.py b/tensorflow/python/ops/parallel_for/control_flow_ops.py index ccf2eb8214..ead7ae5478 100644 --- a/tensorflow/python/ops/parallel_for/control_flow_ops.py +++ b/tensorflow/python/ops/parallel_for/control_flow_ops.py @@ -46,6 +46,7 @@ def for_loop(loop_fn, loop_fn_dtypes, iters): """ flat_loop_fn_dtypes = nest.flatten(loop_fn_dtypes) + is_none_list = [] def while_body(i, *ta_list): """Body of while loop.""" @@ -56,10 +57,13 @@ def for_loop(loop_fn, loop_fn_dtypes, iters): "actual outputs, %d, from loop_fn" % (len(flat_loop_fn_dtypes), len(fn_output))) outputs = [] + del is_none_list[:] + is_none_list.extend([x is None for x in fn_output]) for out, ta in zip(fn_output, ta_list): # TODO(agarwal): support returning Operation objects from loop_fn. - assert isinstance(out, ops.Tensor) - outputs.append(ta.write(i, array_ops.expand_dims(out, 0))) + if out is not None: + ta = ta.write(i, array_ops.expand_dims(out, 0)) + outputs.append(ta) return tuple([i + 1] + outputs) ta_list = control_flow_ops.while_loop( @@ -69,7 +73,10 @@ def for_loop(loop_fn, loop_fn_dtypes, iters): ])[1:] # TODO(rachelim): enable this for sparse tensors - return nest.pack_sequence_as(loop_fn_dtypes, [ta.concat() for ta in ta_list]) + + output = [None if is_none else ta.concat() + for ta, is_none in zip(ta_list, is_none_list)] + return nest.pack_sequence_as(loop_fn_dtypes, output) def pfor(loop_fn, iters): diff --git a/tensorflow/python/ops/parallel_for/gradients.py b/tensorflow/python/ops/parallel_for/gradients.py index ee3d5c9b86..460de0a97f 100644 --- a/tensorflow/python/ops/parallel_for/gradients.py +++ b/tensorflow/python/ops/parallel_for/gradients.py @@ -61,9 +61,10 @@ def jacobian(output, inputs, use_pfor=True): loop_fn, [output.dtype] * len(flat_inputs), output_size) for i, out in enumerate(pfor_outputs): - new_shape = array_ops.concat( - [output_shape, array_ops.shape(out)[1:]], axis=0) - out = array_ops.reshape(out, new_shape) + if out is not None: + new_shape = array_ops.concat( + [output_shape, array_ops.shape(out)[1:]], axis=0) + out = array_ops.reshape(out, new_shape) pfor_outputs[i] = out return nest.pack_sequence_as(inputs, pfor_outputs) @@ -119,6 +120,8 @@ def batch_jacobian(output, inp, use_pfor=True): else: pfor_output = control_flow_ops.for_loop(loop_fn, output.dtype, output_row_size) + if pfor_output is None: + return None pfor_output = array_ops.reshape(pfor_output, [output_row_size, batch_size, -1]) output = array_ops.transpose(pfor_output, [1, 0, 2]) diff --git a/tensorflow/python/ops/parallel_for/gradients_test.py b/tensorflow/python/ops/parallel_for/gradients_test.py index 3a6d9149ad..f9cf16f6a4 100644 --- a/tensorflow/python/ops/parallel_for/gradients_test.py +++ b/tensorflow/python/ops/parallel_for/gradients_test.py @@ -333,6 +333,13 @@ class GradientsTest(test.TestCase): for i in range(n): self.assertAllClose(outputs[i], outputs[i + n], rtol=rtol, atol=atol) + def test_no_path(self): + for grad_func in [gradients.jacobian, gradients.batch_jacobian]: + for use_pfor in [True, False]: + x = constant_op.constant([[1.0]]) + y = constant_op.constant([[2.0]]) + self.assertIsNone(grad_func(y, x, use_pfor=use_pfor)) + def test_jacobian_fixed_shape(self): x = random_ops.random_uniform([2, 2]) y = math_ops.matmul(x, x, transpose_a=True) diff --git a/tensorflow/python/ops/parallel_for/pfor.py b/tensorflow/python/ops/parallel_for/pfor.py index 2e4b2fd64e..3c914f6ff6 100644 --- a/tensorflow/python/ops/parallel_for/pfor.py +++ b/tensorflow/python/ops/parallel_for/pfor.py @@ -1070,6 +1070,8 @@ class PFor(object): If y does not need to be converted, it returns y as is. Else it returns the "converted value" corresponding to y. """ + if y is None: + return None if isinstance(y, sparse_tensor.SparseTensor): return self._convert_sparse(y) output = self._convert_helper(y) diff --git a/tensorflow/python/ops/parsing_ops.py b/tensorflow/python/ops/parsing_ops.py index d8d9af545f..6041e2a0c5 100644 --- a/tensorflow/python/ops/parsing_ops.py +++ b/tensorflow/python/ops/parsing_ops.py @@ -629,76 +629,12 @@ def _parse_example_raw(serialized, Returns: A `dict` mapping keys to `Tensor`s and `SparseTensor`s. - Raises: - ValueError: If sparse and dense key sets intersect, or input lengths do not - match up. """ with ops.name_scope(name, "ParseExample", [serialized, names]): - names = [] if names is None else names - dense_defaults = collections.OrderedDict( - ) if dense_defaults is None else dense_defaults - sparse_keys = [] if sparse_keys is None else sparse_keys - sparse_types = [] if sparse_types is None else sparse_types - dense_keys = [] if dense_keys is None else dense_keys - dense_types = [] if dense_types is None else dense_types - dense_shapes = ( - [[]] * len(dense_keys) if dense_shapes is None else dense_shapes) - - num_dense = len(dense_keys) - num_sparse = len(sparse_keys) - - if len(dense_shapes) != num_dense: - raise ValueError("len(dense_shapes) != len(dense_keys): %d vs. %d" - % (len(dense_shapes), num_dense)) - if len(dense_types) != num_dense: - raise ValueError("len(dense_types) != len(num_dense): %d vs. %d" - % (len(dense_types), num_dense)) - if len(sparse_types) != num_sparse: - raise ValueError("len(sparse_types) != len(sparse_keys): %d vs. %d" - % (len(sparse_types), num_sparse)) - if num_dense + num_sparse == 0: - raise ValueError("Must provide at least one sparse key or dense key") - if not set(dense_keys).isdisjoint(set(sparse_keys)): - raise ValueError( - "Dense and sparse keys must not intersect; intersection: %s" % - set(dense_keys).intersection(set(sparse_keys))) - - # Convert dense_shapes to TensorShape object. - dense_shapes = [tensor_shape.as_shape(shape) for shape in dense_shapes] - - dense_defaults_vec = [] - for i, key in enumerate(dense_keys): - default_value = dense_defaults.get(key) - dense_shape = dense_shapes[i] - if (dense_shape.ndims is not None and dense_shape.ndims > 0 and - dense_shape[0].value is None): - # Variable stride dense shape, the default value should be a - # scalar padding value - if default_value is None: - default_value = ops.convert_to_tensor( - "" if dense_types[i] == dtypes.string else 0, - dtype=dense_types[i]) - else: - # Reshape to a scalar to ensure user gets an error if they - # provide a tensor that's not intended to be a padding value - # (0 or 2+ elements). - key_name = "padding_" + re.sub("[^A-Za-z0-9_.\\-/]", "_", key) - default_value = ops.convert_to_tensor( - default_value, dtype=dense_types[i], name=key_name) - default_value = array_ops.reshape(default_value, []) - else: - if default_value is None: - default_value = constant_op.constant([], dtype=dense_types[i]) - elif not isinstance(default_value, ops.Tensor): - key_name = "key_" + re.sub("[^A-Za-z0-9_.\\-/]", "_", key) - default_value = ops.convert_to_tensor( - default_value, dtype=dense_types[i], name=key_name) - default_value = array_ops.reshape(default_value, dense_shape) - - dense_defaults_vec.append(default_value) - - # Finally, convert dense_shapes to TensorShapeProto - dense_shapes = [shape.as_proto() for shape in dense_shapes] + (names, dense_defaults_vec, sparse_keys, sparse_types, + dense_keys, dense_shapes, _) = _process_raw_parameters( + names, dense_defaults, sparse_keys, sparse_types, dense_keys, + dense_types, dense_shapes) outputs = gen_parsing_ops.parse_example( serialized=serialized, @@ -719,6 +655,112 @@ def _parse_example_raw(serialized, return dict(zip(sparse_keys + dense_keys, sparse_tensors + dense_values)) +def _process_raw_parameters(names, dense_defaults, sparse_keys, sparse_types, + dense_keys, dense_types, dense_shapes): + """Process raw parameters to params used by `gen_parsing_ops`. + + Args: + names: A vector (1-D Tensor) of strings (optional), the names of + the serialized protos. + dense_defaults: A dict mapping string keys to `Tensor`s. + The keys of the dict must match the dense_keys of the feature. + sparse_keys: A list of string keys in the examples' features. + The results for these keys will be returned as `SparseTensor` objects. + sparse_types: A list of `DTypes` of the same length as `sparse_keys`. + Only `tf.float32` (`FloatList`), `tf.int64` (`Int64List`), + and `tf.string` (`BytesList`) are supported. + dense_keys: A list of string keys in the examples' features. + The results for these keys will be returned as `Tensor`s + dense_types: A list of DTypes of the same length as `dense_keys`. + Only `tf.float32` (`FloatList`), `tf.int64` (`Int64List`), + and `tf.string` (`BytesList`) are supported. + dense_shapes: A list of tuples with the same length as `dense_keys`. + The shape of the data for each dense feature referenced by `dense_keys`. + Required for any input tensors identified by `dense_keys`. Must be + either fully defined, or may contain an unknown first dimension. + An unknown first dimension means the feature is treated as having + a variable number of blocks, and the output shape along this dimension + is considered unknown at graph build time. Padding is applied for + minibatch elements smaller than the maximum number of blocks for the + given feature along this dimension. + + Returns: + Tuple of `names`, `dense_defaults_vec`, `sparse_keys`, `sparse_types`, + `dense_keys`, `dense_shapes`. + + Raises: + ValueError: If sparse and dense key sets intersect, or input lengths do not + match up. + """ + names = [] if names is None else names + dense_defaults = collections.OrderedDict( + ) if dense_defaults is None else dense_defaults + sparse_keys = [] if sparse_keys is None else sparse_keys + sparse_types = [] if sparse_types is None else sparse_types + dense_keys = [] if dense_keys is None else dense_keys + dense_types = [] if dense_types is None else dense_types + dense_shapes = ([[]] * len(dense_keys) + if dense_shapes is None else dense_shapes) + + num_dense = len(dense_keys) + num_sparse = len(sparse_keys) + + if len(dense_shapes) != num_dense: + raise ValueError("len(dense_shapes) != len(dense_keys): %d vs. %d" % + (len(dense_shapes), num_dense)) + if len(dense_types) != num_dense: + raise ValueError("len(dense_types) != len(num_dense): %d vs. %d" % + (len(dense_types), num_dense)) + if len(sparse_types) != num_sparse: + raise ValueError("len(sparse_types) != len(sparse_keys): %d vs. %d" % + (len(sparse_types), num_sparse)) + if num_dense + num_sparse == 0: + raise ValueError("Must provide at least one sparse key or dense key") + if not set(dense_keys).isdisjoint(set(sparse_keys)): + raise ValueError( + "Dense and sparse keys must not intersect; intersection: %s" % + set(dense_keys).intersection(set(sparse_keys))) + + # Convert dense_shapes to TensorShape object. + dense_shapes = [tensor_shape.as_shape(shape) for shape in dense_shapes] + + dense_defaults_vec = [] + for i, key in enumerate(dense_keys): + default_value = dense_defaults.get(key) + dense_shape = dense_shapes[i] + if (dense_shape.ndims is not None and dense_shape.ndims > 0 and + dense_shape[0].value is None): + # Variable stride dense shape, the default value should be a + # scalar padding value + if default_value is None: + default_value = ops.convert_to_tensor( + "" if dense_types[i] == dtypes.string else 0, dtype=dense_types[i]) + else: + # Reshape to a scalar to ensure user gets an error if they + # provide a tensor that's not intended to be a padding value + # (0 or 2+ elements). + key_name = "padding_" + re.sub("[^A-Za-z0-9_.\\-/]", "_", key) + default_value = ops.convert_to_tensor( + default_value, dtype=dense_types[i], name=key_name) + default_value = array_ops.reshape(default_value, []) + else: + if default_value is None: + default_value = constant_op.constant([], dtype=dense_types[i]) + elif not isinstance(default_value, ops.Tensor): + key_name = "key_" + re.sub("[^A-Za-z0-9_.\\-/]", "_", key) + default_value = ops.convert_to_tensor( + default_value, dtype=dense_types[i], name=key_name) + default_value = array_ops.reshape(default_value, dense_shape) + + dense_defaults_vec.append(default_value) + + # Finally, convert dense_shapes to TensorShapeProto + dense_shapes_as_proto = [shape.as_proto() for shape in dense_shapes] + + return (names, dense_defaults_vec, sparse_keys, sparse_types, dense_keys, + dense_shapes_as_proto, dense_shapes) + + @tf_export("parse_single_example") def parse_single_example(serialized, features, name=None, example_names=None): """Parses a single `Example` proto. diff --git a/tensorflow/python/ops/resource_variable_ops.py b/tensorflow/python/ops/resource_variable_ops.py index 3d0205f768..4800352ac2 100644 --- a/tensorflow/python/ops/resource_variable_ops.py +++ b/tensorflow/python/ops/resource_variable_ops.py @@ -355,6 +355,15 @@ class ResourceVariable(variables.RefVariable): raise ValueError("initial_value must be specified.") init_from_fn = callable(initial_value) + if isinstance(initial_value, ops.Tensor) and hasattr( + initial_value, "graph") and initial_value.graph.building_function: + raise ValueError("Tensor-typed variable initializers must either be " + "wrapped in an init_scope or callable " + "(e.g., `tf.Variable(lambda : " + "tf.truncated_normal([10, 40]))`) when building " + "functions. Please file a feature request if this " + "restriction inconveniences you.") + if collections is None: collections = [ops.GraphKeys.GLOBAL_VARIABLES] if not isinstance(collections, (list, tuple, set)): @@ -586,6 +595,22 @@ class ResourceVariable(variables.RefVariable): def __bool__(self): return bool(self.read_value()) + def __copy__(self): + return self + + def __deepcopy__(self, memo): + if not context.executing_eagerly(): + raise NotImplementedError( + "__deepcopy__() is only available when eager execution is enabled.") + copied_variable = ResourceVariable( + initial_value=self.read_value(), + trainable=self._trainable, + constraint=self._constraint, + dtype=self._dtype, + name=self._shared_name + "_copy") + memo[self._unique_id] = copied_variable + return copied_variable + @property def dtype(self): """The dtype of this variable.""" @@ -958,6 +983,231 @@ class ResourceVariable(variables.RefVariable): return self._lazy_read(assign_op) return assign_op + def __reduce__(self): + return (ResourceVariable, (self.numpy(),)) + + def scatter_sub(self, sparse_delta, use_locking=False, name=None): + """Subtracts `IndexedSlices` from this variable. + + Args: + sparse_delta: `IndexedSlices` to be subtracted from this variable. + use_locking: If `True`, use locking during the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + if not isinstance(sparse_delta, ops.IndexedSlices): + raise ValueError("sparse_delta is not IndexedSlices: %s" % sparse_delta) + return self._lazy_read(gen_resource_variable_ops.resource_scatter_sub( + self.handle, sparse_delta.indices, + ops.convert_to_tensor(sparse_delta.values, self.dtype), name=name)) + + def scatter_add(self, sparse_delta, use_locking=False, name=None): + """Adds `IndexedSlices` from this variable. + + Args: + sparse_delta: `IndexedSlices` to be added to this variable. + use_locking: If `True`, use locking during the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + if not isinstance(sparse_delta, ops.IndexedSlices): + raise ValueError("sparse_delta is not IndexedSlices: %s" % sparse_delta) + return self._lazy_read(gen_resource_variable_ops.resource_scatter_add( + self.handle, sparse_delta.indices, + ops.convert_to_tensor(sparse_delta.values, self.dtype), name=name)) + + def scatter_update(self, sparse_delta, use_locking=False, name=None): + """Assigns `IndexedSlices` to this variable. + + Args: + sparse_delta: `IndexedSlices` to be assigned to this variable. + use_locking: If `True`, use locking during the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + if not isinstance(sparse_delta, ops.IndexedSlices): + raise ValueError("sparse_delta is not IndexedSlices: %s" % sparse_delta) + return self._lazy_read(gen_resource_variable_ops.resource_scatter_update( + self.handle, sparse_delta.indices, + ops.convert_to_tensor(sparse_delta.values, self.dtype), name=name)) + + def scatter_nd_sub(self, indices, updates, name=None): + """Applies sparse subtraction to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to add 4 scattered elements to a rank-1 tensor to + 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + op = ref.scatter_nd_sub(indices, updates) + with tf.Session() as sess: + print sess.run(op) + ``` + + The resulting update to ref would look like this: + + [1, -9, 3, -6, -6, 6, 7, -4] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + indices: The indices to be used in the operation. + updates: The values to be used in the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + return self._lazy_read(gen_state_ops.resource_scatter_nd_sub( + self.handle, indices, ops.convert_to_tensor(updates, self.dtype), + name=name)) + + def scatter_nd_add(self, indices, updates, name=None): + """Applies sparse addition to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to add 4 scattered elements to a rank-1 tensor to + 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + add = ref.scatter_nd_add(indices, updates) + with tf.Session() as sess: + print sess.run(add) + ``` + + The resulting update to ref would look like this: + + [1, 13, 3, 14, 14, 6, 7, 20] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + indices: The indices to be used in the operation. + updates: The values to be used in the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + return self._lazy_read(gen_state_ops.resource_scatter_nd_add( + self.handle, indices, ops.convert_to_tensor(updates, self.dtype), + name=name)) + + def scatter_nd_update(self, indices, updates, name=None): + """Applies sparse assignment to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to add 4 scattered elements to a rank-1 tensor to + 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + op = ref.scatter_nd_update(indices, updates) + with tf.Session() as sess: + print sess.run(op) + ``` + + The resulting update to ref would look like this: + + [1, 11, 3, 10, 9, 6, 7, 12] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + indices: The indices to be used in the operation. + updates: The values to be used in the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + return self._lazy_read(gen_state_ops.resource_scatter_nd_update( + self.handle, indices, ops.convert_to_tensor(updates, self.dtype), + name=name)) + def _strided_slice_assign(self, begin, end, strides, value, name, begin_mask, end_mask, ellipsis_mask, new_axis_mask, shrink_axis_mask): diff --git a/tensorflow/python/ops/rnn.py b/tensorflow/python/ops/rnn.py index 7b6ab20975..5c00d929bf 100644 --- a/tensorflow/python/ops/rnn.py +++ b/tensorflow/python/ops/rnn.py @@ -24,6 +24,7 @@ from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import tensor_util +from tensorflow.python.keras.engine import base_layer from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import control_flow_util @@ -144,6 +145,28 @@ def _should_cache(): return control_flow_util.GetContainingWhileContext(ctxt) is None +def _is_keras_rnn_cell(rnn_cell): + """Check whether the cell is a Keras RNN cell. + + The Keras RNN cell accept the state as a list even the state is a single + tensor, whereas the TF RNN cell does not wrap single state tensor in list. + This behavior difference should be unified in future version. + + Args: + rnn_cell: An RNN cell instance that either follow the Keras interface or TF + RNN interface. + Returns: + Boolean, whether the cell is an Keras RNN cell. + """ + # Cell type check is not strict enough since there are cells created by other + # library like Deepmind that didn't inherit tf.nn.rnn_cell.RNNCell. + # Keras cells never had zero_state method, which was from the original + # interface from TF RNN cell. + return (not isinstance(rnn_cell, rnn_cell_impl.RNNCell) + and isinstance(rnn_cell, base_layer.Layer) + and getattr(rnn_cell, "zero_state", None) is None) + + # pylint: disable=unused-argument def _rnn_step( time, sequence_length, min_sequence_length, max_sequence_length, @@ -608,7 +631,11 @@ def dynamic_rnn(cell, inputs, sequence_length=None, initial_state=None, else: if not dtype: raise ValueError("If there is no initial_state, you must give a dtype.") - state = cell.zero_state(batch_size, dtype) + if getattr(cell, "get_initial_state", None) is not None: + state = cell.get_initial_state( + inputs=None, batch_size=batch_size, dtype=dtype) + else: + state = cell.zero_state(batch_size, dtype) def _assert_has_shape(x, shape): x_shape = array_ops.shape(x) @@ -788,6 +815,10 @@ def _dynamic_rnn_loop(cell, input_t = tuple(ta[time.numpy()] for ta in input_ta) input_t = nest.pack_sequence_as(structure=inputs, flat_sequence=input_t) + # Keras RNN cells only accept state as list, even if it's a single tensor. + is_keras_rnn_cell = _is_keras_rnn_cell(cell) + if is_keras_rnn_cell and not nest.is_sequence(state): + state = [state] call_cell = lambda: cell(input_t, state) if sequence_length is not None: @@ -804,6 +835,9 @@ def _dynamic_rnn_loop(cell, else: (output, new_state) = call_cell() + # Keras cells always wrap state as list, even if it's a single tensor. + if is_keras_rnn_cell and len(new_state) == 1: + new_state = new_state[0] # Pack state if using state tuples output = nest.flatten(output) @@ -1286,7 +1320,11 @@ def static_rnn(cell, if not dtype: raise ValueError("If no initial_state is provided, " "dtype must be specified") - state = cell.zero_state(batch_size, dtype) + if getattr(cell, "get_initial_state", None) is not None: + state = cell.get_initial_state( + inputs=None, batch_size=batch_size, dtype=dtype) + else: + state = cell.zero_state(batch_size, dtype) if sequence_length is not None: # Prepare variables sequence_length = ops.convert_to_tensor( @@ -1315,6 +1353,10 @@ def static_rnn(cell, min_sequence_length = math_ops.reduce_min(sequence_length) max_sequence_length = math_ops.reduce_max(sequence_length) + # Keras RNN cells only accept state as list, even if it's a single tensor. + is_keras_rnn_cell = _is_keras_rnn_cell(cell) + if is_keras_rnn_cell and not nest.is_sequence(state): + state = [state] for time, input_ in enumerate(inputs): if time > 0: varscope.reuse_variables() @@ -1333,8 +1375,10 @@ def static_rnn(cell, state_size=cell.state_size) else: (output, state) = call_cell() - outputs.append(output) + # Keras RNN cells only return state as list, even if it's a single tensor. + if is_keras_rnn_cell and len(state) == 1: + state = state[0] return (outputs, state) diff --git a/tensorflow/python/ops/rnn_cell_impl.py b/tensorflow/python/ops/rnn_cell_impl.py index 85a6a2233c..c128a1039a 100644 --- a/tensorflow/python/ops/rnn_cell_impl.py +++ b/tensorflow/python/ops/rnn_cell_impl.py @@ -80,13 +80,13 @@ def assert_like_rnncell(cell_name, cell): conditions = [ hasattr(cell, "output_size"), hasattr(cell, "state_size"), - hasattr(cell, "zero_state"), + hasattr(cell, "get_initial_state") or hasattr(cell, "zero_state"), callable(cell), ] errors = [ "'output_size' property is missing", "'state_size' property is missing", - "'zero_state' method is missing", + "either 'zero_state' or 'get_initial_state' method is required", "is not callable" ] @@ -266,6 +266,36 @@ class RNNCell(base_layer.Layer): # self.add_variable() inside the call() method. pass + def get_initial_state(self, inputs=None, batch_size=None, dtype=None): + if inputs is not None: + # Validate the given batch_size and dtype against inputs if provided. + inputs = ops.convert_to_tensor(inputs, name="inputs") + if batch_size is not None: + if tensor_util.is_tensor(batch_size): + static_batch_size = tensor_util.constant_value( + batch_size, partial=True) + else: + static_batch_size = batch_size + if inputs.shape[0].value != static_batch_size: + raise ValueError( + "batch size from input tensor is different from the " + "input param. Input tensor batch: {}, batch_size: {}".format( + inputs.shape[0].value, batch_size)) + + if dtype is not None and inputs.dtype != dtype: + raise ValueError( + "dtype from input tensor is different from the " + "input param. Input tensor dtype: {}, dtype: {}".format( + inputs.dtype, dtype)) + + batch_size = inputs.shape[0].value or array_ops.shape(inputs)[0] + dtype = inputs.dtype + if None in [batch_size, dtype]: + raise ValueError( + "batch_size and dtype cannot be None while constructing initial " + "state: batch_size={}, dtype={}".format(batch_size, dtype)) + return self.zero_state(batch_size, dtype) + def zero_state(self, batch_size, dtype): """Return zero-filled state tensor(s). diff --git a/tensorflow/python/ops/sparse_ops.py b/tensorflow/python/ops/sparse_ops.py index e91813b4a8..d1b8be4df7 100644 --- a/tensorflow/python/ops/sparse_ops.py +++ b/tensorflow/python/ops/sparse_ops.py @@ -41,6 +41,7 @@ from tensorflow.python.ops import math_ops # pylint: disable=wildcard-import from tensorflow.python.ops.gen_sparse_ops import * # pylint: enable=wildcard-import +from tensorflow.python.util import compat from tensorflow.python.util import deprecation from tensorflow.python.util.tf_export import tf_export @@ -85,6 +86,104 @@ def _convert_to_sparse_tensors(sp_inputs): raise TypeError("Inputs must be a list or tuple.") +def _make_int64_tensor(value, name): + if isinstance(value, compat.integral_types): + return ops.convert_to_tensor(value, name=name, dtype=dtypes.int64) + if not isinstance(value, ops.Tensor): + raise TypeError("{} must be an integer value".format(name)) + if value.dtype == dtypes.int64: + return value + return math_ops.cast(value, dtypes.int64) + + +@tf_export("sparse.expand_dims") +def sparse_expand_dims(sp_input, axis=None, name=None): + """Inserts a dimension of 1 into a tensor's shape. + + Given a tensor `sp_input`, this operation inserts a dimension of 1 at the + dimension index `axis` of `sp_input`'s shape. The dimension index `axis` + starts at zero; if you specify a negative number for `axis` it is counted + backwards from the end. + + Args: + sp_input: A `SparseTensor`. + axis: 0-D (scalar). Specifies the dimension index at which to expand the + shape of `input`. Must be in the range `[-rank(sp_input) - 1, + rank(sp_input)]`. + name: The name of the output `SparseTensor`. + + Returns: + A `SparseTensor` with the same data as `sp_input`, but its shape has an + additional dimension of size 1 added. + """ + rank = sp_input.dense_shape.get_shape()[0] + axis = -1 if axis is None else axis + + with ops.name_scope(name, default_name="expand_dims", values=[sp_input]): + if isinstance(axis, compat.integral_types): + axis = ops.convert_to_tensor(axis, name="axis", dtype=dtypes.int32) + elif not isinstance(axis, ops.Tensor): + raise TypeError("axis must be an integer value in range [-rank(sp_input)" + " - 1, rank(sp_input)]") + + # Convert axis to a positive value if it is negative. + axis = array_ops.where(axis >= 0, axis, axis + rank + 1) + + # Create the new column of indices for the sparse tensor by slicing + # the indices and inserting a new column of indices for the new dimension. + column_size = array_ops.shape(sp_input.indices)[0] + new_index = array_ops.zeros([column_size, 1], dtype=dtypes.int64) + indices_before = array_ops.slice(sp_input.indices, [0, 0], [-1, axis]) + indices_after = array_ops.slice(sp_input.indices, [0, axis], [-1, -1]) + indices = array_ops.concat( + [indices_before, new_index, indices_after], axis=1) + + # Create the new dense shape by splicing the tensor [1] in the correct + # dimension of the existing shape. + shape_before = array_ops.slice(sp_input.dense_shape, [0], [axis]) + shape_after = array_ops.slice(sp_input.dense_shape, [axis], [-1]) + new_shape = ops.convert_to_tensor([1], name="new_shape", dtype=dtypes.int64) + shape = array_ops.concat([shape_before, new_shape, shape_after], axis=0) + + # Create the output sparse tensor. + return sparse_tensor.SparseTensor( + indices=indices, values=sp_input.values, dense_shape=shape) + + +@tf_export("sparse.eye") +def sparse_eye(num_rows, + num_columns=None, + dtype=dtypes.float32, + name=None): + """Creates a two-dimensional sparse tensor with ones along the diagonal. + + Args: + num_rows: Non-negative integer or `int32` scalar `tensor` giving the number + of rows in the resulting matrix. + num_columns: Optional non-negative integer or `int32` scalar `tensor` giving + the number of columns in the resulting matrix. Defaults to `num_rows`. + dtype: The type of element in the resulting `Tensor`. + name: A name for this `Op`. Defaults to "eye". + + Returns: + A `SparseTensor` of shape [num_rows, num_columns] with ones along the + diagonal. + """ + with ops.name_scope(name, default_name="eye", values=[num_rows, num_columns]): + num_rows = _make_int64_tensor(num_rows, "num_rows") + num_columns = num_rows if num_columns is None else _make_int64_tensor( + num_columns, "num_columns") + + # Create the sparse tensor. + diag_size = math_ops.minimum(num_rows, num_columns) + diag_range = math_ops.range(diag_size, dtype=dtypes.int64) + + return sparse_tensor.SparseTensor( + indices=array_ops.stack([diag_range, diag_range], axis=1), + values=array_ops.ones(diag_size, dtype=dtype), + dense_shape=[num_rows, num_columns]) + + # pylint: disable=protected-access @tf_export("sparse_concat") @deprecation.deprecated_args( @@ -790,6 +889,9 @@ def sparse_reduce_max(sp_input, axis=None, keepdims=None, `tf.reduce_max()`. In particular, this Op also returns a dense `Tensor` instead of a sparse one. + Note: A gradient is not defined for this function, so it can't be used + in training models that need gradient descent. + Reduces `sp_input` along the dimensions given in `reduction_axes`. Unless `keepdims` is true, the rank of the tensor is reduced by 1 for each entry in `reduction_axes`. If `keepdims` is true, the reduced dimensions are retained @@ -857,6 +959,9 @@ def sparse_reduce_max_sparse(sp_input, `tf.reduce_max()`. In contrast to SparseReduceSum, this Op returns a SparseTensor. + Note: A gradient is not defined for this function, so it can't be used + in training models that need gradient descent. + Reduces `sp_input` along the dimensions given in `reduction_axes`. Unless `keepdims` is true, the rank of the tensor is reduced by 1 for each entry in `reduction_axes`. If `keepdims` is true, the reduced dimensions are retained @@ -958,6 +1063,9 @@ def sparse_reduce_sum_sparse(sp_input, `tf.reduce_sum()`. In contrast to SparseReduceSum, this Op returns a SparseTensor. + Note: A gradient is not defined for this function, so it can't be used + in training models that need gradient descent. + Reduces `sp_input` along the dimensions given in `reduction_axes`. Unless `keepdims` is true, the rank of the tensor is reduced by 1 for each entry in `reduction_axes`. If `keepdims` is true, the reduced dimensions are retained diff --git a/tensorflow/python/ops/sparse_ops_test.py b/tensorflow/python/ops/sparse_ops_test.py new file mode 100644 index 0000000000..4ee1569249 --- /dev/null +++ b/tensorflow/python/ops/sparse_ops_test.py @@ -0,0 +1,81 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for sparse ops.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np + +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import sparse_tensor +from tensorflow.python.framework import test_util +from tensorflow.python.ops import sparse_ops +from tensorflow.python.platform import googletest + + +@test_util.run_all_in_graph_and_eager_modes +class SparseOpsTest(test_util.TensorFlowTestCase): + + def testSparseEye(self): + def test_one(n, m, as_tensors): + expected = np.eye(n, m) + if as_tensors: + m = constant_op.constant(m) + n = constant_op.constant(n) + s = sparse_ops.sparse_eye(n, m) + d = sparse_ops.sparse_to_dense(s.indices, s.dense_shape, s.values) + self.assertAllEqual(self.evaluate(d), expected) + + for n in range(2, 10, 2): + for m in range(2, 10, 2): + # Test with n and m as both constants and tensors. + test_one(n, m, True) + test_one(n, m, False) + + def testSparseExpandDims(self): + for rank in range(1, 4): + # Create a dummy input. When rank=3, shape=[2, 4, 6]. + shape = np.arange(1, rank + 1) * 2 + before = np.arange(np.prod(shape)).reshape(shape) + + # Make entries sparse. + before *= np.random.binomial(1, .2, before.shape) + dense_shape = before.shape + indices = np.array(np.where(before)).T + values = before[before != 0] + + # Try every possible valid value of axis. + for axis in range(-rank - 1, rank): + expected_after = np.expand_dims(before, axis) + + for axis_as_tensor in [False, True]: + dense_shape_t = constant_op.constant(dense_shape, dtype=dtypes.int64) + indices_t = constant_op.constant(indices) + values_t = constant_op.constant(values) + before_t = sparse_tensor.SparseTensor( + indices=indices_t, values=values_t, dense_shape=dense_shape_t) + + if axis_as_tensor: + axis = constant_op.constant(axis) + + s = sparse_ops.sparse_expand_dims(before_t, axis) + d = sparse_ops.sparse_to_dense(s.indices, s.dense_shape, s.values) + self.assertAllEqual(self.evaluate(d), expected_after) + +if __name__ == '__main__': + googletest.main() diff --git a/tensorflow/python/ops/state_ops.py b/tensorflow/python/ops/state_ops.py index 125e6c8dbf..920047f38b 100644 --- a/tensorflow/python/ops/state_ops.py +++ b/tensorflow/python/ops/state_ops.py @@ -24,13 +24,15 @@ from __future__ import print_function from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_shape +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import gen_math_ops from tensorflow.python.ops import gen_resource_variable_ops from tensorflow.python.ops import gen_state_ops # go/tf-wildcard-import # pylint: disable=wildcard-import from tensorflow.python.ops.gen_state_ops import * -from tensorflow.python.util.tf_export import tf_export # pylint: enable=wildcard-import +from tensorflow.python.util.tf_export import tf_export # pylint: disable=protected-access,g-doc-return-or-yield,g-doc-args @@ -129,7 +131,7 @@ def is_variable_initialized(ref, name=None): return ref.is_initialized(name=name) -@tf_export("assign_sub") +@tf_export(v1=["assign_sub"]) def assign_sub(ref, value, use_locking=None, name=None): """Update 'ref' by subtracting 'value' from it. @@ -158,7 +160,7 @@ def assign_sub(ref, value, use_locking=None, name=None): return ref.assign_sub(value) -@tf_export("assign_add") +@tf_export(v1=["assign_add"]) def assign_add(ref, value, use_locking=None, name=None): """Update 'ref' by adding 'value' to it. @@ -187,7 +189,7 @@ def assign_add(ref, value, use_locking=None, name=None): return ref.assign_add(value) -@tf_export("assign") +@tf_export(v1=["assign"]) def assign(ref, value, validate_shape=None, use_locking=None, name=None): """Update 'ref' by assigning 'value' to it. @@ -220,7 +222,7 @@ def assign(ref, value, validate_shape=None, use_locking=None, name=None): return ref.assign(value, name=name) -@tf_export("count_up_to") +@tf_export(v1=["count_up_to"]) def count_up_to(ref, limit, name=None): r"""Increments 'ref' until it reaches 'limit'. @@ -243,7 +245,7 @@ def count_up_to(ref, limit, name=None): ref.handle, limit, T=ref.dtype, name=name) -@tf_export("scatter_update") +@tf_export(v1=["scatter_update"]) def scatter_update(ref, indices, updates, use_locking=True, name=None): # pylint: disable=line-too-long r"""Applies sparse updates to a variable reference. @@ -297,7 +299,7 @@ def scatter_update(ref, indices, updates, use_locking=True, name=None): name=name)) -@tf_export("scatter_nd_update") +@tf_export(v1=["scatter_nd_update"]) def scatter_nd_update(ref, indices, updates, use_locking=True, name=None): r"""Applies sparse `updates` to individual values or slices in a Variable. @@ -359,7 +361,7 @@ def scatter_nd_update(ref, indices, updates, use_locking=True, name=None): name=name)) -@tf_export("scatter_add") +@tf_export(v1=["scatter_add"]) def scatter_add(ref, indices, updates, use_locking=False, name=None): # pylint: disable=line-too-long r"""Adds sparse updates to the variable referenced by `resource`. @@ -411,7 +413,7 @@ def scatter_add(ref, indices, updates, use_locking=False, name=None): name=name)) -@tf_export("scatter_nd_add") +@tf_export(v1=["scatter_nd_add"]) def scatter_nd_add(ref, indices, updates, use_locking=False, name=None): r"""Applies sparse addition to individual values or slices in a Variable. @@ -475,7 +477,7 @@ def scatter_nd_add(ref, indices, updates, use_locking=False, name=None): name=name)) -@tf_export("scatter_sub") +@tf_export(v1=["scatter_sub"]) def scatter_sub(ref, indices, updates, use_locking=False, name=None): r"""Subtracts sparse updates to a variable reference. @@ -527,3 +529,164 @@ def scatter_sub(ref, indices, updates, use_locking=False, name=None): return ref._lazy_read(gen_resource_variable_ops.resource_scatter_sub( # pylint: disable=protected-access ref.handle, indices, ops.convert_to_tensor(updates, ref.dtype), name=name)) + + +@tf_export(v1=["scatter_nd_sub"]) +def scatter_nd_sub(ref, indices, updates, use_locking=False, name=None): + r"""Applies sparse subtraction to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to subtract 4 scattered elements from a rank-1 tensor + to 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + op = tf.scatter_nd_sub(ref, indices, updates) + with tf.Session() as sess: + print sess.run(op) + ``` + + The resulting update to ref would look like this: + + [1, -9, 3, -6, -6, 6, 7, -4] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + ref: A mutable `Tensor`. Must be one of the following types: `float32`, + `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, + `qint8`, `quint8`, `qint32`, `bfloat16`, `uint16`, `complex128`, `half`, + `uint32`, `uint64`. A mutable Tensor. Should be from a Variable node. + indices: A `Tensor`. Must be one of the following types: `int32`, `int64`. + A tensor of indices into ref. + updates: A `Tensor`. Must have the same type as `ref`. + A tensor of updated values to add to ref. + use_locking: An optional `bool`. Defaults to `False`. + An optional bool. Defaults to True. If True, the assignment will + be protected by a lock; otherwise the behavior is undefined, + but may exhibit less contention. + name: A name for the operation (optional). + + Returns: + A mutable `Tensor`. Has the same type as `ref`. + """ + if ref.dtype._is_ref_dtype: + return gen_state_ops.scatter_nd_sub( + ref, indices, updates, use_locking, name) + return ref._lazy_read(gen_state_ops.resource_scatter_nd_sub( # pylint: disable=protected-access + ref.handle, indices, ops.convert_to_tensor(updates, ref.dtype), + name=name)) + + +@tf_export("batch_scatter_update") +def batch_scatter_update(ref, indices, updates, use_locking=True, name=None): + """Generalization of `tf.scatter_update` to axis different than 0. + + Analogous to `batch_gather`. This assumes that `ref`, `indices` and `updates` + have a series of leading dimensions that are the same for all of them, and the + updates are performed on the last dimension of indices. In other words, the + dimensions should be the following: + + `num_prefix_dims = indices.ndims - 1` + `batch_dim = num_prefix_dims + 1` + `updates.shape = indices.shape + var.shape[batch_dim:]` + + where + + `updates.shape[:num_prefix_dims]` + `== indices.shape[:num_prefix_dims]` + `== var.shape[:num_prefix_dims]` + + And the operation performed can be expressed as: + + `var[i_1, ..., i_n, indices[i_1, ..., i_n, j]] = updates[i_1, ..., i_n, j]` + + When indices is a 1D tensor, this operation is equivalent to + `tf.scatter_update`. + + To avoid this operation there would be 2 alternatives: + 1) Reshaping the variable by merging the first `ndims` dimensions. However, + this is not possible because `tf.reshape` returns a Tensor, which we + cannot use `tf.scatter_update` on. + 2) Looping over the first `ndims` of the variable and using + `tf.scatter_update` on the subtensors that result of slicing the first + dimension. This is a valid option for `ndims = 1`, but less efficient than + this implementation. + + See also `tf.scatter_update` and `tf.scatter_nd_update`. + + Args: + ref: `Variable` to scatter onto. + indices: Tensor containing indices as described above. + updates: Tensor of updates to apply to `ref`. + use_locking: Boolean indicating whether to lock the writing operation. + name: Optional scope name string. + + Returns: + Ref to `variable` after it has been modified. + + Raises: + ValueError: If the initial `ndims` of `ref`, `indices`, and `updates` are + not the same. + """ + with ops.name_scope(name): + indices = ops.convert_to_tensor(indices, name="indices") + indices_shape = array_ops.shape(indices) + indices_dimensions = indices.get_shape().ndims + + if indices_dimensions is None: + raise ValueError("batch_gather does not allow indices with unknown " + "shape.") + + nd_indices = array_ops.expand_dims(indices, axis=-1) + nd_indices_list = [] + + # Scatter ND requires indices to have an additional dimension, in which the + # coordinates of the updated things are specified. For this to be adapted to + # the scatter_update with several leading dimensions, we simply make use of + # a tf.range for all the leading dimensions followed by concat of all the + # coordinates we created with the original indices. + + # For example if indices.shape = [2, 3, 4], we should generate the following + # indices for tf.scatter_nd_update: + # nd_indices[:, :, 0] = [[0, 0, 0], [1, 1, 1]] + # nd_indices[:, :, 1] = [[0, 1, 2], [0, 1, 2]] + # nd_indices[:, :, 2] = indices + for dimension in range(indices_dimensions - 1): + # In this loop we generate the following for the example (one for each + # iteration). + # nd_indices[:, :, 0] = [[0, 0, 0], [1, 1, 1]] + # nd_indices[:, :, 1] = [[0, 1, 2], [0, 1, 2]] + # This is done at every iteration with a tf.range over the size of the + # i-th dimension and using broadcasting over the desired shape. + dimension_size = indices_shape[dimension] + shape_to_broadcast = [1] * (indices_dimensions + 1) + shape_to_broadcast[dimension] = dimension_size + dimension_range = array_ops.reshape( + gen_math_ops._range(0, dimension_size, 1), shape_to_broadcast) + if dimension_range.dtype.base_dtype != nd_indices.dtype: + dimension_range = gen_math_ops.cast(dimension_range, nd_indices.dtype) + nd_indices_list.append( + dimension_range * array_ops.ones_like(nd_indices)) + # Add the original indices at the end, as described above, and concat. + nd_indices_list.append(nd_indices) + final_indices = array_ops.concat(nd_indices_list, axis=-1) + return scatter_nd_update( + ref, final_indices, updates, use_locking=use_locking) diff --git a/tensorflow/python/ops/string_ops.py b/tensorflow/python/ops/string_ops.py index 67ae2e6e39..c832ba4e2a 100644 --- a/tensorflow/python/ops/string_ops.py +++ b/tensorflow/python/ops/string_ops.py @@ -24,6 +24,7 @@ from __future__ import print_function import numpy as np +from tensorflow.python.compat import compat from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops @@ -31,6 +32,7 @@ from tensorflow.python.framework import sparse_tensor from tensorflow.python.ops import array_ops from tensorflow.python.ops import gen_string_ops from tensorflow.python.ops import math_ops +from tensorflow.python.util import compat as util_compat # go/tf-wildcard-import # pylint: disable=wildcard-import @@ -42,6 +44,41 @@ from tensorflow.python.util.tf_export import tf_export # Expose regex_full_match in strings namespace tf_export("strings.regex_full_match")(regex_full_match) + +def regex_replace(source, pattern, rewrite, replace_global=True): + r"""Replace elements of `source` matching regex `pattern with `rewrite`. + + Args: + source: string `Tensor`, the source strings to process. + pattern: string or scalar string `Tensor`, regular expression to use, + see more details at https://github.com/google/re2/wiki/Syntax + rewrite: string or scalar string `Tensor`, value to use in match + replacement, supports backslash-escaped digits (\1 to \9) can be to insert + text matching corresponding parenthesized group. + replace_global: `bool`, if `True` replace all non-overlapping matches, + else replace only the first match. + + Returns: + string `Tensor` of the same shape as `source` with specified replacements. + """ + # TODO(b/112455102): Remove compat.forward_compatible once past the horizon. + if not compat.forward_compatible(2018, 10, 10): + return gen_string_ops.regex_replace( + input=source, pattern=pattern, + rewrite=rewrite, replace_global=replace_global) + if (isinstance(pattern, util_compat.bytes_or_text_types) and + isinstance(rewrite, util_compat.bytes_or_text_types)): + # When `pattern` and `rewrite` are static through the life of the op we can + # use a version which performs the expensive regex compilation once at + # creation time. + return gen_string_ops.static_regex_replace( + input=source, pattern=pattern, + rewrite=rewrite, replace_global=replace_global) + return gen_string_ops.regex_replace( + input=source, pattern=pattern, + rewrite=rewrite, replace_global=replace_global) + + @tf_export("string_split") def string_split(source, delimiter=" ", skip_empty=True): # pylint: disable=invalid-name """Split elements of `source` based on `delimiter` into a `SparseTensor`. diff --git a/tensorflow/python/ops/variable_scope.py b/tensorflow/python/ops/variable_scope.py index fdad9c9e77..f53e06fdf9 100644 --- a/tensorflow/python/ops/variable_scope.py +++ b/tensorflow/python/ops/variable_scope.py @@ -40,8 +40,10 @@ from tensorflow.python.ops import init_ops from tensorflow.python.ops import resource_variable_ops from tensorflow.python.ops import variables from tensorflow.python.platform import tf_logging as logging +from tensorflow.python.util import deprecation from tensorflow.python.util import function_utils from tensorflow.python.util import tf_contextlib +from tensorflow.python.util import tf_inspect from tensorflow.python.util.tf_export import tf_export __all__ = [ @@ -204,6 +206,42 @@ it does exist, simply return it. """ +_DEFAULT_USE_RESOURCE = False + + +@tf_export(v1=["enable_resource_variables"]) +def enable_resource_variables(): + """Creates resource variables by default. + + Resource variables are improved versions of TensorFlow variables with a + well-defined memory model. Accessing a resource variable reads its value, and + all ops which access a specific read value of the variable are guaranteed to + see the same value for that tensor. Writes which happen after a read (by + having a control or data dependency on the read) are guaranteed not to affect + the value of the read tensor, and similarly writes which happen before a read + are guaranteed to affect the value. No guarantees are made about unordered + read/write pairs. + + Calling tf.enable_resource_variables() lets you opt-in to this TensorFlow 2.0 + feature. + """ + global _DEFAULT_USE_RESOURCE + _DEFAULT_USE_RESOURCE = True + + +@deprecation.deprecated( + None, "non-resource variables are not supported in the long term") +@tf_export(v1=["disable_resource_variables"]) +def disable_resource_variables(): + """Opts out of resource variables. + + If your code needs tf.disable_resource_variables() to be called to work + properly please file a bug. + """ + global _DEFAULT_USE_RESOURCE + _DEFAULT_USE_RESOURCE = False + + class _VariableStore(object): """Variable store that carries a number of named Variables. @@ -837,9 +875,6 @@ class _VariableStore(object): raise ValueError("Variable %s does not exist, or was not created with " "tf.get_variable(). Did you mean to set " "reuse=tf.AUTO_REUSE in VarScope?" % name) - if not shape.is_fully_defined() and not initializing_from_value: - raise ValueError("Shape of a new variable (%s) must be fully defined, " - "but instead was %s." % (name, shape)) # Create the tensor to initialize the variable with default value. if initializer is None: @@ -854,14 +889,23 @@ class _VariableStore(object): # Instantiate initializer if provided initializer is a type object. if isinstance(initializer, type(init_ops.Initializer)): initializer = initializer(dtype=dtype) - init_val = lambda: initializer( # pylint: disable=g-long-lambda - shape.as_list(), dtype=dtype, partition_info=partition_info) + if shape and shape.is_fully_defined(): + init_val = lambda: initializer( # pylint: disable=g-long-lambda + shape.as_list(), dtype=dtype, partition_info=partition_info) + elif not tf_inspect.getargspec(initializer).args: + init_val = initializer + else: + raise ValueError("You can only pass an initializer function that" + "expects no arguments to its callable when the " + "shape is not fully defined. The given initializer " + "function expects the following args %s" % + tf_inspect.getargspec(initializer).args) variable_dtype = dtype.base_dtype # Create the variable. if use_resource is None: # Set the default value if unspecified. - use_resource = False + use_resource = _DEFAULT_USE_RESOURCE v = variable( initial_value=init_val, name=name, @@ -2362,6 +2406,8 @@ def default_variable_creator(next_creator=None, **kwargs): if use_resource is None: use_resource = get_variable_scope().use_resource + if use_resource is None: + use_resource = _DEFAULT_USE_RESOURCE use_resource = use_resource or context.executing_eagerly() if use_resource: return resource_variable_ops.ResourceVariable( diff --git a/tensorflow/python/ops/variables.py b/tensorflow/python/ops/variables.py index 7a28615ba9..f7da3f7d64 100644 --- a/tensorflow/python/ops/variables.py +++ b/tensorflow/python/ops/variables.py @@ -30,6 +30,7 @@ from tensorflow.python.framework import tensor_shape from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import gen_array_ops +from tensorflow.python.ops import gen_state_ops from tensorflow.python.ops import math_ops from tensorflow.python.ops import state_ops from tensorflow.python.platform import tf_logging as logging @@ -458,7 +459,7 @@ class Variable(six.with_metaclass(VariableMetaclass, """ raise NotImplementedError - def assign(self, value, use_locking=False): + def assign(self, value, use_locking=False, name=None, read_value=True): """Assigns a new value to the variable. This is essentially a shortcut for `assign(self, value)`. @@ -466,6 +467,9 @@ class Variable(six.with_metaclass(VariableMetaclass, Args: value: A `Tensor`. The new value for this variable. use_locking: If `True`, use locking during the assignment. + name: The name of the operation to be created + read_value: if True, will return something which evaluates to the + new value of the variable; if False will return the assign op. Returns: A `Tensor` that will hold the new value of this variable after @@ -473,7 +477,7 @@ class Variable(six.with_metaclass(VariableMetaclass, """ raise NotImplementedError - def assign_add(self, delta, use_locking=False): + def assign_add(self, delta, use_locking=False, name=None, read_value=True): """Adds a value to this variable. This is essentially a shortcut for `assign_add(self, delta)`. @@ -481,6 +485,9 @@ class Variable(six.with_metaclass(VariableMetaclass, Args: delta: A `Tensor`. The value to add to this variable. use_locking: If `True`, use locking during the operation. + name: The name of the operation to be created + read_value: if True, will return something which evaluates to the + new value of the variable; if False will return the assign op. Returns: A `Tensor` that will hold the new value of this variable after @@ -488,7 +495,7 @@ class Variable(six.with_metaclass(VariableMetaclass, """ raise NotImplementedError - def assign_sub(self, delta, use_locking=False): + def assign_sub(self, delta, use_locking=False, name=None, read_value=True): """Subtracts a value from this variable. This is essentially a shortcut for `assign_sub(self, delta)`. @@ -496,6 +503,9 @@ class Variable(six.with_metaclass(VariableMetaclass, Args: delta: A `Tensor`. The value to subtract from this variable. use_locking: If `True`, use locking during the operation. + name: The name of the operation to be created + read_value: if True, will return something which evaluates to the + new value of the variable; if False will return the assign op. Returns: A `Tensor` that will hold the new value of this variable after @@ -503,15 +513,200 @@ class Variable(six.with_metaclass(VariableMetaclass, """ raise NotImplementedError - def scatter_sub(self, sparse_delta, use_locking=False): + def scatter_sub(self, sparse_delta, use_locking=False, name=None): """Subtracts `IndexedSlices` from this variable. - This is essentially a shortcut for `scatter_sub(self, sparse_delta.indices, - sparse_delta.values)`. - Args: sparse_delta: `IndexedSlices` to be subtracted from this variable. use_locking: If `True`, use locking during