
diff options
221 files changed, 6714 insertions, 2079 deletions
@@ -90,6 +90,8 @@ The TensorFlow project strives to abide by generally accepted best practices in | **Windows CPU** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/windows-cpu.html) | [pypi](https://pypi.org/project/tf-nightly/) | | **Windows GPU** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/windows-gpu.html) | [pypi](https://pypi.org/project/tf-nightly-gpu/) | | **Android** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/android.html) | [](https://bintray.com/google/tensorflow/tensorflow/_latestVersion) | +| **Raspberry Pi 0 and 1** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/rpi01-py2.html) [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/rpi01-py3.html) | [Py2](https://storage.googleapis.com/tensorflow-nightly/tensorflow-1.10.0-cp27-none-linux_armv6l.whl) [Py3](https://storage.googleapis.com/tensorflow-nightly/tensorflow-1.10.0-cp34-none-linux_armv6l.whl) | +| **Raspberry Pi 2 and 3** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/rpi23-py2.html) [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/rpi23-py3.html) | [Py2](https://storage.googleapis.com/tensorflow-nightly/tensorflow-1.10.0-cp27-none-linux_armv7l.whl) [Py3](https://storage.googleapis.com/tensorflow-nightly/tensorflow-1.10.0-cp34-none-linux_armv7l.whl) | ### Community Supported Builds diff --git a/configure.py b/configure.py index 7edab53964..361bd4764d 100644 --- a/configure.py +++ b/configure.py @@ -1543,6 +1543,10 @@ def main(): if environ_cp.get('TF_DOWNLOAD_CLANG') != '1': # Set up which clang we should use as the cuda / host compiler. set_clang_cuda_compiler_path(environ_cp) + else: + # Use downloaded LLD for linking. + write_to_bazelrc('build:cuda_clang --config=download_clang_use_lld') + write_to_bazelrc('test:cuda_clang --config=download_clang_use_lld') else: # Set up which gcc nvcc should use as the host compiler # No need to set this on Windows diff --git a/tensorflow/c/BUILD b/tensorflow/c/BUILD index 2c3a877edf..109b3b37aa 100644 --- a/tensorflow/c/BUILD +++ b/tensorflow/c/BUILD @@ -117,6 +117,7 @@ tf_cuda_library( deps = [ ":c_api", ":c_api_internal", + "//tensorflow/c/eager:c_api", "//tensorflow/compiler/jit/legacy_flags:mark_for_compilation_pass_flags", "//tensorflow/contrib/tpu:all_ops", "//tensorflow/core:core_cpu", diff --git a/tensorflow/c/c_api_experimental.h b/tensorflow/c/c_api_experimental.h index 6617c5a572..09d482d6df 100644 --- a/tensorflow/c/c_api_experimental.h +++ b/tensorflow/c/c_api_experimental.h @@ -20,6 +20,7 @@ limitations under the License. #include <stdint.h> #include "tensorflow/c/c_api.h" +#include "tensorflow/c/eager/c_api.h" // -------------------------------------------------------------------------- // Experimental C API for TensorFlow. @@ -131,6 +132,9 @@ TF_CAPI_EXPORT extern void TF_EnqueueNamedTensor(TF_Session* session, TF_Tensor* tensor, TF_Status* status); +TF_CAPI_EXPORT extern TFE_Context* TFE_NewContextFromSession( + const TFE_ContextOptions* opts, TF_Session* sess, TF_Status* status); + #ifdef __cplusplus } /* end extern "C" */ #endif diff --git a/tensorflow/c/eager/c_api.cc b/tensorflow/c/eager/c_api.cc index 1ccae3f138..77e3878a94 100755 --- a/tensorflow/c/eager/c_api.cc +++ b/tensorflow/c/eager/c_api.cc @@ -273,7 +273,20 @@ TFE_Context* TFE_NewContext(const TFE_ContextOptions* opts, TF_Status* status) { new tensorflow::IntraProcessRendezvous(device_mgr.get()); return new TFE_Context(opts->session_options.options, opts->policy, - opts->async, std::move(device_mgr), r); + opts->async, device_mgr.release(), + /*device_mgr_owned*/ true, r); +} + +TFE_Context* TFE_NewContextFromSession(const TFE_ContextOptions* opts, + TF_Session* sess, TF_Status* status) { + const tensorflow::DeviceMgr* device_mgr = nullptr; + status->status = sess->session->LocalDeviceManager(&device_mgr); + if (!status->status.ok()) return nullptr; + tensorflow::Rendezvous* r = + new tensorflow::IntraProcessRendezvous(device_mgr); + return new TFE_Context(opts->session_options.options, opts->policy, + opts->async, device_mgr, /*device_mgr_owned*/ false, + r); } void TFE_DeleteContext(TFE_Context* ctx) { delete ctx; } diff --git a/tensorflow/c/eager/c_api_internal.h b/tensorflow/c/eager/c_api_internal.h index a5c0681e2e..104d52430c 100644 --- a/tensorflow/c/eager/c_api_internal.h +++ b/tensorflow/c/eager/c_api_internal.h @@ -62,15 +62,14 @@ struct TFE_ContextOptions { }; struct TFE_Context { - explicit TFE_Context(const tensorflow::SessionOptions& opts, - TFE_ContextDevicePlacementPolicy default_policy, - bool async, - std::unique_ptr<tensorflow::DeviceMgr> device_mgr, - tensorflow::Rendezvous* rendezvous) + TFE_Context(const tensorflow::SessionOptions& opts, + TFE_ContextDevicePlacementPolicy default_policy, bool async, + const tensorflow::DeviceMgr* device_mgr, bool device_mgr_owned, + tensorflow::Rendezvous* rendezvous) : context(opts, static_cast<tensorflow::ContextDevicePlacementPolicy>( default_policy), - async, std::move(device_mgr), rendezvous) {} + async, device_mgr, device_mgr_owned, rendezvous) {} tensorflow::EagerContext context; }; diff --git a/tensorflow/compiler/tests/BUILD b/tensorflow/compiler/tests/BUILD index cf02926e06..34defe1c7a 100644 --- a/tensorflow/compiler/tests/BUILD +++ b/tensorflow/compiler/tests/BUILD @@ -251,6 +251,7 @@ tf_xla_py_test( tf_xla_py_test( name = "matrix_triangular_solve_op_test", size = "small", + timeout = "moderate", srcs = ["matrix_triangular_solve_op_test.py"], tags = ["optonly"], deps = [ @@ -572,6 +573,7 @@ tf_xla_py_test( tf_xla_py_test( name = "matrix_band_part_test", size = "medium", + timeout = "long", srcs = ["matrix_band_part_test.py"], tags = ["optonly"], deps = [ diff --git a/tensorflow/compiler/xla/BUILD b/tensorflow/compiler/xla/BUILD index d448bad614..76e36f3c46 100644 --- a/tensorflow/compiler/xla/BUILD +++ b/tensorflow/compiler/xla/BUILD @@ -517,6 +517,7 @@ cc_library( ":util", ":xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/base", "@com_google_absl//absl/memory", ], ) diff --git a/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h b/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h index c18087ce6b..0ad01728e6 100644 --- a/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h +++ b/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h @@ -17,7 +17,6 @@ limitations under the License. #define TENSORFLOW_COMPILER_XLA_CLIENT_LIB_CONV_GRAD_SIZE_UTIL_H_ #include "tensorflow/compiler/xla/client/padding.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/types.h" namespace xla { diff --git a/tensorflow/compiler/xla/packed_literal_reader.cc b/tensorflow/compiler/xla/packed_literal_reader.cc index 83429b8fd3..f9473d372b 100644 --- a/tensorflow/compiler/xla/packed_literal_reader.cc +++ b/tensorflow/compiler/xla/packed_literal_reader.cc @@ -19,6 +19,7 @@ limitations under the License. #include <string> #include <utility> +#include "absl/base/casts.h" #include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" @@ -27,7 +28,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/casts.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/types.h" @@ -62,9 +62,9 @@ StatusOr<std::unique_ptr<Literal>> PackedLiteralReader::Read( int64 elements = ShapeUtil::ElementsIn(shape); absl::Span<const float> field = result->data<float>(); - char* data = tensorflow::bit_cast<char*>(field.data()); + char* data = absl::bit_cast<char*>(field.data()); uint64 bytes = elements * sizeof(float); - tensorflow::StringPiece sp; // non-absl OK + absl::string_view sp; auto s = file_->Read(offset_, bytes, &sp, data); offset_ += sp.size(); if (!s.ok()) { @@ -85,7 +85,7 @@ bool PackedLiteralReader::IsExhausted() const { // Try to read a single byte from offset_. If we can't, we've // exhausted the data. char single_byte[1]; - tensorflow::StringPiece sp; // non-absl OK + absl::string_view sp; auto s = file_->Read(offset_, sizeof(single_byte), &sp, single_byte); return !s.ok(); } diff --git a/tensorflow/compiler/xla/service/algebraic_simplifier.cc b/tensorflow/compiler/xla/service/algebraic_simplifier.cc index 95e554c9a5..7c078f07d7 100644 --- a/tensorflow/compiler/xla/service/algebraic_simplifier.cc +++ b/tensorflow/compiler/xla/service/algebraic_simplifier.cc @@ -127,6 +127,8 @@ class AlgebraicSimplifierVisitor : public DfsHloVisitorWithDefault { Status HandleImag(HloInstruction* imag) override; + Status HandleIota(HloInstruction* instruction) override; + Status HandleConvolution(HloInstruction* convolution) override; Status HandleDivide(HloInstruction* divide) override; @@ -1462,6 +1464,19 @@ Status AlgebraicSimplifierVisitor::HandleImag(HloInstruction* imag) { return Status::OK(); } +Status AlgebraicSimplifierVisitor::HandleIota(HloInstruction* instruction) { + // iota -> zero if the iota dimension never produces an element other than + // zero. + auto* iota = Cast<HloIotaInstruction>(instruction); + if (iota->shape().dimensions(iota->iota_dimension()) <= 1) { + auto zero = computation_->AddInstruction(HloInstruction::CreateConstant( + LiteralUtil::Zero(iota->shape().element_type()).CloneToUnique())); + return ReplaceWithNewInstruction( + iota, HloInstruction::CreateBroadcast(iota->shape(), zero, {})); + } + return Status::OK(); +} + Status AlgebraicSimplifierVisitor::HandlePad(HloInstruction* pad) { if (ShapeUtil::IsZeroElementArray(pad->operand(0)->shape())) { return ReplaceWithNewInstruction( diff --git a/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc b/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc index b4ff048db0..43a891e4fa 100644 --- a/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc +++ b/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc @@ -1858,12 +1858,33 @@ TEST_F(AlgebraicSimplifierTest, IotaAndReshapeMerged) { ShapeUtil::Equal(computation->root_instruction()->shape(), result_shape)); } -TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x1_3) { +TEST_F(AlgebraicSimplifierTest, IotaEffectiveScalar) { HloComputation::Builder builder(TestName()); auto iota = builder.AddInstruction( - HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 1}), 1)); + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {1, 1}), 0)); + auto result_shape = iota->shape(); + + auto computation = module().AddEntryComputation(builder.Build()); + + EXPECT_THAT(computation->root_instruction(), op::Iota()); + + AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, + non_bitcasting_callback()); + ASSERT_TRUE(simplifier.Run(&module()).ValueOrDie()); + + auto root = computation->root_instruction(); + EXPECT_THAT(root, op::Broadcast(op::Constant())); + EXPECT_EQ(0.0f, root->operand(0)->literal().GetFirstElement<float>()); + EXPECT_TRUE( + ShapeUtil::Equal(computation->root_instruction()->shape(), result_shape)); +} + +TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x2_6) { + HloComputation::Builder builder(TestName()); + auto iota = builder.AddInstruction( + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 2}), 1)); builder.AddInstruction( - HloInstruction::CreateReshape(ShapeUtil::MakeShape(F32, {3}), iota)); + HloInstruction::CreateReshape(ShapeUtil::MakeShape(F32, {6}), iota)); auto computation = module().AddEntryComputation(builder.Build()); @@ -1897,12 +1918,12 @@ TEST_F(AlgebraicSimplifierTest, IotaAndReshape_4_3x2x4_6x1x1x4) { 3); } -TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x2x1_6x1x1x1) { +TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x2x2_6x1x1x2) { HloComputation::Builder builder(TestName()); auto iota = builder.AddInstruction( - HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 2, 1}), 2)); + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 2, 2}), 2)); builder.AddInstruction(HloInstruction::CreateReshape( - ShapeUtil::MakeShape(F32, {6, 1, 1, 1}), iota)); + ShapeUtil::MakeShape(F32, {6, 1, 1, 2}), iota)); HloComputation* computation = module().AddEntryComputation(builder.Build()); diff --git a/tensorflow/compiler/xla/service/buffer_assignment.cc b/tensorflow/compiler/xla/service/buffer_assignment.cc index b11f15ec7b..8b8c6bfd26 100644 --- a/tensorflow/compiler/xla/service/buffer_assignment.cc +++ b/tensorflow/compiler/xla/service/buffer_assignment.cc @@ -58,12 +58,65 @@ string ColocatedBufferSetsToString(const T& container, const char* title) { return result; } -// Walk the call graph of the HLO module and place each computation into either -// thread_local_computations or global_computations depending upon whether the -// computation requires thread-local allocations or global allocations. The -// elements in thread_local_computations and global_computations are in post -// order (if computation A has an instruction which calls computation B, then A -// will appear after B in the vector). +// Checks that points-to set of 'instruction' is unambiguous and distinct +// (ensured by CopyInsertion), then adds the buffer from the points-to set at +// 'index' to 'colocated_set'. +const LogicalBuffer* AddBufferToColocatedSet( + const HloInstruction* instruction, const ShapeIndex& index, + const TuplePointsToAnalysis& points_to_analysis, + std::vector<const LogicalBuffer*>* colocated_set) { + // CopyInsertion ensures root points-to set is unambiguous and distinct. + const auto& points_to = points_to_analysis.GetPointsToSet(instruction); + DCHECK(!points_to.IsAmbiguous()); + colocated_set->push_back(points_to.element(index)[0]); + return colocated_set->back(); +} + +// Given the interference map of a graph (the list of interfering node indices +// for each node), perform graph coloring such that interfering nodes are +// assigned to different colors. Returns the assigned color of the nodes, where +// the colors are represented as integer values [0, color_count). +std::vector<int64> ColorInterferenceGraph( + const std::vector<std::vector<int64>>& interference_map) { + const int64 node_count = interference_map.size(); + + // Sort the nodes such that we assign nodes with more interference first. This + // relies on the common heuristic of assigning the most constrained node + // first, but it would be good to investigate other ordering heuristics too. + std::vector<int64> nodes(node_count); + std::iota(nodes.begin(), nodes.end(), 0); + std::sort(nodes.begin(), nodes.end(), + [&interference_map](const int64 i, const int64 j) { + return interference_map[i].size() > interference_map[j].size(); + }); + + const int64 kColorUnassigned = -1; + std::vector<int64> assigned_colors(node_count, kColorUnassigned); + for (int64 node : nodes) { + // Mark the colors that are already assigned to the neighbors. + std::vector<bool> available_colors(node_count, true); + for (int64 neighbor : interference_map[node]) { + int64 color = assigned_colors[neighbor]; + if (color != kColorUnassigned) { + available_colors[color] = false; + } + } + + // Find the color that is not yet assigned to the neighbors. + int64 color = kColorUnassigned; + for (color = 0; color < available_colors.size(); ++color) { + if (available_colors[color]) { + break; + } + } + CHECK_NE(color, kColorUnassigned); + assigned_colors[node] = color; + } + return assigned_colors; +} + +} // namespace + Status GatherComputationsByAllocationType( const HloModule* module, std::vector<const HloComputation*>* thread_local_computations, @@ -165,65 +218,6 @@ Status GatherComputationsByAllocationType( return Status::OK(); } -// Checks that points-to set of 'instruction' is unambiguous and distinct -// (ensured by CopyInsertion), then adds the buffer from the points-to set at -// 'index' to 'colocated_set'. -const LogicalBuffer* AddBufferToColocatedSet( - const HloInstruction* instruction, const ShapeIndex& index, - const TuplePointsToAnalysis& points_to_analysis, - std::vector<const LogicalBuffer*>* colocated_set) { - // CopyInsertion ensures root points-to set is unambiguous and distinct. - const auto& points_to = points_to_analysis.GetPointsToSet(instruction); - DCHECK(!points_to.IsAmbiguous()); - colocated_set->push_back(points_to.element(index)[0]); - return colocated_set->back(); -} - -// Given the interference map of a graph (the list of interfering node indices -// for each node), perform graph coloring such that interfering nodes are -// assigned to different colors. Returns the assigned color of the nodes, where -// the colors are represented as integer values [0, color_count). -std::vector<int64> ColorInterferenceGraph( - const std::vector<std::vector<int64>>& interference_map) { - const int64 node_count = interference_map.size(); - - // Sort the nodes such that we assign nodes with more interference first. This - // relies on the common heuristic of assigning the most constrained node - // first, but it would be good to investigate other ordering heuristics too. - std::vector<int64> nodes(node_count); - std::iota(nodes.begin(), nodes.end(), 0); - std::sort(nodes.begin(), nodes.end(), - [&interference_map](const int64 i, const int64 j) { - return interference_map[i].size() > interference_map[j].size(); - }); - - const int64 kColorUnassigned = -1; - std::vector<int64> assigned_colors(node_count, kColorUnassigned); - for (int64 node : nodes) { - // Mark the colors that are already assigned to the neighbors. - std::vector<bool> available_colors(node_count, true); - for (int64 neighbor : interference_map[node]) { - int64 color = assigned_colors[neighbor]; - if (color != kColorUnassigned) { - available_colors[color] = false; - } - } - - // Find the color that is not yet assigned to the neighbors. - int64 color = kColorUnassigned; - for (color = 0; color < available_colors.size(); ++color) { - if (available_colors[color]) { - break; - } - } - CHECK_NE(color, kColorUnassigned); - assigned_colors[node] = color; - } - return assigned_colors; -} - -} // namespace - size_t BufferAllocation::Slice::Hasher::operator()(Slice s) const { uint64 h = std::hash<int64>()(s.index()); h = tensorflow::Hash64Combine(h, std::hash<int64>()(s.offset())); diff --git a/tensorflow/compiler/xla/service/buffer_assignment.h b/tensorflow/compiler/xla/service/buffer_assignment.h index 9617d51a87..24ba7c16f5 100644 --- a/tensorflow/compiler/xla/service/buffer_assignment.h +++ b/tensorflow/compiler/xla/service/buffer_assignment.h @@ -41,6 +41,17 @@ limitations under the License. namespace xla { +// Walk the call graph of the HLO module and place each computation into either +// thread_local_computations or global_computations depending upon whether the +// computation requires thread-local allocations or global allocations. The +// elements in thread_local_computations and global_computations are in post +// order (if computation A has an instruction which calls computation B, then A +// will appear after B in the vector). +Status GatherComputationsByAllocationType( + const HloModule* module, + std::vector<const HloComputation*>* thread_local_computations, + std::vector<const HloComputation*>* global_computations); + // This class abstracts an allocation of contiguous memory which can hold the // values described by LogicalBuffers. Each LogicalBuffer occupies a sub-range // of the allocation, represented by a Slice. A single BufferAllocation may hold diff --git a/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc b/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc index 6420180b13..796f36510e 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc @@ -588,8 +588,7 @@ StatusOr<std::unique_ptr<Executable>> CpuCompiler::RunBackend( ScheduleComputationsInModule(*module, BufferSizeBytesFunction(), DFSMemoryScheduler)); - // Run buffer analysis on the HLO graph. This analysis figures out which - // temporary buffers are required to run the computation. + // Run buffer allocation on the HLO graph. TF_ASSIGN_OR_RETURN( std::unique_ptr<BufferAssignment> assignment, BufferAssigner::Run(module.get(), diff --git a/tensorflow/compiler/xla/service/cpu/cpu_executable.cc b/tensorflow/compiler/xla/service/cpu/cpu_executable.cc index 9b00f2eaa5..29abf38e43 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_executable.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_executable.cc @@ -75,7 +75,7 @@ CpuExecutable::CpuExecutable( StatusOr<std::pair<std::vector<se::DeviceMemoryBase>, std::vector<OwningDeviceMemory>>> -CpuExecutable::CreateTempArray( +CpuExecutable::CreateBufferTable( DeviceMemoryAllocator* memory_allocator, int device_ordinal, absl::Span<const ShapedBuffer* const> arguments) { std::vector<se::DeviceMemoryBase> unowning_buffers( @@ -141,14 +141,14 @@ Status CpuExecutable::ExecuteComputeFunction( // The calling convention for JITed functions is: // // void function(void* result, const void* run_options, void** args_array, - // void** temps_array) + // void** buffer_table) // // result: Points at the result. // run_options: the ExecutableRunOptions object. // args_array: null - // temps_array: An array of pointers, containing pointers to temporary buffers - // required by the executable adn pointers to entry computation - // parameters. + // buffer_table: An array of pointers, containing pointers to temporary + // buffers required by the executable adn pointers to entry computation + // parameters. // uint64 start_micros = tensorflow::Env::Default()->NowMicros(); @@ -172,7 +172,7 @@ Status CpuExecutable::ExecuteComputeFunction( if (VLOG_IS_ON(3)) { VLOG(3) << "Executing compute function:"; VLOG(3) << absl::StrFormat( - " func(void* result, void* params[null], void* temps[%u], " + " func(void* result, void* params[null], void* buffer_table[%u], " "uint64 profile_counters[%u])", buffer_pointers.size(), profile_counters_size); VLOG(3) << absl::StrFormat(" result = %p", result_buffer); @@ -181,7 +181,8 @@ Status CpuExecutable::ExecuteComputeFunction( }; VLOG(3) << " params = nullptr"; VLOG(3) << absl::StrFormat( - " temps = [%s]", absl::StrJoin(buffer_pointers, ", ", ptr_printer)); + " buffer_table = [%s]", + absl::StrJoin(buffer_pointers, ", ", ptr_printer)); VLOG(3) << absl::StrFormat(" profile_counters = %p", profile_counters); } @@ -281,8 +282,8 @@ StatusOr<ScopedShapedBuffer> CpuExecutable::ExecuteAsyncOnStreamImpl( std::vector<se::DeviceMemoryBase> unowning_buffers; TF_ASSIGN_OR_RETURN( std::tie(unowning_buffers, owning_buffers), - CreateTempArray(memory_allocator, stream->parent()->device_ordinal(), - arguments)); + CreateBufferTable(memory_allocator, stream->parent()->device_ordinal(), + arguments)); TF_ASSIGN_OR_RETURN( ScopedShapedBuffer result, diff --git a/tensorflow/compiler/xla/service/cpu/cpu_executable.h b/tensorflow/compiler/xla/service/cpu/cpu_executable.h index 3571513e02..3c3c047bfe 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_executable.h +++ b/tensorflow/compiler/xla/service/cpu/cpu_executable.h @@ -74,9 +74,10 @@ class CpuExecutable : public Executable { static int64 ShapeSizeBytes(const Shape& shape); // Type of the computation function we expect in the JIT. - using ComputeFunctionType = void (*)( - void* /*result*/, const ExecutableRunOptions* /*run_options*/, - const void** /*args*/, void** /*temps*/, int64* /*profile_counters*/); + using ComputeFunctionType = + void (*)(void* /*result*/, const ExecutableRunOptions* /*run_options*/, + const void** /*args*/, void** /*buffer_table*/, + int64* /*profile_counters*/); const ComputeFunctionType& compute_function() const { return compute_function_; @@ -95,15 +96,15 @@ class CpuExecutable : public Executable { absl::Span<const ShapedBuffer* const> arguments, HloExecutionProfile* hlo_execution_profile); - // Creates an array suitable for passing as the "temps" argument to the JIT - // compiled function pointer. + // Creates an array suitable for passing as the "buffer_table" argument to the + // JIT compiled function pointer. // // Returns (unowning_buffers, owning_buffers) where: // - // - unowning_buffers.data() can be passed as the temps argument as-is and - // includes pointers to the scratch storage required by the computation, - // the live-out buffer into which the result will be written and entry - // computation parameters. + // - unowning_buffers.data() can be passed as the buffer_table argument as-is + // and includes pointers to the scratch storage required by the + // computation, the live-out buffer into which the result will be written + // and entry computation parameters. // // - owning_buffers contains owning pointers to the buffers that were // allocated by this routine. This routine allocates buffers for temporary @@ -111,8 +112,8 @@ class CpuExecutable : public Executable { // result. StatusOr<std::pair<std::vector<se::DeviceMemoryBase>, std::vector<OwningDeviceMemory>>> - CreateTempArray(DeviceMemoryAllocator* memory_allocator, int device_ordinal, - absl::Span<const ShapedBuffer* const> arguments); + CreateBufferTable(DeviceMemoryAllocator* memory_allocator, int device_ordinal, + absl::Span<const ShapedBuffer* const> arguments); // Calls the generated function performing the computation with the given // arguments using the supplied buffers. diff --git a/tensorflow/compiler/xla/service/cpu/ir_emitter.cc b/tensorflow/compiler/xla/service/cpu/ir_emitter.cc index 8eaca57680..e5cf15c686 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_emitter.cc +++ b/tensorflow/compiler/xla/service/cpu/ir_emitter.cc @@ -100,6 +100,11 @@ IrEmitter::IrEmitter( b_.setFastMathFlags(llvm_ir::GetFastMathFlags( /*fast_math_enabled=*/hlo_module_config_.debug_options() .xla_cpu_enable_fast_math())); + Status s = GatherComputationsByAllocationType( + &hlo_module, &thread_local_computations_, &global_computations_); + absl::c_sort(thread_local_computations_); + absl::c_sort(global_computations_); + TF_CHECK_OK(s) << "Should have failed buffer assignment."; } StatusOr<llvm::Function*> IrEmitter::EmitComputation( @@ -337,10 +342,10 @@ Status IrEmitter::HandleInfeed(HloInstruction* instruction) { // Write the tuple index table. TF_ASSIGN_OR_RETURN(BufferAllocation::Slice data_slice, assignment_.GetUniqueSlice(infeed, {0})); - llvm::Value* data_address = EmitTempBufferPointer(data_slice, data_shape); + llvm::Value* data_address = EmitBufferPointer(data_slice, data_shape); TF_ASSIGN_OR_RETURN(BufferAllocation::Slice token_slice, assignment_.GetUniqueSlice(infeed, {1})); - llvm::Value* token_address = EmitTempBufferPointer( + llvm::Value* token_address = EmitBufferPointer( token_slice, ShapeUtil::GetTupleElementShape(infeed->shape(), 1)); llvm_ir::EmitTuple(GetIrArrayFor(infeed), {data_address, token_address}, &b_, module_); @@ -363,9 +368,9 @@ Status IrEmitter::HandleInfeed(HloInstruction* instruction) { // Only the outer tuple buffer's target address is obtained from // GetEmittedValueFor, to handle the case when Infeed is the root // instruction. Target addresses for internal elements can be obtained - // from EmitTempBufferPointer. + // from EmitBufferPointer. llvm::Value* tuple_element_address = - EmitTempBufferPointer(buffer, tuple_element_shape); + EmitBufferPointer(buffer, tuple_element_shape); TF_RETURN_IF_ERROR(EmitXfeedTransfer( XfeedKind::kInfeed, tuple_element_shape, tuple_element_address)); @@ -1200,7 +1205,7 @@ Status IrEmitter::HandleCrossReplicaSum(HloInstruction* crs) { const Shape& operand_shape = crs->operand(i)->shape(); CHECK(ShapeUtil::IsArray(operand_shape)) << "Operands to cross-replica-sum must be arrays: " << crs->ToString(); - operand_ptrs.push_back(EmitTempBufferPointer(out_slice, operand_shape)); + operand_ptrs.push_back(EmitBufferPointer(out_slice, operand_shape)); // TODO(b/63762267): Be more aggressive about specifying alignment. MemCpy(operand_ptrs.back(), /*DstAlign=*/1, in_ptr, @@ -2097,7 +2102,7 @@ Status IrEmitter::HandleCall(HloInstruction* call) { {}, &b_, computation->name(), /*return_value_buffer=*/emitted_value_[call], /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), - /*temp_buffers_arg=*/GetTempBuffersArgument(), + /*buffer_table_arg=*/GetBufferTableArgument(), /*profile_counters_arg=*/GetProfileCountersArgument()); HloInstruction* root = computation->root_instruction(); @@ -2617,15 +2622,15 @@ llvm::Value* IrEmitter::GetProfileCountersArgument() { return compute_function_->profile_counters_arg(); } -llvm::Value* IrEmitter::GetTempBuffersArgument() { - return compute_function_->temp_buffers_arg(); +llvm::Value* IrEmitter::GetBufferTableArgument() { + return compute_function_->buffer_table_arg(); } llvm::Value* IrEmitter::GetExecutableRunOptionsArgument() { return compute_function_->exec_run_options_arg(); } -llvm::Value* IrEmitter::EmitThreadLocalTempBufferPointer( +llvm::Value* IrEmitter::EmitThreadLocalBufferPointer( const BufferAllocation::Slice& slice, const Shape& target_shape) { const BufferAllocation& allocation = *slice.allocation(); llvm::Value* tempbuf_address = [&]() -> llvm::Value* { @@ -2684,11 +2689,11 @@ llvm::Value* IrEmitter::EmitThreadLocalTempBufferPointer( return BitCast(tempbuf_address, IrShapeType(target_shape)->getPointerTo()); } -llvm::Value* IrEmitter::EmitGlobalTempBufferPointer( +llvm::Value* IrEmitter::EmitGlobalBufferPointer( const BufferAllocation::Slice& slice, const Shape& target_shape) { const BufferAllocation& allocation = *slice.allocation(); llvm::Value* tempbuf_address_ptr = llvm_ir::EmitBufferIndexingGEP( - GetTempBuffersArgument(), slice.index(), &b_); + GetBufferTableArgument(), slice.index(), &b_); llvm::LoadInst* tempbuf_address_base = Load(tempbuf_address_ptr); if (hlo_module_config_.debug_options() .xla_llvm_enable_invariant_load_metadata()) { @@ -2709,14 +2714,14 @@ llvm::Value* IrEmitter::EmitGlobalTempBufferPointer( IrShapeType(target_shape)->getPointerTo()); } -llvm::Value* IrEmitter::EmitTempBufferPointer( - const BufferAllocation::Slice& slice, const Shape& target_shape) { +llvm::Value* IrEmitter::EmitBufferPointer(const BufferAllocation::Slice& slice, + const Shape& target_shape) { if (slice.allocation()->is_thread_local()) { - return EmitThreadLocalTempBufferPointer(slice, target_shape); + return EmitThreadLocalBufferPointer(slice, target_shape); } else if (slice.allocation()->is_constant()) { return FindOrDie(constant_buffer_to_global_, slice.allocation()->index()); } else { - return EmitGlobalTempBufferPointer(slice, target_shape); + return EmitGlobalBufferPointer(slice, target_shape); } } @@ -2724,7 +2729,7 @@ Status IrEmitter::EmitTargetAddressForOp(const HloInstruction* op) { const Shape& target_shape = op->shape(); TF_ASSIGN_OR_RETURN(const BufferAllocation::Slice slice, assignment_.GetUniqueTopLevelSlice(op)); - llvm::Value* addr = EmitTempBufferPointer(slice, target_shape); + llvm::Value* addr = EmitBufferPointer(slice, target_shape); addr->setName(AsStringRef(IrName(op))); emitted_value_[op] = addr; return Status::OK(); @@ -2753,8 +2758,7 @@ Status IrEmitter::EmitTargetElementLoop( TF_ASSIGN_OR_RETURN(BufferAllocation::Slice slice, assignment_.GetUniqueSlice(target_op, {i})); const Shape& element_shape = ShapeUtil::GetSubshape(target_shape, {i}); - llvm::Value* op_target_address = - EmitTempBufferPointer(slice, element_shape); + llvm::Value* op_target_address = EmitBufferPointer(slice, element_shape); output_arrays.push_back( llvm_ir::IrArray(op_target_address, element_shape)); } @@ -2832,6 +2836,8 @@ Status IrEmitter::DefaultAction(HloInstruction* hlo) { llvm::Value* IrEmitter::EmitThreadLocalCall( const HloComputation& callee, absl::Span<llvm::Value* const> parameters, absl::string_view name) { + CHECK(absl::c_binary_search(thread_local_computations_, &callee)); + const Shape& return_shape = callee.root_instruction()->shape(); // Lifting this restriction to allow "small" arrays should be easy. Allowing @@ -2860,7 +2866,7 @@ llvm::Value* IrEmitter::EmitThreadLocalCall( parameter_addrs, &b_, name, /*return_value_buffer=*/return_value_buffer, /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), - /*temp_buffers_arg=*/ + /*buffer_table_arg=*/ llvm::Constant::getNullValue(b_.getInt8PtrTy()->getPointerTo()), /*profile_counters_arg=*/GetProfileCountersArgument())); @@ -2869,13 +2875,15 @@ llvm::Value* IrEmitter::EmitThreadLocalCall( void IrEmitter::EmitGlobalCall(const HloComputation& callee, absl::string_view name) { + CHECK(absl::c_binary_search(global_computations_, &callee)); + Call(FindOrDie(emitted_functions_, &callee), GetArrayFunctionCallArguments( /*parameter_addresses=*/{}, &b_, name, /*return_value_buffer=*/ llvm::Constant::getNullValue(b_.getInt8PtrTy()), /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), - /*temp_buffers_arg=*/GetTempBuffersArgument(), + /*buffer_table_arg=*/GetBufferTableArgument(), /*profile_counters_arg=*/GetProfileCountersArgument())); } @@ -2888,7 +2896,7 @@ llvm::Value* IrEmitter::GetBufferForGlobalCallReturnValue( const BufferAllocation::Slice root_buffer = assignment_.GetUniqueTopLevelSlice(root_inst).ValueOrDie(); - return EmitTempBufferPointer(root_buffer, root_inst->shape()); + return EmitBufferPointer(root_buffer, root_inst->shape()); } } // namespace cpu diff --git a/tensorflow/compiler/xla/service/cpu/ir_emitter.h b/tensorflow/compiler/xla/service/cpu/ir_emitter.h index 9cb8162327..58a333b8fb 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_emitter.h +++ b/tensorflow/compiler/xla/service/cpu/ir_emitter.h @@ -62,8 +62,8 @@ class IrEmitter : public DfsHloVisitorWithDefault, // Create a new LLVM IR emitter. // // hlo_module: the HLO module we are emitting IR for. - // assignment: a BufferAssignment from which we know which temporary buffers - // are used by the HLO nodes. + // assignment: a BufferAssignment from which we know which buffers are used by + // the HLO nodes. // llvm_module: the LLVM module to emit IR into. // instruction_to_profile_idx: the mapping from HLO instructions to their // index in the profiling array. @@ -219,24 +219,21 @@ class IrEmitter : public DfsHloVisitorWithDefault, // argument of the computation function being emitted by this emitter. llvm::Value* GetExecutableRunOptionsArgument(); - // Get the llvm::Value* that represents the "temps" argument of the + // Get the llvm::Value* that represents the "buffer_table" argument of the // computation function being emitted by this emitter. - llvm::Value* GetTempBuffersArgument(); + llvm::Value* GetBufferTableArgument(); - // Helper for EmitTempBufferPointer. - llvm::Value* EmitGlobalTempBufferPointer(const BufferAllocation::Slice& slice, - const Shape& target_shape); + // Helper for EmitBufferPointer. + llvm::Value* EmitGlobalBufferPointer(const BufferAllocation::Slice& slice, + const Shape& target_shape); - // Helper for EmitTempBufferPointer. - llvm::Value* EmitThreadLocalTempBufferPointer( + // Helper for EmitBufferPointer. + llvm::Value* EmitThreadLocalBufferPointer( const BufferAllocation::Slice& slice, const Shape& target_shape); // Emits code that computes the address of the given buffer allocation slice. - // - // TODO(sanjoy): This should be renamed to reflect that it no longer provides - // access to just temporaries. - llvm::Value* EmitTempBufferPointer(const BufferAllocation::Slice& slice, - const Shape& target_shape); + llvm::Value* EmitBufferPointer(const BufferAllocation::Slice& slice, + const Shape& target_shape); // Emits a function into the current module. This can be used for // computations embedded inside other computations, such as the @@ -390,8 +387,8 @@ class IrEmitter : public DfsHloVisitorWithDefault, const llvm_ir::IrArray& target_array, const llvm_ir::IrArray& source_array); - // Assignment of the temporary buffers needed by the computation and their - // shape information. + // Assignment of the buffers needed by the computation and their shape + // information. const BufferAssignment& assignment_; // The LLVM module into which IR will be emitted. @@ -571,6 +568,9 @@ class IrEmitter : public DfsHloVisitorWithDefault, tensorflow::gtl::FlatMap<BufferAllocation::Index, llvm::Constant*> constant_buffer_to_global_; + std::vector<const HloComputation*> thread_local_computations_; + std::vector<const HloComputation*> global_computations_; + TF_DISALLOW_COPY_AND_ASSIGN(IrEmitter); }; diff --git a/tensorflow/compiler/xla/service/cpu/ir_function.cc b/tensorflow/compiler/xla/service/cpu/ir_function.cc index 3ecf4b69b7..adfb8392bf 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_function.cc +++ b/tensorflow/compiler/xla/service/cpu/ir_function.cc @@ -78,19 +78,20 @@ void IrFunction::Initialize(const string& function_name, const bool optimize_for_size_requested, const bool enable_fast_math) { // The function signature is: - // void function(i8* retval, i8* run_options, i8** params, i8** temps, + // void function(i8* retval, i8* run_options, i8** params, i8** + // buffer_table, // i64* dynamic_loop_bounds, i64* prof_counters) // // For thread local functions: // retval: points to the returned value. // params: address of an array with pointers to parameters. - // temps: is null + // buffer_table: is null // // For global functions: // retval: is null // params: is null - // temps: address of an array with pointers to temporary buffers and entry - // computation parameters. + // buffer_table: address of an array with pointers to temporary buffers and + // entry computation parameters (but not to constant buffers). // // Therefore, the generated function's signature (FunctionType) is statically // determined - parameter unpacking is done in code generated into the @@ -116,7 +117,7 @@ void IrFunction::Initialize(const string& function_name, // \---------/ \---------/ \-----------/ // // /---------------------------------------------\ - // temps ---------> | temp 0 | temp 1 | ..... | temp N-1 | + // buffer_table---> | buff 0 | guff 1 | ..... | buff N-1 | // | addr | addr | | addr | // \---------------------------------------------/ // | | | @@ -134,9 +135,9 @@ void IrFunction::Initialize(const string& function_name, // prof counters -> | counter 0 | counter 1 | ..... | counter N-1 | // \---------------------------------------------/ - // Even though the type of params and temps is void** in the host's view, in - // LLVM IR this is represented by i8*, similarly to void*. It's up to the code - // to use GEPs to unravel the indirection layers. + // Even though the type of params and buffer_table is void** in the host's + // view, in LLVM IR this is represented by i8*, similarly to void*. It's up to + // the code to use GEPs to unravel the indirection layers. llvm::FunctionType* function_type = llvm::FunctionType::get( /*Result=*/llvm::Type::getVoidTy(llvm_module_->getContext()), /*Params=*/ @@ -160,8 +161,8 @@ void IrFunction::Initialize(const string& function_name, exec_run_options_arg_ = &*arg_iter; (++arg_iter)->setName("params"); parameters_arg_ = &*arg_iter; - (++arg_iter)->setName("temps"); - temp_buffers_arg_ = &*arg_iter; + (++arg_iter)->setName("buffer_table"); + buffer_table_arg_ = &*arg_iter; if (num_dynamic_loop_bounds_ > 0) { (++arg_iter)->setName("dynamic_loop_bounds"); dynamic_loop_bounds_arg_ = &*arg_iter; @@ -202,7 +203,7 @@ llvm::Value* IrFunction::GetDynamicLoopBound(const int64 offset) { std::vector<llvm::Value*> GetArrayFunctionCallArguments( absl::Span<llvm::Value* const> parameter_addresses, llvm::IRBuilder<>* b, absl::string_view name, llvm::Value* return_value_buffer, - llvm::Value* exec_run_options_arg, llvm::Value* temp_buffers_arg, + llvm::Value* exec_run_options_arg, llvm::Value* buffer_table_arg, llvm::Value* profile_counters_arg) { llvm::Value* parameter_addresses_buffer; @@ -230,7 +231,7 @@ std::vector<llvm::Value*> GetArrayFunctionCallArguments( }; std::vector<llvm::Value*> arguments{ to_int8_ptr(return_value_buffer), to_int8_ptr(exec_run_options_arg), - parameter_addresses_buffer, temp_buffers_arg}; + parameter_addresses_buffer, buffer_table_arg}; if (profile_counters_arg != nullptr) { arguments.push_back(profile_counters_arg); } diff --git a/tensorflow/compiler/xla/service/cpu/ir_function.h b/tensorflow/compiler/xla/service/cpu/ir_function.h index 28c69c85a9..623a5f185f 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_function.h +++ b/tensorflow/compiler/xla/service/cpu/ir_function.h @@ -80,8 +80,9 @@ class IrFunction { // Get the llvm::Value* that represents this functions parameters argument. llvm::Value* parameters_arg() { return parameters_arg_; } - // Get the llvm::Value* that represents this functions "temps" argument. - llvm::Value* temp_buffers_arg() { return temp_buffers_arg_; } + // Get the llvm::Value* that represents this functions "buffer_table" + // argument. + llvm::Value* buffer_table_arg() { return buffer_table_arg_; } // Get the llvm::Value* that represents this functions "prof_counters" // argument. @@ -108,7 +109,7 @@ class IrFunction { llvm::Argument* result_arg_; llvm::Value* exec_run_options_arg_; llvm::Value* parameters_arg_; - llvm::Value* temp_buffers_arg_; + llvm::Value* buffer_table_arg_; llvm::Value* dynamic_loop_bounds_arg_ = nullptr; llvm::Value* profile_counters_arg_; }; @@ -117,7 +118,7 @@ class IrFunction { std::vector<llvm::Value*> GetArrayFunctionCallArguments( absl::Span<llvm::Value* const> parameter_addresses, llvm::IRBuilder<>* b, absl::string_view name, llvm::Value* return_value_buffer, - llvm::Value* exec_run_options_arg, llvm::Value* temp_buffers_arg, + llvm::Value* exec_run_options_arg, llvm::Value* buffer_table_arg, llvm::Value* profile_counters_arg); // Emits a call to a runtime fork/join function which dispatches parallel diff --git a/tensorflow/compiler/xla/service/cpu/runtime_fork_join.cc b/tensorflow/compiler/xla/service/cpu/runtime_fork_join.cc index a5f34908d7..2d9492eacf 100644 --- a/tensorflow/compiler/xla/service/cpu/runtime_fork_join.cc +++ b/tensorflow/compiler/xla/service/cpu/runtime_fork_join.cc @@ -61,7 +61,7 @@ using ComputeFunctionType = void (*)(void*, const void*, const void**, void**, // TF_ATTRIBUTE_NO_SANITIZE_MEMORY void __xla_cpu_runtime_ParallelForkJoin( void* result_ptr, const void* run_options_ptr, const void** params, - void** temps, uint64* prof_counters, int32 num_partitions, + void** buffer_table, uint64* prof_counters, int32 num_partitions, int64* partitions, int32 num_partitioned_dims, void* function_ptr) { VLOG(2) << "ParallelForkJoin ENTRY" << " num_partitions: " << num_partitions @@ -81,9 +81,9 @@ TF_ATTRIBUTE_NO_SANITIZE_MEMORY void __xla_cpu_runtime_ParallelForkJoin( for (int32 i = 1; i < num_partitions; ++i) { const int64 offset = i * stride; run_options->intra_op_thread_pool()->enqueueNoNotification( - [i, function, result_ptr, run_options_ptr, temps, prof_counters, + [i, function, result_ptr, run_options_ptr, buffer_table, prof_counters, partitions, offset, &bc]() { - function(result_ptr, run_options_ptr, nullptr, temps, + function(result_ptr, run_options_ptr, nullptr, buffer_table, &partitions[offset], prof_counters); bc.DecrementCount(); VLOG(3) << "ParallelForkJoin partition " << i << " done."; @@ -91,7 +91,7 @@ TF_ATTRIBUTE_NO_SANITIZE_MEMORY void __xla_cpu_runtime_ParallelForkJoin( } // Call first compute function inline. - function(result_ptr, run_options_ptr, params, temps, &partitions[0], + function(result_ptr, run_options_ptr, params, buffer_table, &partitions[0], prof_counters); VLOG(3) << "ParallelForkJoin partition 0 done."; bc.Wait(); diff --git a/tensorflow/compiler/xla/service/cpu/runtime_fork_join.h b/tensorflow/compiler/xla/service/cpu/runtime_fork_join.h index 1cf0ec6e3d..a279c7d2d6 100644 --- a/tensorflow/compiler/xla/service/cpu/runtime_fork_join.h +++ b/tensorflow/compiler/xla/service/cpu/runtime_fork_join.h @@ -24,7 +24,7 @@ extern "C" { // threads before returning. See comments in runtime_fork_join.cc for details. extern void __xla_cpu_runtime_ParallelForkJoin( void* result_ptr, const void* run_options_ptr, const void** params, - void** temps, tensorflow::uint64* prof_counters, + void** buffer_table, tensorflow::uint64* prof_counters, tensorflow::int32 num_partitions, tensorflow::int64* partitions, tensorflow::int32 num_partitioned_dims, void* function_ptr); diff --git a/tensorflow/compiler/xla/service/gpu/BUILD b/tensorflow/compiler/xla/service/gpu/BUILD index d780b5751c..a68b7a1bef 100644 --- a/tensorflow/compiler/xla/service/gpu/BUILD +++ b/tensorflow/compiler/xla/service/gpu/BUILD @@ -676,7 +676,6 @@ cc_library( "//tensorflow/compiler/xla/service:buffer_liveness", "//tensorflow/compiler/xla/service:call_inliner", "//tensorflow/compiler/xla/service:conditional_simplifier", - "//tensorflow/compiler/xla/service:convolution_feature_group_converter", "//tensorflow/compiler/xla/service:executable", "//tensorflow/compiler/xla/service:flatten_call_graph", "//tensorflow/compiler/xla/service:hlo", diff --git a/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc b/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc index eea31f3de1..05448d863d 100644 --- a/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc @@ -37,8 +37,8 @@ ConvolutionThunk::ConvolutionThunk( const BufferAllocation::Slice& tuple_result_buffer, const BufferAllocation::Slice& scratch_buffer, const Shape& input_shape, const Shape& filter_shape, const Shape& output_shape, const Window& window, - const ConvolutionDimensionNumbers& dim_nums, int64 algorithm, - bool tensor_ops_enabled, const HloInstruction* hlo) + const ConvolutionDimensionNumbers& dim_nums, int64 feature_group_count, + int64 algorithm, bool tensor_ops_enabled, const HloInstruction* hlo) : Thunk(Kind::kConvolution, hlo), convolution_kind_(convolution_kind), input_buffer_(input_buffer), @@ -51,6 +51,7 @@ ConvolutionThunk::ConvolutionThunk( output_shape_(output_shape), window_(window), dim_nums_(dim_nums), + feature_group_count_(feature_group_count), algorithm_(algorithm), tensor_ops_enabled_(tensor_ops_enabled) {} @@ -72,8 +73,8 @@ Status ConvolutionThunk::ExecuteOnStream( auto op_profiler = profiler->MakeScopedInstructionProfiler(hlo_instruction()); TF_RETURN_IF_ERROR(RunCudnnConvolution( convolution_kind_, input_shape_, filter_shape_, output_shape_, input_data, - filter_data, output_data, scratch, window_, dim_nums_, algorithm_config, - stream)); + filter_data, output_data, scratch, window_, dim_nums_, + feature_group_count_, algorithm_config, stream)); // Figure out which of output/input/filter is the result produced by // this op, and write the result tuple. diff --git a/tensorflow/compiler/xla/service/gpu/convolution_thunk.h b/tensorflow/compiler/xla/service/gpu/convolution_thunk.h index f7952787c1..68d67c40c5 100644 --- a/tensorflow/compiler/xla/service/gpu/convolution_thunk.h +++ b/tensorflow/compiler/xla/service/gpu/convolution_thunk.h @@ -59,7 +59,8 @@ class ConvolutionThunk : public Thunk { const BufferAllocation::Slice& scratch_buffer, const Shape& input_shape, const Shape& filter_shape, const Shape& output_shape, const Window& window, - const ConvolutionDimensionNumbers& dim_nums, int64 algorithm, + const ConvolutionDimensionNumbers& dim_nums, + int64 feature_group_count, int64 algorithm, bool tensor_ops_enabled, const HloInstruction* hlo); ConvolutionThunk(const ConvolutionThunk&) = delete; @@ -71,19 +72,6 @@ class ConvolutionThunk : public Thunk { HloExecutionProfiler* profiler) override; private: - class ScratchAllocator; - - Status Convolve(const se::dnn::BatchDescriptor& input_descriptor, - se::DeviceMemory<float> input_data, - const se::dnn::FilterDescriptor& filter_descriptor, - se::DeviceMemory<float> filter_data, - const se::dnn::BatchDescriptor& output_descriptor, - se::DeviceMemory<float> output_data, - const se::dnn::ConvolutionDescriptor& convolution_descriptor, - const se::dnn::AlgorithmConfig& algorithm_config, - se::Stream* stream, ScratchAllocator* scratch_allocator, - se::dnn::ProfileResult* profile_result); - const CudnnConvKind convolution_kind_; const BufferAllocation::Slice input_buffer_; @@ -98,6 +86,7 @@ class ConvolutionThunk : public Thunk { const Window window_; const ConvolutionDimensionNumbers dim_nums_; + int64 feature_group_count_; int64 algorithm_; bool tensor_ops_enabled_; }; diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc index 2af31a52f9..5c2555148a 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc @@ -178,7 +178,8 @@ StatusOr<std::tuple<int64, bool, int64>> CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( CudnnConvKind kind, const Shape& input_shape, const Shape& filter_shape, const Shape& output_shape, const Window& window, - const ConvolutionDimensionNumbers& dnums, HloInstruction* instr) { + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, + HloInstruction* instr) { CHECK_EQ(input_shape.element_type(), filter_shape.element_type()); CHECK_EQ(input_shape.element_type(), output_shape.element_type()); // TODO(timshen): for now only check fp16. It can be expanded to other types, @@ -192,6 +193,12 @@ CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( // concurrently and then run them sequentially. tensorflow::mutex_lock lock = LockGpu(stream_exec_); + // Make sure any previous activity on this executor is done. We don't want to + // interfere with programs that are still running on the GPU. + if (!stream_exec_->SynchronizeAllActivity()) { + return InternalError("Failed to synchronize GPU for autotuning."); + } + // Create a stream for us to do our work on. se::Stream stream{stream_exec_}; stream.Init(); @@ -233,8 +240,8 @@ CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( CHECK_EQ(0, left_over_bytes % 2); constexpr float kBroadcastedConstant = 0.1f; - Eigen::half halfs[2] = {Eigen::half(kBroadcastedConstant), - Eigen::half(kBroadcastedConstant)}; + static const Eigen::half halfs[2] = {Eigen::half(kBroadcastedConstant), + Eigen::half(kBroadcastedConstant)}; uint32 bits; static_assert(sizeof(bits) == sizeof(halfs), ""); memcpy(&bits, halfs, sizeof(bits)); @@ -258,7 +265,6 @@ CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( .ThenMemZero(&filter_buf, filter_buf.size()) .ThenMemZero(&output_buf, output_buf.size()); } - TF_RETURN_IF_ERROR(stream.BlockHostUntilDone()); DeviceMemoryBase* result_buf = [&] { switch (kind) { @@ -289,10 +295,10 @@ CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( << instr->ToString(); bool launch_ok = - RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - input_buf, filter_buf, output_buf, - &scratch_allocator, window, dnums, - AlgorithmConfig(alg), &stream, &profile_result) + RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, input_buf, + filter_buf, output_buf, &scratch_allocator, window, dnums, + feature_group_count, AlgorithmConfig(alg), &stream, &profile_result) .ok(); if (launch_ok && profile_result.is_valid()) { @@ -378,17 +384,20 @@ StatusOr<bool> CudnnConvolutionAlgorithmPicker::RunOnInstruction( PickBestAlgorithm(CudnnConvKind::kForward, /*input_shape=*/lhs_shape, /*filter_shape=*/rhs_shape, /*output_shape=*/conv_result_shape, instr->window(), - instr->convolution_dimension_numbers(), instr); + instr->convolution_dimension_numbers(), + instr->feature_group_count(), instr); } else if (call_target == kCudnnConvBackwardInputCallTarget) { alg_scratch_and_tc = PickBestAlgorithm( CudnnConvKind::kBackwardInput, /*input_shape=*/conv_result_shape, /*filter_shape=*/rhs_shape, /*output_shape=*/lhs_shape, instr->window(), - instr->convolution_dimension_numbers(), instr); + instr->convolution_dimension_numbers(), instr->feature_group_count(), + instr); } else if (call_target == kCudnnConvBackwardFilterCallTarget) { alg_scratch_and_tc = PickBestAlgorithm( CudnnConvKind::kBackwardFilter, /*input_shape=*/lhs_shape, /*filter_shape=*/conv_result_shape, /*output_shape=*/rhs_shape, - instr->window(), instr->convolution_dimension_numbers(), instr); + instr->window(), instr->convolution_dimension_numbers(), + instr->feature_group_count(), instr); } else { LOG(FATAL) << "Unknown custom call target for cudnn conv: " << instr->ToString(); @@ -422,14 +431,9 @@ StatusOr<bool> CudnnConvolutionAlgorithmPicker::RunOnInstruction( backend_config.set_algorithm(algorithm); backend_config.set_tensor_ops_enabled(tensor_ops_enabled); - HloInstruction* new_call = - computation->AddInstruction(HloInstruction::CreateCustomCall( - new_call_shape, - {instr->mutable_operand(0), instr->mutable_operand(1)}, - instr->custom_call_target())); - new_call->set_window(instr->window()); - new_call->set_convolution_dimension_numbers( - instr->convolution_dimension_numbers()); + HloInstruction* new_call = computation->AddInstruction( + instr->CloneWithNewOperands(new_call_shape, {instr->mutable_operand(0), + instr->mutable_operand(1)})); TF_RETURN_IF_ERROR(new_call->set_backend_config(backend_config)); // Repackage new_call so it has the same shape as the original call, namely diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h index f76d273e8c..0cb01161b0 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h @@ -51,7 +51,8 @@ class CudnnConvolutionAlgorithmPicker : public HloPassInterface { StatusOr<std::tuple<int64, bool, int64>> PickBestAlgorithm( CudnnConvKind kind, const Shape& input_shape, const Shape& filter_shape, const Shape& output_shape, const Window& window, - const ConvolutionDimensionNumbers& dnums, HloInstruction* instr); + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, + HloInstruction* instr); se::StreamExecutor* stream_exec_; // never null DeviceMemoryAllocator* allocator_; // may be null diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc index 0b1ee2dc33..9bf721ecd2 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc @@ -59,6 +59,11 @@ std::tuple<bool, Window, ConvolutionDimensionNumbers> MatchBackwardFilter( HloInstruction* conv) { const auto no_match_result = std::make_tuple(false, Window(), ConvolutionDimensionNumbers()); + // TODO(b/31709653): Figure out if we can use grouped convolutions also on + // backward filter. + if (conv->feature_group_count() > 1) { + return no_match_result; + } // Step 1: match the instruction pattern without considering the paddings and // dimension numbers just yet. We may need some generic pattern matcher // similar to third_party/llvm/llvm/include/llvm/IR/PatternMatch.h @@ -218,6 +223,12 @@ std::tuple<bool, Window, ConvolutionDimensionNumbers> MatchBackwardInput( const auto no_match_result = std::make_tuple(false, Window(), ConvolutionDimensionNumbers()); + // TODO(b/31709653): Figure out if we can use grouped convolutions also on + // backward input. + if (conv->feature_group_count() > 1) { + return no_match_result; + } + // Match instruction pattern. CHECK_EQ(HloOpcode::kConvolution, conv->opcode()); HloInstruction* reverse_filter = conv->mutable_operand(1); @@ -425,7 +436,7 @@ StatusOr<bool> RunOnInstruction(HloInstruction* conv) { if (match) { return CreateCudnnConvBackwardFilter( conv->shape(), conv->mutable_operand(0), conv->mutable_operand(1), - window, dnums); + window, dnums, conv->feature_group_count()); } std::tie(match, window, dnums) = MatchBackwardInput(conv); @@ -435,15 +446,17 @@ StatusOr<bool> RunOnInstruction(HloInstruction* conv) { CHECK_EQ(reverse->opcode(), HloOpcode::kReverse); HloInstruction* rhs = reverse->mutable_operand(0); - return CreateCudnnConvBackwardInput( - conv->shape(), conv->mutable_operand(0), rhs, window, dnums); + return CreateCudnnConvBackwardInput(conv->shape(), + conv->mutable_operand(0), rhs, window, + dnums, conv->feature_group_count()); } // If all else fails, try a forward convolution. if (CanImplementAsCudnnForwardConv(conv)) { return CreateCudnnConvForward(conv->shape(), conv->mutable_operand(0), conv->mutable_operand(1), conv->window(), - conv->convolution_dimension_numbers()); + conv->convolution_dimension_numbers(), + conv->feature_group_count()); } return nullptr; diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc index 07b96fbd3f..05125e9d1f 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc @@ -77,8 +77,9 @@ Status RunCudnnConvolution( const Shape& output_shape, DeviceMemory<T> input_buf, DeviceMemory<T> filter_buf, DeviceMemory<T> output_buf, se::ScratchAllocator* scratch_allocator, const Window& window, - const ConvolutionDimensionNumbers& dnums, AlgorithmConfig algorithm, - Stream* stream, ProfileResult* profile_result /*= nullptr*/) { + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, + AlgorithmConfig algorithm, Stream* stream, + ProfileResult* profile_result /*= nullptr*/) { VLOG(3) << "Convolution Algorithm: " << algorithm.algorithm().algo_id(); VLOG(3) << "tensor_ops_enabled: " << algorithm.algorithm().tensor_ops_enabled(); @@ -144,6 +145,7 @@ Status RunCudnnConvolution( } ConvolutionDescriptor convolution_descriptor(effective_num_dimensions); + convolution_descriptor.set_group_count(feature_group_count); for (int dim = 0; dim < num_dimensions; ++dim) { convolution_descriptor .set_zero_padding( @@ -222,14 +224,14 @@ Status RunCudnnConvolution( const Shape& output_shape, se::DeviceMemoryBase input_buf, se::DeviceMemoryBase filter_buf, se::DeviceMemoryBase output_buf, se::DeviceMemoryBase scratch_buf, const Window& window, - const ConvolutionDimensionNumbers& dnums, + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, se::dnn::AlgorithmConfig algorithm, se::Stream* stream, se::dnn::ProfileResult* profile_result) { ScratchBufAllocator scratch_allocator(scratch_buf); - return RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - input_buf, filter_buf, output_buf, - &scratch_allocator, window, dnums, algorithm, - stream, profile_result); + return RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, input_buf, filter_buf, + output_buf, &scratch_allocator, window, dnums, feature_group_count, + algorithm, stream, profile_result); } Status RunCudnnConvolution( @@ -237,32 +239,32 @@ Status RunCudnnConvolution( const Shape& output_shape, se::DeviceMemoryBase input_buf, se::DeviceMemoryBase filter_buf, se::DeviceMemoryBase output_buf, se::ScratchAllocator* scratch_allocator, const Window& window, - const ConvolutionDimensionNumbers& dnums, + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, se::dnn::AlgorithmConfig algorithm, se::Stream* stream, se::dnn::ProfileResult* profile_result) { PrimitiveType output_primitive_type = output_shape.element_type(); switch (output_primitive_type) { case F16: - return RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - se::DeviceMemory<Eigen::half>(input_buf), - se::DeviceMemory<Eigen::half>(filter_buf), - se::DeviceMemory<Eigen::half>(output_buf), - scratch_allocator, window, dnums, algorithm, - stream, profile_result); + return RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, + se::DeviceMemory<Eigen::half>(input_buf), + se::DeviceMemory<Eigen::half>(filter_buf), + se::DeviceMemory<Eigen::half>(output_buf), scratch_allocator, window, + dnums, feature_group_count, algorithm, stream, profile_result); case F32: - return RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - se::DeviceMemory<float>(input_buf), - se::DeviceMemory<float>(filter_buf), - se::DeviceMemory<float>(output_buf), - scratch_allocator, window, dnums, algorithm, - stream, profile_result); + return RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, + se::DeviceMemory<float>(input_buf), + se::DeviceMemory<float>(filter_buf), + se::DeviceMemory<float>(output_buf), scratch_allocator, window, dnums, + feature_group_count, algorithm, stream, profile_result); case F64: - return RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - se::DeviceMemory<double>(input_buf), - se::DeviceMemory<double>(filter_buf), - se::DeviceMemory<double>(output_buf), - scratch_allocator, window, dnums, algorithm, - stream, profile_result); + return RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, + se::DeviceMemory<double>(input_buf), + se::DeviceMemory<double>(filter_buf), + se::DeviceMemory<double>(output_buf), scratch_allocator, window, + dnums, feature_group_count, algorithm, stream, profile_result); default: LOG(FATAL) << ShapeUtil::HumanString(output_shape); } diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h index 944e4ac686..a1b4fc71d0 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h @@ -75,7 +75,7 @@ Status RunCudnnConvolution( const Shape& output_shape, se::DeviceMemoryBase input_buf, se::DeviceMemoryBase filter_buf, se::DeviceMemoryBase output_buf, se::DeviceMemoryBase scratch_buf, const Window& window, - const ConvolutionDimensionNumbers& dnums, + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, se::dnn::AlgorithmConfig algorithm, se::Stream* stream, se::dnn::ProfileResult* profile_result = nullptr); @@ -84,7 +84,7 @@ Status RunCudnnConvolution( const Shape& output_shape, se::DeviceMemoryBase input_buf, se::DeviceMemoryBase filter_buf, se::DeviceMemoryBase output_buf, se::ScratchAllocator* scratch_allocator, const Window& window, - const ConvolutionDimensionNumbers& dnums, + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, se::dnn::AlgorithmConfig algorithm, se::Stream* stream, se::dnn::ProfileResult* profile_result = nullptr); diff --git a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc index 9c90f4d46b..20d523abe0 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc +++ b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc @@ -144,10 +144,12 @@ bool ImplementedAsLibraryCall(const HloInstruction& hlo) { IsCustomCallToDnnConvolution(hlo); } -static HloInstruction* CreateCudnnConv( - const char* call_target, const Shape& shape, HloInstruction* lhs, - HloInstruction* rhs, const Window& window, - const ConvolutionDimensionNumbers& dnums) { +static HloInstruction* CreateCudnnConv(const char* call_target, + const Shape& shape, HloInstruction* lhs, + HloInstruction* rhs, + const Window& window, + const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count) { HloComputation* computation = lhs->parent(); // This call returns a tuple of (conv_result, scratch_memory), where @@ -165,28 +167,34 @@ static HloInstruction* CreateCudnnConv( HloInstruction::CreateCustomCall(call_shape, {lhs, rhs}, call_target)); custom_call->set_window(window); custom_call->set_convolution_dimension_numbers(dnums); + custom_call->set_feature_group_count(feature_group_count); return custom_call; } -HloInstruction* CreateCudnnConvForward( - const Shape& shape, HloInstruction* input, HloInstruction* kernel, - const Window& window, const ConvolutionDimensionNumbers& dnums) { +HloInstruction* CreateCudnnConvForward(const Shape& shape, + HloInstruction* input, + HloInstruction* kernel, + const Window& window, + const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count) { return CreateCudnnConv(kCudnnConvForwardCallTarget, shape, input, kernel, - window, dnums); + window, dnums, feature_group_count); } HloInstruction* CreateCudnnConvBackwardInput( const Shape& shape, HloInstruction* output, HloInstruction* reverse_filter, - const Window& window, const ConvolutionDimensionNumbers& dnums) { + const Window& window, const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count) { return CreateCudnnConv(kCudnnConvBackwardInputCallTarget, shape, output, - reverse_filter, window, dnums); + reverse_filter, window, dnums, feature_group_count); } HloInstruction* CreateCudnnConvBackwardFilter( const Shape& shape, HloInstruction* input, HloInstruction* output, - const Window& window, const ConvolutionDimensionNumbers& dnums) { + const Window& window, const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count) { return CreateCudnnConv(kCudnnConvBackwardFilterCallTarget, shape, input, - output, window, dnums); + output, window, dnums, feature_group_count); } bool IsReductionToVector(const HloInstruction& reduce) { diff --git a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h index d242897e16..59c65fc268 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h +++ b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h @@ -109,15 +109,20 @@ bool IsCustomCallToDnnConvolution(const HloInstruction& hlo); // // The created cudnn call will use the default cudnn algorithm and no scratch // space. -HloInstruction* CreateCudnnConvForward( - const Shape& shape, HloInstruction* input, HloInstruction* kernel, - const Window& window, const ConvolutionDimensionNumbers& dnums); +HloInstruction* CreateCudnnConvForward(const Shape& shape, + HloInstruction* input, + HloInstruction* kernel, + const Window& window, + const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count); HloInstruction* CreateCudnnConvBackwardInput( const Shape& shape, HloInstruction* output, HloInstruction* reverse_filter, - const Window& window, const ConvolutionDimensionNumbers& dnums); + const Window& window, const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count); HloInstruction* CreateCudnnConvBackwardFilter( const Shape& shape, HloInstruction* input, HloInstruction* output, - const Window& window, const ConvolutionDimensionNumbers& dnums); + const Window& window, const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count); // Returns true if `hlo` will be implemented as a library call, e.g. cuBLAS gemm // or cuDNN convolution. diff --git a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc index 78f61a4987..389a98facb 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc +++ b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc @@ -489,8 +489,8 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { /*filter_shape=*/rhs_shape, /*output_shape=*/conv_result_shape, // custom_call->window(), custom_call->convolution_dimension_numbers(), - backend_config.algorithm(), backend_config.tensor_ops_enabled(), - custom_call); + custom_call->feature_group_count(), backend_config.algorithm(), + backend_config.tensor_ops_enabled(), custom_call); } else if (target == kCudnnConvBackwardInputCallTarget) { thunk = absl::make_unique<ConvolutionThunk>( CudnnConvKind::kBackwardInput, @@ -503,8 +503,8 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { /*filter_shape=*/rhs_shape, /*output_shape=*/lhs_shape, // custom_call->window(), custom_call->convolution_dimension_numbers(), - backend_config.algorithm(), backend_config.tensor_ops_enabled(), - custom_call); + custom_call->feature_group_count(), backend_config.algorithm(), + backend_config.tensor_ops_enabled(), custom_call); } else if (target == kCudnnConvBackwardFilterCallTarget) { thunk = absl::make_unique<ConvolutionThunk>( CudnnConvKind::kBackwardFilter, @@ -517,8 +517,8 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { /*filter_shape=*/conv_result_shape, /*output_shape=*/rhs_shape, // custom_call->window(), custom_call->convolution_dimension_numbers(), - backend_config.algorithm(), backend_config.tensor_ops_enabled(), - custom_call); + custom_call->feature_group_count(), backend_config.algorithm(), + backend_config.tensor_ops_enabled(), custom_call); } else { LOG(FATAL) << "Unexpected custom call target: " << custom_call->custom_call_target(); diff --git a/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc b/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc index 878b0b96a1..e09b8fbd3b 100644 --- a/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc @@ -41,11 +41,7 @@ Status KernelThunk::Initialize(const GpuExecutable& executable, tensorflow::mutex_lock lock(mutex_); if (!loader_spec_) { loader_spec_.reset(new se::MultiKernelLoaderSpec(args_.size())); - absl::string_view ptx = executable.ptx(); - // Convert absl::string_view to se::port::StringPiece because - // StreamExecutor uses the latter. - loader_spec_->AddCudaPtxInMemory( - se::port::StringPiece(ptx.data(), ptx.size()), kernel_name_); + loader_spec_->AddCudaPtxInMemory(executable.ptx(), kernel_name_); if (!executable.cubin().empty()) { loader_spec_->AddCudaCubinInMemory( diff --git a/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc b/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc index 8ce67c03b6..f6325b3368 100644 --- a/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc +++ b/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc @@ -36,7 +36,6 @@ limitations under the License. #include "tensorflow/compiler/xla/service/buffer_liveness.h" #include "tensorflow/compiler/xla/service/call_inliner.h" #include "tensorflow/compiler/xla/service/conditional_simplifier.h" -#include "tensorflow/compiler/xla/service/convolution_feature_group_converter.h" #include "tensorflow/compiler/xla/service/flatten_call_graph.h" #include "tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_rewriter.h" #include "tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h" @@ -208,8 +207,6 @@ Status OptimizeHloModule(HloModule* hlo_module, se::StreamExecutor* stream_exec, HloPassPipeline pipeline("conv_canonicalization"); pipeline.