// Copyright 2017 The TensorFlow Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// DO NOT EDIT
// This file was machine generated by github.com/tensorflow/tensorflow/tensorflow/go/genop/internal
//
// WARNING: This generation of wrapper function for TensorFlow ops is in an
// experimental state. The generated API can change without notice.
package op
import tf "github.com/tensorflow/tensorflow/tensorflow/go"
// optionalAttr is an intentionally un-exported type to hide
// details of how optional attributes to operations are implemented.
type optionalAttr map[string]interface{}
func makeOutputList(op *tf.Operation, start int, output string) ([]tf.Output, int, error) {
size, err := op.OutputListSize(output)
if err != nil {
return nil, start, err
}
list := make([]tf.Output, size)
for i := 0; i < size; i++ {
list[i] = op.Output(start + i)
}
return list, start + size, nil
}
// FakeQuantWithMinMaxVarsPerChannelGradientAttr is an optional argument to FakeQuantWithMinMaxVarsPerChannelGradient.
type FakeQuantWithMinMaxVarsPerChannelGradientAttr func(optionalAttr)
// FakeQuantWithMinMaxVarsPerChannelGradientNumBits sets the optional num_bits attribute to value.
//
// value: The bitwidth of the quantization; between 2 and 16, inclusive.
// If not specified, defaults to 8
func FakeQuantWithMinMaxVarsPerChannelGradientNumBits(value int64) FakeQuantWithMinMaxVarsPerChannelGradientAttr {
return func(m optionalAttr) {
m["num_bits"] = value
}
}
// FakeQuantWithMinMaxVarsPerChannelGradientNarrowRange sets the optional narrow_range attribute to value.
//
// value: Whether to quantize into 2^num_bits - 1 distinct values.
// If not specified, defaults to false
func FakeQuantWithMinMaxVarsPerChannelGradientNarrowRange(value bool) FakeQuantWithMinMaxVarsPerChannelGradientAttr {
return func(m optionalAttr) {
m["narrow_range"] = value
}
}
// Compute gradients for a FakeQuantWithMinMaxVarsPerChannel operation.
//
// Arguments:
// gradients: Backpropagated gradients above the FakeQuantWithMinMaxVars operation,
// shape one of: `[d]`, `[b, d]`, `[b, h, w, d]`.
// inputs: Values passed as inputs to the FakeQuantWithMinMaxVars operation, shape
// same as `gradients`.
// min, max: Quantization interval, floats of shape `[d]`.
//
//
//
// Returns Backpropagated gradients w.r.t. inputs, shape same as
// `inputs`:
// `gradients * (inputs >= min && inputs <= max)`.Backpropagated gradients w.r.t. min parameter, shape `[d]`:
// `sum_per_d(gradients * (inputs < min))`.Backpropagated gradients w.r.t. max parameter, shape `[d]`:
// `sum_per_d(gradients * (inputs > max))`.
func FakeQuantWithMinMaxVarsPerChannelGradient(scope *Scope, gradients tf.Output, inputs tf.Output, min tf.Output, max tf.Output, optional ...FakeQuantWithMinMaxVarsPerChannelGradientAttr) (backprops_wrt_input tf.Output, backprop_wrt_min tf.Output, backprop_wrt_max tf.Output) {
if scope.Err() != nil {
return
}
attrs := map[string]interface{}{}
for _, a := range optional {
a(attrs)
}
opspec := tf.OpSpec{
Type: "FakeQuantWithMinMaxVarsPerChannelGradient",
Input: []tf.Input{
gradients, inputs, min, max,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0), op.Output(1), op.Output(2)
}
// FakeQuantWithMinMaxVarsPerChannelAttr is an optional argument to FakeQuantWithMinMaxVarsPerChannel.
type FakeQuantWithMinMaxVarsPerChannelAttr func(optionalAttr)
// FakeQuantWithMinMaxVarsPerChannelNumBits sets the optional num_bits attribute to value.
// If not specified, defaults to 8
func FakeQuantWithMinMaxVarsPerChannelNumBits(value int64) FakeQuantWithMinMaxVarsPerChannelAttr {
return func(m optionalAttr) {
m["num_bits"] = value
}
}
// FakeQuantWithMinMaxVarsPerChannelNarrowRange sets the optional narrow_range attribute to value.
// If not specified, defaults to false
func FakeQuantWithMinMaxVarsPerChannelNarrowRange(value bool) FakeQuantWithMinMaxVarsPerChannelAttr {
return func(m optionalAttr) {
m["narrow_range"] = value
}
}
// Fake-quantize the 'inputs' tensor of type float and one of the shapes: `[d]`,
//
// `[b, d]` `[b, h, w, d]` via per-channel floats `min` and `max` of shape `[d]`
// to 'outputs' tensor of same shape as `inputs`.
//
// `[min; max]` define the clamping range for the `inputs` data.
// `inputs` values are quantized into the quantization range (`[0; 2^num_bits - 1]`
// when `narrow_range` is false and `[1; 2^num_bits - 1]` when it is true) and
// then de-quantized and output as floats in `[min; max]` interval.
// `num_bits` is the bitwidth of the quantization; between 2 and 16, inclusive.