the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + raise NotImplementedError + + def scatter_add(self, sparse_delta, use_locking=False, name=None): + """Adds `IndexedSlices` to this variable. + + Args: + sparse_delta: `IndexedSlices` to be assigned to this variable. + use_locking: If `True`, use locking during the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + raise NotImplementedError + + def scatter_update(self, sparse_delta, use_locking=False, name=None): + """Assigns `IndexedSlices` to this variable. + + Args: + sparse_delta: `IndexedSlices` to be assigned to this variable. + use_locking: If `True`, use locking during the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + raise NotImplementedError + + def scatter_nd_sub(self, indices, updates, name=None): + """Applies sparse subtraction to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to add 4 scattered elements to a rank-1 tensor to + 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + op = ref.scatter_nd_sub(indices, updates) + with tf.Session() as sess: + print sess.run(op) + ``` + + The resulting update to ref would look like this: + + [1, -9, 3, -6, -6, 6, 7, -4] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + indices: The indices to be used in the operation. + updates: The values to be used in the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + raise NotImplementedError + + def scatter_nd_add(self, indices, updates, name=None): + """Applies sparse addition to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to add 4 scattered elements to a rank-1 tensor to + 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + add = ref.scatter_nd_add(indices, updates) + with tf.Session() as sess: + print sess.run(add) + ``` + + The resulting update to ref would look like this: + + [1, 13, 3, 14, 14, 6, 7, 20] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + indices: The indices to be used in the operation. + updates: The values to be used in the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + raise NotImplementedError + + def scatter_nd_update(self, indices, updates, name=None): + """Applies sparse assignment to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to add 4 scattered elements to a rank-1 tensor to + 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + op = ref.scatter_nd_assign(indices, updates) + with tf.Session() as sess: + print sess.run(op) + ``` + + The resulting update to ref would look like this: + + [1, 11, 3, 10, 9, 6, 7, 12] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + indices: The indices to be used in the operation. + updates: The values to be used in the operation. + name: the name of the operation. Returns: A `Tensor` that will hold the new value of this variable after @@ -1264,7 +1459,7 @@ class RefVariable(Variable): """ return self._constraint - def assign(self, value, use_locking=False): + def assign(self, value, use_locking=False, name=None, read_value=True): """Assigns a new value to the variable. This is essentially a shortcut for `assign(self, value)`. @@ -1272,14 +1467,21 @@ class RefVariable(Variable): Args: value: A `Tensor`. The new value for this variable. use_locking: If `True`, use locking during the assignment. + name: The name of the operation to be created + read_value: if True, will return something which evaluates to the + new value of the variable; if False will return the assign op. Returns: A `Tensor` that will hold the new value of this variable after the assignment has completed. """ - return state_ops.assign(self._variable, value, use_locking=use_locking) + assign = state_ops.assign(self._variable, value, use_locking=use_locking, + name=name) + if read_value: + return assign + return assign.op - def assign_add(self, delta, use_locking=False): + def assign_add(self, delta, use_locking=False, name=None, read_value=True): """Adds a value to this variable. This is essentially a shortcut for `assign_add(self, delta)`. @@ -1287,14 +1489,21 @@ class RefVariable(Variable): Args: delta: A `Tensor`. The value to add to this variable. use_locking: If `True`, use locking during the operation. + name: The name of the operation to be created + read_value: if True, will return something which evaluates to the + new value of the variable; if False will return the assign op. Returns: A `Tensor` that will hold the new value of this variable after the addition has completed. """ - return state_ops.assign_add(self._variable, delta, use_locking=use_locking) + assign = state_ops.assign_add( + self._variable, delta, use_locking=use_locking, name=name) + if read_value: + return assign + return assign.op - def assign_sub(self, delta, use_locking=False): + def assign_sub(self, delta, use_locking=False, name=None, read_value=True): """Subtracts a value from this variable. This is essentially a shortcut for `assign_sub(self, delta)`. @@ -1302,22 +1511,51 @@ class RefVariable(Variable): Args: delta: A `Tensor`. The value to subtract from this variable. use_locking: If `True`, use locking during the operation. + name: The name of the operation to be created + read_value: if True, will return something which evaluates to the + new value of the variable; if False will return the assign op. Returns: A `Tensor` that will hold the new value of this variable after the subtraction has completed. """ - return state_ops.assign_sub(self._variable, delta, use_locking=use_locking) + assign = state_ops.assign_sub( + self._variable, delta, use_locking=use_locking, name=name) + if read_value: + return assign + return assign.op - def scatter_sub(self, sparse_delta, use_locking=False): + def scatter_sub(self, sparse_delta, use_locking=False, name=None): """Subtracts `IndexedSlices` from this variable. - This is essentially a shortcut for `scatter_sub(self, sparse_delta.indices, - sparse_delta.values)`. - Args: sparse_delta: `IndexedSlices` to be subtracted from this variable. use_locking: If `True`, use locking during the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + if not isinstance(sparse_delta, ops.IndexedSlices): + raise ValueError("sparse_delta is not IndexedSlices: %s" % sparse_delta) + return gen_state_ops.scatter_sub( + self._variable, + sparse_delta.indices, + sparse_delta.values, + use_locking=use_locking, + name=name) + + def scatter_add(self, sparse_delta, use_locking=False, name=None): + """Adds `IndexedSlices` from this variable. + + Args: + sparse_delta: `IndexedSlices` to be added to this variable. + use_locking: If `True`, use locking during the operation. + name: the name of the operation. Returns: A `Tensor` that will hold the new value of this variable after @@ -1328,11 +1566,192 @@ class RefVariable(Variable): """ if not isinstance(sparse_delta, ops.IndexedSlices): raise ValueError("sparse_delta is not IndexedSlices: %s" % sparse_delta) - return state_ops.scatter_sub( + return gen_state_ops.scatter_add( self._variable, sparse_delta.indices, sparse_delta.values, - use_locking=use_locking) + use_locking=use_locking, + name=name) + + def scatter_update(self, sparse_delta, use_locking=False, name=None): + """Assigns `IndexedSlices` to this variable. + + Args: + sparse_delta: `IndexedSlices` to be assigned to this variable. + use_locking: If `True`, use locking during the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + if not isinstance(sparse_delta, ops.IndexedSlices): + raise ValueError("sparse_delta is not IndexedSlices: %s" % sparse_delta) + return gen_state_ops.scatter_update( + self._variable, + sparse_delta.indices, + sparse_delta.values, + use_locking=use_locking, + name=name) + + def scatter_nd_sub(self, indices, updates, name=None): + """Applies sparse subtraction to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to add 4 scattered elements to a rank-1 tensor to + 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + op = ref.scatter_nd_sub(indices, updates) + with tf.Session() as sess: + print sess.run(op) + ``` + + The resulting update to ref would look like this: + + [1, -9, 3, -6, -6, 6, 7, -4] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + indices: The indices to be used in the operation. + updates: The values to be used in the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + return gen_state_ops.scatter_nd_sub( + self._variable, indices, updates, use_locking=True, name=name) + + def scatter_nd_add(self, indices, updates, name=None): + """Applies sparse addition to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to add 4 scattered elements to a rank-1 tensor to + 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + add = ref.scatter_nd_add(indices, updates) + with tf.Session() as sess: + print sess.run(add) + ``` + + The resulting update to ref would look like this: + + [1, 13, 3, 14, 14, 6, 7, 20] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + indices: The indices to be used in the operation. + updates: The values to be used in the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + return gen_state_ops.scatter_nd_add( + self._variable, indices, updates, use_locking=True, name=name) + + def scatter_nd_update(self, indices, updates, name=None): + """Applies sparse assignment to individual values or slices in a Variable. + + `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. + + `indices` must be integer tensor, containing indices into `ref`. + It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. + + The innermost dimension of `indices` (with length `K`) corresponds to + indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th + dimension of `ref`. + + `updates` is `Tensor` of rank `Q-1+P-K` with shape: + + ``` + [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. + ``` + + For example, say we want to add 4 scattered elements to a rank-1 tensor to + 8 elements. In Python, that update would look like this: + + ```python + ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) + indices = tf.constant([[4], [3], [1] ,[7]]) + updates = tf.constant([9, 10, 11, 12]) + op = ref.scatter_nd_update(indices, updates) + with tf.Session() as sess: + print sess.run(op) + ``` + + The resulting update to ref would look like this: + + [1, 11, 3, 10, 9, 6, 7, 12] + + See `tf.scatter_nd` for more details about how to make updates to + slices. + + Args: + indices: The indices to be used in the operation. + updates: The values to be used in the operation. + name: the name of the operation. + + Returns: + A `Tensor` that will hold the new value of this variable after + the scattered subtraction has completed. + + Raises: + ValueError: if `sparse_delta` is not an `IndexedSlices`. + """ + return gen_state_ops.scatter_nd_update( + self._variable, indices, updates, use_locking=True, name=name) def _strided_slice_assign(self, begin, @@ -1917,10 +2336,15 @@ class PartitionedVariable(object): def as_tensor(self): """Returns the overall concatenated value as a `Tensor`. + The returned tensor will not inherit the control dependencies from the scope + where the value is used, which is similar to getting the value of + `Variable`. + Returns: `Tensor` containing the concatenated value. """ - return self._concat() + with ops.control_dependencies(None): + return self._concat() @staticmethod def _TensorConversionFunction(v, dtype=None, name=None, as_ref=False): diff --git a/tensorflow/python/pywrap_tfe.i b/tensorflow/python/pywrap_tfe.i index 157f2341e0..e1c233cdd9 100644..100755 --- a/tensorflow/python/pywrap_tfe.i +++ b/tensorflow/python/pywrap_tfe.i @@ -105,20 +105,29 @@ limitations under the License. } } +// For const parameters in a function, SWIG pretty much ignores the const. +// See: http://www.swig.org/Doc2.0/SWIG.html#SWIG_nn13 +// Hence the 'const_cast'. %typemap(in) const char* serialized_function_def { - $1 = TFE_GetPythonString($input); + $1 = const_cast<char*>(TFE_GetPythonString($input)); } +// For const parameters in a function, SWIG pretty much ignores the const. +// See: http://www.swig.org/Doc2.0/SWIG.html#SWIG_nn13 +// Hence the 'const_cast'. %typemap(in) const char* device_name { if ($input == Py_None) { $1 = nullptr; } else { - $1 = TFE_GetPythonString($input); + $1 = const_cast<char*>(TFE_GetPythonString($input)); } } +// For const parameters in a function, SWIG pretty much ignores the const. +// See: http://www.swig.org/Doc2.0/SWIG.html#SWIG_nn13 +// Hence the 'const_cast'. %typemap(in) const char* op_name { - $1 = TFE_GetPythonString($input); + $1 = const_cast<char*>(TFE_GetPythonString($input)); } %typemap(in) (TFE_Context*) { diff --git a/tensorflow/python/saved_model/loader_test.py b/tensorflow/python/saved_model/loader_test.py index 9a0b276a4b..b7e217a35b 100644 --- a/tensorflow/python/saved_model/loader_test.py +++ b/tensorflow/python/saved_model/loader_test.py @@ -79,13 +79,13 @@ class SavedModelLoaderTest(test.TestCase): def test_load_function(self): loader = loader_impl.SavedModelLoader(SIMPLE_ADD_SAVED_MODEL) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo_graph"]) self.assertEqual(5, sess.graph.get_tensor_by_name("x:0").eval()) self.assertEqual(11, sess.graph.get_tensor_by_name("y:0").eval()) loader2 = loader_impl.SavedModelLoader(SAVED_MODEL_WITH_MAIN_OP) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader2.load(sess, ["foo_graph"]) self.assertEqual(5, sess.graph.get_tensor_by_name("x:0").eval()) self.assertEqual(7, sess.graph.get_tensor_by_name("y:0").eval()) @@ -101,7 +101,7 @@ class SavedModelLoaderTest(test.TestCase): with self.assertRaises(KeyError): graph.get_tensor_by_name("z:0") - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: # Check that x and y are not initialized with self.assertRaises(errors.FailedPreconditionError): sess.run(x) @@ -110,7 +110,7 @@ class SavedModelLoaderTest(test.TestCase): def test_load_with_import_scope(self): loader = loader_impl.SavedModelLoader(SAVED_MODEL_WITH_MAIN_OP) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: saver, _ = loader.load_graph( sess.graph, ["foo_graph"], import_scope="baz") @@ -126,14 +126,14 @@ class SavedModelLoaderTest(test.TestCase): # Test combined load function. loader = loader_impl.SavedModelLoader(SAVED_MODEL_WITH_MAIN_OP) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo_graph"], import_scope="baa") self.assertEqual(5, sess.graph.get_tensor_by_name("baa/x:0").eval()) self.assertEqual(7, sess.graph.get_tensor_by_name("baa/y:0").eval()) def test_restore_variables(self): loader = loader_impl.SavedModelLoader(SAVED_MODEL_WITH_MAIN_OP) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: x = variables.Variable(0, name="x") y = variables.Variable(0, name="y") z = x * y @@ -151,7 +151,7 @@ class SavedModelLoaderTest(test.TestCase): loader = loader_impl.SavedModelLoader(SAVED_MODEL_WITH_MAIN_OP) graph = ops.Graph() saver, _ = loader.load_graph(graph, ["foo_graph"]) - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: loader.restore_variables(sess, saver) self.assertEqual(5, sess.graph.get_tensor_by_name("x:0").eval()) self.assertEqual(11, sess.graph.get_tensor_by_name("y:0").eval()) @@ -203,12 +203,12 @@ class SavedModelLoaderTest(test.TestCase): builder.save() loader = loader_impl.SavedModelLoader(path) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: saver, _ = loader.load_graph(sess.graph, ["foo_graph"]) self.assertFalse(variables._all_saveable_objects()) self.assertIsNotNone(saver) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo_graph"]) self.assertEqual(5, sess.graph.get_tensor_by_name("x:0").eval()) self.assertEqual(11, sess.graph.get_tensor_by_name("y:0").eval()) diff --git a/tensorflow/python/saved_model/saved_model_test.py b/tensorflow/python/saved_model/saved_model_test.py index 00b669fc97..49d52d3bee 100644 --- a/tensorflow/python/saved_model/saved_model_test.py +++ b/tensorflow/python/saved_model/saved_model_test.py @@ -97,7 +97,7 @@ class SavedModelTest(test.TestCase): self.assertEqual(expected_asset_tensor_name, asset.tensor_info.name) def _validate_inputs_tensor_info_fail(self, builder, tensor_info): - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) foo_signature = signature_def_utils.build_signature_def({ @@ -110,7 +110,7 @@ class SavedModelTest(test.TestCase): signature_def_map={"foo_key": foo_signature}) def _validate_inputs_tensor_info_accept(self, builder, tensor_info): - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) foo_signature = signature_def_utils.build_signature_def({ @@ -121,7 +121,7 @@ class SavedModelTest(test.TestCase): signature_def_map={"foo_key": foo_signature}) def _validate_outputs_tensor_info_fail(self, builder, tensor_info): - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) foo_signature = signature_def_utils.build_signature_def( @@ -133,7 +133,7 @@ class SavedModelTest(test.TestCase): signature_def_map={"foo_key": foo_signature}) def _validate_outputs_tensor_info_accept(self, builder, tensor_info): - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) foo_signature = signature_def_utils.build_signature_def( @@ -153,7 +153,7 @@ class SavedModelTest(test.TestCase): def testBadSavedModelFileFormat(self): export_dir = self._get_export_dir("test_bad_saved_model_file_format") # Attempt to load a SavedModel from an export directory that does not exist. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: with self.assertRaisesRegexp(IOError, "SavedModel file does not exist at: %s" % export_dir): @@ -164,7 +164,7 @@ class SavedModelTest(test.TestCase): path_to_pb = os.path.join(export_dir, constants.SAVED_MODEL_FILENAME_PB) with open(path_to_pb, "w") as f: f.write("invalid content") - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: with self.assertRaisesRegexp(IOError, "Cannot parse file.*%s" % constants.SAVED_MODEL_FILENAME_PB): loader.load(sess, ["foo"], export_dir) @@ -178,7 +178,7 @@ class SavedModelTest(test.TestCase): constants.SAVED_MODEL_FILENAME_PBTXT) with open(path_to_pbtxt, "w") as f: f.write("invalid content") - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: with self.assertRaisesRegexp(IOError, "Cannot parse file.*%s" % constants.SAVED_MODEL_FILENAME_PBTXT): loader.load(sess, ["foo"], export_dir) @@ -187,7 +187,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_verify_session_graph_usage") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) builder.add_meta_graph_and_variables(sess, [tag_constants.TRAINING]) @@ -209,12 +209,12 @@ class SavedModelTest(test.TestCase): # Expect an assertion error since add_meta_graph_and_variables() should be # invoked before any add_meta_graph() calls. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self.assertRaises(AssertionError, builder.add_meta_graph, ["foo"]) # Expect an assertion error for multiple calls of # add_meta_graph_and_variables() since weights should be saved exactly once. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) builder.add_meta_graph_and_variables(sess, ["bar"]) self.assertRaises(AssertionError, builder.add_meta_graph_and_variables, @@ -227,35 +227,35 @@ class SavedModelTest(test.TestCase): # Graph with a single variable. SavedModel invoked to: # - add with weights. # - a single tag (from predefined constants). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) builder.add_meta_graph_and_variables(sess, [tag_constants.TRAINING]) # Graph that updates the single variable. SavedModel invoked to: # - simply add the model (weights are not updated). # - a single tag (from predefined constants). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 43) builder.add_meta_graph([tag_constants.SERVING]) # Graph that updates the single variable. SavedModel invoked to: # - simply add the model (weights are not updated). # - multiple tags (from predefined constants). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 45) builder.add_meta_graph([tag_constants.SERVING, tag_constants.GPU]) # Graph that updates the single variable. SavedModel invoked to: # - simply add the model (weights are not updated). # - multiple tags (from predefined constants for serving on TPU). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 45) builder.add_meta_graph([tag_constants.SERVING, tag_constants.TPU]) # Graph that updates the single variable. SavedModel is invoked: # - to add the model (weights are not updated). # - multiple custom tags. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 44) builder.add_meta_graph(["foo", "bar"]) @@ -263,49 +263,49 @@ class SavedModelTest(test.TestCase): builder.save() # Restore the graph with a single predefined tag whose variables were saved. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, [tag_constants.TRAINING], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) # Restore the graph with a single predefined tag whose variables were not # saved. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, [tag_constants.SERVING], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) # Restore the graph with multiple predefined tags whose variables were not # saved. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, [tag_constants.SERVING, tag_constants.GPU], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) # Restore the graph with multiple predefined tags (for serving on TPU) # whose variables were not saved. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, [tag_constants.SERVING, tag_constants.TPU], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) # Restore the graph with multiple tags. Provide duplicate tags to test set # semantics. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo", "bar", "foo"], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) # Try restoring a graph with a non-existent tag. This should yield a runtime # error. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self.assertRaises(RuntimeError, loader.load, sess, ["INVALID"], export_dir) # Try restoring a graph where a subset of the tags match. Since tag matching # for meta graph defs follows "all" semantics, this should yield a runtime # error. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self.assertRaises(RuntimeError, loader.load, sess, ["foo", "baz"], export_dir) @@ -315,7 +315,7 @@ class SavedModelTest(test.TestCase): # Graph with two variables. SavedModel invoked to: # - add with weights. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v1", 1) self._init_and_validate_variable(sess, "v2", 2) builder.add_meta_graph_and_variables(sess, ["foo"]) @@ -323,14 +323,14 @@ class SavedModelTest(test.TestCase): # Graph with a single variable (subset of the variables from the previous # graph whose weights were saved). SavedModel invoked to: # - simply add the model (weights are not updated). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v2", 3) builder.add_meta_graph(["bar"]) # Graph with a single variable (disjoint set of variables from the previous # graph whose weights were saved). SavedModel invoked to: # - simply add the model (weights are not updated). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v3", 4) builder.add_meta_graph(["baz"]) @@ -338,7 +338,7 @@ class SavedModelTest(test.TestCase): builder.save() # Restore the graph with tag "foo", whose variables were saved. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) collection_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) self.assertEqual(len(collection_vars), 2) @@ -348,7 +348,7 @@ class SavedModelTest(test.TestCase): # Restore the graph with tag "bar", whose variables were not saved. Only the # subset of the variables added to the graph will be restored with the # checkpointed value. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["bar"], export_dir) collection_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) self.assertEqual(len(collection_vars), 1) @@ -357,7 +357,7 @@ class SavedModelTest(test.TestCase): # Try restoring the graph with tag "baz", whose variables were not saved. # Since this graph has a disjoint set of variables from the set that was # saved, this should raise an error. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self.assertRaises(errors.NotFoundError, loader.load, sess, ["baz"], export_dir) @@ -366,12 +366,12 @@ class SavedModelTest(test.TestCase): builder = saved_model_builder.SavedModelBuilder(export_dir) # Graph with no variables. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: constant_5_name = constant_op.constant(5.0).name builder.add_meta_graph_and_variables(sess, ["foo"]) # Second graph with no variables - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: constant_6_name = constant_op.constant(6.0).name builder.add_meta_graph(["bar"]) @@ -379,7 +379,7 @@ class SavedModelTest(test.TestCase): builder.save() # Restore the graph with tag "foo". - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) # Read the constant a from the graph. a = ops.get_default_graph().get_tensor_by_name(constant_5_name) @@ -388,7 +388,7 @@ class SavedModelTest(test.TestCase): self.assertEqual(30.0, sess.run(c)) # Restore the graph with tag "bar". - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["bar"], export_dir) # Read the constant a from the graph. a = ops.get_default_graph().get_tensor_by_name(constant_6_name) @@ -402,7 +402,7 @@ class SavedModelTest(test.TestCase): # Graph with a single variable. SavedModel invoked to: # - add with weights. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) builder.add_meta_graph_and_variables(sess, ["foo"]) @@ -410,7 +410,7 @@ class SavedModelTest(test.TestCase): builder.save(as_text=True) # Restore the graph with tag "foo", whose variables were saved. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) @@ -426,13 +426,13 @@ class SavedModelTest(test.TestCase): # Graph with a single variable. SavedModel invoked to: # - add with weights. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) builder.add_meta_graph_and_variables(sess, ["foo"]) # Graph with the same single variable. SavedModel invoked to: # - simply add the model (weights are not updated). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 43) builder.add_meta_graph(["bar"]) @@ -440,13 +440,13 @@ class SavedModelTest(test.TestCase): builder.save(as_text=True) # Restore the graph with tag "foo", whose variables were saved. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) # Restore the graph with tag "bar", whose variables were not saved. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["bar"], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) @@ -457,7 +457,7 @@ class SavedModelTest(test.TestCase): # Graph with a single variable added to a collection. SavedModel invoked to: # - add with weights. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v = variables.Variable(42, name="v") ops.add_to_collection("foo_vars", v) sess.run(variables.global_variables_initializer()) @@ -467,7 +467,7 @@ class SavedModelTest(test.TestCase): # Graph with the same single variable added to a different collection. # SavedModel invoked to: # - simply add the model (weights are not updated). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: v = variables.Variable(43, name="v") ops.add_to_collection("bar_vars", v) sess.run(variables.global_variables_initializer()) @@ -480,7 +480,7 @@ class SavedModelTest(test.TestCase): # Restore the graph with tag "foo", whose variables were saved. The # collection 'foo_vars' should contain a single element. The collection # 'bar_vars' should not be found. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) collection_foo_vars = ops.get_collection("foo_vars") self.assertEqual(len(collection_foo_vars), 1) @@ -493,7 +493,7 @@ class SavedModelTest(test.TestCase): # reflect the new collection. The value of the variable in the # collection-def corresponds to the saved value (from the previous graph # with tag "foo"). - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["bar"], export_dir) collection_bar_vars = ops.get_collection("bar_vars") self.assertEqual(len(collection_bar_vars), 1) @@ -507,7 +507,7 @@ class SavedModelTest(test.TestCase): # Graph with a single variable and a single entry in the signature def map. # SavedModel is invoked to add with weights. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) # Build and populate an empty SignatureDef for testing. foo_signature = signature_def_utils.build_signature_def(dict(), @@ -517,7 +517,7 @@ class SavedModelTest(test.TestCase): # Graph with the same single variable and multiple entries in the signature # def map. No weights are saved by SavedModel. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 43) # Build and populate a different SignatureDef for testing. bar_signature = signature_def_utils.build_signature_def(dict(), @@ -539,7 +539,7 @@ class SavedModelTest(test.TestCase): # Restore the graph with tag "foo". The single entry in the SignatureDef map # corresponding to "foo_key" should exist. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: foo_graph = loader.load(sess, ["foo"], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) @@ -551,7 +551,7 @@ class SavedModelTest(test.TestCase): # Restore the graph with tag "bar". The SignatureDef map should have two # entries. One corresponding to "bar_key" and another corresponding to the # new value of "foo_key". - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: bar_graph = loader.load(sess, ["bar"], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) @@ -610,7 +610,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_assets") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) # Build an asset collection. @@ -628,7 +628,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: foo_graph = loader.load(sess, ["foo"], export_dir) self._validate_asset_collection(export_dir, foo_graph.collection_def, "hello42.txt", "foo bar baz", @@ -643,7 +643,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_assets_name_collision_diff_file") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) asset_collection = self._build_asset_collection( @@ -660,7 +660,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: foo_graph = loader.load(sess, ["foo"], export_dir) self._validate_asset_collection(export_dir, foo_graph.collection_def, "hello42.txt", "foo bar bak", @@ -674,7 +674,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_assets_name_collision_same_path") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) asset_collection = self._build_asset_collection( @@ -689,7 +689,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: foo_graph = loader.load(sess, ["foo"], export_dir) self._validate_asset_collection(export_dir, foo_graph.collection_def, "hello42.txt", "foo bar baz", @@ -709,7 +709,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_assets_name_collision_same_file") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) asset_collection = self._build_asset_collection( @@ -726,7 +726,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: foo_graph = loader.load(sess, ["foo"], export_dir) self._validate_asset_collection(export_dir, foo_graph.collection_def, "hello42.txt", "foo bar baz", @@ -746,7 +746,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_assets_name_collision_many_files") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) for i in range(5): @@ -761,7 +761,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: foo_graph = loader.load(sess, ["foo"], export_dir) for i in range(1, 5): idx = str(i) @@ -778,7 +778,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_main_op") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: # Add `v1` and `v2` variables to the graph. v1 = variables.Variable(1, name="v1") ops.add_to_collection("v", v1) @@ -801,7 +801,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) self.assertEqual(1, ops.get_collection("v")[0].eval()) self.assertEqual(2, ops.get_collection("v")[1].eval()) @@ -813,7 +813,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_legacy_init_op") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: # Add `v1` and `v2` variables to the graph. v1 = variables.Variable(1, name="v1") ops.add_to_collection("v", v1) @@ -835,7 +835,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) self.assertEqual(1, ops.get_collection("v")[0].eval()) self.assertEqual(2, ops.get_collection("v")[1].eval()) @@ -858,7 +858,7 @@ class SavedModelTest(test.TestCase): builder = saved_model_builder.SavedModelBuilder(export_dir) g = ops.Graph() - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Initialize variable `v1` to 1. v1 = variables.Variable(1, name="v1") ops.add_to_collection("v", v1) @@ -887,7 +887,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_train_op") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: # Add `v1` and `v2` variables to the graph. v1 = variables.Variable(1, name="v1") ops.add_to_collection("v", v1) @@ -905,7 +905,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) self.assertEqual(3, ops.get_collection("v")[0].eval()) self.assertEqual(2, ops.get_collection("v")[1].eval()) @@ -916,7 +916,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_train_op_group") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: # Add `v1` and `v2` variables to the graph. v1 = variables.Variable(1, name="v1") ops.add_to_collection("v", v1) @@ -934,7 +934,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) self.assertEqual(1, ops.get_collection("v")[0].eval()) self.assertEqual(2, ops.get_collection("v")[1].eval()) @@ -945,7 +945,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_train_op_after_variables") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: # Add `v1` and `v2` variables to the graph. v1 = variables.Variable(1, name="v1") ops.add_to_collection("v", v1) @@ -964,12 +964,12 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["foo"], export_dir) self.assertIsInstance( ops.get_collection(constants.TRAIN_OP_KEY)[0], ops.Tensor) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, ["pre_foo"], export_dir) self.assertFalse(ops.get_collection(constants.TRAIN_OP_KEY)) @@ -977,7 +977,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_multiple_assets") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) # Build an asset collection specific to `foo` graph. @@ -988,7 +988,7 @@ class SavedModelTest(test.TestCase): builder.add_meta_graph_and_variables( sess, ["foo"], assets_collection=asset_collection) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) # Build an asset collection specific to `bar` graph. @@ -1002,14 +1002,14 @@ class SavedModelTest(test.TestCase): builder.save() # Check assets restored for graph with tag "foo". - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: foo_graph = loader.load(sess, ["foo"], export_dir) self._validate_asset_collection(export_dir, foo_graph.collection_def, "foo.txt", "content_foo", "asset_file_tensor:0") # Check assets restored for graph with tag "bar". - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: bar_graph = loader.load(sess, ["bar"], export_dir) self._validate_asset_collection(export_dir, bar_graph.collection_def, "bar.txt", "content_bar", @@ -1019,7 +1019,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_duplicate_assets") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) # Build an asset collection with `foo.txt` that has `foo` specific @@ -1031,7 +1031,7 @@ class SavedModelTest(test.TestCase): builder.add_meta_graph_and_variables( sess, ["foo"], assets_collection=asset_collection) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) # Build an asset collection with `foo.txt` that has `bar` specific @@ -1046,14 +1046,14 @@ class SavedModelTest(test.TestCase): builder.save() # Check assets restored for graph with tag "foo". - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: foo_graph = loader.load(sess, ["foo"], export_dir) self._validate_asset_collection(export_dir, foo_graph.collection_def, "foo.txt", "content_foo", "asset_file_tensor:0") # Check assets restored for graph with tag "bar". - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: bar_graph = loader.load(sess, ["bar"], export_dir) # Validate the assets for `bar` graph. `foo.txt` should contain the @@ -1139,7 +1139,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_custom_saver") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: variables.Variable(1, name="v1") sess.run(variables.global_variables_initializer()) custom_saver = training.Saver(name="my_saver") @@ -1149,7 +1149,7 @@ class SavedModelTest(test.TestCase): builder.save() with ops.Graph().as_default() as graph: - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: saved_graph = loader.load(sess, ["tag"], export_dir) graph_ops = [x.name for x in graph.get_operations()] self.assertTrue("my_saver/restore_all" in graph_ops) @@ -1161,7 +1161,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_no_custom_saver") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: variables.Variable(1, name="v1") sess.run(variables.global_variables_initializer()) training.Saver(name="my_saver") @@ -1171,7 +1171,7 @@ class SavedModelTest(test.TestCase): builder.save() with ops.Graph().as_default() as graph: - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: saved_graph = loader.load(sess, ["tag"], export_dir) graph_ops = [x.name for x in graph.get_operations()] self.assertTrue("my_saver/restore_all" in graph_ops) @@ -1183,7 +1183,7 @@ class SavedModelTest(test.TestCase): export_dir = self._get_export_dir("test_multiple_custom_savers") builder = saved_model_builder.SavedModelBuilder(export_dir) - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: variables.Variable(1, name="v1") sess.run(variables.global_variables_initializer()) builder.add_meta_graph_and_variables(sess, ["tag_0"]) @@ -1199,7 +1199,7 @@ class SavedModelTest(test.TestCase): def _validate_custom_saver(tag_name, saver_name): with ops.Graph().as_default() as graph: - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: saved_graph = loader.load(sess, [tag_name], export_dir) self.assertEqual( saved_graph.saver_def.restore_op_name, @@ -1214,7 +1214,7 @@ class SavedModelTest(test.TestCase): builder = saved_model_builder.SavedModelBuilder(export_dir) # Build a SavedModel with a variable, an asset, and a constant tensor. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: self._init_and_validate_variable(sess, "v", 42) asset_collection = self._build_asset_collection("foo.txt", "content_foo", "asset_file_tensor") @@ -1228,7 +1228,7 @@ class SavedModelTest(test.TestCase): # Save the SavedModel to disk. builder.save() - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: # Restore the SavedModel under an import_scope in a new graph/session. graph_proto = loader.load( sess, ["tag_name"], export_dir, import_scope="scope_name") @@ -1281,7 +1281,7 @@ class SavedModelTest(test.TestCase): # Restore the graph with a single predefined tag whose variables were saved # without any device information. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: loader.load(sess, [tag_constants.TRAINING], export_dir) self.assertEqual( 42, ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)[0].eval()) diff --git a/tensorflow/python/saved_model/simple_save_test.py b/tensorflow/python/saved_model/simple_save_test.py index b2fa40d4f1..18f82daada 100644 --- a/tensorflow/python/saved_model/simple_save_test.py +++ b/tensorflow/python/saved_model/simple_save_test.py @@ -60,7 +60,7 @@ class SimpleSaveTest(test.TestCase): # Initialize input and output variables and save a prediction graph using # the default parameters. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: var_x = self._init_and_validate_variable(sess, "var_x", 1) var_y = self._init_and_validate_variable(sess, "var_y", 2) inputs = {"x": var_x} @@ -69,7 +69,7 @@ class SimpleSaveTest(test.TestCase): # Restore the graph with a valid tag and check the global variables and # signature def map. - with self.test_session(graph=ops.Graph()) as sess: + with self.session(graph=ops.Graph()) as sess: graph = loader.load(sess, [tag_constants.SERVING], export_dir) collection_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES) diff --git a/tensorflow/python/saved_model/utils_impl.py b/tensorflow/python/saved_model/utils_impl.py index 20ff34fd8e..06d09325c8 100644 --- a/tensorflow/python/saved_model/utils_impl.py +++ b/tensorflow/python/saved_model/utils_impl.py @@ -75,7 +75,7 @@ def get_tensor_from_tensor_info(tensor_info, graph=None, import_scope=None): KeyError: If `tensor_info` does not correspond to a tensor in `graph`. ValueError: If `tensor_info` is malformed. """ - graph = graph if graph is not None else ops.get_default_graph() + graph = graph or ops.get_default_graph() def _get_tensor(name): return graph.get_tensor_by_name( ops.prepend_name_scope(name, import_scope=import_scope)) diff --git a/tensorflow/python/summary/summary_test.py b/tensorflow/python/summary/summary_test.py index eb9dbf9645..ac5eb4dbbe 100644 --- a/tensorflow/python/summary/summary_test.py +++ b/tensorflow/python/summary/summary_test.py @@ -32,7 +32,7 @@ from tensorflow.python.summary import summary as summary_lib class ScalarSummaryTest(test.TestCase): def testScalarSummary(self): - with self.test_session() as s: + with self.cached_session() as s: i = constant_op.constant(3) with ops.name_scope('outer'): im = summary_lib.scalar('inner', i) @@ -45,7 +45,7 @@ class ScalarSummaryTest(test.TestCase): self.assertEqual(values[0].simple_value, 3.0) def testScalarSummaryWithFamily(self): - with self.test_session() as s: + with self.cached_session() as s: i = constant_op.constant(7) with ops.name_scope('outer'): im1 = summary_lib.scalar('inner', i, family='family') @@ -68,7 +68,7 @@ class ScalarSummaryTest(test.TestCase): self.assertEqual(values[0].simple_value, 7.0) def testSummarizingVariable(self): - with self.test_session() as s: + with self.cached_session() as s: c = constant_op.constant(42.0) v = variables.Variable(c) ss = summary_lib.scalar('summary', v) @@ -83,7 +83,7 @@ class ScalarSummaryTest(test.TestCase): self.assertEqual(value.simple_value, 42.0) def testImageSummary(self): - with self.test_session() as s: + with self.cached_session() as s: i = array_ops.ones((5, 4, 4, 3)) with ops.name_scope('outer'): im = summary_lib.image('inner', i, max_outputs=3) @@ -97,7 +97,7 @@ class ScalarSummaryTest(test.TestCase): self.assertEqual(tags, expected) def testImageSummaryWithFamily(self): - with self.test_session() as s: + with self.cached_session() as s: i = array_ops.ones((5, 2, 3, 1)) with ops.name_scope('outer'): im = summary_lib.image('inner', i, max_outputs=3, family='family') @@ -113,7 +113,7 @@ class ScalarSummaryTest(test.TestCase): self.assertEqual(tags, expected) def testHistogramSummary(self): - with self.test_session() as s: + with self.cached_session() as s: i = array_ops.ones((5, 4, 4, 3)) with ops.name_scope('outer'): summ_op = summary_lib.histogram('inner', i) @@ -124,7 +124,7 @@ class ScalarSummaryTest(test.TestCase): self.assertEqual(summary.value[0].tag, 'outer/inner') def testHistogramSummaryWithFamily(self): - with self.test_session() as s: + with self.cached_session() as s: i = array_ops.ones((5, 4, 4, 3)) with ops.name_scope('outer'): summ_op = summary_lib.histogram('inner', i, family='family') @@ -136,7 +136,7 @@ class ScalarSummaryTest(test.TestCase): self.assertEqual(summary.value[0].tag, 'family/outer/family/inner') def testAudioSummary(self): - with self.test_session() as s: + with self.cached_session() as s: i = array_ops.ones((5, 3, 4)) with ops.name_scope('outer'): aud = summary_lib.audio('inner', i, 0.2, max_outputs=3) @@ -150,7 +150,7 @@ class ScalarSummaryTest(test.TestCase): self.assertEqual(tags, expected) def testAudioSummaryWithFamily(self): - with self.test_session() as s: + with self.cached_session() as s: i = array_ops.ones((5, 3, 4)) with ops.name_scope('outer'): aud = summary_lib.audio('inner', i, 0.2, max_outputs=3, family='family') @@ -194,7 +194,7 @@ class ScalarSummaryTest(test.TestCase): new_summ_f = g.get_tensor_by_name('new_outer/family/inner:0') # However, the tags are unaffected. - with self.test_session() as s: + with self.cached_session() as s: new_summ_str, new_summ_f_str = s.run([new_summ, new_summ_f]) new_summ_pb = summary_pb2.Summary() new_summ_pb.ParseFromString(new_summ_str) diff --git a/tensorflow/python/summary/text_summary_test.py b/tensorflow/python/summary/text_summary_test.py index 4d357918f6..5b0db43cc1 100644 --- a/tensorflow/python/summary/text_summary_test.py +++ b/tensorflow/python/summary/text_summary_test.py @@ -33,7 +33,7 @@ class TextPluginTest(test_util.TensorFlowTestCase): """ def testTextSummaryAPI(self): - with self.test_session(): + with self.cached_session(): with self.assertRaises(ValueError): num = array_ops.constant(1) diff --git a/tensorflow/python/tensorflow.i b/tensorflow/python/tensorflow.i index 26e8acd897..39174fa589 100644 --- a/tensorflow/python/tensorflow.i +++ b/tensorflow/python/tensorflow.i @@ -54,4 +54,5 @@ limitations under the License. %include "tensorflow/python/grappler/item.i" %include "tensorflow/python/grappler/tf_optimizer.i" %include "tensorflow/python/grappler/cost_analyzer.i" +%include "tensorflow/python/grappler/graph_analyzer.i" %include "tensorflow/python/grappler/model_analyzer.i" diff --git a/tensorflow/python/tools/BUILD b/tensorflow/python/tools/BUILD index 222f856511..01d43e09d1 100644 --- a/tensorflow/python/tools/BUILD +++ b/tensorflow/python/tools/BUILD @@ -114,6 +114,12 @@ py_library( ], ) +py_library( + name = "component_api_helper", + srcs = ["component_api_helper.py"], + srcs_version = "PY2AND3", +) + py_binary( name = "strip_unused", srcs = ["strip_unused.py"], diff --git a/tensorflow/python/tools/api/generator/BUILD b/tensorflow/python/tools/api/generator/BUILD index f87fdb2d88..36af091163 100644 --- a/tensorflow/python/tools/api/generator/BUILD +++ b/tensorflow/python/tools/api/generator/BUILD @@ -14,14 +14,13 @@ exports_files( ], ) -py_binary( +py_library( name = "create_python_api", srcs = ["//tensorflow/python/tools/api/generator:create_python_api.py"], - main = "//tensorflow/python/tools/api/generator:create_python_api.py", srcs_version = "PY2AND3", visibility = ["//visibility:public"], deps = [ - "//tensorflow/python:no_contrib", + "//tensorflow/python:util", "//tensorflow/python/tools/api/generator:doc_srcs", ], ) diff --git a/tensorflow/python/tools/api/generator/api_init_files.bzl b/tensorflow/python/tools/api/generator/api_init_files.bzl index 7001e566ce..64f0469482 100644 --- a/tensorflow/python/tools/api/generator/api_init_files.bzl +++ b/tensorflow/python/tools/api/generator/api_init_files.bzl @@ -25,6 +25,7 @@ TENSORFLOW_API_INIT_FILES = [ "keras/applications/inception_resnet_v2/__init__.py", "keras/applications/inception_v3/__init__.py", "keras/applications/mobilenet/__init__.py", + "keras/applications/mobilenet_v2/__init__.py", "keras/applications/nasnet/__init__.py", "keras/applications/resnet50/__init__.py", "keras/applications/vgg16/__init__.py", diff --git a/tensorflow/python/tools/api/generator/api_init_files_v1.bzl b/tensorflow/python/tools/api/generator/api_init_files_v1.bzl index 73d11199d9..bc2f3516d1 100644 --- a/tensorflow/python/tools/api/generator/api_init_files_v1.bzl +++ b/tensorflow/python/tools/api/generator/api_init_files_v1.bzl @@ -25,6 +25,7 @@ TENSORFLOW_API_INIT_FILES_V1 = [ "keras/applications/inception_resnet_v2/__init__.py", "keras/applications/inception_v3/__init__.py", "keras/applications/mobilenet/__init__.py", + "keras/applications/mobilenet_v2/__init__.py", "keras/applications/nasnet/__init__.py", "keras/applications/resnet50/__init__.py", "keras/applications/vgg16/__init__.py", diff --git a/tensorflow/python/tools/component_api_helper.py b/tensorflow/python/tools/component_api_helper.py new file mode 100644 index 0000000000..988ecc61f0 --- /dev/null +++ b/tensorflow/python/tools/component_api_helper.py @@ -0,0 +1,85 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Helper functions to help integrate TensorFlow components into TF API. +""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import importlib +import os + + +def package_hook(parent_package_str, child_package_str, error_msg=None): + """Used to hook in an external package into the TensorFlow namespace. + + Example usage: + ### tensorflow/__init__.py + from tensorflow.python.tools import component_api_helper + component_api_helper.package_hook( + 'tensorflow', 'tensorflow_estimator.python') + component_api_helper( + 'tensorflow.contrib', 'tensorflow_estimator.contrib.python') + del component_api_helper + + TODO(mikecase): This function has a minor issue, where if the child package + does not exist alone in its directory, sibling packages to it will also be + accessible from the parent. This is because we just add + `child_pkg.__file__/..` to the subpackage search path. This should not be + a big issue because of how our API generation scripts work (the child package + we are hooking up should always be alone). But there might be a better way + of doing this. + + Args: + parent_package_str: Parent package name as a string such as 'tensorflow' or + 'tensorflow.contrib'. This will become the parent package for the + component package being hooked in. + child_package_str: Child package name as a string such as + 'tensorflow_estimator.python'. This package will be added as a subpackage + of the parent. + error_msg: Message to print if child package cannot be found. + """ + parent_pkg = importlib.import_module(parent_package_str) + try: + child_pkg = importlib.import_module(child_package_str) + except ImportError: + if error_msg: + print(error_msg) + return + + def set_child_as_subpackage(): + """Sets child package as a subpackage of parent package. + + Will allow the following import statement to work. + >>> import parent.child + """ + child_pkg_path = [os.path.join(os.path.dirname(child_pkg.__file__), "..")] + try: + parent_pkg.__path__ += child_pkg_path + except AttributeError: + parent_pkg.__path__ = child_pkg_path + + def set_child_as_attr(): + """Sets child package as a attr of the parent package. + + Will allow for the following. + >>> import parent + >>> parent.child + """ + child_pkg_attr_name = child_pkg.__name__.split(".")