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/false, /*allow_mixed_precision=*/false); - // TODO(b/31709653): Directly use the grouped convolution support of Cudnn. - pipeline.AddPass<ConvolutionFeatureGroupConverter>(); pipeline.AddPass<CudnnConvolutionRewriter>(); // CudnnConvolutionRewriter may add instructions of the form // reverse(constant), which it expects will be simplified by constant diff --git a/tensorflow/compiler/xla/service/gpu/pad_insertion.cc b/tensorflow/compiler/xla/service/gpu/pad_insertion.cc index 98cc21ccac..9d85d746d8 100644 --- a/tensorflow/compiler/xla/service/gpu/pad_insertion.cc +++ b/tensorflow/compiler/xla/service/gpu/pad_insertion.cc @@ -166,9 +166,9 @@ bool PadInsertion::CanonicalizeForwardConvolution(HloInstruction* conv) { Shape old_conv_shape = conv->shape().tuple_shapes(0); VLOG(1) << "Canonicalizing forward conv"; - auto new_conv = CreateCudnnConvForward(old_conv_shape, new_input, new_kernel, - new_conv_window, - conv->convolution_dimension_numbers()); + auto new_conv = CreateCudnnConvForward( + old_conv_shape, new_input, new_kernel, new_conv_window, + conv->convolution_dimension_numbers(), conv->feature_group_count()); VLOG(1) << "Replacing:\n " << conv->ToString() << "\nwith:\n " << new_conv->ToString(); TF_CHECK_OK(conv->parent()->ReplaceInstruction(conv, new_conv)); @@ -247,7 +247,7 @@ bool PadInsertion::CanonicalizeBackwardFilterConvolution( Shape backward_conv_shape = backward_conv->shape().tuple_shapes(0); HloInstruction* new_backward_conv = CreateCudnnConvBackwardFilter( backward_conv_shape, padded_input, output, new_backward_conv_window, - backward_conv_dnums); + backward_conv_dnums, backward_conv->feature_group_count()); VLOG(1) << "Canonicalizing backward filter conv"; VLOG(1) << "Replacing:\n " << backward_conv->ToString() << "\nwith:\n " @@ -312,7 +312,7 @@ bool PadInsertion::CanonicalizeBackwardInputConvolution( HloInstruction* new_backward_conv_call = CreateCudnnConvBackwardInput( new_backward_conv_shape, output, filter, new_backward_conv_window, - backward_conv_dnums); + backward_conv_dnums, backward_conv->feature_group_count()); // The CustomCall created above returns a tuple (conv_result, scratch_memory). // Extract out the two elements. diff --git a/tensorflow/compiler/xla/service/hlo_instruction.cc b/tensorflow/compiler/xla/service/hlo_instruction.cc index bd0b6af10d..6d13f85cbb 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.cc +++ b/tensorflow/compiler/xla/service/hlo_instruction.cc @@ -385,6 +385,9 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( ->set_convolution_dimension_numbers( proto.convolution_dimension_numbers()); } + static_cast<HloCustomCallInstruction*>(instruction.get()) + ->set_feature_group_count( + std::max(static_cast<int64>(proto.feature_group_count()), 1LL)); break; case HloOpcode::kPad: TF_RET_CHECK(proto.operand_ids_size() == 2) @@ -3269,7 +3272,15 @@ void HloInstruction::set_convolution_dimension_numbers( } int64 HloInstruction::feature_group_count() const { - return Cast<HloConvolutionInstruction>(this)->feature_group_count(); + if (auto convolution = DynCast<HloConvolutionInstruction>(this)) { + return convolution->feature_group_count(); + } + return Cast<HloCustomCallInstruction>(this)->feature_group_count(); +} + +void HloInstruction::set_feature_group_count(int64 feature_group_count) { + Cast<HloCustomCallInstruction>(this)->set_feature_group_count( + feature_group_count); } HloComputation* HloInstruction::select() const { diff --git a/tensorflow/compiler/xla/service/hlo_instruction.h b/tensorflow/compiler/xla/service/hlo_instruction.h index 08f3d5356f..cca134e8b4 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.h +++ b/tensorflow/compiler/xla/service/hlo_instruction.h @@ -1475,6 +1475,8 @@ class HloInstruction { // dimension and output feature dimension. int64 feature_group_count() const; + void set_feature_group_count(int64 feature_group_count); + // Delegates to HloSelectAndScatterInstruction::select. HloComputation* select() const; diff --git a/tensorflow/compiler/xla/service/hlo_instructions.cc b/tensorflow/compiler/xla/service/hlo_instructions.cc index 6871953755..e46afa764f 100644 --- a/tensorflow/compiler/xla/service/hlo_instructions.cc +++ b/tensorflow/compiler/xla/service/hlo_instructions.cc @@ -1660,6 +1660,7 @@ HloInstructionProto HloConvolutionInstruction::ToProto() const { *proto.mutable_window() = window_; *proto.mutable_convolution_dimension_numbers() = convolution_dimension_numbers_; + proto.set_feature_group_count(feature_group_count_); return proto; } @@ -1681,6 +1682,9 @@ bool HloConvolutionInstruction::IdenticalSlowPath( eq_computations) const { const auto& casted_other = static_cast<const HloConvolutionInstruction&>(other); + if (feature_group_count_ != other.feature_group_count()) { + return false; + } return protobuf_util::ProtobufEquals(window(), casted_other.window()) && protobuf_util::ProtobufEquals( convolution_dimension_numbers(), @@ -1793,8 +1797,8 @@ HloCustomCallInstruction::HloCustomCallInstruction( const Shape& shape, absl::Span<HloInstruction* const> operands, absl::string_view custom_call_target) : HloInstruction(HloOpcode::kCustomCall, shape), - custom_call_target_(custom_call_target.begin(), - custom_call_target.end()) { + custom_call_target_(custom_call_target.begin(), custom_call_target.end()), + feature_group_count_(1) { for (auto operand : operands) { AppendOperand(operand); } @@ -1810,6 +1814,7 @@ HloInstructionProto HloCustomCallInstruction::ToProto() const { *convolution_dimension_numbers_; } proto.set_custom_call_target(custom_call_target_); + proto.set_feature_group_count(feature_group_count_); return proto; } @@ -1824,6 +1829,9 @@ std::vector<string> HloCustomCallInstruction::ExtraAttributesToStringImpl( "dim_labels=", ConvolutionDimensionNumbersToString(*convolution_dimension_numbers_))); } + if (feature_group_count_ != 1) { + extra.push_back(StrCat("feature_group_count=", feature_group_count_)); + } // By contract, we print the custom call target even if // options.print_subcomputation_mode() == kOff, because the call target is not // an HloComputation. @@ -1851,6 +1859,9 @@ bool HloCustomCallInstruction::IdenticalSlowPath( casted_other.convolution_dimension_numbers()))) { return false; } + if (feature_group_count_ != casted_other.feature_group_count_) { + return false; + } return custom_call_target_ == casted_other.custom_call_target_; } @@ -1866,6 +1877,7 @@ HloCustomCallInstruction::CloneWithNewOperandsImpl( if (convolution_dimension_numbers_ != nullptr) { cloned->set_convolution_dimension_numbers(*convolution_dimension_numbers_); } + cloned->set_feature_group_count(feature_group_count_); return std::move(cloned); } diff --git a/tensorflow/compiler/xla/service/hlo_instructions.h b/tensorflow/compiler/xla/service/hlo_instructions.h index 45a648bbe4..3230383579 100644 --- a/tensorflow/compiler/xla/service/hlo_instructions.h +++ b/tensorflow/compiler/xla/service/hlo_instructions.h @@ -1079,6 +1079,10 @@ class HloCustomCallInstruction : public HloInstruction { absl::make_unique<ConvolutionDimensionNumbers>(dnums); } const string& custom_call_target() const { return custom_call_target_; } + void set_feature_group_count(int64 feature_group_count) { + feature_group_count_ = feature_group_count; + } + int64 feature_group_count() const { return feature_group_count_; } // Returns a serialized representation of this instruction. HloInstructionProto ToProto() const override; @@ -1099,6 +1103,8 @@ class HloCustomCallInstruction : public HloInstruction { std::unique_ptr<Window> window_; // Describes the dimension numbers used for a convolution. std::unique_ptr<ConvolutionDimensionNumbers> convolution_dimension_numbers_; + // The number of feature groups. This is used for grouped convolutions. + int64 feature_group_count_; }; class HloPadInstruction : public HloInstruction { diff --git a/tensorflow/compiler/xla/service/hlo_lexer.cc b/tensorflow/compiler/xla/service/hlo_lexer.cc index 8350285e67..d9be841dd7 100644 --- a/tensorflow/compiler/xla/service/hlo_lexer.cc +++ b/tensorflow/compiler/xla/service/hlo_lexer.cc @@ -406,11 +406,7 @@ TokKind HloLexer::LexString() { absl::string_view raw = StringPieceFromPointers(token_start_ + 1, current_ptr_ - 1); string error; - // TODO(b/113077997): Change to absl::CUnescape once it works properly with - // copy-on-write std::string implementations. - if (!tensorflow::str_util::CUnescape( // non-absl ok - tensorflow::StringPiece(raw.data(), raw.size()), // non-absl ok - &str_val_, &error)) { + if (!absl::CUnescape(raw, &str_val_, &error)) { LOG(ERROR) << "Failed unescaping string: " << raw << ". error: " << error; return TokKind::kError; } diff --git a/tensorflow/compiler/xla/service/llvm_ir/BUILD b/tensorflow/compiler/xla/service/llvm_ir/BUILD index d863529671..540bbb7c7a 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/BUILD +++ b/tensorflow/compiler/xla/service/llvm_ir/BUILD @@ -204,6 +204,7 @@ cc_library( "@com_google_absl//absl/strings", "@com_google_absl//absl/types:optional", "@llvm//:core", + "@llvm//:support", ], ) diff --git a/tensorflow/compiler/xla/service/llvm_ir/alias_analysis_test.cc b/tensorflow/compiler/xla/service/llvm_ir/alias_analysis_test.cc index fe5ec1cc66..b6ae4932f5 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/alias_analysis_test.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/alias_analysis_test.cc @@ -61,7 +61,7 @@ ENTRY while3 { ; CHECK: store float %[[add_result]], float* %[[store_dest:.*]], !alias.scope ![[alias_scope_md_for_store:[0-9]+]] ; ; CHECK-LABEL: @condition(i8* %retval, i8* noalias %run_options, i8** noalias %params -; CHECK: %[[cond_state_buf_ptr:.*]] = getelementptr inbounds i8*, i8** %temps, i64 0 +; CHECK: %[[cond_state_buf_ptr:.*]] = getelementptr inbounds i8*, i8** %buffer_table, i64 0 ; CHECK: %[[cond_state_buf_untyped:.*]] = load i8*, i8** %[[cond_state_buf_ptr]] ; CHECK: %[[cond_state_buf_typed:.*]] = bitcast i8* %[[cond_state_buf_untyped]] to float* ; CHECK: load float, float* %[[cond_state_buf_typed]], !alias.scope ![[alias_scope_md_for_store]], !noalias ![[noalias_md_for_load:.*]] diff --git a/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc b/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc index 00dd3f1638..944c79580c 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc @@ -18,6 +18,7 @@ limitations under the License. // IWYU pragma: no_include "llvm/IR/Intrinsics.gen.inc" #include "absl/strings/string_view.h" #include "absl/types/optional.h" +#include "llvm/ADT/APInt.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Constants.h" #include "llvm/IR/Instructions.h" @@ -59,15 +60,39 @@ void EmitCompareLoop(int64 dimension_to_sort, const IrArray::Index& keys_index, SetToFirstInsertPoint(if_data.true_block, b); auto key1 = keys_array.EmitReadArrayElement(keys_index, b); auto key2 = keys_array.EmitReadArrayElement(compare_keys_index, b); + auto compare_key1 = key1; + auto compare_key2 = key2; auto key_type = keys_array.GetShape().element_type(); + bool is_signed_comparison = true; + if (primitive_util::IsFloatingPointType(key_type)) { + // We would like a total order of floating point numbers so that the sort + // has a predictable behavior in the presence of NaNs. Rather than using + // floating point comparison, we use the following trick: + // If f is a float, and + // x = bit_cast<int32>(f); + // y = x < 0 ? 0x7FFFFFFF - x : x; + // then y is ordered as an int32 such that finite values have the obvious + // order, -0 is ordered before 0, and -NaN and NaN appear at the beginning + // and end of the ordering. + auto k = b->getInt(llvm::APInt::getSignedMaxValue( + key1->getType()->getPrimitiveSizeInBits())); + auto comparison_type = k->getType(); + auto zero = llvm::ConstantInt::get(comparison_type, 0); + auto maybe_flip = [&](llvm::Value* v) { + return b->CreateSelect(b->CreateICmp(llvm::ICmpInst::ICMP_SLT, v, zero), + b->CreateSub(k, v), v); + }; + compare_key1 = b->CreateBitCast(key1, comparison_type); + compare_key2 = b->CreateBitCast(key2, comparison_type); + compare_key1 = maybe_flip(compare_key1); + compare_key2 = maybe_flip(compare_key2); + } else if (!primitive_util::IsSignedIntegralType(key_type)) { + is_signed_comparison = false; + } auto comparison = - primitive_util::IsFloatingPointType(key_type) - // TODO(b/26783907): Figure out how to handle NaNs. - ? b->CreateFCmp(llvm::FCmpInst::FCMP_ULT, key2, key1) - : b->CreateICmp(primitive_util::IsSignedIntegralType(key_type) - ? llvm::ICmpInst::ICMP_SLT - : llvm::ICmpInst::ICMP_ULT, - key2, key1); + b->CreateICmp(is_signed_comparison ? llvm::ICmpInst::ICMP_SLT + : llvm::ICmpInst::ICMP_ULT, + compare_key2, compare_key1); // If key2 < key1 auto if_smaller_data = EmitIfThenElse(comparison, "is_smaller_than", b, /*emit_else=*/false); diff --git a/tensorflow/compiler/xla/tools/BUILD b/tensorflow/compiler/xla/tools/BUILD index 22c28a8f4c..3a086c66bb 100644 --- a/tensorflow/compiler/xla/tools/BUILD +++ b/tensorflow/compiler/xla/tools/BUILD @@ -24,6 +24,7 @@ tf_cc_binary( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/base", "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc b/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc index 75b63c3b84..23ce1d235b 100644 --- a/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc +++ b/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc @@ -17,9 +17,9 @@ limitations under the License. #include <string> #include <vector> +#include "absl/base/casts.h" #include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/casts.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/io/buffered_inputstream.h" #include "tensorflow/core/lib/io/random_inputstream.h" @@ -67,9 +67,8 @@ int main(int argc, char** argv) { floats.push_back(value); } - tensorflow::StringPiece content( // non-absl ok - tensorflow::bit_cast<const char*>(floats.data()), - floats.size() * sizeof(float)); + absl::string_view content(absl::bit_cast<const char*>(floats.data()), + floats.size() * sizeof(float)); TF_CHECK_OK(tensorflow::WriteStringToFile(tensorflow::Env::Default(), output_file, content)); return 0; diff --git a/tensorflow/contrib/autograph/examples/integration_tests/BUILD b/tensorflow/contrib/autograph/examples/integration_tests/BUILD index 6c281485b4..3630b41fc8 100644 --- a/tensorflow/contrib/autograph/examples/integration_tests/BUILD +++ b/tensorflow/contrib/autograph/examples/integration_tests/BUILD @@ -23,7 +23,6 @@ py_test( ], srcs_version = "PY2AND3", tags = ["no_windows"], - visibility = ["//visibility:public"], deps = [ "//tensorflow:tensorflow_py", ], diff --git a/tensorflow/contrib/data/python/kernel_tests/BUILD b/tensorflow/contrib/data/python/kernel_tests/BUILD index b86a543fc3..34f594f741 100644 --- a/tensorflow/contrib/data/python/kernel_tests/BUILD +++ b/tensorflow/contrib/data/python/kernel_tests/BUILD @@ -293,6 +293,7 @@ py_test( "//tensorflow/python:client_testlib", "//tensorflow/python:errors", "//tensorflow/python/data/ops:dataset_ops", + "//third_party/py/numpy", "@absl_py//absl/testing:parameterized", ], ) diff --git a/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py index 446bf8d749..089717156c 100644 --- a/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py @@ -18,10 +18,13 @@ from __future__ import division from __future__ import print_function from absl.testing import parameterized +import numpy as np from tensorflow.contrib.data.python.ops import optimization from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors +from tensorflow.python.ops import array_ops from tensorflow.python.ops import random_ops from tensorflow.python.platform import test @@ -62,7 +65,7 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): "Asserted next 2 transformations but encountered only 1."): sess.run(get_next) - def testDefaultOptimizations(self): + def testOptimizationDefault(self): dataset = dataset_ops.Dataset.range(10).apply( optimization.assert_next( ["Map", "Batch"])).map(lambda x: x * x).batch(10).apply( @@ -75,7 +78,7 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(get_next) - def testEmptyOptimizations(self): + def testOptimizationEmpty(self): dataset = dataset_ops.Dataset.range(10).apply( optimization.assert_next( ["Map", "Batch"])).map(lambda x: x * x).batch(10).apply( @@ -88,7 +91,7 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(get_next) - def testOptimization(self): + def testOptimizationFusion(self): dataset = dataset_ops.Dataset.range(10).apply( optimization.assert_next( ["MapAndBatch"])).map(lambda x: x * x).batch(10).apply( @@ -101,11 +104,9 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(get_next) - def testStatefulFunctionOptimization(self): - dataset = dataset_ops.Dataset.range(10).apply( - optimization.assert_next([ - "MapAndBatch" - ])).map(lambda _: random_ops.random_uniform([])).batch(10).apply( + def testOptimizationStatefulFunction(self): + dataset = dataset_ops.Dataset.range(10).map( + lambda _: random_ops.random_uniform([])).batch(10).apply( optimization.optimize(["map_and_batch_fusion"])) iterator = dataset.make_one_shot_iterator() get_next = iterator.get_next() @@ -113,6 +114,30 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): with self.test_session() as sess: sess.run(get_next) + def testOptimizationLargeInputFromTensor(self): + input_t = array_ops.placeholder(dtypes.int32, (None, None, None)) + dataset = dataset_ops.Dataset.from_tensors(input_t).apply( + optimization.optimize()) + iterator = dataset.make_initializable_iterator() + init_op = iterator.initializer + get_next = iterator.get_next() + + with self.test_session() as sess: + sess.run(init_op, {input_t: np.ones([512, 1024, 1025], np.int32)}) + sess.run(get_next) + + def testOptimizationLargeInputFromTensorSlices(self): + input_t = array_ops.placeholder(dtypes.int32, (None, None, None, None)) + dataset = dataset_ops.Dataset.from_tensor_slices(input_t).apply( + optimization.optimize()) + iterator = dataset.make_initializable_iterator() + init_op = iterator.initializer + get_next = iterator.get_next() + + with self.test_session() as sess: + sess.run(init_op, {input_t: np.ones([1, 512, 1024, 1025], np.int32)}) + sess.run(get_next) + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/distribute/BUILD b/tensorflow/contrib/distribute/BUILD index 02feeafb60..a87a5624c8 100644 --- a/tensorflow/contrib/distribute/BUILD +++ b/tensorflow/contrib/distribute/BUILD @@ -36,5 +36,6 @@ py_library( "//tensorflow/python:training", "//tensorflow/python:util", "//tensorflow/python/distribute:distribute_config", + "//tensorflow/python/distribute:distribute_coordinator", ], ) diff --git a/tensorflow/contrib/distribute/README.md b/tensorflow/contrib/distribute/README.md index ba92ea0b12..30e1992c01 100644 --- a/tensorflow/contrib/distribute/README.md +++ b/tensorflow/contrib/distribute/README.md @@ -12,26 +12,108 @@ models and training code with minimal changes to enable distributed training. Moreover, we've designed the API in such a way that it works with both eager and graph execution. -Currently we support one type of strategy, called -[`MirroredStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/MirroredStrategy). -It does in-graph replication with synchronous training +Currently we support several types of strategies: + +* [`MirroredStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/MirroredStrategy): +This does in-graph replication with synchronous training on many GPUs on one machine. Essentially, we create copies of all variables in the model's layers on each device. We then use all-reduce to combine gradients across the devices before applying them to the variables to keep them in sync. -In the future, we intend to support other kinds of training configurations such -as multi-node, synchronous, -[asynchronous](https://www.tensorflow.org/deploy/distributed#putting_it_all_together_example_trainer_program), -parameter servers and model parallelism. +* [`CollectiveAllReduceStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/CollectiveAllReduceStrategy): +This is a version of `MirroredStrategy` for multi-working training. It uses +a collective op to do all-reduce. This supports between-graph communication and +synchronization, and delegates the specifics of the all-reduce implementation to +the runtime (as opposed to encoding it in the graph). This allows it to perform +optimizations like batching and switch between plugins that support different +hardware or algorithms. In the future, this strategy will implement +fault-tolerance to allow training to continue when there is worker failure. + +* [`ParameterServerStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/ParameterServerStrategy): +This strategy supports using parameter servers either for multi-GPU local +training or asynchronous multi-machine training. When used to train locally, +variables are not mirrored, instead they placed on the CPU and operations are +replicated across all local GPUs. In a multi-machine setting, some are +designated as workers and some as parameter servers. Each variable is placed on +one parameter server. Computation operations are replicated across all GPUs of +the workers. + +## Multi-GPU Training + +## Example with Keras API + +Let's see how to scale to multiple GPUs on one machine using `MirroredStrategy` with [tf.keras] (https://www.tensorflow.org/guide/keras). + +Take a very simple model consisting of a single layer: + +```python +inputs = tf.keras.layers.Input(shape=(1,)) +predictions = tf.keras.layers.Dense(1)(inputs) +model = tf.keras.models.Model(inputs=inputs, outputs=predictions) +``` -## Example +Let's also define a simple input dataset for training this model. Note that currently we require using +[`tf.data.Dataset`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset) +with `DistributionStrategy`. + +```python +features = tf.data.Dataset.from_tensors([1.]).repeat(10000).batch(10) +labels = tf.data.Dataset.from_tensors([1.]).repeat(10000).batch(10) +train_dataset = tf.data.Dataset.zip((features, labels)) +``` -Let's demonstrate how to use this API with a simple example. We will use the -[`Estimator`](https://www.tensorflow.org/api_docs/python/tf/estimator/Estimator) -approach, and show you how to scale your model to run on multiple GPUs on one -machine using `MirroredStrategy`. -Let's consider a very simple model function which tries to learn a simple -function. +To distribute this Keras model on multiple GPUs using `MirroredStrategy` we +first instantiate a `MirroredStrategy` object. + +```python +distribution = tf.contrib.distribute.MirroredStrategy() +``` + +We then compile the Keras model and pass the `MirroredStrategy` object in the +`distribute` argument (apart from other usual arguments like `loss` and +`optimizer`). + +```python +model.compile(loss='mean_squared_error', + optimizer=tf.train.GradientDescentOptimizer(learning_rate=0.2), + distribute=strategy) +``` + +To train the model we call Keras `fit` API using the input dataset that we +created earlier, same as how we would in a non-distributed case. + +```python +model.fit(train_dataset, epochs=5, steps_per_epoch=10) +``` + +Similarly, we can also call `evaluate` and `predict` as before using appropriate +datasets. + +```python +model.evaluate(eval_dataset) +model.predict(predict_dataset) +``` + +That's all you need to train your model with Keras on multiple GPUs with +`MirroredStrategy`. It will take care of splitting up +the input dataset, replicating layers and variables on each device, and +combining and applying gradients. + +The model and input code does not have to change because we have changed the +underlying components of TensorFlow (such as +optimizer, batch norm and summaries) to become distribution-aware. +That means those components know how to +combine their state across devices. Further, saving and checkpointing works +seamlessly, so you can save with one or no distribution strategy and resume with +another. + + +## Example with Estimator API + +You can also use Distribution Strategy API with [`Estimator`](https://www.tensorflow.org/api_docs/python/tf/estimator/Estimator). Let's see a simple example of it's usage with `MirroredStrategy`. + + +Consider a very simple model function which tries to learn a simple function. ```python def model_fn(features, labels, mode): @@ -53,17 +135,14 @@ def model_fn(features, labels, mode): return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op) ``` -Let's also define a simple input function to feed data for training this model. -Note that we require using -[`tf.data.Dataset`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset) -with `DistributionStrategy`. +Again, let's define a simple input function to feed data for training this model. ```python def input_fn(): features = tf.data.Dataset.from_tensors([[1.]]).repeat(100) labels = tf.data.Dataset.from_tensors(1.).repeat(100) - return dataset_ops.Dataset.zip((features, labels)) + return tf.data.Dataset.zip((features, labels)) ``` Now that we have a model function and input function defined, we can define the @@ -80,20 +159,14 @@ distribution = tf.contrib.distribute.MirroredStrategy() config = tf.estimator.RunConfig(train_distribute=distribution) classifier = tf.estimator.Estimator(model_fn=model_fn, config=config) classifier.train(input_fn=input_fn) +classifier.evaluate(input_fn=input_fn) ``` That's it! This change will now configure estimator to run on all GPUs on your -machine, with the `MirroredStrategy` approach. It will take care of distributing -the input dataset, replicating layers and variables on each device, and -combining and applying gradients. +machine. -The model and input functions do not have to change because we have changed the -underlying components of TensorFlow (such as -optimizer, batch norm and summaries) to become distribution-aware. -That means those components know how to -combine their state across devices. Further, saving and checkpointing works -seamlessly, so you can save with one or no distribution strategy and resume with -another. + +## Customization and Performance Tips Above, we showed the easiest way to use [`MirroredStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/MirroredStrategy#__init__). There are few things you can customize in practice: @@ -103,8 +176,6 @@ of GPUs (using param `num_gpus`), in case you don't want auto detection. * You can specify various parameters for all reduce with the `cross_tower_ops` param, such as the all reduce algorithm to use, and gradient repacking. -## Performance Tips - We've tried to make it such that you get the best performance for your existing model. We also recommend you follow the tips from [Input Pipeline Performance Guide](https://www.tensorflow.org/performance/datasets_performance). @@ -113,15 +184,177 @@ and [`dataset.prefetch`](https://www.tensorflow.org/performance/datasets_perform in the input function gives a solid boost in performance. When using `dataset.prefetch`, use `buffer_size=None` to let it detect optimal buffer size. +## Multi-worker Training +### Overview + +For multi-worker training, no code change is required to the `Estimator` code. +You can run the same model code for all tasks in your cluster including +parameter servers and the evaluator. But you need to use +`tf.estimator.train_and_evaluator`, explicitly specify `num_gpus_per_workers` +for your strategy object, and set "TF\_CONFIG" environment variables for each +binary running in your cluster. We'll provide a Kubernetes template in the +[tensorflow/ecosystem](https://github.com/tensorflow/ecosystem) repo which sets +"TF\_CONFIG" for your training tasks. + +### TF\_CONFIG environment variable + +The "TF\_CONFIG" environment variables is a JSON string which specifies what +tasks constitute a cluster, their addresses and each task's role in the cluster. +One example of "TF\_CONFIG" is: + +```python +TF_CONFIG='{ + "cluster": { + "worker": ["host1:port", "host2:port", "host3:port"], + "ps": ["host4:port", "host5:port"] + }, + "task": {"type": "worker", "index": 1} +}' +``` + +This "TF\_CONFIG" specifies that there are three workers and two ps tasks in the +cluster along with their hosts and ports. The "task" part specifies that the +role of the current task in the cluster, worker 1. Valid roles in a cluster is +"chief", "worker", "ps" and "evaluator". There should be no "ps" job for +`CollectiveAllReduceStrategy` and `MirroredStrategy`. The "evaluator" job is +optional and can have at most one task. It does single machine evaluation and if +you don't want to do evaluation, you can pass in a dummy `input_fn` to the +`tf.estimator.EvalSpec` of `tf.estimator.train_and_evaluate`. + +### Dataset + +The `input_fn` you provide to estimator code is for one worker. So remember to +scale up your batch if you have multiple GPUs on each worker. + +The same `input_fn` will be used for all workers if you use +`CollectiveAllReduceStrategy` and `ParameterServerStrategy`. Therefore it is +important to shuffle your dataset in your `input_fn`. + +`MirroredStrategy` will insert a `tf.dataset.Dataset.shard` call in you +`input_fn`. As a result, each worker gets a fraction of your input data. + +### Performance Tips + +We have been actively working on multi-worker performance. Currently, prefer +`CollectiveAllReduceStrategy` for synchronous multi-worker training. + +### Example + +Let's use the same example for multi-worker. We'll start a cluster with 3 +workers doing synchronous all-reduce training. In the following code snippet, we +start multi-worker training using `tf.estimator.train_and_evaluate`: + + +```python +def model_main(): + estimator = ... + distribution = tf.contrib.distribute.CollectiveAllReduceStrategy( + num_gpus_per_worker=2) + config = tf.estimator.RunConfig(train_distribute=distribution) + train_spec = tf.estimator.TrainSpec(input_fn=input_fn) + eval_spec = tf.estimator.EvalSpec(input_fn=eval_input_fn) + tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec) +``` + + +**Note**: You don't have to set "TF\_CONFIG" manually if you use our provided +Kubernetes template. + +You'll then need 3 machines, find out their host addresses and one available +port on each machine. Then set "TF\_CONFIG" in each binary and run the above +model code. + +In your worker 0, run: + +```python +os.environ["TF_CONFIG"] = json.dumps({ + "cluster": { + "worker": ["host1:port", "host2:port", "host3:port"] + }, + "task": {"type": "worker", "index": 0} +}) + +# Call the model_main function defined above. +model_main() +``` + +In your worker 1, run: + +```python +os.environ["TF_CONFIG"] = json.dumps({ + "cluster": { + "worker": ["host1:port", "host2:port", "host3:port"] + }, + "task": {"type": "worker", "index": 1} +}) + +# Call the model_main function defined above. +model_main() +``` + +In your worker 2, run: + +```python +os.environ["TF_CONFIG"] = json.dumps({ + "cluster": { + "worker": ["host1:port", "host2:port", "host3:port"] + }, + "task": {"type": "worker", "index": 2} +}) + +# Call the model_main function defined above. +model_main() +``` + +Then you'll find your cluster has started training! You can inspect the logs of +workers or start a tensorboard. + +### Standalone client mode + +We have a new way to run distributed training. You can bring up standard +tensorflow servers in your cluster and run your model code anywhere such as on +your laptop. + +In the above example, instead of calling `model_main`, you can call +`tf.contrib.distribute.run_standard_tensorflow_server().join()`. This will bring +up a cluster running standard tensorflow servers which wait for your request to +start training. + +On your laptop, you can run + +```python +estimator = ... +distribution = tf.contrib.distribute.CollectiveAllReduceStrategy( + num_gpus_per_worker=2) +config = tf.estimator.RunConfig( + experimental_distribute=tf.contrib.distribute.DistributeConfig( + train_distribute=distribution, + remote_cluster={"worker": ["host1:port", "host2:port", "host3:port"]})) +train_spec = tf.estimator.TrainSpec(input_fn=input_fn) +eval_spec = tf.estimator.EvalSpec(input_fn=eval_input_fn) +tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec) +``` + +Then you will see the training logs on your laptop. You can terminate the +training by terminating your process on your laptop. You can also modify your +code and run a new model against the same cluster. + +We've been optimizing the performance of standalone client mode. If you notice +high latency between your laptop and your cluster, you can reduce that latency +by running your model binary in the cluster. + ## Caveats + This feature is in early stages and there are a lot of improvements forthcoming: * Summaries are only computed in the first tower in `MirroredStrategy`. -* Evaluation is not yet distributed. * Eager support is in the works; performance can be more challenging with eager execution. -* As mentioned earlier, multi-node and other distributed strategies will be -introduced in the future. +* We currently support the following predefined Keras callbacks: +`ModelCheckpointCallback`, `TensorBoardCallback`. We will soon be adding support for +some of the other callbacks such as `EarlyStopping`, `ReduceLROnPlateau`, etc. If you +create your own callback, you will not have access to all model properties and +validation data. * If you are [`batching`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#batch) your input data, we will place one batch on each GPU in each step. So your effective batch size will be `num_gpus * batch_size`. Therefore, consider diff --git a/tensorflow/contrib/distribute/__init__.py b/tensorflow/contrib/distribute/__init__.py index bf763215ba..350f81f60f 100644 --- a/tensorflow/contrib/distribute/__init__.py +++ b/tensorflow/contrib/distribute/__init__.py @@ -28,6 +28,7 @@ from tensorflow.contrib.distribute.python.parameter_server_strategy import Param from tensorflow.contrib.distribute.python.step_fn import * from tensorflow.contrib.distribute.python.tpu_strategy import TPUStrategy from tensorflow.python.distribute.distribute_config import DistributeConfig +from tensorflow.python.distribute.distribute_coordinator import run_standard_tensorflow_server from tensorflow.python.training.distribute import * from tensorflow.python.training.distribution_strategy_context import * @@ -56,6 +57,7 @@ _allowed_symbols = [ 'get_tower_context', 'has_distribution_strategy', 'require_tower_context', + 'run_standard_tensorflow_server', 'UpdateContext', ] diff --git a/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py b/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py index ea81301bd9..4fa8aa06cc 100644 --- a/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py +++ b/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py @@ -50,7 +50,8 @@ class CollectiveAllReduceStrategy(mirrored_strategy.MirroredStrategy): """Initializes the object. Args: - num_gpus_per_worker: number of local GPUs or GPUs per worker. + num_gpus_per_worker: number of local GPUs or GPUs per worker, the default + is 0 meaning CPU only. """ self._num_gpus_per_worker = num_gpus_per_worker self._initialize_local_worker(num_gpus_per_worker) diff --git a/tensorflow/contrib/distribute/python/cross_tower_ops.py b/tensorflow/contrib/distribute/python/cross_tower_ops.py index 2219ab2c15..e08ba9c2a6 100644 --- a/tensorflow/contrib/distribute/python/cross_tower_ops.py +++ b/tensorflow/contrib/distribute/python/cross_tower_ops.py @@ -35,13 +35,13 @@ from tensorflow.python.training import device_util def check_destinations(destinations): - """Checks whether `destinations` is not None and not empty. + """Checks whether `destinations` is not empty. Args: destinations: a DistributedValues, Variable, string or a list of strings. Returns: - Boolean indicating whether `destinations` is not None and not empty. + Boolean which is True if `destinations` is not empty. """ # Calling bool() on a ResourceVariable is not allowed. if isinstance(destinations, resource_variable_ops.ResourceVariable): @@ -56,7 +56,7 @@ def validate_destinations(destinations): value_lib.AggregatingVariable, six.string_types, list)): raise ValueError("destinations must be one of a `DistributedValues` object," " a tf.Variable object, a device string, a list of device " - "strings or None") + "strings") if not check_destinations(destinations): raise ValueError("destinations can not be empty") @@ -131,8 +131,7 @@ def _devices_match(left, right): def _all_devices_match(value_destination_pairs): - if not all([d is None or _devices_match(v, d) - for v, d in value_destination_pairs]): + if not all([_devices_match(v, d) for v, d in value_destination_pairs]): return False if not all([_devices_match(v, value_destination_pairs[0][0]) for v, _ in value_destination_pairs[1:]]): @@ -189,7 +188,7 @@ class CrossTowerOps(object): def __init__(self): pass - def reduce(self, aggregation, per_device_value, destinations=None): + def reduce(self, aggregation, per_device_value, destinations): """Reduce `per_device_value` to `destinations`. It runs the reduction operation defined by `aggregation` and put the @@ -210,8 +209,7 @@ class CrossTowerOps(object): if not isinstance(per_device_value, value_lib.PerDevice): per_device_value = _make_tensor_into_per_device(per_device_value) - if destinations is not None: - validate_destinations(destinations) + validate_destinations(destinations) return self._reduce(aggregation, per_device_value, destinations) def batch_reduce(self, aggregation, value_destination_pairs): @@ -224,9 +222,7 @@ class CrossTowerOps(object): aggregation: Indicates how a variable will be aggregated. Accepted values are `tf.VariableAggregation.SUM`, `tf.VariableAggregation.MEAN`. value_destination_pairs: a list or a tuple of tuples of PerDevice objects - (or tensors with device set if there is one tower) and destinations. If - a destination is None, then the destinations are set to match the - devices of the input PerDevice object. + (or tensors with device set if there is one tower) and destinations. Returns: a list of Mirrored objects. @@ -242,8 +238,7 @@ class CrossTowerOps(object): value_destination_pairs) for _, d in value_destination_pairs: - if d is not None: - validate_destinations(d) + validate_destinations(d) return self._batch_reduce(aggregation, value_destination_pairs) @@ -573,7 +568,7 @@ class AllReduceCrossTowerOps(CrossTowerOps): def _reduce(self, aggregation, per_device_value, destinations): contains_indexed_slices = cross_tower_utils.contains_indexed_slices( per_device_value) - if ((destinations is None or _devices_match(per_device_value, destinations)) + if (_devices_match(per_device_value, destinations) and not context.executing_eagerly() and not contains_indexed_slices): return self._batch_all_reduce(aggregation, [per_device_value])[0] @@ -813,7 +808,7 @@ class CollectiveAllReduce(CrossTowerOps): "Eager execution is not supported for Collective All-Reduce") all_reduced = self._batch_all_reduce(aggregation, [per_device_value])[0] - if destinations is None or _devices_match(per_device_value, destinations): + if _devices_match(per_device_value, destinations): return all_reduced else: index = {} diff --git a/tensorflow/contrib/distribute/python/cross_tower_ops_test.py b/tensorflow/contrib/distribute/python/cross_tower_ops_test.py index 2ad91d56e9..490371477a 100644 --- a/tensorflow/contrib/distribute/python/cross_tower_ops_test.py +++ b/tensorflow/contrib/distribute/python/cross_tower_ops_test.py @@ -135,7 +135,7 @@ class CrossTowerOpsTestBase(test.TestCase, parameterized.TestCase): destination_list = devices all_destinations = [ - None, destination_mirrored, destination_different, destination_str, + destination_mirrored, destination_different, destination_str, destination_list ] @@ -146,24 +146,24 @@ class CrossTowerOpsTestBase(test.TestCase, parameterized.TestCase): vs.VariableAggregation.MEAN, per_device, destinations=destinations), - _fake_mirrored(mean, destinations or per_device)) + _fake_mirrored(mean, destinations)) self._assert_values_equal( cross_tower_ops.reduce( vs.VariableAggregation.MEAN, per_device_2, destinations=destinations), - _fake_mirrored(mean_2, destinations or per_device)) + _fake_mirrored(mean_2, destinations)) self._assert_values_equal( cross_tower_ops.reduce( vs.VariableAggregation.SUM, per_device, destinations=destinations), - _fake_mirrored(mean * len(devices), destinations or per_device)) + _fake_mirrored(mean * len(devices), destinations)) self._assert_values_equal( cross_tower_ops.reduce( vs.VariableAggregation.SUM, per_device_2, destinations=destinations), - _fake_mirrored(mean_2 * len(devices), destinations or per_device)) + _fake_mirrored(mean_2 * len(devices), destinations)) # test batch_reduce() for d1, d2 in itertools.product(all_destinations, all_destinations): @@ -171,25 +171,22 @@ class CrossTowerOpsTestBase(test.TestCase, parameterized.TestCase): cross_tower_ops.batch_reduce(vs.VariableAggregation.MEAN, [(per_device, d1), (per_device_2, d2)]), [ - _fake_mirrored(mean, d1 or per_device), - _fake_mirrored(mean_2, d2 or per_device_2) + _fake_mirrored(mean, d1), + _fake_mirrored(mean_2, d2) ]) self._assert_values_equal( cross_tower_ops.batch_reduce(vs.VariableAggregation.SUM, [(per_device, d1), (per_device_2, d2)]), [ - _fake_mirrored(mean * len(devices), d1 or per_device), - _fake_mirrored(mean_2 * len(devices), d2 or per_device_2) + _fake_mirrored(mean * len(devices), d1), + _fake_mirrored(mean_2 * len(devices), d2) ]) # test broadcast() for destinations in all_destinations: - if destinations is None: - continue - else: - self._assert_values_equal( - cross_tower_ops.broadcast(constant_op.constant(1.), destinations), - _fake_mirrored(1., destinations)) + self._assert_values_equal( + cross_tower_ops.broadcast(constant_op.constant(1.), destinations), + _fake_mirrored(1., destinations)) class SingleWorkerCrossTowerOpsTest(CrossTowerOpsTestBase): @@ -494,7 +491,7 @@ class MultiWorkerCollectiveAllReduceTest( destination_list = devices all_destinations = [ - destination_different, None, destination_mirrored, destination_str, + destination_different, destination_mirrored, destination_str, destination_list ] @@ -505,27 +502,27 @@ class MultiWorkerCollectiveAllReduceTest( vs.VariableAggregation.MEAN, per_device, destinations=destinations), - _fake_mirrored(mean, destinations or per_device), sess) + _fake_mirrored(mean, destinations), sess) self._assert_values_equal( collective_all_reduce.reduce( vs.VariableAggregation.MEAN, per_device_2, destinations=destinations), - _fake_mirrored(mean_2, destinations or per_device), sess) + _fake_mirrored(mean_2, destinations), sess) self._assert_values_equal( collective_all_reduce.reduce( vs.VariableAggregation.SUM, per_device, destinations=destinations), - _fake_mirrored(mean * len(devices) * num_workers, destinations or - per_device), sess) + _fake_mirrored(mean * len(devices) * num_workers, destinations), + sess) self._assert_values_equal( collective_all_reduce.reduce( vs.VariableAggregation.SUM, per_device_2, destinations=destinations), - _fake_mirrored(mean_2 * len(devices) * num_workers, destinations or - per_device), sess) + _fake_mirrored(mean_2 * len(devices) * num_workers, destinations), + sess) # test batch_reduce() for d1, d2 in itertools.product(all_destinations, all_destinations): @@ -534,18 +531,16 @@ class MultiWorkerCollectiveAllReduceTest( [(per_device, d1), (per_device_2, d2)]), [ - _fake_mirrored(mean, d1 or per_device), - _fake_mirrored(mean_2, d2 or per_device_2) + _fake_mirrored(mean, d1), + _fake_mirrored(mean_2, d2) ], sess) self._assert_values_equal( collective_all_reduce.batch_reduce(vs.VariableAggregation.SUM, [(per_device, d1), (per_device_2, d2)]), [ - _fake_mirrored(mean * len(devices) * num_workers, d1 or - per_device), - _fake_mirrored(mean_2 * len(devices) * num_workers, d2 or - per_device_2) + _fake_mirrored(mean * len(devices) * num_workers, d1), + _fake_mirrored(mean_2 * len(devices) * num_workers, d2) ], sess) return True diff --git a/tensorflow/contrib/distribute/python/input_ops.py b/tensorflow/contrib/distribute/python/input_ops.py index 1f24f62947..f07ec8234d 100644 --- a/tensorflow/contrib/distribute/python/input_ops.py +++ b/tensorflow/contrib/distribute/python/input_ops.py @@ -47,11 +47,8 @@ def auto_shard_dataset(dataset, num_shards, index): Returns: A modified `Dataset` obtained by updating the pipeline sharded by the - files. - - Raises: - NotImplementedError: If we cannot automatically determine a good way to - shard the input dataset. + files. The input dataset will be returned if we cannot automatically + determine a good way to shard the input dataset. """ # TODO(priyag): Clone datasets instead of updating in place, similar to the @@ -127,8 +124,10 @@ def auto_shard_dataset(dataset, num_shards, index): tf_logging.warn( "Could not find a standard reader in the input pipeline" "(one of TextLineDataset, TFRecordDataset, FixedLengthRecordDataset)." - "Falling back to sharding the dataset anyway. Please verify" - "correctness of auto-sharding for your input.") + "So auto-sharding is not done. Please verify correctness of " + "auto-sharding for your input.") + # TODO(yuefengz): maybe still shard it? + return dataset # TODO(priyag): What do we want to do if the number of filenames is # uneven in the number of shards? By default, this will just return as diff --git a/tensorflow/contrib/distribute/python/one_device_strategy.py b/tensorflow/contrib/distribute/python/one_device_strategy.py index 68561b5bbf..23b220f64b 100644 --- a/tensorflow/contrib/distribute/python/one_device_strategy.py +++ b/tensorflow/contrib/distribute/python/one_device_strategy.py @@ -67,6 +67,7 @@ class OneDeviceStrategy(distribute_lib.DistributionStrategy): self._prefetch_on_device) def _broadcast(self, tensor, destinations): + del destinations return tensor # TODO(priyag): Deal with OutOfRange errors once b/111349762 is fixed. @@ -127,6 +128,7 @@ class OneDeviceStrategy(distribute_lib.DistributionStrategy): return values.MapOutput([fn(m, *args, **kwargs) for m in map_over]) def _reduce(self, aggregation, value, destinations): + del destinations if not isinstance(value, values.MapOutput): return value l = value.get() diff --git a/tensorflow/contrib/distribute/python/parameter_server_strategy.py b/tensorflow/contrib/distribute/python/parameter_server_strategy.py index 74a4984f4c..88d7768b14 100644 --- a/tensorflow/contrib/distribute/python/parameter_server_strategy.py +++ b/tensorflow/contrib/distribute/python/parameter_server_strategy.py @@ -83,19 +83,12 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): create conflicts of device assignment. """ - def __init__(self, - num_gpus_per_worker=0, - cluster_spec=None, - task_type=None, - task_id=None): + def __init__(self, num_gpus_per_worker=0): """Initializes this strategy. Args: - num_gpus_per_worker: number of local GPUs or GPUs per worker. - cluster_spec: a dict, ClusterDef or ClusterSpec object specifying the - cluster configurations. - task_type: the current task type. - task_id: the current task id. + num_gpus_per_worker: number of local GPUs or GPUs per worker, the default + is 0 meaning CPU only. Raises: ValueError: if `cluster_spec` is given but `task_type` or `task_id` is @@ -103,11 +96,7 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): """ super(ParameterServerStrategy, self).__init__() self._num_gpus_per_worker = num_gpus_per_worker - if cluster_spec: - self._initialize_multi_worker(num_gpus_per_worker, cluster_spec, - task_type, task_id) - else: - self._initialize_local(num_gpus_per_worker) + self._initialize_local(num_gpus_per_worker) # We typically don't need to do all-reduce in this strategy. self._cross_tower_ops = ( diff --git a/tensorflow/contrib/distribute/python/strategy_test_lib.py b/tensorflow/contrib/distribute/python/strategy_test_lib.py index 6ee26e19ac..5d498fb629 100644 --- a/tensorflow/contrib/distribute/python/strategy_test_lib.py +++ b/tensorflow/contrib/distribute/python/strategy_test_lib.py @@ -190,7 +190,8 @@ class DistributionTestBase(test.TestCase): with d.scope(): map_in = [constant_op.constant(i) for i in range(10)] map_out = d.map(map_in, lambda x, y: x * y, 2) - observed = d.reduce(variable_scope.VariableAggregation.SUM, map_out) + observed = d.reduce(variable_scope.VariableAggregation.SUM, map_out, + "/device:CPU:0") expected = 90 # 2 * (0 + 1 + ... + 9) self.assertEqual(expected, observed.numpy()) diff --git a/tensorflow/contrib/distribute/python/tpu_strategy.py b/tensorflow/contrib/distribute/python/tpu_strategy.py index d0dbbd0da8..32d7444e42 100644 --- a/tensorflow/contrib/distribute/python/tpu_strategy.py +++ b/tensorflow/contrib/distribute/python/tpu_strategy.py @@ -73,70 +73,98 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): num_cores: Number of cores to use on the TPU. If None specified, then auto-detect the cores and topology of the TPU system. """ - # TODO(isaprykin): Generalize the defaults. They are currently tailored for - # the unit test. + # TODO(sourabhbajaj): OneDeviceStrategy should be initialized with the + # master node fetched from the cluster resolver. super(TPUStrategy, self).__init__('/device:CPU:0') self._tpu_cluster_resolver = tpu_cluster_resolver self._tpu_metadata = get_tpu_system_metadata(self._tpu_cluster_resolver) + # TODO(sourabhbajaj): Change this from num_cores to metadata_override self._num_cores_override = num_cores # TODO(sourabhbajaj): Remove this once performance of running one step # at a time is comparable to multiple steps. self.steps_per_run = steps_per_run - # TODO(frankchn): This should not be hardcoded here for pod purposes. - self._host = self.tpu_host_cpu_device(0) + def _get_enqueue_op_per_host(self, host_id, iterator, input_shapes, + iterations): + """Create an enqueue op for a single host identified using host_id. - def distribute_dataset(self, dataset_fn): - # TODO(priyag): Perhaps distribute across cores here. - return self._call_dataset_fn(dataset_fn) - - # TODO(priyag): Deal with OutOfRange errors once b/111349762 is fixed. - # TODO(sourabhbajaj): Remove the initial_loop_values parameter when we have - # a mechanism to infer the outputs of `fn`. Pending b/110550782. - def _run_steps_on_dataset(self, fn, iterator, iterations, - initial_loop_values=None): + The while_loop op returned will run `iterations` times and in each run + enqueue batches for each shard. - shapes = nest.flatten(iterator.output_shapes) - if any([not s.is_fully_defined() for s in shapes]): - raise ValueError( - 'TPU currently requires fully defined shapes. Either use ' - 'set_shape() on the input tensors or use ' - 'dataset.apply(map_and_batch(..., drop_remainder=True)).') - types = nest.flatten(iterator.output_types) + Args: + host_id: integer, id of the host to run the enqueue ops on. + iterator: `tf.data` iterator to read the input data. + input_shapes: shape of inputs to be enqueue on the queue. This is same as + the value of `nest.flatten(iterator.output_shapes)`. + iterations: integer, number of iterations to be run; determines the + number of batches to be enqueued. + + Returns: + while_loop_op running `iterations` times; in each run we enqueue a batch + on the infeed queue from the host with id `host_id` for each device shard. + """ + host = self.get_host_cpu_device(host_id) - def enqueue_ops_fn(): + def _infeed_enqueue_ops_fn(): """Enqueue ops for one iteration.""" control_deps = [] sharded_inputs = [] - # TODO(sourabhbajaj): Add support for TPU pods - with ops.device(self._host): - for _ in range(self.num_towers): + enqueue_ops = [] + + with ops.device(host): + for _ in range(self.num_towers_per_host): # Use control dependencies to ensure a deterministic ordering. with ops.control_dependencies(control_deps): inputs = nest.flatten(iterator.get_next()) control_deps.extend(inputs) sharded_inputs.append(inputs) - enqueue_ops = [] for core_id, shard_input in enumerate(sharded_inputs): enqueue_ops.append( tpu_ops.infeed_enqueue_tuple( - inputs=shard_input, shapes=shapes, device_ordinal=core_id)) + inputs=shard_input, + shapes=input_shapes, + device_ordinal=core_id)) return enqueue_ops def enqueue_ops_loop_body(i): - with ops.control_dependencies(enqueue_ops_fn()): + """Callable for the loop body of the while_loop instantiated below.""" + with ops.control_dependencies(_infeed_enqueue_ops_fn()): return i + 1 - with ops.device(self._host): - enqueue_ops = control_flow_ops.while_loop( + with ops.device(host): + enqueue_op_per_host = control_flow_ops.while_loop( lambda i: i < iterations, enqueue_ops_loop_body, [constant_op.constant(0)], parallel_iterations=1) + return enqueue_op_per_host + + def distribute_dataset(self, dataset_fn): + # TODO(priyag): Perhaps distribute across cores here. + return self._call_dataset_fn(dataset_fn) + + # TODO(priyag): Deal with OutOfRange errors once b/111349762 is fixed. + # TODO(sourabhbajaj): Remove the initial_loop_values parameter when we have + # a mechanism to infer the outputs of `fn`. Pending b/110550782. + def _run_steps_on_dataset(self, fn, iterator, iterations, + initial_loop_values=None): + + shapes = nest.flatten(iterator.output_shapes) + if any([not s.is_fully_defined() for s in shapes]): + raise ValueError( + 'TPU currently requires fully defined shapes. Either use ' + 'set_shape() on the input tensors or use ' + 'dataset.apply(map_and_batch(..., drop_remainder=True)).') + types = nest.flatten(iterator.output_types) + + enqueue_ops = [ + self._get_enqueue_op_per_host(host_id, iterator, shapes, iterations) + for host_id in range(self.num_hosts)] + def dequeue_fn(): dequeued = tpu_ops.infeed_dequeue_tuple(dtypes=types, shapes=shapes) return nest.pack_sequence_as(iterator.output_shapes, dequeued) @@ -147,6 +175,7 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): initial_loop_values = nest.flatten(initial_loop_values) ctx = values.MultiStepContext() def run_fn(*args, **kwargs): + """Single step on the TPU device.""" del args, kwargs fn_inputs = dequeue_fn() if not isinstance(fn_inputs, tuple): @@ -250,7 +279,7 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): devices = cross_tower_ops_lib.get_devices_from(destinations) if len(devices) == 1: assert device_util.canonicalize(devices[0]) == device_util.canonicalize( - self._host) + self.get_host_cpu_device(0)) else: raise ValueError('Multiple devices are not supported for TPUStrategy') @@ -270,8 +299,15 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): def num_towers(self): return self._num_cores_override or self._tpu_metadata.num_cores - def tpu_host_cpu_device(self, host_id): + @property + def num_hosts(self): + return self._tpu_metadata.num_hosts + + @property + def num_towers_per_host(self): + return self._tpu_metadata.num_of_cores_per_host + + def get_host_cpu_device(self, host_id): if self._tpu_cluster_resolver.get_master() in ('', 'local'): return '/replica:0/task:0/device:CPU:0' - return '/job:%s/task:%d/device:CPU:0' % ('tpu_worker', host_id) - + return '/job:tpu_worker/task:%d/device:CPU:0' % (host_id,) diff --git a/tensorflow/contrib/distribute/python/values.py b/tensorflow/contrib/distribute/python/values.py index 479b7f39d6..fafa6384a1 100644 --- a/tensorflow/contrib/distribute/python/values.py +++ b/tensorflow/contrib/distribute/python/values.py @@ -340,10 +340,6 @@ class MirroredVariable(DistributedVariable, Mirrored, """Holds a map from device to variables whose values are kept in sync.""" def __init__(self, index, primary_var, aggregation): - # Use a weakref to make it easy to map from the contained values - # to the container without introducing a reference cycle. - for v in six.itervalues(index): - v._mirrored_container = weakref.ref(self) # pylint: disable=protected-access self._primary_var = primary_var self._aggregation = aggregation super(MirroredVariable, self).__init__(index) diff --git a/tensorflow/contrib/distribute/python/values_test.py b/tensorflow/contrib/distribute/python/values_test.py index 3602f4d128..15a85a28f5 100644 --- a/tensorflow/contrib/distribute/python/values_test.py +++ b/tensorflow/contrib/distribute/python/values_test.py @@ -521,6 +521,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): return worker_device_map, devices def testDataDistributionOneDevicePerWorker(self): + self.skipTest("Temporarily disabled.") worker_device_map, devices = self._cpu_devices() with context.graph_mode(): dataset_fn = lambda: dataset_ops.Dataset.range(8) @@ -528,6 +529,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): [[0, 1], [2, 3], [4, 5], [6, 7]]) def testDataDistributionTwoDevicePerWorker(self): + self.skipTest("Temporarily disabled.") if context.num_gpus() < 1: self.skipTest("A GPU is not available for this test.") worker_device_map, devices = self._cpu_and_one_gpu_devices() @@ -537,6 +539,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): [[0, 2, 1, 3], [4, 6, 5, 7]]) def testTupleDataset(self): + self.skipTest("Temporarily disabled.") worker_device_map, devices = self._cpu_devices() with context.graph_mode(): @@ -553,6 +556,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): expected_values) def testInitializableIterator(self): + self.skipTest("Temporarily disabled.") worker_device_map, devices = self._cpu_devices() with context.graph_mode(): dataset_fn = lambda: dataset_ops.Dataset.range(8) @@ -570,6 +574,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): [[0, 1], [2, 3], [4, 5], [6, 7]]) def testValueErrorForIterator(self): + self.skipTest("Temporarily disabled.") # Incompatiable arguments. with self.assertRaises(ValueError): values.MultiWorkerDataIterator({"w1": None}, {"w1": "d1", "w2": "d2"}) diff --git a/tensorflow/contrib/distributions/BUILD b/tensorflow/contrib/distributions/BUILD index a8d0d493ab..97c53ae2b9 100644 --- a/tensorflow/contrib/distributions/BUILD +++ b/tensorflow/contrib/distributions/BUILD @@ -445,7 +445,7 @@ cuda_py_test( cuda_py_test( name = "sinh_arcsinh_test", - size = "small", + size = "medium", srcs = ["python/kernel_tests/sinh_arcsinh_test.py"], additional_deps = [ ":distributions_py", diff --git a/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb index 315d7a4893..529c99b37c 100644 --- a/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb +++ b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb @@ -66,7 +66,7 @@ "\n", "[Image Source](https://commons.wikimedia.org/wiki/Surfing#/media/File:Surfing_in_Hawaii.jpg), License: Public Domain\n", "\n", - "Our goal is generate a caption, such as \"a surfer riding on a wave\". Here, we'll use an attention based model. This enables us to see which parts of the image the model focuses on as it generates a caption.\n", + "Our goal is to generate a caption, such as \"a surfer riding on a wave\". Here, we'll use an attention-based model. This enables us to see which parts of the image the model focuses on as it generates a caption.\n", "\n", "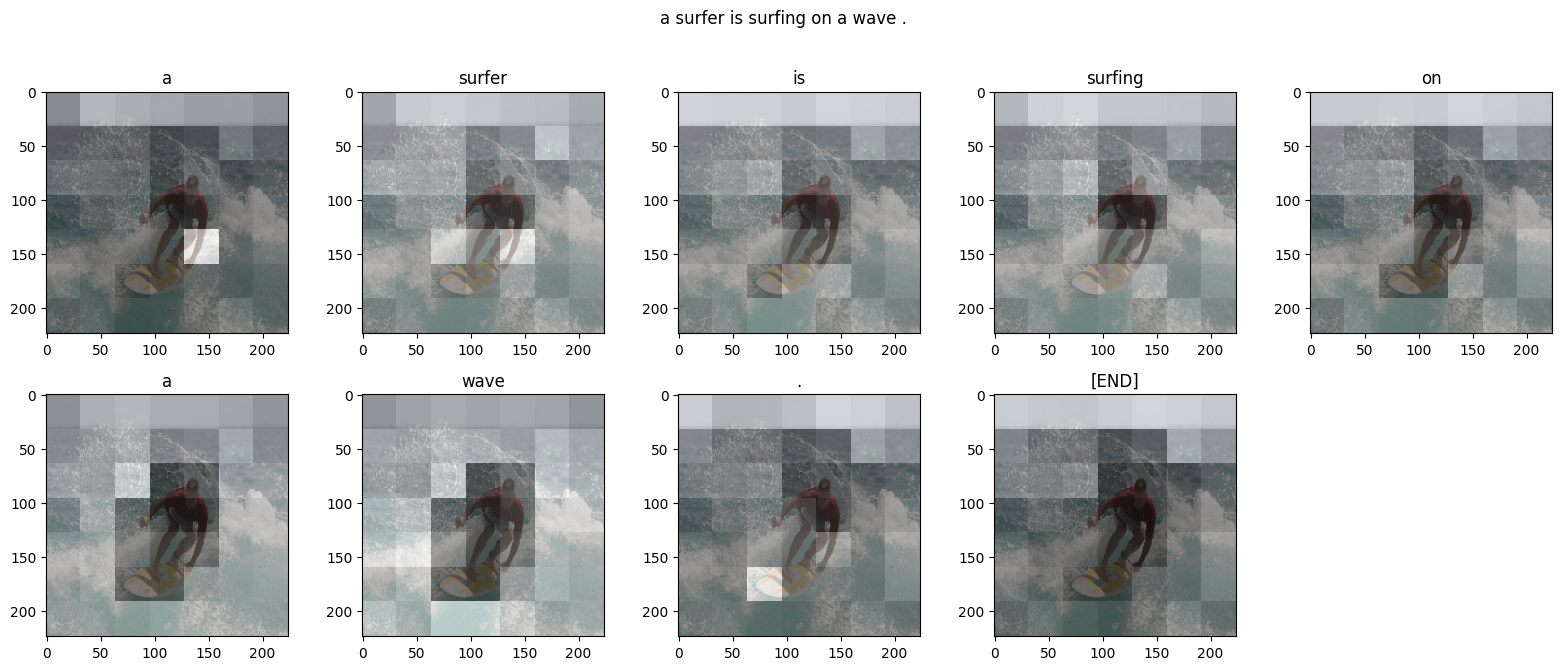\n", "\n", @@ -128,7 +128,7 @@ "source": [ "## Download and prepare the MS-COCO dataset\n", "\n", - "We will use the [MS-COCO dataset](http://cocodataset.org/#home) to train our model. This dataset contains >82,000 images, each of which has been annotated with at least 5 different captions. The code code below will download and extract the dataset automatically. \n", + "We will use the [MS-COCO dataset](http://cocodataset.org/#home) to train our model. This dataset contains >82,000 images, each of which has been annotated with at least 5 different captions. The code below will download and extract the dataset automatically. \n", "\n", "**Caution: large download ahead**. We'll use the training set, it's a 13GB file." ] diff --git a/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb b/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb index ee25d25b52..d60ee18586 100644 --- a/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb +++ b/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb @@ -147,11 +147,12 @@ " # random jittering\n", " \n", " # resizing to 286 x 286 x 3\n", - " # method = 2 indicates using \"ResizeMethod.NEAREST_NEIGHBOR\"\n", " input_image = tf.image.resize_images(input_image, [286, 286], \n", - " align_corners=True, method=2)\n", + " align_corners=True, \n", + " method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)\n", " real_image = tf.image.resize_images(real_image, [286, 286], \n", - " align_corners=True, method=2)\n", + " align_corners=True, \n", + " method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)\n", " \n", " # randomly cropping to 256 x 256 x 3\n", " stacked_image = tf.stack([input_image, real_image], axis=0)\n", diff --git a/tensorflow/contrib/eager/python/metrics_test.py b/tensorflow/contrib/eager/python/metrics_test.py index aa99616810..dcc7b71d79 100644 --- a/tensorflow/contrib/eager/python/metrics_test.py +++ b/tensorflow/contrib/eager/python/metrics_test.py @@ -25,11 +25,14 @@ from tensorflow.contrib.eager.python import metrics from tensorflow.contrib.summary import summary_test_util from tensorflow.python.eager import context from tensorflow.python.eager import test +from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors from tensorflow.python.framework import ops from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import math_ops from tensorflow.python.ops import summary_ops_v2 as summary_ops from tensorflow.python.training import training_util from tensorflow.python.training.checkpointable import util as checkpointable_utils @@ -244,6 +247,48 @@ class MetricsTest(test.TestCase): value = m.value() self.assertEqual(self.evaluate(value), 2.5) + @test_util.run_in_graph_and_eager_modes + def testGraphAndEagerTensorGlobalVariables(self): + m = metrics.Mean(use_global_variables=True) + inputs = ops.convert_to_tensor([1.0, 2.0]) + accumulate = m(inputs) + result = m.result() + self.evaluate(m.init_variables()) + self.evaluate(accumulate) + self.assertEqual(self.evaluate(result), 1.5) + # Second init resets all the variables. + self.evaluate(m.init_variables()) + inputs = ops.convert_to_tensor([2.0, 3.0]) + self.evaluate(m(inputs)) + value = m.value() + self.assertEqual(self.evaluate(value), 2.5) + + @test_util.run_in_graph_and_eager_modes + def testGraphAndEagerTensorWhileLoopDoubleCall(self): + m = metrics.Mean() + init_value = constant_op.constant(1) + cond = lambda i: math_ops.less(i, 3) + def body(x): + with ops.control_dependencies([m(x)]): + return math_ops.add(x, 1) + accumulate = control_flow_ops.while_loop(cond, body, [init_value]) + + result = m.result() + self.evaluate(m.init_variables()) + self.evaluate(accumulate) + self.assertEqual(self.evaluate(result), 1.5) + # Second init resets all the variables. + self.evaluate(m.init_variables()) + inputs = ops.convert_to_tensor([2.0, 3.0]) + self.evaluate(m(inputs)) + if ops.context.executing_eagerly(): + self.evaluate(control_flow_ops.while_loop(cond, body, [init_value])) + else: + # Reuse the loop operators in graph mode + self.evaluate(accumulate) + value = m.value() + self.assertEqual(self.evaluate(value), 2.0) + def testTwoMeansGraph(self): # Verify two metrics with the same name in the same graph raises a # ValueError. diff --git a/tensorflow/contrib/factorization/python/ops/wals.py b/tensorflow/contrib/factorization/python/ops/wals.py index ca46c39baa..b82bf1188f 100644 --- a/tensorflow/contrib/factorization/python/ops/wals.py +++ b/tensorflow/contrib/factorization/python/ops/wals.py @@ -377,64 +377,68 @@ class WALSMatrixFactorization(estimator.Estimator): WALS (Weighted Alternating Least Squares) is an algorithm for weighted matrix factorization. It computes a low-rank approximation of a given sparse (n x m) - matrix A, by a product of two matrices, U * V^T, where U is a (n x k) matrix - and V is a (m x k) matrix. Here k is the rank of the approximation, also - called the embedding dimension. We refer to U as the row factors, and V as the - column factors. + matrix `A`, by a product of two matrices, `U * V^T`, where `U` is a (n x k) + matrix and `V` is a (m x k) matrix. Here k is the rank of the approximation, + also called the embedding dimension. We refer to `U` as the row factors, and + `V` as the column factors. See tensorflow/contrib/factorization/g3doc/wals.md for the precise problem formulation. - The training proceeds in sweeps: during a row_sweep, we fix V and solve for U. - During a column sweep, we fix U and solve for V. Each one of these problems is - an unconstrained quadratic minimization problem and can be solved exactly (it - can also be solved in mini-batches, since the solution decouples nicely). + The training proceeds in sweeps: during a row_sweep, we fix `V` and solve for + `U`. During a column sweep, we fix `U` and solve for `V`. Each one of these + problems is an unconstrained quadratic minimization problem and can be solved + exactly (it can also be solved in mini-batches, since the solution decouples + across rows of each matrix). The alternating between sweeps is achieved by using a hook during training, which is responsible for keeping track of the sweeps and running preparation ops at the beginning of each sweep. It also updates the global_step variable, which keeps track of the number of batches processed since the beginning of training. The current implementation assumes that the training is run on a single - machine, and will fail if config.num_worker_replicas is not equal to one. - Training is done by calling self.fit(input_fn=input_fn), where input_fn + machine, and will fail if `config.num_worker_replicas` is not equal to one. + Training is done by calling `self.fit(input_fn=input_fn)`, where `input_fn` provides two tensors: one for rows of the input matrix, and one for rows of the transposed input matrix (i.e. columns of the original matrix). Note that during a row sweep, only row batches are processed (ignoring column batches) and vice-versa. Also note that every row (respectively every column) of the input matrix must be processed at least once for the sweep to be considered complete. In - particular, training will not make progress if input_fn does not generate some - rows. - - For prediction, given a new set of input rows A' (e.g. new rows of the A - matrix), we compute a corresponding set of row factors U', such that U' * V^T - is a good approximation of A'. We call this operation a row projection. A - similar operation is defined for columns. - Projection is done by calling self.get_projections(input_fn=input_fn), where - input_fn satisfies the constraints given below. - - The input functions must satisfy the following constraints: Calling input_fn - must return a tuple (features, labels) where labels is None, and features is - a dict containing the following keys: + particular, training will not make progress if some rows are not generated by + the `input_fn`. + + For prediction, given a new set of input rows `A'`, we compute a corresponding + set of row factors `U'`, such that `U' * V^T` is a good approximation of `A'`. + We call this operation a row projection. A similar operation is defined for + columns. Projection is done by calling + `self.get_projections(input_fn=input_fn)`, where `input_fn` satisfies the + constraints given below. + + The input functions must satisfy the following constraints: Calling `input_fn` + must return a tuple `(features, labels)` where `labels` is None, and + `features` is a dict containing the following keys: + TRAIN: - - WALSMatrixFactorization.INPUT_ROWS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_ROWS`: float32 SparseTensor (matrix). Rows of the input matrix to process (or to project). - - WALSMatrixFactorization.INPUT_COLS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_COLS`: float32 SparseTensor (matrix). Columns of the input matrix to process (or to project), transposed. + INFER: - - WALSMatrixFactorization.INPUT_ROWS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_ROWS`: float32 SparseTensor (matrix). Rows to project. - - WALSMatrixFactorization.INPUT_COLS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_COLS`: float32 SparseTensor (matrix). Columns to project. - - WALSMatrixFactorization.PROJECT_ROW: Boolean Tensor. Whether to project + * `WALSMatrixFactorization.PROJECT_ROW`: Boolean Tensor. Whether to project the rows or columns. - - WALSMatrixFactorization.PROJECTION_WEIGHTS (Optional): float32 Tensor + * `WALSMatrixFactorization.PROJECTION_WEIGHTS` (Optional): float32 Tensor (vector). The weights to use in the projection. + EVAL: - - WALSMatrixFactorization.INPUT_ROWS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_ROWS`: float32 SparseTensor (matrix). Rows to project. - - WALSMatrixFactorization.INPUT_COLS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_COLS`: float32 SparseTensor (matrix). Columns to project. - - WALSMatrixFactorization.PROJECT_ROW: Boolean Tensor. Whether to project + * `WALSMatrixFactorization.PROJECT_ROW`: Boolean Tensor. Whether to project the rows or columns. """ # Keys to be used in model_fn @@ -469,7 +473,7 @@ class WALSMatrixFactorization(estimator.Estimator): max_sweeps=None, model_dir=None, config=None): - """Creates a model for matrix factorization using the WALS method. + r"""Creates a model for matrix factorization using the WALS method. Args: num_rows: Total number of rows for input matrix. diff --git a/tensorflow/contrib/factorization/python/ops/wals_test.py b/tensorflow/contrib/factorization/python/ops/wals_test.py index 36b483c6d7..31820a18b4 100644 --- a/tensorflow/contrib/factorization/python/ops/wals_test.py +++ b/tensorflow/contrib/factorization/python/ops/wals_test.py @@ -125,11 +125,13 @@ class WALSMatrixFactorizationTest(test.TestCase): nz_row_ids = np.arange(np.shape(np_matrix)[0]) nz_col_ids = np.arange(np.shape(np_matrix)[1]) - def extract_features(row_batch, col_batch, shape): + def extract_features(row_batch, col_batch, num_rows, num_cols): row_ids = row_batch[0] col_ids = col_batch[0] - rows = self.remap_sparse_tensor_rows(row_batch[1], row_ids, shape) - cols = self.remap_sparse_tensor_rows(col_batch[1], col_ids, shape) + rows = self.remap_sparse_tensor_rows( + row_batch[1], row_ids, shape=[num_rows, num_cols]) + cols = self.remap_sparse_tensor_rows( + col_batch[1], col_ids, shape=[num_cols, num_rows]) features = { wals_lib.WALSMatrixFactorization.INPUT_ROWS: rows, wals_lib.WALSMatrixFactorization.INPUT_COLS: cols, @@ -154,7 +156,7 @@ class WALSMatrixFactorizationTest(test.TestCase): capacity=10, enqueue_many=True) - features = extract_features(row_batch, col_batch, sp_mat.dense_shape) + features = extract_features(row_batch, col_batch, num_rows, num_cols) if mode == model_fn.ModeKeys.INFER or mode == model_fn.ModeKeys.EVAL: self.assertTrue( diff --git a/tensorflow/contrib/layers/python/layers/feature_column.py b/tensorflow/contrib/layers/python/layers/feature_column.py index 28d19a0445..53c8ae5d08 100644 --- a/tensorflow/contrib/layers/python/layers/feature_column.py +++ b/tensorflow/contrib/layers/python/layers/feature_column.py @@ -1100,9 +1100,9 @@ class _EmbeddingColumn( raise ValueError("Must specify both `ckpt_to_load_from` and " "`tensor_name_in_ckpt` or none of them.") if initializer is None: - logging.warn("The default stddev value of initializer will change from " - "\"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after " - "2017/02/25.") + logging.warn("The default stddev value of initializer was changed from " + "\"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" in core " + "implementation (tf.feature_column.embedding_column).") stddev = 1 / math.sqrt(sparse_id_column.length) initializer = init_ops.truncated_normal_initializer( mean=0.0, stddev=stddev) @@ -1501,8 +1501,6 @@ class _ScatteredEmbeddingColumn( raise ValueError("initializer must be callable if specified. " "column_name: {}".format(column_name)) if initializer is None: - logging.warn("The default stddev value of initializer will change from " - "\"0.1\" to \"1/sqrt(dimension)\" after 2017/02/25.") stddev = 0.1 initializer = init_ops.truncated_normal_initializer( mean=0.0, stddev=stddev) diff --git a/tensorflow/contrib/layers/python/layers/rev_block_lib.py b/tensorflow/contrib/layers/python/layers/rev_block_lib.py index b25f11b5a6..06da32072f 100644 --- a/tensorflow/contrib/layers/python/layers/rev_block_lib.py +++ b/tensorflow/contrib/layers/python/layers/rev_block_lib.py @@ -30,6 +30,7 @@ import functools import re import numpy as np +import six from six.moves import xrange # pylint: disable=redefined-builtin from tensorflow.contrib.framework.python import ops as contrib_framework_ops @@ -44,6 +45,7 @@ from tensorflow.python.ops import custom_gradient from tensorflow.python.ops import gradients_impl from tensorflow.python.ops import math_ops from tensorflow.python.ops import variable_scope +from tensorflow.python.ops import variables as variables_lib from tensorflow.python.platform import tf_logging as logging from tensorflow.python.util import nest from tensorflow.python.util import tf_inspect @@ -471,7 +473,8 @@ def recompute_grad(fn, use_data_dep=_USE_DEFAULT, tupleize_grads=False): Args: fn: a function that takes Tensors (all as positional arguments) and returns - a tuple of Tensors. + a tuple of Tensors. Note that `fn` should not close over any other + Tensors or Variables. use_data_dep: `bool`, if `True` will use a dummy data dependency to force the recompute to happen. If `False` will use a control dependency. By default will be `True` if in an XLA context and `False` otherwise. XLA @@ -485,7 +488,22 @@ def recompute_grad(fn, use_data_dep=_USE_DEFAULT, tupleize_grads=False): A wrapped fn that is identical to fn when called, but its activations will be discarded and recomputed on the backwards pass (i.e. on a call to tf.gradients). + + Raises: + ValueError: if `fn` closes over any Tensors or Variables. """ + # Check for closed-over Tensors/Variables + if fn.