//
// This operation has a gradient and thus allows for training `min` and `max`
// values.
func FakeQuantWithMinMaxVarsPerChannel(scope *Scope, inputs tf.Output, min tf.Output, max tf.Output, optional ...FakeQuantWithMinMaxVarsPerChannelAttr) (outputs tf.Output) {
if scope.Err() != nil {
return
}
attrs := map[string]interface{}{}
for _, a := range optional {
a(attrs)
}
opspec := tf.OpSpec{
Type: "FakeQuantWithMinMaxVarsPerChannel",
Input: []tf.Input{
inputs, min, max,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
// FakeQuantWithMinMaxVarsGradientAttr is an optional argument to FakeQuantWithMinMaxVarsGradient.
type FakeQuantWithMinMaxVarsGradientAttr func(optionalAttr)
// FakeQuantWithMinMaxVarsGradientNumBits sets the optional num_bits attribute to value.
//
// value: The bitwidth of the quantization; between 2 and 8, inclusive.
// If not specified, defaults to 8
func FakeQuantWithMinMaxVarsGradientNumBits(value int64) FakeQuantWithMinMaxVarsGradientAttr {
return func(m optionalAttr) {
m["num_bits"] = value
}
}
// FakeQuantWithMinMaxVarsGradientNarrowRange sets the optional narrow_range attribute to value.
//
// value: Whether to quantize into 2^num_bits - 1 distinct values.
// If not specified, defaults to false
func FakeQuantWithMinMaxVarsGradientNarrowRange(value bool) FakeQuantWithMinMaxVarsGradientAttr {
return func(m optionalAttr) {
m["narrow_range"] = value
}
}
// Compute gradients for a FakeQuantWithMinMaxVars operation.
//
// Arguments:
// gradients: Backpropagated gradients above the FakeQuantWithMinMaxVars operation.
// inputs: Values passed as inputs to the FakeQuantWithMinMaxVars operation.
// min, max: Quantization interval, scalar floats.
//
//
//
// Returns Backpropagated gradients w.r.t. inputs:
// `gradients * (inputs >= min && inputs <= max)`.Backpropagated gradients w.r.t. min parameter:
// `sum(gradients * (inputs < min))`.Backpropagated gradients w.r.t. max parameter:
// `sum(gradients * (inputs > max))`.
func FakeQuantWithMinMaxVarsGradient(scope *Scope, gradients tf.Output, inputs tf.Output, min tf.Output, max tf.Output, optional ...FakeQuantWithMinMaxVarsGradientAttr) (backprops_wrt_input tf.Output, backprop_wrt_min tf.Output, backprop_wrt_max tf.Output) {
if scope.Err() != nil {
return
}
attrs := map[string]interface{}{}
for _, a := range optional {
a(attrs)
}
opspec := tf.OpSpec{
Type: "FakeQuantWithMinMaxVarsGradient",
Input: []tf.Input{
gradients, inputs, min, max,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0), op.Output(1), op.Output(2)
}
// FakeQuantWithMinMaxArgsGradientAttr is an optional argument to FakeQuantWithMinMaxArgsGradient.
type FakeQuantWithMinMaxArgsGradientAttr func(optionalAttr)
// FakeQuantWithMinMaxArgsGradientMin sets the optional min attribute to value.
// If not specified, defaults to -6
func FakeQuantWithMinMaxArgsGradientMin(value float32) FakeQuantWithMinMaxArgsGradientAttr {
return func(m optionalAttr) {
m["min"] = value
}
}
// FakeQuantWithMinMaxArgsGradientMax sets the optional max attribute to value.
// If not specified, defaults to 6
func FakeQuantWithMinMaxArgsGradientMax(value float32) FakeQuantWithMinMaxArgsGradientAttr {
return func(m optionalAttr) {
m["max"] = value
}
}
// FakeQuantWithMinMaxArgsGradientNumBits sets the optional num_bits attribute to value.
// If not specified, defaults to 8
func FakeQuantWithMinMaxArgsGradientNumBits(value int64) FakeQuantWithMinMaxArgsGradientAttr {
return func(m optionalAttr) {
m["num_bits"] = value
}
}
// FakeQuantWithMinMaxArgsGradientNarrowRange sets the optional narrow_range attribute to value.
// If not specified, defaults to false
func FakeQuantWithMinMaxArgsGradientNarrowRange(value bool) FakeQuantWithMinMaxArgsGradientAttr {
return func(m optionalAttr) {
m["narrow_range"] = value
}
}
// Compute gradients for a FakeQuantWithMinMaxArgs operation.
//
// Arguments:
// gradients: Backpropagated gradients above the FakeQuantWithMinMaxArgs operation.
// inputs: Values passed as inputs to the FakeQuantWithMinMaxArgs operation.
//
// Returns Backpropagated gradients below the FakeQuantWithMinMaxArgs operation:
// `gradients * (inputs >= min && inputs <= max)`.
func FakeQuantWithMinMaxArgsGradient(scope *Scope, gradients tf.Output, inputs tf.Output, optional ...FakeQuantWithMinMaxArgsGradientAttr) (backprops tf.Output) {
if scope.Err() != nil {
return
}
attrs := map[string]interface{}{}
for _, a := range optional {
a(attrs)
}
opspec := tf.OpSpec{
Type: "FakeQuantWithMinMaxArgsGradient",
Input: []tf.Input{
gradients, inputs,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
// FakeQuantWithMinMaxArgsAttr is an optional argument to FakeQuantWithMinMaxArgs.
type FakeQuantWithMinMaxArgsAttr func(optionalAttr)
// FakeQuantWithMinMaxArgsMin sets the optional min attribute to value.