[-1] + setattr(parent_pkg, child_pkg_attr_name, child_pkg) + + set_child_as_subpackage() + set_child_as_attr() diff --git a/tensorflow/python/tools/freeze_graph.py b/tensorflow/python/tools/freeze_graph.py index c7f414c5dc..893309f35a 100644 --- a/tensorflow/python/tools/freeze_graph.py +++ b/tensorflow/python/tools/freeze_graph.py @@ -89,7 +89,37 @@ def freeze_graph_with_def_protos(input_graph_def, input_saved_model_dir=None, saved_model_tags=None, checkpoint_version=saver_pb2.SaverDef.V2): - """Converts all variables in a graph and checkpoint into constants.""" + """Converts all variables in a graph and checkpoint into constants. + + Args: + input_graph_def: A `GraphDef`. + input_saver_def: A `SaverDef` (optional). + input_checkpoint: The prefix of a V1 or V2 checkpoint, with V2 taking + priority. Typically the result of `Saver.save()` or that of + `tf.train.latest_checkpoint()`, regardless of sharded/non-sharded or + V1/V2. + output_node_names: The name(s) of the output nodes, comma separated. + restore_op_name: Unused. + filename_tensor_name: Unused. + output_graph: String where to write the frozen `GraphDef`. + clear_devices: A Bool whether to remove device specifications. + initializer_nodes: Comma separated string of initializer nodes to run before + freezing. + variable_names_whitelist: The set of variable names to convert (optional, by + default, all variables are converted). + variable_names_blacklist: The set of variable names to omit converting + to constants (optional). + input_meta_graph_def: A `MetaGraphDef` (optional), + input_saved_model_dir: Path to the dir with TensorFlow 'SavedModel' file + and variables (optional). + saved_model_tags: Group of comma separated tag(s) of the MetaGraphDef to + load, in string format (optional). + checkpoint_version: Tensorflow variable file format (saver_pb2.SaverDef.V1 + or saver_pb2.SaverDef.V2) + + Returns: + Location of the output_graph_def. + """ del restore_op_name, filename_tensor_name # Unused by updated loading code. # 'input_checkpoint' may be a prefix if we're using Saver V2 format @@ -271,7 +301,37 @@ def freeze_graph(input_graph, input_saved_model_dir=None, saved_model_tags=tag_constants.SERVING, checkpoint_version=saver_pb2.SaverDef.V2): - """Converts all variables in a graph and checkpoint into constants.""" + """Converts all variables in a graph and checkpoint into constants. + + Args: + input_graph: A `GraphDef` file to load. + input_saver: A TensorFlow Saver file. + input_binary: A Bool. True means input_graph is .pb, False indicates .pbtxt. + input_checkpoint: The prefix of a V1 or V2 checkpoint, with V2 taking + priority. Typically the result of `Saver.save()` or that of + `tf.train.latest_checkpoint()`, regardless of sharded/non-sharded or + V1/V2. + output_node_names: The name(s) of the output nodes, comma separated. + restore_op_name: Unused. + filename_tensor_name: Unused. + output_graph: String where to write the frozen `GraphDef`. + clear_devices: A Bool whether to remove device specifications. + initializer_nodes: Comma separated list of initializer nodes to run before + freezing. + variable_names_whitelist: The set of variable names to convert (optional, by + default, all variables are converted), + variable_names_blacklist: The set of variable names to omit converting + to constants (optional). + input_meta_graph: A `MetaGraphDef` file to load (optional). + input_saved_model_dir: Path to the dir with TensorFlow 'SavedModel' file and + variables (optional). + saved_model_tags: Group of comma separated tag(s) of the MetaGraphDef to + load, in string format. + checkpoint_version: Tensorflow variable file format (saver_pb2.SaverDef.V1 + or saver_pb2.SaverDef.V2). + Returns: + String that is the location of frozen GraphDef. + """ input_graph_def = None if input_saved_model_dir: input_graph_def = saved_model_utils.get_meta_graph_def( diff --git a/tensorflow/python/tools/optimize_for_inference_lib.py b/tensorflow/python/tools/optimize_for_inference_lib.py index bb90d1cd6e..108f2b593c 100644 --- a/tensorflow/python/tools/optimize_for_inference_lib.py +++ b/tensorflow/python/tools/optimize_for_inference_lib.py @@ -133,14 +133,14 @@ def ensure_graph_is_valid(graph_def): """ node_map = {} for node in graph_def.node: - if node.name not in node_map.keys(): + if node.name not in node_map: node_map[node.name] = node else: raise ValueError("Duplicate node names detected for ", node.name) for node in graph_def.node: for input_name in node.input: input_node_name = node_name_from_input(input_name) - if input_node_name not in node_map.keys(): + if input_node_name not in node_map: raise ValueError("Input for ", node.name, " not found: ", input_name) @@ -225,7 +225,7 @@ def fold_batch_norms(input_graph_def): """ input_node_map = {} for node in input_graph_def.node: - if node.name not in input_node_map.keys(): + if node.name not in input_node_map: input_node_map[node.name] = node else: raise ValueError("Duplicate node names detected for ", node.name) @@ -390,7 +390,7 @@ def fuse_resize_and_conv(input_graph_def, output_node_names): input_node_map = {} for node in input_graph_def.node: - if node.name not in input_node_map.keys(): + if node.name not in input_node_map: input_node_map[node.name] = node else: raise ValueError("Duplicate node names detected for ", node.name) diff --git a/tensorflow/python/tools/saved_model_cli.py b/tensorflow/python/tools/saved_model_cli.py index 38fed5335e..9b232865dd 100644 --- a/tensorflow/python/tools/saved_model_cli.py +++ b/tensorflow/python/tools/saved_model_cli.py @@ -308,7 +308,7 @@ def run_saved_model_with_feed_dict(saved_model_dir, tag_set, signature_def_key, # Check if input tensor keys are valid. for input_key_name in input_tensor_key_feed_dict.keys(): - if input_key_name not in inputs_tensor_info.keys(): + if input_key_name not in inputs_tensor_info: raise ValueError( '"%s" is not a valid input key. Please choose from %s, or use ' '--show option.' % diff --git a/tensorflow/python/training/adagrad.py b/tensorflow/python/training/adagrad.py index 6778f3c735..3508b98475 100644 --- a/tensorflow/python/training/adagrad.py +++ b/tensorflow/python/training/adagrad.py @@ -70,20 +70,24 @@ class AdagradOptimizer(optimizer.Optimizer): def _create_slots(self, var_list): for v in var_list: - with ops.colocate_with(v): - dtype = v.dtype.base_dtype - if v.get_shape().is_fully_defined(): - init = init_ops.constant_initializer(self._initial_accumulator_value, - dtype=dtype) - else: - # Use a Tensor instead of initializer if variable does not have static - # shape. - init_constant = gen_array_ops.fill(array_ops.shape(v), - self._initial_accumulator_value) - init = math_ops.cast(init_constant, dtype) + dtype = v.dtype.base_dtype + if v.get_shape().is_fully_defined(): + init = init_ops.constant_initializer(self._initial_accumulator_value, + dtype=dtype) + else: + init = self._init_constant_op(v, dtype) self._get_or_make_slot_with_initializer(v, init, v.get_shape(), dtype, "accumulator", self._name) + def _init_constant_op(self, v, dtype): + def init(): + # Use a Tensor instead of initializer if variable does not have + # static shape. + init_constant = gen_array_ops.fill(array_ops.shape(v), + self._initial_accumulator_value) + return math_ops.cast(init_constant, dtype) + return init + def _prepare(self): learning_rate = self._call_if_callable(self._learning_rate) self._learning_rate_tensor = ops.convert_to_tensor( diff --git a/tensorflow/python/training/adagrad_test.py b/tensorflow/python/training/adagrad_test.py index c9aec33d09..4e634fff84 100644 --- a/tensorflow/python/training/adagrad_test.py +++ b/tensorflow/python/training/adagrad_test.py @@ -302,6 +302,39 @@ class AdagradOptimizerTest(test.TestCase): # Creating optimizer should cause no exception. adagrad.AdagradOptimizer(3.0, initial_accumulator_value=0.1) + def testDynamicShapeVariableWithCallableInit(self): + var0 = variable_scope.get_variable("var0", + initializer=constant_op.constant(1.), + validate_shape=False) + self.assertFalse(var0.shape.is_fully_defined()) + + grads0 = constant_op.constant(0.1, dtype=dtypes.float32) + learning_rate = lambda: 3.0 + + ada_opt = adagrad.AdagradOptimizer( + learning_rate, initial_accumulator_value=0.1, use_locking=True) + + if not context.executing_eagerly(): + ada_update = ada_opt.apply_gradients( + zip([grads0], [var0])) + self.evaluate(variables.global_variables_initializer()) + + # Fetch params to validate initial values + v0_val = self.evaluate([var0]) + self.assertAllClose([1.0], v0_val) + + # Run 3 steps of adagrad + for _ in range(3): + if not context.executing_eagerly(): + self.evaluate(ada_update) + else: + ada_opt.apply_gradients(zip([grads0], [var0])) + + # Validate updated params + v0_val = self.evaluate([var0]) + self.assertAllCloseAccordingToType( + np.array([-1.6026098728179932]), v0_val) + if __name__ == "__main__": test.main() diff --git a/tensorflow/python/training/adam.py b/tensorflow/python/training/adam.py index bcbe5907d6..704ad6d3fe 100644 --- a/tensorflow/python/training/adam.py +++ b/tensorflow/python/training/adam.py @@ -43,15 +43,15 @@ class AdamOptimizer(optimizer.Optimizer): Initialization: - $$m_0 := 0 (Initialize initial 1st moment vector)$$ - $$v_0 := 0 (Initialize initial 2nd moment vector)$$ - $$t := 0 (Initialize timestep)$$ + $$m_0 := 0 \text{(Initialize initial 1st moment vector)}$$ + $$v_0 := 0 \text{(Initialize initial 2nd moment vector)}$$ + $$t := 0 \text{(Initialize timestep)}$$ The update rule for `variable` with gradient `g` uses an optimization described at the end of section2 of the paper: $$t := t + 1$$ - $$lr_t := \text{learning_rate} * \sqrt{(1 - beta_2^t) / (1 - beta_1^t)}$$ + $$lr_t := \text{learning\_rate} * \sqrt{1 - beta_2^t} / (1 - beta_1^t)$$ $$m_t := beta_1 * m_{t-1} + (1 - beta_1) * g$$ $$v_t := beta_2 * v_{t-1} + (1 - beta_2) * g * g$$ diff --git a/tensorflow/python/training/adam_test.py b/tensorflow/python/training/adam_test.py index 8f84427654..778c672077 100644 --- a/tensorflow/python/training/adam_test.py +++ b/tensorflow/python/training/adam_test.py @@ -152,7 +152,7 @@ class AdamOptimizerTest(test.TestCase): def doTestBasic(self, use_resource=False, use_callable_params=False): for i, dtype in enumerate([dtypes.half, dtypes.float32, dtypes.float64]): - with self.test_session(graph=ops.Graph()): + with self.session(graph=ops.Graph()): # Initialize variables for numpy implementation. m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 var0_np = np.array([1.0, 2.0], dtype=dtype.as_numpy_dtype) diff --git a/tensorflow/python/training/checkpoint_management.py b/tensorflow/python/training/checkpoint_management.py index 85f2904318..38910fb246 100644 --- a/tensorflow/python/training/checkpoint_management.py +++ b/tensorflow/python/training/checkpoint_management.py @@ -510,7 +510,10 @@ class CheckpointManager(object): max_to_keep: An integer, the number of checkpoints to keep. Unless preserved by `keep_checkpoint_every_n_hours`, checkpoints will be deleted from the active set, oldest first, until only `max_to_keep` - checkpoints remain. + checkpoints remain. If `None`, no checkpoints are deleted and everything + stays in the active set. Note that `max_to_keep=None` will keep all + checkpoint paths in memory and in the checkpoint state protocol buffer + on disk. keep_checkpoint_every_n_hours: Upon removal from the active set, a checkpoint will be preserved if it has been at least `keep_checkpoint_every_n_hours` since the last preserved checkpoint. The @@ -521,9 +524,10 @@ class CheckpointManager(object): """ self._checkpoint = checkpoint self._save_counter_assign = None - if not max_to_keep or max_to_keep < 0: + if max_to_keep is not None and max_to_keep <= 0: raise ValueError( - "Expected a positive integer for `max_to_max_to_keep`, got %d." + ("Expected a positive integer or `None` for `max_to_max_to_keep`, " + "got %d.") % (max_to_keep,)) self._max_to_keep = max_to_keep self._keep_checkpoint_every_n_hours = keep_checkpoint_every_n_hours @@ -534,7 +538,9 @@ class CheckpointManager(object): self._maybe_delete = collections.OrderedDict() if recovered_state is None: self._latest_checkpoint = None - self._last_preserved_timestamp = current_clock + # Set the clock back slightly to avoid race conditions when quckly + # re-creating a CheckpointManager. + self._last_preserved_timestamp = current_clock - 1. else: self._latest_checkpoint = recovered_state.model_checkpoint_path self._last_preserved_timestamp = recovered_state.last_preserved_timestamp @@ -586,6 +592,10 @@ class CheckpointManager(object): def _sweep(self): """Deletes or preserves managed checkpoints.""" + if not self._max_to_keep: + # Does not update self._last_preserved_timestamp, since everything is kept + # in the active set. + return while len(self._maybe_delete) > self._max_to_keep: filename, timestamp = self._maybe_delete.popitem(last=False) # Even if we're keeping this checkpoint due to diff --git a/tensorflow/python/training/checkpoint_management_test.py b/tensorflow/python/training/checkpoint_management_test.py index 1e2827d0a4..8ef5048299 100644 --- a/tensorflow/python/training/checkpoint_management_test.py +++ b/tensorflow/python/training/checkpoint_management_test.py @@ -26,6 +26,7 @@ import tempfile from google.protobuf import text_format from tensorflow.core.protobuf import saver_pb2 +from tensorflow.python.eager import context from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops as ops_lib from tensorflow.python.framework import test_util @@ -272,7 +273,7 @@ class SaverUtilsTest(test.TestCase): def testCheckpointExists(self): for sharded in (False, True): for version in (saver_pb2.SaverDef.V2, saver_pb2.SaverDef.V1): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: unused_v = variables.Variable(1.0, name="v") variables.global_variables_initializer().run() saver = saver_module.Saver(sharded=sharded, write_version=version) @@ -290,7 +291,7 @@ class SaverUtilsTest(test.TestCase): def testGetCheckpointMtimes(self): prefixes = [] for version in (saver_pb2.SaverDef.V2, saver_pb2.SaverDef.V1): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: unused_v = variables.Variable(1.0, name="v") variables.global_variables_initializer().run() saver = saver_module.Saver(write_version=version) @@ -304,7 +305,7 @@ class SaverUtilsTest(test.TestCase): def testRemoveCheckpoint(self): for sharded in (False, True): for version in (saver_pb2.SaverDef.V2, saver_pb2.SaverDef.V1): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: unused_v = variables.Variable(1.0, name="v") variables.global_variables_initializer().run() saver = saver_module.Saver(sharded=sharded, write_version=version) @@ -333,6 +334,49 @@ class CheckpointManagerTest(test.TestCase): self.assertFalse(checkpoint_management.checkpoint_exists(first_path)) @test_util.run_in_graph_and_eager_modes + def testKeepAll(self): + checkpoint = util.Checkpoint() + directory = os.path.join( + self.get_temp_dir(), + # Avoid sharing directories between eager and graph + # TODO(allenl): stop run_in_graph_and_eager_modes reusing directories + str(context.executing_eagerly())) + manager = checkpoint_management.CheckpointManager( + checkpoint, directory, max_to_keep=None) + first_path = manager.save() + second_path = manager.save() + third_path = manager.save() + self.assertTrue(checkpoint_management.checkpoint_exists(third_path)) + self.assertTrue(checkpoint_management.checkpoint_exists(second_path)) + self.assertTrue(checkpoint_management.checkpoint_exists(first_path)) + self.assertEqual(third_path, manager.latest_checkpoint) + self.assertEqual([first_path, second_path, third_path], + manager.checkpoints) + del manager + manager = checkpoint_management.CheckpointManager( + checkpoint, directory, max_to_keep=None) + fourth_path = manager.save() + self.assertEqual([first_path, second_path, third_path, fourth_path], + manager.checkpoints) + del manager + manager = checkpoint_management.CheckpointManager( + checkpoint, directory, max_to_keep=3) + self.assertEqual([first_path, second_path, third_path, fourth_path], + manager.checkpoints) + self.assertTrue(checkpoint_management.checkpoint_exists(fourth_path)) + self.assertTrue(checkpoint_management.checkpoint_exists(third_path)) + self.assertTrue(checkpoint_management.checkpoint_exists(second_path)) + self.assertTrue(checkpoint_management.checkpoint_exists(first_path)) + fifth_path = manager.save() + self.assertEqual([third_path, fourth_path, fifth_path], + manager.checkpoints) + self.assertTrue(checkpoint_management.checkpoint_exists(fifth_path)) + self.assertTrue(checkpoint_management.checkpoint_exists(fourth_path)) + self.assertTrue(checkpoint_management.checkpoint_exists(third_path)) + self.assertFalse(checkpoint_management.checkpoint_exists(second_path)) + self.assertFalse(checkpoint_management.checkpoint_exists(first_path)) + + @test_util.run_in_graph_and_eager_modes @test.mock.patch.object(checkpoint_management, "time") def testSaveRestoreState(self, mock_time): directory = self.get_temp_dir() @@ -345,8 +389,6 @@ class CheckpointManagerTest(test.TestCase): mock_time.time.return_value = first_time first_manager.save() state = checkpoint_management.get_checkpoint_state(directory) - self.assertEqual([first_time], state.all_model_checkpoint_timestamps) - self.assertEqual(3., state.last_preserved_timestamp) second_time = first_time + 3610. second_name = os.path.join(directory, "ckpt-2") mock_time.time.return_value = second_time @@ -354,7 +396,6 @@ class CheckpointManagerTest(test.TestCase): state = checkpoint_management.get_checkpoint_state(directory) self.assertEqual([first_time, second_time], state.all_model_checkpoint_timestamps) - self.assertEqual(3., state.last_preserved_timestamp) self.assertEqual([first_name, second_name], first_manager.checkpoints) self.assertEqual(second_name, first_manager.latest_checkpoint) del first_manager diff --git a/tensorflow/python/training/checkpoint_utils_test.py b/tensorflow/python/training/checkpoint_utils_test.py index 1c1f126ce9..1aab16338a 100644 --- a/tensorflow/python/training/checkpoint_utils_test.py +++ b/tensorflow/python/training/checkpoint_utils_test.py @@ -119,7 +119,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): my1 = variable_scope.get_variable("my1", [1, 10]) with variable_scope.variable_scope("some_other_scope"): @@ -153,7 +153,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope( "some_scope", initializer=init_ops.zeros_initializer()): my1 = variable_scope.get_variable("my1", [1, 10]) @@ -190,7 +190,7 @@ class CheckpointsTest(test.TestCase): checkpoint_utils.init_from_checkpoint(checkpoint_dir, {"useful_scope/": "useful_scope/"}) - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: session.run(variables.global_variables_initializer()) self.assertAllEqual(my4.eval(session), v4) self.assertAllEqual(my5.eval(session), my5_init) @@ -218,7 +218,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): my1 = variable_scope.get_variable("var1", [1, 10]) my2 = variable_scope.get_variable("var2", [10, 10]) @@ -242,7 +242,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: my1 = variable_scope.get_variable("var1", [1, 10]) my2 = variable_scope.get_variable("var2", [10, 10]) my3 = variable_scope.get_variable("var3", [100, 100]) @@ -265,7 +265,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): my1 = variable_scope.get_variable( name="my1", @@ -303,7 +303,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): my1 = variable_scope.get_variable( name="my1", @@ -327,7 +327,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: with variable_scope.variable_scope("some_scope"): _ = variable_scope.get_variable("my1", [10, 10]) _ = variable_scope.get_variable( @@ -372,7 +372,7 @@ class CheckpointsTest(test.TestCase): # New graph and session. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as session: + with self.session(graph=g) as session: my1 = resource_variable_ops.ResourceVariable([[0.0] * 10], name="my1") with ops.name_scope("init_from_checkpoint"): diff --git a/tensorflow/python/training/checkpointable/BUILD b/tensorflow/python/training/checkpointable/BUILD index 6e9b8ff905..d26932c1aa 100644 --- a/tensorflow/python/training/checkpointable/BUILD +++ b/tensorflow/python/training/checkpointable/BUILD @@ -101,15 +101,26 @@ py_library( srcs_version = "PY2AND3", deps = [ ":base", + ":data_structures", ":tracking", + "//tensorflow/core:protos_all_py", "//tensorflow/python:array_ops", + "//tensorflow/python:checkpoint_management", "//tensorflow/python:constant_op", "//tensorflow/python:control_flow_ops", "//tensorflow/python:dtypes", + "//tensorflow/python:errors", + "//tensorflow/python:framework_ops", + "//tensorflow/python:init_ops", "//tensorflow/python:io_ops_gen", - "//tensorflow/python:ops", + "//tensorflow/python:pywrap_tensorflow", "//tensorflow/python:saveable_object", + "//tensorflow/python:saver", + "//tensorflow/python:session", + "//tensorflow/python:tensor_shape", "//tensorflow/python:util", + "//tensorflow/python:variable_scope", + "//tensorflow/python:variables", "//tensorflow/python/eager:context", ], ) diff --git a/tensorflow/python/training/checkpointable/base.py b/tensorflow/python/training/checkpointable/base.py index 390434c0a2..9189d8f3e8 100644 --- a/tensorflow/python/training/checkpointable/base.py +++ b/tensorflow/python/training/checkpointable/base.py @@ -22,6 +22,7 @@ import functools import json import weakref +from tensorflow.python import pywrap_tensorflow from tensorflow.python.eager import context from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes @@ -93,14 +94,17 @@ class CheckpointInitialValue(ops.Tensor): class PythonStringStateSaveable(saveable_object.SaveableObject): """Saves Python state in a checkpoint.""" - def __init__(self, name, state_callback): + def __init__(self, name, state_callback, restore_callback=None): """Configure saving. Args: name: The checkpoint key to write to. state_callback: A function taking no arguments which returns a string. This function is run every time a checkpoint is written. + restore_callback: A function taking a Python string, used to restore + state. Optional; defaults to doing nothing. """ + self._restore_callback = restore_callback if context.executing_eagerly(): self._save_string = ( lambda: constant_op.constant(state_callback(), dtype=dtypes.string)) @@ -113,9 +117,14 @@ class PythonStringStateSaveable(saveable_object.SaveableObject): super(PythonStringStateSaveable, self).__init__( self._save_string, [spec], name) + def python_restore(self, restored_strings): + """Called to restore Python state.""" + if self._restore_callback: + restored, = restored_strings + self._restore_callback(restored) + def restore(self, restored_tensors, restored_shapes): - # TODO(allenl): Add a Python hook for state coming out of a checkpoint - # (currently PythonStringStateSaveable is write-only). + """Called to restore TensorFlow state (nothing to do).""" return control_flow_ops.no_op() @@ -227,7 +236,7 @@ class _CheckpointPosition(object): with ops.device("/cpu:0"): # Run the restore itself on the CPU. value, = io_ops.restore_v2( - prefix=self._checkpoint.save_path, + prefix=self._checkpoint.save_path_tensor, tensor_names=[checkpoint_key], shape_and_slices=[""], dtypes=[base_type], @@ -236,42 +245,99 @@ class _CheckpointPosition(object): value_tensors[serialized_tensor.name] = array_ops.identity(value) return value_tensors - def restore_ops(self): - """Create or fetch restore ops for this object's attributes. - - Requires that the `Checkpointable` Python object has been bound to an object - ID in the checkpoint. - - Returns: - A list of operations when graph building, or an empty list when executing - eagerly. - """ + def _gather_ops_or_named_saveables(self): + """Looks up or creates SaveableObjects which don't have cached ops.""" saveables = self.checkpointable._gather_saveables_for_checkpoint() # pylint: disable=protected-access # Name saveables based on the name this object had when it was checkpointed. named_saveables = {} - restore_ops = [] - building_graph = not context.executing_eagerly() + python_saveables = [] + existing_restore_ops = [] for serialized_tensor in self.object_proto.attributes: - saveable_factory = saveables.get(serialized_tensor.name, None) - if saveable_factory is None: - # Purposefully does not throw an exception if attributes have been added - # or deleted. Stores unused attributes so an exception can be raised if - # the user decides to check that everything in the checkpoint was - # loaded. - self._checkpoint.unused_attributes.setdefault( - self.checkpointable, []).append(serialized_tensor.name) + if context.executing_eagerly(): + existing_op = None + else: + existing_op = self._checkpoint.restore_ops_by_name.get( + serialized_tensor.checkpoint_key, None) + if existing_op is not None: + existing_restore_ops.append(existing_op) continue - if building_graph: - existing_ops = self._checkpoint.restore_ops_by_name.get( - serialized_tensor.name, None) + + # Only if we don't have cached ops for this SaveableObject, we'll see if + # the SaveableObject itself has been cached. If not, we'll make it, and + # either way we'll extract new ops from it (or if it has Python state to + # restore, we'll run that). + if self._checkpoint.saveable_object_cache is None: + # No SaveableObject caching when executing eagerly. + saveable = None else: - existing_ops = None - if existing_ops is None: + # If we've already created and cached a SaveableObject for this + # attribute, we can re-use it to avoid re-creating some ops when graph + # building. + saveable_list = self._checkpoint.saveable_object_cache.get( + self.checkpointable, {}).get(serialized_tensor.name, (None,)) + if len(saveable_list) == 1: + # Almost every attribute will have exactly one SaveableObject. + saveable, = saveable_list + else: + # Don't use cached SaveableObjects for partitioned variables, which is + # the only case where we'd have a list of SaveableObjects. Op caching + # will catch them. + saveable = None + if saveable is not None: + # The name of this attribute has changed, so we need to re-generate + # the SaveableObject. + if serialized_tensor.checkpoint_key not in saveable.name: + saveable = None + del self._checkpoint.saveable_object_cache[self.checkpointable] + break + if saveable is None: + # If there was no cached SaveableObject, we should check if the Python + # object has the attribute. + saveable_factory = saveables.get(serialized_tensor.name, None) + if saveable_factory is None: + # Purposefully does not throw an exception if attributes have been + # added or deleted. Stores unused attributes so an exception can be + # raised if the user decides to check that everything in the + # checkpoint was loaded. + self._checkpoint.unused_attributes.setdefault( + self.checkpointable, []).append(serialized_tensor.name) + continue if callable(saveable_factory): saveable = saveable_factory(name=serialized_tensor.checkpoint_key) else: saveable = saveable_factory + if self._checkpoint.saveable_object_cache is not None: + self._checkpoint.saveable_object_cache.setdefault( + self.checkpointable, {})[serialized_tensor.name] = [saveable] + if isinstance(saveable, PythonStringStateSaveable): + python_saveables.append(saveable) + else: named_saveables[serialized_tensor.checkpoint_key] = saveable + return existing_restore_ops, named_saveables, python_saveables + + def restore_ops(self): + """Create or fetch restore ops for this object's attributes. + + Requires that the `Checkpointable` Python object has been bound to an object + ID in the checkpoint. + + Returns: + A list of operations when graph building, or an empty list when executing + eagerly. + """ + (restore_ops, + named_saveables, + python_saveables) = self._gather_ops_or_named_saveables() + + # Eagerly run restorations for Python state. + reader = pywrap_tensorflow.NewCheckpointReader( + self._checkpoint.save_path_string) + for saveable in python_saveables: + spec_names = [spec.name for spec in saveable.specs] + saveable.python_restore( + [reader.get_tensor(name) for name in spec_names]) + + # If we have new SaveableObjects, extract and cache restore ops. if named_saveables: validated_saveables = ( self._checkpoint.builder._ValidateAndSliceInputs(named_saveables)) # pylint: disable=protected-access @@ -281,7 +347,7 @@ class _CheckpointPosition(object): ("Saveable keys changed when validating. Got back %s, was " "expecting %s") % (named_saveables.keys(), validated_names)) all_tensors = self._checkpoint.builder.bulk_restore( - filename_tensor=self._checkpoint.save_path, + filename_tensor=self._checkpoint.save_path_tensor, saveables=validated_saveables, preferred_shard=-1, restore_sequentially=False) saveable_index = 0 @@ -291,7 +357,7 @@ class _CheckpointPosition(object): saveable_index:saveable_index + num_specs] saveable_index += num_specs restore_op = saveable.restore(saveable_tensors, restored_shapes=None) - if building_graph: + if not context.executing_eagerly(): assert saveable.name not in self._checkpoint.restore_ops_by_name self._checkpoint.restore_ops_by_name[saveable.name] = restore_op restore_ops.append(restore_op) diff --git a/tensorflow/python/training/checkpointable/data_structures.py b/tensorflow/python/training/checkpointable/data_structures.py index 507cda8734..f06cbbfa15 100644 --- a/tensorflow/python/training/checkpointable/data_structures.py +++ b/tensorflow/python/training/checkpointable/data_structures.py @@ -128,7 +128,8 @@ class CheckpointableDataStructure(base.CheckpointableBase): "stored in a List object. Got %s, which does not inherit from " "CheckpointableBase.") % (value,)) if (isinstance(value, CheckpointableDataStructure) - or layer_utils.is_layer(value)): + or layer_utils.is_layer(value) + or layer_utils.has_weights(value)): # Check for object-identity rather than with __eq__ to avoid # de-duplicating empty container types. Automatically generated list # wrappers keep things like "[] == []" true, which means "[] in [[]]" is @@ -149,14 +150,14 @@ class CheckpointableDataStructure(base.CheckpointableBase): def trainable_weights(self): return layer_utils.gather_trainable_weights( trainable=self.trainable, - sub_layers=self.layers, + sub_layers=self._layers, extra_variables=self._extra_variables) @property def non_trainable_weights(self): return layer_utils.gather_non_trainable_weights( trainable=self.trainable, - sub_layers=self.layers, + sub_layers=self._layers, extra_variables=self._extra_variables) @property @@ -183,7 +184,8 @@ class CheckpointableDataStructure(base.CheckpointableBase): # have any inputs. aggregated = [] for layer in self.layers: - aggregated += layer.updates + if hasattr(layer, "updates"): + aggregated += layer.updates return aggregated @property @@ -191,7 +193,8 @@ class CheckpointableDataStructure(base.CheckpointableBase): """Aggregate losses from any `Layer` instances.""" aggregated = [] for layer in self.layers: - aggregated += layer.losses + if hasattr(layer, "losses"): + aggregated += layer.losses return aggregated def __hash__(self): diff --git a/tensorflow/python/training/checkpointable/data_structures_test.py b/tensorflow/python/training/checkpointable/data_structures_test.py index 472b7c32b4..4638917b4c 100644 --- a/tensorflow/python/training/checkpointable/data_structures_test.py +++ b/tensorflow/python/training/checkpointable/data_structures_test.py @@ -31,6 +31,7 @@ from tensorflow.python.layers import core as non_keras_core from tensorflow.python.ops import array_ops from tensorflow.python.ops import math_ops from tensorflow.python.ops import resource_variable_ops +from tensorflow.python.ops import variables from tensorflow.python.training.checkpointable import data_structures from tensorflow.python.training.checkpointable import tracking from tensorflow.python.training.checkpointable import util @@ -96,6 +97,11 @@ class ListTests(test.TestCase): model.load_weights(save_path) self.assertAllEqual([[1., 2., 3.], [4., 5., 6.]], self.evaluate(model.variables[0])) + v = variables.Variable(1.) + model.var_list = [v] + self.assertIn(v, model.variables) + self.assertIn(v, model.trainable_variables) + self.assertNotIn(v, model.non_trainable_variables) def testUpdatesForwarded(self): with context.graph_mode(): diff --git a/tensorflow/python/training/checkpointable/layer_utils.py b/tensorflow/python/training/checkpointable/layer_utils.py index d65b631fe9..ec764bca89 100644 --- a/tensorflow/python/training/checkpointable/layer_utils.py +++ b/tensorflow/python/training/checkpointable/layer_utils.py @@ -30,13 +30,20 @@ def is_layer(obj): and hasattr(obj, "variables")) +def has_weights(obj): + """Implicit check for Layer-like objects.""" + # TODO(b/110718070): Replace with isinstance(obj, base_layer.Layer). + return (hasattr(obj, "trainable_weights") + and hasattr(obj, "non_trainable_weights")) + + def filter_empty_layer_containers(layer_list): """Filter out empty Layer-like containers.""" filtered = [] for obj in layer_list: if is_layer(obj): filtered.append(obj) - else: + elif hasattr(obj, "layers"): # Checkpointable data structures will not show up in ".layers" lists, but # the layers they contain will. filtered.extend(obj.layers) diff --git a/tensorflow/python/training/checkpointable/util.py b/tensorflow/python/training/checkpointable/util.py index e42f989469..45d217e8b1 100644 --- a/tensorflow/python/training/checkpointable/util.py +++ b/tensorflow/python/training/checkpointable/util.py @@ -68,16 +68,25 @@ _OBJECT_ATTRIBUTES_NAME = _ESCAPE_CHAR + "ATTRIBUTES" class _CheckpointRestoreCoordinator(object): """Holds the status of an object-based checkpoint load.""" - def __init__(self, object_graph_proto, save_path, dtype_map=None): + def __init__(self, object_graph_proto, save_path, save_path_tensor, + restore_op_cache, saveable_object_cache): """Specify the checkpoint being loaded. Args: object_graph_proto: The CheckpointableObjectGraph protocol buffer associated with this checkpoint. - save_path: A string `Tensor`. The path to the checkpoint, as returned by + save_path: A string, the path to the checkpoint, as returned by `tf.train.latest_checkpoint`. - dtype_map: When executing eagerly, specifies dtypes for creating slot - variables. None when graph building. + save_path_tensor: A string `Tensor` which contains or will be fed the save + path. + restore_op_cache: A dictionary shared between + `_CheckpointRestoreCoordinator`s for the same Python objects, used to + look up restore ops by name to avoid re-creating them across multiple + `restore()` calls. + saveable_object_cache: A mapping of checkpointable objects -> attribute + names -> list(`SaveableObject`s), used when `SaveableObjects` must be + referenced every restore (e.g. for Python state); otherwise they would + create their own ops every restore. """ self.builder = saver_lib.BulkSaverBuilder() self.object_graph_proto = object_graph_proto @@ -97,12 +106,17 @@ class _CheckpointRestoreCoordinator(object): # loading). Used to make status assertions fail when loading checkpoints # that don't quite match. self.all_python_objects = _ObjectIdentityWeakSet() - self.save_path = save_path - self.dtype_map = dtype_map + self.save_path_tensor = save_path_tensor + self.save_path_string = save_path + self.dtype_map = pywrap_tensorflow.NewCheckpointReader( + save_path).get_variable_to_dtype_map() + # A NewCheckpointReader for the most recent checkpoint, for streaming Python + # state restoration. # When graph building, contains a list of ops to run to restore objects from # this checkpoint. self.restore_ops = [] - self.restore_ops_by_name = {} + self.restore_ops_by_name = restore_op_cache + self.saveable_object_cache = saveable_object_cache self.new_restore_ops_callback = None # A mapping from optimizer proto ids to lists of slot variables to be # restored when the optimizer is tracked. Only includes slot variables whose @@ -185,6 +199,7 @@ class _NameBasedRestoreCoordinator(object): for saveable in self.globally_named_object_attributes( checkpointable): restored_tensors = [] + tensor_missing = False for spec in saveable.specs: if spec.name in self.dtype_map: with ops.device("cpu:0"): @@ -195,9 +210,15 @@ class _NameBasedRestoreCoordinator(object): dtypes=[self.dtype_map[spec.name]], name="%s_checkpoint_read" % (spec.name,)) restored_tensors.append(array_ops.identity(restored)) + else: + tensor_missing = True - saveable.restore(restored_tensors=restored_tensors, - restored_shapes=None) + if not tensor_missing: + # Ignores values missing from the checkpoint, as with object-based + # restore. Status assertions can be used to check exact matches, + # although it's unlikely to ever happen for name-based checkpoints. + saveable.restore(restored_tensors=restored_tensors, + restored_shapes=None) # TODO(allenl): If this ends up in a public API, consider adding LINT.IfChange @@ -820,6 +841,11 @@ class _LoadStatus(object): pass @abc.abstractmethod + def assert_existing_objects_matched(self): + """Raises an exception unless existing Python objects have been matched.""" + pass + + @abc.abstractmethod def run_restore_ops(self, session=None): """Runs restore ops from the checkpoint. Requires a valid checkpoint.""" pass @@ -889,13 +915,11 @@ class CheckpointLoadStatus(_LoadStatus): or if there are any checkpointed values which have not been matched to Python objects. """ + self.assert_existing_objects_matched() for node_id, node in enumerate(self._checkpoint.object_graph_proto.nodes): checkpointable = self._checkpoint.object_by_proto_id.get(node_id, None) if checkpointable is None: raise AssertionError("Unresolved object in checkpoint: %s" % (node,)) - if checkpointable._update_uid < self._checkpoint.restore_uid: # pylint: disable=protected-access - raise AssertionError( - "Object not assigned a value from checkpoint: %s" % (node,)) if self._checkpoint.slot_restorations: # Sanity check; this collection should be clear if everything has been # restored. @@ -906,6 +930,31 @@ class CheckpointLoadStatus(_LoadStatus): ("Unused attributes in these objects (the attributes exist in the " "checkpoint but not in the objects): %s") % ( self._checkpoint.unused_attributes.items(),)) + return self + + def assert_existing_objects_matched(self): + """Asserts that checkpointable Python objects have been matched. + + Note that this is a weaker assertion than `assert_consumed`. It will only + fail for existing Python objects which are (transitive) dependencies of the + root object and which do not have an entry in the checkpoint. + + It will not fail, for example, if a `tf.keras.Layer` object has not yet been + built and so has not created any `tf.Variable` objects. + + Returns: + `self` for chaining. + + Raises: + AssertionError: If a Python object exists in the transitive dependencies + of the root object but does not have a value in the checkpoint. + """ + for node_id, node in enumerate(self._checkpoint.object_graph_proto.nodes): + checkpointable = self._checkpoint.object_by_proto_id.get(node_id, None) + if (checkpointable is not None + and checkpointable._update_uid < self._checkpoint.restore_uid): # pylint: disable=protected-access + raise AssertionError( + "Object not assigned a value from checkpoint: %s" % (node,)) for checkpointable_object in list_objects(self._root_checkpointable): self._checkpoint.all_python_objects.add(checkpointable_object) unused_python_objects = ( @@ -915,7 +964,7 @@ class CheckpointLoadStatus(_LoadStatus): raise AssertionError( ("Some Python objects were not bound to checkpointed values, likely " "due to changes in the Python program: %s") - % (unused_python_objects,)) + % (list(unused_python_objects),)) return self def run_restore_ops(self, session=None): @@ -977,6 +1026,11 @@ class InitializationOnlyStatus(_LoadStatus): raise AssertionError( "No checkpoint specified (save_path=None); nothing is being restored.") + def assert_existing_objects_matched(self): + """Assertion for consistency with `CheckpointLoadStatus`. Always fails.""" + raise AssertionError( + "No checkpoint specified (save_path=None); nothing is being restored.") + def run_restore_ops(self, session=None): """For consistency with `CheckpointLoadStatus`. @@ -1050,6 +1104,15 @@ class NameBasedSaverStatus(_LoadStatus): if checkpointable._update_uid < self._checkpoint.restore_uid: raise AssertionError("Object not restored: %s" % (checkpointable,)) # pylint: enable=protected-access + return self + + def assert_existing_objects_matched(self): + """Raises an exception if currently created objects are unmatched.""" + # For name-based checkpoints there's no object information in the + # checkpoint, so there's no distinction between + # assert_existing_objects_matched and assert_consumed (and both are less + # useful since we don't touch Python objects or Python state). + return self.assert_consumed() def _gather_saveable_objects(self): """Walk the object graph, using global names for SaveableObjects.""" @@ -1153,16 +1216,15 @@ class CheckpointableSaver(object): self._last_save_object_graph = None self._last_save_saver = None - # Op caching for restore - self._last_restore_object_graph = None - self._last_restore_checkpoint = None + # Op caching for restore, shared between _CheckpointRestoreCoordinators + self._restore_op_cache = {} if context.executing_eagerly(): # SaveableObjects are always recreated when executing eagerly. self._saveable_object_cache = None else: - # Maps Checkpointable objects -> attribute names -> SaveableObjects, to - # avoid re-creating SaveableObjects when graph building. + # Maps Checkpointable objects -> attribute names -> list(SaveableObjects), + # to avoid re-creating SaveableObjects when graph building. self._saveable_object_cache = _ObjectIdentityWeakKeyDictionary() @property @@ -1340,22 +1402,12 @@ class CheckpointableSaver(object): object_graph_proto = ( checkpointable_object_graph_pb2.CheckpointableObjectGraph()) object_graph_proto.ParseFromString(object_graph_string) - if graph_building and object_graph_proto == self._last_restore_object_graph: - checkpoint = self._last_restore_checkpoint - else: - checkpoint = _CheckpointRestoreCoordinator( - object_graph_proto=object_graph_proto, - save_path=file_prefix_tensor, - dtype_map=dtype_map) - if graph_building: - if self._last_restore_object_graph is not None: - raise NotImplementedError( - "Using a single Saver to restore different object graphs is not " - "currently supported when graph building. Use a different Saver " - "for each object graph (restore ops will be duplicated), or " - "file a feature request if this limitation bothers you.") - self._last_restore_checkpoint = checkpoint - self._last_restore_object_graph = object_graph_proto + checkpoint = _CheckpointRestoreCoordinator( + object_graph_proto=object_graph_proto, + save_path=save_path, + save_path_tensor=file_prefix_tensor, + restore_op_cache=self._restore_op_cache, + saveable_object_cache=self._saveable_object_cache) base._CheckpointPosition( # pylint: disable=protected-access checkpoint=checkpoint, proto_id=0).restore(self._root_checkpointable) load_status = CheckpointLoadStatus( @@ -1644,6 +1696,17 @@ class Checkpoint(tracking.Checkpointable): Python objects in the dependency graph with no values in the checkpoint. This method returns the status object, and so may be chained with `initialize_or_restore` or `run_restore_ops`. + - `assert_existing_objects_matched()`: + Raises an exception if any existing Python objects in the dependency + graph are unmatched. Unlike `assert_consumed`, this assertion will + pass if values in the checkpoint have no corresponding Python + objects. For example a `tf.keras.Layer` object which has not yet been + built, and so has not created any variables, will pass this assertion + but fail `assert_consumed`. Useful when loading part of a larger + checkpoint into a new Python program, e.g. a training checkpoint with + a `tf.train.Optimizer` was saved but only the state required for + inference is being loaded. This method returns the status object, and + so may be chained with `initialize_or_restore` or `run_restore_ops`. - `initialize_or_restore(session=None)`: When graph building, runs variable initializers if `save_path` is `None`, but otherwise runs restore operations. If no `session` is diff --git a/tensorflow/python/training/checkpointable/util_test.py b/tensorflow/python/training/checkpointable/util_test.py index a0a87b6b79..bef4bf2a16 100644 --- a/tensorflow/python/training/checkpointable/util_test.py +++ b/tensorflow/python/training/checkpointable/util_test.py @@ -384,8 +384,8 @@ class CheckpointingTests(test.TestCase): saver = saver_lib.Saver(var_list=[v]) test_dir = self.get_temp_dir() prefix = os.path.join(test_dir, "ckpt") - self.evaluate(v.non_dep_variable.assign(42.)) with self.test_session() as sess: + self.evaluate(v.non_dep_variable.assign(42.)) save_path = saver.save(sess, prefix) self.evaluate(v.non_dep_variable.assign(43.)) self.evaluate(v.mirrored.assign(44.)) @@ -437,6 +437,9 @@ class CheckpointingTests(test.TestCase): optimizer=on_create_optimizer, model=on_create_model) # Deferred restoration status = on_create_root.restore(save_path=save_path) + status.assert_existing_objects_matched() + with self.assertRaises(AssertionError): + status.assert_consumed() on_create_model(constant_op.constant([[3.]])) # create variables self.assertAllEqual(1, self.evaluate(on_create_root.save_counter)) self.assertAllEqual([42.], @@ -444,6 +447,9 @@ class CheckpointingTests(test.TestCase): on_create_model._named_dense.variables[1])) on_create_m_bias_slot = on_create_optimizer.get_slot( on_create_model._named_dense.variables[1], "m") + status.assert_existing_objects_matched() + with self.assertRaises(AssertionError): + status.assert_consumed() # Optimizer slot variables are created when the original variable is # restored. self.assertAllEqual([1.5], self.evaluate(on_create_m_bias_slot)) @@ -451,6 +457,7 @@ class CheckpointingTests(test.TestCase): self.evaluate(on_create_optimizer.variables())) dummy_var = resource_variable_ops.ResourceVariable([1.]) on_create_optimizer.minimize(loss=dummy_var.read_value) + status.assert_existing_objects_matched() status.assert_consumed() beta1_power, beta2_power = on_create_optimizer._get_beta_accumulators() self.assertAllEqual(optimizer_variables[0], self.evaluate(beta1_power)) @@ -499,15 +506,18 @@ class CheckpointingTests(test.TestCase): global_step=root.global_step) checkpoint_path = checkpoint_management.latest_checkpoint( checkpoint_directory) - with self.test_session(graph=ops.get_default_graph()) as session: + with self.session(graph=ops.get_default_graph()) as session: status = root.restore(save_path=checkpoint_path) status.initialize_or_restore(session=session) if checkpoint_path is None: self.assertEqual(0, training_continuation) with self.assertRaises(AssertionError): status.assert_consumed() + with self.assertRaises(AssertionError): + status.assert_existing_objects_matched() else: status.assert_consumed() + status.assert_existing_objects_matched() for _ in range(num_training_steps): session.run(train_op) root.save(file_prefix=checkpoint_prefix, session=session) @@ -704,11 +714,12 @@ class CheckpointingTests(test.TestCase): load_into = LateDependencies() status = checkpointable_utils.CheckpointableSaver( load_into).restore(save_path) + status.assert_existing_objects_matched() with self.assertRaises(AssertionError): status.assert_consumed() load_into.add_dep() status.assert_consumed() - status.run_restore_ops() + status.assert_existing_objects_matched().run_restore_ops() self.assertEqual(123., self.evaluate(load_into.dep.var)) @test_util.run_in_graph_and_eager_modes @@ -785,6 +796,7 @@ class CheckpointingTests(test.TestCase): no_slot_status.run_restore_ops() self.assertEqual(12., self.evaluate(new_root.var)) new_root.optimizer = adam.AdamOptimizer(0.1) + slot_status.assert_existing_objects_matched() with self.assertRaisesRegexp(AssertionError, "beta1_power"): slot_status.assert_consumed() self.assertEqual(12., self.evaluate(new_root.var)) @@ -884,6 +896,8 @@ class CheckpointingTests(test.TestCase): load_root.dep_one.dep_three, name="var", initializer=0.) with self.assertRaises(AssertionError): status.assert_consumed() + with self.assertRaises(AssertionError): + status.assert_existing_objects_matched() @test_util.run_in_graph_and_eager_modes def testObjectsCombined(self): @@ -907,7 +921,7 @@ class CheckpointingTests(test.TestCase): v2 = checkpointable_utils.add_variable( load_root.dep_one, name="var2", shape=[], dtype=dtypes.float64) status = checkpointable_utils.CheckpointableSaver(load_root).restore( - save_path).assert_consumed() + save_path).assert_consumed().assert_existing_objects_matched() status.run_restore_ops() self.assertEqual(32., self.evaluate(v1)) self.assertEqual(64., self.evaluate(v2)) @@ -994,7 +1008,7 @@ class CheckpointingTests(test.TestCase): """Saves after the first should not modify the graph.""" with context.graph_mode(): graph = ops.Graph() - with graph.as_default(), self.test_session(graph): + with graph.as_default(), self.session(graph): checkpoint_directory = self.get_temp_dir() checkpoint_prefix = os.path.join(checkpoint_directory, "ckpt") obj = tracking.Checkpointable() @@ -1073,22 +1087,17 @@ class CheckpointingTests(test.TestCase): self.assertEqual(5, self.evaluate(checkpoint.var_5)) self.assertEqual(1, self.evaluate(checkpoint.var_1)) self.assertEqual(0, self.evaluate(checkpoint.var_0)) - if context.executing_eagerly(): - checkpoint.restore(checkpoint_prefix + "-10").run_restore_ops() - self.assertEqual(9, self.evaluate(checkpoint.var_9)) - self.assertEqual(8, self.evaluate(checkpoint.var_8)) - self.assertEqual(1, self.evaluate(checkpoint.var_1)) - self.assertEqual(0, self.evaluate(checkpoint.var_0)) - else: - # Restoring into modified graphs is an error while graph building. - with self.assertRaises(NotImplementedError): - checkpoint.restore(checkpoint_prefix + "-10").run_restore_ops() + checkpoint.restore(checkpoint_prefix + "-10").run_restore_ops() + self.assertEqual(9, self.evaluate(checkpoint.var_9)) + self.assertEqual(8, self.evaluate(checkpoint.var_8)) + self.assertEqual(1, self.evaluate(checkpoint.var_1)) + self.assertEqual(0, self.evaluate(checkpoint.var_0)) def testManyRestoresGraph(self): """Restores after the first should not modify the graph.""" with context.graph_mode(): graph = ops.Graph() - with graph.as_default(), self.test_session(graph): + with graph.as_default(), self.session(graph): checkpoint_directory = self.get_temp_dir() checkpoint_prefix = os.path.join(checkpoint_directory, "ckpt") obj = tracking.Checkpointable() @@ -1244,6 +1253,8 @@ class CheckpointingTests(test.TestCase): status.initialize_or_restore() train_fn() with self.assertRaises(AssertionError): + status.assert_existing_objects_matched() + with self.assertRaises(AssertionError): status.assert_consumed() # Make sure initialization doesn't clobber later restores @@ -1456,17 +1467,27 @@ class CheckpointCompatibilityTests(test.TestCase): if context.executing_eagerly(): with self.assertRaisesRegexp(AssertionError, "OBJECT_CONFIG_JSON"): status.assert_consumed() + with self.assertRaisesRegexp(AssertionError, "OBJECT_CONFIG_JSON"): + status.assert_existing_objects_matched() else: # When graph building, we haven't read any keys, so we don't know # whether the restore will be complete. with self.assertRaisesRegexp(AssertionError, "not restored"): status.assert_consumed() + with self.assertRaisesRegexp(AssertionError, "not restored"): + status.assert_existing_objects_matched() status.run_restore_ops() self._check_sentinels(root) self._set_sentinels(root) status = object_saver.restore(save_path) status.initialize_or_restore() self._check_sentinels(root) + # Check that there is no error when keys are missing from the name-based + # checkpoint. + root.not_in_name_checkpoint = resource_variable_ops.ResourceVariable([1.]) + status = object_saver.restore(save_path) + with self.assertRaises(AssertionError): + status.assert_existing_objects_matched() def testSaveGraphLoadEager(self): checkpoint_directory = self.get_temp_dir() diff --git a/tensorflow/python/training/distribute.py b/tensorflow/python/training/distribute.py index 20e031569b..1ac7c39872 100644 --- a/tensorflow/python/training/distribute.py +++ b/tensorflow/python/training/distribute.py @@ -248,6 +248,7 @@ class DistributionStrategy(object): devices. We have then a few approaches we want to support: + * Code written (as if) with no knowledge of class `DistributionStrategy`. This code should work as before, even if some of the layers, etc. used by that code are written to be distribution-aware. This is done diff --git a/tensorflow/python/training/ftrl_test.py b/tensorflow/python/training/ftrl_test.py index 775bdb3f60..76ca5b45c9 100644 --- a/tensorflow/python/training/ftrl_test.py +++ b/tensorflow/python/training/ftrl_test.py @@ -117,8 +117,7 @@ class FtrlOptimizerTest(test.TestCase): # Run 1 step of sgd sgd_op.run() # Validate updated params - self.assertAllCloseAccordingToType( - [[0, 1]], var0.eval(), atol=0.01) + self.assertAllCloseAccordingToType([[0, 1]], var0.eval(), atol=0.01) def testFtrlWithL1(self): for dtype in [dtypes.half, dtypes.float32]: @@ -212,24 +211,96 @@ class FtrlOptimizerTest(test.TestCase): v0_val, v1_val = sess.run([var0, var1]) self.assertAllCloseAccordingToType( - np.array([-0.22078767, -0.41378114]), v0_val) + np.array([-0.22578995, -0.44345796]), v0_val) self.assertAllCloseAccordingToType( - np.array([-0.02919818, -0.07343706]), v1_val) + np.array([-0.14378493, -0.13229476]), v1_val) + + def testFtrlWithL1_L2_L2ShrinkageSparse(self): + """Tests the new FTRL op with support for l2 shrinkage on sparse grads.""" + for dtype in [dtypes.half, dtypes.float32]: + with self.test_session() as sess: + var0 = variables.Variable([[1.0], [2.0]], dtype=dtype) + var1 = variables.Variable([[4.0], [3.0]], dtype=dtype) + grads0 = ops.IndexedSlices( + constant_op.constant([0.1], shape=[1, 1], dtype=dtype), + constant_op.constant([0]), constant_op.constant([2, 1])) + grads1 = ops.IndexedSlices( + constant_op.constant([0.02], shape=[1, 1], dtype=dtype), + constant_op.constant([1]), constant_op.constant([2, 1])) + + opt = ftrl.FtrlOptimizer( + 3.0, + initial_accumulator_value=0.1, + l1_regularization_strength=0.001, + l2_regularization_strength=2.0, + l2_shrinkage_regularization_strength=0.1) + update = opt.apply_gradients(zip([grads0, grads1], [var0, var1])) + variables.global_variables_initializer().run() + + v0_val, v1_val = sess.run([var0, var1]) + self.assertAllCloseAccordingToType([[1.0], [2.0]], v0_val) + self.assertAllCloseAccordingToType([[4.0], [3.0]], v1_val) + + # Run 10 steps FTRL + for _ in range(10): + update.run() + + v0_val, v1_val = sess.run([var0, var1]) + self.assertAllCloseAccordingToType([[-0.22578995], [2.]], v0_val) + self.assertAllCloseAccordingToType([[4.], [-0.13229476]], v1_val) + + def testFtrlWithL2ShrinkageDoesNotChangeLrSchedule(self): + """Verifies