__code__.co_freevars: + closed_over_vars = dict(zip(fn.__code__.co_freevars, + [c.cell_contents for c in fn.__closure__])) + for var_name, value in six.iteritems(closed_over_vars): + if isinstance(value, (framework_ops.Tensor, variables_lib.Variable)): + raise ValueError( + "fn decorated with @recompute_grad closes over Tensor %s " + "(local variable name: %s). The decorated fn must not close over " + "Tensors or Variables because gradients will NOT be computed for " + "them through fn. To ensure correct gradients, make the " + "Tensor an input to fn." % (value.name, var_name)) @_safe_wraps(fn) def wrapped(*args): @@ -500,6 +518,62 @@ def _is_on_tpu(): return control_flow_util.GetContainingXLAContext(ctxt) is not None +def _recomputing_grad_fn(compute_fn, + original_args, + original_vars, + output_grads, + grad_fn_variables, + use_data_dep, + tupleize_grads, + arg_scope, + var_scope, + has_is_recompute_kwarg): + """Grad fn for recompute_grad.""" + variables = grad_fn_variables or [] + + # Identity ops around the inputs ensures correct gradient graph-walking. + inputs = [array_ops.identity(x) for x in list(original_args)] + + # Recompute outputs + # Use a control dependency to ensure that the recompute is not eliminated by + # CSE and that it happens on the backwards pass. + ctrl_dep_grads = [g for g in output_grads if g is not None] + with framework_ops.control_dependencies(ctrl_dep_grads): + if use_data_dep: + inputs = _force_data_dependency(output_grads, inputs) + # Re-enter scopes + with contrib_framework_ops.arg_scope(arg_scope): + with variable_scope.variable_scope(var_scope, reuse=True): + # Re-call the function and ensure that the touched variables are the + # same as in the first call. + with backprop.GradientTape() as tape: + fn_kwargs = {} + if has_is_recompute_kwarg: + fn_kwargs["is_recomputing"] = True + outputs = compute_fn(*inputs, **fn_kwargs) + recompute_vars = set(tape.watched_variables()) + if original_vars != recompute_vars: + raise ValueError(_WRONG_VARS_ERR) + + if not isinstance(outputs, (list, tuple)): + outputs = [outputs] + outputs = list(outputs) + + # Compute gradients + grads = gradients_impl.gradients(outputs, inputs + variables, + output_grads) + + if tupleize_grads: + if use_data_dep: + grads = _tuple_with_data_dep(grads) + else: + grads = control_flow_ops.tuple(grads) + + grad_inputs = grads[:len(inputs)] + grad_vars = grads[len(inputs):] + return grad_inputs, grad_vars + + def _recompute_grad(fn, args, use_data_dep=_USE_DEFAULT, tupleize_grads=False): """See recompute_grad.""" has_is_recompute_kwarg = "is_recomputing" in tf_inspect.getargspec(fn).args @@ -510,12 +584,16 @@ def _recompute_grad(fn, args, use_data_dep=_USE_DEFAULT, tupleize_grads=False): if use_data_dep_ == _USE_DEFAULT: use_data_dep_ = _is_on_tpu() + # Use custom_gradient and return a grad_fn that recomputes on the backwards + # pass. @custom_gradient.custom_gradient def fn_with_recompute(*args): """Wrapper for fn.""" - # Forward pass + # Capture the variable and arg scopes so we can re-enter them when + # recomputing. vs = variable_scope.get_variable_scope() arg_scope = contrib_framework_ops.current_arg_scope() + # Track all variables touched in the function. with backprop.GradientTape() as tape: fn_kwargs = {} if has_is_recompute_kwarg: @@ -523,46 +601,25 @@ def _recompute_grad(fn, args, use_data_dep=_USE_DEFAULT, tupleize_grads=False): outputs = fn(*args, **fn_kwargs) original_vars = set(tape.watched_variables()) - # Backward pass def _grad_fn(output_grads, variables=None): - """Recompute outputs for gradient computation.""" - variables = variables or [] + # Validate that custom_gradient passes the right variables into grad_fn. if original_vars: assert variables, ("Fn created variables but the variables were not " "passed to the gradient fn.") if set(variables) != original_vars: raise ValueError(_WRONG_VARS_ERR) - inputs = [array_ops.identity(x) for x in list(args)] - # Recompute outputs - with framework_ops.control_dependencies(output_grads): - if use_data_dep_: - inputs = _force_data_dependency(output_grads, inputs) - with contrib_framework_ops.arg_scope(arg_scope): - with variable_scope.variable_scope(vs, reuse=True): - with backprop.GradientTape() as tape: - fn_kwargs = {} - if has_is_recompute_kwarg: - fn_kwargs["is_recomputing"] = True - outputs = fn(*inputs, **fn_kwargs) - recompute_vars = set(tape.watched_variables()) - if original_vars != recompute_vars: - raise ValueError(_WRONG_VARS_ERR) - - if not isinstance(outputs, (list, tuple)): - outputs = [outputs] - outputs = list(outputs) - grads = gradients_impl.gradients(outputs, inputs + variables, - output_grads) - - if tupleize_grads: - if use_data_dep_: - grads = _tuple_with_data_dep(grads) - else: - grads = control_flow_ops.tuple(grads) - grad_inputs = grads[:len(inputs)] - grad_vars = grads[len(inputs):] - return grad_inputs, grad_vars + return _recomputing_grad_fn( + compute_fn=fn, + original_args=args, + original_vars=original_vars, + output_grads=output_grads, + grad_fn_variables=variables, + use_data_dep=use_data_dep_, + tupleize_grads=tupleize_grads, + arg_scope=arg_scope, + var_scope=vs, + has_is_recompute_kwarg=has_is_recompute_kwarg) # custom_gradient inspects the signature of the function to determine # whether the user expects variables passed in the grad_fn. If the function diff --git a/tensorflow/contrib/layers/python/layers/rev_block_lib_test.py b/tensorflow/contrib/layers/python/layers/rev_block_lib_test.py index d5971fb9d8..c34b5a8017 100644 --- a/tensorflow/contrib/layers/python/layers/rev_block_lib_test.py +++ b/tensorflow/contrib/layers/python/layers/rev_block_lib_test.py @@ -392,6 +392,16 @@ class RecomputeTest(test.TestCase): with self.test_session() as sess: sess.run(grads) + def testErrorOnClosedOverTensor(self): + x = random_ops.random_uniform((4, 8)) + y = random_ops.random_uniform((4, 8)) + z = x * y + + with self.assertRaisesWithPredicateMatch(ValueError, "closes over"): + @rev_block_lib.recompute_grad + def fn_with_capture(a): # pylint: disable=unused-variable + return a * z + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/linear_optimizer/kernels/g3doc/readme.md b/tensorflow/contrib/linear_optimizer/kernels/g3doc/readme.md index a4f5086dde..5fe883d647 100644 --- a/tensorflow/contrib/linear_optimizer/kernels/g3doc/readme.md +++ b/tensorflow/contrib/linear_optimizer/kernels/g3doc/readme.md @@ -199,6 +199,46 @@ does. However, in practice, convergence with $$x_0 = 0$$ always happens (tested for a sample of generic values for the parameters). +### Poisson log loss + +Poisson log loss is defined as $$ \l(u) = e^u - uy $$ for label $$y \geq 0.$$ +Its dual is + +$$ \l^\star(v) = (y+v) (\log(y+v) - 1) $$ + +and is only defined for $$ y+v > 0 $$. We then have the constraint + +$$ y > \a+\d. $$ + +The dual is + +$$ D(\d) = -(y-\a-\d) (\log(y-\a-\d) - 1) - \bar{y} \d - \frac{A}{2} \d^2 $$ + +and its derivative is, + +$$ D'(\d) = \log(y-\a-\d) - \bar{y} - A\d $$ + +Similar to the logistic loss, we perform a change of variable to handle the +constraint on $$ \d $$ + +$$ y - (\a+\d) = e^x $$ + +After this change of variable, the goal is to find the zero of this function + +$$ H(x) = x - \bar{y} -A(y-\a-e^x) $$ + +whose first derivative is + +$$ H'(x) = 1+Ae^x $$ + +Since this function is always positive, $$H$$ is increasing and has a unique +zero. + +We can start Newton algorithm at $$\d=0$$ which corresponds to $$ x = +\log(y-\a)$$. As before the Newton step is given by + +$$x_{k+1} = x_k - \frac{H(x_k)}{H'(x_k)}. $$ + ### References [1] C. Ma et al., Adding vs. Averaging in Distributed Primal-Dual Optimization, diff --git a/tensorflow/contrib/linear_optimizer/python/kernel_tests/sdca_ops_test.py b/tensorflow/contrib/linear_optimizer/python/kernel_tests/sdca_ops_test.py index ef0e08a777..1d2db1cec8 100644 --- a/tensorflow/contrib/linear_optimizer/python/kernel_tests/sdca_ops_test.py +++ b/tensorflow/contrib/linear_optimizer/python/kernel_tests/sdca_ops_test.py @@ -1192,6 +1192,57 @@ class SdcaWithSmoothHingeLossTest(SdcaModelTest): self.assertAllClose(0.33, unregularized_loss.eval(), atol=0.02) self.assertAllClose(0.44, regularized_loss.eval(), atol=0.02) +class SdcaWithPoissonLossTest(SdcaModelTest): + """SDCA optimizer test class for poisson loss.""" + + def testSimple(self): + # Setup test data + example_protos = [ + make_example_proto({ + 'age': [0], + 'gender': [0] + }, 0), + make_example_proto({ + 'age': [1], + 'gender': [1] + }, 2), + ] + example_weights = [100.0, 100.0] + with self._single_threaded_test_session(): + examples = make_example_dict(example_protos, example_weights) + variables = make_variable_dict(1, 1) + options = dict( + symmetric_l2_regularization=1.0, + symmetric_l1_regularization=0, + loss_type='poisson_loss') + model = SdcaModel(examples, variables, options) + variables_lib.global_variables_initializer().run() + + # Before minimization, the weights default to zero. There is no loss due + # to regularization, only unregularized loss which is 1 for each example. + predictions = model.predictions(examples) + self.assertAllClose([1.0, 1.0], predictions.eval()) + unregularized_loss = model.unregularized_loss(examples) + regularized_loss = model.regularized_loss(examples) + approximate_duality_gap = model.approximate_duality_gap() + self.assertAllClose(1.0, unregularized_loss.eval()) + self.assertAllClose(1.0, regularized_loss.eval()) + + # There are 4 sparse weights: 2 for age (say w1, w2) and 2 for gender + # (say w3 and w4). The minimization leads to: + # w1=w3=-1.96487, argmin of 100*(exp(2*w)-2*w*0)+w**2. + # w2=w4=0.345708, argmin of 100*(exp(2*w)-2*w*2)+w**2. + # This gives an unregularized loss of .3167 and .3366 with regularization. + train_op = model.minimize() + for _ in range(_MAX_ITERATIONS): + train_op.run() + model.update_weights(train_op).run() + + self.assertAllClose([0.0196, 1.9965], predictions.eval(), atol=1e-4) + self.assertAllClose(0.3167, unregularized_loss.eval(), atol=1e-4) + self.assertAllClose(0.3366, regularized_loss.eval(), atol=1e-4) + self.assertAllClose(0., approximate_duality_gap.eval(), atol=1e-6) + class SdcaFprintTest(SdcaModelTest): """Tests for the SdcaFprint op. diff --git a/tensorflow/contrib/linear_optimizer/python/ops/sdca_ops.py b/tensorflow/contrib/linear_optimizer/python/ops/sdca_ops.py index 0047d5753a..14f59a3f64 100644 --- a/tensorflow/contrib/linear_optimizer/python/ops/sdca_ops.py +++ b/tensorflow/contrib/linear_optimizer/python/ops/sdca_ops.py @@ -35,6 +35,7 @@ from tensorflow.python.ops import math_ops from tensorflow.python.ops import nn_ops from tensorflow.python.ops import state_ops from tensorflow.python.ops import variables as var_ops +from tensorflow.python.ops.nn import log_poisson_loss from tensorflow.python.ops.nn import sigmoid_cross_entropy_with_logits from tensorflow.python.summary import summary @@ -51,6 +52,7 @@ class SdcaModel(object): * Squared loss * Hinge loss * Smooth hinge loss + * Poisson log loss This class defines an optimizer API to train a linear model. @@ -112,7 +114,7 @@ class SdcaModel(object): raise ValueError('examples, variables and options must all be specified.') supported_losses = ('logistic_loss', 'squared_loss', 'hinge_loss', - 'smooth_hinge_loss') + 'smooth_hinge_loss', 'poisson_loss') if options['loss_type'] not in supported_losses: raise ValueError('Unsupported loss_type: ', options['loss_type']) @@ -315,6 +317,7 @@ class SdcaModel(object): """Add operations to compute predictions by the model. If logistic_loss is being used, predicted probabilities are returned. + If poisson_loss is being used, predictions are exponentiated. Otherwise, (raw) linear predictions (w*x) are returned. Args: @@ -335,6 +338,10 @@ class SdcaModel(object): # Convert logits to probability for logistic loss predictions. with name_scope('sdca/logistic_prediction'): result = math_ops.sigmoid(result) + elif self._options['loss_type'] == 'poisson_loss': + # Exponeniate the prediction for poisson loss predictions. + with name_scope('sdca/poisson_prediction'): + result = math_ops.exp(result) return result def _get_partitioned_update_ops(self, @@ -624,6 +631,11 @@ class SdcaModel(object): logits=predictions), weights)) / math_ops.reduce_sum(weights) + if self._options['loss_type'] == 'poisson_loss': + return math_ops.reduce_sum(math_ops.multiply( + log_poisson_loss(targets=labels, log_input=predictions), + weights)) / math_ops.reduce_sum(weights) + if self._options['loss_type'] in ['hinge_loss', 'smooth_hinge_loss']: # hinge_loss = max{0, 1 - y_i w*x} where y_i \in {-1, 1}. So, we need to # first convert 0/1 labels into -1/1 labels. diff --git a/tensorflow/contrib/lite/examples/android/app/build.gradle b/tensorflow/contrib/lite/examples/android/app/build.gradle index eb7fd705e1..35e7887852 100644 --- a/tensorflow/contrib/lite/examples/android/app/build.gradle +++ b/tensorflow/contrib/lite/examples/android/app/build.gradle @@ -9,7 +9,6 @@ android { targetSdkVersion 26 versionCode 1 versionName "1.0" - testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner" // Remove this block. jackOptions { @@ -51,10 +50,5 @@ apply from: "download-models.gradle" dependencies { compile fileTree(dir: 'libs', include: ['*.jar']) - androidTestCompile('androidx.test.espresso:espresso-core:3.1.0-alpha3', { - exclude group: 'com.android.support', module: 'support-annotations' - }) compile 'org.tensorflow:tensorflow-lite:0.0.0-nightly' - - testCompile 'junit:junit:4.12' } diff --git a/tensorflow/contrib/lite/g3doc/ios.md b/tensorflow/contrib/lite/g3doc/ios.md index 5ff0412209..a83d2c8fec 100644 --- a/tensorflow/contrib/lite/g3doc/ios.md +++ b/tensorflow/contrib/lite/g3doc/ios.md @@ -36,7 +36,7 @@ brew link libtool Then you need to run a shell script to download the dependencies you need: ```bash -tensorflow/contrib/lite/download_dependencies.sh +tensorflow/contrib/lite/tools/make/download_dependencies.sh ``` This will fetch copies of libraries and data from the web and install them in @@ -46,14 +46,14 @@ With all of the dependencies set up, you can now build the library for all five supported architectures on iOS: ```bash -tensorflow/contrib/lite/build_ios_universal_lib.sh +tensorflow/contrib/lite/tools/make/build_ios_universal_lib.sh ``` Under the hood this uses a makefile in `tensorflow/contrib/lite` to build the different versions of the library, followed by a call to `lipo` to bundle them into a universal file containing armv7, armv7s, arm64, i386, and x86_64 architectures. The resulting library is in -`tensorflow/contrib/lite/gen/lib/libtensorflow-lite.a`. +`tensorflow/contrib/lite/tools/make/gen/lib/libtensorflow-lite.a`. If you get an error such as `no such file or directory: 'x86_64'` when running `build_ios_universal_lib.sh`: open Xcode > Preferences > Locations, and ensure diff --git a/tensorflow/contrib/lite/g3doc/rpi.md b/tensorflow/contrib/lite/g3doc/rpi.md index 8ed8640582..41a1892b6f 100644 --- a/tensorflow/contrib/lite/g3doc/rpi.md +++ b/tensorflow/contrib/lite/g3doc/rpi.md @@ -1,28 +1,36 @@ - # TensorFlow Lite for Raspberry Pi ## Cross compiling -### Installing toolchian -This has been tested on Ubuntu 16.04.3 64bit and Tensorflow devel docker image [tensorflow/tensorflow:nightly-devel](https://hub.docker.com/r/tensorflow/tensorflow/tags/). -To cross compiling TensorFlow Lite. First you should install the toolchain and libs. +### Installing the toolchain + +This has been tested on Ubuntu 16.04.3 64bit and Tensorflow devel docker image +[tensorflow/tensorflow:nightly-devel](https://hub.docker.com/r/tensorflow/tensorflow/tags/). + +To cross compile TensorFlow Lite, first install the toolchain and libs. + ```bash sudo apt-get update sudo apt-get install crossbuild-essential-armhf ``` -> If you are using docker, you may not use `sudo` + +> If you are using Docker, you may not use `sudo`. ### Building + Clone this Tensorflow repository, Run this script at the root of the repository to download all the dependencies: + > The Tensorflow repository is in `/tensorflow` if you are using `tensorflow/tensorflow:nightly-devel` docker image, just try it. + ```bash -./tensorflow/contrib/lite/download_dependencies.sh +./tensorflow/contrib/lite/tools/make/download_dependencies.sh ``` Note that you only need to do this once. You should then be able to compile: + ```bash -./tensorflow/contrib/lite/build_rpi_lib.sh +./tensorflow/contrib/lite/tools/make/build_rpi_lib.sh ``` This should compile a static library in: @@ -31,21 +39,23 @@ This should compile a static library in: ## Native compiling This has been tested on Raspberry Pi 3b, Raspbian GNU/Linux 9.1 (stretch), gcc version 6.3.0 20170516 (Raspbian 6.3.0-18+rpi1). -Log in to you RPI, install the toolchain. +Log in to you Raspberry Pi, install the toolchain. + ```bash sudo apt-get install build-essential ``` -First, clone this TensorFlow repository. Run this at the root of the repository: +First, clone the TensorFlow repository. Run this at the root of the repository: + ```bash -./tensorflow/contrib/lite/download_dependencies.sh +./tensorflow/contrib/lite/tools/make/download_dependencies.sh ``` Note that you only need to do this once. You should then be able to compile: ```bash -./tensorflow/contrib/lite/build_rpi_lib.sh +./tensorflow/contrib/lite/tools/make/build_rpi_lib.sh ``` This should compile a static library in: -`tensorflow/contrib/lite/gen/lib/rpi_armv7/libtensorflow-lite.a`. +`tensorflow/contrib/lite/tools/make/gen/lib/rpi_armv7/libtensorflow-lite.a`. diff --git a/tensorflow/contrib/lite/java/demo/app/build.gradle b/tensorflow/contrib/lite/java/demo/app/build.gradle index 92f04c651c..05301ebf88 100644 --- a/tensorflow/contrib/lite/java/demo/app/build.gradle +++ b/tensorflow/contrib/lite/java/demo/app/build.gradle @@ -10,7 +10,6 @@ android { targetSdkVersion 26 versionCode 1 versionName "1.0" - testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner" // Remove this block. jackOptions { @@ -44,9 +43,6 @@ repositories { dependencies { compile fileTree(dir: 'libs', include: ['*.jar']) - androidTestCompile('androidx.test.espresso:espresso-core:3.1.0-alpha3', { - exclude group: 'com.android.support', module: 'support-annotations' - }) compile 'com.android.support:appcompat-v7:25.2.0' compile 'com.android.support.constraint:constraint-layout:1.0.2' compile 'com.android.support:design:25.2.0' @@ -54,8 +50,6 @@ dependencies { compile 'com.android.support:support-v13:25.2.0' compile 'org.tensorflow:tensorflow-lite:0.0.0-nightly' - - testCompile 'junit:junit:4.12' } def modelDownloadUrl = "https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_224_android_quant_2017_11_08.zip" diff --git a/tensorflow/contrib/lite/java/ovic/demo/app/build.gradle b/tensorflow/contrib/lite/java/ovic/demo/app/build.gradle index 2a08608bbb..4f3a6cdb2f 100644 --- a/tensorflow/contrib/lite/java/ovic/demo/app/build.gradle +++ b/tensorflow/contrib/lite/java/ovic/demo/app/build.gradle @@ -9,7 +9,6 @@ android { targetSdkVersion 26 versionCode 1 versionName "1.0" - testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner" // Remove this block. jackOptions { @@ -43,9 +42,6 @@ repositories { dependencies { compile fileTree(dir: 'libs', include: ['*.jar']) - androidTestCompile('androidx.test.espresso:espresso-core:3.1.0-alpha3', { - exclude group: 'com.android.support', module: 'support-annotations' - }) compile 'com.android.support:appcompat-v7:25.2.0' compile 'com.android.support.constraint:constraint-layout:1.0.2' compile 'com.android.support:design:25.2.0' @@ -53,6 +49,4 @@ dependencies { compile 'com.android.support:support-v13:25.2.0' compile 'org.tensorflow:tensorflow-lite:+' - - testCompile 'junit:junit:4.12' } diff --git a/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm.cc b/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm.cc index a11a59aa05..af47b33922 100644 --- a/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm.cc +++ b/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm.cc @@ -94,18 +94,23 @@ constexpr int kBwProjectionWeightsTensor = 33; // Optional // Projection bias tensor of size {n_output} constexpr int kBwProjectionBiasTensor = 34; // Optional -// Output tensors. -constexpr int kFwOutputStateTensor = 0; -constexpr int kFwCellStateTensor = 1; -constexpr int kFwOutputTensor = 2; +// Stateful input tensors that are variables and will be modified by the Op. +// Activation state tensors of size {n_batch, n_output} +constexpr int kFwInputActivationStateTensor = 35; +// Cell state tensors of size {n_batch, n_cell} +constexpr int kFwInputCellStateTensor = 36; +// Activation state tensors of size {n_batch, n_output} +constexpr int kBwInputActivationStateTensor = 37; +// Cell state tensors of size {n_batch, n_cell} +constexpr int kBwInputCellStateTensor = 38; -constexpr int kBwOutputStateTensor = 3; -constexpr int kBwCellStateTensor = 4; -constexpr int kBwOutputTensor = 5; +// Output tensors. +constexpr int kFwOutputTensor = 0; +constexpr int kBwOutputTensor = 1; void* Init(TfLiteContext* context, const char* buffer, size_t length) { auto* scratch_tensor_index = new int; - context->AddTensors(context, 2, scratch_tensor_index); + context->AddTensors(context, /*tensors_to_add=*/2, scratch_tensor_index); return scratch_tensor_index; } @@ -307,14 +312,14 @@ TfLiteStatus CheckInputTensorDimensions(TfLiteContext* context, return kTfLiteOk; } -// Resize the output, state and scratch tensors based on the sizes of the input +// Resize the output and scratch tensors based on the sizes of the input // tensors. Also check that the size of the input tensors match each other. TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { int* scratch_tensor_index = reinterpret_cast<int*>(node->user_data); // Check we have all the inputs and outputs we need. - TF_LITE_ENSURE_EQ(context, node->inputs->size, 35); - TF_LITE_ENSURE_EQ(context, node->outputs->size, 6); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 39); + TF_LITE_ENSURE_EQ(context, node->outputs->size, 2); // Inferring batch size, number of outputs and sequence length and // number of cells from the input tensors. @@ -343,13 +348,21 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { context, CheckInputTensorDimensions(context, node, n_input, n_fw_output, n_fw_cell)); - // Get the pointer to output, state and scratch buffer tensors. + // Get the pointer to output, activation_state and cell_state buffer tensors. TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); - TfLiteTensor* fw_output_state = - GetOutput(context, node, kFwOutputStateTensor); - TfLiteTensor* fw_cell_state = GetOutput(context, node, kFwCellStateTensor); - - // Resize the output, output_state and cell_state tensors. + TfLiteTensor* fw_activation_state = + GetVariableInput(context, node, kFwInputActivationStateTensor); + TfLiteTensor* fw_cell_state = + GetVariableInput(context, node, kFwInputCellStateTensor); + + // Check the shape of input state tensors. + // These tensor may be 1D or 2D. It's fine as long as the total size is + // correct. + TF_LITE_ENSURE_EQ(context, NumElements(fw_activation_state), + n_batch * n_fw_output); + TF_LITE_ENSURE_EQ(context, NumElements(fw_cell_state), n_batch * n_fw_cell); + + // Resize the output tensors. TfLiteIntArray* fw_output_size = TfLiteIntArrayCreate(3); fw_output_size->data[0] = max_time; fw_output_size->data[1] = n_batch; @@ -357,18 +370,6 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, fw_output, fw_output_size)); - TfLiteIntArray* fw_output_state_size = TfLiteIntArrayCreate(2); - fw_output_state_size->data[0] = n_batch; - fw_output_state_size->data[1] = n_fw_output; - TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, fw_output_state, - fw_output_state_size)); - - TfLiteIntArray* fw_cell_size = TfLiteIntArrayCreate(2); - fw_cell_size->data[0] = n_batch; - fw_cell_size->data[1] = n_fw_cell; - TF_LITE_ENSURE_OK( - context, context->ResizeTensor(context, fw_cell_state, fw_cell_size)); - // Create a scratch buffer tensor. TfLiteIntArrayFree(node->temporaries); node->temporaries = TfLiteIntArrayCreate(2); @@ -377,10 +378,6 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { fw_scratch_buffer->type = input->type; fw_scratch_buffer->allocation_type = kTfLiteArenaRw; - // Mark state tensors as persistent tensors. - fw_output_state->allocation_type = kTfLiteArenaRwPersistent; - fw_cell_state->allocation_type = kTfLiteArenaRwPersistent; - const TfLiteTensor* fw_input_to_input_weights = GetOptionalInputTensor(context, node, kFwInputToInputWeightsTensor); const bool fw_use_cifg = (fw_input_to_input_weights == nullptr); @@ -415,13 +412,14 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { context, CheckInputTensorDimensions(context, node, n_input, n_bw_output, n_bw_cell)); - // Get the pointer to output, output_state and cell_state buffer tensors. + // Get the pointer to output, activation_state and cell_state buffer tensors. TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); - TfLiteTensor* bw_output_state = - GetOutput(context, node, kBwOutputStateTensor); - TfLiteTensor* bw_cell_state = GetOutput(context, node, kBwCellStateTensor); + TfLiteTensor* bw_activation_state = + GetVariableInput(context, node, kBwInputActivationStateTensor); + TfLiteTensor* bw_cell_state = + GetVariableInput(context, node, kBwInputCellStateTensor); - // Resize the output, output_state and cell_state tensors. + // Resize the output tensors. TfLiteIntArray* bw_output_size = TfLiteIntArrayCreate(3); bw_output_size->data[0] = max_time; bw_output_size->data[1] = n_batch; @@ -429,17 +427,12 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, bw_output, bw_output_size)); - TfLiteIntArray* bw_output_state_size = TfLiteIntArrayCreate(2); - bw_output_state_size->data[0] = n_batch; - bw_output_state_size->data[1] = n_bw_output; - TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, bw_output_state, - bw_output_state_size)); - - TfLiteIntArray* bw_cell_size = TfLiteIntArrayCreate(2); - bw_cell_size->data[0] = n_batch; - bw_cell_size->data[1] = n_bw_cell; - TF_LITE_ENSURE_OK( - context, context->ResizeTensor(context, bw_cell_state, bw_cell_size)); + // Check the shape of input state tensors. + // These tensor may be 1D or 2D. It's fine as long as the total size is + // correct. + TF_LITE_ENSURE_EQ(context, NumElements(bw_activation_state), + n_batch * n_bw_output); + TF_LITE_ENSURE_EQ(context, NumElements(bw_cell_state), n_batch * n_bw_cell); // Create a scratch buffer tensor. node->temporaries->data[1] = *(scratch_tensor_index) + 1; @@ -447,10 +440,6 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { bw_scratch_buffer->type = input->type; bw_scratch_buffer->allocation_type = kTfLiteArenaRw; - // Mark state tensors as persistent tensors. - bw_output_state->allocation_type = kTfLiteArenaRwPersistent; - bw_cell_state->allocation_type = kTfLiteArenaRwPersistent; - const TfLiteTensor* bw_input_to_input_weights = GetOptionalInputTensor(context, node, kBwInputToInputWeightsTensor); const bool bw_use_cifg = (bw_input_to_input_weights == nullptr); @@ -518,9 +507,10 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { const TfLiteTensor* fw_projection_bias = GetOptionalInputTensor(context, node, kFwProjectionBiasTensor); - TfLiteTensor* fw_output_state = - GetOutput(context, node, kFwOutputStateTensor); - TfLiteTensor* fw_cell_state = GetOutput(context, node, kFwCellStateTensor); + TfLiteTensor* fw_activation_state = + GetVariableInput(context, node, kFwInputActivationStateTensor); + TfLiteTensor* fw_cell_state = + GetVariableInput(context, node, kFwInputCellStateTensor); TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); // Tensors for the backward cell. @@ -563,9 +553,10 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { const TfLiteTensor* bw_projection_bias = GetOptionalInputTensor(context, node, kBwProjectionBiasTensor); - TfLiteTensor* bw_output_state = - GetOutput(context, node, kBwOutputStateTensor); - TfLiteTensor* bw_cell_state = GetOutput(context, node, kBwCellStateTensor); + TfLiteTensor* bw_activation_state = + GetVariableInput(context, node, kBwInputActivationStateTensor); + TfLiteTensor* bw_cell_state = + GetVariableInput(context, node, kBwInputCellStateTensor); TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); // n_cell and n_output will be the same size when there is no projection. @@ -634,7 +625,7 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { fw_input_gate_bias_ptr, fw_forget_gate_bias->data.f, fw_cell_bias->data.f, fw_output_gate_bias->data.f, fw_projection_weights_ptr, fw_projection_bias_ptr, params, n_batch, - n_fw_cell, n_input, n_fw_output, fw_output_state->data.f, + n_fw_cell, n_input, n_fw_output, fw_activation_state->data.f, fw_cell_state->data.f, fw_input_gate_scratch, fw_forget_gate_scratch, fw_cell_scratch, fw_output_gate_scratch, output_ptr_time); } @@ -705,7 +696,7 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { bw_input_gate_bias_ptr, bw_forget_gate_bias->data.f, bw_cell_bias->data.f, bw_output_gate_bias->data.f, bw_projection_weights_ptr, bw_projection_bias_ptr, params, n_batch, - n_bw_cell, n_input, n_bw_output, bw_output_state->data.f, + n_bw_cell, n_input, n_bw_output, bw_activation_state->data.f, bw_cell_state->data.f, bw_input_gate_scratch, bw_forget_gate_scratch, bw_cell_scratch, bw_output_gate_scratch, output_ptr_time); } diff --git a/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm_test.cc b/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm_test.cc index a18e1bce34..d058fab529 100644 --- a/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm_test.cc +++ b/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm_test.cc @@ -102,10 +102,6 @@ class BidirectionalLSTMOpModel : public SingleOpModel { fw_projection_bias_ = AddNullInput(); } - fw_output_state_ = AddOutput(TensorType_FLOAT32); - fw_cell_state_ = AddOutput(TensorType_FLOAT32); - fw_output_ = AddOutput(TensorType_FLOAT32); - if (use_cifg) { bw_input_to_input_weights_ = AddNullInput(); } else { @@ -161,8 +157,24 @@ class BidirectionalLSTMOpModel : public SingleOpModel { bw_projection_bias_ = AddNullInput(); } - bw_output_state_ = AddOutput(TensorType_FLOAT32); - bw_cell_state_ = AddOutput(TensorType_FLOAT32); + // Adding the 2 input state tensors. + fw_input_activation_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_fw_output_ * n_batch_}}, + /*is_variable=*/true); + fw_input_cell_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_fw_cell_ * n_batch_}}, + /*is_variable=*/true); + + // Adding the 2 input state tensors. + bw_input_activation_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_bw_output_ * n_batch_}}, + /*is_variable=*/true); + bw_input_cell_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_bw_cell_ * n_batch_}}, + /*is_variable=*/true); + + fw_output_ = AddOutput(TensorType_FLOAT32); + bw_output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp(BuiltinOperator_BIDIRECTIONAL_SEQUENCE_LSTM, @@ -259,26 +271,6 @@ class BidirectionalLSTMOpModel : public SingleOpModel { PopulateTensor(bw_projection_bias_, f); } - void ResetFwOutputAndCellStates() { - const int zero_buffer_size = n_fw_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(fw_output_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - PopulateTensor(fw_cell_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - - void ResetBwOutputAndCellStates() { - const int zero_buffer_size = n_bw_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(bw_output_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - PopulateTensor(bw_cell_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - void SetInput(int offset, float* begin, float* end) { PopulateTensor(input_, offset, begin, end); } @@ -340,13 +332,13 @@ class BidirectionalLSTMOpModel : public SingleOpModel { int bw_projection_weights_; int bw_projection_bias_; - int fw_output_; - int fw_output_state_; - int fw_cell_state_; + int fw_input_activation_state_; + int fw_input_cell_state_; + int bw_input_activation_state_; + int bw_input_cell_state_; + int fw_output_; int bw_output_; - int bw_output_state_; - int bw_cell_state_; int n_batch_; int n_input_; @@ -417,6 +409,12 @@ TEST(LSTMOpTest, BlackBoxTestNoCifgNoPeepholeNoProjectionNoClipping) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights({-0.45018822, -0.02338299, -0.0870589, @@ -474,10 +472,6 @@ TEST(LSTMOpTest, BlackBoxTestNoCifgNoPeepholeNoProjectionNoClipping) { -0.0332076, 0.123838, 0.309777, -0.17621, -0.0490733, 0.0739237, 0.067706, -0.0208124}; - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); - float* batch0_start = lstm_input; float* batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); @@ -500,34 +494,151 @@ TEST(LSTMOpTest, BlackBoxTestNoCifgNoPeepholeNoProjectionNoClipping) { bw_expected.insert(bw_expected.end(), bw_golden_start, bw_golden_end); EXPECT_THAT(lstm.GetBwOutput(), ElementsAreArray(ArrayFloatNear(bw_expected))); +} + +TEST(LSTMOpTest, BlackBoxTestNoCifgNoPeepholeNoProjectionNoClippingReverse) { + const int n_batch = 1; + const int n_input = 2; + // n_cell and n_output have the same size when there is no projection. + const int n_cell = 4; + const int n_output = 4; + const int sequence_length = 3; + + BidirectionalLSTMOpModel lstm( + n_batch, n_input, n_cell, n_output, sequence_length, /*use_cifg=*/false, + /*use_peephole=*/false, /*use_projection_weights=*/false, + /*use_projection_bias=*/false, /*cell_clip=*/0.0, /*proj_clip=*/0.0, + { + {sequence_length, n_batch, n_input}, // input tensor + + // Forward cell + {n_cell, n_input}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {n_cell, n_output}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + + {0}, // cell_to_input_weight tensor + {0}, // cell_to_forget_weight tensor + {0}, // cell_to_output_weight tensor + + {n_cell}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {0, 0}, // projection_weight tensor + {0}, // projection_bias tensor + + // Backward cell + {n_cell, n_input}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {n_cell, n_output}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + {0}, // cell_to_input_weight tensor + {0}, // cell_to_forget_weight tensor + {0}, // cell_to_output_weight tensor + + {n_cell}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {0, 0}, // projection_weight tensor + {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + }); + + lstm.SetInputToInputWeights({-0.45018822, -0.02338299, -0.0870589, + -0.34550029, 0.04266912, -0.15680569, + -0.34856534, 0.43890524}); + + lstm.SetInputToCellWeights({-0.50013041, 0.1370284, 0.11810488, 0.2013163, + -0.20583314, 0.44344562, 0.22077113, + -0.29909778}); + + lstm.SetInputToForgetWeights({0.09701663, 0.20334584, -0.50592935, + -0.31343272, -0.40032279, 0.44781327, + 0.01387155, -0.35593212}); + + lstm.SetInputToOutputWeights({-0.25065863, -0.28290087, 0.04613829, + 0.40525138, 0.44272184, 0.03897077, -0.1556896, + 0.19487578}); + + lstm.SetInputGateBias({0., 0., 0., 0.}); + + lstm.SetCellBias({0., 0., 0., 0.}); + + lstm.SetForgetGateBias({1., 1., 1., 1.}); + + lstm.SetOutputGateBias({0., 0., 0., 0.}); + + lstm.SetRecurrentToInputWeights( + {-0.0063535, -0.2042388, 0.31454784, -0.35746509, 0.28902304, 0.08183324, + -0.16555229, 0.02286911, -0.13566875, 0.03034258, 0.48091322, + -0.12528998, 0.24077177, -0.51332325, -0.33502164, 0.10629296}); + + lstm.SetRecurrentToCellWeights( + {-0.3407414, 0.24443203, -0.2078532, 0.26320225, 0.05695659, -0.00123841, + -0.4744786, -0.35869038, -0.06418842, -0.13502428, -0.501764, 0.22830659, + -0.46367589, 0.26016325, -0.03894562, -0.16368064}); + + lstm.SetRecurrentToForgetWeights( + {-0.48684245, -0.06655136, 0.42224967, 0.2112639, 0.27654213, 0.20864892, + -0.07646349, 0.45877004, 0.00141793, -0.14609534, 0.36447752, 0.09196436, + 0.28053468, 0.01560611, -0.20127171, -0.01140004}); + + lstm.SetRecurrentToOutputWeights( + {0.43385774, -0.17194885, 0.2718237, 0.09215671, 0.24107647, -0.39835793, + 0.18212086, 0.01301402, 0.48572797, -0.50656658, 0.20047462, -0.20607421, + -0.51818722, -0.15390486, 0.0468148, 0.39922136}); + + // Input should have n_input * sequence_length many values. // Check reversed inputs. static float lstm_input_reversed[] = {1., 1., 3., 4., 2., 3.}; + static float lstm_fw_golden_output[] = { + -0.02973187, 0.1229473, 0.20885126, -0.15358765, + -0.03716109, 0.12507336, 0.41193449, -0.20860538, + -0.15053082, 0.09120187, 0.24278517, -0.12222792}; + static float lstm_bw_golden_output[] = { + -0.0806187, 0.139077, 0.400476, -0.197842, -0.0332076, 0.123838, + 0.309777, -0.17621, -0.0490733, 0.0739237, 0.067706, -0.0208124}; - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); - - batch0_start = lstm_input_reversed; - batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); + float* batch0_start = lstm_input_reversed; + float* batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); lstm.SetInput(0, batch0_start, batch0_end); lstm.Invoke(); - fw_expected.clear(); + std::vector<float> fw_expected; for (int s = 0; s < lstm.sequence_length(); s++) { - fw_golden_start = lstm_fw_golden_output + s * lstm.num_fw_outputs(); - fw_golden_end = fw_golden_start + lstm.num_fw_outputs(); + float* fw_golden_start = lstm_fw_golden_output + s * lstm.num_fw_outputs(); + float* fw_golden_end = fw_golden_start + lstm.num_fw_outputs(); fw_expected.insert(fw_expected.begin(), fw_golden_start, fw_golden_end); } EXPECT_THAT(lstm.GetBwOutput(), ElementsAreArray(ArrayFloatNear(fw_expected))); - bw_expected.clear(); + std::vector<float> bw_expected; for (int s = 0; s < lstm.sequence_length(); s++) { - bw_golden_start = lstm_bw_golden_output + s * lstm.num_bw_outputs(); - bw_golden_end = bw_golden_start + lstm.num_bw_outputs(); + float* bw_golden_start = lstm_bw_golden_output + s * lstm.num_bw_outputs(); + float* bw_golden_end = bw_golden_start + lstm.num_bw_outputs(); bw_expected.insert(bw_expected.begin(), bw_golden_start, bw_golden_end); } EXPECT_THAT(lstm.GetFwOutput(), @@ -592,6 +703,12 @@ TEST(LSTMOpTest, BlackBoxTestWithCifgWithPeepholeNoProjectionNoClipping) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToCellWeights({-0.49770179, -0.27711356, -0.09624726, 0.05100781, @@ -642,10 +759,6 @@ TEST(LSTMOpTest, BlackBoxTestWithCifgWithPeepholeNoProjectionNoClipping) { -0.401685, -0.0232794, 0.288642, -0.123074, -0.42915, -0.00871577, 0.20912, -0.103567, -0.166398, -0.00486649, 0.0697471, -0.0537578}; - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); - float* batch0_start = lstm_input; float* batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); @@ -668,34 +781,143 @@ TEST(LSTMOpTest, BlackBoxTestWithCifgWithPeepholeNoProjectionNoClipping) { bw_expected.insert(bw_expected.end(), bw_golden_start, bw_golden_end); EXPECT_THAT(lstm.GetBwOutput(), ElementsAreArray(ArrayFloatNear(bw_expected))); +} - // Check reversed inputs. - static float lstm_input_reversed[] = {1., 1., 3., 4., 2., 3.}; +TEST(LSTMOpTest, + BlackBoxTestWithCifgWithPeepholeNoProjectionNoClippingReversed) { + const int n_batch = 1; + const int n_input = 2; + // n_cell and n_output have the same size when there is no projection. + const int n_cell = 4; + const int n_output = 4; + const int sequence_length = 3; - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); + BidirectionalLSTMOpModel lstm( + n_batch, n_input, n_cell, n_output, sequence_length, /*use_cifg=*/true, + /*use_peephole=*/true, /*use_projection_weights=*/false, + /*use_projection_bias=*/false, /*cell_clip=*/0.0, /*proj_clip=*/0.0, + { + {sequence_length, n_batch, n_input}, // input tensor - batch0_start = lstm_input_reversed; - batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); + {0, 0}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {0, 0}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + + {0}, // cell_to_input_weight tensor + {n_cell}, // cell_to_forget_weight tensor + {n_cell}, // cell_to_output_weight tensor + + {0}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {0, 0}, // projection_weight tensor + {0}, // projection_bias tensor + + {0, 0}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {0, 0}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + + {0}, // cell_to_input_weight tensor + {n_cell}, // cell_to_forget_weight tensor + {n_cell}, // cell_to_output_weight tensor + + {0}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {0, 0}, // projection_weight tensor + {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + }); + + lstm.SetInputToCellWeights({-0.49770179, -0.27711356, -0.09624726, 0.05100781, + 0.04717243, 0.48944736, -0.38535351, + -0.17212132}); + + lstm.SetInputToForgetWeights({-0.55291498, -0.42866567, 0.13056988, + -0.3633365, -0.22755712, 0.28253698, 0.24407166, + 0.33826375}); + + lstm.SetInputToOutputWeights({0.10725588, -0.02335852, -0.55932593, + -0.09426838, -0.44257352, 0.54939759, + 0.01533556, 0.42751634}); + + lstm.SetCellBias({0., 0., 0., 0.}); + + lstm.SetForgetGateBias({1., 1., 1., 1.}); + + lstm.SetOutputGateBias({0., 0., 0., 0.}); + + lstm.SetRecurrentToCellWeights( + {0.54066205, -0.32668582, -0.43562764, -0.56094903, 0.42957711, + 0.01841056, -0.32764608, -0.33027974, -0.10826075, 0.20675004, + 0.19069612, -0.03026325, -0.54532051, 0.33003211, 0.44901288, + 0.21193194}); + + lstm.SetRecurrentToForgetWeights( + {-0.13832897, -0.0515101, -0.2359007, -0.16661474, -0.14340827, + 0.36986142, 0.23414481, 0.55899, 0.10798943, -0.41174671, 0.17751795, + -0.34484994, -0.35874045, -0.11352962, 0.27268326, 0.54058349}); + + lstm.SetRecurrentToOutputWeights( + {0.41613156, 0.42610586, -0.16495961, -0.5663873, 0.30579174, -0.05115908, + -0.33941799, 0.23364776, 0.11178309, 0.09481031, -0.26424935, 0.46261835, + 0.50248802, 0.26114327, -0.43736315, 0.33149987}); + + lstm.SetCellToForgetWeights( + {0.47485286, -0.51955009, -0.24458408, 0.31544167}); + lstm.SetCellToOutputWeights( + {-0.17135078, 0.82760304, 0.85573703, -0.77109635}); + + static float lstm_input_reversed[] = {1., 1., 3., 4., 2., 3.}; + static float lstm_fw_golden_output[] = { + -0.36444446, -0.00352185, 0.12886585, -0.05163646, + -0.42312205, -0.01218222, 0.24201041, -0.08124574, + -0.358325, -0.04621704, 0.21641694, -0.06471302}; + static float lstm_bw_golden_output[] = { + -0.401685, -0.0232794, 0.288642, -0.123074, -0.42915, -0.00871577, + 0.20912, -0.103567, -0.166398, -0.00486649, 0.0697471, -0.0537578}; + + float* batch0_start = lstm_input_reversed; + float* batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); lstm.SetInput(0, batch0_start, batch0_end); lstm.Invoke(); - fw_expected.clear(); + std::vector<float> fw_expected; for (int s = 0; s < lstm.sequence_length(); s++) { - fw_golden_start = lstm_fw_golden_output + s * lstm.num_fw_outputs(); - fw_golden_end = fw_golden_start + lstm.num_fw_outputs(); + float* fw_golden_start = lstm_fw_golden_output + s * lstm.num_fw_outputs(); + float* fw_golden_end = fw_golden_start + lstm.num_fw_outputs(); fw_expected.insert(fw_expected.begin(), fw_golden_start, fw_golden_end); } EXPECT_THAT(lstm.GetBwOutput(), ElementsAreArray(ArrayFloatNear(fw_expected))); - bw_expected.clear(); + std::vector<float> bw_expected; for (int s = 0; s < lstm.sequence_length(); s++) { - bw_golden_start = lstm_bw_golden_output + s * lstm.num_bw_outputs(); - bw_golden_end = bw_golden_start + lstm.num_bw_outputs(); + float* bw_golden_start = lstm_bw_golden_output + s * lstm.num_bw_outputs(); + float* bw_golden_end = bw_golden_start + lstm.num_bw_outputs(); bw_expected.insert(bw_expected.begin(), bw_golden_start, bw_golden_end); } EXPECT_THAT(lstm.GetFwOutput(), @@ -759,6 +981,12 @@ TEST(LSTMOpTest, BlackBoxTestWithPeepholeWithProjectionNoClipping) { {n_output, n_cell}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights( @@ -1343,10 +1571,6 @@ TEST(LSTMOpTest, BlackBoxTestWithPeepholeWithProjectionNoClipping) { 0.065133, 0.024321, 0.038473, 0.062438 }}; - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); - for (int i = 0; i < lstm.sequence_length(); i++) { float* batch0_start = lstm_input[0] + i * lstm.num_inputs(); float* batch0_end = batch0_start + lstm.num_inputs(); diff --git a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc index c65bc33d08..d988ef8b33 100644 --- a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc +++ b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc @@ -41,13 +41,27 @@ constexpr int kBwWeightsTensor = 5; constexpr int kBwRecurrentWeightsTensor = 6; constexpr int kBwBiasTensor = 7; constexpr int kBwHiddenStateTensor = 8; +// Auxiliary inputs. +constexpr int kAuxInputTensor = 9; // Optional. +constexpr int kFwAuxWeightsTensor = 10; // Optional. +constexpr int kBwAuxWeightsTensor = 11; // Optional. // Output tensors. constexpr int kFwOutputTensor = 0; constexpr int kBwOutputTensor = 1; +// Temporary tensors. +enum TemporaryTensor { + kInputQuantized = 0, + kFwHiddenStateQuantized = 1, + kBwHiddenStateQuantized = 2, + kScalingFactors = 3, + kAuxInputQuantized = 4, + kNumTemporaryTensors = 5 +}; + void* Init(TfLiteContext* context, const char* buffer, size_t length) { auto* scratch_tensor_index = new int; - context->AddTensors(context, /*tensors_to_add=*/3, scratch_tensor_index); + context->AddTensors(context, kNumTemporaryTensors, scratch_tensor_index); return scratch_tensor_index; } @@ -57,7 +71,7 @@ void Free(TfLiteContext* context, void* buffer) { TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { // Check we have all the inputs and outputs we need. - TF_LITE_ENSURE_EQ(context, node->inputs->size, 9); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 12); TF_LITE_ENSURE_EQ(context, node->outputs->size, 2); const TfLiteTensor* input = GetInput(context, node, kInputTensor); @@ -76,6 +90,21 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { const TfLiteTensor* bw_hidden_state = GetInput(context, node, kBwHiddenStateTensor); + const TfLiteTensor* aux_input = + GetOptionalInputTensor(context, node, kAuxInputTensor); + const TfLiteTensor* fw_aux_input_weights = + GetOptionalInputTensor(context, node, kFwAuxWeightsTensor); + const TfLiteTensor* bw_aux_input_weights = + GetOptionalInputTensor(context, node, kBwAuxWeightsTensor); + + const bool aux_inputs_all_or_none = + ((aux_input != nullptr) && (fw_aux_input_weights != nullptr) && + (bw_aux_input_weights != nullptr)) || + ((aux_input == nullptr) && (fw_aux_input_weights == nullptr) && + (bw_aux_input_weights == nullptr)); + TF_LITE_ENSURE(context, aux_inputs_all_or_none); + const bool has_aux_input = (aux_input != nullptr); + // Check all the parameters of tensor match within themselves and match the // input configuration. TF_LITE_ENSURE_EQ(context, input->type, kTfLiteFloat32); @@ -99,6 +128,20 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_EQ(context, bw_hidden_state->dims->data[0], batch_size); TF_LITE_ENSURE_EQ(context, bw_hidden_state->dims->data[1], bw_num_units); + if (has_aux_input) { + // Check that aux_input has the same dimensions (except last) as the input. + TF_LITE_ASSERT_EQ(aux_input->dims->data[0], input->dims->data[0]); + TF_LITE_ASSERT_EQ(aux_input->dims->data[1], input->dims->data[1]); + // Check that aux_input_weights has the same dimensions (except last) as + // the input_weights. + TF_LITE_ASSERT_EQ(fw_aux_input_weights->dims->data[0], fw_num_units); + TF_LITE_ASSERT_EQ(bw_aux_input_weights->dims->data[0], bw_num_units); + TF_LITE_ASSERT_EQ(aux_input->dims->data[2], + fw_aux_input_weights->dims->data[1]); + TF_LITE_ASSERT_EQ(aux_input->dims->data[2], + bw_aux_input_weights->dims->data[1]); + } + TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); @@ -107,10 +150,19 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { if (is_hybrid_op) { int* scratch_tensor_index = reinterpret_cast<int*>(node->user_data); + TfLiteIntArrayFree(node->temporaries); - node->temporaries = TfLiteIntArrayCreate(2); - node->temporaries->data[0] = *scratch_tensor_index; - TfLiteTensor* input_quantized = GetTemporary(context, node, /*index=*/0); + if (has_aux_input) { + node->temporaries = TfLiteIntArrayCreate(kNumTemporaryTensors); + } else { + // No need to create a temporary tensor for the non-existent aux_input. + node->temporaries = TfLiteIntArrayCreate(kNumTemporaryTensors - 1); + } + + node->temporaries->data[kInputQuantized] = + *scratch_tensor_index + kInputQuantized; + TfLiteTensor* input_quantized = + GetTemporary(context, node, kInputQuantized); input_quantized->type = kTfLiteUInt8; input_quantized->allocation_type = kTfLiteArenaRw; if (!TfLiteIntArrayEqual(input_quantized->dims, input->dims)) { @@ -118,9 +170,11 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, input_quantized, input_quantized_size)); } - node->temporaries->data[1] = *scratch_tensor_index + 1; + + node->temporaries->data[kFwHiddenStateQuantized] = + *scratch_tensor_index + kFwHiddenStateQuantized; TfLiteTensor* fw_hidden_state_quantized = - GetTemporary(context, node, /*index=*/1); + GetTemporary(context, node, kFwHiddenStateQuantized); fw_hidden_state_quantized->type = kTfLiteUInt8; fw_hidden_state_quantized->allocation_type = kTfLiteArenaRw; if (!TfLiteIntArrayEqual(fw_hidden_state_quantized->dims, @@ -131,9 +185,11 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { context, context->ResizeTensor(context, fw_hidden_state_quantized, fw_hidden_state_quantized_size)); } - node->temporaries->data[2] = *scratch_tensor_index + 2; + + node->temporaries->data[kBwHiddenStateQuantized] = + *scratch_tensor_index + kBwHiddenStateQuantized; TfLiteTensor* bw_hidden_state_quantized = - GetTemporary(context, node, /*index=*/2); + GetTemporary(context, node, kBwHiddenStateQuantized); bw_hidden_state_quantized->type = kTfLiteUInt8; bw_hidden_state_quantized->allocation_type = kTfLiteArenaRw; if (!TfLiteIntArrayEqual(bw_hidden_state_quantized->dims, @@ -144,6 +200,36 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { context, context->ResizeTensor(context, bw_hidden_state_quantized, bw_hidden_state_quantized_size)); } + + // Allocate temporary tensors to store scaling factors of quantization. + node->temporaries->data[kScalingFactors] = + *scratch_tensor_index + kScalingFactors; + TfLiteTensor* scaling_factors = + GetTemporary(context, node, kScalingFactors); + scaling_factors->type = kTfLiteFloat32; + scaling_factors->allocation_type = kTfLiteArenaRw; + TfLiteIntArray* scaling_factors_size = TfLiteIntArrayCreate(1); + scaling_factors_size->data[0] = batch_size; + if (!TfLiteIntArrayEqual(scaling_factors->dims, scaling_factors_size)) { + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, scaling_factors, + scaling_factors_size)); + } + + if (has_aux_input) { + node->temporaries->data[kAuxInputQuantized] = + *scratch_tensor_index + kAuxInputQuantized; + TfLiteTensor* aux_input_quantized = + GetTemporary(context, node, kAuxInputQuantized); + aux_input_quantized->type = kTfLiteUInt8; + aux_input_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(aux_input_quantized->dims, aux_input->dims)) { + TfLiteIntArray* aux_input_quantized_size = + TfLiteIntArrayCopy(aux_input->dims); + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, aux_input_quantized, + aux_input_quantized_size)); + } + } } // Resize outputs. @@ -163,19 +249,20 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { return kTfLiteOk; } -TfLiteStatus EvalFloat(const TfLiteTensor* input, - const TfLiteTensor* fw_input_weights, - const TfLiteTensor* fw_recurrent_weights, - const TfLiteTensor* fw_bias, - const TfLiteTensor* bw_input_weights, - const TfLiteTensor* bw_recurrent_weights, - const TfLiteTensor* bw_bias, - const TfLiteSequenceRNNParams* params, - TfLiteTensor* fw_hidden_state, TfLiteTensor* fw_output, - TfLiteTensor* bw_hidden_state, TfLiteTensor* bw_output) { +TfLiteStatus EvalFloat( + const TfLiteTensor* input, const TfLiteTensor* fw_input_weights, + const TfLiteTensor* fw_recurrent_weights, const TfLiteTensor* fw_bias, + const TfLiteTensor* bw_input_weights, + const TfLiteTensor* bw_recurrent_weights, const TfLiteTensor* bw_bias, + const TfLiteTensor* aux_input, const TfLiteTensor* fw_aux_input_weights, + const TfLiteTensor* bw_aux_input_weights, + const TfLiteSequenceRNNParams* params, TfLiteTensor* fw_hidden_state, + TfLiteTensor* fw_output, TfLiteTensor* bw_hidden_state, + TfLiteTensor* bw_output) { const int batch_size = input->dims->data[0]; const int max_time = input->dims->data[1]; const int input_size = input->dims->data[2]; + const int aux_input_size = (aux_input) ? aux_input->dims->data[2] : 0; const int fw_num_units = fw_input_weights->dims->data[0]; const float* fw_bias_ptr = fw_bias->data.f; @@ -187,6 +274,13 @@ TfLiteStatus EvalFloat(const TfLiteTensor* input, const float* bw_input_weights_ptr = bw_input_weights->data.f; const float* bw_recurrent_weights_ptr = bw_recurrent_weights->data.f; + const float* fw_aux_input_weights_ptr = (fw_aux_input_weights != nullptr) + ? fw_aux_input_weights->data.f + : nullptr; + const float* bw_aux_input_weights_ptr = (bw_aux_input_weights != nullptr) + ? bw_aux_input_weights->data.f + : nullptr; + for (int b = 0; b < batch_size; b++) { // Forward cell. float* fw_hidden_state_ptr_batch = @@ -194,12 +288,17 @@ TfLiteStatus EvalFloat(const TfLiteTensor* input, for (int s = 0; s < max_time; s++) { const float* input_ptr_batch = input->data.f + b * input_size * max_time + s * input_size; + const float* aux_input_ptr_batch = + (aux_input != nullptr) + ? aux_input->data.f + b * input_size * max_time + s * input_size + : nullptr; float* output_ptr_batch = fw_output->data.f + b * fw_num_units * max_time + s * fw_num_units; kernel_utils::RnnBatchStep( - input_ptr_batch, fw_input_weights_ptr, fw_recurrent_weights_ptr, - fw_bias_ptr, input_size, fw_num_units, /*batch_size=*/1, + input_ptr_batch, fw_input_weights_ptr, aux_input_ptr_batch, + fw_aux_input_weights_ptr, fw_recurrent_weights_ptr, fw_bias_ptr, + input_size, aux_input_size, fw_num_units, /*batch_size=*/1, params->activation, fw_hidden_state_ptr_batch, output_ptr_batch); } // Backward cell. @@ -208,12 +307,17 @@ TfLiteStatus EvalFloat(const TfLiteTensor* input, for (int s = max_time - 1; s >= 0; s--) { const float* input_ptr_batch = input->data.f + b * input_size * max_time + s * input_size; + const float* aux_input_ptr_batch = + (aux_input != nullptr) + ? aux_input->data.f + b * input_size * max_time + s * input_size + : nullptr; float* output_ptr_batch = bw_output->data.f + b * bw_num_units * max_time + s * bw_num_units; kernel_utils::RnnBatchStep( - input_ptr_batch, bw_input_weights_ptr, bw_recurrent_weights_ptr, - bw_bias_ptr, input_size, bw_num_units, /*batch_size=*/1, + input_ptr_batch, bw_input_weights_ptr, aux_input_ptr_batch, + bw_aux_input_weights_ptr, bw_recurrent_weights_ptr, bw_bias_ptr, + input_size, aux_input_size, bw_num_units, /*batch_size=*/1, params->activation, bw_hidden_state_ptr_batch, output_ptr_batch); } } @@ -225,14 +329,17 @@ TfLiteStatus EvalHybrid( const TfLiteTensor* fw_recurrent_weights, const TfLiteTensor* fw_bias, const TfLiteTensor* bw_input_weights, const TfLiteTensor* bw_recurrent_weights, const TfLiteTensor* bw_bias, - const TfLiteSequenceRNNParams* params, TfLiteTensor* input_quantized, - TfLiteTensor* fw_hidden_state_quantized, TfLiteTensor* fw_scaling_factors, - TfLiteTensor* fw_hidden_state, TfLiteTensor* fw_output, - TfLiteTensor* bw_hidden_state_quantized, TfLiteTensor* bw_scaling_factors, + const TfLiteTensor* aux_input, const TfLiteTensor* aux_fw_input_weights, + const TfLiteTensor* aux_bw_input_weights, + const TfLiteSequenceRNNParams* params, TfLiteTensor* scaling_factors, + TfLiteTensor* input_quantized, TfLiteTensor* aux_input_quantized, + TfLiteTensor* fw_hidden_state_quantized, TfLiteTensor* fw_hidden_state, + TfLiteTensor* fw_output, TfLiteTensor* bw_hidden_state_quantized, TfLiteTensor* bw_hidden_state, TfLiteTensor* bw_output) { const int batch_size = input->dims->data[0]; const int max_time = input->dims->data[1]; const int input_size = input->dims->data[2]; + const int aux_input_size = (aux_input) ? aux_input->dims->data[2] : 0; const int fw_num_units = fw_input_weights->dims->data[0]; const float* fw_bias_ptr = fw_bias->data.f; @@ -252,6 +359,22 @@ TfLiteStatus EvalHybrid( reinterpret_cast<const int8_t*>(bw_recurrent_weights->data.uint8); float bw_recurrent_weights_scale = bw_recurrent_weights->params.scale; + // Set the auxiliary pointers and scales if needed. + int8_t* aux_fw_input_weights_ptr = nullptr; + float aux_fw_input_weights_scale = 0.0f; + int8_t* aux_bw_input_weights_ptr = nullptr; + float aux_bw_input_weights_scale = 0.0f; + int8_t* aux_quantized_input_ptr = nullptr; + if (aux_input_size > 0) { + aux_fw_input_weights_ptr = + reinterpret_cast<int8_t*>(aux_fw_input_weights->data.uint8); + aux_fw_input_weights_scale = aux_fw_input_weights->params.scale; + aux_bw_input_weights_ptr = + reinterpret_cast<int8_t*>(aux_bw_input_weights->data.uint8); + aux_bw_input_weights_scale = aux_bw_input_weights->params.scale; + aux_quantized_input_ptr = reinterpret_cast<int8_t*>(aux_input_quantized); + } + // Initialize temporary storage for quantized values. int8_t* quantized_input_ptr = reinterpret_cast<int8_t*>(input_quantized->data.uint8); @@ -259,8 +382,7 @@ TfLiteStatus EvalHybrid( reinterpret_cast<int8_t*>(fw_hidden_state_quantized->data.uint8); int8_t* bw_quantized_hidden_state_ptr = reinterpret_cast<int8_t*>(bw_hidden_state_quantized->data.uint8); - float* fw_scaling_factors_ptr = fw_scaling_factors->data.f; - float* bw_scaling_factors_ptr = bw_scaling_factors->data.f; + float* scaling_factors_ptr = scaling_factors->data.f; for (int b = 0; b < batch_size; b++) { // Forward cell. @@ -269,15 +391,22 @@ TfLiteStatus EvalHybrid( for (int s = 0; s < max_time; s++) { const float* input_ptr_batch = input->data.f + b * input_size * max_time + s * input_size; + const float* aux_input_ptr_batch = + (aux_input != nullptr) + ? aux_input->data.f + b * input_size * max_time + s * input_size + : nullptr; float* output_ptr_batch = fw_output->data.f + b * fw_num_units * max_time + s * fw_num_units; kernel_utils::RnnBatchStep( input_ptr_batch, fw_input_weights_ptr, fw_input_weights_scale, - fw_recurrent_weights_ptr, fw_recurrent_weights_scale, fw_bias_ptr, - input_size, fw_num_units, /*batch_size=*/1, params->activation, - quantized_input_ptr, fw_quantized_hidden_state_ptr, - fw_scaling_factors_ptr, fw_hidden_state_ptr_batch, output_ptr_batch); + aux_input_ptr_batch, aux_fw_input_weights_ptr, + aux_fw_input_weights_scale, fw_recurrent_weights_ptr, + fw_recurrent_weights_scale, fw_bias_ptr, input_size, aux_input_size, + fw_num_units, /*batch_size=*/1, params->activation, + quantized_input_ptr, aux_quantized_input_ptr, + fw_quantized_hidden_state_ptr, scaling_factors_ptr, + fw_hidden_state_ptr_batch, output_ptr_batch); } // Backward cell. float* bw_hidden_state_ptr_batch = @@ -285,15 +414,22 @@ TfLiteStatus EvalHybrid( for (int s = max_time - 1; s >= 0; s--) { const float* input_ptr_batch = input->data.f + b * input_size * max_time + s * input_size; + const float* aux_input_ptr_batch = + (aux_input != nullptr) + ? aux_input->data.f + b * input_size * max_time + s * input_size + : nullptr; float* output_ptr_batch = bw_output->data.f + b * bw_num_units * max_time + s * bw_num_units; kernel_utils::RnnBatchStep( input_ptr_batch, bw_input_weights_ptr, bw_input_weights_scale, - bw_recurrent_weights_ptr, bw_recurrent_weights_scale, bw_bias_ptr, - input_size, bw_num_units, /*batch_size=*/1, params->activation, - quantized_input_ptr, bw_quantized_hidden_state_ptr, - bw_scaling_factors_ptr, bw_hidden_state_ptr_batch, output_ptr_batch); + aux_input_ptr_batch, aux_bw_input_weights_ptr, + aux_bw_input_weights_scale, bw_recurrent_weights_ptr, + bw_recurrent_weights_scale, bw_bias_ptr, input_size, aux_input_size, + bw_num_units, /*batch_size=*/1, params->activation, + quantized_input_ptr, aux_quantized_input_ptr, + bw_quantized_hidden_state_ptr, scaling_factors_ptr, + bw_hidden_state_ptr_batch, output_ptr_batch); } } return kTfLiteOk; @@ -315,10 +451,18 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { GetInput(context, node, kBwRecurrentWeightsTensor); const TfLiteTensor* bw_bias = GetInput(context, node, kBwBiasTensor); + // Get auxiliary inputs. + const TfLiteTensor* aux_input = + GetOptionalInputTensor(context, node, kAuxInputTensor); + const TfLiteTensor* fw_aux_input_weights = + GetOptionalInputTensor(context, node, kFwAuxWeightsTensor); + const TfLiteTensor* bw_aux_input_weights = + GetOptionalInputTensor(context, node, kBwAuxWeightsTensor); + TfLiteTensor* fw_hidden_state = - const_cast<TfLiteTensor*>(GetInput(context, node, kFwHiddenStateTensor)); + GetVariableInput(context, node, kFwHiddenStateTensor); TfLiteTensor* bw_hidden_state = - const_cast<TfLiteTensor*>(GetInput(context, node, kBwHiddenStateTensor)); + GetVariableInput(context, node, kBwHiddenStateTensor); TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); @@ -326,19 +470,30 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { switch (fw_input_weights->type) { case kTfLiteFloat32: return EvalFloat(input, fw_input_weights, fw_recurrent_weights, fw_bias, - bw_input_weights, bw_recurrent_weights, bw_bias, params, - fw_hidden_state, fw_output, bw_hidden_state, bw_output); + bw_input_weights, bw_recurrent_weights, bw_bias, + aux_input, fw_aux_input_weights, bw_aux_input_weights, + params, fw_hidden_state, fw_output, bw_hidden_state, + bw_output); case kTfLiteUInt8: { - TfLiteTensor* input_quantized = GetTemporary(context, node, 0); - TfLiteTensor* fw_hidden_state_quantized = GetTemporary(context, node, 1); - TfLiteTensor* bw_hidden_state_quantized = GetTemporary(context, node, 2); - TfLiteTensor* fw_scaling_factors = GetTemporary(context, node, 3); - TfLiteTensor* bw_scaling_factors = GetTemporary(context, node, 4); + TfLiteTensor* input_quantized = + GetTemporary(context, node, kInputQuantized); + TfLiteTensor* fw_hidden_state_quantized = + GetTemporary(context, node, kFwHiddenStateQuantized); + TfLiteTensor* bw_hidden_state_quantized = + GetTemporary(context, node, kBwHiddenStateQuantized); + TfLiteTensor* scaling_factors = + GetTemporary(context, node, kScalingFactors); + TfLiteTensor* aux_input_quantized = + (aux_input != nullptr) + ? GetTemporary(context, node, kAuxInputQuantized) + : nullptr; + return