// If not specified, defaults to -6
func FakeQuantWithMinMaxArgsMin(value float32) FakeQuantWithMinMaxArgsAttr {
return func(m optionalAttr) {
m["min"] = value
}
}
// FakeQuantWithMinMaxArgsMax sets the optional max attribute to value.
// If not specified, defaults to 6
func FakeQuantWithMinMaxArgsMax(value float32) FakeQuantWithMinMaxArgsAttr {
return func(m optionalAttr) {
m["max"] = value
}
}
// FakeQuantWithMinMaxArgsNumBits sets the optional num_bits attribute to value.
// If not specified, defaults to 8
func FakeQuantWithMinMaxArgsNumBits(value int64) FakeQuantWithMinMaxArgsAttr {
return func(m optionalAttr) {
m["num_bits"] = value
}
}
// FakeQuantWithMinMaxArgsNarrowRange sets the optional narrow_range attribute to value.
// If not specified, defaults to false
func FakeQuantWithMinMaxArgsNarrowRange(value bool) FakeQuantWithMinMaxArgsAttr {
return func(m optionalAttr) {
m["narrow_range"] = value
}
}
// Fake-quantize the 'inputs' tensor, type float to 'outputs' tensor of same type.
//
// Attributes `[min; max]` define the clamping range for the `inputs` data.