that l2 shrinkage in FTRL does not change lr schedule.""" + for dtype in [dtypes.half, dtypes.float32]: + with self.test_session() as sess: + var0 = variables.Variable([1.0, 2.0], dtype=dtype) + var1 = variables.Variable([1.0, 2.0], dtype=dtype) + grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) + grads1 = constant_op.constant([0.1, 0.2], dtype=dtype) + + opt0 = ftrl.FtrlOptimizer( + 3.0, + initial_accumulator_value=0.1, + l1_regularization_strength=0.001, + l2_regularization_strength=2.0, + l2_shrinkage_regularization_strength=0.1) + opt1 = ftrl.FtrlOptimizer( + 3.0, + initial_accumulator_value=0.1, + l1_regularization_strength=0.001, + l2_regularization_strength=2.0) + update0 = opt0.apply_gradients([(grads0, var0)]) + update1 = opt1.apply_gradients([(grads1, var1)]) + variables.global_variables_initializer().run() + + v0_val, v1_val = sess.run([var0, var1]) + self.assertAllCloseAccordingToType([1.0, 2.0], v0_val) + self.assertAllCloseAccordingToType([1.0, 2.0], v1_val) + + # Run 10 steps FTRL + for _ in range(10): + update0.run() + update1.run() + + v0_val, v1_val = sess.run([var0, var1]) + # var0 is experiencing L2 shrinkage so it should be smaller than var1 + # in magnitude. + self.assertTrue((v0_val**2 < v1_val**2).all()) + accum0 = list(sess.run(opt0._slots)["accum"].values())[0] + accum1 = list(sess.run(opt1._slots)["accum"].values())[0] + # L2 shrinkage should not change how we update grad accumulator. + self.assertAllCloseAccordingToType(accum0, accum1) def applyOptimizer(self, opt, dtype, steps=5, is_sparse=False): if is_sparse: var0 = variables.Variable([[0.0], [0.0]], dtype=dtype) var1 = variables.Variable([[0.0], [0.0]], dtype=dtype) grads0 = ops.IndexedSlices( - constant_op.constant( - [0.1], shape=[1, 1], dtype=dtype), - constant_op.constant([0]), - constant_op.constant([2, 1])) + constant_op.constant([0.1], shape=[1, 1], dtype=dtype), + constant_op.constant([0]), constant_op.constant([2, 1])) grads1 = ops.IndexedSlices( - constant_op.constant( - [0.02], shape=[1, 1], dtype=dtype), - constant_op.constant([1]), - constant_op.constant([2, 1])) + constant_op.constant([0.02], shape=[1, 1], dtype=dtype), + constant_op.constant([1]), constant_op.constant([2, 1])) else: var0 = variables.Variable([0.0, 0.0], dtype=dtype) var1 = variables.Variable([0.0, 0.0], dtype=dtype) @@ -277,8 +348,7 @@ class FtrlOptimizerTest(test.TestCase): with self.test_session(): val2, val3 = self.applyOptimizer( - adagrad.AdagradOptimizer( - 3.0, initial_accumulator_value=0.1), dtype) + adagrad.AdagradOptimizer(3.0, initial_accumulator_value=0.1), dtype) self.assertAllCloseAccordingToType(val0, val2) self.assertAllCloseAccordingToType(val1, val3) @@ -299,8 +369,7 @@ class FtrlOptimizerTest(test.TestCase): with self.test_session(): val2, val3 = self.applyOptimizer( - adagrad.AdagradOptimizer( - 3.0, initial_accumulator_value=0.1), + adagrad.AdagradOptimizer(3.0, initial_accumulator_value=0.1), dtype, is_sparse=True) diff --git a/tensorflow/python/training/monitored_session.py b/tensorflow/python/training/monitored_session.py index c077630de2..8dcc1666e0 100644 --- a/tensorflow/python/training/monitored_session.py +++ b/tensorflow/python/training/monitored_session.py @@ -1363,3 +1363,6 @@ class _HookedSession(_WrappedSession): options.debug_options.debug_tensor_watch_opts.extend( incoming_options.debug_options.debug_tensor_watch_opts) + options.debug_options.reset_disk_byte_usage = ( + options.debug_options.reset_disk_byte_usage or + incoming_options.debug_options.reset_disk_byte_usage) diff --git a/tensorflow/python/training/moving_averages.py b/tensorflow/python/training/moving_averages.py index 4b91d1e963..177a7ddfa5 100644 --- a/tensorflow/python/training/moving_averages.py +++ b/tensorflow/python/training/moving_averages.py @@ -363,10 +363,12 @@ class ExponentialMovingAverage(object): `GraphKeys.ALL_VARIABLES` collection. They will be returned by calls to `tf.global_variables()`. - Returns an op that updates all shadow variables as described above. + Returns an op that updates all shadow variables from the current value of + their associated variables. - Note that `apply()` can be called multiple times with different lists of - variables. + Note that `apply()` can be called multiple times. When eager execution is + enabled each call to apply will update the variables once, so this needs to + be called in a loop. Args: var_list: A list of Variable or Tensor objects. The variables @@ -389,31 +391,30 @@ class ExponentialMovingAverage(object): dtypes.float64]: raise TypeError("The variables must be half, float, or double: %s" % var.name) - if var in self._averages: - raise ValueError("Moving average already computed for: %s" % var.name) - # For variables: to lower communication bandwidth across devices we keep - # the moving averages on the same device as the variables. For other - # tensors, we rely on the existing device allocation mechanism. - with ops.init_scope(): - if isinstance(var, variables.Variable): - avg = slot_creator.create_slot(var, - var.initialized_value(), - self.name, - colocate_with_primary=True) - # NOTE(mrry): We only add `tf.Variable` objects to the - # `MOVING_AVERAGE_VARIABLES` collection. - ops.add_to_collection(ops.GraphKeys.MOVING_AVERAGE_VARIABLES, var) - else: - avg = slot_creator.create_zeros_slot( - var, - self.name, - colocate_with_primary=(var.op.type in ["Variable", - "VariableV2", - "VarHandleOp"])) - if self._zero_debias: - zero_debias_true.add(avg) - self._averages[var] = avg + if var not in self._averages: + # For variables: to lower communication bandwidth across devices we keep + # the moving averages on the same device as the variables. For other + # tensors, we rely on the existing device allocation mechanism. + with ops.init_scope(): + if isinstance(var, variables.Variable): + avg = slot_creator.create_slot(var, + var.initialized_value(), + self.name, + colocate_with_primary=True) + # NOTE(mrry): We only add `tf.Variable` objects to the + # `MOVING_AVERAGE_VARIABLES` collection. + ops.add_to_collection(ops.GraphKeys.MOVING_AVERAGE_VARIABLES, var) + else: + avg = slot_creator.create_zeros_slot( + var, + self.name, + colocate_with_primary=(var.op.type in ["Variable", + "VariableV2", + "VarHandleOp"])) + if self._zero_debias: + zero_debias_true.add(avg) + self._averages[var] = avg with ops.name_scope(self.name) as scope: decay = ops.convert_to_tensor(self._decay, name="decay") diff --git a/tensorflow/python/training/moving_averages_test.py b/tensorflow/python/training/moving_averages_test.py index 3e85e6bfa7..fdb8d795c3 100644 --- a/tensorflow/python/training/moving_averages_test.py +++ b/tensorflow/python/training/moving_averages_test.py @@ -18,9 +18,11 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from tensorflow.python.eager import context from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops +from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops from tensorflow.python.ops import gen_state_ops from tensorflow.python.ops import variable_scope @@ -254,6 +256,25 @@ class ExponentialMovingAverageTest(test.TestCase): self.assertEqual(1, sess.run(v0)) self.assertEqual([17.5], sess.run(v1_avg)) + @test_util.run_in_graph_and_eager_modes + def testBasicEager(self): + v0 = variables.Variable(1.0) + v1 = variables.Variable(2.0) + + ema = moving_averages.ExponentialMovingAverage(0.25) + op = ema.apply([v0, v1]) + if not context.executing_eagerly(): + self.evaluate(variables.global_variables_initializer()) + self.evaluate(op) + + self.evaluate(v0.assign(2.0)) + self.evaluate(v1.assign(4.0)) + + self.evaluate(ema.apply([v0, v1])) + + self.assertAllEqual(self.evaluate(ema.average(v0)), 1.75) + self.assertAllEqual(self.evaluate(ema.average(v1)), 3.5) + def averageVariablesNamesHelper(self, zero_debias): with self.test_session(): v0 = variables.Variable(10.0, name="v0") diff --git a/tensorflow/python/training/optimizer.py b/tensorflow/python/training/optimizer.py index 1b6bce2865..2304a461c1 100644 --- a/tensorflow/python/training/optimizer.py +++ b/tensorflow/python/training/optimizer.py @@ -772,16 +772,15 @@ class Optimizer( Returns: A list of variables. """ - executing_eagerly = context.executing_eagerly() current_graph = ops.get_default_graph() def _from_current_graph(variable): - if executing_eagerly: + if variable._in_graph_mode: # pylint: disable=protected-access + return variable.op.graph is current_graph + else: # No variable.op in eager mode. We don't expect lots of eager graphs, # but behavior should be consistent with graph mode. return variable._graph_key == current_graph._graph_key # pylint: disable=protected-access - else: - return variable.op.graph is current_graph optimizer_variables = [v for v in self._non_slot_variables() if _from_current_graph(v)] diff --git a/tensorflow/python/training/queue_runner_test.py b/tensorflow/python/training/queue_runner_test.py index ac26e75bb9..900f9706ac 100644 --- a/tensorflow/python/training/queue_runner_test.py +++ b/tensorflow/python/training/queue_runner_test.py @@ -303,7 +303,7 @@ class QueueRunnerTest(test.TestCase): init_op = variables.global_variables_initializer() qr = queue_runner_impl.QueueRunner(queue, [count_up_to]) queue_runner_impl.add_queue_runner(qr) - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: init_op.run() threads = queue_runner_impl.start_queue_runners(sess) for t in threads: diff --git a/tensorflow/python/training/saver.py b/tensorflow/python/training/saver.py index e35ea81456..274c856686 100644 --- a/tensorflow/python/training/saver.py +++ b/tensorflow/python/training/saver.py @@ -809,6 +809,22 @@ class BaseSaverBuilder(object): keep_checkpoint_every_n_hours=keep_checkpoint_every_n_hours, version=self._write_version) else: + graph = ops.get_default_graph() + # Do some sanity checking on collections containing + # PartitionedVariables. If a saved collection has a PartitionedVariable, + # the GraphDef needs to include concat ops to get the value (or there'll + # be a lookup error on load). + check_collection_list = graph.get_all_collection_keys() + for collection_type in check_collection_list: + for element in graph.get_collection(collection_type): + if isinstance(element, variables.PartitionedVariable): + try: + graph.get_operation_by_name(element.name) + except KeyError: + # Create a concat op for this PartitionedVariable. The user may + # not need it, but we'll try looking it up on MetaGraph restore + # since it's in a collection. + element.as_tensor() return saver_pb2.SaverDef( filename_tensor_name=filename_tensor.name, save_tensor_name=save_tensor.name, diff --git a/tensorflow/python/training/saver_test.py b/tensorflow/python/training/saver_test.py index b55e64122a..f5b2a22327 100644 --- a/tensorflow/python/training/saver_test.py +++ b/tensorflow/python/training/saver_test.py @@ -84,7 +84,7 @@ class SaverTest(test.TestCase): def basicSaveRestore(self, variable_op): save_path = os.path.join(self.get_temp_dir(), "basic_save_restore") - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Build a graph with 2 parameter nodes, and Save and # Restore nodes for them. v0 = variable_op(10.0, name="v0") @@ -115,7 +115,7 @@ class SaverTest(test.TestCase): # Start a second session. In that session the parameter nodes # have not been initialized either. - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: v0 = variable_op(-1.0, name="v0") v1 = variable_op(-1.0, name="v1") v2 = saver_test_utils.CheckpointedOp(name="v2") @@ -137,7 +137,7 @@ class SaverTest(test.TestCase): # Build another graph with 2 nodes, initialized # differently, and a Restore node for them. - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: v0_2 = variable_op(1000.0, name="v0") v1_2 = variable_op(2000.0, name="v1") v2_2 = saver_test_utils.CheckpointedOp(name="v2") @@ -222,7 +222,7 @@ class SaverTest(test.TestCase): # Save from graph mode and restore from eager mode. graph_ckpt_prefix = os.path.join(self.get_temp_dir(), "graph_ckpt") with context.graph_mode(): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Create a graph model and save the checkpoint. w1 = resource_variable_ops.ResourceVariable(1.0, name="w1") w2 = resource_variable_ops.ResourceVariable(2.0, name="w2") @@ -256,7 +256,7 @@ class SaverTest(test.TestCase): graph_saver.save(None, eager_ckpt_prefix) with context.graph_mode(): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: w3 = resource_variable_ops.ResourceVariable(0.0, name="w3") w4 = resource_variable_ops.ResourceVariable(0.0, name="w4") graph_saver = saver_module.Saver([w3, w4]) @@ -268,7 +268,7 @@ class SaverTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testResourceSaveRestoreCachingDevice(self): save_path = os.path.join(self.get_temp_dir(), "resource_cache") - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: v = resource_variable_ops.ResourceVariable([1], caching_device="/cpu:0", name="v") if context.executing_eagerly(): @@ -465,7 +465,7 @@ class SaverTest(test.TestCase): def testBasicsWithListOfVariables(self): save_path = os.path.join(self.get_temp_dir(), "basics_with_list") - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Build a graph with 2 parameter nodes, and Save and # Restore nodes for them. v0 = variables.Variable(10.0, name="v0") @@ -489,7 +489,7 @@ class SaverTest(test.TestCase): # Start a second session. In that session the variables # have not been initialized either. - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: v0 = variables.Variable(-1.0, name="v0") v1 = variables.Variable(-1.0, name="v1") v2 = saver_test_utils.CheckpointedOp(name="v2") @@ -514,7 +514,7 @@ class SaverTest(test.TestCase): # Build another graph with 2 nodes, initialized # differently, and a Restore node for them. - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: v0_2 = variables.Variable(1000.0, name="v0") v1_2 = variables.Variable(2000.0, name="v1") v2_2 = saver_test_utils.CheckpointedOp(name="v2") @@ -536,14 +536,14 @@ class SaverTest(test.TestCase): self.assertEqual(30.0, v2_2.values().eval()) def _SaveAndLoad(self, var_name, var_value, other_value, save_path): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: var = resource_variable_ops.ResourceVariable(var_value, name=var_name) save = saver_module.Saver({var_name: var}) if not context.executing_eagerly(): self.evaluate(var.initializer) val = save.save(sess, save_path) self.assertEqual(save_path, val) - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: var = resource_variable_ops.ResourceVariable(other_value, name=var_name) save = saver_module.Saver({var_name: var}) save.restore(sess, save_path) @@ -693,7 +693,7 @@ class SaverTest(test.TestCase): # Save and reload one Variable named "var0". self._SaveAndLoad("var0", 0.0, 1.0, save_path) for use_tensor in [True, False]: - with self.test_session(graph=ops_lib.Graph()): + with self.session(graph=ops_lib.Graph()): var = resource_variable_ops.ResourceVariable(1.0, name="var0") save = saver_module.Saver( { @@ -791,7 +791,7 @@ class SaverTest(test.TestCase): save_path = os.path.join(self.get_temp_dir(), "basic_save_restore") # Build the first session. - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: v0 = variable_op(10.0, name="v0", dtype=dtypes.float32) if not context.executing_eagerly(): @@ -801,7 +801,7 @@ class SaverTest(test.TestCase): save.save(sess, save_path) # Start a second session. - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: v0_wrong_dtype = variable_op(1, name="v0", dtype=dtypes.int32) # Restore the saved value with different dtype # in the parameter nodes. @@ -822,7 +822,7 @@ class SaverTest(test.TestCase): return small_v + large_v save_graph = ops_lib.Graph() - with save_graph.as_default(), self.test_session(graph=save_graph) as sess: + with save_graph.as_default(), self.session(graph=save_graph) as sess: orig_vars = _model() sess.run(variables.global_variables_initializer()) save = saver_module.Saver(max_to_keep=1) @@ -999,7 +999,7 @@ class SaveRestoreShardedTest(test.TestCase): call_saver_with_dict = False # updated by test loop below def _save(slices=None, partitioner=None): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Calls .eval() to return the ndarray that makes up the full variable. rnd = random_ops.random_uniform(var_full_shape).eval() @@ -1036,7 +1036,7 @@ class SaveRestoreShardedTest(test.TestCase): return rnd def _restore(slices=None, partitioner=None): - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: if slices: assert not partitioner new_vs = partitioned_variables.create_partitioned_variables( @@ -1549,7 +1549,7 @@ class SaveRestoreWithVariableNameMap(test.TestCase): def _testNonReshape(self, variable_op): save_path = os.path.join(self.get_temp_dir(), "non_reshape") - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Build a graph with 2 parameter nodes, and Save and # Restore nodes for them. v0 = variable_op(10.0, name="v0") @@ -1574,7 +1574,7 @@ class SaveRestoreWithVariableNameMap(test.TestCase): # Verify that the mapped names are present in the Saved file and can be # Restored using remapped names. - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: v0 = variable_op(-1.0, name="v0") v1 = variable_op(-1.0, name="v1") @@ -1594,7 +1594,7 @@ class SaveRestoreWithVariableNameMap(test.TestCase): # Add a prefix to the node names in the current graph and Restore using # remapped names. - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: v0 = variable_op(-1.0, name="restore_prefix/v0") v1 = variable_op(-1.0, name="restore_prefix/v1") @@ -1709,7 +1709,7 @@ class MetaGraphTest(test.TestCase): filename = os.path.join(test_dir, "metafile") saver0_ckpt = os.path.join(test_dir, "saver0.ckpt") saver1_ckpt = os.path.join(test_dir, "saver1.ckpt") - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Creates a graph. v0 = variables.Variable([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]], name="v0") v1 = variables.Variable(11.0, name="v1") @@ -1753,7 +1753,7 @@ class MetaGraphTest(test.TestCase): filename = os.path.join(test_dir, "metafile") saver0_ckpt = os.path.join(test_dir, "saver0.ckpt") saver1_ckpt = os.path.join(test_dir, "saver1.ckpt") - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Imports from meta_graph. saver_module.import_meta_graph(filename) # Retrieves SAVERS collection. Verifies there are 2 entries. @@ -1786,7 +1786,7 @@ class MetaGraphTest(test.TestCase): filename = os.path.join(test_dir, "metafile") saver0_ckpt = os.path.join(test_dir, "saver0.ckpt") saver1_ckpt = os.path.join(test_dir, "saver1.ckpt") - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Creates a graph. v0 = variables.Variable([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]], name="v0") v1 = variables.Variable(11.0, name="v1") @@ -1838,25 +1838,25 @@ class MetaGraphTest(test.TestCase): def testBinaryAndTextFormat(self): test_dir = self._get_test_dir("binary_and_text") filename = os.path.join(test_dir, "metafile") - with self.test_session(graph=ops_lib.Graph()): + with self.session(graph=ops_lib.Graph()): # Creates a graph. variables.Variable(10.0, name="v0") # Exports the graph as binary format. saver_module.export_meta_graph(filename, as_text=False) - with self.test_session(graph=ops_lib.Graph()): + with self.session(graph=ops_lib.Graph()): # Imports the binary format graph. saver = saver_module.import_meta_graph(filename) self.assertIsNotNone(saver) # Exports the graph as text format. saver.export_meta_graph(filename, as_text=True) - with self.test_session(graph=ops_lib.Graph()): + with self.session(graph=ops_lib.Graph()): # Imports the text format graph. saver_module.import_meta_graph(filename) # Writes wrong contents to the file. graph_io.write_graph(saver.as_saver_def(), os.path.dirname(filename), os.path.basename(filename)) - with self.test_session(graph=ops_lib.Graph()): + with self.session(graph=ops_lib.Graph()): # Import should fail. with self.assertRaisesWithPredicateMatch(IOError, lambda e: "Cannot parse file"): @@ -1961,7 +1961,7 @@ class MetaGraphTest(test.TestCase): filename = os.path.join(test_dir, "metafile") train_filename = os.path.join(test_dir, "train_metafile") saver0_ckpt = os.path.join(test_dir, "saver0.ckpt") - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Restores from MetaGraphDef. new_saver = saver_module.import_meta_graph(filename) # Generates a new MetaGraphDef. @@ -1998,7 +1998,7 @@ class MetaGraphTest(test.TestCase): def _testRestoreFromTrainGraphWithControlContext(self, test_dir): train_filename = os.path.join(test_dir, "train_metafile") saver0_ckpt = os.path.join(test_dir, "saver0.ckpt") - with self.test_session(graph=ops_lib.Graph()) as sess: + with self.session(graph=ops_lib.Graph()) as sess: # Restores from MetaGraphDef. new_saver = saver_module.import_meta_graph(train_filename) # Restores from checkpoint. @@ -2177,7 +2177,7 @@ class MetaGraphTest(test.TestCase): # With strip_default_attrs disabled, attributes "T" (float32) and "Tout" # (complex64) in the "Complex" op must *not* be removed, even if they map # to their defaults. - with self.test_session(graph=ops_lib.Graph()): + with self.session(graph=ops_lib.Graph()): real_num = variables.Variable(1.0, dtype=dtypes.float32, name="real") imag_num = variables.Variable(2.0, dtype=dtypes.float32, name="imag") math_ops.complex(real_num, imag_num, name="complex") @@ -2541,7 +2541,7 @@ class ScopedGraphTest(test.TestCase): export_scope="hidden1") self.assertEqual(["biases:0", "weights:0"], sorted(var_list.keys())) - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: sess.run(variables.global_variables_initializer()) saver = saver_module.Saver(var_list=var_list, max_to_keep=1) saver.save(sess, os.path.join(test_dir, ckpt_filename), write_state=False) @@ -2601,7 +2601,7 @@ class ScopedGraphTest(test.TestCase): set(variables.global_variables()) - set(var_list.keys())) init_rest_op = variables.variables_initializer(rest_variables) - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: saver = saver_module.Saver(var_list=var_list, max_to_keep=1) saver.restore(sess, os.path.join(test_dir, ckpt_filename)) # Verify that we have restored weights1 and biases1. @@ -2635,7 +2635,7 @@ class ScopedGraphTest(test.TestCase): nn_ops.relu(math_ops.matmul(images, weights1) + biases1, name="relu") # Run the graph and save scoped checkpoint. - with self.test_session(graph=graph1) as sess: + with self.session(graph=graph1) as sess: sess.run(variables.global_variables_initializer()) _, var_list_1 = meta_graph.export_scoped_meta_graph( export_scope="hidden1") @@ -2656,7 +2656,7 @@ class ScopedGraphTest(test.TestCase): var_list_2 = meta_graph.copy_scoped_meta_graph( from_scope="hidden1", to_scope="hidden2") - with self.test_session(graph=graph1) as sess: + with self.session(graph=graph1) as sess: saver1 = saver_module.Saver(var_list=var_list_1, max_to_keep=1) saver1.restore(sess, saver0_ckpt) saver2 = saver_module.Saver(var_list=var_list_2, max_to_keep=1) @@ -2672,7 +2672,7 @@ class ScopedGraphTest(test.TestCase): from_graph=graph1, to_graph=graph2) - with self.test_session(graph=graph2) as sess: + with self.session(graph=graph2) as sess: saver3 = saver_module.Saver(var_list=new_var_list_1, max_to_keep=1) saver3.restore(sess, saver0_ckpt) self.assertAllClose(expected, sess.run("new_hidden1/relu:0")) @@ -2691,7 +2691,7 @@ class ScopedGraphTest(test.TestCase): nn_ops.relu(math_ops.matmul(images, weights1) + biases1, name="relu") # Run the graph and save scoped checkpoint. - with self.test_session(graph=graph1) as sess: + with self.session(graph=graph1) as sess: sess.run(variables.global_variables_initializer()) _, var_list_1 = meta_graph.export_scoped_meta_graph( graph_def=graph1.as_graph_def(), export_scope="hidden1") @@ -2708,7 +2708,7 @@ class ScopedGraphTest(test.TestCase): from_graph=graph1, to_graph=graph2) - with self.test_session(graph=graph2) as sess: + with self.session(graph=graph2) as sess: saver3 = saver_module.Saver(var_list=new_var_list_1, max_to_keep=1) saver3.restore(sess, saver0_ckpt) self.assertAllClose(expected, sess.run("new_hidden1/relu:0")) @@ -2729,7 +2729,7 @@ class ScopedGraphTest(test.TestCase): saver2 = saver_module.Saver(var_list=[variable2], name="hidden2/") graph.add_to_collection(ops_lib.GraphKeys.SAVERS, saver2) - with self.test_session(graph=graph) as sess: + with self.session(graph=graph) as sess: variables.global_variables_initializer().run() saver1.save(sess, saver1_ckpt, write_state=False) saver2.save(sess, saver2_ckpt, write_state=False) @@ -2745,7 +2745,7 @@ class ScopedGraphTest(test.TestCase): saver_list1 = graph1.get_collection(ops_lib.GraphKeys.SAVERS) self.assertEqual(1, len(saver_list1)) - with self.test_session(graph=graph1) as sess: + with self.session(graph=graph1) as sess: saver_list1[0].restore(sess, saver1_ckpt) self.assertEqual(1.0, var_dict1["variable1:0"].eval()) @@ -2760,7 +2760,7 @@ class ScopedGraphTest(test.TestCase): saver_list2 = graph2.get_collection(ops_lib.GraphKeys.SAVERS) self.assertEqual(1, len(saver_list2)) - with self.test_session(graph=graph2) as sess: + with self.session(graph=graph2) as sess: saver_list2[0].restore(sess, saver2_ckpt) self.assertEqual(2.0, var_dict2["variable2:0"].eval()) @@ -2853,8 +2853,8 @@ class CheckpointableCompatibilityTests(test.TestCase): saver = saver_module.Saver(var_list=[v]) test_dir = self.get_temp_dir() prefix = os.path.join(test_dir, "ckpt") - self.evaluate(v.non_dep_variable.assign(42.)) with self.test_session() as sess: + self.evaluate(v.non_dep_variable.assign(42.)) save_path = saver.save(sess, prefix) self.evaluate(v.non_dep_variable.assign(43.)) saver.restore(sess, save_path) @@ -2979,14 +2979,14 @@ class CheckpointableCompatibilityTests(test.TestCase): a = variables.Variable(1., name="a") a_saver = saver_module.Saver([a]) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sess.run(a.initializer) save_path = a_saver.save(sess=sess, save_path=checkpoint_prefix) with ops_lib.Graph().as_default() as g: a = variables.Variable([1.], name="a") a_saver = saver_module.Saver([a]) - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: with self.assertRaisesRegexp( errors.InvalidArgumentError, "a mismatch between the current graph and the graph"): @@ -2997,7 +2997,7 @@ class CheckpointableCompatibilityTests(test.TestCase): checkpoint_prefix = os.path.join(checkpoint_directory, "ckpt") save_graph = ops_lib.Graph() - with save_graph.as_default(), self.test_session(graph=save_graph) as sess: + with save_graph.as_default(), self.session(graph=save_graph) as sess: root = self._initialized_model() object_saver = checkpointable_utils.CheckpointableSaver(root) save_path = object_saver.save(file_prefix=checkpoint_prefix) @@ -3031,7 +3031,7 @@ class CheckpointableCompatibilityTests(test.TestCase): checkpoint_prefix = os.path.join(checkpoint_directory, "ckpt") save_graph = ops_lib.Graph() - with save_graph.as_default(), self.test_session(graph=save_graph): + with save_graph.as_default(), self.session(graph=save_graph): root = self._initialized_model() object_saver = checkpointable_utils.CheckpointableSaver(root) save_path = object_saver.save(file_prefix=checkpoint_prefix) diff --git a/tensorflow/python/training/sync_replicas_optimizer.py b/tensorflow/python/training/sync_replicas_optimizer.py index 0c6cf910d1..7afaa92699 100644 --- a/tensorflow/python/training/sync_replicas_optimizer.py +++ b/tensorflow/python/training/sync_replicas_optimizer.py @@ -53,7 +53,7 @@ class SyncReplicasOptimizer(optimizer.Optimizer): which replicas can fetch the new variables and continue. The following accumulators/queue are created: - <empty line> + * N `gradient accumulators`, one per variable to train. Gradients are pushed to them and the chief worker will wait until enough gradients are collected and then average them before applying to variables. The accumulator will @@ -68,7 +68,7 @@ class SyncReplicasOptimizer(optimizer.Optimizer): The optimizer adds nodes to the graph to collect gradients and pause the trainers until variables are updated. For the Parameter Server job: - <empty line> + 1. An accumulator is created for each variable, and each replica pushes the gradients into the accumulators instead of directly applying them to the variables. @@ -81,7 +81,7 @@ class SyncReplicasOptimizer(optimizer.Optimizer): update its local_step variable and start the next batch. For the replicas: - <empty line> + 1. Start a step: fetch variables and compute gradients. 2. Once the gradients have been computed, push them into gradient accumulators. Each accumulator will check the staleness and drop the stale. diff --git a/tensorflow/python/training/warm_starting_util.py b/tensorflow/python/training/warm_starting_util.py index 0ba7ba983d..c0dd46bfa5 100644 --- a/tensorflow/python/training/warm_starting_util.py +++ b/tensorflow/python/training/warm_starting_util.py @@ -32,7 +32,7 @@ from tensorflow.python.training import saver from tensorflow.python.util.tf_export import tf_export -@tf_export("train.VocabInfo", allow_multiple_exports=True) +@tf_export("train.VocabInfo") class VocabInfo( collections.namedtuple("VocabInfo", [ "new_vocab", diff --git a/tensorflow/python/training/warm_starting_util_test.py b/tensorflow/python/training/warm_starting_util_test.py index 6a4c207d79..70a84bc3f6 100644 --- a/tensorflow/python/training/warm_starting_util_test.py +++ b/tensorflow/python/training/warm_starting_util_test.py @@ -59,7 +59,7 @@ class WarmStartingUtilTest(test.TestCase): initializer=None, partitioner=None): with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: var = variable_scope.get_variable( var_name, shape=shape, @@ -102,7 +102,7 @@ class WarmStartingUtilTest(test.TestCase): "fruit_weights", initializer=[[0.5], [1.], [1.5], [2.]]) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: fruit_weights = variable_scope.get_variable( "fruit_weights", initializer=[[0.], [0.], [0.], [0.]]) ws_util._warm_start_var(fruit_weights, self.get_temp_dir()) @@ -118,7 +118,7 @@ class WarmStartingUtilTest(test.TestCase): prev_val = np.concatenate([weights[0], weights[1]], axis=0) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: fruit_weights = variable_scope.get_variable( "fruit_weights", initializer=[[0.], [0.], [0.], [0.]]) ws_util._warm_start_var(fruit_weights, self.get_temp_dir()) @@ -130,7 +130,7 @@ class WarmStartingUtilTest(test.TestCase): "fruit_weights", initializer=[[0.5], [1.], [1.5], [2.]]) with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: fruit_weights = variable_scope.get_variable( "fruit_weights", shape=[4, 1], @@ -154,7 +154,7 @@ class WarmStartingUtilTest(test.TestCase): prev_val = np.concatenate([weights[0], weights[1]], axis=0) # New session and new graph. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: fruit_weights = variable_scope.get_variable( "new_scope/fruit_weights", shape=[4, 1], @@ -183,7 +183,7 @@ class WarmStartingUtilTest(test.TestCase): ["orange", "guava", "banana", "apple", "raspberry"], "new_vocab") # New session and new graph. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: fruit_weights = variable_scope.get_variable( "fruit_weights", initializer=[[0.], [0.], [0.], [0.], [0.]]) ws_util._warm_start_var_with_vocab(fruit_weights, new_vocab_path, 5, @@ -203,7 +203,7 @@ class WarmStartingUtilTest(test.TestCase): ["orange", "guava", "banana", "apple", "raspberry"], "new_vocab") # New session and new graph. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: fruit_weights = variable_scope.get_variable( "fruit_weights", initializer=[[0.], [0.], [0.], [0.], [0.]]) ws_util._warm_start_var_with_vocab( @@ -232,7 +232,7 @@ class WarmStartingUtilTest(test.TestCase): ["orange", "guava", "banana", "apple", "raspberry"], "new_vocab") # New session and new graph. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: fruit_weights = variable_scope.get_variable( "fruit_weights", initializer=[[0.], [0.], [0.], [0.], [0.]]) ws_util._warm_start_var_with_vocab(fruit_weights, new_vocab_path, 5, @@ -252,7 +252,7 @@ class WarmStartingUtilTest(test.TestCase): ["orange", "guava", "banana", "apple", "raspberry"], "new_vocab") # New session and new graph. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: fruit_weights = variable_scope.get_variable( "fruit_weights", shape=[6, 1], @@ -289,7 +289,7 @@ class WarmStartingUtilTest(test.TestCase): "blueberry"], "new_vocab") # New session and new graph. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: fruit_weights = variable_scope.get_variable( "fruit_weights", shape=[6, 1], @@ -315,7 +315,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Initialize with zeros. var = variable_scope.get_variable( "v1", @@ -335,7 +335,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: # Initialize with zeros. var = variable_scope.get_variable( "v1", @@ -359,7 +359,7 @@ class WarmStartingUtilTest(test.TestCase): partitioner = lambda shape, dtype: [1] * len(shape) # New graph, new session WITHOUT warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_int], partitioner) sess.run(variables.global_variables_initializer()) # Without warm-starting, the weights should be initialized using default @@ -369,7 +369,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_int], partitioner) ws_util.warm_start(self.get_temp_dir(), vars_to_warm_start=".*sc_int.*") sess.run(variables.global_variables_initializer()) @@ -388,7 +388,7 @@ class WarmStartingUtilTest(test.TestCase): partitioner = lambda shape, dtype: [1] * len(shape) # New graph, new session WITHOUT warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_hash], partitioner) sess.run(variables.global_variables_initializer()) # Without warm-starting, the weights should be initialized using default @@ -398,7 +398,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_hash], partitioner) ws_util.warm_start( self.get_temp_dir(), vars_to_warm_start=".*sc_hash.*") @@ -422,7 +422,7 @@ class WarmStartingUtilTest(test.TestCase): partitioner = lambda shape, dtype: [1] * len(shape) # New graph, new session WITHOUT warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_vocab], partitioner) sess.run(variables.global_variables_initializer()) # Without warm-starting, the weights should be initialized using default @@ -432,7 +432,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_vocab], partitioner) # Since old vocab is not explicitly set in WarmStartSettings, the old # vocab is assumed to be same as new vocab. @@ -458,7 +458,7 @@ class WarmStartingUtilTest(test.TestCase): partitioner = lambda shape, dtype: [1] * len(shape) # New graph, new session WITHOUT warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_vocab], partitioner) sess.run(variables.global_variables_initializer()) # Without warm-starting, the weights should be initialized using default @@ -468,7 +468,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_vocab], partitioner) # Since old vocab is not explicitly set in WarmStartSettings, the old # vocab is assumed to be same as new vocab. @@ -503,7 +503,7 @@ class WarmStartingUtilTest(test.TestCase): partitioner = lambda shape, dtype: [1] * len(shape) # New graph, new session WITHOUT warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_vocab], partitioner) sess.run(variables.global_variables_initializer()) # Without warm-starting, the weights should be initialized using default @@ -513,7 +513,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([sc_vocab], partitioner) vocab_info = ws_util.VocabInfo( new_vocab=sc_vocab.vocabulary_file, @@ -546,7 +546,7 @@ class WarmStartingUtilTest(test.TestCase): partitioner = lambda shape, dtype: [1] * len(shape) # New graph, new session WITHOUT warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([real_bucket], partitioner) sess.run(variables.global_variables_initializer()) # Without warm-starting, the weights should be initialized using default @@ -556,7 +556,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model([real_bucket], partitioner) ws_util.warm_start( self.get_temp_dir(), vars_to_warm_start=".*real_bucketized.*") @@ -586,7 +586,7 @@ class WarmStartingUtilTest(test.TestCase): # Save checkpoint from which to warm-start. Also create a bias variable, # so we can check that it's also warm-started. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: sc_int_weights = variable_scope.get_variable( "linear_model/sc_int/weights", shape=[10, 1], initializer=ones()) sc_hash_weights = variable_scope.get_variable( @@ -617,7 +617,7 @@ class WarmStartingUtilTest(test.TestCase): partitioner = lambda shape, dtype: [1] * len(shape) # New graph, new session WITHOUT warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model(all_linear_cols, partitioner) sess.run(variables.global_variables_initializer()) # Without warm-starting, all weights should be initialized using default @@ -633,7 +633,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model(all_linear_cols, partitioner) vocab_info = ws_util.VocabInfo( new_vocab=sc_vocab.vocabulary_file, @@ -675,7 +675,7 @@ class WarmStartingUtilTest(test.TestCase): # Save checkpoint from which to warm-start. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: variable_scope.get_variable( "linear_model/sc_hash/weights", shape=[15, 1], initializer=norms()) sc_keys_weights = variable_scope.get_variable( @@ -694,7 +694,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model(all_linear_cols, _partitioner) vocab_info = ws_util.VocabInfo( new_vocab=sc_vocab.vocabulary_file, @@ -743,7 +743,7 @@ class WarmStartingUtilTest(test.TestCase): # Save checkpoint from which to warm-start. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: variable_scope.get_variable( "linear_model/sc_hash/weights", shape=[15, 1], initializer=norms()) sc_keys_weights = variable_scope.get_variable( @@ -756,7 +756,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model(all_linear_cols, partitioner=None) vocab_info = ws_util.VocabInfo( @@ -802,7 +802,7 @@ class WarmStartingUtilTest(test.TestCase): # Save checkpoint from which to warm-start. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: variable_scope.get_variable( "linear_model/sc_hash/weights", shape=[15, 1], initializer=norms()) variable_scope.get_variable( @@ -820,7 +820,7 @@ class WarmStartingUtilTest(test.TestCase): # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = self._create_linear_model(all_linear_cols, _partitioner) vocab_info = ws_util.VocabInfo( new_vocab=sc_vocab.vocabulary_file, @@ -866,7 +866,7 @@ class WarmStartingUtilTest(test.TestCase): # Save checkpoint from which to warm-start. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: variable_scope.get_variable( "input_layer/sc_vocab_embedding/embedding_weights", initializer=[[0.5, 0.4], [1., 1.1], [2., 2.2], [3., 3.3]]) @@ -887,7 +887,7 @@ class WarmStartingUtilTest(test.TestCase): all_deep_cols = [emb_vocab_column] # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = {} with variable_scope.variable_scope("", partitioner=_partitioner): # Create the variables. @@ -933,7 +933,7 @@ class WarmStartingUtilTest(test.TestCase): # Save checkpoint from which to warm-start. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: variable_scope.get_variable( "linear_model/sc_vocab_embedding/embedding_weights", initializer=[[0.5, 0.4], [1., 1.1], [2., 2.2], [3., 3.3]]) @@ -957,7 +957,7 @@ class WarmStartingUtilTest(test.TestCase): all_deep_cols = [emb_vocab] # New graph, new session with warm-starting. with ops.Graph().as_default() as g: - with self.test_session(graph=g) as sess: + with self.session(graph=g) as sess: cols_to_vars = {} with variable_scope.variable_scope("", partitioner=_partitioner): # Create the variables. diff --git a/tensorflow/python/util/nest.py b/tensorflow/python/util/nest.py index faae0d89c3..2968ca9c07 100644 --- a/tensorflow/python/util/nest.py +++ b/tensorflow/python/util/nest.py @@ -62,6 +62,10 @@ def _is_namedtuple(instance, strict=False): return _pywrap_tensorflow.IsNamedtuple(instance, strict) +# See the swig file (util.i) for documentation. +_is_mapping = _pywrap_tensorflow.IsMapping + + def _sequence_like(instance, args): """Converts the sequence `args` to the same type as `instance`. @@ -73,7 +77,7 @@ def _sequence_like(instance, args): Returns: `args` with the type of `instance`. """ - if isinstance(instance, (dict, _collections.Mapping)): + if _is_mapping(instance): # Pack dictionaries in a deterministic order by sorting the keys. # Notice this means that we ignore the original order of `OrderedDict` # instances. This is intentional, to avoid potential bugs caused by mixing @@ -89,7 +93,7 @@ def _sequence_like(instance, args): def _yield_value(iterable): - if isinstance(iterable, (dict, _collections.Mapping)): + if _is_mapping(iterable): # Iterate through dictionaries in a deterministic order by sorting the # keys. Notice this means that we ignore the original order of `OrderedDict` # instances. This is intentional, to avoid potential bugs caused by mixing @@ -102,53 +106,16 @@ def _yield_value(iterable): yield value -def is_sequence(seq): - """Returns a true if its input is a collections.Sequence (except strings). +# See the swig file (util.i) for documentation. +is_sequence = _pywrap_tensorflow.IsSequence - Args: - seq: an input sequence. - Returns: - True if the sequence is a not a string and is a collections.Sequence or a - dict. - """ - return _pywrap_tensorflow.IsSequence(seq) +# See the swig file (util.i) for documentation. +flatten = _pywrap_tensorflow.Flatten -def flatten(nest): - """Returns a flat list from a given nested structure. - - If `nest` is not a sequence, tuple, or dict, then returns a single-element - list: `[nest]`. - - In the case of dict instances, the sequence consists of the values, sorted by - key to ensure deterministic behavior. This is true also for `OrderedDict` - instances: their sequence order is ignored, the sorting order of keys is - used instead. The same convention is followed in `pack_sequence_as`. This - correctly repacks dicts and `OrderedDict`s after they have been flattened, - and also allows flattening an `OrderedDict` and then repacking it back using - a corresponding plain dict, or vice-versa. - Dictionaries with non-sortable keys cannot be flattened. - - Users must not modify any collections used in `nest` while this function is - running. - - Args: - nest: an arbitrarily nested structure or a scalar object. Note, numpy - arrays are considered scalars. - - Returns: - A Python list, the flattened version of the input. - - Raises: - TypeError: The nest is or contains a dict with non-sortable keys. - """ - return _pywrap_tensorflow.Flatten(nest) - - -def _same_namedtuples(nest1, nest2): - """Returns True if the two namedtuples have the same name and fields.""" - return _pywrap_tensorflow.SameNamedtuples(nest1, nest2) +# See the swig file (util.i) for documentation. +_same_namedtuples = _pywrap_tensorflow.SameNamedtuples def assert_same_structure(nest1, nest2, check_types=True): @@ -311,14 +278,17 @@ def pack_sequence_as(structure, flat_sequence): % len(flat_sequence)) return flat_sequence[0] - flat_structure = flatten(structure) - if len(flat_structure) != len(flat_sequence): - raise ValueError( - "Could not pack sequence. Structure had %d elements, but flat_sequence " - "had %d elements. Structure: %s, flat_sequence: %s." - % (len(flat_structure), len(flat_sequence), structure, flat_sequence)) - - _, packed = _packed_nest_with_indices(structure, flat_sequence, 0) + try: + final_index, packed = _packed_nest_with_indices(structure, flat_sequence, 0) + if final_index < len(flat_sequence): + raise IndexError + except IndexError: + flat_structure = flatten(structure) + if len(flat_structure) != len(flat_sequence): + raise ValueError( + "Could not pack sequence. Structure had %d elements, but " + "flat_sequence had %d elements. Structure: %s, flat_sequence: %s." % + (len(flat_structure), len(flat_sequence), structure, flat_sequence)) return _sequence_like(structure, packed) diff --git a/tensorflow/python/util/tf_export.py b/tensorflow/python/util/tf_export.py index 274f32c21f..a5ac430ce7 100644 --- a/tensorflow/python/util/tf_export.py +++ b/tensorflow/python/util/tf_export.py @@ -136,11 +136,14 @@ class api_export(object): # pylint: disable=invalid-name has no effect on exporting a constant. api_name: Name of the API you want to generate (e.g. `tensorflow` or `estimator`). Default is `tensorflow`. + allow_multiple_exports: Allow symbol to be exported multiple time under + different names. """ self._names = args self._names_v1 = kwargs.get('v1', args) self._api_name = kwargs.get('api_name', TENSORFLOW_API_NAME) self._overrides = kwargs.get('overrides', []) + self._allow_multiple_exports = kwargs.get('allow_multiple_exports', False) def __call__(self, func): """Calls this decorator. @@ -173,9 +176,10 @@ class api_export(object): # pylint: disable=invalid-name # __dict__ instead of using hasattr to verify that subclasses have # their own _tf_api_names as opposed to just inheriting it. if api_names_attr in func.__dict__: - raise SymbolAlreadyExposedError( - 'Symbol %s is already exposed as %s.' % - (func.__name__, getattr(func, api_names_attr))) # pylint: disable=protected-access + if not self._allow_multiple_exports: + raise SymbolAlreadyExposedError( + 'Symbol %s is already exposed as %s.' % + (func.__name__, getattr(func, api_names_attr))) # pylint: disable=protected-access setattr(func, api_names_attr, names) def export_constant(self, module_name, name): @@ -213,4 +217,5 @@ class api_export(object): # pylint: disable=invalid-name tf_export = functools.partial(api_export, api_name=TENSORFLOW_API_NAME) -estimator_export = functools.partial(tf_export, api_name=ESTIMATOR_API_NAME) +estimator_export = functools.partial( + api_export, api_name=ESTIMATOR_API_NAME, allow_multiple_exports=True) diff --git a/tensorflow/python/util/util.cc b/tensorflow/python/util/util.cc index ebb72079ef..562bbdcfeb 100644 --- a/tensorflow/python/util/util.cc +++ b/tensorflow/python/util/util.cc @@ -470,12 +470,14 @@ void SetDifferentKeysError(PyObject* dict1, PyObject* dict2, string* error_msg, // Leaves `error_msg` empty if structures matched. Else, fills `error_msg` // with appropriate error and sets `is_type_error` to true iff // the error to be raised should be TypeError. -bool AssertSameStructureHelper(PyObject* o1, PyObject* o2, bool check_types, - string* error_msg, bool* is_type_error) { +bool AssertSameStructureHelper( + PyObject* o1, PyObject* o2, bool check_types, string* error_msg, + bool* is_type_error, + const std::function<int(PyObject*)>& is_sequence_helper) { DCHECK(error_msg); DCHECK(is_type_error); - const bool is_seq1 = IsSequence(o1); - const bool is_seq2 = IsSequence(o2); + const bool is_seq1 = is_sequence_helper(o1); + const bool is_seq2 = is_sequence_helper(o2); if (PyErr_Occurred()) return false; if (is_seq1 != is_seq2) { string seq_str = is_seq1 ? PyObjectToString(o1) : PyObjectToString(o2); @@ -487,7 +489,9 @@ bool AssertSameStructureHelper(PyObject* o1, PyObject* o2, bool check_types, return true; } - // Got to scalars, so finished checking. Structures are the same. + // Got to objects that are considered non-sequences. Note that in tf.data + // use case lists and sparse_tensors are not considered sequences. So finished + // checking, structures are the same. if (!is_seq1) return true; if (check_types) { @@ -586,7 +590,7 @@ bool AssertSameStructureHelper(PyObject* o1, PyObject* o2, bool check_types, return false; } bool no_internal_errors = AssertSameStructureHelper( - v1, v2, check_types, error_msg, is_type_error); + v1, v2, check_types, error_msg, is_type_error, is_sequence_helper); Py_LeaveRecursiveCall(); if (!no_internal_errors) return false; if (!error_msg->empty()) return true; @@ -647,6 +651,7 @@ void RegisterSparseTensorValueClass(PyObject* sparse_tensor_value_class) { } bool IsSequence(PyObject* o) { return IsSequenceHelper(o) == 1; } +bool IsMapping(PyObject* o) { return IsMappingHelper(o) == 1; } PyObject* Flatten(PyObject* nested) { PyObject* list = PyList_New(0); @@ -758,7 +763,32 @@ PyObject* SameNamedtuples(PyObject* o1, PyObject* o2) { PyObject* AssertSameStructure(PyObject* o1, PyObject* o2, bool check_types) { string error_msg; bool is_type_error = false; - AssertSameStructureHelper(o1, o2, check_types, &error_msg, &is_type_error); + AssertSameStructureHelper(o1, o2, check_types, &error_msg, &is_type_error, + IsSequenceHelper); + if (PyErr_Occurred()) { + // Don't hide Python exceptions while checking (e.g. errors fetching keys + // from custom mappings). + return nullptr; + } + if (!error_msg.empty()) { + PyErr_SetString( + is_type_error ? PyExc_TypeError : PyExc_ValueError, + tensorflow::strings::StrCat( + "The two structures don't have the same nested structure.