EvalHybrid(input, fw_input_weights, fw_recurrent_weights, fw_bias, - bw_input_weights, bw_recurrent_weights, bw_bias, params, - input_quantized, fw_hidden_state_quantized, - fw_scaling_factors, fw_hidden_state, fw_output, - bw_hidden_state_quantized, bw_scaling_factors, + bw_input_weights, bw_recurrent_weights, bw_bias, + aux_input, fw_aux_input_weights, bw_aux_input_weights, + params, scaling_factors, input_quantized, + aux_input_quantized, fw_hidden_state_quantized, + fw_hidden_state, fw_output, bw_hidden_state_quantized, bw_hidden_state, bw_output); } default: diff --git a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn_test.cc b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn_test.cc index 03236dbcdc..3e34ba6196 100644 --- a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn_test.cc +++ b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn_test.cc @@ -665,12 +665,18 @@ class BidirectionalRNNOpModel : public SingleOpModel { fw_recurrent_weights_ = AddInput(TensorType_FLOAT32); fw_bias_ = AddInput(TensorType_FLOAT32); fw_hidden_state_ = AddInput(TensorType_FLOAT32, true); - fw_output_ = AddOutput(TensorType_FLOAT32); bw_weights_ = AddInput(TensorType_FLOAT32); bw_recurrent_weights_ = AddInput(TensorType_FLOAT32); bw_bias_ = AddInput(TensorType_FLOAT32); bw_hidden_state_ = AddInput(TensorType_FLOAT32, true); + + aux_input_ = AddNullInput(); + aux_fw_weights_ = AddNullInput(); + aux_bw_weights_ = AddNullInput(); + + fw_output_ = AddOutput(TensorType_FLOAT32); bw_output_ = AddOutput(TensorType_FLOAT32); + SetBuiltinOp(BuiltinOperator_BIDIRECTIONAL_SEQUENCE_RNN, BuiltinOptions_SequenceRNNOptions, CreateSequenceRNNOptions(builder_, /*time_major=*/false, @@ -685,7 +691,10 @@ class BidirectionalRNNOpModel : public SingleOpModel { {bw_units_, input_size_}, // bw_weights {bw_units_, bw_units_}, // bw_recurrent_weights {bw_units_}, // bw_bias - {batches_, bw_units_} // bw_hidden_state + {batches_, bw_units_}, // bw_hidden_state + {batches_, sequence_len_, 0}, // aux_input + {fw_units_, 0}, // aux_fw_weights + {bw_units_, 0}, // aux_bw_weights }); } @@ -742,6 +751,9 @@ class BidirectionalRNNOpModel : public SingleOpModel { int bw_bias_; int bw_hidden_state_; int bw_output_; + int aux_input_; + int aux_fw_weights_; + int aux_bw_weights_; int batches_; int sequence_len_; diff --git a/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc b/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc index 88a0622286..360b472c45 100644 --- a/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc +++ b/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc @@ -26,6 +26,21 @@ void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, int input_size, int num_units, int batch_size, TfLiteFusedActivation activation, float* hidden_state_ptr_batch, float* output_ptr_batch) { + RnnBatchStep(input_ptr_batch, input_weights_ptr, + /*aux_input_ptr_batch=*/nullptr, + /*aux_input_weights_ptr=*/nullptr, recurrent_weights_ptr, + bias_ptr, input_size, /*aux_input_size=*/0, num_units, + batch_size, activation, hidden_state_ptr_batch, + output_ptr_batch); +} + +void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, + const float* aux_input_ptr_batch, + const float* aux_input_weights_ptr, + const float* recurrent_weights_ptr, const float* bias_ptr, + int input_size, int aux_input_size, int num_units, + int batch_size, TfLiteFusedActivation activation, + float* hidden_state_ptr_batch, float* output_ptr_batch) { // Output = bias tensor_utils::VectorBatchVectorAssign(bias_ptr, num_units, batch_size, output_ptr_batch); @@ -33,6 +48,12 @@ void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, tensor_utils::MatrixBatchVectorMultiplyAccumulate( input_weights_ptr, num_units, input_size, input_ptr_batch, batch_size, output_ptr_batch, /*result_stride=*/1); + // Output += aux_input * aux_input_weights (if they are not empty). + if (aux_input_size > 0) { + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_weights_ptr, num_units, aux_input_size, aux_input_ptr_batch, + batch_size, output_ptr_batch, /*result_stride=*/1); + } // Output += recurrent_weights * hidden_state tensor_utils::MatrixBatchVectorMultiplyAccumulate( recurrent_weights_ptr, num_units, num_units, hidden_state_ptr_batch, @@ -54,6 +75,28 @@ void RnnBatchStep(const float* input_ptr_batch, const int8_t* input_weights_ptr, int8_t* quantized_hidden_state_ptr_batch, float* scaling_factors, float* hidden_state_ptr_batch, float* output_ptr_batch) { + RnnBatchStep(input_ptr_batch, input_weights_ptr, input_weights_scale, + /*aux_input_ptr_batch=*/nullptr, + /*aux_input_weights_ptr=*/nullptr, + /*aux_input_weights_scale=*/0.0f, recurrent_weights_ptr, + recurrent_weights_scale, bias_ptr, input_size, + /*aux_input_size=*/0, num_units, batch_size, activation, + quantized_input_ptr_batch, + /*aux_quantized_input_ptr_batch=*/nullptr, + quantized_hidden_state_ptr_batch, scaling_factors, + hidden_state_ptr_batch, output_ptr_batch); +} + +void RnnBatchStep( + const float* input_ptr_batch, const int8_t* input_weights_ptr, + float input_weights_scale, const float* aux_input_ptr_batch, + const int8_t* aux_input_weights_ptr, float aux_input_weights_scale, + const int8_t* recurrent_weights_ptr, float recurrent_weights_scale, + const float* bias_ptr, int input_size, int aux_input_size, int num_units, + int batch_size, TfLiteFusedActivation activation, + int8_t* quantized_input_ptr_batch, int8_t* aux_quantized_input_ptr_batch, + int8_t* quantized_hidden_state_ptr_batch, float* scaling_factors, + float* hidden_state_ptr_batch, float* output_ptr_batch) { // Output = bias tensor_utils::VectorBatchVectorAssign(bias_ptr, num_units, batch_size, output_ptr_batch); @@ -80,6 +123,26 @@ void RnnBatchStep(const float* input_ptr_batch, const int8_t* input_weights_ptr, scaling_factors, batch_size, output_ptr_batch, /*result_stride=*/1); } + if (aux_input_ptr_batch && + !tensor_utils::IsZeroVector(aux_input_ptr_batch, + batch_size * aux_input_size)) { + float unused_min, unused_max; + for (int b = 0; b < batch_size; ++b) { + const int offset = b * aux_input_size; + tensor_utils::SymmetricQuantizeFloats( + aux_input_ptr_batch + offset, aux_input_size, + aux_quantized_input_ptr_batch + offset, &unused_min, &unused_max, + &scaling_factors[b]); + scaling_factors[b] *= aux_input_weights_scale; + } + + // Output += aux_input * aux_input_weights + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_weights_ptr, num_units, aux_input_size, + aux_quantized_input_ptr_batch, scaling_factors, batch_size, + output_ptr_batch, /*result_stride=*/1); + } + // Save quantization and matmul computation for all zero input. if (!tensor_utils::IsZeroVector(hidden_state_ptr_batch, batch_size * num_units)) { diff --git a/tensorflow/contrib/lite/kernels/internal/kernel_utils.h b/tensorflow/contrib/lite/kernels/internal/kernel_utils.h index 599850db60..38436c1382 100644 --- a/tensorflow/contrib/lite/kernels/internal/kernel_utils.h +++ b/tensorflow/contrib/lite/kernels/internal/kernel_utils.h @@ -35,6 +35,15 @@ void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, TfLiteFusedActivation activation, float* hidden_state_ptr_batch, float* output_ptr_batch); +// Same as above but includes an auxiliary input with the corresponding weights. +void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, + const float* aux_input_ptr_batch, + const float* aux_input_weights_ptr, + const float* recurrent_weights_ptr, const float* bias_ptr, + int input_size, int aux_input_size, int num_units, + int batch_size, TfLiteFusedActivation activation, + float* hidden_state_ptr_batch, float* output_ptr_batch); + // Performs a quantized RNN batch inference step. Same as above, but for // quantization purposes, we also pass in quantized_hidden_state_ptr_batch and // quantized_input_ptr_batch pointers for temporary storage of the quantized @@ -56,6 +65,17 @@ void RnnBatchStep(const float* input_ptr_batch, const int8_t* input_weights_ptr, float* scaling_factors, float* hidden_state_ptr_batch, float* output_ptr_batch); +void RnnBatchStep( + const float* input_ptr_batch, const int8_t* input_weights_ptr, + float input_weights_scale, const float* aux_input_ptr_batch, + const int8_t* aux_input_weights_ptr, float aux_input_weights_scale, + const int8_t* recurrent_weights_ptr, float recurrent_weights_scale, + const float* bias_ptr, int input_size, int aux_input_size, int num_units, + int batch_size, TfLiteFusedActivation activation, + int8_t* quantized_input_ptr_batch, int8_t* aux_quantized_input_ptr_batch, + int8_t* quantized_hidden_state_ptr_batch, float* scaling_factors, + float* hidden_state_ptr_batch, float* output_ptr_batch); + // Performs an LSTM batch inference step for input specified by input_ptr_batch. // The LSTM cell is specified by the pointers to its weights (*_weights_ptr) and // biases (*_bias_ptr), and buffers (*_scratch), along with additional diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h b/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h index 70adffda3b..9b35648b4e 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h @@ -67,6 +67,7 @@ using reference_ops::Relu6; using reference_ops::ReluX; using reference_ops::Select; using reference_ops::SpaceToBatchND; +using reference_ops::Split; using reference_ops::StridedSlice; using reference_ops::Transpose; diff --git a/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h b/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h index 62f7ade7d5..e5b71f81fa 100644 --- a/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h @@ -2524,32 +2524,69 @@ void LstmCell(const uint8* input_data_uint8, const Dims<4>& input_dims, } template <typename Scalar> +void Split(const SplitParams& params, const RuntimeShape& input_shape, + const Scalar* input_data, const RuntimeShape* const* output_shapes, + Scalar* const* output_data) { + const int concat_dimensions = input_shape.DimensionsCount(); + int axis = params.axis < 0 ? params.axis + concat_dimensions : params.axis; + int outputs_count = params.num_split; + TFLITE_DCHECK_LT(axis, concat_dimensions); + + int64_t concat_size = 0; + for (int i = 0; i < outputs_count; i++) { + TFLITE_DCHECK_EQ(output_shapes[i]->DimensionsCount(), concat_dimensions); + for (int j = 0; j < concat_dimensions; j++) { + if (j != axis) { + MatchingDim(*output_shapes[i], j, input_shape, j); + } + } + concat_size += output_shapes[i]->Dims(axis); + } + TFLITE_DCHECK_EQ(concat_size, input_shape.Dims(axis)); + int64_t outer_size = 1; + for (int i = 0; i < axis; ++i) { + outer_size *= input_shape.Dims(i); + } + // For all output arrays, + // FlatSize() = outer_size * Dims(axis) * base_inner_size; + int64_t base_inner_size = 1; + for (int i = axis + 1; i < concat_dimensions; ++i) { + base_inner_size *= input_shape.Dims(i); + } + + const Scalar* input_ptr = input_data; + for (int k = 0; k < outer_size; k++) { + for (int i = 0; i < outputs_count; ++i) { + const int copy_size = output_shapes[i]->Dims(axis) * base_inner_size; + memcpy(output_data[i] + k * copy_size, input_ptr, + copy_size * sizeof(Scalar)); + input_ptr += copy_size; + } + } +} + +// TODO(b/80418076): Move to legacy ops file, update invocations. +// Legacy Dims<4>. +template <typename Scalar> void TensorFlowSplit(const Scalar* input_data, const Dims<4>& input_dims, int axis, int outputs_count, Scalar* const* output_data, const Dims<4>* const* output_dims) { - const int batches = ArraySize(*output_dims[0], 3); - const int height = ArraySize(*output_dims[0], 2); - const int width = ArraySize(*output_dims[0], 1); - const int depth = ArraySize(*output_dims[0], 0); - - const int slice_size = ArraySize(*output_dims[0], axis); - + std::vector<RuntimeShape> output_shapes(outputs_count); + std::vector<const RuntimeShape*> output_shapes_indirect(outputs_count); for (int i = 0; i < outputs_count; ++i) { - int offset = i * slice_size * input_dims.strides[axis]; - for (int b = 0; b < batches; ++b) { - for (int y = 0; y < height; ++y) { - for (int x = 0; x < width; ++x) { - for (int c = 0; c < depth; ++c) { - auto out = Offset(*output_dims[i], c, x, y, b); - auto in = Offset(input_dims, c, x, y, b); - output_data[i][out] = input_data[offset + in]; - } - } - } - } + ShapeFromDims(*output_dims[i], &output_shapes[i]); + output_shapes_indirect[i] = &output_shapes[i]; } + tflite::SplitParams op_params; + op_params.axis = 3 - axis; + op_params.num_split = outputs_count; + + Split(op_params, DimsToShape(input_dims), input_data, + output_shapes_indirect.data(), output_data); } +// TODO(b/80418076): Move to legacy ops file, update invocations. +// Legacy Dims<4>. template <FusedActivationFunctionType Ac, typename Scalar> void TensorFlowSplit(const Scalar* input_data, const Dims<4>& input_dims, int outputs_count, Scalar* const* output_data, @@ -2560,9 +2597,8 @@ void TensorFlowSplit(const Scalar* input_data, const Dims<4>& input_dims, /* height = */ MatchingArraySize(*output_dims[i], 2, input_dims, 2); /* width = */ MatchingArraySize(*output_dims[i], 1, input_dims, 1); } - // for now we dont have a model with a TensorFlowSplit - // with fused activation function. - TFLITE_DCHECK(Ac == FusedActivationFunctionType::kNone); + // For now we don't have a model with a Split with fused activation. + TFLITE_DCHECK_EQ(Ac, FusedActivationFunctionType::kNone); TensorFlowSplit(input_data, input_dims, /*axis=*/0, outputs_count, output_data, output_dims); diff --git a/tensorflow/contrib/lite/kernels/internal/types.h b/tensorflow/contrib/lite/kernels/internal/types.h index 3b296f024f..6ae4ebc79e 100644 --- a/tensorflow/contrib/lite/kernels/internal/types.h +++ b/tensorflow/contrib/lite/kernels/internal/types.h @@ -889,6 +889,7 @@ struct SplitParams { // Graphs that split into, say, 2000 nodes are encountered. The indices in // OperatorEdges are of type uint16. uint16 num_split; + int16 axis; }; struct SqueezeParams { diff --git a/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm.cc b/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm.cc index 0acd705950..c678f14930 100644 --- a/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm.cc +++ b/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm.cc @@ -64,10 +64,14 @@ constexpr int kProjectionWeightsTensor = 16; // Optional // Projection bias tensor of size {n_output} constexpr int kProjectionBiasTensor = 17; // Optional +// Stateful input tensors that are variables and will be modified by the Op. +// Activation state tensor of size {n_batch, n_output} +constexpr int kInputActivationStateTensor = 18; +// Cell state tensor of size {n_batch, n_cell} +constexpr int kInputCellStateTensor = 19; + // Output tensors. -constexpr int kOutputStateTensor = 0; -constexpr int kCellStateTensor = 1; -constexpr int kOutputTensor = 2; +constexpr int kOutputTensor = 0; // Temporary tensors enum TemporaryTensor { @@ -82,7 +86,7 @@ enum TemporaryTensor { }; void* Init(TfLiteContext* context, const char* buffer, size_t length) { - auto* scratch_tensor_index = new int; + auto* scratch_tensor_index = new int(); context->AddTensors(context, kNumTemporaryTensors, scratch_tensor_index); return scratch_tensor_index; } @@ -247,8 +251,8 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { int* scratch_tensor_index = reinterpret_cast<int*>(node->user_data); // Check we have all the inputs and outputs we need. - TF_LITE_ENSURE_EQ(context, node->inputs->size, 18); - TF_LITE_ENSURE_EQ(context, node->outputs->size, 3); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 20); + TF_LITE_ENSURE_EQ(context, node->outputs->size, 1); // Inferring batch size, number of outputs and sequence length and // number of cells from the input tensors. @@ -276,12 +280,21 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, CheckInputTensorDimensions(context, node, n_input, n_output, n_cell)); - // Get the pointer to output, output_state and cell_state buffer tensors. + // Get the pointer to output, activation_state and cell_state buffer tensors. TfLiteTensor* output = GetOutput(context, node, kOutputTensor); - TfLiteTensor* output_state = GetOutput(context, node, kOutputStateTensor); - TfLiteTensor* cell_state = GetOutput(context, node, kCellStateTensor); - // Resize the output, output_state and cell_state tensors. + TfLiteTensor* activation_state = + GetVariableInput(context, node, kInputActivationStateTensor); + TfLiteTensor* cell_state = + GetVariableInput(context, node, kInputCellStateTensor); + + // Check the shape of input state tensors. + // These tensor may be 1D or 2D. It's fine as long as the total size is + // correct. + TF_LITE_ENSURE_EQ(context, NumElements(activation_state), n_batch * n_output); + TF_LITE_ENSURE_EQ(context, NumElements(cell_state), n_batch * n_cell); + + // Resize the output tensors. TfLiteIntArray* output_size = TfLiteIntArrayCreate(3); output_size->data[0] = max_time; output_size->data[1] = n_batch; @@ -289,22 +302,6 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, output, output_size)); - TfLiteIntArray* output_state_size = TfLiteIntArrayCreate(2); - output_state_size->data[0] = n_batch; - output_state_size->data[1] = n_output; - TF_LITE_ENSURE_OK( - context, context->ResizeTensor(context, output_state, output_state_size)); - - TfLiteIntArray* cell_size = TfLiteIntArrayCreate(2); - cell_size->data[0] = n_batch; - cell_size->data[1] = n_cell; - TF_LITE_ENSURE_OK(context, - context->ResizeTensor(context, cell_state, cell_size)); - - // Mark state tensors as persistent tensors. - output_state->allocation_type = kTfLiteArenaRwPersistent; - cell_state->allocation_type = kTfLiteArenaRwPersistent; - // The weights are of consistent type, so it suffices to check one. // TODO(mirkov): create a utility/macro for this check, so all Ops can use it. const bool is_hybrid_op = (input_to_output_weights->type == kTfLiteUInt8 && @@ -340,7 +337,7 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { if (is_hybrid_op) { // Allocate temporary tensors to store quantized values of input, - // output_state and cell_state tensors. + // activation_state and cell_state tensors. node->temporaries->data[kInputQuantized] = *scratch_tensor_index + kInputQuantized; TfLiteTensor* input_quantized = @@ -354,17 +351,17 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { } node->temporaries->data[kOutputStateQuantized] = *scratch_tensor_index + kOutputStateQuantized; - TfLiteTensor* output_state_quantized = + TfLiteTensor* activation_state_quantized = GetTemporary(context, node, kOutputStateQuantized); - output_state_quantized->type = kTfLiteUInt8; - output_state_quantized->allocation_type = kTfLiteArenaRw; - if (!TfLiteIntArrayEqual(output_state_quantized->dims, - output_state->dims)) { - TfLiteIntArray* output_state_quantized_size = - TfLiteIntArrayCopy(output_state->dims); - TF_LITE_ENSURE_OK(context, - context->ResizeTensor(context, output_state_quantized, - output_state_quantized_size)); + activation_state_quantized->type = kTfLiteUInt8; + activation_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(activation_state_quantized->dims, + activation_state->dims)) { + TfLiteIntArray* activation_state_quantized_size = + TfLiteIntArrayCopy(activation_state->dims); + TF_LITE_ENSURE_OK( + context, context->ResizeTensor(context, activation_state_quantized, + activation_state_quantized_size)); } node->temporaries->data[kCellStateQuantized] = *scratch_tensor_index + kCellStateQuantized; @@ -449,7 +446,7 @@ TfLiteStatus EvalFloat( const TfLiteTensor* cell_bias, const TfLiteTensor* output_gate_bias, const TfLiteTensor* projection_weights, const TfLiteTensor* projection_bias, const TfLiteLSTMParams* params, TfLiteTensor* scratch_buffer, - TfLiteTensor* output_state, TfLiteTensor* cell_state, + TfLiteTensor* activation_state, TfLiteTensor* cell_state, TfLiteTensor* output) { const int max_time = input->dims->data[0]; const int n_batch = input->dims->data[1]; @@ -510,7 +507,7 @@ TfLiteStatus EvalFloat( const float* cell_bias_ptr = cell_bias->data.f; const float* output_gate_bias_ptr = output_gate_bias->data.f; - float* output_state_ptr = output_state->data.f; + float* activation_state_ptr = activation_state->data.f; float* cell_state_ptr = cell_state->data.f; // Feed the sequence into the LSTM step-by-step. @@ -527,7 +524,7 @@ TfLiteStatus EvalFloat( cell_to_forget_weights_ptr, cell_to_output_weights_ptr, input_gate_bias_ptr, forget_gate_bias_ptr, cell_bias_ptr, output_gate_bias_ptr, projection_weights_ptr, projection_bias_ptr, - params, n_batch, n_cell, n_input, n_output, output_state_ptr, + params, n_batch, n_cell, n_input, n_output, activation_state_ptr, cell_state_ptr, input_gate_scratch, forget_gate_scratch, cell_scratch, output_gate_scratch, output_ptr_batch); } @@ -552,9 +549,9 @@ TfLiteStatus EvalHybrid( const TfLiteLSTMParams* params, TfLiteTensor* scratch_buffer, TfLiteTensor* scaling_factors, TfLiteTensor* prod_scaling_factors, TfLiteTensor* recovered_cell_weights, TfLiteTensor* input_quantized, - TfLiteTensor* output_state_quantized, TfLiteTensor* cell_state_quantized, - TfLiteTensor* output_state, TfLiteTensor* cell_state, - TfLiteTensor* output) { + TfLiteTensor* activation_state_quantized, + TfLiteTensor* cell_state_quantized, TfLiteTensor* activation_state, + TfLiteTensor* cell_state, TfLiteTensor* output) { const int max_time = input->dims->data[0]; const int n_batch = input->dims->data[1]; const int n_input = input->dims->data[2]; @@ -655,14 +652,14 @@ TfLiteStatus EvalHybrid( const float* cell_bias_ptr = cell_bias->data.f; const float* output_gate_bias_ptr = output_gate_bias->data.f; - float* output_state_ptr = output_state->data.f; + float* activation_state_ptr = activation_state->data.f; float* cell_state_ptr = cell_state->data.f; // Temporary storage for quantized values and scaling factors. int8_t* quantized_input_ptr = reinterpret_cast<int8_t*>(input_quantized->data.uint8); - int8_t* quantized_output_state_ptr = - reinterpret_cast<int8_t*>(output_state_quantized->data.uint8); + int8_t* quantized_activation_state_ptr = + reinterpret_cast<int8_t*>(activation_state_quantized->data.uint8); int8_t* quantized_cell_state_ptr = reinterpret_cast<int8_t*>(cell_state_quantized->data.uint8); float* scaling_factors_ptr = scaling_factors->data.f; @@ -692,8 +689,8 @@ TfLiteStatus EvalHybrid( n_input, n_output, input_gate_scratch, forget_gate_scratch, cell_scratch, output_gate_scratch, scaling_factors_ptr, prod_scaling_factors_ptr, recovered_cell_weights_ptr, - quantized_input_ptr, quantized_output_state_ptr, - quantized_cell_state_ptr, output_state_ptr, cell_state_ptr, + quantized_input_ptr, quantized_activation_state_ptr, + quantized_cell_state_ptr, activation_state_ptr, cell_state_ptr, output_ptr_batch); } return kTfLiteOk; @@ -744,8 +741,11 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { // Index the scratch buffers pointers to the global scratch buffer. TfLiteTensor* scratch_buffer = GetTemporary(context, node, /*index=*/0); - TfLiteTensor* output_state = GetOutput(context, node, kOutputStateTensor); - TfLiteTensor* cell_state = GetOutput(context, node, kCellStateTensor); + TfLiteTensor* activation_state = + GetVariableInput(context, node, kInputActivationStateTensor); + TfLiteTensor* cell_state = + GetVariableInput(context, node, kInputCellStateTensor); + TfLiteTensor* output = GetOutput(context, node, kOutputTensor); switch (input_to_output_weights->type) { @@ -758,11 +758,11 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { cell_to_output_weights, input_gate_bias, forget_gate_bias, cell_bias, output_gate_bias, projection_weights, projection_bias, params, - scratch_buffer, output_state, cell_state, output); + scratch_buffer, activation_state, cell_state, output); } case kTfLiteUInt8: { TfLiteTensor* input_quantized = GetTemporary(context, node, /*index=*/1); - TfLiteTensor* output_state_quantized = + TfLiteTensor* activation_state_quantized = GetTemporary(context, node, /*index=*/2); TfLiteTensor* cell_state_quantized = GetTemporary(context, node, /*index=*/3); @@ -780,8 +780,8 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { input_gate_bias, forget_gate_bias, cell_bias, output_gate_bias, projection_weights, projection_bias, params, scratch_buffer, scaling_factors, prod_scaling_factors, recovered_cell_weights, - input_quantized, output_state_quantized, cell_state_quantized, - output_state, cell_state, output); + input_quantized, activation_state_quantized, cell_state_quantized, + activation_state, cell_state, output); } default: context->ReportError(context, "Type %d is not currently supported.", diff --git a/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm_test.cc b/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm_test.cc index de38bdef6f..cd3aac0532 100644 --- a/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm_test.cc +++ b/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm_test.cc @@ -100,8 +100,14 @@ class UnidirectionalLSTMOpModel : public SingleOpModel { projection_bias_ = AddNullInput(); } - output_state_ = AddOutput(TensorType_FLOAT32); - cell_state_ = AddOutput(TensorType_FLOAT32); + // Adding the 2 input state tensors. + input_activation_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_output_ * n_batch_}}, + /*is_variable=*/true); + input_cell_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_cell_ * n_batch_}}, + /*is_variable=*/true); + output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp(BuiltinOperator_UNIDIRECTIONAL_SEQUENCE_LSTM, @@ -180,22 +186,6 @@ class UnidirectionalLSTMOpModel : public SingleOpModel { PopulateTensor(projection_bias_, f); } - void ResetOutputState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(output_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - - void ResetCellState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(cell_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - void SetInput(int offset, const float* begin, const float* end) { PopulateTensor(input_, offset, const_cast<float*>(begin), const_cast<float*>(end)); @@ -233,9 +223,10 @@ class UnidirectionalLSTMOpModel : public SingleOpModel { int projection_weights_; int projection_bias_; + int input_activation_state_; + int input_cell_state_; + int output_; - int output_state_; - int cell_state_; int n_batch_; int n_input_; @@ -458,6 +449,9 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights(input_to_input_weights_); @@ -475,10 +469,6 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { lstm.SetRecurrentToForgetWeights(recurrent_to_forget_weights_); lstm.SetRecurrentToOutputWeights(recurrent_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -519,6 +509,9 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights(input_to_input_weights_); @@ -536,10 +529,6 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { lstm.SetRecurrentToForgetWeights(recurrent_to_forget_weights_); lstm.SetRecurrentToOutputWeights(recurrent_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm, /*tolerance=*/0.0157651); } @@ -629,6 +618,9 @@ TEST_F(CifgPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToCellWeights(input_to_cell_weights_); @@ -646,10 +638,6 @@ TEST_F(CifgPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { lstm.SetCellToForgetWeights(cell_to_forget_weights_); lstm.SetCellToOutputWeights(cell_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -691,6 +679,9 @@ TEST_F(CifgPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToCellWeights(input_to_cell_weights_); @@ -708,10 +699,6 @@ TEST_F(CifgPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { lstm.SetCellToForgetWeights(cell_to_forget_weights_); lstm.SetCellToOutputWeights(cell_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm, /*tolerance=*/0.03573); } @@ -1351,6 +1338,9 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, LstmBlackBoxTest) { {n_output, n_cell}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights(input_to_input_weights_); @@ -1374,10 +1364,6 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, LstmBlackBoxTest) { lstm.SetProjectionWeights(projection_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -1418,6 +1404,9 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, HybridLstmBlackBoxTest) { {n_output, n_cell}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights(input_to_input_weights_); @@ -1441,10 +1430,6 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, HybridLstmBlackBoxTest) { lstm.SetProjectionWeights(projection_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm, /*tolerance=*/0.00467); } diff --git a/tensorflow/contrib/lite/python/convert.py b/tensorflow/contrib/lite/python/convert.py index 69a3d562b3..1c5516ae7c 100644 --- a/tensorflow/contrib/lite/python/convert.py +++ b/tensorflow/contrib/lite/python/convert.py @@ -126,7 +126,7 @@ def build_toco_convert_protos(input_tensors, reorder_across_fake_quant=False, allow_custom_ops=False, change_concat_input_ranges=False, - quantize_weights=False, + post_training_quantize=False, dump_graphviz_dir=None, dump_graphviz_video=False): """Builds protocol buffers describing a conversion of a model using TOCO. @@ -173,9 +173,9 @@ def build_toco_convert_protos(input_tensors, change_concat_input_ranges: Boolean to change behavior of min/max ranges for inputs and outputs of the concat operator for quantized models. Changes the ranges of concat operator overlap when true. (default False) - quantize_weights: Boolean indicating whether to store weights as quantized - weights followed by dequantize operations. Computation is still done in - float, but reduces model size (at the cost of accuracy and latency). + post_training_quantize: Boolean indicating whether to quantize the weights + of the converted float model. Model size will be reduced and there will be + latency improvements (at the cost of accuracy). (default False) dump_graphviz_dir: Full filepath of folder to dump the graphs at various stages of processing GraphViz .dot files. Preferred over @@ -204,7 +204,7 @@ def build_toco_convert_protos(input_tensors, toco.drop_control_dependency = drop_control_dependency toco.reorder_across_fake_quant = reorder_across_fake_quant toco.allow_custom_ops = allow_custom_ops - toco.quantize_weights = quantize_weights + toco.post_training_quantize = post_training_quantize if default_ranges_stats: toco.default_ranges_min = default_ranges_stats[0] toco.default_ranges_max = default_ranges_stats[1] diff --git a/tensorflow/contrib/lite/python/lite.py b/tensorflow/contrib/lite/python/lite.py index 80cbb12825..2de97fec86 100644 --- a/tensorflow/contrib/lite/python/lite.py +++ b/tensorflow/contrib/lite/python/lite.py @@ -102,9 +102,9 @@ class TocoConverter(object): created for any op that is unknown. The developer will need to provide these to the TensorFlow Lite runtime with a custom resolver. (default False) - quantize_weights: Boolean indicating whether to store weights as quantized - weights followed by dequantize operations. Computation is still done in - float, but reduces model size (at the cost of accuracy and latency). + post_training_quantize: Boolean indicating whether to quantize the weights + of the converted float model. Model size will be reduced and there will be + latency improvements (at the cost of accuracy). (default False) dump_graphviz_dir: Full filepath of folder to dump the graphs at various stages of processing GraphViz .dot files. Preferred over @@ -175,7 +175,7 @@ class TocoConverter(object): self.reorder_across_fake_quant = False self.change_concat_input_ranges = False self.allow_custom_ops = False - self.quantize_weights = False + self.post_training_quantize = False self.dump_graphviz_dir = None self.dump_graphviz_video = False @@ -425,7 +425,7 @@ class TocoConverter(object): "reorder_across_fake_quant": self.reorder_across_fake_quant, "change_concat_input_ranges": self.change_concat_input_ranges, "allow_custom_ops": self.allow_custom_ops, - "quantize_weights": self.quantize_weights, + "post_training_quantize": self.post_training_quantize, "dump_graphviz_dir": self.dump_graphviz_dir, "dump_graphviz_video": self.dump_graphviz_video } diff --git a/tensorflow/contrib/lite/python/lite_test.py b/tensorflow/contrib/lite/python/lite_test.py index d004c3ecca..1c94ba605a 100644 --- a/tensorflow/contrib/lite/python/lite_test.py +++ b/tensorflow/contrib/lite/python/lite_test.py @@ -372,7 +372,7 @@ class FromSessionTest(test_util.TensorFlowTestCase): self.assertTrue(([1, 16, 16, 3] == output_details[0]['shape']).all()) self.assertTrue(output_details[0]['quantization'][0] > 0) # scale - def testQuantizeWeights(self): + def testPostTrainingQuantize(self): np.random.seed(0) # We need the tensor to have more than 1024 elements for quantize_weights # to kick in. Thus, the [33, 33] shape. @@ -393,14 +393,14 @@ class FromSessionTest(test_util.TensorFlowTestCase): self.assertTrue(float_tflite) # Convert quantized weights model. - quantized_weights_converter = lite.TocoConverter.from_session( + quantized_converter = lite.TocoConverter.from_session( sess, [in_tensor_1], [out_tensor]) - quantized_weights_converter.quantize_weights = True - quantized_weights_tflite = quantized_weights_converter.convert() - self.assertTrue(quantized_weights_tflite) + quantized_converter.post_training_quantize = True + quantized_tflite = quantized_converter.convert() + self.assertTrue(quantized_tflite) # Ensure that the quantized weights tflite model is smaller. - self.assertTrue(len(quantized_weights_tflite) < len(float_tflite)) + self.assertTrue(len(quantized_tflite) < len(float_tflite)) class FromFrozenGraphFile(test_util.TensorFlowTestCase): diff --git a/tensorflow/contrib/lite/python/tflite_convert.py b/tensorflow/contrib/lite/python/tflite_convert.py index dc078ffd21..cc08ed3fe9 100644 --- a/tensorflow/contrib/lite/python/tflite_convert.py +++ b/tensorflow/contrib/lite/python/tflite_convert.py @@ -142,11 +142,14 @@ def _convert_model(flags): flags.change_concat_input_ranges == "TRUE") if flags.allow_custom_ops: converter.allow_custom_ops = flags.allow_custom_ops - if flags.quantize_weights: + + if flags.post_training_quantize: + converter.post_training_quantize = flags.post_training_quantize if flags.inference_type == lite_constants.QUANTIZED_UINT8: - raise ValueError("--quantized_weights is not supported with " - "--inference_type=QUANTIZED_UINT8") - converter.quantize_weights = flags.quantize_weights + print("--post_training_quantize quantizes a graph of inference_type " + "FLOAT. Overriding inference type QUANTIZED_UINT8 to FLOAT.") + converter.inference_type = lite_constants.FLOAT + if flags.dump_graphviz_dir: converter.dump_graphviz_dir = flags.dump_graphviz_dir if flags.dump_graphviz_video: @@ -318,12 +321,20 @@ def run_main(_): help=("Default value for max bound of min/max range values used for all " "arrays without a specified range, Intended for experimenting with " "quantization via \"dummy quantization\". (default None)")) + # quantize_weights is DEPRECATED. parser.add_argument( "--quantize_weights", + dest="post_training_quantize", + action="store_true", + help=argparse.SUPPRESS) + parser.add_argument( + "--post_training_quantize", + dest="post_training_quantize", action="store_true", - help=("Store float weights as quantized weights followed by dequantize " - "operations. Inference is still done in FLOAT, but reduces model " - "size (at the cost of accuracy and latency).")) + help=( + "Boolean indicating whether to quantize the weights of the " + "converted float model. Model size will be reduced and there will " + "be latency improvements (at the cost of accuracy). (default False)")) # Graph manipulation flags. parser.add_argument( diff --git a/tensorflow/contrib/lite/toco/args.h b/tensorflow/contrib/lite/toco/args.h index aef35ad490..84f71dc7a7 100644 --- a/tensorflow/contrib/lite/toco/args.h +++ b/tensorflow/contrib/lite/toco/args.h @@ -236,8 +236,9 @@ struct ParsedTocoFlags { Arg<bool> drop_fake_quant = Arg<bool>(false); Arg<bool> reorder_across_fake_quant = Arg<bool>(false); Arg<bool> allow_custom_ops = Arg<bool>(false); - Arg<bool> quantize_weights = Arg<bool>(false); + Arg<bool> post_training_quantize = Arg<bool>(false); // Deprecated flags + Arg<bool> quantize_weights = Arg<bool>(false); Arg<string> input_type; Arg<string> input_types; Arg<bool> debug_disable_recurrent_cell_fusion = Arg<bool>(false); diff --git a/tensorflow/contrib/lite/toco/export_tensorflow.cc b/tensorflow/contrib/lite/toco/export_tensorflow.cc index 6fdf47dedc..b52a79282c 100644 --- a/tensorflow/contrib/lite/toco/export_tensorflow.cc +++ b/tensorflow/contrib/lite/toco/export_tensorflow.cc @@ -1701,9 +1701,11 @@ void ConvertReduceOperator(const Model& model, const T& src_op, *new_op->add_input() = src_op.inputs[0]; *new_op->add_input() = src_op.inputs[1]; - const tensorflow::DataType params_type = - GetTensorFlowDataType(model, src_op.inputs[0]); - (*new_op->mutable_attr())["T"].set_type(params_type); + if (src_op.type != OperatorType::kAny) { + const tensorflow::DataType params_type = + GetTensorFlowDataType(model, src_op.inputs[0]); + (*new_op->mutable_attr())["T"].set_type(params_type); + } const tensorflow::DataType indices_type = GetTensorFlowDataType(model, src_op.inputs[1]); (*new_op->mutable_attr())["Tidx"].set_type(indices_type); diff --git a/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md b/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md index 1de32f9977..00bc8d4ccb 100644 --- a/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md +++ b/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md @@ -149,10 +149,10 @@ have. true, custom ops are created for any op that is unknown. The developer will need to provide these to the TensorFlow Lite runtime with a custom resolver. -* `--quantize_weights`. Type: boolean. Default: False. Indicates whether to - store weights as quantized weights followed by dequantize operations. - Computation is still done in float, but reduces model size (at the cost of - accuracy and latency). +* `--post_training_quantize`. Type: boolean. Default: False. Boolean + indicating whether to quantize the weights of the converted float model. + Model size will be reduced and there will be latency improvements (at the + cost of accuracy). ## Logging flags diff --git a/tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.h b/tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.h index 34945ecc45..fdd0632451 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.h +++ b/tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.h @@ -177,9 +177,10 @@ DECLARE_GRAPH_TRANSFORMATION(ResolveSpaceToBatchNDAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolveBatchToSpaceNDAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolvePadAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolvePadV2Attributes) -DECLARE_GRAPH_TRANSFORMATION(ResolveStridedSliceAttributes) -DECLARE_GRAPH_TRANSFORMATION(ResolveSliceAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolveReduceAttributes) +DECLARE_GRAPH_TRANSFORMATION(ResolveReshapeAttributes) +DECLARE_GRAPH_TRANSFORMATION(ResolveSliceAttributes) +DECLARE_GRAPH_TRANSFORMATION(ResolveStridedSliceAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolveTransposeAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolveConstantPack) DECLARE_GRAPH_TRANSFORMATION(ResolveConstantRandomUniform) @@ -216,12 +217,6 @@ class PropagateDefaultMinMax : public GraphTransformation { std::vector<std::pair<ArrayDataType, MinMax>> type_ranges_; }; -class ResolveReshapeAttributes : public GraphTransformation { - public: - bool Run(Model* model, std::size_t op_index) override; - const char* Name() const override { return "ResolveReshapeAttributes"; } -}; - class RemoveTrivialReshape : public GraphTransformation { public: bool Run(Model* model, std::size_t op_index) override; diff --git a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc index 28effc2a67..c25be078ff 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc @@ -561,26 +561,38 @@ void ProcessTensorFlowReductionOperator(Model* model, Operator* op) { const bool keep_dims = KeepDims(*op); if (op->inputs.size() == 2) { // There is a reduction_indices input. - const auto& reduction_array = model->GetArray(op->inputs[1]); - if (!reduction_array.buffer) { + const auto& reduction_indices_array = model->GetArray(op->inputs[1]); + if (!reduction_indices_array.buffer) { return; } - CHECK(reduction_array.buffer->type == ArrayDataType::kInt32); - const auto& reduction_array_vals = - reduction_array.GetBuffer<ArrayDataType::kInt32>().data; - auto& output_dims = *output_array.mutable_shape()->mutable_dims(); - output_dims.clear(); - for (int i = 0; i < input_shape.dimensions_count(); i++) { - bool is_reduction_dim = false; - for (int r : reduction_array_vals) { - if (i == r) { - is_reduction_dim = true; - } + CHECK(reduction_indices_array.buffer->type == ArrayDataType::kInt32); + + int input_rank = input_shape.dimensions_count(); + std::set<int32> true_indices; + const auto& reduction_indices = + reduction_indices_array.GetBuffer<ArrayDataType::kInt32>().data; + for (int i = 0; i < reduction_indices.size(); ++i) { + const int32 reduction_index = reduction_indices[i]; + if (reduction_index < -input_rank || reduction_index >= input_rank) { + CHECK(false) << "Invalid reduction dimension " << reduction_index + << " for input with " << input_rank << " dimensions"; + } + int32 wrapped_index = reduction_index; + if (wrapped_index < 0) { + wrapped_index += input_rank; } - if (!is_reduction_dim) { - output_dims.push_back(input_shape.dims(i)); - } else if (keep_dims) { - output_dims.push_back(1); + true_indices.insert(wrapped_index); + } + + auto* mutable_dims = output_array.mutable_shape()->mutable_dims(); + mutable_dims->clear(); + for (int i = 0; i < input_rank; ++i) { + if (true_indices.count(i) > 0) { + if (keep_dims) { + mutable_dims->emplace_back(1); + } + } else { + mutable_dims->emplace_back(input_shape.dims(i)); } } } else { diff --git a/tensorflow/contrib/lite/toco/graph_transformations/resolve_reduce_attributes.cc b/tensorflow/contrib/lite/toco/graph_transformations/resolve_reduce_attributes.cc index 7d456af2fb..73198ac7c0 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/resolve_reduce_attributes.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/resolve_reduce_attributes.cc @@ -52,6 +52,8 @@ bool ResolveReduceAttributes::Run(Model* model, std::size_t op_index) { return ResolveAttributes(model, static_cast<TensorFlowMinOperator*>(op)); case OperatorType::kReduceMax: return ResolveAttributes(model, static_cast<TensorFlowMaxOperator*>(op)); + case OperatorType::kAny: + return ResolveAttributes(model, static_cast<TensorFlowMaxOperator*>(op)); default: return false; } diff --git a/tensorflow/contrib/lite/toco/model.h b/tensorflow/contrib/lite/toco/model.h index fa1c459f0e..2e100e37f6 100644 --- a/tensorflow/contrib/lite/toco/model.h +++ b/tensorflow/contrib/lite/toco/model.h @@ -1768,6 +1768,7 @@ struct PowOperator : Operator { // // Inputs: // Inputs[0]: required: A boolean input tensor. +// Inputs[1]: required: reduction_indices. // // TensorFlow equivalent: tf.reduce_any. struct TensorFlowAnyOperator : Operator { diff --git a/tensorflow/contrib/lite/toco/toco_cmdline_flags.cc b/tensorflow/contrib/lite/toco/toco_cmdline_flags.cc index c6d0a03452..f83a290195 100644 --- a/tensorflow/contrib/lite/toco/toco_cmdline_flags.cc +++ b/tensorflow/contrib/lite/toco/toco_cmdline_flags.cc @@ -160,10 +160,12 @@ bool ParseTocoFlagsFromCommandLineFlags( "Ignored if the output format is not TFLite."), Flag("quantize_weights", parsed_flags.quantize_weights.bind(), parsed_flags.quantize_weights.default_value(), - "Store weights as quantized weights followed by dequantize " - "operations. Computation is still done in float, but reduces model " - "size (at the cost of accuracy and latency)."), - }; + "Deprecated. Please use --post_training_quantize instead."), + Flag("post_training_quantize", parsed_flags.post_training_quantize.bind(), + parsed_flags.post_training_quantize.default_value(), + "Boolean indicating whether to quantize the weights of the " + "converted float model. Model size will be reduced and there will " + "be latency improvements (at the cost of accuracy).")}; bool asked_for_help = *argc == 2 && (!strcmp(argv[1], "--help") || !strcmp(argv[1], "-help")); if (asked_for_help) { @@ -257,6 +259,7 @@ void ReadTocoFlagsFromCommandLineFlags(const ParsedTocoFlags& parsed_toco_flags, READ_TOCO_FLAG(dedupe_array_min_size_bytes, FlagRequirement::kNone); READ_TOCO_FLAG(split_tflite_lstm_inputs, FlagRequirement::kNone); READ_TOCO_FLAG(quantize_weights, FlagRequirement::kNone); + READ_TOCO_FLAG(post_training_quantize, FlagRequirement::kNone); // Deprecated flag handling. if (parsed_toco_flags.input_type.specified()) { @@ -291,9 +294,19 @@ void ReadTocoFlagsFromCommandLineFlags(const ParsedTocoFlags& parsed_toco_flags, toco_flags->set_inference_input_type(input_type); } if (parsed_toco_flags.quantize_weights.value()) { - QCHECK_NE(toco_flags->inference_type(), IODataType::QUANTIZED_UINT8) - << "quantize_weights is not supported with inference_type " - "QUANTIZED_UINT8."; + LOG(WARNING) + << "--quantize_weights is deprecated. Falling back to " + "--post_training_quantize. Please switch --post_training_quantize."; + toco_flags->set_post_training_quantize( + parsed_toco_flags.quantize_weights.value()); + } + if (parsed_toco_flags.quantize_weights.value()) { + if (toco_flags->inference_type() == IODataType::QUANTIZED_UINT8) { + LOG(WARNING) + << "--post_training_quantize quantizes a graph of inference_type " + "FLOAT. Overriding inference type QUANTIZED_UINT8 to FLOAT."; + toco_flags->set_inference_type(IODataType::FLOAT); + } } #undef READ_TOCO_FLAG diff --git a/tensorflow/contrib/lite/toco/toco_flags.proto b/tensorflow/contrib/lite/toco/toco_flags.proto index b4a9870d58..c1dd621429 100644 --- a/tensorflow/contrib/lite/toco/toco_flags.proto +++ b/tensorflow/contrib/lite/toco/toco_flags.proto @@ -37,7 +37,7 @@ enum FileFormat { // of as properties of models, instead describing how models are to be // processed in the context of the present tooling job. // -// Next ID to use: 26. +// Next ID to use: 27. message TocoFlags { // Input file format optional FileFormat input_format = 1; @@ -173,6 +173,7 @@ message TocoFlags { // Store weights as quantized weights followed by dequantize operations. // Computation is still done in float, but reduces model size (at the cost of // accuracy and latency). + // DEPRECATED: Please use post_training_quantize instead. optional bool quantize_weights = 20 [default = false]; // Full filepath of folder to dump the graphs at various stages of processing @@ -183,4 +184,9 @@ message TocoFlags { // Boolean indicating whether to dump the graph after every graph // transformation. optional bool dump_graphviz_include_video = 25; + + // Boolean indicating whether to quantize the weights of the converted float + // model. Model size will be reduced and there will be latency improvements + // (at the cost of accuracy). + optional bool post_training_quantize = 26 [default = false]; } diff --git a/tensorflow/contrib/lite/toco/toco_tooling.cc b/tensorflow/contrib/lite/toco/toco_tooling.cc index 243d0dabdb..7db7acb44d 100644 --- a/tensorflow/contrib/lite/toco/toco_tooling.cc +++ b/tensorflow/contrib/lite/toco/toco_tooling.cc @@ -399,7 +399,8 @@ void Export(const TocoFlags& toco_flags, const Model& model, break; case TFLITE: toco::tflite::Export(model, allow_custom_ops, - toco_flags.quantize_weights(), output_file_contents); + toco_flags.post_training_quantize(), + output_file_contents); break; case GRAPHVIZ_DOT: DumpGraphviz(model, output_file_contents); diff --git a/tensorflow/contrib/lite/tools/accuracy/BUILD b/tensorflow/contrib/lite/tools/accuracy/BUILD index 74f101c573..1b60d6a60d 100644 --- a/tensorflow/contrib/lite/tools/accuracy/BUILD +++ b/tensorflow/contrib/lite/tools/accuracy/BUILD @@ -45,7 +45,10 @@ tf_cc_test( data = ["//tensorflow/contrib/lite:testdata/multi_add.bin"], linkopts = common_linkopts, linkstatic = 1, - tags = ["tflite_not_portable_ios"], + tags = [ + "tflite_not_portable_android", + "tflite_not_portable_ios", + ], deps = [ ":utils", "@com_google_googletest//:gtest", diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc index 1731d2ade6..63616fc3b4 100644 --- a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc @@ -327,7 +327,8 @@ Status ImagenetModelEvaluator::EvaluateModel() const { const auto& image_label = img_labels[i]; const uint64_t shard_id = i + 1; shard_id_image_count_map[shard_id] = image_label.size(); - auto func = [&]() { + auto func = [shard_id, &image_label, &model_labels, this, &observer, &eval, + &counter]() { TF_CHECK_OK(EvaluateModelForShard(shard_id, image_label, model_labels, model_info_, params_, &observer, &eval)); diff --git a/tensorflow/contrib/lite/tools/benchmark/README.md b/tensorflow/contrib/lite/tools/benchmark/README.md index f1e257ad10..8d997639fb 100644 --- a/tensorflow/contrib/lite/tools/benchmark/README.md +++ b/tensorflow/contrib/lite/tools/benchmark/README.md @@ -9,7 +9,7 @@ of runs. Aggregrate latency statistics are reported after running the benchmark. The instructions below are for running the binary on Desktop and Android, for iOS please use the -[iOS benchmark app] (https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite/tools/benchmark/ios). +[iOS benchmark app](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite/tools/benchmark/ios). ## Parameters @@ -17,11 +17,6 @@ The binary takes the following required parameters: * `graph`: `string` \ The path to the TFLite model file. -* `input_layer`: `string` \ - The name of the input layer, this is typically the first layer of the model. -* `input_layer_shape`: `string` \ - The shape of the input layer. This is a comma separated string of the shape - of tensor of input layer. and the following optional parameters: @@ -29,11 +24,13 @@ and the following optional parameters: The number of threads to use for running TFLite interpreter. * `warmup_runs`: `int` (default=1) \ The number of warmup runs to do before starting the benchmark. +* `num_runs`: `int` (default=50) \ + The number of runs. Increase this to reduce variance. * `run_delay`: `float` (default=-1.0) \ The delay in seconds between subsequent benchmark runs. Non-positive values mean use no delay. * `use_nnapi`: `bool` (default=false) \ - Whether to use [Android NNAPI] (https://developer.android.com/ndk/guides/neuralnetworks/). + Whether to use [Android NNAPI](https://developer.android.com/ndk/guides/neuralnetworks/). This API is available on recent Android devices. ## To build/install/run @@ -75,8 +72,6 @@ adb push mobilenet_quant_v1_224.tflite /data/local/tmp ``` adb shell /data/local/tmp/benchmark_model \ --graph=/data/local/tmp/mobilenet_quant_v1_224.tflite \ - --input_layer="input" \ - --input_layer_shape="1,224,224,3" \ --num_threads=4 ``` @@ -93,13 +88,10 @@ For example: ``` bazel-bin/tensorflow/contrib/lite/tools/benchmark/benchmark_model \ --graph=mobilenet_quant_v1_224.tflite \ - --input_layer="Placeholder" \ - --input_layer_shape="1,224,224,3" \ --num_threads=4 ``` -The MobileNet graph used as an example here may be downloaded from -https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_224_android_quant_2017_11_08.zip +The MobileNet graph used as an example here may be downloaded from [here](https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_224_android_quant_2017_11_08.zip). ## Reducing variance between runs on Android. @@ -117,8 +109,6 @@ can use the following command: ``` adb shell taskset f0 /data/local/tmp/benchmark_model \ --graph=/data/local/tmp/mobilenet_quant_v1_224.tflite \ - --input_layer="input" \ - --input_layer_shape="1,224,224,3" \ --num_threads=1 ``` @@ -205,5 +195,3 @@ Memory (bytes): count=0 Average inference timings in us: Warmup: 83235, Init: 38467, no stats: 79760.9 ``` - - diff --git a/tensorflow/contrib/lite/tools/benchmark/ios/README.md b/tensorflow/contrib/lite/tools/benchmark/ios/README.md index c8d3307e29..46144f7bf8 100644 --- a/tensorflow/contrib/lite/tools/benchmark/ios/README.md +++ b/tensorflow/contrib/lite/tools/benchmark/ios/README.md @@ -17,8 +17,8 @@ Mobilenet_1.0_224 model ## To build/install/run -- Follow instructions at [iOS build for TFLite] -(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/ios.md) +- Follow instructions at +[iOS build for TFLite](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/ios.md) to build TFLite. Running diff --git a/tensorflow/contrib/lite/tools/optimize/g3doc/quantize_weights.md b/tensorflow/contrib/lite/tools/optimize/g3doc/quantize_weights.md new file mode 100644 index 0000000000..93fe576583 --- /dev/null +++ b/tensorflow/contrib/lite/tools/optimize/g3doc/quantize_weights.md @@ -0,0 +1,70 @@ +# TFLite Quantize Weights Tool + +## Recommended usage + +The Quantize Weights transformation is integrated with +[tflite_convert](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md#transformation-flags). + +The recommended way of invoking this tool is by simply adding the +`--post_training_quantize` flag to your original tflite_convert invocation. For +example, + +``` +tflite_convert \ + --output_file=/tmp/foo.tflite \ + --saved_model_dir=/tmp/saved_model \ + --post_training_quantize +``` + +## Overview + +The Quantize Weights tool provides a simple way to quantize the weights for a +float TFLite model. + +TODO(raghuramank): Add link to weight quantization tutorial. + +### Size reduction + +float32 weights will be converted to 8 bit integers. This results in a model +that is around 1/4th the size of the original model. + +### Latency reduction + +TFLite also has "hybrid" kernels implemented for many operations. These "hybrid" +kernels take 8 bit integer weights and float inputs, dynamically quantize the +inputs tensor (based on the input tensor's min and max elements), and does +computations using the 8 bit integer values. This results in a 2-4x reduction in +latency for "hybrid" kernels. In this mode the inference type is still FLOAT +since the inputs and output to each operation is still float. + +For operations that do not yet have "hybrid" kernels implemented, we introduce a +Dequantize operation after 8 bit integer weights. These convert weights back to +float32 during inference to allow original float32 kernels to run. Since we +cache dequantized results, the result of each of this dequantized path will be +on-par with the original float model. + +TODO(yunluli): Fill in latency results from latency experiments. + +### Accuracy + +Since this technique quantizes weights after the model has already been trained, +there can be accuracy drops depending on the model. For common CNN networks, the +observed accuracy drops are small and can be seen below. + +TODO(yunluli): Fill in accuracy results from accuracy experiments. + +## Direct usage + +One can also invoke the Quantize Weights directly via C++ if they have a float +`::tflite::Model` that they want to convert. They must provide a +`flatbuffers::FlatBufferBuilder` which owns the underlying buffer of the created +model. Here is an example invocation: + +``` +::tflite::Model* input_model = ...; +flatbuffers::FlatBufferBuilder builder; +TfLiteStatus status = ::tflite::optimize::QuantizeWeights(&builder, input_model); +CHECK(status, kTfLiteStatusOk); +const uint8_t* buffer = builder->GetBufferPointer(); +tflite::Model* output_model = ::tflite::GetModel(buffer); +``` diff --git a/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc b/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc index ec9fb04bf7..e0ed7c7946 100644 --- a/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc +++ b/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc @@ -168,6 +168,7 @@ std::vector<TensorInfo> GetQuantizableTensorsFromOperator(const ModelT* model, bool eval_hybrid = IsHybridEvaluationOp(op, op_code); + bool skipped_tensor = false; std::vector<int32_t> op_input_indices = GetWeightInputIndices(op_code); for (const int32_t op_input_idx : op_input_indices) { int32_t tensor_idx = op->inputs[op_input_idx]; @@ -177,6 +178,7 @@ std::vector<TensorInfo> GetQuantizableTensorsFromOperator(const ModelT* model, if (CountTensorConsumers(model, subgraph, tensor_idx) != 1) { LOG(INFO) << "Skipping quantization of tensor that is shared between " "multiple multiple operations."; + skipped_tensor = true; continue; } @@ -184,6 +186,7 @@ std::vector<TensorInfo> GetQuantizableTensorsFromOperator(const ModelT* model, if (tensor->type != TensorType_FLOAT32) { LOG(INFO) << "Skipping quantization of tensor that is not type float."; + skipped_tensor = true; continue; } @@ -191,6 +194,7 @@ std::vector<TensorInfo> GetQuantizableTensorsFromOperator(const ModelT* model, if (num_elements < kWeightsMinSize) { LOG(INFO) << "Skipping quantization of tensor because it has fewer than " << kWeightsMinSize << " elements (" << num_elements << ")."; + skipped_tensor = true; continue; } @@ -203,6 +207,12 @@ std::vector<TensorInfo> GetQuantizableTensorsFromOperator(const ModelT* model, tensor_infos.push_back(tensor_info); } + // For hybrid operations we either need to quantize all tensors or none. So + // if we skipped any tensors we need to return no quantized tensors. + if (eval_hybrid && skipped_tensor) { + return {}; + } + return tensor_infos; } @@ -212,11 +222,16 @@ TfLiteStatus AsymmetricQuantizeTensor(ModelT* model, TensorT* tensor) { BufferT* buffer = model->buffers[tensor->buffer].get(); float* float_data = reinterpret_cast<float*>(buffer->data.data()); const uint64_t num_elements = NumElements(tensor); - LOG(INFO) << "Quantizing tensor with " << num_elements << " elements."; + LOG(INFO) << "Quantizing tensor " << tensor->name << " with " << num_elements + << " elements for float evaluation."; // Compute the quantization params. float min_value = *std::min_element(float_data, float_data + num_elements); float max_value = *std::max_element(float_data, float_data + num_elements); + + if (tensor->quantization == nullptr) { + tensor->quantization = absl::make_unique<QuantizationParametersT>(); + } GetAsymmetricQuantizationParams(min_value, max_value, 0, 255, tensor->quantization.get()); @@ -251,7 +266,8 @@ TfLiteStatus SymmetricQuantizeTensor(ModelT* model, TensorT* tensor) { BufferT* buffer = model->buffers[tensor->buffer].get(); float* float_data = reinterpret_cast<float*>(buffer->data.data()); const uint64_t num_elements = NumElements(tensor); - LOG(INFO) << "Quantizing tensor with " << num_elements << " elements."; + LOG(INFO) << "Quantizing tensor " << tensor->name << " with " << num_elements + << " elements for hybrid evaluation."; std::vector<int8_t> quantized_buffer; quantized_buffer.resize(num_elements); @@ -260,6 +276,10 @@ TfLiteStatus SymmetricQuantizeTensor(ModelT* model, TensorT* tensor) { tensor_utils::SymmetricQuantizeFloats(float_data, num_elements, quantized_buffer.data(), &min_value, &max_value, &scaling_factor); + + if (tensor->quantization == nullptr) { + tensor->quantization = absl::make_unique<QuantizationParametersT>(); + } tensor->quantization->scale = std::vector<float>(1, scaling_factor); tensor->quantization->zero_point = std::vector<int64_t>(1, 0); diff --git a/tensorflow/contrib/opt/BUILD b/tensorflow/contrib/opt/BUILD index 5319a8b655..93e589907e 100644 --- a/tensorflow/contrib/opt/BUILD +++ b/tensorflow/contrib/opt/BUILD @@ -22,6 +22,7 @@ py_library( "python/training/ggt.py", "python/training/lars_optimizer.py", "python/training/lazy_adam_optimizer.py", + "python/training/matrix_functions.py", "python/training/model_average_optimizer.py", "python/training/moving_average_optimizer.py", "python/training/multitask_optimizer_wrapper.py", @@ -381,3 +382,18 @@ py_test( "@six_archive//:six", ], ) + +py_test( + name = "matrix_functions_test", + srcs = ["python/training/matrix_functions_test.py"], + srcs_version = "PY2AND3", + deps = [ + ":opt_py", + "//tensorflow/python:client", + "//tensorflow/python:client_testlib", + "//tensorflow/python:dtypes", + "//tensorflow/python:variables", + "//third_party/py/numpy", + "@six_archive//:six", + ], +) diff --git a/tensorflow/contrib/opt/python/training/matrix_functions.py b/tensorflow/contrib/opt/python/training/matrix_functions.py new file mode 100644 index 0000000000..baab577638 --- /dev/null +++ b/tensorflow/contrib/opt/python/training/matrix_functions.py @@ -0,0 +1,155 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Matrix functions contains iterative methods for M^p.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import linalg_ops +from tensorflow.python.ops import math_ops + + +def matrix_square_root(mat_a, mat_a_size, iter_count=100, ridge_epsilon=1e-4): + """Iterative method to get matrix square root. + + Stable iterations for the matrix square root, Nicholas J. Higham + + Page 231, Eq 2.6b + http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.6.8799&rep=rep1&type=pdf + + Args: + mat_a: the symmetric PSD matrix whose matrix square root be computed + mat_a_size: size of mat_a. + iter_count: Maximum number of iterations. + ridge_epsilon: Ridge epsilon added to make the matrix positive definite. + + Returns: + mat_a^0.5 + """ + + def _iter_condition(i, unused_mat_y, unused_old_mat_y, unused_mat_z, + unused_old_mat_z, err, old_err): + # This method require that we check for divergence every step. + return math_ops.logical_and(i < iter_count, err < old_err) + + def _iter_body(i, mat_y, unused_old_mat_y, mat_z, unused_old_mat_z, err, + unused_old_err): + current_iterate = 0.5 * (3.0 * identity - math_ops.matmul(mat_z, mat_y)) + current_mat_y = math_ops.matmul(mat_y, current_iterate) + current_mat_z = math_ops.matmul(current_iterate, mat_z) + # Compute the error in approximation. + mat_sqrt_a = current_mat_y * math_ops.sqrt(norm) + mat_a_approx = math_ops.matmul(mat_sqrt_a, mat_sqrt_a) + residual = mat_a - mat_a_approx + current_err = math_ops.sqrt(math_ops.reduce_sum(residual * residual)) / norm + return i + 1, current_mat_y, mat_y, current_mat_z, mat_z, current_err, err + + identity = linalg_ops.eye(math_ops.to_int32(mat_a_size)) + mat_a = mat_a + ridge_epsilon * identity + norm = math_ops.sqrt(math_ops.reduce_sum(mat_a * mat_a)) + mat_init_y = mat_a / norm + mat_init_z = identity + init_err = norm + + _, _, prev_mat_y, _, _, _, _ = control_flow_ops.while_loop( + _iter_condition, _iter_body, [ + 0, mat_init_y, mat_init_y, mat_init_z, mat_init_z, init_err, + init_err + 1.0 + ]) + return prev_mat_y * math_ops.sqrt(norm) + + +def matrix_inverse_pth_root(mat_g, + mat_g_size, + alpha, + iter_count=100, + epsilon=1e-6, + ridge_epsilon=1e-6): + """Computes mat_g^alpha, where alpha = -1/p, p a positive integer. + + We use an iterative Schur-Newton method from equation 3.2 on page 9 of: + + A Schur-Newton Method for the Matrix p-th Root and its Inverse + by Chun-Hua Guo and Nicholas J. Higham + SIAM Journal on Matrix Analysis and Applications, + 2006, Vol. 28, No. 3 : pp. 788-804 + https://pdfs.semanticscholar.org/0abe/7f77433cf5908bfe2b79aa91af881da83858.pdf + + Args: + mat_g: the symmetric PSD matrix whose power it to be computed + mat_g_size: size of mat_g. + alpha: exponent, must be -1/p for p a positive integer. + iter_count: Maximum number of iterations. + epsilon: accuracy indicator, useful for early termination. + ridge_epsilon: Ridge epsilon added to make the matrix positive definite. + + Returns: + mat_g^alpha + """ + + identity = linalg_ops.eye(math_ops.to_int32(mat_g_size)) + + def mat_power(mat_m, p): + """Computes mat_m^p, for p a positive integer. + + Power p is known at graph compile time, so no need for loop and cond. + Args: + mat_m: a square matrix + p: a positive integer + + Returns: + mat_m^p + """ + assert p == int(p) and p > 0 + power = None + while p > 0: + if p % 2 == 1: + power = math_ops.matmul(mat_m, power) if power is not None else mat_m + p //= 2 + mat_m = math_ops.matmul(mat_m, mat_m) + return power + + def _iter_condition(i, mat_m, _): + return math_ops.logical_and( + i < iter_count, + math_ops.reduce_max(math_ops.abs(mat_m - identity)) > epsilon) + + def _iter_body(i, mat_m, mat_x): + mat_m_i = (1 - alpha) * identity + alpha * mat_m + return (i + 1, math_ops.matmul(mat_power(mat_m_i, -1.0 / alpha), mat_m), + math_ops.matmul(mat_x, mat_m_i)) + + if mat_g_size == 1: + mat_h = math_ops.pow(mat_g + ridge_epsilon, alpha) + else: + damped_mat_g = mat_g + ridge_epsilon * identity + z = (1 - 1 / alpha) / (2 * linalg_ops.norm(damped_mat_g)) + # The best value for z is + # (1 - 1/alpha) * (c_max^{-alpha} - c_min^{-alpha}) / + # (c_max^{1-alpha} - c_min^{1-alpha}) + # where c_max and c_min are the largest and smallest singular values of + # damped_mat_g. + # The above estimate assumes that c_max > c_min * 2^p. (p = -1/alpha) + # Can replace above line by the one below, but it is less accurate, + # hence needs more iterations to converge. + # z = (1 - 1/alpha) / math_ops.trace(damped_mat_g) + # If we want the method to always converge, use z = 1 / norm(damped_mat_g) + # or z = 1 / math_ops.trace(damped_mat_g), but these can result in many + # extra iterations. + _, _, mat_h = control_flow_ops.while_loop( + _iter_condition, _iter_body, + [0, damped_mat_g * z, identity * math_ops.pow(z, -alpha)]) + return mat_h diff --git a/tensorflow/contrib/opt/python/training/matrix_functions_test.py b/tensorflow/contrib/opt/python/training/matrix_functions_test.py new file mode 100644 index 0000000000..518fa38233 --- /dev/null +++ b/tensorflow/contrib/opt/python/training/matrix_functions_test.py @@ -0,0 +1,63 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Functional tests for Matrix functions.