// `inputs` values are quantized into the quantization range (`[0; 2^num_bits - 1]`
// when `narrow_range` is false and `[1; 2^num_bits - 1]` when it is true) and
// then de-quantized and output as floats in `[min; max]` interval.
// `num_bits` is the bitwidth of the quantization; between 2 and 16, inclusive.
//
// Quantization is called fake since the output is still in floating point.
func FakeQuantWithMinMaxArgs(scope *Scope, inputs tf.Output, optional ...FakeQuantWithMinMaxArgsAttr) (outputs tf.Output) {
if scope.Err() != nil {
return
}
attrs := map[string]interface{}{}
for _, a := range optional {
a(attrs)
}
opspec := tf.OpSpec{
Type: "FakeQuantWithMinMaxArgs",
Input: []tf.Input{
inputs,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
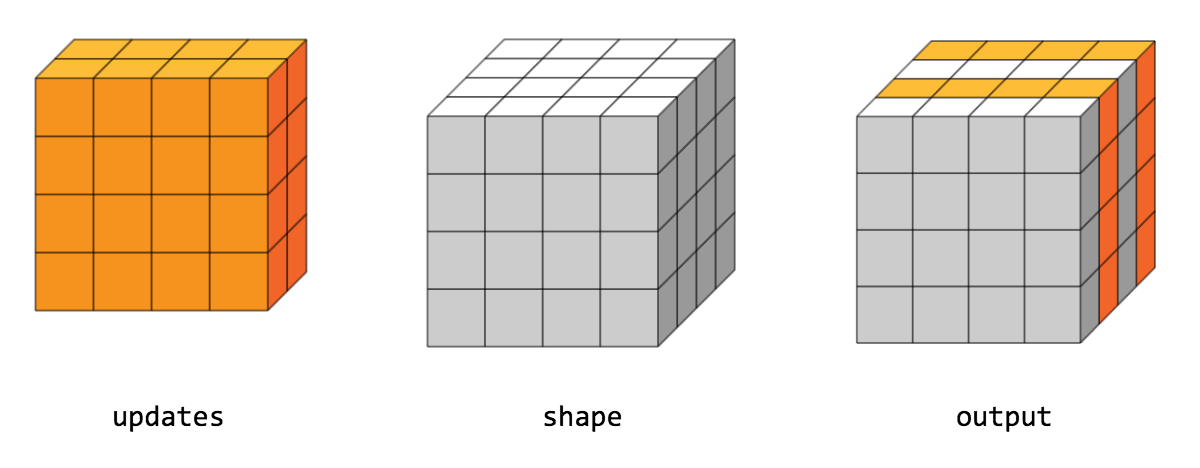
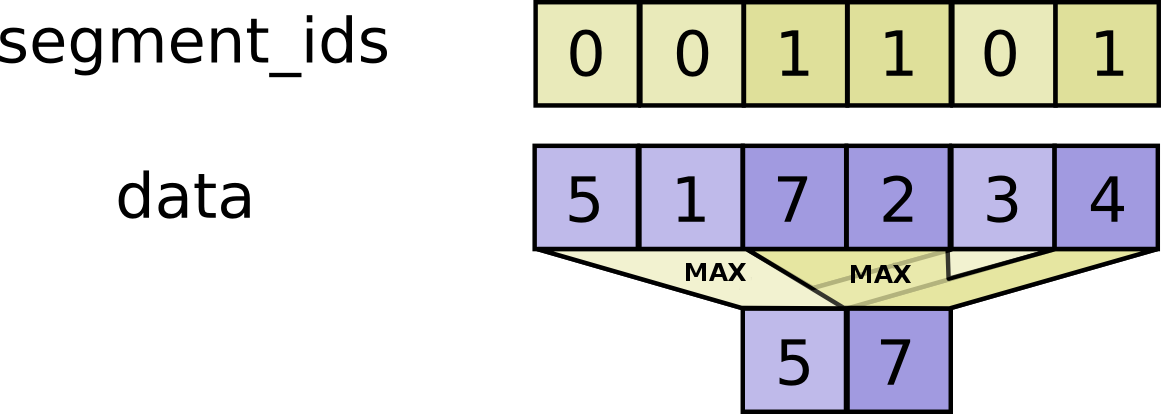
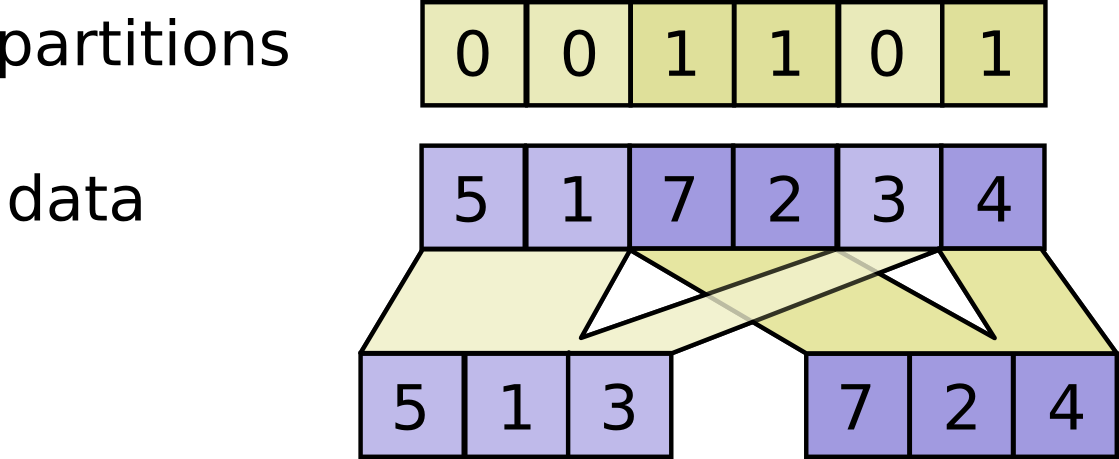
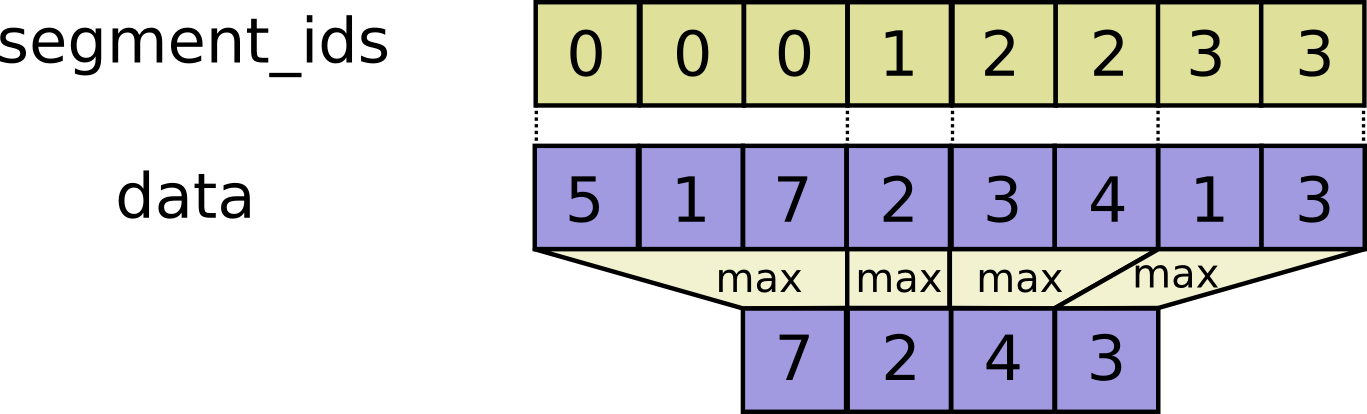
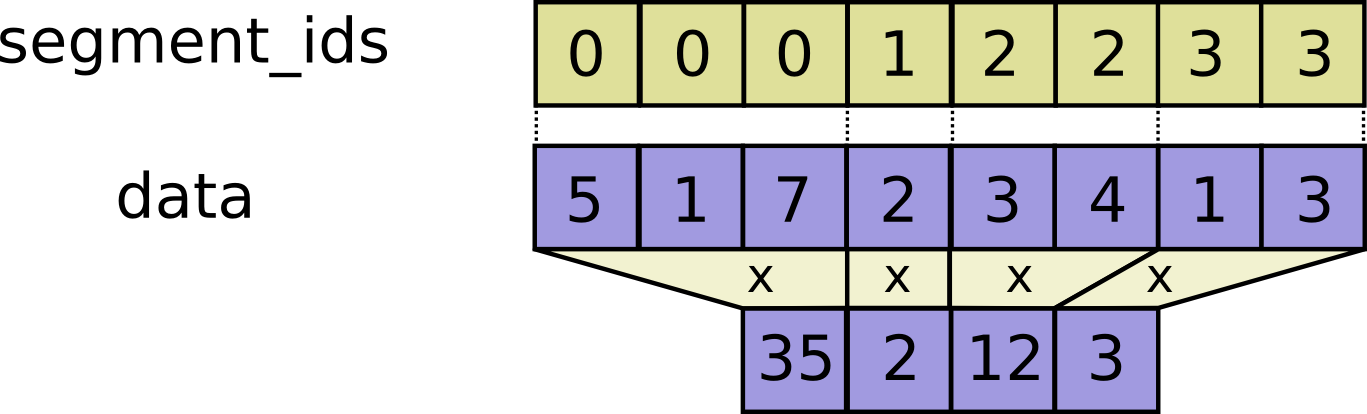
// Scatter `updates` into a new tensor according to `indices`.