\n\n", + "First structure: ", PyObjectToString(o1), "\n\nSecond structure: ", + PyObjectToString(o2), "\n\nMore specifically: ", error_msg) + .c_str()); + return nullptr; + } + Py_RETURN_NONE; +} + +PyObject* AssertSameStructureForData(PyObject* o1, PyObject* o2, + bool check_types) { + string error_msg; + bool is_type_error = false; + AssertSameStructureHelper(o1, o2, check_types, &error_msg, &is_type_error, + IsSequenceForDataHelper); if (PyErr_Occurred()) { // Don't hide Python exceptions while checking (e.g. errors fetching keys // from custom mappings). diff --git a/tensorflow/python/util/util.h b/tensorflow/python/util/util.h index 41dcc969f8..343605285e 100644 --- a/tensorflow/python/util/util.h +++ b/tensorflow/python/util/util.h @@ -47,6 +47,15 @@ bool IsSequence(PyObject* o); // True if `instance` is a `namedtuple`. PyObject* IsNamedtuple(PyObject* o, bool strict); +// Returns a true if its input is a collections.Mapping. +// +// Args: +// seq: the input to be checked. +// +// Returns: +// True if the sequence subclasses mapping. +bool IsMapping(PyObject* o); + // Implements the same interface as tensorflow.util.nest._same_namedtuples // Returns Py_True iff the two namedtuples have the same name and fields. // Raises RuntimeError if `o1` or `o2` don't look like namedtuples (don't have @@ -135,16 +144,20 @@ void RegisterSparseTensorValueClass(PyObject* sparse_tensor_value_class); // 1. It removes support for lists as a level of nesting in nested structures. // 2. It adds support for `SparseTensorValue` as an atomic element. -// IsSequence specialized for the data package. Additional comments about -// difference in functionality can be found in nest.py in tensorflow.data.util -// and in the comments for Flatten above. +// IsSequence specialized for `tf.data`. Additional comments about +// difference in functionality can be found in nest.py in +// `tensorflow.python.data.util` and in the comments for Flatten above. bool IsSequenceForData(PyObject* o); -// IsSequence specialized for the data package. Additional comments about -// difference in functionality can be found in nest.py in tensorflow.data.util -// and in the comments for Flatten above. +// Flatten specialized for `tf.data`. Additional comments about +// difference in functionality can be found in nest.py in +// `tensorflow.python.data.util` and in the comments for Flatten above. PyObject* FlattenForData(PyObject* nested); +// AssertSameStructure specialized for `tf.data`. +PyObject* AssertSameStructureForData(PyObject* o1, PyObject* o2, + bool check_types); + } // namespace swig } // namespace tensorflow diff --git a/tensorflow/python/util/util.i b/tensorflow/python/util/util.i index 6ad1484295..6d336ac39d 100644 --- a/tensorflow/python/util/util.i +++ b/tensorflow/python/util/util.i @@ -37,18 +37,70 @@ limitations under the License. %unignore tensorflow::swig::RegisterSparseTensorValueClass; %noexception tensorflow::swig::RegisterSparseTensorValueClass; +%feature("docstring") tensorflow::swig::IsSequence +"""Returns a true if its input is a collections.Sequence (except strings). + +Args: + seq: an input sequence. + +Returns: + True if the sequence is a not a string and is a collections.Sequence or a + dict. +""" %unignore tensorflow::swig::IsSequence; %noexception tensorflow::swig::IsSequence; %unignore tensorflow::swig::IsNamedtuple; %noexception tensorflow::swig::IsNamedtuple; +%feature("docstring") tensorflow::swig::IsMapping +"""Returns True iff `instance` is a `collections.Mapping`. + +Args: + instance: An instance of a Python object. + +Returns: + True if `instance` is a `collections.Mapping`. +""" +%unignore tensorflow::swig::IsMapping; +%noexception tensorflow::swig::IsMapping; + +%feature("docstring") tensorflow::swig::SameNamedtuples +"Returns True if the two namedtuples have the same name and fields." %unignore tensorflow::swig::SameNamedtuples; %noexception tensorflow::swig::SameNamedtuples; %unignore tensorflow::swig::AssertSameStructure; %noexception tensorflow::swig::AssertSameStructure; +%feature("docstring") tensorflow::swig::Flatten +"""Returns a flat list from a given nested structure. + +If `nest` is not a sequence, tuple, or dict, then returns a single-element +list: `[nest]`. + +In the case of dict instances, the sequence consists of the values, sorted by +key to ensure deterministic behavior. This is true also for `OrderedDict` +instances: their sequence order is ignored, the sorting order of keys is +used instead. The same convention is followed in `pack_sequence_as`. This +correctly repacks dicts and `OrderedDict`s after they have been flattened, +and also allows flattening an `OrderedDict` and then repacking it back using +a corresponding plain dict, or vice-versa. +Dictionaries with non-sortable keys cannot be flattened. + +Users must not modify any collections used in `nest` while this function is +running. + +Args: + nest: an arbitrarily nested structure or a scalar object. Note, numpy + arrays are considered scalars. + +Returns: + A Python list, the flattened version of the input. + +Raises: + TypeError: The nest is or contains a dict with non-sortable keys. +""" %unignore tensorflow::swig::Flatten; %noexception tensorflow::swig::Flatten; @@ -58,6 +110,9 @@ limitations under the License. %unignore tensorflow::swig::FlattenForData; %noexception tensorflow::swig::FlattenForData; +%unignore tensorflow::swig::AssertSameStructureForData; +%noexception tensorflow::swig::AssertSameStructureForData; + %include "tensorflow/python/util/util.h" %unignoreall diff --git a/tensorflow/stream_executor/cuda/cuda_gpu_executor.cc b/tensorflow/stream_executor/cuda/cuda_gpu_executor.cc index 73f05b94db..e30f50ea2a 100644 --- a/tensorflow/stream_executor/cuda/cuda_gpu_executor.cc +++ b/tensorflow/stream_executor/cuda/cuda_gpu_executor.cc @@ -164,8 +164,8 @@ bool CUDAExecutor::FindOnDiskForComputeCapability( VLOG(2) << "could not find compute-capability specific file at: " << cc_specific; - if (port::FileExists(filename.ToString()).ok()) { - *found_filename = filename.ToString(); + if (port::FileExists(string(filename)).ok()) { + *found_filename = string(filename); return true; } diff --git a/tensorflow/stream_executor/dso_loader.cc b/tensorflow/stream_executor/dso_loader.cc index 114143b3ab..ea5dffd15e 100644 --- a/tensorflow/stream_executor/dso_loader.cc +++ b/tensorflow/stream_executor/dso_loader.cc @@ -121,7 +121,7 @@ static mutex& GetRpathMutex() { /* static */ void DsoLoader::RegisterRpath(port::StringPiece path) { mutex_lock lock{GetRpathMutex()}; - GetRpaths()->push_back(path.ToString()); + GetRpaths()->emplace_back(path); } /* static */ port::Status DsoLoader::GetDsoHandle(port::StringPiece path, @@ -131,7 +131,7 @@ static mutex& GetRpathMutex() { return port::Status(port::error::INVALID_ARGUMENT, "Only LoadKind::kLocal is currently supported"); } - string path_string = path.ToString(); + string path_string(path); port::Status s = port::Env::Default()->LoadLibrary(path_string.c_str(), dso_handle); if (!s.ok()) { @@ -154,7 +154,7 @@ static mutex& GetRpathMutex() { /* static */ string DsoLoader::GetBinaryDirectory(bool strip_executable_name) { string exe_path = port::Env::Default()->GetExecutablePath(); - return strip_executable_name ? port::Dirname(exe_path).ToString() : exe_path; + return strip_executable_name ? string(port::Dirname(exe_path)) : exe_path; } // Creates a heap-allocated vector for initial rpaths. @@ -212,7 +212,7 @@ static std::vector<string>* CreatePrimordialRpaths() { } attempted.push_back(candidate); - return library_name.ToString(); + return string(library_name); } /* static */ string DsoLoader::GetCudaLibraryDirPath() { diff --git a/tensorflow/stream_executor/kernel.cc b/tensorflow/stream_executor/kernel.cc index 7c1923da51..e84b7e6cc2 100644 --- a/tensorflow/stream_executor/kernel.cc +++ b/tensorflow/stream_executor/kernel.cc @@ -94,7 +94,7 @@ KernelCacheConfig KernelBase::GetPreferredCacheConfig() const { static const char *kStubPrefix = "__device_stub_"; void KernelBase::set_name(port::StringPiece name) { - name_ = std::string(name); + name_ = string(name); port::StringPiece stubless_name = name; if (tensorflow::str_util::StartsWith(name, kStubPrefix)) { stubless_name.remove_prefix(strlen(kStubPrefix)); diff --git a/tensorflow/stream_executor/kernel_spec.cc b/tensorflow/stream_executor/kernel_spec.cc index 902892af3f..1eaa080699 100644 --- a/tensorflow/stream_executor/kernel_spec.cc +++ b/tensorflow/stream_executor/kernel_spec.cc @@ -18,11 +18,11 @@ limitations under the License. namespace stream_executor { KernelLoaderSpec::KernelLoaderSpec(port::StringPiece kernelname) - : kernelname_(std::string(kernelname)) {} + : kernelname_(string(kernelname)) {} OnDiskKernelLoaderSpec::OnDiskKernelLoaderSpec(port::StringPiece filename, port::StringPiece kernelname) - : KernelLoaderSpec(kernelname), filename_(std::string(filename)) {} + : KernelLoaderSpec(kernelname), filename_(string(filename)) {} CudaPtxOnDisk::CudaPtxOnDisk(port::StringPiece filename, port::StringPiece kernelname) @@ -161,7 +161,7 @@ OpenCLTextOnDisk::OpenCLTextOnDisk(port::StringPiece filename, OpenCLTextInMemory::OpenCLTextInMemory(port::StringPiece text, port::StringPiece kernelname) - : KernelLoaderSpec(kernelname), text_(std::string(text)) {} + : KernelLoaderSpec(kernelname), text_(text) {} OpenCLBinaryOnDisk::OpenCLBinaryOnDisk(port::StringPiece filename, port::StringPiece kernelname) diff --git a/tensorflow/stream_executor/lib/env.h b/tensorflow/stream_executor/lib/env.h index 3ef8deb72e..d78bbfd425 100644 --- a/tensorflow/stream_executor/lib/env.h +++ b/tensorflow/stream_executor/lib/env.h @@ -32,7 +32,7 @@ inline Status FileExists(const string& filename) { } inline Status FileExists(const port::StringPiece& filename) { - return Env::Default()->FileExists(std::string(filename)); + return Env::Default()->FileExists(string(filename)); } } // namespace port diff --git a/tensorflow/stream_executor/lib/path.cc b/tensorflow/stream_executor/lib/path.cc index 58a862206c..3d3da103e1 100644 --- a/tensorflow/stream_executor/lib/path.cc +++ b/tensorflow/stream_executor/lib/path.cc @@ -33,7 +33,7 @@ string JoinPathImpl(std::initializer_list<port::StringPiece> paths) { if (path.empty()) continue; if (result.empty()) { - result = std::string(path); + result = string(path); continue; } diff --git a/tensorflow/stream_executor/lib/statusor_internals.h b/tensorflow/stream_executor/lib/statusor_internals.h index 09f88f5825..a159da57a2 100644 --- a/tensorflow/stream_executor/lib/statusor_internals.h +++ b/tensorflow/stream_executor/lib/statusor_internals.h @@ -16,7 +16,6 @@ limitations under the License. #ifndef TENSORFLOW_STREAM_EXECUTOR_LIB_STATUSOR_INTERNALS_H_ #define TENSORFLOW_STREAM_EXECUTOR_LIB_STATUSOR_INTERNALS_H_ - #include "tensorflow/core/platform/macros.h" #include "tensorflow/stream_executor/lib/status.h" diff --git a/tensorflow/stream_executor/lib/str_util.h b/tensorflow/stream_executor/lib/str_util.h index b02fe4f56f..e77dfcef76 100644 --- a/tensorflow/stream_executor/lib/str_util.h +++ b/tensorflow/stream_executor/lib/str_util.h @@ -31,7 +31,7 @@ inline string StripSuffixString(port::StringPiece str, port::StringPiece suffix) if (tensorflow::str_util::EndsWith(str, suffix)) { str.remove_suffix(suffix.size()); } - return std::string(str); + return string(str); } using tensorflow::str_util::Lowercase; diff --git a/tensorflow/stream_executor/stream.cc b/tensorflow/stream_executor/stream.cc index 9efd34de24..19d3b2389a 100644 --- a/tensorflow/stream_executor/stream.cc +++ b/tensorflow/stream_executor/stream.cc @@ -1959,7 +1959,9 @@ Stream *Stream::GetOrCreateSubStream() { false); Stream *sub_stream = sub_streams_.back().first.get(); sub_stream->Init(); - CHECK(ok_) << "sub-stream failed to be initialized"; + if (!sub_stream->ok_) { + LOG(ERROR) << "sub-stream failed to be initialized"; + } VLOG(1) << DebugStreamPointers() << " created new sub_stream " << sub_stream->DebugStreamPointers(); @@ -5285,12 +5287,11 @@ Stream &Stream::ThenTransformTensor(const dnn::BatchDescriptor &input_desc, Stream &Stream::ThenDoHostCallback(std::function<void()> callback) { VLOG_CALL(PARAM(callback)); - if (ok()) { - CheckError(parent_->HostCallback(this, callback)); - } else { + if (!ok()) { LOG(INFO) << DebugStreamPointers() << " was in error state before adding host callback"; } + CheckError(parent_->HostCallback(this, std::move(callback))); return *this; } @@ -5298,12 +5299,11 @@ Stream &Stream::ThenDoHostCallbackWithStatus( std::function<port::Status()> callback) { VLOG_CALL(PARAM(callback)); - if (ok()) { - CheckError(parent_->HostCallback(this, std::move(callback))); - } else { - LOG(WARNING) << "stream " << DebugStreamPointers() - << " was in error state before adding host callback"; + if (!ok()) { + LOG(INFO) << DebugStreamPointers() + << " was in error state before adding host callback"; } + CheckError(parent_->HostCallback(this, std::move(callback))); return *this; } diff --git a/tensorflow/tensorflow.bzl b/tensorflow/tensorflow.bzl index 14e678d1ca..3562a5192d 100644 --- a/tensorflow/tensorflow.bzl +++ b/tensorflow/tensorflow.bzl @@ -31,6 +31,10 @@ load( "//third_party/mkl_dnn:build_defs.bzl", "if_mkl_open_source_only", ) +load( + "//third_party/ngraph:build_defs.bzl", + "if_ngraph", +) def register_extension_info(**kwargs): pass @@ -233,6 +237,7 @@ def tf_copts(android_optimization_level_override = "-O2", is_external = False): if_tensorrt(["-DGOOGLE_TENSORRT=1"]) + if_mkl(["-DINTEL_MKL=1", "-DEIGEN_USE_VML"]) + if_mkl_open_source_only(["-DINTEL_MKL_DNN_ONLY"]) + + if_ngraph(["-DINTEL_NGRAPH=1"]) + if_mkl_lnx_x64(["-fopenmp"]) + if_android_arm(["-mfpu=neon"]) + if_linux_x86_64(["-msse3"]) + @@ -391,7 +396,7 @@ def tf_cc_binary( srcs = srcs + tf_binary_additional_srcs(), deps = deps + tf_binary_dynamic_kernel_deps(kernels) + if_mkl_ml( [ - "//third_party/mkl:intel_binary_blob", + clean_dep("//third_party/mkl:intel_binary_blob"), ], ), data = data + tf_binary_dynamic_kernel_dsos(kernels), @@ -729,7 +734,7 @@ def tf_cc_test( }) + linkopts + _rpath_linkopts(name), deps = deps + tf_binary_dynamic_kernel_deps(kernels) + if_mkl_ml( [ - "//third_party/mkl:intel_binary_blob", + clean_dep("//third_party/mkl:intel_binary_blob"), ], ), data = data + tf_binary_dynamic_kernel_dsos(kernels), diff --git a/tensorflow/tools/api/golden/v1/tensorflow.-sparse-tensor.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.-sparse-tensor.pbtxt index eac236d498..3add49e90d 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.-sparse-tensor.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.-sparse-tensor.pbtxt @@ -24,6 +24,10 @@ tf_class { mtype: "<type \'property\'>" } member { + name: "shape" + mtype: "<type \'property\'>" + } + member { name: "values" mtype: "<type \'property\'>" } @@ -32,6 +36,10 @@ tf_class { argspec: "args=[\'self\', \'indices\', \'values\', \'dense_shape\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "consumers" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } + member_method { name: "eval" argspec: "args=[\'self\', \'feed_dict\', \'session\'], varargs=None, keywords=None, defaults=[\'None\', \'None\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.-variable.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.-variable.pbtxt index e841c4ad89..05698b03ee 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.-variable.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.-variable.pbtxt @@ -53,15 +53,15 @@ tf_class { } member_method { name: "assign" - argspec: "args=[\'self\', \'value\', \'use_locking\'], varargs=None, keywords=None, defaults=[\'False\'], " + argspec: "args=[\'self\', \'value\', \'use_locking\', \'name\', \'read_value\'], varargs=None, keywords=None, defaults=[\'False\', \'None\', \'True\'], " } member_method { name: "assign_add" - argspec: "args=[\'self\', \'delta\', \'use_locking\'], varargs=None, keywords=None, defaults=[\'False\'], " + argspec: "args=[\'self\', \'delta\', \'use_locking\', \'name\', \'read_value\'], varargs=None, keywords=None, defaults=[\'False\', \'None\', \'True\'], " } member_method { name: "assign_sub" - argspec: "args=[\'self\', \'delta\', \'use_locking\'], varargs=None, keywords=None, defaults=[\'False\'], " + argspec: "args=[\'self\', \'delta\', \'use_locking\', \'name\', \'read_value\'], varargs=None, keywords=None, defaults=[\'False\', \'None\', \'True\'], " } member_method { name: "count_up_to" @@ -92,8 +92,28 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "scatter_add" + argspec: "args=[\'self\', \'sparse_delta\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " + } + member_method { + name: "scatter_nd_add" + argspec: "args=[\'self\', \'indices\', \'updates\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { + name: "scatter_nd_sub" + argspec: "args=[\'self\', \'indices\', \'updates\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { + name: "scatter_nd_update" + argspec: "args=[\'self\', \'indices\', \'updates\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { name: "scatter_sub" - argspec: "args=[\'self\', \'sparse_delta\', \'use_locking\'], varargs=None, keywords=None, defaults=[\'False\'], " + argspec: "args=[\'self\', \'sparse_delta\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " + } + member_method { + name: "scatter_update" + argspec: "args=[\'self\', \'sparse_delta\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " } member_method { name: "set_shape" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-baseline-classifier.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-baseline-classifier.pbtxt index cf22e39d4c..082e26b99b 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-baseline-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-baseline-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-baseline-regressor.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-baseline-regressor.pbtxt index a363bceae3..7cc4191eb3 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-baseline-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-baseline-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-boosted-trees-classifier.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-boosted-trees-classifier.pbtxt index c23b04b4ef..7027e78df4 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-boosted-trees-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-boosted-trees-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-boosted-trees-regressor.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-boosted-trees-regressor.pbtxt index 6878d28fff..d8167ea7cb 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-boosted-trees-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-boosted-trees-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-classifier.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-classifier.pbtxt index 0c6b7e4a82..718f415a77 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-linear-combined-classifier.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-linear-combined-classifier.pbtxt index 9c1c072124..b23c019d6c 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-linear-combined-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-linear-combined-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-linear-combined-regressor.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-linear-combined-regressor.pbtxt index 7391d4b07a..caa9e3f1de 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-linear-combined-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-linear-combined-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-regressor.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-regressor.pbtxt index f50e375f7c..1f5e650940 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-d-n-n-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-estimator.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-estimator.pbtxt index d72b576977..ebd3869c9b 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-estimator.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-estimator.pbtxt @@ -31,6 +31,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-linear-classifier.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-linear-classifier.pbtxt index 154f171e89..53ec5a0c78 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-linear-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-linear-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-linear-regressor.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-linear-regressor.pbtxt index 4d46d1e6b6..3791162619 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-linear-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-linear-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-run-config.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-run-config.pbtxt index bf1f94b6ae..269e18a0a7 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.estimator.-run-config.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.estimator.-run-config.pbtxt @@ -96,7 +96,7 @@ tf_class { } member_method { name: "__init__" - argspec: "args=[\'self\', \'model_dir\', \'tf_random_seed\', \'save_summary_steps\', \'save_checkpoints_steps\', \'save_checkpoints_secs\', \'session_config\', \'keep_checkpoint_max\', \'keep_checkpoint_every_n_hours\', \'log_step_count_steps\', \'train_distribute\', \'device_fn\', \'protocol\', \'eval_distribute\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'100\', \'<object object instance>\', \'<object object instance>\', \'None\', \'5\', \'10000\', \'100\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'model_dir\', \'tf_random_seed\', \'save_summary_steps\', \'save_checkpoints_steps\', \'save_checkpoints_secs\', \'session_config\', \'keep_checkpoint_max\', \'keep_checkpoint_every_n_hours\', \'log_step_count_steps\', \'train_distribute\', \'device_fn\', \'protocol\', \'eval_distribute\', \'experimental_distribute\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'100\', \'<object object instance>\', \'<object object instance>\', \'None\', \'5\', \'10000\', \'100\', \'None\', \'None\', \'None\', \'None\', \'None\'], " } member_method { name: "replace" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.-model.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.-model.pbtxt index e579fe6a1a..d843194ef0 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.-model.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.-model.pbtxt @@ -119,7 +119,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.-sequential.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.-sequential.pbtxt index 97688fcb0f..b8e9baca71 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.-sequential.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.-sequential.pbtxt @@ -124,7 +124,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-activation.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-activation.pbtxt index 86e328888e..5510465d7b 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-activation.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-activation.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-activity-regularization.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-activity-regularization.pbtxt index b0ed545781..38ec8a0aff 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-activity-regularization.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-activity-regularization.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-add.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-add.pbtxt index 42f98ed03d..41cb8e30bf 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-add.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-add.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-alpha-dropout.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-alpha-dropout.pbtxt index 000898a4be..9a7aaa8e96 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-alpha-dropout.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-alpha-dropout.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling1-d.pbtxt index 380b49f99c..c3dd2ad046 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling2-d.pbtxt index 82db5e6137..cc303bf7b9 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling3-d.pbtxt index b6ff688ec3..628447ce35 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average.pbtxt index b41290f8b0..f03c986c22 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-average.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool1-d.pbtxt index 88a033e61f..c440604aae 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool2-d.pbtxt index c1b9b96044..a01eaf8a12 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool3-d.pbtxt index f59f7727a3..0d6698f2ef 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-avg-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-batch-normalization.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-batch-normalization.pbtxt index 7d3744ed92..f1b23be48f 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-batch-normalization.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-batch-normalization.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-bidirectional.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-bidirectional.pbtxt index 3fd4ccdab2..0672cd5b7b 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-bidirectional.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-bidirectional.pbtxt @@ -107,7 +107,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-concatenate.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-concatenate.pbtxt index ba21b50be4..b25ae1e82e 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-concatenate.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-concatenate.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt index 46f9fa2bbb..bb1918eba6 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt @@ -188,7 +188,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv1-d.pbtxt index c3ad326589..16e0fd5a31 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv2-d-transpose.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv2-d-transpose.pbtxt index fd9eb43066..065bb4d35b 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv2-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv2-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv2-d.pbtxt index 40d61688f2..543bae6fa9 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv3-d-transpose.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv3-d-transpose.pbtxt index b8c227d725..c7ba6056f9 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv3-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv3-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv3-d.pbtxt index 095d35e574..072943dc2c 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-conv3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution1-d.pbtxt index 8f99961198..222a1ef4fc 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt index 96d522a016..8f4f7918ab 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution2-d.pbtxt index de2824dab4..f939067178 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt index 1d563241d8..93c442bd55 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution3-d.pbtxt index c87e52c537..471b18ef85 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-convolution3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping1-d.pbtxt index dccf5523e3..0f250a09b7 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping2-d.pbtxt index 7ac4116d92..f52128483c 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping3-d.pbtxt index 024f72705d..98daf3bab1 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cropping3-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt index 4e0233331b..64e7a9046b 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt index 32d46ce8f3..6fdffef776 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dense.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dense.pbtxt index 858486c725..3ac3825759 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dense.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dense.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt index f65d750926..280ec8c25f 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dot.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dot.pbtxt index 2e71ef503d..560f66f9c7 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dot.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dot.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dropout.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dropout.pbtxt index 42533bcd21..c0543529c3 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dropout.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-dropout.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-e-l-u.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-e-l-u.pbtxt index b5df169417..04eb2824b9 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-e-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-e-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-embedding.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-embedding.pbtxt index 0ea17919a9..f400432915 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-embedding.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-embedding.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-flatten.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-flatten.pbtxt index a33248bc00..ab176b441a 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-flatten.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-flatten.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-g-r-u-cell.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-g-r-u-cell.pbtxt index 4ba21a25cd..c3895a0ac1 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-g-r-u-cell.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-g-r-u-cell.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" @@ -133,6 +133,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-g-r-u.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-g-r-u.pbtxt index a7a570418e..a0fe598ab9 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-g-r-u.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-g-r-u.pbtxt @@ -171,7 +171,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-gaussian-dropout.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-gaussian-dropout.pbtxt index 763bc23113..55e0d7ef02 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-gaussian-dropout.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-gaussian-dropout.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-gaussian-noise.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-gaussian-noise.pbtxt index 3c50a3d7f2..38fbff5e4a 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-gaussian-noise.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-gaussian-noise.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt index ac78bdafad..5ea61d118d 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt index 275282d9d2..929f48df23 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt index 0e31e6058b..2e6d59337f 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt index aacd0b1791..11dca17c6d 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt index c236548663..4e3e258430 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt index 6b9c0290aa..fb9166316f 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool1-d.pbtxt index 0d7b2211e6..278429af6f 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool2-d.pbtxt index d080ad6aed..87b7f6797a 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool3-d.pbtxt index fcb0a109da..98bf96fa0c 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt index 1d0e22abd0..935a69ab2f 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt index 653c9f547b..c9d4158d1c 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt index cdbaf82cf6..9953102ff9 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-input-layer.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-input-layer.pbtxt index 230c5e9034..2617f5a95f 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-input-layer.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-input-layer.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt index 511456e740..e9f6ef45aa 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" @@ -133,6 +133,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-l-s-t-m.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-l-s-t-m.pbtxt index 4a3492ebd6..ecdbf48157 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-l-s-t-m.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-l-s-t-m.pbtxt @@ -171,7 +171,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-lambda.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-lambda.pbtxt index 2dff7a6de4..2e0b6bac24 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-lambda.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-lambda.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-layer.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-layer.pbtxt index 7efa29be77..1e93d1118a 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-layer.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-layer.pbtxt @@ -97,7 +97,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-leaky-re-l-u.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-leaky-re-l-u.pbtxt index 0ca8e0b52c..bfd36012a7 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-leaky-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-leaky-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-locally-connected1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-locally-connected1-d.pbtxt index ff19dcc3a3..5ad5990d7e 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-locally-connected1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-locally-connected1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-locally-connected2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-locally-connected2-d.pbtxt index 3c278fead6..40d03369a5 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-locally-connected2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-locally-connected2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-masking.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-masking.pbtxt index 850ecff974..86666b51bb 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-masking.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-masking.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool1-d.pbtxt index 7c69e31f9a..238d96cca6 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool2-d.pbtxt index fba42642d7..85f23df671 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool3-d.pbtxt index 9c277411ea..235806b965 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling1-d.pbtxt index 7c2f6ccc8a..4a45bf7997 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling2-d.pbtxt index 802178dba6..fda2562fc8 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling3-d.pbtxt index e870dfe9ad..71d2d09a8d 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-max-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-maximum.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-maximum.pbtxt index c1337ce0cb..12949b39a6 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-maximum.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-maximum.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-minimum.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-minimum.pbtxt index ed27a62765..ab16d0021e 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-minimum.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-minimum.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-multiply.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-multiply.pbtxt index b9f05cb3e5..61ccbf5962 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-multiply.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-multiply.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-p-re-l-u.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-p-re-l-u.pbtxt index 336d9f76fb..ce2320d703 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-p-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-p-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-permute.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-permute.pbtxt index 46282217e0..69848af8cf 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-permute.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-permute.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-r-n-n.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-r-n-n.pbtxt index 42cd7e87ee..2b6e8af11d 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-r-n-n.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-r-n-n.pbtxt @@ -102,7 +102,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-re-l-u.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-re-l-u.pbtxt index 4d3de58bd1..413f45f018 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-repeat-vector.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-repeat-vector.pbtxt index 9f094a877a..9c61ff6027 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-repeat-vector.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-repeat-vector.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-reshape.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-reshape.pbtxt index 2f519a2438..baa91804c4 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-reshape.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-reshape.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-conv1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-conv1-d.pbtxt index 6b93116ba0..15a5d6ac9e 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-conv1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-conv1-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-conv2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-conv2-d.pbtxt index fd17115e27..be43bd5b3c 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-conv2-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-convolution1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-convolution1-d.pbtxt index 4b37a94478..6105992c7a 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-convolution1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-convolution1-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-convolution2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-convolution2-d.pbtxt index 5bdadca74a..1b6cf1e9ec 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-convolution2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-separable-convolution2-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt index 9dfda96fc8..29488a37f8 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" @@ -133,6 +133,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-simple-r-n-n.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-simple-r-n-n.pbtxt index 7b7684ccd2..182efb83b8 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-simple-r-n-n.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-simple-r-n-n.pbtxt @@ -159,7 +159,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-softmax.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-softmax.pbtxt index 3b15407fca..d29731ecf9 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-softmax.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-softmax.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt index 6d04415267..a6d7494ca7 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt index 04950654d5..c36e802693 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt index c424e6dcc8..9c46cfe40f 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt index 6718e36dc6..8982f78794 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt @@ -106,7 +106,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" @@ -141,6 +141,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-subtract.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-subtract.pbtxt index 740a03367b..ec2cc50298 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-subtract.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-subtract.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt index a08c583adb..d7bc1980f3 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-time-distributed.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-time-distributed.pbtxt index c1294fed0f..fec2de6b49 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-time-distributed.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-time-distributed.pbtxt @@ -103,7 +103,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling1-d.pbtxt index dc401d3ed0..3d285e7f17 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling2-d.pbtxt index 4b5165ae97..40a56a0c94 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling3-d.pbtxt index 789af15fea..728eca415a 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-up-sampling3-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-wrapper.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-wrapper.pbtxt index 0536a7cee7..da64e77c39 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-wrapper.pbtxt @@ -102,7 +102,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding1-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding1-d.pbtxt index 8915353ec3..2f505f9293 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding1-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding2-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding2-d.pbtxt index 6efb5ef15a..f82c77072e 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding2-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding3-d.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding3-d.pbtxt index 4c33c5d0bf..54e01a9917 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding3-d.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.layers.-zero-padding3-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.models.-model.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.models.-model.pbtxt index 56914e1746..472b9818df 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.models.-model.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.models.-model.pbtxt @@ -119,7 +119,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.models.-sequential.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.models.-sequential.pbtxt index acfb3521c0..937516eff1 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.models.-sequential.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.models.-sequential.pbtxt @@ -124,7 +124,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.models.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.models.pbtxt index 8ba0e7480b..7ad4a32d43 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.models.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.models.pbtxt @@ -9,6 +9,10 @@ tf_module { mtype: "<type \'type\'>" } member_method { + name: "clone_model" + argspec: "args=[\'model\', \'input_tensors\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { name: "load_model" argspec: "args=[\'filepath\', \'custom_objects\', \'compile\'], varargs=None, keywords=None, defaults=[\'None\', \'True\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt index e606eab919..88b8f37c4f 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt @@ -152,6 +152,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt index 5deb02d569..a4483fefa2 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt @@ -152,6 +152,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt index 8a63b49180..381c4975d7 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt @@ -151,6 +151,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt index db1aae2757..912365a28b 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt @@ -155,6 +155,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt index 32fa151a8e..a4bb3219c7 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt @@ -152,6 +152,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt index 30c6c2ce3b..715bfd5fc7 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt @@ -152,6 +152,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt index 72b40cc9f7..b66c0f89cc 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt @@ -151,6 +151,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt index a5c2b4aefd..faeb4f3513 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt @@ -150,6 +150,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt index 61d5f04b22..caa2e60080 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt @@ -151,6 +151,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.pbtxt index 4de662fe33..821ca7b140 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.pbtxt @@ -789,6 +789,10 @@ tf_module { argspec: "args=[\'params\', \'indices\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { + name: "batch_scatter_update" + argspec: "args=[\'ref\', \'indices\', \'updates\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'True\', \'None\'], " + } + member_method { name: "batch_to_space" argspec: "args=[\'input\', \'crops\', \'block_size\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } @@ -1001,10 +1005,18 @@ tf_module { argspec: "args=[\'x\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { + name: "disable_resource_variables" + argspec: "args=[], varargs=None, keywords=None, defaults=None" + } + member_method { name: "div" argspec: "args=[\'x\', \'y\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { + name: "div_no_nan" + argspec: "args=[\'x\', \'y\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { name: "divide" argspec: "args=[\'x\', \'y\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } @@ -1029,10 +1041,18 @@ tf_module { argspec: "args=[\'config\', \'device_policy\', \'execution_mode\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " } member_method { + name: "enable_resource_variables" + argspec: "args=[], varargs=None, keywords=None, defaults=None" + } + member_method { name: "encode_base64" argspec: "args=[\'input\', \'pad\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " } member_method { + name: "ensure_shape" + argspec: "args=[\'x\', \'shape\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { name: "equal" argspec: "args=[\'x\', \'y\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } @@ -1273,6 +1293,10 @@ tf_module { argspec: "args=[\'graph_def\', \'input_map\', \'return_elements\', \'name\', \'op_dict\', \'producer_op_list\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "init_scope" + argspec: "args=[], varargs=None, keywords=None, defaults=None" + } + member_method { name: "initialize_all_tables" argspec: "args=[\'name\'], varargs=None, keywords=None, defaults=[\'init_all_tables\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.sparse.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.sparse.pbtxt index bbfe395031..ba9e651b34 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.sparse.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.sparse.pbtxt @@ -8,4 +8,12 @@ tf_module { name: "cross_hashed" argspec: "args=[\'inputs\', \'num_buckets\', \'hash_key\', \'name\'], varargs=None, keywords=None, defaults=[\'0\', \'None\', \'None\'], " } + member_method { + name: "expand_dims" + argspec: "args=[\'sp_input\', \'axis\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\'], " + } + member_method { + name: "eye" + argspec: "args=[\'num_rows\', \'num_columns\', \'dtype\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\", \'None\'], " + } } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.-sparse-tensor.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.-sparse-tensor.pbtxt index eac236d498..3add49e90d 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.-sparse-tensor.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.-sparse-tensor.pbtxt @@ -24,6 +24,10 @@ tf_class { mtype: "<type \'property\'>" } member { + name: "shape" + mtype: "<type \'property\'>" + } + member { name: "values" mtype: "<type \'property\'>" } @@ -32,6 +36,10 @@ tf_class { argspec: "args=[\'self\', \'indices\', \'values\', \'dense_shape\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "consumers" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } + member_method { name: "eval" argspec: "args=[\'self\', \'feed_dict\', \'session\'], varargs=None, keywords=None, defaults=[\'None\', \'None\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.-variable.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.-variable.pbtxt index e841c4ad89..05698b03ee 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.-variable.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.-variable.pbtxt @@ -53,15 +53,15 @@ tf_class { } member_method { name: "assign" - argspec: "args=[\'self\', \'value\', \'use_locking\'], varargs=None, keywords=None, defaults=[\'False\'], " + argspec: "args=[\'self\', \'value\', \'use_locking\', \'name\', \'read_value\'], varargs=None, keywords=None, defaults=[\'False\', \'None\', \'True\'], " } member_method { name: "assign_add" - argspec: "args=[\'self\', \'delta\', \'use_locking\'], varargs=None, keywords=None, defaults=[\'False\'], " + argspec: "args=[\'self\', \'delta\', \'use_locking\', \'name\', \'read_value\'], varargs=None, keywords=None, defaults=[\'False\', \'None\', \'True\'], " } member_method { name: "assign_sub" - argspec: "args=[\'self\', \'delta\', \'use_locking\'], varargs=None, keywords=None, defaults=[\'False\'], " + argspec: "args=[\'self\', \'delta\', \'use_locking\', \'name\', \'read_value\'], varargs=None, keywords=None, defaults=[\'False\', \'None\', \'True\'], " } member_method { name: "count_up_to" @@ -92,8 +92,28 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "scatter_add" + argspec: "args=[\'self\', \'sparse_delta\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " + } + member_method { + name: "scatter_nd_add" + argspec: "args=[\'self\', \'indices\', \'updates\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { + name: "scatter_nd_sub" + argspec: "args=[\'self\', \'indices\', \'updates\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { + name: "scatter_nd_update" + argspec: "args=[\'self\', \'indices\', \'updates\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { name: "scatter_sub" - argspec: "args=[\'self\', \'sparse_delta\', \'use_locking\'], varargs=None, keywords=None, defaults=[\'False\'], " + argspec: "args=[\'self\', \'sparse_delta\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " + } + member_method { + name: "scatter_update" + argspec: "args=[\'self\', \'sparse_delta\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " } member_method { name: "set_shape" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-baseline-classifier.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-baseline-classifier.pbtxt index cf22e39d4c..082e26b99b 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-baseline-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-baseline-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-baseline-regressor.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-baseline-regressor.pbtxt index a363bceae3..7cc4191eb3 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-baseline-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-baseline-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-boosted-trees-classifier.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-boosted-trees-classifier.pbtxt index c23b04b4ef..7027e78df4 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-boosted-trees-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-boosted-trees-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-boosted-trees-regressor.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-boosted-trees-regressor.pbtxt index 6878d28fff..d8167ea7cb 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-boosted-trees-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-boosted-trees-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-classifier.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-classifier.pbtxt index 0c6b7e4a82..718f415a77 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-linear-combined-classifier.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-linear-combined-classifier.pbtxt index 9c1c072124..b23c019d6c 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-linear-combined-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-linear-combined-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-linear-combined-regressor.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-linear-combined-regressor.pbtxt index 7391d4b07a..caa9e3f1de 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-linear-combined-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-linear-combined-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-regressor.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-regressor.pbtxt index f50e375f7c..1f5e650940 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-d-n-n-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-estimator.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-estimator.pbtxt index d72b576977..ebd3869c9b 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-estimator.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-estimator.pbtxt @@ -31,6 +31,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-linear-classifier.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-linear-classifier.pbtxt index 154f171e89..53ec5a0c78 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-linear-classifier.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-linear-classifier.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-linear-regressor.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-linear-regressor.pbtxt index 4d46d1e6b6..3791162619 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-linear-regressor.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-linear-regressor.pbtxt @@ -32,6 +32,10 @@ tf_class { argspec: "args=[\'self\', \'input_fn\', \'steps\', \'hooks\', \'checkpoint_path\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "export_saved_model" + argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\'], " + } + member_method { name: "export_savedmodel" argspec: "args=[\'self\', \'export_dir_base\', \'serving_input_receiver_fn\', \'assets_extra\', \'as_text\', \'checkpoint_path\', \'strip_default_attrs\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-run-config.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-run-config.pbtxt index bf1f94b6ae..269e18a0a7 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.estimator.-run-config.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.estimator.-run-config.pbtxt @@ -96,7 +96,7 @@ tf_class { } member_method { name: "__init__" - argspec: "args=[\'self\', \'model_dir\', \'tf_random_seed\', \'save_summary_steps\', \'save_checkpoints_steps\', \'save_checkpoints_secs\', \'session_config\', \'keep_checkpoint_max\', \'keep_checkpoint_every_n_hours\', \'log_step_count_steps\', \'train_distribute\', \'device_fn\', \'protocol\', \'eval_distribute\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'100\', \'<object object instance>\', \'<object object instance>\', \'None\', \'5\', \'10000\', \'100\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'model_dir\', \'tf_random_seed\', \'save_summary_steps\', \'save_checkpoints_steps\', \'save_checkpoints_secs\', \'session_config\', \'keep_checkpoint_max\', \'keep_checkpoint_every_n_hours\', \'log_step_count_steps\', \'train_distribute\', \'device_fn\', \'protocol\', \'eval_distribute\', \'experimental_distribute\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'100\', \'<object object instance>\', \'<object object instance>\', \'None\', \'5\', \'10000\', \'100\', \'None\', \'None\', \'None\', \'None\', \'None\'], " } member_method { name: "replace" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.-model.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.-model.pbtxt index e579fe6a1a..d843194ef0 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.-model.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.