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np + +from tensorflow.contrib.opt.python.training import matrix_functions +from tensorflow.python.platform import test + +TOLERANCE = 1e-3 + + +def np_power(mat_g, alpha): + """Computes mat_g^alpha for a square symmetric matrix mat_g.""" + + mat_u, diag_d, mat_v = np.linalg.svd(mat_g) + diag_d = np.power(diag_d, alpha) + return np.dot(np.dot(mat_u, np.diag(diag_d)), mat_v) + + +class MatrixFunctionTests(test.TestCase): + + def testMatrixSquareRootFunction(self): + """Tests for matrix square roots.""" + + size = 20 + mat_a = np.random.rand(size, size) + mat = np.dot(mat_a, mat_a.T) + expected_mat = np_power(mat, 0.5) + mat_root = matrix_functions.matrix_square_root(mat, size) + self.assertAllCloseAccordingToType( + expected_mat, mat_root, atol=TOLERANCE, rtol=TOLERANCE) + + def testMatrixInversePthRootFunction(self): + """Tests for matrix inverse pth roots.""" + + size = 20 + mat_a = np.random.rand(size, size) + mat = np.dot(mat_a, mat_a.T) + expected_mat = np_power(mat, -0.125) + mat_root = matrix_functions.matrix_inverse_pth_root(mat, size, -0.125) + self.assertAllCloseAccordingToType( + expected_mat, mat_root, atol=TOLERANCE, rtol=TOLERANCE) + + +if __name__ == '__main__': + test.main() diff --git a/tensorflow/contrib/opt/python/training/shampoo.py b/tensorflow/contrib/opt/python/training/shampoo.py index 294627f42a..f161521b97 100644 --- a/tensorflow/contrib/opt/python/training/shampoo.py +++ b/tensorflow/contrib/opt/python/training/shampoo.py @@ -23,6 +23,7 @@ from __future__ import division from __future__ import print_function import numpy as np +from tensorflow.contrib.opt.python.training import matrix_functions from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops @@ -76,7 +77,7 @@ class ShampooOptimizer(optimizer.Optimizer): learning_rate=1.0, svd_interval=1, precond_update_interval=1, - epsilon=0.1, + epsilon=1e-4, alpha=0.5, use_iterative_root=False, use_locking=False, @@ -255,81 +256,18 @@ class ShampooOptimizer(optimizer.Optimizer): def _compute_power_iter(self, var, mat_g, mat_g_size, alpha, mat_h_slot_name, iter_count=100, epsilon=1e-6): - """Computes mat_g^alpha, where alpha = -1/p, p a positive integer. + """Computes mat_g^alpha, where alpha = -1/p, p a positive integer.""" + + mat_g_sqrt = matrix_functions.matrix_square_root(mat_g, mat_g_size, + iter_count, self._epsilon) + mat_h = matrix_functions.matrix_inverse_pth_root( + mat_g_sqrt, + mat_g_size, + 2 * alpha, + iter_count, + epsilon, + ridge_epsilon=0.0) - We use an iterative Schur-Newton method from equation 3.2 on page 9 of: - - A Schur-Newton Method for the Matrix p-th Root and its Inverse - by Chun-Hua Guo and Nicholas J. Higham - SIAM Journal on Matrix Analysis and Applications, - 2006, Vol. 28, No. 3 : pp. 788-804 - https://pdfs.semanticscholar.org/0abe/7f77433cf5908bfe2b79aa91af881da83858.pdf - - Args: - var: the variable we are updating. - mat_g: the symmetric PSD matrix whose power it to be computed - mat_g_size: size of mat_g. - alpha: exponent, must be -1/p for p a positive integer. - mat_h_slot_name: name of slot to store the power, if needed. - iter_count: Maximum number of iterations. - epsilon: accuracy indicator, useful for early termination. - - Returns: - mat_g^alpha - """ - - identity = linalg_ops.eye(math_ops.to_int32(mat_g_size)) - - def MatPower(mat_m, p): - """Computes mat_m^p, for p a positive integer. - - Power p is known at graph compile time, so no need for loop and cond. - Args: - mat_m: a square matrix - p: a positive integer - - Returns: - mat_m^p - """ - assert p == int(p) and p > 0 - power = None - while p > 0: - if p % 2 == 1: - power = math_ops.matmul(mat_m, power) if power is not None else mat_m - p //= 2 - mat_m = math_ops.matmul(mat_m, mat_m) - return power - - def IterCondition(i, mat_m, _): - return math_ops.logical_and( - i < iter_count, - math_ops.reduce_max(math_ops.abs(mat_m - identity)) > epsilon) - - def IterBody(i, mat_m, mat_x): - mat_m_i = (1 - alpha) * identity + alpha * mat_m - return (i + 1, math_ops.matmul(MatPower(mat_m_i, -1.0/alpha), mat_m), - math_ops.matmul(mat_x, mat_m_i)) - - if mat_g_size == 1: - mat_h = math_ops.pow(mat_g + self._epsilon, alpha) - else: - damped_mat_g = mat_g + self._epsilon * identity - z = (1 - 1 / alpha) / (2 * linalg_ops.norm(damped_mat_g)) - # The best value for z is - # (1 - 1/alpha) * (c_max^{-alpha} - c_min^{-alpha}) / - # (c_max^{1-alpha} - c_min^{1-alpha}) - # where c_max and c_min are the largest and smallest singular values of - # damped_mat_g. - # The above estimate assumes that c_max > c_min * 2^p. (p = -1/alpha) - # Can replace above line by the one below, but it is less accurate, - # hence needs more iterations to converge. - # z = (1 - 1/alpha) / math_ops.trace(damped_mat_g) - # If we want the method to always converge, use z = 1 / norm(damped_mat_g) - # or z = 1 / math_ops.trace(damped_mat_g), but these can result in many - # extra iterations. - _, _, mat_h = control_flow_ops.while_loop( - IterCondition, IterBody, - [0, damped_mat_g * z, identity * math_ops.pow(z, -alpha)]) if mat_h_slot_name is not None: return state_ops.assign(self.get_slot(var, mat_h_slot_name), mat_h) return mat_h @@ -422,6 +360,8 @@ class ShampooOptimizer(optimizer.Optimizer): mat_gbar_weight_t * precond_update_interval, i), lambda: mat_g) + mat_g_updated = mat_g_updated / float(shape[i].value) + if self._svd_interval == 1: mat_h = self._compute_power(var, mat_g_updated, shape[i], neg_alpha) else: @@ -443,7 +383,13 @@ class ShampooOptimizer(optimizer.Optimizer): name="precond_" + str(i)) else: # Tensor size is too large -- perform diagonal Shampoo update - grad_outer = math_ops.reduce_sum(grad * grad, axis=axes) + # Only normalize non-vector cases. + if axes: + normalizer = 1.0 if indices is not None else float(shape[i].value) + grad_outer = math_ops.reduce_sum(grad * grad, axis=axes) / normalizer + else: + grad_outer = grad * grad + if i == 0 and indices is not None: assert self._mat_gbar_decay == 1.0 mat_g_updated = state_ops.scatter_add(mat_g, indices, diff --git a/tensorflow/contrib/opt/python/training/shampoo_test.py b/tensorflow/contrib/opt/python/training/shampoo_test.py index b3688ab181..05bcf2cfa3 100644 --- a/tensorflow/contrib/opt/python/training/shampoo_test.py +++ b/tensorflow/contrib/opt/python/training/shampoo_test.py @@ -31,6 +31,7 @@ from tensorflow.python.ops import variables from tensorflow.python.platform import test TOLERANCE = 1e-3 +RIDGE_EPSILON = 1e-4 def np_power(mat_g, alpha): @@ -77,8 +78,8 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * mat_g^{-0.5} * grad # lr = 1 - mat_g = np.outer(grad_np, grad_np) - mat_h = np_power(mat_g + 0.1 * np.eye(size), -0.5) + mat_g = np.outer(grad_np, grad_np) / grad_np.shape[0] + mat_h = np_power(mat_g + RIDGE_EPSILON * np.eye(size), -0.5) new_val_np = init_var_np - np.dot(mat_h, grad_np) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -88,8 +89,8 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g += np.outer(grad_np_2, grad_np_2) - mat_h = np_power(mat_g + 0.1 * np.eye(size), -0.5) + mat_g += np.outer(grad_np_2, grad_np_2) / grad_np.shape[0] + mat_h = np_power(mat_g + RIDGE_EPSILON * np.eye(size), -0.5) new_val_np -= np.dot(mat_h, grad_np_2) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -128,10 +129,10 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * mat_g1^{-0.25} * grad * mat_g2^{-0.25} # lr = 1 - mat_g1 = np.dot(grad_np, grad_np.transpose()) - mat_left = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.25) - mat_g2 = np.dot(grad_np.transpose(), grad_np) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_g1 = np.dot(grad_np, grad_np.transpose()) / grad_np.shape[0] + mat_left = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.25) + mat_g2 = np.dot(grad_np.transpose(), grad_np) / grad_np.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np = init_var_np - np.dot(np.dot(mat_left, grad_np), mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -141,10 +142,10 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g1 += np.dot(grad_np_2, grad_np_2.transpose()) - mat_left = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.25) - mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_g1 += np.dot(grad_np_2, grad_np_2.transpose()) / grad_np_2.shape[0] + mat_left = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.25) + mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) / grad_np_2.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np -= np.dot(np.dot(mat_left, grad_np_2), mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -188,12 +189,18 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * Prod_i mat_g_i^{-0.5/3} grad # lr = 1 - mat_g1 = np.tensordot(grad_np, grad_np, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 = np.tensordot(grad_np, grad_np, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 = np.tensordot(grad_np, grad_np, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 = ( + np.tensordot(grad_np, grad_np, axes=([1, 2], [1, 2])) / + grad_np.shape[0]) + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 = ( + np.tensordot(grad_np, grad_np, axes=([0, 2], [0, 2])) / + grad_np.shape[1]) + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 = ( + np.tensordot(grad_np, grad_np, axes=([0, 1], [0, 1])) / + grad_np.shape[2]) + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) precond_grad = np.tensordot(grad_np, mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) @@ -207,12 +214,18 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g1 += np.tensordot(grad_np_2, grad_np_2, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 += np.tensordot(grad_np_2, grad_np_2, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 += np.tensordot(grad_np_2, grad_np_2, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 += ( + np.tensordot(grad_np_2, grad_np_2, axes=([1, 2], [1, 2])) / + grad_np_2.shape[0]) + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 += ( + np.tensordot(grad_np_2, grad_np_2, axes=([0, 2], [0, 2])) / + grad_np_2.shape[1]) + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 += ( + np.tensordot(grad_np_2, grad_np_2, axes=([0, 1], [0, 1])) / + grad_np_2.shape[2]) + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) precond_grad = np.tensordot(grad_np_2, mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) @@ -265,19 +278,21 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * gg^{-0.5} * grad # lr = 1 - mat_g = grad_np * grad_np + 0.1 - new_val_np = init_var_np - np.power(mat_g, -0.5) * grad_np - - self.assertAllCloseAccordingToType(new_val_np, new_val) + mat_g = (grad_np * grad_np) + new_val_np = init_var_np - np.power(mat_g + RIDGE_EPSILON, -0.5) * grad_np + self.assertAllCloseAccordingToType( + new_val_np, new_val, atol=TOLERANCE, rtol=TOLERANCE) # Run another step of Shampoo update_2.run() new_val = sess.run(var) - mat_g += grad_np_2 * grad_np_2 - new_val_np -= np.power(mat_g, -0.5) * grad_np_2 + mat_g += (grad_np_2 * grad_np_2) + new_val_np -= np.power(mat_g + RIDGE_EPSILON, -0.5) * grad_np_2 + + self.assertAllCloseAccordingToType( + new_val_np, new_val, atol=TOLERANCE, rtol=TOLERANCE) - self.assertAllCloseAccordingToType(new_val_np, new_val) @parameterized.named_parameters(('Var', False), ('ResourceVar', True)) def testLargeMatrix(self, use_resource_var): @@ -322,10 +337,11 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # with broadcasting # lr = 1 - mat_g1 = np.sum(grad_np * grad_np, axis=1, keepdims=True) - mat_left = np.power(mat_g1 + 0.1, -0.25) - mat_g2 = np.dot(grad_np.transpose(), grad_np) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_g1 = np.sum( + grad_np * grad_np, axis=1, keepdims=True) / grad_np.shape[0] + mat_left = np.power(mat_g1 + RIDGE_EPSILON, -0.25) + mat_g2 = np.dot(grad_np.transpose(), grad_np) / grad_np.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np = init_var_np - np.dot(grad_np * mat_left, mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -335,10 +351,11 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g1 += np.sum(grad_np_2 * grad_np_2, axis=1, keepdims=True) - mat_left = np.power(mat_g1 + 0.1, -0.25) - mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_g1 += np.sum( + grad_np_2 * grad_np_2, axis=1, keepdims=True) / grad_np_2.shape[0] + mat_left = np.power(mat_g1 + RIDGE_EPSILON, -0.25) + mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) / grad_np_2.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np -= np.dot(grad_np_2 * mat_left, mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -405,9 +422,9 @@ class ShampooTest(test.TestCase, parameterized.TestCase): mat_g1 = np.sum(grad_np * grad_np, axis=1, keepdims=True) mat_g1_acc = np.zeros((size[0], 1)) mat_g1_acc[grad_indices] += mat_g1 - mat_left = np.power(mat_g1 + 0.1, -0.25) - mat_g2 = np.dot(grad_np.transpose(), grad_np) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_left = np.power(mat_g1 + RIDGE_EPSILON, -0.25) + mat_g2 = np.dot(grad_np.transpose(), grad_np) / grad_np.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np = init_var_np new_val_np[grad_indices, :] -= np.dot(grad_np * mat_left, mat_right) @@ -420,9 +437,9 @@ class ShampooTest(test.TestCase, parameterized.TestCase): mat_g1 = np.sum(grad_np_2 * grad_np_2, axis=1, keepdims=True) mat_g1_acc[grad_indices_2] += mat_g1 - mat_left = np.power(mat_g1_acc[grad_indices_2] + 0.1, -0.25) - mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_left = np.power(mat_g1_acc[grad_indices_2] + RIDGE_EPSILON, -0.25) + mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) / grad_np_2.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np[grad_indices_2, :] -= np.dot(grad_np_2 * mat_left, mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -474,12 +491,15 @@ class ShampooTest(test.TestCase, parameterized.TestCase): grad_dense = np.zeros_like(init_var_np) grad_dense[grad_indices] = grad_np - mat_g1 = np.tensordot(grad_dense, grad_dense, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 = np.tensordot(grad_dense, grad_dense, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 = np.tensordot(grad_dense, grad_dense, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 = np.tensordot( + grad_dense, grad_dense, axes=([1, 2], [1, 2])) / grad_dense.shape[0] + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 = np.tensordot( + grad_dense, grad_dense, axes=([0, 2], [0, 2])) / grad_dense.shape[1] + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 = np.tensordot( + grad_dense, grad_dense, axes=([0, 1], [0, 1])) / grad_dense.shape[2] + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) precond_grad = np.tensordot(grad_dense, mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) @@ -536,12 +556,15 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * Prod_i mat_g_i^{-0.5/3} grad # lr = 1 - mat_g1 = np.tensordot(grad_np, grad_np, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 = np.tensordot(grad_np, grad_np, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 = np.tensordot(grad_np, grad_np, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 = np.tensordot( + grad_np, grad_np, axes=([1, 2], [1, 2])) / grad_np.shape[0] + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 = np.tensordot( + grad_np, grad_np, axes=([0, 2], [0, 2])) / grad_np.shape[1] + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 = np.tensordot( + grad_np, grad_np, axes=([0, 1], [0, 1])) / grad_np.shape[2] + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) gbar_np = gbar_weight * grad_np precond_grad = np.tensordot(gbar_np, mat_g1_a, axes=([0], [0])) @@ -556,12 +579,15 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g1 += np.tensordot(grad_np_2, grad_np_2, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 += np.tensordot(grad_np_2, grad_np_2, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 += np.tensordot(grad_np_2, grad_np_2, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 += np.tensordot( + grad_np_2, grad_np_2, axes=([1, 2], [1, 2])) / grad_np_2.shape[0] + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 += np.tensordot( + grad_np_2, grad_np_2, axes=([0, 2], [0, 2])) / grad_np_2.shape[1] + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 += np.tensordot( + grad_np_2, grad_np_2, axes=([0, 1], [0, 1])) / grad_np_2.shape[2] + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) gbar_np_2 = gbar_decay * gbar_np + gbar_weight * grad_np_2 precond_grad = np.tensordot(gbar_np_2, mat_g1_a, axes=([0], [0])) @@ -626,13 +652,19 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * Prod_i mat_g_i^{-0.5/3} grad # lr = 1 - mat_g1 += np.tensordot(grad_np[i], grad_np[i], axes=([1, 2], [1, 2])) - mat_g2 += np.tensordot(grad_np[i], grad_np[i], axes=([0, 2], [0, 2])) - mat_g3 += np.tensordot(grad_np[i], grad_np[i], axes=([0, 1], [0, 1])) + mat_g1 += np.tensordot( + grad_np[i], grad_np[i], axes=([1, 2], [1, 2])) / grad_np[i].shape[0] + mat_g2 += np.tensordot( + grad_np[i], grad_np[i], axes=([0, 2], [0, 2])) / grad_np[i].shape[1] + mat_g3 += np.tensordot( + grad_np[i], grad_np[i], axes=([0, 1], [0, 1])) / grad_np[i].shape[2] if (i + 1) % svd_interval == 0: - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), + -0.5 / 3.0) + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), + -0.5 / 3.0) + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), + -0.5 / 3.0) precond_grad = np.tensordot(grad_np[i], mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) @@ -700,17 +732,23 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # Update rule is var = var - lr * Prod_i mat_g_i^{-0.5/3} grad # lr = 1 if (i + 1) % precond_update_interval == 0: - mat_g1 += (np.tensordot(grad_np[i], grad_np[i], axes=([1, 2], [1, 2])) - * precond_update_interval) - mat_g2 += (np.tensordot(grad_np[i], grad_np[i], axes=([0, 2], [0, 2])) - * precond_update_interval) - mat_g3 += (np.tensordot(grad_np[i], grad_np[i], axes=([0, 1], [0, 1])) - * precond_update_interval) + mat_g1 += ( + np.tensordot(grad_np[i], grad_np[i], axes=([1, 2], [1, 2])) / + grad_np[i].shape[0] * precond_update_interval) + mat_g2 += ( + np.tensordot(grad_np[i], grad_np[i], axes=([0, 2], [0, 2])) / + grad_np[i].shape[1] * precond_update_interval) + mat_g3 += ( + np.tensordot(grad_np[i], grad_np[i], axes=([0, 1], [0, 1])) / + grad_np[i].shape[2] * precond_update_interval) if (i + 1) % svd_interval == 0: - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), + -0.5 / 3.0) + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), + -0.5 / 3.0) + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), + -0.5 / 3.0) precond_grad = np.tensordot(grad_np[i], mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) diff --git a/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py b/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py index 29acfc602e..200b0d2008 100644 --- a/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py +++ b/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py @@ -18,6 +18,7 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from tensorflow.contrib.opt.python.training import shampoo from tensorflow.python.framework import ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import resource_variable_ops @@ -361,3 +362,74 @@ class AdamWOptimizer(DecoupledWeightDecayExtension, adam.AdamOptimizer): super(AdamWOptimizer, self).__init__( weight_decay, learning_rate=learning_rate, beta1=beta1, beta2=beta2, epsilon=epsilon, use_locking=use_locking, name=name) + + +@tf_export("contrib.opt.ShampooWOptimizer") +class ShampooWOptimizer(DecoupledWeightDecayExtension, + shampoo.ShampooOptimizer): + """Optimizer that implements the Shampoo algorithm with weight decay. + + For further information see the documentation of the Shampoo Optimizer. + """ + + def __init__(self, + weight_decay, + global_step, + max_matrix_size=768, + gbar_decay=0.0, + gbar_weight=1.0, + mat_gbar_decay=1.0, + mat_gbar_weight=1.0, + learning_rate=1.0, + svd_interval=1, + precond_update_interval=1, + epsilon=1e-4, + alpha=0.5, + use_iterative_root=False, + use_locking=False, + name="ShampooW"): + """Construct a new ShampooW optimizer. + + For further information see the documentation of the Shampoo Optimizer. + + Args: + weight_decay: A `Tensor` or a floating point value. The weight decay. + global_step: tensorflow variable indicating the step. + max_matrix_size: We do not perform SVD for matrices larger than this. + gbar_decay: + gbar_weight: Used to update gbar: gbar[t] = gbar_decay[t] * gbar[t-1] + + gbar_weight[t] * g[t] + mat_gbar_decay: + mat_gbar_weight: Used to update mat_gbar: mat_gbar_j[t] = + mat_gbar_decay[t] * mat_gbar_j[t-1] + mat_gbar_weight[t] * gg_j[t] + learning_rate: Similar to SGD + svd_interval: We should do SVD after this many steps. Default = 1, i.e. + every step. Usually 20 leads to no loss of accuracy, and 50 or 100 is + also OK. May also want more often early, + and less often later - set in caller as for example: + "svd_interval = lambda(T): tf.cond( + T < 2000, lambda: 20.0, lambda: 1000.0)" + precond_update_interval: We should update the preconditioners after this + many steps. Default = 1. Usually less than svd_interval. + epsilon: epsilon * I_n is added to each mat_gbar_j for stability + alpha: total power of the preconditioners. + use_iterative_root: should the optimizer use SVD (faster) or the iterative + root method (for TPU) for finding the roots of PSD matrices. + use_locking: If `True` use locks for update operations. + name: name of optimizer. + """ + super(ShampooWOptimizer, self).__init__( + weight_decay, + global_step=global_step, + max_matrix_size=max_matrix_size, + gbar_decay=gbar_decay, + gbar_weight=gbar_weight, + mat_gbar_decay=mat_gbar_weight, + learning_rate=learning_rate, + svd_interval=svd_interval, + precond_update_interval=precond_update_interval, + epsilon=epsilon, + alpha=alpha, + use_iterative_root=use_iterative_root, + use_locking=use_locking, + name=name) diff --git a/tensorflow/contrib/saved_model/BUILD b/tensorflow/contrib/saved_model/BUILD index e7eb4ac563..b897224c6d 100644 --- a/tensorflow/contrib/saved_model/BUILD +++ b/tensorflow/contrib/saved_model/BUILD @@ -36,6 +36,7 @@ py_library( srcs_version = "PY2AND3", visibility = ["//visibility:public"], deps = [ + ":keras_saved_model", "//tensorflow/core:protos_all_py", "//tensorflow/python:framework_ops", "//tensorflow/python:lib", @@ -101,23 +102,33 @@ py_library( tags = ["no_windows"], visibility = ["//visibility:public"], deps = [ + "//tensorflow/python:array_ops", + "//tensorflow/python:framework_ops", "//tensorflow/python:lib", + "//tensorflow/python:metrics", + "//tensorflow/python:platform", + "//tensorflow/python:saver", "//tensorflow/python:util", + "//tensorflow/python/estimator", + "//tensorflow/python/estimator:export", + "//tensorflow/python/estimator:keras", + "//tensorflow/python/estimator:model_fn", "//tensorflow/python/keras:engine", - "//tensorflow/python/saved_model:constants", + "//tensorflow/python/saved_model", ], ) py_test( name = "keras_saved_model_test", - size = "small", + size = "medium", srcs = ["python/saved_model/keras_saved_model_test.py"], srcs_version = "PY2AND3", deps = [ - ":saved_model_py", + ":keras_saved_model", "//tensorflow/python:client_testlib", "//tensorflow/python:training", "//tensorflow/python/keras", "//third_party/py/numpy", + "@absl_py//absl/testing:parameterized", ], ) diff --git a/tensorflow/contrib/saved_model/__init__.py b/tensorflow/contrib/saved_model/__init__.py index 95e1a8967b..074dc655ac 100644 --- a/tensorflow/contrib/saved_model/__init__.py +++ b/tensorflow/contrib/saved_model/__init__.py @@ -26,10 +26,13 @@ from __future__ import print_function # pylint: disable=unused-import,wildcard-import,line-too-long from tensorflow.contrib.saved_model.python.saved_model.keras_saved_model import * from tensorflow.contrib.saved_model.python.saved_model.signature_def_utils import * -# pylint: enable=unused-import,widcard-import,line-too-long +# pylint: enable=unused-import,wildcard-import,line-too-long from tensorflow.python.util.all_util import remove_undocumented -_allowed_symbols = ["get_signature_def_by_key", "load_model", "save_model"] +_allowed_symbols = [ + "get_signature_def_by_key", + "load_keras_model", + "save_keras_model"] remove_undocumented(__name__, _allowed_symbols) diff --git a/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model.py b/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model.py index e2a969f053..2c5c8c4afd 100644 --- a/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model.py +++ b/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model.py @@ -20,28 +20,69 @@ from __future__ import print_function import os +from tensorflow.python.client import session +from tensorflow.python.estimator import keras as estimator_keras_util +from tensorflow.python.estimator import model_fn as model_fn_lib +from tensorflow.python.estimator.export import export as export_helpers +from tensorflow.python.framework import errors +from tensorflow.python.framework import ops +from tensorflow.python.keras import backend as K +from tensorflow.python.keras import models as models_lib +from tensorflow.python.keras import optimizers from tensorflow.python.keras.models import model_from_json from tensorflow.python.lib.io import file_io +from tensorflow.python.ops import variables +from tensorflow.python.platform import gfile +from tensorflow.python.platform import tf_logging as logging +from tensorflow.python.saved_model import builder as saved_model_builder from tensorflow.python.saved_model import constants +from tensorflow.python.saved_model import utils_impl as saved_model_utils +from tensorflow.python.training import saver as saver_lib +from tensorflow.python.training.checkpointable import util as checkpointable_utils from tensorflow.python.util import compat -def save_model(model, saved_model_path): +def save_keras_model( + model, saved_model_path, custom_objects=None, as_text=None): """Save a `tf.keras.Model` into Tensorflow SavedModel format. - `save_model` generates such files/folders under the `saved_model_path` folder: + `save_model` generates new files/folders under the `saved_model_path` folder: 1) an asset folder containing the json string of the model's - configuration(topology). + configuration (topology). 2) a checkpoint containing the model weights. + 3) a saved_model.pb file containing the model's MetaGraphs. The prediction + graph is always exported. The evaluaton and training graphs are exported + if the following conditions are met: + - Evaluation: model loss is defined. + - Training: model is compiled with an optimizer defined under `tf.train`. + This is because `tf.keras.optimizers.Optimizer` instances cannot be + saved to checkpoints. - Note that subclassed models can not be saved via this function, unless you - provide an implementation for get_config() and from_config(). - Also note that `tf.keras.optimizers.Optimizer` instances can not currently be - saved to checkpoints. Use optimizers from `tf.train`. + Model Requirements: + - Model must be a sequential model or functional model. Subclassed models can + not be saved via this function, unless you provide an implementation for + get_config() and from_config(). + - All variables must be saveable by the model. In general, this condition is + met through the use of layers defined in the keras library. However, + there is currently a bug with variables created in Lambda layer functions + not being saved correctly (see + https://github.com/keras-team/keras/issues/9740). + + Note that each mode is exported in separate graphs, so different modes do not + share variables. To use the train graph with evaluation or prediction graphs, + create a new checkpoint if variable values have been updated. Args: model: A `tf.keras.Model` to be saved. saved_model_path: a string specifying the path to the SavedModel directory. + The SavedModel will be saved to a timestamped folder created within this + directory. + custom_objects: Optional dictionary mapping string names to custom classes + or functions (e.g. custom loss functions). + as_text: whether to write the `SavedModel` proto in text format. + + Returns: + String path to the SavedModel folder, a subdirectory of `saved_model_path`. Raises: NotImplementedError: If the passed in model is a subclassed model. @@ -49,35 +90,200 @@ def save_model(model, saved_model_path): if not model._is_graph_network: raise NotImplementedError - # save model configuration as a json string under assets folder. - model_json = model.to_json() - assets_destination_dir = os.path.join( - compat.as_bytes(saved_model_path), - compat.as_bytes(constants.ASSETS_DIRECTORY)) + export_dir = export_helpers.get_timestamped_export_dir(saved_model_path) + temp_export_dir = export_helpers.get_temp_export_dir(export_dir) + + builder = saved_model_builder.SavedModelBuilder(temp_export_dir) + + # Manually save variables to export them in an object-based checkpoint. This + # skips the `builder.add_meta_graph_and_variables()` step, which saves a + # named-based checkpoint. + # TODO(b/113134168): Add fn to Builder to save with object-based saver. + # TODO(b/113178242): This should only export the model json structure. Only + # one save is needed once the weights can be copied from the model to clone. + checkpoint_path = _export_model_json_and_variables(model, temp_export_dir) + + # Export each mode. Use ModeKeys enums defined for `Estimator` to ensure that + # Keras models and `Estimator`s are exported with the same format. + # Every time a mode is exported, the code checks to see if new variables have + # been created (e.g. optimizer slot variables). If that is the case, the + # checkpoint is re-saved to include the new variables. + export_args = {'builder': builder, + 'model': model, + 'custom_objects': custom_objects, + 'checkpoint_path': checkpoint_path} + + has_saved_vars = False + if model.optimizer: + if isinstance(model.optimizer, optimizers.TFOptimizer): + _export_mode(model_fn_lib.ModeKeys.TRAIN, has_saved_vars, **export_args) + has_saved_vars = True + _export_mode(model_fn_lib.ModeKeys.EVAL, has_saved_vars, **export_args) + else: + logging.warning( + 'Model was compiled with an optimizer, but the optimizer is not from ' + '`tf.train` (e.g. `tf.train.AdagradOptimizer`). Only the serving ' + 'graph was exported. The train and evaluate graphs were not added to ' + 'the SavedModel.') + _export_mode(model_fn_lib.ModeKeys.PREDICT, has_saved_vars, **export_args) + + builder.save(as_text) + + gfile.Rename(temp_export_dir, export_dir) + return export_dir - if not file_io.file_exists(assets_destination_dir): - file_io.recursive_create_dir(assets_destination_dir) +def _export_model_json_and_variables(model, saved_model_path): + """Save model variables and json structure into SavedModel subdirectories.""" + # Save model configuration as a json string under assets folder. + model_json = model.to_json() model_json_filepath = os.path.join( - compat.as_bytes(assets_destination_dir), - compat.as_bytes(constants.SAVED_MODEL_FILENAME_JSON)) + saved_model_utils.get_or_create_assets_dir(saved_model_path), + compat.as_text(constants.SAVED_MODEL_FILENAME_JSON)) file_io.write_string_to_file(model_json_filepath, model_json) - # save model weights in checkpoint format. - checkpoint_destination_dir = os.path.join( - compat.as_bytes(saved_model_path), - compat.as_bytes(constants.VARIABLES_DIRECTORY)) + # Save model weights in checkpoint format under variables folder. + saved_model_utils.get_or_create_variables_dir(saved_model_path) + checkpoint_prefix = saved_model_utils.get_variables_path(saved_model_path) + model.save_weights(checkpoint_prefix, save_format='tf', overwrite=True) + return checkpoint_prefix - if not file_io.file_exists(checkpoint_destination_dir): - file_io.recursive_create_dir(checkpoint_destination_dir) - checkpoint_prefix = os.path.join( - compat.as_text(checkpoint_destination_dir), - compat.as_text(constants.VARIABLES_FILENAME)) - model.save_weights(checkpoint_prefix, save_format='tf', overwrite=True) +def _get_var_list(model): + """Return list of all checkpointed saveable objects in the model.""" + return checkpointable_utils.named_saveables(model) + + +def _export_mode( + mode, has_saved_vars, builder, model, custom_objects, checkpoint_path): + """Export a model, and optionally save new vars from the clone model. + + Args: + mode: A `tf.estimator.ModeKeys` string. + has_saved_vars: A `boolean` indicating whether the SavedModel has already + exported variables. + builder: A `SavedModelBuilder` object. + model: A `tf.keras.Model` object. + custom_objects: A dictionary mapping string names to custom classes + or functions. + checkpoint_path: String path to checkpoint. + + Raises: + ValueError: If the train/eval mode is being exported, but the model does + not have an optimizer. + """ + compile_clone = (mode != model_fn_lib.ModeKeys.PREDICT) + if compile_clone and not model.optimizer: + raise ValueError( + 'Model does not have an optimizer. Cannot export mode %s' % mode) + + model_graph = ops.get_default_graph() + with ops.Graph().as_default() as g: + + K.set_learning_phase(mode == model_fn_lib.ModeKeys.TRAIN) + + # Clone the model into blank graph. This will create placeholders for inputs + # and targets. + clone = models_lib.clone_and_build_model( + model, custom_objects=custom_objects, compile_clone=compile_clone) + + # Make sure that iterations variable is added to the global step collection, + # to ensure that, when the SavedModel graph is loaded, the iterations + # variable is returned by `tf.train.get_global_step()`. This is required for + # compatibility with the SavedModelEstimator. + if compile_clone: + g.add_to_collection(ops.GraphKeys.GLOBAL_STEP, clone.optimizer.iterations) + + # Extract update and train ops from train/test/predict functions. + if mode == model_fn_lib.ModeKeys.TRAIN: + clone._make_train_function() + builder._add_train_op(clone.train_function.updates_op) + elif mode == model_fn_lib.ModeKeys.EVAL: + clone._make_test_function() + else: + clone._make_predict_function() + g.get_collection_ref(ops.GraphKeys.UPDATE_OPS).extend(clone.state_updates) + + clone_var_list = checkpointable_utils.named_saveables(clone) + + with session.Session().as_default(): + if has_saved_vars: + # Confirm all variables in the clone have an entry in the checkpoint. + status = clone.load_weights(checkpoint_path) + status.assert_existing_objects_matched() + else: + # Confirm that variables between the clone and model match up exactly, + # not counting optimizer objects. Optimizer objects are ignored because + # if the model has not trained, the slot variables will not have been + # created yet. + # TODO(b/113179535): Replace with checkpointable equivalence. + _assert_same_non_optimizer_objects(model, model_graph, clone, g) + + # TODO(b/113178242): Use value transfer for checkpointable objects. + clone.load_weights(checkpoint_path) + + # Add graph and variables to SavedModel. + # TODO(b/113134168): Switch to add_meta_graph_and_variables. + clone.save_weights(checkpoint_path, save_format='tf', overwrite=True) + builder._has_saved_variables = True + + # Add graph to the SavedModel builder. + builder.add_meta_graph( + model_fn_lib.EXPORT_TAG_MAP[mode], + signature_def_map=_create_signature_def_map(clone, mode), + saver=saver_lib.Saver(clone_var_list), + main_op=variables.local_variables_initializer()) + return None + + +def _create_signature_def_map(model, mode): + """Create a SignatureDef map from a Keras model.""" + inputs_dict = {name: x for name, x in zip(model.input_names, model.inputs)} + if model.optimizer: + targets_dict = {x.name.split(':')[0]: x + for x in model.targets if x is not None} + inputs_dict.update(targets_dict) + outputs_dict = {name: x + for name, x in zip(model.output_names, model.outputs)} + export_outputs = model_fn_lib.export_outputs_for_mode( + mode, + predictions=outputs_dict, + loss=model.total_loss if model.optimizer else None, + metrics=estimator_keras_util._convert_keras_metrics_to_estimator(model)) + return export_helpers.build_all_signature_defs( + inputs_dict, + export_outputs=export_outputs, + serving_only=(mode == model_fn_lib.ModeKeys.PREDICT)) + + +def _assert_same_non_optimizer_objects(model, model_graph, clone, clone_graph): + """Assert model and clone contain the same checkpointable objects.""" + + def get_non_optimizer_objects(m, g): + """Gather set of model and optimizer checkpointable objects.""" + # Set default graph because optimizer.variables() returns optimizer + # variables defined in the default graph. + with g.as_default(): + all_objects = set(checkpointable_utils.list_objects(m)) + optimizer_and_variables = set() + for obj in all_objects: + if isinstance(obj, optimizers.TFOptimizer): + optimizer_and_variables.update(checkpointable_utils.list_objects(obj)) + optimizer_and_variables.update(set(obj.optimizer.variables())) + return all_objects - optimizer_and_variables + + model_objects = get_non_optimizer_objects(model, model_graph) + clone_objects = get_non_optimizer_objects(clone, clone_graph) + + if len(model_objects) != len(clone_objects): + raise errors.InternalError( + None, None, + 'Model and clone must use the same variables.' + '\n\tModel variables: %s\n\t Clone variables: %s' + % (model_objects, clone_objects)) -def load_model(saved_model_path): +def load_keras_model(saved_model_path): """Load a keras.Model from SavedModel. load_model reinstantiates model state by: diff --git a/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model_test.py b/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model_test.py index 107ae1b07b..8a0dbef788 100644 --- a/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model_test.py +++ b/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model_test.py @@ -20,18 +20,35 @@ from __future__ import print_function import os import shutil + +from absl.testing import parameterized import numpy as np from tensorflow.contrib.saved_model.python.saved_model import keras_saved_model from tensorflow.python import keras +from tensorflow.python.client import session +from tensorflow.python.eager import context +from tensorflow.python.estimator import model_fn as model_fn_lib +from tensorflow.python.framework import errors +from tensorflow.python.framework import ops from tensorflow.python.framework import test_util from tensorflow.python.keras.engine import training +from tensorflow.python.keras.utils import tf_utils +from tensorflow.python.ops import array_ops from tensorflow.python.platform import test +from tensorflow.python.saved_model import constants +from tensorflow.python.saved_model import loader_impl +from tensorflow.python.saved_model import signature_constants from tensorflow.python.training import training as training_module class TestModelSavingandLoading(test.TestCase): + def _save_model_dir(self, dirname='saved_model'): + temp_dir = self.get_temp_dir() + self.addCleanup(shutil.rmtree, temp_dir, ignore_errors=True) + return os.path.join(temp_dir, dirname) + def test_saving_sequential_model(self): with self.test_session(): model = keras.models.Sequential() @@ -48,13 +65,11 @@ class TestModelSavingandLoading(test.TestCase): model.train_on_batch(x, y) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -69,12 +84,9 @@ class TestModelSavingandLoading(test.TestCase): x = np.random.random((1, 3)) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -95,12 +107,10 @@ class TestModelSavingandLoading(test.TestCase): model.train_on_batch(x, y) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -118,12 +128,10 @@ class TestModelSavingandLoading(test.TestCase): y = np.random.random((1, 3)) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -142,14 +150,13 @@ class TestModelSavingandLoading(test.TestCase): x = np.random.random((1, 3)) y = np.random.random((1, 3)) model.train_on_batch(x, y) + model.train_on_batch(x, y) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) loaded_model.compile( loss='mse', optimizer=training_module.RMSPropOptimizer(0.1), @@ -170,8 +177,10 @@ class TestModelSavingandLoading(test.TestCase): self.assertAllClose(ref_y, y, atol=1e-05) # test saving/loading again - keras_saved_model.save_model(loaded_model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model2 = self._save_model_dir('saved_model_2') + output_path2 = keras_saved_model.save_keras_model( + loaded_model, temp_saved_model2) + loaded_model = keras_saved_model.load_keras_model(output_path2) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -190,11 +199,231 @@ class TestModelSavingandLoading(test.TestCase): return self.layer2(self.layer1(inp)) model = SubclassedModel() - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') + + temp_saved_model = self._save_model_dir() with self.assertRaises(NotImplementedError): - keras_saved_model.save_model(model, temp_saved_model) + keras_saved_model.save_keras_model(model, temp_saved_model) + + +class LayerWithLearningPhase(keras.engine.base_layer.Layer): + + def call(self, x): + phase = keras.backend.learning_phase() + output = tf_utils.smart_cond( + phase, lambda: x * 0, lambda: array_ops.identity(x)) + if not context.executing_eagerly(): + output._uses_learning_phase = True # pylint: disable=protected-access + return output + + def compute_output_shape(self, input_shape): + return input_shape + + +def functional_model(uses_learning_phase): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(3)(x) + if uses_learning_phase: + x = LayerWithLearningPhase()(x) + return keras.models.Model(inputs, x) + + +def sequential_model(uses_learning_phase): + model = keras.models.Sequential() + model.add(keras.layers.Dense(2, input_shape=(3,))) + model.add(keras.layers.Dense(3)) + if uses_learning_phase: + model.add(LayerWithLearningPhase()) + return model + + +def load_model(sess, path, mode): + tags = model_fn_lib.EXPORT_TAG_MAP[mode] + sig_def_key = (signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY + if mode == model_fn_lib.ModeKeys.PREDICT else mode) + meta_graph_def = loader_impl.load(sess, tags, path) + inputs = { + k: sess.graph.get_tensor_by_name(v.name) + for k, v in meta_graph_def.signature_def[sig_def_key].inputs.items()} + outputs = { + k: sess.graph.get_tensor_by_name(v.name) + for k, v in meta_graph_def.signature_def[sig_def_key].outputs.items()} + return inputs, outputs + + +@test_util.run_all_in_graph_and_eager_modes +class TestModelSavedModelExport(test.TestCase, parameterized.TestCase): + + def _save_model_dir(self, dirname='saved_model'): + temp_dir = self.get_temp_dir() + self.addCleanup(shutil.rmtree, temp_dir, ignore_errors=True) + return os.path.join(temp_dir, dirname) + + @parameterized.parameters( + (functional_model, True, training_module.AdadeltaOptimizer(), True), + (functional_model, True, training_module.AdadeltaOptimizer(), False), + (functional_model, False, None, False), + (sequential_model, True, training_module.AdadeltaOptimizer(), True), + (sequential_model, True, training_module.AdadeltaOptimizer(), False), + (sequential_model, False, None, False)) + def testSaveAndLoadSavedModelExport( + self, model_builder, uses_learning_phase, optimizer, train_before_export): + saved_model_path = self._save_model_dir() + with self.test_session(graph=ops.Graph()): + input_arr = np.random.random((1, 3)) + target_arr = np.random.random((1, 3)) + + model = model_builder(uses_learning_phase) + if optimizer is not None: + model.compile( + loss='mse', + optimizer=optimizer, + metrics=['mae']) + if train_before_export: + model.train_on_batch(input_arr, target_arr) + + ref_loss, ref_mae = model.evaluate(input_arr, target_arr) + + ref_predict = model.predict(input_arr) + + # Export SavedModel + output_path = keras_saved_model.save_keras_model(model, saved_model_path) + + input_name = model.input_names[0] + output_name = model.output_names[0] + target_name = output_name + '_target' + + # Load predict graph, and test predictions + with session.Session(graph=ops.Graph()) as sess: + inputs, outputs = load_model(sess, output_path, + model_fn_lib.ModeKeys.PREDICT) + + predictions = sess.run(outputs[output_name], + {inputs[input_name]: input_arr}) + self.assertAllClose(ref_predict, predictions, atol=1e-05) + + if optimizer: + # Load eval graph, and test predictions, loss and metric values + with session.Session(graph=ops.Graph()) as sess: + inputs, outputs = load_model(sess, output_path, + model_fn_lib.ModeKeys.EVAL) + + eval_results = sess.run(outputs, {inputs[input_name]: input_arr, + inputs[target_name]: target_arr}) + + self.assertEqual(int(train_before_export), + sess.run(training_module.get_global_step())) + self.assertAllClose(ref_loss, eval_results['loss'], atol=1e-05) + self.assertAllClose( + ref_mae, eval_results['metrics/mae/update_op'], atol=1e-05) + self.assertAllClose( + ref_predict, eval_results['predictions/' + output_name], atol=1e-05) + + # Load train graph, and check for the train op, and prediction values + with session.Session(graph=ops.Graph()) as sess: + inputs, outputs = load_model(sess, output_path, + model_fn_lib.ModeKeys.TRAIN) + self.assertEqual(int(train_before_export), + sess.run(training_module.get_global_step())) + self.assertIn('loss', outputs) + self.assertIn('metrics/mae/update_op', outputs) + self.assertIn('metrics/mae/value', outputs) + self.assertIn('predictions/' + output_name, outputs) + + # Train for a step + train_op = ops.get_collection(constants.TRAIN_OP_KEY) + train_outputs, _ = sess.run( + [outputs, train_op], {inputs[input_name]: input_arr, + inputs[target_name]: target_arr}) + self.assertEqual(int(train_before_export) + 1, + sess.run(training_module.get_global_step())) + + if uses_learning_phase: + self.assertAllClose( + [[0, 0, 0]], train_outputs['predictions/' + output_name], + atol=1e-05) + else: + self.assertNotAllClose( + [[0, 0, 0]], train_outputs['predictions/' + output_name], + atol=1e-05) + + def testSaveAndLoadSavedModelWithCustomObject(self): + saved_model_path = self._save_model_dir() + with session.Session(graph=ops.Graph()) as sess: + def relu6(x): + return keras.backend.relu(x, max_value=6) + inputs = keras.layers.Input(shape=(1,)) + outputs = keras.layers.Activation(relu6)(inputs) + model = keras.models.Model(inputs, outputs) + output_path = keras_saved_model.save_keras_model( + model, saved_model_path, custom_objects={'relu6': relu6}) + with session.Session(graph=ops.Graph()) as sess: + inputs, outputs = load_model(sess, output_path, + model_fn_lib.ModeKeys.PREDICT) + input_name = model.input_names[0] + output_name = model.output_names[0] + predictions = sess.run( + outputs[output_name], {inputs[input_name]: [[7], [-3], [4]]}) + self.assertAllEqual([[6], [0], [4]], predictions) + + def testAssertModelCloneSameObjectsIgnoreOptimizer(self): + input_arr = np.random.random((1, 3)) + target_arr = np.random.random((1, 3)) + + model_graph = ops.Graph() + clone_graph = ops.Graph() + + # Create two models with the same layers but different optimizers. + with session.Session(graph=model_graph): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(3)(x) + model = keras.models.Model(inputs, x) + + model.compile(loss='mse', optimizer=training_module.AdadeltaOptimizer()) + model.train_on_batch(input_arr, target_arr) + + with session.Session(graph=clone_graph): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(3)(x) + clone = keras.models.Model(inputs, x) + clone.compile(loss='mse', optimizer=keras.optimizers.RMSprop(lr=0.0001)) + clone.train_on_batch(input_arr, target_arr) + + keras_saved_model._assert_same_non_optimizer_objects( + model, model_graph, clone, clone_graph) + + def testAssertModelCloneSameObjectsThrowError(self): + input_arr = np.random.random((1, 3)) + target_arr = np.random.random((1, 3)) + + model_graph = ops.Graph() + clone_graph = ops.Graph() + + # Create two models with the same layers but different optimizers. + with session.Session(graph=model_graph): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(3)(x) + model = keras.models.Model(inputs, x) + + model.compile(loss='mse', optimizer=training_module.AdadeltaOptimizer()) + model.train_on_batch(input_arr, target_arr) + + with session.Session(graph=clone_graph): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(4)(x) + x = keras.layers.Dense(3)(x) + clone = keras.models.Model(inputs, x) + clone.compile(loss='mse', optimizer=keras.optimizers.RMSprop(lr=0.0001)) + clone.train_on_batch(input_arr, target_arr) + + with self.assertRaisesRegexp( + errors.InternalError, 'Model and clone must use the same variables.'): + keras_saved_model._assert_same_non_optimizer_objects( + model, model_graph, clone, clone_graph) if __name__ == '__main__': diff --git a/tensorflow/contrib/tpu/BUILD b/tensorflow/contrib/tpu/BUILD index a9e338ee59..298ffc1ded 100644 --- a/tensorflow/contrib/tpu/BUILD +++ b/tensorflow/contrib/tpu/BUILD @@ -167,6 +167,7 @@ py_library( name = "keras_support", srcs = [ "python/tpu/keras_support.py", + "python/tpu/keras_tpu_variables.py", ], srcs_version = "PY2AND3", visibility = [ diff --git a/tensorflow/contrib/tpu/python/tpu/keras_support.py b/tensorflow/contrib/tpu/python/tpu/keras_support.py index e22aeb2ac0..ff88508d03 100644 --- a/tensorflow/contrib/tpu/python/tpu/keras_support.py +++ b/tensorflow/contrib/tpu/python/tpu/keras_support.py @@ -58,6 +58,7 @@ from tensorflow.contrib.cluster_resolver.python.training import tpu_cluster_reso from tensorflow.contrib.framework.python.framework import experimental from tensorflow.contrib.tpu.proto import compilation_result_pb2 as tpu_compilation_result from tensorflow.contrib.tpu.python.ops import tpu_ops +from tensorflow.contrib.tpu.python.tpu import keras_tpu_variables from tensorflow.contrib.tpu.python.tpu import tpu from tensorflow.contrib.tpu.python.tpu import tpu_function from tensorflow.contrib.tpu.python.tpu import tpu_optimizer @@ -65,16 +66,24 @@ from tensorflow.contrib.tpu.python.tpu import tpu_system_metadata as tpu_system_ from tensorflow.core.protobuf import config_pb2 from tensorflow.python.client import session as tf_session from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.data.ops import iterator_ops +from tensorflow.python.eager import context from tensorflow.python.estimator import model_fn as model_fn_lib from tensorflow.python.framework import dtypes +from tensorflow.python.framework import errors from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import tensor_spec from tensorflow.python.keras import backend as K +from tensorflow.python.keras import callbacks as cbks from tensorflow.python.keras import models from tensorflow.python.keras import optimizers as keras_optimizers from tensorflow.python.keras.engine import base_layer +from tensorflow.python.keras.engine import training_arrays +from tensorflow.python.keras.engine import training_utils from tensorflow.python.keras.layers import embeddings +from tensorflow.python.keras.utils.generic_utils import make_batches +from tensorflow.python.keras.utils.generic_utils import slice_arrays from tensorflow.python.ops import array_ops from tensorflow.python.ops import gen_linalg_ops from tensorflow.python.ops import math_ops @@ -96,9 +105,9 @@ def tpu_session(cluster_resolver): if cluster_spec: config.cluster_def.CopyFrom(cluster_spec.as_cluster_def()) + logging.info('Connecting to: %s', master) graph = ops.Graph() session = tf_session.Session(graph=graph, target=master, config=config) - with graph.as_default(): session.run(tpu.initialize_system()) @@ -109,6 +118,11 @@ def tpu_session(cluster_resolver): def reset_tpu_sessions(): _SESSIONS.clear() +try: + from scipy.sparse import issparse # pylint: disable=g-import-not-at-top +except ImportError: + issparse = None + def get_tpu_system_metadata(tpu_cluster_resolver): """Retrieves TPU system metadata given a TPUClusterResolver.""" @@ -147,11 +161,17 @@ class TPUDistributionStrategy(object): if tpu_cluster_resolver is None: tpu_cluster_resolver = tpu_cluster_resolver_lib.TPUClusterResolver('') - num_cores = (1 if using_single_core else - get_tpu_system_metadata(tpu_cluster_resolver).num_cores) - + metadata = get_tpu_system_metadata(tpu_cluster_resolver) + self._tpu_metadata = metadata self._tpu_cluster_resolver = tpu_cluster_resolver - self._num_cores = num_cores + self._num_cores = 1 if using_single_core else metadata.num_cores + + # Walk device list to identify TPU worker for enqueue/dequeue operations. + worker_re = re.compile('/job:([^/]+)') + for device in metadata.devices: + if 'TPU:0' in device.name: + self.worker_name = worker_re.search(device.name).group(1) + break @property def num_towers(self): @@ -514,7 +534,7 @@ class TPUNumpyInfeedManager(TPUInfeedManager): shard_infeed_tensors = [] for shard_id in range(self._strategy.num_towers): - with ops.device('/device:CPU:0'): + with ops.device('/job:%s/device:CPU:0' % self._strategy.worker_name): infeed_tensors = [] with ops.device('/device:TPU:%d' % shard_id): for spec in input_specs: @@ -659,7 +679,7 @@ class TPUDatasetInfeedManager(TPUInfeedManager): assert len(shard_infeed_tensors) == self._strategy.num_towers infeed_ops = [] for shard_id in range(self._strategy.num_towers): - with ops.device('/device:CPU:0'): + with ops.device('/job:%s/device:CPU:0' % self._strategy.worker_name): infeed_ops.append( tpu_ops.infeed_enqueue_tuple( shard_infeed_tensors[shard_id], @@ -737,8 +757,7 @@ class TPUFunction(object): # Clone our CPU model, running within the TPU device context. with TPURewriteContext(tpu_input_map): with variable_scope.variable_scope('tpu_model_%s' % id(self.model)): - # TODO(power): Replicate variables. - with ops.device('/device:TPU:0'): + with keras_tpu_variables.replicated_scope(self._strategy.num_towers): self._cloned_model = models.clone_model(self.model) # Create a copy of the optimizer for this graph. @@ -817,7 +836,7 @@ class TPUFunction(object): # Build output ops. outfeed_op = [] for shard_id in range(self._strategy.num_towers): - with ops.device('/device:CPU:0'): + with ops.device('/job:%s/device:CPU:0' % self._strategy.worker_name): outfeed_op.extend( tpu_ops.outfeed_dequeue_tuple( dtypes=[spec.dtype for spec in self._outfeed_spec], @@ -835,7 +854,7 @@ class TPUFunction(object): def _test_model_compiles(self, tpu_model_ops): """Verifies that the given TPUModelOp can be compiled via XLA.""" logging.info('Started compiling') - start_time = time.clock() + start_time = time.time() result = K.get_session().run(tpu_model_ops.compile_op) proto = tpu_compilation_result.CompilationResultProto() @@ -844,38 +863,52 @@ class TPUFunction(object): raise RuntimeError('Compilation failed: {}'.format( proto.status_error_message)) - end_time = time.clock() + end_time = time.time() logging.info('Finished compiling. Time elapsed: %s secs', end_time - start_time) - def __call__(self, inputs): - assert isinstance(inputs, list) + def _lookup_infeed_manager(self, inputs): + """Return an existing manager, or construct a new InfeedManager for inputs. + + _lookup_infeed_manager will return an existing InfeedManager if one has been + previously assigned for this model and input. If not, it will construct a + new TPUNumpyInfeedManager. + + Args: + inputs: A NumPy input to the model. + + Returns: + A `TPUInfeedManager` object to manage infeeds for this input. + """ + if inputs is None: + return None - infeed_manager = None for x, mgr in self.model._numpy_to_infeed_manager_list: if inputs[0] is x: - infeed_manager = mgr - break - if infeed_manager is None: - infeed_manager = TPUNumpyInfeedManager(self.model._strategy) + return mgr + return TPUNumpyInfeedManager(self.model._strategy) - # Strip sample weight from inputs - if (self.execution_mode == model_fn_lib.ModeKeys.TRAIN or - self.execution_mode == model_fn_lib.ModeKeys.EVAL): - input_tensors = self.model._feed_inputs + self.model._feed_targets - inputs = inputs[:len(input_tensors)] - else: - input_tensors = self.model._feed_inputs + def _tpu_model_ops_for_input_specs(self, input_specs, infeed_manager): + """Looks up the corresponding `TPUModelOp` for a given `input_specs`. - infeed_instance = infeed_manager.make_infeed_instance(inputs) - del inputs # To avoid accident usage. - input_specs = infeed_instance.make_input_specs(input_tensors) + It instantiates a new copy of the model for each unique input shape. + + Args: + input_specs: The specification of the inputs to train on. + infeed_manager: The infeed manager responsible for feeding in data. + + Returns: + A `TPUModelOp` instance that can be used to execute a step of the model. + """ + if input_specs is None or infeed_manager is None: + # Note: this condition is possible during the prologue or epilogue of the + # pipelined loop. + return None # XLA requires every operation in the graph has a fixed shape. To # handle varying batch sizes we recompile a new sub-graph for each # unique input shape. shape_key = tuple([tuple(spec.shape.as_list()) for spec in input_specs]) - if shape_key not in self._compilation_cache: with self.model.tpu_session(): logging.info('New input shapes; (re-)compiling: mode=%s, %s', @@ -885,19 +918,42 @@ class TPUFunction(object): self._compilation_cache[shape_key] = new_tpu_model_ops self._test_model_compiles(new_tpu_model_ops) - # Initialize our TPU weights on the first compile. - self.model._initialize_weights(self._cloned_model) - tpu_model_ops = self._compilation_cache[shape_key] + return self._compilation_cache[shape_key] - infeed_dict = infeed_instance.make_feed_dict(tpu_model_ops) + def _construct_input_tensors_and_inputs(self, inputs): + """Returns input tensors and numpy array inputs corresponding to `inputs`. - with self.model.tpu_session() as session: - _, _, outfeed_outputs = session.run([ - tpu_model_ops.infeed_op, tpu_model_ops.execute_op, - tpu_model_ops.outfeed_op - ], infeed_dict) + Args: + inputs: NumPy inputs. + + Returns: + A tuple of `input_tensors`, and `inputs`. + """ + if inputs is None: + # Note: this condition is possible during the prologue or epilogue of the + # pipelined loop. + return None, None + # Strip sample weight from inputs + if (self.execution_mode == model_fn_lib.ModeKeys.TRAIN or + self.execution_mode == model_fn_lib.ModeKeys.EVAL): + input_tensors = self.model._feed_inputs + self.model._feed_targets + inputs = inputs[:len(input_tensors)] + return input_tensors, inputs + else: + input_tensors = self.model._feed_inputs + return input_tensors, inputs + + def _process_outputs(self, outfeed_outputs): + """Processes the outputs of a model function execution. - # TODO(xiejw): Decide how to reduce outputs, or just discard all but first. + Args: + outfeed_outputs: The sharded outputs of the TPU computation. + + Returns: + The aggregated outputs of the TPU computation to be used in the rest of + the model execution. + """ + # TODO(xiejw): Decide how to reduce outputs, or discard all but first. if self.execution_mode == model_fn_lib.ModeKeys.PREDICT: outputs = [[]] * len(self._outfeed_spec) outputs_per_replica = len(self._outfeed_spec) @@ -910,7 +966,139 @@ class TPUFunction(object): return [np.concatenate(group) for group in outputs] else: - return outfeed_outputs[:len(outfeed_outputs) // self._strategy.num_towers] + return outfeed_outputs[:len(outfeed_outputs) // + self._strategy.num_towers] + + def __call__(self, inputs): + """__call__ executes the function on the computational hardware. + + It handles executing infeed, and preprocessing in addition to executing the + model on the TPU hardware. + + Note: `__call__` has a sibling method `pipeline_run` which performs the same + operations, but with software pipelining. + + Args: + inputs: The inputs to use to train. + + Returns: + The output of the computation for the given mode it is executed in. + + Raises: + RuntimeError: If there is an inappropriate use of the function. + """ + assert isinstance(inputs, list) + + infeed_manager = self._lookup_infeed_manager(inputs) + input_tensors, inputs = self._construct_input_tensors_and_inputs(inputs) + infeed_instance = infeed_manager.make_infeed_instance(inputs) + del inputs # To avoid accident usage. + input_specs = infeed_instance.make_input_specs(input_tensors) + tpu_model_ops = self._tpu_model_ops_for_input_specs(input_specs, + infeed_manager) + infeed_dict = infeed_instance.make_feed_dict(tpu_model_ops) + + # Initialize our TPU weights on the first compile. + self.model._initialize_weights(self._cloned_model) + + with self.model.tpu_session() as session: + _, _, outfeed_outputs = session.run([ + tpu_model_ops.infeed_op, tpu_model_ops.execute_op, + tpu_model_ops.outfeed_op + ], infeed_dict) + return self._process_outputs(outfeed_outputs) + + def pipeline_run(self, cur_step_inputs, next_step_inputs): + """pipeline_run executes the function on the computational hardware. + + pipeline_run performs the same computation as __call__, however it runs the + infeed in a software pipelined fashion compared to the on-device execution. + + Note: it is the responsibility of the caller to call `pipeline_run` in the + following sequence: + - Once with `cur_step_inputs=None` and `next_step_inputs=list(...)` + - `n` times with `cur_step_inputs` and `next_step_inputs` as `list`s + - Once with `cur_step_inputs=list(...)` and `next_step_inputs=None` + Additionally, it is the responsibility of the caller to pass + `next_step_inputs` as `cur_step_inputs` on the next invocation of + `pipeline_run`. + + Args: + cur_step_inputs: The current step's inputs. + next_step_inputs: The next step's inputs. + + Returns: + The output of the computation for the given mode it is executed in. + + Raises: + RuntimeError: If there is an inappropriate use of the function. + """ + # Software pipelined case. + next_step_infeed_manager = self._lookup_infeed_manager(next_step_inputs) + cur_step_infeed_manager = self._lookup_infeed_manager(cur_step_inputs) + + if (next_step_infeed_manager is not None + and cur_step_infeed_manager is not None): + assert type(next_step_infeed_manager) is type(cur_step_infeed_manager) + + next_input_tensors, next_step_inputs = ( + self._construct_input_tensors_and_inputs(next_step_inputs)) + cur_input_tensors, cur_step_inputs = ( + self._construct_input_tensors_and_inputs(cur_step_inputs)) + + cur_infeed_instance = None + if cur_step_infeed_manager: + cur_infeed_instance = cur_step_infeed_manager.make_infeed_instance( + cur_step_inputs) + next_infeed_instance = None + if next_step_infeed_manager: + next_infeed_instance = next_step_infeed_manager.make_infeed_instance( + next_step_inputs) + + del cur_step_inputs # Avoid accidental re-use. + del next_step_inputs # Avoid accidental re-use. + + cur_tpu_model_ops = None + next_tpu_model_ops = None + infeed_dict = None + + if cur_infeed_instance and cur_input_tensors and cur_step_infeed_manager: + cur_input_specs = cur_infeed_instance.make_input_specs( + cur_input_tensors) + cur_tpu_model_ops = self._tpu_model_ops_for_input_specs( + cur_input_specs, cur_step_infeed_manager) + + if (next_infeed_instance + and next_input_tensors + and next_step_infeed_manager): + next_input_specs = next_infeed_instance.make_input_specs( + next_input_tensors) + next_tpu_model_ops = self._tpu_model_ops_for_input_specs( + next_input_specs, next_step_infeed_manager) + infeed_dict = next_infeed_instance.make_feed_dict(next_tpu_model_ops) + + # Initialize our TPU weights on the first compile. + self.model._initialize_weights(self._cloned_model) + + if next_tpu_model_ops and cur_tpu_model_ops: + with self.model.tpu_session() as session: + _, _, outfeed_outputs = session.run([ + next_tpu_model_ops.infeed_op, cur_tpu_model_ops.execute_op, + cur_tpu_model_ops.outfeed_op + ], infeed_dict) + return self._process_outputs(outfeed_outputs) + if cur_tpu_model_ops: + with self.model.tpu_session() as session: + _, outfeed_outputs = session.run([ + cur_tpu_model_ops.execute_op, cur_tpu_model_ops.outfeed_op]) + return self._process_outputs(outfeed_outputs) + if next_tpu_model_ops: + with self.model.tpu_session() as session: + session.run(next_tpu_model_ops.infeed_op, infeed_dict) + return None + raise RuntimeError('Internal error: both current & next tpu_model_ops ' + 'were None') + class KerasTPUModel(models.Model): @@ -940,7 +1128,6 @@ class KerasTPUModel(models.Model): self._tpu_weights_initialized = False self._session = tpu_session(cluster_resolver) - self._graph = self._session.graph # If the input CPU model has already been compiled, compile our TPU model # immediately. @@ -1003,6 +1190,10 @@ class KerasTPUModel(models.Model): steps_per_epoch=None, validation_steps=None, **kwargs): + if context.executing_eagerly(): + raise EnvironmentError('KerasTPUModel currently does not support eager ' + 'mode.') + assert not self._numpy_to_infeed_manager_list # Ensure empty. infeed_managers = [] # Managers to clean up at the end of the fit call. @@ -1015,7 +1206,8 @@ class KerasTPUModel(models.Model): 'https://github.com/tensorflow/tpu/tree/master/models/experimental' '/keras') if callable(x): - with self.tpu_session() as sess: + with self.tpu_session() as sess,\ + ops.device('/job:%s/device:CPU:0' % self._strategy.worker_name): dataset = x() if steps_per_epoch is None: raise ValueError('When using tf.data as input to a model, you ' @@ -1054,7 +1246,28 @@ class KerasTPUModel(models.Model): self._numpy_to_infeed_manager_list = infeed_managers try: - return super(KerasTPUModel, self).fit( + if not kwargs.get('_pipeline', True): + logging.info( + 'Running non-pipelined training loop (`_pipeline=%s`).', + kwargs['_pipeline']) + kwargs.pop('_pipeline') + return super(KerasTPUModel, self).fit( + x, + y, + batch_size, + epochs, + verbose, + callbacks, + validation_split, + validation_data, + shuffle, + class_weight, + sample_weight, + initial_epoch, + steps_per_epoch, + validation_steps, + **kwargs) + return self._pipeline_fit( x, y, batch_size, @@ -1119,6 +1332,411 @@ class KerasTPUModel(models.Model): finally: self._numpy_to_infeed_manager_list = [] + def _pipeline_fit(self, + x, + y, + batch_size, + epochs, + verbose, + callbacks, + validation_split, + validation_data, + shuffle, + class_weight, + sample_weight, + initial_epoch, + steps_per_epoch, + validation_steps, + **kwargs): + # Similar to super.fit(...), but modified to support software pipelining. + + # Backwards compatibility + if batch_size is None and steps_per_epoch is None: + batch_size = 32 + # Legacy support + if 'nb_epoch' in kwargs: + logging.warning('The `nb_epoch` argument in `fit` has been renamed ' + '`epochs`.') + epochs = kwargs.pop('nb_epoch') + if kwargs: + raise TypeError('Unrecognized keyword arguments: ' + str(kwargs)) + + # Validate and standardize user data + x, y, sample_weights = self._standardize_user_data( + x, + y, + sample_weight=sample_weight, + class_weight=class_weight, + batch_size=batch_size, + check_steps=True, + steps_name='steps_per_epoch', + steps=steps_per_epoch, + validation_split=validation_split) + + # Prepare validation data + val_x, val_y, val_sample_weights = self._prepare_validation_data( + validation_data, + validation_split, + validation_steps, + x, + y, + sample_weights, + batch_size) + self._pipeline_fit_loop( + x, + y, + sample_weights=sample_weights, + batch_size=batch_size, + epochs=epochs, + verbose=verbose, + callbacks=callbacks, + val_inputs=val_x, + val_targets=val_y, + val_sample_weights=val_sample_weights, + shuffle=shuffle, + initial_epoch=initial_epoch, + steps_per_epoch=steps_per_epoch, + validation_steps=validation_steps) + + def _pipeline_fit_loop(self, + inputs, + targets, + sample_weights, + batch_size, + epochs, + verbose, + callbacks, + val_inputs, + val_targets, + val_sample_weights, + shuffle, + initial_epoch, + steps_per_epoch, + validation_steps): + self._make_train_function() + sample_weights = sample_weights or [] + val_sample_weights = val_sample_weights or [] + if self.uses_learning_phase and not isinstance(K.learning_phase(), int): + ins = inputs + targets + sample_weights + [1] + else: + ins = inputs + targets + sample_weights + + do_validation = False + if val_inputs: + do_validation = True + if (steps_per_epoch is None and verbose and inputs and + hasattr(inputs[0], 'shape') and hasattr(val_inputs[0], 'shape')): + print('Train on %d samples, validate on %d samples' % + (inputs[0].shape[0], val_inputs[0].shape[0])) + + if validation_steps: + do_validation = True + if steps_per_epoch is None: + raise ValueError('Can only use `validation_steps` when doing step-wise ' + 'training, i.e. `steps_per_epoch` must be set.') + + num_training_samples = training_utils.check_num_samples( + ins, batch_size, steps_per_epoch, 'steps_per_epoch') + count_mode = 'steps' if steps_per_epoch else 'samples' + callbacks = cbks.configure_callbacks( + callbacks, + self, + do_validation=do_validation, + val_inputs=val_inputs, + val_targets=val_targets, + val_sample_weights=val_sample_weights, + batch_size=batch_size, + epochs=epochs, + steps_per_epoch=steps_per_epoch, + samples=num_training_samples, + validation_steps=validation_steps, + verbose=verbose, + count_mode=count_mode) + + if num_training_samples is not None: + index_array = np.arange(num_training_samples) + + # To prevent a slowdown, we find beforehand the arrays that need conversion. + feed = self._feed_inputs + self._feed_targets + self._feed_sample_weights + indices_for_conversion_to_dense = [] + for i in range(len(feed)): + if issparse is not None and issparse(ins[i]) and not K.is_sparse(feed[i]): + indices_for_conversion_to_dense.append(i) + + callbacks.on_train_begin() + for epoch in range(initial_epoch, epochs): + # Reset stateful metrics + for m in self.stateful_metric_functions: + m.reset_states() + # Update callbacks + callbacks.on_epoch_begin(epoch) + epoch_logs = {} + if steps_per_epoch is not None: + # Step-wise fit loop. + self._pipeline_fit_loop_step_wise( + ins=ins, + callbacks=callbacks, + steps_per_epoch=steps_per_epoch, + epochs=epochs, + do_validation=do_validation, + val_inputs=val_inputs, + val_targets=val_targets, + val_sample_weights=val_sample_weights, + validation_steps=validation_steps, + epoch_logs=epoch_logs) + else: + # Sample-wise fit loop. + self._pipeline_fit_loop_sample_wise( + ins=ins, + callbacks=callbacks, + index_array=index_array, + shuffle=shuffle, + batch_size=batch_size, + num_training_samples=num_training_samples, + indices_for_conversion_to_dense=indices_for_conversion_to_dense, + do_validation=do_validation, + val_inputs=val_inputs, + val_targets=val_targets, + val_sample_weights=val_sample_weights, + validation_steps=validation_steps, + epoch_logs=epoch_logs) + + callbacks.on_epoch_end(epoch, epoch_logs) + if callbacks.model.stop_training: + break + callbacks.on_train_end() + return self.history + + def _pipeline_fit_loop_sample_wise(self, + ins, + callbacks, + index_array, + shuffle, + batch_size, + num_training_samples, + indices_for_conversion_to_dense, + do_validation, + val_inputs, + val_targets, + val_sample_weights, + validation_steps, + epoch_logs): + f = self.train_function + if shuffle == 'batch': + index_array = training_utils.batch_shuffle(index_array, batch_size) + elif shuffle: + np.random.shuffle(index_array) + batches = make_batches(num_training_samples, batch_size) + + ins_last_batch = None + last_batch_logs = None + batch_index = 0 + + for batch_index, (batch_start, batch_end) in enumerate(batches): + batch_ids = index_array[batch_start:batch_end] + try: + if isinstance(ins[-1], int): + # Do not slice the training phase flag. + ins_batch = slice_arrays(ins[:-1], batch_ids) + [ins[-1]] + else: + ins_batch = slice_arrays(ins, batch_ids) + except TypeError: + raise TypeError('TypeError while preparing batch. If using HDF5 ' + 'input data, pass shuffle="batch".') + + # Pipeline batch logs + next_batch_logs = {} + next_batch_logs['batch'] = batch_index + next_batch_logs['size'] = len(batch_ids) + if batch_index > 0: + # Callbacks operate one step behind in software pipeline. + callbacks.on_batch_begin(batch_index - 1, last_batch_logs) + for i in indices_for_conversion_to_dense: + ins_batch[i] = ins_batch[i].toarray() + + outs = f.pipeline_run(cur_step_inputs=ins_last_batch, + next_step_inputs=ins_batch) + ins_last_batch = ins_batch + + if batch_index == 0: + assert outs is None + else: + if not isinstance(outs, list): + outs = [outs] + for l, o in zip(self.metrics_names, outs): + last_batch_logs[l] = o # pylint: disable=unsupported-assignment-operation + callbacks.on_batch_end(batch_index - 1, last_batch_logs) + if callbacks.model.stop_training: + return + last_batch_logs = next_batch_logs + + # Final batch + callbacks.on_batch_begin(batch_index, last_batch_logs) + outs = f.pipeline_run(cur_step_inputs=ins_last_batch, next_step_inputs=None) + if not isinstance(outs, list): + outs = [outs] + for l, o in zip(self.metrics_names, outs): + last_batch_logs[l] = o + callbacks.on_batch_end(batch_index, last_batch_logs) + if callbacks.model.stop_training: + return + + if do_validation: + val_outs = training_arrays.test_loop( + self, + val_inputs, + val_targets, + sample_weights=val_sample_weights, + batch_size=batch_size, + steps=validation_steps, + verbose=0) + if not isinstance(val_outs, list): + val_outs = [val_outs] + # Same labels assumed. + for l, o in zip(self.metrics_names, val_outs): + epoch_logs['val_' + l] = o + + def _pipeline_fit_loop_step_wise(self, + ins, + callbacks, + steps_per_epoch, + epochs, + do_validation, + val_inputs, + val_targets, + val_sample_weights, + validation_steps, + epoch_logs): + f = self.train_function + + # Loop prologue + try: + outs = f.pipeline_run(cur_step_inputs=None, next_step_inputs=ins) + assert outs is None # Function shouldn't return anything! + except errors.OutOfRangeError: + logging.warning('Your dataset iterator ran out of data on the first step ' + 'of the epoch, preventing further training. Check to ' + 'make sure your paths are correct and you have ' + 'permissions to read the files. Skipping validation') + + for step_index in range(steps_per_epoch - 1): + batch_logs = {'batch': step_index, 'size': 1} + callbacks.on_batch_begin(step_index, batch_logs) + try: + if step_index < steps_per_epoch - 1: + next_step_inputs = ins + else: + next_step_inputs = None + outs = f.pipeline_run(cur_step_inputs=ins, + next_step_inputs=next_step_inputs) + except errors.OutOfRangeError: + logging.warning('Your dataset iterator ran out of data; ' + 'interrupting training. Make sure that your ' + 'dataset can generate at least `steps_per_batch * ' + 'epochs` batches (in this case, %d batches). You ' + 'may need to use the repeat() function when ' + 'building your dataset.' % steps_per_epoch * epochs) + break + + if not isinstance(outs, list): + outs = [outs] + for l, o in zip(self.metrics_names, outs): + batch_logs[l] = o + + callbacks.on_batch_end(step_index, batch_logs) + if callbacks.model.stop_training: + break + + if do_validation: + val_outs = training_arrays.test_loop(self, + val_inputs, + val_targets, + sample_weights=val_sample_weights, + steps=validation_steps, + verbose=0) + if not isinstance(val_outs, list): + val_outs = [val_outs] + # Same labels assumed. + for l, o in zip(self.metrics_names, val_outs): + epoch_logs['val_' + l] = o + + def _prepare_validation_data(self, + validation_data, + validation_split, + validation_steps, + x, + y, + sample_weights, + batch_size): + """Prepares the validation dataset. + + Args: + validation_data: The validation data (if provided) + validation_split: The validation split (if provided) + validation_steps: The validation steps (if provided) + x: The main training data x (if provided) + y: The main training data y (if provided) + sample_weights: The sample weights (if provided) + batch_size: The training batch size (if provided) + + Returns: + A 3-tuple of (val_x, val_y, val_sample_weights). + + Raises: + ValueError: If the provided arguments are not compatible with + `KerasTPUModel`. + """ + # Note: this is similar to a section of $tf/python/keras/engine/training.py + # It differns in that tf.data objects are not allowed to be passed directly. + # Additionally, it handles validating shapes & types appropriately for use + # in TPUs. + if validation_data: + if (isinstance(validation_data, iterator_ops.Iterator) or + isinstance(validation_data, iterator_ops.EagerIterator) or + isinstance(validation_data, dataset_ops.Dataset)): + raise ValueError('KerasTPUModel cannot handle a Dataset or Iterator ' + 'for validation_data. Please instead pass a function ' + 'that returns a `tf.data.Dataset`.') + if len(validation_data) == 2: + val_x, val_y = validation_data # pylint: disable=unpacking-non-sequence + val_sample_weight = None + elif len(validation_data) == 3: + val_x, val_y, val_sample_weight = validation_data # pylint: disable=unpacking-non-sequence + else: + raise ValueError('When passing a `validation_data` argument, it must ' + 'contain either 2 items (x_val, y_val), or 3 items ' + '(x_val, y_val, val_sample_weights). However we ' + 'received `validation_data=%s`' % validation_data) + val_x, val_y, val_sample_weights = self._standardize_user_data( + val_x, + val_y, + sample_weight=val_sample_weight, + batch_size=batch_size, + steps=validation_steps) + elif validation_split and 0. < validation_split < 1.: + if training_utils.has_symbolic_tensors(x): + raise ValueError('If your data is in the form of symbolic tensors, you ' + 'cannot use `validation_split`.') + if hasattr(x[0], 'shape'): + split_at = int(x[0].shape[0] * (1. - validation_split)) + else: + split_at = int(len(x[0]) * (1. - validation_split)) + + x, val_x = (slice_arrays(x, 0, split_at), slice_arrays(x, split_at)) + y, val_y = (slice_arrays(y, 0, split_at), slice_arrays(y, split_at)) + sample_weights, val_sample_weights = (slice_arrays( + sample_weights, 0, split_at), slice_arrays(sample_weights, split_at)) + elif validation_steps: + val_x = [] + val_y = [] + val_sample_weights = [] + else: + val_x = None + val_y = None + val_sample_weights = None + + return val_x, val_y, val_sample_weights + def _make_train_function(self): if not self.train_function: self.train_function = TPUFunction( @@ -1189,7 +1807,7 @@ class KerasTPUModel(models.Model): @contextlib.contextmanager def tpu_session(self): """Yields a TPU session and sets it as the default Keras session.""" - with self._graph.as_default(): + with self._session.graph.as_default(): default_session = K.get_session() # N.B. We have to call `K.set_session()` AND set our session as the # TF default. `K.get_session()` surprisingly does not return the value diff --git a/tensorflow/contrib/tpu/python/tpu/keras_tpu_variables.py b/tensorflow/contrib/tpu/python/tpu/keras_tpu_variables.py new file mode 100644 index 0000000000..a423aeace7 --- /dev/null +++ b/tensorflow/contrib/tpu/python/tpu/keras_tpu_variables.py @@ -0,0 +1,289 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Distributed variable implementation for TPUs. + +N.B. This is an experimental feature that should only be used for Keras support. + +It is unsupported and will be removed in favor of Distribution Strategy soon. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import contextlib + +from tensorflow.python.client import session as session_lib +from tensorflow.python.framework import ops +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import gen_resource_variable_ops +from tensorflow.python.ops import variable_scope +from tensorflow.python.platform import tf_logging as logging + + +@contextlib.contextmanager +def _handle_graph(handle): + with handle.graph.as_default(): + yield + + +def _enclosing_tpu_context(): + # pylint: disable=protected-access + context = ops.get_default_graph()._get_control_flow_context() + # pylint: enable=protected-access + while context is not None and not isinstance( + context, control_flow_ops.XLAControlFlowContext): + context = context.outer_context + return context + + +class ReplicatedVariable(object): + """A replicated variable for use on TPUs. + + When accessed inside a tpu.replicate() context, this variable acts as if it + is a single variable whose handle is a replicated input to the computation. + + Outside a tpu.replicate() context currently this object has pretty murky + semantics, especially with respect to things such as + * initialization + * colocation. + """ + + def __init__(self, name, variables): + self._name = name + self._primary_var = variables[0] + self._vars = variables + self._cached_value = None + self._dtype = variables[0].dtype + + @property + def handle(self): + tpu_context = _enclosing_tpu_context() + if tpu_context is None: + return self._primary_var.handle + + return tpu_context.get_replicated_var_handle(self) + + @contextlib.contextmanager + def _assign_dependencies(self): + """Makes assignments depend on the cached value, if any. + + This prevents undefined behavior with reads not ordered wrt writes. + + Yields: + None. + """ + if self._cached_value is not None: + with ops.control_dependencies([self._cached_value]): + yield + else: + yield + + @property + def initializer(self): + return control_flow_ops.group([v.initializer for v in self._vars]) + + @property + def graph(self): + return self._primary_var.graph + + @property + def _shared_name(self): + return self._common_name + + @property + def _unique_id(self): + return self._primary_var._unique_id # pylint: disable=protected-access + + @property + def name(self): + return self._name + + @property + def dtype(self): + return self._primary_var.dtype + + @property + def shape(self): + return self._primary_var.shape + + def get_shape(self): + return self._primary_var.get_shape() + + def to_proto(self, export_scope=None): + return self._primary_var.to_proto(export_scope=export_scope) + + @property + def constraint(self): + return None + + @property + def op(self): + return self.get().op + + @property + def is_tensor_like(self): + return True + + def _read_variable_op(self): + if _enclosing_tpu_context() is None: + return self._primary_var.read_value() + v = gen_resource_variable_ops.read_variable_op(self.handle, self._dtype) + return v + + def read_value(self): + return self._read_variable_op() + + def is_initialized(self, name=None): + return self._vars[0].is_initialized(name=name) + + def __getitem__(self, *args): + return self.read_value().__getitem__(*args) + + def assign(self, value, use_locking=None, name=None, read_value=False): + """Assign `value` to all replicas. + + Outside of the tpu.rewrite context, assign explicitly to all replicas. + Inside of the tpu.rewrite context, assigns to the local replica. + + Arguments: + value: Tensor to assign + use_locking: ignored + name: ignored + read_value: return the value from the assignment + Returns: + Assignment operation, or new value of the variable if `read_value` is True + """ + del use_locking + if _enclosing_tpu_context() is None: + assign_ops = [] + with self._assign_dependencies(): + for var in self._vars: + assign_ops.append(var.assign(value, use_locking=None, name=name)) + + if read_value: + with ops.control_dependencies(assign_ops): + return self.read_value() + else: + return control_flow_ops.group(assign_ops) + + with _handle_graph(self.handle), self._assign_dependencies(): + value_tensor = ops.convert_to_tensor(value, dtype=self.dtype) + assign_op = gen_resource_variable_ops.assign_variable_op( + self.handle, value_tensor, name=name) + if read_value: + return self._read_variable_op() + return assign_op + + def assign_add(self, delta, use_locking=None, name=None, read_value=True): + del use_locking + with _handle_graph(self.handle), self._assign_dependencies(): + assign_add_op = gen_resource_variable_ops.assign_add_variable_op( + self.handle, + ops.convert_to_tensor(delta, dtype=self.dtype), + name=name) + if read_value: + return self._read_variable_op() + return assign_add_op + + def assign_sub(self, delta, use_locking=None, name=None, read_value=True): + del use_locking + with _handle_graph(self.handle), self._assign_dependencies(): + assign_sub_op = gen_resource_variable_ops.assign_sub_variable_op( + self.handle, + ops.convert_to_tensor(delta, dtype=self.dtype), + name=name) + if read_value: + return self._read_variable_op() + return assign_sub_op + + def get(self): + return self._primary_var + + def _should_act_as_resource_variable(self): + """Pass resource_variable_ops.is_resource_variable check.""" + pass + + def _dense_var_to_tensor(self, dtype=None, name=None, as_ref=False): + """Converts a variable to a tensor.""" + # pylint: disable=protected-access + if _enclosing_tpu_context() is None: + return self._primary_var._dense_var_to_tensor(dtype, name, as_ref) + # pylint: enable=protected-access + if dtype is not None and dtype != self.dtype: + return NotImplemented + if as_ref: + return self.handle + else: + return self.read_value() + + +# Register a conversion function which reads the value of the variable, +# allowing instances of the class to be used as tensors. +def _tensor_conversion(var, dtype=None, name=None, as_ref=False): + return var._dense_var_to_tensor(dtype=dtype, name=name, as_ref=as_ref) # pylint: disable=protected-access + + +def replicated_fetch_function(var): + # pylint: disable=protected-access + return ([var._dense_var_to_tensor()], lambda v: v[0]) + # pylint: enable=protected-access + + +ops.register_tensor_conversion_function(ReplicatedVariable, _tensor_conversion) +ops.register_dense_tensor_like_type(ReplicatedVariable) +session_lib.register_session_run_conversion_functions( + ReplicatedVariable, replicated_fetch_function) + + +def replicated_scope(num_replicas): + """Variable scope for constructing replicated variables.""" + + def _replicated_variable_getter(getter, name, *args, **kwargs): + """Getter that constructs replicated variables.""" + collections = kwargs.pop("collections", None) + if collections is None: + collections = [ops.GraphKeys.GLOBAL_VARIABLES] + kwargs["collections"] = [] + + logging.info("Constructing replicated variable %s", name) + variables = [] + index = {} + for i in range(num_replicas): + replica_name = "{}/{}".format(name, i) + with ops.device("device:TPU:{}".format(i)): + v = getter(*args, name=replica_name, **kwargs) + variables.append(v) + index[i] = v + result = ReplicatedVariable(name, variables) + + g = ops.get_default_graph() + # If "trainable" is True, next_creator() will add the member variables + # to the TRAINABLE_VARIABLES collection, so we manually remove + # them and replace with the MirroredVariable. We can't set + # "trainable" to False for next_creator() since that causes functions + # like implicit_gradients to skip those variables. + if kwargs.get("trainable", True): + collections.append(ops.GraphKeys.TRAINABLE_VARIABLES) + l = g.get_collection_ref(ops.GraphKeys.TRAINABLE_VARIABLES) + for v in index.values(): + if v in l: + l.remove(v) + g.add_to_collections(collections, result) + + return result + + return variable_scope.variable_scope( + "", custom_getter=_replicated_variable_getter) diff --git a/tensorflow/core/BUILD b/tensorflow/core/BUILD index 07ee21c0ae..5c314f359c 100644 --- a/tensorflow/core/BUILD +++ b/tensorflow/core/BUILD @@ -873,7 +873,6 @@ tf_cuda_library( "util/sparse/sparse_tensor.h", "util/stat_summarizer.h", "util/stat_summarizer_options.h", - "util/status_util.h", "util/stream_executor_util.h", "util/strided_slice_op.h", "util/tensor_format.h", @@ -940,15 +939,6 @@ cc_library( ) cc_library( - name = "status_util", - hdrs = ["util/status_util.h"], - deps = [ - ":graph", - ":lib", - ], -) - -cc_library( name = "reader_base", srcs = ["framework/reader_base.cc"], hdrs = ["framework/reader_base.h"], @@ -3560,7 +3550,6 @@ tf_cc_tests( "util/semver_test.cc", "util/sparse/sparse_tensor_test.cc", "util/stat_summarizer_test.cc", - "util/status_util_test.cc", "util/tensor_format_test.cc", "util/tensor_slice_reader_test.cc", "util/tensor_slice_set_test.cc", @@ -3585,7 +3574,6 @@ tf_cc_tests( ":ops", ":protos_all_cc", ":protos_test_cc", - ":status_util", ":test", ":test_main", ":testlib", @@ -4078,6 +4066,7 @@ tf_cuda_cc_test( ":testlib", "//third_party/eigen3", "//tensorflow/cc:cc_ops", + "//tensorflow/core/kernels:collective_ops", "//tensorflow/core/kernels:control_flow_ops", "//tensorflow/core/kernels:cwise_op", "//tensorflow/core/kernels:dense_update_ops", @@ -4119,6 +4108,7 @@ tf_cc_test( "//tensorflow/cc:cc_ops", # Link with support for TensorFlow Debugger (tfdbg). "//tensorflow/core/debug", + "//tensorflow/core/kernels:collective_ops", "//tensorflow/core/kernels:control_flow_ops", "//tensorflow/core/kernels:cwise_op", "//tensorflow/core/kernels:dense_update_ops", diff --git a/tensorflow/core/api_def/base_api/api_def_StridedSlice.pbtxt b/tensorflow/core/api_def/base_api/api_def_StridedSlice.pbtxt index 8d6fc04847..9a89a4e8e7 100644 --- a/tensorflow/core/api_def/base_api/api_def_StridedSlice.pbtxt +++ b/tensorflow/core/api_def/base_api/api_def_StridedSlice.pbtxt @@ -32,7 +32,7 @@ END description: <<END a bitmask where a bit i being 1 means to ignore the begin value and instead use the largest interval possible. At runtime -begin[i] will be replaced with `[0, n-1) if `stride[i] > 0` or +begin[i] will be replaced with `[0, n-1)` if `stride[i] > 0` or `[-1, n-1]` if `stride[i] < 0` END } diff --git a/tensorflow/core/common_runtime/direct_session.cc b/tensorflow/core/common_runtime/direct_session.cc index bf1d78ec65..eb388202fa 100644 --- a/tensorflow/core/common_runtime/direct_session.cc +++ b/tensorflow/core/common_runtime/direct_session.cc @@ -451,8 +451,22 @@ Status DirectSession::RunInternal(int64 step_id, const RunOptions& run_options, RunState run_state(step_id, &devices_); run_state.rendez = new IntraProcessRendezvous(device_mgr_.get()); #ifndef __ANDROID__ - // Set up for collectives if the RunOption declares a key. - if (run_options.experimental().collective_graph_key() > 0) { + // Set up for collectives if ExecutorsAndKeys declares a key. + if (executors_and_keys->collective_graph_key != + BuildGraphOptions::kNoCollectiveGraphKey) { + if (run_options.experimental().collective_graph_key() != + BuildGraphOptions::kNoCollectiveGraphKey) { + // If a collective_graph_key was specified in run_options, ensure that it + // matches what came out of GraphExecutionState::BuildGraph(). + if (run_options.experimental().collective_graph_key() != + executors_and_keys->collective_graph_key) { + return errors::Internal( + "collective_graph_key in RunOptions ", + run_options.experimental().collective_graph_key(), + " should match collective_graph_key from optimized graph ", + executors_and_keys->collective_graph_key); + } + } if (!collective_executor_mgr_) { std::unique_ptr<DeviceResolverInterface> drl( new DeviceResolverLocal(device_mgr_.get())); @@ -678,10 +692,16 @@ Status DirectSession::Run(const RunOptions& run_options, // Check if we already have an executor for these arguments. ExecutorsAndKeys* executors_and_keys; RunStateArgs run_state_args(run_options.debug_options()); + run_state_args.collective_graph_key = + run_options.experimental().collective_graph_key(); TF_RETURN_IF_ERROR(GetOrCreateExecutors(input_tensor_names, output_names, target_nodes, &executors_and_keys, &run_state_args)); + { + mutex_lock l(collective_graph_key_lock_); + collective_graph_key_ = executors_and_keys->collective_graph_key; + } // Configure a call frame for the step, which we use to feed and // fetch values to and from the executors. @@ -1116,6 +1136,8 @@ Status DirectSession::CreateExecutors( BuildGraphOptions options; options.callable_options = callable_options; options.use_function_convention = !run_state_args->is_partial_run; + options.collective_graph_key = + callable_options.run_options().experimental().collective_graph_key(); std::unique_ptr<FunctionInfo> func_info(new FunctionInfo); std::unique_ptr<ExecutorsAndKeys> ek(new ExecutorsAndKeys); @@ -1123,9 +1145,9 @@ Status DirectSession::CreateExecutors( ek->callable_options = callable_options; std::unordered_map<string, std::unique_ptr<Graph>> graphs; - TF_RETURN_IF_ERROR(CreateGraphs(options, &graphs, &func_info->flib_def, - run_state_args, &ek->input_types, - &ek->output_types)); + TF_RETURN_IF_ERROR(CreateGraphs( + options, &graphs, &func_info->flib_def, run_state_args, &ek->input_types, + &ek->output_types, &ek->collective_graph_key)); if (run_state_args->is_partial_run) { ek->graph = std::move(run_state_args->graph); @@ -1353,6 +1375,9 @@ Status DirectSession::GetOrCreateExecutors( } *callable_options.mutable_run_options()->mutable_debug_options() = run_state_args->debug_options; + callable_options.mutable_run_options() + ->mutable_experimental() + ->set_collective_graph_key(run_state_args->collective_graph_key); std::unique_ptr<ExecutorsAndKeys> ek; std::unique_ptr<FunctionInfo> func_info; TF_RETURN_IF_ERROR( @@ -1379,7 +1404,7 @@ Status DirectSession::CreateGraphs( std::unordered_map<string, std::unique_ptr<Graph>>* outputs, std::unique_ptr<FunctionLibraryDefinition>* flib_def, RunStateArgs* run_state_args, DataTypeVector* input_types, - DataTypeVector* output_types) { + DataTypeVector* output_types, int64* collective_graph_key) { mutex_lock l(graph_def_lock_); std::unique_ptr<ClientGraph> client_graph; @@ -1403,6 +1428,7 @@ Status DirectSession::CreateGraphs( TF_RETURN_IF_ERROR( execution_state->BuildGraph(subgraph_options, &client_graph)); } + *collective_graph_key = client_graph->collective_graph_key; if (subgraph_options.callable_options.feed_size() != client_graph->feed_types.size()) { diff --git a/tensorflow/core/common_runtime/direct_session.h b/tensorflow/core/common_runtime/direct_session.h index 55a6fbce6d..c2cf3c7fd7 100644 --- a/tensorflow/core/common_runtime/direct_session.h +++ b/tensorflow/core/common_runtime/direct_session.h @@ -117,6 +117,9 @@ class DirectSession : public Session { ::tensorflow::Status ReleaseCallable(CallableHandle handle) override; private: + // For access to collective_graph_key_. + friend class DirectSessionCollectiveTest; + // We create one executor and its dependent library runtime for // every partition. struct PerPartitionExecutorsAndLib { @@ -150,6 +153,8 @@ class DirectSession : public Session { DataTypeVector output_types; CallableOptions callable_options; + + int64 collective_graph_key = BuildGraphOptions::kNoCollectiveGraphKey; }; // A FunctionInfo object is created for every unique set of feeds/fetches. @@ -203,6 +208,7 @@ class DirectSession : public Session { string handle; std::unique_ptr<Graph> graph; const DebugOptions& debug_options; + int64 collective_graph_key = BuildGraphOptions::kNoCollectiveGraphKey; }; // Initializes the base execution state given the 'graph', @@ -234,7 +240,7 @@ class DirectSession : public Session { std::unordered_map<string, std::unique_ptr<Graph>>* outputs, std::unique_ptr<FunctionLibraryDefinition>* flib_def, RunStateArgs* run_state_args, DataTypeVector* input_types, - DataTypeVector* output_types); + DataTypeVector* output_types, int64* collective_graph_key); ::tensorflow::Status RunInternal(int64 step_id, const RunOptions& run_options, CallFrameInterface* call_frame, @@ -391,6 +397,10 @@ class DirectSession : public Session { Executor::Args::NodeOutputsCallback node_outputs_callback_ = nullptr; + // For testing collective graph key generation. + mutex collective_graph_key_lock_; + int64 collective_graph_key_ GUARDED_BY(collective_graph_key_lock_) = -1; + TF_DISALLOW_COPY_AND_ASSIGN(DirectSession); // EXPERIMENTAL: debugger (tfdbg) related diff --git a/tensorflow/core/common_runtime/direct_session_test.cc b/tensorflow/core/common_runtime/direct_session_test.cc index 4b51b20bb1..3f2355e530 100644 --- a/tensorflow/core/common_runtime/direct_session_test.cc +++ b/tensorflow/core/common_runtime/direct_session_test.cc @@ -2218,4 +2218,121 @@ BENCHMARK(BM_FeedFetch)->Arg(1)->Arg(2)->Arg(5)->Arg(10); BENCHMARK(BM_FeedFetchCallable)->Arg(1)->Arg(2)->Arg(5)->Arg(10); } // namespace + +class DirectSessionCollectiveTest : public ::testing::Test { + public: + // Creates a graph with CollectiveOps inside functions and runs it. Returns + // the generated collective_graph_key. + Status RunGraphWithCollectiveFunctions(bool add_unused_function, + int64* collective_graph_key) { + GraphDef g = CreateGraph(add_unused_function); + const Tensor t1 = + test::AsTensor<float>({0.1, 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1}); + const Tensor t2 = + test::AsTensor<float>({0.3, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3}); + auto session = CreateSession(); + TF_RETURN_IF_ERROR(session->Create(g)); + std::vector<Tensor> outputs; + TF_RETURN_IF_ERROR( + session->Run({{"input1:0", t1}, {"input2:0", t2}}, {}, + {"collective_call1:0", "collective_call2:0"}, &outputs)); + DirectSession* direct_session = static_cast<DirectSession*>(session.get()); + { + mutex_lock l(direct_session->collective_graph_key_lock_); + *collective_graph_key = direct_session->collective_graph_key_; + } + return Status::OK(); + } + + private: + // Creates a function with name `function_name` and a single CollectiveReduce + // node with instance key set as `instance_key`. + FunctionDef CollectiveFunction(const string& function_name, + int instance_key) { + return FunctionDefHelper::Define( + // Function name + function_name, + // In def + {"arg:float"}, + // Out def + {"reduce:float"}, + // Attr def + {}, + // Node def + {{ + {"reduce"}, + "CollectiveReduce", + {"arg"}, + {{"group_size", 2}, + {"group_key", 1}, + {"instance_key", instance_key}, + {"subdiv_offsets", gtl::ArraySlice<int32>({0})}, + {"merge_op", "Add"}, + {"final_op", "Div"}, + {"T", DT_FLOAT}}, + }}); + } + + // Creates a GraphDef that adds two CollectiveFunctions, one each on CPU0 and + // CPU1, with instance_key 1, and appropriate placeholder inputs. If + // `add_unused_function` is true, adds another CollectiveFunction with + // instance_key 2 that is not invoked in the graph. + GraphDef CreateGraph(bool add_unused_function) { + GraphDef g; + FunctionDef collective_function = + CollectiveFunction("CollectiveFunction1", 1); + FunctionDefLibrary* lib = g.mutable_library(); + *lib->add_function() = collective_function; + if (add_unused_function) { + FunctionDef unused_function = + CollectiveFunction("CollectiveFunction2", 2); + *lib->add_function() = unused_function; + } + + // Inputs. + AttrValue dtype_attr; + SetAttrValue(DT_FLOAT, &dtype_attr); + NodeDef input1; + input1.set_name("input1"); + input1.set_op("Placeholder"); + input1.mutable_attr()->insert({"dtype", dtype_attr}); + NodeDef input2; + input2.set_name("input2"); + input2.set_op("Placeholder"); + input2.mutable_attr()->insert({"dtype", dtype_attr}); + + // CollectiveReduce on CPU0 with instance_key 1. + NodeDef collective_call1; + collective_call1.set_name("collective_call1"); + collective_call1.set_op("CollectiveFunction1"); + collective_call1.add_input("input1"); + collective_call1.set_device("/job:localhost/replica:0/task:0/device:CPU:0"); + // CollectiveReduce on CPU1 with instance_key 1. + NodeDef collective_call2; + collective_call2.set_name("collective_call2"); + collective_call2.set_op("CollectiveFunction1"); + collective_call2.add_input("input2"); + collective_call1.set_device("/job:localhost/replica:0/task:0/device:CPU:1"); + + *g.add_node() = input1; + *g.add_node() = input2; + *g.add_node() = collective_call1; + *g.add_node() = collective_call2; + + return g; + } +}; + +#ifndef GOOGLE_CUDA +// TODO(ayushd): enable this test for GPU builds. +TEST_F(DirectSessionCollectiveTest, + TestCollectiveGraphKeyUsesOnlyCalledFunctions) { + int64 key1; + TF_ASSERT_OK(RunGraphWithCollectiveFunctions(false, &key1)); + int64 key2; + TF_ASSERT_OK(RunGraphWithCollectiveFunctions(true, &key2)); + ASSERT_EQ(key1, key2); +} +#endif + } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/eager/context.cc b/tensorflow/core/common_runtime/eager/context.cc index 39a3b49cd1..879a794368 100644 --- a/tensorflow/core/common_runtime/eager/context.cc +++ b/tensorflow/core/common_runtime/eager/context.cc @@ -36,22 +36,34 @@ bool ReadBoolFromEnvVar(StringPiece env_var_name, bool default_val) { EagerContext::EagerContext(const SessionOptions& opts, ContextDevicePlacementPolicy default_policy, - bool async, std::unique_ptr<DeviceMgr> device_mgr, + bool async, + std::unique_ptr<const DeviceMgr> device_mgr, Rendezvous* rendezvous) + : EagerContext(opts, default_policy, async, device_mgr.release(), + /*device_mgr_owned*/ true, rendezvous) {} + +EagerContext::EagerContext(const SessionOptions& opts, + ContextDevicePlacementPolicy default_policy, + bool async, const DeviceMgr* device_mgr, + bool device_mgr_owned, Rendezvous* rendezvous) : policy_(default_policy), - local_device_manager_(std::move(device_mgr)), - local_unowned_device_manager_(nullptr), - devices_(local_device_manager_->ListDevices()), + devices_(device_mgr->ListDevices()), rendezvous_(rendezvous), thread_pool_(NewThreadPoolFromSessionOptions(opts)), pflr_(new ProcessFunctionLibraryRuntime( - local_device_manager_.get(), opts.env, TF_GRAPH_DEF_VERSION, - &func_lib_def_, {}, thread_pool_.get())), + device_mgr, opts.env, TF_GRAPH_DEF_VERSION, &func_lib_def_, {}, + thread_pool_.get())), log_device_placement_(opts.config.log_device_placement()), num_active_steps_(0), async_default_(async), env_(opts.env), use_send_tensor_rpc_(false) { + if (device_mgr_owned) { + local_device_manager_.reset(device_mgr); + local_unowned_device_manager_ = nullptr; + } else { + local_unowned_device_manager_ = device_mgr; + } InitDeviceMapAndAsync(); if (opts.config.inter_op_parallelism_threads() > 0) { runner_ = [this](std::function<void()> closure) { diff --git a/tensorflow/core/common_runtime/eager/context.h b/tensorflow/core/common_runtime/eager/context.h index 3c95ac590d..eb6eb0d55a 100644 --- a/tensorflow/core/common_runtime/eager/context.h +++ b/tensorflow/core/common_runtime/eager/context.h @@ -65,10 +65,17 @@ enum ContextDevicePlacementPolicy { class EagerContext { public: - explicit EagerContext(const SessionOptions& opts, - ContextDevicePlacementPolicy default_policy, bool async, - std::unique_ptr<DeviceMgr> device_mgr, - Rendezvous* rendezvous); + // TODO: remove this constructor once we migrate all callers to the next one. + EagerContext(const SessionOptions& opts, + ContextDevicePlacementPolicy default_policy, bool async, + std::unique_ptr<const DeviceMgr> device_mgr, + Rendezvous* rendezvous); + + EagerContext(const SessionOptions& opts, + ContextDevicePlacementPolicy default_policy, bool async, + const DeviceMgr* device_mgr, bool device_mgr_owned, + Rendezvous* rendezvous); + ~EagerContext(); // Returns the function library runtime for the given device. @@ -207,8 +214,8 @@ class EagerContext { thread_local_policies_ GUARDED_BY(policy_map_mu_); // Only one of the below is set. - std::unique_ptr<DeviceMgr> local_device_manager_; - DeviceMgr* local_unowned_device_manager_; + std::unique_ptr<const DeviceMgr> local_device_manager_; + const DeviceMgr* local_unowned_device_manager_; std::unique_ptr<DeviceMgr> remote_device_manager_; // Devices owned by device_manager diff --git a/tensorflow/core/common_runtime/executor.cc b/tensorflow/core/common_runtime/executor.cc index 3ef6d35182..84865397bc 100644 --- a/tensorflow/core/common_runtime/executor.cc +++ b/tensorflow/core/common_runtime/executor.cc @@ -1482,6 +1482,7 @@ void ExecutorState::RunAsync(Executor::DoneCallback done) { const Status fill_status = device->FillContextMap(graph, &device_context_map_); if (!fill_status.ok()) { + delete this; done(fill_status); return; } @@ -1492,6 +1493,7 @@ void ExecutorState::RunAsync(Executor::DoneCallback done) { ready.push_back(TaggedNode{n, root_frame_, 0, false}); } if (ready.empty()) { + delete this; done(Status::OK()); } else { num_outstanding_ops_ = ready.size(); diff --git a/tensorflow/core/common_runtime/graph_execution_state.cc b/tensorflow/core/common_runtime/graph_execution_state.cc index 346befc255..7f260b3139 100644 --- a/tensorflow/core/common_runtime/graph_execution_state.cc +++ b/tensorflow/core/common_runtime/graph_execution_state.cc @@ -16,6 +16,7 @@ limitations under the License. #include "tensorflow/core/common_runtime/graph_execution_state.h" #include <memory> +#include <set> #include <string> #include <unordered_set> #include <utility> @@ -727,12 +728,50 @@ Status GraphExecutionState::BuildGraph(const BuildGraphOptions& options, TF_RETURN_IF_ERROR(OptimizationPassRegistry::Global()->RunGrouping( OptimizationPassRegistry::POST_REWRITE_FOR_EXEC, optimization_options)); + int64 collective_graph_key = options.collective_graph_key; + if (collective_graph_key == BuildGraphOptions::kNoCollectiveGraphKey) { + // BuildGraphOptions does not specify a collective_graph_key. Check all + // nodes in the Graph and FunctionLibraryDefinition for collective ops and + // if found, initialize a collective_graph_key as a hash of the ordered set + // of instance keys. + std::set<int32> instance_key_set; + for (Node* node : optimized_graph->nodes()) { + if (node->IsCollective()) { + int32 instance_key; + TF_RETURN_IF_ERROR( + GetNodeAttr(node->attrs(), "instance_key", &instance_key)); + instance_key_set.emplace(instance_key); + } else { + const FunctionDef* fdef = optimized_flib->Find(node->def().op()); + if (fdef != nullptr) { + for (const NodeDef& ndef : fdef->node_def()) { + if (ndef.op() == "CollectiveReduce" || + ndef.op() == "CollectiveBcastSend" || + ndef.op() == "CollectiveBcastRecv") { + int32 instance_key; + TF_RETURN_IF_ERROR( + GetNodeAttr(ndef, "instance_key", &instance_key)); + instance_key_set.emplace(instance_key); + } + } + } + } + } + if (!instance_key_set.empty()) { + uint64 hash = 0x8774aa605c729c72ULL; + for (int32 instance_key : instance_key_set) { + hash = Hash64Combine(instance_key, hash); + } + collective_graph_key = hash; + } + } + // Copy the extracted graph in order to make its node ids dense, // since the local CostModel used to record its stats is sized by // the largest node id. std::unique_ptr<ClientGraph> dense_copy( new ClientGraph(std::move(optimized_flib), rewrite_metadata.feed_types, - rewrite_metadata.fetch_types)); + rewrite_metadata.fetch_types, collective_graph_key)); CopyGraph(*optimized_graph, &dense_copy->graph); // TODO(vrv): We should check invariants of the graph here. diff --git a/tensorflow/core/common_runtime/graph_execution_state.h b/tensorflow/core/common_runtime/graph_execution_state.h index d44a24c87b..9cabe478a6 100644 --- a/tensorflow/core/common_runtime/graph_execution_state.h +++ b/tensorflow/core/common_runtime/graph_execution_state.h @@ -50,17 +50,20 @@ struct GraphExecutionStateOptions { // BuildGraphOptions. struct ClientGraph { explicit ClientGraph(std::unique_ptr<FunctionLibraryDefinition> flib, - DataTypeVector feed_types, DataTypeVector fetch_types) + DataTypeVector feed_types, DataTypeVector fetch_types, + int64 collective_graph_key) : flib_def(std::move(flib)), graph(flib_def.get()), feed_types(std::move(feed_types)), - fetch_types(std::move(fetch_types)) {} + fetch_types(std::move(fetch_types)), + collective_graph_key(collective_graph_key) {} // Each client-graph gets its own function library since optimization passes // post rewrite for execution might want to introduce new functions. std::unique_ptr<FunctionLibraryDefinition> flib_def; Graph graph; DataTypeVector feed_types; DataTypeVector fetch_types; + int64 collective_graph_key; }; // GraphExecutionState is responsible for generating an diff --git a/tensorflow/core/common_runtime/placer.cc b/tensorflow/core/common_runtime/placer.cc index d581f45a90..7f3c25d81d 100644 --- a/tensorflow/core/common_runtime/placer.cc +++ b/tensorflow/core/common_runtime/placer.cc @@ -30,7 +30,6 @@ limitations under the License. #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/util/status_util.h" namespace tensorflow { @@ -934,14 +933,13 @@ bool Placer::ClientHandlesErrorFormatting() const { // Returns the node name in single quotes. If the client handles formatted // errors, appends a formatting tag which the client will reformat into, for // example, " (defined at filename:123)". +// TODO(shikharagarwal): Remove this function once +// client_handles_error_formatting flag is removed. string Placer::RichNodeName(const Node* node) const { - string quoted_name = strings::StrCat("'", node->name(), "'"); if (ClientHandlesErrorFormatting()) { - string file_and_line = error_format_tag(*node, "${defined_at}"); - return strings::StrCat(quoted_name, file_and_line); - } else { - return quoted_name; + return errors::FormatNodeNameForError(node->name()); } + return strings::StrCat("'", node->name(), "'"); } } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/placer_test.cc b/tensorflow/core/common_runtime/placer_test.cc index 87f2f2ceb9..83d27e2730 100644 --- a/tensorflow/core/common_runtime/placer_test.cc +++ b/tensorflow/core/common_runtime/placer_test.cc @@ -1159,9 +1159,8 @@ TEST_F(PlacerTest, TestNonexistentGpuNoAllowSoftPlacementFormatTag) { Status s = Place(&g, &options); EXPECT_EQ(error::INVALID_ARGUMENT, s.code()); LOG(WARNING) << s.error_message(); - EXPECT_TRUE(str_util::StrContains(s.error_message(), - "Cannot assign a device for operation 'in'" - "^^node:in:${defined_at}^^")); + EXPECT_TRUE(str_util::StrContains( + s.error_message(), "Cannot assign a device for operation {{node in}}")); } // Test that the "Cannot assign a device" error message does not contain a diff --git a/tensorflow/core/distributed_runtime/master_session.cc b/tensorflow/core/distributed_runtime/master_session.cc index abd07e37b7..8e9eec1ed9 100644 --- a/tensorflow/core/distributed_runtime/master_session.cc +++ b/tensorflow/core/distributed_runtime/master_session.cc @@ -449,7 +449,7 @@ Status MasterSession::ReffedClientGraph::DoRegisterPartitions( *c->req.mutable_graph_options() = session_opts_.config.graph_options(); *c->req.mutable_debug_options() = callable_opts_.run_options().debug_options(); - c->req.set_collective_graph_key(bg_opts_.collective_graph_key); + c->req.set_collective_graph_key(client_graph()->collective_graph_key); VLOG(2) << "Register " << c->req.graph_def().DebugString(); auto cb = [c, &done](const Status& s) { c->status = s; @@ -1111,10 +1111,6 @@ uint64 HashBuildGraphOptions(const BuildGraphOptions& opts) { h = Hash64(watch_summary.c_str(), watch_summary.size(), h); } - if (opts.collective_graph_key != BuildGraphOptions::kNoCollectiveGraphKey) { - h = Hash64Combine(opts.collective_graph_key, h); - } - return h; } @@ -1788,10 +1784,10 @@ Status MasterSession::PostRunCleanup(MasterSession::ReffedClientGraph* rcg, Status s = run_status; if (s.ok()) { pss->end_micros = Env::Default()->NowMicros(); - if (rcg->build_graph_options().collective_graph_key != + if (rcg->client_graph()->collective_graph_key != BuildGraphOptions::kNoCollectiveGraphKey) { env_->collective_executor_mgr->RetireStepId( - rcg->build_graph_options().collective_graph_key, step_id); + rcg->client_graph()->collective_graph_key, step_id); } // Schedule post-processing and cleanup to be done asynchronously. rcg->ProcessStats(step_id, pss, ph.get(), run_options, out_run_metadata); @@ -1850,7 +1846,7 @@ Status MasterSession::DoRunWithLocalExecution( // Keeps the highest 8 bits 0x01: we reserve some bits of the // step_id for future use. - uint64 step_id = NewStepId(bgopts.collective_graph_key); + uint64 step_id = NewStepId(rcg->client_graph()->collective_graph_key); TRACEPRINTF("stepid %llu", step_id); std::unique_ptr<ProfileHandler> ph; @@ -1914,8 +1910,7 @@ Status MasterSession::DoRunCallable(CallOptions* opts, ReffedClientGraph* rcg, // Prepare. int64 count = rcg->get_and_increment_execution_count(); - const uint64 step_id = - NewStepId(rcg->build_graph_options().collective_graph_key); + const uint64 step_id = NewStepId(rcg->client_graph()->collective_graph_key); TRACEPRINTF("stepid %llu", step_id); const RunOptions& run_options = rcg->callable_options().run_options(); diff --git a/tensorflow/core/framework/dataset.cc b/tensorflow/core/framework/dataset.cc index b0b27ce94f..9ffd8e1ee0 100644 --- a/tensorflow/core/framework/dataset.cc +++ b/tensorflow/core/framework/dataset.cc @@ -179,6 +179,13 @@ Status GraphDefBuilderWrapper::AddFunction(SerializationContext* ctx, return Status::OK(); } +void GraphDefBuilderWrapper::AddPlaceholderInternal(const Tensor& val, + Node** output) { + *output = ops::SourceOp( + "Placeholder", + b_->opts().WithAttr("dtype", val.dtype()).WithAttr("shape", val.shape())); +} + void GraphDefBuilderWrapper::AddTensorInternal(const Tensor& val, Node** output) { *output = ops::SourceOp( diff --git a/tensorflow/core/framework/dataset.h b/tensorflow/core/framework/dataset.h index e06ca68bca..04865a1d4f 100644 --- a/tensorflow/core/framework/dataset.h +++ b/tensorflow/core/framework/dataset.h @@ -110,10 +110,11 @@ class GraphDefBuilderWrapper { return Status::OK(); } - // Adds a Const node with Tensor value to the Graph. + // Adds a `Const` node for the given tensor value to the graph. + // // `*output` contains a pointer to the output `Node`. It is guaranteed to be - // non-null if the method returns with an OK status. - // The returned Node pointer is owned by the backing Graph of GraphDefBuilder. + // non-null if the method returns with an OK status. The returned `Node` + // pointer is owned by the backing graph of `GraphDefBuilder`. Status AddTensor(const Tensor& val, Node** output) { AddTensorInternal(val, output); if (*output == nullptr) { @@ -122,6 +123,20 @@ class GraphDefBuilderWrapper { return Status::OK(); } + // Adds a `Placeholder` node for the given tensor value to the graph. + // + // `*output` contains a pointer to the output `Node`. It is guaranteed to be + // non-null if the method returns with an OK status. The returned `Node` + // pointer is owned by the backing graph of `GraphDefBuilder`. + Status AddPlaceholder(const Tensor& val, Node** output) { + AddPlaceholderInternal(val, output); + if (*output == nullptr) { + return errors::Internal( + "AddPlaceholder: Failed to build Placeholder op."); + } + return Status::OK(); + } + Status AddDataset(const DatasetBase* dataset, const std::vector<Node*>& inputs, Node** output) { return AddDataset(dataset, inputs, {}, output); @@ -168,6 +183,7 @@ class GraphDefBuilderWrapper { } private: + void AddPlaceholderInternal(const Tensor& val, Node** output); void AddTensorInternal(const Tensor& val, Node** output); Status EnsureFunctionIsStateless(const FunctionLibraryDefinition& flib_def, @@ -334,7 +350,8 @@ class SerializationContext { public: struct Params { bool allow_stateful_functions = false; - const FunctionLibraryDefinition* flib_def; // Not owned. + const FunctionLibraryDefinition* flib_def = nullptr; // Not owned. + std::vector<std::pair<string, Tensor>>* input_list = nullptr; // Not owned. }; explicit SerializationContext(Params params) : params_(std::move(params)) {} @@ -343,6 +360,10 @@ class SerializationContext { const FunctionLibraryDefinition& flib_def() { return *params_.flib_def; } + std::vector<std::pair<string, Tensor>>* input_list() { + return params_.input_list; + } + private: Params params_; diff --git a/tensorflow/core/grappler/optimizers/BUILD b/tensorflow/core/grappler/optimizers/BUILD index 70ad9f9a9b..a24004dc16 100644 --- a/tensorflow/core/grappler/optimizers/BUILD +++ b/tensorflow/core/grappler/optimizers/BUILD @@ -110,12 +110,13 @@ cc_library( ], ) -tf_cuda_cc_test( +tf_cc_test( name = "constant_folding_test", srcs = ["constant_folding_test.cc"], - tags = ["requires-gpu-sm35"], + shard_count = 5, deps = [ ":constant_folding", + ":dependency_optimizer", "//tensorflow/cc:cc_ops", "//tensorflow/cc:cc_ops_internal", "//tensorflow/core:all_kernels", diff --git a/tensorflow/core/grappler/optimizers/arithmetic_optimizer.h b/tensorflow/core/grappler/optimizers/arithmetic_optimizer.h index 551c3652bf..d457eb6d21 100644 --- a/tensorflow/core/grappler/optimizers/arithmetic_optimizer.h +++ b/tensorflow/core/grappler/optimizers/arithmetic_optimizer.h @@ -61,7 +61,7 @@ class ArithmeticOptimizer : public GraphOptimizer { bool fold_multiply_into_conv = true; bool fold_transpose_into_matmul = true; bool hoist_common_factor_out_of_aggregation = true; - bool hoist_cwise_unary_chains = false; + bool hoist_cwise_unary_chains = true; bool minimize_broadcasts = true; bool optimize_max_or_min_of_monotonic = true; bool remove_idempotent = true; diff --git a/tensorflow/core/grappler/optimizers/constant_folding.cc b/tensorflow/core/grappler/optimizers/constant_folding.cc index 815bd23307..99737a71eb 100644 --- a/tensorflow/core/grappler/optimizers/constant_folding.cc +++ b/tensorflow/core/grappler/optimizers/constant_folding.cc @@ -136,6 +136,27 @@ bool MaybeRemoveControlInput(const string& old_input, NodeDef* node, return removed_input; } +bool GetConcatAxis(const GraphProperties& properties, NodeDef* node, + int* axis) { + if (node->op() != "ConcatV2" || + properties.GetInputProperties(node->name()).empty()) { + return false; + } + const auto& axis_input = properties.GetInputProperties(node->name()).back(); + if (!TensorShape::IsValid(axis_input.shape()) || !axis_input.has_value()) { + return false; + } + + Tensor axis_tensor(axis_input.dtype(), axis_input.shape()); + if (!axis_tensor.FromProto(axis_input.value())) { + return false; + } + *axis = axis_input.dtype() == DT_INT64 + ? static_cast<int>(axis_tensor.scalar<int64>()()) + : axis_tensor.scalar<int32>()(); + return true; +} + } // namespace ConstantFolding::ConstantFolding(RewriterConfig::Toggle opt_level, @@ -852,19 +873,7 @@ DataType GetDataTypeFromNodeOrProps(const NodeDef& node, } return dtype; } -bool IsValidConstShapeForNCHW(const TensorShapeProto& shape) { - if (shape.dim_size() != 4) { - return false; - } - int num_dim_larger_than_one = 0; - for (const auto& dim : shape.dim()) { - if (dim.size() > 1) ++num_dim_larger_than_one; - } - return num_dim_larger_than_one <= 1; -} -const string& GetShape(const NodeDef& node) { - return node.attr().at("data_format").s(); -} + } // namespace // static @@ -1711,7 +1720,7 @@ Status ConstantFolding::SimplifyNode(bool use_shape_info, NodeDef* node, return Status::OK(); } - if (MulConvPushDown(*properties, optimized_graph, node)) { + if (MulConvPushDown(node, *properties)) { graph_modified_ = true; return Status::OK(); } @@ -1731,6 +1740,11 @@ Status ConstantFolding::SimplifyNode(bool use_shape_info, NodeDef* node, return Status::OK(); } + if (MergeConcat(*properties, use_shape_info, optimized_graph, node)) { + graph_modified_ = true; + return Status::OK(); + } + return Status::OK(); } @@ -2553,9 +2567,8 @@ bool ConstantFolding::ConstantPushDown(NodeDef* node) { return false; } -bool ConstantFolding::MulConvPushDown(const GraphProperties& properties, - GraphDef* optimized_graph, - NodeDef* node) { +bool ConstantFolding::MulConvPushDown(NodeDef* node, + const GraphProperties& properties) { // Push down multiplication on ConvND. // * ConvND // / \ / \ @@ -2631,14 +2644,12 @@ bool ConstantFolding::MulConvPushDown(const GraphProperties& properties, } const auto& const_shape = const_props[0].shape(); - if (GetShape(*conv_node) == "NHWC") { - TensorShapeProto new_filter_shape; - if (!ShapeAfterBroadcast(filter_shape, const_shape, &new_filter_shape)) { - return false; - } - if (!ShapesSymbolicallyEqual(filter_shape, new_filter_shape)) { - return false; - } + TensorShapeProto new_filter_shape; + if (!ShapeAfterBroadcast(filter_shape, const_shape, &new_filter_shape)) { + return false; + } + if (!ShapesSymbolicallyEqual(filter_shape, new_filter_shape)) { + return false; } string mul_new_name = @@ -2672,69 +2683,6 @@ bool ConstantFolding::MulConvPushDown(const GraphProperties& properties, } node_map_->AddNode(mul_new_name, node); - if (GetShape(*conv_node) == "NCHW") { - if (const_node->attr().at("value").tensor().tensor_shape().dim_size() <= - 1) { - // Broadcast should work for scalar or 1D. No need to reshape. - return true; - } - if (!IsValidConstShapeForNCHW( - const_node->attr().at("value").tensor().tensor_shape())) { - return false; - } - // Adds Const node for Reshape. - auto* shape_const_node = optimized_graph->add_node(); - const string shape_const_node_name = - OptimizedNodeName(*const_node, "_new_shape"); - shape_const_node->set_name(shape_const_node_name); - shape_const_node->set_op("Const"); - shape_const_node->set_device(const_node->device()); - (*shape_const_node->mutable_attr())["dtype"].set_type(DT_INT32); - Tensor t(DT_INT32, {4}); - t.flat<int32>()(0) = 1; - t.flat<int32>()(1) = 1; - t.flat<int32>()(2) = 1; - t.flat<int32>()(3) = const_node->attr() - .at("value") - .tensor() - .tensor_shape() - .dim(1) // IsValidConstShapeForNCHW guarantees - // dim 1 is the dim to reshape - .size(); - t.AsProtoTensorContent( - (*shape_const_node->mutable_attr())["value"].mutable_tensor()); - node_map_->AddNode(shape_const_node_name, shape_const_node); - - // Adds Reshape node. - auto* reshape_node = optimized_graph->add_node(); - const string reshape_node_name = - OptimizedNodeName(*const_node, "_reshape"); - reshape_node->set_op("Reshape"); - reshape_node->set_name(reshape_node_name); - reshape_node->set_device(const_node->device()); - (*reshape_node->mutable_attr())["T"].set_type( - const_node->attr().at("dtype").type()); - (*reshape_node->mutable_attr())["Tshape"].set_type(DT_INT32); - node_map_->AddNode(reshape_node_name, reshape_node); - - // const_node -> reshape_node - node_map_->RemoveOutput(const_node->name(), node->name()); - *reshape_node->add_input() = const_node->name(); - node_map_->AddOutput(const_node->name(), reshape_node_name); - - // shape_const_node -> reshape_node - *reshape_node->add_input() = shape_const_node_name; - node_map_->AddOutput(shape_const_node_name, reshape_node_name); - - // reshape_node -> node (Mul) - node_map_->AddOutput(reshape_node_name, node->name()); - if (left_child_is_constant) { - node->set_input(0, reshape_node_name); - } else { - node->set_input(1, reshape_node_name); - } - } - return true; } return false; @@ -2988,6 +2936,55 @@ bool ConstantFolding::PartialConcatConstFolding(GraphDef* optimized_graph, return false; } +bool ConstantFolding::MergeConcat(const GraphProperties& properties, + bool use_shape_info, + GraphDef* optimized_graph, NodeDef* node) { + // We only optimize for ConcatV2. + int axis; + if (!use_shape_info || !GetConcatAxis(properties, node, &axis) || + nodes_to_preserve_.find(node->name()) != nodes_to_preserve_.end() || + node_map_->GetOutputs(node->name()).size() != 1) { + return false; + } + + NodeDef* parent = *node_map_->GetOutputs(node->name()).begin(); + int parent_axis; + if (!GetConcatAxis(properties, parent, &parent_axis) || axis != parent_axis) { + return false; + } + + const int index = NumNonControlInputs(*node) - 1; + auto inputs = parent->input(); + parent->clear_input(); + for (int i = 0; i < inputs.size(); ++i) { + if (IsSameInput(inputs.Get(i), node->name())) { + for (int j = 0; j < node->input_size(); ++j) { + if (j < index) { + // Input tensors (non axis), add to input list of parent. + parent->add_input(node->input(j)); + node_map_->RemoveOutput(node->input(j), node->name()); + node_map_->AddOutput(node->input(j), parent->name()); + } + // Skip j == index, which means axis tensor. + if (j > index) { + // Control Dependencies, push back to inputs so they can be forwarded + // to parent. + *inputs.Add() = node->input(j); + } + } + } else { + parent->add_input(inputs.Get(i)); + } + } + node->clear_input(); + node->set_op("NoOp"); + node->clear_attr(); + node_map_->RemoveNode(node->name()); + (*parent->mutable_attr())["N"].set_i(NumNonControlInputs(*parent) - 1); + + return true; +} + Status ConstantFolding::RunOptimizationPass(Cluster* cluster, const GrapplerItem& item, GraphDef* optimized_graph) { diff --git a/tensorflow/core/grappler/optimizers/constant_folding.h b/tensorflow/core/grappler/optimizers/constant_folding.h index 051dfb681e..8593b3e0b8 100644 --- a/tensorflow/core/grappler/optimizers/constant_folding.h +++ b/tensorflow/core/grappler/optimizers/constant_folding.h @@ -125,8 +125,7 @@ class ConstantFolding : public GraphOptimizer { // Aggregate constants present around a conv operator. Returns true if the // transformation was applied successfully. - bool MulConvPushDown(const GraphProperties& properties, - GraphDef* optimized_graph, NodeDef* node); + bool MulConvPushDown(NodeDef* node, const GraphProperties& properties); // Strength reduces floating point division by a constant Div(x, const) to // multiplication by the reciprocal Mul(x, Reciprocal(const)). @@ -210,6 +209,10 @@ class ConstantFolding : public GraphOptimizer { // Removes Split or SplitV node if possible. bool RemoveSplitOrSplitV(const GraphProperties& properties, GraphDef* optimized_graph, NodeDef* node); + + bool MergeConcat(const GraphProperties& properties, bool use_shape_info, + GraphDef* optimized_graph, NodeDef* node); + // Points to an externally provided device or to owned_device_; RewriterConfig::Toggle opt_level_; DeviceBase* cpu_device_; diff --git a/tensorflow/core/grappler/optimizers/constant_folding_test.cc b/tensorflow/core/grappler/optimizers/constant_folding_test.cc index 0683572dcc..2a19b3f95a 100644 --- a/tensorflow/core/grappler/optimizers/constant_folding_test.cc +++ b/tensorflow/core/grappler/optimizers/constant_folding_test.cc @@ -240,7 +240,7 @@ TEST_F(ConstantFoldingTest, AddTree) { } } -TEST_F(ConstantFoldingTest, ConvPushDownTestNHWC) { +TEST_F(ConstantFoldingTest, ConvPushDownTest) { // Tests if the following rewrite is performed: // // * Conv2D @@ -2030,6 +2030,130 @@ TEST_F(ConstantFoldingTest, TileWithMultipliesBeingOne) { CompareGraphs(want, got); } +TEST_F(ConstantFoldingTest, MergeConcat) { + tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); + + Output in1 = ops::Variable(scope.WithOpName("in1"), {4, 6}, DT_FLOAT); + Output in2 = ops::Variable(scope.WithOpName("in2"), {4, 6}, DT_FLOAT); + Output in3 = ops::Variable(scope.WithOpName("in3"), {4, 6}, DT_FLOAT); + Output axis = ops::Const(scope.WithOpName("axis"), 0, {}); + + ops::Concat c1(scope.WithOpName("c1"), {in1, in2}, axis); + ops::Concat c2(scope.WithOpName("c2"), {Output(c1), in3}, axis); + + GrapplerItem item; + item.fetch = {"c2"}; + TF_CHECK_OK(scope.ToGraphDef(&item.graph)); + + ConstantFolding optimizer(nullptr /* cpu_device */); + GraphDef got; + Status status = optimizer.Optimize(nullptr, item, &got); + TF_EXPECT_OK(status); + + GraphDef want; + AddNode("in1", "VariableV2", {}, {}, &want); + AddNode("in2", "VariableV2", {}, {}, &want); + AddNode("in3", "VariableV2", {}, {}, &want); + AddNode("axis", "Const", {}, {}, &want); + AddNode("c2", "ConcatV2", {"in1", "in2", "in3", "axis"}, {}, &want); + + CompareGraphs(want, got); +} + +TEST_F(ConstantFoldingTest, MergeConcat_SameInput) { + tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); + + Output in1 = ops::Variable(scope.WithOpName("in1"), {4, 6}, DT_FLOAT); + Output in2 = ops::Variable(scope.WithOpName("in2"), {4, 6}, DT_FLOAT); + Output in3 = ops::Variable(scope.WithOpName("in3"), {4, 6}, DT_FLOAT); + Output axis = ops::Const(scope.WithOpName("axis"), 0, {}); + + ops::Concat c1(scope.WithOpName("c1"), {in1, in2}, axis); + ops::Concat c2(scope.WithOpName("c2"), {Output(c1), in3, Output(c1)}, axis); + + GrapplerItem item; + item.fetch = {"c2"}; + TF_CHECK_OK(scope.ToGraphDef(&item.graph)); + + ConstantFolding optimizer(nullptr /* cpu_device */); + GraphDef got; + Status status = optimizer.Optimize(nullptr, item, &got); + TF_EXPECT_OK(status); + + GraphDef want; + AddNode("in1", "VariableV2", {}, {}, &want); + AddNode("in2", "VariableV2", {}, {}, &want); + AddNode("in3", "VariableV2", {}, {}, &want); + AddNode("axis", "Const", {}, {}, &want); + AddNode("c2", "ConcatV2", {"in1", "in2", "in3", "in1", "in2", "axis"}, {}, + &want); + + CompareGraphs(want, got); +} + +TEST_F(ConstantFoldingTest, MergeConcat_ConcatWithConst) { + tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); + + Output in1 = ops::Variable(scope.WithOpName("in1"), {2, 6}, DT_FLOAT); + Output in2 = ops::Variable(scope.WithOpName("in2"), {}, DT_FLOAT); + Output in3 = ops::Variable(scope.WithOpName("in3"), {4, 6}, DT_FLOAT); + Output axis = ops::Const(scope.WithOpName("axis"), 0, {}); + + ops::Concat c1(scope.WithOpName("c1"), {in1, in2}, axis); + ops::Concat c2(scope.WithOpName("c2"), {Output(c1), in3}, axis); + + GrapplerItem item; + item.fetch = {"c2"}; + TF_CHECK_OK(scope.ToGraphDef(&item.graph)); + + ConstantFolding optimizer(nullptr /* cpu_device */); + GraphDef got; + Status status = optimizer.Optimize(nullptr, item, &got); + TF_EXPECT_OK(status); + + GraphDef want; + AddNode("in1", "VariableV2", {}, {}, &want); + AddNode("in2", "VariableV2", {}, {}, &want); + AddNode("in3", "VariableV2", {}, {}, &want); + AddNode("axis", "Const", {}, {}, &want); + AddNode("c2", "ConcatV2", {"in1", "in2", "in3", "axis"}, {}, &want); + + CompareGraphs(want, got); +} + +TEST_F(ConstantFoldingTest, MergeConcat_AxisMismatch) { + tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); + + Output in1 = ops::Variable(scope.WithOpName("in1"), {2, 5}, DT_FLOAT); + Output in2 = ops::Variable(scope.WithOpName("in2"), {}, DT_FLOAT); + Output in3 = ops::Variable(scope.WithOpName("in3"), {4, 6}, DT_FLOAT); + Output axis1 = ops::Const(scope.WithOpName("axis1"), 0, {}); + Output axis2 = ops::Const(scope.WithOpName("axis2"), 1, {}); + + ops::Concat c1(scope.WithOpName("c1"), {in1, in2}, axis2); + ops::Concat c2(scope.WithOpName("c2"), {Output(c1), in3}, axis1); + + GrapplerItem item; + item.fetch = {"c2"}; + TF_CHECK_OK(scope.ToGraphDef(&item.graph)); + + ConstantFolding optimizer(nullptr /* cpu_device */); + GraphDef got; + Status status = optimizer.Optimize(nullptr, item, &got); + TF_EXPECT_OK(status); + + GraphDef want; + AddNode("in1", "VariableV2", {}, {}, &want); + AddNode("in2", "VariableV2", {}, {}, &want); + AddNode("in3", "VariableV2", {}, {}, &want); + AddNode("axis1", "Const", {}, {}, &want); + AddNode("axis2", "Const", {}, {}, &want); + AddNode("c1", "ConcatV2", {"in1", "in2", "axis2"}, {}, &want); + AddNode("c2", "ConcatV2", {"c1", "in3", "axis1"}, {}, &want); + + CompareGraphs(want, got); +} + TEST_F(ConstantFoldingTest, PaddingWithZeroSize) { tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); @@ -3080,110 +3204,6 @@ TEST_F(ConstantFoldingTest, FoldingPreservesDenormalFlushing) { test::ExpectTensorEqual<float>(tensors_expected[0], tensors[0]); } -#if GOOGLE_CUDA -TEST_F(ConstantFoldingTest, ConvPushDownTestNCHW) { - // Tests if the following rewrite is performed: - // - // * Conv2D - // / \ / \ - // c Conv2D --> x (c * filter) - // / \ - // x filter - tensorflow::Scope s = tensorflow::Scope::NewRootScope(); - - int input_channel = 1; - int output_channel = 2; - int filter_size = 1; - - TensorShape filter_shape( - {filter_size, filter_size, input_channel, output_channel}); - - // Filter shape: [1, 1, 1, 2] - // Filter for output channel 0 = {2.f} - // Filter for output channel 1 = {-2.f} - // clang-format off - Output filter = - ops::Const(s.WithOpName("filter"), { - { - {{2.f, -2.f}} - } - }); - // clang-format on - - int batch_size = 1; - int matrix_size = 3; - // input shape: [1,1,3,3] - TensorShape input_shape( - {batch_size, input_channel, matrix_size, matrix_size}); - Output input = ops::Placeholder(s.WithOpName("x"), DT_FLOAT, - ops::Placeholder::Shape(input_shape)); - - Output conv = ops::Conv2D(s.WithOpName("conv"), input, filter, {1, 1, 1, 1}, - "VALID", ops::Conv2D::DataFormat("NCHW")); - Output c = ops::Const(s.WithOpName("c"), 2.0f, /* shape */ {1, 2, 1, 1}); - Output mul = ops::Mul(s.WithOpName("mul"), c, conv); - - GrapplerItem item; - TF_CHECK_OK(s.ToGraphDef(&item.graph)); - - ConstantFolding fold(nullptr); - GraphDef output; - Status status = fold.Optimize(nullptr, item, &output); - TF_EXPECT_OK(status); - - // Here only op/IO are checked. The values are verified by EvaluateNodes - // below. - int found = 0; - for (const auto& node : output.node()) { - if (node.name() == "mul") { - ++found; - EXPECT_EQ("Conv2D", node.op()); - EXPECT_EQ(2, node.input_size()); - EXPECT_EQ("x", node.input(0)); - EXPECT_EQ("conv/merged_input", node.input(1)); - } else if (node.name() == "conv/merged_input") { - ++found; - EXPECT_EQ("Const", node.op()); - EXPECT_EQ(0, node.input_size()); - } - } - EXPECT_EQ(2, found); - - // Check that const folded multiplication node has the expected value. - std::vector<string> fetch = {"mul"}; - // Input shape (NCHW) is [1,1,3,3], filter is [1,1,1,2] output shape should be - // (NCHW) [1,2,3,3] - ::tensorflow::Input::Initializer x{ - { - { - {1.f, 2.f, 3.f}, // H = 0 - {4.f, 5.f, 6.f}, // H = 1 - {7.f, 8.f, 9.f} // H = 2 - } // C = 0 - } // N = 0 - }; - - // |1,2,3| - // conv( |4,5,6|, // input - // |7,8,9| - // [[[2,-2]]]) // filter - // * [1,2,1,1] // mul by const - // = - // [ - // |4, 8, 12| - // |16,20,24| ==> output channel 0 - // |28,32,36| - // - // | -4, -8,-12| - // |-16,-20,-24| ==> output channel 1 - // |-28,-32,-36| - // ] - auto actual = EvaluateNodes(output, fetch, {{"x", x.tensor}}); - auto expected = EvaluateNodes(item.graph, fetch, {{"x", x.tensor}}); - test::ExpectTensorEqual<float>(expected[0], actual[0]); -} -#endif - } // namespace } // namespace grappler } // namespace tensorflow diff --git a/tensorflow/core/grappler/optimizers/memory_optimizer.cc b/tensorflow/core/grappler/optimizers/memory_optimizer.cc index 91794cefe5..c775a26914 100644 --- a/tensorflow/core/grappler/optimizers/memory_optimizer.cc +++ b/tensorflow/core/grappler/optimizers/memory_optimizer.cc @@ -1071,11 +1071,13 @@ static bool IdentifySwappingCandidates( // ensure that swapping the tensor back in won't recreate the memory // bottleneck. Last but not least, we want the tensor to have as few // remaining uses as possible. + // + // Note that we must perform the arithmetic inexactly as "double", since + // the values do not fit into any integral type. mem_info.fitness = - MathUtil::IPow((earliest_use - peak_time).count(), 2); - mem_info.fitness /= MathUtil::IPow(mem_info.uses_left.size(), 2); - mem_info.fitness += - MathUtil::IPow((allocation_time - peak_time).count(), 2); + MathUtil::IPow<double>((earliest_use - peak_time).count(), 2) / + MathUtil::IPow<double>(mem_info.uses_left.size(), 2) + + MathUtil::IPow<double>((allocation_time - peak_time).count(), 2); mem_info.fitness = -mem_info.fitness; mem_state.push_back(mem_info); } diff --git a/tensorflow/core/kernels/BUILD b/tensorflow/core/kernels/BUILD index 633fe9ab77..25063ac823 100644 --- a/tensorflow/core/kernels/BUILD +++ b/tensorflow/core/kernels/BUILD @@ -2296,6 +2296,31 @@ tf_cc_tests( ], ) +cc_library( + name = "eigen_benchmark", + testonly = 1, + hdrs = [ + "eigen_benchmark.h", + ":eigen_helpers", + ], + deps = [ + "//tensorflow/core:framework", + "//third_party/eigen3", + ], +) + +tf_cc_test( + name = "eigen_benchmark_cpu_test", + srcs = ["eigen_benchmark_cpu_test.cc"], + deps = [ + ":eigen_benchmark", + ":eigen_helpers", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + "//third_party/eigen3", + ], +) + tf_cc_tests( name = "basic_ops_benchmark_test", size = "small", @@ -4196,6 +4221,7 @@ cc_library( "hinge-loss.h", "logistic-loss.h", "loss.h", + "poisson-loss.h", "smooth-hinge-loss.h", "squared-loss.h", ], diff --git a/tensorflow/core/kernels/data/BUILD b/tensorflow/core/kernels/data/BUILD index 8d867455e7..e7b3d0c92f 100644 --- a/tensorflow/core/kernels/data/BUILD +++ b/tensorflow/core/kernels/data/BUILD @@ -481,8 +481,7 @@ tf_kernel_library( ":dataset", "//tensorflow/core:dataset_ops_op_lib", "//tensorflow/core:framework", - "//tensorflow/core:lib", - "//tensorflow/core:lib_internal", + "//tensorflow/core:graph", ], ) @@ -505,8 +504,7 @@ tf_kernel_library( ":dataset", "//tensorflow/core:dataset_ops_op_lib", "//tensorflow/core:framework", - "//tensorflow/core:lib", - "//tensorflow/core:lib_internal", + "//tensorflow/core:graph", ], ) diff --git a/tensorflow/core/kernels/data/optimize_dataset_op.cc b/tensorflow/core/kernels/data/optimize_dataset_op.cc index 831e7252da..6263dc3cf8 100644 --- a/tensorflow/core/kernels/data/optimize_dataset_op.cc +++ b/tensorflow/core/kernels/data/optimize_dataset_op.cc @@ -92,8 +92,10 @@ class OptimizeDatasetOp : public UnaryDatasetOpKernel { DatasetGraphDefBuilder db(&b); Node* input_node = nullptr; SerializationContext::Params params; + std::vector<std::pair<string, Tensor>> input_list; params.allow_stateful_functions = true; params.flib_def = ctx->function_library()->GetFunctionLibraryDefinition(); + params.input_list = &input_list; SerializationContext serialization_ctx(params); TF_RETURN_IF_ERROR( db.AddInputDataset(&serialization_ctx, input_, &input_node)); @@ -118,7 +120,7 @@ class OptimizeDatasetOp : public UnaryDatasetOpKernel { GraphRunner graph_runner(ctx->function_library()->device()); TF_RETURN_IF_ERROR( - graph_runner.Run(&graph, lib_, {}, {output_node}, &outputs)); + graph_runner.Run(&graph, lib_, input_list, {output_node}, &outputs)); TF_RETURN_IF_ERROR( GetDatasetFromVariantTensor(outputs[0], &optimized_input_)); optimized_input_->Ref(); diff --git a/tensorflow/core/kernels/data/tensor_dataset_op.cc b/tensorflow/core/kernels/data/tensor_dataset_op.cc index fc21c3235a..1192fafc4c 100644 --- a/tensorflow/core/kernels/data/tensor_dataset_op.cc +++ b/tensorflow/core/kernels/data/tensor_dataset_op.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/core/framework/partial_tensor_shape.h" #include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/graph/graph.h" #include "tensorflow/core/kernels/data/dataset.h" namespace tensorflow { @@ -28,8 +29,6 @@ class TensorDatasetOp : public DatasetOpKernel { explicit TensorDatasetOp(OpKernelConstruction* ctx) : DatasetOpKernel(ctx) {} void MakeDataset(OpKernelContext* ctx, DatasetBase** output) override { - // Create a new TensorDatasetOp::Dataset, insert it in the step - // container, and return it as the output. OpInputList inputs; OP_REQUIRES_OK(ctx, ctx->input_list("components", &inputs)); // TODO(mrry): Validate that the shapes of the "components" tensors match @@ -74,7 +73,13 @@ class TensorDatasetOp : public DatasetOpKernel { components.reserve(tensors_.size()); for (const Tensor& t : tensors_) { Node* node; - TF_RETURN_IF_ERROR(b->AddTensor(t, &node)); + std::vector<std::pair<string, Tensor>>* input_list = ctx->input_list(); + if (input_list) { + TF_RETURN_IF_ERROR(b->AddPlaceholder(t, &node)); + input_list->emplace_back(node->name(), t); + } else { + TF_RETURN_IF_ERROR(b->AddTensor(t, &node)); + } components.emplace_back(node); } AttrValue dtypes; diff --git a/tensorflow/core/kernels/data/tensor_slice_dataset_op.cc b/tensorflow/core/kernels/data/tensor_slice_dataset_op.cc index 5b051e0e08..dc32cd23e5 100644 --- a/tensorflow/core/kernels/data/tensor_slice_dataset_op.cc +++ b/tensorflow/core/kernels/data/tensor_slice_dataset_op.