//
// Creates a new tensor by applying sparse `updates` to individual values or
// slices within a tensor (initially zero for numeric, empty for string) of
// the given `shape` according to indices. This operator is the inverse of the
// `tf.gather_nd` operator which extracts values or slices from a given tensor.
//
// If `indices` contains duplicates, then their updates are accumulated (summed).
//
// **WARNING**: The order in which updates are applied is nondeterministic, so the
// output will be nondeterministic if `indices` contains duplicates -- because
// of some numerical approximation issues, numbers summed in different order
// may yield different results.
//
// `indices` is an integer tensor containing indices into a new tensor of shape
// `shape`. The last dimension of `indices` can be at most the rank of `shape`:
//
// indices.shape[-1] <= shape.rank
//
// The last dimension of `indices` corresponds to indices into elements
// (if `indices.shape[-1] = shape.rank`) or slices
// (if `indices.shape[-1] < shape.rank`) along dimension `indices.shape[-1]` of
// `shape`. `updates` is a tensor with shape
//
// indices.shape[:-1] + shape[indices.shape[-1]:]
//
// The simplest form of scatter is to insert individual elements in a tensor by
// index. For example, say we want to insert 4 scattered elements in a rank-1
// tensor with 8 elements.
//
//
//

//
//
//
//

//
//
//
//
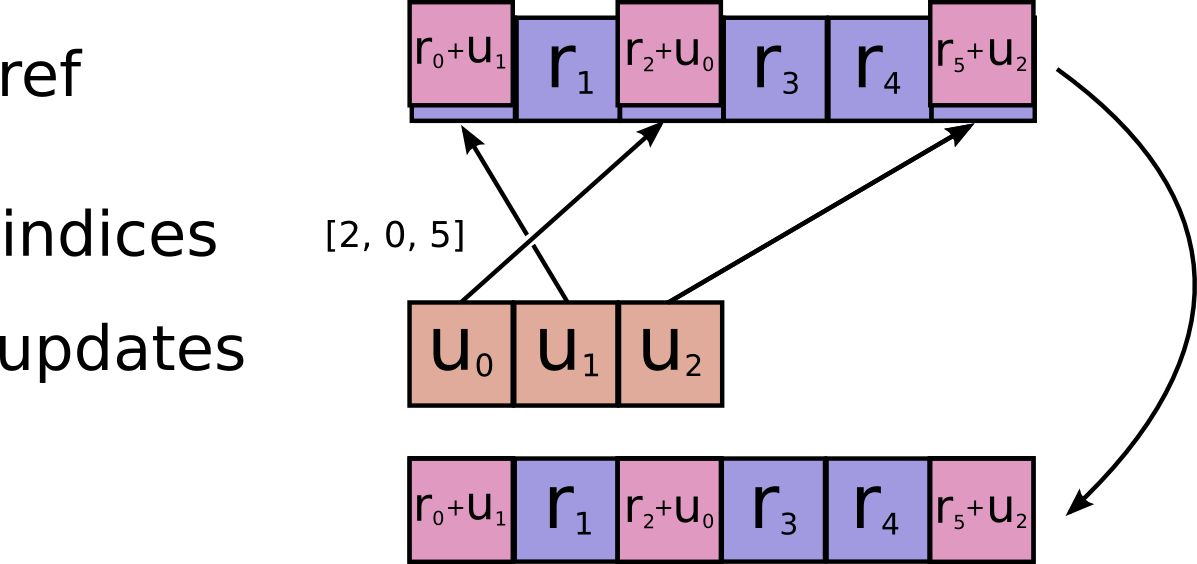
//
//
//
//
//
//
//
//
//
// Shai Shalev-Shwartz, Tong Zhang. 2012
//
// $$Loss Objective = \sum f_{i} (wx_{i}) + (l2 / 2) * |w|^2 + l1 * |w|$$
//
// [Adding vs. Averaging in Distributed Primal-Dual Optimization](http://arxiv.org/abs/1502.03508).
// Chenxin Ma, Virginia Smith, Martin Jaggi, Michael I. Jordan,
// Peter Richtarik, Martin Takac. 2015
//
// [Stochastic Dual Coordinate Ascent with Adaptive Probabilities](https://arxiv.org/abs/1502.08053).
// Dominik Csiba, Zheng Qu, Peter Richtarik. 2015
//
// Arguments:
// sparse_example_indices: a list of vectors which contain example indices.
// sparse_feature_indices: a list of vectors which contain feature indices.
// sparse_feature_values: a list of vectors which contains feature value
// associated with each feature group.
// dense_features: a list of matrices which contains the dense feature values.
// example_weights: a vector which contains the weight associated with each
// example.
// example_labels: a vector which contains the label/target associated with each
// example.
// sparse_indices: a list of vectors where each value is the indices which has
// corresponding weights in sparse_weights. This field maybe omitted for the
// dense approach.
// sparse_weights: a list of vectors where each value is the weight associated with
// a sparse feature group.
// dense_weights: a list of vectors where the values are the weights associated
// with a dense feature group.
// example_state_data: a list of vectors containing the example state data.
// loss_type: Type of the primal loss. Currently SdcaSolver supports logistic,
// squared and hinge losses.
// l1: Symmetric l1 regularization strength.
// l2: Symmetric l2 regularization strength.
// num_loss_partitions: Number of partitions of the global loss function.
// num_inner_iterations: Number of iterations per mini-batch.