-model.pbtxt @@ -119,7 +119,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.-sequential.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.-sequential.pbtxt index 97688fcb0f..b8e9baca71 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.-sequential.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.-sequential.pbtxt @@ -124,7 +124,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-activation.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-activation.pbtxt index 86e328888e..5510465d7b 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-activation.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-activation.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-activity-regularization.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-activity-regularization.pbtxt index b0ed545781..38ec8a0aff 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-activity-regularization.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-activity-regularization.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-add.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-add.pbtxt index 42f98ed03d..41cb8e30bf 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-add.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-add.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-alpha-dropout.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-alpha-dropout.pbtxt index 000898a4be..9a7aaa8e96 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-alpha-dropout.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-alpha-dropout.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling1-d.pbtxt index 380b49f99c..c3dd2ad046 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling2-d.pbtxt index 82db5e6137..cc303bf7b9 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling3-d.pbtxt index b6ff688ec3..628447ce35 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average.pbtxt index b41290f8b0..f03c986c22 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-average.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool1-d.pbtxt index 88a033e61f..c440604aae 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool2-d.pbtxt index c1b9b96044..a01eaf8a12 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool3-d.pbtxt index f59f7727a3..0d6698f2ef 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-avg-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-batch-normalization.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-batch-normalization.pbtxt index 7d3744ed92..f1b23be48f 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-batch-normalization.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-batch-normalization.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-bidirectional.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-bidirectional.pbtxt index 3fd4ccdab2..0672cd5b7b 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-bidirectional.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-bidirectional.pbtxt @@ -107,7 +107,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-concatenate.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-concatenate.pbtxt index ba21b50be4..b25ae1e82e 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-concatenate.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-concatenate.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt index 46f9fa2bbb..bb1918eba6 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt @@ -188,7 +188,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv1-d.pbtxt index c3ad326589..16e0fd5a31 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv2-d-transpose.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv2-d-transpose.pbtxt index fd9eb43066..065bb4d35b 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv2-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv2-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv2-d.pbtxt index 40d61688f2..543bae6fa9 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv3-d-transpose.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv3-d-transpose.pbtxt index b8c227d725..c7ba6056f9 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv3-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv3-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv3-d.pbtxt index 095d35e574..072943dc2c 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-conv3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution1-d.pbtxt index 8f99961198..222a1ef4fc 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt index 96d522a016..8f4f7918ab 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution2-d.pbtxt index de2824dab4..f939067178 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt index 1d563241d8..93c442bd55 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution3-d.pbtxt index c87e52c537..471b18ef85 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-convolution3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping1-d.pbtxt index dccf5523e3..0f250a09b7 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping2-d.pbtxt index 7ac4116d92..f52128483c 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping3-d.pbtxt index 024f72705d..98daf3bab1 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cropping3-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt index 4e0233331b..64e7a9046b 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt index 32d46ce8f3..6fdffef776 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dense.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dense.pbtxt index 858486c725..3ac3825759 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dense.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dense.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt index f65d750926..280ec8c25f 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dot.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dot.pbtxt index 2e71ef503d..560f66f9c7 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dot.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dot.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dropout.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dropout.pbtxt index 42533bcd21..c0543529c3 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dropout.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-dropout.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-e-l-u.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-e-l-u.pbtxt index b5df169417..04eb2824b9 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-e-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-e-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-embedding.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-embedding.pbtxt index 0ea17919a9..f400432915 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-embedding.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-embedding.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-flatten.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-flatten.pbtxt index a33248bc00..ab176b441a 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-flatten.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-flatten.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-g-r-u-cell.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-g-r-u-cell.pbtxt index 4ba21a25cd..c3895a0ac1 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-g-r-u-cell.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-g-r-u-cell.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" @@ -133,6 +133,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-g-r-u.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-g-r-u.pbtxt index a7a570418e..a0fe598ab9 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-g-r-u.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-g-r-u.pbtxt @@ -171,7 +171,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-gaussian-dropout.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-gaussian-dropout.pbtxt index 763bc23113..55e0d7ef02 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-gaussian-dropout.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-gaussian-dropout.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-gaussian-noise.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-gaussian-noise.pbtxt index 3c50a3d7f2..38fbff5e4a 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-gaussian-noise.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-gaussian-noise.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt index ac78bdafad..5ea61d118d 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt index 275282d9d2..929f48df23 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt index 0e31e6058b..2e6d59337f 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt index aacd0b1791..11dca17c6d 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt index c236548663..4e3e258430 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt index 6b9c0290aa..fb9166316f 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool1-d.pbtxt index 0d7b2211e6..278429af6f 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool2-d.pbtxt index d080ad6aed..87b7f6797a 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool3-d.pbtxt index fcb0a109da..98bf96fa0c 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt index 1d0e22abd0..935a69ab2f 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt index 653c9f547b..c9d4158d1c 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt index cdbaf82cf6..9953102ff9 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-input-layer.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-input-layer.pbtxt index 230c5e9034..2617f5a95f 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-input-layer.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-input-layer.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt index 511456e740..e9f6ef45aa 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" @@ -133,6 +133,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-l-s-t-m.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-l-s-t-m.pbtxt index 4a3492ebd6..ecdbf48157 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-l-s-t-m.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-l-s-t-m.pbtxt @@ -171,7 +171,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-lambda.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-lambda.pbtxt index 2dff7a6de4..2e0b6bac24 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-lambda.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-lambda.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-layer.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-layer.pbtxt index 7efa29be77..1e93d1118a 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-layer.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-layer.pbtxt @@ -97,7 +97,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-leaky-re-l-u.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-leaky-re-l-u.pbtxt index 0ca8e0b52c..bfd36012a7 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-leaky-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-leaky-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-locally-connected1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-locally-connected1-d.pbtxt index ff19dcc3a3..5ad5990d7e 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-locally-connected1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-locally-connected1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-locally-connected2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-locally-connected2-d.pbtxt index 3c278fead6..40d03369a5 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-locally-connected2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-locally-connected2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-masking.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-masking.pbtxt index 850ecff974..86666b51bb 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-masking.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-masking.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool1-d.pbtxt index 7c69e31f9a..238d96cca6 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool2-d.pbtxt index fba42642d7..85f23df671 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool3-d.pbtxt index 9c277411ea..235806b965 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling1-d.pbtxt index 7c2f6ccc8a..4a45bf7997 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling2-d.pbtxt index 802178dba6..fda2562fc8 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling3-d.pbtxt index e870dfe9ad..71d2d09a8d 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-max-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-maximum.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-maximum.pbtxt index c1337ce0cb..12949b39a6 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-maximum.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-maximum.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-minimum.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-minimum.pbtxt index ed27a62765..ab16d0021e 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-minimum.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-minimum.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-multiply.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-multiply.pbtxt index b9f05cb3e5..61ccbf5962 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-multiply.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-multiply.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-p-re-l-u.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-p-re-l-u.pbtxt index 336d9f76fb..ce2320d703 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-p-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-p-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-permute.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-permute.pbtxt index 46282217e0..69848af8cf 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-permute.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-permute.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-r-n-n.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-r-n-n.pbtxt index 42cd7e87ee..2b6e8af11d 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-r-n-n.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-r-n-n.pbtxt @@ -102,7 +102,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-re-l-u.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-re-l-u.pbtxt index 4d3de58bd1..413f45f018 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-repeat-vector.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-repeat-vector.pbtxt index 9f094a877a..9c61ff6027 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-repeat-vector.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-repeat-vector.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-reshape.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-reshape.pbtxt index 2f519a2438..baa91804c4 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-reshape.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-reshape.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-conv1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-conv1-d.pbtxt index 6b93116ba0..15a5d6ac9e 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-conv1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-conv1-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-conv2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-conv2-d.pbtxt index fd17115e27..be43bd5b3c 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-conv2-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-convolution1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-convolution1-d.pbtxt index 4b37a94478..6105992c7a 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-convolution1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-convolution1-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-convolution2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-convolution2-d.pbtxt index 5bdadca74a..1b6cf1e9ec 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-convolution2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-separable-convolution2-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt index 9dfda96fc8..29488a37f8 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" @@ -133,6 +133,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-simple-r-n-n.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-simple-r-n-n.pbtxt index 7b7684ccd2..182efb83b8 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-simple-r-n-n.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-simple-r-n-n.pbtxt @@ -159,7 +159,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-softmax.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-softmax.pbtxt index 3b15407fca..d29731ecf9 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-softmax.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-softmax.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt index 6d04415267..a6d7494ca7 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt index 04950654d5..c36e802693 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt index c424e6dcc8..9c46cfe40f 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt index 6718e36dc6..8982f78794 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt @@ -106,7 +106,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" @@ -141,6 +141,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-subtract.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-subtract.pbtxt index 740a03367b..ec2cc50298 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-subtract.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-subtract.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt index a08c583adb..d7bc1980f3 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-time-distributed.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-time-distributed.pbtxt index c1294fed0f..fec2de6b49 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-time-distributed.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-time-distributed.pbtxt @@ -103,7 +103,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling1-d.pbtxt index dc401d3ed0..3d285e7f17 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling2-d.pbtxt index 4b5165ae97..40a56a0c94 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling3-d.pbtxt index 789af15fea..728eca415a 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-up-sampling3-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-wrapper.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-wrapper.pbtxt index 0536a7cee7..da64e77c39 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-wrapper.pbtxt @@ -102,7 +102,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding1-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding1-d.pbtxt index 8915353ec3..2f505f9293 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding1-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding2-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding2-d.pbtxt index 6efb5ef15a..f82c77072e 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding2-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding3-d.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding3-d.pbtxt index 4c33c5d0bf..54e01a9917 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding3-d.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.layers.-zero-padding3-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.models.-model.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.models.-model.pbtxt index 56914e1746..472b9818df 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.models.-model.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.models.-model.pbtxt @@ -119,7 +119,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.models.-sequential.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.models.-sequential.pbtxt index acfb3521c0..937516eff1 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.models.-sequential.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.models.-sequential.pbtxt @@ -124,7 +124,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\'], varargs=None, keywords=kwargs, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.models.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.models.pbtxt index 8ba0e7480b..7ad4a32d43 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.models.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.models.pbtxt @@ -9,6 +9,10 @@ tf_module { mtype: "<type \'type\'>" } member_method { + name: "clone_model" + argspec: "args=[\'model\', \'input_tensors\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { name: "load_model" argspec: "args=[\'filepath\', \'custom_objects\', \'compile\'], varargs=None, keywords=None, defaults=[\'None\', \'True\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt index e606eab919..88b8f37c4f 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt @@ -152,6 +152,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt index 5deb02d569..a4483fefa2 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt @@ -152,6 +152,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt index 8a63b49180..381c4975d7 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt @@ -151,6 +151,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt index db1aae2757..912365a28b 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt @@ -155,6 +155,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt index 32fa151a8e..a4bb3219c7 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt @@ -152,6 +152,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt index 30c6c2ce3b..715bfd5fc7 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt @@ -152,6 +152,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt index 72b40cc9f7..b66c0f89cc 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt @@ -151,6 +151,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt index a5c2b4aefd..faeb4f3513 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt @@ -150,6 +150,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt index 61d5f04b22..caa2e60080 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt @@ -151,6 +151,10 @@ tf_class { argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" } member_method { + name: "get_initial_state" + argspec: "args=[\'self\', \'inputs\', \'batch_size\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " + } + member_method { name: "get_input_at" argspec: "args=[\'self\', \'node_index\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.pbtxt index 4de662fe33..519cf66aa4 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.pbtxt @@ -761,18 +761,6 @@ tf_module { argspec: "args=[\'var_list\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { - name: "assign" - argspec: "args=[\'ref\', \'value\', \'validate_shape\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\'], " - } - member_method { - name: "assign_add" - argspec: "args=[\'ref\', \'value\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\'], " - } - member_method { - name: "assign_sub" - argspec: "args=[\'ref\', \'value\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\'], " - } - member_method { name: "atan" argspec: "args=[\'x\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } @@ -789,6 +777,10 @@ tf_module { argspec: "args=[\'params\', \'indices\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { + name: "batch_scatter_update" + argspec: "args=[\'ref\', \'indices\', \'updates\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'True\', \'None\'], " + } + member_method { name: "batch_to_space" argspec: "args=[\'input\', \'crops\', \'block_size\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } @@ -925,10 +917,6 @@ tf_module { argspec: "args=[\'input_tensor\', \'axis\', \'keepdims\', \'dtype\', \'name\', \'reduction_indices\', \'keep_dims\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \"<dtype: \'int64\'>\", \'None\', \'None\', \'None\'], " } member_method { - name: "count_up_to" - argspec: "args=[\'ref\', \'limit\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " - } - member_method { name: "create_partitioned_variables" argspec: "args=[\'shape\', \'slicing\', \'initializer\', \'dtype\', \'trainable\', \'collections\', \'name\', \'reuse\'], varargs=None, keywords=None, defaults=[\"<dtype: \'float32\'>\", \'True\', \'None\', \'None\', \'None\'], " } @@ -1005,6 +993,10 @@ tf_module { argspec: "args=[\'x\', \'y\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { + name: "div_no_nan" + argspec: "args=[\'x\', \'y\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { name: "divide" argspec: "args=[\'x\', \'y\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } @@ -1033,6 +1025,10 @@ tf_module { argspec: "args=[\'input\', \'pad\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " } member_method { + name: "ensure_shape" + argspec: "args=[\'x\', \'shape\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " + } + member_method { name: "equal" argspec: "args=[\'x\', \'y\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } @@ -1273,6 +1269,10 @@ tf_module { argspec: "args=[\'graph_def\', \'input_map\', \'return_elements\', \'name\', \'op_dict\', \'producer_op_list\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\'], " } member_method { + name: "init_scope" + argspec: "args=[], varargs=None, keywords=None, defaults=None" + } + member_method { name: "initialize_all_tables" argspec: "args=[\'name\'], varargs=None, keywords=None, defaults=[\'init_all_tables\'], " } @@ -1729,10 +1729,6 @@ tf_module { argspec: "args=[\'fn\', \'elems\', \'initializer\', \'parallel_iterations\', \'back_prop\', \'swap_memory\', \'infer_shape\', \'reverse\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'10\', \'True\', \'False\', \'True\', \'False\', \'None\'], " } member_method { - name: "scatter_add" - argspec: "args=[\'ref\', \'indices\', \'updates\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " - } - member_method { name: "scatter_div" argspec: "args=[\'ref\', \'indices\', \'updates\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " } @@ -1753,26 +1749,6 @@ tf_module { argspec: "args=[\'indices\', \'updates\', \'shape\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { - name: "scatter_nd_add" - argspec: "args=[\'ref\', \'indices\', \'updates\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " - } - member_method { - name: "scatter_nd_sub" - argspec: "args=[\'ref\', \'indices\', \'updates\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " - } - member_method { - name: "scatter_nd_update" - argspec: "args=[\'ref\', \'indices\', \'updates\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'True\', \'None\'], " - } - member_method { - name: "scatter_sub" - argspec: "args=[\'ref\', \'indices\', \'updates\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " - } - member_method { - name: "scatter_update" - argspec: "args=[\'ref\', \'indices\', \'updates\', \'use_locking\', \'name\'], varargs=None, keywords=None, defaults=[\'True\', \'None\'], " - } - member_method { name: "segment_max" argspec: "args=[\'data\', \'segment_ids\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.sparse.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.sparse.pbtxt index bbfe395031..ba9e651b34 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.sparse.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.sparse.pbtxt @@ -8,4 +8,12 @@ tf_module { name: "cross_hashed" argspec: "args=[\'inputs\', \'num_buckets\', \'hash_key\', \'name\'], varargs=None, keywords=None, defaults=[\'0\', \'None\', \'None\'], " } + member_method { + name: "expand_dims" + argspec: "args=[\'sp_input\', \'axis\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\'], " + } + member_method { + name: "eye" + argspec: "args=[\'num_rows\', \'num_columns\', \'dtype\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\", \'None\'], " + } } diff --git a/tensorflow/tools/ci_build/Dockerfile.cmake b/tensorflow/tools/ci_build/Dockerfile.cmake index 4587bcf891..b7450c83de 100644 --- a/tensorflow/tools/ci_build/Dockerfile.cmake +++ b/tensorflow/tools/ci_build/Dockerfile.cmake @@ -28,8 +28,8 @@ RUN pip install --upgrade astor RUN pip install --upgrade gast RUN pip install --upgrade numpy RUN pip install --upgrade termcolor -RUN pip install keras_applications==1.0.4 -RUN pip install keras_preprocessing==1.0.2 +RUN pip install keras_applications==1.0.5 +RUN pip install keras_preprocessing==1.0.3 # Install golang RUN apt-get install -t xenial-backports -y golang-1.9 diff --git a/tensorflow/tools/ci_build/ci_sanity.sh b/tensorflow/tools/ci_build/ci_sanity.sh index 866fe95d2b..a98c15d961 100755 --- a/tensorflow/tools/ci_build/ci_sanity.sh +++ b/tensorflow/tools/ci_build/ci_sanity.sh @@ -99,6 +99,7 @@ do_pylint() { "^tensorflow/contrib/layers/python/layers/feature_column\.py.*\[E0110.*abstract-class-instantiated "\ "^tensorflow/contrib/eager/python/evaluator\.py.*\[E0202.*method-hidden "\ "^tensorflow/contrib/eager/python/metrics_impl\.py.*\[E0202.*method-hidden "\ +"^tensorflow/contrib/rate/rate\.py.*\[E0202.*method-hidden "\ "^tensorflow/python/platform/gfile\.py.*\[E0301.*non-iterator "\ "^tensorflow/python/keras/callbacks\.py.*\[E1133.*not-an-iterable "\ "^tensorflow/python/keras/engine/base_layer.py.*\[E0203.*access-member-before-definition "\ diff --git a/tensorflow/tools/ci_build/install/install_pip_packages.sh b/tensorflow/tools/ci_build/install/install_pip_packages.sh index bb316ecfc9..af478eded4 100755 --- a/tensorflow/tools/ci_build/install/install_pip_packages.sh +++ b/tensorflow/tools/ci_build/install/install_pip_packages.sh @@ -115,10 +115,10 @@ pip2 install --upgrade setuptools==39.1.0 pip3 install --upgrade setuptools==39.1.0 # Keras -pip2 install keras_applications==1.0.4 --no-deps -pip3 install keras_applications==1.0.4 --no-deps -pip2 install keras_preprocessing==1.0.2 --no-deps -pip3 install keras_preprocessing==1.0.2 --no-deps +pip2 install keras_applications==1.0.5 --no-deps +pip3 install keras_applications==1.0.5 --no-deps +pip2 install keras_preprocessing==1.0.3 --no-deps +pip3 install keras_preprocessing==1.0.3 --no-deps # Install last working version of setuptools. pip2 install --upgrade setuptools==39.1.0 diff --git a/tensorflow/tools/ci_build/install/install_python3.5_pip_packages.sh b/tensorflow/tools/ci_build/install/install_python3.5_pip_packages.sh index 15e4396ce3..93ea0c3db6 100755 --- a/tensorflow/tools/ci_build/install/install_python3.5_pip_packages.sh +++ b/tensorflow/tools/ci_build/install/install_python3.5_pip_packages.sh @@ -85,8 +85,8 @@ pip3.5 install --upgrade termcolor pip3.5 install --upgrade setuptools==39.1.0 # Keras -pip3.5 install keras_applications==1.0.4 -pip3.5 install keras_preprocessing==1.0.2 +pip3.5 install keras_applications==1.0.5 +pip3.5 install keras_preprocessing==1.0.3 # Install last working version of setuptools. pip3.5 install --upgrade setuptools==39.1.0 diff --git a/tensorflow/tools/ci_build/install/install_python3.6_pip_packages.sh b/tensorflow/tools/ci_build/install/install_python3.6_pip_packages.sh index 0fc3eee71c..7a9eef7c64 100755 --- a/tensorflow/tools/ci_build/install/install_python3.6_pip_packages.sh +++ b/tensorflow/tools/ci_build/install/install_python3.6_pip_packages.sh @@ -101,7 +101,7 @@ pip3 install --upgrade termcolor pip3 install --upgrade setuptools==39.1.0 # Keras -pip3 install keras_applications==1.0.4 -pip3 install keras_preprocessing==1.0.2 +pip3 install keras_applications==1.0.5 +pip3 install keras_preprocessing==1.0.3 # LINT.ThenChange(//tensorflow/tools/ci_build/install/install_python3.5_pip_packages.sh) diff --git a/tensorflow/tools/ci_build/update_version.py b/tensorflow/tools/ci_build/update_version.py index 30c318a58f..4373d464b6 100755 --- a/tensorflow/tools/ci_build/update_version.py +++ b/tensorflow/tools/ci_build/update_version.py @@ -211,44 +211,6 @@ def update_readme(old_version, new_version): "%s-" % pep_440_str, README_MD) -def update_md_files(old_version, new_version): - """Update the md doc files. - - Args: - old_version: Version object of current version - new_version: Version object of new version - """ - - old_pep_version = old_version.pep_440_str - new_pep_version = new_version.pep_440_str - for filename in ["linux", "mac", "windows", "sources"]: - filepath = "%s/docs_src/install/install_%s.md" % (TF_SRC_DIR, - filename) - - if filename == "sources" and "rc0" in new_pep_version: - replace_string_in_line("(?<!<td>)tensorflow-%s" % old_pep_version, - "tensorflow-%s" % new_pep_version, filepath) - replace_string_in_line("(?<!<td>)tensorflow_gpu-%s" % old_pep_version, - "tensorflow_gpu-%s" % new_pep_version, filepath) - else: - replace_string_in_line("tensorflow-%s" % old_pep_version, - "tensorflow-%s" % new_pep_version, filepath) - replace_string_in_line("tensorflow_gpu-%s" % old_pep_version, - "tensorflow_gpu-%s" % new_pep_version, filepath) - replace_string_in_line("TensorFlow %s" % old_pep_version, - "TensorFlow %s" % new_pep_version, filepath) - - for filename in ["java", "go", "c"]: - filepath = "%s/docs_src/install/install_%s.md" % (TF_SRC_DIR, - filename) - replace_string_in_line(r"x86_64-%s" % old_version, - "x86_64-%s" % new_version, filepath) - replace_string_in_line(r"libtensorflow-%s.jar" % old_version, - "libtensorflow-%s.jar" % new_version, filepath) - replace_string_in_line(r"<version>%s<\/version>" % old_version, - "<version>%s</version>" % new_version, filepath) - - def major_minor_change(old_version, new_version): """Check if a major or minor change occurred.""" major_mismatch = old_version.major != new_version.major @@ -350,7 +312,6 @@ def main(): update_version_h(old_version, new_version) update_setup_dot_py(old_version, new_version) update_readme(old_version, new_version) - update_md_files(old_version, new_version) update_dockerfiles(old_version, new_version) # Print transition details. @@ -359,12 +320,6 @@ def main(): print("Patch: %s -> %s\n" % (old_version.patch, new_version.patch)) check_for_old_version(old_version, new_version) - if "rc0" in str(new_version): - print("\n\n\033[93mNOTE: Please update the tensorflow/docs_src/install/" - "install_sources.md and add a line for tensorflow-%s and " - "tensorflow_gpu-%s in the tested source configurations " - "table.\033[0m\n" % (new_version.pep_440_str, - new_version.pep_440_str)) if __name__ == "__main__": diff --git a/tensorflow/tools/ci_build/windows/bazel/bazel_test_lib.sh b/tensorflow/tools/ci_build/windows/bazel/bazel_test_lib.sh index 0482cf619a..27b350e13e 100644 --- a/tensorflow/tools/ci_build/windows/bazel/bazel_test_lib.sh +++ b/tensorflow/tools/ci_build/windows/bazel/bazel_test_lib.sh @@ -27,7 +27,7 @@ function run_configure_for_gpu_build { } function set_remote_cache_options { - echo "build --remote_instance_name=projects/tensorflow-testing-cpu" >> "${TMP_BAZELRC}" + echo "build --remote_instance_name=projects/tensorflow-testing/instances/default_instance" >> "${TMP_BAZELRC}" echo "build --experimental_remote_platform_override='properties:{name:\"build\" value:\"windows-x64\"}'" >> "${TMP_BAZELRC}" echo "build --remote_cache=remotebuildexecution.googleapis.com" >> "${TMP_BAZELRC}" echo "build --tls_enabled=true" >> "${TMP_BAZELRC}" diff --git a/tensorflow/tools/ci_build/windows/cpu/pip/build_tf_windows.sh b/tensorflow/tools/ci_build/windows/cpu/pip/build_tf_windows.sh index 47e0e5dd59..177ef390db 100644 --- a/tensorflow/tools/ci_build/windows/cpu/pip/build_tf_windows.sh +++ b/tensorflow/tools/ci_build/windows/cpu/pip/build_tf_windows.sh @@ -57,8 +57,7 @@ PY_TEST_DIR="py_test_dir" SKIP_TEST=0 RELEASE_BUILD=0 -TEST_TARGET="//${PY_TEST_DIR}/tensorflow/python/... \ - //${PY_TEST_DIR}/tensorflow/contrib/... " +TEST_TARGET="//${PY_TEST_DIR}/tensorflow/python/..." # --skip_test Skip running tests # --enable_remote_cache Add options to enable remote cache for build and test @@ -68,6 +67,7 @@ TEST_TARGET="//${PY_TEST_DIR}/tensorflow/python/... \ # --test_contrib_only Use tensorflow/contrib/... as test target for ARG in "$@"; do case "$ARG" in + --tf_nightly) TF_NIGHTLY=1 ;; --skip_test) SKIP_TEST=1 ;; --enable_remote_cache) set_remote_cache_options ;; --release_build) RELEASE_BUILD=1 ;; @@ -86,6 +86,11 @@ else export TF_OVERRIDE_EIGEN_STRONG_INLINE=1 fi +if [[ "$TF_NIGHTLY" == 1 ]]; then + python tensorflow/tools/ci_build/update_version.py --nightly + EXTRA_PIP_FLAG="--nightly_flag" +fi + # Enable short object file path to avoid long path issue on Windows. echo "startup --output_user_root=${TMPDIR}" >> "${TMP_BAZELRC}" @@ -104,7 +109,11 @@ fi # Create a python test directory to avoid package name conflict create_python_test_dir "${PY_TEST_DIR}" -./bazel-bin/tensorflow/tools/pip_package/build_pip_package "$PWD/${PY_TEST_DIR}" +./bazel-bin/tensorflow/tools/pip_package/build_pip_package "$PWD/${PY_TEST_DIR}" "${EXTRA_PIP_FLAG}" + +if [[ "$TF_NIGHTLY" == 1 ]]; then + exit 0 +fi # Running python tests on Windows needs pip package installed PIP_NAME=$(ls ${PY_TEST_DIR}/tensorflow-*.whl) diff --git a/tensorflow/tools/ci_build/windows/gpu/pip/build_tf_windows.sh b/tensorflow/tools/ci_build/windows/gpu/pip/build_tf_windows.sh index e3eee11080..28d5565b98 100644 --- a/tensorflow/tools/ci_build/windows/gpu/pip/build_tf_windows.sh +++ b/tensorflow/tools/ci_build/windows/gpu/pip/build_tf_windows.sh @@ -57,8 +57,7 @@ PY_TEST_DIR="py_test_dir" SKIP_TEST=0 RELEASE_BUILD=0 -TEST_TARGET="//${PY_TEST_DIR}/tensorflow/python/... \ - //${PY_TEST_DIR}/tensorflow/contrib/... " +TEST_TARGET="//${PY_TEST_DIR}/tensorflow/python/..." # --skip_test Skip running tests # --enable_remote_cache Add options to enable remote cache for build and test @@ -68,6 +67,7 @@ TEST_TARGET="//${PY_TEST_DIR}/tensorflow/python/... \ # --test_contrib_only Use tensorflow/contrib/... as test target for ARG in "$@"; do case "$ARG" in + --tf_nightly) TF_NIGHTLY=1 ;; --skip_test) SKIP_TEST=1 ;; --enable_remote_cache) set_remote_cache_options ;; --release_build) RELEASE_BUILD=1 ;; @@ -86,6 +86,11 @@ else export TF_OVERRIDE_EIGEN_STRONG_INLINE=1 fi +if [[ "$TF_NIGHTLY" == 1 ]]; then + python tensorflow/tools/ci_build/update_version.py --nightly + EXTRA_PIP_FLAG="--nightly_flag" +fi + # Enable short object file path to avoid long path issue on Windows. echo "startup --output_user_root=${TMPDIR}" >> "${TMP_BAZELRC}" @@ -107,10 +112,14 @@ fi # Create a python test directory to avoid package name conflict create_python_test_dir "${PY_TEST_DIR}" -./bazel-bin/tensorflow/tools/pip_package/build_pip_package "$PWD/${PY_TEST_DIR}" +./bazel-bin/tensorflow/tools/pip_package/build_pip_package "$PWD/${PY_TEST_DIR}" --gpu "${EXTRA_PIP_FLAG}" + +if [[ "$TF_NIGHTLY" == 1 ]]; then + exit 0 +fi # Running python tests on Windows needs pip package installed -PIP_NAME=$(ls ${PY_TEST_DIR}/tensorflow-*.whl) +PIP_NAME=$(ls ${PY_TEST_DIR}/tensorflow_gpu-*.whl) reinstall_tensorflow_pip ${PIP_NAME} TF_GPU_COUNT=${TF_GPU_COUNT:-8} diff --git a/tensorflow/tools/common/public_api.py b/tensorflow/tools/common/public_api.py index 09933d266b..82bb0713c4 100644 --- a/tensorflow/tools/common/public_api.py +++ b/tensorflow/tools/common/public_api.py @@ -102,9 +102,10 @@ class PublicAPIVisitor(object): """Override the default root name of 'tf'.""" self._root_name = root_name - def _is_private(self, path, name): + def _is_private(self, path, name, obj=None): """Return whether a name is private.""" # TODO(wicke): Find out what names to exclude. + del obj # Unused. return ((path in self._private_map and name in self._private_map[path]) or (name.startswith('_') and not re.match('__.*__$', name) or @@ -129,7 +130,7 @@ class PublicAPIVisitor(object): # Remove things that are not visible. for name, child in list(children): - if self._is_private(full_path, name): + if self._is_private(full_path, name, child): children.remove((name, child)) self._visitor(path, parent, children) diff --git a/tensorflow/tools/docker/Dockerfile b/tensorflow/tools/docker/Dockerfile index 2c31d784e5..b5a6c05193 100644 --- a/tensorflow/tools/docker/Dockerfile +++ b/tensorflow/tools/docker/Dockerfile @@ -29,10 +29,10 @@ RUN pip --no-cache-dir install \ h5py \ ipykernel \ jupyter \ - keras_applications==1.0.4 \ - keras_preprocessing==1.0.2 \ + keras_applications==1.0.5 \ + keras_preprocessing==1.0.3 \ matplotlib \ - numpy==1.14.5 \ + numpy \ pandas \ scipy \ sklearn \ diff --git a/tensorflow/tools/docker/Dockerfile.devel b/tensorflow/tools/docker/Dockerfile.devel index bacdea72ce..39e7bc8b66 100644 --- a/tensorflow/tools/docker/Dockerfile.devel +++ b/tensorflow/tools/docker/Dockerfile.devel @@ -33,11 +33,11 @@ RUN pip --no-cache-dir install \ h5py \ ipykernel \ jupyter \ - keras_applications==1.0.4 \ - keras_preprocessing==1.0.2 \ + keras_applications==1.0.5 \ + keras_preprocessing==1.0.3 \ matplotlib \ mock \ - numpy==1.14.5 \ + numpy \ scipy \ sklearn \ pandas \ diff --git a/tensorflow/tools/docker/Dockerfile.devel-gpu b/tensorflow/tools/docker/Dockerfile.devel-gpu index 4f89e3f701..b6fa6f6dab 100644 --- a/tensorflow/tools/docker/Dockerfile.devel-gpu +++ b/tensorflow/tools/docker/Dockerfile.devel-gpu @@ -49,11 +49,11 @@ RUN pip --no-cache-dir install \ h5py \ ipykernel \ jupyter \ - keras_applications==1.0.4 \ - keras_preprocessing==1.0.2 \ + keras_applications==1.0.5 \ + keras_preprocessing==1.0.3 \ matplotlib \ mock \ - numpy==1.14.5 \ + numpy \ scipy \ sklearn \ pandas \ diff --git a/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 b/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 index 056b4755f4..eb139ec5f8 100644 --- a/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 +++ b/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 @@ -37,8 +37,8 @@ RUN pip --no-cache-dir install --upgrade \ RUN pip --no-cache-dir install \ ipykernel \ jupyter \ - keras_applications==1.0.4 \ - keras_preprocessing==1.0.2 \ + keras_applications==1.0.5 \ + keras_preprocessing==1.0.3 \ matplotlib \ numpy \ scipy \ diff --git a/tensorflow/tools/docker/Dockerfile.devel-mkl b/tensorflow/tools/docker/Dockerfile.devel-mkl index 2df770e525..371451d2aa 100755 --- a/tensorflow/tools/docker/Dockerfile.devel-mkl +++ b/tensorflow/tools/docker/Dockerfile.devel-mkl @@ -52,8 +52,8 @@ RUN ${PIP} --no-cache-dir install \ h5py \ ipykernel \ jupyter \ - keras_applications==1.0.4 \ - keras_preprocessing==1.0.2 \ + keras_applications==1.0.5 \ + keras_preprocessing==1.0.3 \ matplotlib \ mock \ numpy \ diff --git a/tensorflow/tools/docker/Dockerfile.devel-mkl-horovod b/tensorflow/tools/docker/Dockerfile.devel-mkl-horovod index ab2eec1728..987b582d10 100755 --- a/tensorflow/tools/docker/Dockerfile.devel-mkl-horovod +++ b/tensorflow/tools/docker/Dockerfile.devel-mkl-horovod @@ -45,8 +45,8 @@ RUN ${PIP} --no-cache-dir install \ h5py \ ipykernel \ jupyter \ - keras_applications==1.0.4 \ - keras_preprocessing==1.0.2 \ + keras_applications==1.0.5 \ + keras_preprocessing==1.0.3 \ matplotlib \ mock \ numpy \ diff --git a/tensorflow/tools/docker/Dockerfile.gpu b/tensorflow/tools/docker/Dockerfile.gpu index aa0e0face1..c68082842d 100644 --- a/tensorflow/tools/docker/Dockerfile.gpu +++ b/tensorflow/tools/docker/Dockerfile.gpu @@ -37,10 +37,10 @@ RUN pip --no-cache-dir install \ h5py \ ipykernel \ jupyter \ - keras_applications==1.0.4 \ - keras_preprocessing==1.0.2 \ + keras_applications==1.0.5 \ + keras_preprocessing==1.0.3 \ matplotlib \ - numpy==1.14.5 \ + numpy \ pandas \ scipy \ sklearn \ diff --git a/tensorflow/tools/docker/Dockerfile.mkl b/tensorflow/tools/docker/Dockerfile.mkl index 69553302d8..641c9e3b16 100755 --- a/tensorflow/tools/docker/Dockerfile.mkl +++ b/tensorflow/tools/docker/Dockerfile.mkl @@ -38,8 +38,8 @@ RUN ${PIP} --no-cache-dir install \ h5py \ ipykernel \ jupyter \ - keras_applications==1.0.4 \ - keras_preprocessing==1.0.2 \ + keras_applications==1.0.5 \ + keras_preprocessing==1.0.3 \ matplotlib \ numpy \ pandas \ diff --git a/tensorflow/tools/docker/Dockerfile.mkl-horovod b/tensorflow/tools/docker/Dockerfile.mkl-horovod index 756716ee0e..2b11679f54 100755 --- a/tensorflow/tools/docker/Dockerfile.mkl-horovod +++ b/tensorflow/tools/docker/Dockerfile.mkl-horovod @@ -38,8 +38,8 @@ RUN ${PIP} --no-cache-dir install \ h5py \ ipykernel \ jupyter \ - keras_applications==1.0.4 \ - keras_preprocessing==1.0.2 \ + keras_applications==1.0.5 \ + keras_preprocessing==1.0.3 \ matplotlib \ numpy \ pandas \ diff --git a/tensorflow/tools/docker/README.md b/tensorflow/tools/docker/README.md index a286e8a212..263f25bc48 100644 --- a/tensorflow/tools/docker/README.md +++ b/tensorflow/tools/docker/README.md @@ -1,3 +1,10 @@ +# WARNING: THESE IMAGES ARE DEPRECATED. + +TensorFlow's Dockerfiles are now located in +[`tensorflow/tools/dockerfiles/`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/dockerfiles). + +This directory will eventually be removed. + # Using TensorFlow via Docker This directory contains `Dockerfile`s to make it easy to get up and running with diff --git a/tensorflow/tools/dockerfiles/README.md b/tensorflow/tools/dockerfiles/README.md new file mode 100644 index 0000000000..c484c162cb --- /dev/null +++ b/tensorflow/tools/dockerfiles/README.md @@ -0,0 +1,67 @@ +# TensorFlow Dockerfiles + +This directory houses TensorFlow's Dockerfiles. **DO NOT EDIT THE DOCKERFILES +MANUALLY!** They are maintained by `assembler.py`, which builds Dockerfiles from +the files in `partials/` and the rules in `spec.yml`. See [the Maintaining +section](#maintaining) for more information. + +## Building + +The Dockerfiles in the `dockerfiles` directory must have their build context set +to **the directory with this README.md** to copy in helper files. For example: + +```bash +$ docker build -f ./dockerfiles/cpu.Dockerfile -t tf . +``` + +Each Dockerfile has its own set of available `--build-arg`s which are documented +in the Dockerfile itself. + +## Running + +After building the image with the tag `tf` (for example), use `docker run` to +run the images. Examples are below. + +Note for new Docker users: the `-v` and `-u` flags share directories between +the Docker container and your machine, and very important. Without +`-v`, your work will be wiped once the container quits, and without `-u`, files +created by the container will have the wrong file permissions on your host +machine. If you are confused, check out the [Docker run +documentation](https://docs.docker.com/engine/reference/run/). + +```bash +# Volume mount (-v) is optional but highly recommended, especially for Jupyter. +# User permissions (-u) are required if you use (-v). + +# CPU-based images +$ docker run -u $(id -u):$(id -g) -v $(PWD):/my-devel -it tf + +# GPU-based images (set up nvidia-docker2 first) +$ docker run --runtime=nvidia -u $(id -u):$(id -g) -v $(PWD):/my-devel -it tf + +# Images with Jupyter run on port 8888, and needs a volume for notebooks +$ docker run --user $(id -u):$(id -g) -p 8888:8888 -v $(PWD):/notebooks -it tf +``` + +These images do not come with the TensorFlow source code -- but the development +images have git included, so you can `git clone` it yourself. + +## Contributing + +To make changes to TensorFlow's Dockerfiles, you'll update `spec.yml` and the +`*.partial.Dockerfile` files in the `partials` directory, then run +`assembler.py` to re-generate the full Dockerfiles before creating a pull +request. + +You can use the `Dockerfile` in this directory to build an editing environment +that has all of the Python dependencies you'll need: + +```bash +$ docker build -t tf-assembler -f assembler.Dockerfile . + +# Set --user to set correct permissions on generated files +$ docker run --user $(id -u):$(id -g) -it -v $(pwd):/tf tf-assembler bash + +# In the container... +/tf $ python3 ./assembler.py -o dockerfiles -s spec.yml +``` diff --git a/tensorflow/contrib/kfac/python/ops/op_queue_lib.py b/tensorflow/tools/dockerfiles/assembler.Dockerfile index 09c9a4ab33..7a8e07fced 100644 --- a/tensorflow/contrib/kfac/python/ops/op_queue_lib.py +++ b/tensorflow/tools/dockerfiles/assembler.Dockerfile @@ -1,4 +1,4 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. @@ -12,19 +12,19 @@ # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================== -"""Helper for choosing which op to run next in a distributed setting.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function +# +# TensorFlow Dockerfile Development Container +# +# You can use this image to quickly develop changes to the Dockerfile assembler +# or set of TF Docker partials. See README.md for usage instructions. +FROM debian:stretch +LABEL maintainer="Austin Anderson <angerson@google.com>" -# pylint: disable=unused-import,line-too-long,wildcard-import -from tensorflow.contrib.kfac.python.ops.op_queue import * -from tensorflow.python.util.all_util import remove_undocumented -# pylint: enable=unused-import,line-too-long,wildcard-import +RUN apt-get update && apt-get install -y python3 python3-pip bash +RUN pip3 install --upgrade pip setuptools pyyaml absl-py cerberus -_allowed_symbols = [ - 'OpQueue', -] +WORKDIR /tf +VOLUME ["/tf"] -remove_undocumented(__name__, allowed_exception_list=_allowed_symbols) +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc diff --git a/tensorflow/tools/dockerfiles/assembler.py b/tensorflow/tools/dockerfiles/assembler.py new file mode 100644 index 0000000000..9cdd9bb0cb --- /dev/null +++ b/tensorflow/tools/dockerfiles/assembler.py @@ -0,0 +1,554 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Assemble common TF Dockerfiles from many parts. + +This script constructs TF's Dockerfiles by aggregating partial +Dockerfiles. See README.md for usage examples. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import copy +import errno +import os +import os.path +import re +import shutil +import textwrap + +from absl import app +from absl import flags +import cerberus +import yaml + +FLAGS = flags.FLAGS + +flags.DEFINE_boolean( + 'dry_run', False, 'Do not actually generate Dockerfiles', short_name='n') + +flags.DEFINE_string( + 'spec_file', + './spec.yml', + 'Path to a YAML specification file', + short_name='s') + +flags.DEFINE_string( + 'output_dir', + './dockerfiles', ('Path to an output directory for Dockerfiles. ' + 'Will be created if it doesn\'t exist.'), + short_name='o') + +flags.DEFINE_string( + 'partial_dir', + './partials', + 'Path to a directory containing foo.partial.Dockerfile partial files.', + short_name='p') + +flags.DEFINE_boolean( + 'quiet_dry_run', + True, + 'Do not print contents of dry run Dockerfiles.', + short_name='q') + +flags.DEFINE_boolean( + 'validate', True, 'Validate generated Dockerfiles', short_name='c') + +# Schema to verify the contents of spec.yml with Cerberus. +# Must be converted to a dict from yaml to work. +# Note: can add python references with e.g. +# !!python/name:builtins.str +# !!python/name:__main__.funcname +SCHEMA_TEXT = """ +header: + type: string + +partials: + type: dict + keyschema: + type: string + valueschema: + type: dict + schema: + desc: + type: string + args: + type: dict + keyschema: + type: string + valueschema: + anyof: + - type: [ boolean, number, string ] + - type: dict + schema: + default: + type: [ boolean, number, string ] + desc: + type: string + options: + type: list + schema: + type: string + +images: + keyschema: + type: string + valueschema: + type: dict + schema: + desc: + type: string + arg-defaults: + type: list + schema: + anyof: + - type: dict + keyschema: + type: string + arg_in_use: true + valueschema: + type: string + - type: string + isimage: true + create-dockerfile: + type: boolean + partials: + type: list + schema: + anyof: + - type: dict + keyschema: + type: string + regex: image + valueschema: + type: string + isimage: true + - type: string + ispartial: true +""" + + +class TfDockerValidator(cerberus.Validator): + """Custom Cerberus validator for TF dockerfile spec. + + Note: Each _validate_foo function's docstring must end with a segment + describing its own validation schema, e.g. "The rule's arguments are...". If + you add a new validator, you can copy/paste that section. + """ + + def _validate_ispartial(self, ispartial, field, value): + """Validate that a partial references an existing partial spec. + + Args: + ispartial: Value of the rule, a bool + field: The field being validated + value: The field's value + + The rule's arguments are validated against this schema: + {'type': 'boolean'} + """ + if ispartial and value not in self.root_document.get('partials', dict()): + self._error(field, '{} is not an existing partial.'