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/core/framework/partial_tensor_shape.h" #include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/graph/graph.h" #include "tensorflow/core/kernels/data/dataset.h" #include "tensorflow/core/util/batch_util.h" @@ -30,8 +31,6 @@ class TensorSliceDatasetOp : public DatasetOpKernel { : DatasetOpKernel(ctx) {} void MakeDataset(OpKernelContext* ctx, DatasetBase** output) override { - // Create a new TensorDatasetOp::Dataset, insert it in the step - // container, and return it as the output. OpInputList inputs; OP_REQUIRES_OK(ctx, ctx->input_list("components", &inputs)); std::vector<Tensor> components; @@ -93,7 +92,13 @@ class TensorSliceDatasetOp : public DatasetOpKernel { components.reserve(tensors_.size()); for (const Tensor& t : tensors_) { Node* node; - TF_RETURN_IF_ERROR(b->AddTensor(t, &node)); + std::vector<std::pair<string, Tensor>>* input_list = ctx->input_list(); + if (input_list) { + TF_RETURN_IF_ERROR(b->AddPlaceholder(t, &node)); + input_list->emplace_back(node->name(), t); + } else { + TF_RETURN_IF_ERROR(b->AddTensor(t, &node)); + } components.emplace_back(node); } AttrValue dtypes; diff --git a/tensorflow/core/kernels/eigen_benchmark.h b/tensorflow/core/kernels/eigen_benchmark.h new file mode 100644 index 0000000000..46ad38fb77 --- /dev/null +++ b/tensorflow/core/kernels/eigen_benchmark.h @@ -0,0 +1,298 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_KERNELS_EIGEN_BENCHMARK_H_ +#define TENSORFLOW_CORE_KERNELS_EIGEN_BENCHMARK_H_ + +#include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" +#include "tensorflow/core/framework/tensor_types.h" +#include "tensorflow/core/kernels/eigen_backward_cuboid_convolutions.h" +#include "tensorflow/core/kernels/eigen_backward_spatial_convolutions.h" +#include "tensorflow/core/kernels/eigen_cuboid_convolution.h" +#include "tensorflow/core/kernels/eigen_spatial_convolutions.h" +#include "tensorflow/core/platform/test_benchmark.h" + +using ::tensorflow::TTypes; + +template <typename Scalar, typename Device> +class SpatialConvolutionBenchmarksSuite { + public: + using Input = TTypes<float, 4>::ConstTensor; + using Filter = TTypes<float, 4>::ConstTensor; + using Output = TTypes<float, 4>::Tensor; + + using Dimensions = Eigen::DSizes<Eigen::Index, 4>; + + SpatialConvolutionBenchmarksSuite(int iters, Device& device) + : iters_(iters), device_(device) {} + + Eigen::Index BufferSize(const Dimensions& dims) { + return dims.TotalSize() * sizeof(Scalar); + } + + void SpatialConvolution(Dimensions input_dims, Dimensions filter_dims) { + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + filter_dims[3]); // filter_count + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + Scalar* output_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(filter_data, 123, BufferSize(filter_dims)); + + Input input(input_data, input_dims); + Filter filter(filter_data, filter_dims); + Output output(output_data, output_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + output.device(device_) = Eigen::SpatialConvolution(input, filter); + tensorflow::testing::DoNotOptimize(output); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(filter_data); + device_.deallocate(output_data); + } + + void SpatialConvolutionBackwardInput(Dimensions input_dims, + Dimensions filter_dims) { + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + filter_dims[3]); // filter_count + + // Assuming that the convolution had SAME padding. + Eigen::Index input_rows = input_dims[1]; + Eigen::Index input_cols = input_dims[2]; + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + Scalar* output_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(filter_data, 123, BufferSize(filter_dims)); + + Input input(input_data, input_dims); + Filter filter(filter_data, filter_dims); + Output output(output_data, output_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + output.device(device_) = Eigen::SpatialConvolutionBackwardInput( + filter, input, input_rows, input_cols); + tensorflow::testing::DoNotOptimize(output); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(filter_data); + device_.deallocate(output_data); + } + + void SpatialConvolutionBackwardKernel(Dimensions input_dims, + Dimensions filter_dims) { + using OutputBackward = TTypes<float, 4>::ConstTensor; + using FilterGrad = TTypes<float, 4>::Tensor; + + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + filter_dims[3]); // filter_count + + // Assuming that the convolution had SAME padding. + Eigen::Index filter_rows = filter_dims[0]; + Eigen::Index filter_cols = filter_dims[1]; + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* output_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(output_backward_data, 123, BufferSize(output_dims)); + + Input input(input_data, input_dims); + OutputBackward output_backward(output_backward_data, input_dims); + FilterGrad filter_grad(filter_data, filter_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + filter_grad.device(device_) = Eigen::SpatialConvolutionBackwardKernel( + input, output_backward, filter_rows, filter_cols); + tensorflow::testing::DoNotOptimize(filter_grad); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(output_backward_data); + device_.deallocate(filter_data); + } + + private: + int iters_; + Device& device_; +}; + +template <typename Scalar, typename Device> +class CuboidConvolutionBenchmarksSuite { + public: + using Input = TTypes<float, 5>::ConstTensor; + using Filter = TTypes<float, 5>::ConstTensor; + using Output = TTypes<float, 5>::Tensor; + + using Dimensions = Eigen::DSizes<Eigen::Index, 5>; + + CuboidConvolutionBenchmarksSuite(int iters, Device& device) + : iters_(iters), device_(device) {} + + Eigen::Index BufferSize(const Dimensions& dims) { + return dims.TotalSize() * sizeof(Scalar); + } + + void CuboidConvolution(Dimensions input_dims, Dimensions filter_dims) { + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + input_dims[3], // input_planes + filter_dims[4]); // filter_count + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + Scalar* output_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(filter_data, 123, BufferSize(filter_dims)); + + Input input(input_data, input_dims); + Filter filter(filter_data, filter_dims); + Output output(output_data, output_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + output.device(device_) = Eigen::CuboidConvolution(input, filter); + tensorflow::testing::DoNotOptimize(output); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(filter_data); + device_.deallocate(output_data); + } + + void CuboidConvolutionBackwardInput(Dimensions input_dims, + Dimensions filter_dims) { + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + input_dims[3], // input_planes + filter_dims[4]); // filter_count + + // Assuming that the convolution had SAME padding. + Eigen::Index input_rows = input_dims[1]; + Eigen::Index input_cols = input_dims[2]; + Eigen::Index input_planes = input_dims[3]; + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + Scalar* output_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(filter_data, 123, BufferSize(filter_dims)); + + Input input(input_data, input_dims); + Filter filter(filter_data, filter_dims); + Output output(output_data, output_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + output.device(device_) = Eigen::CuboidConvolutionBackwardInput( + filter, input, input_planes, input_rows, input_cols); + tensorflow::testing::DoNotOptimize(output); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(filter_data); + device_.deallocate(output_data); + } + + void CuboidConvolutionBackwardKernel(Dimensions input_dims, + Dimensions filter_dims) { + using OutputBackward = TTypes<float, 5>::ConstTensor; + using FilterGrad = TTypes<float, 5>::Tensor; + + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + input_dims[3], // input_planes + filter_dims[4]); // filter_count + + // Assuming that the convolution had SAME padding. + Eigen::Index filter_rows = filter_dims[0]; + Eigen::Index filter_cols = filter_dims[1]; + Eigen::Index filter_planes = filter_dims[2]; + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* output_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(output_backward_data, 123, BufferSize(output_dims)); + + Input input(input_data, input_dims); + OutputBackward output_backward(output_backward_data, output_dims); + FilterGrad filter_grad(filter_data, filter_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + filter_grad.device(device_) = Eigen::CuboidConvolutionBackwardKernel( + input, output_backward, filter_planes, filter_rows, filter_cols); + tensorflow::testing::DoNotOptimize(filter_grad); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(output_backward_data); + device_.deallocate(filter_data); + } + + private: + int iters_; + Device& device_; +}; + +#endif // TENSORFLOW_CORE_KERNELS_EIGEN_BENCHMARK_H_ diff --git a/tensorflow/core/kernels/eigen_benchmark_cpu_test.cc b/tensorflow/core/kernels/eigen_benchmark_cpu_test.cc new file mode 100644 index 0000000000..2a8308ef9a --- /dev/null +++ b/tensorflow/core/kernels/eigen_benchmark_cpu_test.cc @@ -0,0 +1,402 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENTE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONT OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#define EIGEN_USE_CUSTOM_THREAD_POOL +#define EIGEN_USE_THREADS + +#include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" +#include "tensorflow/core/kernels/eigen_benchmark.h" +#include "tensorflow/core/platform/test_benchmark.h" + +#define CREATE_THREAD_POOL(threads) \ + Eigen::ThreadPool tp(threads); \ + Eigen::ThreadPoolDevice device(&tp, threads) + +// -------------------------------------------------------------------------- // +// Spatial Convolutions // +// -------------------------------------------------------------------------- // + +void SpatialConvolution(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, int input_width, + int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, int filter_width) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + SpatialConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims(input_batches, input_height, + input_width, input_depth); + typename Benchmark::Dimensions filter_dims(filter_height, filter_width, + input_depth, filter_count); + + benchmark.SpatialConvolution(input_dims, filter_dims); + + auto output_size = input_dims.TotalSize(); + auto flops = output_size * (input_depth * filter_height * filter_width); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +void SpatialConvolutionBackwardInput(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, + int input_width, int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, + int filter_width) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + SpatialConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims(input_batches, input_height, + input_width, input_depth); + typename Benchmark::Dimensions filter_dims(filter_height, filter_width, + input_depth, filter_count); + + benchmark.SpatialConvolutionBackwardInput(input_dims, filter_dims); + + auto output_size = input_dims.TotalSize(); + auto flops = output_size * (input_depth * filter_height * filter_width); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +void SpatialConvolutionBackwardKernel(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, + int input_width, int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, + int filter_width) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + SpatialConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims(input_batches, input_height, + input_width, input_depth); + typename Benchmark::Dimensions filter_dims(filter_height, filter_width, + input_depth, filter_count); + + benchmark.SpatialConvolutionBackwardKernel(input_dims, filter_dims); + + auto filter_size = filter_dims.TotalSize(); + auto flops = filter_size * (input_batches * input_height * input_width); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +// Macro arguments names: --------------------------------------------------- // +// NT: num threads +// N: batch size +// H: height +// W: width +// C: channels +// FC: filter count +// FH: filter height +// FW: filter width + +#define BM_SPATIAL_NAME(prefix, NT, N, H, W, C, FC, FH, FW) \ + BM_##prefix##_CPU_##NT##T_in_##N##_##H##_##W##_##C##_f_##FC##_##FH##_##FW + +#define BM_SpatialConvolution(NT, N, H, W, C, FC, FH, FW, LABEL) \ + static void BM_SPATIAL_NAME(SpatialConvolution, NT, N, H, W, C, FC, FH, \ + FW)(int iters) { \ + SpatialConvolution(iters, NT, N, H, W, C, FC, FH, FW); \ + } \ + BENCHMARK(BM_SPATIAL_NAME(SpatialConvolution, NT, N, H, W, C, FC, FH, FW)) + +#define BM_SpatialConvolutionBwdInput(NT, N, H, W, C, FC, FH, FW, LABEL) \ + static void BM_SPATIAL_NAME(SpatialConvolutionBwdInput, NT, N, H, W, C, FC, \ + FH, FW)(int iters) { \ + SpatialConvolutionBackwardInput(iters, NT, N, H, W, C, FC, FH, FW); \ + } \ + BENCHMARK( \ + BM_SPATIAL_NAME(SpatialConvolutionBwdInput, NT, N, H, W, C, FC, FH, FW)) + +#define BM_SpatialConvolutionBwdKernel(NT, N, H, W, C, FC, FH, FW, LABEL) \ + static void BM_SPATIAL_NAME(SpatialConvolutionBwdKernel, NT, N, H, W, C, FC, \ + FH, FW)(int iters) { \ + SpatialConvolutionBackwardKernel(iters, NT, N, H, W, C, FC, FH, FW); \ + } \ + BENCHMARK(BM_SPATIAL_NAME(SpatialConvolutionBwdKernel, NT, N, H, W, C, FC, \ + FH, FW)) + +#define BM_SpatialConvolutions(N, H, W, C, FC, FH, FW, LABEL) \ + BM_SpatialConvolution(2, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolution(4, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolution(8, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolution(16, N, H, W, C, FC, FH, FW, LABEL); + +#define BM_SpatialConvolutionsBwdInput(N, H, W, C, FC, FH, FW, LABEL) \ + BM_SpatialConvolutionBwdInput(2, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdInput(4, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdInput(8, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdInput(16, N, H, W, C, FC, FH, FW, LABEL); + +#define BM_SpatialConvolutionsBwdKernel(N, H, W, C, FC, FH, FW, LABEL) \ + BM_SpatialConvolutionBwdKernel(2, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdKernel(4, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdKernel(8, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdKernel(16, N, H, W, C, FC, FH, FW, LABEL); + +// ImageNet Forward Convolutions -------------------------------------------- // + +BM_SpatialConvolutions(32, // batch size + 56, 56, 64, // input: height, width, depth + 192, 3, 3, // filter: count, height, width + "conv2_00"); + +BM_SpatialConvolutions(32, 28, 28, 96, 128, 3, 3, "conv3a_00_3x3"); +BM_SpatialConvolutions(32, 28, 28, 16, 32, 5, 5, "conv3a_00_5x5"); +BM_SpatialConvolutions(32, 28, 28, 128, 192, 3, 3, "conv3_00_3x3"); +BM_SpatialConvolutions(32, 28, 28, 32, 96, 5, 5, "conv3_00_5x5"); +BM_SpatialConvolutions(32, 14, 14, 96, 204, 3, 3, "conv4a_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 16, 48, 5, 5, "conv4a_00_5x5"); +BM_SpatialConvolutions(32, 14, 14, 112, 224, 3, 3, "conv4b_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 24, 64, 5, 5, + "conv4b_00_5x5 / conv4c_00_5x5"); +BM_SpatialConvolutions(32, 14, 14, 128, 256, 3, 3, "conv4c_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 144, 288, 3, 3, "conv4d_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 32, 64, 5, 5, "conv4d_00_5x5"); +BM_SpatialConvolutions(32, 14, 14, 160, 320, 3, 3, "conv4_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 32, 128, 5, 5, "conv4_00_5x5"); +BM_SpatialConvolutions(32, 7, 7, 160, 320, 3, 3, "conv5a_00_3x3"); +BM_SpatialConvolutions(32, 7, 7, 48, 128, 5, 5, "conv5a_00_5x5 / conv5_00_5x5"); +BM_SpatialConvolutions(32, 7, 7, 192, 384, 3, 3, "conv5_00_3x3"); + +// Benchmarks from https://github.com/soumith/convnet-benchmarks +BM_SpatialConvolutions(128, 128, 128, 3, 96, 11, 11, "convnet-layer1"); +BM_SpatialConvolutions(128, 64, 64, 64, 128, 9, 9, "convnet-layer2"); +BM_SpatialConvolutions(128, 32, 32, 128, 128, 9, 9, "convnet-layer3"); +BM_SpatialConvolutions(128, 16, 16, 128, 128, 7, 7, "convnet-layer4"); +BM_SpatialConvolutions(128, 13, 13, 384, 384, 3, 3, "convnet-layer5"); + +// ImageNet BackwardInput Convolutions -------------------------------------- // + +BM_SpatialConvolutionsBwdInput(32, 56, 56, 64, 192, 3, 3, "conv2_00"); +BM_SpatialConvolutionsBwdInput(32, 28, 28, 96, 128, 3, 3, "conv3a_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 28, 28, 16, 32, 5, 5, "conv3a_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 28, 28, 128, 192, 3, 3, "conv3_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 28, 28, 32, 96, 5, 5, "conv3_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 96, 204, 3, 3, "conv4a_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 16, 48, 5, 5, "conv4a_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 112, 224, 3, 3, "conv4b_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 24, 64, 5, 5, + "conv4b_00_5x5 / conv4c_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 128, 256, 3, 3, "conv4c_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 144, 288, 3, 3, "conv4d_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 32, 64, 5, 5, "conv4d_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 160, 320, 3, 3, "conv4_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 32, 128, 5, 5, "conv4_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 7, 7, 160, 320, 3, 3, "conv5a_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 7, 7, 48, 128, 5, 5, + "conv5a_00_5x5 / conv5_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 7, 7, 192, 384, 3, 3, "conv5_00_3x3"); + +// ImageNet BackwardKernel Convolutions ------------------------------------- // + +BM_SpatialConvolutionsBwdKernel(32, 56, 56, 64, 192, 3, 3, "conv2_00"); +BM_SpatialConvolutionsBwdKernel(32, 28, 28, 96, 128, 3, 3, "conv3a_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 28, 28, 16, 32, 5, 5, "conv3a_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 28, 28, 128, 192, 3, 3, "conv3_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 28, 28, 32, 96, 5, 5, "conv3_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 96, 204, 3, 3, "conv4a_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 16, 48, 5, 5, "conv4a_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 112, 224, 3, 3, "conv4b_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 24, 64, 5, 5, + "conv4b_00_5x5 / conv4c_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 128, 256, 3, 3, "conv4c_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 144, 288, 3, 3, "conv4d_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 32, 64, 5, 5, "conv4d_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 160, 320, 3, 3, "conv4_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 32, 128, 5, 5, "conv4_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 7, 7, 160, 320, 3, 3, "conv5a_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 7, 7, 48, 128, 5, 5, + "conv5a_00_5x5 / conv5_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 7, 7, 192, 384, 3, 3, "conv5_00_3x3"); + +// -------------------------------------------------------------------------- // +// Cuboid Convolutions // +// -------------------------------------------------------------------------- // + +void CuboidConvolution(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, int input_width, + int input_planes, int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, int filter_width, + int filter_planes) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + CuboidConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims( + input_batches, input_height, input_width, input_planes, input_depth); + typename Benchmark::Dimensions filter_dims( + filter_height, filter_width, filter_planes, input_depth, filter_count); + + benchmark.CuboidConvolution(input_dims, filter_dims); + + auto output_size = input_dims.TotalSize(); + auto flops = output_size * + (input_depth * filter_height * filter_width * filter_planes); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +void CuboidConvolutionBackwardInput(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, + int input_width, int input_planes, + int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, + int filter_width, int filter_planes) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + CuboidConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims( + input_batches, input_height, input_width, input_planes, input_depth); + typename Benchmark::Dimensions filter_dims( + filter_height, filter_width, filter_planes, input_depth, filter_count); + + benchmark.CuboidConvolutionBackwardInput(input_dims, filter_dims); + + auto output_size = input_dims.TotalSize(); + auto flops = output_size * + (input_depth * filter_height * filter_width * filter_planes); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +void CuboidConvolutionBackwardKernel(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, + int input_width, int input_planes, + int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, + int filter_width, int filter_planes) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + CuboidConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims( + input_batches, input_height, input_width, input_planes, input_depth); + typename Benchmark::Dimensions filter_dims( + filter_height, filter_width, filter_planes, input_depth, filter_count); + + benchmark.CuboidConvolutionBackwardKernel(input_dims, filter_dims); + + auto filter_size = filter_dims.TotalSize(); + auto flops = + filter_size * (input_batches * input_height * input_width * input_planes); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +// Macro arguments names: --------------------------------------------------- // +// NT: num threads +// N: batch size +// H: height +// W: width +// P: panes +// C: channels +// FC: filter count +// FH: filter height +// FW: filter width +// FP: filter panes + +#define BM_CONCAT(a, b) a##b + +#define BM_CUBOID_NAME(p, NT, N, H, W, P, C, FC, FH, FW, FP) \ + BM_CONCAT(BM_##p##_CPU_##NT##T_in_##N##_##H##_##W##_##P##_##C, \ + _f_##FC##_##FH##_##FW##_##FP) + +#define BM_CuboidConvolution(NT, N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + static void BM_CUBOID_NAME(CuboidConvolution, NT, N, H, W, P, C, FC, FH, FW, \ + FP)(int iters) { \ + CuboidConvolution(iters, NT, N, H, W, P, C, FC, FH, FW, FP); \ + } \ + BENCHMARK( \ + BM_CUBOID_NAME(CuboidConvolution, NT, N, H, W, P, C, FC, FH, FW, FP)) + +#define BM_CuboidConvolutionBwdInput(NT, N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + static void BM_CUBOID_NAME(CuboidConvolutionBwdInput, NT, N, H, W, P, C, FC, \ + FH, FW, FP)(int iters) { \ + CuboidConvolutionBackwardInput(iters, NT, N, H, W, P, C, FC, FH, FW, FP); \ + } \ + BENCHMARK(BM_CUBOID_NAME(CuboidConvolutionBwdInput, NT, N, H, W, P, C, FC, \ + FH, FW, FP)) + +#define BM_CuboidConvolutionBwdKernel(NT, N, H, W, P, C, FC, FH, FW, FP, \ + LABEL) \ + static void BM_CUBOID_NAME(CuboidConvolutionBwdKernel, NT, N, H, W, P, C, \ + FC, FH, FW, FP)(int iters) { \ + CuboidConvolutionBackwardKernel(iters, NT, N, H, W, P, C, FC, FH, FW, FP); \ + } \ + BENCHMARK(BM_CUBOID_NAME(CuboidConvolutionBwdKernel, NT, N, H, W, P, C, FC, \ + FH, FW, FP)) + +#define BM_CuboidConvolutions(N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + BM_CuboidConvolution(2, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolution(4, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolution(8, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolution(16, N, H, W, P, C, FC, FH, FW, FP, LABEL); + +#define BM_CuboidConvolutionsBwdInput(N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + BM_CuboidConvolutionBwdInput(2, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdInput(4, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdInput(8, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdInput(16, N, H, W, P, C, FC, FH, FW, FP, LABEL); + +#define BM_CuboidConvolutionsBwdKernel(N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + BM_CuboidConvolutionBwdKernel(2, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdKernel(4, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdKernel(8, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdKernel(16, N, H, W, P, C, FC, FH, FW, FP, LABEL); + +// Random Cuboid Convolutions ----------------------------------------------- // +// TODO(ezhulenev): find representative dims for cuboid convolutions (find +// models using Conv3D ops). + +BM_CuboidConvolutions(8, // batch size + 25, 25, 25, 4, // input: height, width, panes, depth + 16, 5, 5, 5, // filter: count, height, width, panes + "conv3d"); + +BM_CuboidConvolutionsBwdInput(8, 25, 25, 25, 4, 16, 5, 5, 5, "conv3d"); + +BM_CuboidConvolutionsBwdKernel(8, 25, 25, 25, 4, 16, 5, 5, 5, "conv3d"); diff --git a/tensorflow/core/kernels/gather_nd_op_cpu_impl.h b/tensorflow/core/kernels/gather_nd_op_cpu_impl.h index ad0112e6cb..66ae7f0894 100644 --- a/tensorflow/core/kernels/gather_nd_op_cpu_impl.h +++ b/tensorflow/core/kernels/gather_nd_op_cpu_impl.h @@ -113,10 +113,25 @@ struct GatherNdSlice<CPUDevice, T, Index, IXDIM> { #endif generator::GatherNdSliceGenerator<T, Index, IXDIM> gather_nd_generator( slice_size, Tindices, Tparams, Tout, &error_loc); + +#ifdef INTEL_MKL +// Eigen implementation below is not highly performant. gather_nd_generator +// does not seem to be called in parallel, leading to very poor performance. +// Additionally, since it uses scalar (Tscratch) to invoke 'generate', it +// needs to go through redundant operations like 'reshape', 'broadcast' and +// 'sum'. OpenMP loop below essentially does same thing as Eigen code, but +// is considerably more efficient. +#pragma omp parallel for + for (Eigen::DenseIndex i = 0; i < batch_size; i++) { + const Eigen::array<Eigen::DenseIndex, 1> loc = i; + gather_nd_generator(loc); + } +#else Tscratch.device(d) = Tscratch.reshape(reshape_dims) .broadcast(broadcast_dims) .generate(gather_nd_generator) .sum(); +#endif // error_loc() returns -1 if there's no out-of-bounds index, // otherwise it returns the location of an OOB index in Tindices. diff --git a/tensorflow/core/kernels/loss_test.cc b/tensorflow/core/kernels/loss_test.cc index 6ab0ce5edb..9209ed2ab7 100644 --- a/tensorflow/core/kernels/loss_test.cc +++ b/tensorflow/core/kernels/loss_test.cc @@ -17,6 +17,7 @@ limitations under the License. #include "tensorflow/core/kernels/hinge-loss.h" #include "tensorflow/core/kernels/logistic-loss.h" +#include "tensorflow/core/kernels/poisson-loss.h" #include "tensorflow/core/kernels/smooth-hinge-loss.h" #include "tensorflow/core/kernels/squared-loss.h" #include "tensorflow/core/lib/core/errors.h" @@ -288,5 +289,68 @@ TEST(SmoothHingeLoss, ComputeUpdatedDual) { 0.8 /* wx */, 10.0 /* weighted_example_norm */); } +TEST(PoissonLoss, ComputePrimalLoss) { + PoissonLossUpdater loss_updater; + EXPECT_NEAR(1.0, + loss_updater.ComputePrimalLoss(0.0 /* wx */, 3.0 /* label */, + 1.0 /* example weight */), + 1e-3); + EXPECT_NEAR(21996.0, + loss_updater.ComputePrimalLoss(10.0 /* wx */, 3.0 /* label */, + 1.0 /* example weight */), + 1.0); + EXPECT_NEAR(0.606, + loss_updater.ComputePrimalLoss(-0.5 /* wx */, 0.0 /* label */, + 1.0 /* example weight */), + 1e-3); + EXPECT_NEAR(6.64, + loss_updater.ComputePrimalLoss(1.2 /* wx */, 0.0 /* label */, + 2.0 /* example weight */), + 1e-2); +} + +TEST(PoissonLoss, ComputeDualLoss) { + PoissonLossUpdater loss_updater; + // Dual is undefined. + EXPECT_NEAR( + std::numeric_limits<double>::max(), + loss_updater.ComputeDualLoss(1.0 /* current dual */, 0.0 /* label */, + 1.0 /* example weight */), + 1e-3); + EXPECT_NEAR( + 0.0, + loss_updater.ComputeDualLoss(0.0 /* current dual */, 0.0 /* label */, + 3.0 /* example weight */), + 1e-3); + EXPECT_NEAR( + -0.847, + loss_updater.ComputeDualLoss(1.5 /* current dual */, 2.0 /* label */, + 1.0 /* example weight */), + 1e-3); + EXPECT_NEAR( + -2.675, + loss_updater.ComputeDualLoss(0.5 /* current dual */, 2.0 /* label */, + 3.0 /* example weight */), + 1e-3); +} + +TEST(PoissonLoss, ConvertLabel) { + PoissonLossUpdater loss_updater; + float example_label = -1.0; + // Negative label should throw an error. + Status status = loss_updater.ConvertLabel(&example_label); + EXPECT_FALSE(status.ok()); +} + +TEST(PoissonLoss, ComputeUpdatedDual) { + PoissonLossUpdater loss_updater; + TestComputeUpdatedDual(loss_updater, 1 /* num partitions */, 2.0 /* label */, + 1.0 /* example weight */, 0.5 /* current_dual */, + 0.3 /* wx */, 10.0 /* weighted_example_norm */); + TestComputeUpdatedDual(loss_updater, 2 /* num partitions */, 0.0 /* label */, + 1.0 /* example weight */, 0.0 /* current_dual */, + -0.8 /* wx */, 10.0 /* weighted_example_norm */); +} + } // namespace } // namespace tensorflow diff --git a/tensorflow/core/kernels/mkl_conv_grad_filter_ops.cc b/tensorflow/core/kernels/mkl_conv_grad_filter_ops.cc index afbfaa83f3..52157ed5fb 100644 --- a/tensorflow/core/kernels/mkl_conv_grad_filter_ops.cc +++ b/tensorflow/core/kernels/mkl_conv_grad_filter_ops.cc @@ -300,19 +300,24 @@ template <typename T> class MklConvBwdFilterPrimitiveFactory : public MklPrimitiveFactory<T> { public: static MklConvBwdFilterPrimitive<T>* Get( - const MklConvBwdFilterParams& convBwdFilterDims) { + const MklConvBwdFilterParams& convBwdFilterDims, bool do_not_cache) { MklConvBwdFilterPrimitive<T>* conv_bwd_filter = nullptr; - // look into the pool for reusable primitive - conv_bwd_filter = dynamic_cast<MklConvBwdFilterPrimitive<T>*>( + if (do_not_cache) { /* Create new primitive always */ + conv_bwd_filter = new MklConvBwdFilterPrimitive<T>(convBwdFilterDims); + } else { + // look into the pool for reusable primitive + conv_bwd_filter = dynamic_cast<MklConvBwdFilterPrimitive<T>*> ( MklConvBwdFilterPrimitiveFactory<T>::GetInstance().GetConvBwdFilter( convBwdFilterDims)); - if (conv_bwd_filter == nullptr) { - conv_bwd_filter = new MklConvBwdFilterPrimitive<T>(convBwdFilterDims); - MklConvBwdFilterPrimitiveFactory<T>::GetInstance().SetConvBwdFilter( - convBwdFilterDims, conv_bwd_filter); + if (conv_bwd_filter == nullptr) { + conv_bwd_filter = new MklConvBwdFilterPrimitive<T>(convBwdFilterDims); + MklConvBwdFilterPrimitiveFactory<T>::GetInstance().SetConvBwdFilter( + convBwdFilterDims, conv_bwd_filter); + } } + return conv_bwd_filter; } @@ -845,8 +850,13 @@ class MklConvCustomBackpropFilterOp MklConvBwdFilterParams convBwdFilterDims(fwd_src_dims, fwd_filter_dims, diff_bias_dims, diff_dst_dims, strides, dilations, padding_left, padding_right, TFPaddingToMklDnnPadding(this->padding_)); - conv_bwd_filter = - MklConvBwdFilterPrimitiveFactory<T>::Get(convBwdFilterDims); + + // MKL DNN allocates large buffers when a conv gradient filter primtive is + // created. So we don't cache conv backward primitives when the env + // variable TF_MKL_OPTIMIZE_PRIMITVE_MEMUSE is set to true. + bool do_not_cache = MklPrimitiveFactory<T>::IsPrimitiveMemOptEnabled(); + conv_bwd_filter = MklConvBwdFilterPrimitiveFactory<T>::Get( + convBwdFilterDims, do_not_cache); auto bwd_filter_pd = conv_bwd_filter->GetPrimitiveDesc(); // allocate output tensors: diff_fitler and diff_bias (w bias) @@ -938,6 +948,9 @@ class MklConvCustomBackpropFilterOp if (diff_filter_reorder_required) { diff_filter.InsertReorderToUserMem(); } + + // delete primitive since it is not cached. + if (do_not_cache) delete conv_bwd_filter; } catch (mkldnn::error& e) { string error_msg = "Status: " + std::to_string(e.status) + ", message: " + string(e.message) + ", in file " + diff --git a/tensorflow/core/kernels/mkl_conv_grad_input_ops.cc b/tensorflow/core/kernels/mkl_conv_grad_input_ops.cc index b5a98301e2..c38c9cc27c 100644 --- a/tensorflow/core/kernels/mkl_conv_grad_input_ops.cc +++ b/tensorflow/core/kernels/mkl_conv_grad_input_ops.cc @@ -174,7 +174,6 @@ class MklConvBwdInputPrimitive : public MklPrimitive { } }; - void Setup(const MklConvBwdInputParams& convBwdInputDims) { // create memory descriptors for convolution data w/ no specified format context_.diff_src_md.reset(new memory::desc( @@ -242,19 +241,23 @@ class MklConvBwdInputPrimitiveFactory : public MklPrimitiveFactory<T> { public: static MklConvBwdInputPrimitive<T>* Get( - const MklConvBwdInputParams& convBwdInputDims) { + const MklConvBwdInputParams& convBwdInputDims, bool do_not_cache) { MklConvBwdInputPrimitive<T>* conv_bwd_input = nullptr; - // look into the pool for reusable primitive - conv_bwd_input = dynamic_cast<MklConvBwdInputPrimitive<T>*>( - MklConvBwdInputPrimitiveFactory<T>::GetInstance().GetConvBwdInput( - convBwdInputDims)); - - if (conv_bwd_input == nullptr) { + if (do_not_cache) { /* Always allocate primitive */ conv_bwd_input = new MklConvBwdInputPrimitive<T>(convBwdInputDims); - MklConvBwdInputPrimitiveFactory<T>::GetInstance().SetConvBwdInput( - convBwdInputDims, conv_bwd_input); + } else { + // look into the pool for reusable primitive + conv_bwd_input = dynamic_cast<MklConvBwdInputPrimitive<T>*>( + MklConvBwdInputPrimitiveFactory<T>::GetInstance().GetConvBwdInput( + convBwdInputDims)); + if (conv_bwd_input == nullptr) { + conv_bwd_input = new MklConvBwdInputPrimitive<T>(convBwdInputDims); + MklConvBwdInputPrimitiveFactory<T>::GetInstance().SetConvBwdInput( + convBwdInputDims, conv_bwd_input); + } } + return conv_bwd_input; } @@ -708,8 +711,18 @@ class MklConvCustomBackpropInputOp : public MklConvBackpropCommonOp<Device, T> { MklConvBwdInputParams convBwdInputDims(fwd_src_dims, fwd_filter_dims, diff_dst_dims, strides, dilations, padding_left, padding_right, TFPaddingToMklDnnPadding(this->padding_)); - conv_bwd_input = - MklConvBwdInputPrimitiveFactory<T>::Get(convBwdInputDims); + + // We don't cache those primitves if the env variable + // TF_MKL_OPTIMIZE_PRIMITVE_MEMUSE is true and if primitve descriptor + // includes potentialy large buffers. MKL DNN allocates buffers + // in the following cases + // 1. Legacy CPU without AVX512/AVX2, or + // 2. 1x1 convolution with stride != 1 + bool do_not_cache = MklPrimitiveFactory<T>::IsPrimitiveMemOptEnabled() && + (MklPrimitiveFactory<T>::IsLegacyPlatform() || + IsConv1x1StrideNot1(fwd_filter_dims, strides)); + conv_bwd_input = MklConvBwdInputPrimitiveFactory<T>::Get(convBwdInputDims, + do_not_cache); auto bwd_input_pd = conv_bwd_input->GetPrimitiveDesc(); // allocate output tensor @@ -755,6 +768,11 @@ class MklConvCustomBackpropInputOp : public MklConvBackpropCommonOp<Device, T> { // execute convolution input bwd conv_bwd_input->Execute(diff_src_data, filter_data, diff_dst_data); + + // delete primitive since it is not cached. + if (do_not_cache) { + delete conv_bwd_input; + } } catch (mkldnn::error& e) { string error_msg = "Status: " + std::to_string(e.status) + ", message: " + string(e.message) + ", in file " + diff --git a/tensorflow/core/kernels/mkl_conv_ops.cc b/tensorflow/core/kernels/mkl_conv_ops.cc index c6295c7280..9b10c3f3d6 100644 --- a/tensorflow/core/kernels/mkl_conv_ops.cc +++ b/tensorflow/core/kernels/mkl_conv_ops.cc @@ -271,18 +271,23 @@ class MklConvFwdPrimitive : public MklPrimitive { template <typename T> class MklConvFwdPrimitiveFactory : public MklPrimitiveFactory<T> { public: - static MklConvFwdPrimitive<T>* Get(const MklConvFwdParams& convFwdDims) { + static MklConvFwdPrimitive<T>* Get(const MklConvFwdParams& convFwdDims, + bool do_not_cache) { MklConvFwdPrimitive<T>* conv_fwd = nullptr; - // try to find a suitable one in pool - conv_fwd = dynamic_cast<MklConvFwdPrimitive<T>*>( - MklConvFwdPrimitiveFactory<T>::GetInstance().GetConvFwd(convFwdDims)); - - if (conv_fwd == nullptr) { + if (do_not_cache) { /* Always create new primitive */ conv_fwd = new MklConvFwdPrimitive<T>(convFwdDims); - MklConvFwdPrimitiveFactory<T>::GetInstance().SetConvFwd(convFwdDims, - conv_fwd); + } else { + // try to find a suitable one in pool + conv_fwd = dynamic_cast<MklConvFwdPrimitive<T>*>( + MklConvFwdPrimitiveFactory<T>::GetInstance().GetConvFwd(convFwdDims)); + if (conv_fwd == nullptr) { + conv_fwd = new MklConvFwdPrimitive<T>(convFwdDims); + MklConvFwdPrimitiveFactory<T>::GetInstance().SetConvFwd(convFwdDims, + conv_fwd); + } } + return conv_fwd; } @@ -894,6 +899,17 @@ class MklConvOp : public OpKernel { // MKLDNN dilation starts from 0. for (int i = 0; i < dilations.size(); i++) dilations[i] -= 1; + // In some cases, primitve descriptor includes potentialy large buffers, + // we don't cache those primitves if the env variable + // TF_MKL_OPTIMIZE_PRIMITVE_MEMUSE is true. MKL DNN allocates buffers + // in the following cases + // 1. Legacy CPU without AVX512/AVX2, or + // 2. 1x1 convolution with stride != 1 + bool do_not_cache = MklPrimitiveFactory<T>::IsPrimitiveMemOptEnabled() && + (src_dims[MklDnnDims::Dim_N] > kSmallBatchSize) && + (MklPrimitiveFactory<T>::IsLegacyPlatform() || + IsConv1x1StrideNot1(filter_dims, strides)); + // get a conv2d fwd from primitive pool MklConvFwdPrimitive<T>* conv_fwd = nullptr; if (biasEnabled) { @@ -902,12 +918,14 @@ class MklConvOp : public OpKernel { MklConvFwdParams convFwdDims(src_dims, filter_dims, bias_dims, dst_dims_mkl_order, strides, dilations, padding_left, padding_right); - conv_fwd = MklConvFwdPrimitiveFactory<T>::Get(convFwdDims); + conv_fwd = MklConvFwdPrimitiveFactory<T>::Get( + convFwdDims, do_not_cache); } else { MklConvFwdParams convFwdDims(src_dims, filter_dims, NONE_DIMS, dst_dims_mkl_order, strides, dilations, padding_left, padding_right); - conv_fwd = MklConvFwdPrimitiveFactory<T>::Get(convFwdDims); + conv_fwd = MklConvFwdPrimitiveFactory<T>::Get( + convFwdDims, do_not_cache); } // allocate output tensors output_tensor and filter_out_tensor @@ -952,6 +970,9 @@ class MklConvOp : public OpKernel { } else { conv_fwd->Execute(src_data, filter_data, dst_data); } + + // delete primitive since it is not cached. + if (do_not_cache) delete conv_fwd; } catch (mkldnn::error &e) { string error_msg = tensorflow::strings::StrCat( "Status: ", e.status, ", message: ", string(e.message), ", in file ", diff --git a/tensorflow/core/kernels/mkl_softmax_op.cc b/tensorflow/core/kernels/mkl_softmax_op.cc index 8bde966be9..04d8a1bdeb 100644 --- a/tensorflow/core/kernels/mkl_softmax_op.cc +++ b/tensorflow/core/kernels/mkl_softmax_op.cc @@ -50,6 +50,7 @@ class MklSoftmaxOp : public OpKernel { // src_tensor now points to the 0-th input of global data struct "context" size_t src_idx = 0; const Tensor& src_tensor = MklGetInput(context, src_idx); + const int input_dims = src_tensor.dims(); // Add: get MklShape MklDnnShape src_mkl_shape; @@ -62,7 +63,32 @@ class MklSoftmaxOp : public OpKernel { : src_tensor.shape(); auto src_dims = TFShapeToMklDnnDims(src_tf_shape); auto output_dims = src_dims; - + memory::format layout_type; + // In MKL, data format passed to mkl softmax op depends on dimension of the input tensor. + // Here "x" data format in MKL is used for 1 dim tensor, "nc" for 2 dim tensor, + // "tnc" for 3 dim tensor, "nchw" for 4 dim tensor, and "ncdhw" for 5 dim tensor. + // Each of the simbols has the following meaning: + // n = batch, c = channels, t = sequence lenght, h = height, + // w = width, d = depth + switch (input_dims) { + case 1: + layout_type = memory::format::x; + break; + case 2: + layout_type = memory::format::nc; + break; + case 3: + layout_type = memory::format::tnc; + break; + case 4: + layout_type = memory::format::nchw; + break; + case 5: + layout_type = memory::format::ncdhw; + break; + default: + OP_REQUIRES_OK(context, errors::Aborted("Input dims must be <= 5 and >=1")); + } // Create softmax memory for src, dst: both are defined in mkl_util.h, // they are wrapper MklDnnData<T> src(&cpu_engine); @@ -75,7 +101,7 @@ class MklSoftmaxOp : public OpKernel { auto src_md = src_mkl_shape.IsMklTensor() ? src_mkl_shape.GetMklLayout() - : memory::desc(src_dims, MklDnnType<T>(), memory::format::nc); + : memory::desc(src_dims, MklDnnType<T>(), layout_type); // src: setting memory descriptor and op memory descriptor // Basically following two functions maps the TF "src_tensor" to mkl @@ -84,10 +110,11 @@ class MklSoftmaxOp : public OpKernel { // data format is "nc" for src and dst; since the src and dst buffer is // always in 2D shape src.SetUsrMem(src_md, &src_tensor); - src.SetOpMemDesc(src_dims, memory::format::nc); + src.SetOpMemDesc(src_dims, layout_type); // creating a memory descriptor - int axis = 1; // axis to which softmax will be applied + // passing outermost dim as default axis, where the softmax is applied + int axis = input_dims - 1; auto softmax_fwd_desc = softmax_forward::desc(prop_kind::forward_scoring, src.GetOpMemDesc(), axis); auto softmax_fwd_pd = @@ -107,7 +134,7 @@ class MklSoftmaxOp : public OpKernel { output_mkl_shape.SetMklLayout(&dst_pd); output_mkl_shape.SetElemType(MklDnnType<T>()); output_mkl_shape.SetTfLayout(output_dims.size(), output_dims, - memory::format::nc); + layout_type); output_tf_shape.AddDim((dst_pd.get_size() / sizeof(T))); } else { // then output is also TF shape output_mkl_shape.SetMklTensor(false); diff --git a/tensorflow/core/kernels/poisson-loss.h b/tensorflow/core/kernels/poisson-loss.h new file mode 100644 index 0000000000..f91244454e --- /dev/null +++ b/tensorflow/core/kernels/poisson-loss.h @@ -0,0 +1,109 @@ +/* Copyright 2016 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_KERNELS_POISSON_LOSS_H_ +#define TENSORFLOW_CORE_KERNELS_POISSON_LOSS_H_ + +#include <cmath> + +#include "tensorflow/core/kernels/loss.h" +#include "tensorflow/core/lib/core/errors.h" + +namespace tensorflow { + +class PoissonLossUpdater : public DualLossUpdater { + public: + // Update is found by a Newton algorithm (see readme.md). + double ComputeUpdatedDual(const int num_loss_partitions, const double label, + const double example_weight, + const double current_dual, const double wx, + const double weighted_example_norm) const final { + // Newton algorithm converges quadratically so 10 steps will be largely + // enough to achieve a very good precision + static const int newton_total_steps = 10; + // Initialize the Newton optimization at x such that + // exp(x) = label - current_dual + const double y_minus_a = label - current_dual; + double x = (y_minus_a > 0) ? log(y_minus_a) : 0; + for (int i = 0; i < newton_total_steps; ++i) { + x = NewtonStep(x, num_loss_partitions, label, wx, example_weight, + weighted_example_norm, current_dual); + } + return label - exp(x); + } + + // Dual of poisson loss function. + // https://en.wikipedia.org/wiki/Convex_conjugate + double ComputeDualLoss(const double current_dual, const double example_label, + const double example_weight) const final { + // Dual of the poisson loss function is + // (y-a)*(log(y-a)-1), where a is the dual variable. + // It is defined only for a<y. + const double y_minus_a = example_label - current_dual; + if (y_minus_a == 0.0) { + // (y-a)*(log(y-a)-1) approaches 0 as y-a approaches 0. + return 0.0; + } + if (y_minus_a < 0.0) { + return std::numeric_limits<double>::max(); + } + return y_minus_a * (log(y_minus_a) - 1) * example_weight; + } + + double ComputePrimalLoss(const double wx, const double example_label, + const double example_weight) const final { + return (exp(wx) - wx * example_label) * example_weight; + } + + double PrimalLossDerivative(const double wx, const double label, + const double example_weight) const final { + return (exp(wx) - label) * example_weight; + } + + // TODO(chapelle): We need to introduce a maximum_prediction parameter, + // expose that parameter to the user and have this method return + // 1.0/maximum_prediction. + // Setting this at 1 for now, it only impacts the adaptive sampling. + double SmoothnessConstant() const final { return 1; } + + Status ConvertLabel(float* const example_label) const final { + if (*example_label < 0.0) { + return errors::InvalidArgument( + "Only non-negative labels can be used with the Poisson log loss. " + "Found example with label: ", *example_label); + } + return Status::OK(); + } + + private: + // One Newton step (see readme.md). + double NewtonStep(const double x, const int num_loss_partitions, + const double label, const double wx, + const double example_weight, + const double weighted_example_norm, + const double current_dual) const { + const double expx = exp(x); + const double numerator = + x - wx - num_loss_partitions * weighted_example_norm * + example_weight * (label - current_dual - expx); + const double denominator = + 1 + num_loss_partitions * weighted_example_norm * example_weight * expx; + return x - numerator / denominator; + } +}; + +} // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_LOGISTIC_LOSS_H_ diff --git a/tensorflow/core/kernels/qr_op_complex128.cc b/tensorflow/core/kernels/qr_op_complex128.cc index d8d589f5aa..8a3e3dc0a9 100644 --- a/tensorflow/core/kernels/qr_op_complex128.cc +++ b/tensorflow/core/kernels/qr_op_complex128.cc @@ -24,7 +24,13 @@ REGISTER_LINALG_OP("Qr", (QrOp<complex128>), complex128); // cuSolver affecting older hardware. The cuSolver team is tracking the issue // (https://partners.nvidia.com/bug/viewbug/2171459) and we will re-enable // this feature when a fix is available. -// REGISTER_LINALG_OP_GPU("Qr", (QrOpGpu<complex128>), complex128); +REGISTER_KERNEL_BUILDER(Name("Qr") + .Device(DEVICE_GPU) + .TypeConstraint<complex128>("T") + .HostMemory("input") + .HostMemory("q") + .HostMemory("r"), + QrOp<complex128>); #endif } // namespace tensorflow diff --git a/tensorflow/core/kernels/qr_op_double.cc b/tensorflow/core/kernels/qr_op_double.cc index 63f2e03b3b..05537a0eaa 100644 --- a/tensorflow/core/kernels/qr_op_double.cc +++ b/tensorflow/core/kernels/qr_op_double.cc @@ -24,7 +24,13 @@ REGISTER_LINALG_OP("Qr", (QrOp<double>), double); // cuSolver affecting older hardware. The cuSolver team is tracking the issue // (https://partners.nvidia.com/bug/viewbug/2171459) and we will re-enable // this feature when a fix is available. -// REGISTER_LINALG_OP_GPU("Qr", (QrOpGpu<double>), double); +REGISTER_KERNEL_BUILDER(Name("Qr") + .Device(DEVICE_GPU) + .TypeConstraint<double>("T") + .HostMemory("input") + .HostMemory("q") + .HostMemory("r"), + QrOp<double>); #endif } // namespace tensorflow diff --git a/tensorflow/core/kernels/qr_op_float.cc b/tensorflow/core/kernels/qr_op_float.cc index 0b1a0aaa76..6aebd98186 100644 --- a/tensorflow/core/kernels/qr_op_float.cc +++ b/tensorflow/core/kernels/qr_op_float.cc @@ -24,7 +24,13 @@ REGISTER_LINALG_OP("Qr", (QrOp<float>), float); // cuSolver affecting older hardware. The cuSolver team is tracking the issue // (https://partners.nvidia.com/bug/viewbug/2171459) and we will re-enable // this feature when a fix is available. -// REGISTER_LINALG_OP_GPU("Qr", (QrOpGpu<float>), float); +REGISTER_KERNEL_BUILDER(Name("Qr") + .Device(DEVICE_GPU) + .TypeConstraint<float>("T") + .HostMemory("input") + .HostMemory("q") + .HostMemory("r"), + QrOp<float>); #endif } // namespace tensorflow diff --git a/tensorflow/core/kernels/sdca_ops.cc b/tensorflow/core/kernels/sdca_ops.cc index 05c835ebc4..3bd4168dc7 100644 --- a/tensorflow/core/kernels/sdca_ops.cc +++ b/tensorflow/core/kernels/sdca_ops.cc @@ -38,6 +38,7 @@ limitations under the License. #include "tensorflow/core/kernels/hinge-loss.h" #include "tensorflow/core/kernels/logistic-loss.h" #include "tensorflow/core/kernels/loss.h" +#include "tensorflow/core/kernels/poisson-loss.h" #include "tensorflow/core/kernels/sdca_internal.h" #include "tensorflow/core/kernels/smooth-hinge-loss.h" #include "tensorflow/core/kernels/squared-loss.h" @@ -75,6 +76,8 @@ struct ComputeOptions { loss_updater.reset(new HingeLossUpdater); } else if (loss_type == "smooth_hinge_loss") { loss_updater.reset(new SmoothHingeLossUpdater); + } else if (loss_type == "poisson_loss") { + loss_updater.reset(new PoissonLossUpdater); } else { OP_REQUIRES( context, false, diff --git a/tensorflow/core/lib/core/errors.h b/tensorflow/core/lib/core/errors.h index 49a8a4dbd4..982901a39c 100644 --- a/tensorflow/core/lib/core/errors.h +++ b/tensorflow/core/lib/core/errors.h @@ -131,11 +131,25 @@ inline string FormatNodeNameForError(const string& name) { // LINT.ThenChange(//tensorflow/python/client/session.py) template <typename T> string FormatNodeNamesForError(const T& names) { - ::tensorflow::str_util::Formatter<string> f( - [](string* output, const string& s) { + return ::tensorflow::str_util::Join( + names, ", ", [](string* output, const string& s) { ::tensorflow::strings::StrAppend(output, FormatNodeNameForError(s)); }); - return ::tensorflow::str_util::Join(names, ", ", f); +} +// TODO(b/113350742): Consolidate the two different formats `{{key value}}` and +// `^^key:value^^` in a follow-on CL. +// LINT.IfChange +inline string FormatColocationNodeForError(const string& name) { + return strings::StrCat("^^colocation_node:", name, "^^"); +} +// LINT.ThenChange(//tensorflow/python/framework/error_interpolation.py) +template <typename T> +string FormatColocationNodeForError(const T& names) { + return ::tensorflow::str_util::Join( + names, ", ", [](string* output, const string& s) { + ::tensorflow::strings::StrAppend(output, + FormatColocationNodeForError(s)); + }); } // The CanonicalCode() for non-errors. diff --git a/tensorflow/core/ops/compat/ops_history.v1.pbtxt b/tensorflow/core/ops/compat/ops_history.v1.pbtxt index 9e67662fa6..cb0cb46752 100644 --- a/tensorflow/core/ops/compat/ops_history.v1.pbtxt +++ b/tensorflow/core/ops/compat/ops_history.v1.pbtxt @@ -56665,6 +56665,125 @@ op { } } op { + name: "SdcaOptimizer" + input_arg { + name: "sparse_example_indices" + type: DT_INT64 + number_attr: "num_sparse_features" + } + input_arg { + name: "sparse_feature_indices" + type: DT_INT64 + number_attr: "num_sparse_features" + } + input_arg { + name: "sparse_feature_values" + type: DT_FLOAT + number_attr: "num_sparse_features_with_values" + } + input_arg { + name: "dense_features" + type: DT_FLOAT + number_attr: "num_dense_features" + } + input_arg { + name: "example_weights" + type: DT_FLOAT + } + input_arg { + name: "example_labels" + type: DT_FLOAT + } + input_arg { + name: "sparse_indices" + type: DT_INT64 + number_attr: "num_sparse_features" + } + input_arg { + name: "sparse_weights" + type: DT_FLOAT + number_attr: "num_sparse_features" + } + input_arg { + name: "dense_weights" + type: DT_FLOAT + number_attr: "num_dense_features" + } + input_arg { + name: "example_state_data" + type: DT_FLOAT + } + output_arg { + name: "out_example_state_data" + type: DT_FLOAT + } + output_arg { + name: "out_delta_sparse_weights" + type: DT_FLOAT + number_attr: "num_sparse_features" + } + output_arg { + name: "out_delta_dense_weights" + type: DT_FLOAT + number_attr: "num_dense_features" + } + attr { + name: "loss_type" + type: "string" + allowed_values { + list { + s: "logistic_loss" + s: "squared_loss" + s: "hinge_loss" + s: "smooth_hinge_loss" + s: "poisson_loss" + } + } + } + attr { + name: "adaptative" + type: "bool" + default_value { + b: false + } + } + attr { + name: "num_sparse_features" + type: "int" + has_minimum: true + } + attr { + name: "num_sparse_features_with_values" + type: "int" + has_minimum: true + } + attr { + name: "num_dense_features" + type: "int" + has_minimum: true + } + attr { + name: "l1" + type: "float" + } + attr { + name: "l2" + type: "float" + } + attr { + name: "num_loss_partitions" + type: "int" + has_minimum: true + minimum: 1 + } + attr { + name: "num_inner_iterations" + type: "int" + has_minimum: true + minimum: 1 + } +} +op { name: "SdcaShrinkL1" input_arg { name: "weights" diff --git a/tensorflow/core/ops/ops.pbtxt b/tensorflow/core/ops/ops.pbtxt index c0376b5721..4419f93d0c 100644 --- a/tensorflow/core/ops/ops.pbtxt +++ b/tensorflow/core/ops/ops.pbtxt @@ -26977,6 +26977,7 @@ op { s: "squared_loss" s: "hinge_loss" s: "smooth_hinge_loss" + s: "poisson_loss" } } } diff --git a/tensorflow/core/ops/sdca_ops.cc b/tensorflow/core/ops/sdca_ops.cc index 4025070adb..fdf53a55dd 100644 --- a/tensorflow/core/ops/sdca_ops.cc +++ b/tensorflow/core/ops/sdca_ops.cc @@ -41,7 +41,7 @@ static Status ApplySdcaOptimizerShapeFn(InferenceContext* c) { REGISTER_OP("SdcaOptimizer") .Attr( "loss_type: {'logistic_loss', 'squared_loss', 'hinge_loss'," - "'smooth_hinge_loss'}") + "'smooth_hinge_loss', 'poisson_loss'}") .Attr("adaptative : bool=false") .Attr("num_sparse_features: int >= 0") .Attr("num_sparse_features_with_values: int >= 0") diff --git a/tensorflow/core/util/mkl_util.h b/tensorflow/core/util/mkl_util.h index 6474319370..680211edff 100644 --- a/tensorflow/core/util/mkl_util.h +++ b/tensorflow/core/util/mkl_util.h @@ -17,6 +17,7 @@ limitations under the License. #define TENSORFLOW_CORE_UTIL_MKL_UTIL_H_ #ifdef INTEL_MKL +#include <string> #include <memory> #include <unordered_map> #include <utility> @@ -56,6 +57,7 @@ limitations under the License. #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/util/padding.h" #include "tensorflow/core/util/tensor_format.h" +#include "tensorflow/core/util/env_var.h" #ifndef INTEL_MKL_ML_ONLY #include "mkldnn.hpp" @@ -102,6 +104,8 @@ typedef enum { Dim3d_I = 1 } MklDnnDims3D; +static const int kSmallBatchSize = 32; + #ifdef INTEL_MKL_ML_ONLY class MklShape { public: @@ -2000,7 +2004,9 @@ const mkldnn::memory::dims NONE_DIMS = {}; template <typename T> class MklPrimitiveFactory { public: - MklPrimitiveFactory() {} + MklPrimitiveFactory() { + } + ~MklPrimitiveFactory() {} MklPrimitive* GetOp(const string& key) { @@ -2023,6 +2029,22 @@ class MklPrimitiveFactory { map[key] = op; } + /// Function to decide whether HW has AVX512 or AVX2 + /// For those legacy device(w/o AVX512 and AVX2), + /// MKL-DNN GEMM will be used. + static inline bool IsLegacyPlatform() { + return (!port::TestCPUFeature(port::CPUFeature::AVX512F) + && !port::TestCPUFeature(port::CPUFeature::AVX2)); + } + + /// Fuction to check whether primitive memory optimization is enabled + static inline bool IsPrimitiveMemOptEnabled() { + bool is_primitive_mem_opt_enabled = true; + TF_CHECK_OK(ReadBoolFromEnvVar("TF_MKL_OPTIMIZE_PRIMITVE_MEMUSE", true, + &is_primitive_mem_opt_enabled)); + return is_primitive_mem_opt_enabled; + } + private: static inline std::unordered_map<string, MklPrimitive*>& GetHashMap() { static thread_local std::unordered_map<string, MklPrimitive*> map_; @@ -2060,7 +2082,7 @@ class FactoryKeyCreator { const char delimiter = 'x'; const int kMaxKeyLength = 256; void Append(StringPiece s) { - key_.append(s.ToString()); + key_.append(string(s)); key_.append(1, delimiter); } }; @@ -2099,7 +2121,7 @@ class MklReorderPrimitive : public MklPrimitive { context_.dst_mem->set_data_handle(to->get_data_handle()); } - private: + private: struct ReorderContext { std::shared_ptr<mkldnn::memory> src_mem; std::shared_ptr<mkldnn::memory> dst_mem; @@ -2141,7 +2163,7 @@ class MklReorderPrimitiveFactory : public MklPrimitiveFactory<T> { return instance_; } - private: + private: MklReorderPrimitiveFactory() {} ~MklReorderPrimitiveFactory() {} @@ -2186,6 +2208,15 @@ inline primitive FindOrCreateReorder(const memory* from, const memory* to) { return *reorder_prim->GetPrimitive(); } +// utility function to determine if it is conv 1x1 and stride != 1 +// for purpose of temporarily disabling primitive reuse +inline bool IsConv1x1StrideNot1(memory::dims filter_dims, memory::dims strides) { + if (filter_dims.size() != 4 || strides.size() != 2) return false; + + return ((filter_dims[2] == 1) && (filter_dims[3] == 1) && + ((strides[0] != 1) || (strides[1] != 1))); +} + #endif // INTEL_MKL_DNN } // namespace tensorflow diff --git a/tensorflow/core/util/status_util.h b/tensorflow/core/util/status_util.h deleted file mode 100644 index ea92f61dce..0000000000 --- a/tensorflow/core/util/status_util.h +++ /dev/null @@ -1,36 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#ifndef TENSORFLOW_CORE_UTIL_STATUS_UTIL_H_ -#define TENSORFLOW_CORE_UTIL_STATUS_UTIL_H_ - -#include "tensorflow/core/graph/graph.h" -#include "tensorflow/core/lib/strings/strcat.h" - -namespace tensorflow { - -// Creates a tag to be used in an exception error message. This can be parsed by -// the Python layer and replaced with information about the node. -// -// For example, error_format_tag(node, "${file}") returns -// "^^node:NODE_NAME:${line}^^" which would be rewritten by the Python layer as -// e.g. "file/where/node/was/created.py". -inline string error_format_tag(const Node& node, const string& format) { - return strings::StrCat("^^node:", node.name(), ":", format, "^^"); -} - -} // namespace tensorflow - -#endif // TENSORFLOW_CORE_UTIL_STATUS_UTIL_H_ diff --git a/tensorflow/core/util/status_util_test.cc b/tensorflow/core/util/status_util_test.cc deleted file mode 100644 index 1f06004db2..0000000000 --- a/tensorflow/core/util/status_util_test.cc +++ /dev/null @@ -1,36 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/core/util/status_util.h" - -#include "tensorflow/core/graph/graph_constructor.h" -#include "tensorflow/core/graph/node_builder.h" -#include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/platform/test.h" - -namespace tensorflow { -namespace { - -TEST(TestStatusUtil, ErrorFormatTagForNode) { - Graph graph(OpRegistry::Global()); - Node* node; - TF_CHECK_OK(NodeBuilder("Foo", "NoOp").Finalize(&graph, &node)); - EXPECT_EQ(error_format_tag(*node, "${line}"), "^^node:Foo:${line}^^"); - EXPECT_EQ(error_format_tag(*node, "${file}:${line}"), - "^^node:Foo:${file}:${line}^^"); -} - -} // namespace -} // namespace tensorflow diff --git a/tensorflow/python/compat/compat.py b/tensorflow/python/compat/compat.py index d31aeae4a3..459f494b48 100644 --- a/tensorflow/python/compat/compat.py +++ b/tensorflow/python/compat/compat.py @@ -26,7 +26,7 @@ import datetime from tensorflow.python.util import tf_contextlib from tensorflow.python.util.tf_export import tf_export -_FORWARD_COMPATIBILITY_HORIZON = datetime.date(2018, 8, 31) +_FORWARD_COMPATIBILITY_HORIZON = datetime.date(2018, 9, 4) @tf_export("compat.forward_compatible") diff --git a/tensorflow/python/distribute/distribute_coordinator.py b/tensorflow/python/distribute/distribute_coordinator.py index d9f78150b9..bd3562f1ff 100644 --- a/tensorflow/python/distribute/distribute_coordinator.py +++ b/tensorflow/python/distribute/distribute_coordinator.py @@ -501,6 +501,79 @@ def _configure_session_config_for_std_servers( del session_config.device_filters[:] +def run_standard_tensorflow_server(session_config=None): + """Starts a standard TensorFlow server. + + This method parses configurations from "TF_CONFIG" environment variable and + starts a TensorFlow server. The "TF_CONFIG" is typically a json string and + must have information of the cluster and the role of the server in the + cluster. One example is: + + TF_CONFIG='{ + "cluster": { + "worker": ["host1:2222", "host2:2222", "host3:2222"], + "ps": ["host4:2222", "host5:2222"] + }, + "task": {"type": "worker", "index": 1} + }' + + This "TF_CONFIG" specifies there are 3 workers and 2 ps tasks in the cluster + and the current role is worker 1. + + Valid task types are "chief", "worker", "ps" and "evaluator" and you can have + at most one "chief" and at most one "evaluator". + + An optional key-value can be specified is "rpc_layer". The default value is + "grpc". + + Args: + session_config: an optional `tf.ConfigProto` object. Users can pass in + the session config object to configure server-local devices. + + Returns: + a `tf.train.Server` object which has already been started. + + Raises: + ValueError: if the "TF_CONFIG" environment is not complete. + """ + tf_config = json.loads(os.environ.get("TF_CONFIG", "{}")) + if "cluster" not in tf_config: + raise ValueError("\"cluster\" is not found in TF_CONFIG.") + cluster_spec = multi_worker_util.normalize_cluster_spec(tf_config["cluster"]) + if "task" not in tf_config: + raise ValueError("\"task\" is not found in TF_CONFIG.") + task_env = tf_config["task"] + if "type" not in task_env: + raise ValueError( + "\"task_type\" is not found in the `task` part of TF_CONFIG.") + task_type = task_env["type"] + task_id = int(task_env.get("index", 0)) + + rpc_layer = tf_config.get("rpc_layer", "grpc") + + session_config = session_config or config_pb2.ConfigProto() + # Set the collective group leader for collective ops to initialize collective + # ops when server starts. + if "chief" in cluster_spec.jobs: + session_config.experimental.collective_group_leader = ( + "/job:chief/replica:0/task:0") + else: + if "worker" not in cluster_spec.jobs: + raise ValueError( + "You must have `chief` or `worker` jobs in the `cluster_spec`.") + session_config.experimental.collective_group_leader = ( + "/job:worker/replica:0/task:0") + + server = _run_std_server( + cluster_spec=cluster_spec, + task_type=task_type, + task_id=task_id, + session_config=session_config, + rpc_layer=rpc_layer) + server.start() + return server + + # TODO(yuefengz): propagate cluster_spec in the STANDALONE_CLIENT mode. # TODO(yuefengz): we may need a smart way to figure out whether the current task # is the special task when we support cluster_spec propagation. diff --git a/tensorflow/python/distribute/distribute_coordinator_test.py b/tensorflow/python/distribute/distribute_coordinator_test.py index ac5dd569ed..b07308a1b5 100644 --- a/tensorflow/python/distribute/distribute_coordinator_test.py +++ b/tensorflow/python/distribute/distribute_coordinator_test.py @@ -23,19 +23,18 @@ import copy import json import os import sys -import time import threading +import time import six -# pylint: disable=invalid-name _portpicker_import_error = None try: import portpicker # pylint: disable=g-import-not-at-top -except ImportError as _error: +except ImportError as _error: # pylint: disable=invalid-name _portpicker_import_error = _error portpicker = None -# pylint: enable=invalid-name +# pylint: disable=g-import-not-at-top from tensorflow.core.protobuf import config_pb2 from tensorflow.python.client import session from tensorflow.python.distribute import distribute_coordinator @@ -144,6 +143,10 @@ class MockServer(object): def __init__(self): self._joined = False + self._started = False + + def start(self): + self._started = True def join(self): assert not self._joined @@ -153,6 +156,10 @@ class MockServer(object): def joined(self): return self._joined + @property + def started(self): + return self._started + class DistributeCoordinatorTestBase(test.TestCase): @@ -161,6 +168,7 @@ class DistributeCoordinatorTestBase(test.TestCase): # We have to create a global in-process cluster because once an in-process # tensorflow server is created, there is no way to terminate it. Please see # multi_worker_test_base.py for more details. + # TODO(yuefengz): use the utitliy from multi_worker_test_base. cls._workers, cls._ps = test_util.create_local_cluster( NUM_WORKERS, num_ps=NUM_PS) cls._cluster_spec = { @@ -185,6 +193,7 @@ class DistributeCoordinatorTestBase(test.TestCase): with session.Session(graph=None, config=config, target=target) as sess: yield sess + # TODO(yuefengz): use the utitliy from multi_worker_test_base. def _create_cluster_spec(self, has_chief=False, num_workers=1, @@ -886,6 +895,38 @@ class StrategyConfigureTest(test.TestCase): self.assertEqual(self._inter_op_parallelism_threads, 2) +class RunStandardTensorflowServerTest(test.TestCase): + + def test_std_server_arguments(self): + cs = {"worker": ["fake_worker"], "ps": ["fake_ps"]} + tf_config = {"cluster": cs, "task": {"type": "ps", "id": 0}} + + def _mock_run_std_server(cluster_spec=None, + task_type=None, + task_id=None, + session_config=None, + rpc_layer=None): + self.assertEqual(cluster_spec.as_dict(), cs) + self.assertEqual(task_type, "ps") + self.assertEqual(task_id, 0) + self.assertEqual(session_config.experimental.collective_group_leader, + "/job:worker/replica:0/task:0") + self.assertEqual(session_config.intra_op_parallelism_threads, 1) + self.assertEqual(rpc_layer, "grpc") + + return MockServer() + + with test.mock.patch.dict( + "os.environ", + {"TF_CONFIG": json.dumps(tf_config)}), test.mock.patch.object( + distribute_coordinator, "_run_std_server", _mock_run_std_server): + session_config = config_pb2.ConfigProto() + session_config.intra_op_parallelism_threads = 1 + mock_server = distribute_coordinator.run_standard_tensorflow_server( + session_config) + self.assertTrue(mock_server.started) + + if __name__ == "__main__": # TODO(yuefengz): find a smart way to terminite std server threads. with test.mock.patch.object(sys, "exit", os._exit): diff --git a/tensorflow/python/eager/backprop.py b/tensorflow/python/eager/backprop.py index 7978383e55..9891068056 100644 --- a/tensorflow/python/eager/backprop.py +++ b/tensorflow/python/eager/backprop.py @@ -522,7 +522,7 @@ def make_vjp(f, params=None, persistent=True): args = _ensure_unique_tensor_objects(parameter_positions, args) for i in parameter_positions: sources.append(args[i]) - tape.watch(args[i]) + tape.watch(this_tape, args[i]) result = f(*args) if result is None: raise ValueError("Cannot differentiate a function that returns None; " @@ -748,7 +748,7 @@ class GradientTape(object): tensor: a Tensor or list of Tensors. """ for t in nest.flatten(tensor): - tape.watch(_handle_or_self(t)) + tape.watch(self._tape, _handle_or_self(t)) @tf_contextlib.contextmanager def stop_recording(self): diff --git a/tensorflow/python/eager/backprop_test.py b/tensorflow/python/eager/backprop_test.py index 45f2d0d6ac..caf36b6a36 100644 --- a/tensorflow/python/eager/backprop_test.py +++ b/tensorflow/python/eager/backprop_test.py @@ -313,6 +313,24 @@ class BackpropTest(test.TestCase): grad = backprop.gradients_function(second, [0])(f)[0] self.assertAllEqual([[0.0]], grad) + @test_util.run_in_graph_and_eager_modes + def testWatchingIsTapeLocal(self): + x1 = resource_variable_ops.ResourceVariable(2.0, trainable=False) + x2 = resource_variable_ops.ResourceVariable(2.0, trainable=False) + + with backprop.GradientTape() as tape1: + with backprop.GradientTape() as tape2: + tape1.watch(x1) + tape2.watch([x1, x2]) + y = x1 ** 3 + z = x2 ** 2 + dy, dz = tape2.gradient([y, z], [x1, x2]) + d2y, d2z = tape1.gradient([dy, dz], [x1, x2]) + + self.evaluate([x1.initializer, x2.initializer]) + self.assertEqual(self.evaluate(d2y), 12.0) + self.assertIsNone(d2z) + @test_util.assert_no_new_tensors def testMakeVJP(self): diff --git a/tensorflow/python/eager/pywrap_tfe.h b/tensorflow/python/eager/pywrap_tfe.h index 823c4078b8..16f8c3c917 100755 --- a/tensorflow/python/eager/pywrap_tfe.h +++ b/tensorflow/python/eager/pywrap_tfe.h @@ -138,7 +138,7 @@ void TFE_Py_TapeSetAdd(PyObject* tape); PyObject* TFE_Py_TapeSetIsEmpty(); PyObject* TFE_Py_TapeSetShouldRecord(PyObject* tensors); -void TFE_Py_TapeSetWatch(PyObject* tensor); +void TFE_Py_TapeWatch(PyObject* tape, PyObject* tensor); void TFE_Py_TapeSetDeleteTrace(tensorflow::int64 tensor_id); // Stops any gradient recording on the current thread. diff --git a/tensorflow/python/eager/pywrap_tfe_src.cc b/tensorflow/python/eager/pywrap_tfe_src.cc index 71ab3e1404..0a33a04dcb 100644 --- a/tensorflow/python/eager/pywrap_tfe_src.cc +++ b/tensorflow/python/eager/pywrap_tfe_src.cc @@ -1154,7 +1154,7 @@ PyObject* TFE_Py_TapeSetShouldRecord(PyObject* tensors) { Py_RETURN_FALSE; } -void TFE_Py_TapeSetWatch(PyObject* tensor) { +void TFE_Py_TapeWatch(PyObject* tape, PyObject* tensor) { if (*ThreadTapeIsStopped()) { return; } @@ -1162,9 +1162,7 @@ void TFE_Py_TapeSetWatch(PyObject* tensor) { if (PyErr_Occurred()) { return; } - for (TFE_Py_Tape* tape : *GetTapeSet()) { - tape->tape->Watch(tensor_id); - } + reinterpret_cast<TFE_Py_Tape*>(tape)->tape->Watch(tensor_id); } static tensorflow::eager::TapeTensor TapeTensorFromTensor(PyObject* tensor) { diff --git a/tensorflow/python/eager/tape.py b/tensorflow/python/eager/tape.py index caa217b70c..6eb62afec4 100644 --- a/tensorflow/python/eager/tape.py +++ b/tensorflow/python/eager/tape.py @@ -44,13 +44,9 @@ def push_tape(tape): pywrap_tensorflow.TFE_Py_TapeSetAdd(tape._tape) # pylint: disable=protected-access -def watch(tensor): - """Marks this tensor to be watched by all tapes in the stack. - - Args: - tensor: tensor to be watched. - """ - pywrap_tensorflow.TFE_Py_TapeSetWatch(tensor) +def watch(tape, tensor): + """Marks this tensor to be watched by the given tape.""" + pywrap_tensorflow.TFE_Py_TapeWatch(tape._tape, tensor) # pylint: disable=protected-access def watch_variable(variable): diff --git a/tensorflow/python/estimator/estimator.py b/tensorflow/python/estimator/estimator.py index 44a60495d8..e44a69b374 100644 --- a/tensorflow/python/estimator/estimator.py +++ b/tensorflow/python/estimator/estimator.py @@ -35,7 +35,6 @@ from tensorflow.python.estimator import model_fn as model_fn_lib from tensorflow.python.estimator import run_config from tensorflow.python.estimator import util as estimator_util from tensorflow.python.estimator.export import export as export_helpers -from tensorflow.python.estimator.export import export_output from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors @@ -46,7 +45,6 @@ from tensorflow.python.keras import metrics from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import metrics as metrics_lib -from tensorflow.python.ops import resources from tensorflow.python.ops import variables from tensorflow.python.platform import gfile from tensorflow.python.platform import tf_logging as logging @@ -958,7 +956,12 @@ class Estimator(object): mode=mode, config=self.config) - export_outputs = self._get_export_outputs_for_spec(estimator_spec) + export_outputs = model_fn_lib.export_outputs_for_mode( + mode=estimator_spec.mode, + serving_export_outputs=estimator_spec.export_outputs, + predictions=estimator_spec.predictions, + loss=estimator_spec.loss, + metrics=estimator_spec.eval_metric_ops) # Build the SignatureDefs from receivers and all outputs signature_def_map = export_helpers.build_all_signature_defs( @@ -1015,45 +1018,6 @@ class Estimator(object): else: builder.add_meta_graph(**meta_graph_kwargs) - def _get_export_outputs_for_spec(self, estimator_spec): - """Given an `EstimatorSpec`, determine what our export outputs should be. - - `EstimatorSpecs` contains `export_outputs` that are used for serving, but - for - training and eval graphs, we must wrap the tensors of interest in - appropriate `tf.estimator.export.ExportOutput` objects. - - Args: - estimator_spec: `tf.estimator.EstimatorSpec` object that will be exported. - - Returns: - a dict mapping `export_output_name` to `tf.estimator.export.ExportOutput` - object. - - Raises: - ValueError: if an appropriate `ExportOutput` cannot be found for the - passed `EstimatorSpec.mode` - """ - mode = estimator_spec.mode - if mode == model_fn_lib.ModeKeys.PREDICT: - outputs = estimator_spec.export_outputs - else: - if mode == model_fn_lib.ModeKeys.TRAIN: - output_class = export_output.TrainOutput - elif mode == model_fn_lib.ModeKeys.EVAL: - output_class = export_output.EvalOutput - else: - raise ValueError( - 'Export output type not found for mode: {}'.format(mode)) - - export_out = output_class( - loss=estimator_spec.loss, - predictions=estimator_spec.predictions, - metrics=estimator_spec.eval_metric_ops) - outputs = {mode: export_out} - - return outputs - def _get_features_from_input_fn(self, input_fn, mode): """Extracts the `features` from return values of `input_fn`.""" result = self._call_input_fn(input_fn, mode) @@ -1644,21 +1608,6 @@ def maybe_overwrite_model_dir_and_session_config(config, model_dir): return config -def create_per_tower_ready_op(scaffold): - """Create a `tf.train.Scaffold.ready_op` inside a tower.""" - if scaffold.ready_op: - return scaffold.ready_op - - def default_ready_op(): - return array_ops.concat([ - variables.report_uninitialized_variables(), - resources.report_uninitialized_resources() - ], 0) - - return monitored_session.Scaffold.get_or_default( - 'ready_op', ops.GraphKeys.READY_OP, default_ready_op) - - def create_per_tower_ready_for_local_init_op(scaffold): """Create a `tf.train.Scaffold.ready_for_local_init_op` inside a tower.""" if scaffold.ready_for_local_init_op: @@ -1708,11 +1657,9 @@ def _combine_distributed_scaffold(grouped_scaffold, distribution): return value[0] ready_op = distribution.call_for_each_tower( - create_per_tower_ready_op, grouped_scaffold) + lambda scaffold: scaffold.ready_op, grouped_scaffold) if ready_op is not None: ready_op = _unwrap_and_concat(ready_op) - else: - ready_op = None ready_for_local_init_op = distribution.call_for_each_tower( create_per_tower_ready_for_local_init_op, grouped_scaffold) diff --git a/tensorflow/python/estimator/keras.py b/tensorflow/python/estimator/keras.py index 6361c6acc1..6b2765be82 100644 --- a/tensorflow/python/estimator/keras.py +++ b/tensorflow/python/estimator/keras.py @@ -182,10 +182,58 @@ def _clone_and_build_model(mode, K.set_learning_phase(mode == model_fn_lib.ModeKeys.TRAIN) input_tensors, target_tensors = _convert_estimator_io_to_keras( keras_model, features, labels) - return models.clone_and_build_model( + + compile_clone = (mode != model_fn_lib.ModeKeys.PREDICT) + + global_step = None + if compile_clone: + # Set iterations to the global step created by tf.train.create_global_step() + # which is automatically run in the estimator framework. + global_step = training_util.get_or_create_global_step() + K.track_variable(global_step) + + clone = models.clone_and_build_model( keras_model, input_tensors, target_tensors, custom_objects, - compile_clone=(mode != model_fn_lib.ModeKeys.PREDICT), - in_place_reset=(not keras_model._is_graph_network)) + compile_clone=compile_clone, + in_place_reset=(not keras_model._is_graph_network), + optimizer_iterations=global_step) + + return clone + + +def _convert_keras_metrics_to_estimator(model): + """Convert metrics from a Keras model to ops used by the Estimator framework. + + Args: + model: A `tf.keras.Model` object. + + Returns: + Dictionary mapping metric names to tuples of (value, update) ops. May return + `None` if the model does not contain any metrics. + """ + if not getattr(model, 'metrics', None): + return None + + # TODO(psv/fchollet): support stateful metrics + eval_metric_ops = {} + # When each metric maps to an output + if isinstance(model.metrics, dict): + for i, output_name in enumerate(model.metrics.keys()): + metric_name = model.metrics[output_name] + if callable(metric_name): + metric_name = metric_name.