//
// Returns a list of vectors containing the updated example state
// data.a list of vectors where each value is the delta
// weights associated with a sparse feature group.a list of vectors where the values are the delta
// weights associated with a dense feature group.
func SdcaOptimizer(scope *Scope, sparse_example_indices []tf.Output, sparse_feature_indices []tf.Output, sparse_feature_values []tf.Output, dense_features []tf.Output, example_weights tf.Output, example_labels tf.Output, sparse_indices []tf.Output, sparse_weights []tf.Output, dense_weights []tf.Output, example_state_data tf.Output, loss_type string, l1 float32, l2 float32, num_loss_partitions int64, num_inner_iterations int64, optional ...SdcaOptimizerAttr) (out_example_state_data tf.Output, out_delta_sparse_weights []tf.Output, out_delta_dense_weights []tf.Output) {
if scope.Err() != nil {
return
}
attrs := map[string]interface{}{"loss_type": loss_type, "l1": l1, "l2": l2, "num_loss_partitions": num_loss_partitions, "num_inner_iterations": num_inner_iterations}
for _, a := range optional {
a(attrs)
}
opspec := tf.OpSpec{
Type: "SdcaOptimizer",
Input: []tf.Input{
tf.OutputList(sparse_example_indices), tf.OutputList(sparse_feature_indices), tf.OutputList(sparse_feature_values), tf.OutputList(dense_features), example_weights, example_labels, tf.OutputList(sparse_indices), tf.OutputList(sparse_weights), tf.OutputList(dense_weights), example_state_data,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
if scope.Err() != nil {
return
}
var idx int
var err error
out_example_state_data = op.Output(idx)
if out_delta_sparse_weights, idx, err = makeOutputList(op, idx, "out_delta_sparse_weights"); err != nil {
scope.UpdateErr("SdcaOptimizer", err)
return
}
if out_delta_dense_weights, idx, err = makeOutputList(op, idx, "out_delta_dense_weights"); err != nil {
scope.UpdateErr("SdcaOptimizer", err)
return
}
return out_example_state_data, out_delta_sparse_weights, out_delta_dense_weights
}
// MatrixTriangularSolveAttr is an optional argument to MatrixTriangularSolve.
type MatrixTriangularSolveAttr func(optionalAttr)
// MatrixTriangularSolveLower sets the optional lower attribute to value.
//
// value: Boolean indicating whether the innermost matrices in `matrix` are
// lower or upper triangular.
// If not specified, defaults to true
func MatrixTriangularSolveLower(value bool) MatrixTriangularSolveAttr {
return func(m optionalAttr) {
m["lower"] = value
}
}
// MatrixTriangularSolveAdjoint sets the optional adjoint attribute to value.
//
// value: Boolean indicating whether to solve with `matrix` or its (block-wise)
// adjoint.
//
// @compatibility(numpy)
// Equivalent to scipy.linalg.solve_triangular
// @end_compatibility
// If not specified, defaults to false
func MatrixTriangularSolveAdjoint(value bool) MatrixTriangularSolveAttr {
return func(m optionalAttr) {
m["adjoint"] = value
}
}
// Solves systems of linear equations with upper or lower triangular matrices by
//
// backsubstitution.
//
// `matrix` is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form
// square matrices. If `lower` is `True` then the strictly upper triangular part
// of each inner-most matrix is assumed to be zero and not accessed.
// If `lower` is False then the strictly lower triangular part of each inner-most
// matrix is assumed to be zero and not accessed.
// `rhs` is a tensor of shape `[..., M, K]`.
//
// The output is a tensor of shape `[..., M, K]`. If `adjoint` is
// `True` then the innermost matrices in `output` satisfy matrix equations
// `matrix[..., :, :] * output[..., :, :] = rhs[..., :, :]`.
// If `adjoint` is `False` then the strictly then the innermost matrices in
// `output` satisfy matrix equations
// `adjoint(matrix[..., i, k]) * output[..., k, j] = rhs[..., i, j]`.
//
// Arguments:
// matrix: Shape is `[..., M, M]`.
// rhs: Shape is `[..., M, K]`.
//
// Returns Shape is `[..., M, K]`.
func MatrixTriangularSolve(scope *Scope, matrix tf.Output, rhs tf.Output, optional ...MatrixTriangularSolveAttr) (output tf.Output) {
if scope.Err() != nil {
return
}
attrs := map[string]interface{}{}
for _, a := range optional {
a(attrs)
}
opspec := tf.OpSpec{
Type: "MatrixTriangularSolve",
Input: []tf.Input{
matrix, rhs,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
// Computes inverse hyperbolic sine of x element-wise.
func Asinh(scope *Scope, x tf.Output) (y tf.Output) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
Type: "Asinh",
Input: []tf.Input{
x,
},
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
// Creates a dataset with a range of values. Corresponds to python's xrange.
//
// Arguments:
// start: corresponds to start in python's xrange().
// stop: corresponds to stop in python's xrange().
// step: corresponds to step in python's xrange().
//
//
func RangeDataset(scope *Scope, start tf.Output, stop tf.Output, step tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
if scope.Err() != nil {
return
}
attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
opspec := tf.OpSpec{
Type: "RangeDataset",
Input: []tf.Input{
start, stop, step,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
// Stops gradient computation.
//
// When executed in a graph, this op outputs its input tensor as-is.
