blob: 0e46c6e1b7e28d0ac1d22a9a0681ce7caa139b07 (
plain)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# Accessing Corpora
If you would like to access the corpora that we are using for your fuzz targets (synthesized by the fuzzing engines), please follow these steps.
## Install Google Cloud SDK
The corpora for fuzz targets are stored on [Google Cloud Storage](https://cloud.google.com/storage/). To access them, you will need to [install](https://cloud.google.com/storage/docs/gsutil_install) the gsutil tool, which is part of the Google Cloud SDK.
Follow the instructions on the installation page to login with a Google account listed in your project's `project.yaml` file.
## Viewing the corpus for a fuzz target
The fuzzer statistics page for your project on [ClusterFuzz](clusterfuzz.md) will contain a link to the Google Cloud console for your corpus under the "corpus_size" column. You can browse and download individual test inputs in the corpus here.

## Downloading the corpus
If you would like to download the entire corpus, from the cloud console link, copy the bucket path highlighted here:
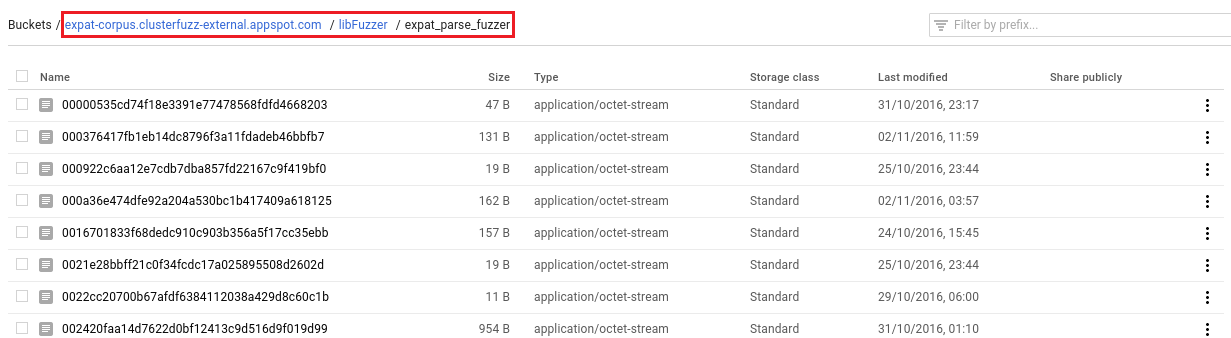
And then run the following command to copy the corpus to a directory on your machine.
```bash
gsutil -m rsync gs://<bucket_path> <local_directory>
```
Following the expat example above, this would be:
```bash
gsutil -m rsync gs://expat-corpus.clusterfuzz-external.appspot.com/libFuzzer/expat_parse_fuzzer <local_directory>
```
|