.format(value)) + + def _validate_isimage(self, isimage, field, value): + """Validate that an image references an existing partial spec. + + Args: + isimage: Value of the rule, a bool + field: The field being validated + value: The field's value + + The rule's arguments are validated against this schema: + {'type': 'boolean'} + """ + if isimage and value not in self.root_document.get('images', dict()): + self._error(field, '{} is not an existing image.'.format(value)) + + def _validate_arg_in_use(self, arg_in_use, field, value): + """Validate that an arg references an existing partial spec's args. + + Args: + arg_in_use: Value of the rule, a bool + field: The field being validated + value: The field's value + + The rule's arguments are validated against this schema: + {'type': 'boolean'} + """ + if arg_in_use: + for partial in self.root_document.get('partials', dict()).values(): + if value in partial.get('args', tuple()): + return + + self._error(field, '{} is not an arg used in any partial.'.format(value)) + + +def build_partial_description(partial_spec): + """Create the documentation lines for a specific partial. + + Generates something like this: + + # This is the partial's description, from spec.yml. + # --build-arg ARG_NAME=argdefault + # this is one of the args. + # --build-arg ANOTHER_ARG=(some|choices) + # another arg. + + Args: + partial_spec: A dict representing one of the partials from spec.yml. Doesn't + include the name of the partial; is a dict like { desc: ..., args: ... }. + + Returns: + A commented string describing this partial. + """ + + # Start from linewrapped desc field + lines = [] + wrapper = textwrap.TextWrapper( + initial_indent='# ', subsequent_indent='# ', width=80) + description = wrapper.fill(partial_spec.get('desc', '( no comments )')) + lines.extend(['#', description]) + + # Document each arg + for arg, arg_data in partial_spec.get('args', dict()).items(): + # Wrap arg description with comment lines + desc = arg_data.get('desc', '( no description )') + desc = textwrap.fill( + desc, + initial_indent='# ', + subsequent_indent='# ', + width=80, + drop_whitespace=False) + + # Document (each|option|like|this) + if 'options' in arg_data: + arg_options = ' ({})'.format('|'.join(arg_data['options'])) + else: + arg_options = '' + + # Add usage sample + arg_use = '# --build-arg {}={}{}'.format(arg, + arg_data.get('default', '(unset)'), + arg_options) + lines.extend([arg_use, desc]) + + return '\n'.join(lines) + + +def construct_contents(partial_specs, image_spec): + """Assemble the dockerfile contents for an image spec. + + It assembles a concrete list of partial references into a single, large + string. + Also expands argument defaults, so that the resulting Dockerfile doesn't have + to be configured with --build-arg=... every time. That is, any ARG directive + will be updated with a new default value. + + Args: + partial_specs: The dict from spec.yml["partials"]. + image_spec: One of the dict values from spec.yml["images"]. + + Returns: + A string containing a valid Dockerfile based on the partials listed in + image_spec. + """ + processed_partial_strings = [] + for partial_name in image_spec['partials']: + # Apply image arg-defaults to existing arg defaults + partial_spec = copy.deepcopy(partial_specs[partial_name]) + args = partial_spec.get('args', dict()) + for k_v in image_spec.get('arg-defaults', []): + arg, value = list(k_v.items())[0] + if arg in args: + args[arg]['default'] = value + + # Read partial file contents + filename = partial_spec.get('file', partial_name) + partial_path = os.path.join(FLAGS.partial_dir, + '{}.partial.Dockerfile'.format(filename)) + with open(partial_path, 'r') as f_partial: + partial_contents = f_partial.read() + + # Replace ARG FOO=BAR with ARG FOO=[new-default] + for arg, arg_data in args.items(): + if 'default' in arg_data and arg_data['default']: + default = '={}'.format(arg_data['default']) + else: + default = '' + partial_contents = re.sub(r'ARG {}.*'.format(arg), 'ARG {}{}'.format( + arg, default), partial_contents) + + # Store updated partial contents + processed_partial_strings.append(partial_contents) + + # Join everything together + return '\n'.join(processed_partial_strings) + + +def mkdir_p(path): + """Create a directory and its parents, even if it already exists.""" + try: + os.makedirs(path) + except OSError as e: + if e.errno != errno.EEXIST: + raise + + +def construct_documentation(header, partial_specs, image_spec): + """Assemble all of the documentation for a single dockerfile. + + Builds explanations of included partials and available build args. + + Args: + header: The string from spec.yml["header"]; will be commented and wrapped. + partial_specs: The dict from spec.yml["partials"]. + image_spec: The spec for the dockerfile being built. + + Returns: + A string containing a commented header that documents the contents of the + dockerfile. + + """ + # Comment and wrap header and image description + commented_header = '\n'.join( + [('# ' + l).rstrip() for l in header.splitlines()]) + commented_desc = '\n'.join( + ['# ' + l for l in image_spec.get('desc', '').splitlines()]) + partial_descriptions = [] + + # Build documentation for each partial in the image + for partial in image_spec['partials']: + # Copy partial data for default args unique to this image + partial_spec = copy.deepcopy(partial_specs[partial]) + args = partial_spec.get('args', dict()) + + # Overwrite any existing arg defaults + for k_v in image_spec.get('arg-defaults', []): + arg, value = list(k_v.items())[0] + if arg in args: + args[arg]['default'] = value + + # Build the description from new args + partial_description = build_partial_description(partial_spec) + partial_descriptions.append(partial_description) + + contents = [commented_header, '#', commented_desc] + partial_descriptions + return '\n'.join(contents) + '\n' + + +def normalize_partial_args(partial_specs): + """Normalize the shorthand form of a partial's args specification. + + Turns this: + + partial: + args: + SOME_ARG: arg_value + + Into this: + + partial: + args: + SOME_ARG: + default: arg_value + + Args: + partial_specs: The dict from spec.yml["partials"]. This dict is modified in + place. + + Returns: + The modified contents of partial_specs. + + """ + for _, partial in partial_specs.items(): + args = partial.get('args', dict()) + for arg, value in args.items(): + if not isinstance(value, dict): + new_value = {'default': value} + args[arg] = new_value + + return partial_specs + + +def flatten_args_references(image_specs): + """Resolve all default-args in each image spec to a concrete dict. + + Turns this: + + example-image: + arg-defaults: + - MY_ARG: ARG_VALUE + + another-example: + arg-defaults: + - ANOTHER_ARG: ANOTHER_VALUE + - example_image + + Into this: + + example-image: + arg-defaults: + - MY_ARG: ARG_VALUE + + another-example: + arg-defaults: + - ANOTHER_ARG: ANOTHER_VALUE + - MY_ARG: ARG_VALUE + + Args: + image_specs: A dict of image_spec dicts; should be the contents of the + "images" key in the global spec.yaml. This dict is modified in place and + then returned. + + Returns: + The modified contents of image_specs. + """ + for _, image_spec in image_specs.items(): + too_deep = 0 + while str in map(type, image_spec.get('arg-defaults', [])) and too_deep < 5: + new_args = [] + for arg in image_spec['arg-defaults']: + if isinstance(arg, str): + new_args.extend(image_specs[arg]['arg-defaults']) + else: + new_args.append(arg) + + image_spec['arg-defaults'] = new_args + too_deep += 1 + + return image_specs + + +def flatten_partial_references(image_specs): + """Resolve all partial references in each image spec to a concrete list. + + Turns this: + + example-image: + partials: + - foo + + another-example: + partials: + - bar + - image: example-image + - bat + + Into this: + + example-image: + partials: + - foo + + another-example: + partials: + - bar + - foo + - bat + Args: + image_specs: A dict of image_spec dicts; should be the contents of the + "images" key in the global spec.yaml. This dict is modified in place and + then returned. + + Returns: + The modified contents of image_specs. + """ + for _, image_spec in image_specs.items(): + too_deep = 0 + while dict in map(type, image_spec['partials']) and too_deep < 5: + new_partials = [] + for partial in image_spec['partials']: + if isinstance(partial, str): + new_partials.append(partial) + else: + new_partials.extend(image_specs[partial['image']]['partials']) + + image_spec['partials'] = new_partials + too_deep += 1 + + return image_specs + + +def construct_dockerfiles(tf_spec): + """Generate a mapping of {"cpu": <cpu dockerfile contents>, ...}. + + Args: + tf_spec: The full spec.yml loaded as a python object. + + Returns: + A string:string dict of short names ("cpu-devel") to Dockerfile contents. + """ + names_to_contents = dict() + image_specs = tf_spec['images'] + image_specs = flatten_partial_references(image_specs) + image_specs = flatten_args_references(image_specs) + partial_specs = tf_spec['partials'] + partial_specs = normalize_partial_args(partial_specs) + + for name, image_spec in image_specs.items(): + if not image_spec.get('create-dockerfile', True): + continue + documentation = construct_documentation(tf_spec['header'], partial_specs, + image_spec) + contents = construct_contents(partial_specs, image_spec) + names_to_contents[name] = '\n'.join([documentation, contents]) + + return names_to_contents + + +def main(argv): + if len(argv) > 1: + raise app.UsageError('Unexpected command line args found: {}'.format(argv)) + + with open(FLAGS.spec_file, 'r') as spec_file: + tf_spec = yaml.load(spec_file) + + # Abort if spec.yaml is invalid + if FLAGS.validate: + schema = yaml.load(SCHEMA_TEXT) + v = TfDockerValidator(schema) + if not v.validate(tf_spec): + print('>> ERROR: {} is an invalid spec! The errors are:'.format( + FLAGS.spec_file)) + print(yaml.dump(v.errors, indent=2)) + exit(1) + else: + print('>> WARNING: Not validating {}'.format(FLAGS.spec_file)) + + # Generate mapping of { "cpu-devel": "<cpu-devel dockerfile contents>", ... } + names_to_contents = construct_dockerfiles(tf_spec) + + # Write each completed Dockerfile + if not FLAGS.dry_run: + print('>> Emptying destination dir "{}"'.format(FLAGS.output_dir)) + shutil.rmtree(FLAGS.output_dir, ignore_errors=True) + mkdir_p(FLAGS.output_dir) + else: + print('>> Skipping creation of {} (dry run)'.format(FLAGS.output_dir)) + for name, contents in names_to_contents.items(): + path = os.path.join(FLAGS.output_dir, name + '.Dockerfile') + if FLAGS.dry_run: + print('>> Skipping writing contents of {} (dry run)'.format(path)) + print(contents) + else: + mkdir_p(FLAGS.output_dir) + print('>> Writing {}'.format(path)) + with open(path, 'w') as f: + f.write(contents) + + +if __name__ == '__main__': + app.run(main) diff --git a/tensorflow/tools/dockerfiles/bashrc b/tensorflow/tools/dockerfiles/bashrc new file mode 100644 index 0000000000..48cacf20f6 --- /dev/null +++ b/tensorflow/tools/dockerfiles/bashrc @@ -0,0 +1,50 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== + +export PS1="\[\e[31m\]tf-docker\[\e[m\] \[\e[33m\]\w\[\e[m\] > " +export TERM=xterm-256color +alias grep="grep --color=auto" +alias ls="ls --color=auto" + +echo -e "\e[1;31m" +cat<<TF +________ _______________ +___ __/__________________________________ ____/__ /________ __ +__ / _ _ \_ __ \_ ___/ __ \_ ___/_ /_ __ /_ __ \_ | /| / / +_ / / __/ / / /(__ )/ /_/ / / _ __/ _ / / /_/ /_ |/ |/ / +/_/ \___//_/ /_//____/ \____//_/ /_/ /_/ \____/____/|__/ + +TF +echo -e "\e[0;33m" + +if [[ $EUID -eq 0 ]]; then + cat <<WARN +WARNING: You are running this container as root, which can cause new files in +mounted volumes to be created as the root user on your host machine. + +To avoid this, run the container by specifying your user's userid: + +$ docker run -u \$(id -u):\$(id -g) args... +WARN +else + cat <<EXPL +You are running this container as user with ID $(id -u) and group $(id -g), +which should map to the ID and group for your user on the Docker host. Great! +EXPL +fi + +# Turn off colors +echo -e "\e[m" diff --git a/tensorflow/tools/dockerfiles/dockerfiles/cpu-devel-jupyter.Dockerfile b/tensorflow/tools/dockerfiles/dockerfiles/cpu-devel-jupyter.Dockerfile new file mode 100644 index 0000000000..dbbad7d03a --- /dev/null +++ b/tensorflow/tools/dockerfiles/dockerfiles/cpu-devel-jupyter.Dockerfile @@ -0,0 +1,100 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================ +# +# THIS IS A GENERATED DOCKERFILE. +# +# This file was assembled from multiple pieces, whose use is documented +# below. Please refer to the the TensorFlow dockerfiles documentation for +# more information. Build args are documented as their default value. +# +# Ubuntu-based, CPU-only environment for developing changes for TensorFlow, with Jupyter included. +# +# Start from Ubuntu, with TF development packages (no GPU support) +# --build-arg UBUNTU_VERSION=16.04 +# ( no description ) +# +# Python is required for TensorFlow and other libraries. +# --build-arg USE_PYTHON_3_NOT_2=True +# Install python 3 over Python 2 +# +# Install the latest version of Bazel and Python development tools. +# +# Configure TensorFlow's shell prompt and login tools. +# +# Launch Jupyter on execution instead of a bash prompt. + +ARG UBUNTU_VERSION=16.04 +FROM ubuntu:${UBUNTU_VERSION} + +RUN apt-get update && apt-get install -y --no-install-recommends \ + build-essential \ + curl \ + git \ + libcurl3-dev \ + libfreetype6-dev \ + libhdf5-serial-dev \ + libpng12-dev \ + libzmq3-dev \ + pkg-config \ + python-dev \ + rsync \ + software-properties-common \ + unzip \ + zip \ + zlib1g-dev \ + openjdk-8-jdk \ + openjdk-8-jre-headless \ + && \ + apt-get clean && \ + rm -rf /var/lib/apt/lists/* + +ARG USE_PYTHON_3_NOT_2=True +ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3} +ARG PYTHON=python${_PY_SUFFIX} +ARG PIP=pip${_PY_SUFFIX} + +RUN apt-get update && apt-get install -y \ + ${PYTHON} \ + ${PYTHON}-pip + +RUN ${PIP} install --upgrade \ + pip \ + setuptools + +RUN apt-get update && apt-get install -y \ + build-essential \ + curl \ + git \ + openjdk-8-jdk \ + ${PYTHON}-dev \ + swig + +# Install bazel +RUN echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | tee /etc/apt/sources.list.d/bazel.list && \ + curl https://bazel.build/bazel-release.pub.gpg | apt-key add - && \ + apt-get update && \ + apt-get install -y bazel + +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc + +RUN ${PIP} install jupyter + +RUN mkdir /notebooks && chmod a+rwx /notebooks +RUN mkdir /.local && chmod a+rwx /.local +WORKDIR /notebooks +EXPOSE 8888 + +CMD ["bash", "-c", "source /etc/bash.bashrc && jupyter notebook --notebook-dir=/notebooks --ip 0.0.0.0 --no-browser --allow-root"] diff --git a/tensorflow/tools/dockerfiles/dockerfiles/cpu-devel.Dockerfile b/tensorflow/tools/dockerfiles/dockerfiles/cpu-devel.Dockerfile new file mode 100644 index 0000000000..160d7c02e2 --- /dev/null +++ b/tensorflow/tools/dockerfiles/dockerfiles/cpu-devel.Dockerfile @@ -0,0 +1,89 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================ +# +# THIS IS A GENERATED DOCKERFILE. +# +# This file was assembled from multiple pieces, whose use is documented +# below. Please refer to the the TensorFlow dockerfiles documentation for +# more information. Build args are documented as their default value. +# +# Ubuntu-based, CPU-only environment for developing changes for TensorFlow. +# +# Start from Ubuntu, with TF development packages (no GPU support) +# --build-arg UBUNTU_VERSION=16.04 +# ( no description ) +# +# Python is required for TensorFlow and other libraries. +# --build-arg USE_PYTHON_3_NOT_2=True +# Install python 3 over Python 2 +# +# Install the latest version of Bazel and Python development tools. +# +# Configure TensorFlow's shell prompt and login tools. + +ARG UBUNTU_VERSION=16.04 +FROM ubuntu:${UBUNTU_VERSION} + +RUN apt-get update && apt-get install -y --no-install-recommends \ + build-essential \ + curl \ + git \ + libcurl3-dev \ + libfreetype6-dev \ + libhdf5-serial-dev \ + libpng12-dev \ + libzmq3-dev \ + pkg-config \ + python-dev \ + rsync \ + software-properties-common \ + unzip \ + zip \ + zlib1g-dev \ + openjdk-8-jdk \ + openjdk-8-jre-headless \ + && \ + apt-get clean && \ + rm -rf /var/lib/apt/lists/* + +ARG USE_PYTHON_3_NOT_2=True +ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3} +ARG PYTHON=python${_PY_SUFFIX} +ARG PIP=pip${_PY_SUFFIX} + +RUN apt-get update && apt-get install -y \ + ${PYTHON} \ + ${PYTHON}-pip + +RUN ${PIP} install --upgrade \ + pip \ + setuptools + +RUN apt-get update && apt-get install -y \ + build-essential \ + curl \ + git \ + openjdk-8-jdk \ + ${PYTHON}-dev \ + swig + +# Install bazel +RUN echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | tee /etc/apt/sources.list.d/bazel.list && \ + curl https://bazel.build/bazel-release.pub.gpg | apt-key add - && \ + apt-get update && \ + apt-get install -y bazel + +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc diff --git a/tensorflow/tools/dockerfiles/dockerfiles/cpu-jupyter.Dockerfile b/tensorflow/tools/dockerfiles/dockerfiles/cpu-jupyter.Dockerfile new file mode 100644 index 0000000000..8d5d653ab7 --- /dev/null +++ b/tensorflow/tools/dockerfiles/dockerfiles/cpu-jupyter.Dockerfile @@ -0,0 +1,69 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================ +# +# THIS IS A GENERATED DOCKERFILE. +# +# This file was assembled from multiple pieces, whose use is documented +# below. Please refer to the the TensorFlow dockerfiles documentation for +# more information. Build args are documented as their default value. +# +# Ubuntu-based, CPU-only environment for using TensorFlow, with Jupyter included. +# +# Start from Ubuntu (no GPU support) +# --build-arg UBUNTU_VERSION=16.04 +# ( no description ) +# +# Python is required for TensorFlow and other libraries. +# --build-arg USE_PYTHON_3_NOT_2=True +# Install python 3 over Python 2 +# +# Install the TensorFlow Python package. +# --build-arg TF_PACKAGE=tensorflow (tensorflow|tensorflow-gpu|tf-nightly|tf-nightly-gpu) +# The specific TensorFlow Python package to install +# +# Configure TensorFlow's shell prompt and login tools. +# +# Launch Jupyter on execution instead of a bash prompt. + +ARG UBUNTU_VERSION=16.04 +FROM ubuntu:${UBUNTU_VERSION} + +ARG USE_PYTHON_3_NOT_2=True +ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3} +ARG PYTHON=python${_PY_SUFFIX} +ARG PIP=pip${_PY_SUFFIX} + +RUN apt-get update && apt-get install -y \ + ${PYTHON} \ + ${PYTHON}-pip + +RUN ${PIP} install --upgrade \ + pip \ + setuptools + +ARG TF_PACKAGE=tensorflow +RUN ${PIP} install ${TF_PACKAGE} + +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc + +RUN ${PIP} install jupyter + +RUN mkdir /notebooks && chmod a+rwx /notebooks +RUN mkdir /.local && chmod a+rwx /.local +WORKDIR /notebooks +EXPOSE 8888 + +CMD ["bash", "-c", "source /etc/bash.bashrc && jupyter notebook --notebook-dir=/notebooks --ip 0.0.0.0 --no-browser --allow-root"] diff --git a/tensorflow/tools/dockerfiles/dockerfiles/cpu.Dockerfile b/tensorflow/tools/dockerfiles/dockerfiles/cpu.Dockerfile new file mode 100644 index 0000000000..35c41b49fd --- /dev/null +++ b/tensorflow/tools/dockerfiles/dockerfiles/cpu.Dockerfile @@ -0,0 +1,58 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================ +# +# THIS IS A GENERATED DOCKERFILE. +# +# This file was assembled from multiple pieces, whose use is documented +# below. Please refer to the the TensorFlow dockerfiles documentation for +# more information. Build args are documented as their default value. +# +# Ubuntu-based, CPU-only environment for using TensorFlow +# +# Start from Ubuntu (no GPU support) +# --build-arg UBUNTU_VERSION=16.04 +# ( no description ) +# +# Python is required for TensorFlow and other libraries. +# --build-arg USE_PYTHON_3_NOT_2=True +# Install python 3 over Python 2 +# +# Install the TensorFlow Python package. +# --build-arg TF_PACKAGE=tensorflow (tensorflow|tensorflow-gpu|tf-nightly|tf-nightly-gpu) +# The specific TensorFlow Python package to install +# +# Configure TensorFlow's shell prompt and login tools. + +ARG UBUNTU_VERSION=16.04 +FROM ubuntu:${UBUNTU_VERSION} + +ARG USE_PYTHON_3_NOT_2=True +ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3} +ARG PYTHON=python${_PY_SUFFIX} +ARG PIP=pip${_PY_SUFFIX} + +RUN apt-get update && apt-get install -y \ + ${PYTHON} \ + ${PYTHON}-pip + +RUN ${PIP} install --upgrade \ + pip \ + setuptools + +ARG TF_PACKAGE=tensorflow +RUN ${PIP} install ${TF_PACKAGE} + +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc diff --git a/tensorflow/tools/dockerfiles/dockerfiles/nvidia-devel-jupyter.Dockerfile b/tensorflow/tools/dockerfiles/dockerfiles/nvidia-devel-jupyter.Dockerfile new file mode 100644 index 0000000000..0f5fedf2fe --- /dev/null +++ b/tensorflow/tools/dockerfiles/dockerfiles/nvidia-devel-jupyter.Dockerfile @@ -0,0 +1,120 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================ +# +# THIS IS A GENERATED DOCKERFILE. +# +# This file was assembled from multiple pieces, whose use is documented +# below. Please refer to the the TensorFlow dockerfiles documentation for +# more information. Build args are documented as their default value. +# +# Ubuntu-based, Nvidia-GPU-enabled environment for developing changes for TensorFlow, with Jupyter included. +# +# Start from Nvidia's Ubuntu base image with CUDA and CuDNN, with TF development +# packages. +# --build-arg UBUNTU_VERSION=16.04 +# ( no description ) +# +# Python is required for TensorFlow and other libraries. +# --build-arg USE_PYTHON_3_NOT_2=True +# Install python 3 over Python 2 +# +# Install the latest version of Bazel and Python development tools. +# +# Configure TensorFlow's shell prompt and login tools. +# +# Launch Jupyter on execution instead of a bash prompt. + +ARG UBUNTU_VERSION=16.04 +FROM nvidia/cuda:9.0-base-ubuntu${UBUNTU_VERSION} + +RUN apt-get update && apt-get install -y --no-install-recommends \ + build-essential \ + cuda-command-line-tools-9-0 \ + cuda-cublas-dev-9-0 \ + cuda-cudart-dev-9-0 \ + cuda-cufft-dev-9-0 \ + cuda-curand-dev-9-0 \ + cuda-cusolver-dev-9-0 \ + cuda-cusparse-dev-9-0 \ + curl \ + git \ + libcudnn7=7.1.4.18-1+cuda9.0 \ + libcudnn7-dev=7.1.4.18-1+cuda9.0 \ + libnccl2=2.2.13-1+cuda9.0 \ + libnccl-dev=2.2.13-1+cuda9.0 \ + libcurl3-dev \ + libfreetype6-dev \ + libhdf5-serial-dev \ + libpng12-dev \ + libzmq3-dev \ + pkg-config \ + rsync \ + software-properties-common \ + unzip \ + zip \ + zlib1g-dev \ + wget \ + && \ + rm -rf /var/lib/apt/lists/* && \ + find /usr/local/cuda-9.0/lib64/ -type f -name 'lib*_static.a' -not -name 'libcudart_static.a' -delete && \ + rm /usr/lib/x86_64-linux-gnu/libcudnn_static_v7.a + +# Link NCCL libray and header where the build script expects them. +RUN mkdir /usr/local/cuda-9.0/lib && \ + ln -s /usr/lib/x86_64-linux-gnu/libnccl.so.2 /usr/local/cuda/lib/libnccl.so.2 && \ + ln -s /usr/include/nccl.h /usr/local/cuda/include/nccl.h + +# TODO(tobyboyd): Remove after license is excluded from BUILD file. +RUN gunzip /usr/share/doc/libnccl2/NCCL-SLA.txt.gz && \ + cp /usr/share/doc/libnccl2/NCCL-SLA.txt /usr/local/cuda/ + +ARG USE_PYTHON_3_NOT_2=True +ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3} +ARG PYTHON=python${_PY_SUFFIX} +ARG PIP=pip${_PY_SUFFIX} + +RUN apt-get update && apt-get install -y \ + ${PYTHON} \ + ${PYTHON}-pip + +RUN ${PIP} install --upgrade \ + pip \ + setuptools + +RUN apt-get update && apt-get install -y \ + build-essential \ + curl \ + git \ + openjdk-8-jdk \ + ${PYTHON}-dev \ + swig + +# Install bazel +RUN echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | tee /etc/apt/sources.list.d/bazel.list && \ + curl https://bazel.build/bazel-release.pub.gpg | apt-key add - && \ + apt-get update && \ + apt-get install -y bazel + +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc + +RUN ${PIP} install jupyter + +RUN mkdir /notebooks && chmod a+rwx /notebooks +RUN mkdir /.local && chmod a+rwx /.local +WORKDIR /notebooks +EXPOSE 8888 + +CMD ["bash", "-c", "source /etc/bash.bashrc && jupyter notebook --notebook-dir=/notebooks --ip 0.0.0.0 --no-browser --allow-root"] diff --git a/tensorflow/tools/dockerfiles/dockerfiles/nvidia-devel.Dockerfile b/tensorflow/tools/dockerfiles/dockerfiles/nvidia-devel.Dockerfile new file mode 100644 index 0000000000..a6e280082e --- /dev/null +++ b/tensorflow/tools/dockerfiles/dockerfiles/nvidia-devel.Dockerfile @@ -0,0 +1,109 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================ +# +# THIS IS A GENERATED DOCKERFILE. +# +# This file was assembled from multiple pieces, whose use is documented +# below. Please refer to the the TensorFlow dockerfiles documentation for +# more information. Build args are documented as their default value. +# +# Ubuntu-based, Nvidia-GPU-enabled environment for developing changes for TensorFlow. +# +# Start from Nvidia's Ubuntu base image with CUDA and CuDNN, with TF development +# packages. +# --build-arg UBUNTU_VERSION=16.04 +# ( no description ) +# +# Python is required for TensorFlow and other libraries. +# --build-arg USE_PYTHON_3_NOT_2=True +# Install python 3 over Python 2 +# +# Install the latest version of Bazel and Python development tools. +# +# Configure TensorFlow's shell prompt and login tools. + +ARG UBUNTU_VERSION=16.04 +FROM nvidia/cuda:9.0-base-ubuntu${UBUNTU_VERSION} + +RUN apt-get update && apt-get install -y --no-install-recommends \ + build-essential \ + cuda-command-line-tools-9-0 \ + cuda-cublas-dev-9-0 \ + cuda-cudart-dev-9-0 \ + cuda-cufft-dev-9-0 \ + cuda-curand-dev-9-0 \ + cuda-cusolver-dev-9-0 \ + cuda-cusparse-dev-9-0 \ + curl \ + git \ + libcudnn7=7.1.4.18-1+cuda9.0 \ + libcudnn7-dev=7.1.4.18-1+cuda9.0 \ + libnccl2=2.2.13-1+cuda9.0 \ + libnccl-dev=2.2.13-1+cuda9.0 \ + libcurl3-dev \ + libfreetype6-dev \ + libhdf5-serial-dev \ + libpng12-dev \ + libzmq3-dev \ + pkg-config \ + rsync \ + software-properties-common \ + unzip \ + zip \ + zlib1g-dev \ + wget \ + && \ + rm -rf /var/lib/apt/lists/* && \ + find /usr/local/cuda-9.0/lib64/ -type f -name 'lib*_static.a' -not -name 'libcudart_static.a' -delete && \ + rm /usr/lib/x86_64-linux-gnu/libcudnn_static_v7.a + +# Link NCCL libray and header where the build script expects them. +RUN mkdir /usr/local/cuda-9.0/lib && \ + ln -s /usr/lib/x86_64-linux-gnu/libnccl.so.2 /usr/local/cuda/lib/libnccl.so.2 && \ + ln -s /usr/include/nccl.h /usr/local/cuda/include/nccl.h + +# TODO(tobyboyd): Remove after license is excluded from BUILD file. +RUN gunzip /usr/share/doc/libnccl2/NCCL-SLA.txt.gz && \ + cp /usr/share/doc/libnccl2/NCCL-SLA.txt /usr/local/cuda/ + +ARG USE_PYTHON_3_NOT_2=True +ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3} +ARG PYTHON=python${_PY_SUFFIX} +ARG PIP=pip${_PY_SUFFIX} + +RUN apt-get update && apt-get install -y \ + ${PYTHON} \ + ${PYTHON}-pip + +RUN ${PIP} install --upgrade \ + pip \ + setuptools + +RUN apt-get update && apt-get install -y \ + build-essential \ + curl \ + git \ + openjdk-8-jdk \ + ${PYTHON}-dev \ + swig + +# Install bazel +RUN echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | tee /etc/apt/sources.list.d/bazel.list && \ + curl https://bazel.build/bazel-release.pub.gpg | apt-key add - && \ + apt-get update && \ + apt-get install -y bazel + +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc diff --git a/tensorflow/tools/dockerfiles/dockerfiles/nvidia-jupyter.Dockerfile b/tensorflow/tools/dockerfiles/dockerfiles/nvidia-jupyter.Dockerfile new file mode 100644 index 0000000000..f1799113b1 --- /dev/null +++ b/tensorflow/tools/dockerfiles/dockerfiles/nvidia-jupyter.Dockerfile @@ -0,0 +1,90 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================ +# +# THIS IS A GENERATED DOCKERFILE. +# +# This file was assembled from multiple pieces, whose use is documented +# below. Please refer to the the TensorFlow dockerfiles documentation for +# more information. Build args are documented as their default value. +# +# Ubuntu-based, Nvidia-GPU-enabled environment for using TensorFlow, with Jupyter included. +# +# NVIDIA with CUDA and CuDNN, no dev stuff +# --build-arg UBUNTU_VERSION=16.04 +# ( no description ) +# +# Python is required for TensorFlow and other libraries. +# --build-arg USE_PYTHON_3_NOT_2=True +# Install python 3 over Python 2 +# +# Install the TensorFlow Python package. +# --build-arg TF_PACKAGE=tensorflow-gpu (tensorflow|tensorflow-gpu|tf-nightly|tf-nightly-gpu) +# The specific TensorFlow Python package to install +# +# Configure TensorFlow's shell prompt and login tools. +# +# Launch Jupyter on execution instead of a bash prompt. + +FROM nvidia/cuda:9.0-base-ubuntu16.04 + +# Pick up some TF dependencies +RUN apt-get update && apt-get install -y --no-install-recommends \ + build-essential \ + cuda-command-line-tools-9-0 \ + cuda-cublas-9-0 \ + cuda-cufft-9-0 \ + cuda-curand-9-0 \ + cuda-cusolver-9-0 \ + cuda-cusparse-9-0 \ + libcudnn7=7.1.4.18-1+cuda9.0 \ + libnccl2=2.2.13-1+cuda9.0 \ + libfreetype6-dev \ + libhdf5-serial-dev \ + libpng12-dev \ + libzmq3-dev \ + pkg-config \ + software-properties-common \ + unzip \ + && \ + apt-get clean && \ + rm -rf /var/lib/apt/lists/* + +ARG USE_PYTHON_3_NOT_2=True +ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3} +ARG PYTHON=python${_PY_SUFFIX} +ARG PIP=pip${_PY_SUFFIX} + +RUN apt-get update && apt-get install -y \ + ${PYTHON} \ + ${PYTHON}-pip + +RUN ${PIP} install --upgrade \ + pip \ + setuptools + +ARG TF_PACKAGE=tensorflow-gpu +RUN ${PIP} install ${TF_PACKAGE} + +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc + +RUN ${PIP} install jupyter + +RUN mkdir /notebooks && chmod a+rwx /notebooks +RUN mkdir /.local && chmod a+rwx /.local +WORKDIR /notebooks +EXPOSE 8888 + +CMD ["bash", "-c", "source /etc/bash.bashrc && jupyter notebook --notebook-dir=/notebooks --ip 0.0.0.0 --no-browser --allow-root"] diff --git a/tensorflow/tools/dockerfiles/dockerfiles/nvidia.Dockerfile b/tensorflow/tools/dockerfiles/dockerfiles/nvidia.Dockerfile new file mode 100644 index 0000000000..690eb68b22 --- /dev/null +++ b/tensorflow/tools/dockerfiles/dockerfiles/nvidia.Dockerfile @@ -0,0 +1,79 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================ +# +# THIS IS A GENERATED DOCKERFILE. +# +# This file was assembled from multiple pieces, whose use is documented +# below. Please refer to the the TensorFlow dockerfiles documentation for +# more information. Build args are documented as their default value. +# +# Ubuntu-based, Nvidia-GPU-enabled environment for using TensorFlow. +# +# NVIDIA with CUDA and CuDNN, no dev stuff +# --build-arg UBUNTU_VERSION=16.04 +# ( no description ) +# +# Python is required for TensorFlow and other libraries. +# --build-arg USE_PYTHON_3_NOT_2=True +# Install python 3 over Python 2 +# +# Install the TensorFlow Python package. +# --build-arg TF_PACKAGE=tensorflow-gpu (tensorflow|tensorflow-gpu|tf-nightly|tf-nightly-gpu) +# The specific TensorFlow Python package to install +# +# Configure TensorFlow's shell prompt and login tools. + +FROM nvidia/cuda:9.0-base-ubuntu16.04 + +# Pick up some TF dependencies +RUN apt-get update && apt-get install -y --no-install-recommends \ + build-essential \ + cuda-command-line-tools-9-0 \ + cuda-cublas-9-0 \ + cuda-cufft-9-0 \ + cuda-curand-9-0 \ + cuda-cusolver-9-0 \ + cuda-cusparse-9-0 \ + libcudnn7=7.1.4.18-1+cuda9.0 \ + libnccl2=2.2.13-1+cuda9.0 \ + libfreetype6-dev \ + libhdf5-serial-dev \ + libpng12-dev \ + libzmq3-dev \ + pkg-config \ + software-properties-common \ + unzip \ + && \ + apt-get clean && \ + rm -rf /var/lib/apt/lists/* + +ARG USE_PYTHON_3_NOT_2=True +ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3} +ARG PYTHON=python${_PY_SUFFIX} +ARG PIP=pip${_PY_SUFFIX} + +RUN apt-get update && apt-get install -y \ + ${PYTHON} \ + ${PYTHON}-pip + +RUN ${PIP} install --upgrade \ + pip \ + setuptools + +ARG TF_PACKAGE=tensorflow-gpu +RUN ${PIP} install ${TF_PACKAGE} + +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc diff --git a/tensorflow/tools/dockerfiles/partials/bazel.partial.Dockerfile b/tensorflow/tools/dockerfiles/partials/bazel.partial.Dockerfile new file mode 100644 index 0000000000..b08d8bdd14 --- /dev/null +++ b/tensorflow/tools/dockerfiles/partials/bazel.partial.Dockerfile @@ -0,0 +1,13 @@ +RUN apt-get update && apt-get install -y \ + build-essential \ + curl \ + git \ + openjdk-8-jdk \ + ${PYTHON}-dev \ + swig + +# Install bazel +RUN echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | tee /etc/apt/sources.list.d/bazel.list && \ + curl https://bazel.build/bazel-release.pub.gpg | apt-key add - && \ + apt-get update && \ + apt-get install -y bazel diff --git a/tensorflow/tools/dockerfiles/partials/jupyter.partial.Dockerfile b/tensorflow/tools/dockerfiles/partials/jupyter.partial.Dockerfile new file mode 100644 index 0000000000..2c9b9f3f9a --- /dev/null +++ b/tensorflow/tools/dockerfiles/partials/jupyter.partial.Dockerfile @@ -0,0 +1,8 @@ +RUN ${PIP} install jupyter + +RUN mkdir /notebooks && chmod a+rwx /notebooks +RUN mkdir /.local && chmod a+rwx /.local +WORKDIR /notebooks +EXPOSE 8888 + +CMD ["bash", "-c", "source /etc/bash.bashrc && jupyter notebook --notebook-dir=/notebooks --ip 0.0.0.0 --no-browser --allow-root"] diff --git a/tensorflow/tools/dockerfiles/partials/nvidia-devel.partial.Dockerfile b/tensorflow/tools/dockerfiles/partials/nvidia-devel.partial.Dockerfile new file mode 100644 index 0000000000..f31b695e77 --- /dev/null +++ b/tensorflow/tools/dockerfiles/partials/nvidia-devel.partial.Dockerfile @@ -0,0 +1,43 @@ +ARG UBUNTU_VERSION=16.04 +FROM nvidia/cuda:9.0-base-ubuntu${UBUNTU_VERSION} + +RUN apt-get update && apt-get install -y --no-install-recommends \ + build-essential \ + cuda-command-line-tools-9-0 \ + cuda-cublas-dev-9-0 \ + cuda-cudart-dev-9-0 \ + cuda-cufft-dev-9-0 \ + cuda-curand-dev-9-0 \ + cuda-cusolver-dev-9-0 \ + cuda-cusparse-dev-9-0 \ + curl \ + git \ + libcudnn7=7.1.4.18-1+cuda9.0 \ + libcudnn7-dev=7.1.4.18-1+cuda9.0 \ + libnccl2=2.2.13-1+cuda9.0 \ + libnccl-dev=2.2.13-1+cuda9.0 \ + libcurl3-dev \ + libfreetype6-dev \ + libhdf5-serial-dev \ + libpng12-dev \ + libzmq3-dev \ + pkg-config \ + rsync \ + software-properties-common \ + unzip \ + zip \ + zlib1g-dev \ + wget \ + && \ + rm -rf /var/lib/apt/lists/* && \ + find /usr/local/cuda-9.0/lib64/ -type f -name 'lib*_static.a' -not -name 'libcudart_static.a' -delete && \ + rm /usr/lib/x86_64-linux-gnu/libcudnn_static_v7.a + +# Link NCCL libray and header where the build script expects them. +RUN mkdir /usr/local/cuda-9.0/lib && \ + ln -s /usr/lib/x86_64-linux-gnu/libnccl.so.2 /usr/local/cuda/lib/libnccl.so.2 && \ + ln -s /usr/include/nccl.h /usr/local/cuda/include/nccl.h + +# TODO(tobyboyd): Remove after license is excluded from BUILD file. +RUN gunzip /usr/share/doc/libnccl2/NCCL-SLA.txt.gz && \ + cp /usr/share/doc/libnccl2/NCCL-SLA.txt /usr/local/cuda/ diff --git a/tensorflow/tools/dockerfiles/partials/nvidia.partial.Dockerfile b/tensorflow/tools/dockerfiles/partials/nvidia.partial.Dockerfile new file mode 100644 index 0000000000..13d865b9d4 --- /dev/null +++ b/tensorflow/tools/dockerfiles/partials/nvidia.partial.Dockerfile @@ -0,0 +1,23 @@ +FROM nvidia/cuda:9.0-base-ubuntu16.04 + +# Pick up some TF dependencies +RUN apt-get update && apt-get install -y --no-install-recommends \ + build-essential \ + cuda-command-line-tools-9-0 \ + cuda-cublas-9-0 \ + cuda-cufft-9-0 \ + cuda-curand-9-0 \ + cuda-cusolver-9-0 \ + cuda-cusparse-9-0 \ + libcudnn7=7.1.4.18-1+cuda9.0 \ + libnccl2=2.2.13-1+cuda9.0 \ + libfreetype6-dev \ + libhdf5-serial-dev \ + libpng12-dev \ + libzmq3-dev \ + pkg-config \ + software-properties-common \ + unzip \ + && \ + apt-get clean && \ + rm -rf /var/lib/apt/lists/* diff --git a/tensorflow/tools/dockerfiles/partials/python.partial.Dockerfile b/tensorflow/tools/dockerfiles/partials/python.partial.Dockerfile new file mode 100644 index 0000000000..6f346236a5 --- /dev/null +++ b/tensorflow/tools/dockerfiles/partials/python.partial.Dockerfile @@ -0,0 +1,12 @@ +ARG USE_PYTHON_3_NOT_2 +ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3} +ARG PYTHON=python${_PY_SUFFIX} +ARG PIP=pip${_PY_SUFFIX} + +RUN apt-get update && apt-get install -y \ + ${PYTHON} \ + ${PYTHON}-pip + +RUN ${PIP} install --upgrade \ + pip \ + setuptools diff --git a/tensorflow/tools/dockerfiles/partials/shell.partial.Dockerfile b/tensorflow/tools/dockerfiles/partials/shell.partial.Dockerfile new file mode 100644 index 0000000000..d641a11b06 --- /dev/null +++ b/tensorflow/tools/dockerfiles/partials/shell.partial.Dockerfile @@ -0,0 +1,2 @@ +COPY bashrc /etc/bash.bashrc +RUN chmod a+rwx /etc/bash.bashrc diff --git a/tensorflow/tools/dockerfiles/partials/tensorflow.partial.Dockerfile b/tensorflow/tools/dockerfiles/partials/tensorflow.partial.Dockerfile new file mode 100644 index 0000000000..96e79547f0 --- /dev/null +++ b/tensorflow/tools/dockerfiles/partials/tensorflow.partial.Dockerfile @@ -0,0 +1,2 @@ +ARG TF_PACKAGE +RUN ${PIP} install ${TF_PACKAGE} diff --git a/tensorflow/tools/dockerfiles/partials/ubuntu-devel.partial.Dockerfile b/tensorflow/tools/dockerfiles/partials/ubuntu-devel.partial.Dockerfile new file mode 100644 index 0000000000..bc79272276 --- /dev/null +++ b/tensorflow/tools/dockerfiles/partials/ubuntu-devel.partial.Dockerfile @@ -0,0 +1,24 @@ +ARG UBUNTU_VERSION=16.04 +FROM ubuntu:${UBUNTU_VERSION} + +RUN apt-get update && apt-get install -y --no-install-recommends \ + build-essential \ + curl \ + git \ + libcurl3-dev \ + libfreetype6-dev \ + libhdf5-serial-dev \ + libpng12-dev \ + libzmq3-dev \ + pkg-config \ + python-dev \ + rsync \ + software-properties-common \ + unzip \ + zip \ + zlib1g-dev \ + openjdk-8-jdk \ + openjdk-8-jre-headless \ + && \ + apt-get clean && \ + rm -rf /var/lib/apt/lists/* diff --git a/tensorflow/tools/dockerfiles/partials/ubuntu.partial.Dockerfile b/tensorflow/tools/dockerfiles/partials/ubuntu.partial.Dockerfile new file mode 100644 index 0000000000..0a50735bf8 --- /dev/null +++ b/tensorflow/tools/dockerfiles/partials/ubuntu.partial.Dockerfile @@ -0,0 +1,2 @@ +ARG UBUNTU_VERSION=16.04 +FROM ubuntu:${UBUNTU_VERSION} diff --git a/tensorflow/tools/dockerfiles/spec.yml b/tensorflow/tools/dockerfiles/spec.yml new file mode 100644 index 0000000000..28bf9a55da --- /dev/null +++ b/tensorflow/tools/dockerfiles/spec.yml @@ -0,0 +1,195 @@ +# ====== +# HEADER +# ====== +# +# This is commented-out and prepended to each generated Dockerfile. +header: | + Copyright 2018 The TensorFlow Authors. All Rights Reserved. + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + + Unless required by applicable law or agreed to in writing, software + distributed under the License is distributed on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + See the License for the specific language governing permissions and + limitations under the License. + ============================================================================ + + THIS IS A GENERATED DOCKERFILE. + + This file was assembled from multiple pieces, whose use is documented + below. Please refer to the the TensorFlow dockerfiles documentation for + more information. Build args are documented as their default value. + +# ======== +# PARTIALS +# ======== +# +# Represent and document pieces of a Dockerfile. Spec: +# +# name: the name of the partial, is referenced from the images section +# desc: A description, inserted later into the Dockerfile +# file: Alternative file prefix, e.g. file.partial.Dockerfile. The default is +# the name of the partial. +# args: A dict of ARGs in the Dockerfile; each entry has the format +# ARG_NAME: VALUE where VALUE is one of: +# - a dict: +# desc: Documentation for the arg +# default: Default value for the arg; is written to the Dockerfile +# options: List of strings, part of documentation +# - a concrete value: the same as a dictionary with default: [value]. + +partials: + ubuntu: + desc: Start from Ubuntu (no GPU support) + args: + UBUNTU_VERSION: 16.04 + + ubuntu-devel: + desc: Start from Ubuntu, with TF development packages (no GPU support) + args: + UBUNTU_VERSION: 16.04 + + bazel: + desc: Install the latest version of Bazel and Python development tools. + + nvidia: + desc: NVIDIA with CUDA and CuDNN, no dev stuff + args: + UBUNTU_VERSION: 16.04 + + nvidia-devel: + desc: > + Start from Nvidia's Ubuntu base image with CUDA and CuDNN, with TF + development packages. + args: + UBUNTU_VERSION: 16.04 + + python: + desc: Python is required for TensorFlow and other libraries. + args: + USE_PYTHON_3_NOT_2: + default: true + desc: Install python 3 over Python 2 + + tensorflow: + desc: Install the TensorFlow Python package. + args: + TF_PACKAGE: + default: tensorflow + options: + - tensorflow + - tensorflow-gpu + - tf-nightly + - tf-nightly-gpu + desc: The specific TensorFlow Python package to install + shell: + desc: Configure TensorFlow's shell prompt and login tools. + jupyter: + desc: Launch Jupyter on execution instead of a bash prompt. + +# ====== +# IMAGES +# ====== +# +# Represent Dockerfiles. Spec: +# +# name: the name of the image, possibly referenced by other images +# desc: A description, inserted later into the Dockerfile +# create-dockerfile: Create a dockerfile based on this. Useful for creating +# extensible base images that don't need a file. Default is true. +# partials: List of VALUEs, where a VALUE is either: +# - the name of a partial, which inserts that partial into this image +# - image: [name of another image], which inserts the partials from that +# image into this image +# arg-defaults: List of VALUEs, where a VALUE is either: +# - ARG_NAME: VALUE, which sets the ARG_NAME to VALUE wherever it appears +# in this image's partials +# - [name of another image], which loads the default args from that image +images: + + nodev: + create-dockerfile: false + partials: + - python + - tensorflow + - shell + + dev: + create-dockerfile: false + partials: + - python + - bazel + - shell + + cpu: + desc: Ubuntu-based, CPU-only environment for using TensorFlow + partials: + - ubuntu + - image: nodev + + cpu-devel: + desc: > + Ubuntu-based, CPU-only environment for developing changes for + TensorFlow. + partials: + - ubuntu-devel + - image: dev + + nvidia: + desc: Ubuntu-based, Nvidia-GPU-enabled environment for using TensorFlow. + arg-defaults: + - TF_PACKAGE: tensorflow-gpu + partials: + - nvidia + - image: nodev + + nvidia-devel: + desc: > + Ubuntu-based, Nvidia-GPU-enabled environment for developing changes + for TensorFlow. + arg-defaults: + - TF_PACKAGE: tensorflow-gpu + partials: + - nvidia-devel + - image: dev + + cpu-jupyter: + desc: > + Ubuntu-based, CPU-only environment for using TensorFlow, with Jupyter + included. + partials: + - image: cpu + - jupyter + + cpu-devel-jupyter: + desc: > + Ubuntu-based, CPU-only environment for developing changes for + TensorFlow, with Jupyter included. + partials: + - image: cpu-devel + - jupyter + + nvidia-jupyter: + desc: > + Ubuntu-based, Nvidia-GPU-enabled environment for using TensorFlow, with + Jupyter included. + arg-defaults: + - nvidia + partials: + - image: nvidia + - jupyter + + nvidia-devel-jupyter: + desc: > + Ubuntu-based, Nvidia-GPU-enabled environment for developing changes for + TensorFlow, with Jupyter included. + arg-defaults: + - nvidia-devel + partials: + - image: nvidia-devel + - jupyter diff --git a/tensorflow/tools/docs/doc_controls_test.py b/tensorflow/tools/docs/doc_controls_test.py index 410342fb69..d5eb4ffc00 100644 --- a/tensorflow/tools/docs/doc_controls_test.py +++ b/tensorflow/tools/docs/doc_controls_test.py @@ -145,7 +145,7 @@ class DocControlsTest(googletest.TestCase): self.assertTrue( doc_controls.should_skip_class_attr(GrandChild, 'my_method')) - def testfor_subclass_implementers(self): + def test_for_subclass_implementers(self): class GrandParent(object): @@ -178,6 +178,43 @@ class DocControlsTest(googletest.TestCase): self.assertTrue( doc_controls.should_skip_class_attr(Grand2Child, 'my_method')) + def test_for_subclass_implementers_short_circuit(self): + + class GrandParent(object): + + @doc_controls.for_subclass_implementers + def my_method(self): + pass + + class Parent(GrandParent): + + def my_method(self): + pass + + class Child(Parent): + + @doc_controls.do_not_doc_inheritable + def my_method(self): + pass + + class GrandChild(Child): + + @doc_controls.for_subclass_implementers + def my_method(self): + pass + + class Grand2Child(Child): + pass + + self.assertFalse( + doc_controls.should_skip_class_attr(GrandParent, 'my_method')) + self.assertTrue(doc_controls.should_skip_class_attr(Parent, 'my_method')) + self.assertTrue(doc_controls.should_skip_class_attr(Child, 'my_method')) + self.assertFalse( + doc_controls.should_skip_class_attr(GrandChild, 'my_method')) + self.assertTrue( + doc_controls.should_skip_class_attr(Grand2Child, 'my_method')) + if __name__ == '__main__': googletest.main() diff --git a/tensorflow/tools/docs/generate.py b/tensorflow/tools/docs/generate.py index f96887e4c7..fc93085e3e 100644 --- a/tensorflow/tools/docs/generate.py +++ b/tensorflow/tools/docs/generate.py @@ -31,11 +31,6 @@ if __name__ == '__main__': doc_generator = generate_lib.DocGenerator() doc_generator.add_output_dir_argument() doc_generator.add_src_dir_argument() - doc_generator.argument_parser.add_argument( - '--site_api_path', - type=str, default='api_docs/python', - help='The path from the site-root to api_docs' - 'directory for this project') # This doc generator works on the TensorFlow codebase. Since this script lives # at tensorflow/tools/docs, and all code is defined somewhere inside diff --git a/tensorflow/tools/docs/generate_lib.py b/tensorflow/tools/docs/generate_lib.py index 9387042224..090cf48a07 100644 --- a/tensorflow/tools/docs/generate_lib.py +++ b/tensorflow/tools/docs/generate_lib.py @@ -22,6 +22,7 @@ import argparse import fnmatch import os import shutil +import tempfile import six @@ -57,7 +58,7 @@ def write_docs(output_dir, yaml_toc, root_title='TensorFlow', search_hints=True, - site_api_path=None): + site_api_path=''): """Write previously extracted docs to disk. Write a docs page for each symbol included in the indices of parser_config to @@ -75,8 +76,8 @@ def write_docs(output_dir, root_title: The title name for the root level index.md. search_hints: (bool) include meta-data search hints at the top of each output file. - site_api_path: Used to write the api-duplicates _redirects.yaml file. if - None (the default) the file is not generated. + site_api_path: The output path relative to the site root. Used in the + `_toc.yaml` and `_redirects.yaml` files. Raises: ValueError: if `output_dir` is not an absolute path @@ -111,9 +112,6 @@ def write_docs(output_dir, _is_free_function(py_object, full_name, parser_config.index)): continue - if doc_controls.should_skip(py_object): - continue - sitepath = os.path.join('api_docs/python', parser.documentation_path(full_name)[:-3]) @@ -160,22 +158,23 @@ def write_docs(output_dir, raise OSError( 'Cannot write documentation for %s to %s' % (full_name, directory)) - if site_api_path: - duplicates = parser_config.duplicates.get(full_name, []) - if not duplicates: - continue + duplicates = parser_config.duplicates.get(full_name, []) + if not duplicates: + continue - duplicates = [item for item in duplicates if item != full_name] + duplicates = [item for item in duplicates if item != full_name] - for dup in duplicates: - from_path = os.path.join(site_api_path, dup.replace('.', '/')) - to_path = os.path.join(site_api_path, full_name.replace('.', '/')) - redirects.append((from_path, to_path)) + for dup in duplicates: + from_path = os.path.join(site_api_path, dup.replace('.', '/')) + to_path = os.path.join(site_api_path, full_name.replace('.', '/')) + redirects.append(( + os.path.join('/', from_path), + os.path.join('/', to_path))) - if site_api_path and redirects: + if redirects: redirects = sorted(redirects) - template = ('- from: /{}\n' - ' to: /{}\n') + template = ('- from: {}\n' + ' to: {}\n') redirects = [template.format(f, t) for f, t in redirects] api_redirects_path = os.path.join(output_dir, '_redirects.yaml') with open(api_redirects_path, 'w') as redirect_file: @@ -210,7 +209,8 @@ def write_docs(output_dir, '- title: ' + title, ' section:', ' - title: Overview', - ' path: /TARGET_DOC_ROOT/VERSION/' + symbol_to_file[module]] + ' path: ' + os.path.join('/', site_api_path, + symbol_to_file[module])] header = ''.join([indent+line+'\n' for line in header]) f.write(header) @@ -221,7 +221,8 @@ def write_docs(output_dir, for full_name in symbols_in_module: item = [ ' - title: ' + full_name[len(module) + 1:], - ' path: /TARGET_DOC_ROOT/VERSION/' + symbol_to_file[full_name]] + ' path: ' + os.path.join('/', site_api_path, + symbol_to_file[full_name])] item = ''.join([indent+line+'\n' for line in item]) f.write(item) @@ -295,6 +296,15 @@ def _get_default_do_not_descend_map(): } +class DocControlsAwareCrawler(public_api.PublicAPIVisitor): + """A `docs_controls` aware API-crawler.""" + + def _is_private(self, path, name, obj): + if doc_controls.should_skip(obj): + return True + return super(DocControlsAwareCrawler, self)._is_private(path, name, obj) + + def extract(py_modules, private_map, do_not_descend_map, @@ -302,7 +312,7 @@ def extract(py_modules, """Extract docs from tf namespace and write them to disk.""" # Traverse the first module. visitor = visitor_cls(py_modules[0][0]) - api_visitor = public_api.PublicAPIVisitor(visitor) + api_visitor = DocControlsAwareCrawler(visitor) api_visitor.set_root_name(py_modules[0][0]) add_dict_to_dict(private_map, api_visitor.private_map) add_dict_to_dict(do_not_descend_map, api_visitor.do_not_descend_map) @@ -532,6 +542,12 @@ class DocGenerator(object): action='store_false', default=True) + self.argument_parser.add_argument( + '--site_api_path', + type=str, default='', + help='The path from the site-root to api_docs' + 'directory for this project') + def add_output_dir_argument(self): self.argument_parser.add_argument( '--output_dir', @@ -544,9 +560,9 @@ class DocGenerator(object): self.argument_parser.add_argument( '--src_dir', type=str, - default=None, - required=True, - help='Directory with the source docs.') + default=tempfile.mkdtemp(), + required=False, + help='Optional directory of source docs to add api_docs links to') def add_base_dir_argument(self, default_base_dir): self.argument_parser.add_argument( @@ -648,7 +664,7 @@ class DocGenerator(object): yaml_toc=self.yaml_toc, root_title=root_title, search_hints=getattr(flags, 'search_hints', True), - site_api_path=getattr(flags, 'site_api_path', None)) + site_api_path=getattr(flags, 'site_api_path', '')) # Replace all the @{} references in files under `FLAGS.src_dir` replace_refs(flags.src_dir, flags.output_dir, reference_resolver, '*.md') diff --git a/tensorflow/tools/docs/parser.py b/tensorflow/tools/docs/parser.py index 801c8bcb4a..8e444a15cf 100644 --- a/tensorflow/tools/docs/parser.py +++ b/tensorflow/tools/docs/parser.py @@ -1695,15 +1695,18 @@ class _Metadata(object): Attributes: name: The name of the page being described by the Metadata block. + version: The source version. """ - def __init__(self, name): + def __init__(self, name, version='stable'): """Creates a Metadata builder. Args: name: The name of the page being described by the Metadata block. + version: The source version. """ self.name = name + self.version = version self._content = [] def append(self, item): @@ -1720,6 +1723,7 @@ class _Metadata(object): parts = ['<div itemscope itemtype="%s">' % schema] parts.append('<meta itemprop="name" content="%s" />' % self.name) + parts.append('<meta itemprop="path" content="%s" />' % self.version) for item in self._content: parts.append('<meta itemprop="property" content="%s"/>' % item) diff --git a/tensorflow/tools/graph_transforms/fold_constants_lib.cc b/tensorflow/tools/graph_transforms/fold_constants_lib.cc index f858411876..6df2718e61 100644 --- a/tensorflow/tools/graph_transforms/fold_constants_lib.cc +++ b/tensorflow/tools/graph_transforms/fold_constants_lib.cc @@ -121,7 +121,7 @@ Status RewriteInputsAsPlaceholders(const TransformFuncContext& context, GraphDef* graph_def) { std::unordered_set<string> input_names; for (const string& input_name : context.input_names) { - input_names.insert(ParseTensorName(input_name).first.ToString()); + input_names.emplace(ParseTensorName(input_name).first); } for (NodeDef& node : *graph_def->mutable_node()) { diff --git a/tensorflow/tools/graph_transforms/fold_constants_lib.h b/tensorflow/tools/graph_transforms/fold_constants_lib.h index 8aefa6ae0f..0802ebb815 100644 --- a/tensorflow/tools/graph_transforms/fold_constants_lib.h +++ b/tensorflow/tools/graph_transforms/fold_constants_lib.