//
// When building ops to compute gradients, this op prevents the contribution of
// its inputs to be taken into account. Normally, the gradient generator adds ops
// to a graph to compute the derivatives of a specified 'loss' by recursively
// finding out inputs that contributed to its computation. If you insert this op
// in the graph it inputs are masked from the gradient generator. They are not
// taken into account for computing gradients.
//
// This is useful any time you want to compute a value with TensorFlow but need
// to pretend that the value was a constant. Some examples include:
//
// * The *EM* algorithm where the *M-step* should not involve backpropagation
// through the output of the *E-step*.
// * Contrastive divergence training of Boltzmann machines where, when
// differentiating the energy function, the training must not backpropagate
// through the graph that generated the samples from the model.
// * Adversarial training, where no backprop should happen through the adversarial
// example generation process.
func StopGradient(scope *Scope, input tf.Output) (output tf.Output) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
Type: "StopGradient",
Input: []tf.Input{
input,
},
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
// Eagerly executes a python function to compute func(input)->output. The
//
// semantics of the input, output, and attributes are the same as those for
// PyFunc.
func EagerPyFunc(scope *Scope, input []tf.Output, token string, Tout []tf.DataType) (output []tf.Output) {
if scope.Err() != nil {
return
}
attrs := map[string]interface{}{"token": token, "Tout": Tout}
opspec := tf.OpSpec{
Type: "EagerPyFunc",
Input: []tf.Input{
tf.OutputList(input),
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
if scope.Err() != nil {
return
}
var idx int
var err error
if output, idx, err = makeOutputList(op, idx, "output"); err != nil {
scope.UpdateErr("EagerPyFunc", err)
return
}
return output
}
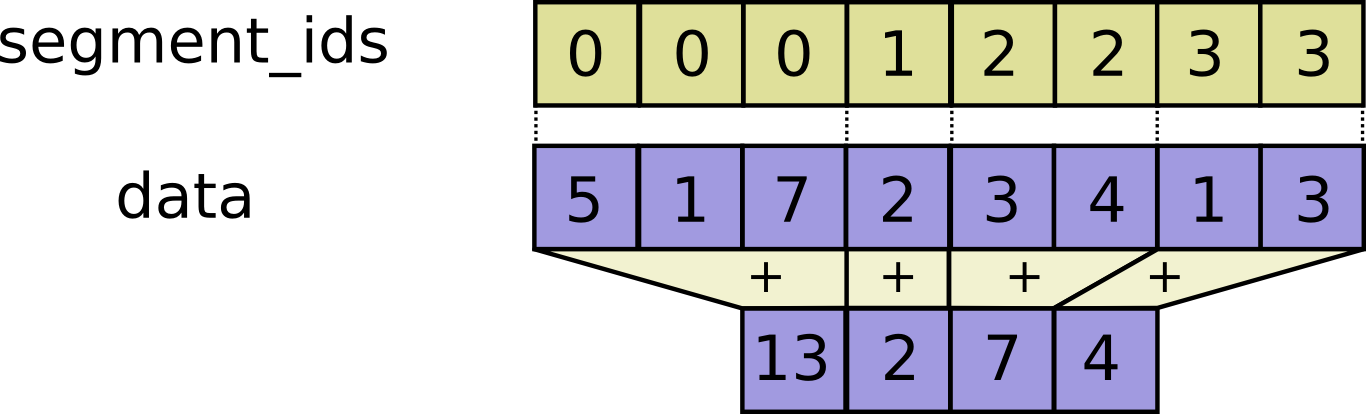
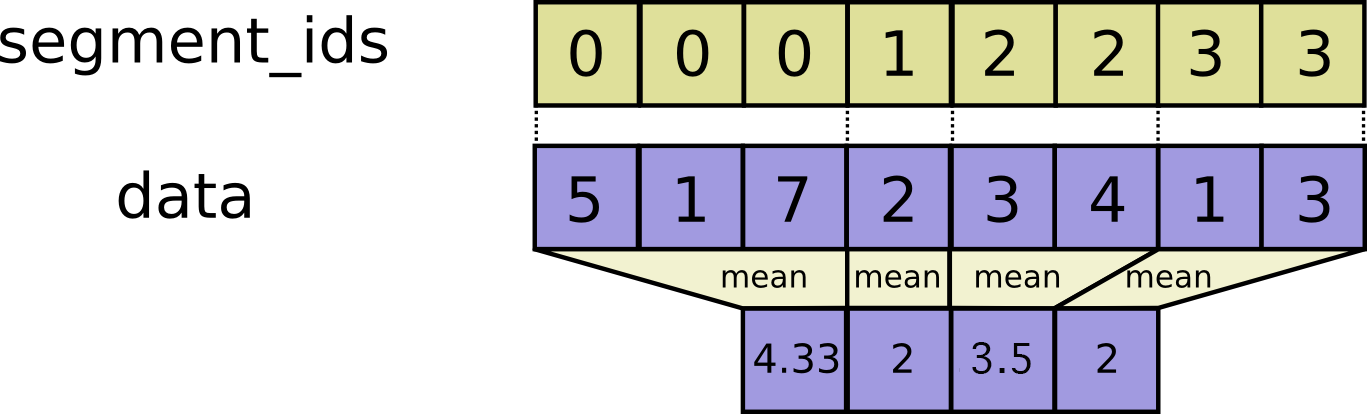
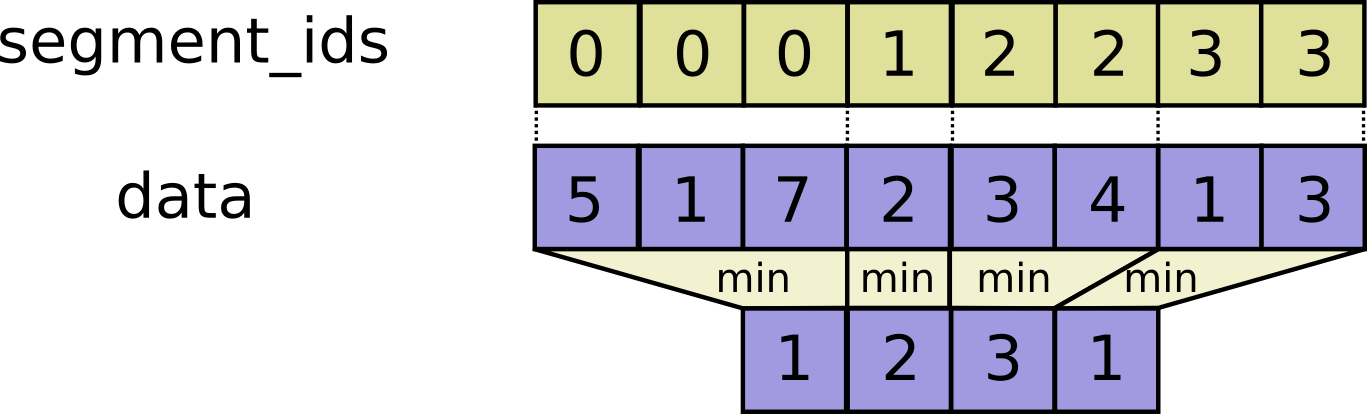
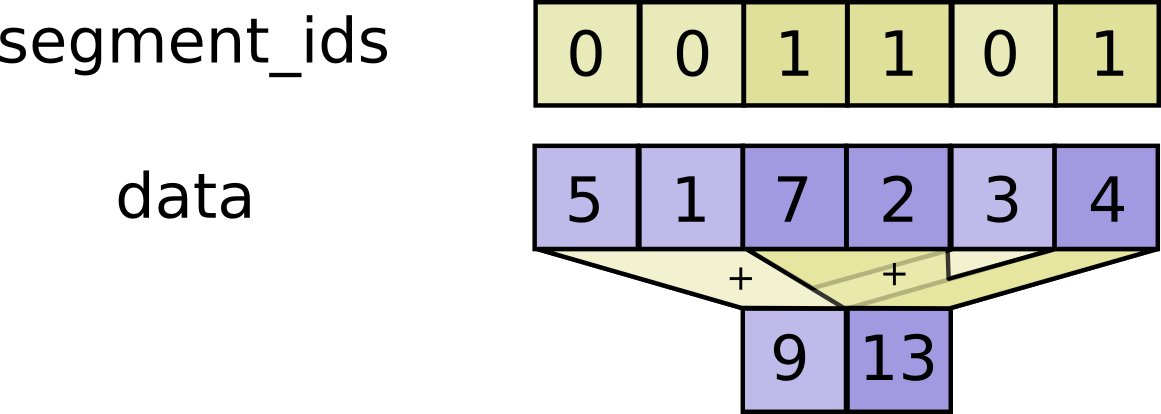
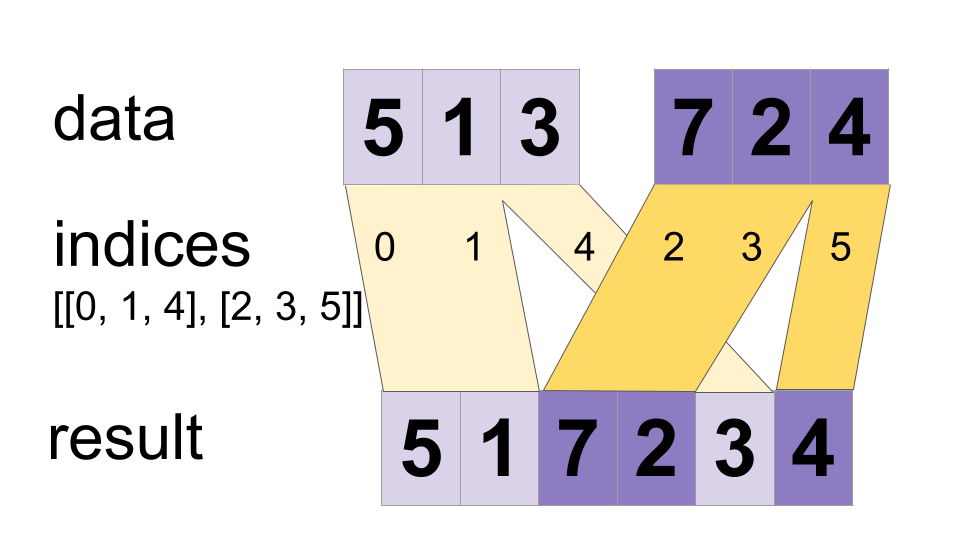
// Adds sparse updates to the variable referenced by `resource`.
//
// This operation computes
//
// # Scalar indices
// ref[indices, ...] += updates[...]
//
// # Vector indices (for each i)
// ref[indices[i], ...] += updates[i, ...]
//
// # High rank indices (for each i, ..., j)
// ref[indices[i, ..., j], ...] += updates[i, ..., j, ...]
//
// Duplicate entries are handled correctly: if multiple `indices` reference
// the same location, their contributions add.
//
// Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//
//