__name__ + # When some outputs use the same metric + if list(model.metrics.values()).count(metric_name) > 1: + metric_name += '_' + output_name + eval_metric_ops[metric_name] = metrics_module.mean( + model.metrics_tensors[i - len(model.metrics)]) + else: + for i, metric_name in enumerate(model.metrics): + if callable(metric_name): + metric_name = metric_name.__name__ + eval_metric_ops[metric_name] = metrics_module.mean( + model.metrics_tensors[i]) + return eval_metric_ops def _create_keras_model_fn(keras_model, custom_objects=None): @@ -237,26 +285,7 @@ def _create_keras_model_fn(keras_model, custom_objects=None): model._make_test_function() # pylint: disable=protected-access loss = model.total_loss - if model.metrics: - # TODO(psv/fchollet): support stateful metrics - eval_metric_ops = {} - # When each metric maps to an output - if isinstance(model.metrics, dict): - for i, output_name in enumerate(model.metrics.keys()): - metric_name = model.metrics[output_name] - if callable(metric_name): - metric_name = metric_name.__name__ - # When some outputs use the same metric - if list(model.metrics.values()).count(metric_name) > 1: - metric_name += '_' + output_name - eval_metric_ops[metric_name] = metrics_module.mean( - model.metrics_tensors[i - len(model.metrics)]) - else: - for i, metric_name in enumerate(model.metrics): - if callable(metric_name): - metric_name = metric_name.__name__ - eval_metric_ops[metric_name] = metrics_module.mean( - model.metrics_tensors[i]) + eval_metric_ops = _convert_keras_metrics_to_estimator(model) # Set train_op only during train. if mode is model_fn_lib.ModeKeys.TRAIN: diff --git a/tensorflow/python/estimator/model_fn.py b/tensorflow/python/estimator/model_fn.py index fd2787aeaf..439cc2e3a4 100644 --- a/tensorflow/python/estimator/model_fn.py +++ b/tensorflow/python/estimator/model_fn.py @@ -142,7 +142,7 @@ class EstimatorSpec( prediction. predictions: Predictions `Tensor` or dict of `Tensor`. loss: Training loss `Tensor`. Must be either scalar, or with shape `[1]`. - train_op: Op to run one training step. + train_op: Op for the training step. eval_metric_ops: Dict of metric results keyed by name. The values of the dict can be one of the following: (1) instance of `Metric` class. @@ -475,3 +475,44 @@ def _check_is_tensor(x, tensor_name): if not isinstance(x, ops.Tensor): raise TypeError('{} must be Tensor, given: {}'.format(tensor_name, x)) return x + + +def export_outputs_for_mode( + mode, serving_export_outputs=None, predictions=None, loss=None, + metrics=None): + """Util function for constructing a `ExportOutput` dict given a mode. + + The returned dict can be directly passed to `build_all_signature_defs` helper + function as the `export_outputs` argument, used for generating a SignatureDef + map. + + Args: + mode: A `ModeKeys` specifying the mode. + serving_export_outputs: Describes the output signatures to be exported to + `SavedModel` and used during serving. Should be a dict or None. + predictions: A dict of Tensors or single Tensor representing model + predictions. This argument is only used if serving_export_outputs is not + set. + loss: A dict of Tensors or single Tensor representing calculated loss. + metrics: A dict of (metric_value, update_op) tuples, or a single tuple. + metric_value must be a Tensor, and update_op must be a Tensor or Op + + Returns: + Dictionary mapping the a key to an `tf.estimator.export.ExportOutput` object + The key is the expected SignatureDef key for the mode. + + Raises: + ValueError: if an appropriate ExportOutput cannot be found for the mode. + """ + # TODO(b/113185250): move all model export helper functions into an util file. + if mode == ModeKeys.PREDICT: + return _get_export_outputs(serving_export_outputs, predictions) + elif mode == ModeKeys.TRAIN: + return {mode: export_output_lib.TrainOutput( + loss=loss, predictions=predictions, metrics=metrics)} + elif mode == ModeKeys.EVAL: + return {mode: export_output_lib.EvalOutput( + loss=loss, predictions=predictions, metrics=metrics)} + else: + raise ValueError( + 'Export output type not found for mode: {}'.format(mode)) diff --git a/tensorflow/python/framework/error_interpolation.py b/tensorflow/python/framework/error_interpolation.py index 6e844e14b9..a69018d00d 100644 --- a/tensorflow/python/framework/error_interpolation.py +++ b/tensorflow/python/framework/error_interpolation.py @@ -26,21 +26,17 @@ import collections import itertools import os import re -import string import six from tensorflow.python.util import tf_stack - _NAME_REGEX = r"[A-Za-z0-9.][A-Za-z0-9_.\-/]*?" -_FORMAT_REGEX = r"[A-Za-z0-9_.\-/${}:]+" -_TAG_REGEX = r"\^\^({name}):({name}):({fmt})\^\^".format( - name=_NAME_REGEX, fmt=_FORMAT_REGEX) +_TAG_REGEX = r"\^\^({name}):({name})\^\^".format(name=_NAME_REGEX) _INTERPOLATION_REGEX = r"^(.*?)({tag})".format(tag=_TAG_REGEX) _INTERPOLATION_PATTERN = re.compile(_INTERPOLATION_REGEX) -_ParseTag = collections.namedtuple("_ParseTag", ["type", "name", "format"]) +_ParseTag = collections.namedtuple("_ParseTag", ["type", "name"]) _BAD_FILE_SUBSTRINGS = [ os.path.join("tensorflow", "python"), @@ -52,16 +48,9 @@ def _parse_message(message): """Parses the message. Splits the message into separators and tags. Tags are named tuples - representing the string ^^type:name:format^^ and they are separated by - separators. For example, in - "123^^node:Foo:${file}^^456^^node:Bar:${line}^^789", there are two tags and - three separators. The separators are the numeric characters. - - Supported tags after node:<node_name> - file: Replaced with the filename in which the node was defined. - line: Replaced by the line number at which the node was defined. - colocations: Replaced by a multi-line message describing the file and - line numbers at which this node was colocated with other nodes. + representing the string ^^type:name^^ and they are separated by + separators. For example, in "123^^node:Foo^^456^^node:Bar^^789", there are + two tags and three separators. The separators are the numeric characters. Args: message: String to parse @@ -69,8 +58,8 @@ def _parse_message(message): Returns: (list of separator strings, list of _ParseTags). - For example, if message is "123^^node:Foo:${file}^^456" then this function - returns (["123", "456"], [_ParseTag("node", "Foo", "${file}")]) + For example, if message is "123^^node:Foo^^456" then this function + returns (["123", "456"], [_ParseTag("node", "Foo")]) """ seps = [] tags = [] @@ -79,7 +68,7 @@ def _parse_message(message): match = re.match(_INTERPOLATION_PATTERN, message[pos:]) if match: seps.append(match.group(1)) - tags.append(_ParseTag(match.group(3), match.group(4), match.group(5))) + tags.append(_ParseTag(match.group(3), match.group(4))) pos += match.end() else: break @@ -111,12 +100,12 @@ def _compute_device_summary_from_list(name, device_assignment_list, prefix=""): return prefix + message str_list = [] - str_list.append("%sDevice assignments active during op '%s' creation:" - % (prefix, name)) + str_list.append( + "%sDevice assignments active during op '%s' creation:" % (prefix, name)) for traceable_obj in device_assignment_list: - location_summary = "<{file}:{line}>".format(file=traceable_obj.filename, - line=traceable_obj.lineno) + location_summary = "<{file}:{line}>".format( + file=traceable_obj.filename, line=traceable_obj.lineno) subs = { "prefix": prefix, "indent": " ", @@ -160,12 +149,12 @@ def _compute_colocation_summary_from_dict(name, colocation_dict, prefix=""): return prefix + message str_list = [] - str_list.append("%sNode-device colocations active during op '%s' creation:" - % (prefix, name)) + str_list.append("%sNode-device colocations active during op '%s' creation:" % + (prefix, name)) for coloc_name, location in colocation_dict.items(): - location_summary = "<{file}:{line}>".format(file=location.filename, - line=location.lineno) + location_summary = "<{file}:{line}>".format( + file=location.filename, line=location.lineno) subs = { "prefix": prefix, "indent": " ", @@ -180,8 +169,10 @@ def _compute_colocation_summary_from_dict(name, colocation_dict, prefix=""): def _compute_colocation_summary_from_op(op, prefix=""): """Fetch colocation file, line, and nesting and return a summary string.""" - return _compute_colocation_summary_from_dict( - op.name, op._colocation_dict, prefix) # pylint: disable=protected-access + # pylint: disable=protected-access + return _compute_colocation_summary_from_dict(op.name, op._colocation_dict, + prefix) + # pylint: enable=protected-access def _find_index_of_defining_frame_for_op(op): @@ -276,7 +267,7 @@ def compute_field_dict(op): def interpolate(error_message, graph): """Interpolates an error message. - The error message can contain tags of the form ^^type:name:format^^ which will + The error message can contain tags of the form ^^type:name^^ which will be replaced. Args: @@ -285,29 +276,29 @@ def interpolate(error_message, graph): message. Returns: - The string with tags of the form ^^type:name:format^^ interpolated. + The string with tags of the form ^^type:name^^ interpolated. """ seps, tags = _parse_message(error_message) + subs = [] + end_msg = "" - node_name_to_substitution_dict = {} - for name in [t.name for t in tags]: - if name in node_name_to_substitution_dict: - continue + for t in tags: try: - op = graph.get_operation_by_name(name) + op = graph.get_operation_by_name(t.name) except KeyError: op = None + msg = "^^%s:%s^^" % (t.type, t.name) if op is not None: field_dict = compute_field_dict(op) - else: - msg = "<NA>" - field_dict = collections.defaultdict(lambda s=msg: s) - node_name_to_substitution_dict[name] = field_dict - - subs = [ - string.Template(tag.format).safe_substitute( - node_name_to_substitution_dict[tag.name]) for tag in tags - ] + if t.type == "node": + msg = "node %s%s " % (t.name, field_dict["defined_at"]) + elif t.type == "colocation_node": + msg = "node %s%s having device %s " % (t.name, field_dict["defined_at"], + field_dict["devices"]) + end_msg += "\n\n" + field_dict["devs_and_colocs"] + subs.append(msg) + subs.append(end_msg) + return "".join( itertools.chain(*six.moves.zip_longest(seps, subs, fillvalue=""))) diff --git a/tensorflow/python/framework/error_interpolation_test.py b/tensorflow/python/framework/error_interpolation_test.py index 0427156b2b..a7c7bbf28b 100644 --- a/tensorflow/python/framework/error_interpolation_test.py +++ b/tensorflow/python/framework/error_interpolation_test.py @@ -50,9 +50,9 @@ def _modify_op_stack_with_filenames(op, num_user_frames, user_filename, stack = [] for idx in range(0, num_outer_frames): stack.append(op._traceback[idx]) - for idx in range(len(stack), len(stack)+num_user_frames): + for idx in range(len(stack), len(stack) + num_user_frames): stack.append(_make_frame_with_filename(op, idx, user_filename % idx)) - for idx in range(len(stack), len(stack)+num_inner_tf_frames): + for idx in range(len(stack), len(stack) + num_inner_tf_frames): stack.append(_make_frame_with_filename(op, idx, tf_filename % idx)) op._traceback = stack @@ -62,13 +62,11 @@ class ComputeDeviceSummaryFromOpTest(test.TestCase): def testCorrectFormatWithActiveDeviceAssignments(self): assignments = [] assignments.append( - traceable_stack.TraceableObject("/cpu:0", - filename="hope.py", - lineno=24)) + traceable_stack.TraceableObject( + "/cpu:0", filename="hope.py", lineno=24)) assignments.append( - traceable_stack.TraceableObject("/gpu:2", - filename="please.py", - lineno=42)) + traceable_stack.TraceableObject( + "/gpu:2", filename="please.py", lineno=42)) summary = error_interpolation._compute_device_summary_from_list( "nodename", assignments, prefix=" ") @@ -90,12 +88,10 @@ class ComputeDeviceSummaryFromOpTest(test.TestCase): class ComputeColocationSummaryFromOpTest(test.TestCase): def testCorrectFormatWithActiveColocations(self): - t_obj_1 = traceable_stack.TraceableObject(None, - filename="test_1.py", - lineno=27) - t_obj_2 = traceable_stack.TraceableObject(None, - filename="test_2.py", - lineno=38) + t_obj_1 = traceable_stack.TraceableObject( + None, filename="test_1.py", lineno=27) + t_obj_2 = traceable_stack.TraceableObject( + None, filename="test_2.py", lineno=38) colocation_dict = { "test_node_1": t_obj_1, "test_node_2": t_obj_2, @@ -140,10 +136,11 @@ class InterpolateFilenamesAndLineNumbersTest(test.TestCase): def testFindIndexOfDefiningFrameForOp(self): local_op = constant_op.constant(42).op user_filename = "hope.py" - _modify_op_stack_with_filenames(local_op, - num_user_frames=3, - user_filename=user_filename, - num_inner_tf_frames=5) + _modify_op_stack_with_filenames( + local_op, + num_user_frames=3, + user_filename=user_filename, + num_inner_tf_frames=5) idx = error_interpolation._find_index_of_defining_frame_for_op(local_op) # Expected frame is 6th from the end because there are 5 inner frames witih # TF filenames. @@ -155,44 +152,39 @@ class InterpolateFilenamesAndLineNumbersTest(test.TestCase): # Truncate stack to known length. local_op._traceback = local_op._traceback[:7] # Ensure all frames look like TF frames. - _modify_op_stack_with_filenames(local_op, - num_user_frames=0, - user_filename="user_file.py", - num_inner_tf_frames=7) + _modify_op_stack_with_filenames( + local_op, + num_user_frames=0, + user_filename="user_file.py", + num_inner_tf_frames=7) idx = error_interpolation._find_index_of_defining_frame_for_op(local_op) self.assertEqual(0, idx) def testNothingToDo(self): normal_string = "This is just a normal string" - interpolated_string = error_interpolation.interpolate(normal_string, - self.graph) + interpolated_string = error_interpolation.interpolate( + normal_string, self.graph) self.assertEqual(interpolated_string, normal_string) - def testOneTag(self): - one_tag_string = "^^node:Two:${file}^^" - interpolated_string = error_interpolation.interpolate(one_tag_string, - self.graph) - self.assertTrue(interpolated_string.endswith("constant_op.py"), - "interpolated_string '%s' did not end with constant_op.py" - % interpolated_string) - def testOneTagWithAFakeNameResultsInPlaceholders(self): - one_tag_string = "^^node:MinusOne:${file}^^" - interpolated_string = error_interpolation.interpolate(one_tag_string, - self.graph) - self.assertEqual("<NA>", interpolated_string) + one_tag_string = "^^node:MinusOne^^" + interpolated_string = error_interpolation.interpolate( + one_tag_string, self.graph) + self.assertEqual(one_tag_string, interpolated_string) def testTwoTagsNoSeps(self): - two_tags_no_seps = "^^node:One:${file}^^^^node:Three:${line}^^" - interpolated_string = error_interpolation.interpolate(two_tags_no_seps, - self.graph) - self.assertRegexpMatches(interpolated_string, "constant_op.py[0-9]+") + two_tags_no_seps = "^^node:One^^^^node:Three^^" + interpolated_string = error_interpolation.interpolate( + two_tags_no_seps, self.graph) + self.assertRegexpMatches(interpolated_string, + "constant_op.py:[0-9]+.*constant_op.py:[0-9]+") def testTwoTagsWithSeps(self): - two_tags_with_seps = ";;;^^node:Two:${file}^^,,,^^node:Three:${line}^^;;;" - interpolated_string = error_interpolation.interpolate(two_tags_with_seps, - self.graph) - expected_regex = "^;;;.*constant_op.py,,,[0-9]*;;;$" + two_tags_with_seps = ";;;^^node:Two^^,,,^^node:Three^^;;;" + interpolated_string = error_interpolation.interpolate( + two_tags_with_seps, self.graph) + expected_regex = ( + r"^;;;.*constant_op.py:[0-9]+\) ,,,.*constant_op.py:[0-9]*\) ;;;$") self.assertRegexpMatches(interpolated_string, expected_regex) @@ -214,30 +206,26 @@ class InterpolateDeviceSummaryTest(test.TestCase): self.graph = self.three.graph def testNodeZeroHasNoDeviceSummaryInfo(self): - message = "^^node:zero:${devices}^^" + message = "^^colocation_node:zero^^" result = error_interpolation.interpolate(message, self.graph) self.assertIn("No device assignments were active", result) def testNodeOneHasExactlyOneInterpolatedDevice(self): - message = "^^node:one:${devices}^^" + message = "^^colocation_node:one^^" result = error_interpolation.interpolate(message, self.graph) - num_devices = result.count("tf.device") - self.assertEqual(1, num_devices) - self.assertIn("tf.device(/cpu)", result) + self.assertEqual(2, result.count("tf.device(/cpu)")) def testNodeTwoHasTwoInterpolatedDevice(self): - message = "^^node:two:${devices}^^" + message = "^^colocation_node:two^^" result = error_interpolation.interpolate(message, self.graph) - num_devices = result.count("tf.device") - self.assertEqual(2, num_devices) - self.assertIn("tf.device(/cpu)", result) - self.assertIn("tf.device(/cpu:0)", result) + self.assertEqual(2, result.count("tf.device(/cpu)")) + self.assertEqual(2, result.count("tf.device(/cpu:0)")) def testNodeThreeHasFancyFunctionDisplayNameForInterpolatedDevice(self): - message = "^^node:three:${devices}^^" + message = "^^colocation_node:three^^" result = error_interpolation.interpolate(message, self.graph) num_devices = result.count("tf.device") - self.assertEqual(1, num_devices) + self.assertEqual(2, num_devices) name_re = r"_fancy_device_function<.*error_interpolation_test.py, [0-9]+>" expected_re = r"with tf.device\(.*%s\)" % name_re self.assertRegexpMatches(result, expected_re) @@ -268,27 +256,26 @@ class InterpolateColocationSummaryTest(test.TestCase): self.graph = node_three.graph def testNodeThreeHasColocationInterpolation(self): - message = "^^node:Three_with_one:${colocations}^^" + message = "^^colocation_node:Three_with_one^^" result = error_interpolation.interpolate(message, self.graph) self.assertIn("colocate_with(One)", result) def testNodeFourHasColocationInterpolationForNodeThreeOnly(self): - message = "^^node:Four_with_three:${colocations}^^" + message = "^^colocation_node:Four_with_three^^" result = error_interpolation.interpolate(message, self.graph) self.assertIn("colocate_with(Three_with_one)", result) self.assertNotIn( "One", result, - "Node One should not appear in Four_with_three's summary:\n%s" - % result) + "Node One should not appear in Four_with_three's summary:\n%s" % result) def testNodeFiveHasColocationInterpolationForNodeOneAndTwo(self): - message = "^^node:Five_with_one_with_two:${colocations}^^" + message = "^^colocation_node:Five_with_one_with_two^^" result = error_interpolation.interpolate(message, self.graph) self.assertIn("colocate_with(One)", result) self.assertIn("colocate_with(Two)", result) def testColocationInterpolationForNodeLackingColocation(self): - message = "^^node:One:${colocations}^^" + message = "^^colocation_node:One^^" result = error_interpolation.interpolate(message, self.graph) self.assertIn("No node-device colocations", result) self.assertNotIn("Two", result) diff --git a/tensorflow/python/framework/errors_impl.py b/tensorflow/python/framework/errors_impl.py index 9f973de400..5af71f2cfb 100644 --- a/tensorflow/python/framework/errors_impl.py +++ b/tensorflow/python/framework/errors_impl.py @@ -25,6 +25,7 @@ from tensorflow.core.lib.core import error_codes_pb2 from tensorflow.python import pywrap_tensorflow as c_api from tensorflow.python.framework import c_api_util from tensorflow.python.util import compat +from tensorflow.python.util import tf_inspect from tensorflow.python.util.tf_export import tf_export @@ -47,11 +48,17 @@ class OpError(Exception): error_code: The `error_codes_pb2.Code` describing the error. """ super(OpError, self).__init__() - self._message = message self._node_def = node_def self._op = op + self._message = message self._error_code = error_code + def __reduce__(self): + # Allow the subclasses to accept less arguments in their __init__. + init_argspec = tf_inspect.getargspec(self.__class__.__init__) + args = tuple(getattr(self, arg) for arg in init_argspec.args[1:]) + return self.__class__, args + @property def message(self): """The error message that describes the error.""" diff --git a/tensorflow/python/framework/errors_test.py b/tensorflow/python/framework/errors_test.py index 62f8ab030c..574b126cae 100644 --- a/tensorflow/python/framework/errors_test.py +++ b/tensorflow/python/framework/errors_test.py @@ -19,6 +19,7 @@ from __future__ import division from __future__ import print_function import gc +import pickle import warnings from tensorflow.core.lib.core import error_codes_pb2 @@ -107,6 +108,34 @@ class ErrorsTest(test.TestCase): gc.collect() self.assertEqual(0, self._CountReferences(c_api_util.ScopedTFStatus)) + def testPickleable(self): + for error_code in [ + errors.CANCELLED, + errors.UNKNOWN, + errors.INVALID_ARGUMENT, + errors.DEADLINE_EXCEEDED, + errors.NOT_FOUND, + errors.ALREADY_EXISTS, + errors.PERMISSION_DENIED, + errors.UNAUTHENTICATED, + errors.RESOURCE_EXHAUSTED, + errors.FAILED_PRECONDITION, + errors.ABORTED, + errors.OUT_OF_RANGE, + errors.UNIMPLEMENTED, + errors.INTERNAL, + errors.UNAVAILABLE, + errors.DATA_LOSS, + ]: + # pylint: disable=protected-access + exc = errors_impl._make_specific_exception(None, None, None, error_code) + # pylint: enable=protected-access + unpickled = pickle.loads(pickle.dumps(exc)) + self.assertEqual(exc.node_def, unpickled.node_def) + self.assertEqual(exc.op, unpickled.op) + self.assertEqual(exc.message, unpickled.message) + self.assertEqual(exc.error_code, unpickled.error_code) + if __name__ == "__main__": test.main() diff --git a/tensorflow/python/keras/initializers.py b/tensorflow/python/keras/initializers.py index 2f12fae8f9..cac78c44ca 100644 --- a/tensorflow/python/keras/initializers.py +++ b/tensorflow/python/keras/initializers.py @@ -27,8 +27,8 @@ from tensorflow.python.keras.utils.generic_utils import serialize_keras_object # These imports are brought in so that keras.initializers.deserialize # has them available in module_objects. from tensorflow.python.ops.init_ops import Constant -from tensorflow.python.ops.init_ops import glorot_normal_initializer -from tensorflow.python.ops.init_ops import glorot_uniform_initializer +from tensorflow.python.ops.init_ops import GlorotNormal +from tensorflow.python.ops.init_ops import GlorotUniform from tensorflow.python.ops.init_ops import he_normal # pylint: disable=unused-import from tensorflow.python.ops.init_ops import he_uniform # pylint: disable=unused-import from tensorflow.python.ops.init_ops import Identity @@ -126,8 +126,8 @@ normal = random_normal = RandomNormal truncated_normal = TruncatedNormal identity = Identity orthogonal = Orthogonal -glorot_normal = glorot_normal_initializer -glorot_uniform = glorot_uniform_initializer +glorot_normal = GlorotNormal +glorot_uniform = GlorotUniform # Utility functions diff --git a/tensorflow/python/keras/models.py b/tensorflow/python/keras/models.py index 39b6042597..c3b7301eba 100644 --- a/tensorflow/python/keras/models.py +++ b/tensorflow/python/keras/models.py @@ -30,7 +30,6 @@ from tensorflow.python.keras.engine.input_layer import InputLayer from tensorflow.python.keras.engine.network import Network from tensorflow.python.keras.utils import generic_utils from tensorflow.python.keras.utils.generic_utils import CustomObjectScope -from tensorflow.python.training import training_util from tensorflow.python.training.checkpointable import base as checkpointable from tensorflow.python.training.checkpointable import data_structures from tensorflow.python.util.tf_export import tf_export @@ -394,10 +393,11 @@ def in_place_subclassed_model_state_restoration(model): def clone_and_build_model( model, input_tensors=None, target_tensors=None, custom_objects=None, - compile_clone=True, in_place_reset=False): + compile_clone=True, in_place_reset=False, optimizer_iterations=None): """Clone a `Model` and build/compile it with the same settings used before. - This function should be run in the same graph as the model. + This function can be be run in the same graph or in a separate graph from the + model. When using a separate graph, `in_place_reset` must be `False`. Args: model: `tf.keras.Model` object. Can be Functional, Sequential, or @@ -414,6 +414,10 @@ def clone_and_build_model( this argument must be set to `True` (default `False`). To restore the original model, use the function `in_place_subclassed_model_state_restoration(model)`. + optimizer_iterations: An iterations variable to pass to the optimizer if + the model uses a TFOptimizer, and if the clone is compiled. This is used + when a Keras model is cloned into an Estimator model function, because + Estimators create their own global step variable. Returns: Clone of the model. @@ -448,14 +452,12 @@ def clone_and_build_model( clone.build() elif model.optimizer: if isinstance(model.optimizer, optimizers.TFOptimizer): - optimizer = model.optimizer + optimizer = optimizers.TFOptimizer( + model.optimizer.optimizer, optimizer_iterations) K.track_tf_optimizer(optimizer) else: optimizer_config = model.optimizer.get_config() optimizer = model.optimizer.__class__.from_config(optimizer_config) - global_step = training_util.get_or_create_global_step() - K.track_variable(global_step) - optimizer.iterations = global_step clone.compile( optimizer, diff --git a/tensorflow/python/keras/optimizers.py b/tensorflow/python/keras/optimizers.py index 2ce79285db..ab13e5c632 100644 --- a/tensorflow/python/keras/optimizers.py +++ b/tensorflow/python/keras/optimizers.py @@ -692,11 +692,15 @@ class TFOptimizer(Optimizer, checkpointable.CheckpointableBase): """Wrapper class for native TensorFlow optimizers. """ - def __init__(self, optimizer): # pylint: disable=super-init-not-called + def __init__(self, optimizer, iterations=None): # pylint: disable=super-init-not-called self.optimizer = optimizer self._track_checkpointable(optimizer, name='optimizer') - with K.name_scope(self.__class__.__name__): - self.iterations = K.variable(0, dtype='int64', name='iterations') + if iterations is None: + with K.name_scope(self.__class__.__name__): + self.iterations = K.variable(0, dtype='int64', name='iterations') + else: + self.iterations = iterations + self._track_checkpointable(self.iterations, name='global_step') def apply_gradients(self, grads): self.optimizer.apply_gradients(grads, global_step=self.iterations) diff --git a/tensorflow/python/kernel_tests/sparse_ops_test.py b/tensorflow/python/kernel_tests/sparse_ops_test.py index cb5a66312f..fc39de150e 100644 --- a/tensorflow/python/kernel_tests/sparse_ops_test.py +++ b/tensorflow/python/kernel_tests/sparse_ops_test.py @@ -22,6 +22,7 @@ import numpy as np from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops from tensorflow.python.framework import sparse_tensor from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops @@ -205,6 +206,22 @@ class SparseMergeTest(test_util.TensorFlowTestCase): output = sess.run(sp_output) self._AssertResultsNotSorted(output, vocab_size) + def testShouldSetLastDimensionInDynamicShape(self): + with ops.Graph().as_default(): + shape = constant_op.constant([2, 2], dtype=dtypes.int64) + dynamic_shape = array_ops.placeholder_with_default(shape, shape=[2]) + ids = sparse_tensor.SparseTensor( + indices=[[0, 0], [0, 1]], + values=[1, 3], + dense_shape=dynamic_shape) + values = sparse_tensor.SparseTensor( + indices=[[0, 0], [0, 1]], + values=[0.4, 0.7], + dense_shape=dynamic_shape) + merged = sparse_ops.sparse_merge( + sp_ids=ids, sp_values=values, vocab_size=5) + self.assertEqual(5, merged.get_shape()[1]) + class SparseMergeHighDimTest(test_util.TensorFlowTestCase): diff --git a/tensorflow/python/ops/collective_ops_test.py b/tensorflow/python/ops/collective_ops_test.py index 6f3cd74406..78c4b4bfe0 100644 --- a/tensorflow/python/ops/collective_ops_test.py +++ b/tensorflow/python/ops/collective_ops_test.py @@ -29,7 +29,7 @@ from tensorflow.python.platform import test class CollectiveOpTest(test.TestCase): - def _testCollectiveReduce(self, t0, t1, expected): + def _testCollectiveReduce(self, t0, t1, expected, set_graph_key): group_key = 1 instance_key = 1 with self.test_session( @@ -43,7 +43,8 @@ class CollectiveOpTest(test.TestCase): colred1 = collective_ops.all_reduce(in1, 2, group_key, instance_key, 'Add', 'Div') run_options = config_pb2.RunOptions() - run_options.experimental.collective_graph_key = 1 + if set_graph_key: + run_options.experimental.collective_graph_key = 1 results = sess.run([colred0, colred1], options=run_options) self.assertAllClose(results[0], expected, rtol=1e-5, atol=1e-5) self.assertAllClose(results[1], expected, rtol=1e-5, atol=1e-5) @@ -51,10 +52,15 @@ class CollectiveOpTest(test.TestCase): def testCollectiveReduce(self): self._testCollectiveReduce([0.1, 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1], [0.3, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3], - [0.2, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2]) + [0.2, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2], True) + + def testCollectiveAutoGraphKey(self): + self._testCollectiveReduce([0.1, 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1], + [0.3, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3], + [0.2, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2], False) def testCollectiveReduceScalar(self): - self._testCollectiveReduce(0.1, 0.3, 0.2) + self._testCollectiveReduce(0.1, 0.3, 0.2, True) def _testCollectiveBroadcast(self, t0): group_key = 1 diff --git a/tensorflow/python/ops/custom_gradient.py b/tensorflow/python/ops/custom_gradient.py index 871f236f78..d7834ba350 100644 --- a/tensorflow/python/ops/custom_gradient.py +++ b/tensorflow/python/ops/custom_gradient.py @@ -82,11 +82,10 @@ def custom_gradient(f): scope must be using `ResourceVariable`s. Args: - f: function `f(x)` that returns a tuple `(y, grad_fn)` where: - - `x` is a `Tensor` or sequence of `Tensor` inputs to the function. + f: function `f(*x)` that returns a tuple `(y, grad_fn)` where: + - `x` is a sequence of `Tensor` inputs to the function. - `y` is a `Tensor` or sequence of `Tensor` outputs of applying - TensorFlow - operations in `f` to `x`. + TensorFlow operations in `f` to `x`. - `grad_fn` is a function with the signature `g(*grad_ys)` which returns a list of `Tensor`s - the derivatives of `Tensor`s in `y` with respect to the `Tensor`s in `x`. `grad_ys` is a `Tensor` or sequence of @@ -96,7 +95,8 @@ def custom_gradient(f): signature `g(*grad_ys, variables=None)`, where `variables` is a list of the `Variable`s, and return a 2-tuple `(grad_xs, grad_vars)`, where `grad_xs` is the same as above, and `grad_vars` is a `list<Tensor>` - with the derivatives of `Tensor`s in `y` with respect to the variables. + with the derivatives of `Tensor`s in `y` with respect to the variables + (that is, grad_vars has one Tensor per variable in variables). Returns: A function `h(x)` which returns the same value as `f(x)[0]` and whose diff --git a/tensorflow/python/ops/init_ops.py b/tensorflow/python/ops/init_ops.py index e0695f01e6..fff3d9b930 100644 --- a/tensorflow/python/ops/init_ops.py +++ b/tensorflow/python/ops/init_ops.py @@ -36,13 +36,11 @@ import math import numpy as np -from tensorflow.python.eager import context from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes -from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops -from tensorflow.python.ops import linalg_ops_impl from tensorflow.python.ops import gen_linalg_ops +from tensorflow.python.ops import linalg_ops_impl from tensorflow.python.ops import math_ops from tensorflow.python.ops import random_ops from tensorflow.python.util.deprecation import deprecated @@ -542,11 +540,7 @@ class Orthogonal(Initializer): # Generate a random matrix a = random_ops.random_normal(flat_shape, dtype=dtype, seed=self.seed) # Compute the qr factorization - if context.executing_eagerly(): - with ops.device("cpu:0"): # TODO(b/73102536) - q, r = gen_linalg_ops.qr(a, full_matrices=False) - else: - q, r = gen_linalg_ops.qr(a, full_matrices=False) + q, r = gen_linalg_ops.qr(a, full_matrices=False) # Make Q uniform d = array_ops.diag_part(r) q *= math_ops.sign(d) @@ -596,11 +590,7 @@ class ConvolutionDeltaOrthogonal(Initializer): a = random_ops.random_normal([shape[-1], shape[-1]], dtype=dtype, seed=self.seed) # Compute the qr factorization - if context.executing_eagerly(): - with ops.device("cpu:0"): # TODO(b/73102536) - q, r = gen_linalg_ops.qr(a, full_matrices=False) - else: - q, r = gen_linalg_ops.qr(a, full_matrices=False) + q, r = gen_linalg_ops.qr(a, full_matrices=False) # Make Q uniform d = array_ops.diag_part(r) q *= math_ops.sign(d) @@ -1120,29 +1110,10 @@ class Identity(Initializer): def get_config(self): return {"gain": self.gain, "dtype": self.dtype.name} -# Aliases. - -# pylint: disable=invalid-name -zeros_initializer = Zeros -ones_initializer = Ones -constant_initializer = Constant -random_uniform_initializer = RandomUniform -random_normal_initializer = RandomNormal -truncated_normal_initializer = TruncatedNormal -uniform_unit_scaling_initializer = UniformUnitScaling -variance_scaling_initializer = VarianceScaling -orthogonal_initializer = Orthogonal -identity_initializer = Identity -convolutional_delta_orthogonal = ConvolutionDeltaOrthogonal -convolutional_orthogonal_1d = ConvolutionOrthogonal1D -convolutional_orthogonal_2d = ConvolutionOrthogonal2D -convolutional_orthogonal_3d = ConvolutionOrthogonal3D -# pylint: enable=invalid-name - @tf_export("glorot_uniform_initializer", "keras.initializers.glorot_uniform", "initializers.glorot_uniform") -def glorot_uniform_initializer(seed=None, dtype=dtypes.float32): +class GlorotUniform(VarianceScaling): """The Glorot uniform initializer, also called Xavier uniform initializer. It draws samples from a uniform distribution within [-limit, limit] @@ -1157,17 +1128,28 @@ def glorot_uniform_initializer(seed=None, dtype=dtypes.float32): `tf.set_random_seed` for behavior. dtype: The data type. Only floating point types are supported. - - Returns: - An initializer. """ - return variance_scaling_initializer( - scale=1.0, mode="fan_avg", distribution="uniform", seed=seed, dtype=dtype) + + def __init__(self, + seed=None, + dtype=dtypes.float32): + super(GlorotUniform, self).__init__( + scale=1.0, + mode="fan_avg", + distribution="uniform", + seed=seed, + dtype=dtype) + + def get_config(self): + return { + "seed": self.seed, + "dtype": self.dtype.name + } @tf_export("glorot_normal_initializer", "keras.initializers.glorot_normal", "initializers.glorot_normal") -def glorot_normal_initializer(seed=None, dtype=dtypes.float32): +class GlorotNormal(VarianceScaling): """The Glorot normal initializer, also called Xavier normal initializer. It draws samples from a truncated normal distribution centered on 0 @@ -1182,16 +1164,45 @@ def glorot_normal_initializer(seed=None, dtype=dtypes.float32): `tf.set_random_seed` for behavior. dtype: The data type. Only floating point types are supported. - - Returns: - An initializer. """ - return variance_scaling_initializer( - scale=1.0, - mode="fan_avg", - distribution="truncated_normal", - seed=seed, - dtype=dtype) + + def __init__(self, + seed=None, + dtype=dtypes.float32): + super(GlorotNormal, self).__init__( + scale=1.0, + mode="fan_avg", + distribution="truncated_normal", + seed=seed, + dtype=dtype) + + def get_config(self): + return { + "seed": self.seed, + "dtype": self.dtype.name + } + + +# Aliases. + +# pylint: disable=invalid-name +zeros_initializer = Zeros +ones_initializer = Ones +constant_initializer = Constant +random_uniform_initializer = RandomUniform +random_normal_initializer = RandomNormal +truncated_normal_initializer = TruncatedNormal +uniform_unit_scaling_initializer = UniformUnitScaling +variance_scaling_initializer = VarianceScaling +glorot_uniform_initializer = GlorotUniform +glorot_normal_initializer = GlorotNormal +orthogonal_initializer = Orthogonal +identity_initializer = Identity +convolutional_delta_orthogonal = ConvolutionDeltaOrthogonal +convolutional_orthogonal_1d = ConvolutionOrthogonal1D +convolutional_orthogonal_2d = ConvolutionOrthogonal2D +convolutional_orthogonal_3d = ConvolutionOrthogonal3D +# pylint: enable=invalid-name @tf_export("keras.initializers.lecun_normal", "initializers.lecun_normal") diff --git a/tensorflow/python/ops/init_ops_test.py b/tensorflow/python/ops/init_ops_test.py index 6a1fe17119..5693c3caaf 100644 --- a/tensorflow/python/ops/init_ops_test.py +++ b/tensorflow/python/ops/init_ops_test.py @@ -20,10 +20,14 @@ from __future__ import print_function import numpy as np +from tensorflow.core.protobuf import config_pb2 +from tensorflow.python.client import session from tensorflow.python.eager import context from tensorflow.python.framework import ops from tensorflow.python.ops import init_ops from tensorflow.python.ops import resource_variable_ops +from tensorflow.python.ops import variable_scope +from tensorflow.python.ops import variables from tensorflow.python.platform import test @@ -163,6 +167,40 @@ class InitializersTest(test.TestCase): with self.cached_session(): self._runner(init_ops.Orthogonal(seed=123), tensor_shape, target_mean=0.) + def testVariablePlacementWithOrthogonalInitializer(self): + if not context.context().num_gpus(): + self.skipTest('No devices other than CPUs found') + with ops.Graph().as_default() as g: + with ops.device('gpu:0'): + variable_scope.get_variable( + name='v', shape=[8, 2], initializer=init_ops.Orthogonal) + variable_scope.get_variable( + name='w', shape=[8, 2], initializer=init_ops.RandomNormal) + run_metadata = config_pb2.RunMetadata() + run_options = config_pb2.RunOptions( + trace_level=config_pb2.RunOptions.FULL_TRACE) + config = config_pb2.ConfigProto( + allow_soft_placement=False, log_device_placement=True) + + # Note: allow_soft_placement=False will fail whenever we cannot satisfy + # the colocation constraints. + with session.Session(config=config, graph=g) as sess: + sess.run( + variables.global_variables_initializer(), + options=run_options, + run_metadata=run_metadata) + + def test_eager_orthogonal_gpu(self): + if not context.context().num_gpus(): + self.skipTest('No devices other than CPUs found') + with context.eager_mode(): + v = variable_scope.get_variable( + name='v', shape=[8, 2], initializer=init_ops.Orthogonal) + w = variable_scope.get_variable( + name='w', shape=[8, 2], initializer=init_ops.RandomNormal) + self.assertTrue('GPU' in v.handle.device) + self.assertTrue('GPU' in w.handle.device) + def test_Identity(self): with self.cached_session(): tensor_shape = (3, 4, 5) diff --git a/tensorflow/python/ops/sparse_ops.py b/tensorflow/python/ops/sparse_ops.py index d1b8be4df7..400a42a3c0 100644 --- a/tensorflow/python/ops/sparse_ops.py +++ b/tensorflow/python/ops/sparse_ops.py @@ -1351,7 +1351,11 @@ def sparse_merge(sp_ids, sp_values, vocab_size, name=None, new_shape = array_ops.concat([sp_ids[0].dense_shape[:-1], vocab_size], 0) result = sparse_tensor.SparseTensor(new_indices, new_values, new_shape) - return result if already_sorted else sparse_reorder(result) + if already_sorted: + return result + sorted_result = sparse_reorder(result) + return sparse_tensor.SparseTensor( + sorted_result.indices, sorted_result.values, new_shape) @tf_export("sparse_retain") diff --git a/tensorflow/python/pywrap_tfe.i b/tensorflow/python/pywrap_tfe.i index e1c233cdd9..a31861ae40 100755 --- a/tensorflow/python/pywrap_tfe.i +++ b/tensorflow/python/pywrap_tfe.i @@ -50,11 +50,11 @@ limitations under the License. %rename("%s") TFE_Py_TapeSetRestartOnThread; %rename("%s") TFE_Py_TapeSetIsEmpty; %rename("%s") TFE_Py_TapeSetShouldRecord; -%rename("%s") TFE_Py_TapeSetWatch; %rename("%s") TFE_Py_TapeSetDeleteTrace; %rename("%s") TFE_Py_TapeSetRecordOperation; %rename("%s") TFE_Py_TapeSetWatchVariable; %rename("%s") TFE_Py_TapeGradient; +%rename("%s") TFE_Py_TapeWatch; %rename("%s") TFE_Py_TapeWatchedVariables; %rename("%s") TFE_NewContextOptions; %rename("%s") TFE_ContextOptionsSetConfig; diff --git a/tensorflow/python/training/checkpointable/util.py b/tensorflow/python/training/checkpointable/util.py index 45d217e8b1..13dddd37ac 100644 --- a/tensorflow/python/training/checkpointable/util.py +++ b/tensorflow/python/training/checkpointable/util.py @@ -685,6 +685,11 @@ def _serialize_object_graph(root_checkpointable, saveables_cache): saveables_cache=saveables_cache) +def named_saveables(root_checkpointable): + """Gather list of all SaveableObjects in the Checkpointable object.""" + return _serialize_object_graph(root_checkpointable, None)[0] + + def list_objects(root_checkpointable): """Traverse the object graph and list all accessible objects. diff --git a/tensorflow/python/training/distribute.py b/tensorflow/python/training/distribute.py index ac92238d57..21ca1735e0 100644 --- a/tensorflow/python/training/distribute.py +++ b/tensorflow/python/training/distribute.py @@ -372,7 +372,7 @@ class DistributionStrategy(object): use its API, including `merge_call()` to get back to cross-tower context), once for each tower. May use values with locality T or M, and any variable. - * `d.reduce(m, t)`: in cross-tower context, accepts t with locality T + * `d.reduce(m, t, t)`: in cross-tower context, accepts t with locality T and produces a value with locality M. * `d.reduce(m, t, v)`: in cross-tower context, accepts t with locality T and produces a value with locality V(`v`). @@ -405,10 +405,11 @@ class DistributionStrategy(object): Another thing you might want to do in the middle of your tower function is an all-reduce of some intermediate value, using `d.reduce()` or - `d.batch_reduce()` without supplying a variable as the destination. + `d.batch_reduce()`. You simply provide the same tensor as the input and + destination. Layers should expect to be called in a tower context, and can use - the `get_tower_context()` function to get a `TowerContext` object. The + the `get_tower_context()` function to get a `TowerContext` object. The `TowerContext` object has a `merge_call()` method for entering cross-tower context where you can use `reduce()` (or `batch_reduce()`) and then optionally `update()` to update state. @@ -719,7 +720,7 @@ class DistributionStrategy(object): def _call_for_each_tower(self, fn, *args, **kwargs): raise NotImplementedError("must be implemented in descendants") - def reduce(self, aggregation, value, destinations=None): + def reduce(self, aggregation, value, destinations): """Combine (via e.g. sum or mean) values across towers. Args: @@ -727,11 +728,10 @@ class DistributionStrategy(object): are `tf.VariableAggregation.SUM`, `tf.VariableAggregation.MEAN`, `tf.VariableAggregation.ONLY_FIRST_TOWER`. value: A per-device value with one value per tower. - destinations: An optional mirrored variable, a device string, - list of device strings. The return value will be copied to all - destination devices (or all the devices where the mirrored - variable resides). If `None` or unspecified, the destinations - will match the devices `value` resides on. + destinations: A mirrored variable, a per-device tensor, a device string, + or list of device strings. The return value will be copied to all + destination devices (or all the devices where the `destinations` value + resides). To perform an all-reduction, pass `value` to `destinations`. Returns: A value mirrored to `destinations`. @@ -1077,10 +1077,15 @@ class TowerContext(object): require_tower_context(self) return device_util.current() - # TODO(josh11b): Implement `start_all_reduce(method, t)` that returns - # a function returning the result of reducing `t` across all - # towers. Most likely can be implemented in terms of `merge_call()` - # and `batch_reduce()`. + # TODO(josh11b): Implement `start_all_reduce(method, t)` for efficient + # all-reduce. It would return a function returning the result of reducing `t` + # across all towers. The caller would wait to call this function until they + # needed the reduce result, allowing an efficient implementation: + # * With eager execution, the reduction could be performed asynchronously + # in the background, not blocking until the result was needed. + # * When constructing a graph, it could batch up all reduction requests up + # to that point that the first result is needed. Most likely this can be + # implemented in terms of `merge_call()` and `batch_reduce()`. # ------------------------------------------------------------------------------ diff --git a/tensorflow/tools/api/golden/v1/tensorflow.glorot_normal_initializer.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.glorot_normal_initializer.pbtxt new file mode 100644 index 0000000000..483d1f8ba0 --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.glorot_normal_initializer.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.glorot_normal_initializer" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.glorot_uniform_initializer.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.glorot_uniform_initializer.pbtxt new file mode 100644 index 0000000000..bb8540d0fd --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.glorot_uniform_initializer.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.glorot_uniform_initializer" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_normal.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_normal.pbtxt new file mode 100644 index 0000000000..4a81e52df9 --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_normal.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.initializers.glorot_normal" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_uniform.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_uniform.pbtxt new file mode 100644 index 0000000000..815dc81dff --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_uniform.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.initializers.glorot_uniform" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.initializers.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.initializers.pbtxt index bc0426f2f1..d499c67d89 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.initializers.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.initializers.pbtxt @@ -5,6 +5,14 @@ tf_module { mtype: "<type \'type\'>" } member { + name: "glorot_normal" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform" + mtype: "<type \'type\'>" + } + member { name: "identity" mtype: "<type \'type\'>" } @@ -45,14 +53,6 @@ tf_module { argspec: "args=[], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "he_normal" argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_normal.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_normal.pbtxt new file mode 100644 index 0000000000..ef0815972d --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_normal.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.keras.initializers.glorot_normal" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_uniform.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_uniform.pbtxt new file mode 100644 index 0000000000..439b5ada9b --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_uniform.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.keras.initializers.glorot_uniform" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.pbtxt index 8645e54302..1540c2915b 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.pbtxt @@ -45,6 +45,14 @@ tf_module { mtype: "<type \'type\'>" } member { + name: "glorot_normal" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform" + mtype: "<type \'type\'>" + } + member { name: "identity" mtype: "<type \'type\'>" } @@ -89,14 +97,6 @@ tf_module { argspec: "args=[\'identifier\'], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "he_normal" argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.pbtxt index e30f9d034d..dd9f7c49e0 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.pbtxt @@ -365,6 +365,14 @@ tf_module { mtype: "<type \'module\'>" } member { + name: "glorot_normal_initializer" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform_initializer" + mtype: "<type \'type\'>" + } + member { name: "graph_util" mtype: "<type \'module\'>" } @@ -1217,14 +1225,6 @@ tf_module { argspec: "args=[], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal_initializer" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform_initializer" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "gradients" argspec: "args=[\'ys\', \'xs\', \'grad_ys\', \'name\', \'colocate_gradients_with_ops\', \'gate_gradients\', \'aggregation_method\', \'stop_gradients\'], varargs=None, keywords=None, defaults=[\'None\', \'gradients\', \'False\', \'False\', \'None\', \'None\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.glorot_normal_initializer.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.glorot_normal_initializer.pbtxt new file mode 100644 index 0000000000..483d1f8ba0 --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.glorot_normal_initializer.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.glorot_normal_initializer" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.glorot_uniform_initializer.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.glorot_uniform_initializer.pbtxt new file mode 100644 index 0000000000..bb8540d0fd --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.glorot_uniform_initializer.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.glorot_uniform_initializer" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_normal.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_normal.pbtxt new file mode 100644 index 0000000000..4a81e52df9 --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_normal.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.initializers.glorot_normal" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_uniform.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_uniform.pbtxt new file mode 100644 index 0000000000..815dc81dff --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_uniform.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.initializers.glorot_uniform" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.initializers.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.initializers.pbtxt index bc0426f2f1..d499c67d89 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.initializers.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.initializers.pbtxt @@ -5,6 +5,14 @@ tf_module { mtype: "<type \'type\'>" } member { + name: "glorot_normal" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform" + mtype: "<type \'type\'>" + } + member { name: "identity" mtype: "<type \'type\'>" } @@ -45,14 +53,6 @@ tf_module { argspec: "args=[], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "he_normal" argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_normal.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_normal.pbtxt new file mode 100644 index 0000000000..ef0815972d --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_normal.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.keras.initializers.glorot_normal" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_uniform.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_uniform.pbtxt new file mode 100644 index 0000000000..439b5ada9b --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_uniform.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.keras.initializers.glorot_uniform" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.pbtxt index 8645e54302..1540c2915b 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.pbtxt @@ -45,6 +45,14 @@ tf_module { mtype: "<type \'type\'>" } member { + name: "glorot_normal" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform" + mtype: "<type \'type\'>" + } + member { name: "identity" mtype: "<type \'type\'>" } @@ -89,14 +97,6 @@ tf_module { argspec: "args=[\'identifier\'], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "he_normal" argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.pbtxt index 695bd1c522..7d45ea22c8 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.pbtxt @@ -365,6 +365,14 @@ tf_module { mtype: "<type \'module\'>" } member { + name: "glorot_normal_initializer" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform_initializer" + mtype: "<type \'type\'>" + } + member { name: "graph_util" mtype: "<type \'module\'>" } @@ -1193,14 +1201,6 @@ tf_module { argspec: "args=[], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal_initializer" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform_initializer" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "gradients" argspec: "args=[\'ys\', \'xs\', \'grad_ys\', \'name\', \'colocate_gradients_with_ops\', \'gate_gradients\', \'aggregation_method\', \'stop_gradients\'], varargs=None, keywords=None, defaults=[\'None\', \'gradients\', \'False\', \'False\', \'None\', \'None\'], " } diff --git a/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 b/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 deleted file mode 100644 index 62b04fe540..0000000000 --- a/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 +++ /dev/null @@ -1,124 +0,0 @@ -FROM nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04 - -LABEL maintainer="Gunhan Gulsoy <gunan@google.com>" - -# It is possible to override these for releases. -ARG TF_BRANCH=master -ARG BAZEL_VERSION=0.15.0 -ARG TF_AVAILABLE_CPUS=32 - -RUN apt-get update && apt-get install -y --no-install-recommends \ - build-essential \ - curl \ - git \ - golang \ - libcurl3-dev \ - libfreetype6-dev \ - libpng12-dev \ - libzmq3-dev \ - pkg-config \ - python-dev \ - python-pip \ - rsync \ - software-properties-common \ - unzip \ - zip \ - zlib1g-dev \ - openjdk-8-jdk \ - openjdk-8-jre-headless \ - wget \ - && \ - apt-get clean && \ - rm -rf /var/lib/apt/lists/* - -RUN apt-get update && \ - apt-get install nvinfer-runtime-trt-repo-ubuntu1604-4.0.1-ga-cuda9.0 && \ - apt-get update && \ - apt-get install libnvinfer4=4.1.2-1+cuda9.0 && \ - apt-get install libnvinfer-dev=4.1.2-1+cuda9.0 - -RUN pip --no-cache-dir install --upgrade \ - pip setuptools - -RUN pip --no-cache-dir install \ - ipykernel \ - jupyter \ - keras_applications==1.0.5 \ - keras_preprocessing==1.0.3 \ - matplotlib \ - numpy \ - scipy \ - sklearn \ - pandas \ - wheel \ - && \ - python -m ipykernel.kernelspec - -# Set up our notebook config. -COPY jupyter_notebook_config.py /root/.jupyter/ - -# Jupyter has issues with being run directly: -# https://github.com/ipython/ipython/issues/7062 -# We just add a little wrapper script. -COPY run_jupyter.sh / - -# Set up Bazel. - -# Running bazel inside a `docker build` command causes trouble, cf: -# https://github.com/bazelbuild/bazel/issues/134 -# The easiest solution is to set up a bazelrc file forcing --batch. -RUN echo "startup --batch" >>/etc/bazel.bazelrc -# Similarly, we need to workaround sandboxing issues: -# https://github.com/bazelbuild/bazel/issues/418 -RUN echo "build --spawn_strategy=standalone --genrule_strategy=standalone" \ - >>/etc/bazel.bazelrc -WORKDIR / -RUN mkdir /bazel && \ - cd /bazel && \ - wget --quiet https://github.com/bazelbuild/bazel/releases/download/$BAZEL_VERSION/bazel-$BAZEL_VERSION-installer-linux-x86_64.sh && \ - wget --quiet https://raw.githubusercontent.com/bazelbuild/bazel/master/LICENSE && \ - chmod +x bazel-*.sh && \ - ./bazel-$BAZEL_VERSION-installer-linux-x86_64.sh && \ - rm -f /bazel/bazel-$BAZEL_VERSION-installer-linux-x86_64.sh - -# Download and build TensorFlow. -WORKDIR / -RUN git clone https://github.com/tensorflow/tensorflow.git && \ - cd tensorflow && \ - git checkout ${TF_BRANCH} -WORKDIR /tensorflow - -# Configure the build for our CUDA configuration. -ENV CI_BUILD_PYTHON=python \ - LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:${LD_LIBRARY_PATH} \ - CUDNN_INSTALL_PATH=/usr/lib/x86_64-linux-gnu \ - PYTHON_BIN_PATH=/usr/bin/python \ - PYTHON_LIB_PATH=/usr/local/lib/python2.7/dist-packages \ - TF_NEED_CUDA=1 \ - TF_NEED_TENSORRT 1 \ - TF_CUDA_VERSION=9.0 \ - TF_CUDA_COMPUTE_CAPABILITIES=3.0,3.5,5.2,6.0,6.1,7.0 \ - TF_CUDNN_VERSION=7 -RUN ./configure - -# Build and Install TensorFlow. -RUN ln -s /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/stubs/libcuda.so.1 && \ - LD_LIBRARY_PATH=/usr/local/cuda/lib64/stubs:${LD_LIBRARY_PATH} \ - bazel build -c opt \ - --config=cuda \ - --cxxopt="-D_GLIBCXX_USE_CXX11_ABI=0" \ - --jobs=${TF_AVAILABLE_CPUS} \ - tensorflow/tools/pip_package:build_pip_package && \ - mkdir /pip_pkg && \ - bazel-bin/tensorflow/tools/pip_package/build_pip_package /pip_pkg && \ - pip --no-cache-dir install --upgrade /pip_pkg/tensorflow-*.whl && \ - rm -rf /pip_pkg && \ - rm -rf /root/.cache -# Clean up pip wheel and Bazel cache when done. - -WORKDIR /root - -# TensorBoard -EXPOSE 6006 -# IPython -EXPOSE 8888 diff --git a/tensorflow/workspace.bzl b/tensorflow/workspace.bzl index e131c532cb..fdbb1bf383 100755 --- a/tensorflow/workspace.bzl +++ b/tensorflow/workspace.bzl @@ -106,11 +106,11 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): tf_http_archive( name = "com_google_absl", urls = [ - "https://mirror.bazel.build/github.com/abseil/abseil-cpp/archive/f0f15c2778b0e4959244dd25e63f445a455870f5.tar.gz", - "https://github.com/abseil/abseil-cpp/archive/f0f15c2778b0e4959244dd25e63f445a455870f5.tar.gz", + "https://mirror.bazel.build/github.com/abseil/abseil-cpp/archive/c075ad321696fa5072e097f0a51e4fe76a6fe13e.tar.gz", + "https://github.com/abseil/abseil-cpp/archive/c075ad321696fa5072e097f0a51e4fe76a6fe13e.tar.gz", ], - sha256 = "4ee36dacb75846eaa209ce8060bb269a42b7b3903612ca6d9e86a692659fe8c1", - strip_prefix = "abseil-cpp-f0f15c2778b0e4959244dd25e63f445a455870f5", + sha256 = "cb4e11259742954f88802be6f33c1007c16502d90d68e8898b5e5084264ca8a9", + strip_prefix = "abseil-cpp-c075ad321696fa5072e097f0a51e4fe76a6fe13e", build_file = clean_dep("//third_party:com_google_absl.BUILD"), ) @@ -491,11 +491,11 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): tf_http_archive( name = "llvm", urls = [ - "https://mirror.bazel.build/github.com/llvm-mirror/llvm/archive/10a4287278d70f44ea14cee48aef3697b2ef1321.tar.gz", - "https://github.com/llvm-mirror/llvm/archive/10a4287278d70f44ea14cee48aef3697b2ef1321.tar.gz", + "https://mirror.bazel.build/github.com/llvm-mirror/llvm/archive/67bd0d9a0f5597f57f272061fd70f24dffb3d223.tar.gz", + "https://github.com/llvm-mirror/llvm/archive/67bd0d9a0f5597f57f272061fd70f24dffb3d223.tar.gz", ], - sha256 = "ef679201e323429ca65a25d7ac42dbfbd6c9368613de6d82faee952bb72827d3", - strip_prefix = "llvm-10a4287278d70f44ea14cee48aef3697b2ef1321", + sha256 = "b8f4ffbcaeea345e2245fd7028c7e960d71c2a2007c20bbfc5d79ecc86992a5e", + strip_prefix = "llvm-67bd0d9a0f5597f57f272061fd70f24dffb3d223", build_file = clean_dep("//third_party/llvm:llvm.autogenerated.BUILD"), ) diff --git a/third_party/clang_toolchain/download_clang.bzl b/third_party/clang_toolchain/download_clang.bzl index 5ef47cdd0d..e782739661 100644 --- a/third_party/clang_toolchain/download_clang.bzl +++ b/third_party/clang_toolchain/download_clang.bzl @@ -39,15 +39,15 @@ def download_clang(repo_ctx, out_folder): # Latest CLANG_REVISION and CLANG_SUB_REVISION of the Chromiums's release # can be found in https://chromium.googlesource.com/chromium/src/tools/clang/+/master/scripts/update.py - CLANG_REVISION = "338452" + CLANG_REVISION = "340427" CLANG_SUB_REVISION = 1 package_version = "%s-%s" % (CLANG_REVISION, CLANG_SUB_REVISION) checksums = { - "Linux_x64": "213ba23a0a9855ede5041f66661caa9c5c59a573ec60b82a31839f9a97f397bf", - "Mac": "4267774201f8cb50c25e081375e87038d58db80064a20a0d9d7fe57ea4357ece", - "Win": "a8a5d5b25443c099e2c20d1a0cdce2f1d17e2dba84de66a6dc6a239ce3e78c34", + "Linux_x64": "8a8f21fb624fc7be7e91e439a13114847185375bb932db51ba590174ecaf764b", + "Mac": "ba894536b7c8d37103a5ddba784f268d55e65bb2ea1200a2cf9f2ef1590eaacd", + "Win": "c3f5bd977266dfd011411c94a13e00974b643b70fb0225a5fb030f7f703fa474", } platform_folder = _get_platform_folder(repo_ctx.os.name) diff --git a/third_party/gpus/crosstool/CROSSTOOL.tpl b/third_party/gpus/crosstool/CROSSTOOL.tpl index 3972c96a2f..3189cf8e31 100644 --- a/third_party/gpus/crosstool/CROSSTOOL.tpl +++ b/third_party/gpus/crosstool/CROSSTOOL.tpl @@ -208,7 +208,7 @@ toolchain { action: "c++-link-dynamic-library" action: "c++-link-nodeps-dynamic-library" flag_group { - flag: "-B/usr/bin/" + %{linker_bin_path_flag} } } } @@ -446,7 +446,7 @@ toolchain { action: "c++-link-dynamic-library" action: "c++-link-nodeps-dynamic-library" flag_group { - flag: "-B/usr/bin/" + %{linker_bin_path_flag} } } } diff --git a/third_party/gpus/cuda_configure.bzl b/third_party/gpus/cuda_configure.bzl index f6a39aeaf1..5648b1525a 100644 --- a/third_party/gpus/cuda_configure.bzl +++ b/third_party/gpus/cuda_configure.bzl @@ -1303,6 +1303,19 @@ def _create_local_cuda_repository(repository_ctx): host_compiler_includes = _host_compiler_includes(repository_ctx, cc_fullpath) cuda_defines = {} + # Bazel sets '-B/usr/bin' flag to workaround build errors on RHEL (see + # https://github.com/bazelbuild/bazel/issues/760). + # However, this stops our custom clang toolchain from picking the provided + # LLD linker, so we're only adding '-B/usr/bin' when using non-downloaded + # toolchain. + # TODO: when bazel stops adding '-B/usr/bin' by default, remove this + # flag from the CROSSTOOL completely (see + # https://github.com/bazelbuild/bazel/issues/5634) + if should_download_clang: + cuda_defines["%{linker_bin_path_flag}"] = "" + else: + cuda_defines["%{linker_bin_path_flag}"] = 'flag: "-B/usr/bin"' + if is_cuda_clang: cuda_defines["%{host_compiler_path}"] = str(cc) cuda_defines["%{host_compiler_warnings}"] = """ diff --git a/tools/bazel.rc b/tools/bazel.rc index 660e3d3280..601e07ffdd 100644 --- a/tools/bazel.rc +++ b/tools/bazel.rc @@ -33,6 +33,11 @@ build:mkl_open_source_only --define=using_mkl_dnn_only=true build:download_clang --crosstool_top=@local_config_download_clang//:toolchain build:download_clang --define=using_clang=true +# Instruct clang to use LLD for linking. +# This only works with GPU builds currently, since Bazel sets -B/usr/bin in +# auto-generated CPU crosstool, forcing /usr/bin/ld.lld to be preferred over +# the downloaded one. +build:download_clang_use_lld --linkopt='-fuse-ld=lld' build:cuda --crosstool_top=@local_config_cuda//crosstool:toolchain build:cuda --define=using_cuda=true --define=using_cuda_nvcc=true |