
diff options
| -rw-r--r-- | tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb | 4 |
1 files changed, 2 insertions, 2 deletions
diff --git a/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb index 315d7a4893..529c99b37c 100644 --- a/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb +++ b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb @@ -66,7 +66,7 @@ "\n", "[Image Source](https://commons.wikimedia.org/wiki/Surfing#/media/File:Surfing_in_Hawaii.jpg), License: Public Domain\n", "\n", - "Our goal is generate a caption, such as \"a surfer riding on a wave\". Here, we'll use an attention based model. This enables us to see which parts of the image the model focuses on as it generates a caption.\n", + "Our goal is to generate a caption, such as \"a surfer riding on a wave\". Here, we'll use an attention-based model. This enables us to see which parts of the image the model focuses on as it generates a caption.\n", "\n", "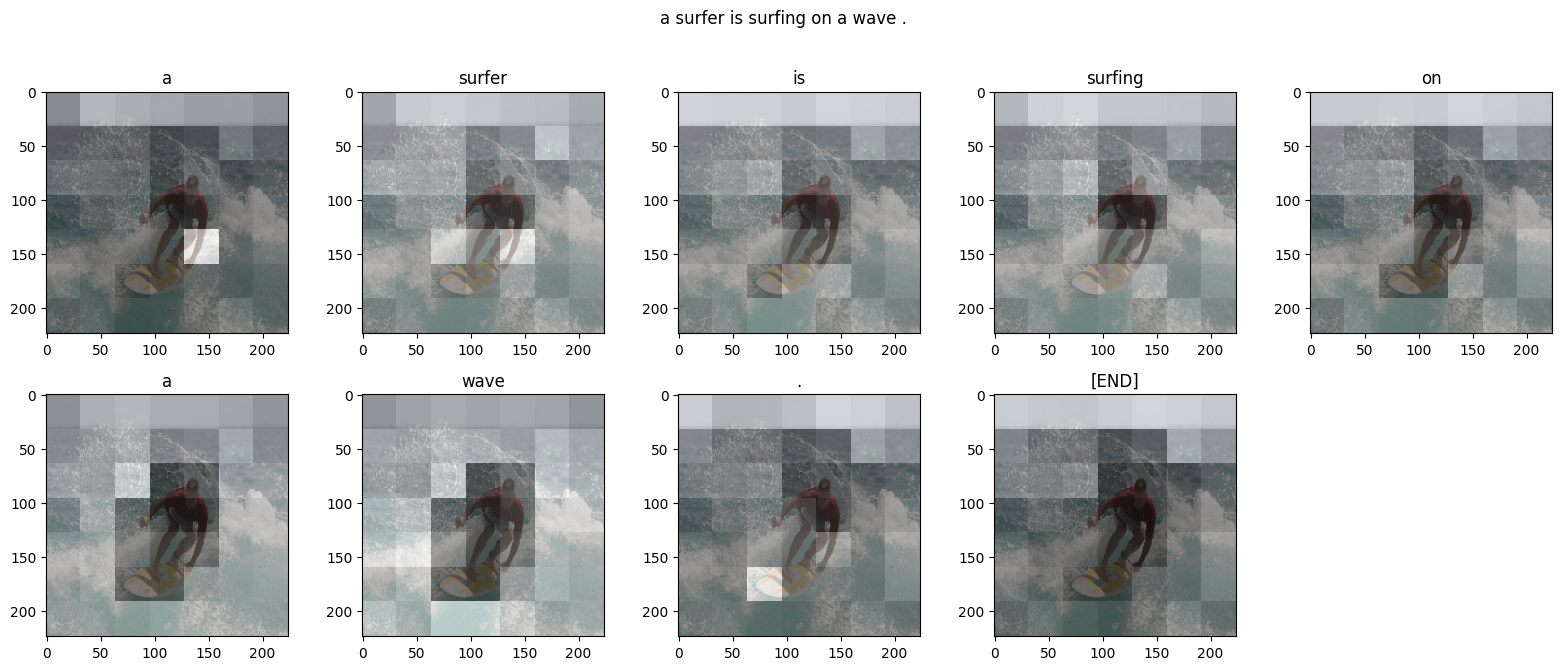\n", "\n", @@ -128,7 +128,7 @@ "source": [ "## Download and prepare the MS-COCO dataset\n", "\n", - "We will use the [MS-COCO dataset](http://cocodataset.org/#home) to train our model. This dataset contains >82,000 images, each of which has been annotated with at least 5 different captions. The code code below will download and extract the dataset automatically. \n", + "We will use the [MS-COCO dataset](http://cocodataset.org/#home) to train our model. This dataset contains >82,000 images, each of which has been annotated with at least 5 different captions. The code below will download and extract the dataset automatically. \n", "\n", "**Caution: large download ahead**. We'll use the training set, it's a 13GB file." ] |