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_TOOLS_GRAPH_TRANSFORMS_FOLD_CONSTANTS_H_ -#define TENSORFLOW_TOOLS_GRAPH_TRANSFORMS_FOLD_CONSTANTS_H_ +#ifndef TENSORFLOW_TOOLS_GRAPH_TRANSFORMS_FOLD_CONSTANTS_LIB_H_ +#define TENSORFLOW_TOOLS_GRAPH_TRANSFORMS_FOLD_CONSTANTS_LIB_H_ #include "tensorflow/core/framework/graph.pb.h" #include "tensorflow/core/lib/core/status.h" @@ -40,4 +40,4 @@ Status RemoveUnusedNodes(const GraphDef& input_graph_def, } // namespace graph_transforms } // namespace tensorflow -#endif // TENSORFLOW_TOOLS_GRAPH_TRANSFORMS_FOLD_CONSTANTS_H_ +#endif // TENSORFLOW_TOOLS_GRAPH_TRANSFORMS_FOLD_CONSTANTS_LIB_H_ diff --git a/tensorflow/tools/pip_package/BUILD b/tensorflow/tools/pip_package/BUILD index 00c1337b19..91c5cd094c 100644 --- a/tensorflow/tools/pip_package/BUILD +++ b/tensorflow/tools/pip_package/BUILD @@ -13,6 +13,10 @@ load("//third_party/mkl:build_defs.bzl", "if_mkl", "if_mkl_ml") load("//tensorflow:tensorflow.bzl", "if_cuda") load("@local_config_syslibs//:build_defs.bzl", "if_not_system_lib") load("//tensorflow/core:platform/default/build_config_root.bzl", "tf_additional_license_deps") +load( + "//third_party/ngraph:build_defs.bzl", + "if_ngraph", +) # This returns a list of headers of all public header libraries (e.g., # framework, lib), and all of the transitive dependencies of those @@ -71,6 +75,7 @@ COMMON_PIP_DEPS = [ "//tensorflow/contrib/constrained_optimization:constrained_optimization_pip", "//tensorflow/contrib/data/python/kernel_tests/serialization:dataset_serialization_test_base", "//tensorflow/contrib/data/python/kernel_tests:stats_dataset_test_base", + "//tensorflow/contrib/data/python/kernel_tests:test_utils", "//tensorflow/contrib/data/python/ops:contrib_op_loader", "//tensorflow/contrib/eager/python/examples:examples_pip", "//tensorflow/contrib/eager/python:evaluator", @@ -82,6 +87,7 @@ COMMON_PIP_DEPS = [ "//tensorflow/contrib/predictor:predictor_pip", "//tensorflow/contrib/proto:proto", "//tensorflow/contrib/receptive_field:receptive_field_pip", + "//tensorflow/contrib/rate:rate", "//tensorflow/contrib/rpc:rpc_pip", "//tensorflow/contrib/session_bundle:session_bundle_pip", "//tensorflow/contrib/signal:signal_py", @@ -200,14 +206,23 @@ filegroup( "@grpc//third_party/nanopb:LICENSE.txt", "@grpc//third_party/address_sorting:LICENSE", ], - ) + tf_additional_license_deps(), + ) + if_ngraph([ + "@ngraph//:LICENSE", + "@ngraph_tf//:LICENSE", + "@nlohmann_json_lib//:LICENSE.MIT", + ]) + tf_additional_license_deps(), ) sh_binary( name = "build_pip_package", srcs = ["build_pip_package.sh"], data = select({ - "//tensorflow:windows": [":simple_console_for_windows"], + "//tensorflow:windows": [ + ":simple_console_for_windows", + "//tensorflow/contrib/lite/python:interpreter_test_data", + "//tensorflow/contrib/lite/python:tflite_convert", + "//tensorflow/contrib/lite/toco/python:toco_from_protos", + ], "//conditions:default": COMMON_PIP_DEPS + [ ":simple_console", "//tensorflow/contrib/lite/python:interpreter_test_data", diff --git a/tensorflow/tools/pip_package/MANIFEST.in b/tensorflow/tools/pip_package/MANIFEST.in index 86c5e4776d..c4b4af93b8 100644 --- a/tensorflow/tools/pip_package/MANIFEST.in +++ b/tensorflow/tools/pip_package/MANIFEST.in @@ -1,5 +1,6 @@ include README recursive-include * *.py +recursive-include * *.pd recursive-include * *.so recursive-include * *.dll recursive-include * *.lib diff --git a/tensorflow/tools/pip_package/setup.py b/tensorflow/tools/pip_package/setup.py index 5e179079c5..61419f25ae 100644 --- a/tensorflow/tools/pip_package/setup.py +++ b/tensorflow/tools/pip_package/setup.py @@ -51,9 +51,9 @@ REQUIRED_PACKAGES = [ 'absl-py >= 0.1.6', 'astor >= 0.6.0', 'gast >= 0.2.0', - 'keras_applications == 1.0.4', - 'keras_preprocessing == 1.0.2', - 'numpy >= 1.13.3, <= 1.14.5', + 'keras_applications >= 1.0.5', + 'keras_preprocessing >= 1.0.3', + 'numpy >= 1.13.3', 'six >= 1.10.0', 'protobuf >= 3.6.0', 'setuptools <= 39.1.0', diff --git a/tensorflow/tools/proto_text/gen_proto_text_functions_lib.h b/tensorflow/tools/proto_text/gen_proto_text_functions_lib.h index e18d749cff..20aa605480 100644 --- a/tensorflow/tools/proto_text/gen_proto_text_functions_lib.h +++ b/tensorflow/tools/proto_text/gen_proto_text_functions_lib.h @@ -13,8 +13,8 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -#ifndef TENSORFLOW_CORE_UTIL_CREATE_PROTO_DEBUG_STRING_LIB_H_ -#define TENSORFLOW_CORE_UTIL_CREATE_PROTO_DEBUG_STRING_LIB_H_ +#ifndef TENSORFLOW_TOOLS_PROTO_TEXT_GEN_PROTO_TEXT_FUNCTIONS_LIB_H_ +#define TENSORFLOW_TOOLS_PROTO_TEXT_GEN_PROTO_TEXT_FUNCTIONS_LIB_H_ #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/types.h" @@ -50,4 +50,4 @@ ProtoTextFunctionCode GetProtoTextFunctionCode( } // namespace tensorflow -#endif // TENSORFLOW_CORE_UTIL_CREATE_PROTO_DEBUG_STRING_LIB_H_ +#endif // TENSORFLOW_TOOLS_PROTO_TEXT_GEN_PROTO_TEXT_FUNCTIONS_LIB_H_ diff --git a/tensorflow/workspace.bzl b/tensorflow/workspace.bzl index 1847335656..de38f8c0c2 100644..100755 --- a/tensorflow/workspace.bzl +++ b/tensorflow/workspace.bzl @@ -106,11 +106,11 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): tf_http_archive( name = "com_google_absl", urls = [ - "https://mirror.bazel.build/github.com/abseil/abseil-cpp/archive/9613678332c976568272c8f4a78631a29159271d.tar.gz", - "https://github.com/abseil/abseil-cpp/archive/9613678332c976568272c8f4a78631a29159271d.tar.gz", + "https://mirror.bazel.build/github.com/abseil/abseil-cpp/archive/f0f15c2778b0e4959244dd25e63f445a455870f5.tar.gz", + "https://github.com/abseil/abseil-cpp/archive/f0f15c2778b0e4959244dd25e63f445a455870f5.tar.gz", ], - sha256 = "1273a1434ced93bc3e703a48c5dced058c95e995c8c009e9bdcb24a69e2180e9", - strip_prefix = "abseil-cpp-9613678332c976568272c8f4a78631a29159271d", + sha256 = "4ee36dacb75846eaa209ce8060bb269a42b7b3903612ca6d9e86a692659fe8c1", + strip_prefix = "abseil-cpp-f0f15c2778b0e4959244dd25e63f445a455870f5", build_file = clean_dep("//third_party:com_google_absl.BUILD"), ) @@ -365,14 +365,18 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): }, ) + PROTOBUF_URLS = [ + "https://mirror.bazel.build/github.com/google/protobuf/archive/v3.6.0.tar.gz", + "https://github.com/google/protobuf/archive/v3.6.0.tar.gz", + ] + PROTOBUF_SHA256 = "50a5753995b3142627ac55cfd496cebc418a2e575ca0236e29033c67bd5665f4" + PROTOBUF_STRIP_PREFIX = "protobuf-3.6.0" + tf_http_archive( name = "protobuf_archive", - urls = [ - "https://mirror.bazel.build/github.com/google/protobuf/archive/v3.6.0.tar.gz", - "https://github.com/google/protobuf/archive/v3.6.0.tar.gz", - ], - sha256 = "50a5753995b3142627ac55cfd496cebc418a2e575ca0236e29033c67bd5665f4", - strip_prefix = "protobuf-3.6.0", + urls = PROTOBUF_URLS, + sha256 = PROTOBUF_SHA256, + strip_prefix = PROTOBUF_STRIP_PREFIX, ) # We need to import the protobuf library under the names com_google_protobuf @@ -380,32 +384,27 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): # Unfortunately there is no way to alias http_archives at the moment. tf_http_archive( name = "com_google_protobuf", - urls = [ - "https://mirror.bazel.build/github.com/google/protobuf/archive/v3.6.0.tar.gz", - "https://github.com/google/protobuf/archive/v3.6.0.tar.gz", - ], - sha256 = "50a5753995b3142627ac55cfd496cebc418a2e575ca0236e29033c67bd5665f4", - strip_prefix = "protobuf-3.6.0", + urls = PROTOBUF_URLS, + sha256 = PROTOBUF_SHA256, + strip_prefix = PROTOBUF_STRIP_PREFIX, ) tf_http_archive( name = "com_google_protobuf_cc", - urls = [ - "https://mirror.bazel.build/github.com/google/protobuf/archive/v3.6.0.tar.gz", - "https://github.com/google/protobuf/archive/v3.6.0.tar.gz", - ], - sha256 = "50a5753995b3142627ac55cfd496cebc418a2e575ca0236e29033c67bd5665f4", - strip_prefix = "protobuf-3.6.0", + urls = PROTOBUF_URLS, + sha256 = PROTOBUF_SHA256, + strip_prefix = PROTOBUF_STRIP_PREFIX, ) tf_http_archive( name = "nsync", urls = [ - "https://mirror.bazel.build/github.com/google/nsync/archive/1.20.0.tar.gz", - "https://github.com/google/nsync/archive/1.20.0.tar.gz", + "https://mirror.bazel.build/github.com/google/nsync/archive/1.20.1.tar.gz", + "https://github.com/google/nsync/archive/1.20.1.tar.gz", ], - sha256 = "0c1b03962b2f8450f21e74a5a46116bf2d6009a807c57eb4207e974a8c4bb7dd", - strip_prefix = "nsync-1.20.0", + sha256 = "692f9b30e219f71a6371b98edd39cef3cbda35ac3abc4cd99ce19db430a5591a", + strip_prefix = "nsync-1.20.1", + system_build_file = clean_dep("//third_party/systemlibs:nsync.BUILD"), ) tf_http_archive( @@ -492,11 +491,11 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): tf_http_archive( name = "llvm", urls = [ - "https://mirror.bazel.build/github.com/llvm-mirror/llvm/archive/6203c9bd082a877a20c218033636712135a3c2db.tar.gz", - "https://github.com/llvm-mirror/llvm/archive/6203c9bd082a877a20c218033636712135a3c2db.tar.gz", + "https://mirror.bazel.build/github.com/llvm-mirror/llvm/archive/deac5c28e00179be248aaf03abd329a848e8fac8.tar.gz", + "https://github.com/llvm-mirror/llvm/archive/deac5c28e00179be248aaf03abd329a848e8fac8.tar.gz", ], - sha256 = "83a80f9fb2a5949ca77e526344cbd4581388c3ec7fea5c59e488d46fd38e06d9", - strip_prefix = "llvm-6203c9bd082a877a20c218033636712135a3c2db", + sha256 = "bb55a553facff0408574a7bbd0d93c7371dbf527c7020fc6f4b9adeb0d83f780", + strip_prefix = "llvm-deac5c28e00179be248aaf03abd329a848e8fac8", build_file = clean_dep("//third_party/llvm:llvm.autogenerated.BUILD"), ) @@ -527,11 +526,11 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): tf_http_archive( name = "boringssl", urls = [ - "https://mirror.bazel.build/github.com/google/boringssl/archive/45c4a87ae97eb95a8fc2906c035d6a8d0e02e1b8.tar.gz", - "https://github.com/google/boringssl/archive/45c4a87ae97eb95a8fc2906c035d6a8d0e02e1b8.tar.gz", + "https://mirror.bazel.build/github.com/google/boringssl/archive/7f634429a04abc48e2eb041c81c5235816c96514.tar.gz", + "https://github.com/google/boringssl/archive/7f634429a04abc48e2eb041c81c5235816c96514.tar.gz", ], - sha256 = "972e8d8a9d1daf9892fff7155312b1af46b4754446575a7b285e62f917424c78", - strip_prefix = "boringssl-45c4a87ae97eb95a8fc2906c035d6a8d0e02e1b8", + sha256 = "1188e29000013ed6517168600fc35a010d58c5d321846d6a6dfee74e4c788b45", + strip_prefix = "boringssl-7f634429a04abc48e2eb041c81c5235816c96514", ) tf_http_archive( @@ -582,11 +581,11 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): tf_http_archive( name = "kafka", urls = [ - "https://mirror.bazel.build/github.com/edenhill/librdkafka/archive/v0.11.4.tar.gz", - "https://github.com/edenhill/librdkafka/archive/v0.11.4.tar.gz", + "https://mirror.bazel.build/github.com/edenhill/librdkafka/archive/v0.11.5.tar.gz", + "https://github.com/edenhill/librdkafka/archive/v0.11.5.tar.gz", ], - sha256 = "9d8f1eb7b0e29e9ab1168347c939cb7ae5dff00a39cef99e7ef033fd8f92737c", - strip_prefix = "librdkafka-0.11.4", + sha256 = "cc6ebbcd0a826eec1b8ce1f625ffe71b53ef3290f8192b6cae38412a958f4fd3", + strip_prefix = "librdkafka-0.11.5", build_file = clean_dep("//third_party:kafka/BUILD"), patch_file = clean_dep("//third_party/kafka:config.patch"), ) @@ -768,6 +767,7 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): ], build_file = str(Label("//third_party:tflite_mobilenet.BUILD")), ) + tf_http_archive( name = "tflite_mobilenet_ssd_quant", sha256 = "a809cd290b4d6a2e8a9d5dad076e0bd695b8091974e0eed1052b480b2f21b6dc", @@ -779,6 +779,17 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): ) tf_http_archive( + name = "tflite_mobilenet_ssd_quant_protobuf", + sha256 = "09280972c5777f1aa775ef67cb4ac5d5ed21970acd8535aeca62450ef14f0d79", + urls = [ + "https://mirror.bazel.build/storage.googleapis.com/download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_quantized_300x300_coco14_sync_2018_07_18.tar.gz", + "http://storage.googleapis.com/download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_quantized_300x300_coco14_sync_2018_07_18.tar.gz", + ], + strip_prefix = "ssd_mobilenet_v1_quantized_300x300_coco14_sync_2018_07_18", + build_file = str(Label("//third_party:tflite_mobilenet.BUILD")), + ) + + tf_http_archive( name = "tflite_conv_actions_frozen", sha256 = "d947b38cba389b5e2d0bfc3ea6cc49c784e187b41a071387b3742d1acac7691e", urls = [ @@ -819,6 +830,39 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): strip_prefix = "rules_android-0.1.1", ) + tf_http_archive( + name = "ngraph", + urls = [ + "https://mirror.bazel.build/github.com/NervanaSystems/ngraph/archive/v0.5.0.tar.gz", + "https://github.com/NervanaSystems/ngraph/archive/v0.5.0.tar.gz", + ], + sha256 = "cb35d3d98836f615408afd18371fb13e3400711247e0d822ba7f306c45e9bb2c", + strip_prefix = "ngraph-0.5.0", + build_file = clean_dep("//third_party/ngraph:ngraph.BUILD"), + ) + + tf_http_archive( + name = "nlohmann_json_lib", + urls = [ + "https://mirror.bazel.build/github.com/nlohmann/json/archive/v3.1.1.tar.gz", + "https://github.com/nlohmann/json/archive/v3.1.1.tar.gz", + ], + sha256 = "9f3549824af3ca7e9707a2503959886362801fb4926b869789d6929098a79e47", + strip_prefix = "json-3.1.1", + build_file = clean_dep("//third_party/ngraph:nlohmann_json.BUILD"), + ) + + tf_http_archive( + name = "ngraph_tf", + urls = [ + "https://mirror.bazel.build/github.com/NervanaSystems/ngraph-tf/archive/v0.3.0-rc1.tar.gz", + "https://github.com/NervanaSystems/ngraph-tf/archive/v0.3.0-rc1.tar.gz", + ], + sha256 = "7919332cb15120101c3e05c1b969a5e029a6411581312583c8f80b6aaaa83072", + strip_prefix = "ngraph-tf-0.3.0-rc1", + build_file = clean_dep("//third_party/ngraph:ngraph_tf.BUILD"), + ) + ############################################################################## # BIND DEFINITIONS # diff --git a/third_party/flatbuffers/build_defs.bzl b/third_party/flatbuffers/build_defs.bzl index ba763f3360..2f25156668 100644 --- a/third_party/flatbuffers/build_defs.bzl +++ b/third_party/flatbuffers/build_defs.bzl @@ -1,5 +1,4 @@ -# Description: -# BUILD rules for generating flatbuffer files. +"""BUILD rules for generating flatbuffer files.""" flatc_path = "@flatbuffers//:flatc" diff --git a/third_party/gpus/cuda/BUILD.windows.tpl b/third_party/gpus/cuda/BUILD.windows.tpl index ff6b3cc351..325d18b9cb 100644 --- a/third_party/gpus/cuda/BUILD.windows.tpl +++ b/third_party/gpus/cuda/BUILD.windows.tpl @@ -142,6 +142,7 @@ cc_library( ], includes = [ ".", + "cuda/", "cuda/extras/CUPTI/include/", ], visibility = ["//visibility:public"], diff --git a/third_party/hadoop/hdfs.h b/third_party/hadoop/hdfs.h index a664f3b50c..30c277a450 100644 --- a/third_party/hadoop/hdfs.h +++ b/third_party/hadoop/hdfs.h @@ -16,8 +16,8 @@ * limitations under the License. */ -#ifndef LIBHDFS_HDFS_H -#define LIBHDFS_HDFS_H +#ifndef TENSORFLOW_THIRD_PARTY_HADOOP_HDFS_H_ +#define TENSORFLOW_THIRD_PARTY_HADOOP_HDFS_H_ #include <errno.h> /* for EINTERNAL, etc. */ #include <fcntl.h> /* for O_RDONLY, O_WRONLY */ @@ -904,7 +904,7 @@ void hadoopRzBufferFree(hdfsFile file, struct hadoopRzBuffer *buffer); #endif #undef LIBHDFS_EXTERNAL -#endif /*LIBHDFS_HDFS_H*/ +#endif // TENSORFLOW_THIRD_PARTY_HADOOP_HDFS_H_ /** * vim: ts=4: sw=4: et diff --git a/third_party/kafka/BUILD b/third_party/kafka/BUILD index 3c50b8cf52..11ec50069a 100644 --- a/third_party/kafka/BUILD +++ b/third_party/kafka/BUILD @@ -48,8 +48,13 @@ cc_library( "src/rdinterval.h", "src/rdkafka.c", "src/rdkafka.h", + "src/rdkafka_admin.c", + "src/rdkafka_admin.h", "src/rdkafka_assignor.c", "src/rdkafka_assignor.h", + "src/rdkafka_aux.c", + "src/rdkafka_aux.h", + "src/rdkafka_background.c", "src/rdkafka_broker.c", "src/rdkafka_broker.h", "src/rdkafka_buf.c", @@ -58,6 +63,7 @@ cc_library( "src/rdkafka_cgrp.h", "src/rdkafka_conf.c", "src/rdkafka_conf.h", + "src/rdkafka_confval.h", "src/rdkafka_event.h", "src/rdkafka_feature.c", "src/rdkafka_feature.h", diff --git a/third_party/mkl/build_defs.bzl b/third_party/mkl/build_defs.bzl index 06a8c3518c..b645c0fc5c 100644 --- a/third_party/mkl/build_defs.bzl +++ b/third_party/mkl/build_defs.bzl @@ -11,10 +11,8 @@ mkl_repository depends on the following environment variables: * `TF_MKL_ROOT`: The root folder where a copy of libmkl is located. """ - _TF_MKL_ROOT = "TF_MKL_ROOT" - def if_mkl(if_true, if_false = []): """Shorthand for select()'ing on whether we're building with MKL. @@ -26,7 +24,7 @@ def if_mkl(if_true, if_false = []): a select evaluating to either if_true or if_false as appropriate. """ return select({ - "//third_party/mkl:using_mkl": if_true, + str(Label("//third_party/mkl:using_mkl")): if_true, "//conditions:default": if_false, }) @@ -42,11 +40,10 @@ def if_mkl_ml(if_true, if_false = []): a select evaluating to either if_true or if_false as appropriate. """ return select({ - "//third_party/mkl_dnn:using_mkl_dnn_only": - if_false, - "//third_party/mkl:using_mkl": if_true, + str(Label("//third_party/mkl_dnn:using_mkl_dnn_only")): if_false, + str(Label("//third_party/mkl:using_mkl")): if_true, "//conditions:default": if_false, - }) + }) def if_mkl_ml_only(if_true, if_false = []): """Shorthand for select()'ing on whether we're building with MKL-ML only. @@ -59,7 +56,7 @@ def if_mkl_ml_only(if_true, if_false = []): a select evaluating to either if_true or if_false as appropriate. """ return select({ - "//third_party/mkl:using_mkl_ml_only": if_true, + str(Label("//third_party/mkl:using_mkl_ml_only")): if_true, "//conditions:default": if_false, }) @@ -76,7 +73,7 @@ def if_mkl_lnx_x64(if_true, if_false = []): a select evaluating to either if_true or if_false as appropriate. """ return select({ - "//third_party/mkl:using_mkl_lnx_x64": if_true, + str(Label("//third_party/mkl:using_mkl_lnx_x64")): if_true, "//conditions:default": if_false, }) @@ -90,45 +87,40 @@ def mkl_deps(): inclusion in the deps attribute of rules. """ return select({ - "//third_party/mkl_dnn:using_mkl_dnn_only": - ["@mkl_dnn"], - "//third_party/mkl:using_mkl_ml_only": - ["//third_party/mkl:intel_binary_blob"], - "//third_party/mkl:using_mkl": - [ + str(Label("//third_party/mkl_dnn:using_mkl_dnn_only")): ["@mkl_dnn"], + str(Label("//third_party/mkl:using_mkl_ml_only")): ["//third_party/mkl:intel_binary_blob"], + str(Label("//third_party/mkl:using_mkl")): [ "//third_party/mkl:intel_binary_blob", - "@mkl_dnn" + "@mkl_dnn", ], - "//conditions:default": [] - }) + "//conditions:default": [], + }) def _enable_local_mkl(repository_ctx): - return _TF_MKL_ROOT in repository_ctx.os.environ - + return _TF_MKL_ROOT in repository_ctx.os.environ def _mkl_autoconf_impl(repository_ctx): - """Implementation of the local_mkl_autoconf repository rule.""" - - if _enable_local_mkl(repository_ctx): - # Symlink lib and include local folders. - mkl_root = repository_ctx.os.environ[_TF_MKL_ROOT] - mkl_lib_path = "%s/lib" % mkl_root - repository_ctx.symlink(mkl_lib_path, "lib") - mkl_include_path = "%s/include" % mkl_root - repository_ctx.symlink(mkl_include_path, "include") - mkl_license_path = "%s/license.txt" % mkl_root - repository_ctx.symlink(mkl_license_path, "license.txt") - else: - # setup remote mkl repository. - repository_ctx.download_and_extract( - repository_ctx.attr.urls, - sha256=repository_ctx.attr.sha256, - stripPrefix=repository_ctx.attr.strip_prefix, - ) - - # Also setup BUILD file. - repository_ctx.symlink(repository_ctx.attr.build_file, "BUILD") - + """Implementation of the local_mkl_autoconf repository rule.""" + + if _enable_local_mkl(repository_ctx): + # Symlink lib and include local folders. + mkl_root = repository_ctx.os.environ[_TF_MKL_ROOT] + mkl_lib_path = "%s/lib" % mkl_root + repository_ctx.symlink(mkl_lib_path, "lib") + mkl_include_path = "%s/include" % mkl_root + repository_ctx.symlink(mkl_include_path, "include") + mkl_license_path = "%s/license.txt" % mkl_root + repository_ctx.symlink(mkl_license_path, "license.txt") + else: + # setup remote mkl repository. + repository_ctx.download_and_extract( + repository_ctx.attr.urls, + sha256 = repository_ctx.attr.sha256, + stripPrefix = repository_ctx.attr.strip_prefix, + ) + + # Also setup BUILD file. + repository_ctx.symlink(repository_ctx.attr.build_file, "BUILD") mkl_repository = repository_rule( implementation = _mkl_autoconf_impl, diff --git a/third_party/ngraph/BUILD b/third_party/ngraph/BUILD new file mode 100644 index 0000000000..067771b43f --- /dev/null +++ b/third_party/ngraph/BUILD @@ -0,0 +1 @@ +licenses(["notice"]) # 3-Clause BSD diff --git a/third_party/ngraph/LICENSE b/third_party/ngraph/LICENSE new file mode 100644 index 0000000000..9c8f3ea087 --- /dev/null +++ b/third_party/ngraph/LICENSE @@ -0,0 +1,201 @@ + Apache License + Version 2.0, January 2004 + http://www.apache.org/licenses/ + + TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION + + 1. Definitions. + + "License" shall mean the terms and conditions for use, reproduction, + and distribution as defined by Sections 1 through 9 of this document. + + "Licensor" shall mean the copyright owner or entity authorized by + the copyright owner that is granting the License. + + "Legal Entity" shall mean the union of the acting entity and all + other entities that control, are controlled by, or are under common + control with that entity. For the purposes of this definition, + "control" means (i) the power, direct or indirect, to cause the + direction or management of such entity, whether by contract or + otherwise, or (ii) ownership of fifty percent (50%) or more of the + outstanding shares, or (iii) beneficial ownership of such entity. + + "You" (or "Your") shall mean an individual or Legal Entity + exercising permissions granted by this License. + + "Source" form shall mean the preferred form for making modifications, + including but not limited to software source code, documentation + source, and configuration files. + + "Object" form shall mean any form resulting from mechanical + transformation or translation of a Source form, including but + not limited to compiled object code, generated documentation, + and conversions to other media types. + + "Work" shall mean the work of authorship, whether in Source or + Object form, made available under the License, as indicated by a + copyright notice that is included in or attached to the work + (an example is provided in the Appendix below). + + "Derivative Works" shall mean any work, whether in Source or Object + form, that is based on (or derived from) the Work and for which the + editorial revisions, annotations, elaborations, or other modifications + represent, as a whole, an original work of authorship. For the purposes + of this License, Derivative Works shall not include works that remain + separable from, or merely link (or bind by name) to the interfaces of, + the Work and Derivative Works thereof. + + "Contribution" shall mean any work of authorship, including + the original version of the Work and any modifications or additions + to that Work or Derivative Works thereof, that is intentionally + submitted to Licensor for inclusion in the Work by the copyright owner + or by an individual or Legal Entity authorized to submit on behalf of + the copyright owner. For the purposes of this definition, "submitted" + means any form of electronic, verbal, or written communication sent + to the Licensor or its representatives, including but not limited to + communication on electronic mailing lists, source code control systems, + and issue tracking systems that are managed by, or on behalf of, the + Licensor for the purpose of discussing and improving the Work, but + excluding communication that is conspicuously marked or otherwise + designated in writing by the copyright owner as "Not a Contribution." + + "Contributor" shall mean Licensor and any individual or Legal Entity + on behalf of whom a Contribution has been received by Licensor and + subsequently incorporated within the Work. + + 2. Grant of Copyright License. Subject to the terms and conditions of + this License, each Contributor hereby grants to You a perpetual, + worldwide, non-exclusive, no-charge, royalty-free, irrevocable + copyright license to reproduce, prepare Derivative Works of, + publicly display, publicly perform, sublicense, and distribute the + Work and such Derivative Works in Source or Object form. + + 3. Grant of Patent License. Subject to the terms and conditions of + this License, each Contributor hereby grants to You a perpetual, + worldwide, non-exclusive, no-charge, royalty-free, irrevocable + (except as stated in this section) patent license to make, have made, + use, offer to sell, sell, import, and otherwise transfer the Work, + where such license applies only to those patent claims licensable + by such Contributor that are necessarily infringed by their + Contribution(s) alone or by combination of their Contribution(s) + with the Work to which such Contribution(s) was submitted. If You + institute patent litigation against any entity (including a + cross-claim or counterclaim in a lawsuit) alleging that the Work + or a Contribution incorporated within the Work constitutes direct + or contributory patent infringement, then any patent licenses + granted to You under this License for that Work shall terminate + as of the date such litigation is filed. + + 4. Redistribution. You may reproduce and distribute copies of the + Work or Derivative Works thereof in any medium, with or without + modifications, and in Source or Object form, provided that You + meet the following conditions: + + (a) You must give any other recipients of the Work or + Derivative Works a copy of this License; and + + (b) You must cause any modified files to carry prominent notices + stating that You changed the files; and + + (c) You must retain, in the Source form of any Derivative Works + that You distribute, all copyright, patent, trademark, and + attribution notices from the Source form of the Work, + excluding those notices that do not pertain to any part of + the Derivative Works; and + + (d) If the Work includes a "NOTICE" text file as part of its + distribution, then any Derivative Works that You distribute must + include a readable copy of the attribution notices contained + within such NOTICE file, excluding those notices that do not + pertain to any part of the Derivative Works, in at least one + of the following places: within a NOTICE text file distributed + as part of the Derivative Works; within the Source form or + documentation, if provided along with the Derivative Works; or, + within a display generated by the Derivative Works, if and + wherever such third-party notices normally appear. The contents + of the NOTICE file are for informational purposes only and + do not modify the License. You may add Your own attribution + notices within Derivative Works that You distribute, alongside + or as an addendum to the NOTICE text from the Work, provided + that such additional attribution notices cannot be construed + as modifying the License. + + You may add Your own copyright statement to Your modifications and + may provide additional or different license terms and conditions + for use, reproduction, or distribution of Your modifications, or + for any such Derivative Works as a whole, provided Your use, + reproduction, and distribution of the Work otherwise complies with + the conditions stated in this License. + + 5. Submission of Contributions. Unless You explicitly state otherwise, + any Contribution intentionally submitted for inclusion in the Work + by You to the Licensor shall be under the terms and conditions of + this License, without any additional terms or conditions. + Notwithstanding the above, nothing herein shall supersede or modify + the terms of any separate license agreement you may have executed + with Licensor regarding such Contributions. + + 6. Trademarks. This License does not grant permission to use the trade + names, trademarks, service marks, or product names of the Licensor, + except as required for reasonable and customary use in describing the + origin of the Work and reproducing the content of the NOTICE file. + + 7. Disclaimer of Warranty. Unless required by applicable law or + agreed to in writing, Licensor provides the Work (and each + Contributor provides its Contributions) on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or + implied, including, without limitation, any warranties or conditions + of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A + PARTICULAR PURPOSE. You are solely responsible for determining the + appropriateness of using or redistributing the Work and assume any + risks associated with Your exercise of permissions under this License. + + 8. Limitation of Liability. In no event and under no legal theory, + whether in tort (including negligence), contract, or otherwise, + unless required by applicable law (such as deliberate and grossly + negligent acts) or agreed to in writing, shall any Contributor be + liable to You for damages, including any direct, indirect, special, + incidental, or consequential damages of any character arising as a + result of this License or out of the use or inability to use the + Work (including but not limited to damages for loss of goodwill, + work stoppage, computer failure or malfunction, or any and all + other commercial damages or losses), even if such Contributor + has been advised of the possibility of such damages. + + 9. Accepting Warranty or Additional Liability. While redistributing + the Work or Derivative Works thereof, You may choose to offer, + and charge a fee for, acceptance of support, warranty, indemnity, + or other liability obligations and/or rights consistent with this + License. However, in accepting such obligations, You may act only + on Your own behalf and on Your sole responsibility, not on behalf + of any other Contributor, and only if You agree to indemnify, + defend, and hold each Contributor harmless for any liability + incurred by, or claims asserted against, such Contributor by reason + of your accepting any such warranty or additional liability. + + END OF TERMS AND CONDITIONS + + APPENDIX: How to apply the Apache License to your work. + + To apply the Apache License to your work, attach the following + boilerplate notice, with the fields enclosed by brackets "{}" + replaced with your own identifying information. (Don't include + the brackets!) The text should be enclosed in the appropriate + comment syntax for the file format. We also recommend that a + file or class name and description of purpose be included on the + same "printed page" as the copyright notice for easier + identification within third-party archives. + + Copyright {yyyy} {name of copyright owner} + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + + Unless required by applicable law or agreed to in writing, software + distributed under the License is distributed on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + See the License for the specific language governing permissions and + limitations under the License.
\ No newline at end of file diff --git a/third_party/ngraph/NGRAPH_LICENSE b/third_party/ngraph/NGRAPH_LICENSE new file mode 100644 index 0000000000..9c8f3ea087 --- /dev/null +++ b/third_party/ngraph/NGRAPH_LICENSE @@ -0,0 +1,201 @@ + Apache License + Version 2.0, January 2004 + http://www.apache.org/licenses/ + + TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION + + 1. Definitions. + + "License" shall mean the terms and conditions for use, reproduction, + and distribution as defined by Sections 1 through 9 of this document. + + "Licensor" shall mean the copyright owner or entity authorized by + the copyright owner that is granting the License. + + "Legal Entity" shall mean the union of the acting entity and all + other entities that control, are controlled by, or are under common + control with that entity. For the purposes of this definition, + "control" means (i) the power, direct or indirect, to cause the + direction or management of such entity, whether by contract or + otherwise, or (ii) ownership of fifty percent (50%) or more of the + outstanding shares, or (iii) beneficial ownership of such entity. + + "You" (or "Your") shall mean an individual or Legal Entity + exercising permissions granted by this License. + + "Source" form shall mean the preferred form for making modifications, + including but not limited to software source code, documentation + source, and configuration files. + + "Object" form shall mean any form resulting from mechanical + transformation or translation of a Source form, including but + not limited to compiled object code, generated documentation, + and conversions to other media types. + + "Work" shall mean the work of authorship, whether in Source or + Object form, made available under the License, as indicated by a + copyright notice that is included in or attached to the work + (an example is provided in the Appendix below). + + "Derivative Works" shall mean any work, whether in Source or Object + form, that is based on (or derived from) the Work and for which the + editorial revisions, annotations, elaborations, or other modifications + represent, as a whole, an original work of authorship. For the purposes + of this License, Derivative Works shall not include works that remain + separable from, or merely link (or bind by name) to the interfaces of, + the Work and Derivative Works thereof. + + "Contribution" shall mean any work of authorship, including + the original version of the Work and any modifications or additions + to that Work or Derivative Works thereof, that is intentionally + submitted to Licensor for inclusion in the Work by the copyright owner + or by an individual or Legal Entity authorized to submit on behalf of + the copyright owner. For the purposes of this definition, "submitted" + means any form of electronic, verbal, or written communication sent + to the Licensor or its representatives, including but not limited to + communication on electronic mailing lists, source code control systems, + and issue tracking systems that are managed by, or on behalf of, the + Licensor for the purpose of discussing and improving the Work, but + excluding communication that is conspicuously marked or otherwise + designated in writing by the copyright owner as "Not a Contribution." + + "Contributor" shall mean Licensor and any individual or Legal Entity + on behalf of whom a Contribution has been received by Licensor and + subsequently incorporated within the Work. + + 2. Grant of Copyright License. Subject to the terms and conditions of + this License, each Contributor hereby grants to You a perpetual, + worldwide, non-exclusive, no-charge, royalty-free, irrevocable + copyright license to reproduce, prepare Derivative Works of, + publicly display, publicly perform, sublicense, and distribute the + Work and such Derivative Works in Source or Object form. + + 3. Grant of Patent License. Subject to the terms and conditions of + this License, each Contributor hereby grants to You a perpetual, + worldwide, non-exclusive, no-charge, royalty-free, irrevocable + (except as stated in this section) patent license to make, have made, + use, offer to sell, sell, import, and otherwise transfer the Work, + where such license applies only to those patent claims licensable + by such Contributor that are necessarily infringed by their + Contribution(s) alone or by combination of their Contribution(s) + with the Work to which such Contribution(s) was submitted. If You + institute patent litigation against any entity (including a + cross-claim or counterclaim in a lawsuit) alleging that the Work + or a Contribution incorporated within the Work constitutes direct + or contributory patent infringement, then any patent licenses + granted to You under this License for that Work shall terminate + as of the date such litigation is filed. + + 4. Redistribution. You may reproduce and distribute copies of the + Work or Derivative Works thereof in any medium, with or without + modifications, and in Source or Object form, provided that You + meet the following conditions: + + (a) You must give any other recipients of the Work or + Derivative Works a copy of this License; and + + (b) You must cause any modified files to carry prominent notices + stating that You changed the files; and + + (c) You must retain, in the Source form of any Derivative Works + that You distribute, all copyright, patent, trademark, and + attribution notices from the Source form of the Work, + excluding those notices that do not pertain to any part of + the Derivative Works; and + + (d) If the Work includes a "NOTICE" text file as part of its + distribution, then any Derivative Works that You distribute must + include a readable copy of the attribution notices contained + within such NOTICE file, excluding those notices that do not + pertain to any part of the Derivative Works, in at least one + of the following places: within a NOTICE text file distributed + as part of the Derivative Works; within the Source form or + documentation, if provided along with the Derivative Works; or, + within a display generated by the Derivative Works, if and + wherever such third-party notices normally appear. The contents + of the NOTICE file are for informational purposes only and + do not modify the License. You may add Your own attribution + notices within Derivative Works that You distribute, alongside + or as an addendum to the NOTICE text from the Work, provided + that such additional attribution notices cannot be construed + as modifying the License. + + You may add Your own copyright statement to Your modifications and + may provide additional or different license terms and conditions + for use, reproduction, or distribution of Your modifications, or + for any such Derivative Works as a whole, provided Your use, + reproduction, and distribution of the Work otherwise complies with + the conditions stated in this License. + + 5. Submission of Contributions. Unless You explicitly state otherwise, + any Contribution intentionally submitted for inclusion in the Work + by You to the Licensor shall be under the terms and conditions of + this License, without any additional terms or conditions. + Notwithstanding the above, nothing herein shall supersede or modify + the terms of any separate license agreement you may have executed + with Licensor regarding such Contributions. + + 6. Trademarks. This License does not grant permission to use the trade + names, trademarks, service marks, or product names of the Licensor, + except as required for reasonable and customary use in describing the + origin of the Work and reproducing the content of the NOTICE file. + + 7. Disclaimer of Warranty. Unless required by applicable law or + agreed to in writing, Licensor provides the Work (and each + Contributor provides its Contributions) on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or + implied, including, without limitation, any warranties or conditions + of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A + PARTICULAR PURPOSE. You are solely responsible for determining the + appropriateness of using or redistributing the Work and assume any + risks associated with Your exercise of permissions under this License. + + 8. Limitation of Liability. In no event and under no legal theory, + whether in tort (including negligence), contract, or otherwise, + unless required by applicable law (such as deliberate and grossly + negligent acts) or agreed to in writing, shall any Contributor be + liable to You for damages, including any direct, indirect, special, + incidental, or consequential damages of any character arising as a + result of this License or out of the use or inability to use the + Work (including but not limited to damages for loss of goodwill, + work stoppage, computer failure or malfunction, or any and all + other commercial damages or losses), even if such Contributor + has been advised of the possibility of such damages. + + 9. Accepting Warranty or Additional Liability. While redistributing + the Work or Derivative Works thereof, You may choose to offer, + and charge a fee for, acceptance of support, warranty, indemnity, + or other liability obligations and/or rights consistent with this + License. However, in accepting such obligations, You may act only + on Your own behalf and on Your sole responsibility, not on behalf + of any other Contributor, and only if You agree to indemnify, + defend, and hold each Contributor harmless for any liability + incurred by, or claims asserted against, such Contributor by reason + of your accepting any such warranty or additional liability. + + END OF TERMS AND CONDITIONS + + APPENDIX: How to apply the Apache License to your work. + + To apply the Apache License to your work, attach the following + boilerplate notice, with the fields enclosed by brackets "{}" + replaced with your own identifying information. (Don't include + the brackets!) The text should be enclosed in the appropriate + comment syntax for the file format. We also recommend that a + file or class name and description of purpose be included on the + same "printed page" as the copyright notice for easier + identification within third-party archives. + + Copyright {yyyy} {name of copyright owner} + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + + Unless required by applicable law or agreed to in writing, software + distributed under the License is distributed on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + See the License for the specific language governing permissions and + limitations under the License.
\ No newline at end of file diff --git a/third_party/ngraph/build_defs.bzl b/third_party/ngraph/build_defs.bzl new file mode 100644 index 0000000000..3c34be524b --- /dev/null +++ b/third_party/ngraph/build_defs.bzl @@ -0,0 +1,11 @@ +"""Build configurations for nGraph.""" + +def clean_dep(dep): + return str(Label(dep)) + +def if_ngraph(if_true, if_false = []): + """select()'ing on whether we're building with nGraph support.""" + return select({ + clean_dep("//tensorflow:with_ngraph_support"): if_true, + "//conditions:default": if_false, + }) diff --git a/third_party/ngraph/ngraph.BUILD b/third_party/ngraph/ngraph.BUILD new file mode 100644 index 0000000000..31aa3cee51 --- /dev/null +++ b/third_party/ngraph/ngraph.BUILD @@ -0,0 +1,37 @@ +licenses(["notice"]) # 3-Clause BSD + +exports_files(["LICENSE"]) + +cc_library( + name = "ngraph_core", + srcs = glob([ + "src/ngraph/*.cpp", + "src/ngraph/autodiff/*.cpp", + "src/ngraph/builder/*.cpp", + "src/ngraph/descriptor/*.cpp", + "src/ngraph/descriptor/layout/*.cpp", + "src/ngraph/op/*.cpp", + "src/ngraph/op/util/*.cpp", + "src/ngraph/pattern/*.cpp", + "src/ngraph/pattern/*.hpp", + "src/ngraph/pass/*.cpp", + "src/ngraph/pass/*.hpp", + "src/ngraph/runtime/*.cpp", + "src/ngraph/type/*.cpp", + "src/ngraph/runtime/interpreter/*.cpp", + "src/ngraph/runtime/interpreter/*.hpp", + ]), + hdrs = glob(["src/ngraph/**/*.hpp"]), + deps = [ + "@eigen_archive//:eigen", + "@nlohmann_json_lib", + ], + copts = [ + "-I external/ngraph/src", + "-I external/nlohmann_json_lib/include/", + '-D SHARED_LIB_EXT=\\".so\\"', + '-D NGRAPH_VERSION=\\"0.5.0\\"', + ], + visibility = ["//visibility:public"], + alwayslink = 1, +) diff --git a/third_party/ngraph/ngraph_tf.BUILD b/third_party/ngraph/ngraph_tf.BUILD new file mode 100644 index 0000000000..4d96ccf2f2 --- /dev/null +++ b/third_party/ngraph/ngraph_tf.BUILD @@ -0,0 +1,88 @@ +licenses(["notice"]) # 3-Clause BSD + +exports_files(["LICENSE"]) + +load( + "@org_tensorflow//tensorflow:tensorflow.bzl", + "tf_cc_test", +) + +cc_library( + name = "ngraph_libs_linux", + srcs = [ + "lib/libiomp5.so", + "lib/libmklml_intel.so", + ], + visibility = ["//visibility:public"], +) + +cc_library( + name = "ngraph_tf", + srcs = [ + "src/ngraph_builder.h", + "src/ngraph_builder.cc", + "src/ngraph_cluster.h", + "src/ngraph_cluster.cc", + "src/ngraph_cluster_manager.h", + "src/ngraph_cluster_manager.cc", + "src/ngraph_confirm_pass.cc", + "src/ngraph_device.cc", + "src/ngraph_encapsulate_op.cc", + "src/ngraph_encapsulate_pass.cc", + "src/ngraph_freshness_tracker.h", + "src/ngraph_freshness_tracker.cc", + "src/ngraph_graph_rewrite_passes.cc", + "src/ngraph_liberate_pass.cc", + "src/ngraph_op_kernels.cc", + "src/ngraph_stub_ops.cc", + "src/ngraph_utils.h", + "src/ngraph_utils.cc", + "src/ngraph_send_recv_ops.cc", + "src/ngraph_variable_ops.cc", + "src/tf_graphcycles.cc", + "logging/ngraph_log.h", + "logging/ngraph_log.cc", + "logging/tf_graph_writer.h", + "logging/tf_graph_writer.cc", + ], + hdrs = [ + "src/tf_graphcycles.h", + ], + deps = [ + "@org_tensorflow//tensorflow/core:protos_all_proto_text", + "@org_tensorflow//tensorflow/core:framework_headers_lib", + "@org_tensorflow//tensorflow/core:core_cpu_headers_lib", + "@ngraph//:ngraph_core", + ], + copts = [ + "-I external/ngraph_tf/src", + "-I external/ngraph_tf/logging", + "-I external/ngraph/src", + "-D NGRAPH_EMBEDDED_IN_TENSORFLOW=1", + ], + alwayslink = 1, + visibility = ["//visibility:public"], +) + +tf_cc_test( + name = "ngraph_tf_tests", + size = "small", + srcs = [ + "test/tf_exec.cpp", + "test/main.cpp", + ], + deps = [ + ":ngraph_tf", + "@com_google_googletest//:gtest", + "@org_tensorflow//tensorflow/cc:cc_ops", + "@org_tensorflow//tensorflow/cc:client_session", + "@org_tensorflow//tensorflow/core:tensorflow", + ], + extra_copts = [ + "-fexceptions ", + "-D NGRAPH_EMBEDDED_IN_TENSORFLOW=1", + "-I external/ngraph_tf/src", + "-I external/ngraph_tf/logging", + "-I external/ngraph/src", + ], +) diff --git a/third_party/ngraph/nlohmann_json.BUILD b/third_party/ngraph/nlohmann_json.BUILD new file mode 100644 index 0000000000..04c8db6a96 --- /dev/null +++ b/third_party/ngraph/nlohmann_json.BUILD @@ -0,0 +1,15 @@ +licenses(["notice"]) # 3-Clause BSD + +exports_files(["LICENSE.MIT"]) + +cc_library( + name = "nlohmann_json_lib", + hdrs = glob([ + "include/nlohmann/**/*.hpp", + ]), + copts = [ + "-I external/nlohmann_json_lib", + ], + visibility = ["//visibility:public"], + alwayslink = 1, +) diff --git a/third_party/systemlibs/nsync.BUILD b/third_party/systemlibs/nsync.BUILD new file mode 100644 index 0000000000..c5d4ad0a76 --- /dev/null +++ b/third_party/systemlibs/nsync.BUILD @@ -0,0 +1,23 @@ +licenses(["notice"]) # BSD 3-Clause + +filegroup( + name = "LICENSE", + visibility = ["//visibility:public"], +) + +cc_library( + name = "nsync_headers", + visibility = ["//visibility:public"], +) + +cc_library( + name = "nsync", + linkopts = ["-lnsync"], + visibility = ["//visibility:public"], +) + +cc_library( + name = "nsync_cpp", + linkopts = ["-lnsync_cpp"], + visibility = ["//visibility:public"], +) diff --git a/third_party/systemlibs/syslibs_configure.bzl b/third_party/systemlibs/syslibs_configure.bzl index 07a44c317e..8b09c9ac1f 100644 --- a/third_party/systemlibs/syslibs_configure.bzl +++ b/third_party/systemlibs/syslibs_configure.bzl @@ -7,9 +7,9 @@ the system version instead """ -_TF_SYSTEM_LIBS="TF_SYSTEM_LIBS" +_TF_SYSTEM_LIBS = "TF_SYSTEM_LIBS" -VALID_LIBS=[ +VALID_LIBS = [ "astor_archive", "com_googlesource_code_re2", "curl", @@ -22,6 +22,7 @@ VALID_LIBS=[ "jsoncpp_git", "lmdb", "nasm", + "nsync", "org_sqlite", "pcre", "png_archive", @@ -32,112 +33,109 @@ VALID_LIBS=[ "zlib_archive", ] - def auto_configure_fail(msg): - """Output failure message when syslibs configuration fails.""" - red = "\033[0;31m" - no_color = "\033[0m" - fail("\n%sSystem Library Configuration Error:%s %s\n" % (red, no_color, msg)) - + """Output failure message when syslibs configuration fails.""" + red = "\033[0;31m" + no_color = "\033[0m" + fail("\n%sSystem Library Configuration Error:%s %s\n" % (red, no_color, msg)) def _is_windows(repository_ctx): - """Returns true if the host operating system is windows.""" - os_name = repository_ctx.os.name.lower() - if os_name.find("windows") != -1: - return True - return False - + """Returns true if the host operating system is windows.""" + os_name = repository_ctx.os.name.lower() + if os_name.find("windows") != -1: + return True + return False def _enable_syslibs(repository_ctx): - s = repository_ctx.os.environ.get(_TF_SYSTEM_LIBS, '').strip() - if not _is_windows(repository_ctx) and s != None and s != '': - return True - return False - + s = repository_ctx.os.environ.get(_TF_SYSTEM_LIBS, "").strip() + if not _is_windows(repository_ctx) and s != None and s != "": + return True + return False def _get_system_lib_list(repository_ctx): - """Gets the list of deps that should use the system lib. + """Gets the list of deps that should use the system lib. - Args: - repository_ctx: The repository context. + Args: + repository_ctx: The repository context. - Returns: - A string version of a python list - """ - if _TF_SYSTEM_LIBS not in repository_ctx.os.environ: - return [] + Returns: + A string version of a python list + """ + if _TF_SYSTEM_LIBS not in repository_ctx.os.environ: + return [] - libenv = repository_ctx.os.environ[_TF_SYSTEM_LIBS].strip() - libs = [] + libenv = repository_ctx.os.environ[_TF_SYSTEM_LIBS].strip() + libs = [] - for lib in list(libenv.split(',')): - lib = lib.strip() - if lib == "": - continue - if lib not in VALID_LIBS: - auto_configure_fail("Invalid system lib set: %s" % lib) - return [] - libs.append(lib) - - return libs + for lib in list(libenv.split(",")): + lib = lib.strip() + if lib == "": + continue + if lib not in VALID_LIBS: + auto_configure_fail("Invalid system lib set: %s" % lib) + return [] + libs.append(lib) + return libs def _format_system_lib_list(repository_ctx): - """Formats the list of deps that should use the system lib. - - Args: - repository_ctx: The repository context. - - Returns: - A list of the names of deps that should use the system lib. - """ - libs = _get_system_lib_list(repository_ctx) - ret = '' - for lib in libs: - ret += "'%s',\n" % lib - - return ret - - -def _tpl(repository_ctx, tpl, substitutions={}, out=None): - if not out: - out = tpl.replace(":", "") - repository_ctx.template( - out, - Label("//third_party/systemlibs%s.tpl" % tpl), - substitutions, - False) - + """Formats the list of deps that should use the system lib. + + Args: + repository_ctx: The repository context. + + Returns: + A list of the names of deps that should use the system lib. + """ + libs = _get_system_lib_list(repository_ctx) + ret = "" + for lib in libs: + ret += "'%s',\n" % lib + + return ret + +def _tpl(repository_ctx, tpl, substitutions = {}, out = None): + if not out: + out = tpl.replace(":", "") + repository_ctx.template( + out, + Label("//third_party/systemlibs%s.tpl" % tpl), + substitutions, + False, + ) def _create_dummy_repository(repository_ctx): - """Creates the dummy repository to build with all bundled libraries.""" - - _tpl(repository_ctx, ":BUILD") - _tpl(repository_ctx, ":build_defs.bzl", - { - "%{syslibs_enabled}": 'False', - "%{syslibs_list}": '', - }) - + """Creates the dummy repository to build with all bundled libraries.""" + + _tpl(repository_ctx, ":BUILD") + _tpl( + repository_ctx, + ":build_defs.bzl", + { + "%{syslibs_enabled}": "False", + "%{syslibs_list}": "", + }, + ) def _create_local_repository(repository_ctx): - """Creates the repository to build with system libraries.""" - - _tpl(repository_ctx, ":BUILD") - _tpl(repository_ctx, ":build_defs.bzl", - { - "%{syslibs_enabled}": 'True', - "%{syslibs_list}": _format_system_lib_list(repository_ctx), - }) - + """Creates the repository to build with system libraries.""" + + _tpl(repository_ctx, ":BUILD") + _tpl( + repository_ctx, + ":build_defs.bzl", + { + "%{syslibs_enabled}": "True", + "%{syslibs_list}": _format_system_lib_list(repository_ctx), + }, + ) def _syslibs_autoconf_impl(repository_ctx): - """Implementation of the syslibs_configure repository rule.""" - if not _enable_syslibs(repository_ctx): - _create_dummy_repository(repository_ctx) - else: - _create_local_repository(repository_ctx) - + """Implementation of the syslibs_configure repository rule.""" + if not _enable_syslibs(repository_ctx): + _create_dummy_repository(repository_ctx) + else: + _create_local_repository(repository_ctx) syslibs_configure = repository_rule( implementation = _syslibs_autoconf_impl, |
{kind=link}
{kind=link}